
fiddler
【知乎】火车采集器V9:采集知乎问答
采集交流 • 优采云 发表了文章 • 0 个评论 • 533 次浏览 • 2020-06-24 08:02
今天给你们分享知乎网站问题及第一条回答内容的采集采集,通过搜索guanjianci采集相应的内容,本案例须要用到抓包工具来获取入口网址,以及获得UA。下面的案例讲解给你们简单作讲解!
本规则采集知乎网站问题信息为例,本规则以通过guanjianci搜索问题,采集相应文章及第一条回答等内容。
本规则为列车采集器V9版规则,其他低版本不可使用。
本规则免费版用户也可使用
本规则仅供广大用户学习交流参考,不可用以违规目的或商业用途,我们不对因使用此规则导致的任何法律问题承当责任。
商业版用户有问题或付费定做规则请联系官方客服QQ:800019423 服务热线:
火车采集器V9知乎采集规则分享.rar(44.5 KB, 下载次数: 194)
【案例讲解】
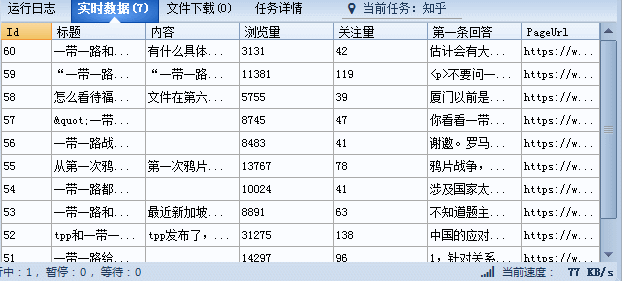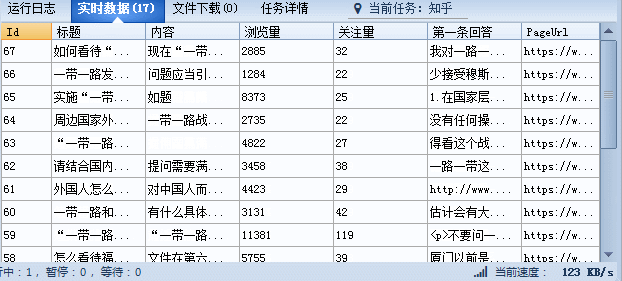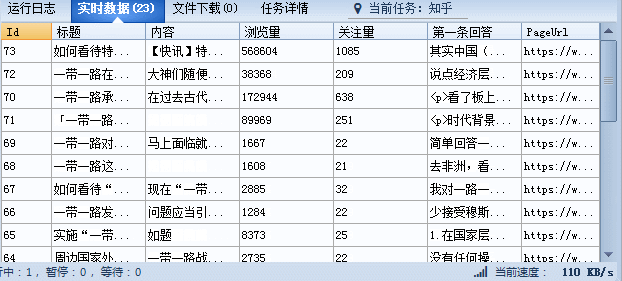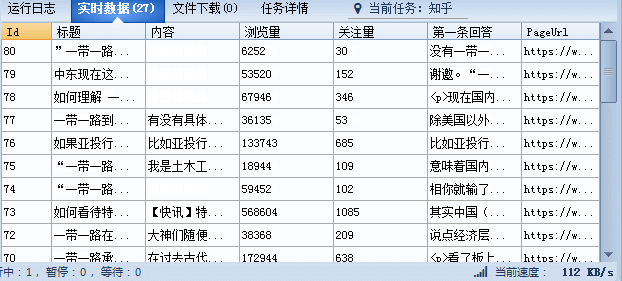
第一步:打开网址之后登陆帐号,然后搜索你想要的guanjianci,如“一带一路”,参照右图:
第二步:使用Fiddler 抓包软件(关于Fiddler软件介绍请查看:;keyword=Fiddler之前介绍过,这里不再讲解,也可以查看之前的东哥福利)打开软件,然后点击网页上的更多,参照右图:
然后回到抓包软件,寻找抓到的网址,参照右图
然后通过获取到的网址: ... e=content&offset=10
发现网址中的10为分页参数,并且1-20任意值代表第一个分页,11-20任意值代表第2个分页,依此类推,那换到规律,我可以从1开始,然后每次递增10,这样就是1、11、21、31……等,我们根据这样的规则设置分页参数,这里仅设置5页,如下图:
第三步:采集内容网址,通过源码剖析,发现网址是这样的“\/question\/49185959\”,如下图:
因网址中间有特殊符号,不能直接采集,我们可以这样设置规则,只采集其中的数字火车采集器v9实战,前面是固定值,变化的只有数字,然后进行网址拼接,如下图:
第四步:内容采集设置,在这里要注意的是,知乎须要设置下UA,才能进行采集火车采集器v9实战,否则将采不到内容,如何获得UA,首先打开抓包软件,然后找开要采集的内容网址页,然后抓包获得UA值,参照以下三个图:
先找到内容网址
然后两侧点击 RAW 再点击右下解的按键
然后在记事本中复制UA值 ,然后我们在采集器中打开其他设置,将UA值粘贴到UA上面,如下图:
然后回到内容采集设置,进行内容规则设置,这里没有哪些非常的难点,就不再细讲,设置好后,进行测试,如下图:
显示上图这样,就表示 设置OK了,我们可以进行采集啦! 你学会了吗?
联系我们
客服QQ:800019423
客服电话:
软件订购: 查看全部
本规则采集知乎网站问题信息为例,本规则以通过guanjianci搜索问题,采集相应文章及第一条回答等内容。
本规则为列车采集器V9版规则,其他低版本不可使用。
本规则免费版用户也可使用
本规则仅供广大用户学习交流参考,不可用以违规目的或商业用途,我们不对因使用此规则导致的任何法律问题承当责任。
商业版用户有问题或付费定做规则请联系官方客服QQ:800019423 服务热线:
火车采集器V9知乎采集规则分享.rar(44.5 KB, 下载次数: 194)
【案例讲解】
第一步:打开网址之后登陆帐号,然后搜索你想要的guanjianci,如“一带一路”,参照右图:
第二步:使用Fiddler 抓包软件(关于Fiddler软件介绍请查看:;keyword=Fiddler之前介绍过,这里不再讲解,也可以查看之前的东哥福利)打开软件,然后点击网页上的更多,参照右图:
然后回到抓包软件,寻找抓到的网址,参照右图
然后通过获取到的网址: ... e=content&offset=10
发现网址中的10为分页参数,并且1-20任意值代表第一个分页,11-20任意值代表第2个分页,依此类推,那换到规律,我可以从1开始,然后每次递增10,这样就是1、11、21、31……等,我们根据这样的规则设置分页参数,这里仅设置5页,如下图:
第三步:采集内容网址,通过源码剖析,发现网址是这样的“\/question\/49185959\”,如下图:
因网址中间有特殊符号,不能直接采集,我们可以这样设置规则,只采集其中的数字火车采集器v9实战,前面是固定值,变化的只有数字,然后进行网址拼接,如下图:
第四步:内容采集设置,在这里要注意的是,知乎须要设置下UA,才能进行采集火车采集器v9实战,否则将采不到内容,如何获得UA,首先打开抓包软件,然后找开要采集的内容网址页,然后抓包获得UA值,参照以下三个图:
先找到内容网址
然后两侧点击 RAW 再点击右下解的按键
然后在记事本中复制UA值 ,然后我们在采集器中打开其他设置,将UA值粘贴到UA上面,如下图:
然后回到内容采集设置,进行内容规则设置,这里没有哪些非常的难点,就不再细讲,设置好后,进行测试,如下图:
显示上图这样,就表示 设置OK了,我们可以进行采集啦! 你学会了吗?
联系我们
客服QQ:800019423
客服电话:
软件订购: 查看全部
今天给你们分享知乎网站问题及第一条回答内容的采集采集,通过搜索guanjianci采集相应的内容,本案例须要用到抓包工具来获取入口网址,以及获得UA。下面的案例讲解给你们简单作讲解!
本规则采集知乎网站问题信息为例,本规则以通过guanjianci搜索问题,采集相应文章及第一条回答等内容。
本规则为列车采集器V9版规则,其他低版本不可使用。
本规则免费版用户也可使用
本规则仅供广大用户学习交流参考,不可用以违规目的或商业用途,我们不对因使用此规则导致的任何法律问题承当责任。
商业版用户有问题或付费定做规则请联系官方客服QQ:800019423 服务热线:

火车采集器V9知乎采集规则分享.rar(44.5 KB, 下载次数: 194)
【案例讲解】
第一步:打开网址之后登陆帐号,然后搜索你想要的guanjianci,如“一带一路”,参照右图:
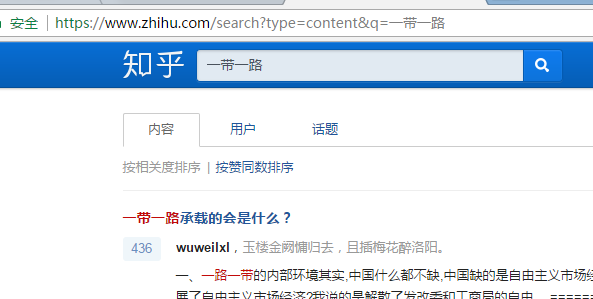
第二步:使用Fiddler 抓包软件(关于Fiddler软件介绍请查看:;keyword=Fiddler之前介绍过,这里不再讲解,也可以查看之前的东哥福利)打开软件,然后点击网页上的更多,参照右图:
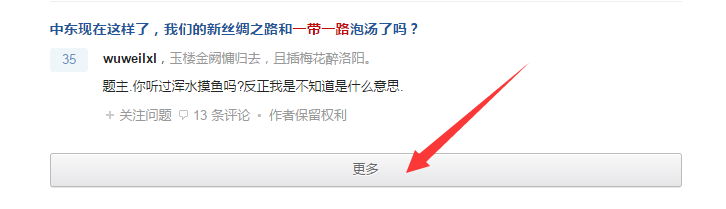
然后回到抓包软件,寻找抓到的网址,参照右图
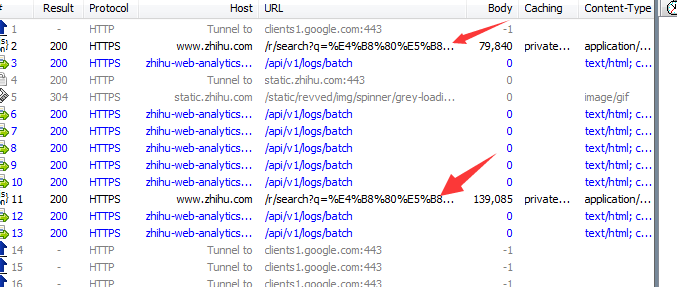
然后通过获取到的网址: ... e=content&offset=10
发现网址中的10为分页参数,并且1-20任意值代表第一个分页,11-20任意值代表第2个分页,依此类推,那换到规律,我可以从1开始,然后每次递增10,这样就是1、11、21、31……等,我们根据这样的规则设置分页参数,这里仅设置5页,如下图:
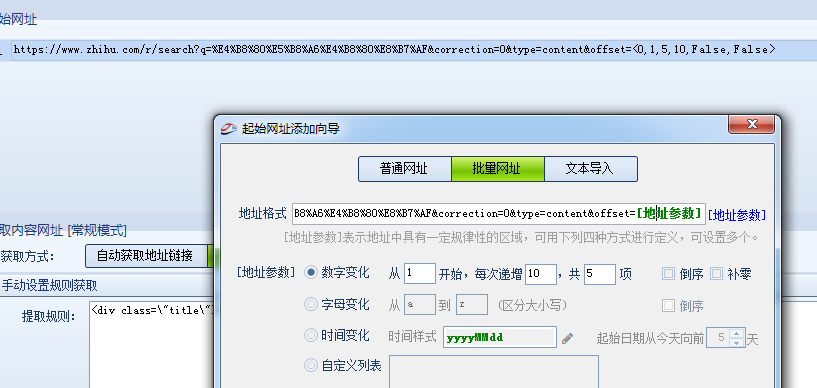
第三步:采集内容网址,通过源码剖析,发现网址是这样的“\/question\/49185959\”,如下图:
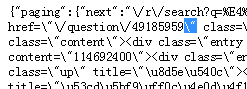
因网址中间有特殊符号,不能直接采集,我们可以这样设置规则,只采集其中的数字火车采集器v9实战,前面是固定值,变化的只有数字,然后进行网址拼接,如下图:
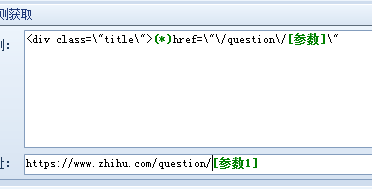
第四步:内容采集设置,在这里要注意的是,知乎须要设置下UA,才能进行采集火车采集器v9实战,否则将采不到内容,如何获得UA,首先打开抓包软件,然后找开要采集的内容网址页,然后抓包获得UA值,参照以下三个图:

先找到内容网址
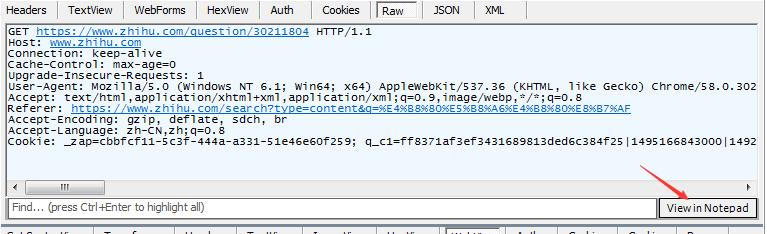
然后两侧点击 RAW 再点击右下解的按键
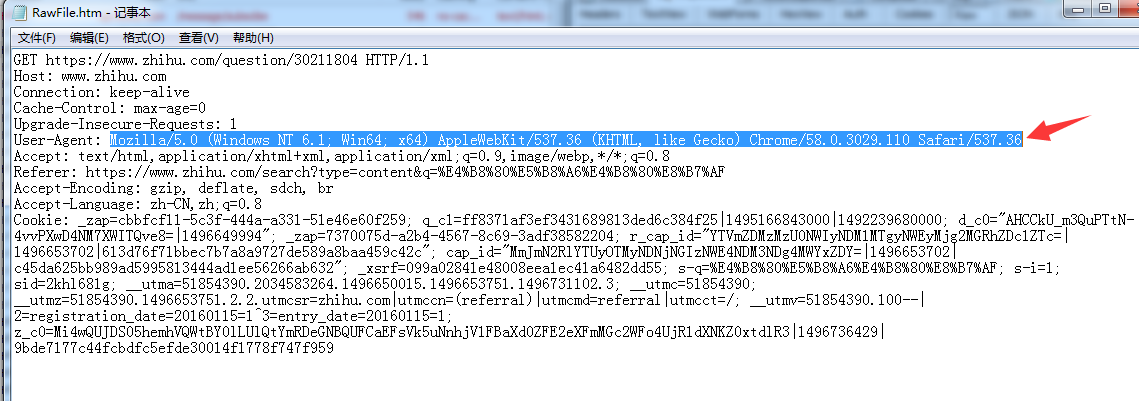
然后在记事本中复制UA值 ,然后我们在采集器中打开其他设置,将UA值粘贴到UA上面,如下图:
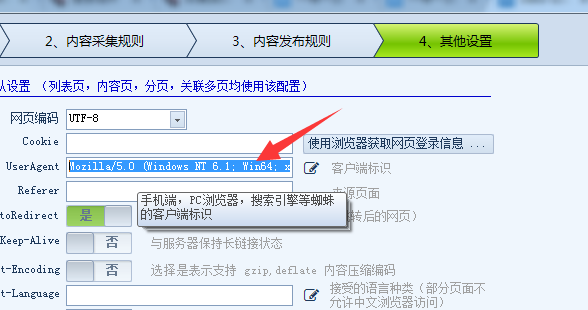
然后回到内容采集设置,进行内容规则设置,这里没有哪些非常的难点,就不再细讲,设置好后,进行测试,如下图:
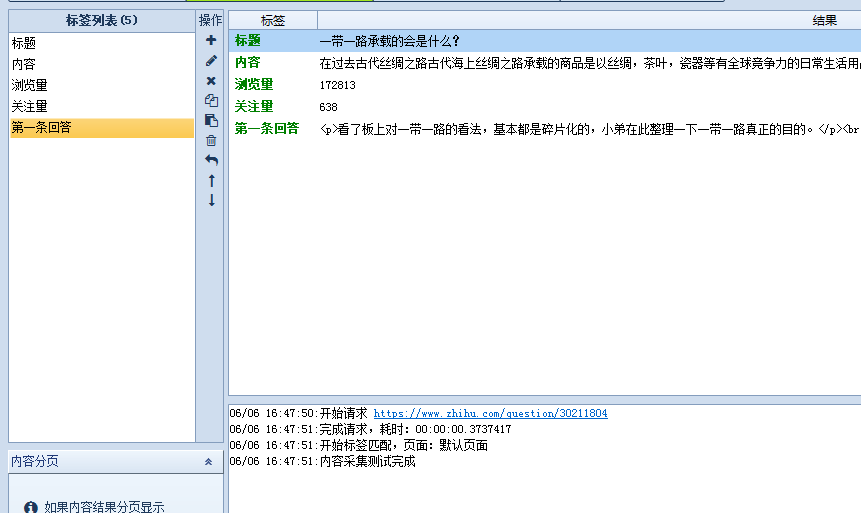
显示上图这样,就表示 设置OK了,我们可以进行采集啦! 你学会了吗?
联系我们
客服QQ:800019423
客服电话:
软件订购:
如何进行手机APP的数据爬取?
采集交流 • 优采云 发表了文章 • 0 个评论 • 517 次浏览 • 2020-05-30 08:00
作者:xiaoyu
微信公众号:Python数据科学
知乎:Python数据分析师
平时我们的爬虫多是针对网页的,但是随着手机端APP应用数目的增多,相应的爬取需求也就越来越多,因此手机端APP的数据爬取对于一名爬虫工程师来说是一项必备的技能。我们晓得手机上爬虫软件,网页爬取的时侯我常常使用F12开发者工具或则fiddler之类的工具来帮助我们剖析浏览器行为。那对于手机的APP该怎么使用呢?同样的,我们也可以使用fiddler来剖析。好了,本篇博主将会给你们介绍怎样在笔记本端使用fiddler进行手机APP的抓包。
首先了解一下fiddler(百度百科):
Fiddler是一个http合同调试代理工具,它就能记录并检测所有你的笔记本和互联网之间的http通信,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件,这些都可以使你胡乱更改的意思)。 Fiddler 要比其他的网路调试器要愈发简单,因为它不仅仅曝露http通信还提供了一个用户友好的格式。
完成此项工作的整个流程可分为如下几个步骤。
fiddler的官方下载链接:
安装步骤没哪些非常,常规下一步完成即可。
这里有两点须要说明一下。
操作很简单,打开下载好的fiddler手机上爬虫软件,找到 Tools -> Options,然后再HTTPS的工具栏下勾选Decrpt HTTPS traffic,在新弹出的选项栏下勾选Ignore server certificate errors。
相同的,在Connections选项栏下勾选Allow remote computers to connect,并记住前面的端口号8888,后面会使用到。
好了,需要的fiddler设置就配置完成了。
设置手机端之前,我们须要记住一点:电脑和手机须要在同一个网路下进行操作。
可以使用wifi或则手机热点等来完成。
假如你已然使笔记本和手机处于同一个网路下了,这时候我们须要晓得此网路的ip地址,可以在命令行输入ipconfig简单的获得,如图。
好了,下面我们开始手机端的设置。
手机APP的抓取操作对于Android和Apple系统都可用,博主使用的苹果系统,在此以苹果系统为例。
进入到手机wifi的设置界面,选择当前联接网路的更多信息,在苹果中是一个感叹号。然后在最下边你会看见HTTP代理的选项,点击步入。
进入后,填写里面记住的ip地址和端口号,确定保存。
在手机上打开浏览器输入一个里面ip地址和端口号组成的url::8888,然后点击FiddlerRoot certificate下载fiddler证书。
以上就简单完成了所有的操作,最后我们测试一下是否好用。
就以知乎APP为例,在手机上打开 知乎APP。下面是笔记本上fiddler的抓包结果。
结果没有问题,抓到信息包。然后就可以使用我们剖析网页的方式来进行后续的操作了。 查看全部
微信公众号:Python数据科学
知乎:Python数据分析师
平时我们的爬虫多是针对网页的,但是随着手机端APP应用数目的增多,相应的爬取需求也就越来越多,因此手机端APP的数据爬取对于一名爬虫工程师来说是一项必备的技能。我们晓得手机上爬虫软件,网页爬取的时侯我常常使用F12开发者工具或则fiddler之类的工具来帮助我们剖析浏览器行为。那对于手机的APP该怎么使用呢?同样的,我们也可以使用fiddler来剖析。好了,本篇博主将会给你们介绍怎样在笔记本端使用fiddler进行手机APP的抓包。
首先了解一下fiddler(百度百科):
Fiddler是一个http合同调试代理工具,它就能记录并检测所有你的笔记本和互联网之间的http通信,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件,这些都可以使你胡乱更改的意思)。 Fiddler 要比其他的网路调试器要愈发简单,因为它不仅仅曝露http通信还提供了一个用户友好的格式。
完成此项工作的整个流程可分为如下几个步骤。
fiddler的官方下载链接:
安装步骤没哪些非常,常规下一步完成即可。
这里有两点须要说明一下。
操作很简单,打开下载好的fiddler手机上爬虫软件,找到 Tools -> Options,然后再HTTPS的工具栏下勾选Decrpt HTTPS traffic,在新弹出的选项栏下勾选Ignore server certificate errors。
相同的,在Connections选项栏下勾选Allow remote computers to connect,并记住前面的端口号8888,后面会使用到。
好了,需要的fiddler设置就配置完成了。
设置手机端之前,我们须要记住一点:电脑和手机须要在同一个网路下进行操作。
可以使用wifi或则手机热点等来完成。
假如你已然使笔记本和手机处于同一个网路下了,这时候我们须要晓得此网路的ip地址,可以在命令行输入ipconfig简单的获得,如图。
好了,下面我们开始手机端的设置。
手机APP的抓取操作对于Android和Apple系统都可用,博主使用的苹果系统,在此以苹果系统为例。
进入到手机wifi的设置界面,选择当前联接网路的更多信息,在苹果中是一个感叹号。然后在最下边你会看见HTTP代理的选项,点击步入。
进入后,填写里面记住的ip地址和端口号,确定保存。
在手机上打开浏览器输入一个里面ip地址和端口号组成的url::8888,然后点击FiddlerRoot certificate下载fiddler证书。
以上就简单完成了所有的操作,最后我们测试一下是否好用。
就以知乎APP为例,在手机上打开 知乎APP。下面是笔记本上fiddler的抓包结果。
结果没有问题,抓到信息包。然后就可以使用我们剖析网页的方式来进行后续的操作了。 查看全部
作者:xiaoyu
微信公众号:Python数据科学
知乎:Python数据分析师
平时我们的爬虫多是针对网页的,但是随着手机端APP应用数目的增多,相应的爬取需求也就越来越多,因此手机端APP的数据爬取对于一名爬虫工程师来说是一项必备的技能。我们晓得手机上爬虫软件,网页爬取的时侯我常常使用F12开发者工具或则fiddler之类的工具来帮助我们剖析浏览器行为。那对于手机的APP该怎么使用呢?同样的,我们也可以使用fiddler来剖析。好了,本篇博主将会给你们介绍怎样在笔记本端使用fiddler进行手机APP的抓包。
首先了解一下fiddler(百度百科):
Fiddler是一个http合同调试代理工具,它就能记录并检测所有你的笔记本和互联网之间的http通信,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件,这些都可以使你胡乱更改的意思)。 Fiddler 要比其他的网路调试器要愈发简单,因为它不仅仅曝露http通信还提供了一个用户友好的格式。
完成此项工作的整个流程可分为如下几个步骤。
fiddler的官方下载链接:
安装步骤没哪些非常,常规下一步完成即可。
这里有两点须要说明一下。
操作很简单,打开下载好的fiddler手机上爬虫软件,找到 Tools -> Options,然后再HTTPS的工具栏下勾选Decrpt HTTPS traffic,在新弹出的选项栏下勾选Ignore server certificate errors。

相同的,在Connections选项栏下勾选Allow remote computers to connect,并记住前面的端口号8888,后面会使用到。

好了,需要的fiddler设置就配置完成了。
设置手机端之前,我们须要记住一点:电脑和手机须要在同一个网路下进行操作。
可以使用wifi或则手机热点等来完成。
假如你已然使笔记本和手机处于同一个网路下了,这时候我们须要晓得此网路的ip地址,可以在命令行输入ipconfig简单的获得,如图。

好了,下面我们开始手机端的设置。
手机APP的抓取操作对于Android和Apple系统都可用,博主使用的苹果系统,在此以苹果系统为例。
进入到手机wifi的设置界面,选择当前联接网路的更多信息,在苹果中是一个感叹号。然后在最下边你会看见HTTP代理的选项,点击步入。

进入后,填写里面记住的ip地址和端口号,确定保存。

在手机上打开浏览器输入一个里面ip地址和端口号组成的url::8888,然后点击FiddlerRoot certificate下载fiddler证书。

以上就简单完成了所有的操作,最后我们测试一下是否好用。
就以知乎APP为例,在手机上打开 知乎APP。下面是笔记本上fiddler的抓包结果。

结果没有问题,抓到信息包。然后就可以使用我们剖析网页的方式来进行后续的操作了。
【知乎】火车采集器V9:采集知乎问答
采集交流 • 优采云 发表了文章 • 0 个评论 • 533 次浏览 • 2020-06-24 08:02
今天给你们分享知乎网站问题及第一条回答内容的采集采集,通过搜索guanjianci采集相应的内容,本案例须要用到抓包工具来获取入口网址,以及获得UA。下面的案例讲解给你们简单作讲解!
本规则采集知乎网站问题信息为例,本规则以通过guanjianci搜索问题,采集相应文章及第一条回答等内容。
本规则为列车采集器V9版规则,其他低版本不可使用。
本规则免费版用户也可使用
本规则仅供广大用户学习交流参考,不可用以违规目的或商业用途,我们不对因使用此规则导致的任何法律问题承当责任。
商业版用户有问题或付费定做规则请联系官方客服QQ:800019423 服务热线:
火车采集器V9知乎采集规则分享.rar(44.5 KB, 下载次数: 194)
【案例讲解】
第一步:打开网址之后登陆帐号,然后搜索你想要的guanjianci,如“一带一路”,参照右图:
第二步:使用Fiddler 抓包软件(关于Fiddler软件介绍请查看:;keyword=Fiddler之前介绍过,这里不再讲解,也可以查看之前的东哥福利)打开软件,然后点击网页上的更多,参照右图:
然后回到抓包软件,寻找抓到的网址,参照右图
然后通过获取到的网址: ... e=content&offset=10
发现网址中的10为分页参数,并且1-20任意值代表第一个分页,11-20任意值代表第2个分页,依此类推,那换到规律,我可以从1开始,然后每次递增10,这样就是1、11、21、31……等,我们根据这样的规则设置分页参数,这里仅设置5页,如下图:
第三步:采集内容网址,通过源码剖析,发现网址是这样的“\/question\/49185959\”,如下图:
因网址中间有特殊符号,不能直接采集,我们可以这样设置规则,只采集其中的数字火车采集器v9实战,前面是固定值,变化的只有数字,然后进行网址拼接,如下图:
第四步:内容采集设置,在这里要注意的是,知乎须要设置下UA,才能进行采集火车采集器v9实战,否则将采不到内容,如何获得UA,首先打开抓包软件,然后找开要采集的内容网址页,然后抓包获得UA值,参照以下三个图:
先找到内容网址
然后两侧点击 RAW 再点击右下解的按键
然后在记事本中复制UA值 ,然后我们在采集器中打开其他设置,将UA值粘贴到UA上面,如下图:
然后回到内容采集设置,进行内容规则设置,这里没有哪些非常的难点,就不再细讲,设置好后,进行测试,如下图:
显示上图这样,就表示 设置OK了,我们可以进行采集啦! 你学会了吗?
联系我们
客服QQ:800019423
客服电话:
软件订购: 查看全部
本规则采集知乎网站问题信息为例,本规则以通过guanjianci搜索问题,采集相应文章及第一条回答等内容。
本规则为列车采集器V9版规则,其他低版本不可使用。
本规则免费版用户也可使用
本规则仅供广大用户学习交流参考,不可用以违规目的或商业用途,我们不对因使用此规则导致的任何法律问题承当责任。
商业版用户有问题或付费定做规则请联系官方客服QQ:800019423 服务热线:
火车采集器V9知乎采集规则分享.rar(44.5 KB, 下载次数: 194)
【案例讲解】
第一步:打开网址之后登陆帐号,然后搜索你想要的guanjianci,如“一带一路”,参照右图:
第二步:使用Fiddler 抓包软件(关于Fiddler软件介绍请查看:;keyword=Fiddler之前介绍过,这里不再讲解,也可以查看之前的东哥福利)打开软件,然后点击网页上的更多,参照右图:
然后回到抓包软件,寻找抓到的网址,参照右图
然后通过获取到的网址: ... e=content&offset=10
发现网址中的10为分页参数,并且1-20任意值代表第一个分页,11-20任意值代表第2个分页,依此类推,那换到规律,我可以从1开始,然后每次递增10,这样就是1、11、21、31……等,我们根据这样的规则设置分页参数,这里仅设置5页,如下图:
第三步:采集内容网址,通过源码剖析,发现网址是这样的“\/question\/49185959\”,如下图:
因网址中间有特殊符号,不能直接采集,我们可以这样设置规则,只采集其中的数字火车采集器v9实战,前面是固定值,变化的只有数字,然后进行网址拼接,如下图:
第四步:内容采集设置,在这里要注意的是,知乎须要设置下UA,才能进行采集火车采集器v9实战,否则将采不到内容,如何获得UA,首先打开抓包软件,然后找开要采集的内容网址页,然后抓包获得UA值,参照以下三个图:
先找到内容网址
然后两侧点击 RAW 再点击右下解的按键
然后在记事本中复制UA值 ,然后我们在采集器中打开其他设置,将UA值粘贴到UA上面,如下图:
然后回到内容采集设置,进行内容规则设置,这里没有哪些非常的难点,就不再细讲,设置好后,进行测试,如下图:
显示上图这样,就表示 设置OK了,我们可以进行采集啦! 你学会了吗?
联系我们
客服QQ:800019423
客服电话:
软件订购: 查看全部
今天给你们分享知乎网站问题及第一条回答内容的采集采集,通过搜索guanjianci采集相应的内容,本案例须要用到抓包工具来获取入口网址,以及获得UA。下面的案例讲解给你们简单作讲解!
本规则采集知乎网站问题信息为例,本规则以通过guanjianci搜索问题,采集相应文章及第一条回答等内容。
本规则为列车采集器V9版规则,其他低版本不可使用。
本规则免费版用户也可使用
本规则仅供广大用户学习交流参考,不可用以违规目的或商业用途,我们不对因使用此规则导致的任何法律问题承当责任。
商业版用户有问题或付费定做规则请联系官方客服QQ:800019423 服务热线:
火车采集器V9知乎采集规则分享.rar(44.5 KB, 下载次数: 194)
【案例讲解】
第一步:打开网址之后登陆帐号,然后搜索你想要的guanjianci,如“一带一路”,参照右图:
第二步:使用Fiddler 抓包软件(关于Fiddler软件介绍请查看:;keyword=Fiddler之前介绍过,这里不再讲解,也可以查看之前的东哥福利)打开软件,然后点击网页上的更多,参照右图:
然后回到抓包软件,寻找抓到的网址,参照右图
然后通过获取到的网址: ... e=content&offset=10
发现网址中的10为分页参数,并且1-20任意值代表第一个分页,11-20任意值代表第2个分页,依此类推,那换到规律,我可以从1开始,然后每次递增10,这样就是1、11、21、31……等,我们根据这样的规则设置分页参数,这里仅设置5页,如下图:
第三步:采集内容网址,通过源码剖析,发现网址是这样的“\/question\/49185959\”,如下图:
因网址中间有特殊符号,不能直接采集,我们可以这样设置规则,只采集其中的数字火车采集器v9实战,前面是固定值,变化的只有数字,然后进行网址拼接,如下图:
第四步:内容采集设置,在这里要注意的是,知乎须要设置下UA,才能进行采集火车采集器v9实战,否则将采不到内容,如何获得UA,首先打开抓包软件,然后找开要采集的内容网址页,然后抓包获得UA值,参照以下三个图:
先找到内容网址
然后两侧点击 RAW 再点击右下解的按键
然后在记事本中复制UA值 ,然后我们在采集器中打开其他设置,将UA值粘贴到UA上面,如下图:
然后回到内容采集设置,进行内容规则设置,这里没有哪些非常的难点,就不再细讲,设置好后,进行测试,如下图:
显示上图这样,就表示 设置OK了,我们可以进行采集啦! 你学会了吗?
联系我们
客服QQ:800019423
客服电话:
软件订购:
如何进行手机APP的数据爬取?
采集交流 • 优采云 发表了文章 • 0 个评论 • 517 次浏览 • 2020-05-30 08:00
作者:xiaoyu
微信公众号:Python数据科学
知乎:Python数据分析师
平时我们的爬虫多是针对网页的,但是随着手机端APP应用数目的增多,相应的爬取需求也就越来越多,因此手机端APP的数据爬取对于一名爬虫工程师来说是一项必备的技能。我们晓得手机上爬虫软件,网页爬取的时侯我常常使用F12开发者工具或则fiddler之类的工具来帮助我们剖析浏览器行为。那对于手机的APP该怎么使用呢?同样的,我们也可以使用fiddler来剖析。好了,本篇博主将会给你们介绍怎样在笔记本端使用fiddler进行手机APP的抓包。
首先了解一下fiddler(百度百科):
Fiddler是一个http合同调试代理工具,它就能记录并检测所有你的笔记本和互联网之间的http通信,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件,这些都可以使你胡乱更改的意思)。 Fiddler 要比其他的网路调试器要愈发简单,因为它不仅仅曝露http通信还提供了一个用户友好的格式。
完成此项工作的整个流程可分为如下几个步骤。
fiddler的官方下载链接:
安装步骤没哪些非常,常规下一步完成即可。
这里有两点须要说明一下。
操作很简单,打开下载好的fiddler手机上爬虫软件,找到 Tools -> Options,然后再HTTPS的工具栏下勾选Decrpt HTTPS traffic,在新弹出的选项栏下勾选Ignore server certificate errors。
相同的,在Connections选项栏下勾选Allow remote computers to connect,并记住前面的端口号8888,后面会使用到。
好了,需要的fiddler设置就配置完成了。
设置手机端之前,我们须要记住一点:电脑和手机须要在同一个网路下进行操作。
可以使用wifi或则手机热点等来完成。
假如你已然使笔记本和手机处于同一个网路下了,这时候我们须要晓得此网路的ip地址,可以在命令行输入ipconfig简单的获得,如图。
好了,下面我们开始手机端的设置。
手机APP的抓取操作对于Android和Apple系统都可用,博主使用的苹果系统,在此以苹果系统为例。
进入到手机wifi的设置界面,选择当前联接网路的更多信息,在苹果中是一个感叹号。然后在最下边你会看见HTTP代理的选项,点击步入。
进入后,填写里面记住的ip地址和端口号,确定保存。
在手机上打开浏览器输入一个里面ip地址和端口号组成的url::8888,然后点击FiddlerRoot certificate下载fiddler证书。
以上就简单完成了所有的操作,最后我们测试一下是否好用。
就以知乎APP为例,在手机上打开 知乎APP。下面是笔记本上fiddler的抓包结果。
结果没有问题,抓到信息包。然后就可以使用我们剖析网页的方式来进行后续的操作了。 查看全部
微信公众号:Python数据科学
知乎:Python数据分析师
平时我们的爬虫多是针对网页的,但是随着手机端APP应用数目的增多,相应的爬取需求也就越来越多,因此手机端APP的数据爬取对于一名爬虫工程师来说是一项必备的技能。我们晓得手机上爬虫软件,网页爬取的时侯我常常使用F12开发者工具或则fiddler之类的工具来帮助我们剖析浏览器行为。那对于手机的APP该怎么使用呢?同样的,我们也可以使用fiddler来剖析。好了,本篇博主将会给你们介绍怎样在笔记本端使用fiddler进行手机APP的抓包。
首先了解一下fiddler(百度百科):
Fiddler是一个http合同调试代理工具,它就能记录并检测所有你的笔记本和互联网之间的http通信,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件,这些都可以使你胡乱更改的意思)。 Fiddler 要比其他的网路调试器要愈发简单,因为它不仅仅曝露http通信还提供了一个用户友好的格式。
完成此项工作的整个流程可分为如下几个步骤。
fiddler的官方下载链接:
安装步骤没哪些非常,常规下一步完成即可。
这里有两点须要说明一下。
操作很简单,打开下载好的fiddler手机上爬虫软件,找到 Tools -> Options,然后再HTTPS的工具栏下勾选Decrpt HTTPS traffic,在新弹出的选项栏下勾选Ignore server certificate errors。
相同的,在Connections选项栏下勾选Allow remote computers to connect,并记住前面的端口号8888,后面会使用到。
好了,需要的fiddler设置就配置完成了。
设置手机端之前,我们须要记住一点:电脑和手机须要在同一个网路下进行操作。
可以使用wifi或则手机热点等来完成。
假如你已然使笔记本和手机处于同一个网路下了,这时候我们须要晓得此网路的ip地址,可以在命令行输入ipconfig简单的获得,如图。
好了,下面我们开始手机端的设置。
手机APP的抓取操作对于Android和Apple系统都可用,博主使用的苹果系统,在此以苹果系统为例。
进入到手机wifi的设置界面,选择当前联接网路的更多信息,在苹果中是一个感叹号。然后在最下边你会看见HTTP代理的选项,点击步入。
进入后,填写里面记住的ip地址和端口号,确定保存。
在手机上打开浏览器输入一个里面ip地址和端口号组成的url::8888,然后点击FiddlerRoot certificate下载fiddler证书。
以上就简单完成了所有的操作,最后我们测试一下是否好用。
就以知乎APP为例,在手机上打开 知乎APP。下面是笔记本上fiddler的抓包结果。
结果没有问题,抓到信息包。然后就可以使用我们剖析网页的方式来进行后续的操作了。 查看全部
作者:xiaoyu
微信公众号:Python数据科学
知乎:Python数据分析师
平时我们的爬虫多是针对网页的,但是随着手机端APP应用数目的增多,相应的爬取需求也就越来越多,因此手机端APP的数据爬取对于一名爬虫工程师来说是一项必备的技能。我们晓得手机上爬虫软件,网页爬取的时侯我常常使用F12开发者工具或则fiddler之类的工具来帮助我们剖析浏览器行为。那对于手机的APP该怎么使用呢?同样的,我们也可以使用fiddler来剖析。好了,本篇博主将会给你们介绍怎样在笔记本端使用fiddler进行手机APP的抓包。
首先了解一下fiddler(百度百科):
Fiddler是一个http合同调试代理工具,它就能记录并检测所有你的笔记本和互联网之间的http通信,设置断点,查看所有的“进出”Fiddler的数据(指cookie,html,js,css等文件,这些都可以使你胡乱更改的意思)。 Fiddler 要比其他的网路调试器要愈发简单,因为它不仅仅曝露http通信还提供了一个用户友好的格式。
完成此项工作的整个流程可分为如下几个步骤。
fiddler的官方下载链接:
安装步骤没哪些非常,常规下一步完成即可。
这里有两点须要说明一下。
操作很简单,打开下载好的fiddler手机上爬虫软件,找到 Tools -> Options,然后再HTTPS的工具栏下勾选Decrpt HTTPS traffic,在新弹出的选项栏下勾选Ignore server certificate errors。
相同的,在Connections选项栏下勾选Allow remote computers to connect,并记住前面的端口号8888,后面会使用到。
好了,需要的fiddler设置就配置完成了。
设置手机端之前,我们须要记住一点:电脑和手机须要在同一个网路下进行操作。
可以使用wifi或则手机热点等来完成。
假如你已然使笔记本和手机处于同一个网路下了,这时候我们须要晓得此网路的ip地址,可以在命令行输入ipconfig简单的获得,如图。
好了,下面我们开始手机端的设置。
手机APP的抓取操作对于Android和Apple系统都可用,博主使用的苹果系统,在此以苹果系统为例。
进入到手机wifi的设置界面,选择当前联接网路的更多信息,在苹果中是一个感叹号。然后在最下边你会看见HTTP代理的选项,点击步入。
进入后,填写里面记住的ip地址和端口号,确定保存。
在手机上打开浏览器输入一个里面ip地址和端口号组成的url::8888,然后点击FiddlerRoot certificate下载fiddler证书。
以上就简单完成了所有的操作,最后我们测试一下是否好用。
就以知乎APP为例,在手机上打开 知乎APP。下面是笔记本上fiddler的抓包结果。
结果没有问题,抓到信息包。然后就可以使用我们剖析网页的方式来进行后续的操作了。

