python网页数据抓取( Python/162717和前面一样的网页分析(一)-Python)
优采云 发布时间: 2021-10-24 06:20python网页数据抓取(
Python/162717和前面一样的网页分析(一)-Python)
Python进阶多线程爬取网页项目实战
一、网络分析
这次我们选择爬取的网站是水木社区的Python页面
网页:#!board/Python?p=1
按照惯例,我们的第一步是分析页面结构和翻页请求。
分析前三个页面的链接后,我们知道每个页面的链接中最后一个参数是页数,我们可以修改它来获取其他页面的数据。
我们再分析一下,我们需要在id为body的section下拿到帖子的链接,然后一层一层的找到里面的表格,我们就可以遍历这些链接的标题了。
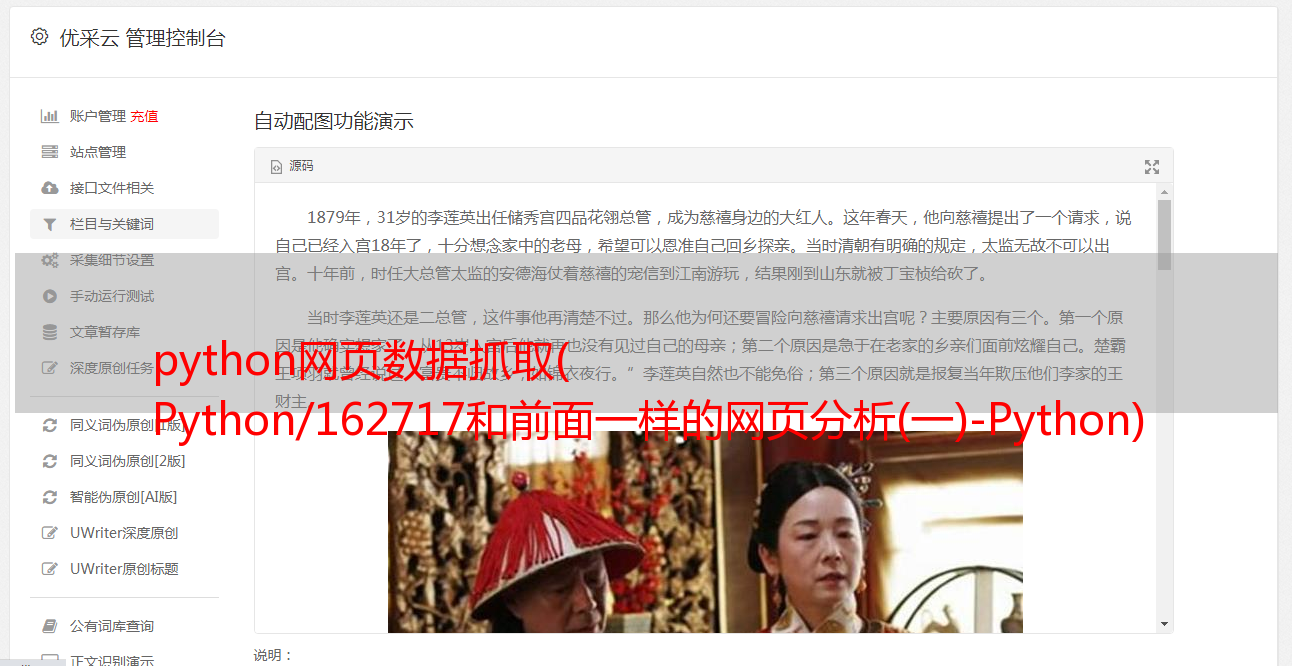
我们点击打开一个帖子:#!article/Python/162717
和之前一样,我们先分析一下网页中标题和内容的结构
不难发现,在subject section中,只需要找到b-head角下的第二个span和id为main的section下的class即可。
主题部分
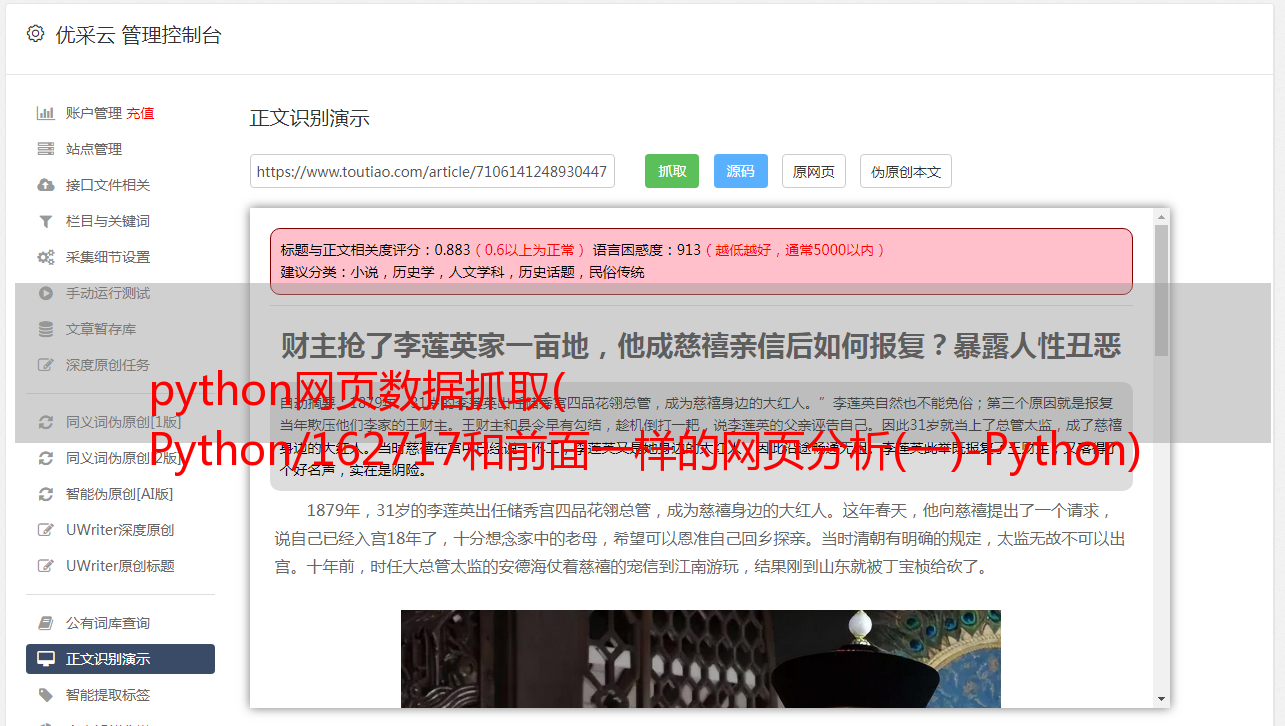
在内容部分,只需找到类为 a-wrap 角的 div 并找到下面的 a-content。
内容部分
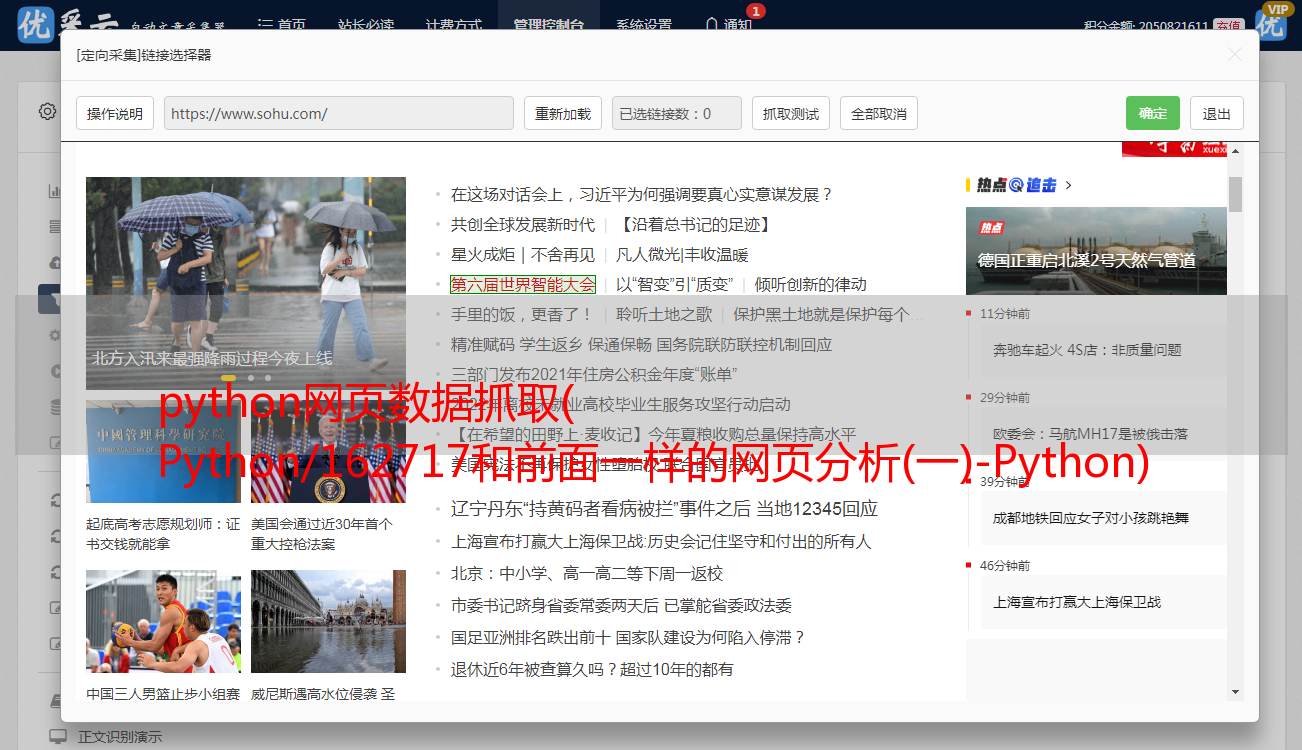
分析完页面的结构,我们就可以开始写代码了!
二、代码实现
首先确定要保存的内容:这次我们保存了水木社区Python版前面10页的所有帖子标题和帖子首页的所有回复。
解析列表页面以获取所有帖子链接
from bs4 import BeautifulSoup
# 解析列表页内容,得到这一页的内容链接
def parse_list_page(text):
soup = BeautifulSoup(text, 'html.parser')
# 下面相当于 soup.find('table', class_='board-list tiz').find('tbody')
tbody = soup.find('table', class_='board-list tiz').tbody
urls = []
for tr in tbody:
td = tr.find('td', class_='title_9')
urls.append(td.a.attrs['href'])
return urls
解析内容页面以获取该页面上的标题和所有帖子内容
# 解析内容页,得到标题和所有帖子内容
def parse_content_page(text):
soup = BeautifulSoup(text, 'html.parser')
title = soup.find('span', class_='n-left').text.strip('文章主题:').strip()
content_div = soup.find('div', class_='b-content corner')
contents = []
for awrap in content_div.find_all('div', class_='a-wrap corner'):
content = awrap.p.text
contents.append(content)
return title, contents
将列表页的链接转换成我们要抓取的链接
def convert_content_url(path):
URL_PREFIX = 'http://www.mysmth.net'
path += '?ajax'
return URL_PREFIX + path
为前 10 页生成列表页面链接
list_urls = []
for i in range(1, 11):
url = 'http://www.mysmth.net/nForum/board/Python?ajax&p='
url += str(i)
list_urls.append(url)
下面是获取前 10 页列表页面中所有文本的链接。这时候我们使用线程池来运行
import requests
from concurrent import futures
session = requests.Session()
executor = futures.ThreadPoolExecutor(max_workers=5)
# 这个函数获取列表页数据,解析出链接,并转换成真实链接
def get_content_urls(list_url):
res = session.get(list_url)
content_urls = parse_list_page(res.text)
real_content_urls = []
for url in content_urls:
url = convert_content_url(url)
real_content_urls.append(url)
return real_content_urls
# 根据刚刚生成的十个列表页链接,开始提交任务
fs = []
for list_url in list_urls:
fs.append(executor.submit(get_content_urls, list_url))
futures.wait(fs)
content_urls = set()
for f in fs:
for url in f.result():
content_urls.add(url)
这里需要注意的是,在第 23 行中我们使用了 set() 函数,该函数用于删除重复值。它的原理是创建一个Set,它是Python中的一种特殊数据类型,可以收录多个元素,但不能重复。我们来看看set()的用法
numbers = [1, 1, 2, 2, 2, 3, 4]
unique = set(numbers)
print(type(unique))
# 输出:
print(unique)
# 输出:{1, 2, 3, 4}
我们看到 set() 将列表编号转换为集合 {1, 2, 3, 4} 而没有重复元素。
我们使用这个特性首先在第 23 行用 content_urls = set() 创建一个空集,然后向它添加链接,它会自动删除多次出现的链接。
得到所有的文本链接后,我们解析文本页面的内容并放入字典中
# 获取正文页内容,解析出标题和帖子
def get_content(url):
r = session.get(url)
title, contents = parse_content_page(r.text)
return title, contents
# 提交解析正文的任务
fs = []
for url in content_urls:
fs.append(executor.submit(get_content, url))
futures.wait(fs)
results = {}
for f in fs:
title, contents = f.result()
results[title] = contents
print(results.keys())
这样,我们就完成了多线程的Mizuki社区爬虫。打印 results.keys() 以查看所有帖子的标题。
这次抓取了前十页的所有主题,以及他们的第一页回复。共解析了 10 个列表页、300 个主题页和 1533 条回复。在网络良好、性能正常的机器上,测试执行只用了大约 13 秒。
完整代码如下
import requests
from concurrent import futures
from bs4 import BeautifulSoup
# 解析列表页内容,得到这一页的内容链接
def parse_list_page(text):
soup = BeautifulSoup(text, 'html.parser')
tbody = soup.find('table', class_='board-list tiz').tbody
urls = []
for tr in tbody:
td = tr.find('td', class_='title_9')
urls.append(td.a.attrs['href'])
return urls
# 解析内容页,得到标题和所有帖子内容
def parse_content_page(text):
soup = BeautifulSoup(text, 'html.parser')
title = soup.find('span', class_='n-left').text.strip('文章主题:').strip()
content_div = soup.find('div', class_='b-content corner')
contents = []
for awrap in content_div.find_all('div', class_='a-wrap corner'):
content = awrap.p.text
contents.append(content)
return title, contents
# 把列表页得到的链接转换成我们要抓取的链接
def convert_content_url(path):
URL_PREFIX = 'http://www.mysmth.net'
path += '?ajax'
return URL_PREFIX + path
# 生成前十页的链接
list_urls = []
for i in range(1, 11):
url = 'http://www.mysmth.net/nForum/board/Python?ajax&p='
url += str(i)
list_urls.append(url)
session = requests.Session()
executor = futures.ThreadPoolExecutor(max_workers=5)
# 这个函数获取列表页数据,解析出链接,并转换成真实链接
def get_content_urls(list_url):
res = session.get(list_url)
content_urls = parse_list_page(res.text)
real_content_urls = []
for url in content_urls:
url = convert_content_url(url)
real_content_urls.append(url)
return real_content_urls
# 根据刚刚生成的十个列表页链接,开始提交任务
fs = []
for list_url in list_urls:
fs.append(executor.submit(get_content_urls, list_url))
futures.wait(fs)
content_urls = set()
for f in fs:
for url in f.result():
content_urls.add(url)
# 获取正文页内容,解析出标题和帖子
def get_content(url):
r = session.get(url)
title, contents = parse_content_page(r.text)
return title, contents
# 提交解析正文的任务
fs = []
for url in content_urls:
fs.append(executor.submit(get_content, url))
futures.wait(fs)
results = {}
for f in fs:
title, contents = f.result()
results[title] = contents
print(results.keys())
本次分享到此结束,感谢阅读!!

