
ajax抓取网页内容
ajax抓取网页内容(以今日头条为例分析Ajax请求抓取网页数据(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-13 13:20
)
以今日头条为例,分析Ajax请求获取网页数据。这次把今日头条街拍关键词对应的图片抓起来保存到本地
一、分析
打开今日头条首页,在搜索框中输入街拍这个词,打开开发者工具,发现浏览器显示的数据不在源码中。这样我们就可以初步判断这些内容是由
Ajax 被加载,然后使用 JavaScript 呈现。
切换到 XHR 过滤选项卡以查看其 Ajax 请求。点击其中一个进入,进入数据展开,发现其中一个标题字段对应的值正是页面上某条数据的标题。看其他数据,刚好是一一对应的,说明这些数据确实是Ajax加载的。
这次的目的是捕捉图像内容。数据中的每个元素都是一个文章,元素中的image_list字段收录了文章的图片内容。它采用列表的形式,其中收录所有图片的列表。我们只需要下载列表中的url字段,并为每个文章创建一个文件夹,文件夹名就是文章的标题。
在使用 Python 爬取之前,您还需要分析 URL 的规则。切换到标题选项卡以查看标题信息。如您所见,这是一个 GET 请求。请求的参数有:aid、app_name、offset、format、keyword、autoload、count、en_qc、cur_tab、from、pd、timestamp。继续往下滑,加载更多数据,找出规律。
经过观察可以发现,唯一改变的参数是offset和timestamp。第一次请求的offset值是0,第二次是20,第三次是40,key推断这个offset就是offset,count是每次请求的数据量,timestamp是时间戳。这样我们就可以通过offset参数来控制分页,通过模拟ajax请求获取数据,最后解析数据并下载。
二、爬
刚才分析了整个Ajax请求,接下来就是用代码来实现这个过程了。
# _*_ coding=utf-8 _*_
import requests
import time
import os
from hashlib import md5
from urllib.parse import urlencode
from multiprocessing.pool import Pool
def get_data(offset):
"""
构造URL,发送请求
:param offset:
:return:
"""
timestamp = int(time.time())
params = {
\'aid\': \'24\',
\'app_name\': \'web_search\',
\'offset\': offset,
\'format\': \'json\',
\'autoload\': \'true\',
\'count\': \'20\',
\'en_qc\': \'1\',
\'cur_tab\': \'1\',
\'from\': \'search_tab\',
\'pd\': \'synthesis\',
\'timestamp\': timestamp
}
base_url = \'https://www.toutiao.com/api/search/content/?keyword=%E8%A1%97%E6%8B%8D\'
url = base_url + urlencode(params)
try:
res = requests.get(url)
if res.status_code == 200:
return res.json()
except requests.ConnectionError:
return \'555...\'
def get_img(data):
"""
提取每一张图片连接,与标题一并返回,构造生成器
:param data:
:return:
"""
if data.get(\'data\'):
page_data = data.get(\'data\')
for item in page_data:
# cell_type字段不存在的这类文章不爬取,它没有title,和image_list字段,会出错
if item.get(\'cell_type\') is not None:
continue
title = item.get(\'title\').replace(\' |\', \' \') # 去掉某些可能导致文件名错误而不能创建文件的特殊符号,根据具体情况而定
imgs = item.get(\'image_list\')
for img in imgs:
yield {
\'title\': title,
\'img\': img.get(\'url\')
}
def save(item):
"""
根据title创建文件夹,将图片以二进制形式写入,
图片名称使用其内容的md5值,可以去除重复的图片
:param item:
:return:
"""
img_path = \'img\' + \'/\' + item.get(\'title\')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
res = requests.get(item.get(\'img\'))
if res.status_code == 200:
file_path = img_path + \'/\' + \'{name}.{suffix}\'.format(
name=md5(res.content).hexdigest(),
suffix=\'jpg\')
if not os.path.exists(file_path):
with open(file_path, \'wb\') as f:
f.write(res.content)
print(\'Successful\')
else:
print(\'Already Download\')
except requests.ConnectionError:
print(\'Failed to save images\')
def main(offset):
data = get_data(offset)
for item in get_img(data):
print(item)
save(item)
START = 0
END = 10
if __name__ == "__main__":
pool = Pool()
offsets = ([n * 20 for n in range(START, END + 1)])
pool.map(main, offsets)
pool.close()
pool.join()
这里定义了起始页START和结束页END,可以自定义设置。然后使用多进程进程池调用map()方法实现多进程下载。运行后,发现图片被保存了。
查看全部
ajax抓取网页内容(以今日头条为例分析Ajax请求抓取网页数据(一)
)
以今日头条为例,分析Ajax请求获取网页数据。这次把今日头条街拍关键词对应的图片抓起来保存到本地
一、分析
打开今日头条首页,在搜索框中输入街拍这个词,打开开发者工具,发现浏览器显示的数据不在源码中。这样我们就可以初步判断这些内容是由
Ajax 被加载,然后使用 JavaScript 呈现。
切换到 XHR 过滤选项卡以查看其 Ajax 请求。点击其中一个进入,进入数据展开,发现其中一个标题字段对应的值正是页面上某条数据的标题。看其他数据,刚好是一一对应的,说明这些数据确实是Ajax加载的。
这次的目的是捕捉图像内容。数据中的每个元素都是一个文章,元素中的image_list字段收录了文章的图片内容。它采用列表的形式,其中收录所有图片的列表。我们只需要下载列表中的url字段,并为每个文章创建一个文件夹,文件夹名就是文章的标题。
在使用 Python 爬取之前,您还需要分析 URL 的规则。切换到标题选项卡以查看标题信息。如您所见,这是一个 GET 请求。请求的参数有:aid、app_name、offset、format、keyword、autoload、count、en_qc、cur_tab、from、pd、timestamp。继续往下滑,加载更多数据,找出规律。
经过观察可以发现,唯一改变的参数是offset和timestamp。第一次请求的offset值是0,第二次是20,第三次是40,key推断这个offset就是offset,count是每次请求的数据量,timestamp是时间戳。这样我们就可以通过offset参数来控制分页,通过模拟ajax请求获取数据,最后解析数据并下载。
二、爬
刚才分析了整个Ajax请求,接下来就是用代码来实现这个过程了。
# _*_ coding=utf-8 _*_
import requests
import time
import os
from hashlib import md5
from urllib.parse import urlencode
from multiprocessing.pool import Pool
def get_data(offset):
"""
构造URL,发送请求
:param offset:
:return:
"""
timestamp = int(time.time())
params = {
\'aid\': \'24\',
\'app_name\': \'web_search\',
\'offset\': offset,
\'format\': \'json\',
\'autoload\': \'true\',
\'count\': \'20\',
\'en_qc\': \'1\',
\'cur_tab\': \'1\',
\'from\': \'search_tab\',
\'pd\': \'synthesis\',
\'timestamp\': timestamp
}
base_url = \'https://www.toutiao.com/api/search/content/?keyword=%E8%A1%97%E6%8B%8D\'
url = base_url + urlencode(params)
try:
res = requests.get(url)
if res.status_code == 200:
return res.json()
except requests.ConnectionError:
return \'555...\'
def get_img(data):
"""
提取每一张图片连接,与标题一并返回,构造生成器
:param data:
:return:
"""
if data.get(\'data\'):
page_data = data.get(\'data\')
for item in page_data:
# cell_type字段不存在的这类文章不爬取,它没有title,和image_list字段,会出错
if item.get(\'cell_type\') is not None:
continue
title = item.get(\'title\').replace(\' |\', \' \') # 去掉某些可能导致文件名错误而不能创建文件的特殊符号,根据具体情况而定
imgs = item.get(\'image_list\')
for img in imgs:
yield {
\'title\': title,
\'img\': img.get(\'url\')
}
def save(item):
"""
根据title创建文件夹,将图片以二进制形式写入,
图片名称使用其内容的md5值,可以去除重复的图片
:param item:
:return:
"""
img_path = \'img\' + \'/\' + item.get(\'title\')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
res = requests.get(item.get(\'img\'))
if res.status_code == 200:
file_path = img_path + \'/\' + \'{name}.{suffix}\'.format(
name=md5(res.content).hexdigest(),
suffix=\'jpg\')
if not os.path.exists(file_path):
with open(file_path, \'wb\') as f:
f.write(res.content)
print(\'Successful\')
else:
print(\'Already Download\')
except requests.ConnectionError:
print(\'Failed to save images\')
def main(offset):
data = get_data(offset)
for item in get_img(data):
print(item)
save(item)
START = 0
END = 10
if __name__ == "__main__":
pool = Pool()
offsets = ([n * 20 for n in range(START, END + 1)])
pool.map(main, offsets)
pool.close()
pool.join()
这里定义了起始页START和结束页END,可以自定义设置。然后使用多进程进程池调用map()方法实现多进程下载。运行后,发现图片被保存了。
ajax抓取网页内容(网络传输格式(json)(异步JavaScript和XML))
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-12 20:22
阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML 或 HTML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
列子
比如今日头条的街拍,一般只有在获取到网页内容后,一个frame没有具体的内容,只有通过特定的XHR(异步加载技术)才能动态加载网页和内容可以加载,如下图所示
https://www.toutiao.com/api/se ... et%3D{}&format=json&keyword={}&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1556365185857
这是一种很常见的传输格式(json),类似于python的字典用于网络传输
有我们需要的加载元素,只要我们提取它们。 查看全部
ajax抓取网页内容(网络传输格式(json)(异步JavaScript和XML))
阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML 或 HTML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
列子
比如今日头条的街拍,一般只有在获取到网页内容后,一个frame没有具体的内容,只有通过特定的XHR(异步加载技术)才能动态加载网页和内容可以加载,如下图所示
https://www.toutiao.com/api/se ... et%3D{}&format=json&keyword={}&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1556365185857

这是一种很常见的传输格式(json),类似于python的字典用于网络传输
有我们需要的加载元素,只要我们提取它们。
ajax抓取网页内容(【Ajax】Ajax请求的请求和请求的原理是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-12 20:18
)
阿贾克斯介绍:
有时我们使用Requests抓取页面时,结果可能与我们在浏览器中看到的不一样。可以看到浏览器正常显示的页面数据,但是得到的响应并没有对应的响应。内容。
这样做的原因是Requests获取的是原创HTML文档,浏览器中的页面是页面经过JavaScript处理后生成的结果。这些数据的来源有很多:
今天我们将讨论Ajax加载类型的网页数据。
阿贾克斯的概念
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。对于 Ajax 渲染的页面,数据加载是一种异步加载方式。原创页面最初不会收录某些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后将数据进行处理后才呈现在网页上,这实际上就是发送一个ajax请求。
这就是为什么我们不能直接使用 requests 来请求页面的实际内容。
这时候需要做的就是分析网页后台向界面发送的Ajax请求,然后用Requests模拟Ajax请求,就可以成功捕获了。
了解了ajax的原理后,一切都变得有点头绪了~
阿贾克斯观察
对于 Ajax 请求,我们已经在现实生活中遇到过。我来形容你知道:“当你在浏览网页或APP的时候,当你把进度条拉到最下面的时候,你会看到进度条突然跳到中间,下面出现新的内容”
其实这就是Ajax的使用。
今天,我们用微博作为爬取对象。
网址 = ""
浏览器发起请求
老规矩,进入开发者模式。然后在Network下,点击XHR进行过滤(只过滤掉Ajax请求的请求响应消息)
我们先看第一个入口信息,观察它的Response
于是我们进行了测试,将进度条拖到底部,发现浏览器和服务器暗中进行了消息交互,效果如下:
查看全部
ajax抓取网页内容(【Ajax】Ajax请求的请求和请求的原理是什么?
)
阿贾克斯介绍:
有时我们使用Requests抓取页面时,结果可能与我们在浏览器中看到的不一样。可以看到浏览器正常显示的页面数据,但是得到的响应并没有对应的响应。内容。
这样做的原因是Requests获取的是原创HTML文档,浏览器中的页面是页面经过JavaScript处理后生成的结果。这些数据的来源有很多:
今天我们将讨论Ajax加载类型的网页数据。
阿贾克斯的概念
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。对于 Ajax 渲染的页面,数据加载是一种异步加载方式。原创页面最初不会收录某些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后将数据进行处理后才呈现在网页上,这实际上就是发送一个ajax请求。
这就是为什么我们不能直接使用 requests 来请求页面的实际内容。
这时候需要做的就是分析网页后台向界面发送的Ajax请求,然后用Requests模拟Ajax请求,就可以成功捕获了。

了解了ajax的原理后,一切都变得有点头绪了~
阿贾克斯观察
对于 Ajax 请求,我们已经在现实生活中遇到过。我来形容你知道:“当你在浏览网页或APP的时候,当你把进度条拉到最下面的时候,你会看到进度条突然跳到中间,下面出现新的内容”
其实这就是Ajax的使用。
今天,我们用微博作为爬取对象。
网址 = ""
浏览器发起请求
老规矩,进入开发者模式。然后在Network下,点击XHR进行过滤(只过滤掉Ajax请求的请求响应消息)
我们先看第一个入口信息,观察它的Response
于是我们进行了测试,将进度条拖到底部,发现浏览器和服务器暗中进行了消息交互,效果如下:
ajax抓取网页内容(DOM结构怎么查看,浏览器快捷菜单中没有这功能吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-09 19:12
因为是ajax获取的
当然,javascript操作的结果不在html中。
可以在dom结构中查看。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
当然,javascript操作的结果不在html中。
可以在dom结构中查看。
如何检查DOM结构?浏览器快捷菜单中没有该功能。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
真的不
document.write之后html已经更新了,为什么浏览器给不出新版本的html。
新版本的 HTML。
对于 IE,可以使用 c&p 到 Word 或 IE 的富文本编辑器。其他浏览器我没试过。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
真的不
document.write之后html已经更新了,为什么浏览器给不出新版本的html。
您必须了解基本的 html 原理。无论 html 是静态存储在硬盘上还是由编程语言生成的 html,Web 服务器始终返回 html 内容。
浏览器的作用就是显示这些html内容。
客户端脚本语言的内容由脚本引擎处理,例如 chrome 的 v8 引擎。
它负责解释脚本并在必要时重新绘制页面。脚本的所有操作都是在dom中完成的。.
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签:网页显示的内容在源文件中找不到是什么原因 查看全部
ajax抓取网页内容(DOM结构怎么查看,浏览器快捷菜单中没有这功能吧)
因为是ajax获取的
当然,javascript操作的结果不在html中。
可以在dom结构中查看。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
当然,javascript操作的结果不在html中。
可以在dom结构中查看。
如何检查DOM结构?浏览器快捷菜单中没有该功能。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
真的不
document.write之后html已经更新了,为什么浏览器给不出新版本的html。
新版本的 HTML。
对于 IE,可以使用 c&p 到 Word 或 IE 的富文本编辑器。其他浏览器我没试过。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
真的不
document.write之后html已经更新了,为什么浏览器给不出新版本的html。
您必须了解基本的 html 原理。无论 html 是静态存储在硬盘上还是由编程语言生成的 html,Web 服务器始终返回 html 内容。
浏览器的作用就是显示这些html内容。
客户端脚本语言的内容由脚本引擎处理,例如 chrome 的 v8 引擎。
它负责解释脚本并在必要时重新绘制页面。脚本的所有操作都是在dom中完成的。.

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签:网页显示的内容在源文件中找不到是什么原因
ajax抓取网页内容(有待开发者network如果看ajax加载需要Doc标签待有机会 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-11-09 11:06
)
先解释一下什么是ajax动态网页。扫微博的时候经常会遇到这个。一直往下拉,就会一直有数据加载,然后就会显示在你的界面上,类似下图。
通过改变offset也可以发现网页加载了数据(步长为20)(观察修改通过的XHR标签)
然后获取数据。
待学习谷歌开发者 F12
网络
如果你看ajax加载,你需要XHR标签
如果你看源码,你需要Doc标签
有机会我们会详细分析代码。目前只有崔老师爬取成功的代码。有一个池层。
from requests.exceptions import RequestException
import json
import re
from bs4 import BeautifulSoup
import requests
from urllib.parse import urlencode
from requests import codes # ?from 和 import 的区别
import os
from hashlib import md5 # ?
from multiprocessing.pool import Pool # 多进程池
def get_page_index(offset, keyword):
data = {
'offsets': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': 3
}
url = 'http://www.toutiao.com/search_content/?' + urlencode(data) # 这是网页的地址,urlencode是url的一种编码方式
try:
response = requests.get(url)
if response.status_code == codes.ok:
return response.json()
except requests.ConnectionError:
print('请求索引出错')
return None
def get_images(json):
if json.get('data'):
data = json.get('data')
for item in data:
if item.get('cell_type') is not None:
continue
title = item.get('title')
images = item.get('image_list')
for image in images:
yield {
'image': 'https:' + image.get('url'),
'title': title
}
def save_image(item):
img_path = 'img' + os.path.sep + item.get('title')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
resp = requests.get(item.get('image'))
if codes.ok == resp.status_code:
file_path = img_path + os.path.sep + '{file_name}.{file_suffix}'.format(
file_name=md5(resp.content).hexdigest(),
file_suffix='jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(resp.content)
print('Downloaded image path is %s' % file_path)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image,item %s' % item)
def main(offset):
json = get_page_index(offset,'街拍')
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 0
GROUP_END = 7
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START,GROUP_END + 1)])
pool.map(main,groups) # 池化匹配
pool.close()
pool.join() 查看全部
ajax抓取网页内容(有待开发者network如果看ajax加载需要Doc标签待有机会
)
先解释一下什么是ajax动态网页。扫微博的时候经常会遇到这个。一直往下拉,就会一直有数据加载,然后就会显示在你的界面上,类似下图。
通过改变offset也可以发现网页加载了数据(步长为20)(观察修改通过的XHR标签)
然后获取数据。
待学习谷歌开发者 F12
网络
如果你看ajax加载,你需要XHR标签
如果你看源码,你需要Doc标签
有机会我们会详细分析代码。目前只有崔老师爬取成功的代码。有一个池层。
from requests.exceptions import RequestException
import json
import re
from bs4 import BeautifulSoup
import requests
from urllib.parse import urlencode
from requests import codes # ?from 和 import 的区别
import os
from hashlib import md5 # ?
from multiprocessing.pool import Pool # 多进程池
def get_page_index(offset, keyword):
data = {
'offsets': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': 3
}
url = 'http://www.toutiao.com/search_content/?' + urlencode(data) # 这是网页的地址,urlencode是url的一种编码方式
try:
response = requests.get(url)
if response.status_code == codes.ok:
return response.json()
except requests.ConnectionError:
print('请求索引出错')
return None
def get_images(json):
if json.get('data'):
data = json.get('data')
for item in data:
if item.get('cell_type') is not None:
continue
title = item.get('title')
images = item.get('image_list')
for image in images:
yield {
'image': 'https:' + image.get('url'),
'title': title
}
def save_image(item):
img_path = 'img' + os.path.sep + item.get('title')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
resp = requests.get(item.get('image'))
if codes.ok == resp.status_code:
file_path = img_path + os.path.sep + '{file_name}.{file_suffix}'.format(
file_name=md5(resp.content).hexdigest(),
file_suffix='jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(resp.content)
print('Downloaded image path is %s' % file_path)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image,item %s' % item)
def main(offset):
json = get_page_index(offset,'街拍')
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 0
GROUP_END = 7
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START,GROUP_END + 1)])
pool.map(main,groups) # 池化匹配
pool.close()
pool.join()
ajax抓取网页内容(新版简书网站为例的评论信息和哪些专题进行了收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-11-09 11:05
以新版短书网站为例,新版网站在很多地方使用了ajax(异步JavaScript和XML),大大提高了页面加载速度。
对于一些数据的抓取,增加了复杂度,在源码中找不到ajax数据。如下图所示,文章页面中的评论信息以及哪些话题已经被收录在源码中是看不到的。
一、 抓包分析
使用抓包工具 Fiddler 或 Chrome“检查”进行分析。本文使用 Chrome 工具。Chrome——“检查”——切换到“网络”,然后刷新网页。找到发送主题收录的请求。
注意:一个页面通常有几十个请求(这个页面有89个),包括网页文档(document)、脚本(script)、图片(jpeg),还有另外一种叫做xhl的类型,就是XMLHttpRequest。我们正在寻找异步请求类型。比较名称并找到我们想要的请求。
单击它,您将看到完整的 URL。
http://www.jianshu.com/notes/8 ... e%3D1
注意这个URL放在地址栏中访问,发现返回的不是我们想要的数据,而是一个404页面。但是看看返回的Response,就是我们需要的JSON数据。
怎么做?把url改成.json的结尾,就可以访问地址栏中的数据了。
http://www.jianshu.com/notes/8 ... .json
第一步到这里就完成了。最关键的问题是如何获取url中的id 8777855。如果能找到id,就可以构造一个url来获取json数据。
二、构造目标地址
方法:查看网页源代码。我刚才不是说源码里没有我们需要的数据吗?查什么,搜索编号id 8777855,看看,确实如此,是在一些标签中,作为内容值的一部分。
那么它会更容易。解析元标记并获取 id。
def parse(self,response):
selector = Selector(response)
infos = selector.xpath("//meta/@content").extract()
id = ''
for info in infos:
if (str(info).find('jianshu://notes/')) ==0 :
id = filter(str.isdigit,str(info))
break;
collection_url ='http://www.jianshu.com/notes/%s/included_collections.json'%id
yield Request(collection_url,callback=self.parse_json)
OK,一个目标url就是这样构造的。
三、解析json数据
这一步比较简单,引入json包进行分析。当然,在做这一步的时候,需要先发送一个请求。
def parse_json(self,response):
data = json.loads(response.body)
collect = data['collections']
cols=''
if len(collect) >0 :
for cc in collect:
cols += cc['title']+';'
上述步骤中解析json的方法也适用于一般的Python爬虫。 查看全部
ajax抓取网页内容(新版简书网站为例的评论信息和哪些专题进行了收录)
以新版短书网站为例,新版网站在很多地方使用了ajax(异步JavaScript和XML),大大提高了页面加载速度。
对于一些数据的抓取,增加了复杂度,在源码中找不到ajax数据。如下图所示,文章页面中的评论信息以及哪些话题已经被收录在源码中是看不到的。
一、 抓包分析
使用抓包工具 Fiddler 或 Chrome“检查”进行分析。本文使用 Chrome 工具。Chrome——“检查”——切换到“网络”,然后刷新网页。找到发送主题收录的请求。

注意:一个页面通常有几十个请求(这个页面有89个),包括网页文档(document)、脚本(script)、图片(jpeg),还有另外一种叫做xhl的类型,就是XMLHttpRequest。我们正在寻找异步请求类型。比较名称并找到我们想要的请求。
单击它,您将看到完整的 URL。
http://www.jianshu.com/notes/8 ... e%3D1
注意这个URL放在地址栏中访问,发现返回的不是我们想要的数据,而是一个404页面。但是看看返回的Response,就是我们需要的JSON数据。
怎么做?把url改成.json的结尾,就可以访问地址栏中的数据了。
http://www.jianshu.com/notes/8 ... .json
第一步到这里就完成了。最关键的问题是如何获取url中的id 8777855。如果能找到id,就可以构造一个url来获取json数据。
二、构造目标地址
方法:查看网页源代码。我刚才不是说源码里没有我们需要的数据吗?查什么,搜索编号id 8777855,看看,确实如此,是在一些标签中,作为内容值的一部分。
那么它会更容易。解析元标记并获取 id。
def parse(self,response):
selector = Selector(response)
infos = selector.xpath("//meta/@content").extract()
id = ''
for info in infos:
if (str(info).find('jianshu://notes/')) ==0 :
id = filter(str.isdigit,str(info))
break;
collection_url ='http://www.jianshu.com/notes/%s/included_collections.json'%id
yield Request(collection_url,callback=self.parse_json)
OK,一个目标url就是这样构造的。
三、解析json数据
这一步比较简单,引入json包进行分析。当然,在做这一步的时候,需要先发送一个请求。
def parse_json(self,response):
data = json.loads(response.body)
collect = data['collections']
cols=''
if len(collect) >0 :
for cc in collect:
cols += cc['title']+';'
上述步骤中解析json的方法也适用于一般的Python爬虫。
ajax抓取网页内容( ():)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-09 06:10
():)
ajax获取网页的cookie值并处理页面信息
注意:没有必要。后台可以直接操作数据,不用ajax更简单
($sn_arr = $_COOKIE;) ---------------获取所有cookies进行过滤操作
1.js(函数执行后页面加载0.5ms)
$(function(){
setTimeout(function () {
$.ajax({
url:"/supplierbuyer/order/getCookie",
data:{
},
type:"POST",
dataType:"JSON",
success:function(data){
if(data.status==true){
//处理cookie的数据
var cookie_content = data['sn_arr'];
$.each(cookie_content, function(index, item){
if (index.startsWith("order_sn_")) {
var order_sn = index.substr(9);
$('.'+order_sn).text('');
$('.'+order_sn).parent().prev().css("background","");
}
});
}else{
console.log(data);
return false;
}
}
});
}, 0.5);
});
2.php
/**
* 获取cookie
*/
public function getCookie()
{
$sn_arr = $_COOKIE;
if ($sn_arr) {
$data['status'] = true;
$data['sn_arr'] = $sn_arr;
$data['msg'] = 'ok';
} else {
$data['status'] = false;
$data['sn_arr'] = '';
$data['msg'] = '网络错误,请稍后重试~';
}
echo json_encode($data);
exit();
}
posted @ 2018-12-05 16:13 很有趣。阅读(4664)评论(0)编辑 查看全部
ajax抓取网页内容(
():)
ajax获取网页的cookie值并处理页面信息
注意:没有必要。后台可以直接操作数据,不用ajax更简单
($sn_arr = $_COOKIE;) ---------------获取所有cookies进行过滤操作
1.js(函数执行后页面加载0.5ms)
$(function(){
setTimeout(function () {
$.ajax({
url:"/supplierbuyer/order/getCookie",
data:{
},
type:"POST",
dataType:"JSON",
success:function(data){
if(data.status==true){
//处理cookie的数据
var cookie_content = data['sn_arr'];
$.each(cookie_content, function(index, item){
if (index.startsWith("order_sn_")) {
var order_sn = index.substr(9);
$('.'+order_sn).text('');
$('.'+order_sn).parent().prev().css("background","");
}
});
}else{
console.log(data);
return false;
}
}
});
}, 0.5);
});
2.php
/**
* 获取cookie
*/
public function getCookie()
{
$sn_arr = $_COOKIE;
if ($sn_arr) {
$data['status'] = true;
$data['sn_arr'] = $sn_arr;
$data['msg'] = 'ok';
} else {
$data['status'] = false;
$data['sn_arr'] = '';
$data['msg'] = '网络错误,请稍后重试~';
}
echo json_encode($data);
exit();
}
posted @ 2018-12-05 16:13 很有趣。阅读(4664)评论(0)编辑
ajax抓取网页内容(一个非常好用的JQuery插件怎么用?图片卡卡网Html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-05 23:30
今天介绍一个非常好用的JQuery插件,可以将网页或者div或者table的内容转换成图片并下载保存。这个插件叫做html2canvas,它只有一个js文件html2canvas.js,使用起来非常简单。
先看一个示例html代码,然后介绍如何使用。
html-content-holder">
卡卡旺
Html 转图片
卡卡网旨在为广大网站建设人员提供专业的网站测速和优化服务,同时为广大网友提供网速测试服务。
html2canvas 脚本可以直接在用户的浏览器上使用来截取网页或其部分内容的屏幕截图。截图基于DOM,所以可能不完全准确。
btn-Preview-Image" type="button" value="Preview"/>
预览:
预览图片">
execcodegetcode
下面介绍插件的使用方法,主要分为三个步骤。第一步:调用jquery库文件和html2canvas.js文件
jquery库文件可以调用百度公共库文件,html2canvas.js文件需要下载到本地才能调用。本文后面会附上下载地址。
代码如下:
第 2 步:预览和下载 html 代码
点击“预览”查看生成的图片,点击“下载”下载并保存图片。
代码如下:
btn-Preview-Image" type="button" value="Preview"/>
预览:
预览图片">
第三部分:JQuery生成下载图片的实现代码
代码如下:
在编写代码时,只需要将jquery实现代码的每个id名称与html代码中的每个id匹配即可。
插件下载
下载 html2canvas.js 文件。
链接:
提取码:ks6r 查看全部
ajax抓取网页内容(一个非常好用的JQuery插件怎么用?图片卡卡网Html)
今天介绍一个非常好用的JQuery插件,可以将网页或者div或者table的内容转换成图片并下载保存。这个插件叫做html2canvas,它只有一个js文件html2canvas.js,使用起来非常简单。
先看一个示例html代码,然后介绍如何使用。
html-content-holder">
卡卡旺
Html 转图片
卡卡网旨在为广大网站建设人员提供专业的网站测速和优化服务,同时为广大网友提供网速测试服务。
html2canvas 脚本可以直接在用户的浏览器上使用来截取网页或其部分内容的屏幕截图。截图基于DOM,所以可能不完全准确。
btn-Preview-Image" type="button" value="Preview"/>
预览:
预览图片">
execcodegetcode
下面介绍插件的使用方法,主要分为三个步骤。第一步:调用jquery库文件和html2canvas.js文件
jquery库文件可以调用百度公共库文件,html2canvas.js文件需要下载到本地才能调用。本文后面会附上下载地址。
代码如下:
第 2 步:预览和下载 html 代码
点击“预览”查看生成的图片,点击“下载”下载并保存图片。
代码如下:
btn-Preview-Image" type="button" value="Preview"/>
预览:
预览图片">
第三部分:JQuery生成下载图片的实现代码
代码如下:
在编写代码时,只需要将jquery实现代码的每个id名称与html代码中的每个id匹配即可。
插件下载
下载 html2canvas.js 文件。
链接:
提取码:ks6r
ajax抓取网页内容(PHP脚本将异步执行一系列任务(1)_经济学网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-11-05 07:30
问题
你好,
我不熟悉网络编程,但我在这里遇到了一个问题。
我有一个页面。当用户单击按钮时,我将使用 AJAX 请求一个 PHP 脚本,该脚本将异步执行一系列任务。
这些任务可能需要很长时间,所以我希望用户理解
进步。问题是只有PHP脚本知道
进度,网页如何从PHP脚本中获取这些信息?
如果有人能帮我解决这个问题,我将不胜感激。
解决方案
张马文写道:
你好,
我对网络编程不熟悉,但我在这里遇到了一个问题。
我有一个页面。当用户单击按钮时,我将使用 AJAX 请求一个 PHP 脚本,该脚本将异步执行一系列任务。
这些任务可能需要很长时间,所以我希望用户理解
进步。问题是只有PHP脚本知道
进度,网页如何从PHP脚本中获取这些信息?
如果有人能帮我解决这个问题,我将不胜感激。
这只是一个想法,做过的人可能更清楚。
-让您的原创 PHP 将信息存储在其“状态”会话中
变数论
_SESSION [" status_data"] 这是一个运行时更新
- Javascript 端有一个计时器,用于创建第二个 Ajax 调用
到一个新的 getstatus.php,然后从会话中读取状态并
在第二个 Ajax 调用中将其发送回浏览器。
没有做太多的 Ajax,我想你可以再打一次 ajax 调用,然后
它目前正在运行吗?
当您的 b$b 调用 getstatus.php 时,您可能需要将 PHP 会话 ID 发送回服务器,不确定。
我们不在乎你做什么:)
-让您的原创 PHP 将信息存储在其“状态”会话中
变数论 查看全部
ajax抓取网页内容(PHP脚本将异步执行一系列任务(1)_经济学网)
问题
你好,
我不熟悉网络编程,但我在这里遇到了一个问题。
我有一个页面。当用户单击按钮时,我将使用 AJAX 请求一个 PHP 脚本,该脚本将异步执行一系列任务。
这些任务可能需要很长时间,所以我希望用户理解
进步。问题是只有PHP脚本知道
进度,网页如何从PHP脚本中获取这些信息?
如果有人能帮我解决这个问题,我将不胜感激。
解决方案
张马文写道:
你好,
我对网络编程不熟悉,但我在这里遇到了一个问题。
我有一个页面。当用户单击按钮时,我将使用 AJAX 请求一个 PHP 脚本,该脚本将异步执行一系列任务。
这些任务可能需要很长时间,所以我希望用户理解
进步。问题是只有PHP脚本知道
进度,网页如何从PHP脚本中获取这些信息?
如果有人能帮我解决这个问题,我将不胜感激。
这只是一个想法,做过的人可能更清楚。
-让您的原创 PHP 将信息存储在其“状态”会话中
变数论
_SESSION [" status_data"] 这是一个运行时更新
- Javascript 端有一个计时器,用于创建第二个 Ajax 调用
到一个新的 getstatus.php,然后从会话中读取状态并
在第二个 Ajax 调用中将其发送回浏览器。
没有做太多的 Ajax,我想你可以再打一次 ajax 调用,然后
它目前正在运行吗?
当您的 b$b 调用 getstatus.php 时,您可能需要将 PHP 会话 ID 发送回服务器,不确定。
我们不在乎你做什么:)
-让您的原创 PHP 将信息存储在其“状态”会话中
变数论
ajax抓取网页内容(网页更新的一个Ajax请求是怎样的?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-11-03 04:10
)
未完待续
前言:
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用reuqest得到的结果是不同的。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是通过 JavaScript 处理数据的结果。它可能是通过Ajax加载的,可能是收录在HTML文档中,也可能是JavaScript和计算后生成的特定算法。
现在对于第一种情况,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
什么是阿贾克斯:
Ajax,Asynchronous JavaScript and XML,即异步 JavaScript 和 XML。一种使用 JavaScript 与服务器交换数据并更新某些网页,同时确保页面不会刷新和页面链接不会更改的技术。
示例介绍:
在浏览网页时,我们会发现很多网页都有向下滚动查看更多选项。以youtube为例,如下图所示,一直往下滑,可以发现,滑动几次后,会出现一个加载动画。一段时间后,新内容将继续出现在下方。这个过程其实就是Ajax加载的过程。
基本的:
在初步了解了 Ajax 之后,我们将进一步了解其基本原理。向网页更新发送ajax请求的过程可以简单分为以下3个步骤:
发送请求解析内容并渲染网页
发送请求
我们知道JavaScript可以实现页面的各种交互功能。Ajax 也不例外,它也是由 JavaScript 实现的,实际执行如下代码:
var xmlHttp;
if (window.XMLHttpRequest){
// code for IE7+,Firefox,chrome,Opera,Safari
xmlhttp = new XMLHttpRequest();
}else{
// code for IE6,IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function(){
if (xmlhttp.readyState==4 && xmlhttp.status == 200){
document.getElementById("myDiv").innerHTML = xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax",true);
xmlhttp.send();
这是 JavaScript 的 Ajax 的最低级别实现。实际上,它创建了一个新的 XMLHttpRequest 对象,然后调用 onreadystatechange 属性设置侦听器,然后调用 open() 和 send() 方法向链接(即服务器)发送请求。Python中发送请求后,可以得到响应结果,但是这里的请求发送是由JavaScript完成的。由于设置了监听,当服务器返回响应时,就会触发onreadystatechange对应的方法,然后就可以在这个方法中解析响应内容了。
解析内容
得到响应后,会触发onreadystatechange属性对应的方法。这时候可以通过xmlhttp的responseText属性获取响应内容。这类似于Python中使用requests向服务器发起请求,然后得到响应的过程。那么返回的内容可能是HTML或者JSON,那么你只需要在方法中使用JavaScript进行进一步处理即可。
例如,如果是 JSON,则可以对其进行解析和转换。
渲染网页
JavaScript 具有更改网页内容的能力。解析响应内容后,您可以调用 JavaScript 对解析后的内容执行网页的下一步处理。比如通过document.getElementById().innerHTML等操作,可以对元素中的源代码进行更改、删除等操作。
上例中document.getElementById("myDiv").innerHTML = xmlhttp.responseText会将ID为myDiv的节点内部的HTML代码改为服务器返回的内容,这样服务器返回的新数据就会出现在里面myDiv 元素,页面的一部分似乎已更新。
我们看到这三步其实是由JavaScript来完成的,它完成了请求、解析、渲染的整个过程。回想youtube的下拉刷新,这其实就是JavaScript向服务器发送Ajax请求,然后获取新数据,解析,渲染到网页上。
因此,我们知道真正的数据实际上是通过一次又一次的ajax请求获取的。如果要抓取这些数据,就需要知道请求是如何发送的,发送到哪里,以及发送了哪些参数。如果我们知道这一点,我们可以用Python模拟发送操作并得到结果吗?
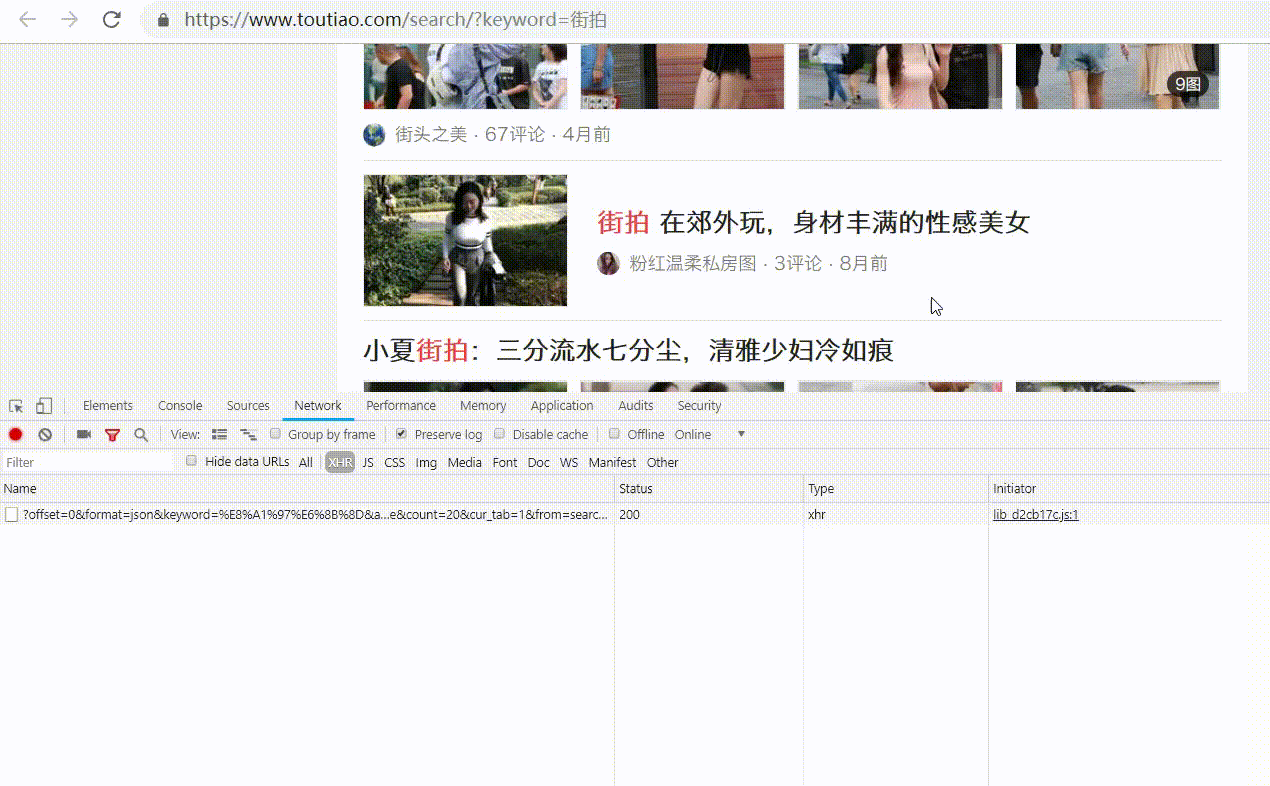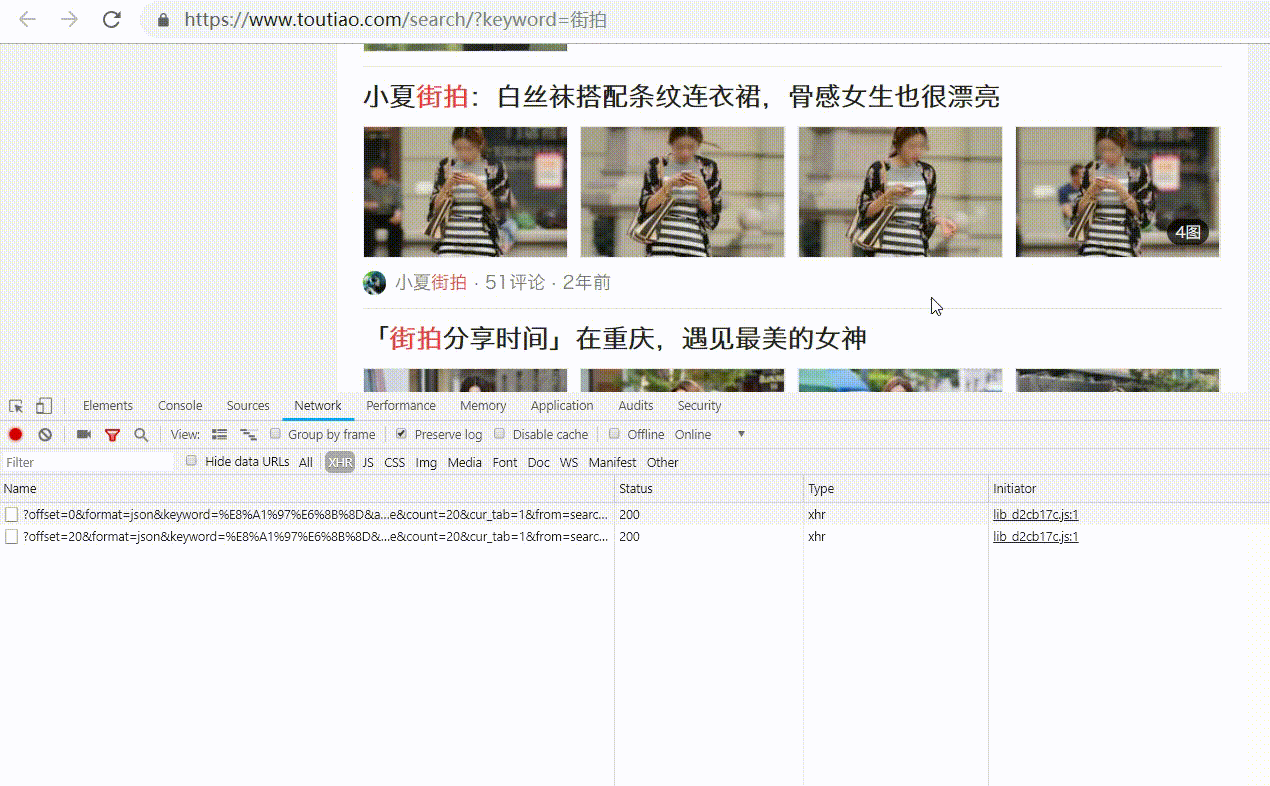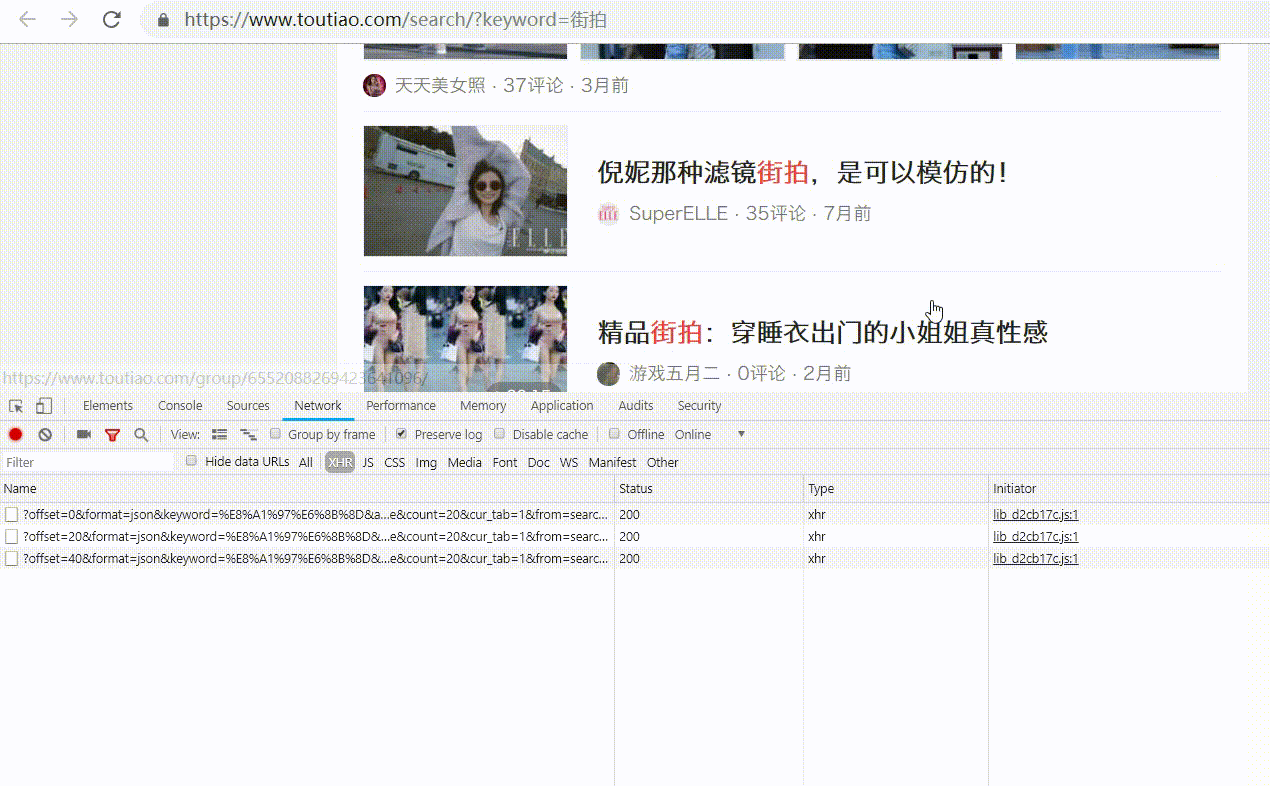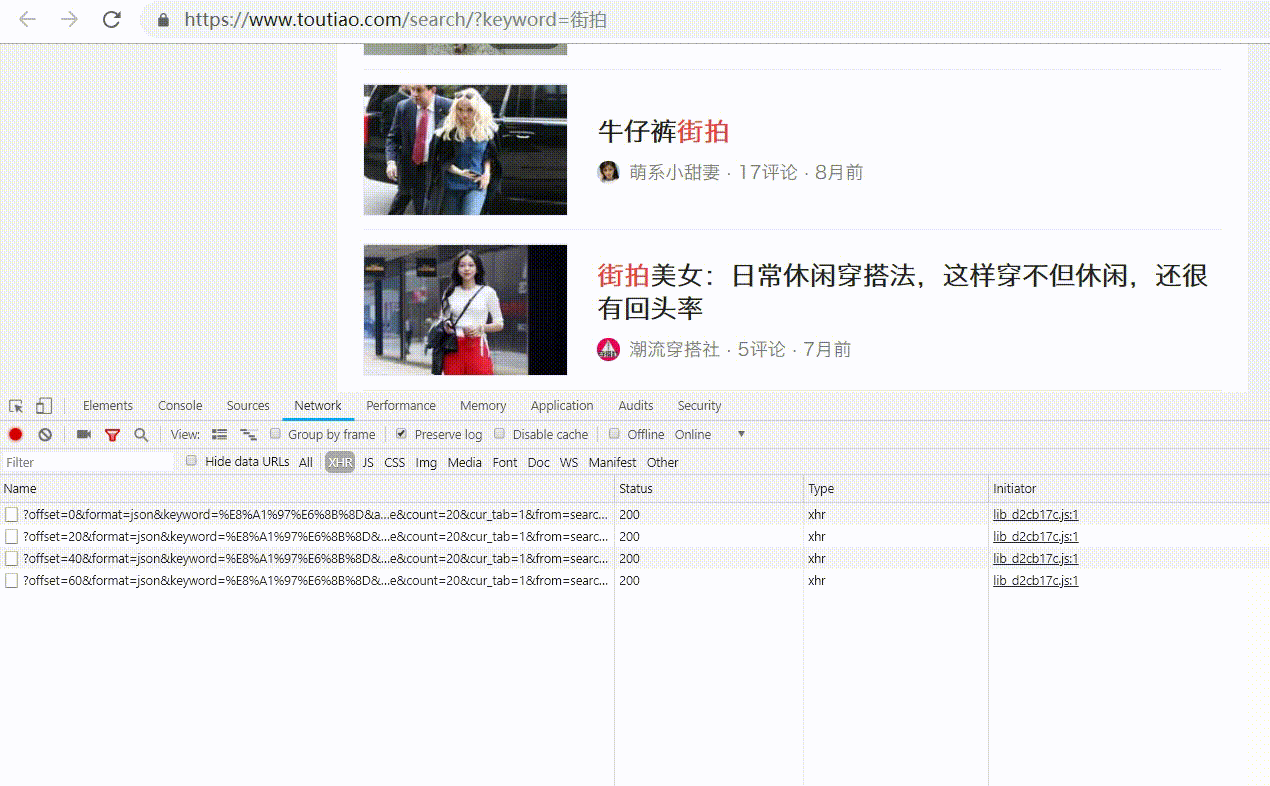
我们来看看哪里可以看到这些后台Ajax操作,它们是如何发送的,以及发送了什么参数。
Ajax分析方法
以之前的youtube为例。我们知道拖拽刷新的内容是ajax加载的,页面的url没有变化,那么这些ajax请求应该去哪里找呢?
1.查看请求
这里还需要用到浏览器的开发者工具,下面以chrome浏览器为例介绍。
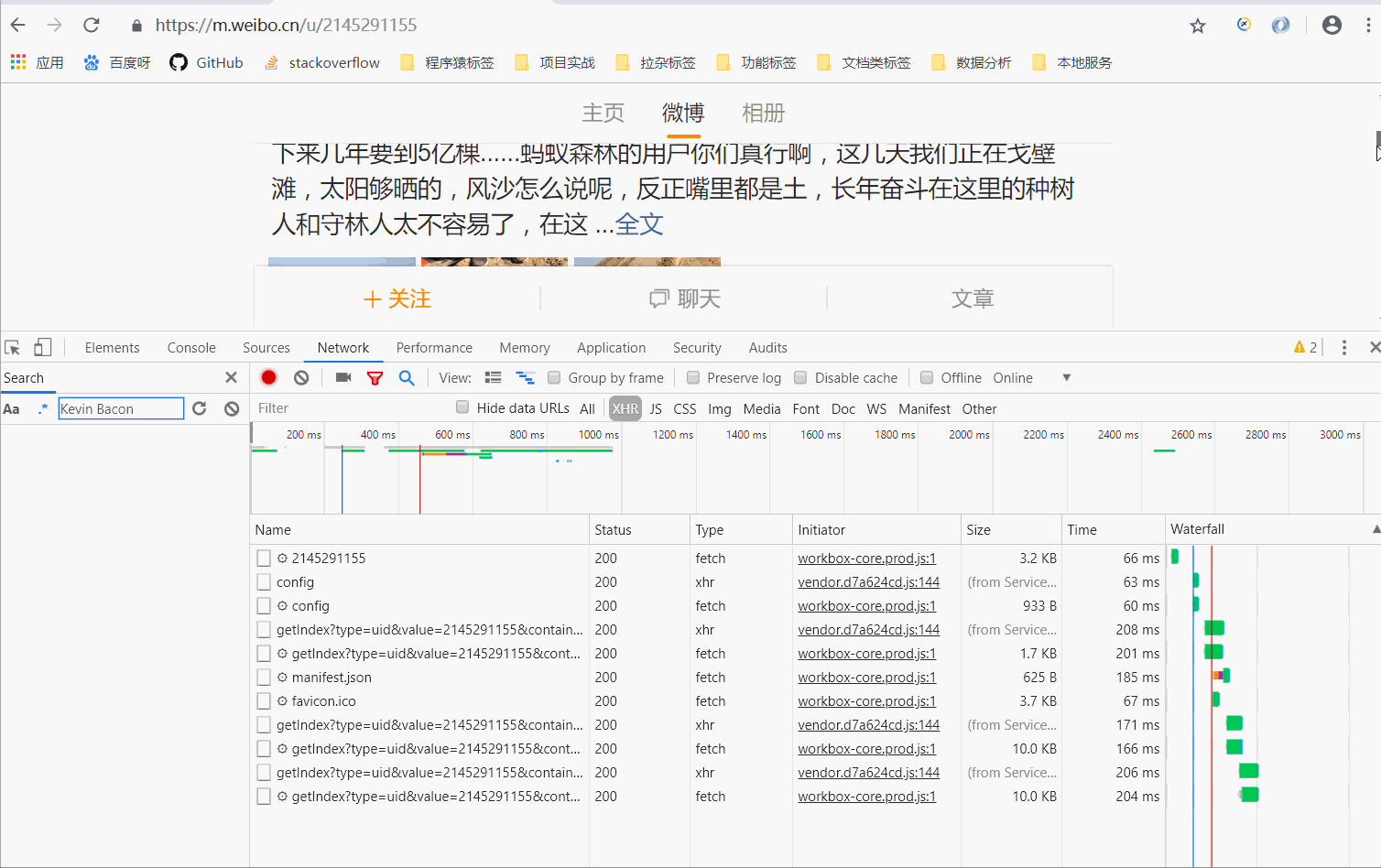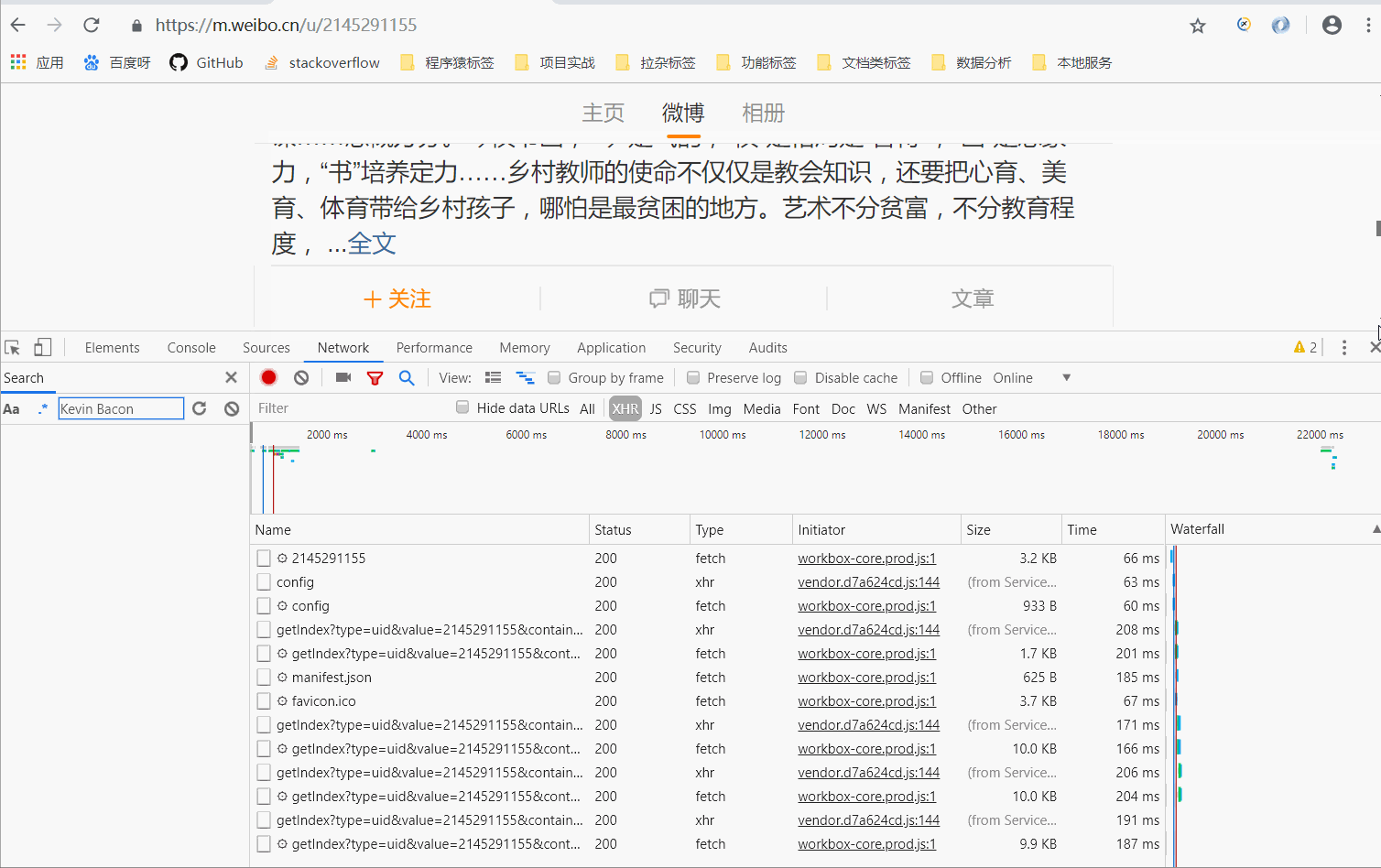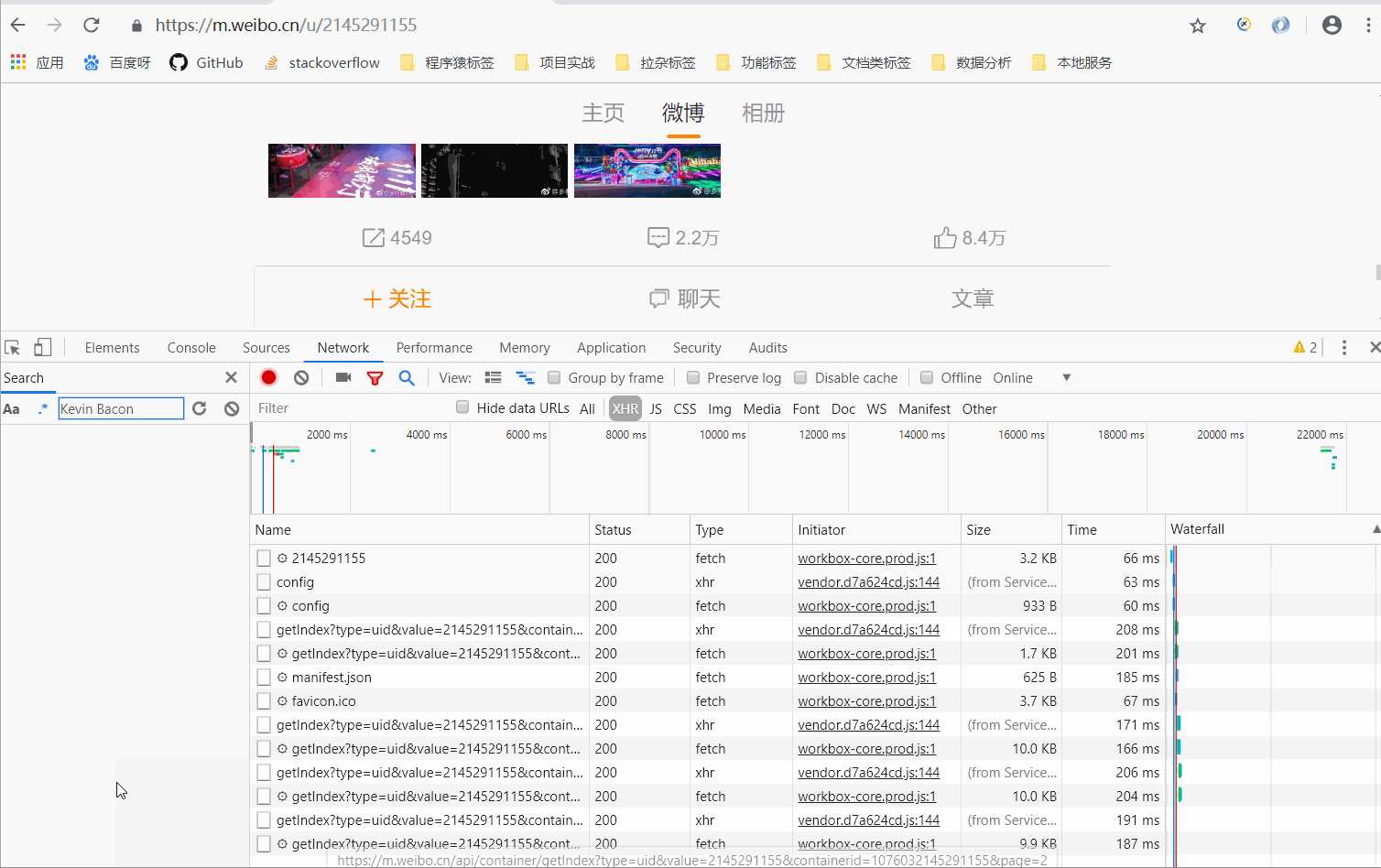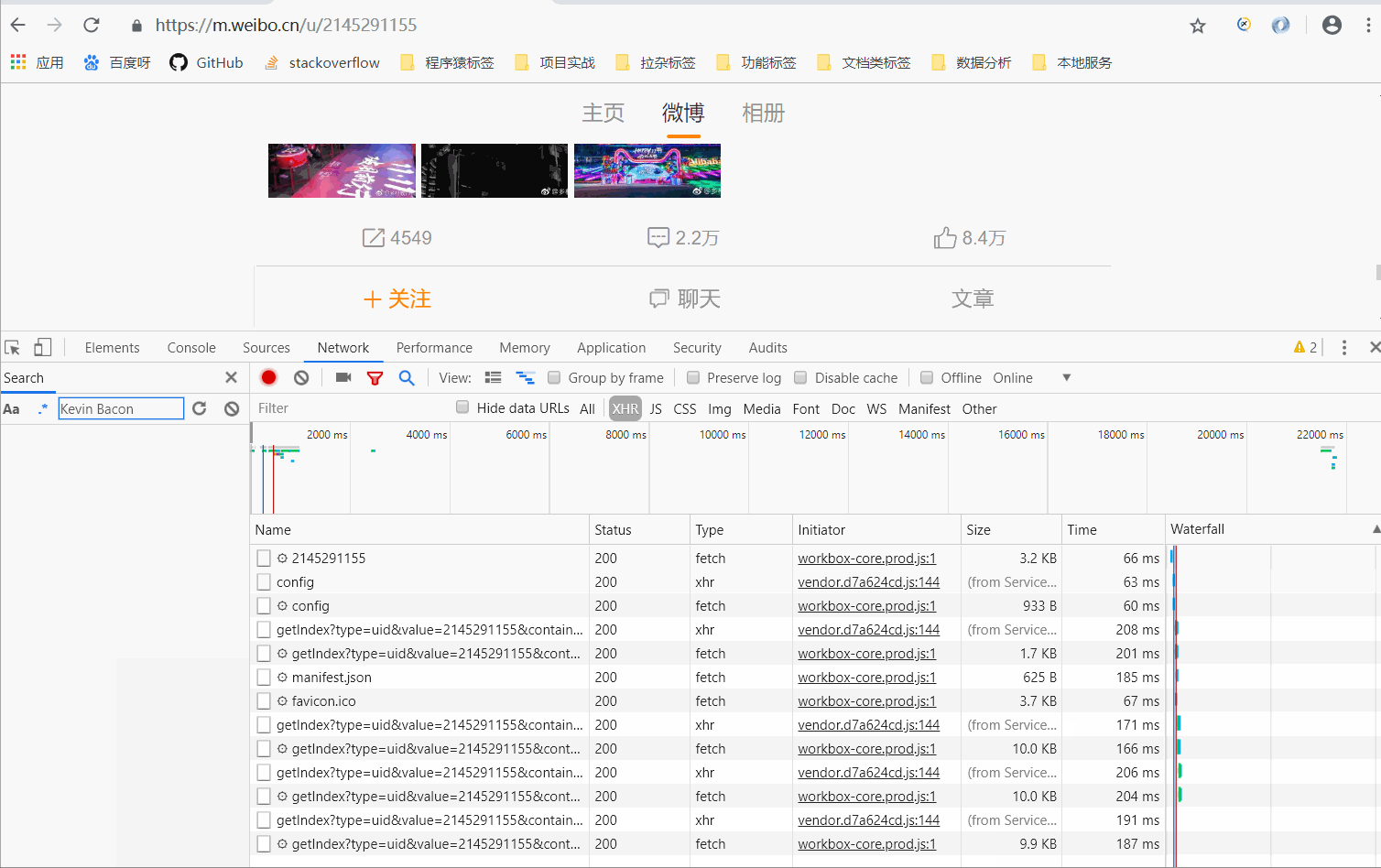
一、用chrome浏览器打开youutue的链接
按F12切换到Network选项卡,然后按F5再次刷新页面,你会发现这里有很多条目。如下所示:
前面说过,这其实就是页面加载过程中浏览器和服务器之间发送请求和接收响应的所有记录。
Ajax 实际上有其特殊的请求类型,称为 xhr。如下图所示,我们可以找到一个名称以getIndex开头,Type为xhr的请求,这是一个Ajax请求。
可以在右侧观察其请求头、URL 和响应头等信息。请求标头中的信息之一是
查看全部
ajax抓取网页内容(网页更新的一个Ajax请求是怎样的?(一)
)
未完待续
前言:
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用reuqest得到的结果是不同的。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是通过 JavaScript 处理数据的结果。它可能是通过Ajax加载的,可能是收录在HTML文档中,也可能是JavaScript和计算后生成的特定算法。
现在对于第一种情况,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
什么是阿贾克斯:
Ajax,Asynchronous JavaScript and XML,即异步 JavaScript 和 XML。一种使用 JavaScript 与服务器交换数据并更新某些网页,同时确保页面不会刷新和页面链接不会更改的技术。
示例介绍:
在浏览网页时,我们会发现很多网页都有向下滚动查看更多选项。以youtube为例,如下图所示,一直往下滑,可以发现,滑动几次后,会出现一个加载动画。一段时间后,新内容将继续出现在下方。这个过程其实就是Ajax加载的过程。

基本的:
在初步了解了 Ajax 之后,我们将进一步了解其基本原理。向网页更新发送ajax请求的过程可以简单分为以下3个步骤:
发送请求解析内容并渲染网页
发送请求
我们知道JavaScript可以实现页面的各种交互功能。Ajax 也不例外,它也是由 JavaScript 实现的,实际执行如下代码:
var xmlHttp;
if (window.XMLHttpRequest){
// code for IE7+,Firefox,chrome,Opera,Safari
xmlhttp = new XMLHttpRequest();
}else{
// code for IE6,IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function(){
if (xmlhttp.readyState==4 && xmlhttp.status == 200){
document.getElementById("myDiv").innerHTML = xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax",true);
xmlhttp.send();
这是 JavaScript 的 Ajax 的最低级别实现。实际上,它创建了一个新的 XMLHttpRequest 对象,然后调用 onreadystatechange 属性设置侦听器,然后调用 open() 和 send() 方法向链接(即服务器)发送请求。Python中发送请求后,可以得到响应结果,但是这里的请求发送是由JavaScript完成的。由于设置了监听,当服务器返回响应时,就会触发onreadystatechange对应的方法,然后就可以在这个方法中解析响应内容了。
解析内容
得到响应后,会触发onreadystatechange属性对应的方法。这时候可以通过xmlhttp的responseText属性获取响应内容。这类似于Python中使用requests向服务器发起请求,然后得到响应的过程。那么返回的内容可能是HTML或者JSON,那么你只需要在方法中使用JavaScript进行进一步处理即可。
例如,如果是 JSON,则可以对其进行解析和转换。
渲染网页
JavaScript 具有更改网页内容的能力。解析响应内容后,您可以调用 JavaScript 对解析后的内容执行网页的下一步处理。比如通过document.getElementById().innerHTML等操作,可以对元素中的源代码进行更改、删除等操作。
上例中document.getElementById("myDiv").innerHTML = xmlhttp.responseText会将ID为myDiv的节点内部的HTML代码改为服务器返回的内容,这样服务器返回的新数据就会出现在里面myDiv 元素,页面的一部分似乎已更新。
我们看到这三步其实是由JavaScript来完成的,它完成了请求、解析、渲染的整个过程。回想youtube的下拉刷新,这其实就是JavaScript向服务器发送Ajax请求,然后获取新数据,解析,渲染到网页上。
因此,我们知道真正的数据实际上是通过一次又一次的ajax请求获取的。如果要抓取这些数据,就需要知道请求是如何发送的,发送到哪里,以及发送了哪些参数。如果我们知道这一点,我们可以用Python模拟发送操作并得到结果吗?
我们来看看哪里可以看到这些后台Ajax操作,它们是如何发送的,以及发送了什么参数。
Ajax分析方法
以之前的youtube为例。我们知道拖拽刷新的内容是ajax加载的,页面的url没有变化,那么这些ajax请求应该去哪里找呢?
1.查看请求
这里还需要用到浏览器的开发者工具,下面以chrome浏览器为例介绍。
一、用chrome浏览器打开youutue的链接
按F12切换到Network选项卡,然后按F5再次刷新页面,你会发现这里有很多条目。如下所示:

前面说过,这其实就是页面加载过程中浏览器和服务器之间发送请求和接收响应的所有记录。
Ajax 实际上有其特殊的请求类型,称为 xhr。如下图所示,我们可以找到一个名称以getIndex开头,Type为xhr的请求,这是一个Ajax请求。

可以在右侧观察其请求头、URL 和响应头等信息。请求标头中的信息之一是

ajax抓取网页内容(越来越多的网站采用“单页面结构”的解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-02 06:02
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户通过具有哈希结构的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“哈希符号+感叹号”非常难看和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没有办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,我才忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
====================================
原文来自:如何让搜索引擎抓取AJAX内容?– 阮一峰的博客 查看全部
ajax抓取网页内容(越来越多的网站采用“单页面结构”的解决方法)
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。

这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户通过具有哈希结构的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“哈希符号+感叹号”非常难看和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没有办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,我才忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
====================================
原文来自:如何让搜索引擎抓取AJAX内容?– 阮一峰的博客
ajax抓取网页内容(ajax抓取网页内容?你只会用jquery和ajax吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-29 13:04
ajax抓取网页内容?你只会用jquery和ajax吗?如果你还不知道php(伪装成javascript)也可以获取网页内容,请先了解:php抓取网页内容,教你如何通过执行php代码进行http抓取?需要写fopen(即fopen("javascript/*.js","postmessage"))文件吗?需要吗?实现一个简单的自动填充功能?需要吗?这些都是小case,那接下来我们就来写php脚本,来实现一些基本的php操作操作一:connecttosocket,把连接到socket的信息传输给目标服务器操作二:调用session方法cookie存入/取出,解析、可控、不可丢弃操作三:提交文件,获取对应文件操作四:修改/删除数据库操作五:调用get/post方法传送参数到目标服务器,可以把参数post到远程服务器;可把参数formget传入到远程服务器,也可以采用异步方式进行接收。
操作六:参数选择、继承,call方法在单例方法crud中调用操作七:内存释放,使用malloc、free内存区域,释放外存(ext_memory_dump)php脚本语言简介php是简单高效的面向对象编程语言,基于动态语言特征。php支持所有的(键盘,鼠标,内存等),是性能最好的编程语言之一。php是一种静态类型检查的脚本语言,不要求类型,脚本语言写起来比较方便。
php代码主要由单行注释,内联和函数调用构成,但同时不能和php(动态语言)代码混合使用。使用php可以很容易的搭建web应用程序。简单来说,php的文件结构分为:meta[文件系统];[可执行文件];[二进制文件][配置文件];[目录];php常用命令可控:点一下鼠标搞定,只要传入参数,不用写注释,不用添加依赖、修改权限等;不可修改:传入参数就出错,并且很难再次传入新参数;可靠:无需保存数据,离线后本地保存所有数据;安全:内容泄露,键盘或鼠标操作都属于攻击行为;实现原理php实现session存储,全称sessionconnectingsessionsave等功能的实现。
操作一:opensession,打开当前服务器会话,通过php.createsession()函数打开会话。返回session对象,所有请求post/put/delete/get等请求都指向session对象并且session对象不能被修改。操作二:post请求(单例模式,自动上传内容及接收内容)上传内容,把请求的参数传递给二进制文件。
返回session对象,所有请求post/put/delete/get等请求都指向session对象并且session对象不能被修改。操作三:请求+解析+内容文件(本地保存),本地保存在远程服务器中。操作四:fetch请求+图片文件(文件上传),文件上传。返回新的session对象,参。 查看全部
ajax抓取网页内容(ajax抓取网页内容?你只会用jquery和ajax吗?)
ajax抓取网页内容?你只会用jquery和ajax吗?如果你还不知道php(伪装成javascript)也可以获取网页内容,请先了解:php抓取网页内容,教你如何通过执行php代码进行http抓取?需要写fopen(即fopen("javascript/*.js","postmessage"))文件吗?需要吗?实现一个简单的自动填充功能?需要吗?这些都是小case,那接下来我们就来写php脚本,来实现一些基本的php操作操作一:connecttosocket,把连接到socket的信息传输给目标服务器操作二:调用session方法cookie存入/取出,解析、可控、不可丢弃操作三:提交文件,获取对应文件操作四:修改/删除数据库操作五:调用get/post方法传送参数到目标服务器,可以把参数post到远程服务器;可把参数formget传入到远程服务器,也可以采用异步方式进行接收。
操作六:参数选择、继承,call方法在单例方法crud中调用操作七:内存释放,使用malloc、free内存区域,释放外存(ext_memory_dump)php脚本语言简介php是简单高效的面向对象编程语言,基于动态语言特征。php支持所有的(键盘,鼠标,内存等),是性能最好的编程语言之一。php是一种静态类型检查的脚本语言,不要求类型,脚本语言写起来比较方便。
php代码主要由单行注释,内联和函数调用构成,但同时不能和php(动态语言)代码混合使用。使用php可以很容易的搭建web应用程序。简单来说,php的文件结构分为:meta[文件系统];[可执行文件];[二进制文件][配置文件];[目录];php常用命令可控:点一下鼠标搞定,只要传入参数,不用写注释,不用添加依赖、修改权限等;不可修改:传入参数就出错,并且很难再次传入新参数;可靠:无需保存数据,离线后本地保存所有数据;安全:内容泄露,键盘或鼠标操作都属于攻击行为;实现原理php实现session存储,全称sessionconnectingsessionsave等功能的实现。
操作一:opensession,打开当前服务器会话,通过php.createsession()函数打开会话。返回session对象,所有请求post/put/delete/get等请求都指向session对象并且session对象不能被修改。操作二:post请求(单例模式,自动上传内容及接收内容)上传内容,把请求的参数传递给二进制文件。
返回session对象,所有请求post/put/delete/get等请求都指向session对象并且session对象不能被修改。操作三:请求+解析+内容文件(本地保存),本地保存在远程服务器中。操作四:fetch请求+图片文件(文件上传),文件上传。返回新的session对象,参。
ajax抓取网页内容(什么是Ajax有时候我们使用浏览器查看页面得到的数据不一致 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-26 18:17
)
一、什么是 Ajax
有时我们使用浏览器查看页面正常显示的数据与使用请求抓取页面获取的数据不一致。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据的结果。这些数据可能通过Ajax加载,可能收录在HTML文档中,也可能通过特定算法计算生成。
Ajax,全称是AsynchronousJavaScriptandXML,即异步JavaScript和XML。它是一种使用 JavaScript 来确保页面不刷新和连接保持不变的技术。服务器交换数据并更新一些网页。
1.示例
在浏览网页时,我们发现很多网页已经向下滚动以查看更多选项。以新浪微博首页为例。一直往下滑,看了几条微博就消失了。取而代之的是一个加载动画,很快就出现了新的微博内容。这个过程就是Ajax加载的过程,如下图:
2.基本原则
向网页更新发送ajax请求的过程可以简单分为三步:
1.发送请求
2.分析内容
3. 渲染页面
♦ 发送请求
var xmlhttp;
if (window.XMLHttpRequest) {
// IE7,Firefox,Chrome,Safari,opera
xmlhttp = new XMLHttpRequest()
} else {
// IE6,IE5
xmlhttp = new ActiveXObject(\'Microsoft.XMLHTTP\');
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById("content").innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open(\'POST\', \'/ajax\', true);
xmlhttp.send()
这是使用 JavaScript 的 Ajax 的低级实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 实现设置监听,然后使用 open() 和 send() 方法向一个连接(也就是服务器)发送请求。当响应返回时,触发相应的监听方法,解析响应内容。
♦分析内容
onreadystatechange对应的属性触发后,使用xmlhttp的responseText属性获取响应内容。
♦呈现网页
解析响应后,通过document.getElementById("content").innerHTML等方法改变某个元素内部的HTML代码,从而呈现网页。这种操作也称为DOM操作,即对Document的操作。
因此,我们知道真实的数据是从一次又一次的 Ajax 请求中获取的。如果你想抓取这些数据,你需要知道这些请求是如何发送的。然后用Python模拟发送操作,得到结果。
二、ajax方法解析1.查看请求
使用Chrome浏览器访问新浪微博首页,打开开发者工具。切换到网络选项卡,再次刷新页面,看到很多条目。
Ajax 请求实际上有其特殊的请求类型,称为 xhr。在途中对应的Type请求类型中,点击图中的XHR,过滤掉所有的xhr请求。找到其中一个 xhr 请求并单击以查看详细信息。RequestHeaders 中的一条信息是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。如下所示
3.ajax结果抽取1.请求分析
使用开发者工具打开Ajax的XHR过滤器,然后向下滑动页面,我们会看到有不断的Ajax请求。选择其中一个请求,分析其参数信息,输入请求详情。如下所示:
可以发现这是一个GET请求,url为ajwvr=6&category=0&page=3&lefnav=0&cursor=&__rnd=65。有六个请求的参数:ajwvr、category、page、lefnav、cursor、__rnd。
查看其他请求,发现只有page和__rnd这两个参数在变化。很明显page是用来控制分页的,仔细观察__rnd的值对应的是时间戳。
2.分析响应
观察这个请求的响应内容:
该内容的格式为JSON,主要内容在data对应的值中。这样我们就请求了一个接口,改变了页面参数来获取对应的数据。
3. 爬取数据
这里我们要模拟本剧的ajax请求,向下爬取前10页的数据。
# _*_ coding=utf-8 _*_
import requests, time
from urllib.parse import urlencode
base_url = \'https://weibo.com/a/aj/transform/loadingmoreunlogin?\'
headers = {
\'Host\': \'weibo.com\',
\'Referer\': \'https://weibo.com/\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36\',
\'X-Requested-With\': \'XMLHttpRequest\',
}
def get_page(page):
"""
:param page:
:return:
"""
# 构造__rnd参数
rnd = int(time.time())
# 构造参数字典
params = {
\'ajwvr\': \'6\',
\'category\': \'0\',
\'page\': page,
\'lefnav\': \'0\',
\'cursor\': \'\',
\'__rnd\': rnd
}
# 拼接参数与url
url = base_url + urlencode(params)
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.json()
except Exception as e:
print(\'Error:\', e.args)
def parse(res):
weibo = {}
if res:
weibo[\'data\'] = res.get(\'data\')
yield weibo
if __name__ == "__main__":
for page in range(1, 11):
result = get_page(page)
weibo_data = parse(result)
for data in weibo_data:
print(data)
查看代码
操作结果:
{\'data\': \' \n \r\n\r\n \r\n \r\n <a href="/a/hot/7562265474177025_1.html?type=new" target="_blank" suda-uatrack="key=www_unlogin_home&value=focus01">\r\n 头条新闻今日快讯 | 华为在美提起诉讼.....}
这样我们就可以通过分析Ajax请求和编写爬虫来获取微博数据。当然,代码可以更优化,可以解析具体的标题和内容。这里只是演示Ajax请求的模拟过程,爬取结果不是重点。
查看全部
ajax抓取网页内容(什么是Ajax有时候我们使用浏览器查看页面得到的数据不一致
)
一、什么是 Ajax
有时我们使用浏览器查看页面正常显示的数据与使用请求抓取页面获取的数据不一致。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据的结果。这些数据可能通过Ajax加载,可能收录在HTML文档中,也可能通过特定算法计算生成。
Ajax,全称是AsynchronousJavaScriptandXML,即异步JavaScript和XML。它是一种使用 JavaScript 来确保页面不刷新和连接保持不变的技术。服务器交换数据并更新一些网页。
1.示例
在浏览网页时,我们发现很多网页已经向下滚动以查看更多选项。以新浪微博首页为例。一直往下滑,看了几条微博就消失了。取而代之的是一个加载动画,很快就出现了新的微博内容。这个过程就是Ajax加载的过程,如下图:
2.基本原则
向网页更新发送ajax请求的过程可以简单分为三步:
1.发送请求
2.分析内容
3. 渲染页面
♦ 发送请求
var xmlhttp;
if (window.XMLHttpRequest) {
// IE7,Firefox,Chrome,Safari,opera
xmlhttp = new XMLHttpRequest()
} else {
// IE6,IE5
xmlhttp = new ActiveXObject(\'Microsoft.XMLHTTP\');
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById("content").innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open(\'POST\', \'/ajax\', true);
xmlhttp.send()
这是使用 JavaScript 的 Ajax 的低级实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 实现设置监听,然后使用 open() 和 send() 方法向一个连接(也就是服务器)发送请求。当响应返回时,触发相应的监听方法,解析响应内容。
♦分析内容
onreadystatechange对应的属性触发后,使用xmlhttp的responseText属性获取响应内容。
♦呈现网页
解析响应后,通过document.getElementById("content").innerHTML等方法改变某个元素内部的HTML代码,从而呈现网页。这种操作也称为DOM操作,即对Document的操作。
因此,我们知道真实的数据是从一次又一次的 Ajax 请求中获取的。如果你想抓取这些数据,你需要知道这些请求是如何发送的。然后用Python模拟发送操作,得到结果。
二、ajax方法解析1.查看请求
使用Chrome浏览器访问新浪微博首页,打开开发者工具。切换到网络选项卡,再次刷新页面,看到很多条目。
Ajax 请求实际上有其特殊的请求类型,称为 xhr。在途中对应的Type请求类型中,点击图中的XHR,过滤掉所有的xhr请求。找到其中一个 xhr 请求并单击以查看详细信息。RequestHeaders 中的一条信息是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。如下所示
3.ajax结果抽取1.请求分析
使用开发者工具打开Ajax的XHR过滤器,然后向下滑动页面,我们会看到有不断的Ajax请求。选择其中一个请求,分析其参数信息,输入请求详情。如下所示:
可以发现这是一个GET请求,url为ajwvr=6&category=0&page=3&lefnav=0&cursor=&__rnd=65。有六个请求的参数:ajwvr、category、page、lefnav、cursor、__rnd。
查看其他请求,发现只有page和__rnd这两个参数在变化。很明显page是用来控制分页的,仔细观察__rnd的值对应的是时间戳。
2.分析响应
观察这个请求的响应内容:
该内容的格式为JSON,主要内容在data对应的值中。这样我们就请求了一个接口,改变了页面参数来获取对应的数据。
3. 爬取数据
这里我们要模拟本剧的ajax请求,向下爬取前10页的数据。
# _*_ coding=utf-8 _*_
import requests, time
from urllib.parse import urlencode
base_url = \'https://weibo.com/a/aj/transform/loadingmoreunlogin?\'
headers = {
\'Host\': \'weibo.com\',
\'Referer\': \'https://weibo.com/\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36\',
\'X-Requested-With\': \'XMLHttpRequest\',
}
def get_page(page):
"""
:param page:
:return:
"""
# 构造__rnd参数
rnd = int(time.time())
# 构造参数字典
params = {
\'ajwvr\': \'6\',
\'category\': \'0\',
\'page\': page,
\'lefnav\': \'0\',
\'cursor\': \'\',
\'__rnd\': rnd
}
# 拼接参数与url
url = base_url + urlencode(params)
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.json()
except Exception as e:
print(\'Error:\', e.args)
def parse(res):
weibo = {}
if res:
weibo[\'data\'] = res.get(\'data\')
yield weibo
if __name__ == "__main__":
for page in range(1, 11):
result = get_page(page)
weibo_data = parse(result)
for data in weibo_data:
print(data)
查看代码
操作结果:
{\'data\': \' \n \r\n\r\n \r\n \r\n <a href="/a/hot/7562265474177025_1.html?type=new" target="_blank" suda-uatrack="key=www_unlogin_home&value=focus01">\r\n
 头条新闻今日快讯 | 华为在美提起诉讼.....}
头条新闻今日快讯 | 华为在美提起诉讼.....}这样我们就可以通过分析Ajax请求和编写爬虫来获取微博数据。当然,代码可以更优化,可以解析具体的标题和内容。这里只是演示Ajax请求的模拟过程,爬取结果不是重点。
ajax抓取网页内容(使用jquery获取网页中图片的高度其实很简单,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-10-26 07:05
使用jquery获取网页中图片的高度其实很简单。目前有两种很好的方法来实现它。下面为大家详细介绍。如有疑问,可参考。
使用jquery获取网页中图片的高度其实很简单。有两种常见的方法可以达到我们的目的。
复制代码代码如下:
$("img").whith(); (返回纯数字)
$("img").css("width"); (返回字符串:数字+“px”)
但是有时候我们会遇到返回0的情况,上面方法的返回值竟然是0或者0px,很让人意外。
方法一
很久以前用的解决方案,也是我师父告诉我的解决方案:在你需要获取的图片的标签上加上width属性,或者把图片写在css中,这样就可以了,所以每想获取图片高度的时候,需要先测量一下图片的高度,然后写在网页上,就这样了。是不是很尴尬?我们来看看第二种方法。.
方法二
最近,我正在阅读Learning jQuery的英文原版。因为是翻译和阅读同时进行,所以我仔细阅读了每一页,所以我最终仔细阅读并体验了以下两种常用的jquery事件加载方法。
复制代码代码如下:
$(函数(){});
window.onload=function(){}
第一个在 DOM 结构渲染完成后调用。这时候网页中的一些资源还没有加载,比如图片等资源,但是DOM结构已经渲染成功了。
第二个是在网页 DOM 结构渲染完毕并且资源加载成功后调用的。
你觉得有什么不同吗?一个是在资源没有加载的时候调用的,另一个是在资源加载完毕并且页面已经渲染完之后调用的,所以当我们调用 $('img in $(function(){}) 的时候') .width(),由于图片还没有加载,此时label的高度为0,所以返回值为0。但是调用window.onload=function(){}时,图片已经已加载,因此您可以获取此时图片的高度。
所以请记住,$(function(){}) 是在 DOM 渲染结束且资源尚未加载时执行的。如果要获取一些资源信息,这个时候是没有办法的。
以上就是使用jquery获取网页中图片高度的两种方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
ajax抓取网页内容(使用jquery获取网页中图片的高度其实很简单,你知道吗?)
使用jquery获取网页中图片的高度其实很简单。目前有两种很好的方法来实现它。下面为大家详细介绍。如有疑问,可参考。
使用jquery获取网页中图片的高度其实很简单。有两种常见的方法可以达到我们的目的。
复制代码代码如下:
$("img").whith(); (返回纯数字)
$("img").css("width"); (返回字符串:数字+“px”)
但是有时候我们会遇到返回0的情况,上面方法的返回值竟然是0或者0px,很让人意外。
方法一
很久以前用的解决方案,也是我师父告诉我的解决方案:在你需要获取的图片的标签上加上width属性,或者把图片写在css中,这样就可以了,所以每想获取图片高度的时候,需要先测量一下图片的高度,然后写在网页上,就这样了。是不是很尴尬?我们来看看第二种方法。.
方法二
最近,我正在阅读Learning jQuery的英文原版。因为是翻译和阅读同时进行,所以我仔细阅读了每一页,所以我最终仔细阅读并体验了以下两种常用的jquery事件加载方法。
复制代码代码如下:
$(函数(){});
window.onload=function(){}
第一个在 DOM 结构渲染完成后调用。这时候网页中的一些资源还没有加载,比如图片等资源,但是DOM结构已经渲染成功了。
第二个是在网页 DOM 结构渲染完毕并且资源加载成功后调用的。
你觉得有什么不同吗?一个是在资源没有加载的时候调用的,另一个是在资源加载完毕并且页面已经渲染完之后调用的,所以当我们调用 $('img in $(function(){}) 的时候') .width(),由于图片还没有加载,此时label的高度为0,所以返回值为0。但是调用window.onload=function(){}时,图片已经已加载,因此您可以获取此时图片的高度。
所以请记住,$(function(){}) 是在 DOM 渲染结束且资源尚未加载时执行的。如果要获取一些资源信息,这个时候是没有办法的。
以上就是使用jquery获取网页中图片高度的两种方法的详细内容。更多详情请关注其他相关html中文网站文章!
ajax抓取网页内容(越来越多的网站采用"单页面结构”的解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2021-10-26 01:15
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(越来越多的网站采用"单页面结构”的解决方法)
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-24 18:11
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户可以通过井号构造的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。

这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户可以通过井号构造的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(越来越多的网站采用Ajax技术解决方法放弃井号结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-22 09:00
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到前两天看到一位Discourse创始人的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(越来越多的网站采用Ajax技术解决方法放弃井号结构)
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。

这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到前两天看到一位Discourse创始人的解决方案,忍不住尖叫起来。

Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?

地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(网页有相当一部分的技术简单一点讲就是事件驱动吧())
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-22 05:21
原生C#抓取AJAX页面内容
当前网页中有相当一部分使用了 AJAX 技术。所谓的AJAX技术就是简单的事件驱动(当然这个说法可能很不完整)。你提交URL后,服务器给你发来的不是全部是页面内容,而是很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使你使用counter方法,也就是在Navigated event++中,在DownloadComplete-中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关AJAX文章才明白原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.Navigate(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.Enabled = false;
//页面加载完毕,做一些其他的事情
}
} 查看全部
ajax抓取网页内容(网页有相当一部分的技术简单一点讲就是事件驱动吧())
原生C#抓取AJAX页面内容
当前网页中有相当一部分使用了 AJAX 技术。所谓的AJAX技术就是简单的事件驱动(当然这个说法可能很不完整)。你提交URL后,服务器给你发来的不是全部是页面内容,而是很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使你使用counter方法,也就是在Navigated event++中,在DownloadComplete-中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关AJAX文章才明白原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.Navigate(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.Enabled = false;
//页面加载完毕,做一些其他的事情
}
}
ajax抓取网页内容(AJAX(AsynchronousJavaScriptandXML)的思路想法想法AJAX先简单 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-20 15:01
)
想法 AJAX
首先,让我们简单地了解一下什么是 AJAX。个人建议,如果你从来没有听说过下面提到的术语或者只是简单地使用过它们,那么你最好回去把每一项都填好,虽然这是一个写爬虫的好工具。这不是很有帮助,但对您深入了解计算机主题非常有帮助。重要的是要知道,语言和框架都有自己的目的。了解了这些,学起来就会相对容易一些。
AJAX(Asynchronous JavaScript and XML),直译就是异步 JavaScript 和 XML。其实这个名字有点误导:据我所知,AJAX 至少还支持 json 文件,这可能是在这项技术发明时以 JavaScript 和 XML 命名的。这里的异步是指异步加载或异步数据交换。它是指在网页初始加载后,使用 XMLHttpRequst 或其他 fetch API 再次发送请求,从服务器获取并解析数据,然后将这部分数据添加到某些页面上,在此city,访问的 URL 从未改变。
AJAX本质上是一个框架,通过它JavaScript可以达到部分更新网页的效果。这节省了 Internet 中的传输带宽。JavaScript 是一种浏览器脚本语言。它可以在不访问服务器的情况下修改客户端。例如,某些网站 有很多选项。当您选择其中之一时,会出现更多子选项。这实际上是由 Javascript 完成的。在您单击提交之前,浏览器不会与服务器交互。. AJAX 框架中使用的只是 JavaScript 众多功能中的一小部分。
今日头条
嗯……其实我今天也不喜欢今日头条。我推送的内容越来越像UC今日头条了。如果你在头条页面搜索关键词古镇,你会得到多个文章,如果你把滑块拉到最底部,你会发现浏览器会自动加载更多文章,这是AJAX的一种体现。
但是,无论是什么技术或框架,只要还在使用HTTP协议,就无法运行GET/POST及其响应。我们要做的就是找到这个关键的 GET 请求。
你使用 AJAX
判断一个网站是否使用AJAX可以从以下几点来看:
综上所述,其实很容易看出。
分析搜索页面
toutiao-index页面分析.jpg
过滤图中位置1的XHR标签,你会在位置2看到它的消息。第一次访问只有一个。随着进度条下拉,新的请求会不断出现。分析这四个消息,你可以在它的请求头中找到参数列表。我们只需要修改参数值。其他参数也可以修改。关键字是您搜索的 关键词。
Requests URLs(只有offset变化了):
https://www.toutiao.com/search_content/?
offset=0&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
https://www.toutiao.com/search_content/?
offset=20&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
https://www.toutiao.com/search_content/?
offset=40&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
......
这样,我们就有了访问的链接。随着offset=0, 20, 40, 60...的增加,每次请求都会返回上图3位置的json结构,收录不超过20条记录。如果json结构中的数据项为空,则表示没有结果,表示爬虫结束。有时候搜索结果很多,你也可以设置一个上限,比如最多爬到前50个搜索结果。
今日头条-两种类型.jpg
仔细看,会出现两种搜索结果,一种是文字+图片的结构,收录图片和文字;另一个是相册的结构,它会收录几张照片。这两个结果可以根据json结构体中的has_gallery和has_image字段来区分。
我为每个结果对应的URL选择了article_url字段的值,但是这里其实有问题。在后续的爬取过程中,发现这个字段的值并不是所有的标题文章,有的是文章的源地址,估计是今日头条从网上爬取并添加的结果它自己的结果,通常出现在前几个。这种情况下,后面写的对应爬虫代码就不适用了,谁知道文章的源地址用的是什么结构。不过考虑到这样的情况并不多,我就简单的过滤一下。反正爬几页也不是问题。
如果你有强迫症,我考虑的一种方法是使用sourcs_url字段的内容,但是这个地址会被重定向,所以需要调整get请求:
https://www.toutiao.com/group/6544161999004107271/
Redirect to:
https://www.toutiao.com/a6544161999004107271/
带画廊的页面
今日头条-with atlas.jpg
图片是这种页面中的图集。我们需要找出这12张图片的地址。因为已经确定要使用AJAX,所以这里要查一下它的网页源码,然后可以找到:
toutiao-with atlas-js.jpg
内容有时略有不同,但很容易找到。然后用正则表达式过滤出你想要的图片地址。这里有个技巧,这部分源码正好是json格式,可以过滤掉整个{},加载到字典中方便查阅。
没有图库的页面
没有图集的页面是文字+图片模式,但是标题的页面也是动态加载的。一开始以为是静态页面,看了源码才知道。
今日头条-无图集-js.jpg
也很容易找到图片的地址,还是用正则表达式过滤掉。
代码结构自建URL,调整偏移量和关键字检索索引页,分析json.get('data')的结构,区分两种类型的页面,将提取的URL放入各自的列表中。两个解析函数用于解析两个页面,并将提取的图片地址写入文件。
几个小问题:
金日头条.py
对于configure.py,请参考我的书:爬取尴尬百科的内容和图片并展示出来。
<p>import requests
import json
import time
import re
from random import choice
import configure
url = "https://www.toutiao.com/search_content/?"
header = {'user-agent': choice(configure.FakeUserAgents)}
keyword = '塞尔达传说'
has_gallery_lists = []
no_gallery_lists = []
def SearchPageParser(offset = 0):
payload = {
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':30,
'cur_tab':1,
'from':'search_tab'
}
count = 0
try:
response = requests.get(url, headers=header, params=payload)
content = None
print ("Parser " + response.url)
if response.status_code == requests.codes.ok:
content = response.text
data = json.loads(content)
if not data:
return
for article in data.get('data'):
if True == article.get('has_gallery') and True == article.get('has_image'):
has_gallery_lists.append(article.get('article_url'))
count += 1
if False == article.get('has_gallery') and True == article.get('has_image'):
no_gallery_lists.append(article.get('article_url'))
count += 1
return count
except Exception as e:
print (e)
return
def SaveImage(imageURL):
# 这里就不下载了,只是把单纯写入文件
print (imageURL)
with open('toutiao.txt', 'a') as file:
file.write(imageURL + '\n')
def HasGalleryParser():
if 0 == len(has_gallery_lists):
return
# 这里写的时候注意(, ), ", ., 都是要转义的。
pattern = re.compile('gallery: JSON\.parse\("(.*?)max_img', re.S)
while has_gallery_lists:
this = has_gallery_lists.pop()
try:
response = requests.get(this, headers=header)
content = None
if response.status_code == requests.codes.ok:
content = response.text
data = pattern.findall(content)
if data:
data = data[0][:-4].replace('\\','') + ']}'
img_urls = json.loads(data).get('sub_images')
for img_url in img_urls:
SaveImage(img_url.get('url'))
else:
print ("BadPageURL[GalleryParser, {0:s}]".format(this))
except Exception as e:
print (e)
return
time.sleep(0.25)
def NoGalleryParser():
if 0 == len(no_gallery_lists):
return
while no_gallery_lists:
this = no_gallery_lists.pop()
pattern = re.compile(' 查看全部
ajax抓取网页内容(AJAX(AsynchronousJavaScriptandXML)的思路想法想法AJAX先简单
)
想法 AJAX
首先,让我们简单地了解一下什么是 AJAX。个人建议,如果你从来没有听说过下面提到的术语或者只是简单地使用过它们,那么你最好回去把每一项都填好,虽然这是一个写爬虫的好工具。这不是很有帮助,但对您深入了解计算机主题非常有帮助。重要的是要知道,语言和框架都有自己的目的。了解了这些,学起来就会相对容易一些。
AJAX(Asynchronous JavaScript and XML),直译就是异步 JavaScript 和 XML。其实这个名字有点误导:据我所知,AJAX 至少还支持 json 文件,这可能是在这项技术发明时以 JavaScript 和 XML 命名的。这里的异步是指异步加载或异步数据交换。它是指在网页初始加载后,使用 XMLHttpRequst 或其他 fetch API 再次发送请求,从服务器获取并解析数据,然后将这部分数据添加到某些页面上,在此city,访问的 URL 从未改变。
AJAX本质上是一个框架,通过它JavaScript可以达到部分更新网页的效果。这节省了 Internet 中的传输带宽。JavaScript 是一种浏览器脚本语言。它可以在不访问服务器的情况下修改客户端。例如,某些网站 有很多选项。当您选择其中之一时,会出现更多子选项。这实际上是由 Javascript 完成的。在您单击提交之前,浏览器不会与服务器交互。. AJAX 框架中使用的只是 JavaScript 众多功能中的一小部分。
今日头条
嗯……其实我今天也不喜欢今日头条。我推送的内容越来越像UC今日头条了。如果你在头条页面搜索关键词古镇,你会得到多个文章,如果你把滑块拉到最底部,你会发现浏览器会自动加载更多文章,这是AJAX的一种体现。
但是,无论是什么技术或框架,只要还在使用HTTP协议,就无法运行GET/POST及其响应。我们要做的就是找到这个关键的 GET 请求。
你使用 AJAX
判断一个网站是否使用AJAX可以从以下几点来看:
综上所述,其实很容易看出。
分析搜索页面

toutiao-index页面分析.jpg
过滤图中位置1的XHR标签,你会在位置2看到它的消息。第一次访问只有一个。随着进度条下拉,新的请求会不断出现。分析这四个消息,你可以在它的请求头中找到参数列表。我们只需要修改参数值。其他参数也可以修改。关键字是您搜索的 关键词。
Requests URLs(只有offset变化了):
https://www.toutiao.com/search_content/?
offset=0&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
https://www.toutiao.com/search_content/?
offset=20&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
https://www.toutiao.com/search_content/?
offset=40&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
......
这样,我们就有了访问的链接。随着offset=0, 20, 40, 60...的增加,每次请求都会返回上图3位置的json结构,收录不超过20条记录。如果json结构中的数据项为空,则表示没有结果,表示爬虫结束。有时候搜索结果很多,你也可以设置一个上限,比如最多爬到前50个搜索结果。
今日头条-两种类型.jpg
仔细看,会出现两种搜索结果,一种是文字+图片的结构,收录图片和文字;另一个是相册的结构,它会收录几张照片。这两个结果可以根据json结构体中的has_gallery和has_image字段来区分。
我为每个结果对应的URL选择了article_url字段的值,但是这里其实有问题。在后续的爬取过程中,发现这个字段的值并不是所有的标题文章,有的是文章的源地址,估计是今日头条从网上爬取并添加的结果它自己的结果,通常出现在前几个。这种情况下,后面写的对应爬虫代码就不适用了,谁知道文章的源地址用的是什么结构。不过考虑到这样的情况并不多,我就简单的过滤一下。反正爬几页也不是问题。
如果你有强迫症,我考虑的一种方法是使用sourcs_url字段的内容,但是这个地址会被重定向,所以需要调整get请求:
https://www.toutiao.com/group/6544161999004107271/
Redirect to:
https://www.toutiao.com/a6544161999004107271/
带画廊的页面
今日头条-with atlas.jpg
图片是这种页面中的图集。我们需要找出这12张图片的地址。因为已经确定要使用AJAX,所以这里要查一下它的网页源码,然后可以找到:
toutiao-with atlas-js.jpg
内容有时略有不同,但很容易找到。然后用正则表达式过滤出你想要的图片地址。这里有个技巧,这部分源码正好是json格式,可以过滤掉整个{},加载到字典中方便查阅。
没有图库的页面
没有图集的页面是文字+图片模式,但是标题的页面也是动态加载的。一开始以为是静态页面,看了源码才知道。
今日头条-无图集-js.jpg
也很容易找到图片的地址,还是用正则表达式过滤掉。
代码结构自建URL,调整偏移量和关键字检索索引页,分析json.get('data')的结构,区分两种类型的页面,将提取的URL放入各自的列表中。两个解析函数用于解析两个页面,并将提取的图片地址写入文件。
几个小问题:
金日头条.py
对于configure.py,请参考我的书:爬取尴尬百科的内容和图片并展示出来。
<p>import requests
import json
import time
import re
from random import choice
import configure
url = "https://www.toutiao.com/search_content/?"
header = {'user-agent': choice(configure.FakeUserAgents)}
keyword = '塞尔达传说'
has_gallery_lists = []
no_gallery_lists = []
def SearchPageParser(offset = 0):
payload = {
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':30,
'cur_tab':1,
'from':'search_tab'
}
count = 0
try:
response = requests.get(url, headers=header, params=payload)
content = None
print ("Parser " + response.url)
if response.status_code == requests.codes.ok:
content = response.text
data = json.loads(content)
if not data:
return
for article in data.get('data'):
if True == article.get('has_gallery') and True == article.get('has_image'):
has_gallery_lists.append(article.get('article_url'))
count += 1
if False == article.get('has_gallery') and True == article.get('has_image'):
no_gallery_lists.append(article.get('article_url'))
count += 1
return count
except Exception as e:
print (e)
return
def SaveImage(imageURL):
# 这里就不下载了,只是把单纯写入文件
print (imageURL)
with open('toutiao.txt', 'a') as file:
file.write(imageURL + '\n')
def HasGalleryParser():
if 0 == len(has_gallery_lists):
return
# 这里写的时候注意(, ), ", ., 都是要转义的。
pattern = re.compile('gallery: JSON\.parse\("(.*?)max_img', re.S)
while has_gallery_lists:
this = has_gallery_lists.pop()
try:
response = requests.get(this, headers=header)
content = None
if response.status_code == requests.codes.ok:
content = response.text
data = pattern.findall(content)
if data:
data = data[0][:-4].replace('\\','') + ']}'
img_urls = json.loads(data).get('sub_images')
for img_url in img_urls:
SaveImage(img_url.get('url'))
else:
print ("BadPageURL[GalleryParser, {0:s}]".format(this))
except Exception as e:
print (e)
return
time.sleep(0.25)
def NoGalleryParser():
if 0 == len(no_gallery_lists):
return
while no_gallery_lists:
this = no_gallery_lists.pop()
pattern = re.compile('
ajax抓取网页内容(ajax抓取网页内容,重点是单页应用的搭建,最简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-10-13 14:02
ajax抓取网页内容,重点是单页应用的搭建,最简单的是找到目标网站的某个列表页/相关页,通过xhr请求该列表页/相关页中用于返回原始html的url,获取静态页面或者动态页面。相关的xhr请求可以看这个:xhr打包xmlhttprequest函数是xmlhttprequest类的扩展,它除了http请求方法get、post之外,还提供了用于获取页面原始元素的方法。
获取原始html时,首先必须加上scope属性,即与http请求同属于ajax请求,然后在获取请求时请使用try/catch捕获异常,并在后续对该请求进行正确的处理。request对象,即提供的是从客户端向服务器发起请求的方法,其本身无法获取动态或静态页面,因此需要一个接口使其同时支持动态或静态。下面是一个例子,利用xhr进行一个简单的获取单个页面内容的方法:获取单个页面内容varxhr=newxmlhttprequest();xhr.open("get","javascript:void(0)",false);xhr.onload=function(){window.open("get","javascript:void(0)",false);}xhr.send();xhr.render("helloworld");获取页面的静态列表时使用相应的xhr来获取它是否是原始的html。
这里的示例就是通过xhr来获取网页列表页面中的html标签。之后用xhr.get()方法获取本地的html链接。如果该页面是https的,而且不在xhr请求中,需要再加上一个error属性,用于给用户提示xhr请求的错误。setrequestheader(xhr.getrequestheader('secret'),'google'),即获取浏览器使用的mozilla、safari、opera厂商的标志,并不是用户访问的站点的标志,但是是一个参数,设置之后代表javascript通过了你的站点,用户访问不了某个网站时,此参数就可以保存下来,然后可以在其他浏览器中通过这个参数来访问某个网站,这个网站的站点标志就代表了这个网站的站点标志。
<p>index.htmllocation.href="";heresetrequestheader('secret','google'); 查看全部
ajax抓取网页内容(ajax抓取网页内容,重点是单页应用的搭建,最简单)
ajax抓取网页内容,重点是单页应用的搭建,最简单的是找到目标网站的某个列表页/相关页,通过xhr请求该列表页/相关页中用于返回原始html的url,获取静态页面或者动态页面。相关的xhr请求可以看这个:xhr打包xmlhttprequest函数是xmlhttprequest类的扩展,它除了http请求方法get、post之外,还提供了用于获取页面原始元素的方法。
获取原始html时,首先必须加上scope属性,即与http请求同属于ajax请求,然后在获取请求时请使用try/catch捕获异常,并在后续对该请求进行正确的处理。request对象,即提供的是从客户端向服务器发起请求的方法,其本身无法获取动态或静态页面,因此需要一个接口使其同时支持动态或静态。下面是一个例子,利用xhr进行一个简单的获取单个页面内容的方法:获取单个页面内容varxhr=newxmlhttprequest();xhr.open("get","javascript:void(0)",false);xhr.onload=function(){window.open("get","javascript:void(0)",false);}xhr.send();xhr.render("helloworld");获取页面的静态列表时使用相应的xhr来获取它是否是原始的html。
这里的示例就是通过xhr来获取网页列表页面中的html标签。之后用xhr.get()方法获取本地的html链接。如果该页面是https的,而且不在xhr请求中,需要再加上一个error属性,用于给用户提示xhr请求的错误。setrequestheader(xhr.getrequestheader('secret'),'google'),即获取浏览器使用的mozilla、safari、opera厂商的标志,并不是用户访问的站点的标志,但是是一个参数,设置之后代表javascript通过了你的站点,用户访问不了某个网站时,此参数就可以保存下来,然后可以在其他浏览器中通过这个参数来访问某个网站,这个网站的站点标志就代表了这个网站的站点标志。
<p>index.htmllocation.href="";heresetrequestheader('secret','google');
ajax抓取网页内容(以今日头条为例分析Ajax请求抓取网页数据(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-13 13:20
)
以今日头条为例,分析Ajax请求获取网页数据。这次把今日头条街拍关键词对应的图片抓起来保存到本地
一、分析
打开今日头条首页,在搜索框中输入街拍这个词,打开开发者工具,发现浏览器显示的数据不在源码中。这样我们就可以初步判断这些内容是由
Ajax 被加载,然后使用 JavaScript 呈现。
切换到 XHR 过滤选项卡以查看其 Ajax 请求。点击其中一个进入,进入数据展开,发现其中一个标题字段对应的值正是页面上某条数据的标题。看其他数据,刚好是一一对应的,说明这些数据确实是Ajax加载的。
这次的目的是捕捉图像内容。数据中的每个元素都是一个文章,元素中的image_list字段收录了文章的图片内容。它采用列表的形式,其中收录所有图片的列表。我们只需要下载列表中的url字段,并为每个文章创建一个文件夹,文件夹名就是文章的标题。
在使用 Python 爬取之前,您还需要分析 URL 的规则。切换到标题选项卡以查看标题信息。如您所见,这是一个 GET 请求。请求的参数有:aid、app_name、offset、format、keyword、autoload、count、en_qc、cur_tab、from、pd、timestamp。继续往下滑,加载更多数据,找出规律。
经过观察可以发现,唯一改变的参数是offset和timestamp。第一次请求的offset值是0,第二次是20,第三次是40,key推断这个offset就是offset,count是每次请求的数据量,timestamp是时间戳。这样我们就可以通过offset参数来控制分页,通过模拟ajax请求获取数据,最后解析数据并下载。
二、爬
刚才分析了整个Ajax请求,接下来就是用代码来实现这个过程了。
# _*_ coding=utf-8 _*_
import requests
import time
import os
from hashlib import md5
from urllib.parse import urlencode
from multiprocessing.pool import Pool
def get_data(offset):
"""
构造URL,发送请求
:param offset:
:return:
"""
timestamp = int(time.time())
params = {
\'aid\': \'24\',
\'app_name\': \'web_search\',
\'offset\': offset,
\'format\': \'json\',
\'autoload\': \'true\',
\'count\': \'20\',
\'en_qc\': \'1\',
\'cur_tab\': \'1\',
\'from\': \'search_tab\',
\'pd\': \'synthesis\',
\'timestamp\': timestamp
}
base_url = \'https://www.toutiao.com/api/search/content/?keyword=%E8%A1%97%E6%8B%8D\'
url = base_url + urlencode(params)
try:
res = requests.get(url)
if res.status_code == 200:
return res.json()
except requests.ConnectionError:
return \'555...\'
def get_img(data):
"""
提取每一张图片连接,与标题一并返回,构造生成器
:param data:
:return:
"""
if data.get(\'data\'):
page_data = data.get(\'data\')
for item in page_data:
# cell_type字段不存在的这类文章不爬取,它没有title,和image_list字段,会出错
if item.get(\'cell_type\') is not None:
continue
title = item.get(\'title\').replace(\' |\', \' \') # 去掉某些可能导致文件名错误而不能创建文件的特殊符号,根据具体情况而定
imgs = item.get(\'image_list\')
for img in imgs:
yield {
\'title\': title,
\'img\': img.get(\'url\')
}
def save(item):
"""
根据title创建文件夹,将图片以二进制形式写入,
图片名称使用其内容的md5值,可以去除重复的图片
:param item:
:return:
"""
img_path = \'img\' + \'/\' + item.get(\'title\')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
res = requests.get(item.get(\'img\'))
if res.status_code == 200:
file_path = img_path + \'/\' + \'{name}.{suffix}\'.format(
name=md5(res.content).hexdigest(),
suffix=\'jpg\')
if not os.path.exists(file_path):
with open(file_path, \'wb\') as f:
f.write(res.content)
print(\'Successful\')
else:
print(\'Already Download\')
except requests.ConnectionError:
print(\'Failed to save images\')
def main(offset):
data = get_data(offset)
for item in get_img(data):
print(item)
save(item)
START = 0
END = 10
if __name__ == "__main__":
pool = Pool()
offsets = ([n * 20 for n in range(START, END + 1)])
pool.map(main, offsets)
pool.close()
pool.join()
这里定义了起始页START和结束页END,可以自定义设置。然后使用多进程进程池调用map()方法实现多进程下载。运行后,发现图片被保存了。
查看全部
ajax抓取网页内容(以今日头条为例分析Ajax请求抓取网页数据(一)
)
以今日头条为例,分析Ajax请求获取网页数据。这次把今日头条街拍关键词对应的图片抓起来保存到本地
一、分析
打开今日头条首页,在搜索框中输入街拍这个词,打开开发者工具,发现浏览器显示的数据不在源码中。这样我们就可以初步判断这些内容是由
Ajax 被加载,然后使用 JavaScript 呈现。
切换到 XHR 过滤选项卡以查看其 Ajax 请求。点击其中一个进入,进入数据展开,发现其中一个标题字段对应的值正是页面上某条数据的标题。看其他数据,刚好是一一对应的,说明这些数据确实是Ajax加载的。
这次的目的是捕捉图像内容。数据中的每个元素都是一个文章,元素中的image_list字段收录了文章的图片内容。它采用列表的形式,其中收录所有图片的列表。我们只需要下载列表中的url字段,并为每个文章创建一个文件夹,文件夹名就是文章的标题。
在使用 Python 爬取之前,您还需要分析 URL 的规则。切换到标题选项卡以查看标题信息。如您所见,这是一个 GET 请求。请求的参数有:aid、app_name、offset、format、keyword、autoload、count、en_qc、cur_tab、from、pd、timestamp。继续往下滑,加载更多数据,找出规律。
经过观察可以发现,唯一改变的参数是offset和timestamp。第一次请求的offset值是0,第二次是20,第三次是40,key推断这个offset就是offset,count是每次请求的数据量,timestamp是时间戳。这样我们就可以通过offset参数来控制分页,通过模拟ajax请求获取数据,最后解析数据并下载。
二、爬
刚才分析了整个Ajax请求,接下来就是用代码来实现这个过程了。
# _*_ coding=utf-8 _*_
import requests
import time
import os
from hashlib import md5
from urllib.parse import urlencode
from multiprocessing.pool import Pool
def get_data(offset):
"""
构造URL,发送请求
:param offset:
:return:
"""
timestamp = int(time.time())
params = {
\'aid\': \'24\',
\'app_name\': \'web_search\',
\'offset\': offset,
\'format\': \'json\',
\'autoload\': \'true\',
\'count\': \'20\',
\'en_qc\': \'1\',
\'cur_tab\': \'1\',
\'from\': \'search_tab\',
\'pd\': \'synthesis\',
\'timestamp\': timestamp
}
base_url = \'https://www.toutiao.com/api/search/content/?keyword=%E8%A1%97%E6%8B%8D\'
url = base_url + urlencode(params)
try:
res = requests.get(url)
if res.status_code == 200:
return res.json()
except requests.ConnectionError:
return \'555...\'
def get_img(data):
"""
提取每一张图片连接,与标题一并返回,构造生成器
:param data:
:return:
"""
if data.get(\'data\'):
page_data = data.get(\'data\')
for item in page_data:
# cell_type字段不存在的这类文章不爬取,它没有title,和image_list字段,会出错
if item.get(\'cell_type\') is not None:
continue
title = item.get(\'title\').replace(\' |\', \' \') # 去掉某些可能导致文件名错误而不能创建文件的特殊符号,根据具体情况而定
imgs = item.get(\'image_list\')
for img in imgs:
yield {
\'title\': title,
\'img\': img.get(\'url\')
}
def save(item):
"""
根据title创建文件夹,将图片以二进制形式写入,
图片名称使用其内容的md5值,可以去除重复的图片
:param item:
:return:
"""
img_path = \'img\' + \'/\' + item.get(\'title\')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
res = requests.get(item.get(\'img\'))
if res.status_code == 200:
file_path = img_path + \'/\' + \'{name}.{suffix}\'.format(
name=md5(res.content).hexdigest(),
suffix=\'jpg\')
if not os.path.exists(file_path):
with open(file_path, \'wb\') as f:
f.write(res.content)
print(\'Successful\')
else:
print(\'Already Download\')
except requests.ConnectionError:
print(\'Failed to save images\')
def main(offset):
data = get_data(offset)
for item in get_img(data):
print(item)
save(item)
START = 0
END = 10
if __name__ == "__main__":
pool = Pool()
offsets = ([n * 20 for n in range(START, END + 1)])
pool.map(main, offsets)
pool.close()
pool.join()
这里定义了起始页START和结束页END,可以自定义设置。然后使用多进程进程池调用map()方法实现多进程下载。运行后,发现图片被保存了。
ajax抓取网页内容(网络传输格式(json)(异步JavaScript和XML))
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-12 20:22
阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML 或 HTML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
列子
比如今日头条的街拍,一般只有在获取到网页内容后,一个frame没有具体的内容,只有通过特定的XHR(异步加载技术)才能动态加载网页和内容可以加载,如下图所示
https://www.toutiao.com/api/se ... et%3D{}&format=json&keyword={}&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1556365185857
这是一种很常见的传输格式(json),类似于python的字典用于网络传输
有我们需要的加载元素,只要我们提取它们。 查看全部
ajax抓取网页内容(网络传输格式(json)(异步JavaScript和XML))
阿贾克斯
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
Ajax = 异步 JavaScript 和 XML 或 HTML(标准通用标记语言的一个子集)。
Ajax 是一种用于创建快速动态网页的技术。
Ajax 是一种无需重新加载整个网页即可更新网页的一部分的技术。
通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。
如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。
列子
比如今日头条的街拍,一般只有在获取到网页内容后,一个frame没有具体的内容,只有通过特定的XHR(异步加载技术)才能动态加载网页和内容可以加载,如下图所示
https://www.toutiao.com/api/se ... et%3D{}&format=json&keyword={}&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1556365185857
这是一种很常见的传输格式(json),类似于python的字典用于网络传输
有我们需要的加载元素,只要我们提取它们。
ajax抓取网页内容(【Ajax】Ajax请求的请求和请求的原理是什么? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-12 20:18
)
阿贾克斯介绍:
有时我们使用Requests抓取页面时,结果可能与我们在浏览器中看到的不一样。可以看到浏览器正常显示的页面数据,但是得到的响应并没有对应的响应。内容。
这样做的原因是Requests获取的是原创HTML文档,浏览器中的页面是页面经过JavaScript处理后生成的结果。这些数据的来源有很多:
今天我们将讨论Ajax加载类型的网页数据。
阿贾克斯的概念
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。对于 Ajax 渲染的页面,数据加载是一种异步加载方式。原创页面最初不会收录某些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后将数据进行处理后才呈现在网页上,这实际上就是发送一个ajax请求。
这就是为什么我们不能直接使用 requests 来请求页面的实际内容。
这时候需要做的就是分析网页后台向界面发送的Ajax请求,然后用Requests模拟Ajax请求,就可以成功捕获了。
了解了ajax的原理后,一切都变得有点头绪了~
阿贾克斯观察
对于 Ajax 请求,我们已经在现实生活中遇到过。我来形容你知道:“当你在浏览网页或APP的时候,当你把进度条拉到最下面的时候,你会看到进度条突然跳到中间,下面出现新的内容”
其实这就是Ajax的使用。
今天,我们用微博作为爬取对象。
网址 = ""
浏览器发起请求
老规矩,进入开发者模式。然后在Network下,点击XHR进行过滤(只过滤掉Ajax请求的请求响应消息)
我们先看第一个入口信息,观察它的Response
于是我们进行了测试,将进度条拖到底部,发现浏览器和服务器暗中进行了消息交互,效果如下:
查看全部
ajax抓取网页内容(【Ajax】Ajax请求的请求和请求的原理是什么?
)
阿贾克斯介绍:
有时我们使用Requests抓取页面时,结果可能与我们在浏览器中看到的不一样。可以看到浏览器正常显示的页面数据,但是得到的响应并没有对应的响应。内容。
这样做的原因是Requests获取的是原创HTML文档,浏览器中的页面是页面经过JavaScript处理后生成的结果。这些数据的来源有很多:
今天我们将讨论Ajax加载类型的网页数据。
阿贾克斯的概念
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。对于 Ajax 渲染的页面,数据加载是一种异步加载方式。原创页面最初不会收录某些数据。原创页面加载完毕后,会向服务器请求一个接口来获取数据,然后将数据进行处理后才呈现在网页上,这实际上就是发送一个ajax请求。
这就是为什么我们不能直接使用 requests 来请求页面的实际内容。
这时候需要做的就是分析网页后台向界面发送的Ajax请求,然后用Requests模拟Ajax请求,就可以成功捕获了。
了解了ajax的原理后,一切都变得有点头绪了~
阿贾克斯观察
对于 Ajax 请求,我们已经在现实生活中遇到过。我来形容你知道:“当你在浏览网页或APP的时候,当你把进度条拉到最下面的时候,你会看到进度条突然跳到中间,下面出现新的内容”
其实这就是Ajax的使用。
今天,我们用微博作为爬取对象。
网址 = ""
浏览器发起请求
老规矩,进入开发者模式。然后在Network下,点击XHR进行过滤(只过滤掉Ajax请求的请求响应消息)
我们先看第一个入口信息,观察它的Response
于是我们进行了测试,将进度条拖到底部,发现浏览器和服务器暗中进行了消息交互,效果如下:
ajax抓取网页内容(DOM结构怎么查看,浏览器快捷菜单中没有这功能吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-09 19:12
因为是ajax获取的
当然,javascript操作的结果不在html中。
可以在dom结构中查看。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
当然,javascript操作的结果不在html中。
可以在dom结构中查看。
如何检查DOM结构?浏览器快捷菜单中没有该功能。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
真的不
document.write之后html已经更新了,为什么浏览器给不出新版本的html。
新版本的 HTML。
对于 IE,可以使用 c&p 到 Word 或 IE 的富文本编辑器。其他浏览器我没试过。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
真的不
document.write之后html已经更新了,为什么浏览器给不出新版本的html。
您必须了解基本的 html 原理。无论 html 是静态存储在硬盘上还是由编程语言生成的 html,Web 服务器始终返回 html 内容。
浏览器的作用就是显示这些html内容。
客户端脚本语言的内容由脚本引擎处理,例如 chrome 的 v8 引擎。
它负责解释脚本并在必要时重新绘制页面。脚本的所有操作都是在dom中完成的。.
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签:网页显示的内容在源文件中找不到是什么原因 查看全部
ajax抓取网页内容(DOM结构怎么查看,浏览器快捷菜单中没有这功能吧)
因为是ajax获取的
当然,javascript操作的结果不在html中。
可以在dom结构中查看。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
当然,javascript操作的结果不在html中。
可以在dom结构中查看。
如何检查DOM结构?浏览器快捷菜单中没有该功能。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
真的不
document.write之后html已经更新了,为什么浏览器给不出新版本的html。
新版本的 HTML。
对于 IE,可以使用 c&p 到 Word 或 IE 的富文本编辑器。其他浏览器我没试过。
因为是ajax获取的
ajax获取的内容一定不能显示,你验证了吗?ajax确实改变了当前页面的html内容,也就是我们看到的是ajax执行后的页面,所以网页的源代码不会改变?
document.write("hello world");
执行完这个,html源码里面有hello world吗?
真的不
document.write之后html已经更新了,为什么浏览器给不出新版本的html。
您必须了解基本的 html 原理。无论 html 是静态存储在硬盘上还是由编程语言生成的 html,Web 服务器始终返回 html 内容。
浏览器的作用就是显示这些html内容。
客户端脚本语言的内容由脚本引擎处理,例如 chrome 的 v8 引擎。
它负责解释脚本并在必要时重新绘制页面。脚本的所有操作都是在dom中完成的。.
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签:网页显示的内容在源文件中找不到是什么原因
ajax抓取网页内容(有待开发者network如果看ajax加载需要Doc标签待有机会 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-11-09 11:06
)
先解释一下什么是ajax动态网页。扫微博的时候经常会遇到这个。一直往下拉,就会一直有数据加载,然后就会显示在你的界面上,类似下图。
通过改变offset也可以发现网页加载了数据(步长为20)(观察修改通过的XHR标签)
然后获取数据。
待学习谷歌开发者 F12
网络
如果你看ajax加载,你需要XHR标签
如果你看源码,你需要Doc标签
有机会我们会详细分析代码。目前只有崔老师爬取成功的代码。有一个池层。
from requests.exceptions import RequestException
import json
import re
from bs4 import BeautifulSoup
import requests
from urllib.parse import urlencode
from requests import codes # ?from 和 import 的区别
import os
from hashlib import md5 # ?
from multiprocessing.pool import Pool # 多进程池
def get_page_index(offset, keyword):
data = {
'offsets': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': 3
}
url = 'http://www.toutiao.com/search_content/?' + urlencode(data) # 这是网页的地址,urlencode是url的一种编码方式
try:
response = requests.get(url)
if response.status_code == codes.ok:
return response.json()
except requests.ConnectionError:
print('请求索引出错')
return None
def get_images(json):
if json.get('data'):
data = json.get('data')
for item in data:
if item.get('cell_type') is not None:
continue
title = item.get('title')
images = item.get('image_list')
for image in images:
yield {
'image': 'https:' + image.get('url'),
'title': title
}
def save_image(item):
img_path = 'img' + os.path.sep + item.get('title')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
resp = requests.get(item.get('image'))
if codes.ok == resp.status_code:
file_path = img_path + os.path.sep + '{file_name}.{file_suffix}'.format(
file_name=md5(resp.content).hexdigest(),
file_suffix='jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(resp.content)
print('Downloaded image path is %s' % file_path)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image,item %s' % item)
def main(offset):
json = get_page_index(offset,'街拍')
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 0
GROUP_END = 7
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START,GROUP_END + 1)])
pool.map(main,groups) # 池化匹配
pool.close()
pool.join() 查看全部
ajax抓取网页内容(有待开发者network如果看ajax加载需要Doc标签待有机会
)
先解释一下什么是ajax动态网页。扫微博的时候经常会遇到这个。一直往下拉,就会一直有数据加载,然后就会显示在你的界面上,类似下图。
通过改变offset也可以发现网页加载了数据(步长为20)(观察修改通过的XHR标签)
然后获取数据。
待学习谷歌开发者 F12
网络
如果你看ajax加载,你需要XHR标签
如果你看源码,你需要Doc标签
有机会我们会详细分析代码。目前只有崔老师爬取成功的代码。有一个池层。
from requests.exceptions import RequestException
import json
import re
from bs4 import BeautifulSoup
import requests
from urllib.parse import urlencode
from requests import codes # ?from 和 import 的区别
import os
from hashlib import md5 # ?
from multiprocessing.pool import Pool # 多进程池
def get_page_index(offset, keyword):
data = {
'offsets': offset,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': '20',
'cur_tab': 3
}
url = 'http://www.toutiao.com/search_content/?' + urlencode(data) # 这是网页的地址,urlencode是url的一种编码方式
try:
response = requests.get(url)
if response.status_code == codes.ok:
return response.json()
except requests.ConnectionError:
print('请求索引出错')
return None
def get_images(json):
if json.get('data'):
data = json.get('data')
for item in data:
if item.get('cell_type') is not None:
continue
title = item.get('title')
images = item.get('image_list')
for image in images:
yield {
'image': 'https:' + image.get('url'),
'title': title
}
def save_image(item):
img_path = 'img' + os.path.sep + item.get('title')
if not os.path.exists(img_path):
os.makedirs(img_path)
try:
resp = requests.get(item.get('image'))
if codes.ok == resp.status_code:
file_path = img_path + os.path.sep + '{file_name}.{file_suffix}'.format(
file_name=md5(resp.content).hexdigest(),
file_suffix='jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(resp.content)
print('Downloaded image path is %s' % file_path)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image,item %s' % item)
def main(offset):
json = get_page_index(offset,'街拍')
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 0
GROUP_END = 7
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START,GROUP_END + 1)])
pool.map(main,groups) # 池化匹配
pool.close()
pool.join()
ajax抓取网页内容(新版简书网站为例的评论信息和哪些专题进行了收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-11-09 11:05
以新版短书网站为例,新版网站在很多地方使用了ajax(异步JavaScript和XML),大大提高了页面加载速度。
对于一些数据的抓取,增加了复杂度,在源码中找不到ajax数据。如下图所示,文章页面中的评论信息以及哪些话题已经被收录在源码中是看不到的。
一、 抓包分析
使用抓包工具 Fiddler 或 Chrome“检查”进行分析。本文使用 Chrome 工具。Chrome——“检查”——切换到“网络”,然后刷新网页。找到发送主题收录的请求。
注意:一个页面通常有几十个请求(这个页面有89个),包括网页文档(document)、脚本(script)、图片(jpeg),还有另外一种叫做xhl的类型,就是XMLHttpRequest。我们正在寻找异步请求类型。比较名称并找到我们想要的请求。
单击它,您将看到完整的 URL。
http://www.jianshu.com/notes/8 ... e%3D1
注意这个URL放在地址栏中访问,发现返回的不是我们想要的数据,而是一个404页面。但是看看返回的Response,就是我们需要的JSON数据。
怎么做?把url改成.json的结尾,就可以访问地址栏中的数据了。
http://www.jianshu.com/notes/8 ... .json
第一步到这里就完成了。最关键的问题是如何获取url中的id 8777855。如果能找到id,就可以构造一个url来获取json数据。
二、构造目标地址
方法:查看网页源代码。我刚才不是说源码里没有我们需要的数据吗?查什么,搜索编号id 8777855,看看,确实如此,是在一些标签中,作为内容值的一部分。
那么它会更容易。解析元标记并获取 id。
def parse(self,response):
selector = Selector(response)
infos = selector.xpath("//meta/@content").extract()
id = ''
for info in infos:
if (str(info).find('jianshu://notes/')) ==0 :
id = filter(str.isdigit,str(info))
break;
collection_url ='http://www.jianshu.com/notes/%s/included_collections.json'%id
yield Request(collection_url,callback=self.parse_json)
OK,一个目标url就是这样构造的。
三、解析json数据
这一步比较简单,引入json包进行分析。当然,在做这一步的时候,需要先发送一个请求。
def parse_json(self,response):
data = json.loads(response.body)
collect = data['collections']
cols=''
if len(collect) >0 :
for cc in collect:
cols += cc['title']+';'
上述步骤中解析json的方法也适用于一般的Python爬虫。 查看全部
ajax抓取网页内容(新版简书网站为例的评论信息和哪些专题进行了收录)
以新版短书网站为例,新版网站在很多地方使用了ajax(异步JavaScript和XML),大大提高了页面加载速度。
对于一些数据的抓取,增加了复杂度,在源码中找不到ajax数据。如下图所示,文章页面中的评论信息以及哪些话题已经被收录在源码中是看不到的。
一、 抓包分析
使用抓包工具 Fiddler 或 Chrome“检查”进行分析。本文使用 Chrome 工具。Chrome——“检查”——切换到“网络”,然后刷新网页。找到发送主题收录的请求。
注意:一个页面通常有几十个请求(这个页面有89个),包括网页文档(document)、脚本(script)、图片(jpeg),还有另外一种叫做xhl的类型,就是XMLHttpRequest。我们正在寻找异步请求类型。比较名称并找到我们想要的请求。
单击它,您将看到完整的 URL。
http://www.jianshu.com/notes/8 ... e%3D1
注意这个URL放在地址栏中访问,发现返回的不是我们想要的数据,而是一个404页面。但是看看返回的Response,就是我们需要的JSON数据。
怎么做?把url改成.json的结尾,就可以访问地址栏中的数据了。
http://www.jianshu.com/notes/8 ... .json
第一步到这里就完成了。最关键的问题是如何获取url中的id 8777855。如果能找到id,就可以构造一个url来获取json数据。
二、构造目标地址
方法:查看网页源代码。我刚才不是说源码里没有我们需要的数据吗?查什么,搜索编号id 8777855,看看,确实如此,是在一些标签中,作为内容值的一部分。
那么它会更容易。解析元标记并获取 id。
def parse(self,response):
selector = Selector(response)
infos = selector.xpath("//meta/@content").extract()
id = ''
for info in infos:
if (str(info).find('jianshu://notes/')) ==0 :
id = filter(str.isdigit,str(info))
break;
collection_url ='http://www.jianshu.com/notes/%s/included_collections.json'%id
yield Request(collection_url,callback=self.parse_json)
OK,一个目标url就是这样构造的。
三、解析json数据
这一步比较简单,引入json包进行分析。当然,在做这一步的时候,需要先发送一个请求。
def parse_json(self,response):
data = json.loads(response.body)
collect = data['collections']
cols=''
if len(collect) >0 :
for cc in collect:
cols += cc['title']+';'
上述步骤中解析json的方法也适用于一般的Python爬虫。
ajax抓取网页内容( ():)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-09 06:10
():)
ajax获取网页的cookie值并处理页面信息
注意:没有必要。后台可以直接操作数据,不用ajax更简单
($sn_arr = $_COOKIE;) ---------------获取所有cookies进行过滤操作
1.js(函数执行后页面加载0.5ms)
$(function(){
setTimeout(function () {
$.ajax({
url:"/supplierbuyer/order/getCookie",
data:{
},
type:"POST",
dataType:"JSON",
success:function(data){
if(data.status==true){
//处理cookie的数据
var cookie_content = data['sn_arr'];
$.each(cookie_content, function(index, item){
if (index.startsWith("order_sn_")) {
var order_sn = index.substr(9);
$('.'+order_sn).text('');
$('.'+order_sn).parent().prev().css("background","");
}
});
}else{
console.log(data);
return false;
}
}
});
}, 0.5);
});
2.php
/**
* 获取cookie
*/
public function getCookie()
{
$sn_arr = $_COOKIE;
if ($sn_arr) {
$data['status'] = true;
$data['sn_arr'] = $sn_arr;
$data['msg'] = 'ok';
} else {
$data['status'] = false;
$data['sn_arr'] = '';
$data['msg'] = '网络错误,请稍后重试~';
}
echo json_encode($data);
exit();
}
posted @ 2018-12-05 16:13 很有趣。阅读(4664)评论(0)编辑 查看全部
ajax抓取网页内容(
():)
ajax获取网页的cookie值并处理页面信息
注意:没有必要。后台可以直接操作数据,不用ajax更简单
($sn_arr = $_COOKIE;) ---------------获取所有cookies进行过滤操作
1.js(函数执行后页面加载0.5ms)
$(function(){
setTimeout(function () {
$.ajax({
url:"/supplierbuyer/order/getCookie",
data:{
},
type:"POST",
dataType:"JSON",
success:function(data){
if(data.status==true){
//处理cookie的数据
var cookie_content = data['sn_arr'];
$.each(cookie_content, function(index, item){
if (index.startsWith("order_sn_")) {
var order_sn = index.substr(9);
$('.'+order_sn).text('');
$('.'+order_sn).parent().prev().css("background","");
}
});
}else{
console.log(data);
return false;
}
}
});
}, 0.5);
});
2.php
/**
* 获取cookie
*/
public function getCookie()
{
$sn_arr = $_COOKIE;
if ($sn_arr) {
$data['status'] = true;
$data['sn_arr'] = $sn_arr;
$data['msg'] = 'ok';
} else {
$data['status'] = false;
$data['sn_arr'] = '';
$data['msg'] = '网络错误,请稍后重试~';
}
echo json_encode($data);
exit();
}
posted @ 2018-12-05 16:13 很有趣。阅读(4664)评论(0)编辑
ajax抓取网页内容(一个非常好用的JQuery插件怎么用?图片卡卡网Html)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-05 23:30
今天介绍一个非常好用的JQuery插件,可以将网页或者div或者table的内容转换成图片并下载保存。这个插件叫做html2canvas,它只有一个js文件html2canvas.js,使用起来非常简单。
先看一个示例html代码,然后介绍如何使用。
html-content-holder">
卡卡旺
Html 转图片
卡卡网旨在为广大网站建设人员提供专业的网站测速和优化服务,同时为广大网友提供网速测试服务。
html2canvas 脚本可以直接在用户的浏览器上使用来截取网页或其部分内容的屏幕截图。截图基于DOM,所以可能不完全准确。
btn-Preview-Image" type="button" value="Preview"/>
预览:
预览图片">
execcodegetcode
下面介绍插件的使用方法,主要分为三个步骤。第一步:调用jquery库文件和html2canvas.js文件
jquery库文件可以调用百度公共库文件,html2canvas.js文件需要下载到本地才能调用。本文后面会附上下载地址。
代码如下:
第 2 步:预览和下载 html 代码
点击“预览”查看生成的图片,点击“下载”下载并保存图片。
代码如下:
btn-Preview-Image" type="button" value="Preview"/>
预览:
预览图片">
第三部分:JQuery生成下载图片的实现代码
代码如下:
在编写代码时,只需要将jquery实现代码的每个id名称与html代码中的每个id匹配即可。
插件下载
下载 html2canvas.js 文件。
链接:
提取码:ks6r 查看全部
ajax抓取网页内容(一个非常好用的JQuery插件怎么用?图片卡卡网Html)
今天介绍一个非常好用的JQuery插件,可以将网页或者div或者table的内容转换成图片并下载保存。这个插件叫做html2canvas,它只有一个js文件html2canvas.js,使用起来非常简单。
先看一个示例html代码,然后介绍如何使用。
html-content-holder">
卡卡旺
Html 转图片
卡卡网旨在为广大网站建设人员提供专业的网站测速和优化服务,同时为广大网友提供网速测试服务。
html2canvas 脚本可以直接在用户的浏览器上使用来截取网页或其部分内容的屏幕截图。截图基于DOM,所以可能不完全准确。
btn-Preview-Image" type="button" value="Preview"/>
预览:
预览图片">
execcodegetcode
下面介绍插件的使用方法,主要分为三个步骤。第一步:调用jquery库文件和html2canvas.js文件
jquery库文件可以调用百度公共库文件,html2canvas.js文件需要下载到本地才能调用。本文后面会附上下载地址。
代码如下:
第 2 步:预览和下载 html 代码
点击“预览”查看生成的图片,点击“下载”下载并保存图片。
代码如下:
btn-Preview-Image" type="button" value="Preview"/>
预览:
预览图片">
第三部分:JQuery生成下载图片的实现代码
代码如下:
在编写代码时,只需要将jquery实现代码的每个id名称与html代码中的每个id匹配即可。
插件下载
下载 html2canvas.js 文件。
链接:
提取码:ks6r
ajax抓取网页内容(PHP脚本将异步执行一系列任务(1)_经济学网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-11-05 07:30
问题
你好,
我不熟悉网络编程,但我在这里遇到了一个问题。
我有一个页面。当用户单击按钮时,我将使用 AJAX 请求一个 PHP 脚本,该脚本将异步执行一系列任务。
这些任务可能需要很长时间,所以我希望用户理解
进步。问题是只有PHP脚本知道
进度,网页如何从PHP脚本中获取这些信息?
如果有人能帮我解决这个问题,我将不胜感激。
解决方案
张马文写道:
你好,
我对网络编程不熟悉,但我在这里遇到了一个问题。
我有一个页面。当用户单击按钮时,我将使用 AJAX 请求一个 PHP 脚本,该脚本将异步执行一系列任务。
这些任务可能需要很长时间,所以我希望用户理解
进步。问题是只有PHP脚本知道
进度,网页如何从PHP脚本中获取这些信息?
如果有人能帮我解决这个问题,我将不胜感激。
这只是一个想法,做过的人可能更清楚。
-让您的原创 PHP 将信息存储在其“状态”会话中
变数论
_SESSION [" status_data"] 这是一个运行时更新
- Javascript 端有一个计时器,用于创建第二个 Ajax 调用
到一个新的 getstatus.php,然后从会话中读取状态并
在第二个 Ajax 调用中将其发送回浏览器。
没有做太多的 Ajax,我想你可以再打一次 ajax 调用,然后
它目前正在运行吗?
当您的 b$b 调用 getstatus.php 时,您可能需要将 PHP 会话 ID 发送回服务器,不确定。
我们不在乎你做什么:)
-让您的原创 PHP 将信息存储在其“状态”会话中
变数论 查看全部
ajax抓取网页内容(PHP脚本将异步执行一系列任务(1)_经济学网)
问题
你好,
我不熟悉网络编程,但我在这里遇到了一个问题。
我有一个页面。当用户单击按钮时,我将使用 AJAX 请求一个 PHP 脚本,该脚本将异步执行一系列任务。
这些任务可能需要很长时间,所以我希望用户理解
进步。问题是只有PHP脚本知道
进度,网页如何从PHP脚本中获取这些信息?
如果有人能帮我解决这个问题,我将不胜感激。
解决方案
张马文写道:
你好,
我对网络编程不熟悉,但我在这里遇到了一个问题。
我有一个页面。当用户单击按钮时,我将使用 AJAX 请求一个 PHP 脚本,该脚本将异步执行一系列任务。
这些任务可能需要很长时间,所以我希望用户理解
进步。问题是只有PHP脚本知道
进度,网页如何从PHP脚本中获取这些信息?
如果有人能帮我解决这个问题,我将不胜感激。
这只是一个想法,做过的人可能更清楚。
-让您的原创 PHP 将信息存储在其“状态”会话中
变数论
_SESSION [" status_data"] 这是一个运行时更新
- Javascript 端有一个计时器,用于创建第二个 Ajax 调用
到一个新的 getstatus.php,然后从会话中读取状态并
在第二个 Ajax 调用中将其发送回浏览器。
没有做太多的 Ajax,我想你可以再打一次 ajax 调用,然后
它目前正在运行吗?
当您的 b$b 调用 getstatus.php 时,您可能需要将 PHP 会话 ID 发送回服务器,不确定。
我们不在乎你做什么:)
-让您的原创 PHP 将信息存储在其“状态”会话中
变数论
ajax抓取网页内容(网页更新的一个Ajax请求是怎样的?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-11-03 04:10
)
未完待续
前言:
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用reuqest得到的结果是不同的。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是通过 JavaScript 处理数据的结果。它可能是通过Ajax加载的,可能是收录在HTML文档中,也可能是JavaScript和计算后生成的特定算法。
现在对于第一种情况,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
什么是阿贾克斯:
Ajax,Asynchronous JavaScript and XML,即异步 JavaScript 和 XML。一种使用 JavaScript 与服务器交换数据并更新某些网页,同时确保页面不会刷新和页面链接不会更改的技术。
示例介绍:
在浏览网页时,我们会发现很多网页都有向下滚动查看更多选项。以youtube为例,如下图所示,一直往下滑,可以发现,滑动几次后,会出现一个加载动画。一段时间后,新内容将继续出现在下方。这个过程其实就是Ajax加载的过程。
基本的:
在初步了解了 Ajax 之后,我们将进一步了解其基本原理。向网页更新发送ajax请求的过程可以简单分为以下3个步骤:
发送请求解析内容并渲染网页
发送请求
我们知道JavaScript可以实现页面的各种交互功能。Ajax 也不例外,它也是由 JavaScript 实现的,实际执行如下代码:
var xmlHttp;
if (window.XMLHttpRequest){
// code for IE7+,Firefox,chrome,Opera,Safari
xmlhttp = new XMLHttpRequest();
}else{
// code for IE6,IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function(){
if (xmlhttp.readyState==4 && xmlhttp.status == 200){
document.getElementById("myDiv").innerHTML = xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax",true);
xmlhttp.send();
这是 JavaScript 的 Ajax 的最低级别实现。实际上,它创建了一个新的 XMLHttpRequest 对象,然后调用 onreadystatechange 属性设置侦听器,然后调用 open() 和 send() 方法向链接(即服务器)发送请求。Python中发送请求后,可以得到响应结果,但是这里的请求发送是由JavaScript完成的。由于设置了监听,当服务器返回响应时,就会触发onreadystatechange对应的方法,然后就可以在这个方法中解析响应内容了。
解析内容
得到响应后,会触发onreadystatechange属性对应的方法。这时候可以通过xmlhttp的responseText属性获取响应内容。这类似于Python中使用requests向服务器发起请求,然后得到响应的过程。那么返回的内容可能是HTML或者JSON,那么你只需要在方法中使用JavaScript进行进一步处理即可。
例如,如果是 JSON,则可以对其进行解析和转换。
渲染网页
JavaScript 具有更改网页内容的能力。解析响应内容后,您可以调用 JavaScript 对解析后的内容执行网页的下一步处理。比如通过document.getElementById().innerHTML等操作,可以对元素中的源代码进行更改、删除等操作。
上例中document.getElementById("myDiv").innerHTML = xmlhttp.responseText会将ID为myDiv的节点内部的HTML代码改为服务器返回的内容,这样服务器返回的新数据就会出现在里面myDiv 元素,页面的一部分似乎已更新。
我们看到这三步其实是由JavaScript来完成的,它完成了请求、解析、渲染的整个过程。回想youtube的下拉刷新,这其实就是JavaScript向服务器发送Ajax请求,然后获取新数据,解析,渲染到网页上。
因此,我们知道真正的数据实际上是通过一次又一次的ajax请求获取的。如果要抓取这些数据,就需要知道请求是如何发送的,发送到哪里,以及发送了哪些参数。如果我们知道这一点,我们可以用Python模拟发送操作并得到结果吗?
我们来看看哪里可以看到这些后台Ajax操作,它们是如何发送的,以及发送了什么参数。
Ajax分析方法
以之前的youtube为例。我们知道拖拽刷新的内容是ajax加载的,页面的url没有变化,那么这些ajax请求应该去哪里找呢?
1.查看请求
这里还需要用到浏览器的开发者工具,下面以chrome浏览器为例介绍。
一、用chrome浏览器打开youutue的链接
按F12切换到Network选项卡,然后按F5再次刷新页面,你会发现这里有很多条目。如下所示:
前面说过,这其实就是页面加载过程中浏览器和服务器之间发送请求和接收响应的所有记录。
Ajax 实际上有其特殊的请求类型,称为 xhr。如下图所示,我们可以找到一个名称以getIndex开头,Type为xhr的请求,这是一个Ajax请求。
可以在右侧观察其请求头、URL 和响应头等信息。请求标头中的信息之一是
查看全部
ajax抓取网页内容(网页更新的一个Ajax请求是怎样的?(一)
)
未完待续
前言:
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用reuqest得到的结果是不同的。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是通过 JavaScript 处理数据的结果。它可能是通过Ajax加载的,可能是收录在HTML文档中,也可能是JavaScript和计算后生成的特定算法。
现在对于第一种情况,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
什么是阿贾克斯:
Ajax,Asynchronous JavaScript and XML,即异步 JavaScript 和 XML。一种使用 JavaScript 与服务器交换数据并更新某些网页,同时确保页面不会刷新和页面链接不会更改的技术。
示例介绍:
在浏览网页时,我们会发现很多网页都有向下滚动查看更多选项。以youtube为例,如下图所示,一直往下滑,可以发现,滑动几次后,会出现一个加载动画。一段时间后,新内容将继续出现在下方。这个过程其实就是Ajax加载的过程。
基本的:
在初步了解了 Ajax 之后,我们将进一步了解其基本原理。向网页更新发送ajax请求的过程可以简单分为以下3个步骤:
发送请求解析内容并渲染网页
发送请求
我们知道JavaScript可以实现页面的各种交互功能。Ajax 也不例外,它也是由 JavaScript 实现的,实际执行如下代码:
var xmlHttp;
if (window.XMLHttpRequest){
// code for IE7+,Firefox,chrome,Opera,Safari
xmlhttp = new XMLHttpRequest();
}else{
// code for IE6,IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function(){
if (xmlhttp.readyState==4 && xmlhttp.status == 200){
document.getElementById("myDiv").innerHTML = xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax",true);
xmlhttp.send();
这是 JavaScript 的 Ajax 的最低级别实现。实际上,它创建了一个新的 XMLHttpRequest 对象,然后调用 onreadystatechange 属性设置侦听器,然后调用 open() 和 send() 方法向链接(即服务器)发送请求。Python中发送请求后,可以得到响应结果,但是这里的请求发送是由JavaScript完成的。由于设置了监听,当服务器返回响应时,就会触发onreadystatechange对应的方法,然后就可以在这个方法中解析响应内容了。
解析内容
得到响应后,会触发onreadystatechange属性对应的方法。这时候可以通过xmlhttp的responseText属性获取响应内容。这类似于Python中使用requests向服务器发起请求,然后得到响应的过程。那么返回的内容可能是HTML或者JSON,那么你只需要在方法中使用JavaScript进行进一步处理即可。
例如,如果是 JSON,则可以对其进行解析和转换。
渲染网页
JavaScript 具有更改网页内容的能力。解析响应内容后,您可以调用 JavaScript 对解析后的内容执行网页的下一步处理。比如通过document.getElementById().innerHTML等操作,可以对元素中的源代码进行更改、删除等操作。
上例中document.getElementById("myDiv").innerHTML = xmlhttp.responseText会将ID为myDiv的节点内部的HTML代码改为服务器返回的内容,这样服务器返回的新数据就会出现在里面myDiv 元素,页面的一部分似乎已更新。
我们看到这三步其实是由JavaScript来完成的,它完成了请求、解析、渲染的整个过程。回想youtube的下拉刷新,这其实就是JavaScript向服务器发送Ajax请求,然后获取新数据,解析,渲染到网页上。
因此,我们知道真正的数据实际上是通过一次又一次的ajax请求获取的。如果要抓取这些数据,就需要知道请求是如何发送的,发送到哪里,以及发送了哪些参数。如果我们知道这一点,我们可以用Python模拟发送操作并得到结果吗?
我们来看看哪里可以看到这些后台Ajax操作,它们是如何发送的,以及发送了什么参数。
Ajax分析方法
以之前的youtube为例。我们知道拖拽刷新的内容是ajax加载的,页面的url没有变化,那么这些ajax请求应该去哪里找呢?
1.查看请求
这里还需要用到浏览器的开发者工具,下面以chrome浏览器为例介绍。
一、用chrome浏览器打开youutue的链接
按F12切换到Network选项卡,然后按F5再次刷新页面,你会发现这里有很多条目。如下所示:
前面说过,这其实就是页面加载过程中浏览器和服务器之间发送请求和接收响应的所有记录。
Ajax 实际上有其特殊的请求类型,称为 xhr。如下图所示,我们可以找到一个名称以getIndex开头,Type为xhr的请求,这是一个Ajax请求。
可以在右侧观察其请求头、URL 和响应头等信息。请求标头中的信息之一是
ajax抓取网页内容(越来越多的网站采用“单页面结构”的解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-02 06:02
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户通过具有哈希结构的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“哈希符号+感叹号”非常难看和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没有办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,我才忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
====================================
原文来自:如何让搜索引擎抓取AJAX内容?– 阮一峰的博客 查看全部
ajax抓取网页内容(越来越多的网站采用“单页面结构”的解决方法)
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户通过具有哈希结构的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“哈希符号+感叹号”非常难看和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没有办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,我才忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
====================================
原文来自:如何让搜索引擎抓取AJAX内容?– 阮一峰的博客
ajax抓取网页内容(ajax抓取网页内容?你只会用jquery和ajax吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-29 13:04
ajax抓取网页内容?你只会用jquery和ajax吗?如果你还不知道php(伪装成javascript)也可以获取网页内容,请先了解:php抓取网页内容,教你如何通过执行php代码进行http抓取?需要写fopen(即fopen("javascript/*.js","postmessage"))文件吗?需要吗?实现一个简单的自动填充功能?需要吗?这些都是小case,那接下来我们就来写php脚本,来实现一些基本的php操作操作一:connecttosocket,把连接到socket的信息传输给目标服务器操作二:调用session方法cookie存入/取出,解析、可控、不可丢弃操作三:提交文件,获取对应文件操作四:修改/删除数据库操作五:调用get/post方法传送参数到目标服务器,可以把参数post到远程服务器;可把参数formget传入到远程服务器,也可以采用异步方式进行接收。
操作六:参数选择、继承,call方法在单例方法crud中调用操作七:内存释放,使用malloc、free内存区域,释放外存(ext_memory_dump)php脚本语言简介php是简单高效的面向对象编程语言,基于动态语言特征。php支持所有的(键盘,鼠标,内存等),是性能最好的编程语言之一。php是一种静态类型检查的脚本语言,不要求类型,脚本语言写起来比较方便。
php代码主要由单行注释,内联和函数调用构成,但同时不能和php(动态语言)代码混合使用。使用php可以很容易的搭建web应用程序。简单来说,php的文件结构分为:meta[文件系统];[可执行文件];[二进制文件][配置文件];[目录];php常用命令可控:点一下鼠标搞定,只要传入参数,不用写注释,不用添加依赖、修改权限等;不可修改:传入参数就出错,并且很难再次传入新参数;可靠:无需保存数据,离线后本地保存所有数据;安全:内容泄露,键盘或鼠标操作都属于攻击行为;实现原理php实现session存储,全称sessionconnectingsessionsave等功能的实现。
操作一:opensession,打开当前服务器会话,通过php.createsession()函数打开会话。返回session对象,所有请求post/put/delete/get等请求都指向session对象并且session对象不能被修改。操作二:post请求(单例模式,自动上传内容及接收内容)上传内容,把请求的参数传递给二进制文件。
返回session对象,所有请求post/put/delete/get等请求都指向session对象并且session对象不能被修改。操作三:请求+解析+内容文件(本地保存),本地保存在远程服务器中。操作四:fetch请求+图片文件(文件上传),文件上传。返回新的session对象,参。 查看全部
ajax抓取网页内容(ajax抓取网页内容?你只会用jquery和ajax吗?)
ajax抓取网页内容?你只会用jquery和ajax吗?如果你还不知道php(伪装成javascript)也可以获取网页内容,请先了解:php抓取网页内容,教你如何通过执行php代码进行http抓取?需要写fopen(即fopen("javascript/*.js","postmessage"))文件吗?需要吗?实现一个简单的自动填充功能?需要吗?这些都是小case,那接下来我们就来写php脚本,来实现一些基本的php操作操作一:connecttosocket,把连接到socket的信息传输给目标服务器操作二:调用session方法cookie存入/取出,解析、可控、不可丢弃操作三:提交文件,获取对应文件操作四:修改/删除数据库操作五:调用get/post方法传送参数到目标服务器,可以把参数post到远程服务器;可把参数formget传入到远程服务器,也可以采用异步方式进行接收。
操作六:参数选择、继承,call方法在单例方法crud中调用操作七:内存释放,使用malloc、free内存区域,释放外存(ext_memory_dump)php脚本语言简介php是简单高效的面向对象编程语言,基于动态语言特征。php支持所有的(键盘,鼠标,内存等),是性能最好的编程语言之一。php是一种静态类型检查的脚本语言,不要求类型,脚本语言写起来比较方便。
php代码主要由单行注释,内联和函数调用构成,但同时不能和php(动态语言)代码混合使用。使用php可以很容易的搭建web应用程序。简单来说,php的文件结构分为:meta[文件系统];[可执行文件];[二进制文件][配置文件];[目录];php常用命令可控:点一下鼠标搞定,只要传入参数,不用写注释,不用添加依赖、修改权限等;不可修改:传入参数就出错,并且很难再次传入新参数;可靠:无需保存数据,离线后本地保存所有数据;安全:内容泄露,键盘或鼠标操作都属于攻击行为;实现原理php实现session存储,全称sessionconnectingsessionsave等功能的实现。
操作一:opensession,打开当前服务器会话,通过php.createsession()函数打开会话。返回session对象,所有请求post/put/delete/get等请求都指向session对象并且session对象不能被修改。操作二:post请求(单例模式,自动上传内容及接收内容)上传内容,把请求的参数传递给二进制文件。
返回session对象,所有请求post/put/delete/get等请求都指向session对象并且session对象不能被修改。操作三:请求+解析+内容文件(本地保存),本地保存在远程服务器中。操作四:fetch请求+图片文件(文件上传),文件上传。返回新的session对象,参。
ajax抓取网页内容(什么是Ajax有时候我们使用浏览器查看页面得到的数据不一致 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-26 18:17
)
一、什么是 Ajax
有时我们使用浏览器查看页面正常显示的数据与使用请求抓取页面获取的数据不一致。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据的结果。这些数据可能通过Ajax加载,可能收录在HTML文档中,也可能通过特定算法计算生成。
Ajax,全称是AsynchronousJavaScriptandXML,即异步JavaScript和XML。它是一种使用 JavaScript 来确保页面不刷新和连接保持不变的技术。服务器交换数据并更新一些网页。
1.示例
在浏览网页时,我们发现很多网页已经向下滚动以查看更多选项。以新浪微博首页为例。一直往下滑,看了几条微博就消失了。取而代之的是一个加载动画,很快就出现了新的微博内容。这个过程就是Ajax加载的过程,如下图:
2.基本原则
向网页更新发送ajax请求的过程可以简单分为三步:
1.发送请求
2.分析内容
3. 渲染页面
♦ 发送请求
var xmlhttp;
if (window.XMLHttpRequest) {
// IE7,Firefox,Chrome,Safari,opera
xmlhttp = new XMLHttpRequest()
} else {
// IE6,IE5
xmlhttp = new ActiveXObject(\'Microsoft.XMLHTTP\');
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById("content").innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open(\'POST\', \'/ajax\', true);
xmlhttp.send()
这是使用 JavaScript 的 Ajax 的低级实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 实现设置监听,然后使用 open() 和 send() 方法向一个连接(也就是服务器)发送请求。当响应返回时,触发相应的监听方法,解析响应内容。
♦分析内容
onreadystatechange对应的属性触发后,使用xmlhttp的responseText属性获取响应内容。
♦呈现网页
解析响应后,通过document.getElementById("content").innerHTML等方法改变某个元素内部的HTML代码,从而呈现网页。这种操作也称为DOM操作,即对Document的操作。
因此,我们知道真实的数据是从一次又一次的 Ajax 请求中获取的。如果你想抓取这些数据,你需要知道这些请求是如何发送的。然后用Python模拟发送操作,得到结果。
二、ajax方法解析1.查看请求
使用Chrome浏览器访问新浪微博首页,打开开发者工具。切换到网络选项卡,再次刷新页面,看到很多条目。
Ajax 请求实际上有其特殊的请求类型,称为 xhr。在途中对应的Type请求类型中,点击图中的XHR,过滤掉所有的xhr请求。找到其中一个 xhr 请求并单击以查看详细信息。RequestHeaders 中的一条信息是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。如下所示
3.ajax结果抽取1.请求分析
使用开发者工具打开Ajax的XHR过滤器,然后向下滑动页面,我们会看到有不断的Ajax请求。选择其中一个请求,分析其参数信息,输入请求详情。如下所示:
可以发现这是一个GET请求,url为ajwvr=6&category=0&page=3&lefnav=0&cursor=&__rnd=65。有六个请求的参数:ajwvr、category、page、lefnav、cursor、__rnd。
查看其他请求,发现只有page和__rnd这两个参数在变化。很明显page是用来控制分页的,仔细观察__rnd的值对应的是时间戳。
2.分析响应
观察这个请求的响应内容:
该内容的格式为JSON,主要内容在data对应的值中。这样我们就请求了一个接口,改变了页面参数来获取对应的数据。
3. 爬取数据
这里我们要模拟本剧的ajax请求,向下爬取前10页的数据。
# _*_ coding=utf-8 _*_
import requests, time
from urllib.parse import urlencode
base_url = \'https://weibo.com/a/aj/transform/loadingmoreunlogin?\'
headers = {
\'Host\': \'weibo.com\',
\'Referer\': \'https://weibo.com/\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36\',
\'X-Requested-With\': \'XMLHttpRequest\',
}
def get_page(page):
"""
:param page:
:return:
"""
# 构造__rnd参数
rnd = int(time.time())
# 构造参数字典
params = {
\'ajwvr\': \'6\',
\'category\': \'0\',
\'page\': page,
\'lefnav\': \'0\',
\'cursor\': \'\',
\'__rnd\': rnd
}
# 拼接参数与url
url = base_url + urlencode(params)
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.json()
except Exception as e:
print(\'Error:\', e.args)
def parse(res):
weibo = {}
if res:
weibo[\'data\'] = res.get(\'data\')
yield weibo
if __name__ == "__main__":
for page in range(1, 11):
result = get_page(page)
weibo_data = parse(result)
for data in weibo_data:
print(data)
查看代码
操作结果:
{\'data\': \' \n \r\n\r\n \r\n \r\n <a href="/a/hot/7562265474177025_1.html?type=new" target="_blank" suda-uatrack="key=www_unlogin_home&value=focus01">\r\n 头条新闻今日快讯 | 华为在美提起诉讼.....}
这样我们就可以通过分析Ajax请求和编写爬虫来获取微博数据。当然,代码可以更优化,可以解析具体的标题和内容。这里只是演示Ajax请求的模拟过程,爬取结果不是重点。
查看全部
ajax抓取网页内容(什么是Ajax有时候我们使用浏览器查看页面得到的数据不一致
)
一、什么是 Ajax
有时我们使用浏览器查看页面正常显示的数据与使用请求抓取页面获取的数据不一致。这是因为获取的请求是原创的 HTML 文档,浏览器中的页面是 JavaScript 处理数据的结果。这些数据可能通过Ajax加载,可能收录在HTML文档中,也可能通过特定算法计算生成。
Ajax,全称是AsynchronousJavaScriptandXML,即异步JavaScript和XML。它是一种使用 JavaScript 来确保页面不刷新和连接保持不变的技术。服务器交换数据并更新一些网页。
1.示例
在浏览网页时,我们发现很多网页已经向下滚动以查看更多选项。以新浪微博首页为例。一直往下滑,看了几条微博就消失了。取而代之的是一个加载动画,很快就出现了新的微博内容。这个过程就是Ajax加载的过程,如下图:
2.基本原则
向网页更新发送ajax请求的过程可以简单分为三步:
1.发送请求
2.分析内容
3. 渲染页面
♦ 发送请求
var xmlhttp;
if (window.XMLHttpRequest) {
// IE7,Firefox,Chrome,Safari,opera
xmlhttp = new XMLHttpRequest()
} else {
// IE6,IE5
xmlhttp = new ActiveXObject(\'Microsoft.XMLHTTP\');
}
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == 200) {
document.getElementById("content").innerHTML = xmlhttp.responseText;
}
};
xmlhttp.open(\'POST\', \'/ajax\', true);
xmlhttp.send()
这是使用 JavaScript 的 Ajax 的低级实现。其实就是新建一个 XMLHttpRequest 对象,然后调用 onreadystatechange 实现设置监听,然后使用 open() 和 send() 方法向一个连接(也就是服务器)发送请求。当响应返回时,触发相应的监听方法,解析响应内容。
♦分析内容
onreadystatechange对应的属性触发后,使用xmlhttp的responseText属性获取响应内容。
♦呈现网页
解析响应后,通过document.getElementById("content").innerHTML等方法改变某个元素内部的HTML代码,从而呈现网页。这种操作也称为DOM操作,即对Document的操作。
因此,我们知道真实的数据是从一次又一次的 Ajax 请求中获取的。如果你想抓取这些数据,你需要知道这些请求是如何发送的。然后用Python模拟发送操作,得到结果。
二、ajax方法解析1.查看请求
使用Chrome浏览器访问新浪微博首页,打开开发者工具。切换到网络选项卡,再次刷新页面,看到很多条目。
Ajax 请求实际上有其特殊的请求类型,称为 xhr。在途中对应的Type请求类型中,点击图中的XHR,过滤掉所有的xhr请求。找到其中一个 xhr 请求并单击以查看详细信息。RequestHeaders 中的一条信息是 X-Requested-With:XMLHttpRequest,它将请求标记为 Ajax 请求。如下所示
3.ajax结果抽取1.请求分析
使用开发者工具打开Ajax的XHR过滤器,然后向下滑动页面,我们会看到有不断的Ajax请求。选择其中一个请求,分析其参数信息,输入请求详情。如下所示:
可以发现这是一个GET请求,url为ajwvr=6&category=0&page=3&lefnav=0&cursor=&__rnd=65。有六个请求的参数:ajwvr、category、page、lefnav、cursor、__rnd。
查看其他请求,发现只有page和__rnd这两个参数在变化。很明显page是用来控制分页的,仔细观察__rnd的值对应的是时间戳。
2.分析响应
观察这个请求的响应内容:
该内容的格式为JSON,主要内容在data对应的值中。这样我们就请求了一个接口,改变了页面参数来获取对应的数据。
3. 爬取数据
这里我们要模拟本剧的ajax请求,向下爬取前10页的数据。
# _*_ coding=utf-8 _*_
import requests, time
from urllib.parse import urlencode
base_url = \'https://weibo.com/a/aj/transform/loadingmoreunlogin?\'
headers = {
\'Host\': \'weibo.com\',
\'Referer\': \'https://weibo.com/\',
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36\',
\'X-Requested-With\': \'XMLHttpRequest\',
}
def get_page(page):
"""
:param page:
:return:
"""
# 构造__rnd参数
rnd = int(time.time())
# 构造参数字典
params = {
\'ajwvr\': \'6\',
\'category\': \'0\',
\'page\': page,
\'lefnav\': \'0\',
\'cursor\': \'\',
\'__rnd\': rnd
}
# 拼接参数与url
url = base_url + urlencode(params)
try:
res = requests.get(url, headers=headers)
if res.status_code == 200:
return res.json()
except Exception as e:
print(\'Error:\', e.args)
def parse(res):
weibo = {}
if res:
weibo[\'data\'] = res.get(\'data\')
yield weibo
if __name__ == "__main__":
for page in range(1, 11):
result = get_page(page)
weibo_data = parse(result)
for data in weibo_data:
print(data)
查看代码
操作结果:
{\'data\': \' \n \r\n\r\n \r\n \r\n <a href="/a/hot/7562265474177025_1.html?type=new" target="_blank" suda-uatrack="key=www_unlogin_home&value=focus01">\r\n
头条新闻今日快讯 | 华为在美提起诉讼.....}这样我们就可以通过分析Ajax请求和编写爬虫来获取微博数据。当然,代码可以更优化,可以解析具体的标题和内容。这里只是演示Ajax请求的模拟过程,爬取结果不是重点。
ajax抓取网页内容(使用jquery获取网页中图片的高度其实很简单,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-10-26 07:05
使用jquery获取网页中图片的高度其实很简单。目前有两种很好的方法来实现它。下面为大家详细介绍。如有疑问,可参考。
使用jquery获取网页中图片的高度其实很简单。有两种常见的方法可以达到我们的目的。
复制代码代码如下:
$("img").whith(); (返回纯数字)
$("img").css("width"); (返回字符串:数字+“px”)
但是有时候我们会遇到返回0的情况,上面方法的返回值竟然是0或者0px,很让人意外。
方法一
很久以前用的解决方案,也是我师父告诉我的解决方案:在你需要获取的图片的标签上加上width属性,或者把图片写在css中,这样就可以了,所以每想获取图片高度的时候,需要先测量一下图片的高度,然后写在网页上,就这样了。是不是很尴尬?我们来看看第二种方法。.
方法二
最近,我正在阅读Learning jQuery的英文原版。因为是翻译和阅读同时进行,所以我仔细阅读了每一页,所以我最终仔细阅读并体验了以下两种常用的jquery事件加载方法。
复制代码代码如下:
$(函数(){});
window.onload=function(){}
第一个在 DOM 结构渲染完成后调用。这时候网页中的一些资源还没有加载,比如图片等资源,但是DOM结构已经渲染成功了。
第二个是在网页 DOM 结构渲染完毕并且资源加载成功后调用的。
你觉得有什么不同吗?一个是在资源没有加载的时候调用的,另一个是在资源加载完毕并且页面已经渲染完之后调用的,所以当我们调用 $('img in $(function(){}) 的时候') .width(),由于图片还没有加载,此时label的高度为0,所以返回值为0。但是调用window.onload=function(){}时,图片已经已加载,因此您可以获取此时图片的高度。
所以请记住,$(function(){}) 是在 DOM 渲染结束且资源尚未加载时执行的。如果要获取一些资源信息,这个时候是没有办法的。
以上就是使用jquery获取网页中图片高度的两种方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
ajax抓取网页内容(使用jquery获取网页中图片的高度其实很简单,你知道吗?)
使用jquery获取网页中图片的高度其实很简单。目前有两种很好的方法来实现它。下面为大家详细介绍。如有疑问,可参考。
使用jquery获取网页中图片的高度其实很简单。有两种常见的方法可以达到我们的目的。
复制代码代码如下:
$("img").whith(); (返回纯数字)
$("img").css("width"); (返回字符串:数字+“px”)
但是有时候我们会遇到返回0的情况,上面方法的返回值竟然是0或者0px,很让人意外。
方法一
很久以前用的解决方案,也是我师父告诉我的解决方案:在你需要获取的图片的标签上加上width属性,或者把图片写在css中,这样就可以了,所以每想获取图片高度的时候,需要先测量一下图片的高度,然后写在网页上,就这样了。是不是很尴尬?我们来看看第二种方法。.
方法二
最近,我正在阅读Learning jQuery的英文原版。因为是翻译和阅读同时进行,所以我仔细阅读了每一页,所以我最终仔细阅读并体验了以下两种常用的jquery事件加载方法。
复制代码代码如下:
$(函数(){});
window.onload=function(){}
第一个在 DOM 结构渲染完成后调用。这时候网页中的一些资源还没有加载,比如图片等资源,但是DOM结构已经渲染成功了。
第二个是在网页 DOM 结构渲染完毕并且资源加载成功后调用的。
你觉得有什么不同吗?一个是在资源没有加载的时候调用的,另一个是在资源加载完毕并且页面已经渲染完之后调用的,所以当我们调用 $('img in $(function(){}) 的时候') .width(),由于图片还没有加载,此时label的高度为0,所以返回值为0。但是调用window.onload=function(){}时,图片已经已加载,因此您可以获取此时图片的高度。
所以请记住,$(function(){}) 是在 DOM 渲染结束且资源尚未加载时执行的。如果要获取一些资源信息,这个时候是没有办法的。
以上就是使用jquery获取网页中图片高度的两种方法的详细内容。更多详情请关注其他相关html中文网站文章!
ajax抓取网页内容(越来越多的网站采用"单页面结构”的解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2021-10-26 01:15
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(越来越多的网站采用"单页面结构”的解决方法)
越来越多的网站开始采用“单页应用”。整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-24 18:11
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户可以通过井号构造的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户可以通过井号构造的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(越来越多的网站采用Ajax技术解决方法放弃井号结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-22 09:00
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到前两天看到一位Discourse创始人的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
ajax抓取网页内容(越来越多的网站采用Ajax技术解决方法放弃井号结构)
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,利用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个 网站。
用户可以通过井号构造的 URL 看到不同的内容。
#1
#2
#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
只要你把 AJAX 内容放到这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
改成
#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到前两天看到一位Discourse创始人的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录 内容。它的解决方案是放弃hash结构,使用History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先,用History API替换hash结构,让每个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
/1
/2
/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
功能锚点击(链接){
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click','a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户单击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
锚点击(位置。路径名);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们将所有我们想要搜索引擎的内容放在了 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
ajax抓取网页内容(网页有相当一部分的技术简单一点讲就是事件驱动吧())
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-22 05:21
原生C#抓取AJAX页面内容
当前网页中有相当一部分使用了 AJAX 技术。所谓的AJAX技术就是简单的事件驱动(当然这个说法可能很不完整)。你提交URL后,服务器给你发来的不是全部是页面内容,而是很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使你使用counter方法,也就是在Navigated event++中,在DownloadComplete-中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关AJAX文章才明白原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.Navigate(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.Enabled = false;
//页面加载完毕,做一些其他的事情
}
} 查看全部
ajax抓取网页内容(网页有相当一部分的技术简单一点讲就是事件驱动吧())
原生C#抓取AJAX页面内容
当前网页中有相当一部分使用了 AJAX 技术。所谓的AJAX技术就是简单的事件驱动(当然这个说法可能很不完整)。你提交URL后,服务器给你发来的不是全部是页面内容,而是很大一部分是JS脚本,可以使用了
但是我们用IE浏览页面是正常的,所以只有一种解决方法就是使用WebBrowser控件
但是使用Webbrowser,你会发现在DownloadComplete事件中,你无法知道页面什么时候真正加载了!
当然,个别带有 Frame 的网页可能会多次触发 Complete。即使你使用counter方法,也就是在Navigated event++中,在DownloadComplete-中做,在JS完成执行后依然得不到结果。一开始也觉得很奇怪,直到后来GG相关AJAX文章才明白原委。
最终的解决方案是使用WebBrowser+Timer解决页面爬行问题
关键还是页面状态,我们可以使用webBrowser1.StatusText,如果返回“Done”,则表示页面已加载!
示例代码如下:
private void timer1_Tick(object sender, EventArgs e)
{
webBrowser1.Navigate(Url);
if (webBrowser1.StatusText == "Done")
{
定时器1.Enabled = false;
//页面加载完毕,做一些其他的事情
}
}
ajax抓取网页内容(AJAX(AsynchronousJavaScriptandXML)的思路想法想法AJAX先简单 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-20 15:01
)
想法 AJAX
首先,让我们简单地了解一下什么是 AJAX。个人建议,如果你从来没有听说过下面提到的术语或者只是简单地使用过它们,那么你最好回去把每一项都填好,虽然这是一个写爬虫的好工具。这不是很有帮助,但对您深入了解计算机主题非常有帮助。重要的是要知道,语言和框架都有自己的目的。了解了这些,学起来就会相对容易一些。
AJAX(Asynchronous JavaScript and XML),直译就是异步 JavaScript 和 XML。其实这个名字有点误导:据我所知,AJAX 至少还支持 json 文件,这可能是在这项技术发明时以 JavaScript 和 XML 命名的。这里的异步是指异步加载或异步数据交换。它是指在网页初始加载后,使用 XMLHttpRequst 或其他 fetch API 再次发送请求,从服务器获取并解析数据,然后将这部分数据添加到某些页面上,在此city,访问的 URL 从未改变。
AJAX本质上是一个框架,通过它JavaScript可以达到部分更新网页的效果。这节省了 Internet 中的传输带宽。JavaScript 是一种浏览器脚本语言。它可以在不访问服务器的情况下修改客户端。例如,某些网站 有很多选项。当您选择其中之一时,会出现更多子选项。这实际上是由 Javascript 完成的。在您单击提交之前,浏览器不会与服务器交互。. AJAX 框架中使用的只是 JavaScript 众多功能中的一小部分。
今日头条
嗯……其实我今天也不喜欢今日头条。我推送的内容越来越像UC今日头条了。如果你在头条页面搜索关键词古镇,你会得到多个文章,如果你把滑块拉到最底部,你会发现浏览器会自动加载更多文章,这是AJAX的一种体现。
但是,无论是什么技术或框架,只要还在使用HTTP协议,就无法运行GET/POST及其响应。我们要做的就是找到这个关键的 GET 请求。
你使用 AJAX
判断一个网站是否使用AJAX可以从以下几点来看:
综上所述,其实很容易看出。
分析搜索页面
toutiao-index页面分析.jpg
过滤图中位置1的XHR标签,你会在位置2看到它的消息。第一次访问只有一个。随着进度条下拉,新的请求会不断出现。分析这四个消息,你可以在它的请求头中找到参数列表。我们只需要修改参数值。其他参数也可以修改。关键字是您搜索的 关键词。
Requests URLs(只有offset变化了):
https://www.toutiao.com/search_content/?
offset=0&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
https://www.toutiao.com/search_content/?
offset=20&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
https://www.toutiao.com/search_content/?
offset=40&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
......
这样,我们就有了访问的链接。随着offset=0, 20, 40, 60...的增加,每次请求都会返回上图3位置的json结构,收录不超过20条记录。如果json结构中的数据项为空,则表示没有结果,表示爬虫结束。有时候搜索结果很多,你也可以设置一个上限,比如最多爬到前50个搜索结果。
今日头条-两种类型.jpg
仔细看,会出现两种搜索结果,一种是文字+图片的结构,收录图片和文字;另一个是相册的结构,它会收录几张照片。这两个结果可以根据json结构体中的has_gallery和has_image字段来区分。
我为每个结果对应的URL选择了article_url字段的值,但是这里其实有问题。在后续的爬取过程中,发现这个字段的值并不是所有的标题文章,有的是文章的源地址,估计是今日头条从网上爬取并添加的结果它自己的结果,通常出现在前几个。这种情况下,后面写的对应爬虫代码就不适用了,谁知道文章的源地址用的是什么结构。不过考虑到这样的情况并不多,我就简单的过滤一下。反正爬几页也不是问题。
如果你有强迫症,我考虑的一种方法是使用sourcs_url字段的内容,但是这个地址会被重定向,所以需要调整get请求:
https://www.toutiao.com/group/6544161999004107271/
Redirect to:
https://www.toutiao.com/a6544161999004107271/
带画廊的页面
今日头条-with atlas.jpg
图片是这种页面中的图集。我们需要找出这12张图片的地址。因为已经确定要使用AJAX,所以这里要查一下它的网页源码,然后可以找到:
toutiao-with atlas-js.jpg
内容有时略有不同,但很容易找到。然后用正则表达式过滤出你想要的图片地址。这里有个技巧,这部分源码正好是json格式,可以过滤掉整个{},加载到字典中方便查阅。
没有图库的页面
没有图集的页面是文字+图片模式,但是标题的页面也是动态加载的。一开始以为是静态页面,看了源码才知道。
今日头条-无图集-js.jpg
也很容易找到图片的地址,还是用正则表达式过滤掉。
代码结构自建URL,调整偏移量和关键字检索索引页,分析json.get('data')的结构,区分两种类型的页面,将提取的URL放入各自的列表中。两个解析函数用于解析两个页面,并将提取的图片地址写入文件。
几个小问题:
金日头条.py
对于configure.py,请参考我的书:爬取尴尬百科的内容和图片并展示出来。
<p>import requests
import json
import time
import re
from random import choice
import configure
url = "https://www.toutiao.com/search_content/?"
header = {'user-agent': choice(configure.FakeUserAgents)}
keyword = '塞尔达传说'
has_gallery_lists = []
no_gallery_lists = []
def SearchPageParser(offset = 0):
payload = {
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':30,
'cur_tab':1,
'from':'search_tab'
}
count = 0
try:
response = requests.get(url, headers=header, params=payload)
content = None
print ("Parser " + response.url)
if response.status_code == requests.codes.ok:
content = response.text
data = json.loads(content)
if not data:
return
for article in data.get('data'):
if True == article.get('has_gallery') and True == article.get('has_image'):
has_gallery_lists.append(article.get('article_url'))
count += 1
if False == article.get('has_gallery') and True == article.get('has_image'):
no_gallery_lists.append(article.get('article_url'))
count += 1
return count
except Exception as e:
print (e)
return
def SaveImage(imageURL):
# 这里就不下载了,只是把单纯写入文件
print (imageURL)
with open('toutiao.txt', 'a') as file:
file.write(imageURL + '\n')
def HasGalleryParser():
if 0 == len(has_gallery_lists):
return
# 这里写的时候注意(, ), ", ., 都是要转义的。
pattern = re.compile('gallery: JSON\.parse\("(.*?)max_img', re.S)
while has_gallery_lists:
this = has_gallery_lists.pop()
try:
response = requests.get(this, headers=header)
content = None
if response.status_code == requests.codes.ok:
content = response.text
data = pattern.findall(content)
if data:
data = data[0][:-4].replace('\\','') + ']}'
img_urls = json.loads(data).get('sub_images')
for img_url in img_urls:
SaveImage(img_url.get('url'))
else:
print ("BadPageURL[GalleryParser, {0:s}]".format(this))
except Exception as e:
print (e)
return
time.sleep(0.25)
def NoGalleryParser():
if 0 == len(no_gallery_lists):
return
while no_gallery_lists:
this = no_gallery_lists.pop()
pattern = re.compile(' 查看全部
ajax抓取网页内容(AJAX(AsynchronousJavaScriptandXML)的思路想法想法AJAX先简单
)
想法 AJAX
首先,让我们简单地了解一下什么是 AJAX。个人建议,如果你从来没有听说过下面提到的术语或者只是简单地使用过它们,那么你最好回去把每一项都填好,虽然这是一个写爬虫的好工具。这不是很有帮助,但对您深入了解计算机主题非常有帮助。重要的是要知道,语言和框架都有自己的目的。了解了这些,学起来就会相对容易一些。
AJAX(Asynchronous JavaScript and XML),直译就是异步 JavaScript 和 XML。其实这个名字有点误导:据我所知,AJAX 至少还支持 json 文件,这可能是在这项技术发明时以 JavaScript 和 XML 命名的。这里的异步是指异步加载或异步数据交换。它是指在网页初始加载后,使用 XMLHttpRequst 或其他 fetch API 再次发送请求,从服务器获取并解析数据,然后将这部分数据添加到某些页面上,在此city,访问的 URL 从未改变。
AJAX本质上是一个框架,通过它JavaScript可以达到部分更新网页的效果。这节省了 Internet 中的传输带宽。JavaScript 是一种浏览器脚本语言。它可以在不访问服务器的情况下修改客户端。例如,某些网站 有很多选项。当您选择其中之一时,会出现更多子选项。这实际上是由 Javascript 完成的。在您单击提交之前,浏览器不会与服务器交互。. AJAX 框架中使用的只是 JavaScript 众多功能中的一小部分。
今日头条
嗯……其实我今天也不喜欢今日头条。我推送的内容越来越像UC今日头条了。如果你在头条页面搜索关键词古镇,你会得到多个文章,如果你把滑块拉到最底部,你会发现浏览器会自动加载更多文章,这是AJAX的一种体现。
但是,无论是什么技术或框架,只要还在使用HTTP协议,就无法运行GET/POST及其响应。我们要做的就是找到这个关键的 GET 请求。
你使用 AJAX
判断一个网站是否使用AJAX可以从以下几点来看:
综上所述,其实很容易看出。
分析搜索页面
toutiao-index页面分析.jpg
过滤图中位置1的XHR标签,你会在位置2看到它的消息。第一次访问只有一个。随着进度条下拉,新的请求会不断出现。分析这四个消息,你可以在它的请求头中找到参数列表。我们只需要修改参数值。其他参数也可以修改。关键字是您搜索的 关键词。
Requests URLs(只有offset变化了):
https://www.toutiao.com/search_content/?
offset=0&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
https://www.toutiao.com/search_content/?
offset=20&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
https://www.toutiao.com/search_content/?
offset=40&format=json&keyword=%E5%A1%9E%E5%B0%94%E8%BE%BE%E4%BC%A0%E8%AF%B4&autoload=true&count=20&cur_tab=1&from=search_tab
......
这样,我们就有了访问的链接。随着offset=0, 20, 40, 60...的增加,每次请求都会返回上图3位置的json结构,收录不超过20条记录。如果json结构中的数据项为空,则表示没有结果,表示爬虫结束。有时候搜索结果很多,你也可以设置一个上限,比如最多爬到前50个搜索结果。
今日头条-两种类型.jpg
仔细看,会出现两种搜索结果,一种是文字+图片的结构,收录图片和文字;另一个是相册的结构,它会收录几张照片。这两个结果可以根据json结构体中的has_gallery和has_image字段来区分。
我为每个结果对应的URL选择了article_url字段的值,但是这里其实有问题。在后续的爬取过程中,发现这个字段的值并不是所有的标题文章,有的是文章的源地址,估计是今日头条从网上爬取并添加的结果它自己的结果,通常出现在前几个。这种情况下,后面写的对应爬虫代码就不适用了,谁知道文章的源地址用的是什么结构。不过考虑到这样的情况并不多,我就简单的过滤一下。反正爬几页也不是问题。
如果你有强迫症,我考虑的一种方法是使用sourcs_url字段的内容,但是这个地址会被重定向,所以需要调整get请求:
https://www.toutiao.com/group/6544161999004107271/
Redirect to:
https://www.toutiao.com/a6544161999004107271/
带画廊的页面
今日头条-with atlas.jpg
图片是这种页面中的图集。我们需要找出这12张图片的地址。因为已经确定要使用AJAX,所以这里要查一下它的网页源码,然后可以找到:
toutiao-with atlas-js.jpg
内容有时略有不同,但很容易找到。然后用正则表达式过滤出你想要的图片地址。这里有个技巧,这部分源码正好是json格式,可以过滤掉整个{},加载到字典中方便查阅。
没有图库的页面
没有图集的页面是文字+图片模式,但是标题的页面也是动态加载的。一开始以为是静态页面,看了源码才知道。
今日头条-无图集-js.jpg
也很容易找到图片的地址,还是用正则表达式过滤掉。
代码结构自建URL,调整偏移量和关键字检索索引页,分析json.get('data')的结构,区分两种类型的页面,将提取的URL放入各自的列表中。两个解析函数用于解析两个页面,并将提取的图片地址写入文件。
几个小问题:
金日头条.py
对于configure.py,请参考我的书:爬取尴尬百科的内容和图片并展示出来。
<p>import requests
import json
import time
import re
from random import choice
import configure
url = "https://www.toutiao.com/search_content/?"
header = {'user-agent': choice(configure.FakeUserAgents)}
keyword = '塞尔达传说'
has_gallery_lists = []
no_gallery_lists = []
def SearchPageParser(offset = 0):
payload = {
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':30,
'cur_tab':1,
'from':'search_tab'
}
count = 0
try:
response = requests.get(url, headers=header, params=payload)
content = None
print ("Parser " + response.url)
if response.status_code == requests.codes.ok:
content = response.text
data = json.loads(content)
if not data:
return
for article in data.get('data'):
if True == article.get('has_gallery') and True == article.get('has_image'):
has_gallery_lists.append(article.get('article_url'))
count += 1
if False == article.get('has_gallery') and True == article.get('has_image'):
no_gallery_lists.append(article.get('article_url'))
count += 1
return count
except Exception as e:
print (e)
return
def SaveImage(imageURL):
# 这里就不下载了,只是把单纯写入文件
print (imageURL)
with open('toutiao.txt', 'a') as file:
file.write(imageURL + '\n')
def HasGalleryParser():
if 0 == len(has_gallery_lists):
return
# 这里写的时候注意(, ), ", ., 都是要转义的。
pattern = re.compile('gallery: JSON\.parse\("(.*?)max_img', re.S)
while has_gallery_lists:
this = has_gallery_lists.pop()
try:
response = requests.get(this, headers=header)
content = None
if response.status_code == requests.codes.ok:
content = response.text
data = pattern.findall(content)
if data:
data = data[0][:-4].replace('\\','') + ']}'
img_urls = json.loads(data).get('sub_images')
for img_url in img_urls:
SaveImage(img_url.get('url'))
else:
print ("BadPageURL[GalleryParser, {0:s}]".format(this))
except Exception as e:
print (e)
return
time.sleep(0.25)
def NoGalleryParser():
if 0 == len(no_gallery_lists):
return
while no_gallery_lists:
this = no_gallery_lists.pop()
pattern = re.compile('
ajax抓取网页内容(ajax抓取网页内容,重点是单页应用的搭建,最简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-10-13 14:02
ajax抓取网页内容,重点是单页应用的搭建,最简单的是找到目标网站的某个列表页/相关页,通过xhr请求该列表页/相关页中用于返回原始html的url,获取静态页面或者动态页面。相关的xhr请求可以看这个:xhr打包xmlhttprequest函数是xmlhttprequest类的扩展,它除了http请求方法get、post之外,还提供了用于获取页面原始元素的方法。
获取原始html时,首先必须加上scope属性,即与http请求同属于ajax请求,然后在获取请求时请使用try/catch捕获异常,并在后续对该请求进行正确的处理。request对象,即提供的是从客户端向服务器发起请求的方法,其本身无法获取动态或静态页面,因此需要一个接口使其同时支持动态或静态。下面是一个例子,利用xhr进行一个简单的获取单个页面内容的方法:获取单个页面内容varxhr=newxmlhttprequest();xhr.open("get","javascript:void(0)",false);xhr.onload=function(){window.open("get","javascript:void(0)",false);}xhr.send();xhr.render("helloworld");获取页面的静态列表时使用相应的xhr来获取它是否是原始的html。
这里的示例就是通过xhr来获取网页列表页面中的html标签。之后用xhr.get()方法获取本地的html链接。如果该页面是https的,而且不在xhr请求中,需要再加上一个error属性,用于给用户提示xhr请求的错误。setrequestheader(xhr.getrequestheader('secret'),'google'),即获取浏览器使用的mozilla、safari、opera厂商的标志,并不是用户访问的站点的标志,但是是一个参数,设置之后代表javascript通过了你的站点,用户访问不了某个网站时,此参数就可以保存下来,然后可以在其他浏览器中通过这个参数来访问某个网站,这个网站的站点标志就代表了这个网站的站点标志。
<p>index.htmllocation.href="";heresetrequestheader('secret','google'); 查看全部
ajax抓取网页内容(ajax抓取网页内容,重点是单页应用的搭建,最简单)
ajax抓取网页内容,重点是单页应用的搭建,最简单的是找到目标网站的某个列表页/相关页,通过xhr请求该列表页/相关页中用于返回原始html的url,获取静态页面或者动态页面。相关的xhr请求可以看这个:xhr打包xmlhttprequest函数是xmlhttprequest类的扩展,它除了http请求方法get、post之外,还提供了用于获取页面原始元素的方法。
获取原始html时,首先必须加上scope属性,即与http请求同属于ajax请求,然后在获取请求时请使用try/catch捕获异常,并在后续对该请求进行正确的处理。request对象,即提供的是从客户端向服务器发起请求的方法,其本身无法获取动态或静态页面,因此需要一个接口使其同时支持动态或静态。下面是一个例子,利用xhr进行一个简单的获取单个页面内容的方法:获取单个页面内容varxhr=newxmlhttprequest();xhr.open("get","javascript:void(0)",false);xhr.onload=function(){window.open("get","javascript:void(0)",false);}xhr.send();xhr.render("helloworld");获取页面的静态列表时使用相应的xhr来获取它是否是原始的html。
这里的示例就是通过xhr来获取网页列表页面中的html标签。之后用xhr.get()方法获取本地的html链接。如果该页面是https的,而且不在xhr请求中,需要再加上一个error属性,用于给用户提示xhr请求的错误。setrequestheader(xhr.getrequestheader('secret'),'google'),即获取浏览器使用的mozilla、safari、opera厂商的标志,并不是用户访问的站点的标志,但是是一个参数,设置之后代表javascript通过了你的站点,用户访问不了某个网站时,此参数就可以保存下来,然后可以在其他浏览器中通过这个参数来访问某个网站,这个网站的站点标志就代表了这个网站的站点标志。
<p>index.htmllocation.href="";heresetrequestheader('secret','google');

