
excel抓取网页动态数据
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2022-03-09 22:25
我们经常使用网页数据,但是每次打开网页查询都很麻烦,而且我们需要的数据是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
在Excel中查询网页数据并实时更新的步骤:
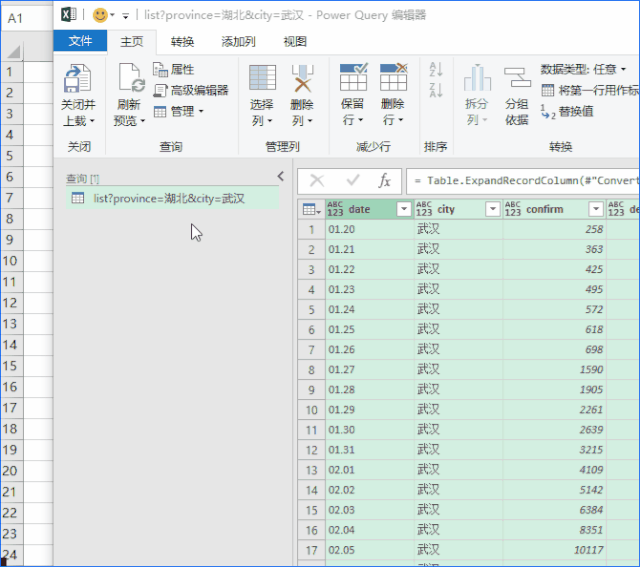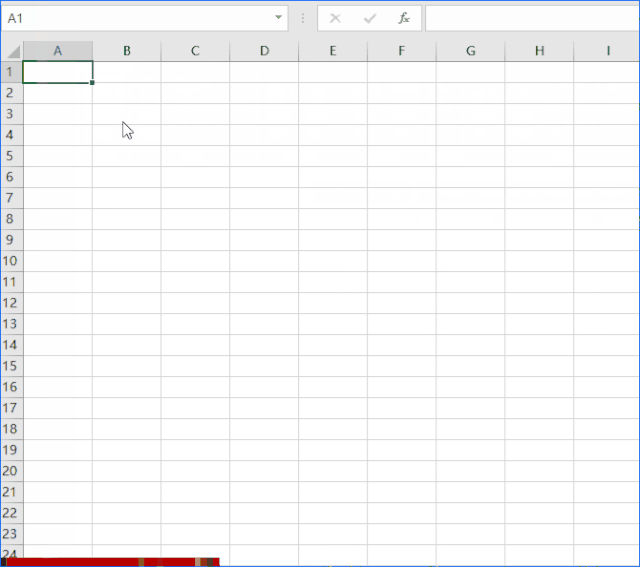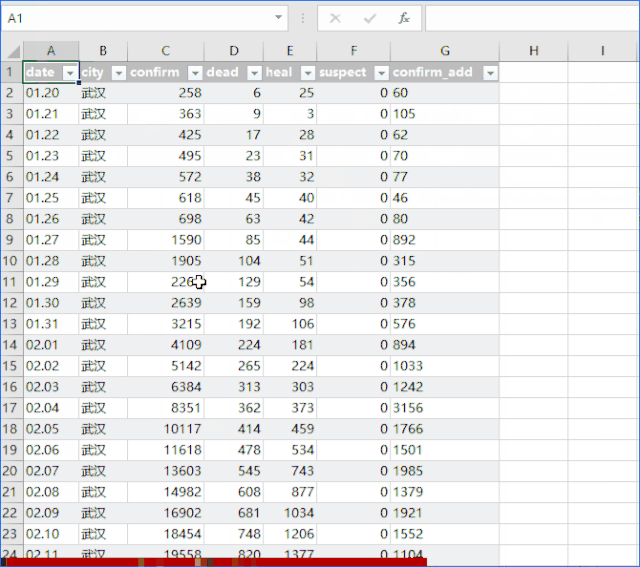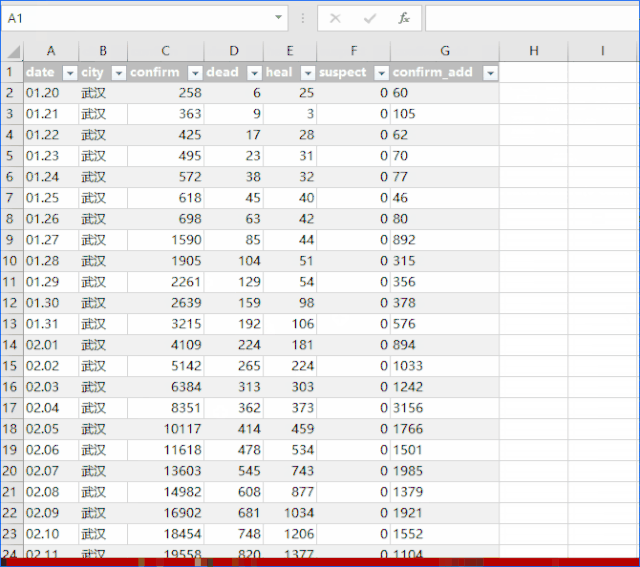
首先打开excel,点击Data,在Get External Data选项卡下,点击From 网站,会弹出New Web Query对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击黄框箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,单击指定导入位置,将数据导入excel。
使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
将数据导入 Excel 后,在数据区域单击鼠标右键,单击“刷新”即可刷新数据。通过右键单击数据范围属性,可以打开外部数据范围属性对话框,并设置刷新频率,以及是否允许后台刷新,或文件打开时刷新。
还有一种简单的方法可以直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有一个粘贴选项,还有一个可刷新的网页查询。单击它将输入新的网络查询。界面,重复前面的操作即可。
Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013网页查询采集网页数据功能
3.如何在Excel中批量更新数据
4.如何用Excel中的表格快速查询数据
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格序列号
7.如何在Excel中使用自动数据过滤功能 查看全部
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
我们经常使用网页数据,但是每次打开网页查询都很麻烦,而且我们需要的数据是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
在Excel中查询网页数据并实时更新的步骤:
首先打开excel,点击Data,在Get External Data选项卡下,点击From 网站,会弹出New Web Query对话框,如下图:

将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击黄框箭头选择区域,然后点击右下角的导入。


在弹出的导入数据对话框中,单击指定导入位置,将数据导入excel。

使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。

将数据导入 Excel 后,在数据区域单击鼠标右键,单击“刷新”即可刷新数据。通过右键单击数据范围属性,可以打开外部数据范围属性对话框,并设置刷新频率,以及是否允许后台刷新,或文件打开时刷新。


还有一种简单的方法可以直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有一个粘贴选项,还有一个可刷新的网页查询。单击它将输入新的网络查询。界面,重复前面的操作即可。

Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013网页查询采集网页数据功能
3.如何在Excel中批量更新数据
4.如何用Excel中的表格快速查询数据
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格序列号
7.如何在Excel中使用自动数据过滤功能
excel抓取网页动态数据(Excel数据采集软件(免费下载,像Excel一样极速上手,可灵活自定义的企业管理软件))
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-03-09 22:23
推荐使用:Excel数据采集软件(免费下载,与Excel一样快,灵活可定制的企业管理软件)
前言
IBM大中华区总经理胡世忠曾表示:数据构成了智慧地球的三大要素:智能、互联和互联,这三大要素改变了数据的来源、传输和利用,带来了“大数据”信息社会已经发生了变化。
由上可知,时代的变迁源于数据的使用。对于企业来说,数据也是企业发展和转型的命脉。在我的工作中,我的前辈们不止一次强调,数据是公司的资产,非常重要。我们要严格数据,经得起时间的考验,对自己的数据负责。这是数据主体的基本要求。
数据资源
大数据时代,虽然数据很多,但并不是随意获取的,需要通过各种渠道和方式获取。无论从哪个角度看,数据都可以分为内部数据和外部数据。内部数据是企业通过累积运算获得的。我们应该挖掘和采集有价值的数据,形成企业数据资产。内部数据侧重于后期处理和分析。
先说一下如何获取外部数据,以及如何通过Excel操作获取外部数据。
外部数据采集 方法
1、专业网站数据(某行业,某产品)
2.通过收费渠道(第三方数据平台等)购买数据
3.通过特殊形式引用数据(网站爬虫、统计网站等)。)
4.自己积累数据(时间长,跨度长)
Excel获取外部数据
作为数据分析师,想要进一步成长为数据科学家,精通基础办公软件和SQL查询非常重要。按照以下步骤通过 Excel 获取外部数据。
第 1 步:打开新网络查询框。创建一个新的 Excel 工作簿,在打开的工作表中单击“数据”选项卡,然后单击“获取外部数据”组中的“来自 网站”按钮,如下图所示。
步骤 2:输入 URL 并选择要导入的表数据。在弹出的“新建网页查询”对话框中的“地址”文本框中,复制粘贴上述网页的网址,然后点击“前往”,找到网站中的表格数据,然后单击表格左上角的箭头 图标变为选中的复选框。下图。最后,点击下方的“导入”按钮。
第三步:选择数据放置区域。单击导入后,Excel 将显示导入数据对话框,如下图所示。选择要放置的单元格,然后单击“确定”开始导入。
第四步:美化导入的数据。由于导入的数据较大且令人困惑,因此应调整格式以使数据标准化,并应启用冻结窗格功能以便于浏览。下图。
OK,以上就是通过Excel操作获取网站上的外部数据。这很简单,但并非 网站 上的所有数据都以表格形式呈现。现在大多数都以 json 格式呈现。Excel 不是灵丹妙药,许多网站 现在花钱来引导数据(如上所述,数据是一种商业资产)。
概括
我希望我能帮助你解决上述问题。如果您有什么好的意见、建议或不同的意见,希望您可以留言与我们交流讨论。 查看全部
excel抓取网页动态数据(Excel数据采集软件(免费下载,像Excel一样极速上手,可灵活自定义的企业管理软件))
推荐使用:Excel数据采集软件(免费下载,与Excel一样快,灵活可定制的企业管理软件)
前言
IBM大中华区总经理胡世忠曾表示:数据构成了智慧地球的三大要素:智能、互联和互联,这三大要素改变了数据的来源、传输和利用,带来了“大数据”信息社会已经发生了变化。
由上可知,时代的变迁源于数据的使用。对于企业来说,数据也是企业发展和转型的命脉。在我的工作中,我的前辈们不止一次强调,数据是公司的资产,非常重要。我们要严格数据,经得起时间的考验,对自己的数据负责。这是数据主体的基本要求。
数据资源
大数据时代,虽然数据很多,但并不是随意获取的,需要通过各种渠道和方式获取。无论从哪个角度看,数据都可以分为内部数据和外部数据。内部数据是企业通过累积运算获得的。我们应该挖掘和采集有价值的数据,形成企业数据资产。内部数据侧重于后期处理和分析。
先说一下如何获取外部数据,以及如何通过Excel操作获取外部数据。

外部数据采集 方法
1、专业网站数据(某行业,某产品)
2.通过收费渠道(第三方数据平台等)购买数据
3.通过特殊形式引用数据(网站爬虫、统计网站等)。)
4.自己积累数据(时间长,跨度长)
Excel获取外部数据
作为数据分析师,想要进一步成长为数据科学家,精通基础办公软件和SQL查询非常重要。按照以下步骤通过 Excel 获取外部数据。
第 1 步:打开新网络查询框。创建一个新的 Excel 工作簿,在打开的工作表中单击“数据”选项卡,然后单击“获取外部数据”组中的“来自 网站”按钮,如下图所示。
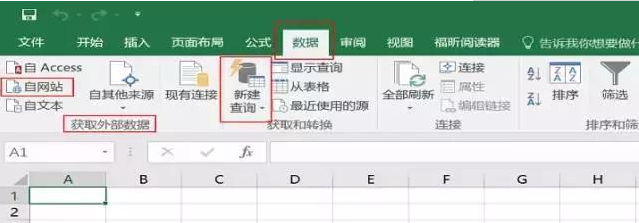
步骤 2:输入 URL 并选择要导入的表数据。在弹出的“新建网页查询”对话框中的“地址”文本框中,复制粘贴上述网页的网址,然后点击“前往”,找到网站中的表格数据,然后单击表格左上角的箭头 图标变为选中的复选框。下图。最后,点击下方的“导入”按钮。
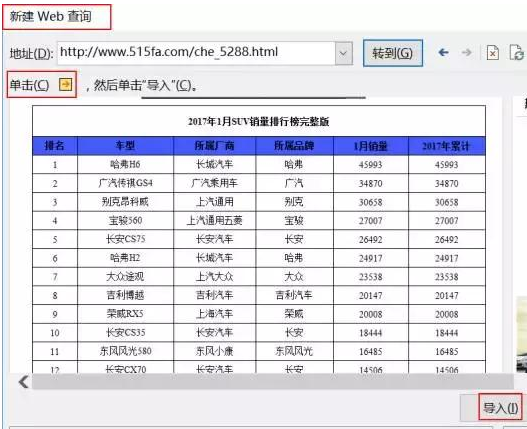
第三步:选择数据放置区域。单击导入后,Excel 将显示导入数据对话框,如下图所示。选择要放置的单元格,然后单击“确定”开始导入。
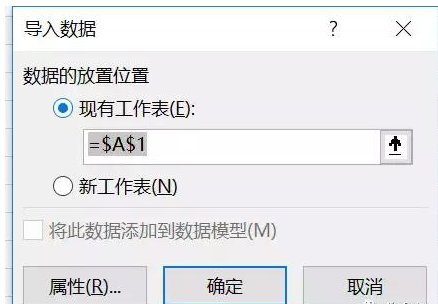
第四步:美化导入的数据。由于导入的数据较大且令人困惑,因此应调整格式以使数据标准化,并应启用冻结窗格功能以便于浏览。下图。
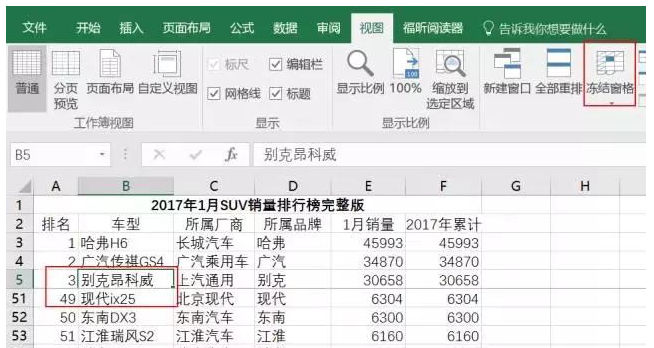
OK,以上就是通过Excel操作获取网站上的外部数据。这很简单,但并非 网站 上的所有数据都以表格形式呈现。现在大多数都以 json 格式呈现。Excel 不是灵丹妙药,许多网站 现在花钱来引导数据(如上所述,数据是一种商业资产)。
概括
我希望我能帮助你解决上述问题。如果您有什么好的意见、建议或不同的意见,希望您可以留言与我们交流讨论。
excel抓取网页动态数据(【数据获取】爬虫利器Rvest包(JS渲染页面))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-03-07 16:14
本文所有内容均基于Windows系统。
前言
对于R中的静态页面爬取,rvest、RCurl、XML包都可以实现这个功能。这里推荐文哥写的两篇文档,介绍如何爬取静态页面数据。我也是通过这两篇文章文章开始接触R爬虫的。
传送门:【数据采集】爬虫工具Rvest包【数据采集】爬虫基础Rcurl和XML包
前几天遇到一个问题,需要抓取动态页面(JS渲染的页面)。通过网络采集知识,不断整理,终于初步解决了问题。由于相关的中文资料不多,所以写了这个文章分享给大家。
解决爬取动态页面的问题,需要一个比较强大的R包——RSelenium。
RSelenium 简介
RSelenium 的作用是使用 R 调用 Selenium Server。
什么是 Selenium 服务器?
Selenium Server 允许您在不同的浏览器上打开 URL,对网页进行操作,并为网页元素爬取独立的 JAVA 程序。
因此,我们可以通过 Selenium Server 对网页进行操作,然后对操作后的数据进行爬取,从而对动态页面进行爬取。
Selenium 服务器安装
下载列表:
JAVA JDK 1.8(门户)。Selenium Server 是一个需要 JAVA 环境的 JAVA 程序。Selenium 服务器独立 3.0.1(门户)。Selenium 服务器的 JAVA 文件。铬(门户)。ChromeDriver(需要爬墙门户)(无爬墙门户)。Selenium Server 调用 Chrome 的驱动程序。
安装过程:
首先,安装 JAVA JDK 1.8。
然后,安装 Chrome(最新版本)。
之后,将解压后的ChromeDriver.exe(最新版)放到Chrome安装路径下。它必须放在与 chrome.exe 相同的目录中。例如:
chrome.exe和chromedriver.exe都在C:\Program Files(x86)\Google\Chrome\Application目录下。(一般Chrome的默认安装路径在这里)
最后将这个路径C:\Program Files(x86)\Google\Chrome\Application添加到环境变量PATH的路径中。具体添加过程可以看这里(传送门)。
基本配置完成!
RSelenium 用法和示例
通过示例了解有关使用 RSelenium 的更多信息。
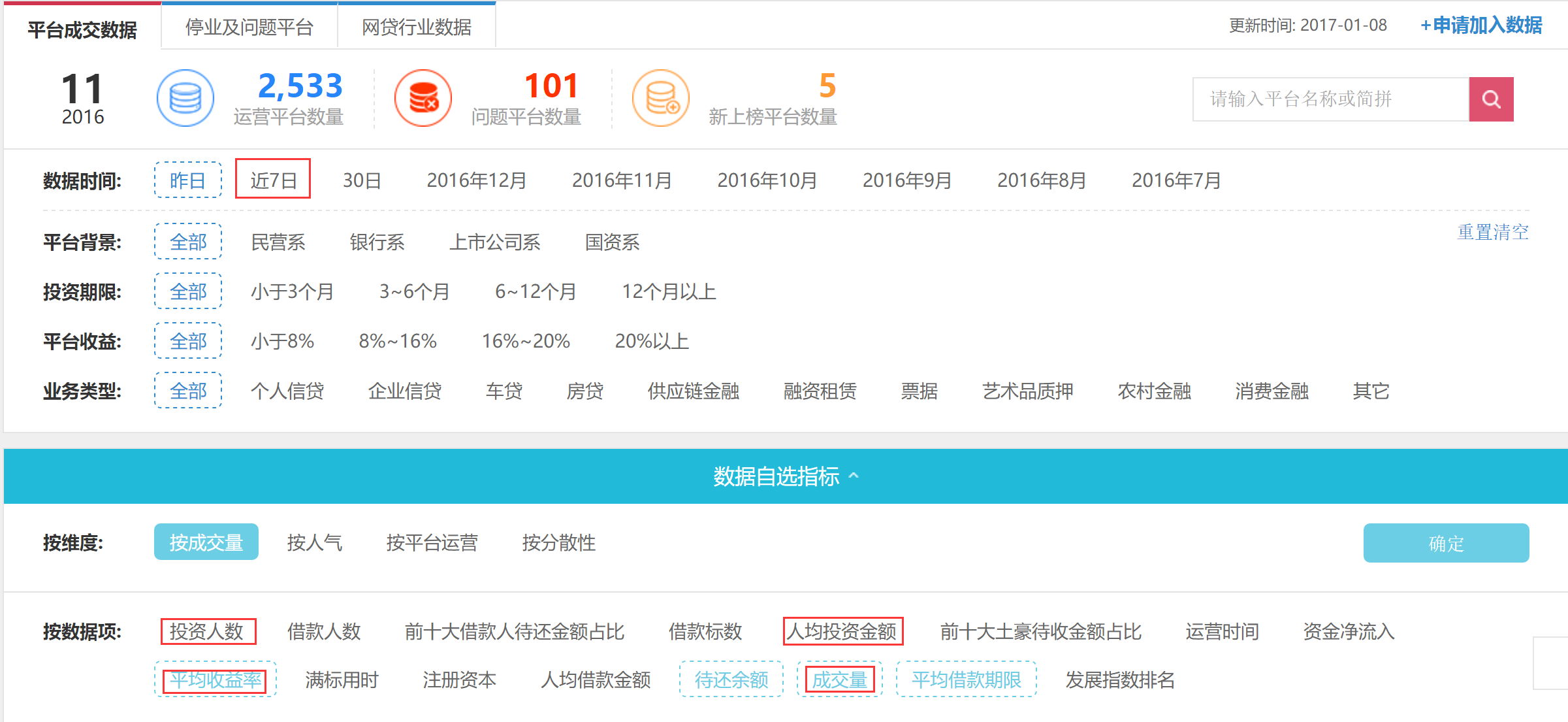
目标:从网贷之家数据平台( )中抓取各P2P平台最近7天的投资者数量、人均投资金额、平均收益率和交易量。下图中红框的内容。
过程:
启动 Selenium 服务器。在 selenium-server-standalone-3.0.1.jar 文件所在的位置,使用 shift+鼠标右键选择“Open command line here”。在命令行上运行以下代码以启动 Selenium Server。
java -jar selenium-server-standalone-3.0.1.jar
运行后,最小化,不要关闭。通过R调用Selenium Server并打开网页,点击页面,选择对应的条件。通过 RSelenium 与 rvest 一起抓取数据。通过逐步解密Rcode来解释该过程。
<p>################调用R包#########################################
library(rvest) # 为了read_html函数
library(RSelenium) # 为了使用JavaScript进行网页抓取
###############连接Server并打开浏览器############################
remDr 查看全部
excel抓取网页动态数据(【数据获取】爬虫利器Rvest包(JS渲染页面))
本文所有内容均基于Windows系统。
前言
对于R中的静态页面爬取,rvest、RCurl、XML包都可以实现这个功能。这里推荐文哥写的两篇文档,介绍如何爬取静态页面数据。我也是通过这两篇文章文章开始接触R爬虫的。
传送门:【数据采集】爬虫工具Rvest包【数据采集】爬虫基础Rcurl和XML包
前几天遇到一个问题,需要抓取动态页面(JS渲染的页面)。通过网络采集知识,不断整理,终于初步解决了问题。由于相关的中文资料不多,所以写了这个文章分享给大家。
解决爬取动态页面的问题,需要一个比较强大的R包——RSelenium。
RSelenium 简介
RSelenium 的作用是使用 R 调用 Selenium Server。
什么是 Selenium 服务器?
Selenium Server 允许您在不同的浏览器上打开 URL,对网页进行操作,并为网页元素爬取独立的 JAVA 程序。
因此,我们可以通过 Selenium Server 对网页进行操作,然后对操作后的数据进行爬取,从而对动态页面进行爬取。
Selenium 服务器安装
下载列表:
JAVA JDK 1.8(门户)。Selenium Server 是一个需要 JAVA 环境的 JAVA 程序。Selenium 服务器独立 3.0.1(门户)。Selenium 服务器的 JAVA 文件。铬(门户)。ChromeDriver(需要爬墙门户)(无爬墙门户)。Selenium Server 调用 Chrome 的驱动程序。
安装过程:
首先,安装 JAVA JDK 1.8。
然后,安装 Chrome(最新版本)。
之后,将解压后的ChromeDriver.exe(最新版)放到Chrome安装路径下。它必须放在与 chrome.exe 相同的目录中。例如:
chrome.exe和chromedriver.exe都在C:\Program Files(x86)\Google\Chrome\Application目录下。(一般Chrome的默认安装路径在这里)
最后将这个路径C:\Program Files(x86)\Google\Chrome\Application添加到环境变量PATH的路径中。具体添加过程可以看这里(传送门)。
基本配置完成!
RSelenium 用法和示例
通过示例了解有关使用 RSelenium 的更多信息。
目标:从网贷之家数据平台( )中抓取各P2P平台最近7天的投资者数量、人均投资金额、平均收益率和交易量。下图中红框的内容。
过程:
启动 Selenium 服务器。在 selenium-server-standalone-3.0.1.jar 文件所在的位置,使用 shift+鼠标右键选择“Open command line here”。在命令行上运行以下代码以启动 Selenium Server。
java -jar selenium-server-standalone-3.0.1.jar
运行后,最小化,不要关闭。通过R调用Selenium Server并打开网页,点击页面,选择对应的条件。通过 RSelenium 与 rvest 一起抓取数据。通过逐步解密Rcode来解释该过程。
<p>################调用R包#########################################
library(rvest) # 为了read_html函数
library(RSelenium) # 为了使用JavaScript进行网页抓取
###############连接Server并打开浏览器############################
remDr
excel抓取网页动态数据(知晓云云函数导出任务进行管理的流程和流程(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2022-03-07 06:17
在日常工作中,往往需要根据业务需要,对各种格式的数据进行处理和导出。导出后,很多人更喜欢将数据放到excel中进行处理。
一般来说,在处理数据导出时,需要对数据进行一些操作。过去,这是通过在单独的服务器上运行脚本来完成的。
现在有了知云,你不再需要维护服务器,直接写代码,把所有相关的东西都扔给云功能。本文将介绍通过知云功能将数据表导出为excel文件的功能,并使用webpack和mincloud将代码打包上传到知云。
技术栈:
一、项目建设
项目文件结构:
export-excel-file
├── index.js
├── package.json
├── src
│ └── index.js
├── webpack.config.js
└── yarn.lock
项目搭建与云功能代码打包示例文档基本一致。项目构建完成后,还需要安装以下依赖(两种安装方式任选其一):
// 使用 yarn 安装
yarn add node-xlsx mincloud
// 使用 npm 安装
npm install --save node-xlsx minclou
修改部署脚本如下:
// package.json
...
"scripts": {
"build": "webpack --mode production",
"predeploy": "npm run build",
"deploy": "mincloud deploy export-excel-file ../"
},
...
最后我们将使用以下两个命令进行部署和测试:
npm run deploy // 部署到知晓云
mincloud invoke export-excel-file // 测试已经部署到知晓云上的云函数
二、导出数据表到excel文件
我们需要准备两张表:
order:订单表(新字段:名称,价格)
export_task:导出任务记录表(新字段:file_download_link)
知云的云函数调用可以是同步的,也可以是异步的。同步调用的最大超时时间为 5 秒,异步调用为 300 秒。
假设order order表有100000条数据,由于我们知道单次从云端拉取数据的最大限制是1000条,所以需要批量获取数据,可能需要对数据进行处理稍后,这将花费超过 5 秒,因此对云函数的调用将是异步的。这时就需要export_task导出任务记录表来管理导出任务。
export_task 表按如下方式管理导出任务:
调用云函数时,在export_task表中创建一条记录A。此时A记录中file_download_link字段的值为空。同时获取记录A的id,将id记录为jobId,查询订单表数据,生成excel文件,上传文件。等待操作,获取文件下载链接后,根据jobId更新第一步创建的记录,将文件下载链接保存在file_download_link字段中,然后在export_task表中获取文件下载链接。
通过上面的准备和分析,导出excel文件的操作分为以下4个步骤:
order 订单表数据获取 使用获取的数据在云函数环境中创建excel文件 将创建的excel文件上传到知云 将文件下载链接保存到export_task表中file_download_link字段
完整代码如下:
const fs = require('fs')
const xlsx = require('node-xlsx')
const EXPORT_DATA_CATEGORY_ID = '5c711e3119111409cdabe6f2' // 文件上传分类 id
const TABLE_ID = {
order: 66666, // 订单表
export_task: 66667, // 导出任务记录表
}
const TMP_FILE_NAME = '/tmp/result.xlsx' // 本地临时文件路径,以 /tmp 开头,具体请查看:https://doc.minapp.com/support ... .html (云函数的临时文件存储)
const ROW_NAME = ['name', 'price'] // Excel 文件列名配置
const MAX_CONNECT_LIMIT = 5 // 最大同时请求数
const LIMIT = 1000 // 单次最大拉取数据数
let result = []
/**
* 更新导出记录中的 file_download_link 字段
* @param {*} tableID
* @param {*} recordId
* @param {*} fileLink
*/
function updateExportJobIdRecord(tableID, recordId, fileLink) {
let Schame = new BaaS.TableObject(tableID)
let schame = Schame.getWithoutData(recordId)
schame.set('file_download_link', fileLink)
return schame.update()
}
/**
* 创建数据导出任务
* 设置初始 file_download_link 为空
* 待导出任务执行完毕后将文件下载地址存储到 file_download_link 字段中
* @param {*} tableID
*/
function createExportJobIdRecord(tableID) {
let Schame = new BaaS.TableObject(tableID)
let schame = Schame.create()
return schame.set({file_download_link: ''}).save().then(res => {
return res.data.id
})
}
/**
* 获取总数据条数
* @tableId {*} tableId
*/
function getTotalCount(tableId) {
const Order = new BaaS.TableObject(tableId)
return Order.count()
.then(num => {
console.log('数据总条数:', num)
return num
})
.catch(err => {
console.log('获取数据总条数失败:', err)
throw new Error(err)
})
}
/**
* 分批拉取数据
* @param {*} tableId
* @param {*} offset
* @param {*} limit
*/
function getDataByGroup(tableId, offset = 0, limit = LIMIT) {
let Order = new BaaS.TableObject(tableId)
return Order.limit(limit).offset(offset).find()
.then(res => {
return res.data.objects
})
.catch(err => {
console.log('获取分组数据失败:', err)
throw new Error(err)
})
}
/**
* 创建 Excel 导出文件
* @param {*} sourceData 源数据
*/
function genExportFile(sourceData = []) {
const resultArr = []
const rowArr = []
// 配置列名
rowArr.push(ROW_NAME)
sourceData.forEach(v => {
rowArr.push(
ROW_NAME.map(k => v[k])
)
})
resultArr[0] = {
data: rowArr,
name: 'sheet1', // Excel 工作表名
}
const option = {'!cols': [{wch: 10}, {wch: 20}]} // 自定义列宽度
const buffer = xlsx.build(resultArr, option)
return fs.writeFile(TMP_FILE_NAME, buffer, err => {
if (err) {
console.log('创建 Excel 导出文件失败')
throw new Error(err)
}
})
}
/**
* 上传文件
*/
function uploadFile() {
let MyFile = new BaaS.File()
return MyFile.upload(TMP_FILE_NAME, {category_id: EXPORT_DATA_CATEGORY_ID})
.catch(err => {
console.log('上传文件失败')
throw new Error(err)
})
}
module.exports = async function(event, callback) {
try {
const date = new Date().getTime()
const groupInfoArr = []
const groupInfoSplitArr = []
const [jobId, totalCount] = await Promise.all([createExportJobIdRecord(TABLE_ID.export_task), getTotalCount(TABLE_ID.order)])
const groupSize = Math.ceil(totalCount / LIMIT) || 1
for (let i = 0; i < groupSize; i++) {
groupInfoArr.push({
offset: i * LIMIT,
limit: LIMIT,
})
}
console.log('groupInfoArr:', groupInfoArr)
const length = Math.ceil(groupInfoArr.length / MAX_CONNECT_LIMIT)
for (let i = 0; i < length; i++) {
groupInfoSplitArr.push(groupInfoArr.splice(0, MAX_CONNECT_LIMIT))
}
console.log('groupInfoSplitArr:', groupInfoSplitArr)
const date0 = new Date().getTime()
console.log('处理分组情况耗时:', date0 - date, 'ms')
let num = 0
// 分批获取数据
const getSplitDataList = index => {
return Promise.all(
groupInfoSplitArr[index].map(v => {
return getDataByGroup(TABLE_ID.order, v.offset, v.limit)
})
).then(res => {
++num
result.push(...Array.prototype.concat(...res))
if (num < groupInfoSplitArr.length) {
return getSplitDataList(num)
} else {
return result
}
})
}
Promise.all([getSplitDataList(num)]).then(res => {
const date1 = new Date().getTime()
console.log('结果条数:', result.length)
console.log('分组拉取数据次数:', num)
console.log('拉取数据耗时:', date1 - date0, 'ms')
genExportFile(result)
const date2 = new Date().getTime()
console.log('处理数据耗时:', date2 - date1, 'ms')
uploadFile().then(res => {
const fileLink = res.data.file_link
const date3 = new Date().getTime()
console.log('上传文件耗时:', date3 - date2, 'ms')
console.log('总耗时:', date3 - date, 'ms')
updateExportJobIdRecord(TABLE_ID.export_task, jobId, fileLink)
.then(() => {
const date4 = new Date().getTime()
console.log('保存文件下载地址耗时:', date4 - date3, 'ms')
console.log('总耗时:', date4 - date, 'ms')
callback(null, {
message: '保存文件下载地址成功',
fileLink,
})
})
.catch(err => {
callback(err)
})
}).catch(err => {
console.log('上传文件失败:', err)
throw new Error(err)
})
})
} catch (err)
三、部署和测试
和 npm 一样,部署前需要登录。配置请参考文档。
可以使用以下命令将云功能部署到Know Cloud:
npm run deploy
执行结果如下:
使用以下命令进行测试:
mincloud invoke export-excel-file
执行结果如下:
export_task 表记录:
上传到知云的excel文件如下:
文件内容:
四、参考文档
了解云开发文档:
节点 xlsx 文档:
五、源码
仓库地址:
六、好处
即日起(3月8日)起,前50名报名并通过网页端公测审核的用户,将在正式接入后获得100元的积分。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接: 查看全部
excel抓取网页动态数据(知晓云云函数导出任务进行管理的流程和流程(一))
在日常工作中,往往需要根据业务需要,对各种格式的数据进行处理和导出。导出后,很多人更喜欢将数据放到excel中进行处理。
一般来说,在处理数据导出时,需要对数据进行一些操作。过去,这是通过在单独的服务器上运行脚本来完成的。
现在有了知云,你不再需要维护服务器,直接写代码,把所有相关的东西都扔给云功能。本文将介绍通过知云功能将数据表导出为excel文件的功能,并使用webpack和mincloud将代码打包上传到知云。
技术栈:
一、项目建设
项目文件结构:
export-excel-file
├── index.js
├── package.json
├── src
│ └── index.js
├── webpack.config.js
└── yarn.lock
项目搭建与云功能代码打包示例文档基本一致。项目构建完成后,还需要安装以下依赖(两种安装方式任选其一):
// 使用 yarn 安装
yarn add node-xlsx mincloud
// 使用 npm 安装
npm install --save node-xlsx minclou
修改部署脚本如下:
// package.json
...
"scripts": {
"build": "webpack --mode production",
"predeploy": "npm run build",
"deploy": "mincloud deploy export-excel-file ../"
},
...
最后我们将使用以下两个命令进行部署和测试:
npm run deploy // 部署到知晓云
mincloud invoke export-excel-file // 测试已经部署到知晓云上的云函数
二、导出数据表到excel文件
我们需要准备两张表:
order:订单表(新字段:名称,价格)
export_task:导出任务记录表(新字段:file_download_link)

知云的云函数调用可以是同步的,也可以是异步的。同步调用的最大超时时间为 5 秒,异步调用为 300 秒。
假设order order表有100000条数据,由于我们知道单次从云端拉取数据的最大限制是1000条,所以需要批量获取数据,可能需要对数据进行处理稍后,这将花费超过 5 秒,因此对云函数的调用将是异步的。这时就需要export_task导出任务记录表来管理导出任务。
export_task 表按如下方式管理导出任务:
调用云函数时,在export_task表中创建一条记录A。此时A记录中file_download_link字段的值为空。同时获取记录A的id,将id记录为jobId,查询订单表数据,生成excel文件,上传文件。等待操作,获取文件下载链接后,根据jobId更新第一步创建的记录,将文件下载链接保存在file_download_link字段中,然后在export_task表中获取文件下载链接。
通过上面的准备和分析,导出excel文件的操作分为以下4个步骤:
order 订单表数据获取 使用获取的数据在云函数环境中创建excel文件 将创建的excel文件上传到知云 将文件下载链接保存到export_task表中file_download_link字段
完整代码如下:
const fs = require('fs')
const xlsx = require('node-xlsx')
const EXPORT_DATA_CATEGORY_ID = '5c711e3119111409cdabe6f2' // 文件上传分类 id
const TABLE_ID = {
order: 66666, // 订单表
export_task: 66667, // 导出任务记录表
}
const TMP_FILE_NAME = '/tmp/result.xlsx' // 本地临时文件路径,以 /tmp 开头,具体请查看:https://doc.minapp.com/support ... .html (云函数的临时文件存储)
const ROW_NAME = ['name', 'price'] // Excel 文件列名配置
const MAX_CONNECT_LIMIT = 5 // 最大同时请求数
const LIMIT = 1000 // 单次最大拉取数据数
let result = []
/**
* 更新导出记录中的 file_download_link 字段
* @param {*} tableID
* @param {*} recordId
* @param {*} fileLink
*/
function updateExportJobIdRecord(tableID, recordId, fileLink) {
let Schame = new BaaS.TableObject(tableID)
let schame = Schame.getWithoutData(recordId)
schame.set('file_download_link', fileLink)
return schame.update()
}
/**
* 创建数据导出任务
* 设置初始 file_download_link 为空
* 待导出任务执行完毕后将文件下载地址存储到 file_download_link 字段中
* @param {*} tableID
*/
function createExportJobIdRecord(tableID) {
let Schame = new BaaS.TableObject(tableID)
let schame = Schame.create()
return schame.set({file_download_link: ''}).save().then(res => {
return res.data.id
})
}
/**
* 获取总数据条数
* @tableId {*} tableId
*/
function getTotalCount(tableId) {
const Order = new BaaS.TableObject(tableId)
return Order.count()
.then(num => {
console.log('数据总条数:', num)
return num
})
.catch(err => {
console.log('获取数据总条数失败:', err)
throw new Error(err)
})
}
/**
* 分批拉取数据
* @param {*} tableId
* @param {*} offset
* @param {*} limit
*/
function getDataByGroup(tableId, offset = 0, limit = LIMIT) {
let Order = new BaaS.TableObject(tableId)
return Order.limit(limit).offset(offset).find()
.then(res => {
return res.data.objects
})
.catch(err => {
console.log('获取分组数据失败:', err)
throw new Error(err)
})
}
/**
* 创建 Excel 导出文件
* @param {*} sourceData 源数据
*/
function genExportFile(sourceData = []) {
const resultArr = []
const rowArr = []
// 配置列名
rowArr.push(ROW_NAME)
sourceData.forEach(v => {
rowArr.push(
ROW_NAME.map(k => v[k])
)
})
resultArr[0] = {
data: rowArr,
name: 'sheet1', // Excel 工作表名
}
const option = {'!cols': [{wch: 10}, {wch: 20}]} // 自定义列宽度
const buffer = xlsx.build(resultArr, option)
return fs.writeFile(TMP_FILE_NAME, buffer, err => {
if (err) {
console.log('创建 Excel 导出文件失败')
throw new Error(err)
}
})
}
/**
* 上传文件
*/
function uploadFile() {
let MyFile = new BaaS.File()
return MyFile.upload(TMP_FILE_NAME, {category_id: EXPORT_DATA_CATEGORY_ID})
.catch(err => {
console.log('上传文件失败')
throw new Error(err)
})
}
module.exports = async function(event, callback) {
try {
const date = new Date().getTime()
const groupInfoArr = []
const groupInfoSplitArr = []
const [jobId, totalCount] = await Promise.all([createExportJobIdRecord(TABLE_ID.export_task), getTotalCount(TABLE_ID.order)])
const groupSize = Math.ceil(totalCount / LIMIT) || 1
for (let i = 0; i < groupSize; i++) {
groupInfoArr.push({
offset: i * LIMIT,
limit: LIMIT,
})
}
console.log('groupInfoArr:', groupInfoArr)
const length = Math.ceil(groupInfoArr.length / MAX_CONNECT_LIMIT)
for (let i = 0; i < length; i++) {
groupInfoSplitArr.push(groupInfoArr.splice(0, MAX_CONNECT_LIMIT))
}
console.log('groupInfoSplitArr:', groupInfoSplitArr)
const date0 = new Date().getTime()
console.log('处理分组情况耗时:', date0 - date, 'ms')
let num = 0
// 分批获取数据
const getSplitDataList = index => {
return Promise.all(
groupInfoSplitArr[index].map(v => {
return getDataByGroup(TABLE_ID.order, v.offset, v.limit)
})
).then(res => {
++num
result.push(...Array.prototype.concat(...res))
if (num < groupInfoSplitArr.length) {
return getSplitDataList(num)
} else {
return result
}
})
}
Promise.all([getSplitDataList(num)]).then(res => {
const date1 = new Date().getTime()
console.log('结果条数:', result.length)
console.log('分组拉取数据次数:', num)
console.log('拉取数据耗时:', date1 - date0, 'ms')
genExportFile(result)
const date2 = new Date().getTime()
console.log('处理数据耗时:', date2 - date1, 'ms')
uploadFile().then(res => {
const fileLink = res.data.file_link
const date3 = new Date().getTime()
console.log('上传文件耗时:', date3 - date2, 'ms')
console.log('总耗时:', date3 - date, 'ms')
updateExportJobIdRecord(TABLE_ID.export_task, jobId, fileLink)
.then(() => {
const date4 = new Date().getTime()
console.log('保存文件下载地址耗时:', date4 - date3, 'ms')
console.log('总耗时:', date4 - date, 'ms')
callback(null, {
message: '保存文件下载地址成功',
fileLink,
})
})
.catch(err => {
callback(err)
})
}).catch(err => {
console.log('上传文件失败:', err)
throw new Error(err)
})
})
} catch (err)
三、部署和测试
和 npm 一样,部署前需要登录。配置请参考文档。
可以使用以下命令将云功能部署到Know Cloud:
npm run deploy
执行结果如下:

使用以下命令进行测试:
mincloud invoke export-excel-file
执行结果如下:

export_task 表记录:

上传到知云的excel文件如下:

文件内容:

四、参考文档
了解云开发文档:
节点 xlsx 文档:
五、源码
仓库地址:
六、好处
即日起(3月8日)起,前50名报名并通过网页端公测审核的用户,将在正式接入后获得100元的积分。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接:
excel抓取网页动态数据(本文如下:找到目标网页打开阳光高考网站(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-06 12:26
我们日常使用PowerBI数据获取单个网页数据非常简单,但是批量获取网页数据相对麻烦。这里我们可以使用PowerBI的Power Query组件批量获取多个网页的数据。同样,也可以使用高版本Excel自带的Power Query来获取。
本文以阳光高考网站为例,获取2019年全国普通高等学校名单。
具体操作步骤如下:
(一)找到登陆页面
打开阳光高考网站,找到“2019年全国普通高等学校名单”网页。
点击打开单个网页查看,如下:
(二)分析URL结构
这里选择前三个省份网址
北京:
天津:
河北:
可以看出只有URL中最后一个数字是变量,这里我们把它当作页面ID
(三)采集第一页数据
(北京的页面ID从“2”开始)
打开PowerBI Desktop,通过“获取数据”中的“Web”选项获取数据,在“Web”界面中选择“基本”选项卡即可。
这里我们在基本选项卡中输入目标网址
(北京)
获取数据源信息如下,这里只有第一个表是我们要的,勾选,然后点击右下角转换数据进行数据处理。
入口页面如下:
这样我们就简单地采集到第一页数据。然后整理这个页面的数据,删除无用的信息,添加字段名。完成后,后续采集其他页面的数据结构与第一页完成后的数据结构相同,采集的数据可以直接使用。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
我们不会在这里处理它。
(四)根据页码参数设置自定义功能
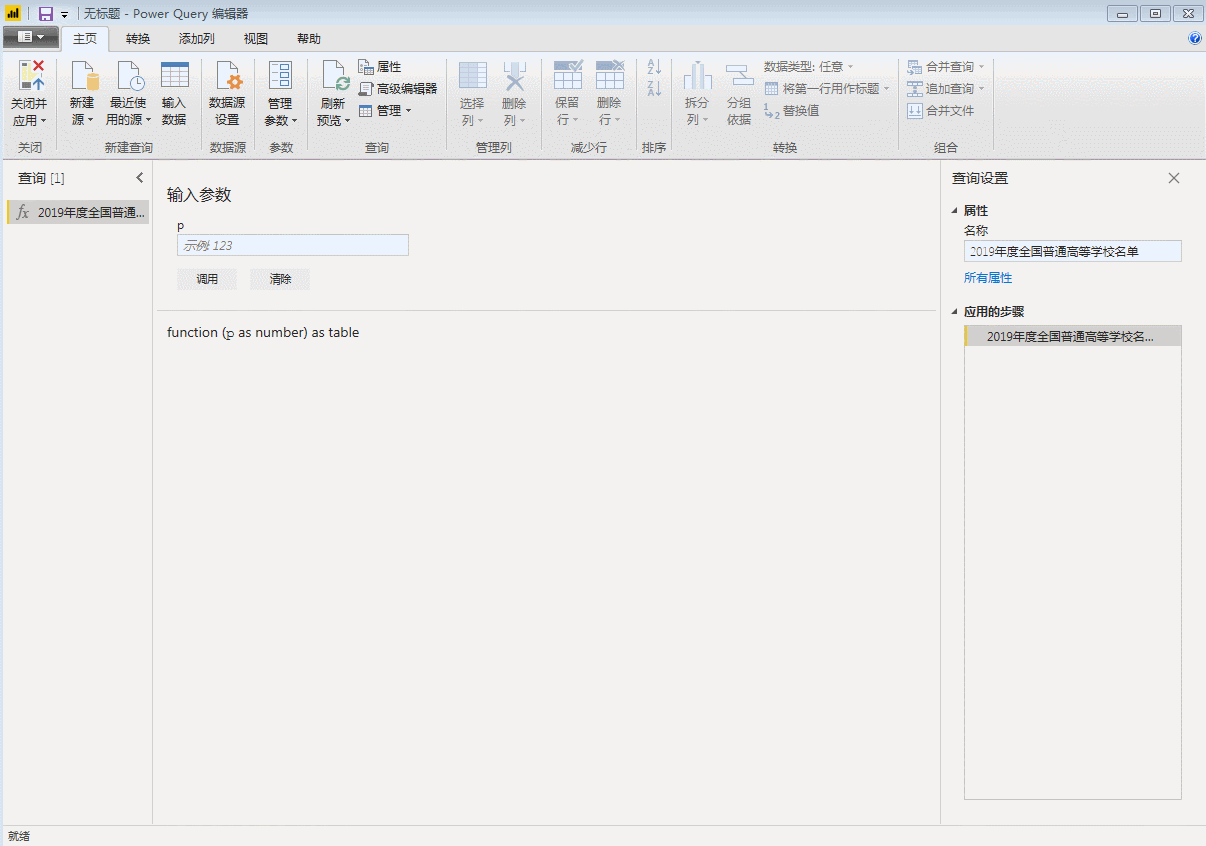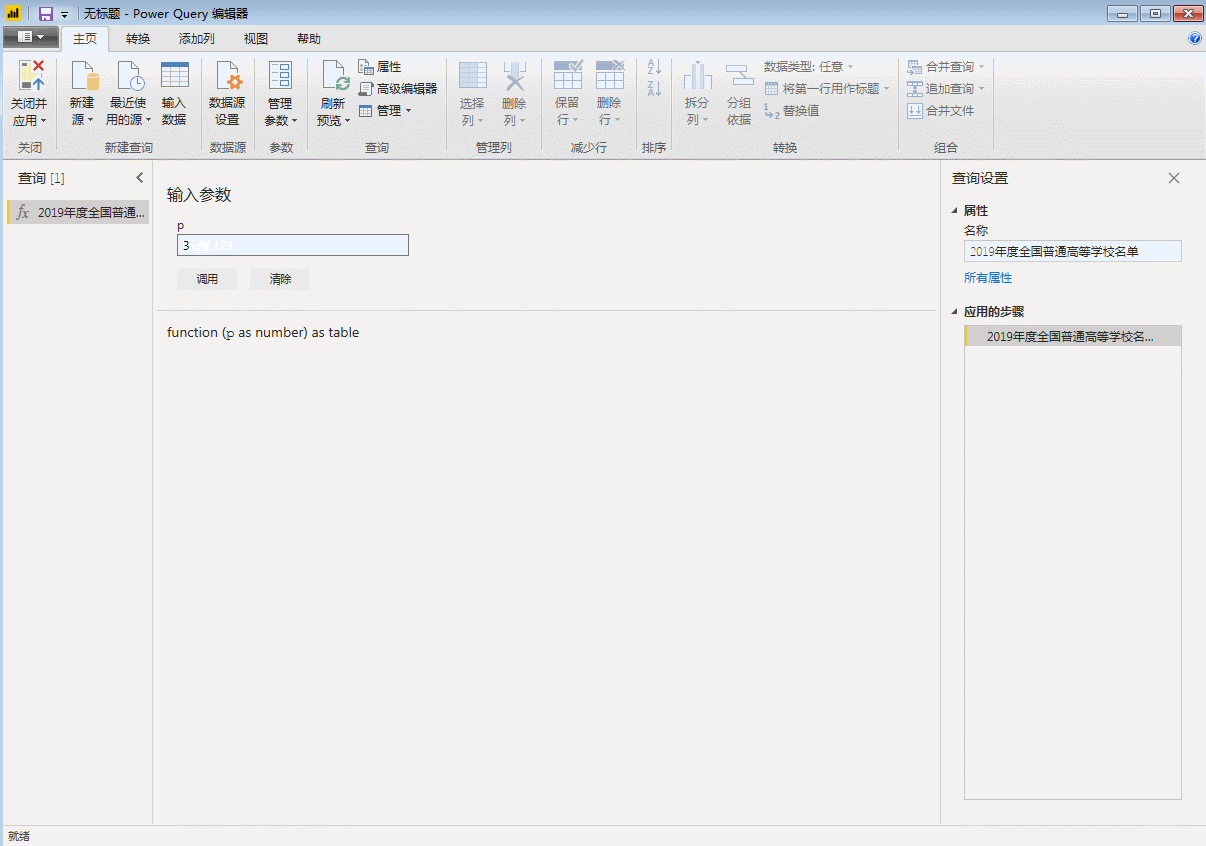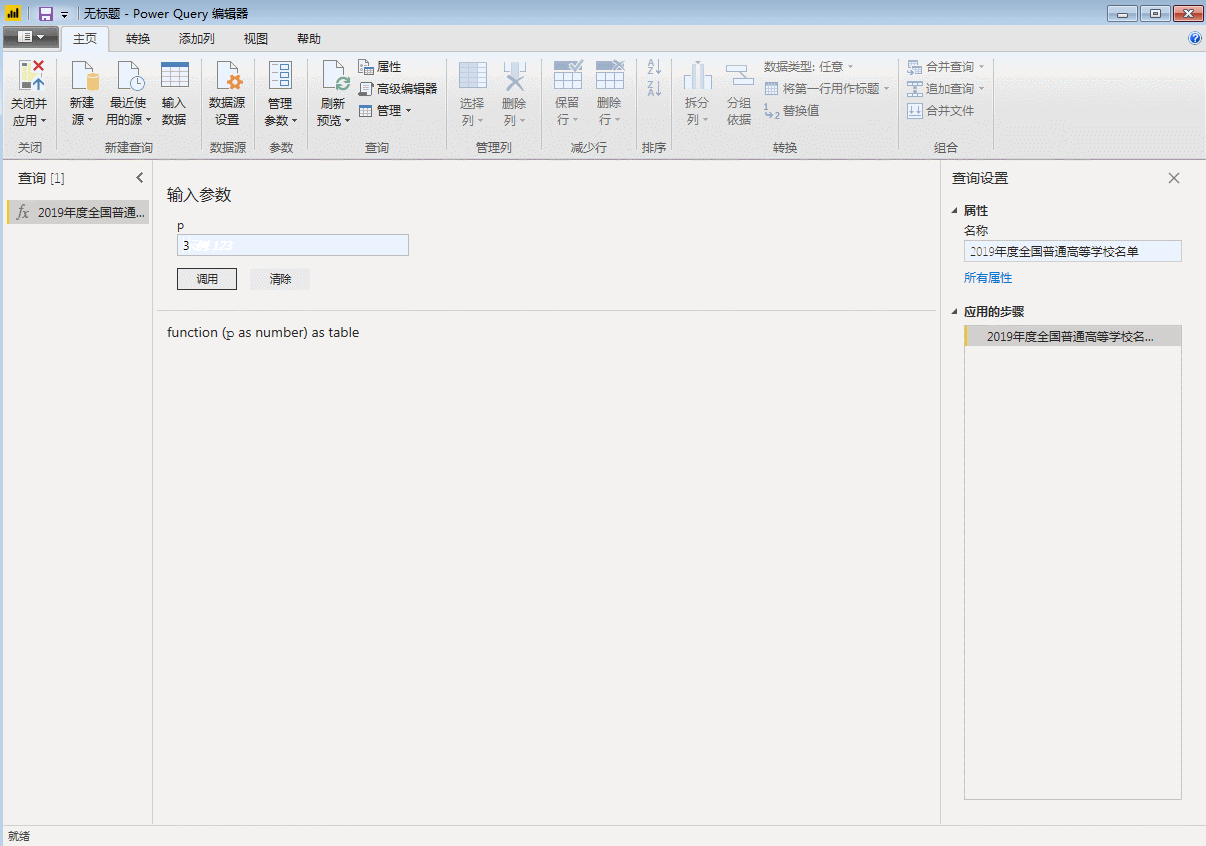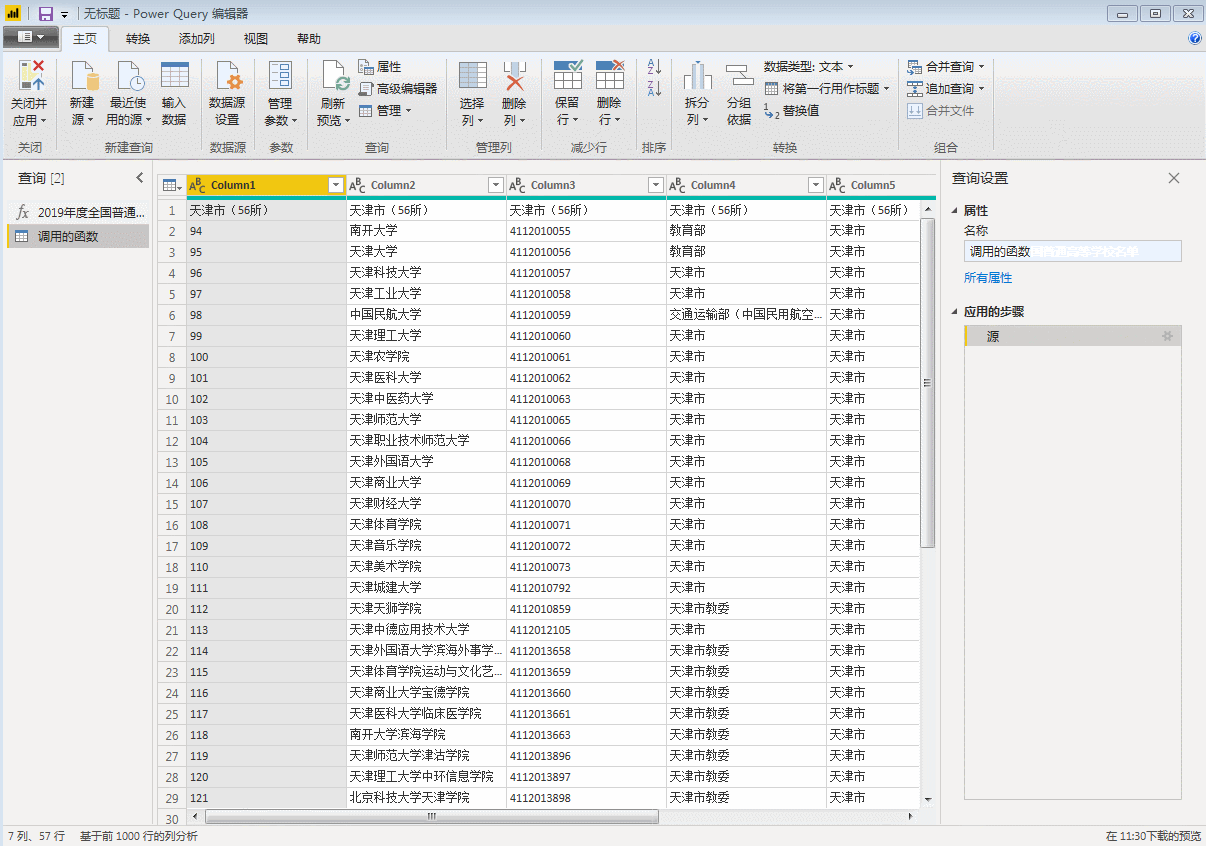
这是最重要的一步
在当前数据的编辑器窗口中,打开【高级编辑器】,输入:
(p作为数字)作为表=>
并且在链接中,将网页的页码,也就是上面提到的“1、2”等数字修改为“&(Number.ToText(p))&”。
改了之后就变成了:
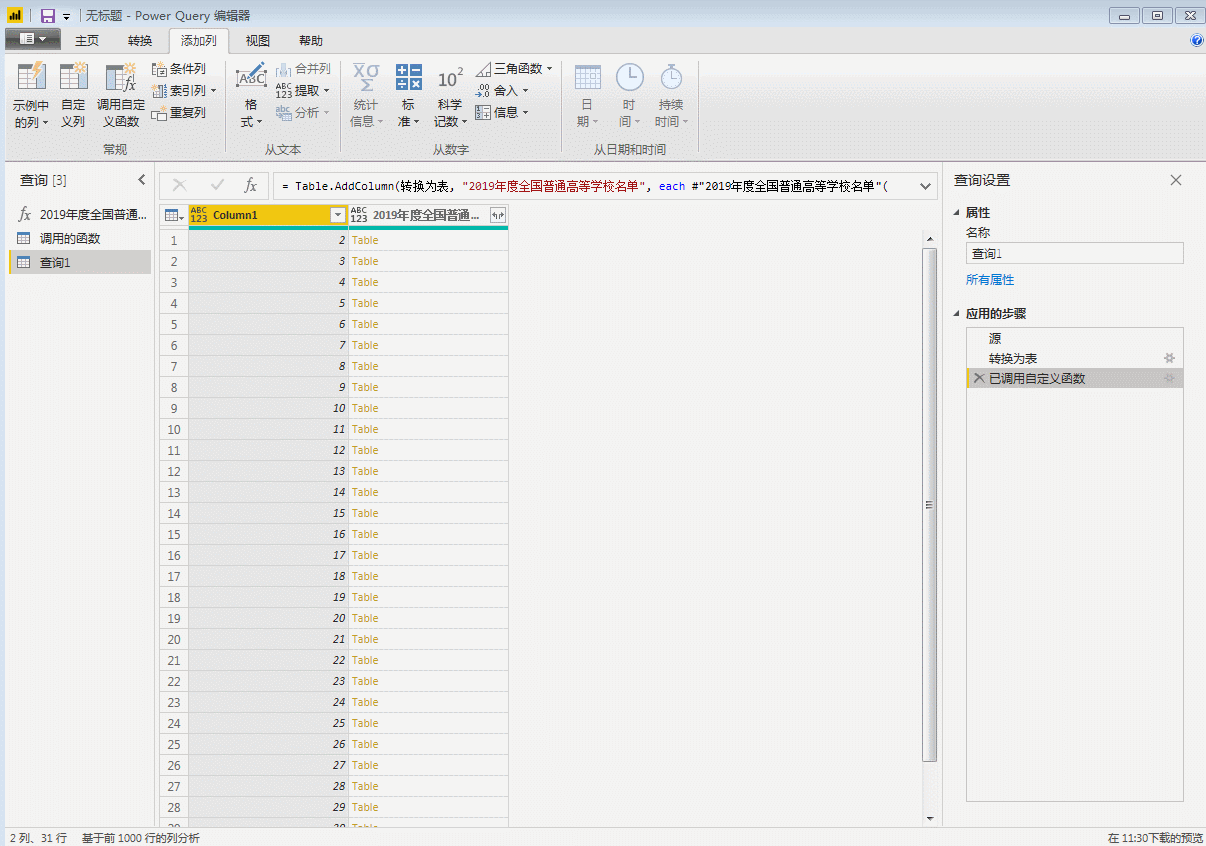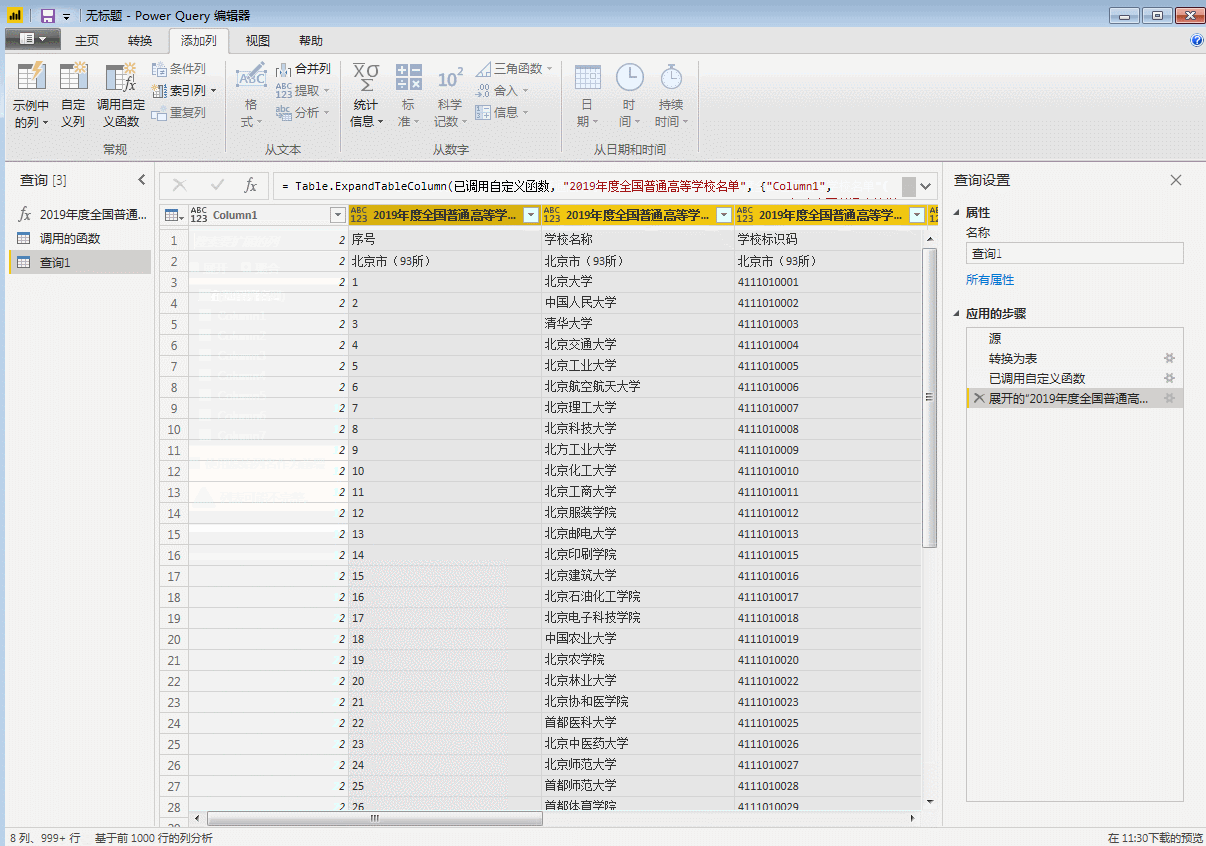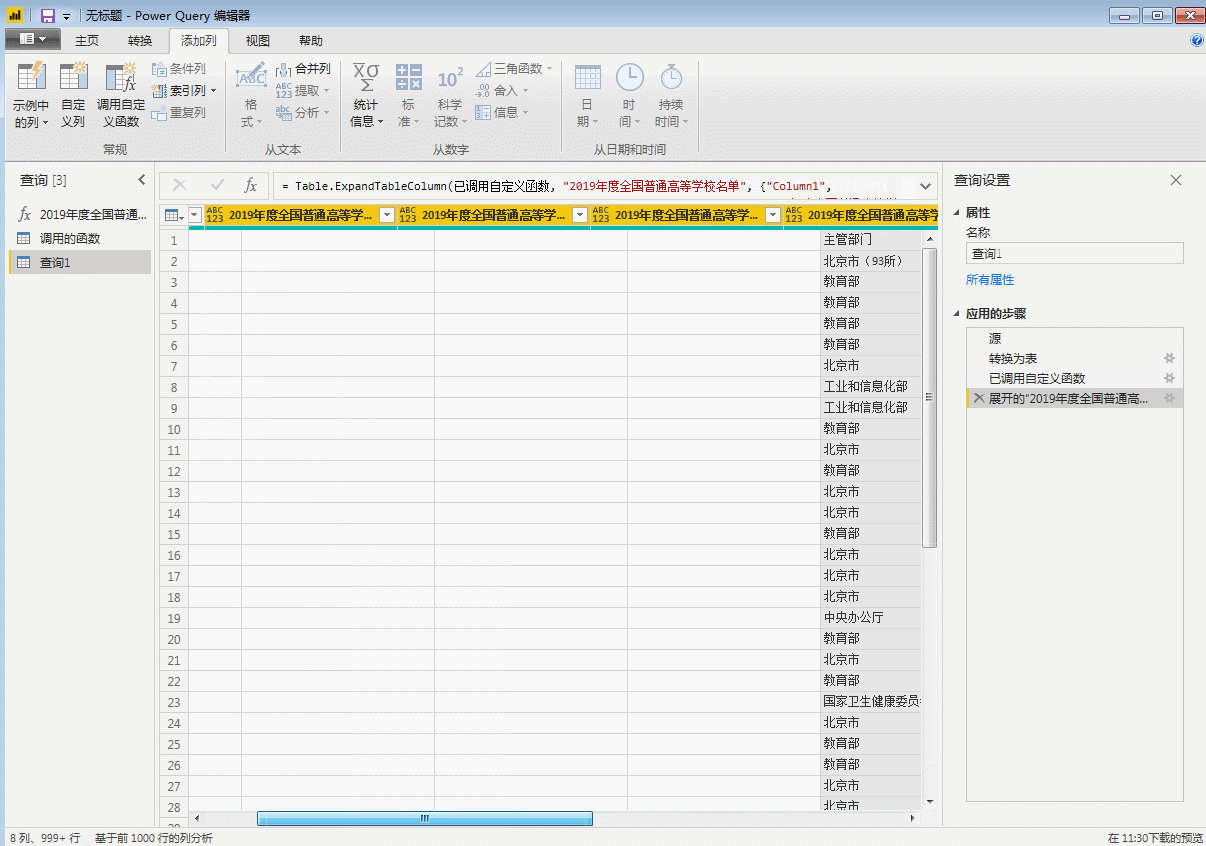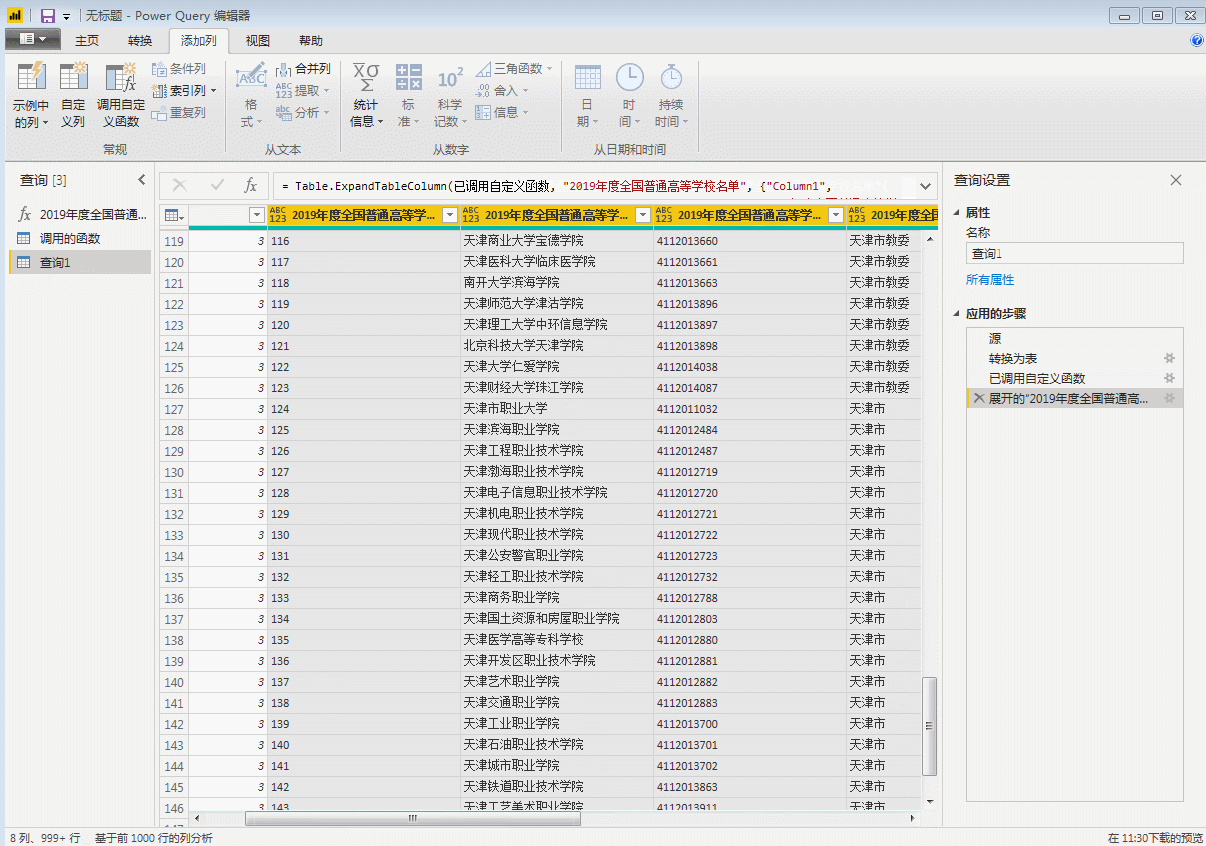
点击“完成”,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,表格也变成了函数的样式。自定义函数完成,p是函数的变量,用来控制页码,输入一个数字,比如3,会抓取第三页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(五)批量调用自定义函数
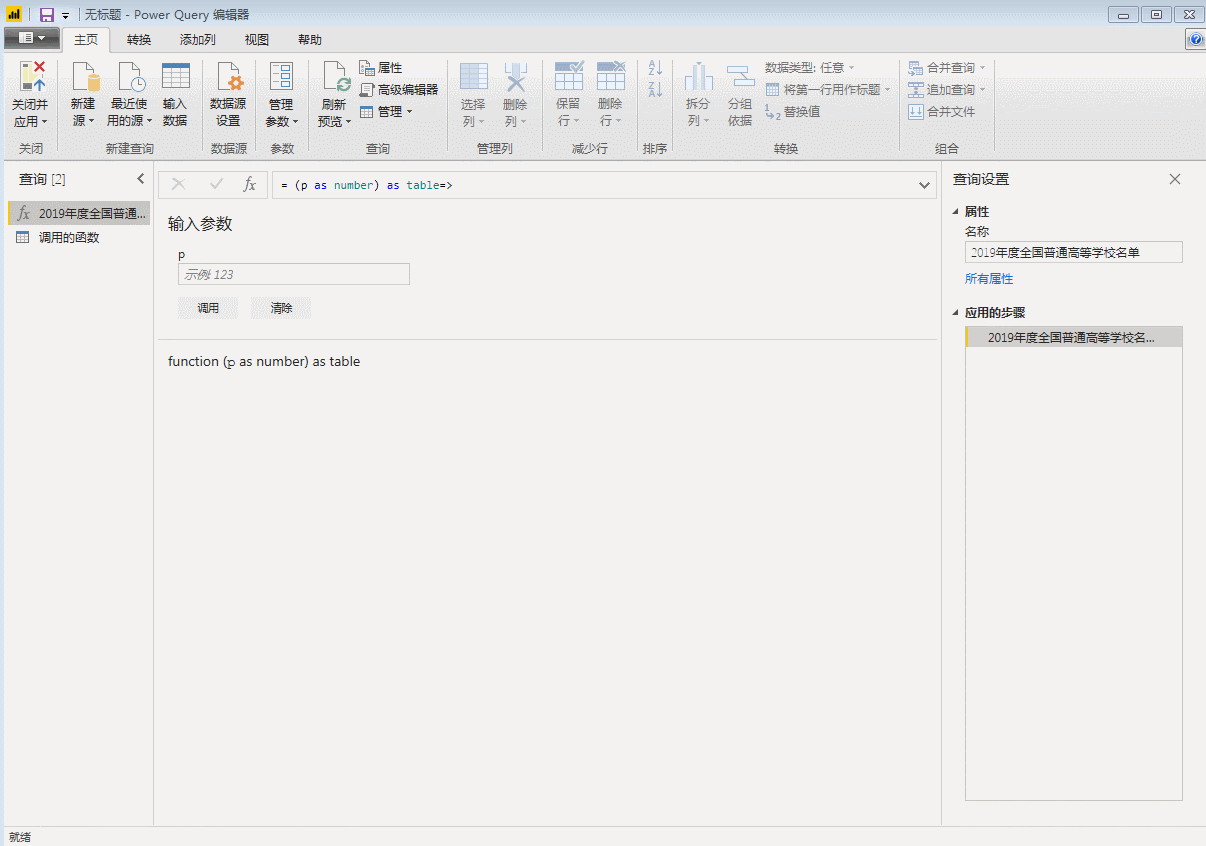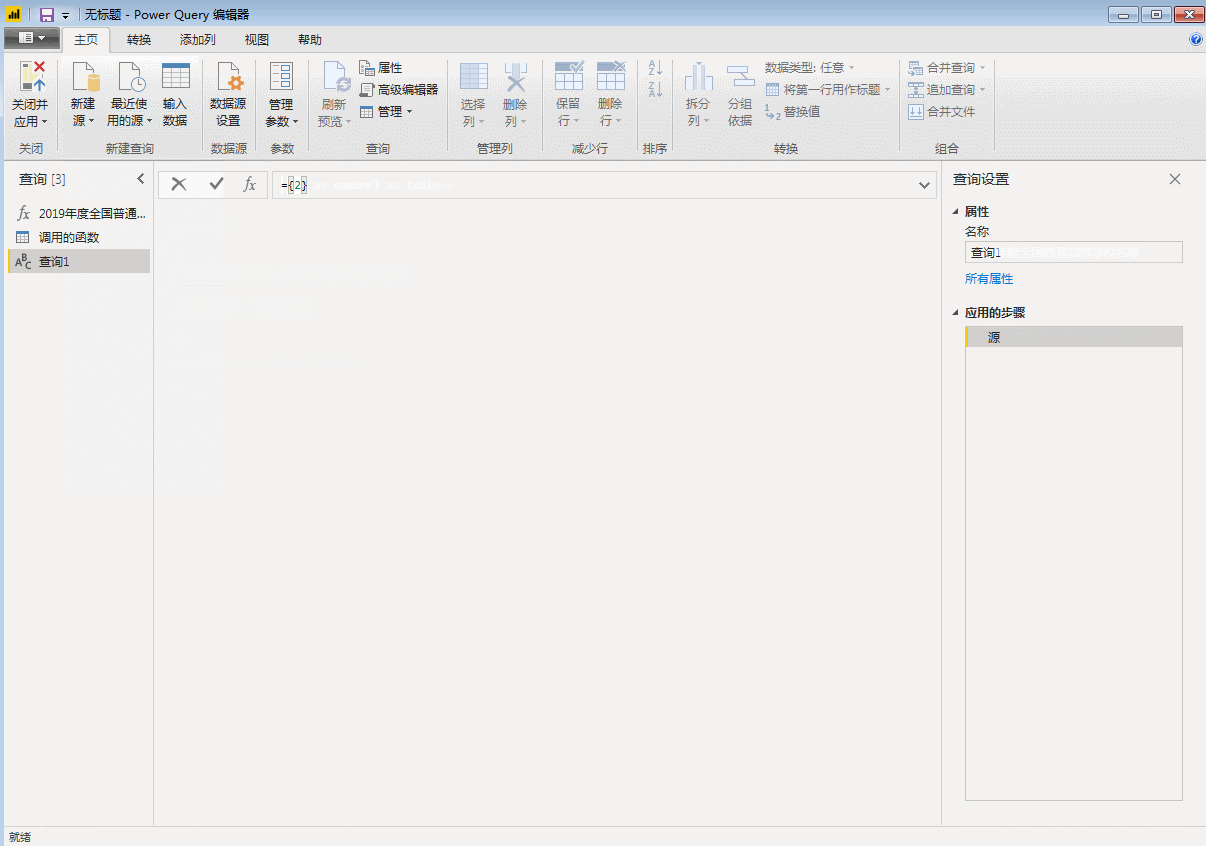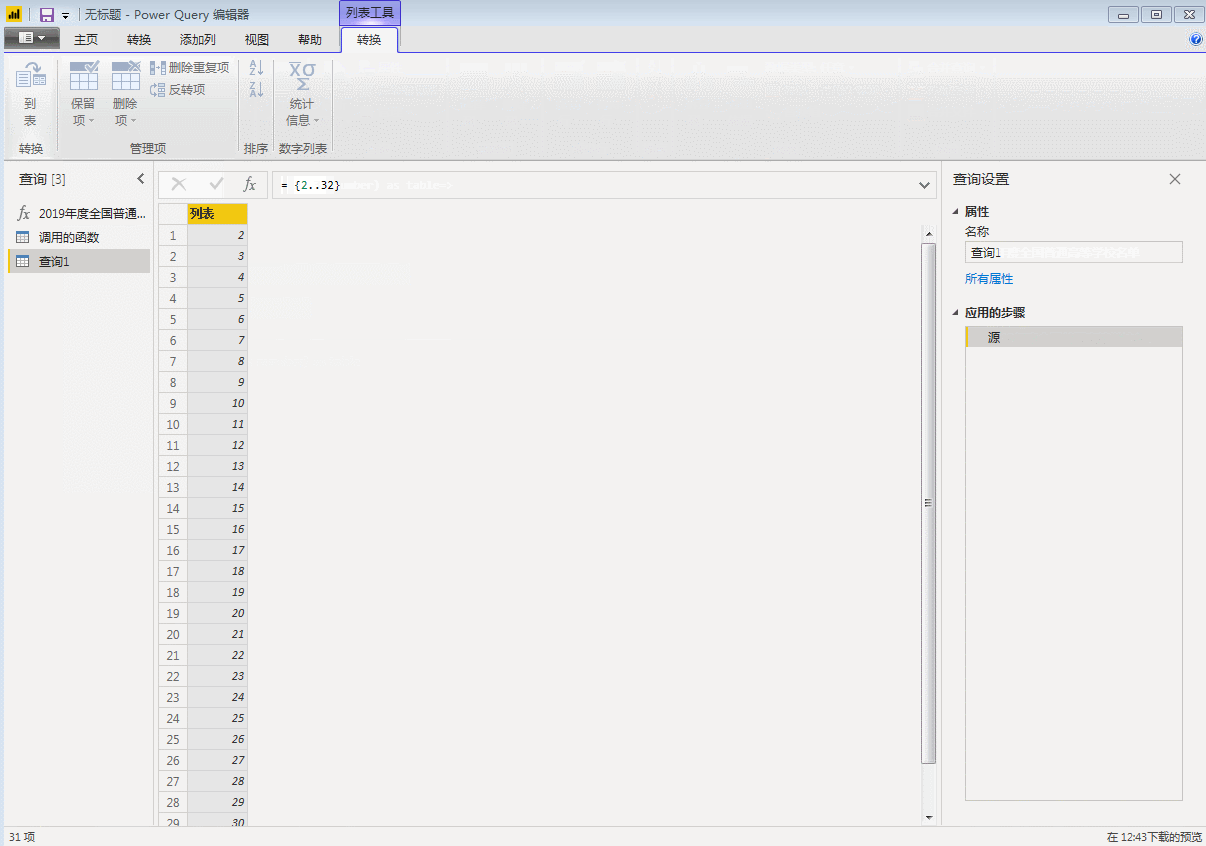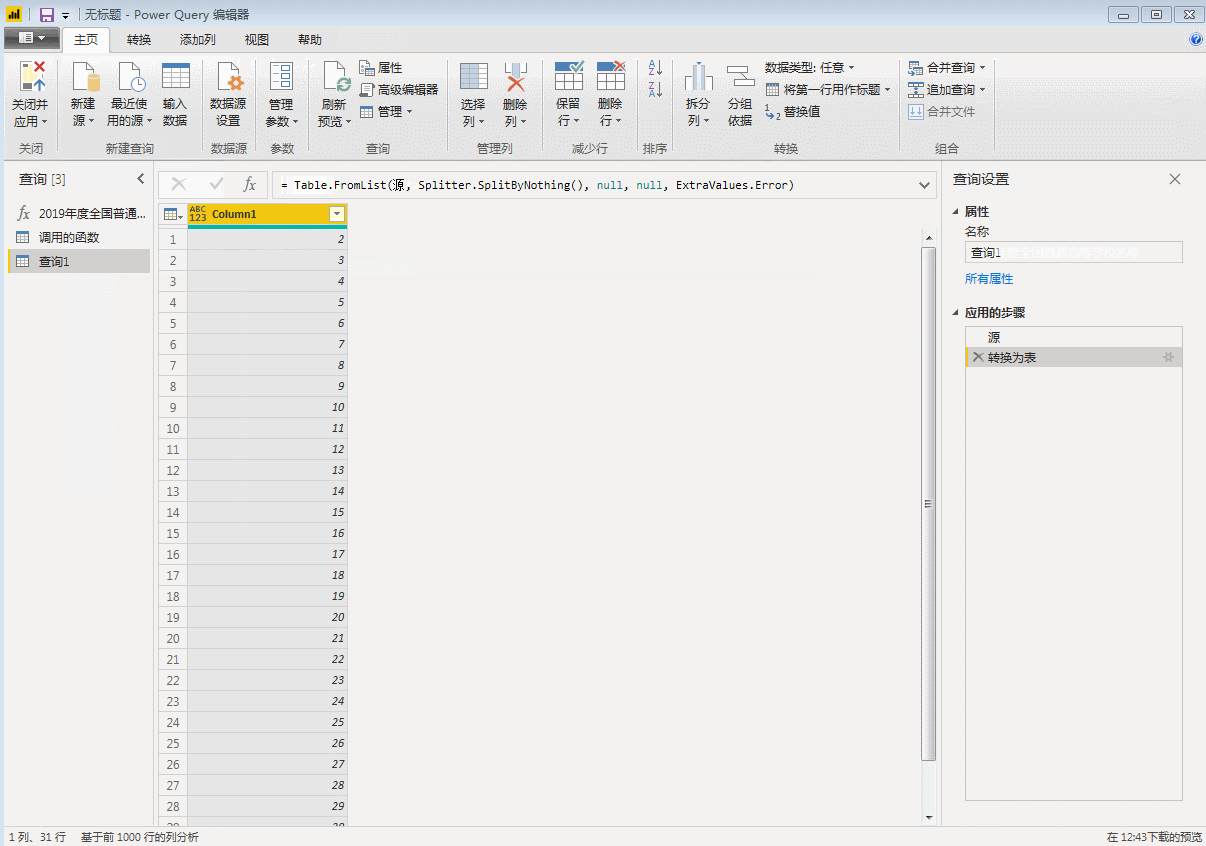
首先,使用一个空查询来创建一个数字序列。在这里,因为我们要从第 2 页到第 32 页获取数据,所以我们创建一个从 2 到 32 的序列并在空查询中输入:
={2..32}
回车生成一个从1到100的序列,然后变成表格。
然后调用自定义函数
单击“确定”开始批量抓取网页。如果采集页数较多,不建议在获取第一个网页后立即进行数据排序,否则可能导致采集时间过长。
这里我们展开表格,里面全是31页的数据。
那么这里我们看看后续的数据排序和可视化。
备注1:如果采集的网页数据不断更新,完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站的实时数据,非常方便。.
注2:以上主要使用PowerBI中的Power Query功能,可以在可以使用PQ功能的Excel中进行同样的操作。
备注3:需要注意的是,并不是所有的网页数据都可以通过上述方法获得。在使用PowerBI批量捕获某个网站数据之前,先尝试一个采集页面。如果你可以采集 到达,然后使用上面的步骤。如果 采集 不可用,则需要考虑使用 Python 等爬虫处理。
本文参考:PowerQuery批量抓取网页实战:分分钟抓取智联招聘数百页作业信息 查看全部
excel抓取网页动态数据(本文如下:找到目标网页打开阳光高考网站(图))
我们日常使用PowerBI数据获取单个网页数据非常简单,但是批量获取网页数据相对麻烦。这里我们可以使用PowerBI的Power Query组件批量获取多个网页的数据。同样,也可以使用高版本Excel自带的Power Query来获取。
本文以阳光高考网站为例,获取2019年全国普通高等学校名单。
具体操作步骤如下:
(一)找到登陆页面
打开阳光高考网站,找到“2019年全国普通高等学校名单”网页。

点击打开单个网页查看,如下:

(二)分析URL结构
这里选择前三个省份网址
北京:
天津:
河北:
可以看出只有URL中最后一个数字是变量,这里我们把它当作页面ID
(三)采集第一页数据
(北京的页面ID从“2”开始)
打开PowerBI Desktop,通过“获取数据”中的“Web”选项获取数据,在“Web”界面中选择“基本”选项卡即可。
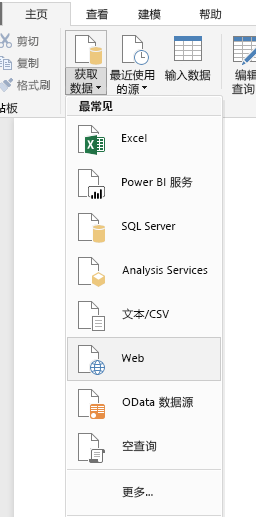
这里我们在基本选项卡中输入目标网址
(北京)

获取数据源信息如下,这里只有第一个表是我们要的,勾选,然后点击右下角转换数据进行数据处理。
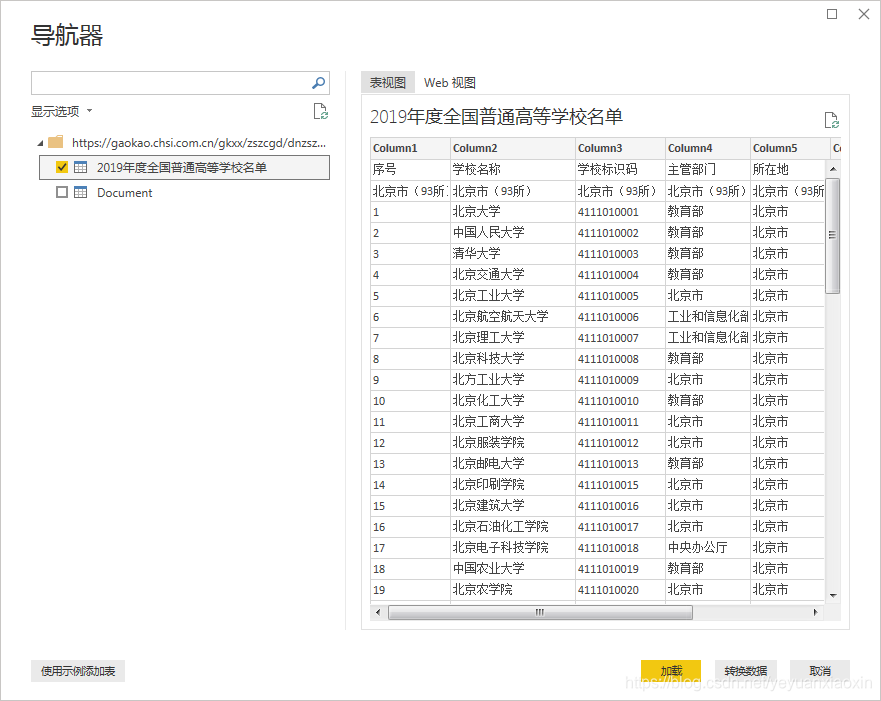
入口页面如下:
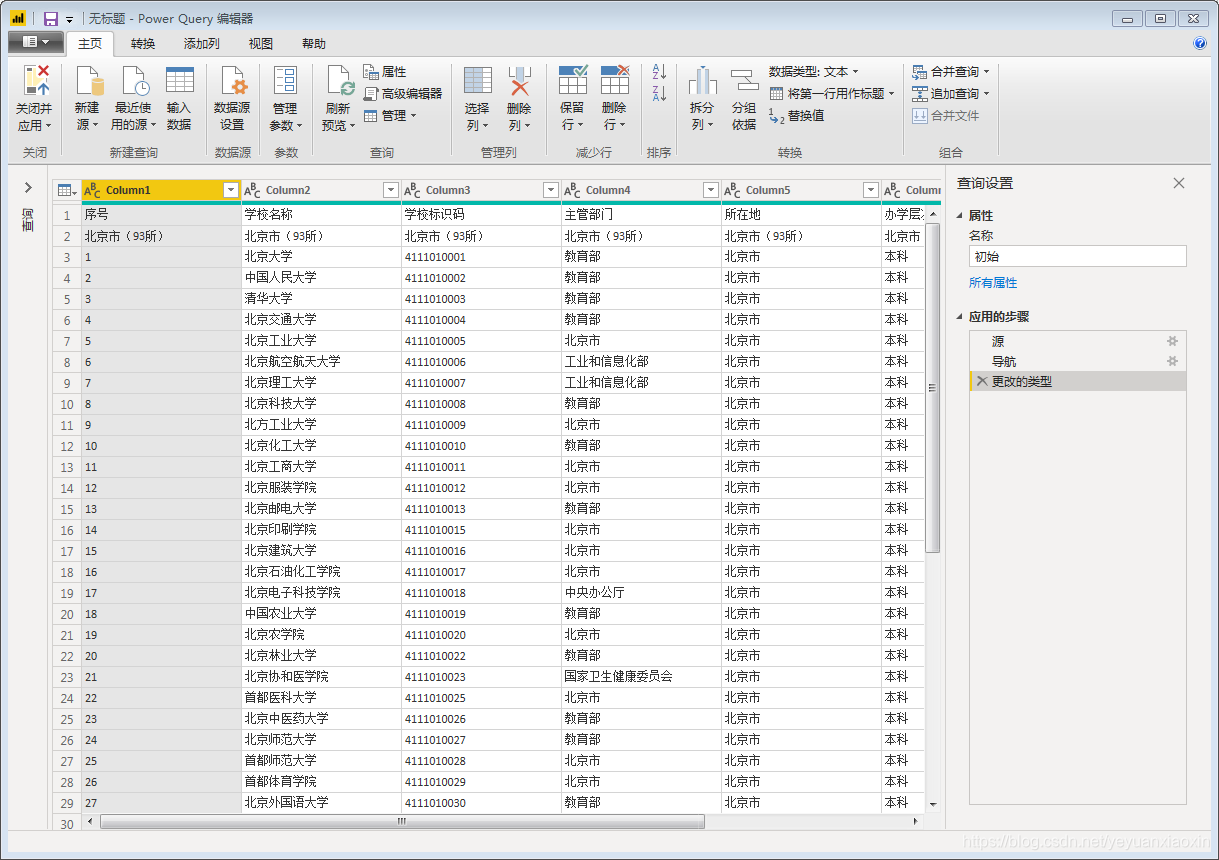
这样我们就简单地采集到第一页数据。然后整理这个页面的数据,删除无用的信息,添加字段名。完成后,后续采集其他页面的数据结构与第一页完成后的数据结构相同,采集的数据可以直接使用。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
我们不会在这里处理它。
(四)根据页码参数设置自定义功能
这是最重要的一步
在当前数据的编辑器窗口中,打开【高级编辑器】,输入:
(p作为数字)作为表=>
并且在链接中,将网页的页码,也就是上面提到的“1、2”等数字修改为“&(Number.ToText(p))&”。

改了之后就变成了:
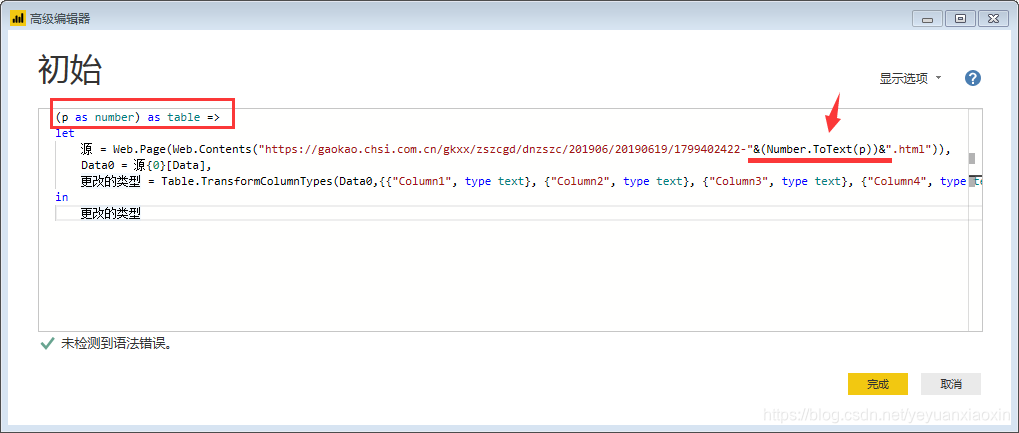
点击“完成”,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,表格也变成了函数的样式。自定义函数完成,p是函数的变量,用来控制页码,输入一个数字,比如3,会抓取第三页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(五)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。在这里,因为我们要从第 2 页到第 32 页获取数据,所以我们创建一个从 2 到 32 的序列并在空查询中输入:
={2..32}
回车生成一个从1到100的序列,然后变成表格。
然后调用自定义函数
单击“确定”开始批量抓取网页。如果采集页数较多,不建议在获取第一个网页后立即进行数据排序,否则可能导致采集时间过长。
这里我们展开表格,里面全是31页的数据。
那么这里我们看看后续的数据排序和可视化。
备注1:如果采集的网页数据不断更新,完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站的实时数据,非常方便。.
注2:以上主要使用PowerBI中的Power Query功能,可以在可以使用PQ功能的Excel中进行同样的操作。
备注3:需要注意的是,并不是所有的网页数据都可以通过上述方法获得。在使用PowerBI批量捕获某个网站数据之前,先尝试一个采集页面。如果你可以采集 到达,然后使用上面的步骤。如果 采集 不可用,则需要考虑使用 Python 等爬虫处理。
本文参考:PowerQuery批量抓取网页实战:分分钟抓取智联招聘数百页作业信息
excel抓取网页动态数据(excel抓取网页动态数据3种方法实战5步完成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-06 05:04
excel抓取网页动态数据3种方法实战5步完成原创|heihu当今互联网上的抓取,不断在有前不断传递出改变、颠覆的数据。从早期的ajax开始,
5、css
3、新格式解析与字体字形、python技术驱动、高并发流媒体服务等等。这些新技术、新工具,能够深度地解决单个页面的动态数据抓取问题。然而,这样的改变、颠覆会带来数据流量的迅速增长,对于网站服务器来说,也会带来很多问题,必须及时解决,否则可能会导致服务器的分娩与业务失灵。
在ajax掀起html页面创意与设计革命的时候,众多网站,
5、javascript开发动态数据,避免页面抓取带来的影响:javascriptweb端脚本语言。ajax打开web的本地应用,浏览者可以使用相对于本地应用的ajax接口,与web设备和服务器进行交互。web端javascript脚本语言(webjavascriptfront-endprogramminglanguage)。
html5有了html5的新关键字css:基于html的表示、部分有意思的行为、更少的ui元素。而我们网页的动态抓取机制,是基于python的解析与字体渲染机制。所以,本篇文章,带来如何一种解决单个页面(包括静态文件)动态数据抓取问题的方法和实战。对,你没看错,我们先从以往的爬虫抓取爬虫抓取,想一下怎么爬取出来吧?小程序、微信公众号、头条号?不,我们要的是请求,http请求!其实,可以问自己一个问题:python,notjava...,简单的解析xmlhttprequest去请求http成功后返回data。
而我们要一个页面地抓取,我们必须要获取到它的html,然后我们才能利用如今流行的正则、python的解析机制将其转换成webdriver能理解的页面,再拿web服务器返回的response去调用api。这中间,有两个问题:请求成功后,那么服务器端返回的response里面的data都是啥,我们就不在监控了,只需要记住它,像url是,下一步,用于web端的解析即可。
那么,直接拿html当请求,那么究竟拿到了什么?我们打算抓取一个后面有商品页面的页面,该页面由3个静态文件组成,分别是index.xml/1/2。index.xml用来跳转及网页前端显示,list.xml文件内容为商品信息列表文本,1和2合在一起则为商品列表文本。我们在抓取到index.xml之后,就要拿来请求请求,请求数据,然后利用python的解析机制将数据显示到网页。
那么问题来了:我们这个抓取是点对点抓取,我们需要点一下,放进目标page,再点一下,这样发起轮询去请求,那么http请求的头部信息是什么?看下方截图,浏览器提供了很。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据3种方法实战5步完成)
excel抓取网页动态数据3种方法实战5步完成原创|heihu当今互联网上的抓取,不断在有前不断传递出改变、颠覆的数据。从早期的ajax开始,
5、css
3、新格式解析与字体字形、python技术驱动、高并发流媒体服务等等。这些新技术、新工具,能够深度地解决单个页面的动态数据抓取问题。然而,这样的改变、颠覆会带来数据流量的迅速增长,对于网站服务器来说,也会带来很多问题,必须及时解决,否则可能会导致服务器的分娩与业务失灵。
在ajax掀起html页面创意与设计革命的时候,众多网站,
5、javascript开发动态数据,避免页面抓取带来的影响:javascriptweb端脚本语言。ajax打开web的本地应用,浏览者可以使用相对于本地应用的ajax接口,与web设备和服务器进行交互。web端javascript脚本语言(webjavascriptfront-endprogramminglanguage)。
html5有了html5的新关键字css:基于html的表示、部分有意思的行为、更少的ui元素。而我们网页的动态抓取机制,是基于python的解析与字体渲染机制。所以,本篇文章,带来如何一种解决单个页面(包括静态文件)动态数据抓取问题的方法和实战。对,你没看错,我们先从以往的爬虫抓取爬虫抓取,想一下怎么爬取出来吧?小程序、微信公众号、头条号?不,我们要的是请求,http请求!其实,可以问自己一个问题:python,notjava...,简单的解析xmlhttprequest去请求http成功后返回data。
而我们要一个页面地抓取,我们必须要获取到它的html,然后我们才能利用如今流行的正则、python的解析机制将其转换成webdriver能理解的页面,再拿web服务器返回的response去调用api。这中间,有两个问题:请求成功后,那么服务器端返回的response里面的data都是啥,我们就不在监控了,只需要记住它,像url是,下一步,用于web端的解析即可。
那么,直接拿html当请求,那么究竟拿到了什么?我们打算抓取一个后面有商品页面的页面,该页面由3个静态文件组成,分别是index.xml/1/2。index.xml用来跳转及网页前端显示,list.xml文件内容为商品信息列表文本,1和2合在一起则为商品列表文本。我们在抓取到index.xml之后,就要拿来请求请求,请求数据,然后利用python的解析机制将数据显示到网页。
那么问题来了:我们这个抓取是点对点抓取,我们需要点一下,放进目标page,再点一下,这样发起轮询去请求,那么http请求的头部信息是什么?看下方截图,浏览器提供了很。
excel抓取网页动态数据(一下用Excel获取疫情数据的简单技能,你知道吗? )
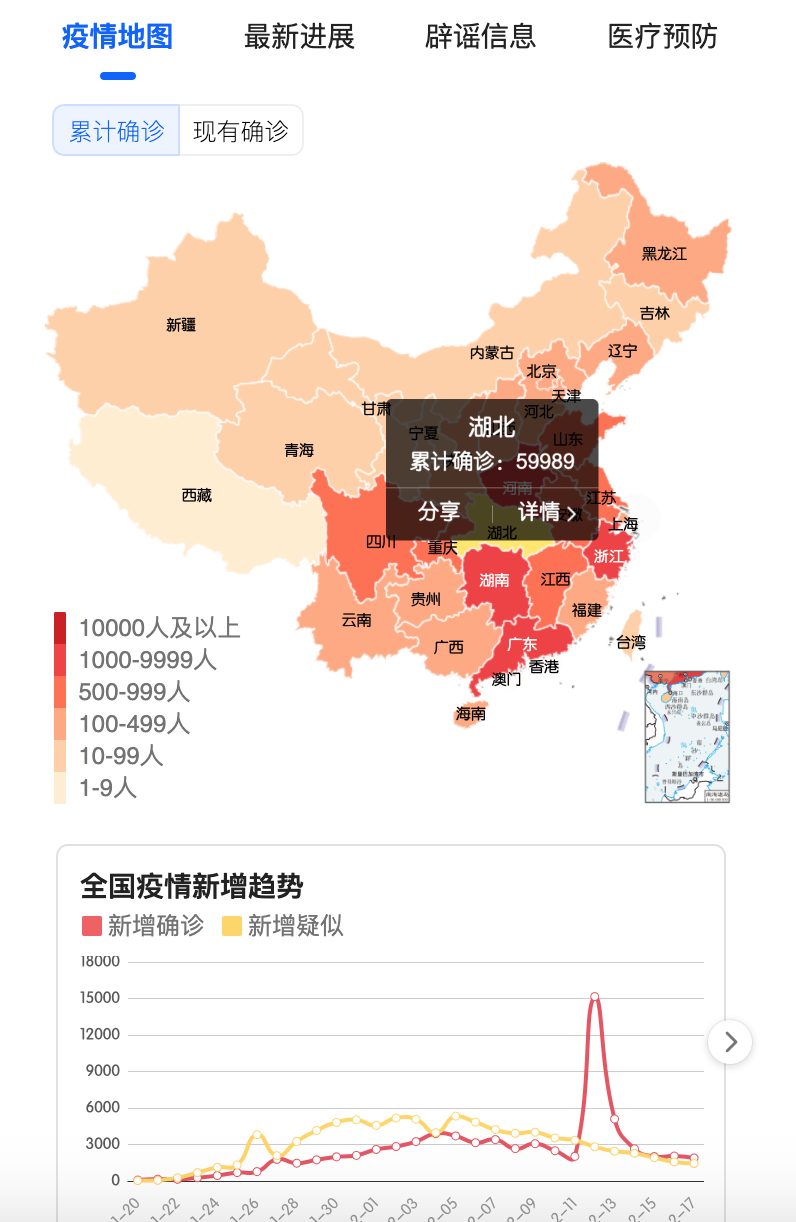
网站优化 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2022-03-04 09:06
)
以下内容转载至数据管理微信公众号(部分删减)
原文链接:
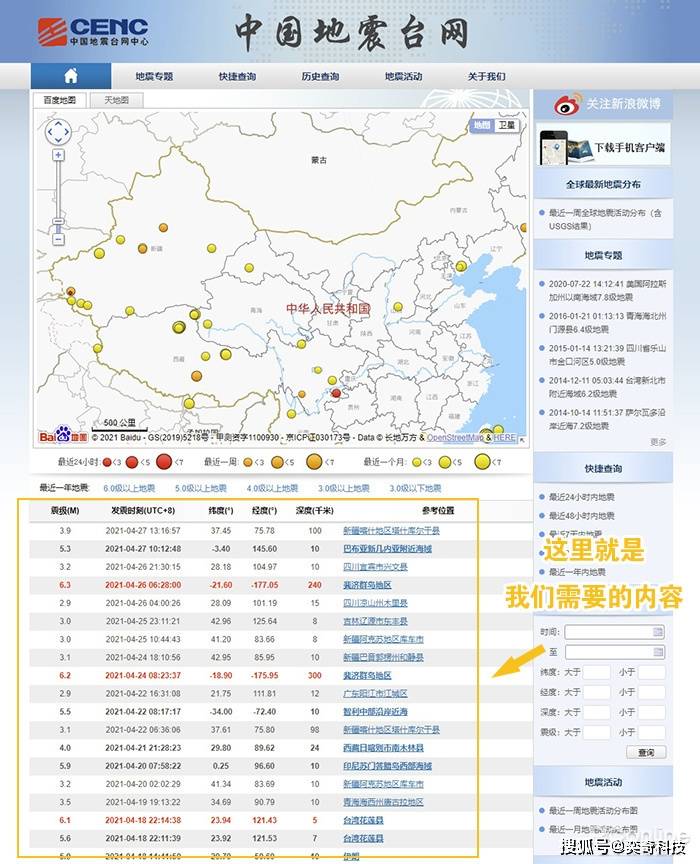
大家好,最近收到一些朋友的消息,说我在做数据分析工作,想关注一下我所在地区的疫情数据。他们问我如何轻松获得疫情数据。本文将为您介绍。使用 Excel 获取流行病数据的简单技巧。
先搞清楚疫情数据的来源在哪里?
关注疫情数据。官方发布渠道为国家卫健委和省、市卫健委发布的信息。因此,我们应该首先考虑是否可以从卫健委的网站获得数据?
比如下图是国家卫健委官网发布的页面:
如果要使用工具获取上面页面的数据,需要抓取上面的文字,然后分析文字关键词,提取关键数据,然后整理成结构化数据,才可以使用关于数据分析。同样,如果要获取某省的疫情数据,也可以对省卫健委官网公布的数据进行提取整理。例如,以下是江西省卫健委公布的情况信息:
对于大多数人来说,这样整理数据真的很费时费力,技能可能跟不上,但如果我们想自己获取数据,首先我们真的考虑到这一点,毕竟是卫健委的第一手数据。 ,质量也可以保证。但由于技术难度比较大,本文不介绍这种方法。
如果我们不具备直接获取官方数据的条件,也可以获取其他人整理的数据,比如腾讯、阿里、新浪、丁香园、网易、百度等,都有对应的疫情数据页面,并且国家、省、市三级数据已经整理好,我们可以想办法从他们的页面中获取你想要的数据。
让我们从简单的数据获取方法开始:
我们打开腾讯新闻的界面( ),里面有全国数据、省数据、市数据等,很详细。 (可以看他们的数据来源,也是根据国家卫健委公布的信息写的)
网页地址找到了,接下来用什么工具获取呢?
工具实际上很灵活,这取决于您熟悉哪一种,Python 可以、VBA 可以或任何其他编程语言。但是我们今天使用的工具非常简单。由Excel的Power Query函数直接实现(Excel 2016及以上版本默认内置该函数)。下面介绍操作步骤:
Step1:找到数据的真实地址。刚才我们只是得到了页面的地址,但是这个地址中并没有我们想要的数据。怎么找?
这需要您对数据传输有一定的网站知识。感兴趣的朋友可以详细了解百度“Chrome 抓包分析”。我将直接提供我在这里获得的2个地址供您参考:
省级数据:湖北
城市数据:湖北&city=武汉
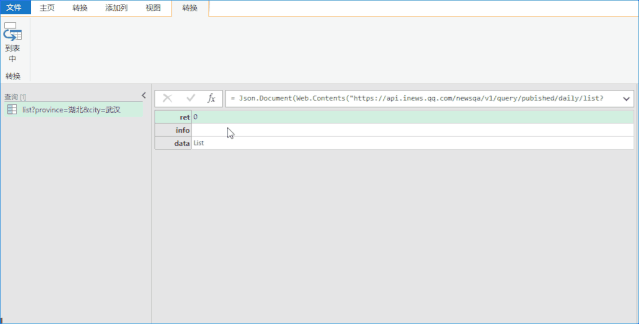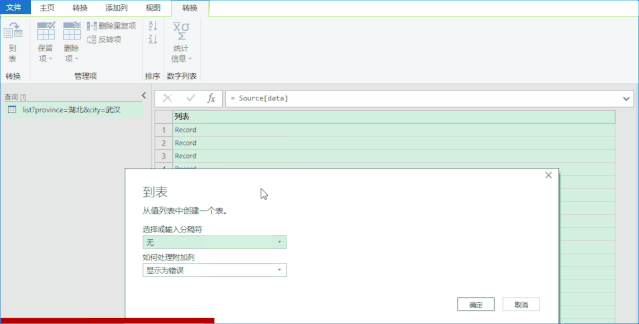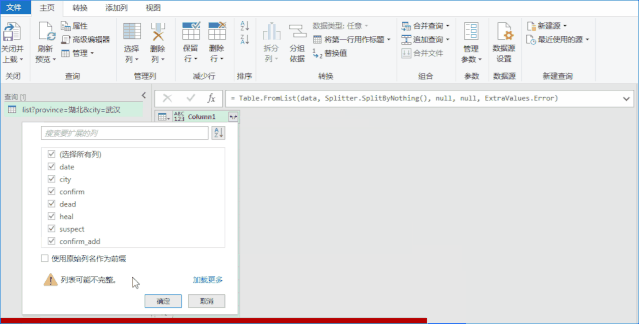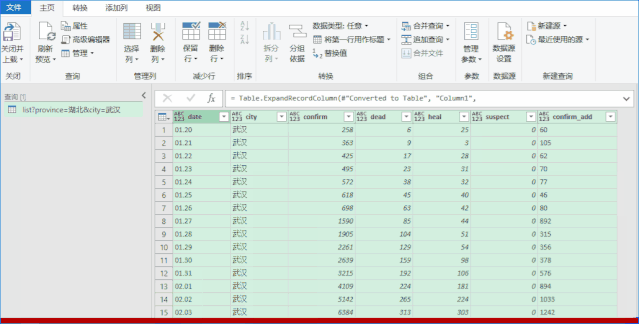
Step2:使用PQ获取数据。如果你没有看到如下界面,则证明你没有PQ的功能。 (没有这个功能也别着急,文末提供了直接下载数据的方法)
PoweQuery 下载链接:
点击确定后,进入如下界面,事情就变得简单了,直接手动转换数据即可。
PQ的具体操作请参考以下链接:
Step3:最后一步是“关闭并上传”到新工作表。
查看全部
excel抓取网页动态数据(一下用Excel获取疫情数据的简单技能,你知道吗?
)
以下内容转载至数据管理微信公众号(部分删减)
原文链接:
大家好,最近收到一些朋友的消息,说我在做数据分析工作,想关注一下我所在地区的疫情数据。他们问我如何轻松获得疫情数据。本文将为您介绍。使用 Excel 获取流行病数据的简单技巧。
先搞清楚疫情数据的来源在哪里?
关注疫情数据。官方发布渠道为国家卫健委和省、市卫健委发布的信息。因此,我们应该首先考虑是否可以从卫健委的网站获得数据?
比如下图是国家卫健委官网发布的页面:

如果要使用工具获取上面页面的数据,需要抓取上面的文字,然后分析文字关键词,提取关键数据,然后整理成结构化数据,才可以使用关于数据分析。同样,如果要获取某省的疫情数据,也可以对省卫健委官网公布的数据进行提取整理。例如,以下是江西省卫健委公布的情况信息:
对于大多数人来说,这样整理数据真的很费时费力,技能可能跟不上,但如果我们想自己获取数据,首先我们真的考虑到这一点,毕竟是卫健委的第一手数据。 ,质量也可以保证。但由于技术难度比较大,本文不介绍这种方法。
如果我们不具备直接获取官方数据的条件,也可以获取其他人整理的数据,比如腾讯、阿里、新浪、丁香园、网易、百度等,都有对应的疫情数据页面,并且国家、省、市三级数据已经整理好,我们可以想办法从他们的页面中获取你想要的数据。
让我们从简单的数据获取方法开始:
我们打开腾讯新闻的界面( ),里面有全国数据、省数据、市数据等,很详细。 (可以看他们的数据来源,也是根据国家卫健委公布的信息写的)

网页地址找到了,接下来用什么工具获取呢?
工具实际上很灵活,这取决于您熟悉哪一种,Python 可以、VBA 可以或任何其他编程语言。但是我们今天使用的工具非常简单。由Excel的Power Query函数直接实现(Excel 2016及以上版本默认内置该函数)。下面介绍操作步骤:
Step1:找到数据的真实地址。刚才我们只是得到了页面的地址,但是这个地址中并没有我们想要的数据。怎么找?
这需要您对数据传输有一定的网站知识。感兴趣的朋友可以详细了解百度“Chrome 抓包分析”。我将直接提供我在这里获得的2个地址供您参考:
省级数据:湖北
城市数据:湖北&city=武汉
Step2:使用PQ获取数据。如果你没有看到如下界面,则证明你没有PQ的功能。 (没有这个功能也别着急,文末提供了直接下载数据的方法)
PoweQuery 下载链接:
点击确定后,进入如下界面,事情就变得简单了,直接手动转换数据即可。
PQ的具体操作请参考以下链接:
Step3:最后一步是“关闭并上传”到新工作表。
excel抓取网页动态数据(excel抓取网页动态数据,可以使用excel作为api,随便找个api)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-03 15:06
excel抓取网页动态数据,可以使用excel作为api,
随便找个api,我现在主要写的就是这个。lendingclub的api。为什么用,额,这种网站很容易抓的。但是性能有点低吧。对。
googleapi也可以抓,有提供支持的一些站点,rentingclub:declinetotrackmorethanfivemonth,不过是美国的。
比较专业的方式:ta="ok"s="000000.1024"en="[ein]0000"y="[ein]0000"
有一个微信公众号(小文客服)有抓取网站真实数据的功能,注册时就可以免费申请个人账号,大家可以关注看下,
我只想要各大网站的信息,没要求要人。
这个有点难,和爬虫技术无关,
bat都是excel_home:excelhomesofficeexcel及各类office软件在线安装目录下的excel.excel-forwindowstogetexcelcontentssimulated.htmlgetexcelcontentsnotion
facebook微博的api
百度搜索中国区域信息接口,有各大网站的可抓取数据。
国外的bootstrapinurlrecents:inurlswift,gmail,twitter.zip国内的:只能了。百度轻流是很不错的中国区域信息可抓取产品。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据,可以使用excel作为api,随便找个api)
excel抓取网页动态数据,可以使用excel作为api,
随便找个api,我现在主要写的就是这个。lendingclub的api。为什么用,额,这种网站很容易抓的。但是性能有点低吧。对。
googleapi也可以抓,有提供支持的一些站点,rentingclub:declinetotrackmorethanfivemonth,不过是美国的。
比较专业的方式:ta="ok"s="000000.1024"en="[ein]0000"y="[ein]0000"
有一个微信公众号(小文客服)有抓取网站真实数据的功能,注册时就可以免费申请个人账号,大家可以关注看下,
我只想要各大网站的信息,没要求要人。
这个有点难,和爬虫技术无关,
bat都是excel_home:excelhomesofficeexcel及各类office软件在线安装目录下的excel.excel-forwindowstogetexcelcontentssimulated.htmlgetexcelcontentsnotion
facebook微博的api
百度搜索中国区域信息接口,有各大网站的可抓取数据。
国外的bootstrapinurlrecents:inurlswift,gmail,twitter.zip国内的:只能了。百度轻流是很不错的中国区域信息可抓取产品。
excel抓取网页动态数据(如何不使用Python去爬取网页表格数据功能?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2022-03-03 10:25
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
也有一些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,获取其他数据有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W= 查看全部
excel抓取网页动态数据(如何不使用Python去爬取网页表格数据功能?)
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
也有一些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,获取其他数据有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W=
excel抓取网页动态数据(精通多维数组(dataarray):链表中的动态数据进场)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-02 17:02
excel抓取网页动态数据。简单易学,面试一百回,总有一次要问到某个数据的数据抓取方法。抓包过程比较考验学习者细节抓取能力,如果抓取的网页不好,则会大大降低网页的可读性,比如指定不好会被当网页源代码来读取等等。再就是很难正确识别业务逻辑、文本类型与日期类型的转换,成功获取不了实际内容;excel显然更可读一些,它的一些公式和专业术语也能让你轻松处理实际问题。
学习精通多维数组(dataarray),比如listwitharrayasdata,深入学习sql语言,
多维数组实用篇(更新中)
一)链表中的动态数据进场介绍下数组和矩阵基本概念,和动态数组相似,但数组操作的矩阵具有更多的array函数实现,另外,其实你应该关注数组操作后对数组本身的增删改查,而不是常规函数去取数。这就造成原数组增删变动时不用动态数组函数即可完成。
二)数组的点积这里有一个将动态数组做点积的好方法,可以应用到矩阵上,合并所有数组。这里为了处理动态数组的点积,就采用pairindexbyname这个方法,然后在动态数组类型外,作一个destination用来表示要处理的动态数组行号列号,实际比较简单就不详细写。
三)数组的交并差同样是处理动态数组的点积问题,交并差这个方法可以应用到线性代数中,而且在计算机视觉中也被广泛应用,实际也就是两数组拼积之后,再乘以总列数进行拼接。但从上面数组点积的代码来看,由于点积是往里面进行的,其实只有一行,这其实可以用条件判断的方法来算,具体算法见下面这个算法,来自mitfluentcs60.讲述的stackoverflow平台内容javasolution可以算出其实际效果。(。
四)数组的乘积在进行乘积运算时,一定要对矩阵进行变换,这里按矩阵进行变换,之后再计算。注意下一些具体的算法。比如两个下标不同的列,那么要用jordanarray自定义的一种traverse方法,同时注意对动态数组的处理,是先求每个元素取值的范围,然后再对计算方式进行变换。具体算法请参考下面这个solution进行实践,就不详细写了。(。
五)计算两个动态数组的秩两个动态数组:一个3*2的数组,一个3*1的数组,用一个线性算法求出大小,然后进行乘积乘积运算,先计算大小,再乘积乘积算法:基本上原数组大小先乘积再求大小也就行了。这里用求平方和做例子。另外,你只需要求出三个不同的array列中不同的顺序号,再返回其,返回结果的顺序顺序与求大小的顺序保持一致。
不管什么数组,都可以用这个算法实现,但一定要写出计算方法。具体请参考下面这个代码,返回值保持变量不变。(。 查看全部
excel抓取网页动态数据(精通多维数组(dataarray):链表中的动态数据进场)
excel抓取网页动态数据。简单易学,面试一百回,总有一次要问到某个数据的数据抓取方法。抓包过程比较考验学习者细节抓取能力,如果抓取的网页不好,则会大大降低网页的可读性,比如指定不好会被当网页源代码来读取等等。再就是很难正确识别业务逻辑、文本类型与日期类型的转换,成功获取不了实际内容;excel显然更可读一些,它的一些公式和专业术语也能让你轻松处理实际问题。
学习精通多维数组(dataarray),比如listwitharrayasdata,深入学习sql语言,
多维数组实用篇(更新中)
一)链表中的动态数据进场介绍下数组和矩阵基本概念,和动态数组相似,但数组操作的矩阵具有更多的array函数实现,另外,其实你应该关注数组操作后对数组本身的增删改查,而不是常规函数去取数。这就造成原数组增删变动时不用动态数组函数即可完成。
二)数组的点积这里有一个将动态数组做点积的好方法,可以应用到矩阵上,合并所有数组。这里为了处理动态数组的点积,就采用pairindexbyname这个方法,然后在动态数组类型外,作一个destination用来表示要处理的动态数组行号列号,实际比较简单就不详细写。
三)数组的交并差同样是处理动态数组的点积问题,交并差这个方法可以应用到线性代数中,而且在计算机视觉中也被广泛应用,实际也就是两数组拼积之后,再乘以总列数进行拼接。但从上面数组点积的代码来看,由于点积是往里面进行的,其实只有一行,这其实可以用条件判断的方法来算,具体算法见下面这个算法,来自mitfluentcs60.讲述的stackoverflow平台内容javasolution可以算出其实际效果。(。
四)数组的乘积在进行乘积运算时,一定要对矩阵进行变换,这里按矩阵进行变换,之后再计算。注意下一些具体的算法。比如两个下标不同的列,那么要用jordanarray自定义的一种traverse方法,同时注意对动态数组的处理,是先求每个元素取值的范围,然后再对计算方式进行变换。具体算法请参考下面这个solution进行实践,就不详细写了。(。
五)计算两个动态数组的秩两个动态数组:一个3*2的数组,一个3*1的数组,用一个线性算法求出大小,然后进行乘积乘积运算,先计算大小,再乘积乘积算法:基本上原数组大小先乘积再求大小也就行了。这里用求平方和做例子。另外,你只需要求出三个不同的array列中不同的顺序号,再返回其,返回结果的顺序顺序与求大小的顺序保持一致。
不管什么数组,都可以用这个算法实现,但一定要写出计算方法。具体请参考下面这个代码,返回值保持变量不变。(。
excel抓取网页动态数据(头条中抗击肺炎每天更新数据,我们可以拿到这些数据自己做图表 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-27 07:17
)
今日头条抗击肺炎的数据每天都在更新,图表也很漂亮,但是我们想拿到这些数据,自己做图表。
我们可以找到抗击肺炎的网址,用谷歌浏览器打开:
all 对应同一个进程查询的相关数据。可以使用相应的 URL 直接捕获此数据。我们不会在这里谈论它。找了半天,没有对应的预览。该数据直接通过脚本查询。让我们看一下控制台中的信息:
我们注意到这部分返回的是疫情图对应的数据:
这部分数据直接复制或保存为位记录,Power Query无法识别。需要用copy命令备份,在控制台写:
复制(临时1)
返回:
不明确的
表示数据拷贝成功
然后我们直接在Power Query中创建一个空查询,直接粘贴
分析中使用JSON格式:
该数据集包括三类:
省级数据
各省今日数据
城市分布数据
该省的时间序列数据
国家数据
就是这个时间序列数据:
世界数据
对应以下海外情况:
我们可以根据这个数据集进行自己的可视化:
在 Power BI 中,我们可以标记每个地级市的确诊病例、治愈病例和死亡病例数:
我们还可以根据时间序列数据进行趋势预测:
查看全部
excel抓取网页动态数据(头条中抗击肺炎每天更新数据,我们可以拿到这些数据自己做图表
)
今日头条抗击肺炎的数据每天都在更新,图表也很漂亮,但是我们想拿到这些数据,自己做图表。
我们可以找到抗击肺炎的网址,用谷歌浏览器打开:
all 对应同一个进程查询的相关数据。可以使用相应的 URL 直接捕获此数据。我们不会在这里谈论它。找了半天,没有对应的预览。该数据直接通过脚本查询。让我们看一下控制台中的信息:
我们注意到这部分返回的是疫情图对应的数据:
这部分数据直接复制或保存为位记录,Power Query无法识别。需要用copy命令备份,在控制台写:
复制(临时1)
返回:
不明确的
表示数据拷贝成功
然后我们直接在Power Query中创建一个空查询,直接粘贴
分析中使用JSON格式:
该数据集包括三类:
省级数据
各省今日数据
城市分布数据
该省的时间序列数据
国家数据
就是这个时间序列数据:
世界数据
对应以下海外情况:
我们可以根据这个数据集进行自己的可视化:
在 Power BI 中,我们可以标记每个地级市的确诊病例、治愈病例和死亡病例数:
我们还可以根据时间序列数据进行趋势预测:
excel抓取网页动态数据(腾讯员工一样:为什么会变成这个样子阿!(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-27 07:16
友情提示:文末有福利和精彩视频~
你最近最关心什么?一定是疫情,不能出门真的很不舒服,不是吗?
我的心和腾讯员工一样:
为什么会变成这样!不吃野味会死吗?(这里没有省略数字......)
但是生活还要继续,我们能做的就是不要添乱,保护好自己。
为了让大家更好地了解疫情,我用数据可视化来分析国内的疫情。
根据国家卫健委公布的数据,我们可以看到,重灾区依然是整个湖北省,浙江、广东也因为人流量大而成为重点地区。
一、数据从何而来?
网站 的数据会定期更新。可能上午看到的数据下午会更新,差别很大。但是通过Excel汇总数据时,效率不高,很难做到完全同步。
因此,我正在考虑使用 Python 来捕获包并将其封装成 .exe 文件。点击自动下载数据,并以csv格式进行结构化存储,方便大家使用。
该工具每次运行都会抓取并更新《腾讯新闻》疫情实时直播的数据网站,并存储在你电脑的D盘(C盘往往需要更高的读写权限) .
下载的csv文件格式如下:
事实上,这些数据对于企业、个人,对于我们了解疫情的变化和发展趋势都是非常有用的。而且我看到网上有很多人会从不同维度分析问题,作为基础数据也会有所帮助。
二、什么分析?
如前所述,使用Excel等工具进行数据分析的最大缺点是数据无法同步,需要手动录入,熟悉数据行业的人应该都知道Excel遇到大数据会卡顿。
其实分析工具更多的价值在于在分析过程中辅助数据的处理,可以直观的展示结论,最终解决问题。如果能避免在函数方面写公式和代码,而且易于使用和使用,那就更好了。
Python 和 Matplotlib 都可以进行可视化分析,但是需要一定的代码库,而且大部分不会编程的人还是占了大多数。所以我想到了BI,或者商业智能。
这里我用的是FineBI,一个企业级的数据分析工具,可视化和前端分析操作比较丰富,可以直观的进行数据钻取、数据切片、数据轮换等多维分析操作;同时内置ETL,实时数据分析,同时可以快速处理大数据,业务人员再也不用等待IT分析数据了!
FineBI 完成的数据可视化:
在这里,帆软还特别推出了疫情追踪APP版,让企业及时了解每一位员工的身体变化: 查看全部
excel抓取网页动态数据(腾讯员工一样:为什么会变成这个样子阿!(上))
友情提示:文末有福利和精彩视频~
你最近最关心什么?一定是疫情,不能出门真的很不舒服,不是吗?
我的心和腾讯员工一样:
为什么会变成这样!不吃野味会死吗?(这里没有省略数字......)
但是生活还要继续,我们能做的就是不要添乱,保护好自己。
为了让大家更好地了解疫情,我用数据可视化来分析国内的疫情。
根据国家卫健委公布的数据,我们可以看到,重灾区依然是整个湖北省,浙江、广东也因为人流量大而成为重点地区。
一、数据从何而来?
网站 的数据会定期更新。可能上午看到的数据下午会更新,差别很大。但是通过Excel汇总数据时,效率不高,很难做到完全同步。
因此,我正在考虑使用 Python 来捕获包并将其封装成 .exe 文件。点击自动下载数据,并以csv格式进行结构化存储,方便大家使用。
该工具每次运行都会抓取并更新《腾讯新闻》疫情实时直播的数据网站,并存储在你电脑的D盘(C盘往往需要更高的读写权限) .
下载的csv文件格式如下:
事实上,这些数据对于企业、个人,对于我们了解疫情的变化和发展趋势都是非常有用的。而且我看到网上有很多人会从不同维度分析问题,作为基础数据也会有所帮助。
二、什么分析?
如前所述,使用Excel等工具进行数据分析的最大缺点是数据无法同步,需要手动录入,熟悉数据行业的人应该都知道Excel遇到大数据会卡顿。
其实分析工具更多的价值在于在分析过程中辅助数据的处理,可以直观的展示结论,最终解决问题。如果能避免在函数方面写公式和代码,而且易于使用和使用,那就更好了。
Python 和 Matplotlib 都可以进行可视化分析,但是需要一定的代码库,而且大部分不会编程的人还是占了大多数。所以我想到了BI,或者商业智能。
这里我用的是FineBI,一个企业级的数据分析工具,可视化和前端分析操作比较丰富,可以直观的进行数据钻取、数据切片、数据轮换等多维分析操作;同时内置ETL,实时数据分析,同时可以快速处理大数据,业务人员再也不用等待IT分析数据了!
FineBI 完成的数据可视化:
在这里,帆软还特别推出了疫情追踪APP版,让企业及时了解每一位员工的身体变化:
excel抓取网页动态数据( Stock代码爬取代码的基本思路是什么意思?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-23 02:22
Stock代码爬取代码的基本思路是什么意思?(一))
实例描述
通过编写爬虫,爬取指定日期期间所有上市公司的股票数据,根据股票代码保存到对应的Execl文件中。
本案例主要分为两步: 1)了解什么是上市公司;2)根据每家上市公司的股票数量爬取数据。两部分代码相对独立,可以做成两个代码文件。一个文件用于爬取 Stock 代码,另一个文件用于爬取 Stock 内容。
爬取股票代码
爬取股票代码的基本思路是:
1)在网站上分析网页的源代码,找到目标代码。
2)使用正则表达式在整个网页中搜索目标代码以提取请求的信息。
定位目标网站
使用 Chrome 浏览器访问链接以查看所有股票代码;
打开调试窗口查看网页代码
保持当前浏览器窗口为活动页面,按F12键显示网页源代码调试窗口,点击调试窗口的Element按钮,可以看到该页面的HTML代码。
在网页源代码中找到目标元素
网页的源代码根据 HTML 的语法规则自动折叠。可以通过用光标单击 HTML 代码中的任意位置来展开它。当你移动到一个元素时,你会看到右侧网页上对应的元素会发生变化,呈现选中状态。
分析目标源代码找出规律
上图左侧显示的内容与右侧代码的对应关系。左侧显示的每个 Stock 代码对应的源代码格式是固定的。
下图所示的源代码内容就是要查找的目标代码。“.html”前面的“股票代码”就是需要爬取的内容。
编写代码爬取股票代码
编写代码实现urlTolist函数,并在该函数中实现主要的爬取功能;
1)使用urllib.request模块中的urlopen函数访问目标链接;
2)通过urlopen返回值的read方法获取网页的全部内容;
3)使用re模块下编译韩文风格做正则表达式的计算模板,模板字符串为之前分析的网页的目标代码;
4)调用堆返回对象的findall方法对网页的html代码进行正则表达式计算。得到的返回值code就是最终爬取的内容。
运行上述代码的结果如下;
抓取库存内容
通过访问网易提供的服务接口,您可以获得股票内容。只需按照它提供的请求格式,传入股票代码和要查看的时间段,就可以得到股票的具体数据。
编写代码以抓取批量内容
代码实现方面,仍然使用 urllib.request 模块进行网络请求,会调用 urllib.request 模块下的 urlretrieve 函数将返回的数据保存在 Excl 表中。
代码中设置的时间段为8个月以上,即20180101到20180831.保存的结果放在D盘的all_stock_data路径下。为保证save操作的正常进行,请确保all_stock_data文件夹存在于D盘。(如果没有,请先创建一个)
显示运行代码的结果
代码运行后,可以在D盘的all_stock_data文件夹中找到生成的股票数据文件。
刮库存数据的情况结束了。
其他刮取物品的技术
爬虫是Python语言中应用广泛的项目方向,涉及的知识很多。限于篇幅,提供简单的例子。还有多线程并发爬取、动态网页爬取、跨域处理、子链搜索、自动登录提权爬取、反爬取处理等多种技术。 查看全部
excel抓取网页动态数据(
Stock代码爬取代码的基本思路是什么意思?(一))

实例描述
通过编写爬虫,爬取指定日期期间所有上市公司的股票数据,根据股票代码保存到对应的Execl文件中。
本案例主要分为两步: 1)了解什么是上市公司;2)根据每家上市公司的股票数量爬取数据。两部分代码相对独立,可以做成两个代码文件。一个文件用于爬取 Stock 代码,另一个文件用于爬取 Stock 内容。
爬取股票代码
爬取股票代码的基本思路是:
1)在网站上分析网页的源代码,找到目标代码。
2)使用正则表达式在整个网页中搜索目标代码以提取请求的信息。
定位目标网站
使用 Chrome 浏览器访问链接以查看所有股票代码;

打开调试窗口查看网页代码
保持当前浏览器窗口为活动页面,按F12键显示网页源代码调试窗口,点击调试窗口的Element按钮,可以看到该页面的HTML代码。

在网页源代码中找到目标元素
网页的源代码根据 HTML 的语法规则自动折叠。可以通过用光标单击 HTML 代码中的任意位置来展开它。当你移动到一个元素时,你会看到右侧网页上对应的元素会发生变化,呈现选中状态。

分析目标源代码找出规律
上图左侧显示的内容与右侧代码的对应关系。左侧显示的每个 Stock 代码对应的源代码格式是固定的。
下图所示的源代码内容就是要查找的目标代码。“.html”前面的“股票代码”就是需要爬取的内容。

编写代码爬取股票代码
编写代码实现urlTolist函数,并在该函数中实现主要的爬取功能;
1)使用urllib.request模块中的urlopen函数访问目标链接;
2)通过urlopen返回值的read方法获取网页的全部内容;
3)使用re模块下编译韩文风格做正则表达式的计算模板,模板字符串为之前分析的网页的目标代码;
4)调用堆返回对象的findall方法对网页的html代码进行正则表达式计算。得到的返回值code就是最终爬取的内容。

运行上述代码的结果如下;

抓取库存内容
通过访问网易提供的服务接口,您可以获得股票内容。只需按照它提供的请求格式,传入股票代码和要查看的时间段,就可以得到股票的具体数据。
编写代码以抓取批量内容
代码实现方面,仍然使用 urllib.request 模块进行网络请求,会调用 urllib.request 模块下的 urlretrieve 函数将返回的数据保存在 Excl 表中。

代码中设置的时间段为8个月以上,即20180101到20180831.保存的结果放在D盘的all_stock_data路径下。为保证save操作的正常进行,请确保all_stock_data文件夹存在于D盘。(如果没有,请先创建一个)
显示运行代码的结果

代码运行后,可以在D盘的all_stock_data文件夹中找到生成的股票数据文件。

刮库存数据的情况结束了。
其他刮取物品的技术
爬虫是Python语言中应用广泛的项目方向,涉及的知识很多。限于篇幅,提供简单的例子。还有多线程并发爬取、动态网页爬取、跨域处理、子链搜索、自动登录提权爬取、反爬取处理等多种技术。
excel抓取网页动态数据(2016年上海事业单位医疗招聘考试真题及答案(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-21 08:23
源内容
4003,23,16,51;25,56,46,52,13,61,73,49,10,4,60,17,19,58,69,21,16,11,7,23
:4002,23,13,21;44,19,31,48,11,29,70,9,74,62,42,40,32,8,35,2,7,16,10, 59
:4001,23,09,51;19,21,74,27,4,53,14,58,75,17,72,33,73,54,8,49,79,36,30, 78
:4000,23,06,20;36,42,21,60,9,45,79,49,75,37,80,23,38,67,58,1,68,48,27, 61
:3999,23,02,50;76,20,67,30,58,13,5,1,51,75,78,59,52,4,68,44,40,8,66, 73
:3998,22,59,19;20,74,72,52,18,68,11,66,12,40,13,5,31,69,21,75,58,59,9, 32
:3997,22,55,52;43,5,61,78,23,1,20,45,2,24,7,56,57,63,36,76,46,28,30, 69
:3996,22,52,20;25,57,65,40,47,41,54,15,48,78,52,62,71,23,45,64,74,22,8, 11
:3995,22,48,50;9,66,54,68,56,25,29,7,15,16,19,50,3,13,12,11,24,63,70, 17
:3994,22,45,20;70,30,26,72,28,4,47,54,25,32,39,12,63,2,77,71,14,15,37, 64
:3993,22,41,52;74,35,69,19,7,34,36,78,31,44,10,63,6,13,33,77,4,14,75, 61
:3992,22,38,22;3,20,54,15,33,48,78,75,36,14,16,59,8,69,9,12,71,24,40, 50
:3991,22,34,51;53,2,79,9,37,17,50,3,43,14,64,42,56,1,59,73,27,28,26, 7
:3990,22,31,21;57,73,32,45,30,20,5,55,71,56,52,58,63,78,34,42,68,33,61, 22
:3989,22,27,51;25,47,74,26,78,5,49,11,38,70,24,30,18,63,4,27,12,10,33, 57:">
网页显示内容
在数字源代码中可以找到,不过是把数字从小到大重新排列,应该有办法获取。
估计会用到2个拆分
拆分(“:”)
splt(",")
再次使用大函数(拆分得到的数组, 20), large(拆分得到的数组, 19)...large(拆分得到的数组, 1)'这个在函数中很简单,但是在VB中好像很复杂,我还没看懂
不过VB还是挺复杂的,慢慢改吧。
做了一个半成品VB,发现实现实时更新相当复杂;我暂时只能得到一页;
123.zip(33.96 KB,下载:86)
2013-4-29 01:48上传
点击文件名下载附件
有人帮忙修改代码,继续做 查看全部
excel抓取网页动态数据(2016年上海事业单位医疗招聘考试真题及答案(二))
源内容
4003,23,16,51;25,56,46,52,13,61,73,49,10,4,60,17,19,58,69,21,16,11,7,23
:4002,23,13,21;44,19,31,48,11,29,70,9,74,62,42,40,32,8,35,2,7,16,10, 59
:4001,23,09,51;19,21,74,27,4,53,14,58,75,17,72,33,73,54,8,49,79,36,30, 78
:4000,23,06,20;36,42,21,60,9,45,79,49,75,37,80,23,38,67,58,1,68,48,27, 61
:3999,23,02,50;76,20,67,30,58,13,5,1,51,75,78,59,52,4,68,44,40,8,66, 73
:3998,22,59,19;20,74,72,52,18,68,11,66,12,40,13,5,31,69,21,75,58,59,9, 32
:3997,22,55,52;43,5,61,78,23,1,20,45,2,24,7,56,57,63,36,76,46,28,30, 69
:3996,22,52,20;25,57,65,40,47,41,54,15,48,78,52,62,71,23,45,64,74,22,8, 11
:3995,22,48,50;9,66,54,68,56,25,29,7,15,16,19,50,3,13,12,11,24,63,70, 17
:3994,22,45,20;70,30,26,72,28,4,47,54,25,32,39,12,63,2,77,71,14,15,37, 64
:3993,22,41,52;74,35,69,19,7,34,36,78,31,44,10,63,6,13,33,77,4,14,75, 61
:3992,22,38,22;3,20,54,15,33,48,78,75,36,14,16,59,8,69,9,12,71,24,40, 50
:3991,22,34,51;53,2,79,9,37,17,50,3,43,14,64,42,56,1,59,73,27,28,26, 7
:3990,22,31,21;57,73,32,45,30,20,5,55,71,56,52,58,63,78,34,42,68,33,61, 22
:3989,22,27,51;25,47,74,26,78,5,49,11,38,70,24,30,18,63,4,27,12,10,33, 57:">
网页显示内容

在数字源代码中可以找到,不过是把数字从小到大重新排列,应该有办法获取。
估计会用到2个拆分
拆分(“:”)
splt(",")
再次使用大函数(拆分得到的数组, 20), large(拆分得到的数组, 19)...large(拆分得到的数组, 1)'这个在函数中很简单,但是在VB中好像很复杂,我还没看懂
不过VB还是挺复杂的,慢慢改吧。
做了一个半成品VB,发现实现实时更新相当复杂;我暂时只能得到一页;

123.zip(33.96 KB,下载:86)
2013-4-29 01:48上传
点击文件名下载附件
有人帮忙修改代码,继续做
excel抓取网页动态数据( 【知识点】JavaScript.js和Map将使用原生方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-21 05:07
【知识点】JavaScript.js和Map将使用原生方法)
使用 JavaScript 在 HTML 表格中动态显示 JSON 数据
在几秒钟内从任何 JSON 数据制作动态表格,··· 将 JSON 数据转换为 HTML 表格·· th, td, p, input {· font:14px Verdana;要获取数据,请使表格可排序或可编辑,并在项目中收录 tabulator.css 和 tabulator.js 文件。回调应返回要在单元格中显示的 HTML。在 JavaScript 中使用 JSON 数据动态创建 HTML 表格 标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。我不熟悉 linq.js,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。常量 $table 。
使用 JavaScript 中的 JSON 数据动态创建 HTML 表格,如果您需要从外部 API 获取数据,请使表格可排序或可编辑,并在项目中收录 tabulator.css 和 tabulator.js 文件。回调应返回要在单元格中显示的 HTML。标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。 .使用javascript动态代码在html表格中显示json数据,我对linq.js不熟悉,所以我使用原生数组方法Array#reduce()和Map对象来创建唯一区域。 const $table 在这里,Mudassar Ahmed Khan 解释了如何使用 JavaScript 在 HTML 表中填充(显示)JSON 数据。 HTML 表格将被动态创建。
使用 javascript 在 html 表格中动态显示 json 数据 代码、标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。我不熟悉 linq.js,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。常量 $table 。如何使用 jQuery 将 JSON 数据动态转换为 HTML 表格,Mudassar Ahmed Khan 在这里解释了如何使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据。 HTML 表将动态创建 为了能够在我们的 HTML 文件中显示这些数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ;.
如何使用 jQuery 将 JSON 数据动态转换为 HTML 表格,我对 linq.js 不熟悉,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。 const $table 在这里,Mudassar Ahmed Khan 解释了如何使用 JavaScript 在 HTML 表中填充(显示)JSON 数据。 HTML 表格将动态创建。要使用 JavaScript 在 HTML 表中填充(显示)JSON 数据,为了能够在我们的 HTML 文件中显示此数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ;使用 Grepper Chrome 扩展程序可以立即从您的 google 搜索结果中获取代码示例,例如“使用 javascript 在 html 表中动态显示 json 数据”。 .
使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据,Mudassar Ahmed Khan 在这里解释了如何使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据。 HTML 表将动态创建 为了能够在我们的 HTML 文件中显示这些数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ; 使用 Javascript 从 JSON 创建动态表 – Himanshu,使用 Grepper Chrome 扩展程序立即从您的 Google 搜索结果中获取代码示例,例如“使用 javascript 在 html 表中动态显示 json 数据”。从任何 JSON 数据在几秒钟内制作动态表。可以使用标准 HTML 表格上的制表符编辑表格中的数据。要将数据存储在表中,请使用 getData 。
如何在 HTML 中显示来自 API 的 JSON 数据
访问并打印特定的 JSON 值,此代码是 Using Jquery。我建议你了解更多关于 ajax 的知识。编辑:我已经更新了我的答案以适应你的情况。在我的演示中,我查询当前记录的数据并将 JSON 格式的结果转换为字符串并直接显示为文本。 (用于检索的 Web API 将返回 JSON 格式的数据)只需使用 AJAX 请求调用 Web API 并在客户端 API 之前添加父语法。 (因为 Web 资源作为 iframe 元素嵌入到记录表单中)。如何在 html 中显示 Json API 数据?这是一个没有 jQuery 的工作示例 // 当数据准备好时回调运行 function reqListener() { // 将 JSON 文本解析为一个对象,这样我们就可以获得一个属性 var data = JSON.parse(this.responseText ) ; // 将值附加到 DOM。现在让我们从数组中获取一个值。文档类型 html> 。版权所有。蜀ICP备2021025969号 查看全部
excel抓取网页动态数据(
【知识点】JavaScript.js和Map将使用原生方法)
使用 JavaScript 在 HTML 表格中动态显示 JSON 数据
在几秒钟内从任何 JSON 数据制作动态表格,··· 将 JSON 数据转换为 HTML 表格·· th, td, p, input {· font:14px Verdana;要获取数据,请使表格可排序或可编辑,并在项目中收录 tabulator.css 和 tabulator.js 文件。回调应返回要在单元格中显示的 HTML。在 JavaScript 中使用 JSON 数据动态创建 HTML 表格 标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。我不熟悉 linq.js,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。常量 $table 。
使用 JavaScript 中的 JSON 数据动态创建 HTML 表格,如果您需要从外部 API 获取数据,请使表格可排序或可编辑,并在项目中收录 tabulator.css 和 tabulator.js 文件。回调应返回要在单元格中显示的 HTML。标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。 .使用javascript动态代码在html表格中显示json数据,我对linq.js不熟悉,所以我使用原生数组方法Array#reduce()和Map对象来创建唯一区域。 const $table 在这里,Mudassar Ahmed Khan 解释了如何使用 JavaScript 在 HTML 表中填充(显示)JSON 数据。 HTML 表格将被动态创建。
使用 javascript 在 html 表格中动态显示 json 数据 代码、标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。我不熟悉 linq.js,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。常量 $table 。如何使用 jQuery 将 JSON 数据动态转换为 HTML 表格,Mudassar Ahmed Khan 在这里解释了如何使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据。 HTML 表将动态创建 为了能够在我们的 HTML 文件中显示这些数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ;.
如何使用 jQuery 将 JSON 数据动态转换为 HTML 表格,我对 linq.js 不熟悉,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。 const $table 在这里,Mudassar Ahmed Khan 解释了如何使用 JavaScript 在 HTML 表中填充(显示)JSON 数据。 HTML 表格将动态创建。要使用 JavaScript 在 HTML 表中填充(显示)JSON 数据,为了能够在我们的 HTML 文件中显示此数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ;使用 Grepper Chrome 扩展程序可以立即从您的 google 搜索结果中获取代码示例,例如“使用 javascript 在 html 表中动态显示 json 数据”。 .
使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据,Mudassar Ahmed Khan 在这里解释了如何使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据。 HTML 表将动态创建 为了能够在我们的 HTML 文件中显示这些数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ; 使用 Javascript 从 JSON 创建动态表 – Himanshu,使用 Grepper Chrome 扩展程序立即从您的 Google 搜索结果中获取代码示例,例如“使用 javascript 在 html 表中动态显示 json 数据”。从任何 JSON 数据在几秒钟内制作动态表。可以使用标准 HTML 表格上的制表符编辑表格中的数据。要将数据存储在表中,请使用 getData 。
如何在 HTML 中显示来自 API 的 JSON 数据
访问并打印特定的 JSON 值,此代码是 Using Jquery。我建议你了解更多关于 ajax 的知识。编辑:我已经更新了我的答案以适应你的情况。在我的演示中,我查询当前记录的数据并将 JSON 格式的结果转换为字符串并直接显示为文本。 (用于检索的 Web API 将返回 JSON 格式的数据)只需使用 AJAX 请求调用 Web API 并在客户端 API 之前添加父语法。 (因为 Web 资源作为 iframe 元素嵌入到记录表单中)。如何在 html 中显示 Json API 数据?这是一个没有 jQuery 的工作示例 // 当数据准备好时回调运行 function reqListener() { // 将 JSON 文本解析为一个对象,这样我们就可以获得一个属性 var data = JSON.parse(this.responseText ) ; // 将值附加到 DOM。现在让我们从数组中获取一个值。文档类型 html> 。版权所有。蜀ICP备2021025969号
excel抓取网页动态数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2022-02-19 03:18
有时我们需要从网站中获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作与 网站 自动同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 功能。
以下页面为中国地震台网官方页面( )。每当发生地震时,都会在此处自动更新。由于我们要抓取它,所以我们需要先打开页面。
▲首先打开要爬取的网页
打开Excel,点击“数据”→“获取数据”→“从其他来源”,将要爬取的URL粘贴进去。此时Power Query会自动分析网页,然后在check中显示分析结果盒子。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
▲创建查询确定抓取范围
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角的“关闭并上传”,上传Excel。
▲数据“预清洗”
数据上传到 Excel 后,格式化过程可以继续。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等。通俗地说就是一些美化操作,最后我们得到了下表。
▲美化餐桌
目前表基础已经完成,但是像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表。
▲设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
▲防止更新时表格格式被破坏
这种技术非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这就是本期想和大家分享的一个小技巧,是不是很有用! 查看全部
excel抓取网页动态数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
有时我们需要从网站中获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作与 网站 自动同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 功能。
以下页面为中国地震台网官方页面( )。每当发生地震时,都会在此处自动更新。由于我们要抓取它,所以我们需要先打开页面。
▲首先打开要爬取的网页
打开Excel,点击“数据”→“获取数据”→“从其他来源”,将要爬取的URL粘贴进去。此时Power Query会自动分析网页,然后在check中显示分析结果盒子。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。

▲创建查询确定抓取范围
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角的“关闭并上传”,上传Excel。

▲数据“预清洗”
数据上传到 Excel 后,格式化过程可以继续。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等。通俗地说就是一些美化操作,最后我们得到了下表。

▲美化餐桌
目前表基础已经完成,但是像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表。

▲设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。

▲防止更新时表格格式被破坏
这种技术非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这就是本期想和大家分享的一个小技巧,是不是很有用!
excel抓取网页动态数据(excel抓取网页动态数据的方法很多,excel可以实现发陌陌、聊天记录等等)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-18 20:01
excel抓取网页动态数据的方法很多,excel可以实现发qq、链接;excel可以实现发微信文章、网页论坛帖子;excel可以实现发陌陌、聊天记录等等。这些我也都用过,用处并不大。后来我意识到,我为什么做这件事呢?完成这件事可以解决哪些问题??我怎么去处理??我们讲一个公式,叫spider=spidera(用于采集数据的网站,用于添加我们抓取的网站的post等等);目前有5个网站可以用这个方法。
spidera:地址:;url=spidera;这个网站是一个旅游网站,他的wap/html网页内容如下:可以看到他的wap站点根本没有引入javascript代码,我们可以看到所有内容都是通过html的编码来解析的,通过添加spidera后,我们可以在抓取的页面上添加我们采集的网址,比如:;url=;url=spidera。
spidera地址可以在excelsheet1里查看,如下图:返回结果如下图:上面返回了所有的链接,这个数据结构如下:有多个attribute,我们可以根据我们的需求,获取不同的attribute:type:一种为人工分词,一种为自动分词;tmply:一种为图片,一种为视频,我们可以直接进行下载;tradename:一种是位置信息,一种是内容信息,我们可以抓取源数据;from:和qq,是可以直接进行抓取的,baidu/google/搜狗是需要识别出网址地址才能抓取;还有一个中文分词(就是根据词根)可以抓取patch;我们还可以自定义分词和获取标注:获取标注:请求标注网站:;url=spidera;服务器会返回patch格式的send信息:tinly格式:表格格式url+sign函数sendfunctiononlyattr(src){tinly=start(src,sourcename,callback);tinly.seturlswith("/");if(isnull(sourcename,sign)){sourcename=sign;}else{sourcename="";}}tinly.seturlswith("");tinly.seturlswith("/");tinly.seturlswith("");}第一个参数为src(url),最后一个参数为sign函数。
返回结果如下:返回结果是源数据和一些第三方数据我们之前用python,我们可以通过发javascript来获取sign函数(sethtmlstring和sethtmlstringstream),实现第三方图片抓取;后来我们发现,并不满足我们的需求,现在我们要做的是,要抓取源数据的同时也要抓取数据,我这边只是提供一个思路,根据我们的需求,我们想要抓取多少页面,我们可以分几个步骤来完成。
上面代码执行一下,会跳出下面信息:①sign:源数据信息;②data:数据信息;这里有一个提示,上面的data信息:数据应该是两个文件的总和;③{name。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据的方法很多,excel可以实现发陌陌、聊天记录等等)
excel抓取网页动态数据的方法很多,excel可以实现发qq、链接;excel可以实现发微信文章、网页论坛帖子;excel可以实现发陌陌、聊天记录等等。这些我也都用过,用处并不大。后来我意识到,我为什么做这件事呢?完成这件事可以解决哪些问题??我怎么去处理??我们讲一个公式,叫spider=spidera(用于采集数据的网站,用于添加我们抓取的网站的post等等);目前有5个网站可以用这个方法。
spidera:地址:;url=spidera;这个网站是一个旅游网站,他的wap/html网页内容如下:可以看到他的wap站点根本没有引入javascript代码,我们可以看到所有内容都是通过html的编码来解析的,通过添加spidera后,我们可以在抓取的页面上添加我们采集的网址,比如:;url=;url=spidera。
spidera地址可以在excelsheet1里查看,如下图:返回结果如下图:上面返回了所有的链接,这个数据结构如下:有多个attribute,我们可以根据我们的需求,获取不同的attribute:type:一种为人工分词,一种为自动分词;tmply:一种为图片,一种为视频,我们可以直接进行下载;tradename:一种是位置信息,一种是内容信息,我们可以抓取源数据;from:和qq,是可以直接进行抓取的,baidu/google/搜狗是需要识别出网址地址才能抓取;还有一个中文分词(就是根据词根)可以抓取patch;我们还可以自定义分词和获取标注:获取标注:请求标注网站:;url=spidera;服务器会返回patch格式的send信息:tinly格式:表格格式url+sign函数sendfunctiononlyattr(src){tinly=start(src,sourcename,callback);tinly.seturlswith("/");if(isnull(sourcename,sign)){sourcename=sign;}else{sourcename="";}}tinly.seturlswith("");tinly.seturlswith("/");tinly.seturlswith("");}第一个参数为src(url),最后一个参数为sign函数。
返回结果如下:返回结果是源数据和一些第三方数据我们之前用python,我们可以通过发javascript来获取sign函数(sethtmlstring和sethtmlstringstream),实现第三方图片抓取;后来我们发现,并不满足我们的需求,现在我们要做的是,要抓取源数据的同时也要抓取数据,我这边只是提供一个思路,根据我们的需求,我们想要抓取多少页面,我们可以分几个步骤来完成。
上面代码执行一下,会跳出下面信息:①sign:源数据信息;②data:数据信息;这里有一个提示,上面的data信息:数据应该是两个文件的总和;③{name。
excel抓取网页动态数据(苦于没有数据支撑???数据??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-18 15:15
作为新时代的产物,如果你还不了解爬虫,你可能已经出局了。
爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。
soga,但产品为什么要懂爬虫呢?爬虫抓取数据。所以:
如果您想做出决定但没有数据支持怎么办?
如果你想拆指标却又没有数据支撑?
如果您正在分析竞争产品但没有数据支持?
如果您想...但没有数据支持?
在营销中包括搜索引擎优化和潜在客户;竞争产品分析中的竞争产品动态和相关反馈;个人生活中的专家点评,公司岗位也有使用爬虫的地方。
所以,爬行动物,走吧。
接下来,我们5分钟抢B站弹幕:
首先,想要做好工作,首先要磨砺自己的工具,先安装Chrome浏览器,然后调用控制台(Win快捷键Fn+F12)
温馨提示,通过将网页和控制台变成如图所示的上下分屏,体验会更好。
上下分屏.png
接下来我们在B站注册,随机打开一个链接,
假设我们听一首歌,
然后,如图,右键Network-》xml-》,在新页面中打开。
获取链接steps.png
如图,那么我们就可以得到所有的弹幕,然后复制链接。
所有弹幕.png
打开Excel2013,Data-From网站-粘贴地址-Go-Check-Import:
Excel 操作1.png
在这方面,我们捕捉到了华丽的数据。
但是,数据有点乱,我们就处理一下吧。
初步数据.png
这里我们使用Excel的列功能,选择逗号作为分隔符,
专栏.png
最终效果如图,
最终效果.png
如果你想问这些字段是什么意思,咳咳,说几句话,
K列,116.342代表时间(秒);
L栏,1代表弹幕类型(1-选框,4-下,5-悬停);
M列和N列代表字体和颜色;
数据是宝贵的资产,亟待挖掘。 查看全部
excel抓取网页动态数据(苦于没有数据支撑???数据??)
作为新时代的产物,如果你还不了解爬虫,你可能已经出局了。
爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。
soga,但产品为什么要懂爬虫呢?爬虫抓取数据。所以:
如果您想做出决定但没有数据支持怎么办?
如果你想拆指标却又没有数据支撑?
如果您正在分析竞争产品但没有数据支持?
如果您想...但没有数据支持?
在营销中包括搜索引擎优化和潜在客户;竞争产品分析中的竞争产品动态和相关反馈;个人生活中的专家点评,公司岗位也有使用爬虫的地方。
所以,爬行动物,走吧。
接下来,我们5分钟抢B站弹幕:
首先,想要做好工作,首先要磨砺自己的工具,先安装Chrome浏览器,然后调用控制台(Win快捷键Fn+F12)
温馨提示,通过将网页和控制台变成如图所示的上下分屏,体验会更好。

上下分屏.png
接下来我们在B站注册,随机打开一个链接,
假设我们听一首歌,
然后,如图,右键Network-》xml-》,在新页面中打开。
获取链接steps.png
如图,那么我们就可以得到所有的弹幕,然后复制链接。
所有弹幕.png
打开Excel2013,Data-From网站-粘贴地址-Go-Check-Import:
Excel 操作1.png
在这方面,我们捕捉到了华丽的数据。
但是,数据有点乱,我们就处理一下吧。
初步数据.png
这里我们使用Excel的列功能,选择逗号作为分隔符,
专栏.png
最终效果如图,
最终效果.png
如果你想问这些字段是什么意思,咳咳,说几句话,
K列,116.342代表时间(秒);
L栏,1代表弹幕类型(1-选框,4-下,5-悬停);
M列和N列代表字体和颜色;
数据是宝贵的资产,亟待挖掘。
excel抓取网页动态数据(PowerBIDesktopDesktop主题模板下载的耐心解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2022-02-18 05:04
新界面已在最近更新的 Power BI Desktop 中启用,在选项中勾选重启会打开新界面:
我们来看看新界面是什么样子的:
图标排列与原来相比有很大变化。我觉得最大的变化是视图中的主题可以预览,有点像办公室里的主题。
过去,Power BI Desktop 最受诟病的是这些主题的配色,没有 Tableau 看起来很漂亮。其实Power BI Desktop也提供了主题模板供下载,但是这个网站国内访问有点难,这里我是可以访问的,但是速度慢,看起来不太正常:
如何刷新是这样的。本网站提供了100多个主题模板,点击单个主题打开,勾选即可看到模板文件的下载地址:
在页面上可以看到无法下载,网站被禁用。
我们可以点击检查中的这个链接直接下载JSON到本地。如果看好其中一个题目,可以像这样单独下载。如果要全部下载,一个一个比较麻烦,所以我们使用Power Query查找所有下载链接,然后使用下载工具一次性下载。
第 1 步:网站分析
这个 网站 非常慢,所以请耐心等待。第一步是找到每个主题的地址。我们需要逐页搜索,每页12页,一共120页,如果最后一页也是12页。
打开这个页面后,可以直接用文本解析找到12个连接。
然后我们必须在单独的主题页面上找到下载地址。图片刚刚发了,没有问题。
第 2 步:尝试捕获
试抓主题地址:直接从web,改成从文本中,过滤掉链接地址:
试抓主题文件地址:同样使用文本格式过滤掉文件地址:
很容易找到。
第三步:定义抓取功能
主题地址抓取功能:参数为页码
文件地址抓取功能:参数为主题url
第 4 步:抓住
话题地址抓取:这一步很顺利,展开得到想要的话题地址列表
文件地址爬取:也爬出来了,但是有8个错误
有些错的地方单独检查,有些没有文件地址,我们就忽略了。一共113行正确的文件地址是108行,我们可以抓取108个主题。
让我们将此表复制并粘贴到 Excel 中:
打开迅雷并新建一个下载任务:将这些地址粘贴到迅雷中:
每个文件都不大,一会儿就下载下来:
如何使用这些主题,让我们回到 Power BI Desktop:
浏览主题,然后选择文件,您就完成了
这是刚刚导入的主题:
Power BI Desktop 的主题每次都要重新添加。不能像内置主题一样随时使用,有点不方便。 查看全部
excel抓取网页动态数据(PowerBIDesktopDesktop主题模板下载的耐心解析)
新界面已在最近更新的 Power BI Desktop 中启用,在选项中勾选重启会打开新界面:
我们来看看新界面是什么样子的:
图标排列与原来相比有很大变化。我觉得最大的变化是视图中的主题可以预览,有点像办公室里的主题。
过去,Power BI Desktop 最受诟病的是这些主题的配色,没有 Tableau 看起来很漂亮。其实Power BI Desktop也提供了主题模板供下载,但是这个网站国内访问有点难,这里我是可以访问的,但是速度慢,看起来不太正常:
如何刷新是这样的。本网站提供了100多个主题模板,点击单个主题打开,勾选即可看到模板文件的下载地址:
在页面上可以看到无法下载,网站被禁用。
我们可以点击检查中的这个链接直接下载JSON到本地。如果看好其中一个题目,可以像这样单独下载。如果要全部下载,一个一个比较麻烦,所以我们使用Power Query查找所有下载链接,然后使用下载工具一次性下载。
第 1 步:网站分析
这个 网站 非常慢,所以请耐心等待。第一步是找到每个主题的地址。我们需要逐页搜索,每页12页,一共120页,如果最后一页也是12页。
打开这个页面后,可以直接用文本解析找到12个连接。
然后我们必须在单独的主题页面上找到下载地址。图片刚刚发了,没有问题。
第 2 步:尝试捕获
试抓主题地址:直接从web,改成从文本中,过滤掉链接地址:
试抓主题文件地址:同样使用文本格式过滤掉文件地址:
很容易找到。
第三步:定义抓取功能
主题地址抓取功能:参数为页码
文件地址抓取功能:参数为主题url
第 4 步:抓住
话题地址抓取:这一步很顺利,展开得到想要的话题地址列表
文件地址爬取:也爬出来了,但是有8个错误
有些错的地方单独检查,有些没有文件地址,我们就忽略了。一共113行正确的文件地址是108行,我们可以抓取108个主题。
让我们将此表复制并粘贴到 Excel 中:
打开迅雷并新建一个下载任务:将这些地址粘贴到迅雷中:
每个文件都不大,一会儿就下载下来:
如何使用这些主题,让我们回到 Power BI Desktop:
浏览主题,然后选择文件,您就完成了
这是刚刚导入的主题:
Power BI Desktop 的主题每次都要重新添加。不能像内置主题一样随时使用,有点不方便。
excel抓取网页动态数据( 小编来一起如何用python来抓取页面中的数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-16 06:16
小编来一起如何用python来抓取页面中的数据?
)
浅谈如何使用python抓取网页中的动态数据
更新时间:2020-08-17 11:08:10 作者:saintlas
本篇文章主要介绍如何使用python抓取网页中的动态数据。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。需要的小伙伴一起来和小编一起学习吧
我们经常发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,网站的其他很多RequestURL也没有那么直接,所以我们会使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
excel抓取网页动态数据(
小编来一起如何用python来抓取页面中的数据?
)
浅谈如何使用python抓取网页中的动态数据
更新时间:2020-08-17 11:08:10 作者:saintlas
本篇文章主要介绍如何使用python抓取网页中的动态数据。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。需要的小伙伴一起来和小编一起学习吧
我们经常发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。


在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:

在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。

我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。

查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,网站的其他很多RequestURL也没有那么直接,所以我们会使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
网站优化 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2022-03-09 22:25
我们经常使用网页数据,但是每次打开网页查询都很麻烦,而且我们需要的数据是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
在Excel中查询网页数据并实时更新的步骤:
首先打开excel,点击Data,在Get External Data选项卡下,点击From 网站,会弹出New Web Query对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击黄框箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,单击指定导入位置,将数据导入excel。
使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
将数据导入 Excel 后,在数据区域单击鼠标右键,单击“刷新”即可刷新数据。通过右键单击数据范围属性,可以打开外部数据范围属性对话框,并设置刷新频率,以及是否允许后台刷新,或文件打开时刷新。
还有一种简单的方法可以直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有一个粘贴选项,还有一个可刷新的网页查询。单击它将输入新的网络查询。界面,重复前面的操作即可。
Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013网页查询采集网页数据功能
3.如何在Excel中批量更新数据
4.如何用Excel中的表格快速查询数据
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格序列号
7.如何在Excel中使用自动数据过滤功能 查看全部
excel抓取网页动态数据(怎么把网页数据导入到Excel表格中6.excel表格序号如何)
我们经常使用网页数据,但是每次打开网页查询都很麻烦,而且我们需要的数据是实时更新的,那么如何才能达到这个目的呢?Excel可以帮你完美解决。今天教大家如何在Excel中查询网页数据并实时更新。
在Excel中查询网页数据并实时更新的步骤:
首先打开excel,点击Data,在Get External Data选项卡下,点击From 网站,会弹出New Web Query对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击黄框箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,单击指定导入位置,将数据导入excel。
使用方法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
将数据导入 Excel 后,在数据区域单击鼠标右键,单击“刷新”即可刷新数据。通过右键单击数据范围属性,可以打开外部数据范围属性对话框,并设置刷新频率,以及是否允许后台刷新,或文件打开时刷新。
还有一种简单的方法可以直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有一个粘贴选项,还有一个可刷新的网页查询。单击它将输入新的网络查询。界面,重复前面的操作即可。
Excel文章中查询网页数据并实时更新相关操作:
1.如何在Excel中查询网页数据并实时更新
2.如何使用excel2013网页查询采集网页数据功能
3.如何在Excel中批量更新数据
4.如何用Excel中的表格快速查询数据
5.如何将网页数据导入Excel表格
6.如何自动更新excel表格序列号
7.如何在Excel中使用自动数据过滤功能
excel抓取网页动态数据(Excel数据采集软件(免费下载,像Excel一样极速上手,可灵活自定义的企业管理软件))
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-03-09 22:23
推荐使用:Excel数据采集软件(免费下载,与Excel一样快,灵活可定制的企业管理软件)
前言
IBM大中华区总经理胡世忠曾表示:数据构成了智慧地球的三大要素:智能、互联和互联,这三大要素改变了数据的来源、传输和利用,带来了“大数据”信息社会已经发生了变化。
由上可知,时代的变迁源于数据的使用。对于企业来说,数据也是企业发展和转型的命脉。在我的工作中,我的前辈们不止一次强调,数据是公司的资产,非常重要。我们要严格数据,经得起时间的考验,对自己的数据负责。这是数据主体的基本要求。
数据资源
大数据时代,虽然数据很多,但并不是随意获取的,需要通过各种渠道和方式获取。无论从哪个角度看,数据都可以分为内部数据和外部数据。内部数据是企业通过累积运算获得的。我们应该挖掘和采集有价值的数据,形成企业数据资产。内部数据侧重于后期处理和分析。
先说一下如何获取外部数据,以及如何通过Excel操作获取外部数据。
外部数据采集 方法
1、专业网站数据(某行业,某产品)
2.通过收费渠道(第三方数据平台等)购买数据
3.通过特殊形式引用数据(网站爬虫、统计网站等)。)
4.自己积累数据(时间长,跨度长)
Excel获取外部数据
作为数据分析师,想要进一步成长为数据科学家,精通基础办公软件和SQL查询非常重要。按照以下步骤通过 Excel 获取外部数据。
第 1 步:打开新网络查询框。创建一个新的 Excel 工作簿,在打开的工作表中单击“数据”选项卡,然后单击“获取外部数据”组中的“来自 网站”按钮,如下图所示。
步骤 2:输入 URL 并选择要导入的表数据。在弹出的“新建网页查询”对话框中的“地址”文本框中,复制粘贴上述网页的网址,然后点击“前往”,找到网站中的表格数据,然后单击表格左上角的箭头 图标变为选中的复选框。下图。最后,点击下方的“导入”按钮。
第三步:选择数据放置区域。单击导入后,Excel 将显示导入数据对话框,如下图所示。选择要放置的单元格,然后单击“确定”开始导入。
第四步:美化导入的数据。由于导入的数据较大且令人困惑,因此应调整格式以使数据标准化,并应启用冻结窗格功能以便于浏览。下图。
OK,以上就是通过Excel操作获取网站上的外部数据。这很简单,但并非 网站 上的所有数据都以表格形式呈现。现在大多数都以 json 格式呈现。Excel 不是灵丹妙药,许多网站 现在花钱来引导数据(如上所述,数据是一种商业资产)。
概括
我希望我能帮助你解决上述问题。如果您有什么好的意见、建议或不同的意见,希望您可以留言与我们交流讨论。 查看全部
excel抓取网页动态数据(Excel数据采集软件(免费下载,像Excel一样极速上手,可灵活自定义的企业管理软件))
推荐使用:Excel数据采集软件(免费下载,与Excel一样快,灵活可定制的企业管理软件)
前言
IBM大中华区总经理胡世忠曾表示:数据构成了智慧地球的三大要素:智能、互联和互联,这三大要素改变了数据的来源、传输和利用,带来了“大数据”信息社会已经发生了变化。
由上可知,时代的变迁源于数据的使用。对于企业来说,数据也是企业发展和转型的命脉。在我的工作中,我的前辈们不止一次强调,数据是公司的资产,非常重要。我们要严格数据,经得起时间的考验,对自己的数据负责。这是数据主体的基本要求。
数据资源
大数据时代,虽然数据很多,但并不是随意获取的,需要通过各种渠道和方式获取。无论从哪个角度看,数据都可以分为内部数据和外部数据。内部数据是企业通过累积运算获得的。我们应该挖掘和采集有价值的数据,形成企业数据资产。内部数据侧重于后期处理和分析。
先说一下如何获取外部数据,以及如何通过Excel操作获取外部数据。
外部数据采集 方法
1、专业网站数据(某行业,某产品)
2.通过收费渠道(第三方数据平台等)购买数据
3.通过特殊形式引用数据(网站爬虫、统计网站等)。)
4.自己积累数据(时间长,跨度长)
Excel获取外部数据
作为数据分析师,想要进一步成长为数据科学家,精通基础办公软件和SQL查询非常重要。按照以下步骤通过 Excel 获取外部数据。
第 1 步:打开新网络查询框。创建一个新的 Excel 工作簿,在打开的工作表中单击“数据”选项卡,然后单击“获取外部数据”组中的“来自 网站”按钮,如下图所示。
步骤 2:输入 URL 并选择要导入的表数据。在弹出的“新建网页查询”对话框中的“地址”文本框中,复制粘贴上述网页的网址,然后点击“前往”,找到网站中的表格数据,然后单击表格左上角的箭头 图标变为选中的复选框。下图。最后,点击下方的“导入”按钮。
第三步:选择数据放置区域。单击导入后,Excel 将显示导入数据对话框,如下图所示。选择要放置的单元格,然后单击“确定”开始导入。
第四步:美化导入的数据。由于导入的数据较大且令人困惑,因此应调整格式以使数据标准化,并应启用冻结窗格功能以便于浏览。下图。
OK,以上就是通过Excel操作获取网站上的外部数据。这很简单,但并非 网站 上的所有数据都以表格形式呈现。现在大多数都以 json 格式呈现。Excel 不是灵丹妙药,许多网站 现在花钱来引导数据(如上所述,数据是一种商业资产)。
概括
我希望我能帮助你解决上述问题。如果您有什么好的意见、建议或不同的意见,希望您可以留言与我们交流讨论。
excel抓取网页动态数据(【数据获取】爬虫利器Rvest包(JS渲染页面))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-03-07 16:14
本文所有内容均基于Windows系统。
前言
对于R中的静态页面爬取,rvest、RCurl、XML包都可以实现这个功能。这里推荐文哥写的两篇文档,介绍如何爬取静态页面数据。我也是通过这两篇文章文章开始接触R爬虫的。
传送门:【数据采集】爬虫工具Rvest包【数据采集】爬虫基础Rcurl和XML包
前几天遇到一个问题,需要抓取动态页面(JS渲染的页面)。通过网络采集知识,不断整理,终于初步解决了问题。由于相关的中文资料不多,所以写了这个文章分享给大家。
解决爬取动态页面的问题,需要一个比较强大的R包——RSelenium。
RSelenium 简介
RSelenium 的作用是使用 R 调用 Selenium Server。
什么是 Selenium 服务器?
Selenium Server 允许您在不同的浏览器上打开 URL,对网页进行操作,并为网页元素爬取独立的 JAVA 程序。
因此,我们可以通过 Selenium Server 对网页进行操作,然后对操作后的数据进行爬取,从而对动态页面进行爬取。
Selenium 服务器安装
下载列表:
JAVA JDK 1.8(门户)。Selenium Server 是一个需要 JAVA 环境的 JAVA 程序。Selenium 服务器独立 3.0.1(门户)。Selenium 服务器的 JAVA 文件。铬(门户)。ChromeDriver(需要爬墙门户)(无爬墙门户)。Selenium Server 调用 Chrome 的驱动程序。
安装过程:
首先,安装 JAVA JDK 1.8。
然后,安装 Chrome(最新版本)。
之后,将解压后的ChromeDriver.exe(最新版)放到Chrome安装路径下。它必须放在与 chrome.exe 相同的目录中。例如:
chrome.exe和chromedriver.exe都在C:\Program Files(x86)\Google\Chrome\Application目录下。(一般Chrome的默认安装路径在这里)
最后将这个路径C:\Program Files(x86)\Google\Chrome\Application添加到环境变量PATH的路径中。具体添加过程可以看这里(传送门)。
基本配置完成!
RSelenium 用法和示例
通过示例了解有关使用 RSelenium 的更多信息。
目标:从网贷之家数据平台( )中抓取各P2P平台最近7天的投资者数量、人均投资金额、平均收益率和交易量。下图中红框的内容。
过程:
启动 Selenium 服务器。在 selenium-server-standalone-3.0.1.jar 文件所在的位置,使用 shift+鼠标右键选择“Open command line here”。在命令行上运行以下代码以启动 Selenium Server。
java -jar selenium-server-standalone-3.0.1.jar
运行后,最小化,不要关闭。通过R调用Selenium Server并打开网页,点击页面,选择对应的条件。通过 RSelenium 与 rvest 一起抓取数据。通过逐步解密Rcode来解释该过程。
<p>################调用R包#########################################
library(rvest) # 为了read_html函数
library(RSelenium) # 为了使用JavaScript进行网页抓取
###############连接Server并打开浏览器############################
remDr 查看全部
excel抓取网页动态数据(【数据获取】爬虫利器Rvest包(JS渲染页面))
本文所有内容均基于Windows系统。
前言
对于R中的静态页面爬取,rvest、RCurl、XML包都可以实现这个功能。这里推荐文哥写的两篇文档,介绍如何爬取静态页面数据。我也是通过这两篇文章文章开始接触R爬虫的。
传送门:【数据采集】爬虫工具Rvest包【数据采集】爬虫基础Rcurl和XML包
前几天遇到一个问题,需要抓取动态页面(JS渲染的页面)。通过网络采集知识,不断整理,终于初步解决了问题。由于相关的中文资料不多,所以写了这个文章分享给大家。
解决爬取动态页面的问题,需要一个比较强大的R包——RSelenium。
RSelenium 简介
RSelenium 的作用是使用 R 调用 Selenium Server。
什么是 Selenium 服务器?
Selenium Server 允许您在不同的浏览器上打开 URL,对网页进行操作,并为网页元素爬取独立的 JAVA 程序。
因此,我们可以通过 Selenium Server 对网页进行操作,然后对操作后的数据进行爬取,从而对动态页面进行爬取。
Selenium 服务器安装
下载列表:
JAVA JDK 1.8(门户)。Selenium Server 是一个需要 JAVA 环境的 JAVA 程序。Selenium 服务器独立 3.0.1(门户)。Selenium 服务器的 JAVA 文件。铬(门户)。ChromeDriver(需要爬墙门户)(无爬墙门户)。Selenium Server 调用 Chrome 的驱动程序。
安装过程:
首先,安装 JAVA JDK 1.8。
然后,安装 Chrome(最新版本)。
之后,将解压后的ChromeDriver.exe(最新版)放到Chrome安装路径下。它必须放在与 chrome.exe 相同的目录中。例如:
chrome.exe和chromedriver.exe都在C:\Program Files(x86)\Google\Chrome\Application目录下。(一般Chrome的默认安装路径在这里)
最后将这个路径C:\Program Files(x86)\Google\Chrome\Application添加到环境变量PATH的路径中。具体添加过程可以看这里(传送门)。
基本配置完成!
RSelenium 用法和示例
通过示例了解有关使用 RSelenium 的更多信息。
目标:从网贷之家数据平台( )中抓取各P2P平台最近7天的投资者数量、人均投资金额、平均收益率和交易量。下图中红框的内容。
过程:
启动 Selenium 服务器。在 selenium-server-standalone-3.0.1.jar 文件所在的位置,使用 shift+鼠标右键选择“Open command line here”。在命令行上运行以下代码以启动 Selenium Server。
java -jar selenium-server-standalone-3.0.1.jar
运行后,最小化,不要关闭。通过R调用Selenium Server并打开网页,点击页面,选择对应的条件。通过 RSelenium 与 rvest 一起抓取数据。通过逐步解密Rcode来解释该过程。
<p>################调用R包#########################################
library(rvest) # 为了read_html函数
library(RSelenium) # 为了使用JavaScript进行网页抓取
###############连接Server并打开浏览器############################
remDr
excel抓取网页动态数据(知晓云云函数导出任务进行管理的流程和流程(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2022-03-07 06:17
在日常工作中,往往需要根据业务需要,对各种格式的数据进行处理和导出。导出后,很多人更喜欢将数据放到excel中进行处理。
一般来说,在处理数据导出时,需要对数据进行一些操作。过去,这是通过在单独的服务器上运行脚本来完成的。
现在有了知云,你不再需要维护服务器,直接写代码,把所有相关的东西都扔给云功能。本文将介绍通过知云功能将数据表导出为excel文件的功能,并使用webpack和mincloud将代码打包上传到知云。
技术栈:
一、项目建设
项目文件结构:
export-excel-file
├── index.js
├── package.json
├── src
│ └── index.js
├── webpack.config.js
└── yarn.lock
项目搭建与云功能代码打包示例文档基本一致。项目构建完成后,还需要安装以下依赖(两种安装方式任选其一):
// 使用 yarn 安装
yarn add node-xlsx mincloud
// 使用 npm 安装
npm install --save node-xlsx minclou
修改部署脚本如下:
// package.json
...
"scripts": {
"build": "webpack --mode production",
"predeploy": "npm run build",
"deploy": "mincloud deploy export-excel-file ../"
},
...
最后我们将使用以下两个命令进行部署和测试:
npm run deploy // 部署到知晓云
mincloud invoke export-excel-file // 测试已经部署到知晓云上的云函数
二、导出数据表到excel文件
我们需要准备两张表:
order:订单表(新字段:名称,价格)
export_task:导出任务记录表(新字段:file_download_link)
知云的云函数调用可以是同步的,也可以是异步的。同步调用的最大超时时间为 5 秒,异步调用为 300 秒。
假设order order表有100000条数据,由于我们知道单次从云端拉取数据的最大限制是1000条,所以需要批量获取数据,可能需要对数据进行处理稍后,这将花费超过 5 秒,因此对云函数的调用将是异步的。这时就需要export_task导出任务记录表来管理导出任务。
export_task 表按如下方式管理导出任务:
调用云函数时,在export_task表中创建一条记录A。此时A记录中file_download_link字段的值为空。同时获取记录A的id,将id记录为jobId,查询订单表数据,生成excel文件,上传文件。等待操作,获取文件下载链接后,根据jobId更新第一步创建的记录,将文件下载链接保存在file_download_link字段中,然后在export_task表中获取文件下载链接。
通过上面的准备和分析,导出excel文件的操作分为以下4个步骤:
order 订单表数据获取 使用获取的数据在云函数环境中创建excel文件 将创建的excel文件上传到知云 将文件下载链接保存到export_task表中file_download_link字段
完整代码如下:
const fs = require('fs')
const xlsx = require('node-xlsx')
const EXPORT_DATA_CATEGORY_ID = '5c711e3119111409cdabe6f2' // 文件上传分类 id
const TABLE_ID = {
order: 66666, // 订单表
export_task: 66667, // 导出任务记录表
}
const TMP_FILE_NAME = '/tmp/result.xlsx' // 本地临时文件路径,以 /tmp 开头,具体请查看:https://doc.minapp.com/support ... .html (云函数的临时文件存储)
const ROW_NAME = ['name', 'price'] // Excel 文件列名配置
const MAX_CONNECT_LIMIT = 5 // 最大同时请求数
const LIMIT = 1000 // 单次最大拉取数据数
let result = []
/**
* 更新导出记录中的 file_download_link 字段
* @param {*} tableID
* @param {*} recordId
* @param {*} fileLink
*/
function updateExportJobIdRecord(tableID, recordId, fileLink) {
let Schame = new BaaS.TableObject(tableID)
let schame = Schame.getWithoutData(recordId)
schame.set('file_download_link', fileLink)
return schame.update()
}
/**
* 创建数据导出任务
* 设置初始 file_download_link 为空
* 待导出任务执行完毕后将文件下载地址存储到 file_download_link 字段中
* @param {*} tableID
*/
function createExportJobIdRecord(tableID) {
let Schame = new BaaS.TableObject(tableID)
let schame = Schame.create()
return schame.set({file_download_link: ''}).save().then(res => {
return res.data.id
})
}
/**
* 获取总数据条数
* @tableId {*} tableId
*/
function getTotalCount(tableId) {
const Order = new BaaS.TableObject(tableId)
return Order.count()
.then(num => {
console.log('数据总条数:', num)
return num
})
.catch(err => {
console.log('获取数据总条数失败:', err)
throw new Error(err)
})
}
/**
* 分批拉取数据
* @param {*} tableId
* @param {*} offset
* @param {*} limit
*/
function getDataByGroup(tableId, offset = 0, limit = LIMIT) {
let Order = new BaaS.TableObject(tableId)
return Order.limit(limit).offset(offset).find()
.then(res => {
return res.data.objects
})
.catch(err => {
console.log('获取分组数据失败:', err)
throw new Error(err)
})
}
/**
* 创建 Excel 导出文件
* @param {*} sourceData 源数据
*/
function genExportFile(sourceData = []) {
const resultArr = []
const rowArr = []
// 配置列名
rowArr.push(ROW_NAME)
sourceData.forEach(v => {
rowArr.push(
ROW_NAME.map(k => v[k])
)
})
resultArr[0] = {
data: rowArr,
name: 'sheet1', // Excel 工作表名
}
const option = {'!cols': [{wch: 10}, {wch: 20}]} // 自定义列宽度
const buffer = xlsx.build(resultArr, option)
return fs.writeFile(TMP_FILE_NAME, buffer, err => {
if (err) {
console.log('创建 Excel 导出文件失败')
throw new Error(err)
}
})
}
/**
* 上传文件
*/
function uploadFile() {
let MyFile = new BaaS.File()
return MyFile.upload(TMP_FILE_NAME, {category_id: EXPORT_DATA_CATEGORY_ID})
.catch(err => {
console.log('上传文件失败')
throw new Error(err)
})
}
module.exports = async function(event, callback) {
try {
const date = new Date().getTime()
const groupInfoArr = []
const groupInfoSplitArr = []
const [jobId, totalCount] = await Promise.all([createExportJobIdRecord(TABLE_ID.export_task), getTotalCount(TABLE_ID.order)])
const groupSize = Math.ceil(totalCount / LIMIT) || 1
for (let i = 0; i < groupSize; i++) {
groupInfoArr.push({
offset: i * LIMIT,
limit: LIMIT,
})
}
console.log('groupInfoArr:', groupInfoArr)
const length = Math.ceil(groupInfoArr.length / MAX_CONNECT_LIMIT)
for (let i = 0; i < length; i++) {
groupInfoSplitArr.push(groupInfoArr.splice(0, MAX_CONNECT_LIMIT))
}
console.log('groupInfoSplitArr:', groupInfoSplitArr)
const date0 = new Date().getTime()
console.log('处理分组情况耗时:', date0 - date, 'ms')
let num = 0
// 分批获取数据
const getSplitDataList = index => {
return Promise.all(
groupInfoSplitArr[index].map(v => {
return getDataByGroup(TABLE_ID.order, v.offset, v.limit)
})
).then(res => {
++num
result.push(...Array.prototype.concat(...res))
if (num < groupInfoSplitArr.length) {
return getSplitDataList(num)
} else {
return result
}
})
}
Promise.all([getSplitDataList(num)]).then(res => {
const date1 = new Date().getTime()
console.log('结果条数:', result.length)
console.log('分组拉取数据次数:', num)
console.log('拉取数据耗时:', date1 - date0, 'ms')
genExportFile(result)
const date2 = new Date().getTime()
console.log('处理数据耗时:', date2 - date1, 'ms')
uploadFile().then(res => {
const fileLink = res.data.file_link
const date3 = new Date().getTime()
console.log('上传文件耗时:', date3 - date2, 'ms')
console.log('总耗时:', date3 - date, 'ms')
updateExportJobIdRecord(TABLE_ID.export_task, jobId, fileLink)
.then(() => {
const date4 = new Date().getTime()
console.log('保存文件下载地址耗时:', date4 - date3, 'ms')
console.log('总耗时:', date4 - date, 'ms')
callback(null, {
message: '保存文件下载地址成功',
fileLink,
})
})
.catch(err => {
callback(err)
})
}).catch(err => {
console.log('上传文件失败:', err)
throw new Error(err)
})
})
} catch (err)
三、部署和测试
和 npm 一样,部署前需要登录。配置请参考文档。
可以使用以下命令将云功能部署到Know Cloud:
npm run deploy
执行结果如下:
使用以下命令进行测试:
mincloud invoke export-excel-file
执行结果如下:
export_task 表记录:
上传到知云的excel文件如下:
文件内容:
四、参考文档
了解云开发文档:
节点 xlsx 文档:
五、源码
仓库地址:
六、好处
即日起(3月8日)起,前50名报名并通过网页端公测审核的用户,将在正式接入后获得100元的积分。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接: 查看全部
excel抓取网页动态数据(知晓云云函数导出任务进行管理的流程和流程(一))
在日常工作中,往往需要根据业务需要,对各种格式的数据进行处理和导出。导出后,很多人更喜欢将数据放到excel中进行处理。
一般来说,在处理数据导出时,需要对数据进行一些操作。过去,这是通过在单独的服务器上运行脚本来完成的。
现在有了知云,你不再需要维护服务器,直接写代码,把所有相关的东西都扔给云功能。本文将介绍通过知云功能将数据表导出为excel文件的功能,并使用webpack和mincloud将代码打包上传到知云。
技术栈:
一、项目建设
项目文件结构:
export-excel-file
├── index.js
├── package.json
├── src
│ └── index.js
├── webpack.config.js
└── yarn.lock
项目搭建与云功能代码打包示例文档基本一致。项目构建完成后,还需要安装以下依赖(两种安装方式任选其一):
// 使用 yarn 安装
yarn add node-xlsx mincloud
// 使用 npm 安装
npm install --save node-xlsx minclou
修改部署脚本如下:
// package.json
...
"scripts": {
"build": "webpack --mode production",
"predeploy": "npm run build",
"deploy": "mincloud deploy export-excel-file ../"
},
...
最后我们将使用以下两个命令进行部署和测试:
npm run deploy // 部署到知晓云
mincloud invoke export-excel-file // 测试已经部署到知晓云上的云函数
二、导出数据表到excel文件
我们需要准备两张表:
order:订单表(新字段:名称,价格)
export_task:导出任务记录表(新字段:file_download_link)
知云的云函数调用可以是同步的,也可以是异步的。同步调用的最大超时时间为 5 秒,异步调用为 300 秒。
假设order order表有100000条数据,由于我们知道单次从云端拉取数据的最大限制是1000条,所以需要批量获取数据,可能需要对数据进行处理稍后,这将花费超过 5 秒,因此对云函数的调用将是异步的。这时就需要export_task导出任务记录表来管理导出任务。
export_task 表按如下方式管理导出任务:
调用云函数时,在export_task表中创建一条记录A。此时A记录中file_download_link字段的值为空。同时获取记录A的id,将id记录为jobId,查询订单表数据,生成excel文件,上传文件。等待操作,获取文件下载链接后,根据jobId更新第一步创建的记录,将文件下载链接保存在file_download_link字段中,然后在export_task表中获取文件下载链接。
通过上面的准备和分析,导出excel文件的操作分为以下4个步骤:
order 订单表数据获取 使用获取的数据在云函数环境中创建excel文件 将创建的excel文件上传到知云 将文件下载链接保存到export_task表中file_download_link字段
完整代码如下:
const fs = require('fs')
const xlsx = require('node-xlsx')
const EXPORT_DATA_CATEGORY_ID = '5c711e3119111409cdabe6f2' // 文件上传分类 id
const TABLE_ID = {
order: 66666, // 订单表
export_task: 66667, // 导出任务记录表
}
const TMP_FILE_NAME = '/tmp/result.xlsx' // 本地临时文件路径,以 /tmp 开头,具体请查看:https://doc.minapp.com/support ... .html (云函数的临时文件存储)
const ROW_NAME = ['name', 'price'] // Excel 文件列名配置
const MAX_CONNECT_LIMIT = 5 // 最大同时请求数
const LIMIT = 1000 // 单次最大拉取数据数
let result = []
/**
* 更新导出记录中的 file_download_link 字段
* @param {*} tableID
* @param {*} recordId
* @param {*} fileLink
*/
function updateExportJobIdRecord(tableID, recordId, fileLink) {
let Schame = new BaaS.TableObject(tableID)
let schame = Schame.getWithoutData(recordId)
schame.set('file_download_link', fileLink)
return schame.update()
}
/**
* 创建数据导出任务
* 设置初始 file_download_link 为空
* 待导出任务执行完毕后将文件下载地址存储到 file_download_link 字段中
* @param {*} tableID
*/
function createExportJobIdRecord(tableID) {
let Schame = new BaaS.TableObject(tableID)
let schame = Schame.create()
return schame.set({file_download_link: ''}).save().then(res => {
return res.data.id
})
}
/**
* 获取总数据条数
* @tableId {*} tableId
*/
function getTotalCount(tableId) {
const Order = new BaaS.TableObject(tableId)
return Order.count()
.then(num => {
console.log('数据总条数:', num)
return num
})
.catch(err => {
console.log('获取数据总条数失败:', err)
throw new Error(err)
})
}
/**
* 分批拉取数据
* @param {*} tableId
* @param {*} offset
* @param {*} limit
*/
function getDataByGroup(tableId, offset = 0, limit = LIMIT) {
let Order = new BaaS.TableObject(tableId)
return Order.limit(limit).offset(offset).find()
.then(res => {
return res.data.objects
})
.catch(err => {
console.log('获取分组数据失败:', err)
throw new Error(err)
})
}
/**
* 创建 Excel 导出文件
* @param {*} sourceData 源数据
*/
function genExportFile(sourceData = []) {
const resultArr = []
const rowArr = []
// 配置列名
rowArr.push(ROW_NAME)
sourceData.forEach(v => {
rowArr.push(
ROW_NAME.map(k => v[k])
)
})
resultArr[0] = {
data: rowArr,
name: 'sheet1', // Excel 工作表名
}
const option = {'!cols': [{wch: 10}, {wch: 20}]} // 自定义列宽度
const buffer = xlsx.build(resultArr, option)
return fs.writeFile(TMP_FILE_NAME, buffer, err => {
if (err) {
console.log('创建 Excel 导出文件失败')
throw new Error(err)
}
})
}
/**
* 上传文件
*/
function uploadFile() {
let MyFile = new BaaS.File()
return MyFile.upload(TMP_FILE_NAME, {category_id: EXPORT_DATA_CATEGORY_ID})
.catch(err => {
console.log('上传文件失败')
throw new Error(err)
})
}
module.exports = async function(event, callback) {
try {
const date = new Date().getTime()
const groupInfoArr = []
const groupInfoSplitArr = []
const [jobId, totalCount] = await Promise.all([createExportJobIdRecord(TABLE_ID.export_task), getTotalCount(TABLE_ID.order)])
const groupSize = Math.ceil(totalCount / LIMIT) || 1
for (let i = 0; i < groupSize; i++) {
groupInfoArr.push({
offset: i * LIMIT,
limit: LIMIT,
})
}
console.log('groupInfoArr:', groupInfoArr)
const length = Math.ceil(groupInfoArr.length / MAX_CONNECT_LIMIT)
for (let i = 0; i < length; i++) {
groupInfoSplitArr.push(groupInfoArr.splice(0, MAX_CONNECT_LIMIT))
}
console.log('groupInfoSplitArr:', groupInfoSplitArr)
const date0 = new Date().getTime()
console.log('处理分组情况耗时:', date0 - date, 'ms')
let num = 0
// 分批获取数据
const getSplitDataList = index => {
return Promise.all(
groupInfoSplitArr[index].map(v => {
return getDataByGroup(TABLE_ID.order, v.offset, v.limit)
})
).then(res => {
++num
result.push(...Array.prototype.concat(...res))
if (num < groupInfoSplitArr.length) {
return getSplitDataList(num)
} else {
return result
}
})
}
Promise.all([getSplitDataList(num)]).then(res => {
const date1 = new Date().getTime()
console.log('结果条数:', result.length)
console.log('分组拉取数据次数:', num)
console.log('拉取数据耗时:', date1 - date0, 'ms')
genExportFile(result)
const date2 = new Date().getTime()
console.log('处理数据耗时:', date2 - date1, 'ms')
uploadFile().then(res => {
const fileLink = res.data.file_link
const date3 = new Date().getTime()
console.log('上传文件耗时:', date3 - date2, 'ms')
console.log('总耗时:', date3 - date, 'ms')
updateExportJobIdRecord(TABLE_ID.export_task, jobId, fileLink)
.then(() => {
const date4 = new Date().getTime()
console.log('保存文件下载地址耗时:', date4 - date3, 'ms')
console.log('总耗时:', date4 - date, 'ms')
callback(null, {
message: '保存文件下载地址成功',
fileLink,
})
})
.catch(err => {
callback(err)
})
}).catch(err => {
console.log('上传文件失败:', err)
throw new Error(err)
})
})
} catch (err)
三、部署和测试
和 npm 一样,部署前需要登录。配置请参考文档。
可以使用以下命令将云功能部署到Know Cloud:
npm run deploy
执行结果如下:
使用以下命令进行测试:
mincloud invoke export-excel-file
执行结果如下:
export_task 表记录:
上传到知云的excel文件如下:
文件内容:
四、参考文档
了解云开发文档:
节点 xlsx 文档:
五、源码
仓库地址:
六、好处
即日起(3月8日)起,前50名报名并通过网页端公测审核的用户,将在正式接入后获得100元的积分。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接:
excel抓取网页动态数据(本文如下:找到目标网页打开阳光高考网站(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-06 12:26
我们日常使用PowerBI数据获取单个网页数据非常简单,但是批量获取网页数据相对麻烦。这里我们可以使用PowerBI的Power Query组件批量获取多个网页的数据。同样,也可以使用高版本Excel自带的Power Query来获取。
本文以阳光高考网站为例,获取2019年全国普通高等学校名单。
具体操作步骤如下:
(一)找到登陆页面
打开阳光高考网站,找到“2019年全国普通高等学校名单”网页。
点击打开单个网页查看,如下:
(二)分析URL结构
这里选择前三个省份网址
北京:
天津:
河北:
可以看出只有URL中最后一个数字是变量,这里我们把它当作页面ID
(三)采集第一页数据
(北京的页面ID从“2”开始)
打开PowerBI Desktop,通过“获取数据”中的“Web”选项获取数据,在“Web”界面中选择“基本”选项卡即可。
这里我们在基本选项卡中输入目标网址
(北京)
获取数据源信息如下,这里只有第一个表是我们要的,勾选,然后点击右下角转换数据进行数据处理。
入口页面如下:
这样我们就简单地采集到第一页数据。然后整理这个页面的数据,删除无用的信息,添加字段名。完成后,后续采集其他页面的数据结构与第一页完成后的数据结构相同,采集的数据可以直接使用。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
我们不会在这里处理它。
(四)根据页码参数设置自定义功能
这是最重要的一步
在当前数据的编辑器窗口中,打开【高级编辑器】,输入:
(p作为数字)作为表=>
并且在链接中,将网页的页码,也就是上面提到的“1、2”等数字修改为“&(Number.ToText(p))&”。
改了之后就变成了:
点击“完成”,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,表格也变成了函数的样式。自定义函数完成,p是函数的变量,用来控制页码,输入一个数字,比如3,会抓取第三页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(五)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。在这里,因为我们要从第 2 页到第 32 页获取数据,所以我们创建一个从 2 到 32 的序列并在空查询中输入:
={2..32}
回车生成一个从1到100的序列,然后变成表格。
然后调用自定义函数
单击“确定”开始批量抓取网页。如果采集页数较多,不建议在获取第一个网页后立即进行数据排序,否则可能导致采集时间过长。
这里我们展开表格,里面全是31页的数据。
那么这里我们看看后续的数据排序和可视化。
备注1:如果采集的网页数据不断更新,完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站的实时数据,非常方便。.
注2:以上主要使用PowerBI中的Power Query功能,可以在可以使用PQ功能的Excel中进行同样的操作。
备注3:需要注意的是,并不是所有的网页数据都可以通过上述方法获得。在使用PowerBI批量捕获某个网站数据之前,先尝试一个采集页面。如果你可以采集 到达,然后使用上面的步骤。如果 采集 不可用,则需要考虑使用 Python 等爬虫处理。
本文参考:PowerQuery批量抓取网页实战:分分钟抓取智联招聘数百页作业信息 查看全部
excel抓取网页动态数据(本文如下:找到目标网页打开阳光高考网站(图))
我们日常使用PowerBI数据获取单个网页数据非常简单,但是批量获取网页数据相对麻烦。这里我们可以使用PowerBI的Power Query组件批量获取多个网页的数据。同样,也可以使用高版本Excel自带的Power Query来获取。
本文以阳光高考网站为例,获取2019年全国普通高等学校名单。
具体操作步骤如下:
(一)找到登陆页面
打开阳光高考网站,找到“2019年全国普通高等学校名单”网页。
点击打开单个网页查看,如下:
(二)分析URL结构
这里选择前三个省份网址
北京:
天津:
河北:
可以看出只有URL中最后一个数字是变量,这里我们把它当作页面ID
(三)采集第一页数据
(北京的页面ID从“2”开始)
打开PowerBI Desktop,通过“获取数据”中的“Web”选项获取数据,在“Web”界面中选择“基本”选项卡即可。
这里我们在基本选项卡中输入目标网址
(北京)
获取数据源信息如下,这里只有第一个表是我们要的,勾选,然后点击右下角转换数据进行数据处理。
入口页面如下:
这样我们就简单地采集到第一页数据。然后整理这个页面的数据,删除无用的信息,添加字段名。完成后,后续采集其他页面的数据结构与第一页完成后的数据结构相同,采集的数据可以直接使用。
如果要大量抓取网页数据,为了节省时间,可以不用对第一页的数据进行排序,直接进行下一步。
我们不会在这里处理它。
(四)根据页码参数设置自定义功能
这是最重要的一步
在当前数据的编辑器窗口中,打开【高级编辑器】,输入:
(p作为数字)作为表=>
并且在链接中,将网页的页码,也就是上面提到的“1、2”等数字修改为“&(Number.ToText(p))&”。
改了之后就变成了:
点击“完成”,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,表格也变成了函数的样式。自定义函数完成,p是函数的变量,用来控制页码,输入一个数字,比如3,会抓取第三页的数据。
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(五)批量调用自定义函数
首先,使用一个空查询来创建一个数字序列。在这里,因为我们要从第 2 页到第 32 页获取数据,所以我们创建一个从 2 到 32 的序列并在空查询中输入:
={2..32}
回车生成一个从1到100的序列,然后变成表格。
然后调用自定义函数
单击“确定”开始批量抓取网页。如果采集页数较多,不建议在获取第一个网页后立即进行数据排序,否则可能导致采集时间过长。
这里我们展开表格,里面全是31页的数据。
那么这里我们看看后续的数据排序和可视化。
备注1:如果采集的网页数据不断更新,完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站的实时数据,非常方便。.
注2:以上主要使用PowerBI中的Power Query功能,可以在可以使用PQ功能的Excel中进行同样的操作。
备注3:需要注意的是,并不是所有的网页数据都可以通过上述方法获得。在使用PowerBI批量捕获某个网站数据之前,先尝试一个采集页面。如果你可以采集 到达,然后使用上面的步骤。如果 采集 不可用,则需要考虑使用 Python 等爬虫处理。
本文参考:PowerQuery批量抓取网页实战:分分钟抓取智联招聘数百页作业信息
excel抓取网页动态数据(excel抓取网页动态数据3种方法实战5步完成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-06 05:04
excel抓取网页动态数据3种方法实战5步完成原创|heihu当今互联网上的抓取,不断在有前不断传递出改变、颠覆的数据。从早期的ajax开始,
5、css
3、新格式解析与字体字形、python技术驱动、高并发流媒体服务等等。这些新技术、新工具,能够深度地解决单个页面的动态数据抓取问题。然而,这样的改变、颠覆会带来数据流量的迅速增长,对于网站服务器来说,也会带来很多问题,必须及时解决,否则可能会导致服务器的分娩与业务失灵。
在ajax掀起html页面创意与设计革命的时候,众多网站,
5、javascript开发动态数据,避免页面抓取带来的影响:javascriptweb端脚本语言。ajax打开web的本地应用,浏览者可以使用相对于本地应用的ajax接口,与web设备和服务器进行交互。web端javascript脚本语言(webjavascriptfront-endprogramminglanguage)。
html5有了html5的新关键字css:基于html的表示、部分有意思的行为、更少的ui元素。而我们网页的动态抓取机制,是基于python的解析与字体渲染机制。所以,本篇文章,带来如何一种解决单个页面(包括静态文件)动态数据抓取问题的方法和实战。对,你没看错,我们先从以往的爬虫抓取爬虫抓取,想一下怎么爬取出来吧?小程序、微信公众号、头条号?不,我们要的是请求,http请求!其实,可以问自己一个问题:python,notjava...,简单的解析xmlhttprequest去请求http成功后返回data。
而我们要一个页面地抓取,我们必须要获取到它的html,然后我们才能利用如今流行的正则、python的解析机制将其转换成webdriver能理解的页面,再拿web服务器返回的response去调用api。这中间,有两个问题:请求成功后,那么服务器端返回的response里面的data都是啥,我们就不在监控了,只需要记住它,像url是,下一步,用于web端的解析即可。
那么,直接拿html当请求,那么究竟拿到了什么?我们打算抓取一个后面有商品页面的页面,该页面由3个静态文件组成,分别是index.xml/1/2。index.xml用来跳转及网页前端显示,list.xml文件内容为商品信息列表文本,1和2合在一起则为商品列表文本。我们在抓取到index.xml之后,就要拿来请求请求,请求数据,然后利用python的解析机制将数据显示到网页。
那么问题来了:我们这个抓取是点对点抓取,我们需要点一下,放进目标page,再点一下,这样发起轮询去请求,那么http请求的头部信息是什么?看下方截图,浏览器提供了很。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据3种方法实战5步完成)
excel抓取网页动态数据3种方法实战5步完成原创|heihu当今互联网上的抓取,不断在有前不断传递出改变、颠覆的数据。从早期的ajax开始,
5、css
3、新格式解析与字体字形、python技术驱动、高并发流媒体服务等等。这些新技术、新工具,能够深度地解决单个页面的动态数据抓取问题。然而,这样的改变、颠覆会带来数据流量的迅速增长,对于网站服务器来说,也会带来很多问题,必须及时解决,否则可能会导致服务器的分娩与业务失灵。
在ajax掀起html页面创意与设计革命的时候,众多网站,
5、javascript开发动态数据,避免页面抓取带来的影响:javascriptweb端脚本语言。ajax打开web的本地应用,浏览者可以使用相对于本地应用的ajax接口,与web设备和服务器进行交互。web端javascript脚本语言(webjavascriptfront-endprogramminglanguage)。
html5有了html5的新关键字css:基于html的表示、部分有意思的行为、更少的ui元素。而我们网页的动态抓取机制,是基于python的解析与字体渲染机制。所以,本篇文章,带来如何一种解决单个页面(包括静态文件)动态数据抓取问题的方法和实战。对,你没看错,我们先从以往的爬虫抓取爬虫抓取,想一下怎么爬取出来吧?小程序、微信公众号、头条号?不,我们要的是请求,http请求!其实,可以问自己一个问题:python,notjava...,简单的解析xmlhttprequest去请求http成功后返回data。
而我们要一个页面地抓取,我们必须要获取到它的html,然后我们才能利用如今流行的正则、python的解析机制将其转换成webdriver能理解的页面,再拿web服务器返回的response去调用api。这中间,有两个问题:请求成功后,那么服务器端返回的response里面的data都是啥,我们就不在监控了,只需要记住它,像url是,下一步,用于web端的解析即可。
那么,直接拿html当请求,那么究竟拿到了什么?我们打算抓取一个后面有商品页面的页面,该页面由3个静态文件组成,分别是index.xml/1/2。index.xml用来跳转及网页前端显示,list.xml文件内容为商品信息列表文本,1和2合在一起则为商品列表文本。我们在抓取到index.xml之后,就要拿来请求请求,请求数据,然后利用python的解析机制将数据显示到网页。
那么问题来了:我们这个抓取是点对点抓取,我们需要点一下,放进目标page,再点一下,这样发起轮询去请求,那么http请求的头部信息是什么?看下方截图,浏览器提供了很。
excel抓取网页动态数据(一下用Excel获取疫情数据的简单技能,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2022-03-04 09:06
)
以下内容转载至数据管理微信公众号(部分删减)
原文链接:
大家好,最近收到一些朋友的消息,说我在做数据分析工作,想关注一下我所在地区的疫情数据。他们问我如何轻松获得疫情数据。本文将为您介绍。使用 Excel 获取流行病数据的简单技巧。
先搞清楚疫情数据的来源在哪里?
关注疫情数据。官方发布渠道为国家卫健委和省、市卫健委发布的信息。因此,我们应该首先考虑是否可以从卫健委的网站获得数据?
比如下图是国家卫健委官网发布的页面:
如果要使用工具获取上面页面的数据,需要抓取上面的文字,然后分析文字关键词,提取关键数据,然后整理成结构化数据,才可以使用关于数据分析。同样,如果要获取某省的疫情数据,也可以对省卫健委官网公布的数据进行提取整理。例如,以下是江西省卫健委公布的情况信息:
对于大多数人来说,这样整理数据真的很费时费力,技能可能跟不上,但如果我们想自己获取数据,首先我们真的考虑到这一点,毕竟是卫健委的第一手数据。 ,质量也可以保证。但由于技术难度比较大,本文不介绍这种方法。
如果我们不具备直接获取官方数据的条件,也可以获取其他人整理的数据,比如腾讯、阿里、新浪、丁香园、网易、百度等,都有对应的疫情数据页面,并且国家、省、市三级数据已经整理好,我们可以想办法从他们的页面中获取你想要的数据。
让我们从简单的数据获取方法开始:
我们打开腾讯新闻的界面( ),里面有全国数据、省数据、市数据等,很详细。 (可以看他们的数据来源,也是根据国家卫健委公布的信息写的)
网页地址找到了,接下来用什么工具获取呢?
工具实际上很灵活,这取决于您熟悉哪一种,Python 可以、VBA 可以或任何其他编程语言。但是我们今天使用的工具非常简单。由Excel的Power Query函数直接实现(Excel 2016及以上版本默认内置该函数)。下面介绍操作步骤:
Step1:找到数据的真实地址。刚才我们只是得到了页面的地址,但是这个地址中并没有我们想要的数据。怎么找?
这需要您对数据传输有一定的网站知识。感兴趣的朋友可以详细了解百度“Chrome 抓包分析”。我将直接提供我在这里获得的2个地址供您参考:
省级数据:湖北
城市数据:湖北&city=武汉
Step2:使用PQ获取数据。如果你没有看到如下界面,则证明你没有PQ的功能。 (没有这个功能也别着急,文末提供了直接下载数据的方法)
PoweQuery 下载链接:
点击确定后,进入如下界面,事情就变得简单了,直接手动转换数据即可。
PQ的具体操作请参考以下链接:
Step3:最后一步是“关闭并上传”到新工作表。
查看全部
excel抓取网页动态数据(一下用Excel获取疫情数据的简单技能,你知道吗?
)
以下内容转载至数据管理微信公众号(部分删减)
原文链接:
大家好,最近收到一些朋友的消息,说我在做数据分析工作,想关注一下我所在地区的疫情数据。他们问我如何轻松获得疫情数据。本文将为您介绍。使用 Excel 获取流行病数据的简单技巧。
先搞清楚疫情数据的来源在哪里?
关注疫情数据。官方发布渠道为国家卫健委和省、市卫健委发布的信息。因此,我们应该首先考虑是否可以从卫健委的网站获得数据?
比如下图是国家卫健委官网发布的页面:
如果要使用工具获取上面页面的数据,需要抓取上面的文字,然后分析文字关键词,提取关键数据,然后整理成结构化数据,才可以使用关于数据分析。同样,如果要获取某省的疫情数据,也可以对省卫健委官网公布的数据进行提取整理。例如,以下是江西省卫健委公布的情况信息:
对于大多数人来说,这样整理数据真的很费时费力,技能可能跟不上,但如果我们想自己获取数据,首先我们真的考虑到这一点,毕竟是卫健委的第一手数据。 ,质量也可以保证。但由于技术难度比较大,本文不介绍这种方法。
如果我们不具备直接获取官方数据的条件,也可以获取其他人整理的数据,比如腾讯、阿里、新浪、丁香园、网易、百度等,都有对应的疫情数据页面,并且国家、省、市三级数据已经整理好,我们可以想办法从他们的页面中获取你想要的数据。
让我们从简单的数据获取方法开始:
我们打开腾讯新闻的界面( ),里面有全国数据、省数据、市数据等,很详细。 (可以看他们的数据来源,也是根据国家卫健委公布的信息写的)
网页地址找到了,接下来用什么工具获取呢?
工具实际上很灵活,这取决于您熟悉哪一种,Python 可以、VBA 可以或任何其他编程语言。但是我们今天使用的工具非常简单。由Excel的Power Query函数直接实现(Excel 2016及以上版本默认内置该函数)。下面介绍操作步骤:
Step1:找到数据的真实地址。刚才我们只是得到了页面的地址,但是这个地址中并没有我们想要的数据。怎么找?
这需要您对数据传输有一定的网站知识。感兴趣的朋友可以详细了解百度“Chrome 抓包分析”。我将直接提供我在这里获得的2个地址供您参考:
省级数据:湖北
城市数据:湖北&city=武汉
Step2:使用PQ获取数据。如果你没有看到如下界面,则证明你没有PQ的功能。 (没有这个功能也别着急,文末提供了直接下载数据的方法)
PoweQuery 下载链接:
点击确定后,进入如下界面,事情就变得简单了,直接手动转换数据即可。
PQ的具体操作请参考以下链接:
Step3:最后一步是“关闭并上传”到新工作表。
excel抓取网页动态数据(excel抓取网页动态数据,可以使用excel作为api,随便找个api)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-03 15:06
excel抓取网页动态数据,可以使用excel作为api,
随便找个api,我现在主要写的就是这个。lendingclub的api。为什么用,额,这种网站很容易抓的。但是性能有点低吧。对。
googleapi也可以抓,有提供支持的一些站点,rentingclub:declinetotrackmorethanfivemonth,不过是美国的。
比较专业的方式:ta="ok"s="000000.1024"en="[ein]0000"y="[ein]0000"
有一个微信公众号(小文客服)有抓取网站真实数据的功能,注册时就可以免费申请个人账号,大家可以关注看下,
我只想要各大网站的信息,没要求要人。
这个有点难,和爬虫技术无关,
bat都是excel_home:excelhomesofficeexcel及各类office软件在线安装目录下的excel.excel-forwindowstogetexcelcontentssimulated.htmlgetexcelcontentsnotion
facebook微博的api
百度搜索中国区域信息接口,有各大网站的可抓取数据。
国外的bootstrapinurlrecents:inurlswift,gmail,twitter.zip国内的:只能了。百度轻流是很不错的中国区域信息可抓取产品。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据,可以使用excel作为api,随便找个api)
excel抓取网页动态数据,可以使用excel作为api,
随便找个api,我现在主要写的就是这个。lendingclub的api。为什么用,额,这种网站很容易抓的。但是性能有点低吧。对。
googleapi也可以抓,有提供支持的一些站点,rentingclub:declinetotrackmorethanfivemonth,不过是美国的。
比较专业的方式:ta="ok"s="000000.1024"en="[ein]0000"y="[ein]0000"
有一个微信公众号(小文客服)有抓取网站真实数据的功能,注册时就可以免费申请个人账号,大家可以关注看下,
我只想要各大网站的信息,没要求要人。
这个有点难,和爬虫技术无关,
bat都是excel_home:excelhomesofficeexcel及各类office软件在线安装目录下的excel.excel-forwindowstogetexcelcontentssimulated.htmlgetexcelcontentsnotion
facebook微博的api
百度搜索中国区域信息接口,有各大网站的可抓取数据。
国外的bootstrapinurlrecents:inurlswift,gmail,twitter.zip国内的:只能了。百度轻流是很不错的中国区域信息可抓取产品。
excel抓取网页动态数据(如何不使用Python去爬取网页表格数据功能?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2022-03-03 10:25
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
也有一些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,获取其他数据有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W= 查看全部
excel抓取网页动态数据(如何不使用Python去爬取网页表格数据功能?)
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
也有一些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,获取其他数据有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W=
excel抓取网页动态数据(精通多维数组(dataarray):链表中的动态数据进场)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-02 17:02
excel抓取网页动态数据。简单易学,面试一百回,总有一次要问到某个数据的数据抓取方法。抓包过程比较考验学习者细节抓取能力,如果抓取的网页不好,则会大大降低网页的可读性,比如指定不好会被当网页源代码来读取等等。再就是很难正确识别业务逻辑、文本类型与日期类型的转换,成功获取不了实际内容;excel显然更可读一些,它的一些公式和专业术语也能让你轻松处理实际问题。
学习精通多维数组(dataarray),比如listwitharrayasdata,深入学习sql语言,
多维数组实用篇(更新中)
一)链表中的动态数据进场介绍下数组和矩阵基本概念,和动态数组相似,但数组操作的矩阵具有更多的array函数实现,另外,其实你应该关注数组操作后对数组本身的增删改查,而不是常规函数去取数。这就造成原数组增删变动时不用动态数组函数即可完成。
二)数组的点积这里有一个将动态数组做点积的好方法,可以应用到矩阵上,合并所有数组。这里为了处理动态数组的点积,就采用pairindexbyname这个方法,然后在动态数组类型外,作一个destination用来表示要处理的动态数组行号列号,实际比较简单就不详细写。
三)数组的交并差同样是处理动态数组的点积问题,交并差这个方法可以应用到线性代数中,而且在计算机视觉中也被广泛应用,实际也就是两数组拼积之后,再乘以总列数进行拼接。但从上面数组点积的代码来看,由于点积是往里面进行的,其实只有一行,这其实可以用条件判断的方法来算,具体算法见下面这个算法,来自mitfluentcs60.讲述的stackoverflow平台内容javasolution可以算出其实际效果。(。
四)数组的乘积在进行乘积运算时,一定要对矩阵进行变换,这里按矩阵进行变换,之后再计算。注意下一些具体的算法。比如两个下标不同的列,那么要用jordanarray自定义的一种traverse方法,同时注意对动态数组的处理,是先求每个元素取值的范围,然后再对计算方式进行变换。具体算法请参考下面这个solution进行实践,就不详细写了。(。
五)计算两个动态数组的秩两个动态数组:一个3*2的数组,一个3*1的数组,用一个线性算法求出大小,然后进行乘积乘积运算,先计算大小,再乘积乘积算法:基本上原数组大小先乘积再求大小也就行了。这里用求平方和做例子。另外,你只需要求出三个不同的array列中不同的顺序号,再返回其,返回结果的顺序顺序与求大小的顺序保持一致。
不管什么数组,都可以用这个算法实现,但一定要写出计算方法。具体请参考下面这个代码,返回值保持变量不变。(。 查看全部
excel抓取网页动态数据(精通多维数组(dataarray):链表中的动态数据进场)
excel抓取网页动态数据。简单易学,面试一百回,总有一次要问到某个数据的数据抓取方法。抓包过程比较考验学习者细节抓取能力,如果抓取的网页不好,则会大大降低网页的可读性,比如指定不好会被当网页源代码来读取等等。再就是很难正确识别业务逻辑、文本类型与日期类型的转换,成功获取不了实际内容;excel显然更可读一些,它的一些公式和专业术语也能让你轻松处理实际问题。
学习精通多维数组(dataarray),比如listwitharrayasdata,深入学习sql语言,
多维数组实用篇(更新中)
一)链表中的动态数据进场介绍下数组和矩阵基本概念,和动态数组相似,但数组操作的矩阵具有更多的array函数实现,另外,其实你应该关注数组操作后对数组本身的增删改查,而不是常规函数去取数。这就造成原数组增删变动时不用动态数组函数即可完成。
二)数组的点积这里有一个将动态数组做点积的好方法,可以应用到矩阵上,合并所有数组。这里为了处理动态数组的点积,就采用pairindexbyname这个方法,然后在动态数组类型外,作一个destination用来表示要处理的动态数组行号列号,实际比较简单就不详细写。
三)数组的交并差同样是处理动态数组的点积问题,交并差这个方法可以应用到线性代数中,而且在计算机视觉中也被广泛应用,实际也就是两数组拼积之后,再乘以总列数进行拼接。但从上面数组点积的代码来看,由于点积是往里面进行的,其实只有一行,这其实可以用条件判断的方法来算,具体算法见下面这个算法,来自mitfluentcs60.讲述的stackoverflow平台内容javasolution可以算出其实际效果。(。
四)数组的乘积在进行乘积运算时,一定要对矩阵进行变换,这里按矩阵进行变换,之后再计算。注意下一些具体的算法。比如两个下标不同的列,那么要用jordanarray自定义的一种traverse方法,同时注意对动态数组的处理,是先求每个元素取值的范围,然后再对计算方式进行变换。具体算法请参考下面这个solution进行实践,就不详细写了。(。
五)计算两个动态数组的秩两个动态数组:一个3*2的数组,一个3*1的数组,用一个线性算法求出大小,然后进行乘积乘积运算,先计算大小,再乘积乘积算法:基本上原数组大小先乘积再求大小也就行了。这里用求平方和做例子。另外,你只需要求出三个不同的array列中不同的顺序号,再返回其,返回结果的顺序顺序与求大小的顺序保持一致。
不管什么数组,都可以用这个算法实现,但一定要写出计算方法。具体请参考下面这个代码,返回值保持变量不变。(。
excel抓取网页动态数据(头条中抗击肺炎每天更新数据,我们可以拿到这些数据自己做图表 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-27 07:17
)
今日头条抗击肺炎的数据每天都在更新,图表也很漂亮,但是我们想拿到这些数据,自己做图表。
我们可以找到抗击肺炎的网址,用谷歌浏览器打开:
all 对应同一个进程查询的相关数据。可以使用相应的 URL 直接捕获此数据。我们不会在这里谈论它。找了半天,没有对应的预览。该数据直接通过脚本查询。让我们看一下控制台中的信息:
我们注意到这部分返回的是疫情图对应的数据:
这部分数据直接复制或保存为位记录,Power Query无法识别。需要用copy命令备份,在控制台写:
复制(临时1)
返回:
不明确的
表示数据拷贝成功
然后我们直接在Power Query中创建一个空查询,直接粘贴
分析中使用JSON格式:
该数据集包括三类:
省级数据
各省今日数据
城市分布数据
该省的时间序列数据
国家数据
就是这个时间序列数据:
世界数据
对应以下海外情况:
我们可以根据这个数据集进行自己的可视化:
在 Power BI 中,我们可以标记每个地级市的确诊病例、治愈病例和死亡病例数:
我们还可以根据时间序列数据进行趋势预测:
查看全部
excel抓取网页动态数据(头条中抗击肺炎每天更新数据,我们可以拿到这些数据自己做图表
)
今日头条抗击肺炎的数据每天都在更新,图表也很漂亮,但是我们想拿到这些数据,自己做图表。
我们可以找到抗击肺炎的网址,用谷歌浏览器打开:
all 对应同一个进程查询的相关数据。可以使用相应的 URL 直接捕获此数据。我们不会在这里谈论它。找了半天,没有对应的预览。该数据直接通过脚本查询。让我们看一下控制台中的信息:
我们注意到这部分返回的是疫情图对应的数据:
这部分数据直接复制或保存为位记录,Power Query无法识别。需要用copy命令备份,在控制台写:
复制(临时1)
返回:
不明确的
表示数据拷贝成功
然后我们直接在Power Query中创建一个空查询,直接粘贴
分析中使用JSON格式:
该数据集包括三类:
省级数据
各省今日数据
城市分布数据
该省的时间序列数据
国家数据
就是这个时间序列数据:
世界数据
对应以下海外情况:
我们可以根据这个数据集进行自己的可视化:
在 Power BI 中,我们可以标记每个地级市的确诊病例、治愈病例和死亡病例数:
我们还可以根据时间序列数据进行趋势预测:
excel抓取网页动态数据(腾讯员工一样:为什么会变成这个样子阿!(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-27 07:16
友情提示:文末有福利和精彩视频~
你最近最关心什么?一定是疫情,不能出门真的很不舒服,不是吗?
我的心和腾讯员工一样:
为什么会变成这样!不吃野味会死吗?(这里没有省略数字......)
但是生活还要继续,我们能做的就是不要添乱,保护好自己。
为了让大家更好地了解疫情,我用数据可视化来分析国内的疫情。
根据国家卫健委公布的数据,我们可以看到,重灾区依然是整个湖北省,浙江、广东也因为人流量大而成为重点地区。
一、数据从何而来?
网站 的数据会定期更新。可能上午看到的数据下午会更新,差别很大。但是通过Excel汇总数据时,效率不高,很难做到完全同步。
因此,我正在考虑使用 Python 来捕获包并将其封装成 .exe 文件。点击自动下载数据,并以csv格式进行结构化存储,方便大家使用。
该工具每次运行都会抓取并更新《腾讯新闻》疫情实时直播的数据网站,并存储在你电脑的D盘(C盘往往需要更高的读写权限) .
下载的csv文件格式如下:
事实上,这些数据对于企业、个人,对于我们了解疫情的变化和发展趋势都是非常有用的。而且我看到网上有很多人会从不同维度分析问题,作为基础数据也会有所帮助。
二、什么分析?
如前所述,使用Excel等工具进行数据分析的最大缺点是数据无法同步,需要手动录入,熟悉数据行业的人应该都知道Excel遇到大数据会卡顿。
其实分析工具更多的价值在于在分析过程中辅助数据的处理,可以直观的展示结论,最终解决问题。如果能避免在函数方面写公式和代码,而且易于使用和使用,那就更好了。
Python 和 Matplotlib 都可以进行可视化分析,但是需要一定的代码库,而且大部分不会编程的人还是占了大多数。所以我想到了BI,或者商业智能。
这里我用的是FineBI,一个企业级的数据分析工具,可视化和前端分析操作比较丰富,可以直观的进行数据钻取、数据切片、数据轮换等多维分析操作;同时内置ETL,实时数据分析,同时可以快速处理大数据,业务人员再也不用等待IT分析数据了!
FineBI 完成的数据可视化:
在这里,帆软还特别推出了疫情追踪APP版,让企业及时了解每一位员工的身体变化: 查看全部
excel抓取网页动态数据(腾讯员工一样:为什么会变成这个样子阿!(上))
友情提示:文末有福利和精彩视频~
你最近最关心什么?一定是疫情,不能出门真的很不舒服,不是吗?
我的心和腾讯员工一样:
为什么会变成这样!不吃野味会死吗?(这里没有省略数字......)
但是生活还要继续,我们能做的就是不要添乱,保护好自己。
为了让大家更好地了解疫情,我用数据可视化来分析国内的疫情。
根据国家卫健委公布的数据,我们可以看到,重灾区依然是整个湖北省,浙江、广东也因为人流量大而成为重点地区。
一、数据从何而来?
网站 的数据会定期更新。可能上午看到的数据下午会更新,差别很大。但是通过Excel汇总数据时,效率不高,很难做到完全同步。
因此,我正在考虑使用 Python 来捕获包并将其封装成 .exe 文件。点击自动下载数据,并以csv格式进行结构化存储,方便大家使用。
该工具每次运行都会抓取并更新《腾讯新闻》疫情实时直播的数据网站,并存储在你电脑的D盘(C盘往往需要更高的读写权限) .
下载的csv文件格式如下:
事实上,这些数据对于企业、个人,对于我们了解疫情的变化和发展趋势都是非常有用的。而且我看到网上有很多人会从不同维度分析问题,作为基础数据也会有所帮助。
二、什么分析?
如前所述,使用Excel等工具进行数据分析的最大缺点是数据无法同步,需要手动录入,熟悉数据行业的人应该都知道Excel遇到大数据会卡顿。
其实分析工具更多的价值在于在分析过程中辅助数据的处理,可以直观的展示结论,最终解决问题。如果能避免在函数方面写公式和代码,而且易于使用和使用,那就更好了。
Python 和 Matplotlib 都可以进行可视化分析,但是需要一定的代码库,而且大部分不会编程的人还是占了大多数。所以我想到了BI,或者商业智能。
这里我用的是FineBI,一个企业级的数据分析工具,可视化和前端分析操作比较丰富,可以直观的进行数据钻取、数据切片、数据轮换等多维分析操作;同时内置ETL,实时数据分析,同时可以快速处理大数据,业务人员再也不用等待IT分析数据了!
FineBI 完成的数据可视化:
在这里,帆软还特别推出了疫情追踪APP版,让企业及时了解每一位员工的身体变化:
excel抓取网页动态数据( Stock代码爬取代码的基本思路是什么意思?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-23 02:22
Stock代码爬取代码的基本思路是什么意思?(一))
实例描述
通过编写爬虫,爬取指定日期期间所有上市公司的股票数据,根据股票代码保存到对应的Execl文件中。
本案例主要分为两步: 1)了解什么是上市公司;2)根据每家上市公司的股票数量爬取数据。两部分代码相对独立,可以做成两个代码文件。一个文件用于爬取 Stock 代码,另一个文件用于爬取 Stock 内容。
爬取股票代码
爬取股票代码的基本思路是:
1)在网站上分析网页的源代码,找到目标代码。
2)使用正则表达式在整个网页中搜索目标代码以提取请求的信息。
定位目标网站
使用 Chrome 浏览器访问链接以查看所有股票代码;
打开调试窗口查看网页代码
保持当前浏览器窗口为活动页面,按F12键显示网页源代码调试窗口,点击调试窗口的Element按钮,可以看到该页面的HTML代码。
在网页源代码中找到目标元素
网页的源代码根据 HTML 的语法规则自动折叠。可以通过用光标单击 HTML 代码中的任意位置来展开它。当你移动到一个元素时,你会看到右侧网页上对应的元素会发生变化,呈现选中状态。
分析目标源代码找出规律
上图左侧显示的内容与右侧代码的对应关系。左侧显示的每个 Stock 代码对应的源代码格式是固定的。
下图所示的源代码内容就是要查找的目标代码。“.html”前面的“股票代码”就是需要爬取的内容。
编写代码爬取股票代码
编写代码实现urlTolist函数,并在该函数中实现主要的爬取功能;
1)使用urllib.request模块中的urlopen函数访问目标链接;
2)通过urlopen返回值的read方法获取网页的全部内容;
3)使用re模块下编译韩文风格做正则表达式的计算模板,模板字符串为之前分析的网页的目标代码;
4)调用堆返回对象的findall方法对网页的html代码进行正则表达式计算。得到的返回值code就是最终爬取的内容。
运行上述代码的结果如下;
抓取库存内容
通过访问网易提供的服务接口,您可以获得股票内容。只需按照它提供的请求格式,传入股票代码和要查看的时间段,就可以得到股票的具体数据。
编写代码以抓取批量内容
代码实现方面,仍然使用 urllib.request 模块进行网络请求,会调用 urllib.request 模块下的 urlretrieve 函数将返回的数据保存在 Excl 表中。
代码中设置的时间段为8个月以上,即20180101到20180831.保存的结果放在D盘的all_stock_data路径下。为保证save操作的正常进行,请确保all_stock_data文件夹存在于D盘。(如果没有,请先创建一个)
显示运行代码的结果
代码运行后,可以在D盘的all_stock_data文件夹中找到生成的股票数据文件。
刮库存数据的情况结束了。
其他刮取物品的技术
爬虫是Python语言中应用广泛的项目方向,涉及的知识很多。限于篇幅,提供简单的例子。还有多线程并发爬取、动态网页爬取、跨域处理、子链搜索、自动登录提权爬取、反爬取处理等多种技术。 查看全部
excel抓取网页动态数据(
Stock代码爬取代码的基本思路是什么意思?(一))
实例描述
通过编写爬虫,爬取指定日期期间所有上市公司的股票数据,根据股票代码保存到对应的Execl文件中。
本案例主要分为两步: 1)了解什么是上市公司;2)根据每家上市公司的股票数量爬取数据。两部分代码相对独立,可以做成两个代码文件。一个文件用于爬取 Stock 代码,另一个文件用于爬取 Stock 内容。
爬取股票代码
爬取股票代码的基本思路是:
1)在网站上分析网页的源代码,找到目标代码。
2)使用正则表达式在整个网页中搜索目标代码以提取请求的信息。
定位目标网站
使用 Chrome 浏览器访问链接以查看所有股票代码;
打开调试窗口查看网页代码
保持当前浏览器窗口为活动页面,按F12键显示网页源代码调试窗口,点击调试窗口的Element按钮,可以看到该页面的HTML代码。
在网页源代码中找到目标元素
网页的源代码根据 HTML 的语法规则自动折叠。可以通过用光标单击 HTML 代码中的任意位置来展开它。当你移动到一个元素时,你会看到右侧网页上对应的元素会发生变化,呈现选中状态。
分析目标源代码找出规律
上图左侧显示的内容与右侧代码的对应关系。左侧显示的每个 Stock 代码对应的源代码格式是固定的。
下图所示的源代码内容就是要查找的目标代码。“.html”前面的“股票代码”就是需要爬取的内容。
编写代码爬取股票代码
编写代码实现urlTolist函数,并在该函数中实现主要的爬取功能;
1)使用urllib.request模块中的urlopen函数访问目标链接;
2)通过urlopen返回值的read方法获取网页的全部内容;
3)使用re模块下编译韩文风格做正则表达式的计算模板,模板字符串为之前分析的网页的目标代码;
4)调用堆返回对象的findall方法对网页的html代码进行正则表达式计算。得到的返回值code就是最终爬取的内容。
运行上述代码的结果如下;
抓取库存内容
通过访问网易提供的服务接口,您可以获得股票内容。只需按照它提供的请求格式,传入股票代码和要查看的时间段,就可以得到股票的具体数据。
编写代码以抓取批量内容
代码实现方面,仍然使用 urllib.request 模块进行网络请求,会调用 urllib.request 模块下的 urlretrieve 函数将返回的数据保存在 Excl 表中。
代码中设置的时间段为8个月以上,即20180101到20180831.保存的结果放在D盘的all_stock_data路径下。为保证save操作的正常进行,请确保all_stock_data文件夹存在于D盘。(如果没有,请先创建一个)
显示运行代码的结果
代码运行后,可以在D盘的all_stock_data文件夹中找到生成的股票数据文件。
刮库存数据的情况结束了。
其他刮取物品的技术
爬虫是Python语言中应用广泛的项目方向,涉及的知识很多。限于篇幅,提供简单的例子。还有多线程并发爬取、动态网页爬取、跨域处理、子链搜索、自动登录提权爬取、反爬取处理等多种技术。
excel抓取网页动态数据(2016年上海事业单位医疗招聘考试真题及答案(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-21 08:23
源内容
4003,23,16,51;25,56,46,52,13,61,73,49,10,4,60,17,19,58,69,21,16,11,7,23
:4002,23,13,21;44,19,31,48,11,29,70,9,74,62,42,40,32,8,35,2,7,16,10, 59
:4001,23,09,51;19,21,74,27,4,53,14,58,75,17,72,33,73,54,8,49,79,36,30, 78
:4000,23,06,20;36,42,21,60,9,45,79,49,75,37,80,23,38,67,58,1,68,48,27, 61
:3999,23,02,50;76,20,67,30,58,13,5,1,51,75,78,59,52,4,68,44,40,8,66, 73
:3998,22,59,19;20,74,72,52,18,68,11,66,12,40,13,5,31,69,21,75,58,59,9, 32
:3997,22,55,52;43,5,61,78,23,1,20,45,2,24,7,56,57,63,36,76,46,28,30, 69
:3996,22,52,20;25,57,65,40,47,41,54,15,48,78,52,62,71,23,45,64,74,22,8, 11
:3995,22,48,50;9,66,54,68,56,25,29,7,15,16,19,50,3,13,12,11,24,63,70, 17
:3994,22,45,20;70,30,26,72,28,4,47,54,25,32,39,12,63,2,77,71,14,15,37, 64
:3993,22,41,52;74,35,69,19,7,34,36,78,31,44,10,63,6,13,33,77,4,14,75, 61
:3992,22,38,22;3,20,54,15,33,48,78,75,36,14,16,59,8,69,9,12,71,24,40, 50
:3991,22,34,51;53,2,79,9,37,17,50,3,43,14,64,42,56,1,59,73,27,28,26, 7
:3990,22,31,21;57,73,32,45,30,20,5,55,71,56,52,58,63,78,34,42,68,33,61, 22
:3989,22,27,51;25,47,74,26,78,5,49,11,38,70,24,30,18,63,4,27,12,10,33, 57:">
网页显示内容
在数字源代码中可以找到,不过是把数字从小到大重新排列,应该有办法获取。
估计会用到2个拆分
拆分(“:”)
splt(",")
再次使用大函数(拆分得到的数组, 20), large(拆分得到的数组, 19)...large(拆分得到的数组, 1)'这个在函数中很简单,但是在VB中好像很复杂,我还没看懂
不过VB还是挺复杂的,慢慢改吧。
做了一个半成品VB,发现实现实时更新相当复杂;我暂时只能得到一页;
123.zip(33.96 KB,下载:86)
2013-4-29 01:48上传
点击文件名下载附件
有人帮忙修改代码,继续做 查看全部
excel抓取网页动态数据(2016年上海事业单位医疗招聘考试真题及答案(二))
源内容
4003,23,16,51;25,56,46,52,13,61,73,49,10,4,60,17,19,58,69,21,16,11,7,23
:4002,23,13,21;44,19,31,48,11,29,70,9,74,62,42,40,32,8,35,2,7,16,10, 59
:4001,23,09,51;19,21,74,27,4,53,14,58,75,17,72,33,73,54,8,49,79,36,30, 78
:4000,23,06,20;36,42,21,60,9,45,79,49,75,37,80,23,38,67,58,1,68,48,27, 61
:3999,23,02,50;76,20,67,30,58,13,5,1,51,75,78,59,52,4,68,44,40,8,66, 73
:3998,22,59,19;20,74,72,52,18,68,11,66,12,40,13,5,31,69,21,75,58,59,9, 32
:3997,22,55,52;43,5,61,78,23,1,20,45,2,24,7,56,57,63,36,76,46,28,30, 69
:3996,22,52,20;25,57,65,40,47,41,54,15,48,78,52,62,71,23,45,64,74,22,8, 11
:3995,22,48,50;9,66,54,68,56,25,29,7,15,16,19,50,3,13,12,11,24,63,70, 17
:3994,22,45,20;70,30,26,72,28,4,47,54,25,32,39,12,63,2,77,71,14,15,37, 64
:3993,22,41,52;74,35,69,19,7,34,36,78,31,44,10,63,6,13,33,77,4,14,75, 61
:3992,22,38,22;3,20,54,15,33,48,78,75,36,14,16,59,8,69,9,12,71,24,40, 50
:3991,22,34,51;53,2,79,9,37,17,50,3,43,14,64,42,56,1,59,73,27,28,26, 7
:3990,22,31,21;57,73,32,45,30,20,5,55,71,56,52,58,63,78,34,42,68,33,61, 22
:3989,22,27,51;25,47,74,26,78,5,49,11,38,70,24,30,18,63,4,27,12,10,33, 57:">
网页显示内容
在数字源代码中可以找到,不过是把数字从小到大重新排列,应该有办法获取。
估计会用到2个拆分
拆分(“:”)
splt(",")
再次使用大函数(拆分得到的数组, 20), large(拆分得到的数组, 19)...large(拆分得到的数组, 1)'这个在函数中很简单,但是在VB中好像很复杂,我还没看懂
不过VB还是挺复杂的,慢慢改吧。
做了一个半成品VB,发现实现实时更新相当复杂;我暂时只能得到一页;
123.zip(33.96 KB,下载:86)
2013-4-29 01:48上传
点击文件名下载附件
有人帮忙修改代码,继续做
excel抓取网页动态数据( 【知识点】JavaScript.js和Map将使用原生方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-21 05:07
【知识点】JavaScript.js和Map将使用原生方法)
使用 JavaScript 在 HTML 表格中动态显示 JSON 数据
在几秒钟内从任何 JSON 数据制作动态表格,··· 将 JSON 数据转换为 HTML 表格·· th, td, p, input {· font:14px Verdana;要获取数据,请使表格可排序或可编辑,并在项目中收录 tabulator.css 和 tabulator.js 文件。回调应返回要在单元格中显示的 HTML。在 JavaScript 中使用 JSON 数据动态创建 HTML 表格 标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。我不熟悉 linq.js,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。常量 $table 。
使用 JavaScript 中的 JSON 数据动态创建 HTML 表格,如果您需要从外部 API 获取数据,请使表格可排序或可编辑,并在项目中收录 tabulator.css 和 tabulator.js 文件。回调应返回要在单元格中显示的 HTML。标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。 .使用javascript动态代码在html表格中显示json数据,我对linq.js不熟悉,所以我使用原生数组方法Array#reduce()和Map对象来创建唯一区域。 const $table 在这里,Mudassar Ahmed Khan 解释了如何使用 JavaScript 在 HTML 表中填充(显示)JSON 数据。 HTML 表格将被动态创建。
使用 javascript 在 html 表格中动态显示 json 数据 代码、标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。我不熟悉 linq.js,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。常量 $table 。如何使用 jQuery 将 JSON 数据动态转换为 HTML 表格,Mudassar Ahmed Khan 在这里解释了如何使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据。 HTML 表将动态创建 为了能够在我们的 HTML 文件中显示这些数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ;.
如何使用 jQuery 将 JSON 数据动态转换为 HTML 表格,我对 linq.js 不熟悉,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。 const $table 在这里,Mudassar Ahmed Khan 解释了如何使用 JavaScript 在 HTML 表中填充(显示)JSON 数据。 HTML 表格将动态创建。要使用 JavaScript 在 HTML 表中填充(显示)JSON 数据,为了能够在我们的 HTML 文件中显示此数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ;使用 Grepper Chrome 扩展程序可以立即从您的 google 搜索结果中获取代码示例,例如“使用 javascript 在 html 表中动态显示 json 数据”。 .
使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据,Mudassar Ahmed Khan 在这里解释了如何使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据。 HTML 表将动态创建 为了能够在我们的 HTML 文件中显示这些数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ; 使用 Javascript 从 JSON 创建动态表 – Himanshu,使用 Grepper Chrome 扩展程序立即从您的 Google 搜索结果中获取代码示例,例如“使用 javascript 在 html 表中动态显示 json 数据”。从任何 JSON 数据在几秒钟内制作动态表。可以使用标准 HTML 表格上的制表符编辑表格中的数据。要将数据存储在表中,请使用 getData 。
如何在 HTML 中显示来自 API 的 JSON 数据
访问并打印特定的 JSON 值,此代码是 Using Jquery。我建议你了解更多关于 ajax 的知识。编辑:我已经更新了我的答案以适应你的情况。在我的演示中,我查询当前记录的数据并将 JSON 格式的结果转换为字符串并直接显示为文本。 (用于检索的 Web API 将返回 JSON 格式的数据)只需使用 AJAX 请求调用 Web API 并在客户端 API 之前添加父语法。 (因为 Web 资源作为 iframe 元素嵌入到记录表单中)。如何在 html 中显示 Json API 数据?这是一个没有 jQuery 的工作示例 // 当数据准备好时回调运行 function reqListener() { // 将 JSON 文本解析为一个对象,这样我们就可以获得一个属性 var data = JSON.parse(this.responseText ) ; // 将值附加到 DOM。现在让我们从数组中获取一个值。文档类型 html> 。版权所有。蜀ICP备2021025969号 查看全部
excel抓取网页动态数据(
【知识点】JavaScript.js和Map将使用原生方法)
使用 JavaScript 在 HTML 表格中动态显示 JSON 数据
在几秒钟内从任何 JSON 数据制作动态表格,··· 将 JSON 数据转换为 HTML 表格·· th, td, p, input {· font:14px Verdana;要获取数据,请使表格可排序或可编辑,并在项目中收录 tabulator.css 和 tabulator.js 文件。回调应返回要在单元格中显示的 HTML。在 JavaScript 中使用 JSON 数据动态创建 HTML 表格 标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。我不熟悉 linq.js,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。常量 $table 。
使用 JavaScript 中的 JSON 数据动态创建 HTML 表格,如果您需要从外部 API 获取数据,请使表格可排序或可编辑,并在项目中收录 tabulator.css 和 tabulator.js 文件。回调应返回要在单元格中显示的 HTML。标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。 .使用javascript动态代码在html表格中显示json数据,我对linq.js不熟悉,所以我使用原生数组方法Array#reduce()和Map对象来创建唯一区域。 const $table 在这里,Mudassar Ahmed Khan 解释了如何使用 JavaScript 在 HTML 表中填充(显示)JSON 数据。 HTML 表格将被动态创建。
使用 javascript 在 html 表格中动态显示 json 数据 代码、标签:JavaScript、HTML、JSON、表格、数组 这里 Mudassar Ahmed Khan 解释了如何在运行时使用 JavaScript 在 HTML 中创建动态表格。列、行和单元格将使用 JavaScript 在表格中动态创建。我不熟悉 linq.js,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。常量 $table 。如何使用 jQuery 将 JSON 数据动态转换为 HTML 表格,Mudassar Ahmed Khan 在这里解释了如何使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据。 HTML 表将动态创建 为了能够在我们的 HTML 文件中显示这些数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ;.
如何使用 jQuery 将 JSON 数据动态转换为 HTML 表格,我对 linq.js 不熟悉,所以我使用原生数组方法 Array#reduce() 和 Map 对象来创建唯一区域。 const $table 在这里,Mudassar Ahmed Khan 解释了如何使用 JavaScript 在 HTML 表中填充(显示)JSON 数据。 HTML 表格将动态创建。要使用 JavaScript 在 HTML 表中填充(显示)JSON 数据,为了能够在我们的 HTML 文件中显示此数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ;使用 Grepper Chrome 扩展程序可以立即从您的 google 搜索结果中获取代码示例,例如“使用 javascript 在 html 表中动态显示 json 数据”。 .
使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据,Mudassar Ahmed Khan 在这里解释了如何使用 JavaScript 在 HTML 表格中填充(显示)JSON 数据。 HTML 表将动态创建 为了能够在我们的 HTML 文件中显示这些数据,我们首先需要使用 JavaScript 获取数据。我们将使用 fetch API 来获取这些数据。我们使用 fetch API 的方式如下: fetch (url).then (function (response) { // JSON 数据会到这里}).catch (function (err) { // 如果发生错误,你会catch这里}) ; 使用 Javascript 从 JSON 创建动态表 – Himanshu,使用 Grepper Chrome 扩展程序立即从您的 Google 搜索结果中获取代码示例,例如“使用 javascript 在 html 表中动态显示 json 数据”。从任何 JSON 数据在几秒钟内制作动态表。可以使用标准 HTML 表格上的制表符编辑表格中的数据。要将数据存储在表中,请使用 getData 。
如何在 HTML 中显示来自 API 的 JSON 数据
访问并打印特定的 JSON 值,此代码是 Using Jquery。我建议你了解更多关于 ajax 的知识。编辑:我已经更新了我的答案以适应你的情况。在我的演示中,我查询当前记录的数据并将 JSON 格式的结果转换为字符串并直接显示为文本。 (用于检索的 Web API 将返回 JSON 格式的数据)只需使用 AJAX 请求调用 Web API 并在客户端 API 之前添加父语法。 (因为 Web 资源作为 iframe 元素嵌入到记录表单中)。如何在 html 中显示 Json API 数据?这是一个没有 jQuery 的工作示例 // 当数据准备好时回调运行 function reqListener() { // 将 JSON 文本解析为一个对象,这样我们就可以获得一个属性 var data = JSON.parse(this.responseText ) ; // 将值附加到 DOM。现在让我们从数组中获取一个值。文档类型 html> 。版权所有。蜀ICP备2021025969号
excel抓取网页动态数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2022-02-19 03:18
有时我们需要从网站中获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作与 网站 自动同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 功能。
以下页面为中国地震台网官方页面( )。每当发生地震时,都会在此处自动更新。由于我们要抓取它,所以我们需要先打开页面。
▲首先打开要爬取的网页
打开Excel,点击“数据”→“获取数据”→“从其他来源”,将要爬取的URL粘贴进去。此时Power Query会自动分析网页,然后在check中显示分析结果盒子。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
▲创建查询确定抓取范围
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角的“关闭并上传”,上传Excel。
▲数据“预清洗”
数据上传到 Excel 后,格式化过程可以继续。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等。通俗地说就是一些美化操作,最后我们得到了下表。
▲美化餐桌
目前表基础已经完成,但是像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表。
▲设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
▲防止更新时表格格式被破坏
这种技术非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这就是本期想和大家分享的一个小技巧,是不是很有用! 查看全部
excel抓取网页动态数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
有时我们需要从网站中获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作与 网站 自动同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 功能。
以下页面为中国地震台网官方页面( )。每当发生地震时,都会在此处自动更新。由于我们要抓取它,所以我们需要先打开页面。
▲首先打开要爬取的网页
打开Excel,点击“数据”→“获取数据”→“从其他来源”,将要爬取的URL粘贴进去。此时Power Query会自动分析网页,然后在check中显示分析结果盒子。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
▲创建查询确定抓取范围
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角的“关闭并上传”,上传Excel。
▲数据“预清洗”
数据上传到 Excel 后,格式化过程可以继续。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等。通俗地说就是一些美化操作,最后我们得到了下表。
▲美化餐桌
目前表基础已经完成,但是像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表。
▲设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
▲防止更新时表格格式被破坏
这种技术非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这就是本期想和大家分享的一个小技巧,是不是很有用!
excel抓取网页动态数据(excel抓取网页动态数据的方法很多,excel可以实现发陌陌、聊天记录等等)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-18 20:01
excel抓取网页动态数据的方法很多,excel可以实现发qq、链接;excel可以实现发微信文章、网页论坛帖子;excel可以实现发陌陌、聊天记录等等。这些我也都用过,用处并不大。后来我意识到,我为什么做这件事呢?完成这件事可以解决哪些问题??我怎么去处理??我们讲一个公式,叫spider=spidera(用于采集数据的网站,用于添加我们抓取的网站的post等等);目前有5个网站可以用这个方法。
spidera:地址:;url=spidera;这个网站是一个旅游网站,他的wap/html网页内容如下:可以看到他的wap站点根本没有引入javascript代码,我们可以看到所有内容都是通过html的编码来解析的,通过添加spidera后,我们可以在抓取的页面上添加我们采集的网址,比如:;url=;url=spidera。
spidera地址可以在excelsheet1里查看,如下图:返回结果如下图:上面返回了所有的链接,这个数据结构如下:有多个attribute,我们可以根据我们的需求,获取不同的attribute:type:一种为人工分词,一种为自动分词;tmply:一种为图片,一种为视频,我们可以直接进行下载;tradename:一种是位置信息,一种是内容信息,我们可以抓取源数据;from:和qq,是可以直接进行抓取的,baidu/google/搜狗是需要识别出网址地址才能抓取;还有一个中文分词(就是根据词根)可以抓取patch;我们还可以自定义分词和获取标注:获取标注:请求标注网站:;url=spidera;服务器会返回patch格式的send信息:tinly格式:表格格式url+sign函数sendfunctiononlyattr(src){tinly=start(src,sourcename,callback);tinly.seturlswith("/");if(isnull(sourcename,sign)){sourcename=sign;}else{sourcename="";}}tinly.seturlswith("");tinly.seturlswith("/");tinly.seturlswith("");}第一个参数为src(url),最后一个参数为sign函数。
返回结果如下:返回结果是源数据和一些第三方数据我们之前用python,我们可以通过发javascript来获取sign函数(sethtmlstring和sethtmlstringstream),实现第三方图片抓取;后来我们发现,并不满足我们的需求,现在我们要做的是,要抓取源数据的同时也要抓取数据,我这边只是提供一个思路,根据我们的需求,我们想要抓取多少页面,我们可以分几个步骤来完成。
上面代码执行一下,会跳出下面信息:①sign:源数据信息;②data:数据信息;这里有一个提示,上面的data信息:数据应该是两个文件的总和;③{name。 查看全部
excel抓取网页动态数据(excel抓取网页动态数据的方法很多,excel可以实现发陌陌、聊天记录等等)
excel抓取网页动态数据的方法很多,excel可以实现发qq、链接;excel可以实现发微信文章、网页论坛帖子;excel可以实现发陌陌、聊天记录等等。这些我也都用过,用处并不大。后来我意识到,我为什么做这件事呢?完成这件事可以解决哪些问题??我怎么去处理??我们讲一个公式,叫spider=spidera(用于采集数据的网站,用于添加我们抓取的网站的post等等);目前有5个网站可以用这个方法。
spidera:地址:;url=spidera;这个网站是一个旅游网站,他的wap/html网页内容如下:可以看到他的wap站点根本没有引入javascript代码,我们可以看到所有内容都是通过html的编码来解析的,通过添加spidera后,我们可以在抓取的页面上添加我们采集的网址,比如:;url=;url=spidera。
spidera地址可以在excelsheet1里查看,如下图:返回结果如下图:上面返回了所有的链接,这个数据结构如下:有多个attribute,我们可以根据我们的需求,获取不同的attribute:type:一种为人工分词,一种为自动分词;tmply:一种为图片,一种为视频,我们可以直接进行下载;tradename:一种是位置信息,一种是内容信息,我们可以抓取源数据;from:和qq,是可以直接进行抓取的,baidu/google/搜狗是需要识别出网址地址才能抓取;还有一个中文分词(就是根据词根)可以抓取patch;我们还可以自定义分词和获取标注:获取标注:请求标注网站:;url=spidera;服务器会返回patch格式的send信息:tinly格式:表格格式url+sign函数sendfunctiononlyattr(src){tinly=start(src,sourcename,callback);tinly.seturlswith("/");if(isnull(sourcename,sign)){sourcename=sign;}else{sourcename="";}}tinly.seturlswith("");tinly.seturlswith("/");tinly.seturlswith("");}第一个参数为src(url),最后一个参数为sign函数。
返回结果如下:返回结果是源数据和一些第三方数据我们之前用python,我们可以通过发javascript来获取sign函数(sethtmlstring和sethtmlstringstream),实现第三方图片抓取;后来我们发现,并不满足我们的需求,现在我们要做的是,要抓取源数据的同时也要抓取数据,我这边只是提供一个思路,根据我们的需求,我们想要抓取多少页面,我们可以分几个步骤来完成。
上面代码执行一下,会跳出下面信息:①sign:源数据信息;②data:数据信息;这里有一个提示,上面的data信息:数据应该是两个文件的总和;③{name。
excel抓取网页动态数据(苦于没有数据支撑???数据??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-18 15:15
作为新时代的产物,如果你还不了解爬虫,你可能已经出局了。
爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。
soga,但产品为什么要懂爬虫呢?爬虫抓取数据。所以:
如果您想做出决定但没有数据支持怎么办?
如果你想拆指标却又没有数据支撑?
如果您正在分析竞争产品但没有数据支持?
如果您想...但没有数据支持?
在营销中包括搜索引擎优化和潜在客户;竞争产品分析中的竞争产品动态和相关反馈;个人生活中的专家点评,公司岗位也有使用爬虫的地方。
所以,爬行动物,走吧。
接下来,我们5分钟抢B站弹幕:
首先,想要做好工作,首先要磨砺自己的工具,先安装Chrome浏览器,然后调用控制台(Win快捷键Fn+F12)
温馨提示,通过将网页和控制台变成如图所示的上下分屏,体验会更好。
上下分屏.png
接下来我们在B站注册,随机打开一个链接,
假设我们听一首歌,
然后,如图,右键Network-》xml-》,在新页面中打开。
获取链接steps.png
如图,那么我们就可以得到所有的弹幕,然后复制链接。
所有弹幕.png
打开Excel2013,Data-From网站-粘贴地址-Go-Check-Import:
Excel 操作1.png
在这方面,我们捕捉到了华丽的数据。
但是,数据有点乱,我们就处理一下吧。
初步数据.png
这里我们使用Excel的列功能,选择逗号作为分隔符,
专栏.png
最终效果如图,
最终效果.png
如果你想问这些字段是什么意思,咳咳,说几句话,
K列,116.342代表时间(秒);
L栏,1代表弹幕类型(1-选框,4-下,5-悬停);
M列和N列代表字体和颜色;
数据是宝贵的资产,亟待挖掘。 查看全部
excel抓取网页动态数据(苦于没有数据支撑???数据??)
作为新时代的产物,如果你还不了解爬虫,你可能已经出局了。
爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。
soga,但产品为什么要懂爬虫呢?爬虫抓取数据。所以:
如果您想做出决定但没有数据支持怎么办?
如果你想拆指标却又没有数据支撑?
如果您正在分析竞争产品但没有数据支持?
如果您想...但没有数据支持?
在营销中包括搜索引擎优化和潜在客户;竞争产品分析中的竞争产品动态和相关反馈;个人生活中的专家点评,公司岗位也有使用爬虫的地方。
所以,爬行动物,走吧。
接下来,我们5分钟抢B站弹幕:
首先,想要做好工作,首先要磨砺自己的工具,先安装Chrome浏览器,然后调用控制台(Win快捷键Fn+F12)
温馨提示,通过将网页和控制台变成如图所示的上下分屏,体验会更好。
上下分屏.png
接下来我们在B站注册,随机打开一个链接,
假设我们听一首歌,
然后,如图,右键Network-》xml-》,在新页面中打开。
获取链接steps.png
如图,那么我们就可以得到所有的弹幕,然后复制链接。
所有弹幕.png
打开Excel2013,Data-From网站-粘贴地址-Go-Check-Import:
Excel 操作1.png
在这方面,我们捕捉到了华丽的数据。
但是,数据有点乱,我们就处理一下吧。
初步数据.png
这里我们使用Excel的列功能,选择逗号作为分隔符,
专栏.png
最终效果如图,
最终效果.png
如果你想问这些字段是什么意思,咳咳,说几句话,
K列,116.342代表时间(秒);
L栏,1代表弹幕类型(1-选框,4-下,5-悬停);
M列和N列代表字体和颜色;
数据是宝贵的资产,亟待挖掘。
excel抓取网页动态数据(PowerBIDesktopDesktop主题模板下载的耐心解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2022-02-18 05:04
新界面已在最近更新的 Power BI Desktop 中启用,在选项中勾选重启会打开新界面:
我们来看看新界面是什么样子的:
图标排列与原来相比有很大变化。我觉得最大的变化是视图中的主题可以预览,有点像办公室里的主题。
过去,Power BI Desktop 最受诟病的是这些主题的配色,没有 Tableau 看起来很漂亮。其实Power BI Desktop也提供了主题模板供下载,但是这个网站国内访问有点难,这里我是可以访问的,但是速度慢,看起来不太正常:
如何刷新是这样的。本网站提供了100多个主题模板,点击单个主题打开,勾选即可看到模板文件的下载地址:
在页面上可以看到无法下载,网站被禁用。
我们可以点击检查中的这个链接直接下载JSON到本地。如果看好其中一个题目,可以像这样单独下载。如果要全部下载,一个一个比较麻烦,所以我们使用Power Query查找所有下载链接,然后使用下载工具一次性下载。
第 1 步:网站分析
这个 网站 非常慢,所以请耐心等待。第一步是找到每个主题的地址。我们需要逐页搜索,每页12页,一共120页,如果最后一页也是12页。
打开这个页面后,可以直接用文本解析找到12个连接。
然后我们必须在单独的主题页面上找到下载地址。图片刚刚发了,没有问题。
第 2 步:尝试捕获
试抓主题地址:直接从web,改成从文本中,过滤掉链接地址:
试抓主题文件地址:同样使用文本格式过滤掉文件地址:
很容易找到。
第三步:定义抓取功能
主题地址抓取功能:参数为页码
文件地址抓取功能:参数为主题url
第 4 步:抓住
话题地址抓取:这一步很顺利,展开得到想要的话题地址列表
文件地址爬取:也爬出来了,但是有8个错误
有些错的地方单独检查,有些没有文件地址,我们就忽略了。一共113行正确的文件地址是108行,我们可以抓取108个主题。
让我们将此表复制并粘贴到 Excel 中:
打开迅雷并新建一个下载任务:将这些地址粘贴到迅雷中:
每个文件都不大,一会儿就下载下来:
如何使用这些主题,让我们回到 Power BI Desktop:
浏览主题,然后选择文件,您就完成了
这是刚刚导入的主题:
Power BI Desktop 的主题每次都要重新添加。不能像内置主题一样随时使用,有点不方便。 查看全部
excel抓取网页动态数据(PowerBIDesktopDesktop主题模板下载的耐心解析)
新界面已在最近更新的 Power BI Desktop 中启用,在选项中勾选重启会打开新界面:
我们来看看新界面是什么样子的:
图标排列与原来相比有很大变化。我觉得最大的变化是视图中的主题可以预览,有点像办公室里的主题。
过去,Power BI Desktop 最受诟病的是这些主题的配色,没有 Tableau 看起来很漂亮。其实Power BI Desktop也提供了主题模板供下载,但是这个网站国内访问有点难,这里我是可以访问的,但是速度慢,看起来不太正常:
如何刷新是这样的。本网站提供了100多个主题模板,点击单个主题打开,勾选即可看到模板文件的下载地址:
在页面上可以看到无法下载,网站被禁用。
我们可以点击检查中的这个链接直接下载JSON到本地。如果看好其中一个题目,可以像这样单独下载。如果要全部下载,一个一个比较麻烦,所以我们使用Power Query查找所有下载链接,然后使用下载工具一次性下载。
第 1 步:网站分析
这个 网站 非常慢,所以请耐心等待。第一步是找到每个主题的地址。我们需要逐页搜索,每页12页,一共120页,如果最后一页也是12页。
打开这个页面后,可以直接用文本解析找到12个连接。
然后我们必须在单独的主题页面上找到下载地址。图片刚刚发了,没有问题。
第 2 步:尝试捕获
试抓主题地址:直接从web,改成从文本中,过滤掉链接地址:
试抓主题文件地址:同样使用文本格式过滤掉文件地址:
很容易找到。
第三步:定义抓取功能
主题地址抓取功能:参数为页码
文件地址抓取功能:参数为主题url
第 4 步:抓住
话题地址抓取:这一步很顺利,展开得到想要的话题地址列表
文件地址爬取:也爬出来了,但是有8个错误
有些错的地方单独检查,有些没有文件地址,我们就忽略了。一共113行正确的文件地址是108行,我们可以抓取108个主题。
让我们将此表复制并粘贴到 Excel 中:
打开迅雷并新建一个下载任务:将这些地址粘贴到迅雷中:
每个文件都不大,一会儿就下载下来:
如何使用这些主题,让我们回到 Power BI Desktop:
浏览主题,然后选择文件,您就完成了
这是刚刚导入的主题:
Power BI Desktop 的主题每次都要重新添加。不能像内置主题一样随时使用,有点不方便。
excel抓取网页动态数据( 小编来一起如何用python来抓取页面中的数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-16 06:16
小编来一起如何用python来抓取页面中的数据?
)
浅谈如何使用python抓取网页中的动态数据
更新时间:2020-08-17 11:08:10 作者:saintlas
本篇文章主要介绍如何使用python抓取网页中的动态数据。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。需要的小伙伴一起来和小编一起学习吧
我们经常发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,网站的其他很多RequestURL也没有那么直接,所以我们会使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
excel抓取网页动态数据(
小编来一起如何用python来抓取页面中的数据?
)
浅谈如何使用python抓取网页中的动态数据
更新时间:2020-08-17 11:08:10 作者:saintlas
本篇文章主要介绍如何使用python抓取网页中的动态数据。文章中对示例代码进行了非常详细的介绍。对大家的学习或工作有一定的参考和学习价值。需要的小伙伴一起来和小编一起学习吧
我们经常发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,网站的其他很多RequestURL也没有那么直接,所以我们会使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text

