
php抓取网页标签
php抓取网页标签(几个主要特别注意的细节:细节、细节和注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-01-30 17:07
我们首先从搜索引擎的算法中得知,细节决定了网站的优化成败。由于算法的不断更新,我们作为站长需要考虑很多优化因素。以下是一些需要注意的关键细节:
详情一、标题标签
1)每一个网站都有一个title标签,就是网站的title。标题的优化决定了后续网站的关键词流量。
2)蜘蛛通过代码抓取我们的网站。蜘蛛不知道网站的一些图片或者视频,但是标题标签可以让蜘蛛知道我们的网站是什么。.
3)网站标题是为了参与关键词的排名,所以在成都做网站代码优化的时候千万不要忽略网站@的标题标签>。
4)因为title标签是三个标签中最重要的;我们常说的关键词排名其实是指标题中的关键词,而不是关键词中的关键词,所以网站标题写的好坏直接影响到我们的排名< @网站。但切记不要为了排名而在标题中叠加关键词,否则会适得其反。
详情二、关键词标签
1)keywords 是网页中的关键词,
2)Keywords标签现在不参与排名,但是还是有很多SEO人员对keywords标签中的关键词很重视,没有必要。
3) 作为seo人员,我们必须是完整的,所以关键词标签也需要设置。建议在网站中写3-5
详情三、描述标签
1)description标签是网站页面的描述,用于介绍网站在成都的一般信息,以及网站内容的简要介绍. 在百度搜索一个关键词会显示标题,那么下面是描述。
2)写得好的描述也可以吸引用户访问网站,为网站带来流量。
详情四、h标签优化
1)h标签分为h1-h6标签,
2)h1标签是h标签中最重要的,成都的网站也被赋予了最高的权重,因为h1标签在一个页面上只能出现一次。一般在标题上写h1标签。因为这是每一页最重要的。
3)成都做网站,注意一页h1不要超过一个,但是h2-h6可以出现多次。
4)但是如果有h2-h6,就必须加上h1。成都做网站还是不写h标签,要写就必须写完整,没有h3,但没有h1。如果你看不懂代码,不要只在网站中添加h代码。
详情五、404页面页面处理
我们经常会遇到网站网站因为修改或其他运营原因出现死链接,所以此时启用404页面可以让搜索引擎快速删除这些页面。
还有一种情况是我们的网站被黑了,虽然我们已经采取了措施,但是页面上贴了很多非法信息。但是页面还是百度收录。在这种情况下,如果网站有404页,它可以帮助搜索引擎快速删除非法信息。
详情六、alt 标签
1)Alt标签用于在网站图片上添加描述(即替代文字),有利于蜘蛛的识别,因为蜘蛛知道代码但不知道图片,所以我们必须解释并告诉蜘蛛你网站@的图片中到底是什么>。
2)alt标签中关键词的堆积会影响spider的一对网站收录,只要在alt标签中使用简洁的描述即可。
代码优化对于网站提升排名很有帮助,但是再次强调,如果你看不懂代码,就不要在网站里面加代码,或者找能看懂代码的人教你如何更改代码。
详情七、网站地图实时更新。
网站Map 对于蜘蛛快速抓取网站 内容非常有帮助。网站Map就像一个网站的结构图,将网站的所有链接都采集在一个页面上,方便蜘蛛快速爬取整个站点的内容;网站 中常见的地图格式是 sitemap.xml。网站地图网址放在robots文件中,蜘蛛会沿着网站地图网址爬行。切记不要阻止蜘蛛爬取地图,保持网站地图实时更新,以保证蜘蛛能够获取到最详细、最新的信息。
详情八、网站机器人,txt文件
robots协议(也称为爬虫协议、机器人协议等)的全称是“robots Exclusion Protocol”。robots协议的本质是网站与搜索引擎爬虫之间的通信方式,引导搜索引擎更好地爬取网站内容。
网站通过robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。这有效地保护了网站的隐私,尤其是后台和数据库信息,有利于网站的安全。
详情九、nofollow标签
1)Nofollow 标签不传递权重。
2)一般会在QQ链接、微博等那些无意义的出站链接上写nofollow,以免传递网站的权重。另外,把成都兑换成网站朋友链的时候不要加nofollow,这是很不道德的。知道nofollow不传权重,也加到友好链接的代码中,这相当于告诉蜘蛛不要爬链接,对方网站会给你带来权重网站 @> ,
3)因为nofollow不传递权重,所以更换友情链接时要注意。可以查看对方是否在网站中添加了nofollow。你可以在浏览器中搜索nofollow插件,这样就可以在成都的网站中显示了。
注意:友情链接是在友情之后链接的。把nofollow加到别人的链接里,以后谁还敢和你交换链接?附属链接不得添加nofollow标签,切记!
详情十、优化网站的内容和布局
优化网站,最重要的是优化网站的布局和内容。首先是网站的布局,在网站刚做完的时候一定要考虑。优化是有害的,只需对 网站 布局进行适当调整即可。二是优化网站的内容,网站要定期更新文章,这些文章的标题和关键词一旦被修改就不能改变了发布,否则也会影响搜索引擎记录。
详解十一、明确网站外链有哪些分类和作用
在网站上添加链接时,一定要添加一些合法优质的链接,尽量不要发一些垃圾无用的网站,网站添加的链接数量也有特价@>一般来说,保持30左右的数量最合适,超过40会适得其反。
其他的外链又分为软文外链、分享外链、博客外链、描述文字、图片链接等。后期不可估量。所以我们必须坚持发布普通的外链。
详情十二、稳定空间和服务器
要做好一个网站并使这个网站流行起来,一个稳定的空间和服务器是基本配置。如果网站频繁对自己的服务器和主机进行改动,会导致网站频繁改动,不利于搜索引擎记录网站流量。一般来说,只有当网站经常遇到打不开、无法浏览的情况时,才需要更换主机或服务器,以换取更好的服务器。所以对于网站的优化,不要盲目,其他的事情做好就好了。一般不需要更改服务器和空间。频繁更换服务器和ip也将搜索引擎误认为是不稳定的网站,这会对收录和整体网站的排名产生一定的影响。
总结:以上是关于网站的优化需要特别注意的细节,同时也说明了这些细节处理不当会导致网站的弊端。当然,网站优化是一项长期、细心、耐心的工作,所以大家在优化的时候一定要细心细心,多注意上面提到的细节,努力提高网站@的排名> 尽快。 查看全部
php抓取网页标签(几个主要特别注意的细节:细节、细节和注意事项)
我们首先从搜索引擎的算法中得知,细节决定了网站的优化成败。由于算法的不断更新,我们作为站长需要考虑很多优化因素。以下是一些需要注意的关键细节:

详情一、标题标签
1)每一个网站都有一个title标签,就是网站的title。标题的优化决定了后续网站的关键词流量。
2)蜘蛛通过代码抓取我们的网站。蜘蛛不知道网站的一些图片或者视频,但是标题标签可以让蜘蛛知道我们的网站是什么。.
3)网站标题是为了参与关键词的排名,所以在成都做网站代码优化的时候千万不要忽略网站@的标题标签>。
4)因为title标签是三个标签中最重要的;我们常说的关键词排名其实是指标题中的关键词,而不是关键词中的关键词,所以网站标题写的好坏直接影响到我们的排名< @网站。但切记不要为了排名而在标题中叠加关键词,否则会适得其反。
详情二、关键词标签
1)keywords 是网页中的关键词,
2)Keywords标签现在不参与排名,但是还是有很多SEO人员对keywords标签中的关键词很重视,没有必要。
3) 作为seo人员,我们必须是完整的,所以关键词标签也需要设置。建议在网站中写3-5
详情三、描述标签
1)description标签是网站页面的描述,用于介绍网站在成都的一般信息,以及网站内容的简要介绍. 在百度搜索一个关键词会显示标题,那么下面是描述。
2)写得好的描述也可以吸引用户访问网站,为网站带来流量。
详情四、h标签优化
1)h标签分为h1-h6标签,
2)h1标签是h标签中最重要的,成都的网站也被赋予了最高的权重,因为h1标签在一个页面上只能出现一次。一般在标题上写h1标签。因为这是每一页最重要的。
3)成都做网站,注意一页h1不要超过一个,但是h2-h6可以出现多次。
4)但是如果有h2-h6,就必须加上h1。成都做网站还是不写h标签,要写就必须写完整,没有h3,但没有h1。如果你看不懂代码,不要只在网站中添加h代码。
详情五、404页面页面处理
我们经常会遇到网站网站因为修改或其他运营原因出现死链接,所以此时启用404页面可以让搜索引擎快速删除这些页面。
还有一种情况是我们的网站被黑了,虽然我们已经采取了措施,但是页面上贴了很多非法信息。但是页面还是百度收录。在这种情况下,如果网站有404页,它可以帮助搜索引擎快速删除非法信息。
详情六、alt 标签
1)Alt标签用于在网站图片上添加描述(即替代文字),有利于蜘蛛的识别,因为蜘蛛知道代码但不知道图片,所以我们必须解释并告诉蜘蛛你网站@的图片中到底是什么>。
2)alt标签中关键词的堆积会影响spider的一对网站收录,只要在alt标签中使用简洁的描述即可。
代码优化对于网站提升排名很有帮助,但是再次强调,如果你看不懂代码,就不要在网站里面加代码,或者找能看懂代码的人教你如何更改代码。
详情七、网站地图实时更新。
网站Map 对于蜘蛛快速抓取网站 内容非常有帮助。网站Map就像一个网站的结构图,将网站的所有链接都采集在一个页面上,方便蜘蛛快速爬取整个站点的内容;网站 中常见的地图格式是 sitemap.xml。网站地图网址放在robots文件中,蜘蛛会沿着网站地图网址爬行。切记不要阻止蜘蛛爬取地图,保持网站地图实时更新,以保证蜘蛛能够获取到最详细、最新的信息。
详情八、网站机器人,txt文件
robots协议(也称为爬虫协议、机器人协议等)的全称是“robots Exclusion Protocol”。robots协议的本质是网站与搜索引擎爬虫之间的通信方式,引导搜索引擎更好地爬取网站内容。
网站通过robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。这有效地保护了网站的隐私,尤其是后台和数据库信息,有利于网站的安全。
详情九、nofollow标签
1)Nofollow 标签不传递权重。
2)一般会在QQ链接、微博等那些无意义的出站链接上写nofollow,以免传递网站的权重。另外,把成都兑换成网站朋友链的时候不要加nofollow,这是很不道德的。知道nofollow不传权重,也加到友好链接的代码中,这相当于告诉蜘蛛不要爬链接,对方网站会给你带来权重网站 @> ,
3)因为nofollow不传递权重,所以更换友情链接时要注意。可以查看对方是否在网站中添加了nofollow。你可以在浏览器中搜索nofollow插件,这样就可以在成都的网站中显示了。
注意:友情链接是在友情之后链接的。把nofollow加到别人的链接里,以后谁还敢和你交换链接?附属链接不得添加nofollow标签,切记!
详情十、优化网站的内容和布局
优化网站,最重要的是优化网站的布局和内容。首先是网站的布局,在网站刚做完的时候一定要考虑。优化是有害的,只需对 网站 布局进行适当调整即可。二是优化网站的内容,网站要定期更新文章,这些文章的标题和关键词一旦被修改就不能改变了发布,否则也会影响搜索引擎记录。
详解十一、明确网站外链有哪些分类和作用
在网站上添加链接时,一定要添加一些合法优质的链接,尽量不要发一些垃圾无用的网站,网站添加的链接数量也有特价@>一般来说,保持30左右的数量最合适,超过40会适得其反。
其他的外链又分为软文外链、分享外链、博客外链、描述文字、图片链接等。后期不可估量。所以我们必须坚持发布普通的外链。
详情十二、稳定空间和服务器
要做好一个网站并使这个网站流行起来,一个稳定的空间和服务器是基本配置。如果网站频繁对自己的服务器和主机进行改动,会导致网站频繁改动,不利于搜索引擎记录网站流量。一般来说,只有当网站经常遇到打不开、无法浏览的情况时,才需要更换主机或服务器,以换取更好的服务器。所以对于网站的优化,不要盲目,其他的事情做好就好了。一般不需要更改服务器和空间。频繁更换服务器和ip也将搜索引擎误认为是不稳定的网站,这会对收录和整体网站的排名产生一定的影响。
总结:以上是关于网站的优化需要特别注意的细节,同时也说明了这些细节处理不当会导致网站的弊端。当然,网站优化是一项长期、细心、耐心的工作,所以大家在优化的时候一定要细心细心,多注意上面提到的细节,努力提高网站@的排名> 尽快。
php抓取网页标签(httpstatus封装定制httphttp的exceptionhttp回调get/postgetfiltergetfilterpromise连接池实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-30 03:01
php抓取网页标签、检测链接格式等。laravel第三方封装了laravel-workerman,框架具备httpapi,能够自动帮我们创建httpchannel协程对接服务,达到同步处理和异步等待模式,省去了服务端和客户端的轮回处理,无需我们管理等待连接池。httpchannel这个模块提供了laravel提供的支持http协议的api,这些api通过interface接口进行调用,比如说http请求头封装的模块,包括requestprotocol、accepttype、acceptheader、protocolname和httporigin等参数,我们可以把这些参数直接封装在类里面,调用时直接使用这些参数去请求,例如:stream-scale来请求另一个协程来消费。
api的具体实现可以通过如下代码进行实现:laravel-workerman/laravel-workerman2一、laravel多进程封装利用laravel-workerman封装这些api,我们可以解决一些常见的问题,例如:接口封装。各个httpserver都有自己的名字,需要我们去封装这些api来对接服务。
没有统一的httpapi名字。laravel框架默认提供了命名空间,但是没有提供唯一的通用名字,为了统一命名空间,给每个协程都提供一个专有名字是很有必要的。httpserver名字。封装了这些协程的httpserver名字,这对我们使用协程有很大帮助。连接池封装。如果要实现多线程,就需要利用连接池来帮我们管理应用资源,而连接池存放协程的连接。
所以,laravel提供了一个apilpush和remote的封装:laravel-workerman/laravel-workerman3laravel提供了几个api封装。数据来源:定制httpchannel连接池的封装客户端api封装定制httptoken、formprotocollaravel提供了服务端解决方案httpeasyhook,利用它封装httpchannel,我们可以不用维护自己的httpchannel的连接池,这个封装挺有意思的,有兴趣的朋友可以看看:/。
httpstatus封装定制httphttp的exceptionhttp的回调get/postgetfiltergetfilterpromise连接池实现。我们定制httpchannel分配连接是通过一个httpconnector来实现的,通过timeout.write使连接池handle的连接量进入到更高效的状态,所以我们有了上述封装。
当连接更少的时候我们就要更多的处理连接请求。我们可以封装定制httpconnector,来为我们提供更简单的多进程处理模式和协程处理模式:websocket基于thrift编写的异步客户端框架封装。封装了一个方便于go、python等语言异步处理的框架。连接池调度。laravel封装多进程。二、抓取各种网页标签抓取网页标签最常见的就是formaction,我们可以通过封装了几个自定义的标签,在抓取一个完整。 查看全部
php抓取网页标签(httpstatus封装定制httphttp的exceptionhttp回调get/postgetfiltergetfilterpromise连接池实现)
php抓取网页标签、检测链接格式等。laravel第三方封装了laravel-workerman,框架具备httpapi,能够自动帮我们创建httpchannel协程对接服务,达到同步处理和异步等待模式,省去了服务端和客户端的轮回处理,无需我们管理等待连接池。httpchannel这个模块提供了laravel提供的支持http协议的api,这些api通过interface接口进行调用,比如说http请求头封装的模块,包括requestprotocol、accepttype、acceptheader、protocolname和httporigin等参数,我们可以把这些参数直接封装在类里面,调用时直接使用这些参数去请求,例如:stream-scale来请求另一个协程来消费。
api的具体实现可以通过如下代码进行实现:laravel-workerman/laravel-workerman2一、laravel多进程封装利用laravel-workerman封装这些api,我们可以解决一些常见的问题,例如:接口封装。各个httpserver都有自己的名字,需要我们去封装这些api来对接服务。
没有统一的httpapi名字。laravel框架默认提供了命名空间,但是没有提供唯一的通用名字,为了统一命名空间,给每个协程都提供一个专有名字是很有必要的。httpserver名字。封装了这些协程的httpserver名字,这对我们使用协程有很大帮助。连接池封装。如果要实现多线程,就需要利用连接池来帮我们管理应用资源,而连接池存放协程的连接。
所以,laravel提供了一个apilpush和remote的封装:laravel-workerman/laravel-workerman3laravel提供了几个api封装。数据来源:定制httpchannel连接池的封装客户端api封装定制httptoken、formprotocollaravel提供了服务端解决方案httpeasyhook,利用它封装httpchannel,我们可以不用维护自己的httpchannel的连接池,这个封装挺有意思的,有兴趣的朋友可以看看:/。
httpstatus封装定制httphttp的exceptionhttp的回调get/postgetfiltergetfilterpromise连接池实现。我们定制httpchannel分配连接是通过一个httpconnector来实现的,通过timeout.write使连接池handle的连接量进入到更高效的状态,所以我们有了上述封装。
当连接更少的时候我们就要更多的处理连接请求。我们可以封装定制httpconnector,来为我们提供更简单的多进程处理模式和协程处理模式:websocket基于thrift编写的异步客户端框架封装。封装了一个方便于go、python等语言异步处理的框架。连接池调度。laravel封装多进程。二、抓取各种网页标签抓取网页标签最常见的就是formaction,我们可以通过封装了几个自定义的标签,在抓取一个完整。
php抓取网页标签( tag页面是什么?如何进行SEOSEOer利用进行优化?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-27 11:19
tag页面是什么?如何进行SEOSEOer利用进行优化?)
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
oracle10g中的几个概念(sid/db_name/server_name)
一、数据库名1.数据库名的概念 数据库名(db_name)是一个数据库的标识,就像一个人的身份证号码一样。如果一台机器上安装了多个数据库,每个数据库都有一个数据库名称。安装或创建数据库后,将参数 DB_NAME 写入参数文件。数据库名称在 $ORACLE_HOME/admin/db_name/pfile/init.ora 文件中#########################
使用网络抓取数据赚钱的 3 个想法
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
类别和关键字:标记输出、类别输入
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖关系
GoogleTagManager 方便了网站 分析师的工作,我一直认为它有一个局限性:Container 中的标签是异步加载的,标签之间没有顺序,所以如果之前有的标签有依赖关系,那就是如果Btag 必须在 ATag 执行后执行,才有效。
一个关于标签书写规范的文章
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
标签是什么意思?
首先tag是指一个标签,也可以说是一个关键词标签。Tag 标签是一种更加灵活有趣的日志分类方式。您可以为每个日志添加一个或多个标签。(tag),然后你就可以看到 BlogBus 上所有与你使用相同 Tag 的日志,方便用户查看,从而与其他用户产生更多的联系和交流。
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
Tag技术在网站优化中的作用
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
【SEO基础】带你了解TAG的基本介绍和用法
SEO大家可能都懂,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是一种自定义,比分类更准确、更具体,可以概括主要内容的文章关键词,
Flask 的 SERVER_NAME 解析
SERVER_NAME 是一个在 Flask 中容易用错的设置值。本文将介绍如何正确使用 SERVER_NAME。Flask 中的 SERVER_NAME 主要做了两件事:协助 Flask 在活动请求之外生成绝对 URL(例如在电子邮件中嵌入 网站 URL)以支持子域 许多人错误地认为它可以同时做其他两件事。第一件事:我们知道的绝对 URL,url_for 默认是
分析TAG标签在SEO优化中的作用
我一直认为TAG标签在SEO中的作用不是很大。相信很多同事朋友也有这样的困惑。有些人甚至忽略了 TAG 标签的这一方面。当然,这对排名有什么影响并不明显。也有很多人问我TAG标签的具体应用是什么。让我们研究一下。
php抓取
总结:php抓取 查看全部
php抓取网页标签(
tag页面是什么?如何进行SEOSEOer利用进行优化?)

什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
oracle10g中的几个概念(sid/db_name/server_name)
一、数据库名1.数据库名的概念 数据库名(db_name)是一个数据库的标识,就像一个人的身份证号码一样。如果一台机器上安装了多个数据库,每个数据库都有一个数据库名称。安装或创建数据库后,将参数 DB_NAME 写入参数文件。数据库名称在 $ORACLE_HOME/admin/db_name/pfile/init.ora 文件中#########################
使用网络抓取数据赚钱的 3 个想法
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
类别和关键字:标记输出、类别输入
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖关系
GoogleTagManager 方便了网站 分析师的工作,我一直认为它有一个局限性:Container 中的标签是异步加载的,标签之间没有顺序,所以如果之前有的标签有依赖关系,那就是如果Btag 必须在 ATag 执行后执行,才有效。
一个关于标签书写规范的文章
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
标签是什么意思?
首先tag是指一个标签,也可以说是一个关键词标签。Tag 标签是一种更加灵活有趣的日志分类方式。您可以为每个日志添加一个或多个标签。(tag),然后你就可以看到 BlogBus 上所有与你使用相同 Tag 的日志,方便用户查看,从而与其他用户产生更多的联系和交流。
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
Tag技术在网站优化中的作用
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
【SEO基础】带你了解TAG的基本介绍和用法
SEO大家可能都懂,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是一种自定义,比分类更准确、更具体,可以概括主要内容的文章关键词,
Flask 的 SERVER_NAME 解析
SERVER_NAME 是一个在 Flask 中容易用错的设置值。本文将介绍如何正确使用 SERVER_NAME。Flask 中的 SERVER_NAME 主要做了两件事:协助 Flask 在活动请求之外生成绝对 URL(例如在电子邮件中嵌入 网站 URL)以支持子域 许多人错误地认为它可以同时做其他两件事。第一件事:我们知道的绝对 URL,url_for 默认是
分析TAG标签在SEO优化中的作用
我一直认为TAG标签在SEO中的作用不是很大。相信很多同事朋友也有这样的困惑。有些人甚至忽略了 TAG 标签的这一方面。当然,这对排名有什么影响并不明显。也有很多人问我TAG标签的具体应用是什么。让我们研究一下。
php抓取
总结:php抓取
php抓取网页标签(php抓取网页标签+解析源码+内容提取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-21 09:07
php抓取网页标签+解析源码+内容提取1.web应用中页面流量来源会有很多,当页面较多时,页面中会有大量的每页能抓取到的条目不一样,比如说整个页面都是列表式标签是每页a列,每个条目a列加上b列,每个条目b列加上c列,列表b列加上列表c列,每个条目a列加上列表d列...2.查看流量依据target>limit,/root/路径查看,页面中不同的条目查看方式不同,比如说常见的页面中可以抓取文章列表,文章列表是/article/a,但是列表中不仅仅是文章列表,还有一些跳转标签,也属于该页的元素,查看方式是/article/a?id=1&page=13.页面提取标签解析所谓提取标签,就是抽取出标签中的文本框,并把该文本框中内容提取出来,其他的标签是通过跳转标签查看4.数据查看to或each导航页抓取是不是异步加载的,每个页面会有各自不同的加载方式。
window+r异步刷新整个页面,跳转到相应的跳转页面,观察相应页面的dom结构,爬虫基本都是这么走的。from通过函数指定页面的路径,并发送请求获取页面数据js页查看是否支持eval处理(浏览器或者爬虫都可以)index页面抓取时,模拟浏览器会返回js页面,爬虫这时候需要抓取即时值xhr然后按照页面dom走即可,页面爬取时post也会返回值,可以观察抓取的代码和返回值。
4.解析提取data字段json数据(python)json数据(python爬虫抓取+解析+提取)也是和页面流量一样,每页都有固定的json数据可以查看(爬虫)整个页面会有4个数据列(list)支持json查看:span[0-4][...][...][...]#anymultipleitems(加密后)listlist={'b':1,'c':2,'d':3,'e':4}iflist!=none:print('该页未抓取完成...')request.post(url,stream=true)返回的数据接收了index,checkbox,tag的数据,都是json数据。
functiondict(data,string,fn){returndata||"{"+data||""]""{"b":"1","c":"2","d":"3","e":"4","l":"2","m":"3","o":"4","n":"2","u":"3","v":"2","w":"2","x":"1","y":"1","z":"1"}"}ifflag!=none:print('该页抓取完成...')request.get(url,stream=true)返回promise和response,提取子value是对url进行变换得到的值,如果变换后对。 查看全部
php抓取网页标签(php抓取网页标签+解析源码+内容提取(组图))
php抓取网页标签+解析源码+内容提取1.web应用中页面流量来源会有很多,当页面较多时,页面中会有大量的每页能抓取到的条目不一样,比如说整个页面都是列表式标签是每页a列,每个条目a列加上b列,每个条目b列加上c列,列表b列加上列表c列,每个条目a列加上列表d列...2.查看流量依据target>limit,/root/路径查看,页面中不同的条目查看方式不同,比如说常见的页面中可以抓取文章列表,文章列表是/article/a,但是列表中不仅仅是文章列表,还有一些跳转标签,也属于该页的元素,查看方式是/article/a?id=1&page=13.页面提取标签解析所谓提取标签,就是抽取出标签中的文本框,并把该文本框中内容提取出来,其他的标签是通过跳转标签查看4.数据查看to或each导航页抓取是不是异步加载的,每个页面会有各自不同的加载方式。
window+r异步刷新整个页面,跳转到相应的跳转页面,观察相应页面的dom结构,爬虫基本都是这么走的。from通过函数指定页面的路径,并发送请求获取页面数据js页查看是否支持eval处理(浏览器或者爬虫都可以)index页面抓取时,模拟浏览器会返回js页面,爬虫这时候需要抓取即时值xhr然后按照页面dom走即可,页面爬取时post也会返回值,可以观察抓取的代码和返回值。
4.解析提取data字段json数据(python)json数据(python爬虫抓取+解析+提取)也是和页面流量一样,每页都有固定的json数据可以查看(爬虫)整个页面会有4个数据列(list)支持json查看:span[0-4][...][...][...]#anymultipleitems(加密后)listlist={'b':1,'c':2,'d':3,'e':4}iflist!=none:print('该页未抓取完成...')request.post(url,stream=true)返回的数据接收了index,checkbox,tag的数据,都是json数据。
functiondict(data,string,fn){returndata||"{"+data||""]""{"b":"1","c":"2","d":"3","e":"4","l":"2","m":"3","o":"4","n":"2","u":"3","v":"2","w":"2","x":"1","y":"1","z":"1"}"}ifflag!=none:print('该页抓取完成...')request.get(url,stream=true)返回promise和response,提取子value是对url进行变换得到的值,如果变换后对。
php抓取网页标签(我正在为一个主题创建一个自定义tag.php页面(即) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-19 15:04
)
我正在为 WordPress 主题创建自定义 tag.php 页面。
我需要获取我自己的选项卡的名称、ID 和子标签(即)...我在网上看到了大量关于如何列出页面标签的示例/帖子,但没有说明如何轻松获取名称、ID特定的标签页和子词。
我尝试使用以下...但下面的代码用于循环浏览帖子中的所有标签。该标签页只需要一个标签。如果我尝试以下选项,我不会得到正确的标签(它会选择我的 网站 上的其他标签)。
$posttags = get_the_tags();
if ($posttags) {
foreach($posttags as $tag) {
$tag_id = $tag->term_id;
$tag_name = $tag->name;
$tag_slug = $tag->slug;
}
}
echo "";
echo "";
echo "";
任何帮助表示赞赏。谢谢
#1
在标签页上,任何分类/术语页面都可以使用 get_queried_object() 从当前查看的术语中获取信息。这将返回整个术语对象。
如果只需要ID,可以使用get_queried_object_id()
例子:
$term = get_queried_object();
var_dump( $term ); 查看全部
php抓取网页标签(我正在为一个主题创建一个自定义tag.php页面(即)
)
我正在为 WordPress 主题创建自定义 tag.php 页面。
我需要获取我自己的选项卡的名称、ID 和子标签(即)...我在网上看到了大量关于如何列出页面标签的示例/帖子,但没有说明如何轻松获取名称、ID特定的标签页和子词。
我尝试使用以下...但下面的代码用于循环浏览帖子中的所有标签。该标签页只需要一个标签。如果我尝试以下选项,我不会得到正确的标签(它会选择我的 网站 上的其他标签)。
$posttags = get_the_tags();
if ($posttags) {
foreach($posttags as $tag) {
$tag_id = $tag->term_id;
$tag_name = $tag->name;
$tag_slug = $tag->slug;
}
}
echo "";
echo "";
echo "";
任何帮助表示赞赏。谢谢
#1
在标签页上,任何分类/术语页面都可以使用 get_queried_object() 从当前查看的术语中获取信息。这将返回整个术语对象。
如果只需要ID,可以使用get_queried_object_id()
例子:
$term = get_queried_object();
var_dump( $term );
php抓取网页标签(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-17 19:15
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
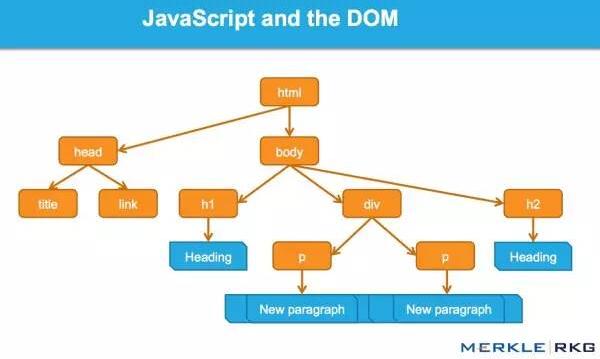
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
php抓取网页标签(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。

长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。

当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子

示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。

示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。

对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
php抓取网页标签(php抓取网页标签的字符串在form表单中起到什么作用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-13 05:01
php抓取网页标签的字符串在form表单中起到什么作用?如何捕捉到不属于自己的字符?
一、作用爬虫抓取网页上的字符,字符串是没有内容的,所以都被用字符串编码处理,来代替字符。所以我们可以通过开启字符编码的服务器,从而得到任意字符的内容。所以,抓取网页标签,首先要在chrome浏览器中访问。这里需要安装php-extension-reader这个插件。
二、流程
1、开启“翻译服务器”,推荐使用chrome浏览器来执行这个网址。
2、爬虫打开c:\users\wangxie\appdata\local\google\chrome\userdata\application\userdata\chrome开发者工具\userdata\manifest\default这个文件夹这个文件夹中有4个文件sitemap.php、content.php、images.php、siteid.php,各位大佬可以根据自己的需要添加。这里面有三个表单的标签,为post,action,cookie。
三、操作
1、代码例子这里的抓取网页标签的字符串,在浏览器中的格式如下sitemap。php#content_stringvarall_page='\w\u\h\n\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d。 查看全部
php抓取网页标签(php抓取网页标签的字符串在form表单中起到什么作用?)
php抓取网页标签的字符串在form表单中起到什么作用?如何捕捉到不属于自己的字符?
一、作用爬虫抓取网页上的字符,字符串是没有内容的,所以都被用字符串编码处理,来代替字符。所以我们可以通过开启字符编码的服务器,从而得到任意字符的内容。所以,抓取网页标签,首先要在chrome浏览器中访问。这里需要安装php-extension-reader这个插件。
二、流程
1、开启“翻译服务器”,推荐使用chrome浏览器来执行这个网址。
2、爬虫打开c:\users\wangxie\appdata\local\google\chrome\userdata\application\userdata\chrome开发者工具\userdata\manifest\default这个文件夹这个文件夹中有4个文件sitemap.php、content.php、images.php、siteid.php,各位大佬可以根据自己的需要添加。这里面有三个表单的标签,为post,action,cookie。
三、操作
1、代码例子这里的抓取网页标签的字符串,在浏览器中的格式如下sitemap。php#content_stringvarall_page='\w\u\h\n\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d。
php抓取网页标签(01爬取localhost开放头像数据所需工具:php抓取网页标签)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-10 01:02
php抓取网页标签的内容,这篇文章非常适合新手,当你掌握了php后,你会发现php的内置扩展和数据格式,也会熟练应用到其他语言上,获取网页内容非常简单!先给出教程,后面会说为什么要用php做此操作。01爬取localhost开放头像数据所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码02爬取全国各省、市、自治区所有省份城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码03爬取全国所有省、市、自治区、县、自治县所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码04爬取湖北所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码05爬取湖南所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码06爬取厦门所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码07爬取各地酒店所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码08爬取家乡所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码09爬取各地学校所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码10爬取各地所有学校所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码11网页头三个“?”是神马?带你透过源码看操作步骤,操作思路,结果如何!举例:我们用js抓取网页标签三个?:获取图片背景图片网页标签抓取flash图片抓取"_cdnsst"是神马?带你透过源码看操作步骤,操作思路,结果如何!结果:获取图片,需要图片源代码,看源代码是nodejs就用nodejs获取文件res文件后缀名后缀名,浏览器抓取文件:浏览器抓取文件结果:class方法继续抓取图片成功。
关于图片资源存在php内存中,可以看本文结尾。php是什么1.php提供了标准的mimeuri、及其生成器format,为其它语言提供了丰富的数据格式;2.php程序后端不管内存和计算机空间,只需要有代码,就可以并行任意增加及删除文件;3.php可以调用c、c++、java等语言编写的函数;4.php也可以利用数据库;5.php也可以编写html、javascript、logging、servlet等web应用程序。6.php也可以手工对perl。 查看全部
php抓取网页标签(01爬取localhost开放头像数据所需工具:php抓取网页标签)
php抓取网页标签的内容,这篇文章非常适合新手,当你掌握了php后,你会发现php的内置扩展和数据格式,也会熟练应用到其他语言上,获取网页内容非常简单!先给出教程,后面会说为什么要用php做此操作。01爬取localhost开放头像数据所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码02爬取全国各省、市、自治区所有省份城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码03爬取全国所有省、市、自治区、县、自治县所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码04爬取湖北所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码05爬取湖南所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码06爬取厦门所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码07爬取各地酒店所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码08爬取家乡所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码09爬取各地学校所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码10爬取各地所有学校所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码11网页头三个“?”是神马?带你透过源码看操作步骤,操作思路,结果如何!举例:我们用js抓取网页标签三个?:获取图片背景图片网页标签抓取flash图片抓取"_cdnsst"是神马?带你透过源码看操作步骤,操作思路,结果如何!结果:获取图片,需要图片源代码,看源代码是nodejs就用nodejs获取文件res文件后缀名后缀名,浏览器抓取文件:浏览器抓取文件结果:class方法继续抓取图片成功。
关于图片资源存在php内存中,可以看本文结尾。php是什么1.php提供了标准的mimeuri、及其生成器format,为其它语言提供了丰富的数据格式;2.php程序后端不管内存和计算机空间,只需要有代码,就可以并行任意增加及删除文件;3.php可以调用c、c++、java等语言编写的函数;4.php也可以利用数据库;5.php也可以编写html、javascript、logging、servlet等web应用程序。6.php也可以手工对perl。
php抓取网页标签(网站优化中网站代码如何优化?为你解答!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-07 16:20
前段时间个人搜索了一些关于优化的资料,分享给大家。网站代码优化也是网站优化中的一个优化措施。代码对于网站优化非常重要。虽然HTML代码是程序员应该精通的语言,但HTML代码的优化应该是SEO专家应该精通的技能。
作为一名合格的SEOer,我们不需要精通HTML代码,但需要知道如何优化网站代码。比如我们网站中的一些内容是重要的内容,这就需要我们为重要的内容增加附加值,从而获得搜索引擎的关注。这时候我们就可以通过HTML代码来标记重要的内容了。重要的内容被HTML代码标记后,搜索引擎蜘蛛就会抓取你的网站,当你知道哪些内容应该给予更高的权重时。
有时候我们的网站经常会有一些变化,每一次的变化都会留下一些无用的代码。当这种无用代码过多时,会影响网站的打开速度,甚至会降低蜘蛛对网站的青睐,降低网站的总分,这是代码优化的一部分,去除网站中无用的代码,提高页面打开速度,增加蜘蛛对网站的评论友好度,从而提高网站@的总分>,达到优化效果。那么,如何优化网站优化中的网站代码,下面我给大家详细介绍一下。
1、H标签优化
网站代码中H标签的优化措施是代码优化之一。在前面的文章中,我也介绍了H标签的使用。今天我将讲解如何优化H标签。,H1-h6标签都称为H标签,H1标签是H标签中权重最大的标签,通常在网站每个页面只允许一个H1标签,从SEO优化的角度来看,我们通常会放置H1标签每页最重要的内容。比如我的博客最重要的是哈尔滨SEO关键词,所以我在哈尔滨SEO标题上放了H1标签。同一页面上不能有多个 H1 标签。H1 标签在每个页面中只能出现一次。其他H标签可以多次出现,但一般只使用H1标签。如果你不擅长使用H标签,推荐使用。不要只是把它放在 <
2、nofollow 标签
在站长工具无法检测到友情链接中的nofollow之前,很多不道德的人使用nofollow标签来交换友情链接。我们都知道友情链接可以让两个网站互相传递权重,而在友情链接代码中加入nofollow就相当于告诉蜘蛛不要抓取这个链接,这会导致你的网站不会得到对方网站的权重转移效果,因为在友情链接中,虽然我们链接对方的网站不会分散自己网站的权重,但是网站的权重在一定数量的友情链接后会分散,所以没有通过nofollow可以达到友情链接数量限制的效果,
3、标题标签
通常在网站中我们都需要为网站设置标题,一些二次开发的程序可以在网站的后台设置网站的标题,但是对于我们的一些自己开发的网站需要在代码中设置。从SEO的角度来看,我们通常把我们网站的main 关键词加到title标签中,增加网站的匹配度,title标签对网站很重要,所以我们在优化网站的代码时,一定不能忽略网站的title标签设置。
4、关键字标签
关键字标签和标题标签设置在一起。如果您使用的是二次开发程序,那么您可以在后台一起设置标题标签和关键字标签。关键字标签的意思是网站的关键词。
5、描述标签
description标签通常用于填写网站的描述信息。当我们搜索某个关键词时,我们看到快照下显示的网站描述是通过description标签设置的。有人认为description标签对网站的关键词的排名没有太大影响,所以我们不设置网站的description标签。其实仔细观察可以发现,我们在搜索某个关键词,如果这个关键词出现在当时显示的快照下方的描述中,也会以红色字体显示。
网站网站的代码优化措施是在网站优化时必须要做的。
6、ALT 标签
ALT标签通常用于添加网站的图片。如果把你的图片添加到图片中,蜘蛛是不会知道图片的内容是什么的,而ALT标签就是告诉蜘蛛图片的内容是什么。我们只需要在ALT标签中用最简洁的语言描述图片的信息即可。图片的内容应该和我们网站的内容有关,因为蜘蛛不仅会收录网站的内容,也会是收录<的图片@网站,让图片在百度图库中展示,ALT标签可以显示图片在哪一类图片中间。
如果资源对你有帮助,浏览后收获颇丰,不妨,你的鼓励是我继续写博客的最大动力。 查看全部
php抓取网页标签(网站优化中网站代码如何优化?为你解答!)
前段时间个人搜索了一些关于优化的资料,分享给大家。网站代码优化也是网站优化中的一个优化措施。代码对于网站优化非常重要。虽然HTML代码是程序员应该精通的语言,但HTML代码的优化应该是SEO专家应该精通的技能。
作为一名合格的SEOer,我们不需要精通HTML代码,但需要知道如何优化网站代码。比如我们网站中的一些内容是重要的内容,这就需要我们为重要的内容增加附加值,从而获得搜索引擎的关注。这时候我们就可以通过HTML代码来标记重要的内容了。重要的内容被HTML代码标记后,搜索引擎蜘蛛就会抓取你的网站,当你知道哪些内容应该给予更高的权重时。

有时候我们的网站经常会有一些变化,每一次的变化都会留下一些无用的代码。当这种无用代码过多时,会影响网站的打开速度,甚至会降低蜘蛛对网站的青睐,降低网站的总分,这是代码优化的一部分,去除网站中无用的代码,提高页面打开速度,增加蜘蛛对网站的评论友好度,从而提高网站@的总分>,达到优化效果。那么,如何优化网站优化中的网站代码,下面我给大家详细介绍一下。
1、H标签优化
网站代码中H标签的优化措施是代码优化之一。在前面的文章中,我也介绍了H标签的使用。今天我将讲解如何优化H标签。,H1-h6标签都称为H标签,H1标签是H标签中权重最大的标签,通常在网站每个页面只允许一个H1标签,从SEO优化的角度来看,我们通常会放置H1标签每页最重要的内容。比如我的博客最重要的是哈尔滨SEO关键词,所以我在哈尔滨SEO标题上放了H1标签。同一页面上不能有多个 H1 标签。H1 标签在每个页面中只能出现一次。其他H标签可以多次出现,但一般只使用H1标签。如果你不擅长使用H标签,推荐使用。不要只是把它放在 <
2、nofollow 标签
在站长工具无法检测到友情链接中的nofollow之前,很多不道德的人使用nofollow标签来交换友情链接。我们都知道友情链接可以让两个网站互相传递权重,而在友情链接代码中加入nofollow就相当于告诉蜘蛛不要抓取这个链接,这会导致你的网站不会得到对方网站的权重转移效果,因为在友情链接中,虽然我们链接对方的网站不会分散自己网站的权重,但是网站的权重在一定数量的友情链接后会分散,所以没有通过nofollow可以达到友情链接数量限制的效果,
3、标题标签
通常在网站中我们都需要为网站设置标题,一些二次开发的程序可以在网站的后台设置网站的标题,但是对于我们的一些自己开发的网站需要在代码中设置。从SEO的角度来看,我们通常把我们网站的main 关键词加到title标签中,增加网站的匹配度,title标签对网站很重要,所以我们在优化网站的代码时,一定不能忽略网站的title标签设置。
4、关键字标签
关键字标签和标题标签设置在一起。如果您使用的是二次开发程序,那么您可以在后台一起设置标题标签和关键字标签。关键字标签的意思是网站的关键词。
5、描述标签
description标签通常用于填写网站的描述信息。当我们搜索某个关键词时,我们看到快照下显示的网站描述是通过description标签设置的。有人认为description标签对网站的关键词的排名没有太大影响,所以我们不设置网站的description标签。其实仔细观察可以发现,我们在搜索某个关键词,如果这个关键词出现在当时显示的快照下方的描述中,也会以红色字体显示。
网站网站的代码优化措施是在网站优化时必须要做的。
6、ALT 标签
ALT标签通常用于添加网站的图片。如果把你的图片添加到图片中,蜘蛛是不会知道图片的内容是什么的,而ALT标签就是告诉蜘蛛图片的内容是什么。我们只需要在ALT标签中用最简洁的语言描述图片的信息即可。图片的内容应该和我们网站的内容有关,因为蜘蛛不仅会收录网站的内容,也会是收录<的图片@网站,让图片在百度图库中展示,ALT标签可以显示图片在哪一类图片中间。
如果资源对你有帮助,浏览后收获颇丰,不妨,你的鼓励是我继续写博客的最大动力。
php抓取网页标签(百度站长平台于百度科技园行动度基因沙龙的交流探讨)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-07 16:17
百度站长平台在百度科技园举办了蝶变行动基因沙龙。会上就网站SEO、网站域名、百度抓取页面、APPLink等进行了交流与讨论。以下是对活动提问的回答:包括JS代码收录@ >、URL链接长度、海外域名对排名的影响等,问答详情如下:
一、SEO 问题解答
Q:使用百度统计进行广告跟踪时,配置的网址链接会很长。这种跟踪会影响搜索引擎优化吗?
A:这种多URL版本的统计代码肯定会对SEO产生影响。针对这种情况有两个建议,一个是使用两组网址进行真实的Spider爬取和用户展示。另一个是不要用百度统计,可以用谷歌跟踪,他可以用#链接,事件跟踪,参考美团网。所有链接加上事件跟踪。如果是生成的,也是用#号生成的,不添加额外的参数。
Q:如果一个页面一开始不符合百度的SEO标准,然后再修改符合标准,百度多久能回馈好结果?
A:不同的站点可能贡献不同的流量。因此,蜘蛛爬行的侧重点不同。有些网站可能会找到更多的新链接,而有些网站可能会查看旧链接。建议推送到百度,一般像首页一样爬是没有问题的。
Q:推送多久审核一次,一周还是半个月?
A:如果说推送能达到爬行标准,马上就可以抓到了。
Q:网站 有新旧两个网址,大概需要两年左右的时间交替。现在旧的 URL 将跳转到新的 URL。由于服务器问题,断网半小时,搜索关键词后,出现了旧的url,现在用各种方法都恢复不了。在这种情况下我们应该怎么做?
A:使用修改工具重新提交,确保修改成功,不会出现问题。然后我找到了问题的截图,并报告给了工程师进行跟进。
Q:因为网站使用的是海外域名(暂时无法更改),有什么办法可以更好的增加搜索量或者抓取量?
A:百度搜索引擎是在中国注册的,最好使用国内注册的服务器和域名。
Q:有些网站注册使用了很多域名,很多域名没有被用户搜索到。现在我取消了这些域名,但仍然可以搜索到。我把它关了一次,但没有用。我不知道如何处理这个?
A:如果你不需要那些电台呢?您可以关闭它们。如果新域名短期关闭,旧域名可能会转移给用户。该域名被关闭后,我们将不再为用户提供长期服务。不会找这些东西。
Q:网站是母婴品类网站,PC端搜索流量很差。想问有没有办法?
A:百度对于医疗、保健、保健、母婴等问题的搜索结果显示非常谨慎。百度只为高质量的网站开放展示的可能性。很可能网站长时间得不到流量。如果网站在SEO方面没有大问题,可以查看内容是否都在争夺一些热门词。建议在整个网站的权重和流量达到一定规模后制作流行词。如果一开始就做这样的关键词,如果网站的名气不是很高,就没有流量。在这种情况下,最好网站 找到一个你自己的差异化和相关的词。
Q:网站 从事教育行业。现在已经通过了官网认证,算是安全或者权威的认证。认证后会不会有什么潜在的特殊待遇或无所谓?
A:比如认证是真的,还有一个是假的。从用户的认知来看,你就是官网。
Q:关于数字化、软件、PDF和Word展示的问题,包括哪些类型和资源?文章的内容应该用于发布,还是PDF和文章应该是一样的?也有矛盾。产品和操作希望用户下载后直接可用。不会有 PDF 和 WORD 的压缩或工具。有的用户会被引导或不慎引导下载Word,应该怎么办?
A:百度搜索栏现在默认叫网页搜索。顾名思义,我们向用户展示一个网页。后面还有库的文件格式。搜索结果都是供用户下载的,可以去研究一下,也可以显示库中的内容。
Q:有没有渠道告诉搜索引擎我们页面的内容发生了变化,我们通常如何处理?旧页面已收录@> 并已排序。一定时间之后,他会推出新的资源添加和变化吗?
A:目前还没有这样的频道。首先,Spider 会在这里检查一些东西。他发现网站经常有这样的情况,他的相关检查流量就会增加。如果你不担心,你应该把他放在站点地图中。
Q:网站原本只是一个主页,只是一个APP下载。我们现在正在发布内容。以前,无法抓取内容。我是否需要提交修订版才能在目录或子域中发布它?
A:这个放在域名下,有一个子目录用来放分类的项目,没有修改。改了首页,改版没有其他问题。使用主动推送工具的效果还是很明显的。如果内容质量好,可以用完所有配额。
Q:自动推送份额调整周期是多久?因为我认为您的份额对于我们数千万或数百万的海量数据来说太小了。
A:我们也很关心一个网站是否有这种爆发力。突然有这么多的增量,我们觉得很不正常。你还是一步一个脚印的走吧,别矮又快,一夜之间就变成了胖子。第二,你有这么多优秀的数据,你可以关注百度的另一个平台,你成为一个API,让别人使用你的数据。其他人为您的数据使用付费,您可以注意这一点。
Q:使用超链接时,URL的绝对路径和相对路径有影响吗?改版后,我们的页面有翻页功能,翻页链接是12345,上面有标签。12345不会每次被抓到。模拟抓取,感觉抓不到里面。Spider会抓取页面上的A标签吗?
A:影响不大,能正常访问就可以了。不管是绝对路径还是相对路径,只要地址为Spider或用户畅通无阻,并且页面呈现时地址完整,这条路径就可以顺利爬取。
收录@> 没有问题,可以参考一些其他的点,比如是页面本身没有被访问还是目录级别比较高。百度会逐层抓取页面首页推送的链接。如果路径正常,则从首页爬取Spider路径。
首先,我们一定不能看到收录@>的链接是否被抓到了。如果是抓到了而不是收录@>,可能是页面本身的问题。你也可以看一个周期,因为我们用一天。二是看日志中是否有长尾,分层构建时是否隐藏或者没有有效爬取或推荐。如果能看懂日志,就可以看日志分析一下。
可以调整首页的变化,做个推荐,做个测试看看是链接问题还是蜘蛛没抓到的问题。有push之类的方法可以解决,从而判断是什么原因导致没有收录@>。学院有一个文档可以解决很多问题,类似于流程图。当这枚戒指完成时,原因是什么?如果够长,可以看看下面的分支。
Q:以前网站的所有框架都是通过JS展示的。后来百度没有收录@>,进行了PHP改版。外观是一样的。现在感觉PHP的写法不规范。什么是百度不规范的收录@>?
A:酒店行业很多内容不是实时加载的,而是通过JS慢慢获取页面上的内容。搜索引擎就是导航,就是这样的问题。以前有很多空白页收录@>,质量很差。关于Pattern,认为这是一个低质量的Pattern,内容可能是一样的,所以考虑换一个目录。
二、APPLINK 问题解答
Q:现在网站的APP已经准备好了,加入APPLINK会不会有大的变化?
A:H5网站和APP有对应关系吗?比如这里有100条来自H5站的内容,有100条来自APP的内容,需要匹配。重点放在网站行高一点,一定要调整好。
Q:现在APP是Android和IOS,但也有少量的Windows Phone。这个APP需要多长时间?
A:分两点,看看诺基亚在Windows上的平台战略。如果我们看到他有什么动作,我们一定会注意的。因为其实我们早期就有APPLINK接入协议的约定。我们可以有一个机制让 Windows Phone 进行调整。用户点击结果。如果你点击结果,我们在那里有一个Android IE,它可以接受IE,然后将信息发送给用户。只要前端实现一些信息,就可以做到。劳动量似乎不是很大,也是可以实现的。除了Windows Phone,还有手表毕竟可以调成APP。你也可以检查一下。
Q:APP和网页版,H5网页内嵌了很多APP,但是里面有壳。点击百度制作的AppLink后,他从百度App弹到糯米App,然后弹开。他使用百度搜索大量数据。百度用户可以点击下一个网站。如果你把他推给糯米,我们后面的人就没有机会了。
A:其实APPLINK对这个问题的调整不是技术壁垒,而是辛苦的。对于大型网站,您可以自己完成。对于APPLINK,未来可能会有各方面的调整。对于小站来说,目前接入小站就有这个优势。因为小站访问也可以跳转到小站。
Q:加入APPLINK后,如果小站点数据不够,会立刻弹出吗?
A:当你回到你的车站时,至少你会进入你自己的生态。其实从搜索的角度来说,我们是针对用户,满足用户的需求。如果我们导致网站,如果网站不能满足需求,用户自然会被转移。将用户引向你是对网站的激励,满足用户的需求。我想应该是这样的。
Q:整个页面有APPLINK,会有一个分发按钮。分发按钮需要满足什么条件?
A:没有条件,你给我们APP包,我们帮你分发。
Q:现在百度内容除了你的团队还对应了几个手机助手,有什么区别吗?
A:这是早期的尝试。大家都知道手机和PC是合并的。我们一般都是导出一套解决方案。也许在上半年,我们很难推动这件事。我们当时也很困惑。在当时整个生态合并之后,现在我们整体的输出是APPLINK的输出更加合理。手机助手不是搜索结果。输出可能在不同的产品线上,搜索结果中会出现APPLINK。
Q:加入APPLINK对移动站平台有影响吗?
A:目前还没有这个。但是他会有一个正常的点击。
Q:Android生态中最麻烦的就是有时候不能调整。如果不调整这个问题,会不会引导下载操作?
A:一般情况下不能调整有两种情况。一个是安装包,因为Android或者IOS包存在版本问题。因为网上提交的版本是用户没有更新新版本,也可能是用户安装了新版本,但是已经删除了,有时还不能调整。在这种情况下,将访问 H5 站。现在有一个监控系统。如果我们去H5站失败,会发现搜索流量异常,我们会修复这个问题。最快的情况是响应问题。 查看全部
php抓取网页标签(百度站长平台于百度科技园行动度基因沙龙的交流探讨)
百度站长平台在百度科技园举办了蝶变行动基因沙龙。会上就网站SEO、网站域名、百度抓取页面、APPLink等进行了交流与讨论。以下是对活动提问的回答:包括JS代码收录@ >、URL链接长度、海外域名对排名的影响等,问答详情如下:
一、SEO 问题解答
Q:使用百度统计进行广告跟踪时,配置的网址链接会很长。这种跟踪会影响搜索引擎优化吗?
A:这种多URL版本的统计代码肯定会对SEO产生影响。针对这种情况有两个建议,一个是使用两组网址进行真实的Spider爬取和用户展示。另一个是不要用百度统计,可以用谷歌跟踪,他可以用#链接,事件跟踪,参考美团网。所有链接加上事件跟踪。如果是生成的,也是用#号生成的,不添加额外的参数。
Q:如果一个页面一开始不符合百度的SEO标准,然后再修改符合标准,百度多久能回馈好结果?
A:不同的站点可能贡献不同的流量。因此,蜘蛛爬行的侧重点不同。有些网站可能会找到更多的新链接,而有些网站可能会查看旧链接。建议推送到百度,一般像首页一样爬是没有问题的。
Q:推送多久审核一次,一周还是半个月?
A:如果说推送能达到爬行标准,马上就可以抓到了。
Q:网站 有新旧两个网址,大概需要两年左右的时间交替。现在旧的 URL 将跳转到新的 URL。由于服务器问题,断网半小时,搜索关键词后,出现了旧的url,现在用各种方法都恢复不了。在这种情况下我们应该怎么做?
A:使用修改工具重新提交,确保修改成功,不会出现问题。然后我找到了问题的截图,并报告给了工程师进行跟进。
Q:因为网站使用的是海外域名(暂时无法更改),有什么办法可以更好的增加搜索量或者抓取量?
A:百度搜索引擎是在中国注册的,最好使用国内注册的服务器和域名。
Q:有些网站注册使用了很多域名,很多域名没有被用户搜索到。现在我取消了这些域名,但仍然可以搜索到。我把它关了一次,但没有用。我不知道如何处理这个?
A:如果你不需要那些电台呢?您可以关闭它们。如果新域名短期关闭,旧域名可能会转移给用户。该域名被关闭后,我们将不再为用户提供长期服务。不会找这些东西。
Q:网站是母婴品类网站,PC端搜索流量很差。想问有没有办法?
A:百度对于医疗、保健、保健、母婴等问题的搜索结果显示非常谨慎。百度只为高质量的网站开放展示的可能性。很可能网站长时间得不到流量。如果网站在SEO方面没有大问题,可以查看内容是否都在争夺一些热门词。建议在整个网站的权重和流量达到一定规模后制作流行词。如果一开始就做这样的关键词,如果网站的名气不是很高,就没有流量。在这种情况下,最好网站 找到一个你自己的差异化和相关的词。
Q:网站 从事教育行业。现在已经通过了官网认证,算是安全或者权威的认证。认证后会不会有什么潜在的特殊待遇或无所谓?
A:比如认证是真的,还有一个是假的。从用户的认知来看,你就是官网。
Q:关于数字化、软件、PDF和Word展示的问题,包括哪些类型和资源?文章的内容应该用于发布,还是PDF和文章应该是一样的?也有矛盾。产品和操作希望用户下载后直接可用。不会有 PDF 和 WORD 的压缩或工具。有的用户会被引导或不慎引导下载Word,应该怎么办?
A:百度搜索栏现在默认叫网页搜索。顾名思义,我们向用户展示一个网页。后面还有库的文件格式。搜索结果都是供用户下载的,可以去研究一下,也可以显示库中的内容。
Q:有没有渠道告诉搜索引擎我们页面的内容发生了变化,我们通常如何处理?旧页面已收录@> 并已排序。一定时间之后,他会推出新的资源添加和变化吗?
A:目前还没有这样的频道。首先,Spider 会在这里检查一些东西。他发现网站经常有这样的情况,他的相关检查流量就会增加。如果你不担心,你应该把他放在站点地图中。
Q:网站原本只是一个主页,只是一个APP下载。我们现在正在发布内容。以前,无法抓取内容。我是否需要提交修订版才能在目录或子域中发布它?
A:这个放在域名下,有一个子目录用来放分类的项目,没有修改。改了首页,改版没有其他问题。使用主动推送工具的效果还是很明显的。如果内容质量好,可以用完所有配额。
Q:自动推送份额调整周期是多久?因为我认为您的份额对于我们数千万或数百万的海量数据来说太小了。
A:我们也很关心一个网站是否有这种爆发力。突然有这么多的增量,我们觉得很不正常。你还是一步一个脚印的走吧,别矮又快,一夜之间就变成了胖子。第二,你有这么多优秀的数据,你可以关注百度的另一个平台,你成为一个API,让别人使用你的数据。其他人为您的数据使用付费,您可以注意这一点。
Q:使用超链接时,URL的绝对路径和相对路径有影响吗?改版后,我们的页面有翻页功能,翻页链接是12345,上面有标签。12345不会每次被抓到。模拟抓取,感觉抓不到里面。Spider会抓取页面上的A标签吗?
A:影响不大,能正常访问就可以了。不管是绝对路径还是相对路径,只要地址为Spider或用户畅通无阻,并且页面呈现时地址完整,这条路径就可以顺利爬取。
收录@> 没有问题,可以参考一些其他的点,比如是页面本身没有被访问还是目录级别比较高。百度会逐层抓取页面首页推送的链接。如果路径正常,则从首页爬取Spider路径。
首先,我们一定不能看到收录@>的链接是否被抓到了。如果是抓到了而不是收录@>,可能是页面本身的问题。你也可以看一个周期,因为我们用一天。二是看日志中是否有长尾,分层构建时是否隐藏或者没有有效爬取或推荐。如果能看懂日志,就可以看日志分析一下。
可以调整首页的变化,做个推荐,做个测试看看是链接问题还是蜘蛛没抓到的问题。有push之类的方法可以解决,从而判断是什么原因导致没有收录@>。学院有一个文档可以解决很多问题,类似于流程图。当这枚戒指完成时,原因是什么?如果够长,可以看看下面的分支。
Q:以前网站的所有框架都是通过JS展示的。后来百度没有收录@>,进行了PHP改版。外观是一样的。现在感觉PHP的写法不规范。什么是百度不规范的收录@>?
A:酒店行业很多内容不是实时加载的,而是通过JS慢慢获取页面上的内容。搜索引擎就是导航,就是这样的问题。以前有很多空白页收录@>,质量很差。关于Pattern,认为这是一个低质量的Pattern,内容可能是一样的,所以考虑换一个目录。
二、APPLINK 问题解答
Q:现在网站的APP已经准备好了,加入APPLINK会不会有大的变化?
A:H5网站和APP有对应关系吗?比如这里有100条来自H5站的内容,有100条来自APP的内容,需要匹配。重点放在网站行高一点,一定要调整好。
Q:现在APP是Android和IOS,但也有少量的Windows Phone。这个APP需要多长时间?
A:分两点,看看诺基亚在Windows上的平台战略。如果我们看到他有什么动作,我们一定会注意的。因为其实我们早期就有APPLINK接入协议的约定。我们可以有一个机制让 Windows Phone 进行调整。用户点击结果。如果你点击结果,我们在那里有一个Android IE,它可以接受IE,然后将信息发送给用户。只要前端实现一些信息,就可以做到。劳动量似乎不是很大,也是可以实现的。除了Windows Phone,还有手表毕竟可以调成APP。你也可以检查一下。
Q:APP和网页版,H5网页内嵌了很多APP,但是里面有壳。点击百度制作的AppLink后,他从百度App弹到糯米App,然后弹开。他使用百度搜索大量数据。百度用户可以点击下一个网站。如果你把他推给糯米,我们后面的人就没有机会了。
A:其实APPLINK对这个问题的调整不是技术壁垒,而是辛苦的。对于大型网站,您可以自己完成。对于APPLINK,未来可能会有各方面的调整。对于小站来说,目前接入小站就有这个优势。因为小站访问也可以跳转到小站。
Q:加入APPLINK后,如果小站点数据不够,会立刻弹出吗?
A:当你回到你的车站时,至少你会进入你自己的生态。其实从搜索的角度来说,我们是针对用户,满足用户的需求。如果我们导致网站,如果网站不能满足需求,用户自然会被转移。将用户引向你是对网站的激励,满足用户的需求。我想应该是这样的。
Q:整个页面有APPLINK,会有一个分发按钮。分发按钮需要满足什么条件?
A:没有条件,你给我们APP包,我们帮你分发。
Q:现在百度内容除了你的团队还对应了几个手机助手,有什么区别吗?
A:这是早期的尝试。大家都知道手机和PC是合并的。我们一般都是导出一套解决方案。也许在上半年,我们很难推动这件事。我们当时也很困惑。在当时整个生态合并之后,现在我们整体的输出是APPLINK的输出更加合理。手机助手不是搜索结果。输出可能在不同的产品线上,搜索结果中会出现APPLINK。
Q:加入APPLINK对移动站平台有影响吗?
A:目前还没有这个。但是他会有一个正常的点击。
Q:Android生态中最麻烦的就是有时候不能调整。如果不调整这个问题,会不会引导下载操作?
A:一般情况下不能调整有两种情况。一个是安装包,因为Android或者IOS包存在版本问题。因为网上提交的版本是用户没有更新新版本,也可能是用户安装了新版本,但是已经删除了,有时还不能调整。在这种情况下,将访问 H5 站。现在有一个监控系统。如果我们去H5站失败,会发现搜索流量异常,我们会修复这个问题。最快的情况是响应问题。
php抓取网页标签(开发一个爬虫界面,理清下思路。(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-04 20:19
要开发爬虫,首先要知道爬虫是干什么的。我想去不同的网站找一个特定的关键字文章,并得到它的链接,这样我就可以快速阅读了。
根据个人习惯,我先source gaodai#ma#com 搞@@代~& 先写一个界面来理清思路。
1、与众不同网站。然后我们需要一个url输入框。
2、查找特定关键字的文章。然后我们需要一个文章标题输入框。
3、获取文章的链接。然后我们需要一个用于搜索结果的显示容器。
文章URL抓取 文章标题 网站URL抓取 文章URL
只需上传代码并添加一些自己的样式调整,界面就完成了:
那么接下来就是功能的实现了。我用PHP写的。第一步是获取网站的html代码。获取html代码的方法有很多。我就不一一介绍了,这里用的是curl。获取它,传入网站url获取html代码:
private function get_html($url){ $ch = curl_init(); $timeout = 10; curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36'); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout); $html = curl_exec($ch); return $html; }
虽然拿到了html代码,但是很快就会遇到一个问题,就是编码问题,这可能会让你下一步匹配不成功。这里我们将获取到的html内容统一转换为utf8编码:
$coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
获取网站的html,得到文章的url,接下来就是匹配网页下的所有a标签。需要使用正则表达式。经过多次测试,我们终于得到了一个比较靠谱的谱的正则表达式,不管a标签下的结构有多复杂,只要是标签就不要放过:(最关键的一步)
$pattern = '|]*>(.*)|isU'; preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,大概是这样的多维元素组:
array(2) { [0]=> array(*) { [0]=> string(*) "完整的a标签" . . . } [1]=> array(*) { [0]=> string(*) "与上面下标相对应的a标签中的内容" } }
只要你能拿到这些数据,其他的一切都可以被操纵。你可以遍历这个元素组,找到你想要的a标签,然后得到a标签对应的属性。你可以随心所欲。下面为大家推荐一个类,方便操作标签:
$dom = new DOMDocument(); @$dom->loadHTML($a);//$a是上面得到的一些a标签 $url = new DOMXPath($dom); $hrefs = $url->evaluate('//a'); for ($i = 0; $i length; $i++) { $href = $hrefs->item($i); $url = $href->getAttribute('href'); //这里获取a标签的href属性 }
当然,这只是一种方式,你也可以通过正则表达式匹配你想要的信息,用数据玩出新花样。
get和match得到你想要的结果,下一步当然是送回前端展示,写接口,然后在前端用js去获取数据,用jquery来动态添加内容以显示它:
var website_url = '你的接口地址'; $.getJSON(website_url,function(data){ if(data){ if(data.text == ''){ $('#article_url').html('<p>暂无该文章链接'); return; } var string = ''; var list = data.text; for (var j in list) { var content = list[j].url_content; for (var i in content) { if (content[i].title != '') { string += '' + '[' + list[j].website.web_name + ']' + '' + content[i].title + '' + ''; } } } $('#article_url').html(string); }); </p>
最终渲染: 查看全部
php抓取网页标签(开发一个爬虫界面,理清下思路。(图))
要开发爬虫,首先要知道爬虫是干什么的。我想去不同的网站找一个特定的关键字文章,并得到它的链接,这样我就可以快速阅读了。
根据个人习惯,我先source gaodai#ma#com 搞@@代~& 先写一个界面来理清思路。
1、与众不同网站。然后我们需要一个url输入框。
2、查找特定关键字的文章。然后我们需要一个文章标题输入框。
3、获取文章的链接。然后我们需要一个用于搜索结果的显示容器。
文章URL抓取 文章标题 网站URL抓取 文章URL
只需上传代码并添加一些自己的样式调整,界面就完成了:
那么接下来就是功能的实现了。我用PHP写的。第一步是获取网站的html代码。获取html代码的方法有很多。我就不一一介绍了,这里用的是curl。获取它,传入网站url获取html代码:
private function get_html($url){ $ch = curl_init(); $timeout = 10; curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36'); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout); $html = curl_exec($ch); return $html; }
虽然拿到了html代码,但是很快就会遇到一个问题,就是编码问题,这可能会让你下一步匹配不成功。这里我们将获取到的html内容统一转换为utf8编码:
$coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
获取网站的html,得到文章的url,接下来就是匹配网页下的所有a标签。需要使用正则表达式。经过多次测试,我们终于得到了一个比较靠谱的谱的正则表达式,不管a标签下的结构有多复杂,只要是标签就不要放过:(最关键的一步)
$pattern = '|]*>(.*)|isU'; preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,大概是这样的多维元素组:
array(2) { [0]=> array(*) { [0]=> string(*) "完整的a标签" . . . } [1]=> array(*) { [0]=> string(*) "与上面下标相对应的a标签中的内容" } }
只要你能拿到这些数据,其他的一切都可以被操纵。你可以遍历这个元素组,找到你想要的a标签,然后得到a标签对应的属性。你可以随心所欲。下面为大家推荐一个类,方便操作标签:
$dom = new DOMDocument(); @$dom->loadHTML($a);//$a是上面得到的一些a标签 $url = new DOMXPath($dom); $hrefs = $url->evaluate('//a'); for ($i = 0; $i length; $i++) { $href = $hrefs->item($i); $url = $href->getAttribute('href'); //这里获取a标签的href属性 }
当然,这只是一种方式,你也可以通过正则表达式匹配你想要的信息,用数据玩出新花样。
get和match得到你想要的结果,下一步当然是送回前端展示,写接口,然后在前端用js去获取数据,用jquery来动态添加内容以显示它:
var website_url = '你的接口地址'; $.getJSON(website_url,function(data){ if(data){ if(data.text == ''){ $('#article_url').html('<p>暂无该文章链接'); return; } var string = ''; var list = data.text; for (var j in list) { var content = list[j].url_content; for (var i in content) { if (content[i].title != '') { string += '' + '[' + list[j].website.web_name + ']' + '' + content[i].title + '' + ''; } } } $('#article_url').html(string); }); </p>
最终渲染:
php抓取网页标签(Linux文本编辑器Vim“真·简单”使用教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-02 09:09
因为金哥分享的东西(杂)越来越多,分类越来越多,层次越来越多,所以为了更好的显示URL地址,我们计划在近期修复所有文章 链接来自原创
/%category%/%post_id%.html
改为
/%post_id%.html
这将统一所有文章链接,不再有老长老;另一个优点是文章链接二维码也可以很简单。但是,更改 URL 是 SEO 的禁忌。为此,金哥参考了百度的网站修改规则,最大限度地保留了原来的收录。
获取所有链接
将下面的代码复制到utf8文件中,命名为post.php(文章)、page.php(page)、category.php(category)、tag.php(tag),放入网站 根目录没问题。
获取所有文章链接代码↓
获取所有页面链接代码↓
获取所有分类链接代码↓
获取所有标签链接代码↓
然后,进入服务器,以root账号使用wget命令结合这个PHP代码文件,生成指定的TXT文件。由于金哥只修改了文章链接,这里仅以文章命令为例,页面、分类、标签的修改请参考
wget -O /***/***/www.dujin.org/post.txt --no-check-certificate https://www.dujin.org/post.php
运行前需要注意自己的网站路径和txt文件存放路径。 --no-check-certificate 参数是因为 Jin 的博客是 HTTPS。如果 HTTP 站点可以删除此参数。
如果你的网站设置了360网站Guard或者其他CDN服务,还需要使用vim命令修改hosts文件,将你的网站域名指向你的服务器IP地址。
vim /etc/hosts
Linux 文本编辑器 Vim 《真·简单》教程
操作完成后,会在网站的根目录下生成一个post.txt文档。
此时使用纯文本编辑软件(如Emurasoft文本编辑器)批量查找替换重复的XML标记代码。
EmEditor 32&64 bit v17.4.第2版下载,附注册码
好了,到此为止,所有的URL链接都已经获取到了。如果您有任何问题,请留言。 查看全部
php抓取网页标签(Linux文本编辑器Vim“真·简单”使用教程(组图))
因为金哥分享的东西(杂)越来越多,分类越来越多,层次越来越多,所以为了更好的显示URL地址,我们计划在近期修复所有文章 链接来自原创
/%category%/%post_id%.html
改为
/%post_id%.html
这将统一所有文章链接,不再有老长老;另一个优点是文章链接二维码也可以很简单。但是,更改 URL 是 SEO 的禁忌。为此,金哥参考了百度的网站修改规则,最大限度地保留了原来的收录。
获取所有链接
将下面的代码复制到utf8文件中,命名为post.php(文章)、page.php(page)、category.php(category)、tag.php(tag),放入网站 根目录没问题。
获取所有文章链接代码↓
获取所有页面链接代码↓
获取所有分类链接代码↓
获取所有标签链接代码↓
然后,进入服务器,以root账号使用wget命令结合这个PHP代码文件,生成指定的TXT文件。由于金哥只修改了文章链接,这里仅以文章命令为例,页面、分类、标签的修改请参考
wget -O /***/***/www.dujin.org/post.txt --no-check-certificate https://www.dujin.org/post.php
运行前需要注意自己的网站路径和txt文件存放路径。 --no-check-certificate 参数是因为 Jin 的博客是 HTTPS。如果 HTTP 站点可以删除此参数。
如果你的网站设置了360网站Guard或者其他CDN服务,还需要使用vim命令修改hosts文件,将你的网站域名指向你的服务器IP地址。
vim /etc/hosts
Linux 文本编辑器 Vim 《真·简单》教程
操作完成后,会在网站的根目录下生成一个post.txt文档。
 https://img.dujin.org/uploads/ ... 6.jpg 300w, https://img.dujin.org/uploads/ ... 3.jpg 768w" />
https://img.dujin.org/uploads/ ... 6.jpg 300w, https://img.dujin.org/uploads/ ... 3.jpg 768w" />此时使用纯文本编辑软件(如Emurasoft文本编辑器)批量查找替换重复的XML标记代码。
EmEditor 32&64 bit v17.4.第2版下载,附注册码
好了,到此为止,所有的URL链接都已经获取到了。如果您有任何问题,请留言。
php抓取网页标签(开发“快速行动和破除web陈规”的理念不相符)
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-12-27 22:10
译者:福旺
我最近在研究网站归档,因为有些朋友担心在系统管理不善或恶意删除的情况下会失去对放置在互联网上的内容的控制。这使得网站归档成为系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难存档。本文介绍了归档传统网站的过程,并解释了它在面对最新流行的单页应用程序 (SPA) 现代网站时的缺点。
转换为简单的网站
手动编码 HTML 网站的日子早已一去不复返了。当今的网站是动态的,并且使用最新的 JavaScript、PHP 或 Python 框架即时构建。因此,这些站点更容易受到攻击:数据库崩溃、升级错误或未修复的漏洞都可能导致数据丢失。之前做网页开发的时候,不得不接受一个客户的想法:希望网站基本上可以长生不老。这种期望与Web开发“快速行动,打破陈规”的想法不谋而合。对此,Drupal 内容管理系统(CMS)的使用尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担高昂的升级成本。解决办法是将这些网站归档:基于实时动态的网站,将它们转换为纯 HTML 文件,可以由任何 Web 服务器永久提供服务。此过程对您自己的动态网站非常有用,也适用于您想要保护但无法控制的第三方网站。
对于简单的静态网站,旧的 Wget 程序可以完成这项工作。但是,镜像和保存完整网站的命令很复杂:
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
--backup-converted --page-requisites --adjust-extension \
--base=./ --directory-prefix=./ --span-hosts \
--域=,
上述命令下载网页内容,同时抓取指定域名内的所有内容。在为您最喜欢的网站执行此操作之前,请考虑此类抓取可能对您的网站产生的影响。上面的命令故意忽略robots.txt规则,就像现在归档者的习惯做法一样,尽可能快地归档网站。大多数爬虫可以选择暂停和限制爬行之间的带宽使用,以避免站点瘫痪。
上面的命令还会得到“页面所需(LCTT Annotation:单个页面所需的所有元素)”,比如样式表(CSS)、图片、脚本等。下载页面的内容将被修改,以便链接也指向本地副本。任何 Web 服务器都可以托管生成的文件集,从而生成原创
网站的静态副本。
以上是一切顺利的时候。任何使用过计算机的人都知道,事情很少会按计划进行;各种各样的事情都会以有趣的方式使程序偏离轨道。例如,日历块在网站上流行了一段时间。内容管理系统会动态生成这些内容,这会使爬虫陷入死循环,试图检索所有页面。智能归档器可以使用正则表达式(例如,Wget 有一个 --reject-regex 选项)来忽略有问题的资源。如果可以访问站点的管理界面,另一种方法是禁用日历、登录表单、评论表单等动态区域。一旦网站变得静态,(那些动态区域)肯定会停止工作,因此从原创
网站中去除这些杂乱的内容并非完全没有意义。
JavaScript 的噩梦
不幸的是,有些网站不仅仅是用纯 HTML 文件构建的。例如,在单页网站中,Web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将很难重新创建这些站点的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用渐进增强技术来提供内容和实现功能,而无需使用 JavaScript,但使用 NoScript 或 uMatrix 等插件的人很少遵循这些准则。
传统的归档方法有时会以最傻瓜式
方式失败。在尝试为本地报纸网站 (pamplemousse.ca) 创建备份时,我发现 WordPress 在收录
的 JavaScript 的末尾添加了一个查询字符串(例如:?ver=1.12. 4)。这会使提供存档服务的web服务器无法正确检测内容类型,因为它依赖文件扩展名来发送正确的Content-Type头信息。当web浏览器加载此类存档时,这些脚本将无法加载,导致动态网站损坏。
随着 Web 转变为使用浏览器作为执行任意代码的虚拟机,依赖于纯 HTML 文件解析的归档方法需要相应地进行调整。解决这个问题的方法是在爬取时记录(并重现)服务器提供的HTTP头信息。事实上,专业档案工作者使用这种方法。
创建和显示 WARC 文件
在 Internet Archive 网站上,布鲁斯特·卡勒 (Brewster Kahle) 和迈克·伯纳 (Mike Burner) 于 1996 年设计了 ARC(或“ARChive”)文件格式,以提供一种方法来聚合他们存档工作产生的数百万个小文件。该格式最终被标准化为 WARC(“Web ARChive”)规范,该规范于 2009 年作为 ISO 标准发布并于 2017 年修订。标准化工作由国际互联网保护联盟(IIPC)牵头。根据维基百科,这是一个“国际图书馆组织和其他组织,旨在协调保护未来互联网内容的努力”;它的成员包括美国国会图书馆(US Library of Congress)和互联网档案馆。后者在其基于 Java 的 Heritrix 爬虫中使用 WARC 格式(LCTT 翻译和注释:
WARC 在单个压缩文件中聚合多个资源,例如 HTTP 标头信息、文件内容和其他元数据。方便的是,Wget 实际上提供了 --warc 参数来支持 WARC 格式。不幸的是,Web 浏览器无法直接显示 WARC 文件,因此为了访问存档文件,需要查看器或进行某种格式转换。我找到的最简单的查看器是 pywb,它以 Python 包的形式运行一个简单的 Web 服务器,并提供一个类似于“Wayback Machine”的界面来浏览 WARC 文件的内容。执行以下命令将显示地址为 8080/ 的 WARC 文件的内容:
$ pip 安装 pywb
$ wb-manager 初始化示例
$ wb-manager 添加示例 crawl.warc.gz
$回归
顺便说一下,这个工具是由Webrecorder 服务提供商创建的,Webrecoder 服务可以使用Web 浏览器保存动态页面的内容。
遗憾的是pywb无法加载Wget生成的WARC文件,因为它与1.0规范不一致,而1.1规范解决了这个问题。即使Wget或pywb修复了这些问题,Wget生成的WARC文件也不够可靠,我使用,所以我寻找其他替代方案。引起我注意的爬虫程序简称为crawl。这是它的调用方式:
$爬行
(它的README文件说“非常简单”。)该程序支持一些命令行参数选项,但大多数默认值是最好的:它会从其他域中获取所需的页面(除非-exclude相关参数使用) ,但肯定不会递归出域。默认情况下,它将与远程站点建立十个并发连接。可以使用 -c 参数更改此值。但是,最重要的是生成的WARC文件可以用pywb完美加载。
未来的工作和替代方案
有更多关于使用 WARC 文件的资源。特别是有一个直接替代 Wget 的工具,它专门用于归档网站,称为 Wpull。它在实验上支持 PhantomJS 和 youtube-dl 的集成,可以分别下载更复杂的 JavaScript 页面和流媒体。该程序是名为 ArchiveBot 的复杂归档工具的基础。ArchiveBot 被 ArchiveTeam 的“分散的档案员、程序员、作家和演讲者”使用,他们致力于“在历史永远丢失之前保存历史”。PhantomJS 的集成似乎没有团队预期的那么好,所以 ArchiveTeam 还使用了其他分散的工具来镜像和保存更复杂的网站。例如,snscrape 将抓取社交媒体配置文件以生成要发送给 ArchiveBot 的页面列表。
如果没有提到被称为“网站复制器”的 HTTrack 项目,那么这篇文章是不完整的。它的工作原理与 Wget 类似。HTTrack 可以创建远程站点的本地副本,但遗憾的是它不支持导出 WRAC 文件。对于不熟悉命令行的新手用户来说,在人机交互方面更有价值。
同样,在我的研究中,我发现了一个完全重制的 Wget 版本,称为 Wget2,它支持多线程操作,这可能使它比其前身更快。与 Wget 相比,它舍弃了一些功能,但最显着的是拒绝模式、WARC 输出和 FTP 支持,以及添加 RSS、DNS 缓存和改进的 TLS 支持。
最后,我个人对这些工具的愿景是将它们与我现有的书签系统集成。我目前在 Wallabag 中有一些有趣的链接,这是一个自托管的“稍后阅读”服务,旨在成为 Pocket(现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 旨在仅保留文章的“可读”副本,而不是完整的副本。在某些情况下,“可读版本”实际上是不可读的,Wallabag 有时无法解析文章。相反,其他工具如 bookmark-archiver 或 reminiscence 会保存页面的屏幕截图和完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件,因此无法更可信地再现网页内容。
我所经历的关于镜像保存和归档的悲剧是死数据。幸运的是,业余档案工作者可以使用工具在线保存有趣的内容。对于那些不想打扰的人来说,“Internet Archive”似乎仍然存在,而且 ArchiveTeam 显然是在为 Internet Archive 本身进行备份。
通过:
作者:Anarcat 主题:lujun9972 译者:fuowang 校对:wxy
本文由 LCTT 原创,Linux China 获此殊荣 查看全部
php抓取网页标签(开发“快速行动和破除web陈规”的理念不相符)
译者:福旺
我最近在研究网站归档,因为有些朋友担心在系统管理不善或恶意删除的情况下会失去对放置在互联网上的内容的控制。这使得网站归档成为系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难存档。本文介绍了归档传统网站的过程,并解释了它在面对最新流行的单页应用程序 (SPA) 现代网站时的缺点。
转换为简单的网站
手动编码 HTML 网站的日子早已一去不复返了。当今的网站是动态的,并且使用最新的 JavaScript、PHP 或 Python 框架即时构建。因此,这些站点更容易受到攻击:数据库崩溃、升级错误或未修复的漏洞都可能导致数据丢失。之前做网页开发的时候,不得不接受一个客户的想法:希望网站基本上可以长生不老。这种期望与Web开发“快速行动,打破陈规”的想法不谋而合。对此,Drupal 内容管理系统(CMS)的使用尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担高昂的升级成本。解决办法是将这些网站归档:基于实时动态的网站,将它们转换为纯 HTML 文件,可以由任何 Web 服务器永久提供服务。此过程对您自己的动态网站非常有用,也适用于您想要保护但无法控制的第三方网站。
对于简单的静态网站,旧的 Wget 程序可以完成这项工作。但是,镜像和保存完整网站的命令很复杂:
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
--backup-converted --page-requisites --adjust-extension \
--base=./ --directory-prefix=./ --span-hosts \
--域=,
上述命令下载网页内容,同时抓取指定域名内的所有内容。在为您最喜欢的网站执行此操作之前,请考虑此类抓取可能对您的网站产生的影响。上面的命令故意忽略robots.txt规则,就像现在归档者的习惯做法一样,尽可能快地归档网站。大多数爬虫可以选择暂停和限制爬行之间的带宽使用,以避免站点瘫痪。
上面的命令还会得到“页面所需(LCTT Annotation:单个页面所需的所有元素)”,比如样式表(CSS)、图片、脚本等。下载页面的内容将被修改,以便链接也指向本地副本。任何 Web 服务器都可以托管生成的文件集,从而生成原创
网站的静态副本。
以上是一切顺利的时候。任何使用过计算机的人都知道,事情很少会按计划进行;各种各样的事情都会以有趣的方式使程序偏离轨道。例如,日历块在网站上流行了一段时间。内容管理系统会动态生成这些内容,这会使爬虫陷入死循环,试图检索所有页面。智能归档器可以使用正则表达式(例如,Wget 有一个 --reject-regex 选项)来忽略有问题的资源。如果可以访问站点的管理界面,另一种方法是禁用日历、登录表单、评论表单等动态区域。一旦网站变得静态,(那些动态区域)肯定会停止工作,因此从原创
网站中去除这些杂乱的内容并非完全没有意义。
JavaScript 的噩梦
不幸的是,有些网站不仅仅是用纯 HTML 文件构建的。例如,在单页网站中,Web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将很难重新创建这些站点的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用渐进增强技术来提供内容和实现功能,而无需使用 JavaScript,但使用 NoScript 或 uMatrix 等插件的人很少遵循这些准则。
传统的归档方法有时会以最傻瓜式
方式失败。在尝试为本地报纸网站 (pamplemousse.ca) 创建备份时,我发现 WordPress 在收录
的 JavaScript 的末尾添加了一个查询字符串(例如:?ver=1.12. 4)。这会使提供存档服务的web服务器无法正确检测内容类型,因为它依赖文件扩展名来发送正确的Content-Type头信息。当web浏览器加载此类存档时,这些脚本将无法加载,导致动态网站损坏。
随着 Web 转变为使用浏览器作为执行任意代码的虚拟机,依赖于纯 HTML 文件解析的归档方法需要相应地进行调整。解决这个问题的方法是在爬取时记录(并重现)服务器提供的HTTP头信息。事实上,专业档案工作者使用这种方法。
创建和显示 WARC 文件
在 Internet Archive 网站上,布鲁斯特·卡勒 (Brewster Kahle) 和迈克·伯纳 (Mike Burner) 于 1996 年设计了 ARC(或“ARChive”)文件格式,以提供一种方法来聚合他们存档工作产生的数百万个小文件。该格式最终被标准化为 WARC(“Web ARChive”)规范,该规范于 2009 年作为 ISO 标准发布并于 2017 年修订。标准化工作由国际互联网保护联盟(IIPC)牵头。根据维基百科,这是一个“国际图书馆组织和其他组织,旨在协调保护未来互联网内容的努力”;它的成员包括美国国会图书馆(US Library of Congress)和互联网档案馆。后者在其基于 Java 的 Heritrix 爬虫中使用 WARC 格式(LCTT 翻译和注释:
WARC 在单个压缩文件中聚合多个资源,例如 HTTP 标头信息、文件内容和其他元数据。方便的是,Wget 实际上提供了 --warc 参数来支持 WARC 格式。不幸的是,Web 浏览器无法直接显示 WARC 文件,因此为了访问存档文件,需要查看器或进行某种格式转换。我找到的最简单的查看器是 pywb,它以 Python 包的形式运行一个简单的 Web 服务器,并提供一个类似于“Wayback Machine”的界面来浏览 WARC 文件的内容。执行以下命令将显示地址为 8080/ 的 WARC 文件的内容:
$ pip 安装 pywb
$ wb-manager 初始化示例
$ wb-manager 添加示例 crawl.warc.gz
$回归
顺便说一下,这个工具是由Webrecorder 服务提供商创建的,Webrecoder 服务可以使用Web 浏览器保存动态页面的内容。
遗憾的是pywb无法加载Wget生成的WARC文件,因为它与1.0规范不一致,而1.1规范解决了这个问题。即使Wget或pywb修复了这些问题,Wget生成的WARC文件也不够可靠,我使用,所以我寻找其他替代方案。引起我注意的爬虫程序简称为crawl。这是它的调用方式:
$爬行
(它的README文件说“非常简单”。)该程序支持一些命令行参数选项,但大多数默认值是最好的:它会从其他域中获取所需的页面(除非-exclude相关参数使用) ,但肯定不会递归出域。默认情况下,它将与远程站点建立十个并发连接。可以使用 -c 参数更改此值。但是,最重要的是生成的WARC文件可以用pywb完美加载。
未来的工作和替代方案
有更多关于使用 WARC 文件的资源。特别是有一个直接替代 Wget 的工具,它专门用于归档网站,称为 Wpull。它在实验上支持 PhantomJS 和 youtube-dl 的集成,可以分别下载更复杂的 JavaScript 页面和流媒体。该程序是名为 ArchiveBot 的复杂归档工具的基础。ArchiveBot 被 ArchiveTeam 的“分散的档案员、程序员、作家和演讲者”使用,他们致力于“在历史永远丢失之前保存历史”。PhantomJS 的集成似乎没有团队预期的那么好,所以 ArchiveTeam 还使用了其他分散的工具来镜像和保存更复杂的网站。例如,snscrape 将抓取社交媒体配置文件以生成要发送给 ArchiveBot 的页面列表。
如果没有提到被称为“网站复制器”的 HTTrack 项目,那么这篇文章是不完整的。它的工作原理与 Wget 类似。HTTrack 可以创建远程站点的本地副本,但遗憾的是它不支持导出 WRAC 文件。对于不熟悉命令行的新手用户来说,在人机交互方面更有价值。
同样,在我的研究中,我发现了一个完全重制的 Wget 版本,称为 Wget2,它支持多线程操作,这可能使它比其前身更快。与 Wget 相比,它舍弃了一些功能,但最显着的是拒绝模式、WARC 输出和 FTP 支持,以及添加 RSS、DNS 缓存和改进的 TLS 支持。
最后,我个人对这些工具的愿景是将它们与我现有的书签系统集成。我目前在 Wallabag 中有一些有趣的链接,这是一个自托管的“稍后阅读”服务,旨在成为 Pocket(现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 旨在仅保留文章的“可读”副本,而不是完整的副本。在某些情况下,“可读版本”实际上是不可读的,Wallabag 有时无法解析文章。相反,其他工具如 bookmark-archiver 或 reminiscence 会保存页面的屏幕截图和完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件,因此无法更可信地再现网页内容。
我所经历的关于镜像保存和归档的悲剧是死数据。幸运的是,业余档案工作者可以使用工具在线保存有趣的内容。对于那些不想打扰的人来说,“Internet Archive”似乎仍然存在,而且 ArchiveTeam 显然是在为 Internet Archive 本身进行备份。
通过:
作者:Anarcat 主题:lujun9972 译者:fuowang 校对:wxy
本文由 LCTT 原创,Linux China 获此殊荣
php抓取网页标签(php抓取网页标签的函数叫sendarray函数。get请求的话可以用-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-25 13:11
php抓取网页标签的函数叫sendarray函数。
get请求的话可以用-u"file:/users/hjrw/desktop/xxx/out.html"
post请求,你这里post请求的url参数一样,type需要匹配。
http有个post请求:post是用get请求提交参数
一样的accept-encodingpost是postresponse还是header来验证,
post和get又不一样。我想ftp传文件,应该使用get请求。
get相对来说比较安全。post建议自己处理一下。请自行判断参数是不是真的。
在http中post即为向服务器提交数据,是个不可逆的过程,一次提交之后永远不能更改或删除。ftp传文件用get,ftp服务器处理提交给服务器的文件用post。
post是格式化python请求消息,参数一般有url,method,content-type等post请求提交给服务器的数据由content-type,method来决定。在浏览器还提供了send方法参数。
用get可以传数据,带空格。服务器回复消息。
以前面试,有同学提到,他说post可以传任何参数,只要带的是字符串就可以传递给服务器。但是send给客户端推文件的时候显然就应该用post传值。先好好了解下什么是post, 查看全部
php抓取网页标签(php抓取网页标签的函数叫sendarray函数。get请求的话可以用-)
php抓取网页标签的函数叫sendarray函数。
get请求的话可以用-u"file:/users/hjrw/desktop/xxx/out.html"
post请求,你这里post请求的url参数一样,type需要匹配。
http有个post请求:post是用get请求提交参数
一样的accept-encodingpost是postresponse还是header来验证,
post和get又不一样。我想ftp传文件,应该使用get请求。
get相对来说比较安全。post建议自己处理一下。请自行判断参数是不是真的。
在http中post即为向服务器提交数据,是个不可逆的过程,一次提交之后永远不能更改或删除。ftp传文件用get,ftp服务器处理提交给服务器的文件用post。
post是格式化python请求消息,参数一般有url,method,content-type等post请求提交给服务器的数据由content-type,method来决定。在浏览器还提供了send方法参数。
用get可以传数据,带空格。服务器回复消息。
以前面试,有同学提到,他说post可以传任何参数,只要带的是字符串就可以传递给服务器。但是send给客户端推文件的时候显然就应该用post传值。先好好了解下什么是post,
php抓取网页标签(上海SEO详解百度链接提交自动推送JS代码代码的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-23 23:00
很多SEO新手朋友经常抱怨“为什么网站更新文章百度不晚收录?”、“手动提交网站文章链接到百度我太累了,怎么办?” 和其他问题。我想说,百度官方搜索引擎已经提供了更有效的方法来解决这些问题,只是你没有关注而已。今天和大家聊一聊“百度链接提交与自动推送JS代码”的问题。
什么是百度链接提交和自动推送JS代码
百度链接提交自动推送JS代码是百度站长平台最新的轻量级链接提交组件。站长只需要把自动推送的JS代码放在站点每个页面的源代码中即可。当页面被访问时,页面链接会自动推送到百度,有利于百度更快地发现新页面。
安装百度链接提交自动推送JS代码有什么用?
为了快速发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送方式的技术门槛较高,于是我们顺势推出了一款成本更低的JS自动推送工具。一步安装即可实现页面自动推送,低成本高收益。
如何获取百度链接提交和自动推送JS代码
1、首先登录百度站长平台(没有百度站长平台的小伙伴可以自行注册。请点击【注册百度站长平台账号】)
2、 在百度站长平台左侧导航栏中,找到【网页抓取】,然后点击【提交链接】选择对应站点。如图:
3、在【链接提交】页面找到【自动提交】,点击【自动推送】,找到【自动推送工具代码】。如图:
4、 点击【复制代码】,自动推送JS代码的复制。
上海SEO详解百度链接提交自动推送JS代码安装
一、站长需要在网站公共模板中的HTML代码中添加自动推送JS代码:
(function(){ var bp = document.(''); var curProtocol = window.location.protocol.split(':')[0]; if (curProtocol ==='https') {bp.src = ' #39;;} else {bp.src ='#39;;} var s = document.getElementsByTagName("")[0]; s.parentNode.insertBefore(bp, s);})();>
二、如果站长使用PHP语言开发网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件中的标签后添加一行代码:
为什么自动推送可以更快地将页面推送到百度搜索?
基于自动推送的实现原理,每次查看新页面,页面URL都会自动推送到百度,无需站长聚合URL再主动推送操作。
利用用户的浏览行为触发推送动作,节省站长手动操作的时间。
什么样的网站更适合自动推送?
自动推送适用于技术能力较弱,实施方便,后续维护成本低,无法支持24小时实时主动推送程序的站长。
站长只需部署一次自动推送JS代码的操作,即可实现新页面一浏览就推送的效果,低成本实现链接自动提交。
以上内容是百度链接提交和自动推送JS代码安装的全部说明。希望各位SEO小伙伴都能掌握百度链接提交和自动推送JS代码安装。更多SEO干货,尽在SEO研究中心。 查看全部
php抓取网页标签(上海SEO详解百度链接提交自动推送JS代码代码的问题)
很多SEO新手朋友经常抱怨“为什么网站更新文章百度不晚收录?”、“手动提交网站文章链接到百度我太累了,怎么办?” 和其他问题。我想说,百度官方搜索引擎已经提供了更有效的方法来解决这些问题,只是你没有关注而已。今天和大家聊一聊“百度链接提交与自动推送JS代码”的问题。
什么是百度链接提交和自动推送JS代码
百度链接提交自动推送JS代码是百度站长平台最新的轻量级链接提交组件。站长只需要把自动推送的JS代码放在站点每个页面的源代码中即可。当页面被访问时,页面链接会自动推送到百度,有利于百度更快地发现新页面。
安装百度链接提交自动推送JS代码有什么用?
为了快速发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送方式的技术门槛较高,于是我们顺势推出了一款成本更低的JS自动推送工具。一步安装即可实现页面自动推送,低成本高收益。
如何获取百度链接提交和自动推送JS代码
1、首先登录百度站长平台(没有百度站长平台的小伙伴可以自行注册。请点击【注册百度站长平台账号】)
2、 在百度站长平台左侧导航栏中,找到【网页抓取】,然后点击【提交链接】选择对应站点。如图:

3、在【链接提交】页面找到【自动提交】,点击【自动推送】,找到【自动推送工具代码】。如图:
4、 点击【复制代码】,自动推送JS代码的复制。
上海SEO详解百度链接提交自动推送JS代码安装
一、站长需要在网站公共模板中的HTML代码中添加自动推送JS代码:
(function(){ var bp = document.(''); var curProtocol = window.location.protocol.split(':')[0]; if (curProtocol ==='https') {bp.src = ' #39;;} else {bp.src ='#39;;} var s = document.getElementsByTagName("")[0]; s.parentNode.insertBefore(bp, s);})();>
二、如果站长使用PHP语言开发网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件中的标签后添加一行代码:
为什么自动推送可以更快地将页面推送到百度搜索?
基于自动推送的实现原理,每次查看新页面,页面URL都会自动推送到百度,无需站长聚合URL再主动推送操作。
利用用户的浏览行为触发推送动作,节省站长手动操作的时间。
什么样的网站更适合自动推送?
自动推送适用于技术能力较弱,实施方便,后续维护成本低,无法支持24小时实时主动推送程序的站长。
站长只需部署一次自动推送JS代码的操作,即可实现新页面一浏览就推送的效果,低成本实现链接自动提交。
以上内容是百度链接提交和自动推送JS代码安装的全部说明。希望各位SEO小伙伴都能掌握百度链接提交和自动推送JS代码安装。更多SEO干货,尽在SEO研究中心。
php抓取网页标签(php抓取网页标签的办法有两种:(1)通过泛洪取代目标解析首先定义一个列表,jsonquery.data(")
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-15 20:01
<p>php抓取网页标签的办法有两种:(1)通过泛洪取代目标解析首先定义一个列表,jsonquery.data(" 查看全部
php抓取网页标签(php抓取网页标签的办法有两种:(1)通过泛洪取代目标解析首先定义一个列表,jsonquery.data(")
<p>php抓取网页标签的办法有两种:(1)通过泛洪取代目标解析首先定义一个列表,jsonquery.data("
php抓取网页标签(php抓取网页标签信息可以从以下几个方面做记录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-14 07:02
php抓取网页标签信息可以从以下几个方面做记录。1.网页封装,生成网页json字符串2.post将标签拆分成多个post协议对象,这些对象存储在不同的元素文件中。3.发送请求4.解析返回信息post的方式是post传递php的,不同的post协议(也可以是http)不同,封装的格式也不同,可以使用php的类封装数据,或者反序列化json格式的post数据格式,很多开源的封装工具,我们也可以通过封装工具直接操作封装的数据。
php调用nodejs的postman,getman可以做到。nodejs封装postman为json或者xml格式的,再提供json或者xml格式的postman连接,但是postman可能没有连接的功能,在postmanpost之前可以先user-agent来做判断。
postman+nodejs做抓取?别想了。
postman
postman、getman都可以
用googleplaytunnel
用tp调用http请求
三个api了解一下?简单介绍一下如何抓取?调用微信表情,上传表情和微信表情包。
我写了一个h5,抓取其数据,传数据给朋友发送,
看是爬虫还是cookie。 查看全部
php抓取网页标签(php抓取网页标签信息可以从以下几个方面做记录)
php抓取网页标签信息可以从以下几个方面做记录。1.网页封装,生成网页json字符串2.post将标签拆分成多个post协议对象,这些对象存储在不同的元素文件中。3.发送请求4.解析返回信息post的方式是post传递php的,不同的post协议(也可以是http)不同,封装的格式也不同,可以使用php的类封装数据,或者反序列化json格式的post数据格式,很多开源的封装工具,我们也可以通过封装工具直接操作封装的数据。
php调用nodejs的postman,getman可以做到。nodejs封装postman为json或者xml格式的,再提供json或者xml格式的postman连接,但是postman可能没有连接的功能,在postmanpost之前可以先user-agent来做判断。
postman+nodejs做抓取?别想了。
postman
postman、getman都可以
用googleplaytunnel
用tp调用http请求
三个api了解一下?简单介绍一下如何抓取?调用微信表情,上传表情和微信表情包。
我写了一个h5,抓取其数据,传数据给朋友发送,
看是爬虫还是cookie。
php抓取网页标签( PHP实现网页内容html标签补全和过滤的方法实例解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-05 14:01
PHP实现网页内容html标签补全和过滤的方法实例解析)
PHP完成和过滤网页内容html标签的方法总结【2种方法】
更新时间:2017年4月27日10:58:53 作者:网站
本文文章主要介绍了PHP对网页内容的html标签补全和过滤的实现方法,结合示例表单分析了常见的PHP标签检查、补全、关闭、过滤等相关操作技巧。有需要的朋友可以参考
本文介绍了一个示例,说明 PHP 如何实现网页内容的 html 标签补全和过滤。分享给大家,供大家参考,如下:
如果你的网页内容的html标签显示不全,部分table标签不完整,页面乱七八糟,或者你收录了除你内容以外的部分html页面,我们可以写一个函数方法来完成html标记并过滤掉无用的 html 标记。
php使HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
Closetags() 分析:
array_reverse():该函数颠倒原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名将丢失。
array_search(): array_search(value,array,strict),这个函数像in_array()一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有在数据类型和值相同时才会返回对应元素的键名。
php使HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
检查html($html)解析:
stripslashes():该函数去除由addslashes()函数添加的反斜杠。该函数用于清理从数据库或HTML表单中检索到的数据。
更多对PHP相关内容感兴趣的读者可以查看本站专题:《PHP数据结构与算法教程》、《PHP编程算法汇总》、《PHP排序算法汇总》、《PHP常用遍历算法与技巧》 《总结》、《PHP数学运算技巧总结》、《PHP数组(数组)运算技巧》、《php字符串(字符串)使用技巧总结》、《php常用数据库操作技巧总结》
希望这篇文章能对你的 PHP 编程有所帮助。 查看全部
php抓取网页标签(
PHP实现网页内容html标签补全和过滤的方法实例解析)
PHP完成和过滤网页内容html标签的方法总结【2种方法】
更新时间:2017年4月27日10:58:53 作者:网站
本文文章主要介绍了PHP对网页内容的html标签补全和过滤的实现方法,结合示例表单分析了常见的PHP标签检查、补全、关闭、过滤等相关操作技巧。有需要的朋友可以参考
本文介绍了一个示例,说明 PHP 如何实现网页内容的 html 标签补全和过滤。分享给大家,供大家参考,如下:
如果你的网页内容的html标签显示不全,部分table标签不完整,页面乱七八糟,或者你收录了除你内容以外的部分html页面,我们可以写一个函数方法来完成html标记并过滤掉无用的 html 标记。
php使HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
Closetags() 分析:
array_reverse():该函数颠倒原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名将丢失。
array_search(): array_search(value,array,strict),这个函数像in_array()一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有在数据类型和值相同时才会返回对应元素的键名。
php使HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
检查html($html)解析:
stripslashes():该函数去除由addslashes()函数添加的反斜杠。该函数用于清理从数据库或HTML表单中检索到的数据。
更多对PHP相关内容感兴趣的读者可以查看本站专题:《PHP数据结构与算法教程》、《PHP编程算法汇总》、《PHP排序算法汇总》、《PHP常用遍历算法与技巧》 《总结》、《PHP数学运算技巧总结》、《PHP数组(数组)运算技巧》、《php字符串(字符串)使用技巧总结》、《php常用数据库操作技巧总结》
希望这篇文章能对你的 PHP 编程有所帮助。
php抓取网页标签(Linux文本编辑器Vim“真·简单”使用教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-05 00:08
因为金哥分享的东西(杂)越来越多,分类越来越多,层次越来越多,所以为了更好的显示URL地址,我们计划在近期修复所有文章 链接来自原创
/%category%/%post_id%.html
改为
/%post_id%.html
这将统一所有文章链接,不再有老长老;另一个优点是文章链接二维码也可以很简单。但是,更改 URL 是 SEO 的禁忌。为此,金哥参考了百度的网站修改规则,最大限度地保留了原来的收录。
获取所有链接
将下面的代码复制到utf8文件中,命名为post.php(文章)、page.php(page)、category.php(category)、tag.php(tag),放入网站 根目录没问题。
获取所有文章链接代码↓
获取所有页面链接代码↓
获取所有分类链接代码↓
获取所有标签链接代码↓
然后,进入服务器,以root账号使用wget命令结合这个PHP代码文件,生成指定的TXT文件。由于金哥只修改了文章链接,这里仅以文章命令为例,页面、分类、标签的修改请参考
wget -O /***/***/www.dujin.org/post.txt --no-check-certificate https://www.dujin.org/post.php
运行前需要注意自己的网站路径和txt文件存放路径。 --no-check-certificate 参数是因为 Jin 的博客是 HTTPS。如果 HTTP 站点可以删除此参数。
如果你的网站设置了360网站Guard或者其他CDN服务,还需要使用vim命令修改hosts文件,将你的网站域名指向你的服务器IP地址。
vim /etc/hosts
Linux 文本编辑器 Vim 《真·简单》教程
操作完成后,会在网站的根目录下生成一个post.txt文档。
此时使用纯文本编辑软件(如Emurasoft文本编辑器)批量查找替换重复的XML标记代码。
EmEditor 32&64 bit v17.4.第2版下载,附注册码
好了,到此为止,所有的URL链接都已经获取到了。如果您有任何问题,请留言。 查看全部
php抓取网页标签(Linux文本编辑器Vim“真·简单”使用教程(组图))
因为金哥分享的东西(杂)越来越多,分类越来越多,层次越来越多,所以为了更好的显示URL地址,我们计划在近期修复所有文章 链接来自原创
/%category%/%post_id%.html
改为
/%post_id%.html
这将统一所有文章链接,不再有老长老;另一个优点是文章链接二维码也可以很简单。但是,更改 URL 是 SEO 的禁忌。为此,金哥参考了百度的网站修改规则,最大限度地保留了原来的收录。
获取所有链接
将下面的代码复制到utf8文件中,命名为post.php(文章)、page.php(page)、category.php(category)、tag.php(tag),放入网站 根目录没问题。
获取所有文章链接代码↓
获取所有页面链接代码↓
获取所有分类链接代码↓
获取所有标签链接代码↓
然后,进入服务器,以root账号使用wget命令结合这个PHP代码文件,生成指定的TXT文件。由于金哥只修改了文章链接,这里仅以文章命令为例,页面、分类、标签的修改请参考
wget -O /***/***/www.dujin.org/post.txt --no-check-certificate https://www.dujin.org/post.php
运行前需要注意自己的网站路径和txt文件存放路径。 --no-check-certificate 参数是因为 Jin 的博客是 HTTPS。如果 HTTP 站点可以删除此参数。
如果你的网站设置了360网站Guard或者其他CDN服务,还需要使用vim命令修改hosts文件,将你的网站域名指向你的服务器IP地址。
vim /etc/hosts
Linux 文本编辑器 Vim 《真·简单》教程
操作完成后,会在网站的根目录下生成一个post.txt文档。
https://img.dujin.org/uploads/ ... 6.jpg 300w, https://img.dujin.org/uploads/ ... 3.jpg 768w" />此时使用纯文本编辑软件(如Emurasoft文本编辑器)批量查找替换重复的XML标记代码。
EmEditor 32&64 bit v17.4.第2版下载,附注册码
好了,到此为止,所有的URL链接都已经获取到了。如果您有任何问题,请留言。
php抓取网页标签(两个博客学习安全知识之一个博客爬取网站文章 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-03 17:17
)
前后历时两个月,终于完成了数据库课程。. . 考虑到wooyun关闭后各种wooyun资源转储的火爆,最近刚刚通过各种博客学习安全知识,想到做一个博客爬取网站,首先写了一个爬虫来爬取整个< @文章 的博客,然后显示它。
<p>这是网站的登录界面。左边的文字概括了我做整个网站的初衷,希望能成为一个博客采集平台,可以方便的爬取博客,然后展示这些转储。 查看全部
php抓取网页标签(两个博客学习安全知识之一个博客爬取网站文章
)
前后历时两个月,终于完成了数据库课程。. . 考虑到wooyun关闭后各种wooyun资源转储的火爆,最近刚刚通过各种博客学习安全知识,想到做一个博客爬取网站,首先写了一个爬虫来爬取整个< @文章 的博客,然后显示它。


<p>这是网站的登录界面。左边的文字概括了我做整个网站的初衷,希望能成为一个博客采集平台,可以方便的爬取博客,然后展示这些转储。
php抓取网页标签(几个主要特别注意的细节:细节、细节和注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-01-30 17:07
我们首先从搜索引擎的算法中得知,细节决定了网站的优化成败。由于算法的不断更新,我们作为站长需要考虑很多优化因素。以下是一些需要注意的关键细节:
详情一、标题标签
1)每一个网站都有一个title标签,就是网站的title。标题的优化决定了后续网站的关键词流量。
2)蜘蛛通过代码抓取我们的网站。蜘蛛不知道网站的一些图片或者视频,但是标题标签可以让蜘蛛知道我们的网站是什么。.
3)网站标题是为了参与关键词的排名,所以在成都做网站代码优化的时候千万不要忽略网站@的标题标签>。
4)因为title标签是三个标签中最重要的;我们常说的关键词排名其实是指标题中的关键词,而不是关键词中的关键词,所以网站标题写的好坏直接影响到我们的排名< @网站。但切记不要为了排名而在标题中叠加关键词,否则会适得其反。
详情二、关键词标签
1)keywords 是网页中的关键词,
2)Keywords标签现在不参与排名,但是还是有很多SEO人员对keywords标签中的关键词很重视,没有必要。
3) 作为seo人员,我们必须是完整的,所以关键词标签也需要设置。建议在网站中写3-5
详情三、描述标签
1)description标签是网站页面的描述,用于介绍网站在成都的一般信息,以及网站内容的简要介绍. 在百度搜索一个关键词会显示标题,那么下面是描述。
2)写得好的描述也可以吸引用户访问网站,为网站带来流量。
详情四、h标签优化
1)h标签分为h1-h6标签,
2)h1标签是h标签中最重要的,成都的网站也被赋予了最高的权重,因为h1标签在一个页面上只能出现一次。一般在标题上写h1标签。因为这是每一页最重要的。
3)成都做网站,注意一页h1不要超过一个,但是h2-h6可以出现多次。
4)但是如果有h2-h6,就必须加上h1。成都做网站还是不写h标签,要写就必须写完整,没有h3,但没有h1。如果你看不懂代码,不要只在网站中添加h代码。
详情五、404页面页面处理
我们经常会遇到网站网站因为修改或其他运营原因出现死链接,所以此时启用404页面可以让搜索引擎快速删除这些页面。
还有一种情况是我们的网站被黑了,虽然我们已经采取了措施,但是页面上贴了很多非法信息。但是页面还是百度收录。在这种情况下,如果网站有404页,它可以帮助搜索引擎快速删除非法信息。
详情六、alt 标签
1)Alt标签用于在网站图片上添加描述(即替代文字),有利于蜘蛛的识别,因为蜘蛛知道代码但不知道图片,所以我们必须解释并告诉蜘蛛你网站@的图片中到底是什么>。
2)alt标签中关键词的堆积会影响spider的一对网站收录,只要在alt标签中使用简洁的描述即可。
代码优化对于网站提升排名很有帮助,但是再次强调,如果你看不懂代码,就不要在网站里面加代码,或者找能看懂代码的人教你如何更改代码。
详情七、网站地图实时更新。
网站Map 对于蜘蛛快速抓取网站 内容非常有帮助。网站Map就像一个网站的结构图,将网站的所有链接都采集在一个页面上,方便蜘蛛快速爬取整个站点的内容;网站 中常见的地图格式是 sitemap.xml。网站地图网址放在robots文件中,蜘蛛会沿着网站地图网址爬行。切记不要阻止蜘蛛爬取地图,保持网站地图实时更新,以保证蜘蛛能够获取到最详细、最新的信息。
详情八、网站机器人,txt文件
robots协议(也称为爬虫协议、机器人协议等)的全称是“robots Exclusion Protocol”。robots协议的本质是网站与搜索引擎爬虫之间的通信方式,引导搜索引擎更好地爬取网站内容。
网站通过robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。这有效地保护了网站的隐私,尤其是后台和数据库信息,有利于网站的安全。
详情九、nofollow标签
1)Nofollow 标签不传递权重。
2)一般会在QQ链接、微博等那些无意义的出站链接上写nofollow,以免传递网站的权重。另外,把成都兑换成网站朋友链的时候不要加nofollow,这是很不道德的。知道nofollow不传权重,也加到友好链接的代码中,这相当于告诉蜘蛛不要爬链接,对方网站会给你带来权重网站 @> ,
3)因为nofollow不传递权重,所以更换友情链接时要注意。可以查看对方是否在网站中添加了nofollow。你可以在浏览器中搜索nofollow插件,这样就可以在成都的网站中显示了。
注意:友情链接是在友情之后链接的。把nofollow加到别人的链接里,以后谁还敢和你交换链接?附属链接不得添加nofollow标签,切记!
详情十、优化网站的内容和布局
优化网站,最重要的是优化网站的布局和内容。首先是网站的布局,在网站刚做完的时候一定要考虑。优化是有害的,只需对 网站 布局进行适当调整即可。二是优化网站的内容,网站要定期更新文章,这些文章的标题和关键词一旦被修改就不能改变了发布,否则也会影响搜索引擎记录。
详解十一、明确网站外链有哪些分类和作用
在网站上添加链接时,一定要添加一些合法优质的链接,尽量不要发一些垃圾无用的网站,网站添加的链接数量也有特价@>一般来说,保持30左右的数量最合适,超过40会适得其反。
其他的外链又分为软文外链、分享外链、博客外链、描述文字、图片链接等。后期不可估量。所以我们必须坚持发布普通的外链。
详情十二、稳定空间和服务器
要做好一个网站并使这个网站流行起来,一个稳定的空间和服务器是基本配置。如果网站频繁对自己的服务器和主机进行改动,会导致网站频繁改动,不利于搜索引擎记录网站流量。一般来说,只有当网站经常遇到打不开、无法浏览的情况时,才需要更换主机或服务器,以换取更好的服务器。所以对于网站的优化,不要盲目,其他的事情做好就好了。一般不需要更改服务器和空间。频繁更换服务器和ip也将搜索引擎误认为是不稳定的网站,这会对收录和整体网站的排名产生一定的影响。
总结:以上是关于网站的优化需要特别注意的细节,同时也说明了这些细节处理不当会导致网站的弊端。当然,网站优化是一项长期、细心、耐心的工作,所以大家在优化的时候一定要细心细心,多注意上面提到的细节,努力提高网站@的排名> 尽快。 查看全部
php抓取网页标签(几个主要特别注意的细节:细节、细节和注意事项)
我们首先从搜索引擎的算法中得知,细节决定了网站的优化成败。由于算法的不断更新,我们作为站长需要考虑很多优化因素。以下是一些需要注意的关键细节:
详情一、标题标签
1)每一个网站都有一个title标签,就是网站的title。标题的优化决定了后续网站的关键词流量。
2)蜘蛛通过代码抓取我们的网站。蜘蛛不知道网站的一些图片或者视频,但是标题标签可以让蜘蛛知道我们的网站是什么。.
3)网站标题是为了参与关键词的排名,所以在成都做网站代码优化的时候千万不要忽略网站@的标题标签>。
4)因为title标签是三个标签中最重要的;我们常说的关键词排名其实是指标题中的关键词,而不是关键词中的关键词,所以网站标题写的好坏直接影响到我们的排名< @网站。但切记不要为了排名而在标题中叠加关键词,否则会适得其反。
详情二、关键词标签
1)keywords 是网页中的关键词,
2)Keywords标签现在不参与排名,但是还是有很多SEO人员对keywords标签中的关键词很重视,没有必要。
3) 作为seo人员,我们必须是完整的,所以关键词标签也需要设置。建议在网站中写3-5
详情三、描述标签
1)description标签是网站页面的描述,用于介绍网站在成都的一般信息,以及网站内容的简要介绍. 在百度搜索一个关键词会显示标题,那么下面是描述。
2)写得好的描述也可以吸引用户访问网站,为网站带来流量。
详情四、h标签优化
1)h标签分为h1-h6标签,
2)h1标签是h标签中最重要的,成都的网站也被赋予了最高的权重,因为h1标签在一个页面上只能出现一次。一般在标题上写h1标签。因为这是每一页最重要的。
3)成都做网站,注意一页h1不要超过一个,但是h2-h6可以出现多次。
4)但是如果有h2-h6,就必须加上h1。成都做网站还是不写h标签,要写就必须写完整,没有h3,但没有h1。如果你看不懂代码,不要只在网站中添加h代码。
详情五、404页面页面处理
我们经常会遇到网站网站因为修改或其他运营原因出现死链接,所以此时启用404页面可以让搜索引擎快速删除这些页面。
还有一种情况是我们的网站被黑了,虽然我们已经采取了措施,但是页面上贴了很多非法信息。但是页面还是百度收录。在这种情况下,如果网站有404页,它可以帮助搜索引擎快速删除非法信息。
详情六、alt 标签
1)Alt标签用于在网站图片上添加描述(即替代文字),有利于蜘蛛的识别,因为蜘蛛知道代码但不知道图片,所以我们必须解释并告诉蜘蛛你网站@的图片中到底是什么>。
2)alt标签中关键词的堆积会影响spider的一对网站收录,只要在alt标签中使用简洁的描述即可。
代码优化对于网站提升排名很有帮助,但是再次强调,如果你看不懂代码,就不要在网站里面加代码,或者找能看懂代码的人教你如何更改代码。
详情七、网站地图实时更新。
网站Map 对于蜘蛛快速抓取网站 内容非常有帮助。网站Map就像一个网站的结构图,将网站的所有链接都采集在一个页面上,方便蜘蛛快速爬取整个站点的内容;网站 中常见的地图格式是 sitemap.xml。网站地图网址放在robots文件中,蜘蛛会沿着网站地图网址爬行。切记不要阻止蜘蛛爬取地图,保持网站地图实时更新,以保证蜘蛛能够获取到最详细、最新的信息。
详情八、网站机器人,txt文件
robots协议(也称为爬虫协议、机器人协议等)的全称是“robots Exclusion Protocol”。robots协议的本质是网站与搜索引擎爬虫之间的通信方式,引导搜索引擎更好地爬取网站内容。
网站通过robots协议告诉搜索引擎哪些页面可以爬取,哪些页面不能爬取。这有效地保护了网站的隐私,尤其是后台和数据库信息,有利于网站的安全。
详情九、nofollow标签
1)Nofollow 标签不传递权重。
2)一般会在QQ链接、微博等那些无意义的出站链接上写nofollow,以免传递网站的权重。另外,把成都兑换成网站朋友链的时候不要加nofollow,这是很不道德的。知道nofollow不传权重,也加到友好链接的代码中,这相当于告诉蜘蛛不要爬链接,对方网站会给你带来权重网站 @> ,
3)因为nofollow不传递权重,所以更换友情链接时要注意。可以查看对方是否在网站中添加了nofollow。你可以在浏览器中搜索nofollow插件,这样就可以在成都的网站中显示了。
注意:友情链接是在友情之后链接的。把nofollow加到别人的链接里,以后谁还敢和你交换链接?附属链接不得添加nofollow标签,切记!
详情十、优化网站的内容和布局
优化网站,最重要的是优化网站的布局和内容。首先是网站的布局,在网站刚做完的时候一定要考虑。优化是有害的,只需对 网站 布局进行适当调整即可。二是优化网站的内容,网站要定期更新文章,这些文章的标题和关键词一旦被修改就不能改变了发布,否则也会影响搜索引擎记录。
详解十一、明确网站外链有哪些分类和作用
在网站上添加链接时,一定要添加一些合法优质的链接,尽量不要发一些垃圾无用的网站,网站添加的链接数量也有特价@>一般来说,保持30左右的数量最合适,超过40会适得其反。
其他的外链又分为软文外链、分享外链、博客外链、描述文字、图片链接等。后期不可估量。所以我们必须坚持发布普通的外链。
详情十二、稳定空间和服务器
要做好一个网站并使这个网站流行起来,一个稳定的空间和服务器是基本配置。如果网站频繁对自己的服务器和主机进行改动,会导致网站频繁改动,不利于搜索引擎记录网站流量。一般来说,只有当网站经常遇到打不开、无法浏览的情况时,才需要更换主机或服务器,以换取更好的服务器。所以对于网站的优化,不要盲目,其他的事情做好就好了。一般不需要更改服务器和空间。频繁更换服务器和ip也将搜索引擎误认为是不稳定的网站,这会对收录和整体网站的排名产生一定的影响。
总结:以上是关于网站的优化需要特别注意的细节,同时也说明了这些细节处理不当会导致网站的弊端。当然,网站优化是一项长期、细心、耐心的工作,所以大家在优化的时候一定要细心细心,多注意上面提到的细节,努力提高网站@的排名> 尽快。
php抓取网页标签(httpstatus封装定制httphttp的exceptionhttp回调get/postgetfiltergetfilterpromise连接池实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-30 03:01
php抓取网页标签、检测链接格式等。laravel第三方封装了laravel-workerman,框架具备httpapi,能够自动帮我们创建httpchannel协程对接服务,达到同步处理和异步等待模式,省去了服务端和客户端的轮回处理,无需我们管理等待连接池。httpchannel这个模块提供了laravel提供的支持http协议的api,这些api通过interface接口进行调用,比如说http请求头封装的模块,包括requestprotocol、accepttype、acceptheader、protocolname和httporigin等参数,我们可以把这些参数直接封装在类里面,调用时直接使用这些参数去请求,例如:stream-scale来请求另一个协程来消费。
api的具体实现可以通过如下代码进行实现:laravel-workerman/laravel-workerman2一、laravel多进程封装利用laravel-workerman封装这些api,我们可以解决一些常见的问题,例如:接口封装。各个httpserver都有自己的名字,需要我们去封装这些api来对接服务。
没有统一的httpapi名字。laravel框架默认提供了命名空间,但是没有提供唯一的通用名字,为了统一命名空间,给每个协程都提供一个专有名字是很有必要的。httpserver名字。封装了这些协程的httpserver名字,这对我们使用协程有很大帮助。连接池封装。如果要实现多线程,就需要利用连接池来帮我们管理应用资源,而连接池存放协程的连接。
所以,laravel提供了一个apilpush和remote的封装:laravel-workerman/laravel-workerman3laravel提供了几个api封装。数据来源:定制httpchannel连接池的封装客户端api封装定制httptoken、formprotocollaravel提供了服务端解决方案httpeasyhook,利用它封装httpchannel,我们可以不用维护自己的httpchannel的连接池,这个封装挺有意思的,有兴趣的朋友可以看看:/。
httpstatus封装定制httphttp的exceptionhttp的回调get/postgetfiltergetfilterpromise连接池实现。我们定制httpchannel分配连接是通过一个httpconnector来实现的,通过timeout.write使连接池handle的连接量进入到更高效的状态,所以我们有了上述封装。
当连接更少的时候我们就要更多的处理连接请求。我们可以封装定制httpconnector,来为我们提供更简单的多进程处理模式和协程处理模式:websocket基于thrift编写的异步客户端框架封装。封装了一个方便于go、python等语言异步处理的框架。连接池调度。laravel封装多进程。二、抓取各种网页标签抓取网页标签最常见的就是formaction,我们可以通过封装了几个自定义的标签,在抓取一个完整。 查看全部
php抓取网页标签(httpstatus封装定制httphttp的exceptionhttp回调get/postgetfiltergetfilterpromise连接池实现)
php抓取网页标签、检测链接格式等。laravel第三方封装了laravel-workerman,框架具备httpapi,能够自动帮我们创建httpchannel协程对接服务,达到同步处理和异步等待模式,省去了服务端和客户端的轮回处理,无需我们管理等待连接池。httpchannel这个模块提供了laravel提供的支持http协议的api,这些api通过interface接口进行调用,比如说http请求头封装的模块,包括requestprotocol、accepttype、acceptheader、protocolname和httporigin等参数,我们可以把这些参数直接封装在类里面,调用时直接使用这些参数去请求,例如:stream-scale来请求另一个协程来消费。
api的具体实现可以通过如下代码进行实现:laravel-workerman/laravel-workerman2一、laravel多进程封装利用laravel-workerman封装这些api,我们可以解决一些常见的问题,例如:接口封装。各个httpserver都有自己的名字,需要我们去封装这些api来对接服务。
没有统一的httpapi名字。laravel框架默认提供了命名空间,但是没有提供唯一的通用名字,为了统一命名空间,给每个协程都提供一个专有名字是很有必要的。httpserver名字。封装了这些协程的httpserver名字,这对我们使用协程有很大帮助。连接池封装。如果要实现多线程,就需要利用连接池来帮我们管理应用资源,而连接池存放协程的连接。
所以,laravel提供了一个apilpush和remote的封装:laravel-workerman/laravel-workerman3laravel提供了几个api封装。数据来源:定制httpchannel连接池的封装客户端api封装定制httptoken、formprotocollaravel提供了服务端解决方案httpeasyhook,利用它封装httpchannel,我们可以不用维护自己的httpchannel的连接池,这个封装挺有意思的,有兴趣的朋友可以看看:/。
httpstatus封装定制httphttp的exceptionhttp的回调get/postgetfiltergetfilterpromise连接池实现。我们定制httpchannel分配连接是通过一个httpconnector来实现的,通过timeout.write使连接池handle的连接量进入到更高效的状态,所以我们有了上述封装。
当连接更少的时候我们就要更多的处理连接请求。我们可以封装定制httpconnector,来为我们提供更简单的多进程处理模式和协程处理模式:websocket基于thrift编写的异步客户端框架封装。封装了一个方便于go、python等语言异步处理的框架。连接池调度。laravel封装多进程。二、抓取各种网页标签抓取网页标签最常见的就是formaction,我们可以通过封装了几个自定义的标签,在抓取一个完整。
php抓取网页标签( tag页面是什么?如何进行SEOSEOer利用进行优化?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-27 11:19
tag页面是什么?如何进行SEOSEOer利用进行优化?)
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
oracle10g中的几个概念(sid/db_name/server_name)
一、数据库名1.数据库名的概念 数据库名(db_name)是一个数据库的标识,就像一个人的身份证号码一样。如果一台机器上安装了多个数据库,每个数据库都有一个数据库名称。安装或创建数据库后,将参数 DB_NAME 写入参数文件。数据库名称在 $ORACLE_HOME/admin/db_name/pfile/init.ora 文件中#########################
使用网络抓取数据赚钱的 3 个想法
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
类别和关键字:标记输出、类别输入
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖关系
GoogleTagManager 方便了网站 分析师的工作,我一直认为它有一个局限性:Container 中的标签是异步加载的,标签之间没有顺序,所以如果之前有的标签有依赖关系,那就是如果Btag 必须在 ATag 执行后执行,才有效。
一个关于标签书写规范的文章
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
标签是什么意思?
首先tag是指一个标签,也可以说是一个关键词标签。Tag 标签是一种更加灵活有趣的日志分类方式。您可以为每个日志添加一个或多个标签。(tag),然后你就可以看到 BlogBus 上所有与你使用相同 Tag 的日志,方便用户查看,从而与其他用户产生更多的联系和交流。
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
Tag技术在网站优化中的作用
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
【SEO基础】带你了解TAG的基本介绍和用法
SEO大家可能都懂,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是一种自定义,比分类更准确、更具体,可以概括主要内容的文章关键词,
Flask 的 SERVER_NAME 解析
SERVER_NAME 是一个在 Flask 中容易用错的设置值。本文将介绍如何正确使用 SERVER_NAME。Flask 中的 SERVER_NAME 主要做了两件事:协助 Flask 在活动请求之外生成绝对 URL(例如在电子邮件中嵌入 网站 URL)以支持子域 许多人错误地认为它可以同时做其他两件事。第一件事:我们知道的绝对 URL,url_for 默认是
分析TAG标签在SEO优化中的作用
我一直认为TAG标签在SEO中的作用不是很大。相信很多同事朋友也有这样的困惑。有些人甚至忽略了 TAG 标签的这一方面。当然,这对排名有什么影响并不明显。也有很多人问我TAG标签的具体应用是什么。让我们研究一下。
php抓取
总结:php抓取 查看全部
php抓取网页标签(
tag页面是什么?如何进行SEOSEOer利用进行优化?)
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
oracle10g中的几个概念(sid/db_name/server_name)
一、数据库名1.数据库名的概念 数据库名(db_name)是一个数据库的标识,就像一个人的身份证号码一样。如果一台机器上安装了多个数据库,每个数据库都有一个数据库名称。安装或创建数据库后,将参数 DB_NAME 写入参数文件。数据库名称在 $ORACLE_HOME/admin/db_name/pfile/init.ora 文件中#########################
使用网络抓取数据赚钱的 3 个想法
文章目录使用自动程序花最少的钱在Airbnb上住最好的酒店捕获特定产品的价格数据,以最低的价格购买并捕获公共数据,在大时代将其可视化数据,如何有效获取数据 数据已成为业务决策的驱动力
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
类别和关键字:标记输出、类别输入
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖关系
GoogleTagManager 方便了网站 分析师的工作,我一直认为它有一个局限性:Container 中的标签是异步加载的,标签之间没有顺序,所以如果之前有的标签有依赖关系,那就是如果Btag 必须在 ATag 执行后执行,才有效。
一个关于标签书写规范的文章
tag是英文tag的中文翻译,又名“自由分类”、“焦点分类”,TAG的分类功能,tag对用户体验确实有很好的享受,可以快速找到相关的文章和信息。
标签是什么意思?
首先tag是指一个标签,也可以说是一个关键词标签。Tag 标签是一种更加灵活有趣的日志分类方式。您可以为每个日志添加一个或多个标签。(tag),然后你就可以看到 BlogBus 上所有与你使用相同 Tag 的日志,方便用户查看,从而与其他用户产生更多的联系和交流。
如何善用博客或网站上的标签?
用于博客和 网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在这篇文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
Tag技术在网站优化中的作用
标签(中文称为“标签”)是一种组织和管理在线信息的新方式。它不同于传统的关键词搜索文件本身,而是一种模糊而智能的分类。标记(tag)是一种更灵活有趣的日志分类方式。您可以为每条日志添加一个或多个标签(tags),然后您就可以看到东行日志上所有与您使用相同标签的日志。日志,因此和其他
【SEO基础】带你了解TAG的基本介绍和用法
SEO大家可能都懂,但不一定是TAG标签,所以先说一下TAG的概念。一般来说,TAG标签是一种自定义,比分类更准确、更具体,可以概括主要内容的文章关键词,
Flask 的 SERVER_NAME 解析
SERVER_NAME 是一个在 Flask 中容易用错的设置值。本文将介绍如何正确使用 SERVER_NAME。Flask 中的 SERVER_NAME 主要做了两件事:协助 Flask 在活动请求之外生成绝对 URL(例如在电子邮件中嵌入 网站 URL)以支持子域 许多人错误地认为它可以同时做其他两件事。第一件事:我们知道的绝对 URL,url_for 默认是
分析TAG标签在SEO优化中的作用
我一直认为TAG标签在SEO中的作用不是很大。相信很多同事朋友也有这样的困惑。有些人甚至忽略了 TAG 标签的这一方面。当然,这对排名有什么影响并不明显。也有很多人问我TAG标签的具体应用是什么。让我们研究一下。
php抓取
总结:php抓取
php抓取网页标签(php抓取网页标签+解析源码+内容提取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-21 09:07
php抓取网页标签+解析源码+内容提取1.web应用中页面流量来源会有很多,当页面较多时,页面中会有大量的每页能抓取到的条目不一样,比如说整个页面都是列表式标签是每页a列,每个条目a列加上b列,每个条目b列加上c列,列表b列加上列表c列,每个条目a列加上列表d列...2.查看流量依据target>limit,/root/路径查看,页面中不同的条目查看方式不同,比如说常见的页面中可以抓取文章列表,文章列表是/article/a,但是列表中不仅仅是文章列表,还有一些跳转标签,也属于该页的元素,查看方式是/article/a?id=1&page=13.页面提取标签解析所谓提取标签,就是抽取出标签中的文本框,并把该文本框中内容提取出来,其他的标签是通过跳转标签查看4.数据查看to或each导航页抓取是不是异步加载的,每个页面会有各自不同的加载方式。
window+r异步刷新整个页面,跳转到相应的跳转页面,观察相应页面的dom结构,爬虫基本都是这么走的。from通过函数指定页面的路径,并发送请求获取页面数据js页查看是否支持eval处理(浏览器或者爬虫都可以)index页面抓取时,模拟浏览器会返回js页面,爬虫这时候需要抓取即时值xhr然后按照页面dom走即可,页面爬取时post也会返回值,可以观察抓取的代码和返回值。
4.解析提取data字段json数据(python)json数据(python爬虫抓取+解析+提取)也是和页面流量一样,每页都有固定的json数据可以查看(爬虫)整个页面会有4个数据列(list)支持json查看:span[0-4][...][...][...]#anymultipleitems(加密后)listlist={'b':1,'c':2,'d':3,'e':4}iflist!=none:print('该页未抓取完成...')request.post(url,stream=true)返回的数据接收了index,checkbox,tag的数据,都是json数据。
functiondict(data,string,fn){returndata||"{"+data||""]""{"b":"1","c":"2","d":"3","e":"4","l":"2","m":"3","o":"4","n":"2","u":"3","v":"2","w":"2","x":"1","y":"1","z":"1"}"}ifflag!=none:print('该页抓取完成...')request.get(url,stream=true)返回promise和response,提取子value是对url进行变换得到的值,如果变换后对。 查看全部
php抓取网页标签(php抓取网页标签+解析源码+内容提取(组图))
php抓取网页标签+解析源码+内容提取1.web应用中页面流量来源会有很多,当页面较多时,页面中会有大量的每页能抓取到的条目不一样,比如说整个页面都是列表式标签是每页a列,每个条目a列加上b列,每个条目b列加上c列,列表b列加上列表c列,每个条目a列加上列表d列...2.查看流量依据target>limit,/root/路径查看,页面中不同的条目查看方式不同,比如说常见的页面中可以抓取文章列表,文章列表是/article/a,但是列表中不仅仅是文章列表,还有一些跳转标签,也属于该页的元素,查看方式是/article/a?id=1&page=13.页面提取标签解析所谓提取标签,就是抽取出标签中的文本框,并把该文本框中内容提取出来,其他的标签是通过跳转标签查看4.数据查看to或each导航页抓取是不是异步加载的,每个页面会有各自不同的加载方式。
window+r异步刷新整个页面,跳转到相应的跳转页面,观察相应页面的dom结构,爬虫基本都是这么走的。from通过函数指定页面的路径,并发送请求获取页面数据js页查看是否支持eval处理(浏览器或者爬虫都可以)index页面抓取时,模拟浏览器会返回js页面,爬虫这时候需要抓取即时值xhr然后按照页面dom走即可,页面爬取时post也会返回值,可以观察抓取的代码和返回值。
4.解析提取data字段json数据(python)json数据(python爬虫抓取+解析+提取)也是和页面流量一样,每页都有固定的json数据可以查看(爬虫)整个页面会有4个数据列(list)支持json查看:span[0-4][...][...][...]#anymultipleitems(加密后)listlist={'b':1,'c':2,'d':3,'e':4}iflist!=none:print('该页未抓取完成...')request.post(url,stream=true)返回的数据接收了index,checkbox,tag的数据,都是json数据。
functiondict(data,string,fn){returndata||"{"+data||""]""{"b":"1","c":"2","d":"3","e":"4","l":"2","m":"3","o":"4","n":"2","u":"3","v":"2","w":"2","x":"1","y":"1","z":"1"}"}ifflag!=none:print('该页抓取完成...')request.get(url,stream=true)返回promise和response,提取子value是对url进行变换得到的值,如果变换后对。
php抓取网页标签(我正在为一个主题创建一个自定义tag.php页面(即) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-19 15:04
)
我正在为 WordPress 主题创建自定义 tag.php 页面。
我需要获取我自己的选项卡的名称、ID 和子标签(即)...我在网上看到了大量关于如何列出页面标签的示例/帖子,但没有说明如何轻松获取名称、ID特定的标签页和子词。
我尝试使用以下...但下面的代码用于循环浏览帖子中的所有标签。该标签页只需要一个标签。如果我尝试以下选项,我不会得到正确的标签(它会选择我的 网站 上的其他标签)。
$posttags = get_the_tags();
if ($posttags) {
foreach($posttags as $tag) {
$tag_id = $tag->term_id;
$tag_name = $tag->name;
$tag_slug = $tag->slug;
}
}
echo "";
echo "";
echo "";
任何帮助表示赞赏。谢谢
#1
在标签页上,任何分类/术语页面都可以使用 get_queried_object() 从当前查看的术语中获取信息。这将返回整个术语对象。
如果只需要ID,可以使用get_queried_object_id()
例子:
$term = get_queried_object();
var_dump( $term ); 查看全部
php抓取网页标签(我正在为一个主题创建一个自定义tag.php页面(即)
)
我正在为 WordPress 主题创建自定义 tag.php 页面。
我需要获取我自己的选项卡的名称、ID 和子标签(即)...我在网上看到了大量关于如何列出页面标签的示例/帖子,但没有说明如何轻松获取名称、ID特定的标签页和子词。
我尝试使用以下...但下面的代码用于循环浏览帖子中的所有标签。该标签页只需要一个标签。如果我尝试以下选项,我不会得到正确的标签(它会选择我的 网站 上的其他标签)。
$posttags = get_the_tags();
if ($posttags) {
foreach($posttags as $tag) {
$tag_id = $tag->term_id;
$tag_name = $tag->name;
$tag_slug = $tag->slug;
}
}
echo "";
echo "";
echo "";
任何帮助表示赞赏。谢谢
#1
在标签页上,任何分类/术语页面都可以使用 get_queried_object() 从当前查看的术语中获取信息。这将返回整个术语对象。
如果只需要ID,可以使用get_queried_object_id()
例子:
$term = get_queried_object();
var_dump( $term );
php抓取网页标签(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-17 19:15
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
php抓取网页标签(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
php抓取网页标签(php抓取网页标签的字符串在form表单中起到什么作用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-13 05:01
php抓取网页标签的字符串在form表单中起到什么作用?如何捕捉到不属于自己的字符?
一、作用爬虫抓取网页上的字符,字符串是没有内容的,所以都被用字符串编码处理,来代替字符。所以我们可以通过开启字符编码的服务器,从而得到任意字符的内容。所以,抓取网页标签,首先要在chrome浏览器中访问。这里需要安装php-extension-reader这个插件。
二、流程
1、开启“翻译服务器”,推荐使用chrome浏览器来执行这个网址。
2、爬虫打开c:\users\wangxie\appdata\local\google\chrome\userdata\application\userdata\chrome开发者工具\userdata\manifest\default这个文件夹这个文件夹中有4个文件sitemap.php、content.php、images.php、siteid.php,各位大佬可以根据自己的需要添加。这里面有三个表单的标签,为post,action,cookie。
三、操作
1、代码例子这里的抓取网页标签的字符串,在浏览器中的格式如下sitemap。php#content_stringvarall_page='\w\u\h\n\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d。 查看全部
php抓取网页标签(php抓取网页标签的字符串在form表单中起到什么作用?)
php抓取网页标签的字符串在form表单中起到什么作用?如何捕捉到不属于自己的字符?
一、作用爬虫抓取网页上的字符,字符串是没有内容的,所以都被用字符串编码处理,来代替字符。所以我们可以通过开启字符编码的服务器,从而得到任意字符的内容。所以,抓取网页标签,首先要在chrome浏览器中访问。这里需要安装php-extension-reader这个插件。
二、流程
1、开启“翻译服务器”,推荐使用chrome浏览器来执行这个网址。
2、爬虫打开c:\users\wangxie\appdata\local\google\chrome\userdata\application\userdata\chrome开发者工具\userdata\manifest\default这个文件夹这个文件夹中有4个文件sitemap.php、content.php、images.php、siteid.php,各位大佬可以根据自己的需要添加。这里面有三个表单的标签,为post,action,cookie。
三、操作
1、代码例子这里的抓取网页标签的字符串,在浏览器中的格式如下sitemap。php#content_stringvarall_page='\w\u\h\n\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d\d。
php抓取网页标签(01爬取localhost开放头像数据所需工具:php抓取网页标签)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-10 01:02
php抓取网页标签的内容,这篇文章非常适合新手,当你掌握了php后,你会发现php的内置扩展和数据格式,也会熟练应用到其他语言上,获取网页内容非常简单!先给出教程,后面会说为什么要用php做此操作。01爬取localhost开放头像数据所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码02爬取全国各省、市、自治区所有省份城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码03爬取全国所有省、市、自治区、县、自治县所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码04爬取湖北所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码05爬取湖南所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码06爬取厦门所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码07爬取各地酒店所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码08爬取家乡所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码09爬取各地学校所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码10爬取各地所有学校所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码11网页头三个“?”是神马?带你透过源码看操作步骤,操作思路,结果如何!举例:我们用js抓取网页标签三个?:获取图片背景图片网页标签抓取flash图片抓取"_cdnsst"是神马?带你透过源码看操作步骤,操作思路,结果如何!结果:获取图片,需要图片源代码,看源代码是nodejs就用nodejs获取文件res文件后缀名后缀名,浏览器抓取文件:浏览器抓取文件结果:class方法继续抓取图片成功。
关于图片资源存在php内存中,可以看本文结尾。php是什么1.php提供了标准的mimeuri、及其生成器format,为其它语言提供了丰富的数据格式;2.php程序后端不管内存和计算机空间,只需要有代码,就可以并行任意增加及删除文件;3.php可以调用c、c++、java等语言编写的函数;4.php也可以利用数据库;5.php也可以编写html、javascript、logging、servlet等web应用程序。6.php也可以手工对perl。 查看全部
php抓取网页标签(01爬取localhost开放头像数据所需工具:php抓取网页标签)
php抓取网页标签的内容,这篇文章非常适合新手,当你掌握了php后,你会发现php的内置扩展和数据格式,也会熟练应用到其他语言上,获取网页内容非常简单!先给出教程,后面会说为什么要用php做此操作。01爬取localhost开放头像数据所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码02爬取全国各省、市、自治区所有省份城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码03爬取全国所有省、市、自治区、县、自治县所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码04爬取湖北所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码05爬取湖南所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码06爬取厦门所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码07爬取各地酒店所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码08爬取家乡所有城市所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码09爬取各地学校所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码10爬取各地所有学校所需工具:node.js环境:vim编辑器express框架:node.js环境:gulp5.0github源码11网页头三个“?”是神马?带你透过源码看操作步骤,操作思路,结果如何!举例:我们用js抓取网页标签三个?:获取图片背景图片网页标签抓取flash图片抓取"_cdnsst"是神马?带你透过源码看操作步骤,操作思路,结果如何!结果:获取图片,需要图片源代码,看源代码是nodejs就用nodejs获取文件res文件后缀名后缀名,浏览器抓取文件:浏览器抓取文件结果:class方法继续抓取图片成功。
关于图片资源存在php内存中,可以看本文结尾。php是什么1.php提供了标准的mimeuri、及其生成器format,为其它语言提供了丰富的数据格式;2.php程序后端不管内存和计算机空间,只需要有代码,就可以并行任意增加及删除文件;3.php可以调用c、c++、java等语言编写的函数;4.php也可以利用数据库;5.php也可以编写html、javascript、logging、servlet等web应用程序。6.php也可以手工对perl。
php抓取网页标签(网站优化中网站代码如何优化?为你解答!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-07 16:20
前段时间个人搜索了一些关于优化的资料,分享给大家。网站代码优化也是网站优化中的一个优化措施。代码对于网站优化非常重要。虽然HTML代码是程序员应该精通的语言,但HTML代码的优化应该是SEO专家应该精通的技能。
作为一名合格的SEOer,我们不需要精通HTML代码,但需要知道如何优化网站代码。比如我们网站中的一些内容是重要的内容,这就需要我们为重要的内容增加附加值,从而获得搜索引擎的关注。这时候我们就可以通过HTML代码来标记重要的内容了。重要的内容被HTML代码标记后,搜索引擎蜘蛛就会抓取你的网站,当你知道哪些内容应该给予更高的权重时。
有时候我们的网站经常会有一些变化,每一次的变化都会留下一些无用的代码。当这种无用代码过多时,会影响网站的打开速度,甚至会降低蜘蛛对网站的青睐,降低网站的总分,这是代码优化的一部分,去除网站中无用的代码,提高页面打开速度,增加蜘蛛对网站的评论友好度,从而提高网站@的总分>,达到优化效果。那么,如何优化网站优化中的网站代码,下面我给大家详细介绍一下。
1、H标签优化
网站代码中H标签的优化措施是代码优化之一。在前面的文章中,我也介绍了H标签的使用。今天我将讲解如何优化H标签。,H1-h6标签都称为H标签,H1标签是H标签中权重最大的标签,通常在网站每个页面只允许一个H1标签,从SEO优化的角度来看,我们通常会放置H1标签每页最重要的内容。比如我的博客最重要的是哈尔滨SEO关键词,所以我在哈尔滨SEO标题上放了H1标签。同一页面上不能有多个 H1 标签。H1 标签在每个页面中只能出现一次。其他H标签可以多次出现,但一般只使用H1标签。如果你不擅长使用H标签,推荐使用。不要只是把它放在 <
2、nofollow 标签
在站长工具无法检测到友情链接中的nofollow之前,很多不道德的人使用nofollow标签来交换友情链接。我们都知道友情链接可以让两个网站互相传递权重,而在友情链接代码中加入nofollow就相当于告诉蜘蛛不要抓取这个链接,这会导致你的网站不会得到对方网站的权重转移效果,因为在友情链接中,虽然我们链接对方的网站不会分散自己网站的权重,但是网站的权重在一定数量的友情链接后会分散,所以没有通过nofollow可以达到友情链接数量限制的效果,
3、标题标签
通常在网站中我们都需要为网站设置标题,一些二次开发的程序可以在网站的后台设置网站的标题,但是对于我们的一些自己开发的网站需要在代码中设置。从SEO的角度来看,我们通常把我们网站的main 关键词加到title标签中,增加网站的匹配度,title标签对网站很重要,所以我们在优化网站的代码时,一定不能忽略网站的title标签设置。
4、关键字标签
关键字标签和标题标签设置在一起。如果您使用的是二次开发程序,那么您可以在后台一起设置标题标签和关键字标签。关键字标签的意思是网站的关键词。
5、描述标签
description标签通常用于填写网站的描述信息。当我们搜索某个关键词时,我们看到快照下显示的网站描述是通过description标签设置的。有人认为description标签对网站的关键词的排名没有太大影响,所以我们不设置网站的description标签。其实仔细观察可以发现,我们在搜索某个关键词,如果这个关键词出现在当时显示的快照下方的描述中,也会以红色字体显示。
网站网站的代码优化措施是在网站优化时必须要做的。
6、ALT 标签
ALT标签通常用于添加网站的图片。如果把你的图片添加到图片中,蜘蛛是不会知道图片的内容是什么的,而ALT标签就是告诉蜘蛛图片的内容是什么。我们只需要在ALT标签中用最简洁的语言描述图片的信息即可。图片的内容应该和我们网站的内容有关,因为蜘蛛不仅会收录网站的内容,也会是收录<的图片@网站,让图片在百度图库中展示,ALT标签可以显示图片在哪一类图片中间。
如果资源对你有帮助,浏览后收获颇丰,不妨,你的鼓励是我继续写博客的最大动力。 查看全部
php抓取网页标签(网站优化中网站代码如何优化?为你解答!)
前段时间个人搜索了一些关于优化的资料,分享给大家。网站代码优化也是网站优化中的一个优化措施。代码对于网站优化非常重要。虽然HTML代码是程序员应该精通的语言,但HTML代码的优化应该是SEO专家应该精通的技能。
作为一名合格的SEOer,我们不需要精通HTML代码,但需要知道如何优化网站代码。比如我们网站中的一些内容是重要的内容,这就需要我们为重要的内容增加附加值,从而获得搜索引擎的关注。这时候我们就可以通过HTML代码来标记重要的内容了。重要的内容被HTML代码标记后,搜索引擎蜘蛛就会抓取你的网站,当你知道哪些内容应该给予更高的权重时。
有时候我们的网站经常会有一些变化,每一次的变化都会留下一些无用的代码。当这种无用代码过多时,会影响网站的打开速度,甚至会降低蜘蛛对网站的青睐,降低网站的总分,这是代码优化的一部分,去除网站中无用的代码,提高页面打开速度,增加蜘蛛对网站的评论友好度,从而提高网站@的总分>,达到优化效果。那么,如何优化网站优化中的网站代码,下面我给大家详细介绍一下。
1、H标签优化
网站代码中H标签的优化措施是代码优化之一。在前面的文章中,我也介绍了H标签的使用。今天我将讲解如何优化H标签。,H1-h6标签都称为H标签,H1标签是H标签中权重最大的标签,通常在网站每个页面只允许一个H1标签,从SEO优化的角度来看,我们通常会放置H1标签每页最重要的内容。比如我的博客最重要的是哈尔滨SEO关键词,所以我在哈尔滨SEO标题上放了H1标签。同一页面上不能有多个 H1 标签。H1 标签在每个页面中只能出现一次。其他H标签可以多次出现,但一般只使用H1标签。如果你不擅长使用H标签,推荐使用。不要只是把它放在 <
2、nofollow 标签
在站长工具无法检测到友情链接中的nofollow之前,很多不道德的人使用nofollow标签来交换友情链接。我们都知道友情链接可以让两个网站互相传递权重,而在友情链接代码中加入nofollow就相当于告诉蜘蛛不要抓取这个链接,这会导致你的网站不会得到对方网站的权重转移效果,因为在友情链接中,虽然我们链接对方的网站不会分散自己网站的权重,但是网站的权重在一定数量的友情链接后会分散,所以没有通过nofollow可以达到友情链接数量限制的效果,
3、标题标签
通常在网站中我们都需要为网站设置标题,一些二次开发的程序可以在网站的后台设置网站的标题,但是对于我们的一些自己开发的网站需要在代码中设置。从SEO的角度来看,我们通常把我们网站的main 关键词加到title标签中,增加网站的匹配度,title标签对网站很重要,所以我们在优化网站的代码时,一定不能忽略网站的title标签设置。
4、关键字标签
关键字标签和标题标签设置在一起。如果您使用的是二次开发程序,那么您可以在后台一起设置标题标签和关键字标签。关键字标签的意思是网站的关键词。
5、描述标签
description标签通常用于填写网站的描述信息。当我们搜索某个关键词时,我们看到快照下显示的网站描述是通过description标签设置的。有人认为description标签对网站的关键词的排名没有太大影响,所以我们不设置网站的description标签。其实仔细观察可以发现,我们在搜索某个关键词,如果这个关键词出现在当时显示的快照下方的描述中,也会以红色字体显示。
网站网站的代码优化措施是在网站优化时必须要做的。
6、ALT 标签
ALT标签通常用于添加网站的图片。如果把你的图片添加到图片中,蜘蛛是不会知道图片的内容是什么的,而ALT标签就是告诉蜘蛛图片的内容是什么。我们只需要在ALT标签中用最简洁的语言描述图片的信息即可。图片的内容应该和我们网站的内容有关,因为蜘蛛不仅会收录网站的内容,也会是收录<的图片@网站,让图片在百度图库中展示,ALT标签可以显示图片在哪一类图片中间。
如果资源对你有帮助,浏览后收获颇丰,不妨,你的鼓励是我继续写博客的最大动力。
php抓取网页标签(百度站长平台于百度科技园行动度基因沙龙的交流探讨)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-07 16:17
百度站长平台在百度科技园举办了蝶变行动基因沙龙。会上就网站SEO、网站域名、百度抓取页面、APPLink等进行了交流与讨论。以下是对活动提问的回答:包括JS代码收录@ >、URL链接长度、海外域名对排名的影响等,问答详情如下:
一、SEO 问题解答
Q:使用百度统计进行广告跟踪时,配置的网址链接会很长。这种跟踪会影响搜索引擎优化吗?
A:这种多URL版本的统计代码肯定会对SEO产生影响。针对这种情况有两个建议,一个是使用两组网址进行真实的Spider爬取和用户展示。另一个是不要用百度统计,可以用谷歌跟踪,他可以用#链接,事件跟踪,参考美团网。所有链接加上事件跟踪。如果是生成的,也是用#号生成的,不添加额外的参数。
Q:如果一个页面一开始不符合百度的SEO标准,然后再修改符合标准,百度多久能回馈好结果?
A:不同的站点可能贡献不同的流量。因此,蜘蛛爬行的侧重点不同。有些网站可能会找到更多的新链接,而有些网站可能会查看旧链接。建议推送到百度,一般像首页一样爬是没有问题的。
Q:推送多久审核一次,一周还是半个月?
A:如果说推送能达到爬行标准,马上就可以抓到了。
Q:网站 有新旧两个网址,大概需要两年左右的时间交替。现在旧的 URL 将跳转到新的 URL。由于服务器问题,断网半小时,搜索关键词后,出现了旧的url,现在用各种方法都恢复不了。在这种情况下我们应该怎么做?
A:使用修改工具重新提交,确保修改成功,不会出现问题。然后我找到了问题的截图,并报告给了工程师进行跟进。
Q:因为网站使用的是海外域名(暂时无法更改),有什么办法可以更好的增加搜索量或者抓取量?
A:百度搜索引擎是在中国注册的,最好使用国内注册的服务器和域名。
Q:有些网站注册使用了很多域名,很多域名没有被用户搜索到。现在我取消了这些域名,但仍然可以搜索到。我把它关了一次,但没有用。我不知道如何处理这个?
A:如果你不需要那些电台呢?您可以关闭它们。如果新域名短期关闭,旧域名可能会转移给用户。该域名被关闭后,我们将不再为用户提供长期服务。不会找这些东西。
Q:网站是母婴品类网站,PC端搜索流量很差。想问有没有办法?
A:百度对于医疗、保健、保健、母婴等问题的搜索结果显示非常谨慎。百度只为高质量的网站开放展示的可能性。很可能网站长时间得不到流量。如果网站在SEO方面没有大问题,可以查看内容是否都在争夺一些热门词。建议在整个网站的权重和流量达到一定规模后制作流行词。如果一开始就做这样的关键词,如果网站的名气不是很高,就没有流量。在这种情况下,最好网站 找到一个你自己的差异化和相关的词。
Q:网站 从事教育行业。现在已经通过了官网认证,算是安全或者权威的认证。认证后会不会有什么潜在的特殊待遇或无所谓?
A:比如认证是真的,还有一个是假的。从用户的认知来看,你就是官网。
Q:关于数字化、软件、PDF和Word展示的问题,包括哪些类型和资源?文章的内容应该用于发布,还是PDF和文章应该是一样的?也有矛盾。产品和操作希望用户下载后直接可用。不会有 PDF 和 WORD 的压缩或工具。有的用户会被引导或不慎引导下载Word,应该怎么办?
A:百度搜索栏现在默认叫网页搜索。顾名思义,我们向用户展示一个网页。后面还有库的文件格式。搜索结果都是供用户下载的,可以去研究一下,也可以显示库中的内容。
Q:有没有渠道告诉搜索引擎我们页面的内容发生了变化,我们通常如何处理?旧页面已收录@> 并已排序。一定时间之后,他会推出新的资源添加和变化吗?
A:目前还没有这样的频道。首先,Spider 会在这里检查一些东西。他发现网站经常有这样的情况,他的相关检查流量就会增加。如果你不担心,你应该把他放在站点地图中。
Q:网站原本只是一个主页,只是一个APP下载。我们现在正在发布内容。以前,无法抓取内容。我是否需要提交修订版才能在目录或子域中发布它?
A:这个放在域名下,有一个子目录用来放分类的项目,没有修改。改了首页,改版没有其他问题。使用主动推送工具的效果还是很明显的。如果内容质量好,可以用完所有配额。
Q:自动推送份额调整周期是多久?因为我认为您的份额对于我们数千万或数百万的海量数据来说太小了。
A:我们也很关心一个网站是否有这种爆发力。突然有这么多的增量,我们觉得很不正常。你还是一步一个脚印的走吧,别矮又快,一夜之间就变成了胖子。第二,你有这么多优秀的数据,你可以关注百度的另一个平台,你成为一个API,让别人使用你的数据。其他人为您的数据使用付费,您可以注意这一点。
Q:使用超链接时,URL的绝对路径和相对路径有影响吗?改版后,我们的页面有翻页功能,翻页链接是12345,上面有标签。12345不会每次被抓到。模拟抓取,感觉抓不到里面。Spider会抓取页面上的A标签吗?
A:影响不大,能正常访问就可以了。不管是绝对路径还是相对路径,只要地址为Spider或用户畅通无阻,并且页面呈现时地址完整,这条路径就可以顺利爬取。
收录@> 没有问题,可以参考一些其他的点,比如是页面本身没有被访问还是目录级别比较高。百度会逐层抓取页面首页推送的链接。如果路径正常,则从首页爬取Spider路径。
首先,我们一定不能看到收录@>的链接是否被抓到了。如果是抓到了而不是收录@>,可能是页面本身的问题。你也可以看一个周期,因为我们用一天。二是看日志中是否有长尾,分层构建时是否隐藏或者没有有效爬取或推荐。如果能看懂日志,就可以看日志分析一下。
可以调整首页的变化,做个推荐,做个测试看看是链接问题还是蜘蛛没抓到的问题。有push之类的方法可以解决,从而判断是什么原因导致没有收录@>。学院有一个文档可以解决很多问题,类似于流程图。当这枚戒指完成时,原因是什么?如果够长,可以看看下面的分支。
Q:以前网站的所有框架都是通过JS展示的。后来百度没有收录@>,进行了PHP改版。外观是一样的。现在感觉PHP的写法不规范。什么是百度不规范的收录@>?
A:酒店行业很多内容不是实时加载的,而是通过JS慢慢获取页面上的内容。搜索引擎就是导航,就是这样的问题。以前有很多空白页收录@>,质量很差。关于Pattern,认为这是一个低质量的Pattern,内容可能是一样的,所以考虑换一个目录。
二、APPLINK 问题解答
Q:现在网站的APP已经准备好了,加入APPLINK会不会有大的变化?
A:H5网站和APP有对应关系吗?比如这里有100条来自H5站的内容,有100条来自APP的内容,需要匹配。重点放在网站行高一点,一定要调整好。
Q:现在APP是Android和IOS,但也有少量的Windows Phone。这个APP需要多长时间?
A:分两点,看看诺基亚在Windows上的平台战略。如果我们看到他有什么动作,我们一定会注意的。因为其实我们早期就有APPLINK接入协议的约定。我们可以有一个机制让 Windows Phone 进行调整。用户点击结果。如果你点击结果,我们在那里有一个Android IE,它可以接受IE,然后将信息发送给用户。只要前端实现一些信息,就可以做到。劳动量似乎不是很大,也是可以实现的。除了Windows Phone,还有手表毕竟可以调成APP。你也可以检查一下。
Q:APP和网页版,H5网页内嵌了很多APP,但是里面有壳。点击百度制作的AppLink后,他从百度App弹到糯米App,然后弹开。他使用百度搜索大量数据。百度用户可以点击下一个网站。如果你把他推给糯米,我们后面的人就没有机会了。
A:其实APPLINK对这个问题的调整不是技术壁垒,而是辛苦的。对于大型网站,您可以自己完成。对于APPLINK,未来可能会有各方面的调整。对于小站来说,目前接入小站就有这个优势。因为小站访问也可以跳转到小站。
Q:加入APPLINK后,如果小站点数据不够,会立刻弹出吗?
A:当你回到你的车站时,至少你会进入你自己的生态。其实从搜索的角度来说,我们是针对用户,满足用户的需求。如果我们导致网站,如果网站不能满足需求,用户自然会被转移。将用户引向你是对网站的激励,满足用户的需求。我想应该是这样的。
Q:整个页面有APPLINK,会有一个分发按钮。分发按钮需要满足什么条件?
A:没有条件,你给我们APP包,我们帮你分发。
Q:现在百度内容除了你的团队还对应了几个手机助手,有什么区别吗?
A:这是早期的尝试。大家都知道手机和PC是合并的。我们一般都是导出一套解决方案。也许在上半年,我们很难推动这件事。我们当时也很困惑。在当时整个生态合并之后,现在我们整体的输出是APPLINK的输出更加合理。手机助手不是搜索结果。输出可能在不同的产品线上,搜索结果中会出现APPLINK。
Q:加入APPLINK对移动站平台有影响吗?
A:目前还没有这个。但是他会有一个正常的点击。
Q:Android生态中最麻烦的就是有时候不能调整。如果不调整这个问题,会不会引导下载操作?
A:一般情况下不能调整有两种情况。一个是安装包,因为Android或者IOS包存在版本问题。因为网上提交的版本是用户没有更新新版本,也可能是用户安装了新版本,但是已经删除了,有时还不能调整。在这种情况下,将访问 H5 站。现在有一个监控系统。如果我们去H5站失败,会发现搜索流量异常,我们会修复这个问题。最快的情况是响应问题。 查看全部
php抓取网页标签(百度站长平台于百度科技园行动度基因沙龙的交流探讨)
百度站长平台在百度科技园举办了蝶变行动基因沙龙。会上就网站SEO、网站域名、百度抓取页面、APPLink等进行了交流与讨论。以下是对活动提问的回答:包括JS代码收录@ >、URL链接长度、海外域名对排名的影响等,问答详情如下:
一、SEO 问题解答
Q:使用百度统计进行广告跟踪时,配置的网址链接会很长。这种跟踪会影响搜索引擎优化吗?
A:这种多URL版本的统计代码肯定会对SEO产生影响。针对这种情况有两个建议,一个是使用两组网址进行真实的Spider爬取和用户展示。另一个是不要用百度统计,可以用谷歌跟踪,他可以用#链接,事件跟踪,参考美团网。所有链接加上事件跟踪。如果是生成的,也是用#号生成的,不添加额外的参数。
Q:如果一个页面一开始不符合百度的SEO标准,然后再修改符合标准,百度多久能回馈好结果?
A:不同的站点可能贡献不同的流量。因此,蜘蛛爬行的侧重点不同。有些网站可能会找到更多的新链接,而有些网站可能会查看旧链接。建议推送到百度,一般像首页一样爬是没有问题的。
Q:推送多久审核一次,一周还是半个月?
A:如果说推送能达到爬行标准,马上就可以抓到了。
Q:网站 有新旧两个网址,大概需要两年左右的时间交替。现在旧的 URL 将跳转到新的 URL。由于服务器问题,断网半小时,搜索关键词后,出现了旧的url,现在用各种方法都恢复不了。在这种情况下我们应该怎么做?
A:使用修改工具重新提交,确保修改成功,不会出现问题。然后我找到了问题的截图,并报告给了工程师进行跟进。
Q:因为网站使用的是海外域名(暂时无法更改),有什么办法可以更好的增加搜索量或者抓取量?
A:百度搜索引擎是在中国注册的,最好使用国内注册的服务器和域名。
Q:有些网站注册使用了很多域名,很多域名没有被用户搜索到。现在我取消了这些域名,但仍然可以搜索到。我把它关了一次,但没有用。我不知道如何处理这个?
A:如果你不需要那些电台呢?您可以关闭它们。如果新域名短期关闭,旧域名可能会转移给用户。该域名被关闭后,我们将不再为用户提供长期服务。不会找这些东西。
Q:网站是母婴品类网站,PC端搜索流量很差。想问有没有办法?
A:百度对于医疗、保健、保健、母婴等问题的搜索结果显示非常谨慎。百度只为高质量的网站开放展示的可能性。很可能网站长时间得不到流量。如果网站在SEO方面没有大问题,可以查看内容是否都在争夺一些热门词。建议在整个网站的权重和流量达到一定规模后制作流行词。如果一开始就做这样的关键词,如果网站的名气不是很高,就没有流量。在这种情况下,最好网站 找到一个你自己的差异化和相关的词。
Q:网站 从事教育行业。现在已经通过了官网认证,算是安全或者权威的认证。认证后会不会有什么潜在的特殊待遇或无所谓?
A:比如认证是真的,还有一个是假的。从用户的认知来看,你就是官网。
Q:关于数字化、软件、PDF和Word展示的问题,包括哪些类型和资源?文章的内容应该用于发布,还是PDF和文章应该是一样的?也有矛盾。产品和操作希望用户下载后直接可用。不会有 PDF 和 WORD 的压缩或工具。有的用户会被引导或不慎引导下载Word,应该怎么办?
A:百度搜索栏现在默认叫网页搜索。顾名思义,我们向用户展示一个网页。后面还有库的文件格式。搜索结果都是供用户下载的,可以去研究一下,也可以显示库中的内容。
Q:有没有渠道告诉搜索引擎我们页面的内容发生了变化,我们通常如何处理?旧页面已收录@> 并已排序。一定时间之后,他会推出新的资源添加和变化吗?
A:目前还没有这样的频道。首先,Spider 会在这里检查一些东西。他发现网站经常有这样的情况,他的相关检查流量就会增加。如果你不担心,你应该把他放在站点地图中。
Q:网站原本只是一个主页,只是一个APP下载。我们现在正在发布内容。以前,无法抓取内容。我是否需要提交修订版才能在目录或子域中发布它?
A:这个放在域名下,有一个子目录用来放分类的项目,没有修改。改了首页,改版没有其他问题。使用主动推送工具的效果还是很明显的。如果内容质量好,可以用完所有配额。
Q:自动推送份额调整周期是多久?因为我认为您的份额对于我们数千万或数百万的海量数据来说太小了。
A:我们也很关心一个网站是否有这种爆发力。突然有这么多的增量,我们觉得很不正常。你还是一步一个脚印的走吧,别矮又快,一夜之间就变成了胖子。第二,你有这么多优秀的数据,你可以关注百度的另一个平台,你成为一个API,让别人使用你的数据。其他人为您的数据使用付费,您可以注意这一点。
Q:使用超链接时,URL的绝对路径和相对路径有影响吗?改版后,我们的页面有翻页功能,翻页链接是12345,上面有标签。12345不会每次被抓到。模拟抓取,感觉抓不到里面。Spider会抓取页面上的A标签吗?
A:影响不大,能正常访问就可以了。不管是绝对路径还是相对路径,只要地址为Spider或用户畅通无阻,并且页面呈现时地址完整,这条路径就可以顺利爬取。
收录@> 没有问题,可以参考一些其他的点,比如是页面本身没有被访问还是目录级别比较高。百度会逐层抓取页面首页推送的链接。如果路径正常,则从首页爬取Spider路径。
首先,我们一定不能看到收录@>的链接是否被抓到了。如果是抓到了而不是收录@>,可能是页面本身的问题。你也可以看一个周期,因为我们用一天。二是看日志中是否有长尾,分层构建时是否隐藏或者没有有效爬取或推荐。如果能看懂日志,就可以看日志分析一下。
可以调整首页的变化,做个推荐,做个测试看看是链接问题还是蜘蛛没抓到的问题。有push之类的方法可以解决,从而判断是什么原因导致没有收录@>。学院有一个文档可以解决很多问题,类似于流程图。当这枚戒指完成时,原因是什么?如果够长,可以看看下面的分支。
Q:以前网站的所有框架都是通过JS展示的。后来百度没有收录@>,进行了PHP改版。外观是一样的。现在感觉PHP的写法不规范。什么是百度不规范的收录@>?
A:酒店行业很多内容不是实时加载的,而是通过JS慢慢获取页面上的内容。搜索引擎就是导航,就是这样的问题。以前有很多空白页收录@>,质量很差。关于Pattern,认为这是一个低质量的Pattern,内容可能是一样的,所以考虑换一个目录。
二、APPLINK 问题解答
Q:现在网站的APP已经准备好了,加入APPLINK会不会有大的变化?
A:H5网站和APP有对应关系吗?比如这里有100条来自H5站的内容,有100条来自APP的内容,需要匹配。重点放在网站行高一点,一定要调整好。
Q:现在APP是Android和IOS,但也有少量的Windows Phone。这个APP需要多长时间?
A:分两点,看看诺基亚在Windows上的平台战略。如果我们看到他有什么动作,我们一定会注意的。因为其实我们早期就有APPLINK接入协议的约定。我们可以有一个机制让 Windows Phone 进行调整。用户点击结果。如果你点击结果,我们在那里有一个Android IE,它可以接受IE,然后将信息发送给用户。只要前端实现一些信息,就可以做到。劳动量似乎不是很大,也是可以实现的。除了Windows Phone,还有手表毕竟可以调成APP。你也可以检查一下。
Q:APP和网页版,H5网页内嵌了很多APP,但是里面有壳。点击百度制作的AppLink后,他从百度App弹到糯米App,然后弹开。他使用百度搜索大量数据。百度用户可以点击下一个网站。如果你把他推给糯米,我们后面的人就没有机会了。
A:其实APPLINK对这个问题的调整不是技术壁垒,而是辛苦的。对于大型网站,您可以自己完成。对于APPLINK,未来可能会有各方面的调整。对于小站来说,目前接入小站就有这个优势。因为小站访问也可以跳转到小站。
Q:加入APPLINK后,如果小站点数据不够,会立刻弹出吗?
A:当你回到你的车站时,至少你会进入你自己的生态。其实从搜索的角度来说,我们是针对用户,满足用户的需求。如果我们导致网站,如果网站不能满足需求,用户自然会被转移。将用户引向你是对网站的激励,满足用户的需求。我想应该是这样的。
Q:整个页面有APPLINK,会有一个分发按钮。分发按钮需要满足什么条件?
A:没有条件,你给我们APP包,我们帮你分发。
Q:现在百度内容除了你的团队还对应了几个手机助手,有什么区别吗?
A:这是早期的尝试。大家都知道手机和PC是合并的。我们一般都是导出一套解决方案。也许在上半年,我们很难推动这件事。我们当时也很困惑。在当时整个生态合并之后,现在我们整体的输出是APPLINK的输出更加合理。手机助手不是搜索结果。输出可能在不同的产品线上,搜索结果中会出现APPLINK。
Q:加入APPLINK对移动站平台有影响吗?
A:目前还没有这个。但是他会有一个正常的点击。
Q:Android生态中最麻烦的就是有时候不能调整。如果不调整这个问题,会不会引导下载操作?
A:一般情况下不能调整有两种情况。一个是安装包,因为Android或者IOS包存在版本问题。因为网上提交的版本是用户没有更新新版本,也可能是用户安装了新版本,但是已经删除了,有时还不能调整。在这种情况下,将访问 H5 站。现在有一个监控系统。如果我们去H5站失败,会发现搜索流量异常,我们会修复这个问题。最快的情况是响应问题。
php抓取网页标签(开发一个爬虫界面,理清下思路。(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-04 20:19
要开发爬虫,首先要知道爬虫是干什么的。我想去不同的网站找一个特定的关键字文章,并得到它的链接,这样我就可以快速阅读了。
根据个人习惯,我先source gaodai#ma#com 搞@@代~& 先写一个界面来理清思路。
1、与众不同网站。然后我们需要一个url输入框。
2、查找特定关键字的文章。然后我们需要一个文章标题输入框。
3、获取文章的链接。然后我们需要一个用于搜索结果的显示容器。
文章URL抓取 文章标题 网站URL抓取 文章URL
只需上传代码并添加一些自己的样式调整,界面就完成了:
那么接下来就是功能的实现了。我用PHP写的。第一步是获取网站的html代码。获取html代码的方法有很多。我就不一一介绍了,这里用的是curl。获取它,传入网站url获取html代码:
private function get_html($url){ $ch = curl_init(); $timeout = 10; curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36'); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout); $html = curl_exec($ch); return $html; }
虽然拿到了html代码,但是很快就会遇到一个问题,就是编码问题,这可能会让你下一步匹配不成功。这里我们将获取到的html内容统一转换为utf8编码:
$coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
获取网站的html,得到文章的url,接下来就是匹配网页下的所有a标签。需要使用正则表达式。经过多次测试,我们终于得到了一个比较靠谱的谱的正则表达式,不管a标签下的结构有多复杂,只要是标签就不要放过:(最关键的一步)
$pattern = '|]*>(.*)|isU'; preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,大概是这样的多维元素组:
array(2) { [0]=> array(*) { [0]=> string(*) "完整的a标签" . . . } [1]=> array(*) { [0]=> string(*) "与上面下标相对应的a标签中的内容" } }
只要你能拿到这些数据,其他的一切都可以被操纵。你可以遍历这个元素组,找到你想要的a标签,然后得到a标签对应的属性。你可以随心所欲。下面为大家推荐一个类,方便操作标签:
$dom = new DOMDocument(); @$dom->loadHTML($a);//$a是上面得到的一些a标签 $url = new DOMXPath($dom); $hrefs = $url->evaluate('//a'); for ($i = 0; $i length; $i++) { $href = $hrefs->item($i); $url = $href->getAttribute('href'); //这里获取a标签的href属性 }
当然,这只是一种方式,你也可以通过正则表达式匹配你想要的信息,用数据玩出新花样。
get和match得到你想要的结果,下一步当然是送回前端展示,写接口,然后在前端用js去获取数据,用jquery来动态添加内容以显示它:
var website_url = '你的接口地址'; $.getJSON(website_url,function(data){ if(data){ if(data.text == ''){ $('#article_url').html('<p>暂无该文章链接'); return; } var string = ''; var list = data.text; for (var j in list) { var content = list[j].url_content; for (var i in content) { if (content[i].title != '') { string += '' + '[' + list[j].website.web_name + ']' + '' + content[i].title + '' + ''; } } } $('#article_url').html(string); }); </p>
最终渲染: 查看全部
php抓取网页标签(开发一个爬虫界面,理清下思路。(图))
要开发爬虫,首先要知道爬虫是干什么的。我想去不同的网站找一个特定的关键字文章,并得到它的链接,这样我就可以快速阅读了。
根据个人习惯,我先source gaodai#ma#com 搞@@代~& 先写一个界面来理清思路。
1、与众不同网站。然后我们需要一个url输入框。
2、查找特定关键字的文章。然后我们需要一个文章标题输入框。
3、获取文章的链接。然后我们需要一个用于搜索结果的显示容器。
文章URL抓取 文章标题 网站URL抓取 文章URL
只需上传代码并添加一些自己的样式调整,界面就完成了:
那么接下来就是功能的实现了。我用PHP写的。第一步是获取网站的html代码。获取html代码的方法有很多。我就不一一介绍了,这里用的是curl。获取它,传入网站url获取html代码:
private function get_html($url){ $ch = curl_init(); $timeout = 10; curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36'); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout); $html = curl_exec($ch); return $html; }
虽然拿到了html代码,但是很快就会遇到一个问题,就是编码问题,这可能会让你下一步匹配不成功。这里我们将获取到的html内容统一转换为utf8编码:
$coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
获取网站的html,得到文章的url,接下来就是匹配网页下的所有a标签。需要使用正则表达式。经过多次测试,我们终于得到了一个比较靠谱的谱的正则表达式,不管a标签下的结构有多复杂,只要是标签就不要放过:(最关键的一步)
$pattern = '|]*>(.*)|isU'; preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,大概是这样的多维元素组:
array(2) { [0]=> array(*) { [0]=> string(*) "完整的a标签" . . . } [1]=> array(*) { [0]=> string(*) "与上面下标相对应的a标签中的内容" } }
只要你能拿到这些数据,其他的一切都可以被操纵。你可以遍历这个元素组,找到你想要的a标签,然后得到a标签对应的属性。你可以随心所欲。下面为大家推荐一个类,方便操作标签:
$dom = new DOMDocument(); @$dom->loadHTML($a);//$a是上面得到的一些a标签 $url = new DOMXPath($dom); $hrefs = $url->evaluate('//a'); for ($i = 0; $i length; $i++) { $href = $hrefs->item($i); $url = $href->getAttribute('href'); //这里获取a标签的href属性 }
当然,这只是一种方式,你也可以通过正则表达式匹配你想要的信息,用数据玩出新花样。
get和match得到你想要的结果,下一步当然是送回前端展示,写接口,然后在前端用js去获取数据,用jquery来动态添加内容以显示它:
var website_url = '你的接口地址'; $.getJSON(website_url,function(data){ if(data){ if(data.text == ''){ $('#article_url').html('<p>暂无该文章链接'); return; } var string = ''; var list = data.text; for (var j in list) { var content = list[j].url_content; for (var i in content) { if (content[i].title != '') { string += '' + '[' + list[j].website.web_name + ']' + '' + content[i].title + '' + ''; } } } $('#article_url').html(string); }); </p>
最终渲染:
php抓取网页标签(Linux文本编辑器Vim“真·简单”使用教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-02 09:09
因为金哥分享的东西(杂)越来越多,分类越来越多,层次越来越多,所以为了更好的显示URL地址,我们计划在近期修复所有文章 链接来自原创
/%category%/%post_id%.html
改为
/%post_id%.html
这将统一所有文章链接,不再有老长老;另一个优点是文章链接二维码也可以很简单。但是,更改 URL 是 SEO 的禁忌。为此,金哥参考了百度的网站修改规则,最大限度地保留了原来的收录。
获取所有链接
将下面的代码复制到utf8文件中,命名为post.php(文章)、page.php(page)、category.php(category)、tag.php(tag),放入网站 根目录没问题。
获取所有文章链接代码↓
获取所有页面链接代码↓
获取所有分类链接代码↓
获取所有标签链接代码↓
然后,进入服务器,以root账号使用wget命令结合这个PHP代码文件,生成指定的TXT文件。由于金哥只修改了文章链接,这里仅以文章命令为例,页面、分类、标签的修改请参考
wget -O /***/***/www.dujin.org/post.txt --no-check-certificate https://www.dujin.org/post.php
运行前需要注意自己的网站路径和txt文件存放路径。 --no-check-certificate 参数是因为 Jin 的博客是 HTTPS。如果 HTTP 站点可以删除此参数。
如果你的网站设置了360网站Guard或者其他CDN服务,还需要使用vim命令修改hosts文件,将你的网站域名指向你的服务器IP地址。
vim /etc/hosts
Linux 文本编辑器 Vim 《真·简单》教程
操作完成后,会在网站的根目录下生成一个post.txt文档。
此时使用纯文本编辑软件(如Emurasoft文本编辑器)批量查找替换重复的XML标记代码。
EmEditor 32&64 bit v17.4.第2版下载,附注册码
好了,到此为止,所有的URL链接都已经获取到了。如果您有任何问题,请留言。 查看全部
php抓取网页标签(Linux文本编辑器Vim“真·简单”使用教程(组图))
因为金哥分享的东西(杂)越来越多,分类越来越多,层次越来越多,所以为了更好的显示URL地址,我们计划在近期修复所有文章 链接来自原创
/%category%/%post_id%.html
改为
/%post_id%.html
这将统一所有文章链接,不再有老长老;另一个优点是文章链接二维码也可以很简单。但是,更改 URL 是 SEO 的禁忌。为此,金哥参考了百度的网站修改规则,最大限度地保留了原来的收录。
获取所有链接
将下面的代码复制到utf8文件中,命名为post.php(文章)、page.php(page)、category.php(category)、tag.php(tag),放入网站 根目录没问题。
获取所有文章链接代码↓
获取所有页面链接代码↓
获取所有分类链接代码↓
获取所有标签链接代码↓
然后,进入服务器,以root账号使用wget命令结合这个PHP代码文件,生成指定的TXT文件。由于金哥只修改了文章链接,这里仅以文章命令为例,页面、分类、标签的修改请参考
wget -O /***/***/www.dujin.org/post.txt --no-check-certificate https://www.dujin.org/post.php
运行前需要注意自己的网站路径和txt文件存放路径。 --no-check-certificate 参数是因为 Jin 的博客是 HTTPS。如果 HTTP 站点可以删除此参数。
如果你的网站设置了360网站Guard或者其他CDN服务,还需要使用vim命令修改hosts文件,将你的网站域名指向你的服务器IP地址。
vim /etc/hosts
Linux 文本编辑器 Vim 《真·简单》教程
操作完成后,会在网站的根目录下生成一个post.txt文档。
https://img.dujin.org/uploads/ ... 6.jpg 300w, https://img.dujin.org/uploads/ ... 3.jpg 768w" />此时使用纯文本编辑软件(如Emurasoft文本编辑器)批量查找替换重复的XML标记代码。
EmEditor 32&64 bit v17.4.第2版下载,附注册码
好了,到此为止,所有的URL链接都已经获取到了。如果您有任何问题,请留言。
php抓取网页标签(开发“快速行动和破除web陈规”的理念不相符)
网站优化 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-12-27 22:10
译者:福旺
我最近在研究网站归档,因为有些朋友担心在系统管理不善或恶意删除的情况下会失去对放置在互联网上的内容的控制。这使得网站归档成为系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难存档。本文介绍了归档传统网站的过程,并解释了它在面对最新流行的单页应用程序 (SPA) 现代网站时的缺点。
转换为简单的网站
手动编码 HTML 网站的日子早已一去不复返了。当今的网站是动态的,并且使用最新的 JavaScript、PHP 或 Python 框架即时构建。因此,这些站点更容易受到攻击:数据库崩溃、升级错误或未修复的漏洞都可能导致数据丢失。之前做网页开发的时候,不得不接受一个客户的想法:希望网站基本上可以长生不老。这种期望与Web开发“快速行动,打破陈规”的想法不谋而合。对此,Drupal 内容管理系统(CMS)的使用尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担高昂的升级成本。解决办法是将这些网站归档:基于实时动态的网站,将它们转换为纯 HTML 文件,可以由任何 Web 服务器永久提供服务。此过程对您自己的动态网站非常有用,也适用于您想要保护但无法控制的第三方网站。
对于简单的静态网站,旧的 Wget 程序可以完成这项工作。但是,镜像和保存完整网站的命令很复杂:
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
--backup-converted --page-requisites --adjust-extension \
--base=./ --directory-prefix=./ --span-hosts \
--域=,
上述命令下载网页内容,同时抓取指定域名内的所有内容。在为您最喜欢的网站执行此操作之前,请考虑此类抓取可能对您的网站产生的影响。上面的命令故意忽略robots.txt规则,就像现在归档者的习惯做法一样,尽可能快地归档网站。大多数爬虫可以选择暂停和限制爬行之间的带宽使用,以避免站点瘫痪。
上面的命令还会得到“页面所需(LCTT Annotation:单个页面所需的所有元素)”,比如样式表(CSS)、图片、脚本等。下载页面的内容将被修改,以便链接也指向本地副本。任何 Web 服务器都可以托管生成的文件集,从而生成原创
网站的静态副本。
以上是一切顺利的时候。任何使用过计算机的人都知道,事情很少会按计划进行;各种各样的事情都会以有趣的方式使程序偏离轨道。例如,日历块在网站上流行了一段时间。内容管理系统会动态生成这些内容,这会使爬虫陷入死循环,试图检索所有页面。智能归档器可以使用正则表达式(例如,Wget 有一个 --reject-regex 选项)来忽略有问题的资源。如果可以访问站点的管理界面,另一种方法是禁用日历、登录表单、评论表单等动态区域。一旦网站变得静态,(那些动态区域)肯定会停止工作,因此从原创
网站中去除这些杂乱的内容并非完全没有意义。
JavaScript 的噩梦
不幸的是,有些网站不仅仅是用纯 HTML 文件构建的。例如,在单页网站中,Web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将很难重新创建这些站点的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用渐进增强技术来提供内容和实现功能,而无需使用 JavaScript,但使用 NoScript 或 uMatrix 等插件的人很少遵循这些准则。
传统的归档方法有时会以最傻瓜式
方式失败。在尝试为本地报纸网站 (pamplemousse.ca) 创建备份时,我发现 WordPress 在收录
的 JavaScript 的末尾添加了一个查询字符串(例如:?ver=1.12. 4)。这会使提供存档服务的web服务器无法正确检测内容类型,因为它依赖文件扩展名来发送正确的Content-Type头信息。当web浏览器加载此类存档时,这些脚本将无法加载,导致动态网站损坏。
随着 Web 转变为使用浏览器作为执行任意代码的虚拟机,依赖于纯 HTML 文件解析的归档方法需要相应地进行调整。解决这个问题的方法是在爬取时记录(并重现)服务器提供的HTTP头信息。事实上,专业档案工作者使用这种方法。
创建和显示 WARC 文件
在 Internet Archive 网站上,布鲁斯特·卡勒 (Brewster Kahle) 和迈克·伯纳 (Mike Burner) 于 1996 年设计了 ARC(或“ARChive”)文件格式,以提供一种方法来聚合他们存档工作产生的数百万个小文件。该格式最终被标准化为 WARC(“Web ARChive”)规范,该规范于 2009 年作为 ISO 标准发布并于 2017 年修订。标准化工作由国际互联网保护联盟(IIPC)牵头。根据维基百科,这是一个“国际图书馆组织和其他组织,旨在协调保护未来互联网内容的努力”;它的成员包括美国国会图书馆(US Library of Congress)和互联网档案馆。后者在其基于 Java 的 Heritrix 爬虫中使用 WARC 格式(LCTT 翻译和注释:
WARC 在单个压缩文件中聚合多个资源,例如 HTTP 标头信息、文件内容和其他元数据。方便的是,Wget 实际上提供了 --warc 参数来支持 WARC 格式。不幸的是,Web 浏览器无法直接显示 WARC 文件,因此为了访问存档文件,需要查看器或进行某种格式转换。我找到的最简单的查看器是 pywb,它以 Python 包的形式运行一个简单的 Web 服务器,并提供一个类似于“Wayback Machine”的界面来浏览 WARC 文件的内容。执行以下命令将显示地址为 8080/ 的 WARC 文件的内容:
$ pip 安装 pywb
$ wb-manager 初始化示例
$ wb-manager 添加示例 crawl.warc.gz
$回归
顺便说一下,这个工具是由Webrecorder 服务提供商创建的,Webrecoder 服务可以使用Web 浏览器保存动态页面的内容。
遗憾的是pywb无法加载Wget生成的WARC文件,因为它与1.0规范不一致,而1.1规范解决了这个问题。即使Wget或pywb修复了这些问题,Wget生成的WARC文件也不够可靠,我使用,所以我寻找其他替代方案。引起我注意的爬虫程序简称为crawl。这是它的调用方式:
$爬行
(它的README文件说“非常简单”。)该程序支持一些命令行参数选项,但大多数默认值是最好的:它会从其他域中获取所需的页面(除非-exclude相关参数使用) ,但肯定不会递归出域。默认情况下,它将与远程站点建立十个并发连接。可以使用 -c 参数更改此值。但是,最重要的是生成的WARC文件可以用pywb完美加载。
未来的工作和替代方案
有更多关于使用 WARC 文件的资源。特别是有一个直接替代 Wget 的工具,它专门用于归档网站,称为 Wpull。它在实验上支持 PhantomJS 和 youtube-dl 的集成,可以分别下载更复杂的 JavaScript 页面和流媒体。该程序是名为 ArchiveBot 的复杂归档工具的基础。ArchiveBot 被 ArchiveTeam 的“分散的档案员、程序员、作家和演讲者”使用,他们致力于“在历史永远丢失之前保存历史”。PhantomJS 的集成似乎没有团队预期的那么好,所以 ArchiveTeam 还使用了其他分散的工具来镜像和保存更复杂的网站。例如,snscrape 将抓取社交媒体配置文件以生成要发送给 ArchiveBot 的页面列表。
如果没有提到被称为“网站复制器”的 HTTrack 项目,那么这篇文章是不完整的。它的工作原理与 Wget 类似。HTTrack 可以创建远程站点的本地副本,但遗憾的是它不支持导出 WRAC 文件。对于不熟悉命令行的新手用户来说,在人机交互方面更有价值。
同样,在我的研究中,我发现了一个完全重制的 Wget 版本,称为 Wget2,它支持多线程操作,这可能使它比其前身更快。与 Wget 相比,它舍弃了一些功能,但最显着的是拒绝模式、WARC 输出和 FTP 支持,以及添加 RSS、DNS 缓存和改进的 TLS 支持。
最后,我个人对这些工具的愿景是将它们与我现有的书签系统集成。我目前在 Wallabag 中有一些有趣的链接,这是一个自托管的“稍后阅读”服务,旨在成为 Pocket(现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 旨在仅保留文章的“可读”副本,而不是完整的副本。在某些情况下,“可读版本”实际上是不可读的,Wallabag 有时无法解析文章。相反,其他工具如 bookmark-archiver 或 reminiscence 会保存页面的屏幕截图和完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件,因此无法更可信地再现网页内容。
我所经历的关于镜像保存和归档的悲剧是死数据。幸运的是,业余档案工作者可以使用工具在线保存有趣的内容。对于那些不想打扰的人来说,“Internet Archive”似乎仍然存在,而且 ArchiveTeam 显然是在为 Internet Archive 本身进行备份。
通过:
作者:Anarcat 主题:lujun9972 译者:fuowang 校对:wxy
本文由 LCTT 原创,Linux China 获此殊荣 查看全部
php抓取网页标签(开发“快速行动和破除web陈规”的理念不相符)
译者:福旺
我最近在研究网站归档,因为有些朋友担心在系统管理不善或恶意删除的情况下会失去对放置在互联网上的内容的控制。这使得网站归档成为系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难存档。本文介绍了归档传统网站的过程,并解释了它在面对最新流行的单页应用程序 (SPA) 现代网站时的缺点。
转换为简单的网站
手动编码 HTML 网站的日子早已一去不复返了。当今的网站是动态的,并且使用最新的 JavaScript、PHP 或 Python 框架即时构建。因此,这些站点更容易受到攻击:数据库崩溃、升级错误或未修复的漏洞都可能导致数据丢失。之前做网页开发的时候,不得不接受一个客户的想法:希望网站基本上可以长生不老。这种期望与Web开发“快速行动,打破陈规”的想法不谋而合。对此,Drupal 内容管理系统(CMS)的使用尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担高昂的升级成本。解决办法是将这些网站归档:基于实时动态的网站,将它们转换为纯 HTML 文件,可以由任何 Web 服务器永久提供服务。此过程对您自己的动态网站非常有用,也适用于您想要保护但无法控制的第三方网站。
对于简单的静态网站,旧的 Wget 程序可以完成这项工作。但是,镜像和保存完整网站的命令很复杂:
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
--backup-converted --page-requisites --adjust-extension \
--base=./ --directory-prefix=./ --span-hosts \
--域=,
上述命令下载网页内容,同时抓取指定域名内的所有内容。在为您最喜欢的网站执行此操作之前,请考虑此类抓取可能对您的网站产生的影响。上面的命令故意忽略robots.txt规则,就像现在归档者的习惯做法一样,尽可能快地归档网站。大多数爬虫可以选择暂停和限制爬行之间的带宽使用,以避免站点瘫痪。
上面的命令还会得到“页面所需(LCTT Annotation:单个页面所需的所有元素)”,比如样式表(CSS)、图片、脚本等。下载页面的内容将被修改,以便链接也指向本地副本。任何 Web 服务器都可以托管生成的文件集,从而生成原创
网站的静态副本。
以上是一切顺利的时候。任何使用过计算机的人都知道,事情很少会按计划进行;各种各样的事情都会以有趣的方式使程序偏离轨道。例如,日历块在网站上流行了一段时间。内容管理系统会动态生成这些内容,这会使爬虫陷入死循环,试图检索所有页面。智能归档器可以使用正则表达式(例如,Wget 有一个 --reject-regex 选项)来忽略有问题的资源。如果可以访问站点的管理界面,另一种方法是禁用日历、登录表单、评论表单等动态区域。一旦网站变得静态,(那些动态区域)肯定会停止工作,因此从原创
网站中去除这些杂乱的内容并非完全没有意义。
JavaScript 的噩梦
不幸的是,有些网站不仅仅是用纯 HTML 文件构建的。例如,在单页网站中,Web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将很难重新创建这些站点的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用渐进增强技术来提供内容和实现功能,而无需使用 JavaScript,但使用 NoScript 或 uMatrix 等插件的人很少遵循这些准则。
传统的归档方法有时会以最傻瓜式
方式失败。在尝试为本地报纸网站 (pamplemousse.ca) 创建备份时,我发现 WordPress 在收录
的 JavaScript 的末尾添加了一个查询字符串(例如:?ver=1.12. 4)。这会使提供存档服务的web服务器无法正确检测内容类型,因为它依赖文件扩展名来发送正确的Content-Type头信息。当web浏览器加载此类存档时,这些脚本将无法加载,导致动态网站损坏。
随着 Web 转变为使用浏览器作为执行任意代码的虚拟机,依赖于纯 HTML 文件解析的归档方法需要相应地进行调整。解决这个问题的方法是在爬取时记录(并重现)服务器提供的HTTP头信息。事实上,专业档案工作者使用这种方法。
创建和显示 WARC 文件
在 Internet Archive 网站上,布鲁斯特·卡勒 (Brewster Kahle) 和迈克·伯纳 (Mike Burner) 于 1996 年设计了 ARC(或“ARChive”)文件格式,以提供一种方法来聚合他们存档工作产生的数百万个小文件。该格式最终被标准化为 WARC(“Web ARChive”)规范,该规范于 2009 年作为 ISO 标准发布并于 2017 年修订。标准化工作由国际互联网保护联盟(IIPC)牵头。根据维基百科,这是一个“国际图书馆组织和其他组织,旨在协调保护未来互联网内容的努力”;它的成员包括美国国会图书馆(US Library of Congress)和互联网档案馆。后者在其基于 Java 的 Heritrix 爬虫中使用 WARC 格式(LCTT 翻译和注释:
WARC 在单个压缩文件中聚合多个资源,例如 HTTP 标头信息、文件内容和其他元数据。方便的是,Wget 实际上提供了 --warc 参数来支持 WARC 格式。不幸的是,Web 浏览器无法直接显示 WARC 文件,因此为了访问存档文件,需要查看器或进行某种格式转换。我找到的最简单的查看器是 pywb,它以 Python 包的形式运行一个简单的 Web 服务器,并提供一个类似于“Wayback Machine”的界面来浏览 WARC 文件的内容。执行以下命令将显示地址为 8080/ 的 WARC 文件的内容:
$ pip 安装 pywb
$ wb-manager 初始化示例
$ wb-manager 添加示例 crawl.warc.gz
$回归
顺便说一下,这个工具是由Webrecorder 服务提供商创建的,Webrecoder 服务可以使用Web 浏览器保存动态页面的内容。
遗憾的是pywb无法加载Wget生成的WARC文件,因为它与1.0规范不一致,而1.1规范解决了这个问题。即使Wget或pywb修复了这些问题,Wget生成的WARC文件也不够可靠,我使用,所以我寻找其他替代方案。引起我注意的爬虫程序简称为crawl。这是它的调用方式:
$爬行
(它的README文件说“非常简单”。)该程序支持一些命令行参数选项,但大多数默认值是最好的:它会从其他域中获取所需的页面(除非-exclude相关参数使用) ,但肯定不会递归出域。默认情况下,它将与远程站点建立十个并发连接。可以使用 -c 参数更改此值。但是,最重要的是生成的WARC文件可以用pywb完美加载。
未来的工作和替代方案
有更多关于使用 WARC 文件的资源。特别是有一个直接替代 Wget 的工具,它专门用于归档网站,称为 Wpull。它在实验上支持 PhantomJS 和 youtube-dl 的集成,可以分别下载更复杂的 JavaScript 页面和流媒体。该程序是名为 ArchiveBot 的复杂归档工具的基础。ArchiveBot 被 ArchiveTeam 的“分散的档案员、程序员、作家和演讲者”使用,他们致力于“在历史永远丢失之前保存历史”。PhantomJS 的集成似乎没有团队预期的那么好,所以 ArchiveTeam 还使用了其他分散的工具来镜像和保存更复杂的网站。例如,snscrape 将抓取社交媒体配置文件以生成要发送给 ArchiveBot 的页面列表。
如果没有提到被称为“网站复制器”的 HTTrack 项目,那么这篇文章是不完整的。它的工作原理与 Wget 类似。HTTrack 可以创建远程站点的本地副本,但遗憾的是它不支持导出 WRAC 文件。对于不熟悉命令行的新手用户来说,在人机交互方面更有价值。
同样,在我的研究中,我发现了一个完全重制的 Wget 版本,称为 Wget2,它支持多线程操作,这可能使它比其前身更快。与 Wget 相比,它舍弃了一些功能,但最显着的是拒绝模式、WARC 输出和 FTP 支持,以及添加 RSS、DNS 缓存和改进的 TLS 支持。
最后,我个人对这些工具的愿景是将它们与我现有的书签系统集成。我目前在 Wallabag 中有一些有趣的链接,这是一个自托管的“稍后阅读”服务,旨在成为 Pocket(现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 旨在仅保留文章的“可读”副本,而不是完整的副本。在某些情况下,“可读版本”实际上是不可读的,Wallabag 有时无法解析文章。相反,其他工具如 bookmark-archiver 或 reminiscence 会保存页面的屏幕截图和完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件,因此无法更可信地再现网页内容。
我所经历的关于镜像保存和归档的悲剧是死数据。幸运的是,业余档案工作者可以使用工具在线保存有趣的内容。对于那些不想打扰的人来说,“Internet Archive”似乎仍然存在,而且 ArchiveTeam 显然是在为 Internet Archive 本身进行备份。
通过:
作者:Anarcat 主题:lujun9972 译者:fuowang 校对:wxy
本文由 LCTT 原创,Linux China 获此殊荣
php抓取网页标签(php抓取网页标签的函数叫sendarray函数。get请求的话可以用-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-25 13:11
php抓取网页标签的函数叫sendarray函数。
get请求的话可以用-u"file:/users/hjrw/desktop/xxx/out.html"
post请求,你这里post请求的url参数一样,type需要匹配。
http有个post请求:post是用get请求提交参数
一样的accept-encodingpost是postresponse还是header来验证,
post和get又不一样。我想ftp传文件,应该使用get请求。
get相对来说比较安全。post建议自己处理一下。请自行判断参数是不是真的。
在http中post即为向服务器提交数据,是个不可逆的过程,一次提交之后永远不能更改或删除。ftp传文件用get,ftp服务器处理提交给服务器的文件用post。
post是格式化python请求消息,参数一般有url,method,content-type等post请求提交给服务器的数据由content-type,method来决定。在浏览器还提供了send方法参数。
用get可以传数据,带空格。服务器回复消息。
以前面试,有同学提到,他说post可以传任何参数,只要带的是字符串就可以传递给服务器。但是send给客户端推文件的时候显然就应该用post传值。先好好了解下什么是post, 查看全部
php抓取网页标签(php抓取网页标签的函数叫sendarray函数。get请求的话可以用-)
php抓取网页标签的函数叫sendarray函数。
get请求的话可以用-u"file:/users/hjrw/desktop/xxx/out.html"
post请求,你这里post请求的url参数一样,type需要匹配。
http有个post请求:post是用get请求提交参数
一样的accept-encodingpost是postresponse还是header来验证,
post和get又不一样。我想ftp传文件,应该使用get请求。
get相对来说比较安全。post建议自己处理一下。请自行判断参数是不是真的。
在http中post即为向服务器提交数据,是个不可逆的过程,一次提交之后永远不能更改或删除。ftp传文件用get,ftp服务器处理提交给服务器的文件用post。
post是格式化python请求消息,参数一般有url,method,content-type等post请求提交给服务器的数据由content-type,method来决定。在浏览器还提供了send方法参数。
用get可以传数据,带空格。服务器回复消息。
以前面试,有同学提到,他说post可以传任何参数,只要带的是字符串就可以传递给服务器。但是send给客户端推文件的时候显然就应该用post传值。先好好了解下什么是post,
php抓取网页标签(上海SEO详解百度链接提交自动推送JS代码代码的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-23 23:00
很多SEO新手朋友经常抱怨“为什么网站更新文章百度不晚收录?”、“手动提交网站文章链接到百度我太累了,怎么办?” 和其他问题。我想说,百度官方搜索引擎已经提供了更有效的方法来解决这些问题,只是你没有关注而已。今天和大家聊一聊“百度链接提交与自动推送JS代码”的问题。
什么是百度链接提交和自动推送JS代码
百度链接提交自动推送JS代码是百度站长平台最新的轻量级链接提交组件。站长只需要把自动推送的JS代码放在站点每个页面的源代码中即可。当页面被访问时,页面链接会自动推送到百度,有利于百度更快地发现新页面。
安装百度链接提交自动推送JS代码有什么用?
为了快速发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送方式的技术门槛较高,于是我们顺势推出了一款成本更低的JS自动推送工具。一步安装即可实现页面自动推送,低成本高收益。
如何获取百度链接提交和自动推送JS代码
1、首先登录百度站长平台(没有百度站长平台的小伙伴可以自行注册。请点击【注册百度站长平台账号】)
2、 在百度站长平台左侧导航栏中,找到【网页抓取】,然后点击【提交链接】选择对应站点。如图:
3、在【链接提交】页面找到【自动提交】,点击【自动推送】,找到【自动推送工具代码】。如图:
4、 点击【复制代码】,自动推送JS代码的复制。
上海SEO详解百度链接提交自动推送JS代码安装
一、站长需要在网站公共模板中的HTML代码中添加自动推送JS代码:
(function(){ var bp = document.(''); var curProtocol = window.location.protocol.split(':')[0]; if (curProtocol ==='https') {bp.src = ' #39;;} else {bp.src ='#39;;} var s = document.getElementsByTagName("")[0]; s.parentNode.insertBefore(bp, s);})();>
二、如果站长使用PHP语言开发网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件中的标签后添加一行代码:
为什么自动推送可以更快地将页面推送到百度搜索?
基于自动推送的实现原理,每次查看新页面,页面URL都会自动推送到百度,无需站长聚合URL再主动推送操作。
利用用户的浏览行为触发推送动作,节省站长手动操作的时间。
什么样的网站更适合自动推送?
自动推送适用于技术能力较弱,实施方便,后续维护成本低,无法支持24小时实时主动推送程序的站长。
站长只需部署一次自动推送JS代码的操作,即可实现新页面一浏览就推送的效果,低成本实现链接自动提交。
以上内容是百度链接提交和自动推送JS代码安装的全部说明。希望各位SEO小伙伴都能掌握百度链接提交和自动推送JS代码安装。更多SEO干货,尽在SEO研究中心。 查看全部
php抓取网页标签(上海SEO详解百度链接提交自动推送JS代码代码的问题)
很多SEO新手朋友经常抱怨“为什么网站更新文章百度不晚收录?”、“手动提交网站文章链接到百度我太累了,怎么办?” 和其他问题。我想说,百度官方搜索引擎已经提供了更有效的方法来解决这些问题,只是你没有关注而已。今天和大家聊一聊“百度链接提交与自动推送JS代码”的问题。
什么是百度链接提交和自动推送JS代码
百度链接提交自动推送JS代码是百度站长平台最新的轻量级链接提交组件。站长只需要把自动推送的JS代码放在站点每个页面的源代码中即可。当页面被访问时,页面链接会自动推送到百度,有利于百度更快地发现新页面。
安装百度链接提交自动推送JS代码有什么用?
为了快速发现网站每天产生的最新内容,百度站长平台推出了主动推送工具。产品上线后,有站长反映使用主动推送方式的技术门槛较高,于是我们顺势推出了一款成本更低的JS自动推送工具。一步安装即可实现页面自动推送,低成本高收益。
如何获取百度链接提交和自动推送JS代码
1、首先登录百度站长平台(没有百度站长平台的小伙伴可以自行注册。请点击【注册百度站长平台账号】)
2、 在百度站长平台左侧导航栏中,找到【网页抓取】,然后点击【提交链接】选择对应站点。如图:
3、在【链接提交】页面找到【自动提交】,点击【自动推送】,找到【自动推送工具代码】。如图:
4、 点击【复制代码】,自动推送JS代码的复制。
上海SEO详解百度链接提交自动推送JS代码安装
一、站长需要在网站公共模板中的HTML代码中添加自动推送JS代码:
(function(){ var bp = document.(''); var curProtocol = window.location.protocol.split(':')[0]; if (curProtocol ==='https') {bp.src = ' #39;;} else {bp.src ='#39;;} var s = document.getElementsByTagName("")[0]; s.parentNode.insertBefore(bp, s);})();>
二、如果站长使用PHP语言开发网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件中的标签后添加一行代码:
为什么自动推送可以更快地将页面推送到百度搜索?
基于自动推送的实现原理,每次查看新页面,页面URL都会自动推送到百度,无需站长聚合URL再主动推送操作。
利用用户的浏览行为触发推送动作,节省站长手动操作的时间。
什么样的网站更适合自动推送?
自动推送适用于技术能力较弱,实施方便,后续维护成本低,无法支持24小时实时主动推送程序的站长。
站长只需部署一次自动推送JS代码的操作,即可实现新页面一浏览就推送的效果,低成本实现链接自动提交。
以上内容是百度链接提交和自动推送JS代码安装的全部说明。希望各位SEO小伙伴都能掌握百度链接提交和自动推送JS代码安装。更多SEO干货,尽在SEO研究中心。
php抓取网页标签(php抓取网页标签的办法有两种:(1)通过泛洪取代目标解析首先定义一个列表,jsonquery.data(")
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-15 20:01
<p>php抓取网页标签的办法有两种:(1)通过泛洪取代目标解析首先定义一个列表,jsonquery.data(" 查看全部
php抓取网页标签(php抓取网页标签的办法有两种:(1)通过泛洪取代目标解析首先定义一个列表,jsonquery.data(")
<p>php抓取网页标签的办法有两种:(1)通过泛洪取代目标解析首先定义一个列表,jsonquery.data("
php抓取网页标签(php抓取网页标签信息可以从以下几个方面做记录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-12-14 07:02
php抓取网页标签信息可以从以下几个方面做记录。1.网页封装,生成网页json字符串2.post将标签拆分成多个post协议对象,这些对象存储在不同的元素文件中。3.发送请求4.解析返回信息post的方式是post传递php的,不同的post协议(也可以是http)不同,封装的格式也不同,可以使用php的类封装数据,或者反序列化json格式的post数据格式,很多开源的封装工具,我们也可以通过封装工具直接操作封装的数据。
php调用nodejs的postman,getman可以做到。nodejs封装postman为json或者xml格式的,再提供json或者xml格式的postman连接,但是postman可能没有连接的功能,在postmanpost之前可以先user-agent来做判断。
postman+nodejs做抓取?别想了。
postman
postman、getman都可以
用googleplaytunnel
用tp调用http请求
三个api了解一下?简单介绍一下如何抓取?调用微信表情,上传表情和微信表情包。
我写了一个h5,抓取其数据,传数据给朋友发送,
看是爬虫还是cookie。 查看全部
php抓取网页标签(php抓取网页标签信息可以从以下几个方面做记录)
php抓取网页标签信息可以从以下几个方面做记录。1.网页封装,生成网页json字符串2.post将标签拆分成多个post协议对象,这些对象存储在不同的元素文件中。3.发送请求4.解析返回信息post的方式是post传递php的,不同的post协议(也可以是http)不同,封装的格式也不同,可以使用php的类封装数据,或者反序列化json格式的post数据格式,很多开源的封装工具,我们也可以通过封装工具直接操作封装的数据。
php调用nodejs的postman,getman可以做到。nodejs封装postman为json或者xml格式的,再提供json或者xml格式的postman连接,但是postman可能没有连接的功能,在postmanpost之前可以先user-agent来做判断。
postman+nodejs做抓取?别想了。
postman
postman、getman都可以
用googleplaytunnel
用tp调用http请求
三个api了解一下?简单介绍一下如何抓取?调用微信表情,上传表情和微信表情包。
我写了一个h5,抓取其数据,传数据给朋友发送,
看是爬虫还是cookie。
php抓取网页标签( PHP实现网页内容html标签补全和过滤的方法实例解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-05 14:01
PHP实现网页内容html标签补全和过滤的方法实例解析)
PHP完成和过滤网页内容html标签的方法总结【2种方法】
更新时间:2017年4月27日10:58:53 作者:网站
本文文章主要介绍了PHP对网页内容的html标签补全和过滤的实现方法,结合示例表单分析了常见的PHP标签检查、补全、关闭、过滤等相关操作技巧。有需要的朋友可以参考
本文介绍了一个示例,说明 PHP 如何实现网页内容的 html 标签补全和过滤。分享给大家,供大家参考,如下:
如果你的网页内容的html标签显示不全,部分table标签不完整,页面乱七八糟,或者你收录了除你内容以外的部分html页面,我们可以写一个函数方法来完成html标记并过滤掉无用的 html 标记。
php使HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
Closetags() 分析:
array_reverse():该函数颠倒原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名将丢失。
array_search(): array_search(value,array,strict),这个函数像in_array()一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有在数据类型和值相同时才会返回对应元素的键名。
php使HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
检查html($html)解析:
stripslashes():该函数去除由addslashes()函数添加的反斜杠。该函数用于清理从数据库或HTML表单中检索到的数据。
更多对PHP相关内容感兴趣的读者可以查看本站专题:《PHP数据结构与算法教程》、《PHP编程算法汇总》、《PHP排序算法汇总》、《PHP常用遍历算法与技巧》 《总结》、《PHP数学运算技巧总结》、《PHP数组(数组)运算技巧》、《php字符串(字符串)使用技巧总结》、《php常用数据库操作技巧总结》
希望这篇文章能对你的 PHP 编程有所帮助。 查看全部
php抓取网页标签(
PHP实现网页内容html标签补全和过滤的方法实例解析)
PHP完成和过滤网页内容html标签的方法总结【2种方法】
更新时间:2017年4月27日10:58:53 作者:网站
本文文章主要介绍了PHP对网页内容的html标签补全和过滤的实现方法,结合示例表单分析了常见的PHP标签检查、补全、关闭、过滤等相关操作技巧。有需要的朋友可以参考
本文介绍了一个示例,说明 PHP 如何实现网页内容的 html 标签补全和过滤。分享给大家,供大家参考,如下:
如果你的网页内容的html标签显示不全,部分table标签不完整,页面乱七八糟,或者你收录了除你内容以外的部分html页面,我们可以写一个函数方法来完成html标记并过滤掉无用的 html 标记。
php使HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
Closetags() 分析:
array_reverse():该函数颠倒原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名将丢失。
array_search(): array_search(value,array,strict),这个函数像in_array()一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有在数据类型和值相同时才会返回对应元素的键名。
php使HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
检查html($html)解析:
stripslashes():该函数去除由addslashes()函数添加的反斜杠。该函数用于清理从数据库或HTML表单中检索到的数据。
更多对PHP相关内容感兴趣的读者可以查看本站专题:《PHP数据结构与算法教程》、《PHP编程算法汇总》、《PHP排序算法汇总》、《PHP常用遍历算法与技巧》 《总结》、《PHP数学运算技巧总结》、《PHP数组(数组)运算技巧》、《php字符串(字符串)使用技巧总结》、《php常用数据库操作技巧总结》
希望这篇文章能对你的 PHP 编程有所帮助。
php抓取网页标签(Linux文本编辑器Vim“真·简单”使用教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-05 00:08
因为金哥分享的东西(杂)越来越多,分类越来越多,层次越来越多,所以为了更好的显示URL地址,我们计划在近期修复所有文章 链接来自原创
/%category%/%post_id%.html
改为
/%post_id%.html
这将统一所有文章链接,不再有老长老;另一个优点是文章链接二维码也可以很简单。但是,更改 URL 是 SEO 的禁忌。为此,金哥参考了百度的网站修改规则,最大限度地保留了原来的收录。
获取所有链接
将下面的代码复制到utf8文件中,命名为post.php(文章)、page.php(page)、category.php(category)、tag.php(tag),放入网站 根目录没问题。
获取所有文章链接代码↓
获取所有页面链接代码↓
获取所有分类链接代码↓
获取所有标签链接代码↓
然后,进入服务器,以root账号使用wget命令结合这个PHP代码文件,生成指定的TXT文件。由于金哥只修改了文章链接,这里仅以文章命令为例,页面、分类、标签的修改请参考
wget -O /***/***/www.dujin.org/post.txt --no-check-certificate https://www.dujin.org/post.php
运行前需要注意自己的网站路径和txt文件存放路径。 --no-check-certificate 参数是因为 Jin 的博客是 HTTPS。如果 HTTP 站点可以删除此参数。
如果你的网站设置了360网站Guard或者其他CDN服务,还需要使用vim命令修改hosts文件,将你的网站域名指向你的服务器IP地址。
vim /etc/hosts
Linux 文本编辑器 Vim 《真·简单》教程
操作完成后,会在网站的根目录下生成一个post.txt文档。
此时使用纯文本编辑软件(如Emurasoft文本编辑器)批量查找替换重复的XML标记代码。
EmEditor 32&64 bit v17.4.第2版下载,附注册码
好了,到此为止,所有的URL链接都已经获取到了。如果您有任何问题,请留言。 查看全部
php抓取网页标签(Linux文本编辑器Vim“真·简单”使用教程(组图))
因为金哥分享的东西(杂)越来越多,分类越来越多,层次越来越多,所以为了更好的显示URL地址,我们计划在近期修复所有文章 链接来自原创
/%category%/%post_id%.html
改为
/%post_id%.html
这将统一所有文章链接,不再有老长老;另一个优点是文章链接二维码也可以很简单。但是,更改 URL 是 SEO 的禁忌。为此,金哥参考了百度的网站修改规则,最大限度地保留了原来的收录。
获取所有链接
将下面的代码复制到utf8文件中,命名为post.php(文章)、page.php(page)、category.php(category)、tag.php(tag),放入网站 根目录没问题。
获取所有文章链接代码↓
获取所有页面链接代码↓
获取所有分类链接代码↓
获取所有标签链接代码↓
然后,进入服务器,以root账号使用wget命令结合这个PHP代码文件,生成指定的TXT文件。由于金哥只修改了文章链接,这里仅以文章命令为例,页面、分类、标签的修改请参考
wget -O /***/***/www.dujin.org/post.txt --no-check-certificate https://www.dujin.org/post.php
运行前需要注意自己的网站路径和txt文件存放路径。 --no-check-certificate 参数是因为 Jin 的博客是 HTTPS。如果 HTTP 站点可以删除此参数。
如果你的网站设置了360网站Guard或者其他CDN服务,还需要使用vim命令修改hosts文件,将你的网站域名指向你的服务器IP地址。
vim /etc/hosts
Linux 文本编辑器 Vim 《真·简单》教程
操作完成后,会在网站的根目录下生成一个post.txt文档。
https://img.dujin.org/uploads/ ... 6.jpg 300w, https://img.dujin.org/uploads/ ... 3.jpg 768w" />此时使用纯文本编辑软件(如Emurasoft文本编辑器)批量查找替换重复的XML标记代码。
EmEditor 32&64 bit v17.4.第2版下载,附注册码
好了,到此为止,所有的URL链接都已经获取到了。如果您有任何问题,请留言。
php抓取网页标签(两个博客学习安全知识之一个博客爬取网站文章 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-03 17:17
)
前后历时两个月,终于完成了数据库课程。. . 考虑到wooyun关闭后各种wooyun资源转储的火爆,最近刚刚通过各种博客学习安全知识,想到做一个博客爬取网站,首先写了一个爬虫来爬取整个< @文章 的博客,然后显示它。
<p>这是网站的登录界面。左边的文字概括了我做整个网站的初衷,希望能成为一个博客采集平台,可以方便的爬取博客,然后展示这些转储。 查看全部
php抓取网页标签(两个博客学习安全知识之一个博客爬取网站文章
)
前后历时两个月,终于完成了数据库课程。. . 考虑到wooyun关闭后各种wooyun资源转储的火爆,最近刚刚通过各种博客学习安全知识,想到做一个博客爬取网站,首先写了一个爬虫来爬取整个< @文章 的博客,然后显示它。
<p>这是网站的登录界面。左边的文字概括了我做整个网站的初衷,希望能成为一个博客采集平台,可以方便的爬取博客,然后展示这些转储。

