
vb抓取网页内容
vb抓取网页内容(vb抓取网页内容,建议看python来写http服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-25 05:04
vb抓取网页内容,建议看python来写http服务器。flask有很多框架,简单的可以参照django,用loader。如果要抓页面内容比较详细,还是flask自带的login和session也有很多教程。
我给你一些资料,你可以看看。
python抓取百度内容
对于http协议了解,了解http协议里面各个文件是做什么用的。你就能抓取整个页面的内容,前提是得了解http协议,请求。能把请求发送出去。利用后端程序(爬虫)把返回的http字符串解析出来,然后返回给前端。接着如果想继续抓取更多内容,就能深入了解一下http的各个参数、http状态码、状态机、带状态的http请求头,然后再拿来验证一下http请求头是否为http安全协议的协议头。能知道什么时候用什么协议,什么时候用http安全协议。
分三步:
1、爬虫代码
2、信息分析代码
3、爬虫再交给人工去解析爬虫配置爬虫代码。如果发现某页面返回的内容都是乱码,查看白名单并且解析,或者人工去对白名单内的内容进行分析解析,最后回传后端查看解析后的页面。如果要抓包,前端自己可以看,也可以用工具,必须人工解析后端对爬虫抓包抓到的内容进行解析。
我从头学习的是python,之前我觉得比较难的是爬虫,其实程序员并不是每次都要爬一次,你觉得难,是因为还没有掌握一定的编程能力,每个人都有自己的学习方法,这只是个学习过程中的适应问题,从最基础的开始学起吧,不要一下就要求自己学到多么厉害的程度。 查看全部
vb抓取网页内容(vb抓取网页内容,建议看python来写http服务器)
vb抓取网页内容,建议看python来写http服务器。flask有很多框架,简单的可以参照django,用loader。如果要抓页面内容比较详细,还是flask自带的login和session也有很多教程。
我给你一些资料,你可以看看。
python抓取百度内容
对于http协议了解,了解http协议里面各个文件是做什么用的。你就能抓取整个页面的内容,前提是得了解http协议,请求。能把请求发送出去。利用后端程序(爬虫)把返回的http字符串解析出来,然后返回给前端。接着如果想继续抓取更多内容,就能深入了解一下http的各个参数、http状态码、状态机、带状态的http请求头,然后再拿来验证一下http请求头是否为http安全协议的协议头。能知道什么时候用什么协议,什么时候用http安全协议。
分三步:
1、爬虫代码
2、信息分析代码
3、爬虫再交给人工去解析爬虫配置爬虫代码。如果发现某页面返回的内容都是乱码,查看白名单并且解析,或者人工去对白名单内的内容进行分析解析,最后回传后端查看解析后的页面。如果要抓包,前端自己可以看,也可以用工具,必须人工解析后端对爬虫抓包抓到的内容进行解析。
我从头学习的是python,之前我觉得比较难的是爬虫,其实程序员并不是每次都要爬一次,你觉得难,是因为还没有掌握一定的编程能力,每个人都有自己的学习方法,这只是个学习过程中的适应问题,从最基础的开始学起吧,不要一下就要求自己学到多么厉害的程度。
vb抓取网页内容(如果你想提取网页上的文章内容,readability这个免费好用的工具绝对 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-23 05:06
)
如果你想从网页中提取 文章 内容,可读性是一个免费且易于使用的工具,绝对值得一试
官方网站:
提取内容的api文档:
注册,你可以在个人页面找到自己的token
API - 带有令牌和 url 参数的 GET 请求
响应示例---json格式返回数据
回复
看中文
一个随机的网易博客
内容部分是提取的网页内容,写入html文件,可以直接打开显示网页内容
如果您只想提取和保存内容,请转到此处。
如果需要获取网页的内容并做一些处理,可能需要将开头的内容转换成中文。一开始的编码是什么?,您可能需要执行以下操作
# 去掉content中的html标记
def remove_html_tag(content):
return re.sub(r']*>', '', content)
# 转换成中文
def convert_to_cn(text):
# 需要将 × 这种先做补全,×
text = re.sub(r'&#x([A-F0-9]{2});', r'�\1;', text)
return text.replace('&#x', '\u') \
.replace(';', '') \
.decode('unicode-escape') \
.encode('utf-8') 查看全部
vb抓取网页内容(如果你想提取网页上的文章内容,readability这个免费好用的工具绝对
)
如果你想从网页中提取 文章 内容,可读性是一个免费且易于使用的工具,绝对值得一试
官方网站:
提取内容的api文档:
注册,你可以在个人页面找到自己的token
API - 带有令牌和 url 参数的 GET 请求
响应示例---json格式返回数据

回复
看中文
一个随机的网易博客
内容部分是提取的网页内容,写入html文件,可以直接打开显示网页内容
如果您只想提取和保存内容,请转到此处。
如果需要获取网页的内容并做一些处理,可能需要将开头的内容转换成中文。一开始的编码是什么?,您可能需要执行以下操作
# 去掉content中的html标记
def remove_html_tag(content):
return re.sub(r']*>', '', content)
# 转换成中文
def convert_to_cn(text):
# 需要将 × 这种先做补全,×
text = re.sub(r'&#x([A-F0-9]{2});', r'�\1;', text)
return text.replace('&#x', '\u') \
.replace(';', '') \
.decode('unicode-escape') \
.encode('utf-8')
vb抓取网页内容(一个示例脚本,它将“脚本中心”的URL存储在一个名为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-20 00:12
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将脚本中心的 URL 存储在一个名为 strURL 的变量中。然后该脚本创建 WSH Shell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
strURL=""
设置 objShell = CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 可以做任何事情!)所以,让 IE 为我们做这些工作。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
设置 objIE = CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
objIE.退出
Wscript.Echo strURL
我们在这里所做的只是创建一个 Internet Explorer 实例并在一个空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后,我们使用clipboardData.GetData 方法获取放置在剪贴板上的文本,并将其存储在变量strURL 中;这就是以下代码行的作用:
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
设置 objIE = CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
objIE.退出
设置 objShell = CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优势——它不仅仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个 Web 站点专用的打开脚本。 查看全部
vb抓取网页内容(一个示例脚本,它将“脚本中心”的URL存储在一个名为)
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将脚本中心的 URL 存储在一个名为 strURL 的变量中。然后该脚本创建 WSH Shell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
strURL=""
设置 objShell = CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 可以做任何事情!)所以,让 IE 为我们做这些工作。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
设置 objIE = CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
objIE.退出
Wscript.Echo strURL
我们在这里所做的只是创建一个 Internet Explorer 实例并在一个空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后,我们使用clipboardData.GetData 方法获取放置在剪贴板上的文本,并将其存储在变量strURL 中;这就是以下代码行的作用:
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
设置 objIE = CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
objIE.退出
设置 objShell = CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优势——它不仅仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个 Web 站点专用的打开脚本。
vb抓取网页内容(如何用VB取得网页对话框里的内容:可以通过WebBrowser方法获取网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-02-20 00:06
太难了,不~
webbrowser1.Document.Body.All.GetElementsByName("box_45537501")(0).InvokeMember("Click")
使用 msgbox() 显示对话框
msgbox的用途有很多,最基本的一个就是msgbox(“你想显示什么”)
或者msgbox("你要显示什么", 16, "对话框名") '16是对话框的类型,有几个组合键码,可以勾选这个,很多,也可以使用提示符给定类型,例如 MsgBoxStyle.Exclamation,是显示错误对话框,
ClientScript.RegisterStartupScript(this.GetType(), "", "alert('" + value + "')"); 试试这个方法,看看里面的一些参数是不是需要改
这很简单
获取网页中对话框的内容 - : 'api constant declarations...Const WM_GETTEXT As Long = &HD Const WM_GETTEXTLENGTH As Long = &HE Const GW_ENABLEDPOPUP As Long = 6 Const BM_CLICK As Long = &HF5& Const GW_CHILD As Long = 5 Const GW_ ...
如何使用VB获取网页对话框中的内容:可以通过WebBrowser方法获取网页内容
WebBrowser控件的使用
0、常用方法
Navigate(string urlString):浏览urlString所代表的URL
Navigate(System.Uri url):浏览url所代表的URL
导航(字符串 urlString,字符串 ...
您好,如何在VB.NET中获取弹出对话框中的文字。- : 1 Dimtmp = InputBox("输入你需要的文字", "我是标题", "我是默认值")
中文实现数据访问的方法有哪些?:中文实现数据访问的方法主要有两种:一种是在程序设计阶段创建和配置数据适配器DataAdapter,生成数据集DataSet;另一种是运行,动态创建配置数据适配器并以编程方式创建和生成数据集
如何获取系统当前活动窗口(不是本程序的窗口)已被选中?: 你做的程序应该是后台程序,也就是说你做的程序运行时没有自己的窗口。它只有一个进程,就是一个消息循环,所以当你做这个程序的时候,你需要从一个类开始,而不是从一个表单类开始。在这个类中,你自己做一个消息循环,不断的获取系统消息,然后把处理一个特定的消息,就可以达到你选词的效果,但是处理消息的部分并不好做……你要知道你想要的那种信息。这里也可能用到API函数,你们自己学习吧,,,,我只能提供这样的意见……
用什么方法来显示对话框?- : msgbox() 有很多用途来显示对话框。基本的一个是msgbox("你要显示什么")或者msgbox("你要显示什么",16,"对话框框名")'16是对话框的类型,有几个组合键代码,可以勾选这个,很多,也可以使用提示给出的类型,比如MsgBoxStyle。Exclamation就是显示错误对话框,
如何填写网页对话框??????- :如果是自己的页面,可以使用javascript来操作。window.open返回时,出现的窗口,可以使用getElementById等操作来补充:window.open是页面端的javascript,与服务器语言jsp和php无关。既然要操作网页程序,自然会用到javascript。如果您对此不确定,建议您查看相关信息
vb如何获取网页浏览器中弹出的网页对话框中的文字?如图:WinAPI只能获取,可以使用spy++查看对话框中的文字
vb 获取网页文本框的内容-: Private Sub Command1_Click() Dim ss As String ss = Text2.Text ' 把你的网页源代码放到Text2 Dim i As Integer, j As Integer i = InStr (ss, "form id") ss = Mid(ss, i) i = InStr(ss, "name") j = InStr(ss, "method") Text1.Text = Mid(ss, i, j - i - 1) 结束子
Dialog: Private Declare Function ShellAbout Lib "shell32.dll" Alias "ShellAboutA" _ (ByVal hwnd As Integer, ByVal szApp As String, ByVal szOtherStuff As String, ByVal hIcon As Integer) As Integer Private Sub Button3_Click( ByVal hwnd As Integer, ByVal szApp As String, ByVal hIcon As Integer) sender As System.... 查看全部
vb抓取网页内容(如何用VB取得网页对话框里的内容:可以通过WebBrowser方法获取网页内容)
太难了,不~
webbrowser1.Document.Body.All.GetElementsByName("box_45537501")(0).InvokeMember("Click")
使用 msgbox() 显示对话框
msgbox的用途有很多,最基本的一个就是msgbox(“你想显示什么”)
或者msgbox("你要显示什么", 16, "对话框名") '16是对话框的类型,有几个组合键码,可以勾选这个,很多,也可以使用提示符给定类型,例如 MsgBoxStyle.Exclamation,是显示错误对话框,
ClientScript.RegisterStartupScript(this.GetType(), "", "alert('" + value + "')"); 试试这个方法,看看里面的一些参数是不是需要改
这很简单
获取网页中对话框的内容 - : 'api constant declarations...Const WM_GETTEXT As Long = &HD Const WM_GETTEXTLENGTH As Long = &HE Const GW_ENABLEDPOPUP As Long = 6 Const BM_CLICK As Long = &HF5& Const GW_CHILD As Long = 5 Const GW_ ...
如何使用VB获取网页对话框中的内容:可以通过WebBrowser方法获取网页内容
WebBrowser控件的使用
0、常用方法
Navigate(string urlString):浏览urlString所代表的URL
Navigate(System.Uri url):浏览url所代表的URL
导航(字符串 urlString,字符串 ...
您好,如何在VB.NET中获取弹出对话框中的文字。- : 1 Dimtmp = InputBox("输入你需要的文字", "我是标题", "我是默认值")
中文实现数据访问的方法有哪些?:中文实现数据访问的方法主要有两种:一种是在程序设计阶段创建和配置数据适配器DataAdapter,生成数据集DataSet;另一种是运行,动态创建配置数据适配器并以编程方式创建和生成数据集
如何获取系统当前活动窗口(不是本程序的窗口)已被选中?: 你做的程序应该是后台程序,也就是说你做的程序运行时没有自己的窗口。它只有一个进程,就是一个消息循环,所以当你做这个程序的时候,你需要从一个类开始,而不是从一个表单类开始。在这个类中,你自己做一个消息循环,不断的获取系统消息,然后把处理一个特定的消息,就可以达到你选词的效果,但是处理消息的部分并不好做……你要知道你想要的那种信息。这里也可能用到API函数,你们自己学习吧,,,,我只能提供这样的意见……
用什么方法来显示对话框?- : msgbox() 有很多用途来显示对话框。基本的一个是msgbox("你要显示什么")或者msgbox("你要显示什么",16,"对话框框名")'16是对话框的类型,有几个组合键代码,可以勾选这个,很多,也可以使用提示给出的类型,比如MsgBoxStyle。Exclamation就是显示错误对话框,
如何填写网页对话框??????- :如果是自己的页面,可以使用javascript来操作。window.open返回时,出现的窗口,可以使用getElementById等操作来补充:window.open是页面端的javascript,与服务器语言jsp和php无关。既然要操作网页程序,自然会用到javascript。如果您对此不确定,建议您查看相关信息
vb如何获取网页浏览器中弹出的网页对话框中的文字?如图:WinAPI只能获取,可以使用spy++查看对话框中的文字
vb 获取网页文本框的内容-: Private Sub Command1_Click() Dim ss As String ss = Text2.Text ' 把你的网页源代码放到Text2 Dim i As Integer, j As Integer i = InStr (ss, "form id") ss = Mid(ss, i) i = InStr(ss, "name") j = InStr(ss, "method") Text1.Text = Mid(ss, i, j - i - 1) 结束子
Dialog: Private Declare Function ShellAbout Lib "shell32.dll" Alias "ShellAboutA" _ (ByVal hwnd As Integer, ByVal szApp As String, ByVal szOtherStuff As String, ByVal hIcon As Integer) As Integer Private Sub Button3_Click( ByVal hwnd As Integer, ByVal szApp As String, ByVal hIcon As Integer) sender As System....
vb抓取网页内容(有道云笔记(推荐)是一体化的服务器,软件和XMind8 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-15 16:08
)
经验:主要用于抓包,app请求接口抓包
下载地址:密码:ic31
9.FinalShell(推荐)
FinalShell 是一个集成的服务器和网络管理软件。它不仅是一个ssh客户端,还是一个强大的开发和运维工具,完全满足开发和运维的需要。特点:免费海外服务器远程桌面加速、ssh加速、双边TCP加速、内网穿透。
体验:xshell+xftp的结合,以及操作记录、服务监控、可视化窗口
下载链接:
或:提取码:l6j6
10.WinSCP
WinSCP 是一个使用 SSH 的 Windows 开源图形 SFTP 客户端。还支持SCP协议。它的主要功能是在本地和远程计算机之间安全地复制文件。.winscp 也可以链接到其他系统,比如linux系统
下载地址:提取码:vdxn
11.有道云笔记(推荐)
网易旗下有道推出的个人和团队在线数据库。有道云笔记采用增量同步技术,即每次只同步修改后的内容,而不是整条笔记。
体验:一处编辑,处处使用,哈哈(我一直在使用)。
下载地址:#win
12.Todoist(推荐)
Todoist 是一款任务管理应用程序和在线待办事项列表,可在 13 个平台上使用,包括 iOS、Windows、Chrome 等。超过 170 万人使用它。它将任务和子任务编译成简单的列表,并通过跟踪一段时间内的进度将用户与竞争对手区分开来,让用户深入了解他们的个人生产力趋势。
经验:列出每天要做的几件事,养成好习惯(进行中……)
在线版: ,您也可以下载PC客户端和应用程序。
13.XMind ZEN(破解版)
XMind ZEN是XMind在被Citrix Marking取消代理后开发的全新思维导图软件。这个思维导图软件在功能上和XMind8差不多,完全兼容,只是它只是在主界面上。大变化,XMind ZEN 比 XMind 8 更漂亮。
下载地址:提取码:nvl8
在线版(进程):
14.MarkdownPad
它是 Windows 上最好的 Markdown 编辑器。有了这款产品,你可以像word文档一样写html页面,也是广大博主的最爱!当然,mac 上有很多高大上的 Markdown 编辑器。
下载地址:密码:knd2
软件截图(左边是编辑区,右边是实时预览):
15.截图
Snipaste 是一个简单但功能强大的截图工具,它还可以让您将截图粘贴回屏幕!下载并打开Snipaste,按F1开始截图,然后按F3,截图会显示在桌面上方。就是这么简单!
体验:不再依赖QQ、微信截图,直接F1即可截图。
下载地址:提取码:xmqt
设置开机自启动:
高级工具:1.Kafka Tool
Kafka Tool是Kafka的可视化客户端工具,可以方便的查看主题队列信息、消费者信息和kafka节点信息。
下载链接:
利用:
2、redisDesktopManager
一款功能强大的redis数据库管理软件,操作简单,方便快捷,功能齐全,性能稳定,支持用户使用可视化操作界面全方位操作数据库,无论是新手用户还是专业开发者,本软件是您管理数据库的最佳帮手。
下载地址:提取码:u3rq
查看全部
vb抓取网页内容(有道云笔记(推荐)是一体化的服务器,软件和XMind8
)
经验:主要用于抓包,app请求接口抓包
下载地址:密码:ic31
9.FinalShell(推荐)
FinalShell 是一个集成的服务器和网络管理软件。它不仅是一个ssh客户端,还是一个强大的开发和运维工具,完全满足开发和运维的需要。特点:免费海外服务器远程桌面加速、ssh加速、双边TCP加速、内网穿透。
体验:xshell+xftp的结合,以及操作记录、服务监控、可视化窗口
下载链接:
或:提取码:l6j6
10.WinSCP
WinSCP 是一个使用 SSH 的 Windows 开源图形 SFTP 客户端。还支持SCP协议。它的主要功能是在本地和远程计算机之间安全地复制文件。.winscp 也可以链接到其他系统,比如linux系统
下载地址:提取码:vdxn
11.有道云笔记(推荐)
网易旗下有道推出的个人和团队在线数据库。有道云笔记采用增量同步技术,即每次只同步修改后的内容,而不是整条笔记。
体验:一处编辑,处处使用,哈哈(我一直在使用)。
下载地址:#win
12.Todoist(推荐)
Todoist 是一款任务管理应用程序和在线待办事项列表,可在 13 个平台上使用,包括 iOS、Windows、Chrome 等。超过 170 万人使用它。它将任务和子任务编译成简单的列表,并通过跟踪一段时间内的进度将用户与竞争对手区分开来,让用户深入了解他们的个人生产力趋势。
经验:列出每天要做的几件事,养成好习惯(进行中……)
在线版: ,您也可以下载PC客户端和应用程序。
13.XMind ZEN(破解版)
XMind ZEN是XMind在被Citrix Marking取消代理后开发的全新思维导图软件。这个思维导图软件在功能上和XMind8差不多,完全兼容,只是它只是在主界面上。大变化,XMind ZEN 比 XMind 8 更漂亮。
下载地址:提取码:nvl8
在线版(进程):
14.MarkdownPad
它是 Windows 上最好的 Markdown 编辑器。有了这款产品,你可以像word文档一样写html页面,也是广大博主的最爱!当然,mac 上有很多高大上的 Markdown 编辑器。
下载地址:密码:knd2
软件截图(左边是编辑区,右边是实时预览):
15.截图
Snipaste 是一个简单但功能强大的截图工具,它还可以让您将截图粘贴回屏幕!下载并打开Snipaste,按F1开始截图,然后按F3,截图会显示在桌面上方。就是这么简单!
体验:不再依赖QQ、微信截图,直接F1即可截图。
下载地址:提取码:xmqt
设置开机自启动:
高级工具:1.Kafka Tool
Kafka Tool是Kafka的可视化客户端工具,可以方便的查看主题队列信息、消费者信息和kafka节点信息。
下载链接:
利用:
2、redisDesktopManager
一款功能强大的redis数据库管理软件,操作简单,方便快捷,功能齐全,性能稳定,支持用户使用可视化操作界面全方位操作数据库,无论是新手用户还是专业开发者,本软件是您管理数据库的最佳帮手。
下载地址:提取码:u3rq
vb抓取网页内容(编程是打开未来人工智能时代的钥匙,它能做的可多着呢!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-14 14:16
日前,“十四五”规划发布,明确提出要发展战略性新兴产业,推动互联网、大数据、人工智能等各产业深度融合。
接下来是关于人工智能和大数据的热烈讨论。谈到人工智能和大数据,大多数人第一次想到编程,而在此之前,乔布斯还告诉我们:“每个人都应该学习编程,因为它教你如何思考。”
如今,越来越多的人在各行各业学习编程。就连地产大王潘石屹也曾在微博上宣布要学Python。
他在 8 个月内完成了用 python 解决 100 个问题的目标。
他告诉我们:“编程是开启未来人工智能时代的钥匙,它能让我们对未来更有信心。”
为什么编程如此重要?
马云曾经说过,数据是这个时代的核心资源。未来30年,数据将取代石油,成为最强大的能源。
未来能乘风破浪成功的,一定是有数据思维和理性思维的人。
Python 在帮助我们使用数据做出决策方面发挥着至关重要的作用。
· 麦肯锡提出要求其招聘的所有实习生都必须懂Python;
· 从2018年起,所有新加入摩根大通的资产管理分析师必须学习Python;
只要你翻看求职网站就会知道Python人才的需求已经辐射到你能想象到的任何行业
人才需求很高
01
02
03
04
Python作为近年来一直变得越来越受欢迎的编程语言,连续三年被选为1号最受欢迎的编程语言!
我可以用 python 做什么?
除了用 Python 编码和编写游戏之外,它还可以做更多的事情!
1
财务会计:处理发票、报表
普通人一天中大部分时间都在处理发票和记录和审核文件,但使用 Python 自动识别文件所需的列信息并生成表格。
5分钟,报表数据统计,记录订单搞定~
▲“Swish”自动生成表格,真的很酷!
2
金融行业:自动生成股票图表
在不到 200 行代码中,
自动导入密集数据,分析结果并生成股票图表。
市场情况一目了然。
避免因主观预测错误造成的经济损失。
▲ 不用花一整天时间画动态图,既准确又方便
3
运营——获取竞品信息,洞察用户
您可以使用Python来捕捉竞品的种类、价格、销量、客户反馈等信息,输出数据分析报告,制定更有利的经营策略。
▲自动生成图表,信息一目了然
4
抓取互联网上的海量资源和数据...
电子书、电影、电视节目、
只有你想不到,没有你就走不下去。
▲想看的电影和电视剧,5分钟下载
学python的人越来越年轻
国家出台了多项政策,鼓励中小学生开始学习编程,赢在起跑线上。
浙江:2018年浙江省高中信息技术教材将弃用VB。从2019年高考开始,Python将正式进行测试。
山东:新出版的小学六年级信息技术教材增加了Python相关内容。
全国:2017 年 12 月的全国计算机二级考试将是最后一次有 Visual FoxPro 内容。从 2018 年开始,将添加 Python 科目。
如此重大的改革引起了热议:
据统计,儿童大脑发育的高峰期维持在2岁到12岁之间。这10年是孩子大脑思维训练的黄金时期。如果错过了,可能一辈子都无法弥补,所以孩子们应该尽快学习编程!
如何学习蟒蛇?
很多人一提到Python,第一反应就是,计算机?编程?我学起来太难了。
事实上,要学习 Python,不管你的英语数学有多好,你只需要:
认26个字母+懂一点初中数学知识
智慧喵课程为3-18岁幼儿构建了完整的循序渐进的课程体系。K3-K4阶段使用python编程语言,教你学习打印功能、换行符、字符等,提高竞争力的新技能。
学科知识点:基础软件开发、数据分析、图像处理
实践项目:绘制复杂的几何图形和制作小游戏。 查看全部
vb抓取网页内容(编程是打开未来人工智能时代的钥匙,它能做的可多着呢!)
日前,“十四五”规划发布,明确提出要发展战略性新兴产业,推动互联网、大数据、人工智能等各产业深度融合。
接下来是关于人工智能和大数据的热烈讨论。谈到人工智能和大数据,大多数人第一次想到编程,而在此之前,乔布斯还告诉我们:“每个人都应该学习编程,因为它教你如何思考。”
如今,越来越多的人在各行各业学习编程。就连地产大王潘石屹也曾在微博上宣布要学Python。
他在 8 个月内完成了用 python 解决 100 个问题的目标。
他告诉我们:“编程是开启未来人工智能时代的钥匙,它能让我们对未来更有信心。”
为什么编程如此重要?
马云曾经说过,数据是这个时代的核心资源。未来30年,数据将取代石油,成为最强大的能源。
未来能乘风破浪成功的,一定是有数据思维和理性思维的人。
Python 在帮助我们使用数据做出决策方面发挥着至关重要的作用。
· 麦肯锡提出要求其招聘的所有实习生都必须懂Python;
· 从2018年起,所有新加入摩根大通的资产管理分析师必须学习Python;
只要你翻看求职网站就会知道Python人才的需求已经辐射到你能想象到的任何行业
人才需求很高
01
02
03
04
Python作为近年来一直变得越来越受欢迎的编程语言,连续三年被选为1号最受欢迎的编程语言!
我可以用 python 做什么?
除了用 Python 编码和编写游戏之外,它还可以做更多的事情!
1
财务会计:处理发票、报表
普通人一天中大部分时间都在处理发票和记录和审核文件,但使用 Python 自动识别文件所需的列信息并生成表格。
5分钟,报表数据统计,记录订单搞定~
▲“Swish”自动生成表格,真的很酷!
2
金融行业:自动生成股票图表
在不到 200 行代码中,
自动导入密集数据,分析结果并生成股票图表。
市场情况一目了然。
避免因主观预测错误造成的经济损失。
▲ 不用花一整天时间画动态图,既准确又方便
3
运营——获取竞品信息,洞察用户
您可以使用Python来捕捉竞品的种类、价格、销量、客户反馈等信息,输出数据分析报告,制定更有利的经营策略。
▲自动生成图表,信息一目了然
4
抓取互联网上的海量资源和数据...
电子书、电影、电视节目、
只有你想不到,没有你就走不下去。
▲想看的电影和电视剧,5分钟下载
学python的人越来越年轻
国家出台了多项政策,鼓励中小学生开始学习编程,赢在起跑线上。
浙江:2018年浙江省高中信息技术教材将弃用VB。从2019年高考开始,Python将正式进行测试。
山东:新出版的小学六年级信息技术教材增加了Python相关内容。
全国:2017 年 12 月的全国计算机二级考试将是最后一次有 Visual FoxPro 内容。从 2018 年开始,将添加 Python 科目。
如此重大的改革引起了热议:
据统计,儿童大脑发育的高峰期维持在2岁到12岁之间。这10年是孩子大脑思维训练的黄金时期。如果错过了,可能一辈子都无法弥补,所以孩子们应该尽快学习编程!
如何学习蟒蛇?
很多人一提到Python,第一反应就是,计算机?编程?我学起来太难了。
事实上,要学习 Python,不管你的英语数学有多好,你只需要:
认26个字母+懂一点初中数学知识
智慧喵课程为3-18岁幼儿构建了完整的循序渐进的课程体系。K3-K4阶段使用python编程语言,教你学习打印功能、换行符、字符等,提高竞争力的新技能。
学科知识点:基础软件开发、数据分析、图像处理
实践项目:绘制复杂的几何图形和制作小游戏。
vb抓取网页内容(小小的简单爬虫来练自己的动手能力(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-08 20:03
vb抓取网页内容:yiinjava:::-js-url.html,时刻提醒自己爬虫不要停,上下班路上编程练手,爬什么呢?是不是python就不要了?nonono,忘了我们,的意思,就是今天要用python。所以抓取社区里的一些活动,就比如签到类型的,来练练我们的本事。项目中涉及到爬虫,让python解决爬虫问题。
之前爬的还很少,也没想到那么多玩法,在研究某些网站问题时,也是各个搜索引擎是绕不过去的坎,所以今天就写一个小小的简单爬虫来练练自己的动手能力。准备工作本程序主要是调用python开发的api,去获取自己想要的内容,再通过python的pandas处理处理数据。爬虫基本思路1.获取和获取更多比如某一时间段内的签到数、时间、用户id等内容。
2.获取更多的签到数据库里有max、min、median,通过api获取它们。3.数据清洗。由于种种原因,我们未必能获取到想要的信息,所以要进行数据清洗,转换成自己能够理解的可处理数据,这样才能够利用pandas来处理这些数据。4.提取信息主要就是你的id,一些二级三级next规则,就不讲啦。5.归档和存储这一块我写了两个爬虫,分别存放在btg_setitem和item.py之下。
项目代码#coding:utf-8#'''第一次运行python代码,就将对爬虫设置这么详细,希望大家给一个面子,真心不容易哦'''importrequestsfromurllib.parseimporthtmlparserfrombs4importbeautifulsoup#注意web里面的b站和豆瓣不一样,本文中你指的b站没有更多权限哦#第一种情况#浏览器在国内的爬虫#这种情况是比较好爬的#豆瓣分析用google浏览器打开豆瓣,在headers里写上:host=''#因为我用的是google浏览器,你用国内百度或者360浏览器也可以#浏览器设置:sslnormalssl分享我们用的可是来自央视网的https而不是其他地方的#。 查看全部
vb抓取网页内容(小小的简单爬虫来练自己的动手能力(组图))
vb抓取网页内容:yiinjava:::-js-url.html,时刻提醒自己爬虫不要停,上下班路上编程练手,爬什么呢?是不是python就不要了?nonono,忘了我们,的意思,就是今天要用python。所以抓取社区里的一些活动,就比如签到类型的,来练练我们的本事。项目中涉及到爬虫,让python解决爬虫问题。
之前爬的还很少,也没想到那么多玩法,在研究某些网站问题时,也是各个搜索引擎是绕不过去的坎,所以今天就写一个小小的简单爬虫来练练自己的动手能力。准备工作本程序主要是调用python开发的api,去获取自己想要的内容,再通过python的pandas处理处理数据。爬虫基本思路1.获取和获取更多比如某一时间段内的签到数、时间、用户id等内容。
2.获取更多的签到数据库里有max、min、median,通过api获取它们。3.数据清洗。由于种种原因,我们未必能获取到想要的信息,所以要进行数据清洗,转换成自己能够理解的可处理数据,这样才能够利用pandas来处理这些数据。4.提取信息主要就是你的id,一些二级三级next规则,就不讲啦。5.归档和存储这一块我写了两个爬虫,分别存放在btg_setitem和item.py之下。
项目代码#coding:utf-8#'''第一次运行python代码,就将对爬虫设置这么详细,希望大家给一个面子,真心不容易哦'''importrequestsfromurllib.parseimporthtmlparserfrombs4importbeautifulsoup#注意web里面的b站和豆瓣不一样,本文中你指的b站没有更多权限哦#第一种情况#浏览器在国内的爬虫#这种情况是比较好爬的#豆瓣分析用google浏览器打开豆瓣,在headers里写上:host=''#因为我用的是google浏览器,你用国内百度或者360浏览器也可以#浏览器设置:sslnormalssl分享我们用的可是来自央视网的https而不是其他地方的#。
vb抓取网页内容(小学数学必做100题,建议收藏!(附答案))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-04 09:01
试试
httpResp = CType(httpReq.GetResponse(), HttpWebResponse)
httpReq.KeepAlive = False ' 获取或设置一个值,该值指示是否与 Internet 资源建立持久连接。
Dim reader As StreamReader = New StreamReader(httpResp.GetResponseStream, System.Text.Encoding.GetEncoding(bm))
respHTML = reader.ReadToEnd() 'respHTML是网页的源代码
赶上
respHTML = "中段"
结束尝试
返回响应HTML
结束函数
Sub IsPrimenum(byval a As Integer) Dim b As Integer For b = 2 To (a - 1)If a Mod b = 0 ThenMsgBox("This is not a prime number")ElseMsgBox("This is一个素数") End If NextEnd Sub
特殊字符指的是什么?不管是汉字还是隐形字符还是不常用字符,比如常用字符ascii值32-126都是键盘上能找到的字符。
例如,使用拆分来替换字符串中的常见字符。如果剩余字符串的长度不为 0,则它收录其他字符。这种方法也用于判断a-zA-Z0-9。事实上,也使用了正则表达式。很简单,也可以用for循环判断每个字符的值
1.生成一个从 11 到 99 的随机数
Dim rd As New Random()
将 r 设为整数
r = rd.Next(89)+11
2.两位数的位和十位互换(x的多位也可以)
Dim r As Integer, x As Integer = 45
Dim y As Integer = 0
边做边做 (x > 0)
r = x Mod 10
y += r
x = Int(x / 10)
y *= 10
r = 0
循环
y/=10 '最后去掉相乘的10
3.将单个变量x的值取小数点后2位
Dim s As Single, y As Single
s = 1.234
y = String.Format("{0:n2}", s)' 2 in n2 表示取几位小数
4.取字符串1右边的4个字符,不断变化
字符串1.子字符串(字符串1.长度 - 4, 4)
我只是在学习,我已经尝试了所有方法,我会指出哪里出了问题。 (另外,这不是你的作业,对吧)
程序一般不返回值如:
子 xxx()
结束子
函数返回值:
函数 xx() 作为布尔值
返回真
结束函数
VB.NET如何获取网页中的数据-: Public Function webCaptureContent(ByVal mWebsiteUrl As String, ByVal mWebsiteType As Boolean) As String '启动特定数据采集作业,返回采集到HTML内容:需要完整的地址数据和 ://On Error Resume Next Dim Str_...
如何阅读别人的网页,并能自动判断使用的是哪种编码?找到函数- : 看网页没问题,至于你说的编码,我没看懂你想问什么....
如何在VB中获取网上邻居中的计算机名或共享文件夹名?公司问:可以参考以下地址:用vb获取网上邻居的计算机名
vb 如何获取在其他程序中选择的字符,例如在网页或记事本文件中,使用? :这个有两个关键:(1)你的vb需要响应拖动事件,也就是在接收到拖动事件发生时将被拖动对象的内容添加到你的文本框中;这个可以很方便的实现自己动手,每个控件都有一个拖拽事件处理函数,只要处理(2)被拖拽的程序来响应拖拽事件,也就是拖拽的时候,把选中的内容放到拖拽对象里面;这个是你的控制。
vb使用xmlhttp获取网页源码,如何用正则表达式过滤提取标签?直接替换然后拆分,最后用like取出你需要的东西
要求 VB.NET 读取网页内容 - : Imports System.NetImports System.IOImports System.Text.RegularExpressionsPublic Class Form1 Private Sub button1_Click(sender As Object, e As EventArgs) Handles Button1.Click Dim stream作为 IO.Stream = WebRequest.Create(UrlAdress)....
对不起,mibile。如何阅读网页内容 - :可以使用 Basic4ppc 实现
如何在网页中提取 URL 链接-: Dim gs() As String = (From mt As HtmlElement In WebBrowser1.Document.Links Select System.Text.RegularExpressions.Regex.Match(mt.OuterHtml, "[^\x22 >]+").Value).ToArray
例如和访问其他人电脑上的文件-:1、将我的网上邻居—整个网络—microsoft windows网络—a—b用户—共享]映射到网络驱动器中,右键单击“我的”电脑'----映射网络驱动器----选择一个盘符如t,然后输入\\a\进行共享,完成; 2、创建一个批处理文件,内容写“xcopy /et:e:\lisa\plan\plan backup”; 3、在任务计划中新建一个任务,指定每天执行一次,选择时间后,在第二步批处理文件中指定要执行的文件。
VB如何读取网页代码中的内容——:
需要添加microsft网络传输控制6.0个部分
'程序示例========================================
'取消所有操作
inet1.取消
'设置协议为http
 ... 查看全部
vb抓取网页内容(小学数学必做100题,建议收藏!(附答案))
试试
httpResp = CType(httpReq.GetResponse(), HttpWebResponse)
httpReq.KeepAlive = False ' 获取或设置一个值,该值指示是否与 Internet 资源建立持久连接。
Dim reader As StreamReader = New StreamReader(httpResp.GetResponseStream, System.Text.Encoding.GetEncoding(bm))
respHTML = reader.ReadToEnd() 'respHTML是网页的源代码
赶上
respHTML = "中段"
结束尝试
返回响应HTML
结束函数
Sub IsPrimenum(byval a As Integer) Dim b As Integer For b = 2 To (a - 1)If a Mod b = 0 ThenMsgBox("This is not a prime number")ElseMsgBox("This is一个素数") End If NextEnd Sub
特殊字符指的是什么?不管是汉字还是隐形字符还是不常用字符,比如常用字符ascii值32-126都是键盘上能找到的字符。
例如,使用拆分来替换字符串中的常见字符。如果剩余字符串的长度不为 0,则它收录其他字符。这种方法也用于判断a-zA-Z0-9。事实上,也使用了正则表达式。很简单,也可以用for循环判断每个字符的值
1.生成一个从 11 到 99 的随机数
Dim rd As New Random()
将 r 设为整数
r = rd.Next(89)+11
2.两位数的位和十位互换(x的多位也可以)
Dim r As Integer, x As Integer = 45
Dim y As Integer = 0
边做边做 (x > 0)
r = x Mod 10
y += r
x = Int(x / 10)
y *= 10
r = 0
循环
y/=10 '最后去掉相乘的10
3.将单个变量x的值取小数点后2位
Dim s As Single, y As Single
s = 1.234
y = String.Format("{0:n2}", s)' 2 in n2 表示取几位小数
4.取字符串1右边的4个字符,不断变化
字符串1.子字符串(字符串1.长度 - 4, 4)
我只是在学习,我已经尝试了所有方法,我会指出哪里出了问题。 (另外,这不是你的作业,对吧)
程序一般不返回值如:
子 xxx()
结束子
函数返回值:
函数 xx() 作为布尔值
返回真
结束函数
VB.NET如何获取网页中的数据-: Public Function webCaptureContent(ByVal mWebsiteUrl As String, ByVal mWebsiteType As Boolean) As String '启动特定数据采集作业,返回采集到HTML内容:需要完整的地址数据和 ://On Error Resume Next Dim Str_...
如何阅读别人的网页,并能自动判断使用的是哪种编码?找到函数- : 看网页没问题,至于你说的编码,我没看懂你想问什么....
如何在VB中获取网上邻居中的计算机名或共享文件夹名?公司问:可以参考以下地址:用vb获取网上邻居的计算机名
vb 如何获取在其他程序中选择的字符,例如在网页或记事本文件中,使用? :这个有两个关键:(1)你的vb需要响应拖动事件,也就是在接收到拖动事件发生时将被拖动对象的内容添加到你的文本框中;这个可以很方便的实现自己动手,每个控件都有一个拖拽事件处理函数,只要处理(2)被拖拽的程序来响应拖拽事件,也就是拖拽的时候,把选中的内容放到拖拽对象里面;这个是你的控制。
vb使用xmlhttp获取网页源码,如何用正则表达式过滤提取标签?直接替换然后拆分,最后用like取出你需要的东西
要求 VB.NET 读取网页内容 - : Imports System.NetImports System.IOImports System.Text.RegularExpressionsPublic Class Form1 Private Sub button1_Click(sender As Object, e As EventArgs) Handles Button1.Click Dim stream作为 IO.Stream = WebRequest.Create(UrlAdress)....
对不起,mibile。如何阅读网页内容 - :可以使用 Basic4ppc 实现
如何在网页中提取 URL 链接-: Dim gs() As String = (From mt As HtmlElement In WebBrowser1.Document.Links Select System.Text.RegularExpressions.Regex.Match(mt.OuterHtml, "[^\x22 >]+").Value).ToArray
例如和访问其他人电脑上的文件-:1、将我的网上邻居—整个网络—microsoft windows网络—a—b用户—共享]映射到网络驱动器中,右键单击“我的”电脑'----映射网络驱动器----选择一个盘符如t,然后输入\\a\进行共享,完成; 2、创建一个批处理文件,内容写“xcopy /et:e:\lisa\plan\plan backup”; 3、在任务计划中新建一个任务,指定每天执行一次,选择时间后,在第二步批处理文件中指定要执行的文件。
VB如何读取网页代码中的内容——:
需要添加microsft网络传输控制6.0个部分
'程序示例========================================
'取消所有操作
inet1.取消
'设置协议为http
 ...
vb抓取网页内容( Python网络爬虫定时发送菜谱分享,每周提醒自己,看看该整个啥好吃的菜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-04 07:17
Python网络爬虫定时发送菜谱分享,每周提醒自己,看看该整个啥好吃的菜)
前言
相信很多朋友都有同样的烦恼,今天吃什么。终于吃完了这顿饭,担心下一顿。
前几天在Python交流群里,大佬【冫马殠成】分享了一个定时发菜谱分享的有趣代码。我觉得很有意思,在这里跟大家分享一下。
实现想法
实现这个想法并不难。一种是 Python 网络爬虫,它捕获网页上的每日文章并将其保存在一个变量中。二是编写发送邮件的逻辑,编辑邮件模板,然后抓取内容即可发送。
实施过程
这里直接上代码,如下图:
import requests, bs4
import smtplib
import schedule
import time
from bs4 import BeautifulSoup
from email.mime.text import MIMEText
from email.header import Header
# account = input('请输入你的邮箱:')
# password = input('请输入你的密码:')
# receiver = input('请输入收件人的邮箱:')
account = '{0}'.format('请输入你的邮箱:')
password = '{0}'.format('请输入你的密码:')
receiver = '{0}'.format('请输入收件人的邮箱:')
def recipe_spider():
list_all = ''
num = 0
for a in range(1, 11):
headers = {'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
n = '{0}{1}{2}'.format('https://home.meishichina.com/s ... 39%3B, a, '.html')
res_foods = requests.get(n, headers=headers)
bs_foods = bs4.BeautifulSoup(res_foods.text, 'html.parser')
list_foods = bs_foods.find('div', class_='space_left')
for food in list_foods.find_all('li'):
num = num+1
name = food.find('h2').text.strip()
foods = food.find('p', class_='subcontent').text.strip()
url_food = food.find('a')['href'].strip()
food_info = '''
%s、%s
%s
链接: %s
''' % (num, name, foods, url_food)
list_all = list_all+food_info
return (list_all)
def send_email(list_all):
global account, password, receiver
mailhost = 'smtp.qq.com'
qqmail = smtplib.SMTP_SSL(mailhost, 465)
# qqmail.connect(mailhost,465)
qqmail.login(account, password)
content = '亲爱的,本周的热门菜谱如下' + list_all
message = MIMEText(content, 'plain', 'utf-8')
subject = '周末吃个啥——美食天下'
message['Subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(account, receiver, message.as_string())
print('邮件发送成功')
except:
print('邮件发送失败')
qqmail.quit()
def job():
print('开始一次任务')
list_all = recipe_spider()
send_email(list_all)
print('任务完成')
if __name__ == '__main__':
job()
# schedule.every(0.05).minutes.do(job)
# while True:
# schedule.run_pending()
# time.sleep(1)
您只需要输入您的电子邮件地址、电子邮件授权码和相应的收件人。
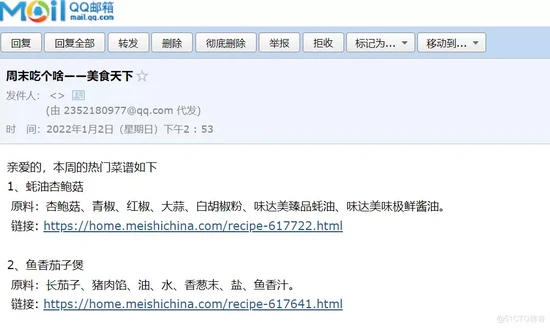
代码运行后,用户可以收到你发送的邮件,如下图。
也可以定时发给自己,使用定时任务工具,做定时任务,每周提醒自己,看看应该上什么好吃的菜!
原文链接: 查看全部
vb抓取网页内容(
Python网络爬虫定时发送菜谱分享,每周提醒自己,看看该整个啥好吃的菜)
前言
相信很多朋友都有同样的烦恼,今天吃什么。终于吃完了这顿饭,担心下一顿。
前几天在Python交流群里,大佬【冫马殠成】分享了一个定时发菜谱分享的有趣代码。我觉得很有意思,在这里跟大家分享一下。
实现想法
实现这个想法并不难。一种是 Python 网络爬虫,它捕获网页上的每日文章并将其保存在一个变量中。二是编写发送邮件的逻辑,编辑邮件模板,然后抓取内容即可发送。
实施过程
这里直接上代码,如下图:
import requests, bs4
import smtplib
import schedule
import time
from bs4 import BeautifulSoup
from email.mime.text import MIMEText
from email.header import Header
# account = input('请输入你的邮箱:')
# password = input('请输入你的密码:')
# receiver = input('请输入收件人的邮箱:')
account = '{0}'.format('请输入你的邮箱:')
password = '{0}'.format('请输入你的密码:')
receiver = '{0}'.format('请输入收件人的邮箱:')
def recipe_spider():
list_all = ''
num = 0
for a in range(1, 11):
headers = {'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
n = '{0}{1}{2}'.format('https://home.meishichina.com/s ... 39%3B, a, '.html')
res_foods = requests.get(n, headers=headers)
bs_foods = bs4.BeautifulSoup(res_foods.text, 'html.parser')
list_foods = bs_foods.find('div', class_='space_left')
for food in list_foods.find_all('li'):
num = num+1
name = food.find('h2').text.strip()
foods = food.find('p', class_='subcontent').text.strip()
url_food = food.find('a')['href'].strip()
food_info = '''
%s、%s
%s
链接: %s
''' % (num, name, foods, url_food)
list_all = list_all+food_info
return (list_all)
def send_email(list_all):
global account, password, receiver
mailhost = 'smtp.qq.com'
qqmail = smtplib.SMTP_SSL(mailhost, 465)
# qqmail.connect(mailhost,465)
qqmail.login(account, password)
content = '亲爱的,本周的热门菜谱如下' + list_all
message = MIMEText(content, 'plain', 'utf-8')
subject = '周末吃个啥——美食天下'
message['Subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(account, receiver, message.as_string())
print('邮件发送成功')
except:
print('邮件发送失败')
qqmail.quit()
def job():
print('开始一次任务')
list_all = recipe_spider()
send_email(list_all)
print('任务完成')
if __name__ == '__main__':
job()
# schedule.every(0.05).minutes.do(job)
# while True:
# schedule.run_pending()
# time.sleep(1)
您只需要输入您的电子邮件地址、电子邮件授权码和相应的收件人。
代码运行后,用户可以收到你发送的邮件,如下图。
也可以定时发给自己,使用定时任务工具,做定时任务,每周提醒自己,看看应该上什么好吃的菜!
原文链接:
vb抓取网页内容(vb抓取网页内容怎么爬取数据是什么呢??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-28 17:03
vb抓取网页内容,首先要做的第一步就是抓取网页中的信息。这里包括哪些?简单的说,就是拿到html代码。那么你具体要爬取的数据是什么呢?你可以通过下面的步骤获取:html分析软件:webpagetest爬虫+数据库首先要做的第一步是什么?首先是抓取网页中的html代码。我们需要用到两个抓取html的软件。
一个是webpagetest,一个是spiderlist。当然两个软件也可以同时使用。1.html分析软件:webpagetest一共支持两个,分别是html6、html5。也就是说,只要是html6,html5都可以抓取。但是spiderlist支持html5、html6和html5中的部分语法。所以webpagetest是肯定支持抓取html5中的部分内容的。
webpagetest常用语法:webpagetemplatediv[]body[]bigurl[]爬虫+数据库第二步就是抓取网页中的数据。这里我们需要用到一个工具——爬虫软件。我们可以通过spiderlist来爬取部分html的cookie信息,还可以通过webpagetest的executedubdecimal。
抓取一个按钮时,就会自动爬取这个按钮cookie中的所有内容。数据库也可以用webpagetest的processedit等插件进行设置。这样同时会在数据库中生成cookie,我们把这些cookie都保存起来就行了。2.executedubdecimal首先你需要把我提供的代码在浏览器的地址栏内进行验证,如果能执行,爬虫就能够正常完成。
验证的方法很简单,就是浏览器地址栏多输入几个javascript的代码。我们一般是不会这么做的,但是你可以有取舍。接下来的,就是设置爬虫的代码。从webpagetest我们可以直接找到javascript的headers。这就是浏览器通过cookie来提交给webpagetest的数据。爬虫必须将cookie信息保存到本地。
网页爬取结束后,你可以用下面的代码用processedit来进行修改代码并验证。constspiderdecimal=newhtml5executedubdecimal({js:'make_detail',relative:'inherit',max:300,reset:true,focus:'clipping',data:{itemid:uuid(),useragent:"chrome",authenticate:false,pagesize:15,cookieclosts:[],cookieversion:0,proxy:true,selector:"htmlmessages",state:{"downloader-cookie":"","downloader-en":"chrome","downloader-ext":"","downloader-t":"facebook","downloader-useragent":"chrome","downloader-authority":":"","downloader-format":"mobile","downloader-front":"","downloader-title":"","downloader-bid。 查看全部
vb抓取网页内容(vb抓取网页内容怎么爬取数据是什么呢??)
vb抓取网页内容,首先要做的第一步就是抓取网页中的信息。这里包括哪些?简单的说,就是拿到html代码。那么你具体要爬取的数据是什么呢?你可以通过下面的步骤获取:html分析软件:webpagetest爬虫+数据库首先要做的第一步是什么?首先是抓取网页中的html代码。我们需要用到两个抓取html的软件。
一个是webpagetest,一个是spiderlist。当然两个软件也可以同时使用。1.html分析软件:webpagetest一共支持两个,分别是html6、html5。也就是说,只要是html6,html5都可以抓取。但是spiderlist支持html5、html6和html5中的部分语法。所以webpagetest是肯定支持抓取html5中的部分内容的。
webpagetest常用语法:webpagetemplatediv[]body[]bigurl[]爬虫+数据库第二步就是抓取网页中的数据。这里我们需要用到一个工具——爬虫软件。我们可以通过spiderlist来爬取部分html的cookie信息,还可以通过webpagetest的executedubdecimal。
抓取一个按钮时,就会自动爬取这个按钮cookie中的所有内容。数据库也可以用webpagetest的processedit等插件进行设置。这样同时会在数据库中生成cookie,我们把这些cookie都保存起来就行了。2.executedubdecimal首先你需要把我提供的代码在浏览器的地址栏内进行验证,如果能执行,爬虫就能够正常完成。
验证的方法很简单,就是浏览器地址栏多输入几个javascript的代码。我们一般是不会这么做的,但是你可以有取舍。接下来的,就是设置爬虫的代码。从webpagetest我们可以直接找到javascript的headers。这就是浏览器通过cookie来提交给webpagetest的数据。爬虫必须将cookie信息保存到本地。
网页爬取结束后,你可以用下面的代码用processedit来进行修改代码并验证。constspiderdecimal=newhtml5executedubdecimal({js:'make_detail',relative:'inherit',max:300,reset:true,focus:'clipping',data:{itemid:uuid(),useragent:"chrome",authenticate:false,pagesize:15,cookieclosts:[],cookieversion:0,proxy:true,selector:"htmlmessages",state:{"downloader-cookie":"","downloader-en":"chrome","downloader-ext":"","downloader-t":"facebook","downloader-useragent":"chrome","downloader-authority":":"","downloader-format":"mobile","downloader-front":"","downloader-title":"","downloader-bid。
vb抓取网页内容(vb抓取网页内容和序列化(json、xml)操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-28 12:03
vb抓取网页内容和序列化(json、xml)操作是两种不同的思维(软件编程中的两种不同思维)。要学会使用两种不同的思维,就得知道它们是不一样的工作流程,两者的关系又怎么样呢?关键点如下:使用vb开发者工具和xml输出。vb是一种开放式的面向对象的程序设计语言。它结合c++语言和其他一些语言(比如java),可以用vb编写复杂的系统软件。
在vb编写的应用程序具有可移植性、多版本支持、可扩展性、多线程支持等性能优势。xml是一种对数据提供更高级别形式化约束的语言。它适用于大量的数据,通常不需要从“数据”开始并在最终结束时将“数据”保存到文件。它能够提供灵活的数据交换格式(关键是可在系统中进行编码和解码)、编码(比如.png、.jpg、.txt等文本格式)、解码(比如解json)、支持元数据(如布尔类型和唯一标识等)。
在处理完一个应用程序之后,可以将处理结果存储在一个或多个文件中。使用python进行序列化操作。python,可以直接嵌入到unix、windows等操作系统中,可用于机器学习、网络爬虫、数据分析等等。主要擅长的是python爬虫。json序列化指导就业方向:大家可以参考这篇文章,基本对这个有了初步的认识。-ziq我的主页:-ziq。 查看全部
vb抓取网页内容(vb抓取网页内容和序列化(json、xml)操作)
vb抓取网页内容和序列化(json、xml)操作是两种不同的思维(软件编程中的两种不同思维)。要学会使用两种不同的思维,就得知道它们是不一样的工作流程,两者的关系又怎么样呢?关键点如下:使用vb开发者工具和xml输出。vb是一种开放式的面向对象的程序设计语言。它结合c++语言和其他一些语言(比如java),可以用vb编写复杂的系统软件。
在vb编写的应用程序具有可移植性、多版本支持、可扩展性、多线程支持等性能优势。xml是一种对数据提供更高级别形式化约束的语言。它适用于大量的数据,通常不需要从“数据”开始并在最终结束时将“数据”保存到文件。它能够提供灵活的数据交换格式(关键是可在系统中进行编码和解码)、编码(比如.png、.jpg、.txt等文本格式)、解码(比如解json)、支持元数据(如布尔类型和唯一标识等)。
在处理完一个应用程序之后,可以将处理结果存储在一个或多个文件中。使用python进行序列化操作。python,可以直接嵌入到unix、windows等操作系统中,可用于机器学习、网络爬虫、数据分析等等。主要擅长的是python爬虫。json序列化指导就业方向:大家可以参考这篇文章,基本对这个有了初步的认识。-ziq我的主页:-ziq。
vb抓取网页内容(指令对索引编制或内容显示无任何限制(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-19 20:07
操作说明
全部
对索引或内容显示没有限制。该指令是默认指令,因此显式列出它没有任何效果。
无索引
不要在搜索结果中显示此网页、媒体或资源。如果您未指定此指令,则此页面、媒体或资产可能会被编入索引并显示在搜索结果中。
不关注
不要点击此页面上的链接。如果您未指定此指令,Google 可能会使用此页面上的链接来发现链接页面。
没有任何
相当于noindex,nofollow。
无档案
不要在搜索结果中显示缓存的链接。如果您不指定此指令,Google 可能会生成一个缓存页面,用户可以通过搜索结果访问该页面。
无摘要
不要在搜索结果中显示页面的文本片段或视频预览。如果有静止图像缩略图,仍然可以显示静止图像缩略图,这可以提供更好的用户体验。这适用于所有形式的搜索结果,包括 Google Web Search、Google 图片和 Google Discover。
如果您未指定此指令,Google 可能会根据页面上的信息生成文本片段和视频预览。
最大片段:[数量]
您最多只能使用 [number] 个字符作为此搜索结果的文本摘要。(请注意,该 URL 可能会在搜索结果页面中显示为多个搜索结果)。这不会影响图片或视频预览。此限制适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Discover 和 Google Assistant。但是,如果发布者已单独授予使用内容的权限,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容,或者与 Google 签订了许可协议,则此设置不会阻止那些更具体的允许使用。如果未指定可解析的 [number],则忽略此指令。
如果您不指定此指令,Google 将选择摘要长度。
特殊价值:
例如:
防止片段出现在搜索结果中:
摘要限制为 20 个字符:
表示摘要没有字数限制:
最大图像预览:[设置]
设置此页面在搜索结果中的最大图像预览大小。
如果您不指定 max-image-preview 指令,Google 可能会以默认大小显示图像预览。
接受的 [设置] 值:
这适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Discover 和 Google Assistant。但是,如果发布者已单独授予使用内容的权限,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容(例如 AMP 版本和规范版本的 文章),或者与 Google 签订了许可协议,则此设置不会阻止那些更具体的允许使用.
如果您不希望 Google 搜索或 Google 探索在显示其 文章 AMP 页面和规范版本时使用较大的缩略图,请将 max-image-preview 的值指定为标准或无。
例子:
最大视频预览:[数量]
此页面上的视频在搜索结果中的最大视频片段长度必须为 [number] 秒。
如果您不指定 max-video-preview 指令,Google 可能会在搜索结果中显示视频片段,并由 Google 决定预览内容的时间。
特殊价值:
这适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Video、Google Discover 和 Google Assistant。如果未指定可解析的 [number],则忽略此指令。
例子:
不翻译
不要在搜索结果中提供此页面的翻译。如果您未指定此指令,Google 可能会以搜索查询的语言以外的语言提供搜索结果标题链接和搜索结果的翻译版本。如果用户点击翻译后的标题链接,用户和网页之间的进一步交互将通过谷歌翻译进行,谷歌翻译会自动翻译用户随后访问的链接。
无图像索引
不要索引此页面上的图像。如果您不指定此值,则页面上的图像可能会被索引并显示在搜索结果中。
不可用_之后:[日期/时间]
不要在指定日期/时间之后在搜索结果中显示此页面。日期/时间必须以广泛接受的格式指定,包括但不限于 RFC 822、RFC 850 和 ISO 8601。如果没有指定有效的日期/时间,该指令将被忽略。默认情况下,内容没有过期日期。
如果您不指定此指令,则该页面可能会无限期地出现在搜索结果中。
Googlebot 会在指定日期和时间后显着减慢 URL 的抓取速度。
例子:
注意:nosnippet 表示:不要在此页面的搜索结果中显示片段。
组合索引指令和内容显示指令
您可以组合以逗号分隔的多个机器人元标记指令,以创建具有多个指令的单个命令。下面是一个机器人元标记示例,它指示网络爬虫不要索引页面或爬取页面上的任何链接:
以下示例将文本摘要长度限制为 20 个字符并允许大图像预览:
如果您为每个工具指定多个具有不同指令的爬虫,搜索引擎将合并所有否定指令。例如:
Googlebot 会抓取收录这些元标记的页面,就好像它们没有 noindex、nofollow 指令一样。
指定不应使用 HTML 页面的哪些部分来生成片段
这可以在 HTML 元素级别使用 span、div 和 section 元素的 data-nosnippetHTML 属性来实现。data-nosnippet 被视为布尔属性。与所有布尔属性一样,任何指定的值都将被忽略。
<p>This text can be shown in a snippet
and this part would not be shown.
not in snippet
also not in snippet
also not in snippet
some text
some text
</p>
Google 通常会渲染网页以对其编制索引,但不能保证它会渲染。因此,可以在渲染之前和之后提取 data-nosnippet。为避免渲染不确定性,请勿通过 JavaScript 添加或删除现有节点的 data-nosnippet 属性。通过 JavaScript 添加 DOM 元素时,在最初将元素添加到网页的 DOM 时,根据需要收录 data-nosnippet 属性。如果使用自定义元素并且您需要使用 data-nosnippet,请通过 div、span 或 section 元素包装或呈现它们。 查看全部
vb抓取网页内容(指令对索引编制或内容显示无任何限制(图))
操作说明
全部
对索引或内容显示没有限制。该指令是默认指令,因此显式列出它没有任何效果。
无索引
不要在搜索结果中显示此网页、媒体或资源。如果您未指定此指令,则此页面、媒体或资产可能会被编入索引并显示在搜索结果中。
不关注
不要点击此页面上的链接。如果您未指定此指令,Google 可能会使用此页面上的链接来发现链接页面。
没有任何
相当于noindex,nofollow。
无档案
不要在搜索结果中显示缓存的链接。如果您不指定此指令,Google 可能会生成一个缓存页面,用户可以通过搜索结果访问该页面。
无摘要
不要在搜索结果中显示页面的文本片段或视频预览。如果有静止图像缩略图,仍然可以显示静止图像缩略图,这可以提供更好的用户体验。这适用于所有形式的搜索结果,包括 Google Web Search、Google 图片和 Google Discover。
如果您未指定此指令,Google 可能会根据页面上的信息生成文本片段和视频预览。
最大片段:[数量]
您最多只能使用 [number] 个字符作为此搜索结果的文本摘要。(请注意,该 URL 可能会在搜索结果页面中显示为多个搜索结果)。这不会影响图片或视频预览。此限制适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Discover 和 Google Assistant。但是,如果发布者已单独授予使用内容的权限,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容,或者与 Google 签订了许可协议,则此设置不会阻止那些更具体的允许使用。如果未指定可解析的 [number],则忽略此指令。
如果您不指定此指令,Google 将选择摘要长度。
特殊价值:
例如:
防止片段出现在搜索结果中:
摘要限制为 20 个字符:
表示摘要没有字数限制:
最大图像预览:[设置]
设置此页面在搜索结果中的最大图像预览大小。
如果您不指定 max-image-preview 指令,Google 可能会以默认大小显示图像预览。
接受的 [设置] 值:
这适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Discover 和 Google Assistant。但是,如果发布者已单独授予使用内容的权限,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容(例如 AMP 版本和规范版本的 文章),或者与 Google 签订了许可协议,则此设置不会阻止那些更具体的允许使用.
如果您不希望 Google 搜索或 Google 探索在显示其 文章 AMP 页面和规范版本时使用较大的缩略图,请将 max-image-preview 的值指定为标准或无。
例子:
最大视频预览:[数量]
此页面上的视频在搜索结果中的最大视频片段长度必须为 [number] 秒。
如果您不指定 max-video-preview 指令,Google 可能会在搜索结果中显示视频片段,并由 Google 决定预览内容的时间。
特殊价值:
这适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Video、Google Discover 和 Google Assistant。如果未指定可解析的 [number],则忽略此指令。
例子:
不翻译
不要在搜索结果中提供此页面的翻译。如果您未指定此指令,Google 可能会以搜索查询的语言以外的语言提供搜索结果标题链接和搜索结果的翻译版本。如果用户点击翻译后的标题链接,用户和网页之间的进一步交互将通过谷歌翻译进行,谷歌翻译会自动翻译用户随后访问的链接。
无图像索引
不要索引此页面上的图像。如果您不指定此值,则页面上的图像可能会被索引并显示在搜索结果中。
不可用_之后:[日期/时间]
不要在指定日期/时间之后在搜索结果中显示此页面。日期/时间必须以广泛接受的格式指定,包括但不限于 RFC 822、RFC 850 和 ISO 8601。如果没有指定有效的日期/时间,该指令将被忽略。默认情况下,内容没有过期日期。
如果您不指定此指令,则该页面可能会无限期地出现在搜索结果中。
Googlebot 会在指定日期和时间后显着减慢 URL 的抓取速度。
例子:
注意:nosnippet 表示:不要在此页面的搜索结果中显示片段。
组合索引指令和内容显示指令
您可以组合以逗号分隔的多个机器人元标记指令,以创建具有多个指令的单个命令。下面是一个机器人元标记示例,它指示网络爬虫不要索引页面或爬取页面上的任何链接:
以下示例将文本摘要长度限制为 20 个字符并允许大图像预览:
如果您为每个工具指定多个具有不同指令的爬虫,搜索引擎将合并所有否定指令。例如:
Googlebot 会抓取收录这些元标记的页面,就好像它们没有 noindex、nofollow 指令一样。
指定不应使用 HTML 页面的哪些部分来生成片段
这可以在 HTML 元素级别使用 span、div 和 section 元素的 data-nosnippetHTML 属性来实现。data-nosnippet 被视为布尔属性。与所有布尔属性一样,任何指定的值都将被忽略。
<p>This text can be shown in a snippet
and this part would not be shown.
not in snippet
also not in snippet
also not in snippet
some text
some text
</p>
Google 通常会渲染网页以对其编制索引,但不能保证它会渲染。因此,可以在渲染之前和之后提取 data-nosnippet。为避免渲染不确定性,请勿通过 JavaScript 添加或删除现有节点的 data-nosnippet 属性。通过 JavaScript 添加 DOM 元素时,在最初将元素添加到网页的 DOM 时,根据需要收录 data-nosnippet 属性。如果使用自定义元素并且您需要使用 data-nosnippet,请通过 div、span 或 section 元素包装或呈现它们。
vb抓取网页内容(请问加上“onclick=”的脚本在哪里?分享到:更多…)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-17 03:03
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享到:更多...
4. Python3使用requests包抓取并保存网页源代码。
简介:本文文章主要介绍Python3使用requests包抓取和保存网页源代码的方法,并举例分析Python3环境下requests模块的相关技巧。有需要的朋友可以参考以下
5.在网页源码中看到一句话看不懂,求大神解答
简介:在网页的源码中看到一句话,看不懂,求大神解答{code...} 这个文件完整内容如下:求大神解答上面这句话是什么意思? ? ?
6. php通过网页地址获取地址下的内容 php获取网页内容 php获取网页源代码 php打开网络
介绍:网页地址,php:php通过网页地址获取地址下的内容:方法一(PHP5及以后):$readcontents = fopen("", "rb"); $contents = stream_get_contents($readcontents) ; fclose($readcontents); 回声$内容;方法二:echo file_get_contents(“h
7. 以网页源代码为例,如何判断网页是手机用_html/css_WEB-ITnose
简介:以网页源码为例,如何判断网页是否为移动端
8. PHP如何获取指定网页的源代码?
简介:PHP如何获取指定网页的源代码?
9. 定期获取网页源代码的关键字和描述,彩蛋有点蛋疼
简介:定期获取网页源代码的关键字和描述,蛋有点蛋疼
10.获取网页源代码problem_html/css_WEB-ITnose
简介:获取网页源代码的问题
11.简单理解网页源码(HTML源码)_html/css_WEB-ITnose
简介:网页源码的简单理解(HTML源码)
12. 求去除div标签的解决方案
简介:PHP去除div标签,爬取网页源码后,去除所有DIV标签,正则表达式怎么写?例如
13.为什么新学的静态函数返回空数据?
简介:为什么新学的静态函数返回空数据?最近我正在学习静态函数并构建这样的代码。CURL 获取网页的源代码,定期获取标题等。为什么我的代码什么都没有返回?哪里有问题?你能详细解释一下吗?谢谢。$网址&nbs
14.正则采集相关问题,解决
简介:常规采集问题、解答、在线等目标页面:查看其网页源代码,想要获取第425行的数据,即“今天是2013年10月16日星期三,农历十二”和第621行“沉阳天气预报(发布于2013-10-1618:00)”
15. PHP命令行运行时,没有列出语法异常信息
简介: PHP命令行运行时,没有列出语法错误信息。当我在命令行运行PHP文件时,没有语法错误,也没有提示。什么都没有输出。在没有错误的情况下,可以正确输出运行结果(网页源代码)。我在editplus中配置调试功能时,没有出现语法错误,也没有显示错误信息,只是输出“输出完成(时间0秒)-正常终止”,在没有错误的情况下可以正确输出。是吗
16. 这个地方如何运作
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享至:更多
17.关于php采集网页数据获取js动态数据相关问题
简介:关于从php采集网页数据获取js动态数据的问题,给个网页地址,我想得到这个视频的下载地址,来自虎鱼网,然后没有下载地址在网页源代码中,这是关于视频播放的。段的代码然后就可以在控制台看到视频加载后的地址,也就是&
18.定期获取网页源码的关键字和描述,彩蛋有点蛋疼
简介:定期获取网页源代码的关键字和描述,蛋蛋有点蛋疼。情况一:
19. 这个地方是如何运作的
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享至:更多
20. PHP命令行运行时,没有列出语法异常信息
简介: PHP命令行运行时,没有列出语法错误信息。当我在命令行运行PHP文件时,没有语法错误,也没有提示。什么都没有输出。在没有错误的情况下,可以正确输出运行结果(网页源代码)。我在editplus中配置调试功能时,没有出现语法错误,也没有显示错误信息,只是输出“输出完成(时间0秒)-正常终止”,在没有错误的情况下可以正确输出。是吗
21.正则采集相关问题,解决
简介:常规采集问题、解答、在线等目标页面:查看其网页源代码,想要获取第425行的数据,即“今天是2013年10月16日星期三,农历十二”和第621行“沉阳天气预报(发布于2013-10-1618:00)”和
22.为什么新学的静态函数返回空数据?
简介:为什么新学的静态函数返回空数据?最近我正在学习静态函数并构建这样的代码。CURL 获取网页的源代码,定期获取标题等。为什么我的代码什么都没有返回?哪里有问题?你能详细解释一下吗?谢谢。$网址=
23. 求去除div标签的解决方案
简介:PHP去除div标签,爬取网页源码后,去除所有DIV标签,正则表达式怎么写?例如
24. 批量移除PHP文件中bom的PHP代码_php实例
简介:我在搜索查看网页源代码的时候发现了为什么开头有一个空行的问题,并批量删除了php文件中bom的php代码
25.thinkphp网页源码dock中空行的解决方法
简介:无意中查看了博客和博客页面的源码,发现源码顶部有7行,如图:怎么回事?我检查了模板,发现顶部没有空行。于是打开控制器,发现问题,如图:代码有空行!去掉“”前后的空行,然后查看网页的源代码。有几个空行,但仍然有两三个空行。打开项目模型类,再次删除“”前后的空行。再次打开网页源代码,发现顶部的空行完全消除了!
【相关问答推荐】:
如何在python中获取网页元素之前的所有源代码?
如何判断 URLConnection 超时并自动重连?
android webview在线网页如何加载本地字体库?
WordPress微信分享不显示描述和图标
selenium + PhantomJS 得到的网页数据为什么和chrome调试查看的源码不一样?
以上就是详细说一下网页源代码的现状、前景和机会。更多信息请关注代码高代马文章的其他相关话题! 查看全部
vb抓取网页内容(请问加上“onclick=”的脚本在哪里?分享到:更多…)
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享到:更多...
4. Python3使用requests包抓取并保存网页源代码。
简介:本文文章主要介绍Python3使用requests包抓取和保存网页源代码的方法,并举例分析Python3环境下requests模块的相关技巧。有需要的朋友可以参考以下
5.在网页源码中看到一句话看不懂,求大神解答
简介:在网页的源码中看到一句话,看不懂,求大神解答{code...} 这个文件完整内容如下:求大神解答上面这句话是什么意思? ? ?
6. php通过网页地址获取地址下的内容 php获取网页内容 php获取网页源代码 php打开网络
介绍:网页地址,php:php通过网页地址获取地址下的内容:方法一(PHP5及以后):$readcontents = fopen("", "rb"); $contents = stream_get_contents($readcontents) ; fclose($readcontents); 回声$内容;方法二:echo file_get_contents(“h
7. 以网页源代码为例,如何判断网页是手机用_html/css_WEB-ITnose
简介:以网页源码为例,如何判断网页是否为移动端
8. PHP如何获取指定网页的源代码?
简介:PHP如何获取指定网页的源代码?
9. 定期获取网页源代码的关键字和描述,彩蛋有点蛋疼
简介:定期获取网页源代码的关键字和描述,蛋有点蛋疼
10.获取网页源代码problem_html/css_WEB-ITnose
简介:获取网页源代码的问题
11.简单理解网页源码(HTML源码)_html/css_WEB-ITnose
简介:网页源码的简单理解(HTML源码)
12. 求去除div标签的解决方案
简介:PHP去除div标签,爬取网页源码后,去除所有DIV标签,正则表达式怎么写?例如
13.为什么新学的静态函数返回空数据?
简介:为什么新学的静态函数返回空数据?最近我正在学习静态函数并构建这样的代码。CURL 获取网页的源代码,定期获取标题等。为什么我的代码什么都没有返回?哪里有问题?你能详细解释一下吗?谢谢。$网址&nbs
14.正则采集相关问题,解决
简介:常规采集问题、解答、在线等目标页面:查看其网页源代码,想要获取第425行的数据,即“今天是2013年10月16日星期三,农历十二”和第621行“沉阳天气预报(发布于2013-10-1618:00)”
15. PHP命令行运行时,没有列出语法异常信息
简介: PHP命令行运行时,没有列出语法错误信息。当我在命令行运行PHP文件时,没有语法错误,也没有提示。什么都没有输出。在没有错误的情况下,可以正确输出运行结果(网页源代码)。我在editplus中配置调试功能时,没有出现语法错误,也没有显示错误信息,只是输出“输出完成(时间0秒)-正常终止”,在没有错误的情况下可以正确输出。是吗
16. 这个地方如何运作
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享至:更多
17.关于php采集网页数据获取js动态数据相关问题
简介:关于从php采集网页数据获取js动态数据的问题,给个网页地址,我想得到这个视频的下载地址,来自虎鱼网,然后没有下载地址在网页源代码中,这是关于视频播放的。段的代码然后就可以在控制台看到视频加载后的地址,也就是&
18.定期获取网页源码的关键字和描述,彩蛋有点蛋疼
简介:定期获取网页源代码的关键字和描述,蛋蛋有点蛋疼。情况一:
19. 这个地方是如何运作的
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享至:更多
20. PHP命令行运行时,没有列出语法异常信息
简介: PHP命令行运行时,没有列出语法错误信息。当我在命令行运行PHP文件时,没有语法错误,也没有提示。什么都没有输出。在没有错误的情况下,可以正确输出运行结果(网页源代码)。我在editplus中配置调试功能时,没有出现语法错误,也没有显示错误信息,只是输出“输出完成(时间0秒)-正常终止”,在没有错误的情况下可以正确输出。是吗
21.正则采集相关问题,解决
简介:常规采集问题、解答、在线等目标页面:查看其网页源代码,想要获取第425行的数据,即“今天是2013年10月16日星期三,农历十二”和第621行“沉阳天气预报(发布于2013-10-1618:00)”和
22.为什么新学的静态函数返回空数据?
简介:为什么新学的静态函数返回空数据?最近我正在学习静态函数并构建这样的代码。CURL 获取网页的源代码,定期获取标题等。为什么我的代码什么都没有返回?哪里有问题?你能详细解释一下吗?谢谢。$网址=
23. 求去除div标签的解决方案
简介:PHP去除div标签,爬取网页源码后,去除所有DIV标签,正则表达式怎么写?例如
24. 批量移除PHP文件中bom的PHP代码_php实例
简介:我在搜索查看网页源代码的时候发现了为什么开头有一个空行的问题,并批量删除了php文件中bom的php代码
25.thinkphp网页源码dock中空行的解决方法
简介:无意中查看了博客和博客页面的源码,发现源码顶部有7行,如图:怎么回事?我检查了模板,发现顶部没有空行。于是打开控制器,发现问题,如图:代码有空行!去掉“”前后的空行,然后查看网页的源代码。有几个空行,但仍然有两三个空行。打开项目模型类,再次删除“”前后的空行。再次打开网页源代码,发现顶部的空行完全消除了!
【相关问答推荐】:
如何在python中获取网页元素之前的所有源代码?
如何判断 URLConnection 超时并自动重连?
android webview在线网页如何加载本地字体库?
WordPress微信分享不显示描述和图标
selenium + PhantomJS 得到的网页数据为什么和chrome调试查看的源码不一样?
以上就是详细说一下网页源代码的现状、前景和机会。更多信息请关注代码高代马文章的其他相关话题!
vb抓取网页内容(vb抓取网页内容抓取的格式差异有哪些??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-16 03:02
vb抓取网页内容vb只是一种语言,而python也是有第三方类库提供类似功能,除此之外python爬虫和vb比,vb比较简单,获取网页的内容更容易,从来都是设计得比较文明。针对不同的网站,根据类库的扩展形式不同,或许获取的格式也有所差异。iifesvb是基于web的函数式编程语言,由于其优美的风格,github上一个非常流行的开源库:iifes可以自动的对网页中的语句进行重写,输出的结果基于vb的text函数进行排版,但这个东西设计成这样只适合放在单页面内部,不会影响到用户的浏览,也不会影响到flash。
同时,它既可以当成ruby以及python的类库,也可以扩展到node.js等其他语言上。pygal可以生成javascript代码并返回,然后你可以用js和javascript进行交互。pygal有着simplexpath函数(单元格和文本中)、concatenate函数以及pageranswers等一系列快速的函数。
vlookupiifesvb中每个html文件中的url可以用iifesbyurl取值并匹配查询之后的url;而vlookup则是可以获取多个查询,只要查询不超过一个url就行。iifesbyurl是双向的,如果你要先取url的第一个字符,再取一个url的全部字符(注意字符串的索引是index+1);如果要先取查询第一个字符,再获取剩下的两个字符,这个是单向的。
如果不要求双向,并且只允许匹配两个字符,那么你也可以试试bloom_documents。substitute对于相同的数据,比如两个list的name字段,如果可以substitute一个,那么它们可以进行匹配:substitute(url,oldurl);但是比如你第一个不可以,对于url存在相同元素的情况,substitute(url,newurl)都可以进行匹配。
apply在vb中你只需要写apply()方法即可,返回的结果是你传递进来的参数,对方如果需要,则会从newurl获取(并且返回oldurl的值)。但是python就不好直接使用dict的apply函数了,dict是把所有元素的组合和列表进行混合的实现。需要额外定义几个方法:p1=list(dict('x','f','x','y','x','y'))p2=list(dict(x,y))apply(x,y)下面这个截图是随便复制粘贴的,python不用你自己写代码的话,当然apply()方法可以省略了,直接在后面加个python的函数名就行。
isclick显示并点击的文本,从vb来看,相当于vbscript里面的isclick,是否是这样比vb更简单,并且更灵活呢?当然,也可以用其他方法来实现,比如document.write方法就可以,不过比较过于简单。ifnothttp.isapproximately(metho。 查看全部
vb抓取网页内容(vb抓取网页内容抓取的格式差异有哪些??)
vb抓取网页内容vb只是一种语言,而python也是有第三方类库提供类似功能,除此之外python爬虫和vb比,vb比较简单,获取网页的内容更容易,从来都是设计得比较文明。针对不同的网站,根据类库的扩展形式不同,或许获取的格式也有所差异。iifesvb是基于web的函数式编程语言,由于其优美的风格,github上一个非常流行的开源库:iifes可以自动的对网页中的语句进行重写,输出的结果基于vb的text函数进行排版,但这个东西设计成这样只适合放在单页面内部,不会影响到用户的浏览,也不会影响到flash。
同时,它既可以当成ruby以及python的类库,也可以扩展到node.js等其他语言上。pygal可以生成javascript代码并返回,然后你可以用js和javascript进行交互。pygal有着simplexpath函数(单元格和文本中)、concatenate函数以及pageranswers等一系列快速的函数。
vlookupiifesvb中每个html文件中的url可以用iifesbyurl取值并匹配查询之后的url;而vlookup则是可以获取多个查询,只要查询不超过一个url就行。iifesbyurl是双向的,如果你要先取url的第一个字符,再取一个url的全部字符(注意字符串的索引是index+1);如果要先取查询第一个字符,再获取剩下的两个字符,这个是单向的。
如果不要求双向,并且只允许匹配两个字符,那么你也可以试试bloom_documents。substitute对于相同的数据,比如两个list的name字段,如果可以substitute一个,那么它们可以进行匹配:substitute(url,oldurl);但是比如你第一个不可以,对于url存在相同元素的情况,substitute(url,newurl)都可以进行匹配。
apply在vb中你只需要写apply()方法即可,返回的结果是你传递进来的参数,对方如果需要,则会从newurl获取(并且返回oldurl的值)。但是python就不好直接使用dict的apply函数了,dict是把所有元素的组合和列表进行混合的实现。需要额外定义几个方法:p1=list(dict('x','f','x','y','x','y'))p2=list(dict(x,y))apply(x,y)下面这个截图是随便复制粘贴的,python不用你自己写代码的话,当然apply()方法可以省略了,直接在后面加个python的函数名就行。
isclick显示并点击的文本,从vb来看,相当于vbscript里面的isclick,是否是这样比vb更简单,并且更灵活呢?当然,也可以用其他方法来实现,比如document.write方法就可以,不过比较过于简单。ifnothttp.isapproximately(metho。
vb抓取网页内容(网上无法下载的“小说在线阅读”内容?有种 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-11 08:12
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多yii,想找点东西调整一下……= =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网......再次声明,我们不对任何版权负责......
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
要替换为换行符,是网页中的占位符,即空格,替换为空格即可。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
# -*- coding: utf-8 -*- import urllib2 import re import chardet class Book_Spider: def __init__(self): self.pages = [] # 抓取一个章节 def GetPage(self): myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } request = urllib2.Request(myUrl, headers = headers) myResponse = urllib2.urlopen(request) myPage = myResponse.read() #先检测网页的字符编码,最后统一转为 utf-8 charset = chardet.detect(myPage) charset = charset['encoding'] if charset == 'utf-8' or charset == 'UTF-8': myPage = myPage else: myPage = myPage.decode('gb2312','ignore').encode('utf-8') unicodePage = myPage.decode("utf-8") try: #抓取标题 my_title = re.search('(.*?)',unicodePage,re.S) my_title = my_title.group(1) except: print '标题 HTML 变化,请重新分析!' return False try: #抓取章节内容 my_content = re.search('(.*?) 查看全部
vb抓取网页内容(网上无法下载的“小说在线阅读”内容?有种
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多yii,想找点东西调整一下……= =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网......再次声明,我们不对任何版权负责......
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
要替换为换行符,是网页中的占位符,即空格,替换为空格即可。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
# -*- coding: utf-8 -*- import urllib2 import re import chardet class Book_Spider: def __init__(self): self.pages = [] # 抓取一个章节 def GetPage(self): myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } request = urllib2.Request(myUrl, headers = headers) myResponse = urllib2.urlopen(request) myPage = myResponse.read() #先检测网页的字符编码,最后统一转为 utf-8 charset = chardet.detect(myPage) charset = charset['encoding'] if charset == 'utf-8' or charset == 'UTF-8': myPage = myPage else: myPage = myPage.decode('gb2312','ignore').encode('utf-8') unicodePage = myPage.decode("utf-8") try: #抓取标题 my_title = re.search('(.*?)',unicodePage,re.S) my_title = my_title.group(1) except: print '标题 HTML 变化,请重新分析!' return False try: #抓取章节内容 my_content = re.search('(.*?)
vb抓取网页内容(自动跳转如何获取完你要的代码(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-10 18:06
我用vb一个一个的下载页面。如何获得我需要的内容?我需要拦截功能。提到内容后,如何自动跳转到下一页。请教高手,我用的是webbrowser控件,你的问题有点大,直接在DOCUMENTCOMPLETE事件中写webbrowser获取HTML1.document.body.outhtml
这就是所有的HTML代码,然后分析你想要什么。你可以通过分析字符串来截取你想要的内容
你也可以根据HTML代码的属性获取你想要的内容。
自动跳跃更容易。得到你想要的代码后,webbrowser1.再次导航url。
'提取每个文本分区标签(div)中的源代码
VB代码:
私有子Form_Load()
WebBrowser1.导航“”
结束子
Private Sub WebBrowser1_DocumentComplete(ByVal pDisp As Object, URL As Variant)
j = WebBrowser1.Document.getElementsByTagName("div").Length - 1
将 aa 调暗为对象
对于 i = 0 到 j
设置 aa = WebBrowser1.Document.getElementsByTagName("div")(i)
s = s & aa.innerHTML & vbCrLf & "---------------------------th" & i & " div 来源--------------------------------" & vbCrLf的代码
下一个
静态 k 作为整数
k = k + 1
如果 s "" 那么
s1 = App.Path & "\" & k & ".txt"
打开 s1 输出为 #1
打印 #1,s
关闭#1
Shell "notepad.exe" & s1, vbNormalFocus
如果结束
结束子 查看全部
vb抓取网页内容(自动跳转如何获取完你要的代码(图))
我用vb一个一个的下载页面。如何获得我需要的内容?我需要拦截功能。提到内容后,如何自动跳转到下一页。请教高手,我用的是webbrowser控件,你的问题有点大,直接在DOCUMENTCOMPLETE事件中写webbrowser获取HTML1.document.body.outhtml
这就是所有的HTML代码,然后分析你想要什么。你可以通过分析字符串来截取你想要的内容
你也可以根据HTML代码的属性获取你想要的内容。
自动跳跃更容易。得到你想要的代码后,webbrowser1.再次导航url。
'提取每个文本分区标签(div)中的源代码
VB代码:
私有子Form_Load()
WebBrowser1.导航“”
结束子
Private Sub WebBrowser1_DocumentComplete(ByVal pDisp As Object, URL As Variant)
j = WebBrowser1.Document.getElementsByTagName("div").Length - 1
将 aa 调暗为对象
对于 i = 0 到 j
设置 aa = WebBrowser1.Document.getElementsByTagName("div")(i)
s = s & aa.innerHTML & vbCrLf & "---------------------------th" & i & " div 来源--------------------------------" & vbCrLf的代码
下一个
静态 k 作为整数
k = k + 1
如果 s "" 那么
s1 = App.Path & "\" & k & ".txt"
打开 s1 输出为 #1
打印 #1,s
关闭#1
Shell "notepad.exe" & s1, vbNormalFocus
如果结束
结束子
vb抓取网页内容(soup,文中通过示例代码介绍的详细内容介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-10 17:18
本篇文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
本篇文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
简单爬取网页信息的思路一般是
1、查看网页源代码
2、爬取网页信息
3、解析网页内容
4、保存到文件
现在使用BeautifulSoup解析库爬取刺猬实习Python职位的工资
一、查看网页源代码
这部分是我们需要的,对应的源码为:
分析源码,我们可以知道:
1、职位信息在
2、每条消息都在
3、每条信息,我们需要提取公司名称、职位、工资
二、爬取网页信息
使用request.get()抓取,返回的soup是网页的文本信息
def get_one_page(url): response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser") return soup
三、解析网页内容
1、找到起始位置
2、匹配的信息
3、返回要存储的信息列表
def parse_page(soup): #待存储的信息列表 return_list = [] #起始位置 grid = soup.find('section', attrs={"class": "widget-job-list"}) if grid: #找到所有的岗位列表 job_list = soup.find_all('article', attrs={"class": "widget item"}) #匹配各项内容 for job in job_list: #find()是寻找第一个符合的标签 company = job.find('a', attrs={"class": "crop"}).get_text().strip()#返回类型为string,用strip()可以去除空白符,换行符 title = job.find('code').get_text() salary = job.find('span', attrs={"class": "color-3"}).get_text() #将信息存到列表中并返回 return_list.append(company + " " + title + " " + salary) return return_list
四、保存到文件
将列表信息存储到 shixi.csv 文件中
def write_to_file(content): #以追加的方式打开,设置编码格式防止乱码 with open("shixi.csv", "a", encoding="gb18030")as f: f.write("\n".join(content))
五、爬取多页信息
在网页url中可以看到最后一页代表页码信息
所以在main方法中传入一个页面,然后循环运行main(page)爬取多页信息
def main(page): url = 'https://www.ciweishixi.com/search?key=python&page=' + str(page) soup = get_one_page(url) return_list = parse_page(soup) write_to_file(return_list) if __name__ == "__main__": for i in range(4): main(i)
六、运行结果
七、完整代码
import requests import re from bs4 import BeautifulSoup def get_one_page(url): response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser") return soup def parse_page(soup): #待存储的信息列表 return_list = [] #起始位置 grid = soup.find('section', attrs={"class": "widget-job-list"}) if grid: #找到所有的岗位列表 job_list = soup.find_all('article', attrs={"class": "widget item"}) #匹配各项内容 for job in job_list: #find()是寻找第一个符合的标签 company = job.find('a', attrs={"class": "crop"}).get_text().strip()#返回类型为string,用strip()可以去除空白符,换行符 title = job.find('code').get_text() salary = job.find('span', attrs={"class": "color-3"}).get_text() #将信息存到列表中并返回 return_list.append(company + " " + title + " " + salary) return return_list def write_to_file(content): #以追加的方式打开,设置编码格式防止乱码 with open("shixi.csv", "a", encoding="gb18030")as f: f.write("\n".join(content)) def main(page): url = 'https://www.ciweishixi.com/search?key=python&page=' + str(page) soup = get_one_page(url) return_list = parse_page(soup) write_to_file(return_list) if __name__ == "__main__": for i in range(4): main(i)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网站。
以上就是Python如何使用BeautifulSoup抓取网页信息的详细内容。更多内容请关注html中文网文章其他相关话题! 查看全部
vb抓取网页内容(soup,文中通过示例代码介绍的详细内容介绍-乐题库)
本篇文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
本篇文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
简单爬取网页信息的思路一般是
1、查看网页源代码
2、爬取网页信息
3、解析网页内容
4、保存到文件
现在使用BeautifulSoup解析库爬取刺猬实习Python职位的工资
一、查看网页源代码

这部分是我们需要的,对应的源码为:

分析源码,我们可以知道:
1、职位信息在
2、每条消息都在
3、每条信息,我们需要提取公司名称、职位、工资
二、爬取网页信息
使用request.get()抓取,返回的soup是网页的文本信息
def get_one_page(url): response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser") return soup
三、解析网页内容
1、找到起始位置
2、匹配的信息
3、返回要存储的信息列表
def parse_page(soup): #待存储的信息列表 return_list = [] #起始位置 grid = soup.find('section', attrs={"class": "widget-job-list"}) if grid: #找到所有的岗位列表 job_list = soup.find_all('article', attrs={"class": "widget item"}) #匹配各项内容 for job in job_list: #find()是寻找第一个符合的标签 company = job.find('a', attrs={"class": "crop"}).get_text().strip()#返回类型为string,用strip()可以去除空白符,换行符 title = job.find('code').get_text() salary = job.find('span', attrs={"class": "color-3"}).get_text() #将信息存到列表中并返回 return_list.append(company + " " + title + " " + salary) return return_list
四、保存到文件
将列表信息存储到 shixi.csv 文件中
def write_to_file(content): #以追加的方式打开,设置编码格式防止乱码 with open("shixi.csv", "a", encoding="gb18030")as f: f.write("\n".join(content))
五、爬取多页信息
在网页url中可以看到最后一页代表页码信息
所以在main方法中传入一个页面,然后循环运行main(page)爬取多页信息
def main(page): url = 'https://www.ciweishixi.com/search?key=python&page=' + str(page) soup = get_one_page(url) return_list = parse_page(soup) write_to_file(return_list) if __name__ == "__main__": for i in range(4): main(i)
六、运行结果

七、完整代码
import requests import re from bs4 import BeautifulSoup def get_one_page(url): response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser") return soup def parse_page(soup): #待存储的信息列表 return_list = [] #起始位置 grid = soup.find('section', attrs={"class": "widget-job-list"}) if grid: #找到所有的岗位列表 job_list = soup.find_all('article', attrs={"class": "widget item"}) #匹配各项内容 for job in job_list: #find()是寻找第一个符合的标签 company = job.find('a', attrs={"class": "crop"}).get_text().strip()#返回类型为string,用strip()可以去除空白符,换行符 title = job.find('code').get_text() salary = job.find('span', attrs={"class": "color-3"}).get_text() #将信息存到列表中并返回 return_list.append(company + " " + title + " " + salary) return return_list def write_to_file(content): #以追加的方式打开,设置编码格式防止乱码 with open("shixi.csv", "a", encoding="gb18030")as f: f.write("\n".join(content)) def main(page): url = 'https://www.ciweishixi.com/search?key=python&page=' + str(page) soup = get_one_page(url) return_list = parse_page(soup) write_to_file(return_list) if __name__ == "__main__": for i in range(4): main(i)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网站。
以上就是Python如何使用BeautifulSoup抓取网页信息的详细内容。更多内容请关注html中文网文章其他相关话题!
vb抓取网页内容(xml能做些什么?代表一种xml数据格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-08 17:03
vb抓取网页内容,一般都用xml类型抓取。xml代表一种xml-root。xml代表一种xml数据格式。对于将来的产品或服务需要传输数据时,我一般都使用xml。特别是对于在移动端使用的人,xml数据会显得更加方便。接下来,我们就一起看看xml能做些什么?在说xml能做什么之前,首先要说说一个基本概念:基本的文本格式。
我们看看ide或ide的快捷键,i:基本排版格式i:基本语句格式t:基本表格格式t:基本声明格式w:基本程序格式i:符号表格格式..当然,它们在实际应用中会发生多种多样的作用,我会在后面一一阐述。现在来看xml可以做些什么,以c51程序的xml实例为例。首先,我们要为网页自定义语法。xmlxml代表一种xml数据格式。也就是说,在web编程中,xml就是一种自定义语法。下面我们通过一个xml实例,为你感受一下。
1、创建xml文件使用windows和linux创建一个xml文件,一般有三种方式。windows的xml建立非常简单,只需要在cmd命令行中运行xml.exe,打开的便是xml文件。而linux系统使用的命令是xml.local。这个local目录下面有6个文件,而我们要使用的xml.exe便在这个local目录下。
由于linux系统对中文支持不好,因此我们还需要手动处理中文字符。由于linux系统支持中文,因此我们还需要手动处理中文字符。通过查看文件名,我们能够得知xml.exe所在的目录,我们可以在home目录下创建一个xml.woff文件。
2、在windows和linux上定义xml文件我们以windows上的定义xml文件为例,而且xml文件必须在指定的文件夹下。在windows上,xml文件可以使用以下几种文件名的组合形式。windowsxml文件的名称以.exe结尾。在linux系统上,xml文件的名称就是网页名称。我们看一下exe的代码。
如下图所示:windowsxml文件实例,图片显示方法windowsxml文件实例,代码实现、页面显示完成windowsxml文件实例,页面显示完成与此相同,在linux系统上也是这样操作。因此,我们可以通过上面我们定义的一个xml文件定义,在linux系统上去更改它。下面代码为windowsxml文件实例,里面的代码非常有必要。
3、在linux上定义xml文件接下来,为你介绍linux系统上使用xml.local来定义xml文件。我们可以直接运行gccgen.xml命令生成一个xml文件。如下图所示。gccgen.xml1.exexml文件里面有以下3种text数据:elementnode以及content,前者对应页面节点,后者对应页面文本。代码实现通过gccgen.xml1.exe。 查看全部
vb抓取网页内容(xml能做些什么?代表一种xml数据格式)
vb抓取网页内容,一般都用xml类型抓取。xml代表一种xml-root。xml代表一种xml数据格式。对于将来的产品或服务需要传输数据时,我一般都使用xml。特别是对于在移动端使用的人,xml数据会显得更加方便。接下来,我们就一起看看xml能做些什么?在说xml能做什么之前,首先要说说一个基本概念:基本的文本格式。
我们看看ide或ide的快捷键,i:基本排版格式i:基本语句格式t:基本表格格式t:基本声明格式w:基本程序格式i:符号表格格式..当然,它们在实际应用中会发生多种多样的作用,我会在后面一一阐述。现在来看xml可以做些什么,以c51程序的xml实例为例。首先,我们要为网页自定义语法。xmlxml代表一种xml数据格式。也就是说,在web编程中,xml就是一种自定义语法。下面我们通过一个xml实例,为你感受一下。
1、创建xml文件使用windows和linux创建一个xml文件,一般有三种方式。windows的xml建立非常简单,只需要在cmd命令行中运行xml.exe,打开的便是xml文件。而linux系统使用的命令是xml.local。这个local目录下面有6个文件,而我们要使用的xml.exe便在这个local目录下。
由于linux系统对中文支持不好,因此我们还需要手动处理中文字符。由于linux系统支持中文,因此我们还需要手动处理中文字符。通过查看文件名,我们能够得知xml.exe所在的目录,我们可以在home目录下创建一个xml.woff文件。
2、在windows和linux上定义xml文件我们以windows上的定义xml文件为例,而且xml文件必须在指定的文件夹下。在windows上,xml文件可以使用以下几种文件名的组合形式。windowsxml文件的名称以.exe结尾。在linux系统上,xml文件的名称就是网页名称。我们看一下exe的代码。
如下图所示:windowsxml文件实例,图片显示方法windowsxml文件实例,代码实现、页面显示完成windowsxml文件实例,页面显示完成与此相同,在linux系统上也是这样操作。因此,我们可以通过上面我们定义的一个xml文件定义,在linux系统上去更改它。下面代码为windowsxml文件实例,里面的代码非常有必要。
3、在linux上定义xml文件接下来,为你介绍linux系统上使用xml.local来定义xml文件。我们可以直接运行gccgen.xml命令生成一个xml文件。如下图所示。gccgen.xml1.exexml文件里面有以下3种text数据:elementnode以及content,前者对应页面节点,后者对应页面文本。代码实现通过gccgen.xml1.exe。
vb抓取网页内容(我是想一直让他循环找元素,还要找不同网页的元素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-05 07:00
我想让他循环搜索元素,以及来自不同网页的元素。如果我每次进入网页时都点击该按钮,它将是半自动的。我只是点击了按钮并一直在寻找它。从那些网页中获取元素,这样我就不用整天看电脑了
建议:
1)您应该创建一个列表并以固定格式修复它。例如:
网站地址+1个空格+要查找的元素
2)使用文本文件将其保存在与exe相同的目录中。
3)Form_Load 期间,请动态使用 System.IO.ReadAllLines 读出所有的行,并将它们存储在表单类(String[])类型的公共变量中。同时声明一个WebBrowser类的实体,使用Do...While循环来做(示例代码如下,请根据实际情况更正):
Public Class gb2
Dim wb As New WebBrowser
Dim strings() As String = Nothing
'下标
Dim index As Integer = 0
Private Sub Form1_Load(sender As System.Object, e As System.EventArgs) Handles MyBase.Load
'加载全部内容
strings = System.IO.File.ReadAllLines("C:\\try.txt")
'声明一个新的WebBrowser实体类
AddHandler wb.DocumentCompleted, AddressOf SelfCompleted
Do
wb.Navigate(strings(index).Split(" ")(0)) '取出空格前面部分,也就是url地址
While (wb.ReadyState WebBrowserReadyState.Complete)
Thread.Sleep(10)
End While
If (index>strings.Length)
index = 0
End If
Loop
End Sub
Private Sub SelfCompleted(sender As Object, e As WebBrowserDocumentCompletedEventArgs)
wb.Document.Window.Frames(0).Document.GetElementsByTagName(strings(index).Split(" ")(0)) '处理你找到的东西
End Sub
End Class
QQ我:
下载 MSDN 桌面工具 (Vista,Win7)
我的博客园
慈善点击,点击这里 查看全部
vb抓取网页内容(我是想一直让他循环找元素,还要找不同网页的元素)
我想让他循环搜索元素,以及来自不同网页的元素。如果我每次进入网页时都点击该按钮,它将是半自动的。我只是点击了按钮并一直在寻找它。从那些网页中获取元素,这样我就不用整天看电脑了
建议:
1)您应该创建一个列表并以固定格式修复它。例如:
网站地址+1个空格+要查找的元素
2)使用文本文件将其保存在与exe相同的目录中。
3)Form_Load 期间,请动态使用 System.IO.ReadAllLines 读出所有的行,并将它们存储在表单类(String[])类型的公共变量中。同时声明一个WebBrowser类的实体,使用Do...While循环来做(示例代码如下,请根据实际情况更正):
Public Class gb2
Dim wb As New WebBrowser
Dim strings() As String = Nothing
'下标
Dim index As Integer = 0
Private Sub Form1_Load(sender As System.Object, e As System.EventArgs) Handles MyBase.Load
'加载全部内容
strings = System.IO.File.ReadAllLines("C:\\try.txt")
'声明一个新的WebBrowser实体类
AddHandler wb.DocumentCompleted, AddressOf SelfCompleted
Do
wb.Navigate(strings(index).Split(" ")(0)) '取出空格前面部分,也就是url地址
While (wb.ReadyState WebBrowserReadyState.Complete)
Thread.Sleep(10)
End While
If (index>strings.Length)
index = 0
End If
Loop
End Sub
Private Sub SelfCompleted(sender As Object, e As WebBrowserDocumentCompletedEventArgs)
wb.Document.Window.Frames(0).Document.GetElementsByTagName(strings(index).Split(" ")(0)) '处理你找到的东西
End Sub
End Class
QQ我:
下载 MSDN 桌面工具 (Vista,Win7)
我的博客园
慈善点击,点击这里
vb抓取网页内容(网页上无法复制的文字多半是什么意思?两种方法可以取文字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-15 19:12
网页上不能复制的大部分文字都受到网络技术的限制。在这种情况下,常规的“鼠标选择+复制粘贴”无法完成文本复制,甚至“查看源代码”、F12开发者模式等方法也无法获取文本。但是下面两种方法可以得到想要的文字。
1、截图OCR
这种方法的原理很简单,就是通过截图的方式对网页上的可见文字进行截图,通过OCR算法立即识别出图片中的文字。以目前的OCR识别技术,文字识别还是相当准确的。这个方法的前提是下载一个好用的工具,我一直在用“Tino OCR”这个小软件。
,指示
首先,双击启动“Tano OCR”。软件启动后,会最小化到任务栏的右下角。然后,打开要复制的网页。最后双击“Tino OCR”图标,鼠标会变成十字进行截屏,您可以选择要截取的文字。选中框后,软件会自动识别里面的文字。这时候你只需要简单的复制粘贴即可。
, 的优点和缺点
优点:只要是可见的网页文字都可以进行截图OCR,没有任何技术可以限制,而且OCR的速度非常快。
缺点:必须运行该工具,会占用系统资源的一小部分,基本可以忽略。另外,如果需要VIP来展示内容,也不能绕过VIP。
2、使用搜索或翻译功能
这种方法特别适用于“一定程度图书馆”的文章。其原理是利用一定程度上提供的搜索或翻译功能来获取文章的文本。因为搜索和翻译本身需要获取文章的文本。
,指示
打开某个学位库的文章后,选择一段你想要的文字。这时候系统会自动弹出一个浮动框,里面有“搜索、复制、发送到手机、翻译”4个选项。当您单击搜索或翻译这两个菜单时,Web 浏览器会自动打开一个新选项卡并在搜索框或翻译框中显示文本。这时候就可以自由复制粘贴了。(注:菜单中的副本只有开通VIP后才能使用)
, 的优点和缺点
优点:无需购买VIP,即可自由复制库内容;
缺点:只适用于一定程度的图书馆。同时,如果预览查看部分被限制在一定程度上,也是无法实现的。
总结
目前,很多禁止复制的网站都采用了先进的限制技术。普通的查看源码和开发者模式已经应付不来了,但是截图OCR还是经得起时间考验的,只要能看,就能被OCR识别和复制。至于一定程度的图书馆,也可以复制,自带搜索翻译功能。 查看全部
vb抓取网页内容(网页上无法复制的文字多半是什么意思?两种方法可以取文字)
网页上不能复制的大部分文字都受到网络技术的限制。在这种情况下,常规的“鼠标选择+复制粘贴”无法完成文本复制,甚至“查看源代码”、F12开发者模式等方法也无法获取文本。但是下面两种方法可以得到想要的文字。
1、截图OCR
这种方法的原理很简单,就是通过截图的方式对网页上的可见文字进行截图,通过OCR算法立即识别出图片中的文字。以目前的OCR识别技术,文字识别还是相当准确的。这个方法的前提是下载一个好用的工具,我一直在用“Tino OCR”这个小软件。
,指示
首先,双击启动“Tano OCR”。软件启动后,会最小化到任务栏的右下角。然后,打开要复制的网页。最后双击“Tino OCR”图标,鼠标会变成十字进行截屏,您可以选择要截取的文字。选中框后,软件会自动识别里面的文字。这时候你只需要简单的复制粘贴即可。
, 的优点和缺点
优点:只要是可见的网页文字都可以进行截图OCR,没有任何技术可以限制,而且OCR的速度非常快。
缺点:必须运行该工具,会占用系统资源的一小部分,基本可以忽略。另外,如果需要VIP来展示内容,也不能绕过VIP。
2、使用搜索或翻译功能
这种方法特别适用于“一定程度图书馆”的文章。其原理是利用一定程度上提供的搜索或翻译功能来获取文章的文本。因为搜索和翻译本身需要获取文章的文本。
,指示
打开某个学位库的文章后,选择一段你想要的文字。这时候系统会自动弹出一个浮动框,里面有“搜索、复制、发送到手机、翻译”4个选项。当您单击搜索或翻译这两个菜单时,Web 浏览器会自动打开一个新选项卡并在搜索框或翻译框中显示文本。这时候就可以自由复制粘贴了。(注:菜单中的副本只有开通VIP后才能使用)
, 的优点和缺点
优点:无需购买VIP,即可自由复制库内容;
缺点:只适用于一定程度的图书馆。同时,如果预览查看部分被限制在一定程度上,也是无法实现的。
总结
目前,很多禁止复制的网站都采用了先进的限制技术。普通的查看源码和开发者模式已经应付不来了,但是截图OCR还是经得起时间考验的,只要能看,就能被OCR识别和复制。至于一定程度的图书馆,也可以复制,自带搜索翻译功能。
vb抓取网页内容(vb抓取网页内容,建议看python来写http服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-25 05:04
vb抓取网页内容,建议看python来写http服务器。flask有很多框架,简单的可以参照django,用loader。如果要抓页面内容比较详细,还是flask自带的login和session也有很多教程。
我给你一些资料,你可以看看。
python抓取百度内容
对于http协议了解,了解http协议里面各个文件是做什么用的。你就能抓取整个页面的内容,前提是得了解http协议,请求。能把请求发送出去。利用后端程序(爬虫)把返回的http字符串解析出来,然后返回给前端。接着如果想继续抓取更多内容,就能深入了解一下http的各个参数、http状态码、状态机、带状态的http请求头,然后再拿来验证一下http请求头是否为http安全协议的协议头。能知道什么时候用什么协议,什么时候用http安全协议。
分三步:
1、爬虫代码
2、信息分析代码
3、爬虫再交给人工去解析爬虫配置爬虫代码。如果发现某页面返回的内容都是乱码,查看白名单并且解析,或者人工去对白名单内的内容进行分析解析,最后回传后端查看解析后的页面。如果要抓包,前端自己可以看,也可以用工具,必须人工解析后端对爬虫抓包抓到的内容进行解析。
我从头学习的是python,之前我觉得比较难的是爬虫,其实程序员并不是每次都要爬一次,你觉得难,是因为还没有掌握一定的编程能力,每个人都有自己的学习方法,这只是个学习过程中的适应问题,从最基础的开始学起吧,不要一下就要求自己学到多么厉害的程度。 查看全部
vb抓取网页内容(vb抓取网页内容,建议看python来写http服务器)
vb抓取网页内容,建议看python来写http服务器。flask有很多框架,简单的可以参照django,用loader。如果要抓页面内容比较详细,还是flask自带的login和session也有很多教程。
我给你一些资料,你可以看看。
python抓取百度内容
对于http协议了解,了解http协议里面各个文件是做什么用的。你就能抓取整个页面的内容,前提是得了解http协议,请求。能把请求发送出去。利用后端程序(爬虫)把返回的http字符串解析出来,然后返回给前端。接着如果想继续抓取更多内容,就能深入了解一下http的各个参数、http状态码、状态机、带状态的http请求头,然后再拿来验证一下http请求头是否为http安全协议的协议头。能知道什么时候用什么协议,什么时候用http安全协议。
分三步:
1、爬虫代码
2、信息分析代码
3、爬虫再交给人工去解析爬虫配置爬虫代码。如果发现某页面返回的内容都是乱码,查看白名单并且解析,或者人工去对白名单内的内容进行分析解析,最后回传后端查看解析后的页面。如果要抓包,前端自己可以看,也可以用工具,必须人工解析后端对爬虫抓包抓到的内容进行解析。
我从头学习的是python,之前我觉得比较难的是爬虫,其实程序员并不是每次都要爬一次,你觉得难,是因为还没有掌握一定的编程能力,每个人都有自己的学习方法,这只是个学习过程中的适应问题,从最基础的开始学起吧,不要一下就要求自己学到多么厉害的程度。
vb抓取网页内容(如果你想提取网页上的文章内容,readability这个免费好用的工具绝对 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-23 05:06
)
如果你想从网页中提取 文章 内容,可读性是一个免费且易于使用的工具,绝对值得一试
官方网站:
提取内容的api文档:
注册,你可以在个人页面找到自己的token
API - 带有令牌和 url 参数的 GET 请求
响应示例---json格式返回数据
回复
看中文
一个随机的网易博客
内容部分是提取的网页内容,写入html文件,可以直接打开显示网页内容
如果您只想提取和保存内容,请转到此处。
如果需要获取网页的内容并做一些处理,可能需要将开头的内容转换成中文。一开始的编码是什么?,您可能需要执行以下操作
# 去掉content中的html标记
def remove_html_tag(content):
return re.sub(r']*>', '', content)
# 转换成中文
def convert_to_cn(text):
# 需要将 × 这种先做补全,×
text = re.sub(r'&#x([A-F0-9]{2});', r'�\1;', text)
return text.replace('&#x', '\u') \
.replace(';', '') \
.decode('unicode-escape') \
.encode('utf-8') 查看全部
vb抓取网页内容(如果你想提取网页上的文章内容,readability这个免费好用的工具绝对
)
如果你想从网页中提取 文章 内容,可读性是一个免费且易于使用的工具,绝对值得一试
官方网站:
提取内容的api文档:
注册,你可以在个人页面找到自己的token
API - 带有令牌和 url 参数的 GET 请求
响应示例---json格式返回数据
回复
看中文
一个随机的网易博客
内容部分是提取的网页内容,写入html文件,可以直接打开显示网页内容
如果您只想提取和保存内容,请转到此处。
如果需要获取网页的内容并做一些处理,可能需要将开头的内容转换成中文。一开始的编码是什么?,您可能需要执行以下操作
# 去掉content中的html标记
def remove_html_tag(content):
return re.sub(r']*>', '', content)
# 转换成中文
def convert_to_cn(text):
# 需要将 × 这种先做补全,×
text = re.sub(r'&#x([A-F0-9]{2});', r'�\1;', text)
return text.replace('&#x', '\u') \
.replace(';', '') \
.decode('unicode-escape') \
.encode('utf-8')
vb抓取网页内容(一个示例脚本,它将“脚本中心”的URL存储在一个名为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-20 00:12
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将脚本中心的 URL 存储在一个名为 strURL 的变量中。然后该脚本创建 WSH Shell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
strURL=""
设置 objShell = CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 可以做任何事情!)所以,让 IE 为我们做这些工作。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
设置 objIE = CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
objIE.退出
Wscript.Echo strURL
我们在这里所做的只是创建一个 Internet Explorer 实例并在一个空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后,我们使用clipboardData.GetData 方法获取放置在剪贴板上的文本,并将其存储在变量strURL 中;这就是以下代码行的作用:
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
设置 objIE = CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
objIE.退出
设置 objShell = CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优势——它不仅仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个 Web 站点专用的打开脚本。 查看全部
vb抓取网页内容(一个示例脚本,它将“脚本中心”的URL存储在一个名为)
嗨,CL。这是一个有趣的问题,或者我们应该说,两个非常有趣的问题。因为你实际上问了两个问题。第一个问题很简单:我可以使用脚本打开特定的网站吗?您可能已经知道答案,我可以大声回答您,是的!下面是一个示例脚本,它将脚本中心的 URL 存储在一个名为 strURL 的变量中。然后该脚本创建 WSH Shell 对象的实例并使用 Run 方法打开默认 Web 浏览器并导航到指定的 URL:
strURL=""
设置 objShell = CreateObject("Wscript.Shell")
objShell.Run(strURL)
第二个问题有点棘手:我可以使用脚本从剪贴板中获取信息吗?这个问题的答案也是“是”,尽管您必须通过后门进入剪贴板。
WSH 和 VBScript 都不能与剪贴板交互:它们都不允许您将数据复制到剪贴板或从剪贴板粘贴数据。另一方面,Internet Explorer 可以与剪贴板交互。(看,Internet Explorer 可以做任何事情!)所以,让 IE 为我们做这些工作。如果要从剪贴板中抓取数据,可以使用类似于以下的代码:
设置 objIE = CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
objIE.退出
Wscript.Echo strURL
我们在这里所做的只是创建一个 Internet Explorer 实例并在一个空白页面中打开它。请注意,您实际上看不到这个 IE 实例,因为我们没有将 Visible 属性设置为 TRUE。一切都发生在后台。
然后,我们使用clipboardData.GetData 方法获取放置在剪贴板上的文本,并将其存储在变量strURL 中;这就是以下代码行的作用:
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
我们关闭这个 IE 实例 (objIE.Quit) 并回显我们从剪贴板检索到的值。
试试这个:将一些文本复制到剪贴板,然后运行脚本。您应该会看到一个消息框,其中收录您刚刚复制到剪贴板的文本。
现在只剩下一件事要做:将脚本的两半组合成一个完整的脚本。以下脚本从剪贴板中获取 URL 并在默认 Web 浏览器中打开该网站:
设置 objIE = CreateObject("InternetExplorer.Application")
objIE.Navigate("关于:空白")
strURL = objIE.document.parentwindow.clipboardData.GetData("text")
objIE.退出
设置 objShell = CreateObject("Wscript.Shell")
objShell.Run(strURL)
这个脚本还不错。它还有一个优势——它不仅仅用于打开网站。假设您的剪贴板上有一个文件路径,例如“C:\Scripts\ScriptLog.txt”。运行此脚本,文件将在记事本(或您设置为与 .txt 文件关联的任何应用程序)中打开。如果剪贴板上有 .doc 文件的路径,此脚本将在 Microsoft Word 中打开该文档。它实际上是一个通用的文件打开脚本,而不仅仅是一个 Web 站点专用的打开脚本。
vb抓取网页内容(如何用VB取得网页对话框里的内容:可以通过WebBrowser方法获取网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2022-02-20 00:06
太难了,不~
webbrowser1.Document.Body.All.GetElementsByName("box_45537501")(0).InvokeMember("Click")
使用 msgbox() 显示对话框
msgbox的用途有很多,最基本的一个就是msgbox(“你想显示什么”)
或者msgbox("你要显示什么", 16, "对话框名") '16是对话框的类型,有几个组合键码,可以勾选这个,很多,也可以使用提示符给定类型,例如 MsgBoxStyle.Exclamation,是显示错误对话框,
ClientScript.RegisterStartupScript(this.GetType(), "", "alert('" + value + "')"); 试试这个方法,看看里面的一些参数是不是需要改
这很简单
获取网页中对话框的内容 - : 'api constant declarations...Const WM_GETTEXT As Long = &HD Const WM_GETTEXTLENGTH As Long = &HE Const GW_ENABLEDPOPUP As Long = 6 Const BM_CLICK As Long = &HF5& Const GW_CHILD As Long = 5 Const GW_ ...
如何使用VB获取网页对话框中的内容:可以通过WebBrowser方法获取网页内容
WebBrowser控件的使用
0、常用方法
Navigate(string urlString):浏览urlString所代表的URL
Navigate(System.Uri url):浏览url所代表的URL
导航(字符串 urlString,字符串 ...
您好,如何在VB.NET中获取弹出对话框中的文字。- : 1 Dimtmp = InputBox("输入你需要的文字", "我是标题", "我是默认值")
中文实现数据访问的方法有哪些?:中文实现数据访问的方法主要有两种:一种是在程序设计阶段创建和配置数据适配器DataAdapter,生成数据集DataSet;另一种是运行,动态创建配置数据适配器并以编程方式创建和生成数据集
如何获取系统当前活动窗口(不是本程序的窗口)已被选中?: 你做的程序应该是后台程序,也就是说你做的程序运行时没有自己的窗口。它只有一个进程,就是一个消息循环,所以当你做这个程序的时候,你需要从一个类开始,而不是从一个表单类开始。在这个类中,你自己做一个消息循环,不断的获取系统消息,然后把处理一个特定的消息,就可以达到你选词的效果,但是处理消息的部分并不好做……你要知道你想要的那种信息。这里也可能用到API函数,你们自己学习吧,,,,我只能提供这样的意见……
用什么方法来显示对话框?- : msgbox() 有很多用途来显示对话框。基本的一个是msgbox("你要显示什么")或者msgbox("你要显示什么",16,"对话框框名")'16是对话框的类型,有几个组合键代码,可以勾选这个,很多,也可以使用提示给出的类型,比如MsgBoxStyle。Exclamation就是显示错误对话框,
如何填写网页对话框??????- :如果是自己的页面,可以使用javascript来操作。window.open返回时,出现的窗口,可以使用getElementById等操作来补充:window.open是页面端的javascript,与服务器语言jsp和php无关。既然要操作网页程序,自然会用到javascript。如果您对此不确定,建议您查看相关信息
vb如何获取网页浏览器中弹出的网页对话框中的文字?如图:WinAPI只能获取,可以使用spy++查看对话框中的文字
vb 获取网页文本框的内容-: Private Sub Command1_Click() Dim ss As String ss = Text2.Text ' 把你的网页源代码放到Text2 Dim i As Integer, j As Integer i = InStr (ss, "form id") ss = Mid(ss, i) i = InStr(ss, "name") j = InStr(ss, "method") Text1.Text = Mid(ss, i, j - i - 1) 结束子
Dialog: Private Declare Function ShellAbout Lib "shell32.dll" Alias "ShellAboutA" _ (ByVal hwnd As Integer, ByVal szApp As String, ByVal szOtherStuff As String, ByVal hIcon As Integer) As Integer Private Sub Button3_Click( ByVal hwnd As Integer, ByVal szApp As String, ByVal hIcon As Integer) sender As System.... 查看全部
vb抓取网页内容(如何用VB取得网页对话框里的内容:可以通过WebBrowser方法获取网页内容)
太难了,不~
webbrowser1.Document.Body.All.GetElementsByName("box_45537501")(0).InvokeMember("Click")
使用 msgbox() 显示对话框
msgbox的用途有很多,最基本的一个就是msgbox(“你想显示什么”)
或者msgbox("你要显示什么", 16, "对话框名") '16是对话框的类型,有几个组合键码,可以勾选这个,很多,也可以使用提示符给定类型,例如 MsgBoxStyle.Exclamation,是显示错误对话框,
ClientScript.RegisterStartupScript(this.GetType(), "", "alert('" + value + "')"); 试试这个方法,看看里面的一些参数是不是需要改
这很简单
获取网页中对话框的内容 - : 'api constant declarations...Const WM_GETTEXT As Long = &HD Const WM_GETTEXTLENGTH As Long = &HE Const GW_ENABLEDPOPUP As Long = 6 Const BM_CLICK As Long = &HF5& Const GW_CHILD As Long = 5 Const GW_ ...
如何使用VB获取网页对话框中的内容:可以通过WebBrowser方法获取网页内容
WebBrowser控件的使用
0、常用方法
Navigate(string urlString):浏览urlString所代表的URL
Navigate(System.Uri url):浏览url所代表的URL
导航(字符串 urlString,字符串 ...
您好,如何在VB.NET中获取弹出对话框中的文字。- : 1 Dimtmp = InputBox("输入你需要的文字", "我是标题", "我是默认值")
中文实现数据访问的方法有哪些?:中文实现数据访问的方法主要有两种:一种是在程序设计阶段创建和配置数据适配器DataAdapter,生成数据集DataSet;另一种是运行,动态创建配置数据适配器并以编程方式创建和生成数据集
如何获取系统当前活动窗口(不是本程序的窗口)已被选中?: 你做的程序应该是后台程序,也就是说你做的程序运行时没有自己的窗口。它只有一个进程,就是一个消息循环,所以当你做这个程序的时候,你需要从一个类开始,而不是从一个表单类开始。在这个类中,你自己做一个消息循环,不断的获取系统消息,然后把处理一个特定的消息,就可以达到你选词的效果,但是处理消息的部分并不好做……你要知道你想要的那种信息。这里也可能用到API函数,你们自己学习吧,,,,我只能提供这样的意见……
用什么方法来显示对话框?- : msgbox() 有很多用途来显示对话框。基本的一个是msgbox("你要显示什么")或者msgbox("你要显示什么",16,"对话框框名")'16是对话框的类型,有几个组合键代码,可以勾选这个,很多,也可以使用提示给出的类型,比如MsgBoxStyle。Exclamation就是显示错误对话框,
如何填写网页对话框??????- :如果是自己的页面,可以使用javascript来操作。window.open返回时,出现的窗口,可以使用getElementById等操作来补充:window.open是页面端的javascript,与服务器语言jsp和php无关。既然要操作网页程序,自然会用到javascript。如果您对此不确定,建议您查看相关信息
vb如何获取网页浏览器中弹出的网页对话框中的文字?如图:WinAPI只能获取,可以使用spy++查看对话框中的文字
vb 获取网页文本框的内容-: Private Sub Command1_Click() Dim ss As String ss = Text2.Text ' 把你的网页源代码放到Text2 Dim i As Integer, j As Integer i = InStr (ss, "form id") ss = Mid(ss, i) i = InStr(ss, "name") j = InStr(ss, "method") Text1.Text = Mid(ss, i, j - i - 1) 结束子
Dialog: Private Declare Function ShellAbout Lib "shell32.dll" Alias "ShellAboutA" _ (ByVal hwnd As Integer, ByVal szApp As String, ByVal szOtherStuff As String, ByVal hIcon As Integer) As Integer Private Sub Button3_Click( ByVal hwnd As Integer, ByVal szApp As String, ByVal hIcon As Integer) sender As System....
vb抓取网页内容(有道云笔记(推荐)是一体化的服务器,软件和XMind8 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-15 16:08
)
经验:主要用于抓包,app请求接口抓包
下载地址:密码:ic31
9.FinalShell(推荐)
FinalShell 是一个集成的服务器和网络管理软件。它不仅是一个ssh客户端,还是一个强大的开发和运维工具,完全满足开发和运维的需要。特点:免费海外服务器远程桌面加速、ssh加速、双边TCP加速、内网穿透。
体验:xshell+xftp的结合,以及操作记录、服务监控、可视化窗口
下载链接:
或:提取码:l6j6
10.WinSCP
WinSCP 是一个使用 SSH 的 Windows 开源图形 SFTP 客户端。还支持SCP协议。它的主要功能是在本地和远程计算机之间安全地复制文件。.winscp 也可以链接到其他系统,比如linux系统
下载地址:提取码:vdxn
11.有道云笔记(推荐)
网易旗下有道推出的个人和团队在线数据库。有道云笔记采用增量同步技术,即每次只同步修改后的内容,而不是整条笔记。
体验:一处编辑,处处使用,哈哈(我一直在使用)。
下载地址:#win
12.Todoist(推荐)
Todoist 是一款任务管理应用程序和在线待办事项列表,可在 13 个平台上使用,包括 iOS、Windows、Chrome 等。超过 170 万人使用它。它将任务和子任务编译成简单的列表,并通过跟踪一段时间内的进度将用户与竞争对手区分开来,让用户深入了解他们的个人生产力趋势。
经验:列出每天要做的几件事,养成好习惯(进行中……)
在线版: ,您也可以下载PC客户端和应用程序。
13.XMind ZEN(破解版)
XMind ZEN是XMind在被Citrix Marking取消代理后开发的全新思维导图软件。这个思维导图软件在功能上和XMind8差不多,完全兼容,只是它只是在主界面上。大变化,XMind ZEN 比 XMind 8 更漂亮。
下载地址:提取码:nvl8
在线版(进程):
14.MarkdownPad
它是 Windows 上最好的 Markdown 编辑器。有了这款产品,你可以像word文档一样写html页面,也是广大博主的最爱!当然,mac 上有很多高大上的 Markdown 编辑器。
下载地址:密码:knd2
软件截图(左边是编辑区,右边是实时预览):
15.截图
Snipaste 是一个简单但功能强大的截图工具,它还可以让您将截图粘贴回屏幕!下载并打开Snipaste,按F1开始截图,然后按F3,截图会显示在桌面上方。就是这么简单!
体验:不再依赖QQ、微信截图,直接F1即可截图。
下载地址:提取码:xmqt
设置开机自启动:
高级工具:1.Kafka Tool
Kafka Tool是Kafka的可视化客户端工具,可以方便的查看主题队列信息、消费者信息和kafka节点信息。
下载链接:
利用:
2、redisDesktopManager
一款功能强大的redis数据库管理软件,操作简单,方便快捷,功能齐全,性能稳定,支持用户使用可视化操作界面全方位操作数据库,无论是新手用户还是专业开发者,本软件是您管理数据库的最佳帮手。
下载地址:提取码:u3rq
查看全部
vb抓取网页内容(有道云笔记(推荐)是一体化的服务器,软件和XMind8
)
经验:主要用于抓包,app请求接口抓包
下载地址:密码:ic31
9.FinalShell(推荐)
FinalShell 是一个集成的服务器和网络管理软件。它不仅是一个ssh客户端,还是一个强大的开发和运维工具,完全满足开发和运维的需要。特点:免费海外服务器远程桌面加速、ssh加速、双边TCP加速、内网穿透。
体验:xshell+xftp的结合,以及操作记录、服务监控、可视化窗口
下载链接:
或:提取码:l6j6
10.WinSCP
WinSCP 是一个使用 SSH 的 Windows 开源图形 SFTP 客户端。还支持SCP协议。它的主要功能是在本地和远程计算机之间安全地复制文件。.winscp 也可以链接到其他系统,比如linux系统
下载地址:提取码:vdxn
11.有道云笔记(推荐)
网易旗下有道推出的个人和团队在线数据库。有道云笔记采用增量同步技术,即每次只同步修改后的内容,而不是整条笔记。
体验:一处编辑,处处使用,哈哈(我一直在使用)。
下载地址:#win
12.Todoist(推荐)
Todoist 是一款任务管理应用程序和在线待办事项列表,可在 13 个平台上使用,包括 iOS、Windows、Chrome 等。超过 170 万人使用它。它将任务和子任务编译成简单的列表,并通过跟踪一段时间内的进度将用户与竞争对手区分开来,让用户深入了解他们的个人生产力趋势。
经验:列出每天要做的几件事,养成好习惯(进行中……)
在线版: ,您也可以下载PC客户端和应用程序。
13.XMind ZEN(破解版)
XMind ZEN是XMind在被Citrix Marking取消代理后开发的全新思维导图软件。这个思维导图软件在功能上和XMind8差不多,完全兼容,只是它只是在主界面上。大变化,XMind ZEN 比 XMind 8 更漂亮。
下载地址:提取码:nvl8
在线版(进程):
14.MarkdownPad
它是 Windows 上最好的 Markdown 编辑器。有了这款产品,你可以像word文档一样写html页面,也是广大博主的最爱!当然,mac 上有很多高大上的 Markdown 编辑器。
下载地址:密码:knd2
软件截图(左边是编辑区,右边是实时预览):
15.截图
Snipaste 是一个简单但功能强大的截图工具,它还可以让您将截图粘贴回屏幕!下载并打开Snipaste,按F1开始截图,然后按F3,截图会显示在桌面上方。就是这么简单!
体验:不再依赖QQ、微信截图,直接F1即可截图。
下载地址:提取码:xmqt
设置开机自启动:
高级工具:1.Kafka Tool
Kafka Tool是Kafka的可视化客户端工具,可以方便的查看主题队列信息、消费者信息和kafka节点信息。
下载链接:
利用:
2、redisDesktopManager
一款功能强大的redis数据库管理软件,操作简单,方便快捷,功能齐全,性能稳定,支持用户使用可视化操作界面全方位操作数据库,无论是新手用户还是专业开发者,本软件是您管理数据库的最佳帮手。
下载地址:提取码:u3rq
vb抓取网页内容(编程是打开未来人工智能时代的钥匙,它能做的可多着呢!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-14 14:16
日前,“十四五”规划发布,明确提出要发展战略性新兴产业,推动互联网、大数据、人工智能等各产业深度融合。
接下来是关于人工智能和大数据的热烈讨论。谈到人工智能和大数据,大多数人第一次想到编程,而在此之前,乔布斯还告诉我们:“每个人都应该学习编程,因为它教你如何思考。”
如今,越来越多的人在各行各业学习编程。就连地产大王潘石屹也曾在微博上宣布要学Python。
他在 8 个月内完成了用 python 解决 100 个问题的目标。
他告诉我们:“编程是开启未来人工智能时代的钥匙,它能让我们对未来更有信心。”
为什么编程如此重要?
马云曾经说过,数据是这个时代的核心资源。未来30年,数据将取代石油,成为最强大的能源。
未来能乘风破浪成功的,一定是有数据思维和理性思维的人。
Python 在帮助我们使用数据做出决策方面发挥着至关重要的作用。
· 麦肯锡提出要求其招聘的所有实习生都必须懂Python;
· 从2018年起,所有新加入摩根大通的资产管理分析师必须学习Python;
只要你翻看求职网站就会知道Python人才的需求已经辐射到你能想象到的任何行业
人才需求很高
01
02
03
04
Python作为近年来一直变得越来越受欢迎的编程语言,连续三年被选为1号最受欢迎的编程语言!
我可以用 python 做什么?
除了用 Python 编码和编写游戏之外,它还可以做更多的事情!
1
财务会计:处理发票、报表
普通人一天中大部分时间都在处理发票和记录和审核文件,但使用 Python 自动识别文件所需的列信息并生成表格。
5分钟,报表数据统计,记录订单搞定~
▲“Swish”自动生成表格,真的很酷!
2
金融行业:自动生成股票图表
在不到 200 行代码中,
自动导入密集数据,分析结果并生成股票图表。
市场情况一目了然。
避免因主观预测错误造成的经济损失。
▲ 不用花一整天时间画动态图,既准确又方便
3
运营——获取竞品信息,洞察用户
您可以使用Python来捕捉竞品的种类、价格、销量、客户反馈等信息,输出数据分析报告,制定更有利的经营策略。
▲自动生成图表,信息一目了然
4
抓取互联网上的海量资源和数据...
电子书、电影、电视节目、
只有你想不到,没有你就走不下去。
▲想看的电影和电视剧,5分钟下载
学python的人越来越年轻
国家出台了多项政策,鼓励中小学生开始学习编程,赢在起跑线上。
浙江:2018年浙江省高中信息技术教材将弃用VB。从2019年高考开始,Python将正式进行测试。
山东:新出版的小学六年级信息技术教材增加了Python相关内容。
全国:2017 年 12 月的全国计算机二级考试将是最后一次有 Visual FoxPro 内容。从 2018 年开始,将添加 Python 科目。
如此重大的改革引起了热议:
据统计,儿童大脑发育的高峰期维持在2岁到12岁之间。这10年是孩子大脑思维训练的黄金时期。如果错过了,可能一辈子都无法弥补,所以孩子们应该尽快学习编程!
如何学习蟒蛇?
很多人一提到Python,第一反应就是,计算机?编程?我学起来太难了。
事实上,要学习 Python,不管你的英语数学有多好,你只需要:
认26个字母+懂一点初中数学知识
智慧喵课程为3-18岁幼儿构建了完整的循序渐进的课程体系。K3-K4阶段使用python编程语言,教你学习打印功能、换行符、字符等,提高竞争力的新技能。
学科知识点:基础软件开发、数据分析、图像处理
实践项目:绘制复杂的几何图形和制作小游戏。 查看全部
vb抓取网页内容(编程是打开未来人工智能时代的钥匙,它能做的可多着呢!)
日前,“十四五”规划发布,明确提出要发展战略性新兴产业,推动互联网、大数据、人工智能等各产业深度融合。
接下来是关于人工智能和大数据的热烈讨论。谈到人工智能和大数据,大多数人第一次想到编程,而在此之前,乔布斯还告诉我们:“每个人都应该学习编程,因为它教你如何思考。”
如今,越来越多的人在各行各业学习编程。就连地产大王潘石屹也曾在微博上宣布要学Python。
他在 8 个月内完成了用 python 解决 100 个问题的目标。
他告诉我们:“编程是开启未来人工智能时代的钥匙,它能让我们对未来更有信心。”
为什么编程如此重要?
马云曾经说过,数据是这个时代的核心资源。未来30年,数据将取代石油,成为最强大的能源。
未来能乘风破浪成功的,一定是有数据思维和理性思维的人。
Python 在帮助我们使用数据做出决策方面发挥着至关重要的作用。
· 麦肯锡提出要求其招聘的所有实习生都必须懂Python;
· 从2018年起,所有新加入摩根大通的资产管理分析师必须学习Python;
只要你翻看求职网站就会知道Python人才的需求已经辐射到你能想象到的任何行业
人才需求很高
01
02
03
04
Python作为近年来一直变得越来越受欢迎的编程语言,连续三年被选为1号最受欢迎的编程语言!
我可以用 python 做什么?
除了用 Python 编码和编写游戏之外,它还可以做更多的事情!
1
财务会计:处理发票、报表
普通人一天中大部分时间都在处理发票和记录和审核文件,但使用 Python 自动识别文件所需的列信息并生成表格。
5分钟,报表数据统计,记录订单搞定~
▲“Swish”自动生成表格,真的很酷!
2
金融行业:自动生成股票图表
在不到 200 行代码中,
自动导入密集数据,分析结果并生成股票图表。
市场情况一目了然。
避免因主观预测错误造成的经济损失。
▲ 不用花一整天时间画动态图,既准确又方便
3
运营——获取竞品信息,洞察用户
您可以使用Python来捕捉竞品的种类、价格、销量、客户反馈等信息,输出数据分析报告,制定更有利的经营策略。
▲自动生成图表,信息一目了然
4
抓取互联网上的海量资源和数据...
电子书、电影、电视节目、
只有你想不到,没有你就走不下去。
▲想看的电影和电视剧,5分钟下载
学python的人越来越年轻
国家出台了多项政策,鼓励中小学生开始学习编程,赢在起跑线上。
浙江:2018年浙江省高中信息技术教材将弃用VB。从2019年高考开始,Python将正式进行测试。
山东:新出版的小学六年级信息技术教材增加了Python相关内容。
全国:2017 年 12 月的全国计算机二级考试将是最后一次有 Visual FoxPro 内容。从 2018 年开始,将添加 Python 科目。
如此重大的改革引起了热议:
据统计,儿童大脑发育的高峰期维持在2岁到12岁之间。这10年是孩子大脑思维训练的黄金时期。如果错过了,可能一辈子都无法弥补,所以孩子们应该尽快学习编程!
如何学习蟒蛇?
很多人一提到Python,第一反应就是,计算机?编程?我学起来太难了。
事实上,要学习 Python,不管你的英语数学有多好,你只需要:
认26个字母+懂一点初中数学知识
智慧喵课程为3-18岁幼儿构建了完整的循序渐进的课程体系。K3-K4阶段使用python编程语言,教你学习打印功能、换行符、字符等,提高竞争力的新技能。
学科知识点:基础软件开发、数据分析、图像处理
实践项目:绘制复杂的几何图形和制作小游戏。
vb抓取网页内容(小小的简单爬虫来练自己的动手能力(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-08 20:03
vb抓取网页内容:yiinjava:::-js-url.html,时刻提醒自己爬虫不要停,上下班路上编程练手,爬什么呢?是不是python就不要了?nonono,忘了我们,的意思,就是今天要用python。所以抓取社区里的一些活动,就比如签到类型的,来练练我们的本事。项目中涉及到爬虫,让python解决爬虫问题。
之前爬的还很少,也没想到那么多玩法,在研究某些网站问题时,也是各个搜索引擎是绕不过去的坎,所以今天就写一个小小的简单爬虫来练练自己的动手能力。准备工作本程序主要是调用python开发的api,去获取自己想要的内容,再通过python的pandas处理处理数据。爬虫基本思路1.获取和获取更多比如某一时间段内的签到数、时间、用户id等内容。
2.获取更多的签到数据库里有max、min、median,通过api获取它们。3.数据清洗。由于种种原因,我们未必能获取到想要的信息,所以要进行数据清洗,转换成自己能够理解的可处理数据,这样才能够利用pandas来处理这些数据。4.提取信息主要就是你的id,一些二级三级next规则,就不讲啦。5.归档和存储这一块我写了两个爬虫,分别存放在btg_setitem和item.py之下。
项目代码#coding:utf-8#'''第一次运行python代码,就将对爬虫设置这么详细,希望大家给一个面子,真心不容易哦'''importrequestsfromurllib.parseimporthtmlparserfrombs4importbeautifulsoup#注意web里面的b站和豆瓣不一样,本文中你指的b站没有更多权限哦#第一种情况#浏览器在国内的爬虫#这种情况是比较好爬的#豆瓣分析用google浏览器打开豆瓣,在headers里写上:host=''#因为我用的是google浏览器,你用国内百度或者360浏览器也可以#浏览器设置:sslnormalssl分享我们用的可是来自央视网的https而不是其他地方的#。 查看全部
vb抓取网页内容(小小的简单爬虫来练自己的动手能力(组图))
vb抓取网页内容:yiinjava:::-js-url.html,时刻提醒自己爬虫不要停,上下班路上编程练手,爬什么呢?是不是python就不要了?nonono,忘了我们,的意思,就是今天要用python。所以抓取社区里的一些活动,就比如签到类型的,来练练我们的本事。项目中涉及到爬虫,让python解决爬虫问题。
之前爬的还很少,也没想到那么多玩法,在研究某些网站问题时,也是各个搜索引擎是绕不过去的坎,所以今天就写一个小小的简单爬虫来练练自己的动手能力。准备工作本程序主要是调用python开发的api,去获取自己想要的内容,再通过python的pandas处理处理数据。爬虫基本思路1.获取和获取更多比如某一时间段内的签到数、时间、用户id等内容。
2.获取更多的签到数据库里有max、min、median,通过api获取它们。3.数据清洗。由于种种原因,我们未必能获取到想要的信息,所以要进行数据清洗,转换成自己能够理解的可处理数据,这样才能够利用pandas来处理这些数据。4.提取信息主要就是你的id,一些二级三级next规则,就不讲啦。5.归档和存储这一块我写了两个爬虫,分别存放在btg_setitem和item.py之下。
项目代码#coding:utf-8#'''第一次运行python代码,就将对爬虫设置这么详细,希望大家给一个面子,真心不容易哦'''importrequestsfromurllib.parseimporthtmlparserfrombs4importbeautifulsoup#注意web里面的b站和豆瓣不一样,本文中你指的b站没有更多权限哦#第一种情况#浏览器在国内的爬虫#这种情况是比较好爬的#豆瓣分析用google浏览器打开豆瓣,在headers里写上:host=''#因为我用的是google浏览器,你用国内百度或者360浏览器也可以#浏览器设置:sslnormalssl分享我们用的可是来自央视网的https而不是其他地方的#。
vb抓取网页内容(小学数学必做100题,建议收藏!(附答案))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-04 09:01
试试
httpResp = CType(httpReq.GetResponse(), HttpWebResponse)
httpReq.KeepAlive = False ' 获取或设置一个值,该值指示是否与 Internet 资源建立持久连接。
Dim reader As StreamReader = New StreamReader(httpResp.GetResponseStream, System.Text.Encoding.GetEncoding(bm))
respHTML = reader.ReadToEnd() 'respHTML是网页的源代码
赶上
respHTML = "中段"
结束尝试
返回响应HTML
结束函数
Sub IsPrimenum(byval a As Integer) Dim b As Integer For b = 2 To (a - 1)If a Mod b = 0 ThenMsgBox("This is not a prime number")ElseMsgBox("This is一个素数") End If NextEnd Sub
特殊字符指的是什么?不管是汉字还是隐形字符还是不常用字符,比如常用字符ascii值32-126都是键盘上能找到的字符。
例如,使用拆分来替换字符串中的常见字符。如果剩余字符串的长度不为 0,则它收录其他字符。这种方法也用于判断a-zA-Z0-9。事实上,也使用了正则表达式。很简单,也可以用for循环判断每个字符的值
1.生成一个从 11 到 99 的随机数
Dim rd As New Random()
将 r 设为整数
r = rd.Next(89)+11
2.两位数的位和十位互换(x的多位也可以)
Dim r As Integer, x As Integer = 45
Dim y As Integer = 0
边做边做 (x > 0)
r = x Mod 10
y += r
x = Int(x / 10)
y *= 10
r = 0
循环
y/=10 '最后去掉相乘的10
3.将单个变量x的值取小数点后2位
Dim s As Single, y As Single
s = 1.234
y = String.Format("{0:n2}", s)' 2 in n2 表示取几位小数
4.取字符串1右边的4个字符,不断变化
字符串1.子字符串(字符串1.长度 - 4, 4)
我只是在学习,我已经尝试了所有方法,我会指出哪里出了问题。 (另外,这不是你的作业,对吧)
程序一般不返回值如:
子 xxx()
结束子
函数返回值:
函数 xx() 作为布尔值
返回真
结束函数
VB.NET如何获取网页中的数据-: Public Function webCaptureContent(ByVal mWebsiteUrl As String, ByVal mWebsiteType As Boolean) As String '启动特定数据采集作业,返回采集到HTML内容:需要完整的地址数据和 ://On Error Resume Next Dim Str_...
如何阅读别人的网页,并能自动判断使用的是哪种编码?找到函数- : 看网页没问题,至于你说的编码,我没看懂你想问什么....
如何在VB中获取网上邻居中的计算机名或共享文件夹名?公司问:可以参考以下地址:用vb获取网上邻居的计算机名
vb 如何获取在其他程序中选择的字符,例如在网页或记事本文件中,使用? :这个有两个关键:(1)你的vb需要响应拖动事件,也就是在接收到拖动事件发生时将被拖动对象的内容添加到你的文本框中;这个可以很方便的实现自己动手,每个控件都有一个拖拽事件处理函数,只要处理(2)被拖拽的程序来响应拖拽事件,也就是拖拽的时候,把选中的内容放到拖拽对象里面;这个是你的控制。
vb使用xmlhttp获取网页源码,如何用正则表达式过滤提取标签?直接替换然后拆分,最后用like取出你需要的东西
要求 VB.NET 读取网页内容 - : Imports System.NetImports System.IOImports System.Text.RegularExpressionsPublic Class Form1 Private Sub button1_Click(sender As Object, e As EventArgs) Handles Button1.Click Dim stream作为 IO.Stream = WebRequest.Create(UrlAdress)....
对不起,mibile。如何阅读网页内容 - :可以使用 Basic4ppc 实现
如何在网页中提取 URL 链接-: Dim gs() As String = (From mt As HtmlElement In WebBrowser1.Document.Links Select System.Text.RegularExpressions.Regex.Match(mt.OuterHtml, "[^\x22 >]+").Value).ToArray
例如和访问其他人电脑上的文件-:1、将我的网上邻居—整个网络—microsoft windows网络—a—b用户—共享]映射到网络驱动器中,右键单击“我的”电脑'----映射网络驱动器----选择一个盘符如t,然后输入\\a\进行共享,完成; 2、创建一个批处理文件,内容写“xcopy /et:e:\lisa\plan\plan backup”; 3、在任务计划中新建一个任务,指定每天执行一次,选择时间后,在第二步批处理文件中指定要执行的文件。
VB如何读取网页代码中的内容——:
需要添加microsft网络传输控制6.0个部分
'程序示例========================================
'取消所有操作
inet1.取消
'设置协议为http
 ... 查看全部
vb抓取网页内容(小学数学必做100题,建议收藏!(附答案))
试试
httpResp = CType(httpReq.GetResponse(), HttpWebResponse)
httpReq.KeepAlive = False ' 获取或设置一个值,该值指示是否与 Internet 资源建立持久连接。
Dim reader As StreamReader = New StreamReader(httpResp.GetResponseStream, System.Text.Encoding.GetEncoding(bm))
respHTML = reader.ReadToEnd() 'respHTML是网页的源代码
赶上
respHTML = "中段"
结束尝试
返回响应HTML
结束函数
Sub IsPrimenum(byval a As Integer) Dim b As Integer For b = 2 To (a - 1)If a Mod b = 0 ThenMsgBox("This is not a prime number")ElseMsgBox("This is一个素数") End If NextEnd Sub
特殊字符指的是什么?不管是汉字还是隐形字符还是不常用字符,比如常用字符ascii值32-126都是键盘上能找到的字符。
例如,使用拆分来替换字符串中的常见字符。如果剩余字符串的长度不为 0,则它收录其他字符。这种方法也用于判断a-zA-Z0-9。事实上,也使用了正则表达式。很简单,也可以用for循环判断每个字符的值
1.生成一个从 11 到 99 的随机数
Dim rd As New Random()
将 r 设为整数
r = rd.Next(89)+11
2.两位数的位和十位互换(x的多位也可以)
Dim r As Integer, x As Integer = 45
Dim y As Integer = 0
边做边做 (x > 0)
r = x Mod 10
y += r
x = Int(x / 10)
y *= 10
r = 0
循环
y/=10 '最后去掉相乘的10
3.将单个变量x的值取小数点后2位
Dim s As Single, y As Single
s = 1.234
y = String.Format("{0:n2}", s)' 2 in n2 表示取几位小数
4.取字符串1右边的4个字符,不断变化
字符串1.子字符串(字符串1.长度 - 4, 4)
我只是在学习,我已经尝试了所有方法,我会指出哪里出了问题。 (另外,这不是你的作业,对吧)
程序一般不返回值如:
子 xxx()
结束子
函数返回值:
函数 xx() 作为布尔值
返回真
结束函数
VB.NET如何获取网页中的数据-: Public Function webCaptureContent(ByVal mWebsiteUrl As String, ByVal mWebsiteType As Boolean) As String '启动特定数据采集作业,返回采集到HTML内容:需要完整的地址数据和 ://On Error Resume Next Dim Str_...
如何阅读别人的网页,并能自动判断使用的是哪种编码?找到函数- : 看网页没问题,至于你说的编码,我没看懂你想问什么....
如何在VB中获取网上邻居中的计算机名或共享文件夹名?公司问:可以参考以下地址:用vb获取网上邻居的计算机名
vb 如何获取在其他程序中选择的字符,例如在网页或记事本文件中,使用? :这个有两个关键:(1)你的vb需要响应拖动事件,也就是在接收到拖动事件发生时将被拖动对象的内容添加到你的文本框中;这个可以很方便的实现自己动手,每个控件都有一个拖拽事件处理函数,只要处理(2)被拖拽的程序来响应拖拽事件,也就是拖拽的时候,把选中的内容放到拖拽对象里面;这个是你的控制。
vb使用xmlhttp获取网页源码,如何用正则表达式过滤提取标签?直接替换然后拆分,最后用like取出你需要的东西
要求 VB.NET 读取网页内容 - : Imports System.NetImports System.IOImports System.Text.RegularExpressionsPublic Class Form1 Private Sub button1_Click(sender As Object, e As EventArgs) Handles Button1.Click Dim stream作为 IO.Stream = WebRequest.Create(UrlAdress)....
对不起,mibile。如何阅读网页内容 - :可以使用 Basic4ppc 实现
如何在网页中提取 URL 链接-: Dim gs() As String = (From mt As HtmlElement In WebBrowser1.Document.Links Select System.Text.RegularExpressions.Regex.Match(mt.OuterHtml, "[^\x22 >]+").Value).ToArray
例如和访问其他人电脑上的文件-:1、将我的网上邻居—整个网络—microsoft windows网络—a—b用户—共享]映射到网络驱动器中,右键单击“我的”电脑'----映射网络驱动器----选择一个盘符如t,然后输入\\a\进行共享,完成; 2、创建一个批处理文件,内容写“xcopy /et:e:\lisa\plan\plan backup”; 3、在任务计划中新建一个任务,指定每天执行一次,选择时间后,在第二步批处理文件中指定要执行的文件。
VB如何读取网页代码中的内容——:
需要添加microsft网络传输控制6.0个部分
'程序示例========================================
'取消所有操作
inet1.取消
'设置协议为http
 ...
vb抓取网页内容( Python网络爬虫定时发送菜谱分享,每周提醒自己,看看该整个啥好吃的菜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-04 07:17
Python网络爬虫定时发送菜谱分享,每周提醒自己,看看该整个啥好吃的菜)
前言
相信很多朋友都有同样的烦恼,今天吃什么。终于吃完了这顿饭,担心下一顿。
前几天在Python交流群里,大佬【冫马殠成】分享了一个定时发菜谱分享的有趣代码。我觉得很有意思,在这里跟大家分享一下。
实现想法
实现这个想法并不难。一种是 Python 网络爬虫,它捕获网页上的每日文章并将其保存在一个变量中。二是编写发送邮件的逻辑,编辑邮件模板,然后抓取内容即可发送。
实施过程
这里直接上代码,如下图:
import requests, bs4
import smtplib
import schedule
import time
from bs4 import BeautifulSoup
from email.mime.text import MIMEText
from email.header import Header
# account = input('请输入你的邮箱:')
# password = input('请输入你的密码:')
# receiver = input('请输入收件人的邮箱:')
account = '{0}'.format('请输入你的邮箱:')
password = '{0}'.format('请输入你的密码:')
receiver = '{0}'.format('请输入收件人的邮箱:')
def recipe_spider():
list_all = ''
num = 0
for a in range(1, 11):
headers = {'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
n = '{0}{1}{2}'.format('https://home.meishichina.com/s ... 39%3B, a, '.html')
res_foods = requests.get(n, headers=headers)
bs_foods = bs4.BeautifulSoup(res_foods.text, 'html.parser')
list_foods = bs_foods.find('div', class_='space_left')
for food in list_foods.find_all('li'):
num = num+1
name = food.find('h2').text.strip()
foods = food.find('p', class_='subcontent').text.strip()
url_food = food.find('a')['href'].strip()
food_info = '''
%s、%s
%s
链接: %s
''' % (num, name, foods, url_food)
list_all = list_all+food_info
return (list_all)
def send_email(list_all):
global account, password, receiver
mailhost = 'smtp.qq.com'
qqmail = smtplib.SMTP_SSL(mailhost, 465)
# qqmail.connect(mailhost,465)
qqmail.login(account, password)
content = '亲爱的,本周的热门菜谱如下' + list_all
message = MIMEText(content, 'plain', 'utf-8')
subject = '周末吃个啥——美食天下'
message['Subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(account, receiver, message.as_string())
print('邮件发送成功')
except:
print('邮件发送失败')
qqmail.quit()
def job():
print('开始一次任务')
list_all = recipe_spider()
send_email(list_all)
print('任务完成')
if __name__ == '__main__':
job()
# schedule.every(0.05).minutes.do(job)
# while True:
# schedule.run_pending()
# time.sleep(1)
您只需要输入您的电子邮件地址、电子邮件授权码和相应的收件人。
代码运行后,用户可以收到你发送的邮件,如下图。
也可以定时发给自己,使用定时任务工具,做定时任务,每周提醒自己,看看应该上什么好吃的菜!
原文链接: 查看全部
vb抓取网页内容(
Python网络爬虫定时发送菜谱分享,每周提醒自己,看看该整个啥好吃的菜)
前言
相信很多朋友都有同样的烦恼,今天吃什么。终于吃完了这顿饭,担心下一顿。
前几天在Python交流群里,大佬【冫马殠成】分享了一个定时发菜谱分享的有趣代码。我觉得很有意思,在这里跟大家分享一下。
实现想法
实现这个想法并不难。一种是 Python 网络爬虫,它捕获网页上的每日文章并将其保存在一个变量中。二是编写发送邮件的逻辑,编辑邮件模板,然后抓取内容即可发送。
实施过程
这里直接上代码,如下图:
import requests, bs4
import smtplib
import schedule
import time
from bs4 import BeautifulSoup
from email.mime.text import MIMEText
from email.header import Header
# account = input('请输入你的邮箱:')
# password = input('请输入你的密码:')
# receiver = input('请输入收件人的邮箱:')
account = '{0}'.format('请输入你的邮箱:')
password = '{0}'.format('请输入你的密码:')
receiver = '{0}'.format('请输入收件人的邮箱:')
def recipe_spider():
list_all = ''
num = 0
for a in range(1, 11):
headers = {'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
n = '{0}{1}{2}'.format('https://home.meishichina.com/s ... 39%3B, a, '.html')
res_foods = requests.get(n, headers=headers)
bs_foods = bs4.BeautifulSoup(res_foods.text, 'html.parser')
list_foods = bs_foods.find('div', class_='space_left')
for food in list_foods.find_all('li'):
num = num+1
name = food.find('h2').text.strip()
foods = food.find('p', class_='subcontent').text.strip()
url_food = food.find('a')['href'].strip()
food_info = '''
%s、%s
%s
链接: %s
''' % (num, name, foods, url_food)
list_all = list_all+food_info
return (list_all)
def send_email(list_all):
global account, password, receiver
mailhost = 'smtp.qq.com'
qqmail = smtplib.SMTP_SSL(mailhost, 465)
# qqmail.connect(mailhost,465)
qqmail.login(account, password)
content = '亲爱的,本周的热门菜谱如下' + list_all
message = MIMEText(content, 'plain', 'utf-8')
subject = '周末吃个啥——美食天下'
message['Subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(account, receiver, message.as_string())
print('邮件发送成功')
except:
print('邮件发送失败')
qqmail.quit()
def job():
print('开始一次任务')
list_all = recipe_spider()
send_email(list_all)
print('任务完成')
if __name__ == '__main__':
job()
# schedule.every(0.05).minutes.do(job)
# while True:
# schedule.run_pending()
# time.sleep(1)
您只需要输入您的电子邮件地址、电子邮件授权码和相应的收件人。
代码运行后,用户可以收到你发送的邮件,如下图。
也可以定时发给自己,使用定时任务工具,做定时任务,每周提醒自己,看看应该上什么好吃的菜!
原文链接:
vb抓取网页内容(vb抓取网页内容怎么爬取数据是什么呢??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-28 17:03
vb抓取网页内容,首先要做的第一步就是抓取网页中的信息。这里包括哪些?简单的说,就是拿到html代码。那么你具体要爬取的数据是什么呢?你可以通过下面的步骤获取:html分析软件:webpagetest爬虫+数据库首先要做的第一步是什么?首先是抓取网页中的html代码。我们需要用到两个抓取html的软件。
一个是webpagetest,一个是spiderlist。当然两个软件也可以同时使用。1.html分析软件:webpagetest一共支持两个,分别是html6、html5。也就是说,只要是html6,html5都可以抓取。但是spiderlist支持html5、html6和html5中的部分语法。所以webpagetest是肯定支持抓取html5中的部分内容的。
webpagetest常用语法:webpagetemplatediv[]body[]bigurl[]爬虫+数据库第二步就是抓取网页中的数据。这里我们需要用到一个工具——爬虫软件。我们可以通过spiderlist来爬取部分html的cookie信息,还可以通过webpagetest的executedubdecimal。
抓取一个按钮时,就会自动爬取这个按钮cookie中的所有内容。数据库也可以用webpagetest的processedit等插件进行设置。这样同时会在数据库中生成cookie,我们把这些cookie都保存起来就行了。2.executedubdecimal首先你需要把我提供的代码在浏览器的地址栏内进行验证,如果能执行,爬虫就能够正常完成。
验证的方法很简单,就是浏览器地址栏多输入几个javascript的代码。我们一般是不会这么做的,但是你可以有取舍。接下来的,就是设置爬虫的代码。从webpagetest我们可以直接找到javascript的headers。这就是浏览器通过cookie来提交给webpagetest的数据。爬虫必须将cookie信息保存到本地。
网页爬取结束后,你可以用下面的代码用processedit来进行修改代码并验证。constspiderdecimal=newhtml5executedubdecimal({js:'make_detail',relative:'inherit',max:300,reset:true,focus:'clipping',data:{itemid:uuid(),useragent:"chrome",authenticate:false,pagesize:15,cookieclosts:[],cookieversion:0,proxy:true,selector:"htmlmessages",state:{"downloader-cookie":"","downloader-en":"chrome","downloader-ext":"","downloader-t":"facebook","downloader-useragent":"chrome","downloader-authority":":"","downloader-format":"mobile","downloader-front":"","downloader-title":"","downloader-bid。 查看全部
vb抓取网页内容(vb抓取网页内容怎么爬取数据是什么呢??)
vb抓取网页内容,首先要做的第一步就是抓取网页中的信息。这里包括哪些?简单的说,就是拿到html代码。那么你具体要爬取的数据是什么呢?你可以通过下面的步骤获取:html分析软件:webpagetest爬虫+数据库首先要做的第一步是什么?首先是抓取网页中的html代码。我们需要用到两个抓取html的软件。
一个是webpagetest,一个是spiderlist。当然两个软件也可以同时使用。1.html分析软件:webpagetest一共支持两个,分别是html6、html5。也就是说,只要是html6,html5都可以抓取。但是spiderlist支持html5、html6和html5中的部分语法。所以webpagetest是肯定支持抓取html5中的部分内容的。
webpagetest常用语法:webpagetemplatediv[]body[]bigurl[]爬虫+数据库第二步就是抓取网页中的数据。这里我们需要用到一个工具——爬虫软件。我们可以通过spiderlist来爬取部分html的cookie信息,还可以通过webpagetest的executedubdecimal。
抓取一个按钮时,就会自动爬取这个按钮cookie中的所有内容。数据库也可以用webpagetest的processedit等插件进行设置。这样同时会在数据库中生成cookie,我们把这些cookie都保存起来就行了。2.executedubdecimal首先你需要把我提供的代码在浏览器的地址栏内进行验证,如果能执行,爬虫就能够正常完成。
验证的方法很简单,就是浏览器地址栏多输入几个javascript的代码。我们一般是不会这么做的,但是你可以有取舍。接下来的,就是设置爬虫的代码。从webpagetest我们可以直接找到javascript的headers。这就是浏览器通过cookie来提交给webpagetest的数据。爬虫必须将cookie信息保存到本地。
网页爬取结束后,你可以用下面的代码用processedit来进行修改代码并验证。constspiderdecimal=newhtml5executedubdecimal({js:'make_detail',relative:'inherit',max:300,reset:true,focus:'clipping',data:{itemid:uuid(),useragent:"chrome",authenticate:false,pagesize:15,cookieclosts:[],cookieversion:0,proxy:true,selector:"htmlmessages",state:{"downloader-cookie":"","downloader-en":"chrome","downloader-ext":"","downloader-t":"facebook","downloader-useragent":"chrome","downloader-authority":":"","downloader-format":"mobile","downloader-front":"","downloader-title":"","downloader-bid。
vb抓取网页内容(vb抓取网页内容和序列化(json、xml)操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-28 12:03
vb抓取网页内容和序列化(json、xml)操作是两种不同的思维(软件编程中的两种不同思维)。要学会使用两种不同的思维,就得知道它们是不一样的工作流程,两者的关系又怎么样呢?关键点如下:使用vb开发者工具和xml输出。vb是一种开放式的面向对象的程序设计语言。它结合c++语言和其他一些语言(比如java),可以用vb编写复杂的系统软件。
在vb编写的应用程序具有可移植性、多版本支持、可扩展性、多线程支持等性能优势。xml是一种对数据提供更高级别形式化约束的语言。它适用于大量的数据,通常不需要从“数据”开始并在最终结束时将“数据”保存到文件。它能够提供灵活的数据交换格式(关键是可在系统中进行编码和解码)、编码(比如.png、.jpg、.txt等文本格式)、解码(比如解json)、支持元数据(如布尔类型和唯一标识等)。
在处理完一个应用程序之后,可以将处理结果存储在一个或多个文件中。使用python进行序列化操作。python,可以直接嵌入到unix、windows等操作系统中,可用于机器学习、网络爬虫、数据分析等等。主要擅长的是python爬虫。json序列化指导就业方向:大家可以参考这篇文章,基本对这个有了初步的认识。-ziq我的主页:-ziq。 查看全部
vb抓取网页内容(vb抓取网页内容和序列化(json、xml)操作)
vb抓取网页内容和序列化(json、xml)操作是两种不同的思维(软件编程中的两种不同思维)。要学会使用两种不同的思维,就得知道它们是不一样的工作流程,两者的关系又怎么样呢?关键点如下:使用vb开发者工具和xml输出。vb是一种开放式的面向对象的程序设计语言。它结合c++语言和其他一些语言(比如java),可以用vb编写复杂的系统软件。
在vb编写的应用程序具有可移植性、多版本支持、可扩展性、多线程支持等性能优势。xml是一种对数据提供更高级别形式化约束的语言。它适用于大量的数据,通常不需要从“数据”开始并在最终结束时将“数据”保存到文件。它能够提供灵活的数据交换格式(关键是可在系统中进行编码和解码)、编码(比如.png、.jpg、.txt等文本格式)、解码(比如解json)、支持元数据(如布尔类型和唯一标识等)。
在处理完一个应用程序之后,可以将处理结果存储在一个或多个文件中。使用python进行序列化操作。python,可以直接嵌入到unix、windows等操作系统中,可用于机器学习、网络爬虫、数据分析等等。主要擅长的是python爬虫。json序列化指导就业方向:大家可以参考这篇文章,基本对这个有了初步的认识。-ziq我的主页:-ziq。
vb抓取网页内容(指令对索引编制或内容显示无任何限制(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-19 20:07
操作说明
全部
对索引或内容显示没有限制。该指令是默认指令,因此显式列出它没有任何效果。
无索引
不要在搜索结果中显示此网页、媒体或资源。如果您未指定此指令,则此页面、媒体或资产可能会被编入索引并显示在搜索结果中。
不关注
不要点击此页面上的链接。如果您未指定此指令,Google 可能会使用此页面上的链接来发现链接页面。
没有任何
相当于noindex,nofollow。
无档案
不要在搜索结果中显示缓存的链接。如果您不指定此指令,Google 可能会生成一个缓存页面,用户可以通过搜索结果访问该页面。
无摘要
不要在搜索结果中显示页面的文本片段或视频预览。如果有静止图像缩略图,仍然可以显示静止图像缩略图,这可以提供更好的用户体验。这适用于所有形式的搜索结果,包括 Google Web Search、Google 图片和 Google Discover。
如果您未指定此指令,Google 可能会根据页面上的信息生成文本片段和视频预览。
最大片段:[数量]
您最多只能使用 [number] 个字符作为此搜索结果的文本摘要。(请注意,该 URL 可能会在搜索结果页面中显示为多个搜索结果)。这不会影响图片或视频预览。此限制适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Discover 和 Google Assistant。但是,如果发布者已单独授予使用内容的权限,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容,或者与 Google 签订了许可协议,则此设置不会阻止那些更具体的允许使用。如果未指定可解析的 [number],则忽略此指令。
如果您不指定此指令,Google 将选择摘要长度。
特殊价值:
例如:
防止片段出现在搜索结果中:
摘要限制为 20 个字符:
表示摘要没有字数限制:
最大图像预览:[设置]
设置此页面在搜索结果中的最大图像预览大小。
如果您不指定 max-image-preview 指令,Google 可能会以默认大小显示图像预览。
接受的 [设置] 值:
这适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Discover 和 Google Assistant。但是,如果发布者已单独授予使用内容的权限,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容(例如 AMP 版本和规范版本的 文章),或者与 Google 签订了许可协议,则此设置不会阻止那些更具体的允许使用.
如果您不希望 Google 搜索或 Google 探索在显示其 文章 AMP 页面和规范版本时使用较大的缩略图,请将 max-image-preview 的值指定为标准或无。
例子:
最大视频预览:[数量]
此页面上的视频在搜索结果中的最大视频片段长度必须为 [number] 秒。
如果您不指定 max-video-preview 指令,Google 可能会在搜索结果中显示视频片段,并由 Google 决定预览内容的时间。
特殊价值:
这适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Video、Google Discover 和 Google Assistant。如果未指定可解析的 [number],则忽略此指令。
例子:
不翻译
不要在搜索结果中提供此页面的翻译。如果您未指定此指令,Google 可能会以搜索查询的语言以外的语言提供搜索结果标题链接和搜索结果的翻译版本。如果用户点击翻译后的标题链接,用户和网页之间的进一步交互将通过谷歌翻译进行,谷歌翻译会自动翻译用户随后访问的链接。
无图像索引
不要索引此页面上的图像。如果您不指定此值,则页面上的图像可能会被索引并显示在搜索结果中。
不可用_之后:[日期/时间]
不要在指定日期/时间之后在搜索结果中显示此页面。日期/时间必须以广泛接受的格式指定,包括但不限于 RFC 822、RFC 850 和 ISO 8601。如果没有指定有效的日期/时间,该指令将被忽略。默认情况下,内容没有过期日期。
如果您不指定此指令,则该页面可能会无限期地出现在搜索结果中。
Googlebot 会在指定日期和时间后显着减慢 URL 的抓取速度。
例子:
注意:nosnippet 表示:不要在此页面的搜索结果中显示片段。
组合索引指令和内容显示指令
您可以组合以逗号分隔的多个机器人元标记指令,以创建具有多个指令的单个命令。下面是一个机器人元标记示例,它指示网络爬虫不要索引页面或爬取页面上的任何链接:
以下示例将文本摘要长度限制为 20 个字符并允许大图像预览:
如果您为每个工具指定多个具有不同指令的爬虫,搜索引擎将合并所有否定指令。例如:
Googlebot 会抓取收录这些元标记的页面,就好像它们没有 noindex、nofollow 指令一样。
指定不应使用 HTML 页面的哪些部分来生成片段
这可以在 HTML 元素级别使用 span、div 和 section 元素的 data-nosnippetHTML 属性来实现。data-nosnippet 被视为布尔属性。与所有布尔属性一样,任何指定的值都将被忽略。
<p>This text can be shown in a snippet
and this part would not be shown.
not in snippet
also not in snippet
also not in snippet
some text
some text
</p>
Google 通常会渲染网页以对其编制索引,但不能保证它会渲染。因此,可以在渲染之前和之后提取 data-nosnippet。为避免渲染不确定性,请勿通过 JavaScript 添加或删除现有节点的 data-nosnippet 属性。通过 JavaScript 添加 DOM 元素时,在最初将元素添加到网页的 DOM 时,根据需要收录 data-nosnippet 属性。如果使用自定义元素并且您需要使用 data-nosnippet,请通过 div、span 或 section 元素包装或呈现它们。 查看全部
vb抓取网页内容(指令对索引编制或内容显示无任何限制(图))
操作说明
全部
对索引或内容显示没有限制。该指令是默认指令,因此显式列出它没有任何效果。
无索引
不要在搜索结果中显示此网页、媒体或资源。如果您未指定此指令,则此页面、媒体或资产可能会被编入索引并显示在搜索结果中。
不关注
不要点击此页面上的链接。如果您未指定此指令,Google 可能会使用此页面上的链接来发现链接页面。
没有任何
相当于noindex,nofollow。
无档案
不要在搜索结果中显示缓存的链接。如果您不指定此指令,Google 可能会生成一个缓存页面,用户可以通过搜索结果访问该页面。
无摘要
不要在搜索结果中显示页面的文本片段或视频预览。如果有静止图像缩略图,仍然可以显示静止图像缩略图,这可以提供更好的用户体验。这适用于所有形式的搜索结果,包括 Google Web Search、Google 图片和 Google Discover。
如果您未指定此指令,Google 可能会根据页面上的信息生成文本片段和视频预览。
最大片段:[数量]
您最多只能使用 [number] 个字符作为此搜索结果的文本摘要。(请注意,该 URL 可能会在搜索结果页面中显示为多个搜索结果)。这不会影响图片或视频预览。此限制适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Discover 和 Google Assistant。但是,如果发布者已单独授予使用内容的权限,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容,或者与 Google 签订了许可协议,则此设置不会阻止那些更具体的允许使用。如果未指定可解析的 [number],则忽略此指令。
如果您不指定此指令,Google 将选择摘要长度。
特殊价值:
例如:
防止片段出现在搜索结果中:
摘要限制为 20 个字符:
表示摘要没有字数限制:
最大图像预览:[设置]
设置此页面在搜索结果中的最大图像预览大小。
如果您不指定 max-image-preview 指令,Google 可能会以默认大小显示图像预览。
接受的 [设置] 值:
这适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Discover 和 Google Assistant。但是,如果发布者已单独授予使用内容的权限,则此限制不适用。例如,如果发布商以页内结构化数据的形式提供内容(例如 AMP 版本和规范版本的 文章),或者与 Google 签订了许可协议,则此设置不会阻止那些更具体的允许使用.
如果您不希望 Google 搜索或 Google 探索在显示其 文章 AMP 页面和规范版本时使用较大的缩略图,请将 max-image-preview 的值指定为标准或无。
例子:
最大视频预览:[数量]
此页面上的视频在搜索结果中的最大视频片段长度必须为 [number] 秒。
如果您不指定 max-video-preview 指令,Google 可能会在搜索结果中显示视频片段,并由 Google 决定预览内容的时间。
特殊价值:
这适用于所有形式的搜索结果,例如 Google Web Search、Google 图片、Google Video、Google Discover 和 Google Assistant。如果未指定可解析的 [number],则忽略此指令。
例子:
不翻译
不要在搜索结果中提供此页面的翻译。如果您未指定此指令,Google 可能会以搜索查询的语言以外的语言提供搜索结果标题链接和搜索结果的翻译版本。如果用户点击翻译后的标题链接,用户和网页之间的进一步交互将通过谷歌翻译进行,谷歌翻译会自动翻译用户随后访问的链接。
无图像索引
不要索引此页面上的图像。如果您不指定此值,则页面上的图像可能会被索引并显示在搜索结果中。
不可用_之后:[日期/时间]
不要在指定日期/时间之后在搜索结果中显示此页面。日期/时间必须以广泛接受的格式指定,包括但不限于 RFC 822、RFC 850 和 ISO 8601。如果没有指定有效的日期/时间,该指令将被忽略。默认情况下,内容没有过期日期。
如果您不指定此指令,则该页面可能会无限期地出现在搜索结果中。
Googlebot 会在指定日期和时间后显着减慢 URL 的抓取速度。
例子:
注意:nosnippet 表示:不要在此页面的搜索结果中显示片段。
组合索引指令和内容显示指令
您可以组合以逗号分隔的多个机器人元标记指令,以创建具有多个指令的单个命令。下面是一个机器人元标记示例,它指示网络爬虫不要索引页面或爬取页面上的任何链接:
以下示例将文本摘要长度限制为 20 个字符并允许大图像预览:
如果您为每个工具指定多个具有不同指令的爬虫,搜索引擎将合并所有否定指令。例如:
Googlebot 会抓取收录这些元标记的页面,就好像它们没有 noindex、nofollow 指令一样。
指定不应使用 HTML 页面的哪些部分来生成片段
这可以在 HTML 元素级别使用 span、div 和 section 元素的 data-nosnippetHTML 属性来实现。data-nosnippet 被视为布尔属性。与所有布尔属性一样,任何指定的值都将被忽略。
<p>This text can be shown in a snippet
and this part would not be shown.
not in snippet
also not in snippet
also not in snippet
some text
some text
</p>
Google 通常会渲染网页以对其编制索引,但不能保证它会渲染。因此,可以在渲染之前和之后提取 data-nosnippet。为避免渲染不确定性,请勿通过 JavaScript 添加或删除现有节点的 data-nosnippet 属性。通过 JavaScript 添加 DOM 元素时,在最初将元素添加到网页的 DOM 时,根据需要收录 data-nosnippet 属性。如果使用自定义元素并且您需要使用 data-nosnippet,请通过 div、span 或 section 元素包装或呈现它们。
vb抓取网页内容(请问加上“onclick=”的脚本在哪里?分享到:更多…)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-17 03:03
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享到:更多...
4. Python3使用requests包抓取并保存网页源代码。
简介:本文文章主要介绍Python3使用requests包抓取和保存网页源代码的方法,并举例分析Python3环境下requests模块的相关技巧。有需要的朋友可以参考以下
5.在网页源码中看到一句话看不懂,求大神解答
简介:在网页的源码中看到一句话,看不懂,求大神解答{code...} 这个文件完整内容如下:求大神解答上面这句话是什么意思? ? ?
6. php通过网页地址获取地址下的内容 php获取网页内容 php获取网页源代码 php打开网络
介绍:网页地址,php:php通过网页地址获取地址下的内容:方法一(PHP5及以后):$readcontents = fopen("", "rb"); $contents = stream_get_contents($readcontents) ; fclose($readcontents); 回声$内容;方法二:echo file_get_contents(“h
7. 以网页源代码为例,如何判断网页是手机用_html/css_WEB-ITnose
简介:以网页源码为例,如何判断网页是否为移动端
8. PHP如何获取指定网页的源代码?
简介:PHP如何获取指定网页的源代码?
9. 定期获取网页源代码的关键字和描述,彩蛋有点蛋疼
简介:定期获取网页源代码的关键字和描述,蛋有点蛋疼
10.获取网页源代码problem_html/css_WEB-ITnose
简介:获取网页源代码的问题
11.简单理解网页源码(HTML源码)_html/css_WEB-ITnose
简介:网页源码的简单理解(HTML源码)
12. 求去除div标签的解决方案
简介:PHP去除div标签,爬取网页源码后,去除所有DIV标签,正则表达式怎么写?例如
13.为什么新学的静态函数返回空数据?
简介:为什么新学的静态函数返回空数据?最近我正在学习静态函数并构建这样的代码。CURL 获取网页的源代码,定期获取标题等。为什么我的代码什么都没有返回?哪里有问题?你能详细解释一下吗?谢谢。$网址&nbs
14.正则采集相关问题,解决
简介:常规采集问题、解答、在线等目标页面:查看其网页源代码,想要获取第425行的数据,即“今天是2013年10月16日星期三,农历十二”和第621行“沉阳天气预报(发布于2013-10-1618:00)”
15. PHP命令行运行时,没有列出语法异常信息
简介: PHP命令行运行时,没有列出语法错误信息。当我在命令行运行PHP文件时,没有语法错误,也没有提示。什么都没有输出。在没有错误的情况下,可以正确输出运行结果(网页源代码)。我在editplus中配置调试功能时,没有出现语法错误,也没有显示错误信息,只是输出“输出完成(时间0秒)-正常终止”,在没有错误的情况下可以正确输出。是吗
16. 这个地方如何运作
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享至:更多
17.关于php采集网页数据获取js动态数据相关问题
简介:关于从php采集网页数据获取js动态数据的问题,给个网页地址,我想得到这个视频的下载地址,来自虎鱼网,然后没有下载地址在网页源代码中,这是关于视频播放的。段的代码然后就可以在控制台看到视频加载后的地址,也就是&
18.定期获取网页源码的关键字和描述,彩蛋有点蛋疼
简介:定期获取网页源代码的关键字和描述,蛋蛋有点蛋疼。情况一:
19. 这个地方是如何运作的
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享至:更多
20. PHP命令行运行时,没有列出语法异常信息
简介: PHP命令行运行时,没有列出语法错误信息。当我在命令行运行PHP文件时,没有语法错误,也没有提示。什么都没有输出。在没有错误的情况下,可以正确输出运行结果(网页源代码)。我在editplus中配置调试功能时,没有出现语法错误,也没有显示错误信息,只是输出“输出完成(时间0秒)-正常终止”,在没有错误的情况下可以正确输出。是吗
21.正则采集相关问题,解决
简介:常规采集问题、解答、在线等目标页面:查看其网页源代码,想要获取第425行的数据,即“今天是2013年10月16日星期三,农历十二”和第621行“沉阳天气预报(发布于2013-10-1618:00)”和
22.为什么新学的静态函数返回空数据?
简介:为什么新学的静态函数返回空数据?最近我正在学习静态函数并构建这样的代码。CURL 获取网页的源代码,定期获取标题等。为什么我的代码什么都没有返回?哪里有问题?你能详细解释一下吗?谢谢。$网址=
23. 求去除div标签的解决方案
简介:PHP去除div标签,爬取网页源码后,去除所有DIV标签,正则表达式怎么写?例如
24. 批量移除PHP文件中bom的PHP代码_php实例
简介:我在搜索查看网页源代码的时候发现了为什么开头有一个空行的问题,并批量删除了php文件中bom的php代码
25.thinkphp网页源码dock中空行的解决方法
简介:无意中查看了博客和博客页面的源码,发现源码顶部有7行,如图:怎么回事?我检查了模板,发现顶部没有空行。于是打开控制器,发现问题,如图:代码有空行!去掉“”前后的空行,然后查看网页的源代码。有几个空行,但仍然有两三个空行。打开项目模型类,再次删除“”前后的空行。再次打开网页源代码,发现顶部的空行完全消除了!
【相关问答推荐】:
如何在python中获取网页元素之前的所有源代码?
如何判断 URLConnection 超时并自动重连?
android webview在线网页如何加载本地字体库?
WordPress微信分享不显示描述和图标
selenium + PhantomJS 得到的网页数据为什么和chrome调试查看的源码不一样?
以上就是详细说一下网页源代码的现状、前景和机会。更多信息请关注代码高代马文章的其他相关话题! 查看全部
vb抓取网页内容(请问加上“onclick=”的脚本在哪里?分享到:更多…)
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享到:更多...
4. Python3使用requests包抓取并保存网页源代码。
简介:本文文章主要介绍Python3使用requests包抓取和保存网页源代码的方法,并举例分析Python3环境下requests模块的相关技巧。有需要的朋友可以参考以下
5.在网页源码中看到一句话看不懂,求大神解答
简介:在网页的源码中看到一句话,看不懂,求大神解答{code...} 这个文件完整内容如下:求大神解答上面这句话是什么意思? ? ?
6. php通过网页地址获取地址下的内容 php获取网页内容 php获取网页源代码 php打开网络
介绍:网页地址,php:php通过网页地址获取地址下的内容:方法一(PHP5及以后):$readcontents = fopen("", "rb"); $contents = stream_get_contents($readcontents) ; fclose($readcontents); 回声$内容;方法二:echo file_get_contents(“h
7. 以网页源代码为例,如何判断网页是手机用_html/css_WEB-ITnose
简介:以网页源码为例,如何判断网页是否为移动端
8. PHP如何获取指定网页的源代码?
简介:PHP如何获取指定网页的源代码?
9. 定期获取网页源代码的关键字和描述,彩蛋有点蛋疼
简介:定期获取网页源代码的关键字和描述,蛋有点蛋疼
10.获取网页源代码problem_html/css_WEB-ITnose
简介:获取网页源代码的问题
11.简单理解网页源码(HTML源码)_html/css_WEB-ITnose
简介:网页源码的简单理解(HTML源码)
12. 求去除div标签的解决方案
简介:PHP去除div标签,爬取网页源码后,去除所有DIV标签,正则表达式怎么写?例如
13.为什么新学的静态函数返回空数据?
简介:为什么新学的静态函数返回空数据?最近我正在学习静态函数并构建这样的代码。CURL 获取网页的源代码,定期获取标题等。为什么我的代码什么都没有返回?哪里有问题?你能详细解释一下吗?谢谢。$网址&nbs
14.正则采集相关问题,解决
简介:常规采集问题、解答、在线等目标页面:查看其网页源代码,想要获取第425行的数据,即“今天是2013年10月16日星期三,农历十二”和第621行“沉阳天气预报(发布于2013-10-1618:00)”
15. PHP命令行运行时,没有列出语法异常信息
简介: PHP命令行运行时,没有列出语法错误信息。当我在命令行运行PHP文件时,没有语法错误,也没有提示。什么都没有输出。在没有错误的情况下,可以正确输出运行结果(网页源代码)。我在editplus中配置调试功能时,没有出现语法错误,也没有显示错误信息,只是输出“输出完成(时间0秒)-正常终止”,在没有错误的情况下可以正确输出。是吗
16. 这个地方如何运作
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享至:更多
17.关于php采集网页数据获取js动态数据相关问题
简介:关于从php采集网页数据获取js动态数据的问题,给个网页地址,我想得到这个视频的下载地址,来自虎鱼网,然后没有下载地址在网页源代码中,这是关于视频播放的。段的代码然后就可以在控制台看到视频加载后的地址,也就是&
18.定期获取网页源码的关键字和描述,彩蛋有点蛋疼
简介:定期获取网页源代码的关键字和描述,蛋蛋有点蛋疼。情况一:
19. 这个地方是如何运作的
简介:这个地方是怎么来的?鼠标点击时显示图片中的小喇叭,但网页源码中看不到“onclick=”字样。添加了“onclick=”的脚本在哪里?分享至:更多
20. PHP命令行运行时,没有列出语法异常信息
简介: PHP命令行运行时,没有列出语法错误信息。当我在命令行运行PHP文件时,没有语法错误,也没有提示。什么都没有输出。在没有错误的情况下,可以正确输出运行结果(网页源代码)。我在editplus中配置调试功能时,没有出现语法错误,也没有显示错误信息,只是输出“输出完成(时间0秒)-正常终止”,在没有错误的情况下可以正确输出。是吗
21.正则采集相关问题,解决
简介:常规采集问题、解答、在线等目标页面:查看其网页源代码,想要获取第425行的数据,即“今天是2013年10月16日星期三,农历十二”和第621行“沉阳天气预报(发布于2013-10-1618:00)”和
22.为什么新学的静态函数返回空数据?
简介:为什么新学的静态函数返回空数据?最近我正在学习静态函数并构建这样的代码。CURL 获取网页的源代码,定期获取标题等。为什么我的代码什么都没有返回?哪里有问题?你能详细解释一下吗?谢谢。$网址=
23. 求去除div标签的解决方案
简介:PHP去除div标签,爬取网页源码后,去除所有DIV标签,正则表达式怎么写?例如
24. 批量移除PHP文件中bom的PHP代码_php实例
简介:我在搜索查看网页源代码的时候发现了为什么开头有一个空行的问题,并批量删除了php文件中bom的php代码
25.thinkphp网页源码dock中空行的解决方法
简介:无意中查看了博客和博客页面的源码,发现源码顶部有7行,如图:怎么回事?我检查了模板,发现顶部没有空行。于是打开控制器,发现问题,如图:代码有空行!去掉“”前后的空行,然后查看网页的源代码。有几个空行,但仍然有两三个空行。打开项目模型类,再次删除“”前后的空行。再次打开网页源代码,发现顶部的空行完全消除了!
【相关问答推荐】:
如何在python中获取网页元素之前的所有源代码?
如何判断 URLConnection 超时并自动重连?
android webview在线网页如何加载本地字体库?
WordPress微信分享不显示描述和图标
selenium + PhantomJS 得到的网页数据为什么和chrome调试查看的源码不一样?
以上就是详细说一下网页源代码的现状、前景和机会。更多信息请关注代码高代马文章的其他相关话题!
vb抓取网页内容(vb抓取网页内容抓取的格式差异有哪些??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-16 03:02
vb抓取网页内容vb只是一种语言,而python也是有第三方类库提供类似功能,除此之外python爬虫和vb比,vb比较简单,获取网页的内容更容易,从来都是设计得比较文明。针对不同的网站,根据类库的扩展形式不同,或许获取的格式也有所差异。iifesvb是基于web的函数式编程语言,由于其优美的风格,github上一个非常流行的开源库:iifes可以自动的对网页中的语句进行重写,输出的结果基于vb的text函数进行排版,但这个东西设计成这样只适合放在单页面内部,不会影响到用户的浏览,也不会影响到flash。
同时,它既可以当成ruby以及python的类库,也可以扩展到node.js等其他语言上。pygal可以生成javascript代码并返回,然后你可以用js和javascript进行交互。pygal有着simplexpath函数(单元格和文本中)、concatenate函数以及pageranswers等一系列快速的函数。
vlookupiifesvb中每个html文件中的url可以用iifesbyurl取值并匹配查询之后的url;而vlookup则是可以获取多个查询,只要查询不超过一个url就行。iifesbyurl是双向的,如果你要先取url的第一个字符,再取一个url的全部字符(注意字符串的索引是index+1);如果要先取查询第一个字符,再获取剩下的两个字符,这个是单向的。
如果不要求双向,并且只允许匹配两个字符,那么你也可以试试bloom_documents。substitute对于相同的数据,比如两个list的name字段,如果可以substitute一个,那么它们可以进行匹配:substitute(url,oldurl);但是比如你第一个不可以,对于url存在相同元素的情况,substitute(url,newurl)都可以进行匹配。
apply在vb中你只需要写apply()方法即可,返回的结果是你传递进来的参数,对方如果需要,则会从newurl获取(并且返回oldurl的值)。但是python就不好直接使用dict的apply函数了,dict是把所有元素的组合和列表进行混合的实现。需要额外定义几个方法:p1=list(dict('x','f','x','y','x','y'))p2=list(dict(x,y))apply(x,y)下面这个截图是随便复制粘贴的,python不用你自己写代码的话,当然apply()方法可以省略了,直接在后面加个python的函数名就行。
isclick显示并点击的文本,从vb来看,相当于vbscript里面的isclick,是否是这样比vb更简单,并且更灵活呢?当然,也可以用其他方法来实现,比如document.write方法就可以,不过比较过于简单。ifnothttp.isapproximately(metho。 查看全部
vb抓取网页内容(vb抓取网页内容抓取的格式差异有哪些??)
vb抓取网页内容vb只是一种语言,而python也是有第三方类库提供类似功能,除此之外python爬虫和vb比,vb比较简单,获取网页的内容更容易,从来都是设计得比较文明。针对不同的网站,根据类库的扩展形式不同,或许获取的格式也有所差异。iifesvb是基于web的函数式编程语言,由于其优美的风格,github上一个非常流行的开源库:iifes可以自动的对网页中的语句进行重写,输出的结果基于vb的text函数进行排版,但这个东西设计成这样只适合放在单页面内部,不会影响到用户的浏览,也不会影响到flash。
同时,它既可以当成ruby以及python的类库,也可以扩展到node.js等其他语言上。pygal可以生成javascript代码并返回,然后你可以用js和javascript进行交互。pygal有着simplexpath函数(单元格和文本中)、concatenate函数以及pageranswers等一系列快速的函数。
vlookupiifesvb中每个html文件中的url可以用iifesbyurl取值并匹配查询之后的url;而vlookup则是可以获取多个查询,只要查询不超过一个url就行。iifesbyurl是双向的,如果你要先取url的第一个字符,再取一个url的全部字符(注意字符串的索引是index+1);如果要先取查询第一个字符,再获取剩下的两个字符,这个是单向的。
如果不要求双向,并且只允许匹配两个字符,那么你也可以试试bloom_documents。substitute对于相同的数据,比如两个list的name字段,如果可以substitute一个,那么它们可以进行匹配:substitute(url,oldurl);但是比如你第一个不可以,对于url存在相同元素的情况,substitute(url,newurl)都可以进行匹配。
apply在vb中你只需要写apply()方法即可,返回的结果是你传递进来的参数,对方如果需要,则会从newurl获取(并且返回oldurl的值)。但是python就不好直接使用dict的apply函数了,dict是把所有元素的组合和列表进行混合的实现。需要额外定义几个方法:p1=list(dict('x','f','x','y','x','y'))p2=list(dict(x,y))apply(x,y)下面这个截图是随便复制粘贴的,python不用你自己写代码的话,当然apply()方法可以省略了,直接在后面加个python的函数名就行。
isclick显示并点击的文本,从vb来看,相当于vbscript里面的isclick,是否是这样比vb更简单,并且更灵活呢?当然,也可以用其他方法来实现,比如document.write方法就可以,不过比较过于简单。ifnothttp.isapproximately(metho。
vb抓取网页内容(网上无法下载的“小说在线阅读”内容?有种 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-11 08:12
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多yii,想找点东西调整一下……= =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网......再次声明,我们不对任何版权负责......
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
要替换为换行符,是网页中的占位符,即空格,替换为空格即可。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
# -*- coding: utf-8 -*- import urllib2 import re import chardet class Book_Spider: def __init__(self): self.pages = [] # 抓取一个章节 def GetPage(self): myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } request = urllib2.Request(myUrl, headers = headers) myResponse = urllib2.urlopen(request) myPage = myResponse.read() #先检测网页的字符编码,最后统一转为 utf-8 charset = chardet.detect(myPage) charset = charset['encoding'] if charset == 'utf-8' or charset == 'UTF-8': myPage = myPage else: myPage = myPage.decode('gb2312','ignore').encode('utf-8') unicodePage = myPage.decode("utf-8") try: #抓取标题 my_title = re.search('(.*?)',unicodePage,re.S) my_title = my_title.group(1) except: print '标题 HTML 变化,请重新分析!' return False try: #抓取章节内容 my_content = re.search('(.*?) 查看全部
vb抓取网页内容(网上无法下载的“小说在线阅读”内容?有种
)
你还在为无法在线下载的“小说在线阅读”内容而烦恼吗?或者是一些文章的内容让你有采集的冲动,却找不到下载链接?你有没有想自己写一个程序来完成这一切的冲动?你是不是学了python,想找点东西炫耀一下自己,告诉别人“兄弟真棒!”?所以让我们开始吧!哈哈~
嗯,最近刚写了很多yii,想找点东西调整一下……= =
本项目以研究为目的。在所有版权问题上,我们都站在作者一边。想看盗版小说的读者,要自己面对墙!
说了这么多,我们要做的就是从网页中爬取小说正文的内容。我们的研究对象是全本小说网......再次声明,我们不对任何版权负责......
一开始,做最基础的内容,即抓取某一章的内容。
环境:Ubuntu,Python 2.7
基础知识
本程序涉及到的知识点有几个,这里罗列一下,不赘述,会有一堆直接百度的疑惑。
1. urllib2 模块的请求对象,用于设置 HTTP 请求,包括获取的 url,以及伪装成浏览器代理。然后就是urlopen和read方法,很好理解。
2.chardet 模块,用于检测网页的编码。网页抓取数据时容易遇到乱码问题。为了判断网页是gtk编码还是utf-8,使用chardet的detect函数进行检测。使用Windows的同学可以在这里下载,解压到python的lib目录下。
3. decode函数将字符串从某种编码转换为unicode字符,encode将unicode字符转换为指定编码格式的字符串。
4. re 模块正则表达式的应用。搜索功能可以找到匹配正则表达式的项目,replace是替换匹配的字符串。
思路分析:
我们选择的网址是斗罗大陆第一章。可以查看网页的源码,会发现只有一个内容标签收录了所有章节的内容,所以可以使用正则表达式匹配内容标签并抓取。试着把这部分打印出来,你会发现很多
和 ,
要替换为换行符,是网页中的占位符,即空格,替换为空格即可。这一章的内容非常漂亮。为了完整起见,也使用正则来爬下标题。
程序
# -*- coding: utf-8 -*- import urllib2 import re import chardet class Book_Spider: def __init__(self): self.pages = [] # 抓取一个章节 def GetPage(self): myUrl = "http://www.quanben.com/xiaoshu ... 3B%3B user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } request = urllib2.Request(myUrl, headers = headers) myResponse = urllib2.urlopen(request) myPage = myResponse.read() #先检测网页的字符编码,最后统一转为 utf-8 charset = chardet.detect(myPage) charset = charset['encoding'] if charset == 'utf-8' or charset == 'UTF-8': myPage = myPage else: myPage = myPage.decode('gb2312','ignore').encode('utf-8') unicodePage = myPage.decode("utf-8") try: #抓取标题 my_title = re.search('(.*?)',unicodePage,re.S) my_title = my_title.group(1) except: print '标题 HTML 变化,请重新分析!' return False try: #抓取章节内容 my_content = re.search('(.*?)
vb抓取网页内容(自动跳转如何获取完你要的代码(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-10 18:06
我用vb一个一个的下载页面。如何获得我需要的内容?我需要拦截功能。提到内容后,如何自动跳转到下一页。请教高手,我用的是webbrowser控件,你的问题有点大,直接在DOCUMENTCOMPLETE事件中写webbrowser获取HTML1.document.body.outhtml
这就是所有的HTML代码,然后分析你想要什么。你可以通过分析字符串来截取你想要的内容
你也可以根据HTML代码的属性获取你想要的内容。
自动跳跃更容易。得到你想要的代码后,webbrowser1.再次导航url。
'提取每个文本分区标签(div)中的源代码
VB代码:
私有子Form_Load()
WebBrowser1.导航“”
结束子
Private Sub WebBrowser1_DocumentComplete(ByVal pDisp As Object, URL As Variant)
j = WebBrowser1.Document.getElementsByTagName("div").Length - 1
将 aa 调暗为对象
对于 i = 0 到 j
设置 aa = WebBrowser1.Document.getElementsByTagName("div")(i)
s = s & aa.innerHTML & vbCrLf & "---------------------------th" & i & " div 来源--------------------------------" & vbCrLf的代码
下一个
静态 k 作为整数
k = k + 1
如果 s "" 那么
s1 = App.Path & "\" & k & ".txt"
打开 s1 输出为 #1
打印 #1,s
关闭#1
Shell "notepad.exe" & s1, vbNormalFocus
如果结束
结束子 查看全部
vb抓取网页内容(自动跳转如何获取完你要的代码(图))
我用vb一个一个的下载页面。如何获得我需要的内容?我需要拦截功能。提到内容后,如何自动跳转到下一页。请教高手,我用的是webbrowser控件,你的问题有点大,直接在DOCUMENTCOMPLETE事件中写webbrowser获取HTML1.document.body.outhtml
这就是所有的HTML代码,然后分析你想要什么。你可以通过分析字符串来截取你想要的内容
你也可以根据HTML代码的属性获取你想要的内容。
自动跳跃更容易。得到你想要的代码后,webbrowser1.再次导航url。
'提取每个文本分区标签(div)中的源代码
VB代码:
私有子Form_Load()
WebBrowser1.导航“”
结束子
Private Sub WebBrowser1_DocumentComplete(ByVal pDisp As Object, URL As Variant)
j = WebBrowser1.Document.getElementsByTagName("div").Length - 1
将 aa 调暗为对象
对于 i = 0 到 j
设置 aa = WebBrowser1.Document.getElementsByTagName("div")(i)
s = s & aa.innerHTML & vbCrLf & "---------------------------th" & i & " div 来源--------------------------------" & vbCrLf的代码
下一个
静态 k 作为整数
k = k + 1
如果 s "" 那么
s1 = App.Path & "\" & k & ".txt"
打开 s1 输出为 #1
打印 #1,s
关闭#1
Shell "notepad.exe" & s1, vbNormalFocus
如果结束
结束子
vb抓取网页内容(soup,文中通过示例代码介绍的详细内容介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-10 17:18
本篇文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
本篇文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
简单爬取网页信息的思路一般是
1、查看网页源代码
2、爬取网页信息
3、解析网页内容
4、保存到文件
现在使用BeautifulSoup解析库爬取刺猬实习Python职位的工资
一、查看网页源代码
这部分是我们需要的,对应的源码为:
分析源码,我们可以知道:
1、职位信息在
2、每条消息都在
3、每条信息,我们需要提取公司名称、职位、工资
二、爬取网页信息
使用request.get()抓取,返回的soup是网页的文本信息
def get_one_page(url): response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser") return soup
三、解析网页内容
1、找到起始位置
2、匹配的信息
3、返回要存储的信息列表
def parse_page(soup): #待存储的信息列表 return_list = [] #起始位置 grid = soup.find('section', attrs={"class": "widget-job-list"}) if grid: #找到所有的岗位列表 job_list = soup.find_all('article', attrs={"class": "widget item"}) #匹配各项内容 for job in job_list: #find()是寻找第一个符合的标签 company = job.find('a', attrs={"class": "crop"}).get_text().strip()#返回类型为string,用strip()可以去除空白符,换行符 title = job.find('code').get_text() salary = job.find('span', attrs={"class": "color-3"}).get_text() #将信息存到列表中并返回 return_list.append(company + " " + title + " " + salary) return return_list
四、保存到文件
将列表信息存储到 shixi.csv 文件中
def write_to_file(content): #以追加的方式打开,设置编码格式防止乱码 with open("shixi.csv", "a", encoding="gb18030")as f: f.write("\n".join(content))
五、爬取多页信息
在网页url中可以看到最后一页代表页码信息
所以在main方法中传入一个页面,然后循环运行main(page)爬取多页信息
def main(page): url = 'https://www.ciweishixi.com/search?key=python&page=' + str(page) soup = get_one_page(url) return_list = parse_page(soup) write_to_file(return_list) if __name__ == "__main__": for i in range(4): main(i)
六、运行结果
七、完整代码
import requests import re from bs4 import BeautifulSoup def get_one_page(url): response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser") return soup def parse_page(soup): #待存储的信息列表 return_list = [] #起始位置 grid = soup.find('section', attrs={"class": "widget-job-list"}) if grid: #找到所有的岗位列表 job_list = soup.find_all('article', attrs={"class": "widget item"}) #匹配各项内容 for job in job_list: #find()是寻找第一个符合的标签 company = job.find('a', attrs={"class": "crop"}).get_text().strip()#返回类型为string,用strip()可以去除空白符,换行符 title = job.find('code').get_text() salary = job.find('span', attrs={"class": "color-3"}).get_text() #将信息存到列表中并返回 return_list.append(company + " " + title + " " + salary) return return_list def write_to_file(content): #以追加的方式打开,设置编码格式防止乱码 with open("shixi.csv", "a", encoding="gb18030")as f: f.write("\n".join(content)) def main(page): url = 'https://www.ciweishixi.com/search?key=python&page=' + str(page) soup = get_one_page(url) return_list = parse_page(soup) write_to_file(return_list) if __name__ == "__main__": for i in range(4): main(i)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网站。
以上就是Python如何使用BeautifulSoup抓取网页信息的详细内容。更多内容请关注html中文网文章其他相关话题! 查看全部
vb抓取网页内容(soup,文中通过示例代码介绍的详细内容介绍-乐题库)
本篇文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
本篇文章主要介绍Python如何使用BeautifulSoup抓取网页信息。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。有需要的朋友可以参考以下
简单爬取网页信息的思路一般是
1、查看网页源代码
2、爬取网页信息
3、解析网页内容
4、保存到文件
现在使用BeautifulSoup解析库爬取刺猬实习Python职位的工资
一、查看网页源代码
这部分是我们需要的,对应的源码为:
分析源码,我们可以知道:
1、职位信息在
2、每条消息都在
3、每条信息,我们需要提取公司名称、职位、工资
二、爬取网页信息
使用request.get()抓取,返回的soup是网页的文本信息
def get_one_page(url): response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser") return soup
三、解析网页内容
1、找到起始位置
2、匹配的信息
3、返回要存储的信息列表
def parse_page(soup): #待存储的信息列表 return_list = [] #起始位置 grid = soup.find('section', attrs={"class": "widget-job-list"}) if grid: #找到所有的岗位列表 job_list = soup.find_all('article', attrs={"class": "widget item"}) #匹配各项内容 for job in job_list: #find()是寻找第一个符合的标签 company = job.find('a', attrs={"class": "crop"}).get_text().strip()#返回类型为string,用strip()可以去除空白符,换行符 title = job.find('code').get_text() salary = job.find('span', attrs={"class": "color-3"}).get_text() #将信息存到列表中并返回 return_list.append(company + " " + title + " " + salary) return return_list
四、保存到文件
将列表信息存储到 shixi.csv 文件中
def write_to_file(content): #以追加的方式打开,设置编码格式防止乱码 with open("shixi.csv", "a", encoding="gb18030")as f: f.write("\n".join(content))
五、爬取多页信息
在网页url中可以看到最后一页代表页码信息
所以在main方法中传入一个页面,然后循环运行main(page)爬取多页信息
def main(page): url = 'https://www.ciweishixi.com/search?key=python&page=' + str(page) soup = get_one_page(url) return_list = parse_page(soup) write_to_file(return_list) if __name__ == "__main__": for i in range(4): main(i)
六、运行结果
七、完整代码
import requests import re from bs4 import BeautifulSoup def get_one_page(url): response = requests.get(url) soup = BeautifulSoup(response.text, "html.parser") return soup def parse_page(soup): #待存储的信息列表 return_list = [] #起始位置 grid = soup.find('section', attrs={"class": "widget-job-list"}) if grid: #找到所有的岗位列表 job_list = soup.find_all('article', attrs={"class": "widget item"}) #匹配各项内容 for job in job_list: #find()是寻找第一个符合的标签 company = job.find('a', attrs={"class": "crop"}).get_text().strip()#返回类型为string,用strip()可以去除空白符,换行符 title = job.find('code').get_text() salary = job.find('span', attrs={"class": "color-3"}).get_text() #将信息存到列表中并返回 return_list.append(company + " " + title + " " + salary) return return_list def write_to_file(content): #以追加的方式打开,设置编码格式防止乱码 with open("shixi.csv", "a", encoding="gb18030")as f: f.write("\n".join(content)) def main(page): url = 'https://www.ciweishixi.com/search?key=python&page=' + str(page) soup = get_one_page(url) return_list = parse_page(soup) write_to_file(return_list) if __name__ == "__main__": for i in range(4): main(i)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持html中文网站。
以上就是Python如何使用BeautifulSoup抓取网页信息的详细内容。更多内容请关注html中文网文章其他相关话题!
vb抓取网页内容(xml能做些什么?代表一种xml数据格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-08 17:03
vb抓取网页内容,一般都用xml类型抓取。xml代表一种xml-root。xml代表一种xml数据格式。对于将来的产品或服务需要传输数据时,我一般都使用xml。特别是对于在移动端使用的人,xml数据会显得更加方便。接下来,我们就一起看看xml能做些什么?在说xml能做什么之前,首先要说说一个基本概念:基本的文本格式。
我们看看ide或ide的快捷键,i:基本排版格式i:基本语句格式t:基本表格格式t:基本声明格式w:基本程序格式i:符号表格格式..当然,它们在实际应用中会发生多种多样的作用,我会在后面一一阐述。现在来看xml可以做些什么,以c51程序的xml实例为例。首先,我们要为网页自定义语法。xmlxml代表一种xml数据格式。也就是说,在web编程中,xml就是一种自定义语法。下面我们通过一个xml实例,为你感受一下。
1、创建xml文件使用windows和linux创建一个xml文件,一般有三种方式。windows的xml建立非常简单,只需要在cmd命令行中运行xml.exe,打开的便是xml文件。而linux系统使用的命令是xml.local。这个local目录下面有6个文件,而我们要使用的xml.exe便在这个local目录下。
由于linux系统对中文支持不好,因此我们还需要手动处理中文字符。由于linux系统支持中文,因此我们还需要手动处理中文字符。通过查看文件名,我们能够得知xml.exe所在的目录,我们可以在home目录下创建一个xml.woff文件。
2、在windows和linux上定义xml文件我们以windows上的定义xml文件为例,而且xml文件必须在指定的文件夹下。在windows上,xml文件可以使用以下几种文件名的组合形式。windowsxml文件的名称以.exe结尾。在linux系统上,xml文件的名称就是网页名称。我们看一下exe的代码。
如下图所示:windowsxml文件实例,图片显示方法windowsxml文件实例,代码实现、页面显示完成windowsxml文件实例,页面显示完成与此相同,在linux系统上也是这样操作。因此,我们可以通过上面我们定义的一个xml文件定义,在linux系统上去更改它。下面代码为windowsxml文件实例,里面的代码非常有必要。
3、在linux上定义xml文件接下来,为你介绍linux系统上使用xml.local来定义xml文件。我们可以直接运行gccgen.xml命令生成一个xml文件。如下图所示。gccgen.xml1.exexml文件里面有以下3种text数据:elementnode以及content,前者对应页面节点,后者对应页面文本。代码实现通过gccgen.xml1.exe。 查看全部
vb抓取网页内容(xml能做些什么?代表一种xml数据格式)
vb抓取网页内容,一般都用xml类型抓取。xml代表一种xml-root。xml代表一种xml数据格式。对于将来的产品或服务需要传输数据时,我一般都使用xml。特别是对于在移动端使用的人,xml数据会显得更加方便。接下来,我们就一起看看xml能做些什么?在说xml能做什么之前,首先要说说一个基本概念:基本的文本格式。
我们看看ide或ide的快捷键,i:基本排版格式i:基本语句格式t:基本表格格式t:基本声明格式w:基本程序格式i:符号表格格式..当然,它们在实际应用中会发生多种多样的作用,我会在后面一一阐述。现在来看xml可以做些什么,以c51程序的xml实例为例。首先,我们要为网页自定义语法。xmlxml代表一种xml数据格式。也就是说,在web编程中,xml就是一种自定义语法。下面我们通过一个xml实例,为你感受一下。
1、创建xml文件使用windows和linux创建一个xml文件,一般有三种方式。windows的xml建立非常简单,只需要在cmd命令行中运行xml.exe,打开的便是xml文件。而linux系统使用的命令是xml.local。这个local目录下面有6个文件,而我们要使用的xml.exe便在这个local目录下。
由于linux系统对中文支持不好,因此我们还需要手动处理中文字符。由于linux系统支持中文,因此我们还需要手动处理中文字符。通过查看文件名,我们能够得知xml.exe所在的目录,我们可以在home目录下创建一个xml.woff文件。
2、在windows和linux上定义xml文件我们以windows上的定义xml文件为例,而且xml文件必须在指定的文件夹下。在windows上,xml文件可以使用以下几种文件名的组合形式。windowsxml文件的名称以.exe结尾。在linux系统上,xml文件的名称就是网页名称。我们看一下exe的代码。
如下图所示:windowsxml文件实例,图片显示方法windowsxml文件实例,代码实现、页面显示完成windowsxml文件实例,页面显示完成与此相同,在linux系统上也是这样操作。因此,我们可以通过上面我们定义的一个xml文件定义,在linux系统上去更改它。下面代码为windowsxml文件实例,里面的代码非常有必要。
3、在linux上定义xml文件接下来,为你介绍linux系统上使用xml.local来定义xml文件。我们可以直接运行gccgen.xml命令生成一个xml文件。如下图所示。gccgen.xml1.exexml文件里面有以下3种text数据:elementnode以及content,前者对应页面节点,后者对应页面文本。代码实现通过gccgen.xml1.exe。
vb抓取网页内容(我是想一直让他循环找元素,还要找不同网页的元素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-01-05 07:00
我想让他循环搜索元素,以及来自不同网页的元素。如果我每次进入网页时都点击该按钮,它将是半自动的。我只是点击了按钮并一直在寻找它。从那些网页中获取元素,这样我就不用整天看电脑了
建议:
1)您应该创建一个列表并以固定格式修复它。例如:
网站地址+1个空格+要查找的元素
2)使用文本文件将其保存在与exe相同的目录中。
3)Form_Load 期间,请动态使用 System.IO.ReadAllLines 读出所有的行,并将它们存储在表单类(String[])类型的公共变量中。同时声明一个WebBrowser类的实体,使用Do...While循环来做(示例代码如下,请根据实际情况更正):
Public Class gb2
Dim wb As New WebBrowser
Dim strings() As String = Nothing
'下标
Dim index As Integer = 0
Private Sub Form1_Load(sender As System.Object, e As System.EventArgs) Handles MyBase.Load
'加载全部内容
strings = System.IO.File.ReadAllLines("C:\\try.txt")
'声明一个新的WebBrowser实体类
AddHandler wb.DocumentCompleted, AddressOf SelfCompleted
Do
wb.Navigate(strings(index).Split(" ")(0)) '取出空格前面部分,也就是url地址
While (wb.ReadyState WebBrowserReadyState.Complete)
Thread.Sleep(10)
End While
If (index>strings.Length)
index = 0
End If
Loop
End Sub
Private Sub SelfCompleted(sender As Object, e As WebBrowserDocumentCompletedEventArgs)
wb.Document.Window.Frames(0).Document.GetElementsByTagName(strings(index).Split(" ")(0)) '处理你找到的东西
End Sub
End Class
QQ我:
下载 MSDN 桌面工具 (Vista,Win7)
我的博客园
慈善点击,点击这里 查看全部
vb抓取网页内容(我是想一直让他循环找元素,还要找不同网页的元素)
我想让他循环搜索元素,以及来自不同网页的元素。如果我每次进入网页时都点击该按钮,它将是半自动的。我只是点击了按钮并一直在寻找它。从那些网页中获取元素,这样我就不用整天看电脑了
建议:
1)您应该创建一个列表并以固定格式修复它。例如:
网站地址+1个空格+要查找的元素
2)使用文本文件将其保存在与exe相同的目录中。
3)Form_Load 期间,请动态使用 System.IO.ReadAllLines 读出所有的行,并将它们存储在表单类(String[])类型的公共变量中。同时声明一个WebBrowser类的实体,使用Do...While循环来做(示例代码如下,请根据实际情况更正):
Public Class gb2
Dim wb As New WebBrowser
Dim strings() As String = Nothing
'下标
Dim index As Integer = 0
Private Sub Form1_Load(sender As System.Object, e As System.EventArgs) Handles MyBase.Load
'加载全部内容
strings = System.IO.File.ReadAllLines("C:\\try.txt")
'声明一个新的WebBrowser实体类
AddHandler wb.DocumentCompleted, AddressOf SelfCompleted
Do
wb.Navigate(strings(index).Split(" ")(0)) '取出空格前面部分,也就是url地址
While (wb.ReadyState WebBrowserReadyState.Complete)
Thread.Sleep(10)
End While
If (index>strings.Length)
index = 0
End If
Loop
End Sub
Private Sub SelfCompleted(sender As Object, e As WebBrowserDocumentCompletedEventArgs)
wb.Document.Window.Frames(0).Document.GetElementsByTagName(strings(index).Split(" ")(0)) '处理你找到的东西
End Sub
End Class
QQ我:
下载 MSDN 桌面工具 (Vista,Win7)
我的博客园
慈善点击,点击这里
vb抓取网页内容(网页上无法复制的文字多半是什么意思?两种方法可以取文字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-15 19:12
网页上不能复制的大部分文字都受到网络技术的限制。在这种情况下,常规的“鼠标选择+复制粘贴”无法完成文本复制,甚至“查看源代码”、F12开发者模式等方法也无法获取文本。但是下面两种方法可以得到想要的文字。
1、截图OCR
这种方法的原理很简单,就是通过截图的方式对网页上的可见文字进行截图,通过OCR算法立即识别出图片中的文字。以目前的OCR识别技术,文字识别还是相当准确的。这个方法的前提是下载一个好用的工具,我一直在用“Tino OCR”这个小软件。
,指示
首先,双击启动“Tano OCR”。软件启动后,会最小化到任务栏的右下角。然后,打开要复制的网页。最后双击“Tino OCR”图标,鼠标会变成十字进行截屏,您可以选择要截取的文字。选中框后,软件会自动识别里面的文字。这时候你只需要简单的复制粘贴即可。
, 的优点和缺点
优点:只要是可见的网页文字都可以进行截图OCR,没有任何技术可以限制,而且OCR的速度非常快。
缺点:必须运行该工具,会占用系统资源的一小部分,基本可以忽略。另外,如果需要VIP来展示内容,也不能绕过VIP。
2、使用搜索或翻译功能
这种方法特别适用于“一定程度图书馆”的文章。其原理是利用一定程度上提供的搜索或翻译功能来获取文章的文本。因为搜索和翻译本身需要获取文章的文本。
,指示
打开某个学位库的文章后,选择一段你想要的文字。这时候系统会自动弹出一个浮动框,里面有“搜索、复制、发送到手机、翻译”4个选项。当您单击搜索或翻译这两个菜单时,Web 浏览器会自动打开一个新选项卡并在搜索框或翻译框中显示文本。这时候就可以自由复制粘贴了。(注:菜单中的副本只有开通VIP后才能使用)
, 的优点和缺点
优点:无需购买VIP,即可自由复制库内容;
缺点:只适用于一定程度的图书馆。同时,如果预览查看部分被限制在一定程度上,也是无法实现的。
总结
目前,很多禁止复制的网站都采用了先进的限制技术。普通的查看源码和开发者模式已经应付不来了,但是截图OCR还是经得起时间考验的,只要能看,就能被OCR识别和复制。至于一定程度的图书馆,也可以复制,自带搜索翻译功能。 查看全部
vb抓取网页内容(网页上无法复制的文字多半是什么意思?两种方法可以取文字)
网页上不能复制的大部分文字都受到网络技术的限制。在这种情况下,常规的“鼠标选择+复制粘贴”无法完成文本复制,甚至“查看源代码”、F12开发者模式等方法也无法获取文本。但是下面两种方法可以得到想要的文字。
1、截图OCR
这种方法的原理很简单,就是通过截图的方式对网页上的可见文字进行截图,通过OCR算法立即识别出图片中的文字。以目前的OCR识别技术,文字识别还是相当准确的。这个方法的前提是下载一个好用的工具,我一直在用“Tino OCR”这个小软件。
,指示
首先,双击启动“Tano OCR”。软件启动后,会最小化到任务栏的右下角。然后,打开要复制的网页。最后双击“Tino OCR”图标,鼠标会变成十字进行截屏,您可以选择要截取的文字。选中框后,软件会自动识别里面的文字。这时候你只需要简单的复制粘贴即可。
, 的优点和缺点
优点:只要是可见的网页文字都可以进行截图OCR,没有任何技术可以限制,而且OCR的速度非常快。
缺点:必须运行该工具,会占用系统资源的一小部分,基本可以忽略。另外,如果需要VIP来展示内容,也不能绕过VIP。
2、使用搜索或翻译功能
这种方法特别适用于“一定程度图书馆”的文章。其原理是利用一定程度上提供的搜索或翻译功能来获取文章的文本。因为搜索和翻译本身需要获取文章的文本。
,指示
打开某个学位库的文章后,选择一段你想要的文字。这时候系统会自动弹出一个浮动框,里面有“搜索、复制、发送到手机、翻译”4个选项。当您单击搜索或翻译这两个菜单时,Web 浏览器会自动打开一个新选项卡并在搜索框或翻译框中显示文本。这时候就可以自由复制粘贴了。(注:菜单中的副本只有开通VIP后才能使用)
, 的优点和缺点
优点:无需购买VIP,即可自由复制库内容;
缺点:只适用于一定程度的图书馆。同时,如果预览查看部分被限制在一定程度上,也是无法实现的。
总结
目前,很多禁止复制的网站都采用了先进的限制技术。普通的查看源码和开发者模式已经应付不来了,但是截图OCR还是经得起时间考验的,只要能看,就能被OCR识别和复制。至于一定程度的图书馆,也可以复制,自带搜索翻译功能。

