
wecenter采集接口
使用wecenter采集接口和优采云SEO优化软件的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2023-02-11 16:32
wecenter采集接口既可以用于采集文本信息,也可以用于采集图片和视频。它还能够将所采集到的信息存储到本地,方便用户之后使用。此外,它还能够追踪并分析数据,帮助用户精准地判断所采集到的信息是否有用。
优采云是一款强大的SEO优化软件,它可以帮助企业进行网络营销、品牌传播、信息传递等,实现SEO优化目标。此外,它还能够帮助企业利用wecenter采集接口进行数据采集,将有效的信息存储到本地,并对所采集到的信息进行分类和归类。
通过使用优采云,企业不仅能够快速、准确地获取有用的信息,而且还能够根据所需要的内容对所采集到的信息进行归类和分类,从而大大地减少时间成本和人力成本。此外,它还能够帮助企业通过wecenter采集接口对信息进行分析和评估,从而将关键词应用于SEO优化中。
总之,wecenter采集接口是一种非常好的数据采集方式,通过使用优采云SEO优化软件,不仅能够快速、准确地对所需要的内容进行归类和分类;而且还能够根据所需要的关键词将其应用于SEO优化中。通过使用wecenter采集接口和优采云SEO优化软件(官网:www.ucaiyun.com)),企业不但能够快速获取有效信息,还能够大大减少时间成本和人力成本,使SEO优化工作受益。 查看全部
wecenter采集接口是一种非常有效的数据采集方式,它可以让用户轻松地从网络上获取有用的信息。它为用户提供了一个快速、简单、安全的数据采集方式,可以大大提高用户的工作效率和工作质量。

wecenter采集接口既可以用于采集文本信息,也可以用于采集图片和视频。它还能够将所采集到的信息存储到本地,方便用户之后使用。此外,它还能够追踪并分析数据,帮助用户精准地判断所采集到的信息是否有用。

优采云是一款强大的SEO优化软件,它可以帮助企业进行网络营销、品牌传播、信息传递等,实现SEO优化目标。此外,它还能够帮助企业利用wecenter采集接口进行数据采集,将有效的信息存储到本地,并对所采集到的信息进行分类和归类。

通过使用优采云,企业不仅能够快速、准确地获取有用的信息,而且还能够根据所需要的内容对所采集到的信息进行归类和分类,从而大大地减少时间成本和人力成本。此外,它还能够帮助企业通过wecenter采集接口对信息进行分析和评估,从而将关键词应用于SEO优化中。
总之,wecenter采集接口是一种非常好的数据采集方式,通过使用优采云SEO优化软件,不仅能够快速、准确地对所需要的内容进行归类和分类;而且还能够根据所需要的关键词将其应用于SEO优化中。通过使用wecenter采集接口和优采云SEO优化软件(官网:www.ucaiyun.com)),企业不但能够快速获取有效信息,还能够大大减少时间成本和人力成本,使SEO优化工作受益。
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-29 13:15
介绍文档参考。对于一个完整的容器平台来说,容器日志采集也是一个重要的环节。尤其是在微服务架构大行其道的时候,很多程序的访问监控和健康状态检查都依赖于日志信息的采集。由于 Docker 的存在,容器平台中的日志采集与传统方式有很大不同。日志的输出和采集不同于传统的方式。以前很不一样。本文讨论如何在 Rancher 平台采集容器日志。现状 纵观目前容器日志采集的解决方案,无外乎两种方式:一、直接采集Docker标准输出,可以通过Docker的日志驱动(log driver)发送给对应的采集程序;二、非标准输出,延续传统的日志写入方式,容器内的服务直接将日志写入Log文件,以及通过Docker卷映射形式将日志文件映射到Host,日志采集程序直接采集映射后的Log文件。三、通过 Journald 采集二进制日志数据。PS:标准输出:通过docker logs查看的日志信息。在 Ubuntu OS 下,这些信息默认保存在 /var/lib/docker/containers 路径下名为 container ID 的文件夹下的 -json.log 文件中,并以容器 ID 为前缀。非标准输出:根据Docker容器的特点,
如果一个容器要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,默认情况下,这些后台运行的服务生成的日志无法获取为标准输出,生成的日志默认存放在/var/log目录下。第一种方法比较简单,可以直接配置相关的日志驱动(Log driver),但是这种方法也有一些缺点:当宿主机的容器密度比较高的时候,Docker Engine的压力比较大,之后all,容器的标准输出全部由 Docker Engine 处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候,很难做到所有服务的标准输出日志。采集日志日志的方法。虽然我们可以从很多种 Log Drivers 中进行选择,但有些 Log Drivers 会破坏 Docker 的原生体验。例如,日志输出到其他日志服务器后,docker logs 将无法看到容器日志。基于以上考虑,一个完整的日志采集方案必须同时满足标准输出采集和日志量(非标准输出)采集或通过journald采集二进制日志数据。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,普通用户会有自己喜欢的选择。而UI展示是每个公司都有自己的需求,很难形成更好的标准,一般通过定制来解决。因此,本文的主要解决方案是 log采集 解决方案。当然,存储和 UI 显示将连接到开源实现。如果没有特殊要求,也可以有完整的体验。
Rancher下的解决方案(json-file驱动)如上图介绍,ElasticSearch & Kibana可以直接用于日志存储和UI展示。日志采集方面如前所述,需要连接采集两种模式(标准输出日志和非标准输出)。在这个解决方案中,log采集 部分使用了 Fluentd & Logging Helper 的组合。Fluentd 是一个非常通用的 log采集 程序,性能非常好。与Logstash相比,同等压力下它的内存消耗要少很多。为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常见;二、这两个驱动,docker日志还是可以有内容输出的,确保体验的完整性。实现流程实现流程:Fluentd连接Json-file或Journald驱动获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:
方案部署 ElasticSearch & Kibana 部署 通过web登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情,进入后修改最后一个Public端口,默认为80端口,改成其他端口,避免端口冲突。然后去应用商店搜索 Kibana。
在配置选项中,需要选择 Elasticsearch-clients
最终的Public端口根据实际情况修改,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署 目前Rancher日志不在官方仓库中,所以需要添加自定义的存储地址才能使用Rancher日志。点击缩略图管理系统设置进入,点击添加应用商店,名称:rancher -logging 地址:分支:master 最后点击保存返回应用商店。进入应用商店登录搜索:
点击查看详情进入进入配置页面: 本例中,除了Elasticsearch源配置如图所示,其他保持默认:
以上部署完成后,部署一些应用并生成一些访问日志,在Kibana界面可以看到:
使用日志卷方式,需要在Service启动时配置Volume,并且Volume名称需要与之前设置的Volume Pattern相匹配: 查看全部
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一))
介绍文档参考。对于一个完整的容器平台来说,容器日志采集也是一个重要的环节。尤其是在微服务架构大行其道的时候,很多程序的访问监控和健康状态检查都依赖于日志信息的采集。由于 Docker 的存在,容器平台中的日志采集与传统方式有很大不同。日志的输出和采集不同于传统的方式。以前很不一样。本文讨论如何在 Rancher 平台采集容器日志。现状 纵观目前容器日志采集的解决方案,无外乎两种方式:一、直接采集Docker标准输出,可以通过Docker的日志驱动(log driver)发送给对应的采集程序;二、非标准输出,延续传统的日志写入方式,容器内的服务直接将日志写入Log文件,以及通过Docker卷映射形式将日志文件映射到Host,日志采集程序直接采集映射后的Log文件。三、通过 Journald 采集二进制日志数据。PS:标准输出:通过docker logs查看的日志信息。在 Ubuntu OS 下,这些信息默认保存在 /var/lib/docker/containers 路径下名为 container ID 的文件夹下的 -json.log 文件中,并以容器 ID 为前缀。非标准输出:根据Docker容器的特点,
如果一个容器要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,默认情况下,这些后台运行的服务生成的日志无法获取为标准输出,生成的日志默认存放在/var/log目录下。第一种方法比较简单,可以直接配置相关的日志驱动(Log driver),但是这种方法也有一些缺点:当宿主机的容器密度比较高的时候,Docker Engine的压力比较大,之后all,容器的标准输出全部由 Docker Engine 处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候,很难做到所有服务的标准输出日志。采集日志日志的方法。虽然我们可以从很多种 Log Drivers 中进行选择,但有些 Log Drivers 会破坏 Docker 的原生体验。例如,日志输出到其他日志服务器后,docker logs 将无法看到容器日志。基于以上考虑,一个完整的日志采集方案必须同时满足标准输出采集和日志量(非标准输出)采集或通过journald采集二进制日志数据。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,普通用户会有自己喜欢的选择。而UI展示是每个公司都有自己的需求,很难形成更好的标准,一般通过定制来解决。因此,本文的主要解决方案是 log采集 解决方案。当然,存储和 UI 显示将连接到开源实现。如果没有特殊要求,也可以有完整的体验。

Rancher下的解决方案(json-file驱动)如上图介绍,ElasticSearch & Kibana可以直接用于日志存储和UI展示。日志采集方面如前所述,需要连接采集两种模式(标准输出日志和非标准输出)。在这个解决方案中,log采集 部分使用了 Fluentd & Logging Helper 的组合。Fluentd 是一个非常通用的 log采集 程序,性能非常好。与Logstash相比,同等压力下它的内存消耗要少很多。为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常见;二、这两个驱动,docker日志还是可以有内容输出的,确保体验的完整性。实现流程实现流程:Fluentd连接Json-file或Journald驱动获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:

方案部署 ElasticSearch & Kibana 部署 通过web登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。

点击查看详情,进入后修改最后一个Public端口,默认为80端口,改成其他端口,避免端口冲突。然后去应用商店搜索 Kibana。

在配置选项中,需要选择 Elasticsearch-clients

最终的Public端口根据实际情况修改,避免冲突。

服务正常启动后,即可通过该端口访问 Kibana 网页。

Rancher日志服务部署 目前Rancher日志不在官方仓库中,所以需要添加自定义的存储地址才能使用Rancher日志。点击缩略图管理系统设置进入,点击添加应用商店,名称:rancher -logging 地址:分支:master 最后点击保存返回应用商店。进入应用商店登录搜索:

点击查看详情进入进入配置页面: 本例中,除了Elasticsearch源配置如图所示,其他保持默认:

以上部署完成后,部署一些应用并生成一些访问日志,在Kibana界面可以看到:

使用日志卷方式,需要在Service启动时配置Volume,并且Volume名称需要与之前设置的Volume Pattern相匹配:
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-11-15 22:23
)
介绍
文档参考。
对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。现状
看目前容器日志采集的各种解决方案,无非两种方式:一、直接采集Docker标准输出,可以通过Docker日志驱动发送到对应的采集程序;二、非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。Log采集 程序直接采集映射的Log文件。三、通过Journald采集二进制日志数据。
PS:
标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。
非标准输出:根据Docker容器的特点,容器启动后必须有一个服务保持前台运行。如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,默认情况下,这些后台运行的服务生成的日志无法作为标准输出获取,生成的日志默认保存在/var/log目录下。
第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:
当宿主机的容器密度比较高时,对Docker Engine的压力比较大。毕竟,容器的标准输出必须由 Docker Engine 处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。
基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald采集二进制日志数据。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是日志采集解决方案。当然,存储和 UI 显示与开源实现对接。没有特殊要求,也可以有完整的体验。
Rancher解决方案(json-文件驱动)解决方案介绍
如上图所示,ElasticSearch & Kibana 可以直接用于日志存储和UI展示。日志采集如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中日志采集部分采用了Fluentd & Logging Helper组合。Fluentd 是一个非常通用的日志程序,具有出色的性能。与Logstash相比,在同样的压力下,它的内存消耗要少得多。
为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常用;二、这两个驱动,docker日志依然可以输出内容,保证了体验的完整性。实施过程
方案实现过程:Fluentd连接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别映射到容器日志卷的路径(非标准输出),并通知Fluentd进行采集。Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。
下面开始讲解整个程序的部署过程。先用一张图来描述整体部署结构,如下:
解决方案部署 ElasticSearch & Kibana 部署
网页登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。
然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后根据实际情况修改Public端口,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,
名称:rancher -logging
地址:
分支:大师
最后点击保存并返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面: 本例中,除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要匹配之前设置的Volume Pattern:
查看全部
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一)
)
介绍
文档参考。
对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。现状
看目前容器日志采集的各种解决方案,无非两种方式:一、直接采集Docker标准输出,可以通过Docker日志驱动发送到对应的采集程序;二、非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。Log采集 程序直接采集映射的Log文件。三、通过Journald采集二进制日志数据。
PS:
标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。
非标准输出:根据Docker容器的特点,容器启动后必须有一个服务保持前台运行。如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,默认情况下,这些后台运行的服务生成的日志无法作为标准输出获取,生成的日志默认保存在/var/log目录下。
第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:
当宿主机的容器密度比较高时,对Docker Engine的压力比较大。毕竟,容器的标准输出必须由 Docker Engine 处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。
基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald采集二进制日志数据。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是日志采集解决方案。当然,存储和 UI 显示与开源实现对接。没有特殊要求,也可以有完整的体验。
Rancher解决方案(json-文件驱动)解决方案介绍
如上图所示,ElasticSearch & Kibana 可以直接用于日志存储和UI展示。日志采集如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中日志采集部分采用了Fluentd & Logging Helper组合。Fluentd 是一个非常通用的日志程序,具有出色的性能。与Logstash相比,在同样的压力下,它的内存消耗要少得多。
为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常用;二、这两个驱动,docker日志依然可以输出内容,保证了体验的完整性。实施过程
方案实现过程:Fluentd连接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别映射到容器日志卷的路径(非标准输出),并通知Fluentd进行采集。Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。
下面开始讲解整个程序的部署过程。先用一张图来描述整体部署结构,如下:
解决方案部署 ElasticSearch & Kibana 部署
网页登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。
然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后根据实际情况修改Public端口,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,
名称:rancher -logging
地址:
分支:大师
最后点击保存并返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面: 本例中,除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要匹配之前设置的Volume Pattern:

wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-10-27 11:18
)
介绍
文档参考。
对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。现状
看目前容器日志采集的各种解决方案,无非两种方式:一、直接采集Docker标准输出,可以通过Docker日志驱动发送到对应的采集程序;二、非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。Log采集 程序直接采集映射的Log文件。三、通过Journald采集二进制日志数据。
PS:
标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。
非标准输出:根据Docker容器的特点,容器启动后必须有一个服务来保持前台运行。如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,这些后台运行的服务生成的日志默认无法作为标准输出获取,生成的日志默认会保存在/var/log目录下。
第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:
当宿主机的容器密度比较高时,对Docker Engine的压力比较大。毕竟,容器的标准输出必须由 Docker Engine 处理。虽然原则上我们要遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。
基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald进行二进制日志数据采集。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是日志采集解决方案。当然,存储和 UI 显示与开源实现对接。没有特殊要求,也可以有完整的体验。
Rancher解决方案(json-文件驱动)解决方案介绍
如上图所示,ElasticSearch & Kibana 可以直接用于日志存储和UI展示。日志采集如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中日志采集部分采用了Fluentd & Logging Helper组合。Fluentd 是一个非常通用的日志程序,具有出色的性能。与Logstash相比,在同样的压力下,它的内存消耗要少得多。
为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常用;二、这两个驱动,docker日志依然可以输出内容,保证了体验的完整性。实施过程
方案实现过程:Fluentd连接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别映射到容器日志卷的路径(非标准输出),并通知Fluentd进行采集。Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。
下面开始讲解整个程序的部署过程。先用一张图来描述整体的部署结构,如下:
解决方案部署 ElasticSearch & Kibana 部署
网页登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。
然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后根据实际情况修改Public端口,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,
名称:rancher -logging
地址:
分支:大师
最后点击保存并返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面: 本例中,除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要匹配之前设置的Volume Pattern:
查看全部
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一)
)
介绍
文档参考。
对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。现状
看目前容器日志采集的各种解决方案,无非两种方式:一、直接采集Docker标准输出,可以通过Docker日志驱动发送到对应的采集程序;二、非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。Log采集 程序直接采集映射的Log文件。三、通过Journald采集二进制日志数据。
PS:
标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。
非标准输出:根据Docker容器的特点,容器启动后必须有一个服务来保持前台运行。如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,这些后台运行的服务生成的日志默认无法作为标准输出获取,生成的日志默认会保存在/var/log目录下。
第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:
当宿主机的容器密度比较高时,对Docker Engine的压力比较大。毕竟,容器的标准输出必须由 Docker Engine 处理。虽然原则上我们要遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。
基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald进行二进制日志数据采集。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是日志采集解决方案。当然,存储和 UI 显示与开源实现对接。没有特殊要求,也可以有完整的体验。
Rancher解决方案(json-文件驱动)解决方案介绍
如上图所示,ElasticSearch & Kibana 可以直接用于日志存储和UI展示。日志采集如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中日志采集部分采用了Fluentd & Logging Helper组合。Fluentd 是一个非常通用的日志程序,具有出色的性能。与Logstash相比,在同样的压力下,它的内存消耗要少得多。
为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常用;二、这两个驱动,docker日志依然可以输出内容,保证了体验的完整性。实施过程
方案实现过程:Fluentd连接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别映射到容器日志卷的路径(非标准输出),并通知Fluentd进行采集。Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。
下面开始讲解整个程序的部署过程。先用一张图来描述整体的部署结构,如下:
解决方案部署 ElasticSearch & Kibana 部署
网页登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。
然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后根据实际情况修改Public端口,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,
名称:rancher -logging
地址:
分支:大师
最后点击保存并返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面: 本例中,除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要匹配之前设置的Volume Pattern:
wecenter采集接口 2019独角兽企业重金招聘Python工程师标准(gt)(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-08-18 00:17
2019年独角兽企业重磅Python工程师招聘标准>>>
背景
随着酒店业务的快速发展,我们为用户和企业提供的服务越来越精细,系统的服务化程度和复杂程度也逐渐提高。微服务虽然可以很好的解决问题,但也有副作用,比如问题定位。
每次定位到问题,都需要找同事帮我从源头查日志。一个简单的例子:
“这个详情页的价格是如何计算的?”
一次访问用户的酒店空房页面(POI详情页面),流量最多需要经过73个服务节点。在排查问题的时候,我们需要找到4到5个关键节点的同学,帮助我们登录十多个不同节点的机器,查询具体的日志。沟通成本很高,效率很低。
为了解决这个问题,基础架构同学提供了MTrace(详见技术博客:《分布式会话跟踪系统架构的设计与实践》)协助业务方排查长链接问题.
但同时,也有许多不确定因素使故障排除过程变得更加困难,甚至徒劳无功:
各个服务节点存储日志的时间长度不一致;一些服务节点,因为QPS太高,只能不打印或随机打印日志,最终查到问题时,会因为没有日志而导致线索断掉;一些服务节点使用异步逻辑(线程池、Hystrix、异步RPC等),导致日志中缺少trace ID,无法链接在一起;每个服务节点的采样率不同,链路数据的上报率也是随机的,线索很容易被破解; MTrace只有链接信息,没有与每个服务节点相关联的日志信息;动态扩展节点上的日志收缩后找不到了。
总结如图:
目标
有两个核心需求:
根据用户行为快速定位到具体的Trace ID,然后查询服务调用链路上所有节点的日志;实时查询必须准实时(以秒为单位输出),相关链接日志必须在独立的外部存储系统中存储半年以上。
然后我们进一步拆分上诉:
记录所有日志是不现实的。需要有选择地记录,记录日志中最有价值的部分;链路数据需要所有服务节点上传,避免链路数据因不同步等原因中断上传;访问方式尽量简单,避免所有服务节点都需要修改具体的服务代码才能访问。最好拦截日志,其他保持透明;日志格式化,部分字段(AppKey、主机名、IP、时间戳等)不需要在业务RD中重复输入,自动填充;在不阻塞原有业务操作的情况下,准实时展示链接和日志;链路数据和日志数据的存储不依赖于每个业务节点,需要在独立的存储系统上存储半年以上。系统
明确核心需求后,我们进行了大量针对性研究,最终确定了一个整体的系统设计方案。这就是已经上线、实践已久的“卫星系统”。
接下来,我们将详细介绍系统,包括一些核心细节。
架构
如下图所示,卫星系统横向分为链路和日志两部分。
图2 全链路日志系统整体架构
链接部分基于MTrace,使用支持超时回退Trace信息传输的Hystrix-Trace插件覆盖所有场景,保证链接完整采集。
日志部分在接入端有三个核心步骤。首先是基于日志拦截组件以零侵入业务代码的方式采集系统中所有的日志内容,然后按照统一的日志规范对日志进行格式化,最后通过logcenter实现日志到Kafka的传输——基于日志传输机制。
从纵向来看,分为:
业务接入层,根据策略采集Trace和业务日志;
数据处理层,通过storm流处理日志信息;
数据存储层,用于支持实时查询松鼠(美团点评Redis集群)和持久化存储ES(ElasticSearch),以及面向用户的展示层。
日志抽样计划
接入点是所有数据的来源,因此程序设计极为关键。需要解决的问题有:采集策略、链接完整性保护、日志拦截、日志格式化、日志传输。
在一些业务中,单机日总日志量超过100G,很多业务因为QPS高,选择不正常打印日志,只在排查时通过动态日志级别调整临时输出。因此,我们在最初采集日志时必须进行权衡。经过分析发现,在大多数情况下,排查问题时,发起方都是自己的(RD、PM、Operations)。如果我们只记录这些人发起的链接日志,目标日志量会非常高。自然解决了日志量过大导致的缩减量大、存储时间短、查询时效性差的问题。
所以我们开发了这个采集 策略:
通过判断发起者在链接入口服务是否遇到特定人群(住宿业务部员工),决定是否登录采集,通过MTrace将采集标识传递给整个链接。这样可以保证链路上的所有节点都可以一致的选择是否上报日志,保证链路上日志的完整性。
日志阻塞
作为日志的核心元素,如何采集是个棘手的问题。强制业务端使用我们的接口进行日志输出会带来很多麻烦。一方面会影响业务端原有的日志输出策略;另一方面,系统原有的日志输出点众多,涉及的业务也是多种多样、变化多端的。一点很简单,但是如果一刀切的改变,很难保证不会有未知的影响。因此,有必要尽可能减少访问方代码的入侵。
由于酒店的核心业务已经完全集成到log4j2中,经过研究,我们发现可以注册一个全局Filter来遍历系统的所有日志。这一发现使我们能够以零代码更改采集系统的所有日志。
图3 基于log4j2过滤机制的日志采集策略
日志格式
业务系统输出的日志格式不同。比如有的不打印TraceID信息,有的不打印日志位置信息,定位困难。这主要带来两个问题。一方面不利于人为主导的调查分析工作,另一方面也不利于后续系统优化升级,如日志、告警的自动分析。
针对这些问题,我们设计了统一的日志规范,框架完成了缺失内容的填充。同时,我们为业务端提供了标准化的日志接口。业务端可以通过该接口定义日志的元数据,为后续的自动化支持分析奠定基础。
框架填充统一日志信息的过程利用了log4j2的Plugins机制,通过Properties、Lookups、ContextMap实现业务无感知操作。
图4 通过Plugins机制支持格式化日志属性传输
日志处理
在最后的日志传输环节,我们利用日志中心的传输机制,利用日志中心的ScribeAppender实现日志传输到本地agent,再上报到远程Kafka。这种设计有几个优点:
依托公司成熟的基础服务,相对更加可靠稳定,也无需搭建服务,保障服务安全;日志可以直接传输到日志中心ES进行持久化存储,同时支持快速灵活的数据检索;日志可通过Storm进行流式传输,支持灵活的系统扩展,如实时检索、基于日志的实时业务检查、告警等,为后续系统扩展升级奠定基础。
我们的数据处理逻辑全部在Storm中处理,主要包括日志存储Squirrel(美团点评基于Redis Cluster开发的纯内存存储)、实时检索和Trace同步。
目前日志中心ES可以保证分钟级的实时性,但对于RD排查来说还不够。它必须支持第二级的实时性能。因此,我们选择将特定目标用户的日志直接存储到 Squirrel 中。过期时间只有半小时。在查询日志的时候,结合ES和Squirrel,这样既满足了秒级的实时性,又保证了日志量不会太大。压力可以忽略不计。
我们系统的核心数据有链接和日志。链接信息是通过MTrace服务获取的,但是MTrace服务对于链接数据的存储时间有限,不能满足我们的需求。因此,我们通过延迟队列从MTrace获取最近的链路信息并存储在地面上,从而实现数据的闭环,保证数据的完整性。
链接完整性保证
MTrace组件的trace传递功能基于ThreadLocal,酒店业务使用大量异步逻辑(线程池,Hystrix),会造成传输的信息丢失,破坏链路完整性。
一方面,Sonar对关键环节进行检查和梳理,确保业务端使用transmittable-thread-local中类似于ExecutorServiceTtlWrapper.java和ExecutorTtlWrapper.java的包,将ThreadLocal中的Trace信息传输到异步线程(上面提到的MTrace也提供了这样的包)。
另一方面,Hystrix 的线程池模式会导致线程变量丢失。为了解决这个问题,MTrace 提供了 Mtrace Hystrix Support Plugin 来实现跨线程调用时线程变量的传递。但是由于Hystrix有专门的定时器线程池用于超时回退调用,在超时的情况下会进入回退逻辑之后的链接。信息丢失。
针对这个问题,我们对Hystrix机制进行了深入研究,最终结合Hystrix Command Execution Hook、Hystrix Concurrency Strategy、Hystrix Request Context实现了一个覆盖整个Hystrix-Trace插件场景,保证链接的完整性。
HystrixPlugins.getInstance().registerCommandExecutionHook(new HystrixCommandExecutionHook() {
@Override
public void onStart(HystrixInvokable commandInstance) {
// 执行command之前将trace信息保存至hystrix上下文,实现超时子线程的trace传递
if (!HystrixRequestContext.isCurrentThreadInitialized()) {
HystrixRequestContext.initializeContext();
}
spanVariable.set(Tracer.getServerSpan());
}
@Override
public Exception onError(HystrixInvokable commandInstance, HystrixRuntimeException.FailureType failureType, Exception e) {
// 执行结束后清空hystrix上下文信息
HystrixRequestContext context = HystrixRequestContext.getContextForCurrentThread();
if (context != null) {
context.shutdown();
}
return e;
}
@Override
public void onSuccess(HystrixInvokable commandInstance) {
// 执行结束后清空hystrix上下文信息
HystrixRequestContext context = HystrixRequestContext.getContextForCurrentThread();
if (context != null) {
context.shutdown();
}
}
});
HystrixPlugins.getInstance().registerConcurrencyStrategy(new HystrixConcurrencyStrategy() {
@Override
public Callable wrapCallable(Callable callable) {
// 通过自定义callable保存trace信息
return WithTraceCallable.get(callable);
}
});
业绩展示
例如,以用户单击 POI 详细信息页面的 TraceID 为例进行故障排除:
我们可以看到他在MTrace中的调用链接是这样的:
在卫星系统中,显示如下效果:
可以看出,系统在保存链路数据的基础上,还将所有链路节点日志聚合在一起,提高了调查效率。
后续规划
目前该系统还处于起步阶段,主要用于解决RD在排查中的两大痛点:不完整和过于分散的日志信息。这个需求现在已经得到满足。但是,全链接日志系统可以做的远不止这些。主要后续计划如下:
支持多链接日志相关搜索,如列表页刷新和后续详情页展示,虽然有多个链接,但实际上是在一个相关的场景中。支持关联搜索,可以将日志调查对象从单个动作维度扩展到多个动作组成的场景维度。支持业务侧自定义策略规则,自动进行基于日志的业务正确性检查。如发现问题,可直接将详细信息通知相关人员,实现日志实时监控、问题实时发现、实时通知到位,省去人工和人工。有效的劳动。作者介绍
雅辉,2015年加入美团点评,在后端研发团队工作。
曾军,2013年加入美团点评,在后端研发团队工作。
最后,我会发布一个广告。后端研发团队长期招聘Java后端及架构人才。有兴趣的同学可以把简历发到xuguanfei#。
转载于: 查看全部
wecenter采集接口 2019独角兽企业重金招聘Python工程师标准(gt)(图)
2019年独角兽企业重磅Python工程师招聘标准>>>

背景
随着酒店业务的快速发展,我们为用户和企业提供的服务越来越精细,系统的服务化程度和复杂程度也逐渐提高。微服务虽然可以很好的解决问题,但也有副作用,比如问题定位。

每次定位到问题,都需要找同事帮我从源头查日志。一个简单的例子:
“这个详情页的价格是如何计算的?”
一次访问用户的酒店空房页面(POI详情页面),流量最多需要经过73个服务节点。在排查问题的时候,我们需要找到4到5个关键节点的同学,帮助我们登录十多个不同节点的机器,查询具体的日志。沟通成本很高,效率很低。
为了解决这个问题,基础架构同学提供了MTrace(详见技术博客:《分布式会话跟踪系统架构的设计与实践》)协助业务方排查长链接问题.
但同时,也有许多不确定因素使故障排除过程变得更加困难,甚至徒劳无功:
各个服务节点存储日志的时间长度不一致;一些服务节点,因为QPS太高,只能不打印或随机打印日志,最终查到问题时,会因为没有日志而导致线索断掉;一些服务节点使用异步逻辑(线程池、Hystrix、异步RPC等),导致日志中缺少trace ID,无法链接在一起;每个服务节点的采样率不同,链路数据的上报率也是随机的,线索很容易被破解; MTrace只有链接信息,没有与每个服务节点相关联的日志信息;动态扩展节点上的日志收缩后找不到了。
总结如图:

目标
有两个核心需求:
根据用户行为快速定位到具体的Trace ID,然后查询服务调用链路上所有节点的日志;实时查询必须准实时(以秒为单位输出),相关链接日志必须在独立的外部存储系统中存储半年以上。
然后我们进一步拆分上诉:
记录所有日志是不现实的。需要有选择地记录,记录日志中最有价值的部分;链路数据需要所有服务节点上传,避免链路数据因不同步等原因中断上传;访问方式尽量简单,避免所有服务节点都需要修改具体的服务代码才能访问。最好拦截日志,其他保持透明;日志格式化,部分字段(AppKey、主机名、IP、时间戳等)不需要在业务RD中重复输入,自动填充;在不阻塞原有业务操作的情况下,准实时展示链接和日志;链路数据和日志数据的存储不依赖于每个业务节点,需要在独立的存储系统上存储半年以上。系统
明确核心需求后,我们进行了大量针对性研究,最终确定了一个整体的系统设计方案。这就是已经上线、实践已久的“卫星系统”。
接下来,我们将详细介绍系统,包括一些核心细节。
架构
如下图所示,卫星系统横向分为链路和日志两部分。

图2 全链路日志系统整体架构
链接部分基于MTrace,使用支持超时回退Trace信息传输的Hystrix-Trace插件覆盖所有场景,保证链接完整采集。
日志部分在接入端有三个核心步骤。首先是基于日志拦截组件以零侵入业务代码的方式采集系统中所有的日志内容,然后按照统一的日志规范对日志进行格式化,最后通过logcenter实现日志到Kafka的传输——基于日志传输机制。
从纵向来看,分为:
业务接入层,根据策略采集Trace和业务日志;
数据处理层,通过storm流处理日志信息;
数据存储层,用于支持实时查询松鼠(美团点评Redis集群)和持久化存储ES(ElasticSearch),以及面向用户的展示层。
日志抽样计划
接入点是所有数据的来源,因此程序设计极为关键。需要解决的问题有:采集策略、链接完整性保护、日志拦截、日志格式化、日志传输。
在一些业务中,单机日总日志量超过100G,很多业务因为QPS高,选择不正常打印日志,只在排查时通过动态日志级别调整临时输出。因此,我们在最初采集日志时必须进行权衡。经过分析发现,在大多数情况下,排查问题时,发起方都是自己的(RD、PM、Operations)。如果我们只记录这些人发起的链接日志,目标日志量会非常高。自然解决了日志量过大导致的缩减量大、存储时间短、查询时效性差的问题。
所以我们开发了这个采集 策略:
通过判断发起者在链接入口服务是否遇到特定人群(住宿业务部员工),决定是否登录采集,通过MTrace将采集标识传递给整个链接。这样可以保证链路上的所有节点都可以一致的选择是否上报日志,保证链路上日志的完整性。
日志阻塞
作为日志的核心元素,如何采集是个棘手的问题。强制业务端使用我们的接口进行日志输出会带来很多麻烦。一方面会影响业务端原有的日志输出策略;另一方面,系统原有的日志输出点众多,涉及的业务也是多种多样、变化多端的。一点很简单,但是如果一刀切的改变,很难保证不会有未知的影响。因此,有必要尽可能减少访问方代码的入侵。
由于酒店的核心业务已经完全集成到log4j2中,经过研究,我们发现可以注册一个全局Filter来遍历系统的所有日志。这一发现使我们能够以零代码更改采集系统的所有日志。

图3 基于log4j2过滤机制的日志采集策略
日志格式
业务系统输出的日志格式不同。比如有的不打印TraceID信息,有的不打印日志位置信息,定位困难。这主要带来两个问题。一方面不利于人为主导的调查分析工作,另一方面也不利于后续系统优化升级,如日志、告警的自动分析。
针对这些问题,我们设计了统一的日志规范,框架完成了缺失内容的填充。同时,我们为业务端提供了标准化的日志接口。业务端可以通过该接口定义日志的元数据,为后续的自动化支持分析奠定基础。
框架填充统一日志信息的过程利用了log4j2的Plugins机制,通过Properties、Lookups、ContextMap实现业务无感知操作。

图4 通过Plugins机制支持格式化日志属性传输
日志处理
在最后的日志传输环节,我们利用日志中心的传输机制,利用日志中心的ScribeAppender实现日志传输到本地agent,再上报到远程Kafka。这种设计有几个优点:
依托公司成熟的基础服务,相对更加可靠稳定,也无需搭建服务,保障服务安全;日志可以直接传输到日志中心ES进行持久化存储,同时支持快速灵活的数据检索;日志可通过Storm进行流式传输,支持灵活的系统扩展,如实时检索、基于日志的实时业务检查、告警等,为后续系统扩展升级奠定基础。
我们的数据处理逻辑全部在Storm中处理,主要包括日志存储Squirrel(美团点评基于Redis Cluster开发的纯内存存储)、实时检索和Trace同步。
目前日志中心ES可以保证分钟级的实时性,但对于RD排查来说还不够。它必须支持第二级的实时性能。因此,我们选择将特定目标用户的日志直接存储到 Squirrel 中。过期时间只有半小时。在查询日志的时候,结合ES和Squirrel,这样既满足了秒级的实时性,又保证了日志量不会太大。压力可以忽略不计。
我们系统的核心数据有链接和日志。链接信息是通过MTrace服务获取的,但是MTrace服务对于链接数据的存储时间有限,不能满足我们的需求。因此,我们通过延迟队列从MTrace获取最近的链路信息并存储在地面上,从而实现数据的闭环,保证数据的完整性。
链接完整性保证
MTrace组件的trace传递功能基于ThreadLocal,酒店业务使用大量异步逻辑(线程池,Hystrix),会造成传输的信息丢失,破坏链路完整性。
一方面,Sonar对关键环节进行检查和梳理,确保业务端使用transmittable-thread-local中类似于ExecutorServiceTtlWrapper.java和ExecutorTtlWrapper.java的包,将ThreadLocal中的Trace信息传输到异步线程(上面提到的MTrace也提供了这样的包)。
另一方面,Hystrix 的线程池模式会导致线程变量丢失。为了解决这个问题,MTrace 提供了 Mtrace Hystrix Support Plugin 来实现跨线程调用时线程变量的传递。但是由于Hystrix有专门的定时器线程池用于超时回退调用,在超时的情况下会进入回退逻辑之后的链接。信息丢失。
针对这个问题,我们对Hystrix机制进行了深入研究,最终结合Hystrix Command Execution Hook、Hystrix Concurrency Strategy、Hystrix Request Context实现了一个覆盖整个Hystrix-Trace插件场景,保证链接的完整性。
HystrixPlugins.getInstance().registerCommandExecutionHook(new HystrixCommandExecutionHook() {
@Override
public void onStart(HystrixInvokable commandInstance) {
// 执行command之前将trace信息保存至hystrix上下文,实现超时子线程的trace传递
if (!HystrixRequestContext.isCurrentThreadInitialized()) {
HystrixRequestContext.initializeContext();
}
spanVariable.set(Tracer.getServerSpan());
}
@Override
public Exception onError(HystrixInvokable commandInstance, HystrixRuntimeException.FailureType failureType, Exception e) {
// 执行结束后清空hystrix上下文信息
HystrixRequestContext context = HystrixRequestContext.getContextForCurrentThread();
if (context != null) {
context.shutdown();
}
return e;
}
@Override
public void onSuccess(HystrixInvokable commandInstance) {
// 执行结束后清空hystrix上下文信息
HystrixRequestContext context = HystrixRequestContext.getContextForCurrentThread();
if (context != null) {
context.shutdown();
}
}
});
HystrixPlugins.getInstance().registerConcurrencyStrategy(new HystrixConcurrencyStrategy() {
@Override
public Callable wrapCallable(Callable callable) {
// 通过自定义callable保存trace信息
return WithTraceCallable.get(callable);
}
});
业绩展示
例如,以用户单击 POI 详细信息页面的 TraceID 为例进行故障排除:
我们可以看到他在MTrace中的调用链接是这样的:

在卫星系统中,显示如下效果:

可以看出,系统在保存链路数据的基础上,还将所有链路节点日志聚合在一起,提高了调查效率。
后续规划
目前该系统还处于起步阶段,主要用于解决RD在排查中的两大痛点:不完整和过于分散的日志信息。这个需求现在已经得到满足。但是,全链接日志系统可以做的远不止这些。主要后续计划如下:
支持多链接日志相关搜索,如列表页刷新和后续详情页展示,虽然有多个链接,但实际上是在一个相关的场景中。支持关联搜索,可以将日志调查对象从单个动作维度扩展到多个动作组成的场景维度。支持业务侧自定义策略规则,自动进行基于日志的业务正确性检查。如发现问题,可直接将详细信息通知相关人员,实现日志实时监控、问题实时发现、实时通知到位,省去人工和人工。有效的劳动。作者介绍
雅辉,2015年加入美团点评,在后端研发团队工作。
曾军,2013年加入美团点评,在后端研发团队工作。
最后,我会发布一个广告。后端研发团队长期招聘Java后端及架构人才。有兴趣的同学可以把简历发到xuguanfei#。
转载于:
QQAPI智能调用系统php版v1.1资源介绍:Windows/Linux/Mac资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-11 18:31
[资源属性]:
资源名称:QQAPI智能呼叫系统php版v1.1
资源大小:8.75MB
资源类别:源码下载》php源码
更新时间:2021-06-24
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
QQAPI智能调用系统是用php开发的调用api接口的源码。
收录API:网址加群/网址加好友/网址获取QQ头像/网址获取空间头像
安装说明:
环境要求:PHP5.2及以上丨Windows/Linux丨IIS/Apache/nginx
安装步骤:上传所有文件到主机根目录
目录说明:
/api/----------网站interface 文件目录(不要修改接口文件以防出错)
/config/-------网站data 文件目录(配置网站homepage相关内容)
/css/----------网站样式文件目录(首页样式可根据自己的需要修改)
/img/---------网站图片文件目录(首页图片可根据需要修改)
/js/-----------网站特效文件目录
/videos/-------网站动态后台和静态后台存放目录
index.php------网站首页
QQAPI智能呼叫系统更新日志:
V1.1 bulid2017.01.25
-->添加接口:获取QQ秀API
界面介绍:URL+QQ号直接获取QQ秀图片
-->添加接口:手机号码信息查询API
界面介绍:URL+手机号直接获取手机号相关信息
-->添加接口:IP地址定位API
界面介绍:URL+IP地址直接标示IP在百度地图中的位置
-->添加接口:视频C值分析API
界面介绍:URL+C值可以直接在线播放C值的视频
特别感谢:本界面由可可电视网友情提供()
--> 目录更新:搭建云API接口,供使用本系统的站长直接调用 查看全部
QQAPI智能调用系统php版v1.1资源介绍:Windows/Linux/Mac资源
[资源属性]:
资源名称:QQAPI智能呼叫系统php版v1.1
资源大小:8.75MB
资源类别:源码下载》php源码
更新时间:2021-06-24
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
QQAPI智能调用系统是用php开发的调用api接口的源码。
收录API:网址加群/网址加好友/网址获取QQ头像/网址获取空间头像
安装说明:
环境要求:PHP5.2及以上丨Windows/Linux丨IIS/Apache/nginx
安装步骤:上传所有文件到主机根目录
目录说明:
/api/----------网站interface 文件目录(不要修改接口文件以防出错)
/config/-------网站data 文件目录(配置网站homepage相关内容)
/css/----------网站样式文件目录(首页样式可根据自己的需要修改)
/img/---------网站图片文件目录(首页图片可根据需要修改)
/js/-----------网站特效文件目录
/videos/-------网站动态后台和静态后台存放目录
index.php------网站首页
QQAPI智能呼叫系统更新日志:
V1.1 bulid2017.01.25
-->添加接口:获取QQ秀API
界面介绍:URL+QQ号直接获取QQ秀图片
-->添加接口:手机号码信息查询API
界面介绍:URL+手机号直接获取手机号相关信息
-->添加接口:IP地址定位API
界面介绍:URL+IP地址直接标示IP在百度地图中的位置
-->添加接口:视频C值分析API
界面介绍:URL+C值可以直接在线播放C值的视频
特别感谢:本界面由可可电视网友情提供()
--> 目录更新:搭建云API接口,供使用本系统的站长直接调用
wecenter采集接口 阿里蜘蛛池php版v3.0资源大小:10.7MB资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-08 03:43
[资源属性]:
资源名称:阿里蜘蛛池php版本v3.0
资源大小:10.7MB
资源类别:源码下载》php源码
更新时间:2021-06-25
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
阿里蜘蛛池是一个蜘蛛算法引导程序,可以快速提升网站在搜索引擎中的排名。阿里巴巴蜘蛛池采用最新技术防K,秒采集,秒排,持久稳定,无任何租借时间,打造自己的超级收录。
软件功能:
1、免费,免费,免费
国内首个官方免费版蜘蛛池程序
2、技术实力雄厚
阿里蜘蛛池由中国促进会和先知教育共同开发。它采用PHP+MYSQL架构,采用先进的PHP技术,资源占用低,速度快,支持大数据、大并发。页面生成速度比其他TXT蜘蛛池快一百倍以上
3、第一个跨平台蜘蛛池
完美支持Linux系统的所有发行版。降低服务器开销,低配置服务器依然可以高速吸引蜘蛛
4、Spider 算法进展
中促院卡卡老师亲自提供蜘蛛算法技术指导。最新技术防K,秒采集,秒排,持久稳定
5、Massive 模板免费下载
避免创建用户模板的痛苦。也可根据用户实际情况免费单独定制
6、根据关键词自动跳转页面
用户可以根据页面关键词重定向到不同的目标网站,不影响蜘蛛正常访问
7、url 自动推送
集成自动外推,24小时不间断外推运行,增加蜘蛛访问量
8、热新闻Auto采集
热点新闻标题和内容自动采集,采集间隔可自定义。 采集无需写规则,随官网更新。
9、强站群功能、模板定制
站群使用智能链轮减少被K的几率。模板可以自定义标题、关键词、描述、页面URL样式、文字标题和后台文章内容构成结构
10、 Spider Pool 退房出租
后台开启蜘蛛池平台,格子可以出租。个人用户管理界面
11、PC模板和手机模板分别指定
可以为蜘蛛池中的每个域名指定PC模板和手机模板,不同的蜘蛛和用户可以访问不同的模板
12、蜘蛛统计系统
实时日志分析系统,准确实时统计如百度、360、Google、手机蜘蛛等,各种图表分析让您一目了然看到蜘蛛访问情况,无需浪费时间并努力分析各种日志
13、Spider源码随意控制
带有搜索引擎蜘蛛开关,可随意控制7个搜索蜘蛛
14、程序自带一键升级
后台一键升级,时刻保持蜘蛛池程序最新技术,无需频繁登录操作服务器
15、稳定的交流平台
阿里巴巴蜘蛛池论坛一直致力于打造中国最大的SEO交流平台,为互联网从业者提供良好的交流平台和技术支持,助力站长成长
16、专业售后维护
所有用户都会有专属的交流群,方便技术交流、软件bug提交、建议反馈等。
v3.0 更新日志:
添加功能:
1、加入权重池,锚链接+锚文本
2、Backstage 添加外推函数链接
3、判断移动蜘蛛和移动蜘蛛统计
4、区分句子和段落
5、添加对多个冷门后缀域名的支持
6、add 关键词跳转
7、为域名分别指定PC模板和手机模板,并增加一键指定和一键随机按钮
8、添加了api接口,方便其他程序(如寄生虫)自动向阿里蜘蛛池添加数据
9、自定义缓存更新时间
优化:
1、去掉页面底部阿里蜘蛛池的版权代码
2、外链管理强化成索引池
3、优化所有模板和网址样式
4、Background蜘蛛切换100%盾蜘蛛
5、采集文章伪原创处理标题和内容
6、Background 所有链接自动添加确定“//”开头,没有添加的自动添加。
7、optimization采集,推断执行效率
8、去除打开缓存URL样式设置无效
9、采集文章少于100个汉字的内容不会存入数据库
10、采集文章标题内容对应
11、重新优化标题、关键词、描述、url样式、文章title、文章content
12、优化链轮结构
13、采集文章打开图片采集
14、开php5.4,支持win2003,放弃iis全系列支持,只支持apache
15、程序自带10000个段落,3000个句子,关键词4000,外推页面1300条
16、根据蜘蛛和用户情况,分别调用PC模板和手机模板
修复:
1、搜狗蜘蛛统计失败
2、帮助地址无效
3、bing 蜘蛛统计失败
4、Index pool和weight pool为空,导致空链接 查看全部
wecenter采集接口 阿里蜘蛛池php版v3.0资源大小:10.7MB资源
[资源属性]:
资源名称:阿里蜘蛛池php版本v3.0
资源大小:10.7MB
资源类别:源码下载》php源码
更新时间:2021-06-25
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
阿里蜘蛛池是一个蜘蛛算法引导程序,可以快速提升网站在搜索引擎中的排名。阿里巴巴蜘蛛池采用最新技术防K,秒采集,秒排,持久稳定,无任何租借时间,打造自己的超级收录。
软件功能:
1、免费,免费,免费
国内首个官方免费版蜘蛛池程序
2、技术实力雄厚
阿里蜘蛛池由中国促进会和先知教育共同开发。它采用PHP+MYSQL架构,采用先进的PHP技术,资源占用低,速度快,支持大数据、大并发。页面生成速度比其他TXT蜘蛛池快一百倍以上
3、第一个跨平台蜘蛛池
完美支持Linux系统的所有发行版。降低服务器开销,低配置服务器依然可以高速吸引蜘蛛
4、Spider 算法进展
中促院卡卡老师亲自提供蜘蛛算法技术指导。最新技术防K,秒采集,秒排,持久稳定
5、Massive 模板免费下载
避免创建用户模板的痛苦。也可根据用户实际情况免费单独定制
6、根据关键词自动跳转页面
用户可以根据页面关键词重定向到不同的目标网站,不影响蜘蛛正常访问
7、url 自动推送
集成自动外推,24小时不间断外推运行,增加蜘蛛访问量
8、热新闻Auto采集
热点新闻标题和内容自动采集,采集间隔可自定义。 采集无需写规则,随官网更新。
9、强站群功能、模板定制
站群使用智能链轮减少被K的几率。模板可以自定义标题、关键词、描述、页面URL样式、文字标题和后台文章内容构成结构
10、 Spider Pool 退房出租
后台开启蜘蛛池平台,格子可以出租。个人用户管理界面
11、PC模板和手机模板分别指定
可以为蜘蛛池中的每个域名指定PC模板和手机模板,不同的蜘蛛和用户可以访问不同的模板
12、蜘蛛统计系统
实时日志分析系统,准确实时统计如百度、360、Google、手机蜘蛛等,各种图表分析让您一目了然看到蜘蛛访问情况,无需浪费时间并努力分析各种日志
13、Spider源码随意控制
带有搜索引擎蜘蛛开关,可随意控制7个搜索蜘蛛
14、程序自带一键升级
后台一键升级,时刻保持蜘蛛池程序最新技术,无需频繁登录操作服务器
15、稳定的交流平台
阿里巴巴蜘蛛池论坛一直致力于打造中国最大的SEO交流平台,为互联网从业者提供良好的交流平台和技术支持,助力站长成长
16、专业售后维护
所有用户都会有专属的交流群,方便技术交流、软件bug提交、建议反馈等。
v3.0 更新日志:
添加功能:
1、加入权重池,锚链接+锚文本
2、Backstage 添加外推函数链接
3、判断移动蜘蛛和移动蜘蛛统计
4、区分句子和段落
5、添加对多个冷门后缀域名的支持
6、add 关键词跳转
7、为域名分别指定PC模板和手机模板,并增加一键指定和一键随机按钮
8、添加了api接口,方便其他程序(如寄生虫)自动向阿里蜘蛛池添加数据
9、自定义缓存更新时间
优化:
1、去掉页面底部阿里蜘蛛池的版权代码
2、外链管理强化成索引池
3、优化所有模板和网址样式
4、Background蜘蛛切换100%盾蜘蛛
5、采集文章伪原创处理标题和内容
6、Background 所有链接自动添加确定“//”开头,没有添加的自动添加。
7、optimization采集,推断执行效率
8、去除打开缓存URL样式设置无效
9、采集文章少于100个汉字的内容不会存入数据库
10、采集文章标题内容对应
11、重新优化标题、关键词、描述、url样式、文章title、文章content
12、优化链轮结构
13、采集文章打开图片采集
14、开php5.4,支持win2003,放弃iis全系列支持,只支持apache
15、程序自带10000个段落,3000个句子,关键词4000,外推页面1300条
16、根据蜘蛛和用户情况,分别调用PC模板和手机模板
修复:
1、搜狗蜘蛛统计失败
2、帮助地址无效
3、bing 蜘蛛统计失败
4、Index pool和weight pool为空,导致空链接
苹果CMS程序添加自定义资源库(图)未绑定分类
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-04 00:42
Applecms程序是一个运行在PHP+MYSQL环境下的完整而强大的快速建站系统。经过近年的开发经验和技术积累,苹果cms程序已经逐渐成熟,已经...
Applecms程序是一个运行在PHP+MYSQL环境下的完整而强大的快速建站系统。经过近多年的开发经验和技术积累,苹果cms程序已经逐渐成熟,在易用性和功能性方面已经成为行业的佼佼者。
添加自定义资源库
首先进入系统后台-->采集-->自定义资源库-->添加。
添加采集网站的接口地址并命名,接口类型选择xml,资源类型选择video。然后选择测试,如图所示成功,保存。
保存后点击采集day。
后面会看到类似的界面,我这里已经绑定了。如果你之前没有使用过这个采集站,你会想要在下图中的“动画[绑定]”,点击“绑定”。这次是绑定分类,根据自己的想法自定义分类。
具体设置在基础-->分类管理-->添加。绑定好分类后,当天再次点击采集就会看到视频可以入库了。一些未绑定的类别不会存入库中,然后根据自己的需要采集当周,或者采集All。
汽车采集
我们不可能每天都自己点击采集按钮,需要添加自动化任务。这里需要打开三个标签。
1个自定义资源库(采集-->自定义资源库)
2 计时任务(系统 --> 计时任务)
3宝塔后台定时任务(登录宝塔后左侧任务栏-->定时任务)
自定义采集库中采集button右键复制当天链接地址
修改复制的地址,删除ac=cj&前面的东西。
转到定时任务选项卡(上面提到的2)
将上面修改的东西复制到“Additional Parameters”中,选择“Select All”,其他随便填,保存。点击“测试”,如下所示。
之后,右击“测试”按钮复制链接地址。
然后去宝塔中的定时任务,选择任务类型访问URL,名称任意,执行周期自行设置,URL地址填写你刚才复制的链接地址并保存。
您可能遇到的问题
1.未经授权的访问
新添加的分类需要修改权限,否则无法访问,提示没有权限。
修改权限在User-->Member Group,修改相应设置。
勾选新添加的分类权限并保存。
2.没有播放选项
问题是没有添加自定义资源库的播放器。
添加视频-->播放器-->.
这里,添加各个资源站的玩家。不同的资源站玩家是不同的。应该有关于如何添加资源站的介绍。这里就不写了。
查看全部
苹果CMS程序添加自定义资源库(图)未绑定分类
Applecms程序是一个运行在PHP+MYSQL环境下的完整而强大的快速建站系统。经过近年的开发经验和技术积累,苹果cms程序已经逐渐成熟,已经...
Applecms程序是一个运行在PHP+MYSQL环境下的完整而强大的快速建站系统。经过近多年的开发经验和技术积累,苹果cms程序已经逐渐成熟,在易用性和功能性方面已经成为行业的佼佼者。
添加自定义资源库
首先进入系统后台-->采集-->自定义资源库-->添加。
 https://www.qingmo.net/wp-cont ... 9.jpg 768w" />
https://www.qingmo.net/wp-cont ... 9.jpg 768w" />添加采集网站的接口地址并命名,接口类型选择xml,资源类型选择video。然后选择测试,如图所示成功,保存。
 https://www.qingmo.net/wp-cont ... 3.jpg 768w" />
https://www.qingmo.net/wp-cont ... 3.jpg 768w" />保存后点击采集day。
 https://www.qingmo.net/wp-cont ... 3.jpg 768w" />
https://www.qingmo.net/wp-cont ... 3.jpg 768w" />后面会看到类似的界面,我这里已经绑定了。如果你之前没有使用过这个采集站,你会想要在下图中的“动画[绑定]”,点击“绑定”。这次是绑定分类,根据自己的想法自定义分类。

具体设置在基础-->分类管理-->添加。绑定好分类后,当天再次点击采集就会看到视频可以入库了。一些未绑定的类别不会存入库中,然后根据自己的需要采集当周,或者采集All。
汽车采集
我们不可能每天都自己点击采集按钮,需要添加自动化任务。这里需要打开三个标签。
1个自定义资源库(采集-->自定义资源库)
2 计时任务(系统 --> 计时任务)
3宝塔后台定时任务(登录宝塔后左侧任务栏-->定时任务)
自定义采集库中采集button右键复制当天链接地址
修改复制的地址,删除ac=cj&前面的东西。
 https://www.qingmo.net/wp-cont ... 3.jpg 768w" />
https://www.qingmo.net/wp-cont ... 3.jpg 768w" />转到定时任务选项卡(上面提到的2)
 https://www.qingmo.net/wp-cont ... 2.jpg 768w" />
https://www.qingmo.net/wp-cont ... 2.jpg 768w" />将上面修改的东西复制到“Additional Parameters”中,选择“Select All”,其他随便填,保存。点击“测试”,如下所示。
之后,右击“测试”按钮复制链接地址。
然后去宝塔中的定时任务,选择任务类型访问URL,名称任意,执行周期自行设置,URL地址填写你刚才复制的链接地址并保存。
您可能遇到的问题
1.未经授权的访问
新添加的分类需要修改权限,否则无法访问,提示没有权限。
修改权限在User-->Member Group,修改相应设置。
 https://www.qingmo.net/wp-cont ... 6.jpg 768w" />
https://www.qingmo.net/wp-cont ... 6.jpg 768w" />勾选新添加的分类权限并保存。
 https://www.qingmo.net/wp-cont ... 7.jpg 768w" />
https://www.qingmo.net/wp-cont ... 7.jpg 768w" />2.没有播放选项
问题是没有添加自定义资源库的播放器。
添加视频-->播放器-->.
这里,添加各个资源站的玩家。不同的资源站玩家是不同的。应该有关于如何添加资源站的介绍。这里就不写了。
 https://www.qingmo.net/wp-cont ... 4.jpg 768w" />
https://www.qingmo.net/wp-cont ... 4.jpg 768w" /> Java用户接口工具箱AWT的使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-08-03 00:23
Java 用户界面工具箱 AWT 的使用
Java 编程语言类库提供了一个名为抽象窗口工具的用户界面工具箱
Box,简称AWT(AbstractWindowingToolkit)。 AWT 不仅功能强大,而且
而且使用起来简单灵活。本文介绍了 AWT 的基本原理以及如何创建一个小程序或一个
创建简单用户界面的应用方法。
一、什么是用户界面
所谓的用户界面就是程序中与程序的用户进行交互的部分。用户访问
端口有多种形式,从简单的命令行界面到图形用户界面。
在系统的最底层,操作系统将鼠标和键盘输入的信息传递给程序,
并提供像素作为程序输出。 AWT 旨在防止程序员使用
关心鼠标的跟踪或键盘的细节,更别说写屏幕工作了
。 AWT 提供了一个精心设计的、面向对象的
对于这些低级服务和资源
界面。
由于 Java 编程语言是平台无关的,因此 AWT 也是平台无关的。
AWT 为在不同平台上工作的图形用户界面设计了一个通用工具集
。 AWT 提供的用户界面元素使用每个平台自己的 GUI 工具箱,所以有保证
留下对应操作平台的外观。这是 AWT 最突出的特点之一。但是这种处理
该方法的缺点是在某个软件平台上设计的图形用户界面在另一个平台上是平的。
当它在舞台上运行时,它会改变。
二、组件和容器
图形用户界面由图形元素组件组成。典型组件包
包括按钮、滚动条和文本框。该组件允许用户继续程序
交互,并以视觉反馈的形式向用户提供程序状态。在 AWT 中,所有
用户界面组件都是组件类或组件类的子类型的实例。
组件不能单独存在,它总是放在容器中。容器收录和控制
组件的布局,容器本身也是一个组件,也可以放在其他容器中。在 AWT 中
在
,所有容器都是容器类的实例或容器类的子类型。
图 1 描绘了在 Windows95 平台上显示的简单图形用户界面
。图2显示了图1中界面组件的树状关系。
三、组件类型
图 3 展示了 AWT 提供的用户界面组件类之间的继承关系。组件类
(组件类)定义了所有组件必须遵守的接口。
图一
图二
图 3
AWT 提供了 9 个基本的无容器组件类。使用它们来构建用户界面
(当然,新的组件类可以从其中任何一个获取,也可以从组件类本身获取)。这9个
类是按钮、画布、复选框、选择、标签、列表
类、滚动条类、TextArea 类、TextField 类。
四、容器类型
AWT 提供了 4 个容器类。它们是 Windows 类及其两个子类型——Fram
e 类和 Dialog 类和 Panel 类。除了AWT提供的容器外,Applet类也是
一个容器,它是 Panel 类的子类型,可以容纳组件。图4显示
AWT 提供的每个容器的简要说明。图4
五、创建容器
在添加构成用户界面的组件之前,程序员必须创建一个容器。什么时候
在构建应用程序时,程序员必须首先创建一个Windows类或Frame类
示例。构造Applet时,Frame类的实例已经存在,无需处理
由音序器创建。由于Applet类是Panel类的子类,程序员可以申请Appl
将组件添加到 et 类的实例中。
代码 1 创建一个空框架。框架的标题(“Example1”)在构造函数中
设置数字。 Frame一开始是不可见的,必须调用它的show()方法才能使之
可见。
代码 1:空帧
importjava.awt.*;
publicclassExample1
{
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1");
f.show();
}
}
代码2扩展了代码1,新类继承了Panel类。在 main() 方法中,创建
通过调用Frame类的add()方法构建并添加了这个新类的一个实例
我对象。
代码 2:带有空面板的框架
importjava.awt.*;
publicclassExamplelaextendsPanel
{
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1a");
Examplelaex=newExample1a();
f.add("Center",ex);
f.pack();
f.show();
}
}
以下示例中的新类继承自 Applet 类,而不是继承自 Panel 类。
所以这个例子可以作为一个独立的应用程序或者嵌入到一个网页中
上的小程序
。此示例显示在代码 3 中。
代码 3:一个带有空小程序的框架
importjava.awt.*;
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1b");
Exammple1bex=newExample1b();
f.add("Center",ex);
f.pack();
f.show();
}
}
注意:Windows 对象和 Dialog 对象在某些情况下可以替代 Frame 对
大象。它们都是有效的容器。组件可以用同样的方式添加到每个容器中
进入。
六、将组件添加到容器中
为了实用性,用户界面可以收录多个容器——每个容器收录
组件。组件可以通过容器的 add() 方法添加到容器中。共有三个 add() 方法
一种基本形式。使用的方法取决于容器上的布局管理器。
代码4在代码3中添加了两个按钮的创建,创建在init()方法中
当然。因为在小程序初始化的时候会自动调用。因此,无论程序如何打开
一开始可以创建按钮,可以通过浏览器或者main()方法调用init()。
代码 4:工具中有两个按钮的小程序
importjava.awt.*;
publicclassExample3extendsjava.applet.Applet
{
publicvoidinit()
{
add(newButton("one"));
add(newButton("two"));
}
publicDimesionpreferredSize()
{
returnnewDimesion(200,100);
}
publicstaticvoidmain(stringargs[])
{
Framef=newFrame("Example3");
Example3ex=newExample3();
ex.init();
f.add("Center",ex);
f.pack();
f.show();
}
七、组件布局
到目前为止,我们还没有提到添加到容器中的组件是如何进行版本控制的
表面布局。布局不是由容器控制,而是由容器相关的布局管理
由进程控制。布局管理器决定了所有组件在容器中的放置方式
。在 AWT 中,所有布局管理器类都实现了 LayoutManager 接口。
AWT 提供了五种类型的布局管理程序,从简单到复杂不等。它
我们是BorderLayout类、CardLayout类、FlowLayout类、GridBagLayou
t 类,GridLayout 类。
1.BorderLayout 类是所有窗口(框架和对话框)的默认布局
管理程序。它有 5 个区域,如图 5 所示。这些区域被称为“北”,“
南”、“东”、“西”和“中心”。图 5
单个组件可以放置在这 5 个区域中的任何一个。什么时候改
当封闭容器的大小发生变化时,每个边界区域的大小也会发生变化以使其足够
该空间容纳放置在其中的组件。任何多余的空间都合并到中心区域。内容
设备的 add() 方法用于向其添加组件。 add() 方法有两个参数,其中第一个
参数是一个字符串对象,其中放置了组件区域的名称。
2.当某个区域在不同时间收录不同的组件时,应该使用Carde
rLayout 类。此类通常与 Choice 相关联。
3.FlowLayout 类是所有 Panel 类(和 Applet 类)的默认布局管理程序
前言。在容器中,它从左到右放置组件。当一行空间用完时,更新
线
开始存储。
4.GridBagLayout 类是 AWT 提供的最复杂、最灵活的布局管理程序
。可以水平和垂直排列组件,并且组件可以有不同的大小。
5.GridLayout 只是在需要的行号中显示一串大小相同的组件
以及由列号决定的位置。
代码 5 使用布局管理器和更多用户界面组件。
代码 5:一个更复杂的例子
importjava.awt.*;
publicclassExample4extendsjava.applet.Applet
{
publicvoidinit()
{
面板;
setLayout(newBorderLayout());
p=newPanel();
p.add(newTextArea());
add("中心",p);
p=newPanel();
p.add(newButton("one"));
p.add(newButton("two"));
Choicec=newChoice()
c.addItem("one");
c.addItem("两个");
c.addItem("三");
p.add(c);
add("南",P);
}
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example4");
Example4ex=newExample4();
ex.init();
f.add("Center",ex);
f.pack();
f.show();
}
}
上面的例子只是展示了一个没有交互功能的用户界面。如果你让用户
界面具有交互能力,所以必须涉及事件处理。
每个事件收录以下参数:
id 标识符;
target-事件发生的对象;
arg-任意参数;
事件发生的x,y坐标;
when 事件的时间印记;
evt-相邻事件;
key-键盘事件中按下的键;
modifers-修饰键的状态(即ALT、CTRL)。
用户将需要处理三种类型的事件,即键盘、鼠标、GUI/窗口
。所有事件都在一般的handleEvent(Eventevt)方法中处理,但使用
用户可以使用以下预定义的方法:
可以在 KeyDown() 和 KeyUp() 方法中处理键盘事件;
鼠标事件可以在mouseXXXX()方法中处理;
GUI 事件在 action() 方法中处理。
下面两段代码是等价的。
publicbooleankeyDown(Eventevt,intkey)
{
System.out.println(key);
返回假;
}
publicbooleanhandleEvent(Eventevt)
{
开关(evt.id)
{
caseEvent.KEY-PRESS:
{
System.out.println(evt.key);
返回真;
}
默认:
返回假;
}
}
事件既可以发生在组件中,也可以发生在容器中,因为对于每个
对于要处理的信息,它们都需要一个“扩展”类。所以处理容器中的事件
比在组件中处理事件更好。
--
※来源:.南大百合信息交换站。 [来自:] 查看全部
Java用户接口工具箱AWT的使用
Java 用户界面工具箱 AWT 的使用
Java 编程语言类库提供了一个名为抽象窗口工具的用户界面工具箱
Box,简称AWT(AbstractWindowingToolkit)。 AWT 不仅功能强大,而且
而且使用起来简单灵活。本文介绍了 AWT 的基本原理以及如何创建一个小程序或一个
创建简单用户界面的应用方法。
一、什么是用户界面
所谓的用户界面就是程序中与程序的用户进行交互的部分。用户访问
端口有多种形式,从简单的命令行界面到图形用户界面。
在系统的最底层,操作系统将鼠标和键盘输入的信息传递给程序,
并提供像素作为程序输出。 AWT 旨在防止程序员使用
关心鼠标的跟踪或键盘的细节,更别说写屏幕工作了
。 AWT 提供了一个精心设计的、面向对象的
对于这些低级服务和资源
界面。
由于 Java 编程语言是平台无关的,因此 AWT 也是平台无关的。
AWT 为在不同平台上工作的图形用户界面设计了一个通用工具集
。 AWT 提供的用户界面元素使用每个平台自己的 GUI 工具箱,所以有保证
留下对应操作平台的外观。这是 AWT 最突出的特点之一。但是这种处理
该方法的缺点是在某个软件平台上设计的图形用户界面在另一个平台上是平的。
当它在舞台上运行时,它会改变。
二、组件和容器
图形用户界面由图形元素组件组成。典型组件包
包括按钮、滚动条和文本框。该组件允许用户继续程序
交互,并以视觉反馈的形式向用户提供程序状态。在 AWT 中,所有
用户界面组件都是组件类或组件类的子类型的实例。
组件不能单独存在,它总是放在容器中。容器收录和控制
组件的布局,容器本身也是一个组件,也可以放在其他容器中。在 AWT 中
在
,所有容器都是容器类的实例或容器类的子类型。
图 1 描绘了在 Windows95 平台上显示的简单图形用户界面
。图2显示了图1中界面组件的树状关系。
三、组件类型
图 3 展示了 AWT 提供的用户界面组件类之间的继承关系。组件类
(组件类)定义了所有组件必须遵守的接口。
图一
图二
图 3
AWT 提供了 9 个基本的无容器组件类。使用它们来构建用户界面
(当然,新的组件类可以从其中任何一个获取,也可以从组件类本身获取)。这9个
类是按钮、画布、复选框、选择、标签、列表
类、滚动条类、TextArea 类、TextField 类。
四、容器类型
AWT 提供了 4 个容器类。它们是 Windows 类及其两个子类型——Fram
e 类和 Dialog 类和 Panel 类。除了AWT提供的容器外,Applet类也是
一个容器,它是 Panel 类的子类型,可以容纳组件。图4显示
AWT 提供的每个容器的简要说明。图4
五、创建容器
在添加构成用户界面的组件之前,程序员必须创建一个容器。什么时候
在构建应用程序时,程序员必须首先创建一个Windows类或Frame类
示例。构造Applet时,Frame类的实例已经存在,无需处理
由音序器创建。由于Applet类是Panel类的子类,程序员可以申请Appl
将组件添加到 et 类的实例中。
代码 1 创建一个空框架。框架的标题(“Example1”)在构造函数中
设置数字。 Frame一开始是不可见的,必须调用它的show()方法才能使之
可见。
代码 1:空帧
importjava.awt.*;
publicclassExample1
{
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1");
f.show();
}
}
代码2扩展了代码1,新类继承了Panel类。在 main() 方法中,创建
通过调用Frame类的add()方法构建并添加了这个新类的一个实例
我对象。
代码 2:带有空面板的框架
importjava.awt.*;
publicclassExamplelaextendsPanel
{
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1a");
Examplelaex=newExample1a();
f.add("Center",ex);
f.pack();
f.show();
}
}
以下示例中的新类继承自 Applet 类,而不是继承自 Panel 类。
所以这个例子可以作为一个独立的应用程序或者嵌入到一个网页中
上的小程序
。此示例显示在代码 3 中。
代码 3:一个带有空小程序的框架
importjava.awt.*;
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1b");
Exammple1bex=newExample1b();
f.add("Center",ex);
f.pack();
f.show();
}
}
注意:Windows 对象和 Dialog 对象在某些情况下可以替代 Frame 对
大象。它们都是有效的容器。组件可以用同样的方式添加到每个容器中
进入。
六、将组件添加到容器中
为了实用性,用户界面可以收录多个容器——每个容器收录
组件。组件可以通过容器的 add() 方法添加到容器中。共有三个 add() 方法
一种基本形式。使用的方法取决于容器上的布局管理器。
代码4在代码3中添加了两个按钮的创建,创建在init()方法中
当然。因为在小程序初始化的时候会自动调用。因此,无论程序如何打开
一开始可以创建按钮,可以通过浏览器或者main()方法调用init()。
代码 4:工具中有两个按钮的小程序
importjava.awt.*;
publicclassExample3extendsjava.applet.Applet
{
publicvoidinit()
{
add(newButton("one"));
add(newButton("two"));
}
publicDimesionpreferredSize()
{
returnnewDimesion(200,100);
}
publicstaticvoidmain(stringargs[])
{
Framef=newFrame("Example3");
Example3ex=newExample3();
ex.init();
f.add("Center",ex);
f.pack();
f.show();
}
七、组件布局
到目前为止,我们还没有提到添加到容器中的组件是如何进行版本控制的
表面布局。布局不是由容器控制,而是由容器相关的布局管理
由进程控制。布局管理器决定了所有组件在容器中的放置方式
。在 AWT 中,所有布局管理器类都实现了 LayoutManager 接口。
AWT 提供了五种类型的布局管理程序,从简单到复杂不等。它
我们是BorderLayout类、CardLayout类、FlowLayout类、GridBagLayou
t 类,GridLayout 类。
1.BorderLayout 类是所有窗口(框架和对话框)的默认布局
管理程序。它有 5 个区域,如图 5 所示。这些区域被称为“北”,“
南”、“东”、“西”和“中心”。图 5
单个组件可以放置在这 5 个区域中的任何一个。什么时候改
当封闭容器的大小发生变化时,每个边界区域的大小也会发生变化以使其足够
该空间容纳放置在其中的组件。任何多余的空间都合并到中心区域。内容
设备的 add() 方法用于向其添加组件。 add() 方法有两个参数,其中第一个
参数是一个字符串对象,其中放置了组件区域的名称。
2.当某个区域在不同时间收录不同的组件时,应该使用Carde
rLayout 类。此类通常与 Choice 相关联。
3.FlowLayout 类是所有 Panel 类(和 Applet 类)的默认布局管理程序
前言。在容器中,它从左到右放置组件。当一行空间用完时,更新
线
开始存储。
4.GridBagLayout 类是 AWT 提供的最复杂、最灵活的布局管理程序
。可以水平和垂直排列组件,并且组件可以有不同的大小。
5.GridLayout 只是在需要的行号中显示一串大小相同的组件
以及由列号决定的位置。
代码 5 使用布局管理器和更多用户界面组件。
代码 5:一个更复杂的例子
importjava.awt.*;
publicclassExample4extendsjava.applet.Applet
{
publicvoidinit()
{
面板;
setLayout(newBorderLayout());
p=newPanel();
p.add(newTextArea());
add("中心",p);
p=newPanel();
p.add(newButton("one"));
p.add(newButton("two"));
Choicec=newChoice()
c.addItem("one");
c.addItem("两个");
c.addItem("三");
p.add(c);
add("南",P);
}
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example4");
Example4ex=newExample4();
ex.init();
f.add("Center",ex);
f.pack();
f.show();
}
}
上面的例子只是展示了一个没有交互功能的用户界面。如果你让用户
界面具有交互能力,所以必须涉及事件处理。
每个事件收录以下参数:
id 标识符;
target-事件发生的对象;
arg-任意参数;
事件发生的x,y坐标;
when 事件的时间印记;
evt-相邻事件;
key-键盘事件中按下的键;
modifers-修饰键的状态(即ALT、CTRL)。
用户将需要处理三种类型的事件,即键盘、鼠标、GUI/窗口
。所有事件都在一般的handleEvent(Eventevt)方法中处理,但使用
用户可以使用以下预定义的方法:
可以在 KeyDown() 和 KeyUp() 方法中处理键盘事件;
鼠标事件可以在mouseXXXX()方法中处理;
GUI 事件在 action() 方法中处理。
下面两段代码是等价的。
publicbooleankeyDown(Eventevt,intkey)
{
System.out.println(key);
返回假;
}
publicbooleanhandleEvent(Eventevt)
{
开关(evt.id)
{
caseEvent.KEY-PRESS:
{
System.out.println(evt.key);
返回真;
}
默认:
返回假;
}
}
事件既可以发生在组件中,也可以发生在容器中,因为对于每个
对于要处理的信息,它们都需要一个“扩展”类。所以处理容器中的事件
比在组件中处理事件更好。
--
※来源:.南大百合信息交换站。 [来自:]
nginx服务影响修改nginx配置文件限制因素分析及操作建议
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-07-31 07:02
第一步:下载并获取动态网站code信息
官方网站开源代码:dedecms/phpcms
代码下载地址
phpcms
/html/download/phpcms/#content
dedecms
产品/Dedecms/软件下载_织梦cms
(三),搭建动态论坛网站
第一步:下载并获取动态网站code信息
论坛网站开源代码:discuz
代码下载地址
配件·DiscuzX/Discuz X3.4-码云
(四),建动态知乎网站
第一步:下载并获取动态网站code信息
知乎网站开源代码:wecenter
代码下载地址
免费获取WeCenter | WeCenter 创建您的知乎
(五),构建动态视频网站
第一步:下载并获取动态网站code信息
视频网站开源代码:movcms
代码下载地址
下载-电影节目-MOVcms官方-Powered by movcms
动态网站构建后上传数据
动态网站交互模式
权限不足,无法上传数据
修改php-fpm服务程序进程用户与nginxworker进程用户一致
客户端数据上传大小有限制
限制因素1:由于nginx服务的影响
修改nginx配置文件
server {
listen 80;
server_name blog.oldboy.com;
root /html/blog;
index index.php index.html;
client_max_body_size 10m;
}
限制因素二:受PHP服务影响
修改php配置文件
vim /etc/php.ini
799 upload_max_filesize = 10M -- 调整大小为10M
六、LNMP 架构数据库分离
数据库分离的原因:可以实现数据共享和存储
(一),数据库服务迁移过程
第一步:备份数据信息
(迁移前的 Web 服务器)
mysqldump -uroot -poldboy123 -A > /tmp/backup.sql
第 2 步:迁移数据
(迁移前的 Web 服务器)
scp -rp /tmp/backup.sql 172.16.1.51:/tmp/
第 3 步:恢复数据
(迁移后的mysql服务器)
mysql -uroot -poldboy123 < /tmp/backup.sql
数据库数据迁移完成后需要进行操作
第一步:迁移前关闭服务器数据库服务
systemctl stop mariadb.service
systemctl disable mariadb.service
第2步:需要修改连接数据库的代码信息
vim /html/blog/wp-config.php
32 define( 'DB_HOST', '172.16.1.51' );
第三步:需要调整数据库用户配置信息
grant all on wordpress.* to 'wordpress'@'172.16.1.%' identified by 'oldboy123';
七、LNMP架构网站系列存储服务
串联原因:实现数据共享和存储
(一),系列过程
第一步:保存并备份本地存储的数据
mkdir /tmp/blog_backup
mv /html/blog/wp-content/uploads/* /tmp/blog_backup/
步骤二:检查存储服务是否可以正常使用
showmount -e 172.16.1.31
第三步:进行存储服务挂载操作
mount -t nfs 172.16.1.31:/data/blog/ /html/blog/wp-content/uploads/
第四步:恢复之前备份的数据
cp /tmp/blog_backup/* /html/blog/wp-content/uploads/
八、编译安装PHP
第一步:检查PHP是否安装
systemctl status php-fpm.service
systemctl stop php-fpm.service
步骤二:获取PHP源码包
wget http://php.net/distributions/php-7.1.0.tar.gz
第 3 步:解决 PHP 依赖
yum install -y libxml2 libxml2-devel openssl openssl-devel bzip2 bzip2-devel libcurl libcurl-devel libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel gmp gmp-devel libmcrypt libmcrypt-devel readline readline-devel libxslt libxslt-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel ncurses curl gdbm-devel db4-devel libXpm-devel libX11-devel gd-devel gmp-devel expat-devel xmlrpc-c xmlrpc-c-devel libicu-devel libmcrypt-devel libmemcached-devel
步骤 4:: 解压软件程序
tar -zxvf php-7.1.0.tar.gz
第五步:编译安装
1、将解压后的目录移动到指定目录并创建软链接
mv php-7.1.0 /app
cd /app
ln -s php-7.1.0/ php
2、进入php目录并编译
cd php
./configure --prefix=/application/php-7.1 --enable-fpm --enable-inline-optimization --disable-debug --disable-rpath --enable-shared --enable-soap --with-libxml-dir --with-xmlrpc --with-openssl --with-mcrypt --with-mhash --with-pcre-regex --with-sqlite3 --with-zlib --enable-bcmath --with-iconv --with-bz2 --enable-calendar --with-curl --with-cdb --enable-dom --enable-exif --enable-fileinfo --enable-filter --with-pcre-dir --enable-ftp --with-gd --with-openssl-dir --with-jpeg-dir --with-png-dir --with-zlib-dir --with-freetype-dir --enable-gd-native-ttf --enable-gd-jis-conv --with-gettext --with-gmp --with-mhash --enable-json --enable-mbstring --enable-mbregex --enable-mbregex-backtrack --with-libmbfl --with-onig --enable-pdo --with-mysqli=mysqlnd --with-pdo-mysql=mysqlnd --with-zlib-dir --with-pdo-sqlite --with-readline --enable-session --enable-shmop --enable-simplexml --enable-sockets --enable-sysvmsg --enable-sysvsem --enable-sysvshm --enable-wddx --with-libxml-dir --with-xsl --enable-zip --enable-mysqlnd-compression-support --with-pear --enable-opcache
3、安装
make && make install
第六步:调整或创建配置文件
cd /application/php-7.1/ #进入到程序目录
cp etc/php-fpm.conf.default etc/php-fpm.conf
cp etc/php-fpm.d/www.conf.default etc/php-fpm.d/www.conf
cd /app/php #进入到源码包目录
cp php.ini-production /application/php-7.1/lib/php.ini
第七步:启动php服务程序
/application/php/sbin/php-fpm
第八步:测试PHP是否启动成功
写网站配置文件
vim /etc/nginx/conf.d/www.conf
server {
listen 80;
server_name www.oldboy.com;
root /html/www;
index index.html index.php;
location ~ \.php$ {
root /html/www;
fastcgi_index index.php;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
编写测试页面站点文件
/html/www/test_php.php
页面访问测试文件
第九步:检查PHP安装过程中编译了哪些参数
/application/php/bin/php -i|grep configure
九、PHP 优化(一)、PHP 缓存加速器优化
功能
缓存加速器主要用于提高动态分析的效率
实现方法
部署前准备
配置环境变量
echo 'export LC_ALL=C'>> /etc/profile
source /etc/profile
安装 Perl 相关软件依赖
yum -y install perl-devel
方法一:使用电子加速器
1、eAccelerator 介绍
安装和配置参数比较简单,加速效果也不错。
Ÿ 文档很多,但是软件官方更新很慢,社区不活跃。
Y 仅适用于 PHP 版本5.4 以下的程序
2、eAccelerator 安装
进入源码包目录
cd /server/tools
获取源码包
wget https://github.com/downloads/e ... r.bz2
解压源码包
tar xf eaccelerator-0.9.6.1.tar.bz2
编译安装
cd eaccelerator-0.9.6.1
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-eaccelerator --with-php-config=/application/php-7.1/bin/php-config
make && make install
方法二:使用xcache
1、xcache 介绍
经过测试,XCache 的效率更高,速度更快。
XCache 软件开发社区更加活跃,最新版本将于 2014 年底发布。
支持更高版本的PHP,如PHP5.5、PHP 5.6。
2、xcache 安装
进入源码包目录
cd /server/tools
获取源码包
wget http://xcache.lighttpd.net/pub ... r.bz2
解压源码包
tar xf xcache-3.2.0.tar.bz2
编译安装包
cd xcache-3.2.0
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-xcache --with-php-config=/application/php/bin/php-config
make && make install
方法三:使用zend opcache
1、zend opcache 介绍
默认已集成在php程序中,无需单独安装加速软件
2、zend opcache 安装
进入源码包目录
cd /server/tools
获取源码包
wget -q http://pecl.php.net/get/zendopcache-7.0.5.tgz
解压源码包
tar xf zendopcache-7.0.5.tgz
编译安装
cd zendopcache-7.0.5
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-opcache --with-php-config=/application/php/bin/php-config
make && make install
(二),PHP缓存功能优化1、memcache缓存插件
PHP缓存优化原理
Mencache 插件安装部署
第一步:获取插件源码包
wget https://github.com/websupport- ... 7.zip
步骤二:将源码包解压到指定目录
cd /server/tools
unzip NON_BLOCKING_IO_php7.zip
第三步:编译安装memcache
cd pecl-memcache-NON_BLOCKING_IO_php7/
/application/php-7.1/bin/phpize
./configure --enable-memcache --with-php-config=/application/php-7.1/bin/php-config
make && make install
memcache 插件应用配置
第一步:修改配置文件
PS:添加到最后
vim /application/php-7.1/lib/php.ini
extension = "/application/php-7.1/lib/php/extensions/no-debug-non-zts-20160303/memcache.so"
第 2 步:重启 php-fpm 查看全部
nginx服务影响修改nginx配置文件限制因素分析及操作建议
第一步:下载并获取动态网站code信息
官方网站开源代码:dedecms/phpcms
代码下载地址
phpcms
/html/download/phpcms/#content
dedecms
产品/Dedecms/软件下载_织梦cms
(三),搭建动态论坛网站
第一步:下载并获取动态网站code信息
论坛网站开源代码:discuz
代码下载地址
配件·DiscuzX/Discuz X3.4-码云
(四),建动态知乎网站
第一步:下载并获取动态网站code信息
知乎网站开源代码:wecenter
代码下载地址
免费获取WeCenter | WeCenter 创建您的知乎
(五),构建动态视频网站
第一步:下载并获取动态网站code信息
视频网站开源代码:movcms
代码下载地址
下载-电影节目-MOVcms官方-Powered by movcms
动态网站构建后上传数据
动态网站交互模式
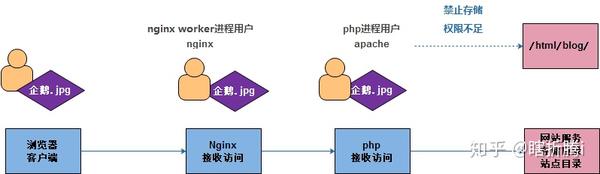
权限不足,无法上传数据
修改php-fpm服务程序进程用户与nginxworker进程用户一致
客户端数据上传大小有限制
限制因素1:由于nginx服务的影响
修改nginx配置文件
server {
listen 80;
server_name blog.oldboy.com;
root /html/blog;
index index.php index.html;
client_max_body_size 10m;
}
限制因素二:受PHP服务影响
修改php配置文件
vim /etc/php.ini
799 upload_max_filesize = 10M -- 调整大小为10M
六、LNMP 架构数据库分离
数据库分离的原因:可以实现数据共享和存储
(一),数据库服务迁移过程
第一步:备份数据信息
(迁移前的 Web 服务器)
mysqldump -uroot -poldboy123 -A > /tmp/backup.sql
第 2 步:迁移数据
(迁移前的 Web 服务器)
scp -rp /tmp/backup.sql 172.16.1.51:/tmp/
第 3 步:恢复数据
(迁移后的mysql服务器)
mysql -uroot -poldboy123 < /tmp/backup.sql
数据库数据迁移完成后需要进行操作
第一步:迁移前关闭服务器数据库服务
systemctl stop mariadb.service
systemctl disable mariadb.service
第2步:需要修改连接数据库的代码信息
vim /html/blog/wp-config.php
32 define( 'DB_HOST', '172.16.1.51' );
第三步:需要调整数据库用户配置信息
grant all on wordpress.* to 'wordpress'@'172.16.1.%' identified by 'oldboy123';
七、LNMP架构网站系列存储服务
串联原因:实现数据共享和存储
(一),系列过程
第一步:保存并备份本地存储的数据
mkdir /tmp/blog_backup
mv /html/blog/wp-content/uploads/* /tmp/blog_backup/
步骤二:检查存储服务是否可以正常使用
showmount -e 172.16.1.31
第三步:进行存储服务挂载操作
mount -t nfs 172.16.1.31:/data/blog/ /html/blog/wp-content/uploads/
第四步:恢复之前备份的数据
cp /tmp/blog_backup/* /html/blog/wp-content/uploads/
八、编译安装PHP
第一步:检查PHP是否安装
systemctl status php-fpm.service
systemctl stop php-fpm.service
步骤二:获取PHP源码包
wget http://php.net/distributions/php-7.1.0.tar.gz
第 3 步:解决 PHP 依赖
yum install -y libxml2 libxml2-devel openssl openssl-devel bzip2 bzip2-devel libcurl libcurl-devel libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel gmp gmp-devel libmcrypt libmcrypt-devel readline readline-devel libxslt libxslt-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel ncurses curl gdbm-devel db4-devel libXpm-devel libX11-devel gd-devel gmp-devel expat-devel xmlrpc-c xmlrpc-c-devel libicu-devel libmcrypt-devel libmemcached-devel
步骤 4:: 解压软件程序
tar -zxvf php-7.1.0.tar.gz
第五步:编译安装
1、将解压后的目录移动到指定目录并创建软链接
mv php-7.1.0 /app
cd /app
ln -s php-7.1.0/ php
2、进入php目录并编译
cd php
./configure --prefix=/application/php-7.1 --enable-fpm --enable-inline-optimization --disable-debug --disable-rpath --enable-shared --enable-soap --with-libxml-dir --with-xmlrpc --with-openssl --with-mcrypt --with-mhash --with-pcre-regex --with-sqlite3 --with-zlib --enable-bcmath --with-iconv --with-bz2 --enable-calendar --with-curl --with-cdb --enable-dom --enable-exif --enable-fileinfo --enable-filter --with-pcre-dir --enable-ftp --with-gd --with-openssl-dir --with-jpeg-dir --with-png-dir --with-zlib-dir --with-freetype-dir --enable-gd-native-ttf --enable-gd-jis-conv --with-gettext --with-gmp --with-mhash --enable-json --enable-mbstring --enable-mbregex --enable-mbregex-backtrack --with-libmbfl --with-onig --enable-pdo --with-mysqli=mysqlnd --with-pdo-mysql=mysqlnd --with-zlib-dir --with-pdo-sqlite --with-readline --enable-session --enable-shmop --enable-simplexml --enable-sockets --enable-sysvmsg --enable-sysvsem --enable-sysvshm --enable-wddx --with-libxml-dir --with-xsl --enable-zip --enable-mysqlnd-compression-support --with-pear --enable-opcache
3、安装
make && make install
第六步:调整或创建配置文件
cd /application/php-7.1/ #进入到程序目录
cp etc/php-fpm.conf.default etc/php-fpm.conf
cp etc/php-fpm.d/www.conf.default etc/php-fpm.d/www.conf
cd /app/php #进入到源码包目录
cp php.ini-production /application/php-7.1/lib/php.ini
第七步:启动php服务程序
/application/php/sbin/php-fpm
第八步:测试PHP是否启动成功
写网站配置文件
vim /etc/nginx/conf.d/www.conf
server {
listen 80;
server_name www.oldboy.com;
root /html/www;
index index.html index.php;
location ~ \.php$ {
root /html/www;
fastcgi_index index.php;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
编写测试页面站点文件
/html/www/test_php.php
页面访问测试文件
第九步:检查PHP安装过程中编译了哪些参数
/application/php/bin/php -i|grep configure
九、PHP 优化(一)、PHP 缓存加速器优化
功能
缓存加速器主要用于提高动态分析的效率
实现方法
部署前准备
配置环境变量
echo 'export LC_ALL=C'>> /etc/profile
source /etc/profile
安装 Perl 相关软件依赖
yum -y install perl-devel
方法一:使用电子加速器
1、eAccelerator 介绍
安装和配置参数比较简单,加速效果也不错。
Ÿ 文档很多,但是软件官方更新很慢,社区不活跃。
Y 仅适用于 PHP 版本5.4 以下的程序
2、eAccelerator 安装
进入源码包目录
cd /server/tools
获取源码包
wget https://github.com/downloads/e ... r.bz2
解压源码包
tar xf eaccelerator-0.9.6.1.tar.bz2
编译安装
cd eaccelerator-0.9.6.1
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-eaccelerator --with-php-config=/application/php-7.1/bin/php-config
make && make install
方法二:使用xcache
1、xcache 介绍
经过测试,XCache 的效率更高,速度更快。
XCache 软件开发社区更加活跃,最新版本将于 2014 年底发布。
支持更高版本的PHP,如PHP5.5、PHP 5.6。
2、xcache 安装
进入源码包目录
cd /server/tools
获取源码包
wget http://xcache.lighttpd.net/pub ... r.bz2
解压源码包
tar xf xcache-3.2.0.tar.bz2
编译安装包
cd xcache-3.2.0
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-xcache --with-php-config=/application/php/bin/php-config
make && make install
方法三:使用zend opcache
1、zend opcache 介绍
默认已集成在php程序中,无需单独安装加速软件
2、zend opcache 安装
进入源码包目录
cd /server/tools
获取源码包
wget -q http://pecl.php.net/get/zendopcache-7.0.5.tgz
解压源码包
tar xf zendopcache-7.0.5.tgz
编译安装
cd zendopcache-7.0.5
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-opcache --with-php-config=/application/php/bin/php-config
make && make install
(二),PHP缓存功能优化1、memcache缓存插件
PHP缓存优化原理
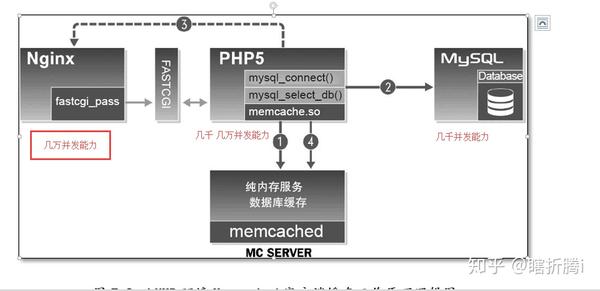
Mencache 插件安装部署
第一步:获取插件源码包
wget https://github.com/websupport- ... 7.zip
步骤二:将源码包解压到指定目录
cd /server/tools
unzip NON_BLOCKING_IO_php7.zip
第三步:编译安装memcache
cd pecl-memcache-NON_BLOCKING_IO_php7/
/application/php-7.1/bin/phpize
./configure --enable-memcache --with-php-config=/application/php-7.1/bin/php-config
make && make install
memcache 插件应用配置
第一步:修改配置文件
PS:添加到最后
vim /application/php-7.1/lib/php.ini
extension = "/application/php-7.1/lib/php/extensions/no-debug-non-zts-20160303/memcache.so"
第 2 步:重启 php-fpm
真正的独家,伊人集全部功能及付费功能整合版(带整站数据)演示站:(LmSail)内附详细安装教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-07-30 03:44
真人机最新全功能及付费功能集成版(附全站资料),演示站:(LmSail)附详细安装使用教程!
基本流程+顶部签到+专栏+商城+就近+充值+牛评+音乐+活动+图库等功能。礼物奖励功能!
本源代码为易人机官方源代码,完美修复,功能齐全。不是10元20元的那种。修复分享功能、伪静态、栏目、手机发布图片展示、首页LOGO修改、SEO优化设置、导航栏目混乱等问题。新增商城、图库、打赏等功能!
Demonstration网站:(LmSail 社区)【注册经验】
宜人机基础程序官方售价为260元。
完美的插件更新:
01.[16-02-28] 易人机模板,易人机201602最新升级包
02.[16-03-11] 易人集模板3月专题页面调整升级包
03.[16-03-31] 易人记模板大事记模块包下载
04.[16-04-05]爱人机顶和签到日历插件相关下载价值50元
05.[16-04-08] 易人机模板用户展示频道图片轮播效果插件
06.[16-04-18] 易人集站分类前后端调整插件
07.[16-05-04] 易人记模板栏目模块用户版价值260元
08.[16-05-26] 易人集模板升级包:附近人和会员页面调整包
09.[16-06-08] 易人集微信模板二次公开调用升级包
10.[16-06-08]宜人机模板充值模块包在线充值模块辅助包
11.[16-06-08] 易人集活动模块升级调整充值插件包
12.[16-06-11] 易人记抗CC刷新攻击插件升级包
13.[16-06-12] 亿人集模板商城频道模块下载包价值260元
14.[16-06-12] 易人集模板专栏|用户列表|雷锋列表|分类调整升级包
15.[16-06-24] 易人集附近的人,找人盖升级包
16.[16-07-03] 易人集模板频道分类升级包
17.[16-07-08] 价值60元的易人记地图集模块和表情插件升级包
18.[16-08-10] 益人机答题功能模块包+价值200元升级包
全站最新Wecenter易人集生鲜社区源码分享,Wecenter易人集社区完美修复BUG一键安装版,参考网上部分已有模板,重写模板CSS。其他方面也进行了修改,特别是我发现的一个官方错误。另外活动和工单已经合并,一键安装全功能!
编辑地点:
1.root 目录 ad 为广告图片(均在轮播中使用)。如果要删除,在views/default/block中找到收录ad的两个文件,然后清除里面的内容,或者换成自己的's ads
2.Carousel 模板在模板文件夹中修改为block或者global或者m,以及收录lunbo的文件(共有三个carousel文件,目前没有实现后台管理,因为官方升级不容易拿到)
3.安装时添加活动和工单并安装到数据库中
4.Revised the email issue in a official error model(不知道官方有没有做过测试,不管用户的声音半死不活)
5. 添加了一个有用的过滤系统/class/cls_format.inc 为前台电话铺路
6. 修复了 system/services/VideoUrlParser 为添加音乐 mp3 铺平了道路
7.加入轮播,有两个地方(头和首页,不想要的可以修改删除)
8.修改models下的module文件,增加top_hot_users(方便调用头像的用户),增加bolock下的调用
9.修复官方手机版的一个错误
10. 继续在模板块下添加调用。
11.修改了app下的调用(请自行对比文件)
下载地址
[支付点=”30″]链接:密码:5pux[/pay]
1.本站所有资源均来自用户上传和互联网,不收录技术服务,请见谅!
2. 本站不保证所提供下载资源的准确性、安全性和完整性。资源仅供下载学习使用!如有链接无法下载、失效、广告等问题,请联系客服!
3.您必须在下载后24小时内将以上内容资源从您的电脑中彻底删除!如用于商业或非法用途,与本站无关,一切后果由用户负责!
4.如果你也有好的资源或者教程,可以提交论文发表。分享成功后,将有现场币奖励和额外收益! 查看全部
真正的独家,伊人集全部功能及付费功能整合版(带整站数据)演示站:(LmSail)内附详细安装教程
真人机最新全功能及付费功能集成版(附全站资料),演示站:(LmSail)附详细安装使用教程!
基本流程+顶部签到+专栏+商城+就近+充值+牛评+音乐+活动+图库等功能。礼物奖励功能!
本源代码为易人机官方源代码,完美修复,功能齐全。不是10元20元的那种。修复分享功能、伪静态、栏目、手机发布图片展示、首页LOGO修改、SEO优化设置、导航栏目混乱等问题。新增商城、图库、打赏等功能!
Demonstration网站:(LmSail 社区)【注册经验】
宜人机基础程序官方售价为260元。
完美的插件更新:
01.[16-02-28] 易人机模板,易人机201602最新升级包
02.[16-03-11] 易人集模板3月专题页面调整升级包
03.[16-03-31] 易人记模板大事记模块包下载
04.[16-04-05]爱人机顶和签到日历插件相关下载价值50元
05.[16-04-08] 易人机模板用户展示频道图片轮播效果插件
06.[16-04-18] 易人集站分类前后端调整插件
07.[16-05-04] 易人记模板栏目模块用户版价值260元
08.[16-05-26] 易人集模板升级包:附近人和会员页面调整包
09.[16-06-08] 易人集微信模板二次公开调用升级包
10.[16-06-08]宜人机模板充值模块包在线充值模块辅助包
11.[16-06-08] 易人集活动模块升级调整充值插件包
12.[16-06-11] 易人记抗CC刷新攻击插件升级包
13.[16-06-12] 亿人集模板商城频道模块下载包价值260元
14.[16-06-12] 易人集模板专栏|用户列表|雷锋列表|分类调整升级包
15.[16-06-24] 易人集附近的人,找人盖升级包
16.[16-07-03] 易人集模板频道分类升级包
17.[16-07-08] 价值60元的易人记地图集模块和表情插件升级包
18.[16-08-10] 益人机答题功能模块包+价值200元升级包
全站最新Wecenter易人集生鲜社区源码分享,Wecenter易人集社区完美修复BUG一键安装版,参考网上部分已有模板,重写模板CSS。其他方面也进行了修改,特别是我发现的一个官方错误。另外活动和工单已经合并,一键安装全功能!
编辑地点:
1.root 目录 ad 为广告图片(均在轮播中使用)。如果要删除,在views/default/block中找到收录ad的两个文件,然后清除里面的内容,或者换成自己的's ads
2.Carousel 模板在模板文件夹中修改为block或者global或者m,以及收录lunbo的文件(共有三个carousel文件,目前没有实现后台管理,因为官方升级不容易拿到)
3.安装时添加活动和工单并安装到数据库中
4.Revised the email issue in a official error model(不知道官方有没有做过测试,不管用户的声音半死不活)
5. 添加了一个有用的过滤系统/class/cls_format.inc 为前台电话铺路
6. 修复了 system/services/VideoUrlParser 为添加音乐 mp3 铺平了道路
7.加入轮播,有两个地方(头和首页,不想要的可以修改删除)
8.修改models下的module文件,增加top_hot_users(方便调用头像的用户),增加bolock下的调用
9.修复官方手机版的一个错误
10. 继续在模板块下添加调用。
11.修改了app下的调用(请自行对比文件)




下载地址
[支付点=”30″]链接:密码:5pux[/pay]
1.本站所有资源均来自用户上传和互联网,不收录技术服务,请见谅!
2. 本站不保证所提供下载资源的准确性、安全性和完整性。资源仅供下载学习使用!如有链接无法下载、失效、广告等问题,请联系客服!
3.您必须在下载后24小时内将以上内容资源从您的电脑中彻底删除!如用于商业或非法用途,与本站无关,一切后果由用户负责!
4.如果你也有好的资源或者教程,可以提交论文发表。分享成功后,将有现场币奖励和额外收益!
Rancher平台内如何做容器日志收集(一)_微服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-07-25 06:38
介绍文档参考。对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。目前容器日志采集解决方案的现状概述,无非两种方式:一、直接采集Docker标准输出,通过Docker日志驱动(log driver)可以发送到相应的采集程序; 二、 非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。 log采集程序直接采集映射的Log文档。 三、通Journald 采集二进制日志数据。 PS:标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。非标准输出:根据Docker容器的特点,容器启动后必须有服务保持前台运行。
如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,这些后台运行的服务生成的日志默认无法作为标准输出获取,生成的日志默认会保存在/var/log目录下。第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:当宿主机的容器密度比较高的时候,对Docker Engine的压力比较大,毕竟,容器标准输出必须经过Docker Engine处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald进行二进制日志数据采集。当然,在完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。 UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是 log采集 解决方案。当然,开源的实现是对接在存储和UI展示上的。没有特殊要求,也可以有完整的体验。
Rancher(json-file driver)下的解决方案介绍如上图所示。 ElasticSearch & Kibana 可以直接用于日志存储和 UI 展示。日志采集,如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中,日志采集部分使用了Fluentd & Logging Helper的组合。 Fluentd 是一个非常通用的日志采集 程序,性能卓越。与Logstash相比,在同样的压力下,它的内存消耗要少得多。为了保证 Dokcer 和 Rancher 体验的完整性,Docker Log Driver 选择 Json-file 或 Journald 的原因是:一、json-file 和 journald 比较常见; 二、这两个驱动,docker Logs还是可以有内容输出的,保证了体验的完整性。实施流程方案实施流程:Fluentd对接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据; Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd进行采集。 Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。下面开始讲解整个程序的部署过程。先用一张图来描述整体的部署结构,如下:
方案部署 ElasticSearch & Kibana 部署 Web 登录 Rancher,进入应用商店,搜索 ElasticSearch,建议安装2.x 版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后一个Public端口根据实际情况修改,避免冲突。
服务正常启动后,即可通过该端口访问Kibana网页。
Rancher日志服务部署 目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,名称:rancher-logging 地址:branch:master 最后点击保存,返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面:本例中除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要与之前设置的Volume Pattern一致: 查看全部
Rancher平台内如何做容器日志收集(一)_微服务
介绍文档参考。对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。目前容器日志采集解决方案的现状概述,无非两种方式:一、直接采集Docker标准输出,通过Docker日志驱动(log driver)可以发送到相应的采集程序; 二、 非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。 log采集程序直接采集映射的Log文档。 三、通Journald 采集二进制日志数据。 PS:标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。非标准输出:根据Docker容器的特点,容器启动后必须有服务保持前台运行。
如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,这些后台运行的服务生成的日志默认无法作为标准输出获取,生成的日志默认会保存在/var/log目录下。第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:当宿主机的容器密度比较高的时候,对Docker Engine的压力比较大,毕竟,容器标准输出必须经过Docker Engine处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald进行二进制日志数据采集。当然,在完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。 UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是 log采集 解决方案。当然,开源的实现是对接在存储和UI展示上的。没有特殊要求,也可以有完整的体验。
Rancher(json-file driver)下的解决方案介绍如上图所示。 ElasticSearch & Kibana 可以直接用于日志存储和 UI 展示。日志采集,如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中,日志采集部分使用了Fluentd & Logging Helper的组合。 Fluentd 是一个非常通用的日志采集 程序,性能卓越。与Logstash相比,在同样的压力下,它的内存消耗要少得多。为了保证 Dokcer 和 Rancher 体验的完整性,Docker Log Driver 选择 Json-file 或 Journald 的原因是:一、json-file 和 journald 比较常见; 二、这两个驱动,docker Logs还是可以有内容输出的,保证了体验的完整性。实施流程方案实施流程:Fluentd对接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据; Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd进行采集。 Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。下面开始讲解整个程序的部署过程。先用一张图来描述整体的部署结构,如下:
方案部署 ElasticSearch & Kibana 部署 Web 登录 Rancher,进入应用商店,搜索 ElasticSearch,建议安装2.x 版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后一个Public端口根据实际情况修改,避免冲突。
服务正常启动后,即可通过该端口访问Kibana网页。
Rancher日志服务部署 目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,名称:rancher-logging 地址:branch:master 最后点击保存,返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面:本例中除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要与之前设置的Volume Pattern一致:
干货教程:【wecenter 免费采集插件--优采云云采集 V3.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-11-09 08:00
优采云Cloud采集由大数据公司宽艺科技自主研发。它使用分布式架构,是一种云在线智能爬虫,它使用JS呈现,代理IP,防阻塞,验证代码识别和数据发布等一系列技术,例如导出,图表控制等,可在其中实现准确,快速的数据。整个网络采集,无需任何专业知识,您只需单击一下即可抓取微信官方帐户知乎,优酷,微博和其他大量网站数据,然后自动发布到网站。 -------------------------------------------------- -------------------------------------------------- -------------全面的采集功能:无论是文章,问答,视频,图片还是资源,它都可以快速显示采集;采集速度快如雷电:大规模的代理IP和顶级服务器配置确保了采集器的执行速度和效率;业界领先的采集配置:只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程; -------------------------------------------------- -------------------------------------------------- ------------- Cloud Online采集:一站式云服务模式,在云上完成采集任务,实现24小时无人值守;强大的监控更新:通过新的监控和变更监控实时更新目标网站的最新数据;先进的语义接口:关键字提取,伪原创,情感分析等多种技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;多个类别发布:支持插入指定类别的选项,并且来自不同来源网站的数据可以发布到不同类别。 -------------------------------------------------- -------------------------------------------------- -------------客户服务支持和沟通联系信息客户服务QQ:2879835984QQ交流组:174631869 优采云cloud采集官方网站:优采云cloud采集 wecenter插件下载:/ s / 1eRr4oca插件教程:/pdoc/wecenter.html 查看全部
[wecenter free采集插件-优采云cloud采集 V3.0
优采云Cloud采集由大数据公司宽艺科技自主研发。它使用分布式架构,是一种云在线智能爬虫,它使用JS呈现,代理IP,防阻塞,验证代码识别和数据发布等一系列技术,例如导出,图表控制等,可在其中实现准确,快速的数据。整个网络采集,无需任何专业知识,您只需单击一下即可抓取微信官方帐户知乎,优酷,微博和其他大量网站数据,然后自动发布到网站。 -------------------------------------------------- -------------------------------------------------- -------------全面的采集功能:无论是文章,问答,视频,图片还是资源,它都可以快速显示采集;采集速度快如雷电:大规模的代理IP和顶级服务器配置确保了采集器的执行速度和效率;业界领先的采集配置:只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程; -------------------------------------------------- -------------------------------------------------- ------------- Cloud Online采集:一站式云服务模式,在云上完成采集任务,实现24小时无人值守;强大的监控更新:通过新的监控和变更监控实时更新目标网站的最新数据;先进的语义接口:关键字提取,伪原创,情感分析等多种技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;多个类别发布:支持插入指定类别的选项,并且来自不同来源网站的数据可以发布到不同类别。 -------------------------------------------------- -------------------------------------------------- -------------客户服务支持和沟通联系信息客户服务QQ:2879835984QQ交流组:174631869 优采云cloud采集官方网站:优采云cloud采集 wecenter插件下载:/ s / 1eRr4oca插件教程:/pdoc/wecenter.html
免费获取:【wecenter 免费采集插件--优采云云采集 V3.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 448 次浏览 • 2020-09-15 17:09
优采云 Cloud 采集由大数据公司宽艺科技自主研发。它采用分布式架构,是一种云在线智能爬虫,它使用JS呈现,代理IP,防阻塞,验证代码识别和数据发布等一系列技术,例如导出,图表控制等,可实现准确,快速的数据。在整个网络采集中,无需任何专业知识,您只需单击一下即可抓取微信官方帐户知乎,优酷,微博和其他海量网站数据,然后自动发布到网站。 -------------------------------------------------- -------------------------------------------------- -------------全面的采集功能:无论是文章,问答,视频,图片还是资源,它都可以快速显示采集; 采集速度快如雷电:大规模的代理IP和顶级服务器配置确保了采集器的执行速度和效率;行业领导者采集的配置:只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程; -------------------------------------------------- -------------------------------------------------- ------------- Cloud Online 采集:一站式云服务模式,在云上完成采集任务,实现24小时无人值守;强大的监控更新:通过新的监控和变更监控实时更新目标网站的最新数据;先进的语义接口:关键字提取,伪原创,情感分析等多种技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;多个类别发布:支持选择插入指定的类别,并且可以将来自不同来源网站的数据发布到不同的类别。 -------------------------------------------------- -------------------------------------------------- -------------客户服务支持和沟通联系信息客户服务QQ:2879835984QQ交流组:174631869 优采云 cloud 采集官方网站:优采云 cloud 采集 wecenter插件下载:/ s / 1eRr4oca插件教程:/pdoc/wecenter.html 查看全部
[wecenter free 采集插件-优采云 cloud 采集 V 3. 0
优采云 Cloud 采集由大数据公司宽艺科技自主研发。它采用分布式架构,是一种云在线智能爬虫,它使用JS呈现,代理IP,防阻塞,验证代码识别和数据发布等一系列技术,例如导出,图表控制等,可实现准确,快速的数据。在整个网络采集中,无需任何专业知识,您只需单击一下即可抓取微信官方帐户知乎,优酷,微博和其他海量网站数据,然后自动发布到网站。 -------------------------------------------------- -------------------------------------------------- -------------全面的采集功能:无论是文章,问答,视频,图片还是资源,它都可以快速显示采集; 采集速度快如雷电:大规模的代理IP和顶级服务器配置确保了采集器的执行速度和效率;行业领导者采集的配置:只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程; -------------------------------------------------- -------------------------------------------------- ------------- Cloud Online 采集:一站式云服务模式,在云上完成采集任务,实现24小时无人值守;强大的监控更新:通过新的监控和变更监控实时更新目标网站的最新数据;先进的语义接口:关键字提取,伪原创,情感分析等多种技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;多个类别发布:支持选择插入指定的类别,并且可以将来自不同来源网站的数据发布到不同的类别。 -------------------------------------------------- -------------------------------------------------- -------------客户服务支持和沟通联系信息客户服务QQ:2879835984QQ交流组:174631869 优采云 cloud 采集官方网站:优采云 cloud 采集 wecenter插件下载:/ s / 1eRr4oca插件教程:/pdoc/wecenter.html
WeCenter采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2020-08-31 02:38
优采云Cloud采集是由大数据公司Fast Memory Technology独立研发的. 它采用分布式架构,是一种使用JS呈现,代理IP,防屏蔽,验证码识别和数据发布的云在线智能爬虫,导出和图表控制等一系列技术可实现对整个网络的准确,快速采集. 数据,无需任何专业知识,您就可以抓取大量网站数据,例如微信官方帐户,知乎,优酷,微博等,并自动将其发布到Discuz网站.
优采云Cloud采集功能
无所不包的采集功能: 无论是文章,问答,视频,图片还是资源,都可以快速采集;
采集速度快如闪电: 海量的代理IP和顶级服务器配置确保了爬虫的执行速度和效率;
业界领先者的采集配置: 只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程;
优采云云采集功能:
云在线采集: 一站式云服务模式,在云上完成采集任务,实现24小时无人值守操作;
强大的监视更新: 通过新监视和更改监视实时更新目标网站的最新数据;
高级语义接口: 关键字提取,伪原创,情感分析等是多种技术;
智能匹配映射: 可以自动匹配字段,也可以由您自己设置字段映射;
多类别发布: 支持选择插入指定的类别,并且可以将来自不同来源的数据发布到不同的类别.
优采云Cloud采集更新日志:
2016.08.02 v3.1.3
1. 添加了安装教程的地址和使用文档
2. 修复某些字段失败,然后尝试再次插入
3. 获取头像的问题 查看全部
WeCenter采集插件
优采云Cloud采集是由大数据公司Fast Memory Technology独立研发的. 它采用分布式架构,是一种使用JS呈现,代理IP,防屏蔽,验证码识别和数据发布的云在线智能爬虫,导出和图表控制等一系列技术可实现对整个网络的准确,快速采集. 数据,无需任何专业知识,您就可以抓取大量网站数据,例如微信官方帐户,知乎,优酷,微博等,并自动将其发布到Discuz网站.
优采云Cloud采集功能
无所不包的采集功能: 无论是文章,问答,视频,图片还是资源,都可以快速采集;
采集速度快如闪电: 海量的代理IP和顶级服务器配置确保了爬虫的执行速度和效率;
业界领先者的采集配置: 只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程;
优采云云采集功能:
云在线采集: 一站式云服务模式,在云上完成采集任务,实现24小时无人值守操作;
强大的监视更新: 通过新监视和更改监视实时更新目标网站的最新数据;
高级语义接口: 关键字提取,伪原创,情感分析等是多种技术;
智能匹配映射: 可以自动匹配字段,也可以由您自己设置字段映射;
多类别发布: 支持选择插入指定的类别,并且可以将来自不同来源的数据发布到不同的类别.
优采云Cloud采集更新日志:
2016.08.02 v3.1.3
1. 添加了安装教程的地址和使用文档
2. 修复某些字段失败,然后尝试再次插入
3. 获取头像的问题
API接口设计,需要注意这4点
采集交流 • 优采云 发表了文章 • 0 个评论 • 378 次浏览 • 2020-08-26 06:07
笔者查阅了百度、腾讯、旷视、阿里的云平台发觉在视觉方面均都采用的是https合同;对于视觉,图片数据本身收录的信息就太丰富,尤其是人脸,因此采用https还是有利于保护用户隐私信息的。
2. 接口的恳求形式
了解插口的恳求形式有助于了解用户端和服务端间的交互方法,基于http合同的常用恳求方法是post和get;两者的主要区别如下:
(1)直观区别:get恳求方法是将恳求参数放在url中,post是将参数放在requst body中,所带来的的直接影响是get的恳求参数存在宽度限制,post无限制;其次是get将参数放在url中安全性弱于post;
(2)深度区别:get恳求形式用户端和服务端只形成一次交互,post恳求形式用户端会和服务端形成两次交互,举例:快递小哥是用户端,你是服务端,则get如同常来大家新村和你认识的快递员直接将快递送到你家,你跟他说声感谢;post如同新来的快递员先打个电话问下你在家吗?你告诉他你在家呢,过了5分钟他将快件送到你家了,你跟他说声感谢;
目前百度、腾讯、旷视的图象辨识插口均采用的是post恳求形式
3. 接口响应机制
最后了解插口的响应机制:同步插口和异步插口;简单理解同步插口即实时返回消息给调用方,异步插口就是可以延后返回消息给调用方;实时性要求高的且只能线性工作的须要采用同步插口,其他可以优先使用异步接口;当然不同的场景,同样的服务插口会被要求同步或异步;以人脸辨识中的人脸注册为例:
(1)刷脸支付:以支付宝为例,使用之前须要根据步骤采集人脸,后台会调用人脸注册将当前人脸注册进人脸库并和该支付宝帐号信息绑定,这一步人脸注册一般是同步插口,因为不会要求用户在APP前等待很久,需要及时返回注册成功信息;
(2)客流系统:现在商超使用的客流系统通常早已采用人脸辨识代替头肩模型,这样除了可以统计人数还可以统计人次,其中对于首次辨识的陌生人脸一般须要注册进陌生人脸库,这里的人脸注册通常为异步接口,因为小型商超每晚数十万客流且对于陌生人无会员信息,所以不需要实时注册,只要步入队列能在当天24小时内注册完即可;
小结
以上关于API的插口常识在设计插口的时侯,开发通常还会要求产品确定插口的响应机制;其他的开发就会自己完成;但作为开放平台的产品常常会对接开发,多了解些常识既可以跟自己的开发有更多的共同语言沟通,也可以在对接用户的时侯可以跟用户的开发简单解释。
二、核心业务主键&接口约束
产品总监其实不需要定义API所有的数组信息,但是跟业务需求有关的数组产品总监须要明晰清晰。
1. 入参
(1)鉴权数组信息
调用第三方平台插口一般须要进行插口信令,服务端判定用户端是否有调用插口的权限;这里跟产品总监相关的是作为产品须要设计应用管理,包括:应用列表、应用创建、应用详情、应用配置、应用删掉等操作;以百度AI平台,应用列表如下:
其中AppID、API Key和Secret Key为创建应用时手动生成,接口信令所须要的access_token必须通过API key和Secret key恳求服务端获取。
(2)核心业务主键
产品总监须要依照业务需求明晰插口入参中须要什么数组信息以及数组支持的类型,以百度AI平台的食材辨识为例:
业务需求:识别图片中是哪种食材;
产品需求:
输入图片,图片支持一般采用base64和URL格式;top_num,提高插口的通用性,方便用户后续场景扩充,因此支持配置返回食材数目且排序;阈值,开放辨识阀值,方便用户按照实际辨识疗效调整,提高准确率;
注意点:设计插口核心业务主键,要尽量提升插口的通用性,以此适配更多的用户场景,比如top_num和阀值的开放,即泛化插口能力,将更多的主动权交由插口用户配置。
(3)字段信息约束条件
字段约束条件是为了保证插口的安全性,这点是产品总监跟业务方沟通达成一致后提供给开发小伙伴的;仍然以里面的食材辨识为例:
图片须要限制文件大小和帧率大小,文件大小只须要上限,分辨率大小须要包括上限和下限,下限是为了保证算法疗效,比如在目标测量中小目标容易测量失败;top_num须要限制下限,不得大于0,不设上限,可以接受算法返回的所有结果;阈值按照格式确定,可以是0-100,可以是0-1;
注:设置参数的一点小技巧,为了保证算法疗效,有时算法会默认设置参数,即用户设置的阀值高于默认参数,则不接受输入,采用默认,用户是无感知的;
2. 出参
调用插口都会有返回信息,产品须要依照业务需求定义返回的核心数组信息,这次以百度AI开放平台手势辨识为例,其中跟业务需求相关的关键数组包括:
三、接口限流
接口限流也是为了保障系统的安全性,因为有时业务方由于业务扩充造成调用量猛增,容易造成服务端宕机;限流就类似于空开的保险丝保证恳求量超过插口上限时系统可以拒绝恳求或排队,以此保证系统的安全性;
产品总监须要实现对业务充分评估,给出合理评估量,如TPS(每秒处理的恳求量);这样既不会导致系统资源的浪费,也保证业务正常运行;
注:与前面插口响应机制对应,同步插口通常须要给出峰值tps和响应时间,异步插口须要给出日调量即可;
四、接口测试
接口测试似乎是测试小妹哥的工作,测试内容也覆盖诸多,但是作为产品可以简单了解以下内容即可,如,
(1)接口可用性,即插口是否可以正常调用,正常返回结果,异常正确处理,正常返回错误码等;
(2)业务需求覆盖,即插口输入输出是否遵守产品需求文档描述;
(3)边界规则依循,即插口是否满足业务规则和数组约束条件;
(4)性能条件,通常插口上线前须要经过压测达到性能指标才可,包括某并发量下的tps和历时等;
结语 查看全部
API接口设计,需要注意这4点
笔者查阅了百度、腾讯、旷视、阿里的云平台发觉在视觉方面均都采用的是https合同;对于视觉,图片数据本身收录的信息就太丰富,尤其是人脸,因此采用https还是有利于保护用户隐私信息的。
2. 接口的恳求形式
了解插口的恳求形式有助于了解用户端和服务端间的交互方法,基于http合同的常用恳求方法是post和get;两者的主要区别如下:
(1)直观区别:get恳求方法是将恳求参数放在url中,post是将参数放在requst body中,所带来的的直接影响是get的恳求参数存在宽度限制,post无限制;其次是get将参数放在url中安全性弱于post;
(2)深度区别:get恳求形式用户端和服务端只形成一次交互,post恳求形式用户端会和服务端形成两次交互,举例:快递小哥是用户端,你是服务端,则get如同常来大家新村和你认识的快递员直接将快递送到你家,你跟他说声感谢;post如同新来的快递员先打个电话问下你在家吗?你告诉他你在家呢,过了5分钟他将快件送到你家了,你跟他说声感谢;
目前百度、腾讯、旷视的图象辨识插口均采用的是post恳求形式
3. 接口响应机制
最后了解插口的响应机制:同步插口和异步插口;简单理解同步插口即实时返回消息给调用方,异步插口就是可以延后返回消息给调用方;实时性要求高的且只能线性工作的须要采用同步插口,其他可以优先使用异步接口;当然不同的场景,同样的服务插口会被要求同步或异步;以人脸辨识中的人脸注册为例:
(1)刷脸支付:以支付宝为例,使用之前须要根据步骤采集人脸,后台会调用人脸注册将当前人脸注册进人脸库并和该支付宝帐号信息绑定,这一步人脸注册一般是同步插口,因为不会要求用户在APP前等待很久,需要及时返回注册成功信息;
(2)客流系统:现在商超使用的客流系统通常早已采用人脸辨识代替头肩模型,这样除了可以统计人数还可以统计人次,其中对于首次辨识的陌生人脸一般须要注册进陌生人脸库,这里的人脸注册通常为异步接口,因为小型商超每晚数十万客流且对于陌生人无会员信息,所以不需要实时注册,只要步入队列能在当天24小时内注册完即可;
小结
以上关于API的插口常识在设计插口的时侯,开发通常还会要求产品确定插口的响应机制;其他的开发就会自己完成;但作为开放平台的产品常常会对接开发,多了解些常识既可以跟自己的开发有更多的共同语言沟通,也可以在对接用户的时侯可以跟用户的开发简单解释。
二、核心业务主键&接口约束
产品总监其实不需要定义API所有的数组信息,但是跟业务需求有关的数组产品总监须要明晰清晰。
1. 入参
(1)鉴权数组信息
调用第三方平台插口一般须要进行插口信令,服务端判定用户端是否有调用插口的权限;这里跟产品总监相关的是作为产品须要设计应用管理,包括:应用列表、应用创建、应用详情、应用配置、应用删掉等操作;以百度AI平台,应用列表如下:

其中AppID、API Key和Secret Key为创建应用时手动生成,接口信令所须要的access_token必须通过API key和Secret key恳求服务端获取。
(2)核心业务主键
产品总监须要依照业务需求明晰插口入参中须要什么数组信息以及数组支持的类型,以百度AI平台的食材辨识为例:

业务需求:识别图片中是哪种食材;
产品需求:
输入图片,图片支持一般采用base64和URL格式;top_num,提高插口的通用性,方便用户后续场景扩充,因此支持配置返回食材数目且排序;阈值,开放辨识阀值,方便用户按照实际辨识疗效调整,提高准确率;
注意点:设计插口核心业务主键,要尽量提升插口的通用性,以此适配更多的用户场景,比如top_num和阀值的开放,即泛化插口能力,将更多的主动权交由插口用户配置。
(3)字段信息约束条件
字段约束条件是为了保证插口的安全性,这点是产品总监跟业务方沟通达成一致后提供给开发小伙伴的;仍然以里面的食材辨识为例:
图片须要限制文件大小和帧率大小,文件大小只须要上限,分辨率大小须要包括上限和下限,下限是为了保证算法疗效,比如在目标测量中小目标容易测量失败;top_num须要限制下限,不得大于0,不设上限,可以接受算法返回的所有结果;阈值按照格式确定,可以是0-100,可以是0-1;
注:设置参数的一点小技巧,为了保证算法疗效,有时算法会默认设置参数,即用户设置的阀值高于默认参数,则不接受输入,采用默认,用户是无感知的;
2. 出参
调用插口都会有返回信息,产品须要依照业务需求定义返回的核心数组信息,这次以百度AI开放平台手势辨识为例,其中跟业务需求相关的关键数组包括:

三、接口限流
接口限流也是为了保障系统的安全性,因为有时业务方由于业务扩充造成调用量猛增,容易造成服务端宕机;限流就类似于空开的保险丝保证恳求量超过插口上限时系统可以拒绝恳求或排队,以此保证系统的安全性;
产品总监须要实现对业务充分评估,给出合理评估量,如TPS(每秒处理的恳求量);这样既不会导致系统资源的浪费,也保证业务正常运行;
注:与前面插口响应机制对应,同步插口通常须要给出峰值tps和响应时间,异步插口须要给出日调量即可;
四、接口测试
接口测试似乎是测试小妹哥的工作,测试内容也覆盖诸多,但是作为产品可以简单了解以下内容即可,如,
(1)接口可用性,即插口是否可以正常调用,正常返回结果,异常正确处理,正常返回错误码等;
(2)业务需求覆盖,即插口输入输出是否遵守产品需求文档描述;
(3)边界规则依循,即插口是否满足业务规则和数组约束条件;
(4)性能条件,通常插口上线前须要经过压测达到性能指标才可,包括某并发量下的tps和历时等;
结语
如何塑造“数据中心”的功能清单 第一讲
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2020-08-26 00:26
自第三次技术革命以来,随着信息技术在产业体系中不同程序的应用,完成了不同层次的信息化,产生了各行各业的海量信息。这些信息构成了以信息化为基础的时代。随着信息化不断的发展,数据已不再是简单的信息载体,而是一种能为企业和人类带来更大价值的资产。至此,我们迎来了大数据时代。在这样一个大数据时代,我们须要将被数据化的虚拟世界和现实世界相关联,从数据、信息、知识、智慧、客观规律的数据资产价值链中,将数据的价值逐渐呈现并最终可视化,以应对和解决企业和人类的生存和发展问题。为了实现数据价值从隐性不可看到显性并可见,并满足市场快速变化的业务需求。其中,数据采集是数据中心最为基本也最为关键的能力。
数据采集能力
采集数据的结构
在大数据的时代下,企业和组织的数据呈现出多种款式的数据,但大致可以分成两大类:
第一类:结构化数据,这类数据是一种可预见,经常出现的数据格式,数据结构包括:记录属性,键和索引等。可以通过传统的数据库管理系统加以管理和储存。
例如:交易数据,付款数据,销售活动数据,医疗过程数据等。
第二类:非结构化数据,这类数据可以进一步界定为,重复型和非重复型。
例如:电话记录数据,天气数据等。
例如:电子邮件,医疗记录,呼叫中心数据,交易数据,付款数据。
采集数据的插口
由于结构化数据格式与非结构化的数据格式完全不同,并呈现出多样性,这就要求数据采集能够具有不同的采集接口,以满足不同企业和组织的数据格式要求,从而达到有数据可以剖析的目的。
在采集应用中须要具有如下分类的采集接口:
1.NOSQL数据采集接口:该类插口用于联接非结构化数据对应的数据库和文件系统数据采集。
2. 关系型数据库采集接口:该类插口用于联接传统的关系型数据库数据采集。
包括:MYSQL,ORACLE,TERADATA,SYBASE,SQLSERVER,INFORMIX,ACCESS等商用和开源的关系型数据库。
3. 文件类数据采集接口:该类插口主要是针对各种文件数据采集。
包括:TXT格式文件,CSV格式文件,EXCEL文件,特定分割符格式文件。
4. 网络类数据采集接口:该类插口主要通过服务方式调用或服务恳求采集数据。
包括:webservice服务调用,rest服务调用。
数据处理能力
由于数据所处的业务领域不同,导致数据结构的复杂性也有所不同。使得数据处理过程中须要考虑数据的状态特点。主要包括如下4个特点:
1. 不变性,例如:网络安全的基础信息。
2. 实时性,例如:零售行业高频交易形成的数据,传感装置形成的异常检测数据等。
3. 近实时性,例如:零售行业的行为剖析数据。
4. 高延后和低延后(毫秒和秒级别),例如:气象数据。
以上4种能力决定了数据处理过程中须要采用不同的处理模式。主要模式有以下三种。
数据批处理模式
批处理是一种常见的数据处理模式,批处理模式比较简单,输入一批待处理的文件,启动处理过程。
等待处理结束后输出一个剖析结果文件。批处理模式的输入和输出都是文件的方式。数据剖析启动后用户即难以干预算法过程。批处理常常用于剖析大的文件或则大批量的文件。且剖析过程比较长。
例如:MapReduce 和 HDFS,每个文件输入输出都是HDFS文件,而每位MapReduce任务就是一个批处理过程。
数据流式处理模式
批处理指出的数据的批量处理,有明晰的剖析开始时间和结束时间。而在高延后和低延后数据状态下,数据须要源源不断的流入处理系统,系统就能不停地连续估算,这种估算处理模式及流式处理模式。流处理指出数据估算的连续性,一般具有高实时性,大吞吐量特性。
适合于实时统计,分析和实时决策的应用场景。
例如:基于Storm和内存数据库,可以实现网站在线点击率的实时统计。
Spark Streaming上运行自然语言处理组件,可以实现网路舆情实时监控。
图(交互式)处理模式
交互式处理模式是一种对实时性要求介于批处理和流处理之间的一种模式,这种模式通常面向业务剖析人员,交互式模式要求提供剖析结果的可视化。这种模式容许业务剖析人员在统一的工具框架内,开速开发剖析脚本,并在可容忍的时间内得到结果。并通过可视化诠释方法见到结果的一种数据处理模式,底层的具象数据模型通常是结构化或半结构化的数据。
例如:通过Spark SQL,Impala提供的SQL插口,对数据进行查询和统计剖析。
由于数据的多元化,数据状态的不同数据中心应当具有不同业务场景需求的处理能力。 查看全部
如何塑造“数据中心”的功能清单 第一讲
自第三次技术革命以来,随着信息技术在产业体系中不同程序的应用,完成了不同层次的信息化,产生了各行各业的海量信息。这些信息构成了以信息化为基础的时代。随着信息化不断的发展,数据已不再是简单的信息载体,而是一种能为企业和人类带来更大价值的资产。至此,我们迎来了大数据时代。在这样一个大数据时代,我们须要将被数据化的虚拟世界和现实世界相关联,从数据、信息、知识、智慧、客观规律的数据资产价值链中,将数据的价值逐渐呈现并最终可视化,以应对和解决企业和人类的生存和发展问题。为了实现数据价值从隐性不可看到显性并可见,并满足市场快速变化的业务需求。其中,数据采集是数据中心最为基本也最为关键的能力。
数据采集能力
采集数据的结构
在大数据的时代下,企业和组织的数据呈现出多种款式的数据,但大致可以分成两大类:
第一类:结构化数据,这类数据是一种可预见,经常出现的数据格式,数据结构包括:记录属性,键和索引等。可以通过传统的数据库管理系统加以管理和储存。
例如:交易数据,付款数据,销售活动数据,医疗过程数据等。
第二类:非结构化数据,这类数据可以进一步界定为,重复型和非重复型。
例如:电话记录数据,天气数据等。
例如:电子邮件,医疗记录,呼叫中心数据,交易数据,付款数据。
采集数据的插口
由于结构化数据格式与非结构化的数据格式完全不同,并呈现出多样性,这就要求数据采集能够具有不同的采集接口,以满足不同企业和组织的数据格式要求,从而达到有数据可以剖析的目的。
在采集应用中须要具有如下分类的采集接口:
1.NOSQL数据采集接口:该类插口用于联接非结构化数据对应的数据库和文件系统数据采集。
2. 关系型数据库采集接口:该类插口用于联接传统的关系型数据库数据采集。
包括:MYSQL,ORACLE,TERADATA,SYBASE,SQLSERVER,INFORMIX,ACCESS等商用和开源的关系型数据库。
3. 文件类数据采集接口:该类插口主要是针对各种文件数据采集。
包括:TXT格式文件,CSV格式文件,EXCEL文件,特定分割符格式文件。
4. 网络类数据采集接口:该类插口主要通过服务方式调用或服务恳求采集数据。
包括:webservice服务调用,rest服务调用。
数据处理能力
由于数据所处的业务领域不同,导致数据结构的复杂性也有所不同。使得数据处理过程中须要考虑数据的状态特点。主要包括如下4个特点:
1. 不变性,例如:网络安全的基础信息。
2. 实时性,例如:零售行业高频交易形成的数据,传感装置形成的异常检测数据等。
3. 近实时性,例如:零售行业的行为剖析数据。
4. 高延后和低延后(毫秒和秒级别),例如:气象数据。
以上4种能力决定了数据处理过程中须要采用不同的处理模式。主要模式有以下三种。
数据批处理模式
批处理是一种常见的数据处理模式,批处理模式比较简单,输入一批待处理的文件,启动处理过程。
等待处理结束后输出一个剖析结果文件。批处理模式的输入和输出都是文件的方式。数据剖析启动后用户即难以干预算法过程。批处理常常用于剖析大的文件或则大批量的文件。且剖析过程比较长。
例如:MapReduce 和 HDFS,每个文件输入输出都是HDFS文件,而每位MapReduce任务就是一个批处理过程。
数据流式处理模式
批处理指出的数据的批量处理,有明晰的剖析开始时间和结束时间。而在高延后和低延后数据状态下,数据须要源源不断的流入处理系统,系统就能不停地连续估算,这种估算处理模式及流式处理模式。流处理指出数据估算的连续性,一般具有高实时性,大吞吐量特性。
适合于实时统计,分析和实时决策的应用场景。
例如:基于Storm和内存数据库,可以实现网站在线点击率的实时统计。
Spark Streaming上运行自然语言处理组件,可以实现网路舆情实时监控。
图(交互式)处理模式
交互式处理模式是一种对实时性要求介于批处理和流处理之间的一种模式,这种模式通常面向业务剖析人员,交互式模式要求提供剖析结果的可视化。这种模式容许业务剖析人员在统一的工具框架内,开速开发剖析脚本,并在可容忍的时间内得到结果。并通过可视化诠释方法见到结果的一种数据处理模式,底层的具象数据模型通常是结构化或半结构化的数据。
例如:通过Spark SQL,Impala提供的SQL插口,对数据进行查询和统计剖析。
由于数据的多元化,数据状态的不同数据中心应当具有不同业务场景需求的处理能力。
自主研制wecenter 采集软件 正式面世!
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-08-13 09:10
软件自主研制,全部轮子模块从底层自已造,通用所有开源程序采集与发布的对接,不卖软件,卖的是服务,请往下看:支持图片本地化 支持列表图片本地化 支持图片缩略图(WC似乎用不着),支持图片水印,图片压缩全手动定时采集 +计划多任务同时进行采集软件自带动词功能 wecenter程序采集发布 wecenter可手动生成话题。支持对采集任一内容二次加工,如替换 提取 去除HTML标答 同义词转换软件免费使用!!!软件免费使用!!!软件免费使用!!!下载地址:www . lj55 .net===========以下服务为收费=========wecenter接口(问题+回答+随机用户评论+ 图片本地化)+ 1个网站栏目采集规则+软件配置好 一条龙采集发布设置服务 ! 收费约300 (每个人的需求不一样,那300是底价,接口也不是全通用的,购买者使用水平不一,总要收额外人工费)wecenter插口(文章+评论+随机用户评论)+ 图片本地化+ 1个网站栏目采集规则+软件配置好 一条龙采集发布设置服务 ! 收费约300第二杯五折!===============通过更改规则,wecenter可采集360问答 搜狗问答 天涯问答 知乎问答(只有2条回答) 大部份discuz峰会类程序(其他小型问答类 期盼你的合作再进行测试);文章类程序,就更简单了.===============本人QQ:31699~02984 【优采云】 我也在官方QQ群里请先提供目标网站入口网址,及采集需求,经本人测试后,能采集,再订购。
使用wecenter采集接口和优采云SEO优化软件的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2023-02-11 16:32
wecenter采集接口既可以用于采集文本信息,也可以用于采集图片和视频。它还能够将所采集到的信息存储到本地,方便用户之后使用。此外,它还能够追踪并分析数据,帮助用户精准地判断所采集到的信息是否有用。
优采云是一款强大的SEO优化软件,它可以帮助企业进行网络营销、品牌传播、信息传递等,实现SEO优化目标。此外,它还能够帮助企业利用wecenter采集接口进行数据采集,将有效的信息存储到本地,并对所采集到的信息进行分类和归类。
通过使用优采云,企业不仅能够快速、准确地获取有用的信息,而且还能够根据所需要的内容对所采集到的信息进行归类和分类,从而大大地减少时间成本和人力成本。此外,它还能够帮助企业通过wecenter采集接口对信息进行分析和评估,从而将关键词应用于SEO优化中。
总之,wecenter采集接口是一种非常好的数据采集方式,通过使用优采云SEO优化软件,不仅能够快速、准确地对所需要的内容进行归类和分类;而且还能够根据所需要的关键词将其应用于SEO优化中。通过使用wecenter采集接口和优采云SEO优化软件(官网:www.ucaiyun.com)),企业不但能够快速获取有效信息,还能够大大减少时间成本和人力成本,使SEO优化工作受益。 查看全部
wecenter采集接口是一种非常有效的数据采集方式,它可以让用户轻松地从网络上获取有用的信息。它为用户提供了一个快速、简单、安全的数据采集方式,可以大大提高用户的工作效率和工作质量。
wecenter采集接口既可以用于采集文本信息,也可以用于采集图片和视频。它还能够将所采集到的信息存储到本地,方便用户之后使用。此外,它还能够追踪并分析数据,帮助用户精准地判断所采集到的信息是否有用。
优采云是一款强大的SEO优化软件,它可以帮助企业进行网络营销、品牌传播、信息传递等,实现SEO优化目标。此外,它还能够帮助企业利用wecenter采集接口进行数据采集,将有效的信息存储到本地,并对所采集到的信息进行分类和归类。
通过使用优采云,企业不仅能够快速、准确地获取有用的信息,而且还能够根据所需要的内容对所采集到的信息进行归类和分类,从而大大地减少时间成本和人力成本。此外,它还能够帮助企业通过wecenter采集接口对信息进行分析和评估,从而将关键词应用于SEO优化中。
总之,wecenter采集接口是一种非常好的数据采集方式,通过使用优采云SEO优化软件,不仅能够快速、准确地对所需要的内容进行归类和分类;而且还能够根据所需要的关键词将其应用于SEO优化中。通过使用wecenter采集接口和优采云SEO优化软件(官网:www.ucaiyun.com)),企业不但能够快速获取有效信息,还能够大大减少时间成本和人力成本,使SEO优化工作受益。
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-29 13:15
介绍文档参考。对于一个完整的容器平台来说,容器日志采集也是一个重要的环节。尤其是在微服务架构大行其道的时候,很多程序的访问监控和健康状态检查都依赖于日志信息的采集。由于 Docker 的存在,容器平台中的日志采集与传统方式有很大不同。日志的输出和采集不同于传统的方式。以前很不一样。本文讨论如何在 Rancher 平台采集容器日志。现状 纵观目前容器日志采集的解决方案,无外乎两种方式:一、直接采集Docker标准输出,可以通过Docker的日志驱动(log driver)发送给对应的采集程序;二、非标准输出,延续传统的日志写入方式,容器内的服务直接将日志写入Log文件,以及通过Docker卷映射形式将日志文件映射到Host,日志采集程序直接采集映射后的Log文件。三、通过 Journald 采集二进制日志数据。PS:标准输出:通过docker logs查看的日志信息。在 Ubuntu OS 下,这些信息默认保存在 /var/lib/docker/containers 路径下名为 container ID 的文件夹下的 -json.log 文件中,并以容器 ID 为前缀。非标准输出:根据Docker容器的特点,
如果一个容器要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,默认情况下,这些后台运行的服务生成的日志无法获取为标准输出,生成的日志默认存放在/var/log目录下。第一种方法比较简单,可以直接配置相关的日志驱动(Log driver),但是这种方法也有一些缺点:当宿主机的容器密度比较高的时候,Docker Engine的压力比较大,之后all,容器的标准输出全部由 Docker Engine 处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候,很难做到所有服务的标准输出日志。采集日志日志的方法。虽然我们可以从很多种 Log Drivers 中进行选择,但有些 Log Drivers 会破坏 Docker 的原生体验。例如,日志输出到其他日志服务器后,docker logs 将无法看到容器日志。基于以上考虑,一个完整的日志采集方案必须同时满足标准输出采集和日志量(非标准输出)采集或通过journald采集二进制日志数据。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,普通用户会有自己喜欢的选择。而UI展示是每个公司都有自己的需求,很难形成更好的标准,一般通过定制来解决。因此,本文的主要解决方案是 log采集 解决方案。当然,存储和 UI 显示将连接到开源实现。如果没有特殊要求,也可以有完整的体验。
Rancher下的解决方案(json-file驱动)如上图介绍,ElasticSearch & Kibana可以直接用于日志存储和UI展示。日志采集方面如前所述,需要连接采集两种模式(标准输出日志和非标准输出)。在这个解决方案中,log采集 部分使用了 Fluentd & Logging Helper 的组合。Fluentd 是一个非常通用的 log采集 程序,性能非常好。与Logstash相比,同等压力下它的内存消耗要少很多。为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常见;二、这两个驱动,docker日志还是可以有内容输出的,确保体验的完整性。实现流程实现流程:Fluentd连接Json-file或Journald驱动获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:
方案部署 ElasticSearch & Kibana 部署 通过web登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情,进入后修改最后一个Public端口,默认为80端口,改成其他端口,避免端口冲突。然后去应用商店搜索 Kibana。
在配置选项中,需要选择 Elasticsearch-clients
最终的Public端口根据实际情况修改,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署 目前Rancher日志不在官方仓库中,所以需要添加自定义的存储地址才能使用Rancher日志。点击缩略图管理系统设置进入,点击添加应用商店,名称:rancher -logging 地址:分支:master 最后点击保存返回应用商店。进入应用商店登录搜索:
点击查看详情进入进入配置页面: 本例中,除了Elasticsearch源配置如图所示,其他保持默认:
以上部署完成后,部署一些应用并生成一些访问日志,在Kibana界面可以看到:
使用日志卷方式,需要在Service启动时配置Volume,并且Volume名称需要与之前设置的Volume Pattern相匹配: 查看全部
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一))
介绍文档参考。对于一个完整的容器平台来说,容器日志采集也是一个重要的环节。尤其是在微服务架构大行其道的时候,很多程序的访问监控和健康状态检查都依赖于日志信息的采集。由于 Docker 的存在,容器平台中的日志采集与传统方式有很大不同。日志的输出和采集不同于传统的方式。以前很不一样。本文讨论如何在 Rancher 平台采集容器日志。现状 纵观目前容器日志采集的解决方案,无外乎两种方式:一、直接采集Docker标准输出,可以通过Docker的日志驱动(log driver)发送给对应的采集程序;二、非标准输出,延续传统的日志写入方式,容器内的服务直接将日志写入Log文件,以及通过Docker卷映射形式将日志文件映射到Host,日志采集程序直接采集映射后的Log文件。三、通过 Journald 采集二进制日志数据。PS:标准输出:通过docker logs查看的日志信息。在 Ubuntu OS 下,这些信息默认保存在 /var/lib/docker/containers 路径下名为 container ID 的文件夹下的 -json.log 文件中,并以容器 ID 为前缀。非标准输出:根据Docker容器的特点,
如果一个容器要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,默认情况下,这些后台运行的服务生成的日志无法获取为标准输出,生成的日志默认存放在/var/log目录下。第一种方法比较简单,可以直接配置相关的日志驱动(Log driver),但是这种方法也有一些缺点:当宿主机的容器密度比较高的时候,Docker Engine的压力比较大,之后all,容器的标准输出全部由 Docker Engine 处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候,很难做到所有服务的标准输出日志。采集日志日志的方法。虽然我们可以从很多种 Log Drivers 中进行选择,但有些 Log Drivers 会破坏 Docker 的原生体验。例如,日志输出到其他日志服务器后,docker logs 将无法看到容器日志。基于以上考虑,一个完整的日志采集方案必须同时满足标准输出采集和日志量(非标准输出)采集或通过journald采集二进制日志数据。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,普通用户会有自己喜欢的选择。而UI展示是每个公司都有自己的需求,很难形成更好的标准,一般通过定制来解决。因此,本文的主要解决方案是 log采集 解决方案。当然,存储和 UI 显示将连接到开源实现。如果没有特殊要求,也可以有完整的体验。
Rancher下的解决方案(json-file驱动)如上图介绍,ElasticSearch & Kibana可以直接用于日志存储和UI展示。日志采集方面如前所述,需要连接采集两种模式(标准输出日志和非标准输出)。在这个解决方案中,log采集 部分使用了 Fluentd & Logging Helper 的组合。Fluentd 是一个非常通用的 log采集 程序,性能非常好。与Logstash相比,同等压力下它的内存消耗要少很多。为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常见;二、这两个驱动,docker日志还是可以有内容输出的,确保体验的完整性。实现流程实现流程:Fluentd连接Json-file或Journald驱动获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd到采集。Fluentd 采集到数据后,再将数据传递到 ES 中存储,最后 Kibana 直接在 ES 中展示数据。下面开始描述整个程序的部署过程。先用一张图来描述一下整体的部署结构,如下:
方案部署 ElasticSearch & Kibana 部署 通过web登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情,进入后修改最后一个Public端口,默认为80端口,改成其他端口,避免端口冲突。然后去应用商店搜索 Kibana。
在配置选项中,需要选择 Elasticsearch-clients
最终的Public端口根据实际情况修改,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署 目前Rancher日志不在官方仓库中,所以需要添加自定义的存储地址才能使用Rancher日志。点击缩略图管理系统设置进入,点击添加应用商店,名称:rancher -logging 地址:分支:master 最后点击保存返回应用商店。进入应用商店登录搜索:
点击查看详情进入进入配置页面: 本例中,除了Elasticsearch源配置如图所示,其他保持默认:
以上部署完成后,部署一些应用并生成一些访问日志,在Kibana界面可以看到:
使用日志卷方式,需要在Service启动时配置Volume,并且Volume名称需要与之前设置的Volume Pattern相匹配:
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-11-15 22:23
)
介绍
文档参考。
对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。现状
看目前容器日志采集的各种解决方案,无非两种方式:一、直接采集Docker标准输出,可以通过Docker日志驱动发送到对应的采集程序;二、非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。Log采集 程序直接采集映射的Log文件。三、通过Journald采集二进制日志数据。
PS:
标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。
非标准输出:根据Docker容器的特点,容器启动后必须有一个服务保持前台运行。如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,默认情况下,这些后台运行的服务生成的日志无法作为标准输出获取,生成的日志默认保存在/var/log目录下。
第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:
当宿主机的容器密度比较高时,对Docker Engine的压力比较大。毕竟,容器的标准输出必须由 Docker Engine 处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。
基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald采集二进制日志数据。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是日志采集解决方案。当然,存储和 UI 显示与开源实现对接。没有特殊要求,也可以有完整的体验。
Rancher解决方案(json-文件驱动)解决方案介绍
如上图所示,ElasticSearch & Kibana 可以直接用于日志存储和UI展示。日志采集如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中日志采集部分采用了Fluentd & Logging Helper组合。Fluentd 是一个非常通用的日志程序,具有出色的性能。与Logstash相比,在同样的压力下,它的内存消耗要少得多。
为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常用;二、这两个驱动,docker日志依然可以输出内容,保证了体验的完整性。实施过程
方案实现过程:Fluentd连接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别映射到容器日志卷的路径(非标准输出),并通知Fluentd进行采集。Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。
下面开始讲解整个程序的部署过程。先用一张图来描述整体部署结构,如下:
解决方案部署 ElasticSearch & Kibana 部署
网页登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。
然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后根据实际情况修改Public端口,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,
名称:rancher -logging
地址:
分支:大师
最后点击保存并返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面: 本例中,除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要匹配之前设置的Volume Pattern:
查看全部
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一)
)
介绍
文档参考。
对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。现状
看目前容器日志采集的各种解决方案,无非两种方式:一、直接采集Docker标准输出,可以通过Docker日志驱动发送到对应的采集程序;二、非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。Log采集 程序直接采集映射的Log文件。三、通过Journald采集二进制日志数据。
PS:
标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。
非标准输出:根据Docker容器的特点,容器启动后必须有一个服务保持前台运行。如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,默认情况下,这些后台运行的服务生成的日志无法作为标准输出获取,生成的日志默认保存在/var/log目录下。
第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:
当宿主机的容器密度比较高时,对Docker Engine的压力比较大。毕竟,容器的标准输出必须由 Docker Engine 处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。
基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald采集二进制日志数据。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是日志采集解决方案。当然,存储和 UI 显示与开源实现对接。没有特殊要求,也可以有完整的体验。
Rancher解决方案(json-文件驱动)解决方案介绍
如上图所示,ElasticSearch & Kibana 可以直接用于日志存储和UI展示。日志采集如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中日志采集部分采用了Fluentd & Logging Helper组合。Fluentd 是一个非常通用的日志程序,具有出色的性能。与Logstash相比,在同样的压力下,它的内存消耗要少得多。
为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常用;二、这两个驱动,docker日志依然可以输出内容,保证了体验的完整性。实施过程
方案实现过程:Fluentd连接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别映射到容器日志卷的路径(非标准输出),并通知Fluentd进行采集。Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。
下面开始讲解整个程序的部署过程。先用一张图来描述整体部署结构,如下:
解决方案部署 ElasticSearch & Kibana 部署
网页登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。
然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后根据实际情况修改Public端口,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,
名称:rancher -logging
地址:
分支:大师
最后点击保存并返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面: 本例中,除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要匹配之前设置的Volume Pattern:
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-10-27 11:18
)
介绍
文档参考。
对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。现状
看目前容器日志采集的各种解决方案,无非两种方式:一、直接采集Docker标准输出,可以通过Docker日志驱动发送到对应的采集程序;二、非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。Log采集 程序直接采集映射的Log文件。三、通过Journald采集二进制日志数据。
PS:
标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。
非标准输出:根据Docker容器的特点,容器启动后必须有一个服务来保持前台运行。如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,这些后台运行的服务生成的日志默认无法作为标准输出获取,生成的日志默认会保存在/var/log目录下。
第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:
当宿主机的容器密度比较高时,对Docker Engine的压力比较大。毕竟,容器的标准输出必须由 Docker Engine 处理。虽然原则上我们要遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。
基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald进行二进制日志数据采集。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是日志采集解决方案。当然,存储和 UI 显示与开源实现对接。没有特殊要求,也可以有完整的体验。
Rancher解决方案(json-文件驱动)解决方案介绍
如上图所示,ElasticSearch & Kibana 可以直接用于日志存储和UI展示。日志采集如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中日志采集部分采用了Fluentd & Logging Helper组合。Fluentd 是一个非常通用的日志程序,具有出色的性能。与Logstash相比,在同样的压力下,它的内存消耗要少得多。
为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常用;二、这两个驱动,docker日志依然可以输出内容,保证了体验的完整性。实施过程
方案实现过程:Fluentd连接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别映射到容器日志卷的路径(非标准输出),并通知Fluentd进行采集。Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。
下面开始讲解整个程序的部署过程。先用一张图来描述整体的部署结构,如下:
解决方案部署 ElasticSearch & Kibana 部署
网页登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。
然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后根据实际情况修改Public端口,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,
名称:rancher -logging
地址:
分支:大师
最后点击保存并返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面: 本例中,除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要匹配之前设置的Volume Pattern:
查看全部
wecenter采集接口(Rancher平台内如何做容器日志收集现状纵览(一)
)
介绍
文档参考。
对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。现状
看目前容器日志采集的各种解决方案,无非两种方式:一、直接采集Docker标准输出,可以通过Docker日志驱动发送到对应的采集程序;二、非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。Log采集 程序直接采集映射的Log文件。三、通过Journald采集二进制日志数据。
PS:
标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。
非标准输出:根据Docker容器的特点,容器启动后必须有一个服务来保持前台运行。如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,这些后台运行的服务生成的日志默认无法作为标准输出获取,生成的日志默认会保存在/var/log目录下。
第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:
当宿主机的容器密度比较高时,对Docker Engine的压力比较大。毕竟,容器的标准输出必须由 Docker Engine 处理。虽然原则上我们要遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。
基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald进行二进制日志数据采集。当然,在一个完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是日志采集解决方案。当然,存储和 UI 显示与开源实现对接。没有特殊要求,也可以有完整的体验。
Rancher解决方案(json-文件驱动)解决方案介绍
如上图所示,ElasticSearch & Kibana 可以直接用于日志存储和UI展示。日志采集如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中日志采集部分采用了Fluentd & Logging Helper组合。Fluentd 是一个非常通用的日志程序,具有出色的性能。与Logstash相比,在同样的压力下,它的内存消耗要少得多。
为了保证Dokcer和Rancher体验的完整性,Docker Log Driver选择Json-file或者Journald的原因是:一、json-file和journald比较常用;二、这两个驱动,docker日志依然可以输出内容,保证了体验的完整性。实施过程
方案实现过程:Fluentd连接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据;Logging Helper可以理解为Fluentd的助手,可以识别映射到容器日志卷的路径(非标准输出),并通知Fluentd进行采集。Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。
下面开始讲解整个程序的部署过程。先用一张图来描述整体的部署结构,如下:
解决方案部署 ElasticSearch & Kibana 部署
网页登录Rancher,进入应用商店,搜索ElasticSearch,推荐安装2.x版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。
然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后根据实际情况修改Public端口,避免冲突。
服务正常启动后,即可通过该端口访问 Kibana 网页。
Rancher日志服务部署目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,
名称:rancher -logging
地址:
分支:大师
最后点击保存并返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面: 本例中,除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要匹配之前设置的Volume Pattern:
wecenter采集接口 2019独角兽企业重金招聘Python工程师标准(gt)(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-08-18 00:17
2019年独角兽企业重磅Python工程师招聘标准>>>
背景
随着酒店业务的快速发展,我们为用户和企业提供的服务越来越精细,系统的服务化程度和复杂程度也逐渐提高。微服务虽然可以很好的解决问题,但也有副作用,比如问题定位。
每次定位到问题,都需要找同事帮我从源头查日志。一个简单的例子:
“这个详情页的价格是如何计算的?”
一次访问用户的酒店空房页面(POI详情页面),流量最多需要经过73个服务节点。在排查问题的时候,我们需要找到4到5个关键节点的同学,帮助我们登录十多个不同节点的机器,查询具体的日志。沟通成本很高,效率很低。
为了解决这个问题,基础架构同学提供了MTrace(详见技术博客:《分布式会话跟踪系统架构的设计与实践》)协助业务方排查长链接问题.
但同时,也有许多不确定因素使故障排除过程变得更加困难,甚至徒劳无功:
各个服务节点存储日志的时间长度不一致;一些服务节点,因为QPS太高,只能不打印或随机打印日志,最终查到问题时,会因为没有日志而导致线索断掉;一些服务节点使用异步逻辑(线程池、Hystrix、异步RPC等),导致日志中缺少trace ID,无法链接在一起;每个服务节点的采样率不同,链路数据的上报率也是随机的,线索很容易被破解; MTrace只有链接信息,没有与每个服务节点相关联的日志信息;动态扩展节点上的日志收缩后找不到了。
总结如图:
目标
有两个核心需求:
根据用户行为快速定位到具体的Trace ID,然后查询服务调用链路上所有节点的日志;实时查询必须准实时(以秒为单位输出),相关链接日志必须在独立的外部存储系统中存储半年以上。
然后我们进一步拆分上诉:
记录所有日志是不现实的。需要有选择地记录,记录日志中最有价值的部分;链路数据需要所有服务节点上传,避免链路数据因不同步等原因中断上传;访问方式尽量简单,避免所有服务节点都需要修改具体的服务代码才能访问。最好拦截日志,其他保持透明;日志格式化,部分字段(AppKey、主机名、IP、时间戳等)不需要在业务RD中重复输入,自动填充;在不阻塞原有业务操作的情况下,准实时展示链接和日志;链路数据和日志数据的存储不依赖于每个业务节点,需要在独立的存储系统上存储半年以上。系统
明确核心需求后,我们进行了大量针对性研究,最终确定了一个整体的系统设计方案。这就是已经上线、实践已久的“卫星系统”。
接下来,我们将详细介绍系统,包括一些核心细节。
架构
如下图所示,卫星系统横向分为链路和日志两部分。
图2 全链路日志系统整体架构
链接部分基于MTrace,使用支持超时回退Trace信息传输的Hystrix-Trace插件覆盖所有场景,保证链接完整采集。
日志部分在接入端有三个核心步骤。首先是基于日志拦截组件以零侵入业务代码的方式采集系统中所有的日志内容,然后按照统一的日志规范对日志进行格式化,最后通过logcenter实现日志到Kafka的传输——基于日志传输机制。
从纵向来看,分为:
业务接入层,根据策略采集Trace和业务日志;
数据处理层,通过storm流处理日志信息;
数据存储层,用于支持实时查询松鼠(美团点评Redis集群)和持久化存储ES(ElasticSearch),以及面向用户的展示层。
日志抽样计划
接入点是所有数据的来源,因此程序设计极为关键。需要解决的问题有:采集策略、链接完整性保护、日志拦截、日志格式化、日志传输。
在一些业务中,单机日总日志量超过100G,很多业务因为QPS高,选择不正常打印日志,只在排查时通过动态日志级别调整临时输出。因此,我们在最初采集日志时必须进行权衡。经过分析发现,在大多数情况下,排查问题时,发起方都是自己的(RD、PM、Operations)。如果我们只记录这些人发起的链接日志,目标日志量会非常高。自然解决了日志量过大导致的缩减量大、存储时间短、查询时效性差的问题。
所以我们开发了这个采集 策略:
通过判断发起者在链接入口服务是否遇到特定人群(住宿业务部员工),决定是否登录采集,通过MTrace将采集标识传递给整个链接。这样可以保证链路上的所有节点都可以一致的选择是否上报日志,保证链路上日志的完整性。
日志阻塞
作为日志的核心元素,如何采集是个棘手的问题。强制业务端使用我们的接口进行日志输出会带来很多麻烦。一方面会影响业务端原有的日志输出策略;另一方面,系统原有的日志输出点众多,涉及的业务也是多种多样、变化多端的。一点很简单,但是如果一刀切的改变,很难保证不会有未知的影响。因此,有必要尽可能减少访问方代码的入侵。
由于酒店的核心业务已经完全集成到log4j2中,经过研究,我们发现可以注册一个全局Filter来遍历系统的所有日志。这一发现使我们能够以零代码更改采集系统的所有日志。
图3 基于log4j2过滤机制的日志采集策略
日志格式
业务系统输出的日志格式不同。比如有的不打印TraceID信息,有的不打印日志位置信息,定位困难。这主要带来两个问题。一方面不利于人为主导的调查分析工作,另一方面也不利于后续系统优化升级,如日志、告警的自动分析。
针对这些问题,我们设计了统一的日志规范,框架完成了缺失内容的填充。同时,我们为业务端提供了标准化的日志接口。业务端可以通过该接口定义日志的元数据,为后续的自动化支持分析奠定基础。
框架填充统一日志信息的过程利用了log4j2的Plugins机制,通过Properties、Lookups、ContextMap实现业务无感知操作。
图4 通过Plugins机制支持格式化日志属性传输
日志处理
在最后的日志传输环节,我们利用日志中心的传输机制,利用日志中心的ScribeAppender实现日志传输到本地agent,再上报到远程Kafka。这种设计有几个优点:
依托公司成熟的基础服务,相对更加可靠稳定,也无需搭建服务,保障服务安全;日志可以直接传输到日志中心ES进行持久化存储,同时支持快速灵活的数据检索;日志可通过Storm进行流式传输,支持灵活的系统扩展,如实时检索、基于日志的实时业务检查、告警等,为后续系统扩展升级奠定基础。
我们的数据处理逻辑全部在Storm中处理,主要包括日志存储Squirrel(美团点评基于Redis Cluster开发的纯内存存储)、实时检索和Trace同步。
目前日志中心ES可以保证分钟级的实时性,但对于RD排查来说还不够。它必须支持第二级的实时性能。因此,我们选择将特定目标用户的日志直接存储到 Squirrel 中。过期时间只有半小时。在查询日志的时候,结合ES和Squirrel,这样既满足了秒级的实时性,又保证了日志量不会太大。压力可以忽略不计。
我们系统的核心数据有链接和日志。链接信息是通过MTrace服务获取的,但是MTrace服务对于链接数据的存储时间有限,不能满足我们的需求。因此,我们通过延迟队列从MTrace获取最近的链路信息并存储在地面上,从而实现数据的闭环,保证数据的完整性。
链接完整性保证
MTrace组件的trace传递功能基于ThreadLocal,酒店业务使用大量异步逻辑(线程池,Hystrix),会造成传输的信息丢失,破坏链路完整性。
一方面,Sonar对关键环节进行检查和梳理,确保业务端使用transmittable-thread-local中类似于ExecutorServiceTtlWrapper.java和ExecutorTtlWrapper.java的包,将ThreadLocal中的Trace信息传输到异步线程(上面提到的MTrace也提供了这样的包)。
另一方面,Hystrix 的线程池模式会导致线程变量丢失。为了解决这个问题,MTrace 提供了 Mtrace Hystrix Support Plugin 来实现跨线程调用时线程变量的传递。但是由于Hystrix有专门的定时器线程池用于超时回退调用,在超时的情况下会进入回退逻辑之后的链接。信息丢失。
针对这个问题,我们对Hystrix机制进行了深入研究,最终结合Hystrix Command Execution Hook、Hystrix Concurrency Strategy、Hystrix Request Context实现了一个覆盖整个Hystrix-Trace插件场景,保证链接的完整性。
HystrixPlugins.getInstance().registerCommandExecutionHook(new HystrixCommandExecutionHook() {
@Override
public void onStart(HystrixInvokable commandInstance) {
// 执行command之前将trace信息保存至hystrix上下文,实现超时子线程的trace传递
if (!HystrixRequestContext.isCurrentThreadInitialized()) {
HystrixRequestContext.initializeContext();
}
spanVariable.set(Tracer.getServerSpan());
}
@Override
public Exception onError(HystrixInvokable commandInstance, HystrixRuntimeException.FailureType failureType, Exception e) {
// 执行结束后清空hystrix上下文信息
HystrixRequestContext context = HystrixRequestContext.getContextForCurrentThread();
if (context != null) {
context.shutdown();
}
return e;
}
@Override
public void onSuccess(HystrixInvokable commandInstance) {
// 执行结束后清空hystrix上下文信息
HystrixRequestContext context = HystrixRequestContext.getContextForCurrentThread();
if (context != null) {
context.shutdown();
}
}
});
HystrixPlugins.getInstance().registerConcurrencyStrategy(new HystrixConcurrencyStrategy() {
@Override
public Callable wrapCallable(Callable callable) {
// 通过自定义callable保存trace信息
return WithTraceCallable.get(callable);
}
});
业绩展示
例如,以用户单击 POI 详细信息页面的 TraceID 为例进行故障排除:
我们可以看到他在MTrace中的调用链接是这样的:
在卫星系统中,显示如下效果:
可以看出,系统在保存链路数据的基础上,还将所有链路节点日志聚合在一起,提高了调查效率。
后续规划
目前该系统还处于起步阶段,主要用于解决RD在排查中的两大痛点:不完整和过于分散的日志信息。这个需求现在已经得到满足。但是,全链接日志系统可以做的远不止这些。主要后续计划如下:
支持多链接日志相关搜索,如列表页刷新和后续详情页展示,虽然有多个链接,但实际上是在一个相关的场景中。支持关联搜索,可以将日志调查对象从单个动作维度扩展到多个动作组成的场景维度。支持业务侧自定义策略规则,自动进行基于日志的业务正确性检查。如发现问题,可直接将详细信息通知相关人员,实现日志实时监控、问题实时发现、实时通知到位,省去人工和人工。有效的劳动。作者介绍
雅辉,2015年加入美团点评,在后端研发团队工作。
曾军,2013年加入美团点评,在后端研发团队工作。
最后,我会发布一个广告。后端研发团队长期招聘Java后端及架构人才。有兴趣的同学可以把简历发到xuguanfei#。
转载于: 查看全部
wecenter采集接口 2019独角兽企业重金招聘Python工程师标准(gt)(图)
2019年独角兽企业重磅Python工程师招聘标准>>>
背景
随着酒店业务的快速发展,我们为用户和企业提供的服务越来越精细,系统的服务化程度和复杂程度也逐渐提高。微服务虽然可以很好的解决问题,但也有副作用,比如问题定位。
每次定位到问题,都需要找同事帮我从源头查日志。一个简单的例子:
“这个详情页的价格是如何计算的?”
一次访问用户的酒店空房页面(POI详情页面),流量最多需要经过73个服务节点。在排查问题的时候,我们需要找到4到5个关键节点的同学,帮助我们登录十多个不同节点的机器,查询具体的日志。沟通成本很高,效率很低。
为了解决这个问题,基础架构同学提供了MTrace(详见技术博客:《分布式会话跟踪系统架构的设计与实践》)协助业务方排查长链接问题.
但同时,也有许多不确定因素使故障排除过程变得更加困难,甚至徒劳无功:
各个服务节点存储日志的时间长度不一致;一些服务节点,因为QPS太高,只能不打印或随机打印日志,最终查到问题时,会因为没有日志而导致线索断掉;一些服务节点使用异步逻辑(线程池、Hystrix、异步RPC等),导致日志中缺少trace ID,无法链接在一起;每个服务节点的采样率不同,链路数据的上报率也是随机的,线索很容易被破解; MTrace只有链接信息,没有与每个服务节点相关联的日志信息;动态扩展节点上的日志收缩后找不到了。
总结如图:
目标
有两个核心需求:
根据用户行为快速定位到具体的Trace ID,然后查询服务调用链路上所有节点的日志;实时查询必须准实时(以秒为单位输出),相关链接日志必须在独立的外部存储系统中存储半年以上。
然后我们进一步拆分上诉:
记录所有日志是不现实的。需要有选择地记录,记录日志中最有价值的部分;链路数据需要所有服务节点上传,避免链路数据因不同步等原因中断上传;访问方式尽量简单,避免所有服务节点都需要修改具体的服务代码才能访问。最好拦截日志,其他保持透明;日志格式化,部分字段(AppKey、主机名、IP、时间戳等)不需要在业务RD中重复输入,自动填充;在不阻塞原有业务操作的情况下,准实时展示链接和日志;链路数据和日志数据的存储不依赖于每个业务节点,需要在独立的存储系统上存储半年以上。系统
明确核心需求后,我们进行了大量针对性研究,最终确定了一个整体的系统设计方案。这就是已经上线、实践已久的“卫星系统”。
接下来,我们将详细介绍系统,包括一些核心细节。
架构
如下图所示,卫星系统横向分为链路和日志两部分。
图2 全链路日志系统整体架构
链接部分基于MTrace,使用支持超时回退Trace信息传输的Hystrix-Trace插件覆盖所有场景,保证链接完整采集。
日志部分在接入端有三个核心步骤。首先是基于日志拦截组件以零侵入业务代码的方式采集系统中所有的日志内容,然后按照统一的日志规范对日志进行格式化,最后通过logcenter实现日志到Kafka的传输——基于日志传输机制。
从纵向来看,分为:
业务接入层,根据策略采集Trace和业务日志;
数据处理层,通过storm流处理日志信息;
数据存储层,用于支持实时查询松鼠(美团点评Redis集群)和持久化存储ES(ElasticSearch),以及面向用户的展示层。
日志抽样计划
接入点是所有数据的来源,因此程序设计极为关键。需要解决的问题有:采集策略、链接完整性保护、日志拦截、日志格式化、日志传输。
在一些业务中,单机日总日志量超过100G,很多业务因为QPS高,选择不正常打印日志,只在排查时通过动态日志级别调整临时输出。因此,我们在最初采集日志时必须进行权衡。经过分析发现,在大多数情况下,排查问题时,发起方都是自己的(RD、PM、Operations)。如果我们只记录这些人发起的链接日志,目标日志量会非常高。自然解决了日志量过大导致的缩减量大、存储时间短、查询时效性差的问题。
所以我们开发了这个采集 策略:
通过判断发起者在链接入口服务是否遇到特定人群(住宿业务部员工),决定是否登录采集,通过MTrace将采集标识传递给整个链接。这样可以保证链路上的所有节点都可以一致的选择是否上报日志,保证链路上日志的完整性。
日志阻塞
作为日志的核心元素,如何采集是个棘手的问题。强制业务端使用我们的接口进行日志输出会带来很多麻烦。一方面会影响业务端原有的日志输出策略;另一方面,系统原有的日志输出点众多,涉及的业务也是多种多样、变化多端的。一点很简单,但是如果一刀切的改变,很难保证不会有未知的影响。因此,有必要尽可能减少访问方代码的入侵。
由于酒店的核心业务已经完全集成到log4j2中,经过研究,我们发现可以注册一个全局Filter来遍历系统的所有日志。这一发现使我们能够以零代码更改采集系统的所有日志。
图3 基于log4j2过滤机制的日志采集策略
日志格式
业务系统输出的日志格式不同。比如有的不打印TraceID信息,有的不打印日志位置信息,定位困难。这主要带来两个问题。一方面不利于人为主导的调查分析工作,另一方面也不利于后续系统优化升级,如日志、告警的自动分析。
针对这些问题,我们设计了统一的日志规范,框架完成了缺失内容的填充。同时,我们为业务端提供了标准化的日志接口。业务端可以通过该接口定义日志的元数据,为后续的自动化支持分析奠定基础。
框架填充统一日志信息的过程利用了log4j2的Plugins机制,通过Properties、Lookups、ContextMap实现业务无感知操作。
图4 通过Plugins机制支持格式化日志属性传输
日志处理
在最后的日志传输环节,我们利用日志中心的传输机制,利用日志中心的ScribeAppender实现日志传输到本地agent,再上报到远程Kafka。这种设计有几个优点:
依托公司成熟的基础服务,相对更加可靠稳定,也无需搭建服务,保障服务安全;日志可以直接传输到日志中心ES进行持久化存储,同时支持快速灵活的数据检索;日志可通过Storm进行流式传输,支持灵活的系统扩展,如实时检索、基于日志的实时业务检查、告警等,为后续系统扩展升级奠定基础。
我们的数据处理逻辑全部在Storm中处理,主要包括日志存储Squirrel(美团点评基于Redis Cluster开发的纯内存存储)、实时检索和Trace同步。
目前日志中心ES可以保证分钟级的实时性,但对于RD排查来说还不够。它必须支持第二级的实时性能。因此,我们选择将特定目标用户的日志直接存储到 Squirrel 中。过期时间只有半小时。在查询日志的时候,结合ES和Squirrel,这样既满足了秒级的实时性,又保证了日志量不会太大。压力可以忽略不计。
我们系统的核心数据有链接和日志。链接信息是通过MTrace服务获取的,但是MTrace服务对于链接数据的存储时间有限,不能满足我们的需求。因此,我们通过延迟队列从MTrace获取最近的链路信息并存储在地面上,从而实现数据的闭环,保证数据的完整性。
链接完整性保证
MTrace组件的trace传递功能基于ThreadLocal,酒店业务使用大量异步逻辑(线程池,Hystrix),会造成传输的信息丢失,破坏链路完整性。
一方面,Sonar对关键环节进行检查和梳理,确保业务端使用transmittable-thread-local中类似于ExecutorServiceTtlWrapper.java和ExecutorTtlWrapper.java的包,将ThreadLocal中的Trace信息传输到异步线程(上面提到的MTrace也提供了这样的包)。
另一方面,Hystrix 的线程池模式会导致线程变量丢失。为了解决这个问题,MTrace 提供了 Mtrace Hystrix Support Plugin 来实现跨线程调用时线程变量的传递。但是由于Hystrix有专门的定时器线程池用于超时回退调用,在超时的情况下会进入回退逻辑之后的链接。信息丢失。
针对这个问题,我们对Hystrix机制进行了深入研究,最终结合Hystrix Command Execution Hook、Hystrix Concurrency Strategy、Hystrix Request Context实现了一个覆盖整个Hystrix-Trace插件场景,保证链接的完整性。
HystrixPlugins.getInstance().registerCommandExecutionHook(new HystrixCommandExecutionHook() {
@Override
public void onStart(HystrixInvokable commandInstance) {
// 执行command之前将trace信息保存至hystrix上下文,实现超时子线程的trace传递
if (!HystrixRequestContext.isCurrentThreadInitialized()) {
HystrixRequestContext.initializeContext();
}
spanVariable.set(Tracer.getServerSpan());
}
@Override
public Exception onError(HystrixInvokable commandInstance, HystrixRuntimeException.FailureType failureType, Exception e) {
// 执行结束后清空hystrix上下文信息
HystrixRequestContext context = HystrixRequestContext.getContextForCurrentThread();
if (context != null) {
context.shutdown();
}
return e;
}
@Override
public void onSuccess(HystrixInvokable commandInstance) {
// 执行结束后清空hystrix上下文信息
HystrixRequestContext context = HystrixRequestContext.getContextForCurrentThread();
if (context != null) {
context.shutdown();
}
}
});
HystrixPlugins.getInstance().registerConcurrencyStrategy(new HystrixConcurrencyStrategy() {
@Override
public Callable wrapCallable(Callable callable) {
// 通过自定义callable保存trace信息
return WithTraceCallable.get(callable);
}
});
业绩展示
例如,以用户单击 POI 详细信息页面的 TraceID 为例进行故障排除:
我们可以看到他在MTrace中的调用链接是这样的:
在卫星系统中,显示如下效果:
可以看出,系统在保存链路数据的基础上,还将所有链路节点日志聚合在一起,提高了调查效率。
后续规划
目前该系统还处于起步阶段,主要用于解决RD在排查中的两大痛点:不完整和过于分散的日志信息。这个需求现在已经得到满足。但是,全链接日志系统可以做的远不止这些。主要后续计划如下:
支持多链接日志相关搜索,如列表页刷新和后续详情页展示,虽然有多个链接,但实际上是在一个相关的场景中。支持关联搜索,可以将日志调查对象从单个动作维度扩展到多个动作组成的场景维度。支持业务侧自定义策略规则,自动进行基于日志的业务正确性检查。如发现问题,可直接将详细信息通知相关人员,实现日志实时监控、问题实时发现、实时通知到位,省去人工和人工。有效的劳动。作者介绍
雅辉,2015年加入美团点评,在后端研发团队工作。
曾军,2013年加入美团点评,在后端研发团队工作。
最后,我会发布一个广告。后端研发团队长期招聘Java后端及架构人才。有兴趣的同学可以把简历发到xuguanfei#。
转载于:
QQAPI智能调用系统php版v1.1资源介绍:Windows/Linux/Mac资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-11 18:31
[资源属性]:
资源名称:QQAPI智能呼叫系统php版v1.1
资源大小:8.75MB
资源类别:源码下载》php源码
更新时间:2021-06-24
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
QQAPI智能调用系统是用php开发的调用api接口的源码。
收录API:网址加群/网址加好友/网址获取QQ头像/网址获取空间头像
安装说明:
环境要求:PHP5.2及以上丨Windows/Linux丨IIS/Apache/nginx
安装步骤:上传所有文件到主机根目录
目录说明:
/api/----------网站interface 文件目录(不要修改接口文件以防出错)
/config/-------网站data 文件目录(配置网站homepage相关内容)
/css/----------网站样式文件目录(首页样式可根据自己的需要修改)
/img/---------网站图片文件目录(首页图片可根据需要修改)
/js/-----------网站特效文件目录
/videos/-------网站动态后台和静态后台存放目录
index.php------网站首页
QQAPI智能呼叫系统更新日志:
V1.1 bulid2017.01.25
-->添加接口:获取QQ秀API
界面介绍:URL+QQ号直接获取QQ秀图片
-->添加接口:手机号码信息查询API
界面介绍:URL+手机号直接获取手机号相关信息
-->添加接口:IP地址定位API
界面介绍:URL+IP地址直接标示IP在百度地图中的位置
-->添加接口:视频C值分析API
界面介绍:URL+C值可以直接在线播放C值的视频
特别感谢:本界面由可可电视网友情提供()
--> 目录更新:搭建云API接口,供使用本系统的站长直接调用 查看全部
QQAPI智能调用系统php版v1.1资源介绍:Windows/Linux/Mac资源
[资源属性]:
资源名称:QQAPI智能呼叫系统php版v1.1
资源大小:8.75MB
资源类别:源码下载》php源码
更新时间:2021-06-24
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
QQAPI智能调用系统是用php开发的调用api接口的源码。
收录API:网址加群/网址加好友/网址获取QQ头像/网址获取空间头像
安装说明:
环境要求:PHP5.2及以上丨Windows/Linux丨IIS/Apache/nginx
安装步骤:上传所有文件到主机根目录
目录说明:
/api/----------网站interface 文件目录(不要修改接口文件以防出错)
/config/-------网站data 文件目录(配置网站homepage相关内容)
/css/----------网站样式文件目录(首页样式可根据自己的需要修改)
/img/---------网站图片文件目录(首页图片可根据需要修改)
/js/-----------网站特效文件目录
/videos/-------网站动态后台和静态后台存放目录
index.php------网站首页
QQAPI智能呼叫系统更新日志:
V1.1 bulid2017.01.25
-->添加接口:获取QQ秀API
界面介绍:URL+QQ号直接获取QQ秀图片
-->添加接口:手机号码信息查询API
界面介绍:URL+手机号直接获取手机号相关信息
-->添加接口:IP地址定位API
界面介绍:URL+IP地址直接标示IP在百度地图中的位置
-->添加接口:视频C值分析API
界面介绍:URL+C值可以直接在线播放C值的视频
特别感谢:本界面由可可电视网友情提供()
--> 目录更新:搭建云API接口,供使用本系统的站长直接调用
wecenter采集接口 阿里蜘蛛池php版v3.0资源大小:10.7MB资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-08 03:43
[资源属性]:
资源名称:阿里蜘蛛池php版本v3.0
资源大小:10.7MB
资源类别:源码下载》php源码
更新时间:2021-06-25
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
阿里蜘蛛池是一个蜘蛛算法引导程序,可以快速提升网站在搜索引擎中的排名。阿里巴巴蜘蛛池采用最新技术防K,秒采集,秒排,持久稳定,无任何租借时间,打造自己的超级收录。
软件功能:
1、免费,免费,免费
国内首个官方免费版蜘蛛池程序
2、技术实力雄厚
阿里蜘蛛池由中国促进会和先知教育共同开发。它采用PHP+MYSQL架构,采用先进的PHP技术,资源占用低,速度快,支持大数据、大并发。页面生成速度比其他TXT蜘蛛池快一百倍以上
3、第一个跨平台蜘蛛池
完美支持Linux系统的所有发行版。降低服务器开销,低配置服务器依然可以高速吸引蜘蛛
4、Spider 算法进展
中促院卡卡老师亲自提供蜘蛛算法技术指导。最新技术防K,秒采集,秒排,持久稳定
5、Massive 模板免费下载
避免创建用户模板的痛苦。也可根据用户实际情况免费单独定制
6、根据关键词自动跳转页面
用户可以根据页面关键词重定向到不同的目标网站,不影响蜘蛛正常访问
7、url 自动推送
集成自动外推,24小时不间断外推运行,增加蜘蛛访问量
8、热新闻Auto采集
热点新闻标题和内容自动采集,采集间隔可自定义。 采集无需写规则,随官网更新。
9、强站群功能、模板定制
站群使用智能链轮减少被K的几率。模板可以自定义标题、关键词、描述、页面URL样式、文字标题和后台文章内容构成结构
10、 Spider Pool 退房出租
后台开启蜘蛛池平台,格子可以出租。个人用户管理界面
11、PC模板和手机模板分别指定
可以为蜘蛛池中的每个域名指定PC模板和手机模板,不同的蜘蛛和用户可以访问不同的模板
12、蜘蛛统计系统
实时日志分析系统,准确实时统计如百度、360、Google、手机蜘蛛等,各种图表分析让您一目了然看到蜘蛛访问情况,无需浪费时间并努力分析各种日志
13、Spider源码随意控制
带有搜索引擎蜘蛛开关,可随意控制7个搜索蜘蛛
14、程序自带一键升级
后台一键升级,时刻保持蜘蛛池程序最新技术,无需频繁登录操作服务器
15、稳定的交流平台
阿里巴巴蜘蛛池论坛一直致力于打造中国最大的SEO交流平台,为互联网从业者提供良好的交流平台和技术支持,助力站长成长
16、专业售后维护
所有用户都会有专属的交流群,方便技术交流、软件bug提交、建议反馈等。
v3.0 更新日志:
添加功能:
1、加入权重池,锚链接+锚文本
2、Backstage 添加外推函数链接
3、判断移动蜘蛛和移动蜘蛛统计
4、区分句子和段落
5、添加对多个冷门后缀域名的支持
6、add 关键词跳转
7、为域名分别指定PC模板和手机模板,并增加一键指定和一键随机按钮
8、添加了api接口,方便其他程序(如寄生虫)自动向阿里蜘蛛池添加数据
9、自定义缓存更新时间
优化:
1、去掉页面底部阿里蜘蛛池的版权代码
2、外链管理强化成索引池
3、优化所有模板和网址样式
4、Background蜘蛛切换100%盾蜘蛛
5、采集文章伪原创处理标题和内容
6、Background 所有链接自动添加确定“//”开头,没有添加的自动添加。
7、optimization采集,推断执行效率
8、去除打开缓存URL样式设置无效
9、采集文章少于100个汉字的内容不会存入数据库
10、采集文章标题内容对应
11、重新优化标题、关键词、描述、url样式、文章title、文章content
12、优化链轮结构
13、采集文章打开图片采集
14、开php5.4,支持win2003,放弃iis全系列支持,只支持apache
15、程序自带10000个段落,3000个句子,关键词4000,外推页面1300条
16、根据蜘蛛和用户情况,分别调用PC模板和手机模板
修复:
1、搜狗蜘蛛统计失败
2、帮助地址无效
3、bing 蜘蛛统计失败
4、Index pool和weight pool为空,导致空链接 查看全部
wecenter采集接口 阿里蜘蛛池php版v3.0资源大小:10.7MB资源
[资源属性]:
资源名称:阿里蜘蛛池php版本v3.0
资源大小:10.7MB
资源类别:源码下载》php源码
更新时间:2021-06-25
资源语言:简体中文
授权方式:免费下载
使用平台:Windows/Linux/Mac
资源介绍:
阿里蜘蛛池是一个蜘蛛算法引导程序,可以快速提升网站在搜索引擎中的排名。阿里巴巴蜘蛛池采用最新技术防K,秒采集,秒排,持久稳定,无任何租借时间,打造自己的超级收录。
软件功能:
1、免费,免费,免费
国内首个官方免费版蜘蛛池程序
2、技术实力雄厚
阿里蜘蛛池由中国促进会和先知教育共同开发。它采用PHP+MYSQL架构,采用先进的PHP技术,资源占用低,速度快,支持大数据、大并发。页面生成速度比其他TXT蜘蛛池快一百倍以上
3、第一个跨平台蜘蛛池
完美支持Linux系统的所有发行版。降低服务器开销,低配置服务器依然可以高速吸引蜘蛛
4、Spider 算法进展
中促院卡卡老师亲自提供蜘蛛算法技术指导。最新技术防K,秒采集,秒排,持久稳定
5、Massive 模板免费下载
避免创建用户模板的痛苦。也可根据用户实际情况免费单独定制
6、根据关键词自动跳转页面
用户可以根据页面关键词重定向到不同的目标网站,不影响蜘蛛正常访问
7、url 自动推送
集成自动外推,24小时不间断外推运行,增加蜘蛛访问量
8、热新闻Auto采集
热点新闻标题和内容自动采集,采集间隔可自定义。 采集无需写规则,随官网更新。
9、强站群功能、模板定制
站群使用智能链轮减少被K的几率。模板可以自定义标题、关键词、描述、页面URL样式、文字标题和后台文章内容构成结构
10、 Spider Pool 退房出租
后台开启蜘蛛池平台,格子可以出租。个人用户管理界面
11、PC模板和手机模板分别指定
可以为蜘蛛池中的每个域名指定PC模板和手机模板,不同的蜘蛛和用户可以访问不同的模板
12、蜘蛛统计系统
实时日志分析系统,准确实时统计如百度、360、Google、手机蜘蛛等,各种图表分析让您一目了然看到蜘蛛访问情况,无需浪费时间并努力分析各种日志
13、Spider源码随意控制
带有搜索引擎蜘蛛开关,可随意控制7个搜索蜘蛛
14、程序自带一键升级
后台一键升级,时刻保持蜘蛛池程序最新技术,无需频繁登录操作服务器
15、稳定的交流平台
阿里巴巴蜘蛛池论坛一直致力于打造中国最大的SEO交流平台,为互联网从业者提供良好的交流平台和技术支持,助力站长成长
16、专业售后维护
所有用户都会有专属的交流群,方便技术交流、软件bug提交、建议反馈等。
v3.0 更新日志:
添加功能:
1、加入权重池,锚链接+锚文本
2、Backstage 添加外推函数链接
3、判断移动蜘蛛和移动蜘蛛统计
4、区分句子和段落
5、添加对多个冷门后缀域名的支持
6、add 关键词跳转
7、为域名分别指定PC模板和手机模板,并增加一键指定和一键随机按钮
8、添加了api接口,方便其他程序(如寄生虫)自动向阿里蜘蛛池添加数据
9、自定义缓存更新时间
优化:
1、去掉页面底部阿里蜘蛛池的版权代码
2、外链管理强化成索引池
3、优化所有模板和网址样式
4、Background蜘蛛切换100%盾蜘蛛
5、采集文章伪原创处理标题和内容
6、Background 所有链接自动添加确定“//”开头,没有添加的自动添加。
7、optimization采集,推断执行效率
8、去除打开缓存URL样式设置无效
9、采集文章少于100个汉字的内容不会存入数据库
10、采集文章标题内容对应
11、重新优化标题、关键词、描述、url样式、文章title、文章content
12、优化链轮结构
13、采集文章打开图片采集
14、开php5.4,支持win2003,放弃iis全系列支持,只支持apache
15、程序自带10000个段落,3000个句子,关键词4000,外推页面1300条
16、根据蜘蛛和用户情况,分别调用PC模板和手机模板
修复:
1、搜狗蜘蛛统计失败
2、帮助地址无效
3、bing 蜘蛛统计失败
4、Index pool和weight pool为空,导致空链接
苹果CMS程序添加自定义资源库(图)未绑定分类
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-04 00:42
Applecms程序是一个运行在PHP+MYSQL环境下的完整而强大的快速建站系统。经过近年的开发经验和技术积累,苹果cms程序已经逐渐成熟,已经...
Applecms程序是一个运行在PHP+MYSQL环境下的完整而强大的快速建站系统。经过近多年的开发经验和技术积累,苹果cms程序已经逐渐成熟,在易用性和功能性方面已经成为行业的佼佼者。
添加自定义资源库
首先进入系统后台-->采集-->自定义资源库-->添加。
添加采集网站的接口地址并命名,接口类型选择xml,资源类型选择video。然后选择测试,如图所示成功,保存。
保存后点击采集day。
后面会看到类似的界面,我这里已经绑定了。如果你之前没有使用过这个采集站,你会想要在下图中的“动画[绑定]”,点击“绑定”。这次是绑定分类,根据自己的想法自定义分类。
具体设置在基础-->分类管理-->添加。绑定好分类后,当天再次点击采集就会看到视频可以入库了。一些未绑定的类别不会存入库中,然后根据自己的需要采集当周,或者采集All。
汽车采集
我们不可能每天都自己点击采集按钮,需要添加自动化任务。这里需要打开三个标签。
1个自定义资源库(采集-->自定义资源库)
2 计时任务(系统 --> 计时任务)
3宝塔后台定时任务(登录宝塔后左侧任务栏-->定时任务)
自定义采集库中采集button右键复制当天链接地址
修改复制的地址,删除ac=cj&前面的东西。
转到定时任务选项卡(上面提到的2)
将上面修改的东西复制到“Additional Parameters”中,选择“Select All”,其他随便填,保存。点击“测试”,如下所示。
之后,右击“测试”按钮复制链接地址。
然后去宝塔中的定时任务,选择任务类型访问URL,名称任意,执行周期自行设置,URL地址填写你刚才复制的链接地址并保存。
您可能遇到的问题
1.未经授权的访问
新添加的分类需要修改权限,否则无法访问,提示没有权限。
修改权限在User-->Member Group,修改相应设置。
勾选新添加的分类权限并保存。
2.没有播放选项
问题是没有添加自定义资源库的播放器。
添加视频-->播放器-->.
这里,添加各个资源站的玩家。不同的资源站玩家是不同的。应该有关于如何添加资源站的介绍。这里就不写了。
查看全部
苹果CMS程序添加自定义资源库(图)未绑定分类
Applecms程序是一个运行在PHP+MYSQL环境下的完整而强大的快速建站系统。经过近年的开发经验和技术积累,苹果cms程序已经逐渐成熟,已经...
Applecms程序是一个运行在PHP+MYSQL环境下的完整而强大的快速建站系统。经过近多年的开发经验和技术积累,苹果cms程序已经逐渐成熟,在易用性和功能性方面已经成为行业的佼佼者。
添加自定义资源库
首先进入系统后台-->采集-->自定义资源库-->添加。
https://www.qingmo.net/wp-cont ... 9.jpg 768w" />添加采集网站的接口地址并命名,接口类型选择xml,资源类型选择video。然后选择测试,如图所示成功,保存。
https://www.qingmo.net/wp-cont ... 3.jpg 768w" />保存后点击采集day。
https://www.qingmo.net/wp-cont ... 3.jpg 768w" />后面会看到类似的界面,我这里已经绑定了。如果你之前没有使用过这个采集站,你会想要在下图中的“动画[绑定]”,点击“绑定”。这次是绑定分类,根据自己的想法自定义分类。
具体设置在基础-->分类管理-->添加。绑定好分类后,当天再次点击采集就会看到视频可以入库了。一些未绑定的类别不会存入库中,然后根据自己的需要采集当周,或者采集All。
汽车采集
我们不可能每天都自己点击采集按钮,需要添加自动化任务。这里需要打开三个标签。
1个自定义资源库(采集-->自定义资源库)
2 计时任务(系统 --> 计时任务)
3宝塔后台定时任务(登录宝塔后左侧任务栏-->定时任务)
自定义采集库中采集button右键复制当天链接地址
修改复制的地址,删除ac=cj&前面的东西。
https://www.qingmo.net/wp-cont ... 3.jpg 768w" />转到定时任务选项卡(上面提到的2)
https://www.qingmo.net/wp-cont ... 2.jpg 768w" />将上面修改的东西复制到“Additional Parameters”中,选择“Select All”,其他随便填,保存。点击“测试”,如下所示。
之后,右击“测试”按钮复制链接地址。
然后去宝塔中的定时任务,选择任务类型访问URL,名称任意,执行周期自行设置,URL地址填写你刚才复制的链接地址并保存。
您可能遇到的问题
1.未经授权的访问
新添加的分类需要修改权限,否则无法访问,提示没有权限。
修改权限在User-->Member Group,修改相应设置。
https://www.qingmo.net/wp-cont ... 6.jpg 768w" />勾选新添加的分类权限并保存。
https://www.qingmo.net/wp-cont ... 7.jpg 768w" />2.没有播放选项
问题是没有添加自定义资源库的播放器。
添加视频-->播放器-->.
这里,添加各个资源站的玩家。不同的资源站玩家是不同的。应该有关于如何添加资源站的介绍。这里就不写了。
https://www.qingmo.net/wp-cont ... 4.jpg 768w" /> Java用户接口工具箱AWT的使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-08-03 00:23
Java 用户界面工具箱 AWT 的使用
Java 编程语言类库提供了一个名为抽象窗口工具的用户界面工具箱
Box,简称AWT(AbstractWindowingToolkit)。 AWT 不仅功能强大,而且
而且使用起来简单灵活。本文介绍了 AWT 的基本原理以及如何创建一个小程序或一个
创建简单用户界面的应用方法。
一、什么是用户界面
所谓的用户界面就是程序中与程序的用户进行交互的部分。用户访问
端口有多种形式,从简单的命令行界面到图形用户界面。
在系统的最底层,操作系统将鼠标和键盘输入的信息传递给程序,
并提供像素作为程序输出。 AWT 旨在防止程序员使用
关心鼠标的跟踪或键盘的细节,更别说写屏幕工作了
。 AWT 提供了一个精心设计的、面向对象的
对于这些低级服务和资源
界面。
由于 Java 编程语言是平台无关的,因此 AWT 也是平台无关的。
AWT 为在不同平台上工作的图形用户界面设计了一个通用工具集
。 AWT 提供的用户界面元素使用每个平台自己的 GUI 工具箱,所以有保证
留下对应操作平台的外观。这是 AWT 最突出的特点之一。但是这种处理
该方法的缺点是在某个软件平台上设计的图形用户界面在另一个平台上是平的。
当它在舞台上运行时,它会改变。
二、组件和容器
图形用户界面由图形元素组件组成。典型组件包
包括按钮、滚动条和文本框。该组件允许用户继续程序
交互,并以视觉反馈的形式向用户提供程序状态。在 AWT 中,所有
用户界面组件都是组件类或组件类的子类型的实例。
组件不能单独存在,它总是放在容器中。容器收录和控制
组件的布局,容器本身也是一个组件,也可以放在其他容器中。在 AWT 中
在
,所有容器都是容器类的实例或容器类的子类型。
图 1 描绘了在 Windows95 平台上显示的简单图形用户界面
。图2显示了图1中界面组件的树状关系。
三、组件类型
图 3 展示了 AWT 提供的用户界面组件类之间的继承关系。组件类
(组件类)定义了所有组件必须遵守的接口。
图一
图二
图 3
AWT 提供了 9 个基本的无容器组件类。使用它们来构建用户界面
(当然,新的组件类可以从其中任何一个获取,也可以从组件类本身获取)。这9个
类是按钮、画布、复选框、选择、标签、列表
类、滚动条类、TextArea 类、TextField 类。
四、容器类型
AWT 提供了 4 个容器类。它们是 Windows 类及其两个子类型——Fram
e 类和 Dialog 类和 Panel 类。除了AWT提供的容器外,Applet类也是
一个容器,它是 Panel 类的子类型,可以容纳组件。图4显示
AWT 提供的每个容器的简要说明。图4
五、创建容器
在添加构成用户界面的组件之前,程序员必须创建一个容器。什么时候
在构建应用程序时,程序员必须首先创建一个Windows类或Frame类
示例。构造Applet时,Frame类的实例已经存在,无需处理
由音序器创建。由于Applet类是Panel类的子类,程序员可以申请Appl
将组件添加到 et 类的实例中。
代码 1 创建一个空框架。框架的标题(“Example1”)在构造函数中
设置数字。 Frame一开始是不可见的,必须调用它的show()方法才能使之
可见。
代码 1:空帧
importjava.awt.*;
publicclassExample1
{
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1");
f.show();
}
}
代码2扩展了代码1,新类继承了Panel类。在 main() 方法中,创建
通过调用Frame类的add()方法构建并添加了这个新类的一个实例
我对象。
代码 2:带有空面板的框架
importjava.awt.*;
publicclassExamplelaextendsPanel
{
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1a");
Examplelaex=newExample1a();
f.add("Center",ex);
f.pack();
f.show();
}
}
以下示例中的新类继承自 Applet 类,而不是继承自 Panel 类。
所以这个例子可以作为一个独立的应用程序或者嵌入到一个网页中
上的小程序
。此示例显示在代码 3 中。
代码 3:一个带有空小程序的框架
importjava.awt.*;
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1b");
Exammple1bex=newExample1b();
f.add("Center",ex);
f.pack();
f.show();
}
}
注意:Windows 对象和 Dialog 对象在某些情况下可以替代 Frame 对
大象。它们都是有效的容器。组件可以用同样的方式添加到每个容器中
进入。
六、将组件添加到容器中
为了实用性,用户界面可以收录多个容器——每个容器收录
组件。组件可以通过容器的 add() 方法添加到容器中。共有三个 add() 方法
一种基本形式。使用的方法取决于容器上的布局管理器。
代码4在代码3中添加了两个按钮的创建,创建在init()方法中
当然。因为在小程序初始化的时候会自动调用。因此,无论程序如何打开
一开始可以创建按钮,可以通过浏览器或者main()方法调用init()。
代码 4:工具中有两个按钮的小程序
importjava.awt.*;
publicclassExample3extendsjava.applet.Applet
{
publicvoidinit()
{
add(newButton("one"));
add(newButton("two"));
}
publicDimesionpreferredSize()
{
returnnewDimesion(200,100);
}
publicstaticvoidmain(stringargs[])
{
Framef=newFrame("Example3");
Example3ex=newExample3();
ex.init();
f.add("Center",ex);
f.pack();
f.show();
}
七、组件布局
到目前为止,我们还没有提到添加到容器中的组件是如何进行版本控制的
表面布局。布局不是由容器控制,而是由容器相关的布局管理
由进程控制。布局管理器决定了所有组件在容器中的放置方式
。在 AWT 中,所有布局管理器类都实现了 LayoutManager 接口。
AWT 提供了五种类型的布局管理程序,从简单到复杂不等。它
我们是BorderLayout类、CardLayout类、FlowLayout类、GridBagLayou
t 类,GridLayout 类。
1.BorderLayout 类是所有窗口(框架和对话框)的默认布局
管理程序。它有 5 个区域,如图 5 所示。这些区域被称为“北”,“
南”、“东”、“西”和“中心”。图 5
单个组件可以放置在这 5 个区域中的任何一个。什么时候改
当封闭容器的大小发生变化时,每个边界区域的大小也会发生变化以使其足够
该空间容纳放置在其中的组件。任何多余的空间都合并到中心区域。内容
设备的 add() 方法用于向其添加组件。 add() 方法有两个参数,其中第一个
参数是一个字符串对象,其中放置了组件区域的名称。
2.当某个区域在不同时间收录不同的组件时,应该使用Carde
rLayout 类。此类通常与 Choice 相关联。
3.FlowLayout 类是所有 Panel 类(和 Applet 类)的默认布局管理程序
前言。在容器中,它从左到右放置组件。当一行空间用完时,更新
线
开始存储。
4.GridBagLayout 类是 AWT 提供的最复杂、最灵活的布局管理程序
。可以水平和垂直排列组件,并且组件可以有不同的大小。
5.GridLayout 只是在需要的行号中显示一串大小相同的组件
以及由列号决定的位置。
代码 5 使用布局管理器和更多用户界面组件。
代码 5:一个更复杂的例子
importjava.awt.*;
publicclassExample4extendsjava.applet.Applet
{
publicvoidinit()
{
面板;
setLayout(newBorderLayout());
p=newPanel();
p.add(newTextArea());
add("中心",p);
p=newPanel();
p.add(newButton("one"));
p.add(newButton("two"));
Choicec=newChoice()
c.addItem("one");
c.addItem("两个");
c.addItem("三");
p.add(c);
add("南",P);
}
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example4");
Example4ex=newExample4();
ex.init();
f.add("Center",ex);
f.pack();
f.show();
}
}
上面的例子只是展示了一个没有交互功能的用户界面。如果你让用户
界面具有交互能力,所以必须涉及事件处理。
每个事件收录以下参数:
id 标识符;
target-事件发生的对象;
arg-任意参数;
事件发生的x,y坐标;
when 事件的时间印记;
evt-相邻事件;
key-键盘事件中按下的键;
modifers-修饰键的状态(即ALT、CTRL)。
用户将需要处理三种类型的事件,即键盘、鼠标、GUI/窗口
。所有事件都在一般的handleEvent(Eventevt)方法中处理,但使用
用户可以使用以下预定义的方法:
可以在 KeyDown() 和 KeyUp() 方法中处理键盘事件;
鼠标事件可以在mouseXXXX()方法中处理;
GUI 事件在 action() 方法中处理。
下面两段代码是等价的。
publicbooleankeyDown(Eventevt,intkey)
{
System.out.println(key);
返回假;
}
publicbooleanhandleEvent(Eventevt)
{
开关(evt.id)
{
caseEvent.KEY-PRESS:
{
System.out.println(evt.key);
返回真;
}
默认:
返回假;
}
}
事件既可以发生在组件中,也可以发生在容器中,因为对于每个
对于要处理的信息,它们都需要一个“扩展”类。所以处理容器中的事件
比在组件中处理事件更好。
--
※来源:.南大百合信息交换站。 [来自:] 查看全部
Java用户接口工具箱AWT的使用
Java 用户界面工具箱 AWT 的使用
Java 编程语言类库提供了一个名为抽象窗口工具的用户界面工具箱
Box,简称AWT(AbstractWindowingToolkit)。 AWT 不仅功能强大,而且
而且使用起来简单灵活。本文介绍了 AWT 的基本原理以及如何创建一个小程序或一个
创建简单用户界面的应用方法。
一、什么是用户界面
所谓的用户界面就是程序中与程序的用户进行交互的部分。用户访问
端口有多种形式,从简单的命令行界面到图形用户界面。
在系统的最底层,操作系统将鼠标和键盘输入的信息传递给程序,
并提供像素作为程序输出。 AWT 旨在防止程序员使用
关心鼠标的跟踪或键盘的细节,更别说写屏幕工作了
。 AWT 提供了一个精心设计的、面向对象的
对于这些低级服务和资源
界面。
由于 Java 编程语言是平台无关的,因此 AWT 也是平台无关的。
AWT 为在不同平台上工作的图形用户界面设计了一个通用工具集
。 AWT 提供的用户界面元素使用每个平台自己的 GUI 工具箱,所以有保证
留下对应操作平台的外观。这是 AWT 最突出的特点之一。但是这种处理
该方法的缺点是在某个软件平台上设计的图形用户界面在另一个平台上是平的。
当它在舞台上运行时,它会改变。
二、组件和容器
图形用户界面由图形元素组件组成。典型组件包
包括按钮、滚动条和文本框。该组件允许用户继续程序
交互,并以视觉反馈的形式向用户提供程序状态。在 AWT 中,所有
用户界面组件都是组件类或组件类的子类型的实例。
组件不能单独存在,它总是放在容器中。容器收录和控制
组件的布局,容器本身也是一个组件,也可以放在其他容器中。在 AWT 中
在
,所有容器都是容器类的实例或容器类的子类型。
图 1 描绘了在 Windows95 平台上显示的简单图形用户界面
。图2显示了图1中界面组件的树状关系。
三、组件类型
图 3 展示了 AWT 提供的用户界面组件类之间的继承关系。组件类
(组件类)定义了所有组件必须遵守的接口。
图一
图二
图 3
AWT 提供了 9 个基本的无容器组件类。使用它们来构建用户界面
(当然,新的组件类可以从其中任何一个获取,也可以从组件类本身获取)。这9个
类是按钮、画布、复选框、选择、标签、列表
类、滚动条类、TextArea 类、TextField 类。
四、容器类型
AWT 提供了 4 个容器类。它们是 Windows 类及其两个子类型——Fram
e 类和 Dialog 类和 Panel 类。除了AWT提供的容器外,Applet类也是
一个容器,它是 Panel 类的子类型,可以容纳组件。图4显示
AWT 提供的每个容器的简要说明。图4
五、创建容器
在添加构成用户界面的组件之前,程序员必须创建一个容器。什么时候
在构建应用程序时,程序员必须首先创建一个Windows类或Frame类
示例。构造Applet时,Frame类的实例已经存在,无需处理
由音序器创建。由于Applet类是Panel类的子类,程序员可以申请Appl
将组件添加到 et 类的实例中。
代码 1 创建一个空框架。框架的标题(“Example1”)在构造函数中
设置数字。 Frame一开始是不可见的,必须调用它的show()方法才能使之
可见。
代码 1:空帧
importjava.awt.*;
publicclassExample1
{
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1");
f.show();
}
}
代码2扩展了代码1,新类继承了Panel类。在 main() 方法中,创建
通过调用Frame类的add()方法构建并添加了这个新类的一个实例
我对象。
代码 2:带有空面板的框架
importjava.awt.*;
publicclassExamplelaextendsPanel
{
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1a");
Examplelaex=newExample1a();
f.add("Center",ex);
f.pack();
f.show();
}
}
以下示例中的新类继承自 Applet 类,而不是继承自 Panel 类。
所以这个例子可以作为一个独立的应用程序或者嵌入到一个网页中
上的小程序
。此示例显示在代码 3 中。
代码 3:一个带有空小程序的框架
importjava.awt.*;
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example1b");
Exammple1bex=newExample1b();
f.add("Center",ex);
f.pack();
f.show();
}
}
注意:Windows 对象和 Dialog 对象在某些情况下可以替代 Frame 对
大象。它们都是有效的容器。组件可以用同样的方式添加到每个容器中
进入。
六、将组件添加到容器中
为了实用性,用户界面可以收录多个容器——每个容器收录
组件。组件可以通过容器的 add() 方法添加到容器中。共有三个 add() 方法
一种基本形式。使用的方法取决于容器上的布局管理器。
代码4在代码3中添加了两个按钮的创建,创建在init()方法中
当然。因为在小程序初始化的时候会自动调用。因此,无论程序如何打开
一开始可以创建按钮,可以通过浏览器或者main()方法调用init()。
代码 4:工具中有两个按钮的小程序
importjava.awt.*;
publicclassExample3extendsjava.applet.Applet
{
publicvoidinit()
{
add(newButton("one"));
add(newButton("two"));
}
publicDimesionpreferredSize()
{
returnnewDimesion(200,100);
}
publicstaticvoidmain(stringargs[])
{
Framef=newFrame("Example3");
Example3ex=newExample3();
ex.init();
f.add("Center",ex);
f.pack();
f.show();
}
七、组件布局
到目前为止,我们还没有提到添加到容器中的组件是如何进行版本控制的
表面布局。布局不是由容器控制,而是由容器相关的布局管理
由进程控制。布局管理器决定了所有组件在容器中的放置方式
。在 AWT 中,所有布局管理器类都实现了 LayoutManager 接口。
AWT 提供了五种类型的布局管理程序,从简单到复杂不等。它
我们是BorderLayout类、CardLayout类、FlowLayout类、GridBagLayou
t 类,GridLayout 类。
1.BorderLayout 类是所有窗口(框架和对话框)的默认布局
管理程序。它有 5 个区域,如图 5 所示。这些区域被称为“北”,“
南”、“东”、“西”和“中心”。图 5
单个组件可以放置在这 5 个区域中的任何一个。什么时候改
当封闭容器的大小发生变化时,每个边界区域的大小也会发生变化以使其足够
该空间容纳放置在其中的组件。任何多余的空间都合并到中心区域。内容
设备的 add() 方法用于向其添加组件。 add() 方法有两个参数,其中第一个
参数是一个字符串对象,其中放置了组件区域的名称。
2.当某个区域在不同时间收录不同的组件时,应该使用Carde
rLayout 类。此类通常与 Choice 相关联。
3.FlowLayout 类是所有 Panel 类(和 Applet 类)的默认布局管理程序
前言。在容器中,它从左到右放置组件。当一行空间用完时,更新
线
开始存储。
4.GridBagLayout 类是 AWT 提供的最复杂、最灵活的布局管理程序
。可以水平和垂直排列组件,并且组件可以有不同的大小。
5.GridLayout 只是在需要的行号中显示一串大小相同的组件
以及由列号决定的位置。
代码 5 使用布局管理器和更多用户界面组件。
代码 5:一个更复杂的例子
importjava.awt.*;
publicclassExample4extendsjava.applet.Applet
{
publicvoidinit()
{
面板;
setLayout(newBorderLayout());
p=newPanel();
p.add(newTextArea());
add("中心",p);
p=newPanel();
p.add(newButton("one"));
p.add(newButton("two"));
Choicec=newChoice()
c.addItem("one");
c.addItem("两个");
c.addItem("三");
p.add(c);
add("南",P);
}
publicstaticvoidmain(Stringargs[])
{
Framef=newFrame("Example4");
Example4ex=newExample4();
ex.init();
f.add("Center",ex);
f.pack();
f.show();
}
}
上面的例子只是展示了一个没有交互功能的用户界面。如果你让用户
界面具有交互能力,所以必须涉及事件处理。
每个事件收录以下参数:
id 标识符;
target-事件发生的对象;
arg-任意参数;
事件发生的x,y坐标;
when 事件的时间印记;
evt-相邻事件;
key-键盘事件中按下的键;
modifers-修饰键的状态(即ALT、CTRL)。
用户将需要处理三种类型的事件,即键盘、鼠标、GUI/窗口
。所有事件都在一般的handleEvent(Eventevt)方法中处理,但使用
用户可以使用以下预定义的方法:
可以在 KeyDown() 和 KeyUp() 方法中处理键盘事件;
鼠标事件可以在mouseXXXX()方法中处理;
GUI 事件在 action() 方法中处理。
下面两段代码是等价的。
publicbooleankeyDown(Eventevt,intkey)
{
System.out.println(key);
返回假;
}
publicbooleanhandleEvent(Eventevt)
{
开关(evt.id)
{
caseEvent.KEY-PRESS:
{
System.out.println(evt.key);
返回真;
}
默认:
返回假;
}
}
事件既可以发生在组件中,也可以发生在容器中,因为对于每个
对于要处理的信息,它们都需要一个“扩展”类。所以处理容器中的事件
比在组件中处理事件更好。
--
※来源:.南大百合信息交换站。 [来自:]
nginx服务影响修改nginx配置文件限制因素分析及操作建议
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-07-31 07:02
第一步:下载并获取动态网站code信息
官方网站开源代码:dedecms/phpcms
代码下载地址
phpcms
/html/download/phpcms/#content
dedecms
产品/Dedecms/软件下载_织梦cms
(三),搭建动态论坛网站
第一步:下载并获取动态网站code信息
论坛网站开源代码:discuz
代码下载地址
配件·DiscuzX/Discuz X3.4-码云
(四),建动态知乎网站
第一步:下载并获取动态网站code信息
知乎网站开源代码:wecenter
代码下载地址
免费获取WeCenter | WeCenter 创建您的知乎
(五),构建动态视频网站
第一步:下载并获取动态网站code信息
视频网站开源代码:movcms
代码下载地址
下载-电影节目-MOVcms官方-Powered by movcms
动态网站构建后上传数据
动态网站交互模式
权限不足,无法上传数据
修改php-fpm服务程序进程用户与nginxworker进程用户一致
客户端数据上传大小有限制
限制因素1:由于nginx服务的影响
修改nginx配置文件
server {
listen 80;
server_name blog.oldboy.com;
root /html/blog;
index index.php index.html;
client_max_body_size 10m;
}
限制因素二:受PHP服务影响
修改php配置文件
vim /etc/php.ini
799 upload_max_filesize = 10M -- 调整大小为10M
六、LNMP 架构数据库分离
数据库分离的原因:可以实现数据共享和存储
(一),数据库服务迁移过程
第一步:备份数据信息
(迁移前的 Web 服务器)
mysqldump -uroot -poldboy123 -A > /tmp/backup.sql
第 2 步:迁移数据
(迁移前的 Web 服务器)
scp -rp /tmp/backup.sql 172.16.1.51:/tmp/
第 3 步:恢复数据
(迁移后的mysql服务器)
mysql -uroot -poldboy123 < /tmp/backup.sql
数据库数据迁移完成后需要进行操作
第一步:迁移前关闭服务器数据库服务
systemctl stop mariadb.service
systemctl disable mariadb.service
第2步:需要修改连接数据库的代码信息
vim /html/blog/wp-config.php
32 define( 'DB_HOST', '172.16.1.51' );
第三步:需要调整数据库用户配置信息
grant all on wordpress.* to 'wordpress'@'172.16.1.%' identified by 'oldboy123';
七、LNMP架构网站系列存储服务
串联原因:实现数据共享和存储
(一),系列过程
第一步:保存并备份本地存储的数据
mkdir /tmp/blog_backup
mv /html/blog/wp-content/uploads/* /tmp/blog_backup/
步骤二:检查存储服务是否可以正常使用
showmount -e 172.16.1.31
第三步:进行存储服务挂载操作
mount -t nfs 172.16.1.31:/data/blog/ /html/blog/wp-content/uploads/
第四步:恢复之前备份的数据
cp /tmp/blog_backup/* /html/blog/wp-content/uploads/
八、编译安装PHP
第一步:检查PHP是否安装
systemctl status php-fpm.service
systemctl stop php-fpm.service
步骤二:获取PHP源码包
wget http://php.net/distributions/php-7.1.0.tar.gz
第 3 步:解决 PHP 依赖
yum install -y libxml2 libxml2-devel openssl openssl-devel bzip2 bzip2-devel libcurl libcurl-devel libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel gmp gmp-devel libmcrypt libmcrypt-devel readline readline-devel libxslt libxslt-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel ncurses curl gdbm-devel db4-devel libXpm-devel libX11-devel gd-devel gmp-devel expat-devel xmlrpc-c xmlrpc-c-devel libicu-devel libmcrypt-devel libmemcached-devel
步骤 4:: 解压软件程序
tar -zxvf php-7.1.0.tar.gz
第五步:编译安装
1、将解压后的目录移动到指定目录并创建软链接
mv php-7.1.0 /app
cd /app
ln -s php-7.1.0/ php
2、进入php目录并编译
cd php
./configure --prefix=/application/php-7.1 --enable-fpm --enable-inline-optimization --disable-debug --disable-rpath --enable-shared --enable-soap --with-libxml-dir --with-xmlrpc --with-openssl --with-mcrypt --with-mhash --with-pcre-regex --with-sqlite3 --with-zlib --enable-bcmath --with-iconv --with-bz2 --enable-calendar --with-curl --with-cdb --enable-dom --enable-exif --enable-fileinfo --enable-filter --with-pcre-dir --enable-ftp --with-gd --with-openssl-dir --with-jpeg-dir --with-png-dir --with-zlib-dir --with-freetype-dir --enable-gd-native-ttf --enable-gd-jis-conv --with-gettext --with-gmp --with-mhash --enable-json --enable-mbstring --enable-mbregex --enable-mbregex-backtrack --with-libmbfl --with-onig --enable-pdo --with-mysqli=mysqlnd --with-pdo-mysql=mysqlnd --with-zlib-dir --with-pdo-sqlite --with-readline --enable-session --enable-shmop --enable-simplexml --enable-sockets --enable-sysvmsg --enable-sysvsem --enable-sysvshm --enable-wddx --with-libxml-dir --with-xsl --enable-zip --enable-mysqlnd-compression-support --with-pear --enable-opcache
3、安装
make && make install
第六步:调整或创建配置文件
cd /application/php-7.1/ #进入到程序目录
cp etc/php-fpm.conf.default etc/php-fpm.conf
cp etc/php-fpm.d/www.conf.default etc/php-fpm.d/www.conf
cd /app/php #进入到源码包目录
cp php.ini-production /application/php-7.1/lib/php.ini
第七步:启动php服务程序
/application/php/sbin/php-fpm
第八步:测试PHP是否启动成功
写网站配置文件
vim /etc/nginx/conf.d/www.conf
server {
listen 80;
server_name www.oldboy.com;
root /html/www;
index index.html index.php;
location ~ \.php$ {
root /html/www;
fastcgi_index index.php;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
编写测试页面站点文件
/html/www/test_php.php
页面访问测试文件
第九步:检查PHP安装过程中编译了哪些参数
/application/php/bin/php -i|grep configure
九、PHP 优化(一)、PHP 缓存加速器优化
功能
缓存加速器主要用于提高动态分析的效率
实现方法
部署前准备
配置环境变量
echo 'export LC_ALL=C'>> /etc/profile
source /etc/profile
安装 Perl 相关软件依赖
yum -y install perl-devel
方法一:使用电子加速器
1、eAccelerator 介绍
安装和配置参数比较简单,加速效果也不错。
Ÿ 文档很多,但是软件官方更新很慢,社区不活跃。
Y 仅适用于 PHP 版本5.4 以下的程序
2、eAccelerator 安装
进入源码包目录
cd /server/tools
获取源码包
wget https://github.com/downloads/e ... r.bz2
解压源码包
tar xf eaccelerator-0.9.6.1.tar.bz2
编译安装
cd eaccelerator-0.9.6.1
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-eaccelerator --with-php-config=/application/php-7.1/bin/php-config
make && make install
方法二:使用xcache
1、xcache 介绍
经过测试,XCache 的效率更高,速度更快。
XCache 软件开发社区更加活跃,最新版本将于 2014 年底发布。
支持更高版本的PHP,如PHP5.5、PHP 5.6。
2、xcache 安装
进入源码包目录
cd /server/tools
获取源码包
wget http://xcache.lighttpd.net/pub ... r.bz2
解压源码包
tar xf xcache-3.2.0.tar.bz2
编译安装包
cd xcache-3.2.0
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-xcache --with-php-config=/application/php/bin/php-config
make && make install
方法三:使用zend opcache
1、zend opcache 介绍
默认已集成在php程序中,无需单独安装加速软件
2、zend opcache 安装
进入源码包目录
cd /server/tools
获取源码包
wget -q http://pecl.php.net/get/zendopcache-7.0.5.tgz
解压源码包
tar xf zendopcache-7.0.5.tgz
编译安装
cd zendopcache-7.0.5
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-opcache --with-php-config=/application/php/bin/php-config
make && make install
(二),PHP缓存功能优化1、memcache缓存插件
PHP缓存优化原理
Mencache 插件安装部署
第一步:获取插件源码包
wget https://github.com/websupport- ... 7.zip
步骤二:将源码包解压到指定目录
cd /server/tools
unzip NON_BLOCKING_IO_php7.zip
第三步:编译安装memcache
cd pecl-memcache-NON_BLOCKING_IO_php7/
/application/php-7.1/bin/phpize
./configure --enable-memcache --with-php-config=/application/php-7.1/bin/php-config
make && make install
memcache 插件应用配置
第一步:修改配置文件
PS:添加到最后
vim /application/php-7.1/lib/php.ini
extension = "/application/php-7.1/lib/php/extensions/no-debug-non-zts-20160303/memcache.so"
第 2 步:重启 php-fpm 查看全部
nginx服务影响修改nginx配置文件限制因素分析及操作建议
第一步:下载并获取动态网站code信息
官方网站开源代码:dedecms/phpcms
代码下载地址
phpcms
/html/download/phpcms/#content
dedecms
产品/Dedecms/软件下载_织梦cms
(三),搭建动态论坛网站
第一步:下载并获取动态网站code信息
论坛网站开源代码:discuz
代码下载地址
配件·DiscuzX/Discuz X3.4-码云
(四),建动态知乎网站
第一步:下载并获取动态网站code信息
知乎网站开源代码:wecenter
代码下载地址
免费获取WeCenter | WeCenter 创建您的知乎
(五),构建动态视频网站
第一步:下载并获取动态网站code信息
视频网站开源代码:movcms
代码下载地址
下载-电影节目-MOVcms官方-Powered by movcms
动态网站构建后上传数据
动态网站交互模式
权限不足,无法上传数据
修改php-fpm服务程序进程用户与nginxworker进程用户一致
客户端数据上传大小有限制
限制因素1:由于nginx服务的影响
修改nginx配置文件
server {
listen 80;
server_name blog.oldboy.com;
root /html/blog;
index index.php index.html;
client_max_body_size 10m;
}
限制因素二:受PHP服务影响
修改php配置文件
vim /etc/php.ini
799 upload_max_filesize = 10M -- 调整大小为10M
六、LNMP 架构数据库分离
数据库分离的原因:可以实现数据共享和存储
(一),数据库服务迁移过程
第一步:备份数据信息
(迁移前的 Web 服务器)
mysqldump -uroot -poldboy123 -A > /tmp/backup.sql
第 2 步:迁移数据
(迁移前的 Web 服务器)
scp -rp /tmp/backup.sql 172.16.1.51:/tmp/
第 3 步:恢复数据
(迁移后的mysql服务器)
mysql -uroot -poldboy123 < /tmp/backup.sql
数据库数据迁移完成后需要进行操作
第一步:迁移前关闭服务器数据库服务
systemctl stop mariadb.service
systemctl disable mariadb.service
第2步:需要修改连接数据库的代码信息
vim /html/blog/wp-config.php
32 define( 'DB_HOST', '172.16.1.51' );
第三步:需要调整数据库用户配置信息
grant all on wordpress.* to 'wordpress'@'172.16.1.%' identified by 'oldboy123';
七、LNMP架构网站系列存储服务
串联原因:实现数据共享和存储
(一),系列过程
第一步:保存并备份本地存储的数据
mkdir /tmp/blog_backup
mv /html/blog/wp-content/uploads/* /tmp/blog_backup/
步骤二:检查存储服务是否可以正常使用
showmount -e 172.16.1.31
第三步:进行存储服务挂载操作
mount -t nfs 172.16.1.31:/data/blog/ /html/blog/wp-content/uploads/
第四步:恢复之前备份的数据
cp /tmp/blog_backup/* /html/blog/wp-content/uploads/
八、编译安装PHP
第一步:检查PHP是否安装
systemctl status php-fpm.service
systemctl stop php-fpm.service
步骤二:获取PHP源码包
wget http://php.net/distributions/php-7.1.0.tar.gz
第 3 步:解决 PHP 依赖
yum install -y libxml2 libxml2-devel openssl openssl-devel bzip2 bzip2-devel libcurl libcurl-devel libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel gmp gmp-devel libmcrypt libmcrypt-devel readline readline-devel libxslt libxslt-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel ncurses curl gdbm-devel db4-devel libXpm-devel libX11-devel gd-devel gmp-devel expat-devel xmlrpc-c xmlrpc-c-devel libicu-devel libmcrypt-devel libmemcached-devel
步骤 4:: 解压软件程序
tar -zxvf php-7.1.0.tar.gz
第五步:编译安装
1、将解压后的目录移动到指定目录并创建软链接
mv php-7.1.0 /app
cd /app
ln -s php-7.1.0/ php
2、进入php目录并编译
cd php
./configure --prefix=/application/php-7.1 --enable-fpm --enable-inline-optimization --disable-debug --disable-rpath --enable-shared --enable-soap --with-libxml-dir --with-xmlrpc --with-openssl --with-mcrypt --with-mhash --with-pcre-regex --with-sqlite3 --with-zlib --enable-bcmath --with-iconv --with-bz2 --enable-calendar --with-curl --with-cdb --enable-dom --enable-exif --enable-fileinfo --enable-filter --with-pcre-dir --enable-ftp --with-gd --with-openssl-dir --with-jpeg-dir --with-png-dir --with-zlib-dir --with-freetype-dir --enable-gd-native-ttf --enable-gd-jis-conv --with-gettext --with-gmp --with-mhash --enable-json --enable-mbstring --enable-mbregex --enable-mbregex-backtrack --with-libmbfl --with-onig --enable-pdo --with-mysqli=mysqlnd --with-pdo-mysql=mysqlnd --with-zlib-dir --with-pdo-sqlite --with-readline --enable-session --enable-shmop --enable-simplexml --enable-sockets --enable-sysvmsg --enable-sysvsem --enable-sysvshm --enable-wddx --with-libxml-dir --with-xsl --enable-zip --enable-mysqlnd-compression-support --with-pear --enable-opcache
3、安装
make && make install
第六步:调整或创建配置文件
cd /application/php-7.1/ #进入到程序目录
cp etc/php-fpm.conf.default etc/php-fpm.conf
cp etc/php-fpm.d/www.conf.default etc/php-fpm.d/www.conf
cd /app/php #进入到源码包目录
cp php.ini-production /application/php-7.1/lib/php.ini
第七步:启动php服务程序
/application/php/sbin/php-fpm
第八步:测试PHP是否启动成功
写网站配置文件
vim /etc/nginx/conf.d/www.conf
server {
listen 80;
server_name www.oldboy.com;
root /html/www;
index index.html index.php;
location ~ \.php$ {
root /html/www;
fastcgi_index index.php;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
编写测试页面站点文件
/html/www/test_php.php
页面访问测试文件
第九步:检查PHP安装过程中编译了哪些参数
/application/php/bin/php -i|grep configure
九、PHP 优化(一)、PHP 缓存加速器优化
功能
缓存加速器主要用于提高动态分析的效率
实现方法
部署前准备
配置环境变量
echo 'export LC_ALL=C'>> /etc/profile
source /etc/profile
安装 Perl 相关软件依赖
yum -y install perl-devel
方法一:使用电子加速器
1、eAccelerator 介绍
安装和配置参数比较简单,加速效果也不错。
Ÿ 文档很多,但是软件官方更新很慢,社区不活跃。
Y 仅适用于 PHP 版本5.4 以下的程序
2、eAccelerator 安装
进入源码包目录
cd /server/tools
获取源码包
wget https://github.com/downloads/e ... r.bz2
解压源码包
tar xf eaccelerator-0.9.6.1.tar.bz2
编译安装
cd eaccelerator-0.9.6.1
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-eaccelerator --with-php-config=/application/php-7.1/bin/php-config
make && make install
方法二:使用xcache
1、xcache 介绍
经过测试,XCache 的效率更高,速度更快。
XCache 软件开发社区更加活跃,最新版本将于 2014 年底发布。
支持更高版本的PHP,如PHP5.5、PHP 5.6。
2、xcache 安装
进入源码包目录
cd /server/tools
获取源码包
wget http://xcache.lighttpd.net/pub ... r.bz2
解压源码包
tar xf xcache-3.2.0.tar.bz2
编译安装包
cd xcache-3.2.0
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-xcache --with-php-config=/application/php/bin/php-config
make && make install
方法三:使用zend opcache
1、zend opcache 介绍
默认已集成在php程序中,无需单独安装加速软件
2、zend opcache 安装
进入源码包目录
cd /server/tools
获取源码包
wget -q http://pecl.php.net/get/zendopcache-7.0.5.tgz
解压源码包
tar xf zendopcache-7.0.5.tgz
编译安装
cd zendopcache-7.0.5
/application/php-7.1/bin/phpize #可以让缓存加速软件源码包中生成配置命令文件信息
./configure --enable-opcache --with-php-config=/application/php/bin/php-config
make && make install
(二),PHP缓存功能优化1、memcache缓存插件
PHP缓存优化原理
Mencache 插件安装部署
第一步:获取插件源码包
wget https://github.com/websupport- ... 7.zip
步骤二:将源码包解压到指定目录
cd /server/tools
unzip NON_BLOCKING_IO_php7.zip
第三步:编译安装memcache
cd pecl-memcache-NON_BLOCKING_IO_php7/
/application/php-7.1/bin/phpize
./configure --enable-memcache --with-php-config=/application/php-7.1/bin/php-config
make && make install
memcache 插件应用配置
第一步:修改配置文件
PS:添加到最后
vim /application/php-7.1/lib/php.ini
extension = "/application/php-7.1/lib/php/extensions/no-debug-non-zts-20160303/memcache.so"
第 2 步:重启 php-fpm
真正的独家,伊人集全部功能及付费功能整合版(带整站数据)演示站:(LmSail)内附详细安装教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-07-30 03:44
真人机最新全功能及付费功能集成版(附全站资料),演示站:(LmSail)附详细安装使用教程!
基本流程+顶部签到+专栏+商城+就近+充值+牛评+音乐+活动+图库等功能。礼物奖励功能!
本源代码为易人机官方源代码,完美修复,功能齐全。不是10元20元的那种。修复分享功能、伪静态、栏目、手机发布图片展示、首页LOGO修改、SEO优化设置、导航栏目混乱等问题。新增商城、图库、打赏等功能!
Demonstration网站:(LmSail 社区)【注册经验】
宜人机基础程序官方售价为260元。
完美的插件更新:
01.[16-02-28] 易人机模板,易人机201602最新升级包
02.[16-03-11] 易人集模板3月专题页面调整升级包
03.[16-03-31] 易人记模板大事记模块包下载
04.[16-04-05]爱人机顶和签到日历插件相关下载价值50元
05.[16-04-08] 易人机模板用户展示频道图片轮播效果插件
06.[16-04-18] 易人集站分类前后端调整插件
07.[16-05-04] 易人记模板栏目模块用户版价值260元
08.[16-05-26] 易人集模板升级包:附近人和会员页面调整包
09.[16-06-08] 易人集微信模板二次公开调用升级包
10.[16-06-08]宜人机模板充值模块包在线充值模块辅助包
11.[16-06-08] 易人集活动模块升级调整充值插件包
12.[16-06-11] 易人记抗CC刷新攻击插件升级包
13.[16-06-12] 亿人集模板商城频道模块下载包价值260元
14.[16-06-12] 易人集模板专栏|用户列表|雷锋列表|分类调整升级包
15.[16-06-24] 易人集附近的人,找人盖升级包
16.[16-07-03] 易人集模板频道分类升级包
17.[16-07-08] 价值60元的易人记地图集模块和表情插件升级包
18.[16-08-10] 益人机答题功能模块包+价值200元升级包
全站最新Wecenter易人集生鲜社区源码分享,Wecenter易人集社区完美修复BUG一键安装版,参考网上部分已有模板,重写模板CSS。其他方面也进行了修改,特别是我发现的一个官方错误。另外活动和工单已经合并,一键安装全功能!
编辑地点:
1.root 目录 ad 为广告图片(均在轮播中使用)。如果要删除,在views/default/block中找到收录ad的两个文件,然后清除里面的内容,或者换成自己的's ads
2.Carousel 模板在模板文件夹中修改为block或者global或者m,以及收录lunbo的文件(共有三个carousel文件,目前没有实现后台管理,因为官方升级不容易拿到)
3.安装时添加活动和工单并安装到数据库中
4.Revised the email issue in a official error model(不知道官方有没有做过测试,不管用户的声音半死不活)
5. 添加了一个有用的过滤系统/class/cls_format.inc 为前台电话铺路
6. 修复了 system/services/VideoUrlParser 为添加音乐 mp3 铺平了道路
7.加入轮播,有两个地方(头和首页,不想要的可以修改删除)
8.修改models下的module文件,增加top_hot_users(方便调用头像的用户),增加bolock下的调用
9.修复官方手机版的一个错误
10. 继续在模板块下添加调用。
11.修改了app下的调用(请自行对比文件)
下载地址
[支付点=”30″]链接:密码:5pux[/pay]
1.本站所有资源均来自用户上传和互联网,不收录技术服务,请见谅!
2. 本站不保证所提供下载资源的准确性、安全性和完整性。资源仅供下载学习使用!如有链接无法下载、失效、广告等问题,请联系客服!
3.您必须在下载后24小时内将以上内容资源从您的电脑中彻底删除!如用于商业或非法用途,与本站无关,一切后果由用户负责!
4.如果你也有好的资源或者教程,可以提交论文发表。分享成功后,将有现场币奖励和额外收益! 查看全部
真正的独家,伊人集全部功能及付费功能整合版(带整站数据)演示站:(LmSail)内附详细安装教程
真人机最新全功能及付费功能集成版(附全站资料),演示站:(LmSail)附详细安装使用教程!
基本流程+顶部签到+专栏+商城+就近+充值+牛评+音乐+活动+图库等功能。礼物奖励功能!
本源代码为易人机官方源代码,完美修复,功能齐全。不是10元20元的那种。修复分享功能、伪静态、栏目、手机发布图片展示、首页LOGO修改、SEO优化设置、导航栏目混乱等问题。新增商城、图库、打赏等功能!
Demonstration网站:(LmSail 社区)【注册经验】
宜人机基础程序官方售价为260元。
完美的插件更新:
01.[16-02-28] 易人机模板,易人机201602最新升级包
02.[16-03-11] 易人集模板3月专题页面调整升级包
03.[16-03-31] 易人记模板大事记模块包下载
04.[16-04-05]爱人机顶和签到日历插件相关下载价值50元
05.[16-04-08] 易人机模板用户展示频道图片轮播效果插件
06.[16-04-18] 易人集站分类前后端调整插件
07.[16-05-04] 易人记模板栏目模块用户版价值260元
08.[16-05-26] 易人集模板升级包:附近人和会员页面调整包
09.[16-06-08] 易人集微信模板二次公开调用升级包
10.[16-06-08]宜人机模板充值模块包在线充值模块辅助包
11.[16-06-08] 易人集活动模块升级调整充值插件包
12.[16-06-11] 易人记抗CC刷新攻击插件升级包
13.[16-06-12] 亿人集模板商城频道模块下载包价值260元
14.[16-06-12] 易人集模板专栏|用户列表|雷锋列表|分类调整升级包
15.[16-06-24] 易人集附近的人,找人盖升级包
16.[16-07-03] 易人集模板频道分类升级包
17.[16-07-08] 价值60元的易人记地图集模块和表情插件升级包
18.[16-08-10] 益人机答题功能模块包+价值200元升级包
全站最新Wecenter易人集生鲜社区源码分享,Wecenter易人集社区完美修复BUG一键安装版,参考网上部分已有模板,重写模板CSS。其他方面也进行了修改,特别是我发现的一个官方错误。另外活动和工单已经合并,一键安装全功能!
编辑地点:
1.root 目录 ad 为广告图片(均在轮播中使用)。如果要删除,在views/default/block中找到收录ad的两个文件,然后清除里面的内容,或者换成自己的's ads
2.Carousel 模板在模板文件夹中修改为block或者global或者m,以及收录lunbo的文件(共有三个carousel文件,目前没有实现后台管理,因为官方升级不容易拿到)
3.安装时添加活动和工单并安装到数据库中
4.Revised the email issue in a official error model(不知道官方有没有做过测试,不管用户的声音半死不活)
5. 添加了一个有用的过滤系统/class/cls_format.inc 为前台电话铺路
6. 修复了 system/services/VideoUrlParser 为添加音乐 mp3 铺平了道路
7.加入轮播,有两个地方(头和首页,不想要的可以修改删除)
8.修改models下的module文件,增加top_hot_users(方便调用头像的用户),增加bolock下的调用
9.修复官方手机版的一个错误
10. 继续在模板块下添加调用。
11.修改了app下的调用(请自行对比文件)
下载地址
[支付点=”30″]链接:密码:5pux[/pay]
1.本站所有资源均来自用户上传和互联网,不收录技术服务,请见谅!
2. 本站不保证所提供下载资源的准确性、安全性和完整性。资源仅供下载学习使用!如有链接无法下载、失效、广告等问题,请联系客服!
3.您必须在下载后24小时内将以上内容资源从您的电脑中彻底删除!如用于商业或非法用途,与本站无关,一切后果由用户负责!
4.如果你也有好的资源或者教程,可以提交论文发表。分享成功后,将有现场币奖励和额外收益!
Rancher平台内如何做容器日志收集(一)_微服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-07-25 06:38
介绍文档参考。对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。目前容器日志采集解决方案的现状概述,无非两种方式:一、直接采集Docker标准输出,通过Docker日志驱动(log driver)可以发送到相应的采集程序; 二、 非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。 log采集程序直接采集映射的Log文档。 三、通Journald 采集二进制日志数据。 PS:标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。非标准输出:根据Docker容器的特点,容器启动后必须有服务保持前台运行。
如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,这些后台运行的服务生成的日志默认无法作为标准输出获取,生成的日志默认会保存在/var/log目录下。第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:当宿主机的容器密度比较高的时候,对Docker Engine的压力比较大,毕竟,容器标准输出必须经过Docker Engine处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald进行二进制日志数据采集。当然,在完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。 UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是 log采集 解决方案。当然,开源的实现是对接在存储和UI展示上的。没有特殊要求,也可以有完整的体验。
Rancher(json-file driver)下的解决方案介绍如上图所示。 ElasticSearch & Kibana 可以直接用于日志存储和 UI 展示。日志采集,如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中,日志采集部分使用了Fluentd & Logging Helper的组合。 Fluentd 是一个非常通用的日志采集 程序,性能卓越。与Logstash相比,在同样的压力下,它的内存消耗要少得多。为了保证 Dokcer 和 Rancher 体验的完整性,Docker Log Driver 选择 Json-file 或 Journald 的原因是:一、json-file 和 journald 比较常见; 二、这两个驱动,docker Logs还是可以有内容输出的,保证了体验的完整性。实施流程方案实施流程:Fluentd对接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据; Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd进行采集。 Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。下面开始讲解整个程序的部署过程。先用一张图来描述整体的部署结构,如下:
方案部署 ElasticSearch & Kibana 部署 Web 登录 Rancher,进入应用商店,搜索 ElasticSearch,建议安装2.x 版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后一个Public端口根据实际情况修改,避免冲突。
服务正常启动后,即可通过该端口访问Kibana网页。
Rancher日志服务部署 目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,名称:rancher-logging 地址:branch:master 最后点击保存,返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面:本例中除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要与之前设置的Volume Pattern一致: 查看全部
Rancher平台内如何做容器日志收集(一)_微服务
介绍文档参考。对于一个完整的容器平台,容器日志采集也是一个重要的环节。尤其是在微服务架构盛行的情况下,很多程序的访问监控和健康检查都依赖于日志信息的采集。由于Docker的存在,容器平台中的日志采集方式不同于传统的方式。日志的输出和采集不同于传统的方法。它曾经非常不同。本文讨论如何在 Rancher 平台中采集容器日志。目前容器日志采集解决方案的现状概述,无非两种方式:一、直接采集Docker标准输出,通过Docker日志驱动(log driver)可以发送到相应的采集程序; 二、 非标准输出,延续传统的日志写入方式。容器中的服务直接将日志写入Log文件,通过Docker卷映射形式将日志文件映射到Host。 log采集程序直接采集映射的Log文档。 三、通Journald 采集二进制日志数据。 PS:标准输出:通过docker logs查看的日志信息。在Ubuntu OS下,该信息默认保存在以容器ID为前缀的-json.log文件中的/var/lib/docker/containers路径下以容器ID命名的文件夹中。非标准输出:根据Docker容器的特点,容器启动后必须有服务保持前台运行。
如果一个容器需要运行多个服务,那么按照启动顺序,前面的服务必须在后台运行。因此,这些后台运行的服务生成的日志默认无法作为标准输出获取,生成的日志默认会保存在/var/log目录下。第一种方法很简单,可以直接配置相关的日志驱动(Log driver),但是这种方法有一些缺点:当宿主机的容器密度比较高的时候,对Docker Engine的压力比较大,毕竟,容器标准输出必须经过Docker Engine处理。虽然原则上我们希望遵循每个容器部署一个服务的原则,但有时在特殊情况下,容器中存在多个业务服务是不可避免的。这时候很难实现所有服务的标准输出日志,这就需要使用传统的方式来采集日志。虽然我们可以选择多种 Log Drivers,但有些 Log Drivers 会破坏 Docker 原生体验。例如,日志输出到其他日志服务器后,docker logs 将看不到容器日志。基于以上考虑,一个完整的日志采集程序必须同时满足标准输出采集和日志卷(非标准输出)采集或通过journald进行二进制日志数据采集。当然,在完整的日志系统中,不仅仅是采集,还有日志存储和UI展示。日志存储的开源实现有很多,一般用户都会有自己喜欢的选择。 UI展示对各个公司的要求就更高了,很难形成更好的标准,一般都是通过定制的方式来解决的。因此,本文提出的主要解决方案是 log采集 解决方案。当然,开源的实现是对接在存储和UI展示上的。没有特殊要求,也可以有完整的体验。
Rancher(json-file driver)下的解决方案介绍如上图所示。 ElasticSearch & Kibana 可以直接用于日志存储和 UI 展示。日志采集,如前所述,需要连接两种采集模式(标准输出日志和非标准输出)。本方案中,日志采集部分使用了Fluentd & Logging Helper的组合。 Fluentd 是一个非常通用的日志采集 程序,性能卓越。与Logstash相比,在同样的压力下,它的内存消耗要少得多。为了保证 Dokcer 和 Rancher 体验的完整性,Docker Log Driver 选择 Json-file 或 Journald 的原因是:一、json-file 和 journald 比较常见; 二、这两个驱动,docker Logs还是可以有内容输出的,保证了体验的完整性。实施流程方案实施流程:Fluentd对接Json-file或Journald驱动,获取标准输出日志数据或二进制日志数据; Logging Helper可以理解为Fluentd的助手,可以识别容器日志卷(非标准输出)映射的路径,并通知Fluentd进行采集。 Fluentd 采集数据后,将数据传输并存储到 ES,最后 Kibana 直接将数据显示在 ES 中。下面开始讲解整个程序的部署过程。先用一张图来描述整体的部署结构,如下:
方案部署 ElasticSearch & Kibana 部署 Web 登录 Rancher,进入应用商店,搜索 ElasticSearch,建议安装2.x 版本。
点击查看详情。进入后,修改最后一个Public端口。默认为 80 端口。更改为其他端口以避免端口冲突。然后进入应用商店,搜索 Kibana。
在配置选项中,需要选择Elasticsearch-clients
最后一个Public端口根据实际情况修改,避免冲突。
服务正常启动后,即可通过该端口访问Kibana网页。
Rancher日志服务部署 目前Rancher日志不在官方仓库,需要使用Rancher日志,需要添加自定义存储地址。点击小图管理系统设置进入,点击添加应用商店,名称:rancher-logging 地址:branch:master 最后点击保存,返回应用商店。在应用商店输入log进行搜索:
点击查看详情进入并进入配置页面:本例中除了Elasticsearch源的配置如图所示,保持默认:
以上部署完成后,部署一些应用,生成一些访问日志,在Kibana界面可以看到:
如果要使用日志卷方式,需要在Service启动时配置Volume,Volume名称需要与之前设置的Volume Pattern一致:
干货教程:【wecenter 免费采集插件--优采云云采集 V3.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-11-09 08:00
优采云Cloud采集由大数据公司宽艺科技自主研发。它使用分布式架构,是一种云在线智能爬虫,它使用JS呈现,代理IP,防阻塞,验证代码识别和数据发布等一系列技术,例如导出,图表控制等,可在其中实现准确,快速的数据。整个网络采集,无需任何专业知识,您只需单击一下即可抓取微信官方帐户知乎,优酷,微博和其他大量网站数据,然后自动发布到网站。 -------------------------------------------------- -------------------------------------------------- -------------全面的采集功能:无论是文章,问答,视频,图片还是资源,它都可以快速显示采集;采集速度快如雷电:大规模的代理IP和顶级服务器配置确保了采集器的执行速度和效率;业界领先的采集配置:只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程; -------------------------------------------------- -------------------------------------------------- ------------- Cloud Online采集:一站式云服务模式,在云上完成采集任务,实现24小时无人值守;强大的监控更新:通过新的监控和变更监控实时更新目标网站的最新数据;先进的语义接口:关键字提取,伪原创,情感分析等多种技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;多个类别发布:支持插入指定类别的选项,并且来自不同来源网站的数据可以发布到不同类别。 -------------------------------------------------- -------------------------------------------------- -------------客户服务支持和沟通联系信息客户服务QQ:2879835984QQ交流组:174631869 优采云cloud采集官方网站:优采云cloud采集 wecenter插件下载:/ s / 1eRr4oca插件教程:/pdoc/wecenter.html 查看全部
[wecenter free采集插件-优采云cloud采集 V3.0
优采云Cloud采集由大数据公司宽艺科技自主研发。它使用分布式架构,是一种云在线智能爬虫,它使用JS呈现,代理IP,防阻塞,验证代码识别和数据发布等一系列技术,例如导出,图表控制等,可在其中实现准确,快速的数据。整个网络采集,无需任何专业知识,您只需单击一下即可抓取微信官方帐户知乎,优酷,微博和其他大量网站数据,然后自动发布到网站。 -------------------------------------------------- -------------------------------------------------- -------------全面的采集功能:无论是文章,问答,视频,图片还是资源,它都可以快速显示采集;采集速度快如雷电:大规模的代理IP和顶级服务器配置确保了采集器的执行速度和效率;业界领先的采集配置:只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程; -------------------------------------------------- -------------------------------------------------- ------------- Cloud Online采集:一站式云服务模式,在云上完成采集任务,实现24小时无人值守;强大的监控更新:通过新的监控和变更监控实时更新目标网站的最新数据;先进的语义接口:关键字提取,伪原创,情感分析等多种技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;多个类别发布:支持插入指定类别的选项,并且来自不同来源网站的数据可以发布到不同类别。 -------------------------------------------------- -------------------------------------------------- -------------客户服务支持和沟通联系信息客户服务QQ:2879835984QQ交流组:174631869 优采云cloud采集官方网站:优采云cloud采集 wecenter插件下载:/ s / 1eRr4oca插件教程:/pdoc/wecenter.html
免费获取:【wecenter 免费采集插件--优采云云采集 V3.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 448 次浏览 • 2020-09-15 17:09
优采云 Cloud 采集由大数据公司宽艺科技自主研发。它采用分布式架构,是一种云在线智能爬虫,它使用JS呈现,代理IP,防阻塞,验证代码识别和数据发布等一系列技术,例如导出,图表控制等,可实现准确,快速的数据。在整个网络采集中,无需任何专业知识,您只需单击一下即可抓取微信官方帐户知乎,优酷,微博和其他海量网站数据,然后自动发布到网站。 -------------------------------------------------- -------------------------------------------------- -------------全面的采集功能:无论是文章,问答,视频,图片还是资源,它都可以快速显示采集; 采集速度快如雷电:大规模的代理IP和顶级服务器配置确保了采集器的执行速度和效率;行业领导者采集的配置:只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程; -------------------------------------------------- -------------------------------------------------- ------------- Cloud Online 采集:一站式云服务模式,在云上完成采集任务,实现24小时无人值守;强大的监控更新:通过新的监控和变更监控实时更新目标网站的最新数据;先进的语义接口:关键字提取,伪原创,情感分析等多种技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;多个类别发布:支持选择插入指定的类别,并且可以将来自不同来源网站的数据发布到不同的类别。 -------------------------------------------------- -------------------------------------------------- -------------客户服务支持和沟通联系信息客户服务QQ:2879835984QQ交流组:174631869 优采云 cloud 采集官方网站:优采云 cloud 采集 wecenter插件下载:/ s / 1eRr4oca插件教程:/pdoc/wecenter.html 查看全部
[wecenter free 采集插件-优采云 cloud 采集 V 3. 0
优采云 Cloud 采集由大数据公司宽艺科技自主研发。它采用分布式架构,是一种云在线智能爬虫,它使用JS呈现,代理IP,防阻塞,验证代码识别和数据发布等一系列技术,例如导出,图表控制等,可实现准确,快速的数据。在整个网络采集中,无需任何专业知识,您只需单击一下即可抓取微信官方帐户知乎,优酷,微博和其他海量网站数据,然后自动发布到网站。 -------------------------------------------------- -------------------------------------------------- -------------全面的采集功能:无论是文章,问答,视频,图片还是资源,它都可以快速显示采集; 采集速度快如雷电:大规模的代理IP和顶级服务器配置确保了采集器的执行速度和效率;行业领导者采集的配置:只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程; -------------------------------------------------- -------------------------------------------------- ------------- Cloud Online 采集:一站式云服务模式,在云上完成采集任务,实现24小时无人值守;强大的监控更新:通过新的监控和变更监控实时更新目标网站的最新数据;先进的语义接口:关键字提取,伪原创,情感分析等多种技术;智能匹配映射:可以自动匹配字段,也可以自己设置字段映射;多个类别发布:支持选择插入指定的类别,并且可以将来自不同来源网站的数据发布到不同的类别。 -------------------------------------------------- -------------------------------------------------- -------------客户服务支持和沟通联系信息客户服务QQ:2879835984QQ交流组:174631869 优采云 cloud 采集官方网站:优采云 cloud 采集 wecenter插件下载:/ s / 1eRr4oca插件教程:/pdoc/wecenter.html
WeCenter采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2020-08-31 02:38
优采云Cloud采集是由大数据公司Fast Memory Technology独立研发的. 它采用分布式架构,是一种使用JS呈现,代理IP,防屏蔽,验证码识别和数据发布的云在线智能爬虫,导出和图表控制等一系列技术可实现对整个网络的准确,快速采集. 数据,无需任何专业知识,您就可以抓取大量网站数据,例如微信官方帐户,知乎,优酷,微博等,并自动将其发布到Discuz网站.
优采云Cloud采集功能
无所不包的采集功能: 无论是文章,问答,视频,图片还是资源,都可以快速采集;
采集速度快如闪电: 海量的代理IP和顶级服务器配置确保了爬虫的执行速度和效率;
业界领先者的采集配置: 只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程;
优采云云采集功能:
云在线采集: 一站式云服务模式,在云上完成采集任务,实现24小时无人值守操作;
强大的监视更新: 通过新监视和更改监视实时更新目标网站的最新数据;
高级语义接口: 关键字提取,伪原创,情感分析等是多种技术;
智能匹配映射: 可以自动匹配字段,也可以由您自己设置字段映射;
多类别发布: 支持选择插入指定的类别,并且可以将来自不同来源的数据发布到不同的类别.
优采云Cloud采集更新日志:
2016.08.02 v3.1.3
1. 添加了安装教程的地址和使用文档
2. 修复某些字段失败,然后尝试再次插入
3. 获取头像的问题 查看全部
WeCenter采集插件
优采云Cloud采集是由大数据公司Fast Memory Technology独立研发的. 它采用分布式架构,是一种使用JS呈现,代理IP,防屏蔽,验证码识别和数据发布的云在线智能爬虫,导出和图表控制等一系列技术可实现对整个网络的准确,快速采集. 数据,无需任何专业知识,您就可以抓取大量网站数据,例如微信官方帐户,知乎,优酷,微博等,并自动将其发布到Discuz网站.
优采云Cloud采集功能
无所不包的采集功能: 无论是文章,问答,视频,图片还是资源,都可以快速采集;
采集速度快如闪电: 海量的代理IP和顶级服务器配置确保了爬虫的执行速度和效率;
业界领先者的采集配置: 只需单击几下鼠标,就不需要任务专业知识即可完成从采集到发布的整个过程;
优采云云采集功能:
云在线采集: 一站式云服务模式,在云上完成采集任务,实现24小时无人值守操作;
强大的监视更新: 通过新监视和更改监视实时更新目标网站的最新数据;
高级语义接口: 关键字提取,伪原创,情感分析等是多种技术;
智能匹配映射: 可以自动匹配字段,也可以由您自己设置字段映射;
多类别发布: 支持选择插入指定的类别,并且可以将来自不同来源的数据发布到不同的类别.
优采云Cloud采集更新日志:
2016.08.02 v3.1.3
1. 添加了安装教程的地址和使用文档
2. 修复某些字段失败,然后尝试再次插入
3. 获取头像的问题
API接口设计,需要注意这4点
采集交流 • 优采云 发表了文章 • 0 个评论 • 378 次浏览 • 2020-08-26 06:07
笔者查阅了百度、腾讯、旷视、阿里的云平台发觉在视觉方面均都采用的是https合同;对于视觉,图片数据本身收录的信息就太丰富,尤其是人脸,因此采用https还是有利于保护用户隐私信息的。
2. 接口的恳求形式
了解插口的恳求形式有助于了解用户端和服务端间的交互方法,基于http合同的常用恳求方法是post和get;两者的主要区别如下:
(1)直观区别:get恳求方法是将恳求参数放在url中,post是将参数放在requst body中,所带来的的直接影响是get的恳求参数存在宽度限制,post无限制;其次是get将参数放在url中安全性弱于post;
(2)深度区别:get恳求形式用户端和服务端只形成一次交互,post恳求形式用户端会和服务端形成两次交互,举例:快递小哥是用户端,你是服务端,则get如同常来大家新村和你认识的快递员直接将快递送到你家,你跟他说声感谢;post如同新来的快递员先打个电话问下你在家吗?你告诉他你在家呢,过了5分钟他将快件送到你家了,你跟他说声感谢;
目前百度、腾讯、旷视的图象辨识插口均采用的是post恳求形式
3. 接口响应机制
最后了解插口的响应机制:同步插口和异步插口;简单理解同步插口即实时返回消息给调用方,异步插口就是可以延后返回消息给调用方;实时性要求高的且只能线性工作的须要采用同步插口,其他可以优先使用异步接口;当然不同的场景,同样的服务插口会被要求同步或异步;以人脸辨识中的人脸注册为例:
(1)刷脸支付:以支付宝为例,使用之前须要根据步骤采集人脸,后台会调用人脸注册将当前人脸注册进人脸库并和该支付宝帐号信息绑定,这一步人脸注册一般是同步插口,因为不会要求用户在APP前等待很久,需要及时返回注册成功信息;
(2)客流系统:现在商超使用的客流系统通常早已采用人脸辨识代替头肩模型,这样除了可以统计人数还可以统计人次,其中对于首次辨识的陌生人脸一般须要注册进陌生人脸库,这里的人脸注册通常为异步接口,因为小型商超每晚数十万客流且对于陌生人无会员信息,所以不需要实时注册,只要步入队列能在当天24小时内注册完即可;
小结
以上关于API的插口常识在设计插口的时侯,开发通常还会要求产品确定插口的响应机制;其他的开发就会自己完成;但作为开放平台的产品常常会对接开发,多了解些常识既可以跟自己的开发有更多的共同语言沟通,也可以在对接用户的时侯可以跟用户的开发简单解释。
二、核心业务主键&接口约束
产品总监其实不需要定义API所有的数组信息,但是跟业务需求有关的数组产品总监须要明晰清晰。
1. 入参
(1)鉴权数组信息
调用第三方平台插口一般须要进行插口信令,服务端判定用户端是否有调用插口的权限;这里跟产品总监相关的是作为产品须要设计应用管理,包括:应用列表、应用创建、应用详情、应用配置、应用删掉等操作;以百度AI平台,应用列表如下:
其中AppID、API Key和Secret Key为创建应用时手动生成,接口信令所须要的access_token必须通过API key和Secret key恳求服务端获取。
(2)核心业务主键
产品总监须要依照业务需求明晰插口入参中须要什么数组信息以及数组支持的类型,以百度AI平台的食材辨识为例:
业务需求:识别图片中是哪种食材;
产品需求:
输入图片,图片支持一般采用base64和URL格式;top_num,提高插口的通用性,方便用户后续场景扩充,因此支持配置返回食材数目且排序;阈值,开放辨识阀值,方便用户按照实际辨识疗效调整,提高准确率;
注意点:设计插口核心业务主键,要尽量提升插口的通用性,以此适配更多的用户场景,比如top_num和阀值的开放,即泛化插口能力,将更多的主动权交由插口用户配置。
(3)字段信息约束条件
字段约束条件是为了保证插口的安全性,这点是产品总监跟业务方沟通达成一致后提供给开发小伙伴的;仍然以里面的食材辨识为例:
图片须要限制文件大小和帧率大小,文件大小只须要上限,分辨率大小须要包括上限和下限,下限是为了保证算法疗效,比如在目标测量中小目标容易测量失败;top_num须要限制下限,不得大于0,不设上限,可以接受算法返回的所有结果;阈值按照格式确定,可以是0-100,可以是0-1;
注:设置参数的一点小技巧,为了保证算法疗效,有时算法会默认设置参数,即用户设置的阀值高于默认参数,则不接受输入,采用默认,用户是无感知的;
2. 出参
调用插口都会有返回信息,产品须要依照业务需求定义返回的核心数组信息,这次以百度AI开放平台手势辨识为例,其中跟业务需求相关的关键数组包括:
三、接口限流
接口限流也是为了保障系统的安全性,因为有时业务方由于业务扩充造成调用量猛增,容易造成服务端宕机;限流就类似于空开的保险丝保证恳求量超过插口上限时系统可以拒绝恳求或排队,以此保证系统的安全性;
产品总监须要实现对业务充分评估,给出合理评估量,如TPS(每秒处理的恳求量);这样既不会导致系统资源的浪费,也保证业务正常运行;
注:与前面插口响应机制对应,同步插口通常须要给出峰值tps和响应时间,异步插口须要给出日调量即可;
四、接口测试
接口测试似乎是测试小妹哥的工作,测试内容也覆盖诸多,但是作为产品可以简单了解以下内容即可,如,
(1)接口可用性,即插口是否可以正常调用,正常返回结果,异常正确处理,正常返回错误码等;
(2)业务需求覆盖,即插口输入输出是否遵守产品需求文档描述;
(3)边界规则依循,即插口是否满足业务规则和数组约束条件;
(4)性能条件,通常插口上线前须要经过压测达到性能指标才可,包括某并发量下的tps和历时等;
结语 查看全部
API接口设计,需要注意这4点
笔者查阅了百度、腾讯、旷视、阿里的云平台发觉在视觉方面均都采用的是https合同;对于视觉,图片数据本身收录的信息就太丰富,尤其是人脸,因此采用https还是有利于保护用户隐私信息的。
2. 接口的恳求形式
了解插口的恳求形式有助于了解用户端和服务端间的交互方法,基于http合同的常用恳求方法是post和get;两者的主要区别如下:
(1)直观区别:get恳求方法是将恳求参数放在url中,post是将参数放在requst body中,所带来的的直接影响是get的恳求参数存在宽度限制,post无限制;其次是get将参数放在url中安全性弱于post;
(2)深度区别:get恳求形式用户端和服务端只形成一次交互,post恳求形式用户端会和服务端形成两次交互,举例:快递小哥是用户端,你是服务端,则get如同常来大家新村和你认识的快递员直接将快递送到你家,你跟他说声感谢;post如同新来的快递员先打个电话问下你在家吗?你告诉他你在家呢,过了5分钟他将快件送到你家了,你跟他说声感谢;
目前百度、腾讯、旷视的图象辨识插口均采用的是post恳求形式
3. 接口响应机制
最后了解插口的响应机制:同步插口和异步插口;简单理解同步插口即实时返回消息给调用方,异步插口就是可以延后返回消息给调用方;实时性要求高的且只能线性工作的须要采用同步插口,其他可以优先使用异步接口;当然不同的场景,同样的服务插口会被要求同步或异步;以人脸辨识中的人脸注册为例:
(1)刷脸支付:以支付宝为例,使用之前须要根据步骤采集人脸,后台会调用人脸注册将当前人脸注册进人脸库并和该支付宝帐号信息绑定,这一步人脸注册一般是同步插口,因为不会要求用户在APP前等待很久,需要及时返回注册成功信息;
(2)客流系统:现在商超使用的客流系统通常早已采用人脸辨识代替头肩模型,这样除了可以统计人数还可以统计人次,其中对于首次辨识的陌生人脸一般须要注册进陌生人脸库,这里的人脸注册通常为异步接口,因为小型商超每晚数十万客流且对于陌生人无会员信息,所以不需要实时注册,只要步入队列能在当天24小时内注册完即可;
小结
以上关于API的插口常识在设计插口的时侯,开发通常还会要求产品确定插口的响应机制;其他的开发就会自己完成;但作为开放平台的产品常常会对接开发,多了解些常识既可以跟自己的开发有更多的共同语言沟通,也可以在对接用户的时侯可以跟用户的开发简单解释。
二、核心业务主键&接口约束
产品总监其实不需要定义API所有的数组信息,但是跟业务需求有关的数组产品总监须要明晰清晰。
1. 入参
(1)鉴权数组信息
调用第三方平台插口一般须要进行插口信令,服务端判定用户端是否有调用插口的权限;这里跟产品总监相关的是作为产品须要设计应用管理,包括:应用列表、应用创建、应用详情、应用配置、应用删掉等操作;以百度AI平台,应用列表如下:
其中AppID、API Key和Secret Key为创建应用时手动生成,接口信令所须要的access_token必须通过API key和Secret key恳求服务端获取。
(2)核心业务主键
产品总监须要依照业务需求明晰插口入参中须要什么数组信息以及数组支持的类型,以百度AI平台的食材辨识为例:
业务需求:识别图片中是哪种食材;
产品需求:
输入图片,图片支持一般采用base64和URL格式;top_num,提高插口的通用性,方便用户后续场景扩充,因此支持配置返回食材数目且排序;阈值,开放辨识阀值,方便用户按照实际辨识疗效调整,提高准确率;
注意点:设计插口核心业务主键,要尽量提升插口的通用性,以此适配更多的用户场景,比如top_num和阀值的开放,即泛化插口能力,将更多的主动权交由插口用户配置。
(3)字段信息约束条件
字段约束条件是为了保证插口的安全性,这点是产品总监跟业务方沟通达成一致后提供给开发小伙伴的;仍然以里面的食材辨识为例:
图片须要限制文件大小和帧率大小,文件大小只须要上限,分辨率大小须要包括上限和下限,下限是为了保证算法疗效,比如在目标测量中小目标容易测量失败;top_num须要限制下限,不得大于0,不设上限,可以接受算法返回的所有结果;阈值按照格式确定,可以是0-100,可以是0-1;
注:设置参数的一点小技巧,为了保证算法疗效,有时算法会默认设置参数,即用户设置的阀值高于默认参数,则不接受输入,采用默认,用户是无感知的;
2. 出参
调用插口都会有返回信息,产品须要依照业务需求定义返回的核心数组信息,这次以百度AI开放平台手势辨识为例,其中跟业务需求相关的关键数组包括:
三、接口限流
接口限流也是为了保障系统的安全性,因为有时业务方由于业务扩充造成调用量猛增,容易造成服务端宕机;限流就类似于空开的保险丝保证恳求量超过插口上限时系统可以拒绝恳求或排队,以此保证系统的安全性;
产品总监须要实现对业务充分评估,给出合理评估量,如TPS(每秒处理的恳求量);这样既不会导致系统资源的浪费,也保证业务正常运行;
注:与前面插口响应机制对应,同步插口通常须要给出峰值tps和响应时间,异步插口须要给出日调量即可;
四、接口测试
接口测试似乎是测试小妹哥的工作,测试内容也覆盖诸多,但是作为产品可以简单了解以下内容即可,如,
(1)接口可用性,即插口是否可以正常调用,正常返回结果,异常正确处理,正常返回错误码等;
(2)业务需求覆盖,即插口输入输出是否遵守产品需求文档描述;
(3)边界规则依循,即插口是否满足业务规则和数组约束条件;
(4)性能条件,通常插口上线前须要经过压测达到性能指标才可,包括某并发量下的tps和历时等;
结语
如何塑造“数据中心”的功能清单 第一讲
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2020-08-26 00:26
自第三次技术革命以来,随着信息技术在产业体系中不同程序的应用,完成了不同层次的信息化,产生了各行各业的海量信息。这些信息构成了以信息化为基础的时代。随着信息化不断的发展,数据已不再是简单的信息载体,而是一种能为企业和人类带来更大价值的资产。至此,我们迎来了大数据时代。在这样一个大数据时代,我们须要将被数据化的虚拟世界和现实世界相关联,从数据、信息、知识、智慧、客观规律的数据资产价值链中,将数据的价值逐渐呈现并最终可视化,以应对和解决企业和人类的生存和发展问题。为了实现数据价值从隐性不可看到显性并可见,并满足市场快速变化的业务需求。其中,数据采集是数据中心最为基本也最为关键的能力。
数据采集能力
采集数据的结构
在大数据的时代下,企业和组织的数据呈现出多种款式的数据,但大致可以分成两大类:
第一类:结构化数据,这类数据是一种可预见,经常出现的数据格式,数据结构包括:记录属性,键和索引等。可以通过传统的数据库管理系统加以管理和储存。
例如:交易数据,付款数据,销售活动数据,医疗过程数据等。
第二类:非结构化数据,这类数据可以进一步界定为,重复型和非重复型。
例如:电话记录数据,天气数据等。
例如:电子邮件,医疗记录,呼叫中心数据,交易数据,付款数据。
采集数据的插口
由于结构化数据格式与非结构化的数据格式完全不同,并呈现出多样性,这就要求数据采集能够具有不同的采集接口,以满足不同企业和组织的数据格式要求,从而达到有数据可以剖析的目的。
在采集应用中须要具有如下分类的采集接口:
1.NOSQL数据采集接口:该类插口用于联接非结构化数据对应的数据库和文件系统数据采集。
2. 关系型数据库采集接口:该类插口用于联接传统的关系型数据库数据采集。
包括:MYSQL,ORACLE,TERADATA,SYBASE,SQLSERVER,INFORMIX,ACCESS等商用和开源的关系型数据库。
3. 文件类数据采集接口:该类插口主要是针对各种文件数据采集。
包括:TXT格式文件,CSV格式文件,EXCEL文件,特定分割符格式文件。
4. 网络类数据采集接口:该类插口主要通过服务方式调用或服务恳求采集数据。
包括:webservice服务调用,rest服务调用。
数据处理能力
由于数据所处的业务领域不同,导致数据结构的复杂性也有所不同。使得数据处理过程中须要考虑数据的状态特点。主要包括如下4个特点:
1. 不变性,例如:网络安全的基础信息。
2. 实时性,例如:零售行业高频交易形成的数据,传感装置形成的异常检测数据等。
3. 近实时性,例如:零售行业的行为剖析数据。
4. 高延后和低延后(毫秒和秒级别),例如:气象数据。
以上4种能力决定了数据处理过程中须要采用不同的处理模式。主要模式有以下三种。
数据批处理模式
批处理是一种常见的数据处理模式,批处理模式比较简单,输入一批待处理的文件,启动处理过程。
等待处理结束后输出一个剖析结果文件。批处理模式的输入和输出都是文件的方式。数据剖析启动后用户即难以干预算法过程。批处理常常用于剖析大的文件或则大批量的文件。且剖析过程比较长。
例如:MapReduce 和 HDFS,每个文件输入输出都是HDFS文件,而每位MapReduce任务就是一个批处理过程。
数据流式处理模式
批处理指出的数据的批量处理,有明晰的剖析开始时间和结束时间。而在高延后和低延后数据状态下,数据须要源源不断的流入处理系统,系统就能不停地连续估算,这种估算处理模式及流式处理模式。流处理指出数据估算的连续性,一般具有高实时性,大吞吐量特性。
适合于实时统计,分析和实时决策的应用场景。
例如:基于Storm和内存数据库,可以实现网站在线点击率的实时统计。
Spark Streaming上运行自然语言处理组件,可以实现网路舆情实时监控。
图(交互式)处理模式
交互式处理模式是一种对实时性要求介于批处理和流处理之间的一种模式,这种模式通常面向业务剖析人员,交互式模式要求提供剖析结果的可视化。这种模式容许业务剖析人员在统一的工具框架内,开速开发剖析脚本,并在可容忍的时间内得到结果。并通过可视化诠释方法见到结果的一种数据处理模式,底层的具象数据模型通常是结构化或半结构化的数据。
例如:通过Spark SQL,Impala提供的SQL插口,对数据进行查询和统计剖析。
由于数据的多元化,数据状态的不同数据中心应当具有不同业务场景需求的处理能力。 查看全部
如何塑造“数据中心”的功能清单 第一讲
自第三次技术革命以来,随着信息技术在产业体系中不同程序的应用,完成了不同层次的信息化,产生了各行各业的海量信息。这些信息构成了以信息化为基础的时代。随着信息化不断的发展,数据已不再是简单的信息载体,而是一种能为企业和人类带来更大价值的资产。至此,我们迎来了大数据时代。在这样一个大数据时代,我们须要将被数据化的虚拟世界和现实世界相关联,从数据、信息、知识、智慧、客观规律的数据资产价值链中,将数据的价值逐渐呈现并最终可视化,以应对和解决企业和人类的生存和发展问题。为了实现数据价值从隐性不可看到显性并可见,并满足市场快速变化的业务需求。其中,数据采集是数据中心最为基本也最为关键的能力。
数据采集能力
采集数据的结构
在大数据的时代下,企业和组织的数据呈现出多种款式的数据,但大致可以分成两大类:
第一类:结构化数据,这类数据是一种可预见,经常出现的数据格式,数据结构包括:记录属性,键和索引等。可以通过传统的数据库管理系统加以管理和储存。
例如:交易数据,付款数据,销售活动数据,医疗过程数据等。
第二类:非结构化数据,这类数据可以进一步界定为,重复型和非重复型。
例如:电话记录数据,天气数据等。
例如:电子邮件,医疗记录,呼叫中心数据,交易数据,付款数据。
采集数据的插口
由于结构化数据格式与非结构化的数据格式完全不同,并呈现出多样性,这就要求数据采集能够具有不同的采集接口,以满足不同企业和组织的数据格式要求,从而达到有数据可以剖析的目的。
在采集应用中须要具有如下分类的采集接口:
1.NOSQL数据采集接口:该类插口用于联接非结构化数据对应的数据库和文件系统数据采集。
2. 关系型数据库采集接口:该类插口用于联接传统的关系型数据库数据采集。
包括:MYSQL,ORACLE,TERADATA,SYBASE,SQLSERVER,INFORMIX,ACCESS等商用和开源的关系型数据库。
3. 文件类数据采集接口:该类插口主要是针对各种文件数据采集。
包括:TXT格式文件,CSV格式文件,EXCEL文件,特定分割符格式文件。
4. 网络类数据采集接口:该类插口主要通过服务方式调用或服务恳求采集数据。
包括:webservice服务调用,rest服务调用。
数据处理能力
由于数据所处的业务领域不同,导致数据结构的复杂性也有所不同。使得数据处理过程中须要考虑数据的状态特点。主要包括如下4个特点:
1. 不变性,例如:网络安全的基础信息。
2. 实时性,例如:零售行业高频交易形成的数据,传感装置形成的异常检测数据等。
3. 近实时性,例如:零售行业的行为剖析数据。
4. 高延后和低延后(毫秒和秒级别),例如:气象数据。
以上4种能力决定了数据处理过程中须要采用不同的处理模式。主要模式有以下三种。
数据批处理模式
批处理是一种常见的数据处理模式,批处理模式比较简单,输入一批待处理的文件,启动处理过程。
等待处理结束后输出一个剖析结果文件。批处理模式的输入和输出都是文件的方式。数据剖析启动后用户即难以干预算法过程。批处理常常用于剖析大的文件或则大批量的文件。且剖析过程比较长。
例如:MapReduce 和 HDFS,每个文件输入输出都是HDFS文件,而每位MapReduce任务就是一个批处理过程。
数据流式处理模式
批处理指出的数据的批量处理,有明晰的剖析开始时间和结束时间。而在高延后和低延后数据状态下,数据须要源源不断的流入处理系统,系统就能不停地连续估算,这种估算处理模式及流式处理模式。流处理指出数据估算的连续性,一般具有高实时性,大吞吐量特性。
适合于实时统计,分析和实时决策的应用场景。
例如:基于Storm和内存数据库,可以实现网站在线点击率的实时统计。
Spark Streaming上运行自然语言处理组件,可以实现网路舆情实时监控。
图(交互式)处理模式
交互式处理模式是一种对实时性要求介于批处理和流处理之间的一种模式,这种模式通常面向业务剖析人员,交互式模式要求提供剖析结果的可视化。这种模式容许业务剖析人员在统一的工具框架内,开速开发剖析脚本,并在可容忍的时间内得到结果。并通过可视化诠释方法见到结果的一种数据处理模式,底层的具象数据模型通常是结构化或半结构化的数据。
例如:通过Spark SQL,Impala提供的SQL插口,对数据进行查询和统计剖析。
由于数据的多元化,数据状态的不同数据中心应当具有不同业务场景需求的处理能力。
自主研制wecenter 采集软件 正式面世!
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-08-13 09:10
软件自主研制,全部轮子模块从底层自已造,通用所有开源程序采集与发布的对接,不卖软件,卖的是服务,请往下看:支持图片本地化 支持列表图片本地化 支持图片缩略图(WC似乎用不着),支持图片水印,图片压缩全手动定时采集 +计划多任务同时进行采集软件自带动词功能 wecenter程序采集发布 wecenter可手动生成话题。支持对采集任一内容二次加工,如替换 提取 去除HTML标答 同义词转换软件免费使用!!!软件免费使用!!!软件免费使用!!!下载地址:www . lj55 .net===========以下服务为收费=========wecenter接口(问题+回答+随机用户评论+ 图片本地化)+ 1个网站栏目采集规则+软件配置好 一条龙采集发布设置服务 ! 收费约300 (每个人的需求不一样,那300是底价,接口也不是全通用的,购买者使用水平不一,总要收额外人工费)wecenter插口(文章+评论+随机用户评论)+ 图片本地化+ 1个网站栏目采集规则+软件配置好 一条龙采集发布设置服务 ! 收费约300第二杯五折!===============通过更改规则,wecenter可采集360问答 搜狗问答 天涯问答 知乎问答(只有2条回答) 大部份discuz峰会类程序(其他小型问答类 期盼你的合作再进行测试);文章类程序,就更简单了.===============本人QQ:31699~02984 【优采云】 我也在官方QQ群里请先提供目标网站入口网址,及采集需求,经本人测试后,能采集,再订购。

