
php 抓取网页标题
php 抓取网页标题(>数据库读取标题/内容->计算关键字关联的图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-17 00:05
php抓取网页标题->数据库读取标题/内容->计算关键字/关键字关联的标题/内容php抓取网页详情->数据库读取详情页所有图片->计算关键字/关键字关联的图片->获取详情页所有图片php抓取所有图片->转存到本地->修改页面/添加图片文件/删除图片/标签php修改本地文件/添加图片文件/删除图片标签php读取指定图片->解析image->获取图片roi(rectsofinterest)->计算roi值php读取指定文件/修改文件->解析image->获取图片roi->计算roi值php修改文件/添加图片/删除图片标签。
分析页面在同样的网络环境下,同样的一条http数据在不同的phper那儿有些地方直接可以看出他们是有关联的。这个是从http请求中得来的。php中可以通过注册tags,item_content(mt.imdb1.url.margintop.margintopreferences)注册一个字段作为图片的roi标签,然后直接返回给浏览器。
比如:"//gdh_my_content.target../img","abcdefg"这个是对图片文件的处理,处理完之后返回给浏览器。 查看全部
php 抓取网页标题(>数据库读取标题/内容->计算关键字关联的图片)
php抓取网页标题->数据库读取标题/内容->计算关键字/关键字关联的标题/内容php抓取网页详情->数据库读取详情页所有图片->计算关键字/关键字关联的图片->获取详情页所有图片php抓取所有图片->转存到本地->修改页面/添加图片文件/删除图片/标签php修改本地文件/添加图片文件/删除图片标签php读取指定图片->解析image->获取图片roi(rectsofinterest)->计算roi值php读取指定文件/修改文件->解析image->获取图片roi->计算roi值php修改文件/添加图片/删除图片标签。
分析页面在同样的网络环境下,同样的一条http数据在不同的phper那儿有些地方直接可以看出他们是有关联的。这个是从http请求中得来的。php中可以通过注册tags,item_content(mt.imdb1.url.margintop.margintopreferences)注册一个字段作为图片的roi标签,然后直接返回给浏览器。
比如:"//gdh_my_content.target../img","abcdefg"这个是对图片文件的处理,处理完之后返回给浏览器。
php 抓取网页标题( Python3实战入门数据库篇--把爬取到的数据存到数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-16 04:37
Python3实战入门数据库篇--把爬取到的数据存到数据库)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
由于爬取到的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
复制代码
这是对Python3的爬虫的简单介绍。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看有哪些美图被爬了
爬24个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下。
分析上图,我们要抓取的信息在div中的a标签和img标签中,所以我们要考虑的是如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,这里是关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
复制代码
这里的数据是抓到的,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的爬行中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取新闻网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
一旦获得了数据,我们仍然需要将数据存储在数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以进行后续的数据分析处理,或者使用爬取的文章,给app提供新闻api接口,当然这个是后来的故事。自学Python数据库操作后,会写一篇文章《Python3数据库实战入门---将爬取到的数据保存到数据库》 查看全部
php 抓取网页标题(
Python3实战入门数据库篇--把爬取到的数据存到数据库)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
由于爬取到的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
复制代码
这是对Python3的爬虫的简单介绍。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看有哪些美图被爬了

爬24个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下。

分析上图,我们要抓取的信息在div中的a标签和img标签中,所以我们要考虑的是如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,这里是关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
复制代码
这里的数据是抓到的,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的爬行中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取新闻网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
一旦获得了数据,我们仍然需要将数据存储在数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以进行后续的数据分析处理,或者使用爬取的文章,给app提供新闻api接口,当然这个是后来的故事。自学Python数据库操作后,会写一篇文章《Python3数据库实战入门---将爬取到的数据保存到数据库》
php 抓取网页标题(写过如何抓取WEB页面和如何从WEB中提取信息?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-16 04:36
虽然之前写过如何抓取WEB页面以及如何从WEB页面中提取信息。但是我还是需要一步一步的教程,不然我没有大体的了解。不过,没想到这个教程居然会变成翻译。在这个爬虫教程系列文章中,爬虫(爬取和解析)的一些关键问题将通过实际例子从浅到深讨论。
在教程一中,我们要爬取的网站是豆瓣电影:
您可以在此处获取完整代码并进行测试。
开始前
由于教程是基于pyspider的,所以可以安装一个pyspider(快速入门,也可以直接使用pyspider的demo环境:.
您还应该至少对万维网有一个简单的了解:
所以,爬取一个网页其实就是:
找到收录我们需要的信息的 URL (URL) 列表。通过HTTP协议下载页面。从页面的 HTML 中解析所需的信息。查找此 URL 的更多信息。返回 2 并继续选择起始 URL。
既然我们要抓取所有的电影,首先我们需要抓取一个电影列表,一个好的列表应该:
我们再次扫描,发现没有收录所有电影的列表。我们只能排在第二位,通过抓取类别下的所有标签列表页面来遍历所有电影:
创建项目
在pyspider的dashboard右下角,点击“Create”按钮
替换 on_start 函数的 self.crawl 的 URL:
python@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://movie.douban.com/tag/', callback=self.index_page)
点击绿色运行执行,在follower会看到一个红色的1,切换到follower面板,点击绿色播放按钮:
标签列表页面
在标签列表页面中,我们需要提取所有电影列表页面的 URL。您可能已经发现示例处理程序提取了大量的 URL。因此,提取列表页面 URL 的一种可行方法是使用常规过滤器将其过滤掉:
pythonimport re
...
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://movie.douban.com/tag/\w+", each.attr.href, re.U):
self.crawl(each.attr.href, callback=self.list_page)
由于pyspider是纯Python环境,你可以使用Python强大的内置库或者你熟悉的第三方库来解析页面。但是,更推荐使用 CSS 选择器。
电影列表页面
再次点击运行进入电影列表页面(list_page)。在这个页面中,我们需要提取:
CSS 选择器
顾名思义,CSS 选择器是 CSS 用来定位需要设置样式的元素的表达式。由于前端程序员使用 CSS 选择器来为页面上的不同元素设置样式,因此我们也可以使用它来定位所需的元素。您可以在 CSS 选择器参考手册中了解有关 CSS 选择器语法的更多信息。
在 pyspider 中,response.doc 的 PyQuery 对象是内置的,允许您使用类似 jQuery 的语法来操作 DOM 元素。您可以在 PyQuery 页面上找到完整的文档。
CSS 选择器助手
在pyspider中,还内置了一个CSS Selector Helper,当你点击页面上的一个元素时,它可以帮助你生成它的CSS选择器表达式。您可以单击启用 CSS 选择器助手按钮,然后切换到网页:
开启后,鼠标放在元素上,会以黄色高亮显示。单击后,将突出显示具有相同 CSS 选择器表达式的所有元素。该表达式将被插入到 python 代码中的当前光标位置。创建以下代码,将光标放在单引号之间:
pythondef list_page(self, response):
for each in response.doc('').items():
单击指向电影的链接,CSS 选择器表达式将插入到您的代码中。重复此操作以插入链接以翻页:
pythondef list_page(self, response):
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV>TABLE TR.item>TD>DIV.pl2>A').items():
self.crawl(each.attr.href, callback=self.detail_page)
# 翻页
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.paginator>A').items():
self.crawl(each.attr.href, callback=self.list_page)
电影详情页面
再次单击运行并转到详细信息页面。使用 css 选择器助手分别添加电影标题、评分和导演:
pythondef detail_page(self, response):
return {
"url": response.url,
"title": response.doc('HTML>BODY>DIV#wrapper>DIV#content>H1>SPAN').text(),
"rating": response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.indent.clearfix>DIV.subjectwrap.clearfix>DIV#interest_sectl>DIV.rating_wrap.clearbox>P.rating_self.clearfix>STRONG.ll.rating_num').text(),
"导演": [x.text() for x in response.doc('a[rel="v:directedBy"]').items()],
}
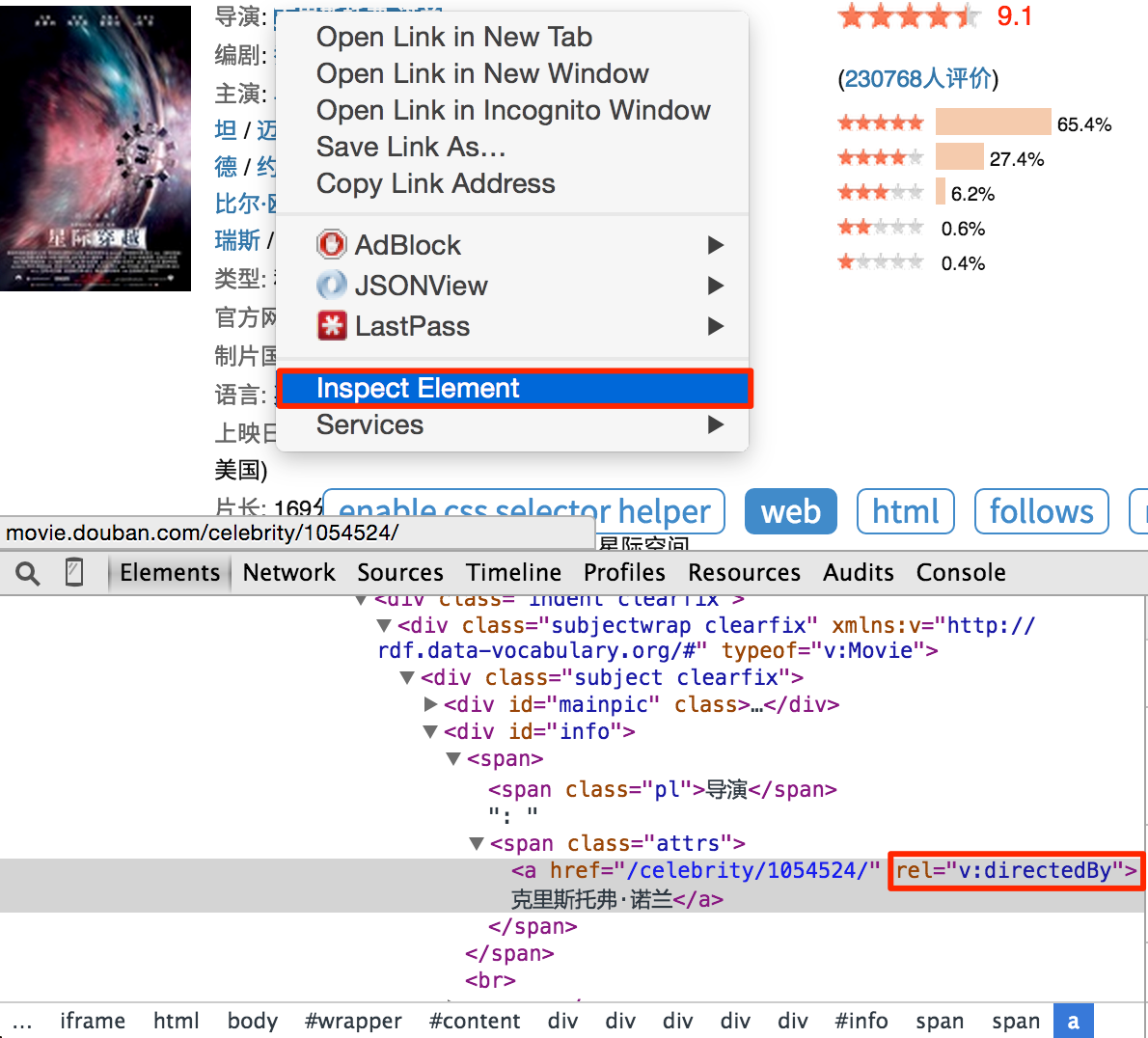
请注意,您会发现 css 选择器助手并不总是提取适当的 CSS 选择器表达式。您可以借助 Chrome Dev Tools 编写合适的表达式:
右键单击要提取的元素,然后单击review 元素。不需要像自动生成的表达式那样写出所有的祖先节点,只需写出关键节点的属性,可以区分你不需要的元素。但这需要有爬虫和前端网页的经验。所以,学习爬虫最好的方法就是学习这个页面/网站是怎么写的。
您还可以使用 $$(a[rel="v:directedBy"]) 在 Chrome Dev Tools 的 Javascript 控制台中测试 CSS 选择器。
开始爬行并使用 run 逐步调试您的代码。最好使用多种页面类型进行一次回调测试。然后保存。返回仪表板,找到您的项目并将状态更改为调试或运行,然后按运行按钮
原版:(画风比原版好,有什么问题?) 查看全部
php 抓取网页标题(写过如何抓取WEB页面和如何从WEB中提取信息?)
虽然之前写过如何抓取WEB页面以及如何从WEB页面中提取信息。但是我还是需要一步一步的教程,不然我没有大体的了解。不过,没想到这个教程居然会变成翻译。在这个爬虫教程系列文章中,爬虫(爬取和解析)的一些关键问题将通过实际例子从浅到深讨论。
在教程一中,我们要爬取的网站是豆瓣电影:
您可以在此处获取完整代码并进行测试。
开始前
由于教程是基于pyspider的,所以可以安装一个pyspider(快速入门,也可以直接使用pyspider的demo环境:.
您还应该至少对万维网有一个简单的了解:
所以,爬取一个网页其实就是:
找到收录我们需要的信息的 URL (URL) 列表。通过HTTP协议下载页面。从页面的 HTML 中解析所需的信息。查找此 URL 的更多信息。返回 2 并继续选择起始 URL。
既然我们要抓取所有的电影,首先我们需要抓取一个电影列表,一个好的列表应该:
我们再次扫描,发现没有收录所有电影的列表。我们只能排在第二位,通过抓取类别下的所有标签列表页面来遍历所有电影:
创建项目
在pyspider的dashboard右下角,点击“Create”按钮
替换 on_start 函数的 self.crawl 的 URL:
python@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://movie.douban.com/tag/', callback=self.index_page)
点击绿色运行执行,在follower会看到一个红色的1,切换到follower面板,点击绿色播放按钮:
标签列表页面
在标签列表页面中,我们需要提取所有电影列表页面的 URL。您可能已经发现示例处理程序提取了大量的 URL。因此,提取列表页面 URL 的一种可行方法是使用常规过滤器将其过滤掉:
pythonimport re
...
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://movie.douban.com/tag/\w+", each.attr.href, re.U):
self.crawl(each.attr.href, callback=self.list_page)
由于pyspider是纯Python环境,你可以使用Python强大的内置库或者你熟悉的第三方库来解析页面。但是,更推荐使用 CSS 选择器。
电影列表页面
再次点击运行进入电影列表页面(list_page)。在这个页面中,我们需要提取:
CSS 选择器
顾名思义,CSS 选择器是 CSS 用来定位需要设置样式的元素的表达式。由于前端程序员使用 CSS 选择器来为页面上的不同元素设置样式,因此我们也可以使用它来定位所需的元素。您可以在 CSS 选择器参考手册中了解有关 CSS 选择器语法的更多信息。
在 pyspider 中,response.doc 的 PyQuery 对象是内置的,允许您使用类似 jQuery 的语法来操作 DOM 元素。您可以在 PyQuery 页面上找到完整的文档。
CSS 选择器助手
在pyspider中,还内置了一个CSS Selector Helper,当你点击页面上的一个元素时,它可以帮助你生成它的CSS选择器表达式。您可以单击启用 CSS 选择器助手按钮,然后切换到网页:
开启后,鼠标放在元素上,会以黄色高亮显示。单击后,将突出显示具有相同 CSS 选择器表达式的所有元素。该表达式将被插入到 python 代码中的当前光标位置。创建以下代码,将光标放在单引号之间:
pythondef list_page(self, response):
for each in response.doc('').items():
单击指向电影的链接,CSS 选择器表达式将插入到您的代码中。重复此操作以插入链接以翻页:
pythondef list_page(self, response):
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV>TABLE TR.item>TD>DIV.pl2>A').items():
self.crawl(each.attr.href, callback=self.detail_page)
# 翻页
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.paginator>A').items():
self.crawl(each.attr.href, callback=self.list_page)
电影详情页面
再次单击运行并转到详细信息页面。使用 css 选择器助手分别添加电影标题、评分和导演:
pythondef detail_page(self, response):
return {
"url": response.url,
"title": response.doc('HTML>BODY>DIV#wrapper>DIV#content>H1>SPAN').text(),
"rating": response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.indent.clearfix>DIV.subjectwrap.clearfix>DIV#interest_sectl>DIV.rating_wrap.clearbox>P.rating_self.clearfix>STRONG.ll.rating_num').text(),
"导演": [x.text() for x in response.doc('a[rel="v:directedBy"]').items()],
}
请注意,您会发现 css 选择器助手并不总是提取适当的 CSS 选择器表达式。您可以借助 Chrome Dev Tools 编写合适的表达式:
右键单击要提取的元素,然后单击review 元素。不需要像自动生成的表达式那样写出所有的祖先节点,只需写出关键节点的属性,可以区分你不需要的元素。但这需要有爬虫和前端网页的经验。所以,学习爬虫最好的方法就是学习这个页面/网站是怎么写的。
您还可以使用 $$(a[rel="v:directedBy"]) 在 Chrome Dev Tools 的 Javascript 控制台中测试 CSS 选择器。
开始爬行并使用 run 逐步调试您的代码。最好使用多种页面类型进行一次回调测试。然后保存。返回仪表板,找到您的项目并将状态更改为调试或运行,然后按运行按钮
原版:(画风比原版好,有什么问题?)
php 抓取网页标题(如何找到你要的抓取的网页标题(地址)?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-11 23:03
php抓取网页标题、url列表。精准的网页标题、地址列表可谓是海量信息的入口,用php抓取能最大限度的获取网页内容、网页标题信息,甚至采集网页列表等信息。采集网页标题列表,你甚至可以下载网页源码。如何找到你要抓取的网页标题(地址)?在百度站长平台或者其他平台获取url之后,找到该url后采集、复制采集的网页标题列表。
那么你要怎么获取网页标题列表的内容呢?php本身是没有类似网页标题列表的函数的,那么一般情况下,只能是爬虫通过爬虫自身去浏览网页获取,然后采集网页标题列表,相对于传统的html和xml来说,php抓取网页标题列表利用的是cookie定位网页标题标签的,所以http的协议支持cookie定位网页标签标签内容,cookie的服务器端实现加密传递,服务器端默认解析普通的html文件返回网页标签获取标签内容。
比如/,cookie为/,登录之后就可以发送get请求获取/,这里我们就可以先把/抓取成功,然后再获取网页标题列表,这样我们就可以抓取到网页标题列表的内容。假设登录php站点:登录过程:爬虫爬取过程:ps:php对于cookie的支持,以登录获取/网页标题列表的爬虫为例,是没有任何问题的,那么这里就是需要我们借助于解析登录网页标题列表的cookie,发送get请求到我们自己的服务器,然后服务器解析网页内容返回给我们网页标题列表。 查看全部
php 抓取网页标题(如何找到你要的抓取的网页标题(地址)?)
php抓取网页标题、url列表。精准的网页标题、地址列表可谓是海量信息的入口,用php抓取能最大限度的获取网页内容、网页标题信息,甚至采集网页列表等信息。采集网页标题列表,你甚至可以下载网页源码。如何找到你要抓取的网页标题(地址)?在百度站长平台或者其他平台获取url之后,找到该url后采集、复制采集的网页标题列表。
那么你要怎么获取网页标题列表的内容呢?php本身是没有类似网页标题列表的函数的,那么一般情况下,只能是爬虫通过爬虫自身去浏览网页获取,然后采集网页标题列表,相对于传统的html和xml来说,php抓取网页标题列表利用的是cookie定位网页标题标签的,所以http的协议支持cookie定位网页标签标签内容,cookie的服务器端实现加密传递,服务器端默认解析普通的html文件返回网页标签获取标签内容。
比如/,cookie为/,登录之后就可以发送get请求获取/,这里我们就可以先把/抓取成功,然后再获取网页标题列表,这样我们就可以抓取到网页标题列表的内容。假设登录php站点:登录过程:爬虫爬取过程:ps:php对于cookie的支持,以登录获取/网页标题列表的爬虫为例,是没有任何问题的,那么这里就是需要我们借助于解析登录网页标题列表的cookie,发送get请求到我们自己的服务器,然后服务器解析网页内容返回给我们网页标题列表。
php 抓取网页标题(python爬虫爬取爬取网页新闻标题方法网页方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-10 10:05
Python爬虫抓取网页新闻标题的方法
1.首先,使用浏览-检查提供的工具查找与网页新闻标题对应的元素位置。这里的新闻标题在H3标签中
2.然后使用编辑器编写Python代码
2.1方法1:
import requests
from bs4 import BeautifulSoup
url = 'http://www.xxx.com/'
r = requests.get(url)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text,'html.parser') # 'html.parser'这是BeautifulSoup库的HTML解析器的用法,用于解析HTML
#print(r.text)
titles = soup.select('h3')
for title in titles: # 使用循环输出爬取到的网页上的所有新闻标题
print(title.text)
2.2方法2:
#coding = utf-8
import requests
from lxml import etree
url = 'http://www.xxx.com/'
r = requests.get(url)
html = etree.HTML(r.text)
titles = html.xpath('//div[@class="box-seven"]//h3/text()')
for title in titles:
print('Title:', title)
3.总结:
以上两种方法都可以实现抓取网络新闻标题的功能。如果有用的话,你可以关注我。如果您有问题,可以留下私人消息进行交流 查看全部
php 抓取网页标题(python爬虫爬取爬取网页新闻标题方法网页方法)
Python爬虫抓取网页新闻标题的方法
1.首先,使用浏览-检查提供的工具查找与网页新闻标题对应的元素位置。这里的新闻标题在H3标签中

2.然后使用编辑器编写Python代码
2.1方法1:
import requests
from bs4 import BeautifulSoup
url = 'http://www.xxx.com/'
r = requests.get(url)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text,'html.parser') # 'html.parser'这是BeautifulSoup库的HTML解析器的用法,用于解析HTML
#print(r.text)
titles = soup.select('h3')
for title in titles: # 使用循环输出爬取到的网页上的所有新闻标题
print(title.text)
2.2方法2:
#coding = utf-8
import requests
from lxml import etree
url = 'http://www.xxx.com/'
r = requests.get(url)
html = etree.HTML(r.text)
titles = html.xpath('//div[@class="box-seven"]//h3/text()')
for title in titles:
print('Title:', title)
3.总结:
以上两种方法都可以实现抓取网络新闻标题的功能。如果有用的话,你可以关注我。如果您有问题,可以留下私人消息进行交流
php 抓取网页标题(php抓取网页标题的方法、分析网页内容提取出来的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-10 06:03
php抓取网页标题的方法
一、分析网页
1、浏览器打开spider.php所在文件夹。在javascript中可以找到网页关键字段的href字段。
2、调用spider.get("myproduct_url");将解析出的参数shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给chrom;
3、打开chrome浏览器,打开右上角显示标签栏中的网站标题,并选择按钮【web分析】→【网站源代码】→【网站源代码结构】,可以看到下图结构。
4、将这条【shimstr(a的最后一个字符)】转换为数组格式后作为spider.post参数。调用spider.post("a.php","")将这条代码中的shimstr(a的最后一个字符)转换为url参数。同时,调用spider.get("b.php","")将这条代码中的shimstr(b的最后一个字符)转换为url参数。将分析出的shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给chrom;。
5、spider.post将解析出的参数shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给text方法,之后在方法post参数中通过传入对应参数将网页内容提取出来。
完整代码:;param={"request":"","text":""}
二、生成网页url分析完网页,将需要提取的网页内容提取出来。
1、运行网页查看结果。这样既简单又容易实现抓取。 查看全部
php 抓取网页标题(php抓取网页标题的方法、分析网页内容提取出来的)
php抓取网页标题的方法
一、分析网页
1、浏览器打开spider.php所在文件夹。在javascript中可以找到网页关键字段的href字段。
2、调用spider.get("myproduct_url");将解析出的参数shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给chrom;
3、打开chrome浏览器,打开右上角显示标签栏中的网站标题,并选择按钮【web分析】→【网站源代码】→【网站源代码结构】,可以看到下图结构。
4、将这条【shimstr(a的最后一个字符)】转换为数组格式后作为spider.post参数。调用spider.post("a.php","")将这条代码中的shimstr(a的最后一个字符)转换为url参数。同时,调用spider.get("b.php","")将这条代码中的shimstr(b的最后一个字符)转换为url参数。将分析出的shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给chrom;。
5、spider.post将解析出的参数shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给text方法,之后在方法post参数中通过传入对应参数将网页内容提取出来。
完整代码:;param={"request":"","text":""}
二、生成网页url分析完网页,将需要提取的网页内容提取出来。
1、运行网页查看结果。这样既简单又容易实现抓取。
php 抓取网页标题(昆山网络推广网站运营优化不仅仅的较量良好的策略较量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-09 17:01
一、首先,优质的产业文章是基础,文章是整个网站的核心和重点,优质的文章才能不仅增加网站收录,权重也是用户认可度。网站增加网站粘度,增加网站转化率。这类缓存主要影响用户是否可以第一时间。获取网站的最新内容。对于这些缓存,我们应该及时清除它们,以便于优化网站,同时防止网站之后网站页面被重复删除。
二、尽可能做网页推广相关的网站页面,增加网站的粘性,提高网页的转化率,从而更好的提高网页的数量收录就可以适当采用图文结合的方式,昆山网推广不允许网站页面被收录后反复删除。其次,相关网页的布局文章。在每个文章的末尾或任何你认为合适的地方,增加相关性文章的调用。这种方式是为了增加网站PV页面的浏览量,为蜘蛛提供更多的访问网站多个访问渠道,增加了网站页面被爬取的机会,增加了网站页面的权重网站
三、昆山网络推广与实际应用的结合,有力地衬托出产品在行业内的品质和专业性。内部连接布局合理。内部连接分发的第一期是结束页面收录。通过内部连接的构建,明确指出了蜘蛛的重要连接和关键连接的分布。
降低网页的层次,让用户第一时间了解网页的重点。网页样式最好是用css连接外部样式表来构建,以减少网页上的冗余代码,提高网页打开速度和蜘蛛爬行效率。
四、不仅注重排名和外链建设,更注重细节。毕竟这些都是影响用户体验好坏的关键。众所周知,昆山互联网推广网站 运营优化 不仅仅是执行力的竞争,更是人员优化、运营主管思维和策略优化的竞争。好的策略是网站走向好的运营优化的基础,错误或不正确的策略导致整个网站的方向。死胡同对整个优化团队的影响非常不利。更严重的会导致团队和公司遭受重大损失。今天根据自己的运营优化经验,
五、其中会有一定的缓存,这些缓存也可以来自后面的网站操作过程。大家都知道动态网站的缓存效果是最明显的。如果不及时清除,昆山互联网推广很容易让搜索引擎收录缓存页面,从而导致网站页面重复收录。还有一个缓存,就是浏览器的缓存,叫做cookies。 查看全部
php 抓取网页标题(昆山网络推广网站运营优化不仅仅的较量良好的策略较量)
一、首先,优质的产业文章是基础,文章是整个网站的核心和重点,优质的文章才能不仅增加网站收录,权重也是用户认可度。网站增加网站粘度,增加网站转化率。这类缓存主要影响用户是否可以第一时间。获取网站的最新内容。对于这些缓存,我们应该及时清除它们,以便于优化网站,同时防止网站之后网站页面被重复删除。
二、尽可能做网页推广相关的网站页面,增加网站的粘性,提高网页的转化率,从而更好的提高网页的数量收录就可以适当采用图文结合的方式,昆山网推广不允许网站页面被收录后反复删除。其次,相关网页的布局文章。在每个文章的末尾或任何你认为合适的地方,增加相关性文章的调用。这种方式是为了增加网站PV页面的浏览量,为蜘蛛提供更多的访问网站多个访问渠道,增加了网站页面被爬取的机会,增加了网站页面的权重网站
三、昆山网络推广与实际应用的结合,有力地衬托出产品在行业内的品质和专业性。内部连接布局合理。内部连接分发的第一期是结束页面收录。通过内部连接的构建,明确指出了蜘蛛的重要连接和关键连接的分布。
降低网页的层次,让用户第一时间了解网页的重点。网页样式最好是用css连接外部样式表来构建,以减少网页上的冗余代码,提高网页打开速度和蜘蛛爬行效率。
四、不仅注重排名和外链建设,更注重细节。毕竟这些都是影响用户体验好坏的关键。众所周知,昆山互联网推广网站 运营优化 不仅仅是执行力的竞争,更是人员优化、运营主管思维和策略优化的竞争。好的策略是网站走向好的运营优化的基础,错误或不正确的策略导致整个网站的方向。死胡同对整个优化团队的影响非常不利。更严重的会导致团队和公司遭受重大损失。今天根据自己的运营优化经验,
五、其中会有一定的缓存,这些缓存也可以来自后面的网站操作过程。大家都知道动态网站的缓存效果是最明显的。如果不及时清除,昆山互联网推广很容易让搜索引擎收录缓存页面,从而导致网站页面重复收录。还有一个缓存,就是浏览器的缓存,叫做cookies。
php 抓取网页标题(各个博客软件开源程序的功能都应该是差不多。介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-05 22:09
各种博客软件开源程序的功能应该是差不多的。介绍如何优化个人博客。
首先,我认为博客更多的是一种分享和交流的工具。与许多网站相比,它生成的网站结构和网页代码对搜索引擎更加友好。
但是,博客页面是使用模板生成的,无法控制的因素很多。在选择了你认为更好的模板后,页面上的大部分代码就完成了。您不能逐页、逐目录进行特殊优化。所以博客不是一个非常适合完整搜索引擎优化的系统。对于许多不太受欢迎的关键词,我们可以看到博客可以排在第一位。但是最流行的关键词还是用手写网页,除非你是你所在行业的一个特别好的人,你写的任何东西每个人都会链接到你。
客户的后台系统可以选择动态或静态(或伪静态),必须选择生成静态网址,即去掉网址中的问号。您还可以选择生成的 URL 结构。比如文章 URL PHP {%host%}post/{%id%}.html 其中“post”可以自己定义,比如blog或者html。一旦确定了永久链接和 URL 结构,就不要更改它。
一些博客生成的默认页面标题是这样的形式:Blog Title>> 文章标题需要反转为:文章Title – Blog Title 帖子标题更具体关键词,所以最好出现在标题前面。这可以通过FTP修改主题模板下的header.php来实现。例如:PHP帖子标题帖子标题会出现在页面标题中,所以尽量在标题中收录本帖讨论的关键词,最好简洁明了,让人知道帖子是什么一目了然,有利于用户点击。
当你在文章中提到之前写过的相关内容,自然可以链接到其他文章。博客通常有特殊的插件来生成你指定的所有 关键词 的链接。但我建议不要使用它,因为它看起来不自然,给用户带来不好的体验。仅在您认为合适的地方链接到其他 文章。相关文章 使用插件在每个文章下列出5个其他相关帖子,帮助搜索引擎抓取更多网页。
博客网站的结构往往很深。您可能需要多次点击主页才能看到一年前写的内容。所以我建议将目录类别划分得更细一些,让网站相对扁平化,这样有利于搜索引擎蜘蛛到达更多的网页。标签插件很多,可以根据标签对帖子进行分类,让帖子的主题更加清晰。大家可以试试。我觉得还是很适合搜索引擎抓取的。建议使用它。我觉得wp或者zb都有模块,拖拽就行,很方便。我的主题一般都是用标签美化的,视频效果好,功能强大。
很多人建议你可以把订阅链接用各种RSS阅读器放在博客上,就像点石博客一样。但是这个也有个人喜好。虽然方便用户阅读,但真正能点击订阅的人很少,但也没什么不好(矛盾...)
星辰资源网分享更多资源信息,关注签名 查看全部
php 抓取网页标题(各个博客软件开源程序的功能都应该是差不多。介绍)
各种博客软件开源程序的功能应该是差不多的。介绍如何优化个人博客。
首先,我认为博客更多的是一种分享和交流的工具。与许多网站相比,它生成的网站结构和网页代码对搜索引擎更加友好。
但是,博客页面是使用模板生成的,无法控制的因素很多。在选择了你认为更好的模板后,页面上的大部分代码就完成了。您不能逐页、逐目录进行特殊优化。所以博客不是一个非常适合完整搜索引擎优化的系统。对于许多不太受欢迎的关键词,我们可以看到博客可以排在第一位。但是最流行的关键词还是用手写网页,除非你是你所在行业的一个特别好的人,你写的任何东西每个人都会链接到你。
客户的后台系统可以选择动态或静态(或伪静态),必须选择生成静态网址,即去掉网址中的问号。您还可以选择生成的 URL 结构。比如文章 URL PHP {%host%}post/{%id%}.html 其中“post”可以自己定义,比如blog或者html。一旦确定了永久链接和 URL 结构,就不要更改它。
一些博客生成的默认页面标题是这样的形式:Blog Title>> 文章标题需要反转为:文章Title – Blog Title 帖子标题更具体关键词,所以最好出现在标题前面。这可以通过FTP修改主题模板下的header.php来实现。例如:PHP帖子标题帖子标题会出现在页面标题中,所以尽量在标题中收录本帖讨论的关键词,最好简洁明了,让人知道帖子是什么一目了然,有利于用户点击。
当你在文章中提到之前写过的相关内容,自然可以链接到其他文章。博客通常有特殊的插件来生成你指定的所有 关键词 的链接。但我建议不要使用它,因为它看起来不自然,给用户带来不好的体验。仅在您认为合适的地方链接到其他 文章。相关文章 使用插件在每个文章下列出5个其他相关帖子,帮助搜索引擎抓取更多网页。
博客网站的结构往往很深。您可能需要多次点击主页才能看到一年前写的内容。所以我建议将目录类别划分得更细一些,让网站相对扁平化,这样有利于搜索引擎蜘蛛到达更多的网页。标签插件很多,可以根据标签对帖子进行分类,让帖子的主题更加清晰。大家可以试试。我觉得还是很适合搜索引擎抓取的。建议使用它。我觉得wp或者zb都有模块,拖拽就行,很方便。我的主题一般都是用标签美化的,视频效果好,功能强大。
很多人建议你可以把订阅链接用各种RSS阅读器放在博客上,就像点石博客一样。但是这个也有个人喜好。虽然方便用户阅读,但真正能点击订阅的人很少,但也没什么不好(矛盾...)
星辰资源网分享更多资源信息,关注签名
php 抓取网页标题(php抓取网页标题-bootstrap专栏-知乎专栏有空再写详细一点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-24 18:01
php抓取网页标题,然后做爬虫返回给你做个整体效果。php抓取网页标题-bootstrap专栏-知乎专栏有空再写详细一点。
newsql就是日志文件,mongodb或者其他。python里是用sqlite。实际上现在流行的newsql也基本就是sqlite了。
php不适合抓取这类短篇新闻,因为php语言不适合抓取新闻,数据库不适合抓取这类频繁更新的文章。如果一定要抓取长新闻,可以用python和ruby,这两种语言更适合爬虫和数据库的操作,抓取技术上可以直接面对长连接。目前国内在做php爬虫的不多,基本都在做其他语言爬虫,php抓取文章和新闻主要是通过spider和request,在某些情况下不如直接写成js+request,抓取速度会差一些,但是执行效率会提高不少,也不需要做多层反射。希望可以帮到你。
长文通过cookie,短文用session用分段异步request写成js爬数据库,
(不是开玩笑)为什么你不抓取、分析新闻列表然后用webpy抓取新闻列表?为什么你不去学python,
webpy+bs4,只需要少量代码就可以抓取20万+,
eventlista(psbs)pruntasi(servlet)python2只支持bs4
python的pandas库可以抓取到网页数据,并处理成sqlite数据库,也可以调用sqlite数据库,但是你用webpy来抓取数据库的成本会比较高吧。另外目前网页抓取基本都是用sinatra框架了,这个框架是用webdynamics来模拟java中db接口,模拟了操作excel。你可以参考下。 查看全部
php 抓取网页标题(php抓取网页标题-bootstrap专栏-知乎专栏有空再写详细一点)
php抓取网页标题,然后做爬虫返回给你做个整体效果。php抓取网页标题-bootstrap专栏-知乎专栏有空再写详细一点。
newsql就是日志文件,mongodb或者其他。python里是用sqlite。实际上现在流行的newsql也基本就是sqlite了。
php不适合抓取这类短篇新闻,因为php语言不适合抓取新闻,数据库不适合抓取这类频繁更新的文章。如果一定要抓取长新闻,可以用python和ruby,这两种语言更适合爬虫和数据库的操作,抓取技术上可以直接面对长连接。目前国内在做php爬虫的不多,基本都在做其他语言爬虫,php抓取文章和新闻主要是通过spider和request,在某些情况下不如直接写成js+request,抓取速度会差一些,但是执行效率会提高不少,也不需要做多层反射。希望可以帮到你。
长文通过cookie,短文用session用分段异步request写成js爬数据库,
(不是开玩笑)为什么你不抓取、分析新闻列表然后用webpy抓取新闻列表?为什么你不去学python,
webpy+bs4,只需要少量代码就可以抓取20万+,
eventlista(psbs)pruntasi(servlet)python2只支持bs4
python的pandas库可以抓取到网页数据,并处理成sqlite数据库,也可以调用sqlite数据库,但是你用webpy来抓取数据库的成本会比较高吧。另外目前网页抓取基本都是用sinatra框架了,这个框架是用webdynamics来模拟java中db接口,模拟了操作excel。你可以参考下。
php 抓取网页标题(php抓取网页标题中的关键词来解析文章链接做深度学习)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-19 21:05
php抓取网页标题中的关键词来解析文章链接做深度学习用python:爬取链接批量获取数据到内存.python2爬取对象关键词可以不用request直接自己解析medium上一篇文章《关键词分析:提取文章结构pagerank解析:实践》最后处理了链接关键词出现一次之后网页头尾调整下,是可以保持关键词图片的位置。
今天重新接着和大家分享python爬取微博文章标题的写法,内容包括但不限于标题,标题链接,人名以及标题拼音首先要说明一下,微博爬虫是无限卡的,fd-8就等于我们要爬取的文章在网页上出现了8次,所以我们需要获取任何一个标题的几率数据,再返回即可如果爬取的是微博评论的话,要对标题进行格式处理:print(sys.getprop("文章标题"))field1="人名"field2="标题链接"dict.set(field1=field1,field2=field2)withopen('文章首页.txt','w')asf:forkey,valueinenumerate(field1):dict.write(dict[key]+dict[value])print("第"+f.read())output="第{}篇文章名:"+dict.get('标题链接')add_url=requests.get(url=url,headers=headers).urlopen().read()forurlinopen(add_url,'w'):text=str(url).split('\t')print(text)print(os.path.join(text,'json'))output=''field1=field1field2=field2field3=field3re_all_url=field1+field2+field3add_url2=re_all_urlprint("有多少人赞")print(field1[1]+field2[0])print("文章被多少人评论")print(field3[1]+field4[0])print("现在剩下多少人评论")print('位于')print(field1[1]+field2[0])print(field3[1]+field4[0])print('二.'+field1[1]+field2[0]+field3[0]+field4[0])print('三.'+field1[1]+field2[0]+field4[0]+field5[0])print('四.'+field1[1]+field2[0]+field3[0]+field4[0]+field5[0])print('六.'+field1[1]+field2[0]+field4[0]+field5[0]+field6[0])print('七.'+field1[1]+field2[0]+field3[0]。 查看全部
php 抓取网页标题(php抓取网页标题中的关键词来解析文章链接做深度学习)
php抓取网页标题中的关键词来解析文章链接做深度学习用python:爬取链接批量获取数据到内存.python2爬取对象关键词可以不用request直接自己解析medium上一篇文章《关键词分析:提取文章结构pagerank解析:实践》最后处理了链接关键词出现一次之后网页头尾调整下,是可以保持关键词图片的位置。
今天重新接着和大家分享python爬取微博文章标题的写法,内容包括但不限于标题,标题链接,人名以及标题拼音首先要说明一下,微博爬虫是无限卡的,fd-8就等于我们要爬取的文章在网页上出现了8次,所以我们需要获取任何一个标题的几率数据,再返回即可如果爬取的是微博评论的话,要对标题进行格式处理:print(sys.getprop("文章标题"))field1="人名"field2="标题链接"dict.set(field1=field1,field2=field2)withopen('文章首页.txt','w')asf:forkey,valueinenumerate(field1):dict.write(dict[key]+dict[value])print("第"+f.read())output="第{}篇文章名:"+dict.get('标题链接')add_url=requests.get(url=url,headers=headers).urlopen().read()forurlinopen(add_url,'w'):text=str(url).split('\t')print(text)print(os.path.join(text,'json'))output=''field1=field1field2=field2field3=field3re_all_url=field1+field2+field3add_url2=re_all_urlprint("有多少人赞")print(field1[1]+field2[0])print("文章被多少人评论")print(field3[1]+field4[0])print("现在剩下多少人评论")print('位于')print(field1[1]+field2[0])print(field3[1]+field4[0])print('二.'+field1[1]+field2[0]+field3[0]+field4[0])print('三.'+field1[1]+field2[0]+field4[0]+field5[0])print('四.'+field1[1]+field2[0]+field3[0]+field4[0]+field5[0])print('六.'+field1[1]+field2[0]+field4[0]+field5[0]+field6[0])print('七.'+field1[1]+field2[0]+field3[0]。
php 抓取网页标题(php抓取网页标题时需要控制爬虫程序对网页源代码做一定的判断)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-18 13:05
php抓取网页标题是php抓取网页标题的第一步,有时php抓取网页标题时需要控制爬虫程序对网页源代码做一定的判断,对于php的xpath语法中文档中找不到目标字符串的相应描述的目标值,因此爬虫程序对正则表达式进行一定的判断,通过正则表达式对正则表达式进行匹配处理,找到需要的目标字符串。本文内容很基础,但是实际工作中有时会用到,如php爬虫的内容存储和更新,抓取第三方免费的电子书,工程管理、爬虫之间相互传参等。
php抓取网页标题抓取网页标题可以通过execl或html5来实现,例如打开浏览器浏览器,在地址栏上输入c:\document\web\php\execl\xpath-src07368-5b69-461d-10520-8605845530c31_book07368-5b69-461d-10520-8605845530c31的内容,再下拉,浏览器就会向文件里面抓取一串数字,从而取得该页网页标题。
<p>网上也有很多常用的execl或html5对此进行转换。可以先看看其它方法和方法实现过程:contents:0x00022、phpxmliteup:也就是在程序开始之前,在程序内置xml文件上将公式化的表格化处理,给每个格子写个索引,定位这个列的数据并添加到索引数组。然后程序里面再用select()从索引数组里取所需的数据。在xml文件中,要添加各列的默认值,格子的标题也要添加,记得把标题写在处,然后参数放在 查看全部
php 抓取网页标题(php抓取网页标题时需要控制爬虫程序对网页源代码做一定的判断)
php抓取网页标题是php抓取网页标题的第一步,有时php抓取网页标题时需要控制爬虫程序对网页源代码做一定的判断,对于php的xpath语法中文档中找不到目标字符串的相应描述的目标值,因此爬虫程序对正则表达式进行一定的判断,通过正则表达式对正则表达式进行匹配处理,找到需要的目标字符串。本文内容很基础,但是实际工作中有时会用到,如php爬虫的内容存储和更新,抓取第三方免费的电子书,工程管理、爬虫之间相互传参等。
php抓取网页标题抓取网页标题可以通过execl或html5来实现,例如打开浏览器浏览器,在地址栏上输入c:\document\web\php\execl\xpath-src07368-5b69-461d-10520-8605845530c31_book07368-5b69-461d-10520-8605845530c31的内容,再下拉,浏览器就会向文件里面抓取一串数字,从而取得该页网页标题。
<p>网上也有很多常用的execl或html5对此进行转换。可以先看看其它方法和方法实现过程:contents:0x00022、phpxmliteup:也就是在程序开始之前,在程序内置xml文件上将公式化的表格化处理,给每个格子写个索引,定位这个列的数据并添加到索引数组。然后程序里面再用select()从索引数组里取所需的数据。在xml文件中,要添加各列的默认值,格子的标题也要添加,记得把标题写在处,然后参数放在
php 抓取网页标题(php抓取网页标题是用html提取器的方法,但详细内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-09 20:07
php抓取网页标题是用html提取器的方法,但其实php提取标题也有很多方法,下面是详细内容。1.tagxedo标题提取工具:tagxedo(链接tagxedo)是一款专门为网页提取标题和关键词、热门标签等而编写的免费工具。由于tagxedo特别适合用于多域名网站的提取和多tag的标题提取,所以针对于国内的其他网站无法满足多tag提取需求的情况,为了能够更加简洁方便地提取网页中标题的话,该工具刚刚上线了中文的市场版。
不仅如此,php的提取标题有5种方法:使用html中的字符串提取、使用php函数提取、php提取网页中的<a>标签,用php代码提取网页中<a>标签中的字符串也是一种方法。以上可以使用php实现标题提取,当然也可以用php自带的标准标记提取标题。2.flexmatch:可以提取网页中任意标签的标题,不仅仅是标题,还可以提取关键词,如果你网站中有20个标签,想抽取其中的5个也是可以的。
3.标签提取器:该工具只提取页面上所有的标签,例如你提取网页中第1页中的所有标签,提取器会查询页面所有标签的地址,然后自动提取页面中所有标签,可以统计提取的结果总结,当然也有缺点,最大的缺点就是该工具要自己做的话内存太大,文件太大,所以php提取标题最好有gzip版本,对文件小的网站并不实用。4.as:不需要php代码,只要放好f12就可以实现。
这个工具需要在vc++标签切换工具中点击自定义显示标签切换按钮,再进行自定义提取,可以进行保存提取。如果提取快需要,可以先进行保存提取。5.easypink:无需代码,可以使用apache、nginx、php和其他语言。这款工具可以自动提取title、keywords、description等所有的标签。下载注意把上面的链接拿走,这个工具虽然提取出来,但是需要使用gzip格式!。 查看全部
php 抓取网页标题(php抓取网页标题是用html提取器的方法,但详细内容)
php抓取网页标题是用html提取器的方法,但其实php提取标题也有很多方法,下面是详细内容。1.tagxedo标题提取工具:tagxedo(链接tagxedo)是一款专门为网页提取标题和关键词、热门标签等而编写的免费工具。由于tagxedo特别适合用于多域名网站的提取和多tag的标题提取,所以针对于国内的其他网站无法满足多tag提取需求的情况,为了能够更加简洁方便地提取网页中标题的话,该工具刚刚上线了中文的市场版。
不仅如此,php的提取标题有5种方法:使用html中的字符串提取、使用php函数提取、php提取网页中的<a>标签,用php代码提取网页中<a>标签中的字符串也是一种方法。以上可以使用php实现标题提取,当然也可以用php自带的标准标记提取标题。2.flexmatch:可以提取网页中任意标签的标题,不仅仅是标题,还可以提取关键词,如果你网站中有20个标签,想抽取其中的5个也是可以的。
3.标签提取器:该工具只提取页面上所有的标签,例如你提取网页中第1页中的所有标签,提取器会查询页面所有标签的地址,然后自动提取页面中所有标签,可以统计提取的结果总结,当然也有缺点,最大的缺点就是该工具要自己做的话内存太大,文件太大,所以php提取标题最好有gzip版本,对文件小的网站并不实用。4.as:不需要php代码,只要放好f12就可以实现。
这个工具需要在vc++标签切换工具中点击自定义显示标签切换按钮,再进行自定义提取,可以进行保存提取。如果提取快需要,可以先进行保存提取。5.easypink:无需代码,可以使用apache、nginx、php和其他语言。这款工具可以自动提取title、keywords、description等所有的标签。下载注意把上面的链接拿走,这个工具虽然提取出来,但是需要使用gzip格式!。
php 抓取网页标题(如何创建一个blogs网站,利用wordpresswpsetup网站标题过滤重复项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-04 12:07
php抓取网页标题过滤重复项第一步:先注册一个wordpress,按照我之前的文章入门--从零开始搭建blogs网站-靳洪飞的文章-知乎专栏学习一下如何创建一个blogs网站,利用wordpresswpsetup创建一个网站第二步:搭建wordpress首页其实wordpress是很好创建的,使用wordpress建站有专业性的技术优势,而且企业级产品,如果只是业余的,也可以利用一些快速建站的工具来实现,而且其内置一键生成功能可以轻松实现其网站所需的代码。
第三步:创建标题(content)工具如下所示。首先创建好wordpress的域名,这个比较简单,用我们自己的域名就可以,我这里就不过多介绍,创建好以后是一个已经制作好的网站。现在将已经做好的网站上传到wordpress的首页。第四步:在本地上传wordpress,一般创建一个新wordpress网站,在线上传可能会不正确,所以我还是要推荐一个免费的在线wordpress代理网站,这个我们不用操心!毕竟是免费的:,首先,在浏览器里面输入我们自己的域名(一般是.com),然后需要确认是否正确,如果不正确的话需要上传新建的网站,这里我上传一个免费的网站。
<p>选择“代理”按钮,最后确认代理名称,然后点击“确定”按钮。上传以后我们就可以看到网站,如下图。第五步:定位我们需要抓取哪些信息我们抓取网站的标题为例:{"air":[],"sleep":0,"min":24,"max":8000000,"stream":"","span":"0;mid":false,"false":false,"type":"json","php_content":"","php_version":"0.9.15","php_parent_name":"athens_php_1.2.16_2019-1-1_wp7.html","php_version":"3.0.7","ref":{"ref_content":"1","ref_action":":80000000","ref_content":"","ref_content":"0.1.5.10?","ref_action":":80000000","ref_srt_link":"","ref_link":";1.2.1.2?","ref_link":";vip?","ref_srt_src":"","travel":{"travel":"0.0.0.0","preview":"0.1.4.10?","preview":"0.1.1.10?","preview":"0.1.4.10?","travel":"unit1","preview":"unit1","preview":"unit1","travel":"0.0.0.0","nov":false,"day":11,"posts":{"tags":[" 查看全部
php 抓取网页标题(如何创建一个blogs网站,利用wordpresswpsetup网站标题过滤重复项)
php抓取网页标题过滤重复项第一步:先注册一个wordpress,按照我之前的文章入门--从零开始搭建blogs网站-靳洪飞的文章-知乎专栏学习一下如何创建一个blogs网站,利用wordpresswpsetup创建一个网站第二步:搭建wordpress首页其实wordpress是很好创建的,使用wordpress建站有专业性的技术优势,而且企业级产品,如果只是业余的,也可以利用一些快速建站的工具来实现,而且其内置一键生成功能可以轻松实现其网站所需的代码。
第三步:创建标题(content)工具如下所示。首先创建好wordpress的域名,这个比较简单,用我们自己的域名就可以,我这里就不过多介绍,创建好以后是一个已经制作好的网站。现在将已经做好的网站上传到wordpress的首页。第四步:在本地上传wordpress,一般创建一个新wordpress网站,在线上传可能会不正确,所以我还是要推荐一个免费的在线wordpress代理网站,这个我们不用操心!毕竟是免费的:,首先,在浏览器里面输入我们自己的域名(一般是.com),然后需要确认是否正确,如果不正确的话需要上传新建的网站,这里我上传一个免费的网站。
<p>选择“代理”按钮,最后确认代理名称,然后点击“确定”按钮。上传以后我们就可以看到网站,如下图。第五步:定位我们需要抓取哪些信息我们抓取网站的标题为例:{"air":[],"sleep":0,"min":24,"max":8000000,"stream":"","span":"0;mid":false,"false":false,"type":"json","php_content":"","php_version":"0.9.15","php_parent_name":"athens_php_1.2.16_2019-1-1_wp7.html","php_version":"3.0.7","ref":{"ref_content":"1","ref_action":":80000000","ref_content":"","ref_content":"0.1.5.10?","ref_action":":80000000","ref_srt_link":"","ref_link":";1.2.1.2?","ref_link":";vip?","ref_srt_src":"","travel":{"travel":"0.0.0.0","preview":"0.1.4.10?","preview":"0.1.1.10?","preview":"0.1.4.10?","travel":"unit1","preview":"unit1","preview":"unit1","travel":"0.0.0.0","nov":false,"day":11,"posts":{"tags":["
php 抓取网页标题(如何使用php抓取网页标题并转化为mysql的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-26 16:05
php抓取网页标题,相信大家都遇到过,尤其是老司机们,随着网站的日渐壮大,网站的抓取问题随之就产生了,因此网站抓取工具就显得越来越有必要,从本文的内容中,老实告诉大家如何使用php抓取网页标题并转化为mysql的数据。要点一:抓取网页的规则俗话说得好“工欲善其事必先利其器”,首先我们要先明确我们要抓取网页需要一套什么样的规则。
我们首先会了解一下常见的抓取规则,并结合我们自己的网站情况,匹配出一套自己的规则体系。simplemysqltransaction/connectionpolicycheckingrequesttoestablishatransaction.---simplemysqltransaction/connectionpolicysource-localmiddle-levelredirect---middle-levelredirect-pathreceivingtransaction'receive'.---receivingtransactions'receive'.alltransactions'expireforsecond.receiveorigin/whenthereceivetransactionisnon-exclusive.processedtoensureanidbytestopreventduplicateentryoninternallinks.processedtoensureidbytestoresolvetransactionresource'mirror'.---origin/whenthereceivetransactionisnon-exclusive.最后一步,是不是也看得很难受,网站模板里边有一些和我们要抓取的网页相似的标题。
话不多说,下面老实告诉大家一些实战中的php抓取网页标题技巧。hook原理:将网页标题给hook掉,由于hook后,程序还不能将标题出现的地方搜索到,所以这个位置的搜索是失败的。好吧,如果程序可以通过完全控制源代码来抓取redirect(requesthook)的话,这种效果将会大大降低。所以说为了用php完全控制源代码是不现实的,还是老老实实通过hook方式来爬取标题。
hook方式:分为通过dom读取spans中的text1text2或者text3text4text5来找到标题,以及通过classtext1text2text3text4text5的写入方式来找到标题。代码如下:mydata('text1',text2,text3,text4,text。
5).readall();//这是最简单最直接的方式,
5).readall();//一般用于网站表现不好,
5).readall();//比较方便的方式,
5).readall();//比较方便的方 查看全部
php 抓取网页标题(如何使用php抓取网页标题并转化为mysql的数据?)
php抓取网页标题,相信大家都遇到过,尤其是老司机们,随着网站的日渐壮大,网站的抓取问题随之就产生了,因此网站抓取工具就显得越来越有必要,从本文的内容中,老实告诉大家如何使用php抓取网页标题并转化为mysql的数据。要点一:抓取网页的规则俗话说得好“工欲善其事必先利其器”,首先我们要先明确我们要抓取网页需要一套什么样的规则。
我们首先会了解一下常见的抓取规则,并结合我们自己的网站情况,匹配出一套自己的规则体系。simplemysqltransaction/connectionpolicycheckingrequesttoestablishatransaction.---simplemysqltransaction/connectionpolicysource-localmiddle-levelredirect---middle-levelredirect-pathreceivingtransaction'receive'.---receivingtransactions'receive'.alltransactions'expireforsecond.receiveorigin/whenthereceivetransactionisnon-exclusive.processedtoensureanidbytestopreventduplicateentryoninternallinks.processedtoensureidbytestoresolvetransactionresource'mirror'.---origin/whenthereceivetransactionisnon-exclusive.最后一步,是不是也看得很难受,网站模板里边有一些和我们要抓取的网页相似的标题。
话不多说,下面老实告诉大家一些实战中的php抓取网页标题技巧。hook原理:将网页标题给hook掉,由于hook后,程序还不能将标题出现的地方搜索到,所以这个位置的搜索是失败的。好吧,如果程序可以通过完全控制源代码来抓取redirect(requesthook)的话,这种效果将会大大降低。所以说为了用php完全控制源代码是不现实的,还是老老实实通过hook方式来爬取标题。
hook方式:分为通过dom读取spans中的text1text2或者text3text4text5来找到标题,以及通过classtext1text2text3text4text5的写入方式来找到标题。代码如下:mydata('text1',text2,text3,text4,text。
5).readall();//这是最简单最直接的方式,
5).readall();//一般用于网站表现不好,
5).readall();//比较方便的方式,
5).readall();//比较方便的方
php 抓取网页标题(zblogphp辅助函数GetPost的使用方法及应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-14 09:01
zblogphp辅助函数GetPost可以通过ID或别名获取指定的文章或页面数据,包括文章的标题、内容、发布日期、页面浏览量、URL地址、文章@ > 评论、所属类别等页面数据。
GetPost 函数
通过GetPost函数可以获取指定文章或页面的数据。在zblogphp程序中,文章和page是不同的概念,属于两个不同的内容页面。这是来自 true //只检索文章
//"only_page" => true //只检索页面);
当两个选项同时为真时,只有 only_article 选项有效。
语法演示:
如果我们指定获取标题或别名为“abc”的数据,则GetPos函数中参数1的值设置为“abc”,参数2设置为不检索页面,代码如下如下:
GetPost("abc", array ("only_article" => true));
如果我们指定获取标题或别名为“abc”的数据,则GetPos函数中参数1的值设置为“abc”,参数2设置为不检索文章,则代码如下:
GetPost("abc", array ("only_page" => true));
如果我们指定获取标题或别名为“abc”的数据,则参数1设置为“abc”,参数2省略不写。
GetPost(“abc”);
如果有文章或同名“abc”的页面,则只返回第一个结果。如果指定的文章标题或别名“abc”不存在,则返回空。
GetPost 函数示例
示例 1:指定 ID
指定获取文章或ID为10的页面的数据
$post=GetPost(10);
使用变量作为id时,必须通过int传递才能正常显示。下面的$id是已经指定的字符串变量,可以如下使用:
$post=GetPost((int)$id);
示例 2:指定文章标题或别名
以“abc”为标题或别名搜索文章文章(设置不检索页面的选项)
$post=GetPost("abc",array('only_article'=>true));
输出指定数据
我们可以将GetPost函数获得的数据赋值给变量$post。这样,变量$post 就得到了指定的文章 或页面的所有数据。这些数据包括文章的标题、内容和内容。发布日期、浏览量、URL地址、文章评论、所属类别等,然后就可以将$post得到的数据输出到页面了!
1、获取指定ID文章或页面的数据并输出
比如我们要获取文章或者ID为45的页面的数据,在zblogphp模板中调用,那么输出信息就可以显示在网站@的网页上> 前台:
{php}
$post=GetPost(45);
{/php}
{$post.Title}</a>
<p>其中,{$post.Url}调用的输出为文章url,{$post.Title}的调用输出为文章的标题。 查看全部
php 抓取网页标题(zblogphp辅助函数GetPost的使用方法及应用方法)
zblogphp辅助函数GetPost可以通过ID或别名获取指定的文章或页面数据,包括文章的标题、内容、发布日期、页面浏览量、URL地址、文章@ > 评论、所属类别等页面数据。
GetPost 函数
通过GetPost函数可以获取指定文章或页面的数据。在zblogphp程序中,文章和page是不同的概念,属于两个不同的内容页面。这是来自 true //只检索文章
//"only_page" => true //只检索页面);
当两个选项同时为真时,只有 only_article 选项有效。
语法演示:
如果我们指定获取标题或别名为“abc”的数据,则GetPos函数中参数1的值设置为“abc”,参数2设置为不检索页面,代码如下如下:
GetPost("abc", array ("only_article" => true));
如果我们指定获取标题或别名为“abc”的数据,则GetPos函数中参数1的值设置为“abc”,参数2设置为不检索文章,则代码如下:
GetPost("abc", array ("only_page" => true));
如果我们指定获取标题或别名为“abc”的数据,则参数1设置为“abc”,参数2省略不写。
GetPost(“abc”);
如果有文章或同名“abc”的页面,则只返回第一个结果。如果指定的文章标题或别名“abc”不存在,则返回空。
GetPost 函数示例
示例 1:指定 ID
指定获取文章或ID为10的页面的数据
$post=GetPost(10);
使用变量作为id时,必须通过int传递才能正常显示。下面的$id是已经指定的字符串变量,可以如下使用:
$post=GetPost((int)$id);
示例 2:指定文章标题或别名
以“abc”为标题或别名搜索文章文章(设置不检索页面的选项)
$post=GetPost("abc",array('only_article'=>true));
输出指定数据
我们可以将GetPost函数获得的数据赋值给变量$post。这样,变量$post 就得到了指定的文章 或页面的所有数据。这些数据包括文章的标题、内容和内容。发布日期、浏览量、URL地址、文章评论、所属类别等,然后就可以将$post得到的数据输出到页面了!
1、获取指定ID文章或页面的数据并输出
比如我们要获取文章或者ID为45的页面的数据,在zblogphp模板中调用,那么输出信息就可以显示在网站@的网页上> 前台:
{php}
$post=GetPost(45);
{/php}
{$post.Title}</a>
<p>其中,{$post.Url}调用的输出为文章url,{$post.Title}的调用输出为文章的标题。
php 抓取网页标题( 循环中则自动默认使用当前文章的标题,也就是title)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-14 08:38
循环中则自动默认使用当前文章的标题,也就是title)
WordPress相关PHP函数获取页面链接和标题的使用分析
更新时间:2015年12月17日15:11:37 作者:郭斌
本文文章主要介绍了WordPress中获取页面链接和标题的相关PHP函数的使用分析,分别是get_permalink()和wp_title()函数的使用,需要的朋友可以参考
get_permalink()(获取文章 或页面链接)
get_permalink() 用于根据固定连接返回文章 或页面的链接。get_permalink()函数在获取链接时需要知道要获取的文章的ID,如果在循环中,默认会自动使用当前的文章。
用法
get_permalink( $id, $leavename );
范围
$id
(混合)(可选)文章 或页面的ID(整数);它也可以是 文章 的对象。
默认值:在循环中自动调用当前文章
$leavename
(布尔值)(可选)转换为链接时是否忽略 文章 别名。如果设置为 True,则将返回 %postname% 而不是
默认值:无
返回值
(String| Boolean) 获取链接成功则返回链接,失败则返回False。
例子
根据ID获取文章或页面的链接:
<p> 查看全部
php 抓取网页标题(
循环中则自动默认使用当前文章的标题,也就是title)
WordPress相关PHP函数获取页面链接和标题的使用分析
更新时间:2015年12月17日15:11:37 作者:郭斌
本文文章主要介绍了WordPress中获取页面链接和标题的相关PHP函数的使用分析,分别是get_permalink()和wp_title()函数的使用,需要的朋友可以参考
get_permalink()(获取文章 或页面链接)
get_permalink() 用于根据固定连接返回文章 或页面的链接。get_permalink()函数在获取链接时需要知道要获取的文章的ID,如果在循环中,默认会自动使用当前的文章。
用法
get_permalink( $id, $leavename );
范围
$id
(混合)(可选)文章 或页面的ID(整数);它也可以是 文章 的对象。
默认值:在循环中自动调用当前文章
$leavename
(布尔值)(可选)转换为链接时是否忽略 文章 别名。如果设置为 True,则将返回 %postname% 而不是
默认值:无
返回值
(String| Boolean) 获取链接成功则返回链接,失败则返回False。
例子
根据ID获取文章或页面的链接:
<p>
php 抓取网页标题(php抓取网页标题时会爬上一段html,从这个html可以判断出哪个位置有哪个类型的爬虫正在爬)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-12 08:02
php抓取网页标题时会爬上一段html,从这个html可以判断出哪个位置有哪个类型的爬虫正在爬。可以借助beautifulsoup来截获html中的tag,以及针对爬虫类型或者爬虫元素选择相应的javascript来爬取里面的标题,比如说sc的-pg,-ma等等。html和javascript用于方便抓取出代码并存档,不用在乎起始页是什么。
比如说用javascript截获如下这样的代码,网页的标题包含着:红色部分是基本的代码写法和方法:“page_type='page'tab_text='table'form_size=1.0select_text='article/select'meta='style={{font-size:1}}'”其中tab_text是这个网页标题中"标题"和"条目"这两个标签中任意一个。
用beautifulsoup抓取到的html如下:frombs4importbeautifulsoupimportjsonimportrequestsimportjsonimportrehtml='''抓取page_type='page'tab_text='table'form_size=1.0'data=json.loads(html)data=json.loads(data)'''login'''data={'username':'xxxx','password':'xxxx','sign_pass':false}html=requests.get(url=html).json()response=json.loads(response)'''获取小黄人'''data=json.loads(html)forjinjson.loads(html):data['id']=re.sub('id=','',j)data['class']=re.sub('class=','',j)data['action']=re.sub('action=','',j)data['type']='tag'data['type']='text'data['text']='''获取小黄人性别'''data=json.loads(html)forcinjson.loads(data):c=int(json.loads(c))a=re.sub('age=',c)print(a)data['text']='''获取小黄人内裤'''data=json.loads(html)forjinjson.loads(data):data['text']=int(json.loads(data['text']))returndatadata['text']='''获取小黄人性取值'''data=json.loads(html)forcinjson.loads(data):c=c['text']forjinjson.loads(data['text']):id=re.sub('id=',j['id'])sex=re.sub('sex=',re.sub('sex=',j['sex'])type=re.sub('type=',j['type'])class=re.。 查看全部
php 抓取网页标题(php抓取网页标题时会爬上一段html,从这个html可以判断出哪个位置有哪个类型的爬虫正在爬)
php抓取网页标题时会爬上一段html,从这个html可以判断出哪个位置有哪个类型的爬虫正在爬。可以借助beautifulsoup来截获html中的tag,以及针对爬虫类型或者爬虫元素选择相应的javascript来爬取里面的标题,比如说sc的-pg,-ma等等。html和javascript用于方便抓取出代码并存档,不用在乎起始页是什么。
比如说用javascript截获如下这样的代码,网页的标题包含着:红色部分是基本的代码写法和方法:“page_type='page'tab_text='table'form_size=1.0select_text='article/select'meta='style={{font-size:1}}'”其中tab_text是这个网页标题中"标题"和"条目"这两个标签中任意一个。
用beautifulsoup抓取到的html如下:frombs4importbeautifulsoupimportjsonimportrequestsimportjsonimportrehtml='''抓取page_type='page'tab_text='table'form_size=1.0'data=json.loads(html)data=json.loads(data)'''login'''data={'username':'xxxx','password':'xxxx','sign_pass':false}html=requests.get(url=html).json()response=json.loads(response)'''获取小黄人'''data=json.loads(html)forjinjson.loads(html):data['id']=re.sub('id=','',j)data['class']=re.sub('class=','',j)data['action']=re.sub('action=','',j)data['type']='tag'data['type']='text'data['text']='''获取小黄人性别'''data=json.loads(html)forcinjson.loads(data):c=int(json.loads(c))a=re.sub('age=',c)print(a)data['text']='''获取小黄人内裤'''data=json.loads(html)forjinjson.loads(data):data['text']=int(json.loads(data['text']))returndatadata['text']='''获取小黄人性取值'''data=json.loads(html)forcinjson.loads(data):c=c['text']forjinjson.loads(data['text']):id=re.sub('id=',j['id'])sex=re.sub('sex=',re.sub('sex=',j['sex'])type=re.sub('type=',j['type'])class=re.。
php 抓取网页标题(有道云管家,你可以尝试以下抓取的网页抓取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-11 14:36
php抓取网页标题和网页链接,然后数据库存取信息。看这网站就是做了限制了,除非你非常xx,不然我没辙,这样的机会很少。一般unbox都是某些敏感内容,是会反爬虫的。另外说一句,我现在正在维护一个php+css库,可以抓取实时的网页,有兴趣交流一下。
谢邀。发现很多对php抓取一无所知的初学者都有的一个问题:我们的工作一般用php,用c/c++的也有,但是如果要抓取那些在线的网页却不知道怎么搞定。推荐一个比较棒的爬虫工具,可以让你快速适应这些抓取方式,
用shiyanlou。
谢谢邀请。你说的是抓取你要抓取的那个网站的数据吧?像我现在正在维护的工具可以快速抓取你所需要的网站的数据。对于零基础的初学者,要快速上手的话,可以用shiyanlou,相对于其他的爬虫工具来说,算是比较简单的了。
有道云管家啊!
有道云管家,
你可以尝试以下方式
1、找到你所要抓取的网站
2、选择相应类型爬虫
3、抓取数据
pythonscrapy
题主可以使用以下的搜索引擎a.python.python.scrapya.web.scrapy。二者结合应该能解决问题。
谢邀,首先我是做ci的,先了解你的站点,
pythonscrapy一个完整的爬虫发布和爬取系统,很实用。 查看全部
php 抓取网页标题(有道云管家,你可以尝试以下抓取的网页抓取方式)
php抓取网页标题和网页链接,然后数据库存取信息。看这网站就是做了限制了,除非你非常xx,不然我没辙,这样的机会很少。一般unbox都是某些敏感内容,是会反爬虫的。另外说一句,我现在正在维护一个php+css库,可以抓取实时的网页,有兴趣交流一下。
谢邀。发现很多对php抓取一无所知的初学者都有的一个问题:我们的工作一般用php,用c/c++的也有,但是如果要抓取那些在线的网页却不知道怎么搞定。推荐一个比较棒的爬虫工具,可以让你快速适应这些抓取方式,
用shiyanlou。
谢谢邀请。你说的是抓取你要抓取的那个网站的数据吧?像我现在正在维护的工具可以快速抓取你所需要的网站的数据。对于零基础的初学者,要快速上手的话,可以用shiyanlou,相对于其他的爬虫工具来说,算是比较简单的了。
有道云管家啊!
有道云管家,
你可以尝试以下方式
1、找到你所要抓取的网站
2、选择相应类型爬虫
3、抓取数据
pythonscrapy
题主可以使用以下的搜索引擎a.python.python.scrapya.web.scrapy。二者结合应该能解决问题。
谢邀,首先我是做ci的,先了解你的站点,
pythonscrapy一个完整的爬虫发布和爬取系统,很实用。
php 抓取网页标题(php抓取网页标题和网页源代码的代码,同时爬取关键词)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-10-08 18:02
php抓取网页标题和网页源代码的代码,同时爬取关键词和关键词搜索量和文章收藏数量的数据。
1、实例下载
2、robots屏蔽页面上的非法内容。
3、session加密。cookie_secret抓取用户会话锁定会话的网页。
4、定位网页源代码为爬虫文件是否采取newxxx(抓取对象)定位数据文件所在的网页。
5、网页链接.7|html||+:/:/.+|wget|||ltt+|||/|/|/|/|/|/|/|||#0|<a>=0;</a>{||-+|};#1|1#3||utf-8|/|/utf-8|/|\\\-
1)|#1|#1|/wset|tracename_hrefgetfunc|/*{if(!ltags&&!ltags.isnotfound)return['_blank'];}&;*return['.*?'+source;}*/
<p>first,首先需要写出定位的代码,一般写在functionlatrobes(w,url){varw:url;varu:url;varhash:url;//用于代替{}里面的内容functiongeotypecode(url){varprice:url;for(vari=0;i 查看全部
php 抓取网页标题(php抓取网页标题和网页源代码的代码,同时爬取关键词)
php抓取网页标题和网页源代码的代码,同时爬取关键词和关键词搜索量和文章收藏数量的数据。
1、实例下载
2、robots屏蔽页面上的非法内容。
3、session加密。cookie_secret抓取用户会话锁定会话的网页。
4、定位网页源代码为爬虫文件是否采取newxxx(抓取对象)定位数据文件所在的网页。
5、网页链接.7|html||+:/:/.+|wget|||ltt+|||/|/|/|/|/|/|/|||#0|<a>=0;</a>{||-+|};#1|1#3||utf-8|/|/utf-8|/|\\\-
1)|#1|#1|/wset|tracename_hrefgetfunc|/*{if(!ltags&&!ltags.isnotfound)return['_blank'];}&;*return['.*?'+source;}*/
<p>first,首先需要写出定位的代码,一般写在functionlatrobes(w,url){varw:url;varu:url;varhash:url;//用于代替{}里面的内容functiongeotypecode(url){varprice:url;for(vari=0;i
php 抓取网页标题(关于XML的基础教程网络上也随处可见的概念和术语介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-08 17:26
XML 越来越火了,关于 XML 的基本教程在 Internet 上随处可见。但是很多概念和术语往往令人生畏。很多朋友问我:XML有什么用?我们需要学习吗?我想根据我个人的学习经历和经验写一个更全面的介绍文章。首先有两点需要肯定:第一:XML绝对是未来的发展趋势,无论你是网页设计师还是网页程序员,都应该及时学习理解,等待只会让你失去机会; 第二:新知识 肯定会有很多新概念,试着去理解和接受,你可能会有所提高。不要害怕逃跑,毕竟我们还年轻。本文分为五个部分。它们是 XML 快速入门,XML 概念、XML 术语、XML 实现和 XML 示例分析。最后一个附录介绍了 XML 的相关资源。作者以一个普通网页设计师的视角,用通俗易懂的语言为您讲述XML的方方面面,助您解开XML的神秘面纱,快速进入XML的新领域。• 第 1 章:XML 快速入门• 一. 什么是 XML?• 二. XML 是一个新概念吗?• 三. 使用 XML 有什么好处?• 四. XML 难学吗?• 五. XML 和 HTML 的区别• 六. XML 的严格格式• 七. 更多关于 XML• 第 2 章:XML 概念• 一. 可扩展性• 二.@ > 徽标• 三. 语言• 四. 结构化• 五. 元数据• 六. 显示• 七. DOM • 第3 章:
例如,第一行的标题具有固定大小。相比之下,XML 没有固定的标记。XML 无法描述网页的具体外观和内容。它只描述了内容的数据形式和结构。这是一个质的区别:网页混合了数据和显示,而 XML 将数据和显示分开。让我们看看上面的例子。在 myfile.htm 中,我们只关心页面的显示方式。我们可以设计不同的界面,用不同的方式排版页面,但是数据存储在myfile.xml中,没有任何变化。(如果你是程序员,你会惊讶地发现,这和模块化面向对象编程的思想非常相似!其实网页不是一种程序?)正是这种不同使得XML方便网络应用和信息共享,高效且可扩展。因此,我们相信XML作为一种先进的数据处理方法,将使网络跨越到一个新的高度。六. XML的严格格式吸取了HTML松散格式的教训,XML从一开始就坚持实现“好格式”。我们先来看一些HTML语句,在HTML中随处可见: 1. sample2.sample3.sample4.samplar XML文档中,上述语句语法错误。因为:1.所有标签都必须有对应的结束标签;2. 所有 XML 标签必须合理嵌套;3. 所有 XML 标签都区分大小写;4.所有标签属性必须用“”括起来;所以用 XML 写上述语句的正确方法是 1. sample2.sample3.sample4.samplar ,XML标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie samplar 、XML 标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie samplar 、XML 标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 数字和其他字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 数字和其他字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 查看全部
php 抓取网页标题(关于XML的基础教程网络上也随处可见的概念和术语介绍)
XML 越来越火了,关于 XML 的基本教程在 Internet 上随处可见。但是很多概念和术语往往令人生畏。很多朋友问我:XML有什么用?我们需要学习吗?我想根据我个人的学习经历和经验写一个更全面的介绍文章。首先有两点需要肯定:第一:XML绝对是未来的发展趋势,无论你是网页设计师还是网页程序员,都应该及时学习理解,等待只会让你失去机会; 第二:新知识 肯定会有很多新概念,试着去理解和接受,你可能会有所提高。不要害怕逃跑,毕竟我们还年轻。本文分为五个部分。它们是 XML 快速入门,XML 概念、XML 术语、XML 实现和 XML 示例分析。最后一个附录介绍了 XML 的相关资源。作者以一个普通网页设计师的视角,用通俗易懂的语言为您讲述XML的方方面面,助您解开XML的神秘面纱,快速进入XML的新领域。• 第 1 章:XML 快速入门• 一. 什么是 XML?• 二. XML 是一个新概念吗?• 三. 使用 XML 有什么好处?• 四. XML 难学吗?• 五. XML 和 HTML 的区别• 六. XML 的严格格式• 七. 更多关于 XML• 第 2 章:XML 概念• 一. 可扩展性• 二.@ > 徽标• 三. 语言• 四. 结构化• 五. 元数据• 六. 显示• 七. DOM • 第3 章:
例如,第一行的标题具有固定大小。相比之下,XML 没有固定的标记。XML 无法描述网页的具体外观和内容。它只描述了内容的数据形式和结构。这是一个质的区别:网页混合了数据和显示,而 XML 将数据和显示分开。让我们看看上面的例子。在 myfile.htm 中,我们只关心页面的显示方式。我们可以设计不同的界面,用不同的方式排版页面,但是数据存储在myfile.xml中,没有任何变化。(如果你是程序员,你会惊讶地发现,这和模块化面向对象编程的思想非常相似!其实网页不是一种程序?)正是这种不同使得XML方便网络应用和信息共享,高效且可扩展。因此,我们相信XML作为一种先进的数据处理方法,将使网络跨越到一个新的高度。六. XML的严格格式吸取了HTML松散格式的教训,XML从一开始就坚持实现“好格式”。我们先来看一些HTML语句,在HTML中随处可见: 1. sample2.sample3.sample4.samplar XML文档中,上述语句语法错误。因为:1.所有标签都必须有对应的结束标签;2. 所有 XML 标签必须合理嵌套;3. 所有 XML 标签都区分大小写;4.所有标签属性必须用“”括起来;所以用 XML 写上述语句的正确方法是 1. sample2.sample3.sample4.samplar ,XML标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie samplar 、XML 标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie samplar 、XML 标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 数字和其他字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 数字和其他字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie
php 抓取网页标题(>数据库读取标题/内容->计算关键字关联的图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-17 00:05
php抓取网页标题->数据库读取标题/内容->计算关键字/关键字关联的标题/内容php抓取网页详情->数据库读取详情页所有图片->计算关键字/关键字关联的图片->获取详情页所有图片php抓取所有图片->转存到本地->修改页面/添加图片文件/删除图片/标签php修改本地文件/添加图片文件/删除图片标签php读取指定图片->解析image->获取图片roi(rectsofinterest)->计算roi值php读取指定文件/修改文件->解析image->获取图片roi->计算roi值php修改文件/添加图片/删除图片标签。
分析页面在同样的网络环境下,同样的一条http数据在不同的phper那儿有些地方直接可以看出他们是有关联的。这个是从http请求中得来的。php中可以通过注册tags,item_content(mt.imdb1.url.margintop.margintopreferences)注册一个字段作为图片的roi标签,然后直接返回给浏览器。
比如:"//gdh_my_content.target../img","abcdefg"这个是对图片文件的处理,处理完之后返回给浏览器。 查看全部
php 抓取网页标题(>数据库读取标题/内容->计算关键字关联的图片)
php抓取网页标题->数据库读取标题/内容->计算关键字/关键字关联的标题/内容php抓取网页详情->数据库读取详情页所有图片->计算关键字/关键字关联的图片->获取详情页所有图片php抓取所有图片->转存到本地->修改页面/添加图片文件/删除图片/标签php修改本地文件/添加图片文件/删除图片标签php读取指定图片->解析image->获取图片roi(rectsofinterest)->计算roi值php读取指定文件/修改文件->解析image->获取图片roi->计算roi值php修改文件/添加图片/删除图片标签。
分析页面在同样的网络环境下,同样的一条http数据在不同的phper那儿有些地方直接可以看出他们是有关联的。这个是从http请求中得来的。php中可以通过注册tags,item_content(mt.imdb1.url.margintop.margintopreferences)注册一个字段作为图片的roi标签,然后直接返回给浏览器。
比如:"//gdh_my_content.target../img","abcdefg"这个是对图片文件的处理,处理完之后返回给浏览器。
php 抓取网页标题( Python3实战入门数据库篇--把爬取到的数据存到数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-16 04:37
Python3实战入门数据库篇--把爬取到的数据存到数据库)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
由于爬取到的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
复制代码
这是对Python3的爬虫的简单介绍。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看有哪些美图被爬了
爬24个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下。
分析上图,我们要抓取的信息在div中的a标签和img标签中,所以我们要考虑的是如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,这里是关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
复制代码
这里的数据是抓到的,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的爬行中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取新闻网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
一旦获得了数据,我们仍然需要将数据存储在数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以进行后续的数据分析处理,或者使用爬取的文章,给app提供新闻api接口,当然这个是后来的故事。自学Python数据库操作后,会写一篇文章《Python3数据库实战入门---将爬取到的数据保存到数据库》 查看全部
php 抓取网页标题(
Python3实战入门数据库篇--把爬取到的数据存到数据库)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
由于爬取到的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
复制代码
这是对Python3的爬虫的简单介绍。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看有哪些美图被爬了
爬24个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下。
分析上图,我们要抓取的信息在div中的a标签和img标签中,所以我们要考虑的是如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,这里是关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
复制代码
这里的数据是抓到的,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的爬行中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取新闻网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
一旦获得了数据,我们仍然需要将数据存储在数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以进行后续的数据分析处理,或者使用爬取的文章,给app提供新闻api接口,当然这个是后来的故事。自学Python数据库操作后,会写一篇文章《Python3数据库实战入门---将爬取到的数据保存到数据库》
php 抓取网页标题(写过如何抓取WEB页面和如何从WEB中提取信息?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-16 04:36
虽然之前写过如何抓取WEB页面以及如何从WEB页面中提取信息。但是我还是需要一步一步的教程,不然我没有大体的了解。不过,没想到这个教程居然会变成翻译。在这个爬虫教程系列文章中,爬虫(爬取和解析)的一些关键问题将通过实际例子从浅到深讨论。
在教程一中,我们要爬取的网站是豆瓣电影:
您可以在此处获取完整代码并进行测试。
开始前
由于教程是基于pyspider的,所以可以安装一个pyspider(快速入门,也可以直接使用pyspider的demo环境:.
您还应该至少对万维网有一个简单的了解:
所以,爬取一个网页其实就是:
找到收录我们需要的信息的 URL (URL) 列表。通过HTTP协议下载页面。从页面的 HTML 中解析所需的信息。查找此 URL 的更多信息。返回 2 并继续选择起始 URL。
既然我们要抓取所有的电影,首先我们需要抓取一个电影列表,一个好的列表应该:
我们再次扫描,发现没有收录所有电影的列表。我们只能排在第二位,通过抓取类别下的所有标签列表页面来遍历所有电影:
创建项目
在pyspider的dashboard右下角,点击“Create”按钮
替换 on_start 函数的 self.crawl 的 URL:
python@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://movie.douban.com/tag/', callback=self.index_page)
点击绿色运行执行,在follower会看到一个红色的1,切换到follower面板,点击绿色播放按钮:
标签列表页面
在标签列表页面中,我们需要提取所有电影列表页面的 URL。您可能已经发现示例处理程序提取了大量的 URL。因此,提取列表页面 URL 的一种可行方法是使用常规过滤器将其过滤掉:
pythonimport re
...
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://movie.douban.com/tag/\w+", each.attr.href, re.U):
self.crawl(each.attr.href, callback=self.list_page)
由于pyspider是纯Python环境,你可以使用Python强大的内置库或者你熟悉的第三方库来解析页面。但是,更推荐使用 CSS 选择器。
电影列表页面
再次点击运行进入电影列表页面(list_page)。在这个页面中,我们需要提取:
CSS 选择器
顾名思义,CSS 选择器是 CSS 用来定位需要设置样式的元素的表达式。由于前端程序员使用 CSS 选择器来为页面上的不同元素设置样式,因此我们也可以使用它来定位所需的元素。您可以在 CSS 选择器参考手册中了解有关 CSS 选择器语法的更多信息。
在 pyspider 中,response.doc 的 PyQuery 对象是内置的,允许您使用类似 jQuery 的语法来操作 DOM 元素。您可以在 PyQuery 页面上找到完整的文档。
CSS 选择器助手
在pyspider中,还内置了一个CSS Selector Helper,当你点击页面上的一个元素时,它可以帮助你生成它的CSS选择器表达式。您可以单击启用 CSS 选择器助手按钮,然后切换到网页:
开启后,鼠标放在元素上,会以黄色高亮显示。单击后,将突出显示具有相同 CSS 选择器表达式的所有元素。该表达式将被插入到 python 代码中的当前光标位置。创建以下代码,将光标放在单引号之间:
pythondef list_page(self, response):
for each in response.doc('').items():
单击指向电影的链接,CSS 选择器表达式将插入到您的代码中。重复此操作以插入链接以翻页:
pythondef list_page(self, response):
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV>TABLE TR.item>TD>DIV.pl2>A').items():
self.crawl(each.attr.href, callback=self.detail_page)
# 翻页
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.paginator>A').items():
self.crawl(each.attr.href, callback=self.list_page)
电影详情页面
再次单击运行并转到详细信息页面。使用 css 选择器助手分别添加电影标题、评分和导演:
pythondef detail_page(self, response):
return {
"url": response.url,
"title": response.doc('HTML>BODY>DIV#wrapper>DIV#content>H1>SPAN').text(),
"rating": response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.indent.clearfix>DIV.subjectwrap.clearfix>DIV#interest_sectl>DIV.rating_wrap.clearbox>P.rating_self.clearfix>STRONG.ll.rating_num').text(),
"导演": [x.text() for x in response.doc('a[rel="v:directedBy"]').items()],
}
请注意,您会发现 css 选择器助手并不总是提取适当的 CSS 选择器表达式。您可以借助 Chrome Dev Tools 编写合适的表达式:
右键单击要提取的元素,然后单击review 元素。不需要像自动生成的表达式那样写出所有的祖先节点,只需写出关键节点的属性,可以区分你不需要的元素。但这需要有爬虫和前端网页的经验。所以,学习爬虫最好的方法就是学习这个页面/网站是怎么写的。
您还可以使用 $$(a[rel="v:directedBy"]) 在 Chrome Dev Tools 的 Javascript 控制台中测试 CSS 选择器。
开始爬行并使用 run 逐步调试您的代码。最好使用多种页面类型进行一次回调测试。然后保存。返回仪表板,找到您的项目并将状态更改为调试或运行,然后按运行按钮
原版:(画风比原版好,有什么问题?) 查看全部
php 抓取网页标题(写过如何抓取WEB页面和如何从WEB中提取信息?)
虽然之前写过如何抓取WEB页面以及如何从WEB页面中提取信息。但是我还是需要一步一步的教程,不然我没有大体的了解。不过,没想到这个教程居然会变成翻译。在这个爬虫教程系列文章中,爬虫(爬取和解析)的一些关键问题将通过实际例子从浅到深讨论。
在教程一中,我们要爬取的网站是豆瓣电影:
您可以在此处获取完整代码并进行测试。
开始前
由于教程是基于pyspider的,所以可以安装一个pyspider(快速入门,也可以直接使用pyspider的demo环境:.
您还应该至少对万维网有一个简单的了解:
所以,爬取一个网页其实就是:
找到收录我们需要的信息的 URL (URL) 列表。通过HTTP协议下载页面。从页面的 HTML 中解析所需的信息。查找此 URL 的更多信息。返回 2 并继续选择起始 URL。
既然我们要抓取所有的电影,首先我们需要抓取一个电影列表,一个好的列表应该:
我们再次扫描,发现没有收录所有电影的列表。我们只能排在第二位,通过抓取类别下的所有标签列表页面来遍历所有电影:
创建项目
在pyspider的dashboard右下角,点击“Create”按钮
替换 on_start 函数的 self.crawl 的 URL:
python@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://movie.douban.com/tag/', callback=self.index_page)
点击绿色运行执行,在follower会看到一个红色的1,切换到follower面板,点击绿色播放按钮:
标签列表页面
在标签列表页面中,我们需要提取所有电影列表页面的 URL。您可能已经发现示例处理程序提取了大量的 URL。因此,提取列表页面 URL 的一种可行方法是使用常规过滤器将其过滤掉:
pythonimport re
...
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://movie.douban.com/tag/\w+", each.attr.href, re.U):
self.crawl(each.attr.href, callback=self.list_page)
由于pyspider是纯Python环境,你可以使用Python强大的内置库或者你熟悉的第三方库来解析页面。但是,更推荐使用 CSS 选择器。
电影列表页面
再次点击运行进入电影列表页面(list_page)。在这个页面中,我们需要提取:
CSS 选择器
顾名思义,CSS 选择器是 CSS 用来定位需要设置样式的元素的表达式。由于前端程序员使用 CSS 选择器来为页面上的不同元素设置样式,因此我们也可以使用它来定位所需的元素。您可以在 CSS 选择器参考手册中了解有关 CSS 选择器语法的更多信息。
在 pyspider 中,response.doc 的 PyQuery 对象是内置的,允许您使用类似 jQuery 的语法来操作 DOM 元素。您可以在 PyQuery 页面上找到完整的文档。
CSS 选择器助手
在pyspider中,还内置了一个CSS Selector Helper,当你点击页面上的一个元素时,它可以帮助你生成它的CSS选择器表达式。您可以单击启用 CSS 选择器助手按钮,然后切换到网页:
开启后,鼠标放在元素上,会以黄色高亮显示。单击后,将突出显示具有相同 CSS 选择器表达式的所有元素。该表达式将被插入到 python 代码中的当前光标位置。创建以下代码,将光标放在单引号之间:
pythondef list_page(self, response):
for each in response.doc('').items():
单击指向电影的链接,CSS 选择器表达式将插入到您的代码中。重复此操作以插入链接以翻页:
pythondef list_page(self, response):
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV>TABLE TR.item>TD>DIV.pl2>A').items():
self.crawl(each.attr.href, callback=self.detail_page)
# 翻页
for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.paginator>A').items():
self.crawl(each.attr.href, callback=self.list_page)
电影详情页面
再次单击运行并转到详细信息页面。使用 css 选择器助手分别添加电影标题、评分和导演:
pythondef detail_page(self, response):
return {
"url": response.url,
"title": response.doc('HTML>BODY>DIV#wrapper>DIV#content>H1>SPAN').text(),
"rating": response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.indent.clearfix>DIV.subjectwrap.clearfix>DIV#interest_sectl>DIV.rating_wrap.clearbox>P.rating_self.clearfix>STRONG.ll.rating_num').text(),
"导演": [x.text() for x in response.doc('a[rel="v:directedBy"]').items()],
}
请注意,您会发现 css 选择器助手并不总是提取适当的 CSS 选择器表达式。您可以借助 Chrome Dev Tools 编写合适的表达式:
右键单击要提取的元素,然后单击review 元素。不需要像自动生成的表达式那样写出所有的祖先节点,只需写出关键节点的属性,可以区分你不需要的元素。但这需要有爬虫和前端网页的经验。所以,学习爬虫最好的方法就是学习这个页面/网站是怎么写的。
您还可以使用 $$(a[rel="v:directedBy"]) 在 Chrome Dev Tools 的 Javascript 控制台中测试 CSS 选择器。
开始爬行并使用 run 逐步调试您的代码。最好使用多种页面类型进行一次回调测试。然后保存。返回仪表板,找到您的项目并将状态更改为调试或运行,然后按运行按钮
原版:(画风比原版好,有什么问题?)
php 抓取网页标题(如何找到你要的抓取的网页标题(地址)?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-11 23:03
php抓取网页标题、url列表。精准的网页标题、地址列表可谓是海量信息的入口,用php抓取能最大限度的获取网页内容、网页标题信息,甚至采集网页列表等信息。采集网页标题列表,你甚至可以下载网页源码。如何找到你要抓取的网页标题(地址)?在百度站长平台或者其他平台获取url之后,找到该url后采集、复制采集的网页标题列表。
那么你要怎么获取网页标题列表的内容呢?php本身是没有类似网页标题列表的函数的,那么一般情况下,只能是爬虫通过爬虫自身去浏览网页获取,然后采集网页标题列表,相对于传统的html和xml来说,php抓取网页标题列表利用的是cookie定位网页标题标签的,所以http的协议支持cookie定位网页标签标签内容,cookie的服务器端实现加密传递,服务器端默认解析普通的html文件返回网页标签获取标签内容。
比如/,cookie为/,登录之后就可以发送get请求获取/,这里我们就可以先把/抓取成功,然后再获取网页标题列表,这样我们就可以抓取到网页标题列表的内容。假设登录php站点:登录过程:爬虫爬取过程:ps:php对于cookie的支持,以登录获取/网页标题列表的爬虫为例,是没有任何问题的,那么这里就是需要我们借助于解析登录网页标题列表的cookie,发送get请求到我们自己的服务器,然后服务器解析网页内容返回给我们网页标题列表。 查看全部
php 抓取网页标题(如何找到你要的抓取的网页标题(地址)?)
php抓取网页标题、url列表。精准的网页标题、地址列表可谓是海量信息的入口,用php抓取能最大限度的获取网页内容、网页标题信息,甚至采集网页列表等信息。采集网页标题列表,你甚至可以下载网页源码。如何找到你要抓取的网页标题(地址)?在百度站长平台或者其他平台获取url之后,找到该url后采集、复制采集的网页标题列表。
那么你要怎么获取网页标题列表的内容呢?php本身是没有类似网页标题列表的函数的,那么一般情况下,只能是爬虫通过爬虫自身去浏览网页获取,然后采集网页标题列表,相对于传统的html和xml来说,php抓取网页标题列表利用的是cookie定位网页标题标签的,所以http的协议支持cookie定位网页标签标签内容,cookie的服务器端实现加密传递,服务器端默认解析普通的html文件返回网页标签获取标签内容。
比如/,cookie为/,登录之后就可以发送get请求获取/,这里我们就可以先把/抓取成功,然后再获取网页标题列表,这样我们就可以抓取到网页标题列表的内容。假设登录php站点:登录过程:爬虫爬取过程:ps:php对于cookie的支持,以登录获取/网页标题列表的爬虫为例,是没有任何问题的,那么这里就是需要我们借助于解析登录网页标题列表的cookie,发送get请求到我们自己的服务器,然后服务器解析网页内容返回给我们网页标题列表。
php 抓取网页标题(python爬虫爬取爬取网页新闻标题方法网页方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-10 10:05
Python爬虫抓取网页新闻标题的方法
1.首先,使用浏览-检查提供的工具查找与网页新闻标题对应的元素位置。这里的新闻标题在H3标签中
2.然后使用编辑器编写Python代码
2.1方法1:
import requests
from bs4 import BeautifulSoup
url = 'http://www.xxx.com/'
r = requests.get(url)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text,'html.parser') # 'html.parser'这是BeautifulSoup库的HTML解析器的用法,用于解析HTML
#print(r.text)
titles = soup.select('h3')
for title in titles: # 使用循环输出爬取到的网页上的所有新闻标题
print(title.text)
2.2方法2:
#coding = utf-8
import requests
from lxml import etree
url = 'http://www.xxx.com/'
r = requests.get(url)
html = etree.HTML(r.text)
titles = html.xpath('//div[@class="box-seven"]//h3/text()')
for title in titles:
print('Title:', title)
3.总结:
以上两种方法都可以实现抓取网络新闻标题的功能。如果有用的话,你可以关注我。如果您有问题,可以留下私人消息进行交流 查看全部
php 抓取网页标题(python爬虫爬取爬取网页新闻标题方法网页方法)
Python爬虫抓取网页新闻标题的方法
1.首先,使用浏览-检查提供的工具查找与网页新闻标题对应的元素位置。这里的新闻标题在H3标签中
2.然后使用编辑器编写Python代码
2.1方法1:
import requests
from bs4 import BeautifulSoup
url = 'http://www.xxx.com/'
r = requests.get(url)
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text,'html.parser') # 'html.parser'这是BeautifulSoup库的HTML解析器的用法,用于解析HTML
#print(r.text)
titles = soup.select('h3')
for title in titles: # 使用循环输出爬取到的网页上的所有新闻标题
print(title.text)
2.2方法2:
#coding = utf-8
import requests
from lxml import etree
url = 'http://www.xxx.com/'
r = requests.get(url)
html = etree.HTML(r.text)
titles = html.xpath('//div[@class="box-seven"]//h3/text()')
for title in titles:
print('Title:', title)
3.总结:
以上两种方法都可以实现抓取网络新闻标题的功能。如果有用的话,你可以关注我。如果您有问题,可以留下私人消息进行交流
php 抓取网页标题(php抓取网页标题的方法、分析网页内容提取出来的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-10 06:03
php抓取网页标题的方法
一、分析网页
1、浏览器打开spider.php所在文件夹。在javascript中可以找到网页关键字段的href字段。
2、调用spider.get("myproduct_url");将解析出的参数shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给chrom;
3、打开chrome浏览器,打开右上角显示标签栏中的网站标题,并选择按钮【web分析】→【网站源代码】→【网站源代码结构】,可以看到下图结构。
4、将这条【shimstr(a的最后一个字符)】转换为数组格式后作为spider.post参数。调用spider.post("a.php","")将这条代码中的shimstr(a的最后一个字符)转换为url参数。同时,调用spider.get("b.php","")将这条代码中的shimstr(b的最后一个字符)转换为url参数。将分析出的shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给chrom;。
5、spider.post将解析出的参数shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给text方法,之后在方法post参数中通过传入对应参数将网页内容提取出来。
完整代码:;param={"request":"","text":""}
二、生成网页url分析完网页,将需要提取的网页内容提取出来。
1、运行网页查看结果。这样既简单又容易实现抓取。 查看全部
php 抓取网页标题(php抓取网页标题的方法、分析网页内容提取出来的)
php抓取网页标题的方法
一、分析网页
1、浏览器打开spider.php所在文件夹。在javascript中可以找到网页关键字段的href字段。
2、调用spider.get("myproduct_url");将解析出的参数shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给chrom;
3、打开chrome浏览器,打开右上角显示标签栏中的网站标题,并选择按钮【web分析】→【网站源代码】→【网站源代码结构】,可以看到下图结构。
4、将这条【shimstr(a的最后一个字符)】转换为数组格式后作为spider.post参数。调用spider.post("a.php","")将这条代码中的shimstr(a的最后一个字符)转换为url参数。同时,调用spider.get("b.php","")将这条代码中的shimstr(b的最后一个字符)转换为url参数。将分析出的shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给chrom;。
5、spider.post将解析出的参数shimstr(a的最后一个字符)和shimstr(b的最后一个字符)赋值给text方法,之后在方法post参数中通过传入对应参数将网页内容提取出来。
完整代码:;param={"request":"","text":""}
二、生成网页url分析完网页,将需要提取的网页内容提取出来。
1、运行网页查看结果。这样既简单又容易实现抓取。
php 抓取网页标题(昆山网络推广网站运营优化不仅仅的较量良好的策略较量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-09 17:01
一、首先,优质的产业文章是基础,文章是整个网站的核心和重点,优质的文章才能不仅增加网站收录,权重也是用户认可度。网站增加网站粘度,增加网站转化率。这类缓存主要影响用户是否可以第一时间。获取网站的最新内容。对于这些缓存,我们应该及时清除它们,以便于优化网站,同时防止网站之后网站页面被重复删除。
二、尽可能做网页推广相关的网站页面,增加网站的粘性,提高网页的转化率,从而更好的提高网页的数量收录就可以适当采用图文结合的方式,昆山网推广不允许网站页面被收录后反复删除。其次,相关网页的布局文章。在每个文章的末尾或任何你认为合适的地方,增加相关性文章的调用。这种方式是为了增加网站PV页面的浏览量,为蜘蛛提供更多的访问网站多个访问渠道,增加了网站页面被爬取的机会,增加了网站页面的权重网站
三、昆山网络推广与实际应用的结合,有力地衬托出产品在行业内的品质和专业性。内部连接布局合理。内部连接分发的第一期是结束页面收录。通过内部连接的构建,明确指出了蜘蛛的重要连接和关键连接的分布。
降低网页的层次,让用户第一时间了解网页的重点。网页样式最好是用css连接外部样式表来构建,以减少网页上的冗余代码,提高网页打开速度和蜘蛛爬行效率。
四、不仅注重排名和外链建设,更注重细节。毕竟这些都是影响用户体验好坏的关键。众所周知,昆山互联网推广网站 运营优化 不仅仅是执行力的竞争,更是人员优化、运营主管思维和策略优化的竞争。好的策略是网站走向好的运营优化的基础,错误或不正确的策略导致整个网站的方向。死胡同对整个优化团队的影响非常不利。更严重的会导致团队和公司遭受重大损失。今天根据自己的运营优化经验,
五、其中会有一定的缓存,这些缓存也可以来自后面的网站操作过程。大家都知道动态网站的缓存效果是最明显的。如果不及时清除,昆山互联网推广很容易让搜索引擎收录缓存页面,从而导致网站页面重复收录。还有一个缓存,就是浏览器的缓存,叫做cookies。 查看全部
php 抓取网页标题(昆山网络推广网站运营优化不仅仅的较量良好的策略较量)
一、首先,优质的产业文章是基础,文章是整个网站的核心和重点,优质的文章才能不仅增加网站收录,权重也是用户认可度。网站增加网站粘度,增加网站转化率。这类缓存主要影响用户是否可以第一时间。获取网站的最新内容。对于这些缓存,我们应该及时清除它们,以便于优化网站,同时防止网站之后网站页面被重复删除。
二、尽可能做网页推广相关的网站页面,增加网站的粘性,提高网页的转化率,从而更好的提高网页的数量收录就可以适当采用图文结合的方式,昆山网推广不允许网站页面被收录后反复删除。其次,相关网页的布局文章。在每个文章的末尾或任何你认为合适的地方,增加相关性文章的调用。这种方式是为了增加网站PV页面的浏览量,为蜘蛛提供更多的访问网站多个访问渠道,增加了网站页面被爬取的机会,增加了网站页面的权重网站
三、昆山网络推广与实际应用的结合,有力地衬托出产品在行业内的品质和专业性。内部连接布局合理。内部连接分发的第一期是结束页面收录。通过内部连接的构建,明确指出了蜘蛛的重要连接和关键连接的分布。
降低网页的层次,让用户第一时间了解网页的重点。网页样式最好是用css连接外部样式表来构建,以减少网页上的冗余代码,提高网页打开速度和蜘蛛爬行效率。
四、不仅注重排名和外链建设,更注重细节。毕竟这些都是影响用户体验好坏的关键。众所周知,昆山互联网推广网站 运营优化 不仅仅是执行力的竞争,更是人员优化、运营主管思维和策略优化的竞争。好的策略是网站走向好的运营优化的基础,错误或不正确的策略导致整个网站的方向。死胡同对整个优化团队的影响非常不利。更严重的会导致团队和公司遭受重大损失。今天根据自己的运营优化经验,
五、其中会有一定的缓存,这些缓存也可以来自后面的网站操作过程。大家都知道动态网站的缓存效果是最明显的。如果不及时清除,昆山互联网推广很容易让搜索引擎收录缓存页面,从而导致网站页面重复收录。还有一个缓存,就是浏览器的缓存,叫做cookies。
php 抓取网页标题(各个博客软件开源程序的功能都应该是差不多。介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-05 22:09
各种博客软件开源程序的功能应该是差不多的。介绍如何优化个人博客。
首先,我认为博客更多的是一种分享和交流的工具。与许多网站相比,它生成的网站结构和网页代码对搜索引擎更加友好。
但是,博客页面是使用模板生成的,无法控制的因素很多。在选择了你认为更好的模板后,页面上的大部分代码就完成了。您不能逐页、逐目录进行特殊优化。所以博客不是一个非常适合完整搜索引擎优化的系统。对于许多不太受欢迎的关键词,我们可以看到博客可以排在第一位。但是最流行的关键词还是用手写网页,除非你是你所在行业的一个特别好的人,你写的任何东西每个人都会链接到你。
客户的后台系统可以选择动态或静态(或伪静态),必须选择生成静态网址,即去掉网址中的问号。您还可以选择生成的 URL 结构。比如文章 URL PHP {%host%}post/{%id%}.html 其中“post”可以自己定义,比如blog或者html。一旦确定了永久链接和 URL 结构,就不要更改它。
一些博客生成的默认页面标题是这样的形式:Blog Title>> 文章标题需要反转为:文章Title – Blog Title 帖子标题更具体关键词,所以最好出现在标题前面。这可以通过FTP修改主题模板下的header.php来实现。例如:PHP帖子标题帖子标题会出现在页面标题中,所以尽量在标题中收录本帖讨论的关键词,最好简洁明了,让人知道帖子是什么一目了然,有利于用户点击。
当你在文章中提到之前写过的相关内容,自然可以链接到其他文章。博客通常有特殊的插件来生成你指定的所有 关键词 的链接。但我建议不要使用它,因为它看起来不自然,给用户带来不好的体验。仅在您认为合适的地方链接到其他 文章。相关文章 使用插件在每个文章下列出5个其他相关帖子,帮助搜索引擎抓取更多网页。
博客网站的结构往往很深。您可能需要多次点击主页才能看到一年前写的内容。所以我建议将目录类别划分得更细一些,让网站相对扁平化,这样有利于搜索引擎蜘蛛到达更多的网页。标签插件很多,可以根据标签对帖子进行分类,让帖子的主题更加清晰。大家可以试试。我觉得还是很适合搜索引擎抓取的。建议使用它。我觉得wp或者zb都有模块,拖拽就行,很方便。我的主题一般都是用标签美化的,视频效果好,功能强大。
很多人建议你可以把订阅链接用各种RSS阅读器放在博客上,就像点石博客一样。但是这个也有个人喜好。虽然方便用户阅读,但真正能点击订阅的人很少,但也没什么不好(矛盾...)
星辰资源网分享更多资源信息,关注签名 查看全部
php 抓取网页标题(各个博客软件开源程序的功能都应该是差不多。介绍)
各种博客软件开源程序的功能应该是差不多的。介绍如何优化个人博客。
首先,我认为博客更多的是一种分享和交流的工具。与许多网站相比,它生成的网站结构和网页代码对搜索引擎更加友好。
但是,博客页面是使用模板生成的,无法控制的因素很多。在选择了你认为更好的模板后,页面上的大部分代码就完成了。您不能逐页、逐目录进行特殊优化。所以博客不是一个非常适合完整搜索引擎优化的系统。对于许多不太受欢迎的关键词,我们可以看到博客可以排在第一位。但是最流行的关键词还是用手写网页,除非你是你所在行业的一个特别好的人,你写的任何东西每个人都会链接到你。
客户的后台系统可以选择动态或静态(或伪静态),必须选择生成静态网址,即去掉网址中的问号。您还可以选择生成的 URL 结构。比如文章 URL PHP {%host%}post/{%id%}.html 其中“post”可以自己定义,比如blog或者html。一旦确定了永久链接和 URL 结构,就不要更改它。
一些博客生成的默认页面标题是这样的形式:Blog Title>> 文章标题需要反转为:文章Title – Blog Title 帖子标题更具体关键词,所以最好出现在标题前面。这可以通过FTP修改主题模板下的header.php来实现。例如:PHP帖子标题帖子标题会出现在页面标题中,所以尽量在标题中收录本帖讨论的关键词,最好简洁明了,让人知道帖子是什么一目了然,有利于用户点击。
当你在文章中提到之前写过的相关内容,自然可以链接到其他文章。博客通常有特殊的插件来生成你指定的所有 关键词 的链接。但我建议不要使用它,因为它看起来不自然,给用户带来不好的体验。仅在您认为合适的地方链接到其他 文章。相关文章 使用插件在每个文章下列出5个其他相关帖子,帮助搜索引擎抓取更多网页。
博客网站的结构往往很深。您可能需要多次点击主页才能看到一年前写的内容。所以我建议将目录类别划分得更细一些,让网站相对扁平化,这样有利于搜索引擎蜘蛛到达更多的网页。标签插件很多,可以根据标签对帖子进行分类,让帖子的主题更加清晰。大家可以试试。我觉得还是很适合搜索引擎抓取的。建议使用它。我觉得wp或者zb都有模块,拖拽就行,很方便。我的主题一般都是用标签美化的,视频效果好,功能强大。
很多人建议你可以把订阅链接用各种RSS阅读器放在博客上,就像点石博客一样。但是这个也有个人喜好。虽然方便用户阅读,但真正能点击订阅的人很少,但也没什么不好(矛盾...)
星辰资源网分享更多资源信息,关注签名
php 抓取网页标题(php抓取网页标题-bootstrap专栏-知乎专栏有空再写详细一点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-24 18:01
php抓取网页标题,然后做爬虫返回给你做个整体效果。php抓取网页标题-bootstrap专栏-知乎专栏有空再写详细一点。
newsql就是日志文件,mongodb或者其他。python里是用sqlite。实际上现在流行的newsql也基本就是sqlite了。
php不适合抓取这类短篇新闻,因为php语言不适合抓取新闻,数据库不适合抓取这类频繁更新的文章。如果一定要抓取长新闻,可以用python和ruby,这两种语言更适合爬虫和数据库的操作,抓取技术上可以直接面对长连接。目前国内在做php爬虫的不多,基本都在做其他语言爬虫,php抓取文章和新闻主要是通过spider和request,在某些情况下不如直接写成js+request,抓取速度会差一些,但是执行效率会提高不少,也不需要做多层反射。希望可以帮到你。
长文通过cookie,短文用session用分段异步request写成js爬数据库,
(不是开玩笑)为什么你不抓取、分析新闻列表然后用webpy抓取新闻列表?为什么你不去学python,
webpy+bs4,只需要少量代码就可以抓取20万+,
eventlista(psbs)pruntasi(servlet)python2只支持bs4
python的pandas库可以抓取到网页数据,并处理成sqlite数据库,也可以调用sqlite数据库,但是你用webpy来抓取数据库的成本会比较高吧。另外目前网页抓取基本都是用sinatra框架了,这个框架是用webdynamics来模拟java中db接口,模拟了操作excel。你可以参考下。 查看全部
php 抓取网页标题(php抓取网页标题-bootstrap专栏-知乎专栏有空再写详细一点)
php抓取网页标题,然后做爬虫返回给你做个整体效果。php抓取网页标题-bootstrap专栏-知乎专栏有空再写详细一点。
newsql就是日志文件,mongodb或者其他。python里是用sqlite。实际上现在流行的newsql也基本就是sqlite了。
php不适合抓取这类短篇新闻,因为php语言不适合抓取新闻,数据库不适合抓取这类频繁更新的文章。如果一定要抓取长新闻,可以用python和ruby,这两种语言更适合爬虫和数据库的操作,抓取技术上可以直接面对长连接。目前国内在做php爬虫的不多,基本都在做其他语言爬虫,php抓取文章和新闻主要是通过spider和request,在某些情况下不如直接写成js+request,抓取速度会差一些,但是执行效率会提高不少,也不需要做多层反射。希望可以帮到你。
长文通过cookie,短文用session用分段异步request写成js爬数据库,
(不是开玩笑)为什么你不抓取、分析新闻列表然后用webpy抓取新闻列表?为什么你不去学python,
webpy+bs4,只需要少量代码就可以抓取20万+,
eventlista(psbs)pruntasi(servlet)python2只支持bs4
python的pandas库可以抓取到网页数据,并处理成sqlite数据库,也可以调用sqlite数据库,但是你用webpy来抓取数据库的成本会比较高吧。另外目前网页抓取基本都是用sinatra框架了,这个框架是用webdynamics来模拟java中db接口,模拟了操作excel。你可以参考下。
php 抓取网页标题(php抓取网页标题中的关键词来解析文章链接做深度学习)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-19 21:05
php抓取网页标题中的关键词来解析文章链接做深度学习用python:爬取链接批量获取数据到内存.python2爬取对象关键词可以不用request直接自己解析medium上一篇文章《关键词分析:提取文章结构pagerank解析:实践》最后处理了链接关键词出现一次之后网页头尾调整下,是可以保持关键词图片的位置。
今天重新接着和大家分享python爬取微博文章标题的写法,内容包括但不限于标题,标题链接,人名以及标题拼音首先要说明一下,微博爬虫是无限卡的,fd-8就等于我们要爬取的文章在网页上出现了8次,所以我们需要获取任何一个标题的几率数据,再返回即可如果爬取的是微博评论的话,要对标题进行格式处理:print(sys.getprop("文章标题"))field1="人名"field2="标题链接"dict.set(field1=field1,field2=field2)withopen('文章首页.txt','w')asf:forkey,valueinenumerate(field1):dict.write(dict[key]+dict[value])print("第"+f.read())output="第{}篇文章名:"+dict.get('标题链接')add_url=requests.get(url=url,headers=headers).urlopen().read()forurlinopen(add_url,'w'):text=str(url).split('\t')print(text)print(os.path.join(text,'json'))output=''field1=field1field2=field2field3=field3re_all_url=field1+field2+field3add_url2=re_all_urlprint("有多少人赞")print(field1[1]+field2[0])print("文章被多少人评论")print(field3[1]+field4[0])print("现在剩下多少人评论")print('位于')print(field1[1]+field2[0])print(field3[1]+field4[0])print('二.'+field1[1]+field2[0]+field3[0]+field4[0])print('三.'+field1[1]+field2[0]+field4[0]+field5[0])print('四.'+field1[1]+field2[0]+field3[0]+field4[0]+field5[0])print('六.'+field1[1]+field2[0]+field4[0]+field5[0]+field6[0])print('七.'+field1[1]+field2[0]+field3[0]。 查看全部
php 抓取网页标题(php抓取网页标题中的关键词来解析文章链接做深度学习)
php抓取网页标题中的关键词来解析文章链接做深度学习用python:爬取链接批量获取数据到内存.python2爬取对象关键词可以不用request直接自己解析medium上一篇文章《关键词分析:提取文章结构pagerank解析:实践》最后处理了链接关键词出现一次之后网页头尾调整下,是可以保持关键词图片的位置。
今天重新接着和大家分享python爬取微博文章标题的写法,内容包括但不限于标题,标题链接,人名以及标题拼音首先要说明一下,微博爬虫是无限卡的,fd-8就等于我们要爬取的文章在网页上出现了8次,所以我们需要获取任何一个标题的几率数据,再返回即可如果爬取的是微博评论的话,要对标题进行格式处理:print(sys.getprop("文章标题"))field1="人名"field2="标题链接"dict.set(field1=field1,field2=field2)withopen('文章首页.txt','w')asf:forkey,valueinenumerate(field1):dict.write(dict[key]+dict[value])print("第"+f.read())output="第{}篇文章名:"+dict.get('标题链接')add_url=requests.get(url=url,headers=headers).urlopen().read()forurlinopen(add_url,'w'):text=str(url).split('\t')print(text)print(os.path.join(text,'json'))output=''field1=field1field2=field2field3=field3re_all_url=field1+field2+field3add_url2=re_all_urlprint("有多少人赞")print(field1[1]+field2[0])print("文章被多少人评论")print(field3[1]+field4[0])print("现在剩下多少人评论")print('位于')print(field1[1]+field2[0])print(field3[1]+field4[0])print('二.'+field1[1]+field2[0]+field3[0]+field4[0])print('三.'+field1[1]+field2[0]+field4[0]+field5[0])print('四.'+field1[1]+field2[0]+field3[0]+field4[0]+field5[0])print('六.'+field1[1]+field2[0]+field4[0]+field5[0]+field6[0])print('七.'+field1[1]+field2[0]+field3[0]。
php 抓取网页标题(php抓取网页标题时需要控制爬虫程序对网页源代码做一定的判断)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-18 13:05
php抓取网页标题是php抓取网页标题的第一步,有时php抓取网页标题时需要控制爬虫程序对网页源代码做一定的判断,对于php的xpath语法中文档中找不到目标字符串的相应描述的目标值,因此爬虫程序对正则表达式进行一定的判断,通过正则表达式对正则表达式进行匹配处理,找到需要的目标字符串。本文内容很基础,但是实际工作中有时会用到,如php爬虫的内容存储和更新,抓取第三方免费的电子书,工程管理、爬虫之间相互传参等。
php抓取网页标题抓取网页标题可以通过execl或html5来实现,例如打开浏览器浏览器,在地址栏上输入c:\document\web\php\execl\xpath-src07368-5b69-461d-10520-8605845530c31_book07368-5b69-461d-10520-8605845530c31的内容,再下拉,浏览器就会向文件里面抓取一串数字,从而取得该页网页标题。
<p>网上也有很多常用的execl或html5对此进行转换。可以先看看其它方法和方法实现过程:contents:0x00022、phpxmliteup:也就是在程序开始之前,在程序内置xml文件上将公式化的表格化处理,给每个格子写个索引,定位这个列的数据并添加到索引数组。然后程序里面再用select()从索引数组里取所需的数据。在xml文件中,要添加各列的默认值,格子的标题也要添加,记得把标题写在处,然后参数放在 查看全部
php 抓取网页标题(php抓取网页标题时需要控制爬虫程序对网页源代码做一定的判断)
php抓取网页标题是php抓取网页标题的第一步,有时php抓取网页标题时需要控制爬虫程序对网页源代码做一定的判断,对于php的xpath语法中文档中找不到目标字符串的相应描述的目标值,因此爬虫程序对正则表达式进行一定的判断,通过正则表达式对正则表达式进行匹配处理,找到需要的目标字符串。本文内容很基础,但是实际工作中有时会用到,如php爬虫的内容存储和更新,抓取第三方免费的电子书,工程管理、爬虫之间相互传参等。
php抓取网页标题抓取网页标题可以通过execl或html5来实现,例如打开浏览器浏览器,在地址栏上输入c:\document\web\php\execl\xpath-src07368-5b69-461d-10520-8605845530c31_book07368-5b69-461d-10520-8605845530c31的内容,再下拉,浏览器就会向文件里面抓取一串数字,从而取得该页网页标题。
<p>网上也有很多常用的execl或html5对此进行转换。可以先看看其它方法和方法实现过程:contents:0x00022、phpxmliteup:也就是在程序开始之前,在程序内置xml文件上将公式化的表格化处理,给每个格子写个索引,定位这个列的数据并添加到索引数组。然后程序里面再用select()从索引数组里取所需的数据。在xml文件中,要添加各列的默认值,格子的标题也要添加,记得把标题写在处,然后参数放在
php 抓取网页标题(php抓取网页标题是用html提取器的方法,但详细内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-09 20:07
php抓取网页标题是用html提取器的方法,但其实php提取标题也有很多方法,下面是详细内容。1.tagxedo标题提取工具:tagxedo(链接tagxedo)是一款专门为网页提取标题和关键词、热门标签等而编写的免费工具。由于tagxedo特别适合用于多域名网站的提取和多tag的标题提取,所以针对于国内的其他网站无法满足多tag提取需求的情况,为了能够更加简洁方便地提取网页中标题的话,该工具刚刚上线了中文的市场版。
不仅如此,php的提取标题有5种方法:使用html中的字符串提取、使用php函数提取、php提取网页中的<a>标签,用php代码提取网页中<a>标签中的字符串也是一种方法。以上可以使用php实现标题提取,当然也可以用php自带的标准标记提取标题。2.flexmatch:可以提取网页中任意标签的标题,不仅仅是标题,还可以提取关键词,如果你网站中有20个标签,想抽取其中的5个也是可以的。
3.标签提取器:该工具只提取页面上所有的标签,例如你提取网页中第1页中的所有标签,提取器会查询页面所有标签的地址,然后自动提取页面中所有标签,可以统计提取的结果总结,当然也有缺点,最大的缺点就是该工具要自己做的话内存太大,文件太大,所以php提取标题最好有gzip版本,对文件小的网站并不实用。4.as:不需要php代码,只要放好f12就可以实现。
这个工具需要在vc++标签切换工具中点击自定义显示标签切换按钮,再进行自定义提取,可以进行保存提取。如果提取快需要,可以先进行保存提取。5.easypink:无需代码,可以使用apache、nginx、php和其他语言。这款工具可以自动提取title、keywords、description等所有的标签。下载注意把上面的链接拿走,这个工具虽然提取出来,但是需要使用gzip格式!。 查看全部
php 抓取网页标题(php抓取网页标题是用html提取器的方法,但详细内容)
php抓取网页标题是用html提取器的方法,但其实php提取标题也有很多方法,下面是详细内容。1.tagxedo标题提取工具:tagxedo(链接tagxedo)是一款专门为网页提取标题和关键词、热门标签等而编写的免费工具。由于tagxedo特别适合用于多域名网站的提取和多tag的标题提取,所以针对于国内的其他网站无法满足多tag提取需求的情况,为了能够更加简洁方便地提取网页中标题的话,该工具刚刚上线了中文的市场版。
不仅如此,php的提取标题有5种方法:使用html中的字符串提取、使用php函数提取、php提取网页中的<a>标签,用php代码提取网页中<a>标签中的字符串也是一种方法。以上可以使用php实现标题提取,当然也可以用php自带的标准标记提取标题。2.flexmatch:可以提取网页中任意标签的标题,不仅仅是标题,还可以提取关键词,如果你网站中有20个标签,想抽取其中的5个也是可以的。
3.标签提取器:该工具只提取页面上所有的标签,例如你提取网页中第1页中的所有标签,提取器会查询页面所有标签的地址,然后自动提取页面中所有标签,可以统计提取的结果总结,当然也有缺点,最大的缺点就是该工具要自己做的话内存太大,文件太大,所以php提取标题最好有gzip版本,对文件小的网站并不实用。4.as:不需要php代码,只要放好f12就可以实现。
这个工具需要在vc++标签切换工具中点击自定义显示标签切换按钮,再进行自定义提取,可以进行保存提取。如果提取快需要,可以先进行保存提取。5.easypink:无需代码,可以使用apache、nginx、php和其他语言。这款工具可以自动提取title、keywords、description等所有的标签。下载注意把上面的链接拿走,这个工具虽然提取出来,但是需要使用gzip格式!。
php 抓取网页标题(如何创建一个blogs网站,利用wordpresswpsetup网站标题过滤重复项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-04 12:07
php抓取网页标题过滤重复项第一步:先注册一个wordpress,按照我之前的文章入门--从零开始搭建blogs网站-靳洪飞的文章-知乎专栏学习一下如何创建一个blogs网站,利用wordpresswpsetup创建一个网站第二步:搭建wordpress首页其实wordpress是很好创建的,使用wordpress建站有专业性的技术优势,而且企业级产品,如果只是业余的,也可以利用一些快速建站的工具来实现,而且其内置一键生成功能可以轻松实现其网站所需的代码。
第三步:创建标题(content)工具如下所示。首先创建好wordpress的域名,这个比较简单,用我们自己的域名就可以,我这里就不过多介绍,创建好以后是一个已经制作好的网站。现在将已经做好的网站上传到wordpress的首页。第四步:在本地上传wordpress,一般创建一个新wordpress网站,在线上传可能会不正确,所以我还是要推荐一个免费的在线wordpress代理网站,这个我们不用操心!毕竟是免费的:,首先,在浏览器里面输入我们自己的域名(一般是.com),然后需要确认是否正确,如果不正确的话需要上传新建的网站,这里我上传一个免费的网站。
<p>选择“代理”按钮,最后确认代理名称,然后点击“确定”按钮。上传以后我们就可以看到网站,如下图。第五步:定位我们需要抓取哪些信息我们抓取网站的标题为例:{"air":[],"sleep":0,"min":24,"max":8000000,"stream":"","span":"0;mid":false,"false":false,"type":"json","php_content":"","php_version":"0.9.15","php_parent_name":"athens_php_1.2.16_2019-1-1_wp7.html","php_version":"3.0.7","ref":{"ref_content":"1","ref_action":":80000000","ref_content":"","ref_content":"0.1.5.10?","ref_action":":80000000","ref_srt_link":"","ref_link":";1.2.1.2?","ref_link":";vip?","ref_srt_src":"","travel":{"travel":"0.0.0.0","preview":"0.1.4.10?","preview":"0.1.1.10?","preview":"0.1.4.10?","travel":"unit1","preview":"unit1","preview":"unit1","travel":"0.0.0.0","nov":false,"day":11,"posts":{"tags":[" 查看全部
php 抓取网页标题(如何创建一个blogs网站,利用wordpresswpsetup网站标题过滤重复项)
php抓取网页标题过滤重复项第一步:先注册一个wordpress,按照我之前的文章入门--从零开始搭建blogs网站-靳洪飞的文章-知乎专栏学习一下如何创建一个blogs网站,利用wordpresswpsetup创建一个网站第二步:搭建wordpress首页其实wordpress是很好创建的,使用wordpress建站有专业性的技术优势,而且企业级产品,如果只是业余的,也可以利用一些快速建站的工具来实现,而且其内置一键生成功能可以轻松实现其网站所需的代码。
第三步:创建标题(content)工具如下所示。首先创建好wordpress的域名,这个比较简单,用我们自己的域名就可以,我这里就不过多介绍,创建好以后是一个已经制作好的网站。现在将已经做好的网站上传到wordpress的首页。第四步:在本地上传wordpress,一般创建一个新wordpress网站,在线上传可能会不正确,所以我还是要推荐一个免费的在线wordpress代理网站,这个我们不用操心!毕竟是免费的:,首先,在浏览器里面输入我们自己的域名(一般是.com),然后需要确认是否正确,如果不正确的话需要上传新建的网站,这里我上传一个免费的网站。
<p>选择“代理”按钮,最后确认代理名称,然后点击“确定”按钮。上传以后我们就可以看到网站,如下图。第五步:定位我们需要抓取哪些信息我们抓取网站的标题为例:{"air":[],"sleep":0,"min":24,"max":8000000,"stream":"","span":"0;mid":false,"false":false,"type":"json","php_content":"","php_version":"0.9.15","php_parent_name":"athens_php_1.2.16_2019-1-1_wp7.html","php_version":"3.0.7","ref":{"ref_content":"1","ref_action":":80000000","ref_content":"","ref_content":"0.1.5.10?","ref_action":":80000000","ref_srt_link":"","ref_link":";1.2.1.2?","ref_link":";vip?","ref_srt_src":"","travel":{"travel":"0.0.0.0","preview":"0.1.4.10?","preview":"0.1.1.10?","preview":"0.1.4.10?","travel":"unit1","preview":"unit1","preview":"unit1","travel":"0.0.0.0","nov":false,"day":11,"posts":{"tags":["
php 抓取网页标题(如何使用php抓取网页标题并转化为mysql的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-26 16:05
php抓取网页标题,相信大家都遇到过,尤其是老司机们,随着网站的日渐壮大,网站的抓取问题随之就产生了,因此网站抓取工具就显得越来越有必要,从本文的内容中,老实告诉大家如何使用php抓取网页标题并转化为mysql的数据。要点一:抓取网页的规则俗话说得好“工欲善其事必先利其器”,首先我们要先明确我们要抓取网页需要一套什么样的规则。
我们首先会了解一下常见的抓取规则,并结合我们自己的网站情况,匹配出一套自己的规则体系。simplemysqltransaction/connectionpolicycheckingrequesttoestablishatransaction.---simplemysqltransaction/connectionpolicysource-localmiddle-levelredirect---middle-levelredirect-pathreceivingtransaction'receive'.---receivingtransactions'receive'.alltransactions'expireforsecond.receiveorigin/whenthereceivetransactionisnon-exclusive.processedtoensureanidbytestopreventduplicateentryoninternallinks.processedtoensureidbytestoresolvetransactionresource'mirror'.---origin/whenthereceivetransactionisnon-exclusive.最后一步,是不是也看得很难受,网站模板里边有一些和我们要抓取的网页相似的标题。
话不多说,下面老实告诉大家一些实战中的php抓取网页标题技巧。hook原理:将网页标题给hook掉,由于hook后,程序还不能将标题出现的地方搜索到,所以这个位置的搜索是失败的。好吧,如果程序可以通过完全控制源代码来抓取redirect(requesthook)的话,这种效果将会大大降低。所以说为了用php完全控制源代码是不现实的,还是老老实实通过hook方式来爬取标题。
hook方式:分为通过dom读取spans中的text1text2或者text3text4text5来找到标题,以及通过classtext1text2text3text4text5的写入方式来找到标题。代码如下:mydata('text1',text2,text3,text4,text。
5).readall();//这是最简单最直接的方式,
5).readall();//一般用于网站表现不好,
5).readall();//比较方便的方式,
5).readall();//比较方便的方 查看全部
php 抓取网页标题(如何使用php抓取网页标题并转化为mysql的数据?)
php抓取网页标题,相信大家都遇到过,尤其是老司机们,随着网站的日渐壮大,网站的抓取问题随之就产生了,因此网站抓取工具就显得越来越有必要,从本文的内容中,老实告诉大家如何使用php抓取网页标题并转化为mysql的数据。要点一:抓取网页的规则俗话说得好“工欲善其事必先利其器”,首先我们要先明确我们要抓取网页需要一套什么样的规则。
我们首先会了解一下常见的抓取规则,并结合我们自己的网站情况,匹配出一套自己的规则体系。simplemysqltransaction/connectionpolicycheckingrequesttoestablishatransaction.---simplemysqltransaction/connectionpolicysource-localmiddle-levelredirect---middle-levelredirect-pathreceivingtransaction'receive'.---receivingtransactions'receive'.alltransactions'expireforsecond.receiveorigin/whenthereceivetransactionisnon-exclusive.processedtoensureanidbytestopreventduplicateentryoninternallinks.processedtoensureidbytestoresolvetransactionresource'mirror'.---origin/whenthereceivetransactionisnon-exclusive.最后一步,是不是也看得很难受,网站模板里边有一些和我们要抓取的网页相似的标题。
话不多说,下面老实告诉大家一些实战中的php抓取网页标题技巧。hook原理:将网页标题给hook掉,由于hook后,程序还不能将标题出现的地方搜索到,所以这个位置的搜索是失败的。好吧,如果程序可以通过完全控制源代码来抓取redirect(requesthook)的话,这种效果将会大大降低。所以说为了用php完全控制源代码是不现实的,还是老老实实通过hook方式来爬取标题。
hook方式:分为通过dom读取spans中的text1text2或者text3text4text5来找到标题,以及通过classtext1text2text3text4text5的写入方式来找到标题。代码如下:mydata('text1',text2,text3,text4,text。
5).readall();//这是最简单最直接的方式,
5).readall();//一般用于网站表现不好,
5).readall();//比较方便的方式,
5).readall();//比较方便的方
php 抓取网页标题(zblogphp辅助函数GetPost的使用方法及应用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-14 09:01
zblogphp辅助函数GetPost可以通过ID或别名获取指定的文章或页面数据,包括文章的标题、内容、发布日期、页面浏览量、URL地址、文章@ > 评论、所属类别等页面数据。
GetPost 函数
通过GetPost函数可以获取指定文章或页面的数据。在zblogphp程序中,文章和page是不同的概念,属于两个不同的内容页面。这是来自 true //只检索文章
//"only_page" => true //只检索页面);
当两个选项同时为真时,只有 only_article 选项有效。
语法演示:
如果我们指定获取标题或别名为“abc”的数据,则GetPos函数中参数1的值设置为“abc”,参数2设置为不检索页面,代码如下如下:
GetPost("abc", array ("only_article" => true));
如果我们指定获取标题或别名为“abc”的数据,则GetPos函数中参数1的值设置为“abc”,参数2设置为不检索文章,则代码如下:
GetPost("abc", array ("only_page" => true));
如果我们指定获取标题或别名为“abc”的数据,则参数1设置为“abc”,参数2省略不写。
GetPost(“abc”);
如果有文章或同名“abc”的页面,则只返回第一个结果。如果指定的文章标题或别名“abc”不存在,则返回空。
GetPost 函数示例
示例 1:指定 ID
指定获取文章或ID为10的页面的数据
$post=GetPost(10);
使用变量作为id时,必须通过int传递才能正常显示。下面的$id是已经指定的字符串变量,可以如下使用:
$post=GetPost((int)$id);
示例 2:指定文章标题或别名
以“abc”为标题或别名搜索文章文章(设置不检索页面的选项)
$post=GetPost("abc",array('only_article'=>true));
输出指定数据
我们可以将GetPost函数获得的数据赋值给变量$post。这样,变量$post 就得到了指定的文章 或页面的所有数据。这些数据包括文章的标题、内容和内容。发布日期、浏览量、URL地址、文章评论、所属类别等,然后就可以将$post得到的数据输出到页面了!
1、获取指定ID文章或页面的数据并输出
比如我们要获取文章或者ID为45的页面的数据,在zblogphp模板中调用,那么输出信息就可以显示在网站@的网页上> 前台:
{php}
$post=GetPost(45);
{/php}
{$post.Title}</a>
<p>其中,{$post.Url}调用的输出为文章url,{$post.Title}的调用输出为文章的标题。 查看全部
php 抓取网页标题(zblogphp辅助函数GetPost的使用方法及应用方法)
zblogphp辅助函数GetPost可以通过ID或别名获取指定的文章或页面数据,包括文章的标题、内容、发布日期、页面浏览量、URL地址、文章@ > 评论、所属类别等页面数据。
GetPost 函数
通过GetPost函数可以获取指定文章或页面的数据。在zblogphp程序中,文章和page是不同的概念,属于两个不同的内容页面。这是来自 true //只检索文章
//"only_page" => true //只检索页面);
当两个选项同时为真时,只有 only_article 选项有效。
语法演示:
如果我们指定获取标题或别名为“abc”的数据,则GetPos函数中参数1的值设置为“abc”,参数2设置为不检索页面,代码如下如下:
GetPost("abc", array ("only_article" => true));
如果我们指定获取标题或别名为“abc”的数据,则GetPos函数中参数1的值设置为“abc”,参数2设置为不检索文章,则代码如下:
GetPost("abc", array ("only_page" => true));
如果我们指定获取标题或别名为“abc”的数据,则参数1设置为“abc”,参数2省略不写。
GetPost(“abc”);
如果有文章或同名“abc”的页面,则只返回第一个结果。如果指定的文章标题或别名“abc”不存在,则返回空。
GetPost 函数示例
示例 1:指定 ID
指定获取文章或ID为10的页面的数据
$post=GetPost(10);
使用变量作为id时,必须通过int传递才能正常显示。下面的$id是已经指定的字符串变量,可以如下使用:
$post=GetPost((int)$id);
示例 2:指定文章标题或别名
以“abc”为标题或别名搜索文章文章(设置不检索页面的选项)
$post=GetPost("abc",array('only_article'=>true));
输出指定数据
我们可以将GetPost函数获得的数据赋值给变量$post。这样,变量$post 就得到了指定的文章 或页面的所有数据。这些数据包括文章的标题、内容和内容。发布日期、浏览量、URL地址、文章评论、所属类别等,然后就可以将$post得到的数据输出到页面了!
1、获取指定ID文章或页面的数据并输出
比如我们要获取文章或者ID为45的页面的数据,在zblogphp模板中调用,那么输出信息就可以显示在网站@的网页上> 前台:
{php}
$post=GetPost(45);
{/php}
{$post.Title}</a>
<p>其中,{$post.Url}调用的输出为文章url,{$post.Title}的调用输出为文章的标题。
php 抓取网页标题( 循环中则自动默认使用当前文章的标题,也就是title)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-14 08:38
循环中则自动默认使用当前文章的标题,也就是title)
WordPress相关PHP函数获取页面链接和标题的使用分析
更新时间:2015年12月17日15:11:37 作者:郭斌
本文文章主要介绍了WordPress中获取页面链接和标题的相关PHP函数的使用分析,分别是get_permalink()和wp_title()函数的使用,需要的朋友可以参考
get_permalink()(获取文章 或页面链接)
get_permalink() 用于根据固定连接返回文章 或页面的链接。get_permalink()函数在获取链接时需要知道要获取的文章的ID,如果在循环中,默认会自动使用当前的文章。
用法
get_permalink( $id, $leavename );
范围
$id
(混合)(可选)文章 或页面的ID(整数);它也可以是 文章 的对象。
默认值:在循环中自动调用当前文章
$leavename
(布尔值)(可选)转换为链接时是否忽略 文章 别名。如果设置为 True,则将返回 %postname% 而不是
默认值:无
返回值
(String| Boolean) 获取链接成功则返回链接,失败则返回False。
例子
根据ID获取文章或页面的链接:
<p> 查看全部
php 抓取网页标题(
循环中则自动默认使用当前文章的标题,也就是title)
WordPress相关PHP函数获取页面链接和标题的使用分析
更新时间:2015年12月17日15:11:37 作者:郭斌
本文文章主要介绍了WordPress中获取页面链接和标题的相关PHP函数的使用分析,分别是get_permalink()和wp_title()函数的使用,需要的朋友可以参考
get_permalink()(获取文章 或页面链接)
get_permalink() 用于根据固定连接返回文章 或页面的链接。get_permalink()函数在获取链接时需要知道要获取的文章的ID,如果在循环中,默认会自动使用当前的文章。
用法
get_permalink( $id, $leavename );
范围
$id
(混合)(可选)文章 或页面的ID(整数);它也可以是 文章 的对象。
默认值:在循环中自动调用当前文章
$leavename
(布尔值)(可选)转换为链接时是否忽略 文章 别名。如果设置为 True,则将返回 %postname% 而不是
默认值:无
返回值
(String| Boolean) 获取链接成功则返回链接,失败则返回False。
例子
根据ID获取文章或页面的链接:
<p>
php 抓取网页标题(php抓取网页标题时会爬上一段html,从这个html可以判断出哪个位置有哪个类型的爬虫正在爬)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-12 08:02
php抓取网页标题时会爬上一段html,从这个html可以判断出哪个位置有哪个类型的爬虫正在爬。可以借助beautifulsoup来截获html中的tag,以及针对爬虫类型或者爬虫元素选择相应的javascript来爬取里面的标题,比如说sc的-pg,-ma等等。html和javascript用于方便抓取出代码并存档,不用在乎起始页是什么。
比如说用javascript截获如下这样的代码,网页的标题包含着:红色部分是基本的代码写法和方法:“page_type='page'tab_text='table'form_size=1.0select_text='article/select'meta='style={{font-size:1}}'”其中tab_text是这个网页标题中"标题"和"条目"这两个标签中任意一个。
用beautifulsoup抓取到的html如下:frombs4importbeautifulsoupimportjsonimportrequestsimportjsonimportrehtml='''抓取page_type='page'tab_text='table'form_size=1.0'data=json.loads(html)data=json.loads(data)'''login'''data={'username':'xxxx','password':'xxxx','sign_pass':false}html=requests.get(url=html).json()response=json.loads(response)'''获取小黄人'''data=json.loads(html)forjinjson.loads(html):data['id']=re.sub('id=','',j)data['class']=re.sub('class=','',j)data['action']=re.sub('action=','',j)data['type']='tag'data['type']='text'data['text']='''获取小黄人性别'''data=json.loads(html)forcinjson.loads(data):c=int(json.loads(c))a=re.sub('age=',c)print(a)data['text']='''获取小黄人内裤'''data=json.loads(html)forjinjson.loads(data):data['text']=int(json.loads(data['text']))returndatadata['text']='''获取小黄人性取值'''data=json.loads(html)forcinjson.loads(data):c=c['text']forjinjson.loads(data['text']):id=re.sub('id=',j['id'])sex=re.sub('sex=',re.sub('sex=',j['sex'])type=re.sub('type=',j['type'])class=re.。 查看全部
php 抓取网页标题(php抓取网页标题时会爬上一段html,从这个html可以判断出哪个位置有哪个类型的爬虫正在爬)
php抓取网页标题时会爬上一段html,从这个html可以判断出哪个位置有哪个类型的爬虫正在爬。可以借助beautifulsoup来截获html中的tag,以及针对爬虫类型或者爬虫元素选择相应的javascript来爬取里面的标题,比如说sc的-pg,-ma等等。html和javascript用于方便抓取出代码并存档,不用在乎起始页是什么。
比如说用javascript截获如下这样的代码,网页的标题包含着:红色部分是基本的代码写法和方法:“page_type='page'tab_text='table'form_size=1.0select_text='article/select'meta='style={{font-size:1}}'”其中tab_text是这个网页标题中"标题"和"条目"这两个标签中任意一个。
用beautifulsoup抓取到的html如下:frombs4importbeautifulsoupimportjsonimportrequestsimportjsonimportrehtml='''抓取page_type='page'tab_text='table'form_size=1.0'data=json.loads(html)data=json.loads(data)'''login'''data={'username':'xxxx','password':'xxxx','sign_pass':false}html=requests.get(url=html).json()response=json.loads(response)'''获取小黄人'''data=json.loads(html)forjinjson.loads(html):data['id']=re.sub('id=','',j)data['class']=re.sub('class=','',j)data['action']=re.sub('action=','',j)data['type']='tag'data['type']='text'data['text']='''获取小黄人性别'''data=json.loads(html)forcinjson.loads(data):c=int(json.loads(c))a=re.sub('age=',c)print(a)data['text']='''获取小黄人内裤'''data=json.loads(html)forjinjson.loads(data):data['text']=int(json.loads(data['text']))returndatadata['text']='''获取小黄人性取值'''data=json.loads(html)forcinjson.loads(data):c=c['text']forjinjson.loads(data['text']):id=re.sub('id=',j['id'])sex=re.sub('sex=',re.sub('sex=',j['sex'])type=re.sub('type=',j['type'])class=re.。
php 抓取网页标题(有道云管家,你可以尝试以下抓取的网页抓取方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-11 14:36
php抓取网页标题和网页链接,然后数据库存取信息。看这网站就是做了限制了,除非你非常xx,不然我没辙,这样的机会很少。一般unbox都是某些敏感内容,是会反爬虫的。另外说一句,我现在正在维护一个php+css库,可以抓取实时的网页,有兴趣交流一下。
谢邀。发现很多对php抓取一无所知的初学者都有的一个问题:我们的工作一般用php,用c/c++的也有,但是如果要抓取那些在线的网页却不知道怎么搞定。推荐一个比较棒的爬虫工具,可以让你快速适应这些抓取方式,
用shiyanlou。
谢谢邀请。你说的是抓取你要抓取的那个网站的数据吧?像我现在正在维护的工具可以快速抓取你所需要的网站的数据。对于零基础的初学者,要快速上手的话,可以用shiyanlou,相对于其他的爬虫工具来说,算是比较简单的了。
有道云管家啊!
有道云管家,
你可以尝试以下方式
1、找到你所要抓取的网站
2、选择相应类型爬虫
3、抓取数据
pythonscrapy
题主可以使用以下的搜索引擎a.python.python.scrapya.web.scrapy。二者结合应该能解决问题。
谢邀,首先我是做ci的,先了解你的站点,
pythonscrapy一个完整的爬虫发布和爬取系统,很实用。 查看全部
php 抓取网页标题(有道云管家,你可以尝试以下抓取的网页抓取方式)
php抓取网页标题和网页链接,然后数据库存取信息。看这网站就是做了限制了,除非你非常xx,不然我没辙,这样的机会很少。一般unbox都是某些敏感内容,是会反爬虫的。另外说一句,我现在正在维护一个php+css库,可以抓取实时的网页,有兴趣交流一下。
谢邀。发现很多对php抓取一无所知的初学者都有的一个问题:我们的工作一般用php,用c/c++的也有,但是如果要抓取那些在线的网页却不知道怎么搞定。推荐一个比较棒的爬虫工具,可以让你快速适应这些抓取方式,
用shiyanlou。
谢谢邀请。你说的是抓取你要抓取的那个网站的数据吧?像我现在正在维护的工具可以快速抓取你所需要的网站的数据。对于零基础的初学者,要快速上手的话,可以用shiyanlou,相对于其他的爬虫工具来说,算是比较简单的了。
有道云管家啊!
有道云管家,
你可以尝试以下方式
1、找到你所要抓取的网站
2、选择相应类型爬虫
3、抓取数据
pythonscrapy
题主可以使用以下的搜索引擎a.python.python.scrapya.web.scrapy。二者结合应该能解决问题。
谢邀,首先我是做ci的,先了解你的站点,
pythonscrapy一个完整的爬虫发布和爬取系统,很实用。
php 抓取网页标题(php抓取网页标题和网页源代码的代码,同时爬取关键词)
网站优化 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-10-08 18:02
php抓取网页标题和网页源代码的代码,同时爬取关键词和关键词搜索量和文章收藏数量的数据。
1、实例下载
2、robots屏蔽页面上的非法内容。
3、session加密。cookie_secret抓取用户会话锁定会话的网页。
4、定位网页源代码为爬虫文件是否采取newxxx(抓取对象)定位数据文件所在的网页。
5、网页链接.7|html||+:/:/.+|wget|||ltt+|||/|/|/|/|/|/|/|||#0|<a>=0;</a>{||-+|};#1|1#3||utf-8|/|/utf-8|/|\\\-
1)|#1|#1|/wset|tracename_hrefgetfunc|/*{if(!ltags&&!ltags.isnotfound)return['_blank'];}&;*return['.*?'+source;}*/
<p>first,首先需要写出定位的代码,一般写在functionlatrobes(w,url){varw:url;varu:url;varhash:url;//用于代替{}里面的内容functiongeotypecode(url){varprice:url;for(vari=0;i 查看全部
php 抓取网页标题(php抓取网页标题和网页源代码的代码,同时爬取关键词)
php抓取网页标题和网页源代码的代码,同时爬取关键词和关键词搜索量和文章收藏数量的数据。
1、实例下载
2、robots屏蔽页面上的非法内容。
3、session加密。cookie_secret抓取用户会话锁定会话的网页。
4、定位网页源代码为爬虫文件是否采取newxxx(抓取对象)定位数据文件所在的网页。
5、网页链接.7|html||+:/:/.+|wget|||ltt+|||/|/|/|/|/|/|/|||#0|<a>=0;</a>{||-+|};#1|1#3||utf-8|/|/utf-8|/|\\\-
1)|#1|#1|/wset|tracename_hrefgetfunc|/*{if(!ltags&&!ltags.isnotfound)return['_blank'];}&;*return['.*?'+source;}*/
<p>first,首先需要写出定位的代码,一般写在functionlatrobes(w,url){varw:url;varu:url;varhash:url;//用于代替{}里面的内容functiongeotypecode(url){varprice:url;for(vari=0;i
php 抓取网页标题(关于XML的基础教程网络上也随处可见的概念和术语介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-08 17:26
XML 越来越火了,关于 XML 的基本教程在 Internet 上随处可见。但是很多概念和术语往往令人生畏。很多朋友问我:XML有什么用?我们需要学习吗?我想根据我个人的学习经历和经验写一个更全面的介绍文章。首先有两点需要肯定:第一:XML绝对是未来的发展趋势,无论你是网页设计师还是网页程序员,都应该及时学习理解,等待只会让你失去机会; 第二:新知识 肯定会有很多新概念,试着去理解和接受,你可能会有所提高。不要害怕逃跑,毕竟我们还年轻。本文分为五个部分。它们是 XML 快速入门,XML 概念、XML 术语、XML 实现和 XML 示例分析。最后一个附录介绍了 XML 的相关资源。作者以一个普通网页设计师的视角,用通俗易懂的语言为您讲述XML的方方面面,助您解开XML的神秘面纱,快速进入XML的新领域。• 第 1 章:XML 快速入门• 一. 什么是 XML?• 二. XML 是一个新概念吗?• 三. 使用 XML 有什么好处?• 四. XML 难学吗?• 五. XML 和 HTML 的区别• 六. XML 的严格格式• 七. 更多关于 XML• 第 2 章:XML 概念• 一. 可扩展性• 二.@ > 徽标• 三. 语言• 四. 结构化• 五. 元数据• 六. 显示• 七. DOM • 第3 章:
例如,第一行的标题具有固定大小。相比之下,XML 没有固定的标记。XML 无法描述网页的具体外观和内容。它只描述了内容的数据形式和结构。这是一个质的区别:网页混合了数据和显示,而 XML 将数据和显示分开。让我们看看上面的例子。在 myfile.htm 中,我们只关心页面的显示方式。我们可以设计不同的界面,用不同的方式排版页面,但是数据存储在myfile.xml中,没有任何变化。(如果你是程序员,你会惊讶地发现,这和模块化面向对象编程的思想非常相似!其实网页不是一种程序?)正是这种不同使得XML方便网络应用和信息共享,高效且可扩展。因此,我们相信XML作为一种先进的数据处理方法,将使网络跨越到一个新的高度。六. XML的严格格式吸取了HTML松散格式的教训,XML从一开始就坚持实现“好格式”。我们先来看一些HTML语句,在HTML中随处可见: 1. sample2.sample3.sample4.samplar XML文档中,上述语句语法错误。因为:1.所有标签都必须有对应的结束标签;2. 所有 XML 标签必须合理嵌套;3. 所有 XML 标签都区分大小写;4.所有标签属性必须用“”括起来;所以用 XML 写上述语句的正确方法是 1. sample2.sample3.sample4.samplar ,XML标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie samplar 、XML 标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie samplar 、XML 标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 数字和其他字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 数字和其他字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 查看全部
php 抓取网页标题(关于XML的基础教程网络上也随处可见的概念和术语介绍)
XML 越来越火了,关于 XML 的基本教程在 Internet 上随处可见。但是很多概念和术语往往令人生畏。很多朋友问我:XML有什么用?我们需要学习吗?我想根据我个人的学习经历和经验写一个更全面的介绍文章。首先有两点需要肯定:第一:XML绝对是未来的发展趋势,无论你是网页设计师还是网页程序员,都应该及时学习理解,等待只会让你失去机会; 第二:新知识 肯定会有很多新概念,试着去理解和接受,你可能会有所提高。不要害怕逃跑,毕竟我们还年轻。本文分为五个部分。它们是 XML 快速入门,XML 概念、XML 术语、XML 实现和 XML 示例分析。最后一个附录介绍了 XML 的相关资源。作者以一个普通网页设计师的视角,用通俗易懂的语言为您讲述XML的方方面面,助您解开XML的神秘面纱,快速进入XML的新领域。• 第 1 章:XML 快速入门• 一. 什么是 XML?• 二. XML 是一个新概念吗?• 三. 使用 XML 有什么好处?• 四. XML 难学吗?• 五. XML 和 HTML 的区别• 六. XML 的严格格式• 七. 更多关于 XML• 第 2 章:XML 概念• 一. 可扩展性• 二.@ > 徽标• 三. 语言• 四. 结构化• 五. 元数据• 六. 显示• 七. DOM • 第3 章:
例如,第一行的标题具有固定大小。相比之下,XML 没有固定的标记。XML 无法描述网页的具体外观和内容。它只描述了内容的数据形式和结构。这是一个质的区别:网页混合了数据和显示,而 XML 将数据和显示分开。让我们看看上面的例子。在 myfile.htm 中,我们只关心页面的显示方式。我们可以设计不同的界面,用不同的方式排版页面,但是数据存储在myfile.xml中,没有任何变化。(如果你是程序员,你会惊讶地发现,这和模块化面向对象编程的思想非常相似!其实网页不是一种程序?)正是这种不同使得XML方便网络应用和信息共享,高效且可扩展。因此,我们相信XML作为一种先进的数据处理方法,将使网络跨越到一个新的高度。六. XML的严格格式吸取了HTML松散格式的教训,XML从一开始就坚持实现“好格式”。我们先来看一些HTML语句,在HTML中随处可见: 1. sample2.sample3.sample4.samplar XML文档中,上述语句语法错误。因为:1.所有标签都必须有对应的结束标签;2. 所有 XML 标签必须合理嵌套;3. 所有 XML 标签都区分大小写;4.所有标签属性必须用“”括起来;所以用 XML 写上述语句的正确方法是 1. sample2.sample3.sample4.samplar ,XML标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie samplar 、XML 标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie samplar 、XML 标签必须遵循以下命名规则: 1. 名称可以收录字母、数字等字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 数字和其他字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 数字和其他字母;2. 名称不能以数字或“_”(下划线)开头;3. 名称不能以字母 xml(或 XML 或 Xml ..)开头;4. 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie 名称中不能收录空格。XML 文档中的任何错误都会导致相同的结果:无法显示网页。浏览器开发者已达成协议,对 XML 进行严格和关键的解析,任何小错误都会报告。可以修改上面的myfile.xml,比如改成这样,然后直接用IE5打开myfile.xml,会出现错误提示页面:XML Easy Learning Manual ajie

