
vba 抓取php网页
vba 抓取php网页(大半年一下,,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-16 00:20
背景:首先声明,我不是专业的IT程序开发人员,而是VBA爱好者和EXCEL用户;我从事市场营销工作,会涉及到相当程度的数据分析、财务分析和市场分析;最早从EXCEL95开始接触VBA,被它的灵活性深深吸引;关于VBA的网络爬虫,我在罐子上潜水了半年多,非常感谢几位大神的精彩分享。在此先表示诚挚的感谢,包括:liucqa 夏、尹子轩、xmyjk、kangatang、优采云、狼版、ldy 版;尤其是liucqa大侠整理的网络爬虫教程,由浅入深,前所未有,后...(希望有人{:soso_e113:});
因为是笔记本式的苹果系统,基本上是在虚拟机上运行Win8x64 + EXCEL2010;
我发现在EH论坛上讨论网页抓取的兄弟(当然还有姐妹们),大部分都是在抓取特定的网页,基本上有证券信息,发票相关,在线资格审核数据,高考数据分数线查询,优采云tickets...等,因为是针对具体的网站,代码比较固定;前面提到过,我的工作是和市场营销相关的,所以我需要抓取网站 @网站 会收录多种来源,常见的有:搜索引擎(谷歌的网页搜索、论坛搜索、博客搜索) ,百度的网页搜索,新闻搜索...),行业论坛的数据抓取(针对特定的关键词,或特定的URL),新浪微博等。
为了满足爬取不同网站内容的灵活配置,我基本使用数据字典和正则表达式处理;即把不同网站的抓取内容放到一个EXCEL表中,读入字典,通过字典完成对不同网站抓取内容的配置,获取到的内容字段的每一部分也以正则表达式参数的形式写入字典。
爬取网页内容的方式,尽量使用XMLhttp方法[CreateObject("Msxml2.XMLHTTP.3.0")],确实快很多,但是一旦出现问题,调试还不够直观,所以也会辅助IE[CreateObject("InternetExplorer.Application")]的使用。界面比较直观。一旦数据采集出现问题,通过实际显示的网页就可以判断出了什么问题: 网络连接中断?捕获的数据不存在?需要验证码吗?登录失败?...
IE的方式确实慢了很多(我测了一下比XML快5-15倍左右),但是还有一个好处,就是比较简单,尤其是涉及到用户名、密码、登录、cookie的时候,等,程序处理更容易。
解释了半天背景,回到本帖的主题!《新浪微博数据采集方法》
坦率地说,虽然我已经潜水了半年多,但我仍然对替换 cookie 或referer 更复杂的操作感到困惑。好像xmlhttp不能改变cookies(18/19/20楼),我看大部分jar都是用winhttp 5.1来实现的;
在新浪微博上抓取数据,除了一些简单的搜索查询,其他任务都需要用户登录才能获取数据。
在EH和其他一些论坛,我也看到了一些关于新浪微博的登录方法,但大多是用PHP、Java或python编写的,而且还涉及到相对复杂的加密算法(RSA);而新浪微博的算法似乎在不断更新。解决新浪微博登录问题,基本上可以分为3种方式:
1. 通过用户名和密码,破译加密算法实现登录(示例)
2. 手动或网页模拟登录,获取cookie,通过设置cookie(xml或winhttp)方式登录(绕过复杂的加密算法)
3.完全模拟登录获取数据(我目前用的比较笨的方法,但是如果数据查询太多,账号也会被新浪封号,所以需要几个不同的用户依次登录)
在这里请教各位大神,1、2的登录和抓包方法如何更容易实现?
先谢谢大家了!!{:soso_e183:} 查看全部
vba 抓取php网页(大半年一下,,)
背景:首先声明,我不是专业的IT程序开发人员,而是VBA爱好者和EXCEL用户;我从事市场营销工作,会涉及到相当程度的数据分析、财务分析和市场分析;最早从EXCEL95开始接触VBA,被它的灵活性深深吸引;关于VBA的网络爬虫,我在罐子上潜水了半年多,非常感谢几位大神的精彩分享。在此先表示诚挚的感谢,包括:liucqa 夏、尹子轩、xmyjk、kangatang、优采云、狼版、ldy 版;尤其是liucqa大侠整理的网络爬虫教程,由浅入深,前所未有,后...(希望有人{:soso_e113:});
因为是笔记本式的苹果系统,基本上是在虚拟机上运行Win8x64 + EXCEL2010;
我发现在EH论坛上讨论网页抓取的兄弟(当然还有姐妹们),大部分都是在抓取特定的网页,基本上有证券信息,发票相关,在线资格审核数据,高考数据分数线查询,优采云tickets...等,因为是针对具体的网站,代码比较固定;前面提到过,我的工作是和市场营销相关的,所以我需要抓取网站 @网站 会收录多种来源,常见的有:搜索引擎(谷歌的网页搜索、论坛搜索、博客搜索) ,百度的网页搜索,新闻搜索...),行业论坛的数据抓取(针对特定的关键词,或特定的URL),新浪微博等。
为了满足爬取不同网站内容的灵活配置,我基本使用数据字典和正则表达式处理;即把不同网站的抓取内容放到一个EXCEL表中,读入字典,通过字典完成对不同网站抓取内容的配置,获取到的内容字段的每一部分也以正则表达式参数的形式写入字典。
爬取网页内容的方式,尽量使用XMLhttp方法[CreateObject("Msxml2.XMLHTTP.3.0")],确实快很多,但是一旦出现问题,调试还不够直观,所以也会辅助IE[CreateObject("InternetExplorer.Application")]的使用。界面比较直观。一旦数据采集出现问题,通过实际显示的网页就可以判断出了什么问题: 网络连接中断?捕获的数据不存在?需要验证码吗?登录失败?...
IE的方式确实慢了很多(我测了一下比XML快5-15倍左右),但是还有一个好处,就是比较简单,尤其是涉及到用户名、密码、登录、cookie的时候,等,程序处理更容易。
解释了半天背景,回到本帖的主题!《新浪微博数据采集方法》
坦率地说,虽然我已经潜水了半年多,但我仍然对替换 cookie 或referer 更复杂的操作感到困惑。好像xmlhttp不能改变cookies(18/19/20楼),我看大部分jar都是用winhttp 5.1来实现的;
在新浪微博上抓取数据,除了一些简单的搜索查询,其他任务都需要用户登录才能获取数据。
在EH和其他一些论坛,我也看到了一些关于新浪微博的登录方法,但大多是用PHP、Java或python编写的,而且还涉及到相对复杂的加密算法(RSA);而新浪微博的算法似乎在不断更新。解决新浪微博登录问题,基本上可以分为3种方式:
1. 通过用户名和密码,破译加密算法实现登录(示例)
2. 手动或网页模拟登录,获取cookie,通过设置cookie(xml或winhttp)方式登录(绕过复杂的加密算法)
3.完全模拟登录获取数据(我目前用的比较笨的方法,但是如果数据查询太多,账号也会被新浪封号,所以需要几个不同的用户依次登录)
在这里请教各位大神,1、2的登录和抓包方法如何更容易实现?
先谢谢大家了!!{:soso_e183:}
vba 抓取php网页(大半年一下,,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-06 05:12
背景:首先声明,我不是专业的IT程序开发人员,而是VBA爱好者和EXCEL用户;我从事市场营销工作,会涉及到相当程度的数据分析、财务分析和市场分析;最早从EXCEL95开始接触VBA,被它的灵活性深深吸引;关于VBA的网页抓取,我在罐子上潜水了半年多,非常感谢几位大神的精彩分享。在此表示衷心的感谢,包括:liucqa 夏、尹子轩、xmyjk、kangatang、优采云、狼版、ldy版;尤其是liucqa大侠整理的网络爬虫教程,由浅入深,前所未有,后...(希望有人{:soso_e113:});
因为是笔记本式的苹果系统,基本上是在虚拟机上运行Win8x64 + EXCEL2010;
我发现在EH论坛上讨论网页抓取的兄弟(当然还有姐妹们),大部分都是在抓取特定的网页,基本上有证券信息,发票相关,在线资格审核数据,高考数据分数线查询,优采云tickets...等,因为是针对具体的网站,代码比较固定;前面提到过,我的工作是和市场营销相关的,所以我需要抓取网站 @网站 会收录多种来源,常见的有:搜索引擎(谷歌的网页搜索、论坛搜索、博客搜索) ,百度的网页搜索,新闻搜索...),行业论坛的数据抓取(针对特定的关键词,或特定的URL),新浪微博等。
为了满足爬取不同网站内容的灵活配置,我基本使用数据字典和正则表达式处理;即把不同网站的抓取内容放到一个EXCEL表中,读入字典,通过字典完成对不同网站抓取内容的配置,获取到的内容字段的每一部分也以正则表达式参数的形式写入字典。
爬取网页内容的方式,尽量使用XMLhttp方法[CreateObject("Msxml2.XMLHTTP.3.0")],确实快很多,但是一旦出现问题,调试还不够直观,所以也会辅助IE[CreateObject("InternetExplorer.Application")]的使用。界面比较直观。一旦数据采集出现问题,通过实际显示的网页就可以判断出了什么问题: 网络连接中断?捕获的数据不存在?需要验证码吗?登录失败?...
IE方式确实慢了很多(我测了一下比XML快5-15倍左右),但是还有一个优点,就是比较简单,尤其是涉及到用户名、密码、登录、cookie的时候,等,程序处理更容易。
解释了半天背景,我再回到本帖的主题!《新浪微博数据采集方法》
坦白说,虽然我已经潜水了半年多,但是对于更换cookies或者referrer这种比较复杂的操作,我还是一头雾水。似乎 xmlhttp 无法更改 cookie(18/19/20 楼)。我看大部分jar都是用winhttp 5.1来实现的;
在新浪微博上抓取数据,除了一些简单的搜索查询,其他任务都需要用户登录才能获取数据。
在EH等一些论坛上,我也看到了一些关于新浪微博的登录方式,但是大部分都是用PHP、Java或者python编写的,而且还涉及到比较复杂的加密算法(RSA);而新浪微博的算法似乎在不断更新。解决新浪微博登录问题,基本上可以分为3种方式:
1. 通过用户名和密码,破译加密算法实现登录(示例)
2. 手动或网页模拟登录,获取cookie,通过设置cookie(xml或winhttp)登录(绕过复杂的加密算法)
3.完全模拟登录获取数据(我目前用的比较笨的方法,但是如果数据查询太多,账号也会被新浪封号,所以需要几个不同的用户依次登录)
在这里请教各位大神,如何更方便的实现1、2的登录和抓包方式?
先谢谢大家了!!{:soso_e183:} 查看全部
vba 抓取php网页(大半年一下,,)
背景:首先声明,我不是专业的IT程序开发人员,而是VBA爱好者和EXCEL用户;我从事市场营销工作,会涉及到相当程度的数据分析、财务分析和市场分析;最早从EXCEL95开始接触VBA,被它的灵活性深深吸引;关于VBA的网页抓取,我在罐子上潜水了半年多,非常感谢几位大神的精彩分享。在此表示衷心的感谢,包括:liucqa 夏、尹子轩、xmyjk、kangatang、优采云、狼版、ldy版;尤其是liucqa大侠整理的网络爬虫教程,由浅入深,前所未有,后...(希望有人{:soso_e113:});
因为是笔记本式的苹果系统,基本上是在虚拟机上运行Win8x64 + EXCEL2010;
我发现在EH论坛上讨论网页抓取的兄弟(当然还有姐妹们),大部分都是在抓取特定的网页,基本上有证券信息,发票相关,在线资格审核数据,高考数据分数线查询,优采云tickets...等,因为是针对具体的网站,代码比较固定;前面提到过,我的工作是和市场营销相关的,所以我需要抓取网站 @网站 会收录多种来源,常见的有:搜索引擎(谷歌的网页搜索、论坛搜索、博客搜索) ,百度的网页搜索,新闻搜索...),行业论坛的数据抓取(针对特定的关键词,或特定的URL),新浪微博等。
为了满足爬取不同网站内容的灵活配置,我基本使用数据字典和正则表达式处理;即把不同网站的抓取内容放到一个EXCEL表中,读入字典,通过字典完成对不同网站抓取内容的配置,获取到的内容字段的每一部分也以正则表达式参数的形式写入字典。
爬取网页内容的方式,尽量使用XMLhttp方法[CreateObject("Msxml2.XMLHTTP.3.0")],确实快很多,但是一旦出现问题,调试还不够直观,所以也会辅助IE[CreateObject("InternetExplorer.Application")]的使用。界面比较直观。一旦数据采集出现问题,通过实际显示的网页就可以判断出了什么问题: 网络连接中断?捕获的数据不存在?需要验证码吗?登录失败?...
IE方式确实慢了很多(我测了一下比XML快5-15倍左右),但是还有一个优点,就是比较简单,尤其是涉及到用户名、密码、登录、cookie的时候,等,程序处理更容易。
解释了半天背景,我再回到本帖的主题!《新浪微博数据采集方法》
坦白说,虽然我已经潜水了半年多,但是对于更换cookies或者referrer这种比较复杂的操作,我还是一头雾水。似乎 xmlhttp 无法更改 cookie(18/19/20 楼)。我看大部分jar都是用winhttp 5.1来实现的;
在新浪微博上抓取数据,除了一些简单的搜索查询,其他任务都需要用户登录才能获取数据。
在EH等一些论坛上,我也看到了一些关于新浪微博的登录方式,但是大部分都是用PHP、Java或者python编写的,而且还涉及到比较复杂的加密算法(RSA);而新浪微博的算法似乎在不断更新。解决新浪微博登录问题,基本上可以分为3种方式:
1. 通过用户名和密码,破译加密算法实现登录(示例)
2. 手动或网页模拟登录,获取cookie,通过设置cookie(xml或winhttp)登录(绕过复杂的加密算法)
3.完全模拟登录获取数据(我目前用的比较笨的方法,但是如果数据查询太多,账号也会被新浪封号,所以需要几个不同的用户依次登录)
在这里请教各位大神,如何更方便的实现1、2的登录和抓包方式?
先谢谢大家了!!{:soso_e183:}
vba 抓取php网页(P.S.@AJAX数据库实例讲解(有时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-16 04:08
故事起源
以前有个小网站发表了几篇关于使用SAS抓取网页数据的小文章,然后在人大论坛上放了一个链接。后来因为懒,这个站就挂了,问的人一个接一个。从新获得这篇文章后
其中一个简单易懂,其他译文已由@收录翻译,链接会在文章的最后贴出。
适用性
在以下情况下,可以用同样的方法得到理论。
PS @AJAX 数据库实例 || @AJAX 数据库实例说明
文字前戏
有时我们经常需要保存和备份一些在线数据,比如银行利率、股票报价,或者来自统计局、各种金融机构或者其他类型的网站的数据。有时这些 网站 提供历史数据,而另一些则不提供。但是我们可以每天通过SAS运行程序,获取积累的历史数据,供以后分析。下面我以收购主页上海银行同业拆借利率为例进行说明。
以下是我们要在首页的数据
当我们打开这个网页并输入网页的源代码时,我们会惊奇地发现。什么情况,主页上看到的数据在源码中找不到,是不是用了其他技术。我们来看看源码代表什么
网页布局。
按照网页的布局,最新Shibor数据的源代码应该放在一大块文字之后,他放了一句话。
这是html内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入到主页中。好,那我们打开这个页面
并查看源代码,发现该网页中存在数据,然后我们开始用SAS进行抓取。
高潮
首先介绍Filename,通过添加infile语句可以将网页作为文件导入SAS数据集。BaseSAS 中的FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。此语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入 SAS 数据集。我们知道网络数据是一种标记语言,受制于一定的规范,所有的属性设置都包括在内。所以我们用 dlm=">" 来分隔并导入到一个变量中,因为数据太杂乱,我们无法区分并导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们使用 dlm=">" 进行分隔,所以我们知道采集到的观察结果只需要以 查看全部
vba 抓取php网页(P.S.@AJAX数据库实例讲解(有时))
故事起源
以前有个小网站发表了几篇关于使用SAS抓取网页数据的小文章,然后在人大论坛上放了一个链接。后来因为懒,这个站就挂了,问的人一个接一个。从新获得这篇文章后
其中一个简单易懂,其他译文已由@收录翻译,链接会在文章的最后贴出。
适用性
在以下情况下,可以用同样的方法得到理论。
PS @AJAX 数据库实例 || @AJAX 数据库实例说明
文字前戏
有时我们经常需要保存和备份一些在线数据,比如银行利率、股票报价,或者来自统计局、各种金融机构或者其他类型的网站的数据。有时这些 网站 提供历史数据,而另一些则不提供。但是我们可以每天通过SAS运行程序,获取积累的历史数据,供以后分析。下面我以收购主页上海银行同业拆借利率为例进行说明。
以下是我们要在首页的数据

当我们打开这个网页并输入网页的源代码时,我们会惊奇地发现。什么情况,主页上看到的数据在源码中找不到,是不是用了其他技术。我们来看看源码代表什么
网页布局。
按照网页的布局,最新Shibor数据的源代码应该放在一大块文字之后,他放了一句话。
这是html内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入到主页中。好,那我们打开这个页面
并查看源代码,发现该网页中存在数据,然后我们开始用SAS进行抓取。
高潮
首先介绍Filename,通过添加infile语句可以将网页作为文件导入SAS数据集。BaseSAS 中的FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。此语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入 SAS 数据集。我们知道网络数据是一种标记语言,受制于一定的规范,所有的属性设置都包括在内。所以我们用 dlm=">" 来分隔并导入到一个变量中,因为数据太杂乱,我们无法区分并导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们使用 dlm=">" 进行分隔,所以我们知道采集到的观察结果只需要以
vba 抓取php网页(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-12 18:18
这里有新鲜出炉的PHP教程,看看程序狗速!
PHP开源脚本语言PHP(外文名:Hypertext Preprocessor,中文名:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。 PHP的文件扩展名为php。
本文是一个php函数获取远程网页内容的用法,file_get_contents,有兴趣的同学请参考。
在网上看了半天file_get_contents不稳定,遇到了。 . .
另一方面,也说明程序的容错性很差。 . .
好吧,让我们开始吧。
我遇到了这个错误:
file_get_contents(***.php):打开流失败:HTTP 请求失败!
G,决定用curl
你可以使用这个功能:
/**
*
* 获取远程内容
* @param $url 接口url地址
* @param $timeout 超时时间
*/
函数 pc_file_get_contents($url, $timeout=30) {
$stream = stream_context_create(array('http' => array('timeout' => $timeout)));
返回@file_get_contents($url, 0, $stream);
}
该函数提取自phpcms,可以完美解决爬取网页时file_get_contents挂起的问题。 查看全部
vba 抓取php网页(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
这里有新鲜出炉的PHP教程,看看程序狗速!
PHP开源脚本语言PHP(外文名:Hypertext Preprocessor,中文名:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。 PHP的文件扩展名为php。
本文是一个php函数获取远程网页内容的用法,file_get_contents,有兴趣的同学请参考。
在网上看了半天file_get_contents不稳定,遇到了。 . .
另一方面,也说明程序的容错性很差。 . .
好吧,让我们开始吧。
我遇到了这个错误:
file_get_contents(***.php):打开流失败:HTTP 请求失败!
G,决定用curl
你可以使用这个功能:
/**
*
* 获取远程内容
* @param $url 接口url地址
* @param $timeout 超时时间
*/
函数 pc_file_get_contents($url, $timeout=30) {
$stream = stream_context_create(array('http' => array('timeout' => $timeout)));
返回@file_get_contents($url, 0, $stream);
}
该函数提取自phpcms,可以完美解决爬取网页时file_get_contents挂起的问题。
vba 抓取php网页(我的目标:让职场人士能高效使用office为其服务)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-16 23:38
我的目标:让中国大学生在走出校门的那一刻就具备了这些办公技能,让专业人士能够高效地利用办公为他们服务。支持我,为自己加油!
人们总是问我VBA难学吗?
怎么说呢,如果能掌握VBA的精髓,学起来也没那么复杂。
跟大家分享一下学习网络爬虫的过程。之前对VBA网页抓取技术一窍不通,今天抽空研究了一下。虽然还有很多不明白的地方,但我大概知道如何进一步学习了。
之前写过一篇文章文章,是PowerQuery技术抓取的网页数据,大家可以看一下:
在 网站 上将多页数据导入 Excel 真是太棒了!》
今天我们使用VBA代码从以下网页爬取数据:
很多人看到自己看不懂的代码总是会一头雾水。其实只要仔细分析一下,你就会觉得没那么复杂。只要你知道VBA的本质就是用代码来操作对象,你永远学不完对象,所以遇到不熟悉的对象也不用怕,套路都差不多!
起初,我在 网站 上阅读了一篇关于网络抓取的文章 文章:
最终代码如下:
然后文章说可以抓到网站上的数据,搞得我一头雾水。乍一看,文章 并不完整。后来找到原链接,是老外写的一篇文章的文章,不过也是不完整的。
但是上面的文章让我明白了,其实网页抓取使用了两个对象:Microsoft HTML Object Library和Microsoft Internet Controls,就像当时学字典一样,如果不想直接创建对象用代码,那么在声明对象变量之前应该绑定两个对象,这称为早期引用。
我从上面的代码得到的信息是:首先根据URL获取网页文档,文档收录很多内容,文档是一个对象,可以使用getElementsByTagName()函数从中提取表格object,提取出来的table也是object,其他不清楚。
所以我的目标是调查 getElementsByTagName() 到底得到了什么?
网上搜索后,看到如下代码:
在这一点上,我可能明白发生了什么。
先根据url获取网页文档doc,然后使用doc.getElementsByTagName("table")获取doc中的表格,不一定只有一个表格,所以使用索引来指定哪个表格,表格收录行,每行收录单元格,循环遍历表格每一行的每个单元格,单元格的innerText属性就是单元格中的值,类似于Excel中单元格的Value属性。
于是根据猫和虎,我处理了如下代码:
测试完全正确:
然后看到黑图中的代码使用了后期绑定,于是学习了后期绑定的写法,改成如下代码:
测试也很完美。
以上只提取一页数据,如何提取多页?明天继续写!
接下来我应该重点介绍 HTML 代码中文档对象的基本元素、结构以及其他方法和属性。 查看全部
vba 抓取php网页(我的目标:让职场人士能高效使用office为其服务)
我的目标:让中国大学生在走出校门的那一刻就具备了这些办公技能,让专业人士能够高效地利用办公为他们服务。支持我,为自己加油!
人们总是问我VBA难学吗?
怎么说呢,如果能掌握VBA的精髓,学起来也没那么复杂。
跟大家分享一下学习网络爬虫的过程。之前对VBA网页抓取技术一窍不通,今天抽空研究了一下。虽然还有很多不明白的地方,但我大概知道如何进一步学习了。
之前写过一篇文章文章,是PowerQuery技术抓取的网页数据,大家可以看一下:
在 网站 上将多页数据导入 Excel 真是太棒了!》
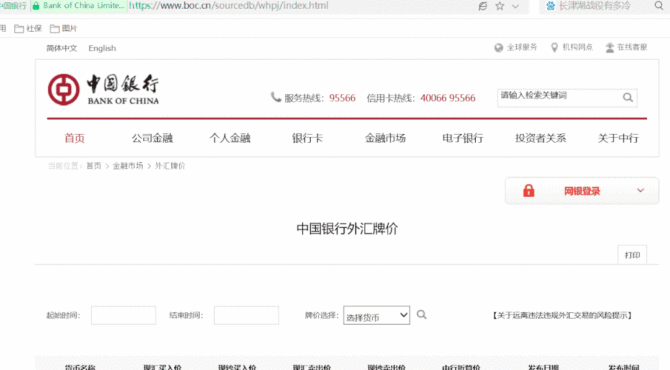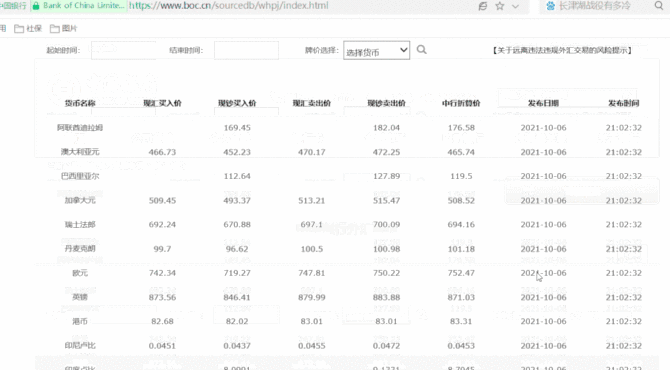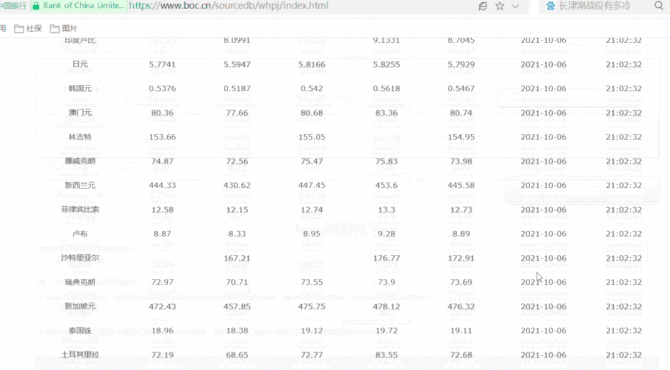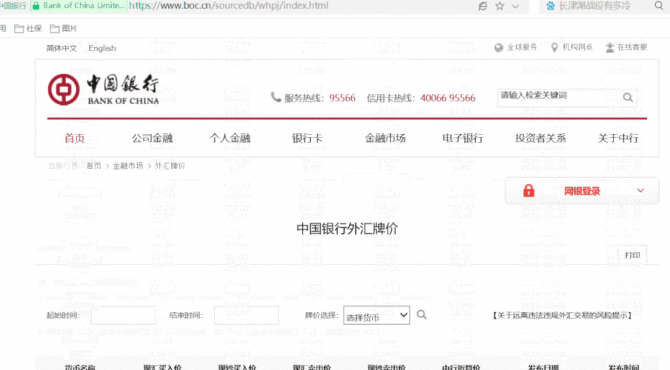
今天我们使用VBA代码从以下网页爬取数据:
很多人看到自己看不懂的代码总是会一头雾水。其实只要仔细分析一下,你就会觉得没那么复杂。只要你知道VBA的本质就是用代码来操作对象,你永远学不完对象,所以遇到不熟悉的对象也不用怕,套路都差不多!
起初,我在 网站 上阅读了一篇关于网络抓取的文章 文章:
最终代码如下:
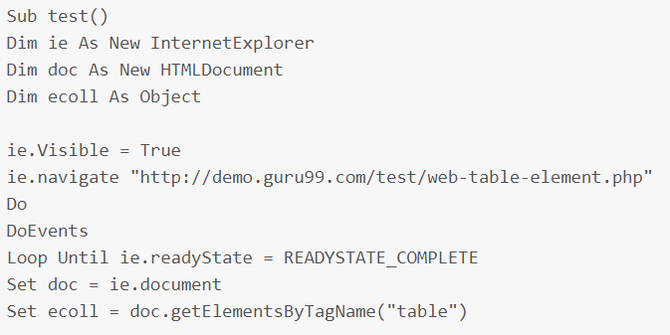
然后文章说可以抓到网站上的数据,搞得我一头雾水。乍一看,文章 并不完整。后来找到原链接,是老外写的一篇文章的文章,不过也是不完整的。
但是上面的文章让我明白了,其实网页抓取使用了两个对象:Microsoft HTML Object Library和Microsoft Internet Controls,就像当时学字典一样,如果不想直接创建对象用代码,那么在声明对象变量之前应该绑定两个对象,这称为早期引用。
我从上面的代码得到的信息是:首先根据URL获取网页文档,文档收录很多内容,文档是一个对象,可以使用getElementsByTagName()函数从中提取表格object,提取出来的table也是object,其他不清楚。
所以我的目标是调查 getElementsByTagName() 到底得到了什么?
网上搜索后,看到如下代码:
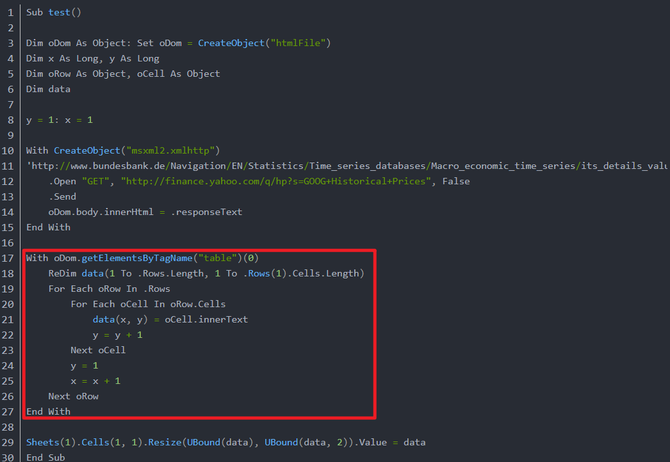
在这一点上,我可能明白发生了什么。
先根据url获取网页文档doc,然后使用doc.getElementsByTagName("table")获取doc中的表格,不一定只有一个表格,所以使用索引来指定哪个表格,表格收录行,每行收录单元格,循环遍历表格每一行的每个单元格,单元格的innerText属性就是单元格中的值,类似于Excel中单元格的Value属性。
于是根据猫和虎,我处理了如下代码:

测试完全正确:

然后看到黑图中的代码使用了后期绑定,于是学习了后期绑定的写法,改成如下代码:

测试也很完美。
以上只提取一页数据,如何提取多页?明天继续写!
接下来我应该重点介绍 HTML 代码中文档对象的基本元素、结构以及其他方法和属性。
vba 抓取php网页(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-22 08:16
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都因为生硬的爬虫爬取而被屏蔽。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档的处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键字符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python的语法非常简洁,同一句话可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索脚本之家之前的文章或继续浏览下面的相关文章,希望大家以后多多支持Scripthome! 查看全部
vba 抓取php网页(PHP解析器和PHP相比较,python适合做爬虫吗?)
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都因为生硬的爬虫爬取而被屏蔽。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档的处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键字符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python的语法非常简洁,同一句话可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索脚本之家之前的文章或继续浏览下面的相关文章,希望大家以后多多支持Scripthome!
vba 抓取php网页( Python技术ID:生成PDF的正确方法是什么?(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-13 19:04
Python技术ID:生成PDF的正确方法是什么?(二))
Python实现精准搜索,提取网页核心内容
更新时间:2021.11.01 10:30:31 作者:Python Technology
本文文章主要介绍python实现网页核心内容精准搜索和提取的实现。有需要的朋友可以借鉴。我希望它能有所帮助。祝大家进步很多。
内容
正文|李小飞
来源:Python技术《ID:pythonall》
每个人都必须熟悉爬虫程序。随便写一个获取网页信息,甚至通过请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有head、tail、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构完整。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
数以万计的数据超过 200 GB。如果数据量达到存储,那将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构,可读性会很差。更糟糕的是,网页上还有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
于是写了一段代码,我用Scrapy[4]作为爬虫框架,这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,更喜欢p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
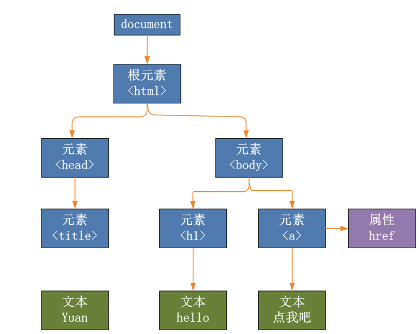
还有一点,网页结构是一棵DOM树[6]
那么离标签p越近,就越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,即离中心越近,密度越高,离中心越远,密度呈指数下降,这样就可以滤除密度中心。
50%的斜率是如何得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章 主题的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,应付日常的编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。
我希望这篇短文能给你带来启发。欢迎大家在留言区交流讨论,大展身手!
参考
[1]
卷曲 ת Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮痧:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246
以上就是python实现精准搜索和提取网页核心内容的详细过程。更多关于python搜索和提取网页内容的信息,请关注其他相关脚本文章! 查看全部
vba 抓取php网页(
Python技术ID:生成PDF的正确方法是什么?(二))
Python实现精准搜索,提取网页核心内容
更新时间:2021.11.01 10:30:31 作者:Python Technology
本文文章主要介绍python实现网页核心内容精准搜索和提取的实现。有需要的朋友可以借鉴。我希望它能有所帮助。祝大家进步很多。
内容

正文|李小飞
来源:Python技术《ID:pythonall》
每个人都必须熟悉爬虫程序。随便写一个获取网页信息,甚至通过请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有head、tail、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构完整。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
数以万计的数据超过 200 GB。如果数据量达到存储,那将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构,可读性会很差。更糟糕的是,网页上还有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
于是写了一段代码,我用Scrapy[4]作为爬虫框架,这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,更喜欢p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离标签p越近,就越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,即离中心越近,密度越高,离中心越远,密度呈指数下降,这样就可以滤除密度中心。
50%的斜率是如何得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章 主题的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,应付日常的编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。
我希望这篇短文能给你带来启发。欢迎大家在留言区交流讨论,大展身手!
参考
[1]
卷曲 ת Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮痧:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246
以上就是python实现精准搜索和提取网页核心内容的详细过程。更多关于python搜索和提取网页内容的信息,请关注其他相关脚本文章!
vba 抓取php网页(开发的VB和VBA语言的缺点及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-12 09:09
VB
Visual Basic(简称VB)是一种通用的基于对象的编程语言。它是一种结构化、模块化、面向对象和事件驱动的可视化编程语言,可在开发环境中提供帮助。它是一种可以用于开发微软自己产品的语言。
“可视化”是指开发图形用户界面(GUI)的方法——你不需要编写大量代码来描述界面元素的外观和位置,而只需在一个点上添加一个预先构建的对象屏幕。“Basic”是指BASIC(Beginners All-Purpose Symbolic Instruction Code)语言,它是计算技术发展史上使用最广泛的语言。
Visual Basic 源自 BASIC 编程语言。VB具有图形用户界面(GUI)和快速应用程序开发(RAD)系统,可以方便地使用DAO、RDO、ADO连接数据库,或轻松创建Active X控件,高效生成类型安全和面向对象应用 [2] 。程序员可以很方便地使用VB提供的组件来快速构建应用程序,对新手来说相当友好。后面提到的VBS和VBA其实都是VB语言的分支。
缺点
一、不支持继承
VB 5.0 和VB 6.0 都是基于对象的编程语言,但不包括继承特性。VB提供了特殊的类函数,但仍然不能满足程序员的需要。
二、没有对多线程的原生支持
Visual Basic 没有对多线程的原生支持,只能通过 Windows API 调用来实现,而且极其不稳定。由于运行时库不会在API创建的线程中自动初始化,因此部分功能无法使用。一般在VB6等早期的VB开发环境中,使用API创建线程的目的是为了完成大量容易使程序挂掉的数据或逻辑计算。
三、异常处理不当
Visual Basic 具有内置的异常处理。即使没有编写异常处理代码,一旦用户出错,也会弹出一个对话框,指明出错的原因,然后程序就会终止。
您可以使用 Err.Raise 在 Visual Basic 中引发异常。处理系统和用户抛出的异常有两种常用的模式:一种是使用On Error Resume Next来处理错误;另一种是使用 On Error Goto 将错误处理代码引入操作。但是和C++等语言相比,这样的异常处理破坏了代码的结构。
但是,上述缺点在中得到了改进。
VBS
VBScript 是 Visual Basic Script 的缩写,有时缩写为 VBS。VBScript是微软公司开发的一种脚本语言,可以看作是VB语言的简化版,与VBA有着非常密切的关系。它具有原语言易学易学的特点,并继承了JavaScript的跨平台特性。目前这种语言广泛用于网页和ASP程序的制作,也可以直接作为可执行程序使用。调试简单的VB语句非常方便。有心机的同学可以去看看用VBS语言制作恶搞小程序
因为VBScript可以通过Windows脚本宿主调用COM,所以可以使用Windows操作系统可以使用的程序库。例如,它可以使用 Microsoft Office 的库,尤其是 Microsoft Access 和 Microsoft SQL Server 的库。当然,它也可以使用。使用操作系统本身的其他程序和库。在实践中,VBScript一般用于以下三个方面:
一、Windows 操作系统
VBScript 可用于自动执行重复的 Windows 操作系统任务。在Windows 操作系统中,VBScript 可以在Windows Script Host 的范围内运行。Windows 操作系统可以自动识别和执行 *.VBS 和 *.WSF 文件格式。此外,Internet Explorer 可以执行 *.HTA 和 *.CHM 文件格式。VBS 和 WSF 文件完全基于文本,它们只能通过几个对话窗口与用户交流。HTA 和 CHM 文件使用 HTML 格式,它们的程序代码可以像 HTML 一样编辑和检查。WSF、HTA 和 CHM 文件中的 VBScript 和 JavaScript 程序代码可以任意混合。HTA 文件实际上是添加了 VBS 和 JavaScript 组件的 HTML 文件。CHM 文件是一种在线帮助,用户可以使用专门的编辑程序将 HTML 程序编辑成 CHM。
二、Web 浏览器(客户的 VBS)
网页中的VBS可以用来命令客户端的网页浏览器(浏览器执行VBS程序)。VBS 和 JavaScript 在这方面是竞争对手。它们可用于实现动态 HTML,甚至可以将整个程序集成到一个网页中。
到目前为止,VBS 还没有在客户中占据主导地位,因为它只有 Microsoft Internet Explorer 支持(Mozilla Suite 可以通过安装插件来支持 VBS)。所有网络浏览器都支持 JavaScript。在 Internet Explorer 中,VBS 和 JavaScript 使用相同的权限,它们只能在有限的范围内使用 Windows 操作系统中的对象。
三、Web服务器(服务器端的VBS)
在 Web 服务器方面,VBS 是微软 Active Server Pages 的一部分,它是 JavaServer Pages 和 PHP 的竞争对手。在这里,VBS 代码直接嵌入到 HTML 页面中,这样的页面以 ASP 结尾。Web服务器Internet信息服务执行ASP页面中的程序部分,将结果转换为HTML,传送到Web浏览器供用户使用。这样服务器就可以监听数据库,把结果放到HTML页面中。
VBScript 的主要优点
1、 由于 VBScript 是由操作系统解释的,而不是由 Web 浏览器解释的,因此它的文件相对较小且易于学习。
2、 2000/98SE以后的所有Windows版本都可以直接使用。
缺点
1、VBS 现在不能用作电子邮件的附件。Microsoft Outlook 拒绝接受 VBS 作为附件,收件人不能直接使用 VBS 附件。
2、VBS 的各种编辑器并不流行。
操作系统没有任何特殊的保护设施。VBS 程序的处理方式与其他 JS、EXE、BAT 或 CMD 程序相同。操作系统不具备监控恶意功能的能力。
与VB的区别
一、不能为变量定义类型
在VB中,Dim variable name As type用于变量定义类型,但是在VBScript中写这个是错误的。只能使用Dim变量名,解释器会根据赋值的类型自动定义变量类型。
二、不能使用条件编译
在VB中,可以使用#If... Then、#ElseIf... Then、#Else、#End If、#Const... =...等语句来定义编译时使用的语句,而且由于VBScript不需要编译和可以直接执行,不是不需要条件编译语句。
三、安全
在微软决定 Outlook 和 Outlook Express 中的 HTML 电子邮件可以使用 VBScript 之后,出现了许多使用 Windows Script Host 和 ActiveX 功能的计算机病毒。这些病毒之所以能够传播开来,也是因为这些系统功能一开始就完全没有受到保护。尽管 VBScript 和 JavaScript 使用操作系统的相同功能安全措施,但通常很难保护 VBScript 代码不被用户看到。
VBA
VBA(Visual Basic for Applications)是Visual Basic 的一种宏语言,是一种用于在其桌面应用程序中执行通用自动化(OLE)任务的编程语言。主要可用于扩展Windows应用程序的功能,尤其是Microsoft Office软件。也可以说是一个应用可视化的Basic脚本。
在语言结构上,VBA是VB的一个子集,它们的语法结构是一样的。两者的开发环境也差不多。但是,VB是一个独立的开发工具,它不需要附加任何其他应用程序,它有自己完全独立的工作环境和编译链接系统。VBA 没有自己独立的工作环境。它必须附加到某个主应用程序中,并且只能在 Office 应用程序中使用,例如 Word、Excel、Access 等。
与VB的区别
1、VB 旨在创建标准应用程序,而 VBA 旨在自动化现有应用程序(EXCEL 等)。
2、VB 有自己的开发环境,VBA 必须寄生在现有的应用程序上。
3、运行VB开发的应用程序,用户不需要安装VB,因为VB开发的应用程序是一个可执行文件(*.EXE),VBA开发的程序必须依赖其父应用程序. 查看全部
vba 抓取php网页(开发的VB和VBA语言的缺点及解决办法)
VB
Visual Basic(简称VB)是一种通用的基于对象的编程语言。它是一种结构化、模块化、面向对象和事件驱动的可视化编程语言,可在开发环境中提供帮助。它是一种可以用于开发微软自己产品的语言。

“可视化”是指开发图形用户界面(GUI)的方法——你不需要编写大量代码来描述界面元素的外观和位置,而只需在一个点上添加一个预先构建的对象屏幕。“Basic”是指BASIC(Beginners All-Purpose Symbolic Instruction Code)语言,它是计算技术发展史上使用最广泛的语言。
Visual Basic 源自 BASIC 编程语言。VB具有图形用户界面(GUI)和快速应用程序开发(RAD)系统,可以方便地使用DAO、RDO、ADO连接数据库,或轻松创建Active X控件,高效生成类型安全和面向对象应用 [2] 。程序员可以很方便地使用VB提供的组件来快速构建应用程序,对新手来说相当友好。后面提到的VBS和VBA其实都是VB语言的分支。
缺点
一、不支持继承
VB 5.0 和VB 6.0 都是基于对象的编程语言,但不包括继承特性。VB提供了特殊的类函数,但仍然不能满足程序员的需要。
二、没有对多线程的原生支持
Visual Basic 没有对多线程的原生支持,只能通过 Windows API 调用来实现,而且极其不稳定。由于运行时库不会在API创建的线程中自动初始化,因此部分功能无法使用。一般在VB6等早期的VB开发环境中,使用API创建线程的目的是为了完成大量容易使程序挂掉的数据或逻辑计算。
三、异常处理不当
Visual Basic 具有内置的异常处理。即使没有编写异常处理代码,一旦用户出错,也会弹出一个对话框,指明出错的原因,然后程序就会终止。
您可以使用 Err.Raise 在 Visual Basic 中引发异常。处理系统和用户抛出的异常有两种常用的模式:一种是使用On Error Resume Next来处理错误;另一种是使用 On Error Goto 将错误处理代码引入操作。但是和C++等语言相比,这样的异常处理破坏了代码的结构。
但是,上述缺点在中得到了改进。
VBS
VBScript 是 Visual Basic Script 的缩写,有时缩写为 VBS。VBScript是微软公司开发的一种脚本语言,可以看作是VB语言的简化版,与VBA有着非常密切的关系。它具有原语言易学易学的特点,并继承了JavaScript的跨平台特性。目前这种语言广泛用于网页和ASP程序的制作,也可以直接作为可执行程序使用。调试简单的VB语句非常方便。有心机的同学可以去看看用VBS语言制作恶搞小程序

因为VBScript可以通过Windows脚本宿主调用COM,所以可以使用Windows操作系统可以使用的程序库。例如,它可以使用 Microsoft Office 的库,尤其是 Microsoft Access 和 Microsoft SQL Server 的库。当然,它也可以使用。使用操作系统本身的其他程序和库。在实践中,VBScript一般用于以下三个方面:
一、Windows 操作系统
VBScript 可用于自动执行重复的 Windows 操作系统任务。在Windows 操作系统中,VBScript 可以在Windows Script Host 的范围内运行。Windows 操作系统可以自动识别和执行 *.VBS 和 *.WSF 文件格式。此外,Internet Explorer 可以执行 *.HTA 和 *.CHM 文件格式。VBS 和 WSF 文件完全基于文本,它们只能通过几个对话窗口与用户交流。HTA 和 CHM 文件使用 HTML 格式,它们的程序代码可以像 HTML 一样编辑和检查。WSF、HTA 和 CHM 文件中的 VBScript 和 JavaScript 程序代码可以任意混合。HTA 文件实际上是添加了 VBS 和 JavaScript 组件的 HTML 文件。CHM 文件是一种在线帮助,用户可以使用专门的编辑程序将 HTML 程序编辑成 CHM。
二、Web 浏览器(客户的 VBS)
网页中的VBS可以用来命令客户端的网页浏览器(浏览器执行VBS程序)。VBS 和 JavaScript 在这方面是竞争对手。它们可用于实现动态 HTML,甚至可以将整个程序集成到一个网页中。
到目前为止,VBS 还没有在客户中占据主导地位,因为它只有 Microsoft Internet Explorer 支持(Mozilla Suite 可以通过安装插件来支持 VBS)。所有网络浏览器都支持 JavaScript。在 Internet Explorer 中,VBS 和 JavaScript 使用相同的权限,它们只能在有限的范围内使用 Windows 操作系统中的对象。
三、Web服务器(服务器端的VBS)
在 Web 服务器方面,VBS 是微软 Active Server Pages 的一部分,它是 JavaServer Pages 和 PHP 的竞争对手。在这里,VBS 代码直接嵌入到 HTML 页面中,这样的页面以 ASP 结尾。Web服务器Internet信息服务执行ASP页面中的程序部分,将结果转换为HTML,传送到Web浏览器供用户使用。这样服务器就可以监听数据库,把结果放到HTML页面中。
VBScript 的主要优点
1、 由于 VBScript 是由操作系统解释的,而不是由 Web 浏览器解释的,因此它的文件相对较小且易于学习。
2、 2000/98SE以后的所有Windows版本都可以直接使用。
缺点
1、VBS 现在不能用作电子邮件的附件。Microsoft Outlook 拒绝接受 VBS 作为附件,收件人不能直接使用 VBS 附件。
2、VBS 的各种编辑器并不流行。
操作系统没有任何特殊的保护设施。VBS 程序的处理方式与其他 JS、EXE、BAT 或 CMD 程序相同。操作系统不具备监控恶意功能的能力。
与VB的区别
一、不能为变量定义类型
在VB中,Dim variable name As type用于变量定义类型,但是在VBScript中写这个是错误的。只能使用Dim变量名,解释器会根据赋值的类型自动定义变量类型。
二、不能使用条件编译
在VB中,可以使用#If... Then、#ElseIf... Then、#Else、#End If、#Const... =...等语句来定义编译时使用的语句,而且由于VBScript不需要编译和可以直接执行,不是不需要条件编译语句。
三、安全
在微软决定 Outlook 和 Outlook Express 中的 HTML 电子邮件可以使用 VBScript 之后,出现了许多使用 Windows Script Host 和 ActiveX 功能的计算机病毒。这些病毒之所以能够传播开来,也是因为这些系统功能一开始就完全没有受到保护。尽管 VBScript 和 JavaScript 使用操作系统的相同功能安全措施,但通常很难保护 VBScript 代码不被用户看到。
VBA
VBA(Visual Basic for Applications)是Visual Basic 的一种宏语言,是一种用于在其桌面应用程序中执行通用自动化(OLE)任务的编程语言。主要可用于扩展Windows应用程序的功能,尤其是Microsoft Office软件。也可以说是一个应用可视化的Basic脚本。

在语言结构上,VBA是VB的一个子集,它们的语法结构是一样的。两者的开发环境也差不多。但是,VB是一个独立的开发工具,它不需要附加任何其他应用程序,它有自己完全独立的工作环境和编译链接系统。VBA 没有自己独立的工作环境。它必须附加到某个主应用程序中,并且只能在 Office 应用程序中使用,例如 Word、Excel、Access 等。
与VB的区别
1、VB 旨在创建标准应用程序,而 VBA 旨在自动化现有应用程序(EXCEL 等)。
2、VB 有自己的开发环境,VBA 必须寄生在现有的应用程序上。
3、运行VB开发的应用程序,用户不需要安装VB,因为VB开发的应用程序是一个可执行文件(*.EXE),VBA开发的程序必须依赖其父应用程序.
vba 抓取php网页(如何融合到一个更灵活的网站爬虫中?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-10-15 18:05
在这个 文章 中,您将学习将这些基本方法集成到一个更灵活的 网站 爬虫中,该爬虫可以跟踪任何遵循特定 URL 模式的链接。
此爬虫非常适合从 网站 中抓取所有数据的项目,但不适用于从特定搜索结果或页面列表中抓取数据的项目。它也非常适用于 网站 页面组织不佳或非常分散的情况。
这些类型的爬虫不需要上一节中使用的定位链接的结构化方法来爬取搜索页面,因此不需要在网站对象中收录描述搜索页面的属性。但是因为爬虫不知道要找到链接的位置,所以需要一些规则来告诉它选择哪个页面。您可以使用 targetPattern(目标 URL 的正则表达式)和布尔变量 absoluteUrl 来实现此目标:
class Website:
def __init__(self, name, url, targetPattern, absoluteUrl,
titleTag, bodyTag):
self.name = name
self.url = url
self.targetPattern = targetPattern
self.absoluteUrl=absoluteUrl
self.titleTag = titleTag
self.bodyTag = bodyTag
class Content:
def __init__(self, url, title, body):
self.url = url
self.title = title
self.body = body
def print(self):
print("URL: {}".format(self.url))
print("TITLE: {}".format(self.title))
print("BODY:\n{}".format(self.body))
Content 类与第一个爬虫示例中使用的类相同。
Crawler类从每个网站的首页开始,定位内链,解析每个内链页面上找到的内容:
import re
class Crawler:
def __init__(self, site):
self.site = site
self.visited = []
def getPage(self, url):
try:
req = requests.get(url)
except requests.exceptions.RequestException:
return None
return BeautifulSoup(req.text, 'html.parser')
def safeGet(self, pageObj, selector):
selectedElems = pageObj.select(selector)
if selectedElems is not None and len(selectedElems) > 0:
return '\n'.join([elem.get_text() for
elem in selectedElems])
return ''
def parse(self, url):
bs = self.getPage(url)
if bs is not None:
title = self.safeGet(bs, self.site.titleTag)
body = self.safeGet(bs, self.site.bodyTag)
if title != '' and body != '':
content = Content(url, title, body)
content.print()
def crawl(self):
"""
获取网站主页的页面链接
"""
bs = self.getPage(self.site.url)
targetPages = bs.findAll('a',
href=re.compile(self.site.targetPattern))
for targetPage in targetPages:
targetPage = targetPage.attrs['href']
if targetPage not in self.visited:
self.visited.append(targetPage)
if not self.site.absoluteUrl:
targetPage = '{}{}'.format(self.site.url, targetPage)
self.parse(targetPage)
reuters = Website('Reuters', 'https://www.reuters.com', '^(/article/)', False,
'h1', 'div.StandardArticleBody_body_1gnLA')
crawler = Crawler(reuters)
crawler.crawl()
与前面的示例相比,这里的另一个变化是网站对象(在本示例中为变量 reuters)是 Crawler 对象本身的一个属性。这样做的效果是将访问过的页面存储在爬虫中,但这也意味着必须为每个 网站 实例化一个新的爬虫,而不是重复使用爬虫来抓取 网站 的列表。
是选择与网站无关的爬虫,还是使用网站作为爬虫的一个属性,这都是需要根据自己的需要权衡的决定。这两种方法在功能实现上都没有问题。
还有一点需要注意的是,这个爬虫会从首页开始爬取,但是所有的页面都记录完之后,就不会继续爬取了。您可能希望编写一个收录第 3 章中介绍的一些模式的爬虫,然后在您访问的每个页面中查看更多目标 URL。您甚至可以跟踪每个页面中涉及的所有 URL(不仅仅是匹配目标模式的 URL),然后检查这些 URL 是否收录目标模式。
以上就是关于python爬取的相关知识点网站,感谢大家对脚本屋的学习和支持。 查看全部
vba 抓取php网页(如何融合到一个更灵活的网站爬虫中?)
在这个 文章 中,您将学习将这些基本方法集成到一个更灵活的 网站 爬虫中,该爬虫可以跟踪任何遵循特定 URL 模式的链接。
此爬虫非常适合从 网站 中抓取所有数据的项目,但不适用于从特定搜索结果或页面列表中抓取数据的项目。它也非常适用于 网站 页面组织不佳或非常分散的情况。
这些类型的爬虫不需要上一节中使用的定位链接的结构化方法来爬取搜索页面,因此不需要在网站对象中收录描述搜索页面的属性。但是因为爬虫不知道要找到链接的位置,所以需要一些规则来告诉它选择哪个页面。您可以使用 targetPattern(目标 URL 的正则表达式)和布尔变量 absoluteUrl 来实现此目标:
class Website:
def __init__(self, name, url, targetPattern, absoluteUrl,
titleTag, bodyTag):
self.name = name
self.url = url
self.targetPattern = targetPattern
self.absoluteUrl=absoluteUrl
self.titleTag = titleTag
self.bodyTag = bodyTag
class Content:
def __init__(self, url, title, body):
self.url = url
self.title = title
self.body = body
def print(self):
print("URL: {}".format(self.url))
print("TITLE: {}".format(self.title))
print("BODY:\n{}".format(self.body))
Content 类与第一个爬虫示例中使用的类相同。
Crawler类从每个网站的首页开始,定位内链,解析每个内链页面上找到的内容:
import re
class Crawler:
def __init__(self, site):
self.site = site
self.visited = []
def getPage(self, url):
try:
req = requests.get(url)
except requests.exceptions.RequestException:
return None
return BeautifulSoup(req.text, 'html.parser')
def safeGet(self, pageObj, selector):
selectedElems = pageObj.select(selector)
if selectedElems is not None and len(selectedElems) > 0:
return '\n'.join([elem.get_text() for
elem in selectedElems])
return ''
def parse(self, url):
bs = self.getPage(url)
if bs is not None:
title = self.safeGet(bs, self.site.titleTag)
body = self.safeGet(bs, self.site.bodyTag)
if title != '' and body != '':
content = Content(url, title, body)
content.print()
def crawl(self):
"""
获取网站主页的页面链接
"""
bs = self.getPage(self.site.url)
targetPages = bs.findAll('a',
href=re.compile(self.site.targetPattern))
for targetPage in targetPages:
targetPage = targetPage.attrs['href']
if targetPage not in self.visited:
self.visited.append(targetPage)
if not self.site.absoluteUrl:
targetPage = '{}{}'.format(self.site.url, targetPage)
self.parse(targetPage)
reuters = Website('Reuters', 'https://www.reuters.com', '^(/article/)', False,
'h1', 'div.StandardArticleBody_body_1gnLA')
crawler = Crawler(reuters)
crawler.crawl()
与前面的示例相比,这里的另一个变化是网站对象(在本示例中为变量 reuters)是 Crawler 对象本身的一个属性。这样做的效果是将访问过的页面存储在爬虫中,但这也意味着必须为每个 网站 实例化一个新的爬虫,而不是重复使用爬虫来抓取 网站 的列表。
是选择与网站无关的爬虫,还是使用网站作为爬虫的一个属性,这都是需要根据自己的需要权衡的决定。这两种方法在功能实现上都没有问题。
还有一点需要注意的是,这个爬虫会从首页开始爬取,但是所有的页面都记录完之后,就不会继续爬取了。您可能希望编写一个收录第 3 章中介绍的一些模式的爬虫,然后在您访问的每个页面中查看更多目标 URL。您甚至可以跟踪每个页面中涉及的所有 URL(不仅仅是匹配目标模式的 URL),然后检查这些 URL 是否收录目标模式。
以上就是关于python爬取的相关知识点网站,感谢大家对脚本屋的学习和支持。
vba 抓取php网页(Python的参数里的:和->是什么意思?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-03 18:19
Python参数中的:和->是什么意思
我的阿里云ECs昨晚被攻击了。网络带宽已满
echart X坐标轴的名称位于左侧,并与Y坐标比例重叠。如何解决
当iPhone上传图片时,图片将旋转90度。如果你选择相册,你不会,Android手机也不会。如何解决
Ubuntu服务器PHP成功上传了该文件,但文件夹为空
react本机状态由redux控制。如何根据状态判断和执行导航跳转
您使用vuex的场景有哪些?你把后端数据扔进状态了吗
Python如何优雅地过滤字符
您自己编写的网页CPU和内存消耗高的原因是什么?如何对其进行优化
我知道中心点和半径,以及如何设置地图的显示范围
如何处理降价标准字符串
Mongodb将a字段等于某个值的记录的B字段更新为指定值
关于在开源中国使用git代码托管
Split()问题,解决
刷新网页后是否会释放内存
密码的正则表达式
PHP访问类定义中的属性。为什么属性名有时会添加“$”但有时不会
字符串和数据比较
将数据从节点插入Mongo时,插入成功,但将返回错误消息
spring引导服务器启动后,用户SSH注销,服务停止 查看全部
vba 抓取php网页(Python的参数里的:和->是什么意思?(图))
Python参数中的:和->是什么意思
我的阿里云ECs昨晚被攻击了。网络带宽已满
echart X坐标轴的名称位于左侧,并与Y坐标比例重叠。如何解决
当iPhone上传图片时,图片将旋转90度。如果你选择相册,你不会,Android手机也不会。如何解决
Ubuntu服务器PHP成功上传了该文件,但文件夹为空
react本机状态由redux控制。如何根据状态判断和执行导航跳转
您使用vuex的场景有哪些?你把后端数据扔进状态了吗
Python如何优雅地过滤字符
您自己编写的网页CPU和内存消耗高的原因是什么?如何对其进行优化
我知道中心点和半径,以及如何设置地图的显示范围
如何处理降价标准字符串
Mongodb将a字段等于某个值的记录的B字段更新为指定值
关于在开源中国使用git代码托管
Split()问题,解决
刷新网页后是否会释放内存
密码的正则表达式
PHP访问类定义中的属性。为什么属性名有时会添加“$”但有时不会
字符串和数据比较
将数据从节点插入Mongo时,插入成功,但将返回错误消息
spring引导服务器启动后,用户SSH注销,服务停止
vba 抓取php网页(大半年一下,,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-16 00:20
背景:首先声明,我不是专业的IT程序开发人员,而是VBA爱好者和EXCEL用户;我从事市场营销工作,会涉及到相当程度的数据分析、财务分析和市场分析;最早从EXCEL95开始接触VBA,被它的灵活性深深吸引;关于VBA的网络爬虫,我在罐子上潜水了半年多,非常感谢几位大神的精彩分享。在此先表示诚挚的感谢,包括:liucqa 夏、尹子轩、xmyjk、kangatang、优采云、狼版、ldy 版;尤其是liucqa大侠整理的网络爬虫教程,由浅入深,前所未有,后...(希望有人{:soso_e113:});
因为是笔记本式的苹果系统,基本上是在虚拟机上运行Win8x64 + EXCEL2010;
我发现在EH论坛上讨论网页抓取的兄弟(当然还有姐妹们),大部分都是在抓取特定的网页,基本上有证券信息,发票相关,在线资格审核数据,高考数据分数线查询,优采云tickets...等,因为是针对具体的网站,代码比较固定;前面提到过,我的工作是和市场营销相关的,所以我需要抓取网站 @网站 会收录多种来源,常见的有:搜索引擎(谷歌的网页搜索、论坛搜索、博客搜索) ,百度的网页搜索,新闻搜索...),行业论坛的数据抓取(针对特定的关键词,或特定的URL),新浪微博等。
为了满足爬取不同网站内容的灵活配置,我基本使用数据字典和正则表达式处理;即把不同网站的抓取内容放到一个EXCEL表中,读入字典,通过字典完成对不同网站抓取内容的配置,获取到的内容字段的每一部分也以正则表达式参数的形式写入字典。
爬取网页内容的方式,尽量使用XMLhttp方法[CreateObject("Msxml2.XMLHTTP.3.0")],确实快很多,但是一旦出现问题,调试还不够直观,所以也会辅助IE[CreateObject("InternetExplorer.Application")]的使用。界面比较直观。一旦数据采集出现问题,通过实际显示的网页就可以判断出了什么问题: 网络连接中断?捕获的数据不存在?需要验证码吗?登录失败?...
IE的方式确实慢了很多(我测了一下比XML快5-15倍左右),但是还有一个好处,就是比较简单,尤其是涉及到用户名、密码、登录、cookie的时候,等,程序处理更容易。
解释了半天背景,回到本帖的主题!《新浪微博数据采集方法》
坦率地说,虽然我已经潜水了半年多,但我仍然对替换 cookie 或referer 更复杂的操作感到困惑。好像xmlhttp不能改变cookies(18/19/20楼),我看大部分jar都是用winhttp 5.1来实现的;
在新浪微博上抓取数据,除了一些简单的搜索查询,其他任务都需要用户登录才能获取数据。
在EH和其他一些论坛,我也看到了一些关于新浪微博的登录方法,但大多是用PHP、Java或python编写的,而且还涉及到相对复杂的加密算法(RSA);而新浪微博的算法似乎在不断更新。解决新浪微博登录问题,基本上可以分为3种方式:
1. 通过用户名和密码,破译加密算法实现登录(示例)
2. 手动或网页模拟登录,获取cookie,通过设置cookie(xml或winhttp)方式登录(绕过复杂的加密算法)
3.完全模拟登录获取数据(我目前用的比较笨的方法,但是如果数据查询太多,账号也会被新浪封号,所以需要几个不同的用户依次登录)
在这里请教各位大神,1、2的登录和抓包方法如何更容易实现?
先谢谢大家了!!{:soso_e183:} 查看全部
vba 抓取php网页(大半年一下,,)
背景:首先声明,我不是专业的IT程序开发人员,而是VBA爱好者和EXCEL用户;我从事市场营销工作,会涉及到相当程度的数据分析、财务分析和市场分析;最早从EXCEL95开始接触VBA,被它的灵活性深深吸引;关于VBA的网络爬虫,我在罐子上潜水了半年多,非常感谢几位大神的精彩分享。在此先表示诚挚的感谢,包括:liucqa 夏、尹子轩、xmyjk、kangatang、优采云、狼版、ldy 版;尤其是liucqa大侠整理的网络爬虫教程,由浅入深,前所未有,后...(希望有人{:soso_e113:});
因为是笔记本式的苹果系统,基本上是在虚拟机上运行Win8x64 + EXCEL2010;
我发现在EH论坛上讨论网页抓取的兄弟(当然还有姐妹们),大部分都是在抓取特定的网页,基本上有证券信息,发票相关,在线资格审核数据,高考数据分数线查询,优采云tickets...等,因为是针对具体的网站,代码比较固定;前面提到过,我的工作是和市场营销相关的,所以我需要抓取网站 @网站 会收录多种来源,常见的有:搜索引擎(谷歌的网页搜索、论坛搜索、博客搜索) ,百度的网页搜索,新闻搜索...),行业论坛的数据抓取(针对特定的关键词,或特定的URL),新浪微博等。
为了满足爬取不同网站内容的灵活配置,我基本使用数据字典和正则表达式处理;即把不同网站的抓取内容放到一个EXCEL表中,读入字典,通过字典完成对不同网站抓取内容的配置,获取到的内容字段的每一部分也以正则表达式参数的形式写入字典。
爬取网页内容的方式,尽量使用XMLhttp方法[CreateObject("Msxml2.XMLHTTP.3.0")],确实快很多,但是一旦出现问题,调试还不够直观,所以也会辅助IE[CreateObject("InternetExplorer.Application")]的使用。界面比较直观。一旦数据采集出现问题,通过实际显示的网页就可以判断出了什么问题: 网络连接中断?捕获的数据不存在?需要验证码吗?登录失败?...
IE的方式确实慢了很多(我测了一下比XML快5-15倍左右),但是还有一个好处,就是比较简单,尤其是涉及到用户名、密码、登录、cookie的时候,等,程序处理更容易。
解释了半天背景,回到本帖的主题!《新浪微博数据采集方法》
坦率地说,虽然我已经潜水了半年多,但我仍然对替换 cookie 或referer 更复杂的操作感到困惑。好像xmlhttp不能改变cookies(18/19/20楼),我看大部分jar都是用winhttp 5.1来实现的;
在新浪微博上抓取数据,除了一些简单的搜索查询,其他任务都需要用户登录才能获取数据。
在EH和其他一些论坛,我也看到了一些关于新浪微博的登录方法,但大多是用PHP、Java或python编写的,而且还涉及到相对复杂的加密算法(RSA);而新浪微博的算法似乎在不断更新。解决新浪微博登录问题,基本上可以分为3种方式:
1. 通过用户名和密码,破译加密算法实现登录(示例)
2. 手动或网页模拟登录,获取cookie,通过设置cookie(xml或winhttp)方式登录(绕过复杂的加密算法)
3.完全模拟登录获取数据(我目前用的比较笨的方法,但是如果数据查询太多,账号也会被新浪封号,所以需要几个不同的用户依次登录)
在这里请教各位大神,1、2的登录和抓包方法如何更容易实现?
先谢谢大家了!!{:soso_e183:}
vba 抓取php网页(大半年一下,,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-06 05:12
背景:首先声明,我不是专业的IT程序开发人员,而是VBA爱好者和EXCEL用户;我从事市场营销工作,会涉及到相当程度的数据分析、财务分析和市场分析;最早从EXCEL95开始接触VBA,被它的灵活性深深吸引;关于VBA的网页抓取,我在罐子上潜水了半年多,非常感谢几位大神的精彩分享。在此表示衷心的感谢,包括:liucqa 夏、尹子轩、xmyjk、kangatang、优采云、狼版、ldy版;尤其是liucqa大侠整理的网络爬虫教程,由浅入深,前所未有,后...(希望有人{:soso_e113:});
因为是笔记本式的苹果系统,基本上是在虚拟机上运行Win8x64 + EXCEL2010;
我发现在EH论坛上讨论网页抓取的兄弟(当然还有姐妹们),大部分都是在抓取特定的网页,基本上有证券信息,发票相关,在线资格审核数据,高考数据分数线查询,优采云tickets...等,因为是针对具体的网站,代码比较固定;前面提到过,我的工作是和市场营销相关的,所以我需要抓取网站 @网站 会收录多种来源,常见的有:搜索引擎(谷歌的网页搜索、论坛搜索、博客搜索) ,百度的网页搜索,新闻搜索...),行业论坛的数据抓取(针对特定的关键词,或特定的URL),新浪微博等。
为了满足爬取不同网站内容的灵活配置,我基本使用数据字典和正则表达式处理;即把不同网站的抓取内容放到一个EXCEL表中,读入字典,通过字典完成对不同网站抓取内容的配置,获取到的内容字段的每一部分也以正则表达式参数的形式写入字典。
爬取网页内容的方式,尽量使用XMLhttp方法[CreateObject("Msxml2.XMLHTTP.3.0")],确实快很多,但是一旦出现问题,调试还不够直观,所以也会辅助IE[CreateObject("InternetExplorer.Application")]的使用。界面比较直观。一旦数据采集出现问题,通过实际显示的网页就可以判断出了什么问题: 网络连接中断?捕获的数据不存在?需要验证码吗?登录失败?...
IE方式确实慢了很多(我测了一下比XML快5-15倍左右),但是还有一个优点,就是比较简单,尤其是涉及到用户名、密码、登录、cookie的时候,等,程序处理更容易。
解释了半天背景,我再回到本帖的主题!《新浪微博数据采集方法》
坦白说,虽然我已经潜水了半年多,但是对于更换cookies或者referrer这种比较复杂的操作,我还是一头雾水。似乎 xmlhttp 无法更改 cookie(18/19/20 楼)。我看大部分jar都是用winhttp 5.1来实现的;
在新浪微博上抓取数据,除了一些简单的搜索查询,其他任务都需要用户登录才能获取数据。
在EH等一些论坛上,我也看到了一些关于新浪微博的登录方式,但是大部分都是用PHP、Java或者python编写的,而且还涉及到比较复杂的加密算法(RSA);而新浪微博的算法似乎在不断更新。解决新浪微博登录问题,基本上可以分为3种方式:
1. 通过用户名和密码,破译加密算法实现登录(示例)
2. 手动或网页模拟登录,获取cookie,通过设置cookie(xml或winhttp)登录(绕过复杂的加密算法)
3.完全模拟登录获取数据(我目前用的比较笨的方法,但是如果数据查询太多,账号也会被新浪封号,所以需要几个不同的用户依次登录)
在这里请教各位大神,如何更方便的实现1、2的登录和抓包方式?
先谢谢大家了!!{:soso_e183:} 查看全部
vba 抓取php网页(大半年一下,,)
背景:首先声明,我不是专业的IT程序开发人员,而是VBA爱好者和EXCEL用户;我从事市场营销工作,会涉及到相当程度的数据分析、财务分析和市场分析;最早从EXCEL95开始接触VBA,被它的灵活性深深吸引;关于VBA的网页抓取,我在罐子上潜水了半年多,非常感谢几位大神的精彩分享。在此表示衷心的感谢,包括:liucqa 夏、尹子轩、xmyjk、kangatang、优采云、狼版、ldy版;尤其是liucqa大侠整理的网络爬虫教程,由浅入深,前所未有,后...(希望有人{:soso_e113:});
因为是笔记本式的苹果系统,基本上是在虚拟机上运行Win8x64 + EXCEL2010;
我发现在EH论坛上讨论网页抓取的兄弟(当然还有姐妹们),大部分都是在抓取特定的网页,基本上有证券信息,发票相关,在线资格审核数据,高考数据分数线查询,优采云tickets...等,因为是针对具体的网站,代码比较固定;前面提到过,我的工作是和市场营销相关的,所以我需要抓取网站 @网站 会收录多种来源,常见的有:搜索引擎(谷歌的网页搜索、论坛搜索、博客搜索) ,百度的网页搜索,新闻搜索...),行业论坛的数据抓取(针对特定的关键词,或特定的URL),新浪微博等。
为了满足爬取不同网站内容的灵活配置,我基本使用数据字典和正则表达式处理;即把不同网站的抓取内容放到一个EXCEL表中,读入字典,通过字典完成对不同网站抓取内容的配置,获取到的内容字段的每一部分也以正则表达式参数的形式写入字典。
爬取网页内容的方式,尽量使用XMLhttp方法[CreateObject("Msxml2.XMLHTTP.3.0")],确实快很多,但是一旦出现问题,调试还不够直观,所以也会辅助IE[CreateObject("InternetExplorer.Application")]的使用。界面比较直观。一旦数据采集出现问题,通过实际显示的网页就可以判断出了什么问题: 网络连接中断?捕获的数据不存在?需要验证码吗?登录失败?...
IE方式确实慢了很多(我测了一下比XML快5-15倍左右),但是还有一个优点,就是比较简单,尤其是涉及到用户名、密码、登录、cookie的时候,等,程序处理更容易。
解释了半天背景,我再回到本帖的主题!《新浪微博数据采集方法》
坦白说,虽然我已经潜水了半年多,但是对于更换cookies或者referrer这种比较复杂的操作,我还是一头雾水。似乎 xmlhttp 无法更改 cookie(18/19/20 楼)。我看大部分jar都是用winhttp 5.1来实现的;
在新浪微博上抓取数据,除了一些简单的搜索查询,其他任务都需要用户登录才能获取数据。
在EH等一些论坛上,我也看到了一些关于新浪微博的登录方式,但是大部分都是用PHP、Java或者python编写的,而且还涉及到比较复杂的加密算法(RSA);而新浪微博的算法似乎在不断更新。解决新浪微博登录问题,基本上可以分为3种方式:
1. 通过用户名和密码,破译加密算法实现登录(示例)
2. 手动或网页模拟登录,获取cookie,通过设置cookie(xml或winhttp)登录(绕过复杂的加密算法)
3.完全模拟登录获取数据(我目前用的比较笨的方法,但是如果数据查询太多,账号也会被新浪封号,所以需要几个不同的用户依次登录)
在这里请教各位大神,如何更方便的实现1、2的登录和抓包方式?
先谢谢大家了!!{:soso_e183:}
vba 抓取php网页(P.S.@AJAX数据库实例讲解(有时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-16 04:08
故事起源
以前有个小网站发表了几篇关于使用SAS抓取网页数据的小文章,然后在人大论坛上放了一个链接。后来因为懒,这个站就挂了,问的人一个接一个。从新获得这篇文章后
其中一个简单易懂,其他译文已由@收录翻译,链接会在文章的最后贴出。
适用性
在以下情况下,可以用同样的方法得到理论。
PS @AJAX 数据库实例 || @AJAX 数据库实例说明
文字前戏
有时我们经常需要保存和备份一些在线数据,比如银行利率、股票报价,或者来自统计局、各种金融机构或者其他类型的网站的数据。有时这些 网站 提供历史数据,而另一些则不提供。但是我们可以每天通过SAS运行程序,获取积累的历史数据,供以后分析。下面我以收购主页上海银行同业拆借利率为例进行说明。
以下是我们要在首页的数据
当我们打开这个网页并输入网页的源代码时,我们会惊奇地发现。什么情况,主页上看到的数据在源码中找不到,是不是用了其他技术。我们来看看源码代表什么
网页布局。
按照网页的布局,最新Shibor数据的源代码应该放在一大块文字之后,他放了一句话。
这是html内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入到主页中。好,那我们打开这个页面
并查看源代码,发现该网页中存在数据,然后我们开始用SAS进行抓取。
高潮
首先介绍Filename,通过添加infile语句可以将网页作为文件导入SAS数据集。BaseSAS 中的FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。此语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入 SAS 数据集。我们知道网络数据是一种标记语言,受制于一定的规范,所有的属性设置都包括在内。所以我们用 dlm=">" 来分隔并导入到一个变量中,因为数据太杂乱,我们无法区分并导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们使用 dlm=">" 进行分隔,所以我们知道采集到的观察结果只需要以 查看全部
vba 抓取php网页(P.S.@AJAX数据库实例讲解(有时))
故事起源
以前有个小网站发表了几篇关于使用SAS抓取网页数据的小文章,然后在人大论坛上放了一个链接。后来因为懒,这个站就挂了,问的人一个接一个。从新获得这篇文章后
其中一个简单易懂,其他译文已由@收录翻译,链接会在文章的最后贴出。
适用性
在以下情况下,可以用同样的方法得到理论。
PS @AJAX 数据库实例 || @AJAX 数据库实例说明
文字前戏
有时我们经常需要保存和备份一些在线数据,比如银行利率、股票报价,或者来自统计局、各种金融机构或者其他类型的网站的数据。有时这些 网站 提供历史数据,而另一些则不提供。但是我们可以每天通过SAS运行程序,获取积累的历史数据,供以后分析。下面我以收购主页上海银行同业拆借利率为例进行说明。
以下是我们要在首页的数据
当我们打开这个网页并输入网页的源代码时,我们会惊奇地发现。什么情况,主页上看到的数据在源码中找不到,是不是用了其他技术。我们来看看源码代表什么
网页布局。
按照网页的布局,最新Shibor数据的源代码应该放在一大块文字之后,他放了一句话。
这是html内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入到主页中。好,那我们打开这个页面
并查看源代码,发现该网页中存在数据,然后我们开始用SAS进行抓取。
高潮
首先介绍Filename,通过添加infile语句可以将网页作为文件导入SAS数据集。BaseSAS 中的FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。此语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入 SAS 数据集。我们知道网络数据是一种标记语言,受制于一定的规范,所有的属性设置都包括在内。所以我们用 dlm=">" 来分隔并导入到一个变量中,因为数据太杂乱,我们无法区分并导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们使用 dlm=">" 进行分隔,所以我们知道采集到的观察结果只需要以
vba 抓取php网页(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-02-12 18:18
这里有新鲜出炉的PHP教程,看看程序狗速!
PHP开源脚本语言PHP(外文名:Hypertext Preprocessor,中文名:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。 PHP的文件扩展名为php。
本文是一个php函数获取远程网页内容的用法,file_get_contents,有兴趣的同学请参考。
在网上看了半天file_get_contents不稳定,遇到了。 . .
另一方面,也说明程序的容错性很差。 . .
好吧,让我们开始吧。
我遇到了这个错误:
file_get_contents(***.php):打开流失败:HTTP 请求失败!
G,决定用curl
你可以使用这个功能:
/**
*
* 获取远程内容
* @param $url 接口url地址
* @param $timeout 超时时间
*/
函数 pc_file_get_contents($url, $timeout=30) {
$stream = stream_context_create(array('http' => array('timeout' => $timeout)));
返回@file_get_contents($url, 0, $stream);
}
该函数提取自phpcms,可以完美解决爬取网页时file_get_contents挂起的问题。 查看全部
vba 抓取php网页(这里有新鲜出炉的PHP教程,程序狗速度看过来!)
这里有新鲜出炉的PHP教程,看看程序狗速!
PHP开源脚本语言PHP(外文名:Hypertext Preprocessor,中文名:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。 PHP的文件扩展名为php。
本文是一个php函数获取远程网页内容的用法,file_get_contents,有兴趣的同学请参考。
在网上看了半天file_get_contents不稳定,遇到了。 . .
另一方面,也说明程序的容错性很差。 . .
好吧,让我们开始吧。
我遇到了这个错误:
file_get_contents(***.php):打开流失败:HTTP 请求失败!
G,决定用curl
你可以使用这个功能:
/**
*
* 获取远程内容
* @param $url 接口url地址
* @param $timeout 超时时间
*/
函数 pc_file_get_contents($url, $timeout=30) {
$stream = stream_context_create(array('http' => array('timeout' => $timeout)));
返回@file_get_contents($url, 0, $stream);
}
该函数提取自phpcms,可以完美解决爬取网页时file_get_contents挂起的问题。
vba 抓取php网页(我的目标:让职场人士能高效使用office为其服务)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-16 23:38
我的目标:让中国大学生在走出校门的那一刻就具备了这些办公技能,让专业人士能够高效地利用办公为他们服务。支持我,为自己加油!
人们总是问我VBA难学吗?
怎么说呢,如果能掌握VBA的精髓,学起来也没那么复杂。
跟大家分享一下学习网络爬虫的过程。之前对VBA网页抓取技术一窍不通,今天抽空研究了一下。虽然还有很多不明白的地方,但我大概知道如何进一步学习了。
之前写过一篇文章文章,是PowerQuery技术抓取的网页数据,大家可以看一下:
在 网站 上将多页数据导入 Excel 真是太棒了!》
今天我们使用VBA代码从以下网页爬取数据:
很多人看到自己看不懂的代码总是会一头雾水。其实只要仔细分析一下,你就会觉得没那么复杂。只要你知道VBA的本质就是用代码来操作对象,你永远学不完对象,所以遇到不熟悉的对象也不用怕,套路都差不多!
起初,我在 网站 上阅读了一篇关于网络抓取的文章 文章:
最终代码如下:
然后文章说可以抓到网站上的数据,搞得我一头雾水。乍一看,文章 并不完整。后来找到原链接,是老外写的一篇文章的文章,不过也是不完整的。
但是上面的文章让我明白了,其实网页抓取使用了两个对象:Microsoft HTML Object Library和Microsoft Internet Controls,就像当时学字典一样,如果不想直接创建对象用代码,那么在声明对象变量之前应该绑定两个对象,这称为早期引用。
我从上面的代码得到的信息是:首先根据URL获取网页文档,文档收录很多内容,文档是一个对象,可以使用getElementsByTagName()函数从中提取表格object,提取出来的table也是object,其他不清楚。
所以我的目标是调查 getElementsByTagName() 到底得到了什么?
网上搜索后,看到如下代码:
在这一点上,我可能明白发生了什么。
先根据url获取网页文档doc,然后使用doc.getElementsByTagName("table")获取doc中的表格,不一定只有一个表格,所以使用索引来指定哪个表格,表格收录行,每行收录单元格,循环遍历表格每一行的每个单元格,单元格的innerText属性就是单元格中的值,类似于Excel中单元格的Value属性。
于是根据猫和虎,我处理了如下代码:
测试完全正确:
然后看到黑图中的代码使用了后期绑定,于是学习了后期绑定的写法,改成如下代码:
测试也很完美。
以上只提取一页数据,如何提取多页?明天继续写!
接下来我应该重点介绍 HTML 代码中文档对象的基本元素、结构以及其他方法和属性。 查看全部
vba 抓取php网页(我的目标:让职场人士能高效使用office为其服务)
我的目标:让中国大学生在走出校门的那一刻就具备了这些办公技能,让专业人士能够高效地利用办公为他们服务。支持我,为自己加油!
人们总是问我VBA难学吗?
怎么说呢,如果能掌握VBA的精髓,学起来也没那么复杂。
跟大家分享一下学习网络爬虫的过程。之前对VBA网页抓取技术一窍不通,今天抽空研究了一下。虽然还有很多不明白的地方,但我大概知道如何进一步学习了。
之前写过一篇文章文章,是PowerQuery技术抓取的网页数据,大家可以看一下:
在 网站 上将多页数据导入 Excel 真是太棒了!》
今天我们使用VBA代码从以下网页爬取数据:
很多人看到自己看不懂的代码总是会一头雾水。其实只要仔细分析一下,你就会觉得没那么复杂。只要你知道VBA的本质就是用代码来操作对象,你永远学不完对象,所以遇到不熟悉的对象也不用怕,套路都差不多!
起初,我在 网站 上阅读了一篇关于网络抓取的文章 文章:
最终代码如下:
然后文章说可以抓到网站上的数据,搞得我一头雾水。乍一看,文章 并不完整。后来找到原链接,是老外写的一篇文章的文章,不过也是不完整的。
但是上面的文章让我明白了,其实网页抓取使用了两个对象:Microsoft HTML Object Library和Microsoft Internet Controls,就像当时学字典一样,如果不想直接创建对象用代码,那么在声明对象变量之前应该绑定两个对象,这称为早期引用。
我从上面的代码得到的信息是:首先根据URL获取网页文档,文档收录很多内容,文档是一个对象,可以使用getElementsByTagName()函数从中提取表格object,提取出来的table也是object,其他不清楚。
所以我的目标是调查 getElementsByTagName() 到底得到了什么?
网上搜索后,看到如下代码:
在这一点上,我可能明白发生了什么。
先根据url获取网页文档doc,然后使用doc.getElementsByTagName("table")获取doc中的表格,不一定只有一个表格,所以使用索引来指定哪个表格,表格收录行,每行收录单元格,循环遍历表格每一行的每个单元格,单元格的innerText属性就是单元格中的值,类似于Excel中单元格的Value属性。
于是根据猫和虎,我处理了如下代码:
测试完全正确:
然后看到黑图中的代码使用了后期绑定,于是学习了后期绑定的写法,改成如下代码:
测试也很完美。
以上只提取一页数据,如何提取多页?明天继续写!
接下来我应该重点介绍 HTML 代码中文档对象的基本元素、结构以及其他方法和属性。
vba 抓取php网页(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-22 08:16
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都因为生硬的爬虫爬取而被屏蔽。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档的处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键字符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python的语法非常简洁,同一句话可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索脚本之家之前的文章或继续浏览下面的相关文章,希望大家以后多多支持Scripthome! 查看全部
vba 抓取php网页(PHP解析器和PHP相比较,python适合做爬虫吗?)
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都因为生硬的爬虫爬取而被屏蔽。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档的处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 架构选择太多(主要的GUI架构包括wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的一个扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键字符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。由于网络是异步的,它基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如必须等待上一页被爬取到数据,下一页才能被爬取,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python的语法非常简洁,同一句话可以少打很多次。那么,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索脚本之家之前的文章或继续浏览下面的相关文章,希望大家以后多多支持Scripthome!
vba 抓取php网页( Python技术ID:生成PDF的正确方法是什么?(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-13 19:04
Python技术ID:生成PDF的正确方法是什么?(二))
Python实现精准搜索,提取网页核心内容
更新时间:2021.11.01 10:30:31 作者:Python Technology
本文文章主要介绍python实现网页核心内容精准搜索和提取的实现。有需要的朋友可以借鉴。我希望它能有所帮助。祝大家进步很多。
内容
正文|李小飞
来源:Python技术《ID:pythonall》
每个人都必须熟悉爬虫程序。随便写一个获取网页信息,甚至通过请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有head、tail、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构完整。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
数以万计的数据超过 200 GB。如果数据量达到存储,那将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构,可读性会很差。更糟糕的是,网页上还有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
于是写了一段代码,我用Scrapy[4]作为爬虫框架,这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,更喜欢p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离标签p越近,就越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,即离中心越近,密度越高,离中心越远,密度呈指数下降,这样就可以滤除密度中心。
50%的斜率是如何得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章 主题的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,应付日常的编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。
我希望这篇短文能给你带来启发。欢迎大家在留言区交流讨论,大展身手!
参考
[1]
卷曲 ת Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮痧:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246
以上就是python实现精准搜索和提取网页核心内容的详细过程。更多关于python搜索和提取网页内容的信息,请关注其他相关脚本文章! 查看全部
vba 抓取php网页(
Python技术ID:生成PDF的正确方法是什么?(二))
Python实现精准搜索,提取网页核心内容
更新时间:2021.11.01 10:30:31 作者:Python Technology
本文文章主要介绍python实现网页核心内容精准搜索和提取的实现。有需要的朋友可以借鉴。我希望它能有所帮助。祝大家进步很多。
内容
正文|李小飞
来源:Python技术《ID:pythonall》
每个人都必须熟悉爬虫程序。随便写一个获取网页信息,甚至通过请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有head、tail、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构完整。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
数以万计的数据超过 200 GB。如果数据量达到存储,那将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构,可读性会很差。更糟糕的是,网页上还有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
于是写了一段代码,我用Scrapy[4]作为爬虫框架,这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,更喜欢p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离标签p越近,就越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,即离中心越近,密度越高,离中心越远,密度呈指数下降,这样就可以滤除密度中心。
50%的斜率是如何得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章 主题的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,应付日常的编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。
我希望这篇短文能给你带来启发。欢迎大家在留言区交流讨论,大展身手!
参考
[1]
卷曲 ת Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮痧:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246
以上就是python实现精准搜索和提取网页核心内容的详细过程。更多关于python搜索和提取网页内容的信息,请关注其他相关脚本文章!
vba 抓取php网页(开发的VB和VBA语言的缺点及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-12 09:09
VB
Visual Basic(简称VB)是一种通用的基于对象的编程语言。它是一种结构化、模块化、面向对象和事件驱动的可视化编程语言,可在开发环境中提供帮助。它是一种可以用于开发微软自己产品的语言。
“可视化”是指开发图形用户界面(GUI)的方法——你不需要编写大量代码来描述界面元素的外观和位置,而只需在一个点上添加一个预先构建的对象屏幕。“Basic”是指BASIC(Beginners All-Purpose Symbolic Instruction Code)语言,它是计算技术发展史上使用最广泛的语言。
Visual Basic 源自 BASIC 编程语言。VB具有图形用户界面(GUI)和快速应用程序开发(RAD)系统,可以方便地使用DAO、RDO、ADO连接数据库,或轻松创建Active X控件,高效生成类型安全和面向对象应用 [2] 。程序员可以很方便地使用VB提供的组件来快速构建应用程序,对新手来说相当友好。后面提到的VBS和VBA其实都是VB语言的分支。
缺点
一、不支持继承
VB 5.0 和VB 6.0 都是基于对象的编程语言,但不包括继承特性。VB提供了特殊的类函数,但仍然不能满足程序员的需要。
二、没有对多线程的原生支持
Visual Basic 没有对多线程的原生支持,只能通过 Windows API 调用来实现,而且极其不稳定。由于运行时库不会在API创建的线程中自动初始化,因此部分功能无法使用。一般在VB6等早期的VB开发环境中,使用API创建线程的目的是为了完成大量容易使程序挂掉的数据或逻辑计算。
三、异常处理不当
Visual Basic 具有内置的异常处理。即使没有编写异常处理代码,一旦用户出错,也会弹出一个对话框,指明出错的原因,然后程序就会终止。
您可以使用 Err.Raise 在 Visual Basic 中引发异常。处理系统和用户抛出的异常有两种常用的模式:一种是使用On Error Resume Next来处理错误;另一种是使用 On Error Goto 将错误处理代码引入操作。但是和C++等语言相比,这样的异常处理破坏了代码的结构。
但是,上述缺点在中得到了改进。
VBS
VBScript 是 Visual Basic Script 的缩写,有时缩写为 VBS。VBScript是微软公司开发的一种脚本语言,可以看作是VB语言的简化版,与VBA有着非常密切的关系。它具有原语言易学易学的特点,并继承了JavaScript的跨平台特性。目前这种语言广泛用于网页和ASP程序的制作,也可以直接作为可执行程序使用。调试简单的VB语句非常方便。有心机的同学可以去看看用VBS语言制作恶搞小程序
因为VBScript可以通过Windows脚本宿主调用COM,所以可以使用Windows操作系统可以使用的程序库。例如,它可以使用 Microsoft Office 的库,尤其是 Microsoft Access 和 Microsoft SQL Server 的库。当然,它也可以使用。使用操作系统本身的其他程序和库。在实践中,VBScript一般用于以下三个方面:
一、Windows 操作系统
VBScript 可用于自动执行重复的 Windows 操作系统任务。在Windows 操作系统中,VBScript 可以在Windows Script Host 的范围内运行。Windows 操作系统可以自动识别和执行 *.VBS 和 *.WSF 文件格式。此外,Internet Explorer 可以执行 *.HTA 和 *.CHM 文件格式。VBS 和 WSF 文件完全基于文本,它们只能通过几个对话窗口与用户交流。HTA 和 CHM 文件使用 HTML 格式,它们的程序代码可以像 HTML 一样编辑和检查。WSF、HTA 和 CHM 文件中的 VBScript 和 JavaScript 程序代码可以任意混合。HTA 文件实际上是添加了 VBS 和 JavaScript 组件的 HTML 文件。CHM 文件是一种在线帮助,用户可以使用专门的编辑程序将 HTML 程序编辑成 CHM。
二、Web 浏览器(客户的 VBS)
网页中的VBS可以用来命令客户端的网页浏览器(浏览器执行VBS程序)。VBS 和 JavaScript 在这方面是竞争对手。它们可用于实现动态 HTML,甚至可以将整个程序集成到一个网页中。
到目前为止,VBS 还没有在客户中占据主导地位,因为它只有 Microsoft Internet Explorer 支持(Mozilla Suite 可以通过安装插件来支持 VBS)。所有网络浏览器都支持 JavaScript。在 Internet Explorer 中,VBS 和 JavaScript 使用相同的权限,它们只能在有限的范围内使用 Windows 操作系统中的对象。
三、Web服务器(服务器端的VBS)
在 Web 服务器方面,VBS 是微软 Active Server Pages 的一部分,它是 JavaServer Pages 和 PHP 的竞争对手。在这里,VBS 代码直接嵌入到 HTML 页面中,这样的页面以 ASP 结尾。Web服务器Internet信息服务执行ASP页面中的程序部分,将结果转换为HTML,传送到Web浏览器供用户使用。这样服务器就可以监听数据库,把结果放到HTML页面中。
VBScript 的主要优点
1、 由于 VBScript 是由操作系统解释的,而不是由 Web 浏览器解释的,因此它的文件相对较小且易于学习。
2、 2000/98SE以后的所有Windows版本都可以直接使用。
缺点
1、VBS 现在不能用作电子邮件的附件。Microsoft Outlook 拒绝接受 VBS 作为附件,收件人不能直接使用 VBS 附件。
2、VBS 的各种编辑器并不流行。
操作系统没有任何特殊的保护设施。VBS 程序的处理方式与其他 JS、EXE、BAT 或 CMD 程序相同。操作系统不具备监控恶意功能的能力。
与VB的区别
一、不能为变量定义类型
在VB中,Dim variable name As type用于变量定义类型,但是在VBScript中写这个是错误的。只能使用Dim变量名,解释器会根据赋值的类型自动定义变量类型。
二、不能使用条件编译
在VB中,可以使用#If... Then、#ElseIf... Then、#Else、#End If、#Const... =...等语句来定义编译时使用的语句,而且由于VBScript不需要编译和可以直接执行,不是不需要条件编译语句。
三、安全
在微软决定 Outlook 和 Outlook Express 中的 HTML 电子邮件可以使用 VBScript 之后,出现了许多使用 Windows Script Host 和 ActiveX 功能的计算机病毒。这些病毒之所以能够传播开来,也是因为这些系统功能一开始就完全没有受到保护。尽管 VBScript 和 JavaScript 使用操作系统的相同功能安全措施,但通常很难保护 VBScript 代码不被用户看到。
VBA
VBA(Visual Basic for Applications)是Visual Basic 的一种宏语言,是一种用于在其桌面应用程序中执行通用自动化(OLE)任务的编程语言。主要可用于扩展Windows应用程序的功能,尤其是Microsoft Office软件。也可以说是一个应用可视化的Basic脚本。
在语言结构上,VBA是VB的一个子集,它们的语法结构是一样的。两者的开发环境也差不多。但是,VB是一个独立的开发工具,它不需要附加任何其他应用程序,它有自己完全独立的工作环境和编译链接系统。VBA 没有自己独立的工作环境。它必须附加到某个主应用程序中,并且只能在 Office 应用程序中使用,例如 Word、Excel、Access 等。
与VB的区别
1、VB 旨在创建标准应用程序,而 VBA 旨在自动化现有应用程序(EXCEL 等)。
2、VB 有自己的开发环境,VBA 必须寄生在现有的应用程序上。
3、运行VB开发的应用程序,用户不需要安装VB,因为VB开发的应用程序是一个可执行文件(*.EXE),VBA开发的程序必须依赖其父应用程序. 查看全部
vba 抓取php网页(开发的VB和VBA语言的缺点及解决办法)
VB
Visual Basic(简称VB)是一种通用的基于对象的编程语言。它是一种结构化、模块化、面向对象和事件驱动的可视化编程语言,可在开发环境中提供帮助。它是一种可以用于开发微软自己产品的语言。
“可视化”是指开发图形用户界面(GUI)的方法——你不需要编写大量代码来描述界面元素的外观和位置,而只需在一个点上添加一个预先构建的对象屏幕。“Basic”是指BASIC(Beginners All-Purpose Symbolic Instruction Code)语言,它是计算技术发展史上使用最广泛的语言。
Visual Basic 源自 BASIC 编程语言。VB具有图形用户界面(GUI)和快速应用程序开发(RAD)系统,可以方便地使用DAO、RDO、ADO连接数据库,或轻松创建Active X控件,高效生成类型安全和面向对象应用 [2] 。程序员可以很方便地使用VB提供的组件来快速构建应用程序,对新手来说相当友好。后面提到的VBS和VBA其实都是VB语言的分支。
缺点
一、不支持继承
VB 5.0 和VB 6.0 都是基于对象的编程语言,但不包括继承特性。VB提供了特殊的类函数,但仍然不能满足程序员的需要。
二、没有对多线程的原生支持
Visual Basic 没有对多线程的原生支持,只能通过 Windows API 调用来实现,而且极其不稳定。由于运行时库不会在API创建的线程中自动初始化,因此部分功能无法使用。一般在VB6等早期的VB开发环境中,使用API创建线程的目的是为了完成大量容易使程序挂掉的数据或逻辑计算。
三、异常处理不当
Visual Basic 具有内置的异常处理。即使没有编写异常处理代码,一旦用户出错,也会弹出一个对话框,指明出错的原因,然后程序就会终止。
您可以使用 Err.Raise 在 Visual Basic 中引发异常。处理系统和用户抛出的异常有两种常用的模式:一种是使用On Error Resume Next来处理错误;另一种是使用 On Error Goto 将错误处理代码引入操作。但是和C++等语言相比,这样的异常处理破坏了代码的结构。
但是,上述缺点在中得到了改进。
VBS
VBScript 是 Visual Basic Script 的缩写,有时缩写为 VBS。VBScript是微软公司开发的一种脚本语言,可以看作是VB语言的简化版,与VBA有着非常密切的关系。它具有原语言易学易学的特点,并继承了JavaScript的跨平台特性。目前这种语言广泛用于网页和ASP程序的制作,也可以直接作为可执行程序使用。调试简单的VB语句非常方便。有心机的同学可以去看看用VBS语言制作恶搞小程序
因为VBScript可以通过Windows脚本宿主调用COM,所以可以使用Windows操作系统可以使用的程序库。例如,它可以使用 Microsoft Office 的库,尤其是 Microsoft Access 和 Microsoft SQL Server 的库。当然,它也可以使用。使用操作系统本身的其他程序和库。在实践中,VBScript一般用于以下三个方面:
一、Windows 操作系统
VBScript 可用于自动执行重复的 Windows 操作系统任务。在Windows 操作系统中,VBScript 可以在Windows Script Host 的范围内运行。Windows 操作系统可以自动识别和执行 *.VBS 和 *.WSF 文件格式。此外,Internet Explorer 可以执行 *.HTA 和 *.CHM 文件格式。VBS 和 WSF 文件完全基于文本,它们只能通过几个对话窗口与用户交流。HTA 和 CHM 文件使用 HTML 格式,它们的程序代码可以像 HTML 一样编辑和检查。WSF、HTA 和 CHM 文件中的 VBScript 和 JavaScript 程序代码可以任意混合。HTA 文件实际上是添加了 VBS 和 JavaScript 组件的 HTML 文件。CHM 文件是一种在线帮助,用户可以使用专门的编辑程序将 HTML 程序编辑成 CHM。
二、Web 浏览器(客户的 VBS)
网页中的VBS可以用来命令客户端的网页浏览器(浏览器执行VBS程序)。VBS 和 JavaScript 在这方面是竞争对手。它们可用于实现动态 HTML,甚至可以将整个程序集成到一个网页中。
到目前为止,VBS 还没有在客户中占据主导地位,因为它只有 Microsoft Internet Explorer 支持(Mozilla Suite 可以通过安装插件来支持 VBS)。所有网络浏览器都支持 JavaScript。在 Internet Explorer 中,VBS 和 JavaScript 使用相同的权限,它们只能在有限的范围内使用 Windows 操作系统中的对象。
三、Web服务器(服务器端的VBS)
在 Web 服务器方面,VBS 是微软 Active Server Pages 的一部分,它是 JavaServer Pages 和 PHP 的竞争对手。在这里,VBS 代码直接嵌入到 HTML 页面中,这样的页面以 ASP 结尾。Web服务器Internet信息服务执行ASP页面中的程序部分,将结果转换为HTML,传送到Web浏览器供用户使用。这样服务器就可以监听数据库,把结果放到HTML页面中。
VBScript 的主要优点
1、 由于 VBScript 是由操作系统解释的,而不是由 Web 浏览器解释的,因此它的文件相对较小且易于学习。
2、 2000/98SE以后的所有Windows版本都可以直接使用。
缺点
1、VBS 现在不能用作电子邮件的附件。Microsoft Outlook 拒绝接受 VBS 作为附件,收件人不能直接使用 VBS 附件。
2、VBS 的各种编辑器并不流行。
操作系统没有任何特殊的保护设施。VBS 程序的处理方式与其他 JS、EXE、BAT 或 CMD 程序相同。操作系统不具备监控恶意功能的能力。
与VB的区别
一、不能为变量定义类型
在VB中,Dim variable name As type用于变量定义类型,但是在VBScript中写这个是错误的。只能使用Dim变量名,解释器会根据赋值的类型自动定义变量类型。
二、不能使用条件编译
在VB中,可以使用#If... Then、#ElseIf... Then、#Else、#End If、#Const... =...等语句来定义编译时使用的语句,而且由于VBScript不需要编译和可以直接执行,不是不需要条件编译语句。
三、安全
在微软决定 Outlook 和 Outlook Express 中的 HTML 电子邮件可以使用 VBScript 之后,出现了许多使用 Windows Script Host 和 ActiveX 功能的计算机病毒。这些病毒之所以能够传播开来,也是因为这些系统功能一开始就完全没有受到保护。尽管 VBScript 和 JavaScript 使用操作系统的相同功能安全措施,但通常很难保护 VBScript 代码不被用户看到。
VBA
VBA(Visual Basic for Applications)是Visual Basic 的一种宏语言,是一种用于在其桌面应用程序中执行通用自动化(OLE)任务的编程语言。主要可用于扩展Windows应用程序的功能,尤其是Microsoft Office软件。也可以说是一个应用可视化的Basic脚本。
在语言结构上,VBA是VB的一个子集,它们的语法结构是一样的。两者的开发环境也差不多。但是,VB是一个独立的开发工具,它不需要附加任何其他应用程序,它有自己完全独立的工作环境和编译链接系统。VBA 没有自己独立的工作环境。它必须附加到某个主应用程序中,并且只能在 Office 应用程序中使用,例如 Word、Excel、Access 等。
与VB的区别
1、VB 旨在创建标准应用程序,而 VBA 旨在自动化现有应用程序(EXCEL 等)。
2、VB 有自己的开发环境,VBA 必须寄生在现有的应用程序上。
3、运行VB开发的应用程序,用户不需要安装VB,因为VB开发的应用程序是一个可执行文件(*.EXE),VBA开发的程序必须依赖其父应用程序.
vba 抓取php网页(如何融合到一个更灵活的网站爬虫中?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-10-15 18:05
在这个 文章 中,您将学习将这些基本方法集成到一个更灵活的 网站 爬虫中,该爬虫可以跟踪任何遵循特定 URL 模式的链接。
此爬虫非常适合从 网站 中抓取所有数据的项目,但不适用于从特定搜索结果或页面列表中抓取数据的项目。它也非常适用于 网站 页面组织不佳或非常分散的情况。
这些类型的爬虫不需要上一节中使用的定位链接的结构化方法来爬取搜索页面,因此不需要在网站对象中收录描述搜索页面的属性。但是因为爬虫不知道要找到链接的位置,所以需要一些规则来告诉它选择哪个页面。您可以使用 targetPattern(目标 URL 的正则表达式)和布尔变量 absoluteUrl 来实现此目标:
class Website:
def __init__(self, name, url, targetPattern, absoluteUrl,
titleTag, bodyTag):
self.name = name
self.url = url
self.targetPattern = targetPattern
self.absoluteUrl=absoluteUrl
self.titleTag = titleTag
self.bodyTag = bodyTag
class Content:
def __init__(self, url, title, body):
self.url = url
self.title = title
self.body = body
def print(self):
print("URL: {}".format(self.url))
print("TITLE: {}".format(self.title))
print("BODY:\n{}".format(self.body))
Content 类与第一个爬虫示例中使用的类相同。
Crawler类从每个网站的首页开始,定位内链,解析每个内链页面上找到的内容:
import re
class Crawler:
def __init__(self, site):
self.site = site
self.visited = []
def getPage(self, url):
try:
req = requests.get(url)
except requests.exceptions.RequestException:
return None
return BeautifulSoup(req.text, 'html.parser')
def safeGet(self, pageObj, selector):
selectedElems = pageObj.select(selector)
if selectedElems is not None and len(selectedElems) > 0:
return '\n'.join([elem.get_text() for
elem in selectedElems])
return ''
def parse(self, url):
bs = self.getPage(url)
if bs is not None:
title = self.safeGet(bs, self.site.titleTag)
body = self.safeGet(bs, self.site.bodyTag)
if title != '' and body != '':
content = Content(url, title, body)
content.print()
def crawl(self):
"""
获取网站主页的页面链接
"""
bs = self.getPage(self.site.url)
targetPages = bs.findAll('a',
href=re.compile(self.site.targetPattern))
for targetPage in targetPages:
targetPage = targetPage.attrs['href']
if targetPage not in self.visited:
self.visited.append(targetPage)
if not self.site.absoluteUrl:
targetPage = '{}{}'.format(self.site.url, targetPage)
self.parse(targetPage)
reuters = Website('Reuters', 'https://www.reuters.com', '^(/article/)', False,
'h1', 'div.StandardArticleBody_body_1gnLA')
crawler = Crawler(reuters)
crawler.crawl()
与前面的示例相比,这里的另一个变化是网站对象(在本示例中为变量 reuters)是 Crawler 对象本身的一个属性。这样做的效果是将访问过的页面存储在爬虫中,但这也意味着必须为每个 网站 实例化一个新的爬虫,而不是重复使用爬虫来抓取 网站 的列表。
是选择与网站无关的爬虫,还是使用网站作为爬虫的一个属性,这都是需要根据自己的需要权衡的决定。这两种方法在功能实现上都没有问题。
还有一点需要注意的是,这个爬虫会从首页开始爬取,但是所有的页面都记录完之后,就不会继续爬取了。您可能希望编写一个收录第 3 章中介绍的一些模式的爬虫,然后在您访问的每个页面中查看更多目标 URL。您甚至可以跟踪每个页面中涉及的所有 URL(不仅仅是匹配目标模式的 URL),然后检查这些 URL 是否收录目标模式。
以上就是关于python爬取的相关知识点网站,感谢大家对脚本屋的学习和支持。 查看全部
vba 抓取php网页(如何融合到一个更灵活的网站爬虫中?)
在这个 文章 中,您将学习将这些基本方法集成到一个更灵活的 网站 爬虫中,该爬虫可以跟踪任何遵循特定 URL 模式的链接。
此爬虫非常适合从 网站 中抓取所有数据的项目,但不适用于从特定搜索结果或页面列表中抓取数据的项目。它也非常适用于 网站 页面组织不佳或非常分散的情况。
这些类型的爬虫不需要上一节中使用的定位链接的结构化方法来爬取搜索页面,因此不需要在网站对象中收录描述搜索页面的属性。但是因为爬虫不知道要找到链接的位置,所以需要一些规则来告诉它选择哪个页面。您可以使用 targetPattern(目标 URL 的正则表达式)和布尔变量 absoluteUrl 来实现此目标:
class Website:
def __init__(self, name, url, targetPattern, absoluteUrl,
titleTag, bodyTag):
self.name = name
self.url = url
self.targetPattern = targetPattern
self.absoluteUrl=absoluteUrl
self.titleTag = titleTag
self.bodyTag = bodyTag
class Content:
def __init__(self, url, title, body):
self.url = url
self.title = title
self.body = body
def print(self):
print("URL: {}".format(self.url))
print("TITLE: {}".format(self.title))
print("BODY:\n{}".format(self.body))
Content 类与第一个爬虫示例中使用的类相同。
Crawler类从每个网站的首页开始,定位内链,解析每个内链页面上找到的内容:
import re
class Crawler:
def __init__(self, site):
self.site = site
self.visited = []
def getPage(self, url):
try:
req = requests.get(url)
except requests.exceptions.RequestException:
return None
return BeautifulSoup(req.text, 'html.parser')
def safeGet(self, pageObj, selector):
selectedElems = pageObj.select(selector)
if selectedElems is not None and len(selectedElems) > 0:
return '\n'.join([elem.get_text() for
elem in selectedElems])
return ''
def parse(self, url):
bs = self.getPage(url)
if bs is not None:
title = self.safeGet(bs, self.site.titleTag)
body = self.safeGet(bs, self.site.bodyTag)
if title != '' and body != '':
content = Content(url, title, body)
content.print()
def crawl(self):
"""
获取网站主页的页面链接
"""
bs = self.getPage(self.site.url)
targetPages = bs.findAll('a',
href=re.compile(self.site.targetPattern))
for targetPage in targetPages:
targetPage = targetPage.attrs['href']
if targetPage not in self.visited:
self.visited.append(targetPage)
if not self.site.absoluteUrl:
targetPage = '{}{}'.format(self.site.url, targetPage)
self.parse(targetPage)
reuters = Website('Reuters', 'https://www.reuters.com', '^(/article/)', False,
'h1', 'div.StandardArticleBody_body_1gnLA')
crawler = Crawler(reuters)
crawler.crawl()
与前面的示例相比,这里的另一个变化是网站对象(在本示例中为变量 reuters)是 Crawler 对象本身的一个属性。这样做的效果是将访问过的页面存储在爬虫中,但这也意味着必须为每个 网站 实例化一个新的爬虫,而不是重复使用爬虫来抓取 网站 的列表。
是选择与网站无关的爬虫,还是使用网站作为爬虫的一个属性,这都是需要根据自己的需要权衡的决定。这两种方法在功能实现上都没有问题。
还有一点需要注意的是,这个爬虫会从首页开始爬取,但是所有的页面都记录完之后,就不会继续爬取了。您可能希望编写一个收录第 3 章中介绍的一些模式的爬虫,然后在您访问的每个页面中查看更多目标 URL。您甚至可以跟踪每个页面中涉及的所有 URL(不仅仅是匹配目标模式的 URL),然后检查这些 URL 是否收录目标模式。
以上就是关于python爬取的相关知识点网站,感谢大家对脚本屋的学习和支持。
vba 抓取php网页(Python的参数里的:和->是什么意思?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-03 18:19
Python参数中的:和->是什么意思
我的阿里云ECs昨晚被攻击了。网络带宽已满
echart X坐标轴的名称位于左侧,并与Y坐标比例重叠。如何解决
当iPhone上传图片时,图片将旋转90度。如果你选择相册,你不会,Android手机也不会。如何解决
Ubuntu服务器PHP成功上传了该文件,但文件夹为空
react本机状态由redux控制。如何根据状态判断和执行导航跳转
您使用vuex的场景有哪些?你把后端数据扔进状态了吗
Python如何优雅地过滤字符
您自己编写的网页CPU和内存消耗高的原因是什么?如何对其进行优化
我知道中心点和半径,以及如何设置地图的显示范围
如何处理降价标准字符串
Mongodb将a字段等于某个值的记录的B字段更新为指定值
关于在开源中国使用git代码托管
Split()问题,解决
刷新网页后是否会释放内存
密码的正则表达式
PHP访问类定义中的属性。为什么属性名有时会添加“$”但有时不会
字符串和数据比较
将数据从节点插入Mongo时,插入成功,但将返回错误消息
spring引导服务器启动后,用户SSH注销,服务停止 查看全部
vba 抓取php网页(Python的参数里的:和->是什么意思?(图))
Python参数中的:和->是什么意思
我的阿里云ECs昨晚被攻击了。网络带宽已满
echart X坐标轴的名称位于左侧,并与Y坐标比例重叠。如何解决
当iPhone上传图片时,图片将旋转90度。如果你选择相册,你不会,Android手机也不会。如何解决
Ubuntu服务器PHP成功上传了该文件,但文件夹为空
react本机状态由redux控制。如何根据状态判断和执行导航跳转
您使用vuex的场景有哪些?你把后端数据扔进状态了吗
Python如何优雅地过滤字符
您自己编写的网页CPU和内存消耗高的原因是什么?如何对其进行优化
我知道中心点和半径,以及如何设置地图的显示范围
如何处理降价标准字符串
Mongodb将a字段等于某个值的记录的B字段更新为指定值
关于在开源中国使用git代码托管
Split()问题,解决
刷新网页后是否会释放内存
密码的正则表达式
PHP访问类定义中的属性。为什么属性名有时会添加“$”但有时不会
字符串和数据比较
将数据从节点插入Mongo时,插入成功,但将返回错误消息
spring引导服务器启动后,用户SSH注销,服务停止

