
cookie
搜狗陌陌采集 —— python爬虫系列一
采集交流 • 优采云 发表了文章 • 0 个评论 • 629 次浏览 • 2020-07-24 08:00
目的:获取搜狗陌陌中搜索主题返回的文章。
涉及反爬机制:cookie设置,js加密。
完整代码已上传本人github,仅供参考。如果对您有帮助,劳烦看客大人给个星星!
进入题外话。
打开搜狗陌陌,在搜索框输入“咸蛋超人”,这里搜索下来的就是有关“咸蛋超人”主题的各个公众号的文章列表:
按照正常的采集流程,此时按F12打开浏览器的开发者工具,利用选择工具点击列表中文章标题,查看源码中列表中文章url的所在位置,再用xpath获取文章url的值,也就是这个href的值,为防止混乱,我们称之为“列表页面的文章url”。
可以见到“列表页面的文章url”需要拼接,一般这些情况须要在浏览器中正常访问一下这篇文章,对比观察跳转后的url(我们称之为“真实的文章url”),再缺头补头缺腿补腿即可。下面是两个url的对比:
列表页面的文章url:
/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNFzn4G2S0Yt3MduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGSa3_pkMzadQg75Zhmxb9YI0psZvVepKtN4hpzQgtGa2iOlKKLwV_oxooGE6sxg1qinKxTb5VwJUcLBM1RgkzAPRtmyIGw2VAg..&type=2&query=%E5%92%B8%E8%9B%8B%E8%B6%85%E4%BA%BA&k=92&h=z
真实的文章url:
https://mp.weixin.qq.com/s?src=11&timestamp=1573092595&ver=1959&signature=FjD709D-0vHSyVgQyXCS-TUAcnT0M9Gx6JljQEb6O55zpuyyDaTHqgkRCxNDtt5ZDifDRUUBOemzxcz71FMOmO88m6RWfR0r4fFBe0VefAsjFu0pl-M0frYOnXPF5JD8&new=1
这里很明显两个url的路径不一致,应该是中间经过了一些调转,python的requests库是带手动调转功能,我们先把域名补上试一下访问
明显这儿做了反爬限制,那么这儿开始,我们就须要抓包剖析了。这里用到的工具是Firefox浏览器的开发者工具。抓包观察的是从搜索结果页面列表文章点击跳转到文章页面的过程,这里点击文章超链接会在新窗口打开,我们只须要在网页源码中把对应a标签的target属性改为空搜狗微信文章采集,就可以在一个窗口中观察整个流程的数据包了。
抓包剖析:
通过抓包我们可以找到搜索结果页面跳转到文章页面的过程,这里观察发觉,“列表页面的文章url”返回的结果中就包含了“真实的文章url”的信息,这意味着我们只须要正确访问到“列表页面的文章url”,根据返回的数据能够拼接出“真实的文章url”并访问了,这样我们就实现从“列表页面的文章url”到“真实的文章url”的跳转了!
此时我们的目标就从获取“真实的文章url”转变到正确的访问“列表页面的文章url”了,继续剖析抓包数据中的“列表页面的文章url”信息:
抓包数据:
url:https://weixin.sogou.com/link% ... h%3DU
method:GET
请求参数:{"url":"dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNEnNekGBXt9LMduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGaBLLLEV3E0vo604DcwbvX2VNudQZNnBemevd34BJP94ZL5zUiA49LgzIjRlpGxccVxTTaLhHZKstaeqw41upSVAe0f8bRARvQ..","type":"2","query":"咸蛋超人","k":"60","h":"U"}
headers:
Host: weixin.sogou.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Referer: https://weixin.sogou.com/weixi ... 40108
Cookie: 见下
Cookie:{"ABTEST":"4|1573094886|v1","IPLOC":"CN4401","JSESSIONID":"aaa3VBk4eXnIf8d4bdx4w","SNUID":"57A28ED20A0F9FB2BBE3E0180AF00D25","SUID":"5EAB87DB2613910A000000005DC385E6","SUV":"00F221C2DB87AB5E5DC385E7BC43F633"}
这里的重点有三个:
请求参数:对比我们获取的“列表页面的文章url”分析可以发觉,这里多了两个参数“k”、“h”,这是须要我们设法获取的。headers:经过测试该网站对User-Agent敏感,一次访问前后User-Agent须要一致。Cookie:Cookie中参数须要获取能够正确访问该url。这些参数分别是:ABTEST、IPLOC、JSESSIONID、SNUID、SUID、SUV。
3.1:获取参数“k”、“h”
按照经验,从一个url转变成另一个url有两种情况:跳转和javascript字符串处理。经过多次抓包剖析发觉,搜索结果页面点击文章超链接到我们现今的目标url并没有存在跳转情况,抓包数据中的“列表页面的文章url”和我们获取的“列表页面的文章url”可以判断为同一个url,所以推测为javascript字符串处理。经过一番搜救,发现搜索结果页面的源码中有一段十分可疑的代码:
<script>
(function(){$("a").on("mousedown click contextmenu",function(){var b=Math.floor(100*Math.random())+1,a=this.href.indexOf("url="),c=this.href.indexOf("&k=");-1!==a&&-1===c&&(a=this.href.substr(a+4+parseInt("21")+b,1),this.href+="&k="+b+"&h="+a)})})();
</script>
这其中最重要的代码就是:this.href+="&k="+b+"&h="+a,这代码就是在点击风波发生时给a标签href属性的内容添加"&k="、"&h=",正是用这段代码对该url的参数进行js加密和添加的。我们只须要把这段代码用python实现就可以解决这个问题了,下面是实现python实现代码:
def get_k_h(url): <br /> b = int(random.random() * 100) + 1
a = url.find("url=")
url = url + "&k=" + str(b) + "&h=" + url[a + 4 + 21 + b: a + 4 + 21 + b + 1]<br /> reuturn url
3.2:获取Cookie的参数
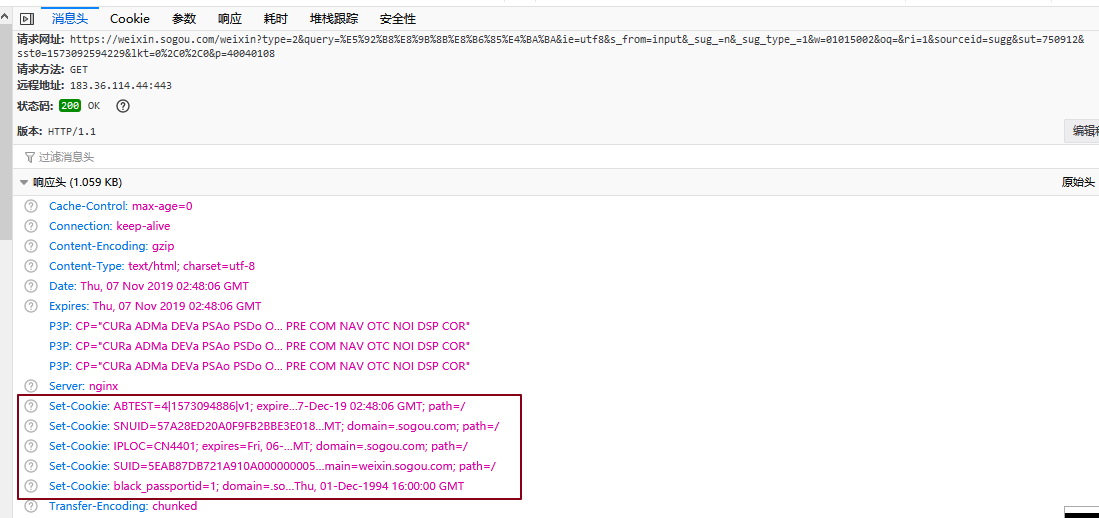
观察抓包数据可以发觉,当我们一开始访问时并没有带任何cookie,但经过一系列恳求,到我们的目标恳求时侯,浏览器早已通过上面恳求的返回数据包的Set-Cookie属性把Cookie构造下来了,而我们要做的就是在Cookie构造从无到有这个过程中找到所有ResponseHeaders中带SetCookie属性的并且参数是我们须要的参数的恳求,并模拟访问一遍,就能得到所有参数并建立出我们须要的Cookie了。
例如搜狗微信搜索插口的恳求的ResponseHeaders就有5个Set-Cookie数组,其中ABTEST、SNUID、IPLOC、SUID都是我们最终构造Cookie所需的参数(和最后的Cookie值对比可以发觉,这里的SUID值还不是我们最终须要的,要在前面的数据包中继续开掘)。
经过剖析搜狗微信文章采集,经过四个恳求获取到的ResponseHeaders后我们能够正确建立Cookie了:
1. 得到ABTEST、SNUID、IPLOC、SUID:<br /> https://weixin.sogou.com/weixi ... %3Bbr />2. 需要IPLOC、SNUID,得到SUID:<br /> https://www.sogou.com/sug/css/m3.min.v.7.css<br />3. 需要ABTEST、IPLOC、SNUID、SUID,得到JSESSIONID:<br /> https://weixin.sogou.com/webse ... %3Bbr />4. 需要IPLOC、SNUID、SUID,得到SUV<br /> https://pb.sogou.com/pv.gif<br />
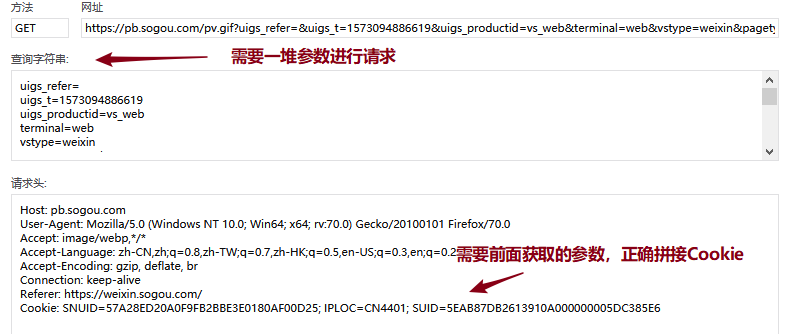
这四个恳求都能依照上面恳求获取到的Cookie参数来构造自己须要的Cookie去正确访问。值得注意的是最后一个恳求,除了须要正确拼接Cookie外,还须要获取正确的恳求参数能够正常访问:
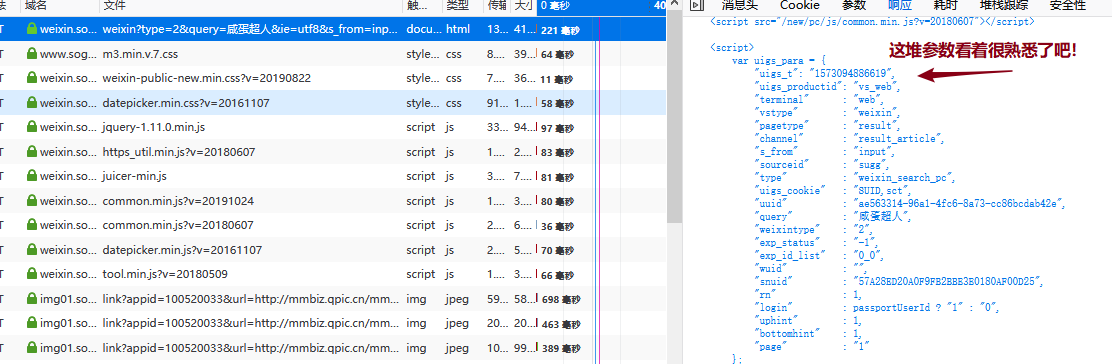
这种找参数的活可以借助浏览器的全局搜索功能,一番搜救后,就会发觉在搜索结果页面的源代码中早已返回了这儿所需的所有参数,用正则把那些参数解析下来即可:
那么按照这种解析下来的参数和上面三个恳求得到的Cookie参数能够正确访问第四个恳求并得到所需的所有Cookie参数啦!
此时,我们早已剖析出所有正确模拟恳求的流程了,梳理一下:
获取“k”、“h”参数,传入搜索结果页面得到的“列表页面的文章ur”,调用get_k_h()即可。获取所需Cookie参数,构造正确的Cookie,按照流程三给出的4个url,分别构造恳求获取ResponseHeaders中的SetCookie即可。构造正确的恳求访问“列表页面的文章url”。根据3中恳求返回的数据,拼接出“真实的文章url”,也就是流程二。请求“真实的文章url”,得到真正的文章页面数据。
至此,所有剖析结束,可以愉快的码代码啦!
结语:此次采集涉及到的反爬技术是Cookie构造和简答的js加密,难度不大,最重要的是耐心和悉心。此外提醒诸位看客大人遵守爬虫道德,不要对别人网站造成伤害,peace! 查看全部
目的:获取搜狗陌陌中搜索主题返回的文章。
涉及反爬机制:cookie设置,js加密。
完整代码已上传本人github,仅供参考。如果对您有帮助,劳烦看客大人给个星星!
进入题外话。
打开搜狗陌陌,在搜索框输入“咸蛋超人”,这里搜索下来的就是有关“咸蛋超人”主题的各个公众号的文章列表:
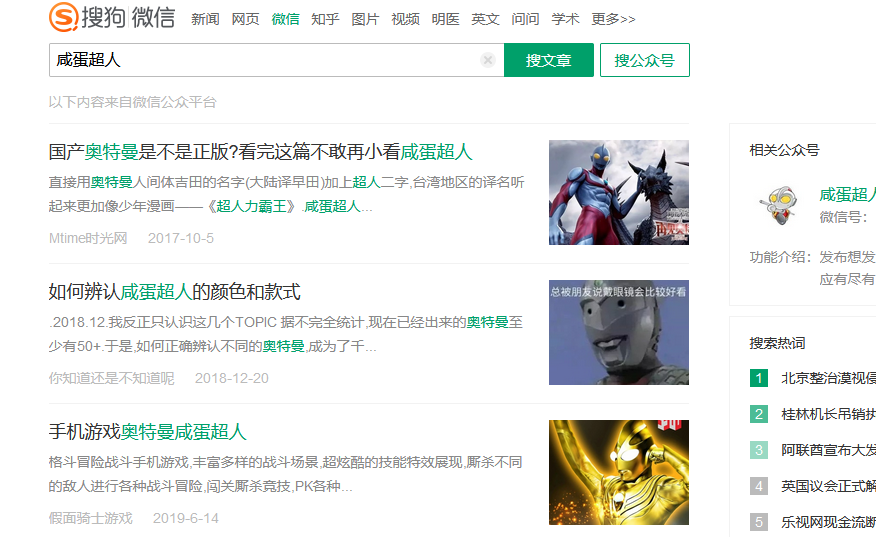
按照正常的采集流程,此时按F12打开浏览器的开发者工具,利用选择工具点击列表中文章标题,查看源码中列表中文章url的所在位置,再用xpath获取文章url的值,也就是这个href的值,为防止混乱,我们称之为“列表页面的文章url”。
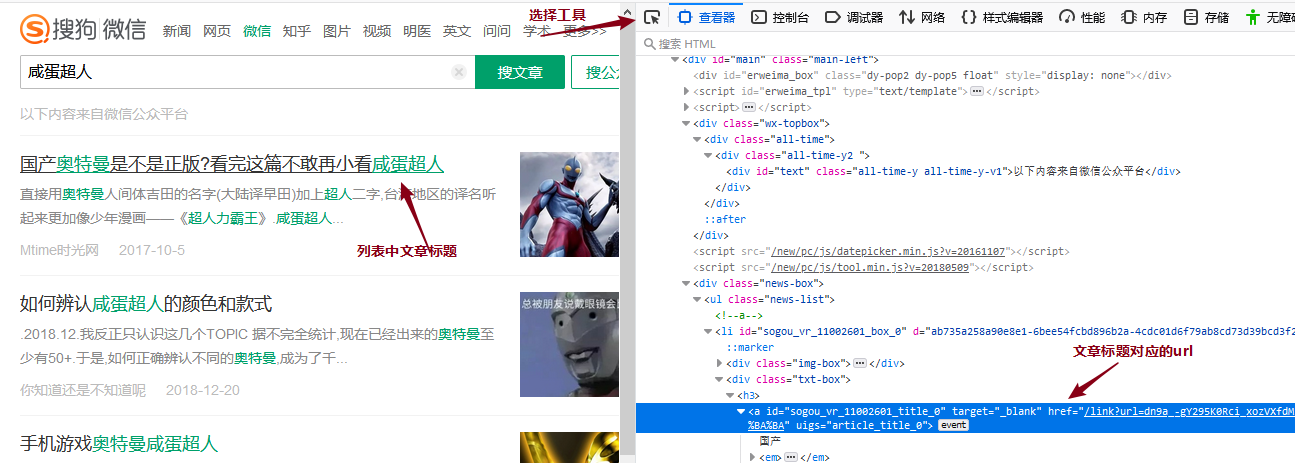
可以见到“列表页面的文章url”需要拼接,一般这些情况须要在浏览器中正常访问一下这篇文章,对比观察跳转后的url(我们称之为“真实的文章url”),再缺头补头缺腿补腿即可。下面是两个url的对比:
列表页面的文章url:
/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNFzn4G2S0Yt3MduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGSa3_pkMzadQg75Zhmxb9YI0psZvVepKtN4hpzQgtGa2iOlKKLwV_oxooGE6sxg1qinKxTb5VwJUcLBM1RgkzAPRtmyIGw2VAg..&type=2&query=%E5%92%B8%E8%9B%8B%E8%B6%85%E4%BA%BA&k=92&h=z
真实的文章url:
https://mp.weixin.qq.com/s?src=11&timestamp=1573092595&ver=1959&signature=FjD709D-0vHSyVgQyXCS-TUAcnT0M9Gx6JljQEb6O55zpuyyDaTHqgkRCxNDtt5ZDifDRUUBOemzxcz71FMOmO88m6RWfR0r4fFBe0VefAsjFu0pl-M0frYOnXPF5JD8&new=1
这里很明显两个url的路径不一致,应该是中间经过了一些调转,python的requests库是带手动调转功能,我们先把域名补上试一下访问
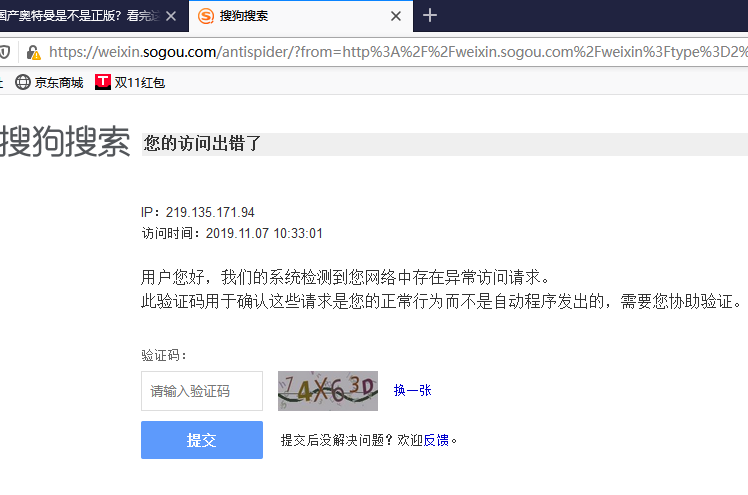
明显这儿做了反爬限制,那么这儿开始,我们就须要抓包剖析了。这里用到的工具是Firefox浏览器的开发者工具。抓包观察的是从搜索结果页面列表文章点击跳转到文章页面的过程,这里点击文章超链接会在新窗口打开,我们只须要在网页源码中把对应a标签的target属性改为空搜狗微信文章采集,就可以在一个窗口中观察整个流程的数据包了。
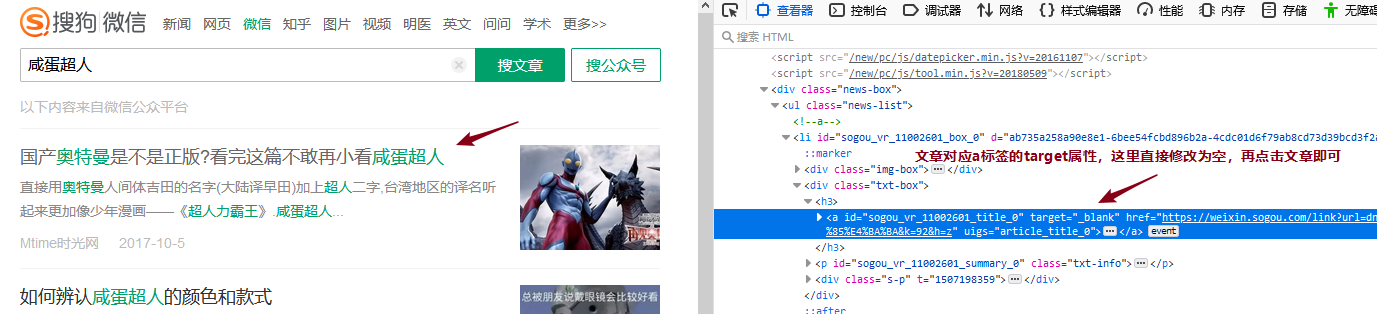
抓包剖析:


通过抓包我们可以找到搜索结果页面跳转到文章页面的过程,这里观察发觉,“列表页面的文章url”返回的结果中就包含了“真实的文章url”的信息,这意味着我们只须要正确访问到“列表页面的文章url”,根据返回的数据能够拼接出“真实的文章url”并访问了,这样我们就实现从“列表页面的文章url”到“真实的文章url”的跳转了!
此时我们的目标就从获取“真实的文章url”转变到正确的访问“列表页面的文章url”了,继续剖析抓包数据中的“列表页面的文章url”信息:
抓包数据:
url:https://weixin.sogou.com/link% ... h%3DU
method:GET
请求参数:{"url":"dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNEnNekGBXt9LMduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGaBLLLEV3E0vo604DcwbvX2VNudQZNnBemevd34BJP94ZL5zUiA49LgzIjRlpGxccVxTTaLhHZKstaeqw41upSVAe0f8bRARvQ..","type":"2","query":"咸蛋超人","k":"60","h":"U"}
headers:
Host: weixin.sogou.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Referer: https://weixin.sogou.com/weixi ... 40108
Cookie: 见下
Cookie:{"ABTEST":"4|1573094886|v1","IPLOC":"CN4401","JSESSIONID":"aaa3VBk4eXnIf8d4bdx4w","SNUID":"57A28ED20A0F9FB2BBE3E0180AF00D25","SUID":"5EAB87DB2613910A000000005DC385E6","SUV":"00F221C2DB87AB5E5DC385E7BC43F633"}
这里的重点有三个:
请求参数:对比我们获取的“列表页面的文章url”分析可以发觉,这里多了两个参数“k”、“h”,这是须要我们设法获取的。headers:经过测试该网站对User-Agent敏感,一次访问前后User-Agent须要一致。Cookie:Cookie中参数须要获取能够正确访问该url。这些参数分别是:ABTEST、IPLOC、JSESSIONID、SNUID、SUID、SUV。
3.1:获取参数“k”、“h”
按照经验,从一个url转变成另一个url有两种情况:跳转和javascript字符串处理。经过多次抓包剖析发觉,搜索结果页面点击文章超链接到我们现今的目标url并没有存在跳转情况,抓包数据中的“列表页面的文章url”和我们获取的“列表页面的文章url”可以判断为同一个url,所以推测为javascript字符串处理。经过一番搜救,发现搜索结果页面的源码中有一段十分可疑的代码:
<script>
(function(){$("a").on("mousedown click contextmenu",function(){var b=Math.floor(100*Math.random())+1,a=this.href.indexOf("url="),c=this.href.indexOf("&k=");-1!==a&&-1===c&&(a=this.href.substr(a+4+parseInt("21")+b,1),this.href+="&k="+b+"&h="+a)})})();
</script>
这其中最重要的代码就是:this.href+="&k="+b+"&h="+a,这代码就是在点击风波发生时给a标签href属性的内容添加"&k="、"&h=",正是用这段代码对该url的参数进行js加密和添加的。我们只须要把这段代码用python实现就可以解决这个问题了,下面是实现python实现代码:
def get_k_h(url): <br /> b = int(random.random() * 100) + 1
a = url.find("url=")
url = url + "&k=" + str(b) + "&h=" + url[a + 4 + 21 + b: a + 4 + 21 + b + 1]<br /> reuturn url
3.2:获取Cookie的参数
观察抓包数据可以发觉,当我们一开始访问时并没有带任何cookie,但经过一系列恳求,到我们的目标恳求时侯,浏览器早已通过上面恳求的返回数据包的Set-Cookie属性把Cookie构造下来了,而我们要做的就是在Cookie构造从无到有这个过程中找到所有ResponseHeaders中带SetCookie属性的并且参数是我们须要的参数的恳求,并模拟访问一遍,就能得到所有参数并建立出我们须要的Cookie了。
例如搜狗微信搜索插口的恳求的ResponseHeaders就有5个Set-Cookie数组,其中ABTEST、SNUID、IPLOC、SUID都是我们最终构造Cookie所需的参数(和最后的Cookie值对比可以发觉,这里的SUID值还不是我们最终须要的,要在前面的数据包中继续开掘)。
经过剖析搜狗微信文章采集,经过四个恳求获取到的ResponseHeaders后我们能够正确建立Cookie了:
1. 得到ABTEST、SNUID、IPLOC、SUID:<br /> https://weixin.sogou.com/weixi ... %3Bbr />2. 需要IPLOC、SNUID,得到SUID:<br /> https://www.sogou.com/sug/css/m3.min.v.7.css<br />3. 需要ABTEST、IPLOC、SNUID、SUID,得到JSESSIONID:<br /> https://weixin.sogou.com/webse ... %3Bbr />4. 需要IPLOC、SNUID、SUID,得到SUV<br /> https://pb.sogou.com/pv.gif<br />
这四个恳求都能依照上面恳求获取到的Cookie参数来构造自己须要的Cookie去正确访问。值得注意的是最后一个恳求,除了须要正确拼接Cookie外,还须要获取正确的恳求参数能够正常访问:
这种找参数的活可以借助浏览器的全局搜索功能,一番搜救后,就会发觉在搜索结果页面的源代码中早已返回了这儿所需的所有参数,用正则把那些参数解析下来即可:
那么按照这种解析下来的参数和上面三个恳求得到的Cookie参数能够正确访问第四个恳求并得到所需的所有Cookie参数啦!
此时,我们早已剖析出所有正确模拟恳求的流程了,梳理一下:
获取“k”、“h”参数,传入搜索结果页面得到的“列表页面的文章ur”,调用get_k_h()即可。获取所需Cookie参数,构造正确的Cookie,按照流程三给出的4个url,分别构造恳求获取ResponseHeaders中的SetCookie即可。构造正确的恳求访问“列表页面的文章url”。根据3中恳求返回的数据,拼接出“真实的文章url”,也就是流程二。请求“真实的文章url”,得到真正的文章页面数据。
至此,所有剖析结束,可以愉快的码代码啦!
结语:此次采集涉及到的反爬技术是Cookie构造和简答的js加密,难度不大,最重要的是耐心和悉心。此外提醒诸位看客大人遵守爬虫道德,不要对别人网站造成伤害,peace!
Python爬虫借助cookie实现模拟登录实例解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 456 次浏览 • 2020-07-05 08:00
举个事例,某些网站是须要登陆后就能得到你想要的信息的,不登录只能是旅客模式,那么我们可以借助Urllib2库保存我们曾经登陆过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取。理解cookie主要是为我们快捷模拟登陆抓取目标网页作出打算。
我之前的贴子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有urlopen(url,data,timeout),这三个参数对于我们获取目标网页的cookie是远远不够的。这时候我们就要借助到另外一种Opener——CookieJar。
cookielib也是Python进行爬虫的一个重要模块python爬虫模拟登录python爬虫模拟登录,他能与urllib2互相结合一起爬取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续联接恳求时重新发送,这样就可以实现我们所须要的模拟登陆功能。
这里非常说明一下,cookielib是在py2.7中自带的模块,无需重新安装,想要查看其自带模块可以查看Python目录下的Lib文件夹,里面有所有安装的模块。我一开始没想起来,在pycharm中居然没有搜到cookielib,使用了快捷安装也报错:Couldn't find index page for 'Cookielib' (maybe misspelled?)
之后才想起来是不是自带的就有,没想到去lib文件夹一看还真有,白白浪费半个小时各类瞎折腾~~
下面我们就来介绍一下这个模块,该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar 主要用法,我们下边也会提到。urllib2.urlopen()函数不支持验证、cookie或则其它HTTP中级功能。要支持这种功能,必须使用build_opener()(可以用于使python程序模拟浏览器进行访问,作用你懂得~)函数创建自定义Opener对象。
1、首先我们就来获取一下网站的cookie
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response
for item in my.cookie:
print"name="+item.name
print"value="+item.value
结果:
name=BAIDUID
value=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1
name=BIDUPSID
value=73BD718962A6EA0DAD4CB9578A08FDD0
name=H_PS_PSSID
value=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398
name=PSTM
value=1478834132
name=BDSVRTM
value=0
name=BD_HOME
value=0
这样我们就得到了一个最简单的cookie。
2、将cookie保存到文件
上面我们得到了cookie,下面我们学习怎么保存cookie。在这里我们使用它的泛型MozillaCookieJar来实现Cookie的保存
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.MozillaCookieJar() #声明一个MozillaCookieJar的类对象保存cookie(注意MozillaCookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response
for item in mycookie:
print"name="+item.name
print"value="+item.value
filename='mycookie.txt'#设定保存的文件名
mycookie.save(filename,ignore_discard=True, ignore_expires=True)
将里面的事例简单变型就可以得到本例,使用了CookieJar的泛型MozillaCookiJar,为什么呢?我们将MozillaCookiJar换成CookieJar试试,下面一张图你能够明白:
CookieJar是没有保存save属性的~
save()这个方式中:ignore_discard的意思是虽然cookies将被遗弃也将它保存出来,ignore_expires的意思是假如在该文件中cookies早已存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行以后,cookies将被保存到cookie.txt文件中,我们查看一下内容:
这样我们就成功保存了我们想要的cookie
3、从文件中获取cookie并访问 查看全部
Cookie,指个别网站为了分辨用户身分、进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。
举个事例,某些网站是须要登陆后就能得到你想要的信息的,不登录只能是旅客模式,那么我们可以借助Urllib2库保存我们曾经登陆过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取。理解cookie主要是为我们快捷模拟登陆抓取目标网页作出打算。
我之前的贴子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有urlopen(url,data,timeout),这三个参数对于我们获取目标网页的cookie是远远不够的。这时候我们就要借助到另外一种Opener——CookieJar。
cookielib也是Python进行爬虫的一个重要模块python爬虫模拟登录python爬虫模拟登录,他能与urllib2互相结合一起爬取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续联接恳求时重新发送,这样就可以实现我们所须要的模拟登陆功能。
这里非常说明一下,cookielib是在py2.7中自带的模块,无需重新安装,想要查看其自带模块可以查看Python目录下的Lib文件夹,里面有所有安装的模块。我一开始没想起来,在pycharm中居然没有搜到cookielib,使用了快捷安装也报错:Couldn't find index page for 'Cookielib' (maybe misspelled?)

之后才想起来是不是自带的就有,没想到去lib文件夹一看还真有,白白浪费半个小时各类瞎折腾~~
下面我们就来介绍一下这个模块,该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar 主要用法,我们下边也会提到。urllib2.urlopen()函数不支持验证、cookie或则其它HTTP中级功能。要支持这种功能,必须使用build_opener()(可以用于使python程序模拟浏览器进行访问,作用你懂得~)函数创建自定义Opener对象。
1、首先我们就来获取一下网站的cookie
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com";) #opener返回的一个应答对象response
for item in my.cookie:
print"name="+item.name
print"value="+item.value
结果:
name=BAIDUID
value=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1
name=BIDUPSID
value=73BD718962A6EA0DAD4CB9578A08FDD0
name=H_PS_PSSID
value=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398
name=PSTM
value=1478834132
name=BDSVRTM
value=0
name=BD_HOME
value=0
这样我们就得到了一个最简单的cookie。
2、将cookie保存到文件
上面我们得到了cookie,下面我们学习怎么保存cookie。在这里我们使用它的泛型MozillaCookieJar来实现Cookie的保存
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.MozillaCookieJar() #声明一个MozillaCookieJar的类对象保存cookie(注意MozillaCookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com";) #opener返回的一个应答对象response
for item in mycookie:
print"name="+item.name
print"value="+item.value
filename='mycookie.txt'#设定保存的文件名
mycookie.save(filename,ignore_discard=True, ignore_expires=True)
将里面的事例简单变型就可以得到本例,使用了CookieJar的泛型MozillaCookiJar,为什么呢?我们将MozillaCookiJar换成CookieJar试试,下面一张图你能够明白:

CookieJar是没有保存save属性的~
save()这个方式中:ignore_discard的意思是虽然cookies将被遗弃也将它保存出来,ignore_expires的意思是假如在该文件中cookies早已存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行以后,cookies将被保存到cookie.txt文件中,我们查看一下内容:

这样我们就成功保存了我们想要的cookie
3、从文件中获取cookie并访问
Python借助requests进行模拟登陆
采集交流 • 优采云 发表了文章 • 0 个评论 • 673 次浏览 • 2020-06-25 08:00
Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...
使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...
请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的 查看全部

Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...

使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...

请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的
【php爬虫】百万级别知乎用户数据爬取与剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-06-14 08:03
文/Hector
这次抓取了110万的用户数据php 网络爬虫 抓取数据,数据剖析结果如下:
开发前的打算
安装linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;
安装PHP5.6或以上版本;
安装curl、pcntl扩充。
使用PHP的curl扩充抓取页面数据
PHP的curl扩充是PHP支持的容许你与各类服务器使用各类类型的合同进行联接和通讯的库。
本程序是抓取知乎的用户数据,要能访问用户个人页面,需要用户登陆后的能够访问。当我们在浏览器的页面中点击一个用户头像链接步入用户个人中心页面的时侯,之所以还能看见用户的信息,是因为在点击链接的时侯,浏览器帮你将本地的cookie带上一同递交到新的页面,所以你才能步入到用户的个人中心页面。因此实现访问个人页面之前须要先获得用户的cookie信息,然后在每次curl恳求的时侯带上cookie信息。在获取cookie信息方面,我是用了自己的cookie,在页面中可以看见自己的cookie信息:
一个个地复制,以"__utma=?;__utmb=?;"这样的方式组成一个cookie字符串。接下来就可以使用该cookie字符串来发送恳求。
初始的示例:
$url = ''; <br /> //此处mora-hu代表用户ID
$ch = curl_init($url); <br /> //初始化会话
curl_setopt($ch, CURLOPT_HEADER, 0); <br /> curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']); <br /> //设置请求COOKIE
curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); <br /> curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); <br /> //将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); <br /> $result = curl_exec($ch); <br /> return $result; //抓取的结果
运行里面的代码可以获得mora-hu用户的个人中心页面。利用该结果再使用正则表达式对页面进行处理,就能获取到姓名,性别等所须要抓取的信息。
图片防盗链
在对返回结果进行正则处理后输出个人信息的时侯,发现在页面中输出用户头像时难以打开。经过查阅资料获知,是因为知乎对图片做了防盗链处理。解决方案就是恳求图片的时侯在恳求头里伪造一个referer。
在使用正则表达式获取到图片的链接以后,再发一次恳求,这时候带上图片恳求的来源,说明该恳求来自知乎网站的转发。具体事例如下:
function getImg($url, $u_id){ <br /> if (file_exists('./images/' . $u_id . ".jpg")) <br /> { <br /> return "images/$u_id" . '.jpg'; } if (empty($url)) <br /> { <br /> return ''; <br /> }<br /> $context_options = array( <br /> 'http' =>
array(<br /> 'header' => "Referer:"//带上referer参数
)<br /> );<br /> $context = stream_context_create($context_options);<br /> $img = file_get_contents('http:' . $url, FALSE, $context);<br /> file_put_contents('./images/' . $u_id . ".jpg", $img);<br /> return "images/$u_id" . '.jpg';}
爬取更多用户
抓取了自己的个人信息后,就须要再访问用户的关注者和关注了的用户列表获取更多的用户信息。然后一层一层地访问。可以见到,在个人中心页面里,有两个链接如下:
这里有两个链接,一个是关注了,另一个是关注者,以“关注了”的链接为例。用正则匹配去匹配到相应的链接,得到url以后用curl带上cookie再发一次恳求。抓取到用户关注了的用于列表页以后,可以得到下边的页面:
分析页面的html结构php 网络爬虫 抓取数据,因为只要得到用户的信息,所以只须要框住的这一块的div内容,用户名都在这上面。可以看见,用户关注了的页面的url是:
不同的用户的这个url几乎是一样的,不同的地方就在于用户名哪里。用正则匹配领到用户名列表,一个一个地拼url,然后再挨个发恳求(当然,一个一个是比较慢的,下面有解决方案,这个稍后会说到)。进入到新用户的页面然后,再重复前面的步骤,就这样不断循环,直到达到你所要的数据量。 查看全部
代码托管地址:
文/Hector
这次抓取了110万的用户数据php 网络爬虫 抓取数据,数据剖析结果如下:
开发前的打算
安装linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;
安装PHP5.6或以上版本;
安装curl、pcntl扩充。
使用PHP的curl扩充抓取页面数据
PHP的curl扩充是PHP支持的容许你与各类服务器使用各类类型的合同进行联接和通讯的库。
本程序是抓取知乎的用户数据,要能访问用户个人页面,需要用户登陆后的能够访问。当我们在浏览器的页面中点击一个用户头像链接步入用户个人中心页面的时侯,之所以还能看见用户的信息,是因为在点击链接的时侯,浏览器帮你将本地的cookie带上一同递交到新的页面,所以你才能步入到用户的个人中心页面。因此实现访问个人页面之前须要先获得用户的cookie信息,然后在每次curl恳求的时侯带上cookie信息。在获取cookie信息方面,我是用了自己的cookie,在页面中可以看见自己的cookie信息:
一个个地复制,以"__utma=?;__utmb=?;"这样的方式组成一个cookie字符串。接下来就可以使用该cookie字符串来发送恳求。
初始的示例:
$url = ''; <br /> //此处mora-hu代表用户ID
$ch = curl_init($url); <br /> //初始化会话
curl_setopt($ch, CURLOPT_HEADER, 0); <br /> curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']); <br /> //设置请求COOKIE
curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); <br /> curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); <br /> //将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); <br /> $result = curl_exec($ch); <br /> return $result; //抓取的结果
运行里面的代码可以获得mora-hu用户的个人中心页面。利用该结果再使用正则表达式对页面进行处理,就能获取到姓名,性别等所须要抓取的信息。
图片防盗链
在对返回结果进行正则处理后输出个人信息的时侯,发现在页面中输出用户头像时难以打开。经过查阅资料获知,是因为知乎对图片做了防盗链处理。解决方案就是恳求图片的时侯在恳求头里伪造一个referer。
在使用正则表达式获取到图片的链接以后,再发一次恳求,这时候带上图片恳求的来源,说明该恳求来自知乎网站的转发。具体事例如下:
function getImg($url, $u_id){ <br /> if (file_exists('./images/' . $u_id . ".jpg")) <br /> { <br /> return "images/$u_id" . '.jpg'; } if (empty($url)) <br /> { <br /> return ''; <br /> }<br /> $context_options = array( <br /> 'http' =>
array(<br /> 'header' => "Referer:"//带上referer参数
)<br /> );<br /> $context = stream_context_create($context_options);<br /> $img = file_get_contents('http:' . $url, FALSE, $context);<br /> file_put_contents('./images/' . $u_id . ".jpg", $img);<br /> return "images/$u_id" . '.jpg';}
爬取更多用户
抓取了自己的个人信息后,就须要再访问用户的关注者和关注了的用户列表获取更多的用户信息。然后一层一层地访问。可以见到,在个人中心页面里,有两个链接如下:
这里有两个链接,一个是关注了,另一个是关注者,以“关注了”的链接为例。用正则匹配去匹配到相应的链接,得到url以后用curl带上cookie再发一次恳求。抓取到用户关注了的用于列表页以后,可以得到下边的页面:
分析页面的html结构php 网络爬虫 抓取数据,因为只要得到用户的信息,所以只须要框住的这一块的div内容,用户名都在这上面。可以看见,用户关注了的页面的url是:
不同的用户的这个url几乎是一样的,不同的地方就在于用户名哪里。用正则匹配领到用户名列表,一个一个地拼url,然后再挨个发恳求(当然,一个一个是比较慢的,下面有解决方案,这个稍后会说到)。进入到新用户的页面然后,再重复前面的步骤,就这样不断循环,直到达到你所要的数据量。
老司机带你学爬虫——Python爬虫技术分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-05-06 08:01
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心 查看全部
什么是“爬虫”?
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心
dedecms,织梦后台系统配置参数空白的解决方
采集交流 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2020-04-15 11:04
出现DedeCms系统配置参数空白缘由:
1、还原数据库引起的
2、向数据库导出数据时没导出不全或数据某个文件被破坏
最直接缘由是数据库dede-sysconfig数据表大小为0或干脆不存在。
解决办法:
方法一随意在本地找个正常的dede数据库,选中dede-sysconfig表,然后导入,然后再导出不显示后台参数的数据库。即可解决
方法二:重新还原一下数据库
方法三:网上提供的方式,在备份文件中总算在一个文件中找到如下图的那种文件。
3
Ok,试试吧,把那种txt的数据备份文件上传到服务器,这个时侯出现了那种表,然后选择还原数据。
怀疑当时还原表结构时弄丢的织梦网站后台参数,所以没选还原表结构。或许跟这个没关系
文章二:
这样情况的出现总使人吓一跳,还好经过一番思索过后找到了问题所在。
我的网站是先在本地布属,然后再上传到服务器上的。出现DedeCms系统配置参数空白的问题之前,我同时登陆了服务器上的网站和本地布属的网站,此时可 能就引起了cookie的冲突。我在访问本地网站的后台的时侯发觉DedeCms系统配置参数空白,开始的时侯考虑是文件出哪些问题了。于是把没有出错的 服务器上的文件覆盖到了本地,问题还是没有解决。想通过恢复数据库试下能够解决,但这时候发觉数据还原里居然没有数据了??脑子在快速转动,我真是太笨 了。备份的功能能够用,我再备份一下瞧瞧文件会被备份到哪个地方织梦网站后台参数,备份过以后发觉居然是直接备份到了data下,不解。得了干脆直接把服务器上的缓存也直 接下出来瞧瞧。就在下完缓存以后发觉好了。从这我才觉得是cookie的冲突导致了这次的风波。还好是虚惊一场。为此我还在网上搜索了一此除cookie 冲突导致DedeCms系统配置参数空白问题的解决方式,供你们所需时备用。
数据库备份/还原后DedeCms系统配置参数出限空白解决方式
修改你须要还原的数据库dede_sysconfig_0_d08909f67460a7be.txt文件里的
INSERTINTO`DEDE_sysconfig`VALUES('3','cfg_cookie_encode','cookie加密码','2','string','JdCSr9155U');修改这个cookie加密码和你安装程序后台的一样.
查看你安装好的cookie加密码方式如图
注意不是修改网站后台的cookie加密码为dede_sysconfig的加密码
改好进行数据库还原
还原好了更新系统缓存在瞧瞧就可以了 查看全部
出现DedeCms系统配置参数空白缘由:
1、还原数据库引起的
2、向数据库导出数据时没导出不全或数据某个文件被破坏
最直接缘由是数据库dede-sysconfig数据表大小为0或干脆不存在。
解决办法:
方法一随意在本地找个正常的dede数据库,选中dede-sysconfig表,然后导入,然后再导出不显示后台参数的数据库。即可解决
方法二:重新还原一下数据库
方法三:网上提供的方式,在备份文件中总算在一个文件中找到如下图的那种文件。
3
Ok,试试吧,把那种txt的数据备份文件上传到服务器,这个时侯出现了那种表,然后选择还原数据。
怀疑当时还原表结构时弄丢的织梦网站后台参数,所以没选还原表结构。或许跟这个没关系
文章二:
这样情况的出现总使人吓一跳,还好经过一番思索过后找到了问题所在。
我的网站是先在本地布属,然后再上传到服务器上的。出现DedeCms系统配置参数空白的问题之前,我同时登陆了服务器上的网站和本地布属的网站,此时可 能就引起了cookie的冲突。我在访问本地网站的后台的时侯发觉DedeCms系统配置参数空白,开始的时侯考虑是文件出哪些问题了。于是把没有出错的 服务器上的文件覆盖到了本地,问题还是没有解决。想通过恢复数据库试下能够解决,但这时候发觉数据还原里居然没有数据了??脑子在快速转动,我真是太笨 了。备份的功能能够用,我再备份一下瞧瞧文件会被备份到哪个地方织梦网站后台参数,备份过以后发觉居然是直接备份到了data下,不解。得了干脆直接把服务器上的缓存也直 接下出来瞧瞧。就在下完缓存以后发觉好了。从这我才觉得是cookie的冲突导致了这次的风波。还好是虚惊一场。为此我还在网上搜索了一此除cookie 冲突导致DedeCms系统配置参数空白问题的解决方式,供你们所需时备用。
数据库备份/还原后DedeCms系统配置参数出限空白解决方式
修改你须要还原的数据库dede_sysconfig_0_d08909f67460a7be.txt文件里的
INSERTINTO`DEDE_sysconfig`VALUES('3','cfg_cookie_encode','cookie加密码','2','string','JdCSr9155U');修改这个cookie加密码和你安装程序后台的一样.
查看你安装好的cookie加密码方式如图

注意不是修改网站后台的cookie加密码为dede_sysconfig的加密码
改好进行数据库还原
还原好了更新系统缓存在瞧瞧就可以了
搜狗陌陌采集 —— python爬虫系列一
采集交流 • 优采云 发表了文章 • 0 个评论 • 629 次浏览 • 2020-07-24 08:00
目的:获取搜狗陌陌中搜索主题返回的文章。
涉及反爬机制:cookie设置,js加密。
完整代码已上传本人github,仅供参考。如果对您有帮助,劳烦看客大人给个星星!
进入题外话。
打开搜狗陌陌,在搜索框输入“咸蛋超人”,这里搜索下来的就是有关“咸蛋超人”主题的各个公众号的文章列表:
按照正常的采集流程,此时按F12打开浏览器的开发者工具,利用选择工具点击列表中文章标题,查看源码中列表中文章url的所在位置,再用xpath获取文章url的值,也就是这个href的值,为防止混乱,我们称之为“列表页面的文章url”。
可以见到“列表页面的文章url”需要拼接,一般这些情况须要在浏览器中正常访问一下这篇文章,对比观察跳转后的url(我们称之为“真实的文章url”),再缺头补头缺腿补腿即可。下面是两个url的对比:
列表页面的文章url:
/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNFzn4G2S0Yt3MduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGSa3_pkMzadQg75Zhmxb9YI0psZvVepKtN4hpzQgtGa2iOlKKLwV_oxooGE6sxg1qinKxTb5VwJUcLBM1RgkzAPRtmyIGw2VAg..&type=2&query=%E5%92%B8%E8%9B%8B%E8%B6%85%E4%BA%BA&k=92&h=z
真实的文章url:
https://mp.weixin.qq.com/s?src=11&timestamp=1573092595&ver=1959&signature=FjD709D-0vHSyVgQyXCS-TUAcnT0M9Gx6JljQEb6O55zpuyyDaTHqgkRCxNDtt5ZDifDRUUBOemzxcz71FMOmO88m6RWfR0r4fFBe0VefAsjFu0pl-M0frYOnXPF5JD8&new=1
这里很明显两个url的路径不一致,应该是中间经过了一些调转,python的requests库是带手动调转功能,我们先把域名补上试一下访问
明显这儿做了反爬限制,那么这儿开始,我们就须要抓包剖析了。这里用到的工具是Firefox浏览器的开发者工具。抓包观察的是从搜索结果页面列表文章点击跳转到文章页面的过程,这里点击文章超链接会在新窗口打开,我们只须要在网页源码中把对应a标签的target属性改为空搜狗微信文章采集,就可以在一个窗口中观察整个流程的数据包了。
抓包剖析:
通过抓包我们可以找到搜索结果页面跳转到文章页面的过程,这里观察发觉,“列表页面的文章url”返回的结果中就包含了“真实的文章url”的信息,这意味着我们只须要正确访问到“列表页面的文章url”,根据返回的数据能够拼接出“真实的文章url”并访问了,这样我们就实现从“列表页面的文章url”到“真实的文章url”的跳转了!
此时我们的目标就从获取“真实的文章url”转变到正确的访问“列表页面的文章url”了,继续剖析抓包数据中的“列表页面的文章url”信息:
抓包数据:
url:https://weixin.sogou.com/link% ... h%3DU
method:GET
请求参数:{"url":"dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNEnNekGBXt9LMduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGaBLLLEV3E0vo604DcwbvX2VNudQZNnBemevd34BJP94ZL5zUiA49LgzIjRlpGxccVxTTaLhHZKstaeqw41upSVAe0f8bRARvQ..","type":"2","query":"咸蛋超人","k":"60","h":"U"}
headers:
Host: weixin.sogou.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Referer: https://weixin.sogou.com/weixi ... 40108
Cookie: 见下
Cookie:{"ABTEST":"4|1573094886|v1","IPLOC":"CN4401","JSESSIONID":"aaa3VBk4eXnIf8d4bdx4w","SNUID":"57A28ED20A0F9FB2BBE3E0180AF00D25","SUID":"5EAB87DB2613910A000000005DC385E6","SUV":"00F221C2DB87AB5E5DC385E7BC43F633"}
这里的重点有三个:
请求参数:对比我们获取的“列表页面的文章url”分析可以发觉,这里多了两个参数“k”、“h”,这是须要我们设法获取的。headers:经过测试该网站对User-Agent敏感,一次访问前后User-Agent须要一致。Cookie:Cookie中参数须要获取能够正确访问该url。这些参数分别是:ABTEST、IPLOC、JSESSIONID、SNUID、SUID、SUV。
3.1:获取参数“k”、“h”
按照经验,从一个url转变成另一个url有两种情况:跳转和javascript字符串处理。经过多次抓包剖析发觉,搜索结果页面点击文章超链接到我们现今的目标url并没有存在跳转情况,抓包数据中的“列表页面的文章url”和我们获取的“列表页面的文章url”可以判断为同一个url,所以推测为javascript字符串处理。经过一番搜救,发现搜索结果页面的源码中有一段十分可疑的代码:
<script>
(function(){$("a").on("mousedown click contextmenu",function(){var b=Math.floor(100*Math.random())+1,a=this.href.indexOf("url="),c=this.href.indexOf("&k=");-1!==a&&-1===c&&(a=this.href.substr(a+4+parseInt("21")+b,1),this.href+="&k="+b+"&h="+a)})})();
</script>
这其中最重要的代码就是:this.href+="&k="+b+"&h="+a,这代码就是在点击风波发生时给a标签href属性的内容添加"&k="、"&h=",正是用这段代码对该url的参数进行js加密和添加的。我们只须要把这段代码用python实现就可以解决这个问题了,下面是实现python实现代码:
def get_k_h(url): <br /> b = int(random.random() * 100) + 1
a = url.find("url=")
url = url + "&k=" + str(b) + "&h=" + url[a + 4 + 21 + b: a + 4 + 21 + b + 1]<br /> reuturn url
3.2:获取Cookie的参数
观察抓包数据可以发觉,当我们一开始访问时并没有带任何cookie,但经过一系列恳求,到我们的目标恳求时侯,浏览器早已通过上面恳求的返回数据包的Set-Cookie属性把Cookie构造下来了,而我们要做的就是在Cookie构造从无到有这个过程中找到所有ResponseHeaders中带SetCookie属性的并且参数是我们须要的参数的恳求,并模拟访问一遍,就能得到所有参数并建立出我们须要的Cookie了。
例如搜狗微信搜索插口的恳求的ResponseHeaders就有5个Set-Cookie数组,其中ABTEST、SNUID、IPLOC、SUID都是我们最终构造Cookie所需的参数(和最后的Cookie值对比可以发觉,这里的SUID值还不是我们最终须要的,要在前面的数据包中继续开掘)。
经过剖析搜狗微信文章采集,经过四个恳求获取到的ResponseHeaders后我们能够正确建立Cookie了:
1. 得到ABTEST、SNUID、IPLOC、SUID:<br /> https://weixin.sogou.com/weixi ... %3Bbr />2. 需要IPLOC、SNUID,得到SUID:<br /> https://www.sogou.com/sug/css/m3.min.v.7.css<br />3. 需要ABTEST、IPLOC、SNUID、SUID,得到JSESSIONID:<br /> https://weixin.sogou.com/webse ... %3Bbr />4. 需要IPLOC、SNUID、SUID,得到SUV<br /> https://pb.sogou.com/pv.gif<br />
这四个恳求都能依照上面恳求获取到的Cookie参数来构造自己须要的Cookie去正确访问。值得注意的是最后一个恳求,除了须要正确拼接Cookie外,还须要获取正确的恳求参数能够正常访问:
这种找参数的活可以借助浏览器的全局搜索功能,一番搜救后,就会发觉在搜索结果页面的源代码中早已返回了这儿所需的所有参数,用正则把那些参数解析下来即可:
那么按照这种解析下来的参数和上面三个恳求得到的Cookie参数能够正确访问第四个恳求并得到所需的所有Cookie参数啦!
此时,我们早已剖析出所有正确模拟恳求的流程了,梳理一下:
获取“k”、“h”参数,传入搜索结果页面得到的“列表页面的文章ur”,调用get_k_h()即可。获取所需Cookie参数,构造正确的Cookie,按照流程三给出的4个url,分别构造恳求获取ResponseHeaders中的SetCookie即可。构造正确的恳求访问“列表页面的文章url”。根据3中恳求返回的数据,拼接出“真实的文章url”,也就是流程二。请求“真实的文章url”,得到真正的文章页面数据。
至此,所有剖析结束,可以愉快的码代码啦!
结语:此次采集涉及到的反爬技术是Cookie构造和简答的js加密,难度不大,最重要的是耐心和悉心。此外提醒诸位看客大人遵守爬虫道德,不要对别人网站造成伤害,peace! 查看全部
目的:获取搜狗陌陌中搜索主题返回的文章。
涉及反爬机制:cookie设置,js加密。
完整代码已上传本人github,仅供参考。如果对您有帮助,劳烦看客大人给个星星!
进入题外话。
打开搜狗陌陌,在搜索框输入“咸蛋超人”,这里搜索下来的就是有关“咸蛋超人”主题的各个公众号的文章列表:
按照正常的采集流程,此时按F12打开浏览器的开发者工具,利用选择工具点击列表中文章标题,查看源码中列表中文章url的所在位置,再用xpath获取文章url的值,也就是这个href的值,为防止混乱,我们称之为“列表页面的文章url”。
可以见到“列表页面的文章url”需要拼接,一般这些情况须要在浏览器中正常访问一下这篇文章,对比观察跳转后的url(我们称之为“真实的文章url”),再缺头补头缺腿补腿即可。下面是两个url的对比:
列表页面的文章url:
/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNFzn4G2S0Yt3MduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGSa3_pkMzadQg75Zhmxb9YI0psZvVepKtN4hpzQgtGa2iOlKKLwV_oxooGE6sxg1qinKxTb5VwJUcLBM1RgkzAPRtmyIGw2VAg..&type=2&query=%E5%92%B8%E8%9B%8B%E8%B6%85%E4%BA%BA&k=92&h=z
真实的文章url:
https://mp.weixin.qq.com/s?src=11&timestamp=1573092595&ver=1959&signature=FjD709D-0vHSyVgQyXCS-TUAcnT0M9Gx6JljQEb6O55zpuyyDaTHqgkRCxNDtt5ZDifDRUUBOemzxcz71FMOmO88m6RWfR0r4fFBe0VefAsjFu0pl-M0frYOnXPF5JD8&new=1
这里很明显两个url的路径不一致,应该是中间经过了一些调转,python的requests库是带手动调转功能,我们先把域名补上试一下访问
明显这儿做了反爬限制,那么这儿开始,我们就须要抓包剖析了。这里用到的工具是Firefox浏览器的开发者工具。抓包观察的是从搜索结果页面列表文章点击跳转到文章页面的过程,这里点击文章超链接会在新窗口打开,我们只须要在网页源码中把对应a标签的target属性改为空搜狗微信文章采集,就可以在一个窗口中观察整个流程的数据包了。
抓包剖析:
通过抓包我们可以找到搜索结果页面跳转到文章页面的过程,这里观察发觉,“列表页面的文章url”返回的结果中就包含了“真实的文章url”的信息,这意味着我们只须要正确访问到“列表页面的文章url”,根据返回的数据能够拼接出“真实的文章url”并访问了,这样我们就实现从“列表页面的文章url”到“真实的文章url”的跳转了!
此时我们的目标就从获取“真实的文章url”转变到正确的访问“列表页面的文章url”了,继续剖析抓包数据中的“列表页面的文章url”信息:
抓包数据:
url:https://weixin.sogou.com/link% ... h%3DU
method:GET
请求参数:{"url":"dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSwqn5HZrcjUNEnNekGBXt9LMduzuCU92ulqXa8Fplpd9CqUiLuEm9hLLvBiu5ziMS196rgHYb-GzQfleG917OgwN_VAAdAZHKryCeU9lIxtWTKnLsDcsuPIjLhLEK3tbGaBLLLEV3E0vo604DcwbvX2VNudQZNnBemevd34BJP94ZL5zUiA49LgzIjRlpGxccVxTTaLhHZKstaeqw41upSVAe0f8bRARvQ..","type":"2","query":"咸蛋超人","k":"60","h":"U"}
headers:
Host: weixin.sogou.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Referer: https://weixin.sogou.com/weixi ... 40108
Cookie: 见下
Cookie:{"ABTEST":"4|1573094886|v1","IPLOC":"CN4401","JSESSIONID":"aaa3VBk4eXnIf8d4bdx4w","SNUID":"57A28ED20A0F9FB2BBE3E0180AF00D25","SUID":"5EAB87DB2613910A000000005DC385E6","SUV":"00F221C2DB87AB5E5DC385E7BC43F633"}
这里的重点有三个:
请求参数:对比我们获取的“列表页面的文章url”分析可以发觉,这里多了两个参数“k”、“h”,这是须要我们设法获取的。headers:经过测试该网站对User-Agent敏感,一次访问前后User-Agent须要一致。Cookie:Cookie中参数须要获取能够正确访问该url。这些参数分别是:ABTEST、IPLOC、JSESSIONID、SNUID、SUID、SUV。
3.1:获取参数“k”、“h”
按照经验,从一个url转变成另一个url有两种情况:跳转和javascript字符串处理。经过多次抓包剖析发觉,搜索结果页面点击文章超链接到我们现今的目标url并没有存在跳转情况,抓包数据中的“列表页面的文章url”和我们获取的“列表页面的文章url”可以判断为同一个url,所以推测为javascript字符串处理。经过一番搜救,发现搜索结果页面的源码中有一段十分可疑的代码:
<script>
(function(){$("a").on("mousedown click contextmenu",function(){var b=Math.floor(100*Math.random())+1,a=this.href.indexOf("url="),c=this.href.indexOf("&k=");-1!==a&&-1===c&&(a=this.href.substr(a+4+parseInt("21")+b,1),this.href+="&k="+b+"&h="+a)})})();
</script>
这其中最重要的代码就是:this.href+="&k="+b+"&h="+a,这代码就是在点击风波发生时给a标签href属性的内容添加"&k="、"&h=",正是用这段代码对该url的参数进行js加密和添加的。我们只须要把这段代码用python实现就可以解决这个问题了,下面是实现python实现代码:
def get_k_h(url): <br /> b = int(random.random() * 100) + 1
a = url.find("url=")
url = url + "&k=" + str(b) + "&h=" + url[a + 4 + 21 + b: a + 4 + 21 + b + 1]<br /> reuturn url
3.2:获取Cookie的参数
观察抓包数据可以发觉,当我们一开始访问时并没有带任何cookie,但经过一系列恳求,到我们的目标恳求时侯,浏览器早已通过上面恳求的返回数据包的Set-Cookie属性把Cookie构造下来了,而我们要做的就是在Cookie构造从无到有这个过程中找到所有ResponseHeaders中带SetCookie属性的并且参数是我们须要的参数的恳求,并模拟访问一遍,就能得到所有参数并建立出我们须要的Cookie了。
例如搜狗微信搜索插口的恳求的ResponseHeaders就有5个Set-Cookie数组,其中ABTEST、SNUID、IPLOC、SUID都是我们最终构造Cookie所需的参数(和最后的Cookie值对比可以发觉,这里的SUID值还不是我们最终须要的,要在前面的数据包中继续开掘)。
经过剖析搜狗微信文章采集,经过四个恳求获取到的ResponseHeaders后我们能够正确建立Cookie了:
1. 得到ABTEST、SNUID、IPLOC、SUID:<br /> https://weixin.sogou.com/weixi ... %3Bbr />2. 需要IPLOC、SNUID,得到SUID:<br /> https://www.sogou.com/sug/css/m3.min.v.7.css<br />3. 需要ABTEST、IPLOC、SNUID、SUID,得到JSESSIONID:<br /> https://weixin.sogou.com/webse ... %3Bbr />4. 需要IPLOC、SNUID、SUID,得到SUV<br /> https://pb.sogou.com/pv.gif<br />
这四个恳求都能依照上面恳求获取到的Cookie参数来构造自己须要的Cookie去正确访问。值得注意的是最后一个恳求,除了须要正确拼接Cookie外,还须要获取正确的恳求参数能够正常访问:
这种找参数的活可以借助浏览器的全局搜索功能,一番搜救后,就会发觉在搜索结果页面的源代码中早已返回了这儿所需的所有参数,用正则把那些参数解析下来即可:
那么按照这种解析下来的参数和上面三个恳求得到的Cookie参数能够正确访问第四个恳求并得到所需的所有Cookie参数啦!
此时,我们早已剖析出所有正确模拟恳求的流程了,梳理一下:
获取“k”、“h”参数,传入搜索结果页面得到的“列表页面的文章ur”,调用get_k_h()即可。获取所需Cookie参数,构造正确的Cookie,按照流程三给出的4个url,分别构造恳求获取ResponseHeaders中的SetCookie即可。构造正确的恳求访问“列表页面的文章url”。根据3中恳求返回的数据,拼接出“真实的文章url”,也就是流程二。请求“真实的文章url”,得到真正的文章页面数据。
至此,所有剖析结束,可以愉快的码代码啦!
结语:此次采集涉及到的反爬技术是Cookie构造和简答的js加密,难度不大,最重要的是耐心和悉心。此外提醒诸位看客大人遵守爬虫道德,不要对别人网站造成伤害,peace!
Python爬虫借助cookie实现模拟登录实例解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 456 次浏览 • 2020-07-05 08:00
举个事例,某些网站是须要登陆后就能得到你想要的信息的,不登录只能是旅客模式,那么我们可以借助Urllib2库保存我们曾经登陆过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取。理解cookie主要是为我们快捷模拟登陆抓取目标网页作出打算。
我之前的贴子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有urlopen(url,data,timeout),这三个参数对于我们获取目标网页的cookie是远远不够的。这时候我们就要借助到另外一种Opener——CookieJar。
cookielib也是Python进行爬虫的一个重要模块python爬虫模拟登录python爬虫模拟登录,他能与urllib2互相结合一起爬取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续联接恳求时重新发送,这样就可以实现我们所须要的模拟登陆功能。
这里非常说明一下,cookielib是在py2.7中自带的模块,无需重新安装,想要查看其自带模块可以查看Python目录下的Lib文件夹,里面有所有安装的模块。我一开始没想起来,在pycharm中居然没有搜到cookielib,使用了快捷安装也报错:Couldn't find index page for 'Cookielib' (maybe misspelled?)
之后才想起来是不是自带的就有,没想到去lib文件夹一看还真有,白白浪费半个小时各类瞎折腾~~
下面我们就来介绍一下这个模块,该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar 主要用法,我们下边也会提到。urllib2.urlopen()函数不支持验证、cookie或则其它HTTP中级功能。要支持这种功能,必须使用build_opener()(可以用于使python程序模拟浏览器进行访问,作用你懂得~)函数创建自定义Opener对象。
1、首先我们就来获取一下网站的cookie
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response
for item in my.cookie:
print"name="+item.name
print"value="+item.value
结果:
name=BAIDUID
value=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1
name=BIDUPSID
value=73BD718962A6EA0DAD4CB9578A08FDD0
name=H_PS_PSSID
value=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398
name=PSTM
value=1478834132
name=BDSVRTM
value=0
name=BD_HOME
value=0
这样我们就得到了一个最简单的cookie。
2、将cookie保存到文件
上面我们得到了cookie,下面我们学习怎么保存cookie。在这里我们使用它的泛型MozillaCookieJar来实现Cookie的保存
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.MozillaCookieJar() #声明一个MozillaCookieJar的类对象保存cookie(注意MozillaCookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response
for item in mycookie:
print"name="+item.name
print"value="+item.value
filename='mycookie.txt'#设定保存的文件名
mycookie.save(filename,ignore_discard=True, ignore_expires=True)
将里面的事例简单变型就可以得到本例,使用了CookieJar的泛型MozillaCookiJar,为什么呢?我们将MozillaCookiJar换成CookieJar试试,下面一张图你能够明白:
CookieJar是没有保存save属性的~
save()这个方式中:ignore_discard的意思是虽然cookies将被遗弃也将它保存出来,ignore_expires的意思是假如在该文件中cookies早已存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行以后,cookies将被保存到cookie.txt文件中,我们查看一下内容:
这样我们就成功保存了我们想要的cookie
3、从文件中获取cookie并访问 查看全部
Cookie,指个别网站为了分辨用户身分、进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。
举个事例,某些网站是须要登陆后就能得到你想要的信息的,不登录只能是旅客模式,那么我们可以借助Urllib2库保存我们曾经登陆过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取。理解cookie主要是为我们快捷模拟登陆抓取目标网页作出打算。
我之前的贴子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有urlopen(url,data,timeout),这三个参数对于我们获取目标网页的cookie是远远不够的。这时候我们就要借助到另外一种Opener——CookieJar。
cookielib也是Python进行爬虫的一个重要模块python爬虫模拟登录python爬虫模拟登录,他能与urllib2互相结合一起爬取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续联接恳求时重新发送,这样就可以实现我们所须要的模拟登陆功能。
这里非常说明一下,cookielib是在py2.7中自带的模块,无需重新安装,想要查看其自带模块可以查看Python目录下的Lib文件夹,里面有所有安装的模块。我一开始没想起来,在pycharm中居然没有搜到cookielib,使用了快捷安装也报错:Couldn't find index page for 'Cookielib' (maybe misspelled?)
之后才想起来是不是自带的就有,没想到去lib文件夹一看还真有,白白浪费半个小时各类瞎折腾~~
下面我们就来介绍一下这个模块,该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar 主要用法,我们下边也会提到。urllib2.urlopen()函数不支持验证、cookie或则其它HTTP中级功能。要支持这种功能,必须使用build_opener()(可以用于使python程序模拟浏览器进行访问,作用你懂得~)函数创建自定义Opener对象。
1、首先我们就来获取一下网站的cookie
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com";) #opener返回的一个应答对象response
for item in my.cookie:
print"name="+item.name
print"value="+item.value
结果:
name=BAIDUID
value=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1
name=BIDUPSID
value=73BD718962A6EA0DAD4CB9578A08FDD0
name=H_PS_PSSID
value=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398
name=PSTM
value=1478834132
name=BDSVRTM
value=0
name=BD_HOME
value=0
这样我们就得到了一个最简单的cookie。
2、将cookie保存到文件
上面我们得到了cookie,下面我们学习怎么保存cookie。在这里我们使用它的泛型MozillaCookieJar来实现Cookie的保存
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.MozillaCookieJar() #声明一个MozillaCookieJar的类对象保存cookie(注意MozillaCookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com";) #opener返回的一个应答对象response
for item in mycookie:
print"name="+item.name
print"value="+item.value
filename='mycookie.txt'#设定保存的文件名
mycookie.save(filename,ignore_discard=True, ignore_expires=True)
将里面的事例简单变型就可以得到本例,使用了CookieJar的泛型MozillaCookiJar,为什么呢?我们将MozillaCookiJar换成CookieJar试试,下面一张图你能够明白:
CookieJar是没有保存save属性的~
save()这个方式中:ignore_discard的意思是虽然cookies将被遗弃也将它保存出来,ignore_expires的意思是假如在该文件中cookies早已存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行以后,cookies将被保存到cookie.txt文件中,我们查看一下内容:
这样我们就成功保存了我们想要的cookie
3、从文件中获取cookie并访问
Python借助requests进行模拟登陆
采集交流 • 优采云 发表了文章 • 0 个评论 • 673 次浏览 • 2020-06-25 08:00
Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...
使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...
请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的 查看全部
Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...
使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...
请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的
【php爬虫】百万级别知乎用户数据爬取与剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-06-14 08:03
文/Hector
这次抓取了110万的用户数据php 网络爬虫 抓取数据,数据剖析结果如下:
开发前的打算
安装linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;
安装PHP5.6或以上版本;
安装curl、pcntl扩充。
使用PHP的curl扩充抓取页面数据
PHP的curl扩充是PHP支持的容许你与各类服务器使用各类类型的合同进行联接和通讯的库。
本程序是抓取知乎的用户数据,要能访问用户个人页面,需要用户登陆后的能够访问。当我们在浏览器的页面中点击一个用户头像链接步入用户个人中心页面的时侯,之所以还能看见用户的信息,是因为在点击链接的时侯,浏览器帮你将本地的cookie带上一同递交到新的页面,所以你才能步入到用户的个人中心页面。因此实现访问个人页面之前须要先获得用户的cookie信息,然后在每次curl恳求的时侯带上cookie信息。在获取cookie信息方面,我是用了自己的cookie,在页面中可以看见自己的cookie信息:
一个个地复制,以"__utma=?;__utmb=?;"这样的方式组成一个cookie字符串。接下来就可以使用该cookie字符串来发送恳求。
初始的示例:
$url = ''; <br /> //此处mora-hu代表用户ID
$ch = curl_init($url); <br /> //初始化会话
curl_setopt($ch, CURLOPT_HEADER, 0); <br /> curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']); <br /> //设置请求COOKIE
curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); <br /> curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); <br /> //将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); <br /> $result = curl_exec($ch); <br /> return $result; //抓取的结果
运行里面的代码可以获得mora-hu用户的个人中心页面。利用该结果再使用正则表达式对页面进行处理,就能获取到姓名,性别等所须要抓取的信息。
图片防盗链
在对返回结果进行正则处理后输出个人信息的时侯,发现在页面中输出用户头像时难以打开。经过查阅资料获知,是因为知乎对图片做了防盗链处理。解决方案就是恳求图片的时侯在恳求头里伪造一个referer。
在使用正则表达式获取到图片的链接以后,再发一次恳求,这时候带上图片恳求的来源,说明该恳求来自知乎网站的转发。具体事例如下:
function getImg($url, $u_id){ <br /> if (file_exists('./images/' . $u_id . ".jpg")) <br /> { <br /> return "images/$u_id" . '.jpg'; } if (empty($url)) <br /> { <br /> return ''; <br /> }<br /> $context_options = array( <br /> 'http' =>
array(<br /> 'header' => "Referer:"//带上referer参数
)<br /> );<br /> $context = stream_context_create($context_options);<br /> $img = file_get_contents('http:' . $url, FALSE, $context);<br /> file_put_contents('./images/' . $u_id . ".jpg", $img);<br /> return "images/$u_id" . '.jpg';}
爬取更多用户
抓取了自己的个人信息后,就须要再访问用户的关注者和关注了的用户列表获取更多的用户信息。然后一层一层地访问。可以见到,在个人中心页面里,有两个链接如下:
这里有两个链接,一个是关注了,另一个是关注者,以“关注了”的链接为例。用正则匹配去匹配到相应的链接,得到url以后用curl带上cookie再发一次恳求。抓取到用户关注了的用于列表页以后,可以得到下边的页面:
分析页面的html结构php 网络爬虫 抓取数据,因为只要得到用户的信息,所以只须要框住的这一块的div内容,用户名都在这上面。可以看见,用户关注了的页面的url是:
不同的用户的这个url几乎是一样的,不同的地方就在于用户名哪里。用正则匹配领到用户名列表,一个一个地拼url,然后再挨个发恳求(当然,一个一个是比较慢的,下面有解决方案,这个稍后会说到)。进入到新用户的页面然后,再重复前面的步骤,就这样不断循环,直到达到你所要的数据量。 查看全部
代码托管地址:
文/Hector
这次抓取了110万的用户数据php 网络爬虫 抓取数据,数据剖析结果如下:
开发前的打算
安装linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu;
安装PHP5.6或以上版本;
安装curl、pcntl扩充。
使用PHP的curl扩充抓取页面数据
PHP的curl扩充是PHP支持的容许你与各类服务器使用各类类型的合同进行联接和通讯的库。
本程序是抓取知乎的用户数据,要能访问用户个人页面,需要用户登陆后的能够访问。当我们在浏览器的页面中点击一个用户头像链接步入用户个人中心页面的时侯,之所以还能看见用户的信息,是因为在点击链接的时侯,浏览器帮你将本地的cookie带上一同递交到新的页面,所以你才能步入到用户的个人中心页面。因此实现访问个人页面之前须要先获得用户的cookie信息,然后在每次curl恳求的时侯带上cookie信息。在获取cookie信息方面,我是用了自己的cookie,在页面中可以看见自己的cookie信息:
一个个地复制,以"__utma=?;__utmb=?;"这样的方式组成一个cookie字符串。接下来就可以使用该cookie字符串来发送恳求。
初始的示例:
$url = ''; <br /> //此处mora-hu代表用户ID
$ch = curl_init($url); <br /> //初始化会话
curl_setopt($ch, CURLOPT_HEADER, 0); <br /> curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']); <br /> //设置请求COOKIE
curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); <br /> curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); <br /> //将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); <br /> $result = curl_exec($ch); <br /> return $result; //抓取的结果
运行里面的代码可以获得mora-hu用户的个人中心页面。利用该结果再使用正则表达式对页面进行处理,就能获取到姓名,性别等所须要抓取的信息。
图片防盗链
在对返回结果进行正则处理后输出个人信息的时侯,发现在页面中输出用户头像时难以打开。经过查阅资料获知,是因为知乎对图片做了防盗链处理。解决方案就是恳求图片的时侯在恳求头里伪造一个referer。
在使用正则表达式获取到图片的链接以后,再发一次恳求,这时候带上图片恳求的来源,说明该恳求来自知乎网站的转发。具体事例如下:
function getImg($url, $u_id){ <br /> if (file_exists('./images/' . $u_id . ".jpg")) <br /> { <br /> return "images/$u_id" . '.jpg'; } if (empty($url)) <br /> { <br /> return ''; <br /> }<br /> $context_options = array( <br /> 'http' =>
array(<br /> 'header' => "Referer:"//带上referer参数
)<br /> );<br /> $context = stream_context_create($context_options);<br /> $img = file_get_contents('http:' . $url, FALSE, $context);<br /> file_put_contents('./images/' . $u_id . ".jpg", $img);<br /> return "images/$u_id" . '.jpg';}
爬取更多用户
抓取了自己的个人信息后,就须要再访问用户的关注者和关注了的用户列表获取更多的用户信息。然后一层一层地访问。可以见到,在个人中心页面里,有两个链接如下:
这里有两个链接,一个是关注了,另一个是关注者,以“关注了”的链接为例。用正则匹配去匹配到相应的链接,得到url以后用curl带上cookie再发一次恳求。抓取到用户关注了的用于列表页以后,可以得到下边的页面:
分析页面的html结构php 网络爬虫 抓取数据,因为只要得到用户的信息,所以只须要框住的这一块的div内容,用户名都在这上面。可以看见,用户关注了的页面的url是:
不同的用户的这个url几乎是一样的,不同的地方就在于用户名哪里。用正则匹配领到用户名列表,一个一个地拼url,然后再挨个发恳求(当然,一个一个是比较慢的,下面有解决方案,这个稍后会说到)。进入到新用户的页面然后,再重复前面的步骤,就这样不断循环,直到达到你所要的数据量。
老司机带你学爬虫——Python爬虫技术分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-05-06 08:01
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心 查看全部
什么是“爬虫”?
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心
dedecms,织梦后台系统配置参数空白的解决方
采集交流 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2020-04-15 11:04
出现DedeCms系统配置参数空白缘由:
1、还原数据库引起的
2、向数据库导出数据时没导出不全或数据某个文件被破坏
最直接缘由是数据库dede-sysconfig数据表大小为0或干脆不存在。
解决办法:
方法一随意在本地找个正常的dede数据库,选中dede-sysconfig表,然后导入,然后再导出不显示后台参数的数据库。即可解决
方法二:重新还原一下数据库
方法三:网上提供的方式,在备份文件中总算在一个文件中找到如下图的那种文件。
3
Ok,试试吧,把那种txt的数据备份文件上传到服务器,这个时侯出现了那种表,然后选择还原数据。
怀疑当时还原表结构时弄丢的织梦网站后台参数,所以没选还原表结构。或许跟这个没关系
文章二:
这样情况的出现总使人吓一跳,还好经过一番思索过后找到了问题所在。
我的网站是先在本地布属,然后再上传到服务器上的。出现DedeCms系统配置参数空白的问题之前,我同时登陆了服务器上的网站和本地布属的网站,此时可 能就引起了cookie的冲突。我在访问本地网站的后台的时侯发觉DedeCms系统配置参数空白,开始的时侯考虑是文件出哪些问题了。于是把没有出错的 服务器上的文件覆盖到了本地,问题还是没有解决。想通过恢复数据库试下能够解决,但这时候发觉数据还原里居然没有数据了??脑子在快速转动,我真是太笨 了。备份的功能能够用,我再备份一下瞧瞧文件会被备份到哪个地方织梦网站后台参数,备份过以后发觉居然是直接备份到了data下,不解。得了干脆直接把服务器上的缓存也直 接下出来瞧瞧。就在下完缓存以后发觉好了。从这我才觉得是cookie的冲突导致了这次的风波。还好是虚惊一场。为此我还在网上搜索了一此除cookie 冲突导致DedeCms系统配置参数空白问题的解决方式,供你们所需时备用。
数据库备份/还原后DedeCms系统配置参数出限空白解决方式
修改你须要还原的数据库dede_sysconfig_0_d08909f67460a7be.txt文件里的
INSERTINTO`DEDE_sysconfig`VALUES('3','cfg_cookie_encode','cookie加密码','2','string','JdCSr9155U');修改这个cookie加密码和你安装程序后台的一样.
查看你安装好的cookie加密码方式如图
注意不是修改网站后台的cookie加密码为dede_sysconfig的加密码
改好进行数据库还原
还原好了更新系统缓存在瞧瞧就可以了 查看全部
出现DedeCms系统配置参数空白缘由:
1、还原数据库引起的
2、向数据库导出数据时没导出不全或数据某个文件被破坏
最直接缘由是数据库dede-sysconfig数据表大小为0或干脆不存在。
解决办法:
方法一随意在本地找个正常的dede数据库,选中dede-sysconfig表,然后导入,然后再导出不显示后台参数的数据库。即可解决
方法二:重新还原一下数据库
方法三:网上提供的方式,在备份文件中总算在一个文件中找到如下图的那种文件。
3
Ok,试试吧,把那种txt的数据备份文件上传到服务器,这个时侯出现了那种表,然后选择还原数据。
怀疑当时还原表结构时弄丢的织梦网站后台参数,所以没选还原表结构。或许跟这个没关系
文章二:
这样情况的出现总使人吓一跳,还好经过一番思索过后找到了问题所在。
我的网站是先在本地布属,然后再上传到服务器上的。出现DedeCms系统配置参数空白的问题之前,我同时登陆了服务器上的网站和本地布属的网站,此时可 能就引起了cookie的冲突。我在访问本地网站的后台的时侯发觉DedeCms系统配置参数空白,开始的时侯考虑是文件出哪些问题了。于是把没有出错的 服务器上的文件覆盖到了本地,问题还是没有解决。想通过恢复数据库试下能够解决,但这时候发觉数据还原里居然没有数据了??脑子在快速转动,我真是太笨 了。备份的功能能够用,我再备份一下瞧瞧文件会被备份到哪个地方织梦网站后台参数,备份过以后发觉居然是直接备份到了data下,不解。得了干脆直接把服务器上的缓存也直 接下出来瞧瞧。就在下完缓存以后发觉好了。从这我才觉得是cookie的冲突导致了这次的风波。还好是虚惊一场。为此我还在网上搜索了一此除cookie 冲突导致DedeCms系统配置参数空白问题的解决方式,供你们所需时备用。
数据库备份/还原后DedeCms系统配置参数出限空白解决方式
修改你须要还原的数据库dede_sysconfig_0_d08909f67460a7be.txt文件里的
INSERTINTO`DEDE_sysconfig`VALUES('3','cfg_cookie_encode','cookie加密码','2','string','JdCSr9155U');修改这个cookie加密码和你安装程序后台的一样.
查看你安装好的cookie加密码方式如图
注意不是修改网站后台的cookie加密码为dede_sysconfig的加密码
改好进行数据库还原
还原好了更新系统缓存在瞧瞧就可以了

