
php 爬虫抓取网页数据
php 爬虫抓取网页数据(玩C一定用得到的19款Java开源Web爬虫作者:行者武松人(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-04-16 16:31
阿里云 > 云栖社区 > 主题图 > P > PHP网络爬虫开源
推荐活动:
更多优惠>
当前话题:php网络爬虫开源加入采集
相关话题:
php网络爬虫开源相关博客查看更多博客
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
玩C必备的19个Java开源网络爬虫
作者:沃克武松 1249人浏览评论:04年前
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。今天给大家介绍19款Java开源网络爬虫。
阅读全文
玩大数据必用的19个Java开源网络爬虫
作者:消音器 1432 观众评论:04年前
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。今天给大家介绍19款Java开源网络爬虫。
阅读全文
Python爬虫框架-PySpider
作者:shadowcat7965 浏览评论:05年前
From: From: PySpider PySpider github地址PySpider官方文档PySpi
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
php网络爬虫开源相关问答
爬虫数据管理【问答合集】
作者:我是管理员28342人查看评论:223年前
互联网爬虫的自然语言处理目前前景如何?artTemplate:arttemplate生成的页面可以爬取到数据吗?
阅读全文 查看全部
php 爬虫抓取网页数据(玩C一定用得到的19款Java开源Web爬虫作者:行者武松人(组图))
阿里云 > 云栖社区 > 主题图 > P > PHP网络爬虫开源

推荐活动:
更多优惠>
当前话题:php网络爬虫开源加入采集
相关话题:
php网络爬虫开源相关博客查看更多博客
构建网络爬虫?太简单


作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
开源爬虫软件总结


作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
开源爬虫软件总结


作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
开源爬虫框架的优缺点是什么?

作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
玩C必备的19个Java开源网络爬虫


作者:沃克武松 1249人浏览评论:04年前
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。今天给大家介绍19款Java开源网络爬虫。
阅读全文
玩大数据必用的19个Java开源网络爬虫

作者:消音器 1432 观众评论:04年前
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。今天给大家介绍19款Java开源网络爬虫。
阅读全文
Python爬虫框架-PySpider


作者:shadowcat7965 浏览评论:05年前
From: From: PySpider PySpider github地址PySpider官方文档PySpi
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
php网络爬虫开源相关问答
爬虫数据管理【问答合集】


作者:我是管理员28342人查看评论:223年前
互联网爬虫的自然语言处理目前前景如何?artTemplate:arttemplate生成的页面可以爬取到数据吗?
阅读全文
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-16 09:42
与PHP相比,python更适合爬虫。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构方面主要有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用在以下三个方面:
服务器脚本。这是 PHP 最传统和主要的目标领域。完成这项工作需要三件事:PHP 解析器(CGI 或服务器模块)、Web
服务器和网络浏览器。运行Web服务器时需要安装和配置PHP,然后可以使用Web浏览器访问PHP程序的输出,即浏览服务
侧 PHP 页面。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。请参阅安装章节了解更多信息。命令行脚本。
可以编写一个 PHP 脚本,它不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器即可执行。这种用法适用于
非常适合在 cron(Unix 或 Linux 环境)或任务计划程序(Windows 环境)上运行的日常脚本。这些脚本也可用于
简单的文字。有关详细信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不是
最好的语言之一,但是如果用户非常精通 PHP,并且想在客户端应用程序中使用 PHP 的一些高级功能,则可以使用 PHP-GTK 编写
一些程序。这样,你也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,不收录在 PHP 包的通常分发中。
扩大网友观点:
我已经用 PHP Node.js Python 编写了抓取脚本,让我们稍微谈谈它。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报时,由于crontab定时执行,没有优化,打开的php进程太多,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。
至此,这篇关于python和php更适合写爬虫的文章文章就介绍到这里了。更多关于哪些php和python适合爬取的信息,请搜索脚本之家之前的文章或继续浏览下方的相关文章,希望以后多多支持脚本之家! 查看全部
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
与PHP相比,python更适合爬虫。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构方面主要有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用在以下三个方面:
服务器脚本。这是 PHP 最传统和主要的目标领域。完成这项工作需要三件事:PHP 解析器(CGI 或服务器模块)、Web
服务器和网络浏览器。运行Web服务器时需要安装和配置PHP,然后可以使用Web浏览器访问PHP程序的输出,即浏览服务
侧 PHP 页面。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。请参阅安装章节了解更多信息。命令行脚本。
可以编写一个 PHP 脚本,它不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器即可执行。这种用法适用于
非常适合在 cron(Unix 或 Linux 环境)或任务计划程序(Windows 环境)上运行的日常脚本。这些脚本也可用于
简单的文字。有关详细信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不是
最好的语言之一,但是如果用户非常精通 PHP,并且想在客户端应用程序中使用 PHP 的一些高级功能,则可以使用 PHP-GTK 编写
一些程序。这样,你也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,不收录在 PHP 包的通常分发中。
扩大网友观点:
我已经用 PHP Node.js Python 编写了抓取脚本,让我们稍微谈谈它。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报时,由于crontab定时执行,没有优化,打开的php进程太多,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。
至此,这篇关于python和php更适合写爬虫的文章文章就介绍到这里了。更多关于哪些php和python适合爬取的信息,请搜索脚本之家之前的文章或继续浏览下方的相关文章,希望以后多多支持脚本之家!
php 爬虫抓取网页数据(基于目标网页特征的爬虫所抓取行为的关键所在所研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-12 15:11
网络爬虫技术是指在万维网上按照一定的规则自动爬取信息的技术。网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,更多的时候是网络追逐者;其他不太常用的名称是蚂蚁、自动索引器、模拟器或蠕虫。
网络爬虫技术是指按照一定的规则自动从万维网上抓取信息的技术。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
现有的焦点爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
基于着陆页特征
爬虫根据目标网页的特征爬取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3) 由用户行为决定的抓取目标示例分为:
(a) 在用户浏览过程中显示标记的抓取样本;
(b) 通过用户日志挖掘获取访问模式和相关样本。
网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据架构
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般符合一定的模式,或者可以转化或映射成目标数据模式。
基于领域的概念
另一种描述是构建目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。 查看全部
php 爬虫抓取网页数据(基于目标网页特征的爬虫所抓取行为的关键所在所研究)
网络爬虫技术是指在万维网上按照一定的规则自动爬取信息的技术。网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,更多的时候是网络追逐者;其他不太常用的名称是蚂蚁、自动索引器、模拟器或蠕虫。

网络爬虫技术是指按照一定的规则自动从万维网上抓取信息的技术。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
现有的焦点爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
基于着陆页特征
爬虫根据目标网页的特征爬取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3) 由用户行为决定的抓取目标示例分为:
(a) 在用户浏览过程中显示标记的抓取样本;
(b) 通过用户日志挖掘获取访问模式和相关样本。
网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据架构
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般符合一定的模式,或者可以转化或映射成目标数据模式。
基于领域的概念
另一种描述是构建目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
php 爬虫抓取网页数据(【每日一题】网络爬虫的爬行策略(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2022-04-10 12:31
1、网络爬虫原理网络爬虫是指按照一定的规则自动爬取互联网上的程序(模拟手动登录网页的方式)。简单的说就是获取和存储你在互联网上看到的页面上的内容。网络爬虫的爬取策略分为深度优先和广度优先。如下图所示,深度优先的遍历方法是A到B到D到E到C到F(ABDECF)和广度优先的遍历方法ABCDEF。2、写网络爬虫的原因(1)互联网数据量巨大,我们不能手动采集数据,会浪费时间和金钱...
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说网络爬虫的原理解析【通俗易懂】,希望可以帮助大家进步!!!
1、网络爬虫原理
网络爬虫是指按照一定的规则自动爬取网络上的程序(模拟手动登录网页的方式)。简单的说就是获取和存储你在互联网上看到的页面上的内容。网络爬虫的爬取策略分为深度优先和广度优先。如下图所示,深度优先的遍历方法是A到B到D到E到C到F(ABDECF)和广度优先的遍历方法ABCDEF。
2、写网络爬虫的原因
(1)互联网数据量很大,我们不能手动采集数据,浪费时间和金钱。爬虫的一个特点是可以批量自动获取和处理数据。例如,主要汽车论坛 互联网上的爬虫、大众点评网、tripadvisor的爬虫(国外网站)已经爬取了千万条数据,我想如果你一个一个复制,你是做不完的直到你死。
(2)爬虫很酷。前段时间看到有人爬到腾讯的3000万QQ数据,包括(QQ号、昵称、空间名、会员等级、头像、最新谈话内容、最新讲座)发布时间、空间剖面、性别、生日、省、市、婚姻状况等详细数据,绘制各种有趣的图表。
(3)对于攻读研究生、博士、数据挖掘和数据分析的人来说,没有数据做实验是一件非常痛苦的事情。你可能每天在各种论坛上问这个那个。数据,是不是很烦?
3、网络爬虫的进程
通过上图可以完成一个简单的网络爬虫。首先给出一个待爬取的URL队列,然后通过抓包得到数据的真实请求地址。然后用httpclient模拟浏览器抓取对应的数据(一般是html文件或者json数据)。因为网页中的内容很大很复杂,很多内容不是我们需要的,所以需要解析。html的解析非常简单,可以通过Jsoup(Dom解析工具)和正则表达式来完成。对于Json数据的解析,这里推荐一个快速解析工具fastjson(阿里开源的一个工具)
4、网络抓包
网络抓包(packet capture)是对网络传输发送和接收的数据包进行拦截、重传、编辑、转储等,常用于数据拦截。当数据响应是Json或者需要用户名密码才能登录的网站时,抓包就显得尤为重要,抓包也是编写网络爬虫的第一步。
图为东方财富网,抓包结果,可以看到真实的响应地址:Request URL和上面网页请求的地址不一样,我们看一下股票数据的回应。响应的数据格式是 JSON 文件。这里我们可以看到股票数据一共有61页,其中当前页的数据是data[Json数据]。
因此,使用网络抓包是网络爬虫的第一步,可以直观的看到数据请求的真实地址、请求方式(post、get请求)、数据类型(html或Json数据) 查看全部
php 爬虫抓取网页数据(【每日一题】网络爬虫的爬行策略(一))
1、网络爬虫原理网络爬虫是指按照一定的规则自动爬取互联网上的程序(模拟手动登录网页的方式)。简单的说就是获取和存储你在互联网上看到的页面上的内容。网络爬虫的爬取策略分为深度优先和广度优先。如下图所示,深度优先的遍历方法是A到B到D到E到C到F(ABDECF)和广度优先的遍历方法ABCDEF。2、写网络爬虫的原因(1)互联网数据量巨大,我们不能手动采集数据,会浪费时间和金钱...

大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说网络爬虫的原理解析【通俗易懂】,希望可以帮助大家进步!!!
1、网络爬虫原理
网络爬虫是指按照一定的规则自动爬取网络上的程序(模拟手动登录网页的方式)。简单的说就是获取和存储你在互联网上看到的页面上的内容。网络爬虫的爬取策略分为深度优先和广度优先。如下图所示,深度优先的遍历方法是A到B到D到E到C到F(ABDECF)和广度优先的遍历方法ABCDEF。

2、写网络爬虫的原因
(1)互联网数据量很大,我们不能手动采集数据,浪费时间和金钱。爬虫的一个特点是可以批量自动获取和处理数据。例如,主要汽车论坛 互联网上的爬虫、大众点评网、tripadvisor的爬虫(国外网站)已经爬取了千万条数据,我想如果你一个一个复制,你是做不完的直到你死。
(2)爬虫很酷。前段时间看到有人爬到腾讯的3000万QQ数据,包括(QQ号、昵称、空间名、会员等级、头像、最新谈话内容、最新讲座)发布时间、空间剖面、性别、生日、省、市、婚姻状况等详细数据,绘制各种有趣的图表。
(3)对于攻读研究生、博士、数据挖掘和数据分析的人来说,没有数据做实验是一件非常痛苦的事情。你可能每天在各种论坛上问这个那个。数据,是不是很烦?
3、网络爬虫的进程
通过上图可以完成一个简单的网络爬虫。首先给出一个待爬取的URL队列,然后通过抓包得到数据的真实请求地址。然后用httpclient模拟浏览器抓取对应的数据(一般是html文件或者json数据)。因为网页中的内容很大很复杂,很多内容不是我们需要的,所以需要解析。html的解析非常简单,可以通过Jsoup(Dom解析工具)和正则表达式来完成。对于Json数据的解析,这里推荐一个快速解析工具fastjson(阿里开源的一个工具)
4、网络抓包
网络抓包(packet capture)是对网络传输发送和接收的数据包进行拦截、重传、编辑、转储等,常用于数据拦截。当数据响应是Json或者需要用户名密码才能登录的网站时,抓包就显得尤为重要,抓包也是编写网络爬虫的第一步。
图为东方财富网,抓包结果,可以看到真实的响应地址:Request URL和上面网页请求的地址不一样,我们看一下股票数据的回应。响应的数据格式是 JSON 文件。这里我们可以看到股票数据一共有61页,其中当前页的数据是data[Json数据]。
因此,使用网络抓包是网络爬虫的第一步,可以直观的看到数据请求的真实地址、请求方式(post、get请求)、数据类型(html或Json数据)
php 爬虫抓取网页数据(python和PHP相比较,python适合做爬虫吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-10 11:23
与PHP相比,python更适合爬虫。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构主要有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用在以下三个方面:
服务器脚本。这是 PHP 最传统和主要的目标领域。完成这项工作需要三件事:PHP 解析器(CGI 或服务器模块)、Web
服务器和网络浏览器。运行Web服务器时需要安装和配置PHP,然后可以使用Web浏览器访问PHP程序的输出,即浏览服务
侧 PHP 页面。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。请参阅安装章节了解更多信息。命令行脚本。
可以编写一个 PHP 脚本,它不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器即可执行。这种用法适用于
非常适合在 cron(Unix 或 Linux 环境)或任务计划程序(Windows 环境)上运行的日常脚本。这些脚本也可用于
简单的文字。有关详细信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不是
最好的语言之一,但是如果用户对 PHP 非常精通,并且想在客户端应用程序中使用 PHP 的一些高级功能,可以使用 PHP-GTK 来编写这个
一些程序。这样,你也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,不收录在 PHP 包的通常分发中。
扩大网友观点:
我已经用 PHP Node.js Python 编写了抓取脚本,让我们稍微谈谈它。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报的时候,因为定时执行crontab,没有做任何优化,打开了太多的php进程,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。
至此,这篇关于python和php哪个更适合爬虫写的文章文章就介绍到这里了。更多适合爬虫内容的相关php和python,请搜索服务器之家以前的文章或继续浏览下方相关文章,希望大家以后多多支持服务器之家!
原文链接: 查看全部
php 爬虫抓取网页数据(python和PHP相比较,python适合做爬虫吗?(一))
与PHP相比,python更适合爬虫。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构主要有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用在以下三个方面:
服务器脚本。这是 PHP 最传统和主要的目标领域。完成这项工作需要三件事:PHP 解析器(CGI 或服务器模块)、Web
服务器和网络浏览器。运行Web服务器时需要安装和配置PHP,然后可以使用Web浏览器访问PHP程序的输出,即浏览服务
侧 PHP 页面。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。请参阅安装章节了解更多信息。命令行脚本。
可以编写一个 PHP 脚本,它不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器即可执行。这种用法适用于
非常适合在 cron(Unix 或 Linux 环境)或任务计划程序(Windows 环境)上运行的日常脚本。这些脚本也可用于
简单的文字。有关详细信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不是
最好的语言之一,但是如果用户对 PHP 非常精通,并且想在客户端应用程序中使用 PHP 的一些高级功能,可以使用 PHP-GTK 来编写这个
一些程序。这样,你也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,不收录在 PHP 包的通常分发中。
扩大网友观点:
我已经用 PHP Node.js Python 编写了抓取脚本,让我们稍微谈谈它。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报的时候,因为定时执行crontab,没有做任何优化,打开了太多的php进程,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。
至此,这篇关于python和php哪个更适合爬虫写的文章文章就介绍到这里了。更多适合爬虫内容的相关php和python,请搜索服务器之家以前的文章或继续浏览下方相关文章,希望大家以后多多支持服务器之家!
原文链接:
php 爬虫抓取网页数据( Python爬虫|如何实现爬虫4.的应用爬虫的基本流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-04-10 11:23
Python爬虫|如何实现爬虫4.的应用爬虫的基本流程
)
什么是爬行动物?
1. 爬虫介绍
'''
近年来,随着网络应用的逐渐扩展和深入,如何高效获取在线数据成为无数公司和个人的追求。在大数据时代,谁拥有更多的数据,谁就能获得更高的收益。网络爬虫是最常用的从网络上爬取数据的手段之一。
网络爬虫,或者Web Spider,是一个很形象的名字。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络蜘蛛通过它们的链接地址寻找网页。网站从某个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,以此类推以此类推,直到 网站 直到所有网页都被爬取为止。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
'''
1、什么是互联网?<br />互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样。2、互联网建立的目的?<br />互联网的核心价值在于数据的共享/传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿U盘去别人的计算机上拷贝数据了。3、什么是上网?爬虫要做的是什么?<br />我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。<br />3.1 只不过,用户获取网络数据的方式是:<br />浏览器提交请求->下载网页代码->解析/渲染成页面。<br />3.2 而爬虫程序要做的就是:<br />模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中<br />3.1与3.2的区别在于:<br />我们的爬虫程序只提取网页代码中对我们有用的数据<br />4、总结爬虫<br />4.1 爬虫的比喻:<br />如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据<br />4.2 爬虫的定义:<br />向网站发起请求,获取资源后分析并提取有用数据的程序 <br />4.3 爬虫的价值:<br />互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能,你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
2. 哪些语言可以实现爬虫
1.php:<br />可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆卖瓜的意思),但是php在实现爬虫中支持多线程和多进程方面做的不好。2.java:<br />可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。3.c、c++:<br />可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。4.python:<br />可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)且一句难以言表的好!没有但是!
4.爬虫应用
# 1.通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。<br /> 1)搜索引擎如何抓取互联网上的网站数据?<br /> a)门户网站主动向搜索引擎公司提供其网站的url<br /> b)搜索引擎公司与DNS服务商合作,获取网站的url<br /> c)门户网站主动挂靠在一些知名网站的友情链接中<br /># 2.聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。<br /> 例如:<br /> 获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
爬虫的基本流程
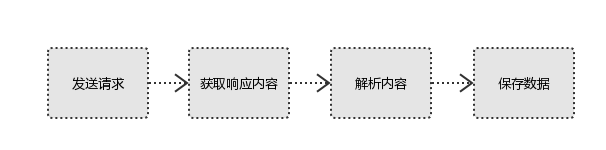
tip1:发送请求就是模拟浏览器发送请求,说明底层是怎么走的。请求需要用到请求库,请求库帮助我们实现了哪些功能。
1、发起请求: <br /> 使用http库向目标站点发起请求,即发送一个Request<br /> Request包含:请求头、请求体等<br />2、获取响应内容<br /> 如果服务器能正常响应,则会得到一个Response<br /> Response包含:html,json,图片,视频等<br />3、解析内容<br /> 解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等<br /> 解析json数据:json模块<br /> 解析二进制数据:以b的方式写入文件<br />4、保存数据<br /> 数据库<br /> 文件
请求和响应
tip2:使用浏览器访问百度解说。
URL:即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。<br />互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它<br />URL的格式由三部分组成:<br /> ①第一部分是协议(或称为服务方式)。<br /> ②第二部分是存有该资源的主机IP地址(有时也包括端口号)。<br /> ③第三部分是主机资源的具体地址,如目录和文件名等<br />http协议:<br /> https://www.cnblogs.com/kermit ... %3Bbr />robots协议: <br /> https://www.cnblogs.com/kermit ... %3Bbr />Request:<br /> 用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)<br />Response:<br /> 服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)<br />ps:<br /> 浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
要求
1、请求方式:<br /> 常用的请求方式:<br /> GET,POST<br /> 其他请求方式:<br /> HEAD,PUT,DELETE,OPTHONS<br /> ps:用浏览器演示get与post的区别,(用登录演示post)<br /> post与get请求最终都会拼接成这种形式:<br /> k1=xxx&k2=yyy&k3=zzz<br /> post请求的参数放在请求体内:<br /> 可用浏览器查看,存放于form data内<br /> get请求的参数直接放在url后2、请求url<br /> url全称统一资源定位符,如一个网页文档,一张图片<br /> 一个视频等都可以用url唯一来确定<br /> url编码: <br /> https://www.baidu.com/s?wd=图片<br /> 图片会被编码(看示例代码)<br /> 网页的加载过程是:<br /> 加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求。3、请求头<br /> User-agent:<br /> 请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户。<br /> Cookies:<br /> cookie用来保存登录信息。<br /> Referer:<br /> 浏览器上次访问的网页url<br /> 一般做爬虫都会加上请求头4、请求体<br /> 如果是get方式,请求体没有内容<br /> 如果是post方式,请求体是format data<br /> ps:<br /> 1、登录窗口,文件上传等,信息都会被附加到请求体内<br /> 2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
1、响应状态: <br /> 200:代表成功<br /> 301:代表跳转<br /> 404:文件不存在<br /> 403:权限<br /> 502:服务器错误2、响应头: Respone header<br /> set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来。3、网页源代码: preview<br /> 最主要的部分,包含了请求资源的内容,如网页html、图片和二进制数据等。
总结
1、总结爬虫流程:<br /> 爬取--->解析--->存储2、爬虫所需工具:<br /> 请求库:requests,selenium<br /> 解析库:正则,beautifulsoup,pyquery<br /> 存储库:文件,MySQL,Mongodb,Redis3、爬虫常用框架:<br /> scrapy
过去的亮点:
足够努力,梦想就会绽放 | 上海校区第9期全栈全日制python班开课,老司机带你删库逃跑 | 天天要闻 教你搭建游戏服务器(龙八手游) Python爬虫| 如何提高毛织布的爬行性能?
查看全部
php 爬虫抓取网页数据(
Python爬虫|如何实现爬虫4.的应用爬虫的基本流程
)

什么是爬行动物?

1. 爬虫介绍
'''
近年来,随着网络应用的逐渐扩展和深入,如何高效获取在线数据成为无数公司和个人的追求。在大数据时代,谁拥有更多的数据,谁就能获得更高的收益。网络爬虫是最常用的从网络上爬取数据的手段之一。
网络爬虫,或者Web Spider,是一个很形象的名字。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络蜘蛛通过它们的链接地址寻找网页。网站从某个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,以此类推以此类推,直到 网站 直到所有网页都被爬取为止。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
'''
1、什么是互联网?<br />互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样。2、互联网建立的目的?<br />互联网的核心价值在于数据的共享/传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿U盘去别人的计算机上拷贝数据了。3、什么是上网?爬虫要做的是什么?<br />我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。<br />3.1 只不过,用户获取网络数据的方式是:<br />浏览器提交请求->下载网页代码->解析/渲染成页面。<br />3.2 而爬虫程序要做的就是:<br />模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中<br />3.1与3.2的区别在于:<br />我们的爬虫程序只提取网页代码中对我们有用的数据<br />4、总结爬虫<br />4.1 爬虫的比喻:<br />如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据<br />4.2 爬虫的定义:<br />向网站发起请求,获取资源后分析并提取有用数据的程序 <br />4.3 爬虫的价值:<br />互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能,你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
2. 哪些语言可以实现爬虫
1.php:<br />可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆卖瓜的意思),但是php在实现爬虫中支持多线程和多进程方面做的不好。2.java:<br />可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。3.c、c++:<br />可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。4.python:<br />可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)且一句难以言表的好!没有但是!
4.爬虫应用
# 1.通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。<br /> 1)搜索引擎如何抓取互联网上的网站数据?<br /> a)门户网站主动向搜索引擎公司提供其网站的url<br /> b)搜索引擎公司与DNS服务商合作,获取网站的url<br /> c)门户网站主动挂靠在一些知名网站的友情链接中<br /># 2.聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。<br /> 例如:<br /> 获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
爬虫的基本流程
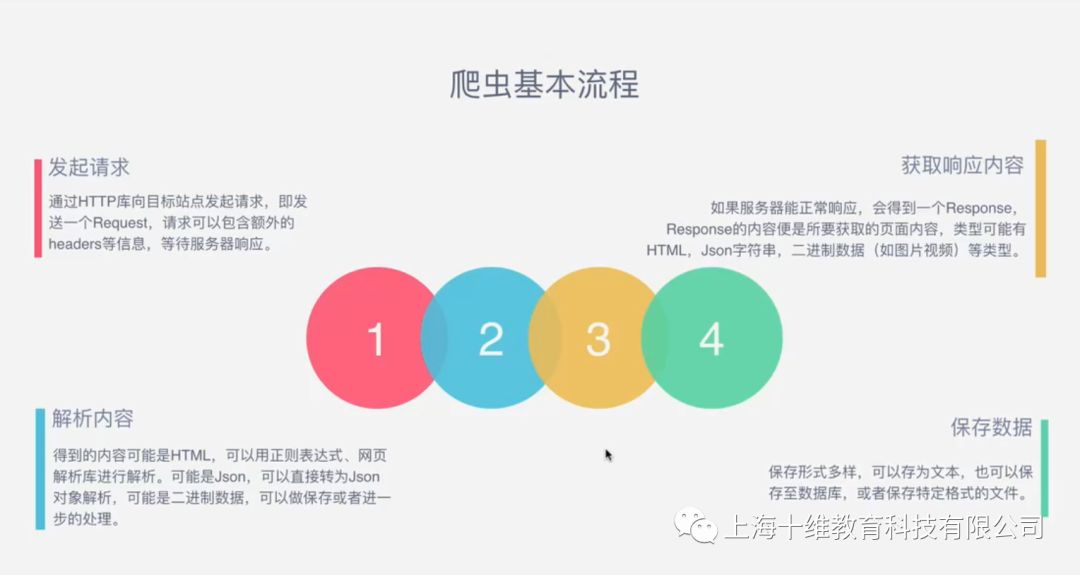
tip1:发送请求就是模拟浏览器发送请求,说明底层是怎么走的。请求需要用到请求库,请求库帮助我们实现了哪些功能。
1、发起请求: <br /> 使用http库向目标站点发起请求,即发送一个Request<br /> Request包含:请求头、请求体等<br />2、获取响应内容<br /> 如果服务器能正常响应,则会得到一个Response<br /> Response包含:html,json,图片,视频等<br />3、解析内容<br /> 解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等<br /> 解析json数据:json模块<br /> 解析二进制数据:以b的方式写入文件<br />4、保存数据<br /> 数据库<br /> 文件
请求和响应
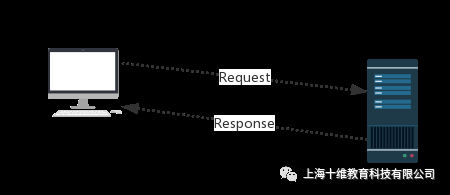
tip2:使用浏览器访问百度解说。
URL:即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。<br />互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它<br />URL的格式由三部分组成:<br /> ①第一部分是协议(或称为服务方式)。<br /> ②第二部分是存有该资源的主机IP地址(有时也包括端口号)。<br /> ③第三部分是主机资源的具体地址,如目录和文件名等<br />http协议:<br /> https://www.cnblogs.com/kermit ... %3Bbr />robots协议: <br /> https://www.cnblogs.com/kermit ... %3Bbr />Request:<br /> 用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)<br />Response:<br /> 服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)<br />ps:<br /> 浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
要求
1、请求方式:<br /> 常用的请求方式:<br /> GET,POST<br /> 其他请求方式:<br /> HEAD,PUT,DELETE,OPTHONS<br /> ps:用浏览器演示get与post的区别,(用登录演示post)<br /> post与get请求最终都会拼接成这种形式:<br /> k1=xxx&k2=yyy&k3=zzz<br /> post请求的参数放在请求体内:<br /> 可用浏览器查看,存放于form data内<br /> get请求的参数直接放在url后2、请求url<br /> url全称统一资源定位符,如一个网页文档,一张图片<br /> 一个视频等都可以用url唯一来确定<br /> url编码: <br /> https://www.baidu.com/s?wd=图片<br /> 图片会被编码(看示例代码)<br /> 网页的加载过程是:<br /> 加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求。3、请求头<br /> User-agent:<br /> 请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户。<br /> Cookies:<br /> cookie用来保存登录信息。<br /> Referer:<br /> 浏览器上次访问的网页url<br /> 一般做爬虫都会加上请求头4、请求体<br /> 如果是get方式,请求体没有内容<br /> 如果是post方式,请求体是format data<br /> ps:<br /> 1、登录窗口,文件上传等,信息都会被附加到请求体内<br /> 2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
1、响应状态: <br /> 200:代表成功<br /> 301:代表跳转<br /> 404:文件不存在<br /> 403:权限<br /> 502:服务器错误2、响应头: Respone header<br /> set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来。3、网页源代码: preview<br /> 最主要的部分,包含了请求资源的内容,如网页html、图片和二进制数据等。
总结
1、总结爬虫流程:<br /> 爬取--->解析--->存储2、爬虫所需工具:<br /> 请求库:requests,selenium<br /> 解析库:正则,beautifulsoup,pyquery<br /> 存储库:文件,MySQL,Mongodb,Redis3、爬虫常用框架:<br /> scrapy

过去的亮点:
足够努力,梦想就会绽放 | 上海校区第9期全栈全日制python班开课,老司机带你删库逃跑 | 天天要闻 教你搭建游戏服务器(龙八手游) Python爬虫| 如何提高毛织布的爬行性能?


php 爬虫抓取网页数据(我用爬虫一天时间“偷了”知乎一百万用户 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-05 04:12
)
前几天,老板让我去抓拍大众点评某店的数据。当然,我理所当然地拒绝了它,理由是我不会。. . 但是我的抗拒也没用,所以还是去查资料,因为我是做php的,首先要找的是php的网络爬虫源码。经过我不懈的努力,终于找到了phpspider,打开phpspider开发文档我惊呆了首页,标题“我用爬虫“偷”了知乎100万用户,只为证明PHP是世界上最好的语言”,正如我所料,PHP 是世界上最好的语言。事不宜迟,让我们开始学习如何使用它。
首先要看的是提供的一个demo,代码如下:
$configs = array(
'name' => '糗事百科',
'domains' => array(
'qiushibaike.com',
'www.qiushibaike.com' ), 'scan_urls' => array( 'http://www.qiushibaike.com/' ), 'content_url_regexes' => array( "http://www.qiushibaike.com/article/\d+" ), 'list_url_regexes' => array( "http://www.qiushibaike.com/8hr/page/\d+\?s=\d+" ), 'fields' => array( array( // 抽取内容页的文章内容 'name' => "article_content", 'selector' => "//*[@id='single-next-link']", 'required' => true ), array( // 抽取内容页的文章作者 'name' => "article_author", 'selector' => "//div[contains(@class,'author')]//h2", 'required' => true ), ), ); $spider = new phpspider($configs); $spider->start();
每个具体的信息大家可以去查一下,哪里比较详细,这里只是我走的弯路,
domains是定义采集的域名,只在该域名下采集,
content_url_regexes是采集的内容页,使用chrome查看网页源码,然后使用selector选择器定位,selector使用xpath格式定位参数,当然也可以用css来选择。
'max_try' => 5,
'export' => array(
'type' => 'db',
'conf' => array(
'host' => 'localhost',
'port' => 3306,
'user' => 'root',
'pass' => 'root',
'name' => 'demo',
),
'table' => '360ky', ),
max_try 同时工作的爬虫任务数。
export采集数据存储,有两种格式,一种是写到数据库中,一种是直接生成.csv格式文件。
只要url规则写的对,就可以运行,不用管框架里面的封装。当然,此框架只能在php-cli命令行下运行,所以使用前要先配置环境变量,或者cd到php安装路径运行。
最后成功采集到大众点评某点的一千多条数据。 查看全部
php 爬虫抓取网页数据(我用爬虫一天时间“偷了”知乎一百万用户
)
前几天,老板让我去抓拍大众点评某店的数据。当然,我理所当然地拒绝了它,理由是我不会。. . 但是我的抗拒也没用,所以还是去查资料,因为我是做php的,首先要找的是php的网络爬虫源码。经过我不懈的努力,终于找到了phpspider,打开phpspider开发文档我惊呆了首页,标题“我用爬虫“偷”了知乎100万用户,只为证明PHP是世界上最好的语言”,正如我所料,PHP 是世界上最好的语言。事不宜迟,让我们开始学习如何使用它。
首先要看的是提供的一个demo,代码如下:

$configs = array(
'name' => '糗事百科',
'domains' => array(
'qiushibaike.com',
'www.qiushibaike.com' ), 'scan_urls' => array( 'http://www.qiushibaike.com/' ), 'content_url_regexes' => array( "http://www.qiushibaike.com/article/\d+" ), 'list_url_regexes' => array( "http://www.qiushibaike.com/8hr/page/\d+\?s=\d+" ), 'fields' => array( array( // 抽取内容页的文章内容 'name' => "article_content", 'selector' => "//*[@id='single-next-link']", 'required' => true ), array( // 抽取内容页的文章作者 'name' => "article_author", 'selector' => "//div[contains(@class,'author')]//h2", 'required' => true ), ), ); $spider = new phpspider($configs); $spider->start();
每个具体的信息大家可以去查一下,哪里比较详细,这里只是我走的弯路,
domains是定义采集的域名,只在该域名下采集,
content_url_regexes是采集的内容页,使用chrome查看网页源码,然后使用selector选择器定位,selector使用xpath格式定位参数,当然也可以用css来选择。
'max_try' => 5,
'export' => array(
'type' => 'db',
'conf' => array(
'host' => 'localhost',
'port' => 3306,
'user' => 'root',
'pass' => 'root',
'name' => 'demo',
),
'table' => '360ky', ),
max_try 同时工作的爬虫任务数。
export采集数据存储,有两种格式,一种是写到数据库中,一种是直接生成.csv格式文件。
只要url规则写的对,就可以运行,不用管框架里面的封装。当然,此框架只能在php-cli命令行下运行,所以使用前要先配置环境变量,或者cd到php安装路径运行。
最后成功采集到大众点评某点的一千多条数据。
php 爬虫抓取网页数据( 网络爬虫的项目地址是什么?如何爬取网站?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-04 11:05
网络爬虫的项目地址是什么?如何爬取网站?)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。现在让我们一起学习这个。
1.Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。. 使用此框架可以轻松爬取亚马逊列表等数据。
项目地址:
2.PySpider
pyspider 是一个用 python 实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
项目地址:
3.克劳利
Crawley可以高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
项目地址:
4.波西亚
Portia 是一个开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。
项目地址:
5.报纸
报纸可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
项目地址:
6.美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的营业时间。
项目地址:
7.抢
Grab 是一个用于构建网络爬虫的 Python 框架。使用 Grab,您可以构建各种复杂的网络爬虫,从简单的 5 行脚本到处理数百万网页的复杂异步网站爬虫。Grab 提供了一个用于执行网络请求和处理接收到的内容的 API,例如与 HTML 文档的 DOM 树进行交互。
项目地址:#grab-spider-user-manual
8.可乐
Cola 是一个分布式爬虫框架。对于用户来说,只需要编写几个具体的功能,无需关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。
项目地址:
感谢阅读,希望大家受益。
转载至:
推荐教程:《python教程》
以上就是史上最高效的Python爬虫框架(推荐)的详细内容。更多详情请关注php中文网文章其他相关话题!
声明:本文转载于:CSDN,如有侵权,请联系删除 查看全部
php 爬虫抓取网页数据(
网络爬虫的项目地址是什么?如何爬取网站?)

网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。现在让我们一起学习这个。
1.Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。. 使用此框架可以轻松爬取亚马逊列表等数据。

项目地址:
2.PySpider
pyspider 是一个用 python 实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
项目地址:
3.克劳利
Crawley可以高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。

项目地址:
4.波西亚
Portia 是一个开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。
项目地址:
5.报纸
报纸可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
项目地址:
6.美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的营业时间。
项目地址:
7.抢
Grab 是一个用于构建网络爬虫的 Python 框架。使用 Grab,您可以构建各种复杂的网络爬虫,从简单的 5 行脚本到处理数百万网页的复杂异步网站爬虫。Grab 提供了一个用于执行网络请求和处理接收到的内容的 API,例如与 HTML 文档的 DOM 树进行交互。
项目地址:#grab-spider-user-manual
8.可乐
Cola 是一个分布式爬虫框架。对于用户来说,只需要编写几个具体的功能,无需关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。
项目地址:
感谢阅读,希望大家受益。
转载至:
推荐教程:《python教程》
以上就是史上最高效的Python爬虫框架(推荐)的详细内容。更多详情请关注php中文网文章其他相关话题!

声明:本文转载于:CSDN,如有侵权,请联系删除
php 爬虫抓取网页数据( 百度排名算法中有哪些是不可用数字来量化的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-02 10:11
百度排名算法中有哪些是不可用数字来量化的?)
话题:
1.你认为百度在删除重复网页时会考虑什么?
2.你觉得百度如何分析网站的用户体验?
3.你觉得百度会根据排名给网站分配CTR任务吗?
4. 一个纯粹的采集 网站,在短时间内获得了不错的流量,并且稳定了几个月。之后被降级,没有任何排名,但两个多月后,排名再次发生变化。回到首页,不做任何修改或操作,让它自动挂在那里采集。Q:既然百度已经检测到网站的质量很差,为什么排在后面?
5、购物网站移动台的产品列表页面使用异步加载数据。对SEO有什么不利影响?具体如何解决?
6、机器人有/A/目录,为什么不能完全阻止搜索引擎爬取A目录下的文件?请从技术层面分享原因。
7、简析CDN对搜索引擎爬虫爬取量的影响?并给出应对负面影响的具体解决方案?
8、我们知道百度的一些排名算法是可以量化的:比如外链数、外链域名数、每日更新数等等,有哪些数字是不可用的在百度的排名算法中?量化?
9、您如何定义网站 SEO 的好坏。
10、品牌词被人搭讪,甚至在排名上超过你,你会怎么做!
话题:
1 303和307跳有什么区别,百度怎么看?
2 使用Apache环境和代码适配网站,.htaccess怎么写可以返回百度可以识别的Vary HTTP header;
3 Adober Flash palye 10.0或更高版本的swf在https环境下请求远程服务器资源,是否会发送referer信息;
4 在早期浏览器中,如何绕过浏览器权限/提示允许用户点击按钮复制信息;
5 公认的观点,在哪种文件处理类型中nginx比apahce性能更好,可以列出两个;
6 按方向分,常见的三种机械分词方法有哪些?对于中文,基于一般实验,( )方向法的准确度要高于( )方向法;
7 在不依赖客户端的前提下,列出一个PC端IE6~IE11、Microsoft Edge、FireFox以及所有Chromium内核浏览器都支持的网络录制方案,写出一个可行的思路;
8 在 PHP 中:
$a='abc';
$a="abc";
哪个执行效率更高;
9 haddop2.0 版本前自带一个经典案例,号称“Mapreduce版”的“Hello Word”,站长SEOer能做什么;
10 在早期的浏览器中,直接在HTML中使用style="XX"可能会影响页面的哪一部分被加载,从而影响打开页面的速度;
嗯,今天就跟大家分享一下这个方法,如果你不明白 查看全部
php 爬虫抓取网页数据(
百度排名算法中有哪些是不可用数字来量化的?)
话题:
1.你认为百度在删除重复网页时会考虑什么?
2.你觉得百度如何分析网站的用户体验?
3.你觉得百度会根据排名给网站分配CTR任务吗?
4. 一个纯粹的采集 网站,在短时间内获得了不错的流量,并且稳定了几个月。之后被降级,没有任何排名,但两个多月后,排名再次发生变化。回到首页,不做任何修改或操作,让它自动挂在那里采集。Q:既然百度已经检测到网站的质量很差,为什么排在后面?
5、购物网站移动台的产品列表页面使用异步加载数据。对SEO有什么不利影响?具体如何解决?
6、机器人有/A/目录,为什么不能完全阻止搜索引擎爬取A目录下的文件?请从技术层面分享原因。
7、简析CDN对搜索引擎爬虫爬取量的影响?并给出应对负面影响的具体解决方案?
8、我们知道百度的一些排名算法是可以量化的:比如外链数、外链域名数、每日更新数等等,有哪些数字是不可用的在百度的排名算法中?量化?
9、您如何定义网站 SEO 的好坏。
10、品牌词被人搭讪,甚至在排名上超过你,你会怎么做!
话题:
1 303和307跳有什么区别,百度怎么看?
2 使用Apache环境和代码适配网站,.htaccess怎么写可以返回百度可以识别的Vary HTTP header;
3 Adober Flash palye 10.0或更高版本的swf在https环境下请求远程服务器资源,是否会发送referer信息;
4 在早期浏览器中,如何绕过浏览器权限/提示允许用户点击按钮复制信息;
5 公认的观点,在哪种文件处理类型中nginx比apahce性能更好,可以列出两个;
6 按方向分,常见的三种机械分词方法有哪些?对于中文,基于一般实验,( )方向法的准确度要高于( )方向法;
7 在不依赖客户端的前提下,列出一个PC端IE6~IE11、Microsoft Edge、FireFox以及所有Chromium内核浏览器都支持的网络录制方案,写出一个可行的思路;
8 在 PHP 中:
$a='abc';
$a="abc";
哪个执行效率更高;
9 haddop2.0 版本前自带一个经典案例,号称“Mapreduce版”的“Hello Word”,站长SEOer能做什么;
10 在早期的浏览器中,直接在HTML中使用style="XX"可能会影响页面的哪一部分被加载,从而影响打开页面的速度;
嗯,今天就跟大家分享一下这个方法,如果你不明白
php 爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-01 19:18
)
首先,我们需要知道什么是爬虫!当我第一次听到爬虫这个词时,我以为它是一种爬行昆虫。想想就觉得可笑……后来才知道是网上的数据抓取工具!
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫能做什么?
1、模拟浏览器打开网页,获取网页中我们想要的部分数据。
2、从技术角度,程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据,存储和使用。
3、仔细观察不难发现,越来越多的人知道和了解爬虫。一方面,可以从互联网上获取越来越多的数据。另一方面,像 Python 这样的编程语言提供了越来越多优秀的工具,让爬虫变得简单易用。
4、利用爬虫,我们可以获取大量有价值的数据,从而获取感性知识无法获取的信息,例如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上图,这就是爬取数据时的流程,是不是很简单?因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析过滤来获取我们想要的资源。
相关学习推荐:python教程
以上就是python爬虫能做什么的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php 爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人)(图)
)
首先,我们需要知道什么是爬虫!当我第一次听到爬虫这个词时,我以为它是一种爬行昆虫。想想就觉得可笑……后来才知道是网上的数据抓取工具!

网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫能做什么?
1、模拟浏览器打开网页,获取网页中我们想要的部分数据。
2、从技术角度,程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据,存储和使用。
3、仔细观察不难发现,越来越多的人知道和了解爬虫。一方面,可以从互联网上获取越来越多的数据。另一方面,像 Python 这样的编程语言提供了越来越多优秀的工具,让爬虫变得简单易用。
4、利用爬虫,我们可以获取大量有价值的数据,从而获取感性知识无法获取的信息,例如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上图,这就是爬取数据时的流程,是不是很简单?因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析过滤来获取我们想要的资源。
相关学习推荐:python教程
以上就是python爬虫能做什么的详细内容。更多详情请关注php中文网文章其他相关话题!
php 爬虫抓取网页数据(大数据行业数据价值不言而喻的技术总结及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-31 10:19
摘要:对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据是弥补其先天数据短板的最佳选择,本文主要从原理、架构、分类、反爬虫技术等方面总结了爬虫技术履带式。
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发使Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium + phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
5、参考资料
[1] 网络爬虫基本原理 查看全部
php 爬虫抓取网页数据(大数据行业数据价值不言而喻的技术总结及解决办法!)
摘要:对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据是弥补其先天数据短板的最佳选择,本文主要从原理、架构、分类、反爬虫技术等方面总结了爬虫技术履带式。
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。

2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。

网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD

2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发使Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。

上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium + phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
5、参考资料
[1] 网络爬虫基本原理
php 爬虫抓取网页数据(一个_selector.xpath.u去重与增量爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-31 10:14
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能被Xpath提取出来,所以也需要定期匹配。如果有异常,必须处理。一般当页面无法匹配到对应字段时,应设置为0,待到item后处理。过滤处理。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:
(1)从待爬取队列中获取url
(2)判断要请求的url是否已经爬取,如果已经爬取则忽略请求,未爬取,继续其他操作,将url插入爬取队列
(3)重复步骤 1
这里我们使用了scrapy-redis的去重组件,所以还没有实现,但是原理还是需要了解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫类反屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为
系统采用以下方法防止爬虫被屏蔽:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.本着君子的约定,降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们屏蔽了cookies的调整,这也有利于我们的身份分歧。
5.人工编码,这应该是无可挑剔的反封杀措施,所有系统都比人工操作好不了多少,只是降低了自动化,效率不高,但确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码以重新访问该页面。为此,我添加了一个邮件提醒模块。当爬虫被封禁时,会发送邮件提醒管理员解除封禁。同时将重定向的请求重新加入下载队列进行爬取,以保证数据的完整性。
防爬虫网站屏蔽原理如下图所示:
(a) 模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性
首先是扩展下载中间件。首先,将中间件添加到seeings.py。
二、扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为列表,如下图:
然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。
总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。
首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1.代理ip池的设计开发流程如下:
一种。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行验证
d。如果达到最大ips数,停止爬取,一定时间后验证数据ips的有效性,删除无效ips
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip模块这里使用七夜代理ip池的开源项目
代理ip爬虫运行截图:
(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有各种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,阻塞组件这是通过捕获 302 状态来实现的。同时,异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:
(d) 数据存储模块
数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。
Scrapy 支持 json、csv、xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:
(e) 抓取场地设计
本文以网络房屋数据为捕获目标,从机端解析捕获现场数据。因此,捕获的内容必须能够客观、准确地反映网络房屋数据的特征。
以抓取58同城的在线房屋数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
现场选择主要是根据本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。降低单机压力。
(f) 数据处理
1)对象定义器
Item 是定义抓取数据的容器。通过创建一个 scrapy.item.Item 类来声明。将该属性定义为一个scrapy.item.Field对象来控制通过实例化所需item获得的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、地点、社区、城市、帖子详情页链接、发布时间。这里对字段的定义是根据数据处理端的需要来定义的。关键代码如下:
class TcZufangItem(Item):
#帖子名称
title=Field()
#租金
money=Field()
#租赁方式
method=Field()
#所在区域
area=Field()
#所在小区
community=Field()
#帖子详情url
targeturl=Field()
#帖子发布时间
pub_time=Field()
#所在城市
city=Field()
2)数据处理程序
保存和输出数据的方法在 Pipeline 类中定义。从 Spider 的 parse 方法返回的 Item 中,数据将被处理并以 ITEM_PIPELINES 列表中 Pipeline 类对应的顶层格式输出。系统发回管道的数据使用Mongodb存储。关键代码如下:
def process_item(self, item, spider):
if item['pub_time'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['method'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['community']==0:
raise DropItem("Duplicate item found: %s" % item)
if item['money']==0:
raise DropItem("Duplicate item found: %s" % item)
if item['area'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['city'] == 0:
raise DropItem("Duplicate item found: %s" % item)
zufang_detail = {
'title': item.get('title'),
'money': item.get('money'),
'method': item.get('method'),
'area': item.get('area', ''),
'community': item.get('community', ''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time', ''),
'city':item.get('city','')
}
result = self.db['zufang_detail'].insert(zufang_detail)
print '[success] the '+item['targeturl']+'wrote to MongoDB database'
return item
(g) 数据可视化设计
实际上,数据的可视化就是将数据库的数据转换成便于我们用户观察的形式。本系统使用 Mongodb 存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:
四、系统操作
系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
Master运行截图:
从端运行截图:
五、系统部署
环境部署,因为分布式部署所需的环境类似,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像部署爬虫,使用Daocloud上的scrapy-env pair。该程序已部署。具体的docker部署过程可以参考网上。 查看全部
php 爬虫抓取网页数据(一个_selector.xpath.u去重与增量爬取)
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能被Xpath提取出来,所以也需要定期匹配。如果有异常,必须处理。一般当页面无法匹配到对应字段时,应设置为0,待到item后处理。过滤处理。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:

(1)从待爬取队列中获取url
(2)判断要请求的url是否已经爬取,如果已经爬取则忽略请求,未爬取,继续其他操作,将url插入爬取队列
(3)重复步骤 1
这里我们使用了scrapy-redis的去重组件,所以还没有实现,但是原理还是需要了解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫类反屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为
系统采用以下方法防止爬虫被屏蔽:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.本着君子的约定,降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们屏蔽了cookies的调整,这也有利于我们的身份分歧。
5.人工编码,这应该是无可挑剔的反封杀措施,所有系统都比人工操作好不了多少,只是降低了自动化,效率不高,但确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码以重新访问该页面。为此,我添加了一个邮件提醒模块。当爬虫被封禁时,会发送邮件提醒管理员解除封禁。同时将重定向的请求重新加入下载队列进行爬取,以保证数据的完整性。
防爬虫网站屏蔽原理如下图所示:

(a) 模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性
首先是扩展下载中间件。首先,将中间件添加到seeings.py。
二、扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为列表,如下图:

然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。

总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。
首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1.代理ip池的设计开发流程如下:

一种。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行验证
d。如果达到最大ips数,停止爬取,一定时间后验证数据ips的有效性,删除无效ips
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip模块这里使用七夜代理ip池的开源项目
代理ip爬虫运行截图:

(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有各种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,阻塞组件这是通过捕获 302 状态来实现的。同时,异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:

(d) 数据存储模块
数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。
Scrapy 支持 json、csv、xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:

(e) 抓取场地设计
本文以网络房屋数据为捕获目标,从机端解析捕获现场数据。因此,捕获的内容必须能够客观、准确地反映网络房屋数据的特征。
以抓取58同城的在线房屋数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
现场选择主要是根据本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。降低单机压力。
(f) 数据处理
1)对象定义器
Item 是定义抓取数据的容器。通过创建一个 scrapy.item.Item 类来声明。将该属性定义为一个scrapy.item.Field对象来控制通过实例化所需item获得的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、地点、社区、城市、帖子详情页链接、发布时间。这里对字段的定义是根据数据处理端的需要来定义的。关键代码如下:
class TcZufangItem(Item):
#帖子名称
title=Field()
#租金
money=Field()
#租赁方式
method=Field()
#所在区域
area=Field()
#所在小区
community=Field()
#帖子详情url
targeturl=Field()
#帖子发布时间
pub_time=Field()
#所在城市
city=Field()
2)数据处理程序
保存和输出数据的方法在 Pipeline 类中定义。从 Spider 的 parse 方法返回的 Item 中,数据将被处理并以 ITEM_PIPELINES 列表中 Pipeline 类对应的顶层格式输出。系统发回管道的数据使用Mongodb存储。关键代码如下:
def process_item(self, item, spider):
if item['pub_time'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['method'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['community']==0:
raise DropItem("Duplicate item found: %s" % item)
if item['money']==0:
raise DropItem("Duplicate item found: %s" % item)
if item['area'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['city'] == 0:
raise DropItem("Duplicate item found: %s" % item)
zufang_detail = {
'title': item.get('title'),
'money': item.get('money'),
'method': item.get('method'),
'area': item.get('area', ''),
'community': item.get('community', ''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time', ''),
'city':item.get('city','')
}
result = self.db['zufang_detail'].insert(zufang_detail)
print '[success] the '+item['targeturl']+'wrote to MongoDB database'
return item
(g) 数据可视化设计
实际上,数据的可视化就是将数据库的数据转换成便于我们用户观察的形式。本系统使用 Mongodb 存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:


四、系统操作
系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
Master运行截图:

从端运行截图:

五、系统部署
环境部署,因为分布式部署所需的环境类似,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像部署爬虫,使用Daocloud上的scrapy-env pair。该程序已部署。具体的docker部署过程可以参考网上。
php 爬虫抓取网页数据( 图片来源网络抓取策略(一)(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-30 03:07
图片来源网络抓取策略(一)(1)_光明网(组图))
图片来源网络
抓取策略
在爬虫系统中,待爬取的 URL 是非常重要的部分。需要爬虫爬取的网页的URL排列在其中,形成队列结构。调度器每次从队列头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被附加到待爬取URL队列的末尾,从而形成一个爬取循环,整个爬虫系统可以说是由这个队列驱动的。
URL队列中待爬取的页面URL的顺序是如何确定的?如上所述,将新下载页面中收录的链接附加到队列末尾。虽然这是一种确定队列中 URL 顺序的方法,但它不是唯一的方法。事实上,也可以采用许多其他技术。获取的 URL 已排序。爬虫的不同爬取策略使用不同的方法来确定待爬取URL队列中URL的优先级顺序。
爬虫的爬取策略有很多,但不管是什么方法,基本目标都是一样的:优先选择重要的网页进行爬取。在爬虫系统中,所谓网页的重要性可以通过不同的方法来判断,但大多是根据网页的流行度来定义的。
爬取策略的方法虽然有很多种,但这里只对已经证明有效或者比较有代表性的方案进行说明,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略和大站点优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。自搜索引擎爬虫出现以来,它就被采用了。新提出的爬取策略经常以这种方法为基准。但值得注意的是,这种策略也是一种非常强大的方法。很多新方法的实际效果不一定比广度优先遍历策略好,所以这个方法其实是目前很多爬虫采用的第一个爬取策略。
如前所述,“将新下载的网页中收录的URL附加到待爬取URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法没有明确提出并以网页的重要性作为衡量标准,只是机械地从新下载的网页中提取链接,并作为下载的URL序列附加到待爬取的URL队列中。下图是这个策略的示意图: 假设队列最前面的网页是1号网页,从1号网页中提取三个链接分别指向2号、3号和1号. 4 分别,所以它们是按照要抓取的数字的顺序排列的。在获取队列中,
实验表明,这种策略效果很好。虽然看起来很机械,但实际的网页爬取顺序基本上是按照网页的重要性排序的。这样做的原因是,有研究人员认为,如果一个网页收录大量的传入链接,则更有可能被广度优先遍历策略及早捕获,而传入链接的数量从侧面,也就是广度优先的遍历策略其实上面也隐含了一些页面优先级的假设。
广度优先遍历策略
02 不完整的PageRank策略
PageRank 是一种著名的链接分析算法,可以用来衡量网页的重要性。很自然会想到PageRank对URL进行优先排序的思路。但是这里有一个问题,PageRank是一个全局算法,也就是说,当所有网页都下载完后,计算结果是可靠的,而爬虫的目的是下载网页,而只有一部分在运行过程中可以看到页面。,因此处于爬取阶段的页面无法获得可靠的 PageRank 分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,连同待爬取的URL队列中的URL,形成一组网页,在这个集合中进行PageRank计算。计算完成后,待爬取的 URL 队列将根据 PageRank 得分从高到低对网页进行排序,形成的序列就是爬虫接下来应该爬取的 URL 列表。这就是为什么它被称为“不完整的PageRank”。
如果每次爬取一个新的网页,就为所有下载的网页重新计算新的不完整PageRank值,这在现实中显然效率太低,不可行。一个折衷方案是:每次有足够的K个页面下载,然后对所有下载的页面重新计算新的不完整PageRank。这种计算效率勉强可以接受,但也带来了新的问题:在开始下一轮PageRank计算之前,从新下载的网页中提取收录的链接。很有可能这些环节非常重要,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 为这些新提取的页面分配一个临时的 PageRank 值但没有 PageRank 值,并将本页所有入站链接的PageRank值作为临时PageRank值。如果是PageRank值高的页面,先下载URL。
下图是不完全PageRank策略的简化示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时{P1,P2,P3}3个网页已经下载到本地,这3个网页中收录的链接指向{P4,P5,P6},形成了一个待抓取的URL队列。如何决定下载顺序?将六个网页组成一个新的集合,并为该集合计算PageRank值。这样,P4、P5和P6就得到了它们对应的PageRank值,可以从大到小排序得到它们的下载顺序。这里可以假设下载顺序为:P5、P4、P6,下载P5页面时,提取链接指向P8页面。此时,一个临时的 PageRank 值被分配给 P8。如果这个值大于P4和P6,如果PageRank值更高,那么先下载P8。在这个连续的循环中,形成了不完全PageRank策略的计算思路。
不完整的PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明不完整的PageRank结果稍好一些,而一些实验结果正好相反。一些研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大的不同。不应作为计算抓取过程中 URL 重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC 字面意思是“在线页面重要性计算”,可以认为是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被赋予了相同的“现金”,每当某个页面P被下载时,P就会将其拥有的“现金”平均分配给该页面所收录的链接页面,并分配自己的“现金” “空。至于待爬取的URL队列中的网页,按照手头现金数量排序,现金最充裕的网页优先下载。OPIC与PageRank基本一致就大框架而言,不同的是PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对于没有链接关系的网页有一个长距离的跳转过程,但是OPIC没有这个计算因子。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略优于广度优先遍历策略。
04 大站优先战略
大站点优先策略的思路很简单:以网站为单位衡量网页的重要性。对于URL队列中待爬取的网页,按照所属的网站进行分类。如果有任何 网站 正在等待下载,如果页面数量最多,则将首先下载这些链接。基本思路是先下载大网站,因为大网站往往收录更多页面。鉴于大型网站往往是知名公司的内容,其网页质量普遍较高,这个思路虽然简单,但有一定的依据。实验表明,该算法的效果略好于广度优先遍历策略。
网页更新策略
互联网的动态特性是其显着特征。随时出现新页面,更改页面内容或删除原创页面。对于爬虫来说,即使任务完成,也不必在本地爬取网页,也能体现互联网的动态性。本地下载的页面可视为互联网页面的“镜像”,爬虫应尽可能保证一致性。可以假设这样一种情况:一个网页被删除或者内容发生了重大变化,而搜索引擎对此一无所知,仍然按照旧的内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取的网页,
网页更新策略的任务是决定何时重新爬取下载的网页,使本地下载的网页和互联网上的原创网页的内容尽可能一致。常用的网页更新策略有三种:历史参考策略、用户体验策略和整群抽样策略。
01历史参考策略
历史参考策略是最直观的更新策略,它基于以下假设:过去频繁更新的网页,未来也会频繁更新。因此,为了估计网页何时更新,可以参考历史更新情况来做出决定。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时再次发生变化,从而指导爬虫的爬取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,重点关注内容变化检测和建模。优越的。
02用户体验策略
一般来说,搜索引擎用户提交查询后,可能会有上千条相关搜索结果,而用户没有耐心等着查看后面的搜索结果,可能只会看前3页搜索内容。用户体验策略就是利用用户的这一特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,以后更新这些过时的网页也不错。因此,最好根据网页内容的变化(通常以搜索结果的排名变化来衡量)带来的搜索质量变化来判断网页何时更新。影响力越大的网页,更新速度越快。
用户体验策略保存网页的多个历史版本,根据过去每次内容变化对搜索质量的影响取一个平均值,作为判断爬虫重新访问时机的参考抓取网页。网页,优先级越高是计划重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略在很大程度上依赖于网页的历史更新信息,这是后续计算的基础。然而实际上,对于每个网页保存其历史信息,搜索系统会增加很多额外的负担。换个角度看,如果是第一次爬取的网页,因为没有历史信息,不可能按照这两种思路估计更新周期。为解决上述不足,提出了整群抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测更新周期,属性相似的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,同一类别内的网页具有相同的更新频率。为了计算某个类别的更新周期,只需要对该类别中的网页进行采样,将这些采样的网页的更新周期作为该类别中所有网页的更新周期。与上述两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,
下图描述了聚类抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页具有相似的更新周期。从类别中提取一部分最具代表性的网页(一般是提取离类别中心最近的那些网页),并计算这些网页的更新周期,然后将这个更新周期用于该类别中的所有网页类别,然后可以根据网页的类别使用更新周期。确定其更新周期。
整群抽样策略
网页更新周期的属性特征分为静态特征和动态特征两类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,比如图片数量的变化、进出链接的变化等。网页可以根据这两类特征进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,一些研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一个网站的网页具有相同的更新周期,则< @网站 采样,计算更新周期,然后网站 中的所有网页都会以这个更新周期为准。虽然这个假设是粗略的,因为很明显同一个网站内的网页的更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类非常困难。
如果你对爬虫感兴趣,还可以阅读:
干货全流程| 入门级爬虫技术原理,这就够了
网络爬虫 | 你不知道的暗网是怎么爬的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗? 查看全部
php 爬虫抓取网页数据(
图片来源网络抓取策略(一)(1)_光明网(组图))

图片来源网络
抓取策略
在爬虫系统中,待爬取的 URL 是非常重要的部分。需要爬虫爬取的网页的URL排列在其中,形成队列结构。调度器每次从队列头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被附加到待爬取URL队列的末尾,从而形成一个爬取循环,整个爬虫系统可以说是由这个队列驱动的。
URL队列中待爬取的页面URL的顺序是如何确定的?如上所述,将新下载页面中收录的链接附加到队列末尾。虽然这是一种确定队列中 URL 顺序的方法,但它不是唯一的方法。事实上,也可以采用许多其他技术。获取的 URL 已排序。爬虫的不同爬取策略使用不同的方法来确定待爬取URL队列中URL的优先级顺序。
爬虫的爬取策略有很多,但不管是什么方法,基本目标都是一样的:优先选择重要的网页进行爬取。在爬虫系统中,所谓网页的重要性可以通过不同的方法来判断,但大多是根据网页的流行度来定义的。
爬取策略的方法虽然有很多种,但这里只对已经证明有效或者比较有代表性的方案进行说明,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略和大站点优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。自搜索引擎爬虫出现以来,它就被采用了。新提出的爬取策略经常以这种方法为基准。但值得注意的是,这种策略也是一种非常强大的方法。很多新方法的实际效果不一定比广度优先遍历策略好,所以这个方法其实是目前很多爬虫采用的第一个爬取策略。
如前所述,“将新下载的网页中收录的URL附加到待爬取URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法没有明确提出并以网页的重要性作为衡量标准,只是机械地从新下载的网页中提取链接,并作为下载的URL序列附加到待爬取的URL队列中。下图是这个策略的示意图: 假设队列最前面的网页是1号网页,从1号网页中提取三个链接分别指向2号、3号和1号. 4 分别,所以它们是按照要抓取的数字的顺序排列的。在获取队列中,
实验表明,这种策略效果很好。虽然看起来很机械,但实际的网页爬取顺序基本上是按照网页的重要性排序的。这样做的原因是,有研究人员认为,如果一个网页收录大量的传入链接,则更有可能被广度优先遍历策略及早捕获,而传入链接的数量从侧面,也就是广度优先的遍历策略其实上面也隐含了一些页面优先级的假设。

广度优先遍历策略
02 不完整的PageRank策略
PageRank 是一种著名的链接分析算法,可以用来衡量网页的重要性。很自然会想到PageRank对URL进行优先排序的思路。但是这里有一个问题,PageRank是一个全局算法,也就是说,当所有网页都下载完后,计算结果是可靠的,而爬虫的目的是下载网页,而只有一部分在运行过程中可以看到页面。,因此处于爬取阶段的页面无法获得可靠的 PageRank 分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,连同待爬取的URL队列中的URL,形成一组网页,在这个集合中进行PageRank计算。计算完成后,待爬取的 URL 队列将根据 PageRank 得分从高到低对网页进行排序,形成的序列就是爬虫接下来应该爬取的 URL 列表。这就是为什么它被称为“不完整的PageRank”。
如果每次爬取一个新的网页,就为所有下载的网页重新计算新的不完整PageRank值,这在现实中显然效率太低,不可行。一个折衷方案是:每次有足够的K个页面下载,然后对所有下载的页面重新计算新的不完整PageRank。这种计算效率勉强可以接受,但也带来了新的问题:在开始下一轮PageRank计算之前,从新下载的网页中提取收录的链接。很有可能这些环节非常重要,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 为这些新提取的页面分配一个临时的 PageRank 值但没有 PageRank 值,并将本页所有入站链接的PageRank值作为临时PageRank值。如果是PageRank值高的页面,先下载URL。
下图是不完全PageRank策略的简化示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时{P1,P2,P3}3个网页已经下载到本地,这3个网页中收录的链接指向{P4,P5,P6},形成了一个待抓取的URL队列。如何决定下载顺序?将六个网页组成一个新的集合,并为该集合计算PageRank值。这样,P4、P5和P6就得到了它们对应的PageRank值,可以从大到小排序得到它们的下载顺序。这里可以假设下载顺序为:P5、P4、P6,下载P5页面时,提取链接指向P8页面。此时,一个临时的 PageRank 值被分配给 P8。如果这个值大于P4和P6,如果PageRank值更高,那么先下载P8。在这个连续的循环中,形成了不完全PageRank策略的计算思路。
不完整的PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明不完整的PageRank结果稍好一些,而一些实验结果正好相反。一些研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大的不同。不应作为计算抓取过程中 URL 重要性的依据。

不完整的 PageRank 策略
03 OPIC战略
OPIC 字面意思是“在线页面重要性计算”,可以认为是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被赋予了相同的“现金”,每当某个页面P被下载时,P就会将其拥有的“现金”平均分配给该页面所收录的链接页面,并分配自己的“现金” “空。至于待爬取的URL队列中的网页,按照手头现金数量排序,现金最充裕的网页优先下载。OPIC与PageRank基本一致就大框架而言,不同的是PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对于没有链接关系的网页有一个长距离的跳转过程,但是OPIC没有这个计算因子。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略优于广度优先遍历策略。
04 大站优先战略
大站点优先策略的思路很简单:以网站为单位衡量网页的重要性。对于URL队列中待爬取的网页,按照所属的网站进行分类。如果有任何 网站 正在等待下载,如果页面数量最多,则将首先下载这些链接。基本思路是先下载大网站,因为大网站往往收录更多页面。鉴于大型网站往往是知名公司的内容,其网页质量普遍较高,这个思路虽然简单,但有一定的依据。实验表明,该算法的效果略好于广度优先遍历策略。
网页更新策略
互联网的动态特性是其显着特征。随时出现新页面,更改页面内容或删除原创页面。对于爬虫来说,即使任务完成,也不必在本地爬取网页,也能体现互联网的动态性。本地下载的页面可视为互联网页面的“镜像”,爬虫应尽可能保证一致性。可以假设这样一种情况:一个网页被删除或者内容发生了重大变化,而搜索引擎对此一无所知,仍然按照旧的内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取的网页,
网页更新策略的任务是决定何时重新爬取下载的网页,使本地下载的网页和互联网上的原创网页的内容尽可能一致。常用的网页更新策略有三种:历史参考策略、用户体验策略和整群抽样策略。
01历史参考策略
历史参考策略是最直观的更新策略,它基于以下假设:过去频繁更新的网页,未来也会频繁更新。因此,为了估计网页何时更新,可以参考历史更新情况来做出决定。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时再次发生变化,从而指导爬虫的爬取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,重点关注内容变化检测和建模。优越的。
02用户体验策略
一般来说,搜索引擎用户提交查询后,可能会有上千条相关搜索结果,而用户没有耐心等着查看后面的搜索结果,可能只会看前3页搜索内容。用户体验策略就是利用用户的这一特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,以后更新这些过时的网页也不错。因此,最好根据网页内容的变化(通常以搜索结果的排名变化来衡量)带来的搜索质量变化来判断网页何时更新。影响力越大的网页,更新速度越快。
用户体验策略保存网页的多个历史版本,根据过去每次内容变化对搜索质量的影响取一个平均值,作为判断爬虫重新访问时机的参考抓取网页。网页,优先级越高是计划重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略在很大程度上依赖于网页的历史更新信息,这是后续计算的基础。然而实际上,对于每个网页保存其历史信息,搜索系统会增加很多额外的负担。换个角度看,如果是第一次爬取的网页,因为没有历史信息,不可能按照这两种思路估计更新周期。为解决上述不足,提出了整群抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测更新周期,属性相似的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,同一类别内的网页具有相同的更新频率。为了计算某个类别的更新周期,只需要对该类别中的网页进行采样,将这些采样的网页的更新周期作为该类别中所有网页的更新周期。与上述两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,
下图描述了聚类抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页具有相似的更新周期。从类别中提取一部分最具代表性的网页(一般是提取离类别中心最近的那些网页),并计算这些网页的更新周期,然后将这个更新周期用于该类别中的所有网页类别,然后可以根据网页的类别使用更新周期。确定其更新周期。

整群抽样策略
网页更新周期的属性特征分为静态特征和动态特征两类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,比如图片数量的变化、进出链接的变化等。网页可以根据这两类特征进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,一些研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一个网站的网页具有相同的更新周期,则< @网站 采样,计算更新周期,然后网站 中的所有网页都会以这个更新周期为准。虽然这个假设是粗略的,因为很明显同一个网站内的网页的更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类非常困难。
如果你对爬虫感兴趣,还可以阅读:
干货全流程| 入门级爬虫技术原理,这就够了
网络爬虫 | 你不知道的暗网是怎么爬的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗?
php 爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-29 05:16
)
首先,我们需要知道什么是爬虫!当我第一次听到爬虫这个词时,我以为它是一种爬行昆虫。想想就觉得可笑……后来才知道是网上的数据抓取工具!
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫能做什么?
1、模拟浏览器打开网页,获取网页中我们想要的部分数据。
2、从技术角度,程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据,存储和使用。
3、仔细观察不难发现,越来越多的人知道和了解爬虫。一方面,可以从互联网上获取越来越多的数据。另一方面,像 Python 这样的编程语言提供了越来越多优秀的工具,让爬虫变得简单易用。
4、利用爬虫,我们可以获取大量有价值的数据,从而获取感性知识无法获取的信息,例如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上图,这就是爬取数据时的流程,是不是很简单?因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析过滤来获取我们想要的资源。
相关学习推荐:python教程
以上就是python爬虫能做什么的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php 爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人)(图)
)
首先,我们需要知道什么是爬虫!当我第一次听到爬虫这个词时,我以为它是一种爬行昆虫。想想就觉得可笑……后来才知道是网上的数据抓取工具!
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫能做什么?
1、模拟浏览器打开网页,获取网页中我们想要的部分数据。
2、从技术角度,程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据,存储和使用。
3、仔细观察不难发现,越来越多的人知道和了解爬虫。一方面,可以从互联网上获取越来越多的数据。另一方面,像 Python 这样的编程语言提供了越来越多优秀的工具,让爬虫变得简单易用。
4、利用爬虫,我们可以获取大量有价值的数据,从而获取感性知识无法获取的信息,例如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上图,这就是爬取数据时的流程,是不是很简单?因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析过滤来获取我们想要的资源。
相关学习推荐:python教程
以上就是python爬虫能做什么的详细内容。更多详情请关注php中文网文章其他相关话题!

php 爬虫抓取网页数据(技术层面上探究一下是如何工作的?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-27 15:20
大家好,我是悦创。
通过前面的介绍,同学们已经弄清楚了爬行动物是什么以及它的作用。除了它的反爬虫和一些古怪的技巧,让我们开始探索它在技术层面是如何工作的。
在 Internet 上,公共数据(各种网页)使用 http(或加密的 http 或 https)协议传输。所以我们这里介绍的爬虫技术都是基于http(https)协议的爬虫。
在 Python 模块的海洋中,支持 http 协议的模块相当丰富,包括官方的 urllib 和知名社区(第三方)的模块请求。它们都很好地封装了http协议请求的各种方法,所以我们只需要熟悉这些模块的用法,http协议本身就不再讨论了。
1. 了解浏览器和服务器
学生应该完全熟悉浏览器。可以说,上网过的人都知道浏览器。不过,了解浏览器各种原理的同学不一定很多。
作为一个想开发爬虫的人,了解浏览器的工作原理是很有必要的。这是您编写爬虫的必备工具,仅此而已。
不知道同学们在面试的时候有没有遇到这么一个很宏观很详细的回答问题:
这真是一个考验知识的问题。有经验的程序员可以讲三天三夜,也可以抽出几分钟的精髓讲一讲。而新手们怕是对整个过程了解的不多。
巧合的是,对这个问题了解得越多,对写爬虫的帮助就越大。也就是说,爬行是一个考验综合能力的领域。那么,学生们准备好迎接这一综合技能挑战了吗?
废话不多说,先从回答这个问题开始,了解浏览器和服务器,看看爬虫需要哪些知识。
前面说了,这个问题可以讨论三天三夜,但是我们没有那么多时间,所以就略过一些细节,结合爬虫说一下大致的流程,分为三个部分:“强迫症或那些想认真弥补它的人。同学们可以点击这个文章阅读“从输入url到页面显示是怎么回事?
浏览器发出请求 服务器响应 浏览器收到响应2. 浏览器发出请求
在浏览器地址栏中输入 URL,然后按 Enter。浏览器要求服务器发出一个网页请求,也就是说,它告诉服务器我想看你的一个网页。
上面这短短的一句话,蕴含着无数的奥秘,让我不得不花点时间说话。主要讲:
2.1 URL 有效吗?
首先,浏览器需要判断你输入的网址(URL)是否合法有效。对应的URL,同学们对那以http(s)开头的长字符串并不陌生,但是你知道它也可以以ftp、mailto、file、data、irc开头吗?以下是其最完整的语法格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
处理的更形象的表示是这样的:
图片来自维基百科
跃创经验:判断URL的合法性
在 Python 中,可以使用 urllib.parse 对 URL 执行各种操作
In [1]: import urllib.parse
In [2]: url = 'http://dachong:the_password@www.yuanrenxue.com/user/info?page=2'
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看到 urlparse 函数将 URL 解析为 6 个部分:
scheme://netloc/path;params?query#fragment
主要是在URL语法定义中netloc不等同于host
2.2 服务器在哪里?
上述 URL 定义中的主机是 Internet 上的服务器。它可以是IP地址,但通常是我们所说的域名。域名通过 DNS 绑定到一个(或多个)IP 地址。
浏览器要访问某个域名的网站,首先要通过DNS服务器解析域名,获取真实IP地址。
这里的域名解析一般由操作系统完成,爬虫不需要关心。但是,当你编写一个大型爬虫时,比如谷歌和百度搜索引擎,效率就变得非常重要,爬虫必须维护自己的 DNS 缓存。
跃创经验:大型爬虫需要自己维护DNS缓存
2.3 浏览器向服务器发送什么?
一旦浏览器获得了网站服务器的IP地址,就可以向服务器发送请求。 查看全部
php 爬虫抓取网页数据(技术层面上探究一下是如何工作的?(上))
大家好,我是悦创。
通过前面的介绍,同学们已经弄清楚了爬行动物是什么以及它的作用。除了它的反爬虫和一些古怪的技巧,让我们开始探索它在技术层面是如何工作的。

在 Internet 上,公共数据(各种网页)使用 http(或加密的 http 或 https)协议传输。所以我们这里介绍的爬虫技术都是基于http(https)协议的爬虫。
在 Python 模块的海洋中,支持 http 协议的模块相当丰富,包括官方的 urllib 和知名社区(第三方)的模块请求。它们都很好地封装了http协议请求的各种方法,所以我们只需要熟悉这些模块的用法,http协议本身就不再讨论了。
1. 了解浏览器和服务器
学生应该完全熟悉浏览器。可以说,上网过的人都知道浏览器。不过,了解浏览器各种原理的同学不一定很多。
作为一个想开发爬虫的人,了解浏览器的工作原理是很有必要的。这是您编写爬虫的必备工具,仅此而已。
不知道同学们在面试的时候有没有遇到这么一个很宏观很详细的回答问题:
这真是一个考验知识的问题。有经验的程序员可以讲三天三夜,也可以抽出几分钟的精髓讲一讲。而新手们怕是对整个过程了解的不多。
巧合的是,对这个问题了解得越多,对写爬虫的帮助就越大。也就是说,爬行是一个考验综合能力的领域。那么,学生们准备好迎接这一综合技能挑战了吗?
废话不多说,先从回答这个问题开始,了解浏览器和服务器,看看爬虫需要哪些知识。
前面说了,这个问题可以讨论三天三夜,但是我们没有那么多时间,所以就略过一些细节,结合爬虫说一下大致的流程,分为三个部分:“强迫症或那些想认真弥补它的人。同学们可以点击这个文章阅读“从输入url到页面显示是怎么回事?
浏览器发出请求 服务器响应 浏览器收到响应2. 浏览器发出请求
在浏览器地址栏中输入 URL,然后按 Enter。浏览器要求服务器发出一个网页请求,也就是说,它告诉服务器我想看你的一个网页。
上面这短短的一句话,蕴含着无数的奥秘,让我不得不花点时间说话。主要讲:
2.1 URL 有效吗?
首先,浏览器需要判断你输入的网址(URL)是否合法有效。对应的URL,同学们对那以http(s)开头的长字符串并不陌生,但是你知道它也可以以ftp、mailto、file、data、irc开头吗?以下是其最完整的语法格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
处理的更形象的表示是这样的:

图片来自维基百科
跃创经验:判断URL的合法性
在 Python 中,可以使用 urllib.parse 对 URL 执行各种操作
In [1]: import urllib.parse
In [2]: url = 'http://dachong:the_password@www.yuanrenxue.com/user/info?page=2'
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看到 urlparse 函数将 URL 解析为 6 个部分:
scheme://netloc/path;params?query#fragment
主要是在URL语法定义中netloc不等同于host
2.2 服务器在哪里?
上述 URL 定义中的主机是 Internet 上的服务器。它可以是IP地址,但通常是我们所说的域名。域名通过 DNS 绑定到一个(或多个)IP 地址。
浏览器要访问某个域名的网站,首先要通过DNS服务器解析域名,获取真实IP地址。
这里的域名解析一般由操作系统完成,爬虫不需要关心。但是,当你编写一个大型爬虫时,比如谷歌和百度搜索引擎,效率就变得非常重要,爬虫必须维护自己的 DNS 缓存。
跃创经验:大型爬虫需要自己维护DNS缓存
2.3 浏览器向服务器发送什么?
一旦浏览器获得了网站服务器的IP地址,就可以向服务器发送请求。
php 爬虫抓取网页数据(Python爬虫架构的原理及应用原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-27 09:01
1.什么是爬虫?
Crawler:自动爬取互联网信息的程序,从互联网上为我们获取有价值的信息。
2.爬虫的原理?
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(爬取有价值的数据)。
调度器:相当于一台计算机的CPU,主要负责调度URL管理器、下载器、解析器之间的协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止URL重复爬取和URL循环爬取。实现 URL 管理器的方式主要有 3 种:内存、数据库和缓存数据库。
网页下载器:通过传入 URL 地址下载网页并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括需要登录、代理和cookies、requests(第三方包)
网页解析器:通过解析一个网页字符串,可以根据我们的需求提取我们有用的信息,或者按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观地说,就是将网页转换成字符串,通过模糊匹配提取有价值的信息,当文档比较复杂时,这种方法提取数据会很困难),html。parser(Python自带),beautifulsoup(第三方插件,可以使用Python自带的html.parser解析,也可以使用lxml,比别人更强大),lxml(第三方插件) ,可以解析xml和HTML),html.parser和beautifulsoup和lxml都是用DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
3.第一个爬虫
导入 cookielib
导入 urllib2 查看全部
php 爬虫抓取网页数据(Python爬虫架构的原理及应用原理)
1.什么是爬虫?
Crawler:自动爬取互联网信息的程序,从互联网上为我们获取有价值的信息。
2.爬虫的原理?
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(爬取有价值的数据)。
调度器:相当于一台计算机的CPU,主要负责调度URL管理器、下载器、解析器之间的协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止URL重复爬取和URL循环爬取。实现 URL 管理器的方式主要有 3 种:内存、数据库和缓存数据库。
网页下载器:通过传入 URL 地址下载网页并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括需要登录、代理和cookies、requests(第三方包)
网页解析器:通过解析一个网页字符串,可以根据我们的需求提取我们有用的信息,或者按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观地说,就是将网页转换成字符串,通过模糊匹配提取有价值的信息,当文档比较复杂时,这种方法提取数据会很困难),html。parser(Python自带),beautifulsoup(第三方插件,可以使用Python自带的html.parser解析,也可以使用lxml,比别人更强大),lxml(第三方插件) ,可以解析xml和HTML),html.parser和beautifulsoup和lxml都是用DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
3.第一个爬虫
导入 cookielib
导入 urllib2
php 爬虫抓取网页数据(网站前期优化,收录很重要,如何快速让搜索引擎收录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-25 21:03
网站前期优化,收录很重要,如何快速制作搜索引擎收录?
最直接的两种方法:
第一个要优化的一、网站提交到搜索引擎入口,作用是告诉搜索引擎“大哥,这个站还行,你可以看看!如果没有大问题,就接受它,成为一个n-room!三个Kos。”。
第一个发送外部链接的二、,引诱百度蜘蛛和谷歌机器人等爬虫爬取你的网站。这个方法这里就不讨论了,作为一个seoer,你懂的!
以下是部分搜索引擎的提交词条汇总,点击提交即可!当然,没有必要每一个都提交。可以提交前几个重要的。
百度搜索百度提交词条
百度单页提交入口
360搜索提交条目
谷歌搜索 谷歌提交条目
搜搜搜搜SOSO提交词条
搜狗搜索提交词条
网易有道搜索提交词条
yahoo 搜索 yahoo 提交条目
必应搜索提交条目
Alexa网站登录门户
写在最后:
向搜索引擎提交网站并发送外部链接,实际上是一种添加“搜索爬虫”进入网站“入口”的方法。入口很重要,入口决定了收录的速度和数量。当然,长期以来,高考也是排名最重要的因素之一。但是不要得意忘形,记住你所做的网站,那就是让每个使用你的人网站都酷。
这篇文章里,有爱花、看花、看花、看爆胎的人。 查看全部
php 爬虫抓取网页数据(网站前期优化,收录很重要,如何快速让搜索引擎收录?)
网站前期优化,收录很重要,如何快速制作搜索引擎收录?
最直接的两种方法:
第一个要优化的一、网站提交到搜索引擎入口,作用是告诉搜索引擎“大哥,这个站还行,你可以看看!如果没有大问题,就接受它,成为一个n-room!三个Kos。”。
第一个发送外部链接的二、,引诱百度蜘蛛和谷歌机器人等爬虫爬取你的网站。这个方法这里就不讨论了,作为一个seoer,你懂的!
以下是部分搜索引擎的提交词条汇总,点击提交即可!当然,没有必要每一个都提交。可以提交前几个重要的。
百度搜索百度提交词条
百度单页提交入口
360搜索提交条目
谷歌搜索 谷歌提交条目
搜搜搜搜SOSO提交词条
搜狗搜索提交词条
网易有道搜索提交词条
yahoo 搜索 yahoo 提交条目
必应搜索提交条目
Alexa网站登录门户
写在最后:
向搜索引擎提交网站并发送外部链接,实际上是一种添加“搜索爬虫”进入网站“入口”的方法。入口很重要,入口决定了收录的速度和数量。当然,长期以来,高考也是排名最重要的因素之一。但是不要得意忘形,记住你所做的网站,那就是让每个使用你的人网站都酷。
这篇文章里,有爱花、看花、看花、看爆胎的人。
php 爬虫抓取网页数据(查看更多写博客PHP爬虫:百万级别知乎用户数据爬取与分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-21 02:16
阿里云>云栖社区>主题图>P>php爬虫网站
推荐活动:
更多优惠>
当前话题:php爬虫网站加入采集
相关话题:
php爬虫网站相关博文看更多博文
PHP爬虫:百万级知乎用户数据爬取分析
作者:沃克武松 2012 浏览评论:04年前
这次抓到110万用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;安装PHP5.6或以上;安装MySQL5.5或以上;安装curl、pcntl扩展。使用PH
阅读全文
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
爬虫和urllib库介绍(一)
作者:蓝の流星 VIP1588 浏览评论:03年前
1 爬虫概述(1)互联网爬虫是根据Url爬取网页并获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:爬虫与反抗之间的博弈) -crawlers(3)爬虫语言php多进程多线程支持java较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高。
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
发现并阻止恶意爬虫
作者:zhoubj1341 浏览评论:04年前
有许多类型的互联网爬虫。本文主要介绍nginx网站是如何发现和拦截恶意爬虫的。一天发现问题的时候,收到了所有反馈网站服务器A打开慢。首先登录A服务器检查nginx、php、mysql运行是否正常。使用top命令检查服务器CPU、内存、系统负载是否正常。
阅读全文
php爬虫网站相关问答题
如何在 js 对象中获取 PHP 爬虫
作者:小旋风柴今848查看评论:16年前
我用php爬了一个网站,但是数据是用js生成的,inspect元素可以找到js对象,php代码怎么获取js中对象的值
阅读全文 查看全部
php 爬虫抓取网页数据(查看更多写博客PHP爬虫:百万级别知乎用户数据爬取与分析(组图))
阿里云>云栖社区>主题图>P>php爬虫网站
推荐活动:
更多优惠>
当前话题:php爬虫网站加入采集
相关话题:
php爬虫网站相关博文看更多博文
PHP爬虫:百万级知乎用户数据爬取分析

作者:沃克武松 2012 浏览评论:04年前
这次抓到110万用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;安装PHP5.6或以上;安装MySQL5.5或以上;安装curl、pcntl扩展。使用PH
阅读全文
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
爬虫和urllib库介绍(一)

作者:蓝の流星 VIP1588 浏览评论:03年前
1 爬虫概述(1)互联网爬虫是根据Url爬取网页并获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:爬虫与反抗之间的博弈) -crawlers(3)爬虫语言php多进程多线程支持java较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高。
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
发现并阻止恶意爬虫


作者:zhoubj1341 浏览评论:04年前
有许多类型的互联网爬虫。本文主要介绍nginx网站是如何发现和拦截恶意爬虫的。一天发现问题的时候,收到了所有反馈网站服务器A打开慢。首先登录A服务器检查nginx、php、mysql运行是否正常。使用top命令检查服务器CPU、内存、系统负载是否正常。
阅读全文
php爬虫网站相关问答题
如何在 js 对象中获取 PHP 爬虫


作者:小旋风柴今848查看评论:16年前
我用php爬了一个网站,但是数据是用js生成的,inspect元素可以找到js对象,php代码怎么获取js中对象的值
阅读全文
php 爬虫抓取网页数据( 五款啥好的办法,既快又省事,当然有! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-20 02:06
五款啥好的办法,既快又省事,当然有!
)
大家好,我是菜鸟兄弟!今天给大家推荐几款好神器!
在网络信息化时代,爬虫是采集信息不可或缺的工具。对于很多小伙伴来说,只是想用爬虫进行快速的内容爬取,并不想对爬虫研究太深。
用python写爬虫程序很酷,但是学习起来需要时间和精力。学习成本非常高。有时候仅仅为了几页数据就学了几个月的爬虫,真是让人难以忍受。
有没有什么好办法,既快又省力,当然!今天菜鸟哥今天就带领大家分享五款免费的数据采集工具,帮助大家省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程也能轻松抓取数据。优采云数据采集稳定性强,配有详细的使用教程,可以快速上手。
门户网站:
我们以采集的名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,选择右侧“全选”,软件会自动识别所有著名文本。接下来按照操作,选择 采集 文本,然后启动 采集 的软件。
采集完成后,选择文本导出的文件类型,点击确定即可导出数据。
2.吉走克
Jisouke为一些流行的网站设置了快速爬虫程序,但是学习成本比优采云高。
门户网站:
我们在 知乎关键词 处抓取:。首先需要根据爬取的类别进行分类,然后输入网址,点击获取数据,开始爬取。捕获的数据如下图所示:
可以看到,极速客抓取到的信息非常丰富,但是下载数据需要消耗积分,20条数据需要消耗1积分。Jisouke会给新用户20分。
以上两款都是非常好用的国产数据采集软件。接下来菜鸟哥就介绍一下chrome浏览器下的爬虫插件。
3.网络爬虫
网络爬虫插件是一个非常好用的爬虫插件。Web爬虫的安装可以参考之前菜鸟小哥分享的文章()。
对于简单的数据抓取,网络抓取工具可以很好地完成这项工作。我们还以名言的 URL 数据抓取为例。
通过选中多个来获取页面中的所有引号。捕获数据后,通过单击“将数据导出为 CSV”导出所有数据。
4.AnyPapa
将网页翻到评测区,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa的数据页面。
首先点击切换数据源,找到“京东商品评论”的数据源。此时界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据将以csv文件的形式下载到本地。
5.你得到
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了来自网站的国内外近80个视频和图片截图,获得了40900个赞!
门户网站: 。
对于you-get的安装,可以通过命令pip install you-get来安装。
我们以B站上的视频为例,网址为:
通过命令:
you-get -o ./ 'https://www.bilibili.com/video/BV1y64y1X7YG?spm_id_from=333.851.b_7265636f6d6d656e64.3' --format=flv360
可以实现视频下载,其中-o是指视频下载的存储地址,--format是指视频下载的格式和定义。
6.总结
以上就是菜鸟哥今天给大家带来的五款自动提取数据的工具。如果是偶尔的爬虫,或者非常低频率的爬虫需求,完全没有必要学习爬虫技术,因为学习成本非常高。比如你只想发几张图,不用学Photoshop就可以直接用美图秀秀。
如果你对爬虫有很多定制需求,需要对采集到的数据进行分析和深度挖掘,而且频率很高,或者你想更深入地使用Python技术,通过爬虫更扎实的学习,那么可以考虑在此学习时间。爬虫。
嗯,以上工具都不错。有兴趣的同学可以试试。下一篇文章见。
推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领AI全套资料! 查看全部
php 爬虫抓取网页数据(
五款啥好的办法,既快又省事,当然有!
)

大家好,我是菜鸟兄弟!今天给大家推荐几款好神器!
在网络信息化时代,爬虫是采集信息不可或缺的工具。对于很多小伙伴来说,只是想用爬虫进行快速的内容爬取,并不想对爬虫研究太深。
用python写爬虫程序很酷,但是学习起来需要时间和精力。学习成本非常高。有时候仅仅为了几页数据就学了几个月的爬虫,真是让人难以忍受。
有没有什么好办法,既快又省力,当然!今天菜鸟哥今天就带领大家分享五款免费的数据采集工具,帮助大家省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程也能轻松抓取数据。优采云数据采集稳定性强,配有详细的使用教程,可以快速上手。
门户网站:

我们以采集的名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,选择右侧“全选”,软件会自动识别所有著名文本。接下来按照操作,选择 采集 文本,然后启动 采集 的软件。

采集完成后,选择文本导出的文件类型,点击确定即可导出数据。

2.吉走克
Jisouke为一些流行的网站设置了快速爬虫程序,但是学习成本比优采云高。
门户网站:

我们在 知乎关键词 处抓取:。首先需要根据爬取的类别进行分类,然后输入网址,点击获取数据,开始爬取。捕获的数据如下图所示:

可以看到,极速客抓取到的信息非常丰富,但是下载数据需要消耗积分,20条数据需要消耗1积分。Jisouke会给新用户20分。
以上两款都是非常好用的国产数据采集软件。接下来菜鸟哥就介绍一下chrome浏览器下的爬虫插件。
3.网络爬虫
网络爬虫插件是一个非常好用的爬虫插件。Web爬虫的安装可以参考之前菜鸟小哥分享的文章()。
对于简单的数据抓取,网络抓取工具可以很好地完成这项工作。我们还以名言的 URL 数据抓取为例。

通过选中多个来获取页面中的所有引号。捕获数据后,通过单击“将数据导出为 CSV”导出所有数据。

4.AnyPapa
将网页翻到评测区,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa的数据页面。

首先点击切换数据源,找到“京东商品评论”的数据源。此时界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据将以csv文件的形式下载到本地。

5.你得到
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了来自网站的国内外近80个视频和图片截图,获得了40900个赞!

门户网站: 。
对于you-get的安装,可以通过命令pip install you-get来安装。

我们以B站上的视频为例,网址为:

通过命令:
you-get -o ./ 'https://www.bilibili.com/video/BV1y64y1X7YG?spm_id_from=333.851.b_7265636f6d6d656e64.3' --format=flv360
可以实现视频下载,其中-o是指视频下载的存储地址,--format是指视频下载的格式和定义。
6.总结
以上就是菜鸟哥今天给大家带来的五款自动提取数据的工具。如果是偶尔的爬虫,或者非常低频率的爬虫需求,完全没有必要学习爬虫技术,因为学习成本非常高。比如你只想发几张图,不用学Photoshop就可以直接用美图秀秀。
如果你对爬虫有很多定制需求,需要对采集到的数据进行分析和深度挖掘,而且频率很高,或者你想更深入地使用Python技术,通过爬虫更扎实的学习,那么可以考虑在此学习时间。爬虫。
嗯,以上工具都不错。有兴趣的同学可以试试。下一篇文章见。
推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领AI全套资料!
php 爬虫抓取网页数据(查看更多写博客PHP爬虫:百万级别知乎用户数据爬取与分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-18 04:04
阿里云>云栖社区>主题图>P>php爬虫网站
推荐活动:
更多优惠>
当前话题:php爬虫网站加入采集
相关话题:
php爬虫网站相关博文看更多博文
PHP爬虫:百万级知乎用户数据爬取分析
作者:沃克武松 2012 浏览评论:04年前
这次抓到110万用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;安装PHP5.6或以上;安装MySQL5.5或以上;安装curl、pcntl扩展。使用PH
阅读全文
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
爬虫和urllib库介绍(一)
作者:蓝の流星 VIP1588 浏览评论:03年前
1 爬虫概述(1)互联网爬虫是根据Url爬取网页并获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:爬虫与反抗之间的博弈) -crawlers(3)爬虫语言php多进程多线程支持java较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高。
阅读全文
发现并阻止恶意爬虫
作者:zhoubj1341 浏览评论:04年前
有许多类型的互联网爬虫。本文主要介绍nginx网站是如何发现和拦截恶意爬虫的。一天发现问题的时候,收到了所有反馈网站服务器A打开慢。首先登录A服务器检查nginx、php、mysql运行是否正常。使用top命令检查服务器CPU、内存、系统负载是否正常。
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,不会操作一个
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,不会操作一个
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
php爬虫网站相关问答题
如何在 js 对象中获取 PHP 爬虫
作者:小旋风柴今848查看评论:16年前
我用php爬取了一个网站,但是数据是用js生成的,通过检查元素可以找到js对象,php代码如何获取js中对象的值
阅读全文 查看全部
php 爬虫抓取网页数据(查看更多写博客PHP爬虫:百万级别知乎用户数据爬取与分析(组图))
阿里云>云栖社区>主题图>P>php爬虫网站
推荐活动:
更多优惠>
当前话题:php爬虫网站加入采集
相关话题:
php爬虫网站相关博文看更多博文
PHP爬虫:百万级知乎用户数据爬取分析
作者:沃克武松 2012 浏览评论:04年前
这次抓到110万用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;安装PHP5.6或以上;安装MySQL5.5或以上;安装curl、pcntl扩展。使用PH
阅读全文
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
爬虫和urllib库介绍(一)
作者:蓝の流星 VIP1588 浏览评论:03年前
1 爬虫概述(1)互联网爬虫是根据Url爬取网页并获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:爬虫与反抗之间的博弈) -crawlers(3)爬虫语言php多进程多线程支持java较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高。
阅读全文
发现并阻止恶意爬虫
作者:zhoubj1341 浏览评论:04年前
有许多类型的互联网爬虫。本文主要介绍nginx网站是如何发现和拦截恶意爬虫的。一天发现问题的时候,收到了所有反馈网站服务器A打开慢。首先登录A服务器检查nginx、php、mysql运行是否正常。使用top命令检查服务器CPU、内存、系统负载是否正常。
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,不会操作一个
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,不会操作一个
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
php爬虫网站相关问答题
如何在 js 对象中获取 PHP 爬虫
作者:小旋风柴今848查看评论:16年前
我用php爬取了一个网站,但是数据是用js生成的,通过检查元素可以找到js对象,php代码如何获取js中对象的值
阅读全文
php 爬虫抓取网页数据(玩C一定用得到的19款Java开源Web爬虫作者:行者武松人(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-04-16 16:31
阿里云 > 云栖社区 > 主题图 > P > PHP网络爬虫开源
推荐活动:
更多优惠>
当前话题:php网络爬虫开源加入采集
相关话题:
php网络爬虫开源相关博客查看更多博客
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
玩C必备的19个Java开源网络爬虫
作者:沃克武松 1249人浏览评论:04年前
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。今天给大家介绍19款Java开源网络爬虫。
阅读全文
玩大数据必用的19个Java开源网络爬虫
作者:消音器 1432 观众评论:04年前
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。今天给大家介绍19款Java开源网络爬虫。
阅读全文
Python爬虫框架-PySpider
作者:shadowcat7965 浏览评论:05年前
From: From: PySpider PySpider github地址PySpider官方文档PySpi
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
php网络爬虫开源相关问答
爬虫数据管理【问答合集】
作者:我是管理员28342人查看评论:223年前
互联网爬虫的自然语言处理目前前景如何?artTemplate:arttemplate生成的页面可以爬取到数据吗?
阅读全文 查看全部
php 爬虫抓取网页数据(玩C一定用得到的19款Java开源Web爬虫作者:行者武松人(组图))
阿里云 > 云栖社区 > 主题图 > P > PHP网络爬虫开源
推荐活动:
更多优惠>
当前话题:php网络爬虫开源加入采集
相关话题:
php网络爬虫开源相关博客查看更多博客
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
玩C必备的19个Java开源网络爬虫
作者:沃克武松 1249人浏览评论:04年前
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。今天给大家介绍19款Java开源网络爬虫。
阅读全文
玩大数据必用的19个Java开源网络爬虫
作者:消音器 1432 观众评论:04年前
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。今天给大家介绍19款Java开源网络爬虫。
阅读全文
Python爬虫框架-PySpider
作者:shadowcat7965 浏览评论:05年前
From: From: PySpider PySpider github地址PySpider官方文档PySpi
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
php网络爬虫开源相关问答
爬虫数据管理【问答合集】
作者:我是管理员28342人查看评论:223年前
互联网爬虫的自然语言处理目前前景如何?artTemplate:arttemplate生成的页面可以爬取到数据吗?
阅读全文
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-16 09:42
与PHP相比,python更适合爬虫。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构方面主要有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用在以下三个方面:
服务器脚本。这是 PHP 最传统和主要的目标领域。完成这项工作需要三件事:PHP 解析器(CGI 或服务器模块)、Web
服务器和网络浏览器。运行Web服务器时需要安装和配置PHP,然后可以使用Web浏览器访问PHP程序的输出,即浏览服务
侧 PHP 页面。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。请参阅安装章节了解更多信息。命令行脚本。
可以编写一个 PHP 脚本,它不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器即可执行。这种用法适用于
非常适合在 cron(Unix 或 Linux 环境)或任务计划程序(Windows 环境)上运行的日常脚本。这些脚本也可用于
简单的文字。有关详细信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不是
最好的语言之一,但是如果用户非常精通 PHP,并且想在客户端应用程序中使用 PHP 的一些高级功能,则可以使用 PHP-GTK 编写
一些程序。这样,你也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,不收录在 PHP 包的通常分发中。
扩大网友观点:
我已经用 PHP Node.js Python 编写了抓取脚本,让我们稍微谈谈它。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报时,由于crontab定时执行,没有优化,打开的php进程太多,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。
至此,这篇关于python和php更适合写爬虫的文章文章就介绍到这里了。更多关于哪些php和python适合爬取的信息,请搜索脚本之家之前的文章或继续浏览下方的相关文章,希望以后多多支持脚本之家! 查看全部
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
与PHP相比,python更适合爬虫。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构方面主要有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用在以下三个方面:
服务器脚本。这是 PHP 最传统和主要的目标领域。完成这项工作需要三件事:PHP 解析器(CGI 或服务器模块)、Web
服务器和网络浏览器。运行Web服务器时需要安装和配置PHP,然后可以使用Web浏览器访问PHP程序的输出,即浏览服务
侧 PHP 页面。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。请参阅安装章节了解更多信息。命令行脚本。
可以编写一个 PHP 脚本,它不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器即可执行。这种用法适用于
非常适合在 cron(Unix 或 Linux 环境)或任务计划程序(Windows 环境)上运行的日常脚本。这些脚本也可用于
简单的文字。有关详细信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不是
最好的语言之一,但是如果用户非常精通 PHP,并且想在客户端应用程序中使用 PHP 的一些高级功能,则可以使用 PHP-GTK 编写
一些程序。这样,你也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,不收录在 PHP 包的通常分发中。
扩大网友观点:
我已经用 PHP Node.js Python 编写了抓取脚本,让我们稍微谈谈它。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报时,由于crontab定时执行,没有优化,打开的php进程太多,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。
至此,这篇关于python和php更适合写爬虫的文章文章就介绍到这里了。更多关于哪些php和python适合爬取的信息,请搜索脚本之家之前的文章或继续浏览下方的相关文章,希望以后多多支持脚本之家!
php 爬虫抓取网页数据(基于目标网页特征的爬虫所抓取行为的关键所在所研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-12 15:11
网络爬虫技术是指在万维网上按照一定的规则自动爬取信息的技术。网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,更多的时候是网络追逐者;其他不太常用的名称是蚂蚁、自动索引器、模拟器或蠕虫。
网络爬虫技术是指按照一定的规则自动从万维网上抓取信息的技术。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
现有的焦点爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
基于着陆页特征
爬虫根据目标网页的特征爬取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3) 由用户行为决定的抓取目标示例分为:
(a) 在用户浏览过程中显示标记的抓取样本;
(b) 通过用户日志挖掘获取访问模式和相关样本。
网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据架构
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般符合一定的模式,或者可以转化或映射成目标数据模式。
基于领域的概念
另一种描述是构建目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。 查看全部
php 爬虫抓取网页数据(基于目标网页特征的爬虫所抓取行为的关键所在所研究)
网络爬虫技术是指在万维网上按照一定的规则自动爬取信息的技术。网络爬虫也被称为网络蜘蛛、网络机器人,在 FOAF 社区中,更多的时候是网络追逐者;其他不太常用的名称是蚂蚁、自动索引器、模拟器或蠕虫。
网络爬虫技术是指按照一定的规则自动从万维网上抓取信息的技术。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网页追逐者)是根据一定的规则自动爬取万维网上信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬取目标的描述和定义是决定如何制定网页分析算法和URL搜索策略的基础。网页分析算法和候选URL排序算法是确定搜索引擎提供的服务形式和爬虫爬取行为的关键。这两部分的算法密切相关。
现有的焦点爬虫对爬取目标的描述可以分为三种类型:基于目标网页的特征、基于目标数据模式和基于领域概念。
基于着陆页特征
爬虫根据目标网页的特征爬取、存储和索引的对象一般为网站或网页。根据种子样品的获取方式,可分为:
(1) 预先给定的初始抓取种子样本;
(2) 预先给定的网页类别和类别对应的种子样本,如Yahoo!类别结构等;
(3) 由用户行为决定的抓取目标示例分为:
(a) 在用户浏览过程中显示标记的抓取样本;
(b) 通过用户日志挖掘获取访问模式和相关样本。
网页特征可以是网页的内容特征,也可以是网页的链接结构特征等。
基于目标数据架构
基于目标数据模式的爬虫针对网页上的数据,抓取到的数据一般符合一定的模式,或者可以转化或映射成目标数据模式。
基于领域的概念
另一种描述是构建目标域的本体或字典,用于从语义角度分析主题中不同特征的重要性。
php 爬虫抓取网页数据(【每日一题】网络爬虫的爬行策略(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2022-04-10 12:31
1、网络爬虫原理网络爬虫是指按照一定的规则自动爬取互联网上的程序(模拟手动登录网页的方式)。简单的说就是获取和存储你在互联网上看到的页面上的内容。网络爬虫的爬取策略分为深度优先和广度优先。如下图所示,深度优先的遍历方法是A到B到D到E到C到F(ABDECF)和广度优先的遍历方法ABCDEF。2、写网络爬虫的原因(1)互联网数据量巨大,我们不能手动采集数据,会浪费时间和金钱...
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说网络爬虫的原理解析【通俗易懂】,希望可以帮助大家进步!!!
1、网络爬虫原理
网络爬虫是指按照一定的规则自动爬取网络上的程序(模拟手动登录网页的方式)。简单的说就是获取和存储你在互联网上看到的页面上的内容。网络爬虫的爬取策略分为深度优先和广度优先。如下图所示,深度优先的遍历方法是A到B到D到E到C到F(ABDECF)和广度优先的遍历方法ABCDEF。
2、写网络爬虫的原因
(1)互联网数据量很大,我们不能手动采集数据,浪费时间和金钱。爬虫的一个特点是可以批量自动获取和处理数据。例如,主要汽车论坛 互联网上的爬虫、大众点评网、tripadvisor的爬虫(国外网站)已经爬取了千万条数据,我想如果你一个一个复制,你是做不完的直到你死。
(2)爬虫很酷。前段时间看到有人爬到腾讯的3000万QQ数据,包括(QQ号、昵称、空间名、会员等级、头像、最新谈话内容、最新讲座)发布时间、空间剖面、性别、生日、省、市、婚姻状况等详细数据,绘制各种有趣的图表。
(3)对于攻读研究生、博士、数据挖掘和数据分析的人来说,没有数据做实验是一件非常痛苦的事情。你可能每天在各种论坛上问这个那个。数据,是不是很烦?
3、网络爬虫的进程
通过上图可以完成一个简单的网络爬虫。首先给出一个待爬取的URL队列,然后通过抓包得到数据的真实请求地址。然后用httpclient模拟浏览器抓取对应的数据(一般是html文件或者json数据)。因为网页中的内容很大很复杂,很多内容不是我们需要的,所以需要解析。html的解析非常简单,可以通过Jsoup(Dom解析工具)和正则表达式来完成。对于Json数据的解析,这里推荐一个快速解析工具fastjson(阿里开源的一个工具)
4、网络抓包
网络抓包(packet capture)是对网络传输发送和接收的数据包进行拦截、重传、编辑、转储等,常用于数据拦截。当数据响应是Json或者需要用户名密码才能登录的网站时,抓包就显得尤为重要,抓包也是编写网络爬虫的第一步。
图为东方财富网,抓包结果,可以看到真实的响应地址:Request URL和上面网页请求的地址不一样,我们看一下股票数据的回应。响应的数据格式是 JSON 文件。这里我们可以看到股票数据一共有61页,其中当前页的数据是data[Json数据]。
因此,使用网络抓包是网络爬虫的第一步,可以直观的看到数据请求的真实地址、请求方式(post、get请求)、数据类型(html或Json数据) 查看全部
php 爬虫抓取网页数据(【每日一题】网络爬虫的爬行策略(一))
1、网络爬虫原理网络爬虫是指按照一定的规则自动爬取互联网上的程序(模拟手动登录网页的方式)。简单的说就是获取和存储你在互联网上看到的页面上的内容。网络爬虫的爬取策略分为深度优先和广度优先。如下图所示,深度优先的遍历方法是A到B到D到E到C到F(ABDECF)和广度优先的遍历方法ABCDEF。2、写网络爬虫的原因(1)互联网数据量巨大,我们不能手动采集数据,会浪费时间和金钱...
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说网络爬虫的原理解析【通俗易懂】,希望可以帮助大家进步!!!
1、网络爬虫原理
网络爬虫是指按照一定的规则自动爬取网络上的程序(模拟手动登录网页的方式)。简单的说就是获取和存储你在互联网上看到的页面上的内容。网络爬虫的爬取策略分为深度优先和广度优先。如下图所示,深度优先的遍历方法是A到B到D到E到C到F(ABDECF)和广度优先的遍历方法ABCDEF。
2、写网络爬虫的原因
(1)互联网数据量很大,我们不能手动采集数据,浪费时间和金钱。爬虫的一个特点是可以批量自动获取和处理数据。例如,主要汽车论坛 互联网上的爬虫、大众点评网、tripadvisor的爬虫(国外网站)已经爬取了千万条数据,我想如果你一个一个复制,你是做不完的直到你死。
(2)爬虫很酷。前段时间看到有人爬到腾讯的3000万QQ数据,包括(QQ号、昵称、空间名、会员等级、头像、最新谈话内容、最新讲座)发布时间、空间剖面、性别、生日、省、市、婚姻状况等详细数据,绘制各种有趣的图表。
(3)对于攻读研究生、博士、数据挖掘和数据分析的人来说,没有数据做实验是一件非常痛苦的事情。你可能每天在各种论坛上问这个那个。数据,是不是很烦?
3、网络爬虫的进程
通过上图可以完成一个简单的网络爬虫。首先给出一个待爬取的URL队列,然后通过抓包得到数据的真实请求地址。然后用httpclient模拟浏览器抓取对应的数据(一般是html文件或者json数据)。因为网页中的内容很大很复杂,很多内容不是我们需要的,所以需要解析。html的解析非常简单,可以通过Jsoup(Dom解析工具)和正则表达式来完成。对于Json数据的解析,这里推荐一个快速解析工具fastjson(阿里开源的一个工具)
4、网络抓包
网络抓包(packet capture)是对网络传输发送和接收的数据包进行拦截、重传、编辑、转储等,常用于数据拦截。当数据响应是Json或者需要用户名密码才能登录的网站时,抓包就显得尤为重要,抓包也是编写网络爬虫的第一步。
图为东方财富网,抓包结果,可以看到真实的响应地址:Request URL和上面网页请求的地址不一样,我们看一下股票数据的回应。响应的数据格式是 JSON 文件。这里我们可以看到股票数据一共有61页,其中当前页的数据是data[Json数据]。
因此,使用网络抓包是网络爬虫的第一步,可以直观的看到数据请求的真实地址、请求方式(post、get请求)、数据类型(html或Json数据)
php 爬虫抓取网页数据(python和PHP相比较,python适合做爬虫吗?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-10 11:23
与PHP相比,python更适合爬虫。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构主要有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用在以下三个方面:
服务器脚本。这是 PHP 最传统和主要的目标领域。完成这项工作需要三件事:PHP 解析器(CGI 或服务器模块)、Web
服务器和网络浏览器。运行Web服务器时需要安装和配置PHP,然后可以使用Web浏览器访问PHP程序的输出,即浏览服务
侧 PHP 页面。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。请参阅安装章节了解更多信息。命令行脚本。
可以编写一个 PHP 脚本,它不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器即可执行。这种用法适用于
非常适合在 cron(Unix 或 Linux 环境)或任务计划程序(Windows 环境)上运行的日常脚本。这些脚本也可用于
简单的文字。有关详细信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不是
最好的语言之一,但是如果用户对 PHP 非常精通,并且想在客户端应用程序中使用 PHP 的一些高级功能,可以使用 PHP-GTK 来编写这个
一些程序。这样,你也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,不收录在 PHP 包的通常分发中。
扩大网友观点:
我已经用 PHP Node.js Python 编写了抓取脚本,让我们稍微谈谈它。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报的时候,因为定时执行crontab,没有做任何优化,打开了太多的php进程,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。
至此,这篇关于python和php哪个更适合爬虫写的文章文章就介绍到这里了。更多适合爬虫内容的相关php和python,请搜索服务器之家以前的文章或继续浏览下方相关文章,希望大家以后多多支持服务器之家!
原文链接: 查看全部
php 爬虫抓取网页数据(python和PHP相比较,python适合做爬虫吗?(一))
与PHP相比,python更适合爬虫。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构主要有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用在以下三个方面:
服务器脚本。这是 PHP 最传统和主要的目标领域。完成这项工作需要三件事:PHP 解析器(CGI 或服务器模块)、Web
服务器和网络浏览器。运行Web服务器时需要安装和配置PHP,然后可以使用Web浏览器访问PHP程序的输出,即浏览服务
侧 PHP 页面。如果您只是在尝试 PHP 编程,那么所有这些都可以在您的家用计算机上运行。请参阅安装章节了解更多信息。命令行脚本。
可以编写一个 PHP 脚本,它不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器即可执行。这种用法适用于
非常适合在 cron(Unix 或 Linux 环境)或任务计划程序(Windows 环境)上运行的日常脚本。这些脚本也可用于
简单的文字。有关详细信息,请参阅 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不是
最好的语言之一,但是如果用户对 PHP 非常精通,并且想在客户端应用程序中使用 PHP 的一些高级功能,可以使用 PHP-GTK 来编写这个
一些程序。这样,你也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,不收录在 PHP 包的通常分发中。
扩大网友观点:
我已经用 PHP Node.js Python 编写了抓取脚本,让我们稍微谈谈它。
第一个 PHP。先说优点:网上一抓一大堆HTML爬取和解析的框架,各种工具就可以直接使用,更省心。缺点:首先,速度/效率是个问题。下载电影海报的时候,因为定时执行crontab,没有做任何优化,打开了太多的php进程,直接爆内存。然后语法也很拖沓。关键字和符号太多,不够简洁。给人一种没有经过精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率或效率。因为网络是异步的,所以基本上和数百个并发进程一样强大,而且内存和CPU使用率都很小。如果没有对抓取的数据进行复杂的处理,那么系统瓶颈基本上就是带宽和写入MySQL等数据库的I/O速度。当然,优势的反面也是劣势。异步网络意味着您需要回调。这时候如果业务需求是线性的,比如必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多的Layer依赖,那么就会出现可怕的多图层回调!基本上这个时候,代码结构和逻辑都会乱七八糟。当然,
最后,让我们谈谈Python。如果你对效率没有极端要求,那么推荐Python!首先,Python 的语法非常简洁,同样的语句可以省去很多键盘上的打字。那么,Python非常适合数据处理,比如函数参数的打包解包,列表推导,矩阵处理,非常方便。
至此,这篇关于python和php哪个更适合爬虫写的文章文章就介绍到这里了。更多适合爬虫内容的相关php和python,请搜索服务器之家以前的文章或继续浏览下方相关文章,希望大家以后多多支持服务器之家!
原文链接:
php 爬虫抓取网页数据( Python爬虫|如何实现爬虫4.的应用爬虫的基本流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-04-10 11:23
Python爬虫|如何实现爬虫4.的应用爬虫的基本流程
)
什么是爬行动物?
1. 爬虫介绍
'''
近年来,随着网络应用的逐渐扩展和深入,如何高效获取在线数据成为无数公司和个人的追求。在大数据时代,谁拥有更多的数据,谁就能获得更高的收益。网络爬虫是最常用的从网络上爬取数据的手段之一。
网络爬虫,或者Web Spider,是一个很形象的名字。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络蜘蛛通过它们的链接地址寻找网页。网站从某个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,以此类推以此类推,直到 网站 直到所有网页都被爬取为止。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
'''
1、什么是互联网?<br />互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样。2、互联网建立的目的?<br />互联网的核心价值在于数据的共享/传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿U盘去别人的计算机上拷贝数据了。3、什么是上网?爬虫要做的是什么?<br />我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。<br />3.1 只不过,用户获取网络数据的方式是:<br />浏览器提交请求->下载网页代码->解析/渲染成页面。<br />3.2 而爬虫程序要做的就是:<br />模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中<br />3.1与3.2的区别在于:<br />我们的爬虫程序只提取网页代码中对我们有用的数据<br />4、总结爬虫<br />4.1 爬虫的比喻:<br />如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据<br />4.2 爬虫的定义:<br />向网站发起请求,获取资源后分析并提取有用数据的程序 <br />4.3 爬虫的价值:<br />互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能,你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
2. 哪些语言可以实现爬虫
1.php:<br />可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆卖瓜的意思),但是php在实现爬虫中支持多线程和多进程方面做的不好。2.java:<br />可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。3.c、c++:<br />可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。4.python:<br />可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)且一句难以言表的好!没有但是!
4.爬虫应用
# 1.通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。<br /> 1)搜索引擎如何抓取互联网上的网站数据?<br /> a)门户网站主动向搜索引擎公司提供其网站的url<br /> b)搜索引擎公司与DNS服务商合作,获取网站的url<br /> c)门户网站主动挂靠在一些知名网站的友情链接中<br /># 2.聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。<br /> 例如:<br /> 获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
爬虫的基本流程
tip1:发送请求就是模拟浏览器发送请求,说明底层是怎么走的。请求需要用到请求库,请求库帮助我们实现了哪些功能。
1、发起请求: <br /> 使用http库向目标站点发起请求,即发送一个Request<br /> Request包含:请求头、请求体等<br />2、获取响应内容<br /> 如果服务器能正常响应,则会得到一个Response<br /> Response包含:html,json,图片,视频等<br />3、解析内容<br /> 解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等<br /> 解析json数据:json模块<br /> 解析二进制数据:以b的方式写入文件<br />4、保存数据<br /> 数据库<br /> 文件
请求和响应
tip2:使用浏览器访问百度解说。
URL:即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。<br />互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它<br />URL的格式由三部分组成:<br /> ①第一部分是协议(或称为服务方式)。<br /> ②第二部分是存有该资源的主机IP地址(有时也包括端口号)。<br /> ③第三部分是主机资源的具体地址,如目录和文件名等<br />http协议:<br /> https://www.cnblogs.com/kermit ... %3Bbr />robots协议: <br /> https://www.cnblogs.com/kermit ... %3Bbr />Request:<br /> 用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)<br />Response:<br /> 服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)<br />ps:<br /> 浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
要求
1、请求方式:<br /> 常用的请求方式:<br /> GET,POST<br /> 其他请求方式:<br /> HEAD,PUT,DELETE,OPTHONS<br /> ps:用浏览器演示get与post的区别,(用登录演示post)<br /> post与get请求最终都会拼接成这种形式:<br /> k1=xxx&k2=yyy&k3=zzz<br /> post请求的参数放在请求体内:<br /> 可用浏览器查看,存放于form data内<br /> get请求的参数直接放在url后2、请求url<br /> url全称统一资源定位符,如一个网页文档,一张图片<br /> 一个视频等都可以用url唯一来确定<br /> url编码: <br /> https://www.baidu.com/s?wd=图片<br /> 图片会被编码(看示例代码)<br /> 网页的加载过程是:<br /> 加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求。3、请求头<br /> User-agent:<br /> 请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户。<br /> Cookies:<br /> cookie用来保存登录信息。<br /> Referer:<br /> 浏览器上次访问的网页url<br /> 一般做爬虫都会加上请求头4、请求体<br /> 如果是get方式,请求体没有内容<br /> 如果是post方式,请求体是format data<br /> ps:<br /> 1、登录窗口,文件上传等,信息都会被附加到请求体内<br /> 2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
1、响应状态: <br /> 200:代表成功<br /> 301:代表跳转<br /> 404:文件不存在<br /> 403:权限<br /> 502:服务器错误2、响应头: Respone header<br /> set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来。3、网页源代码: preview<br /> 最主要的部分,包含了请求资源的内容,如网页html、图片和二进制数据等。
总结
1、总结爬虫流程:<br /> 爬取--->解析--->存储2、爬虫所需工具:<br /> 请求库:requests,selenium<br /> 解析库:正则,beautifulsoup,pyquery<br /> 存储库:文件,MySQL,Mongodb,Redis3、爬虫常用框架:<br /> scrapy
过去的亮点:
足够努力,梦想就会绽放 | 上海校区第9期全栈全日制python班开课,老司机带你删库逃跑 | 天天要闻 教你搭建游戏服务器(龙八手游) Python爬虫| 如何提高毛织布的爬行性能?
查看全部
php 爬虫抓取网页数据(
Python爬虫|如何实现爬虫4.的应用爬虫的基本流程
)
什么是爬行动物?
1. 爬虫介绍
'''
近年来,随着网络应用的逐渐扩展和深入,如何高效获取在线数据成为无数公司和个人的追求。在大数据时代,谁拥有更多的数据,谁就能获得更高的收益。网络爬虫是最常用的从网络上爬取数据的手段之一。
网络爬虫,或者Web Spider,是一个很形象的名字。如果把互联网比作蜘蛛网,那么蜘蛛就是在网上爬行的蜘蛛。网络蜘蛛通过它们的链接地址寻找网页。网站从某个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,以此类推以此类推,直到 网站 直到所有网页都被爬取为止。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。
'''
1、什么是互联网?<br />互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样。2、互联网建立的目的?<br />互联网的核心价值在于数据的共享/传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿U盘去别人的计算机上拷贝数据了。3、什么是上网?爬虫要做的是什么?<br />我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。<br />3.1 只不过,用户获取网络数据的方式是:<br />浏览器提交请求->下载网页代码->解析/渲染成页面。<br />3.2 而爬虫程序要做的就是:<br />模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中<br />3.1与3.2的区别在于:<br />我们的爬虫程序只提取网页代码中对我们有用的数据<br />4、总结爬虫<br />4.1 爬虫的比喻:<br />如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据<br />4.2 爬虫的定义:<br />向网站发起请求,获取资源后分析并提取有用数据的程序 <br />4.3 爬虫的价值:<br />互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能,你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
2. 哪些语言可以实现爬虫
1.php:<br />可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆卖瓜的意思),但是php在实现爬虫中支持多线程和多进程方面做的不好。2.java:<br />可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。3.c、c++:<br />可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。4.python:<br />可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)且一句难以言表的好!没有但是!
4.爬虫应用
# 1.通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。<br /> 1)搜索引擎如何抓取互联网上的网站数据?<br /> a)门户网站主动向搜索引擎公司提供其网站的url<br /> b)搜索引擎公司与DNS服务商合作,获取网站的url<br /> c)门户网站主动挂靠在一些知名网站的友情链接中<br /># 2.聚焦爬虫:聚焦爬虫是根据指定的需求抓取网络上指定的数据。<br /> 例如:<br /> 获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
爬虫的基本流程
tip1:发送请求就是模拟浏览器发送请求,说明底层是怎么走的。请求需要用到请求库,请求库帮助我们实现了哪些功能。
1、发起请求: <br /> 使用http库向目标站点发起请求,即发送一个Request<br /> Request包含:请求头、请求体等<br />2、获取响应内容<br /> 如果服务器能正常响应,则会得到一个Response<br /> Response包含:html,json,图片,视频等<br />3、解析内容<br /> 解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等<br /> 解析json数据:json模块<br /> 解析二进制数据:以b的方式写入文件<br />4、保存数据<br /> 数据库<br /> 文件
请求和响应
tip2:使用浏览器访问百度解说。
URL:即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。<br />互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它<br />URL的格式由三部分组成:<br /> ①第一部分是协议(或称为服务方式)。<br /> ②第二部分是存有该资源的主机IP地址(有时也包括端口号)。<br /> ③第三部分是主机资源的具体地址,如目录和文件名等<br />http协议:<br /> https://www.cnblogs.com/kermit ... %3Bbr />robots协议: <br /> https://www.cnblogs.com/kermit ... %3Bbr />Request:<br /> 用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)<br />Response:<br /> 服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)<br />ps:<br /> 浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
要求
1、请求方式:<br /> 常用的请求方式:<br /> GET,POST<br /> 其他请求方式:<br /> HEAD,PUT,DELETE,OPTHONS<br /> ps:用浏览器演示get与post的区别,(用登录演示post)<br /> post与get请求最终都会拼接成这种形式:<br /> k1=xxx&k2=yyy&k3=zzz<br /> post请求的参数放在请求体内:<br /> 可用浏览器查看,存放于form data内<br /> get请求的参数直接放在url后2、请求url<br /> url全称统一资源定位符,如一个网页文档,一张图片<br /> 一个视频等都可以用url唯一来确定<br /> url编码: <br /> https://www.baidu.com/s?wd=图片<br /> 图片会被编码(看示例代码)<br /> 网页的加载过程是:<br /> 加载一个网页,通常都是先加载document文档,在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求。3、请求头<br /> User-agent:<br /> 请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户。<br /> Cookies:<br /> cookie用来保存登录信息。<br /> Referer:<br /> 浏览器上次访问的网页url<br /> 一般做爬虫都会加上请求头4、请求体<br /> 如果是get方式,请求体没有内容<br /> 如果是post方式,请求体是format data<br /> ps:<br /> 1、登录窗口,文件上传等,信息都会被附加到请求体内<br /> 2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
1、响应状态: <br /> 200:代表成功<br /> 301:代表跳转<br /> 404:文件不存在<br /> 403:权限<br /> 502:服务器错误2、响应头: Respone header<br /> set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来。3、网页源代码: preview<br /> 最主要的部分,包含了请求资源的内容,如网页html、图片和二进制数据等。
总结
1、总结爬虫流程:<br /> 爬取--->解析--->存储2、爬虫所需工具:<br /> 请求库:requests,selenium<br /> 解析库:正则,beautifulsoup,pyquery<br /> 存储库:文件,MySQL,Mongodb,Redis3、爬虫常用框架:<br /> scrapy
过去的亮点:
足够努力,梦想就会绽放 | 上海校区第9期全栈全日制python班开课,老司机带你删库逃跑 | 天天要闻 教你搭建游戏服务器(龙八手游) Python爬虫| 如何提高毛织布的爬行性能?
php 爬虫抓取网页数据(我用爬虫一天时间“偷了”知乎一百万用户 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-05 04:12
)
前几天,老板让我去抓拍大众点评某店的数据。当然,我理所当然地拒绝了它,理由是我不会。. . 但是我的抗拒也没用,所以还是去查资料,因为我是做php的,首先要找的是php的网络爬虫源码。经过我不懈的努力,终于找到了phpspider,打开phpspider开发文档我惊呆了首页,标题“我用爬虫“偷”了知乎100万用户,只为证明PHP是世界上最好的语言”,正如我所料,PHP 是世界上最好的语言。事不宜迟,让我们开始学习如何使用它。
首先要看的是提供的一个demo,代码如下:
$configs = array(
'name' => '糗事百科',
'domains' => array(
'qiushibaike.com',
'www.qiushibaike.com' ), 'scan_urls' => array( 'http://www.qiushibaike.com/' ), 'content_url_regexes' => array( "http://www.qiushibaike.com/article/\d+" ), 'list_url_regexes' => array( "http://www.qiushibaike.com/8hr/page/\d+\?s=\d+" ), 'fields' => array( array( // 抽取内容页的文章内容 'name' => "article_content", 'selector' => "//*[@id='single-next-link']", 'required' => true ), array( // 抽取内容页的文章作者 'name' => "article_author", 'selector' => "//div[contains(@class,'author')]//h2", 'required' => true ), ), ); $spider = new phpspider($configs); $spider->start();
每个具体的信息大家可以去查一下,哪里比较详细,这里只是我走的弯路,
domains是定义采集的域名,只在该域名下采集,
content_url_regexes是采集的内容页,使用chrome查看网页源码,然后使用selector选择器定位,selector使用xpath格式定位参数,当然也可以用css来选择。
'max_try' => 5,
'export' => array(
'type' => 'db',
'conf' => array(
'host' => 'localhost',
'port' => 3306,
'user' => 'root',
'pass' => 'root',
'name' => 'demo',
),
'table' => '360ky', ),
max_try 同时工作的爬虫任务数。
export采集数据存储,有两种格式,一种是写到数据库中,一种是直接生成.csv格式文件。
只要url规则写的对,就可以运行,不用管框架里面的封装。当然,此框架只能在php-cli命令行下运行,所以使用前要先配置环境变量,或者cd到php安装路径运行。
最后成功采集到大众点评某点的一千多条数据。 查看全部
php 爬虫抓取网页数据(我用爬虫一天时间“偷了”知乎一百万用户
)
前几天,老板让我去抓拍大众点评某店的数据。当然,我理所当然地拒绝了它,理由是我不会。. . 但是我的抗拒也没用,所以还是去查资料,因为我是做php的,首先要找的是php的网络爬虫源码。经过我不懈的努力,终于找到了phpspider,打开phpspider开发文档我惊呆了首页,标题“我用爬虫“偷”了知乎100万用户,只为证明PHP是世界上最好的语言”,正如我所料,PHP 是世界上最好的语言。事不宜迟,让我们开始学习如何使用它。
首先要看的是提供的一个demo,代码如下:
$configs = array(
'name' => '糗事百科',
'domains' => array(
'qiushibaike.com',
'www.qiushibaike.com' ), 'scan_urls' => array( 'http://www.qiushibaike.com/' ), 'content_url_regexes' => array( "http://www.qiushibaike.com/article/\d+" ), 'list_url_regexes' => array( "http://www.qiushibaike.com/8hr/page/\d+\?s=\d+" ), 'fields' => array( array( // 抽取内容页的文章内容 'name' => "article_content", 'selector' => "//*[@id='single-next-link']", 'required' => true ), array( // 抽取内容页的文章作者 'name' => "article_author", 'selector' => "//div[contains(@class,'author')]//h2", 'required' => true ), ), ); $spider = new phpspider($configs); $spider->start();
每个具体的信息大家可以去查一下,哪里比较详细,这里只是我走的弯路,
domains是定义采集的域名,只在该域名下采集,
content_url_regexes是采集的内容页,使用chrome查看网页源码,然后使用selector选择器定位,selector使用xpath格式定位参数,当然也可以用css来选择。
'max_try' => 5,
'export' => array(
'type' => 'db',
'conf' => array(
'host' => 'localhost',
'port' => 3306,
'user' => 'root',
'pass' => 'root',
'name' => 'demo',
),
'table' => '360ky', ),
max_try 同时工作的爬虫任务数。
export采集数据存储,有两种格式,一种是写到数据库中,一种是直接生成.csv格式文件。
只要url规则写的对,就可以运行,不用管框架里面的封装。当然,此框架只能在php-cli命令行下运行,所以使用前要先配置环境变量,或者cd到php安装路径运行。
最后成功采集到大众点评某点的一千多条数据。
php 爬虫抓取网页数据( 网络爬虫的项目地址是什么?如何爬取网站?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-04 11:05
网络爬虫的项目地址是什么?如何爬取网站?)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。现在让我们一起学习这个。
1.Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。. 使用此框架可以轻松爬取亚马逊列表等数据。
项目地址:
2.PySpider
pyspider 是一个用 python 实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
项目地址:
3.克劳利
Crawley可以高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
项目地址:
4.波西亚
Portia 是一个开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。
项目地址:
5.报纸
报纸可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
项目地址:
6.美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的营业时间。
项目地址:
7.抢
Grab 是一个用于构建网络爬虫的 Python 框架。使用 Grab,您可以构建各种复杂的网络爬虫,从简单的 5 行脚本到处理数百万网页的复杂异步网站爬虫。Grab 提供了一个用于执行网络请求和处理接收到的内容的 API,例如与 HTML 文档的 DOM 树进行交互。
项目地址:#grab-spider-user-manual
8.可乐
Cola 是一个分布式爬虫框架。对于用户来说,只需要编写几个具体的功能,无需关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。
项目地址:
感谢阅读,希望大家受益。
转载至:
推荐教程:《python教程》
以上就是史上最高效的Python爬虫框架(推荐)的详细内容。更多详情请关注php中文网文章其他相关话题!
声明:本文转载于:CSDN,如有侵权,请联系删除 查看全部
php 爬虫抓取网页数据(
网络爬虫的项目地址是什么?如何爬取网站?)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。现在让我们一起学习这个。
1.Scrapy
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。. 使用此框架可以轻松爬取亚马逊列表等数据。
项目地址:
2.PySpider
pyspider 是一个用 python 实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
项目地址:
3.克劳利
Crawley可以高速爬取网站对应的内容,支持关系型和非关系型数据库,数据可以导出为JSON、XML等。
项目地址:
4.波西亚
Portia 是一个开源的可视化爬虫工具,让你无需任何编程知识即可爬取网站!只需对您感兴趣的页面进行注释,Portia 就会创建一个爬虫来从相似页面中提取数据。
项目地址:
5.报纸
报纸可用于提取新闻、文章 和内容分析。使用多线程,支持10多种语言等。
项目地址:
6.美汤
Beautiful Soup 是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。它支持通过您最喜欢的转换器导航、查找和修改文档的惯用方式。Beautiful Soup 将为您节省数小时甚至数天的营业时间。
项目地址:
7.抢
Grab 是一个用于构建网络爬虫的 Python 框架。使用 Grab,您可以构建各种复杂的网络爬虫,从简单的 5 行脚本到处理数百万网页的复杂异步网站爬虫。Grab 提供了一个用于执行网络请求和处理接收到的内容的 API,例如与 HTML 文档的 DOM 树进行交互。
项目地址:#grab-spider-user-manual
8.可乐
Cola 是一个分布式爬虫框架。对于用户来说,只需要编写几个具体的功能,无需关注分布式操作的细节。任务自动分发到多台机器上,整个过程对用户透明。
项目地址:
感谢阅读,希望大家受益。
转载至:
推荐教程:《python教程》
以上就是史上最高效的Python爬虫框架(推荐)的详细内容。更多详情请关注php中文网文章其他相关话题!
声明:本文转载于:CSDN,如有侵权,请联系删除
php 爬虫抓取网页数据( 百度排名算法中有哪些是不可用数字来量化的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-02 10:11
百度排名算法中有哪些是不可用数字来量化的?)
话题:
1.你认为百度在删除重复网页时会考虑什么?
2.你觉得百度如何分析网站的用户体验?
3.你觉得百度会根据排名给网站分配CTR任务吗?
4. 一个纯粹的采集 网站,在短时间内获得了不错的流量,并且稳定了几个月。之后被降级,没有任何排名,但两个多月后,排名再次发生变化。回到首页,不做任何修改或操作,让它自动挂在那里采集。Q:既然百度已经检测到网站的质量很差,为什么排在后面?
5、购物网站移动台的产品列表页面使用异步加载数据。对SEO有什么不利影响?具体如何解决?
6、机器人有/A/目录,为什么不能完全阻止搜索引擎爬取A目录下的文件?请从技术层面分享原因。
7、简析CDN对搜索引擎爬虫爬取量的影响?并给出应对负面影响的具体解决方案?
8、我们知道百度的一些排名算法是可以量化的:比如外链数、外链域名数、每日更新数等等,有哪些数字是不可用的在百度的排名算法中?量化?
9、您如何定义网站 SEO 的好坏。
10、品牌词被人搭讪,甚至在排名上超过你,你会怎么做!
话题:
1 303和307跳有什么区别,百度怎么看?
2 使用Apache环境和代码适配网站,.htaccess怎么写可以返回百度可以识别的Vary HTTP header;
3 Adober Flash palye 10.0或更高版本的swf在https环境下请求远程服务器资源,是否会发送referer信息;
4 在早期浏览器中,如何绕过浏览器权限/提示允许用户点击按钮复制信息;
5 公认的观点,在哪种文件处理类型中nginx比apahce性能更好,可以列出两个;
6 按方向分,常见的三种机械分词方法有哪些?对于中文,基于一般实验,( )方向法的准确度要高于( )方向法;
7 在不依赖客户端的前提下,列出一个PC端IE6~IE11、Microsoft Edge、FireFox以及所有Chromium内核浏览器都支持的网络录制方案,写出一个可行的思路;
8 在 PHP 中:
$a='abc';
$a="abc";
哪个执行效率更高;
9 haddop2.0 版本前自带一个经典案例,号称“Mapreduce版”的“Hello Word”,站长SEOer能做什么;
10 在早期的浏览器中,直接在HTML中使用style="XX"可能会影响页面的哪一部分被加载,从而影响打开页面的速度;
嗯,今天就跟大家分享一下这个方法,如果你不明白 查看全部
php 爬虫抓取网页数据(
百度排名算法中有哪些是不可用数字来量化的?)
话题:
1.你认为百度在删除重复网页时会考虑什么?
2.你觉得百度如何分析网站的用户体验?
3.你觉得百度会根据排名给网站分配CTR任务吗?
4. 一个纯粹的采集 网站,在短时间内获得了不错的流量,并且稳定了几个月。之后被降级,没有任何排名,但两个多月后,排名再次发生变化。回到首页,不做任何修改或操作,让它自动挂在那里采集。Q:既然百度已经检测到网站的质量很差,为什么排在后面?
5、购物网站移动台的产品列表页面使用异步加载数据。对SEO有什么不利影响?具体如何解决?
6、机器人有/A/目录,为什么不能完全阻止搜索引擎爬取A目录下的文件?请从技术层面分享原因。
7、简析CDN对搜索引擎爬虫爬取量的影响?并给出应对负面影响的具体解决方案?
8、我们知道百度的一些排名算法是可以量化的:比如外链数、外链域名数、每日更新数等等,有哪些数字是不可用的在百度的排名算法中?量化?
9、您如何定义网站 SEO 的好坏。
10、品牌词被人搭讪,甚至在排名上超过你,你会怎么做!
话题:
1 303和307跳有什么区别,百度怎么看?
2 使用Apache环境和代码适配网站,.htaccess怎么写可以返回百度可以识别的Vary HTTP header;
3 Adober Flash palye 10.0或更高版本的swf在https环境下请求远程服务器资源,是否会发送referer信息;
4 在早期浏览器中,如何绕过浏览器权限/提示允许用户点击按钮复制信息;
5 公认的观点,在哪种文件处理类型中nginx比apahce性能更好,可以列出两个;
6 按方向分,常见的三种机械分词方法有哪些?对于中文,基于一般实验,( )方向法的准确度要高于( )方向法;
7 在不依赖客户端的前提下,列出一个PC端IE6~IE11、Microsoft Edge、FireFox以及所有Chromium内核浏览器都支持的网络录制方案,写出一个可行的思路;
8 在 PHP 中:
$a='abc';
$a="abc";
哪个执行效率更高;
9 haddop2.0 版本前自带一个经典案例,号称“Mapreduce版”的“Hello Word”,站长SEOer能做什么;
10 在早期的浏览器中,直接在HTML中使用style="XX"可能会影响页面的哪一部分被加载,从而影响打开页面的速度;
嗯,今天就跟大家分享一下这个方法,如果你不明白
php 爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-04-01 19:18
)
首先,我们需要知道什么是爬虫!当我第一次听到爬虫这个词时,我以为它是一种爬行昆虫。想想就觉得可笑……后来才知道是网上的数据抓取工具!
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫能做什么?
1、模拟浏览器打开网页,获取网页中我们想要的部分数据。
2、从技术角度,程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据,存储和使用。
3、仔细观察不难发现,越来越多的人知道和了解爬虫。一方面,可以从互联网上获取越来越多的数据。另一方面,像 Python 这样的编程语言提供了越来越多优秀的工具,让爬虫变得简单易用。
4、利用爬虫,我们可以获取大量有价值的数据,从而获取感性知识无法获取的信息,例如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上图,这就是爬取数据时的流程,是不是很简单?因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析过滤来获取我们想要的资源。
相关学习推荐:python教程
以上就是python爬虫能做什么的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php 爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人)(图)
)
首先,我们需要知道什么是爬虫!当我第一次听到爬虫这个词时,我以为它是一种爬行昆虫。想想就觉得可笑……后来才知道是网上的数据抓取工具!
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫能做什么?
1、模拟浏览器打开网页,获取网页中我们想要的部分数据。
2、从技术角度,程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据,存储和使用。
3、仔细观察不难发现,越来越多的人知道和了解爬虫。一方面,可以从互联网上获取越来越多的数据。另一方面,像 Python 这样的编程语言提供了越来越多优秀的工具,让爬虫变得简单易用。
4、利用爬虫,我们可以获取大量有价值的数据,从而获取感性知识无法获取的信息,例如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上图,这就是爬取数据时的流程,是不是很简单?因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析过滤来获取我们想要的资源。
相关学习推荐:python教程
以上就是python爬虫能做什么的详细内容。更多详情请关注php中文网文章其他相关话题!
php 爬虫抓取网页数据(大数据行业数据价值不言而喻的技术总结及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-31 10:19
摘要:对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据是弥补其先天数据短板的最佳选择,本文主要从原理、架构、分类、反爬虫技术等方面总结了爬虫技术履带式。
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发使Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium + phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
5、参考资料
[1] 网络爬虫基本原理 查看全部
php 爬虫抓取网页数据(大数据行业数据价值不言而喻的技术总结及解决办法!)
摘要:对于大数据行业来说,数据的价值不言而喻。在这个信息爆炸的时代,互联网上的信息数据太多了。对于中小微企业来说,合理使用爬虫爬取有价值的数据是弥补其先天数据短板的最佳选择,本文主要从原理、架构、分类、反爬虫技术等方面总结了爬虫技术履带式。
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4 部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5 OPIC 政策方针
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.6 大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发使Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,无论大小。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一页面,或者同一账号在短时间内多次执行同一操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium + phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
5、参考资料
[1] 网络爬虫基本原理
php 爬虫抓取网页数据(一个_selector.xpath.u去重与增量爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-31 10:14
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能被Xpath提取出来,所以也需要定期匹配。如果有异常,必须处理。一般当页面无法匹配到对应字段时,应设置为0,待到item后处理。过滤处理。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:
(1)从待爬取队列中获取url
(2)判断要请求的url是否已经爬取,如果已经爬取则忽略请求,未爬取,继续其他操作,将url插入爬取队列
(3)重复步骤 1
这里我们使用了scrapy-redis的去重组件,所以还没有实现,但是原理还是需要了解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫类反屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为
系统采用以下方法防止爬虫被屏蔽:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.本着君子的约定,降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们屏蔽了cookies的调整,这也有利于我们的身份分歧。
5.人工编码,这应该是无可挑剔的反封杀措施,所有系统都比人工操作好不了多少,只是降低了自动化,效率不高,但确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码以重新访问该页面。为此,我添加了一个邮件提醒模块。当爬虫被封禁时,会发送邮件提醒管理员解除封禁。同时将重定向的请求重新加入下载队列进行爬取,以保证数据的完整性。
防爬虫网站屏蔽原理如下图所示:
(a) 模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性
首先是扩展下载中间件。首先,将中间件添加到seeings.py。
二、扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为列表,如下图:
然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。
总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。
首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1.代理ip池的设计开发流程如下:
一种。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行验证
d。如果达到最大ips数,停止爬取,一定时间后验证数据ips的有效性,删除无效ips
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip模块这里使用七夜代理ip池的开源项目
代理ip爬虫运行截图:
(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有各种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,阻塞组件这是通过捕获 302 状态来实现的。同时,异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:
(d) 数据存储模块
数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。
Scrapy 支持 json、csv、xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:
(e) 抓取场地设计
本文以网络房屋数据为捕获目标,从机端解析捕获现场数据。因此,捕获的内容必须能够客观、准确地反映网络房屋数据的特征。
以抓取58同城的在线房屋数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
现场选择主要是根据本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。降低单机压力。
(f) 数据处理
1)对象定义器
Item 是定义抓取数据的容器。通过创建一个 scrapy.item.Item 类来声明。将该属性定义为一个scrapy.item.Field对象来控制通过实例化所需item获得的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、地点、社区、城市、帖子详情页链接、发布时间。这里对字段的定义是根据数据处理端的需要来定义的。关键代码如下:
class TcZufangItem(Item):
#帖子名称
title=Field()
#租金
money=Field()
#租赁方式
method=Field()
#所在区域
area=Field()
#所在小区
community=Field()
#帖子详情url
targeturl=Field()
#帖子发布时间
pub_time=Field()
#所在城市
city=Field()
2)数据处理程序
保存和输出数据的方法在 Pipeline 类中定义。从 Spider 的 parse 方法返回的 Item 中,数据将被处理并以 ITEM_PIPELINES 列表中 Pipeline 类对应的顶层格式输出。系统发回管道的数据使用Mongodb存储。关键代码如下:
def process_item(self, item, spider):
if item['pub_time'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['method'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['community']==0:
raise DropItem("Duplicate item found: %s" % item)
if item['money']==0:
raise DropItem("Duplicate item found: %s" % item)
if item['area'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['city'] == 0:
raise DropItem("Duplicate item found: %s" % item)
zufang_detail = {
'title': item.get('title'),
'money': item.get('money'),
'method': item.get('method'),
'area': item.get('area', ''),
'community': item.get('community', ''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time', ''),
'city':item.get('city','')
}
result = self.db['zufang_detail'].insert(zufang_detail)
print '[success] the '+item['targeturl']+'wrote to MongoDB database'
return item
(g) 数据可视化设计
实际上,数据的可视化就是将数据库的数据转换成便于我们用户观察的形式。本系统使用 Mongodb 存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:
四、系统操作
系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
Master运行截图:
从端运行截图:
五、系统部署
环境部署,因为分布式部署所需的环境类似,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像部署爬虫,使用Daocloud上的scrapy-env pair。该程序已部署。具体的docker部署过程可以参考网上。 查看全部
php 爬虫抓取网页数据(一个_selector.xpath.u去重与增量爬取)
response_selector.xpath(u'//div[contains(@class,"house-title")]/p[contains(@class,"house-update-info c_888 f12")]/text()').extract( )
因为有些数据不能被Xpath提取出来,所以也需要定期匹配。如果有异常,必须处理。一般当页面无法匹配到对应字段时,应设置为0,待到item后处理。过滤处理。
3)去重和增量爬取
去重和增量爬取对服务器来说意义重大,可以减轻服务器的压力,保证数据的准确性。如果不采用去重,爬取的内容会爬取大量的重复内容,大大降低爬虫的效率。事实上,重复数据删除的过程非常简单。核心是判断每个请求是否在已经爬取的队列中。如果它已经存在,则丢弃当前请求。
具体实施步骤:
(1)从待爬取队列中获取url
(2)判断要请求的url是否已经爬取,如果已经爬取则忽略请求,未爬取,继续其他操作,将url插入爬取队列
(3)重复步骤 1
这里我们使用了scrapy-redis的去重组件,所以还没有实现,但是原理还是需要了解的,具体可以看源码。
4)爬虫中间件
爬虫中间件可以帮助我们在scrapy爬取过程中自由扩展自己的程序。以下是爬虫反屏蔽中间件、下载器异常状态中间件和非200状态中间件。
(1)爬虫类反屏蔽组件的实现
当访问一个网站网页时,会给网站带来一定的负载,爬虫程序模拟了我们正常访问网页的过程,但是。大型爬虫会给网站增加很大的负载,影响正常用户的访问。为了保证大部分普通用户可以访问网页,大部分网站都有相应的反爬策略。一旦访问行为被识别为爬虫,网站会采取一定的措施限制你的访问,比如访问过于频繁会提示你输入验证码。您访问 网站。当系统有针对性的抓取网页数据时,会不断的访问网站的内容。如果不采取伪装措施,很容易被网站识别为爬虫行为
系统采用以下方法防止爬虫被屏蔽:
1.模拟不同的浏览器行为
2.一定频率更换代理服务器和网关
3.本着君子的约定,降低爬取网页的频率,减少并发爬取的进程,限制每个ip的并发爬取数量,牺牲一定的效率来换取系统的稳定性。
4.禁用cookies,网站会在用户访问时在cookie中插入一些信息来判断是否是机器人。我们屏蔽了cookies的调整,这也有利于我们的身份分歧。
5.人工编码,这应该是无可挑剔的反封杀措施,所有系统都比人工操作好不了多少,只是降低了自动化,效率不高,但确实是最有效的措施。当爬虫被禁止时,它会被重定向到一个验证码页面。输入验证码以重新访问该页面。为此,我添加了一个邮件提醒模块。当爬虫被封禁时,会发送邮件提醒管理员解除封禁。同时将重定向的请求重新加入下载队列进行爬取,以保证数据的完整性。
防爬虫网站屏蔽原理如下图所示:
(a) 模拟不同浏览器行为的实现思路和代码
原理:从scrapy的介绍可以知道scrapy有下载中间件,在其中我们可以自定义请求和响应,类似于spring面向切面的编程,就像程序运行前后嵌入的一个hook。核心是修改请求的属性
首先是扩展下载中间件。首先,将中间件添加到seeings.py。
二、扩展中间件,主要是写一个useragent列表,将常用的浏览器请求头保存为列表,如下图:
然后让请求的头文件在列表中随机取一个代理值,然后下载到下载器。
总之,每次发出请求时,都会使用不同的浏览器访问目标网站。
(b) 使用代理ip进行爬取的实现思路和代码。
首先在seeings.py中添加中间件,展开下载组件请求的头文件,从代理ip池中随机抽取一个代理值,然后下载到下载器中。
1.代理ip池的设计开发流程如下:
一种。抓取免费代理 ip网站。
湾。存储并验证代理 ip
C。通过存储到数据库中进行验证
d。如果达到最大ips数,停止爬取,一定时间后验证数据ips的有效性,删除无效ips
e. 直到数据库ip小于0,继续爬取ip,重复步骤a。
代理ip模块这里使用七夜代理ip池的开源项目
代理ip爬虫运行截图:
(c)爬虫异常状态组件的处理
当爬虫没有被阻塞并运行时,访问网站并不总是200请求成功,而是有各种状态,比如上面的爬虫被禁止时,返回的状态实际上是302,阻塞组件这是通过捕获 302 状态来实现的。同时,异常状态的处理有利于爬虫的健壮性。
设置中的扩展中间件捕获异常后,将请求重新加入待下载队列的过程如下:
(d) 数据存储模块
数据存储模块主要负责存储slave端爬取和解析的页面。数据使用 Mongodb 存储。
Scrapy 支持 json、csv、xml 等数据存储格式。用户可以在运行爬虫时设置,例如:scrapy crawl spider -o items.json -t json,也可以在Scrapy项目文件和ItemPipline文件中定义。同时Scrapy还支持数据库存储,比如Monogdb、Redis等,当数据量大到一定程度时,可以使用Mongodb或者Reids的集群来解决问题。本系统的数据存储如下图所示:
(e) 抓取场地设计
本文以网络房屋数据为捕获目标,从机端解析捕获现场数据。因此,捕获的内容必须能够客观、准确地反映网络房屋数据的特征。
以抓取58同城的在线房屋数据为例,通过分析网页结构,定义字段的详细信息如下表所示。
现场选择主要是根据本系统的应用研究,因为系统开发单机配置比较低,没有图片文件下载到本机。降低单机压力。
(f) 数据处理
1)对象定义器
Item 是定义抓取数据的容器。通过创建一个 scrapy.item.Item 类来声明。将该属性定义为一个scrapy.item.Field对象来控制通过实例化所需item获得的站点数据。系统定义了九个抓取对象,分别是:帖子标题、租金、租赁方式、地点、社区、城市、帖子详情页链接、发布时间。这里对字段的定义是根据数据处理端的需要来定义的。关键代码如下:
class TcZufangItem(Item):
#帖子名称
title=Field()
#租金
money=Field()
#租赁方式
method=Field()
#所在区域
area=Field()
#所在小区
community=Field()
#帖子详情url
targeturl=Field()
#帖子发布时间
pub_time=Field()
#所在城市
city=Field()
2)数据处理程序
保存和输出数据的方法在 Pipeline 类中定义。从 Spider 的 parse 方法返回的 Item 中,数据将被处理并以 ITEM_PIPELINES 列表中 Pipeline 类对应的顶层格式输出。系统发回管道的数据使用Mongodb存储。关键代码如下:
def process_item(self, item, spider):
if item['pub_time'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['method'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['community']==0:
raise DropItem("Duplicate item found: %s" % item)
if item['money']==0:
raise DropItem("Duplicate item found: %s" % item)
if item['area'] == 0:
raise DropItem("Duplicate item found: %s" % item)
if item['city'] == 0:
raise DropItem("Duplicate item found: %s" % item)
zufang_detail = {
'title': item.get('title'),
'money': item.get('money'),
'method': item.get('method'),
'area': item.get('area', ''),
'community': item.get('community', ''),
'targeturl': item.get('targeturl'),
'pub_time': item.get('pub_time', ''),
'city':item.get('city','')
}
result = self.db['zufang_detail'].insert(zufang_detail)
print '[success] the '+item['targeturl']+'wrote to MongoDB database'
return item
(g) 数据可视化设计
实际上,数据的可视化就是将数据库的数据转换成便于我们用户观察的形式。本系统使用 Mongodb 存储数据。数据的可视化基于Django+Semantiui,效果如下图所示:
四、系统操作
系统以58同城租赁平台为抓拍目标。运行十个小时后,它继续在网络上捕获数以万计的列表。
Master运行截图:
从端运行截图:
五、系统部署
环境部署,因为分布式部署所需的环境类似,如果一个服务器部署程序需要配置环境,就很麻烦了。这里使用docker镜像部署爬虫,使用Daocloud上的scrapy-env pair。该程序已部署。具体的docker部署过程可以参考网上。
php 爬虫抓取网页数据( 图片来源网络抓取策略(一)(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-30 03:07
图片来源网络抓取策略(一)(1)_光明网(组图))
图片来源网络
抓取策略
在爬虫系统中,待爬取的 URL 是非常重要的部分。需要爬虫爬取的网页的URL排列在其中,形成队列结构。调度器每次从队列头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被附加到待爬取URL队列的末尾,从而形成一个爬取循环,整个爬虫系统可以说是由这个队列驱动的。
URL队列中待爬取的页面URL的顺序是如何确定的?如上所述,将新下载页面中收录的链接附加到队列末尾。虽然这是一种确定队列中 URL 顺序的方法,但它不是唯一的方法。事实上,也可以采用许多其他技术。获取的 URL 已排序。爬虫的不同爬取策略使用不同的方法来确定待爬取URL队列中URL的优先级顺序。
爬虫的爬取策略有很多,但不管是什么方法,基本目标都是一样的:优先选择重要的网页进行爬取。在爬虫系统中,所谓网页的重要性可以通过不同的方法来判断,但大多是根据网页的流行度来定义的。
爬取策略的方法虽然有很多种,但这里只对已经证明有效或者比较有代表性的方案进行说明,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略和大站点优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。自搜索引擎爬虫出现以来,它就被采用了。新提出的爬取策略经常以这种方法为基准。但值得注意的是,这种策略也是一种非常强大的方法。很多新方法的实际效果不一定比广度优先遍历策略好,所以这个方法其实是目前很多爬虫采用的第一个爬取策略。
如前所述,“将新下载的网页中收录的URL附加到待爬取URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法没有明确提出并以网页的重要性作为衡量标准,只是机械地从新下载的网页中提取链接,并作为下载的URL序列附加到待爬取的URL队列中。下图是这个策略的示意图: 假设队列最前面的网页是1号网页,从1号网页中提取三个链接分别指向2号、3号和1号. 4 分别,所以它们是按照要抓取的数字的顺序排列的。在获取队列中,
实验表明,这种策略效果很好。虽然看起来很机械,但实际的网页爬取顺序基本上是按照网页的重要性排序的。这样做的原因是,有研究人员认为,如果一个网页收录大量的传入链接,则更有可能被广度优先遍历策略及早捕获,而传入链接的数量从侧面,也就是广度优先的遍历策略其实上面也隐含了一些页面优先级的假设。
广度优先遍历策略
02 不完整的PageRank策略
PageRank 是一种著名的链接分析算法,可以用来衡量网页的重要性。很自然会想到PageRank对URL进行优先排序的思路。但是这里有一个问题,PageRank是一个全局算法,也就是说,当所有网页都下载完后,计算结果是可靠的,而爬虫的目的是下载网页,而只有一部分在运行过程中可以看到页面。,因此处于爬取阶段的页面无法获得可靠的 PageRank 分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,连同待爬取的URL队列中的URL,形成一组网页,在这个集合中进行PageRank计算。计算完成后,待爬取的 URL 队列将根据 PageRank 得分从高到低对网页进行排序,形成的序列就是爬虫接下来应该爬取的 URL 列表。这就是为什么它被称为“不完整的PageRank”。
如果每次爬取一个新的网页,就为所有下载的网页重新计算新的不完整PageRank值,这在现实中显然效率太低,不可行。一个折衷方案是:每次有足够的K个页面下载,然后对所有下载的页面重新计算新的不完整PageRank。这种计算效率勉强可以接受,但也带来了新的问题:在开始下一轮PageRank计算之前,从新下载的网页中提取收录的链接。很有可能这些环节非常重要,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 为这些新提取的页面分配一个临时的 PageRank 值但没有 PageRank 值,并将本页所有入站链接的PageRank值作为临时PageRank值。如果是PageRank值高的页面,先下载URL。
下图是不完全PageRank策略的简化示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时{P1,P2,P3}3个网页已经下载到本地,这3个网页中收录的链接指向{P4,P5,P6},形成了一个待抓取的URL队列。如何决定下载顺序?将六个网页组成一个新的集合,并为该集合计算PageRank值。这样,P4、P5和P6就得到了它们对应的PageRank值,可以从大到小排序得到它们的下载顺序。这里可以假设下载顺序为:P5、P4、P6,下载P5页面时,提取链接指向P8页面。此时,一个临时的 PageRank 值被分配给 P8。如果这个值大于P4和P6,如果PageRank值更高,那么先下载P8。在这个连续的循环中,形成了不完全PageRank策略的计算思路。
不完整的PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明不完整的PageRank结果稍好一些,而一些实验结果正好相反。一些研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大的不同。不应作为计算抓取过程中 URL 重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC 字面意思是“在线页面重要性计算”,可以认为是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被赋予了相同的“现金”,每当某个页面P被下载时,P就会将其拥有的“现金”平均分配给该页面所收录的链接页面,并分配自己的“现金” “空。至于待爬取的URL队列中的网页,按照手头现金数量排序,现金最充裕的网页优先下载。OPIC与PageRank基本一致就大框架而言,不同的是PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对于没有链接关系的网页有一个长距离的跳转过程,但是OPIC没有这个计算因子。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略优于广度优先遍历策略。
04 大站优先战略
大站点优先策略的思路很简单:以网站为单位衡量网页的重要性。对于URL队列中待爬取的网页,按照所属的网站进行分类。如果有任何 网站 正在等待下载,如果页面数量最多,则将首先下载这些链接。基本思路是先下载大网站,因为大网站往往收录更多页面。鉴于大型网站往往是知名公司的内容,其网页质量普遍较高,这个思路虽然简单,但有一定的依据。实验表明,该算法的效果略好于广度优先遍历策略。
网页更新策略
互联网的动态特性是其显着特征。随时出现新页面,更改页面内容或删除原创页面。对于爬虫来说,即使任务完成,也不必在本地爬取网页,也能体现互联网的动态性。本地下载的页面可视为互联网页面的“镜像”,爬虫应尽可能保证一致性。可以假设这样一种情况:一个网页被删除或者内容发生了重大变化,而搜索引擎对此一无所知,仍然按照旧的内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取的网页,
网页更新策略的任务是决定何时重新爬取下载的网页,使本地下载的网页和互联网上的原创网页的内容尽可能一致。常用的网页更新策略有三种:历史参考策略、用户体验策略和整群抽样策略。
01历史参考策略
历史参考策略是最直观的更新策略,它基于以下假设:过去频繁更新的网页,未来也会频繁更新。因此,为了估计网页何时更新,可以参考历史更新情况来做出决定。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时再次发生变化,从而指导爬虫的爬取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,重点关注内容变化检测和建模。优越的。
02用户体验策略
一般来说,搜索引擎用户提交查询后,可能会有上千条相关搜索结果,而用户没有耐心等着查看后面的搜索结果,可能只会看前3页搜索内容。用户体验策略就是利用用户的这一特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,以后更新这些过时的网页也不错。因此,最好根据网页内容的变化(通常以搜索结果的排名变化来衡量)带来的搜索质量变化来判断网页何时更新。影响力越大的网页,更新速度越快。
用户体验策略保存网页的多个历史版本,根据过去每次内容变化对搜索质量的影响取一个平均值,作为判断爬虫重新访问时机的参考抓取网页。网页,优先级越高是计划重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略在很大程度上依赖于网页的历史更新信息,这是后续计算的基础。然而实际上,对于每个网页保存其历史信息,搜索系统会增加很多额外的负担。换个角度看,如果是第一次爬取的网页,因为没有历史信息,不可能按照这两种思路估计更新周期。为解决上述不足,提出了整群抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测更新周期,属性相似的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,同一类别内的网页具有相同的更新频率。为了计算某个类别的更新周期,只需要对该类别中的网页进行采样,将这些采样的网页的更新周期作为该类别中所有网页的更新周期。与上述两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,
下图描述了聚类抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页具有相似的更新周期。从类别中提取一部分最具代表性的网页(一般是提取离类别中心最近的那些网页),并计算这些网页的更新周期,然后将这个更新周期用于该类别中的所有网页类别,然后可以根据网页的类别使用更新周期。确定其更新周期。
整群抽样策略
网页更新周期的属性特征分为静态特征和动态特征两类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,比如图片数量的变化、进出链接的变化等。网页可以根据这两类特征进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,一些研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一个网站的网页具有相同的更新周期,则< @网站 采样,计算更新周期,然后网站 中的所有网页都会以这个更新周期为准。虽然这个假设是粗略的,因为很明显同一个网站内的网页的更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类非常困难。
如果你对爬虫感兴趣,还可以阅读:
干货全流程| 入门级爬虫技术原理,这就够了
网络爬虫 | 你不知道的暗网是怎么爬的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗? 查看全部
php 爬虫抓取网页数据(
图片来源网络抓取策略(一)(1)_光明网(组图))
图片来源网络
抓取策略
在爬虫系统中,待爬取的 URL 是非常重要的部分。需要爬虫爬取的网页的URL排列在其中,形成队列结构。调度器每次从队列头部取出URL,发送给网页下载器下载页面内容。,每个新下载的网页中收录的URL都会被附加到待爬取URL队列的末尾,从而形成一个爬取循环,整个爬虫系统可以说是由这个队列驱动的。
URL队列中待爬取的页面URL的顺序是如何确定的?如上所述,将新下载页面中收录的链接附加到队列末尾。虽然这是一种确定队列中 URL 顺序的方法,但它不是唯一的方法。事实上,也可以采用许多其他技术。获取的 URL 已排序。爬虫的不同爬取策略使用不同的方法来确定待爬取URL队列中URL的优先级顺序。
爬虫的爬取策略有很多,但不管是什么方法,基本目标都是一样的:优先选择重要的网页进行爬取。在爬虫系统中,所谓网页的重要性可以通过不同的方法来判断,但大多是根据网页的流行度来定义的。
爬取策略的方法虽然有很多种,但这里只对已经证明有效或者比较有代表性的方案进行说明,包括以下四种:广度优先遍历策略、不完全PageRank策略、OPIC策略和大站点优先策略。
01 广度优先遍历策略
广度优先遍历策略是一种非常简单直观的遍历方法,历史悠久。自搜索引擎爬虫出现以来,它就被采用了。新提出的爬取策略经常以这种方法为基准。但值得注意的是,这种策略也是一种非常强大的方法。很多新方法的实际效果不一定比广度优先遍历策略好,所以这个方法其实是目前很多爬虫采用的第一个爬取策略。
如前所述,“将新下载的网页中收录的URL附加到待爬取URL队列的末尾”,这就是广度优先遍历的思想。也就是说,该方法没有明确提出并以网页的重要性作为衡量标准,只是机械地从新下载的网页中提取链接,并作为下载的URL序列附加到待爬取的URL队列中。下图是这个策略的示意图: 假设队列最前面的网页是1号网页,从1号网页中提取三个链接分别指向2号、3号和1号. 4 分别,所以它们是按照要抓取的数字的顺序排列的。在获取队列中,
实验表明,这种策略效果很好。虽然看起来很机械,但实际的网页爬取顺序基本上是按照网页的重要性排序的。这样做的原因是,有研究人员认为,如果一个网页收录大量的传入链接,则更有可能被广度优先遍历策略及早捕获,而传入链接的数量从侧面,也就是广度优先的遍历策略其实上面也隐含了一些页面优先级的假设。
广度优先遍历策略
02 不完整的PageRank策略
PageRank 是一种著名的链接分析算法,可以用来衡量网页的重要性。很自然会想到PageRank对URL进行优先排序的思路。但是这里有一个问题,PageRank是一个全局算法,也就是说,当所有网页都下载完后,计算结果是可靠的,而爬虫的目的是下载网页,而只有一部分在运行过程中可以看到页面。,因此处于爬取阶段的页面无法获得可靠的 PageRank 分数。
如果我们仍然坚持在这个不完整的 Internet 页面子集中计算 PageRank 怎么办?这就是不完全PageRank策略的基本思想:对于下载的网页,连同待爬取的URL队列中的URL,形成一组网页,在这个集合中进行PageRank计算。计算完成后,待爬取的 URL 队列将根据 PageRank 得分从高到低对网页进行排序,形成的序列就是爬虫接下来应该爬取的 URL 列表。这就是为什么它被称为“不完整的PageRank”。
如果每次爬取一个新的网页,就为所有下载的网页重新计算新的不完整PageRank值,这在现实中显然效率太低,不可行。一个折衷方案是:每次有足够的K个页面下载,然后对所有下载的页面重新计算新的不完整PageRank。这种计算效率勉强可以接受,但也带来了新的问题:在开始下一轮PageRank计算之前,从新下载的网页中提取收录的链接。很有可能这些环节非常重要,应该优先考虑。下载,这种情况怎么解决?不完整的 PageRank 为这些新提取的页面分配一个临时的 PageRank 值但没有 PageRank 值,并将本页所有入站链接的PageRank值作为临时PageRank值。如果是PageRank值高的页面,先下载URL。
下图是不完全PageRank策略的简化示意图。我们为每下载 3 个网页设置一个新的 PageRank 计算。此时{P1,P2,P3}3个网页已经下载到本地,这3个网页中收录的链接指向{P4,P5,P6},形成了一个待抓取的URL队列。如何决定下载顺序?将六个网页组成一个新的集合,并为该集合计算PageRank值。这样,P4、P5和P6就得到了它们对应的PageRank值,可以从大到小排序得到它们的下载顺序。这里可以假设下载顺序为:P5、P4、P6,下载P5页面时,提取链接指向P8页面。此时,一个临时的 PageRank 值被分配给 P8。如果这个值大于P4和P6,如果PageRank值更高,那么先下载P8。在这个连续的循环中,形成了不完全PageRank策略的计算思路。
不完整的PageRank看起来很复杂,那么效果一定比简单的广度优先遍历策略更好吗?不同的实验结果是有争议的。一些结果表明不完整的PageRank结果稍好一些,而一些实验结果正好相反。一些研究人员指出,不完整的 PageRank 计算的重要性与完整的 PageRank 计算结果有很大的不同。不应作为计算抓取过程中 URL 重要性的依据。
不完整的 PageRank 策略
03 OPIC战略
OPIC 字面意思是“在线页面重要性计算”,可以认为是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被赋予了相同的“现金”,每当某个页面P被下载时,P就会将其拥有的“现金”平均分配给该页面所收录的链接页面,并分配自己的“现金” “空。至于待爬取的URL队列中的网页,按照手头现金数量排序,现金最充裕的网页优先下载。OPIC与PageRank基本一致就大框架而言,不同的是PageRank每次都需要迭代计算,而OPIC策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对于没有链接关系的网页有一个长距离的跳转过程,但是OPIC没有这个计算因子。实验结果表明,OPIC是一种较好的重要性度量策略,其效果略优于广度优先遍历策略。
04 大站优先战略
大站点优先策略的思路很简单:以网站为单位衡量网页的重要性。对于URL队列中待爬取的网页,按照所属的网站进行分类。如果有任何 网站 正在等待下载,如果页面数量最多,则将首先下载这些链接。基本思路是先下载大网站,因为大网站往往收录更多页面。鉴于大型网站往往是知名公司的内容,其网页质量普遍较高,这个思路虽然简单,但有一定的依据。实验表明,该算法的效果略好于广度优先遍历策略。
网页更新策略
互联网的动态特性是其显着特征。随时出现新页面,更改页面内容或删除原创页面。对于爬虫来说,即使任务完成,也不必在本地爬取网页,也能体现互联网的动态性。本地下载的页面可视为互联网页面的“镜像”,爬虫应尽可能保证一致性。可以假设这样一种情况:一个网页被删除或者内容发生了重大变化,而搜索引擎对此一无所知,仍然按照旧的内容进行排序,作为搜索结果提供给用户。用户体验还不错。不言而喻。因此,对于已经爬取的网页,
网页更新策略的任务是决定何时重新爬取下载的网页,使本地下载的网页和互联网上的原创网页的内容尽可能一致。常用的网页更新策略有三种:历史参考策略、用户体验策略和整群抽样策略。
01历史参考策略
历史参考策略是最直观的更新策略,它基于以下假设:过去频繁更新的网页,未来也会频繁更新。因此,为了估计网页何时更新,可以参考历史更新情况来做出决定。
这种方法经常使用泊松过程来对网页的变化进行建模。根据每个网页过去的变化,该模型用于预测未来内容何时再次发生变化,从而指导爬虫的爬取过程。不同的方法有不同的侧重点。例如,一些研究将网页划分为不同的区域。爬取策略应忽略广告栏或导航栏等不重要区域的频繁变化,重点关注内容变化检测和建模。优越的。
02用户体验策略
一般来说,搜索引擎用户提交查询后,可能会有上千条相关搜索结果,而用户没有耐心等着查看后面的搜索结果,可能只会看前3页搜索内容。用户体验策略就是利用用户的这一特性来设计更新策略。
此更新策略以用户体验为中心。即使本地索引的网页内容已经过时,如果不影响用户体验,以后更新这些过时的网页也不错。因此,最好根据网页内容的变化(通常以搜索结果的排名变化来衡量)带来的搜索质量变化来判断网页何时更新。影响力越大的网页,更新速度越快。
用户体验策略保存网页的多个历史版本,根据过去每次内容变化对搜索质量的影响取一个平均值,作为判断爬虫重新访问时机的参考抓取网页。网页,优先级越高是计划重新抓取。
03 整群抽样策略
上面介绍的两种网页更新策略在很大程度上依赖于网页的历史更新信息,这是后续计算的基础。然而实际上,对于每个网页保存其历史信息,搜索系统会增加很多额外的负担。换个角度看,如果是第一次爬取的网页,因为没有历史信息,不可能按照这两种思路估计更新周期。为解决上述不足,提出了整群抽样策略。
聚类抽样策略认为网页具有一些属性,可以根据这些属性预测更新周期,属性相似的网页具有相似的更新周期。因此,可以根据这些属性对网页进行分类,同一类别内的网页具有相同的更新频率。为了计算某个类别的更新周期,只需要对该类别中的网页进行采样,将这些采样的网页的更新周期作为该类别中所有网页的更新周期。与上述两种方法相比,该策略一方面不需要为每个网页保存历史信息;另一方面,对于新的网页,即使没有历史信息,
下图描述了聚类抽样策略的基本流程。首先,根据网页的特点,将它们聚合到不同的类别中,每个类别中的网页具有相似的更新周期。从类别中提取一部分最具代表性的网页(一般是提取离类别中心最近的那些网页),并计算这些网页的更新周期,然后将这个更新周期用于该类别中的所有网页类别,然后可以根据网页的类别使用更新周期。确定其更新周期。
整群抽样策略
网页更新周期的属性特征分为静态特征和动态特征两类。静态特征包括:页面内容、图片数量、页面大小、链接深度、PageRank值等十几个;而动态特征则反映了静态特征随时间的变化,比如图片数量的变化、进出链接的变化等。网页可以根据这两类特征进行聚类。
上图是一个比较笼统的过程,不同的算法在一些细节上有差异。例如,一些研究直接省略了聚类步骤,而是使用网站作为聚类单元,即假设属于同一个网站的网页具有相同的更新周期,则< @网站 采样,计算更新周期,然后网站 中的所有网页都会以这个更新周期为准。虽然这个假设是粗略的,因为很明显同一个网站内的网页的更新周期变化很大,但是可以省略聚类步骤,这样计算效率会更高。
相关实验表明,聚类采样策略优于前两种更新策略,但对亿万网页进行聚类非常困难。
如果你对爬虫感兴趣,还可以阅读:
干货全流程| 入门级爬虫技术原理,这就够了
网络爬虫 | 你不知道的暗网是怎么爬的?
网络爬虫 | 你知道分布式爬虫是如何工作的吗?
php 爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-29 05:16
)
首先,我们需要知道什么是爬虫!当我第一次听到爬虫这个词时,我以为它是一种爬行昆虫。想想就觉得可笑……后来才知道是网上的数据抓取工具!
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫能做什么?
1、模拟浏览器打开网页,获取网页中我们想要的部分数据。
2、从技术角度,程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据,存储和使用。
3、仔细观察不难发现,越来越多的人知道和了解爬虫。一方面,可以从互联网上获取越来越多的数据。另一方面,像 Python 这样的编程语言提供了越来越多优秀的工具,让爬虫变得简单易用。
4、利用爬虫,我们可以获取大量有价值的数据,从而获取感性知识无法获取的信息,例如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上图,这就是爬取数据时的流程,是不是很简单?因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析过滤来获取我们想要的资源。
相关学习推荐:python教程
以上就是python爬虫能做什么的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php 爬虫抓取网页数据(网络爬虫(又被称为网页蜘蛛,网络机器人)(图)
)
首先,我们需要知道什么是爬虫!当我第一次听到爬虫这个词时,我以为它是一种爬行昆虫。想想就觉得可笑……后来才知道是网上的数据抓取工具!
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
爬虫能做什么?
1、模拟浏览器打开网页,获取网页中我们想要的部分数据。
2、从技术角度,程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)爬取到本地,然后提取您需要的数据,存储和使用。
3、仔细观察不难发现,越来越多的人知道和了解爬虫。一方面,可以从互联网上获取越来越多的数据。另一方面,像 Python 这样的编程语言提供了越来越多优秀的工具,让爬虫变得简单易用。
4、利用爬虫,我们可以获取大量有价值的数据,从而获取感性知识无法获取的信息,例如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上图,这就是爬取数据时的流程,是不是很简单?因此,用户看到的浏览器的结果都是由 HTML 代码组成的。我们的爬虫就是获取这些内容,通过对HTML代码的分析过滤来获取我们想要的资源。
相关学习推荐:python教程
以上就是python爬虫能做什么的详细内容。更多详情请关注php中文网文章其他相关话题!
php 爬虫抓取网页数据(技术层面上探究一下是如何工作的?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-27 15:20
大家好,我是悦创。
通过前面的介绍,同学们已经弄清楚了爬行动物是什么以及它的作用。除了它的反爬虫和一些古怪的技巧,让我们开始探索它在技术层面是如何工作的。
在 Internet 上,公共数据(各种网页)使用 http(或加密的 http 或 https)协议传输。所以我们这里介绍的爬虫技术都是基于http(https)协议的爬虫。
在 Python 模块的海洋中,支持 http 协议的模块相当丰富,包括官方的 urllib 和知名社区(第三方)的模块请求。它们都很好地封装了http协议请求的各种方法,所以我们只需要熟悉这些模块的用法,http协议本身就不再讨论了。
1. 了解浏览器和服务器
学生应该完全熟悉浏览器。可以说,上网过的人都知道浏览器。不过,了解浏览器各种原理的同学不一定很多。
作为一个想开发爬虫的人,了解浏览器的工作原理是很有必要的。这是您编写爬虫的必备工具,仅此而已。
不知道同学们在面试的时候有没有遇到这么一个很宏观很详细的回答问题:
这真是一个考验知识的问题。有经验的程序员可以讲三天三夜,也可以抽出几分钟的精髓讲一讲。而新手们怕是对整个过程了解的不多。
巧合的是,对这个问题了解得越多,对写爬虫的帮助就越大。也就是说,爬行是一个考验综合能力的领域。那么,学生们准备好迎接这一综合技能挑战了吗?
废话不多说,先从回答这个问题开始,了解浏览器和服务器,看看爬虫需要哪些知识。
前面说了,这个问题可以讨论三天三夜,但是我们没有那么多时间,所以就略过一些细节,结合爬虫说一下大致的流程,分为三个部分:“强迫症或那些想认真弥补它的人。同学们可以点击这个文章阅读“从输入url到页面显示是怎么回事?
浏览器发出请求 服务器响应 浏览器收到响应2. 浏览器发出请求
在浏览器地址栏中输入 URL,然后按 Enter。浏览器要求服务器发出一个网页请求,也就是说,它告诉服务器我想看你的一个网页。
上面这短短的一句话,蕴含着无数的奥秘,让我不得不花点时间说话。主要讲:
2.1 URL 有效吗?
首先,浏览器需要判断你输入的网址(URL)是否合法有效。对应的URL,同学们对那以http(s)开头的长字符串并不陌生,但是你知道它也可以以ftp、mailto、file、data、irc开头吗?以下是其最完整的语法格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
处理的更形象的表示是这样的:
图片来自维基百科
跃创经验:判断URL的合法性
在 Python 中,可以使用 urllib.parse 对 URL 执行各种操作
In [1]: import urllib.parse
In [2]: url = 'http://dachong:the_password@www.yuanrenxue.com/user/info?page=2'
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看到 urlparse 函数将 URL 解析为 6 个部分:
scheme://netloc/path;params?query#fragment
主要是在URL语法定义中netloc不等同于host
2.2 服务器在哪里?
上述 URL 定义中的主机是 Internet 上的服务器。它可以是IP地址,但通常是我们所说的域名。域名通过 DNS 绑定到一个(或多个)IP 地址。
浏览器要访问某个域名的网站,首先要通过DNS服务器解析域名,获取真实IP地址。
这里的域名解析一般由操作系统完成,爬虫不需要关心。但是,当你编写一个大型爬虫时,比如谷歌和百度搜索引擎,效率就变得非常重要,爬虫必须维护自己的 DNS 缓存。
跃创经验:大型爬虫需要自己维护DNS缓存
2.3 浏览器向服务器发送什么?
一旦浏览器获得了网站服务器的IP地址,就可以向服务器发送请求。 查看全部
php 爬虫抓取网页数据(技术层面上探究一下是如何工作的?(上))
大家好,我是悦创。
通过前面的介绍,同学们已经弄清楚了爬行动物是什么以及它的作用。除了它的反爬虫和一些古怪的技巧,让我们开始探索它在技术层面是如何工作的。
在 Internet 上,公共数据(各种网页)使用 http(或加密的 http 或 https)协议传输。所以我们这里介绍的爬虫技术都是基于http(https)协议的爬虫。
在 Python 模块的海洋中,支持 http 协议的模块相当丰富,包括官方的 urllib 和知名社区(第三方)的模块请求。它们都很好地封装了http协议请求的各种方法,所以我们只需要熟悉这些模块的用法,http协议本身就不再讨论了。
1. 了解浏览器和服务器
学生应该完全熟悉浏览器。可以说,上网过的人都知道浏览器。不过,了解浏览器各种原理的同学不一定很多。
作为一个想开发爬虫的人,了解浏览器的工作原理是很有必要的。这是您编写爬虫的必备工具,仅此而已。
不知道同学们在面试的时候有没有遇到这么一个很宏观很详细的回答问题:
这真是一个考验知识的问题。有经验的程序员可以讲三天三夜,也可以抽出几分钟的精髓讲一讲。而新手们怕是对整个过程了解的不多。
巧合的是,对这个问题了解得越多,对写爬虫的帮助就越大。也就是说,爬行是一个考验综合能力的领域。那么,学生们准备好迎接这一综合技能挑战了吗?
废话不多说,先从回答这个问题开始,了解浏览器和服务器,看看爬虫需要哪些知识。
前面说了,这个问题可以讨论三天三夜,但是我们没有那么多时间,所以就略过一些细节,结合爬虫说一下大致的流程,分为三个部分:“强迫症或那些想认真弥补它的人。同学们可以点击这个文章阅读“从输入url到页面显示是怎么回事?
浏览器发出请求 服务器响应 浏览器收到响应2. 浏览器发出请求
在浏览器地址栏中输入 URL,然后按 Enter。浏览器要求服务器发出一个网页请求,也就是说,它告诉服务器我想看你的一个网页。
上面这短短的一句话,蕴含着无数的奥秘,让我不得不花点时间说话。主要讲:
2.1 URL 有效吗?
首先,浏览器需要判断你输入的网址(URL)是否合法有效。对应的URL,同学们对那以http(s)开头的长字符串并不陌生,但是你知道它也可以以ftp、mailto、file、data、irc开头吗?以下是其最完整的语法格式:
URI = scheme:[//authority]path[?query][#fragment]
# 其中, authority 又是这样的:
authority = [userinfo@]host[:port]
# userinfo可以同时包含user name和password,以:分割
userinfo = [user_name:password]
处理的更形象的表示是这样的:
图片来自维基百科
跃创经验:判断URL的合法性
在 Python 中,可以使用 urllib.parse 对 URL 执行各种操作
In [1]: import urllib.parse
In [2]: url = 'http://dachong:the_password@www.yuanrenxue.com/user/info?page=2'
In [3]: zz = urllib.parse.urlparse(url)
Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看到 urlparse 函数将 URL 解析为 6 个部分:
scheme://netloc/path;params?query#fragment
主要是在URL语法定义中netloc不等同于host
2.2 服务器在哪里?
上述 URL 定义中的主机是 Internet 上的服务器。它可以是IP地址,但通常是我们所说的域名。域名通过 DNS 绑定到一个(或多个)IP 地址。
浏览器要访问某个域名的网站,首先要通过DNS服务器解析域名,获取真实IP地址。
这里的域名解析一般由操作系统完成,爬虫不需要关心。但是,当你编写一个大型爬虫时,比如谷歌和百度搜索引擎,效率就变得非常重要,爬虫必须维护自己的 DNS 缓存。
跃创经验:大型爬虫需要自己维护DNS缓存
2.3 浏览器向服务器发送什么?
一旦浏览器获得了网站服务器的IP地址,就可以向服务器发送请求。
php 爬虫抓取网页数据(Python爬虫架构的原理及应用原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-27 09:01
1.什么是爬虫?
Crawler:自动爬取互联网信息的程序,从互联网上为我们获取有价值的信息。
2.爬虫的原理?
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(爬取有价值的数据)。
调度器:相当于一台计算机的CPU,主要负责调度URL管理器、下载器、解析器之间的协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止URL重复爬取和URL循环爬取。实现 URL 管理器的方式主要有 3 种:内存、数据库和缓存数据库。
网页下载器:通过传入 URL 地址下载网页并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括需要登录、代理和cookies、requests(第三方包)
网页解析器:通过解析一个网页字符串,可以根据我们的需求提取我们有用的信息,或者按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观地说,就是将网页转换成字符串,通过模糊匹配提取有价值的信息,当文档比较复杂时,这种方法提取数据会很困难),html。parser(Python自带),beautifulsoup(第三方插件,可以使用Python自带的html.parser解析,也可以使用lxml,比别人更强大),lxml(第三方插件) ,可以解析xml和HTML),html.parser和beautifulsoup和lxml都是用DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
3.第一个爬虫
导入 cookielib
导入 urllib2 查看全部
php 爬虫抓取网页数据(Python爬虫架构的原理及应用原理)
1.什么是爬虫?
Crawler:自动爬取互联网信息的程序,从互联网上为我们获取有价值的信息。
2.爬虫的原理?
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(爬取有价值的数据)。
调度器:相当于一台计算机的CPU,主要负责调度URL管理器、下载器、解析器之间的协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止URL重复爬取和URL循环爬取。实现 URL 管理器的方式主要有 3 种:内存、数据库和缓存数据库。
网页下载器:通过传入 URL 地址下载网页并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括需要登录、代理和cookies、requests(第三方包)
网页解析器:通过解析一个网页字符串,可以根据我们的需求提取我们有用的信息,或者按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观地说,就是将网页转换成字符串,通过模糊匹配提取有价值的信息,当文档比较复杂时,这种方法提取数据会很困难),html。parser(Python自带),beautifulsoup(第三方插件,可以使用Python自带的html.parser解析,也可以使用lxml,比别人更强大),lxml(第三方插件) ,可以解析xml和HTML),html.parser和beautifulsoup和lxml都是用DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
3.第一个爬虫
导入 cookielib
导入 urllib2
php 爬虫抓取网页数据(网站前期优化,收录很重要,如何快速让搜索引擎收录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-25 21:03
网站前期优化,收录很重要,如何快速制作搜索引擎收录?
最直接的两种方法:
第一个要优化的一、网站提交到搜索引擎入口,作用是告诉搜索引擎“大哥,这个站还行,你可以看看!如果没有大问题,就接受它,成为一个n-room!三个Kos。”。
第一个发送外部链接的二、,引诱百度蜘蛛和谷歌机器人等爬虫爬取你的网站。这个方法这里就不讨论了,作为一个seoer,你懂的!
以下是部分搜索引擎的提交词条汇总,点击提交即可!当然,没有必要每一个都提交。可以提交前几个重要的。
百度搜索百度提交词条
百度单页提交入口
360搜索提交条目
谷歌搜索 谷歌提交条目
搜搜搜搜SOSO提交词条
搜狗搜索提交词条
网易有道搜索提交词条
yahoo 搜索 yahoo 提交条目
必应搜索提交条目
Alexa网站登录门户
写在最后:
向搜索引擎提交网站并发送外部链接,实际上是一种添加“搜索爬虫”进入网站“入口”的方法。入口很重要,入口决定了收录的速度和数量。当然,长期以来,高考也是排名最重要的因素之一。但是不要得意忘形,记住你所做的网站,那就是让每个使用你的人网站都酷。
这篇文章里,有爱花、看花、看花、看爆胎的人。 查看全部
php 爬虫抓取网页数据(网站前期优化,收录很重要,如何快速让搜索引擎收录?)
网站前期优化,收录很重要,如何快速制作搜索引擎收录?
最直接的两种方法:
第一个要优化的一、网站提交到搜索引擎入口,作用是告诉搜索引擎“大哥,这个站还行,你可以看看!如果没有大问题,就接受它,成为一个n-room!三个Kos。”。
第一个发送外部链接的二、,引诱百度蜘蛛和谷歌机器人等爬虫爬取你的网站。这个方法这里就不讨论了,作为一个seoer,你懂的!
以下是部分搜索引擎的提交词条汇总,点击提交即可!当然,没有必要每一个都提交。可以提交前几个重要的。
百度搜索百度提交词条
百度单页提交入口
360搜索提交条目
谷歌搜索 谷歌提交条目
搜搜搜搜SOSO提交词条
搜狗搜索提交词条
网易有道搜索提交词条
yahoo 搜索 yahoo 提交条目
必应搜索提交条目
Alexa网站登录门户
写在最后:
向搜索引擎提交网站并发送外部链接,实际上是一种添加“搜索爬虫”进入网站“入口”的方法。入口很重要,入口决定了收录的速度和数量。当然,长期以来,高考也是排名最重要的因素之一。但是不要得意忘形,记住你所做的网站,那就是让每个使用你的人网站都酷。
这篇文章里,有爱花、看花、看花、看爆胎的人。
php 爬虫抓取网页数据(查看更多写博客PHP爬虫:百万级别知乎用户数据爬取与分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-21 02:16
阿里云>云栖社区>主题图>P>php爬虫网站
推荐活动:
更多优惠>
当前话题:php爬虫网站加入采集
相关话题:
php爬虫网站相关博文看更多博文
PHP爬虫:百万级知乎用户数据爬取分析
作者:沃克武松 2012 浏览评论:04年前
这次抓到110万用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;安装PHP5.6或以上;安装MySQL5.5或以上;安装curl、pcntl扩展。使用PH
阅读全文
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
爬虫和urllib库介绍(一)
作者:蓝の流星 VIP1588 浏览评论:03年前
1 爬虫概述(1)互联网爬虫是根据Url爬取网页并获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:爬虫与反抗之间的博弈) -crawlers(3)爬虫语言php多进程多线程支持java较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高。
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
发现并阻止恶意爬虫
作者:zhoubj1341 浏览评论:04年前
有许多类型的互联网爬虫。本文主要介绍nginx网站是如何发现和拦截恶意爬虫的。一天发现问题的时候,收到了所有反馈网站服务器A打开慢。首先登录A服务器检查nginx、php、mysql运行是否正常。使用top命令检查服务器CPU、内存、系统负载是否正常。
阅读全文
php爬虫网站相关问答题
如何在 js 对象中获取 PHP 爬虫
作者:小旋风柴今848查看评论:16年前
我用php爬了一个网站,但是数据是用js生成的,inspect元素可以找到js对象,php代码怎么获取js中对象的值
阅读全文 查看全部
php 爬虫抓取网页数据(查看更多写博客PHP爬虫:百万级别知乎用户数据爬取与分析(组图))
阿里云>云栖社区>主题图>P>php爬虫网站
推荐活动:
更多优惠>
当前话题:php爬虫网站加入采集
相关话题:
php爬虫网站相关博文看更多博文
PHP爬虫:百万级知乎用户数据爬取分析
作者:沃克武松 2012 浏览评论:04年前
这次抓到110万用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;安装PHP5.6或以上;安装MySQL5.5或以上;安装curl、pcntl扩展。使用PH
阅读全文
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
爬虫和urllib库介绍(一)
作者:蓝の流星 VIP1588 浏览评论:03年前
1 爬虫概述(1)互联网爬虫是根据Url爬取网页并获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:爬虫与反抗之间的博弈) -crawlers(3)爬虫语言php多进程多线程支持java较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高。
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
发现并阻止恶意爬虫
作者:zhoubj1341 浏览评论:04年前
有许多类型的互联网爬虫。本文主要介绍nginx网站是如何发现和拦截恶意爬虫的。一天发现问题的时候,收到了所有反馈网站服务器A打开慢。首先登录A服务器检查nginx、php、mysql运行是否正常。使用top命令检查服务器CPU、内存、系统负载是否正常。
阅读全文
php爬虫网站相关问答题
如何在 js 对象中获取 PHP 爬虫
作者:小旋风柴今848查看评论:16年前
我用php爬了一个网站,但是数据是用js生成的,inspect元素可以找到js对象,php代码怎么获取js中对象的值
阅读全文
php 爬虫抓取网页数据( 五款啥好的办法,既快又省事,当然有! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-20 02:06
五款啥好的办法,既快又省事,当然有!
)
大家好,我是菜鸟兄弟!今天给大家推荐几款好神器!
在网络信息化时代,爬虫是采集信息不可或缺的工具。对于很多小伙伴来说,只是想用爬虫进行快速的内容爬取,并不想对爬虫研究太深。
用python写爬虫程序很酷,但是学习起来需要时间和精力。学习成本非常高。有时候仅仅为了几页数据就学了几个月的爬虫,真是让人难以忍受。
有没有什么好办法,既快又省力,当然!今天菜鸟哥今天就带领大家分享五款免费的数据采集工具,帮助大家省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程也能轻松抓取数据。优采云数据采集稳定性强,配有详细的使用教程,可以快速上手。
门户网站:
我们以采集的名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,选择右侧“全选”,软件会自动识别所有著名文本。接下来按照操作,选择 采集 文本,然后启动 采集 的软件。
采集完成后,选择文本导出的文件类型,点击确定即可导出数据。
2.吉走克
Jisouke为一些流行的网站设置了快速爬虫程序,但是学习成本比优采云高。
门户网站:
我们在 知乎关键词 处抓取:。首先需要根据爬取的类别进行分类,然后输入网址,点击获取数据,开始爬取。捕获的数据如下图所示:
可以看到,极速客抓取到的信息非常丰富,但是下载数据需要消耗积分,20条数据需要消耗1积分。Jisouke会给新用户20分。
以上两款都是非常好用的国产数据采集软件。接下来菜鸟哥就介绍一下chrome浏览器下的爬虫插件。
3.网络爬虫
网络爬虫插件是一个非常好用的爬虫插件。Web爬虫的安装可以参考之前菜鸟小哥分享的文章()。
对于简单的数据抓取,网络抓取工具可以很好地完成这项工作。我们还以名言的 URL 数据抓取为例。
通过选中多个来获取页面中的所有引号。捕获数据后,通过单击“将数据导出为 CSV”导出所有数据。
4.AnyPapa
将网页翻到评测区,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa的数据页面。
首先点击切换数据源,找到“京东商品评论”的数据源。此时界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据将以csv文件的形式下载到本地。
5.你得到
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了来自网站的国内外近80个视频和图片截图,获得了40900个赞!
门户网站: 。
对于you-get的安装,可以通过命令pip install you-get来安装。
我们以B站上的视频为例,网址为:
通过命令:
you-get -o ./ 'https://www.bilibili.com/video/BV1y64y1X7YG?spm_id_from=333.851.b_7265636f6d6d656e64.3' --format=flv360
可以实现视频下载,其中-o是指视频下载的存储地址,--format是指视频下载的格式和定义。
6.总结
以上就是菜鸟哥今天给大家带来的五款自动提取数据的工具。如果是偶尔的爬虫,或者非常低频率的爬虫需求,完全没有必要学习爬虫技术,因为学习成本非常高。比如你只想发几张图,不用学Photoshop就可以直接用美图秀秀。
如果你对爬虫有很多定制需求,需要对采集到的数据进行分析和深度挖掘,而且频率很高,或者你想更深入地使用Python技术,通过爬虫更扎实的学习,那么可以考虑在此学习时间。爬虫。
嗯,以上工具都不错。有兴趣的同学可以试试。下一篇文章见。
推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领AI全套资料! 查看全部
php 爬虫抓取网页数据(
五款啥好的办法,既快又省事,当然有!
)
大家好,我是菜鸟兄弟!今天给大家推荐几款好神器!
在网络信息化时代,爬虫是采集信息不可或缺的工具。对于很多小伙伴来说,只是想用爬虫进行快速的内容爬取,并不想对爬虫研究太深。
用python写爬虫程序很酷,但是学习起来需要时间和精力。学习成本非常高。有时候仅仅为了几页数据就学了几个月的爬虫,真是让人难以忍受。
有没有什么好办法,既快又省力,当然!今天菜鸟哥今天就带领大家分享五款免费的数据采集工具,帮助大家省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程也能轻松抓取数据。优采云数据采集稳定性强,配有详细的使用教程,可以快速上手。
门户网站:
我们以采集的名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,选择右侧“全选”,软件会自动识别所有著名文本。接下来按照操作,选择 采集 文本,然后启动 采集 的软件。
采集完成后,选择文本导出的文件类型,点击确定即可导出数据。
2.吉走克
Jisouke为一些流行的网站设置了快速爬虫程序,但是学习成本比优采云高。
门户网站:
我们在 知乎关键词 处抓取:。首先需要根据爬取的类别进行分类,然后输入网址,点击获取数据,开始爬取。捕获的数据如下图所示:
可以看到,极速客抓取到的信息非常丰富,但是下载数据需要消耗积分,20条数据需要消耗1积分。Jisouke会给新用户20分。
以上两款都是非常好用的国产数据采集软件。接下来菜鸟哥就介绍一下chrome浏览器下的爬虫插件。
3.网络爬虫
网络爬虫插件是一个非常好用的爬虫插件。Web爬虫的安装可以参考之前菜鸟小哥分享的文章()。
对于简单的数据抓取,网络抓取工具可以很好地完成这项工作。我们还以名言的 URL 数据抓取为例。
通过选中多个来获取页面中的所有引号。捕获数据后,通过单击“将数据导出为 CSV”导出所有数据。
4.AnyPapa
将网页翻到评测区,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa的数据页面。
首先点击切换数据源,找到“京东商品评论”的数据源。此时界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据将以csv文件的形式下载到本地。
5.你得到
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了来自网站的国内外近80个视频和图片截图,获得了40900个赞!
门户网站: 。
对于you-get的安装,可以通过命令pip install you-get来安装。
我们以B站上的视频为例,网址为:
通过命令:
you-get -o ./ 'https://www.bilibili.com/video/BV1y64y1X7YG?spm_id_from=333.851.b_7265636f6d6d656e64.3' --format=flv360
可以实现视频下载,其中-o是指视频下载的存储地址,--format是指视频下载的格式和定义。
6.总结
以上就是菜鸟哥今天给大家带来的五款自动提取数据的工具。如果是偶尔的爬虫,或者非常低频率的爬虫需求,完全没有必要学习爬虫技术,因为学习成本非常高。比如你只想发几张图,不用学Photoshop就可以直接用美图秀秀。
如果你对爬虫有很多定制需求,需要对采集到的数据进行分析和深度挖掘,而且频率很高,或者你想更深入地使用Python技术,通过爬虫更扎实的学习,那么可以考虑在此学习时间。爬虫。
嗯,以上工具都不错。有兴趣的同学可以试试。下一篇文章见。
推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领AI全套资料!
php 爬虫抓取网页数据(查看更多写博客PHP爬虫:百万级别知乎用户数据爬取与分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-18 04:04
阿里云>云栖社区>主题图>P>php爬虫网站
推荐活动:
更多优惠>
当前话题:php爬虫网站加入采集
相关话题:
php爬虫网站相关博文看更多博文
PHP爬虫:百万级知乎用户数据爬取分析
作者:沃克武松 2012 浏览评论:04年前
这次抓到110万用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;安装PHP5.6或以上;安装MySQL5.5或以上;安装curl、pcntl扩展。使用PH
阅读全文
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
爬虫和urllib库介绍(一)
作者:蓝の流星 VIP1588 浏览评论:03年前
1 爬虫概述(1)互联网爬虫是根据Url爬取网页并获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:爬虫与反抗之间的博弈) -crawlers(3)爬虫语言php多进程多线程支持java较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高。
阅读全文
发现并阻止恶意爬虫
作者:zhoubj1341 浏览评论:04年前
有许多类型的互联网爬虫。本文主要介绍nginx网站是如何发现和拦截恶意爬虫的。一天发现问题的时候,收到了所有反馈网站服务器A打开慢。首先登录A服务器检查nginx、php、mysql运行是否正常。使用top命令检查服务器CPU、内存、系统负载是否正常。
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,不会操作一个
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,不会操作一个
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
php爬虫网站相关问答题
如何在 js 对象中获取 PHP 爬虫
作者:小旋风柴今848查看评论:16年前
我用php爬取了一个网站,但是数据是用js生成的,通过检查元素可以找到js对象,php代码如何获取js中对象的值
阅读全文 查看全部
php 爬虫抓取网页数据(查看更多写博客PHP爬虫:百万级别知乎用户数据爬取与分析(组图))
阿里云>云栖社区>主题图>P>php爬虫网站
推荐活动:
更多优惠>
当前话题:php爬虫网站加入采集
相关话题:
php爬虫网站相关博文看更多博文
PHP爬虫:百万级知乎用户数据爬取分析
作者:沃克武松 2012 浏览评论:04年前
这次抓到110万用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;安装PHP5.6或以上;安装MySQL5.5或以上;安装curl、pcntl扩展。使用PH
阅读全文
构建网络爬虫?太简单
作者:悠悠然然 1953 观众评论:05年前
网络爬虫一般用于全文检索或内容获取。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据都非常方便。框架特点 强大的节点过滤能力 支持post和get两种数据提交方式,避免网页重复处理功能 支持多站点内容爬取功能
阅读全文
爬虫和urllib库介绍(一)
作者:蓝の流星 VIP1588 浏览评论:03年前
1 爬虫概述(1)互联网爬虫是根据Url爬取网页并获取有用信息的程序(2)抓取网页和解析数据的核心任务难点:爬虫与反抗之间的博弈) -crawlers(3)爬虫语言php多进程多线程支持java较差。目前java爬虫作业需求旺盛,但代码臃肿,重构成本高。
阅读全文
发现并阻止恶意爬虫
作者:zhoubj1341 浏览评论:04年前
有许多类型的互联网爬虫。本文主要介绍nginx网站是如何发现和拦截恶意爬虫的。一天发现问题的时候,收到了所有反馈网站服务器A打开慢。首先登录A服务器检查nginx、php、mysql运行是否正常。使用top命令检查服务器CPU、内存、系统负载是否正常。
阅读全文
开源爬虫框架的优缺点是什么?
作者:于尔伍 1702观众评论:04年前
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他进行开发?这里根据我的经验废话:上面提到的爬虫基本上可以分为3类:1.分布式爬虫:Nutch 2.JAVA单机爬虫:Crawler4j、WebMagi
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,不会操作一个
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,不会操作一个
阅读全文
【nodeJS爬虫】前端爬虫系列——小爬虫《博客园》
作者:长征二号 1512 浏览评论:04年前
其实一开始我是拒绝写这篇博客的,因为爬虫爬取了cnblog博客园。也许编辑看到我的帐户后会屏蔽我的帐户:)。言归正传,前端同学可能一直对爬虫比较陌生,觉得爬虫需要用到后端语言,比如php、python等。当然这是在nodejs之前,n
阅读全文
php爬虫网站相关问答题
如何在 js 对象中获取 PHP 爬虫
作者:小旋风柴今848查看评论:16年前
我用php爬取了一个网站,但是数据是用js生成的,通过检查元素可以找到js对象,php代码如何获取js中对象的值
阅读全文

