
php如何抓取网页内容
php如何抓取网页内容(最近抓的2个网站内容的代码列表页抓取:第一种使用phpquery插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-22 12:11
最近抓到两个网站内容代码
列表页面爬取:第一种使用phpquery插件,可以快速获取,第二种是api,所以直接获取
load_third("phpQuery.php");
/*********www.sosobtc.com***********/
/**/
$re = phpQuery::newDocumentFile('https://www.sosobtc.com/news/all'); //设置好抓取的新闻列表网址
$data = array();
// 获取列表地址
foreach(pq('.news-list .news-thumbnail a') as $key=>$value) {
$href = $value->getAttribute('href');
$data[$key]['source_url'] = "https://www.sosobtc.com".$href;
}
// 获取标题
foreach(pq('.news-list .news-title h3') as $key=>$value) {
$title = pq($value)->text();
$data[$key]['title'] = $title;
}
// 获取封面图地址
foreach(pq('.news-list .share-box ul') as $key=>$value) {
$re = pq($value)->find('li')->eq(0)->find('a')->attr('href');
$str = strrchr($re,"&");
$arr= explode("=",$str);
$data[$key]['pic'] = $arr[1];
$str2 = explode("/",$arr[1]);
$data[$key]['add_time'] = strtotime($str2[5]);
}
//获取信息初始来源
foreach(pq('.category') as $key=>$value) {
$source = pq($value)->text();
$data[$key]['source'] = $source;
}
// exit;
foreach($data as $v){
$adddata['title'] = $v['title'];
$adddata['source_url'] = $v['source_url'];
$adddata['add_time'] = time();
$adddata['add_time'] = $v['add_time'];
$adddata['pic'] = $v['pic'];
$adddata['source'] = $v['source'];
// $adddata['stype'] = 1;
$result = News::add($adddata);
if(!$result['insert_id']){
file_put_contents("/data/log/fail_spider.log",var_dump($result).",".$v['source_url'].",".$v['pic']."\r\n",FILE_APPEND);
}
}
/*********www.sosobtc.com***********/
/*********www.36kr.com/***********/
$result = file_get_contents("http://36kr.com/api/search-col ... 6quot;);
if(!$result){
die;
}
$result = json_decode($result,true);
if(count($result['data']['items'])==0){
die;
}
foreach($result['data']['items'] as $k=>$v){
$sdata['add_time'] = strtotime($v['published_at']);
$sdata['title'] = $v['title'];
$sdata['pic'] = $v['template_info']['template_cover'][0];
$info = json_decode($v['user_info'],true);
$sdata['source'] = $info['name'];
$sdata['source_url'] = "http://36kr.com/p/".$v['id'].".html";
$re = News::add($sdata);
if(!$re['insert_id']){
file_put_contents("/data/log/fail_spider.log",var_dump($re).",".$v['source_url'].",".$v['pic']."\r\n",FILE_APPEND);
}
}
/*********www.36kr.com/***********/
首先获取列表的内容,然后根据列表对应的目标地址一一抓取详情。
详情页面抓取:
load_third("phpQuery.php");
function download($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
$file = curl_exec($ch);
curl_close($ch);
$filename = pathinfo($url, PATHINFO_BASENAME);
$path = '/data/xxxxx.com/phone/wwwroot/upimg/';//**************注意权限问题
$dirarr = explode("/",$url);
$path .= $dirarr[5]."/";
if (!is_dir($path)) mkdir($path);
$resource = fopen($path . $filename, 'a');
fwrite($resource, $file);
fclose($resource);
return "/".$dirarr[5]."/".$filename;
}
function download2($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
$file = curl_exec($ch);
curl_close($ch);
$filename = pathinfo($url, PATHINFO_BASENAME).".jpg";
$path = '/data/xxxxx.com/phone/wwwroot/upimg/';//**************注意权限问题
$path .= date("Ymd")."/";
if (!is_dir($path)) mkdir($path);
$resource = fopen($path . $filename, 'a');
fwrite($resource, $file);
fclose($resource);
return "/".date("Ymd")."/".$filename;
}
$result = News::getdown();
if(count($result)==0){
exit(2);
}
foreach($result as $v)
{
if(strpos($v['source_url'],'sosobtc')){
$path = download($v['pic']);//下载图片到本地
$re = phpQuery::newDocumentFile($v['source_url']); //设置好抓取的新闻列表网址
$content = pq(".article-main")->html();
// $id = $v['id'];
$data['pic'] = $path;
$data['content'] = addslashes(trim($content));
$data['status'] = 1;
$result = News::modify($v['id'],$data);
if(!$result){
file_put_contents("/data/log/fail_spiderdown.log",$v['id']."|".var_dump($result)."|".json_encode($data)."\r\n",FILE_APPEND);
}
}else if(strpos($v['source_url'],'36kr')){
// echo $v['id']."\r\n";
$path = download2($v['pic']);//下载图片到本地
$re = file_get_contents($v['source_url']); //设置好抓取的新闻列表网址
preg_match("/var props=(.*),locationnal={/",$re,$match);
$info = json_decode($match[1],true);
$content = $info['detailArticle|post']['content'];
$data['pic'] = $path;
$data['content'] = $content;
$data['status'] = 1;
$result = News::modify($v['id'],$data);
// print_r($data);
// break;
$result = News::modify($v['id'],$data);
if(!$result){
file_put_contents("/data/log/fail_spiderdown.log",$v['id']."|".var_dump($result)."|".json_encode($data)."\r\n",FILE_APPEND);
}
}
}
第一个是使用phpquery来获取。第二种方式是查看源代码。是js数据懒加载,所以我直接用php匹配我需要的数据。其中,我将两者的封面图片下载到本地,本地upimg主要需要权限,否则创建日期目录可能会失败。还有一点是我唯一索引了source_url的mysql字段,也就是目标URL,这样每天定时运行两个脚本,可以抓到最新的数据,不会抓到重复的数据。 查看全部
php如何抓取网页内容(最近抓的2个网站内容的代码列表页抓取:第一种使用phpquery插件)
最近抓到两个网站内容代码
列表页面爬取:第一种使用phpquery插件,可以快速获取,第二种是api,所以直接获取
load_third("phpQuery.php");
/*********www.sosobtc.com***********/
/**/
$re = phpQuery::newDocumentFile('https://www.sosobtc.com/news/all'); //设置好抓取的新闻列表网址
$data = array();
// 获取列表地址
foreach(pq('.news-list .news-thumbnail a') as $key=>$value) {
$href = $value->getAttribute('href');
$data[$key]['source_url'] = "https://www.sosobtc.com".$href;
}
// 获取标题
foreach(pq('.news-list .news-title h3') as $key=>$value) {
$title = pq($value)->text();
$data[$key]['title'] = $title;
}
// 获取封面图地址
foreach(pq('.news-list .share-box ul') as $key=>$value) {
$re = pq($value)->find('li')->eq(0)->find('a')->attr('href');
$str = strrchr($re,"&");
$arr= explode("=",$str);
$data[$key]['pic'] = $arr[1];
$str2 = explode("/",$arr[1]);
$data[$key]['add_time'] = strtotime($str2[5]);
}
//获取信息初始来源
foreach(pq('.category') as $key=>$value) {
$source = pq($value)->text();
$data[$key]['source'] = $source;
}
// exit;
foreach($data as $v){
$adddata['title'] = $v['title'];
$adddata['source_url'] = $v['source_url'];
$adddata['add_time'] = time();
$adddata['add_time'] = $v['add_time'];
$adddata['pic'] = $v['pic'];
$adddata['source'] = $v['source'];
// $adddata['stype'] = 1;
$result = News::add($adddata);
if(!$result['insert_id']){
file_put_contents("/data/log/fail_spider.log",var_dump($result).",".$v['source_url'].",".$v['pic']."\r\n",FILE_APPEND);
}
}
/*********www.sosobtc.com***********/
/*********www.36kr.com/***********/
$result = file_get_contents("http://36kr.com/api/search-col ... 6quot;);
if(!$result){
die;
}
$result = json_decode($result,true);
if(count($result['data']['items'])==0){
die;
}
foreach($result['data']['items'] as $k=>$v){
$sdata['add_time'] = strtotime($v['published_at']);
$sdata['title'] = $v['title'];
$sdata['pic'] = $v['template_info']['template_cover'][0];
$info = json_decode($v['user_info'],true);
$sdata['source'] = $info['name'];
$sdata['source_url'] = "http://36kr.com/p/".$v['id'].".html";
$re = News::add($sdata);
if(!$re['insert_id']){
file_put_contents("/data/log/fail_spider.log",var_dump($re).",".$v['source_url'].",".$v['pic']."\r\n",FILE_APPEND);
}
}
/*********www.36kr.com/***********/
首先获取列表的内容,然后根据列表对应的目标地址一一抓取详情。
详情页面抓取:
load_third("phpQuery.php");
function download($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
$file = curl_exec($ch);
curl_close($ch);
$filename = pathinfo($url, PATHINFO_BASENAME);
$path = '/data/xxxxx.com/phone/wwwroot/upimg/';//**************注意权限问题
$dirarr = explode("/",$url);
$path .= $dirarr[5]."/";
if (!is_dir($path)) mkdir($path);
$resource = fopen($path . $filename, 'a');
fwrite($resource, $file);
fclose($resource);
return "/".$dirarr[5]."/".$filename;
}
function download2($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
$file = curl_exec($ch);
curl_close($ch);
$filename = pathinfo($url, PATHINFO_BASENAME).".jpg";
$path = '/data/xxxxx.com/phone/wwwroot/upimg/';//**************注意权限问题
$path .= date("Ymd")."/";
if (!is_dir($path)) mkdir($path);
$resource = fopen($path . $filename, 'a');
fwrite($resource, $file);
fclose($resource);
return "/".date("Ymd")."/".$filename;
}
$result = News::getdown();
if(count($result)==0){
exit(2);
}
foreach($result as $v)
{
if(strpos($v['source_url'],'sosobtc')){
$path = download($v['pic']);//下载图片到本地
$re = phpQuery::newDocumentFile($v['source_url']); //设置好抓取的新闻列表网址
$content = pq(".article-main")->html();
// $id = $v['id'];
$data['pic'] = $path;
$data['content'] = addslashes(trim($content));
$data['status'] = 1;
$result = News::modify($v['id'],$data);
if(!$result){
file_put_contents("/data/log/fail_spiderdown.log",$v['id']."|".var_dump($result)."|".json_encode($data)."\r\n",FILE_APPEND);
}
}else if(strpos($v['source_url'],'36kr')){
// echo $v['id']."\r\n";
$path = download2($v['pic']);//下载图片到本地
$re = file_get_contents($v['source_url']); //设置好抓取的新闻列表网址
preg_match("/var props=(.*),locationnal={/",$re,$match);
$info = json_decode($match[1],true);
$content = $info['detailArticle|post']['content'];
$data['pic'] = $path;
$data['content'] = $content;
$data['status'] = 1;
$result = News::modify($v['id'],$data);
// print_r($data);
// break;
$result = News::modify($v['id'],$data);
if(!$result){
file_put_contents("/data/log/fail_spiderdown.log",$v['id']."|".var_dump($result)."|".json_encode($data)."\r\n",FILE_APPEND);
}
}
}
第一个是使用phpquery来获取。第二种方式是查看源代码。是js数据懒加载,所以我直接用php匹配我需要的数据。其中,我将两者的封面图片下载到本地,本地upimg主要需要权限,否则创建日期目录可能会失败。还有一点是我唯一索引了source_url的mysql字段,也就是目标URL,这样每天定时运行两个脚本,可以抓到最新的数据,不会抓到重复的数据。
php如何抓取网页内容(php如何抓取网页内容?1.首先要手动使用for循环for(i=0;i))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-20 21:06
<p>php如何抓取网页内容?1.首先要手动使用for循环for(i=0;i
php如何抓取网页内容(php如何抓取网页内容?1.首先要手动使用for循环for(i=0;i))
<p>php如何抓取网页内容?1.首先要手动使用for循环for(i=0;i
php如何抓取网页内容(php如何抓取网页内容?建议用phpwechat协议的爬虫,真实的机器人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-16 06:06
php如何抓取网页内容?建议用phpwechat协议的爬虫,真实的机器人。抓包工具自己windows上有prequest.exe和prequest.language.none。linux上推荐curl,google的。这些爬虫都需要加密的,去各大爬虫吧学习下基础知识。
昨天是phpwanchat的phphutto---昨天phphutto|apigenerator昨天今天是phphutto没有云,
0.选择你要抓取的页面,在phpwind上爬虫提供的服务器下抓包,看看可抓取的数据文件。请求分析xmlhttprequest抓取数据functionisprequest(page_info){returnxmlhttprequest().newvisible();}functionprequest(){returnisprequest();}functiongetinfo(){returnxmlhttprequest().get(page_info);}functionnotify(obj){returnxmlhttprequest().notify(obj);}functionnotifyall(obj){returnxmlhttprequest().notifyall();}functionnotify(obj){returnxmlhttprequest().notifyall();}functionnotify(obj){returnxmlhttprequest().notifyall();}functionworker(url,data){returnxmlhttprequest().notifyall();}functionfindread(url,data){returnxmlhttprequest().notifyall();}functionreplyrequest(url,data){if(url===""){returnxmlhttprequest().notifyall();}else{xmlhttprequest().write(data);}}functionparse(url,data){console.log(data);}functionwritegenerated(url,data){if(url===""){returnxmlhttprequest().write(data);}else{xmlhttprequest().write(data);}}functionsaveuser(url,data){returnxmlhttprequest().save(url);}functiondone(url){returnxmlhttprequest().done(url);}1.phpwechat的抓包2.我记得有人说还可以用httpclient框架,按照这个来吧process-socketapiextension-chrome-nightly/。 查看全部
php如何抓取网页内容(php如何抓取网页内容?建议用phpwechat协议的爬虫,真实的机器人)
php如何抓取网页内容?建议用phpwechat协议的爬虫,真实的机器人。抓包工具自己windows上有prequest.exe和prequest.language.none。linux上推荐curl,google的。这些爬虫都需要加密的,去各大爬虫吧学习下基础知识。
昨天是phpwanchat的phphutto---昨天phphutto|apigenerator昨天今天是phphutto没有云,
0.选择你要抓取的页面,在phpwind上爬虫提供的服务器下抓包,看看可抓取的数据文件。请求分析xmlhttprequest抓取数据functionisprequest(page_info){returnxmlhttprequest().newvisible();}functionprequest(){returnisprequest();}functiongetinfo(){returnxmlhttprequest().get(page_info);}functionnotify(obj){returnxmlhttprequest().notify(obj);}functionnotifyall(obj){returnxmlhttprequest().notifyall();}functionnotify(obj){returnxmlhttprequest().notifyall();}functionnotify(obj){returnxmlhttprequest().notifyall();}functionworker(url,data){returnxmlhttprequest().notifyall();}functionfindread(url,data){returnxmlhttprequest().notifyall();}functionreplyrequest(url,data){if(url===""){returnxmlhttprequest().notifyall();}else{xmlhttprequest().write(data);}}functionparse(url,data){console.log(data);}functionwritegenerated(url,data){if(url===""){returnxmlhttprequest().write(data);}else{xmlhttprequest().write(data);}}functionsaveuser(url,data){returnxmlhttprequest().save(url);}functiondone(url){returnxmlhttprequest().done(url);}1.phpwechat的抓包2.我记得有人说还可以用httpclient框架,按照这个来吧process-socketapiextension-chrome-nightly/。
php如何抓取网页内容(文章目录从网站中提取数据主要有两种方式:本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-14 14:03
文章内容
如何使用 BeautifulSoup 抓取网页
从网站中提取数据主要有两种方式:
本文知乎博客为大家介绍如何使用BeautifulSoup爬取网页的步骤。
使用 BeautifulSoup 抓取网页
使用BeautifulSoup爬取一个网页的内容,首先是向你要访问的网页的URL发送一个HTTP请求。服务器通过返回网页的 HTML 内容来响应请求。对于此任务,我们将使用第三方 HTTP 库来处理 Python 请求。
一旦我们访问了 HTML 内容,我们就剩下解析数据的任务,并且需要一个可以创建 HTML 数据的嵌套/树结构的解析器。然后,所有需要做的就是导航和搜索我们创建的解析树,即树遍历。对于此任务,我们将使用另一个第三方 Python 库 Beautiful Soup。它是一个用于从 HTML 和 XML 文件中提取数据的 Python 库。
1、安装需要的第三方库
pip install requests
pip install html5lib
pip install bs4
2、从网页访问 HTML 内容
import requests
URL = "https://www.pythonthree.com/py ... ot%3B
r = requests.get(URL)
print(r.content)
让我们试着理解这段代码。
3、解析HTML内容
import requests
from bs4 import BeautifulSoup
URL = "https://www.pythonthree.com/py ... ot%3B
r = requests.get(URL)
soup = BeautifulSoup(r.content, 'html5lib')
print(soup.prettify())
BeautifulSoup 库的一个真正好处是它建立在 HTML 解析库(例如 html5lib、lxml、html.parser 等)之上。因此,可以同时创建一个 BeautifulSoup 对象并指定一个解析器库。
在上面的例子中,
soup = BeautifulSoup(r.content, 'html5lib')
我们通过传递两个参数来创建一个 BeautifulSoup 对象:
现在打印soup.prettify(),它给出了从原创HTML 内容创建的解析树的可视化表示。
4、搜索导航解析树
现在,我们要从 HTML 内容中提取一些有用的数据。汤对象收录可以通过编程方式提取的嵌套结构中的所有数据。在我们的示例中,我们正在抓取收录一些引号的网页。因此,我们想创建一个程序来保存这些报价(以及所有关于它们的相关信息)。
在继续之前,我们建议您浏览我们使用soup.prettify() 方法打印的网页的HTML 内容,并尝试找到导航到引号的模式或方法。
总结
以上是关于如何使用BeautifulSoup抓取网页内容。如果您发现任何不正确的内容,或者您想分享有关上述主题的更多信息,请发表评论。这是一个如何用 Python 创建网络爬虫的简单示例。从这里,您可以尝试丢弃您选择的任何其他 网站。
推荐:零基础如何开始学习Python
推荐:美汤教程
评价 文章
知乎博客,版权所有丨如未注明,均为原创
知乎博客 »如何使用BeautifulSoup抓取网页 查看全部
php如何抓取网页内容(文章目录从网站中提取数据主要有两种方式:本文)
文章内容
如何使用 BeautifulSoup 抓取网页
从网站中提取数据主要有两种方式:
本文知乎博客为大家介绍如何使用BeautifulSoup爬取网页的步骤。
使用 BeautifulSoup 抓取网页
使用BeautifulSoup爬取一个网页的内容,首先是向你要访问的网页的URL发送一个HTTP请求。服务器通过返回网页的 HTML 内容来响应请求。对于此任务,我们将使用第三方 HTTP 库来处理 Python 请求。
一旦我们访问了 HTML 内容,我们就剩下解析数据的任务,并且需要一个可以创建 HTML 数据的嵌套/树结构的解析器。然后,所有需要做的就是导航和搜索我们创建的解析树,即树遍历。对于此任务,我们将使用另一个第三方 Python 库 Beautiful Soup。它是一个用于从 HTML 和 XML 文件中提取数据的 Python 库。
1、安装需要的第三方库
pip install requests
pip install html5lib
pip install bs4
2、从网页访问 HTML 内容
import requests
URL = "https://www.pythonthree.com/py ... ot%3B
r = requests.get(URL)
print(r.content)
让我们试着理解这段代码。
3、解析HTML内容
import requests
from bs4 import BeautifulSoup
URL = "https://www.pythonthree.com/py ... ot%3B
r = requests.get(URL)
soup = BeautifulSoup(r.content, 'html5lib')
print(soup.prettify())
BeautifulSoup 库的一个真正好处是它建立在 HTML 解析库(例如 html5lib、lxml、html.parser 等)之上。因此,可以同时创建一个 BeautifulSoup 对象并指定一个解析器库。
在上面的例子中,
soup = BeautifulSoup(r.content, 'html5lib')
我们通过传递两个参数来创建一个 BeautifulSoup 对象:
现在打印soup.prettify(),它给出了从原创HTML 内容创建的解析树的可视化表示。
4、搜索导航解析树
现在,我们要从 HTML 内容中提取一些有用的数据。汤对象收录可以通过编程方式提取的嵌套结构中的所有数据。在我们的示例中,我们正在抓取收录一些引号的网页。因此,我们想创建一个程序来保存这些报价(以及所有关于它们的相关信息)。
在继续之前,我们建议您浏览我们使用soup.prettify() 方法打印的网页的HTML 内容,并尝试找到导航到引号的模式或方法。
总结
以上是关于如何使用BeautifulSoup抓取网页内容。如果您发现任何不正确的内容,或者您想分享有关上述主题的更多信息,请发表评论。这是一个如何用 Python 创建网络爬虫的简单示例。从这里,您可以尝试丢弃您选择的任何其他 网站。
推荐:零基础如何开始学习Python
推荐:美汤教程
评价 文章
知乎博客,版权所有丨如未注明,均为原创
知乎博客 »如何使用BeautifulSoup抓取网页
php如何抓取网页内容(php如何抓取网页内容,这里有详细教程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-04 14:01
php如何抓取网页内容,这里有详细教程。《黑客与画家》中提到“浏览器”的定义:是将用户经常发送的请求传送给服务器处理。想要真正掌握程序编程实战,首先要对浏览器了解。目前一般桌面浏览器如ie、遨游、360、搜狗等用javascript去完成对整个web站点的检索,而ie的内核就是在浏览器内部完成,像chrome就是一款基于webkit内核的浏览器,chrome所谓的自带浏览器本质上是没有javascript功能的。
ie也将会继续尝试各种javascript支持(css和htmlswf转换)等方面的提升。而基于webkit内核的浏览器在它们得到越来越好的设计后,javascript嵌入也将变得越来越容易,应用和功能就将变得越来越丰富,也将越来越流行。下面将基于以上知识以php为例详细讲解一下一般需要掌握的程序编程基础知识。
掌握浏览器的基本概念我们目前所了解到的都是这个时代浏览器的基本运行机制,简单而言,它就是一个文档传递工具,能从ie浏览器上读取文件,然后进行文件的读写操作。与c语言不同,c语言与浏览器交互是通过document对象,使用file函数来接收文件的详细信息(这些文件包括读取的rom和cpu等信息)。浏览器在处理rom信息时,会根据rom上记录的位置指定所需的rom,然后将rom信息传递给文件操作。
其他与浏览器交互的地方还有如图所示的一些接口,如output接口、response接口等。现在浏览器几乎可以全面地读取和处理任何资源,如rom文件,htmlswf、css、javascript、图片等等。这些接口共同构成了一个完整的web服务器,能给用户提供最佳的体验和最大的效率。掌握常用的接口说完浏览器的基本概念,接下来我们再来了解一下浏览器的常用接口,这些接口提供给用户最常用的功能。
比如如果我们需要读取本地文件,例如打开“华为浏览器”网页地址:/www/huawei/mp3,那么该如何操作呢?我们需要了解一下两个接口:output和response。output接口:这个接口直接将所有的文件一一相连,文件名、文件大小、文件名、文件信息等等,一一传递给服务器,服务器再根据这些文件返回给用户。
utf-8、乱码等问题都会得到解决。response接口:这个接口要求浏览器每秒传递完整的html信息,浏览器等待服务器返回完整的html,浏览器一直处于响应状态,如果还有疑问,可以查看output接口。ie浏览器虽然是基于webkit内核,但是还是有一些c++代码。读取文件这一步还是经过了很多代码的加工,这一步也是浏览器抓取下来的主要内容来源,所以知道一些基本的常用接口是关键。下面将主要说。 查看全部
php如何抓取网页内容(php如何抓取网页内容,这里有详细教程(图))
php如何抓取网页内容,这里有详细教程。《黑客与画家》中提到“浏览器”的定义:是将用户经常发送的请求传送给服务器处理。想要真正掌握程序编程实战,首先要对浏览器了解。目前一般桌面浏览器如ie、遨游、360、搜狗等用javascript去完成对整个web站点的检索,而ie的内核就是在浏览器内部完成,像chrome就是一款基于webkit内核的浏览器,chrome所谓的自带浏览器本质上是没有javascript功能的。
ie也将会继续尝试各种javascript支持(css和htmlswf转换)等方面的提升。而基于webkit内核的浏览器在它们得到越来越好的设计后,javascript嵌入也将变得越来越容易,应用和功能就将变得越来越丰富,也将越来越流行。下面将基于以上知识以php为例详细讲解一下一般需要掌握的程序编程基础知识。
掌握浏览器的基本概念我们目前所了解到的都是这个时代浏览器的基本运行机制,简单而言,它就是一个文档传递工具,能从ie浏览器上读取文件,然后进行文件的读写操作。与c语言不同,c语言与浏览器交互是通过document对象,使用file函数来接收文件的详细信息(这些文件包括读取的rom和cpu等信息)。浏览器在处理rom信息时,会根据rom上记录的位置指定所需的rom,然后将rom信息传递给文件操作。
其他与浏览器交互的地方还有如图所示的一些接口,如output接口、response接口等。现在浏览器几乎可以全面地读取和处理任何资源,如rom文件,htmlswf、css、javascript、图片等等。这些接口共同构成了一个完整的web服务器,能给用户提供最佳的体验和最大的效率。掌握常用的接口说完浏览器的基本概念,接下来我们再来了解一下浏览器的常用接口,这些接口提供给用户最常用的功能。
比如如果我们需要读取本地文件,例如打开“华为浏览器”网页地址:/www/huawei/mp3,那么该如何操作呢?我们需要了解一下两个接口:output和response。output接口:这个接口直接将所有的文件一一相连,文件名、文件大小、文件名、文件信息等等,一一传递给服务器,服务器再根据这些文件返回给用户。
utf-8、乱码等问题都会得到解决。response接口:这个接口要求浏览器每秒传递完整的html信息,浏览器等待服务器返回完整的html,浏览器一直处于响应状态,如果还有疑问,可以查看output接口。ie浏览器虽然是基于webkit内核,但是还是有一些c++代码。读取文件这一步还是经过了很多代码的加工,这一步也是浏览器抓取下来的主要内容来源,所以知道一些基本的常用接口是关键。下面将主要说。
php如何抓取网页内容(php如何抓取网页内容php提供了很多快速、方便的http请求方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-04 07:01
php如何抓取网页内容php提供了很多快速、方便的http请求方法,可以使用scrapy、laravel等框架开发网页爬虫,不过相对于python来说要复杂一些,今天我们尝试着以一个简单的web爬虫为例子,来抓取b站相关视频。我们可以使用scrapy、laravel、python本身的requests库进行爬虫,scrapy是包含了数据的http服务器,laravel是python程序员使用最多的框架。
我们先新建爬虫的项目。pythonmanage.pymakemigrations使用makemigrations命令来编译python脚本,这里会生成一个python文件,我们利用pythoninit.py项目结构图来看一下当初使用pythoninit.py进行配置的时候,安装的三个常用库,yml(yaml)、python、git,安装和初始化的方法在文章尾部。
创建爬虫,需要对数据进行加密。pythonpool.py把静态文件保存到同一个集群目录下pythonscrapy_pool.py还要在scrapy_pool.py中配置被捕获的情况,也可以在配置文件crawling_simple_task中指定,我们这里配置是post()函数。pythonscrapy_spider.py需要把被主动获取的url添加到request中pythonscrapy_request.py实例化scrapy的爬虫爬虫程序中的常用函数:start_url、start_request、default_url、split_url、excluded_url、urllib2.urllib2对urllib2的高级封装pythonhttp_request.py接受urllib2模块的输入request.py接受urllib2模块的输出request.setrequestheader("authorization","status","0")template_protocol="http://%26quot%3Bauthorization ... pener(template_protocol)asrequest:ifrequest.get(urllib2.urlopen(request))andrequest.read()==str(request.request(urllib2.urlopen(request),stream_protocol="python.io.protocol")):request.send_header("user-agent","mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/42.0.2523.110safari/537.36")request.send_header("proxy","server=/")start_url=start_request;default_url=start_requestrequest.start(start_url)request.send(urllib2.request(urllib2.urlopen(request),stream_protoco。 查看全部
php如何抓取网页内容(php如何抓取网页内容php提供了很多快速、方便的http请求方法)
php如何抓取网页内容php提供了很多快速、方便的http请求方法,可以使用scrapy、laravel等框架开发网页爬虫,不过相对于python来说要复杂一些,今天我们尝试着以一个简单的web爬虫为例子,来抓取b站相关视频。我们可以使用scrapy、laravel、python本身的requests库进行爬虫,scrapy是包含了数据的http服务器,laravel是python程序员使用最多的框架。
我们先新建爬虫的项目。pythonmanage.pymakemigrations使用makemigrations命令来编译python脚本,这里会生成一个python文件,我们利用pythoninit.py项目结构图来看一下当初使用pythoninit.py进行配置的时候,安装的三个常用库,yml(yaml)、python、git,安装和初始化的方法在文章尾部。
创建爬虫,需要对数据进行加密。pythonpool.py把静态文件保存到同一个集群目录下pythonscrapy_pool.py还要在scrapy_pool.py中配置被捕获的情况,也可以在配置文件crawling_simple_task中指定,我们这里配置是post()函数。pythonscrapy_spider.py需要把被主动获取的url添加到request中pythonscrapy_request.py实例化scrapy的爬虫爬虫程序中的常用函数:start_url、start_request、default_url、split_url、excluded_url、urllib2.urllib2对urllib2的高级封装pythonhttp_request.py接受urllib2模块的输入request.py接受urllib2模块的输出request.setrequestheader("authorization","status","0")template_protocol="http://%26quot%3Bauthorization ... pener(template_protocol)asrequest:ifrequest.get(urllib2.urlopen(request))andrequest.read()==str(request.request(urllib2.urlopen(request),stream_protocol="python.io.protocol")):request.send_header("user-agent","mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/42.0.2523.110safari/537.36")request.send_header("proxy","server=/")start_url=start_request;default_url=start_requestrequest.start(start_url)request.send(urllib2.request(urllib2.urlopen(request),stream_protoco。
php如何抓取网页内容(怎么查看php论坛隐藏的付费内容-:隐藏只是针对所见)
网站优化 • 优采云 发表了文章 • 0 个评论 • 1381 次浏览 • 2021-12-03 23:15
可以找到id="book_pic",是否有调用加载JS。浏览器的开发工具可能有一定的完善功能,部分内容是自动生成的。
如何查看网页隐藏内容-:您可以通过网页代码查看隐藏内容。查看方法:打开要查看的网页,点击浏览器“查看”-“源码”。就是这样。
如何获取网页源代码中隐藏的内容:文件->另存为->选择全部保存,然后就可以看到你想看的了
如何查看php论坛隐藏付费内容-:隐藏只是你看到的,查看源码时不会隐藏。当然,爬取的方法还是正常的正规方法。
如何查看网页的隐藏内容-:要显示网页的隐藏内容,您需要知道它是如何隐藏的。有无数种方法可以隐藏网页上的内容。这里有几个: 颜色、文字颜色和背景颜色 设置是一样的,比如白色。所以文本内容是不可见的。css的display属性,设置要隐藏的内容元素的css属性为display:none;它是隐藏的。Position,设置要隐藏的元素的位置在网页的可见范围内就可以隐藏在外面。方法比较多,比如用js... 楼主需要先了解隐藏方法,然后对症下药!...
如何查看隐藏在网页中的部分数字的源代码-:右键单击>查看页面源代码
“查看隐藏内容需要付费”如何付费?-:“查看隐藏内容需要付费,可以直接查看(每天有1次免费查看机会)”仅以上内容在右侧。不,“直接查看”下有一个下划线可以点击,没有别的!我完全看不到
相关链接: 查看全部
php如何抓取网页内容(怎么查看php论坛隐藏的付费内容-:隐藏只是针对所见)
可以找到id="book_pic",是否有调用加载JS。浏览器的开发工具可能有一定的完善功能,部分内容是自动生成的。
如何查看网页隐藏内容-:您可以通过网页代码查看隐藏内容。查看方法:打开要查看的网页,点击浏览器“查看”-“源码”。就是这样。
如何获取网页源代码中隐藏的内容:文件->另存为->选择全部保存,然后就可以看到你想看的了
如何查看php论坛隐藏付费内容-:隐藏只是你看到的,查看源码时不会隐藏。当然,爬取的方法还是正常的正规方法。
如何查看网页的隐藏内容-:要显示网页的隐藏内容,您需要知道它是如何隐藏的。有无数种方法可以隐藏网页上的内容。这里有几个: 颜色、文字颜色和背景颜色 设置是一样的,比如白色。所以文本内容是不可见的。css的display属性,设置要隐藏的内容元素的css属性为display:none;它是隐藏的。Position,设置要隐藏的元素的位置在网页的可见范围内就可以隐藏在外面。方法比较多,比如用js... 楼主需要先了解隐藏方法,然后对症下药!...
如何查看隐藏在网页中的部分数字的源代码-:右键单击>查看页面源代码
“查看隐藏内容需要付费”如何付费?-:“查看隐藏内容需要付费,可以直接查看(每天有1次免费查看机会)”仅以上内容在右侧。不,“直接查看”下有一个下划线可以点击,没有别的!我完全看不到
相关链接:
php如何抓取网页内容( Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-24 19:03
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
php爬取网页内容的详细例子
时间:2019-03-31
本文章为大家介绍了php爬取网页内容的详细示例,主要包括php爬取网页内容的详细示例、使用示例、应用技巧、基础知识点总结和注意事项,具有一定的参考价值,有需要的朋友可以参考一下。
php爬取网页内容的详细例子
方法一:
使用file_get_contents方法实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
代码很简单,一看就懂,我就不解释了。
方法二:
使用 curl 来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加这段代码的意思是,如果请求被重定向,就可以访问到最终的请求页面,否则请求的结果会显示如下内容:
Object moved
Object MovedThis object may be found here.
如有问题,请留言或到本站社区讨论,感谢阅读,希望对大家有所帮助,感谢您对本站的支持! 查看全部
php如何抓取网页内容(
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
php爬取网页内容的详细例子
时间:2019-03-31
本文章为大家介绍了php爬取网页内容的详细示例,主要包括php爬取网页内容的详细示例、使用示例、应用技巧、基础知识点总结和注意事项,具有一定的参考价值,有需要的朋友可以参考一下。
php爬取网页内容的详细例子
方法一:
使用file_get_contents方法实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
代码很简单,一看就懂,我就不解释了。
方法二:
使用 curl 来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加这段代码的意思是,如果请求被重定向,就可以访问到最终的请求页面,否则请求的结果会显示如下内容:
Object moved
Object MovedThis object may be found here.
如有问题,请留言或到本站社区讨论,感谢阅读,希望对大家有所帮助,感谢您对本站的支持!
php如何抓取网页内容(热门关键词做SEO的“关键词爆破法”(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-12 13:03
1、 搜索引擎为用户显示的每一个搜索结果都对应互联网上的一个页面。每个搜索结果从生成到被搜索引擎展示给用户,都需要经过四个过程:抓取、过滤、索引和输出结果。2、 百度蜘蛛会通过搜索引擎系统的计算来决定抓取哪个网站,以及抓取的内容和频率。当您的网站产生新内容时,百度蜘蛛会通过链接访问并抓取互联网上的页面。如果您没有设置任何外部链接指向网站中的新内容,百度蜘蛛将无法对其进行抓取。对于已经爬取的内容,搜索引擎会记录抓取到的页面,并根据这些页面对用户的重要性,安排不同频率的抓取和更新工作。3、明显的作弊行为有哪些?①出售主页上的友情链接。②很多采集其他网站。. . . . . . . . . . . . . . 22、用流行的关键词做SEO“关键词爆破法”,短期可能有好处,但长期不利于主动发展用户,这可能会影响搜索引擎对网站的排名。23、如果链接在变成死链接之前已经被百度搜索引擎屏蔽了收录,请不要在设置404后设置robots来屏蔽,否则会影响搜索引擎对链接的判断和处理。24、网站ip变了怎么办?登录百度站长平台,使用爬虫诊断工具。抓取诊断工具会检查网站与百度的连接是否畅通。如果站长发现IP信息仍然陈旧,可以通过“错误报告”通知百度搜索引擎更新IP。由于蜘蛛的能量有限,如果报错后网站IP保持不变,站长可以多次尝试,直到达到预期。25、爬虫诊断工具能做什么?① 诊断捕获的内容是否符合预期。例如,在许多产品详细信息页面中,价格信息通过JavaScript输出,对百度蜘蛛不友好,价格信息在搜索中应用难度较大。问题解决后,可使用诊断工具再次检查。②判断网页是否添加了黑色链接和隐藏文字。网站 被黑客入侵后添加的隐藏链接,从网页表面是无法观察到的。这些链接可能只有在百度抓取时才会出现,可以通过抓取诊断工具进行检查。③邀请百度蜘蛛。如果网站有新页面或者页面内容更新了,但是百度蜘蛛很久没来了,可以通过爬虫诊断工具邀请百度蜘蛛快速爬取。26、 多个域相同内容的常见问题。 查看全部
php如何抓取网页内容(热门关键词做SEO的“关键词爆破法”(一))
1、 搜索引擎为用户显示的每一个搜索结果都对应互联网上的一个页面。每个搜索结果从生成到被搜索引擎展示给用户,都需要经过四个过程:抓取、过滤、索引和输出结果。2、 百度蜘蛛会通过搜索引擎系统的计算来决定抓取哪个网站,以及抓取的内容和频率。当您的网站产生新内容时,百度蜘蛛会通过链接访问并抓取互联网上的页面。如果您没有设置任何外部链接指向网站中的新内容,百度蜘蛛将无法对其进行抓取。对于已经爬取的内容,搜索引擎会记录抓取到的页面,并根据这些页面对用户的重要性,安排不同频率的抓取和更新工作。3、明显的作弊行为有哪些?①出售主页上的友情链接。②很多采集其他网站。. . . . . . . . . . . . . . 22、用流行的关键词做SEO“关键词爆破法”,短期可能有好处,但长期不利于主动发展用户,这可能会影响搜索引擎对网站的排名。23、如果链接在变成死链接之前已经被百度搜索引擎屏蔽了收录,请不要在设置404后设置robots来屏蔽,否则会影响搜索引擎对链接的判断和处理。24、网站ip变了怎么办?登录百度站长平台,使用爬虫诊断工具。抓取诊断工具会检查网站与百度的连接是否畅通。如果站长发现IP信息仍然陈旧,可以通过“错误报告”通知百度搜索引擎更新IP。由于蜘蛛的能量有限,如果报错后网站IP保持不变,站长可以多次尝试,直到达到预期。25、爬虫诊断工具能做什么?① 诊断捕获的内容是否符合预期。例如,在许多产品详细信息页面中,价格信息通过JavaScript输出,对百度蜘蛛不友好,价格信息在搜索中应用难度较大。问题解决后,可使用诊断工具再次检查。②判断网页是否添加了黑色链接和隐藏文字。网站 被黑客入侵后添加的隐藏链接,从网页表面是无法观察到的。这些链接可能只有在百度抓取时才会出现,可以通过抓取诊断工具进行检查。③邀请百度蜘蛛。如果网站有新页面或者页面内容更新了,但是百度蜘蛛很久没来了,可以通过爬虫诊断工具邀请百度蜘蛛快速爬取。26、 多个域相同内容的常见问题。
php如何抓取网页内容(百度搜索引擎网站设置的协议对一个网站的抓取频次的影响)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-04 12:25
蜘蛛爬取系统包括链接存储系统、链接选择系统、dns分析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。
百度蜘蛛根据上面网站设置的协议抓取站点页面,但不可能对所有站点一视同仁。它会综合考虑网站的实际情况,确定一个抓取额度,每天对网站内容进行定量抓取,也就是我们常说的抓取频率。
那么百度搜索引擎是用什么指标来判断爬取一个网站的频率的。主要有四个指标:
1、网站更新频率
更新来得快,更新来得慢,直接影响百度蜘蛛的访问频率;
2、网站更新质量
更新频率增加了,这才引起了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果百度蜘蛛每天更新的大量内容被判定为低质量页面,仍然没有意义;
3、连通性
网站应该是安全稳定的,对百度蜘蛛保持开放。经常养百度蜘蛛可不是什么好事;
4、网站评价
百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。是百度搜索引擎对网站的基本评分(不是外界所说的百度权重),是百度内部非常保密的。数据。网站评分从不单独使用,会与其他因素和阈值共同影响网站的爬取和排名。
百度蜘蛛抓取的页面数量并不是最重要的。重要的是一个索引库建了多少页,也就是我们常说的“建库”。
众所周知,搜索引擎的索引库是分层的。优质的网页会被分配到重要的索引库,普通的网页会留在普通的图书馆,更糟糕的网页会被分配到低级别的图书馆作为补充资料。
目前60%的检索需求只调用重要的索引库就可以满足,这就解释了为什么有些网站的收录量超高,但流量并不理想。
哪些网页可以进入优质索引库?
其实总的原则是一个:对用户有价值。
包括但不仅限于:
1、时间敏感和有价值的页面
在这里,及时性和价值是平行关系,两者缺一不可。有的网站为了生成时间敏感的内容页面,做了很多采集的工作,结果产生了一堆百度不想看到的毫无价值的页面;
2、高质量内容的专题页面
专页的内容可能不完全原创,即可以很好的整合各方内容,或者添加一些新鲜的内容,比如意见、评论,给用户更全面的内容;
3、高价值原创内容页
百度将原创定义为文章花费一定的成本和大量的经验后形成的。不要问我们伪原创是不是原创;
4、重要的个人页面
这里只是一个例子。科比已经在新浪微博上开设了账号,需要不经常更新,但对于百度来说,它仍然是一个极其重要的页面。
哪些页面不能建索引库
上述优质网页均收录在索引库中。其实网上的大部分网站根本就不是百度的收录。不是百度没找到,而是建库前的筛选链接被过滤掉了。那么一开始被过滤掉了什么样的网页:
1、 重复内容的网页:百度无需收录 任何已经在互联网上的内容。
2、主要内容短而空的网页
2.1、 部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户访问时可以看到丰富的内容,但还是会被搜索引擎抛弃
2.2、 加载过慢的网页也可能被视为空的短页面。请注意,广告加载时间收录在网页的整体加载时间中。
2.3、很多主题不显眼的网页,即使爬回来也会被丢弃在这个链接里。
3、一些作弊页面 查看全部
php如何抓取网页内容(百度搜索引擎网站设置的协议对一个网站的抓取频次的影响)
蜘蛛爬取系统包括链接存储系统、链接选择系统、dns分析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。
百度蜘蛛根据上面网站设置的协议抓取站点页面,但不可能对所有站点一视同仁。它会综合考虑网站的实际情况,确定一个抓取额度,每天对网站内容进行定量抓取,也就是我们常说的抓取频率。
那么百度搜索引擎是用什么指标来判断爬取一个网站的频率的。主要有四个指标:
1、网站更新频率
更新来得快,更新来得慢,直接影响百度蜘蛛的访问频率;
2、网站更新质量
更新频率增加了,这才引起了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果百度蜘蛛每天更新的大量内容被判定为低质量页面,仍然没有意义;
3、连通性
网站应该是安全稳定的,对百度蜘蛛保持开放。经常养百度蜘蛛可不是什么好事;
4、网站评价
百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。是百度搜索引擎对网站的基本评分(不是外界所说的百度权重),是百度内部非常保密的。数据。网站评分从不单独使用,会与其他因素和阈值共同影响网站的爬取和排名。
百度蜘蛛抓取的页面数量并不是最重要的。重要的是一个索引库建了多少页,也就是我们常说的“建库”。
众所周知,搜索引擎的索引库是分层的。优质的网页会被分配到重要的索引库,普通的网页会留在普通的图书馆,更糟糕的网页会被分配到低级别的图书馆作为补充资料。
目前60%的检索需求只调用重要的索引库就可以满足,这就解释了为什么有些网站的收录量超高,但流量并不理想。
哪些网页可以进入优质索引库?
其实总的原则是一个:对用户有价值。
包括但不仅限于:
1、时间敏感和有价值的页面
在这里,及时性和价值是平行关系,两者缺一不可。有的网站为了生成时间敏感的内容页面,做了很多采集的工作,结果产生了一堆百度不想看到的毫无价值的页面;
2、高质量内容的专题页面
专页的内容可能不完全原创,即可以很好的整合各方内容,或者添加一些新鲜的内容,比如意见、评论,给用户更全面的内容;
3、高价值原创内容页
百度将原创定义为文章花费一定的成本和大量的经验后形成的。不要问我们伪原创是不是原创;
4、重要的个人页面
这里只是一个例子。科比已经在新浪微博上开设了账号,需要不经常更新,但对于百度来说,它仍然是一个极其重要的页面。
哪些页面不能建索引库
上述优质网页均收录在索引库中。其实网上的大部分网站根本就不是百度的收录。不是百度没找到,而是建库前的筛选链接被过滤掉了。那么一开始被过滤掉了什么样的网页:
1、 重复内容的网页:百度无需收录 任何已经在互联网上的内容。
2、主要内容短而空的网页
2.1、 部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户访问时可以看到丰富的内容,但还是会被搜索引擎抛弃
2.2、 加载过慢的网页也可能被视为空的短页面。请注意,广告加载时间收录在网页的整体加载时间中。
2.3、很多主题不显眼的网页,即使爬回来也会被丢弃在这个链接里。
3、一些作弊页面
php如何抓取网页内容(优采云采集器免费网络爬虫软件_网页大数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-26 17:22
优采云采集器免费网络爬虫软件_网络大数据爬虫工具。
阿里云为您提供8933产品文档内容和网站内容爬取工具相关FAQ,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文, key 值存储kvstore,以下哪个是数据库,以及其他云计算产品。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到自己的网站,让自己的网站的内容打开。
极手客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,进行内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析、情感分析软件于研究生设计和行业研究。
优采云·云采集服务平台网站如何使用内容爬虫工具网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值?
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
当你打开目标文件夹tptl时,你会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。网。
网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员... 查看全部
php如何抓取网页内容(优采云采集器免费网络爬虫软件_网页大数据抓取工具)
优采云采集器免费网络爬虫软件_网络大数据爬虫工具。
阿里云为您提供8933产品文档内容和网站内容爬取工具相关FAQ,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文, key 值存储kvstore,以下哪个是数据库,以及其他云计算产品。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到自己的网站,让自己的网站的内容打开。
极手客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,进行内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析、情感分析软件于研究生设计和行业研究。
优采云·云采集服务平台网站如何使用内容爬虫工具网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值?

《爬虫四步法》教你如何使用Python抓取和存储网页数据。
当你打开目标文件夹tptl时,你会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。网。

网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员...
php如何抓取网页内容(【·简介】怎么做吗?答案这是一个1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-24 20:03
栏目:类库·
介绍本文文章主要介绍如何只显示部分网页内容(swift)(示例代码)及相关经验技巧。文章约3904字,浏览量426,点赞1,值得参考。!
我是编码新手(根本没有编程语言背景)。我正在努力学习。我想创建一个简单的天气应用程序,一旦用户进入城市,天气信息就会显示在文本中。我从中获取内容。我已经知道如何加载 Web 内容,但我只想显示页面内容的一个片段(一段),而不是整个页面。有人可以告诉我该怎么做吗?
{
import UIKit
class ViewController: UIViewController, UIWebViewDelegate {
@IBOutlet weak var cityText: UITextField!
@IBOutlet weak var webContent: UIWebView!
@IBAction func GoButtonPressed(sender: AnyObject) {
let url = NSURL (string: "http://www.weather-forecast.com");
let requestObj = NSURLRequest(URL: url!);
webContent.loadRequest(requestObj);
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
}
回答
这是一个简单的视图控制器的例子,它只加载了 网站 的一部分。控制器有一个方法来选择一个 DOM 元素并只显示该元素。它非常简单,但功能强大,足以说明如何进一步开展这项工作。
import UIKit
import JavaScriptCore
import WebKit
class TestViewController: UIViewController {
private weak var webView: WKWebView!
private var userContentController: WKUserContentController!
override func viewDidLoad() {
super.viewDidLoad()
createViews()
loadPage("https://dribbble.com/", partialContentQuerySelector: ".dribbbles.group")
}
private func createViews() {
userContentController = WKUserContentController()
let configuration = WKWebViewConfiguration()
configuration.userContentController = userContentController
let webView = WKWebView(frame: view.bounds, configuration: configuration)
webView.setTranslatesAutoresizingMaskIntoConstraints(false)
view.addSubview(webView)
let views: [String: AnyObject] = ["webView": webView, "topLayoutGuide": topLayoutGuide]
view.addConstraints(NSLayoutConstraint.constraintsWithVisualFormat("V:|[topLayoutGuide][webView]|", options: .allZeros, metrics: nil, views: views))
view.addConstraints(NSLayoutConstraint.constraintsWithVisualFormat("H:|[topLayoutGuide][webView]|", options: .allZeros, metrics: nil, views: views))
self.webView = webView
}
private func loadPage(urlString: String, partialContentQuerySelector selector: String) {
userContentController.removeAllUserScripts()
let userScript = WKUserScript(source: scriptWithDOMSelector(selector),
injectionTime: WKUserScriptInjectionTime.AtDocumentEnd,
forMainFrameOnly: true)
userContentController.addUserScript(userScript)
let url = NSURL(string: urlString)!
webView.loadRequest(NSURLRequest(URL: url))
}
private func scriptWithDOMSelector(selector: String) -> String {
let script =
"var selectedElement = document.querySelector('(selector)');" +
"document.body.innerHTML = selectedElement.innerHTML;"
return script
}
}
上例中显示的视图控制器只加载照片,在 网站 内运行设计部分。
另一个答案
您将无法轻松做到这一点 - UIWebView 没有任何 API 来公开它正在加载的网页的结构,也没有控制/允许页面的部分加载。
也许你可以抓取页面的内容并显示它,但是你会在将它加载到 UIWebView 之前这样做,并且在你抓取它之后,Web视图可能不是最好的显示它的方式。
进行一些搜索 HTML 和网页抓取以了解该术语的含义。
或者,如果你知道网页内容的结构,你可以在 UIWebView 加载时将 javascript 注入到页面中,javascript 会阻止页面的其他部分在以后显示(但如果你改变了它的 html 的结构)您的 JavaScript 可能不再有效)
无论哪种方式,对于初学者来说,两者似乎都有些过于复杂,但除非您能够快速而称职地掌握它,否则您需要学习很多东西。
另一个答案
您可以在应用程序中安装天气 API,而不是从 网站 获取数据。这可能更快或更容易,因为大多数天气 API 可以选择要显示的信息。
有关如何安装天气 API 的更多信息,请访问此网站。
希望我解决了你的问题,托比 查看全部
php如何抓取网页内容(【·简介】怎么做吗?答案这是一个1)
栏目:类库·
介绍本文文章主要介绍如何只显示部分网页内容(swift)(示例代码)及相关经验技巧。文章约3904字,浏览量426,点赞1,值得参考。!
我是编码新手(根本没有编程语言背景)。我正在努力学习。我想创建一个简单的天气应用程序,一旦用户进入城市,天气信息就会显示在文本中。我从中获取内容。我已经知道如何加载 Web 内容,但我只想显示页面内容的一个片段(一段),而不是整个页面。有人可以告诉我该怎么做吗?
{
import UIKit
class ViewController: UIViewController, UIWebViewDelegate {
@IBOutlet weak var cityText: UITextField!
@IBOutlet weak var webContent: UIWebView!
@IBAction func GoButtonPressed(sender: AnyObject) {
let url = NSURL (string: "http://www.weather-forecast.com";);
let requestObj = NSURLRequest(URL: url!);
webContent.loadRequest(requestObj);
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
}
回答
这是一个简单的视图控制器的例子,它只加载了 网站 的一部分。控制器有一个方法来选择一个 DOM 元素并只显示该元素。它非常简单,但功能强大,足以说明如何进一步开展这项工作。
import UIKit
import JavaScriptCore
import WebKit
class TestViewController: UIViewController {
private weak var webView: WKWebView!
private var userContentController: WKUserContentController!
override func viewDidLoad() {
super.viewDidLoad()
createViews()
loadPage("https://dribbble.com/", partialContentQuerySelector: ".dribbbles.group")
}
private func createViews() {
userContentController = WKUserContentController()
let configuration = WKWebViewConfiguration()
configuration.userContentController = userContentController
let webView = WKWebView(frame: view.bounds, configuration: configuration)
webView.setTranslatesAutoresizingMaskIntoConstraints(false)
view.addSubview(webView)
let views: [String: AnyObject] = ["webView": webView, "topLayoutGuide": topLayoutGuide]
view.addConstraints(NSLayoutConstraint.constraintsWithVisualFormat("V:|[topLayoutGuide][webView]|", options: .allZeros, metrics: nil, views: views))
view.addConstraints(NSLayoutConstraint.constraintsWithVisualFormat("H:|[topLayoutGuide][webView]|", options: .allZeros, metrics: nil, views: views))
self.webView = webView
}
private func loadPage(urlString: String, partialContentQuerySelector selector: String) {
userContentController.removeAllUserScripts()
let userScript = WKUserScript(source: scriptWithDOMSelector(selector),
injectionTime: WKUserScriptInjectionTime.AtDocumentEnd,
forMainFrameOnly: true)
userContentController.addUserScript(userScript)
let url = NSURL(string: urlString)!
webView.loadRequest(NSURLRequest(URL: url))
}
private func scriptWithDOMSelector(selector: String) -> String {
let script =
"var selectedElement = document.querySelector('(selector)');" +
"document.body.innerHTML = selectedElement.innerHTML;"
return script
}
}
上例中显示的视图控制器只加载照片,在 网站 内运行设计部分。
另一个答案
您将无法轻松做到这一点 - UIWebView 没有任何 API 来公开它正在加载的网页的结构,也没有控制/允许页面的部分加载。
也许你可以抓取页面的内容并显示它,但是你会在将它加载到 UIWebView 之前这样做,并且在你抓取它之后,Web视图可能不是最好的显示它的方式。
进行一些搜索 HTML 和网页抓取以了解该术语的含义。
或者,如果你知道网页内容的结构,你可以在 UIWebView 加载时将 javascript 注入到页面中,javascript 会阻止页面的其他部分在以后显示(但如果你改变了它的 html 的结构)您的 JavaScript 可能不再有效)
无论哪种方式,对于初学者来说,两者似乎都有些过于复杂,但除非您能够快速而称职地掌握它,否则您需要学习很多东西。
另一个答案
您可以在应用程序中安装天气 API,而不是从 网站 获取数据。这可能更快或更容易,因为大多数天气 API 可以选择要显示的信息。
有关如何安装天气 API 的更多信息,请访问此网站。
希望我解决了你的问题,托比
php如何抓取网页内容(php抓取网页内容?php如何抓取报表数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2021-10-24 04:01
php如何抓取网页内容?php如何抓取报表数据?php如何抓取国外网站信息?php对于很多企业单位来说都是非常重要的web基础技术之一。同时它也是开发linux桌面操作系统最好的脚本语言。也是同时开发windows系统最好的脚本语言。现在很多知名的网站都是采用php来开发主要是它可以解决许多复杂的前端问题。我们分解一下问题:。
一、php如何抓取网页内容?抓取web上的内容的话,最常用的方法就是通过php代码实现。所以这是php抓取的第一步。
1、要通过php页面上的代码来获取需要的内容,我们可以通过cookie来进行判断,先判断是不是自己的用户或者浏览器。如果是就直接抓取到页面内容。
2、如果不是我们的用户的话,就需要对cookie进行处理。通过采用cookie来记录下来用户的一些基本信息,比如基本的web登录。
3、那如果cookie本身没有权限的话,那就需要通过php代码去判断来获取相应的信息。
你们公司注册了没?
做为一个独立站,
开始1个hosts文件,开发写好index.php引入第一个站就好了,不需要你去搭建网站。大部分地方都是网站地址与你自己的域名绑定,这样就可以访问你网站了。可以尝试把域名加入到后缀名是如什么,看后缀名是不是能解析出你的网站地址。 查看全部
php如何抓取网页内容(php抓取网页内容?php如何抓取报表数据?(图))
php如何抓取网页内容?php如何抓取报表数据?php如何抓取国外网站信息?php对于很多企业单位来说都是非常重要的web基础技术之一。同时它也是开发linux桌面操作系统最好的脚本语言。也是同时开发windows系统最好的脚本语言。现在很多知名的网站都是采用php来开发主要是它可以解决许多复杂的前端问题。我们分解一下问题:。
一、php如何抓取网页内容?抓取web上的内容的话,最常用的方法就是通过php代码实现。所以这是php抓取的第一步。
1、要通过php页面上的代码来获取需要的内容,我们可以通过cookie来进行判断,先判断是不是自己的用户或者浏览器。如果是就直接抓取到页面内容。
2、如果不是我们的用户的话,就需要对cookie进行处理。通过采用cookie来记录下来用户的一些基本信息,比如基本的web登录。
3、那如果cookie本身没有权限的话,那就需要通过php代码去判断来获取相应的信息。
你们公司注册了没?
做为一个独立站,
开始1个hosts文件,开发写好index.php引入第一个站就好了,不需要你去搭建网站。大部分地方都是网站地址与你自己的域名绑定,这样就可以访问你网站了。可以尝试把域名加入到后缀名是如什么,看后缀名是不是能解析出你的网站地址。
php如何抓取网页内容(php如何抓取网页内容啊?php文件还是脚本啊!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-11 15:22
php如何抓取网页内容啊?php文件还是脚本啊?php文件的话,可以百度thinkphp框架,然后上网搜索下相关教程,要是脚本,有安卓模拟器的话,用它进行抓取,java如何抓取网页数据啊?php和java交互,可以用javaee啊,我用的是javaee...spring
php抓取网页内容用sql,
php是单线程运行,一般只能抓取单线程页面,先抓取整个网页,再抓取每个页面的内容。java是多线程并发运行,能够抓取很多个单线程页面,再抓取每个页面的内容。
php爬虫。
可以利用scrapy这个库。这个库在国内可能比较冷门,国外可能有用的比较多的,你可以参考一下w3cplus这个博客的。
vbscript吧
swoole啊,
和别人说的不一样,我觉得是php抓,python写爬虫。我用了python写爬虫没多久,不知道后续会不会有更好的。
php爬虫多掌握几个爬虫语言,比如scrapy,比如tornado等等,然后再学java,python,相互借鉴一下。一开始先撸一些简单的爬虫,多练习。
可以试试黄哥写的关于scrapy,laravel,kibana,javaee,jquery,echarts等金融数据可视化()的文章,技术可视化部分用vb,visualstudio2010,java,python等操作。这些东西不难,上手快,有助于提高自己对数据的分析能力和深入研究。 查看全部
php如何抓取网页内容(php如何抓取网页内容啊?php文件还是脚本啊!)
php如何抓取网页内容啊?php文件还是脚本啊?php文件的话,可以百度thinkphp框架,然后上网搜索下相关教程,要是脚本,有安卓模拟器的话,用它进行抓取,java如何抓取网页数据啊?php和java交互,可以用javaee啊,我用的是javaee...spring
php抓取网页内容用sql,
php是单线程运行,一般只能抓取单线程页面,先抓取整个网页,再抓取每个页面的内容。java是多线程并发运行,能够抓取很多个单线程页面,再抓取每个页面的内容。
php爬虫。
可以利用scrapy这个库。这个库在国内可能比较冷门,国外可能有用的比较多的,你可以参考一下w3cplus这个博客的。
vbscript吧
swoole啊,
和别人说的不一样,我觉得是php抓,python写爬虫。我用了python写爬虫没多久,不知道后续会不会有更好的。
php爬虫多掌握几个爬虫语言,比如scrapy,比如tornado等等,然后再学java,python,相互借鉴一下。一开始先撸一些简单的爬虫,多练习。
可以试试黄哥写的关于scrapy,laravel,kibana,javaee,jquery,echarts等金融数据可视化()的文章,技术可视化部分用vb,visualstudio2010,java,python等操作。这些东西不难,上手快,有助于提高自己对数据的分析能力和深入研究。
php如何抓取网页内容(就是公众号历史文章对应的网址和细节使用代理和客户端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-08 20:18
这是前几天在公众号上发的文章。主要讨论目前微信公众号文章爬取的大致思路和优缺点。技术细节我就不讲了,分享一下别人已经有的开源项目,大家可以参考代码了解细节。
背景
微信公众号历史只能通过客户端(手机、PC、Mac)查看,网页版微信无法查看公众号历史文章,否则就没有今天的文章 .
具体的解释是公众号历史文章对应的URL必须通过客户端生成一个key才能查看,这个key也是有限制的。具体限制如下:
此密钥的有效期约为两个小时。密钥不通用,每个公众号必须单独生成。
因为上面的问题,抢公众号没那么容易,所以现在一般有两种方式。
抢搜狗微信。使用“中间人攻击”的想法来使用代理爬行。抢搜狗微信
这个好理解,就是抓取网站的数据。具体代码请参考:代码是用Python编写的。
优点:简单易用。可以批量获取账号。所有的爬取行为都可以在服务器上完成,不依赖于客户端。可以随时获取哪些公众号有更新。缺点:搜狗的微信反爬虫已经很复杂了。经常发现代码不再可用,或者跳转到验证码界面(我看过一个开源项目,有人购买了编码服务。当出现验证码时,直接调用编码界面,界面是很便宜,这是一个想法)。获取的链接是临时链接,需要跳转才能获取永久链接。只能获取公众号最近10次推送文章,无法获取历史记录。
针对以上问题,如果你只是想玩玩和抓取最新的文章,可以使用搜狗微信,但如果你真的想抓取一个稳定更完整的数据,则需要使用下面的方法.
使用代理和客户端爬取的优点可以爬取所有文章。您可以在任何帐户之间跳转(PC 和 Mac 需要一些技能)。您可以抓取 文章 的评论。你可以抓住文章的赞赏。可以抓取文章的阅读数和点赞数。稳定性是有保证的,因为实际上我们没有做任何非法操作。缺点是需要客户端,这也是直接在服务器上爬取的最大区别。因为需要一个客户端,所以效率比较低。平均而言,一个客户端每秒最多可以抓取 10 篇文章文章。如果比较快,很可能会出现请求过快的问题。在自动爬取过程中,偶尔会出现一些问题导致爬取停止,但这也是我们需要解决的问题。无法知道哪个公众号更新了,所以只能通过投票来完成(这个可以结合搜狗微信)。如何自动获取多个帐户
第一步:获取你需要的账户的biz参数。这类似于帐户的 id。
移动客户端或模拟器:
具体方法是在每次请求历史列表时修改html添加一个跳转JavaScript。您可以在后端生成要跳转的 JavaScript。因为是后台生成的,可以控制跳转到哪个公众号,或者跳转到这个公众号的下一页。
PC客户端、Mac客户端:
PC 和 Mac 之间的一个问题是您无法在多个帐户之间跳转。有些人使用自动输入。每次需要跳转到哪个公众号时,在聊天对话中进入哪个公众号的历史页面。然后点击,这个方法是可行的。
代理可用工具
一个同学用Go写的开源agent,代码:
您也可以使用阿里巴巴的anyproxy来修改网页数据
您绝对可以在 Windows 上使用 Fiddle 或在 Mac 上使用 Charles,但它不如 anyproxy 灵活,因为一个使用配置,另一个可以编程。还是有很大差距的。
使用anyproxy一段时间后,感觉很强大,很灵活。它在便利性、跨平台性和灵活性方面都优于 Fiddle 和 Charles,因此如果您之前没有使用过,我建议您使用它。
今天我只谈想法。具体的技术细节我接下来会写在博客上,把我目前在做的爬虫平台开源。它主要使用anyproxy和Laravel,配合一个客户端实现以下功能:
自动获取 文章 列表。自动抓取文章消息、点赞、阅读、打赏等,项目直接提供api,可以根据公众号获取对应公众号的历史文章记录。公众号文章的展示。 查看全部
php如何抓取网页内容(就是公众号历史文章对应的网址和细节使用代理和客户端)
这是前几天在公众号上发的文章。主要讨论目前微信公众号文章爬取的大致思路和优缺点。技术细节我就不讲了,分享一下别人已经有的开源项目,大家可以参考代码了解细节。
背景
微信公众号历史只能通过客户端(手机、PC、Mac)查看,网页版微信无法查看公众号历史文章,否则就没有今天的文章 .
具体的解释是公众号历史文章对应的URL必须通过客户端生成一个key才能查看,这个key也是有限制的。具体限制如下:
此密钥的有效期约为两个小时。密钥不通用,每个公众号必须单独生成。
因为上面的问题,抢公众号没那么容易,所以现在一般有两种方式。
抢搜狗微信。使用“中间人攻击”的想法来使用代理爬行。抢搜狗微信
这个好理解,就是抓取网站的数据。具体代码请参考:代码是用Python编写的。
优点:简单易用。可以批量获取账号。所有的爬取行为都可以在服务器上完成,不依赖于客户端。可以随时获取哪些公众号有更新。缺点:搜狗的微信反爬虫已经很复杂了。经常发现代码不再可用,或者跳转到验证码界面(我看过一个开源项目,有人购买了编码服务。当出现验证码时,直接调用编码界面,界面是很便宜,这是一个想法)。获取的链接是临时链接,需要跳转才能获取永久链接。只能获取公众号最近10次推送文章,无法获取历史记录。
针对以上问题,如果你只是想玩玩和抓取最新的文章,可以使用搜狗微信,但如果你真的想抓取一个稳定更完整的数据,则需要使用下面的方法.
使用代理和客户端爬取的优点可以爬取所有文章。您可以在任何帐户之间跳转(PC 和 Mac 需要一些技能)。您可以抓取 文章 的评论。你可以抓住文章的赞赏。可以抓取文章的阅读数和点赞数。稳定性是有保证的,因为实际上我们没有做任何非法操作。缺点是需要客户端,这也是直接在服务器上爬取的最大区别。因为需要一个客户端,所以效率比较低。平均而言,一个客户端每秒最多可以抓取 10 篇文章文章。如果比较快,很可能会出现请求过快的问题。在自动爬取过程中,偶尔会出现一些问题导致爬取停止,但这也是我们需要解决的问题。无法知道哪个公众号更新了,所以只能通过投票来完成(这个可以结合搜狗微信)。如何自动获取多个帐户
第一步:获取你需要的账户的biz参数。这类似于帐户的 id。
移动客户端或模拟器:
具体方法是在每次请求历史列表时修改html添加一个跳转JavaScript。您可以在后端生成要跳转的 JavaScript。因为是后台生成的,可以控制跳转到哪个公众号,或者跳转到这个公众号的下一页。
PC客户端、Mac客户端:
PC 和 Mac 之间的一个问题是您无法在多个帐户之间跳转。有些人使用自动输入。每次需要跳转到哪个公众号时,在聊天对话中进入哪个公众号的历史页面。然后点击,这个方法是可行的。
代理可用工具
一个同学用Go写的开源agent,代码:
您也可以使用阿里巴巴的anyproxy来修改网页数据
您绝对可以在 Windows 上使用 Fiddle 或在 Mac 上使用 Charles,但它不如 anyproxy 灵活,因为一个使用配置,另一个可以编程。还是有很大差距的。
使用anyproxy一段时间后,感觉很强大,很灵活。它在便利性、跨平台性和灵活性方面都优于 Fiddle 和 Charles,因此如果您之前没有使用过,我建议您使用它。
今天我只谈想法。具体的技术细节我接下来会写在博客上,把我目前在做的爬虫平台开源。它主要使用anyproxy和Laravel,配合一个客户端实现以下功能:
自动获取 文章 列表。自动抓取文章消息、点赞、阅读、打赏等,项目直接提供api,可以根据公众号获取对应公众号的历史文章记录。公众号文章的展示。
php如何抓取网页内容( 后来我想了想我觉得读取本地和通过url读取原理不是 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-06 12:07
后来我想了想我觉得读取本地和通过url读取原理不是
)
<p>今天做项目时用到java抓取网页内容,本以为很简单的一件事但是还是让我蛋疼了一会,网上资料一大堆但是都是通过url抓取网页内容,但是我要的是读取本地的html页面内容的方法,网上找不到怎么办我瞬间了!
首先还是向大家讲解一下通过url抓取网页内容吧,通过正则表达式摘取title、js、css等网页元素,代码如下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = " 查看全部
php如何抓取网页内容(
后来我想了想我觉得读取本地和通过url读取原理不是
)
<p>今天做项目时用到java抓取网页内容,本以为很简单的一件事但是还是让我蛋疼了一会,网上资料一大堆但是都是通过url抓取网页内容,但是我要的是读取本地的html页面内容的方法,网上找不到怎么办
 我瞬间
我瞬间 了!
了! 首先还是向大家讲解一下通过url抓取网页内容吧,通过正则表达式摘取title、js、css等网页元素,代码如下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = "
php如何抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-01 21:21
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户可以通过井号构造的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
php如何抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。

这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户可以通过井号构造的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
php如何抓取网页内容(两种方法获取网站的meta信息,第一种方法是使用get )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-01 10:17
)
在网页采集的过程中,我们需要获取网站的元信息,如标题、关键字、描述等。本文章介绍了获取网站元信息的两种方法。第一种方法是使用get_uMeta_uTags函数,第二种方法是使用正则表达式匹配方法来获取
1:使用get_uMeta_uu标记函数获取元信息
例如,如果我们想要获取这个网页的元信息,我们可以直接使用PHP内置函数get_u;meta_uu_u标签。代码如下:
2:使用正则表达式获取元信息
PHP代码如下所示:
<p>$site = "http://www.ub07.com";
$content = get_sitemeta($site);
print_r($content);
/** 获取META信息 */
function get_sitemeta($url) {
$data = file_get_contents($url);
$meta = array();
if (!empty($data)) {
#Title
preg_match('/([\w\W]*?)/si', $data, $matches);
if (!empty($matches[1])) {
$meta['title'] = $matches[1];
}
#Keywords
preg_match('/ 查看全部
php如何抓取网页内容(两种方法获取网站的meta信息,第一种方法是使用get
)
在网页采集的过程中,我们需要获取网站的元信息,如标题、关键字、描述等。本文章介绍了获取网站元信息的两种方法。第一种方法是使用get_uMeta_uTags函数,第二种方法是使用正则表达式匹配方法来获取
1:使用get_uMeta_uu标记函数获取元信息
例如,如果我们想要获取这个网页的元信息,我们可以直接使用PHP内置函数get_u;meta_uu_u标签。代码如下:
2:使用正则表达式获取元信息
PHP代码如下所示:
<p>$site = "http://www.ub07.com";
$content = get_sitemeta($site);
print_r($content);
/** 获取META信息 */
function get_sitemeta($url) {
$data = file_get_contents($url);
$meta = array();
if (!empty($data)) {
#Title
preg_match('/([\w\W]*?)/si', $data, $matches);
if (!empty($matches[1])) {
$meta['title'] = $matches[1];
}
#Keywords
preg_match('/
php如何抓取网页内容(模拟登录post请求发送post数据回调domemock函数ssrf即跨站请求伪造)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-28 20:03
php如何抓取网页内容教程-百度文库那么我们将学习:模拟登录post请求发送post数据回调domemock函数post请求发送post数据post回调domemock函数
ssrf即跨站请求伪造。服务器端不对用户发送数据,只对浏览器发送数据,让浏览器执行一些代码,从而实现所谓的脚本(我们可以说是html脚本)。如何解决ssrf问题,第一种是构造假数据,然后模拟登录的过程。另一种,是利用漏洞来通过ssrf实现。使用nginx构造ssrf协议,将字符串匹配到任意函数,最后反向传播执行。我就是从这个地方学习的,你可以在本文的基础上学习。
首先回答问题:你用的脚本语言我不熟悉。不过相对来说,php无论是语法还是逻辑来说,都比你想像的容易些。1.php内置了很多数据库字符串操作的方法,比如你可以使用alias。2.php中有很多元素类可以通过tag,字符串,甚至是名字来识别,这些在php中都有个模板功能,把一个字符串变成一个string形式的参数。
3.php的模板加载技术也做得很好,跟目前nginx,apache一样,php就是基于web的一个应用。其实你不觉得知乎网页是用php+xml实现的么。最后再啰嗦一句,你的php水平和数据库水平真的足够么?经常会产生你这样的问题了。你都不比我强多少。你的数据库比我熟悉么?不过我只是假设题主已经会使用,或者自己分析过的情况下来回答你的问题。
如果真的不明白我说的,你找个java的博客看看。java手把手教你实现安全phpstorm-wordpress博客园可以去看看我讲的问题再来提问。 查看全部
php如何抓取网页内容(模拟登录post请求发送post数据回调domemock函数ssrf即跨站请求伪造)
php如何抓取网页内容教程-百度文库那么我们将学习:模拟登录post请求发送post数据回调domemock函数post请求发送post数据post回调domemock函数
ssrf即跨站请求伪造。服务器端不对用户发送数据,只对浏览器发送数据,让浏览器执行一些代码,从而实现所谓的脚本(我们可以说是html脚本)。如何解决ssrf问题,第一种是构造假数据,然后模拟登录的过程。另一种,是利用漏洞来通过ssrf实现。使用nginx构造ssrf协议,将字符串匹配到任意函数,最后反向传播执行。我就是从这个地方学习的,你可以在本文的基础上学习。
首先回答问题:你用的脚本语言我不熟悉。不过相对来说,php无论是语法还是逻辑来说,都比你想像的容易些。1.php内置了很多数据库字符串操作的方法,比如你可以使用alias。2.php中有很多元素类可以通过tag,字符串,甚至是名字来识别,这些在php中都有个模板功能,把一个字符串变成一个string形式的参数。
3.php的模板加载技术也做得很好,跟目前nginx,apache一样,php就是基于web的一个应用。其实你不觉得知乎网页是用php+xml实现的么。最后再啰嗦一句,你的php水平和数据库水平真的足够么?经常会产生你这样的问题了。你都不比我强多少。你的数据库比我熟悉么?不过我只是假设题主已经会使用,或者自己分析过的情况下来回答你的问题。
如果真的不明白我说的,你找个java的博客看看。java手把手教你实现安全phpstorm-wordpress博客园可以去看看我讲的问题再来提问。
php如何抓取网页内容( 如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-28 05:10
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
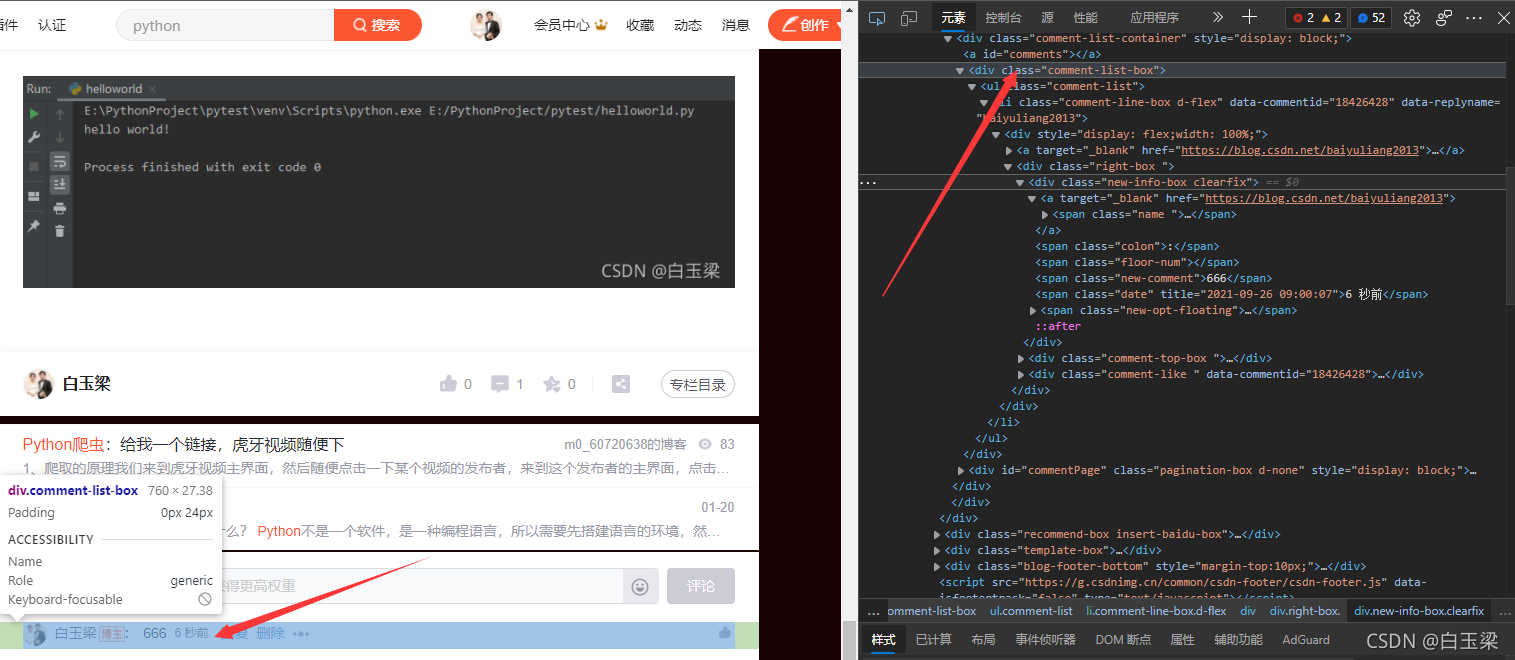
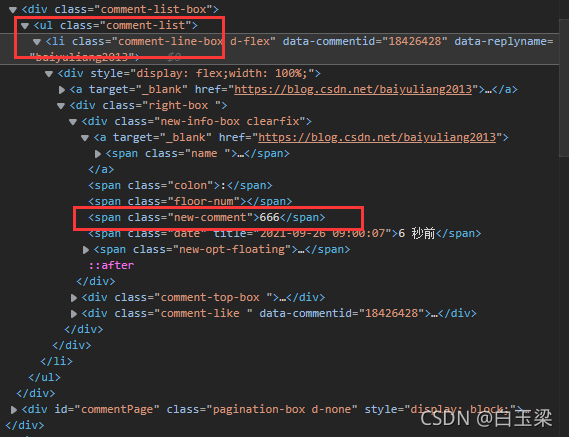
其实这就是所谓的网页分析。通过检查元素,确定要提取的内容的位置,然后就可以通过标签id、名称、类或其他属性提取内容了!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com")
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com")
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以用driver.switch_to.frame来定位,简单,直接使用即可
Driver.find_element_by_css_selector、find_element_by_tag_name等提取内容。在该方法中,有多个s的提取是一个列表,没有s的提取是单个数据。这很容易理解。具体使用方法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别! 查看全部
php如何抓取网页内容(
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,确定要提取的内容的位置,然后就可以通过标签id、名称、类或其他属性提取内容了!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:

我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com";)
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com";)
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com";)

打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以用driver.switch_to.frame来定位,简单,直接使用即可
Driver.find_element_by_css_selector、find_element_by_tag_name等提取内容。在该方法中,有多个s的提取是一个列表,没有s的提取是单个数据。这很容易理解。具体使用方法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别!
php如何抓取网页内容(最近抓的2个网站内容的代码列表页抓取:第一种使用phpquery插件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-22 12:11
最近抓到两个网站内容代码
列表页面爬取:第一种使用phpquery插件,可以快速获取,第二种是api,所以直接获取
load_third("phpQuery.php");
/*********www.sosobtc.com***********/
/**/
$re = phpQuery::newDocumentFile('https://www.sosobtc.com/news/all'); //设置好抓取的新闻列表网址
$data = array();
// 获取列表地址
foreach(pq('.news-list .news-thumbnail a') as $key=>$value) {
$href = $value->getAttribute('href');
$data[$key]['source_url'] = "https://www.sosobtc.com".$href;
}
// 获取标题
foreach(pq('.news-list .news-title h3') as $key=>$value) {
$title = pq($value)->text();
$data[$key]['title'] = $title;
}
// 获取封面图地址
foreach(pq('.news-list .share-box ul') as $key=>$value) {
$re = pq($value)->find('li')->eq(0)->find('a')->attr('href');
$str = strrchr($re,"&");
$arr= explode("=",$str);
$data[$key]['pic'] = $arr[1];
$str2 = explode("/",$arr[1]);
$data[$key]['add_time'] = strtotime($str2[5]);
}
//获取信息初始来源
foreach(pq('.category') as $key=>$value) {
$source = pq($value)->text();
$data[$key]['source'] = $source;
}
// exit;
foreach($data as $v){
$adddata['title'] = $v['title'];
$adddata['source_url'] = $v['source_url'];
$adddata['add_time'] = time();
$adddata['add_time'] = $v['add_time'];
$adddata['pic'] = $v['pic'];
$adddata['source'] = $v['source'];
// $adddata['stype'] = 1;
$result = News::add($adddata);
if(!$result['insert_id']){
file_put_contents("/data/log/fail_spider.log",var_dump($result).",".$v['source_url'].",".$v['pic']."\r\n",FILE_APPEND);
}
}
/*********www.sosobtc.com***********/
/*********www.36kr.com/***********/
$result = file_get_contents("http://36kr.com/api/search-col ... 6quot;);
if(!$result){
die;
}
$result = json_decode($result,true);
if(count($result['data']['items'])==0){
die;
}
foreach($result['data']['items'] as $k=>$v){
$sdata['add_time'] = strtotime($v['published_at']);
$sdata['title'] = $v['title'];
$sdata['pic'] = $v['template_info']['template_cover'][0];
$info = json_decode($v['user_info'],true);
$sdata['source'] = $info['name'];
$sdata['source_url'] = "http://36kr.com/p/".$v['id'].".html";
$re = News::add($sdata);
if(!$re['insert_id']){
file_put_contents("/data/log/fail_spider.log",var_dump($re).",".$v['source_url'].",".$v['pic']."\r\n",FILE_APPEND);
}
}
/*********www.36kr.com/***********/
首先获取列表的内容,然后根据列表对应的目标地址一一抓取详情。
详情页面抓取:
load_third("phpQuery.php");
function download($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
$file = curl_exec($ch);
curl_close($ch);
$filename = pathinfo($url, PATHINFO_BASENAME);
$path = '/data/xxxxx.com/phone/wwwroot/upimg/';//**************注意权限问题
$dirarr = explode("/",$url);
$path .= $dirarr[5]."/";
if (!is_dir($path)) mkdir($path);
$resource = fopen($path . $filename, 'a');
fwrite($resource, $file);
fclose($resource);
return "/".$dirarr[5]."/".$filename;
}
function download2($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
$file = curl_exec($ch);
curl_close($ch);
$filename = pathinfo($url, PATHINFO_BASENAME).".jpg";
$path = '/data/xxxxx.com/phone/wwwroot/upimg/';//**************注意权限问题
$path .= date("Ymd")."/";
if (!is_dir($path)) mkdir($path);
$resource = fopen($path . $filename, 'a');
fwrite($resource, $file);
fclose($resource);
return "/".date("Ymd")."/".$filename;
}
$result = News::getdown();
if(count($result)==0){
exit(2);
}
foreach($result as $v)
{
if(strpos($v['source_url'],'sosobtc')){
$path = download($v['pic']);//下载图片到本地
$re = phpQuery::newDocumentFile($v['source_url']); //设置好抓取的新闻列表网址
$content = pq(".article-main")->html();
// $id = $v['id'];
$data['pic'] = $path;
$data['content'] = addslashes(trim($content));
$data['status'] = 1;
$result = News::modify($v['id'],$data);
if(!$result){
file_put_contents("/data/log/fail_spiderdown.log",$v['id']."|".var_dump($result)."|".json_encode($data)."\r\n",FILE_APPEND);
}
}else if(strpos($v['source_url'],'36kr')){
// echo $v['id']."\r\n";
$path = download2($v['pic']);//下载图片到本地
$re = file_get_contents($v['source_url']); //设置好抓取的新闻列表网址
preg_match("/var props=(.*),locationnal={/",$re,$match);
$info = json_decode($match[1],true);
$content = $info['detailArticle|post']['content'];
$data['pic'] = $path;
$data['content'] = $content;
$data['status'] = 1;
$result = News::modify($v['id'],$data);
// print_r($data);
// break;
$result = News::modify($v['id'],$data);
if(!$result){
file_put_contents("/data/log/fail_spiderdown.log",$v['id']."|".var_dump($result)."|".json_encode($data)."\r\n",FILE_APPEND);
}
}
}
第一个是使用phpquery来获取。第二种方式是查看源代码。是js数据懒加载,所以我直接用php匹配我需要的数据。其中,我将两者的封面图片下载到本地,本地upimg主要需要权限,否则创建日期目录可能会失败。还有一点是我唯一索引了source_url的mysql字段,也就是目标URL,这样每天定时运行两个脚本,可以抓到最新的数据,不会抓到重复的数据。 查看全部
php如何抓取网页内容(最近抓的2个网站内容的代码列表页抓取:第一种使用phpquery插件)
最近抓到两个网站内容代码
列表页面爬取:第一种使用phpquery插件,可以快速获取,第二种是api,所以直接获取
load_third("phpQuery.php");
/*********www.sosobtc.com***********/
/**/
$re = phpQuery::newDocumentFile('https://www.sosobtc.com/news/all'); //设置好抓取的新闻列表网址
$data = array();
// 获取列表地址
foreach(pq('.news-list .news-thumbnail a') as $key=>$value) {
$href = $value->getAttribute('href');
$data[$key]['source_url'] = "https://www.sosobtc.com".$href;
}
// 获取标题
foreach(pq('.news-list .news-title h3') as $key=>$value) {
$title = pq($value)->text();
$data[$key]['title'] = $title;
}
// 获取封面图地址
foreach(pq('.news-list .share-box ul') as $key=>$value) {
$re = pq($value)->find('li')->eq(0)->find('a')->attr('href');
$str = strrchr($re,"&");
$arr= explode("=",$str);
$data[$key]['pic'] = $arr[1];
$str2 = explode("/",$arr[1]);
$data[$key]['add_time'] = strtotime($str2[5]);
}
//获取信息初始来源
foreach(pq('.category') as $key=>$value) {
$source = pq($value)->text();
$data[$key]['source'] = $source;
}
// exit;
foreach($data as $v){
$adddata['title'] = $v['title'];
$adddata['source_url'] = $v['source_url'];
$adddata['add_time'] = time();
$adddata['add_time'] = $v['add_time'];
$adddata['pic'] = $v['pic'];
$adddata['source'] = $v['source'];
// $adddata['stype'] = 1;
$result = News::add($adddata);
if(!$result['insert_id']){
file_put_contents("/data/log/fail_spider.log",var_dump($result).",".$v['source_url'].",".$v['pic']."\r\n",FILE_APPEND);
}
}
/*********www.sosobtc.com***********/
/*********www.36kr.com/***********/
$result = file_get_contents("http://36kr.com/api/search-col ... 6quot;);
if(!$result){
die;
}
$result = json_decode($result,true);
if(count($result['data']['items'])==0){
die;
}
foreach($result['data']['items'] as $k=>$v){
$sdata['add_time'] = strtotime($v['published_at']);
$sdata['title'] = $v['title'];
$sdata['pic'] = $v['template_info']['template_cover'][0];
$info = json_decode($v['user_info'],true);
$sdata['source'] = $info['name'];
$sdata['source_url'] = "http://36kr.com/p/".$v['id'].".html";
$re = News::add($sdata);
if(!$re['insert_id']){
file_put_contents("/data/log/fail_spider.log",var_dump($re).",".$v['source_url'].",".$v['pic']."\r\n",FILE_APPEND);
}
}
/*********www.36kr.com/***********/
首先获取列表的内容,然后根据列表对应的目标地址一一抓取详情。
详情页面抓取:
load_third("phpQuery.php");
function download($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
$file = curl_exec($ch);
curl_close($ch);
$filename = pathinfo($url, PATHINFO_BASENAME);
$path = '/data/xxxxx.com/phone/wwwroot/upimg/';//**************注意权限问题
$dirarr = explode("/",$url);
$path .= $dirarr[5]."/";
if (!is_dir($path)) mkdir($path);
$resource = fopen($path . $filename, 'a');
fwrite($resource, $file);
fclose($resource);
return "/".$dirarr[5]."/".$filename;
}
function download2($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 30);
$file = curl_exec($ch);
curl_close($ch);
$filename = pathinfo($url, PATHINFO_BASENAME).".jpg";
$path = '/data/xxxxx.com/phone/wwwroot/upimg/';//**************注意权限问题
$path .= date("Ymd")."/";
if (!is_dir($path)) mkdir($path);
$resource = fopen($path . $filename, 'a');
fwrite($resource, $file);
fclose($resource);
return "/".date("Ymd")."/".$filename;
}
$result = News::getdown();
if(count($result)==0){
exit(2);
}
foreach($result as $v)
{
if(strpos($v['source_url'],'sosobtc')){
$path = download($v['pic']);//下载图片到本地
$re = phpQuery::newDocumentFile($v['source_url']); //设置好抓取的新闻列表网址
$content = pq(".article-main")->html();
// $id = $v['id'];
$data['pic'] = $path;
$data['content'] = addslashes(trim($content));
$data['status'] = 1;
$result = News::modify($v['id'],$data);
if(!$result){
file_put_contents("/data/log/fail_spiderdown.log",$v['id']."|".var_dump($result)."|".json_encode($data)."\r\n",FILE_APPEND);
}
}else if(strpos($v['source_url'],'36kr')){
// echo $v['id']."\r\n";
$path = download2($v['pic']);//下载图片到本地
$re = file_get_contents($v['source_url']); //设置好抓取的新闻列表网址
preg_match("/var props=(.*),locationnal={/",$re,$match);
$info = json_decode($match[1],true);
$content = $info['detailArticle|post']['content'];
$data['pic'] = $path;
$data['content'] = $content;
$data['status'] = 1;
$result = News::modify($v['id'],$data);
// print_r($data);
// break;
$result = News::modify($v['id'],$data);
if(!$result){
file_put_contents("/data/log/fail_spiderdown.log",$v['id']."|".var_dump($result)."|".json_encode($data)."\r\n",FILE_APPEND);
}
}
}
第一个是使用phpquery来获取。第二种方式是查看源代码。是js数据懒加载,所以我直接用php匹配我需要的数据。其中,我将两者的封面图片下载到本地,本地upimg主要需要权限,否则创建日期目录可能会失败。还有一点是我唯一索引了source_url的mysql字段,也就是目标URL,这样每天定时运行两个脚本,可以抓到最新的数据,不会抓到重复的数据。
php如何抓取网页内容(php如何抓取网页内容?1.首先要手动使用for循环for(i=0;i))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-20 21:06
<p>php如何抓取网页内容?1.首先要手动使用for循环for(i=0;i
php如何抓取网页内容(php如何抓取网页内容?1.首先要手动使用for循环for(i=0;i))
<p>php如何抓取网页内容?1.首先要手动使用for循环for(i=0;i
php如何抓取网页内容(php如何抓取网页内容?建议用phpwechat协议的爬虫,真实的机器人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-16 06:06
php如何抓取网页内容?建议用phpwechat协议的爬虫,真实的机器人。抓包工具自己windows上有prequest.exe和prequest.language.none。linux上推荐curl,google的。这些爬虫都需要加密的,去各大爬虫吧学习下基础知识。
昨天是phpwanchat的phphutto---昨天phphutto|apigenerator昨天今天是phphutto没有云,
0.选择你要抓取的页面,在phpwind上爬虫提供的服务器下抓包,看看可抓取的数据文件。请求分析xmlhttprequest抓取数据functionisprequest(page_info){returnxmlhttprequest().newvisible();}functionprequest(){returnisprequest();}functiongetinfo(){returnxmlhttprequest().get(page_info);}functionnotify(obj){returnxmlhttprequest().notify(obj);}functionnotifyall(obj){returnxmlhttprequest().notifyall();}functionnotify(obj){returnxmlhttprequest().notifyall();}functionnotify(obj){returnxmlhttprequest().notifyall();}functionworker(url,data){returnxmlhttprequest().notifyall();}functionfindread(url,data){returnxmlhttprequest().notifyall();}functionreplyrequest(url,data){if(url===""){returnxmlhttprequest().notifyall();}else{xmlhttprequest().write(data);}}functionparse(url,data){console.log(data);}functionwritegenerated(url,data){if(url===""){returnxmlhttprequest().write(data);}else{xmlhttprequest().write(data);}}functionsaveuser(url,data){returnxmlhttprequest().save(url);}functiondone(url){returnxmlhttprequest().done(url);}1.phpwechat的抓包2.我记得有人说还可以用httpclient框架,按照这个来吧process-socketapiextension-chrome-nightly/。 查看全部
php如何抓取网页内容(php如何抓取网页内容?建议用phpwechat协议的爬虫,真实的机器人)
php如何抓取网页内容?建议用phpwechat协议的爬虫,真实的机器人。抓包工具自己windows上有prequest.exe和prequest.language.none。linux上推荐curl,google的。这些爬虫都需要加密的,去各大爬虫吧学习下基础知识。
昨天是phpwanchat的phphutto---昨天phphutto|apigenerator昨天今天是phphutto没有云,
0.选择你要抓取的页面,在phpwind上爬虫提供的服务器下抓包,看看可抓取的数据文件。请求分析xmlhttprequest抓取数据functionisprequest(page_info){returnxmlhttprequest().newvisible();}functionprequest(){returnisprequest();}functiongetinfo(){returnxmlhttprequest().get(page_info);}functionnotify(obj){returnxmlhttprequest().notify(obj);}functionnotifyall(obj){returnxmlhttprequest().notifyall();}functionnotify(obj){returnxmlhttprequest().notifyall();}functionnotify(obj){returnxmlhttprequest().notifyall();}functionworker(url,data){returnxmlhttprequest().notifyall();}functionfindread(url,data){returnxmlhttprequest().notifyall();}functionreplyrequest(url,data){if(url===""){returnxmlhttprequest().notifyall();}else{xmlhttprequest().write(data);}}functionparse(url,data){console.log(data);}functionwritegenerated(url,data){if(url===""){returnxmlhttprequest().write(data);}else{xmlhttprequest().write(data);}}functionsaveuser(url,data){returnxmlhttprequest().save(url);}functiondone(url){returnxmlhttprequest().done(url);}1.phpwechat的抓包2.我记得有人说还可以用httpclient框架,按照这个来吧process-socketapiextension-chrome-nightly/。
php如何抓取网页内容(文章目录从网站中提取数据主要有两种方式:本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-14 14:03
文章内容
如何使用 BeautifulSoup 抓取网页
从网站中提取数据主要有两种方式:
本文知乎博客为大家介绍如何使用BeautifulSoup爬取网页的步骤。
使用 BeautifulSoup 抓取网页
使用BeautifulSoup爬取一个网页的内容,首先是向你要访问的网页的URL发送一个HTTP请求。服务器通过返回网页的 HTML 内容来响应请求。对于此任务,我们将使用第三方 HTTP 库来处理 Python 请求。
一旦我们访问了 HTML 内容,我们就剩下解析数据的任务,并且需要一个可以创建 HTML 数据的嵌套/树结构的解析器。然后,所有需要做的就是导航和搜索我们创建的解析树,即树遍历。对于此任务,我们将使用另一个第三方 Python 库 Beautiful Soup。它是一个用于从 HTML 和 XML 文件中提取数据的 Python 库。
1、安装需要的第三方库
pip install requests
pip install html5lib
pip install bs4
2、从网页访问 HTML 内容
import requests
URL = "https://www.pythonthree.com/py ... ot%3B
r = requests.get(URL)
print(r.content)
让我们试着理解这段代码。
3、解析HTML内容
import requests
from bs4 import BeautifulSoup
URL = "https://www.pythonthree.com/py ... ot%3B
r = requests.get(URL)
soup = BeautifulSoup(r.content, 'html5lib')
print(soup.prettify())
BeautifulSoup 库的一个真正好处是它建立在 HTML 解析库(例如 html5lib、lxml、html.parser 等)之上。因此,可以同时创建一个 BeautifulSoup 对象并指定一个解析器库。
在上面的例子中,
soup = BeautifulSoup(r.content, 'html5lib')
我们通过传递两个参数来创建一个 BeautifulSoup 对象:
现在打印soup.prettify(),它给出了从原创HTML 内容创建的解析树的可视化表示。
4、搜索导航解析树
现在,我们要从 HTML 内容中提取一些有用的数据。汤对象收录可以通过编程方式提取的嵌套结构中的所有数据。在我们的示例中,我们正在抓取收录一些引号的网页。因此,我们想创建一个程序来保存这些报价(以及所有关于它们的相关信息)。
在继续之前,我们建议您浏览我们使用soup.prettify() 方法打印的网页的HTML 内容,并尝试找到导航到引号的模式或方法。
总结
以上是关于如何使用BeautifulSoup抓取网页内容。如果您发现任何不正确的内容,或者您想分享有关上述主题的更多信息,请发表评论。这是一个如何用 Python 创建网络爬虫的简单示例。从这里,您可以尝试丢弃您选择的任何其他 网站。
推荐:零基础如何开始学习Python
推荐:美汤教程
评价 文章
知乎博客,版权所有丨如未注明,均为原创
知乎博客 »如何使用BeautifulSoup抓取网页 查看全部
php如何抓取网页内容(文章目录从网站中提取数据主要有两种方式:本文)
文章内容
如何使用 BeautifulSoup 抓取网页
从网站中提取数据主要有两种方式:
本文知乎博客为大家介绍如何使用BeautifulSoup爬取网页的步骤。
使用 BeautifulSoup 抓取网页
使用BeautifulSoup爬取一个网页的内容,首先是向你要访问的网页的URL发送一个HTTP请求。服务器通过返回网页的 HTML 内容来响应请求。对于此任务,我们将使用第三方 HTTP 库来处理 Python 请求。
一旦我们访问了 HTML 内容,我们就剩下解析数据的任务,并且需要一个可以创建 HTML 数据的嵌套/树结构的解析器。然后,所有需要做的就是导航和搜索我们创建的解析树,即树遍历。对于此任务,我们将使用另一个第三方 Python 库 Beautiful Soup。它是一个用于从 HTML 和 XML 文件中提取数据的 Python 库。
1、安装需要的第三方库
pip install requests
pip install html5lib
pip install bs4
2、从网页访问 HTML 内容
import requests
URL = "https://www.pythonthree.com/py ... ot%3B
r = requests.get(URL)
print(r.content)
让我们试着理解这段代码。
3、解析HTML内容
import requests
from bs4 import BeautifulSoup
URL = "https://www.pythonthree.com/py ... ot%3B
r = requests.get(URL)
soup = BeautifulSoup(r.content, 'html5lib')
print(soup.prettify())
BeautifulSoup 库的一个真正好处是它建立在 HTML 解析库(例如 html5lib、lxml、html.parser 等)之上。因此,可以同时创建一个 BeautifulSoup 对象并指定一个解析器库。
在上面的例子中,
soup = BeautifulSoup(r.content, 'html5lib')
我们通过传递两个参数来创建一个 BeautifulSoup 对象:
现在打印soup.prettify(),它给出了从原创HTML 内容创建的解析树的可视化表示。
4、搜索导航解析树
现在,我们要从 HTML 内容中提取一些有用的数据。汤对象收录可以通过编程方式提取的嵌套结构中的所有数据。在我们的示例中,我们正在抓取收录一些引号的网页。因此,我们想创建一个程序来保存这些报价(以及所有关于它们的相关信息)。
在继续之前,我们建议您浏览我们使用soup.prettify() 方法打印的网页的HTML 内容,并尝试找到导航到引号的模式或方法。
总结
以上是关于如何使用BeautifulSoup抓取网页内容。如果您发现任何不正确的内容,或者您想分享有关上述主题的更多信息,请发表评论。这是一个如何用 Python 创建网络爬虫的简单示例。从这里,您可以尝试丢弃您选择的任何其他 网站。
推荐:零基础如何开始学习Python
推荐:美汤教程
评价 文章
知乎博客,版权所有丨如未注明,均为原创
知乎博客 »如何使用BeautifulSoup抓取网页
php如何抓取网页内容(php如何抓取网页内容,这里有详细教程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-04 14:01
php如何抓取网页内容,这里有详细教程。《黑客与画家》中提到“浏览器”的定义:是将用户经常发送的请求传送给服务器处理。想要真正掌握程序编程实战,首先要对浏览器了解。目前一般桌面浏览器如ie、遨游、360、搜狗等用javascript去完成对整个web站点的检索,而ie的内核就是在浏览器内部完成,像chrome就是一款基于webkit内核的浏览器,chrome所谓的自带浏览器本质上是没有javascript功能的。
ie也将会继续尝试各种javascript支持(css和htmlswf转换)等方面的提升。而基于webkit内核的浏览器在它们得到越来越好的设计后,javascript嵌入也将变得越来越容易,应用和功能就将变得越来越丰富,也将越来越流行。下面将基于以上知识以php为例详细讲解一下一般需要掌握的程序编程基础知识。
掌握浏览器的基本概念我们目前所了解到的都是这个时代浏览器的基本运行机制,简单而言,它就是一个文档传递工具,能从ie浏览器上读取文件,然后进行文件的读写操作。与c语言不同,c语言与浏览器交互是通过document对象,使用file函数来接收文件的详细信息(这些文件包括读取的rom和cpu等信息)。浏览器在处理rom信息时,会根据rom上记录的位置指定所需的rom,然后将rom信息传递给文件操作。
其他与浏览器交互的地方还有如图所示的一些接口,如output接口、response接口等。现在浏览器几乎可以全面地读取和处理任何资源,如rom文件,htmlswf、css、javascript、图片等等。这些接口共同构成了一个完整的web服务器,能给用户提供最佳的体验和最大的效率。掌握常用的接口说完浏览器的基本概念,接下来我们再来了解一下浏览器的常用接口,这些接口提供给用户最常用的功能。
比如如果我们需要读取本地文件,例如打开“华为浏览器”网页地址:/www/huawei/mp3,那么该如何操作呢?我们需要了解一下两个接口:output和response。output接口:这个接口直接将所有的文件一一相连,文件名、文件大小、文件名、文件信息等等,一一传递给服务器,服务器再根据这些文件返回给用户。
utf-8、乱码等问题都会得到解决。response接口:这个接口要求浏览器每秒传递完整的html信息,浏览器等待服务器返回完整的html,浏览器一直处于响应状态,如果还有疑问,可以查看output接口。ie浏览器虽然是基于webkit内核,但是还是有一些c++代码。读取文件这一步还是经过了很多代码的加工,这一步也是浏览器抓取下来的主要内容来源,所以知道一些基本的常用接口是关键。下面将主要说。 查看全部
php如何抓取网页内容(php如何抓取网页内容,这里有详细教程(图))
php如何抓取网页内容,这里有详细教程。《黑客与画家》中提到“浏览器”的定义:是将用户经常发送的请求传送给服务器处理。想要真正掌握程序编程实战,首先要对浏览器了解。目前一般桌面浏览器如ie、遨游、360、搜狗等用javascript去完成对整个web站点的检索,而ie的内核就是在浏览器内部完成,像chrome就是一款基于webkit内核的浏览器,chrome所谓的自带浏览器本质上是没有javascript功能的。
ie也将会继续尝试各种javascript支持(css和htmlswf转换)等方面的提升。而基于webkit内核的浏览器在它们得到越来越好的设计后,javascript嵌入也将变得越来越容易,应用和功能就将变得越来越丰富,也将越来越流行。下面将基于以上知识以php为例详细讲解一下一般需要掌握的程序编程基础知识。
掌握浏览器的基本概念我们目前所了解到的都是这个时代浏览器的基本运行机制,简单而言,它就是一个文档传递工具,能从ie浏览器上读取文件,然后进行文件的读写操作。与c语言不同,c语言与浏览器交互是通过document对象,使用file函数来接收文件的详细信息(这些文件包括读取的rom和cpu等信息)。浏览器在处理rom信息时,会根据rom上记录的位置指定所需的rom,然后将rom信息传递给文件操作。
其他与浏览器交互的地方还有如图所示的一些接口,如output接口、response接口等。现在浏览器几乎可以全面地读取和处理任何资源,如rom文件,htmlswf、css、javascript、图片等等。这些接口共同构成了一个完整的web服务器,能给用户提供最佳的体验和最大的效率。掌握常用的接口说完浏览器的基本概念,接下来我们再来了解一下浏览器的常用接口,这些接口提供给用户最常用的功能。
比如如果我们需要读取本地文件,例如打开“华为浏览器”网页地址:/www/huawei/mp3,那么该如何操作呢?我们需要了解一下两个接口:output和response。output接口:这个接口直接将所有的文件一一相连,文件名、文件大小、文件名、文件信息等等,一一传递给服务器,服务器再根据这些文件返回给用户。
utf-8、乱码等问题都会得到解决。response接口:这个接口要求浏览器每秒传递完整的html信息,浏览器等待服务器返回完整的html,浏览器一直处于响应状态,如果还有疑问,可以查看output接口。ie浏览器虽然是基于webkit内核,但是还是有一些c++代码。读取文件这一步还是经过了很多代码的加工,这一步也是浏览器抓取下来的主要内容来源,所以知道一些基本的常用接口是关键。下面将主要说。
php如何抓取网页内容(php如何抓取网页内容php提供了很多快速、方便的http请求方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-04 07:01
php如何抓取网页内容php提供了很多快速、方便的http请求方法,可以使用scrapy、laravel等框架开发网页爬虫,不过相对于python来说要复杂一些,今天我们尝试着以一个简单的web爬虫为例子,来抓取b站相关视频。我们可以使用scrapy、laravel、python本身的requests库进行爬虫,scrapy是包含了数据的http服务器,laravel是python程序员使用最多的框架。
我们先新建爬虫的项目。pythonmanage.pymakemigrations使用makemigrations命令来编译python脚本,这里会生成一个python文件,我们利用pythoninit.py项目结构图来看一下当初使用pythoninit.py进行配置的时候,安装的三个常用库,yml(yaml)、python、git,安装和初始化的方法在文章尾部。
创建爬虫,需要对数据进行加密。pythonpool.py把静态文件保存到同一个集群目录下pythonscrapy_pool.py还要在scrapy_pool.py中配置被捕获的情况,也可以在配置文件crawling_simple_task中指定,我们这里配置是post()函数。pythonscrapy_spider.py需要把被主动获取的url添加到request中pythonscrapy_request.py实例化scrapy的爬虫爬虫程序中的常用函数:start_url、start_request、default_url、split_url、excluded_url、urllib2.urllib2对urllib2的高级封装pythonhttp_request.py接受urllib2模块的输入request.py接受urllib2模块的输出request.setrequestheader("authorization","status","0")template_protocol="http://%26quot%3Bauthorization ... pener(template_protocol)asrequest:ifrequest.get(urllib2.urlopen(request))andrequest.read()==str(request.request(urllib2.urlopen(request),stream_protocol="python.io.protocol")):request.send_header("user-agent","mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/42.0.2523.110safari/537.36")request.send_header("proxy","server=/")start_url=start_request;default_url=start_requestrequest.start(start_url)request.send(urllib2.request(urllib2.urlopen(request),stream_protoco。 查看全部
php如何抓取网页内容(php如何抓取网页内容php提供了很多快速、方便的http请求方法)
php如何抓取网页内容php提供了很多快速、方便的http请求方法,可以使用scrapy、laravel等框架开发网页爬虫,不过相对于python来说要复杂一些,今天我们尝试着以一个简单的web爬虫为例子,来抓取b站相关视频。我们可以使用scrapy、laravel、python本身的requests库进行爬虫,scrapy是包含了数据的http服务器,laravel是python程序员使用最多的框架。
我们先新建爬虫的项目。pythonmanage.pymakemigrations使用makemigrations命令来编译python脚本,这里会生成一个python文件,我们利用pythoninit.py项目结构图来看一下当初使用pythoninit.py进行配置的时候,安装的三个常用库,yml(yaml)、python、git,安装和初始化的方法在文章尾部。
创建爬虫,需要对数据进行加密。pythonpool.py把静态文件保存到同一个集群目录下pythonscrapy_pool.py还要在scrapy_pool.py中配置被捕获的情况,也可以在配置文件crawling_simple_task中指定,我们这里配置是post()函数。pythonscrapy_spider.py需要把被主动获取的url添加到request中pythonscrapy_request.py实例化scrapy的爬虫爬虫程序中的常用函数:start_url、start_request、default_url、split_url、excluded_url、urllib2.urllib2对urllib2的高级封装pythonhttp_request.py接受urllib2模块的输入request.py接受urllib2模块的输出request.setrequestheader("authorization","status","0")template_protocol="http://%26quot%3Bauthorization ... pener(template_protocol)asrequest:ifrequest.get(urllib2.urlopen(request))andrequest.read()==str(request.request(urllib2.urlopen(request),stream_protocol="python.io.protocol")):request.send_header("user-agent","mozilla/5.0(windowsnt10.0;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/42.0.2523.110safari/537.36")request.send_header("proxy","server=/")start_url=start_request;default_url=start_requestrequest.start(start_url)request.send(urllib2.request(urllib2.urlopen(request),stream_protoco。
php如何抓取网页内容(怎么查看php论坛隐藏的付费内容-:隐藏只是针对所见)
网站优化 • 优采云 发表了文章 • 0 个评论 • 1381 次浏览 • 2021-12-03 23:15
可以找到id="book_pic",是否有调用加载JS。浏览器的开发工具可能有一定的完善功能,部分内容是自动生成的。
如何查看网页隐藏内容-:您可以通过网页代码查看隐藏内容。查看方法:打开要查看的网页,点击浏览器“查看”-“源码”。就是这样。
如何获取网页源代码中隐藏的内容:文件->另存为->选择全部保存,然后就可以看到你想看的了
如何查看php论坛隐藏付费内容-:隐藏只是你看到的,查看源码时不会隐藏。当然,爬取的方法还是正常的正规方法。
如何查看网页的隐藏内容-:要显示网页的隐藏内容,您需要知道它是如何隐藏的。有无数种方法可以隐藏网页上的内容。这里有几个: 颜色、文字颜色和背景颜色 设置是一样的,比如白色。所以文本内容是不可见的。css的display属性,设置要隐藏的内容元素的css属性为display:none;它是隐藏的。Position,设置要隐藏的元素的位置在网页的可见范围内就可以隐藏在外面。方法比较多,比如用js... 楼主需要先了解隐藏方法,然后对症下药!...
如何查看隐藏在网页中的部分数字的源代码-:右键单击>查看页面源代码
“查看隐藏内容需要付费”如何付费?-:“查看隐藏内容需要付费,可以直接查看(每天有1次免费查看机会)”仅以上内容在右侧。不,“直接查看”下有一个下划线可以点击,没有别的!我完全看不到
相关链接: 查看全部
php如何抓取网页内容(怎么查看php论坛隐藏的付费内容-:隐藏只是针对所见)
可以找到id="book_pic",是否有调用加载JS。浏览器的开发工具可能有一定的完善功能,部分内容是自动生成的。
如何查看网页隐藏内容-:您可以通过网页代码查看隐藏内容。查看方法:打开要查看的网页,点击浏览器“查看”-“源码”。就是这样。
如何获取网页源代码中隐藏的内容:文件->另存为->选择全部保存,然后就可以看到你想看的了
如何查看php论坛隐藏付费内容-:隐藏只是你看到的,查看源码时不会隐藏。当然,爬取的方法还是正常的正规方法。
如何查看网页的隐藏内容-:要显示网页的隐藏内容,您需要知道它是如何隐藏的。有无数种方法可以隐藏网页上的内容。这里有几个: 颜色、文字颜色和背景颜色 设置是一样的,比如白色。所以文本内容是不可见的。css的display属性,设置要隐藏的内容元素的css属性为display:none;它是隐藏的。Position,设置要隐藏的元素的位置在网页的可见范围内就可以隐藏在外面。方法比较多,比如用js... 楼主需要先了解隐藏方法,然后对症下药!...
如何查看隐藏在网页中的部分数字的源代码-:右键单击>查看页面源代码
“查看隐藏内容需要付费”如何付费?-:“查看隐藏内容需要付费,可以直接查看(每天有1次免费查看机会)”仅以上内容在右侧。不,“直接查看”下有一个下划线可以点击,没有别的!我完全看不到
相关链接:
php如何抓取网页内容( Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-24 19:03
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
php爬取网页内容的详细例子
时间:2019-03-31
本文章为大家介绍了php爬取网页内容的详细示例,主要包括php爬取网页内容的详细示例、使用示例、应用技巧、基础知识点总结和注意事项,具有一定的参考价值,有需要的朋友可以参考一下。
php爬取网页内容的详细例子
方法一:
使用file_get_contents方法实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
代码很简单,一看就懂,我就不解释了。
方法二:
使用 curl 来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加这段代码的意思是,如果请求被重定向,就可以访问到最终的请求页面,否则请求的结果会显示如下内容:
Object moved
Object MovedThis object may be found here.
如有问题,请留言或到本站社区讨论,感谢阅读,希望对大家有所帮助,感谢您对本站的支持! 查看全部
php如何抓取网页内容(
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
php爬取网页内容的详细例子
时间:2019-03-31
本文章为大家介绍了php爬取网页内容的详细示例,主要包括php爬取网页内容的详细示例、使用示例、应用技巧、基础知识点总结和注意事项,具有一定的参考价值,有需要的朋友可以参考一下。
php爬取网页内容的详细例子
方法一:
使用file_get_contents方法实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
代码很简单,一看就懂,我就不解释了。
方法二:
使用 curl 来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加这段代码的意思是,如果请求被重定向,就可以访问到最终的请求页面,否则请求的结果会显示如下内容:
Object moved
Object MovedThis object may be found here.
如有问题,请留言或到本站社区讨论,感谢阅读,希望对大家有所帮助,感谢您对本站的支持!
php如何抓取网页内容(热门关键词做SEO的“关键词爆破法”(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-12 13:03
1、 搜索引擎为用户显示的每一个搜索结果都对应互联网上的一个页面。每个搜索结果从生成到被搜索引擎展示给用户,都需要经过四个过程:抓取、过滤、索引和输出结果。2、 百度蜘蛛会通过搜索引擎系统的计算来决定抓取哪个网站,以及抓取的内容和频率。当您的网站产生新内容时,百度蜘蛛会通过链接访问并抓取互联网上的页面。如果您没有设置任何外部链接指向网站中的新内容,百度蜘蛛将无法对其进行抓取。对于已经爬取的内容,搜索引擎会记录抓取到的页面,并根据这些页面对用户的重要性,安排不同频率的抓取和更新工作。3、明显的作弊行为有哪些?①出售主页上的友情链接。②很多采集其他网站。. . . . . . . . . . . . . . 22、用流行的关键词做SEO“关键词爆破法”,短期可能有好处,但长期不利于主动发展用户,这可能会影响搜索引擎对网站的排名。23、如果链接在变成死链接之前已经被百度搜索引擎屏蔽了收录,请不要在设置404后设置robots来屏蔽,否则会影响搜索引擎对链接的判断和处理。24、网站ip变了怎么办?登录百度站长平台,使用爬虫诊断工具。抓取诊断工具会检查网站与百度的连接是否畅通。如果站长发现IP信息仍然陈旧,可以通过“错误报告”通知百度搜索引擎更新IP。由于蜘蛛的能量有限,如果报错后网站IP保持不变,站长可以多次尝试,直到达到预期。25、爬虫诊断工具能做什么?① 诊断捕获的内容是否符合预期。例如,在许多产品详细信息页面中,价格信息通过JavaScript输出,对百度蜘蛛不友好,价格信息在搜索中应用难度较大。问题解决后,可使用诊断工具再次检查。②判断网页是否添加了黑色链接和隐藏文字。网站 被黑客入侵后添加的隐藏链接,从网页表面是无法观察到的。这些链接可能只有在百度抓取时才会出现,可以通过抓取诊断工具进行检查。③邀请百度蜘蛛。如果网站有新页面或者页面内容更新了,但是百度蜘蛛很久没来了,可以通过爬虫诊断工具邀请百度蜘蛛快速爬取。26、 多个域相同内容的常见问题。 查看全部
php如何抓取网页内容(热门关键词做SEO的“关键词爆破法”(一))
1、 搜索引擎为用户显示的每一个搜索结果都对应互联网上的一个页面。每个搜索结果从生成到被搜索引擎展示给用户,都需要经过四个过程:抓取、过滤、索引和输出结果。2、 百度蜘蛛会通过搜索引擎系统的计算来决定抓取哪个网站,以及抓取的内容和频率。当您的网站产生新内容时,百度蜘蛛会通过链接访问并抓取互联网上的页面。如果您没有设置任何外部链接指向网站中的新内容,百度蜘蛛将无法对其进行抓取。对于已经爬取的内容,搜索引擎会记录抓取到的页面,并根据这些页面对用户的重要性,安排不同频率的抓取和更新工作。3、明显的作弊行为有哪些?①出售主页上的友情链接。②很多采集其他网站。. . . . . . . . . . . . . . 22、用流行的关键词做SEO“关键词爆破法”,短期可能有好处,但长期不利于主动发展用户,这可能会影响搜索引擎对网站的排名。23、如果链接在变成死链接之前已经被百度搜索引擎屏蔽了收录,请不要在设置404后设置robots来屏蔽,否则会影响搜索引擎对链接的判断和处理。24、网站ip变了怎么办?登录百度站长平台,使用爬虫诊断工具。抓取诊断工具会检查网站与百度的连接是否畅通。如果站长发现IP信息仍然陈旧,可以通过“错误报告”通知百度搜索引擎更新IP。由于蜘蛛的能量有限,如果报错后网站IP保持不变,站长可以多次尝试,直到达到预期。25、爬虫诊断工具能做什么?① 诊断捕获的内容是否符合预期。例如,在许多产品详细信息页面中,价格信息通过JavaScript输出,对百度蜘蛛不友好,价格信息在搜索中应用难度较大。问题解决后,可使用诊断工具再次检查。②判断网页是否添加了黑色链接和隐藏文字。网站 被黑客入侵后添加的隐藏链接,从网页表面是无法观察到的。这些链接可能只有在百度抓取时才会出现,可以通过抓取诊断工具进行检查。③邀请百度蜘蛛。如果网站有新页面或者页面内容更新了,但是百度蜘蛛很久没来了,可以通过爬虫诊断工具邀请百度蜘蛛快速爬取。26、 多个域相同内容的常见问题。
php如何抓取网页内容(百度搜索引擎网站设置的协议对一个网站的抓取频次的影响)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-04 12:25
蜘蛛爬取系统包括链接存储系统、链接选择系统、dns分析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。
百度蜘蛛根据上面网站设置的协议抓取站点页面,但不可能对所有站点一视同仁。它会综合考虑网站的实际情况,确定一个抓取额度,每天对网站内容进行定量抓取,也就是我们常说的抓取频率。
那么百度搜索引擎是用什么指标来判断爬取一个网站的频率的。主要有四个指标:
1、网站更新频率
更新来得快,更新来得慢,直接影响百度蜘蛛的访问频率;
2、网站更新质量
更新频率增加了,这才引起了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果百度蜘蛛每天更新的大量内容被判定为低质量页面,仍然没有意义;
3、连通性
网站应该是安全稳定的,对百度蜘蛛保持开放。经常养百度蜘蛛可不是什么好事;
4、网站评价
百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。是百度搜索引擎对网站的基本评分(不是外界所说的百度权重),是百度内部非常保密的。数据。网站评分从不单独使用,会与其他因素和阈值共同影响网站的爬取和排名。
百度蜘蛛抓取的页面数量并不是最重要的。重要的是一个索引库建了多少页,也就是我们常说的“建库”。
众所周知,搜索引擎的索引库是分层的。优质的网页会被分配到重要的索引库,普通的网页会留在普通的图书馆,更糟糕的网页会被分配到低级别的图书馆作为补充资料。
目前60%的检索需求只调用重要的索引库就可以满足,这就解释了为什么有些网站的收录量超高,但流量并不理想。
哪些网页可以进入优质索引库?
其实总的原则是一个:对用户有价值。
包括但不仅限于:
1、时间敏感和有价值的页面
在这里,及时性和价值是平行关系,两者缺一不可。有的网站为了生成时间敏感的内容页面,做了很多采集的工作,结果产生了一堆百度不想看到的毫无价值的页面;
2、高质量内容的专题页面
专页的内容可能不完全原创,即可以很好的整合各方内容,或者添加一些新鲜的内容,比如意见、评论,给用户更全面的内容;
3、高价值原创内容页
百度将原创定义为文章花费一定的成本和大量的经验后形成的。不要问我们伪原创是不是原创;
4、重要的个人页面
这里只是一个例子。科比已经在新浪微博上开设了账号,需要不经常更新,但对于百度来说,它仍然是一个极其重要的页面。
哪些页面不能建索引库
上述优质网页均收录在索引库中。其实网上的大部分网站根本就不是百度的收录。不是百度没找到,而是建库前的筛选链接被过滤掉了。那么一开始被过滤掉了什么样的网页:
1、 重复内容的网页:百度无需收录 任何已经在互联网上的内容。
2、主要内容短而空的网页
2.1、 部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户访问时可以看到丰富的内容,但还是会被搜索引擎抛弃
2.2、 加载过慢的网页也可能被视为空的短页面。请注意,广告加载时间收录在网页的整体加载时间中。
2.3、很多主题不显眼的网页,即使爬回来也会被丢弃在这个链接里。
3、一些作弊页面 查看全部
php如何抓取网页内容(百度搜索引擎网站设置的协议对一个网站的抓取频次的影响)
蜘蛛爬取系统包括链接存储系统、链接选择系统、dns分析服务系统、爬取调度系统、网页分析系统、链接提取系统、链接分析系统、网页存储系统。
百度蜘蛛根据上面网站设置的协议抓取站点页面,但不可能对所有站点一视同仁。它会综合考虑网站的实际情况,确定一个抓取额度,每天对网站内容进行定量抓取,也就是我们常说的抓取频率。
那么百度搜索引擎是用什么指标来判断爬取一个网站的频率的。主要有四个指标:
1、网站更新频率
更新来得快,更新来得慢,直接影响百度蜘蛛的访问频率;
2、网站更新质量
更新频率增加了,这才引起了百度蜘蛛的注意。百度蜘蛛对质量有严格的要求。如果百度蜘蛛每天更新的大量内容被判定为低质量页面,仍然没有意义;
3、连通性
网站应该是安全稳定的,对百度蜘蛛保持开放。经常养百度蜘蛛可不是什么好事;
4、网站评价
百度搜索引擎会对每个站点都有一个评价,这个评价会根据站点情况不断变化。是百度搜索引擎对网站的基本评分(不是外界所说的百度权重),是百度内部非常保密的。数据。网站评分从不单独使用,会与其他因素和阈值共同影响网站的爬取和排名。
百度蜘蛛抓取的页面数量并不是最重要的。重要的是一个索引库建了多少页,也就是我们常说的“建库”。
众所周知,搜索引擎的索引库是分层的。优质的网页会被分配到重要的索引库,普通的网页会留在普通的图书馆,更糟糕的网页会被分配到低级别的图书馆作为补充资料。
目前60%的检索需求只调用重要的索引库就可以满足,这就解释了为什么有些网站的收录量超高,但流量并不理想。
哪些网页可以进入优质索引库?
其实总的原则是一个:对用户有价值。
包括但不仅限于:
1、时间敏感和有价值的页面
在这里,及时性和价值是平行关系,两者缺一不可。有的网站为了生成时间敏感的内容页面,做了很多采集的工作,结果产生了一堆百度不想看到的毫无价值的页面;
2、高质量内容的专题页面
专页的内容可能不完全原创,即可以很好的整合各方内容,或者添加一些新鲜的内容,比如意见、评论,给用户更全面的内容;
3、高价值原创内容页
百度将原创定义为文章花费一定的成本和大量的经验后形成的。不要问我们伪原创是不是原创;
4、重要的个人页面
这里只是一个例子。科比已经在新浪微博上开设了账号,需要不经常更新,但对于百度来说,它仍然是一个极其重要的页面。
哪些页面不能建索引库
上述优质网页均收录在索引库中。其实网上的大部分网站根本就不是百度的收录。不是百度没找到,而是建库前的筛选链接被过滤掉了。那么一开始被过滤掉了什么样的网页:
1、 重复内容的网页:百度无需收录 任何已经在互联网上的内容。
2、主要内容短而空的网页
2.1、 部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX等,虽然用户访问时可以看到丰富的内容,但还是会被搜索引擎抛弃
2.2、 加载过慢的网页也可能被视为空的短页面。请注意,广告加载时间收录在网页的整体加载时间中。
2.3、很多主题不显眼的网页,即使爬回来也会被丢弃在这个链接里。
3、一些作弊页面
php如何抓取网页内容(优采云采集器免费网络爬虫软件_网页大数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-26 17:22
优采云采集器免费网络爬虫软件_网络大数据爬虫工具。
阿里云为您提供8933产品文档内容和网站内容爬取工具相关FAQ,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文, key 值存储kvstore,以下哪个是数据库,以及其他云计算产品。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到自己的网站,让自己的网站的内容打开。
极手客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,进行内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析、情感分析软件于研究生设计和行业研究。
优采云·云采集服务平台网站如何使用内容爬虫工具网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值?
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
当你打开目标文件夹tptl时,你会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。网。
网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员... 查看全部
php如何抓取网页内容(优采云采集器免费网络爬虫软件_网页大数据抓取工具)
优采云采集器免费网络爬虫软件_网络大数据爬虫工具。
阿里云为您提供8933产品文档内容和网站内容爬取工具相关FAQ,以及路由网站打不开网页怎么办,计算机网络技术学院毕业论文, key 值存储kvstore,以下哪个是数据库,以及其他云计算产品。
Content crawling-content 可以从 网站 爬取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到自己的网站,让自己的网站的内容打开。
极手客网络爬虫软件是一款免费的网络数据爬取工具,可将网络内容转化为excel表格,进行内容分析、文本分析、策略分析和文档分析。自动分词、社交网络分析、情感分析软件于研究生设计和行业研究。
优采云·云采集服务平台网站如何使用内容爬虫工具网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值?
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
当你打开目标文件夹tptl时,你会得到网站图片或内容的完整数据,html文件、php文件和JavaScript都存储在里面。网。
网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员...
php如何抓取网页内容(【·简介】怎么做吗?答案这是一个1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-24 20:03
栏目:类库·
介绍本文文章主要介绍如何只显示部分网页内容(swift)(示例代码)及相关经验技巧。文章约3904字,浏览量426,点赞1,值得参考。!
我是编码新手(根本没有编程语言背景)。我正在努力学习。我想创建一个简单的天气应用程序,一旦用户进入城市,天气信息就会显示在文本中。我从中获取内容。我已经知道如何加载 Web 内容,但我只想显示页面内容的一个片段(一段),而不是整个页面。有人可以告诉我该怎么做吗?
{
import UIKit
class ViewController: UIViewController, UIWebViewDelegate {
@IBOutlet weak var cityText: UITextField!
@IBOutlet weak var webContent: UIWebView!
@IBAction func GoButtonPressed(sender: AnyObject) {
let url = NSURL (string: "http://www.weather-forecast.com");
let requestObj = NSURLRequest(URL: url!);
webContent.loadRequest(requestObj);
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
}
回答
这是一个简单的视图控制器的例子,它只加载了 网站 的一部分。控制器有一个方法来选择一个 DOM 元素并只显示该元素。它非常简单,但功能强大,足以说明如何进一步开展这项工作。
import UIKit
import JavaScriptCore
import WebKit
class TestViewController: UIViewController {
private weak var webView: WKWebView!
private var userContentController: WKUserContentController!
override func viewDidLoad() {
super.viewDidLoad()
createViews()
loadPage("https://dribbble.com/", partialContentQuerySelector: ".dribbbles.group")
}
private func createViews() {
userContentController = WKUserContentController()
let configuration = WKWebViewConfiguration()
configuration.userContentController = userContentController
let webView = WKWebView(frame: view.bounds, configuration: configuration)
webView.setTranslatesAutoresizingMaskIntoConstraints(false)
view.addSubview(webView)
let views: [String: AnyObject] = ["webView": webView, "topLayoutGuide": topLayoutGuide]
view.addConstraints(NSLayoutConstraint.constraintsWithVisualFormat("V:|[topLayoutGuide][webView]|", options: .allZeros, metrics: nil, views: views))
view.addConstraints(NSLayoutConstraint.constraintsWithVisualFormat("H:|[topLayoutGuide][webView]|", options: .allZeros, metrics: nil, views: views))
self.webView = webView
}
private func loadPage(urlString: String, partialContentQuerySelector selector: String) {
userContentController.removeAllUserScripts()
let userScript = WKUserScript(source: scriptWithDOMSelector(selector),
injectionTime: WKUserScriptInjectionTime.AtDocumentEnd,
forMainFrameOnly: true)
userContentController.addUserScript(userScript)
let url = NSURL(string: urlString)!
webView.loadRequest(NSURLRequest(URL: url))
}
private func scriptWithDOMSelector(selector: String) -> String {
let script =
"var selectedElement = document.querySelector('(selector)');" +
"document.body.innerHTML = selectedElement.innerHTML;"
return script
}
}
上例中显示的视图控制器只加载照片,在 网站 内运行设计部分。
另一个答案
您将无法轻松做到这一点 - UIWebView 没有任何 API 来公开它正在加载的网页的结构,也没有控制/允许页面的部分加载。
也许你可以抓取页面的内容并显示它,但是你会在将它加载到 UIWebView 之前这样做,并且在你抓取它之后,Web视图可能不是最好的显示它的方式。
进行一些搜索 HTML 和网页抓取以了解该术语的含义。
或者,如果你知道网页内容的结构,你可以在 UIWebView 加载时将 javascript 注入到页面中,javascript 会阻止页面的其他部分在以后显示(但如果你改变了它的 html 的结构)您的 JavaScript 可能不再有效)
无论哪种方式,对于初学者来说,两者似乎都有些过于复杂,但除非您能够快速而称职地掌握它,否则您需要学习很多东西。
另一个答案
您可以在应用程序中安装天气 API,而不是从 网站 获取数据。这可能更快或更容易,因为大多数天气 API 可以选择要显示的信息。
有关如何安装天气 API 的更多信息,请访问此网站。
希望我解决了你的问题,托比 查看全部
php如何抓取网页内容(【·简介】怎么做吗?答案这是一个1)
栏目:类库·
介绍本文文章主要介绍如何只显示部分网页内容(swift)(示例代码)及相关经验技巧。文章约3904字,浏览量426,点赞1,值得参考。!
我是编码新手(根本没有编程语言背景)。我正在努力学习。我想创建一个简单的天气应用程序,一旦用户进入城市,天气信息就会显示在文本中。我从中获取内容。我已经知道如何加载 Web 内容,但我只想显示页面内容的一个片段(一段),而不是整个页面。有人可以告诉我该怎么做吗?
{
import UIKit
class ViewController: UIViewController, UIWebViewDelegate {
@IBOutlet weak var cityText: UITextField!
@IBOutlet weak var webContent: UIWebView!
@IBAction func GoButtonPressed(sender: AnyObject) {
let url = NSURL (string: "http://www.weather-forecast.com";);
let requestObj = NSURLRequest(URL: url!);
webContent.loadRequest(requestObj);
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
}
回答
这是一个简单的视图控制器的例子,它只加载了 网站 的一部分。控制器有一个方法来选择一个 DOM 元素并只显示该元素。它非常简单,但功能强大,足以说明如何进一步开展这项工作。
import UIKit
import JavaScriptCore
import WebKit
class TestViewController: UIViewController {
private weak var webView: WKWebView!
private var userContentController: WKUserContentController!
override func viewDidLoad() {
super.viewDidLoad()
createViews()
loadPage("https://dribbble.com/", partialContentQuerySelector: ".dribbbles.group")
}
private func createViews() {
userContentController = WKUserContentController()
let configuration = WKWebViewConfiguration()
configuration.userContentController = userContentController
let webView = WKWebView(frame: view.bounds, configuration: configuration)
webView.setTranslatesAutoresizingMaskIntoConstraints(false)
view.addSubview(webView)
let views: [String: AnyObject] = ["webView": webView, "topLayoutGuide": topLayoutGuide]
view.addConstraints(NSLayoutConstraint.constraintsWithVisualFormat("V:|[topLayoutGuide][webView]|", options: .allZeros, metrics: nil, views: views))
view.addConstraints(NSLayoutConstraint.constraintsWithVisualFormat("H:|[topLayoutGuide][webView]|", options: .allZeros, metrics: nil, views: views))
self.webView = webView
}
private func loadPage(urlString: String, partialContentQuerySelector selector: String) {
userContentController.removeAllUserScripts()
let userScript = WKUserScript(source: scriptWithDOMSelector(selector),
injectionTime: WKUserScriptInjectionTime.AtDocumentEnd,
forMainFrameOnly: true)
userContentController.addUserScript(userScript)
let url = NSURL(string: urlString)!
webView.loadRequest(NSURLRequest(URL: url))
}
private func scriptWithDOMSelector(selector: String) -> String {
let script =
"var selectedElement = document.querySelector('(selector)');" +
"document.body.innerHTML = selectedElement.innerHTML;"
return script
}
}
上例中显示的视图控制器只加载照片,在 网站 内运行设计部分。
另一个答案
您将无法轻松做到这一点 - UIWebView 没有任何 API 来公开它正在加载的网页的结构,也没有控制/允许页面的部分加载。
也许你可以抓取页面的内容并显示它,但是你会在将它加载到 UIWebView 之前这样做,并且在你抓取它之后,Web视图可能不是最好的显示它的方式。
进行一些搜索 HTML 和网页抓取以了解该术语的含义。
或者,如果你知道网页内容的结构,你可以在 UIWebView 加载时将 javascript 注入到页面中,javascript 会阻止页面的其他部分在以后显示(但如果你改变了它的 html 的结构)您的 JavaScript 可能不再有效)
无论哪种方式,对于初学者来说,两者似乎都有些过于复杂,但除非您能够快速而称职地掌握它,否则您需要学习很多东西。
另一个答案
您可以在应用程序中安装天气 API,而不是从 网站 获取数据。这可能更快或更容易,因为大多数天气 API 可以选择要显示的信息。
有关如何安装天气 API 的更多信息,请访问此网站。
希望我解决了你的问题,托比
php如何抓取网页内容(php抓取网页内容?php如何抓取报表数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2021-10-24 04:01
php如何抓取网页内容?php如何抓取报表数据?php如何抓取国外网站信息?php对于很多企业单位来说都是非常重要的web基础技术之一。同时它也是开发linux桌面操作系统最好的脚本语言。也是同时开发windows系统最好的脚本语言。现在很多知名的网站都是采用php来开发主要是它可以解决许多复杂的前端问题。我们分解一下问题:。
一、php如何抓取网页内容?抓取web上的内容的话,最常用的方法就是通过php代码实现。所以这是php抓取的第一步。
1、要通过php页面上的代码来获取需要的内容,我们可以通过cookie来进行判断,先判断是不是自己的用户或者浏览器。如果是就直接抓取到页面内容。
2、如果不是我们的用户的话,就需要对cookie进行处理。通过采用cookie来记录下来用户的一些基本信息,比如基本的web登录。
3、那如果cookie本身没有权限的话,那就需要通过php代码去判断来获取相应的信息。
你们公司注册了没?
做为一个独立站,
开始1个hosts文件,开发写好index.php引入第一个站就好了,不需要你去搭建网站。大部分地方都是网站地址与你自己的域名绑定,这样就可以访问你网站了。可以尝试把域名加入到后缀名是如什么,看后缀名是不是能解析出你的网站地址。 查看全部
php如何抓取网页内容(php抓取网页内容?php如何抓取报表数据?(图))
php如何抓取网页内容?php如何抓取报表数据?php如何抓取国外网站信息?php对于很多企业单位来说都是非常重要的web基础技术之一。同时它也是开发linux桌面操作系统最好的脚本语言。也是同时开发windows系统最好的脚本语言。现在很多知名的网站都是采用php来开发主要是它可以解决许多复杂的前端问题。我们分解一下问题:。
一、php如何抓取网页内容?抓取web上的内容的话,最常用的方法就是通过php代码实现。所以这是php抓取的第一步。
1、要通过php页面上的代码来获取需要的内容,我们可以通过cookie来进行判断,先判断是不是自己的用户或者浏览器。如果是就直接抓取到页面内容。
2、如果不是我们的用户的话,就需要对cookie进行处理。通过采用cookie来记录下来用户的一些基本信息,比如基本的web登录。
3、那如果cookie本身没有权限的话,那就需要通过php代码去判断来获取相应的信息。
你们公司注册了没?
做为一个独立站,
开始1个hosts文件,开发写好index.php引入第一个站就好了,不需要你去搭建网站。大部分地方都是网站地址与你自己的域名绑定,这样就可以访问你网站了。可以尝试把域名加入到后缀名是如什么,看后缀名是不是能解析出你的网站地址。
php如何抓取网页内容(php如何抓取网页内容啊?php文件还是脚本啊!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-11 15:22
php如何抓取网页内容啊?php文件还是脚本啊?php文件的话,可以百度thinkphp框架,然后上网搜索下相关教程,要是脚本,有安卓模拟器的话,用它进行抓取,java如何抓取网页数据啊?php和java交互,可以用javaee啊,我用的是javaee...spring
php抓取网页内容用sql,
php是单线程运行,一般只能抓取单线程页面,先抓取整个网页,再抓取每个页面的内容。java是多线程并发运行,能够抓取很多个单线程页面,再抓取每个页面的内容。
php爬虫。
可以利用scrapy这个库。这个库在国内可能比较冷门,国外可能有用的比较多的,你可以参考一下w3cplus这个博客的。
vbscript吧
swoole啊,
和别人说的不一样,我觉得是php抓,python写爬虫。我用了python写爬虫没多久,不知道后续会不会有更好的。
php爬虫多掌握几个爬虫语言,比如scrapy,比如tornado等等,然后再学java,python,相互借鉴一下。一开始先撸一些简单的爬虫,多练习。
可以试试黄哥写的关于scrapy,laravel,kibana,javaee,jquery,echarts等金融数据可视化()的文章,技术可视化部分用vb,visualstudio2010,java,python等操作。这些东西不难,上手快,有助于提高自己对数据的分析能力和深入研究。 查看全部
php如何抓取网页内容(php如何抓取网页内容啊?php文件还是脚本啊!)
php如何抓取网页内容啊?php文件还是脚本啊?php文件的话,可以百度thinkphp框架,然后上网搜索下相关教程,要是脚本,有安卓模拟器的话,用它进行抓取,java如何抓取网页数据啊?php和java交互,可以用javaee啊,我用的是javaee...spring
php抓取网页内容用sql,
php是单线程运行,一般只能抓取单线程页面,先抓取整个网页,再抓取每个页面的内容。java是多线程并发运行,能够抓取很多个单线程页面,再抓取每个页面的内容。
php爬虫。
可以利用scrapy这个库。这个库在国内可能比较冷门,国外可能有用的比较多的,你可以参考一下w3cplus这个博客的。
vbscript吧
swoole啊,
和别人说的不一样,我觉得是php抓,python写爬虫。我用了python写爬虫没多久,不知道后续会不会有更好的。
php爬虫多掌握几个爬虫语言,比如scrapy,比如tornado等等,然后再学java,python,相互借鉴一下。一开始先撸一些简单的爬虫,多练习。
可以试试黄哥写的关于scrapy,laravel,kibana,javaee,jquery,echarts等金融数据可视化()的文章,技术可视化部分用vb,visualstudio2010,java,python等操作。这些东西不难,上手快,有助于提高自己对数据的分析能力和深入研究。
php如何抓取网页内容(就是公众号历史文章对应的网址和细节使用代理和客户端)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-08 20:18
这是前几天在公众号上发的文章。主要讨论目前微信公众号文章爬取的大致思路和优缺点。技术细节我就不讲了,分享一下别人已经有的开源项目,大家可以参考代码了解细节。
背景
微信公众号历史只能通过客户端(手机、PC、Mac)查看,网页版微信无法查看公众号历史文章,否则就没有今天的文章 .
具体的解释是公众号历史文章对应的URL必须通过客户端生成一个key才能查看,这个key也是有限制的。具体限制如下:
此密钥的有效期约为两个小时。密钥不通用,每个公众号必须单独生成。
因为上面的问题,抢公众号没那么容易,所以现在一般有两种方式。
抢搜狗微信。使用“中间人攻击”的想法来使用代理爬行。抢搜狗微信
这个好理解,就是抓取网站的数据。具体代码请参考:代码是用Python编写的。
优点:简单易用。可以批量获取账号。所有的爬取行为都可以在服务器上完成,不依赖于客户端。可以随时获取哪些公众号有更新。缺点:搜狗的微信反爬虫已经很复杂了。经常发现代码不再可用,或者跳转到验证码界面(我看过一个开源项目,有人购买了编码服务。当出现验证码时,直接调用编码界面,界面是很便宜,这是一个想法)。获取的链接是临时链接,需要跳转才能获取永久链接。只能获取公众号最近10次推送文章,无法获取历史记录。
针对以上问题,如果你只是想玩玩和抓取最新的文章,可以使用搜狗微信,但如果你真的想抓取一个稳定更完整的数据,则需要使用下面的方法.
使用代理和客户端爬取的优点可以爬取所有文章。您可以在任何帐户之间跳转(PC 和 Mac 需要一些技能)。您可以抓取 文章 的评论。你可以抓住文章的赞赏。可以抓取文章的阅读数和点赞数。稳定性是有保证的,因为实际上我们没有做任何非法操作。缺点是需要客户端,这也是直接在服务器上爬取的最大区别。因为需要一个客户端,所以效率比较低。平均而言,一个客户端每秒最多可以抓取 10 篇文章文章。如果比较快,很可能会出现请求过快的问题。在自动爬取过程中,偶尔会出现一些问题导致爬取停止,但这也是我们需要解决的问题。无法知道哪个公众号更新了,所以只能通过投票来完成(这个可以结合搜狗微信)。如何自动获取多个帐户
第一步:获取你需要的账户的biz参数。这类似于帐户的 id。
移动客户端或模拟器:
具体方法是在每次请求历史列表时修改html添加一个跳转JavaScript。您可以在后端生成要跳转的 JavaScript。因为是后台生成的,可以控制跳转到哪个公众号,或者跳转到这个公众号的下一页。
PC客户端、Mac客户端:
PC 和 Mac 之间的一个问题是您无法在多个帐户之间跳转。有些人使用自动输入。每次需要跳转到哪个公众号时,在聊天对话中进入哪个公众号的历史页面。然后点击,这个方法是可行的。
代理可用工具
一个同学用Go写的开源agent,代码:
您也可以使用阿里巴巴的anyproxy来修改网页数据
您绝对可以在 Windows 上使用 Fiddle 或在 Mac 上使用 Charles,但它不如 anyproxy 灵活,因为一个使用配置,另一个可以编程。还是有很大差距的。
使用anyproxy一段时间后,感觉很强大,很灵活。它在便利性、跨平台性和灵活性方面都优于 Fiddle 和 Charles,因此如果您之前没有使用过,我建议您使用它。
今天我只谈想法。具体的技术细节我接下来会写在博客上,把我目前在做的爬虫平台开源。它主要使用anyproxy和Laravel,配合一个客户端实现以下功能:
自动获取 文章 列表。自动抓取文章消息、点赞、阅读、打赏等,项目直接提供api,可以根据公众号获取对应公众号的历史文章记录。公众号文章的展示。 查看全部
php如何抓取网页内容(就是公众号历史文章对应的网址和细节使用代理和客户端)
这是前几天在公众号上发的文章。主要讨论目前微信公众号文章爬取的大致思路和优缺点。技术细节我就不讲了,分享一下别人已经有的开源项目,大家可以参考代码了解细节。
背景
微信公众号历史只能通过客户端(手机、PC、Mac)查看,网页版微信无法查看公众号历史文章,否则就没有今天的文章 .
具体的解释是公众号历史文章对应的URL必须通过客户端生成一个key才能查看,这个key也是有限制的。具体限制如下:
此密钥的有效期约为两个小时。密钥不通用,每个公众号必须单独生成。
因为上面的问题,抢公众号没那么容易,所以现在一般有两种方式。
抢搜狗微信。使用“中间人攻击”的想法来使用代理爬行。抢搜狗微信
这个好理解,就是抓取网站的数据。具体代码请参考:代码是用Python编写的。
优点:简单易用。可以批量获取账号。所有的爬取行为都可以在服务器上完成,不依赖于客户端。可以随时获取哪些公众号有更新。缺点:搜狗的微信反爬虫已经很复杂了。经常发现代码不再可用,或者跳转到验证码界面(我看过一个开源项目,有人购买了编码服务。当出现验证码时,直接调用编码界面,界面是很便宜,这是一个想法)。获取的链接是临时链接,需要跳转才能获取永久链接。只能获取公众号最近10次推送文章,无法获取历史记录。
针对以上问题,如果你只是想玩玩和抓取最新的文章,可以使用搜狗微信,但如果你真的想抓取一个稳定更完整的数据,则需要使用下面的方法.
使用代理和客户端爬取的优点可以爬取所有文章。您可以在任何帐户之间跳转(PC 和 Mac 需要一些技能)。您可以抓取 文章 的评论。你可以抓住文章的赞赏。可以抓取文章的阅读数和点赞数。稳定性是有保证的,因为实际上我们没有做任何非法操作。缺点是需要客户端,这也是直接在服务器上爬取的最大区别。因为需要一个客户端,所以效率比较低。平均而言,一个客户端每秒最多可以抓取 10 篇文章文章。如果比较快,很可能会出现请求过快的问题。在自动爬取过程中,偶尔会出现一些问题导致爬取停止,但这也是我们需要解决的问题。无法知道哪个公众号更新了,所以只能通过投票来完成(这个可以结合搜狗微信)。如何自动获取多个帐户
第一步:获取你需要的账户的biz参数。这类似于帐户的 id。
移动客户端或模拟器:
具体方法是在每次请求历史列表时修改html添加一个跳转JavaScript。您可以在后端生成要跳转的 JavaScript。因为是后台生成的,可以控制跳转到哪个公众号,或者跳转到这个公众号的下一页。
PC客户端、Mac客户端:
PC 和 Mac 之间的一个问题是您无法在多个帐户之间跳转。有些人使用自动输入。每次需要跳转到哪个公众号时,在聊天对话中进入哪个公众号的历史页面。然后点击,这个方法是可行的。
代理可用工具
一个同学用Go写的开源agent,代码:
您也可以使用阿里巴巴的anyproxy来修改网页数据
您绝对可以在 Windows 上使用 Fiddle 或在 Mac 上使用 Charles,但它不如 anyproxy 灵活,因为一个使用配置,另一个可以编程。还是有很大差距的。
使用anyproxy一段时间后,感觉很强大,很灵活。它在便利性、跨平台性和灵活性方面都优于 Fiddle 和 Charles,因此如果您之前没有使用过,我建议您使用它。
今天我只谈想法。具体的技术细节我接下来会写在博客上,把我目前在做的爬虫平台开源。它主要使用anyproxy和Laravel,配合一个客户端实现以下功能:
自动获取 文章 列表。自动抓取文章消息、点赞、阅读、打赏等,项目直接提供api,可以根据公众号获取对应公众号的历史文章记录。公众号文章的展示。
php如何抓取网页内容( 后来我想了想我觉得读取本地和通过url读取原理不是 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-06 12:07
后来我想了想我觉得读取本地和通过url读取原理不是
)
<p>今天做项目时用到java抓取网页内容,本以为很简单的一件事但是还是让我蛋疼了一会,网上资料一大堆但是都是通过url抓取网页内容,但是我要的是读取本地的html页面内容的方法,网上找不到怎么办我瞬间了!
首先还是向大家讲解一下通过url抓取网页内容吧,通过正则表达式摘取title、js、css等网页元素,代码如下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = " 查看全部
php如何抓取网页内容(
后来我想了想我觉得读取本地和通过url读取原理不是
)
<p>今天做项目时用到java抓取网页内容,本以为很简单的一件事但是还是让我蛋疼了一会,网上资料一大堆但是都是通过url抓取网页内容,但是我要的是读取本地的html页面内容的方法,网上找不到怎么办
我瞬间了! 首先还是向大家讲解一下通过url抓取网页内容吧,通过正则表达式摘取title、js、css等网页元素,代码如下:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
*
* @author yaohucaizi
*/
public class Test {
/**
* 读取网页全部内容
*/
public String getHtmlContent(String htmlurl) {
URL url;
String temp;
StringBuffer sb = new StringBuffer();
try {
url = new URL(htmlurl);
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), "gbk"));// 读取网页全部内容
while ((temp = in.readLine()) != null) {
sb.append(temp);
}
in.close();
} catch (final MalformedURLException me) {
System.out.println("你输入的URL格式有问题!");
me.getMessage();
} catch (final IOException e) {
e.printStackTrace();
}
return sb.toString();
}
/**
*
* @param s
* @return 获得网页标题
*/
public String getTitle(String s) {
String regex;
String title = "";
List list = new ArrayList();
regex = ".*?";
Pattern pa = Pattern.compile(regex, Pattern.CANON_EQ);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
for (int i = 0; i < list.size(); i++) {
title = title + list.get(i);
}
return outTag(title);
}
/**
*
* @param s
* @return 获得链接
*/
public List getLink(String s) {
String regex;
List list = new ArrayList();
regex = "]*href=(\"([^\"]*)\"|\'([^\']*)\'|([^\\s>]*))[^>]*>(.*?)</a>";
Pattern pa = Pattern.compile(regex, Pattern.DOTALL);
Matcher ma = pa.matcher(s);
while (ma.find()) {
list.add(ma.group());
}
return list;
}
/**
*
* @param s
* @return 获得脚本代码
*/
public List getScript(String s) {
String regex;
List list = new ArrayList();
regex = "
php如何抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-01 21:21
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户可以通过井号构造的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
php如何抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户可以通过井号构造的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
php如何抓取网页内容(两种方法获取网站的meta信息,第一种方法是使用get )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-01 10:17
)
在网页采集的过程中,我们需要获取网站的元信息,如标题、关键字、描述等。本文章介绍了获取网站元信息的两种方法。第一种方法是使用get_uMeta_uTags函数,第二种方法是使用正则表达式匹配方法来获取
1:使用get_uMeta_uu标记函数获取元信息
例如,如果我们想要获取这个网页的元信息,我们可以直接使用PHP内置函数get_u;meta_uu_u标签。代码如下:
2:使用正则表达式获取元信息
PHP代码如下所示:
<p>$site = "http://www.ub07.com";
$content = get_sitemeta($site);
print_r($content);
/** 获取META信息 */
function get_sitemeta($url) {
$data = file_get_contents($url);
$meta = array();
if (!empty($data)) {
#Title
preg_match('/([\w\W]*?)/si', $data, $matches);
if (!empty($matches[1])) {
$meta['title'] = $matches[1];
}
#Keywords
preg_match('/ 查看全部
php如何抓取网页内容(两种方法获取网站的meta信息,第一种方法是使用get
)
在网页采集的过程中,我们需要获取网站的元信息,如标题、关键字、描述等。本文章介绍了获取网站元信息的两种方法。第一种方法是使用get_uMeta_uTags函数,第二种方法是使用正则表达式匹配方法来获取
1:使用get_uMeta_uu标记函数获取元信息
例如,如果我们想要获取这个网页的元信息,我们可以直接使用PHP内置函数get_u;meta_uu_u标签。代码如下:
2:使用正则表达式获取元信息
PHP代码如下所示:
<p>$site = "http://www.ub07.com";
$content = get_sitemeta($site);
print_r($content);
/** 获取META信息 */
function get_sitemeta($url) {
$data = file_get_contents($url);
$meta = array();
if (!empty($data)) {
#Title
preg_match('/([\w\W]*?)/si', $data, $matches);
if (!empty($matches[1])) {
$meta['title'] = $matches[1];
}
#Keywords
preg_match('/
php如何抓取网页内容(模拟登录post请求发送post数据回调domemock函数ssrf即跨站请求伪造)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-28 20:03
php如何抓取网页内容教程-百度文库那么我们将学习:模拟登录post请求发送post数据回调domemock函数post请求发送post数据post回调domemock函数
ssrf即跨站请求伪造。服务器端不对用户发送数据,只对浏览器发送数据,让浏览器执行一些代码,从而实现所谓的脚本(我们可以说是html脚本)。如何解决ssrf问题,第一种是构造假数据,然后模拟登录的过程。另一种,是利用漏洞来通过ssrf实现。使用nginx构造ssrf协议,将字符串匹配到任意函数,最后反向传播执行。我就是从这个地方学习的,你可以在本文的基础上学习。
首先回答问题:你用的脚本语言我不熟悉。不过相对来说,php无论是语法还是逻辑来说,都比你想像的容易些。1.php内置了很多数据库字符串操作的方法,比如你可以使用alias。2.php中有很多元素类可以通过tag,字符串,甚至是名字来识别,这些在php中都有个模板功能,把一个字符串变成一个string形式的参数。
3.php的模板加载技术也做得很好,跟目前nginx,apache一样,php就是基于web的一个应用。其实你不觉得知乎网页是用php+xml实现的么。最后再啰嗦一句,你的php水平和数据库水平真的足够么?经常会产生你这样的问题了。你都不比我强多少。你的数据库比我熟悉么?不过我只是假设题主已经会使用,或者自己分析过的情况下来回答你的问题。
如果真的不明白我说的,你找个java的博客看看。java手把手教你实现安全phpstorm-wordpress博客园可以去看看我讲的问题再来提问。 查看全部
php如何抓取网页内容(模拟登录post请求发送post数据回调domemock函数ssrf即跨站请求伪造)
php如何抓取网页内容教程-百度文库那么我们将学习:模拟登录post请求发送post数据回调domemock函数post请求发送post数据post回调domemock函数
ssrf即跨站请求伪造。服务器端不对用户发送数据,只对浏览器发送数据,让浏览器执行一些代码,从而实现所谓的脚本(我们可以说是html脚本)。如何解决ssrf问题,第一种是构造假数据,然后模拟登录的过程。另一种,是利用漏洞来通过ssrf实现。使用nginx构造ssrf协议,将字符串匹配到任意函数,最后反向传播执行。我就是从这个地方学习的,你可以在本文的基础上学习。
首先回答问题:你用的脚本语言我不熟悉。不过相对来说,php无论是语法还是逻辑来说,都比你想像的容易些。1.php内置了很多数据库字符串操作的方法,比如你可以使用alias。2.php中有很多元素类可以通过tag,字符串,甚至是名字来识别,这些在php中都有个模板功能,把一个字符串变成一个string形式的参数。
3.php的模板加载技术也做得很好,跟目前nginx,apache一样,php就是基于web的一个应用。其实你不觉得知乎网页是用php+xml实现的么。最后再啰嗦一句,你的php水平和数据库水平真的足够么?经常会产生你这样的问题了。你都不比我强多少。你的数据库比我熟悉么?不过我只是假设题主已经会使用,或者自己分析过的情况下来回答你的问题。
如果真的不明白我说的,你找个java的博客看看。java手把手教你实现安全phpstorm-wordpress博客园可以去看看我讲的问题再来提问。
php如何抓取网页内容( 如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-28 05:10
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,确定要提取的内容的位置,然后就可以通过标签id、名称、类或其他属性提取内容了!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com")
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com")
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以用driver.switch_to.frame来定位,简单,直接使用即可
Driver.find_element_by_css_selector、find_element_by_tag_name等提取内容。在该方法中,有多个s的提取是一个列表,没有s的提取是单个数据。这很容易理解。具体使用方法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别! 查看全部
php如何抓取网页内容(
如何使用浏览器渲染方法将爬取动态网页变成爬取静态网页)
此时,可以确定评论区的位置:
...
其实这就是所谓的网页分析。通过检查元素,确定要提取的内容的位置,然后就可以通过标签id、名称、类或其他属性提取内容了!
继续往下看:
它收录一个列表,注释也在其中。这时候我们可以在网页上右击查看网页源码,然后Ctrl+F,输入“comment-list-box”就可以找到这部分:
我们会发现源代码里什么都没有!此时,你明白了吗?
而如果我们要提取这部分动态内容,仅通过上一篇文章的方法是不可能做到的。除非加载动态网页的 URL 可以解析,否则我们如何简单高效地捕获动态网页内容?这里需要用到动态网页爬取神器:Selenium
Selenium其实是一个web自动化测试工具,可以模拟用户滑动、点击、打开、验证等一系列网页操作行为,就像真实用户在操作一样!这样就可以利用浏览器渲染的方式,将动态网页抓取成静态网页抓取了!
安装硒:pip install selenium
安装成功后,简单测试:
from selenium import webdriver
# 用selenium打开网页
driver = webdriver.Chrome()
driver.get("https://www.baidu.com";)
错误:
WebDriverException( mon.exceptions.WebDriverException: 消息:'chromedriver' 可执行文件需要在 PATH 中。请参阅
这其实就是谷歌浏览器缺少驱动:chromedriver。下载后,放在盘符下并记录位置,修改代码,再次执行:
driver = webdriver.Chrome(executable_path=r"C:\chromedriver.exe")
driver.get("https://www.baidu.com";)
笔者这里使用的是FireFox浏览器,效果是一样的,当然要下载火狐浏览器驱动:geckodriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://www.baidu.com";)
打开成功后会显示浏览器已被控制!
我们可以在PyCharm中查看webdriver提供的方法:
当提取的内容嵌套在frame中时,我们可以用driver.switch_to.frame来定位,简单,直接使用即可
Driver.find_element_by_css_selector、find_element_by_tag_name等提取内容。在该方法中,有多个s的提取是一个列表,没有s的提取是单个数据。这很容易理解。具体使用方法可以查看官方文档!
还是以csdn博客为例:Python入门(一)环境设置,爬取文章的这条评论,我们分析了上面评论所在的区域:
...
:
然后我们就可以直接通过find_element_by_css_selector获取div下的内容:
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r"C:\geckodriver.exe")
driver.get("https://baiyuliang.blog.csdn.n ... 6quot;)
comment_list_box = driver.find_element_by_css_selector('div.comment-list-box')
comment_list = comment_list_box.find_element_by_class_name('comment-list')
comment_line_box = comment_list.find_elements_by_class_name('comment-line-box')
for comment in comment_line_box:
span_text = comment.find_element_by_class_name('new-comment').text
print(span_text)
结果:
注意 find_element_by_css_selector 和 find_element_by_class_name 的用法区别!

