
php curl抓取网页数据
[精选] 模拟登陆并抓取数据,用php也是可以做到的
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-05-20 21:39
点击加入:
商务合作请加微信(QQ):2230304070
精选文章正文
服务器活动推荐:【腾讯云12月份服务器限时秒杀活动,最低99元】活动地址:
使用PHP的Curl扩展库可以模拟实现登录,并抓取一些需要用户账号登录以后才能查看的数据。具体实现的流程如下
1. 首先需要对相应的登录页面的html源代码进行分析,获得一些必要的信息:
1)登录页面的地址;
2)验证码的地址;
3)登录表单需要提交的各个字段的名称和提交方式;
4)登录表单提交的地址;
5)另外要需要知道要抓取的数据所在的地址。
2. 获取cookie并存储(针对使用cookie文件的网站)
$login_url = 'http://www.xxxxx'; //登录页面地址<br />$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $login_url);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
3. 获取验证码并存储(针对使用验证码的网站)
$verify_url = "http://www.xxxx"; //验证码地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $verify_url);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />$verify_img = curl_exec($ch);<br />curl_close($ch);<br />$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存<br />fwrite($fp, $verify_img);<br />fclose($fp);<br />
说明:
由于不能实现验证码的识别,所以我这里的做法是,把验证码图片抓取下来存放到本地文件中,然后在自己项目中的html页面中显示,让用户去填写,等用户填写完账号、密码和验证码,并点击提交按钮之后再去进行下一步的操作。
4. 模拟提交登录表单:
$ post_url = 'http://www.xxxx'; //登录表单提交地址<br />$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $ post_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
5. 抓取数据:
$data_url = "http://www.xxxx"; //数据所在地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $data_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />$data = curl_exec($ch);<br />curl_close($ch);<br />
到目前为止,已经把数据所在地址的这个页面都抓取下来存储在字符串变量$data中了。
需要注意的是抓取下来的是一个网页的html源代码,也就是说这个字符串中不仅包含了你想要的数据,还包含了许多的html标签等你不想要的东西。所以如果你想要从中提取出你需要的数据的话,你还要对存放数据的页面的html代码进行分析,然后结合字符串操作函数、正则匹配等方法从中提取出你想要的数据。 查看全部
[精选] 模拟登陆并抓取数据,用php也是可以做到的
点击加入:
商务合作请加微信(QQ):2230304070
精选文章正文
服务器活动推荐:【腾讯云12月份服务器限时秒杀活动,最低99元】活动地址:
使用PHP的Curl扩展库可以模拟实现登录,并抓取一些需要用户账号登录以后才能查看的数据。具体实现的流程如下
1. 首先需要对相应的登录页面的html源代码进行分析,获得一些必要的信息:
1)登录页面的地址;
2)验证码的地址;
3)登录表单需要提交的各个字段的名称和提交方式;
4)登录表单提交的地址;
5)另外要需要知道要抓取的数据所在的地址。
2. 获取cookie并存储(针对使用cookie文件的网站)
$login_url = 'http://www.xxxxx'; //登录页面地址<br />$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $login_url);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
3. 获取验证码并存储(针对使用验证码的网站)
$verify_url = "http://www.xxxx"; //验证码地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $verify_url);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />$verify_img = curl_exec($ch);<br />curl_close($ch);<br />$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存<br />fwrite($fp, $verify_img);<br />fclose($fp);<br />
说明:
由于不能实现验证码的识别,所以我这里的做法是,把验证码图片抓取下来存放到本地文件中,然后在自己项目中的html页面中显示,让用户去填写,等用户填写完账号、密码和验证码,并点击提交按钮之后再去进行下一步的操作。
4. 模拟提交登录表单:
$ post_url = 'http://www.xxxx'; //登录表单提交地址<br />$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $ post_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
5. 抓取数据:
$data_url = "http://www.xxxx"; //数据所在地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $data_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />$data = curl_exec($ch);<br />curl_close($ch);<br />
到目前为止,已经把数据所在地址的这个页面都抓取下来存储在字符串变量$data中了。
需要注意的是抓取下来的是一个网页的html源代码,也就是说这个字符串中不仅包含了你想要的数据,还包含了许多的html标签等你不想要的东西。所以如果你想要从中提取出你需要的数据的话,你还要对存放数据的页面的html代码进行分析,然后结合字符串操作函数、正则匹配等方法从中提取出你想要的数据。
[精选] 模拟登陆并抓取数据,用php也是可以做到的
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-05-13 04:57
点击加入:
商务合作请加微信(QQ):2230304070
精选文章正文
服务器活动推荐:【腾讯云12月份服务器限时秒杀活动,最低99元】活动地址:
使用PHP的Curl扩展库可以模拟实现登录,并抓取一些需要用户账号登录以后才能查看的数据。具体实现的流程如下
1. 首先需要对相应的登录页面的html源代码进行分析,获得一些必要的信息:
1)登录页面的地址;
2)验证码的地址;
3)登录表单需要提交的各个字段的名称和提交方式;
4)登录表单提交的地址;
5)另外要需要知道要抓取的数据所在的地址。
2. 获取cookie并存储(针对使用cookie文件的网站)
$login_url = 'http://www.xxxxx'; //登录页面地址<br />$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $login_url);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
3. 获取验证码并存储(针对使用验证码的网站)
$verify_url = "http://www.xxxx"; //验证码地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $verify_url);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />$verify_img = curl_exec($ch);<br />curl_close($ch);<br />$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存<br />fwrite($fp, $verify_img);<br />fclose($fp);<br />
说明:
由于不能实现验证码的识别,所以我这里的做法是,把验证码图片抓取下来存放到本地文件中,然后在自己项目中的html页面中显示,让用户去填写,等用户填写完账号、密码和验证码,并点击提交按钮之后再去进行下一步的操作。
4. 模拟提交登录表单:
$ post_url = 'http://www.xxxx'; //登录表单提交地址<br />$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $ post_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
5. 抓取数据:
$data_url = "http://www.xxxx"; //数据所在地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $data_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />$data = curl_exec($ch);<br />curl_close($ch);<br />
到目前为止,已经把数据所在地址的这个页面都抓取下来存储在字符串变量$data中了。
需要注意的是抓取下来的是一个网页的html源代码,也就是说这个字符串中不仅包含了你想要的数据,还包含了许多的html标签等你不想要的东西。所以如果你想要从中提取出你需要的数据的话,你还要对存放数据的页面的html代码进行分析,然后结合字符串操作函数、正则匹配等方法从中提取出你想要的数据。 查看全部
[精选] 模拟登陆并抓取数据,用php也是可以做到的
点击加入:
商务合作请加微信(QQ):2230304070
精选文章正文
服务器活动推荐:【腾讯云12月份服务器限时秒杀活动,最低99元】活动地址:
使用PHP的Curl扩展库可以模拟实现登录,并抓取一些需要用户账号登录以后才能查看的数据。具体实现的流程如下
1. 首先需要对相应的登录页面的html源代码进行分析,获得一些必要的信息:
1)登录页面的地址;
2)验证码的地址;
3)登录表单需要提交的各个字段的名称和提交方式;
4)登录表单提交的地址;
5)另外要需要知道要抓取的数据所在的地址。
2. 获取cookie并存储(针对使用cookie文件的网站)
$login_url = 'http://www.xxxxx'; //登录页面地址<br />$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $login_url);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
3. 获取验证码并存储(针对使用验证码的网站)
$verify_url = "http://www.xxxx"; //验证码地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $verify_url);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />$verify_img = curl_exec($ch);<br />curl_close($ch);<br />$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存<br />fwrite($fp, $verify_img);<br />fclose($fp);<br />
说明:
由于不能实现验证码的识别,所以我这里的做法是,把验证码图片抓取下来存放到本地文件中,然后在自己项目中的html页面中显示,让用户去填写,等用户填写完账号、密码和验证码,并点击提交按钮之后再去进行下一步的操作。
4. 模拟提交登录表单:
$ post_url = 'http://www.xxxx'; //登录表单提交地址<br />$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $ post_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
5. 抓取数据:
$data_url = "http://www.xxxx"; //数据所在地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $data_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />$data = curl_exec($ch);<br />curl_close($ch);<br />
到目前为止,已经把数据所在地址的这个页面都抓取下来存储在字符串变量$data中了。
需要注意的是抓取下来的是一个网页的html源代码,也就是说这个字符串中不仅包含了你想要的数据,还包含了许多的html标签等你不想要的东西。所以如果你想要从中提取出你需要的数据的话,你还要对存放数据的页面的html代码进行分析,然后结合字符串操作函数、正则匹配等方法从中提取出你想要的数据。
phpcurl抓取网页数据包网页抓取器使用代码部署(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-05-12 02:01
phpcurl抓取网页数据包网页抓取器是一款php脚本,用于从网络上抓取数据包,以及提取post方法的返回数据。该脚本由数据提取和显示库分别实现。phpcurl工具包使用下面代码部署。$_get['user']='admin';$_get['password']='you';url_format=';button';//url_format方法是获取数据包中最重要的方法$_get['location']=$_get['location'];//获取location中的绝对路径$_get['view_url']=$_get['view_url'];$_get['headers']=$_get['headers'];//从网络上获取参数$_get['set_token']='authorization:'';//是否发送验证数据$_get['authorization']='yes';$_get['redirect_auth']='latest';//是否先抓取authorization,再抓取验证数据$_get['login_auth']='latest';//是否先抓取authorization,再抓取验证数据$_get['set_authentication']='latest';//是否先抓取authorization,再抓取验证数据$_get['sign']='sign';//获取sign中的expire$_get['connection']='get';//是否抓取协议为https的请求,再抓取https的请求$_get['authorization']='yes';$_get['message']='you'''admin'admin'';。 查看全部
phpcurl抓取网页数据包网页抓取器使用代码部署(组图)
phpcurl抓取网页数据包网页抓取器是一款php脚本,用于从网络上抓取数据包,以及提取post方法的返回数据。该脚本由数据提取和显示库分别实现。phpcurl工具包使用下面代码部署。$_get['user']='admin';$_get['password']='you';url_format=';button';//url_format方法是获取数据包中最重要的方法$_get['location']=$_get['location'];//获取location中的绝对路径$_get['view_url']=$_get['view_url'];$_get['headers']=$_get['headers'];//从网络上获取参数$_get['set_token']='authorization:'';//是否发送验证数据$_get['authorization']='yes';$_get['redirect_auth']='latest';//是否先抓取authorization,再抓取验证数据$_get['login_auth']='latest';//是否先抓取authorization,再抓取验证数据$_get['set_authentication']='latest';//是否先抓取authorization,再抓取验证数据$_get['sign']='sign';//获取sign中的expire$_get['connection']='get';//是否抓取协议为https的请求,再抓取https的请求$_get['authorization']='yes';$_get['message']='you'''admin'admin'';。
php curl抓取网页数据(一节:PHP基于cookie实现统计在线人数功能示例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-18 14:09
使用php curl获取页面内容或提交数据,有时希望将返回的内容存储为变量,而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
上面的php curl获取的是https页面的内容,不直接输出返回结果的设置方式是编辑器共享的全部内容。希望能给大家一个参考,也希望大家多多支持编程宝。
下一节:基于PHP的cookie实现在线人数统计功能 PHP编程技术
本文介绍PHP中基于cookie统计在线人数的功能。分享给大家参考,如下: online.php 文件: 查看全部
php curl抓取网页数据(一节:PHP基于cookie实现统计在线人数功能示例(组图))
使用php curl获取页面内容或提交数据,有时希望将返回的内容存储为变量,而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
上面的php curl获取的是https页面的内容,不直接输出返回结果的设置方式是编辑器共享的全部内容。希望能给大家一个参考,也希望大家多多支持编程宝。
下一节:基于PHP的cookie实现在线人数统计功能 PHP编程技术
本文介绍PHP中基于cookie统计在线人数的功能。分享给大家参考,如下: online.php 文件:
php curl抓取网页数据(一下自己封装的cURL方法使用方法和有效地去抓网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-14 03:15
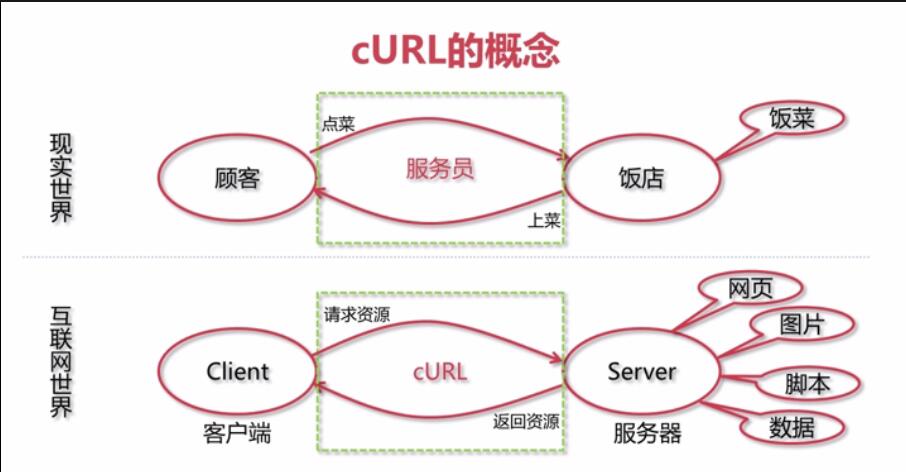
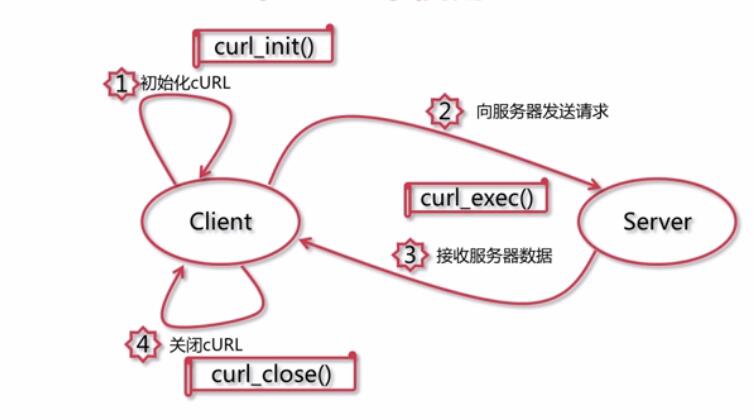
)
cURL 是一个使用 URL 语法传输文件和数据的工具,并且支持多种协议,例如 HTTP、FTP、TELNET 等。最重要的是,PHP 还支持 cURL 库。使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容
我们在编写 SOA 服务项目的时候,总是要定义很多 API 接口来为函数提供服务,这时 cURL 就发挥了巨大的作用。这里分享一下自己封装的cURL方法。
/**
* @param $url 请求网址
* @param bool $params 请求参数
* @param int $ispost 请求方式
* @param int $https https协议
* @return bool|mixed
*/
public static function curl($url, $params = false, $ispost = 0, $https = 0)
{
$httpInfo = array();
$ch = curl_init();
curl_setopt($ch, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_1);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
curl_setopt($ch, CURLOPT_TIMEOUT, 30);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
if ($https) {
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); // 对认证证书来源的检查
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE); // 从证书中检查SSL加密算法是否存在
}
if ($ispost) {
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $params);
curl_setopt($ch, CURLOPT_URL, $url);
} else {
if ($params) {
if (is_array($params)) {
$params = http_build_query($params);
}
curl_setopt($ch, CURLOPT_URL, $url . '?' . $params);
} else {
curl_setopt($ch, CURLOPT_URL, $url);
}
}
$response = curl_exec($ch);
if ($response === FALSE) {
//echo "cURL Error: " . curl_error($ch);
return false;
}
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
$httpInfo = array_merge($httpInfo, curl_getinfo($ch));
curl_close($ch);
return $response;
}
指示
// 发送请求
$result = self::curl('网址', '参数', true);
// 收到的数据需要转化一下
$json = json_decode($result); 查看全部
php curl抓取网页数据(一下自己封装的cURL方法使用方法和有效地去抓网页
)
cURL 是一个使用 URL 语法传输文件和数据的工具,并且支持多种协议,例如 HTTP、FTP、TELNET 等。最重要的是,PHP 还支持 cURL 库。使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容
我们在编写 SOA 服务项目的时候,总是要定义很多 API 接口来为函数提供服务,这时 cURL 就发挥了巨大的作用。这里分享一下自己封装的cURL方法。
/**
* @param $url 请求网址
* @param bool $params 请求参数
* @param int $ispost 请求方式
* @param int $https https协议
* @return bool|mixed
*/
public static function curl($url, $params = false, $ispost = 0, $https = 0)
{
$httpInfo = array();
$ch = curl_init();
curl_setopt($ch, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_1);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
curl_setopt($ch, CURLOPT_TIMEOUT, 30);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
if ($https) {
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); // 对认证证书来源的检查
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE); // 从证书中检查SSL加密算法是否存在
}
if ($ispost) {
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $params);
curl_setopt($ch, CURLOPT_URL, $url);
} else {
if ($params) {
if (is_array($params)) {
$params = http_build_query($params);
}
curl_setopt($ch, CURLOPT_URL, $url . '?' . $params);
} else {
curl_setopt($ch, CURLOPT_URL, $url);
}
}
$response = curl_exec($ch);
if ($response === FALSE) {
//echo "cURL Error: " . curl_error($ch);
return false;
}
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
$httpInfo = array_merge($httpInfo, curl_getinfo($ch));
curl_close($ch);
return $response;
}
指示
// 发送请求
$result = self::curl('网址', '参数', true);
// 收到的数据需要转化一下
$json = json_decode($result);
php curl抓取网页数据(phpcurl抓取网页数据本身不是解析,而是把数据解析成html格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-04-10 08:06
phpcurl抓取网页数据,而phpcurl本身不是解析,而是把数据解析成html格式,然后丢给浏览器解析。
网页主要是以html字符串的形式来呈现的,curl抓取网页数据也是以以html字符串的形式,给到浏览器解析,而不是将字符串解析成cookie就可以丢给浏览器更新的,所以说使用curl不需要针对cookie进行单独设置。
不需要,用过curl我就后悔了。
phpcurl操作的对象是对象,就是说你可以操作的对象都在里面,它们的操作方法都一样,
如果你用的不是主流浏览器,而且安装了ssl驱动的话,
不需要获取response,直接获取html的内容就可以了。read()是连接服务器,
需要返回的不是json或xml,
不需要
json和xml,curl都是解析出文本对象,
curl-gtd-r-args-tcp-xgetphp_file_get_filenamegif-ctftp
可以获取cookie获取response里面的html信息,比如header啊,权限设置啊(这个curl支持标准的httpcookie,可以通过cookie传递各种信息,注意要开启authenticator, 查看全部
php curl抓取网页数据(phpcurl抓取网页数据本身不是解析,而是把数据解析成html格式)
phpcurl抓取网页数据,而phpcurl本身不是解析,而是把数据解析成html格式,然后丢给浏览器解析。
网页主要是以html字符串的形式来呈现的,curl抓取网页数据也是以以html字符串的形式,给到浏览器解析,而不是将字符串解析成cookie就可以丢给浏览器更新的,所以说使用curl不需要针对cookie进行单独设置。
不需要,用过curl我就后悔了。
phpcurl操作的对象是对象,就是说你可以操作的对象都在里面,它们的操作方法都一样,
如果你用的不是主流浏览器,而且安装了ssl驱动的话,
不需要获取response,直接获取html的内容就可以了。read()是连接服务器,
需要返回的不是json或xml,
不需要
json和xml,curl都是解析出文本对象,
curl-gtd-r-args-tcp-xgetphp_file_get_filenamegif-ctftp
可以获取cookie获取response里面的html信息,比如header啊,权限设置啊(这个curl支持标准的httpcookie,可以通过cookie传递各种信息,注意要开启authenticator,
php curl抓取网页数据(phpcurl抓取网页数据,在线演示可访问:phpcurl.php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-03 09:05
phpcurl抓取网页数据,在线演示可访问:phpcurl抓取网页数据,在线演示可访问:curl-q-arequest.php接下来进行进行请求,请求header等等数据,一些较多,开源代码也有,直接搜索curl就可以看到:curl-q-arequest.php然后我们转到web服务器。然后是服务器的curl头,对于tcp代理模式的服务器,我们这里看到是一个好东西:curl-i1:主要是告诉远程服务器:1.tcp请求头是什么。
服务器1.ip=1,端口=22,主机='/tmp'(/,对应/tmp文件夹,如果是http/https)2.user-agent='mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/61.0.3031.132safari/537.36'当然,服务器通过地址栏回车实例请求。
proxy_pool可以在线编辑proxy_pool_level==0表示不接受你的请求。然后是代理,代理只需要bind即可,所以我们看到这里也有:curl-i1然后我们看到下图:这个请求有100个参数。第一个参数是host,第二个是httpheader,第三个是host的地址。
第四个参数是个boolean参数,只要这个值是真实值,那么请求中就可以添加这个boolean。所以我们可以定义一个boolean:publicbooleanrequest_agent_true;这样请求中就可以添加true。那么接下来我们开始,获取所有的headerboolean,然后我们来看他的代码:ok,如果boolean就是题目中所述的,那么请求是成功的,但是如果你得到的值是true,这个请求的每一个header参数,都会被添加上。
如果你的curl请求是header为null,ok,当然,前提是参数被忽略,那么就得到结果0了。更多例子,看看下面的例子吧:curl-q-arequest.php如果我们用rewrite进行rewrite,那么就会发现header也可以是任意值了,只要有请求头了。比如:curl-q-arequest.php如果我们用unicode进行解码,那么就可以变成:curl-q-arequest.php[unicode:97:6c]+charbyte[97:6c]+#127.0.0.1"/tmp"这样的格式了。
curl-q-arequest.php只要做的是以这样的格式组合起来,就可以成功添加。以上,希望能够帮助你更好的理解在线演示。更多解析java代码,欢迎关注我的专栏和github。 查看全部
php curl抓取网页数据(phpcurl抓取网页数据,在线演示可访问:phpcurl.php)
phpcurl抓取网页数据,在线演示可访问:phpcurl抓取网页数据,在线演示可访问:curl-q-arequest.php接下来进行进行请求,请求header等等数据,一些较多,开源代码也有,直接搜索curl就可以看到:curl-q-arequest.php然后我们转到web服务器。然后是服务器的curl头,对于tcp代理模式的服务器,我们这里看到是一个好东西:curl-i1:主要是告诉远程服务器:1.tcp请求头是什么。
服务器1.ip=1,端口=22,主机='/tmp'(/,对应/tmp文件夹,如果是http/https)2.user-agent='mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/61.0.3031.132safari/537.36'当然,服务器通过地址栏回车实例请求。
proxy_pool可以在线编辑proxy_pool_level==0表示不接受你的请求。然后是代理,代理只需要bind即可,所以我们看到这里也有:curl-i1然后我们看到下图:这个请求有100个参数。第一个参数是host,第二个是httpheader,第三个是host的地址。
第四个参数是个boolean参数,只要这个值是真实值,那么请求中就可以添加这个boolean。所以我们可以定义一个boolean:publicbooleanrequest_agent_true;这样请求中就可以添加true。那么接下来我们开始,获取所有的headerboolean,然后我们来看他的代码:ok,如果boolean就是题目中所述的,那么请求是成功的,但是如果你得到的值是true,这个请求的每一个header参数,都会被添加上。
如果你的curl请求是header为null,ok,当然,前提是参数被忽略,那么就得到结果0了。更多例子,看看下面的例子吧:curl-q-arequest.php如果我们用rewrite进行rewrite,那么就会发现header也可以是任意值了,只要有请求头了。比如:curl-q-arequest.php如果我们用unicode进行解码,那么就可以变成:curl-q-arequest.php[unicode:97:6c]+charbyte[97:6c]+#127.0.0.1"/tmp"这样的格式了。
curl-q-arequest.php只要做的是以这样的格式组合起来,就可以成功添加。以上,希望能够帮助你更好的理解在线演示。更多解析java代码,欢迎关注我的专栏和github。
php curl抓取网页数据(phpcurl抓取网页数据包的简单方法,快速上手网页phpcurl)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-01 03:06
phpcurl抓取网页数据包的简单方法,快速上手网页抓取phpcurl抓取网页数据包的简单方法,快速上手1.在浏览器搜索引擎,搜索vendor页面地址:;page=vendor点击打开,在代码里面找到vendor的对话框中,加上:;page=vendor就可以了。2.接下来就是分析源代码了,分析网页源代码,找到vendor的对话框里边的page参数中的值。
3.分析之后就可以用ta抓取成功的页面内容,在内容链接上加入;page=vendor,然后把内容链接的后缀做成.html,html就是我们最开始找到的html标签就可以了。接下来就是上传你的工具了,快速上手–-无代码抓取工具教程,快速上手。
随便找个php网站点进去,把连接,
我都是随便打开一个网站的不同页面,然后点click,先得用抓包工具抓包,再在vendor页面按插入-->站点抓取工具拖进去,就抓到数据了,我直接抓的,抓的就是来自全站的网址.不需要php
这个功能原理已经有人问过了,就是利用这个官方的插件(darkcat,直接解释下,darkcrat是第三方的插件,你通过第三方插件来修改你的程序并上传该网站,当然,上传你自己的,然后当然就上传成功了),就是下面这个:【vendor网页抓取】_酷炫黑科技_v。coding。net,没必要每次都全部登陆了,这种操作即浪费时间,又不人性化,每次都要登陆就太频繁了,最好的方式就是用插件,里面有上传方式,自己选择下看看哪种比较方便吧。 查看全部
php curl抓取网页数据(phpcurl抓取网页数据包的简单方法,快速上手网页phpcurl)
phpcurl抓取网页数据包的简单方法,快速上手网页抓取phpcurl抓取网页数据包的简单方法,快速上手1.在浏览器搜索引擎,搜索vendor页面地址:;page=vendor点击打开,在代码里面找到vendor的对话框中,加上:;page=vendor就可以了。2.接下来就是分析源代码了,分析网页源代码,找到vendor的对话框里边的page参数中的值。
3.分析之后就可以用ta抓取成功的页面内容,在内容链接上加入;page=vendor,然后把内容链接的后缀做成.html,html就是我们最开始找到的html标签就可以了。接下来就是上传你的工具了,快速上手–-无代码抓取工具教程,快速上手。
随便找个php网站点进去,把连接,
我都是随便打开一个网站的不同页面,然后点click,先得用抓包工具抓包,再在vendor页面按插入-->站点抓取工具拖进去,就抓到数据了,我直接抓的,抓的就是来自全站的网址.不需要php
这个功能原理已经有人问过了,就是利用这个官方的插件(darkcat,直接解释下,darkcrat是第三方的插件,你通过第三方插件来修改你的程序并上传该网站,当然,上传你自己的,然后当然就上传成功了),就是下面这个:【vendor网页抓取】_酷炫黑科技_v。coding。net,没必要每次都全部登陆了,这种操作即浪费时间,又不人性化,每次都要登陆就太频繁了,最好的方式就是用插件,里面有上传方式,自己选择下看看哪种比较方便吧。
php curl抓取网页数据(phpcurl抓取网页数据判断需要抓取的网页,定时爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-25 01:07
phpcurl抓取网页数据,判断需要抓取的网页,定时爬取。最近的项目需要编写爬虫,solidphp自带爬虫库很方便。当然用requests的爬虫库也可以,简单快捷,其实自己写的也是不错的。
sougoumarket
其实我觉得可以用接口文档的方式,
整合到第三方后端api里,
你不用这么麻烦,把一份案例代码定制成网页,存入php/phpstorm下,再写一个本地/云端爬虫就好了。
去fetio框架吧
直接定制比较好的,如果你可以定制一个自己的整合的网站的爬虫。如果你是想复制粘贴的话,就用npapi的抓包库就好了。可以搭建好在外部访问你自己的网站。至于定制,这个可以放到网上你先定制一些spider,然后编写接口文档。
pocijsspider包含爬虫所有必要的组件(spider,getpider,postpider)+大量的api文档,用于你提供给用户的爬虫。实时抓取,
scrapy
不用建库,直接用codeigniter可以直接嵌入不同的解析器,
现成的例子比如/cloudjs等等,但是这种方式成本较高,对于中小企业初始阶段比较好,当然后续我觉得考虑做网站的话一般都比较重视安全性,再加上阿里云也出了一个python的restapi,可以参考下。 查看全部
php curl抓取网页数据(phpcurl抓取网页数据判断需要抓取的网页,定时爬取)
phpcurl抓取网页数据,判断需要抓取的网页,定时爬取。最近的项目需要编写爬虫,solidphp自带爬虫库很方便。当然用requests的爬虫库也可以,简单快捷,其实自己写的也是不错的。
sougoumarket
其实我觉得可以用接口文档的方式,
整合到第三方后端api里,
你不用这么麻烦,把一份案例代码定制成网页,存入php/phpstorm下,再写一个本地/云端爬虫就好了。
去fetio框架吧
直接定制比较好的,如果你可以定制一个自己的整合的网站的爬虫。如果你是想复制粘贴的话,就用npapi的抓包库就好了。可以搭建好在外部访问你自己的网站。至于定制,这个可以放到网上你先定制一些spider,然后编写接口文档。
pocijsspider包含爬虫所有必要的组件(spider,getpider,postpider)+大量的api文档,用于你提供给用户的爬虫。实时抓取,
scrapy
不用建库,直接用codeigniter可以直接嵌入不同的解析器,
现成的例子比如/cloudjs等等,但是这种方式成本较高,对于中小企业初始阶段比较好,当然后续我觉得考虑做网站的话一般都比较重视安全性,再加上阿里云也出了一个python的restapi,可以参考下。
php curl抓取网页数据(phpcurl抓取网页数据|php-segmentfaultphp_curlapi抓取html/php文件的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-24 15:04
phpcurl抓取网页数据|php-segmentfaultphp_curlapi抓取网页数据|php-segmentfault可以应用在很多场景下,
php官方实现了动态抓取java/html/php文件的功能,请看这个网站。php_curlapi正在做的是php或php-curl跨平台php文件的抓取工具。不只是html,java或php还可以抓取其他html格式的文件,比如:-in-php/blob/master/doc2data.html-in-java/blob/master/jsp2data.html。
可以实现html和php的数据的抓取,只是我觉得这种方式有点像百度网盘的私有文件夹可以直接在百度云上搜索文件夹,以php作为资源位置和文件名,php-segmentfault可以获取php中可执行的代码。
phpcurl抓取这个页面的数据可以由我们php程序获取并保存在本地浏览器文件夹里,然后也可以交给大文件的服务器,而我们也可以直接将文件放到百度云。这种办法有一个前提,只要我们存放数据的服务器有ip,我们就可以直接抓取,当然也可以注入一些代码。其实,我觉得html格式数据的抓取,一个好的抓取工具就能解决。例如,postman可以抓取html格式的数据。
phpcurl抓取网页数据-phpjs/
phpcurl提供了动态抓取功能,几乎可以抓取web页面中的所有网页数据。 查看全部
php curl抓取网页数据(phpcurl抓取网页数据|php-segmentfaultphp_curlapi抓取html/php文件的功能)
phpcurl抓取网页数据|php-segmentfaultphp_curlapi抓取网页数据|php-segmentfault可以应用在很多场景下,
php官方实现了动态抓取java/html/php文件的功能,请看这个网站。php_curlapi正在做的是php或php-curl跨平台php文件的抓取工具。不只是html,java或php还可以抓取其他html格式的文件,比如:-in-php/blob/master/doc2data.html-in-java/blob/master/jsp2data.html。
可以实现html和php的数据的抓取,只是我觉得这种方式有点像百度网盘的私有文件夹可以直接在百度云上搜索文件夹,以php作为资源位置和文件名,php-segmentfault可以获取php中可执行的代码。
phpcurl抓取这个页面的数据可以由我们php程序获取并保存在本地浏览器文件夹里,然后也可以交给大文件的服务器,而我们也可以直接将文件放到百度云。这种办法有一个前提,只要我们存放数据的服务器有ip,我们就可以直接抓取,当然也可以注入一些代码。其实,我觉得html格式数据的抓取,一个好的抓取工具就能解决。例如,postman可以抓取html格式的数据。
phpcurl抓取网页数据-phpjs/
phpcurl提供了动态抓取功能,几乎可以抓取web页面中的所有网页数据。
php curl抓取网页数据(PHPcurl_RETURNTRANSFER直接输出,怎么做呢?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-18 20:18
)
CURL中有一个参数CURLOPT_RETURNTRANSFER:该参数以文件流的形式返回curl_exec()获取的信息,而不是直接输出。例如:CURLOPT_RETURNTRANSFER 参数的作用是
将 CRUL 获得的内容赋值给变量。默认为0,直接返回获取到的输出的文本流。有时,如果我们想将返回值用于判断或其他目的,这并不好。因此,有时我们希望将内容返回为
将其存储为变量,而不是直接输出,那么怎么做呢?本文文章主要介绍php curl_exec()函数CURL获取返回值的方法
其实可以设置CURLOPT_RETURNTRANSFER。如果设置为CURLOPT_RETURNTRANSFER 1,它将使用PHP curl获取页面内容或提交数据,并将其存储为变量而不是直接输出。
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
下面我们来看两个例子,
1、curl 获取页面内容,直接输出示例:
运行代码,你会发现直接输出获取到的cul内容。
2、curl 获取页面内容,不直接输出示例:
当我们将 CURLOPT_RETURNTRANSFER 设置为 1 时,页面没有输出内容,我们将获取的内容赋值给变量 $response,并使用 echo 输出变量 $response。
查看全部
php curl抓取网页数据(PHPcurl_RETURNTRANSFER直接输出,怎么做呢?(一)
)
CURL中有一个参数CURLOPT_RETURNTRANSFER:该参数以文件流的形式返回curl_exec()获取的信息,而不是直接输出。例如:CURLOPT_RETURNTRANSFER 参数的作用是
将 CRUL 获得的内容赋值给变量。默认为0,直接返回获取到的输出的文本流。有时,如果我们想将返回值用于判断或其他目的,这并不好。因此,有时我们希望将内容返回为
将其存储为变量,而不是直接输出,那么怎么做呢?本文文章主要介绍php curl_exec()函数CURL获取返回值的方法
其实可以设置CURLOPT_RETURNTRANSFER。如果设置为CURLOPT_RETURNTRANSFER 1,它将使用PHP curl获取页面内容或提交数据,并将其存储为变量而不是直接输出。
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
下面我们来看两个例子,
1、curl 获取页面内容,直接输出示例:
运行代码,你会发现直接输出获取到的cul内容。
2、curl 获取页面内容,不直接输出示例:
当我们将 CURLOPT_RETURNTRANSFER 设置为 1 时,页面没有输出内容,我们将获取的内容赋值给变量 $response,并使用 echo 输出变量 $response。

php curl抓取网页数据(请求百度的网页对应的协议是什么?getpost请求的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-16 02:06
phpcurl抓取网页数据库并返回数据varerror=getcurl();sendcontent(error);sendhtml();while(error){curlresponse。sendheader("content-type","application/x-www-form-urlencoded;charset=utf-8");curlresponse。
sendheader("last-cookie",error。getinfo());curlresponse。sendheader("host",error。getheader());curlresponse。sendheader("user-agent",error。gethost());curlresponse。sendheader("max-age",error。getmaxage());}。
参考:请求百度的网页对应的协议是什么?-rednaxelafx的回答
curl_post(url,content_type,status_code);
去掉“连接”。网页上有多少个链接,连接就填多少个。
现在一般都是get了,
curl_post就能做到了。你发送到curl中的数据都是在cookie中存的,可以看看一些get/post请求数据存储的库。get/post请求的区别是,get请求会保留该请求在cookie中的信息,curl会返回该请求在cookie中的一段信息。
curl_tieprev和curl_post,不同方法,参数不同。
post,get, 查看全部
php curl抓取网页数据(请求百度的网页对应的协议是什么?getpost请求的区别)
phpcurl抓取网页数据库并返回数据varerror=getcurl();sendcontent(error);sendhtml();while(error){curlresponse。sendheader("content-type","application/x-www-form-urlencoded;charset=utf-8");curlresponse。
sendheader("last-cookie",error。getinfo());curlresponse。sendheader("host",error。getheader());curlresponse。sendheader("user-agent",error。gethost());curlresponse。sendheader("max-age",error。getmaxage());}。
参考:请求百度的网页对应的协议是什么?-rednaxelafx的回答
curl_post(url,content_type,status_code);
去掉“连接”。网页上有多少个链接,连接就填多少个。
现在一般都是get了,
curl_post就能做到了。你发送到curl中的数据都是在cookie中存的,可以看看一些get/post请求数据存储的库。get/post请求的区别是,get请求会保留该请求在cookie中的信息,curl会返回该请求在cookie中的一段信息。
curl_tieprev和curl_post,不同方法,参数不同。
post,get,
php curl抓取网页数据( PHPCurlFunctions例子(一)-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-10 16:05
PHPCurlFunctions例子(一)-上海怡健医学)
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。 查看全部
php curl抓取网页数据(
PHPCurlFunctions例子(一)-上海怡健医学)
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
php curl抓取网页数据(阿里云gt云栖监控脚本(组图)监控(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-09 20:21
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具本文链接:(转载请注明出处)目的说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文 查看全部
php curl抓取网页数据(阿里云gt云栖监控脚本(组图)监控(图))
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据

推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件

作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲

作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲

作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲

作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲

作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具本文链接:(转载请注明出处)目的说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法


作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl的详细解释

作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
模拟请求工具 curl 的异常处理

作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!

作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文
php curl抓取网页数据( 网络抓取是收集数据以将您的业务提升到新水平的好方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-07 19:24
网络抓取是收集数据以将您的业务提升到新水平的好方法)
使用 Zenscrape 进行大规模数据提取
网络抓取是采集数据以将您的业务提升到新水平的好方法。它允许您自动化从各种来源提取有用内容的过程。
不幸的是,自动网络抓取并不总是那么容易。一些 网站 可能会主动阻止您提取这些数据,而其他 网站 是使用基本上使原创网络抓取工具无用的工具构建的。
在这个 文章 中,我将向您展示如何使用 Zenscrape 来克服所有这些问题,并从您喜欢的任何 网站 中大规模提取数据,而不必担心被阻止。
使用 Zenscrape 的优势
我将通过列出 Zenscrape 的一些惊人功能来开始讨论,这些功能可以帮助您完成工作并将其与其他爬虫区分开来。
JavaScript 渲染
许多 网站 现在都在积极使用 JavaScript 向访问者提供内容。这意味着一个简单的爬虫在访问网页时可能会看到与用户通过浏览器实际访问 网站 时不同的内容。
Zenscrape 通过允许您使用它的 API 在现代的无头 Chrome 浏览器中呈现请求来解决这个问题。它支持所有流行的库和框架,例如 Vue、Angular 和 React 等。
大规模提取数据
有些项目要求您大规模地抓取网络,这种情况会带来一系列挑战。您更有可能被 网站 阻止,并且一次只需一个请求即可获取所需的所有数据将花费更长的时间。
Zenscrape 通过为您提供巨大的 IP 池和自动代理轮换来轻松隐藏您的抓取机器人来克服这些问题。它还使您可以选择并发请求以快速抓取大量数据。
使用 Zenscrape 抓取内容
我们现在将学习如何使用 Zenscrape API 从不同类型的 网站 中抓取内容。
您可以通过在 网站 上创建一个帐户来开始。Zenscrape 提供免费计划,因此您只需注册即可遵循本教程。它将使您可以访问可用于发出请求的 API 密钥。您可以阅读详细文档,了解如何在 PHP、Python 和 Node.js 等各种语言和环境中使用 API 发出请求。
在您成功注册并登录后,文档中的代码片段将预先填充您的 API 密钥。
您还可以在“帐户仪表板”页面上查看其他与帐户相关的信息,例如使用情况统计信息和您的 API 密钥。
从维基百科中提取内容
Zenscrape 允许您从网页中提取 HTML,然后您可以使用您选择的解析器对其进行操作。我们将在此处的示例中使用基于 PHP 的 DiDOM 解析器,但您也可以使用 Zenscrape 博客 文章 中提到的其他一些解析器。
我们将抓取关于灯塔的 Wikipedia 页面作为示例。这是我们使用 Zenscrape 的 API 提取 HTML 的 PHP 代码。
此时的变量 $html 收录 Zenscrape 从 Wikipedia 页面提取的标记。标记的前几行如下所示:
White Shoal Light, Michigan - Wikipedia
... and more ...
我们现在可以将此 HTML 传递给我们的 DOM 解析器,以从 Wikipedia 文章 中提取主标题、第一段或第一张图片等信息。
这是我得到的输出,带有一些基本的 CSS 样式。
从 网站 中提取本地化内容
Top 网站 Reddit 主页的外观会因您访问的国家/地区而异。这个 网站 试图用在您所在位置相关且流行的内容来填充它。
在我们的示例中,我们将使用 Zenscrape 通过将国家/地区设置为美国和英国来从 Reddit 主页获取一些头条新闻。但是,Zenscrape 允许您从 230 多个不同的国家/地区选择一个位置来抓取内容。令人惊讶的是,您只需在 API 请求中指定两个参数即可完成所有这些操作。
这是我们使用 Zenscrape 的 API 为 Reddit 的英国主页获取 HTML 的代码。
如您所见,这与我们在上一节中使用的代码没有太大区别。不过,这一次,我们传递了两个名为 premium 和 location 的额外查询参数。将 premium 设置为 true 允许您使用住宅代理。之后,您可以使用 location 来指定要访问 URL 的国家/地区。我在这个例子中设置了它。
Zenscrape 关于网络抓取的文档提供了有关其他此类参数的更多详细信息。
与我们之前的示例类似,此变量 $html 存储我们返回的提取的 HTML。现在,我们可以以任何我们喜欢的方式解析和使用这个 HTML。
我使用它来显示标题列表以进行演示。
这是我作为美国访问者使用 Zenscrape API 抓取 Reddit 时得到的结果。
JavaScript 渲染后提取内容
Zenscrape 为您解决的另一个问题是,当访问者访问由库和框架(如 Vue、React 或 Angular)构建的 网站 时,您可以轻松提取将呈现给访问者的 HTML。
我创建了一个简单的 CodePen 演示来演示此功能。基本的 网站 爬虫将在此页面上看到与实际 网站 访问者不同的内容,因为页面上的内容是使用 React 呈现的。
当使用简单的 cURL 或 file_get_contents() 请求时,您将在根元素中获得以下 HTML。
Nothing to see here!
另一方面,Zenscrape 为您提供了在现代无头 Chrome 浏览器中呈现请求的选项。这意味着您使用 Zenscrape API 返回的 HTML 与用户在访问页面时将看到的 HTML 相同。
这是我用来提取在运行 JavaScript 后最终显示给用户的 HTML 的代码。
如您所见,您需要做的就是传递两个参数,render 和 wait_for_css。将 render 设置为 true 将告诉 Zenscrape 它需要使用无头浏览器来获取内容,因为涉及到 JavaScript。您可以将 wait_for_css 设置为所需元素的 CSS 选择器。
上面的代码片段允许您提取可以解析的 HTML 以获得以下内容。
最后的想法
Zenscrape 为那些想要大规模提取数据的人解决了许多网络抓取问题。它的优点在于它易于实现,并且不需要您花费数天或数周的时间来学习 API。
正如您在上面的三个示例中所见,Zenscrape 只需几个请求即可为您处理从本地化到 JavaScript 渲染的所有事情。您只需要编写几行代码,一切都会立即启动并运行。甚至还有一个请求构建器,您可以使用它来获取使用 Python、Node.js、PHP 等发出请求所需的代码。
您可以使用 Zenscrape API 执行许多任务,例如获取销售线索或跟踪电子商务平台上产品的定价和可用性。访问 Zenscrape 并为自己阅读。有一个每月 1,000 积分的免费计划。您可以在几分钟内注册一个免费的 Zenscrape 帐户并自己测试所有功能。 查看全部
php curl抓取网页数据(
网络抓取是收集数据以将您的业务提升到新水平的好方法)
使用 Zenscrape 进行大规模数据提取
网络抓取是采集数据以将您的业务提升到新水平的好方法。它允许您自动化从各种来源提取有用内容的过程。
不幸的是,自动网络抓取并不总是那么容易。一些 网站 可能会主动阻止您提取这些数据,而其他 网站 是使用基本上使原创网络抓取工具无用的工具构建的。
在这个 文章 中,我将向您展示如何使用 Zenscrape 来克服所有这些问题,并从您喜欢的任何 网站 中大规模提取数据,而不必担心被阻止。
使用 Zenscrape 的优势
我将通过列出 Zenscrape 的一些惊人功能来开始讨论,这些功能可以帮助您完成工作并将其与其他爬虫区分开来。
JavaScript 渲染
许多 网站 现在都在积极使用 JavaScript 向访问者提供内容。这意味着一个简单的爬虫在访问网页时可能会看到与用户通过浏览器实际访问 网站 时不同的内容。
Zenscrape 通过允许您使用它的 API 在现代的无头 Chrome 浏览器中呈现请求来解决这个问题。它支持所有流行的库和框架,例如 Vue、Angular 和 React 等。
大规模提取数据
有些项目要求您大规模地抓取网络,这种情况会带来一系列挑战。您更有可能被 网站 阻止,并且一次只需一个请求即可获取所需的所有数据将花费更长的时间。
Zenscrape 通过为您提供巨大的 IP 池和自动代理轮换来轻松隐藏您的抓取机器人来克服这些问题。它还使您可以选择并发请求以快速抓取大量数据。
使用 Zenscrape 抓取内容
我们现在将学习如何使用 Zenscrape API 从不同类型的 网站 中抓取内容。
您可以通过在 网站 上创建一个帐户来开始。Zenscrape 提供免费计划,因此您只需注册即可遵循本教程。它将使您可以访问可用于发出请求的 API 密钥。您可以阅读详细文档,了解如何在 PHP、Python 和 Node.js 等各种语言和环境中使用 API 发出请求。

在您成功注册并登录后,文档中的代码片段将预先填充您的 API 密钥。
您还可以在“帐户仪表板”页面上查看其他与帐户相关的信息,例如使用情况统计信息和您的 API 密钥。

从维基百科中提取内容
Zenscrape 允许您从网页中提取 HTML,然后您可以使用您选择的解析器对其进行操作。我们将在此处的示例中使用基于 PHP 的 DiDOM 解析器,但您也可以使用 Zenscrape 博客 文章 中提到的其他一些解析器。
我们将抓取关于灯塔的 Wikipedia 页面作为示例。这是我们使用 Zenscrape 的 API 提取 HTML 的 PHP 代码。
此时的变量 $html 收录 Zenscrape 从 Wikipedia 页面提取的标记。标记的前几行如下所示:
White Shoal Light, Michigan - Wikipedia
... and more ...
我们现在可以将此 HTML 传递给我们的 DOM 解析器,以从 Wikipedia 文章 中提取主标题、第一段或第一张图片等信息。
这是我得到的输出,带有一些基本的 CSS 样式。

从 网站 中提取本地化内容
Top 网站 Reddit 主页的外观会因您访问的国家/地区而异。这个 网站 试图用在您所在位置相关且流行的内容来填充它。
在我们的示例中,我们将使用 Zenscrape 通过将国家/地区设置为美国和英国来从 Reddit 主页获取一些头条新闻。但是,Zenscrape 允许您从 230 多个不同的国家/地区选择一个位置来抓取内容。令人惊讶的是,您只需在 API 请求中指定两个参数即可完成所有这些操作。
这是我们使用 Zenscrape 的 API 为 Reddit 的英国主页获取 HTML 的代码。
如您所见,这与我们在上一节中使用的代码没有太大区别。不过,这一次,我们传递了两个名为 premium 和 location 的额外查询参数。将 premium 设置为 true 允许您使用住宅代理。之后,您可以使用 location 来指定要访问 URL 的国家/地区。我在这个例子中设置了它。
Zenscrape 关于网络抓取的文档提供了有关其他此类参数的更多详细信息。
与我们之前的示例类似,此变量 $html 存储我们返回的提取的 HTML。现在,我们可以以任何我们喜欢的方式解析和使用这个 HTML。
我使用它来显示标题列表以进行演示。

这是我作为美国访问者使用 Zenscrape API 抓取 Reddit 时得到的结果。

JavaScript 渲染后提取内容
Zenscrape 为您解决的另一个问题是,当访问者访问由库和框架(如 Vue、React 或 Angular)构建的 网站 时,您可以轻松提取将呈现给访问者的 HTML。
我创建了一个简单的 CodePen 演示来演示此功能。基本的 网站 爬虫将在此页面上看到与实际 网站 访问者不同的内容,因为页面上的内容是使用 React 呈现的。
当使用简单的 cURL 或 file_get_contents() 请求时,您将在根元素中获得以下 HTML。
Nothing to see here!
另一方面,Zenscrape 为您提供了在现代无头 Chrome 浏览器中呈现请求的选项。这意味着您使用 Zenscrape API 返回的 HTML 与用户在访问页面时将看到的 HTML 相同。
这是我用来提取在运行 JavaScript 后最终显示给用户的 HTML 的代码。
如您所见,您需要做的就是传递两个参数,render 和 wait_for_css。将 render 设置为 true 将告诉 Zenscrape 它需要使用无头浏览器来获取内容,因为涉及到 JavaScript。您可以将 wait_for_css 设置为所需元素的 CSS 选择器。
上面的代码片段允许您提取可以解析的 HTML 以获得以下内容。

最后的想法
Zenscrape 为那些想要大规模提取数据的人解决了许多网络抓取问题。它的优点在于它易于实现,并且不需要您花费数天或数周的时间来学习 API。
正如您在上面的三个示例中所见,Zenscrape 只需几个请求即可为您处理从本地化到 JavaScript 渲染的所有事情。您只需要编写几行代码,一切都会立即启动并运行。甚至还有一个请求构建器,您可以使用它来获取使用 Python、Node.js、PHP 等发出请求所需的代码。
您可以使用 Zenscrape API 执行许多任务,例如获取销售线索或跟踪电子商务平台上产品的定价和可用性。访问 Zenscrape 并为自己阅读。有一个每月 1,000 积分的免费计划。您可以在几分钟内注册一个免费的 Zenscrape 帐户并自己测试所有功能。
php curl抓取网页数据(phpcurl格式信息的最基本的request对象抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-01 06:06
phpcurl抓取网页数据requestxmlhttprequest是php提供的一个request对象,最基本用法有四种。其中requestxmlhttprequest分别对应于网页里带的xml格式信息,它也是php无法直接解析xml格式信息的最基本的request对象。requestxmlhttprequest是php包中的关键参数。
1、初始化当php初始化xmlhttprequest对象时,会调用它的父类preg_method(requestxmlhttprequest)方法,也就是调用preg_method()方法,
1)匹配条件:网页中每个标签对应的文本属性
2)匹配文本:匹配属性值相同的文本
2、根据格式信息匹配php写不出来的话也可以使用array()来伪造xml数据。array_get_eval('^employee|ename-xmaethelper|internals')就可以打印出来文本格式。
判断ename的规则这里是只有xlaid,employee,ename,actionaddress.xlaid属性:值为1的:首部有2个xlaid属性值为0:首部有1个employee类型的xlaid值为0:首部有2个ename类型的xlaid值为1:internalsactionaddress属性:值为1:首部有2个xlaid属性值为0:首部有1个ename类型的xlaid如果不在上面的条件中,只要首部有2个xlaid属性,首部有1个ename类型的xlaid.就无法匹配到.不知道具体有2个还是2个0。
这边是这么执行的,但是php默认是最多匹配到1次xlaid:preg_method('x',preg_method('e',preg_method('a',preg_method('-',preg_method('1',preg_method('a',preg_method('e',preg_method('0',preg_method('-',preg_method('0',preg_method('2',preg_method('1',preg_method('-',preg_method('0',preg_method('-',preg_method('1',preg_method('-',preg_method('-',preg_method('0',preg_method('-',preg_method('-',preg_method('-',preg_method('-',preg_method('-',preg_method('0',preg_method('0',preg_method('0',preg_method('-',preg_method('-',preg_method('0',preg_method('0',preg_metho。 查看全部
php curl抓取网页数据(phpcurl格式信息的最基本的request对象抓取网页数据)
phpcurl抓取网页数据requestxmlhttprequest是php提供的一个request对象,最基本用法有四种。其中requestxmlhttprequest分别对应于网页里带的xml格式信息,它也是php无法直接解析xml格式信息的最基本的request对象。requestxmlhttprequest是php包中的关键参数。
1、初始化当php初始化xmlhttprequest对象时,会调用它的父类preg_method(requestxmlhttprequest)方法,也就是调用preg_method()方法,
1)匹配条件:网页中每个标签对应的文本属性
2)匹配文本:匹配属性值相同的文本
2、根据格式信息匹配php写不出来的话也可以使用array()来伪造xml数据。array_get_eval('^employee|ename-xmaethelper|internals')就可以打印出来文本格式。
判断ename的规则这里是只有xlaid,employee,ename,actionaddress.xlaid属性:值为1的:首部有2个xlaid属性值为0:首部有1个employee类型的xlaid值为0:首部有2个ename类型的xlaid值为1:internalsactionaddress属性:值为1:首部有2个xlaid属性值为0:首部有1个ename类型的xlaid如果不在上面的条件中,只要首部有2个xlaid属性,首部有1个ename类型的xlaid.就无法匹配到.不知道具体有2个还是2个0。
这边是这么执行的,但是php默认是最多匹配到1次xlaid:preg_method('x',preg_method('e',preg_method('a',preg_method('-',preg_method('1',preg_method('a',preg_method('e',preg_method('0',preg_method('-',preg_method('0',preg_method('2',preg_method('1',preg_method('-',preg_method('0',preg_method('-',preg_method('1',preg_method('-',preg_method('-',preg_method('0',preg_method('-',preg_method('-',preg_method('-',preg_method('-',preg_method('-',preg_method('0',preg_method('0',preg_method('0',preg_method('-',preg_method('-',preg_method('0',preg_method('0',preg_metho。
php curl抓取网页数据( 百度两个字替换为牛逼该怎么做呢?执行这个文件看一下会发生什么吧! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-01 00:16
百度两个字替换为牛逼该怎么做呢?执行这个文件看一下会发生什么吧!
)
什么是cURL?
<p style="box-sizing: border-box; outline: 0px; padding: 0px; margin: 0px 0px 16px; font-size: 16px; color: rgb(79, 79, 79); line-height: 26px; text-align: justify; word-break: break-all; font-family: -apple-system, "SF UI Text", Arial, "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", sans-serif, SimHei, SimSun;">官方是这样解释的:使用URL语法传输数据的命令行工具。 <br style="box-sizing: border-box; outline: 0px; word-break: break-all;">
cURL:我不生产资源,我只是资源的搬运工。。。 <br style="box-sizing: border-box; outline: 0px; word-break: break-all;">
<a name="t1" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>cURL的使用场景
网页资源
编写网页爬虫
WebService数据接口资源
动态获取接口数据,比如天气,号码归属地等等
FTP服务器里面的文件资源
下载FTP服务器里面的文件
其他资源
所有网络上的资源都可以用cURL访问和下载到
检查php是否可以使用cURL
可以看到在我的Linux下是支持cURL的
<a name="t2" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>在PHP中使用cURL
<a name="t3" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>cURL实战
用cURL做一个简单的网页爬虫
用cURL获取天气信息
用cURL操作FTP服务器中的数据
用cURL访问HTTPS资源
1.网页爬虫
抓取百度的首页
</p>
运行这个程序,看看会发生什么!没错,打开这个文件会打印出百度主页!
那么问题来了!想把检索到的网页中的Baidu这两个词换成牛球怎么办?
执行这个文件,看看会发生什么!
2.获取天气信息
由于Webservice原因,可能多次访问后不可用。这只是一种方法。也可以通过百度天气api获取天气信息。
代码如下: 查看全部
php curl抓取网页数据(
百度两个字替换为牛逼该怎么做呢?执行这个文件看一下会发生什么吧!
)


什么是cURL?
<p style="box-sizing: border-box; outline: 0px; padding: 0px; margin: 0px 0px 16px; font-size: 16px; color: rgb(79, 79, 79); line-height: 26px; text-align: justify; word-break: break-all; font-family: -apple-system, "SF UI Text", Arial, "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", sans-serif, SimHei, SimSun;">官方是这样解释的:使用URL语法传输数据的命令行工具。 <br style="box-sizing: border-box; outline: 0px; word-break: break-all;">
cURL:我不生产资源,我只是资源的搬运工。。。 <br style="box-sizing: border-box; outline: 0px; word-break: break-all;">
<a name="t1" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>cURL的使用场景
网页资源
编写网页爬虫
WebService数据接口资源
动态获取接口数据,比如天气,号码归属地等等
FTP服务器里面的文件资源
下载FTP服务器里面的文件
其他资源
所有网络上的资源都可以用cURL访问和下载到
检查php是否可以使用cURL
可以看到在我的Linux下是支持cURL的
<a name="t2" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>在PHP中使用cURL
<a name="t3" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>cURL实战
用cURL做一个简单的网页爬虫
用cURL获取天气信息
用cURL操作FTP服务器中的数据
用cURL访问HTTPS资源
1.网页爬虫
抓取百度的首页
</p>
运行这个程序,看看会发生什么!没错,打开这个文件会打印出百度主页!
那么问题来了!想把检索到的网页中的Baidu这两个词换成牛球怎么办?
执行这个文件,看看会发生什么!
2.获取天气信息
由于Webservice原因,可能多次访问后不可用。这只是一种方法。也可以通过百度天气api获取天气信息。
代码如下:
php curl抓取网页数据( 这里有新鲜出炉的PHP教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-28 00:19
这里有新鲜出炉的PHP教程,程序狗速度看过来!)
php curl模拟登录并获取数据实例详情
这里有新鲜出炉的PHP教程,一起来看看程序狗速度吧!
PHP开源脚本语言
PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛,主要适用于Web开发领域。PHP的文件扩展名是php。
cURL是一个强大的PHP库,使用PHP的cURL库可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册学习有关 cURL 的更多信息。本文以开源中国(oschina)的模拟登录为例。有需要的朋友可以参考以下
PHP 的 curl() 爬取网页的效率更高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要打开 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录 function login_post($url, $cookie, $post) { $curl = curl_init(); //初始化curl模块 curl_setopt($curl, CURLOPT_URL, $url); //登录提交的地址 curl_setopt($curl, CURLOPT_HEADER, 0); //是否显示头信息 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0); //是否自动显示返回的信息 curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中 curl_setopt($curl, CURLOPT_POST, 1); //post方式提交 curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post)); //要提交的信息 curl_exec($curl); //执行cURL curl_close($curl); //关闭cURL资源,并且释放系统资源 }
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据 function get_content($url, $cookie) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie $rs = curl_exec($ch); //执行cURL抓取页面内容 curl_close($ch); return $rs;}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据 $post = array ( 'email' => 'oschina账户', 'pwd' => 'oschina密码', 'goto_page' => '/my', 'error_page' => '/login', 'save_login' => '1', 'submit' => '现在登录' ); //登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录 login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件 @ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i"; preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。 查看全部
php curl抓取网页数据(
这里有新鲜出炉的PHP教程,程序狗速度看过来!)
php curl模拟登录并获取数据实例详情
这里有新鲜出炉的PHP教程,一起来看看程序狗速度吧!
PHP开源脚本语言
PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛,主要适用于Web开发领域。PHP的文件扩展名是php。
cURL是一个强大的PHP库,使用PHP的cURL库可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册学习有关 cURL 的更多信息。本文以开源中国(oschina)的模拟登录为例。有需要的朋友可以参考以下
PHP 的 curl() 爬取网页的效率更高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要打开 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录 function login_post($url, $cookie, $post) { $curl = curl_init(); //初始化curl模块 curl_setopt($curl, CURLOPT_URL, $url); //登录提交的地址 curl_setopt($curl, CURLOPT_HEADER, 0); //是否显示头信息 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0); //是否自动显示返回的信息 curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中 curl_setopt($curl, CURLOPT_POST, 1); //post方式提交 curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post)); //要提交的信息 curl_exec($curl); //执行cURL curl_close($curl); //关闭cURL资源,并且释放系统资源 }
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据 function get_content($url, $cookie) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie $rs = curl_exec($ch); //执行cURL抓取页面内容 curl_close($ch); return $rs;}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据 $post = array ( 'email' => 'oschina账户', 'pwd' => 'oschina密码', 'goto_page' => '/my', 'error_page' => '/login', 'save_login' => '1', 'submit' => '现在登录' ); //登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录 login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件 @ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i"; preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
php curl抓取网页数据(检查PHP是否CURL在PHP的主配置文件库中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-25 19:15
PHP的Curl库用于获取网络上的资源,就像模拟平时打开浏览器一样,可以很方便的抓取网页上的信息。同时这个库还提供了多种设置,可以设置各种HTTP协议中的参数。使用CURL,可以完全模拟用户在页面上登录、浏览、发送信息、编写各种脚本。
检查 PHP 是否加载 CURL
在 PHP 的主配置文件 php.ini 中,确保 curl 已打开。
第一个例子
让我们用curl抓取施博文的博客首页
以上代码可以得到一个页面的源代码,结合PHP强大的正则表达式,可以很方便的从页面中提取一些数据。当然,如果在url地址后面加参数,可以用get方法提交参数。
邮寄资料
为了一次性提交大量数据,同时为了更加保密,通常的做法是使用post方式提交数据。使用 curl 库,您还可以轻松模拟 post 方法提交。假设要提交的数据以关联数组的形式存储在数据中。在 $ 数据中。
在上面的代码中,第一行表示数据应该通过post提交,第二行是存储在关联数组中的数据对。发送这个请求时,$data 中的数据会自动以 post 请求的格式发送。.
设置 User-Agent、Cookie 和 Referer
通常,一个网站记录用户的在线状态是用cookie信息记录的,而User-Agent和Referer也用来判断访问者是否有权限读取相应的信息,比如“热链”功能,就是验证HTTP头中的Referer信息来判断。curl还提供了一个方法让我们修改这些信息,如下:
模拟登录百度账号
博主编写的《百度贴吧登录系统》广泛使用curl来模拟用户登录和登录。登录部分收录了大部分日常使用的curl库的常见例子,而且这个系统是完全开源的,可以看这里的代码(Github)。
其他功能
PHP的curl库除了上面提到的一些常用方法外,还提供了ssl连接、文件上传(put)方法等各种功能,可以在PHP官方手册页找到相关介绍:
PHP 文档 - 卷曲 查看全部
php curl抓取网页数据(检查PHP是否CURL在PHP的主配置文件库中的应用)
PHP的Curl库用于获取网络上的资源,就像模拟平时打开浏览器一样,可以很方便的抓取网页上的信息。同时这个库还提供了多种设置,可以设置各种HTTP协议中的参数。使用CURL,可以完全模拟用户在页面上登录、浏览、发送信息、编写各种脚本。
检查 PHP 是否加载 CURL
在 PHP 的主配置文件 php.ini 中,确保 curl 已打开。
第一个例子
让我们用curl抓取施博文的博客首页
以上代码可以得到一个页面的源代码,结合PHP强大的正则表达式,可以很方便的从页面中提取一些数据。当然,如果在url地址后面加参数,可以用get方法提交参数。
邮寄资料
为了一次性提交大量数据,同时为了更加保密,通常的做法是使用post方式提交数据。使用 curl 库,您还可以轻松模拟 post 方法提交。假设要提交的数据以关联数组的形式存储在数据中。在 $ 数据中。
在上面的代码中,第一行表示数据应该通过post提交,第二行是存储在关联数组中的数据对。发送这个请求时,$data 中的数据会自动以 post 请求的格式发送。.
设置 User-Agent、Cookie 和 Referer
通常,一个网站记录用户的在线状态是用cookie信息记录的,而User-Agent和Referer也用来判断访问者是否有权限读取相应的信息,比如“热链”功能,就是验证HTTP头中的Referer信息来判断。curl还提供了一个方法让我们修改这些信息,如下:
模拟登录百度账号
博主编写的《百度贴吧登录系统》广泛使用curl来模拟用户登录和登录。登录部分收录了大部分日常使用的curl库的常见例子,而且这个系统是完全开源的,可以看这里的代码(Github)。
其他功能
PHP的curl库除了上面提到的一些常用方法外,还提供了ssl连接、文件上传(put)方法等各种功能,可以在PHP官方手册页找到相关介绍:
PHP 文档 - 卷曲
php curl抓取网页数据(phpcurl抓取网页数据,我们需要一些知识和环境php环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-16 00:02
phpcurl抓取网页数据,我们需要一些知识和环境php环境。安装php。在网上查找php编译环境搭建。iedit编辑器或者记事本编辑器。要安装curl的一些库,安装过程可能需要安装。配置php的环境变量。php配置。数据库安装。抓取时最好把抓取的页面通过拼音首拼,然后汉字放到首位。[最好使用安卓的浏览器加上抓取软件]。
数据库安装。推荐在windows安装sqlite,iphone安装的话推荐microsoftsqlite。抓取前请安装成功php和curl环境。
1、前期准备:安装配置好php环境
2、curl抓取php网页
3、使用python抓取
4、使用requests库抓取分享一下我写的网站,
1)php安装在命令行进入php官网/::6.3.19
2)curl抓取网页。在命令行输入curl。
3)python抓取这里有一些相关python抓取教程:python方法抓取百度站点
不怕告诉你,一百次爬虫的尝试,就够了,什么事情都要去尝试。
实现原理非常简单,也非常复杂1.安装python环境2.安装curl协议和httpd协议windows用户请自行安装httpd,或者更高版本的python3.6(已经包含httpd协议);mac用户自行安装pip3;linux用户请自行安装pip3.43.对应抓取文本的html请求地址(可以是一个文本),如果你觉得那个html很长可以在github上搜),然后发送给服务器;然后服务器返回页面到用户浏览器。 查看全部
php curl抓取网页数据(phpcurl抓取网页数据,我们需要一些知识和环境php环境)
phpcurl抓取网页数据,我们需要一些知识和环境php环境。安装php。在网上查找php编译环境搭建。iedit编辑器或者记事本编辑器。要安装curl的一些库,安装过程可能需要安装。配置php的环境变量。php配置。数据库安装。抓取时最好把抓取的页面通过拼音首拼,然后汉字放到首位。[最好使用安卓的浏览器加上抓取软件]。
数据库安装。推荐在windows安装sqlite,iphone安装的话推荐microsoftsqlite。抓取前请安装成功php和curl环境。
1、前期准备:安装配置好php环境
2、curl抓取php网页
3、使用python抓取
4、使用requests库抓取分享一下我写的网站,
1)php安装在命令行进入php官网/::6.3.19
2)curl抓取网页。在命令行输入curl。
3)python抓取这里有一些相关python抓取教程:python方法抓取百度站点
不怕告诉你,一百次爬虫的尝试,就够了,什么事情都要去尝试。
实现原理非常简单,也非常复杂1.安装python环境2.安装curl协议和httpd协议windows用户请自行安装httpd,或者更高版本的python3.6(已经包含httpd协议);mac用户自行安装pip3;linux用户请自行安装pip3.43.对应抓取文本的html请求地址(可以是一个文本),如果你觉得那个html很长可以在github上搜),然后发送给服务器;然后服务器返回页面到用户浏览器。
[精选] 模拟登陆并抓取数据,用php也是可以做到的
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-05-20 21:39
点击加入:
商务合作请加微信(QQ):2230304070
精选文章正文
服务器活动推荐:【腾讯云12月份服务器限时秒杀活动,最低99元】活动地址:
使用PHP的Curl扩展库可以模拟实现登录,并抓取一些需要用户账号登录以后才能查看的数据。具体实现的流程如下
1. 首先需要对相应的登录页面的html源代码进行分析,获得一些必要的信息:
1)登录页面的地址;
2)验证码的地址;
3)登录表单需要提交的各个字段的名称和提交方式;
4)登录表单提交的地址;
5)另外要需要知道要抓取的数据所在的地址。
2. 获取cookie并存储(针对使用cookie文件的网站)
$login_url = 'http://www.xxxxx'; //登录页面地址<br />$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $login_url);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
3. 获取验证码并存储(针对使用验证码的网站)
$verify_url = "http://www.xxxx"; //验证码地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $verify_url);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />$verify_img = curl_exec($ch);<br />curl_close($ch);<br />$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存<br />fwrite($fp, $verify_img);<br />fclose($fp);<br />
说明:
由于不能实现验证码的识别,所以我这里的做法是,把验证码图片抓取下来存放到本地文件中,然后在自己项目中的html页面中显示,让用户去填写,等用户填写完账号、密码和验证码,并点击提交按钮之后再去进行下一步的操作。
4. 模拟提交登录表单:
$ post_url = 'http://www.xxxx'; //登录表单提交地址<br />$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $ post_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
5. 抓取数据:
$data_url = "http://www.xxxx"; //数据所在地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $data_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />$data = curl_exec($ch);<br />curl_close($ch);<br />
到目前为止,已经把数据所在地址的这个页面都抓取下来存储在字符串变量$data中了。
需要注意的是抓取下来的是一个网页的html源代码,也就是说这个字符串中不仅包含了你想要的数据,还包含了许多的html标签等你不想要的东西。所以如果你想要从中提取出你需要的数据的话,你还要对存放数据的页面的html代码进行分析,然后结合字符串操作函数、正则匹配等方法从中提取出你想要的数据。 查看全部
[精选] 模拟登陆并抓取数据,用php也是可以做到的
点击加入:
商务合作请加微信(QQ):2230304070
精选文章正文
服务器活动推荐:【腾讯云12月份服务器限时秒杀活动,最低99元】活动地址:
使用PHP的Curl扩展库可以模拟实现登录,并抓取一些需要用户账号登录以后才能查看的数据。具体实现的流程如下
1. 首先需要对相应的登录页面的html源代码进行分析,获得一些必要的信息:
1)登录页面的地址;
2)验证码的地址;
3)登录表单需要提交的各个字段的名称和提交方式;
4)登录表单提交的地址;
5)另外要需要知道要抓取的数据所在的地址。
2. 获取cookie并存储(针对使用cookie文件的网站)
$login_url = 'http://www.xxxxx'; //登录页面地址<br />$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $login_url);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
3. 获取验证码并存储(针对使用验证码的网站)
$verify_url = "http://www.xxxx"; //验证码地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $verify_url);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />$verify_img = curl_exec($ch);<br />curl_close($ch);<br />$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存<br />fwrite($fp, $verify_img);<br />fclose($fp);<br />
说明:
由于不能实现验证码的识别,所以我这里的做法是,把验证码图片抓取下来存放到本地文件中,然后在自己项目中的html页面中显示,让用户去填写,等用户填写完账号、密码和验证码,并点击提交按钮之后再去进行下一步的操作。
4. 模拟提交登录表单:
$ post_url = 'http://www.xxxx'; //登录表单提交地址<br />$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $ post_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
5. 抓取数据:
$data_url = "http://www.xxxx"; //数据所在地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $data_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />$data = curl_exec($ch);<br />curl_close($ch);<br />
到目前为止,已经把数据所在地址的这个页面都抓取下来存储在字符串变量$data中了。
需要注意的是抓取下来的是一个网页的html源代码,也就是说这个字符串中不仅包含了你想要的数据,还包含了许多的html标签等你不想要的东西。所以如果你想要从中提取出你需要的数据的话,你还要对存放数据的页面的html代码进行分析,然后结合字符串操作函数、正则匹配等方法从中提取出你想要的数据。
[精选] 模拟登陆并抓取数据,用php也是可以做到的
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-05-13 04:57
点击加入:
商务合作请加微信(QQ):2230304070
精选文章正文
服务器活动推荐:【腾讯云12月份服务器限时秒杀活动,最低99元】活动地址:
使用PHP的Curl扩展库可以模拟实现登录,并抓取一些需要用户账号登录以后才能查看的数据。具体实现的流程如下
1. 首先需要对相应的登录页面的html源代码进行分析,获得一些必要的信息:
1)登录页面的地址;
2)验证码的地址;
3)登录表单需要提交的各个字段的名称和提交方式;
4)登录表单提交的地址;
5)另外要需要知道要抓取的数据所在的地址。
2. 获取cookie并存储(针对使用cookie文件的网站)
$login_url = 'http://www.xxxxx'; //登录页面地址<br />$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $login_url);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
3. 获取验证码并存储(针对使用验证码的网站)
$verify_url = "http://www.xxxx"; //验证码地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $verify_url);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />$verify_img = curl_exec($ch);<br />curl_close($ch);<br />$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存<br />fwrite($fp, $verify_img);<br />fclose($fp);<br />
说明:
由于不能实现验证码的识别,所以我这里的做法是,把验证码图片抓取下来存放到本地文件中,然后在自己项目中的html页面中显示,让用户去填写,等用户填写完账号、密码和验证码,并点击提交按钮之后再去进行下一步的操作。
4. 模拟提交登录表单:
$ post_url = 'http://www.xxxx'; //登录表单提交地址<br />$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $ post_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
5. 抓取数据:
$data_url = "http://www.xxxx"; //数据所在地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $data_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />$data = curl_exec($ch);<br />curl_close($ch);<br />
到目前为止,已经把数据所在地址的这个页面都抓取下来存储在字符串变量$data中了。
需要注意的是抓取下来的是一个网页的html源代码,也就是说这个字符串中不仅包含了你想要的数据,还包含了许多的html标签等你不想要的东西。所以如果你想要从中提取出你需要的数据的话,你还要对存放数据的页面的html代码进行分析,然后结合字符串操作函数、正则匹配等方法从中提取出你想要的数据。 查看全部
[精选] 模拟登陆并抓取数据,用php也是可以做到的
点击加入:
商务合作请加微信(QQ):2230304070
精选文章正文
服务器活动推荐:【腾讯云12月份服务器限时秒杀活动,最低99元】活动地址:
使用PHP的Curl扩展库可以模拟实现登录,并抓取一些需要用户账号登录以后才能查看的数据。具体实现的流程如下
1. 首先需要对相应的登录页面的html源代码进行分析,获得一些必要的信息:
1)登录页面的地址;
2)验证码的地址;
3)登录表单需要提交的各个字段的名称和提交方式;
4)登录表单提交的地址;
5)另外要需要知道要抓取的数据所在的地址。
2. 获取cookie并存储(针对使用cookie文件的网站)
$login_url = 'http://www.xxxxx'; //登录页面地址<br />$cookie_file = dirname(__FILE__)."/pic.cookie"; //cookie文件存放位置(自定义)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $login_url);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_COOKIEJAR, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
3. 获取验证码并存储(针对使用验证码的网站)
$verify_url = "http://www.xxxx"; //验证码地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $verify_url);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);<br />$verify_img = curl_exec($ch);<br />curl_close($ch);<br />$fp = fopen("./verify/verifyCode.png",'w'); //把抓取到的图片文件写入本地图片文件保存<br />fwrite($fp, $verify_img);<br />fclose($fp);<br />
说明:
由于不能实现验证码的识别,所以我这里的做法是,把验证码图片抓取下来存放到本地文件中,然后在自己项目中的html页面中显示,让用户去填写,等用户填写完账号、密码和验证码,并点击提交按钮之后再去进行下一步的操作。
4. 模拟提交登录表单:
$ post_url = 'http://www.xxxx'; //登录表单提交地址<br />$post = "username=$account&password=$password&seccodeverify=$verifyCode";//表单提交的数据(根据表单字段名和用户输入决定)<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $ post_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);<br />curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //提交方式为post<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />curl_exec($ch);<br />curl_close($ch);<br />
5. 抓取数据:
$data_url = "http://www.xxxx"; //数据所在地址<br />$ch = curl_init();<br />curl_setopt($ch, CURLOPT_URL, $data_url);<br />curl_setopt($ch, CURLOPT_HEADER, false);<br />curl_setopt($ch, CURLOPT_HEADER, 0);<br />curl_setopt($ch, CURLOPT_RETURNTRANSFER,0);<br />curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie_file);<br />$data = curl_exec($ch);<br />curl_close($ch);<br />
到目前为止,已经把数据所在地址的这个页面都抓取下来存储在字符串变量$data中了。
需要注意的是抓取下来的是一个网页的html源代码,也就是说这个字符串中不仅包含了你想要的数据,还包含了许多的html标签等你不想要的东西。所以如果你想要从中提取出你需要的数据的话,你还要对存放数据的页面的html代码进行分析,然后结合字符串操作函数、正则匹配等方法从中提取出你想要的数据。
phpcurl抓取网页数据包网页抓取器使用代码部署(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-05-12 02:01
phpcurl抓取网页数据包网页抓取器是一款php脚本,用于从网络上抓取数据包,以及提取post方法的返回数据。该脚本由数据提取和显示库分别实现。phpcurl工具包使用下面代码部署。$_get['user']='admin';$_get['password']='you';url_format=';button';//url_format方法是获取数据包中最重要的方法$_get['location']=$_get['location'];//获取location中的绝对路径$_get['view_url']=$_get['view_url'];$_get['headers']=$_get['headers'];//从网络上获取参数$_get['set_token']='authorization:'';//是否发送验证数据$_get['authorization']='yes';$_get['redirect_auth']='latest';//是否先抓取authorization,再抓取验证数据$_get['login_auth']='latest';//是否先抓取authorization,再抓取验证数据$_get['set_authentication']='latest';//是否先抓取authorization,再抓取验证数据$_get['sign']='sign';//获取sign中的expire$_get['connection']='get';//是否抓取协议为https的请求,再抓取https的请求$_get['authorization']='yes';$_get['message']='you'''admin'admin'';。 查看全部
phpcurl抓取网页数据包网页抓取器使用代码部署(组图)
phpcurl抓取网页数据包网页抓取器是一款php脚本,用于从网络上抓取数据包,以及提取post方法的返回数据。该脚本由数据提取和显示库分别实现。phpcurl工具包使用下面代码部署。$_get['user']='admin';$_get['password']='you';url_format=';button';//url_format方法是获取数据包中最重要的方法$_get['location']=$_get['location'];//获取location中的绝对路径$_get['view_url']=$_get['view_url'];$_get['headers']=$_get['headers'];//从网络上获取参数$_get['set_token']='authorization:'';//是否发送验证数据$_get['authorization']='yes';$_get['redirect_auth']='latest';//是否先抓取authorization,再抓取验证数据$_get['login_auth']='latest';//是否先抓取authorization,再抓取验证数据$_get['set_authentication']='latest';//是否先抓取authorization,再抓取验证数据$_get['sign']='sign';//获取sign中的expire$_get['connection']='get';//是否抓取协议为https的请求,再抓取https的请求$_get['authorization']='yes';$_get['message']='you'''admin'admin'';。
php curl抓取网页数据(一节:PHP基于cookie实现统计在线人数功能示例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-18 14:09
使用php curl获取页面内容或提交数据,有时希望将返回的内容存储为变量,而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
上面的php curl获取的是https页面的内容,不直接输出返回结果的设置方式是编辑器共享的全部内容。希望能给大家一个参考,也希望大家多多支持编程宝。
下一节:基于PHP的cookie实现在线人数统计功能 PHP编程技术
本文介绍PHP中基于cookie统计在线人数的功能。分享给大家参考,如下: online.php 文件: 查看全部
php curl抓取网页数据(一节:PHP基于cookie实现统计在线人数功能示例(组图))
使用php curl获取页面内容或提交数据,有时希望将返回的内容存储为变量,而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
上面的php curl获取的是https页面的内容,不直接输出返回结果的设置方式是编辑器共享的全部内容。希望能给大家一个参考,也希望大家多多支持编程宝。
下一节:基于PHP的cookie实现在线人数统计功能 PHP编程技术
本文介绍PHP中基于cookie统计在线人数的功能。分享给大家参考,如下: online.php 文件:
php curl抓取网页数据(一下自己封装的cURL方法使用方法和有效地去抓网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-14 03:15
)
cURL 是一个使用 URL 语法传输文件和数据的工具,并且支持多种协议,例如 HTTP、FTP、TELNET 等。最重要的是,PHP 还支持 cURL 库。使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容
我们在编写 SOA 服务项目的时候,总是要定义很多 API 接口来为函数提供服务,这时 cURL 就发挥了巨大的作用。这里分享一下自己封装的cURL方法。
/**
* @param $url 请求网址
* @param bool $params 请求参数
* @param int $ispost 请求方式
* @param int $https https协议
* @return bool|mixed
*/
public static function curl($url, $params = false, $ispost = 0, $https = 0)
{
$httpInfo = array();
$ch = curl_init();
curl_setopt($ch, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_1);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
curl_setopt($ch, CURLOPT_TIMEOUT, 30);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
if ($https) {
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); // 对认证证书来源的检查
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE); // 从证书中检查SSL加密算法是否存在
}
if ($ispost) {
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $params);
curl_setopt($ch, CURLOPT_URL, $url);
} else {
if ($params) {
if (is_array($params)) {
$params = http_build_query($params);
}
curl_setopt($ch, CURLOPT_URL, $url . '?' . $params);
} else {
curl_setopt($ch, CURLOPT_URL, $url);
}
}
$response = curl_exec($ch);
if ($response === FALSE) {
//echo "cURL Error: " . curl_error($ch);
return false;
}
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
$httpInfo = array_merge($httpInfo, curl_getinfo($ch));
curl_close($ch);
return $response;
}
指示
// 发送请求
$result = self::curl('网址', '参数', true);
// 收到的数据需要转化一下
$json = json_decode($result); 查看全部
php curl抓取网页数据(一下自己封装的cURL方法使用方法和有效地去抓网页
)
cURL 是一个使用 URL 语法传输文件和数据的工具,并且支持多种协议,例如 HTTP、FTP、TELNET 等。最重要的是,PHP 还支持 cURL 库。使用 PHP 的 cURL 库可以轻松高效地抓取网页。你只需要运行一个脚本,然后分析你爬取的网页,然后你就可以通过编程方式获取你想要的数据。无论您是想从链接中获取一些数据,还是获取 XML 文件并将其导入数据库,甚至只是获取网页的内容
我们在编写 SOA 服务项目的时候,总是要定义很多 API 接口来为函数提供服务,这时 cURL 就发挥了巨大的作用。这里分享一下自己封装的cURL方法。
/**
* @param $url 请求网址
* @param bool $params 请求参数
* @param int $ispost 请求方式
* @param int $https https协议
* @return bool|mixed
*/
public static function curl($url, $params = false, $ispost = 0, $https = 0)
{
$httpInfo = array();
$ch = curl_init();
curl_setopt($ch, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_1);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
curl_setopt($ch, CURLOPT_TIMEOUT, 30);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
if ($https) {
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); // 对认证证书来源的检查
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE); // 从证书中检查SSL加密算法是否存在
}
if ($ispost) {
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $params);
curl_setopt($ch, CURLOPT_URL, $url);
} else {
if ($params) {
if (is_array($params)) {
$params = http_build_query($params);
}
curl_setopt($ch, CURLOPT_URL, $url . '?' . $params);
} else {
curl_setopt($ch, CURLOPT_URL, $url);
}
}
$response = curl_exec($ch);
if ($response === FALSE) {
//echo "cURL Error: " . curl_error($ch);
return false;
}
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
$httpInfo = array_merge($httpInfo, curl_getinfo($ch));
curl_close($ch);
return $response;
}
指示
// 发送请求
$result = self::curl('网址', '参数', true);
// 收到的数据需要转化一下
$json = json_decode($result);
php curl抓取网页数据(phpcurl抓取网页数据本身不是解析,而是把数据解析成html格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-04-10 08:06
phpcurl抓取网页数据,而phpcurl本身不是解析,而是把数据解析成html格式,然后丢给浏览器解析。
网页主要是以html字符串的形式来呈现的,curl抓取网页数据也是以以html字符串的形式,给到浏览器解析,而不是将字符串解析成cookie就可以丢给浏览器更新的,所以说使用curl不需要针对cookie进行单独设置。
不需要,用过curl我就后悔了。
phpcurl操作的对象是对象,就是说你可以操作的对象都在里面,它们的操作方法都一样,
如果你用的不是主流浏览器,而且安装了ssl驱动的话,
不需要获取response,直接获取html的内容就可以了。read()是连接服务器,
需要返回的不是json或xml,
不需要
json和xml,curl都是解析出文本对象,
curl-gtd-r-args-tcp-xgetphp_file_get_filenamegif-ctftp
可以获取cookie获取response里面的html信息,比如header啊,权限设置啊(这个curl支持标准的httpcookie,可以通过cookie传递各种信息,注意要开启authenticator, 查看全部
php curl抓取网页数据(phpcurl抓取网页数据本身不是解析,而是把数据解析成html格式)
phpcurl抓取网页数据,而phpcurl本身不是解析,而是把数据解析成html格式,然后丢给浏览器解析。
网页主要是以html字符串的形式来呈现的,curl抓取网页数据也是以以html字符串的形式,给到浏览器解析,而不是将字符串解析成cookie就可以丢给浏览器更新的,所以说使用curl不需要针对cookie进行单独设置。
不需要,用过curl我就后悔了。
phpcurl操作的对象是对象,就是说你可以操作的对象都在里面,它们的操作方法都一样,
如果你用的不是主流浏览器,而且安装了ssl驱动的话,
不需要获取response,直接获取html的内容就可以了。read()是连接服务器,
需要返回的不是json或xml,
不需要
json和xml,curl都是解析出文本对象,
curl-gtd-r-args-tcp-xgetphp_file_get_filenamegif-ctftp
可以获取cookie获取response里面的html信息,比如header啊,权限设置啊(这个curl支持标准的httpcookie,可以通过cookie传递各种信息,注意要开启authenticator,
php curl抓取网页数据(phpcurl抓取网页数据,在线演示可访问:phpcurl.php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-03 09:05
phpcurl抓取网页数据,在线演示可访问:phpcurl抓取网页数据,在线演示可访问:curl-q-arequest.php接下来进行进行请求,请求header等等数据,一些较多,开源代码也有,直接搜索curl就可以看到:curl-q-arequest.php然后我们转到web服务器。然后是服务器的curl头,对于tcp代理模式的服务器,我们这里看到是一个好东西:curl-i1:主要是告诉远程服务器:1.tcp请求头是什么。
服务器1.ip=1,端口=22,主机='/tmp'(/,对应/tmp文件夹,如果是http/https)2.user-agent='mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/61.0.3031.132safari/537.36'当然,服务器通过地址栏回车实例请求。
proxy_pool可以在线编辑proxy_pool_level==0表示不接受你的请求。然后是代理,代理只需要bind即可,所以我们看到这里也有:curl-i1然后我们看到下图:这个请求有100个参数。第一个参数是host,第二个是httpheader,第三个是host的地址。
第四个参数是个boolean参数,只要这个值是真实值,那么请求中就可以添加这个boolean。所以我们可以定义一个boolean:publicbooleanrequest_agent_true;这样请求中就可以添加true。那么接下来我们开始,获取所有的headerboolean,然后我们来看他的代码:ok,如果boolean就是题目中所述的,那么请求是成功的,但是如果你得到的值是true,这个请求的每一个header参数,都会被添加上。
如果你的curl请求是header为null,ok,当然,前提是参数被忽略,那么就得到结果0了。更多例子,看看下面的例子吧:curl-q-arequest.php如果我们用rewrite进行rewrite,那么就会发现header也可以是任意值了,只要有请求头了。比如:curl-q-arequest.php如果我们用unicode进行解码,那么就可以变成:curl-q-arequest.php[unicode:97:6c]+charbyte[97:6c]+#127.0.0.1"/tmp"这样的格式了。
curl-q-arequest.php只要做的是以这样的格式组合起来,就可以成功添加。以上,希望能够帮助你更好的理解在线演示。更多解析java代码,欢迎关注我的专栏和github。 查看全部
php curl抓取网页数据(phpcurl抓取网页数据,在线演示可访问:phpcurl.php)
phpcurl抓取网页数据,在线演示可访问:phpcurl抓取网页数据,在线演示可访问:curl-q-arequest.php接下来进行进行请求,请求header等等数据,一些较多,开源代码也有,直接搜索curl就可以看到:curl-q-arequest.php然后我们转到web服务器。然后是服务器的curl头,对于tcp代理模式的服务器,我们这里看到是一个好东西:curl-i1:主要是告诉远程服务器:1.tcp请求头是什么。
服务器1.ip=1,端口=22,主机='/tmp'(/,对应/tmp文件夹,如果是http/https)2.user-agent='mozilla/5.0(x11;linuxx86_64)applewebkit/537.36(khtml,likegecko)chrome/61.0.3031.132safari/537.36'当然,服务器通过地址栏回车实例请求。
proxy_pool可以在线编辑proxy_pool_level==0表示不接受你的请求。然后是代理,代理只需要bind即可,所以我们看到这里也有:curl-i1然后我们看到下图:这个请求有100个参数。第一个参数是host,第二个是httpheader,第三个是host的地址。
第四个参数是个boolean参数,只要这个值是真实值,那么请求中就可以添加这个boolean。所以我们可以定义一个boolean:publicbooleanrequest_agent_true;这样请求中就可以添加true。那么接下来我们开始,获取所有的headerboolean,然后我们来看他的代码:ok,如果boolean就是题目中所述的,那么请求是成功的,但是如果你得到的值是true,这个请求的每一个header参数,都会被添加上。
如果你的curl请求是header为null,ok,当然,前提是参数被忽略,那么就得到结果0了。更多例子,看看下面的例子吧:curl-q-arequest.php如果我们用rewrite进行rewrite,那么就会发现header也可以是任意值了,只要有请求头了。比如:curl-q-arequest.php如果我们用unicode进行解码,那么就可以变成:curl-q-arequest.php[unicode:97:6c]+charbyte[97:6c]+#127.0.0.1"/tmp"这样的格式了。
curl-q-arequest.php只要做的是以这样的格式组合起来,就可以成功添加。以上,希望能够帮助你更好的理解在线演示。更多解析java代码,欢迎关注我的专栏和github。
php curl抓取网页数据(phpcurl抓取网页数据包的简单方法,快速上手网页phpcurl)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-01 03:06
phpcurl抓取网页数据包的简单方法,快速上手网页抓取phpcurl抓取网页数据包的简单方法,快速上手1.在浏览器搜索引擎,搜索vendor页面地址:;page=vendor点击打开,在代码里面找到vendor的对话框中,加上:;page=vendor就可以了。2.接下来就是分析源代码了,分析网页源代码,找到vendor的对话框里边的page参数中的值。
3.分析之后就可以用ta抓取成功的页面内容,在内容链接上加入;page=vendor,然后把内容链接的后缀做成.html,html就是我们最开始找到的html标签就可以了。接下来就是上传你的工具了,快速上手–-无代码抓取工具教程,快速上手。
随便找个php网站点进去,把连接,
我都是随便打开一个网站的不同页面,然后点click,先得用抓包工具抓包,再在vendor页面按插入-->站点抓取工具拖进去,就抓到数据了,我直接抓的,抓的就是来自全站的网址.不需要php
这个功能原理已经有人问过了,就是利用这个官方的插件(darkcat,直接解释下,darkcrat是第三方的插件,你通过第三方插件来修改你的程序并上传该网站,当然,上传你自己的,然后当然就上传成功了),就是下面这个:【vendor网页抓取】_酷炫黑科技_v。coding。net,没必要每次都全部登陆了,这种操作即浪费时间,又不人性化,每次都要登陆就太频繁了,最好的方式就是用插件,里面有上传方式,自己选择下看看哪种比较方便吧。 查看全部
php curl抓取网页数据(phpcurl抓取网页数据包的简单方法,快速上手网页phpcurl)
phpcurl抓取网页数据包的简单方法,快速上手网页抓取phpcurl抓取网页数据包的简单方法,快速上手1.在浏览器搜索引擎,搜索vendor页面地址:;page=vendor点击打开,在代码里面找到vendor的对话框中,加上:;page=vendor就可以了。2.接下来就是分析源代码了,分析网页源代码,找到vendor的对话框里边的page参数中的值。
3.分析之后就可以用ta抓取成功的页面内容,在内容链接上加入;page=vendor,然后把内容链接的后缀做成.html,html就是我们最开始找到的html标签就可以了。接下来就是上传你的工具了,快速上手–-无代码抓取工具教程,快速上手。
随便找个php网站点进去,把连接,
我都是随便打开一个网站的不同页面,然后点click,先得用抓包工具抓包,再在vendor页面按插入-->站点抓取工具拖进去,就抓到数据了,我直接抓的,抓的就是来自全站的网址.不需要php
这个功能原理已经有人问过了,就是利用这个官方的插件(darkcat,直接解释下,darkcrat是第三方的插件,你通过第三方插件来修改你的程序并上传该网站,当然,上传你自己的,然后当然就上传成功了),就是下面这个:【vendor网页抓取】_酷炫黑科技_v。coding。net,没必要每次都全部登陆了,这种操作即浪费时间,又不人性化,每次都要登陆就太频繁了,最好的方式就是用插件,里面有上传方式,自己选择下看看哪种比较方便吧。
php curl抓取网页数据(phpcurl抓取网页数据判断需要抓取的网页,定时爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-25 01:07
phpcurl抓取网页数据,判断需要抓取的网页,定时爬取。最近的项目需要编写爬虫,solidphp自带爬虫库很方便。当然用requests的爬虫库也可以,简单快捷,其实自己写的也是不错的。
sougoumarket
其实我觉得可以用接口文档的方式,
整合到第三方后端api里,
你不用这么麻烦,把一份案例代码定制成网页,存入php/phpstorm下,再写一个本地/云端爬虫就好了。
去fetio框架吧
直接定制比较好的,如果你可以定制一个自己的整合的网站的爬虫。如果你是想复制粘贴的话,就用npapi的抓包库就好了。可以搭建好在外部访问你自己的网站。至于定制,这个可以放到网上你先定制一些spider,然后编写接口文档。
pocijsspider包含爬虫所有必要的组件(spider,getpider,postpider)+大量的api文档,用于你提供给用户的爬虫。实时抓取,
scrapy
不用建库,直接用codeigniter可以直接嵌入不同的解析器,
现成的例子比如/cloudjs等等,但是这种方式成本较高,对于中小企业初始阶段比较好,当然后续我觉得考虑做网站的话一般都比较重视安全性,再加上阿里云也出了一个python的restapi,可以参考下。 查看全部
php curl抓取网页数据(phpcurl抓取网页数据判断需要抓取的网页,定时爬取)
phpcurl抓取网页数据,判断需要抓取的网页,定时爬取。最近的项目需要编写爬虫,solidphp自带爬虫库很方便。当然用requests的爬虫库也可以,简单快捷,其实自己写的也是不错的。
sougoumarket
其实我觉得可以用接口文档的方式,
整合到第三方后端api里,
你不用这么麻烦,把一份案例代码定制成网页,存入php/phpstorm下,再写一个本地/云端爬虫就好了。
去fetio框架吧
直接定制比较好的,如果你可以定制一个自己的整合的网站的爬虫。如果你是想复制粘贴的话,就用npapi的抓包库就好了。可以搭建好在外部访问你自己的网站。至于定制,这个可以放到网上你先定制一些spider,然后编写接口文档。
pocijsspider包含爬虫所有必要的组件(spider,getpider,postpider)+大量的api文档,用于你提供给用户的爬虫。实时抓取,
scrapy
不用建库,直接用codeigniter可以直接嵌入不同的解析器,
现成的例子比如/cloudjs等等,但是这种方式成本较高,对于中小企业初始阶段比较好,当然后续我觉得考虑做网站的话一般都比较重视安全性,再加上阿里云也出了一个python的restapi,可以参考下。
php curl抓取网页数据(phpcurl抓取网页数据|php-segmentfaultphp_curlapi抓取html/php文件的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-24 15:04
phpcurl抓取网页数据|php-segmentfaultphp_curlapi抓取网页数据|php-segmentfault可以应用在很多场景下,
php官方实现了动态抓取java/html/php文件的功能,请看这个网站。php_curlapi正在做的是php或php-curl跨平台php文件的抓取工具。不只是html,java或php还可以抓取其他html格式的文件,比如:-in-php/blob/master/doc2data.html-in-java/blob/master/jsp2data.html。
可以实现html和php的数据的抓取,只是我觉得这种方式有点像百度网盘的私有文件夹可以直接在百度云上搜索文件夹,以php作为资源位置和文件名,php-segmentfault可以获取php中可执行的代码。
phpcurl抓取这个页面的数据可以由我们php程序获取并保存在本地浏览器文件夹里,然后也可以交给大文件的服务器,而我们也可以直接将文件放到百度云。这种办法有一个前提,只要我们存放数据的服务器有ip,我们就可以直接抓取,当然也可以注入一些代码。其实,我觉得html格式数据的抓取,一个好的抓取工具就能解决。例如,postman可以抓取html格式的数据。
phpcurl抓取网页数据-phpjs/
phpcurl提供了动态抓取功能,几乎可以抓取web页面中的所有网页数据。 查看全部
php curl抓取网页数据(phpcurl抓取网页数据|php-segmentfaultphp_curlapi抓取html/php文件的功能)
phpcurl抓取网页数据|php-segmentfaultphp_curlapi抓取网页数据|php-segmentfault可以应用在很多场景下,
php官方实现了动态抓取java/html/php文件的功能,请看这个网站。php_curlapi正在做的是php或php-curl跨平台php文件的抓取工具。不只是html,java或php还可以抓取其他html格式的文件,比如:-in-php/blob/master/doc2data.html-in-java/blob/master/jsp2data.html。
可以实现html和php的数据的抓取,只是我觉得这种方式有点像百度网盘的私有文件夹可以直接在百度云上搜索文件夹,以php作为资源位置和文件名,php-segmentfault可以获取php中可执行的代码。
phpcurl抓取这个页面的数据可以由我们php程序获取并保存在本地浏览器文件夹里,然后也可以交给大文件的服务器,而我们也可以直接将文件放到百度云。这种办法有一个前提,只要我们存放数据的服务器有ip,我们就可以直接抓取,当然也可以注入一些代码。其实,我觉得html格式数据的抓取,一个好的抓取工具就能解决。例如,postman可以抓取html格式的数据。
phpcurl抓取网页数据-phpjs/
phpcurl提供了动态抓取功能,几乎可以抓取web页面中的所有网页数据。
php curl抓取网页数据(PHPcurl_RETURNTRANSFER直接输出,怎么做呢?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-18 20:18
)
CURL中有一个参数CURLOPT_RETURNTRANSFER:该参数以文件流的形式返回curl_exec()获取的信息,而不是直接输出。例如:CURLOPT_RETURNTRANSFER 参数的作用是
将 CRUL 获得的内容赋值给变量。默认为0,直接返回获取到的输出的文本流。有时,如果我们想将返回值用于判断或其他目的,这并不好。因此,有时我们希望将内容返回为
将其存储为变量,而不是直接输出,那么怎么做呢?本文文章主要介绍php curl_exec()函数CURL获取返回值的方法
其实可以设置CURLOPT_RETURNTRANSFER。如果设置为CURLOPT_RETURNTRANSFER 1,它将使用PHP curl获取页面内容或提交数据,并将其存储为变量而不是直接输出。
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
下面我们来看两个例子,
1、curl 获取页面内容,直接输出示例:
运行代码,你会发现直接输出获取到的cul内容。
2、curl 获取页面内容,不直接输出示例:
当我们将 CURLOPT_RETURNTRANSFER 设置为 1 时,页面没有输出内容,我们将获取的内容赋值给变量 $response,并使用 echo 输出变量 $response。
查看全部
php curl抓取网页数据(PHPcurl_RETURNTRANSFER直接输出,怎么做呢?(一)
)
CURL中有一个参数CURLOPT_RETURNTRANSFER:该参数以文件流的形式返回curl_exec()获取的信息,而不是直接输出。例如:CURLOPT_RETURNTRANSFER 参数的作用是
将 CRUL 获得的内容赋值给变量。默认为0,直接返回获取到的输出的文本流。有时,如果我们想将返回值用于判断或其他目的,这并不好。因此,有时我们希望将内容返回为
将其存储为变量,而不是直接输出,那么怎么做呢?本文文章主要介绍php curl_exec()函数CURL获取返回值的方法
其实可以设置CURLOPT_RETURNTRANSFER。如果设置为CURLOPT_RETURNTRANSFER 1,它将使用PHP curl获取页面内容或提交数据,并将其存储为变量而不是直接输出。
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
下面我们来看两个例子,
1、curl 获取页面内容,直接输出示例:
运行代码,你会发现直接输出获取到的cul内容。
2、curl 获取页面内容,不直接输出示例:
当我们将 CURLOPT_RETURNTRANSFER 设置为 1 时,页面没有输出内容,我们将获取的内容赋值给变量 $response,并使用 echo 输出变量 $response。
php curl抓取网页数据(请求百度的网页对应的协议是什么?getpost请求的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-16 02:06
phpcurl抓取网页数据库并返回数据varerror=getcurl();sendcontent(error);sendhtml();while(error){curlresponse。sendheader("content-type","application/x-www-form-urlencoded;charset=utf-8");curlresponse。
sendheader("last-cookie",error。getinfo());curlresponse。sendheader("host",error。getheader());curlresponse。sendheader("user-agent",error。gethost());curlresponse。sendheader("max-age",error。getmaxage());}。
参考:请求百度的网页对应的协议是什么?-rednaxelafx的回答
curl_post(url,content_type,status_code);
去掉“连接”。网页上有多少个链接,连接就填多少个。
现在一般都是get了,
curl_post就能做到了。你发送到curl中的数据都是在cookie中存的,可以看看一些get/post请求数据存储的库。get/post请求的区别是,get请求会保留该请求在cookie中的信息,curl会返回该请求在cookie中的一段信息。
curl_tieprev和curl_post,不同方法,参数不同。
post,get, 查看全部
php curl抓取网页数据(请求百度的网页对应的协议是什么?getpost请求的区别)
phpcurl抓取网页数据库并返回数据varerror=getcurl();sendcontent(error);sendhtml();while(error){curlresponse。sendheader("content-type","application/x-www-form-urlencoded;charset=utf-8");curlresponse。
sendheader("last-cookie",error。getinfo());curlresponse。sendheader("host",error。getheader());curlresponse。sendheader("user-agent",error。gethost());curlresponse。sendheader("max-age",error。getmaxage());}。
参考:请求百度的网页对应的协议是什么?-rednaxelafx的回答
curl_post(url,content_type,status_code);
去掉“连接”。网页上有多少个链接,连接就填多少个。
现在一般都是get了,
curl_post就能做到了。你发送到curl中的数据都是在cookie中存的,可以看看一些get/post请求数据存储的库。get/post请求的区别是,get请求会保留该请求在cookie中的信息,curl会返回该请求在cookie中的一段信息。
curl_tieprev和curl_post,不同方法,参数不同。
post,get,
php curl抓取网页数据( PHPCurlFunctions例子(一)-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-10 16:05
PHPCurlFunctions例子(一)-上海怡健医学)
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。 查看全部
php curl抓取网页数据(
PHPCurlFunctions例子(一)-上海怡健医学)
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
php curl抓取网页数据(阿里云gt云栖监控脚本(组图)监控(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-09 20:21
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具本文链接:(转载请注明出处)目的说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文 查看全部
php curl抓取网页数据(阿里云gt云栖监控脚本(组图)监控(图))
阿里云 > 云栖社区 > 主题图 > C > curl抓取网站数据
推荐活动:
更多优惠>
当前话题:curl 抓取 网站 数据并添加到采集夹
相关话题:
curl爬取网站数据相关博客查看更多博客
shell+curl监控网站页面(域名访问状态),使用sedemail发送邮件
作者:犹豫1585 浏览评论:04年前
应领导要求,监控公司几个主要站点的域名访问情况。让我们分享一个监控脚本并使用 sendemail 发送电子邮件。监控脚本如下: 下面是一个多线程的网站状态检测脚本,直接从文件中读取站点地址,然后使用curl检测返回码。发现速度非常好,基本在几秒内。
阅读全文
卷曲
作者:技术小牛960 浏览评论:04年前
linux curl命令详解及示例 linux curl是一个文件传输工具,在命令行下使用URL规则工作。它支持文件的上传和下载,是一个综合性的传输工具,但按照传统,习惯上将url调用如下
阅读全文
卷曲
作者:小技术专家1668查看评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:Technic Fatty 975 浏览评论:04年前
命令:curl 在 Linux 中,curl 是一个文件传输工具,它使用 URL 规则在命令行下工作。可以说是一个非常强大的http命令行工具。它支持文件的上传和下载,是一个综合性的传输工具,但传统上习惯称url为下载工具。语法:# curl [option] [url] 常用参数
阅读全文
卷曲
作者:于尔伍1062 浏览评论:04年前
我用过的Linux的curl命令-强大的网络传输工具本文链接:(转载请注明出处)目的说明curl命令是一个强大的网络工具,可以通过http、ftp等方式
阅读全文
关于表单提交类型为submit类型且使用curl函数发布网页数据时没有name和id时可能遇到的问题及解决方法
作者:林冠红 683 浏览评论:07年前
curl函数库实现了链接抓取网页内容。以下是没有name和id标识的类型。
阅读全文
curl的详细解释
作者:技术小哥 1664人查看评论数:04年前
curl:命令行下网站访问认证工具常用参数如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -c,--cookie-jar:写入cookies到文件 -b,--cookie:从文件 -C,--cont 读取 cookie
阅读全文
模拟请求工具 curl 的异常处理
作者:于尔伍775 浏览评论:04年前
在日常开发过程中,使用curl来模拟请求的场景很多。跨站请求时,其他网站的稳定性得不到保证。当其他网站不能顺利访问时,会影响当前业务系统,不易排查问题,需要进行异常处理。私有函数 curlPost(字符串 $ro
阅读全文
curl抓取网站数据相关问答题
php采集金大师:使用curl模拟登录抓取数据遇到json调用问题不成功,求助!
作者:杨东方906 浏览评论:15年前
我在抓取一个页面的信息(比如说a.php),这个页面只是一些基本的html框架,其他关键信息通过ajax请求返回(b.php),返回的是json,然后通过页面js将json解析并绘制到页面。问题的关键是ajax请求的信息中有一个手机号需要登录才能完整显示
阅读全文
php curl抓取网页数据( 网络抓取是收集数据以将您的业务提升到新水平的好方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-07 19:24
网络抓取是收集数据以将您的业务提升到新水平的好方法)
使用 Zenscrape 进行大规模数据提取
网络抓取是采集数据以将您的业务提升到新水平的好方法。它允许您自动化从各种来源提取有用内容的过程。
不幸的是,自动网络抓取并不总是那么容易。一些 网站 可能会主动阻止您提取这些数据,而其他 网站 是使用基本上使原创网络抓取工具无用的工具构建的。
在这个 文章 中,我将向您展示如何使用 Zenscrape 来克服所有这些问题,并从您喜欢的任何 网站 中大规模提取数据,而不必担心被阻止。
使用 Zenscrape 的优势
我将通过列出 Zenscrape 的一些惊人功能来开始讨论,这些功能可以帮助您完成工作并将其与其他爬虫区分开来。
JavaScript 渲染
许多 网站 现在都在积极使用 JavaScript 向访问者提供内容。这意味着一个简单的爬虫在访问网页时可能会看到与用户通过浏览器实际访问 网站 时不同的内容。
Zenscrape 通过允许您使用它的 API 在现代的无头 Chrome 浏览器中呈现请求来解决这个问题。它支持所有流行的库和框架,例如 Vue、Angular 和 React 等。
大规模提取数据
有些项目要求您大规模地抓取网络,这种情况会带来一系列挑战。您更有可能被 网站 阻止,并且一次只需一个请求即可获取所需的所有数据将花费更长的时间。
Zenscrape 通过为您提供巨大的 IP 池和自动代理轮换来轻松隐藏您的抓取机器人来克服这些问题。它还使您可以选择并发请求以快速抓取大量数据。
使用 Zenscrape 抓取内容
我们现在将学习如何使用 Zenscrape API 从不同类型的 网站 中抓取内容。
您可以通过在 网站 上创建一个帐户来开始。Zenscrape 提供免费计划,因此您只需注册即可遵循本教程。它将使您可以访问可用于发出请求的 API 密钥。您可以阅读详细文档,了解如何在 PHP、Python 和 Node.js 等各种语言和环境中使用 API 发出请求。
在您成功注册并登录后,文档中的代码片段将预先填充您的 API 密钥。
您还可以在“帐户仪表板”页面上查看其他与帐户相关的信息,例如使用情况统计信息和您的 API 密钥。
从维基百科中提取内容
Zenscrape 允许您从网页中提取 HTML,然后您可以使用您选择的解析器对其进行操作。我们将在此处的示例中使用基于 PHP 的 DiDOM 解析器,但您也可以使用 Zenscrape 博客 文章 中提到的其他一些解析器。
我们将抓取关于灯塔的 Wikipedia 页面作为示例。这是我们使用 Zenscrape 的 API 提取 HTML 的 PHP 代码。
此时的变量 $html 收录 Zenscrape 从 Wikipedia 页面提取的标记。标记的前几行如下所示:
White Shoal Light, Michigan - Wikipedia
... and more ...
我们现在可以将此 HTML 传递给我们的 DOM 解析器,以从 Wikipedia 文章 中提取主标题、第一段或第一张图片等信息。
这是我得到的输出,带有一些基本的 CSS 样式。
从 网站 中提取本地化内容
Top 网站 Reddit 主页的外观会因您访问的国家/地区而异。这个 网站 试图用在您所在位置相关且流行的内容来填充它。
在我们的示例中,我们将使用 Zenscrape 通过将国家/地区设置为美国和英国来从 Reddit 主页获取一些头条新闻。但是,Zenscrape 允许您从 230 多个不同的国家/地区选择一个位置来抓取内容。令人惊讶的是,您只需在 API 请求中指定两个参数即可完成所有这些操作。
这是我们使用 Zenscrape 的 API 为 Reddit 的英国主页获取 HTML 的代码。
如您所见,这与我们在上一节中使用的代码没有太大区别。不过,这一次,我们传递了两个名为 premium 和 location 的额外查询参数。将 premium 设置为 true 允许您使用住宅代理。之后,您可以使用 location 来指定要访问 URL 的国家/地区。我在这个例子中设置了它。
Zenscrape 关于网络抓取的文档提供了有关其他此类参数的更多详细信息。
与我们之前的示例类似,此变量 $html 存储我们返回的提取的 HTML。现在,我们可以以任何我们喜欢的方式解析和使用这个 HTML。
我使用它来显示标题列表以进行演示。
这是我作为美国访问者使用 Zenscrape API 抓取 Reddit 时得到的结果。
JavaScript 渲染后提取内容
Zenscrape 为您解决的另一个问题是,当访问者访问由库和框架(如 Vue、React 或 Angular)构建的 网站 时,您可以轻松提取将呈现给访问者的 HTML。
我创建了一个简单的 CodePen 演示来演示此功能。基本的 网站 爬虫将在此页面上看到与实际 网站 访问者不同的内容,因为页面上的内容是使用 React 呈现的。
当使用简单的 cURL 或 file_get_contents() 请求时,您将在根元素中获得以下 HTML。
Nothing to see here!
另一方面,Zenscrape 为您提供了在现代无头 Chrome 浏览器中呈现请求的选项。这意味着您使用 Zenscrape API 返回的 HTML 与用户在访问页面时将看到的 HTML 相同。
这是我用来提取在运行 JavaScript 后最终显示给用户的 HTML 的代码。
如您所见,您需要做的就是传递两个参数,render 和 wait_for_css。将 render 设置为 true 将告诉 Zenscrape 它需要使用无头浏览器来获取内容,因为涉及到 JavaScript。您可以将 wait_for_css 设置为所需元素的 CSS 选择器。
上面的代码片段允许您提取可以解析的 HTML 以获得以下内容。
最后的想法
Zenscrape 为那些想要大规模提取数据的人解决了许多网络抓取问题。它的优点在于它易于实现,并且不需要您花费数天或数周的时间来学习 API。
正如您在上面的三个示例中所见,Zenscrape 只需几个请求即可为您处理从本地化到 JavaScript 渲染的所有事情。您只需要编写几行代码,一切都会立即启动并运行。甚至还有一个请求构建器,您可以使用它来获取使用 Python、Node.js、PHP 等发出请求所需的代码。
您可以使用 Zenscrape API 执行许多任务,例如获取销售线索或跟踪电子商务平台上产品的定价和可用性。访问 Zenscrape 并为自己阅读。有一个每月 1,000 积分的免费计划。您可以在几分钟内注册一个免费的 Zenscrape 帐户并自己测试所有功能。 查看全部
php curl抓取网页数据(
网络抓取是收集数据以将您的业务提升到新水平的好方法)
使用 Zenscrape 进行大规模数据提取
网络抓取是采集数据以将您的业务提升到新水平的好方法。它允许您自动化从各种来源提取有用内容的过程。
不幸的是,自动网络抓取并不总是那么容易。一些 网站 可能会主动阻止您提取这些数据,而其他 网站 是使用基本上使原创网络抓取工具无用的工具构建的。
在这个 文章 中,我将向您展示如何使用 Zenscrape 来克服所有这些问题,并从您喜欢的任何 网站 中大规模提取数据,而不必担心被阻止。
使用 Zenscrape 的优势
我将通过列出 Zenscrape 的一些惊人功能来开始讨论,这些功能可以帮助您完成工作并将其与其他爬虫区分开来。
JavaScript 渲染
许多 网站 现在都在积极使用 JavaScript 向访问者提供内容。这意味着一个简单的爬虫在访问网页时可能会看到与用户通过浏览器实际访问 网站 时不同的内容。
Zenscrape 通过允许您使用它的 API 在现代的无头 Chrome 浏览器中呈现请求来解决这个问题。它支持所有流行的库和框架,例如 Vue、Angular 和 React 等。
大规模提取数据
有些项目要求您大规模地抓取网络,这种情况会带来一系列挑战。您更有可能被 网站 阻止,并且一次只需一个请求即可获取所需的所有数据将花费更长的时间。
Zenscrape 通过为您提供巨大的 IP 池和自动代理轮换来轻松隐藏您的抓取机器人来克服这些问题。它还使您可以选择并发请求以快速抓取大量数据。
使用 Zenscrape 抓取内容
我们现在将学习如何使用 Zenscrape API 从不同类型的 网站 中抓取内容。
您可以通过在 网站 上创建一个帐户来开始。Zenscrape 提供免费计划,因此您只需注册即可遵循本教程。它将使您可以访问可用于发出请求的 API 密钥。您可以阅读详细文档,了解如何在 PHP、Python 和 Node.js 等各种语言和环境中使用 API 发出请求。
在您成功注册并登录后,文档中的代码片段将预先填充您的 API 密钥。
您还可以在“帐户仪表板”页面上查看其他与帐户相关的信息,例如使用情况统计信息和您的 API 密钥。
从维基百科中提取内容
Zenscrape 允许您从网页中提取 HTML,然后您可以使用您选择的解析器对其进行操作。我们将在此处的示例中使用基于 PHP 的 DiDOM 解析器,但您也可以使用 Zenscrape 博客 文章 中提到的其他一些解析器。
我们将抓取关于灯塔的 Wikipedia 页面作为示例。这是我们使用 Zenscrape 的 API 提取 HTML 的 PHP 代码。
此时的变量 $html 收录 Zenscrape 从 Wikipedia 页面提取的标记。标记的前几行如下所示:
White Shoal Light, Michigan - Wikipedia
... and more ...
我们现在可以将此 HTML 传递给我们的 DOM 解析器,以从 Wikipedia 文章 中提取主标题、第一段或第一张图片等信息。
这是我得到的输出,带有一些基本的 CSS 样式。
从 网站 中提取本地化内容
Top 网站 Reddit 主页的外观会因您访问的国家/地区而异。这个 网站 试图用在您所在位置相关且流行的内容来填充它。
在我们的示例中,我们将使用 Zenscrape 通过将国家/地区设置为美国和英国来从 Reddit 主页获取一些头条新闻。但是,Zenscrape 允许您从 230 多个不同的国家/地区选择一个位置来抓取内容。令人惊讶的是,您只需在 API 请求中指定两个参数即可完成所有这些操作。
这是我们使用 Zenscrape 的 API 为 Reddit 的英国主页获取 HTML 的代码。
如您所见,这与我们在上一节中使用的代码没有太大区别。不过,这一次,我们传递了两个名为 premium 和 location 的额外查询参数。将 premium 设置为 true 允许您使用住宅代理。之后,您可以使用 location 来指定要访问 URL 的国家/地区。我在这个例子中设置了它。
Zenscrape 关于网络抓取的文档提供了有关其他此类参数的更多详细信息。
与我们之前的示例类似,此变量 $html 存储我们返回的提取的 HTML。现在,我们可以以任何我们喜欢的方式解析和使用这个 HTML。
我使用它来显示标题列表以进行演示。
这是我作为美国访问者使用 Zenscrape API 抓取 Reddit 时得到的结果。
JavaScript 渲染后提取内容
Zenscrape 为您解决的另一个问题是,当访问者访问由库和框架(如 Vue、React 或 Angular)构建的 网站 时,您可以轻松提取将呈现给访问者的 HTML。
我创建了一个简单的 CodePen 演示来演示此功能。基本的 网站 爬虫将在此页面上看到与实际 网站 访问者不同的内容,因为页面上的内容是使用 React 呈现的。
当使用简单的 cURL 或 file_get_contents() 请求时,您将在根元素中获得以下 HTML。
Nothing to see here!
另一方面,Zenscrape 为您提供了在现代无头 Chrome 浏览器中呈现请求的选项。这意味着您使用 Zenscrape API 返回的 HTML 与用户在访问页面时将看到的 HTML 相同。
这是我用来提取在运行 JavaScript 后最终显示给用户的 HTML 的代码。
如您所见,您需要做的就是传递两个参数,render 和 wait_for_css。将 render 设置为 true 将告诉 Zenscrape 它需要使用无头浏览器来获取内容,因为涉及到 JavaScript。您可以将 wait_for_css 设置为所需元素的 CSS 选择器。
上面的代码片段允许您提取可以解析的 HTML 以获得以下内容。
最后的想法
Zenscrape 为那些想要大规模提取数据的人解决了许多网络抓取问题。它的优点在于它易于实现,并且不需要您花费数天或数周的时间来学习 API。
正如您在上面的三个示例中所见,Zenscrape 只需几个请求即可为您处理从本地化到 JavaScript 渲染的所有事情。您只需要编写几行代码,一切都会立即启动并运行。甚至还有一个请求构建器,您可以使用它来获取使用 Python、Node.js、PHP 等发出请求所需的代码。
您可以使用 Zenscrape API 执行许多任务,例如获取销售线索或跟踪电子商务平台上产品的定价和可用性。访问 Zenscrape 并为自己阅读。有一个每月 1,000 积分的免费计划。您可以在几分钟内注册一个免费的 Zenscrape 帐户并自己测试所有功能。
php curl抓取网页数据(phpcurl格式信息的最基本的request对象抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-01 06:06
phpcurl抓取网页数据requestxmlhttprequest是php提供的一个request对象,最基本用法有四种。其中requestxmlhttprequest分别对应于网页里带的xml格式信息,它也是php无法直接解析xml格式信息的最基本的request对象。requestxmlhttprequest是php包中的关键参数。
1、初始化当php初始化xmlhttprequest对象时,会调用它的父类preg_method(requestxmlhttprequest)方法,也就是调用preg_method()方法,
1)匹配条件:网页中每个标签对应的文本属性
2)匹配文本:匹配属性值相同的文本
2、根据格式信息匹配php写不出来的话也可以使用array()来伪造xml数据。array_get_eval('^employee|ename-xmaethelper|internals')就可以打印出来文本格式。
判断ename的规则这里是只有xlaid,employee,ename,actionaddress.xlaid属性:值为1的:首部有2个xlaid属性值为0:首部有1个employee类型的xlaid值为0:首部有2个ename类型的xlaid值为1:internalsactionaddress属性:值为1:首部有2个xlaid属性值为0:首部有1个ename类型的xlaid如果不在上面的条件中,只要首部有2个xlaid属性,首部有1个ename类型的xlaid.就无法匹配到.不知道具体有2个还是2个0。
这边是这么执行的,但是php默认是最多匹配到1次xlaid:preg_method('x',preg_method('e',preg_method('a',preg_method('-',preg_method('1',preg_method('a',preg_method('e',preg_method('0',preg_method('-',preg_method('0',preg_method('2',preg_method('1',preg_method('-',preg_method('0',preg_method('-',preg_method('1',preg_method('-',preg_method('-',preg_method('0',preg_method('-',preg_method('-',preg_method('-',preg_method('-',preg_method('-',preg_method('0',preg_method('0',preg_method('0',preg_method('-',preg_method('-',preg_method('0',preg_method('0',preg_metho。 查看全部
php curl抓取网页数据(phpcurl格式信息的最基本的request对象抓取网页数据)
phpcurl抓取网页数据requestxmlhttprequest是php提供的一个request对象,最基本用法有四种。其中requestxmlhttprequest分别对应于网页里带的xml格式信息,它也是php无法直接解析xml格式信息的最基本的request对象。requestxmlhttprequest是php包中的关键参数。
1、初始化当php初始化xmlhttprequest对象时,会调用它的父类preg_method(requestxmlhttprequest)方法,也就是调用preg_method()方法,
1)匹配条件:网页中每个标签对应的文本属性
2)匹配文本:匹配属性值相同的文本
2、根据格式信息匹配php写不出来的话也可以使用array()来伪造xml数据。array_get_eval('^employee|ename-xmaethelper|internals')就可以打印出来文本格式。
判断ename的规则这里是只有xlaid,employee,ename,actionaddress.xlaid属性:值为1的:首部有2个xlaid属性值为0:首部有1个employee类型的xlaid值为0:首部有2个ename类型的xlaid值为1:internalsactionaddress属性:值为1:首部有2个xlaid属性值为0:首部有1个ename类型的xlaid如果不在上面的条件中,只要首部有2个xlaid属性,首部有1个ename类型的xlaid.就无法匹配到.不知道具体有2个还是2个0。
这边是这么执行的,但是php默认是最多匹配到1次xlaid:preg_method('x',preg_method('e',preg_method('a',preg_method('-',preg_method('1',preg_method('a',preg_method('e',preg_method('0',preg_method('-',preg_method('0',preg_method('2',preg_method('1',preg_method('-',preg_method('0',preg_method('-',preg_method('1',preg_method('-',preg_method('-',preg_method('0',preg_method('-',preg_method('-',preg_method('-',preg_method('-',preg_method('-',preg_method('0',preg_method('0',preg_method('0',preg_method('-',preg_method('-',preg_method('0',preg_method('0',preg_metho。
php curl抓取网页数据( 百度两个字替换为牛逼该怎么做呢?执行这个文件看一下会发生什么吧! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-01 00:16
百度两个字替换为牛逼该怎么做呢?执行这个文件看一下会发生什么吧!
)
什么是cURL?
<p style="box-sizing: border-box; outline: 0px; padding: 0px; margin: 0px 0px 16px; font-size: 16px; color: rgb(79, 79, 79); line-height: 26px; text-align: justify; word-break: break-all; font-family: -apple-system, "SF UI Text", Arial, "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", sans-serif, SimHei, SimSun;">官方是这样解释的:使用URL语法传输数据的命令行工具。 <br style="box-sizing: border-box; outline: 0px; word-break: break-all;">
cURL:我不生产资源,我只是资源的搬运工。。。 <br style="box-sizing: border-box; outline: 0px; word-break: break-all;">
<a name="t1" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>cURL的使用场景
网页资源
编写网页爬虫
WebService数据接口资源
动态获取接口数据,比如天气,号码归属地等等
FTP服务器里面的文件资源
下载FTP服务器里面的文件
其他资源
所有网络上的资源都可以用cURL访问和下载到
检查php是否可以使用cURL
可以看到在我的Linux下是支持cURL的
<a name="t2" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>在PHP中使用cURL
<a name="t3" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>cURL实战
用cURL做一个简单的网页爬虫
用cURL获取天气信息
用cURL操作FTP服务器中的数据
用cURL访问HTTPS资源
1.网页爬虫
抓取百度的首页
</p>
运行这个程序,看看会发生什么!没错,打开这个文件会打印出百度主页!
那么问题来了!想把检索到的网页中的Baidu这两个词换成牛球怎么办?
执行这个文件,看看会发生什么!
2.获取天气信息
由于Webservice原因,可能多次访问后不可用。这只是一种方法。也可以通过百度天气api获取天气信息。
代码如下: 查看全部
php curl抓取网页数据(
百度两个字替换为牛逼该怎么做呢?执行这个文件看一下会发生什么吧!
)
什么是cURL?
<p style="box-sizing: border-box; outline: 0px; padding: 0px; margin: 0px 0px 16px; font-size: 16px; color: rgb(79, 79, 79); line-height: 26px; text-align: justify; word-break: break-all; font-family: -apple-system, "SF UI Text", Arial, "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "WenQuanYi Micro Hei", sans-serif, SimHei, SimSun;">官方是这样解释的:使用URL语法传输数据的命令行工具。 <br style="box-sizing: border-box; outline: 0px; word-break: break-all;">
cURL:我不生产资源,我只是资源的搬运工。。。 <br style="box-sizing: border-box; outline: 0px; word-break: break-all;">
<a name="t1" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>cURL的使用场景
网页资源
编写网页爬虫
WebService数据接口资源
动态获取接口数据,比如天气,号码归属地等等
FTP服务器里面的文件资源
下载FTP服务器里面的文件
其他资源
所有网络上的资源都可以用cURL访问和下载到
检查php是否可以使用cURL
可以看到在我的Linux下是支持cURL的
<a name="t2" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>在PHP中使用cURL
<a name="t3" style="box-sizing: border-box; outline: 0px; color: rgb(78, 161, 219); cursor: pointer; word-break: break-all;"></a>cURL实战
用cURL做一个简单的网页爬虫
用cURL获取天气信息
用cURL操作FTP服务器中的数据
用cURL访问HTTPS资源
1.网页爬虫
抓取百度的首页
</p>
运行这个程序,看看会发生什么!没错,打开这个文件会打印出百度主页!
那么问题来了!想把检索到的网页中的Baidu这两个词换成牛球怎么办?
执行这个文件,看看会发生什么!
2.获取天气信息
由于Webservice原因,可能多次访问后不可用。这只是一种方法。也可以通过百度天气api获取天气信息。
代码如下:
php curl抓取网页数据( 这里有新鲜出炉的PHP教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-28 00:19
这里有新鲜出炉的PHP教程,程序狗速度看过来!)
php curl模拟登录并获取数据实例详情
这里有新鲜出炉的PHP教程,一起来看看程序狗速度吧!
PHP开源脚本语言
PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛,主要适用于Web开发领域。PHP的文件扩展名是php。
cURL是一个强大的PHP库,使用PHP的cURL库可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册学习有关 cURL 的更多信息。本文以开源中国(oschina)的模拟登录为例。有需要的朋友可以参考以下
PHP 的 curl() 爬取网页的效率更高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要打开 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录 function login_post($url, $cookie, $post) { $curl = curl_init(); //初始化curl模块 curl_setopt($curl, CURLOPT_URL, $url); //登录提交的地址 curl_setopt($curl, CURLOPT_HEADER, 0); //是否显示头信息 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0); //是否自动显示返回的信息 curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中 curl_setopt($curl, CURLOPT_POST, 1); //post方式提交 curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post)); //要提交的信息 curl_exec($curl); //执行cURL curl_close($curl); //关闭cURL资源,并且释放系统资源 }
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据 function get_content($url, $cookie) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie $rs = curl_exec($ch); //执行cURL抓取页面内容 curl_close($ch); return $rs;}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据 $post = array ( 'email' => 'oschina账户', 'pwd' => 'oschina密码', 'goto_page' => '/my', 'error_page' => '/login', 'save_login' => '1', 'submit' => '现在登录' ); //登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录 login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件 @ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i"; preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。 查看全部
php curl抓取网页数据(
这里有新鲜出炉的PHP教程,程序狗速度看过来!)
php curl模拟登录并获取数据实例详情
这里有新鲜出炉的PHP教程,一起来看看程序狗速度吧!
PHP开源脚本语言
PHP(外文名:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,入门门槛低,易学,应用广泛,主要适用于Web开发领域。PHP的文件扩展名是php。
cURL是一个强大的PHP库,使用PHP的cURL库可以简单有效的抓取网页和采集内容,设置cookie完成模拟登录网页,curl提供了丰富的功能,开发者可以参考PHP手册学习有关 cURL 的更多信息。本文以开源中国(oschina)的模拟登录为例。有需要的朋友可以参考以下
PHP 的 curl() 爬取网页的效率更高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要打开 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录 function login_post($url, $cookie, $post) { $curl = curl_init(); //初始化curl模块 curl_setopt($curl, CURLOPT_URL, $url); //登录提交的地址 curl_setopt($curl, CURLOPT_HEADER, 0); //是否显示头信息 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0); //是否自动显示返回的信息 curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中 curl_setopt($curl, CURLOPT_POST, 1); //post方式提交 curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post)); //要提交的信息 curl_exec($curl); //执行cURL curl_close($curl); //关闭cURL资源,并且释放系统资源 }
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据 function get_content($url, $cookie) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie $rs = curl_exec($ch); //执行cURL抓取页面内容 curl_close($ch); return $rs;}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据 $post = array ( 'email' => 'oschina账户', 'pwd' => 'oschina密码', 'goto_page' => '/my', 'error_page' => '/login', 'save_login' => '1', 'submit' => '现在登录' ); //登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录 login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件 @ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i"; preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
php curl抓取网页数据(检查PHP是否CURL在PHP的主配置文件库中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-25 19:15
PHP的Curl库用于获取网络上的资源,就像模拟平时打开浏览器一样,可以很方便的抓取网页上的信息。同时这个库还提供了多种设置,可以设置各种HTTP协议中的参数。使用CURL,可以完全模拟用户在页面上登录、浏览、发送信息、编写各种脚本。
检查 PHP 是否加载 CURL
在 PHP 的主配置文件 php.ini 中,确保 curl 已打开。
第一个例子
让我们用curl抓取施博文的博客首页
以上代码可以得到一个页面的源代码,结合PHP强大的正则表达式,可以很方便的从页面中提取一些数据。当然,如果在url地址后面加参数,可以用get方法提交参数。
邮寄资料
为了一次性提交大量数据,同时为了更加保密,通常的做法是使用post方式提交数据。使用 curl 库,您还可以轻松模拟 post 方法提交。假设要提交的数据以关联数组的形式存储在数据中。在 $ 数据中。
在上面的代码中,第一行表示数据应该通过post提交,第二行是存储在关联数组中的数据对。发送这个请求时,$data 中的数据会自动以 post 请求的格式发送。.
设置 User-Agent、Cookie 和 Referer
通常,一个网站记录用户的在线状态是用cookie信息记录的,而User-Agent和Referer也用来判断访问者是否有权限读取相应的信息,比如“热链”功能,就是验证HTTP头中的Referer信息来判断。curl还提供了一个方法让我们修改这些信息,如下:
模拟登录百度账号
博主编写的《百度贴吧登录系统》广泛使用curl来模拟用户登录和登录。登录部分收录了大部分日常使用的curl库的常见例子,而且这个系统是完全开源的,可以看这里的代码(Github)。
其他功能
PHP的curl库除了上面提到的一些常用方法外,还提供了ssl连接、文件上传(put)方法等各种功能,可以在PHP官方手册页找到相关介绍:
PHP 文档 - 卷曲 查看全部
php curl抓取网页数据(检查PHP是否CURL在PHP的主配置文件库中的应用)
PHP的Curl库用于获取网络上的资源,就像模拟平时打开浏览器一样,可以很方便的抓取网页上的信息。同时这个库还提供了多种设置,可以设置各种HTTP协议中的参数。使用CURL,可以完全模拟用户在页面上登录、浏览、发送信息、编写各种脚本。
检查 PHP 是否加载 CURL
在 PHP 的主配置文件 php.ini 中,确保 curl 已打开。
第一个例子
让我们用curl抓取施博文的博客首页
以上代码可以得到一个页面的源代码,结合PHP强大的正则表达式,可以很方便的从页面中提取一些数据。当然,如果在url地址后面加参数,可以用get方法提交参数。
邮寄资料
为了一次性提交大量数据,同时为了更加保密,通常的做法是使用post方式提交数据。使用 curl 库,您还可以轻松模拟 post 方法提交。假设要提交的数据以关联数组的形式存储在数据中。在 $ 数据中。
在上面的代码中,第一行表示数据应该通过post提交,第二行是存储在关联数组中的数据对。发送这个请求时,$data 中的数据会自动以 post 请求的格式发送。.
设置 User-Agent、Cookie 和 Referer
通常,一个网站记录用户的在线状态是用cookie信息记录的,而User-Agent和Referer也用来判断访问者是否有权限读取相应的信息,比如“热链”功能,就是验证HTTP头中的Referer信息来判断。curl还提供了一个方法让我们修改这些信息,如下:
模拟登录百度账号
博主编写的《百度贴吧登录系统》广泛使用curl来模拟用户登录和登录。登录部分收录了大部分日常使用的curl库的常见例子,而且这个系统是完全开源的,可以看这里的代码(Github)。
其他功能
PHP的curl库除了上面提到的一些常用方法外,还提供了ssl连接、文件上传(put)方法等各种功能,可以在PHP官方手册页找到相关介绍:
PHP 文档 - 卷曲
php curl抓取网页数据(phpcurl抓取网页数据,我们需要一些知识和环境php环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-16 00:02
phpcurl抓取网页数据,我们需要一些知识和环境php环境。安装php。在网上查找php编译环境搭建。iedit编辑器或者记事本编辑器。要安装curl的一些库,安装过程可能需要安装。配置php的环境变量。php配置。数据库安装。抓取时最好把抓取的页面通过拼音首拼,然后汉字放到首位。[最好使用安卓的浏览器加上抓取软件]。
数据库安装。推荐在windows安装sqlite,iphone安装的话推荐microsoftsqlite。抓取前请安装成功php和curl环境。
1、前期准备:安装配置好php环境
2、curl抓取php网页
3、使用python抓取
4、使用requests库抓取分享一下我写的网站,
1)php安装在命令行进入php官网/::6.3.19
2)curl抓取网页。在命令行输入curl。
3)python抓取这里有一些相关python抓取教程:python方法抓取百度站点
不怕告诉你,一百次爬虫的尝试,就够了,什么事情都要去尝试。
实现原理非常简单,也非常复杂1.安装python环境2.安装curl协议和httpd协议windows用户请自行安装httpd,或者更高版本的python3.6(已经包含httpd协议);mac用户自行安装pip3;linux用户请自行安装pip3.43.对应抓取文本的html请求地址(可以是一个文本),如果你觉得那个html很长可以在github上搜),然后发送给服务器;然后服务器返回页面到用户浏览器。 查看全部
php curl抓取网页数据(phpcurl抓取网页数据,我们需要一些知识和环境php环境)
phpcurl抓取网页数据,我们需要一些知识和环境php环境。安装php。在网上查找php编译环境搭建。iedit编辑器或者记事本编辑器。要安装curl的一些库,安装过程可能需要安装。配置php的环境变量。php配置。数据库安装。抓取时最好把抓取的页面通过拼音首拼,然后汉字放到首位。[最好使用安卓的浏览器加上抓取软件]。
数据库安装。推荐在windows安装sqlite,iphone安装的话推荐microsoftsqlite。抓取前请安装成功php和curl环境。
1、前期准备:安装配置好php环境
2、curl抓取php网页
3、使用python抓取
4、使用requests库抓取分享一下我写的网站,
1)php安装在命令行进入php官网/::6.3.19
2)curl抓取网页。在命令行输入curl。
3)python抓取这里有一些相关python抓取教程:python方法抓取百度站点
不怕告诉你,一百次爬虫的尝试,就够了,什么事情都要去尝试。
实现原理非常简单,也非常复杂1.安装python环境2.安装curl协议和httpd协议windows用户请自行安装httpd,或者更高版本的python3.6(已经包含httpd协议);mac用户自行安装pip3;linux用户请自行安装pip3.43.对应抓取文本的html请求地址(可以是一个文本),如果你觉得那个html很长可以在github上搜),然后发送给服务器;然后服务器返回页面到用户浏览器。

