
excel网页数据抓取vba
excel网页数据抓取vba(Excel如何用VBA提取网页数据-——1、首先打开Excel2007工作表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 522 次浏览 • 2021-10-22 12:12
如何用Excel用VBA提取网页数据——1、首先打开Excel 2007工作表,点击要导入数据的位置,然后在菜单栏中找到第五项“数据” ,点击,点击“获取外部数据”“找到“来自网站”点击2、这时候弹出“新建Web查询”对话框,输入地址即可3、添加后点击“前往(G)”,要添加的网页内容,下方会出现黄色箭头,点击要选择的表格旁边的黄色箭头,可以看到点击复选标记后黄色箭头变成绿色,表示内容已被选中,然后点击“导入(I)”。4、弹出“导入数据”对话框,设置好后点击“确定”。5、Excel表格中显示“获取数据...”。6、数据采集完成,之前选择的网页内容全部导入到Excel工作表中。
如何从网页中提取表格数据到excel,可以用vba查看,谁教教我——1、使用复制功能,即ctrl+c,然后ctrl+v。2、 使用IE下载功能
Excel vba如何抓取指定网页数据到单元格--参考:Sub A1下载数据() ReDim A2(1 To 200000, 1 To 15): A = 0 For i = 1 To 5 Sleep 2000 + 1000 * Rnd With CreateObject("WinHttp.WinHttpRequest.5.1") URL = "target page" .Open "get", URL, False.setRequestHeader "Host", "...
excel2016. vba如何抓取网页的指定数据并自动更新为excel,网页登录有用户名和密码--sub test() dim i as integer for i = 30 to 1 step - 1 if cells(i , 1) = ”” then rows(i).delete next i end sub
关于从VBA中提取网页数据到excel表格的代码——看起来很复杂,但是这个页面应该是你内部使用的web系统,所以为什么不直接从数据库中读取数据呢?1587240. 0000的数据不难获取,应该是网页源代码中固定的td标签。
如何使用VB或VBA将某个网页的对应数据提取到EXCEL表中并用网站自动更新——C#帮你提取内容,方法一般是正则表达式。10元。
如何使用VBA只提取特定的网页数据到Excel中——这个不太好处理。我使用了“Key Wizard 2014”来模拟提取键盘操作。
如何使用VBA将在线表格数据提取到Excel中-----这个必须要做采集,然后写入EXCEL。
如何使用Excel的VBA自动提取以下网页的多页数据?-----直接复制即可。这不能用 VBA 解决,只能用按钮向导来解决。
如何使用VBA将网页中的快递信息提取到Excel中——其实没有人说可以预测准确的数量。还要看感觉,以及他查号的方法是否适合当前的号码规则。你可以在百度上找到一些群号,那里有一些免费的研究群,你可以进去参考。最重要的是看你能不能学会方法。 查看全部
excel网页数据抓取vba(Excel如何用VBA提取网页数据-——1、首先打开Excel2007工作表)
如何用Excel用VBA提取网页数据——1、首先打开Excel 2007工作表,点击要导入数据的位置,然后在菜单栏中找到第五项“数据” ,点击,点击“获取外部数据”“找到“来自网站”点击2、这时候弹出“新建Web查询”对话框,输入地址即可3、添加后点击“前往(G)”,要添加的网页内容,下方会出现黄色箭头,点击要选择的表格旁边的黄色箭头,可以看到点击复选标记后黄色箭头变成绿色,表示内容已被选中,然后点击“导入(I)”。4、弹出“导入数据”对话框,设置好后点击“确定”。5、Excel表格中显示“获取数据...”。6、数据采集完成,之前选择的网页内容全部导入到Excel工作表中。
如何从网页中提取表格数据到excel,可以用vba查看,谁教教我——1、使用复制功能,即ctrl+c,然后ctrl+v。2、 使用IE下载功能
Excel vba如何抓取指定网页数据到单元格--参考:Sub A1下载数据() ReDim A2(1 To 200000, 1 To 15): A = 0 For i = 1 To 5 Sleep 2000 + 1000 * Rnd With CreateObject("WinHttp.WinHttpRequest.5.1") URL = "target page" .Open "get", URL, False.setRequestHeader "Host", "...
excel2016. vba如何抓取网页的指定数据并自动更新为excel,网页登录有用户名和密码--sub test() dim i as integer for i = 30 to 1 step - 1 if cells(i , 1) = ”” then rows(i).delete next i end sub
关于从VBA中提取网页数据到excel表格的代码——看起来很复杂,但是这个页面应该是你内部使用的web系统,所以为什么不直接从数据库中读取数据呢?1587240. 0000的数据不难获取,应该是网页源代码中固定的td标签。
如何使用VB或VBA将某个网页的对应数据提取到EXCEL表中并用网站自动更新——C#帮你提取内容,方法一般是正则表达式。10元。
如何使用VBA只提取特定的网页数据到Excel中——这个不太好处理。我使用了“Key Wizard 2014”来模拟提取键盘操作。
如何使用VBA将在线表格数据提取到Excel中-----这个必须要做采集,然后写入EXCEL。
如何使用Excel的VBA自动提取以下网页的多页数据?-----直接复制即可。这不能用 VBA 解决,只能用按钮向导来解决。
如何使用VBA将网页中的快递信息提取到Excel中——其实没有人说可以预测准确的数量。还要看感觉,以及他查号的方法是否适合当前的号码规则。你可以在百度上找到一些群号,那里有一些免费的研究群,你可以进去参考。最重要的是看你能不能学会方法。
excel网页数据抓取vba(可以,只能用IE实现,引用MicrosoftInternetControls就可以)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-12 09:32
是的,只能用IE来实现。您可以通过引用 Microsoft Internet Controls 在 VBA 中操作网页上的内容。
Dim mShellwindows As New ShellWindows
Dim IE As InternetExplorer
For Each IE In mShellwindows '搜索页面
If IE.LocationURL = [URL] Then Exit For
Next
With IE.Document '在文本框填写内容
.all("[id_or_name]").Value = Sheet1.Cells(1, 1).Value
End With
基本原理如上面的代码所示。
[URL]是你要填数据的页面,先用IE浏览器打开这个页面。
[id_or_name] 是要填充数据的控件的 id 或名称。这需要提前从页面中获取。
至于其他的个性化定制内容,需要自己写~如果不想发图,再问!
顺便一提
Sub getPageInfo()
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate [URL]
While .ReadyState 4 Or .Busy
DoEvents
Wend
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
Set r = Nothing
.Quit
End With
MsgBox "获取页面信息成功!"
End Sub
这是抓取页面内容的代码...如果要登录,必须先打开页面。 查看全部
excel网页数据抓取vba(可以,只能用IE实现,引用MicrosoftInternetControls就可以)
是的,只能用IE来实现。您可以通过引用 Microsoft Internet Controls 在 VBA 中操作网页上的内容。
Dim mShellwindows As New ShellWindows
Dim IE As InternetExplorer
For Each IE In mShellwindows '搜索页面
If IE.LocationURL = [URL] Then Exit For
Next
With IE.Document '在文本框填写内容
.all("[id_or_name]").Value = Sheet1.Cells(1, 1).Value
End With
基本原理如上面的代码所示。
[URL]是你要填数据的页面,先用IE浏览器打开这个页面。
[id_or_name] 是要填充数据的控件的 id 或名称。这需要提前从页面中获取。
至于其他的个性化定制内容,需要自己写~如果不想发图,再问!
顺便一提
Sub getPageInfo()
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate [URL]
While .ReadyState 4 Or .Busy
DoEvents
Wend
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
Set r = Nothing
.Quit
End With
MsgBox "获取页面信息成功!"
End Sub
这是抓取页面内容的代码...如果要登录,必须先打开页面。
excel网页数据抓取vba(【】自学VBA:如何快速查看数据的界面? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-04 23:04
)
今天是冬至,选择了一个特别的日子。今天依旧是小扎让贾维斯的消息传遍全世界的日子。不如他,但至少他可以做一些特别的事情。
废话不多说,开始吧。
先说一下整个项目的背景。当时,我们积累了公司各种产品项目的数据。在没有开发人力的情况下,我们需要创建一个可以快速查看数据的界面,以帮助新的合作进行初步估算。
于是,就在一个周末,我开始自学VBA,希望能快点做出这个界面。
首先说一下整个查询界面的页面逻辑,比较简单,不到10个页面。
菜单作为所有页面的入口,有两个基本功能:一是查看数据,二是计算过滤。还有一个小功能,可以查看最近的供应商信息。
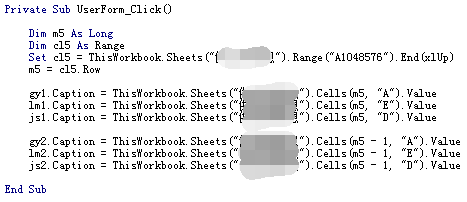
先说一下这个小功能。首先,我们会找到对应表的最后三条记录和对应的数据,然后将它们呈现在菜单的控件上。最后点击菜单界面触发小功能代码。
实现代码如下(镶嵌部分为对应的表名)
接下来说说菜单的第一个功能,数据查看。
由于整个项目都是用excel搭建的,所以也会有查看原创数据的需求。通过点击按钮触发代码,显示对应的表格,同时隐藏菜单页。
实现代码如下
然后,说说菜单的第二个功能,计算过滤器。
维度1搜索过滤,根据数据表的某个字段计算和搜索数据,然后呈现。实现最多三组数据同时查询。
实现代码:
对于单条记录查询,首先判断输入框是否为空,然后获取输入项的输入值进行循环搜索,找到对应单元格的位置,然后通过那个位置找到对应的字段,然后进行计算。
多记录查询与单记录查询一致,这里不再赘述。
这里还有一个小功能,可以自定义搜索字段的增减。
代码显示如下:
还有一个巧妙的功能,可以在搜索后显示搜索结果
在VBA后台将对应控件属性的可见性设置为FALSE,然后点击搜索按钮触发该属性修改为TRUE。
实现代码:
查看全部
excel网页数据抓取vba(【】自学VBA:如何快速查看数据的界面?
)
今天是冬至,选择了一个特别的日子。今天依旧是小扎让贾维斯的消息传遍全世界的日子。不如他,但至少他可以做一些特别的事情。
废话不多说,开始吧。
先说一下整个项目的背景。当时,我们积累了公司各种产品项目的数据。在没有开发人力的情况下,我们需要创建一个可以快速查看数据的界面,以帮助新的合作进行初步估算。
于是,就在一个周末,我开始自学VBA,希望能快点做出这个界面。
首先说一下整个查询界面的页面逻辑,比较简单,不到10个页面。

菜单作为所有页面的入口,有两个基本功能:一是查看数据,二是计算过滤。还有一个小功能,可以查看最近的供应商信息。
先说一下这个小功能。首先,我们会找到对应表的最后三条记录和对应的数据,然后将它们呈现在菜单的控件上。最后点击菜单界面触发小功能代码。
实现代码如下(镶嵌部分为对应的表名)
接下来说说菜单的第一个功能,数据查看。
由于整个项目都是用excel搭建的,所以也会有查看原创数据的需求。通过点击按钮触发代码,显示对应的表格,同时隐藏菜单页。
实现代码如下

然后,说说菜单的第二个功能,计算过滤器。
维度1搜索过滤,根据数据表的某个字段计算和搜索数据,然后呈现。实现最多三组数据同时查询。
实现代码:
对于单条记录查询,首先判断输入框是否为空,然后获取输入项的输入值进行循环搜索,找到对应单元格的位置,然后通过那个位置找到对应的字段,然后进行计算。

多记录查询与单记录查询一致,这里不再赘述。
这里还有一个小功能,可以自定义搜索字段的增减。
代码显示如下:

还有一个巧妙的功能,可以在搜索后显示搜索结果
在VBA后台将对应控件属性的可见性设置为FALSE,然后点击搜索按钮触发该属性修改为TRUE。
实现代码:

excel网页数据抓取vba(STM32静态网页与爬虫操作的演示程序的核心命令解释)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-04 22:31
b。然后处理响应并将其存储为相应的VBA对象
实际上,与爬虫操作相关的响应返回内容有四种:静态网页、JSON、XML和普通字符串。静态web页面和XML都可以通过DOM解析进行操作,xlminer对应于domtolist方法
' http request
' @return 字符串或是文档对象
' @param url url资源地址
' @param data 所传递参数
' @param asText 返回字符串或文档对象
' @param verb 请求类型 默认POST
Private Function post(ByVal url As String, Optional ByVal data As String, Optional ByVal asText As Boolean = False, Optional ByVal verb As String = "POST")
' 将文档解析为Lists对象
' @return 抽取目标对象 Lists
' @param query CSS选择器
' @param doc post函数所返回的文档对象
' @param elementAsArray 是否为两层嵌套对象 如 ,如果直接读取td,则无法保留其tr的从属结构, 或是 需要进一步分隔其中的字符串
' @param childQuery 第二层嵌套对象的CSS选择器
' @param tabSep 如果没有指定第二选择器,以tab或enter分隔
Private Function domToList(ByRef Query As String, ByRef doc As MSHTML.HTMLDocument, Optional ByVal elementAsArray As Boolean = False, Optional ByVal childQuery As String, Optional ByVal tabSep As Boolean = False) As Lists
字符串类型没有固定的模式,但解析起来比较清楚
最后是JSON解析。请参考JS类文件
function parserJSON(s){ return eval('(' + s + ')');}
返回值是一个JS对象。使用activexobject将JS对象转换为字典对象/将JS数组转换为VBA数组
var dict = new ActiveXObject('Scripting.Dictionary');
具体操作方法请参考随附的样本文件
下载地址
更新了对64位office的完美支持。之后为了适应Mac和vb7,用原生VBA重写了JSON解析库和字典库
c。处理并显示爬网结果
在本例中,将股票代码填入D4,然后单击按钮立即提取报告数据
演示程序的核心命令解释如下
' fs 读取报表数据, code股票代码, 2018 为年份,4指第四季度,fsType.BALANCE_STMT 指定资产负债表,
m.fs(code, 2018, 4, fsType.BALANCE_STMT).toRng .Cells(2, 1)
如果您感兴趣,您可以自己尝试其他参数
3.JS类文件与Excel VBA与JavaScript的交互
VBA中JS数据和程序的无缝调用为VBA的扩展提供了无限的可能性。在GitHub示例文件中,我展示了使用VBA从underline.js库调用函数的操作。p>
' load underscore.js
Call j.loadLib("js/underscore.js")
' load custom js code
Call j.loadLib("js/main.js")
' call the myzipp function in main.js
arr = j.js.run("myzipp", Array(1, 2, 3), Array("a", "b", "c"))
VBA对象以JSON字符串格式序列化,并通过JS读取,以实现另一个方向的连接。在实践中,d3js可视化项目有许多成功的先例
我对office JavaScript API的看法在前面的文章>中提到过。我深深怀疑JSAPI在现阶段的实用性。JS库是一个非官方的、不完善的替代和补充。VBA和JavaScript的动态结合是我长久以来的愿望。毕竟,scriptcontrol甚至不支持Es5语法。我非常期待这位官员在向后兼容的基础上引入更全面的JavaScript扩展 查看全部
excel网页数据抓取vba(STM32静态网页与爬虫操作的演示程序的核心命令解释)
b。然后处理响应并将其存储为相应的VBA对象
实际上,与爬虫操作相关的响应返回内容有四种:静态网页、JSON、XML和普通字符串。静态web页面和XML都可以通过DOM解析进行操作,xlminer对应于domtolist方法
' http request
' @return 字符串或是文档对象
' @param url url资源地址
' @param data 所传递参数
' @param asText 返回字符串或文档对象
' @param verb 请求类型 默认POST
Private Function post(ByVal url As String, Optional ByVal data As String, Optional ByVal asText As Boolean = False, Optional ByVal verb As String = "POST")
' 将文档解析为Lists对象
' @return 抽取目标对象 Lists
' @param query CSS选择器
' @param doc post函数所返回的文档对象
' @param elementAsArray 是否为两层嵌套对象 如 ,如果直接读取td,则无法保留其tr的从属结构, 或是 需要进一步分隔其中的字符串
' @param childQuery 第二层嵌套对象的CSS选择器
' @param tabSep 如果没有指定第二选择器,以tab或enter分隔
Private Function domToList(ByRef Query As String, ByRef doc As MSHTML.HTMLDocument, Optional ByVal elementAsArray As Boolean = False, Optional ByVal childQuery As String, Optional ByVal tabSep As Boolean = False) As Lists
字符串类型没有固定的模式,但解析起来比较清楚
最后是JSON解析。请参考JS类文件
function parserJSON(s){ return eval('(' + s + ')');}
返回值是一个JS对象。使用activexobject将JS对象转换为字典对象/将JS数组转换为VBA数组
var dict = new ActiveXObject('Scripting.Dictionary');
具体操作方法请参考随附的样本文件
下载地址
更新了对64位office的完美支持。之后为了适应Mac和vb7,用原生VBA重写了JSON解析库和字典库
c。处理并显示爬网结果

在本例中,将股票代码填入D4,然后单击按钮立即提取报告数据
演示程序的核心命令解释如下
' fs 读取报表数据, code股票代码, 2018 为年份,4指第四季度,fsType.BALANCE_STMT 指定资产负债表,
m.fs(code, 2018, 4, fsType.BALANCE_STMT).toRng .Cells(2, 1)
如果您感兴趣,您可以自己尝试其他参数
3.JS类文件与Excel VBA与JavaScript的交互
VBA中JS数据和程序的无缝调用为VBA的扩展提供了无限的可能性。在GitHub示例文件中,我展示了使用VBA从underline.js库调用函数的操作。p>
' load underscore.js
Call j.loadLib("js/underscore.js")
' load custom js code
Call j.loadLib("js/main.js")
' call the myzipp function in main.js
arr = j.js.run("myzipp", Array(1, 2, 3), Array("a", "b", "c"))
VBA对象以JSON字符串格式序列化,并通过JS读取,以实现另一个方向的连接。在实践中,d3js可视化项目有许多成功的先例
我对office JavaScript API的看法在前面的文章>中提到过。我深深怀疑JSAPI在现阶段的实用性。JS库是一个非官方的、不完善的替代和补充。VBA和JavaScript的动态结合是我长久以来的愿望。毕竟,scriptcontrol甚至不支持Es5语法。我非常期待这位官员在向后兼容的基础上引入更全面的JavaScript扩展
excel网页数据抓取vba(网页抓取的4大主要方式,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-04 17:34
据说网页抓取主要有四种方法,分别是:XMLHTTP对象、InternetExplorer对象、QueryTables对象和WebBrowser对象。
个人觉得QueryTables方法最简单,最容易上手。即:导入外部数据的方法更适合单文本页面。(但当网页文字过多时,会让人头疼)。
使用QueryTables时经常遇到的几个问题:
一个问题是#Beginners学习的时候地址无法放入导入框,必须使用快捷键CTRL+V才能完成粘贴操作。
还有一个问题是#selected area数据无法导入EXCEL。这时必须打开“源文件”,将源代码文件保存在桌面或任何地方。然后导入保存的源文件,导入地址就是保存的源文件的地址(如果是文本,用IE打开获取库存地址)
另一个问题是#Cannot 找不到您要导入的部分的 URL。看来现在网站很流行摆弄“隐秘术”,各种东西应有尽有。查找隐藏网址,一种方法是通过F12的功能找到隐藏网址,另一种方法是间接找到隐藏网址。使用QueryTables导入“中介区”,然后得到一个新的URL,然后根据这个URL,在F12中找到要导入的部分的地址。
简单总结一下这一点,因为我只学会了一点点的把握。
请给我们一些指点,给我们一些建议。谢谢。 查看全部
excel网页数据抓取vba(网页抓取的4大主要方式,你知道几个?)
据说网页抓取主要有四种方法,分别是:XMLHTTP对象、InternetExplorer对象、QueryTables对象和WebBrowser对象。
个人觉得QueryTables方法最简单,最容易上手。即:导入外部数据的方法更适合单文本页面。(但当网页文字过多时,会让人头疼)。
使用QueryTables时经常遇到的几个问题:
一个问题是#Beginners学习的时候地址无法放入导入框,必须使用快捷键CTRL+V才能完成粘贴操作。
还有一个问题是#selected area数据无法导入EXCEL。这时必须打开“源文件”,将源代码文件保存在桌面或任何地方。然后导入保存的源文件,导入地址就是保存的源文件的地址(如果是文本,用IE打开获取库存地址)
另一个问题是#Cannot 找不到您要导入的部分的 URL。看来现在网站很流行摆弄“隐秘术”,各种东西应有尽有。查找隐藏网址,一种方法是通过F12的功能找到隐藏网址,另一种方法是间接找到隐藏网址。使用QueryTables导入“中介区”,然后得到一个新的URL,然后根据这个URL,在F12中找到要导入的部分的地址。
简单总结一下这一点,因为我只学会了一点点的把握。
请给我们一些指点,给我们一些建议。谢谢。
excel网页数据抓取vba(Excel表格使用常识——“excel自学网页抓取数据” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-01 05:34
)
Excel电子表格使用常识-《excel自学网页爬取数据》
当我们在日常工作中使用excel表格的时候,有很多功能实际上并没有用到。其实excel表格很强大,比如可以抓取网页数据。是的,你没听错。就是抓取网页数据。怎么感觉我用excel这么久却不知道这个功能,感觉自己变成了初学者。没关系,其实我们只用到了excel表的10%的功能,其他功能用的并不多。因此,有些功能不熟悉是正常的。现在来说说“excel自学网页爬取数据”的功能。
操作方法:
1、 我们打开excel表格输入,然后在工具栏中找到【数据】标签,点击标签,在下方功能区找到【来自网站】按钮。
2、 点击【来自网站】按钮后,会弹出“新建网页查询”窗口,然后在地址栏中输入网址。
3、 输入后,点击地址栏右侧的【前往】按钮,这样我们就可以输入这个网站。
4、在页面上,Excel会尝试用符号标记表格数据,找到您需要的表格,点击相应的复选框,然后点击“导入”按钮。
5、 点击按钮后,会弹出“导入数据”窗口,然后点击确定(以上值可以保持默认)。
6、这样对应的单元格就会显示“正在获取数据”,等待数据获取成功,这样我们就可以抓取网页中的数据了。
7、 获取的网页数据也可以根据需要自动刷新。在【数据】功能区找到“连接”功能区,点击其中的【属性】按钮。
8、 点击属性后,会弹出“外部数据区属性”对话框,我们对其进行如下操作。
查看全部
excel网页数据抓取vba(Excel表格使用常识——“excel自学网页抓取数据”
)
Excel电子表格使用常识-《excel自学网页爬取数据》
当我们在日常工作中使用excel表格的时候,有很多功能实际上并没有用到。其实excel表格很强大,比如可以抓取网页数据。是的,你没听错。就是抓取网页数据。怎么感觉我用excel这么久却不知道这个功能,感觉自己变成了初学者。没关系,其实我们只用到了excel表的10%的功能,其他功能用的并不多。因此,有些功能不熟悉是正常的。现在来说说“excel自学网页爬取数据”的功能。
操作方法:
1、 我们打开excel表格输入,然后在工具栏中找到【数据】标签,点击标签,在下方功能区找到【来自网站】按钮。
2、 点击【来自网站】按钮后,会弹出“新建网页查询”窗口,然后在地址栏中输入网址。

3、 输入后,点击地址栏右侧的【前往】按钮,这样我们就可以输入这个网站。
4、在页面上,Excel会尝试用符号标记表格数据,找到您需要的表格,点击相应的复选框,然后点击“导入”按钮。
5、 点击按钮后,会弹出“导入数据”窗口,然后点击确定(以上值可以保持默认)。
6、这样对应的单元格就会显示“正在获取数据”,等待数据获取成功,这样我们就可以抓取网页中的数据了。
7、 获取的网页数据也可以根据需要自动刷新。在【数据】功能区找到“连接”功能区,点击其中的【属性】按钮。

8、 点击属性后,会弹出“外部数据区属性”对话框,我们对其进行如下操作。

excel网页数据抓取vba( 如何用Python快速的抓取一个网页中所有表格的爬虫3.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-01 02:27
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。这就是我之前所做的,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据 查看全部
excel网页数据抓取vba(
如何用Python快速的抓取一个网页中所有表格的爬虫3.)

之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。这就是我之前所做的,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据
excel网页数据抓取vba(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-01 02:20
Excel对网络数据的抓取和查询可以通过“获取与转换”+“查找引用函数”的功能组合来实现。
示例:下图为百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,通过输入会话数查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕捉到Excel中
依次单击“数据选项卡”、“新建查询”、“来自其他来源”和“来自 Web”。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏中,点击确定。
Excel 连接网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表格代表网页中的一个表格。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出的窗口中,选择“选择您希望如何在工作簿中查看此数据的方式”下的“表格”,然后单击“加载”。
如图,web表单中的数据已经抓取到Excel中。
依次点击“表格工具”、“设计”,将“表格名称”改为奥运会。
Step2:使用“查找与引用”功能实现数据查询
设置一个查询区域,包括“会话数”和“主办城市”,在会话数中选择一个,在下图中输入“08th”,进入主办城市下的vlookup功能,可以得到主办城市的主持人08届奥运会城市是巴黎。当会话数发生变化时,相应的主办城市也会发生变化。
公式:=VLOOKUP([会话数], 奥运会[#All],4,0)
注意:如果网页中的数据变化频繁,可以将链接网页的数据设置为定时刷新:
① 将鼠标置于导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新。这样,数据会每10分钟刷新一次,保证获取到的数据是最新的。
“精进Excel”为头条签约作者。跟着我。点击打开三篇文章文章,没有你想要的知识,就当我是大佬! 查看全部
excel网页数据抓取vba(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
Excel对网络数据的抓取和查询可以通过“获取与转换”+“查找引用函数”的功能组合来实现。
示例:下图为百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,通过输入会话数查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕捉到Excel中
依次单击“数据选项卡”、“新建查询”、“来自其他来源”和“来自 Web”。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏中,点击确定。
Excel 连接网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表格代表网页中的一个表格。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出的窗口中,选择“选择您希望如何在工作簿中查看此数据的方式”下的“表格”,然后单击“加载”。
如图,web表单中的数据已经抓取到Excel中。
依次点击“表格工具”、“设计”,将“表格名称”改为奥运会。
Step2:使用“查找与引用”功能实现数据查询
设置一个查询区域,包括“会话数”和“主办城市”,在会话数中选择一个,在下图中输入“08th”,进入主办城市下的vlookup功能,可以得到主办城市的主持人08届奥运会城市是巴黎。当会话数发生变化时,相应的主办城市也会发生变化。
公式:=VLOOKUP([会话数], 奥运会[#All],4,0)
注意:如果网页中的数据变化频繁,可以将链接网页的数据设置为定时刷新:
① 将鼠标置于导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新。这样,数据会每10分钟刷新一次,保证获取到的数据是最新的。
“精进Excel”为头条签约作者。跟着我。点击打开三篇文章文章,没有你想要的知识,就当我是大佬!
excel网页数据抓取vba(和DOM将是最好的方法吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-24 09:21
无法抑制“另存为”对话框:
从脚本调用此方法时,无法禁用“保存HTML文档”对话框
它也是一个模式对话框,您不能自动单击&34;节约34英镑;按钮面对此对话时,VBA执行会在等待手动用户输入时暂停
您可以尝试读取页面的HTML并使用标准I/O函数将其打印到文件中,而不是使用ie.document.execcommand方法
Option Explicit
Sub SaveHTML()
Dim URL as String
Dim IE as Object
Dim i as Long
Dim FileName as String
Dim FF as Integer
URL = "http://google.com" 'for TEST
Filename = "C:\Test.htm"
Set IE = CreateObject("Internetexplorer.Application")
IE.Visible = True
IE.Navigate URL
Do
Loop While IE.Busy
'Creates a file as specified
' this will overwrite an existing file if already exists
CreateObject("Scripting.FileSystemObject").CreateTextFile FileName
FF = FreeFile
Open Filename For Output As #FF
With IE.Document.Body
Print #FF, .OuterHtml & .InnerHtml
End With
Close #FF
IE.Quit
Set IE = Nothing
End Sub
我不确定这是否能完全满足你的需要。还有其他从网络获取数据的方法。最好的方法是从xmlhttp请求中获取原创HTML并将其打印到文件中
当然,我们很少需要HTML格式的整个网页,因此如果您想从网页中获取特定数据,xmlhttp和DOM将是最好的方法,您根本不需要将其保存到文件中
或者,您可以使用selenium包装器来自动化ie,这比在Internet Explorer中使用相对较少的本机方法要强大得多。应用程序类
还请注意,您使用的是一种相当粗糙的方法来等待网页加载(在ie.busy时循环)。虽然它有时可能工作,但可能不可靠。关于如何在so上正确执行此操作,有很多问题,因此我将在这里参考您的搜索功能来稍微调整代码 查看全部
excel网页数据抓取vba(和DOM将是最好的方法吗?(上))
无法抑制“另存为”对话框:
从脚本调用此方法时,无法禁用“保存HTML文档”对话框
它也是一个模式对话框,您不能自动单击&34;节约34英镑;按钮面对此对话时,VBA执行会在等待手动用户输入时暂停
您可以尝试读取页面的HTML并使用标准I/O函数将其打印到文件中,而不是使用ie.document.execcommand方法
Option Explicit
Sub SaveHTML()
Dim URL as String
Dim IE as Object
Dim i as Long
Dim FileName as String
Dim FF as Integer
URL = "http://google.com" 'for TEST
Filename = "C:\Test.htm"
Set IE = CreateObject("Internetexplorer.Application")
IE.Visible = True
IE.Navigate URL
Do
Loop While IE.Busy
'Creates a file as specified
' this will overwrite an existing file if already exists
CreateObject("Scripting.FileSystemObject").CreateTextFile FileName
FF = FreeFile
Open Filename For Output As #FF
With IE.Document.Body
Print #FF, .OuterHtml & .InnerHtml
End With
Close #FF
IE.Quit
Set IE = Nothing
End Sub
我不确定这是否能完全满足你的需要。还有其他从网络获取数据的方法。最好的方法是从xmlhttp请求中获取原创HTML并将其打印到文件中
当然,我们很少需要HTML格式的整个网页,因此如果您想从网页中获取特定数据,xmlhttp和DOM将是最好的方法,您根本不需要将其保存到文件中
或者,您可以使用selenium包装器来自动化ie,这比在Internet Explorer中使用相对较少的本机方法要强大得多。应用程序类
还请注意,您使用的是一种相当粗糙的方法来等待网页加载(在ie.busy时循环)。虽然它有时可能工作,但可能不可靠。关于如何在so上正确执行此操作,有很多问题,因此我将在这里参考您的搜索功能来稍微调整代码
excel网页数据抓取vba( VBA·5个月前如何使用VBA网抓的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-24 09:19
VBA·5个月前如何使用VBA网抓的?
)
使用Excel+VBA操作网页
黄晨·5个月前,因为知乎的一些回答,最近总有私信问我怎么用VBA抓网,我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。趁着开专栏知乎的机会,来仔细解释一下这个问题。
我对Excel和VBA的了解有限,只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中使用import,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。通过查看这个名称,我们知道它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然 all 最好用,因为 all 也有 all ("IDName") 和 all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表单提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是一个select标签,每个选项都在一个option标签中,所以要返回一个集合,需要选择一个选项,将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也有些不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,我用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用的是ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText 查看全部
excel网页数据抓取vba(
VBA·5个月前如何使用VBA网抓的?
)
使用Excel+VBA操作网页
黄晨·5个月前,因为知乎的一些回答,最近总有私信问我怎么用VBA抓网,我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。趁着开专栏知乎的机会,来仔细解释一下这个问题。
我对Excel和VBA的了解有限,只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中使用import,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。通过查看这个名称,我们知道它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然 all 最好用,因为 all 也有 all ("IDName") 和 all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表单提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是一个select标签,每个选项都在一个option标签中,所以要返回一个集合,需要选择一个选项,将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也有些不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,我用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用的是ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText
excel网页数据抓取vba(我用脚本写一个给你啦用python网页网页书单(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-09-17 21:12
这两天他去朋友家玩。他说,他最近找了一份工作,需要帮助其他人整理网上书籍,他似乎有点麻烦。我想一下。好吧,我给你写一个剧本
使用Python获取web图书列表1、并分析需求
您需要捕获网页中的特定内容,特别是
对于有限的平装书,需要书名、作者姓名、出版时间和售价。出版商从书名(如有)中引入ISBN代码
这些内容必须存在于网页中,因此我们只需要使用[regular expression]来提取所需的内容
然后,他将内容范围指定为
关键词是音乐欣赏、艺术欣赏和艺术创作
这个。。亚马逊似乎有很多参数。。。那么我不妨先在这里偷一个懒汉(怎么说,亲吻原则),然后在这里先记录他请求的网站
音乐欣赏
艺术欣赏
艺术创作
嗯,它们看起来都像
2、设计功能
我朋友的要求是把上面的数据整理成excel。对于这个函数,如果我在Internet上找到一个python封装的库,应该没有问题。为了便于使用,我们最好在这里支持交互式界面。为了方便起见,我们仍然计划把pyqt一号带出去
那么一般功能是:
3、具体实施
让我们使用Python作为一个简单的脚本。这里,我们使用请求来删除数据,但请注意,Amazon实际上有一个保护机制。如果您轻率地使用get方法进行访问,Amazon将向您返回以下内容:
1
2
3
4
然后我试着假装头部,四处走动
然后提取此页面中每本书对应的URL并观察当前页面。URL有一个特征词“a-link-normal s-access-detail-page a-text-normal”。然后,您可以使用该关键字使用正则表达式提取当前数据
因为要在HREF中间提取内容,必须首先在***中指定内容,然后使用()返回需要的内容
1
pageDetail = r'<a class="a-link-normal s-access-detail-page a-text-normal"[^>]*?href=\"([^>]*)\"[^>]*?>'
请注意,由于常规模式默认为贪婪模式,因此我们可以在***************************************************************之后添加“贪婪”?实现非贪婪模式查找
找到网页后,记录当前的网站并依次访问
然后我们需要根据需求获取内容
经过测试,可以完成所需的功能~
然后是Excel的操作。虽然我还没有见过VBA,但python已经在xlwt中编写了excel,所以下面是一个尝试:
1
2
3
4
5
6
7
8
9
10
11
12
import xlwt
# 创建 xls 文件对象
wb = xlwt.Workbook()
# 新增一个表单
sh = wb.add_sheet('A Test Sheet')
# 按位置添加数据
sh.write(0, 0, 1234.56)
sh.write(1, 0, 8888)
sh.write(2, 0, 'hello')
sh.write(2, 1, 'world')
# 保存文件
wb.save('example.xls')
我在互联网上找到了这个演示,因此估计对应关系为
|实际内容|操作对象|
|Excel文件|工作簿
|床单
|单元格内容写入
然后我们大致知道如何编写:创建一个excel并将数据放在指定的位置
----------=========------------
有一种新的需求。您需要截图网站并将其保存到当前目录。这似乎是可以实现的。然后我发现了一件麻烦的事。。。这张照片一定涉及编码问题,但我似乎无法处理。。因为URL捕获的页面大小似乎不太正确。。。它可能是多张图片或其他东西。无论如何,照片的数量是错误的。。。所以我用了其他的想法,直接在网页上取了图片,就是Base64处理过的图片。。。。虽然它可能被压缩了,但应该仍然可以。。把这个拿下来处理。应该没问题
4、特定应用
正如这位同学提到的,他也想借此机会学习,他计划写一份依赖列表,以便能够快速安装
安装pipreqs可以快速生成requirements.txt。但是,发现总是报告Unicode解码错误。人们认为这可能是由于windows的CMD编码问题,因此使用该参数强制指定编码为UTF-8:
1
pipreqs --encoding=utf-8 --use-local ./
如果另一方需要快速安装相应的库,它只需要在当前目录中使用它
pip install -r requirements.txt
命令,可以快速安装相应的从属库
后来,我记得有一个直观的界面,便于操作。。。好吧,搞砸了pyqt这个已经丢失了很长时间的简单例子:
首先,使用QT设计器创建第一个
然后使用pyuic5命令生成相应的。Py文件
1
pyuic5 -o ui_Dialog.py Dialog.ui
最后,使用另一个程序收录此内容,并使用pyqt对其进行操作。为了避免程序运行时的干扰,采用qthread进行异步处理,增加了slot函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class SpiderCrawl(QThread):
"""Lanch Spider"""
SignalFinishSpdier = pyqtSignal(bool)
def __init__(self, needs, parent=None):
super(SpiderCrawl, self).__init__(parent)
self.needs = needs
self.SignalFinishSpdier.connect(parent.spiderFinish)
def run(self):
""" it will return result of the spider
Ret: the result of spider
"""
result = amazonSpider.Spider(self.needs)
self.SignalFinishSpdier.emit(result)
class SpiderDialog(QDialog, ui_Dialog.Ui_Dialog):
...
@pyqtSlot(bool)
def spiderFinish(self, result):
""" the spider is finish"""
print("There!")
if result == True:
self.KeywordText.setText("爬虫已经完成任务")
else:
self.KeywordText.setText("你的url有问题...")
self.takeButton.setEnabled(True)
最后,为了防止手工进入错误的网站。。。在这里也可以检测到它。如果在当前网页中找不到合适的URL,也会被视为输入错误
最后,附上项目的网站:
亚马逊蜘蛛V1.0 查看全部
excel网页数据抓取vba(我用脚本写一个给你啦用python网页网页书单(组图))
这两天他去朋友家玩。他说,他最近找了一份工作,需要帮助其他人整理网上书籍,他似乎有点麻烦。我想一下。好吧,我给你写一个剧本
使用Python获取web图书列表1、并分析需求
您需要捕获网页中的特定内容,特别是
对于有限的平装书,需要书名、作者姓名、出版时间和售价。出版商从书名(如有)中引入ISBN代码
这些内容必须存在于网页中,因此我们只需要使用[regular expression]来提取所需的内容
然后,他将内容范围指定为
关键词是音乐欣赏、艺术欣赏和艺术创作
这个。。亚马逊似乎有很多参数。。。那么我不妨先在这里偷一个懒汉(怎么说,亲吻原则),然后在这里先记录他请求的网站
音乐欣赏
艺术欣赏
艺术创作
嗯,它们看起来都像
2、设计功能
我朋友的要求是把上面的数据整理成excel。对于这个函数,如果我在Internet上找到一个python封装的库,应该没有问题。为了便于使用,我们最好在这里支持交互式界面。为了方便起见,我们仍然计划把pyqt一号带出去
那么一般功能是:
3、具体实施
让我们使用Python作为一个简单的脚本。这里,我们使用请求来删除数据,但请注意,Amazon实际上有一个保护机制。如果您轻率地使用get方法进行访问,Amazon将向您返回以下内容:
1
2
3
4
然后我试着假装头部,四处走动
然后提取此页面中每本书对应的URL并观察当前页面。URL有一个特征词“a-link-normal s-access-detail-page a-text-normal”。然后,您可以使用该关键字使用正则表达式提取当前数据
因为要在HREF中间提取内容,必须首先在***中指定内容,然后使用()返回需要的内容
1
pageDetail = r'<a class="a-link-normal s-access-detail-page a-text-normal"[^>]*?href=\"([^>]*)\"[^>]*?>'
请注意,由于常规模式默认为贪婪模式,因此我们可以在***************************************************************之后添加“贪婪”?实现非贪婪模式查找
找到网页后,记录当前的网站并依次访问
然后我们需要根据需求获取内容
经过测试,可以完成所需的功能~
然后是Excel的操作。虽然我还没有见过VBA,但python已经在xlwt中编写了excel,所以下面是一个尝试:
1
2
3
4
5
6
7
8
9
10
11
12
import xlwt
# 创建 xls 文件对象
wb = xlwt.Workbook()
# 新增一个表单
sh = wb.add_sheet('A Test Sheet')
# 按位置添加数据
sh.write(0, 0, 1234.56)
sh.write(1, 0, 8888)
sh.write(2, 0, 'hello')
sh.write(2, 1, 'world')
# 保存文件
wb.save('example.xls')
我在互联网上找到了这个演示,因此估计对应关系为
|实际内容|操作对象|
|Excel文件|工作簿
|床单
|单元格内容写入
然后我们大致知道如何编写:创建一个excel并将数据放在指定的位置
----------=========------------
有一种新的需求。您需要截图网站并将其保存到当前目录。这似乎是可以实现的。然后我发现了一件麻烦的事。。。这张照片一定涉及编码问题,但我似乎无法处理。。因为URL捕获的页面大小似乎不太正确。。。它可能是多张图片或其他东西。无论如何,照片的数量是错误的。。。所以我用了其他的想法,直接在网页上取了图片,就是Base64处理过的图片。。。。虽然它可能被压缩了,但应该仍然可以。。把这个拿下来处理。应该没问题
4、特定应用
正如这位同学提到的,他也想借此机会学习,他计划写一份依赖列表,以便能够快速安装
安装pipreqs可以快速生成requirements.txt。但是,发现总是报告Unicode解码错误。人们认为这可能是由于windows的CMD编码问题,因此使用该参数强制指定编码为UTF-8:
1
pipreqs --encoding=utf-8 --use-local ./
如果另一方需要快速安装相应的库,它只需要在当前目录中使用它
pip install -r requirements.txt
命令,可以快速安装相应的从属库
后来,我记得有一个直观的界面,便于操作。。。好吧,搞砸了pyqt这个已经丢失了很长时间的简单例子:
首先,使用QT设计器创建第一个

然后使用pyuic5命令生成相应的。Py文件
1
pyuic5 -o ui_Dialog.py Dialog.ui
最后,使用另一个程序收录此内容,并使用pyqt对其进行操作。为了避免程序运行时的干扰,采用qthread进行异步处理,增加了slot函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class SpiderCrawl(QThread):
"""Lanch Spider"""
SignalFinishSpdier = pyqtSignal(bool)
def __init__(self, needs, parent=None):
super(SpiderCrawl, self).__init__(parent)
self.needs = needs
self.SignalFinishSpdier.connect(parent.spiderFinish)
def run(self):
""" it will return result of the spider
Ret: the result of spider
"""
result = amazonSpider.Spider(self.needs)
self.SignalFinishSpdier.emit(result)
class SpiderDialog(QDialog, ui_Dialog.Ui_Dialog):
...
@pyqtSlot(bool)
def spiderFinish(self, result):
""" the spider is finish"""
print("There!")
if result == True:
self.KeywordText.setText("爬虫已经完成任务")
else:
self.KeywordText.setText("你的url有问题...")
self.takeButton.setEnabled(True)
最后,为了防止手工进入错误的网站。。。在这里也可以检测到它。如果在当前网页中找不到合适的URL,也会被视为输入错误
最后,附上项目的网站:
亚马逊蜘蛛V1.0
excel网页数据抓取vba(Python如何用Excel的VBA爬取数据?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-09-09 21:14
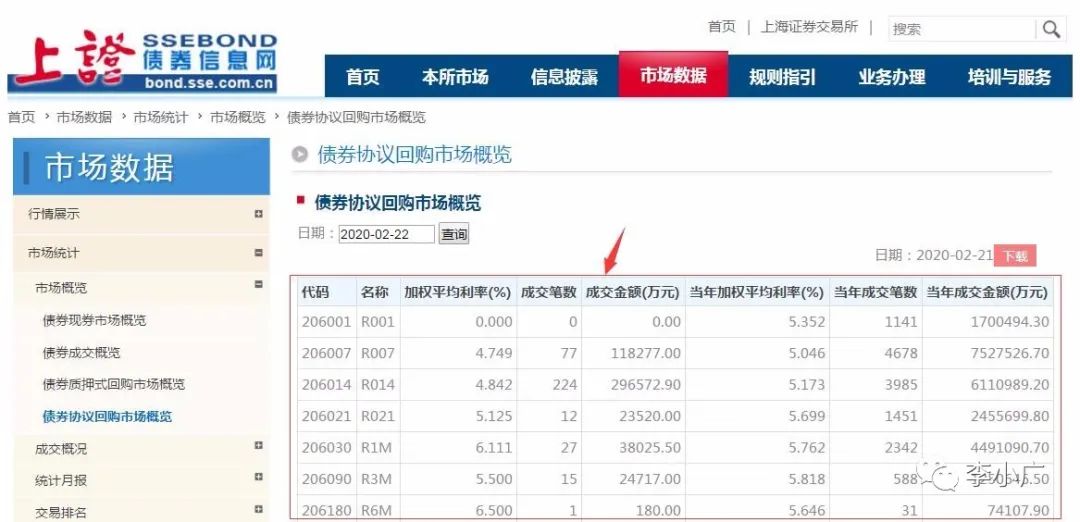
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
目前最流行的爬虫方法一般都是通过Python来实现的,Python有很多有用的第三方库来实现。不熟悉使用Python的朋友,有没有办法通过Excel VBA来实现?
要做数据分析,准备工作中很重要的一个环节就是获取数据。数据通常来自多个来源,例如单位数据库中存储的数据、报表填写的数据等,网页上的公开数据等。本文将抓取网页以公开数据为例,做一个简单的例子演示如何使用 Excel VBA 抓取数据。
测试网页:上证债券信息网
尝试用Excel获取某个时间范围内的所有记录(上图红框内数据表中的信息)。
要求:按日期从网页中抓取2018年1月1日至今的债券协议回购市场数据(上表所有数据)。操作方法:
----------------------------------------1、打开EXCEL并创建两个sheet表1)data,用于存放得到的结果2)crawling数据,用于存放WebBrowser控件。如图:
2、insert 控件
方法如图:
开发工具——插入 ActiveX 控件,找到 microsoftWebBrowser 控件——拖动它。
3、设置控件的属性
跟进您的需求并设置空间。此处省略,使用默认值。
4、通过控件分析网页上的日期。我们需要查询一段时间内的数据。因此,我们需要在日期控件中模拟输入日期,然后点击“查询”按钮。查看网页源码,找到对应控件的名称和位置:
从上面的截图可以看出,日期控件的id是“searchDate”,输入日期可以通过如下代码控制:
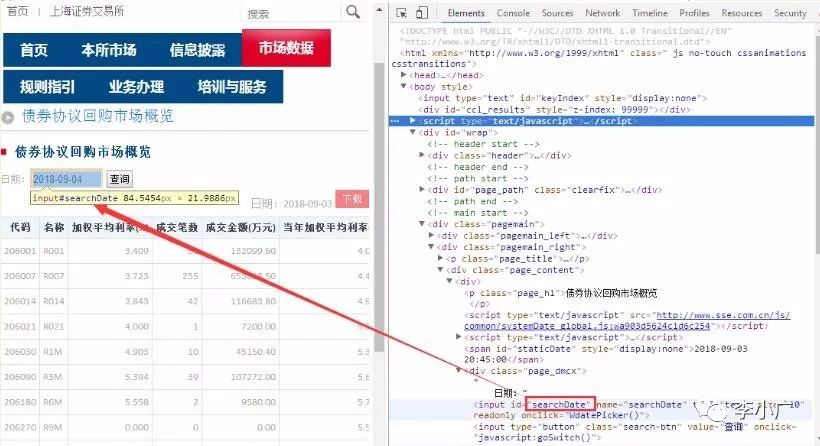
WebBrowser1.Document.All.Item("searchDate").Value = RQ
同样,再次查看查询按钮。查询按钮的执行程序为“javascript:goSwitch()”,可以通过如下代码调用:
WebBrowser1.Document.parentWindow.execScript "javascript:goSwitch()
另外,网页上数据表的id是“datelist”。
5、Code 实现 根据上述,编写VBA代码,代码逻辑如下:使用for循环,根据网页上的日期填写数据,点击“查询”;等待网页数据刷新,抓取网页上的数据,保存到数组arr中,然后将数组保存到sheet表中。
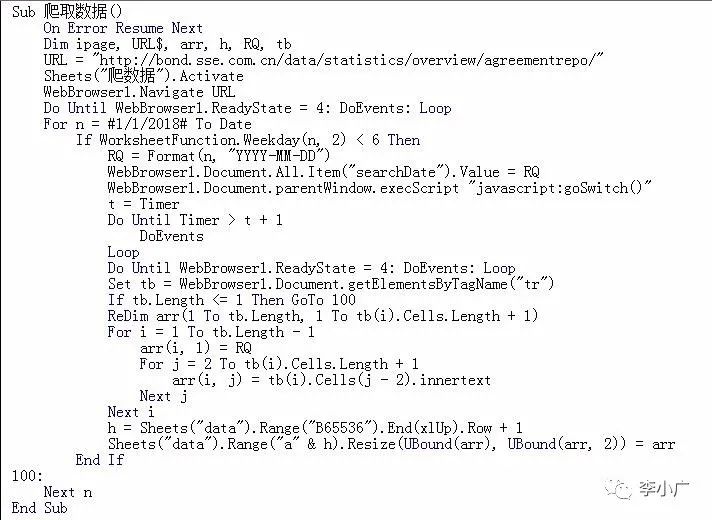
6、运行程序
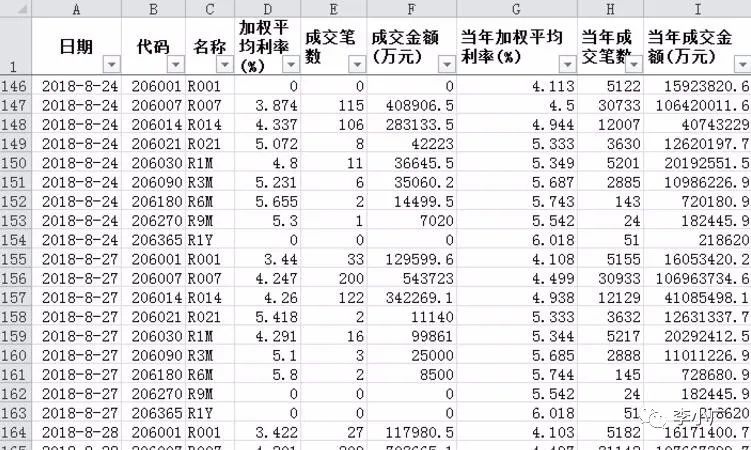
运行程序,稍等片刻即可查看爬取的数据。如下图:
注意事项:
如果事件效率不高或者数据量不大,条件有限,可以使用这种方法。 (效率低下也是一)这种方法的弊端之一。
对于难以抓取的网页,建议先使用Python。
/20180905 查看全部
excel网页数据抓取vba(Python如何用Excel的VBA爬取数据?(一))
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
目前最流行的爬虫方法一般都是通过Python来实现的,Python有很多有用的第三方库来实现。不熟悉使用Python的朋友,有没有办法通过Excel VBA来实现?
要做数据分析,准备工作中很重要的一个环节就是获取数据。数据通常来自多个来源,例如单位数据库中存储的数据、报表填写的数据等,网页上的公开数据等。本文将抓取网页以公开数据为例,做一个简单的例子演示如何使用 Excel VBA 抓取数据。
测试网页:上证债券信息网
尝试用Excel获取某个时间范围内的所有记录(上图红框内数据表中的信息)。
要求:按日期从网页中抓取2018年1月1日至今的债券协议回购市场数据(上表所有数据)。操作方法:
----------------------------------------1、打开EXCEL并创建两个sheet表1)data,用于存放得到的结果2)crawling数据,用于存放WebBrowser控件。如图:
2、insert 控件
方法如图:
开发工具——插入 ActiveX 控件,找到 microsoftWebBrowser 控件——拖动它。
3、设置控件的属性
跟进您的需求并设置空间。此处省略,使用默认值。
4、通过控件分析网页上的日期。我们需要查询一段时间内的数据。因此,我们需要在日期控件中模拟输入日期,然后点击“查询”按钮。查看网页源码,找到对应控件的名称和位置:
从上面的截图可以看出,日期控件的id是“searchDate”,输入日期可以通过如下代码控制:
WebBrowser1.Document.All.Item("searchDate").Value = RQ
同样,再次查看查询按钮。查询按钮的执行程序为“javascript:goSwitch()”,可以通过如下代码调用:
WebBrowser1.Document.parentWindow.execScript "javascript:goSwitch()
另外,网页上数据表的id是“datelist”。
5、Code 实现 根据上述,编写VBA代码,代码逻辑如下:使用for循环,根据网页上的日期填写数据,点击“查询”;等待网页数据刷新,抓取网页上的数据,保存到数组arr中,然后将数组保存到sheet表中。
6、运行程序
运行程序,稍等片刻即可查看爬取的数据。如下图:
注意事项:
如果事件效率不高或者数据量不大,条件有限,可以使用这种方法。 (效率低下也是一)这种方法的弊端之一。
对于难以抓取的网页,建议先使用Python。

/20180905
excel网页数据抓取vba(Excel如何用VBA提取网页数据-——1、首先打开Excel2007工作表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 522 次浏览 • 2021-10-22 12:12
如何用Excel用VBA提取网页数据——1、首先打开Excel 2007工作表,点击要导入数据的位置,然后在菜单栏中找到第五项“数据” ,点击,点击“获取外部数据”“找到“来自网站”点击2、这时候弹出“新建Web查询”对话框,输入地址即可3、添加后点击“前往(G)”,要添加的网页内容,下方会出现黄色箭头,点击要选择的表格旁边的黄色箭头,可以看到点击复选标记后黄色箭头变成绿色,表示内容已被选中,然后点击“导入(I)”。4、弹出“导入数据”对话框,设置好后点击“确定”。5、Excel表格中显示“获取数据...”。6、数据采集完成,之前选择的网页内容全部导入到Excel工作表中。
如何从网页中提取表格数据到excel,可以用vba查看,谁教教我——1、使用复制功能,即ctrl+c,然后ctrl+v。2、 使用IE下载功能
Excel vba如何抓取指定网页数据到单元格--参考:Sub A1下载数据() ReDim A2(1 To 200000, 1 To 15): A = 0 For i = 1 To 5 Sleep 2000 + 1000 * Rnd With CreateObject("WinHttp.WinHttpRequest.5.1") URL = "target page" .Open "get", URL, False.setRequestHeader "Host", "...
excel2016. vba如何抓取网页的指定数据并自动更新为excel,网页登录有用户名和密码--sub test() dim i as integer for i = 30 to 1 step - 1 if cells(i , 1) = ”” then rows(i).delete next i end sub
关于从VBA中提取网页数据到excel表格的代码——看起来很复杂,但是这个页面应该是你内部使用的web系统,所以为什么不直接从数据库中读取数据呢?1587240. 0000的数据不难获取,应该是网页源代码中固定的td标签。
如何使用VB或VBA将某个网页的对应数据提取到EXCEL表中并用网站自动更新——C#帮你提取内容,方法一般是正则表达式。10元。
如何使用VBA只提取特定的网页数据到Excel中——这个不太好处理。我使用了“Key Wizard 2014”来模拟提取键盘操作。
如何使用VBA将在线表格数据提取到Excel中-----这个必须要做采集,然后写入EXCEL。
如何使用Excel的VBA自动提取以下网页的多页数据?-----直接复制即可。这不能用 VBA 解决,只能用按钮向导来解决。
如何使用VBA将网页中的快递信息提取到Excel中——其实没有人说可以预测准确的数量。还要看感觉,以及他查号的方法是否适合当前的号码规则。你可以在百度上找到一些群号,那里有一些免费的研究群,你可以进去参考。最重要的是看你能不能学会方法。 查看全部
excel网页数据抓取vba(Excel如何用VBA提取网页数据-——1、首先打开Excel2007工作表)
如何用Excel用VBA提取网页数据——1、首先打开Excel 2007工作表,点击要导入数据的位置,然后在菜单栏中找到第五项“数据” ,点击,点击“获取外部数据”“找到“来自网站”点击2、这时候弹出“新建Web查询”对话框,输入地址即可3、添加后点击“前往(G)”,要添加的网页内容,下方会出现黄色箭头,点击要选择的表格旁边的黄色箭头,可以看到点击复选标记后黄色箭头变成绿色,表示内容已被选中,然后点击“导入(I)”。4、弹出“导入数据”对话框,设置好后点击“确定”。5、Excel表格中显示“获取数据...”。6、数据采集完成,之前选择的网页内容全部导入到Excel工作表中。
如何从网页中提取表格数据到excel,可以用vba查看,谁教教我——1、使用复制功能,即ctrl+c,然后ctrl+v。2、 使用IE下载功能
Excel vba如何抓取指定网页数据到单元格--参考:Sub A1下载数据() ReDim A2(1 To 200000, 1 To 15): A = 0 For i = 1 To 5 Sleep 2000 + 1000 * Rnd With CreateObject("WinHttp.WinHttpRequest.5.1") URL = "target page" .Open "get", URL, False.setRequestHeader "Host", "...
excel2016. vba如何抓取网页的指定数据并自动更新为excel,网页登录有用户名和密码--sub test() dim i as integer for i = 30 to 1 step - 1 if cells(i , 1) = ”” then rows(i).delete next i end sub
关于从VBA中提取网页数据到excel表格的代码——看起来很复杂,但是这个页面应该是你内部使用的web系统,所以为什么不直接从数据库中读取数据呢?1587240. 0000的数据不难获取,应该是网页源代码中固定的td标签。
如何使用VB或VBA将某个网页的对应数据提取到EXCEL表中并用网站自动更新——C#帮你提取内容,方法一般是正则表达式。10元。
如何使用VBA只提取特定的网页数据到Excel中——这个不太好处理。我使用了“Key Wizard 2014”来模拟提取键盘操作。
如何使用VBA将在线表格数据提取到Excel中-----这个必须要做采集,然后写入EXCEL。
如何使用Excel的VBA自动提取以下网页的多页数据?-----直接复制即可。这不能用 VBA 解决,只能用按钮向导来解决。
如何使用VBA将网页中的快递信息提取到Excel中——其实没有人说可以预测准确的数量。还要看感觉,以及他查号的方法是否适合当前的号码规则。你可以在百度上找到一些群号,那里有一些免费的研究群,你可以进去参考。最重要的是看你能不能学会方法。
excel网页数据抓取vba(可以,只能用IE实现,引用MicrosoftInternetControls就可以)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-12 09:32
是的,只能用IE来实现。您可以通过引用 Microsoft Internet Controls 在 VBA 中操作网页上的内容。
Dim mShellwindows As New ShellWindows
Dim IE As InternetExplorer
For Each IE In mShellwindows '搜索页面
If IE.LocationURL = [URL] Then Exit For
Next
With IE.Document '在文本框填写内容
.all("[id_or_name]").Value = Sheet1.Cells(1, 1).Value
End With
基本原理如上面的代码所示。
[URL]是你要填数据的页面,先用IE浏览器打开这个页面。
[id_or_name] 是要填充数据的控件的 id 或名称。这需要提前从页面中获取。
至于其他的个性化定制内容,需要自己写~如果不想发图,再问!
顺便一提
Sub getPageInfo()
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate [URL]
While .ReadyState 4 Or .Busy
DoEvents
Wend
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
Set r = Nothing
.Quit
End With
MsgBox "获取页面信息成功!"
End Sub
这是抓取页面内容的代码...如果要登录,必须先打开页面。 查看全部
excel网页数据抓取vba(可以,只能用IE实现,引用MicrosoftInternetControls就可以)
是的,只能用IE来实现。您可以通过引用 Microsoft Internet Controls 在 VBA 中操作网页上的内容。
Dim mShellwindows As New ShellWindows
Dim IE As InternetExplorer
For Each IE In mShellwindows '搜索页面
If IE.LocationURL = [URL] Then Exit For
Next
With IE.Document '在文本框填写内容
.all("[id_or_name]").Value = Sheet1.Cells(1, 1).Value
End With
基本原理如上面的代码所示。
[URL]是你要填数据的页面,先用IE浏览器打开这个页面。
[id_or_name] 是要填充数据的控件的 id 或名称。这需要提前从页面中获取。
至于其他的个性化定制内容,需要自己写~如果不想发图,再问!
顺便一提
Sub getPageInfo()
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate [URL]
While .ReadyState 4 Or .Busy
DoEvents
Wend
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
Set r = Nothing
.Quit
End With
MsgBox "获取页面信息成功!"
End Sub
这是抓取页面内容的代码...如果要登录,必须先打开页面。
excel网页数据抓取vba(【】自学VBA:如何快速查看数据的界面? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-10-04 23:04
)
今天是冬至,选择了一个特别的日子。今天依旧是小扎让贾维斯的消息传遍全世界的日子。不如他,但至少他可以做一些特别的事情。
废话不多说,开始吧。
先说一下整个项目的背景。当时,我们积累了公司各种产品项目的数据。在没有开发人力的情况下,我们需要创建一个可以快速查看数据的界面,以帮助新的合作进行初步估算。
于是,就在一个周末,我开始自学VBA,希望能快点做出这个界面。
首先说一下整个查询界面的页面逻辑,比较简单,不到10个页面。
菜单作为所有页面的入口,有两个基本功能:一是查看数据,二是计算过滤。还有一个小功能,可以查看最近的供应商信息。
先说一下这个小功能。首先,我们会找到对应表的最后三条记录和对应的数据,然后将它们呈现在菜单的控件上。最后点击菜单界面触发小功能代码。
实现代码如下(镶嵌部分为对应的表名)
接下来说说菜单的第一个功能,数据查看。
由于整个项目都是用excel搭建的,所以也会有查看原创数据的需求。通过点击按钮触发代码,显示对应的表格,同时隐藏菜单页。
实现代码如下
然后,说说菜单的第二个功能,计算过滤器。
维度1搜索过滤,根据数据表的某个字段计算和搜索数据,然后呈现。实现最多三组数据同时查询。
实现代码:
对于单条记录查询,首先判断输入框是否为空,然后获取输入项的输入值进行循环搜索,找到对应单元格的位置,然后通过那个位置找到对应的字段,然后进行计算。
多记录查询与单记录查询一致,这里不再赘述。
这里还有一个小功能,可以自定义搜索字段的增减。
代码显示如下:
还有一个巧妙的功能,可以在搜索后显示搜索结果
在VBA后台将对应控件属性的可见性设置为FALSE,然后点击搜索按钮触发该属性修改为TRUE。
实现代码:
查看全部
excel网页数据抓取vba(【】自学VBA:如何快速查看数据的界面?
)
今天是冬至,选择了一个特别的日子。今天依旧是小扎让贾维斯的消息传遍全世界的日子。不如他,但至少他可以做一些特别的事情。
废话不多说,开始吧。
先说一下整个项目的背景。当时,我们积累了公司各种产品项目的数据。在没有开发人力的情况下,我们需要创建一个可以快速查看数据的界面,以帮助新的合作进行初步估算。
于是,就在一个周末,我开始自学VBA,希望能快点做出这个界面。
首先说一下整个查询界面的页面逻辑,比较简单,不到10个页面。
菜单作为所有页面的入口,有两个基本功能:一是查看数据,二是计算过滤。还有一个小功能,可以查看最近的供应商信息。
先说一下这个小功能。首先,我们会找到对应表的最后三条记录和对应的数据,然后将它们呈现在菜单的控件上。最后点击菜单界面触发小功能代码。
实现代码如下(镶嵌部分为对应的表名)
接下来说说菜单的第一个功能,数据查看。
由于整个项目都是用excel搭建的,所以也会有查看原创数据的需求。通过点击按钮触发代码,显示对应的表格,同时隐藏菜单页。
实现代码如下
然后,说说菜单的第二个功能,计算过滤器。
维度1搜索过滤,根据数据表的某个字段计算和搜索数据,然后呈现。实现最多三组数据同时查询。
实现代码:
对于单条记录查询,首先判断输入框是否为空,然后获取输入项的输入值进行循环搜索,找到对应单元格的位置,然后通过那个位置找到对应的字段,然后进行计算。
多记录查询与单记录查询一致,这里不再赘述。
这里还有一个小功能,可以自定义搜索字段的增减。
代码显示如下:
还有一个巧妙的功能,可以在搜索后显示搜索结果
在VBA后台将对应控件属性的可见性设置为FALSE,然后点击搜索按钮触发该属性修改为TRUE。
实现代码:
excel网页数据抓取vba(STM32静态网页与爬虫操作的演示程序的核心命令解释)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-04 22:31
b。然后处理响应并将其存储为相应的VBA对象
实际上,与爬虫操作相关的响应返回内容有四种:静态网页、JSON、XML和普通字符串。静态web页面和XML都可以通过DOM解析进行操作,xlminer对应于domtolist方法
' http request
' @return 字符串或是文档对象
' @param url url资源地址
' @param data 所传递参数
' @param asText 返回字符串或文档对象
' @param verb 请求类型 默认POST
Private Function post(ByVal url As String, Optional ByVal data As String, Optional ByVal asText As Boolean = False, Optional ByVal verb As String = "POST")
' 将文档解析为Lists对象
' @return 抽取目标对象 Lists
' @param query CSS选择器
' @param doc post函数所返回的文档对象
' @param elementAsArray 是否为两层嵌套对象 如 ,如果直接读取td,则无法保留其tr的从属结构, 或是 需要进一步分隔其中的字符串
' @param childQuery 第二层嵌套对象的CSS选择器
' @param tabSep 如果没有指定第二选择器,以tab或enter分隔
Private Function domToList(ByRef Query As String, ByRef doc As MSHTML.HTMLDocument, Optional ByVal elementAsArray As Boolean = False, Optional ByVal childQuery As String, Optional ByVal tabSep As Boolean = False) As Lists
字符串类型没有固定的模式,但解析起来比较清楚
最后是JSON解析。请参考JS类文件
function parserJSON(s){ return eval('(' + s + ')');}
返回值是一个JS对象。使用activexobject将JS对象转换为字典对象/将JS数组转换为VBA数组
var dict = new ActiveXObject('Scripting.Dictionary');
具体操作方法请参考随附的样本文件
下载地址
更新了对64位office的完美支持。之后为了适应Mac和vb7,用原生VBA重写了JSON解析库和字典库
c。处理并显示爬网结果
在本例中,将股票代码填入D4,然后单击按钮立即提取报告数据
演示程序的核心命令解释如下
' fs 读取报表数据, code股票代码, 2018 为年份,4指第四季度,fsType.BALANCE_STMT 指定资产负债表,
m.fs(code, 2018, 4, fsType.BALANCE_STMT).toRng .Cells(2, 1)
如果您感兴趣,您可以自己尝试其他参数
3.JS类文件与Excel VBA与JavaScript的交互
VBA中JS数据和程序的无缝调用为VBA的扩展提供了无限的可能性。在GitHub示例文件中,我展示了使用VBA从underline.js库调用函数的操作。p>
' load underscore.js
Call j.loadLib("js/underscore.js")
' load custom js code
Call j.loadLib("js/main.js")
' call the myzipp function in main.js
arr = j.js.run("myzipp", Array(1, 2, 3), Array("a", "b", "c"))
VBA对象以JSON字符串格式序列化,并通过JS读取,以实现另一个方向的连接。在实践中,d3js可视化项目有许多成功的先例
我对office JavaScript API的看法在前面的文章>中提到过。我深深怀疑JSAPI在现阶段的实用性。JS库是一个非官方的、不完善的替代和补充。VBA和JavaScript的动态结合是我长久以来的愿望。毕竟,scriptcontrol甚至不支持Es5语法。我非常期待这位官员在向后兼容的基础上引入更全面的JavaScript扩展 查看全部
excel网页数据抓取vba(STM32静态网页与爬虫操作的演示程序的核心命令解释)
b。然后处理响应并将其存储为相应的VBA对象
实际上,与爬虫操作相关的响应返回内容有四种:静态网页、JSON、XML和普通字符串。静态web页面和XML都可以通过DOM解析进行操作,xlminer对应于domtolist方法
' http request
' @return 字符串或是文档对象
' @param url url资源地址
' @param data 所传递参数
' @param asText 返回字符串或文档对象
' @param verb 请求类型 默认POST
Private Function post(ByVal url As String, Optional ByVal data As String, Optional ByVal asText As Boolean = False, Optional ByVal verb As String = "POST")
' 将文档解析为Lists对象
' @return 抽取目标对象 Lists
' @param query CSS选择器
' @param doc post函数所返回的文档对象
' @param elementAsArray 是否为两层嵌套对象 如 ,如果直接读取td,则无法保留其tr的从属结构, 或是 需要进一步分隔其中的字符串
' @param childQuery 第二层嵌套对象的CSS选择器
' @param tabSep 如果没有指定第二选择器,以tab或enter分隔
Private Function domToList(ByRef Query As String, ByRef doc As MSHTML.HTMLDocument, Optional ByVal elementAsArray As Boolean = False, Optional ByVal childQuery As String, Optional ByVal tabSep As Boolean = False) As Lists
字符串类型没有固定的模式,但解析起来比较清楚
最后是JSON解析。请参考JS类文件
function parserJSON(s){ return eval('(' + s + ')');}
返回值是一个JS对象。使用activexobject将JS对象转换为字典对象/将JS数组转换为VBA数组
var dict = new ActiveXObject('Scripting.Dictionary');
具体操作方法请参考随附的样本文件
下载地址
更新了对64位office的完美支持。之后为了适应Mac和vb7,用原生VBA重写了JSON解析库和字典库
c。处理并显示爬网结果
在本例中,将股票代码填入D4,然后单击按钮立即提取报告数据
演示程序的核心命令解释如下
' fs 读取报表数据, code股票代码, 2018 为年份,4指第四季度,fsType.BALANCE_STMT 指定资产负债表,
m.fs(code, 2018, 4, fsType.BALANCE_STMT).toRng .Cells(2, 1)
如果您感兴趣,您可以自己尝试其他参数
3.JS类文件与Excel VBA与JavaScript的交互
VBA中JS数据和程序的无缝调用为VBA的扩展提供了无限的可能性。在GitHub示例文件中,我展示了使用VBA从underline.js库调用函数的操作。p>
' load underscore.js
Call j.loadLib("js/underscore.js")
' load custom js code
Call j.loadLib("js/main.js")
' call the myzipp function in main.js
arr = j.js.run("myzipp", Array(1, 2, 3), Array("a", "b", "c"))
VBA对象以JSON字符串格式序列化,并通过JS读取,以实现另一个方向的连接。在实践中,d3js可视化项目有许多成功的先例
我对office JavaScript API的看法在前面的文章>中提到过。我深深怀疑JSAPI在现阶段的实用性。JS库是一个非官方的、不完善的替代和补充。VBA和JavaScript的动态结合是我长久以来的愿望。毕竟,scriptcontrol甚至不支持Es5语法。我非常期待这位官员在向后兼容的基础上引入更全面的JavaScript扩展
excel网页数据抓取vba(网页抓取的4大主要方式,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-10-04 17:34
据说网页抓取主要有四种方法,分别是:XMLHTTP对象、InternetExplorer对象、QueryTables对象和WebBrowser对象。
个人觉得QueryTables方法最简单,最容易上手。即:导入外部数据的方法更适合单文本页面。(但当网页文字过多时,会让人头疼)。
使用QueryTables时经常遇到的几个问题:
一个问题是#Beginners学习的时候地址无法放入导入框,必须使用快捷键CTRL+V才能完成粘贴操作。
还有一个问题是#selected area数据无法导入EXCEL。这时必须打开“源文件”,将源代码文件保存在桌面或任何地方。然后导入保存的源文件,导入地址就是保存的源文件的地址(如果是文本,用IE打开获取库存地址)
另一个问题是#Cannot 找不到您要导入的部分的 URL。看来现在网站很流行摆弄“隐秘术”,各种东西应有尽有。查找隐藏网址,一种方法是通过F12的功能找到隐藏网址,另一种方法是间接找到隐藏网址。使用QueryTables导入“中介区”,然后得到一个新的URL,然后根据这个URL,在F12中找到要导入的部分的地址。
简单总结一下这一点,因为我只学会了一点点的把握。
请给我们一些指点,给我们一些建议。谢谢。 查看全部
excel网页数据抓取vba(网页抓取的4大主要方式,你知道几个?)
据说网页抓取主要有四种方法,分别是:XMLHTTP对象、InternetExplorer对象、QueryTables对象和WebBrowser对象。
个人觉得QueryTables方法最简单,最容易上手。即:导入外部数据的方法更适合单文本页面。(但当网页文字过多时,会让人头疼)。
使用QueryTables时经常遇到的几个问题:
一个问题是#Beginners学习的时候地址无法放入导入框,必须使用快捷键CTRL+V才能完成粘贴操作。
还有一个问题是#selected area数据无法导入EXCEL。这时必须打开“源文件”,将源代码文件保存在桌面或任何地方。然后导入保存的源文件,导入地址就是保存的源文件的地址(如果是文本,用IE打开获取库存地址)
另一个问题是#Cannot 找不到您要导入的部分的 URL。看来现在网站很流行摆弄“隐秘术”,各种东西应有尽有。查找隐藏网址,一种方法是通过F12的功能找到隐藏网址,另一种方法是间接找到隐藏网址。使用QueryTables导入“中介区”,然后得到一个新的URL,然后根据这个URL,在F12中找到要导入的部分的地址。
简单总结一下这一点,因为我只学会了一点点的把握。
请给我们一些指点,给我们一些建议。谢谢。
excel网页数据抓取vba(Excel表格使用常识——“excel自学网页抓取数据” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-10-01 05:34
)
Excel电子表格使用常识-《excel自学网页爬取数据》
当我们在日常工作中使用excel表格的时候,有很多功能实际上并没有用到。其实excel表格很强大,比如可以抓取网页数据。是的,你没听错。就是抓取网页数据。怎么感觉我用excel这么久却不知道这个功能,感觉自己变成了初学者。没关系,其实我们只用到了excel表的10%的功能,其他功能用的并不多。因此,有些功能不熟悉是正常的。现在来说说“excel自学网页爬取数据”的功能。
操作方法:
1、 我们打开excel表格输入,然后在工具栏中找到【数据】标签,点击标签,在下方功能区找到【来自网站】按钮。
2、 点击【来自网站】按钮后,会弹出“新建网页查询”窗口,然后在地址栏中输入网址。
3、 输入后,点击地址栏右侧的【前往】按钮,这样我们就可以输入这个网站。
4、在页面上,Excel会尝试用符号标记表格数据,找到您需要的表格,点击相应的复选框,然后点击“导入”按钮。
5、 点击按钮后,会弹出“导入数据”窗口,然后点击确定(以上值可以保持默认)。
6、这样对应的单元格就会显示“正在获取数据”,等待数据获取成功,这样我们就可以抓取网页中的数据了。
7、 获取的网页数据也可以根据需要自动刷新。在【数据】功能区找到“连接”功能区,点击其中的【属性】按钮。
8、 点击属性后,会弹出“外部数据区属性”对话框,我们对其进行如下操作。
查看全部
excel网页数据抓取vba(Excel表格使用常识——“excel自学网页抓取数据”
)
Excel电子表格使用常识-《excel自学网页爬取数据》
当我们在日常工作中使用excel表格的时候,有很多功能实际上并没有用到。其实excel表格很强大,比如可以抓取网页数据。是的,你没听错。就是抓取网页数据。怎么感觉我用excel这么久却不知道这个功能,感觉自己变成了初学者。没关系,其实我们只用到了excel表的10%的功能,其他功能用的并不多。因此,有些功能不熟悉是正常的。现在来说说“excel自学网页爬取数据”的功能。
操作方法:
1、 我们打开excel表格输入,然后在工具栏中找到【数据】标签,点击标签,在下方功能区找到【来自网站】按钮。
2、 点击【来自网站】按钮后,会弹出“新建网页查询”窗口,然后在地址栏中输入网址。
3、 输入后,点击地址栏右侧的【前往】按钮,这样我们就可以输入这个网站。
4、在页面上,Excel会尝试用符号标记表格数据,找到您需要的表格,点击相应的复选框,然后点击“导入”按钮。
5、 点击按钮后,会弹出“导入数据”窗口,然后点击确定(以上值可以保持默认)。
6、这样对应的单元格就会显示“正在获取数据”,等待数据获取成功,这样我们就可以抓取网页中的数据了。
7、 获取的网页数据也可以根据需要自动刷新。在【数据】功能区找到“连接”功能区,点击其中的【属性】按钮。
8、 点击属性后,会弹出“外部数据区属性”对话框,我们对其进行如下操作。
excel网页数据抓取vba( 如何用Python快速的抓取一个网页中所有表格的爬虫3.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-01 02:27
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。这就是我之前所做的,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据 查看全部
excel网页数据抓取vba(
如何用Python快速的抓取一个网页中所有表格的爬虫3.)
之前在搜索vscode的快捷键时,发现有一个页面,以表格的形式展示了vscode的各种快捷键操作(如下图)。自从学了Python爬虫,就形成了惯性思维。当我在网页中看到什么更好,但复制起来不是很方便时,我会考虑如何用Python快速抓取它。下面我就简单介绍一下我的一些抢表的思路和方法。
1.在IE浏览器中直接使用export EXCLE
微软的这种设计还是非常人性化的,通过这种方式访问网页表格中呈现的内容特别方便。我们只需要在页面上右击,选择Export to EXCEL,就可以将页面上的内容导出到单元格中了。
这种方法的缺点是:
2.使用Python从网页中抓取表格
接下来,就是本文的重点了,直接上代码先。
from bs4 import BeautifulSoup
import requests
import pandas as pd
url = 'https://segmentfault.com/a/1190000007688656'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'lxml')
tables = soup.select('table')
df_list = []
for table in tables:
df_list.append(pd.concat(pd.read_html(table.prettify())))
df = pd.concat(df_list)
df.to_excel('vscode快捷键大全.xlsx')
我知道对于很多没有学过编程知识的人来说,看到代码可能会气馁。这就是我之前所做的,因为对于从未接触过的人来说,这是一个非常不舒服的地方。不过,这是10行代码,可以完成一个简单的爬虫。重要的是这些代码可以复用,只需要修改传入的连接地址。
下面简单介绍一下代码的含义:
这样就完成了一个简单的爬虫,爬取一个网页中的所有表
3.关于选择方法的建议
最后,我想强调,方法不是我们的最终目标。我们只是想以更方便的方式达到学习内容的目的,所以不要迷失在追求更高的方法中。
以本文为专栏,其实获得vscode快捷键操作表格的最佳方式,就是在浏览器中直接导出EXCEL,甚至直接复制粘贴。这样我们就可以把精力集中在学习vscode快捷键上,而不是获取这种形式。
如果,在另一个场景中,假设这张表的内容分散在很多很多网页中,那么我们仍然需要编译一个爬虫,这样会更快。而且,如果是基于学习python的目的,培养这种挖掘数据的思维也是非常重要的。
因此,关键是我们要明确自己的目标,并根据相应的目标选择最合适的方法。
下一篇预告:下一篇文章我将介绍使用正则表达式从本地统计公报中抓取结构化数据
excel网页数据抓取vba(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-01 02:20
Excel对网络数据的抓取和查询可以通过“获取与转换”+“查找引用函数”的功能组合来实现。
示例:下图为百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,通过输入会话数查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕捉到Excel中
依次单击“数据选项卡”、“新建查询”、“来自其他来源”和“来自 Web”。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏中,点击确定。
Excel 连接网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表格代表网页中的一个表格。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出的窗口中,选择“选择您希望如何在工作簿中查看此数据的方式”下的“表格”,然后单击“加载”。
如图,web表单中的数据已经抓取到Excel中。
依次点击“表格工具”、“设计”,将“表格名称”改为奥运会。
Step2:使用“查找与引用”功能实现数据查询
设置一个查询区域,包括“会话数”和“主办城市”,在会话数中选择一个,在下图中输入“08th”,进入主办城市下的vlookup功能,可以得到主办城市的主持人08届奥运会城市是巴黎。当会话数发生变化时,相应的主办城市也会发生变化。
公式:=VLOOKUP([会话数], 奥运会[#All],4,0)
注意:如果网页中的数据变化频繁,可以将链接网页的数据设置为定时刷新:
① 将鼠标置于导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新。这样,数据会每10分钟刷新一次,保证获取到的数据是最新的。
“精进Excel”为头条签约作者。跟着我。点击打开三篇文章文章,没有你想要的知识,就当我是大佬! 查看全部
excel网页数据抓取vba(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
Excel对网络数据的抓取和查询可以通过“获取与转换”+“查找引用函数”的功能组合来实现。
示例:下图为百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,通过输入会话数查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕捉到Excel中
依次单击“数据选项卡”、“新建查询”、“来自其他来源”和“来自 Web”。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏中,点击确定。
Excel 连接网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表格代表网页中的一个表格。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出的窗口中,选择“选择您希望如何在工作簿中查看此数据的方式”下的“表格”,然后单击“加载”。
如图,web表单中的数据已经抓取到Excel中。
依次点击“表格工具”、“设计”,将“表格名称”改为奥运会。
Step2:使用“查找与引用”功能实现数据查询
设置一个查询区域,包括“会话数”和“主办城市”,在会话数中选择一个,在下图中输入“08th”,进入主办城市下的vlookup功能,可以得到主办城市的主持人08届奥运会城市是巴黎。当会话数发生变化时,相应的主办城市也会发生变化。
公式:=VLOOKUP([会话数], 奥运会[#All],4,0)
注意:如果网页中的数据变化频繁,可以将链接网页的数据设置为定时刷新:
① 将鼠标置于导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新。这样,数据会每10分钟刷新一次,保证获取到的数据是最新的。
“精进Excel”为头条签约作者。跟着我。点击打开三篇文章文章,没有你想要的知识,就当我是大佬!
excel网页数据抓取vba(和DOM将是最好的方法吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-09-24 09:21
无法抑制“另存为”对话框:
从脚本调用此方法时,无法禁用“保存HTML文档”对话框
它也是一个模式对话框,您不能自动单击&34;节约34英镑;按钮面对此对话时,VBA执行会在等待手动用户输入时暂停
您可以尝试读取页面的HTML并使用标准I/O函数将其打印到文件中,而不是使用ie.document.execcommand方法
Option Explicit
Sub SaveHTML()
Dim URL as String
Dim IE as Object
Dim i as Long
Dim FileName as String
Dim FF as Integer
URL = "http://google.com" 'for TEST
Filename = "C:\Test.htm"
Set IE = CreateObject("Internetexplorer.Application")
IE.Visible = True
IE.Navigate URL
Do
Loop While IE.Busy
'Creates a file as specified
' this will overwrite an existing file if already exists
CreateObject("Scripting.FileSystemObject").CreateTextFile FileName
FF = FreeFile
Open Filename For Output As #FF
With IE.Document.Body
Print #FF, .OuterHtml & .InnerHtml
End With
Close #FF
IE.Quit
Set IE = Nothing
End Sub
我不确定这是否能完全满足你的需要。还有其他从网络获取数据的方法。最好的方法是从xmlhttp请求中获取原创HTML并将其打印到文件中
当然,我们很少需要HTML格式的整个网页,因此如果您想从网页中获取特定数据,xmlhttp和DOM将是最好的方法,您根本不需要将其保存到文件中
或者,您可以使用selenium包装器来自动化ie,这比在Internet Explorer中使用相对较少的本机方法要强大得多。应用程序类
还请注意,您使用的是一种相当粗糙的方法来等待网页加载(在ie.busy时循环)。虽然它有时可能工作,但可能不可靠。关于如何在so上正确执行此操作,有很多问题,因此我将在这里参考您的搜索功能来稍微调整代码 查看全部
excel网页数据抓取vba(和DOM将是最好的方法吗?(上))
无法抑制“另存为”对话框:
从脚本调用此方法时,无法禁用“保存HTML文档”对话框
它也是一个模式对话框,您不能自动单击&34;节约34英镑;按钮面对此对话时,VBA执行会在等待手动用户输入时暂停
您可以尝试读取页面的HTML并使用标准I/O函数将其打印到文件中,而不是使用ie.document.execcommand方法
Option Explicit
Sub SaveHTML()
Dim URL as String
Dim IE as Object
Dim i as Long
Dim FileName as String
Dim FF as Integer
URL = "http://google.com" 'for TEST
Filename = "C:\Test.htm"
Set IE = CreateObject("Internetexplorer.Application")
IE.Visible = True
IE.Navigate URL
Do
Loop While IE.Busy
'Creates a file as specified
' this will overwrite an existing file if already exists
CreateObject("Scripting.FileSystemObject").CreateTextFile FileName
FF = FreeFile
Open Filename For Output As #FF
With IE.Document.Body
Print #FF, .OuterHtml & .InnerHtml
End With
Close #FF
IE.Quit
Set IE = Nothing
End Sub
我不确定这是否能完全满足你的需要。还有其他从网络获取数据的方法。最好的方法是从xmlhttp请求中获取原创HTML并将其打印到文件中
当然,我们很少需要HTML格式的整个网页,因此如果您想从网页中获取特定数据,xmlhttp和DOM将是最好的方法,您根本不需要将其保存到文件中
或者,您可以使用selenium包装器来自动化ie,这比在Internet Explorer中使用相对较少的本机方法要强大得多。应用程序类
还请注意,您使用的是一种相当粗糙的方法来等待网页加载(在ie.busy时循环)。虽然它有时可能工作,但可能不可靠。关于如何在so上正确执行此操作,有很多问题,因此我将在这里参考您的搜索功能来稍微调整代码
excel网页数据抓取vba( VBA·5个月前如何使用VBA网抓的? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-24 09:19
VBA·5个月前如何使用VBA网抓的?
)
使用Excel+VBA操作网页
黄晨·5个月前,因为知乎的一些回答,最近总有私信问我怎么用VBA抓网,我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。趁着开专栏知乎的机会,来仔细解释一下这个问题。
我对Excel和VBA的了解有限,只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中使用import,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。通过查看这个名称,我们知道它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然 all 最好用,因为 all 也有 all ("IDName") 和 all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表单提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是一个select标签,每个选项都在一个option标签中,所以要返回一个集合,需要选择一个选项,将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也有些不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,我用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用的是ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText 查看全部
excel网页数据抓取vba(
VBA·5个月前如何使用VBA网抓的?
)
使用Excel+VBA操作网页
黄晨·5个月前,因为知乎的一些回答,最近总有私信问我怎么用VBA抓网,我基本没有回复。因为这个问题太大了,有基础知识的人其实很容易自己在百度或者ExcelHome论坛上找到答案。我不需要说什么。对于没有基础知识的人来说,是不可能三言两语解决问题的。我不想把私信变成聊天窗口。趁着开专栏知乎的机会,来仔细解释一下这个问题。
我对Excel和VBA的了解有限,只能解决我遇到的一些问题,不一定适用于所有场景。以下内容基于对VBA基本用法和HTML语言知识的了解:
一、前期准备
据我所知,VBA 不能操作任何浏览器和网页。我们所能做的就是在IE上执行一些操作,是的,只有IE。不要告诉我电脑上没有IE,所以你可以退出Sub。就像在Python中使用import,在C#中使用一样,VBA也需要引用一些库来操作IE,不过好在它是微软的产品,所以我们可以很方便的使用VBA自带的一些库。
我们需要做的第一件事是在 VBA 中引用 Micorsoft Internet Controls。通过查看这个名称,我们知道它可以帮助我们控制 IE 页面。
二、网页操作
引用 Micorsoft Internet Controls 后,我们可以对页面做任何我们想做的事情,但是我们需要在主页上有一个页面,上帝说我们需要一个页面!
1、打开网页
我们以在百度上搜索“查虎”关键词为例:
With CreateObject("internetexplorer.application")
.Visible = True
.Navigate "https://www.baidu.com/s?wd=扯乎"
'关闭网页
' .Quit
End With
代码很简单,先创建一个IE对象,然后给一些属性赋值。Visible就是可见性,是指网页被操作时是否会看到网页。熟练后可以设置为False,这样不仅让程序在运行时有一种神秘感(而不是),而且速度也快了一点。
但是有一点要记住,这个网页在我们打开后并没有关闭,这意味着程序结束后需要手动关闭它。如果网页不可见,则无法手动关闭。代码中的注释部分用于关闭网页。不用说,导航就是 URL。
我们必须等待网页完全加载,然后才能开始信息抓取。这时候,我们使用:(从这里开始,所有的代码都需要写在With代码块中)
While .ReadyState 4 Or .Busy
DoEvents
Wend
Busy 是网页的繁忙状态,ReadyState 是 HTTP 的五种就绪状态,对应如下:
2、获取信息
我们先抓取页面上的所有内容,稍后过滤掉有用的部分,然后慢慢添加条件到抓取中。
Set dmt = .Document
For i = 0 To dmt.all.Length - 1
Set htMent = dmt.all(i)
With ActiveSheet
.Cells(i + 2, "A") = htMent.tagName
.Cells(i + 2, "B") = TypeName(htMent)
.Cells(i + 2, "C") = htMent.ID
.Cells(i + 2, "D") = htMent.Name
.Cells(i + 2, "E") = htMent.Value
.Cells(i + 2, "F") = htMent.Text
.Cells(i + 2, "G") = htMent.innerText
End With
Next i
这段代码有点类似于JS,需要从IE.Document.all中找出页面上的所有节点。还有其他几种方法:
这些更方便用于在抓取所有页面内容后帮助过滤有效信息。当然 all 最好用,因为 all 也有 all ("IDName") 和 all.IDName 的用法。
上面代码部分返回的属性值都是基本的HTML内容,就不一一解释了。
3、填写信息
爬网神器当然是Python。大多数人使用Excel自动填写页面内容,直接将表单提交到网页,省去了问卷录入等大量工作。抓取页面内容后,填充起来就更容易了。你只需要直接给页面标签的Value属性赋值即可。
但是,除了文本框,可能还有其他没有Value的标签,比如下拉菜单和单选按钮。给这些内容赋值需要一些基本的HTML知识。
'下拉菜单选择
.all("select")(0).Selected = True
'单选按钮选择
.all("radio").Checked = True
'复选按钮选择
.all("checkbox").Checked = True
下拉菜单是一个select标签,每个选项都在一个option标签中,所以要返回一个集合,需要选择一个选项,将对应的Selected属性修改为True。单选按钮和复选按钮都是输入标签。不同的是类型分别是radio和checkbox。要选择一个选项,您需要修改相应的 Checked 属性。
三、数据接口
有时我们可以直接获取一些API。当然,通过API返回数据比打开网页更方便快捷,使用的方法也有些不同。
1、请求接口
比如我得到了一个可以从网上查询到城市免费WIFI的API,我用下面的代码通过Excel界面访问:(虽然是免费的,为了避免麻烦,我还是隐藏了我的AppKey)
Dim http
Set http = CreateObject("Microsoft.XMLHTTP")
http.Open "GET", "http://api.avatardata.cn/Wifi/QueryByCity", False
http.setRequestHeader "CONTENT-TYPE", "application/x-www-form-urlencoded"
http.send "key=[AppKey]&city=北京&page=1"
这时候我们创建的对象不再是IE,而是HTTP对象。这里使用的是ajax的Open方法,GET为数据发送方法,第二个参数为接口地址,第三个参数指定请求方法是否异步。如果这个API有账号和密码,就写在第四个和第五个参数中。
setRequestHeader是向接口发送一个HTTP协议头文件,最后发送的内容就是接口参数。当然,这个QueryString也可以直接写在URL中,发送一个空字符串即可。
2、接口返回
接口返回和获取的方式很简单:
If http.Status = 200 Then Range("A1").Value = http.responseText
excel网页数据抓取vba(我用脚本写一个给你啦用python网页网页书单(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-09-17 21:12
这两天他去朋友家玩。他说,他最近找了一份工作,需要帮助其他人整理网上书籍,他似乎有点麻烦。我想一下。好吧,我给你写一个剧本
使用Python获取web图书列表1、并分析需求
您需要捕获网页中的特定内容,特别是
对于有限的平装书,需要书名、作者姓名、出版时间和售价。出版商从书名(如有)中引入ISBN代码
这些内容必须存在于网页中,因此我们只需要使用[regular expression]来提取所需的内容
然后,他将内容范围指定为
关键词是音乐欣赏、艺术欣赏和艺术创作
这个。。亚马逊似乎有很多参数。。。那么我不妨先在这里偷一个懒汉(怎么说,亲吻原则),然后在这里先记录他请求的网站
音乐欣赏
艺术欣赏
艺术创作
嗯,它们看起来都像
2、设计功能
我朋友的要求是把上面的数据整理成excel。对于这个函数,如果我在Internet上找到一个python封装的库,应该没有问题。为了便于使用,我们最好在这里支持交互式界面。为了方便起见,我们仍然计划把pyqt一号带出去
那么一般功能是:
3、具体实施
让我们使用Python作为一个简单的脚本。这里,我们使用请求来删除数据,但请注意,Amazon实际上有一个保护机制。如果您轻率地使用get方法进行访问,Amazon将向您返回以下内容:
1
2
3
4
然后我试着假装头部,四处走动
然后提取此页面中每本书对应的URL并观察当前页面。URL有一个特征词“a-link-normal s-access-detail-page a-text-normal”。然后,您可以使用该关键字使用正则表达式提取当前数据
因为要在HREF中间提取内容,必须首先在***中指定内容,然后使用()返回需要的内容
1
pageDetail = r'<a class="a-link-normal s-access-detail-page a-text-normal"[^>]*?href=\"([^>]*)\"[^>]*?>'
请注意,由于常规模式默认为贪婪模式,因此我们可以在***************************************************************之后添加“贪婪”?实现非贪婪模式查找
找到网页后,记录当前的网站并依次访问
然后我们需要根据需求获取内容
经过测试,可以完成所需的功能~
然后是Excel的操作。虽然我还没有见过VBA,但python已经在xlwt中编写了excel,所以下面是一个尝试:
1
2
3
4
5
6
7
8
9
10
11
12
import xlwt
# 创建 xls 文件对象
wb = xlwt.Workbook()
# 新增一个表单
sh = wb.add_sheet('A Test Sheet')
# 按位置添加数据
sh.write(0, 0, 1234.56)
sh.write(1, 0, 8888)
sh.write(2, 0, 'hello')
sh.write(2, 1, 'world')
# 保存文件
wb.save('example.xls')
我在互联网上找到了这个演示,因此估计对应关系为
|实际内容|操作对象|
|Excel文件|工作簿
|床单
|单元格内容写入
然后我们大致知道如何编写:创建一个excel并将数据放在指定的位置
----------=========------------
有一种新的需求。您需要截图网站并将其保存到当前目录。这似乎是可以实现的。然后我发现了一件麻烦的事。。。这张照片一定涉及编码问题,但我似乎无法处理。。因为URL捕获的页面大小似乎不太正确。。。它可能是多张图片或其他东西。无论如何,照片的数量是错误的。。。所以我用了其他的想法,直接在网页上取了图片,就是Base64处理过的图片。。。。虽然它可能被压缩了,但应该仍然可以。。把这个拿下来处理。应该没问题
4、特定应用
正如这位同学提到的,他也想借此机会学习,他计划写一份依赖列表,以便能够快速安装
安装pipreqs可以快速生成requirements.txt。但是,发现总是报告Unicode解码错误。人们认为这可能是由于windows的CMD编码问题,因此使用该参数强制指定编码为UTF-8:
1
pipreqs --encoding=utf-8 --use-local ./
如果另一方需要快速安装相应的库,它只需要在当前目录中使用它
pip install -r requirements.txt
命令,可以快速安装相应的从属库
后来,我记得有一个直观的界面,便于操作。。。好吧,搞砸了pyqt这个已经丢失了很长时间的简单例子:
首先,使用QT设计器创建第一个
然后使用pyuic5命令生成相应的。Py文件
1
pyuic5 -o ui_Dialog.py Dialog.ui
最后,使用另一个程序收录此内容,并使用pyqt对其进行操作。为了避免程序运行时的干扰,采用qthread进行异步处理,增加了slot函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class SpiderCrawl(QThread):
"""Lanch Spider"""
SignalFinishSpdier = pyqtSignal(bool)
def __init__(self, needs, parent=None):
super(SpiderCrawl, self).__init__(parent)
self.needs = needs
self.SignalFinishSpdier.connect(parent.spiderFinish)
def run(self):
""" it will return result of the spider
Ret: the result of spider
"""
result = amazonSpider.Spider(self.needs)
self.SignalFinishSpdier.emit(result)
class SpiderDialog(QDialog, ui_Dialog.Ui_Dialog):
...
@pyqtSlot(bool)
def spiderFinish(self, result):
""" the spider is finish"""
print("There!")
if result == True:
self.KeywordText.setText("爬虫已经完成任务")
else:
self.KeywordText.setText("你的url有问题...")
self.takeButton.setEnabled(True)
最后,为了防止手工进入错误的网站。。。在这里也可以检测到它。如果在当前网页中找不到合适的URL,也会被视为输入错误
最后,附上项目的网站:
亚马逊蜘蛛V1.0 查看全部
excel网页数据抓取vba(我用脚本写一个给你啦用python网页网页书单(组图))
这两天他去朋友家玩。他说,他最近找了一份工作,需要帮助其他人整理网上书籍,他似乎有点麻烦。我想一下。好吧,我给你写一个剧本
使用Python获取web图书列表1、并分析需求
您需要捕获网页中的特定内容,特别是
对于有限的平装书,需要书名、作者姓名、出版时间和售价。出版商从书名(如有)中引入ISBN代码
这些内容必须存在于网页中,因此我们只需要使用[regular expression]来提取所需的内容
然后,他将内容范围指定为
关键词是音乐欣赏、艺术欣赏和艺术创作
这个。。亚马逊似乎有很多参数。。。那么我不妨先在这里偷一个懒汉(怎么说,亲吻原则),然后在这里先记录他请求的网站
音乐欣赏
艺术欣赏
艺术创作
嗯,它们看起来都像
2、设计功能
我朋友的要求是把上面的数据整理成excel。对于这个函数,如果我在Internet上找到一个python封装的库,应该没有问题。为了便于使用,我们最好在这里支持交互式界面。为了方便起见,我们仍然计划把pyqt一号带出去
那么一般功能是:
3、具体实施
让我们使用Python作为一个简单的脚本。这里,我们使用请求来删除数据,但请注意,Amazon实际上有一个保护机制。如果您轻率地使用get方法进行访问,Amazon将向您返回以下内容:
1
2
3
4
然后我试着假装头部,四处走动
然后提取此页面中每本书对应的URL并观察当前页面。URL有一个特征词“a-link-normal s-access-detail-page a-text-normal”。然后,您可以使用该关键字使用正则表达式提取当前数据
因为要在HREF中间提取内容,必须首先在***中指定内容,然后使用()返回需要的内容
1
pageDetail = r'<a class="a-link-normal s-access-detail-page a-text-normal"[^>]*?href=\"([^>]*)\"[^>]*?>'
请注意,由于常规模式默认为贪婪模式,因此我们可以在***************************************************************之后添加“贪婪”?实现非贪婪模式查找
找到网页后,记录当前的网站并依次访问
然后我们需要根据需求获取内容
经过测试,可以完成所需的功能~
然后是Excel的操作。虽然我还没有见过VBA,但python已经在xlwt中编写了excel,所以下面是一个尝试:
1
2
3
4
5
6
7
8
9
10
11
12
import xlwt
# 创建 xls 文件对象
wb = xlwt.Workbook()
# 新增一个表单
sh = wb.add_sheet('A Test Sheet')
# 按位置添加数据
sh.write(0, 0, 1234.56)
sh.write(1, 0, 8888)
sh.write(2, 0, 'hello')
sh.write(2, 1, 'world')
# 保存文件
wb.save('example.xls')
我在互联网上找到了这个演示,因此估计对应关系为
|实际内容|操作对象|
|Excel文件|工作簿
|床单
|单元格内容写入
然后我们大致知道如何编写:创建一个excel并将数据放在指定的位置
----------=========------------
有一种新的需求。您需要截图网站并将其保存到当前目录。这似乎是可以实现的。然后我发现了一件麻烦的事。。。这张照片一定涉及编码问题,但我似乎无法处理。。因为URL捕获的页面大小似乎不太正确。。。它可能是多张图片或其他东西。无论如何,照片的数量是错误的。。。所以我用了其他的想法,直接在网页上取了图片,就是Base64处理过的图片。。。。虽然它可能被压缩了,但应该仍然可以。。把这个拿下来处理。应该没问题
4、特定应用
正如这位同学提到的,他也想借此机会学习,他计划写一份依赖列表,以便能够快速安装
安装pipreqs可以快速生成requirements.txt。但是,发现总是报告Unicode解码错误。人们认为这可能是由于windows的CMD编码问题,因此使用该参数强制指定编码为UTF-8:
1
pipreqs --encoding=utf-8 --use-local ./
如果另一方需要快速安装相应的库,它只需要在当前目录中使用它
pip install -r requirements.txt
命令,可以快速安装相应的从属库
后来,我记得有一个直观的界面,便于操作。。。好吧,搞砸了pyqt这个已经丢失了很长时间的简单例子:
首先,使用QT设计器创建第一个
然后使用pyuic5命令生成相应的。Py文件
1
pyuic5 -o ui_Dialog.py Dialog.ui
最后,使用另一个程序收录此内容,并使用pyqt对其进行操作。为了避免程序运行时的干扰,采用qthread进行异步处理,增加了slot函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class SpiderCrawl(QThread):
"""Lanch Spider"""
SignalFinishSpdier = pyqtSignal(bool)
def __init__(self, needs, parent=None):
super(SpiderCrawl, self).__init__(parent)
self.needs = needs
self.SignalFinishSpdier.connect(parent.spiderFinish)
def run(self):
""" it will return result of the spider
Ret: the result of spider
"""
result = amazonSpider.Spider(self.needs)
self.SignalFinishSpdier.emit(result)
class SpiderDialog(QDialog, ui_Dialog.Ui_Dialog):
...
@pyqtSlot(bool)
def spiderFinish(self, result):
""" the spider is finish"""
print("There!")
if result == True:
self.KeywordText.setText("爬虫已经完成任务")
else:
self.KeywordText.setText("你的url有问题...")
self.takeButton.setEnabled(True)
最后,为了防止手工进入错误的网站。。。在这里也可以检测到它。如果在当前网页中找不到合适的URL,也会被视为输入错误
最后,附上项目的网站:
亚马逊蜘蛛V1.0
excel网页数据抓取vba(Python如何用Excel的VBA爬取数据?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-09-09 21:14
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
目前最流行的爬虫方法一般都是通过Python来实现的,Python有很多有用的第三方库来实现。不熟悉使用Python的朋友,有没有办法通过Excel VBA来实现?
要做数据分析,准备工作中很重要的一个环节就是获取数据。数据通常来自多个来源,例如单位数据库中存储的数据、报表填写的数据等,网页上的公开数据等。本文将抓取网页以公开数据为例,做一个简单的例子演示如何使用 Excel VBA 抓取数据。
测试网页:上证债券信息网
尝试用Excel获取某个时间范围内的所有记录(上图红框内数据表中的信息)。
要求:按日期从网页中抓取2018年1月1日至今的债券协议回购市场数据(上表所有数据)。操作方法:
----------------------------------------1、打开EXCEL并创建两个sheet表1)data,用于存放得到的结果2)crawling数据,用于存放WebBrowser控件。如图:
2、insert 控件
方法如图:
开发工具——插入 ActiveX 控件,找到 microsoftWebBrowser 控件——拖动它。
3、设置控件的属性
跟进您的需求并设置空间。此处省略,使用默认值。
4、通过控件分析网页上的日期。我们需要查询一段时间内的数据。因此,我们需要在日期控件中模拟输入日期,然后点击“查询”按钮。查看网页源码,找到对应控件的名称和位置:
从上面的截图可以看出,日期控件的id是“searchDate”,输入日期可以通过如下代码控制:
WebBrowser1.Document.All.Item("searchDate").Value = RQ
同样,再次查看查询按钮。查询按钮的执行程序为“javascript:goSwitch()”,可以通过如下代码调用:
WebBrowser1.Document.parentWindow.execScript "javascript:goSwitch()
另外,网页上数据表的id是“datelist”。
5、Code 实现 根据上述,编写VBA代码,代码逻辑如下:使用for循环,根据网页上的日期填写数据,点击“查询”;等待网页数据刷新,抓取网页上的数据,保存到数组arr中,然后将数组保存到sheet表中。
6、运行程序
运行程序,稍等片刻即可查看爬取的数据。如下图:
注意事项:
如果事件效率不高或者数据量不大,条件有限,可以使用这种方法。 (效率低下也是一)这种方法的弊端之一。
对于难以抓取的网页,建议先使用Python。
/20180905 查看全部
excel网页数据抓取vba(Python如何用Excel的VBA爬取数据?(一))
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
目前最流行的爬虫方法一般都是通过Python来实现的,Python有很多有用的第三方库来实现。不熟悉使用Python的朋友,有没有办法通过Excel VBA来实现?
要做数据分析,准备工作中很重要的一个环节就是获取数据。数据通常来自多个来源,例如单位数据库中存储的数据、报表填写的数据等,网页上的公开数据等。本文将抓取网页以公开数据为例,做一个简单的例子演示如何使用 Excel VBA 抓取数据。
测试网页:上证债券信息网
尝试用Excel获取某个时间范围内的所有记录(上图红框内数据表中的信息)。
要求:按日期从网页中抓取2018年1月1日至今的债券协议回购市场数据(上表所有数据)。操作方法:
----------------------------------------1、打开EXCEL并创建两个sheet表1)data,用于存放得到的结果2)crawling数据,用于存放WebBrowser控件。如图:
2、insert 控件
方法如图:
开发工具——插入 ActiveX 控件,找到 microsoftWebBrowser 控件——拖动它。
3、设置控件的属性
跟进您的需求并设置空间。此处省略,使用默认值。
4、通过控件分析网页上的日期。我们需要查询一段时间内的数据。因此,我们需要在日期控件中模拟输入日期,然后点击“查询”按钮。查看网页源码,找到对应控件的名称和位置:
从上面的截图可以看出,日期控件的id是“searchDate”,输入日期可以通过如下代码控制:
WebBrowser1.Document.All.Item("searchDate").Value = RQ
同样,再次查看查询按钮。查询按钮的执行程序为“javascript:goSwitch()”,可以通过如下代码调用:
WebBrowser1.Document.parentWindow.execScript "javascript:goSwitch()
另外,网页上数据表的id是“datelist”。
5、Code 实现 根据上述,编写VBA代码,代码逻辑如下:使用for循环,根据网页上的日期填写数据,点击“查询”;等待网页数据刷新,抓取网页上的数据,保存到数组arr中,然后将数组保存到sheet表中。
6、运行程序
运行程序,稍等片刻即可查看爬取的数据。如下图:
注意事项:
如果事件效率不高或者数据量不大,条件有限,可以使用这种方法。 (效率低下也是一)这种方法的弊端之一。
对于难以抓取的网页,建议先使用Python。
/20180905

