
seq搜索引擎优化至少包括那几步?
seq搜索引擎优化至少包括那几步?(面向opendomain的聊天机器人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-18 19:12
面向开放领域的聊天机器人在学术界和工业界都是一个具有挑战性的话题。目前有两种典型的方法:一种是基于检索的模型,另一种是基于Seq2Seq的生成模型。前者以可控的答案回应,但无法处理长尾问题,而后者无法保证一致性和合理性。
本期推荐的纸质笔记来自PaperWeekly社区用户@britin。本文结合检索模型和生成模型各自的优点,提出了一种新的融合模型——AliMe Chat。
阿里小米首先使用检索模型从QA知识库中寻找候选答案集合,然后使用attention-focused Seq2Seq模型对候选答案进行排序。如果第一个候选的分数超过某个阈值,则将其作为最终答案输出,否则使用生成模型生成答案。
作者简介:英国人,中国科学院物理学硕士,研究兴趣为自然语言处理和计算机视觉。
■纸| AliMe Chat:基于序列到排序和重新排名的聊天机器人引擎
■ 链接 |
■ 作者 | 英国人
论文动机
目前,商业聊天机器人正在大量涌现。这种帮助用户回答问题的自然语言对话方式比传统死板的用户界面更加友好。通常Chatbot由两部分组成:IR模块和生成模块。针对用户的问题,IR模块从QA知识库中检索对应的答案,生成模块使用预先训练好的Seq2Seq模型生成最终答案。
然而,现有系统的问题在于,对于一些较长的问题或复杂的问题,在 QA 知识库中无法检索到匹配项,并且生成模块经常生成不匹配或无意义的答案。
本文给出的方法聚合了IR和生成模块,并使用Seq2Seq模型对搜索结果进行评估,从而达到优化效果。
型号介绍
整个方案如图所示:
首先使用IR模型从知识库中检索k个候选QA对,然后使用rerank模型的评分机制计算每个候选答案与问题的匹配程度。如果得分最高的大于预设阈值,则将其作为答案,如果小于阈值,则由生成模型生成答案。
整个系统是从单词层面来分析的。
1. QA 知识库
本文从在线直播用户服务日志中提取QA对作为QA知识库。过滤掉不收录相关关键词的QA,最终得到9,164834个问答对。
2. 红外模块
使用倒排索引法将每个词推断为收录该词的一组问题,并索引这些词的同义词,然后使用BM25算法计算搜索到的问题和输入问题的相似度,取最相似的答案题。
3. 生成模型
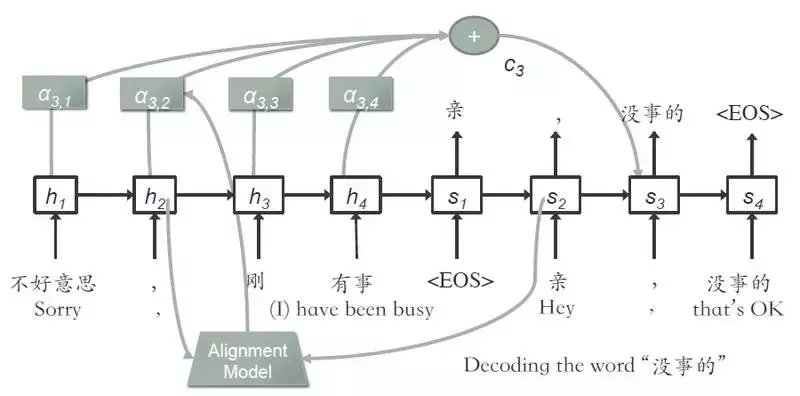
生成模型是一个细心的seq2seq结构,如图:
GRU 用于从问题中生成答案并计算生成单词的概率:
添加上下文向量,由图中的α得到。α 表示当前步骤的输入词与上一步生成的词的匹配度,由对齐模型计算得到。
需要注意的是,当每个QA的长度不等时,使用bucketing和padding机制。另外,使用softmax对词汇表中的单词进行随机采样,而不是使用整个词汇表,从而加快了训练过程。波束搜索解码器仍然用于一次维护前 k 个输出,而不是一次贪婪地搜索一个输出。
4.重新排名模块
使用的模型与上述相同。根据输入的问题对候选答案进行评分,以平均概率作为评分函数:
实验结果
本文对结果进行了详细的评估,首先评估rerank模块的平均概率的结果。然后,对IR、生成、IR+rerank、IR+rerank+生成的不同组合的系统进行性能评估。并对系统和基线聊天机器人进行了在线 A/B 测试。最后比较了这个系统和已经上架的Chatbot的区别。
不同重排模型的效果:
不同模块组合的结果:
与基线比较的结果:
文章评价
本文提出了一个细心的 Seq2Seq 模型,将 IR 和生成模块结合起来,对原创结果进行重新排序和优化。阿里已将此纳入阿里小米的商业用途。
整个系统比较简单,满足商业需求。但由于功能设计过于简单,不排除系统被数据堆砌。毕竟阿里有大量的真实用户数据,所以算法的价值还是比较一般的。如果没有合适的数据,可能很难达到预期的结果。 查看全部
seq搜索引擎优化至少包括那几步?(面向opendomain的聊天机器人)
面向开放领域的聊天机器人在学术界和工业界都是一个具有挑战性的话题。目前有两种典型的方法:一种是基于检索的模型,另一种是基于Seq2Seq的生成模型。前者以可控的答案回应,但无法处理长尾问题,而后者无法保证一致性和合理性。
本期推荐的纸质笔记来自PaperWeekly社区用户@britin。本文结合检索模型和生成模型各自的优点,提出了一种新的融合模型——AliMe Chat。
阿里小米首先使用检索模型从QA知识库中寻找候选答案集合,然后使用attention-focused Seq2Seq模型对候选答案进行排序。如果第一个候选的分数超过某个阈值,则将其作为最终答案输出,否则使用生成模型生成答案。
作者简介:英国人,中国科学院物理学硕士,研究兴趣为自然语言处理和计算机视觉。
■纸| AliMe Chat:基于序列到排序和重新排名的聊天机器人引擎
■ 链接 |
■ 作者 | 英国人
论文动机
目前,商业聊天机器人正在大量涌现。这种帮助用户回答问题的自然语言对话方式比传统死板的用户界面更加友好。通常Chatbot由两部分组成:IR模块和生成模块。针对用户的问题,IR模块从QA知识库中检索对应的答案,生成模块使用预先训练好的Seq2Seq模型生成最终答案。
然而,现有系统的问题在于,对于一些较长的问题或复杂的问题,在 QA 知识库中无法检索到匹配项,并且生成模块经常生成不匹配或无意义的答案。
本文给出的方法聚合了IR和生成模块,并使用Seq2Seq模型对搜索结果进行评估,从而达到优化效果。
型号介绍
整个方案如图所示:

首先使用IR模型从知识库中检索k个候选QA对,然后使用rerank模型的评分机制计算每个候选答案与问题的匹配程度。如果得分最高的大于预设阈值,则将其作为答案,如果小于阈值,则由生成模型生成答案。
整个系统是从单词层面来分析的。
1. QA 知识库
本文从在线直播用户服务日志中提取QA对作为QA知识库。过滤掉不收录相关关键词的QA,最终得到9,164834个问答对。
2. 红外模块
使用倒排索引法将每个词推断为收录该词的一组问题,并索引这些词的同义词,然后使用BM25算法计算搜索到的问题和输入问题的相似度,取最相似的答案题。
3. 生成模型
生成模型是一个细心的seq2seq结构,如图:
GRU 用于从问题中生成答案并计算生成单词的概率:
添加上下文向量,由图中的α得到。α 表示当前步骤的输入词与上一步生成的词的匹配度,由对齐模型计算得到。
需要注意的是,当每个QA的长度不等时,使用bucketing和padding机制。另外,使用softmax对词汇表中的单词进行随机采样,而不是使用整个词汇表,从而加快了训练过程。波束搜索解码器仍然用于一次维护前 k 个输出,而不是一次贪婪地搜索一个输出。
4.重新排名模块
使用的模型与上述相同。根据输入的问题对候选答案进行评分,以平均概率作为评分函数:

实验结果
本文对结果进行了详细的评估,首先评估rerank模块的平均概率的结果。然后,对IR、生成、IR+rerank、IR+rerank+生成的不同组合的系统进行性能评估。并对系统和基线聊天机器人进行了在线 A/B 测试。最后比较了这个系统和已经上架的Chatbot的区别。
不同重排模型的效果:

不同模块组合的结果:

与基线比较的结果:

文章评价
本文提出了一个细心的 Seq2Seq 模型,将 IR 和生成模块结合起来,对原创结果进行重新排序和优化。阿里已将此纳入阿里小米的商业用途。
整个系统比较简单,满足商业需求。但由于功能设计过于简单,不排除系统被数据堆砌。毕竟阿里有大量的真实用户数据,所以算法的价值还是比较一般的。如果没有合适的数据,可能很难达到预期的结果。
seq搜索引擎优化至少包括那几步?(搜索引擎扩展插件、网页版免安装使用引擎的应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-18 15:17
如果您发现在搜索引擎之间来回切换很麻烦,虽然主流浏览器都支持自行添加搜索引擎并在网址栏或专用搜索栏中搜索,但效果并不如您所愿。
不过也有跨浏览器的,内置了几十个我们常用的搜索引擎(包括搜索词、购物、娱乐等),以及在不同浏览器之间导出和导入自定义搜索引擎数据的方法。
并且有浏览器扩展插件和网页版免安装两种形式。但是您需要使用扩展程序才能轻松使用连续点击搜索的功能。
看看其内置引擎收录的现状:
中文的中英文混搭部分
除了以上语言通用的内容,Big Search还提供(可能只是一)中文用户的内容。还在添加中~
可以看到,由于Github和Stack Overflow网站都是收录,这个东西自然是在Github上开源的:
谈谈内部使用的技术
50多个内置引擎,以及为用户添加的自定义私有引擎功能,都是通过JS解析JSON数据,然后绘制DOM节点,点击按钮后发送GET和POST请求来实现的。简单的 JSON 引擎数据,例如:
{
"百度": "https://www.baidu.com/s?wd={0}",
"Google": "https://www.google.com/search?q={0}",
"Yahoo Search": "https://search.yahoo.com/search?q={0}"
}
上面的String引擎只支持GET,使用POST方法的引擎必须换成完整的JSON Object形式来描述一个引擎,比如:
"yahoo": {
"dname": "Yahoo Search",
"addr": "https://search.yahoo.com",
"action": "https://search.yahoo.com/search",
"kw_key": "q"
}
如果是POST方法,添加“method”:“post”。
简而言之,任何引擎都可以用上述方式来描述。其他的描述方式,如Open Search、Firefox profile等,不如本工具提供的描述全面。详情请查看源代码页的说明:
因此,安装浏览器扩展后,使用此工具比直接使用网址栏或搜索栏更主动 查看全部
seq搜索引擎优化至少包括那几步?(搜索引擎扩展插件、网页版免安装使用引擎的应用方法)
如果您发现在搜索引擎之间来回切换很麻烦,虽然主流浏览器都支持自行添加搜索引擎并在网址栏或专用搜索栏中搜索,但效果并不如您所愿。
不过也有跨浏览器的,内置了几十个我们常用的搜索引擎(包括搜索词、购物、娱乐等),以及在不同浏览器之间导出和导入自定义搜索引擎数据的方法。
并且有浏览器扩展插件和网页版免安装两种形式。但是您需要使用扩展程序才能轻松使用连续点击搜索的功能。
看看其内置引擎收录的现状:
中文的中英文混搭部分
除了以上语言通用的内容,Big Search还提供(可能只是一)中文用户的内容。还在添加中~
可以看到,由于Github和Stack Overflow网站都是收录,这个东西自然是在Github上开源的:
谈谈内部使用的技术
50多个内置引擎,以及为用户添加的自定义私有引擎功能,都是通过JS解析JSON数据,然后绘制DOM节点,点击按钮后发送GET和POST请求来实现的。简单的 JSON 引擎数据,例如:
{
"百度": "https://www.baidu.com/s?wd={0}",
"Google": "https://www.google.com/search?q={0}",
"Yahoo Search": "https://search.yahoo.com/search?q={0}"
}
上面的String引擎只支持GET,使用POST方法的引擎必须换成完整的JSON Object形式来描述一个引擎,比如:
"yahoo": {
"dname": "Yahoo Search",
"addr": "https://search.yahoo.com",
"action": "https://search.yahoo.com/search",
"kw_key": "q"
}
如果是POST方法,添加“method”:“post”。
简而言之,任何引擎都可以用上述方式来描述。其他的描述方式,如Open Search、Firefox profile等,不如本工具提供的描述全面。详情请查看源代码页的说明:
因此,安装浏览器扩展后,使用此工具比直接使用网址栏或搜索栏更主动
seq搜索引擎优化至少包括那几步?(JSP众筹管理系统.5开发java语言设计系统源码特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-16 01:19
一、源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp 查看全部
seq搜索引擎优化至少包括那几步?(JSP众筹管理系统.5开发java语言设计系统源码特点)
一、源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp
seq搜索引擎优化至少包括那几步?(企业seq搜索引擎优化至少包括那几步?搜索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-15 18:04
seq搜索引擎优化至少包括那几步?seq是在企业内的搜索引擎优化,所以其优化方向主要是关键字优化。
一、写关键字:企业可以通过网站管理软件如开发工具、站长平台建设系统及国内最大的搜索引擎seo优化平台谷歌站长平台去注册和学习seo优化相关知识,掌握最新的市场发展信息及市场动态,进行关键字的撰写,撰写出最大品牌最想关注的关键字,并尽量往网站首页或其他重要导航进行投放。
二、更新内容:1.权重高的关键字可以让seo站成为该关键字搜索引擎优化的排名第一名。2.不要为了数量而使文章有亮点,最主要的是真实、有趣、有用,同时多观察别人对于关键字优化的套路。3.通过大数据分析每篇文章对优化有什么作用,并将成功的套路总结出来,可以使用关键字分析工具如wordwords,siteapp这样专业的网站优化工具,进行实时监控。
三、更新评论:评论对于网站优化也是非常重要的,多的评论能为网站增加很多权重。通过seo评论工具发掘用户和网站共同爱好,然后每个网站建设好之后,就可以收集大量的评论。
四、seo快速追踪:除了seo投入之外,更多的就是对于竞争对手的分析。分析对手的评论,去除对于网站带来伤害的评论,提高网站的安全性,通过seo快速追踪工具建立一份网站评论与网站流量追踪表,这样我们就知道了哪些内容可以为网站优化带来加分。
五、关键字之外,还需要综合考虑:1.页面上布局关键字的时候,要注意将一些不相关的字去掉,重要的是不要影响到主页的排名。2.在网站中要展示优化的策略、步骤和方法,以及网站上的每个内容和功能使用的位置。
六、为网站优化撰写内容:1.尽量把优化的内容多呈现在网站中,哪怕写的字数不多。2.在写文章的时候应该将产品、服务、解决方案的细节都清楚明白的写出来,这样能增加网站的搜索引擎友好度。3.要善于分析竞争对手的网站首页是怎么做的,哪里你也可以通过自己内容包装成有价值的同行。 查看全部
seq搜索引擎优化至少包括那几步?(企业seq搜索引擎优化至少包括那几步?搜索)
seq搜索引擎优化至少包括那几步?seq是在企业内的搜索引擎优化,所以其优化方向主要是关键字优化。
一、写关键字:企业可以通过网站管理软件如开发工具、站长平台建设系统及国内最大的搜索引擎seo优化平台谷歌站长平台去注册和学习seo优化相关知识,掌握最新的市场发展信息及市场动态,进行关键字的撰写,撰写出最大品牌最想关注的关键字,并尽量往网站首页或其他重要导航进行投放。
二、更新内容:1.权重高的关键字可以让seo站成为该关键字搜索引擎优化的排名第一名。2.不要为了数量而使文章有亮点,最主要的是真实、有趣、有用,同时多观察别人对于关键字优化的套路。3.通过大数据分析每篇文章对优化有什么作用,并将成功的套路总结出来,可以使用关键字分析工具如wordwords,siteapp这样专业的网站优化工具,进行实时监控。
三、更新评论:评论对于网站优化也是非常重要的,多的评论能为网站增加很多权重。通过seo评论工具发掘用户和网站共同爱好,然后每个网站建设好之后,就可以收集大量的评论。
四、seo快速追踪:除了seo投入之外,更多的就是对于竞争对手的分析。分析对手的评论,去除对于网站带来伤害的评论,提高网站的安全性,通过seo快速追踪工具建立一份网站评论与网站流量追踪表,这样我们就知道了哪些内容可以为网站优化带来加分。
五、关键字之外,还需要综合考虑:1.页面上布局关键字的时候,要注意将一些不相关的字去掉,重要的是不要影响到主页的排名。2.在网站中要展示优化的策略、步骤和方法,以及网站上的每个内容和功能使用的位置。
六、为网站优化撰写内容:1.尽量把优化的内容多呈现在网站中,哪怕写的字数不多。2.在写文章的时候应该将产品、服务、解决方案的细节都清楚明白的写出来,这样能增加网站的搜索引擎友好度。3.要善于分析竞争对手的网站首页是怎么做的,哪里你也可以通过自己内容包装成有价值的同行。
seq搜索引擎优化至少包括那几步?( 站长们做seo优化时间久了都有各自的优化原则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-15 10:10
站长们做seo优化时间久了都有各自的优化原则)
站长做seo优化已经很久了,有自己的优化原则。即使按照《百度搜索引擎优化指南》,也会有不合理的seo优化细节。作者可以随意向大家透露一些秘密。搜索引擎优化
其实对于网站优化来说,页面优化还是比较简单的。由于搜索引擎算法技术的进步,它在判断网页的相关性方面越来越好。页面优化所涉及的技术细节不需要详尽无遗。,而且在SEO越来越崇尚平衡和自然的前提下,页面优化做的越细致,越容易涉及过度优化。因此,对于页面优化,只需在页面的几个核心位置添加关键词即可,比如标题、H标签等明显的地方。
分析:对于Meta标签,主要有3个地方:title、keywords、description。如果您不添加其余的元标记,那也没关系。就重要性而言,标题在页面优化中绝对占据非常重要的位置。关于标题的写作,从SEO的角度来说,尽量不要积累太多关键词。如果是长标题,可以收录关键词1-2次,关键词不要靠得太近。比如Q猪博客的标题是同向网站建设-SEO优化排名,如果你在百度上搜索“同向网站优化排名”,你会发现Q猪博客仍然是第一位的。
关键词关键词标签,对于页面优化来说,没有以前那么重要了,甚至很多SEO界大神都说关键词标签没用,不需要也没关系,但是Q猪还是相信该页面优化正在进行中。, 仔细写好关键词标签,即使搜索引擎没有考虑关键词,至少关键词在页面的排名因素中还有提醒搜索引擎的功能。
描述 描述标签。在搜索引擎中搜索关键词时,如果描述标签中收录对应的关键词,搜索引擎会用红色字体标记,如果描述标签写得好,可以改善页面点击率。
分析:正文的写作最重要的因素是自然的写作。如何收录关键词?可以参考高考作文。把关键词想成一个标题,然后自然地围绕关键词写。不要只是将需要优化的关键词直接插入到文章中。比如文章是一篇介绍网站构建文章的文章,但是中间出现了美类关键词,这个肯定不好,自然写文章@ > , 最大的特点之一就是可读性强。
文章的内容页面优化的另一个重要因素是,在文章中,尽量使用关键词的同义词和同义词。比如文章还是引入了网站的构造。在写内容的时候,有些地方,在谈到网站的构建时,可以使用网站生产、网站设计等相关词组。
分析:H标签,主要包括H1、H2标签,H1代表标题,关键词优化。H2是副标题。基本上,文章中很少使用H3之后的标签。按照这个意思,最重要的关键词放在H1标签中,与关键词相关的词组放在H2标签中,然后依次推回。
其实对于网页内容页面的优化,H1、H2标签的作用正在慢慢变弱,但是对于一般的页面写作来说,文章的标题应该出现在H1标签中副标题出现在 H2 标签上。
由于搜索引擎很难读取图片,一般写作中,需要对添加的图片进行ALT标签标注。当然,对于图片的理解,周围的文字也起到一定的作用。比如Q Pig在讲网站页面优化中ALT标签的使用。如果现在插入图片,即使代码中没有解析图片,搜索引擎也会认为这是使用ALT标签的图片。
当然,关键词中也可以放H/ALT标签,作为文章内容的重点,但在这些标签中,关键词不宜过多,会造成堆积的怀疑。一般来说,标签中收录2-3个词关键词就足够了。其他的,比如粗体、斜体等,对关键词也有一定的重视,但是在页面的书写中,最重要的是要自然。如果觉得文中某个词需要强调,可以加粗加粗来强调,不必关键词,只需要对文章有帮助的就行。
分析:关键词的排版中,最重要的位置是开头,尤其是第一段开头的50-150字,需要收录一次关键词,然后是2- 3 出现在文本中间关键词或类似词,文章的结尾,也包括关键词一次。
在关键词的布局中,还有一个概念,关键词密度。前几年,很多SEO前辈都会建议页面的关键词密度应该保持在2-9%到3-8%之间。其实随着搜索引擎算法的更新,关键词的密度已经不那么重要了。搜索引擎可以通过语义分析轻松理解文章的中心思想。
如果文章按照一般命题作文写,关键词自然会出现在文章的首段、尾段和中间,一共出现4-5次。没必要多考虑关键词的密度。
分析:精简代码的主要目的是减少搜索引擎分析网站页面时出现的噪音。对于蜘蛛来说,进入页面时他们最想抓取的是页面的正文。对于那些结构化代码、注释等,都是噪音。
所以,要精简代码,首先要把Javascript、外部代码调用、样式表写成DIV+CSS,也就是外部代码调用,代码中的注释要尽量少。代码简化的核心思想是,如果可以使用外部文件调用,就使用外部文件调用。如果不需要出现,尽量不要出现。在正文中,尽量专注于文本,并使用少量 CSS 代码。
搜索引擎索引网站页面时,经常会在页面文件大小的某个值后截断,而不会出现。如果页面不精简代码,很多flash效果、javascript效果、样式表、图片、视频等,都收录在文件中,你经常会看到很多网站页面带有文件大小超过 300k,如果搜索引擎在第 k 行之后,索引将不再被索引,接下来的 200k 文件将消失。
页面优化的核心就是这几个地方,就是突出重点。要表达的关键内容,关键词,收录在H标签和ALT标签中,在文章的开头、正文和结尾收录关键词的1-2次,以及在页面中保留少量代码,其余部分尝试使用外部文件。当然,页面优化最重要的是写好标题。
分享:模板无忧:关键词Density VS Stacking 关键词 确认关键词后怎么办?它必须适当地出现在 网站 中。关键词的出现频率会影响网站关键词被搜索引擎的排名。当我们了解关键词密度和堆叠关键词时,我们 查看全部
seq搜索引擎优化至少包括那几步?(
站长们做seo优化时间久了都有各自的优化原则)

站长做seo优化已经很久了,有自己的优化原则。即使按照《百度搜索引擎优化指南》,也会有不合理的seo优化细节。作者可以随意向大家透露一些秘密。搜索引擎优化
其实对于网站优化来说,页面优化还是比较简单的。由于搜索引擎算法技术的进步,它在判断网页的相关性方面越来越好。页面优化所涉及的技术细节不需要详尽无遗。,而且在SEO越来越崇尚平衡和自然的前提下,页面优化做的越细致,越容易涉及过度优化。因此,对于页面优化,只需在页面的几个核心位置添加关键词即可,比如标题、H标签等明显的地方。
分析:对于Meta标签,主要有3个地方:title、keywords、description。如果您不添加其余的元标记,那也没关系。就重要性而言,标题在页面优化中绝对占据非常重要的位置。关于标题的写作,从SEO的角度来说,尽量不要积累太多关键词。如果是长标题,可以收录关键词1-2次,关键词不要靠得太近。比如Q猪博客的标题是同向网站建设-SEO优化排名,如果你在百度上搜索“同向网站优化排名”,你会发现Q猪博客仍然是第一位的。
关键词关键词标签,对于页面优化来说,没有以前那么重要了,甚至很多SEO界大神都说关键词标签没用,不需要也没关系,但是Q猪还是相信该页面优化正在进行中。, 仔细写好关键词标签,即使搜索引擎没有考虑关键词,至少关键词在页面的排名因素中还有提醒搜索引擎的功能。
描述 描述标签。在搜索引擎中搜索关键词时,如果描述标签中收录对应的关键词,搜索引擎会用红色字体标记,如果描述标签写得好,可以改善页面点击率。
分析:正文的写作最重要的因素是自然的写作。如何收录关键词?可以参考高考作文。把关键词想成一个标题,然后自然地围绕关键词写。不要只是将需要优化的关键词直接插入到文章中。比如文章是一篇介绍网站构建文章的文章,但是中间出现了美类关键词,这个肯定不好,自然写文章@ > , 最大的特点之一就是可读性强。
文章的内容页面优化的另一个重要因素是,在文章中,尽量使用关键词的同义词和同义词。比如文章还是引入了网站的构造。在写内容的时候,有些地方,在谈到网站的构建时,可以使用网站生产、网站设计等相关词组。
分析:H标签,主要包括H1、H2标签,H1代表标题,关键词优化。H2是副标题。基本上,文章中很少使用H3之后的标签。按照这个意思,最重要的关键词放在H1标签中,与关键词相关的词组放在H2标签中,然后依次推回。
其实对于网页内容页面的优化,H1、H2标签的作用正在慢慢变弱,但是对于一般的页面写作来说,文章的标题应该出现在H1标签中副标题出现在 H2 标签上。
由于搜索引擎很难读取图片,一般写作中,需要对添加的图片进行ALT标签标注。当然,对于图片的理解,周围的文字也起到一定的作用。比如Q Pig在讲网站页面优化中ALT标签的使用。如果现在插入图片,即使代码中没有解析图片,搜索引擎也会认为这是使用ALT标签的图片。
当然,关键词中也可以放H/ALT标签,作为文章内容的重点,但在这些标签中,关键词不宜过多,会造成堆积的怀疑。一般来说,标签中收录2-3个词关键词就足够了。其他的,比如粗体、斜体等,对关键词也有一定的重视,但是在页面的书写中,最重要的是要自然。如果觉得文中某个词需要强调,可以加粗加粗来强调,不必关键词,只需要对文章有帮助的就行。
分析:关键词的排版中,最重要的位置是开头,尤其是第一段开头的50-150字,需要收录一次关键词,然后是2- 3 出现在文本中间关键词或类似词,文章的结尾,也包括关键词一次。
在关键词的布局中,还有一个概念,关键词密度。前几年,很多SEO前辈都会建议页面的关键词密度应该保持在2-9%到3-8%之间。其实随着搜索引擎算法的更新,关键词的密度已经不那么重要了。搜索引擎可以通过语义分析轻松理解文章的中心思想。
如果文章按照一般命题作文写,关键词自然会出现在文章的首段、尾段和中间,一共出现4-5次。没必要多考虑关键词的密度。
分析:精简代码的主要目的是减少搜索引擎分析网站页面时出现的噪音。对于蜘蛛来说,进入页面时他们最想抓取的是页面的正文。对于那些结构化代码、注释等,都是噪音。
所以,要精简代码,首先要把Javascript、外部代码调用、样式表写成DIV+CSS,也就是外部代码调用,代码中的注释要尽量少。代码简化的核心思想是,如果可以使用外部文件调用,就使用外部文件调用。如果不需要出现,尽量不要出现。在正文中,尽量专注于文本,并使用少量 CSS 代码。
搜索引擎索引网站页面时,经常会在页面文件大小的某个值后截断,而不会出现。如果页面不精简代码,很多flash效果、javascript效果、样式表、图片、视频等,都收录在文件中,你经常会看到很多网站页面带有文件大小超过 300k,如果搜索引擎在第 k 行之后,索引将不再被索引,接下来的 200k 文件将消失。
页面优化的核心就是这几个地方,就是突出重点。要表达的关键内容,关键词,收录在H标签和ALT标签中,在文章的开头、正文和结尾收录关键词的1-2次,以及在页面中保留少量代码,其余部分尝试使用外部文件。当然,页面优化最重要的是写好标题。
分享:模板无忧:关键词Density VS Stacking 关键词 确认关键词后怎么办?它必须适当地出现在 网站 中。关键词的出现频率会影响网站关键词被搜索引擎的排名。当我们了解关键词密度和堆叠关键词时,我们
seq搜索引擎优化至少包括那几步?(不要暴增建造外链不然简单激起一些做弊算法,查找引擎以为有弊嫌疑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-15 10:06
②、实际用户多次查看
③、用户实际上说话的频率更高
④ 真实用户重复观看
⑤、用户实际点击的页面内容
5、用户推荐
用户推荐对于提高页面质量也非常有用。比如真实用户的转发和分享,点赞/点赞插件,采集夹,也意味着用户在认为文章不错的时候会保存页面。
6、域权重和得分
域名权重越高,网站关键词的排名就越高。我想大家都知道,在搜索关键词的时候,大而高权重的网站基本上都列在首页了,所以域名比较重要。Bump 也在搜索引擎的排名和排序算法的边缘。
7、外部链接引用
虽然百度的外链算法这几年有所减弱,但优质的外链还是有的。适当添加外链也可以增加页面的权重。另外,请善用好友链接。由于网站的大部分权重都属于首页,所以网站之间的好友链接交流也可以适当增加外链的引荐。另外注意不要建外链,或者干脆挑起一些作弊算法,搜索引擎认为有作弊嫌疑。
二、搜索引擎对新页面的排序方式和后面触发的算法不一样!
搜索引擎对新页面的排序方式和后面触发的算法不一样,这对于大部分没有深入理解的SEOer来说可能是不知道的。在一个新生成的链接中,前期百度搜索引擎通过相关性关键词密度、域名权重、文章原创性等因素决定百度搜索的排名和排名,逐渐被用户改变页面行为、用户交互、用户推荐总是决定页面排名,新页面解析排名的关键词密度和文章关键词密度的原创性会逐渐减弱。这也得益于百度近两年在关键词密度上的作用。弱化,多关注用户体验的原因,算了。看完以上几点常识,让我们都清楚搜索引擎如何判断页面质量,如何对页面关键词进行排名,以及如何优化网站关键词对百度首页的排名?给我们解释一下,网络营销人员网站搜索引擎优化技术如何优化网站关键词在百度首页的排名!
三、提高关键词排名操作技巧
1、网站 相关性补充:关键词布局
陈词滥调的内容,但对于一些新手来说,我必须再说一遍。页面标题、关键词关键词、描述描述等tdk呈现的关键词,尤其是标题标题,必须收录中心关键词。列表页与首页的逻辑布局相同,但列表页的标题必须是列表页下文章这个类别的关键字,具有一定的索引,是一个流行词用户寻找。详情页也是一样,tdk呈现关键词,标题尽量收录关键词。文章 尽量在开头显示中心词并加粗,这样可以突出文章内容的主题。对于正文的自然内容,呈现关键词。但是,我不会傻的!
2、H1重量标签申请
网络营销告诉我们,不得随意使用 h 标签。它的作用是重申搜索引擎页面的重要内容信息。一般在title或者logo标签中使用h1,h1标签填充需要优化的中心词或者品牌。详情页的标题使用了h2标签,一小部分网站使用了h1标签,重点关注内容页的标题信息。这些都是根据个人喜好而定,这些细节不做追踪。
3、 创建具有以下特征的高质量跟踪文本链接:
①. 链接属于软植入,不会影响内容的可读性,锚文本关键词与链接主题高度相关文章。
② 描述文字有引导链接,可以满足用户的其他需求。
③. 控制文章锚文本的数量,一个,不超过三四个。
④. 链接应该多样化,并不是所有的锚文本都指向首页。
4、网站 优质内容不能短
什么是优质内容?用户认为优质的内容就是满足其需求的内容。搜索引擎只能通过后台数据的用户行为来判断页面质量。
①、在页面添加用户的停留时间和粘度
上面的高端营销人员已经说过,如果你想添加一个页面停留,你可以文章能够满足用户的需求,让用户觉得这个文章对他有用。还有文章字体的数量。如果字体太少,用户就会把它们都看了一遍,停留时间不会很长。毕竟内容排版,视觉体验,内容排版注意段落正反面,字体大小控制14~16px,整体看起来规整舒服,不让用户阅读有压力。
②、在网站中添加用户访问
如上所述,高质量的锚文本链接具有引导作用,它们是根据用户阅读此文章后想阅读的内容生成的。网站元素丰富,在页面左侧或右侧,加入推荐文章、新增文章、热门文章、热议等模块添加用户点击. 如果你想要更多的用户点击,一个新颖、有吸引力的标题是必不可少的。据说一个有吸引力的标题已经成功了。其实真的是一样的,那么如何写出吸引人的标题呢?其实这还是基于我的写作经验和头脑风暴。毕竟,我可以看到一些点击率更高的 文章 他们是如何获得标题的。
③ 降低用户在页面的跳出率
其实降低用户在页面跳出率的问题我已经讲过好几次了。这里我粗略的讲一下。事实上,降低跳出率只有在需要用户的心思来降低跳出率时才能做的更细致、更细致。在这个阶段,流程优化,细节和内容掌握成功。那么,如何降低用户跳出率呢?
工艺:步骤
当用户来到网站时,访问页面的加载速度必须让用户满意。5秒前的页面打开速度更加雄心勃勃。超出这个时间值,用户肯定会间接流失,所以服务器的响应速度是基础也是很重要的工作,我们要优化打开页面的速度,提升用户体验。网页代码:众所周知,网页上的任何元素最终都会被转换成代码,被用户的浏览器下载到本地,再被浏览器转换成相应的页面。可见,网页的大小也可以通过网页代码的优化来控制,一个优化过的网页代码往往可以将网页的大小提升30%以上。因此,HTML、JS、CSS 代码的优化更为重要。关于网站的重要内容来说,还是少用为好。视频网站:我们能做的还是尽可能的减小体积,但是视频的处理方式,一般转换成flv格式,会比其他格式小一些。
过程:第二步
落地面优化:主题与落地面要一致、相关,主题内容要突出。不要炫耀行为。
流程:第三步
<p>内容/产品图片 这是支持用户是否继续阅读的关键。内容让用户不满意,产品形象模棱两可,还有什么原因让用户不去?了解自己 查看全部
seq搜索引擎优化至少包括那几步?(不要暴增建造外链不然简单激起一些做弊算法,查找引擎以为有弊嫌疑)
②、实际用户多次查看
③、用户实际上说话的频率更高
④ 真实用户重复观看
⑤、用户实际点击的页面内容
5、用户推荐
用户推荐对于提高页面质量也非常有用。比如真实用户的转发和分享,点赞/点赞插件,采集夹,也意味着用户在认为文章不错的时候会保存页面。
6、域权重和得分
域名权重越高,网站关键词的排名就越高。我想大家都知道,在搜索关键词的时候,大而高权重的网站基本上都列在首页了,所以域名比较重要。Bump 也在搜索引擎的排名和排序算法的边缘。
7、外部链接引用
虽然百度的外链算法这几年有所减弱,但优质的外链还是有的。适当添加外链也可以增加页面的权重。另外,请善用好友链接。由于网站的大部分权重都属于首页,所以网站之间的好友链接交流也可以适当增加外链的引荐。另外注意不要建外链,或者干脆挑起一些作弊算法,搜索引擎认为有作弊嫌疑。
二、搜索引擎对新页面的排序方式和后面触发的算法不一样!
搜索引擎对新页面的排序方式和后面触发的算法不一样,这对于大部分没有深入理解的SEOer来说可能是不知道的。在一个新生成的链接中,前期百度搜索引擎通过相关性关键词密度、域名权重、文章原创性等因素决定百度搜索的排名和排名,逐渐被用户改变页面行为、用户交互、用户推荐总是决定页面排名,新页面解析排名的关键词密度和文章关键词密度的原创性会逐渐减弱。这也得益于百度近两年在关键词密度上的作用。弱化,多关注用户体验的原因,算了。看完以上几点常识,让我们都清楚搜索引擎如何判断页面质量,如何对页面关键词进行排名,以及如何优化网站关键词对百度首页的排名?给我们解释一下,网络营销人员网站搜索引擎优化技术如何优化网站关键词在百度首页的排名!

三、提高关键词排名操作技巧
1、网站 相关性补充:关键词布局
陈词滥调的内容,但对于一些新手来说,我必须再说一遍。页面标题、关键词关键词、描述描述等tdk呈现的关键词,尤其是标题标题,必须收录中心关键词。列表页与首页的逻辑布局相同,但列表页的标题必须是列表页下文章这个类别的关键字,具有一定的索引,是一个流行词用户寻找。详情页也是一样,tdk呈现关键词,标题尽量收录关键词。文章 尽量在开头显示中心词并加粗,这样可以突出文章内容的主题。对于正文的自然内容,呈现关键词。但是,我不会傻的!
2、H1重量标签申请
网络营销告诉我们,不得随意使用 h 标签。它的作用是重申搜索引擎页面的重要内容信息。一般在title或者logo标签中使用h1,h1标签填充需要优化的中心词或者品牌。详情页的标题使用了h2标签,一小部分网站使用了h1标签,重点关注内容页的标题信息。这些都是根据个人喜好而定,这些细节不做追踪。
3、 创建具有以下特征的高质量跟踪文本链接:
①. 链接属于软植入,不会影响内容的可读性,锚文本关键词与链接主题高度相关文章。
② 描述文字有引导链接,可以满足用户的其他需求。
③. 控制文章锚文本的数量,一个,不超过三四个。
④. 链接应该多样化,并不是所有的锚文本都指向首页。
4、网站 优质内容不能短
什么是优质内容?用户认为优质的内容就是满足其需求的内容。搜索引擎只能通过后台数据的用户行为来判断页面质量。
①、在页面添加用户的停留时间和粘度
上面的高端营销人员已经说过,如果你想添加一个页面停留,你可以文章能够满足用户的需求,让用户觉得这个文章对他有用。还有文章字体的数量。如果字体太少,用户就会把它们都看了一遍,停留时间不会很长。毕竟内容排版,视觉体验,内容排版注意段落正反面,字体大小控制14~16px,整体看起来规整舒服,不让用户阅读有压力。
②、在网站中添加用户访问
如上所述,高质量的锚文本链接具有引导作用,它们是根据用户阅读此文章后想阅读的内容生成的。网站元素丰富,在页面左侧或右侧,加入推荐文章、新增文章、热门文章、热议等模块添加用户点击. 如果你想要更多的用户点击,一个新颖、有吸引力的标题是必不可少的。据说一个有吸引力的标题已经成功了。其实真的是一样的,那么如何写出吸引人的标题呢?其实这还是基于我的写作经验和头脑风暴。毕竟,我可以看到一些点击率更高的 文章 他们是如何获得标题的。
③ 降低用户在页面的跳出率
其实降低用户在页面跳出率的问题我已经讲过好几次了。这里我粗略的讲一下。事实上,降低跳出率只有在需要用户的心思来降低跳出率时才能做的更细致、更细致。在这个阶段,流程优化,细节和内容掌握成功。那么,如何降低用户跳出率呢?
工艺:步骤
当用户来到网站时,访问页面的加载速度必须让用户满意。5秒前的页面打开速度更加雄心勃勃。超出这个时间值,用户肯定会间接流失,所以服务器的响应速度是基础也是很重要的工作,我们要优化打开页面的速度,提升用户体验。网页代码:众所周知,网页上的任何元素最终都会被转换成代码,被用户的浏览器下载到本地,再被浏览器转换成相应的页面。可见,网页的大小也可以通过网页代码的优化来控制,一个优化过的网页代码往往可以将网页的大小提升30%以上。因此,HTML、JS、CSS 代码的优化更为重要。关于网站的重要内容来说,还是少用为好。视频网站:我们能做的还是尽可能的减小体积,但是视频的处理方式,一般转换成flv格式,会比其他格式小一些。
过程:第二步
落地面优化:主题与落地面要一致、相关,主题内容要突出。不要炫耀行为。
流程:第三步
<p>内容/产品图片 这是支持用户是否继续阅读的关键。内容让用户不满意,产品形象模棱两可,还有什么原因让用户不去?了解自己
seq搜索引擎优化至少包括那几步?(百度是如何判断网站内容是原创的呢的事?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-15 05:15
互联网鼓励原创,尤其是搜索引擎,希望向用户推荐优质的原创内容。百度站长平台lee发表了一篇文章:谈原创项目那件事。其主要目的是鼓励所有站长支持原创。那么,百度是如何判断网站的内容是原创的呢?在这里谈谈我自己的看法
注意原创的目的:
1、采集 洪水
分析:在互联网上,采集泛滥的区域主要分布在新闻、咨询、小说等领域,随着采集器现在越来越复杂,一般很难预防< @网站 被阻止。采集。
我们在做网站内容的时候,经常发现的一个问题是我们更新了一篇关于网站和原创的文章,但是过几天去百度查排名的时候,你会发现,由于网站的权重等因素,那些转载文章文章的网站排在前列。
对于大多数中小网站来说,搜索流量在总流量中占有非常重要的位置。如果原创长期存在,却得不到合适的排名和流量,站长就会失去原创的兴趣,从而降低原创的比例。
2、提升用户体验
分析:大家都知道原创文章对网站的重要性,但是原创的内容创作是一项非常困难且耗时的工作。会有市场。机会,于是市场上出现了大量的伪原创工具。原理是打乱文章的章节,尝试通过重新组合和添加关键词来替代原来的文章。成为一个新人。
这些 文章 的一个共同点是它们的可读性较差,从而导致用户体验不佳。另一方面,它们也会对搜索引擎的搜索质量产生一定的影响。
提升用户体验是一个永恒的话题。对于搜索引擎来说,虽然很多方面还不够满意,但至少他们一直在朝这个方向努力。
3、鼓励原创作者和原创内容
分析:如第一点所述,只有网站和原创坚持原创的内容被赋予适当的权重和排名。只有原创的作者才能享受。,原创带来的巨大好处,作者会坚持原创。
确定原创内容的难点:
1、冒充原创,篡改关键信息
分析:其实很多坚持原创的网站都是中小网站。但是由于蜘蛛爬行的频率和搜索引擎的重要性,他们在原创文章发表后,其他网站转载后,篡改版权,关键词文章中涉及@>等信息,冒充原创。
由于转载网站在权重方面的优势,搜索引擎蜘蛛很难判断哪个文章是哪个网站抄袭了网站。
2、使用伪原创工具让文章焕然一新,量产“原创文章”。
分析:无论如何判断文章是否为原创,由于网络上数以亿计的文章,判断的主体是由程序检查的。程序有漏洞,可以在程序中探查规则。许多伪原创工具可以利用这些工具和漏洞将文章重新组合成“原创”。
由于制造原创的工具也随着算法的变化而变化,所以在判断过程中会有一定的困难。
从百度的描述可以看出,由于工具产生的所谓“原创文章”,存在语句不一致、用户可读性差等原因。这些内容都在这段时间里。聚焦整改对象。Q Pig 提醒,如果您正在使用这些工具,请停止使用。
3、结构分化
分析:我们知道每个网站的结构是有区别的。当搜索引擎抓取内容时,它通常会进行分析。在同一个网站中,哪些内容是常见的,哪些内容是真正有价值的,然后分析这些有价值的内容,然后索引到数据库中。
但是,不同站点的结构大不相同,html标签的含义和分布也不同。因此,提取标题、作者、时间等关键信息的难度也大不相同。因此,每一个网站都需要一个合理的网站结构,简单明了,清晰明了,不仅能让搜索引擎清晰的捕捉到网站的内容,还能让用户更加流畅浏览网站的内容。
百度为鼓励原创采取的措施:
1、单独成立原创项目组
分析:百度表示,该部门将长期成立,为原创的判断提供技术、产品、运营、法律等方面的支持。
2、 原创识别“起源”算法
百度如何判断原创的内容,这是重点。
一种。首先,通过内容的相似性,将网络上所有主题相似、内容相似的文章,无论是原创还是采集,都归为一组。
湾 然后,根据作者、发布时间、链接方向、用户评论、作者和网站历史原创情况、转发轨迹等因素综合考虑原创的内容。
C。最后通过价值分析系统,判断原创内容的价值,进而适当引导最终的排名顺序。
3、原创星火项目
分析:该方案需要百度和站长共同维护互联网生态环境。站长推荐原创的内容,搜索引擎通过一定的判断后会优先处理原创的内容,共同促进生态的改善,鼓励原创,这是“原创 Spark Project”,旨在快速解决当前的严重问题。
简单来说,就是站长推荐原创的内容,然后百度用算法甚至人类来判断是否是原创。这是一个改进算法的过程,也是一个更快的实现原创发现内容的过程。
基于以上几点,要得到百度鼓励原创政策的照顾,作为站长首先要做的就是网站内部优化结构,坚持原创生产,并鼓励用户评论,确保网站的内部链接畅通无阻,并尽可能保留每个文章的发布时间。 查看全部
seq搜索引擎优化至少包括那几步?(百度是如何判断网站内容是原创的呢的事?)
互联网鼓励原创,尤其是搜索引擎,希望向用户推荐优质的原创内容。百度站长平台lee发表了一篇文章:谈原创项目那件事。其主要目的是鼓励所有站长支持原创。那么,百度是如何判断网站的内容是原创的呢?在这里谈谈我自己的看法
注意原创的目的:
1、采集 洪水
分析:在互联网上,采集泛滥的区域主要分布在新闻、咨询、小说等领域,随着采集器现在越来越复杂,一般很难预防< @网站 被阻止。采集。
我们在做网站内容的时候,经常发现的一个问题是我们更新了一篇关于网站和原创的文章,但是过几天去百度查排名的时候,你会发现,由于网站的权重等因素,那些转载文章文章的网站排在前列。
对于大多数中小网站来说,搜索流量在总流量中占有非常重要的位置。如果原创长期存在,却得不到合适的排名和流量,站长就会失去原创的兴趣,从而降低原创的比例。
2、提升用户体验
分析:大家都知道原创文章对网站的重要性,但是原创的内容创作是一项非常困难且耗时的工作。会有市场。机会,于是市场上出现了大量的伪原创工具。原理是打乱文章的章节,尝试通过重新组合和添加关键词来替代原来的文章。成为一个新人。
这些 文章 的一个共同点是它们的可读性较差,从而导致用户体验不佳。另一方面,它们也会对搜索引擎的搜索质量产生一定的影响。
提升用户体验是一个永恒的话题。对于搜索引擎来说,虽然很多方面还不够满意,但至少他们一直在朝这个方向努力。
3、鼓励原创作者和原创内容
分析:如第一点所述,只有网站和原创坚持原创的内容被赋予适当的权重和排名。只有原创的作者才能享受。,原创带来的巨大好处,作者会坚持原创。
确定原创内容的难点:
1、冒充原创,篡改关键信息
分析:其实很多坚持原创的网站都是中小网站。但是由于蜘蛛爬行的频率和搜索引擎的重要性,他们在原创文章发表后,其他网站转载后,篡改版权,关键词文章中涉及@>等信息,冒充原创。
由于转载网站在权重方面的优势,搜索引擎蜘蛛很难判断哪个文章是哪个网站抄袭了网站。
2、使用伪原创工具让文章焕然一新,量产“原创文章”。
分析:无论如何判断文章是否为原创,由于网络上数以亿计的文章,判断的主体是由程序检查的。程序有漏洞,可以在程序中探查规则。许多伪原创工具可以利用这些工具和漏洞将文章重新组合成“原创”。
由于制造原创的工具也随着算法的变化而变化,所以在判断过程中会有一定的困难。
从百度的描述可以看出,由于工具产生的所谓“原创文章”,存在语句不一致、用户可读性差等原因。这些内容都在这段时间里。聚焦整改对象。Q Pig 提醒,如果您正在使用这些工具,请停止使用。
3、结构分化
分析:我们知道每个网站的结构是有区别的。当搜索引擎抓取内容时,它通常会进行分析。在同一个网站中,哪些内容是常见的,哪些内容是真正有价值的,然后分析这些有价值的内容,然后索引到数据库中。
但是,不同站点的结构大不相同,html标签的含义和分布也不同。因此,提取标题、作者、时间等关键信息的难度也大不相同。因此,每一个网站都需要一个合理的网站结构,简单明了,清晰明了,不仅能让搜索引擎清晰的捕捉到网站的内容,还能让用户更加流畅浏览网站的内容。
百度为鼓励原创采取的措施:
1、单独成立原创项目组
分析:百度表示,该部门将长期成立,为原创的判断提供技术、产品、运营、法律等方面的支持。
2、 原创识别“起源”算法
百度如何判断原创的内容,这是重点。
一种。首先,通过内容的相似性,将网络上所有主题相似、内容相似的文章,无论是原创还是采集,都归为一组。
湾 然后,根据作者、发布时间、链接方向、用户评论、作者和网站历史原创情况、转发轨迹等因素综合考虑原创的内容。
C。最后通过价值分析系统,判断原创内容的价值,进而适当引导最终的排名顺序。
3、原创星火项目
分析:该方案需要百度和站长共同维护互联网生态环境。站长推荐原创的内容,搜索引擎通过一定的判断后会优先处理原创的内容,共同促进生态的改善,鼓励原创,这是“原创 Spark Project”,旨在快速解决当前的严重问题。
简单来说,就是站长推荐原创的内容,然后百度用算法甚至人类来判断是否是原创。这是一个改进算法的过程,也是一个更快的实现原创发现内容的过程。
基于以上几点,要得到百度鼓励原创政策的照顾,作为站长首先要做的就是网站内部优化结构,坚持原创生产,并鼓励用户评论,确保网站的内部链接畅通无阻,并尽可能保留每个文章的发布时间。
seq搜索引擎优化至少包括那几步?(广州seo优化的工作离不开多元化原则,不管是什么类型的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-14 16:00
广州seo优化的工作离不开多元化的原则。不管是什么类型的网站,都离不开一些主要的核心步骤。网站 优化只有做好这些步骤才会受到搜索引擎和用户的影响。其次是!那么,成为网站推广优化专家需要哪些步骤呢?下面我们来简单了解一下这些步骤的重要性!
1、选择目标域名
比如理解域名的作用,域名就相当于家庭的门牌号,就像快递员可以通过地址轻松找到你家一样。目前最常见的主流域名有:.com、.等。在选择域名时,如果是旧域名,所谓旧域名就是指该域名之前已经注册过,并且之前用过灰色网站,然后就取消了。这种域名经常被搜索引擎屏蔽或惩罚,对搜索引擎SEO非常不利。
2、虚拟主机的选择
虚拟主机的选择基于企业的规模和需求。小型企业和个人站长在选择虚拟主机之前通常必须考虑所选的虚拟主机。只有选择一个成熟可靠的虚拟主机,才能保证选择的虚拟主机的质量。
3、程序选择
他们都有自己的程序。比如广州爱助建设网站就有完善的自助建站系统,帮助不懂代码的客户轻松建站。
4、 标签设置
网站的三个主要标签包括:title、关键词和description。整个网页的内容都是围绕这些核心主题编写的。记得控制好字符长度,不要同时堆起关键词。
5、内容构建
内容可以说是网站的灵魂,也很受搜索引擎欢迎。好的内容是用户体验最直接的体现。如何做好网站的内容,网站的内容要定期、合理、持续更新。采集 在进行适当更改时,内容应保持吸引力和节奏感。
6、外链建设
通常,构建外链必须选择权重高、排名好、速度快的收录平台(例如行业门户网站、百度系列、自媒体平台、分类信息, 等等。)。二是建设友好联系。优质链接通过行业相关,对方网站权重不低于自己网站,收录越多越好,快照来自同一个一天就好了,首页链接一般都做好了,没有反向链接的时候,马上沟通或者删除。
7、评估竞争对手
竞争对手,也就是我们所说的同行网站,尤其是网站高权重,收录众多同行网站,我们经常评价竞争对手的网站如何布局关键词,内容怎么写,外链怎么布局等等。
8、学会使用工具
站长工具、百度统计等,利用工具统计不断分析和提升自己。
以上就是网站推广和优化步骤的重要性。真正的成功是建立在坚实的基础之上,是一点一滴的积累。广州seo优化提醒您,如果您想成为网站优化专家,您需要强大的执行力,加上毅力,相信您一定会成功! 查看全部
seq搜索引擎优化至少包括那几步?(广州seo优化的工作离不开多元化原则,不管是什么类型的网站)
广州seo优化的工作离不开多元化的原则。不管是什么类型的网站,都离不开一些主要的核心步骤。网站 优化只有做好这些步骤才会受到搜索引擎和用户的影响。其次是!那么,成为网站推广优化专家需要哪些步骤呢?下面我们来简单了解一下这些步骤的重要性!

1、选择目标域名
比如理解域名的作用,域名就相当于家庭的门牌号,就像快递员可以通过地址轻松找到你家一样。目前最常见的主流域名有:.com、.等。在选择域名时,如果是旧域名,所谓旧域名就是指该域名之前已经注册过,并且之前用过灰色网站,然后就取消了。这种域名经常被搜索引擎屏蔽或惩罚,对搜索引擎SEO非常不利。
2、虚拟主机的选择
虚拟主机的选择基于企业的规模和需求。小型企业和个人站长在选择虚拟主机之前通常必须考虑所选的虚拟主机。只有选择一个成熟可靠的虚拟主机,才能保证选择的虚拟主机的质量。
3、程序选择
他们都有自己的程序。比如广州爱助建设网站就有完善的自助建站系统,帮助不懂代码的客户轻松建站。
4、 标签设置
网站的三个主要标签包括:title、关键词和description。整个网页的内容都是围绕这些核心主题编写的。记得控制好字符长度,不要同时堆起关键词。
5、内容构建
内容可以说是网站的灵魂,也很受搜索引擎欢迎。好的内容是用户体验最直接的体现。如何做好网站的内容,网站的内容要定期、合理、持续更新。采集 在进行适当更改时,内容应保持吸引力和节奏感。
6、外链建设
通常,构建外链必须选择权重高、排名好、速度快的收录平台(例如行业门户网站、百度系列、自媒体平台、分类信息, 等等。)。二是建设友好联系。优质链接通过行业相关,对方网站权重不低于自己网站,收录越多越好,快照来自同一个一天就好了,首页链接一般都做好了,没有反向链接的时候,马上沟通或者删除。
7、评估竞争对手
竞争对手,也就是我们所说的同行网站,尤其是网站高权重,收录众多同行网站,我们经常评价竞争对手的网站如何布局关键词,内容怎么写,外链怎么布局等等。
8、学会使用工具
站长工具、百度统计等,利用工具统计不断分析和提升自己。
以上就是网站推广和优化步骤的重要性。真正的成功是建立在坚实的基础之上,是一点一滴的积累。广州seo优化提醒您,如果您想成为网站优化专家,您需要强大的执行力,加上毅力,相信您一定会成功!
seq搜索引擎优化至少包括那几步?(网站优化的前8个基础点,你了解吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-14 15:22
昨天提到了网站优化的前8个基本点。今天我们就来聊聊接下来的8点。让我们来看看!
?9. 外链、反链接、异地链接的理解:除了网站,外链指向你的网站 url,包括首页和内页,但不带NOFOLLOW标签可以被搜索引擎抓取。外链是决定你的网站pr权重的最重要因素;抽象表达是A网站上有一个链接到B网站,那么A网站上的链接就是B网站的反向链接;即所有站外指向我们目标网站的链接都属于站外链接。
10.pv、uv、ip概念:IP:指独立IP的个数。也就是IP地址,一台电脑一天可能会换多个IP,比如使用ADSL,断线重连后可能会分配另一个IP。
UV:指独立访问者,即访问你的网站的一个电脑客户端就是一个访问者;每天独立访问网站,一个IP下可以有多台电脑,那么这些多台电脑是独立的,即使访问是多个uv。
PV:指页面浏览次数,所有页面被浏览的总次数,每次页面点击计算一次。
11.不要与链接工厂交换链接,交换链接时尽量避免各种陷阱。
12.面包屑导航:面包屑为用户提供了一种回溯到最初访问页面的方式,可以清晰地引导客户从网站内部到首页的路线。最简单的方法是面包屑是水平排列的文本链接,由大于“>”分隔;此符号表示页面相对于链接到它的页面的深度(级别)。
13. 相对链接和绝对链接各有优势。在设计网站时,栏目页面链接都是相对链接。相对链接代码简单易用,可以减少冗余代码。但是相对链接很容易导致断链和死链的存在。所以最好的解决办法是使用绝对链接。使用绝对链接可以避免上面提到的所有潜在问题,是使链接真正起作用的最佳方式。在网站优化的内链优化过程中,也建议大家使用绝对链接来做!
14. 关键词 密度设置,3%-8%。
15. 在超链接的HTML标签中添加Nofollow标签常用短语,指示搜索引擎不要抓取,搜索引擎看到该标签后可能会降低或完全取消超链接的投票权重
16. 黑帽技术是利用作弊手段优化seo。是搜索引擎禁止优化网站的优化技术。黑帽短期内可以提升网站的排名和流量;白帽技术采用了非常正式的方式来优化网站,可以很好的提升网站的用户体验,同时也可以很好的与其他网站链接等交互性交换; 灰帽技术一般在平台网站上介绍较少,很多seo工作的人都不太了解。实际上,灰帽技术介于白帽和黑帽之间。一种优化技术。 查看全部
seq搜索引擎优化至少包括那几步?(网站优化的前8个基础点,你了解吗?)
昨天提到了网站优化的前8个基本点。今天我们就来聊聊接下来的8点。让我们来看看!

?9. 外链、反链接、异地链接的理解:除了网站,外链指向你的网站 url,包括首页和内页,但不带NOFOLLOW标签可以被搜索引擎抓取。外链是决定你的网站pr权重的最重要因素;抽象表达是A网站上有一个链接到B网站,那么A网站上的链接就是B网站的反向链接;即所有站外指向我们目标网站的链接都属于站外链接。
10.pv、uv、ip概念:IP:指独立IP的个数。也就是IP地址,一台电脑一天可能会换多个IP,比如使用ADSL,断线重连后可能会分配另一个IP。
UV:指独立访问者,即访问你的网站的一个电脑客户端就是一个访问者;每天独立访问网站,一个IP下可以有多台电脑,那么这些多台电脑是独立的,即使访问是多个uv。
PV:指页面浏览次数,所有页面被浏览的总次数,每次页面点击计算一次。
11.不要与链接工厂交换链接,交换链接时尽量避免各种陷阱。
12.面包屑导航:面包屑为用户提供了一种回溯到最初访问页面的方式,可以清晰地引导客户从网站内部到首页的路线。最简单的方法是面包屑是水平排列的文本链接,由大于“>”分隔;此符号表示页面相对于链接到它的页面的深度(级别)。
13. 相对链接和绝对链接各有优势。在设计网站时,栏目页面链接都是相对链接。相对链接代码简单易用,可以减少冗余代码。但是相对链接很容易导致断链和死链的存在。所以最好的解决办法是使用绝对链接。使用绝对链接可以避免上面提到的所有潜在问题,是使链接真正起作用的最佳方式。在网站优化的内链优化过程中,也建议大家使用绝对链接来做!
14. 关键词 密度设置,3%-8%。
15. 在超链接的HTML标签中添加Nofollow标签常用短语,指示搜索引擎不要抓取,搜索引擎看到该标签后可能会降低或完全取消超链接的投票权重
16. 黑帽技术是利用作弊手段优化seo。是搜索引擎禁止优化网站的优化技术。黑帽短期内可以提升网站的排名和流量;白帽技术采用了非常正式的方式来优化网站,可以很好的提升网站的用户体验,同时也可以很好的与其他网站链接等交互性交换; 灰帽技术一般在平台网站上介绍较少,很多seo工作的人都不太了解。实际上,灰帽技术介于白帽和黑帽之间。一种优化技术。
seq搜索引擎优化至少包括那几步?(第一章Solr简单介绍速览:·搜索引擎处理的数据特性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-12 22:19
第一章是对Solr的简单介绍
本章快速概述:
·搜索引擎处理的数据特征
·常见的搜索引擎用例
·Solr核心模块介绍
·选择Solr的理由
·功能概述
伴随着社交媒体、云计算、移动互联网、大数据等技术的快速发展。我们正在迎来一个激动人心的计算时代。软件架构师开始面临的主要挑战之一是如何处理庞大的全球用户群生成和使用的海量数据。此外,用户开始期望在线软件应用程序将始终稳定可用。并且可以一直保持响应,这个阶段的应用对扩展性和稳定性提出了更高的要求。为了满足这些需求,一些专门的非关系型数据存储和处理技术被统称为NoSQL(Not Only SQL)技术。开始获得越来越多的青睐。这些系统并不强制要求所有数据都存储在之前已成为事实上的标准的关系数据模型中。它共享一个通用的设计模式。匹配数据存储处理引擎和特定数据类型。换句话说,NoSQL 技术针对特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越流行。NoSQL 技术针对处理特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越受欢迎。NoSQL 技术针对处理特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越受欢迎。
一种数据处理解决方案可以吃遍全世界的日子已经一去不复返了。
本书主要讨论一种特殊的NoSQL技术。即 Apache Solr。与她的其他非关系型兄弟一样,Solr 针对特定类型的问题进行了优化。具体来说,Solr 是一种可扩展的高速部署,针对搜索海量文本中心数据和对返回结果的相关性进行排序进行了优化。
这句话读起来有点混乱。只是没关系。让我们分解一下这个定义中的亮点:
可扩展性:Solr 可以将索引和查询处理操作分发到集群中的多个服务器。
·高速部署:Solr是开源软件,安装配置非常方便。可以直接根据安装包中的Sample配置启动。
·优化搜索功能:Solr搜索速度够快。对于复杂的搜索查询,Solr 可以实现亚秒级处理。通常一个复杂的查询可以在几十毫秒内处理
·海量文本:Solr专为处理百万级别的海量文本而设计,能够很好地处理海量数据。
文本中心的数据:Solr 针对搜索收录自然语言的文本内容(例如电子邮件)进行了优化。网页、简历、PDF 文档,或推特、微博、博客等社交内容,都适合用 Solr 处理。
·结果按相关性排序:Solr的搜索结果按照结果文档与用户查询的相关程度进行排序,保证最相关的结果会先返回。
在本书中,您将学习如何使用 Solr 来设计和实现可扩展的搜索解决方案。
我们的学习之旅从了解 Solr 支持的数据类型和典型用例开始。
这样你就可以更好地了解 Solr 在整个现代软件应用架构全景中的位置,以及 Solr 旨在处理哪些问题。
1.1我需要搜索引擎吗?
我们推测你已经有了一些使用搜索引擎的想法,否则你不会打开这本书。所以。我们不浪费时间去弄清楚你为什么开始考虑 Solr,让我们直接讨论一些干货。查看数据和用例的各个方面。在决定是否使用搜索引擎之前,您必须回答哪些问题?这最终将归结为如何深入了解您的数据和您的用户。选择合适的技术,同时满足两者的需求。
让我们从讨论哪些数据属性适合搜索引擎开始。
1.1.1 在文本中心管理数据
合理选择与数据匹配的存储和处理引擎,是现代软件应用架构的标志性要求之一。假设你是一个优秀的程序员,那么你应该知道根据数据在算法中的使用方式来选择最合适的数据结构。例如,假设您需要实现高速随机搜索,则不会使用链表结构来存储数据。
同样的原则也适用于搜索引擎的选择。以下是适合使用 Solr 等搜索引擎处理的数据的四个主要特征:
文本中心的数据
读取的数据远多于写入的数据
面向文档的数据
灵活的架构
或许这里应该增加第五个数据特征,即:海量数据。那就是“大数据”,但我们主要关注的是 Solr 与其他 NoSQL 技术不同的主要特性。处理大量数据的能力并不是它们的主要区别之一。
虽然这里有像 Solr 这样的搜索引擎可以有效处理的数据类型的四个主要特征,但这只是一个粗略的指导方针,而不是一个严格的标准。
让我们深入讨论这些数据特征,看看为什么它们对搜索如此重要。我们现在只关注概念,详细的实现细节将在后面的章节中讨论。
文本中心的数据
您一定见过人们使用术语“非结构化数据”来描述搜索引擎处理的数据。我们觉得“非结构化”这个词有点含糊,因为无论是基于人类语言生成的文档都是隐式结构化的。
要理解“非结构化”一词,您可以从计算机的角度来考虑它。
在计算机眼中,文本文档就是一串字符流。这个字符流必须通过特定的语言规则解析出语义结构。天赋被找回了。这就是搜索引擎的工作。
我们觉得术语“以文本为中心的数据”更适合描述 Solr 处理的数据类型。因为搜索引擎设计的初衷是提取文本数据的隐藏结构并生成相关索引,以提高查询和检索的效率。“文本中心的数据”一词隐含地表示文档中的文本信息包括用户感兴趣的查询内容。
当然,搜索引擎也支持非文本数据,比如数字数据。但其主要优势在于基于自然语言处理文本数据。
我之前说的是“文本”。其实“中心”部分也很重要。假设您的用户对文本部分的内容不感兴趣,那么搜索引擎可能不是处理您问题的最佳选择。例如,对于员工创建差旅费用报告的应用程序,每个报告都收录一些结构化数据,例如日期。费用类型、汇率、数量等。另外,每笔费用后可能会附上一些备注。用于描述成本的一般情况。
这种应用程序是一种收录文本信息的应用程序。但它不是“以文本为中心的数据”的样本。由于会计部门使用这些员工的费用报表来生成月度费用报表,因此它不是通过查找备注中的文本信息来实现的。正文不是这里关注的主要内容。简单的说。也就是说,并非所有收录文本信息的数据都适合搜索引擎处理。
所以现在花几分钟思考一下您的数据是否是“以文本为中心的数据”。主要考虑的是用户是否会使用数据中的文本信息进行检索。
假设答案是肯定的,那么搜索引擎很可能是一个不错的选择。
我们将在第 5 章和第 6 章讨论如何使用 Solr 的文本分析来提取文本数据的结构细节。
读取的数据远多于写入的数据:
搜索引擎可以有效处理的数据的另一个特征是“读取的数据远多于写入的数据”。首先需要说明的是,Solr 同意更新索引中现有文档的内容。您可以将“读多于写”解释为对文档进行读取操作的频率远高于创建和更新文档的频率。但是不要狭隘地理解你根本不能写数据,否则你将被限制在特定频率更新数据。事实上,Solr4 的一个关键特性是“近实时查询”。此功能允许您每秒索引数千个文档,并且几乎可以立即找到这些新添加的文档。
“读取的数据远多于写入的数据”背后的关键点是,在您的数据写入 Solr 后,在其生命周期中应该多次读取。
可以理解,搜索引擎主要不是用来存储数据的。主要用于查询存储的数据(一个查询请求就是一个读操作)。因此,假设您需要非常频繁地更新数据。那么搜索引擎可能不太适合你的需求,其他的NoSQL技术,比如Cassandra,可能更适合你的高速随机写入需求。
面向文档的数据
到目前为止,我们一直在使用更通用的术语“数据”,但实际上搜索引擎处理文档数据。在搜索引擎中。一个文档是一个独立的字段集合,每个字段只存储数据值。不能嵌套以收录其他值范围。换句话说。在 Solr 等搜索引擎中,文档都是扁平的,文档之间没有相互依赖。Solr中“扁平化”的概念比较松散。一个取值范围可以容纳多个数据值,但取值范围不能嵌套并且收录子范围。
换句话说,您可以在一个范围内存储多个数据值。但是您不能在该范围内嵌套其他范围。
Solr 中这种面向文档的扁平化方法可以很好地处理文档数据。例如,网页、博客。pdf文件等。那么如果你想使用 Solr 来处理关系数据库中的结构化数据呢?在这种情况下,您需要首先提取关系数据库中跨表存储的数据以对其进行解构。然后把它放在一个扁平的、独立的文档结构中。我们将在第 3 章中学习如何处理此类问题。
您还需要考虑文档数据中哪些值范围需要存储在 Solr 中,哪些值范围需要存储在其他系统(例如,数据库)中。简单的说。搜索引擎只存储需要检索的数据和用于显示检索结果的数据。
举个例子。假设您有一个在线视频的搜索索引。您不应该希望将视频文件本身存储在 Solr 中。一个合理的解决方案应该是将大型视频文件放在内容分发网络 (CDN) 上。通常你只需要在搜索引擎中存储满足搜索要求的最少数据。刚才的在线视频示例清楚地表明,Solr 不应被视为一种通用的数据存储技术。Solr 的工作是找到用户感兴趣的视频文件,而不是自己存储视频文件。
灵活的架构
最后搜索引擎数据的主要特点是灵活的模式。
这意味着查询索引中的文档不需要具有统一的结构。在关系数据库中,表中的每一行数据都必须具有相同的结构。在 Solr 中,文档可以有不同的范围。当然,同一个索引中的文档应该至少有每个人都拥有的范围的一部分,以便于检索,但并不要求所有文档中的范围结构完全相同。
举个例子。假设您要制作一个用于查找出租和出售房屋的搜索应用程序。显然,每个上市文件都有一个位置。房间数、卫浴数等常用价值范围,根据是出租还是出售而有所不同。不同的财产文件会有不同的取值范围。待售物业将有售价范围和物业税价值范围。出租房屋文件将具有不同的价值范围,例如月租和宠物政策。
综上所述,搜索引擎Solr专门针对处理文本中心进行了优化,阅读远远超过写作,并且是面向文档的。它用于具有灵活 Schema 的数据。Solr 不是通用的数据存储和处理技术,这也是它区别于其他 NoSQL 技术的主要因素。
有许多不同的数据存储和处理解决方案可供选择。优点是您不必再费力寻找可以满足您所有需求的通用技术解决方案。搜索引擎在某些特定任务上表现良好。但是,其他方面的表现却很差。这意味着在大多数情况下,您可以将 Solr 用作关系数据库和其他 NoSQL 技术的强大补充,而不是取代后者。
现在我们已经讨论了 Solr 优化的数据类型,让我们来讨论 Solr 等搜索引擎主要解决的实际用例。
了解这些用例可以帮助您了解搜索引擎技术与其他数据处理技术的不同之处。
1.1.2 常见的搜索引擎用例
在本节中,我们来看看像 Solr 这样的搜索引擎可以做什么。正如我们在 1.1. 部分 1 中提到的。这些讨论本质上只是指导方针,不要将它们视为严格的使用规则。在我们开始之前。你需要意识到,如果你想做一个优秀的搜索服务,门槛是非常高的。
今天的用户习惯于使用快速高效的网络搜索引擎,如 Google 和 Bing。而且很多热门网站也有自己强大的搜索解决方案,可以帮助用户高速获取自己想要的信息,所以用户对搜索服务并不陌生,会很挑剔。当你在评估像 Solr 这样的搜索引擎时,或者在设计你自己的搜索计划时,你必须有根。应将用户体验视为高优先级。
主关键字查询
显然,作为搜索引擎,首先要能够支持主关键词查询。
这也是搜索引擎的主要功能之一。只是关键词查询功能值得在这里强调,因为这是用户使用搜索引擎最典型的方式。
很少有真正的用户想要填写一个非常完整和复杂的搜索表单,一出现就进行搜索。考虑到 关键词 搜索功能将是用户与搜索引擎之间最常见的交互方式。这个基本功能必须能够为用户提供非常好的用户体验。
一般来说,用户希望输入几个简单的关键词就能得到很好的搜索结果。
这听起来像是一个简单的匹配任务:只需将查询字符串与文档匹配即可。只需考虑几个必须解决的问题才能获得良好的用户体验:
·相关结果必须快速返回,大多数情况要求一秒内返回
·当查询字符串出现拼写错误时,用户可以主动更正
·当用户进入时,通过自己主动完成建议,减少用户输入负担,这在移动应用中并不常见
·处理查询字符串中的同义词和同义词
·匹配收录查询字符串语言变体的文档
· 短语处理。用户是想匹配词组中的所有词,还是只匹配词组中的一些词
·处理一些一般介词,如“a”、“an”、“of”、“the”等。
·假设最上面的查询结果让用户不舒服。如何向用户返回许多其他查询结果
如您所见,没有使用特定的处理方法。这么一堆问题,会很难实现这么简单的功能。但是,有了像 Solr 这样的搜索引擎,这些功能可以立即得到满足,并且变得非常容易实现。在你为用户提供了一个强大的关键词搜索工具之后,那么你就需要考虑如何根据结果和查询请求的相关性来展示查询的结果,从而引出下一个用例. 对搜索返回的查询结果进行排序。
排序的搜索结果
搜索引擎会返回查询的“顶级”结果。在SQL中查询关系型数据库时,一行数据记录要么匹配返回的查询,要么忽略不匹配的查询,查询结果也按照数据记录的某个列属性进行排序。对于搜索引擎,返回的结果文档根据分数降序排列。分数表示文档与查询的匹配程度。匹配分数是根据一系列因素计算出来的。但一般来说,分数越高。表示结果文档和查询之间的相关性越高。
有几个因素决定了结果文档按相关性排序的重要性。首先,现代搜索引擎一般存储着海量的文档,数量都在数百万甚至数十亿。假设不正确的查询结果按相关性排序。那么用户就会被海量的返回结果淹没,无法清晰有效地浏览搜索结果。其次。用户使用其他搜索引擎的经验,让用户习惯于使用几个关键词来获得好的查询结果。它还使用户通常不那么耐心。
他们希望搜索引擎能够按自己的意愿工作,而不管他们输入的信息是否完全正确。例如,对于移动应用程序的后台搜索服务,用户会期望搜索服务在输入一些可能收录拼写错误的简短查询词后返回正确的搜索结果。
假设您想手动干预排序结果,您可以为特定文档、值范围或查询字符串添加权重,或者直接增加文档的相关性分数。例如,如果您想将新添加的文档推送到顶部位置,您可以通过根据创建时间改进文档的排序来实现。我们将在第 3 章中学习文档排序。
除了关键词咨询
使用像 Solr 这样的搜索引擎,用户可以输入几个 关键词 以获得一些搜索结果。然而,对于许多用户来说,这只是查询交互的第一步。他们需要能够继续浏览查询结果。驱动信息发现的交互对话过程也是搜索引擎的一个主要应用场景。往往让用户在搜索之前不是很准确地知道自己想要查询什么样的信息。他们事先不知道您的系统中存储了哪些信息。一个好的搜索引擎可以帮助用户不断提炼自己的信息需求,一步步的到达最需要的信息。
这里的核心思想是在返回用户初始查询对应的文档结果的同时,为用户提供一个工具,让他们可以不断改进查询,获取更多需要的信息。换句话说。除了返回匹配的文档之外,您还应该返回一个工具,让用户知道下一步该做什么。举个例子。可以根据属性对查询结果进行分类,方便用户根据需要进一步浏览。
这样的功能叫做Faceted-Search,这也是Solr的亮点之一。
我们将在1.的第2节看到一个房地产分类检索的例子,分类检索功能的细节将在第8章介绍。
哪些搜索引擎不适合...
最后。我们来讨论一些不适合应用搜索引擎的用例场景。
第一的。搜索引擎的一般设计是为每个查询返回一个小文档集,通常包括 10 到 100 个结果文档。通过 Solr 内置的结果分页功能,可以获得很多其他的结果文档。对于一个查询结果,有数百万个文档。假设您要求一次返回所有匹配的文档,那么您将等待很长时间。
查询本身会运行得非常快,但是从索引结构中重建数百万个文档绝对是一项非常耗时的任务。由于Solr这种存储取值范围在硬盘上的搜索引擎,在假设需要一次生成大量查询结果的情况下,仅适用于高速生成少量文档结果。在这种存储方式下生成大量的文档结果会消耗大量的时间。
另一个不适合应用搜索引擎的使用场景是深度分析任务场景,需要读取索引文件的大部分子集。
即使你避免了结果分页技术刚刚提到的问题。假设一个分析需要读取索引文件中的大量数据。你也会遇到非常大的性能问题,因为索引文件的底层数据结构并不是为大量读取而设计的。
我们前面提到了一点。但是这里我还是要再次强调一下。也就是说,搜索引擎技术不适合查询文档之间的关系。Solr 确实能够支持基于父子关系的查询。但它不支持复杂关系数据结构之间的查询。在第三章。您将学习如何将关系数据结构调整为适合 Solr 处理查询的平面文档结构。
最后,大多数搜索引擎没有直接的文档级安全支持,至少 Solr 没有。
假设您需要严格管理文档权限,则只能在搜索引擎之外想办法。
至此我们已经了解了适合搜索引擎处理的用例场景和数据类型。下一步是讨论 Solr 可以做什么。以及这些功能是如何实现的。在下一节中,您将了解 Solr 的主要功能是什么。以及她如何实施软件设计原则,例如外部系统集成、可扩展性和高可用性。 查看全部
seq搜索引擎优化至少包括那几步?(第一章Solr简单介绍速览:·搜索引擎处理的数据特性)
第一章是对Solr的简单介绍
本章快速概述:
·搜索引擎处理的数据特征
·常见的搜索引擎用例
·Solr核心模块介绍
·选择Solr的理由
·功能概述
伴随着社交媒体、云计算、移动互联网、大数据等技术的快速发展。我们正在迎来一个激动人心的计算时代。软件架构师开始面临的主要挑战之一是如何处理庞大的全球用户群生成和使用的海量数据。此外,用户开始期望在线软件应用程序将始终稳定可用。并且可以一直保持响应,这个阶段的应用对扩展性和稳定性提出了更高的要求。为了满足这些需求,一些专门的非关系型数据存储和处理技术被统称为NoSQL(Not Only SQL)技术。开始获得越来越多的青睐。这些系统并不强制要求所有数据都存储在之前已成为事实上的标准的关系数据模型中。它共享一个通用的设计模式。匹配数据存储处理引擎和特定数据类型。换句话说,NoSQL 技术针对特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越流行。NoSQL 技术针对处理特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越受欢迎。NoSQL 技术针对处理特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越受欢迎。
一种数据处理解决方案可以吃遍全世界的日子已经一去不复返了。
本书主要讨论一种特殊的NoSQL技术。即 Apache Solr。与她的其他非关系型兄弟一样,Solr 针对特定类型的问题进行了优化。具体来说,Solr 是一种可扩展的高速部署,针对搜索海量文本中心数据和对返回结果的相关性进行排序进行了优化。
这句话读起来有点混乱。只是没关系。让我们分解一下这个定义中的亮点:
可扩展性:Solr 可以将索引和查询处理操作分发到集群中的多个服务器。
·高速部署:Solr是开源软件,安装配置非常方便。可以直接根据安装包中的Sample配置启动。
·优化搜索功能:Solr搜索速度够快。对于复杂的搜索查询,Solr 可以实现亚秒级处理。通常一个复杂的查询可以在几十毫秒内处理
·海量文本:Solr专为处理百万级别的海量文本而设计,能够很好地处理海量数据。
文本中心的数据:Solr 针对搜索收录自然语言的文本内容(例如电子邮件)进行了优化。网页、简历、PDF 文档,或推特、微博、博客等社交内容,都适合用 Solr 处理。
·结果按相关性排序:Solr的搜索结果按照结果文档与用户查询的相关程度进行排序,保证最相关的结果会先返回。
在本书中,您将学习如何使用 Solr 来设计和实现可扩展的搜索解决方案。
我们的学习之旅从了解 Solr 支持的数据类型和典型用例开始。
这样你就可以更好地了解 Solr 在整个现代软件应用架构全景中的位置,以及 Solr 旨在处理哪些问题。
1.1我需要搜索引擎吗?
我们推测你已经有了一些使用搜索引擎的想法,否则你不会打开这本书。所以。我们不浪费时间去弄清楚你为什么开始考虑 Solr,让我们直接讨论一些干货。查看数据和用例的各个方面。在决定是否使用搜索引擎之前,您必须回答哪些问题?这最终将归结为如何深入了解您的数据和您的用户。选择合适的技术,同时满足两者的需求。
让我们从讨论哪些数据属性适合搜索引擎开始。
1.1.1 在文本中心管理数据
合理选择与数据匹配的存储和处理引擎,是现代软件应用架构的标志性要求之一。假设你是一个优秀的程序员,那么你应该知道根据数据在算法中的使用方式来选择最合适的数据结构。例如,假设您需要实现高速随机搜索,则不会使用链表结构来存储数据。
同样的原则也适用于搜索引擎的选择。以下是适合使用 Solr 等搜索引擎处理的数据的四个主要特征:
文本中心的数据
读取的数据远多于写入的数据
面向文档的数据
灵活的架构
或许这里应该增加第五个数据特征,即:海量数据。那就是“大数据”,但我们主要关注的是 Solr 与其他 NoSQL 技术不同的主要特性。处理大量数据的能力并不是它们的主要区别之一。
虽然这里有像 Solr 这样的搜索引擎可以有效处理的数据类型的四个主要特征,但这只是一个粗略的指导方针,而不是一个严格的标准。
让我们深入讨论这些数据特征,看看为什么它们对搜索如此重要。我们现在只关注概念,详细的实现细节将在后面的章节中讨论。
文本中心的数据
您一定见过人们使用术语“非结构化数据”来描述搜索引擎处理的数据。我们觉得“非结构化”这个词有点含糊,因为无论是基于人类语言生成的文档都是隐式结构化的。
要理解“非结构化”一词,您可以从计算机的角度来考虑它。
在计算机眼中,文本文档就是一串字符流。这个字符流必须通过特定的语言规则解析出语义结构。天赋被找回了。这就是搜索引擎的工作。
我们觉得术语“以文本为中心的数据”更适合描述 Solr 处理的数据类型。因为搜索引擎设计的初衷是提取文本数据的隐藏结构并生成相关索引,以提高查询和检索的效率。“文本中心的数据”一词隐含地表示文档中的文本信息包括用户感兴趣的查询内容。
当然,搜索引擎也支持非文本数据,比如数字数据。但其主要优势在于基于自然语言处理文本数据。
我之前说的是“文本”。其实“中心”部分也很重要。假设您的用户对文本部分的内容不感兴趣,那么搜索引擎可能不是处理您问题的最佳选择。例如,对于员工创建差旅费用报告的应用程序,每个报告都收录一些结构化数据,例如日期。费用类型、汇率、数量等。另外,每笔费用后可能会附上一些备注。用于描述成本的一般情况。
这种应用程序是一种收录文本信息的应用程序。但它不是“以文本为中心的数据”的样本。由于会计部门使用这些员工的费用报表来生成月度费用报表,因此它不是通过查找备注中的文本信息来实现的。正文不是这里关注的主要内容。简单的说。也就是说,并非所有收录文本信息的数据都适合搜索引擎处理。
所以现在花几分钟思考一下您的数据是否是“以文本为中心的数据”。主要考虑的是用户是否会使用数据中的文本信息进行检索。
假设答案是肯定的,那么搜索引擎很可能是一个不错的选择。
我们将在第 5 章和第 6 章讨论如何使用 Solr 的文本分析来提取文本数据的结构细节。
读取的数据远多于写入的数据:
搜索引擎可以有效处理的数据的另一个特征是“读取的数据远多于写入的数据”。首先需要说明的是,Solr 同意更新索引中现有文档的内容。您可以将“读多于写”解释为对文档进行读取操作的频率远高于创建和更新文档的频率。但是不要狭隘地理解你根本不能写数据,否则你将被限制在特定频率更新数据。事实上,Solr4 的一个关键特性是“近实时查询”。此功能允许您每秒索引数千个文档,并且几乎可以立即找到这些新添加的文档。
“读取的数据远多于写入的数据”背后的关键点是,在您的数据写入 Solr 后,在其生命周期中应该多次读取。
可以理解,搜索引擎主要不是用来存储数据的。主要用于查询存储的数据(一个查询请求就是一个读操作)。因此,假设您需要非常频繁地更新数据。那么搜索引擎可能不太适合你的需求,其他的NoSQL技术,比如Cassandra,可能更适合你的高速随机写入需求。
面向文档的数据
到目前为止,我们一直在使用更通用的术语“数据”,但实际上搜索引擎处理文档数据。在搜索引擎中。一个文档是一个独立的字段集合,每个字段只存储数据值。不能嵌套以收录其他值范围。换句话说。在 Solr 等搜索引擎中,文档都是扁平的,文档之间没有相互依赖。Solr中“扁平化”的概念比较松散。一个取值范围可以容纳多个数据值,但取值范围不能嵌套并且收录子范围。
换句话说,您可以在一个范围内存储多个数据值。但是您不能在该范围内嵌套其他范围。
Solr 中这种面向文档的扁平化方法可以很好地处理文档数据。例如,网页、博客。pdf文件等。那么如果你想使用 Solr 来处理关系数据库中的结构化数据呢?在这种情况下,您需要首先提取关系数据库中跨表存储的数据以对其进行解构。然后把它放在一个扁平的、独立的文档结构中。我们将在第 3 章中学习如何处理此类问题。
您还需要考虑文档数据中哪些值范围需要存储在 Solr 中,哪些值范围需要存储在其他系统(例如,数据库)中。简单的说。搜索引擎只存储需要检索的数据和用于显示检索结果的数据。
举个例子。假设您有一个在线视频的搜索索引。您不应该希望将视频文件本身存储在 Solr 中。一个合理的解决方案应该是将大型视频文件放在内容分发网络 (CDN) 上。通常你只需要在搜索引擎中存储满足搜索要求的最少数据。刚才的在线视频示例清楚地表明,Solr 不应被视为一种通用的数据存储技术。Solr 的工作是找到用户感兴趣的视频文件,而不是自己存储视频文件。
灵活的架构
最后搜索引擎数据的主要特点是灵活的模式。
这意味着查询索引中的文档不需要具有统一的结构。在关系数据库中,表中的每一行数据都必须具有相同的结构。在 Solr 中,文档可以有不同的范围。当然,同一个索引中的文档应该至少有每个人都拥有的范围的一部分,以便于检索,但并不要求所有文档中的范围结构完全相同。
举个例子。假设您要制作一个用于查找出租和出售房屋的搜索应用程序。显然,每个上市文件都有一个位置。房间数、卫浴数等常用价值范围,根据是出租还是出售而有所不同。不同的财产文件会有不同的取值范围。待售物业将有售价范围和物业税价值范围。出租房屋文件将具有不同的价值范围,例如月租和宠物政策。
综上所述,搜索引擎Solr专门针对处理文本中心进行了优化,阅读远远超过写作,并且是面向文档的。它用于具有灵活 Schema 的数据。Solr 不是通用的数据存储和处理技术,这也是它区别于其他 NoSQL 技术的主要因素。
有许多不同的数据存储和处理解决方案可供选择。优点是您不必再费力寻找可以满足您所有需求的通用技术解决方案。搜索引擎在某些特定任务上表现良好。但是,其他方面的表现却很差。这意味着在大多数情况下,您可以将 Solr 用作关系数据库和其他 NoSQL 技术的强大补充,而不是取代后者。
现在我们已经讨论了 Solr 优化的数据类型,让我们来讨论 Solr 等搜索引擎主要解决的实际用例。
了解这些用例可以帮助您了解搜索引擎技术与其他数据处理技术的不同之处。
1.1.2 常见的搜索引擎用例
在本节中,我们来看看像 Solr 这样的搜索引擎可以做什么。正如我们在 1.1. 部分 1 中提到的。这些讨论本质上只是指导方针,不要将它们视为严格的使用规则。在我们开始之前。你需要意识到,如果你想做一个优秀的搜索服务,门槛是非常高的。
今天的用户习惯于使用快速高效的网络搜索引擎,如 Google 和 Bing。而且很多热门网站也有自己强大的搜索解决方案,可以帮助用户高速获取自己想要的信息,所以用户对搜索服务并不陌生,会很挑剔。当你在评估像 Solr 这样的搜索引擎时,或者在设计你自己的搜索计划时,你必须有根。应将用户体验视为高优先级。
主关键字查询
显然,作为搜索引擎,首先要能够支持主关键词查询。
这也是搜索引擎的主要功能之一。只是关键词查询功能值得在这里强调,因为这是用户使用搜索引擎最典型的方式。
很少有真正的用户想要填写一个非常完整和复杂的搜索表单,一出现就进行搜索。考虑到 关键词 搜索功能将是用户与搜索引擎之间最常见的交互方式。这个基本功能必须能够为用户提供非常好的用户体验。
一般来说,用户希望输入几个简单的关键词就能得到很好的搜索结果。
这听起来像是一个简单的匹配任务:只需将查询字符串与文档匹配即可。只需考虑几个必须解决的问题才能获得良好的用户体验:
·相关结果必须快速返回,大多数情况要求一秒内返回
·当查询字符串出现拼写错误时,用户可以主动更正
·当用户进入时,通过自己主动完成建议,减少用户输入负担,这在移动应用中并不常见
·处理查询字符串中的同义词和同义词
·匹配收录查询字符串语言变体的文档
· 短语处理。用户是想匹配词组中的所有词,还是只匹配词组中的一些词
·处理一些一般介词,如“a”、“an”、“of”、“the”等。
·假设最上面的查询结果让用户不舒服。如何向用户返回许多其他查询结果
如您所见,没有使用特定的处理方法。这么一堆问题,会很难实现这么简单的功能。但是,有了像 Solr 这样的搜索引擎,这些功能可以立即得到满足,并且变得非常容易实现。在你为用户提供了一个强大的关键词搜索工具之后,那么你就需要考虑如何根据结果和查询请求的相关性来展示查询的结果,从而引出下一个用例. 对搜索返回的查询结果进行排序。
排序的搜索结果
搜索引擎会返回查询的“顶级”结果。在SQL中查询关系型数据库时,一行数据记录要么匹配返回的查询,要么忽略不匹配的查询,查询结果也按照数据记录的某个列属性进行排序。对于搜索引擎,返回的结果文档根据分数降序排列。分数表示文档与查询的匹配程度。匹配分数是根据一系列因素计算出来的。但一般来说,分数越高。表示结果文档和查询之间的相关性越高。
有几个因素决定了结果文档按相关性排序的重要性。首先,现代搜索引擎一般存储着海量的文档,数量都在数百万甚至数十亿。假设不正确的查询结果按相关性排序。那么用户就会被海量的返回结果淹没,无法清晰有效地浏览搜索结果。其次。用户使用其他搜索引擎的经验,让用户习惯于使用几个关键词来获得好的查询结果。它还使用户通常不那么耐心。
他们希望搜索引擎能够按自己的意愿工作,而不管他们输入的信息是否完全正确。例如,对于移动应用程序的后台搜索服务,用户会期望搜索服务在输入一些可能收录拼写错误的简短查询词后返回正确的搜索结果。
假设您想手动干预排序结果,您可以为特定文档、值范围或查询字符串添加权重,或者直接增加文档的相关性分数。例如,如果您想将新添加的文档推送到顶部位置,您可以通过根据创建时间改进文档的排序来实现。我们将在第 3 章中学习文档排序。
除了关键词咨询
使用像 Solr 这样的搜索引擎,用户可以输入几个 关键词 以获得一些搜索结果。然而,对于许多用户来说,这只是查询交互的第一步。他们需要能够继续浏览查询结果。驱动信息发现的交互对话过程也是搜索引擎的一个主要应用场景。往往让用户在搜索之前不是很准确地知道自己想要查询什么样的信息。他们事先不知道您的系统中存储了哪些信息。一个好的搜索引擎可以帮助用户不断提炼自己的信息需求,一步步的到达最需要的信息。
这里的核心思想是在返回用户初始查询对应的文档结果的同时,为用户提供一个工具,让他们可以不断改进查询,获取更多需要的信息。换句话说。除了返回匹配的文档之外,您还应该返回一个工具,让用户知道下一步该做什么。举个例子。可以根据属性对查询结果进行分类,方便用户根据需要进一步浏览。
这样的功能叫做Faceted-Search,这也是Solr的亮点之一。
我们将在1.的第2节看到一个房地产分类检索的例子,分类检索功能的细节将在第8章介绍。
哪些搜索引擎不适合...
最后。我们来讨论一些不适合应用搜索引擎的用例场景。
第一的。搜索引擎的一般设计是为每个查询返回一个小文档集,通常包括 10 到 100 个结果文档。通过 Solr 内置的结果分页功能,可以获得很多其他的结果文档。对于一个查询结果,有数百万个文档。假设您要求一次返回所有匹配的文档,那么您将等待很长时间。
查询本身会运行得非常快,但是从索引结构中重建数百万个文档绝对是一项非常耗时的任务。由于Solr这种存储取值范围在硬盘上的搜索引擎,在假设需要一次生成大量查询结果的情况下,仅适用于高速生成少量文档结果。在这种存储方式下生成大量的文档结果会消耗大量的时间。
另一个不适合应用搜索引擎的使用场景是深度分析任务场景,需要读取索引文件的大部分子集。
即使你避免了结果分页技术刚刚提到的问题。假设一个分析需要读取索引文件中的大量数据。你也会遇到非常大的性能问题,因为索引文件的底层数据结构并不是为大量读取而设计的。
我们前面提到了一点。但是这里我还是要再次强调一下。也就是说,搜索引擎技术不适合查询文档之间的关系。Solr 确实能够支持基于父子关系的查询。但它不支持复杂关系数据结构之间的查询。在第三章。您将学习如何将关系数据结构调整为适合 Solr 处理查询的平面文档结构。
最后,大多数搜索引擎没有直接的文档级安全支持,至少 Solr 没有。
假设您需要严格管理文档权限,则只能在搜索引擎之外想办法。
至此我们已经了解了适合搜索引擎处理的用例场景和数据类型。下一步是讨论 Solr 可以做什么。以及这些功能是如何实现的。在下一节中,您将了解 Solr 的主要功能是什么。以及她如何实施软件设计原则,例如外部系统集成、可扩展性和高可用性。
seq搜索引擎优化至少包括那几步?(SEO培训,SEO评估方法及工具培训的注意事项!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-12 17:19
优化流程
1:网站诊断分析(网站架构分析,网站内容分析,网站系统分析,网站功能分析)
2:网站竞争分析(行业搜索引擎竞争分析、竞争对手分析、搜索引擎友好度分析、关键词分析、链接分析)
3:SEO培训咨询(SEO基础知识培训、SEO实践专业培训、SEO评估方法及工具培训、SEO实践效果验收与维护)
4:数据追踪分析(数据追踪监测、效果维护与调整、策略评估与调整、流量分析)
5:优化策略结构与实施(全站优化的优化策略是什么,关键词策略,内链优化,外链部署策略,软文编辑和站外推广,搜索引擎性能预言 )
1、网站导航优化
是否锚文本导航,以文本形式做网站导航,不要使用flash、图片、js,因为这不如锚文本导航,锚文本导航蜘蛛更喜欢。
导航锚文本关键词相关性,这是栏目的定位,尽量用你首页的长尾关键词作为你的栏目。
主导航和二级导航,主导航只放栏目和频道,不放无关内容。第二个导航可以放一些相关的关键词页面导航或者栏目导航,但切记不要堆放。
是否有面包屑导航,首页>栏目页>内容页。
面包屑导航优化的细节需要注意:当前页面(登陆页面)一般不需要添加链接;您可以使用 关键词 作为面包屑的锚文本;一个页面可以有多个面包屑(以免给用户造成混淆)。
2、栏目页面优化
三个标签,标题、关键词、描述,合理填写,不要堆砌。标题结构,标题名称>列名>网站名称关键词相关性,检测分页标题重复,不要太多重复。分页链接网址是否加深网址深度,建议网址在3层以内。
3.内容页面优化
内容来源,来源以原创为主,参考写作为辅,不行就伪原创,不需要复制粘贴,对网站没有好处。URL是否收录关键词(英文),最好用关键词制作英文URL,中文拼音也是可以的。标题的格式,简洁明了,应该出现在标题网站main关键词中。要使用 H 标记,请将 H 标记添加到 网站 中第一次出现的 关键词。文章文字是否符合SEO标准,区分主次,合理关键词分布。图片的ALT属性可以增加关键词的密度和搜索引擎对图片的识别。
4. 链接优化
构建 网站 地图。Html 格式的网站 映射基于网站 的结构特征。有必要将网站的功能结构和服务内容罗列有序,力求页面简洁大方,方便用户浏览。
构建机器人文件。注意Robots.txt必须放在站点根目录下,文件名必须全部小写。将 网站 映射写入 Robots 文件。
设置404页面符合网站的设计风格。最好添加网站导航和底部(尤其是网站地图),并保证404页面返回的http状态码为404。
检测网站的死链接并删除,建议使用Xenu工具检测。
一个网站就像一个人,只有变得更好,才能收获更多,创造更多。如果把内链比作经络,那么网站的内容就是血肉之躯。一个网站即使内容丰富,如果经脉不通,最后的结果就是排名不好,收录的提升速度很慢。在网站的构建中,内部链构建的重要性不同于外部链的构建。除了网站和网站之间的链接,还有网站内部网页和网页之间的链接。反向链接也有助于排名。我个人理解,这就是内链的本质。,内链的意义在于用户可以更方便地查找信息。
逆向思维分析
网站内容采集点是关键词,关键词定位访问者。很多人喜欢讲浓度,搜索引擎也是这样看待网站的。标题的作用在细分的未来发展中会更加重要。主题突出,内容丰富,粘性大,领域纵深。这应该是未来几年网站的主流趋势。生活中人人都爱这么说,网站优化也是如此。不要刻意迎合搜索引擎和SEO的喜好,应该多考虑访问者。因为搜索引擎和SEO最终客户都是访问者,都是以人为基础的。一味讨好搜索引擎,容易被当作弊,人讲究个性,< @网站 也是一样。SEO 策略的实施因人而异。在我们研究搜索引擎的同时,搜索引擎也在向我们学习。
6优化方案格式
当你得到一个需要优化的网站时,并不是你得到了网站就去做。网站 优化计划。但这是一种比较简单的网站优化计划编写格式。
网站搜索引擎优化信息
1、ALEXA 排名
2、域名年龄
3、百度权重、谷歌公关及其收录情况
4、网站交通状况
5、关键词 排名
6.网站 外链数据情况
网站优化目标
1.制定目标关键词,并期待排名目标。
2.制定网站IP和PV值,预计增加多少流量网站。
网站站内优化
相信很多新手站长或者SEO新手一开始都会咨询哪里外链比较好,更希望外链遍布全球。其实对于网站优化来说,外链自然很重要,但用户体验更重要。从百度频繁的升级算法中,我们也可以看到,百度对用户体验差的问题不断进行打击网站!因此,叶建辉认为网站的内部优化和网站的用户体验比外链更重要。那么网站内部优化有哪些方面呢?
1.首页标题,观察网站首页标题的数量。
2.网站关键词分布,即页面关键词的密度,不要刻意叠加,就好了。
3.网站内容更新,网站内容更新是否定期很重要,特别是对于新网站,定期更新更能跳出沙盒。
4.网站 内链,无论网站大小,都不能忽视内链的重要性。
5.网站Map 和 网站 static,都影响蜘蛛爬行。
6.图片优化,ALT标签说明。
网站优化策略
网站优化策略需要详细分析。比如企业站和信息站的优化策略不同,企业站需要更新,信息站需要挖掘更多的关键词来拉动流量。
分工
没有完美的个人,只有完美的集体。网站SEO优化也是如此。团队合作,各司其职,才能做得更好。
7个用户组
1.经营大量产品的企业网站
2.行业提供广泛的服务网站
3.至少100个关键词可以总结服务或产品信息
4.专业商场,如服装商场、珠宝礼品商场、化妆品商场等。
5.品牌产品或代理品牌
6.热门行业
8大好处
增加有效流量
全站网站全站优化首先要注意长尾关键词。长尾关键词通常是指网站关键词除了核心关键词和二级核心关键词。一个网站除了核心关键词可以带来很多流量,长尾关键词也可以给网站带来很多流量,其总量为甚至比核心关键词还要大,带来更多的流量。例如,汽车音响店可能选择音响为核心关键词,汽车音响为副核心关键词。那么如果他是做竞价排名的话,选择这两个关键词的价格是很贵的,大概每点击3元左右;那么他可能会选择在google做seo,但是google主页上的都是响亮的网站:慧聪网,英商网、新浪汽车频道、中国汽车影音、中国音响网、太平洋汽车配件频道……如果一个普通的汽车音响店想进前十,你能做到吗?可以,但是很难。但他往往很着急,希望1-3个月内出成果,最后seo服务商不得不用不好的手段去运营。这是国内seo行业的普遍现状。那么,其实换个思路,我们能不能选择长尾词:汽车音响改装、惠威汽车音响、先锋汽车音响、汽车音响论坛、二手车音响、松下汽车音响、漫步者汽车音响、jvc汽车音响、汽车音频解码、汽车音响网络……等等。可能在用户通过搜索引擎检索到的所有关键词中,核心关键词产生了50%的流量,而另外50%的流量是由这些长尾关键词带来的。长尾关键词 通常是不受欢迎的词、词组,甚至是一个句子。当这么多用户使用搜索引擎时,他们可能会输入一些意想不到的东西,比如搜索“”、“北京汽车音响”等词,甚至“哪里可以找到便宜的二手汽车音响?”等短语或句子。在很多情况下,如何优化整个网站的效果表现在模板的修改、链接结构的调整和页面结构的调整,使其更符合搜索引擎的计算规则和同时对观众更加友好。优化整个网站优化指南后,就可以使用搜索引擎' s 排名计算中关键词列表的抽取原理,挖掘出很多关键词,获得好的排名。因此,车站的客流量大大增加。大部分都是好几次好转。如何优化整个网站的最大特点是你不是自己指定某个关键词,而是随着你的内容增加,搜索引擎会自动提取大量关键词进行排序。这种方式非常符合搜索引擎的计算规则。
更好的用户体验
如前所述,seo的目标是用户体验和流量。整个网站的优化是什么?必须考虑网站的结构、内容、美术设计、栏目构成、服务器和域名。这些基础构成了高用户。体验的关键因素,如何优化整个网站也是以此为基础,而关键词优化一般不需要考虑所有这些因素。
提高网站转化率
不管流量多高,提升访客到商机的转化率才是企业最需要的,全站优化的核心思想优化可以显着提升转化率。
从搜索引擎的角度:假设你是一家打印机公司的营销经理,你需要利用互联网来推广打印机。客户通过长尾词“个人家庭用彩色双面打印机”进行搜索,不仅仅是简单地搜索核心词“打印机”。在百度首页看到“打印机”完整列表的客户,清楚地表明前者的需求与网站呈现的内容更加兼容,因此前者更有可能致电打印机公司。
从网站的流程和内容设计来看:服务或产品内容的选择、表达方式,以及方便简单的引导流程的设计,交互方式的设计将大大增加参与度并有效激发游客的购买欲望。
转化率是seo必须关注的数据。良好的转化率可以将有限的流量转化为优质客户。全站优化方案的优化目标是为转化率和流量上下功夫。各种信息和网站结构的调整,将帮助企业获得更高的网站流量转化率,创造更多的利润。
说到底,如何优化整个网站,是企业营销下的功夫。因此,如何优化整个网站的seo,势必更加关注发布的信息量和平台的覆盖范围。这些信息将使企业信息获得更多展示机会。
控制广告成本
一方面,整个网站优化方案的优化可以带来可观的流量和转化。同时,因为竞争对手不可能花那么多精力去琢磨这几百个长尾词,所以不存在恶意点击。另一方面,它们不是点击。收费,因此如果您被竞争对手点击,不会有任何损失。因此,代理和竞争对手在竞价排名中的恶意欺诈点击不存在,投资回报率自然提高。
因此,全站优化和实战密码优化的目的是从根本上提升企业的质量网站,从而带来高质量的持续海量流量;显着提高转化率。这让企业告别竞价排名依赖。很明显,在核心关键词价格被夸大的情况下,全站优化的投资回报远好于竞价排名。
优化与搜索引擎优化的关系
全站优化是通过对网站定位、网站内容和网站结构的整体优化,保证网站的所有页面对搜索引擎友好,所以网站在各大搜索引擎中,收录的搜索量相对较高,整体排名表现良好。如何优化整个站点 优化整个站点是搜索引擎营销的最佳实践。
什么是全站优化?优化和简单的关键词优化的区别
全站如何优化除了考虑排名,全站优化更看重点击率和网站转化率。它不以某个关键词在某个搜索引擎上的排名为得失,而是关注所有高质量相关关键词在所有搜索引擎上的综合表现。
全站优化比关键词竞价更有效
与关键词竞价不同,如何优化全站可以让你网站通过更优质的关键词从更多搜索引擎获得更多自然流量,而无需担心恶意点击和恶意出价
9 优化目标
1、实现目标提升和长尾关键词的关键词优化。
流量分析,时刻关注网站关键词密度分布,提高目标关键词排名。关注准尾关键词和长尾关键词的关注程度及其在首页的分布情况。
2、保证网站搜索引擎会搜索到最新发布的内容收录。
通过优化长尾关键词的分布和选择,大大提高了网站页面被搜索引擎收录搜索到的概率。整体提升网站的有效访问量。随着流量的增加,网站的整体排名有所提升。
10个优化技巧
全站优化是什么意思?优化不是以某个关键词为最终目标,而是对一个网站的综合优化,包括域名选择、网站结构或栏目设置, 查看全部
seq搜索引擎优化至少包括那几步?(SEO培训,SEO评估方法及工具培训的注意事项!)
优化流程
1:网站诊断分析(网站架构分析,网站内容分析,网站系统分析,网站功能分析)
2:网站竞争分析(行业搜索引擎竞争分析、竞争对手分析、搜索引擎友好度分析、关键词分析、链接分析)
3:SEO培训咨询(SEO基础知识培训、SEO实践专业培训、SEO评估方法及工具培训、SEO实践效果验收与维护)
4:数据追踪分析(数据追踪监测、效果维护与调整、策略评估与调整、流量分析)
5:优化策略结构与实施(全站优化的优化策略是什么,关键词策略,内链优化,外链部署策略,软文编辑和站外推广,搜索引擎性能预言 )
1、网站导航优化
是否锚文本导航,以文本形式做网站导航,不要使用flash、图片、js,因为这不如锚文本导航,锚文本导航蜘蛛更喜欢。
导航锚文本关键词相关性,这是栏目的定位,尽量用你首页的长尾关键词作为你的栏目。
主导航和二级导航,主导航只放栏目和频道,不放无关内容。第二个导航可以放一些相关的关键词页面导航或者栏目导航,但切记不要堆放。
是否有面包屑导航,首页>栏目页>内容页。
面包屑导航优化的细节需要注意:当前页面(登陆页面)一般不需要添加链接;您可以使用 关键词 作为面包屑的锚文本;一个页面可以有多个面包屑(以免给用户造成混淆)。
2、栏目页面优化
三个标签,标题、关键词、描述,合理填写,不要堆砌。标题结构,标题名称>列名>网站名称关键词相关性,检测分页标题重复,不要太多重复。分页链接网址是否加深网址深度,建议网址在3层以内。
3.内容页面优化
内容来源,来源以原创为主,参考写作为辅,不行就伪原创,不需要复制粘贴,对网站没有好处。URL是否收录关键词(英文),最好用关键词制作英文URL,中文拼音也是可以的。标题的格式,简洁明了,应该出现在标题网站main关键词中。要使用 H 标记,请将 H 标记添加到 网站 中第一次出现的 关键词。文章文字是否符合SEO标准,区分主次,合理关键词分布。图片的ALT属性可以增加关键词的密度和搜索引擎对图片的识别。
4. 链接优化
构建 网站 地图。Html 格式的网站 映射基于网站 的结构特征。有必要将网站的功能结构和服务内容罗列有序,力求页面简洁大方,方便用户浏览。
构建机器人文件。注意Robots.txt必须放在站点根目录下,文件名必须全部小写。将 网站 映射写入 Robots 文件。
设置404页面符合网站的设计风格。最好添加网站导航和底部(尤其是网站地图),并保证404页面返回的http状态码为404。
检测网站的死链接并删除,建议使用Xenu工具检测。
一个网站就像一个人,只有变得更好,才能收获更多,创造更多。如果把内链比作经络,那么网站的内容就是血肉之躯。一个网站即使内容丰富,如果经脉不通,最后的结果就是排名不好,收录的提升速度很慢。在网站的构建中,内部链构建的重要性不同于外部链的构建。除了网站和网站之间的链接,还有网站内部网页和网页之间的链接。反向链接也有助于排名。我个人理解,这就是内链的本质。,内链的意义在于用户可以更方便地查找信息。
逆向思维分析
网站内容采集点是关键词,关键词定位访问者。很多人喜欢讲浓度,搜索引擎也是这样看待网站的。标题的作用在细分的未来发展中会更加重要。主题突出,内容丰富,粘性大,领域纵深。这应该是未来几年网站的主流趋势。生活中人人都爱这么说,网站优化也是如此。不要刻意迎合搜索引擎和SEO的喜好,应该多考虑访问者。因为搜索引擎和SEO最终客户都是访问者,都是以人为基础的。一味讨好搜索引擎,容易被当作弊,人讲究个性,< @网站 也是一样。SEO 策略的实施因人而异。在我们研究搜索引擎的同时,搜索引擎也在向我们学习。
6优化方案格式
当你得到一个需要优化的网站时,并不是你得到了网站就去做。网站 优化计划。但这是一种比较简单的网站优化计划编写格式。
网站搜索引擎优化信息
1、ALEXA 排名
2、域名年龄
3、百度权重、谷歌公关及其收录情况
4、网站交通状况
5、关键词 排名
6.网站 外链数据情况
网站优化目标
1.制定目标关键词,并期待排名目标。
2.制定网站IP和PV值,预计增加多少流量网站。
网站站内优化
相信很多新手站长或者SEO新手一开始都会咨询哪里外链比较好,更希望外链遍布全球。其实对于网站优化来说,外链自然很重要,但用户体验更重要。从百度频繁的升级算法中,我们也可以看到,百度对用户体验差的问题不断进行打击网站!因此,叶建辉认为网站的内部优化和网站的用户体验比外链更重要。那么网站内部优化有哪些方面呢?
1.首页标题,观察网站首页标题的数量。
2.网站关键词分布,即页面关键词的密度,不要刻意叠加,就好了。
3.网站内容更新,网站内容更新是否定期很重要,特别是对于新网站,定期更新更能跳出沙盒。
4.网站 内链,无论网站大小,都不能忽视内链的重要性。
5.网站Map 和 网站 static,都影响蜘蛛爬行。
6.图片优化,ALT标签说明。
网站优化策略
网站优化策略需要详细分析。比如企业站和信息站的优化策略不同,企业站需要更新,信息站需要挖掘更多的关键词来拉动流量。
分工
没有完美的个人,只有完美的集体。网站SEO优化也是如此。团队合作,各司其职,才能做得更好。
7个用户组
1.经营大量产品的企业网站
2.行业提供广泛的服务网站
3.至少100个关键词可以总结服务或产品信息
4.专业商场,如服装商场、珠宝礼品商场、化妆品商场等。
5.品牌产品或代理品牌
6.热门行业
8大好处
增加有效流量
全站网站全站优化首先要注意长尾关键词。长尾关键词通常是指网站关键词除了核心关键词和二级核心关键词。一个网站除了核心关键词可以带来很多流量,长尾关键词也可以给网站带来很多流量,其总量为甚至比核心关键词还要大,带来更多的流量。例如,汽车音响店可能选择音响为核心关键词,汽车音响为副核心关键词。那么如果他是做竞价排名的话,选择这两个关键词的价格是很贵的,大概每点击3元左右;那么他可能会选择在google做seo,但是google主页上的都是响亮的网站:慧聪网,英商网、新浪汽车频道、中国汽车影音、中国音响网、太平洋汽车配件频道……如果一个普通的汽车音响店想进前十,你能做到吗?可以,但是很难。但他往往很着急,希望1-3个月内出成果,最后seo服务商不得不用不好的手段去运营。这是国内seo行业的普遍现状。那么,其实换个思路,我们能不能选择长尾词:汽车音响改装、惠威汽车音响、先锋汽车音响、汽车音响论坛、二手车音响、松下汽车音响、漫步者汽车音响、jvc汽车音响、汽车音频解码、汽车音响网络……等等。可能在用户通过搜索引擎检索到的所有关键词中,核心关键词产生了50%的流量,而另外50%的流量是由这些长尾关键词带来的。长尾关键词 通常是不受欢迎的词、词组,甚至是一个句子。当这么多用户使用搜索引擎时,他们可能会输入一些意想不到的东西,比如搜索“”、“北京汽车音响”等词,甚至“哪里可以找到便宜的二手汽车音响?”等短语或句子。在很多情况下,如何优化整个网站的效果表现在模板的修改、链接结构的调整和页面结构的调整,使其更符合搜索引擎的计算规则和同时对观众更加友好。优化整个网站优化指南后,就可以使用搜索引擎' s 排名计算中关键词列表的抽取原理,挖掘出很多关键词,获得好的排名。因此,车站的客流量大大增加。大部分都是好几次好转。如何优化整个网站的最大特点是你不是自己指定某个关键词,而是随着你的内容增加,搜索引擎会自动提取大量关键词进行排序。这种方式非常符合搜索引擎的计算规则。
更好的用户体验
如前所述,seo的目标是用户体验和流量。整个网站的优化是什么?必须考虑网站的结构、内容、美术设计、栏目构成、服务器和域名。这些基础构成了高用户。体验的关键因素,如何优化整个网站也是以此为基础,而关键词优化一般不需要考虑所有这些因素。
提高网站转化率
不管流量多高,提升访客到商机的转化率才是企业最需要的,全站优化的核心思想优化可以显着提升转化率。
从搜索引擎的角度:假设你是一家打印机公司的营销经理,你需要利用互联网来推广打印机。客户通过长尾词“个人家庭用彩色双面打印机”进行搜索,不仅仅是简单地搜索核心词“打印机”。在百度首页看到“打印机”完整列表的客户,清楚地表明前者的需求与网站呈现的内容更加兼容,因此前者更有可能致电打印机公司。
从网站的流程和内容设计来看:服务或产品内容的选择、表达方式,以及方便简单的引导流程的设计,交互方式的设计将大大增加参与度并有效激发游客的购买欲望。
转化率是seo必须关注的数据。良好的转化率可以将有限的流量转化为优质客户。全站优化方案的优化目标是为转化率和流量上下功夫。各种信息和网站结构的调整,将帮助企业获得更高的网站流量转化率,创造更多的利润。
说到底,如何优化整个网站,是企业营销下的功夫。因此,如何优化整个网站的seo,势必更加关注发布的信息量和平台的覆盖范围。这些信息将使企业信息获得更多展示机会。
控制广告成本
一方面,整个网站优化方案的优化可以带来可观的流量和转化。同时,因为竞争对手不可能花那么多精力去琢磨这几百个长尾词,所以不存在恶意点击。另一方面,它们不是点击。收费,因此如果您被竞争对手点击,不会有任何损失。因此,代理和竞争对手在竞价排名中的恶意欺诈点击不存在,投资回报率自然提高。
因此,全站优化和实战密码优化的目的是从根本上提升企业的质量网站,从而带来高质量的持续海量流量;显着提高转化率。这让企业告别竞价排名依赖。很明显,在核心关键词价格被夸大的情况下,全站优化的投资回报远好于竞价排名。
优化与搜索引擎优化的关系
全站优化是通过对网站定位、网站内容和网站结构的整体优化,保证网站的所有页面对搜索引擎友好,所以网站在各大搜索引擎中,收录的搜索量相对较高,整体排名表现良好。如何优化整个站点 优化整个站点是搜索引擎营销的最佳实践。
什么是全站优化?优化和简单的关键词优化的区别
全站如何优化除了考虑排名,全站优化更看重点击率和网站转化率。它不以某个关键词在某个搜索引擎上的排名为得失,而是关注所有高质量相关关键词在所有搜索引擎上的综合表现。
全站优化比关键词竞价更有效
与关键词竞价不同,如何优化全站可以让你网站通过更优质的关键词从更多搜索引擎获得更多自然流量,而无需担心恶意点击和恶意出价
9 优化目标
1、实现目标提升和长尾关键词的关键词优化。
流量分析,时刻关注网站关键词密度分布,提高目标关键词排名。关注准尾关键词和长尾关键词的关注程度及其在首页的分布情况。
2、保证网站搜索引擎会搜索到最新发布的内容收录。
通过优化长尾关键词的分布和选择,大大提高了网站页面被搜索引擎收录搜索到的概率。整体提升网站的有效访问量。随着流量的增加,网站的整体排名有所提升。
10个优化技巧
全站优化是什么意思?优化不是以某个关键词为最终目标,而是对一个网站的综合优化,包括域名选择、网站结构或栏目设置,
seq搜索引擎优化至少包括那几步?(本文MySQL优化器如何选择索引和JOIN顺序(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-12 08:07
本文通过一个案例来看看MySQL优化器是如何选择索引和JOIN顺序的。表结构和数据准备参考本文末尾的“测试环境”。本文主要介绍MySQL优化器的主要执行过程,而不是介绍一个优化器的各个组件(这是另一个话题)。
我们知道 MySQL 优化器只有两个自由度:顺序选择;单表访问模式;这里我们将详细分析下面的SQL,看看MySQL优化器在每一步是如何做出选择的。
explain
select *
from
employee as A,department as B
where
A.LastName = 'zhou'
and B.DepartmentID = A.DepartmentID
and B.DepartmentName = 'TBX';
1. 可能的选项
这里可以看到JOIN的顺序可以是A|B也可以是B|A,单表的访问方式有很多种。对于表A,可以选择:全表扫描和索引`IND_L_D`(A.LastName ='zhou')或`IND_DID`(B.DepartmentID = A.DepartmentID)。B也有3个选项:全表扫描、索引IND_D、IND_DN。
2. MySQL 优化器如何做2.1 概述
MySQL优化器的主要工作包括以下几部分:Query Rewrite(包括Outer Join转换等)、const表检测、范围分析、JOIN优化(顺序和访问方式选择)、计划细化。这个案例从范围分析开始。
2.2 范围分析
这部分包括了所有的Range和index合并成本评估(参考1参考2)。这里等价表达式也是一个范围,所以这里会计算成本,找到记录(代表对应的等价表达式,大致将选择多少条记录)。
在这种情况下,极差分析会分别分析表A中的条件A.LastName='zhou'和表B中的B.DepartmentName='TBX'。
表A A.LastName = 'zhou' found records: 51
表B B.DepartmentName = 'TBX' found records: 1
这两个条件都不是范围,但是这里计算出来的值还是会被存储起来,用于后续的ref访问方法求值。这里的值是根据records_in_range接口返回的,InnoDB每次调用这个函数都会对索引页进行采样。这是一个非常消耗性能的操作。对于许多其他关系数据库,使用“直方图”统计数据。避免这种操作(相信后续版本的 MariaDB 也会实现直方图统计)。
2.3 选择顺序和访问方式:穷举列表
MySQL通过枚举all找到最优的执行顺序和访问方式(也可以说所有的左深树都是整个MySQL优化器的搜索空间)。
2.3.1 排序
优化器首先根据找到的记录对所有表进行排序,并将记录较少的表放在最前面。因此,这里的顺序是B,A。
2.3.2 贪婪搜索
当表数较少时(小于search_depth,默认为63),这样直接减少为穷举搜索,优化器会穷尽所有左深树寻找最优执行计划。在另外,为了减少巨大的搜索空间带来的巨大的耗尽消耗,优化器使用了一个“懒惰”的参数prune_level(默认开启),具体如何“懒惰”可以参考JOIN命令的复杂度选择。但至少它需要与“懒惰”相关联的表不止三个,所以这种情况不适用。
2.3.3 精疲力竭
JOIN的第一个表可以是:A或B;如果第一张表选择A,第二张表可以选择B;如果第一张表选择B,第二张表可以选择A;
因为前面的排序,B表找到的记录比较少,所以JOIN顺序的第一个表用完了,先选B(这个很精致)。
(*) 选择第一个JOIN的表为B
(**) 确定B表的访问方式
因为B表为第一个表,所以无法使用索引IND_D(B.DepartmentID = A.DepartmentID),而只能使用IND_DN(B.DepartmentName = 'TBX')
使用IND_DN索引的成本计算:1.2;其中IO成本为1。
是否使用全表扫描:这里会比较使用索引的IO成本和全表扫描的IO成本,前者为1,后者为2;所以忽略全表扫描
所以,B表的访问方式ref,使用索引IND_D
(**) 从剩余的表中穷举选出第二个JOIN的表,这里剩余的表为:A
(**) 将A表加入JOIN,并确定其访问方式
可以使用的索引为:`IND_L_D`(A.LastName = 'zhou')或者`IND_DID`(B.DepartmentID = A.DepartmentID)
依次计算使用索引IND_L_D、IND_DID的成本:
(***) IND_L_D A.LastName = 'zhou'
在range analysis阶段给出了A.LastName = 'zhou'对应的记录约为:51。
所以,计算IO成本为:51;ref做IO成本计算时会做一次修正,将其修正为worst_seek(参考)
修正后IO成本为:15,总成本为:25.2
(***) IND_DID B.DepartmentID = A.DepartmentID
这是一个需要知道前面表的结果,才能计算的成本。所以range analysis是无法分析的
这里,我们看到前面表为B,found_record是1,所以A.DepartmentID只需要对应一条记录就可以了
因为具体取值不知道,也没有直方图,所以只能简单依据索引统计信息来计算:
索引IND_DID的列A.DepartmentID的Cardinality为1349,全表记录数为1349
所以,每一个值对应一条记录,而前面表B只有一条记录,所以这里的found_record计算为1*1 = 1
所以IO成本为:1,总成本为1.2
(***) IND_L_D成本为25.2;IND_DID成本为1.2,所以选择后者为当前表的访问方式
(**) 确定A使用索引IND_DID,访问方式为ref
(**) JOIN顺序B|A,总成本为:1.2+1.2 = 2.4
(*) 选择第一个JOIN的表为A
(**) 确定A表的访问方式
因为A表是第一个表,所以无法使用索引`IND_DID`(B.DepartmentID = A.DepartmentID)
那么只能使用索引`IND_L_D`(A.LastName = 'zhou')
使用IND_L_D索引的成本计算,总成本为25.2;参考前面计算;
(**) 这里访问A表的成本已经是25.2,比之前的最优成本2.4要大,忽略该顺序
所以,这次穷举搜索到此结束
将上述过程简化如下:
(*) 选择第一个JOIN的表为B
(**) 确定B表的访问方式
(**) 从剩余的表中穷举选出第二个JOIN的表,这里剩余的表为:A
(**) 将A表加入JOIN,并确定其访问方式
(***) IND_L_D A.LastName = 'zhou'
(***) IND_DID B.DepartmentID = A.DepartmentID
(***) IND_L_D成本为25.2;IND_DID成本为1.2,所以选择后者为当前表的访问方式
(**) 确定A使用索引IND_DID,访问方式为ref
(**) JOIN顺序B|A,总成本为:1.2+1.2 = 2.4
(*) 选择第一个JOIN的表为A
(**) 确定A表的访问方式
(**) 这里访问A表的成本已经是25.2,比之前的最优成本2.4要大,忽略该顺序
至此,MySQL优化器已经确定了所有表的最佳JOIN顺序和访问方式。
3. 测试环境
MySQL: 5.1.48-debug-log innodb plugin 1.0.9
CREATE TABLE `department` (
`DepartmentID` int(11) DEFAULT NULL,
`DepartmentName` varchar(20) DEFAULT NULL,
KEY `IND_D` (`DepartmentID`),
KEY `IND_DN` (`DepartmentName`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
CREATE TABLE `employee` (
`LastName` varchar(20) DEFAULT NULL,
`DepartmentID` int(11) DEFAULT NULL,
KEY `IND_L_D` (`LastName`),
KEY `IND_DID` (`DepartmentID`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
for i in `seq 1 1000` ; do mysql -vvv -uroot test -e 'insert into department values (600000*rand(),repeat(char(65+rand()*58),rand()*20))'; done
for i in `seq 1 1000` ; do mysql -vvv -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),600000*rand())'; done
for i in `seq 1 50` ; do mysql -vvv -uroot test -e 'insert into employee values ("zhou",27760)'; done
for i in `seq 1 200` ; do mysql -vvv -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),27760)'; done
for i in `seq 1 1` ; do mysql -vvv -uroot test -e 'insert into department values (27760,"TBX")'; done
show index from employee;
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
| employee | 1 | IND_L_D | 1 | LastName | A | 1349 | NULL | NULL | YES | BTREE | |
| employee | 1 | IND_DID | 1 | DepartmentID | A | 1349 | NULL | NULL | YES | BTREE | |
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
show index from department;
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
| department | 1 | IND_D | 1 | DepartmentID | A | 1001 | NULL | NULL | YES | BTREE | |
| department | 1 | IND_DN | 1 | DepartmentName | A | 1001 | NULL | NULL | YES | BTREE | |
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
4. 构建一个坏案例
由于MySQL在关联条件中使用索引统计进行成本估算,因此在数据分布不均时容易做出错误判断。简单地我们构造如下案例:
表和索引结构不变,数据构造如下:
for i in `seq 1 10000` ; do mysql -uroot test -e 'insert into department values (600000*rand(),repeat(char(65+rand()*58),rand()*20))'; done
for i in `seq 1 10000` ; do mysql -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),600000*rand())'; done
for i in `seq 1 1` ; do mysql -uroot test -e 'insert into employee values ("zhou",27760)'; done
for i in `seq 1 10` ; do mysql -uroot test -e 'insert into department values (27760,"TBX")'; done
for i in `seq 1 1000` ; do mysql -uroot test -e 'insert into department values (27760,repeat(char(65+rand()*58),rand()*20))';
done
explain
select *
from
employee as A,department as B
where
A.LastName = 'zhou'
and B.DepartmentID = A.DepartmentID
and B.DepartmentName = 'TBX';
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
| 1 | SIMPLE | A | ref | IND_L_D,IND_DID | IND_L_D | 43 | const | 1 | Using where |
| 1 | SIMPLE | B | ref | IND_D,IND_DN | IND_D | 5 | test.A.DepartmentID | 1 | Using where |
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
在这里可以看到,MySQL执行计划对表部门使用索引IND_D,那么A表中的一条记录是(zhou,27760);根据B.DepartmentID=27760,会返回1010条记录,然后根据条件 DepartmentName = Filter by'TBX'。
这里可以看到如果B表选择索引IND_DN,效果更好,因为DepartmentName='TBX'只返回10条记录,然后根据条件A.DepartmentID=B.DepartmentID进行过滤。
认为 文章 有用吗?即刻:与朋友一起学习进步!
我猜你会喜欢 查看全部
seq搜索引擎优化至少包括那几步?(本文MySQL优化器如何选择索引和JOIN顺序(组图))
本文通过一个案例来看看MySQL优化器是如何选择索引和JOIN顺序的。表结构和数据准备参考本文末尾的“测试环境”。本文主要介绍MySQL优化器的主要执行过程,而不是介绍一个优化器的各个组件(这是另一个话题)。
我们知道 MySQL 优化器只有两个自由度:顺序选择;单表访问模式;这里我们将详细分析下面的SQL,看看MySQL优化器在每一步是如何做出选择的。
explain
select *
from
employee as A,department as B
where
A.LastName = 'zhou'
and B.DepartmentID = A.DepartmentID
and B.DepartmentName = 'TBX';
1. 可能的选项
这里可以看到JOIN的顺序可以是A|B也可以是B|A,单表的访问方式有很多种。对于表A,可以选择:全表扫描和索引`IND_L_D`(A.LastName ='zhou')或`IND_DID`(B.DepartmentID = A.DepartmentID)。B也有3个选项:全表扫描、索引IND_D、IND_DN。
2. MySQL 优化器如何做2.1 概述
MySQL优化器的主要工作包括以下几部分:Query Rewrite(包括Outer Join转换等)、const表检测、范围分析、JOIN优化(顺序和访问方式选择)、计划细化。这个案例从范围分析开始。
2.2 范围分析
这部分包括了所有的Range和index合并成本评估(参考1参考2)。这里等价表达式也是一个范围,所以这里会计算成本,找到记录(代表对应的等价表达式,大致将选择多少条记录)。
在这种情况下,极差分析会分别分析表A中的条件A.LastName='zhou'和表B中的B.DepartmentName='TBX'。
表A A.LastName = 'zhou' found records: 51
表B B.DepartmentName = 'TBX' found records: 1
这两个条件都不是范围,但是这里计算出来的值还是会被存储起来,用于后续的ref访问方法求值。这里的值是根据records_in_range接口返回的,InnoDB每次调用这个函数都会对索引页进行采样。这是一个非常消耗性能的操作。对于许多其他关系数据库,使用“直方图”统计数据。避免这种操作(相信后续版本的 MariaDB 也会实现直方图统计)。
2.3 选择顺序和访问方式:穷举列表
MySQL通过枚举all找到最优的执行顺序和访问方式(也可以说所有的左深树都是整个MySQL优化器的搜索空间)。
2.3.1 排序
优化器首先根据找到的记录对所有表进行排序,并将记录较少的表放在最前面。因此,这里的顺序是B,A。
2.3.2 贪婪搜索
当表数较少时(小于search_depth,默认为63),这样直接减少为穷举搜索,优化器会穷尽所有左深树寻找最优执行计划。在另外,为了减少巨大的搜索空间带来的巨大的耗尽消耗,优化器使用了一个“懒惰”的参数prune_level(默认开启),具体如何“懒惰”可以参考JOIN命令的复杂度选择。但至少它需要与“懒惰”相关联的表不止三个,所以这种情况不适用。
2.3.3 精疲力竭
JOIN的第一个表可以是:A或B;如果第一张表选择A,第二张表可以选择B;如果第一张表选择B,第二张表可以选择A;
因为前面的排序,B表找到的记录比较少,所以JOIN顺序的第一个表用完了,先选B(这个很精致)。
(*) 选择第一个JOIN的表为B
(**) 确定B表的访问方式
因为B表为第一个表,所以无法使用索引IND_D(B.DepartmentID = A.DepartmentID),而只能使用IND_DN(B.DepartmentName = 'TBX')
使用IND_DN索引的成本计算:1.2;其中IO成本为1。
是否使用全表扫描:这里会比较使用索引的IO成本和全表扫描的IO成本,前者为1,后者为2;所以忽略全表扫描
所以,B表的访问方式ref,使用索引IND_D
(**) 从剩余的表中穷举选出第二个JOIN的表,这里剩余的表为:A
(**) 将A表加入JOIN,并确定其访问方式
可以使用的索引为:`IND_L_D`(A.LastName = 'zhou')或者`IND_DID`(B.DepartmentID = A.DepartmentID)
依次计算使用索引IND_L_D、IND_DID的成本:
(***) IND_L_D A.LastName = 'zhou'
在range analysis阶段给出了A.LastName = 'zhou'对应的记录约为:51。
所以,计算IO成本为:51;ref做IO成本计算时会做一次修正,将其修正为worst_seek(参考)
修正后IO成本为:15,总成本为:25.2
(***) IND_DID B.DepartmentID = A.DepartmentID
这是一个需要知道前面表的结果,才能计算的成本。所以range analysis是无法分析的
这里,我们看到前面表为B,found_record是1,所以A.DepartmentID只需要对应一条记录就可以了
因为具体取值不知道,也没有直方图,所以只能简单依据索引统计信息来计算:
索引IND_DID的列A.DepartmentID的Cardinality为1349,全表记录数为1349
所以,每一个值对应一条记录,而前面表B只有一条记录,所以这里的found_record计算为1*1 = 1
所以IO成本为:1,总成本为1.2
(***) IND_L_D成本为25.2;IND_DID成本为1.2,所以选择后者为当前表的访问方式
(**) 确定A使用索引IND_DID,访问方式为ref
(**) JOIN顺序B|A,总成本为:1.2+1.2 = 2.4
(*) 选择第一个JOIN的表为A
(**) 确定A表的访问方式
因为A表是第一个表,所以无法使用索引`IND_DID`(B.DepartmentID = A.DepartmentID)
那么只能使用索引`IND_L_D`(A.LastName = 'zhou')
使用IND_L_D索引的成本计算,总成本为25.2;参考前面计算;
(**) 这里访问A表的成本已经是25.2,比之前的最优成本2.4要大,忽略该顺序
所以,这次穷举搜索到此结束
将上述过程简化如下:
(*) 选择第一个JOIN的表为B
(**) 确定B表的访问方式
(**) 从剩余的表中穷举选出第二个JOIN的表,这里剩余的表为:A
(**) 将A表加入JOIN,并确定其访问方式
(***) IND_L_D A.LastName = 'zhou'
(***) IND_DID B.DepartmentID = A.DepartmentID
(***) IND_L_D成本为25.2;IND_DID成本为1.2,所以选择后者为当前表的访问方式
(**) 确定A使用索引IND_DID,访问方式为ref
(**) JOIN顺序B|A,总成本为:1.2+1.2 = 2.4
(*) 选择第一个JOIN的表为A
(**) 确定A表的访问方式
(**) 这里访问A表的成本已经是25.2,比之前的最优成本2.4要大,忽略该顺序
至此,MySQL优化器已经确定了所有表的最佳JOIN顺序和访问方式。
3. 测试环境
MySQL: 5.1.48-debug-log innodb plugin 1.0.9
CREATE TABLE `department` (
`DepartmentID` int(11) DEFAULT NULL,
`DepartmentName` varchar(20) DEFAULT NULL,
KEY `IND_D` (`DepartmentID`),
KEY `IND_DN` (`DepartmentName`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
CREATE TABLE `employee` (
`LastName` varchar(20) DEFAULT NULL,
`DepartmentID` int(11) DEFAULT NULL,
KEY `IND_L_D` (`LastName`),
KEY `IND_DID` (`DepartmentID`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
for i in `seq 1 1000` ; do mysql -vvv -uroot test -e 'insert into department values (600000*rand(),repeat(char(65+rand()*58),rand()*20))'; done
for i in `seq 1 1000` ; do mysql -vvv -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),600000*rand())'; done
for i in `seq 1 50` ; do mysql -vvv -uroot test -e 'insert into employee values ("zhou",27760)'; done
for i in `seq 1 200` ; do mysql -vvv -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),27760)'; done
for i in `seq 1 1` ; do mysql -vvv -uroot test -e 'insert into department values (27760,"TBX")'; done
show index from employee;
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
| employee | 1 | IND_L_D | 1 | LastName | A | 1349 | NULL | NULL | YES | BTREE | |
| employee | 1 | IND_DID | 1 | DepartmentID | A | 1349 | NULL | NULL | YES | BTREE | |
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
show index from department;
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
| department | 1 | IND_D | 1 | DepartmentID | A | 1001 | NULL | NULL | YES | BTREE | |
| department | 1 | IND_DN | 1 | DepartmentName | A | 1001 | NULL | NULL | YES | BTREE | |
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
4. 构建一个坏案例
由于MySQL在关联条件中使用索引统计进行成本估算,因此在数据分布不均时容易做出错误判断。简单地我们构造如下案例:
表和索引结构不变,数据构造如下:
for i in `seq 1 10000` ; do mysql -uroot test -e 'insert into department values (600000*rand(),repeat(char(65+rand()*58),rand()*20))'; done
for i in `seq 1 10000` ; do mysql -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),600000*rand())'; done
for i in `seq 1 1` ; do mysql -uroot test -e 'insert into employee values ("zhou",27760)'; done
for i in `seq 1 10` ; do mysql -uroot test -e 'insert into department values (27760,"TBX")'; done
for i in `seq 1 1000` ; do mysql -uroot test -e 'insert into department values (27760,repeat(char(65+rand()*58),rand()*20))';
done
explain
select *
from
employee as A,department as B
where
A.LastName = 'zhou'
and B.DepartmentID = A.DepartmentID
and B.DepartmentName = 'TBX';
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
| 1 | SIMPLE | A | ref | IND_L_D,IND_DID | IND_L_D | 43 | const | 1 | Using where |
| 1 | SIMPLE | B | ref | IND_D,IND_DN | IND_D | 5 | test.A.DepartmentID | 1 | Using where |
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
在这里可以看到,MySQL执行计划对表部门使用索引IND_D,那么A表中的一条记录是(zhou,27760);根据B.DepartmentID=27760,会返回1010条记录,然后根据条件 DepartmentName = Filter by'TBX'。
这里可以看到如果B表选择索引IND_DN,效果更好,因为DepartmentName='TBX'只返回10条记录,然后根据条件A.DepartmentID=B.DepartmentID进行过滤。
认为 文章 有用吗?即刻:与朋友一起学习进步!
我猜你会喜欢
seq搜索引擎优化至少包括那几步?(网站SEO优化每天要做的长尾关键词的发掘与建造网站的seo适用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-12 08:05
点击发布信息平台b2b了解更多众赢天下优化排名榜首[众赢天下2c4af64]网站SEO优化每日做长尾关键词挖掘建设网站seo适用方法网站优化应该遵循的基本原则 网站SEO优化每天都要做
网站SEO优化需要每天做
每天发布外部链接到网站
定期、循序渐进地添加链接是做好网站工作的必要条件。外链功能大而规则,为了更好地发挥作用,必须逐步增加。一般来说,排列关键字比较容易。链外,这是优化SEO站点外内容的一个方面;如果没有导入外部链接,蜘蛛程序将很难找到您的踪迹。通过导入链接,蜘蛛将根据其位置找到我们的站点。外链搜索引擎蜘蛛的爬取需要大量优质的外链来支持!坚持每天提升网站质量标准,让您的网站获得良好的排名和流量;
每周写2篇软文
写软文书不难,难的是坚持写作,不断写出高质量的软文书。但是今天的软文是一种低成本的实现方式,它的效果是相当明显的,而且作为一个合格的站长,学习写软文是非常有必要的,如果不熟悉的朋友,能够在 Internet 上查找信息并了解更多信息。
长尾的挖掘与建设关键词
发布原创内容有利于提高收录速度和收录网页量
网站地图和404页面
发现有些小公司对网站建设不是很熟悉。随意找人做公司网站的建设,即使他们甚至没有网站的地图。事实上,网站 地图有很大的作用。可以认为搜索引擎爬虫提供了各个地方的链接网站,可以有效的减少爬虫的工作量,增加搜索引擎的用处。输入文章的数量,所以在做网站图之前一定要规划好栏目分类和产品分类。其他的404页面主要是为了避免出现网站的死链接。当一个文章页面不存在,但出现在搜索引擎索引库中时,那么搜索引擎爬虫会爬到死链接,
长尾的挖掘与建设关键词
外贸网站要在建设过程中获得更多的流量,离不开长尾关键词的挖掘和建设,而长尾关键词想要排位,那只是高-优质的信息内容和文章通过网站关键词的搜索引擎优化优化,可以有效的获得好的排名。当很多长尾关键词搜索引擎优化优化以后,我不会担心网站因为搜索引擎算法或政策的变化关键词,因为即使政策< @关键词排名丢失,长尾关键词搜索引擎优化排名还在,不会造成网站流量消失。
网站SEO适用方法
网站的seo适用方法。“绿萝算法”的引入让网站死了90%。无数站长喊道:“以后网站还能做什么?” 其实站长们需要知道一件事:是不是绿萝算法?只为你网站?你的网站没有排名,其他网站是百度的亲戚吗?搜索相关关键词钢铁网站还能跳出来吗?所以机会是公平的。作者对绿萝算法的建议是规范站点,站点外更严格。绿萝算法以攻击外链着称,但至少网站还是没影响到。很多网站的内容平时很多,但是现在好像很常见。作者不提倡这个,就算你有更多的内容,如果你有很多内容,迟早会降低你的权力。然后是内链,同样是链接,外链是做不到的。为什么不做好内部链接呢?它是结构的标准化。这是一个常见的问题。有很多网站文章非常多,导致内部结构非常混乱。对于每个页面,三个要素基本相同,导致权重无法集中,排名更加困难;外链方面,普通外链做不到,做一些社交标签难吗?百度百科不能做搜索?能' t 搜索百科全书?有福育客优化认为,1个这样的外链至少相当于100个像您之前发布的一样乱七八糟的外链。
网站优化的基本原理
网站优化的基本原理
.网站首页
基于多年的实践经验,我们相信大多数中小企业在网站SEO排名时都会优化网站的首页。因此,我们需要特别注意主页的设置,例如:
首页的TDK标签,尤其是标题标签关键词的匹配;
首页关键词,合理控制首页布局中关键词的密度; 查看全部
seq搜索引擎优化至少包括那几步?(网站SEO优化每天要做的长尾关键词的发掘与建造网站的seo适用方法)
点击发布信息平台b2b了解更多众赢天下优化排名榜首[众赢天下2c4af64]网站SEO优化每日做长尾关键词挖掘建设网站seo适用方法网站优化应该遵循的基本原则 网站SEO优化每天都要做
网站SEO优化需要每天做
每天发布外部链接到网站
定期、循序渐进地添加链接是做好网站工作的必要条件。外链功能大而规则,为了更好地发挥作用,必须逐步增加。一般来说,排列关键字比较容易。链外,这是优化SEO站点外内容的一个方面;如果没有导入外部链接,蜘蛛程序将很难找到您的踪迹。通过导入链接,蜘蛛将根据其位置找到我们的站点。外链搜索引擎蜘蛛的爬取需要大量优质的外链来支持!坚持每天提升网站质量标准,让您的网站获得良好的排名和流量;
每周写2篇软文
写软文书不难,难的是坚持写作,不断写出高质量的软文书。但是今天的软文是一种低成本的实现方式,它的效果是相当明显的,而且作为一个合格的站长,学习写软文是非常有必要的,如果不熟悉的朋友,能够在 Internet 上查找信息并了解更多信息。

长尾的挖掘与建设关键词
发布原创内容有利于提高收录速度和收录网页量
网站地图和404页面
发现有些小公司对网站建设不是很熟悉。随意找人做公司网站的建设,即使他们甚至没有网站的地图。事实上,网站 地图有很大的作用。可以认为搜索引擎爬虫提供了各个地方的链接网站,可以有效的减少爬虫的工作量,增加搜索引擎的用处。输入文章的数量,所以在做网站图之前一定要规划好栏目分类和产品分类。其他的404页面主要是为了避免出现网站的死链接。当一个文章页面不存在,但出现在搜索引擎索引库中时,那么搜索引擎爬虫会爬到死链接,
长尾的挖掘与建设关键词
外贸网站要在建设过程中获得更多的流量,离不开长尾关键词的挖掘和建设,而长尾关键词想要排位,那只是高-优质的信息内容和文章通过网站关键词的搜索引擎优化优化,可以有效的获得好的排名。当很多长尾关键词搜索引擎优化优化以后,我不会担心网站因为搜索引擎算法或政策的变化关键词,因为即使政策< @关键词排名丢失,长尾关键词搜索引擎优化排名还在,不会造成网站流量消失。

网站SEO适用方法
网站的seo适用方法。“绿萝算法”的引入让网站死了90%。无数站长喊道:“以后网站还能做什么?” 其实站长们需要知道一件事:是不是绿萝算法?只为你网站?你的网站没有排名,其他网站是百度的亲戚吗?搜索相关关键词钢铁网站还能跳出来吗?所以机会是公平的。作者对绿萝算法的建议是规范站点,站点外更严格。绿萝算法以攻击外链着称,但至少网站还是没影响到。很多网站的内容平时很多,但是现在好像很常见。作者不提倡这个,就算你有更多的内容,如果你有很多内容,迟早会降低你的权力。然后是内链,同样是链接,外链是做不到的。为什么不做好内部链接呢?它是结构的标准化。这是一个常见的问题。有很多网站文章非常多,导致内部结构非常混乱。对于每个页面,三个要素基本相同,导致权重无法集中,排名更加困难;外链方面,普通外链做不到,做一些社交标签难吗?百度百科不能做搜索?能' t 搜索百科全书?有福育客优化认为,1个这样的外链至少相当于100个像您之前发布的一样乱七八糟的外链。

网站优化的基本原理
网站优化的基本原理
.网站首页
基于多年的实践经验,我们相信大多数中小企业在网站SEO排名时都会优化网站的首页。因此,我们需要特别注意主页的设置,例如:
首页的TDK标签,尤其是标题标签关键词的匹配;
首页关键词,合理控制首页布局中关键词的密度;
seq搜索引擎优化至少包括那几步?( 贯穿搜索引擎优化系统的公式是什么?优化排名技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-12 07:04
贯穿搜索引擎优化系统的公式是什么?优化排名技术)
小苏资源网:搜索引擎优化排名技术分析
搜索引擎优化涉及很多基础知识。除了单一的技术,还包括创新思维。如果你给你50页的内容是否可以排版不同的格式,这需要创新,那么本文将给你分析搜索引擎优化排名技巧。
贯穿搜索引擎优化系统的公式是什么?以下是内容,整理和删除,这是提炼它的价值,你觉得不好,就过滤一下,如果你是做搜索引擎优化的案例,建议你看看,如果不是,你不妨看看看,一切都有它的价值!
搜索引擎优化
1.从眼球到眼球
首先,搜索引擎优化的目的是获取客户流量。无论是销售产品还是推广某些服务,我们都需要客户。这也是搜索引擎优化的价值所在。每一个不同的关键词意味着背后有很多眼球(每个关键词都有一群客户在搜索),那么对于我们来说,没有访客怎么办?
每个行业不同的关键词都已经有眼球了,所以只要去有眼球的地方去获取眼球,这个是最快的,所以SEO第一步就是过滤关键词,并逐渐扩大长尾关键词(详见商七云SEO的《长尾关键词采集方法与技术》(Methods and Technology for Long Tail Keyword 采集)),确定关键词之后,我们开始实施下一步,所以我们需要某个链来获得排名,不知道在哪里建立这个链?
2、从外链到外链
在百度中随机搜索一个排名靠前的网站,然后在百度搜索框中输入DOMAIN+网址就知道发到哪里了。
当然,您也可以进行更详细的分析。也可以搜索他的具体内页网址,会发现更多惊喜,得到大量外链地址(详情请参考《网站上如何构建外链》(How Build网站上的外部链接)相关介绍。
另外,还可以使用外链分析软件进行分析,总之就是通过别人的网站获取外链资源。
如何应对项目运营时间紧?自己做网站,等收录,再发链优化排名周期太长,想快点怎么办?那么我们必须增加网站的权重。
3、从重量到重量
大的网站 已经有一定的重量了。对于百度搜索引擎来说,他们的网页更可信。一般只要发布信息,几分钟到几十分钟就可以收录。
对此,我们可以利用或各种重量级网站发布信息,提供给国外连锁店。关键词在竞争不是很激烈的地方,一般一周内就能拿到名次(见奇云seo“使用高权重或高流量平台推广网络的利弊”相关介绍) .
4.从排名到排名
如果要在半小时内把产品的广告信息放到关键词首页排名怎么办?
比如你在百度上搜索关键词“木门”,仔细往下翻。你看见了吗?
SEO分级爆破技术核心优化思路
在关键字木门搜索结果的第一页,有最新的相关信息。您只需要在这些新闻源发布信息,半小时内就可以让您的广告信息出现在关键词的首页。你只需要使用你的力量,你就能意识到这一点。同时,你也可以利用这些新闻源来导入链接,为你的网站增加权重。
此外,您还可以使用百度产品、图书馆、百科全书、知识等。出于同样的原因。
搜索引擎优化
5、从资源到资源
当优化第一个网站进行搜索引擎优化时,因为你没有足够的资源,这是最关键的问题,但是当你可以优化第一个网站然后优化第二个网站 显然比第一个容易很多,这就是为什么优化第一个 网站 是最困难的。
尚启云认为,所谓的搜索引擎优化专家在技术上并不高人一等。排名的原则其实就是最后拼的就是资源的组合和使用资源的能力,仅此而已!
因此,从现在开始,您必须记住从资源移动到资源!
我知道你在困惑什么,你一定在想,关键是我没有资源?
不,您已经拥有资源和您想要的一切。已经有人在你面前拥有它们了。你要的是用它,以成功为起点,这样你才能更快地走向成功。
简而言之,拥有资源的人不如使用资源的人。您需要的不是您拥有多少资源,而是您可以控制多少资源。这是非常关键的!
从您感兴趣的内容到客户感兴趣的内容
你要像一个真正的营销人员,学会100%站在客户的角度思考,进入客户的世界,感受他的痛苦,然后你就会知道他们最感兴趣的是什么。
例如,您有兴趣让客户参加您的英语培训,但客户对您的培训不感兴趣,他只对自己的演讲感兴趣。所以,你必须先进入客户的世界,然后找出他的痛点,把他从他的世界带到你的世界。理解?
看这里,你应该知道我说的公式是什么了吧?
是的,从二十到二十!
这个公式将同时打开你的几种思维模式。首先,它会自动驱动你的自助思维,让你思考如何从别人已经成功的东西走向自己的成功。其次,它开始你的持续思考。思维问题不是基于点,而是线性思维。也可以说是交互思维。
所以,尚云奇认为网站的搜索引擎优化不是很友好,但是很简单。只有当复杂的事情变得简单时,它才具有更大的价值。
你必须知道 XX 导致 XX。这个公式的原则是从一个成功到另一个成功,而不是从头开始,用最简单的例子。
7、从××到××,每一个爆点都被抓到了
如果你能反复研究这个公式,并把它应用到搜索引擎优化的每一个细节,你会发现它可以帮你把所有搜索引擎优化系统的内容概括成这个公式。在你未来的思考过程中,你会发现你有更多的创造力!
搜索引擎优化
另外,其实这个公式可以用的地方太多了,除了SEO之外,所有地方都可以用,所以尚启云建议大家不仅抓好这些例子,忽略本质,还要深入理解原理,并尽力从一个实例转到另一个实例。比如从内容到内容,从案例到案例,从热点信息到热点流量。
然后找到最适合您的并立即采取行动。如果你只从表面上学习而不用你的大脑,那是没有用的。我相信你同意这个观点,对吗?
同一句话,他山上的石头可以用来攻玉。他应该善于发现事物的价值,然后为我所用。不要被一些所谓的概念误导。学习最简单实用的策略,越容易实施。关键不是看太多,而是看完之后细化,然后严格执行。
知道并不意味着能够执行,只有这样才能取得成果。如果你努力去做简单的事情,你就会成功!
搜索引擎优化排名爆破技术可以说是一个贯穿搜索引擎优化系统的公式。这个内容并不新鲜,但还是很有用的。正确的思维方向永远不会持久。至少我是这么认为的。过去,很多人说这个内容被炒作了。炒作与我无关。我保留我的意见。
一切都有它的价值。没有找到价值是你的遗憾。选择一个好的并遵循它。坏的,扔掉。与其批评和拒绝它,不如提炼它的价值,供我自己使用。他山的石头可以用来攻玉。 查看全部
seq搜索引擎优化至少包括那几步?(
贯穿搜索引擎优化系统的公式是什么?优化排名技术)
小苏资源网:搜索引擎优化排名技术分析
搜索引擎优化涉及很多基础知识。除了单一的技术,还包括创新思维。如果你给你50页的内容是否可以排版不同的格式,这需要创新,那么本文将给你分析搜索引擎优化排名技巧。
贯穿搜索引擎优化系统的公式是什么?以下是内容,整理和删除,这是提炼它的价值,你觉得不好,就过滤一下,如果你是做搜索引擎优化的案例,建议你看看,如果不是,你不妨看看看,一切都有它的价值!

搜索引擎优化
1.从眼球到眼球
首先,搜索引擎优化的目的是获取客户流量。无论是销售产品还是推广某些服务,我们都需要客户。这也是搜索引擎优化的价值所在。每一个不同的关键词意味着背后有很多眼球(每个关键词都有一群客户在搜索),那么对于我们来说,没有访客怎么办?
每个行业不同的关键词都已经有眼球了,所以只要去有眼球的地方去获取眼球,这个是最快的,所以SEO第一步就是过滤关键词,并逐渐扩大长尾关键词(详见商七云SEO的《长尾关键词采集方法与技术》(Methods and Technology for Long Tail Keyword 采集)),确定关键词之后,我们开始实施下一步,所以我们需要某个链来获得排名,不知道在哪里建立这个链?
2、从外链到外链
在百度中随机搜索一个排名靠前的网站,然后在百度搜索框中输入DOMAIN+网址就知道发到哪里了。
当然,您也可以进行更详细的分析。也可以搜索他的具体内页网址,会发现更多惊喜,得到大量外链地址(详情请参考《网站上如何构建外链》(How Build网站上的外部链接)相关介绍。
另外,还可以使用外链分析软件进行分析,总之就是通过别人的网站获取外链资源。
如何应对项目运营时间紧?自己做网站,等收录,再发链优化排名周期太长,想快点怎么办?那么我们必须增加网站的权重。
3、从重量到重量
大的网站 已经有一定的重量了。对于百度搜索引擎来说,他们的网页更可信。一般只要发布信息,几分钟到几十分钟就可以收录。
对此,我们可以利用或各种重量级网站发布信息,提供给国外连锁店。关键词在竞争不是很激烈的地方,一般一周内就能拿到名次(见奇云seo“使用高权重或高流量平台推广网络的利弊”相关介绍) .
4.从排名到排名
如果要在半小时内把产品的广告信息放到关键词首页排名怎么办?
比如你在百度上搜索关键词“木门”,仔细往下翻。你看见了吗?
SEO分级爆破技术核心优化思路
在关键字木门搜索结果的第一页,有最新的相关信息。您只需要在这些新闻源发布信息,半小时内就可以让您的广告信息出现在关键词的首页。你只需要使用你的力量,你就能意识到这一点。同时,你也可以利用这些新闻源来导入链接,为你的网站增加权重。
此外,您还可以使用百度产品、图书馆、百科全书、知识等。出于同样的原因。
搜索引擎优化
5、从资源到资源
当优化第一个网站进行搜索引擎优化时,因为你没有足够的资源,这是最关键的问题,但是当你可以优化第一个网站然后优化第二个网站 显然比第一个容易很多,这就是为什么优化第一个 网站 是最困难的。
尚启云认为,所谓的搜索引擎优化专家在技术上并不高人一等。排名的原则其实就是最后拼的就是资源的组合和使用资源的能力,仅此而已!
因此,从现在开始,您必须记住从资源移动到资源!
我知道你在困惑什么,你一定在想,关键是我没有资源?
不,您已经拥有资源和您想要的一切。已经有人在你面前拥有它们了。你要的是用它,以成功为起点,这样你才能更快地走向成功。
简而言之,拥有资源的人不如使用资源的人。您需要的不是您拥有多少资源,而是您可以控制多少资源。这是非常关键的!
从您感兴趣的内容到客户感兴趣的内容
你要像一个真正的营销人员,学会100%站在客户的角度思考,进入客户的世界,感受他的痛苦,然后你就会知道他们最感兴趣的是什么。
例如,您有兴趣让客户参加您的英语培训,但客户对您的培训不感兴趣,他只对自己的演讲感兴趣。所以,你必须先进入客户的世界,然后找出他的痛点,把他从他的世界带到你的世界。理解?
看这里,你应该知道我说的公式是什么了吧?
是的,从二十到二十!
这个公式将同时打开你的几种思维模式。首先,它会自动驱动你的自助思维,让你思考如何从别人已经成功的东西走向自己的成功。其次,它开始你的持续思考。思维问题不是基于点,而是线性思维。也可以说是交互思维。
所以,尚云奇认为网站的搜索引擎优化不是很友好,但是很简单。只有当复杂的事情变得简单时,它才具有更大的价值。
你必须知道 XX 导致 XX。这个公式的原则是从一个成功到另一个成功,而不是从头开始,用最简单的例子。
7、从××到××,每一个爆点都被抓到了
如果你能反复研究这个公式,并把它应用到搜索引擎优化的每一个细节,你会发现它可以帮你把所有搜索引擎优化系统的内容概括成这个公式。在你未来的思考过程中,你会发现你有更多的创造力!
搜索引擎优化
另外,其实这个公式可以用的地方太多了,除了SEO之外,所有地方都可以用,所以尚启云建议大家不仅抓好这些例子,忽略本质,还要深入理解原理,并尽力从一个实例转到另一个实例。比如从内容到内容,从案例到案例,从热点信息到热点流量。
然后找到最适合您的并立即采取行动。如果你只从表面上学习而不用你的大脑,那是没有用的。我相信你同意这个观点,对吗?
同一句话,他山上的石头可以用来攻玉。他应该善于发现事物的价值,然后为我所用。不要被一些所谓的概念误导。学习最简单实用的策略,越容易实施。关键不是看太多,而是看完之后细化,然后严格执行。
知道并不意味着能够执行,只有这样才能取得成果。如果你努力去做简单的事情,你就会成功!
搜索引擎优化排名爆破技术可以说是一个贯穿搜索引擎优化系统的公式。这个内容并不新鲜,但还是很有用的。正确的思维方向永远不会持久。至少我是这么认为的。过去,很多人说这个内容被炒作了。炒作与我无关。我保留我的意见。
一切都有它的价值。没有找到价值是你的遗憾。选择一个好的并遵循它。坏的,扔掉。与其批评和拒绝它,不如提炼它的价值,供我自己使用。他山的石头可以用来攻玉。
seq搜索引擎优化至少包括那几步?( 【每日一题】第一步爬行和抓取(第二十五期))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-08 19:05
【每日一题】第一步爬行和抓取(第二十五期))
第一步是爬行爬行
1) 搜索引擎用来抓取和访问页面的程序称为蜘蛛或机器人。蜘蛛实际上是搜索引擎的下属。搜索引擎命令它在互联网上浏览网页,获取互联网上的所有数据,然后将这些数据存储在搜索引擎自己的数据库中。我们的网站中不能有死链接。需要蜘蛛在网站网站中畅通无阻地抓取页面。
2)蜘蛛爬行的方法
不管什么级别的蜘蛛爬行方法都一样,有两种:1、深度优先;2、宽度优先。蜘蛛会沿着锚文本爬到最后,所以这里是 网站 内部链接的重要性。
①深度优先。
深度优先是指蜘蛛到达一个页面后,找到一个锚文本链接,也就是爬进另一个页面,然后在另一个页面上找到另一个锚文本链接,然后往里面爬,直到最后爬到这个网站@ >.
②、宽度优先。
宽度优先是指蜘蛛到达一个页面后,发现不是直接输入锚文本,而是爬取整个页面,然后将所有锚文本一起进入另一个页面,直到整个网站爬行完全的。
3)搜索引擎使用什么索引来确定爬取一个网站的频率。主要有四个指标:
一种。网站 更新频率:更新来得快,更新来得慢,直接影响蜘蛛访问的频率
湾 网站的更新质量:更新频率提高了,只会引起蜘蛛的注意。蜘蛛对质量有严格的要求。如果网站每天更新的大量内容被蜘蛛判断为低质量的页面仍然毫无意义。
C。连通性:网站要安全稳定,保证百度蜘蛛畅通无阻。把蜘蛛关起来可不是什么好事。
d. 站点评价:百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。它是百度搜索引擎对该站点的基本评分(不是外界所说的百度权重)。里面是百度一个非常机密的数据。网站评分从不单独使用,会与其他因素和阈值共同影响网站的爬取和排名。
第二步数据库处理
搜索引擎抓取到网页后,还需要做大量的预处理工作,才能提供检索服务。其中,最重要的是提取关键词,构建索引库和索引。其他包括去除重复网页、分词(中文)、判断网页类型、分析超链接以及计算网页的重要性/丰富度。其中,网站数据库是动态网站存储网站数据的空间。索引数据库,索引是一种对数据库表中一个或多个列的值进行排序的结构。使用索引可以快速访问数据库表中的特定信息。简单的说,就是将【爬取】的网页放入数据库中。
第三步,分析搜索服务
用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了页面标题和网址外,还会提供页面摘要等信息。
用户检索的过程是对前两个过程的考验,以检验搜索引擎是否能够提供最准确、最广泛的信息,以及搜索引擎是否能够快速的给出用户最想要的信息。
第四步排名
提取的网页按照不同维度的得分进行综合排序。“不同维度”包括:
相关性:网页内容与用户搜索需求的匹配程度,例如网页中收录的用户勾选关键词的次数,以及这些关键词出现的位置;外部网页用来指向页面的锚文本等。
权限:用户喜欢网站提供的内容,具有一定的权限。相应地,百度搜索引擎也更加相信优质权威网站提供的内容。
时效性:时效性结果是指收录新鲜内容的新网页。目前,时间敏感的结果在搜索引擎中变得越来越重要。
重要性:网页内容与用户检查需求相匹配的重要程度或受欢迎程度
丰富性:丰富性看似简单,但它是一个涵盖范围非常广泛的命题。可以理解为网页内容丰富,完全可以满足用户的需求;既可以满足用户的单一需求,又可以满足用户的扩展需求。
流行度:指网页是否流行。
搜索引擎通过搜索词处理、文件匹配、相关性计算、过滤调整、排名展示等复杂的工作步骤完成最终排名。 查看全部
seq搜索引擎优化至少包括那几步?(
【每日一题】第一步爬行和抓取(第二十五期))

第一步是爬行爬行
1) 搜索引擎用来抓取和访问页面的程序称为蜘蛛或机器人。蜘蛛实际上是搜索引擎的下属。搜索引擎命令它在互联网上浏览网页,获取互联网上的所有数据,然后将这些数据存储在搜索引擎自己的数据库中。我们的网站中不能有死链接。需要蜘蛛在网站网站中畅通无阻地抓取页面。
2)蜘蛛爬行的方法
不管什么级别的蜘蛛爬行方法都一样,有两种:1、深度优先;2、宽度优先。蜘蛛会沿着锚文本爬到最后,所以这里是 网站 内部链接的重要性。
①深度优先。
深度优先是指蜘蛛到达一个页面后,找到一个锚文本链接,也就是爬进另一个页面,然后在另一个页面上找到另一个锚文本链接,然后往里面爬,直到最后爬到这个网站@ >.
②、宽度优先。
宽度优先是指蜘蛛到达一个页面后,发现不是直接输入锚文本,而是爬取整个页面,然后将所有锚文本一起进入另一个页面,直到整个网站爬行完全的。
3)搜索引擎使用什么索引来确定爬取一个网站的频率。主要有四个指标:
一种。网站 更新频率:更新来得快,更新来得慢,直接影响蜘蛛访问的频率
湾 网站的更新质量:更新频率提高了,只会引起蜘蛛的注意。蜘蛛对质量有严格的要求。如果网站每天更新的大量内容被蜘蛛判断为低质量的页面仍然毫无意义。
C。连通性:网站要安全稳定,保证百度蜘蛛畅通无阻。把蜘蛛关起来可不是什么好事。
d. 站点评价:百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。它是百度搜索引擎对该站点的基本评分(不是外界所说的百度权重)。里面是百度一个非常机密的数据。网站评分从不单独使用,会与其他因素和阈值共同影响网站的爬取和排名。
第二步数据库处理
搜索引擎抓取到网页后,还需要做大量的预处理工作,才能提供检索服务。其中,最重要的是提取关键词,构建索引库和索引。其他包括去除重复网页、分词(中文)、判断网页类型、分析超链接以及计算网页的重要性/丰富度。其中,网站数据库是动态网站存储网站数据的空间。索引数据库,索引是一种对数据库表中一个或多个列的值进行排序的结构。使用索引可以快速访问数据库表中的特定信息。简单的说,就是将【爬取】的网页放入数据库中。
第三步,分析搜索服务
用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了页面标题和网址外,还会提供页面摘要等信息。
用户检索的过程是对前两个过程的考验,以检验搜索引擎是否能够提供最准确、最广泛的信息,以及搜索引擎是否能够快速的给出用户最想要的信息。
第四步排名
提取的网页按照不同维度的得分进行综合排序。“不同维度”包括:
相关性:网页内容与用户搜索需求的匹配程度,例如网页中收录的用户勾选关键词的次数,以及这些关键词出现的位置;外部网页用来指向页面的锚文本等。
权限:用户喜欢网站提供的内容,具有一定的权限。相应地,百度搜索引擎也更加相信优质权威网站提供的内容。
时效性:时效性结果是指收录新鲜内容的新网页。目前,时间敏感的结果在搜索引擎中变得越来越重要。
重要性:网页内容与用户检查需求相匹配的重要程度或受欢迎程度
丰富性:丰富性看似简单,但它是一个涵盖范围非常广泛的命题。可以理解为网页内容丰富,完全可以满足用户的需求;既可以满足用户的单一需求,又可以满足用户的扩展需求。
流行度:指网页是否流行。
搜索引擎通过搜索词处理、文件匹配、相关性计算、过滤调整、排名展示等复杂的工作步骤完成最终排名。
seq搜索引擎优化至少包括那几步?(对网站进行SEO优化的最重要的一步对)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-08 04:03
网站 SEO优化最重要的一步是对网站进行基础优化。也就是优化网站的基础代码,优化每个页面,满足搜索引擎的要求。这将使我们的 网站 优化变得顺理成章。那么接下来说说我们优化的具体方法。
页面优化
页面优化就是把合适的关键词放在合适的地方,让搜索引擎知道你的页面是关于什么的。具体可以从以下几个方面入手。
1. 页面标题
标题是页面最重要的部分。它显示在页面顶部的选项卡上。您应该为每个页面内容总结最重要的关键词。为了避免一些笼统的描述,通常你会有多个关键词,你需要把更重要的放在第一位。
2.页面地址
你可以设置自己的页面地址,你应该使用一些有意义的词;当您需要连接两个词时,请使用连字符 (-) 而不是下划线 (_)。尽量减少无意义的乱码。相反,更简洁明了的地址会更容易让蜘蛛爬行。
3. 标题
标题中需要说明页面的主要内容是什么,关键词需要再次出现在这里。如果一个页面有多个标题,尽量指出它们之间的相似之处,否则蜘蛛很难理解你的页面是关于什么的。
4. 文章 主题
如果你的页面标题和文章在标题中重复了你的关键词,那你就不用在文章中重复关键词,Spider就不会太反感了。你很烦人,但你会认为你在作弊。
5.文字链接
适当添加一些文字链接到我们的文章。
6、标签
Alt标签用于描述页面上的图片,提高页面的可访问性(accessibility),也有助于优化搜索排名。
做完上面的网站基础优化后,我们会适当增加一些外链建设和我们的网站内容更新。最重要的是内容。如果我们的内容做好了,排名自然就在那里。但这个过程可能不会在一夜之间发生,所以耐心同样重要。返回搜狐查看更多 查看全部
seq搜索引擎优化至少包括那几步?(对网站进行SEO优化的最重要的一步对)
网站 SEO优化最重要的一步是对网站进行基础优化。也就是优化网站的基础代码,优化每个页面,满足搜索引擎的要求。这将使我们的 网站 优化变得顺理成章。那么接下来说说我们优化的具体方法。
页面优化
页面优化就是把合适的关键词放在合适的地方,让搜索引擎知道你的页面是关于什么的。具体可以从以下几个方面入手。

1. 页面标题
标题是页面最重要的部分。它显示在页面顶部的选项卡上。您应该为每个页面内容总结最重要的关键词。为了避免一些笼统的描述,通常你会有多个关键词,你需要把更重要的放在第一位。
2.页面地址
你可以设置自己的页面地址,你应该使用一些有意义的词;当您需要连接两个词时,请使用连字符 (-) 而不是下划线 (_)。尽量减少无意义的乱码。相反,更简洁明了的地址会更容易让蜘蛛爬行。
3. 标题
标题中需要说明页面的主要内容是什么,关键词需要再次出现在这里。如果一个页面有多个标题,尽量指出它们之间的相似之处,否则蜘蛛很难理解你的页面是关于什么的。

4. 文章 主题
如果你的页面标题和文章在标题中重复了你的关键词,那你就不用在文章中重复关键词,Spider就不会太反感了。你很烦人,但你会认为你在作弊。
5.文字链接
适当添加一些文字链接到我们的文章。
6、标签
Alt标签用于描述页面上的图片,提高页面的可访问性(accessibility),也有助于优化搜索排名。
做完上面的网站基础优化后,我们会适当增加一些外链建设和我们的网站内容更新。最重要的是内容。如果我们的内容做好了,排名自然就在那里。但这个过程可能不会在一夜之间发生,所以耐心同样重要。返回搜狐查看更多
seq搜索引擎优化至少包括那几步?(关键词排名优化服务介绍推广模式介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-07 23:14
关键词排名优化服务介绍
推广方式:用户提供关键词和优化链接,10-30天内可优化到百度首页,按效果付费
价格:根据关键词优化难度,分析后报价,一般每月400-600元一个字(非最终价格)
优化过程:
1.用户提供主要关键词、FTP、管理后台等需要优化的信息
2.0375 NetMedia进行关键词分析,确认报价,优化时间
3.客户确认合作并支付定金(50%优化费),我们开始优化
4. 优化完成,达到预期效果。客户验收后支付余款的50%。
优化周期:
可以优化客户原有的关键词 100以内的排名。如果关键词没有排名,我们会进行相关评估,确定时段和价格。
1.原百度前30:3-10天出结果
2.原创排名百度30-60:8-15天出结果
3. 原手机百度排名11-50:效果后3-20天
4.未排名关键词根据搜索索引进行评估,一般1个月内出结果
关键词**提升排名优势:
**,有效安全,先付一半定金,效果后付余款,资金安全有保障!
seo关键词 优化
SEO关键词优化推广,这对于每一个管理员朋友来说并不陌生,这也是每一个SEO优化者的SEO技巧,如何在搜索引擎中对自己的关键词进行排名,达到自己理想的位置?以下是关键字优化的一些基本步骤。
**,选择合适的cms程序。
一个好的cms是必不可少的seo。现在选择一个cms并不难。许多cms已经完善,基本满足站内需求。同样的cms做同样的类型还是会有成败的,关键是站得住的技巧和心态。重要的是选择你熟悉的cms。
第二,优化。
对于SEO关键词优化,网站优化也是必不可少的。对于网站优化,我们需要注意以下几点:
1.导航清晰,便于搜索引擎蜘蛛掌握;
2.集成JS和CSS进行外部调用。
3.URL要合理设计,栏目不要太深,伪静态。
4. 应该添加图片的Alt属性。
5.制作301;
6. 正确地将关键字布局为倾斜、关键字和描述;
7. 合理安排站内锚文本;
8.创建地图。
做好这几点,你的优化已经基本优化了。
三、文章的优化。
做SEO优化的朋友应该知道“内容为王”的道理。上面的文章也是一个重要的部分,可以称之为精华。内容请尽量避免从搜索引擎抄袭文章,自己写原创内容。文章中关键词的合理布局,尽可能的自然自然。添加文章链接对于提高关键子子的排名也很重要。文章 内容页面的相关推送对于用户体验来说也是必不可少的。
*四、搜索和发布外部链接。外链关联性好,怎么找外链?**几种外链方式: 1.友情链接;2. 与行业的外部链接参考;3.文章提交,软文发布;4.博客、微博平台;5、论坛、帖子栏目;6、采集器、网上摘录和分类信息。我相信这些对于一个小人来说已经足够了。
如何进行搜索引擎优化
从需求结果分析,什么都需要seo操作,不需要去流量。建设和搜索引擎优化是兼容的。不同的组建成后,由于各种原因,会采用不同的方式进行SEO。有些是外包的,有些是由SEO技术人员聘请的。无论哪种方式,都需要满足一个基本要求:有一个预定的关键词 Ranking。
那么,如何进行有效的seo操作呢?一般来说,有两个部分。一部分是seo基础设置,包括但不限于代码、合理的内容模型、安全设置、速度优化等。另一部分是内容组织、外链建设、用户行为建设、良好的呈现。建设等方面。
不同的seo人对如何进行seo有自己的方法和步骤,也有自己的看法。他们个人认为,效率是结果的最终维度,其他一切都只是空谈。在给定的时间内,关键词的排名数,页面上有多少,索引大的词有多少,长尾词有多少,这些决定了seo的结果。
在细化方面,如何进行SEO?
一、优化基本seo的设置。
1、**你要确定**流量词和需求词(通过关键词分析**)。
2、其次,你需要了解你想要做什么类型。它是企业展示类型、行业或其他类型。
3、定位之后,开始思考你要做什么关键词。为此,您可以通过行业常规关键词、百度搜索,看看其他公司在做什么。过滤百度**页面并一一排序。
4、关键词 完成后。需要找到优化目标关键词(要优化的首页)和长尾关键词(要对首页以外的页面进行优化的词)
5、确认关键词后,我开始采集整理内容。你现在找到的关键词,包括目标词,加上长尾词,至少有200个以上。因此,您至少要整理 200 篇文章文章。百度优化原则:内容原创,是**。所以你必须考虑如何组织内容。
6、开始做,优化结构。例如:机器人页面、nofollow 标签、站点地图、域、404 页面。做完这些,开始第七步,关键词布局。
7、第一个要优化的页面是**关键词,3-5是优化数量的范围。布局位置包括:TKD标签、页眉、栏目、页脚、面包屑导航、导航、模块。
8、关键词 布局完成后,开始填写内容信息。
二、上线后对应的seo操作点。
1、*新的高品质文章。
上线前,做好关键词设置布局,规划好栏目页面后,要在本地环境搭建好,填充文章的内容,文章的内容饱和@>应该至少要达到80%以上,填满文章的内容才是我们要做的。
文章上线后,要注意文章的*新规律,保证每天定时定量*新。
<p>在保证了固定时间和定量的*new文章之后,还要保证*new文章内容的质量,这个是**,因为现在搜索引擎对 查看全部
seq搜索引擎优化至少包括那几步?(关键词排名优化服务介绍推广模式介绍)
关键词排名优化服务介绍
推广方式:用户提供关键词和优化链接,10-30天内可优化到百度首页,按效果付费
价格:根据关键词优化难度,分析后报价,一般每月400-600元一个字(非最终价格)
优化过程:
1.用户提供主要关键词、FTP、管理后台等需要优化的信息
2.0375 NetMedia进行关键词分析,确认报价,优化时间
3.客户确认合作并支付定金(50%优化费),我们开始优化
4. 优化完成,达到预期效果。客户验收后支付余款的50%。
优化周期:
可以优化客户原有的关键词 100以内的排名。如果关键词没有排名,我们会进行相关评估,确定时段和价格。
1.原百度前30:3-10天出结果
2.原创排名百度30-60:8-15天出结果
3. 原手机百度排名11-50:效果后3-20天
4.未排名关键词根据搜索索引进行评估,一般1个月内出结果
关键词**提升排名优势:
**,有效安全,先付一半定金,效果后付余款,资金安全有保障!

seo关键词 优化
SEO关键词优化推广,这对于每一个管理员朋友来说并不陌生,这也是每一个SEO优化者的SEO技巧,如何在搜索引擎中对自己的关键词进行排名,达到自己理想的位置?以下是关键字优化的一些基本步骤。
**,选择合适的cms程序。
一个好的cms是必不可少的seo。现在选择一个cms并不难。许多cms已经完善,基本满足站内需求。同样的cms做同样的类型还是会有成败的,关键是站得住的技巧和心态。重要的是选择你熟悉的cms。
第二,优化。
对于SEO关键词优化,网站优化也是必不可少的。对于网站优化,我们需要注意以下几点:
1.导航清晰,便于搜索引擎蜘蛛掌握;
2.集成JS和CSS进行外部调用。
3.URL要合理设计,栏目不要太深,伪静态。
4. 应该添加图片的Alt属性。
5.制作301;
6. 正确地将关键字布局为倾斜、关键字和描述;
7. 合理安排站内锚文本;
8.创建地图。
做好这几点,你的优化已经基本优化了。
三、文章的优化。
做SEO优化的朋友应该知道“内容为王”的道理。上面的文章也是一个重要的部分,可以称之为精华。内容请尽量避免从搜索引擎抄袭文章,自己写原创内容。文章中关键词的合理布局,尽可能的自然自然。添加文章链接对于提高关键子子的排名也很重要。文章 内容页面的相关推送对于用户体验来说也是必不可少的。
*四、搜索和发布外部链接。外链关联性好,怎么找外链?**几种外链方式: 1.友情链接;2. 与行业的外部链接参考;3.文章提交,软文发布;4.博客、微博平台;5、论坛、帖子栏目;6、采集器、网上摘录和分类信息。我相信这些对于一个小人来说已经足够了。

如何进行搜索引擎优化
从需求结果分析,什么都需要seo操作,不需要去流量。建设和搜索引擎优化是兼容的。不同的组建成后,由于各种原因,会采用不同的方式进行SEO。有些是外包的,有些是由SEO技术人员聘请的。无论哪种方式,都需要满足一个基本要求:有一个预定的关键词 Ranking。
那么,如何进行有效的seo操作呢?一般来说,有两个部分。一部分是seo基础设置,包括但不限于代码、合理的内容模型、安全设置、速度优化等。另一部分是内容组织、外链建设、用户行为建设、良好的呈现。建设等方面。
不同的seo人对如何进行seo有自己的方法和步骤,也有自己的看法。他们个人认为,效率是结果的最终维度,其他一切都只是空谈。在给定的时间内,关键词的排名数,页面上有多少,索引大的词有多少,长尾词有多少,这些决定了seo的结果。
在细化方面,如何进行SEO?
一、优化基本seo的设置。
1、**你要确定**流量词和需求词(通过关键词分析**)。
2、其次,你需要了解你想要做什么类型。它是企业展示类型、行业或其他类型。
3、定位之后,开始思考你要做什么关键词。为此,您可以通过行业常规关键词、百度搜索,看看其他公司在做什么。过滤百度**页面并一一排序。
4、关键词 完成后。需要找到优化目标关键词(要优化的首页)和长尾关键词(要对首页以外的页面进行优化的词)
5、确认关键词后,我开始采集整理内容。你现在找到的关键词,包括目标词,加上长尾词,至少有200个以上。因此,您至少要整理 200 篇文章文章。百度优化原则:内容原创,是**。所以你必须考虑如何组织内容。
6、开始做,优化结构。例如:机器人页面、nofollow 标签、站点地图、域、404 页面。做完这些,开始第七步,关键词布局。
7、第一个要优化的页面是**关键词,3-5是优化数量的范围。布局位置包括:TKD标签、页眉、栏目、页脚、面包屑导航、导航、模块。
8、关键词 布局完成后,开始填写内容信息。
二、上线后对应的seo操作点。
1、*新的高品质文章。
上线前,做好关键词设置布局,规划好栏目页面后,要在本地环境搭建好,填充文章的内容,文章的内容饱和@>应该至少要达到80%以上,填满文章的内容才是我们要做的。
文章上线后,要注意文章的*新规律,保证每天定时定量*新。
<p>在保证了固定时间和定量的*new文章之后,还要保证*new文章内容的质量,这个是**,因为现在搜索引擎对
seq搜索引擎优化至少包括那几步?(关于第一个就是数据增强阶段的一些事儿,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-07 03:06
TinyBERT提供了一个经过General Distillation阶段的checkpoint,可以认为是一个小型的BERT,包括6L786H版本和4L312H版本。而我们的后续复刻是基于4L312H v2版本。值得注意的是,TinyBERT 对任务数据集进行了数据增强操作,通过基于 Glove's Embedding Distance 和 BERT MLM 预测替换的相似词替换,将原创数据集扩大到 20 倍。我们遇到的第一个错误是在数据增强阶段。
数据增强中的错误
我们可以根据官方代码对数据进行增强,但是在QNLI上会报错:
索引错误:索引 514 超出维度 1,大小为 512
当数据增强一半时程序崩溃。为什么?
很简单,因为数据增强代码BERT MLM换词模块对很长(> 512)个句子,导致下标越界)没有特殊处理,具体请参考#Issue50。
只需在对应函数中判断边界即可:
def _masked_language_model(self, sent, word_pieces, mask_id):
if mask_id > 511: # if mask id is longer than max length
return []
tokenized_text = self.tokenizer.tokenize(sent)
tokenized_text = ['[CLS]'] + tokenized_text
tokenized_len = len(tokenized_text)
tokenized_text = word_pieces + ['[SEP]'] + tokenized_text[1:] + ['[SEP]']
segments_ids = [0] * (tokenized_len + 1) + [1] * (len(tokenized_text) - tokenized_len - 1)
if len(tokenized_text) > 512: # truncation
tokenized_text = tokenized_text[:512]
segments_ids = segments_ids[:512]
token_ids = self.tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([token_ids]).to(device)
segments_tensor = torch.tensor([segments_ids]).to(device)
self.model.to(device)
predictions = self.model(tokens_tensor, segments_tensor)
word_candidates = torch.argsort(predictions[0, mask_id], descending=True)[:self.M].tolist()
word_candidates = self.tokenizer.convert_ids_to_tokens(word_candidates)
return list(filter(lambda x: x.find("##"), word_candidates))
数据并行加速
在我们辛苦快乐地完成了数据增强之后,下一步就是在Task Specific Distillation中进行Step 1,General Distillation。对于一些像MRPC这样的小数据集,20倍增长后的数据量仍然不到80k,所以训练速度还是很快的,单卡大概半天可以跑20轮。但是对于像MNLI(390k)这样GLUE中最大的数据集,20倍增强的数据集(增强用了2天左右),如果用单卡训练10轮,可能需要半个月。到时候,黄花菜怕是不冷了。所以我计划使用多卡进行培训。乍一看,官方实现通过nn.DataParallel支持Doka。好吧,直接CUDA_VISIBLE_DEVICES="0,1,2,3"加载4张卡。不知道跑不跑 加载数据(标记化,填充)花了 1 个小时,我终于开始了。当我打开 nvidia-smi 时,我震惊了。GPU 利用率在 50% 左右。看看预计的时间,大概是21小时。在一轮中,10 个纪元四舍五入为一周半。男孩,我还能试验这个吗?这时候去查看PyTorch文档,发现PyTorch不再推荐使用nn。数据并行,为什么?主要原因是DataParallel的实现是一个单一的进程。每次主卡读取数据,然后将其发送到其他卡。这部分故障会带来额外的计算开销,并会导致主卡的GPU内存被占用。明显高于其他卡,导致潜在的批量大小限制;此外,在这种模式下,其他 GPU 必须在计算完成后发送回主卡进行同步。这一步会受到 GIL(全局解释器锁)的限制,进一步降低效率。另外,还有一些DataParallel不支持的功能,比如多机、模型切片,但是另一个DistributedDataParallel模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:还有一些DataParallel 不支持的功能,比如多机和模型切片,但另一个DistributedDataParallel 模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:还有一些DataParallel 不支持的功能,比如多机和模型切片,但另一个DistributedDataParallel 模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
# 给 parser 增加一个 local rank 参数来在启动的时候传入 rank
parser.add_argument('--local_rank',
type=int,
default=-1)
# ...
# 初始化
logger.info("Initializing Distributed Environment")
torch.cuda.set_device(args.local_rank)
dist.init_process_group(backend="nccl")
# 设置 devicec
local_rank = args.local_rank
torch.cuda.set_device(local_rank)
# ...
# 初始化模型 并且 放到 device 上
student_model = TinyBertForSequenceClassification.from_pretrained(args.student_model, num_labels=num_labels).to(device)
teacher_model = TinyBertForSequenceClassification.from_pretrained(args.teacher_model, num_labels=num_labels).to(device)
# 用 DDP 包裹模型
student_model = DDP(student_model, device_ids=[local_rank], output_device=local_rank)
teacher_model = DDP(teacher_model, device_ids=[local_rank], output_device=local_rank)
# ..
# 用 DistributedSampler 替换原来的 Random Sampler
train_sampler = torch.utils.data.DistributedSampler(train_data)
然后,你就大功告成了,一键开始:
GPU=”0,1,2,3”
CUDA_VISIBLE_DEVICEES=$GPU python -m torch.distributed.launch –n_proc_per_node 4 task_disti.py
创业成功了吗?模型再次开始处理数据......
一小时后,机器突然卡住,程序日志停止。我打开htop看了看。好家伙,256G内存满了,程序是D状态。怎么了?
数据加载加速
我先尝试了少量数据,下采样到10k,程序运行没问题,DDP速度很快;我试过单卡加载,虽然又加载了一个小时,但是还好,程序还是可以运行的,那么,问题是怎么发生的呢?单卡,我看了一下加载全量数据后的内存使用情况。大约是60G。考虑到DDP是多进程的,每个进程必须独立加载数据。4张卡4个进程,大约是250G内存,所以内存爆了,后续数据的io卡住了(无法从磁盘加载到内存),导致程序D状态。看看下一组的机器,最大的是250G的内存。也就是说,如果我只用3张卡,那么我可以运行,但是如果其他人上来启动程序并吃掉一部分内存,那么很有可能内存会爆炸,然后大家的程序都被抹掉了,这不是很好。一个不太优雅的解决方案是将数据切成块,然后读取一小段训练,然后读取下一段,再次训练,再次读取。我咨询了小组中的一位高级研究员。另一种方式是实现一个数据读取程序,将数据存储在磁盘上,每次使用时将其加载到内存中,从而避免内存爆炸的问题。好吧,让我们做吧,但你不能从头开始制造轮子,对吧?哲哥提到了拥抱脸(yyds)的数据集可以支持这个功能。查了一下文档,发现他实现了一个基于pyarrow的内存映射数据读取。根据我在 Huggingface Transformer 方面的经验,它似乎能够实现这一点。
首先,加载增强数据。datasets提供的load_dataset函数最接近load_dataset('csv', data_file),然后我们就可以逐列获取数据并进行预处理。写了一会儿,发现读了一部分数据后,总是列数不对的错误。我猜原创的 MNLI 数据集不能保证每一列都在那里。我查看了在MnliProcessor中处理的代码,发现Line[8]和line[9]被写成sentence_a和sentence_b。无奈之下,只能用最粗暴的方式用文本方式读入,每一行都是一条数据,然后拆分:
from datasets import
processor = processors[task_name]()
output_mode = output_modes[task_name]
label_list = processor.get_labels()
num_labels = len(label_list)
tokenizer = BertTokenizer.from_pretrained(args.student_model, do_lower_case=args.do_lower_case)
# 用 text
mnli_datasets = load_dataset("text", data_files=os.path.join(args.data_dir, "train_aug.tsv"))
label_classes = processor.get_labels()
label_map = {label: i for i, label in enumerate(label_classes)}
def preprocess_func(examples, max_seq_length=args.max_seq_length):
splits = [e.split('\t') for e in examples['text']] # split
# tokenize for sent1 & sent2
tokens_s1 = [tokenizer.tokenize(e[8]) for e in splits]
tokens_s2 = [tokenizer.tokenize(e[9]) for e in splits]
for t1, t2 in zip(tokens_s1, tokens_s2):
truncate_seq_pair(t1, t2, max_length=max_seq_length - 3)
input_ids_list = []
input_mask_list = []
segment_ids_list = []
seq_length_list = []
labels_list = []
labels = [e[-1] for e in splits] # last column is label column
for token_a, token_b, l in zip(tokens_s1, tokens_s2, labels): # zip(tokens_as, tokens_bs):
tokens = ["[CLS]"] + token_a + ["[SEP]"]
segment_ids = [0] * len(tokens)
tokens += token_b + ["[SEP]"]
segment_ids += [1] * (len(token_b) + 1)
input_ids = tokenizer.convert_tokens_to_ids(tokens) # tokenize to id
input_mask = [1] * len(input_ids)
seq_length = len(input_ids)
padding = [0] * (max_seq_length - len(input_ids))
input_ids += padding
input_mask += padding
segment_ids += padding
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
input_ids_list.append(input_ids)
input_mask_list.append(input_mask)
segment_ids_list.append(segment_ids)
seq_length_list.append(seq_length)
labels_list.append(label_map[l])
results = {"input_ids": input_ids_list,
"input_mask": input_mask_list,
"segment_ids": segment_ids_list,
"seq_length": seq_length_list,
"label_ids": labels_list}
return results
# map datasets
mnli_datasets = mnli_datasets.map(preprocess_func, batched=True)
# remove column
train_data = mnli_datasets['train'].remove_columns('text')
写完这个preprocess_func,我觉得胜利就在眼前,但还有几个坑需要解决:
inputs = {}
for k, v in batch.items():
if isinstance(v, torch.Tensor):
inputs[k] = v.to(device)
elif isinstance(v, List):
inputs[k] = torch.stack(v, dim=1).to(device)
到目前为止,只需将之前代码的 train_data 替换为当前版本即可。
另外,为了进一步加速,我还集成了混合精度。现在Pytorch和自己支持混合精度,代码量很少,但是有一个陷阱就是loss的计算必须用auto()包裹,同时,所有模型的输出都必须参与loss的计算,对于只做预测或者隐藏状态对齐的loss不友好,所以只能手动计算一个系数为0的额外loss项(所以他参与了Training但不影响梯度)。 查看全部
seq搜索引擎优化至少包括那几步?(关于第一个就是数据增强阶段的一些事儿,你知道吗?)
TinyBERT提供了一个经过General Distillation阶段的checkpoint,可以认为是一个小型的BERT,包括6L786H版本和4L312H版本。而我们的后续复刻是基于4L312H v2版本。值得注意的是,TinyBERT 对任务数据集进行了数据增强操作,通过基于 Glove's Embedding Distance 和 BERT MLM 预测替换的相似词替换,将原创数据集扩大到 20 倍。我们遇到的第一个错误是在数据增强阶段。
数据增强中的错误
我们可以根据官方代码对数据进行增强,但是在QNLI上会报错:
索引错误:索引 514 超出维度 1,大小为 512
当数据增强一半时程序崩溃。为什么?
很简单,因为数据增强代码BERT MLM换词模块对很长(> 512)个句子,导致下标越界)没有特殊处理,具体请参考#Issue50。
只需在对应函数中判断边界即可:
def _masked_language_model(self, sent, word_pieces, mask_id):
if mask_id > 511: # if mask id is longer than max length
return []
tokenized_text = self.tokenizer.tokenize(sent)
tokenized_text = ['[CLS]'] + tokenized_text
tokenized_len = len(tokenized_text)
tokenized_text = word_pieces + ['[SEP]'] + tokenized_text[1:] + ['[SEP]']
segments_ids = [0] * (tokenized_len + 1) + [1] * (len(tokenized_text) - tokenized_len - 1)
if len(tokenized_text) > 512: # truncation
tokenized_text = tokenized_text[:512]
segments_ids = segments_ids[:512]
token_ids = self.tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([token_ids]).to(device)
segments_tensor = torch.tensor([segments_ids]).to(device)
self.model.to(device)
predictions = self.model(tokens_tensor, segments_tensor)
word_candidates = torch.argsort(predictions[0, mask_id], descending=True)[:self.M].tolist()
word_candidates = self.tokenizer.convert_ids_to_tokens(word_candidates)
return list(filter(lambda x: x.find("##"), word_candidates))
数据并行加速
在我们辛苦快乐地完成了数据增强之后,下一步就是在Task Specific Distillation中进行Step 1,General Distillation。对于一些像MRPC这样的小数据集,20倍增长后的数据量仍然不到80k,所以训练速度还是很快的,单卡大概半天可以跑20轮。但是对于像MNLI(390k)这样GLUE中最大的数据集,20倍增强的数据集(增强用了2天左右),如果用单卡训练10轮,可能需要半个月。到时候,黄花菜怕是不冷了。所以我计划使用多卡进行培训。乍一看,官方实现通过nn.DataParallel支持Doka。好吧,直接CUDA_VISIBLE_DEVICES="0,1,2,3"加载4张卡。不知道跑不跑 加载数据(标记化,填充)花了 1 个小时,我终于开始了。当我打开 nvidia-smi 时,我震惊了。GPU 利用率在 50% 左右。看看预计的时间,大概是21小时。在一轮中,10 个纪元四舍五入为一周半。男孩,我还能试验这个吗?这时候去查看PyTorch文档,发现PyTorch不再推荐使用nn。数据并行,为什么?主要原因是DataParallel的实现是一个单一的进程。每次主卡读取数据,然后将其发送到其他卡。这部分故障会带来额外的计算开销,并会导致主卡的GPU内存被占用。明显高于其他卡,导致潜在的批量大小限制;此外,在这种模式下,其他 GPU 必须在计算完成后发送回主卡进行同步。这一步会受到 GIL(全局解释器锁)的限制,进一步降低效率。另外,还有一些DataParallel不支持的功能,比如多机、模型切片,但是另一个DistributedDataParallel模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:还有一些DataParallel 不支持的功能,比如多机和模型切片,但另一个DistributedDataParallel 模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:还有一些DataParallel 不支持的功能,比如多机和模型切片,但另一个DistributedDataParallel 模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
# 给 parser 增加一个 local rank 参数来在启动的时候传入 rank
parser.add_argument('--local_rank',
type=int,
default=-1)
# ...
# 初始化
logger.info("Initializing Distributed Environment")
torch.cuda.set_device(args.local_rank)
dist.init_process_group(backend="nccl")
# 设置 devicec
local_rank = args.local_rank
torch.cuda.set_device(local_rank)
# ...
# 初始化模型 并且 放到 device 上
student_model = TinyBertForSequenceClassification.from_pretrained(args.student_model, num_labels=num_labels).to(device)
teacher_model = TinyBertForSequenceClassification.from_pretrained(args.teacher_model, num_labels=num_labels).to(device)
# 用 DDP 包裹模型
student_model = DDP(student_model, device_ids=[local_rank], output_device=local_rank)
teacher_model = DDP(teacher_model, device_ids=[local_rank], output_device=local_rank)
# ..
# 用 DistributedSampler 替换原来的 Random Sampler
train_sampler = torch.utils.data.DistributedSampler(train_data)
然后,你就大功告成了,一键开始:
GPU=”0,1,2,3”
CUDA_VISIBLE_DEVICEES=$GPU python -m torch.distributed.launch –n_proc_per_node 4 task_disti.py
创业成功了吗?模型再次开始处理数据......
一小时后,机器突然卡住,程序日志停止。我打开htop看了看。好家伙,256G内存满了,程序是D状态。怎么了?
数据加载加速
我先尝试了少量数据,下采样到10k,程序运行没问题,DDP速度很快;我试过单卡加载,虽然又加载了一个小时,但是还好,程序还是可以运行的,那么,问题是怎么发生的呢?单卡,我看了一下加载全量数据后的内存使用情况。大约是60G。考虑到DDP是多进程的,每个进程必须独立加载数据。4张卡4个进程,大约是250G内存,所以内存爆了,后续数据的io卡住了(无法从磁盘加载到内存),导致程序D状态。看看下一组的机器,最大的是250G的内存。也就是说,如果我只用3张卡,那么我可以运行,但是如果其他人上来启动程序并吃掉一部分内存,那么很有可能内存会爆炸,然后大家的程序都被抹掉了,这不是很好。一个不太优雅的解决方案是将数据切成块,然后读取一小段训练,然后读取下一段,再次训练,再次读取。我咨询了小组中的一位高级研究员。另一种方式是实现一个数据读取程序,将数据存储在磁盘上,每次使用时将其加载到内存中,从而避免内存爆炸的问题。好吧,让我们做吧,但你不能从头开始制造轮子,对吧?哲哥提到了拥抱脸(yyds)的数据集可以支持这个功能。查了一下文档,发现他实现了一个基于pyarrow的内存映射数据读取。根据我在 Huggingface Transformer 方面的经验,它似乎能够实现这一点。
首先,加载增强数据。datasets提供的load_dataset函数最接近load_dataset('csv', data_file),然后我们就可以逐列获取数据并进行预处理。写了一会儿,发现读了一部分数据后,总是列数不对的错误。我猜原创的 MNLI 数据集不能保证每一列都在那里。我查看了在MnliProcessor中处理的代码,发现Line[8]和line[9]被写成sentence_a和sentence_b。无奈之下,只能用最粗暴的方式用文本方式读入,每一行都是一条数据,然后拆分:
from datasets import
processor = processors[task_name]()
output_mode = output_modes[task_name]
label_list = processor.get_labels()
num_labels = len(label_list)
tokenizer = BertTokenizer.from_pretrained(args.student_model, do_lower_case=args.do_lower_case)
# 用 text
mnli_datasets = load_dataset("text", data_files=os.path.join(args.data_dir, "train_aug.tsv"))
label_classes = processor.get_labels()
label_map = {label: i for i, label in enumerate(label_classes)}
def preprocess_func(examples, max_seq_length=args.max_seq_length):
splits = [e.split('\t') for e in examples['text']] # split
# tokenize for sent1 & sent2
tokens_s1 = [tokenizer.tokenize(e[8]) for e in splits]
tokens_s2 = [tokenizer.tokenize(e[9]) for e in splits]
for t1, t2 in zip(tokens_s1, tokens_s2):
truncate_seq_pair(t1, t2, max_length=max_seq_length - 3)
input_ids_list = []
input_mask_list = []
segment_ids_list = []
seq_length_list = []
labels_list = []
labels = [e[-1] for e in splits] # last column is label column
for token_a, token_b, l in zip(tokens_s1, tokens_s2, labels): # zip(tokens_as, tokens_bs):
tokens = ["[CLS]"] + token_a + ["[SEP]"]
segment_ids = [0] * len(tokens)
tokens += token_b + ["[SEP]"]
segment_ids += [1] * (len(token_b) + 1)
input_ids = tokenizer.convert_tokens_to_ids(tokens) # tokenize to id
input_mask = [1] * len(input_ids)
seq_length = len(input_ids)
padding = [0] * (max_seq_length - len(input_ids))
input_ids += padding
input_mask += padding
segment_ids += padding
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
input_ids_list.append(input_ids)
input_mask_list.append(input_mask)
segment_ids_list.append(segment_ids)
seq_length_list.append(seq_length)
labels_list.append(label_map[l])
results = {"input_ids": input_ids_list,
"input_mask": input_mask_list,
"segment_ids": segment_ids_list,
"seq_length": seq_length_list,
"label_ids": labels_list}
return results
# map datasets
mnli_datasets = mnli_datasets.map(preprocess_func, batched=True)
# remove column
train_data = mnli_datasets['train'].remove_columns('text')
写完这个preprocess_func,我觉得胜利就在眼前,但还有几个坑需要解决:
inputs = {}
for k, v in batch.items():
if isinstance(v, torch.Tensor):
inputs[k] = v.to(device)
elif isinstance(v, List):
inputs[k] = torch.stack(v, dim=1).to(device)
到目前为止,只需将之前代码的 train_data 替换为当前版本即可。
另外,为了进一步加速,我还集成了混合精度。现在Pytorch和自己支持混合精度,代码量很少,但是有一个陷阱就是loss的计算必须用auto()包裹,同时,所有模型的输出都必须参与loss的计算,对于只做预测或者隐藏状态对齐的loss不友好,所以只能手动计算一个系数为0的额外loss项(所以他参与了Training但不影响梯度)。
seq搜索引擎优化至少包括那几步?( 百度算法|87程度就低,适当地,系统将减少相关度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-06 11:02
百度算法|87程度就低,适当地,系统将减少相关度)
当涉及到该短语的有效竞争页数时,竞争的准确性取决于搜索“关键字是该页面的焦点”。
3. 新访客比例:我们调查了从入口到达的访客中有多少是新访客。解释越高,新访客就越感兴趣。
越早开始,对您的公司越好。
潜在语义索引 (LSI) 更进一步,用于语义分析以识别所涉及的网页。
另一方面,如果网页被用户关闭并且网页时间长,则网页的流行度会很低。系统会适当地降低网页的相关性。
地域来源分析 从百度统计数据中获取【地域来源】报表,可以了解返回网站的访问者所在的位置。
标题标签中的关键字是最重要的吗?标题标签是一个网页最重要的搜索关键词位置。
博客搜索谷歌专门为博客搜索打造了一个搜索引擎——GoogleBlogSearch(谷歌博客搜索,名字不准确,因为它实际上是一个RSS提要引擎而不是博客引擎)。
1.水平导航系统。
现在为每个 SearchEngineGuide 和 ISEDB 添加一个目录。
当 Spiders 从其他站点找到您的 网站 链接时,如果 Robots.txt 文件未声明不允许访问该页面,则 Spiders 将不会保存该页面。
这是一个图表,显示了大多数搜索引擎如何与目录交互。
越早开始,对您的公司越好。
这在 网站 优化中起着更重要的作用。
至于如何区分低权限站点和无价值站点,1、大多数网站甚至需要一个网页来识别它们的价值;2、针对网站分析MSN要优化关键词SERP排在前网站,通过对比他们网站的链接,可以大致得出结论,在同时,不会为您找到更多有潜力的Link合作伙伴。
“链接工厂”(也称为“群链接机制”)是指由大量交叉链接的网页组成的网络系统。
如前所述,良好的链接工作和必要的链接文本必须通过在标题和正文中不收录非常丰富的关键字来补充。
许多互联网销售专家创建了他们控制内容的商业模式,人们可以通过页面的主要内容获得相关的广告。
在美国的搜索引擎用户中,女性略多于男性(50.1%:49.9%)。
198 他们可以详细监控互联网用户如何搜索您网站。例如,搜索引擎可以检测到哪个搜索引擎在搜索你,甚至是哪个关键词;你的网站访问者来自哪里,你可以得到日报、周报、月报、年报等。
O'ReillyMedia 已将这本书上传到 Safari Books Online Service。
除了5KH8DE1F000120GR是字母和数字的混合,其余都是显示数字。
环比环比:是指本期数据与上期数据的对比。它反映了数据相互变化的趋势,可以是日环比、环环比、环环比等,比如今年的第n个月和第n个月或者n+ 1个月的比例。
以不道德的方式发生的戏剧性变化代表了投资者所谓的“破坏性事件”——从根本上改变事物的那种事件。 查看全部
seq搜索引擎优化至少包括那几步?(
百度算法|87程度就低,适当地,系统将减少相关度)

当涉及到该短语的有效竞争页数时,竞争的准确性取决于搜索“关键字是该页面的焦点”。
3. 新访客比例:我们调查了从入口到达的访客中有多少是新访客。解释越高,新访客就越感兴趣。
越早开始,对您的公司越好。
潜在语义索引 (LSI) 更进一步,用于语义分析以识别所涉及的网页。
另一方面,如果网页被用户关闭并且网页时间长,则网页的流行度会很低。系统会适当地降低网页的相关性。
地域来源分析 从百度统计数据中获取【地域来源】报表,可以了解返回网站的访问者所在的位置。
标题标签中的关键字是最重要的吗?标题标签是一个网页最重要的搜索关键词位置。
博客搜索谷歌专门为博客搜索打造了一个搜索引擎——GoogleBlogSearch(谷歌博客搜索,名字不准确,因为它实际上是一个RSS提要引擎而不是博客引擎)。
1.水平导航系统。
现在为每个 SearchEngineGuide 和 ISEDB 添加一个目录。
当 Spiders 从其他站点找到您的 网站 链接时,如果 Robots.txt 文件未声明不允许访问该页面,则 Spiders 将不会保存该页面。
这是一个图表,显示了大多数搜索引擎如何与目录交互。
越早开始,对您的公司越好。
这在 网站 优化中起着更重要的作用。
至于如何区分低权限站点和无价值站点,1、大多数网站甚至需要一个网页来识别它们的价值;2、针对网站分析MSN要优化关键词SERP排在前网站,通过对比他们网站的链接,可以大致得出结论,在同时,不会为您找到更多有潜力的Link合作伙伴。
“链接工厂”(也称为“群链接机制”)是指由大量交叉链接的网页组成的网络系统。
如前所述,良好的链接工作和必要的链接文本必须通过在标题和正文中不收录非常丰富的关键字来补充。
许多互联网销售专家创建了他们控制内容的商业模式,人们可以通过页面的主要内容获得相关的广告。
在美国的搜索引擎用户中,女性略多于男性(50.1%:49.9%)。
198 他们可以详细监控互联网用户如何搜索您网站。例如,搜索引擎可以检测到哪个搜索引擎在搜索你,甚至是哪个关键词;你的网站访问者来自哪里,你可以得到日报、周报、月报、年报等。
O'ReillyMedia 已将这本书上传到 Safari Books Online Service。
除了5KH8DE1F000120GR是字母和数字的混合,其余都是显示数字。
环比环比:是指本期数据与上期数据的对比。它反映了数据相互变化的趋势,可以是日环比、环环比、环环比等,比如今年的第n个月和第n个月或者n+ 1个月的比例。
以不道德的方式发生的戏剧性变化代表了投资者所谓的“破坏性事件”——从根本上改变事物的那种事件。
seq搜索引擎优化至少包括那几步?(社交网络营销(sns)优化至少包括那几步?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-05 16:07
seq搜索引擎优化至少包括那几步?seq是一个设计用于搜索引擎排名和关键字优化的http服务器框架,有时候也称soqg,或是seq2g。是alexa网站排名服务,与strwordsmartlists一起被称为搜索引擎优化的第三代框架。服务提供快速索引和转换表,以便用户能够快速灵活地查找他们需要的内容。
搜索引擎优化(seo)的目标是创建提高整个站点知名度和影响力的网站,同时可以保持一个良好的网络收录和排名。seo的主要目标是通过处理关键字来创建描述性和描述性页面,从而成为搜索引擎的良好页面。搜索引擎优化(seo)的第二个目标是支持搜索引擎排名。第三个主要目标是通过外部链接,电子邮件广告和搜索引擎内容来显著提高网站访问者的流量和关注度。
seo是一个系统化的计划,其核心是关键字和内容。该系统通过社交网络的推荐算法、使用页面、标题和tags来连接。接下来我们来介绍三个已知的方法来增加seo,同时可以验证方法的有效性,以及它是否适合于其他搜索引擎。
1)搜索引擎(site)优化它允许用户访问一个排名靠前的网站。例如,如果网站连接的谷歌广告无法收回这一差距,那么用户就不会进入排名第一的网站。根据seo表格中的权重,site中的连接越多,网站的排名就越靠前。但是如果访问并爬取的rss代码过长,速度太慢,也可能造成排名靠后。因此site优化不是一个可控的过程,即使提交的网站连接足够完美,可以将网站快速发布在谷歌商城,也不可能成功地创建site网站。
2)社交网络营销(sns)营销社交网络营销是公认的成功商业运营之一。它可以将人们从搜索引擎引导到社交网络上(比如facebook和twitter)并扩大他们对信息的关注度。这些社交网络包括:twitter,linkedin,facebook和instagram。repo代表了facebook的“follow”功能,会有更多的好友关注它并会根据repo生成一个谷歌搜索页面(对于repo较少的公司或网站来说,这是一个有价值的功能)。
repo同时也能帮助提高用户购买你的产品的倾向。现在很多的社交网络都已经支持该功能。同时在社交网络营销中,常见的手段是创建商业博客或网站。例如ebay营销人员通常建立一个购物网站并把它上传到facebook(即使他们不能使用facebook本身)。虽然发布购物网站可能并不需要seo,但seo人员应该知道企业为什么需要seo。
3)使用搜索引擎营销优化工具现在有些人使用joomla和来支持他们的seo,它们包括linkedin,但是seo仍然可以与更为广泛的搜索引擎营销工具结合起来。例如,如果一个网站上没有linkedin网站, 查看全部
seq搜索引擎优化至少包括那几步?(社交网络营销(sns)优化至少包括那几步?)
seq搜索引擎优化至少包括那几步?seq是一个设计用于搜索引擎排名和关键字优化的http服务器框架,有时候也称soqg,或是seq2g。是alexa网站排名服务,与strwordsmartlists一起被称为搜索引擎优化的第三代框架。服务提供快速索引和转换表,以便用户能够快速灵活地查找他们需要的内容。
搜索引擎优化(seo)的目标是创建提高整个站点知名度和影响力的网站,同时可以保持一个良好的网络收录和排名。seo的主要目标是通过处理关键字来创建描述性和描述性页面,从而成为搜索引擎的良好页面。搜索引擎优化(seo)的第二个目标是支持搜索引擎排名。第三个主要目标是通过外部链接,电子邮件广告和搜索引擎内容来显著提高网站访问者的流量和关注度。
seo是一个系统化的计划,其核心是关键字和内容。该系统通过社交网络的推荐算法、使用页面、标题和tags来连接。接下来我们来介绍三个已知的方法来增加seo,同时可以验证方法的有效性,以及它是否适合于其他搜索引擎。
1)搜索引擎(site)优化它允许用户访问一个排名靠前的网站。例如,如果网站连接的谷歌广告无法收回这一差距,那么用户就不会进入排名第一的网站。根据seo表格中的权重,site中的连接越多,网站的排名就越靠前。但是如果访问并爬取的rss代码过长,速度太慢,也可能造成排名靠后。因此site优化不是一个可控的过程,即使提交的网站连接足够完美,可以将网站快速发布在谷歌商城,也不可能成功地创建site网站。
2)社交网络营销(sns)营销社交网络营销是公认的成功商业运营之一。它可以将人们从搜索引擎引导到社交网络上(比如facebook和twitter)并扩大他们对信息的关注度。这些社交网络包括:twitter,linkedin,facebook和instagram。repo代表了facebook的“follow”功能,会有更多的好友关注它并会根据repo生成一个谷歌搜索页面(对于repo较少的公司或网站来说,这是一个有价值的功能)。
repo同时也能帮助提高用户购买你的产品的倾向。现在很多的社交网络都已经支持该功能。同时在社交网络营销中,常见的手段是创建商业博客或网站。例如ebay营销人员通常建立一个购物网站并把它上传到facebook(即使他们不能使用facebook本身)。虽然发布购物网站可能并不需要seo,但seo人员应该知道企业为什么需要seo。
3)使用搜索引擎营销优化工具现在有些人使用joomla和来支持他们的seo,它们包括linkedin,但是seo仍然可以与更为广泛的搜索引擎营销工具结合起来。例如,如果一个网站上没有linkedin网站,
seq搜索引擎优化至少包括那几步?(面向opendomain的聊天机器人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-18 19:12
面向开放领域的聊天机器人在学术界和工业界都是一个具有挑战性的话题。目前有两种典型的方法:一种是基于检索的模型,另一种是基于Seq2Seq的生成模型。前者以可控的答案回应,但无法处理长尾问题,而后者无法保证一致性和合理性。
本期推荐的纸质笔记来自PaperWeekly社区用户@britin。本文结合检索模型和生成模型各自的优点,提出了一种新的融合模型——AliMe Chat。
阿里小米首先使用检索模型从QA知识库中寻找候选答案集合,然后使用attention-focused Seq2Seq模型对候选答案进行排序。如果第一个候选的分数超过某个阈值,则将其作为最终答案输出,否则使用生成模型生成答案。
作者简介:英国人,中国科学院物理学硕士,研究兴趣为自然语言处理和计算机视觉。
■纸| AliMe Chat:基于序列到排序和重新排名的聊天机器人引擎
■ 链接 |
■ 作者 | 英国人
论文动机
目前,商业聊天机器人正在大量涌现。这种帮助用户回答问题的自然语言对话方式比传统死板的用户界面更加友好。通常Chatbot由两部分组成:IR模块和生成模块。针对用户的问题,IR模块从QA知识库中检索对应的答案,生成模块使用预先训练好的Seq2Seq模型生成最终答案。
然而,现有系统的问题在于,对于一些较长的问题或复杂的问题,在 QA 知识库中无法检索到匹配项,并且生成模块经常生成不匹配或无意义的答案。
本文给出的方法聚合了IR和生成模块,并使用Seq2Seq模型对搜索结果进行评估,从而达到优化效果。
型号介绍
整个方案如图所示:
首先使用IR模型从知识库中检索k个候选QA对,然后使用rerank模型的评分机制计算每个候选答案与问题的匹配程度。如果得分最高的大于预设阈值,则将其作为答案,如果小于阈值,则由生成模型生成答案。
整个系统是从单词层面来分析的。
1. QA 知识库
本文从在线直播用户服务日志中提取QA对作为QA知识库。过滤掉不收录相关关键词的QA,最终得到9,164834个问答对。
2. 红外模块
使用倒排索引法将每个词推断为收录该词的一组问题,并索引这些词的同义词,然后使用BM25算法计算搜索到的问题和输入问题的相似度,取最相似的答案题。
3. 生成模型
生成模型是一个细心的seq2seq结构,如图:
GRU 用于从问题中生成答案并计算生成单词的概率:
添加上下文向量,由图中的α得到。α 表示当前步骤的输入词与上一步生成的词的匹配度,由对齐模型计算得到。
需要注意的是,当每个QA的长度不等时,使用bucketing和padding机制。另外,使用softmax对词汇表中的单词进行随机采样,而不是使用整个词汇表,从而加快了训练过程。波束搜索解码器仍然用于一次维护前 k 个输出,而不是一次贪婪地搜索一个输出。
4.重新排名模块
使用的模型与上述相同。根据输入的问题对候选答案进行评分,以平均概率作为评分函数:
实验结果
本文对结果进行了详细的评估,首先评估rerank模块的平均概率的结果。然后,对IR、生成、IR+rerank、IR+rerank+生成的不同组合的系统进行性能评估。并对系统和基线聊天机器人进行了在线 A/B 测试。最后比较了这个系统和已经上架的Chatbot的区别。
不同重排模型的效果:
不同模块组合的结果:
与基线比较的结果:
文章评价
本文提出了一个细心的 Seq2Seq 模型,将 IR 和生成模块结合起来,对原创结果进行重新排序和优化。阿里已将此纳入阿里小米的商业用途。
整个系统比较简单,满足商业需求。但由于功能设计过于简单,不排除系统被数据堆砌。毕竟阿里有大量的真实用户数据,所以算法的价值还是比较一般的。如果没有合适的数据,可能很难达到预期的结果。 查看全部
seq搜索引擎优化至少包括那几步?(面向opendomain的聊天机器人)
面向开放领域的聊天机器人在学术界和工业界都是一个具有挑战性的话题。目前有两种典型的方法:一种是基于检索的模型,另一种是基于Seq2Seq的生成模型。前者以可控的答案回应,但无法处理长尾问题,而后者无法保证一致性和合理性。
本期推荐的纸质笔记来自PaperWeekly社区用户@britin。本文结合检索模型和生成模型各自的优点,提出了一种新的融合模型——AliMe Chat。
阿里小米首先使用检索模型从QA知识库中寻找候选答案集合,然后使用attention-focused Seq2Seq模型对候选答案进行排序。如果第一个候选的分数超过某个阈值,则将其作为最终答案输出,否则使用生成模型生成答案。
作者简介:英国人,中国科学院物理学硕士,研究兴趣为自然语言处理和计算机视觉。
■纸| AliMe Chat:基于序列到排序和重新排名的聊天机器人引擎
■ 链接 |
■ 作者 | 英国人
论文动机
目前,商业聊天机器人正在大量涌现。这种帮助用户回答问题的自然语言对话方式比传统死板的用户界面更加友好。通常Chatbot由两部分组成:IR模块和生成模块。针对用户的问题,IR模块从QA知识库中检索对应的答案,生成模块使用预先训练好的Seq2Seq模型生成最终答案。
然而,现有系统的问题在于,对于一些较长的问题或复杂的问题,在 QA 知识库中无法检索到匹配项,并且生成模块经常生成不匹配或无意义的答案。
本文给出的方法聚合了IR和生成模块,并使用Seq2Seq模型对搜索结果进行评估,从而达到优化效果。
型号介绍
整个方案如图所示:
首先使用IR模型从知识库中检索k个候选QA对,然后使用rerank模型的评分机制计算每个候选答案与问题的匹配程度。如果得分最高的大于预设阈值,则将其作为答案,如果小于阈值,则由生成模型生成答案。
整个系统是从单词层面来分析的。
1. QA 知识库
本文从在线直播用户服务日志中提取QA对作为QA知识库。过滤掉不收录相关关键词的QA,最终得到9,164834个问答对。
2. 红外模块
使用倒排索引法将每个词推断为收录该词的一组问题,并索引这些词的同义词,然后使用BM25算法计算搜索到的问题和输入问题的相似度,取最相似的答案题。
3. 生成模型
生成模型是一个细心的seq2seq结构,如图:
GRU 用于从问题中生成答案并计算生成单词的概率:
添加上下文向量,由图中的α得到。α 表示当前步骤的输入词与上一步生成的词的匹配度,由对齐模型计算得到。
需要注意的是,当每个QA的长度不等时,使用bucketing和padding机制。另外,使用softmax对词汇表中的单词进行随机采样,而不是使用整个词汇表,从而加快了训练过程。波束搜索解码器仍然用于一次维护前 k 个输出,而不是一次贪婪地搜索一个输出。
4.重新排名模块
使用的模型与上述相同。根据输入的问题对候选答案进行评分,以平均概率作为评分函数:
实验结果
本文对结果进行了详细的评估,首先评估rerank模块的平均概率的结果。然后,对IR、生成、IR+rerank、IR+rerank+生成的不同组合的系统进行性能评估。并对系统和基线聊天机器人进行了在线 A/B 测试。最后比较了这个系统和已经上架的Chatbot的区别。
不同重排模型的效果:
不同模块组合的结果:
与基线比较的结果:
文章评价
本文提出了一个细心的 Seq2Seq 模型,将 IR 和生成模块结合起来,对原创结果进行重新排序和优化。阿里已将此纳入阿里小米的商业用途。
整个系统比较简单,满足商业需求。但由于功能设计过于简单,不排除系统被数据堆砌。毕竟阿里有大量的真实用户数据,所以算法的价值还是比较一般的。如果没有合适的数据,可能很难达到预期的结果。
seq搜索引擎优化至少包括那几步?(搜索引擎扩展插件、网页版免安装使用引擎的应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-18 15:17
如果您发现在搜索引擎之间来回切换很麻烦,虽然主流浏览器都支持自行添加搜索引擎并在网址栏或专用搜索栏中搜索,但效果并不如您所愿。
不过也有跨浏览器的,内置了几十个我们常用的搜索引擎(包括搜索词、购物、娱乐等),以及在不同浏览器之间导出和导入自定义搜索引擎数据的方法。
并且有浏览器扩展插件和网页版免安装两种形式。但是您需要使用扩展程序才能轻松使用连续点击搜索的功能。
看看其内置引擎收录的现状:
中文的中英文混搭部分
除了以上语言通用的内容,Big Search还提供(可能只是一)中文用户的内容。还在添加中~
可以看到,由于Github和Stack Overflow网站都是收录,这个东西自然是在Github上开源的:
谈谈内部使用的技术
50多个内置引擎,以及为用户添加的自定义私有引擎功能,都是通过JS解析JSON数据,然后绘制DOM节点,点击按钮后发送GET和POST请求来实现的。简单的 JSON 引擎数据,例如:
{
"百度": "https://www.baidu.com/s?wd={0}",
"Google": "https://www.google.com/search?q={0}",
"Yahoo Search": "https://search.yahoo.com/search?q={0}"
}
上面的String引擎只支持GET,使用POST方法的引擎必须换成完整的JSON Object形式来描述一个引擎,比如:
"yahoo": {
"dname": "Yahoo Search",
"addr": "https://search.yahoo.com",
"action": "https://search.yahoo.com/search",
"kw_key": "q"
}
如果是POST方法,添加“method”:“post”。
简而言之,任何引擎都可以用上述方式来描述。其他的描述方式,如Open Search、Firefox profile等,不如本工具提供的描述全面。详情请查看源代码页的说明:
因此,安装浏览器扩展后,使用此工具比直接使用网址栏或搜索栏更主动 查看全部
seq搜索引擎优化至少包括那几步?(搜索引擎扩展插件、网页版免安装使用引擎的应用方法)
如果您发现在搜索引擎之间来回切换很麻烦,虽然主流浏览器都支持自行添加搜索引擎并在网址栏或专用搜索栏中搜索,但效果并不如您所愿。
不过也有跨浏览器的,内置了几十个我们常用的搜索引擎(包括搜索词、购物、娱乐等),以及在不同浏览器之间导出和导入自定义搜索引擎数据的方法。
并且有浏览器扩展插件和网页版免安装两种形式。但是您需要使用扩展程序才能轻松使用连续点击搜索的功能。
看看其内置引擎收录的现状:
中文的中英文混搭部分
除了以上语言通用的内容,Big Search还提供(可能只是一)中文用户的内容。还在添加中~
可以看到,由于Github和Stack Overflow网站都是收录,这个东西自然是在Github上开源的:
谈谈内部使用的技术
50多个内置引擎,以及为用户添加的自定义私有引擎功能,都是通过JS解析JSON数据,然后绘制DOM节点,点击按钮后发送GET和POST请求来实现的。简单的 JSON 引擎数据,例如:
{
"百度": "https://www.baidu.com/s?wd={0}",
"Google": "https://www.google.com/search?q={0}",
"Yahoo Search": "https://search.yahoo.com/search?q={0}"
}
上面的String引擎只支持GET,使用POST方法的引擎必须换成完整的JSON Object形式来描述一个引擎,比如:
"yahoo": {
"dname": "Yahoo Search",
"addr": "https://search.yahoo.com",
"action": "https://search.yahoo.com/search",
"kw_key": "q"
}
如果是POST方法,添加“method”:“post”。
简而言之,任何引擎都可以用上述方式来描述。其他的描述方式,如Open Search、Firefox profile等,不如本工具提供的描述全面。详情请查看源代码页的说明:
因此,安装浏览器扩展后,使用此工具比直接使用网址栏或搜索栏更主动
seq搜索引擎优化至少包括那几步?(JSP众筹管理系统.5开发java语言设计系统源码特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-16 01:19
一、源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp 查看全部
seq搜索引擎优化至少包括那几步?(JSP众筹管理系统.5开发java语言设计系统源码特点)
一、源码特点 JSP众筹管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统具有完整的源代码和数据库,系统主要采用B/S模式。发展。 二、功能介绍 前台主要功能:显示项目信息及项目周边相关信息 后台主要功能:(1)权限管理:添加、删除、修改、查看权限信息(2)用户管理:添加、删除、修改、查看用户信息(3)项目分类管理:添加、删除、修改、查看项目分类信息(4)项目管理:添加项目信息),删除、修改和查看(5)日志管理:添加、删除、修改和查看日志信息(6)项目支持管理:添加、删除、修改和查看项目支持信息(7)Project审核管理:添加、删除、修改和查看项目审核信息(8)报告管理:添加、删除、修改和查看报告信息(9)消息管理:对消息信息的添加、删除、修改和查看(8) 招生管理:添加、删除、修改和查看招生信息编队三、注意事项1、管理员账号:admin 密码:admin 数据库配置文件DBO.java2、开发环境为TOMCAT7.0,Myeclipse8.5,数据库为mysql,使用java语言开发。3、数据库文件名为jspfgongchou .mysql,系统名gongchou4、地址:xiangmu.jsp
seq搜索引擎优化至少包括那几步?(企业seq搜索引擎优化至少包括那几步?搜索)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-15 18:04
seq搜索引擎优化至少包括那几步?seq是在企业内的搜索引擎优化,所以其优化方向主要是关键字优化。
一、写关键字:企业可以通过网站管理软件如开发工具、站长平台建设系统及国内最大的搜索引擎seo优化平台谷歌站长平台去注册和学习seo优化相关知识,掌握最新的市场发展信息及市场动态,进行关键字的撰写,撰写出最大品牌最想关注的关键字,并尽量往网站首页或其他重要导航进行投放。
二、更新内容:1.权重高的关键字可以让seo站成为该关键字搜索引擎优化的排名第一名。2.不要为了数量而使文章有亮点,最主要的是真实、有趣、有用,同时多观察别人对于关键字优化的套路。3.通过大数据分析每篇文章对优化有什么作用,并将成功的套路总结出来,可以使用关键字分析工具如wordwords,siteapp这样专业的网站优化工具,进行实时监控。
三、更新评论:评论对于网站优化也是非常重要的,多的评论能为网站增加很多权重。通过seo评论工具发掘用户和网站共同爱好,然后每个网站建设好之后,就可以收集大量的评论。
四、seo快速追踪:除了seo投入之外,更多的就是对于竞争对手的分析。分析对手的评论,去除对于网站带来伤害的评论,提高网站的安全性,通过seo快速追踪工具建立一份网站评论与网站流量追踪表,这样我们就知道了哪些内容可以为网站优化带来加分。
五、关键字之外,还需要综合考虑:1.页面上布局关键字的时候,要注意将一些不相关的字去掉,重要的是不要影响到主页的排名。2.在网站中要展示优化的策略、步骤和方法,以及网站上的每个内容和功能使用的位置。
六、为网站优化撰写内容:1.尽量把优化的内容多呈现在网站中,哪怕写的字数不多。2.在写文章的时候应该将产品、服务、解决方案的细节都清楚明白的写出来,这样能增加网站的搜索引擎友好度。3.要善于分析竞争对手的网站首页是怎么做的,哪里你也可以通过自己内容包装成有价值的同行。 查看全部
seq搜索引擎优化至少包括那几步?(企业seq搜索引擎优化至少包括那几步?搜索)
seq搜索引擎优化至少包括那几步?seq是在企业内的搜索引擎优化,所以其优化方向主要是关键字优化。
一、写关键字:企业可以通过网站管理软件如开发工具、站长平台建设系统及国内最大的搜索引擎seo优化平台谷歌站长平台去注册和学习seo优化相关知识,掌握最新的市场发展信息及市场动态,进行关键字的撰写,撰写出最大品牌最想关注的关键字,并尽量往网站首页或其他重要导航进行投放。
二、更新内容:1.权重高的关键字可以让seo站成为该关键字搜索引擎优化的排名第一名。2.不要为了数量而使文章有亮点,最主要的是真实、有趣、有用,同时多观察别人对于关键字优化的套路。3.通过大数据分析每篇文章对优化有什么作用,并将成功的套路总结出来,可以使用关键字分析工具如wordwords,siteapp这样专业的网站优化工具,进行实时监控。
三、更新评论:评论对于网站优化也是非常重要的,多的评论能为网站增加很多权重。通过seo评论工具发掘用户和网站共同爱好,然后每个网站建设好之后,就可以收集大量的评论。
四、seo快速追踪:除了seo投入之外,更多的就是对于竞争对手的分析。分析对手的评论,去除对于网站带来伤害的评论,提高网站的安全性,通过seo快速追踪工具建立一份网站评论与网站流量追踪表,这样我们就知道了哪些内容可以为网站优化带来加分。
五、关键字之外,还需要综合考虑:1.页面上布局关键字的时候,要注意将一些不相关的字去掉,重要的是不要影响到主页的排名。2.在网站中要展示优化的策略、步骤和方法,以及网站上的每个内容和功能使用的位置。
六、为网站优化撰写内容:1.尽量把优化的内容多呈现在网站中,哪怕写的字数不多。2.在写文章的时候应该将产品、服务、解决方案的细节都清楚明白的写出来,这样能增加网站的搜索引擎友好度。3.要善于分析竞争对手的网站首页是怎么做的,哪里你也可以通过自己内容包装成有价值的同行。
seq搜索引擎优化至少包括那几步?( 站长们做seo优化时间久了都有各自的优化原则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-15 10:10
站长们做seo优化时间久了都有各自的优化原则)
站长做seo优化已经很久了,有自己的优化原则。即使按照《百度搜索引擎优化指南》,也会有不合理的seo优化细节。作者可以随意向大家透露一些秘密。搜索引擎优化
其实对于网站优化来说,页面优化还是比较简单的。由于搜索引擎算法技术的进步,它在判断网页的相关性方面越来越好。页面优化所涉及的技术细节不需要详尽无遗。,而且在SEO越来越崇尚平衡和自然的前提下,页面优化做的越细致,越容易涉及过度优化。因此,对于页面优化,只需在页面的几个核心位置添加关键词即可,比如标题、H标签等明显的地方。
分析:对于Meta标签,主要有3个地方:title、keywords、description。如果您不添加其余的元标记,那也没关系。就重要性而言,标题在页面优化中绝对占据非常重要的位置。关于标题的写作,从SEO的角度来说,尽量不要积累太多关键词。如果是长标题,可以收录关键词1-2次,关键词不要靠得太近。比如Q猪博客的标题是同向网站建设-SEO优化排名,如果你在百度上搜索“同向网站优化排名”,你会发现Q猪博客仍然是第一位的。
关键词关键词标签,对于页面优化来说,没有以前那么重要了,甚至很多SEO界大神都说关键词标签没用,不需要也没关系,但是Q猪还是相信该页面优化正在进行中。, 仔细写好关键词标签,即使搜索引擎没有考虑关键词,至少关键词在页面的排名因素中还有提醒搜索引擎的功能。
描述 描述标签。在搜索引擎中搜索关键词时,如果描述标签中收录对应的关键词,搜索引擎会用红色字体标记,如果描述标签写得好,可以改善页面点击率。
分析:正文的写作最重要的因素是自然的写作。如何收录关键词?可以参考高考作文。把关键词想成一个标题,然后自然地围绕关键词写。不要只是将需要优化的关键词直接插入到文章中。比如文章是一篇介绍网站构建文章的文章,但是中间出现了美类关键词,这个肯定不好,自然写文章@ > , 最大的特点之一就是可读性强。
文章的内容页面优化的另一个重要因素是,在文章中,尽量使用关键词的同义词和同义词。比如文章还是引入了网站的构造。在写内容的时候,有些地方,在谈到网站的构建时,可以使用网站生产、网站设计等相关词组。
分析:H标签,主要包括H1、H2标签,H1代表标题,关键词优化。H2是副标题。基本上,文章中很少使用H3之后的标签。按照这个意思,最重要的关键词放在H1标签中,与关键词相关的词组放在H2标签中,然后依次推回。
其实对于网页内容页面的优化,H1、H2标签的作用正在慢慢变弱,但是对于一般的页面写作来说,文章的标题应该出现在H1标签中副标题出现在 H2 标签上。
由于搜索引擎很难读取图片,一般写作中,需要对添加的图片进行ALT标签标注。当然,对于图片的理解,周围的文字也起到一定的作用。比如Q Pig在讲网站页面优化中ALT标签的使用。如果现在插入图片,即使代码中没有解析图片,搜索引擎也会认为这是使用ALT标签的图片。
当然,关键词中也可以放H/ALT标签,作为文章内容的重点,但在这些标签中,关键词不宜过多,会造成堆积的怀疑。一般来说,标签中收录2-3个词关键词就足够了。其他的,比如粗体、斜体等,对关键词也有一定的重视,但是在页面的书写中,最重要的是要自然。如果觉得文中某个词需要强调,可以加粗加粗来强调,不必关键词,只需要对文章有帮助的就行。
分析:关键词的排版中,最重要的位置是开头,尤其是第一段开头的50-150字,需要收录一次关键词,然后是2- 3 出现在文本中间关键词或类似词,文章的结尾,也包括关键词一次。
在关键词的布局中,还有一个概念,关键词密度。前几年,很多SEO前辈都会建议页面的关键词密度应该保持在2-9%到3-8%之间。其实随着搜索引擎算法的更新,关键词的密度已经不那么重要了。搜索引擎可以通过语义分析轻松理解文章的中心思想。
如果文章按照一般命题作文写,关键词自然会出现在文章的首段、尾段和中间,一共出现4-5次。没必要多考虑关键词的密度。
分析:精简代码的主要目的是减少搜索引擎分析网站页面时出现的噪音。对于蜘蛛来说,进入页面时他们最想抓取的是页面的正文。对于那些结构化代码、注释等,都是噪音。
所以,要精简代码,首先要把Javascript、外部代码调用、样式表写成DIV+CSS,也就是外部代码调用,代码中的注释要尽量少。代码简化的核心思想是,如果可以使用外部文件调用,就使用外部文件调用。如果不需要出现,尽量不要出现。在正文中,尽量专注于文本,并使用少量 CSS 代码。
搜索引擎索引网站页面时,经常会在页面文件大小的某个值后截断,而不会出现。如果页面不精简代码,很多flash效果、javascript效果、样式表、图片、视频等,都收录在文件中,你经常会看到很多网站页面带有文件大小超过 300k,如果搜索引擎在第 k 行之后,索引将不再被索引,接下来的 200k 文件将消失。
页面优化的核心就是这几个地方,就是突出重点。要表达的关键内容,关键词,收录在H标签和ALT标签中,在文章的开头、正文和结尾收录关键词的1-2次,以及在页面中保留少量代码,其余部分尝试使用外部文件。当然,页面优化最重要的是写好标题。
分享:模板无忧:关键词Density VS Stacking 关键词 确认关键词后怎么办?它必须适当地出现在 网站 中。关键词的出现频率会影响网站关键词被搜索引擎的排名。当我们了解关键词密度和堆叠关键词时,我们 查看全部
seq搜索引擎优化至少包括那几步?(
站长们做seo优化时间久了都有各自的优化原则)
站长做seo优化已经很久了,有自己的优化原则。即使按照《百度搜索引擎优化指南》,也会有不合理的seo优化细节。作者可以随意向大家透露一些秘密。搜索引擎优化
其实对于网站优化来说,页面优化还是比较简单的。由于搜索引擎算法技术的进步,它在判断网页的相关性方面越来越好。页面优化所涉及的技术细节不需要详尽无遗。,而且在SEO越来越崇尚平衡和自然的前提下,页面优化做的越细致,越容易涉及过度优化。因此,对于页面优化,只需在页面的几个核心位置添加关键词即可,比如标题、H标签等明显的地方。
分析:对于Meta标签,主要有3个地方:title、keywords、description。如果您不添加其余的元标记,那也没关系。就重要性而言,标题在页面优化中绝对占据非常重要的位置。关于标题的写作,从SEO的角度来说,尽量不要积累太多关键词。如果是长标题,可以收录关键词1-2次,关键词不要靠得太近。比如Q猪博客的标题是同向网站建设-SEO优化排名,如果你在百度上搜索“同向网站优化排名”,你会发现Q猪博客仍然是第一位的。
关键词关键词标签,对于页面优化来说,没有以前那么重要了,甚至很多SEO界大神都说关键词标签没用,不需要也没关系,但是Q猪还是相信该页面优化正在进行中。, 仔细写好关键词标签,即使搜索引擎没有考虑关键词,至少关键词在页面的排名因素中还有提醒搜索引擎的功能。
描述 描述标签。在搜索引擎中搜索关键词时,如果描述标签中收录对应的关键词,搜索引擎会用红色字体标记,如果描述标签写得好,可以改善页面点击率。
分析:正文的写作最重要的因素是自然的写作。如何收录关键词?可以参考高考作文。把关键词想成一个标题,然后自然地围绕关键词写。不要只是将需要优化的关键词直接插入到文章中。比如文章是一篇介绍网站构建文章的文章,但是中间出现了美类关键词,这个肯定不好,自然写文章@ > , 最大的特点之一就是可读性强。
文章的内容页面优化的另一个重要因素是,在文章中,尽量使用关键词的同义词和同义词。比如文章还是引入了网站的构造。在写内容的时候,有些地方,在谈到网站的构建时,可以使用网站生产、网站设计等相关词组。
分析:H标签,主要包括H1、H2标签,H1代表标题,关键词优化。H2是副标题。基本上,文章中很少使用H3之后的标签。按照这个意思,最重要的关键词放在H1标签中,与关键词相关的词组放在H2标签中,然后依次推回。
其实对于网页内容页面的优化,H1、H2标签的作用正在慢慢变弱,但是对于一般的页面写作来说,文章的标题应该出现在H1标签中副标题出现在 H2 标签上。
由于搜索引擎很难读取图片,一般写作中,需要对添加的图片进行ALT标签标注。当然,对于图片的理解,周围的文字也起到一定的作用。比如Q Pig在讲网站页面优化中ALT标签的使用。如果现在插入图片,即使代码中没有解析图片,搜索引擎也会认为这是使用ALT标签的图片。
当然,关键词中也可以放H/ALT标签,作为文章内容的重点,但在这些标签中,关键词不宜过多,会造成堆积的怀疑。一般来说,标签中收录2-3个词关键词就足够了。其他的,比如粗体、斜体等,对关键词也有一定的重视,但是在页面的书写中,最重要的是要自然。如果觉得文中某个词需要强调,可以加粗加粗来强调,不必关键词,只需要对文章有帮助的就行。
分析:关键词的排版中,最重要的位置是开头,尤其是第一段开头的50-150字,需要收录一次关键词,然后是2- 3 出现在文本中间关键词或类似词,文章的结尾,也包括关键词一次。
在关键词的布局中,还有一个概念,关键词密度。前几年,很多SEO前辈都会建议页面的关键词密度应该保持在2-9%到3-8%之间。其实随着搜索引擎算法的更新,关键词的密度已经不那么重要了。搜索引擎可以通过语义分析轻松理解文章的中心思想。
如果文章按照一般命题作文写,关键词自然会出现在文章的首段、尾段和中间,一共出现4-5次。没必要多考虑关键词的密度。
分析:精简代码的主要目的是减少搜索引擎分析网站页面时出现的噪音。对于蜘蛛来说,进入页面时他们最想抓取的是页面的正文。对于那些结构化代码、注释等,都是噪音。
所以,要精简代码,首先要把Javascript、外部代码调用、样式表写成DIV+CSS,也就是外部代码调用,代码中的注释要尽量少。代码简化的核心思想是,如果可以使用外部文件调用,就使用外部文件调用。如果不需要出现,尽量不要出现。在正文中,尽量专注于文本,并使用少量 CSS 代码。
搜索引擎索引网站页面时,经常会在页面文件大小的某个值后截断,而不会出现。如果页面不精简代码,很多flash效果、javascript效果、样式表、图片、视频等,都收录在文件中,你经常会看到很多网站页面带有文件大小超过 300k,如果搜索引擎在第 k 行之后,索引将不再被索引,接下来的 200k 文件将消失。
页面优化的核心就是这几个地方,就是突出重点。要表达的关键内容,关键词,收录在H标签和ALT标签中,在文章的开头、正文和结尾收录关键词的1-2次,以及在页面中保留少量代码,其余部分尝试使用外部文件。当然,页面优化最重要的是写好标题。
分享:模板无忧:关键词Density VS Stacking 关键词 确认关键词后怎么办?它必须适当地出现在 网站 中。关键词的出现频率会影响网站关键词被搜索引擎的排名。当我们了解关键词密度和堆叠关键词时,我们
seq搜索引擎优化至少包括那几步?(不要暴增建造外链不然简单激起一些做弊算法,查找引擎以为有弊嫌疑)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-15 10:06
②、实际用户多次查看
③、用户实际上说话的频率更高
④ 真实用户重复观看
⑤、用户实际点击的页面内容
5、用户推荐
用户推荐对于提高页面质量也非常有用。比如真实用户的转发和分享,点赞/点赞插件,采集夹,也意味着用户在认为文章不错的时候会保存页面。
6、域权重和得分
域名权重越高,网站关键词的排名就越高。我想大家都知道,在搜索关键词的时候,大而高权重的网站基本上都列在首页了,所以域名比较重要。Bump 也在搜索引擎的排名和排序算法的边缘。
7、外部链接引用
虽然百度的外链算法这几年有所减弱,但优质的外链还是有的。适当添加外链也可以增加页面的权重。另外,请善用好友链接。由于网站的大部分权重都属于首页,所以网站之间的好友链接交流也可以适当增加外链的引荐。另外注意不要建外链,或者干脆挑起一些作弊算法,搜索引擎认为有作弊嫌疑。
二、搜索引擎对新页面的排序方式和后面触发的算法不一样!
搜索引擎对新页面的排序方式和后面触发的算法不一样,这对于大部分没有深入理解的SEOer来说可能是不知道的。在一个新生成的链接中,前期百度搜索引擎通过相关性关键词密度、域名权重、文章原创性等因素决定百度搜索的排名和排名,逐渐被用户改变页面行为、用户交互、用户推荐总是决定页面排名,新页面解析排名的关键词密度和文章关键词密度的原创性会逐渐减弱。这也得益于百度近两年在关键词密度上的作用。弱化,多关注用户体验的原因,算了。看完以上几点常识,让我们都清楚搜索引擎如何判断页面质量,如何对页面关键词进行排名,以及如何优化网站关键词对百度首页的排名?给我们解释一下,网络营销人员网站搜索引擎优化技术如何优化网站关键词在百度首页的排名!
三、提高关键词排名操作技巧
1、网站 相关性补充:关键词布局
陈词滥调的内容,但对于一些新手来说,我必须再说一遍。页面标题、关键词关键词、描述描述等tdk呈现的关键词,尤其是标题标题,必须收录中心关键词。列表页与首页的逻辑布局相同,但列表页的标题必须是列表页下文章这个类别的关键字,具有一定的索引,是一个流行词用户寻找。详情页也是一样,tdk呈现关键词,标题尽量收录关键词。文章 尽量在开头显示中心词并加粗,这样可以突出文章内容的主题。对于正文的自然内容,呈现关键词。但是,我不会傻的!
2、H1重量标签申请
网络营销告诉我们,不得随意使用 h 标签。它的作用是重申搜索引擎页面的重要内容信息。一般在title或者logo标签中使用h1,h1标签填充需要优化的中心词或者品牌。详情页的标题使用了h2标签,一小部分网站使用了h1标签,重点关注内容页的标题信息。这些都是根据个人喜好而定,这些细节不做追踪。
3、 创建具有以下特征的高质量跟踪文本链接:
①. 链接属于软植入,不会影响内容的可读性,锚文本关键词与链接主题高度相关文章。
② 描述文字有引导链接,可以满足用户的其他需求。
③. 控制文章锚文本的数量,一个,不超过三四个。
④. 链接应该多样化,并不是所有的锚文本都指向首页。
4、网站 优质内容不能短
什么是优质内容?用户认为优质的内容就是满足其需求的内容。搜索引擎只能通过后台数据的用户行为来判断页面质量。
①、在页面添加用户的停留时间和粘度
上面的高端营销人员已经说过,如果你想添加一个页面停留,你可以文章能够满足用户的需求,让用户觉得这个文章对他有用。还有文章字体的数量。如果字体太少,用户就会把它们都看了一遍,停留时间不会很长。毕竟内容排版,视觉体验,内容排版注意段落正反面,字体大小控制14~16px,整体看起来规整舒服,不让用户阅读有压力。
②、在网站中添加用户访问
如上所述,高质量的锚文本链接具有引导作用,它们是根据用户阅读此文章后想阅读的内容生成的。网站元素丰富,在页面左侧或右侧,加入推荐文章、新增文章、热门文章、热议等模块添加用户点击. 如果你想要更多的用户点击,一个新颖、有吸引力的标题是必不可少的。据说一个有吸引力的标题已经成功了。其实真的是一样的,那么如何写出吸引人的标题呢?其实这还是基于我的写作经验和头脑风暴。毕竟,我可以看到一些点击率更高的 文章 他们是如何获得标题的。
③ 降低用户在页面的跳出率
其实降低用户在页面跳出率的问题我已经讲过好几次了。这里我粗略的讲一下。事实上,降低跳出率只有在需要用户的心思来降低跳出率时才能做的更细致、更细致。在这个阶段,流程优化,细节和内容掌握成功。那么,如何降低用户跳出率呢?
工艺:步骤
当用户来到网站时,访问页面的加载速度必须让用户满意。5秒前的页面打开速度更加雄心勃勃。超出这个时间值,用户肯定会间接流失,所以服务器的响应速度是基础也是很重要的工作,我们要优化打开页面的速度,提升用户体验。网页代码:众所周知,网页上的任何元素最终都会被转换成代码,被用户的浏览器下载到本地,再被浏览器转换成相应的页面。可见,网页的大小也可以通过网页代码的优化来控制,一个优化过的网页代码往往可以将网页的大小提升30%以上。因此,HTML、JS、CSS 代码的优化更为重要。关于网站的重要内容来说,还是少用为好。视频网站:我们能做的还是尽可能的减小体积,但是视频的处理方式,一般转换成flv格式,会比其他格式小一些。
过程:第二步
落地面优化:主题与落地面要一致、相关,主题内容要突出。不要炫耀行为。
流程:第三步
<p>内容/产品图片 这是支持用户是否继续阅读的关键。内容让用户不满意,产品形象模棱两可,还有什么原因让用户不去?了解自己 查看全部
seq搜索引擎优化至少包括那几步?(不要暴增建造外链不然简单激起一些做弊算法,查找引擎以为有弊嫌疑)
②、实际用户多次查看
③、用户实际上说话的频率更高
④ 真实用户重复观看
⑤、用户实际点击的页面内容
5、用户推荐
用户推荐对于提高页面质量也非常有用。比如真实用户的转发和分享,点赞/点赞插件,采集夹,也意味着用户在认为文章不错的时候会保存页面。
6、域权重和得分
域名权重越高,网站关键词的排名就越高。我想大家都知道,在搜索关键词的时候,大而高权重的网站基本上都列在首页了,所以域名比较重要。Bump 也在搜索引擎的排名和排序算法的边缘。
7、外部链接引用
虽然百度的外链算法这几年有所减弱,但优质的外链还是有的。适当添加外链也可以增加页面的权重。另外,请善用好友链接。由于网站的大部分权重都属于首页,所以网站之间的好友链接交流也可以适当增加外链的引荐。另外注意不要建外链,或者干脆挑起一些作弊算法,搜索引擎认为有作弊嫌疑。
二、搜索引擎对新页面的排序方式和后面触发的算法不一样!
搜索引擎对新页面的排序方式和后面触发的算法不一样,这对于大部分没有深入理解的SEOer来说可能是不知道的。在一个新生成的链接中,前期百度搜索引擎通过相关性关键词密度、域名权重、文章原创性等因素决定百度搜索的排名和排名,逐渐被用户改变页面行为、用户交互、用户推荐总是决定页面排名,新页面解析排名的关键词密度和文章关键词密度的原创性会逐渐减弱。这也得益于百度近两年在关键词密度上的作用。弱化,多关注用户体验的原因,算了。看完以上几点常识,让我们都清楚搜索引擎如何判断页面质量,如何对页面关键词进行排名,以及如何优化网站关键词对百度首页的排名?给我们解释一下,网络营销人员网站搜索引擎优化技术如何优化网站关键词在百度首页的排名!
三、提高关键词排名操作技巧
1、网站 相关性补充:关键词布局
陈词滥调的内容,但对于一些新手来说,我必须再说一遍。页面标题、关键词关键词、描述描述等tdk呈现的关键词,尤其是标题标题,必须收录中心关键词。列表页与首页的逻辑布局相同,但列表页的标题必须是列表页下文章这个类别的关键字,具有一定的索引,是一个流行词用户寻找。详情页也是一样,tdk呈现关键词,标题尽量收录关键词。文章 尽量在开头显示中心词并加粗,这样可以突出文章内容的主题。对于正文的自然内容,呈现关键词。但是,我不会傻的!
2、H1重量标签申请
网络营销告诉我们,不得随意使用 h 标签。它的作用是重申搜索引擎页面的重要内容信息。一般在title或者logo标签中使用h1,h1标签填充需要优化的中心词或者品牌。详情页的标题使用了h2标签,一小部分网站使用了h1标签,重点关注内容页的标题信息。这些都是根据个人喜好而定,这些细节不做追踪。
3、 创建具有以下特征的高质量跟踪文本链接:
①. 链接属于软植入,不会影响内容的可读性,锚文本关键词与链接主题高度相关文章。
② 描述文字有引导链接,可以满足用户的其他需求。
③. 控制文章锚文本的数量,一个,不超过三四个。
④. 链接应该多样化,并不是所有的锚文本都指向首页。
4、网站 优质内容不能短
什么是优质内容?用户认为优质的内容就是满足其需求的内容。搜索引擎只能通过后台数据的用户行为来判断页面质量。
①、在页面添加用户的停留时间和粘度
上面的高端营销人员已经说过,如果你想添加一个页面停留,你可以文章能够满足用户的需求,让用户觉得这个文章对他有用。还有文章字体的数量。如果字体太少,用户就会把它们都看了一遍,停留时间不会很长。毕竟内容排版,视觉体验,内容排版注意段落正反面,字体大小控制14~16px,整体看起来规整舒服,不让用户阅读有压力。
②、在网站中添加用户访问
如上所述,高质量的锚文本链接具有引导作用,它们是根据用户阅读此文章后想阅读的内容生成的。网站元素丰富,在页面左侧或右侧,加入推荐文章、新增文章、热门文章、热议等模块添加用户点击. 如果你想要更多的用户点击,一个新颖、有吸引力的标题是必不可少的。据说一个有吸引力的标题已经成功了。其实真的是一样的,那么如何写出吸引人的标题呢?其实这还是基于我的写作经验和头脑风暴。毕竟,我可以看到一些点击率更高的 文章 他们是如何获得标题的。
③ 降低用户在页面的跳出率
其实降低用户在页面跳出率的问题我已经讲过好几次了。这里我粗略的讲一下。事实上,降低跳出率只有在需要用户的心思来降低跳出率时才能做的更细致、更细致。在这个阶段,流程优化,细节和内容掌握成功。那么,如何降低用户跳出率呢?
工艺:步骤
当用户来到网站时,访问页面的加载速度必须让用户满意。5秒前的页面打开速度更加雄心勃勃。超出这个时间值,用户肯定会间接流失,所以服务器的响应速度是基础也是很重要的工作,我们要优化打开页面的速度,提升用户体验。网页代码:众所周知,网页上的任何元素最终都会被转换成代码,被用户的浏览器下载到本地,再被浏览器转换成相应的页面。可见,网页的大小也可以通过网页代码的优化来控制,一个优化过的网页代码往往可以将网页的大小提升30%以上。因此,HTML、JS、CSS 代码的优化更为重要。关于网站的重要内容来说,还是少用为好。视频网站:我们能做的还是尽可能的减小体积,但是视频的处理方式,一般转换成flv格式,会比其他格式小一些。
过程:第二步
落地面优化:主题与落地面要一致、相关,主题内容要突出。不要炫耀行为。
流程:第三步
<p>内容/产品图片 这是支持用户是否继续阅读的关键。内容让用户不满意,产品形象模棱两可,还有什么原因让用户不去?了解自己
seq搜索引擎优化至少包括那几步?(百度是如何判断网站内容是原创的呢的事?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-15 05:15
互联网鼓励原创,尤其是搜索引擎,希望向用户推荐优质的原创内容。百度站长平台lee发表了一篇文章:谈原创项目那件事。其主要目的是鼓励所有站长支持原创。那么,百度是如何判断网站的内容是原创的呢?在这里谈谈我自己的看法
注意原创的目的:
1、采集 洪水
分析:在互联网上,采集泛滥的区域主要分布在新闻、咨询、小说等领域,随着采集器现在越来越复杂,一般很难预防< @网站 被阻止。采集。
我们在做网站内容的时候,经常发现的一个问题是我们更新了一篇关于网站和原创的文章,但是过几天去百度查排名的时候,你会发现,由于网站的权重等因素,那些转载文章文章的网站排在前列。
对于大多数中小网站来说,搜索流量在总流量中占有非常重要的位置。如果原创长期存在,却得不到合适的排名和流量,站长就会失去原创的兴趣,从而降低原创的比例。
2、提升用户体验
分析:大家都知道原创文章对网站的重要性,但是原创的内容创作是一项非常困难且耗时的工作。会有市场。机会,于是市场上出现了大量的伪原创工具。原理是打乱文章的章节,尝试通过重新组合和添加关键词来替代原来的文章。成为一个新人。
这些 文章 的一个共同点是它们的可读性较差,从而导致用户体验不佳。另一方面,它们也会对搜索引擎的搜索质量产生一定的影响。
提升用户体验是一个永恒的话题。对于搜索引擎来说,虽然很多方面还不够满意,但至少他们一直在朝这个方向努力。
3、鼓励原创作者和原创内容
分析:如第一点所述,只有网站和原创坚持原创的内容被赋予适当的权重和排名。只有原创的作者才能享受。,原创带来的巨大好处,作者会坚持原创。
确定原创内容的难点:
1、冒充原创,篡改关键信息
分析:其实很多坚持原创的网站都是中小网站。但是由于蜘蛛爬行的频率和搜索引擎的重要性,他们在原创文章发表后,其他网站转载后,篡改版权,关键词文章中涉及@>等信息,冒充原创。
由于转载网站在权重方面的优势,搜索引擎蜘蛛很难判断哪个文章是哪个网站抄袭了网站。
2、使用伪原创工具让文章焕然一新,量产“原创文章”。
分析:无论如何判断文章是否为原创,由于网络上数以亿计的文章,判断的主体是由程序检查的。程序有漏洞,可以在程序中探查规则。许多伪原创工具可以利用这些工具和漏洞将文章重新组合成“原创”。
由于制造原创的工具也随着算法的变化而变化,所以在判断过程中会有一定的困难。
从百度的描述可以看出,由于工具产生的所谓“原创文章”,存在语句不一致、用户可读性差等原因。这些内容都在这段时间里。聚焦整改对象。Q Pig 提醒,如果您正在使用这些工具,请停止使用。
3、结构分化
分析:我们知道每个网站的结构是有区别的。当搜索引擎抓取内容时,它通常会进行分析。在同一个网站中,哪些内容是常见的,哪些内容是真正有价值的,然后分析这些有价值的内容,然后索引到数据库中。
但是,不同站点的结构大不相同,html标签的含义和分布也不同。因此,提取标题、作者、时间等关键信息的难度也大不相同。因此,每一个网站都需要一个合理的网站结构,简单明了,清晰明了,不仅能让搜索引擎清晰的捕捉到网站的内容,还能让用户更加流畅浏览网站的内容。
百度为鼓励原创采取的措施:
1、单独成立原创项目组
分析:百度表示,该部门将长期成立,为原创的判断提供技术、产品、运营、法律等方面的支持。
2、 原创识别“起源”算法
百度如何判断原创的内容,这是重点。
一种。首先,通过内容的相似性,将网络上所有主题相似、内容相似的文章,无论是原创还是采集,都归为一组。
湾 然后,根据作者、发布时间、链接方向、用户评论、作者和网站历史原创情况、转发轨迹等因素综合考虑原创的内容。
C。最后通过价值分析系统,判断原创内容的价值,进而适当引导最终的排名顺序。
3、原创星火项目
分析:该方案需要百度和站长共同维护互联网生态环境。站长推荐原创的内容,搜索引擎通过一定的判断后会优先处理原创的内容,共同促进生态的改善,鼓励原创,这是“原创 Spark Project”,旨在快速解决当前的严重问题。
简单来说,就是站长推荐原创的内容,然后百度用算法甚至人类来判断是否是原创。这是一个改进算法的过程,也是一个更快的实现原创发现内容的过程。
基于以上几点,要得到百度鼓励原创政策的照顾,作为站长首先要做的就是网站内部优化结构,坚持原创生产,并鼓励用户评论,确保网站的内部链接畅通无阻,并尽可能保留每个文章的发布时间。 查看全部
seq搜索引擎优化至少包括那几步?(百度是如何判断网站内容是原创的呢的事?)
互联网鼓励原创,尤其是搜索引擎,希望向用户推荐优质的原创内容。百度站长平台lee发表了一篇文章:谈原创项目那件事。其主要目的是鼓励所有站长支持原创。那么,百度是如何判断网站的内容是原创的呢?在这里谈谈我自己的看法
注意原创的目的:
1、采集 洪水
分析:在互联网上,采集泛滥的区域主要分布在新闻、咨询、小说等领域,随着采集器现在越来越复杂,一般很难预防< @网站 被阻止。采集。
我们在做网站内容的时候,经常发现的一个问题是我们更新了一篇关于网站和原创的文章,但是过几天去百度查排名的时候,你会发现,由于网站的权重等因素,那些转载文章文章的网站排在前列。
对于大多数中小网站来说,搜索流量在总流量中占有非常重要的位置。如果原创长期存在,却得不到合适的排名和流量,站长就会失去原创的兴趣,从而降低原创的比例。
2、提升用户体验
分析:大家都知道原创文章对网站的重要性,但是原创的内容创作是一项非常困难且耗时的工作。会有市场。机会,于是市场上出现了大量的伪原创工具。原理是打乱文章的章节,尝试通过重新组合和添加关键词来替代原来的文章。成为一个新人。
这些 文章 的一个共同点是它们的可读性较差,从而导致用户体验不佳。另一方面,它们也会对搜索引擎的搜索质量产生一定的影响。
提升用户体验是一个永恒的话题。对于搜索引擎来说,虽然很多方面还不够满意,但至少他们一直在朝这个方向努力。
3、鼓励原创作者和原创内容
分析:如第一点所述,只有网站和原创坚持原创的内容被赋予适当的权重和排名。只有原创的作者才能享受。,原创带来的巨大好处,作者会坚持原创。
确定原创内容的难点:
1、冒充原创,篡改关键信息
分析:其实很多坚持原创的网站都是中小网站。但是由于蜘蛛爬行的频率和搜索引擎的重要性,他们在原创文章发表后,其他网站转载后,篡改版权,关键词文章中涉及@>等信息,冒充原创。
由于转载网站在权重方面的优势,搜索引擎蜘蛛很难判断哪个文章是哪个网站抄袭了网站。
2、使用伪原创工具让文章焕然一新,量产“原创文章”。
分析:无论如何判断文章是否为原创,由于网络上数以亿计的文章,判断的主体是由程序检查的。程序有漏洞,可以在程序中探查规则。许多伪原创工具可以利用这些工具和漏洞将文章重新组合成“原创”。
由于制造原创的工具也随着算法的变化而变化,所以在判断过程中会有一定的困难。
从百度的描述可以看出,由于工具产生的所谓“原创文章”,存在语句不一致、用户可读性差等原因。这些内容都在这段时间里。聚焦整改对象。Q Pig 提醒,如果您正在使用这些工具,请停止使用。
3、结构分化
分析:我们知道每个网站的结构是有区别的。当搜索引擎抓取内容时,它通常会进行分析。在同一个网站中,哪些内容是常见的,哪些内容是真正有价值的,然后分析这些有价值的内容,然后索引到数据库中。
但是,不同站点的结构大不相同,html标签的含义和分布也不同。因此,提取标题、作者、时间等关键信息的难度也大不相同。因此,每一个网站都需要一个合理的网站结构,简单明了,清晰明了,不仅能让搜索引擎清晰的捕捉到网站的内容,还能让用户更加流畅浏览网站的内容。
百度为鼓励原创采取的措施:
1、单独成立原创项目组
分析:百度表示,该部门将长期成立,为原创的判断提供技术、产品、运营、法律等方面的支持。
2、 原创识别“起源”算法
百度如何判断原创的内容,这是重点。
一种。首先,通过内容的相似性,将网络上所有主题相似、内容相似的文章,无论是原创还是采集,都归为一组。
湾 然后,根据作者、发布时间、链接方向、用户评论、作者和网站历史原创情况、转发轨迹等因素综合考虑原创的内容。
C。最后通过价值分析系统,判断原创内容的价值,进而适当引导最终的排名顺序。
3、原创星火项目
分析:该方案需要百度和站长共同维护互联网生态环境。站长推荐原创的内容,搜索引擎通过一定的判断后会优先处理原创的内容,共同促进生态的改善,鼓励原创,这是“原创 Spark Project”,旨在快速解决当前的严重问题。
简单来说,就是站长推荐原创的内容,然后百度用算法甚至人类来判断是否是原创。这是一个改进算法的过程,也是一个更快的实现原创发现内容的过程。
基于以上几点,要得到百度鼓励原创政策的照顾,作为站长首先要做的就是网站内部优化结构,坚持原创生产,并鼓励用户评论,确保网站的内部链接畅通无阻,并尽可能保留每个文章的发布时间。
seq搜索引擎优化至少包括那几步?(广州seo优化的工作离不开多元化原则,不管是什么类型的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-14 16:00
广州seo优化的工作离不开多元化的原则。不管是什么类型的网站,都离不开一些主要的核心步骤。网站 优化只有做好这些步骤才会受到搜索引擎和用户的影响。其次是!那么,成为网站推广优化专家需要哪些步骤呢?下面我们来简单了解一下这些步骤的重要性!
1、选择目标域名
比如理解域名的作用,域名就相当于家庭的门牌号,就像快递员可以通过地址轻松找到你家一样。目前最常见的主流域名有:.com、.等。在选择域名时,如果是旧域名,所谓旧域名就是指该域名之前已经注册过,并且之前用过灰色网站,然后就取消了。这种域名经常被搜索引擎屏蔽或惩罚,对搜索引擎SEO非常不利。
2、虚拟主机的选择
虚拟主机的选择基于企业的规模和需求。小型企业和个人站长在选择虚拟主机之前通常必须考虑所选的虚拟主机。只有选择一个成熟可靠的虚拟主机,才能保证选择的虚拟主机的质量。
3、程序选择
他们都有自己的程序。比如广州爱助建设网站就有完善的自助建站系统,帮助不懂代码的客户轻松建站。
4、 标签设置
网站的三个主要标签包括:title、关键词和description。整个网页的内容都是围绕这些核心主题编写的。记得控制好字符长度,不要同时堆起关键词。
5、内容构建
内容可以说是网站的灵魂,也很受搜索引擎欢迎。好的内容是用户体验最直接的体现。如何做好网站的内容,网站的内容要定期、合理、持续更新。采集 在进行适当更改时,内容应保持吸引力和节奏感。
6、外链建设
通常,构建外链必须选择权重高、排名好、速度快的收录平台(例如行业门户网站、百度系列、自媒体平台、分类信息, 等等。)。二是建设友好联系。优质链接通过行业相关,对方网站权重不低于自己网站,收录越多越好,快照来自同一个一天就好了,首页链接一般都做好了,没有反向链接的时候,马上沟通或者删除。
7、评估竞争对手
竞争对手,也就是我们所说的同行网站,尤其是网站高权重,收录众多同行网站,我们经常评价竞争对手的网站如何布局关键词,内容怎么写,外链怎么布局等等。
8、学会使用工具
站长工具、百度统计等,利用工具统计不断分析和提升自己。
以上就是网站推广和优化步骤的重要性。真正的成功是建立在坚实的基础之上,是一点一滴的积累。广州seo优化提醒您,如果您想成为网站优化专家,您需要强大的执行力,加上毅力,相信您一定会成功! 查看全部
seq搜索引擎优化至少包括那几步?(广州seo优化的工作离不开多元化原则,不管是什么类型的网站)
广州seo优化的工作离不开多元化的原则。不管是什么类型的网站,都离不开一些主要的核心步骤。网站 优化只有做好这些步骤才会受到搜索引擎和用户的影响。其次是!那么,成为网站推广优化专家需要哪些步骤呢?下面我们来简单了解一下这些步骤的重要性!
1、选择目标域名
比如理解域名的作用,域名就相当于家庭的门牌号,就像快递员可以通过地址轻松找到你家一样。目前最常见的主流域名有:.com、.等。在选择域名时,如果是旧域名,所谓旧域名就是指该域名之前已经注册过,并且之前用过灰色网站,然后就取消了。这种域名经常被搜索引擎屏蔽或惩罚,对搜索引擎SEO非常不利。
2、虚拟主机的选择
虚拟主机的选择基于企业的规模和需求。小型企业和个人站长在选择虚拟主机之前通常必须考虑所选的虚拟主机。只有选择一个成熟可靠的虚拟主机,才能保证选择的虚拟主机的质量。
3、程序选择
他们都有自己的程序。比如广州爱助建设网站就有完善的自助建站系统,帮助不懂代码的客户轻松建站。
4、 标签设置
网站的三个主要标签包括:title、关键词和description。整个网页的内容都是围绕这些核心主题编写的。记得控制好字符长度,不要同时堆起关键词。
5、内容构建
内容可以说是网站的灵魂,也很受搜索引擎欢迎。好的内容是用户体验最直接的体现。如何做好网站的内容,网站的内容要定期、合理、持续更新。采集 在进行适当更改时,内容应保持吸引力和节奏感。
6、外链建设
通常,构建外链必须选择权重高、排名好、速度快的收录平台(例如行业门户网站、百度系列、自媒体平台、分类信息, 等等。)。二是建设友好联系。优质链接通过行业相关,对方网站权重不低于自己网站,收录越多越好,快照来自同一个一天就好了,首页链接一般都做好了,没有反向链接的时候,马上沟通或者删除。
7、评估竞争对手
竞争对手,也就是我们所说的同行网站,尤其是网站高权重,收录众多同行网站,我们经常评价竞争对手的网站如何布局关键词,内容怎么写,外链怎么布局等等。
8、学会使用工具
站长工具、百度统计等,利用工具统计不断分析和提升自己。
以上就是网站推广和优化步骤的重要性。真正的成功是建立在坚实的基础之上,是一点一滴的积累。广州seo优化提醒您,如果您想成为网站优化专家,您需要强大的执行力,加上毅力,相信您一定会成功!
seq搜索引擎优化至少包括那几步?(网站优化的前8个基础点,你了解吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-14 15:22
昨天提到了网站优化的前8个基本点。今天我们就来聊聊接下来的8点。让我们来看看!
?9. 外链、反链接、异地链接的理解:除了网站,外链指向你的网站 url,包括首页和内页,但不带NOFOLLOW标签可以被搜索引擎抓取。外链是决定你的网站pr权重的最重要因素;抽象表达是A网站上有一个链接到B网站,那么A网站上的链接就是B网站的反向链接;即所有站外指向我们目标网站的链接都属于站外链接。
10.pv、uv、ip概念:IP:指独立IP的个数。也就是IP地址,一台电脑一天可能会换多个IP,比如使用ADSL,断线重连后可能会分配另一个IP。
UV:指独立访问者,即访问你的网站的一个电脑客户端就是一个访问者;每天独立访问网站,一个IP下可以有多台电脑,那么这些多台电脑是独立的,即使访问是多个uv。
PV:指页面浏览次数,所有页面被浏览的总次数,每次页面点击计算一次。
11.不要与链接工厂交换链接,交换链接时尽量避免各种陷阱。
12.面包屑导航:面包屑为用户提供了一种回溯到最初访问页面的方式,可以清晰地引导客户从网站内部到首页的路线。最简单的方法是面包屑是水平排列的文本链接,由大于“>”分隔;此符号表示页面相对于链接到它的页面的深度(级别)。
13. 相对链接和绝对链接各有优势。在设计网站时,栏目页面链接都是相对链接。相对链接代码简单易用,可以减少冗余代码。但是相对链接很容易导致断链和死链的存在。所以最好的解决办法是使用绝对链接。使用绝对链接可以避免上面提到的所有潜在问题,是使链接真正起作用的最佳方式。在网站优化的内链优化过程中,也建议大家使用绝对链接来做!
14. 关键词 密度设置,3%-8%。
15. 在超链接的HTML标签中添加Nofollow标签常用短语,指示搜索引擎不要抓取,搜索引擎看到该标签后可能会降低或完全取消超链接的投票权重
16. 黑帽技术是利用作弊手段优化seo。是搜索引擎禁止优化网站的优化技术。黑帽短期内可以提升网站的排名和流量;白帽技术采用了非常正式的方式来优化网站,可以很好的提升网站的用户体验,同时也可以很好的与其他网站链接等交互性交换; 灰帽技术一般在平台网站上介绍较少,很多seo工作的人都不太了解。实际上,灰帽技术介于白帽和黑帽之间。一种优化技术。 查看全部
seq搜索引擎优化至少包括那几步?(网站优化的前8个基础点,你了解吗?)
昨天提到了网站优化的前8个基本点。今天我们就来聊聊接下来的8点。让我们来看看!
?9. 外链、反链接、异地链接的理解:除了网站,外链指向你的网站 url,包括首页和内页,但不带NOFOLLOW标签可以被搜索引擎抓取。外链是决定你的网站pr权重的最重要因素;抽象表达是A网站上有一个链接到B网站,那么A网站上的链接就是B网站的反向链接;即所有站外指向我们目标网站的链接都属于站外链接。
10.pv、uv、ip概念:IP:指独立IP的个数。也就是IP地址,一台电脑一天可能会换多个IP,比如使用ADSL,断线重连后可能会分配另一个IP。
UV:指独立访问者,即访问你的网站的一个电脑客户端就是一个访问者;每天独立访问网站,一个IP下可以有多台电脑,那么这些多台电脑是独立的,即使访问是多个uv。
PV:指页面浏览次数,所有页面被浏览的总次数,每次页面点击计算一次。
11.不要与链接工厂交换链接,交换链接时尽量避免各种陷阱。
12.面包屑导航:面包屑为用户提供了一种回溯到最初访问页面的方式,可以清晰地引导客户从网站内部到首页的路线。最简单的方法是面包屑是水平排列的文本链接,由大于“>”分隔;此符号表示页面相对于链接到它的页面的深度(级别)。
13. 相对链接和绝对链接各有优势。在设计网站时,栏目页面链接都是相对链接。相对链接代码简单易用,可以减少冗余代码。但是相对链接很容易导致断链和死链的存在。所以最好的解决办法是使用绝对链接。使用绝对链接可以避免上面提到的所有潜在问题,是使链接真正起作用的最佳方式。在网站优化的内链优化过程中,也建议大家使用绝对链接来做!
14. 关键词 密度设置,3%-8%。
15. 在超链接的HTML标签中添加Nofollow标签常用短语,指示搜索引擎不要抓取,搜索引擎看到该标签后可能会降低或完全取消超链接的投票权重
16. 黑帽技术是利用作弊手段优化seo。是搜索引擎禁止优化网站的优化技术。黑帽短期内可以提升网站的排名和流量;白帽技术采用了非常正式的方式来优化网站,可以很好的提升网站的用户体验,同时也可以很好的与其他网站链接等交互性交换; 灰帽技术一般在平台网站上介绍较少,很多seo工作的人都不太了解。实际上,灰帽技术介于白帽和黑帽之间。一种优化技术。
seq搜索引擎优化至少包括那几步?(第一章Solr简单介绍速览:·搜索引擎处理的数据特性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-12 22:19
第一章是对Solr的简单介绍
本章快速概述:
·搜索引擎处理的数据特征
·常见的搜索引擎用例
·Solr核心模块介绍
·选择Solr的理由
·功能概述
伴随着社交媒体、云计算、移动互联网、大数据等技术的快速发展。我们正在迎来一个激动人心的计算时代。软件架构师开始面临的主要挑战之一是如何处理庞大的全球用户群生成和使用的海量数据。此外,用户开始期望在线软件应用程序将始终稳定可用。并且可以一直保持响应,这个阶段的应用对扩展性和稳定性提出了更高的要求。为了满足这些需求,一些专门的非关系型数据存储和处理技术被统称为NoSQL(Not Only SQL)技术。开始获得越来越多的青睐。这些系统并不强制要求所有数据都存储在之前已成为事实上的标准的关系数据模型中。它共享一个通用的设计模式。匹配数据存储处理引擎和特定数据类型。换句话说,NoSQL 技术针对特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越流行。NoSQL 技术针对处理特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越受欢迎。NoSQL 技术针对处理特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越受欢迎。
一种数据处理解决方案可以吃遍全世界的日子已经一去不复返了。
本书主要讨论一种特殊的NoSQL技术。即 Apache Solr。与她的其他非关系型兄弟一样,Solr 针对特定类型的问题进行了优化。具体来说,Solr 是一种可扩展的高速部署,针对搜索海量文本中心数据和对返回结果的相关性进行排序进行了优化。
这句话读起来有点混乱。只是没关系。让我们分解一下这个定义中的亮点:
可扩展性:Solr 可以将索引和查询处理操作分发到集群中的多个服务器。
·高速部署:Solr是开源软件,安装配置非常方便。可以直接根据安装包中的Sample配置启动。
·优化搜索功能:Solr搜索速度够快。对于复杂的搜索查询,Solr 可以实现亚秒级处理。通常一个复杂的查询可以在几十毫秒内处理
·海量文本:Solr专为处理百万级别的海量文本而设计,能够很好地处理海量数据。
文本中心的数据:Solr 针对搜索收录自然语言的文本内容(例如电子邮件)进行了优化。网页、简历、PDF 文档,或推特、微博、博客等社交内容,都适合用 Solr 处理。
·结果按相关性排序:Solr的搜索结果按照结果文档与用户查询的相关程度进行排序,保证最相关的结果会先返回。
在本书中,您将学习如何使用 Solr 来设计和实现可扩展的搜索解决方案。
我们的学习之旅从了解 Solr 支持的数据类型和典型用例开始。
这样你就可以更好地了解 Solr 在整个现代软件应用架构全景中的位置,以及 Solr 旨在处理哪些问题。
1.1我需要搜索引擎吗?
我们推测你已经有了一些使用搜索引擎的想法,否则你不会打开这本书。所以。我们不浪费时间去弄清楚你为什么开始考虑 Solr,让我们直接讨论一些干货。查看数据和用例的各个方面。在决定是否使用搜索引擎之前,您必须回答哪些问题?这最终将归结为如何深入了解您的数据和您的用户。选择合适的技术,同时满足两者的需求。
让我们从讨论哪些数据属性适合搜索引擎开始。
1.1.1 在文本中心管理数据
合理选择与数据匹配的存储和处理引擎,是现代软件应用架构的标志性要求之一。假设你是一个优秀的程序员,那么你应该知道根据数据在算法中的使用方式来选择最合适的数据结构。例如,假设您需要实现高速随机搜索,则不会使用链表结构来存储数据。
同样的原则也适用于搜索引擎的选择。以下是适合使用 Solr 等搜索引擎处理的数据的四个主要特征:
文本中心的数据
读取的数据远多于写入的数据
面向文档的数据
灵活的架构
或许这里应该增加第五个数据特征,即:海量数据。那就是“大数据”,但我们主要关注的是 Solr 与其他 NoSQL 技术不同的主要特性。处理大量数据的能力并不是它们的主要区别之一。
虽然这里有像 Solr 这样的搜索引擎可以有效处理的数据类型的四个主要特征,但这只是一个粗略的指导方针,而不是一个严格的标准。
让我们深入讨论这些数据特征,看看为什么它们对搜索如此重要。我们现在只关注概念,详细的实现细节将在后面的章节中讨论。
文本中心的数据
您一定见过人们使用术语“非结构化数据”来描述搜索引擎处理的数据。我们觉得“非结构化”这个词有点含糊,因为无论是基于人类语言生成的文档都是隐式结构化的。
要理解“非结构化”一词,您可以从计算机的角度来考虑它。
在计算机眼中,文本文档就是一串字符流。这个字符流必须通过特定的语言规则解析出语义结构。天赋被找回了。这就是搜索引擎的工作。
我们觉得术语“以文本为中心的数据”更适合描述 Solr 处理的数据类型。因为搜索引擎设计的初衷是提取文本数据的隐藏结构并生成相关索引,以提高查询和检索的效率。“文本中心的数据”一词隐含地表示文档中的文本信息包括用户感兴趣的查询内容。
当然,搜索引擎也支持非文本数据,比如数字数据。但其主要优势在于基于自然语言处理文本数据。
我之前说的是“文本”。其实“中心”部分也很重要。假设您的用户对文本部分的内容不感兴趣,那么搜索引擎可能不是处理您问题的最佳选择。例如,对于员工创建差旅费用报告的应用程序,每个报告都收录一些结构化数据,例如日期。费用类型、汇率、数量等。另外,每笔费用后可能会附上一些备注。用于描述成本的一般情况。
这种应用程序是一种收录文本信息的应用程序。但它不是“以文本为中心的数据”的样本。由于会计部门使用这些员工的费用报表来生成月度费用报表,因此它不是通过查找备注中的文本信息来实现的。正文不是这里关注的主要内容。简单的说。也就是说,并非所有收录文本信息的数据都适合搜索引擎处理。
所以现在花几分钟思考一下您的数据是否是“以文本为中心的数据”。主要考虑的是用户是否会使用数据中的文本信息进行检索。
假设答案是肯定的,那么搜索引擎很可能是一个不错的选择。
我们将在第 5 章和第 6 章讨论如何使用 Solr 的文本分析来提取文本数据的结构细节。
读取的数据远多于写入的数据:
搜索引擎可以有效处理的数据的另一个特征是“读取的数据远多于写入的数据”。首先需要说明的是,Solr 同意更新索引中现有文档的内容。您可以将“读多于写”解释为对文档进行读取操作的频率远高于创建和更新文档的频率。但是不要狭隘地理解你根本不能写数据,否则你将被限制在特定频率更新数据。事实上,Solr4 的一个关键特性是“近实时查询”。此功能允许您每秒索引数千个文档,并且几乎可以立即找到这些新添加的文档。
“读取的数据远多于写入的数据”背后的关键点是,在您的数据写入 Solr 后,在其生命周期中应该多次读取。
可以理解,搜索引擎主要不是用来存储数据的。主要用于查询存储的数据(一个查询请求就是一个读操作)。因此,假设您需要非常频繁地更新数据。那么搜索引擎可能不太适合你的需求,其他的NoSQL技术,比如Cassandra,可能更适合你的高速随机写入需求。
面向文档的数据
到目前为止,我们一直在使用更通用的术语“数据”,但实际上搜索引擎处理文档数据。在搜索引擎中。一个文档是一个独立的字段集合,每个字段只存储数据值。不能嵌套以收录其他值范围。换句话说。在 Solr 等搜索引擎中,文档都是扁平的,文档之间没有相互依赖。Solr中“扁平化”的概念比较松散。一个取值范围可以容纳多个数据值,但取值范围不能嵌套并且收录子范围。
换句话说,您可以在一个范围内存储多个数据值。但是您不能在该范围内嵌套其他范围。
Solr 中这种面向文档的扁平化方法可以很好地处理文档数据。例如,网页、博客。pdf文件等。那么如果你想使用 Solr 来处理关系数据库中的结构化数据呢?在这种情况下,您需要首先提取关系数据库中跨表存储的数据以对其进行解构。然后把它放在一个扁平的、独立的文档结构中。我们将在第 3 章中学习如何处理此类问题。
您还需要考虑文档数据中哪些值范围需要存储在 Solr 中,哪些值范围需要存储在其他系统(例如,数据库)中。简单的说。搜索引擎只存储需要检索的数据和用于显示检索结果的数据。
举个例子。假设您有一个在线视频的搜索索引。您不应该希望将视频文件本身存储在 Solr 中。一个合理的解决方案应该是将大型视频文件放在内容分发网络 (CDN) 上。通常你只需要在搜索引擎中存储满足搜索要求的最少数据。刚才的在线视频示例清楚地表明,Solr 不应被视为一种通用的数据存储技术。Solr 的工作是找到用户感兴趣的视频文件,而不是自己存储视频文件。
灵活的架构
最后搜索引擎数据的主要特点是灵活的模式。
这意味着查询索引中的文档不需要具有统一的结构。在关系数据库中,表中的每一行数据都必须具有相同的结构。在 Solr 中,文档可以有不同的范围。当然,同一个索引中的文档应该至少有每个人都拥有的范围的一部分,以便于检索,但并不要求所有文档中的范围结构完全相同。
举个例子。假设您要制作一个用于查找出租和出售房屋的搜索应用程序。显然,每个上市文件都有一个位置。房间数、卫浴数等常用价值范围,根据是出租还是出售而有所不同。不同的财产文件会有不同的取值范围。待售物业将有售价范围和物业税价值范围。出租房屋文件将具有不同的价值范围,例如月租和宠物政策。
综上所述,搜索引擎Solr专门针对处理文本中心进行了优化,阅读远远超过写作,并且是面向文档的。它用于具有灵活 Schema 的数据。Solr 不是通用的数据存储和处理技术,这也是它区别于其他 NoSQL 技术的主要因素。
有许多不同的数据存储和处理解决方案可供选择。优点是您不必再费力寻找可以满足您所有需求的通用技术解决方案。搜索引擎在某些特定任务上表现良好。但是,其他方面的表现却很差。这意味着在大多数情况下,您可以将 Solr 用作关系数据库和其他 NoSQL 技术的强大补充,而不是取代后者。
现在我们已经讨论了 Solr 优化的数据类型,让我们来讨论 Solr 等搜索引擎主要解决的实际用例。
了解这些用例可以帮助您了解搜索引擎技术与其他数据处理技术的不同之处。
1.1.2 常见的搜索引擎用例
在本节中,我们来看看像 Solr 这样的搜索引擎可以做什么。正如我们在 1.1. 部分 1 中提到的。这些讨论本质上只是指导方针,不要将它们视为严格的使用规则。在我们开始之前。你需要意识到,如果你想做一个优秀的搜索服务,门槛是非常高的。
今天的用户习惯于使用快速高效的网络搜索引擎,如 Google 和 Bing。而且很多热门网站也有自己强大的搜索解决方案,可以帮助用户高速获取自己想要的信息,所以用户对搜索服务并不陌生,会很挑剔。当你在评估像 Solr 这样的搜索引擎时,或者在设计你自己的搜索计划时,你必须有根。应将用户体验视为高优先级。
主关键字查询
显然,作为搜索引擎,首先要能够支持主关键词查询。
这也是搜索引擎的主要功能之一。只是关键词查询功能值得在这里强调,因为这是用户使用搜索引擎最典型的方式。
很少有真正的用户想要填写一个非常完整和复杂的搜索表单,一出现就进行搜索。考虑到 关键词 搜索功能将是用户与搜索引擎之间最常见的交互方式。这个基本功能必须能够为用户提供非常好的用户体验。
一般来说,用户希望输入几个简单的关键词就能得到很好的搜索结果。
这听起来像是一个简单的匹配任务:只需将查询字符串与文档匹配即可。只需考虑几个必须解决的问题才能获得良好的用户体验:
·相关结果必须快速返回,大多数情况要求一秒内返回
·当查询字符串出现拼写错误时,用户可以主动更正
·当用户进入时,通过自己主动完成建议,减少用户输入负担,这在移动应用中并不常见
·处理查询字符串中的同义词和同义词
·匹配收录查询字符串语言变体的文档
· 短语处理。用户是想匹配词组中的所有词,还是只匹配词组中的一些词
·处理一些一般介词,如“a”、“an”、“of”、“the”等。
·假设最上面的查询结果让用户不舒服。如何向用户返回许多其他查询结果
如您所见,没有使用特定的处理方法。这么一堆问题,会很难实现这么简单的功能。但是,有了像 Solr 这样的搜索引擎,这些功能可以立即得到满足,并且变得非常容易实现。在你为用户提供了一个强大的关键词搜索工具之后,那么你就需要考虑如何根据结果和查询请求的相关性来展示查询的结果,从而引出下一个用例. 对搜索返回的查询结果进行排序。
排序的搜索结果
搜索引擎会返回查询的“顶级”结果。在SQL中查询关系型数据库时,一行数据记录要么匹配返回的查询,要么忽略不匹配的查询,查询结果也按照数据记录的某个列属性进行排序。对于搜索引擎,返回的结果文档根据分数降序排列。分数表示文档与查询的匹配程度。匹配分数是根据一系列因素计算出来的。但一般来说,分数越高。表示结果文档和查询之间的相关性越高。
有几个因素决定了结果文档按相关性排序的重要性。首先,现代搜索引擎一般存储着海量的文档,数量都在数百万甚至数十亿。假设不正确的查询结果按相关性排序。那么用户就会被海量的返回结果淹没,无法清晰有效地浏览搜索结果。其次。用户使用其他搜索引擎的经验,让用户习惯于使用几个关键词来获得好的查询结果。它还使用户通常不那么耐心。
他们希望搜索引擎能够按自己的意愿工作,而不管他们输入的信息是否完全正确。例如,对于移动应用程序的后台搜索服务,用户会期望搜索服务在输入一些可能收录拼写错误的简短查询词后返回正确的搜索结果。
假设您想手动干预排序结果,您可以为特定文档、值范围或查询字符串添加权重,或者直接增加文档的相关性分数。例如,如果您想将新添加的文档推送到顶部位置,您可以通过根据创建时间改进文档的排序来实现。我们将在第 3 章中学习文档排序。
除了关键词咨询
使用像 Solr 这样的搜索引擎,用户可以输入几个 关键词 以获得一些搜索结果。然而,对于许多用户来说,这只是查询交互的第一步。他们需要能够继续浏览查询结果。驱动信息发现的交互对话过程也是搜索引擎的一个主要应用场景。往往让用户在搜索之前不是很准确地知道自己想要查询什么样的信息。他们事先不知道您的系统中存储了哪些信息。一个好的搜索引擎可以帮助用户不断提炼自己的信息需求,一步步的到达最需要的信息。
这里的核心思想是在返回用户初始查询对应的文档结果的同时,为用户提供一个工具,让他们可以不断改进查询,获取更多需要的信息。换句话说。除了返回匹配的文档之外,您还应该返回一个工具,让用户知道下一步该做什么。举个例子。可以根据属性对查询结果进行分类,方便用户根据需要进一步浏览。
这样的功能叫做Faceted-Search,这也是Solr的亮点之一。
我们将在1.的第2节看到一个房地产分类检索的例子,分类检索功能的细节将在第8章介绍。
哪些搜索引擎不适合...
最后。我们来讨论一些不适合应用搜索引擎的用例场景。
第一的。搜索引擎的一般设计是为每个查询返回一个小文档集,通常包括 10 到 100 个结果文档。通过 Solr 内置的结果分页功能,可以获得很多其他的结果文档。对于一个查询结果,有数百万个文档。假设您要求一次返回所有匹配的文档,那么您将等待很长时间。
查询本身会运行得非常快,但是从索引结构中重建数百万个文档绝对是一项非常耗时的任务。由于Solr这种存储取值范围在硬盘上的搜索引擎,在假设需要一次生成大量查询结果的情况下,仅适用于高速生成少量文档结果。在这种存储方式下生成大量的文档结果会消耗大量的时间。
另一个不适合应用搜索引擎的使用场景是深度分析任务场景,需要读取索引文件的大部分子集。
即使你避免了结果分页技术刚刚提到的问题。假设一个分析需要读取索引文件中的大量数据。你也会遇到非常大的性能问题,因为索引文件的底层数据结构并不是为大量读取而设计的。
我们前面提到了一点。但是这里我还是要再次强调一下。也就是说,搜索引擎技术不适合查询文档之间的关系。Solr 确实能够支持基于父子关系的查询。但它不支持复杂关系数据结构之间的查询。在第三章。您将学习如何将关系数据结构调整为适合 Solr 处理查询的平面文档结构。
最后,大多数搜索引擎没有直接的文档级安全支持,至少 Solr 没有。
假设您需要严格管理文档权限,则只能在搜索引擎之外想办法。
至此我们已经了解了适合搜索引擎处理的用例场景和数据类型。下一步是讨论 Solr 可以做什么。以及这些功能是如何实现的。在下一节中,您将了解 Solr 的主要功能是什么。以及她如何实施软件设计原则,例如外部系统集成、可扩展性和高可用性。 查看全部
seq搜索引擎优化至少包括那几步?(第一章Solr简单介绍速览:·搜索引擎处理的数据特性)
第一章是对Solr的简单介绍
本章快速概述:
·搜索引擎处理的数据特征
·常见的搜索引擎用例
·Solr核心模块介绍
·选择Solr的理由
·功能概述
伴随着社交媒体、云计算、移动互联网、大数据等技术的快速发展。我们正在迎来一个激动人心的计算时代。软件架构师开始面临的主要挑战之一是如何处理庞大的全球用户群生成和使用的海量数据。此外,用户开始期望在线软件应用程序将始终稳定可用。并且可以一直保持响应,这个阶段的应用对扩展性和稳定性提出了更高的要求。为了满足这些需求,一些专门的非关系型数据存储和处理技术被统称为NoSQL(Not Only SQL)技术。开始获得越来越多的青睐。这些系统并不强制要求所有数据都存储在之前已成为事实上的标准的关系数据模型中。它共享一个通用的设计模式。匹配数据存储处理引擎和特定数据类型。换句话说,NoSQL 技术针对特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越流行。NoSQL 技术针对处理特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越受欢迎。NoSQL 技术针对处理特定数据类型的特定类型问题进行了性能优化。由于对可扩展性和性能的需求不断增加,各种 NoSQL 技术和传统关系型数据库开始混合使用。这样的跨界架构越来越受欢迎。
一种数据处理解决方案可以吃遍全世界的日子已经一去不复返了。
本书主要讨论一种特殊的NoSQL技术。即 Apache Solr。与她的其他非关系型兄弟一样,Solr 针对特定类型的问题进行了优化。具体来说,Solr 是一种可扩展的高速部署,针对搜索海量文本中心数据和对返回结果的相关性进行排序进行了优化。
这句话读起来有点混乱。只是没关系。让我们分解一下这个定义中的亮点:
可扩展性:Solr 可以将索引和查询处理操作分发到集群中的多个服务器。
·高速部署:Solr是开源软件,安装配置非常方便。可以直接根据安装包中的Sample配置启动。
·优化搜索功能:Solr搜索速度够快。对于复杂的搜索查询,Solr 可以实现亚秒级处理。通常一个复杂的查询可以在几十毫秒内处理
·海量文本:Solr专为处理百万级别的海量文本而设计,能够很好地处理海量数据。
文本中心的数据:Solr 针对搜索收录自然语言的文本内容(例如电子邮件)进行了优化。网页、简历、PDF 文档,或推特、微博、博客等社交内容,都适合用 Solr 处理。
·结果按相关性排序:Solr的搜索结果按照结果文档与用户查询的相关程度进行排序,保证最相关的结果会先返回。
在本书中,您将学习如何使用 Solr 来设计和实现可扩展的搜索解决方案。
我们的学习之旅从了解 Solr 支持的数据类型和典型用例开始。
这样你就可以更好地了解 Solr 在整个现代软件应用架构全景中的位置,以及 Solr 旨在处理哪些问题。
1.1我需要搜索引擎吗?
我们推测你已经有了一些使用搜索引擎的想法,否则你不会打开这本书。所以。我们不浪费时间去弄清楚你为什么开始考虑 Solr,让我们直接讨论一些干货。查看数据和用例的各个方面。在决定是否使用搜索引擎之前,您必须回答哪些问题?这最终将归结为如何深入了解您的数据和您的用户。选择合适的技术,同时满足两者的需求。
让我们从讨论哪些数据属性适合搜索引擎开始。
1.1.1 在文本中心管理数据
合理选择与数据匹配的存储和处理引擎,是现代软件应用架构的标志性要求之一。假设你是一个优秀的程序员,那么你应该知道根据数据在算法中的使用方式来选择最合适的数据结构。例如,假设您需要实现高速随机搜索,则不会使用链表结构来存储数据。
同样的原则也适用于搜索引擎的选择。以下是适合使用 Solr 等搜索引擎处理的数据的四个主要特征:
文本中心的数据
读取的数据远多于写入的数据
面向文档的数据
灵活的架构
或许这里应该增加第五个数据特征,即:海量数据。那就是“大数据”,但我们主要关注的是 Solr 与其他 NoSQL 技术不同的主要特性。处理大量数据的能力并不是它们的主要区别之一。
虽然这里有像 Solr 这样的搜索引擎可以有效处理的数据类型的四个主要特征,但这只是一个粗略的指导方针,而不是一个严格的标准。
让我们深入讨论这些数据特征,看看为什么它们对搜索如此重要。我们现在只关注概念,详细的实现细节将在后面的章节中讨论。
文本中心的数据
您一定见过人们使用术语“非结构化数据”来描述搜索引擎处理的数据。我们觉得“非结构化”这个词有点含糊,因为无论是基于人类语言生成的文档都是隐式结构化的。
要理解“非结构化”一词,您可以从计算机的角度来考虑它。
在计算机眼中,文本文档就是一串字符流。这个字符流必须通过特定的语言规则解析出语义结构。天赋被找回了。这就是搜索引擎的工作。
我们觉得术语“以文本为中心的数据”更适合描述 Solr 处理的数据类型。因为搜索引擎设计的初衷是提取文本数据的隐藏结构并生成相关索引,以提高查询和检索的效率。“文本中心的数据”一词隐含地表示文档中的文本信息包括用户感兴趣的查询内容。
当然,搜索引擎也支持非文本数据,比如数字数据。但其主要优势在于基于自然语言处理文本数据。
我之前说的是“文本”。其实“中心”部分也很重要。假设您的用户对文本部分的内容不感兴趣,那么搜索引擎可能不是处理您问题的最佳选择。例如,对于员工创建差旅费用报告的应用程序,每个报告都收录一些结构化数据,例如日期。费用类型、汇率、数量等。另外,每笔费用后可能会附上一些备注。用于描述成本的一般情况。
这种应用程序是一种收录文本信息的应用程序。但它不是“以文本为中心的数据”的样本。由于会计部门使用这些员工的费用报表来生成月度费用报表,因此它不是通过查找备注中的文本信息来实现的。正文不是这里关注的主要内容。简单的说。也就是说,并非所有收录文本信息的数据都适合搜索引擎处理。
所以现在花几分钟思考一下您的数据是否是“以文本为中心的数据”。主要考虑的是用户是否会使用数据中的文本信息进行检索。
假设答案是肯定的,那么搜索引擎很可能是一个不错的选择。
我们将在第 5 章和第 6 章讨论如何使用 Solr 的文本分析来提取文本数据的结构细节。
读取的数据远多于写入的数据:
搜索引擎可以有效处理的数据的另一个特征是“读取的数据远多于写入的数据”。首先需要说明的是,Solr 同意更新索引中现有文档的内容。您可以将“读多于写”解释为对文档进行读取操作的频率远高于创建和更新文档的频率。但是不要狭隘地理解你根本不能写数据,否则你将被限制在特定频率更新数据。事实上,Solr4 的一个关键特性是“近实时查询”。此功能允许您每秒索引数千个文档,并且几乎可以立即找到这些新添加的文档。
“读取的数据远多于写入的数据”背后的关键点是,在您的数据写入 Solr 后,在其生命周期中应该多次读取。
可以理解,搜索引擎主要不是用来存储数据的。主要用于查询存储的数据(一个查询请求就是一个读操作)。因此,假设您需要非常频繁地更新数据。那么搜索引擎可能不太适合你的需求,其他的NoSQL技术,比如Cassandra,可能更适合你的高速随机写入需求。
面向文档的数据
到目前为止,我们一直在使用更通用的术语“数据”,但实际上搜索引擎处理文档数据。在搜索引擎中。一个文档是一个独立的字段集合,每个字段只存储数据值。不能嵌套以收录其他值范围。换句话说。在 Solr 等搜索引擎中,文档都是扁平的,文档之间没有相互依赖。Solr中“扁平化”的概念比较松散。一个取值范围可以容纳多个数据值,但取值范围不能嵌套并且收录子范围。
换句话说,您可以在一个范围内存储多个数据值。但是您不能在该范围内嵌套其他范围。
Solr 中这种面向文档的扁平化方法可以很好地处理文档数据。例如,网页、博客。pdf文件等。那么如果你想使用 Solr 来处理关系数据库中的结构化数据呢?在这种情况下,您需要首先提取关系数据库中跨表存储的数据以对其进行解构。然后把它放在一个扁平的、独立的文档结构中。我们将在第 3 章中学习如何处理此类问题。
您还需要考虑文档数据中哪些值范围需要存储在 Solr 中,哪些值范围需要存储在其他系统(例如,数据库)中。简单的说。搜索引擎只存储需要检索的数据和用于显示检索结果的数据。
举个例子。假设您有一个在线视频的搜索索引。您不应该希望将视频文件本身存储在 Solr 中。一个合理的解决方案应该是将大型视频文件放在内容分发网络 (CDN) 上。通常你只需要在搜索引擎中存储满足搜索要求的最少数据。刚才的在线视频示例清楚地表明,Solr 不应被视为一种通用的数据存储技术。Solr 的工作是找到用户感兴趣的视频文件,而不是自己存储视频文件。
灵活的架构
最后搜索引擎数据的主要特点是灵活的模式。
这意味着查询索引中的文档不需要具有统一的结构。在关系数据库中,表中的每一行数据都必须具有相同的结构。在 Solr 中,文档可以有不同的范围。当然,同一个索引中的文档应该至少有每个人都拥有的范围的一部分,以便于检索,但并不要求所有文档中的范围结构完全相同。
举个例子。假设您要制作一个用于查找出租和出售房屋的搜索应用程序。显然,每个上市文件都有一个位置。房间数、卫浴数等常用价值范围,根据是出租还是出售而有所不同。不同的财产文件会有不同的取值范围。待售物业将有售价范围和物业税价值范围。出租房屋文件将具有不同的价值范围,例如月租和宠物政策。
综上所述,搜索引擎Solr专门针对处理文本中心进行了优化,阅读远远超过写作,并且是面向文档的。它用于具有灵活 Schema 的数据。Solr 不是通用的数据存储和处理技术,这也是它区别于其他 NoSQL 技术的主要因素。
有许多不同的数据存储和处理解决方案可供选择。优点是您不必再费力寻找可以满足您所有需求的通用技术解决方案。搜索引擎在某些特定任务上表现良好。但是,其他方面的表现却很差。这意味着在大多数情况下,您可以将 Solr 用作关系数据库和其他 NoSQL 技术的强大补充,而不是取代后者。
现在我们已经讨论了 Solr 优化的数据类型,让我们来讨论 Solr 等搜索引擎主要解决的实际用例。
了解这些用例可以帮助您了解搜索引擎技术与其他数据处理技术的不同之处。
1.1.2 常见的搜索引擎用例
在本节中,我们来看看像 Solr 这样的搜索引擎可以做什么。正如我们在 1.1. 部分 1 中提到的。这些讨论本质上只是指导方针,不要将它们视为严格的使用规则。在我们开始之前。你需要意识到,如果你想做一个优秀的搜索服务,门槛是非常高的。
今天的用户习惯于使用快速高效的网络搜索引擎,如 Google 和 Bing。而且很多热门网站也有自己强大的搜索解决方案,可以帮助用户高速获取自己想要的信息,所以用户对搜索服务并不陌生,会很挑剔。当你在评估像 Solr 这样的搜索引擎时,或者在设计你自己的搜索计划时,你必须有根。应将用户体验视为高优先级。
主关键字查询
显然,作为搜索引擎,首先要能够支持主关键词查询。
这也是搜索引擎的主要功能之一。只是关键词查询功能值得在这里强调,因为这是用户使用搜索引擎最典型的方式。
很少有真正的用户想要填写一个非常完整和复杂的搜索表单,一出现就进行搜索。考虑到 关键词 搜索功能将是用户与搜索引擎之间最常见的交互方式。这个基本功能必须能够为用户提供非常好的用户体验。
一般来说,用户希望输入几个简单的关键词就能得到很好的搜索结果。
这听起来像是一个简单的匹配任务:只需将查询字符串与文档匹配即可。只需考虑几个必须解决的问题才能获得良好的用户体验:
·相关结果必须快速返回,大多数情况要求一秒内返回
·当查询字符串出现拼写错误时,用户可以主动更正
·当用户进入时,通过自己主动完成建议,减少用户输入负担,这在移动应用中并不常见
·处理查询字符串中的同义词和同义词
·匹配收录查询字符串语言变体的文档
· 短语处理。用户是想匹配词组中的所有词,还是只匹配词组中的一些词
·处理一些一般介词,如“a”、“an”、“of”、“the”等。
·假设最上面的查询结果让用户不舒服。如何向用户返回许多其他查询结果
如您所见,没有使用特定的处理方法。这么一堆问题,会很难实现这么简单的功能。但是,有了像 Solr 这样的搜索引擎,这些功能可以立即得到满足,并且变得非常容易实现。在你为用户提供了一个强大的关键词搜索工具之后,那么你就需要考虑如何根据结果和查询请求的相关性来展示查询的结果,从而引出下一个用例. 对搜索返回的查询结果进行排序。
排序的搜索结果
搜索引擎会返回查询的“顶级”结果。在SQL中查询关系型数据库时,一行数据记录要么匹配返回的查询,要么忽略不匹配的查询,查询结果也按照数据记录的某个列属性进行排序。对于搜索引擎,返回的结果文档根据分数降序排列。分数表示文档与查询的匹配程度。匹配分数是根据一系列因素计算出来的。但一般来说,分数越高。表示结果文档和查询之间的相关性越高。
有几个因素决定了结果文档按相关性排序的重要性。首先,现代搜索引擎一般存储着海量的文档,数量都在数百万甚至数十亿。假设不正确的查询结果按相关性排序。那么用户就会被海量的返回结果淹没,无法清晰有效地浏览搜索结果。其次。用户使用其他搜索引擎的经验,让用户习惯于使用几个关键词来获得好的查询结果。它还使用户通常不那么耐心。
他们希望搜索引擎能够按自己的意愿工作,而不管他们输入的信息是否完全正确。例如,对于移动应用程序的后台搜索服务,用户会期望搜索服务在输入一些可能收录拼写错误的简短查询词后返回正确的搜索结果。
假设您想手动干预排序结果,您可以为特定文档、值范围或查询字符串添加权重,或者直接增加文档的相关性分数。例如,如果您想将新添加的文档推送到顶部位置,您可以通过根据创建时间改进文档的排序来实现。我们将在第 3 章中学习文档排序。
除了关键词咨询
使用像 Solr 这样的搜索引擎,用户可以输入几个 关键词 以获得一些搜索结果。然而,对于许多用户来说,这只是查询交互的第一步。他们需要能够继续浏览查询结果。驱动信息发现的交互对话过程也是搜索引擎的一个主要应用场景。往往让用户在搜索之前不是很准确地知道自己想要查询什么样的信息。他们事先不知道您的系统中存储了哪些信息。一个好的搜索引擎可以帮助用户不断提炼自己的信息需求,一步步的到达最需要的信息。
这里的核心思想是在返回用户初始查询对应的文档结果的同时,为用户提供一个工具,让他们可以不断改进查询,获取更多需要的信息。换句话说。除了返回匹配的文档之外,您还应该返回一个工具,让用户知道下一步该做什么。举个例子。可以根据属性对查询结果进行分类,方便用户根据需要进一步浏览。
这样的功能叫做Faceted-Search,这也是Solr的亮点之一。
我们将在1.的第2节看到一个房地产分类检索的例子,分类检索功能的细节将在第8章介绍。
哪些搜索引擎不适合...
最后。我们来讨论一些不适合应用搜索引擎的用例场景。
第一的。搜索引擎的一般设计是为每个查询返回一个小文档集,通常包括 10 到 100 个结果文档。通过 Solr 内置的结果分页功能,可以获得很多其他的结果文档。对于一个查询结果,有数百万个文档。假设您要求一次返回所有匹配的文档,那么您将等待很长时间。
查询本身会运行得非常快,但是从索引结构中重建数百万个文档绝对是一项非常耗时的任务。由于Solr这种存储取值范围在硬盘上的搜索引擎,在假设需要一次生成大量查询结果的情况下,仅适用于高速生成少量文档结果。在这种存储方式下生成大量的文档结果会消耗大量的时间。
另一个不适合应用搜索引擎的使用场景是深度分析任务场景,需要读取索引文件的大部分子集。
即使你避免了结果分页技术刚刚提到的问题。假设一个分析需要读取索引文件中的大量数据。你也会遇到非常大的性能问题,因为索引文件的底层数据结构并不是为大量读取而设计的。
我们前面提到了一点。但是这里我还是要再次强调一下。也就是说,搜索引擎技术不适合查询文档之间的关系。Solr 确实能够支持基于父子关系的查询。但它不支持复杂关系数据结构之间的查询。在第三章。您将学习如何将关系数据结构调整为适合 Solr 处理查询的平面文档结构。
最后,大多数搜索引擎没有直接的文档级安全支持,至少 Solr 没有。
假设您需要严格管理文档权限,则只能在搜索引擎之外想办法。
至此我们已经了解了适合搜索引擎处理的用例场景和数据类型。下一步是讨论 Solr 可以做什么。以及这些功能是如何实现的。在下一节中,您将了解 Solr 的主要功能是什么。以及她如何实施软件设计原则,例如外部系统集成、可扩展性和高可用性。
seq搜索引擎优化至少包括那几步?(SEO培训,SEO评估方法及工具培训的注意事项!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-12 17:19
优化流程
1:网站诊断分析(网站架构分析,网站内容分析,网站系统分析,网站功能分析)
2:网站竞争分析(行业搜索引擎竞争分析、竞争对手分析、搜索引擎友好度分析、关键词分析、链接分析)
3:SEO培训咨询(SEO基础知识培训、SEO实践专业培训、SEO评估方法及工具培训、SEO实践效果验收与维护)
4:数据追踪分析(数据追踪监测、效果维护与调整、策略评估与调整、流量分析)
5:优化策略结构与实施(全站优化的优化策略是什么,关键词策略,内链优化,外链部署策略,软文编辑和站外推广,搜索引擎性能预言 )
1、网站导航优化
是否锚文本导航,以文本形式做网站导航,不要使用flash、图片、js,因为这不如锚文本导航,锚文本导航蜘蛛更喜欢。
导航锚文本关键词相关性,这是栏目的定位,尽量用你首页的长尾关键词作为你的栏目。
主导航和二级导航,主导航只放栏目和频道,不放无关内容。第二个导航可以放一些相关的关键词页面导航或者栏目导航,但切记不要堆放。
是否有面包屑导航,首页>栏目页>内容页。
面包屑导航优化的细节需要注意:当前页面(登陆页面)一般不需要添加链接;您可以使用 关键词 作为面包屑的锚文本;一个页面可以有多个面包屑(以免给用户造成混淆)。
2、栏目页面优化
三个标签,标题、关键词、描述,合理填写,不要堆砌。标题结构,标题名称>列名>网站名称关键词相关性,检测分页标题重复,不要太多重复。分页链接网址是否加深网址深度,建议网址在3层以内。
3.内容页面优化
内容来源,来源以原创为主,参考写作为辅,不行就伪原创,不需要复制粘贴,对网站没有好处。URL是否收录关键词(英文),最好用关键词制作英文URL,中文拼音也是可以的。标题的格式,简洁明了,应该出现在标题网站main关键词中。要使用 H 标记,请将 H 标记添加到 网站 中第一次出现的 关键词。文章文字是否符合SEO标准,区分主次,合理关键词分布。图片的ALT属性可以增加关键词的密度和搜索引擎对图片的识别。
4. 链接优化
构建 网站 地图。Html 格式的网站 映射基于网站 的结构特征。有必要将网站的功能结构和服务内容罗列有序,力求页面简洁大方,方便用户浏览。
构建机器人文件。注意Robots.txt必须放在站点根目录下,文件名必须全部小写。将 网站 映射写入 Robots 文件。
设置404页面符合网站的设计风格。最好添加网站导航和底部(尤其是网站地图),并保证404页面返回的http状态码为404。
检测网站的死链接并删除,建议使用Xenu工具检测。
一个网站就像一个人,只有变得更好,才能收获更多,创造更多。如果把内链比作经络,那么网站的内容就是血肉之躯。一个网站即使内容丰富,如果经脉不通,最后的结果就是排名不好,收录的提升速度很慢。在网站的构建中,内部链构建的重要性不同于外部链的构建。除了网站和网站之间的链接,还有网站内部网页和网页之间的链接。反向链接也有助于排名。我个人理解,这就是内链的本质。,内链的意义在于用户可以更方便地查找信息。
逆向思维分析
网站内容采集点是关键词,关键词定位访问者。很多人喜欢讲浓度,搜索引擎也是这样看待网站的。标题的作用在细分的未来发展中会更加重要。主题突出,内容丰富,粘性大,领域纵深。这应该是未来几年网站的主流趋势。生活中人人都爱这么说,网站优化也是如此。不要刻意迎合搜索引擎和SEO的喜好,应该多考虑访问者。因为搜索引擎和SEO最终客户都是访问者,都是以人为基础的。一味讨好搜索引擎,容易被当作弊,人讲究个性,< @网站 也是一样。SEO 策略的实施因人而异。在我们研究搜索引擎的同时,搜索引擎也在向我们学习。
6优化方案格式
当你得到一个需要优化的网站时,并不是你得到了网站就去做。网站 优化计划。但这是一种比较简单的网站优化计划编写格式。
网站搜索引擎优化信息
1、ALEXA 排名
2、域名年龄
3、百度权重、谷歌公关及其收录情况
4、网站交通状况
5、关键词 排名
6.网站 外链数据情况
网站优化目标
1.制定目标关键词,并期待排名目标。
2.制定网站IP和PV值,预计增加多少流量网站。
网站站内优化
相信很多新手站长或者SEO新手一开始都会咨询哪里外链比较好,更希望外链遍布全球。其实对于网站优化来说,外链自然很重要,但用户体验更重要。从百度频繁的升级算法中,我们也可以看到,百度对用户体验差的问题不断进行打击网站!因此,叶建辉认为网站的内部优化和网站的用户体验比外链更重要。那么网站内部优化有哪些方面呢?
1.首页标题,观察网站首页标题的数量。
2.网站关键词分布,即页面关键词的密度,不要刻意叠加,就好了。
3.网站内容更新,网站内容更新是否定期很重要,特别是对于新网站,定期更新更能跳出沙盒。
4.网站 内链,无论网站大小,都不能忽视内链的重要性。
5.网站Map 和 网站 static,都影响蜘蛛爬行。
6.图片优化,ALT标签说明。
网站优化策略
网站优化策略需要详细分析。比如企业站和信息站的优化策略不同,企业站需要更新,信息站需要挖掘更多的关键词来拉动流量。
分工
没有完美的个人,只有完美的集体。网站SEO优化也是如此。团队合作,各司其职,才能做得更好。
7个用户组
1.经营大量产品的企业网站
2.行业提供广泛的服务网站
3.至少100个关键词可以总结服务或产品信息
4.专业商场,如服装商场、珠宝礼品商场、化妆品商场等。
5.品牌产品或代理品牌
6.热门行业
8大好处
增加有效流量
全站网站全站优化首先要注意长尾关键词。长尾关键词通常是指网站关键词除了核心关键词和二级核心关键词。一个网站除了核心关键词可以带来很多流量,长尾关键词也可以给网站带来很多流量,其总量为甚至比核心关键词还要大,带来更多的流量。例如,汽车音响店可能选择音响为核心关键词,汽车音响为副核心关键词。那么如果他是做竞价排名的话,选择这两个关键词的价格是很贵的,大概每点击3元左右;那么他可能会选择在google做seo,但是google主页上的都是响亮的网站:慧聪网,英商网、新浪汽车频道、中国汽车影音、中国音响网、太平洋汽车配件频道……如果一个普通的汽车音响店想进前十,你能做到吗?可以,但是很难。但他往往很着急,希望1-3个月内出成果,最后seo服务商不得不用不好的手段去运营。这是国内seo行业的普遍现状。那么,其实换个思路,我们能不能选择长尾词:汽车音响改装、惠威汽车音响、先锋汽车音响、汽车音响论坛、二手车音响、松下汽车音响、漫步者汽车音响、jvc汽车音响、汽车音频解码、汽车音响网络……等等。可能在用户通过搜索引擎检索到的所有关键词中,核心关键词产生了50%的流量,而另外50%的流量是由这些长尾关键词带来的。长尾关键词 通常是不受欢迎的词、词组,甚至是一个句子。当这么多用户使用搜索引擎时,他们可能会输入一些意想不到的东西,比如搜索“”、“北京汽车音响”等词,甚至“哪里可以找到便宜的二手汽车音响?”等短语或句子。在很多情况下,如何优化整个网站的效果表现在模板的修改、链接结构的调整和页面结构的调整,使其更符合搜索引擎的计算规则和同时对观众更加友好。优化整个网站优化指南后,就可以使用搜索引擎' s 排名计算中关键词列表的抽取原理,挖掘出很多关键词,获得好的排名。因此,车站的客流量大大增加。大部分都是好几次好转。如何优化整个网站的最大特点是你不是自己指定某个关键词,而是随着你的内容增加,搜索引擎会自动提取大量关键词进行排序。这种方式非常符合搜索引擎的计算规则。
更好的用户体验
如前所述,seo的目标是用户体验和流量。整个网站的优化是什么?必须考虑网站的结构、内容、美术设计、栏目构成、服务器和域名。这些基础构成了高用户。体验的关键因素,如何优化整个网站也是以此为基础,而关键词优化一般不需要考虑所有这些因素。
提高网站转化率
不管流量多高,提升访客到商机的转化率才是企业最需要的,全站优化的核心思想优化可以显着提升转化率。
从搜索引擎的角度:假设你是一家打印机公司的营销经理,你需要利用互联网来推广打印机。客户通过长尾词“个人家庭用彩色双面打印机”进行搜索,不仅仅是简单地搜索核心词“打印机”。在百度首页看到“打印机”完整列表的客户,清楚地表明前者的需求与网站呈现的内容更加兼容,因此前者更有可能致电打印机公司。
从网站的流程和内容设计来看:服务或产品内容的选择、表达方式,以及方便简单的引导流程的设计,交互方式的设计将大大增加参与度并有效激发游客的购买欲望。
转化率是seo必须关注的数据。良好的转化率可以将有限的流量转化为优质客户。全站优化方案的优化目标是为转化率和流量上下功夫。各种信息和网站结构的调整,将帮助企业获得更高的网站流量转化率,创造更多的利润。
说到底,如何优化整个网站,是企业营销下的功夫。因此,如何优化整个网站的seo,势必更加关注发布的信息量和平台的覆盖范围。这些信息将使企业信息获得更多展示机会。
控制广告成本
一方面,整个网站优化方案的优化可以带来可观的流量和转化。同时,因为竞争对手不可能花那么多精力去琢磨这几百个长尾词,所以不存在恶意点击。另一方面,它们不是点击。收费,因此如果您被竞争对手点击,不会有任何损失。因此,代理和竞争对手在竞价排名中的恶意欺诈点击不存在,投资回报率自然提高。
因此,全站优化和实战密码优化的目的是从根本上提升企业的质量网站,从而带来高质量的持续海量流量;显着提高转化率。这让企业告别竞价排名依赖。很明显,在核心关键词价格被夸大的情况下,全站优化的投资回报远好于竞价排名。
优化与搜索引擎优化的关系
全站优化是通过对网站定位、网站内容和网站结构的整体优化,保证网站的所有页面对搜索引擎友好,所以网站在各大搜索引擎中,收录的搜索量相对较高,整体排名表现良好。如何优化整个站点 优化整个站点是搜索引擎营销的最佳实践。
什么是全站优化?优化和简单的关键词优化的区别
全站如何优化除了考虑排名,全站优化更看重点击率和网站转化率。它不以某个关键词在某个搜索引擎上的排名为得失,而是关注所有高质量相关关键词在所有搜索引擎上的综合表现。
全站优化比关键词竞价更有效
与关键词竞价不同,如何优化全站可以让你网站通过更优质的关键词从更多搜索引擎获得更多自然流量,而无需担心恶意点击和恶意出价
9 优化目标
1、实现目标提升和长尾关键词的关键词优化。
流量分析,时刻关注网站关键词密度分布,提高目标关键词排名。关注准尾关键词和长尾关键词的关注程度及其在首页的分布情况。
2、保证网站搜索引擎会搜索到最新发布的内容收录。
通过优化长尾关键词的分布和选择,大大提高了网站页面被搜索引擎收录搜索到的概率。整体提升网站的有效访问量。随着流量的增加,网站的整体排名有所提升。
10个优化技巧
全站优化是什么意思?优化不是以某个关键词为最终目标,而是对一个网站的综合优化,包括域名选择、网站结构或栏目设置, 查看全部
seq搜索引擎优化至少包括那几步?(SEO培训,SEO评估方法及工具培训的注意事项!)
优化流程
1:网站诊断分析(网站架构分析,网站内容分析,网站系统分析,网站功能分析)
2:网站竞争分析(行业搜索引擎竞争分析、竞争对手分析、搜索引擎友好度分析、关键词分析、链接分析)
3:SEO培训咨询(SEO基础知识培训、SEO实践专业培训、SEO评估方法及工具培训、SEO实践效果验收与维护)
4:数据追踪分析(数据追踪监测、效果维护与调整、策略评估与调整、流量分析)
5:优化策略结构与实施(全站优化的优化策略是什么,关键词策略,内链优化,外链部署策略,软文编辑和站外推广,搜索引擎性能预言 )
1、网站导航优化
是否锚文本导航,以文本形式做网站导航,不要使用flash、图片、js,因为这不如锚文本导航,锚文本导航蜘蛛更喜欢。
导航锚文本关键词相关性,这是栏目的定位,尽量用你首页的长尾关键词作为你的栏目。
主导航和二级导航,主导航只放栏目和频道,不放无关内容。第二个导航可以放一些相关的关键词页面导航或者栏目导航,但切记不要堆放。
是否有面包屑导航,首页>栏目页>内容页。
面包屑导航优化的细节需要注意:当前页面(登陆页面)一般不需要添加链接;您可以使用 关键词 作为面包屑的锚文本;一个页面可以有多个面包屑(以免给用户造成混淆)。
2、栏目页面优化
三个标签,标题、关键词、描述,合理填写,不要堆砌。标题结构,标题名称>列名>网站名称关键词相关性,检测分页标题重复,不要太多重复。分页链接网址是否加深网址深度,建议网址在3层以内。
3.内容页面优化
内容来源,来源以原创为主,参考写作为辅,不行就伪原创,不需要复制粘贴,对网站没有好处。URL是否收录关键词(英文),最好用关键词制作英文URL,中文拼音也是可以的。标题的格式,简洁明了,应该出现在标题网站main关键词中。要使用 H 标记,请将 H 标记添加到 网站 中第一次出现的 关键词。文章文字是否符合SEO标准,区分主次,合理关键词分布。图片的ALT属性可以增加关键词的密度和搜索引擎对图片的识别。
4. 链接优化
构建 网站 地图。Html 格式的网站 映射基于网站 的结构特征。有必要将网站的功能结构和服务内容罗列有序,力求页面简洁大方,方便用户浏览。
构建机器人文件。注意Robots.txt必须放在站点根目录下,文件名必须全部小写。将 网站 映射写入 Robots 文件。
设置404页面符合网站的设计风格。最好添加网站导航和底部(尤其是网站地图),并保证404页面返回的http状态码为404。
检测网站的死链接并删除,建议使用Xenu工具检测。
一个网站就像一个人,只有变得更好,才能收获更多,创造更多。如果把内链比作经络,那么网站的内容就是血肉之躯。一个网站即使内容丰富,如果经脉不通,最后的结果就是排名不好,收录的提升速度很慢。在网站的构建中,内部链构建的重要性不同于外部链的构建。除了网站和网站之间的链接,还有网站内部网页和网页之间的链接。反向链接也有助于排名。我个人理解,这就是内链的本质。,内链的意义在于用户可以更方便地查找信息。
逆向思维分析
网站内容采集点是关键词,关键词定位访问者。很多人喜欢讲浓度,搜索引擎也是这样看待网站的。标题的作用在细分的未来发展中会更加重要。主题突出,内容丰富,粘性大,领域纵深。这应该是未来几年网站的主流趋势。生活中人人都爱这么说,网站优化也是如此。不要刻意迎合搜索引擎和SEO的喜好,应该多考虑访问者。因为搜索引擎和SEO最终客户都是访问者,都是以人为基础的。一味讨好搜索引擎,容易被当作弊,人讲究个性,< @网站 也是一样。SEO 策略的实施因人而异。在我们研究搜索引擎的同时,搜索引擎也在向我们学习。
6优化方案格式
当你得到一个需要优化的网站时,并不是你得到了网站就去做。网站 优化计划。但这是一种比较简单的网站优化计划编写格式。
网站搜索引擎优化信息
1、ALEXA 排名
2、域名年龄
3、百度权重、谷歌公关及其收录情况
4、网站交通状况
5、关键词 排名
6.网站 外链数据情况
网站优化目标
1.制定目标关键词,并期待排名目标。
2.制定网站IP和PV值,预计增加多少流量网站。
网站站内优化
相信很多新手站长或者SEO新手一开始都会咨询哪里外链比较好,更希望外链遍布全球。其实对于网站优化来说,外链自然很重要,但用户体验更重要。从百度频繁的升级算法中,我们也可以看到,百度对用户体验差的问题不断进行打击网站!因此,叶建辉认为网站的内部优化和网站的用户体验比外链更重要。那么网站内部优化有哪些方面呢?
1.首页标题,观察网站首页标题的数量。
2.网站关键词分布,即页面关键词的密度,不要刻意叠加,就好了。
3.网站内容更新,网站内容更新是否定期很重要,特别是对于新网站,定期更新更能跳出沙盒。
4.网站 内链,无论网站大小,都不能忽视内链的重要性。
5.网站Map 和 网站 static,都影响蜘蛛爬行。
6.图片优化,ALT标签说明。
网站优化策略
网站优化策略需要详细分析。比如企业站和信息站的优化策略不同,企业站需要更新,信息站需要挖掘更多的关键词来拉动流量。
分工
没有完美的个人,只有完美的集体。网站SEO优化也是如此。团队合作,各司其职,才能做得更好。
7个用户组
1.经营大量产品的企业网站
2.行业提供广泛的服务网站
3.至少100个关键词可以总结服务或产品信息
4.专业商场,如服装商场、珠宝礼品商场、化妆品商场等。
5.品牌产品或代理品牌
6.热门行业
8大好处
增加有效流量
全站网站全站优化首先要注意长尾关键词。长尾关键词通常是指网站关键词除了核心关键词和二级核心关键词。一个网站除了核心关键词可以带来很多流量,长尾关键词也可以给网站带来很多流量,其总量为甚至比核心关键词还要大,带来更多的流量。例如,汽车音响店可能选择音响为核心关键词,汽车音响为副核心关键词。那么如果他是做竞价排名的话,选择这两个关键词的价格是很贵的,大概每点击3元左右;那么他可能会选择在google做seo,但是google主页上的都是响亮的网站:慧聪网,英商网、新浪汽车频道、中国汽车影音、中国音响网、太平洋汽车配件频道……如果一个普通的汽车音响店想进前十,你能做到吗?可以,但是很难。但他往往很着急,希望1-3个月内出成果,最后seo服务商不得不用不好的手段去运营。这是国内seo行业的普遍现状。那么,其实换个思路,我们能不能选择长尾词:汽车音响改装、惠威汽车音响、先锋汽车音响、汽车音响论坛、二手车音响、松下汽车音响、漫步者汽车音响、jvc汽车音响、汽车音频解码、汽车音响网络……等等。可能在用户通过搜索引擎检索到的所有关键词中,核心关键词产生了50%的流量,而另外50%的流量是由这些长尾关键词带来的。长尾关键词 通常是不受欢迎的词、词组,甚至是一个句子。当这么多用户使用搜索引擎时,他们可能会输入一些意想不到的东西,比如搜索“”、“北京汽车音响”等词,甚至“哪里可以找到便宜的二手汽车音响?”等短语或句子。在很多情况下,如何优化整个网站的效果表现在模板的修改、链接结构的调整和页面结构的调整,使其更符合搜索引擎的计算规则和同时对观众更加友好。优化整个网站优化指南后,就可以使用搜索引擎' s 排名计算中关键词列表的抽取原理,挖掘出很多关键词,获得好的排名。因此,车站的客流量大大增加。大部分都是好几次好转。如何优化整个网站的最大特点是你不是自己指定某个关键词,而是随着你的内容增加,搜索引擎会自动提取大量关键词进行排序。这种方式非常符合搜索引擎的计算规则。
更好的用户体验
如前所述,seo的目标是用户体验和流量。整个网站的优化是什么?必须考虑网站的结构、内容、美术设计、栏目构成、服务器和域名。这些基础构成了高用户。体验的关键因素,如何优化整个网站也是以此为基础,而关键词优化一般不需要考虑所有这些因素。
提高网站转化率
不管流量多高,提升访客到商机的转化率才是企业最需要的,全站优化的核心思想优化可以显着提升转化率。
从搜索引擎的角度:假设你是一家打印机公司的营销经理,你需要利用互联网来推广打印机。客户通过长尾词“个人家庭用彩色双面打印机”进行搜索,不仅仅是简单地搜索核心词“打印机”。在百度首页看到“打印机”完整列表的客户,清楚地表明前者的需求与网站呈现的内容更加兼容,因此前者更有可能致电打印机公司。
从网站的流程和内容设计来看:服务或产品内容的选择、表达方式,以及方便简单的引导流程的设计,交互方式的设计将大大增加参与度并有效激发游客的购买欲望。
转化率是seo必须关注的数据。良好的转化率可以将有限的流量转化为优质客户。全站优化方案的优化目标是为转化率和流量上下功夫。各种信息和网站结构的调整,将帮助企业获得更高的网站流量转化率,创造更多的利润。
说到底,如何优化整个网站,是企业营销下的功夫。因此,如何优化整个网站的seo,势必更加关注发布的信息量和平台的覆盖范围。这些信息将使企业信息获得更多展示机会。
控制广告成本
一方面,整个网站优化方案的优化可以带来可观的流量和转化。同时,因为竞争对手不可能花那么多精力去琢磨这几百个长尾词,所以不存在恶意点击。另一方面,它们不是点击。收费,因此如果您被竞争对手点击,不会有任何损失。因此,代理和竞争对手在竞价排名中的恶意欺诈点击不存在,投资回报率自然提高。
因此,全站优化和实战密码优化的目的是从根本上提升企业的质量网站,从而带来高质量的持续海量流量;显着提高转化率。这让企业告别竞价排名依赖。很明显,在核心关键词价格被夸大的情况下,全站优化的投资回报远好于竞价排名。
优化与搜索引擎优化的关系
全站优化是通过对网站定位、网站内容和网站结构的整体优化,保证网站的所有页面对搜索引擎友好,所以网站在各大搜索引擎中,收录的搜索量相对较高,整体排名表现良好。如何优化整个站点 优化整个站点是搜索引擎营销的最佳实践。
什么是全站优化?优化和简单的关键词优化的区别
全站如何优化除了考虑排名,全站优化更看重点击率和网站转化率。它不以某个关键词在某个搜索引擎上的排名为得失,而是关注所有高质量相关关键词在所有搜索引擎上的综合表现。
全站优化比关键词竞价更有效
与关键词竞价不同,如何优化全站可以让你网站通过更优质的关键词从更多搜索引擎获得更多自然流量,而无需担心恶意点击和恶意出价
9 优化目标
1、实现目标提升和长尾关键词的关键词优化。
流量分析,时刻关注网站关键词密度分布,提高目标关键词排名。关注准尾关键词和长尾关键词的关注程度及其在首页的分布情况。
2、保证网站搜索引擎会搜索到最新发布的内容收录。
通过优化长尾关键词的分布和选择,大大提高了网站页面被搜索引擎收录搜索到的概率。整体提升网站的有效访问量。随着流量的增加,网站的整体排名有所提升。
10个优化技巧
全站优化是什么意思?优化不是以某个关键词为最终目标,而是对一个网站的综合优化,包括域名选择、网站结构或栏目设置,
seq搜索引擎优化至少包括那几步?(本文MySQL优化器如何选择索引和JOIN顺序(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-12 08:07
本文通过一个案例来看看MySQL优化器是如何选择索引和JOIN顺序的。表结构和数据准备参考本文末尾的“测试环境”。本文主要介绍MySQL优化器的主要执行过程,而不是介绍一个优化器的各个组件(这是另一个话题)。
我们知道 MySQL 优化器只有两个自由度:顺序选择;单表访问模式;这里我们将详细分析下面的SQL,看看MySQL优化器在每一步是如何做出选择的。
explain
select *
from
employee as A,department as B
where
A.LastName = 'zhou'
and B.DepartmentID = A.DepartmentID
and B.DepartmentName = 'TBX';
1. 可能的选项
这里可以看到JOIN的顺序可以是A|B也可以是B|A,单表的访问方式有很多种。对于表A,可以选择:全表扫描和索引`IND_L_D`(A.LastName ='zhou')或`IND_DID`(B.DepartmentID = A.DepartmentID)。B也有3个选项:全表扫描、索引IND_D、IND_DN。
2. MySQL 优化器如何做2.1 概述
MySQL优化器的主要工作包括以下几部分:Query Rewrite(包括Outer Join转换等)、const表检测、范围分析、JOIN优化(顺序和访问方式选择)、计划细化。这个案例从范围分析开始。
2.2 范围分析
这部分包括了所有的Range和index合并成本评估(参考1参考2)。这里等价表达式也是一个范围,所以这里会计算成本,找到记录(代表对应的等价表达式,大致将选择多少条记录)。
在这种情况下,极差分析会分别分析表A中的条件A.LastName='zhou'和表B中的B.DepartmentName='TBX'。
表A A.LastName = 'zhou' found records: 51
表B B.DepartmentName = 'TBX' found records: 1
这两个条件都不是范围,但是这里计算出来的值还是会被存储起来,用于后续的ref访问方法求值。这里的值是根据records_in_range接口返回的,InnoDB每次调用这个函数都会对索引页进行采样。这是一个非常消耗性能的操作。对于许多其他关系数据库,使用“直方图”统计数据。避免这种操作(相信后续版本的 MariaDB 也会实现直方图统计)。
2.3 选择顺序和访问方式:穷举列表
MySQL通过枚举all找到最优的执行顺序和访问方式(也可以说所有的左深树都是整个MySQL优化器的搜索空间)。
2.3.1 排序
优化器首先根据找到的记录对所有表进行排序,并将记录较少的表放在最前面。因此,这里的顺序是B,A。
2.3.2 贪婪搜索
当表数较少时(小于search_depth,默认为63),这样直接减少为穷举搜索,优化器会穷尽所有左深树寻找最优执行计划。在另外,为了减少巨大的搜索空间带来的巨大的耗尽消耗,优化器使用了一个“懒惰”的参数prune_level(默认开启),具体如何“懒惰”可以参考JOIN命令的复杂度选择。但至少它需要与“懒惰”相关联的表不止三个,所以这种情况不适用。
2.3.3 精疲力竭
JOIN的第一个表可以是:A或B;如果第一张表选择A,第二张表可以选择B;如果第一张表选择B,第二张表可以选择A;
因为前面的排序,B表找到的记录比较少,所以JOIN顺序的第一个表用完了,先选B(这个很精致)。
(*) 选择第一个JOIN的表为B
(**) 确定B表的访问方式
因为B表为第一个表,所以无法使用索引IND_D(B.DepartmentID = A.DepartmentID),而只能使用IND_DN(B.DepartmentName = 'TBX')
使用IND_DN索引的成本计算:1.2;其中IO成本为1。
是否使用全表扫描:这里会比较使用索引的IO成本和全表扫描的IO成本,前者为1,后者为2;所以忽略全表扫描
所以,B表的访问方式ref,使用索引IND_D
(**) 从剩余的表中穷举选出第二个JOIN的表,这里剩余的表为:A
(**) 将A表加入JOIN,并确定其访问方式
可以使用的索引为:`IND_L_D`(A.LastName = 'zhou')或者`IND_DID`(B.DepartmentID = A.DepartmentID)
依次计算使用索引IND_L_D、IND_DID的成本:
(***) IND_L_D A.LastName = 'zhou'
在range analysis阶段给出了A.LastName = 'zhou'对应的记录约为:51。
所以,计算IO成本为:51;ref做IO成本计算时会做一次修正,将其修正为worst_seek(参考)
修正后IO成本为:15,总成本为:25.2
(***) IND_DID B.DepartmentID = A.DepartmentID
这是一个需要知道前面表的结果,才能计算的成本。所以range analysis是无法分析的
这里,我们看到前面表为B,found_record是1,所以A.DepartmentID只需要对应一条记录就可以了
因为具体取值不知道,也没有直方图,所以只能简单依据索引统计信息来计算:
索引IND_DID的列A.DepartmentID的Cardinality为1349,全表记录数为1349
所以,每一个值对应一条记录,而前面表B只有一条记录,所以这里的found_record计算为1*1 = 1
所以IO成本为:1,总成本为1.2
(***) IND_L_D成本为25.2;IND_DID成本为1.2,所以选择后者为当前表的访问方式
(**) 确定A使用索引IND_DID,访问方式为ref
(**) JOIN顺序B|A,总成本为:1.2+1.2 = 2.4
(*) 选择第一个JOIN的表为A
(**) 确定A表的访问方式
因为A表是第一个表,所以无法使用索引`IND_DID`(B.DepartmentID = A.DepartmentID)
那么只能使用索引`IND_L_D`(A.LastName = 'zhou')
使用IND_L_D索引的成本计算,总成本为25.2;参考前面计算;
(**) 这里访问A表的成本已经是25.2,比之前的最优成本2.4要大,忽略该顺序
所以,这次穷举搜索到此结束
将上述过程简化如下:
(*) 选择第一个JOIN的表为B
(**) 确定B表的访问方式
(**) 从剩余的表中穷举选出第二个JOIN的表,这里剩余的表为:A
(**) 将A表加入JOIN,并确定其访问方式
(***) IND_L_D A.LastName = 'zhou'
(***) IND_DID B.DepartmentID = A.DepartmentID
(***) IND_L_D成本为25.2;IND_DID成本为1.2,所以选择后者为当前表的访问方式
(**) 确定A使用索引IND_DID,访问方式为ref
(**) JOIN顺序B|A,总成本为:1.2+1.2 = 2.4
(*) 选择第一个JOIN的表为A
(**) 确定A表的访问方式
(**) 这里访问A表的成本已经是25.2,比之前的最优成本2.4要大,忽略该顺序
至此,MySQL优化器已经确定了所有表的最佳JOIN顺序和访问方式。
3. 测试环境
MySQL: 5.1.48-debug-log innodb plugin 1.0.9
CREATE TABLE `department` (
`DepartmentID` int(11) DEFAULT NULL,
`DepartmentName` varchar(20) DEFAULT NULL,
KEY `IND_D` (`DepartmentID`),
KEY `IND_DN` (`DepartmentName`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
CREATE TABLE `employee` (
`LastName` varchar(20) DEFAULT NULL,
`DepartmentID` int(11) DEFAULT NULL,
KEY `IND_L_D` (`LastName`),
KEY `IND_DID` (`DepartmentID`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
for i in `seq 1 1000` ; do mysql -vvv -uroot test -e 'insert into department values (600000*rand(),repeat(char(65+rand()*58),rand()*20))'; done
for i in `seq 1 1000` ; do mysql -vvv -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),600000*rand())'; done
for i in `seq 1 50` ; do mysql -vvv -uroot test -e 'insert into employee values ("zhou",27760)'; done
for i in `seq 1 200` ; do mysql -vvv -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),27760)'; done
for i in `seq 1 1` ; do mysql -vvv -uroot test -e 'insert into department values (27760,"TBX")'; done
show index from employee;
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
| employee | 1 | IND_L_D | 1 | LastName | A | 1349 | NULL | NULL | YES | BTREE | |
| employee | 1 | IND_DID | 1 | DepartmentID | A | 1349 | NULL | NULL | YES | BTREE | |
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
show index from department;
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
| department | 1 | IND_D | 1 | DepartmentID | A | 1001 | NULL | NULL | YES | BTREE | |
| department | 1 | IND_DN | 1 | DepartmentName | A | 1001 | NULL | NULL | YES | BTREE | |
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
4. 构建一个坏案例
由于MySQL在关联条件中使用索引统计进行成本估算,因此在数据分布不均时容易做出错误判断。简单地我们构造如下案例:
表和索引结构不变,数据构造如下:
for i in `seq 1 10000` ; do mysql -uroot test -e 'insert into department values (600000*rand(),repeat(char(65+rand()*58),rand()*20))'; done
for i in `seq 1 10000` ; do mysql -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),600000*rand())'; done
for i in `seq 1 1` ; do mysql -uroot test -e 'insert into employee values ("zhou",27760)'; done
for i in `seq 1 10` ; do mysql -uroot test -e 'insert into department values (27760,"TBX")'; done
for i in `seq 1 1000` ; do mysql -uroot test -e 'insert into department values (27760,repeat(char(65+rand()*58),rand()*20))';
done
explain
select *
from
employee as A,department as B
where
A.LastName = 'zhou'
and B.DepartmentID = A.DepartmentID
and B.DepartmentName = 'TBX';
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
| 1 | SIMPLE | A | ref | IND_L_D,IND_DID | IND_L_D | 43 | const | 1 | Using where |
| 1 | SIMPLE | B | ref | IND_D,IND_DN | IND_D | 5 | test.A.DepartmentID | 1 | Using where |
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
在这里可以看到,MySQL执行计划对表部门使用索引IND_D,那么A表中的一条记录是(zhou,27760);根据B.DepartmentID=27760,会返回1010条记录,然后根据条件 DepartmentName = Filter by'TBX'。
这里可以看到如果B表选择索引IND_DN,效果更好,因为DepartmentName='TBX'只返回10条记录,然后根据条件A.DepartmentID=B.DepartmentID进行过滤。
认为 文章 有用吗?即刻:与朋友一起学习进步!
我猜你会喜欢 查看全部
seq搜索引擎优化至少包括那几步?(本文MySQL优化器如何选择索引和JOIN顺序(组图))
本文通过一个案例来看看MySQL优化器是如何选择索引和JOIN顺序的。表结构和数据准备参考本文末尾的“测试环境”。本文主要介绍MySQL优化器的主要执行过程,而不是介绍一个优化器的各个组件(这是另一个话题)。
我们知道 MySQL 优化器只有两个自由度:顺序选择;单表访问模式;这里我们将详细分析下面的SQL,看看MySQL优化器在每一步是如何做出选择的。
explain
select *
from
employee as A,department as B
where
A.LastName = 'zhou'
and B.DepartmentID = A.DepartmentID
and B.DepartmentName = 'TBX';
1. 可能的选项
这里可以看到JOIN的顺序可以是A|B也可以是B|A,单表的访问方式有很多种。对于表A,可以选择:全表扫描和索引`IND_L_D`(A.LastName ='zhou')或`IND_DID`(B.DepartmentID = A.DepartmentID)。B也有3个选项:全表扫描、索引IND_D、IND_DN。
2. MySQL 优化器如何做2.1 概述
MySQL优化器的主要工作包括以下几部分:Query Rewrite(包括Outer Join转换等)、const表检测、范围分析、JOIN优化(顺序和访问方式选择)、计划细化。这个案例从范围分析开始。
2.2 范围分析
这部分包括了所有的Range和index合并成本评估(参考1参考2)。这里等价表达式也是一个范围,所以这里会计算成本,找到记录(代表对应的等价表达式,大致将选择多少条记录)。
在这种情况下,极差分析会分别分析表A中的条件A.LastName='zhou'和表B中的B.DepartmentName='TBX'。
表A A.LastName = 'zhou' found records: 51
表B B.DepartmentName = 'TBX' found records: 1
这两个条件都不是范围,但是这里计算出来的值还是会被存储起来,用于后续的ref访问方法求值。这里的值是根据records_in_range接口返回的,InnoDB每次调用这个函数都会对索引页进行采样。这是一个非常消耗性能的操作。对于许多其他关系数据库,使用“直方图”统计数据。避免这种操作(相信后续版本的 MariaDB 也会实现直方图统计)。
2.3 选择顺序和访问方式:穷举列表
MySQL通过枚举all找到最优的执行顺序和访问方式(也可以说所有的左深树都是整个MySQL优化器的搜索空间)。
2.3.1 排序
优化器首先根据找到的记录对所有表进行排序,并将记录较少的表放在最前面。因此,这里的顺序是B,A。
2.3.2 贪婪搜索
当表数较少时(小于search_depth,默认为63),这样直接减少为穷举搜索,优化器会穷尽所有左深树寻找最优执行计划。在另外,为了减少巨大的搜索空间带来的巨大的耗尽消耗,优化器使用了一个“懒惰”的参数prune_level(默认开启),具体如何“懒惰”可以参考JOIN命令的复杂度选择。但至少它需要与“懒惰”相关联的表不止三个,所以这种情况不适用。
2.3.3 精疲力竭
JOIN的第一个表可以是:A或B;如果第一张表选择A,第二张表可以选择B;如果第一张表选择B,第二张表可以选择A;
因为前面的排序,B表找到的记录比较少,所以JOIN顺序的第一个表用完了,先选B(这个很精致)。
(*) 选择第一个JOIN的表为B
(**) 确定B表的访问方式
因为B表为第一个表,所以无法使用索引IND_D(B.DepartmentID = A.DepartmentID),而只能使用IND_DN(B.DepartmentName = 'TBX')
使用IND_DN索引的成本计算:1.2;其中IO成本为1。
是否使用全表扫描:这里会比较使用索引的IO成本和全表扫描的IO成本,前者为1,后者为2;所以忽略全表扫描
所以,B表的访问方式ref,使用索引IND_D
(**) 从剩余的表中穷举选出第二个JOIN的表,这里剩余的表为:A
(**) 将A表加入JOIN,并确定其访问方式
可以使用的索引为:`IND_L_D`(A.LastName = 'zhou')或者`IND_DID`(B.DepartmentID = A.DepartmentID)
依次计算使用索引IND_L_D、IND_DID的成本:
(***) IND_L_D A.LastName = 'zhou'
在range analysis阶段给出了A.LastName = 'zhou'对应的记录约为:51。
所以,计算IO成本为:51;ref做IO成本计算时会做一次修正,将其修正为worst_seek(参考)
修正后IO成本为:15,总成本为:25.2
(***) IND_DID B.DepartmentID = A.DepartmentID
这是一个需要知道前面表的结果,才能计算的成本。所以range analysis是无法分析的
这里,我们看到前面表为B,found_record是1,所以A.DepartmentID只需要对应一条记录就可以了
因为具体取值不知道,也没有直方图,所以只能简单依据索引统计信息来计算:
索引IND_DID的列A.DepartmentID的Cardinality为1349,全表记录数为1349
所以,每一个值对应一条记录,而前面表B只有一条记录,所以这里的found_record计算为1*1 = 1
所以IO成本为:1,总成本为1.2
(***) IND_L_D成本为25.2;IND_DID成本为1.2,所以选择后者为当前表的访问方式
(**) 确定A使用索引IND_DID,访问方式为ref
(**) JOIN顺序B|A,总成本为:1.2+1.2 = 2.4
(*) 选择第一个JOIN的表为A
(**) 确定A表的访问方式
因为A表是第一个表,所以无法使用索引`IND_DID`(B.DepartmentID = A.DepartmentID)
那么只能使用索引`IND_L_D`(A.LastName = 'zhou')
使用IND_L_D索引的成本计算,总成本为25.2;参考前面计算;
(**) 这里访问A表的成本已经是25.2,比之前的最优成本2.4要大,忽略该顺序
所以,这次穷举搜索到此结束
将上述过程简化如下:
(*) 选择第一个JOIN的表为B
(**) 确定B表的访问方式
(**) 从剩余的表中穷举选出第二个JOIN的表,这里剩余的表为:A
(**) 将A表加入JOIN,并确定其访问方式
(***) IND_L_D A.LastName = 'zhou'
(***) IND_DID B.DepartmentID = A.DepartmentID
(***) IND_L_D成本为25.2;IND_DID成本为1.2,所以选择后者为当前表的访问方式
(**) 确定A使用索引IND_DID,访问方式为ref
(**) JOIN顺序B|A,总成本为:1.2+1.2 = 2.4
(*) 选择第一个JOIN的表为A
(**) 确定A表的访问方式
(**) 这里访问A表的成本已经是25.2,比之前的最优成本2.4要大,忽略该顺序
至此,MySQL优化器已经确定了所有表的最佳JOIN顺序和访问方式。
3. 测试环境
MySQL: 5.1.48-debug-log innodb plugin 1.0.9
CREATE TABLE `department` (
`DepartmentID` int(11) DEFAULT NULL,
`DepartmentName` varchar(20) DEFAULT NULL,
KEY `IND_D` (`DepartmentID`),
KEY `IND_DN` (`DepartmentName`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
CREATE TABLE `employee` (
`LastName` varchar(20) DEFAULT NULL,
`DepartmentID` int(11) DEFAULT NULL,
KEY `IND_L_D` (`LastName`),
KEY `IND_DID` (`DepartmentID`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
for i in `seq 1 1000` ; do mysql -vvv -uroot test -e 'insert into department values (600000*rand(),repeat(char(65+rand()*58),rand()*20))'; done
for i in `seq 1 1000` ; do mysql -vvv -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),600000*rand())'; done
for i in `seq 1 50` ; do mysql -vvv -uroot test -e 'insert into employee values ("zhou",27760)'; done
for i in `seq 1 200` ; do mysql -vvv -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),27760)'; done
for i in `seq 1 1` ; do mysql -vvv -uroot test -e 'insert into department values (27760,"TBX")'; done
show index from employee;
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
| employee | 1 | IND_L_D | 1 | LastName | A | 1349 | NULL | NULL | YES | BTREE | |
| employee | 1 | IND_DID | 1 | DepartmentID | A | 1349 | NULL | NULL | YES | BTREE | |
+----------+------------+----------+--------------+--------------+-----------+-------------+----------+--------+------+------------+---------+
show index from department;
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment |
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
| department | 1 | IND_D | 1 | DepartmentID | A | 1001 | NULL | NULL | YES | BTREE | |
| department | 1 | IND_DN | 1 | DepartmentName | A | 1001 | NULL | NULL | YES | BTREE | |
+------------+------------+----------+--------------+----------------+-----------+-------------+----------+--------+------+------------+---------+
4. 构建一个坏案例
由于MySQL在关联条件中使用索引统计进行成本估算,因此在数据分布不均时容易做出错误判断。简单地我们构造如下案例:
表和索引结构不变,数据构造如下:
for i in `seq 1 10000` ; do mysql -uroot test -e 'insert into department values (600000*rand(),repeat(char(65+rand()*58),rand()*20))'; done
for i in `seq 1 10000` ; do mysql -uroot test -e 'insert into employee values (repeat(char(65+rand()*58),rand()*20),600000*rand())'; done
for i in `seq 1 1` ; do mysql -uroot test -e 'insert into employee values ("zhou",27760)'; done
for i in `seq 1 10` ; do mysql -uroot test -e 'insert into department values (27760,"TBX")'; done
for i in `seq 1 1000` ; do mysql -uroot test -e 'insert into department values (27760,repeat(char(65+rand()*58),rand()*20))';
done
explain
select *
from
employee as A,department as B
where
A.LastName = 'zhou'
and B.DepartmentID = A.DepartmentID
and B.DepartmentName = 'TBX';
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
| 1 | SIMPLE | A | ref | IND_L_D,IND_DID | IND_L_D | 43 | const | 1 | Using where |
| 1 | SIMPLE | B | ref | IND_D,IND_DN | IND_D | 5 | test.A.DepartmentID | 1 | Using where |
+----+-------------+-------+------+-----------------+---------+---------+---------------------+------+-------------+
在这里可以看到,MySQL执行计划对表部门使用索引IND_D,那么A表中的一条记录是(zhou,27760);根据B.DepartmentID=27760,会返回1010条记录,然后根据条件 DepartmentName = Filter by'TBX'。
这里可以看到如果B表选择索引IND_DN,效果更好,因为DepartmentName='TBX'只返回10条记录,然后根据条件A.DepartmentID=B.DepartmentID进行过滤。
认为 文章 有用吗?即刻:与朋友一起学习进步!
我猜你会喜欢
seq搜索引擎优化至少包括那几步?(网站SEO优化每天要做的长尾关键词的发掘与建造网站的seo适用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-12 08:05
点击发布信息平台b2b了解更多众赢天下优化排名榜首[众赢天下2c4af64]网站SEO优化每日做长尾关键词挖掘建设网站seo适用方法网站优化应该遵循的基本原则 网站SEO优化每天都要做
网站SEO优化需要每天做
每天发布外部链接到网站
定期、循序渐进地添加链接是做好网站工作的必要条件。外链功能大而规则,为了更好地发挥作用,必须逐步增加。一般来说,排列关键字比较容易。链外,这是优化SEO站点外内容的一个方面;如果没有导入外部链接,蜘蛛程序将很难找到您的踪迹。通过导入链接,蜘蛛将根据其位置找到我们的站点。外链搜索引擎蜘蛛的爬取需要大量优质的外链来支持!坚持每天提升网站质量标准,让您的网站获得良好的排名和流量;
每周写2篇软文
写软文书不难,难的是坚持写作,不断写出高质量的软文书。但是今天的软文是一种低成本的实现方式,它的效果是相当明显的,而且作为一个合格的站长,学习写软文是非常有必要的,如果不熟悉的朋友,能够在 Internet 上查找信息并了解更多信息。
长尾的挖掘与建设关键词
发布原创内容有利于提高收录速度和收录网页量
网站地图和404页面
发现有些小公司对网站建设不是很熟悉。随意找人做公司网站的建设,即使他们甚至没有网站的地图。事实上,网站 地图有很大的作用。可以认为搜索引擎爬虫提供了各个地方的链接网站,可以有效的减少爬虫的工作量,增加搜索引擎的用处。输入文章的数量,所以在做网站图之前一定要规划好栏目分类和产品分类。其他的404页面主要是为了避免出现网站的死链接。当一个文章页面不存在,但出现在搜索引擎索引库中时,那么搜索引擎爬虫会爬到死链接,
长尾的挖掘与建设关键词
外贸网站要在建设过程中获得更多的流量,离不开长尾关键词的挖掘和建设,而长尾关键词想要排位,那只是高-优质的信息内容和文章通过网站关键词的搜索引擎优化优化,可以有效的获得好的排名。当很多长尾关键词搜索引擎优化优化以后,我不会担心网站因为搜索引擎算法或政策的变化关键词,因为即使政策< @关键词排名丢失,长尾关键词搜索引擎优化排名还在,不会造成网站流量消失。
网站SEO适用方法
网站的seo适用方法。“绿萝算法”的引入让网站死了90%。无数站长喊道:“以后网站还能做什么?” 其实站长们需要知道一件事:是不是绿萝算法?只为你网站?你的网站没有排名,其他网站是百度的亲戚吗?搜索相关关键词钢铁网站还能跳出来吗?所以机会是公平的。作者对绿萝算法的建议是规范站点,站点外更严格。绿萝算法以攻击外链着称,但至少网站还是没影响到。很多网站的内容平时很多,但是现在好像很常见。作者不提倡这个,就算你有更多的内容,如果你有很多内容,迟早会降低你的权力。然后是内链,同样是链接,外链是做不到的。为什么不做好内部链接呢?它是结构的标准化。这是一个常见的问题。有很多网站文章非常多,导致内部结构非常混乱。对于每个页面,三个要素基本相同,导致权重无法集中,排名更加困难;外链方面,普通外链做不到,做一些社交标签难吗?百度百科不能做搜索?能' t 搜索百科全书?有福育客优化认为,1个这样的外链至少相当于100个像您之前发布的一样乱七八糟的外链。
网站优化的基本原理
网站优化的基本原理
.网站首页
基于多年的实践经验,我们相信大多数中小企业在网站SEO排名时都会优化网站的首页。因此,我们需要特别注意主页的设置,例如:
首页的TDK标签,尤其是标题标签关键词的匹配;
首页关键词,合理控制首页布局中关键词的密度; 查看全部
seq搜索引擎优化至少包括那几步?(网站SEO优化每天要做的长尾关键词的发掘与建造网站的seo适用方法)
点击发布信息平台b2b了解更多众赢天下优化排名榜首[众赢天下2c4af64]网站SEO优化每日做长尾关键词挖掘建设网站seo适用方法网站优化应该遵循的基本原则 网站SEO优化每天都要做
网站SEO优化需要每天做
每天发布外部链接到网站
定期、循序渐进地添加链接是做好网站工作的必要条件。外链功能大而规则,为了更好地发挥作用,必须逐步增加。一般来说,排列关键字比较容易。链外,这是优化SEO站点外内容的一个方面;如果没有导入外部链接,蜘蛛程序将很难找到您的踪迹。通过导入链接,蜘蛛将根据其位置找到我们的站点。外链搜索引擎蜘蛛的爬取需要大量优质的外链来支持!坚持每天提升网站质量标准,让您的网站获得良好的排名和流量;
每周写2篇软文
写软文书不难,难的是坚持写作,不断写出高质量的软文书。但是今天的软文是一种低成本的实现方式,它的效果是相当明显的,而且作为一个合格的站长,学习写软文是非常有必要的,如果不熟悉的朋友,能够在 Internet 上查找信息并了解更多信息。
长尾的挖掘与建设关键词
发布原创内容有利于提高收录速度和收录网页量
网站地图和404页面
发现有些小公司对网站建设不是很熟悉。随意找人做公司网站的建设,即使他们甚至没有网站的地图。事实上,网站 地图有很大的作用。可以认为搜索引擎爬虫提供了各个地方的链接网站,可以有效的减少爬虫的工作量,增加搜索引擎的用处。输入文章的数量,所以在做网站图之前一定要规划好栏目分类和产品分类。其他的404页面主要是为了避免出现网站的死链接。当一个文章页面不存在,但出现在搜索引擎索引库中时,那么搜索引擎爬虫会爬到死链接,
长尾的挖掘与建设关键词
外贸网站要在建设过程中获得更多的流量,离不开长尾关键词的挖掘和建设,而长尾关键词想要排位,那只是高-优质的信息内容和文章通过网站关键词的搜索引擎优化优化,可以有效的获得好的排名。当很多长尾关键词搜索引擎优化优化以后,我不会担心网站因为搜索引擎算法或政策的变化关键词,因为即使政策< @关键词排名丢失,长尾关键词搜索引擎优化排名还在,不会造成网站流量消失。
网站SEO适用方法
网站的seo适用方法。“绿萝算法”的引入让网站死了90%。无数站长喊道:“以后网站还能做什么?” 其实站长们需要知道一件事:是不是绿萝算法?只为你网站?你的网站没有排名,其他网站是百度的亲戚吗?搜索相关关键词钢铁网站还能跳出来吗?所以机会是公平的。作者对绿萝算法的建议是规范站点,站点外更严格。绿萝算法以攻击外链着称,但至少网站还是没影响到。很多网站的内容平时很多,但是现在好像很常见。作者不提倡这个,就算你有更多的内容,如果你有很多内容,迟早会降低你的权力。然后是内链,同样是链接,外链是做不到的。为什么不做好内部链接呢?它是结构的标准化。这是一个常见的问题。有很多网站文章非常多,导致内部结构非常混乱。对于每个页面,三个要素基本相同,导致权重无法集中,排名更加困难;外链方面,普通外链做不到,做一些社交标签难吗?百度百科不能做搜索?能' t 搜索百科全书?有福育客优化认为,1个这样的外链至少相当于100个像您之前发布的一样乱七八糟的外链。
网站优化的基本原理
网站优化的基本原理
.网站首页
基于多年的实践经验,我们相信大多数中小企业在网站SEO排名时都会优化网站的首页。因此,我们需要特别注意主页的设置,例如:
首页的TDK标签,尤其是标题标签关键词的匹配;
首页关键词,合理控制首页布局中关键词的密度;
seq搜索引擎优化至少包括那几步?( 贯穿搜索引擎优化系统的公式是什么?优化排名技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-12 07:04
贯穿搜索引擎优化系统的公式是什么?优化排名技术)
小苏资源网:搜索引擎优化排名技术分析
搜索引擎优化涉及很多基础知识。除了单一的技术,还包括创新思维。如果你给你50页的内容是否可以排版不同的格式,这需要创新,那么本文将给你分析搜索引擎优化排名技巧。
贯穿搜索引擎优化系统的公式是什么?以下是内容,整理和删除,这是提炼它的价值,你觉得不好,就过滤一下,如果你是做搜索引擎优化的案例,建议你看看,如果不是,你不妨看看看,一切都有它的价值!
搜索引擎优化
1.从眼球到眼球
首先,搜索引擎优化的目的是获取客户流量。无论是销售产品还是推广某些服务,我们都需要客户。这也是搜索引擎优化的价值所在。每一个不同的关键词意味着背后有很多眼球(每个关键词都有一群客户在搜索),那么对于我们来说,没有访客怎么办?
每个行业不同的关键词都已经有眼球了,所以只要去有眼球的地方去获取眼球,这个是最快的,所以SEO第一步就是过滤关键词,并逐渐扩大长尾关键词(详见商七云SEO的《长尾关键词采集方法与技术》(Methods and Technology for Long Tail Keyword 采集)),确定关键词之后,我们开始实施下一步,所以我们需要某个链来获得排名,不知道在哪里建立这个链?
2、从外链到外链
在百度中随机搜索一个排名靠前的网站,然后在百度搜索框中输入DOMAIN+网址就知道发到哪里了。
当然,您也可以进行更详细的分析。也可以搜索他的具体内页网址,会发现更多惊喜,得到大量外链地址(详情请参考《网站上如何构建外链》(How Build网站上的外部链接)相关介绍。
另外,还可以使用外链分析软件进行分析,总之就是通过别人的网站获取外链资源。
如何应对项目运营时间紧?自己做网站,等收录,再发链优化排名周期太长,想快点怎么办?那么我们必须增加网站的权重。
3、从重量到重量
大的网站 已经有一定的重量了。对于百度搜索引擎来说,他们的网页更可信。一般只要发布信息,几分钟到几十分钟就可以收录。
对此,我们可以利用或各种重量级网站发布信息,提供给国外连锁店。关键词在竞争不是很激烈的地方,一般一周内就能拿到名次(见奇云seo“使用高权重或高流量平台推广网络的利弊”相关介绍) .
4.从排名到排名
如果要在半小时内把产品的广告信息放到关键词首页排名怎么办?
比如你在百度上搜索关键词“木门”,仔细往下翻。你看见了吗?
SEO分级爆破技术核心优化思路
在关键字木门搜索结果的第一页,有最新的相关信息。您只需要在这些新闻源发布信息,半小时内就可以让您的广告信息出现在关键词的首页。你只需要使用你的力量,你就能意识到这一点。同时,你也可以利用这些新闻源来导入链接,为你的网站增加权重。
此外,您还可以使用百度产品、图书馆、百科全书、知识等。出于同样的原因。
搜索引擎优化
5、从资源到资源
当优化第一个网站进行搜索引擎优化时,因为你没有足够的资源,这是最关键的问题,但是当你可以优化第一个网站然后优化第二个网站 显然比第一个容易很多,这就是为什么优化第一个 网站 是最困难的。
尚启云认为,所谓的搜索引擎优化专家在技术上并不高人一等。排名的原则其实就是最后拼的就是资源的组合和使用资源的能力,仅此而已!
因此,从现在开始,您必须记住从资源移动到资源!
我知道你在困惑什么,你一定在想,关键是我没有资源?
不,您已经拥有资源和您想要的一切。已经有人在你面前拥有它们了。你要的是用它,以成功为起点,这样你才能更快地走向成功。
简而言之,拥有资源的人不如使用资源的人。您需要的不是您拥有多少资源,而是您可以控制多少资源。这是非常关键的!
从您感兴趣的内容到客户感兴趣的内容
你要像一个真正的营销人员,学会100%站在客户的角度思考,进入客户的世界,感受他的痛苦,然后你就会知道他们最感兴趣的是什么。
例如,您有兴趣让客户参加您的英语培训,但客户对您的培训不感兴趣,他只对自己的演讲感兴趣。所以,你必须先进入客户的世界,然后找出他的痛点,把他从他的世界带到你的世界。理解?
看这里,你应该知道我说的公式是什么了吧?
是的,从二十到二十!
这个公式将同时打开你的几种思维模式。首先,它会自动驱动你的自助思维,让你思考如何从别人已经成功的东西走向自己的成功。其次,它开始你的持续思考。思维问题不是基于点,而是线性思维。也可以说是交互思维。
所以,尚云奇认为网站的搜索引擎优化不是很友好,但是很简单。只有当复杂的事情变得简单时,它才具有更大的价值。
你必须知道 XX 导致 XX。这个公式的原则是从一个成功到另一个成功,而不是从头开始,用最简单的例子。
7、从××到××,每一个爆点都被抓到了
如果你能反复研究这个公式,并把它应用到搜索引擎优化的每一个细节,你会发现它可以帮你把所有搜索引擎优化系统的内容概括成这个公式。在你未来的思考过程中,你会发现你有更多的创造力!
搜索引擎优化
另外,其实这个公式可以用的地方太多了,除了SEO之外,所有地方都可以用,所以尚启云建议大家不仅抓好这些例子,忽略本质,还要深入理解原理,并尽力从一个实例转到另一个实例。比如从内容到内容,从案例到案例,从热点信息到热点流量。
然后找到最适合您的并立即采取行动。如果你只从表面上学习而不用你的大脑,那是没有用的。我相信你同意这个观点,对吗?
同一句话,他山上的石头可以用来攻玉。他应该善于发现事物的价值,然后为我所用。不要被一些所谓的概念误导。学习最简单实用的策略,越容易实施。关键不是看太多,而是看完之后细化,然后严格执行。
知道并不意味着能够执行,只有这样才能取得成果。如果你努力去做简单的事情,你就会成功!
搜索引擎优化排名爆破技术可以说是一个贯穿搜索引擎优化系统的公式。这个内容并不新鲜,但还是很有用的。正确的思维方向永远不会持久。至少我是这么认为的。过去,很多人说这个内容被炒作了。炒作与我无关。我保留我的意见。
一切都有它的价值。没有找到价值是你的遗憾。选择一个好的并遵循它。坏的,扔掉。与其批评和拒绝它,不如提炼它的价值,供我自己使用。他山的石头可以用来攻玉。 查看全部
seq搜索引擎优化至少包括那几步?(
贯穿搜索引擎优化系统的公式是什么?优化排名技术)
小苏资源网:搜索引擎优化排名技术分析
搜索引擎优化涉及很多基础知识。除了单一的技术,还包括创新思维。如果你给你50页的内容是否可以排版不同的格式,这需要创新,那么本文将给你分析搜索引擎优化排名技巧。
贯穿搜索引擎优化系统的公式是什么?以下是内容,整理和删除,这是提炼它的价值,你觉得不好,就过滤一下,如果你是做搜索引擎优化的案例,建议你看看,如果不是,你不妨看看看,一切都有它的价值!
搜索引擎优化
1.从眼球到眼球
首先,搜索引擎优化的目的是获取客户流量。无论是销售产品还是推广某些服务,我们都需要客户。这也是搜索引擎优化的价值所在。每一个不同的关键词意味着背后有很多眼球(每个关键词都有一群客户在搜索),那么对于我们来说,没有访客怎么办?
每个行业不同的关键词都已经有眼球了,所以只要去有眼球的地方去获取眼球,这个是最快的,所以SEO第一步就是过滤关键词,并逐渐扩大长尾关键词(详见商七云SEO的《长尾关键词采集方法与技术》(Methods and Technology for Long Tail Keyword 采集)),确定关键词之后,我们开始实施下一步,所以我们需要某个链来获得排名,不知道在哪里建立这个链?
2、从外链到外链
在百度中随机搜索一个排名靠前的网站,然后在百度搜索框中输入DOMAIN+网址就知道发到哪里了。
当然,您也可以进行更详细的分析。也可以搜索他的具体内页网址,会发现更多惊喜,得到大量外链地址(详情请参考《网站上如何构建外链》(How Build网站上的外部链接)相关介绍。
另外,还可以使用外链分析软件进行分析,总之就是通过别人的网站获取外链资源。
如何应对项目运营时间紧?自己做网站,等收录,再发链优化排名周期太长,想快点怎么办?那么我们必须增加网站的权重。
3、从重量到重量
大的网站 已经有一定的重量了。对于百度搜索引擎来说,他们的网页更可信。一般只要发布信息,几分钟到几十分钟就可以收录。
对此,我们可以利用或各种重量级网站发布信息,提供给国外连锁店。关键词在竞争不是很激烈的地方,一般一周内就能拿到名次(见奇云seo“使用高权重或高流量平台推广网络的利弊”相关介绍) .
4.从排名到排名
如果要在半小时内把产品的广告信息放到关键词首页排名怎么办?
比如你在百度上搜索关键词“木门”,仔细往下翻。你看见了吗?
SEO分级爆破技术核心优化思路
在关键字木门搜索结果的第一页,有最新的相关信息。您只需要在这些新闻源发布信息,半小时内就可以让您的广告信息出现在关键词的首页。你只需要使用你的力量,你就能意识到这一点。同时,你也可以利用这些新闻源来导入链接,为你的网站增加权重。
此外,您还可以使用百度产品、图书馆、百科全书、知识等。出于同样的原因。
搜索引擎优化
5、从资源到资源
当优化第一个网站进行搜索引擎优化时,因为你没有足够的资源,这是最关键的问题,但是当你可以优化第一个网站然后优化第二个网站 显然比第一个容易很多,这就是为什么优化第一个 网站 是最困难的。
尚启云认为,所谓的搜索引擎优化专家在技术上并不高人一等。排名的原则其实就是最后拼的就是资源的组合和使用资源的能力,仅此而已!
因此,从现在开始,您必须记住从资源移动到资源!
我知道你在困惑什么,你一定在想,关键是我没有资源?
不,您已经拥有资源和您想要的一切。已经有人在你面前拥有它们了。你要的是用它,以成功为起点,这样你才能更快地走向成功。
简而言之,拥有资源的人不如使用资源的人。您需要的不是您拥有多少资源,而是您可以控制多少资源。这是非常关键的!
从您感兴趣的内容到客户感兴趣的内容
你要像一个真正的营销人员,学会100%站在客户的角度思考,进入客户的世界,感受他的痛苦,然后你就会知道他们最感兴趣的是什么。
例如,您有兴趣让客户参加您的英语培训,但客户对您的培训不感兴趣,他只对自己的演讲感兴趣。所以,你必须先进入客户的世界,然后找出他的痛点,把他从他的世界带到你的世界。理解?
看这里,你应该知道我说的公式是什么了吧?
是的,从二十到二十!
这个公式将同时打开你的几种思维模式。首先,它会自动驱动你的自助思维,让你思考如何从别人已经成功的东西走向自己的成功。其次,它开始你的持续思考。思维问题不是基于点,而是线性思维。也可以说是交互思维。
所以,尚云奇认为网站的搜索引擎优化不是很友好,但是很简单。只有当复杂的事情变得简单时,它才具有更大的价值。
你必须知道 XX 导致 XX。这个公式的原则是从一个成功到另一个成功,而不是从头开始,用最简单的例子。
7、从××到××,每一个爆点都被抓到了
如果你能反复研究这个公式,并把它应用到搜索引擎优化的每一个细节,你会发现它可以帮你把所有搜索引擎优化系统的内容概括成这个公式。在你未来的思考过程中,你会发现你有更多的创造力!
搜索引擎优化
另外,其实这个公式可以用的地方太多了,除了SEO之外,所有地方都可以用,所以尚启云建议大家不仅抓好这些例子,忽略本质,还要深入理解原理,并尽力从一个实例转到另一个实例。比如从内容到内容,从案例到案例,从热点信息到热点流量。
然后找到最适合您的并立即采取行动。如果你只从表面上学习而不用你的大脑,那是没有用的。我相信你同意这个观点,对吗?
同一句话,他山上的石头可以用来攻玉。他应该善于发现事物的价值,然后为我所用。不要被一些所谓的概念误导。学习最简单实用的策略,越容易实施。关键不是看太多,而是看完之后细化,然后严格执行。
知道并不意味着能够执行,只有这样才能取得成果。如果你努力去做简单的事情,你就会成功!
搜索引擎优化排名爆破技术可以说是一个贯穿搜索引擎优化系统的公式。这个内容并不新鲜,但还是很有用的。正确的思维方向永远不会持久。至少我是这么认为的。过去,很多人说这个内容被炒作了。炒作与我无关。我保留我的意见。
一切都有它的价值。没有找到价值是你的遗憾。选择一个好的并遵循它。坏的,扔掉。与其批评和拒绝它,不如提炼它的价值,供我自己使用。他山的石头可以用来攻玉。
seq搜索引擎优化至少包括那几步?( 【每日一题】第一步爬行和抓取(第二十五期))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-08 19:05
【每日一题】第一步爬行和抓取(第二十五期))
第一步是爬行爬行
1) 搜索引擎用来抓取和访问页面的程序称为蜘蛛或机器人。蜘蛛实际上是搜索引擎的下属。搜索引擎命令它在互联网上浏览网页,获取互联网上的所有数据,然后将这些数据存储在搜索引擎自己的数据库中。我们的网站中不能有死链接。需要蜘蛛在网站网站中畅通无阻地抓取页面。
2)蜘蛛爬行的方法
不管什么级别的蜘蛛爬行方法都一样,有两种:1、深度优先;2、宽度优先。蜘蛛会沿着锚文本爬到最后,所以这里是 网站 内部链接的重要性。
①深度优先。
深度优先是指蜘蛛到达一个页面后,找到一个锚文本链接,也就是爬进另一个页面,然后在另一个页面上找到另一个锚文本链接,然后往里面爬,直到最后爬到这个网站@ >.
②、宽度优先。
宽度优先是指蜘蛛到达一个页面后,发现不是直接输入锚文本,而是爬取整个页面,然后将所有锚文本一起进入另一个页面,直到整个网站爬行完全的。
3)搜索引擎使用什么索引来确定爬取一个网站的频率。主要有四个指标:
一种。网站 更新频率:更新来得快,更新来得慢,直接影响蜘蛛访问的频率
湾 网站的更新质量:更新频率提高了,只会引起蜘蛛的注意。蜘蛛对质量有严格的要求。如果网站每天更新的大量内容被蜘蛛判断为低质量的页面仍然毫无意义。
C。连通性:网站要安全稳定,保证百度蜘蛛畅通无阻。把蜘蛛关起来可不是什么好事。
d. 站点评价:百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。它是百度搜索引擎对该站点的基本评分(不是外界所说的百度权重)。里面是百度一个非常机密的数据。网站评分从不单独使用,会与其他因素和阈值共同影响网站的爬取和排名。
第二步数据库处理
搜索引擎抓取到网页后,还需要做大量的预处理工作,才能提供检索服务。其中,最重要的是提取关键词,构建索引库和索引。其他包括去除重复网页、分词(中文)、判断网页类型、分析超链接以及计算网页的重要性/丰富度。其中,网站数据库是动态网站存储网站数据的空间。索引数据库,索引是一种对数据库表中一个或多个列的值进行排序的结构。使用索引可以快速访问数据库表中的特定信息。简单的说,就是将【爬取】的网页放入数据库中。
第三步,分析搜索服务
用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了页面标题和网址外,还会提供页面摘要等信息。
用户检索的过程是对前两个过程的考验,以检验搜索引擎是否能够提供最准确、最广泛的信息,以及搜索引擎是否能够快速的给出用户最想要的信息。
第四步排名
提取的网页按照不同维度的得分进行综合排序。“不同维度”包括:
相关性:网页内容与用户搜索需求的匹配程度,例如网页中收录的用户勾选关键词的次数,以及这些关键词出现的位置;外部网页用来指向页面的锚文本等。
权限:用户喜欢网站提供的内容,具有一定的权限。相应地,百度搜索引擎也更加相信优质权威网站提供的内容。
时效性:时效性结果是指收录新鲜内容的新网页。目前,时间敏感的结果在搜索引擎中变得越来越重要。
重要性:网页内容与用户检查需求相匹配的重要程度或受欢迎程度
丰富性:丰富性看似简单,但它是一个涵盖范围非常广泛的命题。可以理解为网页内容丰富,完全可以满足用户的需求;既可以满足用户的单一需求,又可以满足用户的扩展需求。
流行度:指网页是否流行。
搜索引擎通过搜索词处理、文件匹配、相关性计算、过滤调整、排名展示等复杂的工作步骤完成最终排名。 查看全部
seq搜索引擎优化至少包括那几步?(
【每日一题】第一步爬行和抓取(第二十五期))
第一步是爬行爬行
1) 搜索引擎用来抓取和访问页面的程序称为蜘蛛或机器人。蜘蛛实际上是搜索引擎的下属。搜索引擎命令它在互联网上浏览网页,获取互联网上的所有数据,然后将这些数据存储在搜索引擎自己的数据库中。我们的网站中不能有死链接。需要蜘蛛在网站网站中畅通无阻地抓取页面。
2)蜘蛛爬行的方法
不管什么级别的蜘蛛爬行方法都一样,有两种:1、深度优先;2、宽度优先。蜘蛛会沿着锚文本爬到最后,所以这里是 网站 内部链接的重要性。
①深度优先。
深度优先是指蜘蛛到达一个页面后,找到一个锚文本链接,也就是爬进另一个页面,然后在另一个页面上找到另一个锚文本链接,然后往里面爬,直到最后爬到这个网站@ >.
②、宽度优先。
宽度优先是指蜘蛛到达一个页面后,发现不是直接输入锚文本,而是爬取整个页面,然后将所有锚文本一起进入另一个页面,直到整个网站爬行完全的。
3)搜索引擎使用什么索引来确定爬取一个网站的频率。主要有四个指标:
一种。网站 更新频率:更新来得快,更新来得慢,直接影响蜘蛛访问的频率
湾 网站的更新质量:更新频率提高了,只会引起蜘蛛的注意。蜘蛛对质量有严格的要求。如果网站每天更新的大量内容被蜘蛛判断为低质量的页面仍然毫无意义。
C。连通性:网站要安全稳定,保证百度蜘蛛畅通无阻。把蜘蛛关起来可不是什么好事。
d. 站点评价:百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。它是百度搜索引擎对该站点的基本评分(不是外界所说的百度权重)。里面是百度一个非常机密的数据。网站评分从不单独使用,会与其他因素和阈值共同影响网站的爬取和排名。
第二步数据库处理
搜索引擎抓取到网页后,还需要做大量的预处理工作,才能提供检索服务。其中,最重要的是提取关键词,构建索引库和索引。其他包括去除重复网页、分词(中文)、判断网页类型、分析超链接以及计算网页的重要性/丰富度。其中,网站数据库是动态网站存储网站数据的空间。索引数据库,索引是一种对数据库表中一个或多个列的值进行排序的结构。使用索引可以快速访问数据库表中的特定信息。简单的说,就是将【爬取】的网页放入数据库中。
第三步,分析搜索服务
用户输入关键词进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了页面标题和网址外,还会提供页面摘要等信息。
用户检索的过程是对前两个过程的考验,以检验搜索引擎是否能够提供最准确、最广泛的信息,以及搜索引擎是否能够快速的给出用户最想要的信息。
第四步排名
提取的网页按照不同维度的得分进行综合排序。“不同维度”包括:
相关性:网页内容与用户搜索需求的匹配程度,例如网页中收录的用户勾选关键词的次数,以及这些关键词出现的位置;外部网页用来指向页面的锚文本等。
权限:用户喜欢网站提供的内容,具有一定的权限。相应地,百度搜索引擎也更加相信优质权威网站提供的内容。
时效性:时效性结果是指收录新鲜内容的新网页。目前,时间敏感的结果在搜索引擎中变得越来越重要。
重要性:网页内容与用户检查需求相匹配的重要程度或受欢迎程度
丰富性:丰富性看似简单,但它是一个涵盖范围非常广泛的命题。可以理解为网页内容丰富,完全可以满足用户的需求;既可以满足用户的单一需求,又可以满足用户的扩展需求。
流行度:指网页是否流行。
搜索引擎通过搜索词处理、文件匹配、相关性计算、过滤调整、排名展示等复杂的工作步骤完成最终排名。
seq搜索引擎优化至少包括那几步?(对网站进行SEO优化的最重要的一步对)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-08 04:03
网站 SEO优化最重要的一步是对网站进行基础优化。也就是优化网站的基础代码,优化每个页面,满足搜索引擎的要求。这将使我们的 网站 优化变得顺理成章。那么接下来说说我们优化的具体方法。
页面优化
页面优化就是把合适的关键词放在合适的地方,让搜索引擎知道你的页面是关于什么的。具体可以从以下几个方面入手。
1. 页面标题
标题是页面最重要的部分。它显示在页面顶部的选项卡上。您应该为每个页面内容总结最重要的关键词。为了避免一些笼统的描述,通常你会有多个关键词,你需要把更重要的放在第一位。
2.页面地址
你可以设置自己的页面地址,你应该使用一些有意义的词;当您需要连接两个词时,请使用连字符 (-) 而不是下划线 (_)。尽量减少无意义的乱码。相反,更简洁明了的地址会更容易让蜘蛛爬行。
3. 标题
标题中需要说明页面的主要内容是什么,关键词需要再次出现在这里。如果一个页面有多个标题,尽量指出它们之间的相似之处,否则蜘蛛很难理解你的页面是关于什么的。
4. 文章 主题
如果你的页面标题和文章在标题中重复了你的关键词,那你就不用在文章中重复关键词,Spider就不会太反感了。你很烦人,但你会认为你在作弊。
5.文字链接
适当添加一些文字链接到我们的文章。
6、标签
Alt标签用于描述页面上的图片,提高页面的可访问性(accessibility),也有助于优化搜索排名。
做完上面的网站基础优化后,我们会适当增加一些外链建设和我们的网站内容更新。最重要的是内容。如果我们的内容做好了,排名自然就在那里。但这个过程可能不会在一夜之间发生,所以耐心同样重要。返回搜狐查看更多 查看全部
seq搜索引擎优化至少包括那几步?(对网站进行SEO优化的最重要的一步对)
网站 SEO优化最重要的一步是对网站进行基础优化。也就是优化网站的基础代码,优化每个页面,满足搜索引擎的要求。这将使我们的 网站 优化变得顺理成章。那么接下来说说我们优化的具体方法。
页面优化
页面优化就是把合适的关键词放在合适的地方,让搜索引擎知道你的页面是关于什么的。具体可以从以下几个方面入手。
1. 页面标题
标题是页面最重要的部分。它显示在页面顶部的选项卡上。您应该为每个页面内容总结最重要的关键词。为了避免一些笼统的描述,通常你会有多个关键词,你需要把更重要的放在第一位。
2.页面地址
你可以设置自己的页面地址,你应该使用一些有意义的词;当您需要连接两个词时,请使用连字符 (-) 而不是下划线 (_)。尽量减少无意义的乱码。相反,更简洁明了的地址会更容易让蜘蛛爬行。
3. 标题
标题中需要说明页面的主要内容是什么,关键词需要再次出现在这里。如果一个页面有多个标题,尽量指出它们之间的相似之处,否则蜘蛛很难理解你的页面是关于什么的。
4. 文章 主题
如果你的页面标题和文章在标题中重复了你的关键词,那你就不用在文章中重复关键词,Spider就不会太反感了。你很烦人,但你会认为你在作弊。
5.文字链接
适当添加一些文字链接到我们的文章。
6、标签
Alt标签用于描述页面上的图片,提高页面的可访问性(accessibility),也有助于优化搜索排名。
做完上面的网站基础优化后,我们会适当增加一些外链建设和我们的网站内容更新。最重要的是内容。如果我们的内容做好了,排名自然就在那里。但这个过程可能不会在一夜之间发生,所以耐心同样重要。返回搜狐查看更多
seq搜索引擎优化至少包括那几步?(关键词排名优化服务介绍推广模式介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-07 23:14
关键词排名优化服务介绍
推广方式:用户提供关键词和优化链接,10-30天内可优化到百度首页,按效果付费
价格:根据关键词优化难度,分析后报价,一般每月400-600元一个字(非最终价格)
优化过程:
1.用户提供主要关键词、FTP、管理后台等需要优化的信息
2.0375 NetMedia进行关键词分析,确认报价,优化时间
3.客户确认合作并支付定金(50%优化费),我们开始优化
4. 优化完成,达到预期效果。客户验收后支付余款的50%。
优化周期:
可以优化客户原有的关键词 100以内的排名。如果关键词没有排名,我们会进行相关评估,确定时段和价格。
1.原百度前30:3-10天出结果
2.原创排名百度30-60:8-15天出结果
3. 原手机百度排名11-50:效果后3-20天
4.未排名关键词根据搜索索引进行评估,一般1个月内出结果
关键词**提升排名优势:
**,有效安全,先付一半定金,效果后付余款,资金安全有保障!
seo关键词 优化
SEO关键词优化推广,这对于每一个管理员朋友来说并不陌生,这也是每一个SEO优化者的SEO技巧,如何在搜索引擎中对自己的关键词进行排名,达到自己理想的位置?以下是关键字优化的一些基本步骤。
**,选择合适的cms程序。
一个好的cms是必不可少的seo。现在选择一个cms并不难。许多cms已经完善,基本满足站内需求。同样的cms做同样的类型还是会有成败的,关键是站得住的技巧和心态。重要的是选择你熟悉的cms。
第二,优化。
对于SEO关键词优化,网站优化也是必不可少的。对于网站优化,我们需要注意以下几点:
1.导航清晰,便于搜索引擎蜘蛛掌握;
2.集成JS和CSS进行外部调用。
3.URL要合理设计,栏目不要太深,伪静态。
4. 应该添加图片的Alt属性。
5.制作301;
6. 正确地将关键字布局为倾斜、关键字和描述;
7. 合理安排站内锚文本;
8.创建地图。
做好这几点,你的优化已经基本优化了。
三、文章的优化。
做SEO优化的朋友应该知道“内容为王”的道理。上面的文章也是一个重要的部分,可以称之为精华。内容请尽量避免从搜索引擎抄袭文章,自己写原创内容。文章中关键词的合理布局,尽可能的自然自然。添加文章链接对于提高关键子子的排名也很重要。文章 内容页面的相关推送对于用户体验来说也是必不可少的。
*四、搜索和发布外部链接。外链关联性好,怎么找外链?**几种外链方式: 1.友情链接;2. 与行业的外部链接参考;3.文章提交,软文发布;4.博客、微博平台;5、论坛、帖子栏目;6、采集器、网上摘录和分类信息。我相信这些对于一个小人来说已经足够了。
如何进行搜索引擎优化
从需求结果分析,什么都需要seo操作,不需要去流量。建设和搜索引擎优化是兼容的。不同的组建成后,由于各种原因,会采用不同的方式进行SEO。有些是外包的,有些是由SEO技术人员聘请的。无论哪种方式,都需要满足一个基本要求:有一个预定的关键词 Ranking。
那么,如何进行有效的seo操作呢?一般来说,有两个部分。一部分是seo基础设置,包括但不限于代码、合理的内容模型、安全设置、速度优化等。另一部分是内容组织、外链建设、用户行为建设、良好的呈现。建设等方面。
不同的seo人对如何进行seo有自己的方法和步骤,也有自己的看法。他们个人认为,效率是结果的最终维度,其他一切都只是空谈。在给定的时间内,关键词的排名数,页面上有多少,索引大的词有多少,长尾词有多少,这些决定了seo的结果。
在细化方面,如何进行SEO?
一、优化基本seo的设置。
1、**你要确定**流量词和需求词(通过关键词分析**)。
2、其次,你需要了解你想要做什么类型。它是企业展示类型、行业或其他类型。
3、定位之后,开始思考你要做什么关键词。为此,您可以通过行业常规关键词、百度搜索,看看其他公司在做什么。过滤百度**页面并一一排序。
4、关键词 完成后。需要找到优化目标关键词(要优化的首页)和长尾关键词(要对首页以外的页面进行优化的词)
5、确认关键词后,我开始采集整理内容。你现在找到的关键词,包括目标词,加上长尾词,至少有200个以上。因此,您至少要整理 200 篇文章文章。百度优化原则:内容原创,是**。所以你必须考虑如何组织内容。
6、开始做,优化结构。例如:机器人页面、nofollow 标签、站点地图、域、404 页面。做完这些,开始第七步,关键词布局。
7、第一个要优化的页面是**关键词,3-5是优化数量的范围。布局位置包括:TKD标签、页眉、栏目、页脚、面包屑导航、导航、模块。
8、关键词 布局完成后,开始填写内容信息。
二、上线后对应的seo操作点。
1、*新的高品质文章。
上线前,做好关键词设置布局,规划好栏目页面后,要在本地环境搭建好,填充文章的内容,文章的内容饱和@>应该至少要达到80%以上,填满文章的内容才是我们要做的。
文章上线后,要注意文章的*新规律,保证每天定时定量*新。
<p>在保证了固定时间和定量的*new文章之后,还要保证*new文章内容的质量,这个是**,因为现在搜索引擎对 查看全部
seq搜索引擎优化至少包括那几步?(关键词排名优化服务介绍推广模式介绍)
关键词排名优化服务介绍
推广方式:用户提供关键词和优化链接,10-30天内可优化到百度首页,按效果付费
价格:根据关键词优化难度,分析后报价,一般每月400-600元一个字(非最终价格)
优化过程:
1.用户提供主要关键词、FTP、管理后台等需要优化的信息
2.0375 NetMedia进行关键词分析,确认报价,优化时间
3.客户确认合作并支付定金(50%优化费),我们开始优化
4. 优化完成,达到预期效果。客户验收后支付余款的50%。
优化周期:
可以优化客户原有的关键词 100以内的排名。如果关键词没有排名,我们会进行相关评估,确定时段和价格。
1.原百度前30:3-10天出结果
2.原创排名百度30-60:8-15天出结果
3. 原手机百度排名11-50:效果后3-20天
4.未排名关键词根据搜索索引进行评估,一般1个月内出结果
关键词**提升排名优势:
**,有效安全,先付一半定金,效果后付余款,资金安全有保障!
seo关键词 优化
SEO关键词优化推广,这对于每一个管理员朋友来说并不陌生,这也是每一个SEO优化者的SEO技巧,如何在搜索引擎中对自己的关键词进行排名,达到自己理想的位置?以下是关键字优化的一些基本步骤。
**,选择合适的cms程序。
一个好的cms是必不可少的seo。现在选择一个cms并不难。许多cms已经完善,基本满足站内需求。同样的cms做同样的类型还是会有成败的,关键是站得住的技巧和心态。重要的是选择你熟悉的cms。
第二,优化。
对于SEO关键词优化,网站优化也是必不可少的。对于网站优化,我们需要注意以下几点:
1.导航清晰,便于搜索引擎蜘蛛掌握;
2.集成JS和CSS进行外部调用。
3.URL要合理设计,栏目不要太深,伪静态。
4. 应该添加图片的Alt属性。
5.制作301;
6. 正确地将关键字布局为倾斜、关键字和描述;
7. 合理安排站内锚文本;
8.创建地图。
做好这几点,你的优化已经基本优化了。
三、文章的优化。
做SEO优化的朋友应该知道“内容为王”的道理。上面的文章也是一个重要的部分,可以称之为精华。内容请尽量避免从搜索引擎抄袭文章,自己写原创内容。文章中关键词的合理布局,尽可能的自然自然。添加文章链接对于提高关键子子的排名也很重要。文章 内容页面的相关推送对于用户体验来说也是必不可少的。
*四、搜索和发布外部链接。外链关联性好,怎么找外链?**几种外链方式: 1.友情链接;2. 与行业的外部链接参考;3.文章提交,软文发布;4.博客、微博平台;5、论坛、帖子栏目;6、采集器、网上摘录和分类信息。我相信这些对于一个小人来说已经足够了。
如何进行搜索引擎优化
从需求结果分析,什么都需要seo操作,不需要去流量。建设和搜索引擎优化是兼容的。不同的组建成后,由于各种原因,会采用不同的方式进行SEO。有些是外包的,有些是由SEO技术人员聘请的。无论哪种方式,都需要满足一个基本要求:有一个预定的关键词 Ranking。
那么,如何进行有效的seo操作呢?一般来说,有两个部分。一部分是seo基础设置,包括但不限于代码、合理的内容模型、安全设置、速度优化等。另一部分是内容组织、外链建设、用户行为建设、良好的呈现。建设等方面。
不同的seo人对如何进行seo有自己的方法和步骤,也有自己的看法。他们个人认为,效率是结果的最终维度,其他一切都只是空谈。在给定的时间内,关键词的排名数,页面上有多少,索引大的词有多少,长尾词有多少,这些决定了seo的结果。
在细化方面,如何进行SEO?
一、优化基本seo的设置。
1、**你要确定**流量词和需求词(通过关键词分析**)。
2、其次,你需要了解你想要做什么类型。它是企业展示类型、行业或其他类型。
3、定位之后,开始思考你要做什么关键词。为此,您可以通过行业常规关键词、百度搜索,看看其他公司在做什么。过滤百度**页面并一一排序。
4、关键词 完成后。需要找到优化目标关键词(要优化的首页)和长尾关键词(要对首页以外的页面进行优化的词)
5、确认关键词后,我开始采集整理内容。你现在找到的关键词,包括目标词,加上长尾词,至少有200个以上。因此,您至少要整理 200 篇文章文章。百度优化原则:内容原创,是**。所以你必须考虑如何组织内容。
6、开始做,优化结构。例如:机器人页面、nofollow 标签、站点地图、域、404 页面。做完这些,开始第七步,关键词布局。
7、第一个要优化的页面是**关键词,3-5是优化数量的范围。布局位置包括:TKD标签、页眉、栏目、页脚、面包屑导航、导航、模块。
8、关键词 布局完成后,开始填写内容信息。
二、上线后对应的seo操作点。
1、*新的高品质文章。
上线前,做好关键词设置布局,规划好栏目页面后,要在本地环境搭建好,填充文章的内容,文章的内容饱和@>应该至少要达到80%以上,填满文章的内容才是我们要做的。
文章上线后,要注意文章的*新规律,保证每天定时定量*新。
<p>在保证了固定时间和定量的*new文章之后,还要保证*new文章内容的质量,这个是**,因为现在搜索引擎对
seq搜索引擎优化至少包括那几步?(关于第一个就是数据增强阶段的一些事儿,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-07 03:06
TinyBERT提供了一个经过General Distillation阶段的checkpoint,可以认为是一个小型的BERT,包括6L786H版本和4L312H版本。而我们的后续复刻是基于4L312H v2版本。值得注意的是,TinyBERT 对任务数据集进行了数据增强操作,通过基于 Glove's Embedding Distance 和 BERT MLM 预测替换的相似词替换,将原创数据集扩大到 20 倍。我们遇到的第一个错误是在数据增强阶段。
数据增强中的错误
我们可以根据官方代码对数据进行增强,但是在QNLI上会报错:
索引错误:索引 514 超出维度 1,大小为 512
当数据增强一半时程序崩溃。为什么?
很简单,因为数据增强代码BERT MLM换词模块对很长(> 512)个句子,导致下标越界)没有特殊处理,具体请参考#Issue50。
只需在对应函数中判断边界即可:
def _masked_language_model(self, sent, word_pieces, mask_id):
if mask_id > 511: # if mask id is longer than max length
return []
tokenized_text = self.tokenizer.tokenize(sent)
tokenized_text = ['[CLS]'] + tokenized_text
tokenized_len = len(tokenized_text)
tokenized_text = word_pieces + ['[SEP]'] + tokenized_text[1:] + ['[SEP]']
segments_ids = [0] * (tokenized_len + 1) + [1] * (len(tokenized_text) - tokenized_len - 1)
if len(tokenized_text) > 512: # truncation
tokenized_text = tokenized_text[:512]
segments_ids = segments_ids[:512]
token_ids = self.tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([token_ids]).to(device)
segments_tensor = torch.tensor([segments_ids]).to(device)
self.model.to(device)
predictions = self.model(tokens_tensor, segments_tensor)
word_candidates = torch.argsort(predictions[0, mask_id], descending=True)[:self.M].tolist()
word_candidates = self.tokenizer.convert_ids_to_tokens(word_candidates)
return list(filter(lambda x: x.find("##"), word_candidates))
数据并行加速
在我们辛苦快乐地完成了数据增强之后,下一步就是在Task Specific Distillation中进行Step 1,General Distillation。对于一些像MRPC这样的小数据集,20倍增长后的数据量仍然不到80k,所以训练速度还是很快的,单卡大概半天可以跑20轮。但是对于像MNLI(390k)这样GLUE中最大的数据集,20倍增强的数据集(增强用了2天左右),如果用单卡训练10轮,可能需要半个月。到时候,黄花菜怕是不冷了。所以我计划使用多卡进行培训。乍一看,官方实现通过nn.DataParallel支持Doka。好吧,直接CUDA_VISIBLE_DEVICES="0,1,2,3"加载4张卡。不知道跑不跑 加载数据(标记化,填充)花了 1 个小时,我终于开始了。当我打开 nvidia-smi 时,我震惊了。GPU 利用率在 50% 左右。看看预计的时间,大概是21小时。在一轮中,10 个纪元四舍五入为一周半。男孩,我还能试验这个吗?这时候去查看PyTorch文档,发现PyTorch不再推荐使用nn。数据并行,为什么?主要原因是DataParallel的实现是一个单一的进程。每次主卡读取数据,然后将其发送到其他卡。这部分故障会带来额外的计算开销,并会导致主卡的GPU内存被占用。明显高于其他卡,导致潜在的批量大小限制;此外,在这种模式下,其他 GPU 必须在计算完成后发送回主卡进行同步。这一步会受到 GIL(全局解释器锁)的限制,进一步降低效率。另外,还有一些DataParallel不支持的功能,比如多机、模型切片,但是另一个DistributedDataParallel模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:还有一些DataParallel 不支持的功能,比如多机和模型切片,但另一个DistributedDataParallel 模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:还有一些DataParallel 不支持的功能,比如多机和模型切片,但另一个DistributedDataParallel 模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
# 给 parser 增加一个 local rank 参数来在启动的时候传入 rank
parser.add_argument('--local_rank',
type=int,
default=-1)
# ...
# 初始化
logger.info("Initializing Distributed Environment")
torch.cuda.set_device(args.local_rank)
dist.init_process_group(backend="nccl")
# 设置 devicec
local_rank = args.local_rank
torch.cuda.set_device(local_rank)
# ...
# 初始化模型 并且 放到 device 上
student_model = TinyBertForSequenceClassification.from_pretrained(args.student_model, num_labels=num_labels).to(device)
teacher_model = TinyBertForSequenceClassification.from_pretrained(args.teacher_model, num_labels=num_labels).to(device)
# 用 DDP 包裹模型
student_model = DDP(student_model, device_ids=[local_rank], output_device=local_rank)
teacher_model = DDP(teacher_model, device_ids=[local_rank], output_device=local_rank)
# ..
# 用 DistributedSampler 替换原来的 Random Sampler
train_sampler = torch.utils.data.DistributedSampler(train_data)
然后,你就大功告成了,一键开始:
GPU=”0,1,2,3”
CUDA_VISIBLE_DEVICEES=$GPU python -m torch.distributed.launch –n_proc_per_node 4 task_disti.py
创业成功了吗?模型再次开始处理数据......
一小时后,机器突然卡住,程序日志停止。我打开htop看了看。好家伙,256G内存满了,程序是D状态。怎么了?
数据加载加速
我先尝试了少量数据,下采样到10k,程序运行没问题,DDP速度很快;我试过单卡加载,虽然又加载了一个小时,但是还好,程序还是可以运行的,那么,问题是怎么发生的呢?单卡,我看了一下加载全量数据后的内存使用情况。大约是60G。考虑到DDP是多进程的,每个进程必须独立加载数据。4张卡4个进程,大约是250G内存,所以内存爆了,后续数据的io卡住了(无法从磁盘加载到内存),导致程序D状态。看看下一组的机器,最大的是250G的内存。也就是说,如果我只用3张卡,那么我可以运行,但是如果其他人上来启动程序并吃掉一部分内存,那么很有可能内存会爆炸,然后大家的程序都被抹掉了,这不是很好。一个不太优雅的解决方案是将数据切成块,然后读取一小段训练,然后读取下一段,再次训练,再次读取。我咨询了小组中的一位高级研究员。另一种方式是实现一个数据读取程序,将数据存储在磁盘上,每次使用时将其加载到内存中,从而避免内存爆炸的问题。好吧,让我们做吧,但你不能从头开始制造轮子,对吧?哲哥提到了拥抱脸(yyds)的数据集可以支持这个功能。查了一下文档,发现他实现了一个基于pyarrow的内存映射数据读取。根据我在 Huggingface Transformer 方面的经验,它似乎能够实现这一点。
首先,加载增强数据。datasets提供的load_dataset函数最接近load_dataset('csv', data_file),然后我们就可以逐列获取数据并进行预处理。写了一会儿,发现读了一部分数据后,总是列数不对的错误。我猜原创的 MNLI 数据集不能保证每一列都在那里。我查看了在MnliProcessor中处理的代码,发现Line[8]和line[9]被写成sentence_a和sentence_b。无奈之下,只能用最粗暴的方式用文本方式读入,每一行都是一条数据,然后拆分:
from datasets import
processor = processors[task_name]()
output_mode = output_modes[task_name]
label_list = processor.get_labels()
num_labels = len(label_list)
tokenizer = BertTokenizer.from_pretrained(args.student_model, do_lower_case=args.do_lower_case)
# 用 text
mnli_datasets = load_dataset("text", data_files=os.path.join(args.data_dir, "train_aug.tsv"))
label_classes = processor.get_labels()
label_map = {label: i for i, label in enumerate(label_classes)}
def preprocess_func(examples, max_seq_length=args.max_seq_length):
splits = [e.split('\t') for e in examples['text']] # split
# tokenize for sent1 & sent2
tokens_s1 = [tokenizer.tokenize(e[8]) for e in splits]
tokens_s2 = [tokenizer.tokenize(e[9]) for e in splits]
for t1, t2 in zip(tokens_s1, tokens_s2):
truncate_seq_pair(t1, t2, max_length=max_seq_length - 3)
input_ids_list = []
input_mask_list = []
segment_ids_list = []
seq_length_list = []
labels_list = []
labels = [e[-1] for e in splits] # last column is label column
for token_a, token_b, l in zip(tokens_s1, tokens_s2, labels): # zip(tokens_as, tokens_bs):
tokens = ["[CLS]"] + token_a + ["[SEP]"]
segment_ids = [0] * len(tokens)
tokens += token_b + ["[SEP]"]
segment_ids += [1] * (len(token_b) + 1)
input_ids = tokenizer.convert_tokens_to_ids(tokens) # tokenize to id
input_mask = [1] * len(input_ids)
seq_length = len(input_ids)
padding = [0] * (max_seq_length - len(input_ids))
input_ids += padding
input_mask += padding
segment_ids += padding
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
input_ids_list.append(input_ids)
input_mask_list.append(input_mask)
segment_ids_list.append(segment_ids)
seq_length_list.append(seq_length)
labels_list.append(label_map[l])
results = {"input_ids": input_ids_list,
"input_mask": input_mask_list,
"segment_ids": segment_ids_list,
"seq_length": seq_length_list,
"label_ids": labels_list}
return results
# map datasets
mnli_datasets = mnli_datasets.map(preprocess_func, batched=True)
# remove column
train_data = mnli_datasets['train'].remove_columns('text')
写完这个preprocess_func,我觉得胜利就在眼前,但还有几个坑需要解决:
inputs = {}
for k, v in batch.items():
if isinstance(v, torch.Tensor):
inputs[k] = v.to(device)
elif isinstance(v, List):
inputs[k] = torch.stack(v, dim=1).to(device)
到目前为止,只需将之前代码的 train_data 替换为当前版本即可。
另外,为了进一步加速,我还集成了混合精度。现在Pytorch和自己支持混合精度,代码量很少,但是有一个陷阱就是loss的计算必须用auto()包裹,同时,所有模型的输出都必须参与loss的计算,对于只做预测或者隐藏状态对齐的loss不友好,所以只能手动计算一个系数为0的额外loss项(所以他参与了Training但不影响梯度)。 查看全部
seq搜索引擎优化至少包括那几步?(关于第一个就是数据增强阶段的一些事儿,你知道吗?)
TinyBERT提供了一个经过General Distillation阶段的checkpoint,可以认为是一个小型的BERT,包括6L786H版本和4L312H版本。而我们的后续复刻是基于4L312H v2版本。值得注意的是,TinyBERT 对任务数据集进行了数据增强操作,通过基于 Glove's Embedding Distance 和 BERT MLM 预测替换的相似词替换,将原创数据集扩大到 20 倍。我们遇到的第一个错误是在数据增强阶段。
数据增强中的错误
我们可以根据官方代码对数据进行增强,但是在QNLI上会报错:
索引错误:索引 514 超出维度 1,大小为 512
当数据增强一半时程序崩溃。为什么?
很简单,因为数据增强代码BERT MLM换词模块对很长(> 512)个句子,导致下标越界)没有特殊处理,具体请参考#Issue50。
只需在对应函数中判断边界即可:
def _masked_language_model(self, sent, word_pieces, mask_id):
if mask_id > 511: # if mask id is longer than max length
return []
tokenized_text = self.tokenizer.tokenize(sent)
tokenized_text = ['[CLS]'] + tokenized_text
tokenized_len = len(tokenized_text)
tokenized_text = word_pieces + ['[SEP]'] + tokenized_text[1:] + ['[SEP]']
segments_ids = [0] * (tokenized_len + 1) + [1] * (len(tokenized_text) - tokenized_len - 1)
if len(tokenized_text) > 512: # truncation
tokenized_text = tokenized_text[:512]
segments_ids = segments_ids[:512]
token_ids = self.tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([token_ids]).to(device)
segments_tensor = torch.tensor([segments_ids]).to(device)
self.model.to(device)
predictions = self.model(tokens_tensor, segments_tensor)
word_candidates = torch.argsort(predictions[0, mask_id], descending=True)[:self.M].tolist()
word_candidates = self.tokenizer.convert_ids_to_tokens(word_candidates)
return list(filter(lambda x: x.find("##"), word_candidates))
数据并行加速
在我们辛苦快乐地完成了数据增强之后,下一步就是在Task Specific Distillation中进行Step 1,General Distillation。对于一些像MRPC这样的小数据集,20倍增长后的数据量仍然不到80k,所以训练速度还是很快的,单卡大概半天可以跑20轮。但是对于像MNLI(390k)这样GLUE中最大的数据集,20倍增强的数据集(增强用了2天左右),如果用单卡训练10轮,可能需要半个月。到时候,黄花菜怕是不冷了。所以我计划使用多卡进行培训。乍一看,官方实现通过nn.DataParallel支持Doka。好吧,直接CUDA_VISIBLE_DEVICES="0,1,2,3"加载4张卡。不知道跑不跑 加载数据(标记化,填充)花了 1 个小时,我终于开始了。当我打开 nvidia-smi 时,我震惊了。GPU 利用率在 50% 左右。看看预计的时间,大概是21小时。在一轮中,10 个纪元四舍五入为一周半。男孩,我还能试验这个吗?这时候去查看PyTorch文档,发现PyTorch不再推荐使用nn。数据并行,为什么?主要原因是DataParallel的实现是一个单一的进程。每次主卡读取数据,然后将其发送到其他卡。这部分故障会带来额外的计算开销,并会导致主卡的GPU内存被占用。明显高于其他卡,导致潜在的批量大小限制;此外,在这种模式下,其他 GPU 必须在计算完成后发送回主卡进行同步。这一步会受到 GIL(全局解释器锁)的限制,进一步降低效率。另外,还有一些DataParallel不支持的功能,比如多机、模型切片,但是另一个DistributedDataParallel模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:还有一些DataParallel 不支持的功能,比如多机和模型切片,但另一个DistributedDataParallel 模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:还有一些DataParallel 不支持的功能,比如多机和模型切片,但另一个DistributedDataParallel 模块支持。所以,废话少说,你得把原来的TinyBERT DataParallel(DP)改成DistributedDataParallel(DDP)。那么,DP转DDP需要几步?答:大概,就这么多步骤。核心代码是做一些初始化,用DDP替换DP:
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
# 给 parser 增加一个 local rank 参数来在启动的时候传入 rank
parser.add_argument('--local_rank',
type=int,
default=-1)
# ...
# 初始化
logger.info("Initializing Distributed Environment")
torch.cuda.set_device(args.local_rank)
dist.init_process_group(backend="nccl")
# 设置 devicec
local_rank = args.local_rank
torch.cuda.set_device(local_rank)
# ...
# 初始化模型 并且 放到 device 上
student_model = TinyBertForSequenceClassification.from_pretrained(args.student_model, num_labels=num_labels).to(device)
teacher_model = TinyBertForSequenceClassification.from_pretrained(args.teacher_model, num_labels=num_labels).to(device)
# 用 DDP 包裹模型
student_model = DDP(student_model, device_ids=[local_rank], output_device=local_rank)
teacher_model = DDP(teacher_model, device_ids=[local_rank], output_device=local_rank)
# ..
# 用 DistributedSampler 替换原来的 Random Sampler
train_sampler = torch.utils.data.DistributedSampler(train_data)
然后,你就大功告成了,一键开始:
GPU=”0,1,2,3”
CUDA_VISIBLE_DEVICEES=$GPU python -m torch.distributed.launch –n_proc_per_node 4 task_disti.py
创业成功了吗?模型再次开始处理数据......
一小时后,机器突然卡住,程序日志停止。我打开htop看了看。好家伙,256G内存满了,程序是D状态。怎么了?
数据加载加速
我先尝试了少量数据,下采样到10k,程序运行没问题,DDP速度很快;我试过单卡加载,虽然又加载了一个小时,但是还好,程序还是可以运行的,那么,问题是怎么发生的呢?单卡,我看了一下加载全量数据后的内存使用情况。大约是60G。考虑到DDP是多进程的,每个进程必须独立加载数据。4张卡4个进程,大约是250G内存,所以内存爆了,后续数据的io卡住了(无法从磁盘加载到内存),导致程序D状态。看看下一组的机器,最大的是250G的内存。也就是说,如果我只用3张卡,那么我可以运行,但是如果其他人上来启动程序并吃掉一部分内存,那么很有可能内存会爆炸,然后大家的程序都被抹掉了,这不是很好。一个不太优雅的解决方案是将数据切成块,然后读取一小段训练,然后读取下一段,再次训练,再次读取。我咨询了小组中的一位高级研究员。另一种方式是实现一个数据读取程序,将数据存储在磁盘上,每次使用时将其加载到内存中,从而避免内存爆炸的问题。好吧,让我们做吧,但你不能从头开始制造轮子,对吧?哲哥提到了拥抱脸(yyds)的数据集可以支持这个功能。查了一下文档,发现他实现了一个基于pyarrow的内存映射数据读取。根据我在 Huggingface Transformer 方面的经验,它似乎能够实现这一点。
首先,加载增强数据。datasets提供的load_dataset函数最接近load_dataset('csv', data_file),然后我们就可以逐列获取数据并进行预处理。写了一会儿,发现读了一部分数据后,总是列数不对的错误。我猜原创的 MNLI 数据集不能保证每一列都在那里。我查看了在MnliProcessor中处理的代码,发现Line[8]和line[9]被写成sentence_a和sentence_b。无奈之下,只能用最粗暴的方式用文本方式读入,每一行都是一条数据,然后拆分:
from datasets import
processor = processors[task_name]()
output_mode = output_modes[task_name]
label_list = processor.get_labels()
num_labels = len(label_list)
tokenizer = BertTokenizer.from_pretrained(args.student_model, do_lower_case=args.do_lower_case)
# 用 text
mnli_datasets = load_dataset("text", data_files=os.path.join(args.data_dir, "train_aug.tsv"))
label_classes = processor.get_labels()
label_map = {label: i for i, label in enumerate(label_classes)}
def preprocess_func(examples, max_seq_length=args.max_seq_length):
splits = [e.split('\t') for e in examples['text']] # split
# tokenize for sent1 & sent2
tokens_s1 = [tokenizer.tokenize(e[8]) for e in splits]
tokens_s2 = [tokenizer.tokenize(e[9]) for e in splits]
for t1, t2 in zip(tokens_s1, tokens_s2):
truncate_seq_pair(t1, t2, max_length=max_seq_length - 3)
input_ids_list = []
input_mask_list = []
segment_ids_list = []
seq_length_list = []
labels_list = []
labels = [e[-1] for e in splits] # last column is label column
for token_a, token_b, l in zip(tokens_s1, tokens_s2, labels): # zip(tokens_as, tokens_bs):
tokens = ["[CLS]"] + token_a + ["[SEP]"]
segment_ids = [0] * len(tokens)
tokens += token_b + ["[SEP]"]
segment_ids += [1] * (len(token_b) + 1)
input_ids = tokenizer.convert_tokens_to_ids(tokens) # tokenize to id
input_mask = [1] * len(input_ids)
seq_length = len(input_ids)
padding = [0] * (max_seq_length - len(input_ids))
input_ids += padding
input_mask += padding
segment_ids += padding
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
input_ids_list.append(input_ids)
input_mask_list.append(input_mask)
segment_ids_list.append(segment_ids)
seq_length_list.append(seq_length)
labels_list.append(label_map[l])
results = {"input_ids": input_ids_list,
"input_mask": input_mask_list,
"segment_ids": segment_ids_list,
"seq_length": seq_length_list,
"label_ids": labels_list}
return results
# map datasets
mnli_datasets = mnli_datasets.map(preprocess_func, batched=True)
# remove column
train_data = mnli_datasets['train'].remove_columns('text')
写完这个preprocess_func,我觉得胜利就在眼前,但还有几个坑需要解决:
inputs = {}
for k, v in batch.items():
if isinstance(v, torch.Tensor):
inputs[k] = v.to(device)
elif isinstance(v, List):
inputs[k] = torch.stack(v, dim=1).to(device)
到目前为止,只需将之前代码的 train_data 替换为当前版本即可。
另外,为了进一步加速,我还集成了混合精度。现在Pytorch和自己支持混合精度,代码量很少,但是有一个陷阱就是loss的计算必须用auto()包裹,同时,所有模型的输出都必须参与loss的计算,对于只做预测或者隐藏状态对齐的loss不友好,所以只能手动计算一个系数为0的额外loss项(所以他参与了Training但不影响梯度)。
seq搜索引擎优化至少包括那几步?( 百度算法|87程度就低,适当地,系统将减少相关度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-06 11:02
百度算法|87程度就低,适当地,系统将减少相关度)
当涉及到该短语的有效竞争页数时,竞争的准确性取决于搜索“关键字是该页面的焦点”。
3. 新访客比例:我们调查了从入口到达的访客中有多少是新访客。解释越高,新访客就越感兴趣。
越早开始,对您的公司越好。
潜在语义索引 (LSI) 更进一步,用于语义分析以识别所涉及的网页。
另一方面,如果网页被用户关闭并且网页时间长,则网页的流行度会很低。系统会适当地降低网页的相关性。
地域来源分析 从百度统计数据中获取【地域来源】报表,可以了解返回网站的访问者所在的位置。
标题标签中的关键字是最重要的吗?标题标签是一个网页最重要的搜索关键词位置。
博客搜索谷歌专门为博客搜索打造了一个搜索引擎——GoogleBlogSearch(谷歌博客搜索,名字不准确,因为它实际上是一个RSS提要引擎而不是博客引擎)。
1.水平导航系统。
现在为每个 SearchEngineGuide 和 ISEDB 添加一个目录。
当 Spiders 从其他站点找到您的 网站 链接时,如果 Robots.txt 文件未声明不允许访问该页面,则 Spiders 将不会保存该页面。
这是一个图表,显示了大多数搜索引擎如何与目录交互。
越早开始,对您的公司越好。
这在 网站 优化中起着更重要的作用。
至于如何区分低权限站点和无价值站点,1、大多数网站甚至需要一个网页来识别它们的价值;2、针对网站分析MSN要优化关键词SERP排在前网站,通过对比他们网站的链接,可以大致得出结论,在同时,不会为您找到更多有潜力的Link合作伙伴。
“链接工厂”(也称为“群链接机制”)是指由大量交叉链接的网页组成的网络系统。
如前所述,良好的链接工作和必要的链接文本必须通过在标题和正文中不收录非常丰富的关键字来补充。
许多互联网销售专家创建了他们控制内容的商业模式,人们可以通过页面的主要内容获得相关的广告。
在美国的搜索引擎用户中,女性略多于男性(50.1%:49.9%)。
198 他们可以详细监控互联网用户如何搜索您网站。例如,搜索引擎可以检测到哪个搜索引擎在搜索你,甚至是哪个关键词;你的网站访问者来自哪里,你可以得到日报、周报、月报、年报等。
O'ReillyMedia 已将这本书上传到 Safari Books Online Service。
除了5KH8DE1F000120GR是字母和数字的混合,其余都是显示数字。
环比环比:是指本期数据与上期数据的对比。它反映了数据相互变化的趋势,可以是日环比、环环比、环环比等,比如今年的第n个月和第n个月或者n+ 1个月的比例。
以不道德的方式发生的戏剧性变化代表了投资者所谓的“破坏性事件”——从根本上改变事物的那种事件。 查看全部
seq搜索引擎优化至少包括那几步?(
百度算法|87程度就低,适当地,系统将减少相关度)
当涉及到该短语的有效竞争页数时,竞争的准确性取决于搜索“关键字是该页面的焦点”。
3. 新访客比例:我们调查了从入口到达的访客中有多少是新访客。解释越高,新访客就越感兴趣。
越早开始,对您的公司越好。
潜在语义索引 (LSI) 更进一步,用于语义分析以识别所涉及的网页。
另一方面,如果网页被用户关闭并且网页时间长,则网页的流行度会很低。系统会适当地降低网页的相关性。
地域来源分析 从百度统计数据中获取【地域来源】报表,可以了解返回网站的访问者所在的位置。
标题标签中的关键字是最重要的吗?标题标签是一个网页最重要的搜索关键词位置。
博客搜索谷歌专门为博客搜索打造了一个搜索引擎——GoogleBlogSearch(谷歌博客搜索,名字不准确,因为它实际上是一个RSS提要引擎而不是博客引擎)。
1.水平导航系统。
现在为每个 SearchEngineGuide 和 ISEDB 添加一个目录。
当 Spiders 从其他站点找到您的 网站 链接时,如果 Robots.txt 文件未声明不允许访问该页面,则 Spiders 将不会保存该页面。
这是一个图表,显示了大多数搜索引擎如何与目录交互。
越早开始,对您的公司越好。
这在 网站 优化中起着更重要的作用。
至于如何区分低权限站点和无价值站点,1、大多数网站甚至需要一个网页来识别它们的价值;2、针对网站分析MSN要优化关键词SERP排在前网站,通过对比他们网站的链接,可以大致得出结论,在同时,不会为您找到更多有潜力的Link合作伙伴。
“链接工厂”(也称为“群链接机制”)是指由大量交叉链接的网页组成的网络系统。
如前所述,良好的链接工作和必要的链接文本必须通过在标题和正文中不收录非常丰富的关键字来补充。
许多互联网销售专家创建了他们控制内容的商业模式,人们可以通过页面的主要内容获得相关的广告。
在美国的搜索引擎用户中,女性略多于男性(50.1%:49.9%)。
198 他们可以详细监控互联网用户如何搜索您网站。例如,搜索引擎可以检测到哪个搜索引擎在搜索你,甚至是哪个关键词;你的网站访问者来自哪里,你可以得到日报、周报、月报、年报等。
O'ReillyMedia 已将这本书上传到 Safari Books Online Service。
除了5KH8DE1F000120GR是字母和数字的混合,其余都是显示数字。
环比环比:是指本期数据与上期数据的对比。它反映了数据相互变化的趋势,可以是日环比、环环比、环环比等,比如今年的第n个月和第n个月或者n+ 1个月的比例。
以不道德的方式发生的戏剧性变化代表了投资者所谓的“破坏性事件”——从根本上改变事物的那种事件。
seq搜索引擎优化至少包括那几步?(社交网络营销(sns)优化至少包括那几步?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-05 16:07
seq搜索引擎优化至少包括那几步?seq是一个设计用于搜索引擎排名和关键字优化的http服务器框架,有时候也称soqg,或是seq2g。是alexa网站排名服务,与strwordsmartlists一起被称为搜索引擎优化的第三代框架。服务提供快速索引和转换表,以便用户能够快速灵活地查找他们需要的内容。
搜索引擎优化(seo)的目标是创建提高整个站点知名度和影响力的网站,同时可以保持一个良好的网络收录和排名。seo的主要目标是通过处理关键字来创建描述性和描述性页面,从而成为搜索引擎的良好页面。搜索引擎优化(seo)的第二个目标是支持搜索引擎排名。第三个主要目标是通过外部链接,电子邮件广告和搜索引擎内容来显著提高网站访问者的流量和关注度。
seo是一个系统化的计划,其核心是关键字和内容。该系统通过社交网络的推荐算法、使用页面、标题和tags来连接。接下来我们来介绍三个已知的方法来增加seo,同时可以验证方法的有效性,以及它是否适合于其他搜索引擎。
1)搜索引擎(site)优化它允许用户访问一个排名靠前的网站。例如,如果网站连接的谷歌广告无法收回这一差距,那么用户就不会进入排名第一的网站。根据seo表格中的权重,site中的连接越多,网站的排名就越靠前。但是如果访问并爬取的rss代码过长,速度太慢,也可能造成排名靠后。因此site优化不是一个可控的过程,即使提交的网站连接足够完美,可以将网站快速发布在谷歌商城,也不可能成功地创建site网站。
2)社交网络营销(sns)营销社交网络营销是公认的成功商业运营之一。它可以将人们从搜索引擎引导到社交网络上(比如facebook和twitter)并扩大他们对信息的关注度。这些社交网络包括:twitter,linkedin,facebook和instagram。repo代表了facebook的“follow”功能,会有更多的好友关注它并会根据repo生成一个谷歌搜索页面(对于repo较少的公司或网站来说,这是一个有价值的功能)。
repo同时也能帮助提高用户购买你的产品的倾向。现在很多的社交网络都已经支持该功能。同时在社交网络营销中,常见的手段是创建商业博客或网站。例如ebay营销人员通常建立一个购物网站并把它上传到facebook(即使他们不能使用facebook本身)。虽然发布购物网站可能并不需要seo,但seo人员应该知道企业为什么需要seo。
3)使用搜索引擎营销优化工具现在有些人使用joomla和来支持他们的seo,它们包括linkedin,但是seo仍然可以与更为广泛的搜索引擎营销工具结合起来。例如,如果一个网站上没有linkedin网站, 查看全部
seq搜索引擎优化至少包括那几步?(社交网络营销(sns)优化至少包括那几步?)
seq搜索引擎优化至少包括那几步?seq是一个设计用于搜索引擎排名和关键字优化的http服务器框架,有时候也称soqg,或是seq2g。是alexa网站排名服务,与strwordsmartlists一起被称为搜索引擎优化的第三代框架。服务提供快速索引和转换表,以便用户能够快速灵活地查找他们需要的内容。
搜索引擎优化(seo)的目标是创建提高整个站点知名度和影响力的网站,同时可以保持一个良好的网络收录和排名。seo的主要目标是通过处理关键字来创建描述性和描述性页面,从而成为搜索引擎的良好页面。搜索引擎优化(seo)的第二个目标是支持搜索引擎排名。第三个主要目标是通过外部链接,电子邮件广告和搜索引擎内容来显著提高网站访问者的流量和关注度。
seo是一个系统化的计划,其核心是关键字和内容。该系统通过社交网络的推荐算法、使用页面、标题和tags来连接。接下来我们来介绍三个已知的方法来增加seo,同时可以验证方法的有效性,以及它是否适合于其他搜索引擎。
1)搜索引擎(site)优化它允许用户访问一个排名靠前的网站。例如,如果网站连接的谷歌广告无法收回这一差距,那么用户就不会进入排名第一的网站。根据seo表格中的权重,site中的连接越多,网站的排名就越靠前。但是如果访问并爬取的rss代码过长,速度太慢,也可能造成排名靠后。因此site优化不是一个可控的过程,即使提交的网站连接足够完美,可以将网站快速发布在谷歌商城,也不可能成功地创建site网站。
2)社交网络营销(sns)营销社交网络营销是公认的成功商业运营之一。它可以将人们从搜索引擎引导到社交网络上(比如facebook和twitter)并扩大他们对信息的关注度。这些社交网络包括:twitter,linkedin,facebook和instagram。repo代表了facebook的“follow”功能,会有更多的好友关注它并会根据repo生成一个谷歌搜索页面(对于repo较少的公司或网站来说,这是一个有价值的功能)。
repo同时也能帮助提高用户购买你的产品的倾向。现在很多的社交网络都已经支持该功能。同时在社交网络营销中,常见的手段是创建商业博客或网站。例如ebay营销人员通常建立一个购物网站并把它上传到facebook(即使他们不能使用facebook本身)。虽然发布购物网站可能并不需要seo,但seo人员应该知道企业为什么需要seo。
3)使用搜索引擎营销优化工具现在有些人使用joomla和来支持他们的seo,它们包括linkedin,但是seo仍然可以与更为广泛的搜索引擎营销工具结合起来。例如,如果一个网站上没有linkedin网站,

