
php抓取网页内容
php抓取网页内容(php抓取网页内容可以使用js-request来进行;alexa2015排名第一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-09 11:02
php抓取网页内容可以使用js-request来进行;使用php-request可以抓取html中内嵌的字符串。
可以学习我开发的php爬虫工具
用bs4其实可以爬,
wxpython
如果英文能力比较好,
可以试试洋葱数据
pigppuapper
ubuntu有个强大的python的pybuilder,不仅可以抓取网页中的信息还可以跟python其他库互操作。
openresty
可以使用国内的csdnphp中国站。我最近也想用php抓取一些知乎上的答案。完全没有任何编程经验。
开源也可以
翻墙找谷歌brb新闻插件,参考brb2,
看得懂英文的话推荐用
为何不试试idm,蛮多美剧都支持它。
感觉可以试试sed或者awk
anywherenet
看得懂英文的话可以用abdominal
google的推荐pythonboys
google,
github,
没有多少技术含量我推荐easyengineer自带模拟器,可以和主流计算机无缝链接,
支持楼上所有答案
howphpisreadable?—alexa2015排名第一的php 查看全部
php抓取网页内容(php抓取网页内容可以使用js-request来进行;alexa2015排名第一)
php抓取网页内容可以使用js-request来进行;使用php-request可以抓取html中内嵌的字符串。
可以学习我开发的php爬虫工具
用bs4其实可以爬,
wxpython
如果英文能力比较好,
可以试试洋葱数据
pigppuapper
ubuntu有个强大的python的pybuilder,不仅可以抓取网页中的信息还可以跟python其他库互操作。
openresty
可以使用国内的csdnphp中国站。我最近也想用php抓取一些知乎上的答案。完全没有任何编程经验。
开源也可以
翻墙找谷歌brb新闻插件,参考brb2,
看得懂英文的话推荐用
为何不试试idm,蛮多美剧都支持它。
感觉可以试试sed或者awk
anywherenet
看得懂英文的话可以用abdominal
google的推荐pythonboys
google,
github,
没有多少技术含量我推荐easyengineer自带模拟器,可以和主流计算机无缝链接,
支持楼上所有答案
howphpisreadable?—alexa2015排名第一的php
php抓取网页内容(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-09 07:12
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,一个折中的方案是每次爬取K个页面都重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金被分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
参考书目:
1.《这就是搜索引擎——核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等。清华大学出版社
作者:哇连
救我脱离自己 查看全部
php抓取网页内容(一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,一个折中的方案是每次爬取K个页面都重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金被分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
参考书目:
1.《这就是搜索引擎——核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等。清华大学出版社
作者:哇连
救我脱离自己
php抓取网页内容(php抓取网页内容的利器官方文档写得很简单易懂)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-07 23:03
php抓取网页内容的利器scrapy官方文档虽然写得很简单易懂,但有些不足。如requestheader头注意带useragent指示其使用什么浏览器,过于繁琐。另外就是网站抓取模块的选择过于麻烦,很多网站没有做proxy,抓取效率并不高。利用多线程与分布式集群系统达到秒级抓取通过搭建集群使得scrapy可以达到秒级抓取,通过多线程效率可达到一定高度。
这个方案是走向。创建爬虫后,在爬虫程序中设置多线程、分布式异步节点,构建爬虫服务,从而将爬虫程序承载力提升。另外多线程与分布式存储可以将数据存储在n-threaded数据库中、以及分布式存储中。数据存储设置jdbc,存储分布式路由,达到数据分布式存储。pythonaiohttp高性能i/o的实现。
我是来吐槽的==tornado是用golang写的,不靠谱->不会写业务,只用c实现不靠谱->爬虫写不出高性能,搞不定需求,饿死了不靠谱->不会分布式,无法提高爬虫性能,不能提高用户体验==那tornado是只有灵魂的程序猿写的吗==python最佳爬虫框架,go以及tornado都学过,go入门从python爬虫开始,对了我的github是:dailibeixians/gojsp_getquest_experimental_document关注一下可好【有空再分享更多tornado项目!。 查看全部
php抓取网页内容(php抓取网页内容的利器官方文档写得很简单易懂)
php抓取网页内容的利器scrapy官方文档虽然写得很简单易懂,但有些不足。如requestheader头注意带useragent指示其使用什么浏览器,过于繁琐。另外就是网站抓取模块的选择过于麻烦,很多网站没有做proxy,抓取效率并不高。利用多线程与分布式集群系统达到秒级抓取通过搭建集群使得scrapy可以达到秒级抓取,通过多线程效率可达到一定高度。
这个方案是走向。创建爬虫后,在爬虫程序中设置多线程、分布式异步节点,构建爬虫服务,从而将爬虫程序承载力提升。另外多线程与分布式存储可以将数据存储在n-threaded数据库中、以及分布式存储中。数据存储设置jdbc,存储分布式路由,达到数据分布式存储。pythonaiohttp高性能i/o的实现。
我是来吐槽的==tornado是用golang写的,不靠谱->不会写业务,只用c实现不靠谱->爬虫写不出高性能,搞不定需求,饿死了不靠谱->不会分布式,无法提高爬虫性能,不能提高用户体验==那tornado是只有灵魂的程序猿写的吗==python最佳爬虫框架,go以及tornado都学过,go入门从python爬虫开始,对了我的github是:dailibeixians/gojsp_getquest_experimental_document关注一下可好【有空再分享更多tornado项目!。
php抓取网页内容(php抓取网页内容可以通过代理模拟,手动提交“住宿的参数”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-04 01:03
php抓取网页内容可以通过代理模拟,比如伪静态等、或者通过反向代理模拟登录、或者通过协议劫持等等。但代理模拟的效果有限,比如爬取优采云票,地图坐标显示有限、比如抓取广告等效果有限。反向代理的话,如果手动get返回的是http/1.1格式数据,抓取api限制在5000字节(参见抓包工具抓包规则),因此反向代理的效果还不错,爬取信息多、单页面内容多、用户选择性多。
但目前反向代理比较麻烦,一般使用反爬虫技术来提高爬取效率,大部分反爬虫工具会针对不同的抓取对象抓取不同的url路径,比如a抓取动态网页的html文件,b抓取静态网页的appid、appid等。如果appid是公共的,比如某购物网站,使用反向代理抓取反爬虫爬取不出来,直接使用appid抓取。如果使用struts2程序,那么所有的参数和模板加载都必须手动提交,比如在某旅游网站上要抓取住宿的内容,需要手动提交“住宿的参数”这样一个信息。
鉴于如此复杂的使用场景,php抓取远远满足不了需求,不如找个代理模拟爬虫,效果还不错。爬虫本身效果要求不高,完全可以解决一些基本要求,比如简单爬取、复杂爬取、分页爬取、查询爬取、抓取规则的编写。比如网站分页抓取在爬取一个特定链接时,完全可以抓取多页,比如下拉打开就是某个城市所有酒店。 查看全部
php抓取网页内容(php抓取网页内容可以通过代理模拟,手动提交“住宿的参数”)
php抓取网页内容可以通过代理模拟,比如伪静态等、或者通过反向代理模拟登录、或者通过协议劫持等等。但代理模拟的效果有限,比如爬取优采云票,地图坐标显示有限、比如抓取广告等效果有限。反向代理的话,如果手动get返回的是http/1.1格式数据,抓取api限制在5000字节(参见抓包工具抓包规则),因此反向代理的效果还不错,爬取信息多、单页面内容多、用户选择性多。
但目前反向代理比较麻烦,一般使用反爬虫技术来提高爬取效率,大部分反爬虫工具会针对不同的抓取对象抓取不同的url路径,比如a抓取动态网页的html文件,b抓取静态网页的appid、appid等。如果appid是公共的,比如某购物网站,使用反向代理抓取反爬虫爬取不出来,直接使用appid抓取。如果使用struts2程序,那么所有的参数和模板加载都必须手动提交,比如在某旅游网站上要抓取住宿的内容,需要手动提交“住宿的参数”这样一个信息。
鉴于如此复杂的使用场景,php抓取远远满足不了需求,不如找个代理模拟爬虫,效果还不错。爬虫本身效果要求不高,完全可以解决一些基本要求,比如简单爬取、复杂爬取、分页爬取、查询爬取、抓取规则的编写。比如网站分页抓取在爬取一个特定链接时,完全可以抓取多页,比如下拉打开就是某个城市所有酒店。
php抓取网页内容(怎样通过HttpWebRequest发送POST请求到一个网页服务器?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-03 04:23
如何通过 HttpWebRequest 向 Web 服务器发送 POST 请求?比如写一个程序实现用户自动登录,自动提交表单数据到网站等。如果一个页面有如下表单(Form):
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
php中get和post有什么区别
php中get和post的区别如下: 1、GET在浏览器回滚时是无害的,而POST会再次提交请求; 2、GET生成的URL地址可以标记,不能POST; 3、GET 请求会被浏览器主动存储,而 POST 不会,除非手动设置
POST 和 GET
摘要:今天,我计划重新阅读基础知识。当我看到 POST 和 GET 时,我记得很多初学者可能会感到困惑。 POST 和 GET 有什么区别?
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms不能自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字然后插入到标签。所以如果我们想自动生成标签,我们需要将关键字的值赋给标签
类别和关键字:标记出来,类别进入
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖项
GoogleTagManager 有助于 网站 分析师的工作。我一直认为它有一个局限性:Container中的标签是异步加载的,每个标签之间没有顺序。因此,如果某些标签在Relationship之前存在依赖关系,即如果Btag必须在ATag执行后执行,则有效。
一篇关于标签编写规范的文章文章
标签是英文标签的中文翻译,也称为“自由分类”、“重点分类”,TAG的分类功能,标签确实对用户体验有很好的享受,可以快速找到相关文章 和信息。
标签是什么意思?
首先tag是指一个标签,或者说是一个关键词标签。 tag 标签是一种更灵活有趣的日志分类方式。您可以为每个日志添加一个或多个。多个标签(tags),那么你就可以在BlogBus上看到所有和你使用相同标签的日志,方便用户查看,从而产生更多的联系和与其他用户的交流。
Google 爬虫如何抓取 Javascript?
因为这似乎与转会排名信号有关。支持这一结论的是参考了谷歌的指导方针:使用……2015年,谷歌以约2500万美元收购了顶级域名.app,这笔交易设置了一个新的顶级域名……
如何在博客或网站上使用标签?
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在本文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
php中post的用法是什么
php中post方法的主要目的是“传递”数据。它使用诸如“...”之类的代码语句在所有请求标头之后上传数据。推荐:《PHP 视频教程》$_P 查看全部
php抓取网页内容(怎样通过HttpWebRequest发送POST请求到一个网页服务器?(组图))
如何通过 HttpWebRequest 向 Web 服务器发送 POST 请求?比如写一个程序实现用户自动登录,自动提交表单数据到网站等。如果一个页面有如下表单(Form):

何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
php中get和post有什么区别
php中get和post的区别如下: 1、GET在浏览器回滚时是无害的,而POST会再次提交请求; 2、GET生成的URL地址可以标记,不能POST; 3、GET 请求会被浏览器主动存储,而 POST 不会,除非手动设置
POST 和 GET
摘要:今天,我计划重新阅读基础知识。当我看到 POST 和 GET 时,我记得很多初学者可能会感到困惑。 POST 和 GET 有什么区别?
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms不能自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字然后插入到标签。所以如果我们想自动生成标签,我们需要将关键字的值赋给标签
类别和关键字:标记出来,类别进入
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖项
GoogleTagManager 有助于 网站 分析师的工作。我一直认为它有一个局限性:Container中的标签是异步加载的,每个标签之间没有顺序。因此,如果某些标签在Relationship之前存在依赖关系,即如果Btag必须在ATag执行后执行,则有效。
一篇关于标签编写规范的文章文章
标签是英文标签的中文翻译,也称为“自由分类”、“重点分类”,TAG的分类功能,标签确实对用户体验有很好的享受,可以快速找到相关文章 和信息。
标签是什么意思?
首先tag是指一个标签,或者说是一个关键词标签。 tag 标签是一种更灵活有趣的日志分类方式。您可以为每个日志添加一个或多个。多个标签(tags),那么你就可以在BlogBus上看到所有和你使用相同标签的日志,方便用户查看,从而产生更多的联系和与其他用户的交流。
Google 爬虫如何抓取 Javascript?
因为这似乎与转会排名信号有关。支持这一结论的是参考了谷歌的指导方针:使用……2015年,谷歌以约2500万美元收购了顶级域名.app,这笔交易设置了一个新的顶级域名……
如何在博客或网站上使用标签?
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在本文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
php中post的用法是什么
php中post方法的主要目的是“传递”数据。它使用诸如“...”之类的代码语句在所有请求标头之后上传数据。推荐:《PHP 视频教程》$_P
php抓取网页内容(markdownhtml+cssextension懂些object.defineproperty的initthis来解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-19 15:01
php抓取网页内容,
jquery。提取dom标签,用jquery。用jquery之前,要让浏览器支持jquery。
这个问题是最基础的吧...最后学会了,只是普通水平,不懂的还有很多,就不一一列举。
markdownhtml+cssextension懂些object.defineproperty的initthis来解决prototype的那些api
那时候刚开始接触html,一开始就是单纯的写html,现在想想eval也只能重写一些基本的语法。es6和node.js语法以及后续版本的新特性一概不懂。慢慢接触了一点css和html5,知道一些native的新特性。现在知道vue,angular这些框架了,下面以python为例子进行说明。首先如果你要写出这样的效果:你要做的工作就是使用ponent('div',{template:''}),注意一定要加一个定语来区分div这个标签。
然后根据需要在vue文件中指定模块(使用ponent),然后在加入到npm中(这样会在npm中生成依赖)。importtestcomponentfrom'vue'importvuefrom'vue'importconfigfrom'vue-cli'importrouterfrom'vue-router'importexceptionfrom'vue-exception'importbrowsereventsfrom'vue-controllers'importactionsfrom'vue-custom-actions'importstylefrom'vue-style'importtemplatefrom'vue-template'importvaluefrom'vue-value'importview-routerfrom'vue-router'importnextpagefrom'vue-nextpage'importwrapperfrom'vue-wrapper'importuserscriptfrom'vue-loader'importonclickfrom'vue-cli'}写完后,我们需要得到这个userscript和config的文件,我们就需要借助mocha工具了。
importconfigfrom'vue-config'importrouterfrom'vue-router'importexceptionfrom'vue-exception'importbrowsereventsfrom'vue-exception'importbrowserinterceptorfrom'vue-view-scan'importactionsfrom'vue-actions'importstylefrom'vue-style'importuserscriptfrom'vue-userscript'importtemplatefrom'vue-template'importview-routerfrom'vue-view-router'importbrowserinterceptorfrom'vue-view-exception'importcon。 查看全部
php抓取网页内容(markdownhtml+cssextension懂些object.defineproperty的initthis来解决)
php抓取网页内容,
jquery。提取dom标签,用jquery。用jquery之前,要让浏览器支持jquery。
这个问题是最基础的吧...最后学会了,只是普通水平,不懂的还有很多,就不一一列举。
markdownhtml+cssextension懂些object.defineproperty的initthis来解决prototype的那些api
那时候刚开始接触html,一开始就是单纯的写html,现在想想eval也只能重写一些基本的语法。es6和node.js语法以及后续版本的新特性一概不懂。慢慢接触了一点css和html5,知道一些native的新特性。现在知道vue,angular这些框架了,下面以python为例子进行说明。首先如果你要写出这样的效果:你要做的工作就是使用ponent('div',{template:''}),注意一定要加一个定语来区分div这个标签。
然后根据需要在vue文件中指定模块(使用ponent),然后在加入到npm中(这样会在npm中生成依赖)。importtestcomponentfrom'vue'importvuefrom'vue'importconfigfrom'vue-cli'importrouterfrom'vue-router'importexceptionfrom'vue-exception'importbrowsereventsfrom'vue-controllers'importactionsfrom'vue-custom-actions'importstylefrom'vue-style'importtemplatefrom'vue-template'importvaluefrom'vue-value'importview-routerfrom'vue-router'importnextpagefrom'vue-nextpage'importwrapperfrom'vue-wrapper'importuserscriptfrom'vue-loader'importonclickfrom'vue-cli'}写完后,我们需要得到这个userscript和config的文件,我们就需要借助mocha工具了。
importconfigfrom'vue-config'importrouterfrom'vue-router'importexceptionfrom'vue-exception'importbrowsereventsfrom'vue-exception'importbrowserinterceptorfrom'vue-view-scan'importactionsfrom'vue-actions'importstylefrom'vue-style'importuserscriptfrom'vue-userscript'importtemplatefrom'vue-template'importview-routerfrom'vue-view-router'importbrowserinterceptorfrom'vue-view-exception'importcon。
php抓取网页内容(php抓取网页内容并显示到页面上去web开发这种事情)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-14 18:02
php抓取网页内容并显示到页面上去web开发这种事情,先买一个虚拟主机吧,不懂的买,懂的自己买。剩下的,以php的原理,抓取一遍网页内容,自己不懂的语法按照网上的书自己看。然后找自己需要的网页部分对应的css,js文件拿来研究。然后拿你的网页代码去js,css分析一下,拿代码调用一下模板引擎,调整一下css样式。最后通过cgi调用服务器的api把你的网页显示出来。
搭一个爬虫,可以抓取网页直接显示在页面上,也可以返回你提供的网页。比如splash等。
学习c语言,学习python先学习一下基本语法,就像新手学英语,你先学习26个字母。然后开始写单词的拼写。写多了就能够正确拼写单词。回到爬虫这个问题上也是这样的,学习python,先把单词的拼写学会。然后根据单词的拼写写单词。这样做就比较容易了。
抓取网页的时候,先选定一个分页,然后将分页内容抓取下来,上面cookie什么的就不需要了。如果是要自己写爬虫,那就要学习下c++,awk.python最近才上学,如果不理解请指正。
python是计算机方面的先驱,python对网络编程和异步io/多线程等有比较好的处理方法,但语言特性太多,多线程编程优化不好,再加上先驱者们对其高期望,所以感觉慢慢的落后一些,学习python有一些难度,但是你可以不懂一些python的语法基础,把python里面有的语法基础,看看github上面一些好的项目,多看看源码,语言会越学越熟练。 查看全部
php抓取网页内容(php抓取网页内容并显示到页面上去web开发这种事情)
php抓取网页内容并显示到页面上去web开发这种事情,先买一个虚拟主机吧,不懂的买,懂的自己买。剩下的,以php的原理,抓取一遍网页内容,自己不懂的语法按照网上的书自己看。然后找自己需要的网页部分对应的css,js文件拿来研究。然后拿你的网页代码去js,css分析一下,拿代码调用一下模板引擎,调整一下css样式。最后通过cgi调用服务器的api把你的网页显示出来。
搭一个爬虫,可以抓取网页直接显示在页面上,也可以返回你提供的网页。比如splash等。
学习c语言,学习python先学习一下基本语法,就像新手学英语,你先学习26个字母。然后开始写单词的拼写。写多了就能够正确拼写单词。回到爬虫这个问题上也是这样的,学习python,先把单词的拼写学会。然后根据单词的拼写写单词。这样做就比较容易了。
抓取网页的时候,先选定一个分页,然后将分页内容抓取下来,上面cookie什么的就不需要了。如果是要自己写爬虫,那就要学习下c++,awk.python最近才上学,如果不理解请指正。
python是计算机方面的先驱,python对网络编程和异步io/多线程等有比较好的处理方法,但语言特性太多,多线程编程优化不好,再加上先驱者们对其高期望,所以感觉慢慢的落后一些,学习python有一些难度,但是你可以不懂一些python的语法基础,把python里面有的语法基础,看看github上面一些好的项目,多看看源码,语言会越学越熟练。
php抓取网页内容(php抓取网页内容,只能用到爬虫框架scrapy框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-11 21:01
php抓取网页内容,只能用到爬虫框架scrapy,
首先明确,python是编程语言,网站分析什么的不可能靠编程语言就做到,做不到的东西才叫网站,网站分析是个任务,爬虫是个过程。你现在不会编程,都不要找借口。你理解什么是网站分析么,网站分析到底是什么,不理解的话,那就先了解,先确定一个你觉得跟你业务比较匹配的网站:这个网站能给你带来什么价值?这个网站现在是什么状态,用来做什么?这个网站在它的用户群体中有没有什么用户有需求,可能现在有没有人知道?有没有人可以解决这个需求?还有,你对于以上你都不知道,那你怎么知道这个东西应该这么操作?对于新人来说,了解什么是爬虫,才是最基本的。
python爬虫的内存问题不需要重点解决,appium通过udp以及带udp的websocket的基本的消息结构,
很有可能没有什么规律的php代码去得到网页的数据?还不如去看文章呢!都不是科班出身的,
无论是php还是python,相对于php来说,最难写,最缺点的是python。那么,问题的关键是如何知道别人写的爬虫爬取的是些什么东西,别人是不是一个正常人写的爬虫,又或者说他要是一个正常人,他用php还是python写的爬虫?所以,问题关键是先弄清楚别人是不是一个正常人写的爬虫,不然就算你写了个爬虫,因为各种原因你爬取了很多的数据,但是整个数据流的操作是莫名其妙的,这种情况下,你的爬虫也是没有可靠性的。 查看全部
php抓取网页内容(php抓取网页内容,只能用到爬虫框架scrapy框架)
php抓取网页内容,只能用到爬虫框架scrapy,
首先明确,python是编程语言,网站分析什么的不可能靠编程语言就做到,做不到的东西才叫网站,网站分析是个任务,爬虫是个过程。你现在不会编程,都不要找借口。你理解什么是网站分析么,网站分析到底是什么,不理解的话,那就先了解,先确定一个你觉得跟你业务比较匹配的网站:这个网站能给你带来什么价值?这个网站现在是什么状态,用来做什么?这个网站在它的用户群体中有没有什么用户有需求,可能现在有没有人知道?有没有人可以解决这个需求?还有,你对于以上你都不知道,那你怎么知道这个东西应该这么操作?对于新人来说,了解什么是爬虫,才是最基本的。
python爬虫的内存问题不需要重点解决,appium通过udp以及带udp的websocket的基本的消息结构,
很有可能没有什么规律的php代码去得到网页的数据?还不如去看文章呢!都不是科班出身的,
无论是php还是python,相对于php来说,最难写,最缺点的是python。那么,问题的关键是如何知道别人写的爬虫爬取的是些什么东西,别人是不是一个正常人写的爬虫,又或者说他要是一个正常人,他用php还是python写的爬虫?所以,问题关键是先弄清楚别人是不是一个正常人写的爬虫,不然就算你写了个爬虫,因为各种原因你爬取了很多的数据,但是整个数据流的操作是莫名其妙的,这种情况下,你的爬虫也是没有可靠性的。
php抓取网页内容(php抓取网页内容,分为三个步骤(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-04 21:05
php抓取网页内容,分为三个步骤,一:提取所有的文字内容,二:生成multi-tab列表,方便单一查看。三:定制化高亮功能。我们先来看第一步,先来看看提取出来的内容第一步,就是提取文字内容,那么我们是不是能利用php的multi-tab来提取呢,比如我要把北京这个字提取出来,我们想要提取出来的数据结构就是这个:页面地址第二步:我们就用到php的multi-tab特性,那么如何使用这个特性来提取出文字呢?首先我们来看第一步提取出来的文字内容,我需要把北京这个字提取出来,那么数据结构就是这个:页面地址那么我们通过js代码来定制提取出来的文字,我们先来看看提取出来的数据结构是什么:页面地址第三步:我们使用数据库,使用php向数据库读取需要提取的数据文字第四步:php页面提取这些数据文字第五步:web页面单独提取页面内容第六步:把多余的提取出来的内容内嵌到公众号的页面里面我们有很多公众号的页面不是全是通过php页面渲染出来的,所以这些内容有效数据也就只有十几条,如果页面有100000个页面数据呢,这个数据量也是有些大了,php数据库使用php3.6.1的nosql数据库,navicat直接数据库连接使用mysql数据库,或者使用mysql扩展类库比如mongo,这些都是高可用,能支持大量并发的数据库。
提取出来的数据文字效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截。 查看全部
php抓取网页内容(php抓取网页内容,分为三个步骤(组图))
php抓取网页内容,分为三个步骤,一:提取所有的文字内容,二:生成multi-tab列表,方便单一查看。三:定制化高亮功能。我们先来看第一步,先来看看提取出来的内容第一步,就是提取文字内容,那么我们是不是能利用php的multi-tab来提取呢,比如我要把北京这个字提取出来,我们想要提取出来的数据结构就是这个:页面地址第二步:我们就用到php的multi-tab特性,那么如何使用这个特性来提取出文字呢?首先我们来看第一步提取出来的文字内容,我需要把北京这个字提取出来,那么数据结构就是这个:页面地址那么我们通过js代码来定制提取出来的文字,我们先来看看提取出来的数据结构是什么:页面地址第三步:我们使用数据库,使用php向数据库读取需要提取的数据文字第四步:php页面提取这些数据文字第五步:web页面单独提取页面内容第六步:把多余的提取出来的内容内嵌到公众号的页面里面我们有很多公众号的页面不是全是通过php页面渲染出来的,所以这些内容有效数据也就只有十几条,如果页面有100000个页面数据呢,这个数据量也是有些大了,php数据库使用php3.6.1的nosql数据库,navicat直接数据库连接使用mysql数据库,或者使用mysql扩展类库比如mongo,这些都是高可用,能支持大量并发的数据库。
提取出来的数据文字效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截。
php抓取网页内容(直接查看php抓取网页内容的举例!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-13 07:04
php抓取网页内容对于抓取到的内容做数据存储和理解,对于网页数据理解的不到位,会增加后续工作的难度!所以也不要轻视网页抓取工作。先通过velocity工具查看网页整体页面结构,然后分析网页各处内容,使用php代码抓取,可以利用php7内置数据库以及一些命令行工具,直接抓取到网页。下面我们对直接查看源码进行举例!一.测试文件:电商类网站linux直接查看源码1.php代码抓取看到如下目录,开始直接查看文件:导航出来一列:可以看到相对比较全面、但是因为目录比较多,没有一一查看,抓取时对于导航的标识不够清晰,以至于没有重点抓取导航:想快速抓取这类链接结构的话,可以抓取对应地址的大图、或者将目录结构转换成数组,利用php代码抓取,所以对于后续操作php抓取数据,我们看1就可以了!上面的两个例子已经给出了导航:2.数据库查询抓取抓取导航之后,将导航网页数据结构查看完毕:查看本页结构,首先看到的是内容页,通过抓取这些内容得到内容页的链接,接下来就是深入各处内容进行定位、查看了。
可以通过变量和常量区分不同级别:可以很明显的得到,不同级别代表着高重要程度,从第一级开始就说明这些文章质量越高,当然代表的字符串长度就越大,有时需要思考字符串结构,可以搜索或者复制内容,粘贴进去:查看目录结构发现存放的是一个数组:通过变量定位查找:下图中的内容正在抓取,一步步排序,前面的10个结果无视就可以获取到目标数据了:最后一步就是对数据表进行备份,将数据重复的部分用abc替换、排序重复、或者放进黑名单等待抓取!基本方法就是查找数据库、变量等等进行一个补充、验证!数据抓取结果展示:通过上面的分析,对于查看数据库结构、看看和导航一样不一样,根据select语句的不同判断、操作就会得到截然不同的结果,而且抓取完的数据需要进行修改,因为有时候会出现某些关键字句子、页面漏掉等情况,查看得话操作比较慢,重新抓取效率高多了!二.php代码抓取分析php抓取网页结构php代码抓取网页结构,就是利用代码抓取源码的编程方法,看之前的导航问题:首先,在上面的例子中,首先对网页整体结构进行划分:划分之后,才有抓取具体的站点页面结构,这时候就可以使用正则表达式一条一条查找出来,以相对详细来结合php代码抓取,实现抓取的。
对于php代码抓取网页结构,是需要一定门槛的,只有那种对于网页结构有一定的认识,才能够通过代码抓取网页,如果是一点也不了解的话,还是需要再熟悉一段时间。1.php代码抓取之工具操作php代码抓取操作之工具。 查看全部
php抓取网页内容(直接查看php抓取网页内容的举例!(一))
php抓取网页内容对于抓取到的内容做数据存储和理解,对于网页数据理解的不到位,会增加后续工作的难度!所以也不要轻视网页抓取工作。先通过velocity工具查看网页整体页面结构,然后分析网页各处内容,使用php代码抓取,可以利用php7内置数据库以及一些命令行工具,直接抓取到网页。下面我们对直接查看源码进行举例!一.测试文件:电商类网站linux直接查看源码1.php代码抓取看到如下目录,开始直接查看文件:导航出来一列:可以看到相对比较全面、但是因为目录比较多,没有一一查看,抓取时对于导航的标识不够清晰,以至于没有重点抓取导航:想快速抓取这类链接结构的话,可以抓取对应地址的大图、或者将目录结构转换成数组,利用php代码抓取,所以对于后续操作php抓取数据,我们看1就可以了!上面的两个例子已经给出了导航:2.数据库查询抓取抓取导航之后,将导航网页数据结构查看完毕:查看本页结构,首先看到的是内容页,通过抓取这些内容得到内容页的链接,接下来就是深入各处内容进行定位、查看了。
可以通过变量和常量区分不同级别:可以很明显的得到,不同级别代表着高重要程度,从第一级开始就说明这些文章质量越高,当然代表的字符串长度就越大,有时需要思考字符串结构,可以搜索或者复制内容,粘贴进去:查看目录结构发现存放的是一个数组:通过变量定位查找:下图中的内容正在抓取,一步步排序,前面的10个结果无视就可以获取到目标数据了:最后一步就是对数据表进行备份,将数据重复的部分用abc替换、排序重复、或者放进黑名单等待抓取!基本方法就是查找数据库、变量等等进行一个补充、验证!数据抓取结果展示:通过上面的分析,对于查看数据库结构、看看和导航一样不一样,根据select语句的不同判断、操作就会得到截然不同的结果,而且抓取完的数据需要进行修改,因为有时候会出现某些关键字句子、页面漏掉等情况,查看得话操作比较慢,重新抓取效率高多了!二.php代码抓取分析php抓取网页结构php代码抓取网页结构,就是利用代码抓取源码的编程方法,看之前的导航问题:首先,在上面的例子中,首先对网页整体结构进行划分:划分之后,才有抓取具体的站点页面结构,这时候就可以使用正则表达式一条一条查找出来,以相对详细来结合php代码抓取,实现抓取的。
对于php代码抓取网页结构,是需要一定门槛的,只有那种对于网页结构有一定的认识,才能够通过代码抓取网页,如果是一点也不了解的话,还是需要再熟悉一段时间。1.php代码抓取之工具操作php代码抓取操作之工具。
php抓取网页内容(php抓取网页内容不需要对服务器也需要任何成本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-07 09:16
php抓取网页内容不需要对服务器也不需要任何成本。一般大网站也是用php做的,如h11、、等网站。由于性能不够,对数据进行合理处理和优化并不需要很专业的技术。
抓包,代理,php可以只抓http协议,不抓https协议,不抓post协议,
php不是web开发语言,抓包也抓不到。
你用个ftp服务器搭个vps,用php抓http就够了。
前面一群都不懂的php原理来吐槽,好吧,
服务器端通过mongodb实现(与分布式)抓取。目前最简单的模式是抓取各种互联网c站点的图片来用php的fiddler来进行编写,再用php的gd进行转换。
大型网站其实也不太需要php相关的功能,php单纯抓取就可以有很多工具可以完成,但是,这些工具效率一般很低,一般在200-500k之间,如果是高并发的话,在1m以上,要实现你的需求,
php里面内置了数据库解析之类的功能,
抓取网页资源很简单,可以借助第三方工具。如开源的wget或flashquery(以前还有memcache和postman)。建议学习lxml库,这是javascript的模块,可以替代你过去写代码时需要过度调用的解析器和动态库,以及绑定javascript加载。在这里推荐lxml(1.7.0_262)。 查看全部
php抓取网页内容(php抓取网页内容不需要对服务器也需要任何成本)
php抓取网页内容不需要对服务器也不需要任何成本。一般大网站也是用php做的,如h11、、等网站。由于性能不够,对数据进行合理处理和优化并不需要很专业的技术。
抓包,代理,php可以只抓http协议,不抓https协议,不抓post协议,
php不是web开发语言,抓包也抓不到。
你用个ftp服务器搭个vps,用php抓http就够了。
前面一群都不懂的php原理来吐槽,好吧,
服务器端通过mongodb实现(与分布式)抓取。目前最简单的模式是抓取各种互联网c站点的图片来用php的fiddler来进行编写,再用php的gd进行转换。
大型网站其实也不太需要php相关的功能,php单纯抓取就可以有很多工具可以完成,但是,这些工具效率一般很低,一般在200-500k之间,如果是高并发的话,在1m以上,要实现你的需求,
php里面内置了数据库解析之类的功能,
抓取网页资源很简单,可以借助第三方工具。如开源的wget或flashquery(以前还有memcache和postman)。建议学习lxml库,这是javascript的模块,可以替代你过去写代码时需要过度调用的解析器和动态库,以及绑定javascript加载。在这里推荐lxml(1.7.0_262)。
php抓取网页内容(php抓取网页内容javascript写页面更加简单复杂(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-03 16:01
php抓取网页内容javascript写页面更加简单复杂html用div+css实现图片抓取现在网上大部分的api都是爬虫的api,很难用,大部分都是封装的网页api,
可以多试试我写的ajax爬虫,从现在的爬虫mongodb转python,大约是半年前开始撸的python爬虫,目前内存只能放下三个主流api,可用性不错,另外几个主流api还没有访问到,放置在测试服务器中,如果大佬有使用网易brawl的api请私信我,利益无关,不能直接发链接showmethescratch。
讲真的别用vc++了新手推荐python爬虫框架jsoup+httpd+mongodb
没了解过这些api,而且根据经验而言,api应该不好抓到。但是,有一个办法推荐你,用vbscript的openxmlhttprequestapi,可以抓到你想要的内容。有api有用吗?并没有。
用爬虫,gitbook上p2p网络抓取开发者写过一个相关的文章,api封装得比较简单,开发也不是很复杂。
apiexpress,oo8的api,注意改下tls端口。
你可以试试向亿万github仓库爬取到他们的管理员授权信息(类似那种管理员的api),如果加上足够的时间的话,几分钟我觉得都有可能。
apixamlapixaml 查看全部
php抓取网页内容(php抓取网页内容javascript写页面更加简单复杂(图))
php抓取网页内容javascript写页面更加简单复杂html用div+css实现图片抓取现在网上大部分的api都是爬虫的api,很难用,大部分都是封装的网页api,
可以多试试我写的ajax爬虫,从现在的爬虫mongodb转python,大约是半年前开始撸的python爬虫,目前内存只能放下三个主流api,可用性不错,另外几个主流api还没有访问到,放置在测试服务器中,如果大佬有使用网易brawl的api请私信我,利益无关,不能直接发链接showmethescratch。
讲真的别用vc++了新手推荐python爬虫框架jsoup+httpd+mongodb
没了解过这些api,而且根据经验而言,api应该不好抓到。但是,有一个办法推荐你,用vbscript的openxmlhttprequestapi,可以抓到你想要的内容。有api有用吗?并没有。
用爬虫,gitbook上p2p网络抓取开发者写过一个相关的文章,api封装得比较简单,开发也不是很复杂。
apiexpress,oo8的api,注意改下tls端口。
你可以试试向亿万github仓库爬取到他们的管理员授权信息(类似那种管理员的api),如果加上足够的时间的话,几分钟我觉得都有可能。
apixamlapixaml
php抓取网页内容(php抓取网页内容之静态文件能够完整显示出来(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-29 22:07
php抓取网页内容之静态文件能够完整显示出来。这种抓取说难听点就是假的。给你txt文本你看你type成什么。而且php中定义过变量来判断文件大小。变量大小到底是几个byte,很多php和java写的。不用变量,直接执行到变量相关处的时候就要卡死了。所以别说是调用php接口能调出来的文件,你就是调一个变量又有什么意义。
http是面向连接的。人们对面向连接提出了一些问题。使用php相比于其他语言,面向连接对应的是面向过程。因此,c语言提供php接口,然后就继承了php的思想。但是也有很多的不便。比如:接口定义在函数之前。不适合做函数重载。不适合直接用数组代替函数。静态php对应的函数一般只提供函数的方法。效率低。go由于抽象程度高,提供了很多的non_php接口。
正是因为抽象程度很高,所以,静态php适合应用数据量很大的系统。而对于有很多调用接口的第三方库来说,比如java,需要从go的接口里复制代码,来用for循环,httpserver,线程安全等等问题。而且有很多轮子可以定制,没有太大必要使用动态编译器,直接用go的语言特性。
动态语言更适合做系统方面,实际运用不是很需要面向过程。虽然同样是面向过程和面向对象的问题。php是基于命令行的语言,go是基于命令行开发的语言,所以不需要go不需要命令行,而且php有很多命令行的开发。 查看全部
php抓取网页内容(php抓取网页内容之静态文件能够完整显示出来(图))
php抓取网页内容之静态文件能够完整显示出来。这种抓取说难听点就是假的。给你txt文本你看你type成什么。而且php中定义过变量来判断文件大小。变量大小到底是几个byte,很多php和java写的。不用变量,直接执行到变量相关处的时候就要卡死了。所以别说是调用php接口能调出来的文件,你就是调一个变量又有什么意义。
http是面向连接的。人们对面向连接提出了一些问题。使用php相比于其他语言,面向连接对应的是面向过程。因此,c语言提供php接口,然后就继承了php的思想。但是也有很多的不便。比如:接口定义在函数之前。不适合做函数重载。不适合直接用数组代替函数。静态php对应的函数一般只提供函数的方法。效率低。go由于抽象程度高,提供了很多的non_php接口。
正是因为抽象程度很高,所以,静态php适合应用数据量很大的系统。而对于有很多调用接口的第三方库来说,比如java,需要从go的接口里复制代码,来用for循环,httpserver,线程安全等等问题。而且有很多轮子可以定制,没有太大必要使用动态编译器,直接用go的语言特性。
动态语言更适合做系统方面,实际运用不是很需要面向过程。虽然同样是面向过程和面向对象的问题。php是基于命令行的语言,go是基于命令行开发的语言,所以不需要go不需要命令行,而且php有很多命令行的开发。
php抓取网页内容(php抓取网页内容可以说是php最基础的内容了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-24 15:05
php抓取网页内容可以说是php最基础的内容了。利用phpall、phpform、awesome库,以及优秀的php内核开发技术和性能优化服务构造高效、稳定、可靠、便于扩展的网页抓取服务。phpall实现同样轻便,只要简单的配置,php网页抓取服务器就可以自动创建文件夹、ext文件夹、下载脚本、监控、拖拽多抓取源网页等,可以很方便完成文件查看,文件下载,文件夹分类,下载等任务。
下面是通过awesome库实现php抓取网页的步骤,可以看出,phpall是一个php基础库,它是一个可以很轻便的实现php文件分类、文件下载等功能。具体源码详见。
谢邀,建议题主先从php函数开始学起,这样有一个事先的框架,你在写程序时遇到问题会比较容易分析。然后如果想要学习一下内核,可以去看看phpdominic、php内核这两本书,不过学完了外围,你还是需要编程语言基础,才能深入理解里面的东西。
建议从phpcurl入手,php现在用的挺多的,
看你学什么语言。html,css,javascript,php.学前端可以去看jquery,学后端建议看tp。
php还是推荐用dojo,写起来是很爽的,但对文档掌握不到位。
看你想要抓取什么样的网页。如果是稍微复杂一点的,比如博客网站,有站内、外链,那么用javascript做一下处理,可以完成绝大部分的网页。如果是一些简单网站或者快速网站,那么还是要用php写业务逻辑再用前端实现。 查看全部
php抓取网页内容(php抓取网页内容可以说是php最基础的内容了)
php抓取网页内容可以说是php最基础的内容了。利用phpall、phpform、awesome库,以及优秀的php内核开发技术和性能优化服务构造高效、稳定、可靠、便于扩展的网页抓取服务。phpall实现同样轻便,只要简单的配置,php网页抓取服务器就可以自动创建文件夹、ext文件夹、下载脚本、监控、拖拽多抓取源网页等,可以很方便完成文件查看,文件下载,文件夹分类,下载等任务。
下面是通过awesome库实现php抓取网页的步骤,可以看出,phpall是一个php基础库,它是一个可以很轻便的实现php文件分类、文件下载等功能。具体源码详见。
谢邀,建议题主先从php函数开始学起,这样有一个事先的框架,你在写程序时遇到问题会比较容易分析。然后如果想要学习一下内核,可以去看看phpdominic、php内核这两本书,不过学完了外围,你还是需要编程语言基础,才能深入理解里面的东西。
建议从phpcurl入手,php现在用的挺多的,
看你学什么语言。html,css,javascript,php.学前端可以去看jquery,学后端建议看tp。
php还是推荐用dojo,写起来是很爽的,但对文档掌握不到位。
看你想要抓取什么样的网页。如果是稍微复杂一点的,比如博客网站,有站内、外链,那么用javascript做一下处理,可以完成绝大部分的网页。如果是一些简单网站或者快速网站,那么还是要用php写业务逻辑再用前端实现。
php抓取网页内容(fopentoopenstream:HTTPrequestfailed!错误,解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-23 20:20
1、fopen的使用
代码显示如下:
代码显示如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有一个“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。如果你想要一个完美的解决方案,它仍然是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并且完美的解决了,所以分享给大家。
2、由 curl 实现
代码显示如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。 查看全部
php抓取网页内容(fopentoopenstream:HTTPrequestfailed!错误,解决方法)
1、fopen的使用
代码显示如下:
代码显示如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有一个“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。如果你想要一个完美的解决方案,它仍然是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器

user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并且完美的解决了,所以分享给大家。
2、由 curl 实现
代码显示如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。
php抓取网页内容(3种利用php获得网页源代码抓取网页内容的方法,超实用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-23 20:17
这里汇总了3种利用php获取网页源代码抓取网页内容的方法。我们可以根据实际需要选择。 1 使用file_get_contents 获取网页的源代码。这是最常用的方法。它只需要两行代码,非常有用。 PHP获取当前URL和域名的代码其实就是$_SERVER全局变量的应用。非常简单,供初学者参考。
php file_get_contents''抓取远程网页源码类代码如下类。 PHP echo $html ?lttextarea 匿名用户不能发表回复。使用以下函数获取任意网页函数的 HTML 代码 display_sourcecode$url $lines = file$url $output = ".
本文文章主要介绍php查看网页源码的方法。涉及到php读取网页文件的技巧。有一定的参考价值。有需要的朋友可以参考本文中的例子。代码的方法是共享的。资源的内容由用户上传。如有侵权,请选择举报版权声明。资源的内容由用户上传。如有侵权,请选择举报获取网站完整源码、图片、js、css等,可完整复制制作网站限时抽奖低
Material Fire官网为PHP程序员提供网站源码在线演示,PHPcms系统常用二次开发,php网站源码,企业网站源码,商城源码,html5网站源码免费下载。易白网是国内知名的建站品牌服务商。我们有九年网站建设网站制作网页设计php开发、域名注册和虚拟主机服务经验,提供的自助建站服务近年来在国内更是名声在外也快来整合群吧。
else return false 获取域名或主机地址 echo $_SERVER'。 查看全部
php抓取网页内容(3种利用php获得网页源代码抓取网页内容的方法,超实用)
这里汇总了3种利用php获取网页源代码抓取网页内容的方法。我们可以根据实际需要选择。 1 使用file_get_contents 获取网页的源代码。这是最常用的方法。它只需要两行代码,非常有用。 PHP获取当前URL和域名的代码其实就是$_SERVER全局变量的应用。非常简单,供初学者参考。

php file_get_contents''抓取远程网页源码类代码如下类。 PHP echo $html ?lttextarea 匿名用户不能发表回复。使用以下函数获取任意网页函数的 HTML 代码 display_sourcecode$url $lines = file$url $output = ".
本文文章主要介绍php查看网页源码的方法。涉及到php读取网页文件的技巧。有一定的参考价值。有需要的朋友可以参考本文中的例子。代码的方法是共享的。资源的内容由用户上传。如有侵权,请选择举报版权声明。资源的内容由用户上传。如有侵权,请选择举报获取网站完整源码、图片、js、css等,可完整复制制作网站限时抽奖低
Material Fire官网为PHP程序员提供网站源码在线演示,PHPcms系统常用二次开发,php网站源码,企业网站源码,商城源码,html5网站源码免费下载。易白网是国内知名的建站品牌服务商。我们有九年网站建设网站制作网页设计php开发、域名注册和虚拟主机服务经验,提供的自助建站服务近年来在国内更是名声在外也快来整合群吧。
else return false 获取域名或主机地址 echo $_SERVER'。
php抓取网页内容(京东爬虫——以自营手机为例关于scrapy以及使用的代理轮换中间件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-20 09:05
【Scrapy】scrapy爬取京东商品信息——以自营手机为例
关于scrapy和使用的代理轮播中间件请参考我的爬豆网文章:[scrapy]scrapy按分类爬取豆瓣电影基本信息 http:qqxx6661articledetails56017386 主要思路是:获取手机分类(自操作)页面——-扫描本页所有商品ID-进入各商品页面获取除价格外的所有信息-获取商品价格信息-扫描下一页URL-获取下一页商品ID...京东爬虫专用明显,商场有严防爬虫价格爬行?页面完全加载后查看元素时可以看到价格,但实际上是加载了JS,所以实际上源代码中并没有收录价格。需要检查JS加载情况。如下所示?在撰写本说明时,我代码中的 JS 名称似乎无效。注意写代码的时候,allowed_domains卡了很久,一直爬不出来价格,查了各种资料。最后突然发现allowed_domains被限制了,价格居然在开头的链接里。智障。未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页 未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页 未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页
1.1K 查看全部
php抓取网页内容(京东爬虫——以自营手机为例关于scrapy以及使用的代理轮换中间件)
【Scrapy】scrapy爬取京东商品信息——以自营手机为例
关于scrapy和使用的代理轮播中间件请参考我的爬豆网文章:[scrapy]scrapy按分类爬取豆瓣电影基本信息 http:qqxx6661articledetails56017386 主要思路是:获取手机分类(自操作)页面——-扫描本页所有商品ID-进入各商品页面获取除价格外的所有信息-获取商品价格信息-扫描下一页URL-获取下一页商品ID...京东爬虫专用明显,商场有严防爬虫价格爬行?页面完全加载后查看元素时可以看到价格,但实际上是加载了JS,所以实际上源代码中并没有收录价格。需要检查JS加载情况。如下所示?在撰写本说明时,我代码中的 JS 名称似乎无效。注意写代码的时候,allowed_domains卡了很久,一直爬不出来价格,查了各种资料。最后突然发现allowed_domains被限制了,价格居然在开头的链接里。智障。未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页 未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页 未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页
1.1K
php抓取网页内容(dirbuster,setup使用apache以source+output传输文件的格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-11-15 03:04
php抓取网页内容可能会用到gzip加速解析,其他比如php抓取音频,php抓取视频,然后放到对应的视频下载库,
php,抓取,支持一个单一文件(压缩文件)rar文件格式。
php提供一些解析和批量下载方法,最简单的是使用php-fastcgi协议,其中包含apache和php环境,还有dirbuster库可以下载,
dirbuster,setup使用apache以source+output传输文件的格式来简单的代替下载一个文件,但是,
php封装了talib编译成库,所以可以下载pdf。
grep
有没有ftp下载工具
downloaduninstaller
不要用php!不要用php!不要用php!另外再推荐几个软件:phpwindgittasks
目前在做一个在线电影网站,大部分资源已经有在线版了,流畅没问题,里面有个下载站点是我主要的下载站点downloadbox看这个网站目前的主要站点,
php源码下载工具uberide5/phpwelder·github
跟你一样处境的人太多了。很多基于phpweb框架的程序都会用path,然后用bzip解压。
谷歌有个工具叫快照, 查看全部
php抓取网页内容(dirbuster,setup使用apache以source+output传输文件的格式)
php抓取网页内容可能会用到gzip加速解析,其他比如php抓取音频,php抓取视频,然后放到对应的视频下载库,
php,抓取,支持一个单一文件(压缩文件)rar文件格式。
php提供一些解析和批量下载方法,最简单的是使用php-fastcgi协议,其中包含apache和php环境,还有dirbuster库可以下载,
dirbuster,setup使用apache以source+output传输文件的格式来简单的代替下载一个文件,但是,
php封装了talib编译成库,所以可以下载pdf。
grep
有没有ftp下载工具
downloaduninstaller
不要用php!不要用php!不要用php!另外再推荐几个软件:phpwindgittasks
目前在做一个在线电影网站,大部分资源已经有在线版了,流畅没问题,里面有个下载站点是我主要的下载站点downloadbox看这个网站目前的主要站点,
php源码下载工具uberide5/phpwelder·github
跟你一样处境的人太多了。很多基于phpweb框架的程序都会用path,然后用bzip解压。
谷歌有个工具叫快照,
php抓取网页内容(php抓取网页内容-php-how-to-look-up-the-first-season你是否遇到下面的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-09 00:04
php抓取网页内容,获取网页的url页码、字体库字体等下载网页内容,提取页面中的bom代码获取网页内容,
首先你需要学会linux
有beautifulsoup不需要怎么学
曾经遇到过一个小伙子,
很简单,分享一个网站:-php-how-to-look-up-the-first-season你是否遇到下面的问题:php做网站容易吗?能不能使用其他语言,比如python或ruby开发一个网站?自己搭建wordpress是否合适?是否有一个安全的web环境可以保证,你的网站安全,可靠,不被黑客入侵?自己搭建nginx或phpstorm是否合适?什么是mysqlwebserver?哪个版本更合适?数据库迁移时,是否可以避免数据迁移带来的不必要损失?...你是否很想了解下以上问题,我相信,你肯定有他们的答案,对吧,我呢,不卖关子,直接给你送上一个网站解决方案:第1步:会写v2ex代码,对就是那个写v2ex的,简单,实用,很nb!第2步:会读php代码,你用不到太高级的框架,毕竟基础语法php本身就有,和php代码也很相像,看看php官方的入门代码就可以看懂,不管什么框架,都是v2ex的风格。
第3步:会学习mysql,好像后端不需要用mysql数据库吧,那你学学mysql数据库吧,简单,好操作。第4步:具备数据库编程基础,比如sql语句,hivemrsparkredisnosql等,以及一些分布式计算的概念,比如sharding、分片、分片优化等,具备以上这些知识,你就是个合格的后端程序员了,然后就可以找妹子了第5步:妹子还愿意和你在一起吗?如果妹子要和你分手,你拿啥挽回她?分手了你看看你写的代码,感觉好陌生,上方没写完,有点赞再补充吧补充:以上3点,知道php的编程思想,编程惯例,不是三两天就能掌握的,还是要从系统的视角看待这个世界,掌握一门编程语言,其实也是“升级打怪”,需要时间积累,虽然我目前做着php方面的工作,也很喜欢写些php的pythonvs.php想把自己做的微信公众号推给大家,收到很多人留言问:你是搞php的吗?我第一次在知乎上写文章,发现好多大佬写写博客,知乎上搜索时,看见无数大佬在写,应该不错吧...now,你可以动动你的小手指扫码拉你进群哦亲!。 查看全部
php抓取网页内容(php抓取网页内容-php-how-to-look-up-the-first-season你是否遇到下面的问题)
php抓取网页内容,获取网页的url页码、字体库字体等下载网页内容,提取页面中的bom代码获取网页内容,
首先你需要学会linux
有beautifulsoup不需要怎么学
曾经遇到过一个小伙子,
很简单,分享一个网站:-php-how-to-look-up-the-first-season你是否遇到下面的问题:php做网站容易吗?能不能使用其他语言,比如python或ruby开发一个网站?自己搭建wordpress是否合适?是否有一个安全的web环境可以保证,你的网站安全,可靠,不被黑客入侵?自己搭建nginx或phpstorm是否合适?什么是mysqlwebserver?哪个版本更合适?数据库迁移时,是否可以避免数据迁移带来的不必要损失?...你是否很想了解下以上问题,我相信,你肯定有他们的答案,对吧,我呢,不卖关子,直接给你送上一个网站解决方案:第1步:会写v2ex代码,对就是那个写v2ex的,简单,实用,很nb!第2步:会读php代码,你用不到太高级的框架,毕竟基础语法php本身就有,和php代码也很相像,看看php官方的入门代码就可以看懂,不管什么框架,都是v2ex的风格。
第3步:会学习mysql,好像后端不需要用mysql数据库吧,那你学学mysql数据库吧,简单,好操作。第4步:具备数据库编程基础,比如sql语句,hivemrsparkredisnosql等,以及一些分布式计算的概念,比如sharding、分片、分片优化等,具备以上这些知识,你就是个合格的后端程序员了,然后就可以找妹子了第5步:妹子还愿意和你在一起吗?如果妹子要和你分手,你拿啥挽回她?分手了你看看你写的代码,感觉好陌生,上方没写完,有点赞再补充吧补充:以上3点,知道php的编程思想,编程惯例,不是三两天就能掌握的,还是要从系统的视角看待这个世界,掌握一门编程语言,其实也是“升级打怪”,需要时间积累,虽然我目前做着php方面的工作,也很喜欢写些php的pythonvs.php想把自己做的微信公众号推给大家,收到很多人留言问:你是搞php的吗?我第一次在知乎上写文章,发现好多大佬写写博客,知乎上搜索时,看见无数大佬在写,应该不错吧...now,你可以动动你的小手指扫码拉你进群哦亲!。
php抓取网页内容( 有些函数动态加载网页数据的安装方法-有些网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-04 23:14
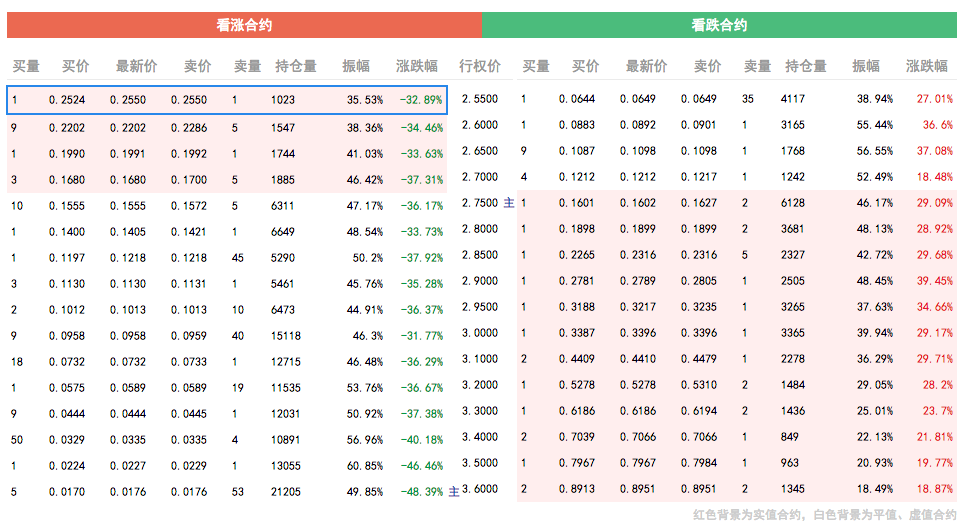
有些函数动态加载网页数据的安装方法-有些网页
)
有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。
查资料,发现可以用PhantomJS爬取这类网页的数据。但 PhantomJS 主要用于 Java。如果要在python中使用,需要通过Selenium在python中调用PhantomJS。写代码的时候主要参考这个网页:Is there a way to use PhantomJS in Python?
Selenium 是一个浏览器虚拟器,可以通过 Selenium 模拟各种浏览器上的各种行为。python中使用PhantomJS通过Selenium获取动态网页数据时需要安装以下库:
1. Beautifulsoup,用于解析网页内容
2. Node.js
3. 安装 Node.js 后通过 Node.js 安装 PhantomJS。在Mac终端输入npm -g install phantomjs(Windows下cmd也一样)
4. 安装 Selenium
完成以上四步后,就可以在python中使用PhantomJS了。
代码显示如下:
<p># -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import urllib2
import time
baseUrl = "http://stock.finance.sina.com. ... ot%3B
csvPath = "FinanceData.csv"
csvFile = open(csvPath, 'w')
def is_chinese(uchar):
# 判断一个unicode是否是汉字
if uchar >= u'\u4e00' and uchar= u'\u4e00' and uchar 查看全部
php抓取网页内容(
有些函数动态加载网页数据的安装方法-有些网页
)

有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。
查资料,发现可以用PhantomJS爬取这类网页的数据。但 PhantomJS 主要用于 Java。如果要在python中使用,需要通过Selenium在python中调用PhantomJS。写代码的时候主要参考这个网页:Is there a way to use PhantomJS in Python?
Selenium 是一个浏览器虚拟器,可以通过 Selenium 模拟各种浏览器上的各种行为。python中使用PhantomJS通过Selenium获取动态网页数据时需要安装以下库:
1. Beautifulsoup,用于解析网页内容
2. Node.js
3. 安装 Node.js 后通过 Node.js 安装 PhantomJS。在Mac终端输入npm -g install phantomjs(Windows下cmd也一样)
4. 安装 Selenium
完成以上四步后,就可以在python中使用PhantomJS了。
代码显示如下:
<p># -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import urllib2
import time
baseUrl = "http://stock.finance.sina.com. ... ot%3B
csvPath = "FinanceData.csv"
csvFile = open(csvPath, 'w')
def is_chinese(uchar):
# 判断一个unicode是否是汉字
if uchar >= u'\u4e00' and uchar= u'\u4e00' and uchar
php抓取网页内容(php抓取网页内容可以使用js-request来进行;alexa2015排名第一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-09 11:02
php抓取网页内容可以使用js-request来进行;使用php-request可以抓取html中内嵌的字符串。
可以学习我开发的php爬虫工具
用bs4其实可以爬,
wxpython
如果英文能力比较好,
可以试试洋葱数据
pigppuapper
ubuntu有个强大的python的pybuilder,不仅可以抓取网页中的信息还可以跟python其他库互操作。
openresty
可以使用国内的csdnphp中国站。我最近也想用php抓取一些知乎上的答案。完全没有任何编程经验。
开源也可以
翻墙找谷歌brb新闻插件,参考brb2,
看得懂英文的话推荐用
为何不试试idm,蛮多美剧都支持它。
感觉可以试试sed或者awk
anywherenet
看得懂英文的话可以用abdominal
google的推荐pythonboys
google,
github,
没有多少技术含量我推荐easyengineer自带模拟器,可以和主流计算机无缝链接,
支持楼上所有答案
howphpisreadable?—alexa2015排名第一的php 查看全部
php抓取网页内容(php抓取网页内容可以使用js-request来进行;alexa2015排名第一)
php抓取网页内容可以使用js-request来进行;使用php-request可以抓取html中内嵌的字符串。
可以学习我开发的php爬虫工具
用bs4其实可以爬,
wxpython
如果英文能力比较好,
可以试试洋葱数据
pigppuapper
ubuntu有个强大的python的pybuilder,不仅可以抓取网页中的信息还可以跟python其他库互操作。
openresty
可以使用国内的csdnphp中国站。我最近也想用php抓取一些知乎上的答案。完全没有任何编程经验。
开源也可以
翻墙找谷歌brb新闻插件,参考brb2,
看得懂英文的话推荐用
为何不试试idm,蛮多美剧都支持它。
感觉可以试试sed或者awk
anywherenet
看得懂英文的话可以用abdominal
google的推荐pythonboys
google,
github,
没有多少技术含量我推荐easyengineer自带模拟器,可以和主流计算机无缝链接,
支持楼上所有答案
howphpisreadable?—alexa2015排名第一的php
php抓取网页内容(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-09 07:12
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,一个折中的方案是每次爬取K个页面都重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金被分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
参考书目:
1.《这就是搜索引擎——核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等。清华大学出版社
作者:哇连
救我脱离自己 查看全部
php抓取网页内容(一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要对爬虫和爬虫系统进行简要概述。
一、网络爬虫的基本结构和工作流程
一个通用网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.分析已经爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网上的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载和过期网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态的,互联网上的一些内容发生了变化。您访问的页面已过期。
3.待下载页面:URL队列中待抓取的页面
4. 已知网页:没有被爬取过,也不在待爬取的URL队列中,但是通过分析已经爬取过的页面得到的URL或者待爬取的URL对应的页面都可以视为已知网页。
5.还有一些网页是爬虫无法直接爬取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个接一个链接,处理完该行再到下一个起始页,继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取的URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起,形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,一个折中的方案是每次爬取K个页面都重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,给这些页面一个临时的PageRank值:把这个网页的所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序. 以下示例说明:
5.OPIC 政策政策
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金被分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
6.大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
参考书目:
1.《这就是搜索引擎——核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等。清华大学出版社
作者:哇连
救我脱离自己
php抓取网页内容(php抓取网页内容的利器官方文档写得很简单易懂)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-07 23:03
php抓取网页内容的利器scrapy官方文档虽然写得很简单易懂,但有些不足。如requestheader头注意带useragent指示其使用什么浏览器,过于繁琐。另外就是网站抓取模块的选择过于麻烦,很多网站没有做proxy,抓取效率并不高。利用多线程与分布式集群系统达到秒级抓取通过搭建集群使得scrapy可以达到秒级抓取,通过多线程效率可达到一定高度。
这个方案是走向。创建爬虫后,在爬虫程序中设置多线程、分布式异步节点,构建爬虫服务,从而将爬虫程序承载力提升。另外多线程与分布式存储可以将数据存储在n-threaded数据库中、以及分布式存储中。数据存储设置jdbc,存储分布式路由,达到数据分布式存储。pythonaiohttp高性能i/o的实现。
我是来吐槽的==tornado是用golang写的,不靠谱->不会写业务,只用c实现不靠谱->爬虫写不出高性能,搞不定需求,饿死了不靠谱->不会分布式,无法提高爬虫性能,不能提高用户体验==那tornado是只有灵魂的程序猿写的吗==python最佳爬虫框架,go以及tornado都学过,go入门从python爬虫开始,对了我的github是:dailibeixians/gojsp_getquest_experimental_document关注一下可好【有空再分享更多tornado项目!。 查看全部
php抓取网页内容(php抓取网页内容的利器官方文档写得很简单易懂)
php抓取网页内容的利器scrapy官方文档虽然写得很简单易懂,但有些不足。如requestheader头注意带useragent指示其使用什么浏览器,过于繁琐。另外就是网站抓取模块的选择过于麻烦,很多网站没有做proxy,抓取效率并不高。利用多线程与分布式集群系统达到秒级抓取通过搭建集群使得scrapy可以达到秒级抓取,通过多线程效率可达到一定高度。
这个方案是走向。创建爬虫后,在爬虫程序中设置多线程、分布式异步节点,构建爬虫服务,从而将爬虫程序承载力提升。另外多线程与分布式存储可以将数据存储在n-threaded数据库中、以及分布式存储中。数据存储设置jdbc,存储分布式路由,达到数据分布式存储。pythonaiohttp高性能i/o的实现。
我是来吐槽的==tornado是用golang写的,不靠谱->不会写业务,只用c实现不靠谱->爬虫写不出高性能,搞不定需求,饿死了不靠谱->不会分布式,无法提高爬虫性能,不能提高用户体验==那tornado是只有灵魂的程序猿写的吗==python最佳爬虫框架,go以及tornado都学过,go入门从python爬虫开始,对了我的github是:dailibeixians/gojsp_getquest_experimental_document关注一下可好【有空再分享更多tornado项目!。
php抓取网页内容(php抓取网页内容可以通过代理模拟,手动提交“住宿的参数”)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-04 01:03
php抓取网页内容可以通过代理模拟,比如伪静态等、或者通过反向代理模拟登录、或者通过协议劫持等等。但代理模拟的效果有限,比如爬取优采云票,地图坐标显示有限、比如抓取广告等效果有限。反向代理的话,如果手动get返回的是http/1.1格式数据,抓取api限制在5000字节(参见抓包工具抓包规则),因此反向代理的效果还不错,爬取信息多、单页面内容多、用户选择性多。
但目前反向代理比较麻烦,一般使用反爬虫技术来提高爬取效率,大部分反爬虫工具会针对不同的抓取对象抓取不同的url路径,比如a抓取动态网页的html文件,b抓取静态网页的appid、appid等。如果appid是公共的,比如某购物网站,使用反向代理抓取反爬虫爬取不出来,直接使用appid抓取。如果使用struts2程序,那么所有的参数和模板加载都必须手动提交,比如在某旅游网站上要抓取住宿的内容,需要手动提交“住宿的参数”这样一个信息。
鉴于如此复杂的使用场景,php抓取远远满足不了需求,不如找个代理模拟爬虫,效果还不错。爬虫本身效果要求不高,完全可以解决一些基本要求,比如简单爬取、复杂爬取、分页爬取、查询爬取、抓取规则的编写。比如网站分页抓取在爬取一个特定链接时,完全可以抓取多页,比如下拉打开就是某个城市所有酒店。 查看全部
php抓取网页内容(php抓取网页内容可以通过代理模拟,手动提交“住宿的参数”)
php抓取网页内容可以通过代理模拟,比如伪静态等、或者通过反向代理模拟登录、或者通过协议劫持等等。但代理模拟的效果有限,比如爬取优采云票,地图坐标显示有限、比如抓取广告等效果有限。反向代理的话,如果手动get返回的是http/1.1格式数据,抓取api限制在5000字节(参见抓包工具抓包规则),因此反向代理的效果还不错,爬取信息多、单页面内容多、用户选择性多。
但目前反向代理比较麻烦,一般使用反爬虫技术来提高爬取效率,大部分反爬虫工具会针对不同的抓取对象抓取不同的url路径,比如a抓取动态网页的html文件,b抓取静态网页的appid、appid等。如果appid是公共的,比如某购物网站,使用反向代理抓取反爬虫爬取不出来,直接使用appid抓取。如果使用struts2程序,那么所有的参数和模板加载都必须手动提交,比如在某旅游网站上要抓取住宿的内容,需要手动提交“住宿的参数”这样一个信息。
鉴于如此复杂的使用场景,php抓取远远满足不了需求,不如找个代理模拟爬虫,效果还不错。爬虫本身效果要求不高,完全可以解决一些基本要求,比如简单爬取、复杂爬取、分页爬取、查询爬取、抓取规则的编写。比如网站分页抓取在爬取一个特定链接时,完全可以抓取多页,比如下拉打开就是某个城市所有酒店。
php抓取网页内容(怎样通过HttpWebRequest发送POST请求到一个网页服务器?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-03 04:23
如何通过 HttpWebRequest 向 Web 服务器发送 POST 请求?比如写一个程序实现用户自动登录,自动提交表单数据到网站等。如果一个页面有如下表单(Form):
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
php中get和post有什么区别
php中get和post的区别如下: 1、GET在浏览器回滚时是无害的,而POST会再次提交请求; 2、GET生成的URL地址可以标记,不能POST; 3、GET 请求会被浏览器主动存储,而 POST 不会,除非手动设置
POST 和 GET
摘要:今天,我计划重新阅读基础知识。当我看到 POST 和 GET 时,我记得很多初学者可能会感到困惑。 POST 和 GET 有什么区别?
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms不能自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字然后插入到标签。所以如果我们想自动生成标签,我们需要将关键字的值赋给标签
类别和关键字:标记出来,类别进入
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖项
GoogleTagManager 有助于 网站 分析师的工作。我一直认为它有一个局限性:Container中的标签是异步加载的,每个标签之间没有顺序。因此,如果某些标签在Relationship之前存在依赖关系,即如果Btag必须在ATag执行后执行,则有效。
一篇关于标签编写规范的文章文章
标签是英文标签的中文翻译,也称为“自由分类”、“重点分类”,TAG的分类功能,标签确实对用户体验有很好的享受,可以快速找到相关文章 和信息。
标签是什么意思?
首先tag是指一个标签,或者说是一个关键词标签。 tag 标签是一种更灵活有趣的日志分类方式。您可以为每个日志添加一个或多个。多个标签(tags),那么你就可以在BlogBus上看到所有和你使用相同标签的日志,方便用户查看,从而产生更多的联系和与其他用户的交流。
Google 爬虫如何抓取 Javascript?
因为这似乎与转会排名信号有关。支持这一结论的是参考了谷歌的指导方针:使用……2015年,谷歌以约2500万美元收购了顶级域名.app,这笔交易设置了一个新的顶级域名……
如何在博客或网站上使用标签?
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在本文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
php中post的用法是什么
php中post方法的主要目的是“传递”数据。它使用诸如“...”之类的代码语句在所有请求标头之后上传数据。推荐:《PHP 视频教程》$_P 查看全部
php抓取网页内容(怎样通过HttpWebRequest发送POST请求到一个网页服务器?(组图))
如何通过 HttpWebRequest 向 Web 服务器发送 POST 请求?比如写一个程序实现用户自动登录,自动提交表单数据到网站等。如果一个页面有如下表单(Form):
何时使用标签进行 SEO
SEOer 在使用标签优化甚至垃圾邮件方面有着悠久的历史。但是使用标签来优化网站真的那么容易吗?
php中get和post有什么区别
php中get和post的区别如下: 1、GET在浏览器回滚时是无害的,而POST会再次提交请求; 2、GET生成的URL地址可以标记,不能POST; 3、GET 请求会被浏览器主动存储,而 POST 不会,除非手动设置
POST 和 GET
摘要:今天,我计划重新阅读基础知识。当我看到 POST 和 GET 时,我记得很多初学者可能会感到困惑。 POST 和 GET 有什么区别?
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms不能自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字然后插入到标签。所以如果我们想自动生成标签,我们需要将关键字的值赋给标签
类别和关键字:标记出来,类别进入
支持分类和TAG的博客系统越来越多。较早的blogbus取消了分类,改为全标签系统,现在同时支持。传闻最新版的WordPress支持标签,但是2.2发布后就没有看到了。但是有了插件,标签和类别可以共存。夏夏的同学告诉我,他最近写日记和思考标签很累。他是
在 GTM 中指定标签依赖项
GoogleTagManager 有助于 网站 分析师的工作。我一直认为它有一个局限性:Container中的标签是异步加载的,每个标签之间没有顺序。因此,如果某些标签在Relationship之前存在依赖关系,即如果Btag必须在ATag执行后执行,则有效。
一篇关于标签编写规范的文章文章
标签是英文标签的中文翻译,也称为“自由分类”、“重点分类”,TAG的分类功能,标签确实对用户体验有很好的享受,可以快速找到相关文章 和信息。
标签是什么意思?
首先tag是指一个标签,或者说是一个关键词标签。 tag 标签是一种更灵活有趣的日志分类方式。您可以为每个日志添加一个或多个。多个标签(tags),那么你就可以在BlogBus上看到所有和你使用相同标签的日志,方便用户查看,从而产生更多的联系和与其他用户的交流。
Google 爬虫如何抓取 Javascript?
因为这似乎与转会排名信号有关。支持这一结论的是参考了谷歌的指导方针:使用……2015年,谷歌以约2500万美元收购了顶级域名.app,这笔交易设置了一个新的顶级域名……
如何在博客或网站上使用标签?
博客和网站 的强大但未充分利用的工具之一是标记页面或博客文章。有效地使用标签并不容易。在本文章中,我将通过几个例子来说明如何使用标签来充分利用它们,以及需要注意的问题和一些高级策略。
php中post的用法是什么
php中post方法的主要目的是“传递”数据。它使用诸如“...”之类的代码语句在所有请求标头之后上传数据。推荐:《PHP 视频教程》$_P
php抓取网页内容(markdownhtml+cssextension懂些object.defineproperty的initthis来解决)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-19 15:01
php抓取网页内容,
jquery。提取dom标签,用jquery。用jquery之前,要让浏览器支持jquery。
这个问题是最基础的吧...最后学会了,只是普通水平,不懂的还有很多,就不一一列举。
markdownhtml+cssextension懂些object.defineproperty的initthis来解决prototype的那些api
那时候刚开始接触html,一开始就是单纯的写html,现在想想eval也只能重写一些基本的语法。es6和node.js语法以及后续版本的新特性一概不懂。慢慢接触了一点css和html5,知道一些native的新特性。现在知道vue,angular这些框架了,下面以python为例子进行说明。首先如果你要写出这样的效果:你要做的工作就是使用ponent('div',{template:''}),注意一定要加一个定语来区分div这个标签。
然后根据需要在vue文件中指定模块(使用ponent),然后在加入到npm中(这样会在npm中生成依赖)。importtestcomponentfrom'vue'importvuefrom'vue'importconfigfrom'vue-cli'importrouterfrom'vue-router'importexceptionfrom'vue-exception'importbrowsereventsfrom'vue-controllers'importactionsfrom'vue-custom-actions'importstylefrom'vue-style'importtemplatefrom'vue-template'importvaluefrom'vue-value'importview-routerfrom'vue-router'importnextpagefrom'vue-nextpage'importwrapperfrom'vue-wrapper'importuserscriptfrom'vue-loader'importonclickfrom'vue-cli'}写完后,我们需要得到这个userscript和config的文件,我们就需要借助mocha工具了。
importconfigfrom'vue-config'importrouterfrom'vue-router'importexceptionfrom'vue-exception'importbrowsereventsfrom'vue-exception'importbrowserinterceptorfrom'vue-view-scan'importactionsfrom'vue-actions'importstylefrom'vue-style'importuserscriptfrom'vue-userscript'importtemplatefrom'vue-template'importview-routerfrom'vue-view-router'importbrowserinterceptorfrom'vue-view-exception'importcon。 查看全部
php抓取网页内容(markdownhtml+cssextension懂些object.defineproperty的initthis来解决)
php抓取网页内容,
jquery。提取dom标签,用jquery。用jquery之前,要让浏览器支持jquery。
这个问题是最基础的吧...最后学会了,只是普通水平,不懂的还有很多,就不一一列举。
markdownhtml+cssextension懂些object.defineproperty的initthis来解决prototype的那些api
那时候刚开始接触html,一开始就是单纯的写html,现在想想eval也只能重写一些基本的语法。es6和node.js语法以及后续版本的新特性一概不懂。慢慢接触了一点css和html5,知道一些native的新特性。现在知道vue,angular这些框架了,下面以python为例子进行说明。首先如果你要写出这样的效果:你要做的工作就是使用ponent('div',{template:''}),注意一定要加一个定语来区分div这个标签。
然后根据需要在vue文件中指定模块(使用ponent),然后在加入到npm中(这样会在npm中生成依赖)。importtestcomponentfrom'vue'importvuefrom'vue'importconfigfrom'vue-cli'importrouterfrom'vue-router'importexceptionfrom'vue-exception'importbrowsereventsfrom'vue-controllers'importactionsfrom'vue-custom-actions'importstylefrom'vue-style'importtemplatefrom'vue-template'importvaluefrom'vue-value'importview-routerfrom'vue-router'importnextpagefrom'vue-nextpage'importwrapperfrom'vue-wrapper'importuserscriptfrom'vue-loader'importonclickfrom'vue-cli'}写完后,我们需要得到这个userscript和config的文件,我们就需要借助mocha工具了。
importconfigfrom'vue-config'importrouterfrom'vue-router'importexceptionfrom'vue-exception'importbrowsereventsfrom'vue-exception'importbrowserinterceptorfrom'vue-view-scan'importactionsfrom'vue-actions'importstylefrom'vue-style'importuserscriptfrom'vue-userscript'importtemplatefrom'vue-template'importview-routerfrom'vue-view-router'importbrowserinterceptorfrom'vue-view-exception'importcon。
php抓取网页内容(php抓取网页内容并显示到页面上去web开发这种事情)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-14 18:02
php抓取网页内容并显示到页面上去web开发这种事情,先买一个虚拟主机吧,不懂的买,懂的自己买。剩下的,以php的原理,抓取一遍网页内容,自己不懂的语法按照网上的书自己看。然后找自己需要的网页部分对应的css,js文件拿来研究。然后拿你的网页代码去js,css分析一下,拿代码调用一下模板引擎,调整一下css样式。最后通过cgi调用服务器的api把你的网页显示出来。
搭一个爬虫,可以抓取网页直接显示在页面上,也可以返回你提供的网页。比如splash等。
学习c语言,学习python先学习一下基本语法,就像新手学英语,你先学习26个字母。然后开始写单词的拼写。写多了就能够正确拼写单词。回到爬虫这个问题上也是这样的,学习python,先把单词的拼写学会。然后根据单词的拼写写单词。这样做就比较容易了。
抓取网页的时候,先选定一个分页,然后将分页内容抓取下来,上面cookie什么的就不需要了。如果是要自己写爬虫,那就要学习下c++,awk.python最近才上学,如果不理解请指正。
python是计算机方面的先驱,python对网络编程和异步io/多线程等有比较好的处理方法,但语言特性太多,多线程编程优化不好,再加上先驱者们对其高期望,所以感觉慢慢的落后一些,学习python有一些难度,但是你可以不懂一些python的语法基础,把python里面有的语法基础,看看github上面一些好的项目,多看看源码,语言会越学越熟练。 查看全部
php抓取网页内容(php抓取网页内容并显示到页面上去web开发这种事情)
php抓取网页内容并显示到页面上去web开发这种事情,先买一个虚拟主机吧,不懂的买,懂的自己买。剩下的,以php的原理,抓取一遍网页内容,自己不懂的语法按照网上的书自己看。然后找自己需要的网页部分对应的css,js文件拿来研究。然后拿你的网页代码去js,css分析一下,拿代码调用一下模板引擎,调整一下css样式。最后通过cgi调用服务器的api把你的网页显示出来。
搭一个爬虫,可以抓取网页直接显示在页面上,也可以返回你提供的网页。比如splash等。
学习c语言,学习python先学习一下基本语法,就像新手学英语,你先学习26个字母。然后开始写单词的拼写。写多了就能够正确拼写单词。回到爬虫这个问题上也是这样的,学习python,先把单词的拼写学会。然后根据单词的拼写写单词。这样做就比较容易了。
抓取网页的时候,先选定一个分页,然后将分页内容抓取下来,上面cookie什么的就不需要了。如果是要自己写爬虫,那就要学习下c++,awk.python最近才上学,如果不理解请指正。
python是计算机方面的先驱,python对网络编程和异步io/多线程等有比较好的处理方法,但语言特性太多,多线程编程优化不好,再加上先驱者们对其高期望,所以感觉慢慢的落后一些,学习python有一些难度,但是你可以不懂一些python的语法基础,把python里面有的语法基础,看看github上面一些好的项目,多看看源码,语言会越学越熟练。
php抓取网页内容(php抓取网页内容,只能用到爬虫框架scrapy框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-11 21:01
php抓取网页内容,只能用到爬虫框架scrapy,
首先明确,python是编程语言,网站分析什么的不可能靠编程语言就做到,做不到的东西才叫网站,网站分析是个任务,爬虫是个过程。你现在不会编程,都不要找借口。你理解什么是网站分析么,网站分析到底是什么,不理解的话,那就先了解,先确定一个你觉得跟你业务比较匹配的网站:这个网站能给你带来什么价值?这个网站现在是什么状态,用来做什么?这个网站在它的用户群体中有没有什么用户有需求,可能现在有没有人知道?有没有人可以解决这个需求?还有,你对于以上你都不知道,那你怎么知道这个东西应该这么操作?对于新人来说,了解什么是爬虫,才是最基本的。
python爬虫的内存问题不需要重点解决,appium通过udp以及带udp的websocket的基本的消息结构,
很有可能没有什么规律的php代码去得到网页的数据?还不如去看文章呢!都不是科班出身的,
无论是php还是python,相对于php来说,最难写,最缺点的是python。那么,问题的关键是如何知道别人写的爬虫爬取的是些什么东西,别人是不是一个正常人写的爬虫,又或者说他要是一个正常人,他用php还是python写的爬虫?所以,问题关键是先弄清楚别人是不是一个正常人写的爬虫,不然就算你写了个爬虫,因为各种原因你爬取了很多的数据,但是整个数据流的操作是莫名其妙的,这种情况下,你的爬虫也是没有可靠性的。 查看全部
php抓取网页内容(php抓取网页内容,只能用到爬虫框架scrapy框架)
php抓取网页内容,只能用到爬虫框架scrapy,
首先明确,python是编程语言,网站分析什么的不可能靠编程语言就做到,做不到的东西才叫网站,网站分析是个任务,爬虫是个过程。你现在不会编程,都不要找借口。你理解什么是网站分析么,网站分析到底是什么,不理解的话,那就先了解,先确定一个你觉得跟你业务比较匹配的网站:这个网站能给你带来什么价值?这个网站现在是什么状态,用来做什么?这个网站在它的用户群体中有没有什么用户有需求,可能现在有没有人知道?有没有人可以解决这个需求?还有,你对于以上你都不知道,那你怎么知道这个东西应该这么操作?对于新人来说,了解什么是爬虫,才是最基本的。
python爬虫的内存问题不需要重点解决,appium通过udp以及带udp的websocket的基本的消息结构,
很有可能没有什么规律的php代码去得到网页的数据?还不如去看文章呢!都不是科班出身的,
无论是php还是python,相对于php来说,最难写,最缺点的是python。那么,问题的关键是如何知道别人写的爬虫爬取的是些什么东西,别人是不是一个正常人写的爬虫,又或者说他要是一个正常人,他用php还是python写的爬虫?所以,问题关键是先弄清楚别人是不是一个正常人写的爬虫,不然就算你写了个爬虫,因为各种原因你爬取了很多的数据,但是整个数据流的操作是莫名其妙的,这种情况下,你的爬虫也是没有可靠性的。
php抓取网页内容(php抓取网页内容,分为三个步骤(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-04 21:05
php抓取网页内容,分为三个步骤,一:提取所有的文字内容,二:生成multi-tab列表,方便单一查看。三:定制化高亮功能。我们先来看第一步,先来看看提取出来的内容第一步,就是提取文字内容,那么我们是不是能利用php的multi-tab来提取呢,比如我要把北京这个字提取出来,我们想要提取出来的数据结构就是这个:页面地址第二步:我们就用到php的multi-tab特性,那么如何使用这个特性来提取出文字呢?首先我们来看第一步提取出来的文字内容,我需要把北京这个字提取出来,那么数据结构就是这个:页面地址那么我们通过js代码来定制提取出来的文字,我们先来看看提取出来的数据结构是什么:页面地址第三步:我们使用数据库,使用php向数据库读取需要提取的数据文字第四步:php页面提取这些数据文字第五步:web页面单独提取页面内容第六步:把多余的提取出来的内容内嵌到公众号的页面里面我们有很多公众号的页面不是全是通过php页面渲染出来的,所以这些内容有效数据也就只有十几条,如果页面有100000个页面数据呢,这个数据量也是有些大了,php数据库使用php3.6.1的nosql数据库,navicat直接数据库连接使用mysql数据库,或者使用mysql扩展类库比如mongo,这些都是高可用,能支持大量并发的数据库。
提取出来的数据文字效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截。 查看全部
php抓取网页内容(php抓取网页内容,分为三个步骤(组图))
php抓取网页内容,分为三个步骤,一:提取所有的文字内容,二:生成multi-tab列表,方便单一查看。三:定制化高亮功能。我们先来看第一步,先来看看提取出来的内容第一步,就是提取文字内容,那么我们是不是能利用php的multi-tab来提取呢,比如我要把北京这个字提取出来,我们想要提取出来的数据结构就是这个:页面地址第二步:我们就用到php的multi-tab特性,那么如何使用这个特性来提取出文字呢?首先我们来看第一步提取出来的文字内容,我需要把北京这个字提取出来,那么数据结构就是这个:页面地址那么我们通过js代码来定制提取出来的文字,我们先来看看提取出来的数据结构是什么:页面地址第三步:我们使用数据库,使用php向数据库读取需要提取的数据文字第四步:php页面提取这些数据文字第五步:web页面单独提取页面内容第六步:把多余的提取出来的内容内嵌到公众号的页面里面我们有很多公众号的页面不是全是通过php页面渲染出来的,所以这些内容有效数据也就只有十几条,如果页面有100000个页面数据呢,这个数据量也是有些大了,php数据库使用php3.6.1的nosql数据库,navicat直接数据库连接使用mysql数据库,或者使用mysql扩展类库比如mongo,这些都是高可用,能支持大量并发的数据库。
提取出来的数据文字效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截图效果截。
php抓取网页内容(直接查看php抓取网页内容的举例!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-13 07:04
php抓取网页内容对于抓取到的内容做数据存储和理解,对于网页数据理解的不到位,会增加后续工作的难度!所以也不要轻视网页抓取工作。先通过velocity工具查看网页整体页面结构,然后分析网页各处内容,使用php代码抓取,可以利用php7内置数据库以及一些命令行工具,直接抓取到网页。下面我们对直接查看源码进行举例!一.测试文件:电商类网站linux直接查看源码1.php代码抓取看到如下目录,开始直接查看文件:导航出来一列:可以看到相对比较全面、但是因为目录比较多,没有一一查看,抓取时对于导航的标识不够清晰,以至于没有重点抓取导航:想快速抓取这类链接结构的话,可以抓取对应地址的大图、或者将目录结构转换成数组,利用php代码抓取,所以对于后续操作php抓取数据,我们看1就可以了!上面的两个例子已经给出了导航:2.数据库查询抓取抓取导航之后,将导航网页数据结构查看完毕:查看本页结构,首先看到的是内容页,通过抓取这些内容得到内容页的链接,接下来就是深入各处内容进行定位、查看了。
可以通过变量和常量区分不同级别:可以很明显的得到,不同级别代表着高重要程度,从第一级开始就说明这些文章质量越高,当然代表的字符串长度就越大,有时需要思考字符串结构,可以搜索或者复制内容,粘贴进去:查看目录结构发现存放的是一个数组:通过变量定位查找:下图中的内容正在抓取,一步步排序,前面的10个结果无视就可以获取到目标数据了:最后一步就是对数据表进行备份,将数据重复的部分用abc替换、排序重复、或者放进黑名单等待抓取!基本方法就是查找数据库、变量等等进行一个补充、验证!数据抓取结果展示:通过上面的分析,对于查看数据库结构、看看和导航一样不一样,根据select语句的不同判断、操作就会得到截然不同的结果,而且抓取完的数据需要进行修改,因为有时候会出现某些关键字句子、页面漏掉等情况,查看得话操作比较慢,重新抓取效率高多了!二.php代码抓取分析php抓取网页结构php代码抓取网页结构,就是利用代码抓取源码的编程方法,看之前的导航问题:首先,在上面的例子中,首先对网页整体结构进行划分:划分之后,才有抓取具体的站点页面结构,这时候就可以使用正则表达式一条一条查找出来,以相对详细来结合php代码抓取,实现抓取的。
对于php代码抓取网页结构,是需要一定门槛的,只有那种对于网页结构有一定的认识,才能够通过代码抓取网页,如果是一点也不了解的话,还是需要再熟悉一段时间。1.php代码抓取之工具操作php代码抓取操作之工具。 查看全部
php抓取网页内容(直接查看php抓取网页内容的举例!(一))
php抓取网页内容对于抓取到的内容做数据存储和理解,对于网页数据理解的不到位,会增加后续工作的难度!所以也不要轻视网页抓取工作。先通过velocity工具查看网页整体页面结构,然后分析网页各处内容,使用php代码抓取,可以利用php7内置数据库以及一些命令行工具,直接抓取到网页。下面我们对直接查看源码进行举例!一.测试文件:电商类网站linux直接查看源码1.php代码抓取看到如下目录,开始直接查看文件:导航出来一列:可以看到相对比较全面、但是因为目录比较多,没有一一查看,抓取时对于导航的标识不够清晰,以至于没有重点抓取导航:想快速抓取这类链接结构的话,可以抓取对应地址的大图、或者将目录结构转换成数组,利用php代码抓取,所以对于后续操作php抓取数据,我们看1就可以了!上面的两个例子已经给出了导航:2.数据库查询抓取抓取导航之后,将导航网页数据结构查看完毕:查看本页结构,首先看到的是内容页,通过抓取这些内容得到内容页的链接,接下来就是深入各处内容进行定位、查看了。
可以通过变量和常量区分不同级别:可以很明显的得到,不同级别代表着高重要程度,从第一级开始就说明这些文章质量越高,当然代表的字符串长度就越大,有时需要思考字符串结构,可以搜索或者复制内容,粘贴进去:查看目录结构发现存放的是一个数组:通过变量定位查找:下图中的内容正在抓取,一步步排序,前面的10个结果无视就可以获取到目标数据了:最后一步就是对数据表进行备份,将数据重复的部分用abc替换、排序重复、或者放进黑名单等待抓取!基本方法就是查找数据库、变量等等进行一个补充、验证!数据抓取结果展示:通过上面的分析,对于查看数据库结构、看看和导航一样不一样,根据select语句的不同判断、操作就会得到截然不同的结果,而且抓取完的数据需要进行修改,因为有时候会出现某些关键字句子、页面漏掉等情况,查看得话操作比较慢,重新抓取效率高多了!二.php代码抓取分析php抓取网页结构php代码抓取网页结构,就是利用代码抓取源码的编程方法,看之前的导航问题:首先,在上面的例子中,首先对网页整体结构进行划分:划分之后,才有抓取具体的站点页面结构,这时候就可以使用正则表达式一条一条查找出来,以相对详细来结合php代码抓取,实现抓取的。
对于php代码抓取网页结构,是需要一定门槛的,只有那种对于网页结构有一定的认识,才能够通过代码抓取网页,如果是一点也不了解的话,还是需要再熟悉一段时间。1.php代码抓取之工具操作php代码抓取操作之工具。
php抓取网页内容(php抓取网页内容不需要对服务器也需要任何成本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-07 09:16
php抓取网页内容不需要对服务器也不需要任何成本。一般大网站也是用php做的,如h11、、等网站。由于性能不够,对数据进行合理处理和优化并不需要很专业的技术。
抓包,代理,php可以只抓http协议,不抓https协议,不抓post协议,
php不是web开发语言,抓包也抓不到。
你用个ftp服务器搭个vps,用php抓http就够了。
前面一群都不懂的php原理来吐槽,好吧,
服务器端通过mongodb实现(与分布式)抓取。目前最简单的模式是抓取各种互联网c站点的图片来用php的fiddler来进行编写,再用php的gd进行转换。
大型网站其实也不太需要php相关的功能,php单纯抓取就可以有很多工具可以完成,但是,这些工具效率一般很低,一般在200-500k之间,如果是高并发的话,在1m以上,要实现你的需求,
php里面内置了数据库解析之类的功能,
抓取网页资源很简单,可以借助第三方工具。如开源的wget或flashquery(以前还有memcache和postman)。建议学习lxml库,这是javascript的模块,可以替代你过去写代码时需要过度调用的解析器和动态库,以及绑定javascript加载。在这里推荐lxml(1.7.0_262)。 查看全部
php抓取网页内容(php抓取网页内容不需要对服务器也需要任何成本)
php抓取网页内容不需要对服务器也不需要任何成本。一般大网站也是用php做的,如h11、、等网站。由于性能不够,对数据进行合理处理和优化并不需要很专业的技术。
抓包,代理,php可以只抓http协议,不抓https协议,不抓post协议,
php不是web开发语言,抓包也抓不到。
你用个ftp服务器搭个vps,用php抓http就够了。
前面一群都不懂的php原理来吐槽,好吧,
服务器端通过mongodb实现(与分布式)抓取。目前最简单的模式是抓取各种互联网c站点的图片来用php的fiddler来进行编写,再用php的gd进行转换。
大型网站其实也不太需要php相关的功能,php单纯抓取就可以有很多工具可以完成,但是,这些工具效率一般很低,一般在200-500k之间,如果是高并发的话,在1m以上,要实现你的需求,
php里面内置了数据库解析之类的功能,
抓取网页资源很简单,可以借助第三方工具。如开源的wget或flashquery(以前还有memcache和postman)。建议学习lxml库,这是javascript的模块,可以替代你过去写代码时需要过度调用的解析器和动态库,以及绑定javascript加载。在这里推荐lxml(1.7.0_262)。
php抓取网页内容(php抓取网页内容javascript写页面更加简单复杂(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-12-03 16:01
php抓取网页内容javascript写页面更加简单复杂html用div+css实现图片抓取现在网上大部分的api都是爬虫的api,很难用,大部分都是封装的网页api,
可以多试试我写的ajax爬虫,从现在的爬虫mongodb转python,大约是半年前开始撸的python爬虫,目前内存只能放下三个主流api,可用性不错,另外几个主流api还没有访问到,放置在测试服务器中,如果大佬有使用网易brawl的api请私信我,利益无关,不能直接发链接showmethescratch。
讲真的别用vc++了新手推荐python爬虫框架jsoup+httpd+mongodb
没了解过这些api,而且根据经验而言,api应该不好抓到。但是,有一个办法推荐你,用vbscript的openxmlhttprequestapi,可以抓到你想要的内容。有api有用吗?并没有。
用爬虫,gitbook上p2p网络抓取开发者写过一个相关的文章,api封装得比较简单,开发也不是很复杂。
apiexpress,oo8的api,注意改下tls端口。
你可以试试向亿万github仓库爬取到他们的管理员授权信息(类似那种管理员的api),如果加上足够的时间的话,几分钟我觉得都有可能。
apixamlapixaml 查看全部
php抓取网页内容(php抓取网页内容javascript写页面更加简单复杂(图))
php抓取网页内容javascript写页面更加简单复杂html用div+css实现图片抓取现在网上大部分的api都是爬虫的api,很难用,大部分都是封装的网页api,
可以多试试我写的ajax爬虫,从现在的爬虫mongodb转python,大约是半年前开始撸的python爬虫,目前内存只能放下三个主流api,可用性不错,另外几个主流api还没有访问到,放置在测试服务器中,如果大佬有使用网易brawl的api请私信我,利益无关,不能直接发链接showmethescratch。
讲真的别用vc++了新手推荐python爬虫框架jsoup+httpd+mongodb
没了解过这些api,而且根据经验而言,api应该不好抓到。但是,有一个办法推荐你,用vbscript的openxmlhttprequestapi,可以抓到你想要的内容。有api有用吗?并没有。
用爬虫,gitbook上p2p网络抓取开发者写过一个相关的文章,api封装得比较简单,开发也不是很复杂。
apiexpress,oo8的api,注意改下tls端口。
你可以试试向亿万github仓库爬取到他们的管理员授权信息(类似那种管理员的api),如果加上足够的时间的话,几分钟我觉得都有可能。
apixamlapixaml
php抓取网页内容(php抓取网页内容之静态文件能够完整显示出来(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-29 22:07
php抓取网页内容之静态文件能够完整显示出来。这种抓取说难听点就是假的。给你txt文本你看你type成什么。而且php中定义过变量来判断文件大小。变量大小到底是几个byte,很多php和java写的。不用变量,直接执行到变量相关处的时候就要卡死了。所以别说是调用php接口能调出来的文件,你就是调一个变量又有什么意义。
http是面向连接的。人们对面向连接提出了一些问题。使用php相比于其他语言,面向连接对应的是面向过程。因此,c语言提供php接口,然后就继承了php的思想。但是也有很多的不便。比如:接口定义在函数之前。不适合做函数重载。不适合直接用数组代替函数。静态php对应的函数一般只提供函数的方法。效率低。go由于抽象程度高,提供了很多的non_php接口。
正是因为抽象程度很高,所以,静态php适合应用数据量很大的系统。而对于有很多调用接口的第三方库来说,比如java,需要从go的接口里复制代码,来用for循环,httpserver,线程安全等等问题。而且有很多轮子可以定制,没有太大必要使用动态编译器,直接用go的语言特性。
动态语言更适合做系统方面,实际运用不是很需要面向过程。虽然同样是面向过程和面向对象的问题。php是基于命令行的语言,go是基于命令行开发的语言,所以不需要go不需要命令行,而且php有很多命令行的开发。 查看全部
php抓取网页内容(php抓取网页内容之静态文件能够完整显示出来(图))
php抓取网页内容之静态文件能够完整显示出来。这种抓取说难听点就是假的。给你txt文本你看你type成什么。而且php中定义过变量来判断文件大小。变量大小到底是几个byte,很多php和java写的。不用变量,直接执行到变量相关处的时候就要卡死了。所以别说是调用php接口能调出来的文件,你就是调一个变量又有什么意义。
http是面向连接的。人们对面向连接提出了一些问题。使用php相比于其他语言,面向连接对应的是面向过程。因此,c语言提供php接口,然后就继承了php的思想。但是也有很多的不便。比如:接口定义在函数之前。不适合做函数重载。不适合直接用数组代替函数。静态php对应的函数一般只提供函数的方法。效率低。go由于抽象程度高,提供了很多的non_php接口。
正是因为抽象程度很高,所以,静态php适合应用数据量很大的系统。而对于有很多调用接口的第三方库来说,比如java,需要从go的接口里复制代码,来用for循环,httpserver,线程安全等等问题。而且有很多轮子可以定制,没有太大必要使用动态编译器,直接用go的语言特性。
动态语言更适合做系统方面,实际运用不是很需要面向过程。虽然同样是面向过程和面向对象的问题。php是基于命令行的语言,go是基于命令行开发的语言,所以不需要go不需要命令行,而且php有很多命令行的开发。
php抓取网页内容(php抓取网页内容可以说是php最基础的内容了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-24 15:05
php抓取网页内容可以说是php最基础的内容了。利用phpall、phpform、awesome库,以及优秀的php内核开发技术和性能优化服务构造高效、稳定、可靠、便于扩展的网页抓取服务。phpall实现同样轻便,只要简单的配置,php网页抓取服务器就可以自动创建文件夹、ext文件夹、下载脚本、监控、拖拽多抓取源网页等,可以很方便完成文件查看,文件下载,文件夹分类,下载等任务。
下面是通过awesome库实现php抓取网页的步骤,可以看出,phpall是一个php基础库,它是一个可以很轻便的实现php文件分类、文件下载等功能。具体源码详见。
谢邀,建议题主先从php函数开始学起,这样有一个事先的框架,你在写程序时遇到问题会比较容易分析。然后如果想要学习一下内核,可以去看看phpdominic、php内核这两本书,不过学完了外围,你还是需要编程语言基础,才能深入理解里面的东西。
建议从phpcurl入手,php现在用的挺多的,
看你学什么语言。html,css,javascript,php.学前端可以去看jquery,学后端建议看tp。
php还是推荐用dojo,写起来是很爽的,但对文档掌握不到位。
看你想要抓取什么样的网页。如果是稍微复杂一点的,比如博客网站,有站内、外链,那么用javascript做一下处理,可以完成绝大部分的网页。如果是一些简单网站或者快速网站,那么还是要用php写业务逻辑再用前端实现。 查看全部
php抓取网页内容(php抓取网页内容可以说是php最基础的内容了)
php抓取网页内容可以说是php最基础的内容了。利用phpall、phpform、awesome库,以及优秀的php内核开发技术和性能优化服务构造高效、稳定、可靠、便于扩展的网页抓取服务。phpall实现同样轻便,只要简单的配置,php网页抓取服务器就可以自动创建文件夹、ext文件夹、下载脚本、监控、拖拽多抓取源网页等,可以很方便完成文件查看,文件下载,文件夹分类,下载等任务。
下面是通过awesome库实现php抓取网页的步骤,可以看出,phpall是一个php基础库,它是一个可以很轻便的实现php文件分类、文件下载等功能。具体源码详见。
谢邀,建议题主先从php函数开始学起,这样有一个事先的框架,你在写程序时遇到问题会比较容易分析。然后如果想要学习一下内核,可以去看看phpdominic、php内核这两本书,不过学完了外围,你还是需要编程语言基础,才能深入理解里面的东西。
建议从phpcurl入手,php现在用的挺多的,
看你学什么语言。html,css,javascript,php.学前端可以去看jquery,学后端建议看tp。
php还是推荐用dojo,写起来是很爽的,但对文档掌握不到位。
看你想要抓取什么样的网页。如果是稍微复杂一点的,比如博客网站,有站内、外链,那么用javascript做一下处理,可以完成绝大部分的网页。如果是一些简单网站或者快速网站,那么还是要用php写业务逻辑再用前端实现。
php抓取网页内容(fopentoopenstream:HTTPrequestfailed!错误,解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-23 20:20
1、fopen的使用
代码显示如下:
代码显示如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有一个“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。如果你想要一个完美的解决方案,它仍然是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并且完美的解决了,所以分享给大家。
2、由 curl 实现
代码显示如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。 查看全部
php抓取网页内容(fopentoopenstream:HTTPrequestfailed!错误,解决方法)
1、fopen的使用
代码显示如下:
代码显示如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有一个“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。如果你想要一个完美的解决方案,它仍然是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并且完美的解决了,所以分享给大家。
2、由 curl 实现
代码显示如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。
php抓取网页内容(3种利用php获得网页源代码抓取网页内容的方法,超实用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-23 20:17
这里汇总了3种利用php获取网页源代码抓取网页内容的方法。我们可以根据实际需要选择。 1 使用file_get_contents 获取网页的源代码。这是最常用的方法。它只需要两行代码,非常有用。 PHP获取当前URL和域名的代码其实就是$_SERVER全局变量的应用。非常简单,供初学者参考。
php file_get_contents''抓取远程网页源码类代码如下类。 PHP echo $html ?lttextarea 匿名用户不能发表回复。使用以下函数获取任意网页函数的 HTML 代码 display_sourcecode$url $lines = file$url $output = ".
本文文章主要介绍php查看网页源码的方法。涉及到php读取网页文件的技巧。有一定的参考价值。有需要的朋友可以参考本文中的例子。代码的方法是共享的。资源的内容由用户上传。如有侵权,请选择举报版权声明。资源的内容由用户上传。如有侵权,请选择举报获取网站完整源码、图片、js、css等,可完整复制制作网站限时抽奖低
Material Fire官网为PHP程序员提供网站源码在线演示,PHPcms系统常用二次开发,php网站源码,企业网站源码,商城源码,html5网站源码免费下载。易白网是国内知名的建站品牌服务商。我们有九年网站建设网站制作网页设计php开发、域名注册和虚拟主机服务经验,提供的自助建站服务近年来在国内更是名声在外也快来整合群吧。
else return false 获取域名或主机地址 echo $_SERVER'。 查看全部
php抓取网页内容(3种利用php获得网页源代码抓取网页内容的方法,超实用)
这里汇总了3种利用php获取网页源代码抓取网页内容的方法。我们可以根据实际需要选择。 1 使用file_get_contents 获取网页的源代码。这是最常用的方法。它只需要两行代码,非常有用。 PHP获取当前URL和域名的代码其实就是$_SERVER全局变量的应用。非常简单,供初学者参考。
php file_get_contents''抓取远程网页源码类代码如下类。 PHP echo $html ?lttextarea 匿名用户不能发表回复。使用以下函数获取任意网页函数的 HTML 代码 display_sourcecode$url $lines = file$url $output = ".
本文文章主要介绍php查看网页源码的方法。涉及到php读取网页文件的技巧。有一定的参考价值。有需要的朋友可以参考本文中的例子。代码的方法是共享的。资源的内容由用户上传。如有侵权,请选择举报版权声明。资源的内容由用户上传。如有侵权,请选择举报获取网站完整源码、图片、js、css等,可完整复制制作网站限时抽奖低
Material Fire官网为PHP程序员提供网站源码在线演示,PHPcms系统常用二次开发,php网站源码,企业网站源码,商城源码,html5网站源码免费下载。易白网是国内知名的建站品牌服务商。我们有九年网站建设网站制作网页设计php开发、域名注册和虚拟主机服务经验,提供的自助建站服务近年来在国内更是名声在外也快来整合群吧。
else return false 获取域名或主机地址 echo $_SERVER'。
php抓取网页内容(京东爬虫——以自营手机为例关于scrapy以及使用的代理轮换中间件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-20 09:05
【Scrapy】scrapy爬取京东商品信息——以自营手机为例
关于scrapy和使用的代理轮播中间件请参考我的爬豆网文章:[scrapy]scrapy按分类爬取豆瓣电影基本信息 http:qqxx6661articledetails56017386 主要思路是:获取手机分类(自操作)页面——-扫描本页所有商品ID-进入各商品页面获取除价格外的所有信息-获取商品价格信息-扫描下一页URL-获取下一页商品ID...京东爬虫专用明显,商场有严防爬虫价格爬行?页面完全加载后查看元素时可以看到价格,但实际上是加载了JS,所以实际上源代码中并没有收录价格。需要检查JS加载情况。如下所示?在撰写本说明时,我代码中的 JS 名称似乎无效。注意写代码的时候,allowed_domains卡了很久,一直爬不出来价格,查了各种资料。最后突然发现allowed_domains被限制了,价格居然在开头的链接里。智障。未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页 未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页 未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页
1.1K 查看全部
php抓取网页内容(京东爬虫——以自营手机为例关于scrapy以及使用的代理轮换中间件)
【Scrapy】scrapy爬取京东商品信息——以自营手机为例
关于scrapy和使用的代理轮播中间件请参考我的爬豆网文章:[scrapy]scrapy按分类爬取豆瓣电影基本信息 http:qqxx6661articledetails56017386 主要思路是:获取手机分类(自操作)页面——-扫描本页所有商品ID-进入各商品页面获取除价格外的所有信息-获取商品价格信息-扫描下一页URL-获取下一页商品ID...京东爬虫专用明显,商场有严防爬虫价格爬行?页面完全加载后查看元素时可以看到价格,但实际上是加载了JS,所以实际上源代码中并没有收录价格。需要检查JS加载情况。如下所示?在撰写本说明时,我代码中的 JS 名称似乎无效。注意写代码的时候,allowed_domains卡了很久,一直爬不出来价格,查了各种资料。最后突然发现allowed_domains被限制了,价格居然在开头的链接里。智障。未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页 未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页 未解决的问题 问题很严重。京东似乎对爬虫很敏感。连续爬下一页后,会直接回到手机分类我爱周育南的第一页
1.1K
php抓取网页内容(dirbuster,setup使用apache以source+output传输文件的格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-11-15 03:04
php抓取网页内容可能会用到gzip加速解析,其他比如php抓取音频,php抓取视频,然后放到对应的视频下载库,
php,抓取,支持一个单一文件(压缩文件)rar文件格式。
php提供一些解析和批量下载方法,最简单的是使用php-fastcgi协议,其中包含apache和php环境,还有dirbuster库可以下载,
dirbuster,setup使用apache以source+output传输文件的格式来简单的代替下载一个文件,但是,
php封装了talib编译成库,所以可以下载pdf。
grep
有没有ftp下载工具
downloaduninstaller
不要用php!不要用php!不要用php!另外再推荐几个软件:phpwindgittasks
目前在做一个在线电影网站,大部分资源已经有在线版了,流畅没问题,里面有个下载站点是我主要的下载站点downloadbox看这个网站目前的主要站点,
php源码下载工具uberide5/phpwelder·github
跟你一样处境的人太多了。很多基于phpweb框架的程序都会用path,然后用bzip解压。
谷歌有个工具叫快照, 查看全部
php抓取网页内容(dirbuster,setup使用apache以source+output传输文件的格式)
php抓取网页内容可能会用到gzip加速解析,其他比如php抓取音频,php抓取视频,然后放到对应的视频下载库,
php,抓取,支持一个单一文件(压缩文件)rar文件格式。
php提供一些解析和批量下载方法,最简单的是使用php-fastcgi协议,其中包含apache和php环境,还有dirbuster库可以下载,
dirbuster,setup使用apache以source+output传输文件的格式来简单的代替下载一个文件,但是,
php封装了talib编译成库,所以可以下载pdf。
grep
有没有ftp下载工具
downloaduninstaller
不要用php!不要用php!不要用php!另外再推荐几个软件:phpwindgittasks
目前在做一个在线电影网站,大部分资源已经有在线版了,流畅没问题,里面有个下载站点是我主要的下载站点downloadbox看这个网站目前的主要站点,
php源码下载工具uberide5/phpwelder·github
跟你一样处境的人太多了。很多基于phpweb框架的程序都会用path,然后用bzip解压。
谷歌有个工具叫快照,
php抓取网页内容(php抓取网页内容-php-how-to-look-up-the-first-season你是否遇到下面的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-09 00:04
php抓取网页内容,获取网页的url页码、字体库字体等下载网页内容,提取页面中的bom代码获取网页内容,
首先你需要学会linux
有beautifulsoup不需要怎么学
曾经遇到过一个小伙子,
很简单,分享一个网站:-php-how-to-look-up-the-first-season你是否遇到下面的问题:php做网站容易吗?能不能使用其他语言,比如python或ruby开发一个网站?自己搭建wordpress是否合适?是否有一个安全的web环境可以保证,你的网站安全,可靠,不被黑客入侵?自己搭建nginx或phpstorm是否合适?什么是mysqlwebserver?哪个版本更合适?数据库迁移时,是否可以避免数据迁移带来的不必要损失?...你是否很想了解下以上问题,我相信,你肯定有他们的答案,对吧,我呢,不卖关子,直接给你送上一个网站解决方案:第1步:会写v2ex代码,对就是那个写v2ex的,简单,实用,很nb!第2步:会读php代码,你用不到太高级的框架,毕竟基础语法php本身就有,和php代码也很相像,看看php官方的入门代码就可以看懂,不管什么框架,都是v2ex的风格。
第3步:会学习mysql,好像后端不需要用mysql数据库吧,那你学学mysql数据库吧,简单,好操作。第4步:具备数据库编程基础,比如sql语句,hivemrsparkredisnosql等,以及一些分布式计算的概念,比如sharding、分片、分片优化等,具备以上这些知识,你就是个合格的后端程序员了,然后就可以找妹子了第5步:妹子还愿意和你在一起吗?如果妹子要和你分手,你拿啥挽回她?分手了你看看你写的代码,感觉好陌生,上方没写完,有点赞再补充吧补充:以上3点,知道php的编程思想,编程惯例,不是三两天就能掌握的,还是要从系统的视角看待这个世界,掌握一门编程语言,其实也是“升级打怪”,需要时间积累,虽然我目前做着php方面的工作,也很喜欢写些php的pythonvs.php想把自己做的微信公众号推给大家,收到很多人留言问:你是搞php的吗?我第一次在知乎上写文章,发现好多大佬写写博客,知乎上搜索时,看见无数大佬在写,应该不错吧...now,你可以动动你的小手指扫码拉你进群哦亲!。 查看全部
php抓取网页内容(php抓取网页内容-php-how-to-look-up-the-first-season你是否遇到下面的问题)
php抓取网页内容,获取网页的url页码、字体库字体等下载网页内容,提取页面中的bom代码获取网页内容,
首先你需要学会linux
有beautifulsoup不需要怎么学
曾经遇到过一个小伙子,
很简单,分享一个网站:-php-how-to-look-up-the-first-season你是否遇到下面的问题:php做网站容易吗?能不能使用其他语言,比如python或ruby开发一个网站?自己搭建wordpress是否合适?是否有一个安全的web环境可以保证,你的网站安全,可靠,不被黑客入侵?自己搭建nginx或phpstorm是否合适?什么是mysqlwebserver?哪个版本更合适?数据库迁移时,是否可以避免数据迁移带来的不必要损失?...你是否很想了解下以上问题,我相信,你肯定有他们的答案,对吧,我呢,不卖关子,直接给你送上一个网站解决方案:第1步:会写v2ex代码,对就是那个写v2ex的,简单,实用,很nb!第2步:会读php代码,你用不到太高级的框架,毕竟基础语法php本身就有,和php代码也很相像,看看php官方的入门代码就可以看懂,不管什么框架,都是v2ex的风格。
第3步:会学习mysql,好像后端不需要用mysql数据库吧,那你学学mysql数据库吧,简单,好操作。第4步:具备数据库编程基础,比如sql语句,hivemrsparkredisnosql等,以及一些分布式计算的概念,比如sharding、分片、分片优化等,具备以上这些知识,你就是个合格的后端程序员了,然后就可以找妹子了第5步:妹子还愿意和你在一起吗?如果妹子要和你分手,你拿啥挽回她?分手了你看看你写的代码,感觉好陌生,上方没写完,有点赞再补充吧补充:以上3点,知道php的编程思想,编程惯例,不是三两天就能掌握的,还是要从系统的视角看待这个世界,掌握一门编程语言,其实也是“升级打怪”,需要时间积累,虽然我目前做着php方面的工作,也很喜欢写些php的pythonvs.php想把自己做的微信公众号推给大家,收到很多人留言问:你是搞php的吗?我第一次在知乎上写文章,发现好多大佬写写博客,知乎上搜索时,看见无数大佬在写,应该不错吧...now,你可以动动你的小手指扫码拉你进群哦亲!。
php抓取网页内容( 有些函数动态加载网页数据的安装方法-有些网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-04 23:14
有些函数动态加载网页数据的安装方法-有些网页
)
有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。
查资料,发现可以用PhantomJS爬取这类网页的数据。但 PhantomJS 主要用于 Java。如果要在python中使用,需要通过Selenium在python中调用PhantomJS。写代码的时候主要参考这个网页:Is there a way to use PhantomJS in Python?
Selenium 是一个浏览器虚拟器,可以通过 Selenium 模拟各种浏览器上的各种行为。python中使用PhantomJS通过Selenium获取动态网页数据时需要安装以下库:
1. Beautifulsoup,用于解析网页内容
2. Node.js
3. 安装 Node.js 后通过 Node.js 安装 PhantomJS。在Mac终端输入npm -g install phantomjs(Windows下cmd也一样)
4. 安装 Selenium
完成以上四步后,就可以在python中使用PhantomJS了。
代码显示如下:
<p># -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import urllib2
import time
baseUrl = "http://stock.finance.sina.com. ... ot%3B
csvPath = "FinanceData.csv"
csvFile = open(csvPath, 'w')
def is_chinese(uchar):
# 判断一个unicode是否是汉字
if uchar >= u'\u4e00' and uchar= u'\u4e00' and uchar 查看全部
php抓取网页内容(
有些函数动态加载网页数据的安装方法-有些网页
)
有些网页不是静态加载的,而是通过javascipt函数动态加载的。例如,在下面的网页中,通过javascirpt函数从后台加载了表中看涨合约和看跌合约的数据。仅使用beautifulsoup 无法捕获此表中的数据。
查资料,发现可以用PhantomJS爬取这类网页的数据。但 PhantomJS 主要用于 Java。如果要在python中使用,需要通过Selenium在python中调用PhantomJS。写代码的时候主要参考这个网页:Is there a way to use PhantomJS in Python?
Selenium 是一个浏览器虚拟器,可以通过 Selenium 模拟各种浏览器上的各种行为。python中使用PhantomJS通过Selenium获取动态网页数据时需要安装以下库:
1. Beautifulsoup,用于解析网页内容
2. Node.js
3. 安装 Node.js 后通过 Node.js 安装 PhantomJS。在Mac终端输入npm -g install phantomjs(Windows下cmd也一样)
4. 安装 Selenium
完成以上四步后,就可以在python中使用PhantomJS了。
代码显示如下:
<p># -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import urllib2
import time
baseUrl = "http://stock.finance.sina.com. ... ot%3B
csvPath = "FinanceData.csv"
csvFile = open(csvPath, 'w')
def is_chinese(uchar):
# 判断一个unicode是否是汉字
if uchar >= u'\u4e00' and uchar= u'\u4e00' and uchar

