
excel vba 网页数据抓取
【Excel数据获取】你会用函数实现网页数据抓取吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-05-11 07:16
随着互联网的高速发展,网页数据愈发成为数据分析过程中最重要的数据来源之一。
也许正是基于这样的考量,从2013版开始,Excel新增了一个名为Web的函数类别,使用其下的函数,可以通过网页链接从Web服务器获取数据,比如股票信息、天气查询、有道翻译等等。
举个小栗子。
输入以下公式,可以将A2单元格的值进行英汉或汉英互译。
=FILTERXML(WEBSERVICE(""&A2&"&doctype=xml"),"//translation")
公式看起来很长,这主要是因为网址长度偏长的缘故,实际上该公式的结构非常简单。
它主要有3部分构成。
第1部分构建网址。
""&A2&"&doctype=xml"
这个是有道在线翻译的网页地址,包含了关键的参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml。只所以返回xml是因为FILTERXML函数可以获取XML结构化内容中的信息。
第2部分读取网址。
WEBSERVICE通过指定的网页地址从Web服务器获取数据(需要计算机联网状态)。
本例中,B2公式
=WEBSERVICE(""&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第3部分获取目标数据。
这里使用了FILTERXML函数,FILTERXML函数语法是:
FILTERXML(xml,xpath)
共有两个参数,xml参数是有效的xml格式文本,xpath参数是需要查询的目标数据在xml中的标准路径。
通过第2部分获取的xml文件内容,我们可以很直接的看到幸福的翻译结果happiness处于translation路径下(标注粉红色的部分),因此第2参数设为” //translation”。
好了,这就是星光今天和大家分享的内容,感兴趣的小伙伴可以尝试使用web函数从百度天气预报获取家乡城市的天气信息~
挥手说晚安~
The End
查看全部
【Excel数据获取】你会用函数实现网页数据抓取吗?
随着互联网的高速发展,网页数据愈发成为数据分析过程中最重要的数据来源之一。
也许正是基于这样的考量,从2013版开始,Excel新增了一个名为Web的函数类别,使用其下的函数,可以通过网页链接从Web服务器获取数据,比如股票信息、天气查询、有道翻译等等。
举个小栗子。
输入以下公式,可以将A2单元格的值进行英汉或汉英互译。
=FILTERXML(WEBSERVICE(""&A2&"&doctype=xml"),"//translation")
公式看起来很长,这主要是因为网址长度偏长的缘故,实际上该公式的结构非常简单。
它主要有3部分构成。
第1部分构建网址。
""&A2&"&doctype=xml"
这个是有道在线翻译的网页地址,包含了关键的参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml。只所以返回xml是因为FILTERXML函数可以获取XML结构化内容中的信息。
第2部分读取网址。
WEBSERVICE通过指定的网页地址从Web服务器获取数据(需要计算机联网状态)。
本例中,B2公式
=WEBSERVICE(""&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第3部分获取目标数据。
这里使用了FILTERXML函数,FILTERXML函数语法是:
FILTERXML(xml,xpath)
共有两个参数,xml参数是有效的xml格式文本,xpath参数是需要查询的目标数据在xml中的标准路径。
通过第2部分获取的xml文件内容,我们可以很直接的看到幸福的翻译结果happiness处于translation路径下(标注粉红色的部分),因此第2参数设为” //translation”。
好了,这就是星光今天和大家分享的内容,感兴趣的小伙伴可以尝试使用web函数从百度天气预报获取家乡城市的天气信息~
挥手说晚安~
The End
使用Excel VBA + Firefox抓取电商数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-05-08 22:14
本文阐述基本思路和关键技术,仅供讨论学习。
长文且艰,慎入。
1)为什么使用Excel VBA + Firefox
免去搭建python编程环境的麻烦。
免去租用爬虫服务器的成本。
有一定的HTML和VB语言基础就很容易上手。
另外,笔者偏好Excel VBA的编程环境。
2)获取销售链接
这个很简单,批量导出即可。结果是N个产品的销售链接。
3)价格数据抓取
笔者的策略是直接抓取第三方比价网站的数据。比价网站的数据本身是爬来的。
需要找到一个比较网站,能够以网页形式提供较长时段的动态价格图。
然后查找背后的数据源,大致有两种情况,一是直接在网页源代码中提供,二是以数据包(如json)形式提供。
前者容易发现,直接在商品页面提取就可以了,关键是找到唯一标识。
后者则需要通过firefox控制台监控得到,需要获取真实网络地址。部分网站设置了秘钥(token),如果是完全的动态秘钥,算法难以破解,则只能放弃;如果是静态秘钥,即每次访问秘钥都相同,或者大部分字符相同,少部分字符不同但不影响访问结果,则可尝试以下方法:先在网页中查找秘钥函数代入的必要参数,然后使用firefox的Greasemonkey插件,在动态网页批量计算秘钥(直接调用计算函数,然后动态植入一个文本框呈现计算结果),拼接后批量生成网址,结果是对应N个销售链接的比价网站价格数据实际地址。
最后,在Excel中用VBA做一个下载提取数据的循环,大致有两种方法:一是采用WebBrowser的innerhtml获取,好处是能够先看到网页的情况,便于调试;缺点是需要做窗体,而且内寸很快占满。如果计算机性能较差,需要做成Excel VBA的AutoOpen(),每下载一定数量就自动退出释放内存,并配合控制Excel反复启动的宏处理软件完成(也许有其他释放内存的方法,但笔者一直没有找到,在循环中unload窗体也无效)。其中,json文件需要注册格式避免出现另存为对话框,另外也要注意使用的IE内核版本。二是调用URLDownloadToFile,缺点是如果出错就没有文件保存下来,也不知道具体为啥,好处是速度快。
4)商品详情数据抓取
基本上都是网页中直接提供的,获取思路同前述价格数据抓取中直接在网页源代码提供的情况。
部分网站以“div id=”的形式给出,这种最简单,因为id都是唯一的。如果没有id,只能用规律性的html代码来作为识别标记。需要注意电商网站中,自营和第三方入驻的,有货或下架的等等之间可能标记会不同,需要调试一定数量。 查看全部
使用Excel VBA + Firefox抓取电商数据
本文阐述基本思路和关键技术,仅供讨论学习。
长文且艰,慎入。
1)为什么使用Excel VBA + Firefox
免去搭建python编程环境的麻烦。
免去租用爬虫服务器的成本。
有一定的HTML和VB语言基础就很容易上手。
另外,笔者偏好Excel VBA的编程环境。
2)获取销售链接
这个很简单,批量导出即可。结果是N个产品的销售链接。
3)价格数据抓取
笔者的策略是直接抓取第三方比价网站的数据。比价网站的数据本身是爬来的。
需要找到一个比较网站,能够以网页形式提供较长时段的动态价格图。
然后查找背后的数据源,大致有两种情况,一是直接在网页源代码中提供,二是以数据包(如json)形式提供。
前者容易发现,直接在商品页面提取就可以了,关键是找到唯一标识。
后者则需要通过firefox控制台监控得到,需要获取真实网络地址。部分网站设置了秘钥(token),如果是完全的动态秘钥,算法难以破解,则只能放弃;如果是静态秘钥,即每次访问秘钥都相同,或者大部分字符相同,少部分字符不同但不影响访问结果,则可尝试以下方法:先在网页中查找秘钥函数代入的必要参数,然后使用firefox的Greasemonkey插件,在动态网页批量计算秘钥(直接调用计算函数,然后动态植入一个文本框呈现计算结果),拼接后批量生成网址,结果是对应N个销售链接的比价网站价格数据实际地址。
最后,在Excel中用VBA做一个下载提取数据的循环,大致有两种方法:一是采用WebBrowser的innerhtml获取,好处是能够先看到网页的情况,便于调试;缺点是需要做窗体,而且内寸很快占满。如果计算机性能较差,需要做成Excel VBA的AutoOpen(),每下载一定数量就自动退出释放内存,并配合控制Excel反复启动的宏处理软件完成(也许有其他释放内存的方法,但笔者一直没有找到,在循环中unload窗体也无效)。其中,json文件需要注册格式避免出现另存为对话框,另外也要注意使用的IE内核版本。二是调用URLDownloadToFile,缺点是如果出错就没有文件保存下来,也不知道具体为啥,好处是速度快。
4)商品详情数据抓取
基本上都是网页中直接提供的,获取思路同前述价格数据抓取中直接在网页源代码提供的情况。
部分网站以“div id=”的形式给出,这种最简单,因为id都是唯一的。如果没有id,只能用规律性的html代码来作为识别标记。需要注意电商网站中,自营和第三方入驻的,有货或下架的等等之间可能标记会不同,需要调试一定数量。
VBA网抓股票历史数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-05-07 08:33
【分享成果,随喜正能量】学会宽容,严以律己,宽以待人。对自己,不要太放纵,对别人,不要太苛刻。人与人之间都是相互的,如果你自己做不到,就没有理由去过分要求别人。在努力做好自己的同时,学会给别人多一些宽容,世界会因此变得更加温暖。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题六“VBA中利用XMLHTTP完成网抓数据”的第7讲:VBA网抓股票历史数据
第七节 利用XMLHTTP抓取网易财经股票历史数据大家好,我们继续网抓数据的讲解,这讲的内容更为实用,我们讲解某支股票历史数据的抓取,对于玩股票的朋友而言,股票的信息有开盘价、最高价、最低价、收盘价、涨跌额、涨跌幅(%)、成交量(手)、成交金额(万元)、振幅(%)、换手率(%),因人而异关注点也是不同的,有人关注资金的流入和流出,有的人关注换手率的多少,当无论你关注什么数据,都希望这些数据不是停留在看板上,而是在我们的EXCEL表格中,然后进行有的放矢的分析。如何把这些数据从网页上抓取处理呢?
实现场景:从网页的数据中提取给定股票的信息到EXCEL表格中,这些信息包括某一段时间的开盘价、最高价、最低价、收盘价、涨跌额、涨跌幅(%)、成交量(手)、成交金额(万元)、振幅(%)、换手率(%)。如下图,要提取出“601899”股票的20年第二季度的数据。
1 应用XMLHTTP实现网抓股票数据的思路分析我们首先仍是建立应用CreateObject("MSXML2.XMLHTTP")和CreateObject("htmlfile")第二个应用用于处理提取出来的网页数据,然后我们在“网易财经”的网址上抓取数据网易财经”的网址:" & 股票名称。抓取时利用 .Open "GET", strURL, False 及 .send 的命令,数据返回时将.responseText赋给第二个引用innerHTML属性。innerHTML 属性返回表格行的开始和结束标签之间的 HTML。提取完数据后我们利用循环语句来提取数据。在循环语句中我们要有行和列的区分,逐一提取行列的数据。在网页表格处理的时候,我们可以利用遍历的方法。可以用类似于工作表的行:Rows,单元格:Cells 的表述方案。最后要记得内存的释放。2 应用XMLHTTP实现网抓股票数据的代码实现下面我们看实现上述思路的代码部分,我直接给出了我的代码:
Sub myNZE() '网易财经股票历史数据的抓取 [代码见教程]End Sub
代码截图:
代码解读:1) Set objXMLHTTP = CreateObject("MSXML2.XMLHTTP")Set objDOM = CreateObject("htmlfile") 上述代码建立了两个引用。2) GPCode = Cells(1, 4).Value GPY= Cells(2, 4).ValueGPJ = Cells(3, 4).Value 上述代码提取股票的名称,历史数据的年,季度。3) strURL = "" & GPCode strURL= strURL & ".html?year=" & GPY strURL= strURL & "&season=" & GPJ 建立网址的代码。4)With objXMLHTTP .Open"GET", strURL, False .send objDOM.body.innerHTML= .responseTextEnd With上述代码从网页中提取数据,并将数据赋值给objDOM.body.innerHTML ,objDOM是我们建立的第二个引用对象。5)For Each objTR In objTable.Rows HRow= HRow + 1 LCol= 0 ForEach objCell In objTR.Cells LCol= LCol + 1 Cells(HRow+ 4, LCol) = objCell.innerText NextobjCellNext上述代码是从("TABLE")(3)中提取数据到工作表中。6) Set objXMLHTTP = Nothing SetobjDOM = Nothing SetobjTable = Nothing SetobjTR = Nothing SetobjCell = Nothing上述代码是释放内存。3 应用XMLHTTP实现网抓股票数据的实现效果最后,我们点击运行按钮,看看随后的实现效果:
将这种数据提取到工作表中后,我们就可以做数据分析处理了。确实,我们在股票分析的时候也非常需要这种数据的提取。
本节知识点回向:
如何提取网页股票的历史数据到工作表中?这种方案和之前的哪节知识点类似?
本讲参考程序文件:006工作表.XLSM
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】:学会高傲,任何时候,都不要妄自菲薄。你要知道,世界不会放弃你,只有你会放弃自己。每一个女人都要适当保持高傲,这并不是过分看高自己,而是给自己一份自信和勇气。毕竟,这个世界,对女人来说,总还是有点不够温柔。 查看全部
VBA网抓股票历史数据
【分享成果,随喜正能量】学会宽容,严以律己,宽以待人。对自己,不要太放纵,对别人,不要太苛刻。人与人之间都是相互的,如果你自己做不到,就没有理由去过分要求别人。在努力做好自己的同时,学会给别人多一些宽容,世界会因此变得更加温暖。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题六“VBA中利用XMLHTTP完成网抓数据”的第7讲:VBA网抓股票历史数据
第七节 利用XMLHTTP抓取网易财经股票历史数据大家好,我们继续网抓数据的讲解,这讲的内容更为实用,我们讲解某支股票历史数据的抓取,对于玩股票的朋友而言,股票的信息有开盘价、最高价、最低价、收盘价、涨跌额、涨跌幅(%)、成交量(手)、成交金额(万元)、振幅(%)、换手率(%),因人而异关注点也是不同的,有人关注资金的流入和流出,有的人关注换手率的多少,当无论你关注什么数据,都希望这些数据不是停留在看板上,而是在我们的EXCEL表格中,然后进行有的放矢的分析。如何把这些数据从网页上抓取处理呢?
实现场景:从网页的数据中提取给定股票的信息到EXCEL表格中,这些信息包括某一段时间的开盘价、最高价、最低价、收盘价、涨跌额、涨跌幅(%)、成交量(手)、成交金额(万元)、振幅(%)、换手率(%)。如下图,要提取出“601899”股票的20年第二季度的数据。
1 应用XMLHTTP实现网抓股票数据的思路分析我们首先仍是建立应用CreateObject("MSXML2.XMLHTTP")和CreateObject("htmlfile")第二个应用用于处理提取出来的网页数据,然后我们在“网易财经”的网址上抓取数据网易财经”的网址:" & 股票名称。抓取时利用 .Open "GET", strURL, False 及 .send 的命令,数据返回时将.responseText赋给第二个引用innerHTML属性。innerHTML 属性返回表格行的开始和结束标签之间的 HTML。提取完数据后我们利用循环语句来提取数据。在循环语句中我们要有行和列的区分,逐一提取行列的数据。在网页表格处理的时候,我们可以利用遍历的方法。可以用类似于工作表的行:Rows,单元格:Cells 的表述方案。最后要记得内存的释放。2 应用XMLHTTP实现网抓股票数据的代码实现下面我们看实现上述思路的代码部分,我直接给出了我的代码:
Sub myNZE() '网易财经股票历史数据的抓取 [代码见教程]End Sub
代码截图:
代码解读:1) Set objXMLHTTP = CreateObject("MSXML2.XMLHTTP")Set objDOM = CreateObject("htmlfile") 上述代码建立了两个引用。2) GPCode = Cells(1, 4).Value GPY= Cells(2, 4).ValueGPJ = Cells(3, 4).Value 上述代码提取股票的名称,历史数据的年,季度。3) strURL = "" & GPCode strURL= strURL & ".html?year=" & GPY strURL= strURL & "&season=" & GPJ 建立网址的代码。4)With objXMLHTTP .Open"GET", strURL, False .send objDOM.body.innerHTML= .responseTextEnd With上述代码从网页中提取数据,并将数据赋值给objDOM.body.innerHTML ,objDOM是我们建立的第二个引用对象。5)For Each objTR In objTable.Rows HRow= HRow + 1 LCol= 0 ForEach objCell In objTR.Cells LCol= LCol + 1 Cells(HRow+ 4, LCol) = objCell.innerText NextobjCellNext上述代码是从("TABLE")(3)中提取数据到工作表中。6) Set objXMLHTTP = Nothing SetobjDOM = Nothing SetobjTable = Nothing SetobjTR = Nothing SetobjCell = Nothing上述代码是释放内存。3 应用XMLHTTP实现网抓股票数据的实现效果最后,我们点击运行按钮,看看随后的实现效果:
将这种数据提取到工作表中后,我们就可以做数据分析处理了。确实,我们在股票分析的时候也非常需要这种数据的提取。
本节知识点回向:
如何提取网页股票的历史数据到工作表中?这种方案和之前的哪节知识点类似?
本讲参考程序文件:006工作表.XLSM
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】:学会高傲,任何时候,都不要妄自菲薄。你要知道,世界不会放弃你,只有你会放弃自己。每一个女人都要适当保持高傲,这并不是过分看高自己,而是给自己一份自信和勇气。毕竟,这个世界,对女人来说,总还是有点不够温柔。
VBA利用IE,抓取深市股票涨跌数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 523 次浏览 • 2022-05-05 07:13
大家好,我们今日讲解“VBA信息获取与处理”教程中第九个专题“利用IE抓取网络数据”的第三节“利用IE,抓取深市股票涨跌数据”,这个专题是非常有用的知识点,希望大家掌握。第三节 利用IE,抓取深市股票涨跌数据大家好,这讲讲解的是利用IE,抓取深市股票涨跌数据,利用的方法和上一讲基本类似,主要是给大家介绍一种实用的场景,供大家选择利用。实用场景:在玩股票的时候,经常要看每天股票涨幅领头的股票,以便分析各种对应,要求利用IE实现提取某网站股票的领涨股票数据,将这些数据放到工作表中以备选查看。选择的网址是: 即搜狐网的数据。1 应用IE实现抓取深市股票涨跌数据的思路分析为了实现上述的场景,我们先看一看提供网页的信息:
上述的网页中,我要提取的是红色框框起来表的数据,我们进行一下思路的分析:首先要建立一个IE对象,然后将网页文档提取出来,在网页文档上提取第二个表的数据,即可。提取表数据的时候可以模拟真正工作表的行列循环,依次提取数据,在我之前的讲解中提到myTR.Cells.Length是指单元格的个数,Cells(j).innertext是指单元格的内容。这两点在写代码的时候要注意。另外,在抓取网页文档的表时可以采用getElementsByTagName("TABLE")(2)的方法,这种方法是查找数据是返回包含带有指定标签名称的所有元素的节点列表。在之前的讲解中我一共讲了三种类似的方法,如下getElementById(id) 获取带有指定 id 的节点(元素)getElementsByTagName() 返回包含带有指定标签名称的所有元素的节点列表(集合/节点数组)。getElementsByClassName() 返回包含带有指定类名的所有元素的节点列表。
ByTagName 是上述的第二种方法,利用较多的还有第一种。2 应用IE实现抓取深市股票涨跌数据的代码实现为了实现上述的思路,我给出了下面的代码:Sub myNZA() '利用IE,抓取深市股票涨跌数据 Sheets("SHEET2").Select DimIE, IEDOM As Object DimmyTable, myTR As Object SetIE = CreateObject("InternetExplorer.Application") WithIE .Visible= False .navigate"" DoUntil .readystate = 4 DoEvents Loop SetIEDOM = .document EndWith Cells.ClearContents SetmyTable = IEDOM.getElementsByTagName("TABLE")(2) ForEach myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext Next Next SetIE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing MsgBox"ok!"End Sub
代码的讲解:1)Set IE = CreateObject("InternetExplorer.Application") 建立IE 的引用。2).Visible = False .navigate"" DoUntil .readystate = 4 DoEvents Loop上述代码令浏览器可见,加载网址,一直到加载完成,其中的DoEvents 是避免软死机的现象出现。3)Set IEDOM = .document 提出网页文档数据4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格5)For Each myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext NextNext提取表格的数据到工作表。6)Set IE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing回收内存。对于回收内存的操作,建议大家利用,在大型的程序中,尤其是注意这点,内存占用过多会导致程序运行减缓。如果不释放内存就只能到END SUB时候再释放了,内存会不足。
代码截图:
通过上述的代码,就可以完成我们的思路。
3 应用IE实现抓取深市股票涨跌数据的实现效果当我们点击运行按钮,如图的箭头所示,程序就会开始运行,抓取网页数据到工作表中
从而验证了我们思路的正确。
本节知识点回向:如何在页面文档中提取表的数据?本节内容参考:009工作表.xlsm
积木编程的思路内涵:在我的系列书籍中一直在强调“搭积木”的编程思路,这也是学习利用VBA的主要方法,特别是职场人员,更是要采用这种方案。其主要的内涵:1 代码不要自己全部的录入。你要做的是把积木放在合适的位置然后去修正代码,一定要拷贝,从你的积木库中去拷贝,然后修正代码,把时间利用到高效的思考上。2 建立自己的“积木库”。平时在学习过程中,把自己认为有用的代码放在一起,多积累,在用到的时候,可以随时拿来。你的积木库资料越多,你做程序的思路就会越广。
VBA的应用界定VBA是利用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA的应用界定。在取代OFFICE新的办公软件没有到来之前,谁能在数据处理方面做到极致,谁就是王者。其中登峰至极的技能非VBA莫属!我记得20年前自己初学VBA时,那时的资料甚少,只能看源码自己琢磨,真的很难。20年过去了,为了不让学习VBA的朋友重复我之前的经历,我根据自己多年VBA实际利用经验,推出了六部VBA专门教程:第一套:VBA代码解决方案是VBA中各个知识点的讲解,教程共147讲,覆盖绝大多数的VBA知识点,初学必备;第二套:VBA数据库解决方案 数据库是数据处理的专业利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法和实例操作,适合中级人员的学习。第三套:VBA数组与字典解决方案 数组和字典是VBA的精华,字典是VBA代码水平提高的有效手段,值得深入的学习,是初级及中级人员代码精进的手段。第四套:VBA代码解决方案之视频是专门面向初学者的视频讲解,可以快速入门,更快的掌握这门技能。这套教程是第一套教程的视频讲解,听元音更易接受。第五套:VBA中类的解读和利用 这是一部高级教程,讲解类的虚无与肉身的度化,类的利用虽然较少,但仔细的学习可以促进自己VBA理论的提高。这套教程的领会主要是读者的领悟了,领悟一种佛学的哲理。第六套教程:《VBA信息获取与处理》,这是一部高级教程,涉及范围更广,实用性更强,面向中高级人员。教程共二十个专题,包括:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪切板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。大家可以根据以上资料1→3→2→6→5或者是4→3→2→6→5的顺序逐渐深入的逐渐学习。教程提供讲解的同时提供了大量的积木,如需要可以WeChat: NZ9668
学习VBA是个过程,也需要经历一种枯燥的感觉如太白诗云:众鸟高飞尽,孤云独去闲。相看两不厌,只有敬亭山。学习的过程也是修心的过程,修一个平静的心。在代码的世界中,心平静了,心情好了,身体自然而然就好。心静则正,内心里没有那么多邪知邪见,也就没有那么多妄想。利人就是利己。这些教程也是为帮助大家起航,助上我自己之力,我的上述教程是我多的经验的传递,“水善利万物而不争”,绵绵密密,微则无声,巨则汹涌。学习亦如此,知道什么是自己所需要的,不要蜷缩在一小块自认为天堂的世界里,待到暮年时再去做自欺欺人的言论。要努力提高自己,用一颗充满生机的心灵,把握现在,这才是进取。越是有意义的事情,困难会越多。愿力决定始终,智慧决定成败。不管遇到什么,都是风景。看淡纷争,看轻得失。茶,满也好,少也好,不要计较;浓也好,淡也好,其中自有值得品的味道。去感悟真实的时间,静下心,多学习,积累福报。而不是天天混日子,也不是天天熬日子。在后疫情更加严峻的存量残杀世界中,为自己的生存进行知识的储备,特别是新知识的储备。学习时微而无声,利用时则巨则汹涌。每一分收获都是成长的记录,怎无凭,正是这种执着,成就了朝霞的灿烂。最后将一阙词送给致力于VBA学习的朋友,让大家感受一下学习过程的枯燥与执着:
浮云掠过,暗语无声,唯有清风,惊了梦中啼莺。望星,疏移北斗,奈将往事雁同行。阡陌人,昏灯明暗,忍顾长亭。 多少VBA人,暗夜中,悄声寻梦,盼却天明。怎无凭!
回向学习利用VBA的历历往事,不胜感慨,谨以这些文字给大家,分享我多年工作实际经验的成果,随喜这些有用的东西,给确实需要利用VBA的同路人。 查看全部
VBA利用IE,抓取深市股票涨跌数据
大家好,我们今日讲解“VBA信息获取与处理”教程中第九个专题“利用IE抓取网络数据”的第三节“利用IE,抓取深市股票涨跌数据”,这个专题是非常有用的知识点,希望大家掌握。第三节 利用IE,抓取深市股票涨跌数据大家好,这讲讲解的是利用IE,抓取深市股票涨跌数据,利用的方法和上一讲基本类似,主要是给大家介绍一种实用的场景,供大家选择利用。实用场景:在玩股票的时候,经常要看每天股票涨幅领头的股票,以便分析各种对应,要求利用IE实现提取某网站股票的领涨股票数据,将这些数据放到工作表中以备选查看。选择的网址是: 即搜狐网的数据。1 应用IE实现抓取深市股票涨跌数据的思路分析为了实现上述的场景,我们先看一看提供网页的信息:
上述的网页中,我要提取的是红色框框起来表的数据,我们进行一下思路的分析:首先要建立一个IE对象,然后将网页文档提取出来,在网页文档上提取第二个表的数据,即可。提取表数据的时候可以模拟真正工作表的行列循环,依次提取数据,在我之前的讲解中提到myTR.Cells.Length是指单元格的个数,Cells(j).innertext是指单元格的内容。这两点在写代码的时候要注意。另外,在抓取网页文档的表时可以采用getElementsByTagName("TABLE")(2)的方法,这种方法是查找数据是返回包含带有指定标签名称的所有元素的节点列表。在之前的讲解中我一共讲了三种类似的方法,如下getElementById(id) 获取带有指定 id 的节点(元素)getElementsByTagName() 返回包含带有指定标签名称的所有元素的节点列表(集合/节点数组)。getElementsByClassName() 返回包含带有指定类名的所有元素的节点列表。
ByTagName 是上述的第二种方法,利用较多的还有第一种。2 应用IE实现抓取深市股票涨跌数据的代码实现为了实现上述的思路,我给出了下面的代码:Sub myNZA() '利用IE,抓取深市股票涨跌数据 Sheets("SHEET2").Select DimIE, IEDOM As Object DimmyTable, myTR As Object SetIE = CreateObject("InternetExplorer.Application") WithIE .Visible= False .navigate"" DoUntil .readystate = 4 DoEvents Loop SetIEDOM = .document EndWith Cells.ClearContents SetmyTable = IEDOM.getElementsByTagName("TABLE")(2) ForEach myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext Next Next SetIE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing MsgBox"ok!"End Sub
代码的讲解:1)Set IE = CreateObject("InternetExplorer.Application") 建立IE 的引用。2).Visible = False .navigate"" DoUntil .readystate = 4 DoEvents Loop上述代码令浏览器可见,加载网址,一直到加载完成,其中的DoEvents 是避免软死机的现象出现。3)Set IEDOM = .document 提出网页文档数据4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格5)For Each myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext NextNext提取表格的数据到工作表。6)Set IE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing回收内存。对于回收内存的操作,建议大家利用,在大型的程序中,尤其是注意这点,内存占用过多会导致程序运行减缓。如果不释放内存就只能到END SUB时候再释放了,内存会不足。
代码截图:
通过上述的代码,就可以完成我们的思路。
3 应用IE实现抓取深市股票涨跌数据的实现效果当我们点击运行按钮,如图的箭头所示,程序就会开始运行,抓取网页数据到工作表中
从而验证了我们思路的正确。
本节知识点回向:如何在页面文档中提取表的数据?本节内容参考:009工作表.xlsm
积木编程的思路内涵:在我的系列书籍中一直在强调“搭积木”的编程思路,这也是学习利用VBA的主要方法,特别是职场人员,更是要采用这种方案。其主要的内涵:1 代码不要自己全部的录入。你要做的是把积木放在合适的位置然后去修正代码,一定要拷贝,从你的积木库中去拷贝,然后修正代码,把时间利用到高效的思考上。2 建立自己的“积木库”。平时在学习过程中,把自己认为有用的代码放在一起,多积累,在用到的时候,可以随时拿来。你的积木库资料越多,你做程序的思路就会越广。
VBA的应用界定VBA是利用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA的应用界定。在取代OFFICE新的办公软件没有到来之前,谁能在数据处理方面做到极致,谁就是王者。其中登峰至极的技能非VBA莫属!我记得20年前自己初学VBA时,那时的资料甚少,只能看源码自己琢磨,真的很难。20年过去了,为了不让学习VBA的朋友重复我之前的经历,我根据自己多年VBA实际利用经验,推出了六部VBA专门教程:第一套:VBA代码解决方案是VBA中各个知识点的讲解,教程共147讲,覆盖绝大多数的VBA知识点,初学必备;第二套:VBA数据库解决方案 数据库是数据处理的专业利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法和实例操作,适合中级人员的学习。第三套:VBA数组与字典解决方案 数组和字典是VBA的精华,字典是VBA代码水平提高的有效手段,值得深入的学习,是初级及中级人员代码精进的手段。第四套:VBA代码解决方案之视频是专门面向初学者的视频讲解,可以快速入门,更快的掌握这门技能。这套教程是第一套教程的视频讲解,听元音更易接受。第五套:VBA中类的解读和利用 这是一部高级教程,讲解类的虚无与肉身的度化,类的利用虽然较少,但仔细的学习可以促进自己VBA理论的提高。这套教程的领会主要是读者的领悟了,领悟一种佛学的哲理。第六套教程:《VBA信息获取与处理》,这是一部高级教程,涉及范围更广,实用性更强,面向中高级人员。教程共二十个专题,包括:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪切板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。大家可以根据以上资料1→3→2→6→5或者是4→3→2→6→5的顺序逐渐深入的逐渐学习。教程提供讲解的同时提供了大量的积木,如需要可以WeChat: NZ9668
学习VBA是个过程,也需要经历一种枯燥的感觉如太白诗云:众鸟高飞尽,孤云独去闲。相看两不厌,只有敬亭山。学习的过程也是修心的过程,修一个平静的心。在代码的世界中,心平静了,心情好了,身体自然而然就好。心静则正,内心里没有那么多邪知邪见,也就没有那么多妄想。利人就是利己。这些教程也是为帮助大家起航,助上我自己之力,我的上述教程是我多的经验的传递,“水善利万物而不争”,绵绵密密,微则无声,巨则汹涌。学习亦如此,知道什么是自己所需要的,不要蜷缩在一小块自认为天堂的世界里,待到暮年时再去做自欺欺人的言论。要努力提高自己,用一颗充满生机的心灵,把握现在,这才是进取。越是有意义的事情,困难会越多。愿力决定始终,智慧决定成败。不管遇到什么,都是风景。看淡纷争,看轻得失。茶,满也好,少也好,不要计较;浓也好,淡也好,其中自有值得品的味道。去感悟真实的时间,静下心,多学习,积累福报。而不是天天混日子,也不是天天熬日子。在后疫情更加严峻的存量残杀世界中,为自己的生存进行知识的储备,特别是新知识的储备。学习时微而无声,利用时则巨则汹涌。每一分收获都是成长的记录,怎无凭,正是这种执着,成就了朝霞的灿烂。最后将一阙词送给致力于VBA学习的朋友,让大家感受一下学习过程的枯燥与执着:
浮云掠过,暗语无声,唯有清风,惊了梦中啼莺。望星,疏移北斗,奈将往事雁同行。阡陌人,昏灯明暗,忍顾长亭。 多少VBA人,暗夜中,悄声寻梦,盼却天明。怎无凭!
回向学习利用VBA的历历往事,不胜感慨,谨以这些文字给大家,分享我多年工作实际经验的成果,随喜这些有用的东西,给确实需要利用VBA的同路人。
excel vba 网页数据抓取 IE抓取资金主力流入的股票
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-29 03:09
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。 查看全部
excel vba 网页数据抓取 IE抓取资金主力流入的股票
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。
excel vba 网页数据抓取( Excel教程Excel函数和操作方法如何通过IE打开指定的网址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-10 08:33
Excel教程Excel函数和操作方法如何通过IE打开指定的网址
)
前言
上次通过Excel VBA的准备设置,我们已经可以用VBA打开IE了,那么如何才能顺利打开指定的网页抓取数据呢?在本节中,解释 Excel VBA 使用 IE 打开指定的 URL。
操作IE打开指定的URL,需要使用InernetExplorer对象的[Navigate(导航的意思)]方法。
当然,Navigate 可以导航到指定的网址(url),如果网页完全读取并处于待机状态,则需要其他方法。在这里,我将通过一个例子来详细解释它,并且易于理解。
下面是通过IE打开指定URL的网页的过程(这里用今天的头条首页[]来演示)
定义变量创建IE动作对象打开并显示IE打开指定URL并等待页面被完全读取
在编辑区输入以下代码,运行,显示结果如下。
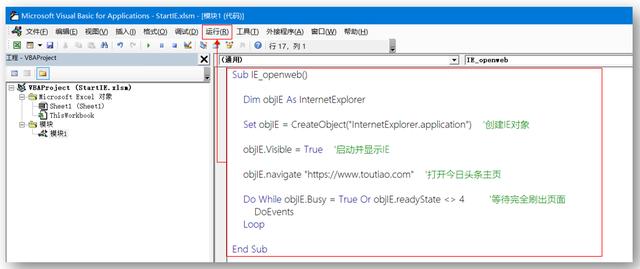
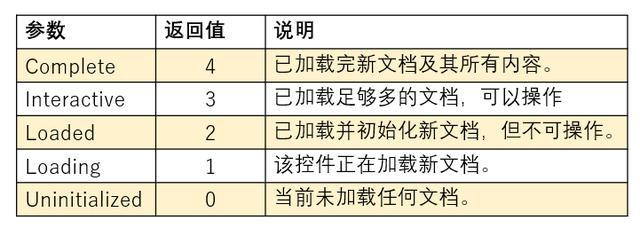
Sub IE_openweb() Dim objIE As InternetExplorer Set objIE = CreateObject("InternetExplorer.application") '创建IE对 objIE.Visible = True '启动并显示IE objIE.navigate "https://www.toutiao.com" '打开今日头条主页 Do While objIE.Busy = True Or objIE.readyState 4 '等待完全刷出页面 DoEvents Loop End Sub
VBE中输入代码显示
运行结果
运行结果打开【今日头条】首页
这样,Excel VBA通过IE打开了今日头条的主页。你打开了吗?
有几个新的功能和方法,需要说明,请耐心等待。
请参阅 VBA 帮助文档
以上就是如何使用Excel VBA通过IE打开指定网址,并讲解了几个功能和操作方法。
在网络爬虫中,这一步是必不可少的。因此,您必须了解并能够熟练使用它。
查看全部
excel vba 网页数据抓取(
Excel教程Excel函数和操作方法如何通过IE打开指定的网址
)


前言
上次通过Excel VBA的准备设置,我们已经可以用VBA打开IE了,那么如何才能顺利打开指定的网页抓取数据呢?在本节中,解释 Excel VBA 使用 IE 打开指定的 URL。
操作IE打开指定的URL,需要使用InernetExplorer对象的[Navigate(导航的意思)]方法。
当然,Navigate 可以导航到指定的网址(url),如果网页完全读取并处于待机状态,则需要其他方法。在这里,我将通过一个例子来详细解释它,并且易于理解。
下面是通过IE打开指定URL的网页的过程(这里用今天的头条首页[]来演示)
定义变量创建IE动作对象打开并显示IE打开指定URL并等待页面被完全读取
在编辑区输入以下代码,运行,显示结果如下。
Sub IE_openweb() Dim objIE As InternetExplorer Set objIE = CreateObject("InternetExplorer.application") '创建IE对 objIE.Visible = True '启动并显示IE objIE.navigate "https://www.toutiao.com" '打开今日头条主页 Do While objIE.Busy = True Or objIE.readyState 4 '等待完全刷出页面 DoEvents Loop End Sub
VBE中输入代码显示
运行结果

运行结果打开【今日头条】首页
这样,Excel VBA通过IE打开了今日头条的主页。你打开了吗?
有几个新的功能和方法,需要说明,请耐心等待。
请参阅 VBA 帮助文档
以上就是如何使用Excel VBA通过IE打开指定网址,并讲解了几个功能和操作方法。
在网络爬虫中,这一步是必不可少的。因此,您必须了解并能够熟练使用它。

excel vba 网页数据抓取(如何用Excel图表炫起来?一截告诉你答案!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-10 02:12
有时表格中的数据太多,生成的图表会变得很复杂。应该是一张一眼就能看懂的图表,但此时也变得繁琐。相反,直接看表格更直观。
但在这段时间里,我一直在寻找有效的图表工具。不管是百度还是知乎,基本都是用Excel图表制作的。各种大牛的教材真的很赞,我自己也在用。Excel,我做了一些测试,感觉和大咖的图表效果差别很大。深深地觉得知识真是个好东西……要成为高手,不知道要多久才能达到……
Excel虽然简单、方便、覆盖面广,但无疑是典型的数据可视化工具。我们通常使用 Excel 来制作简单的表格。它非常强大,我们可以制作一些很好的图表。但是说到可视化就差了一点,因为炫酷炫酷的效果还是需要专门高效的图表工具插件来加强的~
前段时间朋友推荐我使用Smartbi后,我发现制作表格并不太难。
是一个excel图表工具插件,可以自动采集数据、自动清洗、自动建模、自动上报。特别适合那些每天都需要更新文件数据,或者增加新文件的场景,一键刷新可以实现数据的一站式自动分析。功能很多,也很人性化,操作也很方便。
可视化可以使您的图表脱颖而出,如下所示:
或许对于大多数人来说,很难想到这种可视化,只有专业的数据分析师才能做到,而大多数人只能默默仰望星空。其实业内人士都知道,市面上有针对不同人群的可视化工具,比如Smartbi大数据分析工具,可以自由切换个人和专业,还有最新免费的云体验平台提供完整的社区后台支持。展示你,教你,何乐而不为呢?
Smartbi是一款专业的图表制作工具,常用于图表制作和图表样式设计,最终形成专业、酷炫、美观的可视化图表。Smartbi可以直接使用Excel实现各种图形效果,如柱形图、饼图、折线图、雷达图等,结合数据仓库中的动态数据进行数据展示。
第一大特点:操作简单
回想我们使用excel时的场景,复制粘贴数据、处理函数公式、生成表格和图表、设置属性、调整格式等是不是很繁琐?一旦操作完成,半天时间很快。
使用 Smartbi 图表制作工具只需 3 个步骤。首先抓取数据,可以一键连接数据库,也可以一键导入excel或txt中的数据源,然后根据数据自动生成图表或表格,最后做生成的图表。接下来简单的处理就OK了。其实软件默认的图表样式还是蛮好看的。
第二大特点:实时渲染
图表制作中经常遇到的另一个问题是数据源在很多情况下都会发生变化,例如日销售额或周营业额。老板的需求是了解周营业,下面做表的人都在苦苦挣扎。需要每周重新拉取整理数据,然后重新生成图表,那么Smartbi图表制作器是如何处理这个问题的呢?
Smartbi 图表制作工具 图表制作软件可以直接抓取数据库的数据源。这样,只要后端数据源发生变化,前端图表就会自动变化。也就是说,做周营业额报表的时候,只需要做一次,以后就不用再做,因为都是自动更新的。
第三大特点:疯狂酷炫
现代人是视觉动物。如果图表更漂亮,那将是一个很大的优势。因此,视觉也是判断一个图表制作工具的重要因素。
废话不多说,这里小编直接放一些网友使用Smartbi图表工具制作的图表。
目前,仍然有很多excel图表工具。如何做出正确的选择?首先,你应该了解这些常用的工具。只有这样,才能带来好的效果,也能方便日常操作,带来可用的工具。一个特征。
一般选择下载市场占有率较高的免费报表工具,更容易达到较好的效果。现在Smartbi近两年在BI行业口碑不错。国内BI排名前三的厂商。它不仅操作简单,而且功能强大。还有很多图形效果,比如桑基图、词云图、树图等等,在他家是不常见的。制作大数据屏、移动驾驶舱、数据仪表盘效果非常好。它的企业版由项目收费,但个人版永久免费!有兴趣的朋友试试看,好不好就知道了。 查看全部
excel vba 网页数据抓取(如何用Excel图表炫起来?一截告诉你答案!)
有时表格中的数据太多,生成的图表会变得很复杂。应该是一张一眼就能看懂的图表,但此时也变得繁琐。相反,直接看表格更直观。
但在这段时间里,我一直在寻找有效的图表工具。不管是百度还是知乎,基本都是用Excel图表制作的。各种大牛的教材真的很赞,我自己也在用。Excel,我做了一些测试,感觉和大咖的图表效果差别很大。深深地觉得知识真是个好东西……要成为高手,不知道要多久才能达到……
Excel虽然简单、方便、覆盖面广,但无疑是典型的数据可视化工具。我们通常使用 Excel 来制作简单的表格。它非常强大,我们可以制作一些很好的图表。但是说到可视化就差了一点,因为炫酷炫酷的效果还是需要专门高效的图表工具插件来加强的~
前段时间朋友推荐我使用Smartbi后,我发现制作表格并不太难。
是一个excel图表工具插件,可以自动采集数据、自动清洗、自动建模、自动上报。特别适合那些每天都需要更新文件数据,或者增加新文件的场景,一键刷新可以实现数据的一站式自动分析。功能很多,也很人性化,操作也很方便。
可视化可以使您的图表脱颖而出,如下所示:
或许对于大多数人来说,很难想到这种可视化,只有专业的数据分析师才能做到,而大多数人只能默默仰望星空。其实业内人士都知道,市面上有针对不同人群的可视化工具,比如Smartbi大数据分析工具,可以自由切换个人和专业,还有最新免费的云体验平台提供完整的社区后台支持。展示你,教你,何乐而不为呢?
Smartbi是一款专业的图表制作工具,常用于图表制作和图表样式设计,最终形成专业、酷炫、美观的可视化图表。Smartbi可以直接使用Excel实现各种图形效果,如柱形图、饼图、折线图、雷达图等,结合数据仓库中的动态数据进行数据展示。
第一大特点:操作简单
回想我们使用excel时的场景,复制粘贴数据、处理函数公式、生成表格和图表、设置属性、调整格式等是不是很繁琐?一旦操作完成,半天时间很快。
使用 Smartbi 图表制作工具只需 3 个步骤。首先抓取数据,可以一键连接数据库,也可以一键导入excel或txt中的数据源,然后根据数据自动生成图表或表格,最后做生成的图表。接下来简单的处理就OK了。其实软件默认的图表样式还是蛮好看的。

第二大特点:实时渲染
图表制作中经常遇到的另一个问题是数据源在很多情况下都会发生变化,例如日销售额或周营业额。老板的需求是了解周营业,下面做表的人都在苦苦挣扎。需要每周重新拉取整理数据,然后重新生成图表,那么Smartbi图表制作器是如何处理这个问题的呢?
Smartbi 图表制作工具 图表制作软件可以直接抓取数据库的数据源。这样,只要后端数据源发生变化,前端图表就会自动变化。也就是说,做周营业额报表的时候,只需要做一次,以后就不用再做,因为都是自动更新的。
第三大特点:疯狂酷炫
现代人是视觉动物。如果图表更漂亮,那将是一个很大的优势。因此,视觉也是判断一个图表制作工具的重要因素。
废话不多说,这里小编直接放一些网友使用Smartbi图表工具制作的图表。
目前,仍然有很多excel图表工具。如何做出正确的选择?首先,你应该了解这些常用的工具。只有这样,才能带来好的效果,也能方便日常操作,带来可用的工具。一个特征。
一般选择下载市场占有率较高的免费报表工具,更容易达到较好的效果。现在Smartbi近两年在BI行业口碑不错。国内BI排名前三的厂商。它不仅操作简单,而且功能强大。还有很多图形效果,比如桑基图、词云图、树图等等,在他家是不常见的。制作大数据屏、移动驾驶舱、数据仪表盘效果非常好。它的企业版由项目收费,但个人版永久免费!有兴趣的朋友试试看,好不好就知道了。
excel vba 网页数据抓取(【干货】一下的学习心得体会,你值得拥有!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2022-04-05 09:09
作为办公自动化的坚定实践者,经过7年的办公自动化经验,10万行VBA代码,40+实践项目的积累,我想和大家分享一下我的VBA学习心得。
VBA优势
1、办公辅助技能,大大减少人工重复操作,提高工作效率和准确性。
2、学习成本比较低,性价比高,学习快效果好,正反馈强。
3、网上有很多常用功能的现成代码,简单修改即可实现。
VBA学习心得1、一定要了解VBA的基础知识
可以买书或者看视频教程(最基本的变量、循环、数组、字典、正则、事件等都需要懂),不然不知道怎么下手别人的现成代码.
你可以找到适合你的书籍和视频,在网上都是一样的,只要你能看。我是从看我要自学的曾宪智老师的VBA教程开始的。
就这样吧,虽然Excel的版本有点老了,但是教程还是有用的。非常适合初学者学习。
比如关于range的用法,介绍的很详细,再解释一下常用的用法和例子。
2、在电脑上多做动手练习,加深印象
看完书上的讲解或者视频,一定要多上电脑,尝试一下你看过的每个知识点的例子,加深对代码的理解。如果中途遇到问题,赶紧翻书或者看教程如何利用这个知识点解决问题。并尝试再次自己输入代码,或录制宏来修改代码。这将是非常令人印象深刻的。
例如,关于动态获取小区面积的方法,最常用的方法是使用(End)。
但是如果你自己在电脑上写代码,你很可能记不住是range.end(xlup)还是range.xlup(end),还是range.end(3) , range .end(4)有什么区别。
再举一个例子,VBE 编辑器不会提示某些代码写更少的字母。对于新手来说,提出错误信息也令人困惑。
下图其实是一个超低级的错误,Worksheets拼错了一个字母e。
所以你必须自己敲代码并练习手感。光看不练,学不好。
3、学习积累常用代码示例并修改
很多VBA函数都有一个通用的代码框架,网上很多大神都分享过。我们可以把这些常用函数的VBA代码积累起来,记住这个框架,这样在实际工作场景中会更有效率,更有效率。
在你根据自己的需要改了几次之后,你会逐渐养成自己写代码的“感觉”,慢慢的你就会从输入代码变成输出代码。
比如批量操作工作簿的功能,下面的代码就是一个通用的框架:
Sub 批量操作工作簿()
Application.ScreenUpdating = False
myfile = Dir(ThisWorkbook.Path & "\*.xls*")
Do While myfile ""
If myfile ThisWorkbook.Name Then
Set wb = Workbooks.Open(ThisWorkbook.Path & "\" & myfile
(自定义功能的代码)
Else
End If
myfile = Dir
Loop
Application.ScreenUpdating = True
MsgBox "完成"
End Sub
(自定义函数的代码)这个地方是我们实际需要对工作簿进行一些操作的地方。
有了这个框架,我们可以做很多事情:
如果要合并多个工作簿,只需将上面的(自定义功能代码)替换为以下内容:
wb.worksheets(1).range("a1").usedrange.copy ThisWorkbook.Worksheets(1).range("a1")
如果要查找内容为“hello”的单元格的行号并赋值,则只需将上面的(自定义功能代码)替换为以下内容:
ThisWorkbook.Worksheets(1).Cells(a, 1) = wb.worksheets(1).Cells.Find("hello",xlValues).row
类似的例子还有很多,不用背代码也能套用很多代码。只需要多积累和整理,需要时直接使用即可。
以下是我积累整理的一些VBA示例代码,分门别类,方便日后查询和使用。可以查看具体的文章:
细胞操作
示例(1)- 批量生成工资表
示例 (5) - 快速合并 n 个具有相同值的单元格
示例(9)-批量插入,删除表中的空白行
示例(11) - 拆分单元格并自动填充
示例(12)- 如何合并多个单元格而不丢失单元格的数据?
示例(13)-自动生成序号,一键排版(列宽、行高适配等)
示例(29)- 快速实现合并单元格的填充
工作表(书)操作
示例(2) - 将工作表批量拆分为单独的文件
示例(3) - 多个工作簿的批量合并
Instance (4) - 根据已有名称批量新建表
示例(7)- 一键批量打印工作簿
示例(30)- 为多个工作表创建目录和超链接
数据汇总
示例(6)- 多张表数据一键汇总到总表
示例(19)-一键汇总不一样的表到总表
数据提取
示例(8)- 使用正则表达式进行目标提取
示例(10)- 计算同一列中出现的次数并标记它
示例(14) - 根据指定单元格的值复制并插入相同数量的行
示例(15)- 按指定字段一键过滤,获取最低价记录
示例(16) - 按指定字段批量提取内容
示例(17) - 遍历多个工作簿并将内容提取到主表
示例(18) - 一键将单列长数据均匀拆分为多列
示例(20) - 一键填写每月员工访问区域
示例(22) – 一键过滤其他工作表或工作簿中的数据
示例(24) - 一键批量查询新股(债)
示例(27) - 一键按列排序并保存单独的文件
Example (34) - 快速匹配不同名字的数据,这是vlookup做不到的
示例(36) - 一键提取网页中的表格数据
示例(37) - 快速提取手机号和归属地
字操作
示例(23) - 一键批量提取词表内容
示例(26) - 一键批量提取word文本内容
示例(28) - 批量生成word报告
示例(33) - 一键提取word中的粗体文本
数据抓取
示例(39)-一键快速查询基金信息和基金净值
示例(40)-一键快速查询基金代码
示例(41)-一键批量查询汉语拼音、部首、笔画等信息
其他
示例(25) - 班级随机滚动和播放
示例(21) - 如何快速准确地输入数据
示例(31) - 自定义 VBA 代码的快捷键
示例(32) - 批量替换隐藏的神秘字符
示例(35)-一键批量ppt转pdf
示例(38) - 批量插入图片并完美匹配单元格大小
如何在excel中快速聚合多个类别?
VBA运行后添加进度条,爽吗?
两句代码快速提高VBA操作效率
正则表达式,查找和过滤数据的强大工具,你做不到!
你也可以去这里查看这些有组织的 VBA 示例:40+ VBA 示例链接
4、善用宏录制功能
VBA 对新手最友好的方面之一是记录宏的能力。
比如你要实现一个功能,书本和视频教程讲授的案例就不涉及了。毕竟,案例不可能详尽无遗。然后就可以使用录制宏的功能了,点击录制宏,然后在录制的过程中,任何表格操作都会形成对应的VBA代码,让我们很容易知道一些函数的代码是怎么写的。
5、访问更多 vba 论坛
EH论坛是学习vba最好的论坛,到处都是宝。
如果你没有太多的时间去购物,你肯定会收获很多。 查看全部
excel vba 网页数据抓取(【干货】一下的学习心得体会,你值得拥有!!)
作为办公自动化的坚定实践者,经过7年的办公自动化经验,10万行VBA代码,40+实践项目的积累,我想和大家分享一下我的VBA学习心得。
VBA优势
1、办公辅助技能,大大减少人工重复操作,提高工作效率和准确性。
2、学习成本比较低,性价比高,学习快效果好,正反馈强。
3、网上有很多常用功能的现成代码,简单修改即可实现。
VBA学习心得1、一定要了解VBA的基础知识
可以买书或者看视频教程(最基本的变量、循环、数组、字典、正则、事件等都需要懂),不然不知道怎么下手别人的现成代码.
你可以找到适合你的书籍和视频,在网上都是一样的,只要你能看。我是从看我要自学的曾宪智老师的VBA教程开始的。

就这样吧,虽然Excel的版本有点老了,但是教程还是有用的。非常适合初学者学习。
比如关于range的用法,介绍的很详细,再解释一下常用的用法和例子。


2、在电脑上多做动手练习,加深印象
看完书上的讲解或者视频,一定要多上电脑,尝试一下你看过的每个知识点的例子,加深对代码的理解。如果中途遇到问题,赶紧翻书或者看教程如何利用这个知识点解决问题。并尝试再次自己输入代码,或录制宏来修改代码。这将是非常令人印象深刻的。
例如,关于动态获取小区面积的方法,最常用的方法是使用(End)。
但是如果你自己在电脑上写代码,你很可能记不住是range.end(xlup)还是range.xlup(end),还是range.end(3) , range .end(4)有什么区别。
再举一个例子,VBE 编辑器不会提示某些代码写更少的字母。对于新手来说,提出错误信息也令人困惑。
下图其实是一个超低级的错误,Worksheets拼错了一个字母e。
所以你必须自己敲代码并练习手感。光看不练,学不好。
3、学习积累常用代码示例并修改
很多VBA函数都有一个通用的代码框架,网上很多大神都分享过。我们可以把这些常用函数的VBA代码积累起来,记住这个框架,这样在实际工作场景中会更有效率,更有效率。
在你根据自己的需要改了几次之后,你会逐渐养成自己写代码的“感觉”,慢慢的你就会从输入代码变成输出代码。
比如批量操作工作簿的功能,下面的代码就是一个通用的框架:
Sub 批量操作工作簿()
Application.ScreenUpdating = False
myfile = Dir(ThisWorkbook.Path & "\*.xls*")
Do While myfile ""
If myfile ThisWorkbook.Name Then
Set wb = Workbooks.Open(ThisWorkbook.Path & "\" & myfile
(自定义功能的代码)
Else
End If
myfile = Dir
Loop
Application.ScreenUpdating = True
MsgBox "完成"
End Sub
(自定义函数的代码)这个地方是我们实际需要对工作簿进行一些操作的地方。
有了这个框架,我们可以做很多事情:
如果要合并多个工作簿,只需将上面的(自定义功能代码)替换为以下内容:
wb.worksheets(1).range("a1").usedrange.copy ThisWorkbook.Worksheets(1).range("a1")
如果要查找内容为“hello”的单元格的行号并赋值,则只需将上面的(自定义功能代码)替换为以下内容:
ThisWorkbook.Worksheets(1).Cells(a, 1) = wb.worksheets(1).Cells.Find("hello",xlValues).row
类似的例子还有很多,不用背代码也能套用很多代码。只需要多积累和整理,需要时直接使用即可。
以下是我积累整理的一些VBA示例代码,分门别类,方便日后查询和使用。可以查看具体的文章:
细胞操作
示例(1)- 批量生成工资表
示例 (5) - 快速合并 n 个具有相同值的单元格
示例(9)-批量插入,删除表中的空白行
示例(11) - 拆分单元格并自动填充
示例(12)- 如何合并多个单元格而不丢失单元格的数据?
示例(13)-自动生成序号,一键排版(列宽、行高适配等)
示例(29)- 快速实现合并单元格的填充
工作表(书)操作
示例(2) - 将工作表批量拆分为单独的文件
示例(3) - 多个工作簿的批量合并
Instance (4) - 根据已有名称批量新建表
示例(7)- 一键批量打印工作簿
示例(30)- 为多个工作表创建目录和超链接
数据汇总
示例(6)- 多张表数据一键汇总到总表
示例(19)-一键汇总不一样的表到总表
数据提取
示例(8)- 使用正则表达式进行目标提取
示例(10)- 计算同一列中出现的次数并标记它
示例(14) - 根据指定单元格的值复制并插入相同数量的行
示例(15)- 按指定字段一键过滤,获取最低价记录
示例(16) - 按指定字段批量提取内容
示例(17) - 遍历多个工作簿并将内容提取到主表
示例(18) - 一键将单列长数据均匀拆分为多列
示例(20) - 一键填写每月员工访问区域
示例(22) – 一键过滤其他工作表或工作簿中的数据
示例(24) - 一键批量查询新股(债)
示例(27) - 一键按列排序并保存单独的文件
Example (34) - 快速匹配不同名字的数据,这是vlookup做不到的
示例(36) - 一键提取网页中的表格数据
示例(37) - 快速提取手机号和归属地
字操作
示例(23) - 一键批量提取词表内容
示例(26) - 一键批量提取word文本内容
示例(28) - 批量生成word报告
示例(33) - 一键提取word中的粗体文本
数据抓取
示例(39)-一键快速查询基金信息和基金净值
示例(40)-一键快速查询基金代码
示例(41)-一键批量查询汉语拼音、部首、笔画等信息
其他
示例(25) - 班级随机滚动和播放
示例(21) - 如何快速准确地输入数据
示例(31) - 自定义 VBA 代码的快捷键
示例(32) - 批量替换隐藏的神秘字符
示例(35)-一键批量ppt转pdf
示例(38) - 批量插入图片并完美匹配单元格大小
如何在excel中快速聚合多个类别?
VBA运行后添加进度条,爽吗?
两句代码快速提高VBA操作效率
正则表达式,查找和过滤数据的强大工具,你做不到!
你也可以去这里查看这些有组织的 VBA 示例:40+ VBA 示例链接
4、善用宏录制功能
VBA 对新手最友好的方面之一是记录宏的能力。
比如你要实现一个功能,书本和视频教程讲授的案例就不涉及了。毕竟,案例不可能详尽无遗。然后就可以使用录制宏的功能了,点击录制宏,然后在录制的过程中,任何表格操作都会形成对应的VBA代码,让我们很容易知道一些函数的代码是怎么写的。
5、访问更多 vba 论坛
EH论坛是学习vba最好的论坛,到处都是宝。
如果你没有太多的时间去购物,你肯定会收获很多。
excel vba 网页数据抓取(官方版优化内容2.细节更出众,去无踪小编)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-05 09:19
EXCEL批量数据提取正式版是一款高效便捷的批量数据提取软件。可以从该位置提取数据。EXCEL批量数据提取正式版支持单元格内容全匹配、文件部分匹配等功能。
类似软件
印记
软件地址
Excel批量数据提取软件介绍
EXCEL批量数据提取是一款可以根据用户需求批量提取数据的软件。它可以帮助用户节省大量时间,而且操作非常简单。您只需要设置提取参数并保存位置即可提取数据。
EXCEL批量数据提取功能介绍
根据内容从指定文件夹中批量提取所需数据。
支持全单元格内容匹配
支持文件部分匹配
可以保护到同一个文档或创建一个新文档来保存
EXCEL批量数据提取软件特点
1)自定义数据提取、分发规则;
2)自动从不同的文件、不同的工作表中提取数据;
3)自动将一个汇总的文件数据分发到不同的文件中;
4)EXCEL批量数据抽取正式版应用广泛,所有数据抽取和分发都可以灵活使用;
5)易于使用;
EXCEL批量数据提取安装方法
在PC下载网下载EXCEL批量数据提取正式版包
解压到当前文件夹
双击打开文件夹中的应用程序
本软件为绿色软件,无需安装即可使用。
EXCEL 批量数据提取变更日志:
1.优化内容
2.细节更突出,bug都没有了
小编推荐:EXCEL批量数据提取经过多次更新优化,变得更加人性化,操作更简单。PC下载网小编亲测,推荐给大家下载。感兴趣的朋友还可以下载福昕电脑版、工资计算器、百川考试软件、人民币案例换算、知行优采云票务。 查看全部
excel vba 网页数据抓取(官方版优化内容2.细节更出众,去无踪小编)
EXCEL批量数据提取正式版是一款高效便捷的批量数据提取软件。可以从该位置提取数据。EXCEL批量数据提取正式版支持单元格内容全匹配、文件部分匹配等功能。
类似软件
印记
软件地址
Excel批量数据提取软件介绍
EXCEL批量数据提取是一款可以根据用户需求批量提取数据的软件。它可以帮助用户节省大量时间,而且操作非常简单。您只需要设置提取参数并保存位置即可提取数据。
EXCEL批量数据提取功能介绍
根据内容从指定文件夹中批量提取所需数据。
支持全单元格内容匹配
支持文件部分匹配
可以保护到同一个文档或创建一个新文档来保存
EXCEL批量数据提取软件特点
1)自定义数据提取、分发规则;
2)自动从不同的文件、不同的工作表中提取数据;
3)自动将一个汇总的文件数据分发到不同的文件中;
4)EXCEL批量数据抽取正式版应用广泛,所有数据抽取和分发都可以灵活使用;
5)易于使用;
EXCEL批量数据提取安装方法
在PC下载网下载EXCEL批量数据提取正式版包
解压到当前文件夹
双击打开文件夹中的应用程序

本软件为绿色软件,无需安装即可使用。
EXCEL 批量数据提取变更日志:
1.优化内容
2.细节更突出,bug都没有了
小编推荐:EXCEL批量数据提取经过多次更新优化,变得更加人性化,操作更简单。PC下载网小编亲测,推荐给大家下载。感兴趣的朋友还可以下载福昕电脑版、工资计算器、百川考试软件、人民币案例换算、知行优采云票务。
excel vba 网页数据抓取(如何不使用Python去爬取网页表格数据功能?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-04 11:17
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
也有一些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,获取其他数据有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W= 查看全部
excel vba 网页数据抓取(如何不使用Python去爬取网页表格数据功能?)
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
也有一些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,获取其他数据有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W=
excel vba 网页数据抓取(【分享成果,随喜正能量】这套信息获取与处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-12 07:21
【分享成果,因正能量而欢欣鼓舞】如果你喜欢感恩,你会越来越成功;如果你喜欢帮助别人,你就会拥有越来越多高尚的人;喜欢抱怨,麻烦会越来越多;如果你喜欢知足,你就会拥有越来越多的幸福;喜欢逃避 喜欢分享,朋友就会越来越多;如果你喜欢生气,你的病就会越来越多;如果你喜欢占便宜,你就会越来越贫穷;如果你喜欢给钱,你就会拥有越来越多的财富;比如,如果你享受快乐,你会越来越痛苦;如果你喜欢学习,你就会拥有越来越多的智慧。
《VBA信息获取与处理》教程是我推出的第六套教程,目前是第一次改版。这套教程定位在最高级的水平。这是针对初学者和中级的教程。本教程将为大家讲解:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split功能扩展、工作表信息等应用交互、FSO对象的使用、获取工作表和文件夹信息、图形信息获取、自定义工作表信息功能等。程序文件在32位和64位OFFICE系统上测试。它非常抽象,具有更多的研究价值。
本课程由两卷八十四讲组成。今天的内容是主题八VBA和HTML文档,内容是:HTML超文本标记语言
第 1 节 什么是 HTML 超文本标记语言
我们需要一个浏览器来上网。浏览器的作用就是将服务器返回的源代码翻译成一个生动、可见的页面给我们。其功能与VBA代码相同,需要以代码的形式表达各种逻辑关系。服务器返回的源代码是什么语言,通常称为超文本标记语言。超文本标记语言(英文:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。您可以使用 HTML 来构建您自己的 WEB 站点。HTML 在浏览器上运行并由浏览器解析。
1 超文本标记语言的作用
什么是标记语言?顾名思义,它只能用于展示,展示我们看到的网页。不是编程语言。为什么叫超文本?仔细看,这堆源码有什么特点,也就是有很多这样的文字,一般来说,我们称之为标签。我们来看看下面的源代码:
小游戏,4399小游戏,小游戏大全,双人小游戏大全 -
截屏:
网页截图:
浏览器将上面的代码翻译成我们上面的网页。
2 超文本标记语言的基本特征
超文本语言中的标签都是成对出现的,这也是这种语言的一个特点。例如:“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”。
第一个称为开始标签,第二个有一个额外的/称为结束标签。标签之间是网页的文本。比如本例中,就是我们网页的标题文字“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”。因此,标签的作用是标记文本,告诉浏览器如何显示文本。例如本例中,要求浏览器显示“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”作为网页标题。HTML 文档 = 文本 + 标记,这称为超文本。
3 超文本标记语言的一个简单例子
在上面我谈到了HTML语言是什么以及它的特点。让我们通过一个例子进一步了解他:
学习VBA语言
为了更好的掌握VBA的各个知识点,可以参考我的第一套教程:VBA代码解决方案
我们将以上几行代码输入记事本,保存为.html文件。HTML基础学习.HTML
然后正常双击文件,会是浏览器文件:
回到本节的知识点:
什么是 HTML 语言?有什么特点?
本节参考资料:HTML Basic Learning.html
我20多年的VBA实践经验,全部浓缩在以下教程中,教程学习顺序:
【分享成果,以正能量欢欣鼓舞】心修好,就会心平气和,不为琐事、挫折、不愉快而挣扎。生活一帆风顺,生活自然充满福气。的 查看全部
excel vba 网页数据抓取(【分享成果,随喜正能量】这套信息获取与处理)
【分享成果,因正能量而欢欣鼓舞】如果你喜欢感恩,你会越来越成功;如果你喜欢帮助别人,你就会拥有越来越多高尚的人;喜欢抱怨,麻烦会越来越多;如果你喜欢知足,你就会拥有越来越多的幸福;喜欢逃避 喜欢分享,朋友就会越来越多;如果你喜欢生气,你的病就会越来越多;如果你喜欢占便宜,你就会越来越贫穷;如果你喜欢给钱,你就会拥有越来越多的财富;比如,如果你享受快乐,你会越来越痛苦;如果你喜欢学习,你就会拥有越来越多的智慧。
《VBA信息获取与处理》教程是我推出的第六套教程,目前是第一次改版。这套教程定位在最高级的水平。这是针对初学者和中级的教程。本教程将为大家讲解:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split功能扩展、工作表信息等应用交互、FSO对象的使用、获取工作表和文件夹信息、图形信息获取、自定义工作表信息功能等。程序文件在32位和64位OFFICE系统上测试。它非常抽象,具有更多的研究价值。
本课程由两卷八十四讲组成。今天的内容是主题八VBA和HTML文档,内容是:HTML超文本标记语言
第 1 节 什么是 HTML 超文本标记语言
我们需要一个浏览器来上网。浏览器的作用就是将服务器返回的源代码翻译成一个生动、可见的页面给我们。其功能与VBA代码相同,需要以代码的形式表达各种逻辑关系。服务器返回的源代码是什么语言,通常称为超文本标记语言。超文本标记语言(英文:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。您可以使用 HTML 来构建您自己的 WEB 站点。HTML 在浏览器上运行并由浏览器解析。
1 超文本标记语言的作用
什么是标记语言?顾名思义,它只能用于展示,展示我们看到的网页。不是编程语言。为什么叫超文本?仔细看,这堆源码有什么特点,也就是有很多这样的文字,一般来说,我们称之为标签。我们来看看下面的源代码:
小游戏,4399小游戏,小游戏大全,双人小游戏大全 -
截屏:
网页截图:
浏览器将上面的代码翻译成我们上面的网页。
2 超文本标记语言的基本特征
超文本语言中的标签都是成对出现的,这也是这种语言的一个特点。例如:“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”。
第一个称为开始标签,第二个有一个额外的/称为结束标签。标签之间是网页的文本。比如本例中,就是我们网页的标题文字“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”。因此,标签的作用是标记文本,告诉浏览器如何显示文本。例如本例中,要求浏览器显示“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”作为网页标题。HTML 文档 = 文本 + 标记,这称为超文本。
3 超文本标记语言的一个简单例子
在上面我谈到了HTML语言是什么以及它的特点。让我们通过一个例子进一步了解他:
学习VBA语言
为了更好的掌握VBA的各个知识点,可以参考我的第一套教程:VBA代码解决方案
我们将以上几行代码输入记事本,保存为.html文件。HTML基础学习.HTML
然后正常双击文件,会是浏览器文件:
回到本节的知识点:
什么是 HTML 语言?有什么特点?
本节参考资料:HTML Basic Learning.html
我20多年的VBA实践经验,全部浓缩在以下教程中,教程学习顺序:
【分享成果,以正能量欢欣鼓舞】心修好,就会心平气和,不为琐事、挫折、不愉快而挣扎。生活一帆风顺,生活自然充满福气。的
excel vba 网页数据抓取(“VBA之EXCEL应用”的第九章“字符串(String)的操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-12 07:20
今天的内容是《VBA的EXCEL应用》第9章中的“字符串(String)的操作”。这是第四节“反向文本排序的实现”。本套教程从简单的宏录制开始,一直到表单的构建。内容丰富,案例多。每个人都可以很容易地掌握相关知识。这套教程是为初学者准备的。全书三卷十七章。都是我们在使用EXCEL过程中需要掌握的知识点。希望每个人都能掌握和使用。
第四节 文本逆向排序的实现
大家好,我们来说说逆向文本排序的实现。本章的内容是字符串函数。字符串函数可以实现很多功能。这些功能在我们平时写代码的时候可能只是少数几个应用,但这些应用确实是程序应用过程中不可缺少的一部分。为了灵活使用这些功能,我也尝试向大家介绍各种应用。
1 实现反向文本排序的场景
我们看下面的工作表界面:
在上面的工作表界面中,A列有几个字符串,要实现字符串的方向排序,比如原来是123,反是321,就是批量转换。这有时在实际代码中使用。
2 实现逆向文本排序的思路分析
为了实现文本的定向排序,我们需要使用len函数求出字符串中的字符总数,然后在所有字符之间建立一个循环,一次提取一个字符,并且排序提取是从后到前一一提取然后合并。
那么如何逐个提取字符串中的字符呢?这需要使用 mid 函数。该函数可以控制提取字符的起始位置和提取字符的个数。然后我们可以控制每次提取字符的个数为1,控制提取位置从最后一个到最后一个。一一提取。
3 逆向文本排序的代码和代码解释
我们来看下面的代码:
sub mynzD() '实现文本的方向排序操作
将 myName 调暗为字符串
我 = 1
Do While Cells(i, 1) ""
单元格(i, 2).Value = ""
我的姓名 = 单元格(我,1).Value
myLen = Len(我的名字)
对于 t = 0 至 myLen - 1
myTem = myTem & Mid(myName, (myLen - t), 1)
下一个
单元格(i, 2).Value = "'" & myTem
我的 Tem = ""
我 = 我 + 1
环形
结束子
代码截图:
代码解读:
1) Cells(i, 2).Value = "" 清空要回填的单元格
2) myName = 单元格(i, 1).Value
上面的代码将A列的单元格值放入一个变量中
3) myLen = Len(myName)
上面的代码查找单元格字符串的长度
4) 对于 t = 0 到 myLen - 1
...
下一个
上面的代码在所有字符之间创建了一个循环
5) myTem = myTem & Mid(myName, (myLen - t), 1)
上面使用Mid函数提取字符,一次一个,提取位置为(myLen - t),提取后使用“&”函数组合字符串。
6)细胞(i, 2).Value = "'" & myTem
回填得到的新字符串;在回填之前添加“'”会使单元格格式化为文本,这样做是为了将数字转换为文本。
7)myTem = ""
清除 myTem 变量以准备下一个循环。
4 文本逆向排序代码的实现效果
最后,我们看一下代码的实现:
可以看出,我们可以轻松实现文本的逆向排序。
今天的内容回来了:
1) 如何实现字符串的逆向排序?
2) 如何一次提取一个字符串?
3) 如何将单元格设置为文本格式?如何在代码中处理它?
4) 练习:如果通过将提取的每个字符填充到后续的每个单元格中来逐个分解字符串,如何实现代码?
本讲内容参考程序文件:workbook 09.xlsm 查看全部
excel vba 网页数据抓取(“VBA之EXCEL应用”的第九章“字符串(String)的操作)
今天的内容是《VBA的EXCEL应用》第9章中的“字符串(String)的操作”。这是第四节“反向文本排序的实现”。本套教程从简单的宏录制开始,一直到表单的构建。内容丰富,案例多。每个人都可以很容易地掌握相关知识。这套教程是为初学者准备的。全书三卷十七章。都是我们在使用EXCEL过程中需要掌握的知识点。希望每个人都能掌握和使用。
第四节 文本逆向排序的实现
大家好,我们来说说逆向文本排序的实现。本章的内容是字符串函数。字符串函数可以实现很多功能。这些功能在我们平时写代码的时候可能只是少数几个应用,但这些应用确实是程序应用过程中不可缺少的一部分。为了灵活使用这些功能,我也尝试向大家介绍各种应用。
1 实现反向文本排序的场景
我们看下面的工作表界面:
在上面的工作表界面中,A列有几个字符串,要实现字符串的方向排序,比如原来是123,反是321,就是批量转换。这有时在实际代码中使用。
2 实现逆向文本排序的思路分析
为了实现文本的定向排序,我们需要使用len函数求出字符串中的字符总数,然后在所有字符之间建立一个循环,一次提取一个字符,并且排序提取是从后到前一一提取然后合并。
那么如何逐个提取字符串中的字符呢?这需要使用 mid 函数。该函数可以控制提取字符的起始位置和提取字符的个数。然后我们可以控制每次提取字符的个数为1,控制提取位置从最后一个到最后一个。一一提取。
3 逆向文本排序的代码和代码解释
我们来看下面的代码:
sub mynzD() '实现文本的方向排序操作
将 myName 调暗为字符串
我 = 1
Do While Cells(i, 1) ""
单元格(i, 2).Value = ""
我的姓名 = 单元格(我,1).Value
myLen = Len(我的名字)
对于 t = 0 至 myLen - 1
myTem = myTem & Mid(myName, (myLen - t), 1)
下一个
单元格(i, 2).Value = "'" & myTem
我的 Tem = ""
我 = 我 + 1
环形
结束子
代码截图:
代码解读:
1) Cells(i, 2).Value = "" 清空要回填的单元格
2) myName = 单元格(i, 1).Value
上面的代码将A列的单元格值放入一个变量中
3) myLen = Len(myName)
上面的代码查找单元格字符串的长度
4) 对于 t = 0 到 myLen - 1
...
下一个
上面的代码在所有字符之间创建了一个循环
5) myTem = myTem & Mid(myName, (myLen - t), 1)
上面使用Mid函数提取字符,一次一个,提取位置为(myLen - t),提取后使用“&”函数组合字符串。
6)细胞(i, 2).Value = "'" & myTem
回填得到的新字符串;在回填之前添加“'”会使单元格格式化为文本,这样做是为了将数字转换为文本。
7)myTem = ""
清除 myTem 变量以准备下一个循环。
4 文本逆向排序代码的实现效果
最后,我们看一下代码的实现:
可以看出,我们可以轻松实现文本的逆向排序。
今天的内容回来了:
1) 如何实现字符串的逆向排序?
2) 如何一次提取一个字符串?
3) 如何将单元格设置为文本格式?如何在代码中处理它?
4) 练习:如果通过将提取的每个字符填充到后续的每个单元格中来逐个分解字符串,如何实现代码?
本讲内容参考程序文件:workbook 09.xlsm
excel vba 网页数据抓取(P.S.@AJAX数据库实例讲解(有时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-08 22:12
故事起源
以前有个小网站发表了几篇关于使用SAS抓取网页数据的小文章,然后在人大论坛上放了一个链接。后来因为懒,这个站就挂了,问的人一个接一个。从新获得这篇文章后
其中一个简单易懂,其他译文已由@收录翻译,链接会在文章的最后贴出。
适用性
在以下情况下,可以用同样的方法得到理论。
PS @AJAX 数据库实例 || @AJAX 数据库实例说明
文字前戏
有时候我们经常需要保存和备份一些在线数据,比如银行利率、股票报价,或者来自统计局、各种金融机构或者其他类型的网站的数据。有时这些 网站 提供历史数据,而另一些则不提供。但是我们可以每天通过SAS运行程序,获取积累的历史数据,供以后分析。下面我以收购主页上海银行同业拆借利率为例进行说明。
以下是我们要在首页的数据
当我们打开这个网页并输入网页的源代码时,我们会惊奇地发现。什么情况,主页上看到的数据在源码中找不到,是不是用了其他技术。我们来看看源码代表什么
网页布局。
按照网页的布局,最新Shibor数据的源代码应该放在一大块文字之后,他放了一句话。
这是html内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入到主页中。好,那我们打开这个页面
并查看源代码,发现该网页中存在数据,然后我们开始用SAS进行抓取。
高潮
首先介绍Filename,通过添加infile语句可以将网页作为文件导入SAS数据集。BaseSAS 中的FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。此语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入 SAS 数据集。我们知道网络数据是一种标记语言,受制于一定的规范,所有的属性设置都包括在内。所以我们用 dlm=">" 来分隔并导入到一个变量中,因为数据太杂乱,我们无法区分并导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们使用 dlm=">" 进行分隔,所以我们知道采集到的观察结果只需要以 查看全部
excel vba 网页数据抓取(P.S.@AJAX数据库实例讲解(有时))
故事起源
以前有个小网站发表了几篇关于使用SAS抓取网页数据的小文章,然后在人大论坛上放了一个链接。后来因为懒,这个站就挂了,问的人一个接一个。从新获得这篇文章后
其中一个简单易懂,其他译文已由@收录翻译,链接会在文章的最后贴出。
适用性
在以下情况下,可以用同样的方法得到理论。
PS @AJAX 数据库实例 || @AJAX 数据库实例说明
文字前戏
有时候我们经常需要保存和备份一些在线数据,比如银行利率、股票报价,或者来自统计局、各种金融机构或者其他类型的网站的数据。有时这些 网站 提供历史数据,而另一些则不提供。但是我们可以每天通过SAS运行程序,获取积累的历史数据,供以后分析。下面我以收购主页上海银行同业拆借利率为例进行说明。
以下是我们要在首页的数据

当我们打开这个网页并输入网页的源代码时,我们会惊奇地发现。什么情况,主页上看到的数据在源码中找不到,是不是用了其他技术。我们来看看源码代表什么
网页布局。
按照网页的布局,最新Shibor数据的源代码应该放在一大块文字之后,他放了一句话。
这是html内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入到主页中。好,那我们打开这个页面
并查看源代码,发现该网页中存在数据,然后我们开始用SAS进行抓取。
高潮
首先介绍Filename,通过添加infile语句可以将网页作为文件导入SAS数据集。BaseSAS 中的FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。此语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入 SAS 数据集。我们知道网络数据是一种标记语言,受制于一定的规范,所有的属性设置都包括在内。所以我们用 dlm=">" 来分隔并导入到一个变量中,因为数据太杂乱,我们无法区分并导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们使用 dlm=">" 进行分隔,所以我们知道采集到的观察结果只需要以
excel vba 网页数据抓取(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-05 21:17
附件:
原帖内容如下:
使用VBA抓取网页数据,一般可以使用Excel VBA的workbooks.open""语句打开网页,然后使用find和offset定位数据位置,然后复制到指定位置。
或者使用 QueryTableActiveSheet.QueryTables.Add(Connection:="URL;", Destination:=Range("A1"))
但是,在某些情况下,这两种方法可能并不容易实现,例如:
1.导入查询结果页面。 (每次都要先提交表单,才能拿到数据页。数据是分页的,但是每个页面的url都是一样的,没有?page=2)
2.需要提交表单或者点击链接获取数据页面。网页在IE中可以正常显示,但是如果直接用Workbooks.open或者QueryTables.add打开网址会显示超时等错误)
3.批量导入不规则 URL 的页面。 (所有要导入的页面在某个页面上都有链接,但网址不规则)
如果你熟悉html和网页脚本,你可以使用IExplorer对象打开网页,然后使用VB脚本控制网页中每个元素的行为来填写、提交表单或打开超链接,然后获取网页中每个元素的innerText来获取数据。 查看全部
excel vba 网页数据抓取(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
附件:
原帖内容如下:
使用VBA抓取网页数据,一般可以使用Excel VBA的workbooks.open""语句打开网页,然后使用find和offset定位数据位置,然后复制到指定位置。
或者使用 QueryTableActiveSheet.QueryTables.Add(Connection:="URL;", Destination:=Range("A1"))
但是,在某些情况下,这两种方法可能并不容易实现,例如:
1.导入查询结果页面。 (每次都要先提交表单,才能拿到数据页。数据是分页的,但是每个页面的url都是一样的,没有?page=2)
2.需要提交表单或者点击链接获取数据页面。网页在IE中可以正常显示,但是如果直接用Workbooks.open或者QueryTables.add打开网址会显示超时等错误)
3.批量导入不规则 URL 的页面。 (所有要导入的页面在某个页面上都有链接,但网址不规则)
如果你熟悉html和网页脚本,你可以使用IExplorer对象打开网页,然后使用VB脚本控制网页中每个元素的行为来填写、提交表单或打开超链接,然后获取网页中每个元素的innerText来获取数据。
excel vba 网页数据抓取(人人都用得上webscraper进阶教程,人人用得上数据教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-02-01 23:20
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:
最简单的数据抓取教程,人人都可以用
进阶网页爬虫教程,人人都能用
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或者滚动加载的数据不能完全抓取,比如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他变通方法,我们最终将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,就是抓取发布时间,然后放到Excel里面。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标滑动时才会显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。 查看全部
excel vba 网页数据抓取(人人都用得上webscraper进阶教程,人人用得上数据教程)
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:
最简单的数据抓取教程,人人都可以用
进阶网页爬虫教程,人人都能用
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。

另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或者滚动加载的数据不能完全抓取,比如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他变通方法,我们最终将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,就是抓取发布时间,然后放到Excel里面。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?

造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标滑动时才会显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。
excel vba 网页数据抓取( Excel教程Excel函数Excel透视表Excel电子表格Excel实用技巧Excel2010高效办公office2010Excel视频教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-31 02:09
Excel教程Excel函数Excel透视表Excel电子表格Excel实用技巧Excel2010高效办公office2010Excel视频教程
)
前言
上次通过Excel VBA的准备设置,我们已经可以使用VBA打开IE了,那么如何才能顺利打开指定的网页抓取数据呢?在本节中,解释 Excel VBA 使用 IE 打开指定的 URL。
操作IE打开指定的URL,需要使用InernetExplorer对象的[Navigate(导航的意思)]方法。
当然,Navigate 可以导航到指定的网址(url),如果网页完全读取并处于待机状态,则需要其他方法。在这里,我将通过一个例子来详细解释它,并且易于理解。
下面是通过IE打开指定URL的网页的过程(这里用今天头条[]的首页来演示)
定义变量创建IE动作对象打开并显示IE打开指定URL并等待页面被完全读取
在编辑区输入以下代码,运行,显示结果如下。
Sub IE_openweb()
Dim objIE As InternetExplorer
Set objIE = CreateObject("InternetExplorer.application") '创建IE对
objIE.Visible = True '启动并显示IE
objIE.navigate "https://www.toutiao.com" '打开今日头条主页
Do While objIE.Busy = True Or objIE.readyState 4 '等待完全刷出页面
DoEvents
Loop
End Sub
VBE中输入代码显示
运行结果
运行结果打开【今日头条】首页
这样,Excel VBA通过IE打开了今日头条的主页。你打开了吗?
有几个新的功能和方法,需要说明,请耐心等待。
请参阅 VBA 帮助文档
以上就是如何使用Excel VBA通过IE打开指定网址,并讲解了几个功能和操作方法。
在网络爬虫中,这一步是必不可少的。因此,您必须了解并能够熟练使用它。
查看全部
excel vba 网页数据抓取(
Excel教程Excel函数Excel透视表Excel电子表格Excel实用技巧Excel2010高效办公office2010Excel视频教程
)
前言
上次通过Excel VBA的准备设置,我们已经可以使用VBA打开IE了,那么如何才能顺利打开指定的网页抓取数据呢?在本节中,解释 Excel VBA 使用 IE 打开指定的 URL。
操作IE打开指定的URL,需要使用InernetExplorer对象的[Navigate(导航的意思)]方法。
当然,Navigate 可以导航到指定的网址(url),如果网页完全读取并处于待机状态,则需要其他方法。在这里,我将通过一个例子来详细解释它,并且易于理解。
下面是通过IE打开指定URL的网页的过程(这里用今天头条[]的首页来演示)
定义变量创建IE动作对象打开并显示IE打开指定URL并等待页面被完全读取
在编辑区输入以下代码,运行,显示结果如下。
Sub IE_openweb()
Dim objIE As InternetExplorer
Set objIE = CreateObject("InternetExplorer.application") '创建IE对
objIE.Visible = True '启动并显示IE
objIE.navigate "https://www.toutiao.com" '打开今日头条主页
Do While objIE.Busy = True Or objIE.readyState 4 '等待完全刷出页面
DoEvents
Loop
End Sub
VBE中输入代码显示
运行结果
运行结果打开【今日头条】首页
这样,Excel VBA通过IE打开了今日头条的主页。你打开了吗?
有几个新的功能和方法,需要说明,请耐心等待。
请参阅 VBA 帮助文档
以上就是如何使用Excel VBA通过IE打开指定网址,并讲解了几个功能和操作方法。
在网络爬虫中,这一步是必不可少的。因此,您必须了解并能够熟练使用它。
excel vba 网页数据抓取(如何在EXCEL中用正则表达式抓取网页中的信息文章链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-30 03:15
)
上一篇介绍了如何在EXCEL中使用正则表达式爬取网页中的信息,文章链接:使用EXCEL爬取网页中的信息和Python一样优雅,但是有人说,我不会知道正则表达式有没有这么难,不知道VBA怎么这么难。我不想编程。有没有更简单的方法?所以本文文章将介绍一个EXCEL插件,seotoolsforexcel。安装此插件后,即可使用Xpath抓取网页信息。
1.先打开浏览器查看,选择要抓取的元素,复制Xpath表达式,在百度首页抓取“Baidu click”四个字。同样的原则也适用于其他网页。文案下的表达式为“//*[@id="su"]”
复制 Xpth
2.安装seotoolsforexcel后,点击SeoTools选项卡-HTTP按钮-XPathOnUrl功能
XPathOnUrl
3.在弹出的XPathOnUrl属性中,“百度一一”四个字符所在的html段用“”、“.//*[@id='su']”填充,并且值为Yes,具体填充方式和爬取效果如下
XPathOnUrl 填充方法
4.点击Http设置,在弹出的Http设置对话框中,还可以定义请求头,定义认证信息,设置随机请求等,非常强大。
查看全部
excel vba 网页数据抓取(如何在EXCEL中用正则表达式抓取网页中的信息文章链接
)
上一篇介绍了如何在EXCEL中使用正则表达式爬取网页中的信息,文章链接:使用EXCEL爬取网页中的信息和Python一样优雅,但是有人说,我不会知道正则表达式有没有这么难,不知道VBA怎么这么难。我不想编程。有没有更简单的方法?所以本文文章将介绍一个EXCEL插件,seotoolsforexcel。安装此插件后,即可使用Xpath抓取网页信息。
1.先打开浏览器查看,选择要抓取的元素,复制Xpath表达式,在百度首页抓取“Baidu click”四个字。同样的原则也适用于其他网页。文案下的表达式为“//*[@id="su"]”
复制 Xpth
2.安装seotoolsforexcel后,点击SeoTools选项卡-HTTP按钮-XPathOnUrl功能
XPathOnUrl
3.在弹出的XPathOnUrl属性中,“百度一一”四个字符所在的html段用“”、“.//*[@id='su']”填充,并且值为Yes,具体填充方式和爬取效果如下
XPathOnUrl 填充方法
4.点击Http设置,在弹出的Http设置对话框中,还可以定义请求头,定义认证信息,设置随机请求等,非常强大。
excel vba 网页数据抓取(一下excel抓取数据的过程(实验环境win7+office2013))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-22 02:18
当然可以,但是使用起来不是很灵活,也没有python之类的语言可以轻松抓取数据。现在简单介绍一下excel中抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个excel文件,双击打开文件,选择“数据”->“来自网络”,如下:
2.在弹出的子窗口中输入要抓取的页面。这里以抓取页面的数据为例,点击“Go”->“Import”,如下:
3.导入成功后数据如下,我们需要的数据已经成功抓取:
4.如果要定期刷新数据,可以点击“全部刷新”->“连接属性”自定义刷新频率,默认为60分钟:
在弹出的“选择属性”窗口中,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据。总的来说,整个流程还是比较简单的,但是灵活性不是很高,而且如果页面比较复杂,抓取的数据量比较大,后期直接在excel中处理不是很方便,并且主题所有者已经知道python。, 推荐使用python直接抓取,比较灵活。Python提供了很多爬虫包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以了尽快开始。网上也有相关资料和教程。希望以上分享的内容对您有所帮助。 查看全部
excel vba 网页数据抓取(一下excel抓取数据的过程(实验环境win7+office2013))
当然可以,但是使用起来不是很灵活,也没有python之类的语言可以轻松抓取数据。现在简单介绍一下excel中抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个excel文件,双击打开文件,选择“数据”->“来自网络”,如下:
2.在弹出的子窗口中输入要抓取的页面。这里以抓取页面的数据为例,点击“Go”->“Import”,如下:
3.导入成功后数据如下,我们需要的数据已经成功抓取:
4.如果要定期刷新数据,可以点击“全部刷新”->“连接属性”自定义刷新频率,默认为60分钟:
在弹出的“选择属性”窗口中,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据。总的来说,整个流程还是比较简单的,但是灵活性不是很高,而且如果页面比较复杂,抓取的数据量比较大,后期直接在excel中处理不是很方便,并且主题所有者已经知道python。, 推荐使用python直接抓取,比较灵活。Python提供了很多爬虫包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以了尽快开始。网上也有相关资料和教程。希望以上分享的内容对您有所帮助。
excel vba 网页数据抓取(通过Python来一个拉勾网薪资调查的小爬虫(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-13 02:19
想知道用python制作爬虫并将爬取结果保存在excel中的相关内容吗?本文Data&Truth将讲解python制作爬虫并将爬取结果保存在excel中的相关知识以及一些代码示例。欢迎阅读指正,我们先来关注一下:python爬虫,一起来学习吧。
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
获取数据的方式有很多,比如正则表达式re、lxml的etree、json、bs4的BeautifulSoup都是python3获取数据的适用方法。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
相关文章 查看全部
excel vba 网页数据抓取(通过Python来一个拉勾网薪资调查的小爬虫(图))
想知道用python制作爬虫并将爬取结果保存在excel中的相关内容吗?本文Data&Truth将讲解python制作爬虫并将爬取结果保存在excel中的相关知识以及一些代码示例。欢迎阅读指正,我们先来关注一下:python爬虫,一起来学习吧。
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。

可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。

我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。

可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
获取数据的方式有很多,比如正则表达式re、lxml的etree、json、bs4的BeautifulSoup都是python3获取数据的适用方法。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:

到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
相关文章
excel vba 网页数据抓取(我试图在Excel中使用VBA来访问嵌入在网页中的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-10 15:16
我正在尝试在 Excel 中使用 VBA 来访问网页中嵌入的网页中的数据。如果表格位于非嵌入式页面上,我知道该怎么做。我也知道如何使用 VBA 导航到产品页面。我不能只是导航到嵌入式页面,也不能访问数据库,因为有一个产品 ID 查找可以将零件编号转换为 ID。
这是该页面的链接:
为了清楚起见,我会拿出一个元素的图片,但我没有 10 个代表点......
我需要从中获取信息的表是 Product Lifecycle 表。
如果我使用以下代码将页面保存为 VBA 中的 HTMLDocument,我可以在相应键下的 src 属性中看到正确的 url:
For Each cell In Selection
link = "http://support.automation.siem ... ot%3B & cell & "&caller=view"
ie.navigate link
Do
DoEvents
Loop Until ie.readyState = READYSTATE_COMPLETE
Dim doc As HTMLDocument
有没有办法用 VBA 索引这个表,或者我必须联系公司并尝试访问产品 ID,以便我可以直接导航到页面?
关于我下面的评论,这里是记录宏的代码:
ActiveCell.FormulaR1C1 = _
"http://support.automation.siem ... ot%3B
Range("F9").Select
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;http://support.automation.siem ... ot%3B _
, Destination:=Range("$F$9"))
.FieldNames = True
.RowNumbers = False
我知道在哪里可以找到字符串:URL;,但我不知道如何将其保存到变量中。 查看全部
excel vba 网页数据抓取(我试图在Excel中使用VBA来访问嵌入在网页中的数据)
我正在尝试在 Excel 中使用 VBA 来访问网页中嵌入的网页中的数据。如果表格位于非嵌入式页面上,我知道该怎么做。我也知道如何使用 VBA 导航到产品页面。我不能只是导航到嵌入式页面,也不能访问数据库,因为有一个产品 ID 查找可以将零件编号转换为 ID。
这是该页面的链接:
为了清楚起见,我会拿出一个元素的图片,但我没有 10 个代表点......
我需要从中获取信息的表是 Product Lifecycle 表。
如果我使用以下代码将页面保存为 VBA 中的 HTMLDocument,我可以在相应键下的 src 属性中看到正确的 url:
For Each cell In Selection
link = "http://support.automation.siem ... ot%3B & cell & "&caller=view"
ie.navigate link
Do
DoEvents
Loop Until ie.readyState = READYSTATE_COMPLETE
Dim doc As HTMLDocument
有没有办法用 VBA 索引这个表,或者我必须联系公司并尝试访问产品 ID,以便我可以直接导航到页面?
关于我下面的评论,这里是记录宏的代码:
ActiveCell.FormulaR1C1 = _
"http://support.automation.siem ... ot%3B
Range("F9").Select
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;http://support.automation.siem ... ot%3B _
, Destination:=Range("$F$9"))
.FieldNames = True
.RowNumbers = False
我知道在哪里可以找到字符串:URL;,但我不知道如何将其保存到变量中。
【Excel数据获取】你会用函数实现网页数据抓取吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-05-11 07:16
随着互联网的高速发展,网页数据愈发成为数据分析过程中最重要的数据来源之一。
也许正是基于这样的考量,从2013版开始,Excel新增了一个名为Web的函数类别,使用其下的函数,可以通过网页链接从Web服务器获取数据,比如股票信息、天气查询、有道翻译等等。
举个小栗子。
输入以下公式,可以将A2单元格的值进行英汉或汉英互译。
=FILTERXML(WEBSERVICE(""&A2&"&doctype=xml"),"//translation")
公式看起来很长,这主要是因为网址长度偏长的缘故,实际上该公式的结构非常简单。
它主要有3部分构成。
第1部分构建网址。
""&A2&"&doctype=xml"
这个是有道在线翻译的网页地址,包含了关键的参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml。只所以返回xml是因为FILTERXML函数可以获取XML结构化内容中的信息。
第2部分读取网址。
WEBSERVICE通过指定的网页地址从Web服务器获取数据(需要计算机联网状态)。
本例中,B2公式
=WEBSERVICE(""&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第3部分获取目标数据。
这里使用了FILTERXML函数,FILTERXML函数语法是:
FILTERXML(xml,xpath)
共有两个参数,xml参数是有效的xml格式文本,xpath参数是需要查询的目标数据在xml中的标准路径。
通过第2部分获取的xml文件内容,我们可以很直接的看到幸福的翻译结果happiness处于translation路径下(标注粉红色的部分),因此第2参数设为” //translation”。
好了,这就是星光今天和大家分享的内容,感兴趣的小伙伴可以尝试使用web函数从百度天气预报获取家乡城市的天气信息~
挥手说晚安~
The End
查看全部
【Excel数据获取】你会用函数实现网页数据抓取吗?
随着互联网的高速发展,网页数据愈发成为数据分析过程中最重要的数据来源之一。
也许正是基于这样的考量,从2013版开始,Excel新增了一个名为Web的函数类别,使用其下的函数,可以通过网页链接从Web服务器获取数据,比如股票信息、天气查询、有道翻译等等。
举个小栗子。
输入以下公式,可以将A2单元格的值进行英汉或汉英互译。
=FILTERXML(WEBSERVICE(""&A2&"&doctype=xml"),"//translation")
公式看起来很长,这主要是因为网址长度偏长的缘故,实际上该公式的结构非常简单。
它主要有3部分构成。
第1部分构建网址。
""&A2&"&doctype=xml"
这个是有道在线翻译的网页地址,包含了关键的参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml。只所以返回xml是因为FILTERXML函数可以获取XML结构化内容中的信息。
第2部分读取网址。
WEBSERVICE通过指定的网页地址从Web服务器获取数据(需要计算机联网状态)。
本例中,B2公式
=WEBSERVICE(""&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第3部分获取目标数据。
这里使用了FILTERXML函数,FILTERXML函数语法是:
FILTERXML(xml,xpath)
共有两个参数,xml参数是有效的xml格式文本,xpath参数是需要查询的目标数据在xml中的标准路径。
通过第2部分获取的xml文件内容,我们可以很直接的看到幸福的翻译结果happiness处于translation路径下(标注粉红色的部分),因此第2参数设为” //translation”。
好了,这就是星光今天和大家分享的内容,感兴趣的小伙伴可以尝试使用web函数从百度天气预报获取家乡城市的天气信息~
挥手说晚安~
The End
使用Excel VBA + Firefox抓取电商数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-05-08 22:14
本文阐述基本思路和关键技术,仅供讨论学习。
长文且艰,慎入。
1)为什么使用Excel VBA + Firefox
免去搭建python编程环境的麻烦。
免去租用爬虫服务器的成本。
有一定的HTML和VB语言基础就很容易上手。
另外,笔者偏好Excel VBA的编程环境。
2)获取销售链接
这个很简单,批量导出即可。结果是N个产品的销售链接。
3)价格数据抓取
笔者的策略是直接抓取第三方比价网站的数据。比价网站的数据本身是爬来的。
需要找到一个比较网站,能够以网页形式提供较长时段的动态价格图。
然后查找背后的数据源,大致有两种情况,一是直接在网页源代码中提供,二是以数据包(如json)形式提供。
前者容易发现,直接在商品页面提取就可以了,关键是找到唯一标识。
后者则需要通过firefox控制台监控得到,需要获取真实网络地址。部分网站设置了秘钥(token),如果是完全的动态秘钥,算法难以破解,则只能放弃;如果是静态秘钥,即每次访问秘钥都相同,或者大部分字符相同,少部分字符不同但不影响访问结果,则可尝试以下方法:先在网页中查找秘钥函数代入的必要参数,然后使用firefox的Greasemonkey插件,在动态网页批量计算秘钥(直接调用计算函数,然后动态植入一个文本框呈现计算结果),拼接后批量生成网址,结果是对应N个销售链接的比价网站价格数据实际地址。
最后,在Excel中用VBA做一个下载提取数据的循环,大致有两种方法:一是采用WebBrowser的innerhtml获取,好处是能够先看到网页的情况,便于调试;缺点是需要做窗体,而且内寸很快占满。如果计算机性能较差,需要做成Excel VBA的AutoOpen(),每下载一定数量就自动退出释放内存,并配合控制Excel反复启动的宏处理软件完成(也许有其他释放内存的方法,但笔者一直没有找到,在循环中unload窗体也无效)。其中,json文件需要注册格式避免出现另存为对话框,另外也要注意使用的IE内核版本。二是调用URLDownloadToFile,缺点是如果出错就没有文件保存下来,也不知道具体为啥,好处是速度快。
4)商品详情数据抓取
基本上都是网页中直接提供的,获取思路同前述价格数据抓取中直接在网页源代码提供的情况。
部分网站以“div id=”的形式给出,这种最简单,因为id都是唯一的。如果没有id,只能用规律性的html代码来作为识别标记。需要注意电商网站中,自营和第三方入驻的,有货或下架的等等之间可能标记会不同,需要调试一定数量。 查看全部
使用Excel VBA + Firefox抓取电商数据
本文阐述基本思路和关键技术,仅供讨论学习。
长文且艰,慎入。
1)为什么使用Excel VBA + Firefox
免去搭建python编程环境的麻烦。
免去租用爬虫服务器的成本。
有一定的HTML和VB语言基础就很容易上手。
另外,笔者偏好Excel VBA的编程环境。
2)获取销售链接
这个很简单,批量导出即可。结果是N个产品的销售链接。
3)价格数据抓取
笔者的策略是直接抓取第三方比价网站的数据。比价网站的数据本身是爬来的。
需要找到一个比较网站,能够以网页形式提供较长时段的动态价格图。
然后查找背后的数据源,大致有两种情况,一是直接在网页源代码中提供,二是以数据包(如json)形式提供。
前者容易发现,直接在商品页面提取就可以了,关键是找到唯一标识。
后者则需要通过firefox控制台监控得到,需要获取真实网络地址。部分网站设置了秘钥(token),如果是完全的动态秘钥,算法难以破解,则只能放弃;如果是静态秘钥,即每次访问秘钥都相同,或者大部分字符相同,少部分字符不同但不影响访问结果,则可尝试以下方法:先在网页中查找秘钥函数代入的必要参数,然后使用firefox的Greasemonkey插件,在动态网页批量计算秘钥(直接调用计算函数,然后动态植入一个文本框呈现计算结果),拼接后批量生成网址,结果是对应N个销售链接的比价网站价格数据实际地址。
最后,在Excel中用VBA做一个下载提取数据的循环,大致有两种方法:一是采用WebBrowser的innerhtml获取,好处是能够先看到网页的情况,便于调试;缺点是需要做窗体,而且内寸很快占满。如果计算机性能较差,需要做成Excel VBA的AutoOpen(),每下载一定数量就自动退出释放内存,并配合控制Excel反复启动的宏处理软件完成(也许有其他释放内存的方法,但笔者一直没有找到,在循环中unload窗体也无效)。其中,json文件需要注册格式避免出现另存为对话框,另外也要注意使用的IE内核版本。二是调用URLDownloadToFile,缺点是如果出错就没有文件保存下来,也不知道具体为啥,好处是速度快。
4)商品详情数据抓取
基本上都是网页中直接提供的,获取思路同前述价格数据抓取中直接在网页源代码提供的情况。
部分网站以“div id=”的形式给出,这种最简单,因为id都是唯一的。如果没有id,只能用规律性的html代码来作为识别标记。需要注意电商网站中,自营和第三方入驻的,有货或下架的等等之间可能标记会不同,需要调试一定数量。
VBA网抓股票历史数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-05-07 08:33
【分享成果,随喜正能量】学会宽容,严以律己,宽以待人。对自己,不要太放纵,对别人,不要太苛刻。人与人之间都是相互的,如果你自己做不到,就没有理由去过分要求别人。在努力做好自己的同时,学会给别人多一些宽容,世界会因此变得更加温暖。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题六“VBA中利用XMLHTTP完成网抓数据”的第7讲:VBA网抓股票历史数据
第七节 利用XMLHTTP抓取网易财经股票历史数据大家好,我们继续网抓数据的讲解,这讲的内容更为实用,我们讲解某支股票历史数据的抓取,对于玩股票的朋友而言,股票的信息有开盘价、最高价、最低价、收盘价、涨跌额、涨跌幅(%)、成交量(手)、成交金额(万元)、振幅(%)、换手率(%),因人而异关注点也是不同的,有人关注资金的流入和流出,有的人关注换手率的多少,当无论你关注什么数据,都希望这些数据不是停留在看板上,而是在我们的EXCEL表格中,然后进行有的放矢的分析。如何把这些数据从网页上抓取处理呢?
实现场景:从网页的数据中提取给定股票的信息到EXCEL表格中,这些信息包括某一段时间的开盘价、最高价、最低价、收盘价、涨跌额、涨跌幅(%)、成交量(手)、成交金额(万元)、振幅(%)、换手率(%)。如下图,要提取出“601899”股票的20年第二季度的数据。
1 应用XMLHTTP实现网抓股票数据的思路分析我们首先仍是建立应用CreateObject("MSXML2.XMLHTTP")和CreateObject("htmlfile")第二个应用用于处理提取出来的网页数据,然后我们在“网易财经”的网址上抓取数据网易财经”的网址:" & 股票名称。抓取时利用 .Open "GET", strURL, False 及 .send 的命令,数据返回时将.responseText赋给第二个引用innerHTML属性。innerHTML 属性返回表格行的开始和结束标签之间的 HTML。提取完数据后我们利用循环语句来提取数据。在循环语句中我们要有行和列的区分,逐一提取行列的数据。在网页表格处理的时候,我们可以利用遍历的方法。可以用类似于工作表的行:Rows,单元格:Cells 的表述方案。最后要记得内存的释放。2 应用XMLHTTP实现网抓股票数据的代码实现下面我们看实现上述思路的代码部分,我直接给出了我的代码:
Sub myNZE() '网易财经股票历史数据的抓取 [代码见教程]End Sub
代码截图:
代码解读:1) Set objXMLHTTP = CreateObject("MSXML2.XMLHTTP")Set objDOM = CreateObject("htmlfile") 上述代码建立了两个引用。2) GPCode = Cells(1, 4).Value GPY= Cells(2, 4).ValueGPJ = Cells(3, 4).Value 上述代码提取股票的名称,历史数据的年,季度。3) strURL = "" & GPCode strURL= strURL & ".html?year=" & GPY strURL= strURL & "&season=" & GPJ 建立网址的代码。4)With objXMLHTTP .Open"GET", strURL, False .send objDOM.body.innerHTML= .responseTextEnd With上述代码从网页中提取数据,并将数据赋值给objDOM.body.innerHTML ,objDOM是我们建立的第二个引用对象。5)For Each objTR In objTable.Rows HRow= HRow + 1 LCol= 0 ForEach objCell In objTR.Cells LCol= LCol + 1 Cells(HRow+ 4, LCol) = objCell.innerText NextobjCellNext上述代码是从("TABLE")(3)中提取数据到工作表中。6) Set objXMLHTTP = Nothing SetobjDOM = Nothing SetobjTable = Nothing SetobjTR = Nothing SetobjCell = Nothing上述代码是释放内存。3 应用XMLHTTP实现网抓股票数据的实现效果最后,我们点击运行按钮,看看随后的实现效果:
将这种数据提取到工作表中后,我们就可以做数据分析处理了。确实,我们在股票分析的时候也非常需要这种数据的提取。
本节知识点回向:
如何提取网页股票的历史数据到工作表中?这种方案和之前的哪节知识点类似?
本讲参考程序文件:006工作表.XLSM
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】:学会高傲,任何时候,都不要妄自菲薄。你要知道,世界不会放弃你,只有你会放弃自己。每一个女人都要适当保持高傲,这并不是过分看高自己,而是给自己一份自信和勇气。毕竟,这个世界,对女人来说,总还是有点不够温柔。 查看全部
VBA网抓股票历史数据
【分享成果,随喜正能量】学会宽容,严以律己,宽以待人。对自己,不要太放纵,对别人,不要太苛刻。人与人之间都是相互的,如果你自己做不到,就没有理由去过分要求别人。在努力做好自己的同时,学会给别人多一些宽容,世界会因此变得更加温暖。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题六“VBA中利用XMLHTTP完成网抓数据”的第7讲:VBA网抓股票历史数据
第七节 利用XMLHTTP抓取网易财经股票历史数据大家好,我们继续网抓数据的讲解,这讲的内容更为实用,我们讲解某支股票历史数据的抓取,对于玩股票的朋友而言,股票的信息有开盘价、最高价、最低价、收盘价、涨跌额、涨跌幅(%)、成交量(手)、成交金额(万元)、振幅(%)、换手率(%),因人而异关注点也是不同的,有人关注资金的流入和流出,有的人关注换手率的多少,当无论你关注什么数据,都希望这些数据不是停留在看板上,而是在我们的EXCEL表格中,然后进行有的放矢的分析。如何把这些数据从网页上抓取处理呢?
实现场景:从网页的数据中提取给定股票的信息到EXCEL表格中,这些信息包括某一段时间的开盘价、最高价、最低价、收盘价、涨跌额、涨跌幅(%)、成交量(手)、成交金额(万元)、振幅(%)、换手率(%)。如下图,要提取出“601899”股票的20年第二季度的数据。
1 应用XMLHTTP实现网抓股票数据的思路分析我们首先仍是建立应用CreateObject("MSXML2.XMLHTTP")和CreateObject("htmlfile")第二个应用用于处理提取出来的网页数据,然后我们在“网易财经”的网址上抓取数据网易财经”的网址:" & 股票名称。抓取时利用 .Open "GET", strURL, False 及 .send 的命令,数据返回时将.responseText赋给第二个引用innerHTML属性。innerHTML 属性返回表格行的开始和结束标签之间的 HTML。提取完数据后我们利用循环语句来提取数据。在循环语句中我们要有行和列的区分,逐一提取行列的数据。在网页表格处理的时候,我们可以利用遍历的方法。可以用类似于工作表的行:Rows,单元格:Cells 的表述方案。最后要记得内存的释放。2 应用XMLHTTP实现网抓股票数据的代码实现下面我们看实现上述思路的代码部分,我直接给出了我的代码:
Sub myNZE() '网易财经股票历史数据的抓取 [代码见教程]End Sub
代码截图:
代码解读:1) Set objXMLHTTP = CreateObject("MSXML2.XMLHTTP")Set objDOM = CreateObject("htmlfile") 上述代码建立了两个引用。2) GPCode = Cells(1, 4).Value GPY= Cells(2, 4).ValueGPJ = Cells(3, 4).Value 上述代码提取股票的名称,历史数据的年,季度。3) strURL = "" & GPCode strURL= strURL & ".html?year=" & GPY strURL= strURL & "&season=" & GPJ 建立网址的代码。4)With objXMLHTTP .Open"GET", strURL, False .send objDOM.body.innerHTML= .responseTextEnd With上述代码从网页中提取数据,并将数据赋值给objDOM.body.innerHTML ,objDOM是我们建立的第二个引用对象。5)For Each objTR In objTable.Rows HRow= HRow + 1 LCol= 0 ForEach objCell In objTR.Cells LCol= LCol + 1 Cells(HRow+ 4, LCol) = objCell.innerText NextobjCellNext上述代码是从("TABLE")(3)中提取数据到工作表中。6) Set objXMLHTTP = Nothing SetobjDOM = Nothing SetobjTable = Nothing SetobjTR = Nothing SetobjCell = Nothing上述代码是释放内存。3 应用XMLHTTP实现网抓股票数据的实现效果最后,我们点击运行按钮,看看随后的实现效果:
将这种数据提取到工作表中后,我们就可以做数据分析处理了。确实,我们在股票分析的时候也非常需要这种数据的提取。
本节知识点回向:
如何提取网页股票的历史数据到工作表中?这种方案和之前的哪节知识点类似?
本讲参考程序文件:006工作表.XLSM
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】:学会高傲,任何时候,都不要妄自菲薄。你要知道,世界不会放弃你,只有你会放弃自己。每一个女人都要适当保持高傲,这并不是过分看高自己,而是给自己一份自信和勇气。毕竟,这个世界,对女人来说,总还是有点不够温柔。
VBA利用IE,抓取深市股票涨跌数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 523 次浏览 • 2022-05-05 07:13
大家好,我们今日讲解“VBA信息获取与处理”教程中第九个专题“利用IE抓取网络数据”的第三节“利用IE,抓取深市股票涨跌数据”,这个专题是非常有用的知识点,希望大家掌握。第三节 利用IE,抓取深市股票涨跌数据大家好,这讲讲解的是利用IE,抓取深市股票涨跌数据,利用的方法和上一讲基本类似,主要是给大家介绍一种实用的场景,供大家选择利用。实用场景:在玩股票的时候,经常要看每天股票涨幅领头的股票,以便分析各种对应,要求利用IE实现提取某网站股票的领涨股票数据,将这些数据放到工作表中以备选查看。选择的网址是: 即搜狐网的数据。1 应用IE实现抓取深市股票涨跌数据的思路分析为了实现上述的场景,我们先看一看提供网页的信息:
上述的网页中,我要提取的是红色框框起来表的数据,我们进行一下思路的分析:首先要建立一个IE对象,然后将网页文档提取出来,在网页文档上提取第二个表的数据,即可。提取表数据的时候可以模拟真正工作表的行列循环,依次提取数据,在我之前的讲解中提到myTR.Cells.Length是指单元格的个数,Cells(j).innertext是指单元格的内容。这两点在写代码的时候要注意。另外,在抓取网页文档的表时可以采用getElementsByTagName("TABLE")(2)的方法,这种方法是查找数据是返回包含带有指定标签名称的所有元素的节点列表。在之前的讲解中我一共讲了三种类似的方法,如下getElementById(id) 获取带有指定 id 的节点(元素)getElementsByTagName() 返回包含带有指定标签名称的所有元素的节点列表(集合/节点数组)。getElementsByClassName() 返回包含带有指定类名的所有元素的节点列表。
ByTagName 是上述的第二种方法,利用较多的还有第一种。2 应用IE实现抓取深市股票涨跌数据的代码实现为了实现上述的思路,我给出了下面的代码:Sub myNZA() '利用IE,抓取深市股票涨跌数据 Sheets("SHEET2").Select DimIE, IEDOM As Object DimmyTable, myTR As Object SetIE = CreateObject("InternetExplorer.Application") WithIE .Visible= False .navigate"" DoUntil .readystate = 4 DoEvents Loop SetIEDOM = .document EndWith Cells.ClearContents SetmyTable = IEDOM.getElementsByTagName("TABLE")(2) ForEach myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext Next Next SetIE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing MsgBox"ok!"End Sub
代码的讲解:1)Set IE = CreateObject("InternetExplorer.Application") 建立IE 的引用。2).Visible = False .navigate"" DoUntil .readystate = 4 DoEvents Loop上述代码令浏览器可见,加载网址,一直到加载完成,其中的DoEvents 是避免软死机的现象出现。3)Set IEDOM = .document 提出网页文档数据4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格5)For Each myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext NextNext提取表格的数据到工作表。6)Set IE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing回收内存。对于回收内存的操作,建议大家利用,在大型的程序中,尤其是注意这点,内存占用过多会导致程序运行减缓。如果不释放内存就只能到END SUB时候再释放了,内存会不足。
代码截图:
通过上述的代码,就可以完成我们的思路。
3 应用IE实现抓取深市股票涨跌数据的实现效果当我们点击运行按钮,如图的箭头所示,程序就会开始运行,抓取网页数据到工作表中
从而验证了我们思路的正确。
本节知识点回向:如何在页面文档中提取表的数据?本节内容参考:009工作表.xlsm
积木编程的思路内涵:在我的系列书籍中一直在强调“搭积木”的编程思路,这也是学习利用VBA的主要方法,特别是职场人员,更是要采用这种方案。其主要的内涵:1 代码不要自己全部的录入。你要做的是把积木放在合适的位置然后去修正代码,一定要拷贝,从你的积木库中去拷贝,然后修正代码,把时间利用到高效的思考上。2 建立自己的“积木库”。平时在学习过程中,把自己认为有用的代码放在一起,多积累,在用到的时候,可以随时拿来。你的积木库资料越多,你做程序的思路就会越广。
VBA的应用界定VBA是利用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA的应用界定。在取代OFFICE新的办公软件没有到来之前,谁能在数据处理方面做到极致,谁就是王者。其中登峰至极的技能非VBA莫属!我记得20年前自己初学VBA时,那时的资料甚少,只能看源码自己琢磨,真的很难。20年过去了,为了不让学习VBA的朋友重复我之前的经历,我根据自己多年VBA实际利用经验,推出了六部VBA专门教程:第一套:VBA代码解决方案是VBA中各个知识点的讲解,教程共147讲,覆盖绝大多数的VBA知识点,初学必备;第二套:VBA数据库解决方案 数据库是数据处理的专业利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法和实例操作,适合中级人员的学习。第三套:VBA数组与字典解决方案 数组和字典是VBA的精华,字典是VBA代码水平提高的有效手段,值得深入的学习,是初级及中级人员代码精进的手段。第四套:VBA代码解决方案之视频是专门面向初学者的视频讲解,可以快速入门,更快的掌握这门技能。这套教程是第一套教程的视频讲解,听元音更易接受。第五套:VBA中类的解读和利用 这是一部高级教程,讲解类的虚无与肉身的度化,类的利用虽然较少,但仔细的学习可以促进自己VBA理论的提高。这套教程的领会主要是读者的领悟了,领悟一种佛学的哲理。第六套教程:《VBA信息获取与处理》,这是一部高级教程,涉及范围更广,实用性更强,面向中高级人员。教程共二十个专题,包括:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪切板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。大家可以根据以上资料1→3→2→6→5或者是4→3→2→6→5的顺序逐渐深入的逐渐学习。教程提供讲解的同时提供了大量的积木,如需要可以WeChat: NZ9668
学习VBA是个过程,也需要经历一种枯燥的感觉如太白诗云:众鸟高飞尽,孤云独去闲。相看两不厌,只有敬亭山。学习的过程也是修心的过程,修一个平静的心。在代码的世界中,心平静了,心情好了,身体自然而然就好。心静则正,内心里没有那么多邪知邪见,也就没有那么多妄想。利人就是利己。这些教程也是为帮助大家起航,助上我自己之力,我的上述教程是我多的经验的传递,“水善利万物而不争”,绵绵密密,微则无声,巨则汹涌。学习亦如此,知道什么是自己所需要的,不要蜷缩在一小块自认为天堂的世界里,待到暮年时再去做自欺欺人的言论。要努力提高自己,用一颗充满生机的心灵,把握现在,这才是进取。越是有意义的事情,困难会越多。愿力决定始终,智慧决定成败。不管遇到什么,都是风景。看淡纷争,看轻得失。茶,满也好,少也好,不要计较;浓也好,淡也好,其中自有值得品的味道。去感悟真实的时间,静下心,多学习,积累福报。而不是天天混日子,也不是天天熬日子。在后疫情更加严峻的存量残杀世界中,为自己的生存进行知识的储备,特别是新知识的储备。学习时微而无声,利用时则巨则汹涌。每一分收获都是成长的记录,怎无凭,正是这种执着,成就了朝霞的灿烂。最后将一阙词送给致力于VBA学习的朋友,让大家感受一下学习过程的枯燥与执着:
浮云掠过,暗语无声,唯有清风,惊了梦中啼莺。望星,疏移北斗,奈将往事雁同行。阡陌人,昏灯明暗,忍顾长亭。 多少VBA人,暗夜中,悄声寻梦,盼却天明。怎无凭!
回向学习利用VBA的历历往事,不胜感慨,谨以这些文字给大家,分享我多年工作实际经验的成果,随喜这些有用的东西,给确实需要利用VBA的同路人。 查看全部
VBA利用IE,抓取深市股票涨跌数据
大家好,我们今日讲解“VBA信息获取与处理”教程中第九个专题“利用IE抓取网络数据”的第三节“利用IE,抓取深市股票涨跌数据”,这个专题是非常有用的知识点,希望大家掌握。第三节 利用IE,抓取深市股票涨跌数据大家好,这讲讲解的是利用IE,抓取深市股票涨跌数据,利用的方法和上一讲基本类似,主要是给大家介绍一种实用的场景,供大家选择利用。实用场景:在玩股票的时候,经常要看每天股票涨幅领头的股票,以便分析各种对应,要求利用IE实现提取某网站股票的领涨股票数据,将这些数据放到工作表中以备选查看。选择的网址是: 即搜狐网的数据。1 应用IE实现抓取深市股票涨跌数据的思路分析为了实现上述的场景,我们先看一看提供网页的信息:
上述的网页中,我要提取的是红色框框起来表的数据,我们进行一下思路的分析:首先要建立一个IE对象,然后将网页文档提取出来,在网页文档上提取第二个表的数据,即可。提取表数据的时候可以模拟真正工作表的行列循环,依次提取数据,在我之前的讲解中提到myTR.Cells.Length是指单元格的个数,Cells(j).innertext是指单元格的内容。这两点在写代码的时候要注意。另外,在抓取网页文档的表时可以采用getElementsByTagName("TABLE")(2)的方法,这种方法是查找数据是返回包含带有指定标签名称的所有元素的节点列表。在之前的讲解中我一共讲了三种类似的方法,如下getElementById(id) 获取带有指定 id 的节点(元素)getElementsByTagName() 返回包含带有指定标签名称的所有元素的节点列表(集合/节点数组)。getElementsByClassName() 返回包含带有指定类名的所有元素的节点列表。
ByTagName 是上述的第二种方法,利用较多的还有第一种。2 应用IE实现抓取深市股票涨跌数据的代码实现为了实现上述的思路,我给出了下面的代码:Sub myNZA() '利用IE,抓取深市股票涨跌数据 Sheets("SHEET2").Select DimIE, IEDOM As Object DimmyTable, myTR As Object SetIE = CreateObject("InternetExplorer.Application") WithIE .Visible= False .navigate"" DoUntil .readystate = 4 DoEvents Loop SetIEDOM = .document EndWith Cells.ClearContents SetmyTable = IEDOM.getElementsByTagName("TABLE")(2) ForEach myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext Next Next SetIE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing MsgBox"ok!"End Sub
代码的讲解:1)Set IE = CreateObject("InternetExplorer.Application") 建立IE 的引用。2).Visible = False .navigate"" DoUntil .readystate = 4 DoEvents Loop上述代码令浏览器可见,加载网址,一直到加载完成,其中的DoEvents 是避免软死机的现象出现。3)Set IEDOM = .document 提出网页文档数据4)Set myTable = IEDOM.getElementsByTagName("TABLE")(2) 提取网页文档的第二个表格5)For Each myTR In myTable.Rows i= i + 1 Forj = 0 To myTR.Cells.Length - 1 Cells(i,j + 1) = myTR.Cells(j).innertext NextNext提取表格的数据到工作表。6)Set IE = Nothing SetIEDOM = Nothing SetmyTable = Nothing SetmyTR = Nothing回收内存。对于回收内存的操作,建议大家利用,在大型的程序中,尤其是注意这点,内存占用过多会导致程序运行减缓。如果不释放内存就只能到END SUB时候再释放了,内存会不足。
代码截图:
通过上述的代码,就可以完成我们的思路。
3 应用IE实现抓取深市股票涨跌数据的实现效果当我们点击运行按钮,如图的箭头所示,程序就会开始运行,抓取网页数据到工作表中
从而验证了我们思路的正确。
本节知识点回向:如何在页面文档中提取表的数据?本节内容参考:009工作表.xlsm
积木编程的思路内涵:在我的系列书籍中一直在强调“搭积木”的编程思路,这也是学习利用VBA的主要方法,特别是职场人员,更是要采用这种方案。其主要的内涵:1 代码不要自己全部的录入。你要做的是把积木放在合适的位置然后去修正代码,一定要拷贝,从你的积木库中去拷贝,然后修正代码,把时间利用到高效的思考上。2 建立自己的“积木库”。平时在学习过程中,把自己认为有用的代码放在一起,多积累,在用到的时候,可以随时拿来。你的积木库资料越多,你做程序的思路就会越广。
VBA的应用界定VBA是利用Office实现个人小型办公自动化的有效手段(工具)。这是我对VBA的应用界定。在取代OFFICE新的办公软件没有到来之前,谁能在数据处理方面做到极致,谁就是王者。其中登峰至极的技能非VBA莫属!我记得20年前自己初学VBA时,那时的资料甚少,只能看源码自己琢磨,真的很难。20年过去了,为了不让学习VBA的朋友重复我之前的经历,我根据自己多年VBA实际利用经验,推出了六部VBA专门教程:第一套:VBA代码解决方案是VBA中各个知识点的讲解,教程共147讲,覆盖绝大多数的VBA知识点,初学必备;第二套:VBA数据库解决方案 数据库是数据处理的专业利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法和实例操作,适合中级人员的学习。第三套:VBA数组与字典解决方案 数组和字典是VBA的精华,字典是VBA代码水平提高的有效手段,值得深入的学习,是初级及中级人员代码精进的手段。第四套:VBA代码解决方案之视频是专门面向初学者的视频讲解,可以快速入门,更快的掌握这门技能。这套教程是第一套教程的视频讲解,听元音更易接受。第五套:VBA中类的解读和利用 这是一部高级教程,讲解类的虚无与肉身的度化,类的利用虽然较少,但仔细的学习可以促进自己VBA理论的提高。这套教程的领会主要是读者的领悟了,领悟一种佛学的哲理。第六套教程:《VBA信息获取与处理》,这是一部高级教程,涉及范围更广,实用性更强,面向中高级人员。教程共二十个专题,包括:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪切板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。大家可以根据以上资料1→3→2→6→5或者是4→3→2→6→5的顺序逐渐深入的逐渐学习。教程提供讲解的同时提供了大量的积木,如需要可以WeChat: NZ9668
学习VBA是个过程,也需要经历一种枯燥的感觉如太白诗云:众鸟高飞尽,孤云独去闲。相看两不厌,只有敬亭山。学习的过程也是修心的过程,修一个平静的心。在代码的世界中,心平静了,心情好了,身体自然而然就好。心静则正,内心里没有那么多邪知邪见,也就没有那么多妄想。利人就是利己。这些教程也是为帮助大家起航,助上我自己之力,我的上述教程是我多的经验的传递,“水善利万物而不争”,绵绵密密,微则无声,巨则汹涌。学习亦如此,知道什么是自己所需要的,不要蜷缩在一小块自认为天堂的世界里,待到暮年时再去做自欺欺人的言论。要努力提高自己,用一颗充满生机的心灵,把握现在,这才是进取。越是有意义的事情,困难会越多。愿力决定始终,智慧决定成败。不管遇到什么,都是风景。看淡纷争,看轻得失。茶,满也好,少也好,不要计较;浓也好,淡也好,其中自有值得品的味道。去感悟真实的时间,静下心,多学习,积累福报。而不是天天混日子,也不是天天熬日子。在后疫情更加严峻的存量残杀世界中,为自己的生存进行知识的储备,特别是新知识的储备。学习时微而无声,利用时则巨则汹涌。每一分收获都是成长的记录,怎无凭,正是这种执着,成就了朝霞的灿烂。最后将一阙词送给致力于VBA学习的朋友,让大家感受一下学习过程的枯燥与执着:
浮云掠过,暗语无声,唯有清风,惊了梦中啼莺。望星,疏移北斗,奈将往事雁同行。阡陌人,昏灯明暗,忍顾长亭。 多少VBA人,暗夜中,悄声寻梦,盼却天明。怎无凭!
回向学习利用VBA的历历往事,不胜感慨,谨以这些文字给大家,分享我多年工作实际经验的成果,随喜这些有用的东西,给确实需要利用VBA的同路人。
excel vba 网页数据抓取 IE抓取资金主力流入的股票
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-29 03:09
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。 查看全部
excel vba 网页数据抓取 IE抓取资金主力流入的股票
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。
excel vba 网页数据抓取( Excel教程Excel函数和操作方法如何通过IE打开指定的网址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-10 08:33
Excel教程Excel函数和操作方法如何通过IE打开指定的网址
)
前言
上次通过Excel VBA的准备设置,我们已经可以用VBA打开IE了,那么如何才能顺利打开指定的网页抓取数据呢?在本节中,解释 Excel VBA 使用 IE 打开指定的 URL。
操作IE打开指定的URL,需要使用InernetExplorer对象的[Navigate(导航的意思)]方法。
当然,Navigate 可以导航到指定的网址(url),如果网页完全读取并处于待机状态,则需要其他方法。在这里,我将通过一个例子来详细解释它,并且易于理解。
下面是通过IE打开指定URL的网页的过程(这里用今天的头条首页[]来演示)
定义变量创建IE动作对象打开并显示IE打开指定URL并等待页面被完全读取
在编辑区输入以下代码,运行,显示结果如下。
Sub IE_openweb() Dim objIE As InternetExplorer Set objIE = CreateObject("InternetExplorer.application") '创建IE对 objIE.Visible = True '启动并显示IE objIE.navigate "https://www.toutiao.com" '打开今日头条主页 Do While objIE.Busy = True Or objIE.readyState 4 '等待完全刷出页面 DoEvents Loop End Sub
VBE中输入代码显示
运行结果
运行结果打开【今日头条】首页
这样,Excel VBA通过IE打开了今日头条的主页。你打开了吗?
有几个新的功能和方法,需要说明,请耐心等待。
请参阅 VBA 帮助文档
以上就是如何使用Excel VBA通过IE打开指定网址,并讲解了几个功能和操作方法。
在网络爬虫中,这一步是必不可少的。因此,您必须了解并能够熟练使用它。
查看全部
excel vba 网页数据抓取(
Excel教程Excel函数和操作方法如何通过IE打开指定的网址
)
前言
上次通过Excel VBA的准备设置,我们已经可以用VBA打开IE了,那么如何才能顺利打开指定的网页抓取数据呢?在本节中,解释 Excel VBA 使用 IE 打开指定的 URL。
操作IE打开指定的URL,需要使用InernetExplorer对象的[Navigate(导航的意思)]方法。
当然,Navigate 可以导航到指定的网址(url),如果网页完全读取并处于待机状态,则需要其他方法。在这里,我将通过一个例子来详细解释它,并且易于理解。
下面是通过IE打开指定URL的网页的过程(这里用今天的头条首页[]来演示)
定义变量创建IE动作对象打开并显示IE打开指定URL并等待页面被完全读取
在编辑区输入以下代码,运行,显示结果如下。
Sub IE_openweb() Dim objIE As InternetExplorer Set objIE = CreateObject("InternetExplorer.application") '创建IE对 objIE.Visible = True '启动并显示IE objIE.navigate "https://www.toutiao.com" '打开今日头条主页 Do While objIE.Busy = True Or objIE.readyState 4 '等待完全刷出页面 DoEvents Loop End Sub
VBE中输入代码显示
运行结果
运行结果打开【今日头条】首页
这样,Excel VBA通过IE打开了今日头条的主页。你打开了吗?
有几个新的功能和方法,需要说明,请耐心等待。
请参阅 VBA 帮助文档
以上就是如何使用Excel VBA通过IE打开指定网址,并讲解了几个功能和操作方法。
在网络爬虫中,这一步是必不可少的。因此,您必须了解并能够熟练使用它。
excel vba 网页数据抓取(如何用Excel图表炫起来?一截告诉你答案!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-10 02:12
有时表格中的数据太多,生成的图表会变得很复杂。应该是一张一眼就能看懂的图表,但此时也变得繁琐。相反,直接看表格更直观。
但在这段时间里,我一直在寻找有效的图表工具。不管是百度还是知乎,基本都是用Excel图表制作的。各种大牛的教材真的很赞,我自己也在用。Excel,我做了一些测试,感觉和大咖的图表效果差别很大。深深地觉得知识真是个好东西……要成为高手,不知道要多久才能达到……
Excel虽然简单、方便、覆盖面广,但无疑是典型的数据可视化工具。我们通常使用 Excel 来制作简单的表格。它非常强大,我们可以制作一些很好的图表。但是说到可视化就差了一点,因为炫酷炫酷的效果还是需要专门高效的图表工具插件来加强的~
前段时间朋友推荐我使用Smartbi后,我发现制作表格并不太难。
是一个excel图表工具插件,可以自动采集数据、自动清洗、自动建模、自动上报。特别适合那些每天都需要更新文件数据,或者增加新文件的场景,一键刷新可以实现数据的一站式自动分析。功能很多,也很人性化,操作也很方便。
可视化可以使您的图表脱颖而出,如下所示:
或许对于大多数人来说,很难想到这种可视化,只有专业的数据分析师才能做到,而大多数人只能默默仰望星空。其实业内人士都知道,市面上有针对不同人群的可视化工具,比如Smartbi大数据分析工具,可以自由切换个人和专业,还有最新免费的云体验平台提供完整的社区后台支持。展示你,教你,何乐而不为呢?
Smartbi是一款专业的图表制作工具,常用于图表制作和图表样式设计,最终形成专业、酷炫、美观的可视化图表。Smartbi可以直接使用Excel实现各种图形效果,如柱形图、饼图、折线图、雷达图等,结合数据仓库中的动态数据进行数据展示。
第一大特点:操作简单
回想我们使用excel时的场景,复制粘贴数据、处理函数公式、生成表格和图表、设置属性、调整格式等是不是很繁琐?一旦操作完成,半天时间很快。
使用 Smartbi 图表制作工具只需 3 个步骤。首先抓取数据,可以一键连接数据库,也可以一键导入excel或txt中的数据源,然后根据数据自动生成图表或表格,最后做生成的图表。接下来简单的处理就OK了。其实软件默认的图表样式还是蛮好看的。
第二大特点:实时渲染
图表制作中经常遇到的另一个问题是数据源在很多情况下都会发生变化,例如日销售额或周营业额。老板的需求是了解周营业,下面做表的人都在苦苦挣扎。需要每周重新拉取整理数据,然后重新生成图表,那么Smartbi图表制作器是如何处理这个问题的呢?
Smartbi 图表制作工具 图表制作软件可以直接抓取数据库的数据源。这样,只要后端数据源发生变化,前端图表就会自动变化。也就是说,做周营业额报表的时候,只需要做一次,以后就不用再做,因为都是自动更新的。
第三大特点:疯狂酷炫
现代人是视觉动物。如果图表更漂亮,那将是一个很大的优势。因此,视觉也是判断一个图表制作工具的重要因素。
废话不多说,这里小编直接放一些网友使用Smartbi图表工具制作的图表。
目前,仍然有很多excel图表工具。如何做出正确的选择?首先,你应该了解这些常用的工具。只有这样,才能带来好的效果,也能方便日常操作,带来可用的工具。一个特征。
一般选择下载市场占有率较高的免费报表工具,更容易达到较好的效果。现在Smartbi近两年在BI行业口碑不错。国内BI排名前三的厂商。它不仅操作简单,而且功能强大。还有很多图形效果,比如桑基图、词云图、树图等等,在他家是不常见的。制作大数据屏、移动驾驶舱、数据仪表盘效果非常好。它的企业版由项目收费,但个人版永久免费!有兴趣的朋友试试看,好不好就知道了。 查看全部
excel vba 网页数据抓取(如何用Excel图表炫起来?一截告诉你答案!)
有时表格中的数据太多,生成的图表会变得很复杂。应该是一张一眼就能看懂的图表,但此时也变得繁琐。相反,直接看表格更直观。
但在这段时间里,我一直在寻找有效的图表工具。不管是百度还是知乎,基本都是用Excel图表制作的。各种大牛的教材真的很赞,我自己也在用。Excel,我做了一些测试,感觉和大咖的图表效果差别很大。深深地觉得知识真是个好东西……要成为高手,不知道要多久才能达到……
Excel虽然简单、方便、覆盖面广,但无疑是典型的数据可视化工具。我们通常使用 Excel 来制作简单的表格。它非常强大,我们可以制作一些很好的图表。但是说到可视化就差了一点,因为炫酷炫酷的效果还是需要专门高效的图表工具插件来加强的~
前段时间朋友推荐我使用Smartbi后,我发现制作表格并不太难。
是一个excel图表工具插件,可以自动采集数据、自动清洗、自动建模、自动上报。特别适合那些每天都需要更新文件数据,或者增加新文件的场景,一键刷新可以实现数据的一站式自动分析。功能很多,也很人性化,操作也很方便。
可视化可以使您的图表脱颖而出,如下所示:
或许对于大多数人来说,很难想到这种可视化,只有专业的数据分析师才能做到,而大多数人只能默默仰望星空。其实业内人士都知道,市面上有针对不同人群的可视化工具,比如Smartbi大数据分析工具,可以自由切换个人和专业,还有最新免费的云体验平台提供完整的社区后台支持。展示你,教你,何乐而不为呢?
Smartbi是一款专业的图表制作工具,常用于图表制作和图表样式设计,最终形成专业、酷炫、美观的可视化图表。Smartbi可以直接使用Excel实现各种图形效果,如柱形图、饼图、折线图、雷达图等,结合数据仓库中的动态数据进行数据展示。
第一大特点:操作简单
回想我们使用excel时的场景,复制粘贴数据、处理函数公式、生成表格和图表、设置属性、调整格式等是不是很繁琐?一旦操作完成,半天时间很快。
使用 Smartbi 图表制作工具只需 3 个步骤。首先抓取数据,可以一键连接数据库,也可以一键导入excel或txt中的数据源,然后根据数据自动生成图表或表格,最后做生成的图表。接下来简单的处理就OK了。其实软件默认的图表样式还是蛮好看的。
第二大特点:实时渲染
图表制作中经常遇到的另一个问题是数据源在很多情况下都会发生变化,例如日销售额或周营业额。老板的需求是了解周营业,下面做表的人都在苦苦挣扎。需要每周重新拉取整理数据,然后重新生成图表,那么Smartbi图表制作器是如何处理这个问题的呢?
Smartbi 图表制作工具 图表制作软件可以直接抓取数据库的数据源。这样,只要后端数据源发生变化,前端图表就会自动变化。也就是说,做周营业额报表的时候,只需要做一次,以后就不用再做,因为都是自动更新的。
第三大特点:疯狂酷炫
现代人是视觉动物。如果图表更漂亮,那将是一个很大的优势。因此,视觉也是判断一个图表制作工具的重要因素。
废话不多说,这里小编直接放一些网友使用Smartbi图表工具制作的图表。
目前,仍然有很多excel图表工具。如何做出正确的选择?首先,你应该了解这些常用的工具。只有这样,才能带来好的效果,也能方便日常操作,带来可用的工具。一个特征。
一般选择下载市场占有率较高的免费报表工具,更容易达到较好的效果。现在Smartbi近两年在BI行业口碑不错。国内BI排名前三的厂商。它不仅操作简单,而且功能强大。还有很多图形效果,比如桑基图、词云图、树图等等,在他家是不常见的。制作大数据屏、移动驾驶舱、数据仪表盘效果非常好。它的企业版由项目收费,但个人版永久免费!有兴趣的朋友试试看,好不好就知道了。
excel vba 网页数据抓取(【干货】一下的学习心得体会,你值得拥有!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2022-04-05 09:09
作为办公自动化的坚定实践者,经过7年的办公自动化经验,10万行VBA代码,40+实践项目的积累,我想和大家分享一下我的VBA学习心得。
VBA优势
1、办公辅助技能,大大减少人工重复操作,提高工作效率和准确性。
2、学习成本比较低,性价比高,学习快效果好,正反馈强。
3、网上有很多常用功能的现成代码,简单修改即可实现。
VBA学习心得1、一定要了解VBA的基础知识
可以买书或者看视频教程(最基本的变量、循环、数组、字典、正则、事件等都需要懂),不然不知道怎么下手别人的现成代码.
你可以找到适合你的书籍和视频,在网上都是一样的,只要你能看。我是从看我要自学的曾宪智老师的VBA教程开始的。
就这样吧,虽然Excel的版本有点老了,但是教程还是有用的。非常适合初学者学习。
比如关于range的用法,介绍的很详细,再解释一下常用的用法和例子。
2、在电脑上多做动手练习,加深印象
看完书上的讲解或者视频,一定要多上电脑,尝试一下你看过的每个知识点的例子,加深对代码的理解。如果中途遇到问题,赶紧翻书或者看教程如何利用这个知识点解决问题。并尝试再次自己输入代码,或录制宏来修改代码。这将是非常令人印象深刻的。
例如,关于动态获取小区面积的方法,最常用的方法是使用(End)。
但是如果你自己在电脑上写代码,你很可能记不住是range.end(xlup)还是range.xlup(end),还是range.end(3) , range .end(4)有什么区别。
再举一个例子,VBE 编辑器不会提示某些代码写更少的字母。对于新手来说,提出错误信息也令人困惑。
下图其实是一个超低级的错误,Worksheets拼错了一个字母e。
所以你必须自己敲代码并练习手感。光看不练,学不好。
3、学习积累常用代码示例并修改
很多VBA函数都有一个通用的代码框架,网上很多大神都分享过。我们可以把这些常用函数的VBA代码积累起来,记住这个框架,这样在实际工作场景中会更有效率,更有效率。
在你根据自己的需要改了几次之后,你会逐渐养成自己写代码的“感觉”,慢慢的你就会从输入代码变成输出代码。
比如批量操作工作簿的功能,下面的代码就是一个通用的框架:
Sub 批量操作工作簿()
Application.ScreenUpdating = False
myfile = Dir(ThisWorkbook.Path & "\*.xls*")
Do While myfile ""
If myfile ThisWorkbook.Name Then
Set wb = Workbooks.Open(ThisWorkbook.Path & "\" & myfile
(自定义功能的代码)
Else
End If
myfile = Dir
Loop
Application.ScreenUpdating = True
MsgBox "完成"
End Sub
(自定义函数的代码)这个地方是我们实际需要对工作簿进行一些操作的地方。
有了这个框架,我们可以做很多事情:
如果要合并多个工作簿,只需将上面的(自定义功能代码)替换为以下内容:
wb.worksheets(1).range("a1").usedrange.copy ThisWorkbook.Worksheets(1).range("a1")
如果要查找内容为“hello”的单元格的行号并赋值,则只需将上面的(自定义功能代码)替换为以下内容:
ThisWorkbook.Worksheets(1).Cells(a, 1) = wb.worksheets(1).Cells.Find("hello",xlValues).row
类似的例子还有很多,不用背代码也能套用很多代码。只需要多积累和整理,需要时直接使用即可。
以下是我积累整理的一些VBA示例代码,分门别类,方便日后查询和使用。可以查看具体的文章:
细胞操作
示例(1)- 批量生成工资表
示例 (5) - 快速合并 n 个具有相同值的单元格
示例(9)-批量插入,删除表中的空白行
示例(11) - 拆分单元格并自动填充
示例(12)- 如何合并多个单元格而不丢失单元格的数据?
示例(13)-自动生成序号,一键排版(列宽、行高适配等)
示例(29)- 快速实现合并单元格的填充
工作表(书)操作
示例(2) - 将工作表批量拆分为单独的文件
示例(3) - 多个工作簿的批量合并
Instance (4) - 根据已有名称批量新建表
示例(7)- 一键批量打印工作簿
示例(30)- 为多个工作表创建目录和超链接
数据汇总
示例(6)- 多张表数据一键汇总到总表
示例(19)-一键汇总不一样的表到总表
数据提取
示例(8)- 使用正则表达式进行目标提取
示例(10)- 计算同一列中出现的次数并标记它
示例(14) - 根据指定单元格的值复制并插入相同数量的行
示例(15)- 按指定字段一键过滤,获取最低价记录
示例(16) - 按指定字段批量提取内容
示例(17) - 遍历多个工作簿并将内容提取到主表
示例(18) - 一键将单列长数据均匀拆分为多列
示例(20) - 一键填写每月员工访问区域
示例(22) – 一键过滤其他工作表或工作簿中的数据
示例(24) - 一键批量查询新股(债)
示例(27) - 一键按列排序并保存单独的文件
Example (34) - 快速匹配不同名字的数据,这是vlookup做不到的
示例(36) - 一键提取网页中的表格数据
示例(37) - 快速提取手机号和归属地
字操作
示例(23) - 一键批量提取词表内容
示例(26) - 一键批量提取word文本内容
示例(28) - 批量生成word报告
示例(33) - 一键提取word中的粗体文本
数据抓取
示例(39)-一键快速查询基金信息和基金净值
示例(40)-一键快速查询基金代码
示例(41)-一键批量查询汉语拼音、部首、笔画等信息
其他
示例(25) - 班级随机滚动和播放
示例(21) - 如何快速准确地输入数据
示例(31) - 自定义 VBA 代码的快捷键
示例(32) - 批量替换隐藏的神秘字符
示例(35)-一键批量ppt转pdf
示例(38) - 批量插入图片并完美匹配单元格大小
如何在excel中快速聚合多个类别?
VBA运行后添加进度条,爽吗?
两句代码快速提高VBA操作效率
正则表达式,查找和过滤数据的强大工具,你做不到!
你也可以去这里查看这些有组织的 VBA 示例:40+ VBA 示例链接
4、善用宏录制功能
VBA 对新手最友好的方面之一是记录宏的能力。
比如你要实现一个功能,书本和视频教程讲授的案例就不涉及了。毕竟,案例不可能详尽无遗。然后就可以使用录制宏的功能了,点击录制宏,然后在录制的过程中,任何表格操作都会形成对应的VBA代码,让我们很容易知道一些函数的代码是怎么写的。
5、访问更多 vba 论坛
EH论坛是学习vba最好的论坛,到处都是宝。
如果你没有太多的时间去购物,你肯定会收获很多。 查看全部
excel vba 网页数据抓取(【干货】一下的学习心得体会,你值得拥有!!)
作为办公自动化的坚定实践者,经过7年的办公自动化经验,10万行VBA代码,40+实践项目的积累,我想和大家分享一下我的VBA学习心得。
VBA优势
1、办公辅助技能,大大减少人工重复操作,提高工作效率和准确性。
2、学习成本比较低,性价比高,学习快效果好,正反馈强。
3、网上有很多常用功能的现成代码,简单修改即可实现。
VBA学习心得1、一定要了解VBA的基础知识
可以买书或者看视频教程(最基本的变量、循环、数组、字典、正则、事件等都需要懂),不然不知道怎么下手别人的现成代码.
你可以找到适合你的书籍和视频,在网上都是一样的,只要你能看。我是从看我要自学的曾宪智老师的VBA教程开始的。
就这样吧,虽然Excel的版本有点老了,但是教程还是有用的。非常适合初学者学习。
比如关于range的用法,介绍的很详细,再解释一下常用的用法和例子。
2、在电脑上多做动手练习,加深印象
看完书上的讲解或者视频,一定要多上电脑,尝试一下你看过的每个知识点的例子,加深对代码的理解。如果中途遇到问题,赶紧翻书或者看教程如何利用这个知识点解决问题。并尝试再次自己输入代码,或录制宏来修改代码。这将是非常令人印象深刻的。
例如,关于动态获取小区面积的方法,最常用的方法是使用(End)。
但是如果你自己在电脑上写代码,你很可能记不住是range.end(xlup)还是range.xlup(end),还是range.end(3) , range .end(4)有什么区别。
再举一个例子,VBE 编辑器不会提示某些代码写更少的字母。对于新手来说,提出错误信息也令人困惑。
下图其实是一个超低级的错误,Worksheets拼错了一个字母e。
所以你必须自己敲代码并练习手感。光看不练,学不好。
3、学习积累常用代码示例并修改
很多VBA函数都有一个通用的代码框架,网上很多大神都分享过。我们可以把这些常用函数的VBA代码积累起来,记住这个框架,这样在实际工作场景中会更有效率,更有效率。
在你根据自己的需要改了几次之后,你会逐渐养成自己写代码的“感觉”,慢慢的你就会从输入代码变成输出代码。
比如批量操作工作簿的功能,下面的代码就是一个通用的框架:
Sub 批量操作工作簿()
Application.ScreenUpdating = False
myfile = Dir(ThisWorkbook.Path & "\*.xls*")
Do While myfile ""
If myfile ThisWorkbook.Name Then
Set wb = Workbooks.Open(ThisWorkbook.Path & "\" & myfile
(自定义功能的代码)
Else
End If
myfile = Dir
Loop
Application.ScreenUpdating = True
MsgBox "完成"
End Sub
(自定义函数的代码)这个地方是我们实际需要对工作簿进行一些操作的地方。
有了这个框架,我们可以做很多事情:
如果要合并多个工作簿,只需将上面的(自定义功能代码)替换为以下内容:
wb.worksheets(1).range("a1").usedrange.copy ThisWorkbook.Worksheets(1).range("a1")
如果要查找内容为“hello”的单元格的行号并赋值,则只需将上面的(自定义功能代码)替换为以下内容:
ThisWorkbook.Worksheets(1).Cells(a, 1) = wb.worksheets(1).Cells.Find("hello",xlValues).row
类似的例子还有很多,不用背代码也能套用很多代码。只需要多积累和整理,需要时直接使用即可。
以下是我积累整理的一些VBA示例代码,分门别类,方便日后查询和使用。可以查看具体的文章:
细胞操作
示例(1)- 批量生成工资表
示例 (5) - 快速合并 n 个具有相同值的单元格
示例(9)-批量插入,删除表中的空白行
示例(11) - 拆分单元格并自动填充
示例(12)- 如何合并多个单元格而不丢失单元格的数据?
示例(13)-自动生成序号,一键排版(列宽、行高适配等)
示例(29)- 快速实现合并单元格的填充
工作表(书)操作
示例(2) - 将工作表批量拆分为单独的文件
示例(3) - 多个工作簿的批量合并
Instance (4) - 根据已有名称批量新建表
示例(7)- 一键批量打印工作簿
示例(30)- 为多个工作表创建目录和超链接
数据汇总
示例(6)- 多张表数据一键汇总到总表
示例(19)-一键汇总不一样的表到总表
数据提取
示例(8)- 使用正则表达式进行目标提取
示例(10)- 计算同一列中出现的次数并标记它
示例(14) - 根据指定单元格的值复制并插入相同数量的行
示例(15)- 按指定字段一键过滤,获取最低价记录
示例(16) - 按指定字段批量提取内容
示例(17) - 遍历多个工作簿并将内容提取到主表
示例(18) - 一键将单列长数据均匀拆分为多列
示例(20) - 一键填写每月员工访问区域
示例(22) – 一键过滤其他工作表或工作簿中的数据
示例(24) - 一键批量查询新股(债)
示例(27) - 一键按列排序并保存单独的文件
Example (34) - 快速匹配不同名字的数据,这是vlookup做不到的
示例(36) - 一键提取网页中的表格数据
示例(37) - 快速提取手机号和归属地
字操作
示例(23) - 一键批量提取词表内容
示例(26) - 一键批量提取word文本内容
示例(28) - 批量生成word报告
示例(33) - 一键提取word中的粗体文本
数据抓取
示例(39)-一键快速查询基金信息和基金净值
示例(40)-一键快速查询基金代码
示例(41)-一键批量查询汉语拼音、部首、笔画等信息
其他
示例(25) - 班级随机滚动和播放
示例(21) - 如何快速准确地输入数据
示例(31) - 自定义 VBA 代码的快捷键
示例(32) - 批量替换隐藏的神秘字符
示例(35)-一键批量ppt转pdf
示例(38) - 批量插入图片并完美匹配单元格大小
如何在excel中快速聚合多个类别?
VBA运行后添加进度条,爽吗?
两句代码快速提高VBA操作效率
正则表达式,查找和过滤数据的强大工具,你做不到!
你也可以去这里查看这些有组织的 VBA 示例:40+ VBA 示例链接
4、善用宏录制功能
VBA 对新手最友好的方面之一是记录宏的能力。
比如你要实现一个功能,书本和视频教程讲授的案例就不涉及了。毕竟,案例不可能详尽无遗。然后就可以使用录制宏的功能了,点击录制宏,然后在录制的过程中,任何表格操作都会形成对应的VBA代码,让我们很容易知道一些函数的代码是怎么写的。
5、访问更多 vba 论坛
EH论坛是学习vba最好的论坛,到处都是宝。
如果你没有太多的时间去购物,你肯定会收获很多。
excel vba 网页数据抓取(官方版优化内容2.细节更出众,去无踪小编)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-05 09:19
EXCEL批量数据提取正式版是一款高效便捷的批量数据提取软件。可以从该位置提取数据。EXCEL批量数据提取正式版支持单元格内容全匹配、文件部分匹配等功能。
类似软件
印记
软件地址
Excel批量数据提取软件介绍
EXCEL批量数据提取是一款可以根据用户需求批量提取数据的软件。它可以帮助用户节省大量时间,而且操作非常简单。您只需要设置提取参数并保存位置即可提取数据。
EXCEL批量数据提取功能介绍
根据内容从指定文件夹中批量提取所需数据。
支持全单元格内容匹配
支持文件部分匹配
可以保护到同一个文档或创建一个新文档来保存
EXCEL批量数据提取软件特点
1)自定义数据提取、分发规则;
2)自动从不同的文件、不同的工作表中提取数据;
3)自动将一个汇总的文件数据分发到不同的文件中;
4)EXCEL批量数据抽取正式版应用广泛,所有数据抽取和分发都可以灵活使用;
5)易于使用;
EXCEL批量数据提取安装方法
在PC下载网下载EXCEL批量数据提取正式版包
解压到当前文件夹
双击打开文件夹中的应用程序
本软件为绿色软件,无需安装即可使用。
EXCEL 批量数据提取变更日志:
1.优化内容
2.细节更突出,bug都没有了
小编推荐:EXCEL批量数据提取经过多次更新优化,变得更加人性化,操作更简单。PC下载网小编亲测,推荐给大家下载。感兴趣的朋友还可以下载福昕电脑版、工资计算器、百川考试软件、人民币案例换算、知行优采云票务。 查看全部
excel vba 网页数据抓取(官方版优化内容2.细节更出众,去无踪小编)
EXCEL批量数据提取正式版是一款高效便捷的批量数据提取软件。可以从该位置提取数据。EXCEL批量数据提取正式版支持单元格内容全匹配、文件部分匹配等功能。
类似软件
印记
软件地址
Excel批量数据提取软件介绍
EXCEL批量数据提取是一款可以根据用户需求批量提取数据的软件。它可以帮助用户节省大量时间,而且操作非常简单。您只需要设置提取参数并保存位置即可提取数据。
EXCEL批量数据提取功能介绍
根据内容从指定文件夹中批量提取所需数据。
支持全单元格内容匹配
支持文件部分匹配
可以保护到同一个文档或创建一个新文档来保存
EXCEL批量数据提取软件特点
1)自定义数据提取、分发规则;
2)自动从不同的文件、不同的工作表中提取数据;
3)自动将一个汇总的文件数据分发到不同的文件中;
4)EXCEL批量数据抽取正式版应用广泛,所有数据抽取和分发都可以灵活使用;
5)易于使用;
EXCEL批量数据提取安装方法
在PC下载网下载EXCEL批量数据提取正式版包
解压到当前文件夹
双击打开文件夹中的应用程序
本软件为绿色软件,无需安装即可使用。
EXCEL 批量数据提取变更日志:
1.优化内容
2.细节更突出,bug都没有了
小编推荐:EXCEL批量数据提取经过多次更新优化,变得更加人性化,操作更简单。PC下载网小编亲测,推荐给大家下载。感兴趣的朋友还可以下载福昕电脑版、工资计算器、百川考试软件、人民币案例换算、知行优采云票务。
excel vba 网页数据抓取(如何不使用Python去爬取网页表格数据功能?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-04 11:17
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
也有一些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,获取其他数据有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W= 查看全部
excel vba 网页数据抓取(如何不使用Python去爬取网页表格数据功能?)
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
也有一些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,获取其他数据有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W=
excel vba 网页数据抓取(【分享成果,随喜正能量】这套信息获取与处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-12 07:21
【分享成果,因正能量而欢欣鼓舞】如果你喜欢感恩,你会越来越成功;如果你喜欢帮助别人,你就会拥有越来越多高尚的人;喜欢抱怨,麻烦会越来越多;如果你喜欢知足,你就会拥有越来越多的幸福;喜欢逃避 喜欢分享,朋友就会越来越多;如果你喜欢生气,你的病就会越来越多;如果你喜欢占便宜,你就会越来越贫穷;如果你喜欢给钱,你就会拥有越来越多的财富;比如,如果你享受快乐,你会越来越痛苦;如果你喜欢学习,你就会拥有越来越多的智慧。
《VBA信息获取与处理》教程是我推出的第六套教程,目前是第一次改版。这套教程定位在最高级的水平。这是针对初学者和中级的教程。本教程将为大家讲解:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split功能扩展、工作表信息等应用交互、FSO对象的使用、获取工作表和文件夹信息、图形信息获取、自定义工作表信息功能等。程序文件在32位和64位OFFICE系统上测试。它非常抽象,具有更多的研究价值。
本课程由两卷八十四讲组成。今天的内容是主题八VBA和HTML文档,内容是:HTML超文本标记语言
第 1 节 什么是 HTML 超文本标记语言
我们需要一个浏览器来上网。浏览器的作用就是将服务器返回的源代码翻译成一个生动、可见的页面给我们。其功能与VBA代码相同,需要以代码的形式表达各种逻辑关系。服务器返回的源代码是什么语言,通常称为超文本标记语言。超文本标记语言(英文:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。您可以使用 HTML 来构建您自己的 WEB 站点。HTML 在浏览器上运行并由浏览器解析。
1 超文本标记语言的作用
什么是标记语言?顾名思义,它只能用于展示,展示我们看到的网页。不是编程语言。为什么叫超文本?仔细看,这堆源码有什么特点,也就是有很多这样的文字,一般来说,我们称之为标签。我们来看看下面的源代码:
小游戏,4399小游戏,小游戏大全,双人小游戏大全 -
截屏:
网页截图:
浏览器将上面的代码翻译成我们上面的网页。
2 超文本标记语言的基本特征
超文本语言中的标签都是成对出现的,这也是这种语言的一个特点。例如:“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”。
第一个称为开始标签,第二个有一个额外的/称为结束标签。标签之间是网页的文本。比如本例中,就是我们网页的标题文字“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”。因此,标签的作用是标记文本,告诉浏览器如何显示文本。例如本例中,要求浏览器显示“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”作为网页标题。HTML 文档 = 文本 + 标记,这称为超文本。
3 超文本标记语言的一个简单例子
在上面我谈到了HTML语言是什么以及它的特点。让我们通过一个例子进一步了解他:
学习VBA语言
为了更好的掌握VBA的各个知识点,可以参考我的第一套教程:VBA代码解决方案
我们将以上几行代码输入记事本,保存为.html文件。HTML基础学习.HTML
然后正常双击文件,会是浏览器文件:
回到本节的知识点:
什么是 HTML 语言?有什么特点?
本节参考资料:HTML Basic Learning.html
我20多年的VBA实践经验,全部浓缩在以下教程中,教程学习顺序:
【分享成果,以正能量欢欣鼓舞】心修好,就会心平气和,不为琐事、挫折、不愉快而挣扎。生活一帆风顺,生活自然充满福气。的 查看全部
excel vba 网页数据抓取(【分享成果,随喜正能量】这套信息获取与处理)
【分享成果,因正能量而欢欣鼓舞】如果你喜欢感恩,你会越来越成功;如果你喜欢帮助别人,你就会拥有越来越多高尚的人;喜欢抱怨,麻烦会越来越多;如果你喜欢知足,你就会拥有越来越多的幸福;喜欢逃避 喜欢分享,朋友就会越来越多;如果你喜欢生气,你的病就会越来越多;如果你喜欢占便宜,你就会越来越贫穷;如果你喜欢给钱,你就会拥有越来越多的财富;比如,如果你享受快乐,你会越来越痛苦;如果你喜欢学习,你就会拥有越来越多的智慧。
《VBA信息获取与处理》教程是我推出的第六套教程,目前是第一次改版。这套教程定位在最高级的水平。这是针对初学者和中级的教程。本教程将为大家讲解:跨应用信息获取、随机信息的使用、邮件发送、VBA上网数据抓取、VBA延时操作、剪贴板应用、Split功能扩展、工作表信息等应用交互、FSO对象的使用、获取工作表和文件夹信息、图形信息获取、自定义工作表信息功能等。程序文件在32位和64位OFFICE系统上测试。它非常抽象,具有更多的研究价值。
本课程由两卷八十四讲组成。今天的内容是主题八VBA和HTML文档,内容是:HTML超文本标记语言
第 1 节 什么是 HTML 超文本标记语言
我们需要一个浏览器来上网。浏览器的作用就是将服务器返回的源代码翻译成一个生动、可见的页面给我们。其功能与VBA代码相同,需要以代码的形式表达各种逻辑关系。服务器返回的源代码是什么语言,通常称为超文本标记语言。超文本标记语言(英文:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。您可以使用 HTML 来构建您自己的 WEB 站点。HTML 在浏览器上运行并由浏览器解析。
1 超文本标记语言的作用
什么是标记语言?顾名思义,它只能用于展示,展示我们看到的网页。不是编程语言。为什么叫超文本?仔细看,这堆源码有什么特点,也就是有很多这样的文字,一般来说,我们称之为标签。我们来看看下面的源代码:
小游戏,4399小游戏,小游戏大全,双人小游戏大全 -
截屏:
网页截图:
浏览器将上面的代码翻译成我们上面的网页。
2 超文本标记语言的基本特征
超文本语言中的标签都是成对出现的,这也是这种语言的一个特点。例如:“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”。
第一个称为开始标签,第二个有一个额外的/称为结束标签。标签之间是网页的文本。比如本例中,就是我们网页的标题文字“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”。因此,标签的作用是标记文本,告诉浏览器如何显示文本。例如本例中,要求浏览器显示“小游戏、4399小游戏、小游戏大全、双人小游戏大全-”作为网页标题。HTML 文档 = 文本 + 标记,这称为超文本。
3 超文本标记语言的一个简单例子
在上面我谈到了HTML语言是什么以及它的特点。让我们通过一个例子进一步了解他:
学习VBA语言
为了更好的掌握VBA的各个知识点,可以参考我的第一套教程:VBA代码解决方案
我们将以上几行代码输入记事本,保存为.html文件。HTML基础学习.HTML
然后正常双击文件,会是浏览器文件:
回到本节的知识点:
什么是 HTML 语言?有什么特点?
本节参考资料:HTML Basic Learning.html
我20多年的VBA实践经验,全部浓缩在以下教程中,教程学习顺序:
【分享成果,以正能量欢欣鼓舞】心修好,就会心平气和,不为琐事、挫折、不愉快而挣扎。生活一帆风顺,生活自然充满福气。的
excel vba 网页数据抓取(“VBA之EXCEL应用”的第九章“字符串(String)的操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-12 07:20
今天的内容是《VBA的EXCEL应用》第9章中的“字符串(String)的操作”。这是第四节“反向文本排序的实现”。本套教程从简单的宏录制开始,一直到表单的构建。内容丰富,案例多。每个人都可以很容易地掌握相关知识。这套教程是为初学者准备的。全书三卷十七章。都是我们在使用EXCEL过程中需要掌握的知识点。希望每个人都能掌握和使用。
第四节 文本逆向排序的实现
大家好,我们来说说逆向文本排序的实现。本章的内容是字符串函数。字符串函数可以实现很多功能。这些功能在我们平时写代码的时候可能只是少数几个应用,但这些应用确实是程序应用过程中不可缺少的一部分。为了灵活使用这些功能,我也尝试向大家介绍各种应用。
1 实现反向文本排序的场景
我们看下面的工作表界面:
在上面的工作表界面中,A列有几个字符串,要实现字符串的方向排序,比如原来是123,反是321,就是批量转换。这有时在实际代码中使用。
2 实现逆向文本排序的思路分析
为了实现文本的定向排序,我们需要使用len函数求出字符串中的字符总数,然后在所有字符之间建立一个循环,一次提取一个字符,并且排序提取是从后到前一一提取然后合并。
那么如何逐个提取字符串中的字符呢?这需要使用 mid 函数。该函数可以控制提取字符的起始位置和提取字符的个数。然后我们可以控制每次提取字符的个数为1,控制提取位置从最后一个到最后一个。一一提取。
3 逆向文本排序的代码和代码解释
我们来看下面的代码:
sub mynzD() '实现文本的方向排序操作
将 myName 调暗为字符串
我 = 1
Do While Cells(i, 1) ""
单元格(i, 2).Value = ""
我的姓名 = 单元格(我,1).Value
myLen = Len(我的名字)
对于 t = 0 至 myLen - 1
myTem = myTem & Mid(myName, (myLen - t), 1)
下一个
单元格(i, 2).Value = "'" & myTem
我的 Tem = ""
我 = 我 + 1
环形
结束子
代码截图:
代码解读:
1) Cells(i, 2).Value = "" 清空要回填的单元格
2) myName = 单元格(i, 1).Value
上面的代码将A列的单元格值放入一个变量中
3) myLen = Len(myName)
上面的代码查找单元格字符串的长度
4) 对于 t = 0 到 myLen - 1
...
下一个
上面的代码在所有字符之间创建了一个循环
5) myTem = myTem & Mid(myName, (myLen - t), 1)
上面使用Mid函数提取字符,一次一个,提取位置为(myLen - t),提取后使用“&”函数组合字符串。
6)细胞(i, 2).Value = "'" & myTem
回填得到的新字符串;在回填之前添加“'”会使单元格格式化为文本,这样做是为了将数字转换为文本。
7)myTem = ""
清除 myTem 变量以准备下一个循环。
4 文本逆向排序代码的实现效果
最后,我们看一下代码的实现:
可以看出,我们可以轻松实现文本的逆向排序。
今天的内容回来了:
1) 如何实现字符串的逆向排序?
2) 如何一次提取一个字符串?
3) 如何将单元格设置为文本格式?如何在代码中处理它?
4) 练习:如果通过将提取的每个字符填充到后续的每个单元格中来逐个分解字符串,如何实现代码?
本讲内容参考程序文件:workbook 09.xlsm 查看全部
excel vba 网页数据抓取(“VBA之EXCEL应用”的第九章“字符串(String)的操作)
今天的内容是《VBA的EXCEL应用》第9章中的“字符串(String)的操作”。这是第四节“反向文本排序的实现”。本套教程从简单的宏录制开始,一直到表单的构建。内容丰富,案例多。每个人都可以很容易地掌握相关知识。这套教程是为初学者准备的。全书三卷十七章。都是我们在使用EXCEL过程中需要掌握的知识点。希望每个人都能掌握和使用。
第四节 文本逆向排序的实现
大家好,我们来说说逆向文本排序的实现。本章的内容是字符串函数。字符串函数可以实现很多功能。这些功能在我们平时写代码的时候可能只是少数几个应用,但这些应用确实是程序应用过程中不可缺少的一部分。为了灵活使用这些功能,我也尝试向大家介绍各种应用。
1 实现反向文本排序的场景
我们看下面的工作表界面:
在上面的工作表界面中,A列有几个字符串,要实现字符串的方向排序,比如原来是123,反是321,就是批量转换。这有时在实际代码中使用。
2 实现逆向文本排序的思路分析
为了实现文本的定向排序,我们需要使用len函数求出字符串中的字符总数,然后在所有字符之间建立一个循环,一次提取一个字符,并且排序提取是从后到前一一提取然后合并。
那么如何逐个提取字符串中的字符呢?这需要使用 mid 函数。该函数可以控制提取字符的起始位置和提取字符的个数。然后我们可以控制每次提取字符的个数为1,控制提取位置从最后一个到最后一个。一一提取。
3 逆向文本排序的代码和代码解释
我们来看下面的代码:
sub mynzD() '实现文本的方向排序操作
将 myName 调暗为字符串
我 = 1
Do While Cells(i, 1) ""
单元格(i, 2).Value = ""
我的姓名 = 单元格(我,1).Value
myLen = Len(我的名字)
对于 t = 0 至 myLen - 1
myTem = myTem & Mid(myName, (myLen - t), 1)
下一个
单元格(i, 2).Value = "'" & myTem
我的 Tem = ""
我 = 我 + 1
环形
结束子
代码截图:
代码解读:
1) Cells(i, 2).Value = "" 清空要回填的单元格
2) myName = 单元格(i, 1).Value
上面的代码将A列的单元格值放入一个变量中
3) myLen = Len(myName)
上面的代码查找单元格字符串的长度
4) 对于 t = 0 到 myLen - 1
...
下一个
上面的代码在所有字符之间创建了一个循环
5) myTem = myTem & Mid(myName, (myLen - t), 1)
上面使用Mid函数提取字符,一次一个,提取位置为(myLen - t),提取后使用“&”函数组合字符串。
6)细胞(i, 2).Value = "'" & myTem
回填得到的新字符串;在回填之前添加“'”会使单元格格式化为文本,这样做是为了将数字转换为文本。
7)myTem = ""
清除 myTem 变量以准备下一个循环。
4 文本逆向排序代码的实现效果
最后,我们看一下代码的实现:
可以看出,我们可以轻松实现文本的逆向排序。
今天的内容回来了:
1) 如何实现字符串的逆向排序?
2) 如何一次提取一个字符串?
3) 如何将单元格设置为文本格式?如何在代码中处理它?
4) 练习:如果通过将提取的每个字符填充到后续的每个单元格中来逐个分解字符串,如何实现代码?
本讲内容参考程序文件:workbook 09.xlsm
excel vba 网页数据抓取(P.S.@AJAX数据库实例讲解(有时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-08 22:12
故事起源
以前有个小网站发表了几篇关于使用SAS抓取网页数据的小文章,然后在人大论坛上放了一个链接。后来因为懒,这个站就挂了,问的人一个接一个。从新获得这篇文章后
其中一个简单易懂,其他译文已由@收录翻译,链接会在文章的最后贴出。
适用性
在以下情况下,可以用同样的方法得到理论。
PS @AJAX 数据库实例 || @AJAX 数据库实例说明
文字前戏
有时候我们经常需要保存和备份一些在线数据,比如银行利率、股票报价,或者来自统计局、各种金融机构或者其他类型的网站的数据。有时这些 网站 提供历史数据,而另一些则不提供。但是我们可以每天通过SAS运行程序,获取积累的历史数据,供以后分析。下面我以收购主页上海银行同业拆借利率为例进行说明。
以下是我们要在首页的数据
当我们打开这个网页并输入网页的源代码时,我们会惊奇地发现。什么情况,主页上看到的数据在源码中找不到,是不是用了其他技术。我们来看看源码代表什么
网页布局。
按照网页的布局,最新Shibor数据的源代码应该放在一大块文字之后,他放了一句话。
这是html内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入到主页中。好,那我们打开这个页面
并查看源代码,发现该网页中存在数据,然后我们开始用SAS进行抓取。
高潮
首先介绍Filename,通过添加infile语句可以将网页作为文件导入SAS数据集。BaseSAS 中的FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。此语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入 SAS 数据集。我们知道网络数据是一种标记语言,受制于一定的规范,所有的属性设置都包括在内。所以我们用 dlm=">" 来分隔并导入到一个变量中,因为数据太杂乱,我们无法区分并导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们使用 dlm=">" 进行分隔,所以我们知道采集到的观察结果只需要以 查看全部
excel vba 网页数据抓取(P.S.@AJAX数据库实例讲解(有时))
故事起源
以前有个小网站发表了几篇关于使用SAS抓取网页数据的小文章,然后在人大论坛上放了一个链接。后来因为懒,这个站就挂了,问的人一个接一个。从新获得这篇文章后
其中一个简单易懂,其他译文已由@收录翻译,链接会在文章的最后贴出。
适用性
在以下情况下,可以用同样的方法得到理论。
PS @AJAX 数据库实例 || @AJAX 数据库实例说明
文字前戏
有时候我们经常需要保存和备份一些在线数据,比如银行利率、股票报价,或者来自统计局、各种金融机构或者其他类型的网站的数据。有时这些 网站 提供历史数据,而另一些则不提供。但是我们可以每天通过SAS运行程序,获取积累的历史数据,供以后分析。下面我以收购主页上海银行同业拆借利率为例进行说明。
以下是我们要在首页的数据
当我们打开这个网页并输入网页的源代码时,我们会惊奇地发现。什么情况,主页上看到的数据在源码中找不到,是不是用了其他技术。我们来看看源码代表什么
网页布局。
按照网页的布局,最新Shibor数据的源代码应该放在一大块文字之后,他放了一句话。
这是html内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入到主页中。好,那我们打开这个页面
并查看源代码,发现该网页中存在数据,然后我们开始用SAS进行抓取。
高潮
首先介绍Filename,通过添加infile语句可以将网页作为文件导入SAS数据集。BaseSAS 中的FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。此语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入 SAS 数据集。我们知道网络数据是一种标记语言,受制于一定的规范,所有的属性设置都包括在内。所以我们用 dlm=">" 来分隔并导入到一个变量中,因为数据太杂乱,我们无法区分并导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们使用 dlm=">" 进行分隔,所以我们知道采集到的观察结果只需要以
excel vba 网页数据抓取(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-05 21:17
附件:
原帖内容如下:
使用VBA抓取网页数据,一般可以使用Excel VBA的workbooks.open""语句打开网页,然后使用find和offset定位数据位置,然后复制到指定位置。
或者使用 QueryTableActiveSheet.QueryTables.Add(Connection:="URL;", Destination:=Range("A1"))
但是,在某些情况下,这两种方法可能并不容易实现,例如:
1.导入查询结果页面。 (每次都要先提交表单,才能拿到数据页。数据是分页的,但是每个页面的url都是一样的,没有?page=2)
2.需要提交表单或者点击链接获取数据页面。网页在IE中可以正常显示,但是如果直接用Workbooks.open或者QueryTables.add打开网址会显示超时等错误)
3.批量导入不规则 URL 的页面。 (所有要导入的页面在某个页面上都有链接,但网址不规则)
如果你熟悉html和网页脚本,你可以使用IExplorer对象打开网页,然后使用VB脚本控制网页中每个元素的行为来填写、提交表单或打开超链接,然后获取网页中每个元素的innerText来获取数据。 查看全部
excel vba 网页数据抓取(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
附件:
原帖内容如下:
使用VBA抓取网页数据,一般可以使用Excel VBA的workbooks.open""语句打开网页,然后使用find和offset定位数据位置,然后复制到指定位置。
或者使用 QueryTableActiveSheet.QueryTables.Add(Connection:="URL;", Destination:=Range("A1"))
但是,在某些情况下,这两种方法可能并不容易实现,例如:
1.导入查询结果页面。 (每次都要先提交表单,才能拿到数据页。数据是分页的,但是每个页面的url都是一样的,没有?page=2)
2.需要提交表单或者点击链接获取数据页面。网页在IE中可以正常显示,但是如果直接用Workbooks.open或者QueryTables.add打开网址会显示超时等错误)
3.批量导入不规则 URL 的页面。 (所有要导入的页面在某个页面上都有链接,但网址不规则)
如果你熟悉html和网页脚本,你可以使用IExplorer对象打开网页,然后使用VB脚本控制网页中每个元素的行为来填写、提交表单或打开超链接,然后获取网页中每个元素的innerText来获取数据。
excel vba 网页数据抓取(人人都用得上webscraper进阶教程,人人用得上数据教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-02-01 23:20
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:
最简单的数据抓取教程,人人都可以用
进阶网页爬虫教程,人人都能用
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或者滚动加载的数据不能完全抓取,比如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他变通方法,我们最终将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,就是抓取发布时间,然后放到Excel里面。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标滑动时才会显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。 查看全部
excel vba 网页数据抓取(人人都用得上webscraper进阶教程,人人用得上数据教程)
如果你想爬取数据又懒得写代码,可以试试web scraper爬取数据。
相关文章:
最简单的数据抓取教程,人人都可以用
进阶网页爬虫教程,人人都能用
如果你使用网络爬虫抓取数据,很有可能你会遇到以下一个或多个问题,而这些问题可能会直接打乱你的计划,甚至让你放弃网络爬虫。
下面列出了您可能遇到的一些问题及其解决方案。
1、有时候我们想选择一个链接,但是鼠标点击会触发页面跳转,如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标滑到要选择的元素上,按下S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素,按P选择当前元素的父元素,按C选择子元素当前元素的。当前元素是指鼠标所在的元素。
2、分页数据或者滚动加载的数据不能完全抓取,比如知乎和twitter等?
出现此问题的大部分原因是网络问题。在数据可以加载之前,网络爬虫就开始解析数据,但是由于没有及时加载,网络爬虫误认为已经被爬取。
因此,适当增加延迟的大小,延长等待时间,让数据有足够的时间加载。默认延迟为2000,即2秒,可根据网速进行调整。
但是,当数据量比较大时,往往会出现数据采集不完整的情况。因为只要在延迟时间内有翻页或者下拉加载没有加载,爬取就结束了。
3、爬取数据的顺序与网页上的顺序不一致?
web爬虫默认是无序的,可以安装CouchDB来保证数据的有序性。
或者使用其他变通方法,我们最终将数据导出为 CSV 格式。CSV在Excel中打开后,可以按某列排序。比如我们抓取微博数据的时候,就是抓取发布时间,然后放到Excel里面。按发帖时间排序,或者知乎上的数据按点赞数排序。
4、部分页面元素无法通过网络爬虫提供的选择器选择?
造成这种情况的原因可能是因为网站页面本身不符合页面布局规范,或者你想要的数据是动态的,比如只有鼠标滑动时才会显示的元素等。在这些情况下,您需要使用其他方法。
其实就是通过鼠标操作选择元素,最后就是找到该元素对应的xpath。Xpath对应网页来解释,就是定位一个元素的路径,通过元素类型、唯一标识、样式名、上下层关系来找到一个元素或者某种类型的元素。
如果没有遇到这个问题,那么就没有必要去了解xpath,等遇到问题再去学习吧。
这里只是在使用网络爬虫的过程中的几个常见问题。如果遇到其他问题,可以在文章下方留言。
excel vba 网页数据抓取( Excel教程Excel函数Excel透视表Excel电子表格Excel实用技巧Excel2010高效办公office2010Excel视频教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-31 02:09
Excel教程Excel函数Excel透视表Excel电子表格Excel实用技巧Excel2010高效办公office2010Excel视频教程
)
前言
上次通过Excel VBA的准备设置,我们已经可以使用VBA打开IE了,那么如何才能顺利打开指定的网页抓取数据呢?在本节中,解释 Excel VBA 使用 IE 打开指定的 URL。
操作IE打开指定的URL,需要使用InernetExplorer对象的[Navigate(导航的意思)]方法。
当然,Navigate 可以导航到指定的网址(url),如果网页完全读取并处于待机状态,则需要其他方法。在这里,我将通过一个例子来详细解释它,并且易于理解。
下面是通过IE打开指定URL的网页的过程(这里用今天头条[]的首页来演示)
定义变量创建IE动作对象打开并显示IE打开指定URL并等待页面被完全读取
在编辑区输入以下代码,运行,显示结果如下。
Sub IE_openweb()
Dim objIE As InternetExplorer
Set objIE = CreateObject("InternetExplorer.application") '创建IE对
objIE.Visible = True '启动并显示IE
objIE.navigate "https://www.toutiao.com" '打开今日头条主页
Do While objIE.Busy = True Or objIE.readyState 4 '等待完全刷出页面
DoEvents
Loop
End Sub
VBE中输入代码显示
运行结果
运行结果打开【今日头条】首页
这样,Excel VBA通过IE打开了今日头条的主页。你打开了吗?
有几个新的功能和方法,需要说明,请耐心等待。
请参阅 VBA 帮助文档
以上就是如何使用Excel VBA通过IE打开指定网址,并讲解了几个功能和操作方法。
在网络爬虫中,这一步是必不可少的。因此,您必须了解并能够熟练使用它。
查看全部
excel vba 网页数据抓取(
Excel教程Excel函数Excel透视表Excel电子表格Excel实用技巧Excel2010高效办公office2010Excel视频教程
)
前言
上次通过Excel VBA的准备设置,我们已经可以使用VBA打开IE了,那么如何才能顺利打开指定的网页抓取数据呢?在本节中,解释 Excel VBA 使用 IE 打开指定的 URL。
操作IE打开指定的URL,需要使用InernetExplorer对象的[Navigate(导航的意思)]方法。
当然,Navigate 可以导航到指定的网址(url),如果网页完全读取并处于待机状态,则需要其他方法。在这里,我将通过一个例子来详细解释它,并且易于理解。
下面是通过IE打开指定URL的网页的过程(这里用今天头条[]的首页来演示)
定义变量创建IE动作对象打开并显示IE打开指定URL并等待页面被完全读取
在编辑区输入以下代码,运行,显示结果如下。
Sub IE_openweb()
Dim objIE As InternetExplorer
Set objIE = CreateObject("InternetExplorer.application") '创建IE对
objIE.Visible = True '启动并显示IE
objIE.navigate "https://www.toutiao.com" '打开今日头条主页
Do While objIE.Busy = True Or objIE.readyState 4 '等待完全刷出页面
DoEvents
Loop
End Sub
VBE中输入代码显示
运行结果
运行结果打开【今日头条】首页
这样,Excel VBA通过IE打开了今日头条的主页。你打开了吗?
有几个新的功能和方法,需要说明,请耐心等待。
请参阅 VBA 帮助文档
以上就是如何使用Excel VBA通过IE打开指定网址,并讲解了几个功能和操作方法。
在网络爬虫中,这一步是必不可少的。因此,您必须了解并能够熟练使用它。
excel vba 网页数据抓取(如何在EXCEL中用正则表达式抓取网页中的信息文章链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-30 03:15
)
上一篇介绍了如何在EXCEL中使用正则表达式爬取网页中的信息,文章链接:使用EXCEL爬取网页中的信息和Python一样优雅,但是有人说,我不会知道正则表达式有没有这么难,不知道VBA怎么这么难。我不想编程。有没有更简单的方法?所以本文文章将介绍一个EXCEL插件,seotoolsforexcel。安装此插件后,即可使用Xpath抓取网页信息。
1.先打开浏览器查看,选择要抓取的元素,复制Xpath表达式,在百度首页抓取“Baidu click”四个字。同样的原则也适用于其他网页。文案下的表达式为“//*[@id="su"]”
复制 Xpth
2.安装seotoolsforexcel后,点击SeoTools选项卡-HTTP按钮-XPathOnUrl功能
XPathOnUrl
3.在弹出的XPathOnUrl属性中,“百度一一”四个字符所在的html段用“”、“.//*[@id='su']”填充,并且值为Yes,具体填充方式和爬取效果如下
XPathOnUrl 填充方法
4.点击Http设置,在弹出的Http设置对话框中,还可以定义请求头,定义认证信息,设置随机请求等,非常强大。
查看全部
excel vba 网页数据抓取(如何在EXCEL中用正则表达式抓取网页中的信息文章链接
)
上一篇介绍了如何在EXCEL中使用正则表达式爬取网页中的信息,文章链接:使用EXCEL爬取网页中的信息和Python一样优雅,但是有人说,我不会知道正则表达式有没有这么难,不知道VBA怎么这么难。我不想编程。有没有更简单的方法?所以本文文章将介绍一个EXCEL插件,seotoolsforexcel。安装此插件后,即可使用Xpath抓取网页信息。
1.先打开浏览器查看,选择要抓取的元素,复制Xpath表达式,在百度首页抓取“Baidu click”四个字。同样的原则也适用于其他网页。文案下的表达式为“//*[@id="su"]”
复制 Xpth
2.安装seotoolsforexcel后,点击SeoTools选项卡-HTTP按钮-XPathOnUrl功能
XPathOnUrl
3.在弹出的XPathOnUrl属性中,“百度一一”四个字符所在的html段用“”、“.//*[@id='su']”填充,并且值为Yes,具体填充方式和爬取效果如下
XPathOnUrl 填充方法
4.点击Http设置,在弹出的Http设置对话框中,还可以定义请求头,定义认证信息,设置随机请求等,非常强大。
excel vba 网页数据抓取(一下excel抓取数据的过程(实验环境win7+office2013))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-22 02:18
当然可以,但是使用起来不是很灵活,也没有python之类的语言可以轻松抓取数据。现在简单介绍一下excel中抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个excel文件,双击打开文件,选择“数据”->“来自网络”,如下:
2.在弹出的子窗口中输入要抓取的页面。这里以抓取页面的数据为例,点击“Go”->“Import”,如下:
3.导入成功后数据如下,我们需要的数据已经成功抓取:
4.如果要定期刷新数据,可以点击“全部刷新”->“连接属性”自定义刷新频率,默认为60分钟:
在弹出的“选择属性”窗口中,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据。总的来说,整个流程还是比较简单的,但是灵活性不是很高,而且如果页面比较复杂,抓取的数据量比较大,后期直接在excel中处理不是很方便,并且主题所有者已经知道python。, 推荐使用python直接抓取,比较灵活。Python提供了很多爬虫包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以了尽快开始。网上也有相关资料和教程。希望以上分享的内容对您有所帮助。 查看全部
excel vba 网页数据抓取(一下excel抓取数据的过程(实验环境win7+office2013))
当然可以,但是使用起来不是很灵活,也没有python之类的语言可以轻松抓取数据。现在简单介绍一下excel中抓取数据的过程。实验环境为win7+office2013。主要内容如下:
1.新建一个excel文件,双击打开文件,选择“数据”->“来自网络”,如下:
2.在弹出的子窗口中输入要抓取的页面。这里以抓取页面的数据为例,点击“Go”->“Import”,如下:
3.导入成功后数据如下,我们需要的数据已经成功抓取:
4.如果要定期刷新数据,可以点击“全部刷新”->“连接属性”自定义刷新频率,默认为60分钟:
在弹出的“选择属性”窗口中,设计刷新频率,定时刷新数据:
至此,我们就完成了使用excel抓取数据。总的来说,整个流程还是比较简单的,但是灵活性不是很高,而且如果页面比较复杂,抓取的数据量比较大,后期直接在excel中处理不是很方便,并且主题所有者已经知道python。, 推荐使用python直接抓取,比较灵活。Python提供了很多爬虫包和框架,比如requests、bs4、lxml、scrapy等,可以快速抓取数据,方便后期处理(比如pandas、numpy等),学了就可以了尽快开始。网上也有相关资料和教程。希望以上分享的内容对您有所帮助。
excel vba 网页数据抓取(通过Python来一个拉勾网薪资调查的小爬虫(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-13 02:19
想知道用python制作爬虫并将爬取结果保存在excel中的相关内容吗?本文Data&Truth将讲解python制作爬虫并将爬取结果保存在excel中的相关知识以及一些代码示例。欢迎阅读指正,我们先来关注一下:python爬虫,一起来学习吧。
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
获取数据的方式有很多,比如正则表达式re、lxml的etree、json、bs4的BeautifulSoup都是python3获取数据的适用方法。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
相关文章 查看全部
excel vba 网页数据抓取(通过Python来一个拉勾网薪资调查的小爬虫(图))
想知道用python制作爬虫并将爬取结果保存在excel中的相关内容吗?本文Data&Truth将讲解python制作爬虫并将爬取结果保存在excel中的相关知识以及一些代码示例。欢迎阅读指正,我们先来关注一下:python爬虫,一起来学习吧。
学习Python有一段时间了,对各种理论知识都略知一二。今天进入实战练习:用Python写一个拉狗工资调查的小爬虫。
第一步:分析网站的请求流程
当我们在拉狗网看招聘信息时,我们搜索Python,或者PHP等职位信息。实际上,我们向服务器发送相应的请求,服务器会动态响应请求并通过浏览器解析出我们需要的内容。呈现在我们面前。
可以看出,在我们发送的请求中,FormData中的kd参数代表了向服务器请求关键词获取Python招聘信息。
分析复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的杀手锏。不过对于比较简单的响应请求,可以使用浏览器自带的开发者工具,比如火狐的FireBug等,只要轻轻按F12,所有请求的信息都会详细的展现在你面前。
通过分析网站的请求和响应过程可以看出,拉狗网的招聘信息是由XHR动态传递的。
我们发现有两个 POST 请求,companyAjax.json 和 positionAjax.json,分别控制当前显示的页面和页面中收录的职位信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第 2 步:发送请求以获取页面
知道我们想要在哪里获取信息是最重要的。在知道了信息的位置之后,我们需要考虑如何通过 Python 模拟浏览器来获取我们需要的信息。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键步骤是如何模仿浏览器的 Post 方法来包装我们自己的请求。
请求中收录的参数包括要爬取的网页的 URL 和用于伪装的 headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包完成后,就可以像浏览器一样访问拉狗网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据中最重要的一步了:爬取数据。
获取数据的方式有很多,比如正则表达式re、lxml的etree、json、bs4的BeautifulSoup都是python3获取数据的适用方法。您可以根据实际情况使用其中一种,也可以组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第四步:将采集到的信息存入excel
获取原创数据后,为了进一步的整理和分析,我们将抓取到的数据以结构化、有条理的方式存储在excel中,方便数据可视化。
这里我使用了两个不同的框架,旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt,不知道为什么,xlwt存储了100多条数据后,存储不全,excel文件也会出现“部分内容错误,需要修复”我查了很多次,一开始我以为是数据采集不完整,导致存储问题。经过断点检查,发现数据完整。后来改本地数据处理,也没问题。这就是我当时的感受:
到现在还没想通,知道希望的可以告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
直到现在,一个抓取拉狗网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多功能可以添加,比如通过修改城市参数来查看不同城市的招聘信息等,大家可以自己开发。这只是为了吸引别人。欢迎交流。
相关文章
excel vba 网页数据抓取(我试图在Excel中使用VBA来访问嵌入在网页中的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-10 15:16
我正在尝试在 Excel 中使用 VBA 来访问网页中嵌入的网页中的数据。如果表格位于非嵌入式页面上,我知道该怎么做。我也知道如何使用 VBA 导航到产品页面。我不能只是导航到嵌入式页面,也不能访问数据库,因为有一个产品 ID 查找可以将零件编号转换为 ID。
这是该页面的链接:
为了清楚起见,我会拿出一个元素的图片,但我没有 10 个代表点......
我需要从中获取信息的表是 Product Lifecycle 表。
如果我使用以下代码将页面保存为 VBA 中的 HTMLDocument,我可以在相应键下的 src 属性中看到正确的 url:
For Each cell In Selection
link = "http://support.automation.siem ... ot%3B & cell & "&caller=view"
ie.navigate link
Do
DoEvents
Loop Until ie.readyState = READYSTATE_COMPLETE
Dim doc As HTMLDocument
有没有办法用 VBA 索引这个表,或者我必须联系公司并尝试访问产品 ID,以便我可以直接导航到页面?
关于我下面的评论,这里是记录宏的代码:
ActiveCell.FormulaR1C1 = _
"http://support.automation.siem ... ot%3B
Range("F9").Select
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;http://support.automation.siem ... ot%3B _
, Destination:=Range("$F$9"))
.FieldNames = True
.RowNumbers = False
我知道在哪里可以找到字符串:URL;,但我不知道如何将其保存到变量中。 查看全部
excel vba 网页数据抓取(我试图在Excel中使用VBA来访问嵌入在网页中的数据)
我正在尝试在 Excel 中使用 VBA 来访问网页中嵌入的网页中的数据。如果表格位于非嵌入式页面上,我知道该怎么做。我也知道如何使用 VBA 导航到产品页面。我不能只是导航到嵌入式页面,也不能访问数据库,因为有一个产品 ID 查找可以将零件编号转换为 ID。
这是该页面的链接:
为了清楚起见,我会拿出一个元素的图片,但我没有 10 个代表点......
我需要从中获取信息的表是 Product Lifecycle 表。
如果我使用以下代码将页面保存为 VBA 中的 HTMLDocument,我可以在相应键下的 src 属性中看到正确的 url:
For Each cell In Selection
link = "http://support.automation.siem ... ot%3B & cell & "&caller=view"
ie.navigate link
Do
DoEvents
Loop Until ie.readyState = READYSTATE_COMPLETE
Dim doc As HTMLDocument
有没有办法用 VBA 索引这个表,或者我必须联系公司并尝试访问产品 ID,以便我可以直接导航到页面?
关于我下面的评论,这里是记录宏的代码:
ActiveCell.FormulaR1C1 = _
"http://support.automation.siem ... ot%3B
Range("F9").Select
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;http://support.automation.siem ... ot%3B _
, Destination:=Range("$F$9"))
.FieldNames = True
.RowNumbers = False
我知道在哪里可以找到字符串:URL;,但我不知道如何将其保存到变量中。

