
url
batchcollect pagecollect来自官方杰奇jieqi定时采集配
采集交流 • 优采云 发表了文章 • 0 个评论 • 536 次浏览 • 2020-08-03 17:00
更新时间:2008年07月11日 08:44:35 转载作者:
主要的功能页面为pagecollect.php和batchcollect.php要实现采集,默认方法是按照配置好的采集规则,在浏览器递交相应的参数即可完成前面的采集入库全部动作。
前言
要实现采集,默认方法是按照配置好的采集规则文章定时自动采集,在浏览器递交相应的参数即可完成前面的采集入库全部动作。
而实现定时采集,与人工在浏览器递交有些区别,主要分两大步骤:
一、编写采集的url和相关参数,访问这个url即可实现想要的采集模式。(这个url直接在浏览器递交同样可以实现采集)
二、把定时访问这个url的功能加到系统的定时任务上面,实现无人值守的定时采集。
具体实现方式请参考下边内容:
1、对采集配置文件的解释
任何一个采集都会用到两个采集配置文件(跟后台采集规则配置对应),都可以用文本编辑器打开查看。
其中/configs/article/collectsite.php是对总的采集站点配置,记录了一共容许采集哪几个站点。
里面包含类似这样的内容:
$jieqiCollectsite['1']['name']='采集站点一';
$jieqiCollectsite['1']['config']='abc_com';
$jieqiCollectsite['1']['url']='';
$jieqiCollectsite['1']['subarticleid']='floor($articleid/1000)';
$jieqiCollectsite['1']['enable']='1';
$jieqiCollectsite['2']['name']='采集站点二';
$jieqiCollectsite['2']['config']='def_net';
$jieqiCollectsite['2']['url']='';
$jieqiCollectsite['2']['subarticleid']='';
$jieqiCollectsite['2']['enable']='1';
参数涵义解释如下:
['1']-这里的1表示采集网站的数字序号,不同的采集站序号不能重复。
['name']-采集网站名称。
['config']-网站英文标示,这个网站采集规则配置文件有关,比如这个值是abc_com,那么采集规则配置文件就是/configs/article/site_abc_com.php。
['url']-采集网站网址。
['subarticleid']-采集网站,文章子序号运算方法,本项目主要为了兼容原先程序,新版本上面文章子序号可以通过采集获得。
['enable']-是否容许采集,1表示准许,0表示严禁,默认为1。
如上面所说,每个采集网站有个专门的采集规则配置文件,/configs/article/目录下以site_开头的php文件,如/configs/article/site_abc_com.php。
里面内容都与后台采集规则设置相对应,具体细节不一一解释。需要了解的是本文件上面内容分两大部份,前面内容都是对网站内容采集规则的配置,而最前面$jieqiCollect['listcollect']['0'],$jieqiCollect['listcollect']['1']这样的设置是对网站"批量采集规则"的配置,比如按近来更新采集、按排行榜采集,可以设置多个。['0']这里的数字0表示批量采集类别的数字序号,同一个网站也不能重复。
2、编写采集内容的url及参数
这里的采集是针对多篇文章批量采集,分两种模式:
一、按页面批量采集,比如采集最新更新列表或则排行榜列表,每个链接采集一页。
链接格式如下:
参数含意解释如下:
-是指您的网址。
action-字符串,程序执行的动作命令,固定值为collect。
siteid-数字类型,要采集的网站序号,具体那个网站对应哪些序号见配置文件collectsite.php。
collectname-数字类型,按页面批量采集的类别序号,见配置文件site_xxxx.php上面下边的。$jieqiCollect['listcollect']['0']这样配置的数字。
startpageid--页码标志,表示从列表的第几页开始采集。一般是数字类型,有些网站也可能是字符串。
maxpagenum--数字类型,表示表示一共采集几页。(默认为1,如果要采集多页,是须要浏览器跳转的,只有在windows环境下调用浏览器时侯有效,linux下调用wget时侯最多只能采集一页,需要采集多页可设置多个采集命令。)
notaddnew--数字类型,0-表示采集全部文章,1-表示只更新本站已有的文章。
jieqi_username-字符串,用户名(这个用户必须是本站有权限采集的用户)。
jieqi_userpassword-字符串,用户密码。
二、按照文章序号批量采集
链接格式如下:
,234,345&jieqi_username=admin&jieqi_userpassword=1234
参数含意解释如下:
-是指您的网址。
action-字符串,程序执行的动作命令,固定值为bcollect。
siteid-数字类型,要采集的网站序号,具体那个网站对应哪些序号见配置文件collectsite.php。
batchids-要采集的对方网站文章序号(不是本地的文章序号),采集多个文章,序号用英语冒号分开,如123,234,345。
jieqi_username-字符串,用户名(这个用户必须是本站有权限采集的用户)。
jieqi_userpassword-字符串,用户密码。
注:一个url须要放在IE浏览器上面递交的时侯,整个url最大宽度度不要超过2083字节,所以通常建议这儿的url不要设置成很长,文章多的可以分拆成多个url。
3、利用系统任务实现定时采集
一、windows环境下做法
windows上面可以用系统的任务计划来实现定时执行程序,不过首先须要制做一个批处理文件,在这个文件上面用命令来调用浏览器来执行采集url。需要注意的是命令只能打开浏览器而不会采集好以后手动关掉,要实现采集完手动关掉可以通过javascript实现。自动关掉本窗口的js代码为:
这里的参数3000是指延后关掉时间,单位是微秒,3000表示延后3秒关掉。
这段代码可以在两个地方加入:
一个是加入到提示信息模板/themes/风格名称/msgwin.html上面,和之间加入前面那段js。这样的疗效是整个系统任何提示信息页面就会在3秒钟后手动关掉。
如果您希望仅仅手动关掉采集成功后的提示页面,可以在采集提示信息的语言包上面加入以上javascript,这个配置文件是/modules/article/lang/lang_collect.php,里面$jieqiLang['article']['batch_collect_success']是采集成功的提示信息,这个值原先是:
'恭喜您,全部文章采集完成!';
改成下边这样即可手动关掉
'恭喜您,全部文章采集完成!';
建立批处理文件方式如下:
在任意目录构建一个后缀名为.bat的文件文章定时自动采集,比如D:\collect.bat,然后用文本编辑器输入类似下边的代码
@echooff
"explorer"";siteid=1&collectname=0&startpageid=1&maxpagenum=1&notaddnew=0&jieqi_username=admin&jieqi_userpassword=1234"
"explorer"";siteid=1&batchids=123,234,345&jieqi_username=admin&jieqi_userpassword=1234"
exit
其中
第一句@echooff是表示关掉显示
最后一句exit表示执行完退出
中间每行表示一个采集命令(可以设置多行),就是借助系统的浏览器来执行后面编辑好的采集url。
使用这样的格式:
"explorer""url"
前面部份是命令,后面是采集的url,也可以使用这样的格式:
"%programfiles%\InternetExplorer\IEXPLORE.EXE""url"
前面部份是ie浏览器的路径,后面是采集的url。
这两种命令模式的区别是,有多行命令的时侯,前者会打开多个浏览器窗口同时执行;而后者先打开浏览器执行第一个命令,必须等这个浏览器关掉后才能重新打开一个浏览器执行第二个命令。
编辑好里面的bat文件后,开始在任务计划上面添加执行这个任务,主要步骤如下(每半小时执行一次采集):
a、打开"控制面板",进入"任务计划"。
b、点"添加任务计划"打开任务计划向导进行添加任务。
c、点"下一步",然后点"浏览"选择要执行的程序。(例子上面就是选择D:\collect.bat)
d、设置任务名称及执行频度,比如选择"每天",点"下一步"。
e、选择最开始执行的时间和日期,一般设置比当前时间前面一点就行,点"下一步"。
f、设置执行的用户名和密码(本操作系统的账号),点"下一步"。
g、选择"在单击"完成"时,打开此任务的中级属性",点"完成"。
h、在"日程安排"里面,点"高级",选择"重复任务",设置"每30分钟"执行一次。
i、保存以上设置后即完成系统任务计划。
二、linux环境下做法
linux下可以借助的系统定时任务来执行,也同样须要先制做一个批处理的脚本,方法如下
在任意目录构建一个后缀为.sh的文件,比如/www/collect.sh,需要形参可执行权限,如chmod755/www/collect.sh
里面内容如下: 查看全部
batchcollect pagecollect来自官方杰奇jieqi定时采集配置方式参数解读
更新时间:2008年07月11日 08:44:35 转载作者:
主要的功能页面为pagecollect.php和batchcollect.php要实现采集,默认方法是按照配置好的采集规则,在浏览器递交相应的参数即可完成前面的采集入库全部动作。
前言
要实现采集,默认方法是按照配置好的采集规则文章定时自动采集,在浏览器递交相应的参数即可完成前面的采集入库全部动作。
而实现定时采集,与人工在浏览器递交有些区别,主要分两大步骤:
一、编写采集的url和相关参数,访问这个url即可实现想要的采集模式。(这个url直接在浏览器递交同样可以实现采集)
二、把定时访问这个url的功能加到系统的定时任务上面,实现无人值守的定时采集。
具体实现方式请参考下边内容:
1、对采集配置文件的解释
任何一个采集都会用到两个采集配置文件(跟后台采集规则配置对应),都可以用文本编辑器打开查看。
其中/configs/article/collectsite.php是对总的采集站点配置,记录了一共容许采集哪几个站点。
里面包含类似这样的内容:
$jieqiCollectsite['1']['name']='采集站点一';
$jieqiCollectsite['1']['config']='abc_com';
$jieqiCollectsite['1']['url']='';
$jieqiCollectsite['1']['subarticleid']='floor($articleid/1000)';
$jieqiCollectsite['1']['enable']='1';
$jieqiCollectsite['2']['name']='采集站点二';
$jieqiCollectsite['2']['config']='def_net';
$jieqiCollectsite['2']['url']='';
$jieqiCollectsite['2']['subarticleid']='';
$jieqiCollectsite['2']['enable']='1';
参数涵义解释如下:
['1']-这里的1表示采集网站的数字序号,不同的采集站序号不能重复。
['name']-采集网站名称。
['config']-网站英文标示,这个网站采集规则配置文件有关,比如这个值是abc_com,那么采集规则配置文件就是/configs/article/site_abc_com.php。
['url']-采集网站网址。
['subarticleid']-采集网站,文章子序号运算方法,本项目主要为了兼容原先程序,新版本上面文章子序号可以通过采集获得。
['enable']-是否容许采集,1表示准许,0表示严禁,默认为1。
如上面所说,每个采集网站有个专门的采集规则配置文件,/configs/article/目录下以site_开头的php文件,如/configs/article/site_abc_com.php。
里面内容都与后台采集规则设置相对应,具体细节不一一解释。需要了解的是本文件上面内容分两大部份,前面内容都是对网站内容采集规则的配置,而最前面$jieqiCollect['listcollect']['0'],$jieqiCollect['listcollect']['1']这样的设置是对网站"批量采集规则"的配置,比如按近来更新采集、按排行榜采集,可以设置多个。['0']这里的数字0表示批量采集类别的数字序号,同一个网站也不能重复。
2、编写采集内容的url及参数
这里的采集是针对多篇文章批量采集,分两种模式:
一、按页面批量采集,比如采集最新更新列表或则排行榜列表,每个链接采集一页。
链接格式如下:
参数含意解释如下:
-是指您的网址。
action-字符串,程序执行的动作命令,固定值为collect。
siteid-数字类型,要采集的网站序号,具体那个网站对应哪些序号见配置文件collectsite.php。
collectname-数字类型,按页面批量采集的类别序号,见配置文件site_xxxx.php上面下边的。$jieqiCollect['listcollect']['0']这样配置的数字。
startpageid--页码标志,表示从列表的第几页开始采集。一般是数字类型,有些网站也可能是字符串。
maxpagenum--数字类型,表示表示一共采集几页。(默认为1,如果要采集多页,是须要浏览器跳转的,只有在windows环境下调用浏览器时侯有效,linux下调用wget时侯最多只能采集一页,需要采集多页可设置多个采集命令。)
notaddnew--数字类型,0-表示采集全部文章,1-表示只更新本站已有的文章。
jieqi_username-字符串,用户名(这个用户必须是本站有权限采集的用户)。
jieqi_userpassword-字符串,用户密码。
二、按照文章序号批量采集
链接格式如下:
,234,345&jieqi_username=admin&jieqi_userpassword=1234
参数含意解释如下:
-是指您的网址。
action-字符串,程序执行的动作命令,固定值为bcollect。
siteid-数字类型,要采集的网站序号,具体那个网站对应哪些序号见配置文件collectsite.php。
batchids-要采集的对方网站文章序号(不是本地的文章序号),采集多个文章,序号用英语冒号分开,如123,234,345。
jieqi_username-字符串,用户名(这个用户必须是本站有权限采集的用户)。
jieqi_userpassword-字符串,用户密码。
注:一个url须要放在IE浏览器上面递交的时侯,整个url最大宽度度不要超过2083字节,所以通常建议这儿的url不要设置成很长,文章多的可以分拆成多个url。
3、利用系统任务实现定时采集
一、windows环境下做法
windows上面可以用系统的任务计划来实现定时执行程序,不过首先须要制做一个批处理文件,在这个文件上面用命令来调用浏览器来执行采集url。需要注意的是命令只能打开浏览器而不会采集好以后手动关掉,要实现采集完手动关掉可以通过javascript实现。自动关掉本窗口的js代码为:
这里的参数3000是指延后关掉时间,单位是微秒,3000表示延后3秒关掉。
这段代码可以在两个地方加入:
一个是加入到提示信息模板/themes/风格名称/msgwin.html上面,和之间加入前面那段js。这样的疗效是整个系统任何提示信息页面就会在3秒钟后手动关掉。
如果您希望仅仅手动关掉采集成功后的提示页面,可以在采集提示信息的语言包上面加入以上javascript,这个配置文件是/modules/article/lang/lang_collect.php,里面$jieqiLang['article']['batch_collect_success']是采集成功的提示信息,这个值原先是:
'恭喜您,全部文章采集完成!';
改成下边这样即可手动关掉
'恭喜您,全部文章采集完成!';
建立批处理文件方式如下:
在任意目录构建一个后缀名为.bat的文件文章定时自动采集,比如D:\collect.bat,然后用文本编辑器输入类似下边的代码
@echooff
"explorer"";siteid=1&collectname=0&startpageid=1&maxpagenum=1&notaddnew=0&jieqi_username=admin&jieqi_userpassword=1234"
"explorer"";siteid=1&batchids=123,234,345&jieqi_username=admin&jieqi_userpassword=1234"
exit
其中
第一句@echooff是表示关掉显示
最后一句exit表示执行完退出
中间每行表示一个采集命令(可以设置多行),就是借助系统的浏览器来执行后面编辑好的采集url。
使用这样的格式:
"explorer""url"
前面部份是命令,后面是采集的url,也可以使用这样的格式:
"%programfiles%\InternetExplorer\IEXPLORE.EXE""url"
前面部份是ie浏览器的路径,后面是采集的url。
这两种命令模式的区别是,有多行命令的时侯,前者会打开多个浏览器窗口同时执行;而后者先打开浏览器执行第一个命令,必须等这个浏览器关掉后才能重新打开一个浏览器执行第二个命令。
编辑好里面的bat文件后,开始在任务计划上面添加执行这个任务,主要步骤如下(每半小时执行一次采集):
a、打开"控制面板",进入"任务计划"。
b、点"添加任务计划"打开任务计划向导进行添加任务。
c、点"下一步",然后点"浏览"选择要执行的程序。(例子上面就是选择D:\collect.bat)
d、设置任务名称及执行频度,比如选择"每天",点"下一步"。
e、选择最开始执行的时间和日期,一般设置比当前时间前面一点就行,点"下一步"。
f、设置执行的用户名和密码(本操作系统的账号),点"下一步"。
g、选择"在单击"完成"时,打开此任务的中级属性",点"完成"。
h、在"日程安排"里面,点"高级",选择"重复任务",设置"每30分钟"执行一次。
i、保存以上设置后即完成系统任务计划。
二、linux环境下做法
linux下可以借助的系统定时任务来执行,也同样须要先制做一个批处理的脚本,方法如下
在任意目录构建一个后缀为.sh的文件,比如/www/collect.sh,需要形参可执行权限,如chmod755/www/collect.sh
里面内容如下:
最实用的文章采集神器:可依照关键词采集,也能按URL列表采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 678 次浏览 • 2020-08-03 10:54
文章采集来源主要来自以下搜索引擎:
百度网页、百度新闻、搜狗网页、搜狗新闻、微信、360网页、360新闻、今日头条、一点资讯、必应网页、必应新闻、雅虎、谷歌网页、谷歌新闻
下面瞧瞧利器妹的实测报告:
1.根据关键词采集的文章
设定如下:
关键词:人工智能|外星人|虚拟现实
文章发布时间为:最近一天
语言为:简体中文
然后点击开始采集,如下图所示:
采集一会儿后,点击暂停采集,如下图所示,打开文章查看菜单,根据文章采集目录地址查看所采集的每一篇文章,采集的内容可以复制黏贴。
2.根据文章URL列表采集文章
只需将文章URL链接复制黏贴到右边的列表页面中,然后点击开始采集文章,即可进行文章采集。
采集后左侧会显示采集文章的URL,如下图所示
根据弹框消息提示:“已采集403条文章URL!可以将这组URL复制到【根据URL列表采集文章】中采集正文!”,将刚刚采集到的文章URL链接复制到左边那种列表框内,然后就开始采集文章。
采集完成后,再切换到“文章查看”菜单,找到“列表页采集”,按照采集文章的目录就可以查看正文。
另外文章采集还可以进行自定义设置过滤网站。
总结:
这个工具有哪些用途?神器妹觉得,第一类可能就是微信公众号运营者(因为它是支持采集微信文章的)、网站编辑、站长类,采用它采集文章可以提高工作效率。
第二类关键词采集文章,可能就是须要写文章的人关键词采集文章,根据主题关键词采集文章,然后可以借鉴这种文章的思想,七拼八凑就是一篇原创文章,至少也是一篇伪原创文章了,
另外补充一款自媒体全平台文章采集小工具,一并提供下载链接: 查看全部
本期分享一个文章采集神器,支持按照关键词采集文章,以及按照文章URL列表采集文章,可以自定义设置网址过滤,同时,支持在线查看采集的文章。
文章采集来源主要来自以下搜索引擎:
百度网页、百度新闻、搜狗网页、搜狗新闻、微信、360网页、360新闻、今日头条、一点资讯、必应网页、必应新闻、雅虎、谷歌网页、谷歌新闻
下面瞧瞧利器妹的实测报告:
1.根据关键词采集的文章
设定如下:
关键词:人工智能|外星人|虚拟现实
文章发布时间为:最近一天
语言为:简体中文
然后点击开始采集,如下图所示:
采集一会儿后,点击暂停采集,如下图所示,打开文章查看菜单,根据文章采集目录地址查看所采集的每一篇文章,采集的内容可以复制黏贴。
2.根据文章URL列表采集文章
只需将文章URL链接复制黏贴到右边的列表页面中,然后点击开始采集文章,即可进行文章采集。
采集后左侧会显示采集文章的URL,如下图所示
根据弹框消息提示:“已采集403条文章URL!可以将这组URL复制到【根据URL列表采集文章】中采集正文!”,将刚刚采集到的文章URL链接复制到左边那种列表框内,然后就开始采集文章。
采集完成后,再切换到“文章查看”菜单,找到“列表页采集”,按照采集文章的目录就可以查看正文。
另外文章采集还可以进行自定义设置过滤网站。
总结:
这个工具有哪些用途?神器妹觉得,第一类可能就是微信公众号运营者(因为它是支持采集微信文章的)、网站编辑、站长类,采用它采集文章可以提高工作效率。
第二类关键词采集文章,可能就是须要写文章的人关键词采集文章,根据主题关键词采集文章,然后可以借鉴这种文章的思想,七拼八凑就是一篇原创文章,至少也是一篇伪原创文章了,
另外补充一款自媒体全平台文章采集小工具,一并提供下载链接:
网站怎么采集 wordpress怎样实现手动采集
站长必读 • 优采云 发表了文章 • 0 个评论 • 763 次浏览 • 2020-07-18 08:08
WordPress是一种使用PHP语言开发的建站程序平台,现在做博客用wp的早已好多了,很多网站制作培训都使用的是wp,特别是在做采集站的时侯wordpress的共能太强悍。下面就给你们介绍怎样实现wp的手动采集功能。
安装网站采集插件:WP-AutoPost(插件下载地址:)
点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。(这一部分不需要更改设置,唯一须要改动的就是采集的时间。)文章来源设置。在该选项卡下我们须要设置文章来源的文章列表网址及具体文章的匹配规则。我们以采集”新浪互联网新闻“为例,文章列表网址为,因此在手工指定文章列表网址中输入该网址即可,如下所示:
文章网址匹配规则。文章网址匹配规则的设置特别简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配wordpress 文章采集,通常使用URL键值匹配较为简单,但有时使用CSS选择器更为精确。使用URL键值匹配。通过点击列表网址上的文章,我们可以发觉整篇文章的URL都为如下结构:,因此将URL中变化的数字或字母替换为键值(*)即可,如:(*)/(*).shtml 。重复的网址可以使用301重定向。使用CSS选择器进行匹配。使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可,通过查看列表网址的源代码即可轻松设置,找到列表网址下文章超链接的代码,如下所示:
可以看见,文章的超链接A标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为.contList a 即可,如下所示:
设置完成以后,不知道设置是否正确,可以点击上图中的测试按键wordpress 文章采集,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:
其他的设置可以不用更改。以上采集方法适用于WordPress多站点功能。 查看全部
WordPress是一种使用PHP语言开发的建站程序平台,现在做博客用wp的早已好多了,很多网站制作培训都使用的是wp,特别是在做采集站的时侯wordpress的共能太强悍。下面就给你们介绍怎样实现wp的手动采集功能。
安装网站采集插件:WP-AutoPost(插件下载地址:)

点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。(这一部分不需要更改设置,唯一须要改动的就是采集的时间。)文章来源设置。在该选项卡下我们须要设置文章来源的文章列表网址及具体文章的匹配规则。我们以采集”新浪互联网新闻“为例,文章列表网址为,因此在手工指定文章列表网址中输入该网址即可,如下所示:

文章网址匹配规则。文章网址匹配规则的设置特别简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配wordpress 文章采集,通常使用URL键值匹配较为简单,但有时使用CSS选择器更为精确。使用URL键值匹配。通过点击列表网址上的文章,我们可以发觉整篇文章的URL都为如下结构:,因此将URL中变化的数字或字母替换为键值(*)即可,如:(*)/(*).shtml 。重复的网址可以使用301重定向。使用CSS选择器进行匹配。使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可,通过查看列表网址的源代码即可轻松设置,找到列表网址下文章超链接的代码,如下所示:

可以看见,文章的超链接A标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为.contList a 即可,如下所示:

设置完成以后,不知道设置是否正确,可以点击上图中的测试按键wordpress 文章采集,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:

其他的设置可以不用更改。以上采集方法适用于WordPress多站点功能。
爬虫框架(scrapy构架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 578 次浏览 • 2020-07-03 08:00
scrapy主要包括了以下组件: 1.)引擎(scrapy):用来处理整个系统的数据流,触发事务(框架核心) 2.)调度器(Scheduler):用来接受引擎发过来的恳求,压入队列中,并在引擎再度恳求的时侯返回,可以想像成一个url(抓取网页的网址或则说链接)的优先队列,由它来决定下一个要抓取的网址是哪些,同时除去重复的网址。 3.)下载器(Downloader):用于下载网页的内容,并将网页内容返回给蜘蛛(Scrapy下载器是构建在twisted这个高效的异步模型上的) 4.)爬虫(Spiders):爬虫是主要干活的,用于从特定的网页中提取自己想要的信息,即所谓的实体(item)。用户也可以从中提取到链接,让Scrapy继续抓取下一个页面。 5.)项目管线(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管线,并经过几个特定的顺序处理数据。 (只有当调度器中不存在任何request时,整个程序就会停止。(对于下载失败的url,Scrapy也会重新下载))
前置要求: pip下载scrapy模块 yum下载tree包
-确定url地址; -获取页面信息;(urllib,requests) -解析页面提取须要的信息;(xpath,bs4,正则表达时) -保存到本地(scv,json,pymysql,redis) -清洗数据(删除不必要的内容------正则表达式) -分析数据(词云wordcloud,jieba)
-确定url地址(spider) -获取页面信息(Downloader) -解析页面提取须要的信息(spider) -保存到本地(pipeline)
scrapy1.6.0
1.工程创建 1.)命令行在当前目录下创建mySpider
scrapy startproject mySpider
2.)创建成功后,进入mySpider ,tree查看
cd mySpider tree
2.创建一个爬虫
#scrapy genspider 项目名 url scrapy genspider mooc ‘’
3.定义爬取的items内容(items.py)
class CourseItem(scrapy.Item):
#课程标题 title=scrapy.Field() #课程的url地址 url=scrapy.Field() #课程图片的url地址 image_url=scrapy.Field() #课程的描述 introduction=scrapy.Field() #学习人数 student=scrapy.Field()
4.编写spider代码,解析 4.1确定url地址,提取页面须要的信息(mooc.py)
class MoocSpider(scrapy,spider):
#name用于区别爬虫,必须惟一 name=‘mooc’ #允许爬取的域名,其他网站的页面直接跳过 allowd_domains=[‘’,‘’] #爬虫开启时第一个装入调度器的url地址 start_urls=[‘’] #被调用时,每个新的url完成下载后爬虫框架,返回一个响应对象 #下面的方式负责将响应的数据剖析,提取出须要的数据items以及生成下一步须要处理的url地址恳求; def parser(self,response):
##用来检查代码是否达到指定位置,并拿来调试并解析页面信息; #from scrapy.shell import inspect_response #inspect_response(response,self) #1.)实例化对象,CourseItem course=CourseItem() #分析响应的内容 #scrapy剖析页面使用的是xpath方式 #2.)获取每位课程的信息 courseDetails=course.xpath(’.//div[@class=“course-card-container”]’) for courseDetail in courseDetails:
#爬取新的网站, Scrapy上面进行调试(parse命令logging) course[‘title’] = courseDetail.xpath(’.//h3[@class=“course-card-name”]/text()’).extract()[0] #学习人数 course[‘student’] = courseDetail.xpath(’.//span/text()’).extract()[1] #课程描述: course[‘introduction’] = courseDetail.xpath(".//p[@class=‘course-card-desc’]/text()").extract()[0] #课程链接, h获取/learn/9 ====》 course[‘url’] = “” + courseDetail.xpath(’.//a/@href’).extract()[0] #课程的图片url: course[‘image_url’] = ‘http:’ + courseDetail.xpath(’.//img/@src’).extract()[0] yield course #url跟进,获取下一步是否有链接;href url=response.xpath(’.//a[contains[text(),“下一页”]/@href’)[0].extract() if url:
#构建新的url page=‘’+url yield scrapy.Request(page,callback=slef.parse)
4.2保存我们提取的信息(文件格式:scv爬虫框架,json,pymysql)(pipeline.py) 如果多线程,记得在settings.py中分配多个管线并设置优先级:
(1).将爬取的信息保存成json格式
class MyspiderPipeline(object):
def init(self):
self.f=open(Moocfilename,‘w’) #Moocfilename是写在settings.py里的文件名,写在setting.py是因为便捷更改
def process_item(self,item,spider):
#默认传过来的格式是json格式 import json #读取item中的数据,并转化为json格式 line=json.dumps(dict(item),ensure_ascii=False,indent=4) self.f.write(line+’\n’) #一定要返回给调度器 return item
def close_spider(self,spider):
self.f.close()
(2).保存为scv格式
class CsvPipeline(object):
def init(self):
self.f=open(’'mooc.csv",‘w’)
def process_item(self,item,spider):
item=dict(item) self.f.write("{0}:{1}:{2}\n".format(item[‘title’] , item[‘student’] , item[‘url’])) return item
def close_spider(self,spider):
self.f.close()
(3).将爬取的信息保存到数据库中 首先打开数据库创建mooc表
class MysqlPipeline(object):
def init(self):
self.conn=pymysql.connect( host=‘localhost’, user=‘root’, password=‘redhat’, db=‘Mooc’, charset=‘utf8’, ) self.cursor=self.conn.cursor()
def process_item(self,item,spider):
item=dict(item) info=(item[’‘item"] , item[“url”] , item[“image_url”] , item[“introduction”] , item[“student”]) insert_sqil="insert into moocinfo values(’%s’ , ‘%s’ , ‘%s’, ‘%s’ , ‘%s’); " %(info) self.cursor.execute(insert_sqil) mit() return item
def open_spider(self,spider):
create_sqli=“create table if not exists moocinfo (title varchar(50),url varchar(200), image_url varchar(200), introduction varchar(500), student int)” self.cursor.execute(create_sqli)
def close_spider(self,spider):
self.cursor.close() self.conn.close()
(4).通过爬取的图片链接下载图片
class ImagePipeline(object):
def get_media_requests(self,item,info):
#返回一个request请求,包含图片的url
yield scrapy.Request(item['image_url'])
def item_conpleted(self,results,item,info):
#获取下载的地址
image_xpath=[x['path'] for ok , x in results if ok]
if not image_path:
raise Exception('不包含图片')
else:
return item
1.策略一:设置download_delay –作用:设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当于短时间内减小服务器的负载 –缺点:下载等待时间长,不能满足段时间大规模抓取的要求,太短则大大降低了被ban的机率
2.策略二:禁止cookies –cookie有时也用作复数方式cookies,指个别网站为了分辨用户的身分,进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。 –作用:禁止cookies也就避免了可能使用cookies辨识爬虫轨迹的网站得逞 –实现:COOKIES_ENABLES=False
3.策略三:使用user_agent池(拓展:用户代理中间件) –为什么要使用?scrapy本身是使用Scrapy/0.22.2来表明自己的身分。这也就曝露了自己是爬虫的信息。 –user agent ,是指包含浏览器信息,操作系统信息等的一个字符串,也称之为一种特殊的网路合同。服务器通过它判定当前的访问对象是浏览器,邮件客户端还是爬虫。
4.策略四:使用代理中间件 –web server应对爬虫的策略之一就是直接将你的ip或则是整个ip段都封掉严禁访问,这时候,当ip封掉后,转换到其他的ip继续访问即可。
5.策略五:分布式爬虫Scrapy+redis+mysql # 多进程 –Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它借助Redis对用于爬取的恳求(Requests)进行储存和调度(Schedule),并对爬取形成rapy一些比较关键的代码,将Scrapy弄成一个可以在多个主机上同时运行的分布式爬虫。
米鼠网自创立以来仍然专注于从事政府采购、软件项目、人才外包、猎头服务、综合项目等,始终秉持“专业的服务,易用的产品”的经营理念,以“提供高品质的服务、满足顾客的需求、携手共创多赢”为企业目标,为中国境内企业提供国际化、专业化、个性化、的软件项目解决方案,我司拥有一流的项目总监团队,具备过硬的软件项目设计和施行能力,为全省不同行业顾客提供优质的产品和服务,得到了顾客的广泛赞扬。
如有侵权请联系邮箱() 查看全部
1.scrapy构架流程:

scrapy主要包括了以下组件: 1.)引擎(scrapy):用来处理整个系统的数据流,触发事务(框架核心) 2.)调度器(Scheduler):用来接受引擎发过来的恳求,压入队列中,并在引擎再度恳求的时侯返回,可以想像成一个url(抓取网页的网址或则说链接)的优先队列,由它来决定下一个要抓取的网址是哪些,同时除去重复的网址。 3.)下载器(Downloader):用于下载网页的内容,并将网页内容返回给蜘蛛(Scrapy下载器是构建在twisted这个高效的异步模型上的) 4.)爬虫(Spiders):爬虫是主要干活的,用于从特定的网页中提取自己想要的信息,即所谓的实体(item)。用户也可以从中提取到链接,让Scrapy继续抓取下一个页面。 5.)项目管线(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管线,并经过几个特定的顺序处理数据。 (只有当调度器中不存在任何request时,整个程序就会停止。(对于下载失败的url,Scrapy也会重新下载))
前置要求: pip下载scrapy模块 yum下载tree包
-确定url地址; -获取页面信息;(urllib,requests) -解析页面提取须要的信息;(xpath,bs4,正则表达时) -保存到本地(scv,json,pymysql,redis) -清洗数据(删除不必要的内容------正则表达式) -分析数据(词云wordcloud,jieba)
-确定url地址(spider) -获取页面信息(Downloader) -解析页面提取须要的信息(spider) -保存到本地(pipeline)
scrapy1.6.0
1.工程创建 1.)命令行在当前目录下创建mySpider
scrapy startproject mySpider
2.)创建成功后,进入mySpider ,tree查看
cd mySpider tree

2.创建一个爬虫
#scrapy genspider 项目名 url scrapy genspider mooc ‘’
3.定义爬取的items内容(items.py)
class CourseItem(scrapy.Item):
#课程标题 title=scrapy.Field() #课程的url地址 url=scrapy.Field() #课程图片的url地址 image_url=scrapy.Field() #课程的描述 introduction=scrapy.Field() #学习人数 student=scrapy.Field()
4.编写spider代码,解析 4.1确定url地址,提取页面须要的信息(mooc.py)
class MoocSpider(scrapy,spider):
#name用于区别爬虫,必须惟一 name=‘mooc’ #允许爬取的域名,其他网站的页面直接跳过 allowd_domains=[‘’,‘’] #爬虫开启时第一个装入调度器的url地址 start_urls=[‘’] #被调用时,每个新的url完成下载后爬虫框架,返回一个响应对象 #下面的方式负责将响应的数据剖析,提取出须要的数据items以及生成下一步须要处理的url地址恳求; def parser(self,response):
##用来检查代码是否达到指定位置,并拿来调试并解析页面信息; #from scrapy.shell import inspect_response #inspect_response(response,self) #1.)实例化对象,CourseItem course=CourseItem() #分析响应的内容 #scrapy剖析页面使用的是xpath方式 #2.)获取每位课程的信息 courseDetails=course.xpath(’.//div[@class=“course-card-container”]’) for courseDetail in courseDetails:
#爬取新的网站, Scrapy上面进行调试(parse命令logging) course[‘title’] = courseDetail.xpath(’.//h3[@class=“course-card-name”]/text()’).extract()[0] #学习人数 course[‘student’] = courseDetail.xpath(’.//span/text()’).extract()[1] #课程描述: course[‘introduction’] = courseDetail.xpath(".//p[@class=‘course-card-desc’]/text()").extract()[0] #课程链接, h获取/learn/9 ====》 course[‘url’] = “” + courseDetail.xpath(’.//a/@href’).extract()[0] #课程的图片url: course[‘image_url’] = ‘http:’ + courseDetail.xpath(’.//img/@src’).extract()[0] yield course #url跟进,获取下一步是否有链接;href url=response.xpath(’.//a[contains[text(),“下一页”]/@href’)[0].extract() if url:
#构建新的url page=‘’+url yield scrapy.Request(page,callback=slef.parse)
4.2保存我们提取的信息(文件格式:scv爬虫框架,json,pymysql)(pipeline.py) 如果多线程,记得在settings.py中分配多个管线并设置优先级:

(1).将爬取的信息保存成json格式
class MyspiderPipeline(object):
def init(self):
self.f=open(Moocfilename,‘w’) #Moocfilename是写在settings.py里的文件名,写在setting.py是因为便捷更改
def process_item(self,item,spider):
#默认传过来的格式是json格式 import json #读取item中的数据,并转化为json格式 line=json.dumps(dict(item),ensure_ascii=False,indent=4) self.f.write(line+’\n’) #一定要返回给调度器 return item
def close_spider(self,spider):
self.f.close()
(2).保存为scv格式
class CsvPipeline(object):
def init(self):
self.f=open(’'mooc.csv",‘w’)
def process_item(self,item,spider):
item=dict(item) self.f.write("{0}:{1}:{2}\n".format(item[‘title’] , item[‘student’] , item[‘url’])) return item
def close_spider(self,spider):
self.f.close()
(3).将爬取的信息保存到数据库中 首先打开数据库创建mooc表
class MysqlPipeline(object):
def init(self):
self.conn=pymysql.connect( host=‘localhost’, user=‘root’, password=‘redhat’, db=‘Mooc’, charset=‘utf8’, ) self.cursor=self.conn.cursor()
def process_item(self,item,spider):
item=dict(item) info=(item[’‘item"] , item[“url”] , item[“image_url”] , item[“introduction”] , item[“student”]) insert_sqil="insert into moocinfo values(’%s’ , ‘%s’ , ‘%s’, ‘%s’ , ‘%s’); " %(info) self.cursor.execute(insert_sqil) mit() return item
def open_spider(self,spider):
create_sqli=“create table if not exists moocinfo (title varchar(50),url varchar(200), image_url varchar(200), introduction varchar(500), student int)” self.cursor.execute(create_sqli)
def close_spider(self,spider):
self.cursor.close() self.conn.close()
(4).通过爬取的图片链接下载图片
class ImagePipeline(object):
def get_media_requests(self,item,info):
#返回一个request请求,包含图片的url
yield scrapy.Request(item['image_url'])
def item_conpleted(self,results,item,info):
#获取下载的地址
image_xpath=[x['path'] for ok , x in results if ok]
if not image_path:
raise Exception('不包含图片')
else:
return item
1.策略一:设置download_delay –作用:设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当于短时间内减小服务器的负载 –缺点:下载等待时间长,不能满足段时间大规模抓取的要求,太短则大大降低了被ban的机率
2.策略二:禁止cookies –cookie有时也用作复数方式cookies,指个别网站为了分辨用户的身分,进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。 –作用:禁止cookies也就避免了可能使用cookies辨识爬虫轨迹的网站得逞 –实现:COOKIES_ENABLES=False
3.策略三:使用user_agent池(拓展:用户代理中间件) –为什么要使用?scrapy本身是使用Scrapy/0.22.2来表明自己的身分。这也就曝露了自己是爬虫的信息。 –user agent ,是指包含浏览器信息,操作系统信息等的一个字符串,也称之为一种特殊的网路合同。服务器通过它判定当前的访问对象是浏览器,邮件客户端还是爬虫。
4.策略四:使用代理中间件 –web server应对爬虫的策略之一就是直接将你的ip或则是整个ip段都封掉严禁访问,这时候,当ip封掉后,转换到其他的ip继续访问即可。
5.策略五:分布式爬虫Scrapy+redis+mysql # 多进程 –Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它借助Redis对用于爬取的恳求(Requests)进行储存和调度(Schedule),并对爬取形成rapy一些比较关键的代码,将Scrapy弄成一个可以在多个主机上同时运行的分布式爬虫。
米鼠网自创立以来仍然专注于从事政府采购、软件项目、人才外包、猎头服务、综合项目等,始终秉持“专业的服务,易用的产品”的经营理念,以“提供高品质的服务、满足顾客的需求、携手共创多赢”为企业目标,为中国境内企业提供国际化、专业化、个性化、的软件项目解决方案,我司拥有一流的项目总监团队,具备过硬的软件项目设计和施行能力,为全省不同行业顾客提供优质的产品和服务,得到了顾客的广泛赞扬。

如有侵权请联系邮箱()
网络爬虫的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 367 次浏览 • 2020-07-02 08:01
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler 查看全部
第11卷第4期2012年 4月软件导刊Software Guide Vo l. ll NO.4 组己旦2网路爬虫的设计与实现王娟,吴金鹏(贵州|民族学院计算机与信息工程学院,贵州l 贵阳 550025)摘 要:搜索引擎技术随着互联网的日渐壮大而急速发展。作为搜索引擎不可或缺的组成部分,网络爬虫的作用变得尤为重要网络爬虫设计,它的性能直接决定了在庞大的互联网上进行网页信息采集的质量。设计并实现了通用爬虫和限定爬虫。关键词:网络爬虫;通用爬虫;限定爬虫中图分类号 :TP393 文献标识码 :A。哥|言网路爬虫称作网路蜘蛛,它为搜索引擎从万维网上下载网页,并顺着网页的相关链接在 Web 中采集资源,是一个功能太强的网页手动抓取程序,也是搜索引擎的重要组成部份,爬虫设计的优劣直接决定着整个搜索引擎的性能及扩充能力。网络爬虫根据系统结构和实现技术,大致可以分为:通用网路爬虫、主题网路爬虫、增量式网路爬虫、深层网路爬虫 o 实际应用中一般是将几种爬虫技术相结合。1 通用爬虫的设计与实现1. 1 工作原理通用网路爬虫按照预先设定的一个或若干初始种子URL 开始,以此获得初始网页上的 URL 列表,在爬行过程中不断从 URL 队列中获一个个的 URL,进而访问并下载该页面。
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler
Python爬虫的用途
采集交流 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2020-06-30 08:01
Python 爬虫的用途 Python 爬虫是用 Python 编程语言实现的网路爬虫,主要用于网路数据的抓取和处理,相比于其他语言,Python 是一门特别适宜开发网路爬虫的编程语言,大量外置包,可以轻松实现网路爬虫功能。 Python 爬虫可以做的事情好多,如搜索引擎、采集数据、广告过滤等,Python爬虫还可以用于数据剖析,在数据的抓取方面可以作用巨大! n Python 爬虫构架组成 1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取的 url 给网页下载器; 2. 网页下载器:爬取 url 对应的网页,存储成字符串,传送给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管理器。 n Python 爬虫工作原理 Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URL,通过调度器进行传递给下载器网络爬虫 作用,下载 URL 内容,并通过调度器传送给解析器,解析URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值信息的过程。 n Python 爬虫常用框架有: grab:网络爬虫框架(基于 pycurl/multicur); scrapy:网络爬虫框架(基于 twisted),不支持 Python3; pyspider:一个强悍的爬虫系统;cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源,并围绕它完善的对象; demiurge:基于 PyQuery 的爬虫微框架。 Python 爬虫应用领域广泛,在网络爬虫领域处于霸主位置,Scrapy、Request、BeautifuSoap、urlib 等框架的应用,可以实现爬行自如的功能,只要您数据抓取看法网络爬虫 作用,Python 爬虫均可实现!
百度解密百度爬虫对常用的http返回码是如何处理的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2020-06-30 08:00
503返回码的含意是“Service Unavailable”,百度会觉得该网页临时不可访问,通常网站临时关掉,带宽有限等会形成这些情况。对于网页返回503,百度爬虫不会把这 条url直接删掉,短期内会再访问。届时假如网页已恢复,则正常抓取;如果继续返回503,短期内都会反复访问几次。但是若果网页常年返回503,那么这 个url仍会被百度觉得是失效链接,从搜索结果中删掉。
403返回码的含意是“Forbidden”,百度会觉得网页当前严禁访问。对于这些情况,如果是新发觉的url,百度爬虫暂不会抓取,短期内会 再次检测;如果是百度已收录url百度爬虫攻击,当前也不会直接删掉,短期内同样会再访问。届时假如网页容许访问,则正常抓取;如果仍不容许访问,短期内都会反复访问 几次。但是若果网页常年返回403,百度也会觉得是失效链接,从搜索结果中删掉。
404返回码的含意是“NOT FOUND”,百度会觉得网页早已失效,那么一般会从搜索结果中删掉,并且短期内爬虫再度发觉这条url也不会抓取。
301返回码的含意是“Moved Permanently”,百度会觉得网页当前跳转至新url。当遇见站点迁移,域名更换、站点改版的情况时,推荐使用301返回码,尽量降低改版带来的 流量损失。虽然百度爬虫现今对301跳转的响应周期较长,但我们还是推荐你们如此做。
陕西弈聪对于个别常见情况的使用建议:
如果百度爬虫对您的站点抓取压力过大,请尽量不要使用404,同样建议返回503。这样百度爬虫会过段时间再来尝试抓取这个链接,如果哪个时间站点空闲,那它还会被成功抓取了。
有一些网站希望百度只收录部份内容,例如初审后的内容,累积一段时间的新用户页等等。在这些情况,建议新发内容暂时返回403,等初审或做好处理过后,再返回正常状态的返回码。
站点迁移,或域名更换时,请使用301返回码。
如果站点临时关掉,当网页不能打开时,不要立刻返回404,建议使用503状态。503可以告知百度爬虫该页面临时不可访问百度爬虫攻击,请过段时间再重试。
此内容DOC下载
此内容PDF下载
【全文完】 查看全部
百度爬虫对常用的http返回码的处理逻辑?百度爬虫在进行抓取和处理时,是依据http合同规范来设置相应的逻辑的,因此,如果网站/页面发生一些非常状况或则网站某类页面集存在特殊性的时侯,我们必须晓得怎样处理能够更符合百度爬虫,以防止错误的措施给沈阳网站优化带来不必要的风险。在http状态码使用方面做了说明,主要涉及到常见的301、404、403、503状态码的处理建议,非常实用,结合这种知识以及往年遇见的实际情况我会做一点补充应用说明。
503返回码的含意是“Service Unavailable”,百度会觉得该网页临时不可访问,通常网站临时关掉,带宽有限等会形成这些情况。对于网页返回503,百度爬虫不会把这 条url直接删掉,短期内会再访问。届时假如网页已恢复,则正常抓取;如果继续返回503,短期内都会反复访问几次。但是若果网页常年返回503,那么这 个url仍会被百度觉得是失效链接,从搜索结果中删掉。
403返回码的含意是“Forbidden”,百度会觉得网页当前严禁访问。对于这些情况,如果是新发觉的url,百度爬虫暂不会抓取,短期内会 再次检测;如果是百度已收录url百度爬虫攻击,当前也不会直接删掉,短期内同样会再访问。届时假如网页容许访问,则正常抓取;如果仍不容许访问,短期内都会反复访问 几次。但是若果网页常年返回403,百度也会觉得是失效链接,从搜索结果中删掉。
404返回码的含意是“NOT FOUND”,百度会觉得网页早已失效,那么一般会从搜索结果中删掉,并且短期内爬虫再度发觉这条url也不会抓取。
301返回码的含意是“Moved Permanently”,百度会觉得网页当前跳转至新url。当遇见站点迁移,域名更换、站点改版的情况时,推荐使用301返回码,尽量降低改版带来的 流量损失。虽然百度爬虫现今对301跳转的响应周期较长,但我们还是推荐你们如此做。
陕西弈聪对于个别常见情况的使用建议:
如果百度爬虫对您的站点抓取压力过大,请尽量不要使用404,同样建议返回503。这样百度爬虫会过段时间再来尝试抓取这个链接,如果哪个时间站点空闲,那它还会被成功抓取了。
有一些网站希望百度只收录部份内容,例如初审后的内容,累积一段时间的新用户页等等。在这些情况,建议新发内容暂时返回403,等初审或做好处理过后,再返回正常状态的返回码。
站点迁移,或域名更换时,请使用301返回码。
如果站点临时关掉,当网页不能打开时,不要立刻返回404,建议使用503状态。503可以告知百度爬虫该页面临时不可访问百度爬虫攻击,请过段时间再重试。

此内容DOC下载

此内容PDF下载
【全文完】
开源的网路爬虫larbin
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-06-26 08:00
利用larbin,我们可以轻易的获取/确定单个网站的所有连结,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
不过它的最大的亮点还是开源,相信很多人领到larbin源代码的时侯会觉得无从入手,下面是一篇特别不错的开源的网络爬虫/网络蜘蛛larbin结构剖析的文章,有兴趣的最好仔细阅读尝试一下。
互联网是一个庞大的非结构化的数据库,将数据有效的检索并组织呈现下来有着巨大的应用前景,尤其是类似RSS的以XML为基础的结构化的数据越来越 多,内容的组织形式越来越灵活,检索组织并呈现会有着越来越广泛的应用范围,同时在时效性和可读性上也会有越来越高的要求。这一切的基础是爬虫,信息的来 源入口。一个高效,灵活可扩充的爬虫对以上应用都有着无可替代的重要意义。
要设计一个爬虫,首先须要考虑的效率。对于网路而言,基于TCP/IP的通讯编程有几种方式。
第一种是单线程阻塞,这是最简单也最容易实现的一种,一个事例:在Shell中通过curl,pcregrep等一系统命令可以直接实现一个简单的 爬虫,但同时它的效率问题也显而易见:由于是阻塞方法读取,dns解析,建立联接,写入恳求,读取结果这种步骤上就会形成时间的延后,从而未能有效的借助 服务器的全部资源。
第二种是多线程阻塞。建立多个阻塞的线程,分别恳求不同的url。相对于第一种方式,它可以更有效的借助机器的资源,特别是网路资源开源网络爬虫,因为无数线程 在同时工作,所以网路会比较充分的借助,但同时对机器CPU资源的消耗也是比较大,在用户级多线程间的频繁切换对于性能的影响早已值得我们考虑。
第三种是单线程非阻塞。这是目前使用的比较多的一种做法,无论在client还是server都有着广泛的应用。在一个线程内打开多个非阻塞的连 接,通过poll/epoll /select对联接状态进行判定,在第一时间响应恳求,不但充分利用了网路资源,同时也将本机CPU资源的消耗降至最低。这种方式须要对dns恳求,连 接,读写操作都采用异步非阻塞操作,其中第一种比较复杂,可以采用adns作为解决方案,后面三个操作相对简单可以直接在程序内实现。
效率问题解决后就须要考虑具体的设计问题了。
url肯定须要一个单独的类进行处理,包括显示,分析url,得到主机,端口,文件数据。
然后须要对url进行排重,需要一个比较大的url Hash表。
如果还要对网页内容进行排重,则还须要一个Document Hash表。
爬过的url须要记录出来,由于量比较大,我们将它讲到c盘上,所以还须要一个FIFO的类(记作urlsDisk)。
现在须要爬的url同样须要一个FIFO类来处理,重新开始时,url会从定时从爬过的url FIFO里取下来,写到这个FIFO里。正在运行的爬虫须要从这个FIFO里读数据下来,加入到主机类的url列表里。当然,也会从前一个FIFO里直接 读url下来,不过优先级应当比这个上面下来的url低,毕竟是早已爬过的。
爬虫通常是对多个网站进行爬取,但在同时站点内dns的恳求可以只做一次开源网络爬虫,这就须要将主机名独立于url,单独有一个类进行处理。
主机名解析完成后须要有一个解析完成的IP类与之应用,用于connect的时侯使用。
HTML文档的解析类也要有一个,用来剖析网页,取出上面的url,加入到urlsDisk。
再加上一些字符串,调度类,一个简单的爬虫基本上就完成了。
以上基本上是Larbin的设计思路,Larbin在具体实现上还有一些特殊的处理,例如带了一个webserver,以及对特殊文件的处理。 Larbin有一点设计不不太好,就是慢的访问会越来越多,占用大量的联接,需要改进,另外假如对于大规模的爬虫,这仅仅实现了抓取的部份,要分布式的扩 展还须要降低url的集中管理与调度以及前台spider的分布式算法。
Larbin网站爬虫简明使用说明
larbin是一种爬虫工具,我也是前段时间网上见到 Larbin 一种高效的搜索引擎爬虫工具 一文时才晓得有这么个东西,初步认定,我比较喜欢这个工具(比起nutch的crawl来说),因为它是C++写的,类似C嘛,我熟,可以自己改改,顺便 学习一下C++(几年来的经验告诉我说:改他人的东西来学一种技术比从头写helloworld快好多)。于是开始了我辛酸的larbin试用之旅。
回头瞧瞧自己遇见的问题都是因为没认真看文档造成的,唉,老毛病了。下次虽然是E文的也得好好看,不能盲目的试,浪费时间。
larbin官方地址:
一,编译
这也好说,whahahaha,那是!因为从官方网站下出来的代码不能编译通过(linux gcc下)
./configure
make
gcc -O3 -Wall -D_REENTRANT -c -o parse.o parse.c
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
gmake[1]: *** [parse.o] 错误 1
gmake[1]: Leaving directory `/home/leo/leo/larbin-2.6.3/adns’
make: *** [all] 错误 2
函数原型和定义不一致这个好改:
打开./adns/internal.h文件,把568-571行直接注释掉就行了。
二,运行
这个就不说了,./larbin就运行了,larbin.conf中先进行配置就可以了,这个配置就不说了。。
运行后可以:8081 看运行状态,不错的看法。 larbin.conf中有个:inputPort 1976配置,就是可以运行时降低要抓取的URL,这个看法非常好,可是?怎么加呢?象原本那样::1976那样是不行的,报 错???试了很久没结果,最后GDB跟踪了一下,唉,原来直接telnet host 1976进行降低就可以了。后来见到文档里写的亲亲楚楚,晕倒。。。。。
三,结果
哈哈,下班后找了台机子跑了上去,那晚午睡的时侯都梦到自己的搜索引擎赶GOOGLE超BAIDU了,那个激动啊。
第二天下班的时侯取看结果,发现目录下不仅些fifo*文件外哪些都没有,那个纠结。没办法啊,再看文档 How to customize Larbin 发现如此段说明:
The first thing you can define is the module you want to use for ouput. This defines what you want to do with the pages larbin gets. Here are the different options :
DEFAULT_OUTPUT : This module mainly does nothing, except statistics.
SIMPLE_SAVE : This module saves pages on disk. It stores 2000 files per directory (with an index).
MIRROR_SAVE : This module saves pages on disk with the hierarchy of the site they come from. It uses one directory per site.
STATS_OUTPUT : This modules makes some stats on the pages. In order to see the results, see :8081/output.html.
靠,默认哪些都没输出,于是认真的看了官方网站上仅有的两个文档,修改了options.h再编译,终于有结果了。
我的option中改了:
SIMPLE_SAVE 简单输出一个目录两千个文件,包含索引。
CGILEVEL=0 处理服务器端程序,也就是但url中包含? & = 之类的querString时也处理。
NO_DUP
其余可依据各自须要更改,详见: How to customize Larbin 一文。
四,问题
在使用过程中发觉,在抓网页的时侯,如果URL中包含未编码(encodurl)中文时,无法抓取,简单的看了一下在: src/utils/中的fileNormalize 有涉及。于是写了个encodurl函数加在url类的构造函数里,问题就解决了。
由于须要比较好的可定制性,这个工具其实还不大满足我的需求,最终我没使用她,而是自己用perl在WWW:SimpleRobot的基础上搞了个适宜我的。。再说了perl在字符蹿处理上应当不比C++慢,总的来说那种小工具性能还不错。。呵呵。
不过还是把这种写下来,给没看文档的同学(希望极少),也警示自己一定要认真看文档 查看全部
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有连结,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
不过它的最大的亮点还是开源,相信很多人领到larbin源代码的时侯会觉得无从入手,下面是一篇特别不错的开源的网络爬虫/网络蜘蛛larbin结构剖析的文章,有兴趣的最好仔细阅读尝试一下。
互联网是一个庞大的非结构化的数据库,将数据有效的检索并组织呈现下来有着巨大的应用前景,尤其是类似RSS的以XML为基础的结构化的数据越来越 多,内容的组织形式越来越灵活,检索组织并呈现会有着越来越广泛的应用范围,同时在时效性和可读性上也会有越来越高的要求。这一切的基础是爬虫,信息的来 源入口。一个高效,灵活可扩充的爬虫对以上应用都有着无可替代的重要意义。
要设计一个爬虫,首先须要考虑的效率。对于网路而言,基于TCP/IP的通讯编程有几种方式。
第一种是单线程阻塞,这是最简单也最容易实现的一种,一个事例:在Shell中通过curl,pcregrep等一系统命令可以直接实现一个简单的 爬虫,但同时它的效率问题也显而易见:由于是阻塞方法读取,dns解析,建立联接,写入恳求,读取结果这种步骤上就会形成时间的延后,从而未能有效的借助 服务器的全部资源。
第二种是多线程阻塞。建立多个阻塞的线程,分别恳求不同的url。相对于第一种方式,它可以更有效的借助机器的资源,特别是网路资源开源网络爬虫,因为无数线程 在同时工作,所以网路会比较充分的借助,但同时对机器CPU资源的消耗也是比较大,在用户级多线程间的频繁切换对于性能的影响早已值得我们考虑。
第三种是单线程非阻塞。这是目前使用的比较多的一种做法,无论在client还是server都有着广泛的应用。在一个线程内打开多个非阻塞的连 接,通过poll/epoll /select对联接状态进行判定,在第一时间响应恳求,不但充分利用了网路资源,同时也将本机CPU资源的消耗降至最低。这种方式须要对dns恳求,连 接,读写操作都采用异步非阻塞操作,其中第一种比较复杂,可以采用adns作为解决方案,后面三个操作相对简单可以直接在程序内实现。
效率问题解决后就须要考虑具体的设计问题了。
url肯定须要一个单独的类进行处理,包括显示,分析url,得到主机,端口,文件数据。
然后须要对url进行排重,需要一个比较大的url Hash表。
如果还要对网页内容进行排重,则还须要一个Document Hash表。
爬过的url须要记录出来,由于量比较大,我们将它讲到c盘上,所以还须要一个FIFO的类(记作urlsDisk)。
现在须要爬的url同样须要一个FIFO类来处理,重新开始时,url会从定时从爬过的url FIFO里取下来,写到这个FIFO里。正在运行的爬虫须要从这个FIFO里读数据下来,加入到主机类的url列表里。当然,也会从前一个FIFO里直接 读url下来,不过优先级应当比这个上面下来的url低,毕竟是早已爬过的。
爬虫通常是对多个网站进行爬取,但在同时站点内dns的恳求可以只做一次开源网络爬虫,这就须要将主机名独立于url,单独有一个类进行处理。
主机名解析完成后须要有一个解析完成的IP类与之应用,用于connect的时侯使用。
HTML文档的解析类也要有一个,用来剖析网页,取出上面的url,加入到urlsDisk。
再加上一些字符串,调度类,一个简单的爬虫基本上就完成了。
以上基本上是Larbin的设计思路,Larbin在具体实现上还有一些特殊的处理,例如带了一个webserver,以及对特殊文件的处理。 Larbin有一点设计不不太好,就是慢的访问会越来越多,占用大量的联接,需要改进,另外假如对于大规模的爬虫,这仅仅实现了抓取的部份,要分布式的扩 展还须要降低url的集中管理与调度以及前台spider的分布式算法。
Larbin网站爬虫简明使用说明
larbin是一种爬虫工具,我也是前段时间网上见到 Larbin 一种高效的搜索引擎爬虫工具 一文时才晓得有这么个东西,初步认定,我比较喜欢这个工具(比起nutch的crawl来说),因为它是C++写的,类似C嘛,我熟,可以自己改改,顺便 学习一下C++(几年来的经验告诉我说:改他人的东西来学一种技术比从头写helloworld快好多)。于是开始了我辛酸的larbin试用之旅。
回头瞧瞧自己遇见的问题都是因为没认真看文档造成的,唉,老毛病了。下次虽然是E文的也得好好看,不能盲目的试,浪费时间。
larbin官方地址:
一,编译
这也好说,whahahaha,那是!因为从官方网站下出来的代码不能编译通过(linux gcc下)
./configure
make
gcc -O3 -Wall -D_REENTRANT -c -o parse.o parse.c
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
gmake[1]: *** [parse.o] 错误 1
gmake[1]: Leaving directory `/home/leo/leo/larbin-2.6.3/adns’
make: *** [all] 错误 2
函数原型和定义不一致这个好改:
打开./adns/internal.h文件,把568-571行直接注释掉就行了。
二,运行
这个就不说了,./larbin就运行了,larbin.conf中先进行配置就可以了,这个配置就不说了。。
运行后可以:8081 看运行状态,不错的看法。 larbin.conf中有个:inputPort 1976配置,就是可以运行时降低要抓取的URL,这个看法非常好,可是?怎么加呢?象原本那样::1976那样是不行的,报 错???试了很久没结果,最后GDB跟踪了一下,唉,原来直接telnet host 1976进行降低就可以了。后来见到文档里写的亲亲楚楚,晕倒。。。。。
三,结果
哈哈,下班后找了台机子跑了上去,那晚午睡的时侯都梦到自己的搜索引擎赶GOOGLE超BAIDU了,那个激动啊。
第二天下班的时侯取看结果,发现目录下不仅些fifo*文件外哪些都没有,那个纠结。没办法啊,再看文档 How to customize Larbin 发现如此段说明:
The first thing you can define is the module you want to use for ouput. This defines what you want to do with the pages larbin gets. Here are the different options :
DEFAULT_OUTPUT : This module mainly does nothing, except statistics.
SIMPLE_SAVE : This module saves pages on disk. It stores 2000 files per directory (with an index).
MIRROR_SAVE : This module saves pages on disk with the hierarchy of the site they come from. It uses one directory per site.
STATS_OUTPUT : This modules makes some stats on the pages. In order to see the results, see :8081/output.html.
靠,默认哪些都没输出,于是认真的看了官方网站上仅有的两个文档,修改了options.h再编译,终于有结果了。
我的option中改了:
SIMPLE_SAVE 简单输出一个目录两千个文件,包含索引。
CGILEVEL=0 处理服务器端程序,也就是但url中包含? & = 之类的querString时也处理。
NO_DUP
其余可依据各自须要更改,详见: How to customize Larbin 一文。
四,问题
在使用过程中发觉,在抓网页的时侯,如果URL中包含未编码(encodurl)中文时,无法抓取,简单的看了一下在: src/utils/中的fileNormalize 有涉及。于是写了个encodurl函数加在url类的构造函数里,问题就解决了。
由于须要比较好的可定制性,这个工具其实还不大满足我的需求,最终我没使用她,而是自己用perl在WWW:SimpleRobot的基础上搞了个适宜我的。。再说了perl在字符蹿处理上应当不比C++慢,总的来说那种小工具性能还不错。。呵呵。
不过还是把这种写下来,给没看文档的同学(希望极少),也警示自己一定要认真看文档
Python借助requests进行模拟登陆
采集交流 • 优采云 发表了文章 • 0 个评论 • 674 次浏览 • 2020-06-25 08:00
Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...
使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...
请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的 查看全部

Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...

使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...

请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的
【热门】税务局怎么应用网路爬虫技术获取企业涉税信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-06-22 08:01
税务局怎样利用网路爬虫举办工作呢?概括的说,不外乎这样几个方面: 一是有针对性的捕捉互联网上的企业相关信息; 二是利用大数据,整合其他相关涉税信息; 三是通过一系列预警指标剖析比对筛选案源; 四是构建企业交易行为轨迹,定位税收风险疑虑。 其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉 税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、 建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和物流中心等有关 部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、 税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税 人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。 所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。 随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业 的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间, 而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要 途径。 查看全部
税务局怎么应用网路爬虫技术获取企业涉税信息 在互联网上,经常能看到某某税务局借助网路爬虫技术发觉某甲企业涉税问题,并进一步 被取缔的信息。 那么,什么是网络爬虫呢?税务局怎么应用网路爬虫技术发觉企业的涉税谜团呢?本文将 带你一步一步解开其中的奥秘。 网络爬虫称作“网页蜘蛛”,是一个手动提取网页的程序。传统爬虫从一个或若干初始网 页的 URL 开始,获得初始网页上的 URL,在抓取网页的过程中,不断从当前页面上抽取新 的 URL 放入队列税务爬虫软件,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根 据一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的 URL 队列。然后税务爬虫软件,它将按照一定的搜索策略从队列中选择下一步要抓取的网页 URL,并重复上 述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存储, 进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。 以上是引自网路专业的叙述,简单的说,“网络爬虫”是一个手动提取网页的程序,运用 “网络爬虫”技术设定程序,可以按照既定的目标愈发精准选择抓取相关的网页信息,有 助于在互联网海量信息中快捷获取有用的涉税信息。
税务局怎样利用网路爬虫举办工作呢?概括的说,不外乎这样几个方面: 一是有针对性的捕捉互联网上的企业相关信息; 二是利用大数据,整合其他相关涉税信息; 三是通过一系列预警指标剖析比对筛选案源; 四是构建企业交易行为轨迹,定位税收风险疑虑。 其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉 税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、 建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和物流中心等有关 部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、 税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税 人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。 所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。 随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业 的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间, 而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要 途径。
爬虫简介
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-06-17 08:01
网页的三大特点:
是拿来写前端的,对于异步和多任务处理不太好,爬虫是一个工具性的程序爬虫,对效率要求比较高
是Python写爬虫的最大竞争对手,Java语言生态系统比较健全,对各模块的支持也比较友好。但是Java这门语言比较笨重,重构和迭代成本比价高
语言较难,代码成形比较慢
语法简单素雅,第三方模块比较丰富,关于爬虫的网路恳求模块和网路解析模块(Lxml,BeautifulSoup,pyQuery)也比较多,并且有高效稳定的scrapy网路爬虫框架,以及爬scrapy,redis分布式爬虫框架,Python也是一门胶带语言,对于其他语言的调用比较便捷
是搜索引擎的重要组成部份
尽可能的将所有互联网上的网页下载到本地,经过预处理(去噪,分词,去广告),最终将数据存储到本地,做一个镜像备份产生一个检索系统
1.选取一部分的url作为种子url,将这种url装入到带爬取的任务队列上面
2.从待爬取的任务列队中取出url,发起恳求,将获取的网页源码储存到本地
并将早已爬取过的url ,放到已爬取的队列中
3.从已爬取的URL的响应结果中剖析提取其他的url的地址,继续添加到待爬取的队列中,
之后就是不断的循环,直到所有的url都获取完毕。
1.通过网站提交自己的网站地址()
2.搜索引擎会和DNS服务商合作,拿到最新的网站地址
3.网站中包含其他外链
DNS服务:将我们的域名转换为对应的ip的一种技术
数据获取------>预处理(去噪,分词,去广告.....)------>存储------>提供检索插口|排名(网络排行)
网站排名:
1.根据用户的访问量(越多越靠前)
2.竞价排名
1.必须遵循robot合同:就是一个规范,告诉搜索引擎爬虫,哪些目录下的资源容许爬虫,哪些目录下的资源不容许爬虫
"user-agent":这项值拿来表示是哪家的搜索引擎
"allow":允许被爬取的url
"disallow":不容许被爬取的url
2.搜索引擎返回的都是网页,并且返回的90%都是无用的信息
3.不能否按照不同用户的需求返回不同的结果
4.通用爬虫对于多媒体的文件不能够获取
聚焦爬虫是面向主题的爬虫,在爬虫数据的过程中会对数据进行筛选,往往只会爬虫与需求相关的数据 查看全部
网络爬虫机器人,以互联网自由抓取数据的程序
网页的三大特点:
是拿来写前端的,对于异步和多任务处理不太好,爬虫是一个工具性的程序爬虫,对效率要求比较高
是Python写爬虫的最大竞争对手,Java语言生态系统比较健全,对各模块的支持也比较友好。但是Java这门语言比较笨重,重构和迭代成本比价高
语言较难,代码成形比较慢
语法简单素雅,第三方模块比较丰富,关于爬虫的网路恳求模块和网路解析模块(Lxml,BeautifulSoup,pyQuery)也比较多,并且有高效稳定的scrapy网路爬虫框架,以及爬scrapy,redis分布式爬虫框架,Python也是一门胶带语言,对于其他语言的调用比较便捷
是搜索引擎的重要组成部份
尽可能的将所有互联网上的网页下载到本地,经过预处理(去噪,分词,去广告),最终将数据存储到本地,做一个镜像备份产生一个检索系统
1.选取一部分的url作为种子url,将这种url装入到带爬取的任务队列上面
2.从待爬取的任务列队中取出url,发起恳求,将获取的网页源码储存到本地
并将早已爬取过的url ,放到已爬取的队列中
3.从已爬取的URL的响应结果中剖析提取其他的url的地址,继续添加到待爬取的队列中,
之后就是不断的循环,直到所有的url都获取完毕。
1.通过网站提交自己的网站地址()
2.搜索引擎会和DNS服务商合作,拿到最新的网站地址
3.网站中包含其他外链
DNS服务:将我们的域名转换为对应的ip的一种技术
数据获取------>预处理(去噪,分词,去广告.....)------>存储------>提供检索插口|排名(网络排行)
网站排名:
1.根据用户的访问量(越多越靠前)
2.竞价排名
1.必须遵循robot合同:就是一个规范,告诉搜索引擎爬虫,哪些目录下的资源容许爬虫,哪些目录下的资源不容许爬虫
"user-agent":这项值拿来表示是哪家的搜索引擎
"allow":允许被爬取的url
"disallow":不容许被爬取的url
2.搜索引擎返回的都是网页,并且返回的90%都是无用的信息
3.不能否按照不同用户的需求返回不同的结果
4.通用爬虫对于多媒体的文件不能够获取
聚焦爬虫是面向主题的爬虫,在爬虫数据的过程中会对数据进行筛选,往往只会爬虫与需求相关的数据
最详尽爬虫入门教程!花半小时你应当能够去爬一些小东西了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-06-02 08:01
爬虫对目标网页爬取的过程可以参考下边红色文字部份:
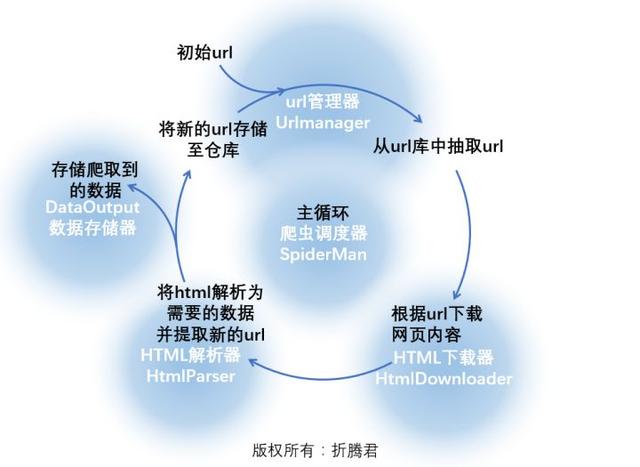
图片中由红色文字组成的循环应当挺好理解,那么具体到编程上来说,则必须将里面的流程进行具象,我们可以编撰几个器件,每个器件完成一项功能,上图中的绿底黄字就是对这一流程的具象:
爬虫调度器即将完成整个循环,下面写出python下爬虫调度器的程序:
存储器、下载器、解析器和url管理器!
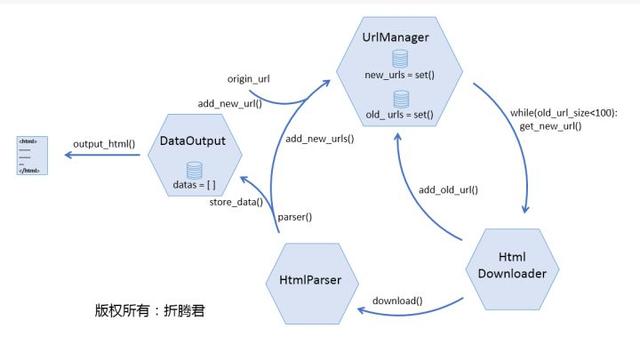
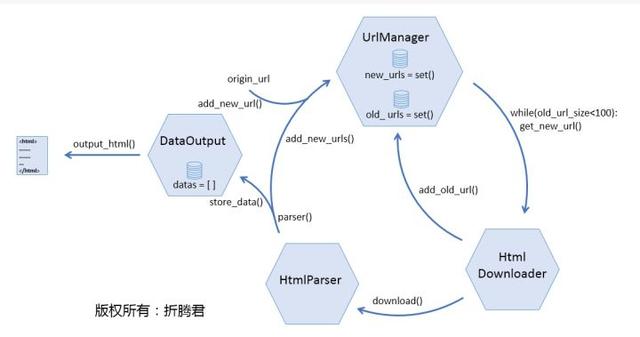
首先网络爬虫软件教程,还是来瞧瞧下边这张图,URL管理器究竟应当具有什么功能?
下面来说说下载器。
下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载出来。python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是获取指定的网页内容。不过网络爬虫软件教程,在这里我们要使用一个愈发简练好用并且功能愈发强悍的模块:Requests(查看文档)。
Requests并非python自带模块,需要安装。关于其具体使用方式请查看相关文档,在此不多做介绍。
下载器接受一个url作为参数,返回值为下载到的网页内容(格式为str)。下面就是一个简单的下载器,其中只有一个简单的函数download():
在requests恳求中设置User-Agent的目的是伪装成浏览器,这是一只优秀的爬虫应当有的觉悟。
URL管理器和下载器相对简单!剩下的上次介绍,希望能帮到零基础小白的你!
进群:125240963 即可获取数十套PDF! 查看全部


爬虫对目标网页爬取的过程可以参考下边红色文字部份:
图片中由红色文字组成的循环应当挺好理解,那么具体到编程上来说,则必须将里面的流程进行具象,我们可以编撰几个器件,每个器件完成一项功能,上图中的绿底黄字就是对这一流程的具象:

爬虫调度器即将完成整个循环,下面写出python下爬虫调度器的程序:

存储器、下载器、解析器和url管理器!
首先网络爬虫软件教程,还是来瞧瞧下边这张图,URL管理器究竟应当具有什么功能?


下面来说说下载器。
下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载出来。python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是获取指定的网页内容。不过网络爬虫软件教程,在这里我们要使用一个愈发简练好用并且功能愈发强悍的模块:Requests(查看文档)。
Requests并非python自带模块,需要安装。关于其具体使用方式请查看相关文档,在此不多做介绍。
下载器接受一个url作为参数,返回值为下载到的网页内容(格式为str)。下面就是一个简单的下载器,其中只有一个简单的函数download():

在requests恳求中设置User-Agent的目的是伪装成浏览器,这是一只优秀的爬虫应当有的觉悟。
URL管理器和下载器相对简单!剩下的上次介绍,希望能帮到零基础小白的你!
进群:125240963 即可获取数十套PDF!
“百行代码”实现简单的Python分布式爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-06-02 08:00
现在搞爬虫的人,可能被问的最多的问题就是“你会不会分布式爬虫?”。给人的觉得就是你不会分布式爬虫,都不好意思说自己是搞爬虫的。但虽然分布式爬虫的原理比较简单,大多数的业务用不到分布式模式。
所谓的分布式爬虫,就是多台机器合作进行爬虫工作,提高工作效率。
分布式爬虫须要考虑的问题有:
(1)如何从一个统一的插口获取待抓取的URL?
(2)如何保证多台机器之间的排重操作?即保证不会出现多台机器同时抓取同一个URL。
(3)当多台机器中的一台或则几台死掉,如何保证任务继续,且数据不会遗失?
这里首先借助Redis数据库解决前两个问题。
Redis数据库是一种key-value数据库,它本身包含了一些比较好的特点,比较适宜解决分布式爬虫的问题。关于Redis的一些基本概念、操作等,建议读者自行百度。我们这儿使用到Redis中自带的“消息队列”,来解决分布式爬虫问题。具体实现步骤如下:
在Redis中初始化两条key-value数据,对应的key分别为spider.wait和spider.all。spider.wait的value是一个list队列,存放我们待抓取的URL。该数据类型便捷我们实现消息队列。我们使用lpush操作添加URL数据,同时使用brpop窃听并获取取URL数据。spider.all的value是一个set集合,存放我们所有待抓取和已抓取的URL。该数据类型便捷我们实现排重操作。我们使用sadd操作添加数据。
在我的代码中,我是在原先爬虫框架的基础上,添加了分布式爬虫模式(一个文件)分布式爬虫 python,该文件的代码行数大约在100行左右,所以文章标题为“百行代码”。但实际上,在每台客户端机器上,我都使用了多线程爬虫框架。即:
(1)每台机器从Redis获取待抓取的URL,执行“抓取--解析--保存”的过程
(2)每台机器本身使用多线程爬虫模式,即有多个线程同时从Redis获取URL并抓取
(3)每台机器解析数据得到的新的URL,会传回Redis数据库,同时保证数据一致性
(4)每台机器单独启动自己的爬虫,之后单独关掉爬虫任务,没有手动功能
具体可查看代码:distributed_threads.py
这里的代码还不够建立,主要还要如下的问题:
有兴趣解决问题的,可以fork代码然后,自行更改分布式爬虫 python,并递交pull-requests。
=============================================================
作者主页:笑虎(Python爱好者,关注爬虫、数据剖析、数据挖掘、数据可视化等)
作者专栏主页:撸代码,学知识 - 知乎专栏
作者GitHub主页:撸代码,学知识 - GitHub
欢迎你们指正、提意见。相互交流,共同进步!
============================================================== 查看全部
本篇文章属于进阶知识,可能会用到曾经出现在专栏文章中的知识,如果你是第一次关注本专栏,建议你先阅读下其他文章:查询--爬虫(计算机网路)
现在搞爬虫的人,可能被问的最多的问题就是“你会不会分布式爬虫?”。给人的觉得就是你不会分布式爬虫,都不好意思说自己是搞爬虫的。但虽然分布式爬虫的原理比较简单,大多数的业务用不到分布式模式。
所谓的分布式爬虫,就是多台机器合作进行爬虫工作,提高工作效率。
分布式爬虫须要考虑的问题有:
(1)如何从一个统一的插口获取待抓取的URL?
(2)如何保证多台机器之间的排重操作?即保证不会出现多台机器同时抓取同一个URL。
(3)当多台机器中的一台或则几台死掉,如何保证任务继续,且数据不会遗失?
这里首先借助Redis数据库解决前两个问题。
Redis数据库是一种key-value数据库,它本身包含了一些比较好的特点,比较适宜解决分布式爬虫的问题。关于Redis的一些基本概念、操作等,建议读者自行百度。我们这儿使用到Redis中自带的“消息队列”,来解决分布式爬虫问题。具体实现步骤如下:
在Redis中初始化两条key-value数据,对应的key分别为spider.wait和spider.all。spider.wait的value是一个list队列,存放我们待抓取的URL。该数据类型便捷我们实现消息队列。我们使用lpush操作添加URL数据,同时使用brpop窃听并获取取URL数据。spider.all的value是一个set集合,存放我们所有待抓取和已抓取的URL。该数据类型便捷我们实现排重操作。我们使用sadd操作添加数据。
在我的代码中,我是在原先爬虫框架的基础上,添加了分布式爬虫模式(一个文件)分布式爬虫 python,该文件的代码行数大约在100行左右,所以文章标题为“百行代码”。但实际上,在每台客户端机器上,我都使用了多线程爬虫框架。即:
(1)每台机器从Redis获取待抓取的URL,执行“抓取--解析--保存”的过程
(2)每台机器本身使用多线程爬虫模式,即有多个线程同时从Redis获取URL并抓取
(3)每台机器解析数据得到的新的URL,会传回Redis数据库,同时保证数据一致性
(4)每台机器单独启动自己的爬虫,之后单独关掉爬虫任务,没有手动功能
具体可查看代码:distributed_threads.py
这里的代码还不够建立,主要还要如下的问题:
有兴趣解决问题的,可以fork代码然后,自行更改分布式爬虫 python,并递交pull-requests。
=============================================================
作者主页:笑虎(Python爱好者,关注爬虫、数据剖析、数据挖掘、数据可视化等)
作者专栏主页:撸代码,学知识 - 知乎专栏
作者GitHub主页:撸代码,学知识 - GitHub
欢迎你们指正、提意见。相互交流,共同进步!
==============================================================
Python爬虫介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-06-02 08:00
什么是爬虫?
在网路的大数据库里,信息是海量的,如何能快速有效的从互联网上将我们所须要的信息挑拣下来呢,这个时侯就须要爬虫技术了。爬虫是指可以手动抓取互联网信息的程序,从互联网上抓取一切有价值的信息,并且把站点的html和js返回的图片爬到本地,并且储存便捷使用。简单点来说,如果我们把互联网有价值的信息都比喻成大的蜘蛛网,而各个节点就是储存的数据,而蜘蛛网的上蜘蛛比喻成爬虫python 爬虫,而蜘蛛抓取的猎物就是我们要门要的数据信息了。
Python爬虫介绍
Python用于爬虫?
很多人不知道python为何叫爬虫,这可能是依据python的特性。Python是纯粹的自由软件,以简约清晰的句型和强制使用空白符进行句子缩进的特征因而受到程序员的喜爱。使用Python来完成编程任务的话,编写的代码量更少,代码简约简略可读性更强,所以说这是一门特别适宜开发网路爬虫的编程语言,而且相比于其他静态编程,python很容易进行配置,对字符的处理也是十分灵活的,在加上python有很多的抓取模块,所以说python通常用于爬虫。
爬虫的组成?
1、URL管理器:管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
2、网页下载器:爬取url对应的网页,存储成字符串,传送给网页解析器;
3、网页解析器:解析出有价值的数据,存储出来,同时补充url到URL管理器
爬虫的工作流程?
爬虫首先要做的工作是获取网页的源代码,源代码里包含了网页的部份有用信息;之后爬虫构造一个恳求并发献给服务器,服务器接收到响应并将其解析下来。
Python爬虫介绍
爬虫是怎样提取信息原理?
最通用的方式是采用正则表达式。网页结构有一定的规则,还有一些依照网页节点属性、CSS选择器或XPath来提取网页信息的库,如Requests、pyquery、lxml等,使用这种库,便可以高效快速地从中提取网页信息,如节点的属性、文本值等,并能简单保存为TXT文本或JSON文本,这些信息可保存到数据库,如MySQL和MongoDB等,也可保存至远程服务器,如利用SFTP进行操作等。提取信息是爬虫十分重要的作用,它可以让零乱的数据显得条理清晰,以便我们后续处理和剖析数据。 查看全部
随着互联网的高速发展python 爬虫,大数据时代早已将至,网络爬虫这个名词也被人们越来越多的提起,但相信很多人对网路爬虫并不是太了解,下面就让小编给你们介绍一下哪些是网络爬虫?网络爬虫有哪些作用呢?
什么是爬虫?
在网路的大数据库里,信息是海量的,如何能快速有效的从互联网上将我们所须要的信息挑拣下来呢,这个时侯就须要爬虫技术了。爬虫是指可以手动抓取互联网信息的程序,从互联网上抓取一切有价值的信息,并且把站点的html和js返回的图片爬到本地,并且储存便捷使用。简单点来说,如果我们把互联网有价值的信息都比喻成大的蜘蛛网,而各个节点就是储存的数据,而蜘蛛网的上蜘蛛比喻成爬虫python 爬虫,而蜘蛛抓取的猎物就是我们要门要的数据信息了。

Python爬虫介绍
Python用于爬虫?
很多人不知道python为何叫爬虫,这可能是依据python的特性。Python是纯粹的自由软件,以简约清晰的句型和强制使用空白符进行句子缩进的特征因而受到程序员的喜爱。使用Python来完成编程任务的话,编写的代码量更少,代码简约简略可读性更强,所以说这是一门特别适宜开发网路爬虫的编程语言,而且相比于其他静态编程,python很容易进行配置,对字符的处理也是十分灵活的,在加上python有很多的抓取模块,所以说python通常用于爬虫。
爬虫的组成?
1、URL管理器:管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
2、网页下载器:爬取url对应的网页,存储成字符串,传送给网页解析器;
3、网页解析器:解析出有价值的数据,存储出来,同时补充url到URL管理器
爬虫的工作流程?
爬虫首先要做的工作是获取网页的源代码,源代码里包含了网页的部份有用信息;之后爬虫构造一个恳求并发献给服务器,服务器接收到响应并将其解析下来。
Python爬虫介绍
爬虫是怎样提取信息原理?
最通用的方式是采用正则表达式。网页结构有一定的规则,还有一些依照网页节点属性、CSS选择器或XPath来提取网页信息的库,如Requests、pyquery、lxml等,使用这种库,便可以高效快速地从中提取网页信息,如节点的属性、文本值等,并能简单保存为TXT文本或JSON文本,这些信息可保存到数据库,如MySQL和MongoDB等,也可保存至远程服务器,如利用SFTP进行操作等。提取信息是爬虫十分重要的作用,它可以让零乱的数据显得条理清晰,以便我们后续处理和剖析数据。
网络爬虫基本原理解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2020-05-28 08:01
“ 只推荐有价值的技术性文章优才学院
网络爬虫是索引擎抓取系统的重要组成部份。爬虫的主要目的是将互联网上的网页下载到本地产生一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
一、网络爬虫的基本结构及工作流程
一个通用的网路爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路以后再转到下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以里面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就产生了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
四、更新策略
互联网是实时变化的,具有太强的动态性。网页更新策略主要是决定何时更新之前早已下载过的页面。常见的更新策略又以下三种:
1.历史参考策略
顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略
尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。
3.降维抽样策略
前面提及的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一网络爬虫原理,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多的系统负担;第二,要是新的网页完全没有历史信息网络爬虫原理,就难以确定更新策略。
这种策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新频度也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样,以她们的更新周期作为整个类别的更新周期。基本思路如图:
五、分布式抓取系统结构
一般来说,抓取系统须要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往须要多个抓取程序一起来处理。一般来说抓取系统常常是一个分布式的三层结构。如图所示:
最下一层是分布在不同地理位置的数据中心,在每位数据中心里有若干台抓取服务器,而每台抓取服务器上可能布署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方法有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器不仅维护待抓取URL队列以及分发URL之外,还要负责调处各个Slave服务器的负载情况。以免个别Slave服务器过分悠闲或则操劳。
这种模式下,Master常常容易成为系统困局。
2.对方程(Peer to Peer)
对等式的基本结构如图所示:
在这些模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后估算H mod m(其中m是服务器的数目,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
举例:假设对于URL ,计算器hash值H=8,m=3,则H mod m=2,因此由编号为2的服务器进行该链接的抓取。假设这时候是0号服务器领到这个URL,那么它将该URL转给服务器2,由服务器2进行抓取。
这种模式有一个问题,当有一台服务器关机或则添加新的服务器,那么所有URL的哈希求余的结果就都要变化。也就是说,这种方法的扩展性不佳。针对这些情况,又有一种改进方案被提下来。这种改进的方案是一致性哈希法来确定服务器分工。其基本结构如图所示:
一致性哈希将URL的主域名进行哈希运算,映射为一个范围在0-232之间的某个数。而将这个范围平均的分配给m台服务器,根据URL主域名哈希运算的值所处的范围判定是哪台服务器来进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则根据顺时针延后,由下一台服务器进行抓取。这样的话,及时某台服务器出现问题,也不会影响其他的工作。 查看全部

“ 只推荐有价值的技术性文章优才学院
网络爬虫是索引擎抓取系统的重要组成部份。爬虫的主要目的是将互联网上的网页下载到本地产生一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
一、网络爬虫的基本结构及工作流程
一个通用的网路爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路以后再转到下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以里面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就产生了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
四、更新策略
互联网是实时变化的,具有太强的动态性。网页更新策略主要是决定何时更新之前早已下载过的页面。常见的更新策略又以下三种:
1.历史参考策略
顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略
尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。
3.降维抽样策略
前面提及的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一网络爬虫原理,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多的系统负担;第二,要是新的网页完全没有历史信息网络爬虫原理,就难以确定更新策略。
这种策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新频度也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样,以她们的更新周期作为整个类别的更新周期。基本思路如图:
五、分布式抓取系统结构
一般来说,抓取系统须要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往须要多个抓取程序一起来处理。一般来说抓取系统常常是一个分布式的三层结构。如图所示:
最下一层是分布在不同地理位置的数据中心,在每位数据中心里有若干台抓取服务器,而每台抓取服务器上可能布署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方法有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器不仅维护待抓取URL队列以及分发URL之外,还要负责调处各个Slave服务器的负载情况。以免个别Slave服务器过分悠闲或则操劳。
这种模式下,Master常常容易成为系统困局。
2.对方程(Peer to Peer)
对等式的基本结构如图所示:
在这些模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后估算H mod m(其中m是服务器的数目,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
举例:假设对于URL ,计算器hash值H=8,m=3,则H mod m=2,因此由编号为2的服务器进行该链接的抓取。假设这时候是0号服务器领到这个URL,那么它将该URL转给服务器2,由服务器2进行抓取。
这种模式有一个问题,当有一台服务器关机或则添加新的服务器,那么所有URL的哈希求余的结果就都要变化。也就是说,这种方法的扩展性不佳。针对这些情况,又有一种改进方案被提下来。这种改进的方案是一致性哈希法来确定服务器分工。其基本结构如图所示:
一致性哈希将URL的主域名进行哈希运算,映射为一个范围在0-232之间的某个数。而将这个范围平均的分配给m台服务器,根据URL主域名哈希运算的值所处的范围判定是哪台服务器来进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则根据顺时针延后,由下一台服务器进行抓取。这样的话,及时某台服务器出现问题,也不会影响其他的工作。
Webmagic(爬虫)抓取新浪博客案例
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-05-19 08:00
我们以作者的新浪博客 作为反例。在这个事例里,我们要从最终的博客文章页面,抓取博客的标题、内容、日期等信息,也要从列表页抓取博客的链接等信息,从而获取这个博客的所有文章。
列表页的格式是““, 其中“0_1”中的“1”是可变的页数。
文章页的格式是“”,其中“95b4e3010102xsua”是可变的字符。
通过前面的剖析新浪博客超级爬虫(网站推广工具) v14绿色版,我先要找到文章的 url,再愈发 url 获取文章。所以怎么发觉这个博客中所有的文章地址,是爬虫的第一步。
我们可以使用正则表达式 +//.html 对 URL 进行一次简略过滤。这里比较复杂的是,这个 URL 过于空泛,可能会抓取到其他博客的信息,所以我们必须从列表页中指定的区域获取 URL。
在这里,我们使用 xpath//div[@class=//”articleList//”]选中所有区域,再使用 links()或者 xpath//a/@href 获取所有链接,最后再使用正则表达式 +//.html,对 URL 进行过滤,去掉一些“编辑”或者“更多”之类的链接。于是,我们可以这样写:
page.addTargetRequests(
page.getHtml().xpath("//div[@class=/"articleList/"]"
).links().regex("http://blog//.sina//.com//.cn/ ... 6quot;).all());
同时,我们须要把所有找到的列表页也加到待下载的 URL 中去:
page.addTargetRequests(
page.getHtml().links().regex(
"http://blog//.sina//.com//.cn/ ... 6quot;).all());
文章页面信息的抽取是比较简单的,写好对应的 xpath 抽取表达式就可以了。
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath(
"//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",page.getHtml().xpath(
"//div[@id='articlebody']//span[@class='time SG_txtc']").regex("//((.*)//)"));
现在,我们早已定义了对列表和目标页进行处理的方法,现在我们须要在处理时对她们进行分辨。在这个反例中,区分方法很简单,因为列表页和目标页在 URL 格式上是不同的,所以直接用 URL 区分就可以了!
这个反例完整的代码如下:
package us.codecraft.webmagic.samples;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class SinaBlogProcessor implements PageProcessor {
public static final String URL_LIST = "http://blog//.sina//.com//.cn/ ... 3B%3B
public static final String URL_POST = "http://blog//.sina//.com//.cn/ ... 3B%3B
private Site site = Site.me().setDomain("blog.sina.com.cn").setSleepTime(3000).setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override public void process(Page page) {
//列表页
if (page.getUrl().regex(URL_LIST).match()) {
page.addTargetRequests(page.getHtml().xpath("//div[@class=/"articleList/"]").links().regex(URL_POST).all());
page.addTargetRequests(page.getHtml().links().regex(URL_LIST).all());
//文章页} else {
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath("//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",page.getHtml().xpath("//div[@id='articlebody']//span[@class='time SG_txtc']").regex("//((.*)//)"));}}
@Override public Site getSite() {
return site;}
public static void main(String[] args) {
Spider.create(new SinaBlogProcessor()).addUrl("http://blog.sina.com.cn/s/arti ... 6quot;).run();
} }
通过这个反例我们可以发觉主要使用几个方式:
如果你认为用 if-else 来分辨不同处理有些不方便新浪博客超级爬虫(网站推广工具) v14绿色版,那么可以使用 SubPageProcessor 来解决这个问题。 查看全部
Webmagic框架更侧重实际的内容抓取。今天为你们分享Webmagic 爬虫框架抓取新浪博客的案例。
我们以作者的新浪博客 作为反例。在这个事例里,我们要从最终的博客文章页面,抓取博客的标题、内容、日期等信息,也要从列表页抓取博客的链接等信息,从而获取这个博客的所有文章。
列表页的格式是““, 其中“0_1”中的“1”是可变的页数。

文章页的格式是“”,其中“95b4e3010102xsua”是可变的字符。

通过前面的剖析新浪博客超级爬虫(网站推广工具) v14绿色版,我先要找到文章的 url,再愈发 url 获取文章。所以怎么发觉这个博客中所有的文章地址,是爬虫的第一步。
我们可以使用正则表达式 +//.html 对 URL 进行一次简略过滤。这里比较复杂的是,这个 URL 过于空泛,可能会抓取到其他博客的信息,所以我们必须从列表页中指定的区域获取 URL。
在这里,我们使用 xpath//div[@class=//”articleList//”]选中所有区域,再使用 links()或者 xpath//a/@href 获取所有链接,最后再使用正则表达式 +//.html,对 URL 进行过滤,去掉一些“编辑”或者“更多”之类的链接。于是,我们可以这样写:
page.addTargetRequests(
page.getHtml().xpath("//div[@class=/"articleList/"]"
).links().regex("http://blog//.sina//.com//.cn/ ... 6quot;).all());
同时,我们须要把所有找到的列表页也加到待下载的 URL 中去:
page.addTargetRequests(
page.getHtml().links().regex(
"http://blog//.sina//.com//.cn/ ... 6quot;).all());
文章页面信息的抽取是比较简单的,写好对应的 xpath 抽取表达式就可以了。
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath(
"//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",page.getHtml().xpath(
"//div[@id='articlebody']//span[@class='time SG_txtc']").regex("//((.*)//)"));
现在,我们早已定义了对列表和目标页进行处理的方法,现在我们须要在处理时对她们进行分辨。在这个反例中,区分方法很简单,因为列表页和目标页在 URL 格式上是不同的,所以直接用 URL 区分就可以了!
这个反例完整的代码如下:
package us.codecraft.webmagic.samples;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class SinaBlogProcessor implements PageProcessor {
public static final String URL_LIST = "http://blog//.sina//.com//.cn/ ... 3B%3B
public static final String URL_POST = "http://blog//.sina//.com//.cn/ ... 3B%3B
private Site site = Site.me().setDomain("blog.sina.com.cn").setSleepTime(3000).setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override public void process(Page page) {
//列表页
if (page.getUrl().regex(URL_LIST).match()) {
page.addTargetRequests(page.getHtml().xpath("//div[@class=/"articleList/"]").links().regex(URL_POST).all());
page.addTargetRequests(page.getHtml().links().regex(URL_LIST).all());
//文章页} else {
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath("//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",page.getHtml().xpath("//div[@id='articlebody']//span[@class='time SG_txtc']").regex("//((.*)//)"));}}
@Override public Site getSite() {
return site;}
public static void main(String[] args) {
Spider.create(new SinaBlogProcessor()).addUrl("http://blog.sina.com.cn/s/arti ... 6quot;).run();
} }
通过这个反例我们可以发觉主要使用几个方式:
如果你认为用 if-else 来分辨不同处理有些不方便新浪博客超级爬虫(网站推广工具) v14绿色版,那么可以使用 SubPageProcessor 来解决这个问题。
网络爬虫的原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 809 次浏览 • 2020-05-18 08:02
在Python的模块海洋里,支持http合同的模块是相当丰富的,既有官方的urllib,也有大名鼎鼎的社区(第三方)模块 requests。它们都挺好的封装了http合同恳求的各类方式,因此,我们只须要熟悉这种模块的用法,不再进一步讨论http合同本身。
大家对浏览器应当一点都不陌生,可以说,只要上过网的人都晓得浏览器。可是,明白浏览器各类原理的人可不一定多。
作为要开发爬虫的小伙伴网络爬虫原理,是一定一定要明白浏览器的工作原理的。这是你写爬虫的必备工具,别无他。
大家在笔试的时侯,有没有遇见如此一个特别宏观而又处处细节的解答题:
这真是一个考验知识面的题啊,经验老道的老猿既可以滔滔不绝的讲上三天三夜,也可以提炼出几分钟的精华讲个大约。大家似乎对整个过程就一知半解了。
巧的是,对这个问题理解的越透彻,越对写爬虫有帮助。换句话说,爬虫是一个考验综合技能的领域。那么,大家打算好迎接这个综合技能挑战了吗?
废话不多说,我们就从解答这个题目开始,认识浏览器和服务器,看看这中间有什么知识是爬虫要用到的。
前面也说过,这个问题可以讲上三天三夜,但我们没那么多时间,其中一些细节就略过,把大致流程结合爬虫讲一讲,分成三部份:
浏览器发出恳求服务器作出响应浏览器接收响应
在浏览器地址栏输入网址后回车,浏览器请服务器提出网页恳求,也就是告诉服务器,我要看你的某个网页。 上面短短一句话,蕴藏了无数玄机啊,让我不得不费点口舌一一道来。主要述说:
首先,浏览器要判定你输入的网址(URL)是否合法有效。对应URL网络爬虫原理,小猿们并不陌生吧,以http(s)开头的那一长串的字符,但是你晓得它还可以以ftp, mailto, file, data, irc开头吗?下面是它最完整的句型格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
用图更形象的表现处理就是这样的:
经验之谈:要判定URL的合法性
Python上面可以用urllib.parse来进行URL的各类操作
In [1]: import urllib.parse
In [2]: url = 'http://dachong:the_password%40 ... 27%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看见,urlparse函数把URL剖析成了6部分: scheme://netloc/path;params?query#fragment 需要主要的是 netloc 并不等同于 URL 语法定义中的host
上面URL定义中的host,就是互联网上的一台服务器,它可以是一个IP地址,但一般是我们所说的域名。域名通过DNS绑定到一个(或多个)IP地址上。浏览器要访问某个域名的网站就要先通过DNS服务器解析域名,得到真实的IP地址。 这里的域名解析通常是由操作系统完成的,爬虫不需要关心。然而,当你写一个小型爬虫,像Google、百度搜索引擎那样的爬虫的时侯,效率显得太主要,爬虫就要维护自己的DNS缓存。 老猿经验:大型爬虫要维护自己的DNS缓存
浏览器获得了网站服务器的IP地址,就可以向服务器发送恳求了。这个恳求就是遵守http合同的。写爬虫须要关心的就是http合同的headers,下面是访问 en.wikipedia.org/wiki/URL 时浏览器发送的恳求 headers:
可能早已从图中看下来些疲态,发送的http请求头是类似一个字典的结构:
path: 访问的网站的路径scheme: 请求的合同类型,这里是httpsaccept: 能够接受的回应内容类型(Content-Types)accept-encoding: 能够接受的编码方法列表accept-language: 能够接受的回应内容的自然语言列表cache-control: 指定在此次的请求/响应链中的所有缓存机制 都必须 遵守的指令cookie: 之前由服务器通过 Set- Cookie发送的一个 超文本传输协议Cookie 这是爬虫太关心的一个东东,登录信息都在这里。upgrade-insecuree-requests: 非标准恳求数组,可忽视之。user-agent: 浏览器身分标示
这也是爬虫太关心的部份。比如,你须要得到手机版页面,就要设置浏览器身分标示为手机浏览器的user-agent。
经验之谈: 通过设置headers跟服务器沟通
如果我们在浏览器地址栏输入一个网页网址(不是文件下载地址),回车后,很快就听到了一个网页,里面包含排版文字、图片、视频等数据,是一个丰富内容格式的页面。然而,我通过浏览器查看源代码,看到的却是一对文本格式的html代码。
没错,就是一堆的代码,却使浏览器给渲染成了漂亮的网页。这对代码上面有:
而我们想要爬取的信息就藏在html代码中,我们可以通过解析方式提取其中我们想要的内容。如果html代码上面没有我们想要的数据,但是在网页上面却看见了,那就是浏览器通过ajax恳求异步加载(偷偷下载)了那部份数据。 查看全部
互联网上,公开数据(各种网页)都是以http(或加密的http即https)协议传输的。所以,我们这儿介绍的爬虫技术都是基于http(https)协议的爬虫。
在Python的模块海洋里,支持http合同的模块是相当丰富的,既有官方的urllib,也有大名鼎鼎的社区(第三方)模块 requests。它们都挺好的封装了http合同恳求的各类方式,因此,我们只须要熟悉这种模块的用法,不再进一步讨论http合同本身。
大家对浏览器应当一点都不陌生,可以说,只要上过网的人都晓得浏览器。可是,明白浏览器各类原理的人可不一定多。
作为要开发爬虫的小伙伴网络爬虫原理,是一定一定要明白浏览器的工作原理的。这是你写爬虫的必备工具,别无他。
大家在笔试的时侯,有没有遇见如此一个特别宏观而又处处细节的解答题:
这真是一个考验知识面的题啊,经验老道的老猿既可以滔滔不绝的讲上三天三夜,也可以提炼出几分钟的精华讲个大约。大家似乎对整个过程就一知半解了。
巧的是,对这个问题理解的越透彻,越对写爬虫有帮助。换句话说,爬虫是一个考验综合技能的领域。那么,大家打算好迎接这个综合技能挑战了吗?
废话不多说,我们就从解答这个题目开始,认识浏览器和服务器,看看这中间有什么知识是爬虫要用到的。
前面也说过,这个问题可以讲上三天三夜,但我们没那么多时间,其中一些细节就略过,把大致流程结合爬虫讲一讲,分成三部份:
浏览器发出恳求服务器作出响应浏览器接收响应
在浏览器地址栏输入网址后回车,浏览器请服务器提出网页恳求,也就是告诉服务器,我要看你的某个网页。 上面短短一句话,蕴藏了无数玄机啊,让我不得不费点口舌一一道来。主要述说:
首先,浏览器要判定你输入的网址(URL)是否合法有效。对应URL网络爬虫原理,小猿们并不陌生吧,以http(s)开头的那一长串的字符,但是你晓得它还可以以ftp, mailto, file, data, irc开头吗?下面是它最完整的句型格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
用图更形象的表现处理就是这样的:
经验之谈:要判定URL的合法性
Python上面可以用urllib.parse来进行URL的各类操作
In [1]: import urllib.parse
In [2]: url = 'the_password@www.yuanrenxue.com/user/info?page=2'" rel="nofollow" target="_blank">http://dachong:the_password%40 ... 27%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看见,urlparse函数把URL剖析成了6部分: scheme://netloc/path;params?query#fragment 需要主要的是 netloc 并不等同于 URL 语法定义中的host
上面URL定义中的host,就是互联网上的一台服务器,它可以是一个IP地址,但一般是我们所说的域名。域名通过DNS绑定到一个(或多个)IP地址上。浏览器要访问某个域名的网站就要先通过DNS服务器解析域名,得到真实的IP地址。 这里的域名解析通常是由操作系统完成的,爬虫不需要关心。然而,当你写一个小型爬虫,像Google、百度搜索引擎那样的爬虫的时侯,效率显得太主要,爬虫就要维护自己的DNS缓存。 老猿经验:大型爬虫要维护自己的DNS缓存
浏览器获得了网站服务器的IP地址,就可以向服务器发送恳求了。这个恳求就是遵守http合同的。写爬虫须要关心的就是http合同的headers,下面是访问 en.wikipedia.org/wiki/URL 时浏览器发送的恳求 headers:
可能早已从图中看下来些疲态,发送的http请求头是类似一个字典的结构:
path: 访问的网站的路径scheme: 请求的合同类型,这里是httpsaccept: 能够接受的回应内容类型(Content-Types)accept-encoding: 能够接受的编码方法列表accept-language: 能够接受的回应内容的自然语言列表cache-control: 指定在此次的请求/响应链中的所有缓存机制 都必须 遵守的指令cookie: 之前由服务器通过 Set- Cookie发送的一个 超文本传输协议Cookie 这是爬虫太关心的一个东东,登录信息都在这里。upgrade-insecuree-requests: 非标准恳求数组,可忽视之。user-agent: 浏览器身分标示
这也是爬虫太关心的部份。比如,你须要得到手机版页面,就要设置浏览器身分标示为手机浏览器的user-agent。
经验之谈: 通过设置headers跟服务器沟通
如果我们在浏览器地址栏输入一个网页网址(不是文件下载地址),回车后,很快就听到了一个网页,里面包含排版文字、图片、视频等数据,是一个丰富内容格式的页面。然而,我通过浏览器查看源代码,看到的却是一对文本格式的html代码。
没错,就是一堆的代码,却使浏览器给渲染成了漂亮的网页。这对代码上面有:
而我们想要爬取的信息就藏在html代码中,我们可以通过解析方式提取其中我们想要的内容。如果html代码上面没有我们想要的数据,但是在网页上面却看见了,那就是浏览器通过ajax恳求异步加载(偷偷下载)了那部份数据。
百度爬虫及工作原理解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-05-16 08:07
俗话说知己知彼能够百战不殆,互联网时代也不例外,想要关键词获取好的排行,想要网站有大量的流量,想要做好搜索引擎优化,那么一定要了解搜索引擎的工作原理,毕竟访问者想要获取信息优选选择的都是搜索引擎,百度作为全球的英文搜索引擎,百度爬虫就是它重要的程序之一。
百度爬虫又被称为百度蜘蛛,是一种网路机器人,按照一定的规则,在各个网站上爬行,访问搜集整理网页、图片、视频等内容,分类别构建数据库,呈现在搜索引擎上,使用户通过搜索一些关键词,能查看到企业网站的页面、图片、视频等。
通俗的说它可以访问,抓取,整理互联网上的多种内容,从而分门别类的构建一个索引数据库,使用户可以通过百度这个搜索引擎在互联网上找到自己想找寻的信息。它主要的工作就是发觉网站,抓取网站,保存网站,分析网站和参与网站。我们所做的一切网站优化,都是为了使爬虫抓取、收录网站的。那么,什么是百度爬虫?它工作原理是哪些呢?
1、发现网站:百度爬虫每晚还会在各个网站上爬,抓取无数的网站与页面,进行评估与初审,优质的内容都会被收录。一个新网站一般都须要一周左右就会被爬虫发觉,只要坚持不断更新网站,内容优质,一定会被发觉的。
2、抓取网站:百度爬虫通常是先按照预先设定的初始网页的URL开始,然后根据一定的规则爬取网页。爬虫沿着网页中的各类链接,从一个页面爬到另一个页面,通过链接剖析连续爬行访问,抓取更多的页面。被抓取的网页就是“百度快照”。
3、保存网站:百度爬虫的喜好跟我们人类的喜好是一样的,喜欢新鲜的、独一无二的东西。如果网站经常更新,内容质量特别高,那么爬虫就喜欢待在这里,顺着链接来回爬,欣赏这独一无二的景色,并且会保存出来。如果网站的内容都是剽窃来的,或其他网站上早就有了,爬虫就觉得是垃圾内容,便会离开网站。
4、分析网站:百度爬虫抓取到网站之后,要提取关键词,建立索引库和索引,同时还要剖析内容是否重复,判断网页的类型,分析超链接,计算网站的重要程度等大量的工作百度爬虫,分析完毕以后,就能提供检索服务。
5、参与网站:当爬虫觉得网站的内容符合它的喜好了,通过一系列的估算工作以后,就被收录上去,当用户输入关键词并进行搜索的时侯,就能从搜索引擎中找到该关键词相关的网站,从而被用户查看到。
详细点来说就是百度爬虫爬行到网站上选购网站中的优质URL(指资源的地址) ,然后将这种优质URL倒入待抓取URL队列,再从待抓取URL队列提取过滤掉重复的URL,解析网页链接特点,得到主机IP并将URL对应的网页信息下载出来存入索引库,然后等待用户搜索提取。当然,已下载的URL仍然会放到已抓取URL队列,再剖析其中的其他URL,然后再倒入待抓取URL的队列,在步入下一个循环。
在这里就不得不提及网站地图了,百度爬虫特别喜欢网站地图,因为网站地图将网站上所有的链接汇总上去,可以便捷蜘蛛的爬行抓取,让爬虫清晰了解网站的整体结构,增加网站重要页面的收录。
当今时代是互联网的时代,互联网时代是一个全新的信息化时代,当然,互联网上的内容也是实时变化,不断更新换旧的,想要信息排行愈发的靠前,只有充分把握搜索引擎的工作原理,并善用每位细节,才能使网站获取更多更好的诠释百度爬虫,毕竟成大业若烹小鲜,做大事必重细节。 查看全部

俗话说知己知彼能够百战不殆,互联网时代也不例外,想要关键词获取好的排行,想要网站有大量的流量,想要做好搜索引擎优化,那么一定要了解搜索引擎的工作原理,毕竟访问者想要获取信息优选选择的都是搜索引擎,百度作为全球的英文搜索引擎,百度爬虫就是它重要的程序之一。
百度爬虫又被称为百度蜘蛛,是一种网路机器人,按照一定的规则,在各个网站上爬行,访问搜集整理网页、图片、视频等内容,分类别构建数据库,呈现在搜索引擎上,使用户通过搜索一些关键词,能查看到企业网站的页面、图片、视频等。
通俗的说它可以访问,抓取,整理互联网上的多种内容,从而分门别类的构建一个索引数据库,使用户可以通过百度这个搜索引擎在互联网上找到自己想找寻的信息。它主要的工作就是发觉网站,抓取网站,保存网站,分析网站和参与网站。我们所做的一切网站优化,都是为了使爬虫抓取、收录网站的。那么,什么是百度爬虫?它工作原理是哪些呢?
1、发现网站:百度爬虫每晚还会在各个网站上爬,抓取无数的网站与页面,进行评估与初审,优质的内容都会被收录。一个新网站一般都须要一周左右就会被爬虫发觉,只要坚持不断更新网站,内容优质,一定会被发觉的。
2、抓取网站:百度爬虫通常是先按照预先设定的初始网页的URL开始,然后根据一定的规则爬取网页。爬虫沿着网页中的各类链接,从一个页面爬到另一个页面,通过链接剖析连续爬行访问,抓取更多的页面。被抓取的网页就是“百度快照”。
3、保存网站:百度爬虫的喜好跟我们人类的喜好是一样的,喜欢新鲜的、独一无二的东西。如果网站经常更新,内容质量特别高,那么爬虫就喜欢待在这里,顺着链接来回爬,欣赏这独一无二的景色,并且会保存出来。如果网站的内容都是剽窃来的,或其他网站上早就有了,爬虫就觉得是垃圾内容,便会离开网站。
4、分析网站:百度爬虫抓取到网站之后,要提取关键词,建立索引库和索引,同时还要剖析内容是否重复,判断网页的类型,分析超链接,计算网站的重要程度等大量的工作百度爬虫,分析完毕以后,就能提供检索服务。
5、参与网站:当爬虫觉得网站的内容符合它的喜好了,通过一系列的估算工作以后,就被收录上去,当用户输入关键词并进行搜索的时侯,就能从搜索引擎中找到该关键词相关的网站,从而被用户查看到。
详细点来说就是百度爬虫爬行到网站上选购网站中的优质URL(指资源的地址) ,然后将这种优质URL倒入待抓取URL队列,再从待抓取URL队列提取过滤掉重复的URL,解析网页链接特点,得到主机IP并将URL对应的网页信息下载出来存入索引库,然后等待用户搜索提取。当然,已下载的URL仍然会放到已抓取URL队列,再剖析其中的其他URL,然后再倒入待抓取URL的队列,在步入下一个循环。
在这里就不得不提及网站地图了,百度爬虫特别喜欢网站地图,因为网站地图将网站上所有的链接汇总上去,可以便捷蜘蛛的爬行抓取,让爬虫清晰了解网站的整体结构,增加网站重要页面的收录。
当今时代是互联网的时代,互联网时代是一个全新的信息化时代,当然,互联网上的内容也是实时变化,不断更新换旧的,想要信息排行愈发的靠前,只有充分把握搜索引擎的工作原理,并善用每位细节,才能使网站获取更多更好的诠释百度爬虫,毕竟成大业若烹小鲜,做大事必重细节。
泛域名解析网站如何避免被百度爬虫爬死(悬赏88元) - 搜外问答
采集交流 • 优采云 发表了文章 • 0 个评论 • 322 次浏览 • 2020-05-14 08:00
那么我们怎么避免访问早已访问过的页面呢?答案很简单,设置一个标志即可。整个互联网就是一个图结构,我们一般使用DFS(深度优先搜索)和BFS(广度优先搜索)进行遍历。所以,像遍历一个简单的图一样,将访问过的结点标记一下即可。
爬虫的基本思路如下:
根据URL获取相应页面的HTML代码
利用正则匹配或则JSoup等库解析HTML代码,提取须要的内容
将获取的内容持久化到数据库中
处理好英文字符的编码问题,可以采用多线程提升效率
爬虫基本原理
更笼统意义上的爬虫着重于若果在大量的URL中找寻出高质量的资源,如何在有限的时间内访问更多页面等等。网络爬虫的基本工作流程如下:
首先选定一部分悉心选购的种子URL;
将这种URL装入待抓取URL队列;
从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
分析已抓取URL对应的网页,分析页面里包含的其他URL,并且将URL装入待抓取URL队列,从而步入下一个循环。
有几个概念,一个是发http请求,一个是正则匹配你感兴趣的链接,一个是多线程,另外还有两个队列。
爬虫难点1支路
网络爬虫有时候会深陷循环或则支路中,比如从页面A,A链接到页面B,B链接到页面C,页面C又会链接到页面A。这样就深陷到支路中。
环路影响:
消耗网路带宽,无法获取其他页面
对Web服务器也是负担,可能击垮该站点,可能制止正常用户访问该站点
即使没有性能影响,但获取大量重复页面也造成数据冗余
解决方案:
简单限定爬虫的最大循环次数网页如何防止爬虫,对于某web站点访问超过一定阀值就跳出,避免无限循环
保存一个已访问url列表,记录页面是否被访问过的技术
1、二叉树和散列表,快速判断某个url是否访问过
2、存在位图
就是newint[length],然后把第几个数置为1,表示早已访问过了。可不可以再优化,int是32位,32位可以表示32个数字。HashCode会存在冲突的情况,
两个URL映射到同一个存在位上,冲突的后果是某个页面被忽视(这比死循环的恶作用小)
3、保存检测
一定要及时把已访问的URL列表保存到硬碟上,防止爬虫崩溃,内存里的数据会遗失
4、集群,分而治之
多台机器一起爬虫,可以按照URL估算HashCode,然后按照HashCode映射到相应机器的id(第0台、第1台、第2台等等)
难点2URL别称
有些URL名称不一样,但是指向同一个资源。
URl1URL2什么时候是别称
默认端口是80
%7F与~相同
%7F与~相同
服务器是大小写无关
默认页面为
ip和域名相同
难点3动态虚拟空间
比如月历程序,它会生成一个指向下一个月的链接,真正的用户是不会不停地恳求下个月的链接的。但是不了解这种内容特点的爬虫蜘蛛可能会不断向那些资源发出无穷的恳求。
抓取策略
一般策略是深度优先或则广度优先。有些技术能促使爬虫蜘蛛有更好的表现
广度优先的爬行,避免深度优先深陷某个站点的支路中,无法访问其他站点。
限制访问次数,限定一段时间内机器人可以从一个web站点获取的页面数目。
内容指纹,根据页面的内容估算出一个校验和,但是动态的内容(日期,评论数量)会妨碍重复测量
维护黑名单
人工监视,特殊情况发出电邮通知
动态变化,根据当前热点新闻等等
规范化URL,把一些转义字符、ip与域名之类的统一
限制URL大小,环路可能会促使URL宽度降低,比如/,/folder/网页如何防止爬虫,/folder/folder/…… 查看全部
话说爬虫为何会深陷循环呢?答案很简单,当我们重新去解析一个早已解析过的网页时,就会身陷无限循环。这意味着我们会重新访问哪个网页的所有链接,然后不久后又会访问到这个网页。最简单的事例就是,网页A包含了网页B的链接,而网页B又包含了网页A的链接,那它们之间都会产生一个闭环。
那么我们怎么避免访问早已访问过的页面呢?答案很简单,设置一个标志即可。整个互联网就是一个图结构,我们一般使用DFS(深度优先搜索)和BFS(广度优先搜索)进行遍历。所以,像遍历一个简单的图一样,将访问过的结点标记一下即可。
爬虫的基本思路如下:
根据URL获取相应页面的HTML代码
利用正则匹配或则JSoup等库解析HTML代码,提取须要的内容
将获取的内容持久化到数据库中
处理好英文字符的编码问题,可以采用多线程提升效率
爬虫基本原理
更笼统意义上的爬虫着重于若果在大量的URL中找寻出高质量的资源,如何在有限的时间内访问更多页面等等。网络爬虫的基本工作流程如下:
首先选定一部分悉心选购的种子URL;
将这种URL装入待抓取URL队列;
从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
分析已抓取URL对应的网页,分析页面里包含的其他URL,并且将URL装入待抓取URL队列,从而步入下一个循环。
有几个概念,一个是发http请求,一个是正则匹配你感兴趣的链接,一个是多线程,另外还有两个队列。
爬虫难点1支路
网络爬虫有时候会深陷循环或则支路中,比如从页面A,A链接到页面B,B链接到页面C,页面C又会链接到页面A。这样就深陷到支路中。
环路影响:
消耗网路带宽,无法获取其他页面
对Web服务器也是负担,可能击垮该站点,可能制止正常用户访问该站点
即使没有性能影响,但获取大量重复页面也造成数据冗余
解决方案:
简单限定爬虫的最大循环次数网页如何防止爬虫,对于某web站点访问超过一定阀值就跳出,避免无限循环
保存一个已访问url列表,记录页面是否被访问过的技术
1、二叉树和散列表,快速判断某个url是否访问过
2、存在位图
就是newint[length],然后把第几个数置为1,表示早已访问过了。可不可以再优化,int是32位,32位可以表示32个数字。HashCode会存在冲突的情况,
两个URL映射到同一个存在位上,冲突的后果是某个页面被忽视(这比死循环的恶作用小)
3、保存检测
一定要及时把已访问的URL列表保存到硬碟上,防止爬虫崩溃,内存里的数据会遗失
4、集群,分而治之
多台机器一起爬虫,可以按照URL估算HashCode,然后按照HashCode映射到相应机器的id(第0台、第1台、第2台等等)
难点2URL别称
有些URL名称不一样,但是指向同一个资源。
URl1URL2什么时候是别称
默认端口是80
%7F与~相同
%7F与~相同
服务器是大小写无关
默认页面为
ip和域名相同
难点3动态虚拟空间
比如月历程序,它会生成一个指向下一个月的链接,真正的用户是不会不停地恳求下个月的链接的。但是不了解这种内容特点的爬虫蜘蛛可能会不断向那些资源发出无穷的恳求。
抓取策略
一般策略是深度优先或则广度优先。有些技术能促使爬虫蜘蛛有更好的表现
广度优先的爬行,避免深度优先深陷某个站点的支路中,无法访问其他站点。
限制访问次数,限定一段时间内机器人可以从一个web站点获取的页面数目。
内容指纹,根据页面的内容估算出一个校验和,但是动态的内容(日期,评论数量)会妨碍重复测量
维护黑名单
人工监视,特殊情况发出电邮通知
动态变化,根据当前热点新闻等等
规范化URL,把一些转义字符、ip与域名之类的统一
限制URL大小,环路可能会促使URL宽度降低,比如/,/folder/网页如何防止爬虫,/folder/folder/……
Python爬虫能做哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2020-05-12 08:03
1251人阅读|16次下载
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料。老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用,爬虫的本质 是借助程序手动的从网路获取信
老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用python爬虫有啥用,爬虫的本质 是借助程序手动的从网路获取信息,爬虫技术也是大数据和云估算的基础。 Python 是一门特别适宜开发网路爬虫的编程语言,相比于其他静态编程语 言,Python 抓取网页文档的插口更简约;相比于其他动态脚本语言,Python 的 urllib2 包提供了较为完整的访问网页文档的 API。此外,python 中有优秀的第 三方包可以高效实现网页抓取,并可用极短的代码完成网页的标签过滤功能。 Python 爬虫构架组成:1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取 的 url 给网页下载器; 2. 网页下载器: 爬取 url 对应的网页, 存储成字符串, 传献给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管 理器。 Python 爬虫工作原理:老男孩 IT 教育,只培养技术精英Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URLpython爬虫有啥用,通过 调度器进行传递给下载器,下载 URL 内容,并通过调度器传送给解析器,解析 URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值 信息的过程。 Python 爬虫常用框架有: grab:网络爬虫框架; scrapy:网络爬虫框架,不支持 Python3; pyspider:一个强悍的爬虫系统; cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源, 并围绕它完善的对象。 demiurge:基于 PyQuery 的爬虫微框架。 Python 是一门特别适宜开发网路爬虫的编程语言,提供了如 urllib、re、 json、pyquery 等模块,同时又有很多成形框架,如 Scrapy 框架、PySpider 爬老男孩 IT 教育,只培养技术精英虫系统等,是网路爬虫首选编程语言! 查看全部
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料
1251人阅读|16次下载
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料。老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用,爬虫的本质 是借助程序手动的从网路获取信
老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用python爬虫有啥用,爬虫的本质 是借助程序手动的从网路获取信息,爬虫技术也是大数据和云估算的基础。 Python 是一门特别适宜开发网路爬虫的编程语言,相比于其他静态编程语 言,Python 抓取网页文档的插口更简约;相比于其他动态脚本语言,Python 的 urllib2 包提供了较为完整的访问网页文档的 API。此外,python 中有优秀的第 三方包可以高效实现网页抓取,并可用极短的代码完成网页的标签过滤功能。 Python 爬虫构架组成:1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取 的 url 给网页下载器; 2. 网页下载器: 爬取 url 对应的网页, 存储成字符串, 传献给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管 理器。 Python 爬虫工作原理:老男孩 IT 教育,只培养技术精英Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URLpython爬虫有啥用,通过 调度器进行传递给下载器,下载 URL 内容,并通过调度器传送给解析器,解析 URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值 信息的过程。 Python 爬虫常用框架有: grab:网络爬虫框架; scrapy:网络爬虫框架,不支持 Python3; pyspider:一个强悍的爬虫系统; cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源, 并围绕它完善的对象。 demiurge:基于 PyQuery 的爬虫微框架。 Python 是一门特别适宜开发网路爬虫的编程语言,提供了如 urllib、re、 json、pyquery 等模块,同时又有很多成形框架,如 Scrapy 框架、PySpider 爬老男孩 IT 教育,只培养技术精英虫系统等,是网路爬虫首选编程语言!
batchcollect pagecollect来自官方杰奇jieqi定时采集配
采集交流 • 优采云 发表了文章 • 0 个评论 • 536 次浏览 • 2020-08-03 17:00
更新时间:2008年07月11日 08:44:35 转载作者:
主要的功能页面为pagecollect.php和batchcollect.php要实现采集,默认方法是按照配置好的采集规则,在浏览器递交相应的参数即可完成前面的采集入库全部动作。
前言
要实现采集,默认方法是按照配置好的采集规则文章定时自动采集,在浏览器递交相应的参数即可完成前面的采集入库全部动作。
而实现定时采集,与人工在浏览器递交有些区别,主要分两大步骤:
一、编写采集的url和相关参数,访问这个url即可实现想要的采集模式。(这个url直接在浏览器递交同样可以实现采集)
二、把定时访问这个url的功能加到系统的定时任务上面,实现无人值守的定时采集。
具体实现方式请参考下边内容:
1、对采集配置文件的解释
任何一个采集都会用到两个采集配置文件(跟后台采集规则配置对应),都可以用文本编辑器打开查看。
其中/configs/article/collectsite.php是对总的采集站点配置,记录了一共容许采集哪几个站点。
里面包含类似这样的内容:
$jieqiCollectsite['1']['name']='采集站点一';
$jieqiCollectsite['1']['config']='abc_com';
$jieqiCollectsite['1']['url']='';
$jieqiCollectsite['1']['subarticleid']='floor($articleid/1000)';
$jieqiCollectsite['1']['enable']='1';
$jieqiCollectsite['2']['name']='采集站点二';
$jieqiCollectsite['2']['config']='def_net';
$jieqiCollectsite['2']['url']='';
$jieqiCollectsite['2']['subarticleid']='';
$jieqiCollectsite['2']['enable']='1';
参数涵义解释如下:
['1']-这里的1表示采集网站的数字序号,不同的采集站序号不能重复。
['name']-采集网站名称。
['config']-网站英文标示,这个网站采集规则配置文件有关,比如这个值是abc_com,那么采集规则配置文件就是/configs/article/site_abc_com.php。
['url']-采集网站网址。
['subarticleid']-采集网站,文章子序号运算方法,本项目主要为了兼容原先程序,新版本上面文章子序号可以通过采集获得。
['enable']-是否容许采集,1表示准许,0表示严禁,默认为1。
如上面所说,每个采集网站有个专门的采集规则配置文件,/configs/article/目录下以site_开头的php文件,如/configs/article/site_abc_com.php。
里面内容都与后台采集规则设置相对应,具体细节不一一解释。需要了解的是本文件上面内容分两大部份,前面内容都是对网站内容采集规则的配置,而最前面$jieqiCollect['listcollect']['0'],$jieqiCollect['listcollect']['1']这样的设置是对网站"批量采集规则"的配置,比如按近来更新采集、按排行榜采集,可以设置多个。['0']这里的数字0表示批量采集类别的数字序号,同一个网站也不能重复。
2、编写采集内容的url及参数
这里的采集是针对多篇文章批量采集,分两种模式:
一、按页面批量采集,比如采集最新更新列表或则排行榜列表,每个链接采集一页。
链接格式如下:
参数含意解释如下:
-是指您的网址。
action-字符串,程序执行的动作命令,固定值为collect。
siteid-数字类型,要采集的网站序号,具体那个网站对应哪些序号见配置文件collectsite.php。
collectname-数字类型,按页面批量采集的类别序号,见配置文件site_xxxx.php上面下边的。$jieqiCollect['listcollect']['0']这样配置的数字。
startpageid--页码标志,表示从列表的第几页开始采集。一般是数字类型,有些网站也可能是字符串。
maxpagenum--数字类型,表示表示一共采集几页。(默认为1,如果要采集多页,是须要浏览器跳转的,只有在windows环境下调用浏览器时侯有效,linux下调用wget时侯最多只能采集一页,需要采集多页可设置多个采集命令。)
notaddnew--数字类型,0-表示采集全部文章,1-表示只更新本站已有的文章。
jieqi_username-字符串,用户名(这个用户必须是本站有权限采集的用户)。
jieqi_userpassword-字符串,用户密码。
二、按照文章序号批量采集
链接格式如下:
,234,345&jieqi_username=admin&jieqi_userpassword=1234
参数含意解释如下:
-是指您的网址。
action-字符串,程序执行的动作命令,固定值为bcollect。
siteid-数字类型,要采集的网站序号,具体那个网站对应哪些序号见配置文件collectsite.php。
batchids-要采集的对方网站文章序号(不是本地的文章序号),采集多个文章,序号用英语冒号分开,如123,234,345。
jieqi_username-字符串,用户名(这个用户必须是本站有权限采集的用户)。
jieqi_userpassword-字符串,用户密码。
注:一个url须要放在IE浏览器上面递交的时侯,整个url最大宽度度不要超过2083字节,所以通常建议这儿的url不要设置成很长,文章多的可以分拆成多个url。
3、利用系统任务实现定时采集
一、windows环境下做法
windows上面可以用系统的任务计划来实现定时执行程序,不过首先须要制做一个批处理文件,在这个文件上面用命令来调用浏览器来执行采集url。需要注意的是命令只能打开浏览器而不会采集好以后手动关掉,要实现采集完手动关掉可以通过javascript实现。自动关掉本窗口的js代码为:
这里的参数3000是指延后关掉时间,单位是微秒,3000表示延后3秒关掉。
这段代码可以在两个地方加入:
一个是加入到提示信息模板/themes/风格名称/msgwin.html上面,和之间加入前面那段js。这样的疗效是整个系统任何提示信息页面就会在3秒钟后手动关掉。
如果您希望仅仅手动关掉采集成功后的提示页面,可以在采集提示信息的语言包上面加入以上javascript,这个配置文件是/modules/article/lang/lang_collect.php,里面$jieqiLang['article']['batch_collect_success']是采集成功的提示信息,这个值原先是:
'恭喜您,全部文章采集完成!';
改成下边这样即可手动关掉
'恭喜您,全部文章采集完成!';
建立批处理文件方式如下:
在任意目录构建一个后缀名为.bat的文件文章定时自动采集,比如D:\collect.bat,然后用文本编辑器输入类似下边的代码
@echooff
"explorer"";siteid=1&collectname=0&startpageid=1&maxpagenum=1&notaddnew=0&jieqi_username=admin&jieqi_userpassword=1234"
"explorer"";siteid=1&batchids=123,234,345&jieqi_username=admin&jieqi_userpassword=1234"
exit
其中
第一句@echooff是表示关掉显示
最后一句exit表示执行完退出
中间每行表示一个采集命令(可以设置多行),就是借助系统的浏览器来执行后面编辑好的采集url。
使用这样的格式:
"explorer""url"
前面部份是命令,后面是采集的url,也可以使用这样的格式:
"%programfiles%\InternetExplorer\IEXPLORE.EXE""url"
前面部份是ie浏览器的路径,后面是采集的url。
这两种命令模式的区别是,有多行命令的时侯,前者会打开多个浏览器窗口同时执行;而后者先打开浏览器执行第一个命令,必须等这个浏览器关掉后才能重新打开一个浏览器执行第二个命令。
编辑好里面的bat文件后,开始在任务计划上面添加执行这个任务,主要步骤如下(每半小时执行一次采集):
a、打开"控制面板",进入"任务计划"。
b、点"添加任务计划"打开任务计划向导进行添加任务。
c、点"下一步",然后点"浏览"选择要执行的程序。(例子上面就是选择D:\collect.bat)
d、设置任务名称及执行频度,比如选择"每天",点"下一步"。
e、选择最开始执行的时间和日期,一般设置比当前时间前面一点就行,点"下一步"。
f、设置执行的用户名和密码(本操作系统的账号),点"下一步"。
g、选择"在单击"完成"时,打开此任务的中级属性",点"完成"。
h、在"日程安排"里面,点"高级",选择"重复任务",设置"每30分钟"执行一次。
i、保存以上设置后即完成系统任务计划。
二、linux环境下做法
linux下可以借助的系统定时任务来执行,也同样须要先制做一个批处理的脚本,方法如下
在任意目录构建一个后缀为.sh的文件,比如/www/collect.sh,需要形参可执行权限,如chmod755/www/collect.sh
里面内容如下: 查看全部
batchcollect pagecollect来自官方杰奇jieqi定时采集配置方式参数解读
更新时间:2008年07月11日 08:44:35 转载作者:
主要的功能页面为pagecollect.php和batchcollect.php要实现采集,默认方法是按照配置好的采集规则,在浏览器递交相应的参数即可完成前面的采集入库全部动作。
前言
要实现采集,默认方法是按照配置好的采集规则文章定时自动采集,在浏览器递交相应的参数即可完成前面的采集入库全部动作。
而实现定时采集,与人工在浏览器递交有些区别,主要分两大步骤:
一、编写采集的url和相关参数,访问这个url即可实现想要的采集模式。(这个url直接在浏览器递交同样可以实现采集)
二、把定时访问这个url的功能加到系统的定时任务上面,实现无人值守的定时采集。
具体实现方式请参考下边内容:
1、对采集配置文件的解释
任何一个采集都会用到两个采集配置文件(跟后台采集规则配置对应),都可以用文本编辑器打开查看。
其中/configs/article/collectsite.php是对总的采集站点配置,记录了一共容许采集哪几个站点。
里面包含类似这样的内容:
$jieqiCollectsite['1']['name']='采集站点一';
$jieqiCollectsite['1']['config']='abc_com';
$jieqiCollectsite['1']['url']='';
$jieqiCollectsite['1']['subarticleid']='floor($articleid/1000)';
$jieqiCollectsite['1']['enable']='1';
$jieqiCollectsite['2']['name']='采集站点二';
$jieqiCollectsite['2']['config']='def_net';
$jieqiCollectsite['2']['url']='';
$jieqiCollectsite['2']['subarticleid']='';
$jieqiCollectsite['2']['enable']='1';
参数涵义解释如下:
['1']-这里的1表示采集网站的数字序号,不同的采集站序号不能重复。
['name']-采集网站名称。
['config']-网站英文标示,这个网站采集规则配置文件有关,比如这个值是abc_com,那么采集规则配置文件就是/configs/article/site_abc_com.php。
['url']-采集网站网址。
['subarticleid']-采集网站,文章子序号运算方法,本项目主要为了兼容原先程序,新版本上面文章子序号可以通过采集获得。
['enable']-是否容许采集,1表示准许,0表示严禁,默认为1。
如上面所说,每个采集网站有个专门的采集规则配置文件,/configs/article/目录下以site_开头的php文件,如/configs/article/site_abc_com.php。
里面内容都与后台采集规则设置相对应,具体细节不一一解释。需要了解的是本文件上面内容分两大部份,前面内容都是对网站内容采集规则的配置,而最前面$jieqiCollect['listcollect']['0'],$jieqiCollect['listcollect']['1']这样的设置是对网站"批量采集规则"的配置,比如按近来更新采集、按排行榜采集,可以设置多个。['0']这里的数字0表示批量采集类别的数字序号,同一个网站也不能重复。
2、编写采集内容的url及参数
这里的采集是针对多篇文章批量采集,分两种模式:
一、按页面批量采集,比如采集最新更新列表或则排行榜列表,每个链接采集一页。
链接格式如下:
参数含意解释如下:
-是指您的网址。
action-字符串,程序执行的动作命令,固定值为collect。
siteid-数字类型,要采集的网站序号,具体那个网站对应哪些序号见配置文件collectsite.php。
collectname-数字类型,按页面批量采集的类别序号,见配置文件site_xxxx.php上面下边的。$jieqiCollect['listcollect']['0']这样配置的数字。
startpageid--页码标志,表示从列表的第几页开始采集。一般是数字类型,有些网站也可能是字符串。
maxpagenum--数字类型,表示表示一共采集几页。(默认为1,如果要采集多页,是须要浏览器跳转的,只有在windows环境下调用浏览器时侯有效,linux下调用wget时侯最多只能采集一页,需要采集多页可设置多个采集命令。)
notaddnew--数字类型,0-表示采集全部文章,1-表示只更新本站已有的文章。
jieqi_username-字符串,用户名(这个用户必须是本站有权限采集的用户)。
jieqi_userpassword-字符串,用户密码。
二、按照文章序号批量采集
链接格式如下:
,234,345&jieqi_username=admin&jieqi_userpassword=1234
参数含意解释如下:
-是指您的网址。
action-字符串,程序执行的动作命令,固定值为bcollect。
siteid-数字类型,要采集的网站序号,具体那个网站对应哪些序号见配置文件collectsite.php。
batchids-要采集的对方网站文章序号(不是本地的文章序号),采集多个文章,序号用英语冒号分开,如123,234,345。
jieqi_username-字符串,用户名(这个用户必须是本站有权限采集的用户)。
jieqi_userpassword-字符串,用户密码。
注:一个url须要放在IE浏览器上面递交的时侯,整个url最大宽度度不要超过2083字节,所以通常建议这儿的url不要设置成很长,文章多的可以分拆成多个url。
3、利用系统任务实现定时采集
一、windows环境下做法
windows上面可以用系统的任务计划来实现定时执行程序,不过首先须要制做一个批处理文件,在这个文件上面用命令来调用浏览器来执行采集url。需要注意的是命令只能打开浏览器而不会采集好以后手动关掉,要实现采集完手动关掉可以通过javascript实现。自动关掉本窗口的js代码为:
这里的参数3000是指延后关掉时间,单位是微秒,3000表示延后3秒关掉。
这段代码可以在两个地方加入:
一个是加入到提示信息模板/themes/风格名称/msgwin.html上面,和之间加入前面那段js。这样的疗效是整个系统任何提示信息页面就会在3秒钟后手动关掉。
如果您希望仅仅手动关掉采集成功后的提示页面,可以在采集提示信息的语言包上面加入以上javascript,这个配置文件是/modules/article/lang/lang_collect.php,里面$jieqiLang['article']['batch_collect_success']是采集成功的提示信息,这个值原先是:
'恭喜您,全部文章采集完成!';
改成下边这样即可手动关掉
'恭喜您,全部文章采集完成!';
建立批处理文件方式如下:
在任意目录构建一个后缀名为.bat的文件文章定时自动采集,比如D:\collect.bat,然后用文本编辑器输入类似下边的代码
@echooff
"explorer"";siteid=1&collectname=0&startpageid=1&maxpagenum=1&notaddnew=0&jieqi_username=admin&jieqi_userpassword=1234"
"explorer"";siteid=1&batchids=123,234,345&jieqi_username=admin&jieqi_userpassword=1234"
exit
其中
第一句@echooff是表示关掉显示
最后一句exit表示执行完退出
中间每行表示一个采集命令(可以设置多行),就是借助系统的浏览器来执行后面编辑好的采集url。
使用这样的格式:
"explorer""url"
前面部份是命令,后面是采集的url,也可以使用这样的格式:
"%programfiles%\InternetExplorer\IEXPLORE.EXE""url"
前面部份是ie浏览器的路径,后面是采集的url。
这两种命令模式的区别是,有多行命令的时侯,前者会打开多个浏览器窗口同时执行;而后者先打开浏览器执行第一个命令,必须等这个浏览器关掉后才能重新打开一个浏览器执行第二个命令。
编辑好里面的bat文件后,开始在任务计划上面添加执行这个任务,主要步骤如下(每半小时执行一次采集):
a、打开"控制面板",进入"任务计划"。
b、点"添加任务计划"打开任务计划向导进行添加任务。
c、点"下一步",然后点"浏览"选择要执行的程序。(例子上面就是选择D:\collect.bat)
d、设置任务名称及执行频度,比如选择"每天",点"下一步"。
e、选择最开始执行的时间和日期,一般设置比当前时间前面一点就行,点"下一步"。
f、设置执行的用户名和密码(本操作系统的账号),点"下一步"。
g、选择"在单击"完成"时,打开此任务的中级属性",点"完成"。
h、在"日程安排"里面,点"高级",选择"重复任务",设置"每30分钟"执行一次。
i、保存以上设置后即完成系统任务计划。
二、linux环境下做法
linux下可以借助的系统定时任务来执行,也同样须要先制做一个批处理的脚本,方法如下
在任意目录构建一个后缀为.sh的文件,比如/www/collect.sh,需要形参可执行权限,如chmod755/www/collect.sh
里面内容如下:
最实用的文章采集神器:可依照关键词采集,也能按URL列表采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 678 次浏览 • 2020-08-03 10:54
文章采集来源主要来自以下搜索引擎:
百度网页、百度新闻、搜狗网页、搜狗新闻、微信、360网页、360新闻、今日头条、一点资讯、必应网页、必应新闻、雅虎、谷歌网页、谷歌新闻
下面瞧瞧利器妹的实测报告:
1.根据关键词采集的文章
设定如下:
关键词:人工智能|外星人|虚拟现实
文章发布时间为:最近一天
语言为:简体中文
然后点击开始采集,如下图所示:
采集一会儿后,点击暂停采集,如下图所示,打开文章查看菜单,根据文章采集目录地址查看所采集的每一篇文章,采集的内容可以复制黏贴。
2.根据文章URL列表采集文章
只需将文章URL链接复制黏贴到右边的列表页面中,然后点击开始采集文章,即可进行文章采集。
采集后左侧会显示采集文章的URL,如下图所示
根据弹框消息提示:“已采集403条文章URL!可以将这组URL复制到【根据URL列表采集文章】中采集正文!”,将刚刚采集到的文章URL链接复制到左边那种列表框内,然后就开始采集文章。
采集完成后,再切换到“文章查看”菜单,找到“列表页采集”,按照采集文章的目录就可以查看正文。
另外文章采集还可以进行自定义设置过滤网站。
总结:
这个工具有哪些用途?神器妹觉得,第一类可能就是微信公众号运营者(因为它是支持采集微信文章的)、网站编辑、站长类,采用它采集文章可以提高工作效率。
第二类关键词采集文章,可能就是须要写文章的人关键词采集文章,根据主题关键词采集文章,然后可以借鉴这种文章的思想,七拼八凑就是一篇原创文章,至少也是一篇伪原创文章了,
另外补充一款自媒体全平台文章采集小工具,一并提供下载链接: 查看全部
本期分享一个文章采集神器,支持按照关键词采集文章,以及按照文章URL列表采集文章,可以自定义设置网址过滤,同时,支持在线查看采集的文章。
文章采集来源主要来自以下搜索引擎:
百度网页、百度新闻、搜狗网页、搜狗新闻、微信、360网页、360新闻、今日头条、一点资讯、必应网页、必应新闻、雅虎、谷歌网页、谷歌新闻
下面瞧瞧利器妹的实测报告:
1.根据关键词采集的文章
设定如下:
关键词:人工智能|外星人|虚拟现实
文章发布时间为:最近一天
语言为:简体中文
然后点击开始采集,如下图所示:
采集一会儿后,点击暂停采集,如下图所示,打开文章查看菜单,根据文章采集目录地址查看所采集的每一篇文章,采集的内容可以复制黏贴。
2.根据文章URL列表采集文章
只需将文章URL链接复制黏贴到右边的列表页面中,然后点击开始采集文章,即可进行文章采集。
采集后左侧会显示采集文章的URL,如下图所示
根据弹框消息提示:“已采集403条文章URL!可以将这组URL复制到【根据URL列表采集文章】中采集正文!”,将刚刚采集到的文章URL链接复制到左边那种列表框内,然后就开始采集文章。
采集完成后,再切换到“文章查看”菜单,找到“列表页采集”,按照采集文章的目录就可以查看正文。
另外文章采集还可以进行自定义设置过滤网站。
总结:
这个工具有哪些用途?神器妹觉得,第一类可能就是微信公众号运营者(因为它是支持采集微信文章的)、网站编辑、站长类,采用它采集文章可以提高工作效率。
第二类关键词采集文章,可能就是须要写文章的人关键词采集文章,根据主题关键词采集文章,然后可以借鉴这种文章的思想,七拼八凑就是一篇原创文章,至少也是一篇伪原创文章了,
另外补充一款自媒体全平台文章采集小工具,一并提供下载链接:
网站怎么采集 wordpress怎样实现手动采集
站长必读 • 优采云 发表了文章 • 0 个评论 • 763 次浏览 • 2020-07-18 08:08
WordPress是一种使用PHP语言开发的建站程序平台,现在做博客用wp的早已好多了,很多网站制作培训都使用的是wp,特别是在做采集站的时侯wordpress的共能太强悍。下面就给你们介绍怎样实现wp的手动采集功能。
安装网站采集插件:WP-AutoPost(插件下载地址:)
点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。(这一部分不需要更改设置,唯一须要改动的就是采集的时间。)文章来源设置。在该选项卡下我们须要设置文章来源的文章列表网址及具体文章的匹配规则。我们以采集”新浪互联网新闻“为例,文章列表网址为,因此在手工指定文章列表网址中输入该网址即可,如下所示:
文章网址匹配规则。文章网址匹配规则的设置特别简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配wordpress 文章采集,通常使用URL键值匹配较为简单,但有时使用CSS选择器更为精确。使用URL键值匹配。通过点击列表网址上的文章,我们可以发觉整篇文章的URL都为如下结构:,因此将URL中变化的数字或字母替换为键值(*)即可,如:(*)/(*).shtml 。重复的网址可以使用301重定向。使用CSS选择器进行匹配。使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可,通过查看列表网址的源代码即可轻松设置,找到列表网址下文章超链接的代码,如下所示:
可以看见,文章的超链接A标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为.contList a 即可,如下所示:
设置完成以后,不知道设置是否正确,可以点击上图中的测试按键wordpress 文章采集,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:
其他的设置可以不用更改。以上采集方法适用于WordPress多站点功能。 查看全部
WordPress是一种使用PHP语言开发的建站程序平台,现在做博客用wp的早已好多了,很多网站制作培训都使用的是wp,特别是在做采集站的时侯wordpress的共能太强悍。下面就给你们介绍怎样实现wp的手动采集功能。
安装网站采集插件:WP-AutoPost(插件下载地址:)
点击“新建任务”后,输入任务名称,即可创建新任务,创建好新任务以后可以在任务列表中查看到该任务,就可对该任务进行更多设置。(这一部分不需要更改设置,唯一须要改动的就是采集的时间。)文章来源设置。在该选项卡下我们须要设置文章来源的文章列表网址及具体文章的匹配规则。我们以采集”新浪互联网新闻“为例,文章列表网址为,因此在手工指定文章列表网址中输入该网址即可,如下所示:
文章网址匹配规则。文章网址匹配规则的设置特别简单,无需复杂设置,提供两种匹配模式,可以使用URL键值匹配,也可以使用CSS选择器进行匹配wordpress 文章采集,通常使用URL键值匹配较为简单,但有时使用CSS选择器更为精确。使用URL键值匹配。通过点击列表网址上的文章,我们可以发觉整篇文章的URL都为如下结构:,因此将URL中变化的数字或字母替换为键值(*)即可,如:(*)/(*).shtml 。重复的网址可以使用301重定向。使用CSS选择器进行匹配。使用CSS选择器进行匹配,我们只须要设置文章网址的CSS选择器即可,通过查看列表网址的源代码即可轻松设置,找到列表网址下文章超链接的代码,如下所示:
可以看见,文章的超链接A标签在class为“contList”的标签内部,因此文章网址的CSS选择器只须要设置为.contList a 即可,如下所示:
设置完成以后,不知道设置是否正确,可以点击上图中的测试按键wordpress 文章采集,如果设置正确,将列举该列表网址下所有文章名称和对应的网页地址,如下所示:
其他的设置可以不用更改。以上采集方法适用于WordPress多站点功能。
爬虫框架(scrapy构架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 578 次浏览 • 2020-07-03 08:00
scrapy主要包括了以下组件: 1.)引擎(scrapy):用来处理整个系统的数据流,触发事务(框架核心) 2.)调度器(Scheduler):用来接受引擎发过来的恳求,压入队列中,并在引擎再度恳求的时侯返回,可以想像成一个url(抓取网页的网址或则说链接)的优先队列,由它来决定下一个要抓取的网址是哪些,同时除去重复的网址。 3.)下载器(Downloader):用于下载网页的内容,并将网页内容返回给蜘蛛(Scrapy下载器是构建在twisted这个高效的异步模型上的) 4.)爬虫(Spiders):爬虫是主要干活的,用于从特定的网页中提取自己想要的信息,即所谓的实体(item)。用户也可以从中提取到链接,让Scrapy继续抓取下一个页面。 5.)项目管线(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管线,并经过几个特定的顺序处理数据。 (只有当调度器中不存在任何request时,整个程序就会停止。(对于下载失败的url,Scrapy也会重新下载))
前置要求: pip下载scrapy模块 yum下载tree包
-确定url地址; -获取页面信息;(urllib,requests) -解析页面提取须要的信息;(xpath,bs4,正则表达时) -保存到本地(scv,json,pymysql,redis) -清洗数据(删除不必要的内容------正则表达式) -分析数据(词云wordcloud,jieba)
-确定url地址(spider) -获取页面信息(Downloader) -解析页面提取须要的信息(spider) -保存到本地(pipeline)
scrapy1.6.0
1.工程创建 1.)命令行在当前目录下创建mySpider
scrapy startproject mySpider
2.)创建成功后,进入mySpider ,tree查看
cd mySpider tree
2.创建一个爬虫
#scrapy genspider 项目名 url scrapy genspider mooc ‘’
3.定义爬取的items内容(items.py)
class CourseItem(scrapy.Item):
#课程标题 title=scrapy.Field() #课程的url地址 url=scrapy.Field() #课程图片的url地址 image_url=scrapy.Field() #课程的描述 introduction=scrapy.Field() #学习人数 student=scrapy.Field()
4.编写spider代码,解析 4.1确定url地址,提取页面须要的信息(mooc.py)
class MoocSpider(scrapy,spider):
#name用于区别爬虫,必须惟一 name=‘mooc’ #允许爬取的域名,其他网站的页面直接跳过 allowd_domains=[‘’,‘’] #爬虫开启时第一个装入调度器的url地址 start_urls=[‘’] #被调用时,每个新的url完成下载后爬虫框架,返回一个响应对象 #下面的方式负责将响应的数据剖析,提取出须要的数据items以及生成下一步须要处理的url地址恳求; def parser(self,response):
##用来检查代码是否达到指定位置,并拿来调试并解析页面信息; #from scrapy.shell import inspect_response #inspect_response(response,self) #1.)实例化对象,CourseItem course=CourseItem() #分析响应的内容 #scrapy剖析页面使用的是xpath方式 #2.)获取每位课程的信息 courseDetails=course.xpath(’.//div[@class=“course-card-container”]’) for courseDetail in courseDetails:
#爬取新的网站, Scrapy上面进行调试(parse命令logging) course[‘title’] = courseDetail.xpath(’.//h3[@class=“course-card-name”]/text()’).extract()[0] #学习人数 course[‘student’] = courseDetail.xpath(’.//span/text()’).extract()[1] #课程描述: course[‘introduction’] = courseDetail.xpath(".//p[@class=‘course-card-desc’]/text()").extract()[0] #课程链接, h获取/learn/9 ====》 course[‘url’] = “” + courseDetail.xpath(’.//a/@href’).extract()[0] #课程的图片url: course[‘image_url’] = ‘http:’ + courseDetail.xpath(’.//img/@src’).extract()[0] yield course #url跟进,获取下一步是否有链接;href url=response.xpath(’.//a[contains[text(),“下一页”]/@href’)[0].extract() if url:
#构建新的url page=‘’+url yield scrapy.Request(page,callback=slef.parse)
4.2保存我们提取的信息(文件格式:scv爬虫框架,json,pymysql)(pipeline.py) 如果多线程,记得在settings.py中分配多个管线并设置优先级:
(1).将爬取的信息保存成json格式
class MyspiderPipeline(object):
def init(self):
self.f=open(Moocfilename,‘w’) #Moocfilename是写在settings.py里的文件名,写在setting.py是因为便捷更改
def process_item(self,item,spider):
#默认传过来的格式是json格式 import json #读取item中的数据,并转化为json格式 line=json.dumps(dict(item),ensure_ascii=False,indent=4) self.f.write(line+’\n’) #一定要返回给调度器 return item
def close_spider(self,spider):
self.f.close()
(2).保存为scv格式
class CsvPipeline(object):
def init(self):
self.f=open(’'mooc.csv",‘w’)
def process_item(self,item,spider):
item=dict(item) self.f.write("{0}:{1}:{2}\n".format(item[‘title’] , item[‘student’] , item[‘url’])) return item
def close_spider(self,spider):
self.f.close()
(3).将爬取的信息保存到数据库中 首先打开数据库创建mooc表
class MysqlPipeline(object):
def init(self):
self.conn=pymysql.connect( host=‘localhost’, user=‘root’, password=‘redhat’, db=‘Mooc’, charset=‘utf8’, ) self.cursor=self.conn.cursor()
def process_item(self,item,spider):
item=dict(item) info=(item[’‘item"] , item[“url”] , item[“image_url”] , item[“introduction”] , item[“student”]) insert_sqil="insert into moocinfo values(’%s’ , ‘%s’ , ‘%s’, ‘%s’ , ‘%s’); " %(info) self.cursor.execute(insert_sqil) mit() return item
def open_spider(self,spider):
create_sqli=“create table if not exists moocinfo (title varchar(50),url varchar(200), image_url varchar(200), introduction varchar(500), student int)” self.cursor.execute(create_sqli)
def close_spider(self,spider):
self.cursor.close() self.conn.close()
(4).通过爬取的图片链接下载图片
class ImagePipeline(object):
def get_media_requests(self,item,info):
#返回一个request请求,包含图片的url
yield scrapy.Request(item['image_url'])
def item_conpleted(self,results,item,info):
#获取下载的地址
image_xpath=[x['path'] for ok , x in results if ok]
if not image_path:
raise Exception('不包含图片')
else:
return item
1.策略一:设置download_delay –作用:设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当于短时间内减小服务器的负载 –缺点:下载等待时间长,不能满足段时间大规模抓取的要求,太短则大大降低了被ban的机率
2.策略二:禁止cookies –cookie有时也用作复数方式cookies,指个别网站为了分辨用户的身分,进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。 –作用:禁止cookies也就避免了可能使用cookies辨识爬虫轨迹的网站得逞 –实现:COOKIES_ENABLES=False
3.策略三:使用user_agent池(拓展:用户代理中间件) –为什么要使用?scrapy本身是使用Scrapy/0.22.2来表明自己的身分。这也就曝露了自己是爬虫的信息。 –user agent ,是指包含浏览器信息,操作系统信息等的一个字符串,也称之为一种特殊的网路合同。服务器通过它判定当前的访问对象是浏览器,邮件客户端还是爬虫。
4.策略四:使用代理中间件 –web server应对爬虫的策略之一就是直接将你的ip或则是整个ip段都封掉严禁访问,这时候,当ip封掉后,转换到其他的ip继续访问即可。
5.策略五:分布式爬虫Scrapy+redis+mysql # 多进程 –Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它借助Redis对用于爬取的恳求(Requests)进行储存和调度(Schedule),并对爬取形成rapy一些比较关键的代码,将Scrapy弄成一个可以在多个主机上同时运行的分布式爬虫。
米鼠网自创立以来仍然专注于从事政府采购、软件项目、人才外包、猎头服务、综合项目等,始终秉持“专业的服务,易用的产品”的经营理念,以“提供高品质的服务、满足顾客的需求、携手共创多赢”为企业目标,为中国境内企业提供国际化、专业化、个性化、的软件项目解决方案,我司拥有一流的项目总监团队,具备过硬的软件项目设计和施行能力,为全省不同行业顾客提供优质的产品和服务,得到了顾客的广泛赞扬。
如有侵权请联系邮箱() 查看全部
1.scrapy构架流程:
scrapy主要包括了以下组件: 1.)引擎(scrapy):用来处理整个系统的数据流,触发事务(框架核心) 2.)调度器(Scheduler):用来接受引擎发过来的恳求,压入队列中,并在引擎再度恳求的时侯返回,可以想像成一个url(抓取网页的网址或则说链接)的优先队列,由它来决定下一个要抓取的网址是哪些,同时除去重复的网址。 3.)下载器(Downloader):用于下载网页的内容,并将网页内容返回给蜘蛛(Scrapy下载器是构建在twisted这个高效的异步模型上的) 4.)爬虫(Spiders):爬虫是主要干活的,用于从特定的网页中提取自己想要的信息,即所谓的实体(item)。用户也可以从中提取到链接,让Scrapy继续抓取下一个页面。 5.)项目管线(Pipeline):负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管线,并经过几个特定的顺序处理数据。 (只有当调度器中不存在任何request时,整个程序就会停止。(对于下载失败的url,Scrapy也会重新下载))
前置要求: pip下载scrapy模块 yum下载tree包
-确定url地址; -获取页面信息;(urllib,requests) -解析页面提取须要的信息;(xpath,bs4,正则表达时) -保存到本地(scv,json,pymysql,redis) -清洗数据(删除不必要的内容------正则表达式) -分析数据(词云wordcloud,jieba)
-确定url地址(spider) -获取页面信息(Downloader) -解析页面提取须要的信息(spider) -保存到本地(pipeline)
scrapy1.6.0
1.工程创建 1.)命令行在当前目录下创建mySpider
scrapy startproject mySpider
2.)创建成功后,进入mySpider ,tree查看
cd mySpider tree
2.创建一个爬虫
#scrapy genspider 项目名 url scrapy genspider mooc ‘’
3.定义爬取的items内容(items.py)
class CourseItem(scrapy.Item):
#课程标题 title=scrapy.Field() #课程的url地址 url=scrapy.Field() #课程图片的url地址 image_url=scrapy.Field() #课程的描述 introduction=scrapy.Field() #学习人数 student=scrapy.Field()
4.编写spider代码,解析 4.1确定url地址,提取页面须要的信息(mooc.py)
class MoocSpider(scrapy,spider):
#name用于区别爬虫,必须惟一 name=‘mooc’ #允许爬取的域名,其他网站的页面直接跳过 allowd_domains=[‘’,‘’] #爬虫开启时第一个装入调度器的url地址 start_urls=[‘’] #被调用时,每个新的url完成下载后爬虫框架,返回一个响应对象 #下面的方式负责将响应的数据剖析,提取出须要的数据items以及生成下一步须要处理的url地址恳求; def parser(self,response):
##用来检查代码是否达到指定位置,并拿来调试并解析页面信息; #from scrapy.shell import inspect_response #inspect_response(response,self) #1.)实例化对象,CourseItem course=CourseItem() #分析响应的内容 #scrapy剖析页面使用的是xpath方式 #2.)获取每位课程的信息 courseDetails=course.xpath(’.//div[@class=“course-card-container”]’) for courseDetail in courseDetails:
#爬取新的网站, Scrapy上面进行调试(parse命令logging) course[‘title’] = courseDetail.xpath(’.//h3[@class=“course-card-name”]/text()’).extract()[0] #学习人数 course[‘student’] = courseDetail.xpath(’.//span/text()’).extract()[1] #课程描述: course[‘introduction’] = courseDetail.xpath(".//p[@class=‘course-card-desc’]/text()").extract()[0] #课程链接, h获取/learn/9 ====》 course[‘url’] = “” + courseDetail.xpath(’.//a/@href’).extract()[0] #课程的图片url: course[‘image_url’] = ‘http:’ + courseDetail.xpath(’.//img/@src’).extract()[0] yield course #url跟进,获取下一步是否有链接;href url=response.xpath(’.//a[contains[text(),“下一页”]/@href’)[0].extract() if url:
#构建新的url page=‘’+url yield scrapy.Request(page,callback=slef.parse)
4.2保存我们提取的信息(文件格式:scv爬虫框架,json,pymysql)(pipeline.py) 如果多线程,记得在settings.py中分配多个管线并设置优先级:
(1).将爬取的信息保存成json格式
class MyspiderPipeline(object):
def init(self):
self.f=open(Moocfilename,‘w’) #Moocfilename是写在settings.py里的文件名,写在setting.py是因为便捷更改
def process_item(self,item,spider):
#默认传过来的格式是json格式 import json #读取item中的数据,并转化为json格式 line=json.dumps(dict(item),ensure_ascii=False,indent=4) self.f.write(line+’\n’) #一定要返回给调度器 return item
def close_spider(self,spider):
self.f.close()
(2).保存为scv格式
class CsvPipeline(object):
def init(self):
self.f=open(’'mooc.csv",‘w’)
def process_item(self,item,spider):
item=dict(item) self.f.write("{0}:{1}:{2}\n".format(item[‘title’] , item[‘student’] , item[‘url’])) return item
def close_spider(self,spider):
self.f.close()
(3).将爬取的信息保存到数据库中 首先打开数据库创建mooc表
class MysqlPipeline(object):
def init(self):
self.conn=pymysql.connect( host=‘localhost’, user=‘root’, password=‘redhat’, db=‘Mooc’, charset=‘utf8’, ) self.cursor=self.conn.cursor()
def process_item(self,item,spider):
item=dict(item) info=(item[’‘item"] , item[“url”] , item[“image_url”] , item[“introduction”] , item[“student”]) insert_sqil="insert into moocinfo values(’%s’ , ‘%s’ , ‘%s’, ‘%s’ , ‘%s’); " %(info) self.cursor.execute(insert_sqil) mit() return item
def open_spider(self,spider):
create_sqli=“create table if not exists moocinfo (title varchar(50),url varchar(200), image_url varchar(200), introduction varchar(500), student int)” self.cursor.execute(create_sqli)
def close_spider(self,spider):
self.cursor.close() self.conn.close()
(4).通过爬取的图片链接下载图片
class ImagePipeline(object):
def get_media_requests(self,item,info):
#返回一个request请求,包含图片的url
yield scrapy.Request(item['image_url'])
def item_conpleted(self,results,item,info):
#获取下载的地址
image_xpath=[x['path'] for ok , x in results if ok]
if not image_path:
raise Exception('不包含图片')
else:
return item
1.策略一:设置download_delay –作用:设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当于短时间内减小服务器的负载 –缺点:下载等待时间长,不能满足段时间大规模抓取的要求,太短则大大降低了被ban的机率
2.策略二:禁止cookies –cookie有时也用作复数方式cookies,指个别网站为了分辨用户的身分,进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。 –作用:禁止cookies也就避免了可能使用cookies辨识爬虫轨迹的网站得逞 –实现:COOKIES_ENABLES=False
3.策略三:使用user_agent池(拓展:用户代理中间件) –为什么要使用?scrapy本身是使用Scrapy/0.22.2来表明自己的身分。这也就曝露了自己是爬虫的信息。 –user agent ,是指包含浏览器信息,操作系统信息等的一个字符串,也称之为一种特殊的网路合同。服务器通过它判定当前的访问对象是浏览器,邮件客户端还是爬虫。
4.策略四:使用代理中间件 –web server应对爬虫的策略之一就是直接将你的ip或则是整个ip段都封掉严禁访问,这时候,当ip封掉后,转换到其他的ip继续访问即可。
5.策略五:分布式爬虫Scrapy+redis+mysql # 多进程 –Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它借助Redis对用于爬取的恳求(Requests)进行储存和调度(Schedule),并对爬取形成rapy一些比较关键的代码,将Scrapy弄成一个可以在多个主机上同时运行的分布式爬虫。
米鼠网自创立以来仍然专注于从事政府采购、软件项目、人才外包、猎头服务、综合项目等,始终秉持“专业的服务,易用的产品”的经营理念,以“提供高品质的服务、满足顾客的需求、携手共创多赢”为企业目标,为中国境内企业提供国际化、专业化、个性化、的软件项目解决方案,我司拥有一流的项目总监团队,具备过硬的软件项目设计和施行能力,为全省不同行业顾客提供优质的产品和服务,得到了顾客的广泛赞扬。
如有侵权请联系邮箱()
网络爬虫的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 367 次浏览 • 2020-07-02 08:01
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler 查看全部
第11卷第4期2012年 4月软件导刊Software Guide Vo l. ll NO.4 组己旦2网路爬虫的设计与实现王娟,吴金鹏(贵州|民族学院计算机与信息工程学院,贵州l 贵阳 550025)摘 要:搜索引擎技术随着互联网的日渐壮大而急速发展。作为搜索引擎不可或缺的组成部分,网络爬虫的作用变得尤为重要网络爬虫设计,它的性能直接决定了在庞大的互联网上进行网页信息采集的质量。设计并实现了通用爬虫和限定爬虫。关键词:网络爬虫;通用爬虫;限定爬虫中图分类号 :TP393 文献标识码 :A。哥|言网路爬虫称作网路蜘蛛,它为搜索引擎从万维网上下载网页,并顺着网页的相关链接在 Web 中采集资源,是一个功能太强的网页手动抓取程序,也是搜索引擎的重要组成部份,爬虫设计的优劣直接决定着整个搜索引擎的性能及扩充能力。网络爬虫根据系统结构和实现技术,大致可以分为:通用网路爬虫、主题网路爬虫、增量式网路爬虫、深层网路爬虫 o 实际应用中一般是将几种爬虫技术相结合。1 通用爬虫的设计与实现1. 1 工作原理通用网路爬虫按照预先设定的一个或若干初始种子URL 开始,以此获得初始网页上的 URL 列表,在爬行过程中不断从 URL 队列中获一个个的 URL,进而访问并下载该页面。
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler
Python爬虫的用途
采集交流 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2020-06-30 08:01
Python 爬虫的用途 Python 爬虫是用 Python 编程语言实现的网路爬虫,主要用于网路数据的抓取和处理,相比于其他语言,Python 是一门特别适宜开发网路爬虫的编程语言,大量外置包,可以轻松实现网路爬虫功能。 Python 爬虫可以做的事情好多,如搜索引擎、采集数据、广告过滤等,Python爬虫还可以用于数据剖析,在数据的抓取方面可以作用巨大! n Python 爬虫构架组成 1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取的 url 给网页下载器; 2. 网页下载器:爬取 url 对应的网页,存储成字符串,传送给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管理器。 n Python 爬虫工作原理 Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URL,通过调度器进行传递给下载器网络爬虫 作用,下载 URL 内容,并通过调度器传送给解析器,解析URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值信息的过程。 n Python 爬虫常用框架有: grab:网络爬虫框架(基于 pycurl/multicur); scrapy:网络爬虫框架(基于 twisted),不支持 Python3; pyspider:一个强悍的爬虫系统;cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源,并围绕它完善的对象; demiurge:基于 PyQuery 的爬虫微框架。 Python 爬虫应用领域广泛,在网络爬虫领域处于霸主位置,Scrapy、Request、BeautifuSoap、urlib 等框架的应用,可以实现爬行自如的功能,只要您数据抓取看法网络爬虫 作用,Python 爬虫均可实现!
百度解密百度爬虫对常用的http返回码是如何处理的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 358 次浏览 • 2020-06-30 08:00
503返回码的含意是“Service Unavailable”,百度会觉得该网页临时不可访问,通常网站临时关掉,带宽有限等会形成这些情况。对于网页返回503,百度爬虫不会把这 条url直接删掉,短期内会再访问。届时假如网页已恢复,则正常抓取;如果继续返回503,短期内都会反复访问几次。但是若果网页常年返回503,那么这 个url仍会被百度觉得是失效链接,从搜索结果中删掉。
403返回码的含意是“Forbidden”,百度会觉得网页当前严禁访问。对于这些情况,如果是新发觉的url,百度爬虫暂不会抓取,短期内会 再次检测;如果是百度已收录url百度爬虫攻击,当前也不会直接删掉,短期内同样会再访问。届时假如网页容许访问,则正常抓取;如果仍不容许访问,短期内都会反复访问 几次。但是若果网页常年返回403,百度也会觉得是失效链接,从搜索结果中删掉。
404返回码的含意是“NOT FOUND”,百度会觉得网页早已失效,那么一般会从搜索结果中删掉,并且短期内爬虫再度发觉这条url也不会抓取。
301返回码的含意是“Moved Permanently”,百度会觉得网页当前跳转至新url。当遇见站点迁移,域名更换、站点改版的情况时,推荐使用301返回码,尽量降低改版带来的 流量损失。虽然百度爬虫现今对301跳转的响应周期较长,但我们还是推荐你们如此做。
陕西弈聪对于个别常见情况的使用建议:
如果百度爬虫对您的站点抓取压力过大,请尽量不要使用404,同样建议返回503。这样百度爬虫会过段时间再来尝试抓取这个链接,如果哪个时间站点空闲,那它还会被成功抓取了。
有一些网站希望百度只收录部份内容,例如初审后的内容,累积一段时间的新用户页等等。在这些情况,建议新发内容暂时返回403,等初审或做好处理过后,再返回正常状态的返回码。
站点迁移,或域名更换时,请使用301返回码。
如果站点临时关掉,当网页不能打开时,不要立刻返回404,建议使用503状态。503可以告知百度爬虫该页面临时不可访问百度爬虫攻击,请过段时间再重试。
此内容DOC下载
此内容PDF下载
【全文完】 查看全部
百度爬虫对常用的http返回码的处理逻辑?百度爬虫在进行抓取和处理时,是依据http合同规范来设置相应的逻辑的,因此,如果网站/页面发生一些非常状况或则网站某类页面集存在特殊性的时侯,我们必须晓得怎样处理能够更符合百度爬虫,以防止错误的措施给沈阳网站优化带来不必要的风险。在http状态码使用方面做了说明,主要涉及到常见的301、404、403、503状态码的处理建议,非常实用,结合这种知识以及往年遇见的实际情况我会做一点补充应用说明。
503返回码的含意是“Service Unavailable”,百度会觉得该网页临时不可访问,通常网站临时关掉,带宽有限等会形成这些情况。对于网页返回503,百度爬虫不会把这 条url直接删掉,短期内会再访问。届时假如网页已恢复,则正常抓取;如果继续返回503,短期内都会反复访问几次。但是若果网页常年返回503,那么这 个url仍会被百度觉得是失效链接,从搜索结果中删掉。
403返回码的含意是“Forbidden”,百度会觉得网页当前严禁访问。对于这些情况,如果是新发觉的url,百度爬虫暂不会抓取,短期内会 再次检测;如果是百度已收录url百度爬虫攻击,当前也不会直接删掉,短期内同样会再访问。届时假如网页容许访问,则正常抓取;如果仍不容许访问,短期内都会反复访问 几次。但是若果网页常年返回403,百度也会觉得是失效链接,从搜索结果中删掉。
404返回码的含意是“NOT FOUND”,百度会觉得网页早已失效,那么一般会从搜索结果中删掉,并且短期内爬虫再度发觉这条url也不会抓取。
301返回码的含意是“Moved Permanently”,百度会觉得网页当前跳转至新url。当遇见站点迁移,域名更换、站点改版的情况时,推荐使用301返回码,尽量降低改版带来的 流量损失。虽然百度爬虫现今对301跳转的响应周期较长,但我们还是推荐你们如此做。
陕西弈聪对于个别常见情况的使用建议:
如果百度爬虫对您的站点抓取压力过大,请尽量不要使用404,同样建议返回503。这样百度爬虫会过段时间再来尝试抓取这个链接,如果哪个时间站点空闲,那它还会被成功抓取了。
有一些网站希望百度只收录部份内容,例如初审后的内容,累积一段时间的新用户页等等。在这些情况,建议新发内容暂时返回403,等初审或做好处理过后,再返回正常状态的返回码。
站点迁移,或域名更换时,请使用301返回码。
如果站点临时关掉,当网页不能打开时,不要立刻返回404,建议使用503状态。503可以告知百度爬虫该页面临时不可访问百度爬虫攻击,请过段时间再重试。
此内容DOC下载
此内容PDF下载
【全文完】
开源的网路爬虫larbin
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-06-26 08:00
利用larbin,我们可以轻易的获取/确定单个网站的所有连结,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
不过它的最大的亮点还是开源,相信很多人领到larbin源代码的时侯会觉得无从入手,下面是一篇特别不错的开源的网络爬虫/网络蜘蛛larbin结构剖析的文章,有兴趣的最好仔细阅读尝试一下。
互联网是一个庞大的非结构化的数据库,将数据有效的检索并组织呈现下来有着巨大的应用前景,尤其是类似RSS的以XML为基础的结构化的数据越来越 多,内容的组织形式越来越灵活,检索组织并呈现会有着越来越广泛的应用范围,同时在时效性和可读性上也会有越来越高的要求。这一切的基础是爬虫,信息的来 源入口。一个高效,灵活可扩充的爬虫对以上应用都有着无可替代的重要意义。
要设计一个爬虫,首先须要考虑的效率。对于网路而言,基于TCP/IP的通讯编程有几种方式。
第一种是单线程阻塞,这是最简单也最容易实现的一种,一个事例:在Shell中通过curl,pcregrep等一系统命令可以直接实现一个简单的 爬虫,但同时它的效率问题也显而易见:由于是阻塞方法读取,dns解析,建立联接,写入恳求,读取结果这种步骤上就会形成时间的延后,从而未能有效的借助 服务器的全部资源。
第二种是多线程阻塞。建立多个阻塞的线程,分别恳求不同的url。相对于第一种方式,它可以更有效的借助机器的资源,特别是网路资源开源网络爬虫,因为无数线程 在同时工作,所以网路会比较充分的借助,但同时对机器CPU资源的消耗也是比较大,在用户级多线程间的频繁切换对于性能的影响早已值得我们考虑。
第三种是单线程非阻塞。这是目前使用的比较多的一种做法,无论在client还是server都有着广泛的应用。在一个线程内打开多个非阻塞的连 接,通过poll/epoll /select对联接状态进行判定,在第一时间响应恳求,不但充分利用了网路资源,同时也将本机CPU资源的消耗降至最低。这种方式须要对dns恳求,连 接,读写操作都采用异步非阻塞操作,其中第一种比较复杂,可以采用adns作为解决方案,后面三个操作相对简单可以直接在程序内实现。
效率问题解决后就须要考虑具体的设计问题了。
url肯定须要一个单独的类进行处理,包括显示,分析url,得到主机,端口,文件数据。
然后须要对url进行排重,需要一个比较大的url Hash表。
如果还要对网页内容进行排重,则还须要一个Document Hash表。
爬过的url须要记录出来,由于量比较大,我们将它讲到c盘上,所以还须要一个FIFO的类(记作urlsDisk)。
现在须要爬的url同样须要一个FIFO类来处理,重新开始时,url会从定时从爬过的url FIFO里取下来,写到这个FIFO里。正在运行的爬虫须要从这个FIFO里读数据下来,加入到主机类的url列表里。当然,也会从前一个FIFO里直接 读url下来,不过优先级应当比这个上面下来的url低,毕竟是早已爬过的。
爬虫通常是对多个网站进行爬取,但在同时站点内dns的恳求可以只做一次开源网络爬虫,这就须要将主机名独立于url,单独有一个类进行处理。
主机名解析完成后须要有一个解析完成的IP类与之应用,用于connect的时侯使用。
HTML文档的解析类也要有一个,用来剖析网页,取出上面的url,加入到urlsDisk。
再加上一些字符串,调度类,一个简单的爬虫基本上就完成了。
以上基本上是Larbin的设计思路,Larbin在具体实现上还有一些特殊的处理,例如带了一个webserver,以及对特殊文件的处理。 Larbin有一点设计不不太好,就是慢的访问会越来越多,占用大量的联接,需要改进,另外假如对于大规模的爬虫,这仅仅实现了抓取的部份,要分布式的扩 展还须要降低url的集中管理与调度以及前台spider的分布式算法。
Larbin网站爬虫简明使用说明
larbin是一种爬虫工具,我也是前段时间网上见到 Larbin 一种高效的搜索引擎爬虫工具 一文时才晓得有这么个东西,初步认定,我比较喜欢这个工具(比起nutch的crawl来说),因为它是C++写的,类似C嘛,我熟,可以自己改改,顺便 学习一下C++(几年来的经验告诉我说:改他人的东西来学一种技术比从头写helloworld快好多)。于是开始了我辛酸的larbin试用之旅。
回头瞧瞧自己遇见的问题都是因为没认真看文档造成的,唉,老毛病了。下次虽然是E文的也得好好看,不能盲目的试,浪费时间。
larbin官方地址:
一,编译
这也好说,whahahaha,那是!因为从官方网站下出来的代码不能编译通过(linux gcc下)
./configure
make
gcc -O3 -Wall -D_REENTRANT -c -o parse.o parse.c
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
gmake[1]: *** [parse.o] 错误 1
gmake[1]: Leaving directory `/home/leo/leo/larbin-2.6.3/adns’
make: *** [all] 错误 2
函数原型和定义不一致这个好改:
打开./adns/internal.h文件,把568-571行直接注释掉就行了。
二,运行
这个就不说了,./larbin就运行了,larbin.conf中先进行配置就可以了,这个配置就不说了。。
运行后可以:8081 看运行状态,不错的看法。 larbin.conf中有个:inputPort 1976配置,就是可以运行时降低要抓取的URL,这个看法非常好,可是?怎么加呢?象原本那样::1976那样是不行的,报 错???试了很久没结果,最后GDB跟踪了一下,唉,原来直接telnet host 1976进行降低就可以了。后来见到文档里写的亲亲楚楚,晕倒。。。。。
三,结果
哈哈,下班后找了台机子跑了上去,那晚午睡的时侯都梦到自己的搜索引擎赶GOOGLE超BAIDU了,那个激动啊。
第二天下班的时侯取看结果,发现目录下不仅些fifo*文件外哪些都没有,那个纠结。没办法啊,再看文档 How to customize Larbin 发现如此段说明:
The first thing you can define is the module you want to use for ouput. This defines what you want to do with the pages larbin gets. Here are the different options :
DEFAULT_OUTPUT : This module mainly does nothing, except statistics.
SIMPLE_SAVE : This module saves pages on disk. It stores 2000 files per directory (with an index).
MIRROR_SAVE : This module saves pages on disk with the hierarchy of the site they come from. It uses one directory per site.
STATS_OUTPUT : This modules makes some stats on the pages. In order to see the results, see :8081/output.html.
靠,默认哪些都没输出,于是认真的看了官方网站上仅有的两个文档,修改了options.h再编译,终于有结果了。
我的option中改了:
SIMPLE_SAVE 简单输出一个目录两千个文件,包含索引。
CGILEVEL=0 处理服务器端程序,也就是但url中包含? & = 之类的querString时也处理。
NO_DUP
其余可依据各自须要更改,详见: How to customize Larbin 一文。
四,问题
在使用过程中发觉,在抓网页的时侯,如果URL中包含未编码(encodurl)中文时,无法抓取,简单的看了一下在: src/utils/中的fileNormalize 有涉及。于是写了个encodurl函数加在url类的构造函数里,问题就解决了。
由于须要比较好的可定制性,这个工具其实还不大满足我的需求,最终我没使用她,而是自己用perl在WWW:SimpleRobot的基础上搞了个适宜我的。。再说了perl在字符蹿处理上应当不比C++慢,总的来说那种小工具性能还不错。。呵呵。
不过还是把这种写下来,给没看文档的同学(希望极少),也警示自己一定要认真看文档 查看全部
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有连结,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
不过它的最大的亮点还是开源,相信很多人领到larbin源代码的时侯会觉得无从入手,下面是一篇特别不错的开源的网络爬虫/网络蜘蛛larbin结构剖析的文章,有兴趣的最好仔细阅读尝试一下。
互联网是一个庞大的非结构化的数据库,将数据有效的检索并组织呈现下来有着巨大的应用前景,尤其是类似RSS的以XML为基础的结构化的数据越来越 多,内容的组织形式越来越灵活,检索组织并呈现会有着越来越广泛的应用范围,同时在时效性和可读性上也会有越来越高的要求。这一切的基础是爬虫,信息的来 源入口。一个高效,灵活可扩充的爬虫对以上应用都有着无可替代的重要意义。
要设计一个爬虫,首先须要考虑的效率。对于网路而言,基于TCP/IP的通讯编程有几种方式。
第一种是单线程阻塞,这是最简单也最容易实现的一种,一个事例:在Shell中通过curl,pcregrep等一系统命令可以直接实现一个简单的 爬虫,但同时它的效率问题也显而易见:由于是阻塞方法读取,dns解析,建立联接,写入恳求,读取结果这种步骤上就会形成时间的延后,从而未能有效的借助 服务器的全部资源。
第二种是多线程阻塞。建立多个阻塞的线程,分别恳求不同的url。相对于第一种方式,它可以更有效的借助机器的资源,特别是网路资源开源网络爬虫,因为无数线程 在同时工作,所以网路会比较充分的借助,但同时对机器CPU资源的消耗也是比较大,在用户级多线程间的频繁切换对于性能的影响早已值得我们考虑。
第三种是单线程非阻塞。这是目前使用的比较多的一种做法,无论在client还是server都有着广泛的应用。在一个线程内打开多个非阻塞的连 接,通过poll/epoll /select对联接状态进行判定,在第一时间响应恳求,不但充分利用了网路资源,同时也将本机CPU资源的消耗降至最低。这种方式须要对dns恳求,连 接,读写操作都采用异步非阻塞操作,其中第一种比较复杂,可以采用adns作为解决方案,后面三个操作相对简单可以直接在程序内实现。
效率问题解决后就须要考虑具体的设计问题了。
url肯定须要一个单独的类进行处理,包括显示,分析url,得到主机,端口,文件数据。
然后须要对url进行排重,需要一个比较大的url Hash表。
如果还要对网页内容进行排重,则还须要一个Document Hash表。
爬过的url须要记录出来,由于量比较大,我们将它讲到c盘上,所以还须要一个FIFO的类(记作urlsDisk)。
现在须要爬的url同样须要一个FIFO类来处理,重新开始时,url会从定时从爬过的url FIFO里取下来,写到这个FIFO里。正在运行的爬虫须要从这个FIFO里读数据下来,加入到主机类的url列表里。当然,也会从前一个FIFO里直接 读url下来,不过优先级应当比这个上面下来的url低,毕竟是早已爬过的。
爬虫通常是对多个网站进行爬取,但在同时站点内dns的恳求可以只做一次开源网络爬虫,这就须要将主机名独立于url,单独有一个类进行处理。
主机名解析完成后须要有一个解析完成的IP类与之应用,用于connect的时侯使用。
HTML文档的解析类也要有一个,用来剖析网页,取出上面的url,加入到urlsDisk。
再加上一些字符串,调度类,一个简单的爬虫基本上就完成了。
以上基本上是Larbin的设计思路,Larbin在具体实现上还有一些特殊的处理,例如带了一个webserver,以及对特殊文件的处理。 Larbin有一点设计不不太好,就是慢的访问会越来越多,占用大量的联接,需要改进,另外假如对于大规模的爬虫,这仅仅实现了抓取的部份,要分布式的扩 展还须要降低url的集中管理与调度以及前台spider的分布式算法。
Larbin网站爬虫简明使用说明
larbin是一种爬虫工具,我也是前段时间网上见到 Larbin 一种高效的搜索引擎爬虫工具 一文时才晓得有这么个东西,初步认定,我比较喜欢这个工具(比起nutch的crawl来说),因为它是C++写的,类似C嘛,我熟,可以自己改改,顺便 学习一下C++(几年来的经验告诉我说:改他人的东西来学一种技术比从头写helloworld快好多)。于是开始了我辛酸的larbin试用之旅。
回头瞧瞧自己遇见的问题都是因为没认真看文档造成的,唉,老毛病了。下次虽然是E文的也得好好看,不能盲目的试,浪费时间。
larbin官方地址:
一,编译
这也好说,whahahaha,那是!因为从官方网站下出来的代码不能编译通过(linux gcc下)
./configure
make
gcc -O3 -Wall -D_REENTRANT -c -o parse.o parse.c
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
gmake[1]: *** [parse.o] 错误 1
gmake[1]: Leaving directory `/home/leo/leo/larbin-2.6.3/adns’
make: *** [all] 错误 2
函数原型和定义不一致这个好改:
打开./adns/internal.h文件,把568-571行直接注释掉就行了。
二,运行
这个就不说了,./larbin就运行了,larbin.conf中先进行配置就可以了,这个配置就不说了。。
运行后可以:8081 看运行状态,不错的看法。 larbin.conf中有个:inputPort 1976配置,就是可以运行时降低要抓取的URL,这个看法非常好,可是?怎么加呢?象原本那样::1976那样是不行的,报 错???试了很久没结果,最后GDB跟踪了一下,唉,原来直接telnet host 1976进行降低就可以了。后来见到文档里写的亲亲楚楚,晕倒。。。。。
三,结果
哈哈,下班后找了台机子跑了上去,那晚午睡的时侯都梦到自己的搜索引擎赶GOOGLE超BAIDU了,那个激动啊。
第二天下班的时侯取看结果,发现目录下不仅些fifo*文件外哪些都没有,那个纠结。没办法啊,再看文档 How to customize Larbin 发现如此段说明:
The first thing you can define is the module you want to use for ouput. This defines what you want to do with the pages larbin gets. Here are the different options :
DEFAULT_OUTPUT : This module mainly does nothing, except statistics.
SIMPLE_SAVE : This module saves pages on disk. It stores 2000 files per directory (with an index).
MIRROR_SAVE : This module saves pages on disk with the hierarchy of the site they come from. It uses one directory per site.
STATS_OUTPUT : This modules makes some stats on the pages. In order to see the results, see :8081/output.html.
靠,默认哪些都没输出,于是认真的看了官方网站上仅有的两个文档,修改了options.h再编译,终于有结果了。
我的option中改了:
SIMPLE_SAVE 简单输出一个目录两千个文件,包含索引。
CGILEVEL=0 处理服务器端程序,也就是但url中包含? & = 之类的querString时也处理。
NO_DUP
其余可依据各自须要更改,详见: How to customize Larbin 一文。
四,问题
在使用过程中发觉,在抓网页的时侯,如果URL中包含未编码(encodurl)中文时,无法抓取,简单的看了一下在: src/utils/中的fileNormalize 有涉及。于是写了个encodurl函数加在url类的构造函数里,问题就解决了。
由于须要比较好的可定制性,这个工具其实还不大满足我的需求,最终我没使用她,而是自己用perl在WWW:SimpleRobot的基础上搞了个适宜我的。。再说了perl在字符蹿处理上应当不比C++慢,总的来说那种小工具性能还不错。。呵呵。
不过还是把这种写下来,给没看文档的同学(希望极少),也警示自己一定要认真看文档
Python借助requests进行模拟登陆
采集交流 • 优采云 发表了文章 • 0 个评论 • 674 次浏览 • 2020-06-25 08:00
Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...
使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...
请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的 查看全部
Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...
使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...
请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的
【热门】税务局怎么应用网路爬虫技术获取企业涉税信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-06-22 08:01
税务局怎样利用网路爬虫举办工作呢?概括的说,不外乎这样几个方面: 一是有针对性的捕捉互联网上的企业相关信息; 二是利用大数据,整合其他相关涉税信息; 三是通过一系列预警指标剖析比对筛选案源; 四是构建企业交易行为轨迹,定位税收风险疑虑。 其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉 税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、 建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和物流中心等有关 部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、 税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税 人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。 所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。 随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业 的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间, 而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要 途径。 查看全部
税务局怎么应用网路爬虫技术获取企业涉税信息 在互联网上,经常能看到某某税务局借助网路爬虫技术发觉某甲企业涉税问题,并进一步 被取缔的信息。 那么,什么是网络爬虫呢?税务局怎么应用网路爬虫技术发觉企业的涉税谜团呢?本文将 带你一步一步解开其中的奥秘。 网络爬虫称作“网页蜘蛛”,是一个手动提取网页的程序。传统爬虫从一个或若干初始网 页的 URL 开始,获得初始网页上的 URL,在抓取网页的过程中,不断从当前页面上抽取新 的 URL 放入队列税务爬虫软件,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根 据一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的 URL 队列。然后税务爬虫软件,它将按照一定的搜索策略从队列中选择下一步要抓取的网页 URL,并重复上 述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存储, 进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。 以上是引自网路专业的叙述,简单的说,“网络爬虫”是一个手动提取网页的程序,运用 “网络爬虫”技术设定程序,可以按照既定的目标愈发精准选择抓取相关的网页信息,有 助于在互联网海量信息中快捷获取有用的涉税信息。
税务局怎样利用网路爬虫举办工作呢?概括的说,不外乎这样几个方面: 一是有针对性的捕捉互联网上的企业相关信息; 二是利用大数据,整合其他相关涉税信息; 三是通过一系列预警指标剖析比对筛选案源; 四是构建企业交易行为轨迹,定位税收风险疑虑。 其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉 税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、 建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和物流中心等有关 部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、 税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税 人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。 所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。 随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业 的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间, 而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要 途径。
爬虫简介
采集交流 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2020-06-17 08:01
网页的三大特点:
是拿来写前端的,对于异步和多任务处理不太好,爬虫是一个工具性的程序爬虫,对效率要求比较高
是Python写爬虫的最大竞争对手,Java语言生态系统比较健全,对各模块的支持也比较友好。但是Java这门语言比较笨重,重构和迭代成本比价高
语言较难,代码成形比较慢
语法简单素雅,第三方模块比较丰富,关于爬虫的网路恳求模块和网路解析模块(Lxml,BeautifulSoup,pyQuery)也比较多,并且有高效稳定的scrapy网路爬虫框架,以及爬scrapy,redis分布式爬虫框架,Python也是一门胶带语言,对于其他语言的调用比较便捷
是搜索引擎的重要组成部份
尽可能的将所有互联网上的网页下载到本地,经过预处理(去噪,分词,去广告),最终将数据存储到本地,做一个镜像备份产生一个检索系统
1.选取一部分的url作为种子url,将这种url装入到带爬取的任务队列上面
2.从待爬取的任务列队中取出url,发起恳求,将获取的网页源码储存到本地
并将早已爬取过的url ,放到已爬取的队列中
3.从已爬取的URL的响应结果中剖析提取其他的url的地址,继续添加到待爬取的队列中,
之后就是不断的循环,直到所有的url都获取完毕。
1.通过网站提交自己的网站地址()
2.搜索引擎会和DNS服务商合作,拿到最新的网站地址
3.网站中包含其他外链
DNS服务:将我们的域名转换为对应的ip的一种技术
数据获取------>预处理(去噪,分词,去广告.....)------>存储------>提供检索插口|排名(网络排行)
网站排名:
1.根据用户的访问量(越多越靠前)
2.竞价排名
1.必须遵循robot合同:就是一个规范,告诉搜索引擎爬虫,哪些目录下的资源容许爬虫,哪些目录下的资源不容许爬虫
"user-agent":这项值拿来表示是哪家的搜索引擎
"allow":允许被爬取的url
"disallow":不容许被爬取的url
2.搜索引擎返回的都是网页,并且返回的90%都是无用的信息
3.不能否按照不同用户的需求返回不同的结果
4.通用爬虫对于多媒体的文件不能够获取
聚焦爬虫是面向主题的爬虫,在爬虫数据的过程中会对数据进行筛选,往往只会爬虫与需求相关的数据 查看全部
网络爬虫机器人,以互联网自由抓取数据的程序
网页的三大特点:
是拿来写前端的,对于异步和多任务处理不太好,爬虫是一个工具性的程序爬虫,对效率要求比较高
是Python写爬虫的最大竞争对手,Java语言生态系统比较健全,对各模块的支持也比较友好。但是Java这门语言比较笨重,重构和迭代成本比价高
语言较难,代码成形比较慢
语法简单素雅,第三方模块比较丰富,关于爬虫的网路恳求模块和网路解析模块(Lxml,BeautifulSoup,pyQuery)也比较多,并且有高效稳定的scrapy网路爬虫框架,以及爬scrapy,redis分布式爬虫框架,Python也是一门胶带语言,对于其他语言的调用比较便捷
是搜索引擎的重要组成部份
尽可能的将所有互联网上的网页下载到本地,经过预处理(去噪,分词,去广告),最终将数据存储到本地,做一个镜像备份产生一个检索系统
1.选取一部分的url作为种子url,将这种url装入到带爬取的任务队列上面
2.从待爬取的任务列队中取出url,发起恳求,将获取的网页源码储存到本地
并将早已爬取过的url ,放到已爬取的队列中
3.从已爬取的URL的响应结果中剖析提取其他的url的地址,继续添加到待爬取的队列中,
之后就是不断的循环,直到所有的url都获取完毕。
1.通过网站提交自己的网站地址()
2.搜索引擎会和DNS服务商合作,拿到最新的网站地址
3.网站中包含其他外链
DNS服务:将我们的域名转换为对应的ip的一种技术
数据获取------>预处理(去噪,分词,去广告.....)------>存储------>提供检索插口|排名(网络排行)
网站排名:
1.根据用户的访问量(越多越靠前)
2.竞价排名
1.必须遵循robot合同:就是一个规范,告诉搜索引擎爬虫,哪些目录下的资源容许爬虫,哪些目录下的资源不容许爬虫
"user-agent":这项值拿来表示是哪家的搜索引擎
"allow":允许被爬取的url
"disallow":不容许被爬取的url
2.搜索引擎返回的都是网页,并且返回的90%都是无用的信息
3.不能否按照不同用户的需求返回不同的结果
4.通用爬虫对于多媒体的文件不能够获取
聚焦爬虫是面向主题的爬虫,在爬虫数据的过程中会对数据进行筛选,往往只会爬虫与需求相关的数据
最详尽爬虫入门教程!花半小时你应当能够去爬一些小东西了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-06-02 08:01
爬虫对目标网页爬取的过程可以参考下边红色文字部份:
图片中由红色文字组成的循环应当挺好理解,那么具体到编程上来说,则必须将里面的流程进行具象,我们可以编撰几个器件,每个器件完成一项功能,上图中的绿底黄字就是对这一流程的具象:
爬虫调度器即将完成整个循环,下面写出python下爬虫调度器的程序:
存储器、下载器、解析器和url管理器!
首先网络爬虫软件教程,还是来瞧瞧下边这张图,URL管理器究竟应当具有什么功能?
下面来说说下载器。
下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载出来。python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是获取指定的网页内容。不过网络爬虫软件教程,在这里我们要使用一个愈发简练好用并且功能愈发强悍的模块:Requests(查看文档)。
Requests并非python自带模块,需要安装。关于其具体使用方式请查看相关文档,在此不多做介绍。
下载器接受一个url作为参数,返回值为下载到的网页内容(格式为str)。下面就是一个简单的下载器,其中只有一个简单的函数download():
在requests恳求中设置User-Agent的目的是伪装成浏览器,这是一只优秀的爬虫应当有的觉悟。
URL管理器和下载器相对简单!剩下的上次介绍,希望能帮到零基础小白的你!
进群:125240963 即可获取数十套PDF! 查看全部
爬虫对目标网页爬取的过程可以参考下边红色文字部份:
图片中由红色文字组成的循环应当挺好理解,那么具体到编程上来说,则必须将里面的流程进行具象,我们可以编撰几个器件,每个器件完成一项功能,上图中的绿底黄字就是对这一流程的具象:
爬虫调度器即将完成整个循环,下面写出python下爬虫调度器的程序:
存储器、下载器、解析器和url管理器!
首先网络爬虫软件教程,还是来瞧瞧下边这张图,URL管理器究竟应当具有什么功能?
下面来说说下载器。
下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载出来。python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是获取指定的网页内容。不过网络爬虫软件教程,在这里我们要使用一个愈发简练好用并且功能愈发强悍的模块:Requests(查看文档)。
Requests并非python自带模块,需要安装。关于其具体使用方式请查看相关文档,在此不多做介绍。
下载器接受一个url作为参数,返回值为下载到的网页内容(格式为str)。下面就是一个简单的下载器,其中只有一个简单的函数download():
在requests恳求中设置User-Agent的目的是伪装成浏览器,这是一只优秀的爬虫应当有的觉悟。
URL管理器和下载器相对简单!剩下的上次介绍,希望能帮到零基础小白的你!
进群:125240963 即可获取数十套PDF!
“百行代码”实现简单的Python分布式爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-06-02 08:00
现在搞爬虫的人,可能被问的最多的问题就是“你会不会分布式爬虫?”。给人的觉得就是你不会分布式爬虫,都不好意思说自己是搞爬虫的。但虽然分布式爬虫的原理比较简单,大多数的业务用不到分布式模式。
所谓的分布式爬虫,就是多台机器合作进行爬虫工作,提高工作效率。
分布式爬虫须要考虑的问题有:
(1)如何从一个统一的插口获取待抓取的URL?
(2)如何保证多台机器之间的排重操作?即保证不会出现多台机器同时抓取同一个URL。
(3)当多台机器中的一台或则几台死掉,如何保证任务继续,且数据不会遗失?
这里首先借助Redis数据库解决前两个问题。
Redis数据库是一种key-value数据库,它本身包含了一些比较好的特点,比较适宜解决分布式爬虫的问题。关于Redis的一些基本概念、操作等,建议读者自行百度。我们这儿使用到Redis中自带的“消息队列”,来解决分布式爬虫问题。具体实现步骤如下:
在Redis中初始化两条key-value数据,对应的key分别为spider.wait和spider.all。spider.wait的value是一个list队列,存放我们待抓取的URL。该数据类型便捷我们实现消息队列。我们使用lpush操作添加URL数据,同时使用brpop窃听并获取取URL数据。spider.all的value是一个set集合,存放我们所有待抓取和已抓取的URL。该数据类型便捷我们实现排重操作。我们使用sadd操作添加数据。
在我的代码中,我是在原先爬虫框架的基础上,添加了分布式爬虫模式(一个文件)分布式爬虫 python,该文件的代码行数大约在100行左右,所以文章标题为“百行代码”。但实际上,在每台客户端机器上,我都使用了多线程爬虫框架。即:
(1)每台机器从Redis获取待抓取的URL,执行“抓取--解析--保存”的过程
(2)每台机器本身使用多线程爬虫模式,即有多个线程同时从Redis获取URL并抓取
(3)每台机器解析数据得到的新的URL,会传回Redis数据库,同时保证数据一致性
(4)每台机器单独启动自己的爬虫,之后单独关掉爬虫任务,没有手动功能
具体可查看代码:distributed_threads.py
这里的代码还不够建立,主要还要如下的问题:
有兴趣解决问题的,可以fork代码然后,自行更改分布式爬虫 python,并递交pull-requests。
=============================================================
作者主页:笑虎(Python爱好者,关注爬虫、数据剖析、数据挖掘、数据可视化等)
作者专栏主页:撸代码,学知识 - 知乎专栏
作者GitHub主页:撸代码,学知识 - GitHub
欢迎你们指正、提意见。相互交流,共同进步!
============================================================== 查看全部
本篇文章属于进阶知识,可能会用到曾经出现在专栏文章中的知识,如果你是第一次关注本专栏,建议你先阅读下其他文章:查询--爬虫(计算机网路)
现在搞爬虫的人,可能被问的最多的问题就是“你会不会分布式爬虫?”。给人的觉得就是你不会分布式爬虫,都不好意思说自己是搞爬虫的。但虽然分布式爬虫的原理比较简单,大多数的业务用不到分布式模式。
所谓的分布式爬虫,就是多台机器合作进行爬虫工作,提高工作效率。
分布式爬虫须要考虑的问题有:
(1)如何从一个统一的插口获取待抓取的URL?
(2)如何保证多台机器之间的排重操作?即保证不会出现多台机器同时抓取同一个URL。
(3)当多台机器中的一台或则几台死掉,如何保证任务继续,且数据不会遗失?
这里首先借助Redis数据库解决前两个问题。
Redis数据库是一种key-value数据库,它本身包含了一些比较好的特点,比较适宜解决分布式爬虫的问题。关于Redis的一些基本概念、操作等,建议读者自行百度。我们这儿使用到Redis中自带的“消息队列”,来解决分布式爬虫问题。具体实现步骤如下:
在Redis中初始化两条key-value数据,对应的key分别为spider.wait和spider.all。spider.wait的value是一个list队列,存放我们待抓取的URL。该数据类型便捷我们实现消息队列。我们使用lpush操作添加URL数据,同时使用brpop窃听并获取取URL数据。spider.all的value是一个set集合,存放我们所有待抓取和已抓取的URL。该数据类型便捷我们实现排重操作。我们使用sadd操作添加数据。
在我的代码中,我是在原先爬虫框架的基础上,添加了分布式爬虫模式(一个文件)分布式爬虫 python,该文件的代码行数大约在100行左右,所以文章标题为“百行代码”。但实际上,在每台客户端机器上,我都使用了多线程爬虫框架。即:
(1)每台机器从Redis获取待抓取的URL,执行“抓取--解析--保存”的过程
(2)每台机器本身使用多线程爬虫模式,即有多个线程同时从Redis获取URL并抓取
(3)每台机器解析数据得到的新的URL,会传回Redis数据库,同时保证数据一致性
(4)每台机器单独启动自己的爬虫,之后单独关掉爬虫任务,没有手动功能
具体可查看代码:distributed_threads.py
这里的代码还不够建立,主要还要如下的问题:
有兴趣解决问题的,可以fork代码然后,自行更改分布式爬虫 python,并递交pull-requests。
=============================================================
作者主页:笑虎(Python爱好者,关注爬虫、数据剖析、数据挖掘、数据可视化等)
作者专栏主页:撸代码,学知识 - 知乎专栏
作者GitHub主页:撸代码,学知识 - GitHub
欢迎你们指正、提意见。相互交流,共同进步!
==============================================================
Python爬虫介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-06-02 08:00
什么是爬虫?
在网路的大数据库里,信息是海量的,如何能快速有效的从互联网上将我们所须要的信息挑拣下来呢,这个时侯就须要爬虫技术了。爬虫是指可以手动抓取互联网信息的程序,从互联网上抓取一切有价值的信息,并且把站点的html和js返回的图片爬到本地,并且储存便捷使用。简单点来说,如果我们把互联网有价值的信息都比喻成大的蜘蛛网,而各个节点就是储存的数据,而蜘蛛网的上蜘蛛比喻成爬虫python 爬虫,而蜘蛛抓取的猎物就是我们要门要的数据信息了。
Python爬虫介绍
Python用于爬虫?
很多人不知道python为何叫爬虫,这可能是依据python的特性。Python是纯粹的自由软件,以简约清晰的句型和强制使用空白符进行句子缩进的特征因而受到程序员的喜爱。使用Python来完成编程任务的话,编写的代码量更少,代码简约简略可读性更强,所以说这是一门特别适宜开发网路爬虫的编程语言,而且相比于其他静态编程,python很容易进行配置,对字符的处理也是十分灵活的,在加上python有很多的抓取模块,所以说python通常用于爬虫。
爬虫的组成?
1、URL管理器:管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
2、网页下载器:爬取url对应的网页,存储成字符串,传送给网页解析器;
3、网页解析器:解析出有价值的数据,存储出来,同时补充url到URL管理器
爬虫的工作流程?
爬虫首先要做的工作是获取网页的源代码,源代码里包含了网页的部份有用信息;之后爬虫构造一个恳求并发献给服务器,服务器接收到响应并将其解析下来。
Python爬虫介绍
爬虫是怎样提取信息原理?
最通用的方式是采用正则表达式。网页结构有一定的规则,还有一些依照网页节点属性、CSS选择器或XPath来提取网页信息的库,如Requests、pyquery、lxml等,使用这种库,便可以高效快速地从中提取网页信息,如节点的属性、文本值等,并能简单保存为TXT文本或JSON文本,这些信息可保存到数据库,如MySQL和MongoDB等,也可保存至远程服务器,如利用SFTP进行操作等。提取信息是爬虫十分重要的作用,它可以让零乱的数据显得条理清晰,以便我们后续处理和剖析数据。 查看全部
随着互联网的高速发展python 爬虫,大数据时代早已将至,网络爬虫这个名词也被人们越来越多的提起,但相信很多人对网路爬虫并不是太了解,下面就让小编给你们介绍一下哪些是网络爬虫?网络爬虫有哪些作用呢?
什么是爬虫?
在网路的大数据库里,信息是海量的,如何能快速有效的从互联网上将我们所须要的信息挑拣下来呢,这个时侯就须要爬虫技术了。爬虫是指可以手动抓取互联网信息的程序,从互联网上抓取一切有价值的信息,并且把站点的html和js返回的图片爬到本地,并且储存便捷使用。简单点来说,如果我们把互联网有价值的信息都比喻成大的蜘蛛网,而各个节点就是储存的数据,而蜘蛛网的上蜘蛛比喻成爬虫python 爬虫,而蜘蛛抓取的猎物就是我们要门要的数据信息了。
Python爬虫介绍
Python用于爬虫?
很多人不知道python为何叫爬虫,这可能是依据python的特性。Python是纯粹的自由软件,以简约清晰的句型和强制使用空白符进行句子缩进的特征因而受到程序员的喜爱。使用Python来完成编程任务的话,编写的代码量更少,代码简约简略可读性更强,所以说这是一门特别适宜开发网路爬虫的编程语言,而且相比于其他静态编程,python很容易进行配置,对字符的处理也是十分灵活的,在加上python有很多的抓取模块,所以说python通常用于爬虫。
爬虫的组成?
1、URL管理器:管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
2、网页下载器:爬取url对应的网页,存储成字符串,传送给网页解析器;
3、网页解析器:解析出有价值的数据,存储出来,同时补充url到URL管理器
爬虫的工作流程?
爬虫首先要做的工作是获取网页的源代码,源代码里包含了网页的部份有用信息;之后爬虫构造一个恳求并发献给服务器,服务器接收到响应并将其解析下来。
Python爬虫介绍
爬虫是怎样提取信息原理?
最通用的方式是采用正则表达式。网页结构有一定的规则,还有一些依照网页节点属性、CSS选择器或XPath来提取网页信息的库,如Requests、pyquery、lxml等,使用这种库,便可以高效快速地从中提取网页信息,如节点的属性、文本值等,并能简单保存为TXT文本或JSON文本,这些信息可保存到数据库,如MySQL和MongoDB等,也可保存至远程服务器,如利用SFTP进行操作等。提取信息是爬虫十分重要的作用,它可以让零乱的数据显得条理清晰,以便我们后续处理和剖析数据。
网络爬虫基本原理解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2020-05-28 08:01
“ 只推荐有价值的技术性文章优才学院
网络爬虫是索引擎抓取系统的重要组成部份。爬虫的主要目的是将互联网上的网页下载到本地产生一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
一、网络爬虫的基本结构及工作流程
一个通用的网路爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路以后再转到下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以里面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就产生了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
四、更新策略
互联网是实时变化的,具有太强的动态性。网页更新策略主要是决定何时更新之前早已下载过的页面。常见的更新策略又以下三种:
1.历史参考策略
顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略
尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。
3.降维抽样策略
前面提及的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一网络爬虫原理,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多的系统负担;第二,要是新的网页完全没有历史信息网络爬虫原理,就难以确定更新策略。
这种策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新频度也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样,以她们的更新周期作为整个类别的更新周期。基本思路如图:
五、分布式抓取系统结构
一般来说,抓取系统须要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往须要多个抓取程序一起来处理。一般来说抓取系统常常是一个分布式的三层结构。如图所示:
最下一层是分布在不同地理位置的数据中心,在每位数据中心里有若干台抓取服务器,而每台抓取服务器上可能布署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方法有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器不仅维护待抓取URL队列以及分发URL之外,还要负责调处各个Slave服务器的负载情况。以免个别Slave服务器过分悠闲或则操劳。
这种模式下,Master常常容易成为系统困局。
2.对方程(Peer to Peer)
对等式的基本结构如图所示:
在这些模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后估算H mod m(其中m是服务器的数目,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
举例:假设对于URL ,计算器hash值H=8,m=3,则H mod m=2,因此由编号为2的服务器进行该链接的抓取。假设这时候是0号服务器领到这个URL,那么它将该URL转给服务器2,由服务器2进行抓取。
这种模式有一个问题,当有一台服务器关机或则添加新的服务器,那么所有URL的哈希求余的结果就都要变化。也就是说,这种方法的扩展性不佳。针对这些情况,又有一种改进方案被提下来。这种改进的方案是一致性哈希法来确定服务器分工。其基本结构如图所示:
一致性哈希将URL的主域名进行哈希运算,映射为一个范围在0-232之间的某个数。而将这个范围平均的分配给m台服务器,根据URL主域名哈希运算的值所处的范围判定是哪台服务器来进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则根据顺时针延后,由下一台服务器进行抓取。这样的话,及时某台服务器出现问题,也不会影响其他的工作。 查看全部
“ 只推荐有价值的技术性文章优才学院
网络爬虫是索引擎抓取系统的重要组成部份。爬虫的主要目的是将互联网上的网页下载到本地产生一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
一、网络爬虫的基本结构及工作流程
一个通用的网路爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路以后再转到下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以里面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就产生了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
四、更新策略
互联网是实时变化的,具有太强的动态性。网页更新策略主要是决定何时更新之前早已下载过的页面。常见的更新策略又以下三种:
1.历史参考策略
顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略
尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。
3.降维抽样策略
前面提及的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一网络爬虫原理,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多的系统负担;第二,要是新的网页完全没有历史信息网络爬虫原理,就难以确定更新策略。
这种策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新频度也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样,以她们的更新周期作为整个类别的更新周期。基本思路如图:
五、分布式抓取系统结构
一般来说,抓取系统须要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往须要多个抓取程序一起来处理。一般来说抓取系统常常是一个分布式的三层结构。如图所示:
最下一层是分布在不同地理位置的数据中心,在每位数据中心里有若干台抓取服务器,而每台抓取服务器上可能布署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方法有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器不仅维护待抓取URL队列以及分发URL之外,还要负责调处各个Slave服务器的负载情况。以免个别Slave服务器过分悠闲或则操劳。
这种模式下,Master常常容易成为系统困局。
2.对方程(Peer to Peer)
对等式的基本结构如图所示:
在这些模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后估算H mod m(其中m是服务器的数目,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
举例:假设对于URL ,计算器hash值H=8,m=3,则H mod m=2,因此由编号为2的服务器进行该链接的抓取。假设这时候是0号服务器领到这个URL,那么它将该URL转给服务器2,由服务器2进行抓取。
这种模式有一个问题,当有一台服务器关机或则添加新的服务器,那么所有URL的哈希求余的结果就都要变化。也就是说,这种方法的扩展性不佳。针对这些情况,又有一种改进方案被提下来。这种改进的方案是一致性哈希法来确定服务器分工。其基本结构如图所示:
一致性哈希将URL的主域名进行哈希运算,映射为一个范围在0-232之间的某个数。而将这个范围平均的分配给m台服务器,根据URL主域名哈希运算的值所处的范围判定是哪台服务器来进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则根据顺时针延后,由下一台服务器进行抓取。这样的话,及时某台服务器出现问题,也不会影响其他的工作。
Webmagic(爬虫)抓取新浪博客案例
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-05-19 08:00
我们以作者的新浪博客 作为反例。在这个事例里,我们要从最终的博客文章页面,抓取博客的标题、内容、日期等信息,也要从列表页抓取博客的链接等信息,从而获取这个博客的所有文章。
列表页的格式是““, 其中“0_1”中的“1”是可变的页数。
文章页的格式是“”,其中“95b4e3010102xsua”是可变的字符。
通过前面的剖析新浪博客超级爬虫(网站推广工具) v14绿色版,我先要找到文章的 url,再愈发 url 获取文章。所以怎么发觉这个博客中所有的文章地址,是爬虫的第一步。
我们可以使用正则表达式 +//.html 对 URL 进行一次简略过滤。这里比较复杂的是,这个 URL 过于空泛,可能会抓取到其他博客的信息,所以我们必须从列表页中指定的区域获取 URL。
在这里,我们使用 xpath//div[@class=//”articleList//”]选中所有区域,再使用 links()或者 xpath//a/@href 获取所有链接,最后再使用正则表达式 +//.html,对 URL 进行过滤,去掉一些“编辑”或者“更多”之类的链接。于是,我们可以这样写:
page.addTargetRequests(
page.getHtml().xpath("//div[@class=/"articleList/"]"
).links().regex("http://blog//.sina//.com//.cn/ ... 6quot;).all());
同时,我们须要把所有找到的列表页也加到待下载的 URL 中去:
page.addTargetRequests(
page.getHtml().links().regex(
"http://blog//.sina//.com//.cn/ ... 6quot;).all());
文章页面信息的抽取是比较简单的,写好对应的 xpath 抽取表达式就可以了。
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath(
"//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",page.getHtml().xpath(
"//div[@id='articlebody']//span[@class='time SG_txtc']").regex("//((.*)//)"));
现在,我们早已定义了对列表和目标页进行处理的方法,现在我们须要在处理时对她们进行分辨。在这个反例中,区分方法很简单,因为列表页和目标页在 URL 格式上是不同的,所以直接用 URL 区分就可以了!
这个反例完整的代码如下:
package us.codecraft.webmagic.samples;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class SinaBlogProcessor implements PageProcessor {
public static final String URL_LIST = "http://blog//.sina//.com//.cn/ ... 3B%3B
public static final String URL_POST = "http://blog//.sina//.com//.cn/ ... 3B%3B
private Site site = Site.me().setDomain("blog.sina.com.cn").setSleepTime(3000).setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override public void process(Page page) {
//列表页
if (page.getUrl().regex(URL_LIST).match()) {
page.addTargetRequests(page.getHtml().xpath("//div[@class=/"articleList/"]").links().regex(URL_POST).all());
page.addTargetRequests(page.getHtml().links().regex(URL_LIST).all());
//文章页} else {
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath("//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",page.getHtml().xpath("//div[@id='articlebody']//span[@class='time SG_txtc']").regex("//((.*)//)"));}}
@Override public Site getSite() {
return site;}
public static void main(String[] args) {
Spider.create(new SinaBlogProcessor()).addUrl("http://blog.sina.com.cn/s/arti ... 6quot;).run();
} }
通过这个反例我们可以发觉主要使用几个方式:
如果你认为用 if-else 来分辨不同处理有些不方便新浪博客超级爬虫(网站推广工具) v14绿色版,那么可以使用 SubPageProcessor 来解决这个问题。 查看全部
Webmagic框架更侧重实际的内容抓取。今天为你们分享Webmagic 爬虫框架抓取新浪博客的案例。
我们以作者的新浪博客 作为反例。在这个事例里,我们要从最终的博客文章页面,抓取博客的标题、内容、日期等信息,也要从列表页抓取博客的链接等信息,从而获取这个博客的所有文章。
列表页的格式是““, 其中“0_1”中的“1”是可变的页数。
文章页的格式是“”,其中“95b4e3010102xsua”是可变的字符。
通过前面的剖析新浪博客超级爬虫(网站推广工具) v14绿色版,我先要找到文章的 url,再愈发 url 获取文章。所以怎么发觉这个博客中所有的文章地址,是爬虫的第一步。
我们可以使用正则表达式 +//.html 对 URL 进行一次简略过滤。这里比较复杂的是,这个 URL 过于空泛,可能会抓取到其他博客的信息,所以我们必须从列表页中指定的区域获取 URL。
在这里,我们使用 xpath//div[@class=//”articleList//”]选中所有区域,再使用 links()或者 xpath//a/@href 获取所有链接,最后再使用正则表达式 +//.html,对 URL 进行过滤,去掉一些“编辑”或者“更多”之类的链接。于是,我们可以这样写:
page.addTargetRequests(
page.getHtml().xpath("//div[@class=/"articleList/"]"
).links().regex("http://blog//.sina//.com//.cn/ ... 6quot;).all());
同时,我们须要把所有找到的列表页也加到待下载的 URL 中去:
page.addTargetRequests(
page.getHtml().links().regex(
"http://blog//.sina//.com//.cn/ ... 6quot;).all());
文章页面信息的抽取是比较简单的,写好对应的 xpath 抽取表达式就可以了。
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath(
"//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",page.getHtml().xpath(
"//div[@id='articlebody']//span[@class='time SG_txtc']").regex("//((.*)//)"));
现在,我们早已定义了对列表和目标页进行处理的方法,现在我们须要在处理时对她们进行分辨。在这个反例中,区分方法很简单,因为列表页和目标页在 URL 格式上是不同的,所以直接用 URL 区分就可以了!
这个反例完整的代码如下:
package us.codecraft.webmagic.samples;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class SinaBlogProcessor implements PageProcessor {
public static final String URL_LIST = "http://blog//.sina//.com//.cn/ ... 3B%3B
public static final String URL_POST = "http://blog//.sina//.com//.cn/ ... 3B%3B
private Site site = Site.me().setDomain("blog.sina.com.cn").setSleepTime(3000).setUserAgent(
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
@Override public void process(Page page) {
//列表页
if (page.getUrl().regex(URL_LIST).match()) {
page.addTargetRequests(page.getHtml().xpath("//div[@class=/"articleList/"]").links().regex(URL_POST).all());
page.addTargetRequests(page.getHtml().links().regex(URL_LIST).all());
//文章页} else {
page.putField("title", page.getHtml().xpath("//div[@class='articalTitle']/h2"));
page.putField("content", page.getHtml().xpath("//div[@id='articlebody']//div[@class='articalContent']"));
page.putField("date",page.getHtml().xpath("//div[@id='articlebody']//span[@class='time SG_txtc']").regex("//((.*)//)"));}}
@Override public Site getSite() {
return site;}
public static void main(String[] args) {
Spider.create(new SinaBlogProcessor()).addUrl("http://blog.sina.com.cn/s/arti ... 6quot;).run();
} }
通过这个反例我们可以发觉主要使用几个方式:
如果你认为用 if-else 来分辨不同处理有些不方便新浪博客超级爬虫(网站推广工具) v14绿色版,那么可以使用 SubPageProcessor 来解决这个问题。
网络爬虫的原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 809 次浏览 • 2020-05-18 08:02
在Python的模块海洋里,支持http合同的模块是相当丰富的,既有官方的urllib,也有大名鼎鼎的社区(第三方)模块 requests。它们都挺好的封装了http合同恳求的各类方式,因此,我们只须要熟悉这种模块的用法,不再进一步讨论http合同本身。
大家对浏览器应当一点都不陌生,可以说,只要上过网的人都晓得浏览器。可是,明白浏览器各类原理的人可不一定多。
作为要开发爬虫的小伙伴网络爬虫原理,是一定一定要明白浏览器的工作原理的。这是你写爬虫的必备工具,别无他。
大家在笔试的时侯,有没有遇见如此一个特别宏观而又处处细节的解答题:
这真是一个考验知识面的题啊,经验老道的老猿既可以滔滔不绝的讲上三天三夜,也可以提炼出几分钟的精华讲个大约。大家似乎对整个过程就一知半解了。
巧的是,对这个问题理解的越透彻,越对写爬虫有帮助。换句话说,爬虫是一个考验综合技能的领域。那么,大家打算好迎接这个综合技能挑战了吗?
废话不多说,我们就从解答这个题目开始,认识浏览器和服务器,看看这中间有什么知识是爬虫要用到的。
前面也说过,这个问题可以讲上三天三夜,但我们没那么多时间,其中一些细节就略过,把大致流程结合爬虫讲一讲,分成三部份:
浏览器发出恳求服务器作出响应浏览器接收响应
在浏览器地址栏输入网址后回车,浏览器请服务器提出网页恳求,也就是告诉服务器,我要看你的某个网页。 上面短短一句话,蕴藏了无数玄机啊,让我不得不费点口舌一一道来。主要述说:
首先,浏览器要判定你输入的网址(URL)是否合法有效。对应URL网络爬虫原理,小猿们并不陌生吧,以http(s)开头的那一长串的字符,但是你晓得它还可以以ftp, mailto, file, data, irc开头吗?下面是它最完整的句型格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
用图更形象的表现处理就是这样的:
经验之谈:要判定URL的合法性
Python上面可以用urllib.parse来进行URL的各类操作
In [1]: import urllib.parse
In [2]: url = 'http://dachong:the_password%40 ... 27%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看见,urlparse函数把URL剖析成了6部分: scheme://netloc/path;params?query#fragment 需要主要的是 netloc 并不等同于 URL 语法定义中的host
上面URL定义中的host,就是互联网上的一台服务器,它可以是一个IP地址,但一般是我们所说的域名。域名通过DNS绑定到一个(或多个)IP地址上。浏览器要访问某个域名的网站就要先通过DNS服务器解析域名,得到真实的IP地址。 这里的域名解析通常是由操作系统完成的,爬虫不需要关心。然而,当你写一个小型爬虫,像Google、百度搜索引擎那样的爬虫的时侯,效率显得太主要,爬虫就要维护自己的DNS缓存。 老猿经验:大型爬虫要维护自己的DNS缓存
浏览器获得了网站服务器的IP地址,就可以向服务器发送恳求了。这个恳求就是遵守http合同的。写爬虫须要关心的就是http合同的headers,下面是访问 en.wikipedia.org/wiki/URL 时浏览器发送的恳求 headers:
可能早已从图中看下来些疲态,发送的http请求头是类似一个字典的结构:
path: 访问的网站的路径scheme: 请求的合同类型,这里是httpsaccept: 能够接受的回应内容类型(Content-Types)accept-encoding: 能够接受的编码方法列表accept-language: 能够接受的回应内容的自然语言列表cache-control: 指定在此次的请求/响应链中的所有缓存机制 都必须 遵守的指令cookie: 之前由服务器通过 Set- Cookie发送的一个 超文本传输协议Cookie 这是爬虫太关心的一个东东,登录信息都在这里。upgrade-insecuree-requests: 非标准恳求数组,可忽视之。user-agent: 浏览器身分标示
这也是爬虫太关心的部份。比如,你须要得到手机版页面,就要设置浏览器身分标示为手机浏览器的user-agent。
经验之谈: 通过设置headers跟服务器沟通
如果我们在浏览器地址栏输入一个网页网址(不是文件下载地址),回车后,很快就听到了一个网页,里面包含排版文字、图片、视频等数据,是一个丰富内容格式的页面。然而,我通过浏览器查看源代码,看到的却是一对文本格式的html代码。
没错,就是一堆的代码,却使浏览器给渲染成了漂亮的网页。这对代码上面有:
而我们想要爬取的信息就藏在html代码中,我们可以通过解析方式提取其中我们想要的内容。如果html代码上面没有我们想要的数据,但是在网页上面却看见了,那就是浏览器通过ajax恳求异步加载(偷偷下载)了那部份数据。 查看全部
互联网上,公开数据(各种网页)都是以http(或加密的http即https)协议传输的。所以,我们这儿介绍的爬虫技术都是基于http(https)协议的爬虫。
在Python的模块海洋里,支持http合同的模块是相当丰富的,既有官方的urllib,也有大名鼎鼎的社区(第三方)模块 requests。它们都挺好的封装了http合同恳求的各类方式,因此,我们只须要熟悉这种模块的用法,不再进一步讨论http合同本身。
大家对浏览器应当一点都不陌生,可以说,只要上过网的人都晓得浏览器。可是,明白浏览器各类原理的人可不一定多。
作为要开发爬虫的小伙伴网络爬虫原理,是一定一定要明白浏览器的工作原理的。这是你写爬虫的必备工具,别无他。
大家在笔试的时侯,有没有遇见如此一个特别宏观而又处处细节的解答题:
这真是一个考验知识面的题啊,经验老道的老猿既可以滔滔不绝的讲上三天三夜,也可以提炼出几分钟的精华讲个大约。大家似乎对整个过程就一知半解了。
巧的是,对这个问题理解的越透彻,越对写爬虫有帮助。换句话说,爬虫是一个考验综合技能的领域。那么,大家打算好迎接这个综合技能挑战了吗?
废话不多说,我们就从解答这个题目开始,认识浏览器和服务器,看看这中间有什么知识是爬虫要用到的。
前面也说过,这个问题可以讲上三天三夜,但我们没那么多时间,其中一些细节就略过,把大致流程结合爬虫讲一讲,分成三部份:
浏览器发出恳求服务器作出响应浏览器接收响应
在浏览器地址栏输入网址后回车,浏览器请服务器提出网页恳求,也就是告诉服务器,我要看你的某个网页。 上面短短一句话,蕴藏了无数玄机啊,让我不得不费点口舌一一道来。主要述说:
首先,浏览器要判定你输入的网址(URL)是否合法有效。对应URL网络爬虫原理,小猿们并不陌生吧,以http(s)开头的那一长串的字符,但是你晓得它还可以以ftp, mailto, file, data, irc开头吗?下面是它最完整的句型格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
用图更形象的表现处理就是这样的:
经验之谈:要判定URL的合法性
Python上面可以用urllib.parse来进行URL的各类操作
In [1]: import urllib.parse
In [2]: url = 'the_password@www.yuanrenxue.com/user/info?page=2'" rel="nofollow" target="_blank">http://dachong:the_password%40 ... 27%3B
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看见,urlparse函数把URL剖析成了6部分: scheme://netloc/path;params?query#fragment 需要主要的是 netloc 并不等同于 URL 语法定义中的host
上面URL定义中的host,就是互联网上的一台服务器,它可以是一个IP地址,但一般是我们所说的域名。域名通过DNS绑定到一个(或多个)IP地址上。浏览器要访问某个域名的网站就要先通过DNS服务器解析域名,得到真实的IP地址。 这里的域名解析通常是由操作系统完成的,爬虫不需要关心。然而,当你写一个小型爬虫,像Google、百度搜索引擎那样的爬虫的时侯,效率显得太主要,爬虫就要维护自己的DNS缓存。 老猿经验:大型爬虫要维护自己的DNS缓存
浏览器获得了网站服务器的IP地址,就可以向服务器发送恳求了。这个恳求就是遵守http合同的。写爬虫须要关心的就是http合同的headers,下面是访问 en.wikipedia.org/wiki/URL 时浏览器发送的恳求 headers:
可能早已从图中看下来些疲态,发送的http请求头是类似一个字典的结构:
path: 访问的网站的路径scheme: 请求的合同类型,这里是httpsaccept: 能够接受的回应内容类型(Content-Types)accept-encoding: 能够接受的编码方法列表accept-language: 能够接受的回应内容的自然语言列表cache-control: 指定在此次的请求/响应链中的所有缓存机制 都必须 遵守的指令cookie: 之前由服务器通过 Set- Cookie发送的一个 超文本传输协议Cookie 这是爬虫太关心的一个东东,登录信息都在这里。upgrade-insecuree-requests: 非标准恳求数组,可忽视之。user-agent: 浏览器身分标示
这也是爬虫太关心的部份。比如,你须要得到手机版页面,就要设置浏览器身分标示为手机浏览器的user-agent。
经验之谈: 通过设置headers跟服务器沟通
如果我们在浏览器地址栏输入一个网页网址(不是文件下载地址),回车后,很快就听到了一个网页,里面包含排版文字、图片、视频等数据,是一个丰富内容格式的页面。然而,我通过浏览器查看源代码,看到的却是一对文本格式的html代码。
没错,就是一堆的代码,却使浏览器给渲染成了漂亮的网页。这对代码上面有:
而我们想要爬取的信息就藏在html代码中,我们可以通过解析方式提取其中我们想要的内容。如果html代码上面没有我们想要的数据,但是在网页上面却看见了,那就是浏览器通过ajax恳求异步加载(偷偷下载)了那部份数据。
百度爬虫及工作原理解析
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-05-16 08:07
俗话说知己知彼能够百战不殆,互联网时代也不例外,想要关键词获取好的排行,想要网站有大量的流量,想要做好搜索引擎优化,那么一定要了解搜索引擎的工作原理,毕竟访问者想要获取信息优选选择的都是搜索引擎,百度作为全球的英文搜索引擎,百度爬虫就是它重要的程序之一。
百度爬虫又被称为百度蜘蛛,是一种网路机器人,按照一定的规则,在各个网站上爬行,访问搜集整理网页、图片、视频等内容,分类别构建数据库,呈现在搜索引擎上,使用户通过搜索一些关键词,能查看到企业网站的页面、图片、视频等。
通俗的说它可以访问,抓取,整理互联网上的多种内容,从而分门别类的构建一个索引数据库,使用户可以通过百度这个搜索引擎在互联网上找到自己想找寻的信息。它主要的工作就是发觉网站,抓取网站,保存网站,分析网站和参与网站。我们所做的一切网站优化,都是为了使爬虫抓取、收录网站的。那么,什么是百度爬虫?它工作原理是哪些呢?
1、发现网站:百度爬虫每晚还会在各个网站上爬,抓取无数的网站与页面,进行评估与初审,优质的内容都会被收录。一个新网站一般都须要一周左右就会被爬虫发觉,只要坚持不断更新网站,内容优质,一定会被发觉的。
2、抓取网站:百度爬虫通常是先按照预先设定的初始网页的URL开始,然后根据一定的规则爬取网页。爬虫沿着网页中的各类链接,从一个页面爬到另一个页面,通过链接剖析连续爬行访问,抓取更多的页面。被抓取的网页就是“百度快照”。
3、保存网站:百度爬虫的喜好跟我们人类的喜好是一样的,喜欢新鲜的、独一无二的东西。如果网站经常更新,内容质量特别高,那么爬虫就喜欢待在这里,顺着链接来回爬,欣赏这独一无二的景色,并且会保存出来。如果网站的内容都是剽窃来的,或其他网站上早就有了,爬虫就觉得是垃圾内容,便会离开网站。
4、分析网站:百度爬虫抓取到网站之后,要提取关键词,建立索引库和索引,同时还要剖析内容是否重复,判断网页的类型,分析超链接,计算网站的重要程度等大量的工作百度爬虫,分析完毕以后,就能提供检索服务。
5、参与网站:当爬虫觉得网站的内容符合它的喜好了,通过一系列的估算工作以后,就被收录上去,当用户输入关键词并进行搜索的时侯,就能从搜索引擎中找到该关键词相关的网站,从而被用户查看到。
详细点来说就是百度爬虫爬行到网站上选购网站中的优质URL(指资源的地址) ,然后将这种优质URL倒入待抓取URL队列,再从待抓取URL队列提取过滤掉重复的URL,解析网页链接特点,得到主机IP并将URL对应的网页信息下载出来存入索引库,然后等待用户搜索提取。当然,已下载的URL仍然会放到已抓取URL队列,再剖析其中的其他URL,然后再倒入待抓取URL的队列,在步入下一个循环。
在这里就不得不提及网站地图了,百度爬虫特别喜欢网站地图,因为网站地图将网站上所有的链接汇总上去,可以便捷蜘蛛的爬行抓取,让爬虫清晰了解网站的整体结构,增加网站重要页面的收录。
当今时代是互联网的时代,互联网时代是一个全新的信息化时代,当然,互联网上的内容也是实时变化,不断更新换旧的,想要信息排行愈发的靠前,只有充分把握搜索引擎的工作原理,并善用每位细节,才能使网站获取更多更好的诠释百度爬虫,毕竟成大业若烹小鲜,做大事必重细节。 查看全部
俗话说知己知彼能够百战不殆,互联网时代也不例外,想要关键词获取好的排行,想要网站有大量的流量,想要做好搜索引擎优化,那么一定要了解搜索引擎的工作原理,毕竟访问者想要获取信息优选选择的都是搜索引擎,百度作为全球的英文搜索引擎,百度爬虫就是它重要的程序之一。
百度爬虫又被称为百度蜘蛛,是一种网路机器人,按照一定的规则,在各个网站上爬行,访问搜集整理网页、图片、视频等内容,分类别构建数据库,呈现在搜索引擎上,使用户通过搜索一些关键词,能查看到企业网站的页面、图片、视频等。
通俗的说它可以访问,抓取,整理互联网上的多种内容,从而分门别类的构建一个索引数据库,使用户可以通过百度这个搜索引擎在互联网上找到自己想找寻的信息。它主要的工作就是发觉网站,抓取网站,保存网站,分析网站和参与网站。我们所做的一切网站优化,都是为了使爬虫抓取、收录网站的。那么,什么是百度爬虫?它工作原理是哪些呢?
1、发现网站:百度爬虫每晚还会在各个网站上爬,抓取无数的网站与页面,进行评估与初审,优质的内容都会被收录。一个新网站一般都须要一周左右就会被爬虫发觉,只要坚持不断更新网站,内容优质,一定会被发觉的。
2、抓取网站:百度爬虫通常是先按照预先设定的初始网页的URL开始,然后根据一定的规则爬取网页。爬虫沿着网页中的各类链接,从一个页面爬到另一个页面,通过链接剖析连续爬行访问,抓取更多的页面。被抓取的网页就是“百度快照”。
3、保存网站:百度爬虫的喜好跟我们人类的喜好是一样的,喜欢新鲜的、独一无二的东西。如果网站经常更新,内容质量特别高,那么爬虫就喜欢待在这里,顺着链接来回爬,欣赏这独一无二的景色,并且会保存出来。如果网站的内容都是剽窃来的,或其他网站上早就有了,爬虫就觉得是垃圾内容,便会离开网站。
4、分析网站:百度爬虫抓取到网站之后,要提取关键词,建立索引库和索引,同时还要剖析内容是否重复,判断网页的类型,分析超链接,计算网站的重要程度等大量的工作百度爬虫,分析完毕以后,就能提供检索服务。
5、参与网站:当爬虫觉得网站的内容符合它的喜好了,通过一系列的估算工作以后,就被收录上去,当用户输入关键词并进行搜索的时侯,就能从搜索引擎中找到该关键词相关的网站,从而被用户查看到。
详细点来说就是百度爬虫爬行到网站上选购网站中的优质URL(指资源的地址) ,然后将这种优质URL倒入待抓取URL队列,再从待抓取URL队列提取过滤掉重复的URL,解析网页链接特点,得到主机IP并将URL对应的网页信息下载出来存入索引库,然后等待用户搜索提取。当然,已下载的URL仍然会放到已抓取URL队列,再剖析其中的其他URL,然后再倒入待抓取URL的队列,在步入下一个循环。
在这里就不得不提及网站地图了,百度爬虫特别喜欢网站地图,因为网站地图将网站上所有的链接汇总上去,可以便捷蜘蛛的爬行抓取,让爬虫清晰了解网站的整体结构,增加网站重要页面的收录。
当今时代是互联网的时代,互联网时代是一个全新的信息化时代,当然,互联网上的内容也是实时变化,不断更新换旧的,想要信息排行愈发的靠前,只有充分把握搜索引擎的工作原理,并善用每位细节,才能使网站获取更多更好的诠释百度爬虫,毕竟成大业若烹小鲜,做大事必重细节。
泛域名解析网站如何避免被百度爬虫爬死(悬赏88元) - 搜外问答
采集交流 • 优采云 发表了文章 • 0 个评论 • 322 次浏览 • 2020-05-14 08:00
那么我们怎么避免访问早已访问过的页面呢?答案很简单,设置一个标志即可。整个互联网就是一个图结构,我们一般使用DFS(深度优先搜索)和BFS(广度优先搜索)进行遍历。所以,像遍历一个简单的图一样,将访问过的结点标记一下即可。
爬虫的基本思路如下:
根据URL获取相应页面的HTML代码
利用正则匹配或则JSoup等库解析HTML代码,提取须要的内容
将获取的内容持久化到数据库中
处理好英文字符的编码问题,可以采用多线程提升效率
爬虫基本原理
更笼统意义上的爬虫着重于若果在大量的URL中找寻出高质量的资源,如何在有限的时间内访问更多页面等等。网络爬虫的基本工作流程如下:
首先选定一部分悉心选购的种子URL;
将这种URL装入待抓取URL队列;
从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
分析已抓取URL对应的网页,分析页面里包含的其他URL,并且将URL装入待抓取URL队列,从而步入下一个循环。
有几个概念,一个是发http请求,一个是正则匹配你感兴趣的链接,一个是多线程,另外还有两个队列。
爬虫难点1支路
网络爬虫有时候会深陷循环或则支路中,比如从页面A,A链接到页面B,B链接到页面C,页面C又会链接到页面A。这样就深陷到支路中。
环路影响:
消耗网路带宽,无法获取其他页面
对Web服务器也是负担,可能击垮该站点,可能制止正常用户访问该站点
即使没有性能影响,但获取大量重复页面也造成数据冗余
解决方案:
简单限定爬虫的最大循环次数网页如何防止爬虫,对于某web站点访问超过一定阀值就跳出,避免无限循环
保存一个已访问url列表,记录页面是否被访问过的技术
1、二叉树和散列表,快速判断某个url是否访问过
2、存在位图
就是newint[length],然后把第几个数置为1,表示早已访问过了。可不可以再优化,int是32位,32位可以表示32个数字。HashCode会存在冲突的情况,
两个URL映射到同一个存在位上,冲突的后果是某个页面被忽视(这比死循环的恶作用小)
3、保存检测
一定要及时把已访问的URL列表保存到硬碟上,防止爬虫崩溃,内存里的数据会遗失
4、集群,分而治之
多台机器一起爬虫,可以按照URL估算HashCode,然后按照HashCode映射到相应机器的id(第0台、第1台、第2台等等)
难点2URL别称
有些URL名称不一样,但是指向同一个资源。
URl1URL2什么时候是别称
默认端口是80
%7F与~相同
%7F与~相同
服务器是大小写无关
默认页面为
ip和域名相同
难点3动态虚拟空间
比如月历程序,它会生成一个指向下一个月的链接,真正的用户是不会不停地恳求下个月的链接的。但是不了解这种内容特点的爬虫蜘蛛可能会不断向那些资源发出无穷的恳求。
抓取策略
一般策略是深度优先或则广度优先。有些技术能促使爬虫蜘蛛有更好的表现
广度优先的爬行,避免深度优先深陷某个站点的支路中,无法访问其他站点。
限制访问次数,限定一段时间内机器人可以从一个web站点获取的页面数目。
内容指纹,根据页面的内容估算出一个校验和,但是动态的内容(日期,评论数量)会妨碍重复测量
维护黑名单
人工监视,特殊情况发出电邮通知
动态变化,根据当前热点新闻等等
规范化URL,把一些转义字符、ip与域名之类的统一
限制URL大小,环路可能会促使URL宽度降低,比如/,/folder/网页如何防止爬虫,/folder/folder/…… 查看全部
话说爬虫为何会深陷循环呢?答案很简单,当我们重新去解析一个早已解析过的网页时,就会身陷无限循环。这意味着我们会重新访问哪个网页的所有链接,然后不久后又会访问到这个网页。最简单的事例就是,网页A包含了网页B的链接,而网页B又包含了网页A的链接,那它们之间都会产生一个闭环。
那么我们怎么避免访问早已访问过的页面呢?答案很简单,设置一个标志即可。整个互联网就是一个图结构,我们一般使用DFS(深度优先搜索)和BFS(广度优先搜索)进行遍历。所以,像遍历一个简单的图一样,将访问过的结点标记一下即可。
爬虫的基本思路如下:
根据URL获取相应页面的HTML代码
利用正则匹配或则JSoup等库解析HTML代码,提取须要的内容
将获取的内容持久化到数据库中
处理好英文字符的编码问题,可以采用多线程提升效率
爬虫基本原理
更笼统意义上的爬虫着重于若果在大量的URL中找寻出高质量的资源,如何在有限的时间内访问更多页面等等。网络爬虫的基本工作流程如下:
首先选定一部分悉心选购的种子URL;
将这种URL装入待抓取URL队列;
从待抓取URL队列中取出待抓取的URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
分析已抓取URL对应的网页,分析页面里包含的其他URL,并且将URL装入待抓取URL队列,从而步入下一个循环。
有几个概念,一个是发http请求,一个是正则匹配你感兴趣的链接,一个是多线程,另外还有两个队列。
爬虫难点1支路
网络爬虫有时候会深陷循环或则支路中,比如从页面A,A链接到页面B,B链接到页面C,页面C又会链接到页面A。这样就深陷到支路中。
环路影响:
消耗网路带宽,无法获取其他页面
对Web服务器也是负担,可能击垮该站点,可能制止正常用户访问该站点
即使没有性能影响,但获取大量重复页面也造成数据冗余
解决方案:
简单限定爬虫的最大循环次数网页如何防止爬虫,对于某web站点访问超过一定阀值就跳出,避免无限循环
保存一个已访问url列表,记录页面是否被访问过的技术
1、二叉树和散列表,快速判断某个url是否访问过
2、存在位图
就是newint[length],然后把第几个数置为1,表示早已访问过了。可不可以再优化,int是32位,32位可以表示32个数字。HashCode会存在冲突的情况,
两个URL映射到同一个存在位上,冲突的后果是某个页面被忽视(这比死循环的恶作用小)
3、保存检测
一定要及时把已访问的URL列表保存到硬碟上,防止爬虫崩溃,内存里的数据会遗失
4、集群,分而治之
多台机器一起爬虫,可以按照URL估算HashCode,然后按照HashCode映射到相应机器的id(第0台、第1台、第2台等等)
难点2URL别称
有些URL名称不一样,但是指向同一个资源。
URl1URL2什么时候是别称
默认端口是80
%7F与~相同
%7F与~相同
服务器是大小写无关
默认页面为
ip和域名相同
难点3动态虚拟空间
比如月历程序,它会生成一个指向下一个月的链接,真正的用户是不会不停地恳求下个月的链接的。但是不了解这种内容特点的爬虫蜘蛛可能会不断向那些资源发出无穷的恳求。
抓取策略
一般策略是深度优先或则广度优先。有些技术能促使爬虫蜘蛛有更好的表现
广度优先的爬行,避免深度优先深陷某个站点的支路中,无法访问其他站点。
限制访问次数,限定一段时间内机器人可以从一个web站点获取的页面数目。
内容指纹,根据页面的内容估算出一个校验和,但是动态的内容(日期,评论数量)会妨碍重复测量
维护黑名单
人工监视,特殊情况发出电邮通知
动态变化,根据当前热点新闻等等
规范化URL,把一些转义字符、ip与域名之类的统一
限制URL大小,环路可能会促使URL宽度降低,比如/,/folder/网页如何防止爬虫,/folder/folder/……
Python爬虫能做哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2020-05-12 08:03
1251人阅读|16次下载
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料。老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用,爬虫的本质 是借助程序手动的从网路获取信
老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用python爬虫有啥用,爬虫的本质 是借助程序手动的从网路获取信息,爬虫技术也是大数据和云估算的基础。 Python 是一门特别适宜开发网路爬虫的编程语言,相比于其他静态编程语 言,Python 抓取网页文档的插口更简约;相比于其他动态脚本语言,Python 的 urllib2 包提供了较为完整的访问网页文档的 API。此外,python 中有优秀的第 三方包可以高效实现网页抓取,并可用极短的代码完成网页的标签过滤功能。 Python 爬虫构架组成:1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取 的 url 给网页下载器; 2. 网页下载器: 爬取 url 对应的网页, 存储成字符串, 传献给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管 理器。 Python 爬虫工作原理:老男孩 IT 教育,只培养技术精英Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URLpython爬虫有啥用,通过 调度器进行传递给下载器,下载 URL 内容,并通过调度器传送给解析器,解析 URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值 信息的过程。 Python 爬虫常用框架有: grab:网络爬虫框架; scrapy:网络爬虫框架,不支持 Python3; pyspider:一个强悍的爬虫系统; cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源, 并围绕它完善的对象。 demiurge:基于 PyQuery 的爬虫微框架。 Python 是一门特别适宜开发网路爬虫的编程语言,提供了如 urllib、re、 json、pyquery 等模块,同时又有很多成形框架,如 Scrapy 框架、PySpider 爬老男孩 IT 教育,只培养技术精英虫系统等,是网路爬虫首选编程语言! 查看全部
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料
1251人阅读|16次下载
Python爬虫能做哪些?_计算机软件及应用_IT/计算机_专业资料。老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用,爬虫的本质 是借助程序手动的从网路获取信
老男孩 IT 教育,只培养技术精英Python 爬虫是哪些?小到从网路上获取数据,大到搜索引擎,都能看到爬虫的应用python爬虫有啥用,爬虫的本质 是借助程序手动的从网路获取信息,爬虫技术也是大数据和云估算的基础。 Python 是一门特别适宜开发网路爬虫的编程语言,相比于其他静态编程语 言,Python 抓取网页文档的插口更简约;相比于其他动态脚本语言,Python 的 urllib2 包提供了较为完整的访问网页文档的 API。此外,python 中有优秀的第 三方包可以高效实现网页抓取,并可用极短的代码完成网页的标签过滤功能。 Python 爬虫构架组成:1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取 的 url 给网页下载器; 2. 网页下载器: 爬取 url 对应的网页, 存储成字符串, 传献给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管 理器。 Python 爬虫工作原理:老男孩 IT 教育,只培养技术精英Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URLpython爬虫有啥用,通过 调度器进行传递给下载器,下载 URL 内容,并通过调度器传送给解析器,解析 URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值 信息的过程。 Python 爬虫常用框架有: grab:网络爬虫框架; scrapy:网络爬虫框架,不支持 Python3; pyspider:一个强悍的爬虫系统; cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源, 并围绕它完善的对象。 demiurge:基于 PyQuery 的爬虫微框架。 Python 是一门特别适宜开发网路爬虫的编程语言,提供了如 urllib、re、 json、pyquery 等模块,同时又有很多成形框架,如 Scrapy 框架、PySpider 爬老男孩 IT 教育,只培养技术精英虫系统等,是网路爬虫首选编程语言!

