
集搜客网页抓取软件
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-31 20:45
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
集搜客网页抓取器的抓取软件是软件不是图片下载器
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-05-31 12:00
集搜客网页抓取软件是集搜客的一款可以爬取网页的抓取软件,在以前网页抓取软件也称为搜狗网页抓取器,因为看到很多同学都说搜狗网页抓取器更方便,那今天小编就给大家介绍一款集搜客网页抓取器。下面就是集搜客网页抓取器官网,点击进入网站去看一下:点击新建操作。新建操作弹出窗口我们直接填写:地址(自定义地址),选择产品类型,选择抓取的网站,输入需要抓取的网址。
集搜客网页抓取器最佳的接口就是百度和谷歌,当然还有其他一些url,大家根据需要抓取。最后点击提交,提交到搜狗网页搜索抓取器,接下来我们就会抓取到你想要的网站:这款集搜客网页抓取器是软件不是图片下载器,因为集搜客网页抓取器是一款专业的网页抓取器软件,可以抓取wap,app,pc网页,商品详情页,店铺页,淘宝大图等,抓取步骤也是图文的,不过相比网页的网页抓取来说,图片的抓取软件大部分图片是识别不出来的,需要大家根据情况来操作一下,可以关注我的公众号小助手小职,后台回复集搜客网页抓取器获取全部抓取软件。
百度或者一搜关键词“本地抓取”可以获取很多网站。
集搜客啊
我在使用网页抓取,分享一个网站吧,有人说它的数据准确率很好,可能国内不多,但是功能,开发,速度上都很不错。 查看全部
集搜客网页抓取器的抓取软件是软件不是图片下载器
集搜客网页抓取软件是集搜客的一款可以爬取网页的抓取软件,在以前网页抓取软件也称为搜狗网页抓取器,因为看到很多同学都说搜狗网页抓取器更方便,那今天小编就给大家介绍一款集搜客网页抓取器。下面就是集搜客网页抓取器官网,点击进入网站去看一下:点击新建操作。新建操作弹出窗口我们直接填写:地址(自定义地址),选择产品类型,选择抓取的网站,输入需要抓取的网址。
集搜客网页抓取器最佳的接口就是百度和谷歌,当然还有其他一些url,大家根据需要抓取。最后点击提交,提交到搜狗网页搜索抓取器,接下来我们就会抓取到你想要的网站:这款集搜客网页抓取器是软件不是图片下载器,因为集搜客网页抓取器是一款专业的网页抓取器软件,可以抓取wap,app,pc网页,商品详情页,店铺页,淘宝大图等,抓取步骤也是图文的,不过相比网页的网页抓取来说,图片的抓取软件大部分图片是识别不出来的,需要大家根据情况来操作一下,可以关注我的公众号小助手小职,后台回复集搜客网页抓取器获取全部抓取软件。
百度或者一搜关键词“本地抓取”可以获取很多网站。
集搜客啊
我在使用网页抓取,分享一个网站吧,有人说它的数据准确率很好,可能国内不多,但是功能,开发,速度上都很不错。
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-05-31 09:11
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-05-28 22:17
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-05-26 03:37
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
爬虫,我想再推荐 6 个工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-05-22 02:14
前天,有个同学加我微信来咨询我:
“老哥,我想抓取近期 5000 条新闻数据,但我是文科生,不会写代码,请问该怎么办?”
有问必答,对于这位同学的问题,我给安排上。
先说说获取数据的方式:一是利用现成的工具,我们只需懂得如何使用工具就能获取数据,不需要关心工具是怎么实现。打个比方,假如我们在岸上,要去海上某个小岛,岸边有一艘船,我们第一想法是选择坐船过去,而不会想着自己来造一艘船再过去。
第二种是自己针对场景需求做些定制化工具,这就需要有点编程基础。
举个例子,我们还是要到海上某个小岛,同时还要求在 30 分钟内将 1 顿货物送到岛上。
因此,前期只是单纯想获取数据,没有什么其他要求的话,优先选择现有工具。
可能是 Python 近来年很火,加上我们会经常看到别人用 Python 来制作网络爬虫抓取数据。从而有一些同学有这样的误区,想从网络上抓取数据就一定要学 Python,一定要去写代码。
其实不然,介绍几个能快速获取网上数据的工具。
1.Microsoft Excel
你没有看错,就是 Office 三剑客之一的 Excel。Excel 是一个强大的工具,能抓取数据就是它的功能之一。
我以耳机作为关键字,抓取京东的商品列表。
等待几秒后,Excel 会将页面上所有的文字信息抓取到表格中。这种方式确实能抓取到数据,但也会引入一些我们不需要的数据。如果你有更高的需求,可以选择后面几个工具。
2.优采云采集器
优采云是爬虫界的老品牌了,是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。
它的优势是采集不限网页,不限内容,同时还是分布式采集,效率会高一些。缺点是对小白用户不是很友好,有一定的知识门槛(了解如网页知识、HTTP 协议等方面知识),还需要花些时间熟悉工具操作。
因为有学习门槛,掌握该工具之后,采集数据上限会很高。有时间和精力的同学可以去折腾折腾。
官网地址:
3.优采云采集器
优采云采集器是一款非常适合新手的采集器。
它具有简单易用的特点,让你能几分钟中就快手上手。优采云提供一些常见抓取网站的模板,使用模板就能快速抓取数据。
如果想抓取没有模板的网站,官网也提供非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现可视化抓取数据,所以存在卡顿、采集数据慢的特点。但这瑕不掩瑜,能基本满足新手在短时间抓取数据的场景,比如翻页查询,Ajax 动态加载数据等。
网站:
4.GooSeeker 集搜客
集搜客也是一款容易上手的可视化采集数据工具。
同样能抓取动态网页,也支持可以抓取手机网站上的数据,还支持抓取在指数图表上悬浮显示的数据。
集搜客是以浏览器插件形式抓取数据。
虽然具有前面所述的优点,但缺点也有,无法多线程采集数据,出现浏览器卡顿也在所难免。
网站:
5.Scrapinghub
如果你想抓取国外的网站数据,可以考虑 Scrapinghub。
Scrapinghub 是一个基于Python 的 Scrapy 框架的云爬虫平台。
Scrapehub 算是市场上非常复杂和强大的网络抓取平台,提供数据抓取的解决方案商。
地址:
6.WebScraper
WebScraper 是一款优秀国外的浏览器插件。
同样也是一款适合新手抓取数据的可视化工具。
我们通过简单设置一些抓取规则,剩下的就交给浏览器去工作。
地址:
留言送书
活动介绍:今日赠书:《Python渗透测试编程技术:方法与实践》PS:最近当当做活动,满 100 减 50
今日留言主题
说说你对渗透测试的看法?
THANDKS- End - 查看全部
爬虫,我想再推荐 6 个工具
前天,有个同学加我微信来咨询我:
“老哥,我想抓取近期 5000 条新闻数据,但我是文科生,不会写代码,请问该怎么办?”
有问必答,对于这位同学的问题,我给安排上。
先说说获取数据的方式:一是利用现成的工具,我们只需懂得如何使用工具就能获取数据,不需要关心工具是怎么实现。打个比方,假如我们在岸上,要去海上某个小岛,岸边有一艘船,我们第一想法是选择坐船过去,而不会想着自己来造一艘船再过去。
第二种是自己针对场景需求做些定制化工具,这就需要有点编程基础。
举个例子,我们还是要到海上某个小岛,同时还要求在 30 分钟内将 1 顿货物送到岛上。
因此,前期只是单纯想获取数据,没有什么其他要求的话,优先选择现有工具。
可能是 Python 近来年很火,加上我们会经常看到别人用 Python 来制作网络爬虫抓取数据。从而有一些同学有这样的误区,想从网络上抓取数据就一定要学 Python,一定要去写代码。
其实不然,介绍几个能快速获取网上数据的工具。
1.Microsoft Excel
你没有看错,就是 Office 三剑客之一的 Excel。Excel 是一个强大的工具,能抓取数据就是它的功能之一。
我以耳机作为关键字,抓取京东的商品列表。
等待几秒后,Excel 会将页面上所有的文字信息抓取到表格中。这种方式确实能抓取到数据,但也会引入一些我们不需要的数据。如果你有更高的需求,可以选择后面几个工具。
2.优采云采集器
优采云是爬虫界的老品牌了,是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。
它的优势是采集不限网页,不限内容,同时还是分布式采集,效率会高一些。缺点是对小白用户不是很友好,有一定的知识门槛(了解如网页知识、HTTP 协议等方面知识),还需要花些时间熟悉工具操作。
因为有学习门槛,掌握该工具之后,采集数据上限会很高。有时间和精力的同学可以去折腾折腾。
官网地址:
3.优采云采集器
优采云采集器是一款非常适合新手的采集器。
它具有简单易用的特点,让你能几分钟中就快手上手。优采云提供一些常见抓取网站的模板,使用模板就能快速抓取数据。
如果想抓取没有模板的网站,官网也提供非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现可视化抓取数据,所以存在卡顿、采集数据慢的特点。但这瑕不掩瑜,能基本满足新手在短时间抓取数据的场景,比如翻页查询,Ajax 动态加载数据等。
网站:
4.GooSeeker 集搜客
集搜客也是一款容易上手的可视化采集数据工具。
同样能抓取动态网页,也支持可以抓取手机网站上的数据,还支持抓取在指数图表上悬浮显示的数据。
集搜客是以浏览器插件形式抓取数据。
虽然具有前面所述的优点,但缺点也有,无法多线程采集数据,出现浏览器卡顿也在所难免。
网站:
5.Scrapinghub
如果你想抓取国外的网站数据,可以考虑 Scrapinghub。
Scrapinghub 是一个基于Python 的 Scrapy 框架的云爬虫平台。
Scrapehub 算是市场上非常复杂和强大的网络抓取平台,提供数据抓取的解决方案商。
地址:
6.WebScraper
WebScraper 是一款优秀国外的浏览器插件。
同样也是一款适合新手抓取数据的可视化工具。
我们通过简单设置一些抓取规则,剩下的就交给浏览器去工作。
地址:
留言送书
活动介绍:今日赠书:《Python渗透测试编程技术:方法与实践》PS:最近当当做活动,满 100 减 50
今日留言主题
说说你对渗透测试的看法?
THANDKS- End -
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-05-18 10:30
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-05-15 17:55
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
社交网络分析工具大搜罗 | 来点方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-05-14 01:54
社交网络分析(Social Network Analysis)是指基于信息学、数学、社会学、管理学、心理学等多学科的融合理论和方法,为理解人类各种社交关系的形成、行为特点分析以及信息传播的规律提供的一种可计算的分析方法。人们对社交网络数据的挖掘和分析都还处于相对初级的阶段,大规模、高维度数据的挖掘方法还在不断地演化。目前来看,文本语言的情感分析等很多基础性问题仍然还不能得到有效解决,对深入研究社交网络造成了一些限制。
本期“来点方法”给大家介绍社交网络分析的工具,分为网页版工具、桌面版工具和数据获取三部分信息,每款工具的应用都是一次学习的过程,新学期,何不来点好玩的?
一
网页版工具1.微博风云榜地址:
微风云(原微博风云)是社会化新媒体营销第一数据平台,为用户提供权威的微博营销、微信营销第三方数据。
2.知微地址:
相比于微博风云榜,知微更专注微博的传播分析,普通版即支持转发小于1000的微博的传播分析。知微提供了传播分析全面的数据,包括传播路径图,转发层级,转发内容的词云,水军识别,地域分布……
知微的功能概要
3.北大PKUVIS微博可视分析工具地址:
北京大学 PKUVIS微博可视分析工具 (WeiboEvents) 是北京大学可视化与可视分析研究组开发的微博传播分析工具。它通过直观的视图清晰地呈现出一个事件中微博转发的过程,让您能够迅速地发现事件中的关键人物、关键微博、重要观点,同时通过可视化的方式帮助您更好地分析新浪微博中事件的发生与发展过程。
4. 独到地址:
独到科技是中国大数据行业的先行者和创新者,依托独创的分布式处理平台 D-Cluster,以及先进的自然语言处理技术和机器学习算法,为企业提供市场分析、舆情监控、品牌营销、广告效果监测、人群定位和渠道筛选等方面提供技术和产品支持。初级版免费。
二桌面版工具1.Gephi下载地址:
Gephi是一款开源免费跨平台基于JVM的复杂网络分析软件, 其主要用于各种网络和复杂系统,动态和分层图的交互可视化与探测开源工具。可用作:探索性数据分析,链接分析,社交网络分析,生物网络分析等。
中文版教程:/gephi
2. NodeXLNodeXL是一个免费、开源的插件,适用于Excel 2007 & 2010。NodeXL的主要功能是社交网络可视化,输入一张网络边(关系)的列表,点击一个按钮就可以看到你的关系图。功能介绍和操作视频:
NodeXL界面
3.IBM SPSS Modeler IBM SPSS Modeler是一个预测性分析平台,能够为个人、团队、系统和企业做决策提供预测性智能。它可提供各种高级算法和技术(包括文本分析、实体分析、决策管理与优化),帮助您选择可实现更佳成果的操作。
文本分析功能
三数据获取1. RweiboRweibo是一个新浪微博的R语言SDK,作为library在R环境中调用,对新浪微博提供的接口进行了实现(见新浪微博API),可以进行微博信息获取、用户信息获取、搜索、发表微博等操作。该应用通过OAuth的方式授权,使用者首先需要到新浪微博开放平台申请一个新的应用,获取App Key和App Secret,然后在R环境中按照提示注册一个应用,从而进行各项操作。2. sinaweibopy地址:
sinaweibopy是Python专用的支持新浪微博API的OAuth 2客户端,无依赖,100%纯Py,单个文件,代码简洁,运行可靠,也是新浪微博官方推荐的Python SDK
3.集搜客地址:
集搜客GooSeeker大数据软件开发始于2007年,2007年正是语义网络走向商用的时期,集搜客致力于提供一套便捷易用的软件,将网页内容进行语义标注和结构化转换。一旦有了语义结构,整个Web就变成了一个大数据库;一旦内容被赋予了意义(语义),就能从中挖掘出有价值的知识,集搜客创造了以下商业应用场景:
(1)集搜客网络爬虫不是一个简单的网页抓取器,她能够集众人之力把语义标签摘取下来
(2)每个语义标签代表大数据知识对象的一个维度,多维度整合,剖析此知识对象
(3)知识对象可以是多个层面的,比如:市场竞争、消费者洞察、品牌地图、企业画像 查看全部
社交网络分析工具大搜罗 | 来点方法
社交网络分析(Social Network Analysis)是指基于信息学、数学、社会学、管理学、心理学等多学科的融合理论和方法,为理解人类各种社交关系的形成、行为特点分析以及信息传播的规律提供的一种可计算的分析方法。人们对社交网络数据的挖掘和分析都还处于相对初级的阶段,大规模、高维度数据的挖掘方法还在不断地演化。目前来看,文本语言的情感分析等很多基础性问题仍然还不能得到有效解决,对深入研究社交网络造成了一些限制。
本期“来点方法”给大家介绍社交网络分析的工具,分为网页版工具、桌面版工具和数据获取三部分信息,每款工具的应用都是一次学习的过程,新学期,何不来点好玩的?
一
网页版工具1.微博风云榜地址:
微风云(原微博风云)是社会化新媒体营销第一数据平台,为用户提供权威的微博营销、微信营销第三方数据。
2.知微地址:
相比于微博风云榜,知微更专注微博的传播分析,普通版即支持转发小于1000的微博的传播分析。知微提供了传播分析全面的数据,包括传播路径图,转发层级,转发内容的词云,水军识别,地域分布……
知微的功能概要
3.北大PKUVIS微博可视分析工具地址:
北京大学 PKUVIS微博可视分析工具 (WeiboEvents) 是北京大学可视化与可视分析研究组开发的微博传播分析工具。它通过直观的视图清晰地呈现出一个事件中微博转发的过程,让您能够迅速地发现事件中的关键人物、关键微博、重要观点,同时通过可视化的方式帮助您更好地分析新浪微博中事件的发生与发展过程。
4. 独到地址:
独到科技是中国大数据行业的先行者和创新者,依托独创的分布式处理平台 D-Cluster,以及先进的自然语言处理技术和机器学习算法,为企业提供市场分析、舆情监控、品牌营销、广告效果监测、人群定位和渠道筛选等方面提供技术和产品支持。初级版免费。
二桌面版工具1.Gephi下载地址:
Gephi是一款开源免费跨平台基于JVM的复杂网络分析软件, 其主要用于各种网络和复杂系统,动态和分层图的交互可视化与探测开源工具。可用作:探索性数据分析,链接分析,社交网络分析,生物网络分析等。
中文版教程:/gephi
2. NodeXLNodeXL是一个免费、开源的插件,适用于Excel 2007 & 2010。NodeXL的主要功能是社交网络可视化,输入一张网络边(关系)的列表,点击一个按钮就可以看到你的关系图。功能介绍和操作视频:
NodeXL界面
3.IBM SPSS Modeler IBM SPSS Modeler是一个预测性分析平台,能够为个人、团队、系统和企业做决策提供预测性智能。它可提供各种高级算法和技术(包括文本分析、实体分析、决策管理与优化),帮助您选择可实现更佳成果的操作。
文本分析功能
三数据获取1. RweiboRweibo是一个新浪微博的R语言SDK,作为library在R环境中调用,对新浪微博提供的接口进行了实现(见新浪微博API),可以进行微博信息获取、用户信息获取、搜索、发表微博等操作。该应用通过OAuth的方式授权,使用者首先需要到新浪微博开放平台申请一个新的应用,获取App Key和App Secret,然后在R环境中按照提示注册一个应用,从而进行各项操作。2. sinaweibopy地址:
sinaweibopy是Python专用的支持新浪微博API的OAuth 2客户端,无依赖,100%纯Py,单个文件,代码简洁,运行可靠,也是新浪微博官方推荐的Python SDK
3.集搜客地址:
集搜客GooSeeker大数据软件开发始于2007年,2007年正是语义网络走向商用的时期,集搜客致力于提供一套便捷易用的软件,将网页内容进行语义标注和结构化转换。一旦有了语义结构,整个Web就变成了一个大数据库;一旦内容被赋予了意义(语义),就能从中挖掘出有价值的知识,集搜客创造了以下商业应用场景:
(1)集搜客网络爬虫不是一个简单的网页抓取器,她能够集众人之力把语义标签摘取下来
(2)每个语义标签代表大数据知识对象的一个维度,多维度整合,剖析此知识对象
(3)知识对象可以是多个层面的,比如:市场竞争、消费者洞察、品牌地图、企业画像
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-13 16:52
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
数据获取与预处理 | 集搜客Gooseeker的简单介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 799 次浏览 • 2022-05-13 07:04
SYH | 是野火
1.3 Gooseeker-数据爬取软件基础操作
1. 爬虫程序/软件
爬虫软件:集搜客Gooseeker、优采云、网络矿工、优采云、优采云平台……
爬虫程序:Java、Python、R、C#、PHP……
2.爬虫软件——集搜客Gooseeker
√ 支持windows/mac/linux三种操作系统,全功能开发
√ 由服务器和客户端两部分组成。服务其是用来存储规则和线索(待抓网址),MS谋数台是用来制作网页抓取规则的,DS打数机是用来采集网页数据的。
① 采用数据最简单的方式——直观标注
将网页在MS谋数台中打开,直接在网页上将想要抓取的内容进行标注,即可将数据采集下来。
② DOM标注
在DOM窗口中可以进行更精准的内容映射,及用@class和@id进行定位标志映射。
整理自沈浩教授《媒体大数据挖掘与实战案例》
这是我的个人公众号 查看全部
数据获取与预处理 | 集搜客Gooseeker的简单介绍
SYH | 是野火
1.3 Gooseeker-数据爬取软件基础操作
1. 爬虫程序/软件
爬虫软件:集搜客Gooseeker、优采云、网络矿工、优采云、优采云平台……
爬虫程序:Java、Python、R、C#、PHP……
2.爬虫软件——集搜客Gooseeker
√ 支持windows/mac/linux三种操作系统,全功能开发
√ 由服务器和客户端两部分组成。服务其是用来存储规则和线索(待抓网址),MS谋数台是用来制作网页抓取规则的,DS打数机是用来采集网页数据的。
① 采用数据最简单的方式——直观标注
将网页在MS谋数台中打开,直接在网页上将想要抓取的内容进行标注,即可将数据采集下来。
② DOM标注
在DOM窗口中可以进行更精准的内容映射,及用@class和@id进行定位标志映射。
整理自沈浩教授《媒体大数据挖掘与实战案例》
这是我的个人公众号
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-05-13 06:49
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
市场研究 | 工具06—介绍爬虫软件工具gooseeker
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-05-09 17:53
今天给大家介绍一款网络爬虫工具:Gooseeker,中文:集搜客
网络爬虫(Web Crawler),又称为网络蜘蛛(Web Spider)或 Web 信息采集器,是一个自动下载网页的计算机程序或自动化脚本,是搜索引擎的重要组成部分。网络爬虫通常从一个称为种子集的 URL集合开始运行,它首先将这些URL 全部放入到一个有序的待爬行队列里,按照一定的顺序从中取出 URL 并下载所指向的页面,分析页面内容,提取新的 URL 并存入待爬行 URL 队列中,如此重复上面的过程,直到 URL 队列为空或满足某个爬行终止条件,从而遍历 Web。
该过程称为网络爬行(Web Crawling)。
集搜客(gooseeker)是一款不需要编程比较容易学习的爬虫工具
下载地址:
这款属于爬虫软件,主要是在火狐狸Foxfire浏览器内运行,总体算来这个还是功能很强大的,包括爬微博数据。
集搜客网络爬虫支持windows/mac/linux三种操作系统,全功能开发,不断优化更新软件版本。
集搜客网络爬虫是由服务器和客户端两部分组成,服务器是用来存储规则和线索(待抓网址),MS谋数台是用来制作网页抓取规则的,DS打数机是用来采集网页数据。
数据采集还有一种方法是API接口使用。
当然需要更灵活和更复杂的爬虫,最好是爬虫程序,一般是Python的Scrapy爬虫框架更好!以后介绍
沈浩老师
——————中国传媒大学新闻学院教授、博士生导师中国传媒大学调查统计研究所所长
大数据挖掘与社会计算实验室主任
中国市场研究行业协会会长
欢迎关注沈浩老师的微信公共号
欢迎关注俺任会长的市场研究协会:
查看全部
市场研究 | 工具06—介绍爬虫软件工具gooseeker
今天给大家介绍一款网络爬虫工具:Gooseeker,中文:集搜客
网络爬虫(Web Crawler),又称为网络蜘蛛(Web Spider)或 Web 信息采集器,是一个自动下载网页的计算机程序或自动化脚本,是搜索引擎的重要组成部分。网络爬虫通常从一个称为种子集的 URL集合开始运行,它首先将这些URL 全部放入到一个有序的待爬行队列里,按照一定的顺序从中取出 URL 并下载所指向的页面,分析页面内容,提取新的 URL 并存入待爬行 URL 队列中,如此重复上面的过程,直到 URL 队列为空或满足某个爬行终止条件,从而遍历 Web。
该过程称为网络爬行(Web Crawling)。
集搜客(gooseeker)是一款不需要编程比较容易学习的爬虫工具
下载地址:
这款属于爬虫软件,主要是在火狐狸Foxfire浏览器内运行,总体算来这个还是功能很强大的,包括爬微博数据。
集搜客网络爬虫支持windows/mac/linux三种操作系统,全功能开发,不断优化更新软件版本。
集搜客网络爬虫是由服务器和客户端两部分组成,服务器是用来存储规则和线索(待抓网址),MS谋数台是用来制作网页抓取规则的,DS打数机是用来采集网页数据。
数据采集还有一种方法是API接口使用。
当然需要更灵活和更复杂的爬虫,最好是爬虫程序,一般是Python的Scrapy爬虫框架更好!以后介绍
沈浩老师
——————中国传媒大学新闻学院教授、博士生导师中国传媒大学调查统计研究所所长
大数据挖掘与社会计算实验室主任
中国市场研究行业协会会长
欢迎关注沈浩老师的微信公共号
欢迎关注俺任会长的市场研究协会:
集搜客网页抓取软件(1.360用户安装和使用集搜客攻略图所示:1.3原因分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-20 11:15
)
近日,极速客技术支持中心收到了部分360安全卫士用户的反馈。在安装和使用极速客的过程中,我们遇到了一些由于360导致的误报,比如服务器连接失败、个别文件被删除、安装过程中不断出现360警告信息等问题。这些问题一直困扰着部分用户,影响了他们正常的数据采集。本文给出了应对措施,并附上Jisouke上第三方检测机构的检测报告。
1.360用户安装使用jisoke策略1.1 安装过程中的警告信息
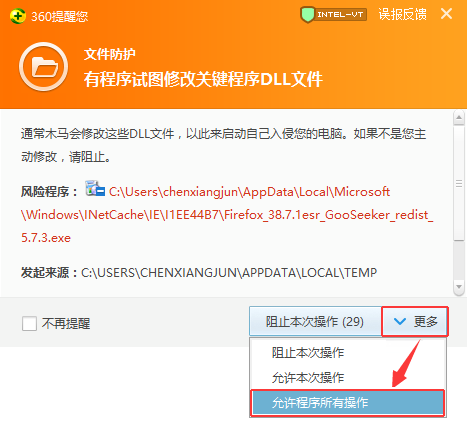
如下所示:
当出现此警告信息时,请点击“更多”下的“允许该程序的所有操作”,如下图:
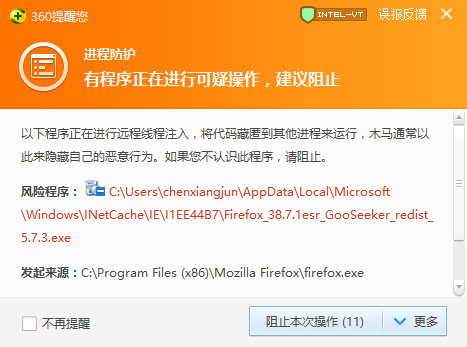
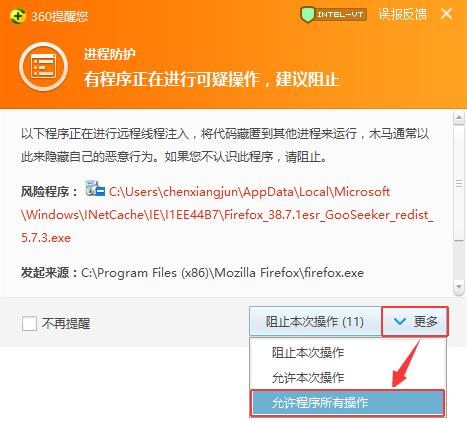
1.2 使用 Firefox 浏览器或使用 MS/DS 计算机时,会出现警告消息
如下所示:
当出现此警告信息时,请点击“更多”下的“允许该程序的所有操作”,如下图:
1.3 原因分析
以下分析基于我们长期的观察(因为观察到的对象没有公开的算法):由于360安全卫士默认开启了云网页检测,在抓取数据时,会出现大量抓取的网页或者其他特性可能会被发送到360进行检测,也可能会导致本地360软件过载,从而影响整个计算机资源的过度消耗。因此,建议在采集数据时,可以
2. 第三方测试
经第三方机构使用国内外数十种病毒检测引擎识别,Jisouke GooSeeker是一款安全无毒的软件,以下为测试报告(原报告可通过查看)
查看全部
集搜客网页抓取软件(1.360用户安装和使用集搜客攻略图所示:1.3原因分析
)
近日,极速客技术支持中心收到了部分360安全卫士用户的反馈。在安装和使用极速客的过程中,我们遇到了一些由于360导致的误报,比如服务器连接失败、个别文件被删除、安装过程中不断出现360警告信息等问题。这些问题一直困扰着部分用户,影响了他们正常的数据采集。本文给出了应对措施,并附上Jisouke上第三方检测机构的检测报告。
1.360用户安装使用jisoke策略1.1 安装过程中的警告信息
如下所示:
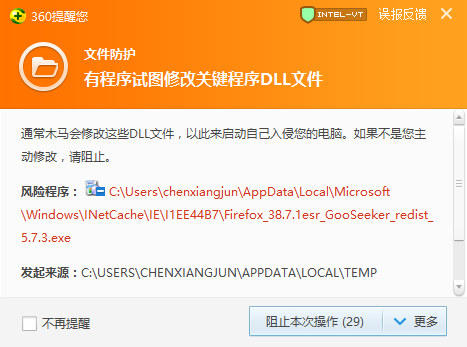
当出现此警告信息时,请点击“更多”下的“允许该程序的所有操作”,如下图:
1.2 使用 Firefox 浏览器或使用 MS/DS 计算机时,会出现警告消息
如下所示:
当出现此警告信息时,请点击“更多”下的“允许该程序的所有操作”,如下图:
1.3 原因分析
以下分析基于我们长期的观察(因为观察到的对象没有公开的算法):由于360安全卫士默认开启了云网页检测,在抓取数据时,会出现大量抓取的网页或者其他特性可能会被发送到360进行检测,也可能会导致本地360软件过载,从而影响整个计算机资源的过度消耗。因此,建议在采集数据时,可以
2. 第三方测试
经第三方机构使用国内外数十种病毒检测引擎识别,Jisouke GooSeeker是一款安全无毒的软件,以下为测试报告(原报告可通过查看)
集搜客网页抓取软件(KumquatHandle拥有IE浏即时监听和本地缓存查找、缓存清理于一身,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-04-19 05:37
【概述】
完全免费的绿色软件
【基本介绍】
KumquatHandle是一款完全免费的绿色软件,集IE缓存监控、本地缓存搜索、缓存清理于一体。是您监控、提取IE缓存文件、分析网页文件来源的最佳助手。
平时使用IE浏览器浏览网页时,可能会在网页上遇到一些好看的小视频、预览音乐、图片等。如果你想保存到本地却找不到提供的下载地址,那就试试KumquatHandle吧!
KumquatHandle 有 IE 浏览器 [概览]
完全免费的绿色软件
【基本介绍】
KumquatHandle是一款完全免费的绿色软件,集IE缓存监控、本地缓存搜索、缓存清理于一体。是您监控、提取IE缓存文件、分析网页文件来源的最佳助手。
平时使用IE浏览器浏览网页时,可能会在网页上遇到一些好看的小视频、预览音乐、图片等。如果你想保存到本地却找不到提供的下载地址,那就试试KumquatHandle吧!
KumquatHandle 具有强大的 IE 浏览器缓存实时监控和本地缓存查找功能。可即时监控IE浏览器缓存的最新动态,视频、音乐、图片……不容错过!KumquatHandle 允许您轻松地从缓存中提取数据。文件下载。
【更新日志】
KumquatHandle - Orange Rod IE 缓存分析 V1.0.0
修改软件下载地址,修改软件描述。 查看全部
集搜客网页抓取软件(KumquatHandle拥有IE浏即时监听和本地缓存查找、缓存清理于一身,)
【概述】
完全免费的绿色软件
【基本介绍】
KumquatHandle是一款完全免费的绿色软件,集IE缓存监控、本地缓存搜索、缓存清理于一体。是您监控、提取IE缓存文件、分析网页文件来源的最佳助手。
平时使用IE浏览器浏览网页时,可能会在网页上遇到一些好看的小视频、预览音乐、图片等。如果你想保存到本地却找不到提供的下载地址,那就试试KumquatHandle吧!
KumquatHandle 有 IE 浏览器 [概览]
完全免费的绿色软件
【基本介绍】
KumquatHandle是一款完全免费的绿色软件,集IE缓存监控、本地缓存搜索、缓存清理于一体。是您监控、提取IE缓存文件、分析网页文件来源的最佳助手。
平时使用IE浏览器浏览网页时,可能会在网页上遇到一些好看的小视频、预览音乐、图片等。如果你想保存到本地却找不到提供的下载地址,那就试试KumquatHandle吧!
KumquatHandle 具有强大的 IE 浏览器缓存实时监控和本地缓存查找功能。可即时监控IE浏览器缓存的最新动态,视频、音乐、图片……不容错过!KumquatHandle 允许您轻松地从缓存中提取数据。文件下载。
【更新日志】
KumquatHandle - Orange Rod IE 缓存分析 V1.0.0
修改软件下载地址,修改软件描述。
集搜客网页抓取软件(import.io:大数据采集软件集搜客GooSeeker对比说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-04-18 02:03
可视化数据采集器import.io与吉索客评测对比 最近国外一款大数据采集软件import.io比较火。在获得90万美元天使轮融资后,近日又获得了1300万美元的A轮融资,引起了众多投资者的关注。笔者也很好奇使用和体验import.io的神奇功能。我是中国大数据采集软件合集GooSeeker的老用户。,所以我喜欢将两者放在一起比较。下面,我将比较和解释最令人印象深刻的功能,对应于import.io的四大特性:Magic、Extractor、Crawler、Connector,并分别进行评估。对数据比较感兴趣的采集,希望能起到吸点新意的作用,一起来分析一下data采集的技术亮点。魔法——就像魔法“魔法”这个词的本义一样,import.io 赋予了魔法一个神奇的功能。只要用户输入 URL,Magic 工具就可以神奇的将网页中的数据整齐、标准地抓取。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。Magic 工具可以神奇地整齐、标准地捕捉网页中的数据。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。Magic 工具可以神奇地整齐、标准地捕捉网页中的数据。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。
当然,还有很多页面几乎没有采集可以下载,比如新浪微博。反正我觉得很神奇:有的网址输入后等待时间短,有的网址输入后等待时间长。真的有人在后台执行 采集 规则吗?图1:Magic自动抓包示例总结:优点:适应任意URL,操作非常简单,自动采集、采集结果可视化。缺点:不能选择具体数据,不能自动翻页采集(没用吗?)。GooSeeker的天眼和千面系列——吉搜客的天眼和千面分别是针对电商和微博发布的数据采集方便的GUI界面,只要输入网址,目标数据可以规范整齐采集 @采集下来。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。微博各种数据的管理接口),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息为采集,如微博内容、转发、评论等数据. 图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。微博各种数据的管理接口),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息为采集,如微博内容、转发、评论等数据. 图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。
优点:操作非常简单,可以自动翻页采集,微博上能看到的重要字段都采集了。缺点:采集数据字段有限,只有采集GooSeeker官方限定网站。从上面的分析可以看出,Magic GooSeeker的天眼和千面操作非常简单,基本上都是纯傻瓜式操作,非常适合只想关注业务问题而不关注业务问题的用户想被技术问题分心。,也是纯白学习数据采集和使用数据结果的一个很好的起点。但是,Magic 在采集 的结果可视化方面比天眼和千眼具有更广泛的适用性。缺点是 采集 数据量大的场景不可控,而天眼和千面则专注于几个主流网站,优势主要体现在能够完成大量数据采集,比如专业市场研究或消费者研究团队需要数百万或数千万的数据,只要你运行足够多的网络爬虫,不会因为采集的数量而阻碍你的数据研究。Extractor (import.io) VS 排序框(collector) Extractor—— Extractor 翻译的时候是个提取器。如果从一个实体的角度来理解,它就是一个从网站中逐一提取想要的信息的小程序(可能是一组脚本);如果按照采集targets 来理解,它是特定网页结构的采集规则。
如图:import.io 的Extractor 很像修改后的浏览器。在工具栏中输入 URL。网页显示出来后,在浏览器中选择要抓取的数据,然后单页就可以用相同的结构进行结构化了。整列数据可以采集 向下排序。图3:Extractor提取数据示例优点:灵活采集,操作简单,可视化程度高。缺点:采集数据的结构化程度很高,对于结构化程度较差的数据,采集不能很好的表现。GooSeeker Organizer - Jisouke 声称是“构建一个盒子并将你想要的内容放入其中”。这个盒子就是所谓的组织者。原理是将需要提取的信息一个一个拖入框内并映射到该框整理好后,吉索克程序可以自动生成提取器(脚本程序),提取器自动存储在云服务器,可以分发给世界各地的网络爬虫进行提取。如图4所示,import.io顶部的一个工具栏在GooSeeker中展开成一个工作台,在工作台上创建一个盒子,然后通过映射操作将网页上的内容扔到盒子里。把你想要的东西扔进盒子里。原理看似简单,但面对大盒子界面和众多HTML节点,对于新手来说有点压力。当然,界面复杂换来的是能够处理更复杂的情况,因为有更多可用的控件。图4:从排序框中提取数据示例优点:提取精度可以微调,提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。
Crawler (import.io) VS Crawler Route (GooSeeker) Crawler—— Crawler 字面意思是网络爬虫。顾名思义,就是在深度和广度上进行扩展,以便采集更多的数据。Crawler在Extractor的基础上实现了自动翻页功能。假设你想要采集网页数据有100个页面,import.io的爬虫采集可以一键下载这100个页面的信息,那么具体的采集流程是什么?为了实现,笔者带大家简单了解一下爬虫的采集流程。如图5所示,以同城58的租房信息为例,搜索关键词后,一共找到N页租房信息,以提取这些租房信息。爬虫的操作如下:(1)
图 6:爬虫添加页面示例 图 7:爬虫训练样本完成 Import.io 的爬虫训练过程 操作非常简单易懂。只需要选择几个结构相同的页面进行测试,相当于告诉爬虫,我就是采集这些相似页面的信息。爬虫理解了这些需求后,就可以下载相同结构采集的信息了,但是也会有一些小问题,当有些字段是细微变化的时候,因为和需要的数据不同在之前的训练中是采集,这个信息会被漏掉,所以Crawler比较适合结构很固定的页面。总结一下:优点:灵活采集,操作简单,采集 流程可视化缺点:继承Extractor的缺点,对数据结构要求高。GooSeeker爬虫路线 - 吉索克的爬虫路线的实现是基于排序框的。原理与Crawler基本相同。类似,但适应性更强,具有操作相对复杂的负面影响。让我们首先回顾一下组织盒子的概念。GooSeeker一直声称是“打造一个盒子,把你需要的内容放进去”。这个概念非常简单。您可以直观地选择所需的 Web 内容并将其存储在一个盒子中。如图8所示,以采集京东手机信息为例,如果要采集手机信息数据的所有页面,操作如下: 创建一个排序框,
不过操作可不是这句话那么简单,而是:在排序框中创建字段,这些字段称为“爬取内容”,也就是网页上的内容要扔到这些字段中,在DOM上选择tree to 将捕获的节点映射到一个字段。既然它说“建立一个盒子并放入你需要的东西”,你为什么不真的在视觉上这样做呢?这个地方需要改进,敬请期待即将到来的新版本中提供的直观注释功能。(2)构造爬虫路线,将“下一页”映射为标记线索(如图8),设置完成后,保存后可自动获取所有页面的信息采集@ >. 这个虽然过程说起来简单,但是操作起来相比Crawer还是有点不直观。它需要做几个简单的映射,即告诉爬虫:“这里是我要点击的”、“这里是我要提取的”,如下图,主要操作是针对数字做的对于 HTML DOM,用户最好有一个简单的 HTML 基础,这样 DOM 节点就可以准确定位,而不仅限于可见文本。图 8:履带式转弯原理页面示例优势:采集精度高,应用范围广。缺点:可视化效果一般,需要学习练习才能上手。综上所述,Import.io的Crawler和GooSeeker的爬虫路由主要完成了网络爬虫的爬取范围和深度的扩展上面的任务,我们只以翻页为例,
爬虫的操作比较简单,但适应性也比较窄,对网站的结构一致性要求比较高,而爬虫路由的功能相对比较强大,可以适应各种复杂的网站,但操作也比较复杂。连接器(import.io) VS 连续点击(采集客户) 连接器—— import.io 连接器是在网页上做动作,主要是为了URL不变,但信息在深层页面. 需要做完才可以显示,但是页面的url没有变化,大大增加了采集数据的难度,因为即使配置了规则,爬虫进入的页面也是初始的页面,不能是 采集 @采集 来定位信息,而连接器的存在就是为了解决这些问题。Connector可以记录这个点击过程,然后给目标页面的信采集也以58同城租房信息为例来测试Connector功能的可操作性。(1)点击可以找到你需要的信息采集所在的页面。如图所示,Connector可以记录用户每次的点击行为。 图9:Connector示例operation (2) 在目标页面建立规则并提取信息。到达目标页面后,需要做的操作和前面一样,提取需要的信息采集@ >.通过动手实践发现,连续点击的失败率比较高,如果是搜索,
如果可能的话,读者可以自己尝试一下,看看究竟是什么原因造成的。有没有似曾相识的感觉?没错,它有点像网络测试工具。它记录动作并回放它们。用户体验非常好。录制有时会失败。似乎有一些代价。估计还是定位不准的问题。当你用Later进行录制时,当网页的HTML DOM稍有变化时,动作可能会做错地方。优点:操作简单,采集过程完全可视化。缺点:点击动作最多只能点击10次,功能比较单一。同时,从使用情况来看,连接器录音功能的故障率很高,很多情况下运行失败,这可能是直观可视化的代价。GooSeeker 连续点击 - GooSeeker 连续点击的功能和它的名字完全一样。实现点击和采集的功能,结合爬虫路由,可以产生更强大的采集效果。这是一个比较高级的收客功能,会产生很多意想不到的采集方式,这里简单举例。如图10所示,到采集微博个人相关信息,因为这些数据必须通过将鼠标放在人物头像上来显示,都需要使用吉索客的连续点击功能。操作如下:采集目标字段,先定位网页,采集字段为采集,方法同上,不再赘述。
不像直观的录制那么简单,需要点击“创建”按钮,创建一个动作,指定点击的位置(一个web节点,用xpath表示),指定什么样的动作,根据需要设置一些高级选项. 如图 11 所示,GooSeeker 也相当于记录了一组动作,也可以重新排序或添加或删除。从图11中可以看出,类似录制过程的界面并没有那么亲民。再次看到 GooSeeker 的特点: 严谨的制作工具 图 10:连续点击操作示例 图 11:连续动作的排列界面 优点:功能强大,采集强大。缺点:上手比较困难,操作比较复杂。总而言之,进口。io Connector在操作上依然坚持一贯的风格,简单易用,Jisouke也再次给人“生产工具”的感觉。在连续动作的功能上,两者基本一致。通过以上对比,相信大家对大数据采集软件import.io的概念有了一定的了解。从各种功能的对比来看,特点主要体现在可视化、易学、操作简单。致力于打造纯傻瓜式操作的采集软件。集搜客的特点主要体现在半可视化、功能齐全、采集能力强,致力于为用户提供完整强大的数据采集功能。总之,两者各有千秋,两者都是非常好的数据采集软件。最后,有兴趣的读者可以去深入体验和研究一下,因为两者所宣称的价值,其实不仅仅是一个软件工具,而是“将互联网数据结构化转换,把网络变成所有人的数据库”的目标。希望以后有机会分享这种经验。 查看全部
集搜客网页抓取软件(import.io:大数据采集软件集搜客GooSeeker对比说明)
可视化数据采集器import.io与吉索客评测对比 最近国外一款大数据采集软件import.io比较火。在获得90万美元天使轮融资后,近日又获得了1300万美元的A轮融资,引起了众多投资者的关注。笔者也很好奇使用和体验import.io的神奇功能。我是中国大数据采集软件合集GooSeeker的老用户。,所以我喜欢将两者放在一起比较。下面,我将比较和解释最令人印象深刻的功能,对应于import.io的四大特性:Magic、Extractor、Crawler、Connector,并分别进行评估。对数据比较感兴趣的采集,希望能起到吸点新意的作用,一起来分析一下data采集的技术亮点。魔法——就像魔法“魔法”这个词的本义一样,import.io 赋予了魔法一个神奇的功能。只要用户输入 URL,Magic 工具就可以神奇的将网页中的数据整齐、标准地抓取。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。Magic 工具可以神奇地整齐、标准地捕捉网页中的数据。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。Magic 工具可以神奇地整齐、标准地捕捉网页中的数据。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。
当然,还有很多页面几乎没有采集可以下载,比如新浪微博。反正我觉得很神奇:有的网址输入后等待时间短,有的网址输入后等待时间长。真的有人在后台执行 采集 规则吗?图1:Magic自动抓包示例总结:优点:适应任意URL,操作非常简单,自动采集、采集结果可视化。缺点:不能选择具体数据,不能自动翻页采集(没用吗?)。GooSeeker的天眼和千面系列——吉搜客的天眼和千面分别是针对电商和微博发布的数据采集方便的GUI界面,只要输入网址,目标数据可以规范整齐采集 @采集下来。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。微博各种数据的管理接口),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息为采集,如微博内容、转发、评论等数据. 图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。微博各种数据的管理接口),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息为采集,如微博内容、转发、评论等数据. 图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。
优点:操作非常简单,可以自动翻页采集,微博上能看到的重要字段都采集了。缺点:采集数据字段有限,只有采集GooSeeker官方限定网站。从上面的分析可以看出,Magic GooSeeker的天眼和千面操作非常简单,基本上都是纯傻瓜式操作,非常适合只想关注业务问题而不关注业务问题的用户想被技术问题分心。,也是纯白学习数据采集和使用数据结果的一个很好的起点。但是,Magic 在采集 的结果可视化方面比天眼和千眼具有更广泛的适用性。缺点是 采集 数据量大的场景不可控,而天眼和千面则专注于几个主流网站,优势主要体现在能够完成大量数据采集,比如专业市场研究或消费者研究团队需要数百万或数千万的数据,只要你运行足够多的网络爬虫,不会因为采集的数量而阻碍你的数据研究。Extractor (import.io) VS 排序框(collector) Extractor—— Extractor 翻译的时候是个提取器。如果从一个实体的角度来理解,它就是一个从网站中逐一提取想要的信息的小程序(可能是一组脚本);如果按照采集targets 来理解,它是特定网页结构的采集规则。
如图:import.io 的Extractor 很像修改后的浏览器。在工具栏中输入 URL。网页显示出来后,在浏览器中选择要抓取的数据,然后单页就可以用相同的结构进行结构化了。整列数据可以采集 向下排序。图3:Extractor提取数据示例优点:灵活采集,操作简单,可视化程度高。缺点:采集数据的结构化程度很高,对于结构化程度较差的数据,采集不能很好的表现。GooSeeker Organizer - Jisouke 声称是“构建一个盒子并将你想要的内容放入其中”。这个盒子就是所谓的组织者。原理是将需要提取的信息一个一个拖入框内并映射到该框整理好后,吉索克程序可以自动生成提取器(脚本程序),提取器自动存储在云服务器,可以分发给世界各地的网络爬虫进行提取。如图4所示,import.io顶部的一个工具栏在GooSeeker中展开成一个工作台,在工作台上创建一个盒子,然后通过映射操作将网页上的内容扔到盒子里。把你想要的东西扔进盒子里。原理看似简单,但面对大盒子界面和众多HTML节点,对于新手来说有点压力。当然,界面复杂换来的是能够处理更复杂的情况,因为有更多可用的控件。图4:从排序框中提取数据示例优点:提取精度可以微调,提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。
Crawler (import.io) VS Crawler Route (GooSeeker) Crawler—— Crawler 字面意思是网络爬虫。顾名思义,就是在深度和广度上进行扩展,以便采集更多的数据。Crawler在Extractor的基础上实现了自动翻页功能。假设你想要采集网页数据有100个页面,import.io的爬虫采集可以一键下载这100个页面的信息,那么具体的采集流程是什么?为了实现,笔者带大家简单了解一下爬虫的采集流程。如图5所示,以同城58的租房信息为例,搜索关键词后,一共找到N页租房信息,以提取这些租房信息。爬虫的操作如下:(1)
图 6:爬虫添加页面示例 图 7:爬虫训练样本完成 Import.io 的爬虫训练过程 操作非常简单易懂。只需要选择几个结构相同的页面进行测试,相当于告诉爬虫,我就是采集这些相似页面的信息。爬虫理解了这些需求后,就可以下载相同结构采集的信息了,但是也会有一些小问题,当有些字段是细微变化的时候,因为和需要的数据不同在之前的训练中是采集,这个信息会被漏掉,所以Crawler比较适合结构很固定的页面。总结一下:优点:灵活采集,操作简单,采集 流程可视化缺点:继承Extractor的缺点,对数据结构要求高。GooSeeker爬虫路线 - 吉索克的爬虫路线的实现是基于排序框的。原理与Crawler基本相同。类似,但适应性更强,具有操作相对复杂的负面影响。让我们首先回顾一下组织盒子的概念。GooSeeker一直声称是“打造一个盒子,把你需要的内容放进去”。这个概念非常简单。您可以直观地选择所需的 Web 内容并将其存储在一个盒子中。如图8所示,以采集京东手机信息为例,如果要采集手机信息数据的所有页面,操作如下: 创建一个排序框,
不过操作可不是这句话那么简单,而是:在排序框中创建字段,这些字段称为“爬取内容”,也就是网页上的内容要扔到这些字段中,在DOM上选择tree to 将捕获的节点映射到一个字段。既然它说“建立一个盒子并放入你需要的东西”,你为什么不真的在视觉上这样做呢?这个地方需要改进,敬请期待即将到来的新版本中提供的直观注释功能。(2)构造爬虫路线,将“下一页”映射为标记线索(如图8),设置完成后,保存后可自动获取所有页面的信息采集@ >. 这个虽然过程说起来简单,但是操作起来相比Crawer还是有点不直观。它需要做几个简单的映射,即告诉爬虫:“这里是我要点击的”、“这里是我要提取的”,如下图,主要操作是针对数字做的对于 HTML DOM,用户最好有一个简单的 HTML 基础,这样 DOM 节点就可以准确定位,而不仅限于可见文本。图 8:履带式转弯原理页面示例优势:采集精度高,应用范围广。缺点:可视化效果一般,需要学习练习才能上手。综上所述,Import.io的Crawler和GooSeeker的爬虫路由主要完成了网络爬虫的爬取范围和深度的扩展上面的任务,我们只以翻页为例,
爬虫的操作比较简单,但适应性也比较窄,对网站的结构一致性要求比较高,而爬虫路由的功能相对比较强大,可以适应各种复杂的网站,但操作也比较复杂。连接器(import.io) VS 连续点击(采集客户) 连接器—— import.io 连接器是在网页上做动作,主要是为了URL不变,但信息在深层页面. 需要做完才可以显示,但是页面的url没有变化,大大增加了采集数据的难度,因为即使配置了规则,爬虫进入的页面也是初始的页面,不能是 采集 @采集 来定位信息,而连接器的存在就是为了解决这些问题。Connector可以记录这个点击过程,然后给目标页面的信采集也以58同城租房信息为例来测试Connector功能的可操作性。(1)点击可以找到你需要的信息采集所在的页面。如图所示,Connector可以记录用户每次的点击行为。 图9:Connector示例operation (2) 在目标页面建立规则并提取信息。到达目标页面后,需要做的操作和前面一样,提取需要的信息采集@ >.通过动手实践发现,连续点击的失败率比较高,如果是搜索,
如果可能的话,读者可以自己尝试一下,看看究竟是什么原因造成的。有没有似曾相识的感觉?没错,它有点像网络测试工具。它记录动作并回放它们。用户体验非常好。录制有时会失败。似乎有一些代价。估计还是定位不准的问题。当你用Later进行录制时,当网页的HTML DOM稍有变化时,动作可能会做错地方。优点:操作简单,采集过程完全可视化。缺点:点击动作最多只能点击10次,功能比较单一。同时,从使用情况来看,连接器录音功能的故障率很高,很多情况下运行失败,这可能是直观可视化的代价。GooSeeker 连续点击 - GooSeeker 连续点击的功能和它的名字完全一样。实现点击和采集的功能,结合爬虫路由,可以产生更强大的采集效果。这是一个比较高级的收客功能,会产生很多意想不到的采集方式,这里简单举例。如图10所示,到采集微博个人相关信息,因为这些数据必须通过将鼠标放在人物头像上来显示,都需要使用吉索客的连续点击功能。操作如下:采集目标字段,先定位网页,采集字段为采集,方法同上,不再赘述。
不像直观的录制那么简单,需要点击“创建”按钮,创建一个动作,指定点击的位置(一个web节点,用xpath表示),指定什么样的动作,根据需要设置一些高级选项. 如图 11 所示,GooSeeker 也相当于记录了一组动作,也可以重新排序或添加或删除。从图11中可以看出,类似录制过程的界面并没有那么亲民。再次看到 GooSeeker 的特点: 严谨的制作工具 图 10:连续点击操作示例 图 11:连续动作的排列界面 优点:功能强大,采集强大。缺点:上手比较困难,操作比较复杂。总而言之,进口。io Connector在操作上依然坚持一贯的风格,简单易用,Jisouke也再次给人“生产工具”的感觉。在连续动作的功能上,两者基本一致。通过以上对比,相信大家对大数据采集软件import.io的概念有了一定的了解。从各种功能的对比来看,特点主要体现在可视化、易学、操作简单。致力于打造纯傻瓜式操作的采集软件。集搜客的特点主要体现在半可视化、功能齐全、采集能力强,致力于为用户提供完整强大的数据采集功能。总之,两者各有千秋,两者都是非常好的数据采集软件。最后,有兴趣的读者可以去深入体验和研究一下,因为两者所宣称的价值,其实不仅仅是一个软件工具,而是“将互联网数据结构化转换,把网络变成所有人的数据库”的目标。希望以后有机会分享这种经验。
集搜客网页抓取软件(集搜客软件去资源库下载规则模板,免去做规则烦恼)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-04-17 19:01
海量规则模板,免去制定规则的烦恼
如果你不知道如何制定规则但真的想直接抓取数据,或者你是初学者,认为制定规则困难且耗时,可以直接从 Jisoke 的资源库下载规则模板并抓取直接数据,体验规则是如何定义和运行的,让你改变对网络爬虫的理解。您无需学习 Python、Java、C++ 等编程语言即可捕获网页数据。可以使用吉搜客软件从资源库中下载规则模板,轻松抓取。获取海量网络数据。
去极搜客资源库,轻松抓取海量数据
一键套用规则模板,只需添加网址线索,即可无限次抓取数据。想想就有点激动! ! !
集搜客资源库拥有海量规则模板,提供微信、微博、电商、新闻、论坛、行业等各种采集规则模板网站。与初学者制定的规则相比,失败率更高。这些规则模板由熟练使用软件的技术大师制作。他们制定的规则解决了许多初学者忽略或无法解决的问题。所以,规则的质量是非常有保证的,而且已经被证明是非常实用的,所以急于获取数据或者不使用软件的人可以放心的下载这些规则模板。
根据网站的行业分类,通过关键词搜索,通过URL搜索,就可以找到你想要的规则模板,一键下载就可以直接用它来抓取数据您需要在 DS 计数器上右键单击规则名称,选择“管理潜在客户”->“添加”URL 潜在客户(无限制),您可以使用它们来抓取新数据。
下载规则需要积分,积分不够怎么办?
积分策略(详见积分规则):
1、注册可得20分
2、完整的个人信息可以获得10分
3、每日签到2分/天,评论1分/条
4、在“个人中心”->“我的资源”发布规则资源赚取积分
5、充值买积分,1元=10积分
无论网页结构多么复杂,总有人可以帮你解决。欢迎来到极速客社区发问题/打赏任务,必有极速客大神来救你。 查看全部
集搜客网页抓取软件(集搜客软件去资源库下载规则模板,免去做规则烦恼)
海量规则模板,免去制定规则的烦恼
如果你不知道如何制定规则但真的想直接抓取数据,或者你是初学者,认为制定规则困难且耗时,可以直接从 Jisoke 的资源库下载规则模板并抓取直接数据,体验规则是如何定义和运行的,让你改变对网络爬虫的理解。您无需学习 Python、Java、C++ 等编程语言即可捕获网页数据。可以使用吉搜客软件从资源库中下载规则模板,轻松抓取。获取海量网络数据。
去极搜客资源库,轻松抓取海量数据
一键套用规则模板,只需添加网址线索,即可无限次抓取数据。想想就有点激动! ! !
集搜客资源库拥有海量规则模板,提供微信、微博、电商、新闻、论坛、行业等各种采集规则模板网站。与初学者制定的规则相比,失败率更高。这些规则模板由熟练使用软件的技术大师制作。他们制定的规则解决了许多初学者忽略或无法解决的问题。所以,规则的质量是非常有保证的,而且已经被证明是非常实用的,所以急于获取数据或者不使用软件的人可以放心的下载这些规则模板。
根据网站的行业分类,通过关键词搜索,通过URL搜索,就可以找到你想要的规则模板,一键下载就可以直接用它来抓取数据您需要在 DS 计数器上右键单击规则名称,选择“管理潜在客户”->“添加”URL 潜在客户(无限制),您可以使用它们来抓取新数据。
下载规则需要积分,积分不够怎么办?
积分策略(详见积分规则):
1、注册可得20分
2、完整的个人信息可以获得10分
3、每日签到2分/天,评论1分/条
4、在“个人中心”->“我的资源”发布规则资源赚取积分
5、充值买积分,1元=10积分
无论网页结构多么复杂,总有人可以帮你解决。欢迎来到极速客社区发问题/打赏任务,必有极速客大神来救你。
集搜客网页抓取软件(V10及更高数据管家—增强版网络爬虫老版本对应教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2022-04-17 11:25
支持软件版本:V10及更高版本数据管理器-增强型网络爬虫
旧版对应教程:V9及更低版本吉索克网络爬虫对应教程为《采集图片网址及下载图片-以途牛旅游网为例》
即搜客数据管理器可以快速抓取网页上某个区域的所有图片或视频,并保存在本地。而不是像《采集图片网址和图片下载(二)—下载途牛多图》)中介绍的定义和示例复制规则那样下载常规图片。
例如,京东搜索“T恤”后会得到一个列表页面。可以抓取整个列表区域中的所有图像。
我们用这个例子来说明操作过程。视频捕获的操作是相同的。
案例任务:所有图表(点击下载)
示例 URL:%E6%A1%96&enc=utf-8&suggest=1.def.0.base&wq=txue&pvid=604cc4d250ad43828165f439a2e7d907
采集内容:列表区域的所有图片
1. 下载并安装 Jisoke 数据管理器
2. 加载网页,进入任务定义模式
在数据管理器中打开网页为采集,网页加载完毕,点击左侧边栏的“+”号进入任务定义模式。
3. 设置下载图片
点击这个列表区域中的任何图片或者文字,都会对应下面DOM窗口中的一个节点,沿着这个节点向上查找,直到有一个可以选择整个T恤列表区域的节点,然后右击当前节点,做内容映射。
您还需要输入数据表的名称和字段的名称。(这些名称是任意的,但最好是有意义的)。
在左侧的工作台上,单击“列表顶部”字段的设置
检查下载图像,然后单击确定。
4. 保存任务和 采集 数据
点击测试看看会不会报错。如果没有报错,保存任务。然后单击“获取数据”按钮开始采集。
5. 查看图片
采集下载的图片一般保存在电脑DataScraperWorks目录下的PageContentDir目录下。
我们有 采集 共有 111 张图片。
6.设置翻页采集多页图片
如果需要采集多页图片,可以按照教程“翻页设置”,在第3步后添加翻页设置,然后按照第4步保存任务和采集数据。
注意,要爬取一个区域内的所有图片,一般需要滚动屏幕。在数据管家设置中,打开滚动屏幕。
Part 1 文章: "采集 图片 URL 和下载图片--下载途牛多图" Part 2 文章: "使用网络爬虫软件自动下载网页文件" 查看全部
集搜客网页抓取软件(V10及更高数据管家—增强版网络爬虫老版本对应教程)
支持软件版本:V10及更高版本数据管理器-增强型网络爬虫
旧版对应教程:V9及更低版本吉索克网络爬虫对应教程为《采集图片网址及下载图片-以途牛旅游网为例》
即搜客数据管理器可以快速抓取网页上某个区域的所有图片或视频,并保存在本地。而不是像《采集图片网址和图片下载(二)—下载途牛多图》)中介绍的定义和示例复制规则那样下载常规图片。
例如,京东搜索“T恤”后会得到一个列表页面。可以抓取整个列表区域中的所有图像。
我们用这个例子来说明操作过程。视频捕获的操作是相同的。

案例任务:所有图表(点击下载)
示例 URL:%E6%A1%96&enc=utf-8&suggest=1.def.0.base&wq=txue&pvid=604cc4d250ad43828165f439a2e7d907
采集内容:列表区域的所有图片
1. 下载并安装 Jisoke 数据管理器
2. 加载网页,进入任务定义模式
在数据管理器中打开网页为采集,网页加载完毕,点击左侧边栏的“+”号进入任务定义模式。

3. 设置下载图片
点击这个列表区域中的任何图片或者文字,都会对应下面DOM窗口中的一个节点,沿着这个节点向上查找,直到有一个可以选择整个T恤列表区域的节点,然后右击当前节点,做内容映射。


您还需要输入数据表的名称和字段的名称。(这些名称是任意的,但最好是有意义的)。

在左侧的工作台上,单击“列表顶部”字段的设置

检查下载图像,然后单击确定。

4. 保存任务和 采集 数据
点击测试看看会不会报错。如果没有报错,保存任务。然后单击“获取数据”按钮开始采集。

5. 查看图片
采集下载的图片一般保存在电脑DataScraperWorks目录下的PageContentDir目录下。

我们有 采集 共有 111 张图片。

6.设置翻页采集多页图片
如果需要采集多页图片,可以按照教程“翻页设置”,在第3步后添加翻页设置,然后按照第4步保存任务和采集数据。
注意,要爬取一个区域内的所有图片,一般需要滚动屏幕。在数据管家设置中,打开滚动屏幕。
Part 1 文章: "采集 图片 URL 和下载图片--下载途牛多图" Part 2 文章: "使用网络爬虫软件自动下载网页文件"
集搜客网页抓取软件(Python网络爬虫内容提取器一文讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-17 11:20
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码就够了证明 Python 的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页中的手机名称和价格被正确抓取
4. 继续阅读
至此,我们通过两篇文章文章演示了如何抓取静态和动态网页内容,均使用xslt一次性从网页中提取出需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。接下来,“1分钟快速生成用于Web内容提取的xslt”将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
5.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第5章:源码下载源码,并替换github源码的URL
文章来源:segmentfault,作者:fullerhua。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
背景 - 系统设置 - 扩展变量 - 移动广告 - 内容正文底部 查看全部
集搜客网页抓取软件(Python网络爬虫内容提取器一文讲解)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码就够了证明 Python 的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页中的手机名称和价格被正确抓取
4. 继续阅读
至此,我们通过两篇文章文章演示了如何抓取静态和动态网页内容,均使用xslt一次性从网页中提取出需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。接下来,“1分钟快速生成用于Web内容提取的xslt”将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
5.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第5章:源码下载源码,并替换github源码的URL
文章来源:segmentfault,作者:fullerhua。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。

背景 - 系统设置 - 扩展变量 - 移动广告 - 内容正文底部
集搜客网页抓取软件(1.《1分钟快速生成用于网页内容提取的xslt模板》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2022-04-15 04:13
1.项目背景
在python即时网络爬虫项目启动说明中,我们讨论了一个数字:程序员在调试内容提取规则上浪费时间,所以我们推出这个项目是为了让程序员从繁琐的调试规则中解放出来,投入更多的高端数据处理工作。
2.解决方案
为了解决这个问题,我们将影响通用性和工作效率的提取器隔离出来,描述数据处理流程图如下:
图中的“可插拔提取器”一定是非常模块化的,所以关键接口是:
3. 提取器代码
可插拔提取器是即时网络爬虫项目的核心组件,定义为一个类:gsExtractor
请从 github 下载 python 源代码文件及其文档
使用模式是这样的:
下面是这个 gsExtractor 类的源代码
#!/usr/bin/python
# -*- coding: utf-8 -*-
# 模块名: gooseeker
# 类名: gsExtractor
# Version: 2.0
# 说明: html内容提取器
# 功能: 使用xslt作为模板,快速提取HTML DOM中的内容。
# released by 集搜客(http://www.gooseeker.com) on May 18, 2016
# github: https://github.com/FullerHua/j ... er.py
from urllib import request
from urllib.parse import quote
from lxml import etree
import time
class gsExtractor(object):
def _init_(self):
self.xslt = ""
# 从文件读取xslt
def setXsltFromFile(self , xsltFilePath):
file = open(xsltFilePath , 'r' , encoding='UTF-8')
try:
self.xslt = file.read()
finally:
file.close()
# 从字符串获得xslt
def setXsltFromMem(self , xsltStr):
self.xslt = xsltStr
# 通过GooSeeker API接口获得xslt
def setXsltFromAPI(self , APIKey , theme, middle=None, bname=None):
apiurl = "http://www.gooseeker.com/api/g ... 3B%2B APIKey +"&theme="+quote(theme)
if (middle):
apiurl = apiurl + "&middle="+quote(middle)
if (bname):
apiurl = apiurl + "&bname="+quote(bname)
apiconn = request.urlopen(apiurl)
self.xslt = apiconn.read()
# 返回当前xslt
def getXslt(self):
return self.xslt
# 提取方法,入参是一个HTML DOM对象,返回是提取结果
def extract(self , html):
xslt_root = etree.XML(self.xslt)
transform = etree.XSLT(xslt_root)
result_tree = transform(html)
return result_tree
4. 使用示例
下面是一个示例程序,演示如何使用 gsExtractor 类提取 GooSeeker 官网的 bbs 帖子列表。这个例子有以下特点
下面是源码,都可以从github下载
#-*_coding:utf8-*-
# 使用gsExtractor类的示例程序
# 访问集搜客论坛,以xslt为模板提取论坛内容
# xslt保存在xslt_bbs.xml中
from urllib import request
from lxml import etree
from gooseeker import gsExtractor
# 访问并读取网页内容
url = "http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
# 生成xsltExtractor对象
bbsExtra = gsExtractor()
# 调用set方法设置xslt内容
bbsExtra.setXsltFromFile("xslt_bbs.xml")
# 调用extract方法提取所需内容
result = bbsExtra.extract(doc)
# 显示提取结果
print(str(result))
提取结果如下图所示:
5. 继续阅读
这篇文章已经解释了提取器的价值和用法,但是并没有说如何生成它。只有快速生成提取器,才能达到节省开发者时间的目的。为网页内容提取生成 xslt 模板"
6. GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史 查看全部
集搜客网页抓取软件(1.《1分钟快速生成用于网页内容提取的xslt模板》)
1.项目背景
在python即时网络爬虫项目启动说明中,我们讨论了一个数字:程序员在调试内容提取规则上浪费时间,所以我们推出这个项目是为了让程序员从繁琐的调试规则中解放出来,投入更多的高端数据处理工作。
2.解决方案
为了解决这个问题,我们将影响通用性和工作效率的提取器隔离出来,描述数据处理流程图如下:

图中的“可插拔提取器”一定是非常模块化的,所以关键接口是:
3. 提取器代码
可插拔提取器是即时网络爬虫项目的核心组件,定义为一个类:gsExtractor
请从 github 下载 python 源代码文件及其文档
使用模式是这样的:
下面是这个 gsExtractor 类的源代码
#!/usr/bin/python
# -*- coding: utf-8 -*-
# 模块名: gooseeker
# 类名: gsExtractor
# Version: 2.0
# 说明: html内容提取器
# 功能: 使用xslt作为模板,快速提取HTML DOM中的内容。
# released by 集搜客(http://www.gooseeker.com) on May 18, 2016
# github: https://github.com/FullerHua/j ... er.py
from urllib import request
from urllib.parse import quote
from lxml import etree
import time
class gsExtractor(object):
def _init_(self):
self.xslt = ""
# 从文件读取xslt
def setXsltFromFile(self , xsltFilePath):
file = open(xsltFilePath , 'r' , encoding='UTF-8')
try:
self.xslt = file.read()
finally:
file.close()
# 从字符串获得xslt
def setXsltFromMem(self , xsltStr):
self.xslt = xsltStr
# 通过GooSeeker API接口获得xslt
def setXsltFromAPI(self , APIKey , theme, middle=None, bname=None):
apiurl = "http://www.gooseeker.com/api/g ... 3B%2B APIKey +"&theme="+quote(theme)
if (middle):
apiurl = apiurl + "&middle="+quote(middle)
if (bname):
apiurl = apiurl + "&bname="+quote(bname)
apiconn = request.urlopen(apiurl)
self.xslt = apiconn.read()
# 返回当前xslt
def getXslt(self):
return self.xslt
# 提取方法,入参是一个HTML DOM对象,返回是提取结果
def extract(self , html):
xslt_root = etree.XML(self.xslt)
transform = etree.XSLT(xslt_root)
result_tree = transform(html)
return result_tree
4. 使用示例
下面是一个示例程序,演示如何使用 gsExtractor 类提取 GooSeeker 官网的 bbs 帖子列表。这个例子有以下特点
下面是源码,都可以从github下载
#-*_coding:utf8-*-
# 使用gsExtractor类的示例程序
# 访问集搜客论坛,以xslt为模板提取论坛内容
# xslt保存在xslt_bbs.xml中
from urllib import request
from lxml import etree
from gooseeker import gsExtractor
# 访问并读取网页内容
url = "http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
# 生成xsltExtractor对象
bbsExtra = gsExtractor()
# 调用set方法设置xslt内容
bbsExtra.setXsltFromFile("xslt_bbs.xml")
# 调用extract方法提取所需内容
result = bbsExtra.extract(doc)
# 显示提取结果
print(str(result))
提取结果如下图所示:

5. 继续阅读
这篇文章已经解释了提取器的价值和用法,但是并没有说如何生成它。只有快速生成提取器,才能达到节省开发者时间的目的。为网页内容提取生成 xslt 模板"
6. GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-31 20:45
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
集搜客网页抓取器的抓取软件是软件不是图片下载器
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-05-31 12:00
集搜客网页抓取软件是集搜客的一款可以爬取网页的抓取软件,在以前网页抓取软件也称为搜狗网页抓取器,因为看到很多同学都说搜狗网页抓取器更方便,那今天小编就给大家介绍一款集搜客网页抓取器。下面就是集搜客网页抓取器官网,点击进入网站去看一下:点击新建操作。新建操作弹出窗口我们直接填写:地址(自定义地址),选择产品类型,选择抓取的网站,输入需要抓取的网址。
集搜客网页抓取器最佳的接口就是百度和谷歌,当然还有其他一些url,大家根据需要抓取。最后点击提交,提交到搜狗网页搜索抓取器,接下来我们就会抓取到你想要的网站:这款集搜客网页抓取器是软件不是图片下载器,因为集搜客网页抓取器是一款专业的网页抓取器软件,可以抓取wap,app,pc网页,商品详情页,店铺页,淘宝大图等,抓取步骤也是图文的,不过相比网页的网页抓取来说,图片的抓取软件大部分图片是识别不出来的,需要大家根据情况来操作一下,可以关注我的公众号小助手小职,后台回复集搜客网页抓取器获取全部抓取软件。
百度或者一搜关键词“本地抓取”可以获取很多网站。
集搜客啊
我在使用网页抓取,分享一个网站吧,有人说它的数据准确率很好,可能国内不多,但是功能,开发,速度上都很不错。 查看全部
集搜客网页抓取器的抓取软件是软件不是图片下载器
集搜客网页抓取软件是集搜客的一款可以爬取网页的抓取软件,在以前网页抓取软件也称为搜狗网页抓取器,因为看到很多同学都说搜狗网页抓取器更方便,那今天小编就给大家介绍一款集搜客网页抓取器。下面就是集搜客网页抓取器官网,点击进入网站去看一下:点击新建操作。新建操作弹出窗口我们直接填写:地址(自定义地址),选择产品类型,选择抓取的网站,输入需要抓取的网址。
集搜客网页抓取器最佳的接口就是百度和谷歌,当然还有其他一些url,大家根据需要抓取。最后点击提交,提交到搜狗网页搜索抓取器,接下来我们就会抓取到你想要的网站:这款集搜客网页抓取器是软件不是图片下载器,因为集搜客网页抓取器是一款专业的网页抓取器软件,可以抓取wap,app,pc网页,商品详情页,店铺页,淘宝大图等,抓取步骤也是图文的,不过相比网页的网页抓取来说,图片的抓取软件大部分图片是识别不出来的,需要大家根据情况来操作一下,可以关注我的公众号小助手小职,后台回复集搜客网页抓取器获取全部抓取软件。
百度或者一搜关键词“本地抓取”可以获取很多网站。
集搜客啊
我在使用网页抓取,分享一个网站吧,有人说它的数据准确率很好,可能国内不多,但是功能,开发,速度上都很不错。
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-05-31 09:11
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-05-28 22:17
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-05-26 03:37
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
爬虫,我想再推荐 6 个工具
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-05-22 02:14
前天,有个同学加我微信来咨询我:
“老哥,我想抓取近期 5000 条新闻数据,但我是文科生,不会写代码,请问该怎么办?”
有问必答,对于这位同学的问题,我给安排上。
先说说获取数据的方式:一是利用现成的工具,我们只需懂得如何使用工具就能获取数据,不需要关心工具是怎么实现。打个比方,假如我们在岸上,要去海上某个小岛,岸边有一艘船,我们第一想法是选择坐船过去,而不会想着自己来造一艘船再过去。
第二种是自己针对场景需求做些定制化工具,这就需要有点编程基础。
举个例子,我们还是要到海上某个小岛,同时还要求在 30 分钟内将 1 顿货物送到岛上。
因此,前期只是单纯想获取数据,没有什么其他要求的话,优先选择现有工具。
可能是 Python 近来年很火,加上我们会经常看到别人用 Python 来制作网络爬虫抓取数据。从而有一些同学有这样的误区,想从网络上抓取数据就一定要学 Python,一定要去写代码。
其实不然,介绍几个能快速获取网上数据的工具。
1.Microsoft Excel
你没有看错,就是 Office 三剑客之一的 Excel。Excel 是一个强大的工具,能抓取数据就是它的功能之一。
我以耳机作为关键字,抓取京东的商品列表。
等待几秒后,Excel 会将页面上所有的文字信息抓取到表格中。这种方式确实能抓取到数据,但也会引入一些我们不需要的数据。如果你有更高的需求,可以选择后面几个工具。
2.优采云采集器
优采云是爬虫界的老品牌了,是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。
它的优势是采集不限网页,不限内容,同时还是分布式采集,效率会高一些。缺点是对小白用户不是很友好,有一定的知识门槛(了解如网页知识、HTTP 协议等方面知识),还需要花些时间熟悉工具操作。
因为有学习门槛,掌握该工具之后,采集数据上限会很高。有时间和精力的同学可以去折腾折腾。
官网地址:
3.优采云采集器
优采云采集器是一款非常适合新手的采集器。
它具有简单易用的特点,让你能几分钟中就快手上手。优采云提供一些常见抓取网站的模板,使用模板就能快速抓取数据。
如果想抓取没有模板的网站,官网也提供非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现可视化抓取数据,所以存在卡顿、采集数据慢的特点。但这瑕不掩瑜,能基本满足新手在短时间抓取数据的场景,比如翻页查询,Ajax 动态加载数据等。
网站:
4.GooSeeker 集搜客
集搜客也是一款容易上手的可视化采集数据工具。
同样能抓取动态网页,也支持可以抓取手机网站上的数据,还支持抓取在指数图表上悬浮显示的数据。
集搜客是以浏览器插件形式抓取数据。
虽然具有前面所述的优点,但缺点也有,无法多线程采集数据,出现浏览器卡顿也在所难免。
网站:
5.Scrapinghub
如果你想抓取国外的网站数据,可以考虑 Scrapinghub。
Scrapinghub 是一个基于Python 的 Scrapy 框架的云爬虫平台。
Scrapehub 算是市场上非常复杂和强大的网络抓取平台,提供数据抓取的解决方案商。
地址:
6.WebScraper
WebScraper 是一款优秀国外的浏览器插件。
同样也是一款适合新手抓取数据的可视化工具。
我们通过简单设置一些抓取规则,剩下的就交给浏览器去工作。
地址:
留言送书
活动介绍:今日赠书:《Python渗透测试编程技术:方法与实践》PS:最近当当做活动,满 100 减 50
今日留言主题
说说你对渗透测试的看法?
THANDKS- End - 查看全部
爬虫,我想再推荐 6 个工具
前天,有个同学加我微信来咨询我:
“老哥,我想抓取近期 5000 条新闻数据,但我是文科生,不会写代码,请问该怎么办?”
有问必答,对于这位同学的问题,我给安排上。
先说说获取数据的方式:一是利用现成的工具,我们只需懂得如何使用工具就能获取数据,不需要关心工具是怎么实现。打个比方,假如我们在岸上,要去海上某个小岛,岸边有一艘船,我们第一想法是选择坐船过去,而不会想着自己来造一艘船再过去。
第二种是自己针对场景需求做些定制化工具,这就需要有点编程基础。
举个例子,我们还是要到海上某个小岛,同时还要求在 30 分钟内将 1 顿货物送到岛上。
因此,前期只是单纯想获取数据,没有什么其他要求的话,优先选择现有工具。
可能是 Python 近来年很火,加上我们会经常看到别人用 Python 来制作网络爬虫抓取数据。从而有一些同学有这样的误区,想从网络上抓取数据就一定要学 Python,一定要去写代码。
其实不然,介绍几个能快速获取网上数据的工具。
1.Microsoft Excel
你没有看错,就是 Office 三剑客之一的 Excel。Excel 是一个强大的工具,能抓取数据就是它的功能之一。
我以耳机作为关键字,抓取京东的商品列表。
等待几秒后,Excel 会将页面上所有的文字信息抓取到表格中。这种方式确实能抓取到数据,但也会引入一些我们不需要的数据。如果你有更高的需求,可以选择后面几个工具。
2.优采云采集器
优采云是爬虫界的老品牌了,是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。
它的优势是采集不限网页,不限内容,同时还是分布式采集,效率会高一些。缺点是对小白用户不是很友好,有一定的知识门槛(了解如网页知识、HTTP 协议等方面知识),还需要花些时间熟悉工具操作。
因为有学习门槛,掌握该工具之后,采集数据上限会很高。有时间和精力的同学可以去折腾折腾。
官网地址:
3.优采云采集器
优采云采集器是一款非常适合新手的采集器。
它具有简单易用的特点,让你能几分钟中就快手上手。优采云提供一些常见抓取网站的模板,使用模板就能快速抓取数据。
如果想抓取没有模板的网站,官网也提供非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现可视化抓取数据,所以存在卡顿、采集数据慢的特点。但这瑕不掩瑜,能基本满足新手在短时间抓取数据的场景,比如翻页查询,Ajax 动态加载数据等。
网站:
4.GooSeeker 集搜客
集搜客也是一款容易上手的可视化采集数据工具。
同样能抓取动态网页,也支持可以抓取手机网站上的数据,还支持抓取在指数图表上悬浮显示的数据。
集搜客是以浏览器插件形式抓取数据。
虽然具有前面所述的优点,但缺点也有,无法多线程采集数据,出现浏览器卡顿也在所难免。
网站:
5.Scrapinghub
如果你想抓取国外的网站数据,可以考虑 Scrapinghub。
Scrapinghub 是一个基于Python 的 Scrapy 框架的云爬虫平台。
Scrapehub 算是市场上非常复杂和强大的网络抓取平台,提供数据抓取的解决方案商。
地址:
6.WebScraper
WebScraper 是一款优秀国外的浏览器插件。
同样也是一款适合新手抓取数据的可视化工具。
我们通过简单设置一些抓取规则,剩下的就交给浏览器去工作。
地址:
留言送书
活动介绍:今日赠书:《Python渗透测试编程技术:方法与实践》PS:最近当当做活动,满 100 减 50
今日留言主题
说说你对渗透测试的看法?
THANDKS- End -
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-05-18 10:30
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-05-15 17:55
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
社交网络分析工具大搜罗 | 来点方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-05-14 01:54
社交网络分析(Social Network Analysis)是指基于信息学、数学、社会学、管理学、心理学等多学科的融合理论和方法,为理解人类各种社交关系的形成、行为特点分析以及信息传播的规律提供的一种可计算的分析方法。人们对社交网络数据的挖掘和分析都还处于相对初级的阶段,大规模、高维度数据的挖掘方法还在不断地演化。目前来看,文本语言的情感分析等很多基础性问题仍然还不能得到有效解决,对深入研究社交网络造成了一些限制。
本期“来点方法”给大家介绍社交网络分析的工具,分为网页版工具、桌面版工具和数据获取三部分信息,每款工具的应用都是一次学习的过程,新学期,何不来点好玩的?
一
网页版工具1.微博风云榜地址:
微风云(原微博风云)是社会化新媒体营销第一数据平台,为用户提供权威的微博营销、微信营销第三方数据。
2.知微地址:
相比于微博风云榜,知微更专注微博的传播分析,普通版即支持转发小于1000的微博的传播分析。知微提供了传播分析全面的数据,包括传播路径图,转发层级,转发内容的词云,水军识别,地域分布……
知微的功能概要
3.北大PKUVIS微博可视分析工具地址:
北京大学 PKUVIS微博可视分析工具 (WeiboEvents) 是北京大学可视化与可视分析研究组开发的微博传播分析工具。它通过直观的视图清晰地呈现出一个事件中微博转发的过程,让您能够迅速地发现事件中的关键人物、关键微博、重要观点,同时通过可视化的方式帮助您更好地分析新浪微博中事件的发生与发展过程。
4. 独到地址:
独到科技是中国大数据行业的先行者和创新者,依托独创的分布式处理平台 D-Cluster,以及先进的自然语言处理技术和机器学习算法,为企业提供市场分析、舆情监控、品牌营销、广告效果监测、人群定位和渠道筛选等方面提供技术和产品支持。初级版免费。
二桌面版工具1.Gephi下载地址:
Gephi是一款开源免费跨平台基于JVM的复杂网络分析软件, 其主要用于各种网络和复杂系统,动态和分层图的交互可视化与探测开源工具。可用作:探索性数据分析,链接分析,社交网络分析,生物网络分析等。
中文版教程:/gephi
2. NodeXLNodeXL是一个免费、开源的插件,适用于Excel 2007 & 2010。NodeXL的主要功能是社交网络可视化,输入一张网络边(关系)的列表,点击一个按钮就可以看到你的关系图。功能介绍和操作视频:
NodeXL界面
3.IBM SPSS Modeler IBM SPSS Modeler是一个预测性分析平台,能够为个人、团队、系统和企业做决策提供预测性智能。它可提供各种高级算法和技术(包括文本分析、实体分析、决策管理与优化),帮助您选择可实现更佳成果的操作。
文本分析功能
三数据获取1. RweiboRweibo是一个新浪微博的R语言SDK,作为library在R环境中调用,对新浪微博提供的接口进行了实现(见新浪微博API),可以进行微博信息获取、用户信息获取、搜索、发表微博等操作。该应用通过OAuth的方式授权,使用者首先需要到新浪微博开放平台申请一个新的应用,获取App Key和App Secret,然后在R环境中按照提示注册一个应用,从而进行各项操作。2. sinaweibopy地址:
sinaweibopy是Python专用的支持新浪微博API的OAuth 2客户端,无依赖,100%纯Py,单个文件,代码简洁,运行可靠,也是新浪微博官方推荐的Python SDK
3.集搜客地址:
集搜客GooSeeker大数据软件开发始于2007年,2007年正是语义网络走向商用的时期,集搜客致力于提供一套便捷易用的软件,将网页内容进行语义标注和结构化转换。一旦有了语义结构,整个Web就变成了一个大数据库;一旦内容被赋予了意义(语义),就能从中挖掘出有价值的知识,集搜客创造了以下商业应用场景:
(1)集搜客网络爬虫不是一个简单的网页抓取器,她能够集众人之力把语义标签摘取下来
(2)每个语义标签代表大数据知识对象的一个维度,多维度整合,剖析此知识对象
(3)知识对象可以是多个层面的,比如:市场竞争、消费者洞察、品牌地图、企业画像 查看全部
社交网络分析工具大搜罗 | 来点方法
社交网络分析(Social Network Analysis)是指基于信息学、数学、社会学、管理学、心理学等多学科的融合理论和方法,为理解人类各种社交关系的形成、行为特点分析以及信息传播的规律提供的一种可计算的分析方法。人们对社交网络数据的挖掘和分析都还处于相对初级的阶段,大规模、高维度数据的挖掘方法还在不断地演化。目前来看,文本语言的情感分析等很多基础性问题仍然还不能得到有效解决,对深入研究社交网络造成了一些限制。
本期“来点方法”给大家介绍社交网络分析的工具,分为网页版工具、桌面版工具和数据获取三部分信息,每款工具的应用都是一次学习的过程,新学期,何不来点好玩的?
一
网页版工具1.微博风云榜地址:
微风云(原微博风云)是社会化新媒体营销第一数据平台,为用户提供权威的微博营销、微信营销第三方数据。
2.知微地址:
相比于微博风云榜,知微更专注微博的传播分析,普通版即支持转发小于1000的微博的传播分析。知微提供了传播分析全面的数据,包括传播路径图,转发层级,转发内容的词云,水军识别,地域分布……
知微的功能概要
3.北大PKUVIS微博可视分析工具地址:
北京大学 PKUVIS微博可视分析工具 (WeiboEvents) 是北京大学可视化与可视分析研究组开发的微博传播分析工具。它通过直观的视图清晰地呈现出一个事件中微博转发的过程,让您能够迅速地发现事件中的关键人物、关键微博、重要观点,同时通过可视化的方式帮助您更好地分析新浪微博中事件的发生与发展过程。
4. 独到地址:
独到科技是中国大数据行业的先行者和创新者,依托独创的分布式处理平台 D-Cluster,以及先进的自然语言处理技术和机器学习算法,为企业提供市场分析、舆情监控、品牌营销、广告效果监测、人群定位和渠道筛选等方面提供技术和产品支持。初级版免费。
二桌面版工具1.Gephi下载地址:
Gephi是一款开源免费跨平台基于JVM的复杂网络分析软件, 其主要用于各种网络和复杂系统,动态和分层图的交互可视化与探测开源工具。可用作:探索性数据分析,链接分析,社交网络分析,生物网络分析等。
中文版教程:/gephi
2. NodeXLNodeXL是一个免费、开源的插件,适用于Excel 2007 & 2010。NodeXL的主要功能是社交网络可视化,输入一张网络边(关系)的列表,点击一个按钮就可以看到你的关系图。功能介绍和操作视频:
NodeXL界面
3.IBM SPSS Modeler IBM SPSS Modeler是一个预测性分析平台,能够为个人、团队、系统和企业做决策提供预测性智能。它可提供各种高级算法和技术(包括文本分析、实体分析、决策管理与优化),帮助您选择可实现更佳成果的操作。
文本分析功能
三数据获取1. RweiboRweibo是一个新浪微博的R语言SDK,作为library在R环境中调用,对新浪微博提供的接口进行了实现(见新浪微博API),可以进行微博信息获取、用户信息获取、搜索、发表微博等操作。该应用通过OAuth的方式授权,使用者首先需要到新浪微博开放平台申请一个新的应用,获取App Key和App Secret,然后在R环境中按照提示注册一个应用,从而进行各项操作。2. sinaweibopy地址:
sinaweibopy是Python专用的支持新浪微博API的OAuth 2客户端,无依赖,100%纯Py,单个文件,代码简洁,运行可靠,也是新浪微博官方推荐的Python SDK
3.集搜客地址:
集搜客GooSeeker大数据软件开发始于2007年,2007年正是语义网络走向商用的时期,集搜客致力于提供一套便捷易用的软件,将网页内容进行语义标注和结构化转换。一旦有了语义结构,整个Web就变成了一个大数据库;一旦内容被赋予了意义(语义),就能从中挖掘出有价值的知识,集搜客创造了以下商业应用场景:
(1)集搜客网络爬虫不是一个简单的网页抓取器,她能够集众人之力把语义标签摘取下来
(2)每个语义标签代表大数据知识对象的一个维度,多维度整合,剖析此知识对象
(3)知识对象可以是多个层面的,比如:市场竞争、消费者洞察、品牌地图、企业画像
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-05-13 16:52
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
数据获取与预处理 | 集搜客Gooseeker的简单介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 799 次浏览 • 2022-05-13 07:04
SYH | 是野火
1.3 Gooseeker-数据爬取软件基础操作
1. 爬虫程序/软件
爬虫软件:集搜客Gooseeker、优采云、网络矿工、优采云、优采云平台……
爬虫程序:Java、Python、R、C#、PHP……
2.爬虫软件——集搜客Gooseeker
√ 支持windows/mac/linux三种操作系统,全功能开发
√ 由服务器和客户端两部分组成。服务其是用来存储规则和线索(待抓网址),MS谋数台是用来制作网页抓取规则的,DS打数机是用来采集网页数据的。
① 采用数据最简单的方式——直观标注
将网页在MS谋数台中打开,直接在网页上将想要抓取的内容进行标注,即可将数据采集下来。
② DOM标注
在DOM窗口中可以进行更精准的内容映射,及用@class和@id进行定位标志映射。
整理自沈浩教授《媒体大数据挖掘与实战案例》
这是我的个人公众号 查看全部
数据获取与预处理 | 集搜客Gooseeker的简单介绍
SYH | 是野火
1.3 Gooseeker-数据爬取软件基础操作
1. 爬虫程序/软件
爬虫软件:集搜客Gooseeker、优采云、网络矿工、优采云、优采云平台……
爬虫程序:Java、Python、R、C#、PHP……
2.爬虫软件——集搜客Gooseeker
√ 支持windows/mac/linux三种操作系统,全功能开发
√ 由服务器和客户端两部分组成。服务其是用来存储规则和线索(待抓网址),MS谋数台是用来制作网页抓取规则的,DS打数机是用来采集网页数据的。
① 采用数据最简单的方式——直观标注
将网页在MS谋数台中打开,直接在网页上将想要抓取的内容进行标注,即可将数据采集下来。
② DOM标注
在DOM窗口中可以进行更精准的内容映射,及用@class和@id进行定位标志映射。
整理自沈浩教授《媒体大数据挖掘与实战案例》
这是我的个人公众号
浅析通用爬虫软件—— 集搜客与优采云采集器
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-05-13 06:49
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。 查看全部
浅析通用爬虫软件—— 集搜客与优采云采集器
大 数 据 人
报道DT时代应用资讯及动态,爆料剖析行业热点新闻
最近想用爬虫软件来采集网页上的一些数据,根据百度的推荐以及相关关键词查询,找到了两款软件:“集搜客”和“优采云”,两款软件都有可视化界面,对于编程思维比较薄弱的用户来说,这两款软件上手容易,操作简单易懂。今天就带大家来了解对比一下这两款通用的网络爬虫软件。
1.软件安装
优采云:优采云安装跟其他独立软件一样,从官网下载,直接点击setup.exe安装。
集搜客:集搜客网站上下载的软件也是一个自解压exe程序,双击启动安装,看到的是火狐浏览器安装过程,原来集搜客软件是作为火狐插件发布的。
2.软件界面布局
优采云:优采云的界面布局可以归为指引型界面,用户进入软件界面可以看到软件使用提示信息,如图一所示,包括向导模式与高级模式,同时列出了学习资源,采集规则,数据下载等等。对于初次使用的用户来说,起到了很好的指引作用。
图一:优采云操作界面展示
集搜客:集搜客软件分成两个操作界面,MS谋数台(图2)和DS打数机(图3),谋数台负责制定规则(网页标注),打数机负责采集数据(网络爬虫),一个谋、一个打,听起来还是比较符合其特征。集搜客启动后的界面没有显示使用帮助资源,而是位于“帮助”菜单中。
图2:集搜客谋数台界面
图3:集搜客打数机界面
3.操作流程
优采云:优采云的操作流程主要分为4个步骤(如图4所示),分别为:
设置基本信息、设计工作流程、设置采集选项、完成。
图4:优采云操作流程
图5:优采云设计流程
集搜客:集搜客的操作没有流程的概念,似乎定义采集规则可以不遵守既定操作顺序,而是有一个要领“建立一个箱子,把你要的内容摘进去”。所以我们称之为4“块”操作(如图6所示):包括命名主题、创建整理箱、规划爬虫路线和定义连续动作。
图6:集搜客的4块功能
综上所述,优采云的工作流程特征十分明显,用户决定软件怎样动作,什么时候动作,动作施加给哪里,从哪里采集内容等。而集搜客想让用户专注于摘什么数据,如果用户在摘取以外还想扩展范围那就定义爬虫路线,如果还想做些动作那就定义连续动作,整个流程细节用户不用关心。
4.数据存储方式
优采云:优采云分成单机运行和云采集,数据导出支持EXCEL、SQL、TXT等常用格式。
集搜客:集搜客没有云采集,因为爬虫都在用户自己电脑上跑,用户想把爬虫放云上那是用户自己的事。跑下来的数据以XML格式存储,可见这是一种中间结果,集搜客官网提供了XML转EXCEL的工具,也在会员中心提供了基于云存储的数据导入和清洗功能,入库后可以导出成EXCEL格式。
5.收费模式
优采云:简单来说是一种软件销售模式(不排除免费版),除此之外用户下规则要积分,跑数据也要积分,而积分可以用钱购买或者参与社区活动换积分。
集搜客:集搜客简单来说是一种服务收费模式,软件功能全部免费,如果需要一些爬虫管理和数据管理的服务,则根据服务类型、数量和时间进行收费。同样,下载规则要积分,如果使用云存储,根据存储量和存储时间收费。积分同样也可以用钱购买,或者参与社区活动赚积分。
市场研究 | 工具06—介绍爬虫软件工具gooseeker
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-05-09 17:53
今天给大家介绍一款网络爬虫工具:Gooseeker,中文:集搜客
网络爬虫(Web Crawler),又称为网络蜘蛛(Web Spider)或 Web 信息采集器,是一个自动下载网页的计算机程序或自动化脚本,是搜索引擎的重要组成部分。网络爬虫通常从一个称为种子集的 URL集合开始运行,它首先将这些URL 全部放入到一个有序的待爬行队列里,按照一定的顺序从中取出 URL 并下载所指向的页面,分析页面内容,提取新的 URL 并存入待爬行 URL 队列中,如此重复上面的过程,直到 URL 队列为空或满足某个爬行终止条件,从而遍历 Web。
该过程称为网络爬行(Web Crawling)。
集搜客(gooseeker)是一款不需要编程比较容易学习的爬虫工具
下载地址:
这款属于爬虫软件,主要是在火狐狸Foxfire浏览器内运行,总体算来这个还是功能很强大的,包括爬微博数据。
集搜客网络爬虫支持windows/mac/linux三种操作系统,全功能开发,不断优化更新软件版本。
集搜客网络爬虫是由服务器和客户端两部分组成,服务器是用来存储规则和线索(待抓网址),MS谋数台是用来制作网页抓取规则的,DS打数机是用来采集网页数据。
数据采集还有一种方法是API接口使用。
当然需要更灵活和更复杂的爬虫,最好是爬虫程序,一般是Python的Scrapy爬虫框架更好!以后介绍
沈浩老师
——————中国传媒大学新闻学院教授、博士生导师中国传媒大学调查统计研究所所长
大数据挖掘与社会计算实验室主任
中国市场研究行业协会会长
欢迎关注沈浩老师的微信公共号
欢迎关注俺任会长的市场研究协会:
查看全部
市场研究 | 工具06—介绍爬虫软件工具gooseeker
今天给大家介绍一款网络爬虫工具:Gooseeker,中文:集搜客
网络爬虫(Web Crawler),又称为网络蜘蛛(Web Spider)或 Web 信息采集器,是一个自动下载网页的计算机程序或自动化脚本,是搜索引擎的重要组成部分。网络爬虫通常从一个称为种子集的 URL集合开始运行,它首先将这些URL 全部放入到一个有序的待爬行队列里,按照一定的顺序从中取出 URL 并下载所指向的页面,分析页面内容,提取新的 URL 并存入待爬行 URL 队列中,如此重复上面的过程,直到 URL 队列为空或满足某个爬行终止条件,从而遍历 Web。
该过程称为网络爬行(Web Crawling)。
集搜客(gooseeker)是一款不需要编程比较容易学习的爬虫工具
下载地址:
这款属于爬虫软件,主要是在火狐狸Foxfire浏览器内运行,总体算来这个还是功能很强大的,包括爬微博数据。
集搜客网络爬虫支持windows/mac/linux三种操作系统,全功能开发,不断优化更新软件版本。
集搜客网络爬虫是由服务器和客户端两部分组成,服务器是用来存储规则和线索(待抓网址),MS谋数台是用来制作网页抓取规则的,DS打数机是用来采集网页数据。
数据采集还有一种方法是API接口使用。
当然需要更灵活和更复杂的爬虫,最好是爬虫程序,一般是Python的Scrapy爬虫框架更好!以后介绍
沈浩老师
——————中国传媒大学新闻学院教授、博士生导师中国传媒大学调查统计研究所所长
大数据挖掘与社会计算实验室主任
中国市场研究行业协会会长
欢迎关注沈浩老师的微信公共号
欢迎关注俺任会长的市场研究协会:
集搜客网页抓取软件(1.360用户安装和使用集搜客攻略图所示:1.3原因分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-20 11:15
)
近日,极速客技术支持中心收到了部分360安全卫士用户的反馈。在安装和使用极速客的过程中,我们遇到了一些由于360导致的误报,比如服务器连接失败、个别文件被删除、安装过程中不断出现360警告信息等问题。这些问题一直困扰着部分用户,影响了他们正常的数据采集。本文给出了应对措施,并附上Jisouke上第三方检测机构的检测报告。
1.360用户安装使用jisoke策略1.1 安装过程中的警告信息
如下所示:
当出现此警告信息时,请点击“更多”下的“允许该程序的所有操作”,如下图:
1.2 使用 Firefox 浏览器或使用 MS/DS 计算机时,会出现警告消息
如下所示:
当出现此警告信息时,请点击“更多”下的“允许该程序的所有操作”,如下图:
1.3 原因分析
以下分析基于我们长期的观察(因为观察到的对象没有公开的算法):由于360安全卫士默认开启了云网页检测,在抓取数据时,会出现大量抓取的网页或者其他特性可能会被发送到360进行检测,也可能会导致本地360软件过载,从而影响整个计算机资源的过度消耗。因此,建议在采集数据时,可以
2. 第三方测试
经第三方机构使用国内外数十种病毒检测引擎识别,Jisouke GooSeeker是一款安全无毒的软件,以下为测试报告(原报告可通过查看)
查看全部
集搜客网页抓取软件(1.360用户安装和使用集搜客攻略图所示:1.3原因分析
)
近日,极速客技术支持中心收到了部分360安全卫士用户的反馈。在安装和使用极速客的过程中,我们遇到了一些由于360导致的误报,比如服务器连接失败、个别文件被删除、安装过程中不断出现360警告信息等问题。这些问题一直困扰着部分用户,影响了他们正常的数据采集。本文给出了应对措施,并附上Jisouke上第三方检测机构的检测报告。
1.360用户安装使用jisoke策略1.1 安装过程中的警告信息
如下所示:
当出现此警告信息时,请点击“更多”下的“允许该程序的所有操作”,如下图:
1.2 使用 Firefox 浏览器或使用 MS/DS 计算机时,会出现警告消息
如下所示:
当出现此警告信息时,请点击“更多”下的“允许该程序的所有操作”,如下图:
1.3 原因分析
以下分析基于我们长期的观察(因为观察到的对象没有公开的算法):由于360安全卫士默认开启了云网页检测,在抓取数据时,会出现大量抓取的网页或者其他特性可能会被发送到360进行检测,也可能会导致本地360软件过载,从而影响整个计算机资源的过度消耗。因此,建议在采集数据时,可以
2. 第三方测试
经第三方机构使用国内外数十种病毒检测引擎识别,Jisouke GooSeeker是一款安全无毒的软件,以下为测试报告(原报告可通过查看)
集搜客网页抓取软件(KumquatHandle拥有IE浏即时监听和本地缓存查找、缓存清理于一身,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-04-19 05:37
【概述】
完全免费的绿色软件
【基本介绍】
KumquatHandle是一款完全免费的绿色软件,集IE缓存监控、本地缓存搜索、缓存清理于一体。是您监控、提取IE缓存文件、分析网页文件来源的最佳助手。
平时使用IE浏览器浏览网页时,可能会在网页上遇到一些好看的小视频、预览音乐、图片等。如果你想保存到本地却找不到提供的下载地址,那就试试KumquatHandle吧!
KumquatHandle 有 IE 浏览器 [概览]
完全免费的绿色软件
【基本介绍】
KumquatHandle是一款完全免费的绿色软件,集IE缓存监控、本地缓存搜索、缓存清理于一体。是您监控、提取IE缓存文件、分析网页文件来源的最佳助手。
平时使用IE浏览器浏览网页时,可能会在网页上遇到一些好看的小视频、预览音乐、图片等。如果你想保存到本地却找不到提供的下载地址,那就试试KumquatHandle吧!
KumquatHandle 具有强大的 IE 浏览器缓存实时监控和本地缓存查找功能。可即时监控IE浏览器缓存的最新动态,视频、音乐、图片……不容错过!KumquatHandle 允许您轻松地从缓存中提取数据。文件下载。
【更新日志】
KumquatHandle - Orange Rod IE 缓存分析 V1.0.0
修改软件下载地址,修改软件描述。 查看全部
集搜客网页抓取软件(KumquatHandle拥有IE浏即时监听和本地缓存查找、缓存清理于一身,)
【概述】
完全免费的绿色软件
【基本介绍】
KumquatHandle是一款完全免费的绿色软件,集IE缓存监控、本地缓存搜索、缓存清理于一体。是您监控、提取IE缓存文件、分析网页文件来源的最佳助手。
平时使用IE浏览器浏览网页时,可能会在网页上遇到一些好看的小视频、预览音乐、图片等。如果你想保存到本地却找不到提供的下载地址,那就试试KumquatHandle吧!
KumquatHandle 有 IE 浏览器 [概览]
完全免费的绿色软件
【基本介绍】
KumquatHandle是一款完全免费的绿色软件,集IE缓存监控、本地缓存搜索、缓存清理于一体。是您监控、提取IE缓存文件、分析网页文件来源的最佳助手。
平时使用IE浏览器浏览网页时,可能会在网页上遇到一些好看的小视频、预览音乐、图片等。如果你想保存到本地却找不到提供的下载地址,那就试试KumquatHandle吧!
KumquatHandle 具有强大的 IE 浏览器缓存实时监控和本地缓存查找功能。可即时监控IE浏览器缓存的最新动态,视频、音乐、图片……不容错过!KumquatHandle 允许您轻松地从缓存中提取数据。文件下载。
【更新日志】
KumquatHandle - Orange Rod IE 缓存分析 V1.0.0
修改软件下载地址,修改软件描述。
集搜客网页抓取软件(import.io:大数据采集软件集搜客GooSeeker对比说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-04-18 02:03
可视化数据采集器import.io与吉索客评测对比 最近国外一款大数据采集软件import.io比较火。在获得90万美元天使轮融资后,近日又获得了1300万美元的A轮融资,引起了众多投资者的关注。笔者也很好奇使用和体验import.io的神奇功能。我是中国大数据采集软件合集GooSeeker的老用户。,所以我喜欢将两者放在一起比较。下面,我将比较和解释最令人印象深刻的功能,对应于import.io的四大特性:Magic、Extractor、Crawler、Connector,并分别进行评估。对数据比较感兴趣的采集,希望能起到吸点新意的作用,一起来分析一下data采集的技术亮点。魔法——就像魔法“魔法”这个词的本义一样,import.io 赋予了魔法一个神奇的功能。只要用户输入 URL,Magic 工具就可以神奇的将网页中的数据整齐、标准地抓取。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。Magic 工具可以神奇地整齐、标准地捕捉网页中的数据。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。Magic 工具可以神奇地整齐、标准地捕捉网页中的数据。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。
当然,还有很多页面几乎没有采集可以下载,比如新浪微博。反正我觉得很神奇:有的网址输入后等待时间短,有的网址输入后等待时间长。真的有人在后台执行 采集 规则吗?图1:Magic自动抓包示例总结:优点:适应任意URL,操作非常简单,自动采集、采集结果可视化。缺点:不能选择具体数据,不能自动翻页采集(没用吗?)。GooSeeker的天眼和千面系列——吉搜客的天眼和千面分别是针对电商和微博发布的数据采集方便的GUI界面,只要输入网址,目标数据可以规范整齐采集 @采集下来。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。微博各种数据的管理接口),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息为采集,如微博内容、转发、评论等数据. 图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。微博各种数据的管理接口),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息为采集,如微博内容、转发、评论等数据. 图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。
优点:操作非常简单,可以自动翻页采集,微博上能看到的重要字段都采集了。缺点:采集数据字段有限,只有采集GooSeeker官方限定网站。从上面的分析可以看出,Magic GooSeeker的天眼和千面操作非常简单,基本上都是纯傻瓜式操作,非常适合只想关注业务问题而不关注业务问题的用户想被技术问题分心。,也是纯白学习数据采集和使用数据结果的一个很好的起点。但是,Magic 在采集 的结果可视化方面比天眼和千眼具有更广泛的适用性。缺点是 采集 数据量大的场景不可控,而天眼和千面则专注于几个主流网站,优势主要体现在能够完成大量数据采集,比如专业市场研究或消费者研究团队需要数百万或数千万的数据,只要你运行足够多的网络爬虫,不会因为采集的数量而阻碍你的数据研究。Extractor (import.io) VS 排序框(collector) Extractor—— Extractor 翻译的时候是个提取器。如果从一个实体的角度来理解,它就是一个从网站中逐一提取想要的信息的小程序(可能是一组脚本);如果按照采集targets 来理解,它是特定网页结构的采集规则。
如图:import.io 的Extractor 很像修改后的浏览器。在工具栏中输入 URL。网页显示出来后,在浏览器中选择要抓取的数据,然后单页就可以用相同的结构进行结构化了。整列数据可以采集 向下排序。图3:Extractor提取数据示例优点:灵活采集,操作简单,可视化程度高。缺点:采集数据的结构化程度很高,对于结构化程度较差的数据,采集不能很好的表现。GooSeeker Organizer - Jisouke 声称是“构建一个盒子并将你想要的内容放入其中”。这个盒子就是所谓的组织者。原理是将需要提取的信息一个一个拖入框内并映射到该框整理好后,吉索克程序可以自动生成提取器(脚本程序),提取器自动存储在云服务器,可以分发给世界各地的网络爬虫进行提取。如图4所示,import.io顶部的一个工具栏在GooSeeker中展开成一个工作台,在工作台上创建一个盒子,然后通过映射操作将网页上的内容扔到盒子里。把你想要的东西扔进盒子里。原理看似简单,但面对大盒子界面和众多HTML节点,对于新手来说有点压力。当然,界面复杂换来的是能够处理更复杂的情况,因为有更多可用的控件。图4:从排序框中提取数据示例优点:提取精度可以微调,提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。
Crawler (import.io) VS Crawler Route (GooSeeker) Crawler—— Crawler 字面意思是网络爬虫。顾名思义,就是在深度和广度上进行扩展,以便采集更多的数据。Crawler在Extractor的基础上实现了自动翻页功能。假设你想要采集网页数据有100个页面,import.io的爬虫采集可以一键下载这100个页面的信息,那么具体的采集流程是什么?为了实现,笔者带大家简单了解一下爬虫的采集流程。如图5所示,以同城58的租房信息为例,搜索关键词后,一共找到N页租房信息,以提取这些租房信息。爬虫的操作如下:(1)
图 6:爬虫添加页面示例 图 7:爬虫训练样本完成 Import.io 的爬虫训练过程 操作非常简单易懂。只需要选择几个结构相同的页面进行测试,相当于告诉爬虫,我就是采集这些相似页面的信息。爬虫理解了这些需求后,就可以下载相同结构采集的信息了,但是也会有一些小问题,当有些字段是细微变化的时候,因为和需要的数据不同在之前的训练中是采集,这个信息会被漏掉,所以Crawler比较适合结构很固定的页面。总结一下:优点:灵活采集,操作简单,采集 流程可视化缺点:继承Extractor的缺点,对数据结构要求高。GooSeeker爬虫路线 - 吉索克的爬虫路线的实现是基于排序框的。原理与Crawler基本相同。类似,但适应性更强,具有操作相对复杂的负面影响。让我们首先回顾一下组织盒子的概念。GooSeeker一直声称是“打造一个盒子,把你需要的内容放进去”。这个概念非常简单。您可以直观地选择所需的 Web 内容并将其存储在一个盒子中。如图8所示,以采集京东手机信息为例,如果要采集手机信息数据的所有页面,操作如下: 创建一个排序框,
不过操作可不是这句话那么简单,而是:在排序框中创建字段,这些字段称为“爬取内容”,也就是网页上的内容要扔到这些字段中,在DOM上选择tree to 将捕获的节点映射到一个字段。既然它说“建立一个盒子并放入你需要的东西”,你为什么不真的在视觉上这样做呢?这个地方需要改进,敬请期待即将到来的新版本中提供的直观注释功能。(2)构造爬虫路线,将“下一页”映射为标记线索(如图8),设置完成后,保存后可自动获取所有页面的信息采集@ >. 这个虽然过程说起来简单,但是操作起来相比Crawer还是有点不直观。它需要做几个简单的映射,即告诉爬虫:“这里是我要点击的”、“这里是我要提取的”,如下图,主要操作是针对数字做的对于 HTML DOM,用户最好有一个简单的 HTML 基础,这样 DOM 节点就可以准确定位,而不仅限于可见文本。图 8:履带式转弯原理页面示例优势:采集精度高,应用范围广。缺点:可视化效果一般,需要学习练习才能上手。综上所述,Import.io的Crawler和GooSeeker的爬虫路由主要完成了网络爬虫的爬取范围和深度的扩展上面的任务,我们只以翻页为例,
爬虫的操作比较简单,但适应性也比较窄,对网站的结构一致性要求比较高,而爬虫路由的功能相对比较强大,可以适应各种复杂的网站,但操作也比较复杂。连接器(import.io) VS 连续点击(采集客户) 连接器—— import.io 连接器是在网页上做动作,主要是为了URL不变,但信息在深层页面. 需要做完才可以显示,但是页面的url没有变化,大大增加了采集数据的难度,因为即使配置了规则,爬虫进入的页面也是初始的页面,不能是 采集 @采集 来定位信息,而连接器的存在就是为了解决这些问题。Connector可以记录这个点击过程,然后给目标页面的信采集也以58同城租房信息为例来测试Connector功能的可操作性。(1)点击可以找到你需要的信息采集所在的页面。如图所示,Connector可以记录用户每次的点击行为。 图9:Connector示例operation (2) 在目标页面建立规则并提取信息。到达目标页面后,需要做的操作和前面一样,提取需要的信息采集@ >.通过动手实践发现,连续点击的失败率比较高,如果是搜索,
如果可能的话,读者可以自己尝试一下,看看究竟是什么原因造成的。有没有似曾相识的感觉?没错,它有点像网络测试工具。它记录动作并回放它们。用户体验非常好。录制有时会失败。似乎有一些代价。估计还是定位不准的问题。当你用Later进行录制时,当网页的HTML DOM稍有变化时,动作可能会做错地方。优点:操作简单,采集过程完全可视化。缺点:点击动作最多只能点击10次,功能比较单一。同时,从使用情况来看,连接器录音功能的故障率很高,很多情况下运行失败,这可能是直观可视化的代价。GooSeeker 连续点击 - GooSeeker 连续点击的功能和它的名字完全一样。实现点击和采集的功能,结合爬虫路由,可以产生更强大的采集效果。这是一个比较高级的收客功能,会产生很多意想不到的采集方式,这里简单举例。如图10所示,到采集微博个人相关信息,因为这些数据必须通过将鼠标放在人物头像上来显示,都需要使用吉索客的连续点击功能。操作如下:采集目标字段,先定位网页,采集字段为采集,方法同上,不再赘述。
不像直观的录制那么简单,需要点击“创建”按钮,创建一个动作,指定点击的位置(一个web节点,用xpath表示),指定什么样的动作,根据需要设置一些高级选项. 如图 11 所示,GooSeeker 也相当于记录了一组动作,也可以重新排序或添加或删除。从图11中可以看出,类似录制过程的界面并没有那么亲民。再次看到 GooSeeker 的特点: 严谨的制作工具 图 10:连续点击操作示例 图 11:连续动作的排列界面 优点:功能强大,采集强大。缺点:上手比较困难,操作比较复杂。总而言之,进口。io Connector在操作上依然坚持一贯的风格,简单易用,Jisouke也再次给人“生产工具”的感觉。在连续动作的功能上,两者基本一致。通过以上对比,相信大家对大数据采集软件import.io的概念有了一定的了解。从各种功能的对比来看,特点主要体现在可视化、易学、操作简单。致力于打造纯傻瓜式操作的采集软件。集搜客的特点主要体现在半可视化、功能齐全、采集能力强,致力于为用户提供完整强大的数据采集功能。总之,两者各有千秋,两者都是非常好的数据采集软件。最后,有兴趣的读者可以去深入体验和研究一下,因为两者所宣称的价值,其实不仅仅是一个软件工具,而是“将互联网数据结构化转换,把网络变成所有人的数据库”的目标。希望以后有机会分享这种经验。 查看全部
集搜客网页抓取软件(import.io:大数据采集软件集搜客GooSeeker对比说明)
可视化数据采集器import.io与吉索客评测对比 最近国外一款大数据采集软件import.io比较火。在获得90万美元天使轮融资后,近日又获得了1300万美元的A轮融资,引起了众多投资者的关注。笔者也很好奇使用和体验import.io的神奇功能。我是中国大数据采集软件合集GooSeeker的老用户。,所以我喜欢将两者放在一起比较。下面,我将比较和解释最令人印象深刻的功能,对应于import.io的四大特性:Magic、Extractor、Crawler、Connector,并分别进行评估。对数据比较感兴趣的采集,希望能起到吸点新意的作用,一起来分析一下data采集的技术亮点。魔法——就像魔法“魔法”这个词的本义一样,import.io 赋予了魔法一个神奇的功能。只要用户输入 URL,Magic 工具就可以神奇的将网页中的数据整齐、标准地抓取。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。Magic 工具可以神奇地整齐、标准地捕捉网页中的数据。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。Magic 工具可以神奇地整齐、标准地捕捉网页中的数据。如图1所示,输入58同城租房信息URL后,Magic会自动采集网页数据,操作简单。但是可以看到可能会漏掉一些栏目,每页都需要点击“下一页”进行采集,无法自动翻页。
当然,还有很多页面几乎没有采集可以下载,比如新浪微博。反正我觉得很神奇:有的网址输入后等待时间短,有的网址输入后等待时间长。真的有人在后台执行 采集 规则吗?图1:Magic自动抓包示例总结:优点:适应任意URL,操作非常简单,自动采集、采集结果可视化。缺点:不能选择具体数据,不能自动翻页采集(没用吗?)。GooSeeker的天眼和千面系列——吉搜客的天眼和千面分别是针对电商和微博发布的数据采集方便的GUI界面,只要输入网址,目标数据可以规范整齐采集 @采集下来。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。如图2:显示博主的采集工具(微博各种数据都有采集管理界面),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息是采集,比如微博内容、转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。微博各种数据的管理接口),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息为采集,如微博内容、转发、评论等数据. 图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。微博各种数据的管理接口),进入博主首页的链接,可以调度爬虫,博主可以首页下的信息为采集,如微博内容、转发、评论等数据. 图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。转发、评论等数据。图2:GooSeeker微博博主采集的示例界面也很简单。与 Import.io 相比,最大的不同是用户自己运行爬虫组。如果采集的量很大,多运行一些,可以直接得到原创数据,是本地硬盘上经过结构化和转换后的XML格式的结果文件。
优点:操作非常简单,可以自动翻页采集,微博上能看到的重要字段都采集了。缺点:采集数据字段有限,只有采集GooSeeker官方限定网站。从上面的分析可以看出,Magic GooSeeker的天眼和千面操作非常简单,基本上都是纯傻瓜式操作,非常适合只想关注业务问题而不关注业务问题的用户想被技术问题分心。,也是纯白学习数据采集和使用数据结果的一个很好的起点。但是,Magic 在采集 的结果可视化方面比天眼和千眼具有更广泛的适用性。缺点是 采集 数据量大的场景不可控,而天眼和千面则专注于几个主流网站,优势主要体现在能够完成大量数据采集,比如专业市场研究或消费者研究团队需要数百万或数千万的数据,只要你运行足够多的网络爬虫,不会因为采集的数量而阻碍你的数据研究。Extractor (import.io) VS 排序框(collector) Extractor—— Extractor 翻译的时候是个提取器。如果从一个实体的角度来理解,它就是一个从网站中逐一提取想要的信息的小程序(可能是一组脚本);如果按照采集targets 来理解,它是特定网页结构的采集规则。
如图:import.io 的Extractor 很像修改后的浏览器。在工具栏中输入 URL。网页显示出来后,在浏览器中选择要抓取的数据,然后单页就可以用相同的结构进行结构化了。整列数据可以采集 向下排序。图3:Extractor提取数据示例优点:灵活采集,操作简单,可视化程度高。缺点:采集数据的结构化程度很高,对于结构化程度较差的数据,采集不能很好的表现。GooSeeker Organizer - Jisouke 声称是“构建一个盒子并将你想要的内容放入其中”。这个盒子就是所谓的组织者。原理是将需要提取的信息一个一个拖入框内并映射到该框整理好后,吉索克程序可以自动生成提取器(脚本程序),提取器自动存储在云服务器,可以分发给世界各地的网络爬虫进行提取。如图4所示,import.io顶部的一个工具栏在GooSeeker中展开成一个工作台,在工作台上创建一个盒子,然后通过映射操作将网页上的内容扔到盒子里。把你想要的东西扔进盒子里。原理看似简单,但面对大盒子界面和众多HTML节点,对于新手来说有点压力。当然,界面复杂换来的是能够处理更复杂的情况,因为有更多可用的控件。图4:从排序框中提取数据示例优点:提取精度可以微调,提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。提取字段灵活,也适用于复杂的网页。缺点:可视化效果一般,需要简单的HTML基础知识信息字段的功能,Extractor操作起来比较简单直观,适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会有无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。适合一些简单结构化的URL,但是对于一些稍微复杂的URL,Extractor会出现无法提取的问题。这时,吉搜客分拣箱的优势就凸显出来了。现在,在特别复杂的情况下,您还可以使用自定义 xpath 来定位数据。
Crawler (import.io) VS Crawler Route (GooSeeker) Crawler—— Crawler 字面意思是网络爬虫。顾名思义,就是在深度和广度上进行扩展,以便采集更多的数据。Crawler在Extractor的基础上实现了自动翻页功能。假设你想要采集网页数据有100个页面,import.io的爬虫采集可以一键下载这100个页面的信息,那么具体的采集流程是什么?为了实现,笔者带大家简单了解一下爬虫的采集流程。如图5所示,以同城58的租房信息为例,搜索关键词后,一共找到N页租房信息,以提取这些租房信息。爬虫的操作如下:(1)
图 6:爬虫添加页面示例 图 7:爬虫训练样本完成 Import.io 的爬虫训练过程 操作非常简单易懂。只需要选择几个结构相同的页面进行测试,相当于告诉爬虫,我就是采集这些相似页面的信息。爬虫理解了这些需求后,就可以下载相同结构采集的信息了,但是也会有一些小问题,当有些字段是细微变化的时候,因为和需要的数据不同在之前的训练中是采集,这个信息会被漏掉,所以Crawler比较适合结构很固定的页面。总结一下:优点:灵活采集,操作简单,采集 流程可视化缺点:继承Extractor的缺点,对数据结构要求高。GooSeeker爬虫路线 - 吉索克的爬虫路线的实现是基于排序框的。原理与Crawler基本相同。类似,但适应性更强,具有操作相对复杂的负面影响。让我们首先回顾一下组织盒子的概念。GooSeeker一直声称是“打造一个盒子,把你需要的内容放进去”。这个概念非常简单。您可以直观地选择所需的 Web 内容并将其存储在一个盒子中。如图8所示,以采集京东手机信息为例,如果要采集手机信息数据的所有页面,操作如下: 创建一个排序框,
不过操作可不是这句话那么简单,而是:在排序框中创建字段,这些字段称为“爬取内容”,也就是网页上的内容要扔到这些字段中,在DOM上选择tree to 将捕获的节点映射到一个字段。既然它说“建立一个盒子并放入你需要的东西”,你为什么不真的在视觉上这样做呢?这个地方需要改进,敬请期待即将到来的新版本中提供的直观注释功能。(2)构造爬虫路线,将“下一页”映射为标记线索(如图8),设置完成后,保存后可自动获取所有页面的信息采集@ >. 这个虽然过程说起来简单,但是操作起来相比Crawer还是有点不直观。它需要做几个简单的映射,即告诉爬虫:“这里是我要点击的”、“这里是我要提取的”,如下图,主要操作是针对数字做的对于 HTML DOM,用户最好有一个简单的 HTML 基础,这样 DOM 节点就可以准确定位,而不仅限于可见文本。图 8:履带式转弯原理页面示例优势:采集精度高,应用范围广。缺点:可视化效果一般,需要学习练习才能上手。综上所述,Import.io的Crawler和GooSeeker的爬虫路由主要完成了网络爬虫的爬取范围和深度的扩展上面的任务,我们只以翻页为例,
爬虫的操作比较简单,但适应性也比较窄,对网站的结构一致性要求比较高,而爬虫路由的功能相对比较强大,可以适应各种复杂的网站,但操作也比较复杂。连接器(import.io) VS 连续点击(采集客户) 连接器—— import.io 连接器是在网页上做动作,主要是为了URL不变,但信息在深层页面. 需要做完才可以显示,但是页面的url没有变化,大大增加了采集数据的难度,因为即使配置了规则,爬虫进入的页面也是初始的页面,不能是 采集 @采集 来定位信息,而连接器的存在就是为了解决这些问题。Connector可以记录这个点击过程,然后给目标页面的信采集也以58同城租房信息为例来测试Connector功能的可操作性。(1)点击可以找到你需要的信息采集所在的页面。如图所示,Connector可以记录用户每次的点击行为。 图9:Connector示例operation (2) 在目标页面建立规则并提取信息。到达目标页面后,需要做的操作和前面一样,提取需要的信息采集@ >.通过动手实践发现,连续点击的失败率比较高,如果是搜索,
如果可能的话,读者可以自己尝试一下,看看究竟是什么原因造成的。有没有似曾相识的感觉?没错,它有点像网络测试工具。它记录动作并回放它们。用户体验非常好。录制有时会失败。似乎有一些代价。估计还是定位不准的问题。当你用Later进行录制时,当网页的HTML DOM稍有变化时,动作可能会做错地方。优点:操作简单,采集过程完全可视化。缺点:点击动作最多只能点击10次,功能比较单一。同时,从使用情况来看,连接器录音功能的故障率很高,很多情况下运行失败,这可能是直观可视化的代价。GooSeeker 连续点击 - GooSeeker 连续点击的功能和它的名字完全一样。实现点击和采集的功能,结合爬虫路由,可以产生更强大的采集效果。这是一个比较高级的收客功能,会产生很多意想不到的采集方式,这里简单举例。如图10所示,到采集微博个人相关信息,因为这些数据必须通过将鼠标放在人物头像上来显示,都需要使用吉索客的连续点击功能。操作如下:采集目标字段,先定位网页,采集字段为采集,方法同上,不再赘述。
不像直观的录制那么简单,需要点击“创建”按钮,创建一个动作,指定点击的位置(一个web节点,用xpath表示),指定什么样的动作,根据需要设置一些高级选项. 如图 11 所示,GooSeeker 也相当于记录了一组动作,也可以重新排序或添加或删除。从图11中可以看出,类似录制过程的界面并没有那么亲民。再次看到 GooSeeker 的特点: 严谨的制作工具 图 10:连续点击操作示例 图 11:连续动作的排列界面 优点:功能强大,采集强大。缺点:上手比较困难,操作比较复杂。总而言之,进口。io Connector在操作上依然坚持一贯的风格,简单易用,Jisouke也再次给人“生产工具”的感觉。在连续动作的功能上,两者基本一致。通过以上对比,相信大家对大数据采集软件import.io的概念有了一定的了解。从各种功能的对比来看,特点主要体现在可视化、易学、操作简单。致力于打造纯傻瓜式操作的采集软件。集搜客的特点主要体现在半可视化、功能齐全、采集能力强,致力于为用户提供完整强大的数据采集功能。总之,两者各有千秋,两者都是非常好的数据采集软件。最后,有兴趣的读者可以去深入体验和研究一下,因为两者所宣称的价值,其实不仅仅是一个软件工具,而是“将互联网数据结构化转换,把网络变成所有人的数据库”的目标。希望以后有机会分享这种经验。
集搜客网页抓取软件(集搜客软件去资源库下载规则模板,免去做规则烦恼)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-04-17 19:01
海量规则模板,免去制定规则的烦恼
如果你不知道如何制定规则但真的想直接抓取数据,或者你是初学者,认为制定规则困难且耗时,可以直接从 Jisoke 的资源库下载规则模板并抓取直接数据,体验规则是如何定义和运行的,让你改变对网络爬虫的理解。您无需学习 Python、Java、C++ 等编程语言即可捕获网页数据。可以使用吉搜客软件从资源库中下载规则模板,轻松抓取。获取海量网络数据。
去极搜客资源库,轻松抓取海量数据
一键套用规则模板,只需添加网址线索,即可无限次抓取数据。想想就有点激动! ! !
集搜客资源库拥有海量规则模板,提供微信、微博、电商、新闻、论坛、行业等各种采集规则模板网站。与初学者制定的规则相比,失败率更高。这些规则模板由熟练使用软件的技术大师制作。他们制定的规则解决了许多初学者忽略或无法解决的问题。所以,规则的质量是非常有保证的,而且已经被证明是非常实用的,所以急于获取数据或者不使用软件的人可以放心的下载这些规则模板。
根据网站的行业分类,通过关键词搜索,通过URL搜索,就可以找到你想要的规则模板,一键下载就可以直接用它来抓取数据您需要在 DS 计数器上右键单击规则名称,选择“管理潜在客户”->“添加”URL 潜在客户(无限制),您可以使用它们来抓取新数据。
下载规则需要积分,积分不够怎么办?
积分策略(详见积分规则):
1、注册可得20分
2、完整的个人信息可以获得10分
3、每日签到2分/天,评论1分/条
4、在“个人中心”->“我的资源”发布规则资源赚取积分
5、充值买积分,1元=10积分
无论网页结构多么复杂,总有人可以帮你解决。欢迎来到极速客社区发问题/打赏任务,必有极速客大神来救你。 查看全部
集搜客网页抓取软件(集搜客软件去资源库下载规则模板,免去做规则烦恼)
海量规则模板,免去制定规则的烦恼
如果你不知道如何制定规则但真的想直接抓取数据,或者你是初学者,认为制定规则困难且耗时,可以直接从 Jisoke 的资源库下载规则模板并抓取直接数据,体验规则是如何定义和运行的,让你改变对网络爬虫的理解。您无需学习 Python、Java、C++ 等编程语言即可捕获网页数据。可以使用吉搜客软件从资源库中下载规则模板,轻松抓取。获取海量网络数据。
去极搜客资源库,轻松抓取海量数据
一键套用规则模板,只需添加网址线索,即可无限次抓取数据。想想就有点激动! ! !
集搜客资源库拥有海量规则模板,提供微信、微博、电商、新闻、论坛、行业等各种采集规则模板网站。与初学者制定的规则相比,失败率更高。这些规则模板由熟练使用软件的技术大师制作。他们制定的规则解决了许多初学者忽略或无法解决的问题。所以,规则的质量是非常有保证的,而且已经被证明是非常实用的,所以急于获取数据或者不使用软件的人可以放心的下载这些规则模板。
根据网站的行业分类,通过关键词搜索,通过URL搜索,就可以找到你想要的规则模板,一键下载就可以直接用它来抓取数据您需要在 DS 计数器上右键单击规则名称,选择“管理潜在客户”->“添加”URL 潜在客户(无限制),您可以使用它们来抓取新数据。
下载规则需要积分,积分不够怎么办?
积分策略(详见积分规则):
1、注册可得20分
2、完整的个人信息可以获得10分
3、每日签到2分/天,评论1分/条
4、在“个人中心”->“我的资源”发布规则资源赚取积分
5、充值买积分,1元=10积分
无论网页结构多么复杂,总有人可以帮你解决。欢迎来到极速客社区发问题/打赏任务,必有极速客大神来救你。
集搜客网页抓取软件(V10及更高数据管家—增强版网络爬虫老版本对应教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2022-04-17 11:25
支持软件版本:V10及更高版本数据管理器-增强型网络爬虫
旧版对应教程:V9及更低版本吉索克网络爬虫对应教程为《采集图片网址及下载图片-以途牛旅游网为例》
即搜客数据管理器可以快速抓取网页上某个区域的所有图片或视频,并保存在本地。而不是像《采集图片网址和图片下载(二)—下载途牛多图》)中介绍的定义和示例复制规则那样下载常规图片。
例如,京东搜索“T恤”后会得到一个列表页面。可以抓取整个列表区域中的所有图像。
我们用这个例子来说明操作过程。视频捕获的操作是相同的。
案例任务:所有图表(点击下载)
示例 URL:%E6%A1%96&enc=utf-8&suggest=1.def.0.base&wq=txue&pvid=604cc4d250ad43828165f439a2e7d907
采集内容:列表区域的所有图片
1. 下载并安装 Jisoke 数据管理器
2. 加载网页,进入任务定义模式
在数据管理器中打开网页为采集,网页加载完毕,点击左侧边栏的“+”号进入任务定义模式。
3. 设置下载图片
点击这个列表区域中的任何图片或者文字,都会对应下面DOM窗口中的一个节点,沿着这个节点向上查找,直到有一个可以选择整个T恤列表区域的节点,然后右击当前节点,做内容映射。
您还需要输入数据表的名称和字段的名称。(这些名称是任意的,但最好是有意义的)。
在左侧的工作台上,单击“列表顶部”字段的设置
检查下载图像,然后单击确定。
4. 保存任务和 采集 数据
点击测试看看会不会报错。如果没有报错,保存任务。然后单击“获取数据”按钮开始采集。
5. 查看图片
采集下载的图片一般保存在电脑DataScraperWorks目录下的PageContentDir目录下。
我们有 采集 共有 111 张图片。
6.设置翻页采集多页图片
如果需要采集多页图片,可以按照教程“翻页设置”,在第3步后添加翻页设置,然后按照第4步保存任务和采集数据。
注意,要爬取一个区域内的所有图片,一般需要滚动屏幕。在数据管家设置中,打开滚动屏幕。
Part 1 文章: "采集 图片 URL 和下载图片--下载途牛多图" Part 2 文章: "使用网络爬虫软件自动下载网页文件" 查看全部
集搜客网页抓取软件(V10及更高数据管家—增强版网络爬虫老版本对应教程)
支持软件版本:V10及更高版本数据管理器-增强型网络爬虫
旧版对应教程:V9及更低版本吉索克网络爬虫对应教程为《采集图片网址及下载图片-以途牛旅游网为例》
即搜客数据管理器可以快速抓取网页上某个区域的所有图片或视频,并保存在本地。而不是像《采集图片网址和图片下载(二)—下载途牛多图》)中介绍的定义和示例复制规则那样下载常规图片。
例如,京东搜索“T恤”后会得到一个列表页面。可以抓取整个列表区域中的所有图像。
我们用这个例子来说明操作过程。视频捕获的操作是相同的。
案例任务:所有图表(点击下载)
示例 URL:%E6%A1%96&enc=utf-8&suggest=1.def.0.base&wq=txue&pvid=604cc4d250ad43828165f439a2e7d907
采集内容:列表区域的所有图片
1. 下载并安装 Jisoke 数据管理器
2. 加载网页,进入任务定义模式
在数据管理器中打开网页为采集,网页加载完毕,点击左侧边栏的“+”号进入任务定义模式。
3. 设置下载图片
点击这个列表区域中的任何图片或者文字,都会对应下面DOM窗口中的一个节点,沿着这个节点向上查找,直到有一个可以选择整个T恤列表区域的节点,然后右击当前节点,做内容映射。
您还需要输入数据表的名称和字段的名称。(这些名称是任意的,但最好是有意义的)。
在左侧的工作台上,单击“列表顶部”字段的设置
检查下载图像,然后单击确定。
4. 保存任务和 采集 数据
点击测试看看会不会报错。如果没有报错,保存任务。然后单击“获取数据”按钮开始采集。
5. 查看图片
采集下载的图片一般保存在电脑DataScraperWorks目录下的PageContentDir目录下。
我们有 采集 共有 111 张图片。
6.设置翻页采集多页图片
如果需要采集多页图片,可以按照教程“翻页设置”,在第3步后添加翻页设置,然后按照第4步保存任务和采集数据。
注意,要爬取一个区域内的所有图片,一般需要滚动屏幕。在数据管家设置中,打开滚动屏幕。
Part 1 文章: "采集 图片 URL 和下载图片--下载途牛多图" Part 2 文章: "使用网络爬虫软件自动下载网页文件"
集搜客网页抓取软件(Python网络爬虫内容提取器一文讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-17 11:20
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码就够了证明 Python 的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页中的手机名称和价格被正确抓取
4. 继续阅读
至此,我们通过两篇文章文章演示了如何抓取静态和动态网页内容,均使用xslt一次性从网页中提取出需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。接下来,“1分钟快速生成用于Web内容提取的xslt”将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
5.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第5章:源码下载源码,并替换github源码的URL
文章来源:segmentfault,作者:fullerhua。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
背景 - 系统设置 - 扩展变量 - 移动广告 - 内容正文底部 查看全部
集搜客网页抓取软件(Python网络爬虫内容提取器一文讲解)
1 简介
在 Python 网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类 gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第二部分。第一部分实验用xslt方法提取静态网页内容,一次性转换成xml格式。一个问题仍然存在:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。
2. 动态内容提取技术组件
上一篇python使用xslt提取网页数据,要提取的内容是直接从网页的源码中获取的。但是有些Ajax动态内容在源码中是找不到的,所以需要找到合适的程序库来加载异步或者动态加载的内容,交给本项目的抽取器进行抽取。
Python可以使用selenium来执行javascript,而selenium可以让浏览器自动加载页面并获取需要的数据。Selenium 没有自己的浏览器,可以使用第三方浏览器如 Firefox、Chrome 等,也可以使用 PhantomJS 等无头浏览器在后台执行。
三、源码及实验过程
假设我们要抓取京东手机页面的手机名称和价格(网页源码中找不到价格),如下图:
Step 1:利用吉搜Kemoji直观的标注功能,可以非常快速的自动生成一个调试好的抓取规则,其实就是一个标准的xslt程序,如下图,将生成的xslt程序复制到程序中的下面。注:本文仅记录实验过程。在实际系统中,将使用各种方法将 xslt 程序注入到内容提取器中。
第二步:执行以下代码(windows10下测试通过,python3.2),请注意:xslt是一个比较长的字符串,如果删除这个字符串,只有几行代码就够了证明 Python 的强大
#/usr/bin/python
from urllib import request
from lxml import etree
from selenium import webdriver
import time
# 京东手机商品页面
url = "http://item.jd.com/1312640.html"
# 下面的xslt是通过集搜客的谋数台图形界面自动生成的
xslt_root = etree.XML("""\
""")
# 使用webdriver.PhantomJS
browser = webdriver.PhantomJS(executable_path='C:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe')
browser.get(url)
time.sleep(3)
transform = etree.XSLT(xslt_root)
# 执行js得到整个dom
html = browser.execute_script("return document.documentElement.outerHTML")
doc = etree.HTML(html)
# 用xslt从dom中提取需要的字段
result_tree = transform(doc)
print(result_tree)
第三步:如下图所示,网页中的手机名称和价格被正确抓取
4. 继续阅读
至此,我们通过两篇文章文章演示了如何抓取静态和动态网页内容,均使用xslt一次性从网页中提取出需要的内容。事实上,xslt 是一种相对复杂的编程语言。如果你手动写xslt,那么最好写成离散的xpath。如果这个xslt不是手工写的,而是程序自动生成的,那是有道理的,程序员也不再需要花时间编写和调试抓取规则,这是一项非常耗时耗力的工作。接下来,“1分钟快速生成用于Web内容提取的xslt”将介绍如何生成xslt。
5. Jisouke GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
5.文档修改历史
2016-05-26:V2.0,添加文字说明
2016-05-29:V2.1,增加第5章:源码下载源码,并替换github源码的URL
文章来源:segmentfault,作者:fullerhua。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:sean.li#ucloud.cn(邮箱中#请改为@)进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
背景 - 系统设置 - 扩展变量 - 移动广告 - 内容正文底部
集搜客网页抓取软件(1.《1分钟快速生成用于网页内容提取的xslt模板》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2022-04-15 04:13
1.项目背景
在python即时网络爬虫项目启动说明中,我们讨论了一个数字:程序员在调试内容提取规则上浪费时间,所以我们推出这个项目是为了让程序员从繁琐的调试规则中解放出来,投入更多的高端数据处理工作。
2.解决方案
为了解决这个问题,我们将影响通用性和工作效率的提取器隔离出来,描述数据处理流程图如下:
图中的“可插拔提取器”一定是非常模块化的,所以关键接口是:
3. 提取器代码
可插拔提取器是即时网络爬虫项目的核心组件,定义为一个类:gsExtractor
请从 github 下载 python 源代码文件及其文档
使用模式是这样的:
下面是这个 gsExtractor 类的源代码
#!/usr/bin/python
# -*- coding: utf-8 -*-
# 模块名: gooseeker
# 类名: gsExtractor
# Version: 2.0
# 说明: html内容提取器
# 功能: 使用xslt作为模板,快速提取HTML DOM中的内容。
# released by 集搜客(http://www.gooseeker.com) on May 18, 2016
# github: https://github.com/FullerHua/j ... er.py
from urllib import request
from urllib.parse import quote
from lxml import etree
import time
class gsExtractor(object):
def _init_(self):
self.xslt = ""
# 从文件读取xslt
def setXsltFromFile(self , xsltFilePath):
file = open(xsltFilePath , 'r' , encoding='UTF-8')
try:
self.xslt = file.read()
finally:
file.close()
# 从字符串获得xslt
def setXsltFromMem(self , xsltStr):
self.xslt = xsltStr
# 通过GooSeeker API接口获得xslt
def setXsltFromAPI(self , APIKey , theme, middle=None, bname=None):
apiurl = "http://www.gooseeker.com/api/g ... 3B%2B APIKey +"&theme="+quote(theme)
if (middle):
apiurl = apiurl + "&middle="+quote(middle)
if (bname):
apiurl = apiurl + "&bname="+quote(bname)
apiconn = request.urlopen(apiurl)
self.xslt = apiconn.read()
# 返回当前xslt
def getXslt(self):
return self.xslt
# 提取方法,入参是一个HTML DOM对象,返回是提取结果
def extract(self , html):
xslt_root = etree.XML(self.xslt)
transform = etree.XSLT(xslt_root)
result_tree = transform(html)
return result_tree
4. 使用示例
下面是一个示例程序,演示如何使用 gsExtractor 类提取 GooSeeker 官网的 bbs 帖子列表。这个例子有以下特点
下面是源码,都可以从github下载
#-*_coding:utf8-*-
# 使用gsExtractor类的示例程序
# 访问集搜客论坛,以xslt为模板提取论坛内容
# xslt保存在xslt_bbs.xml中
from urllib import request
from lxml import etree
from gooseeker import gsExtractor
# 访问并读取网页内容
url = "http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
# 生成xsltExtractor对象
bbsExtra = gsExtractor()
# 调用set方法设置xslt内容
bbsExtra.setXsltFromFile("xslt_bbs.xml")
# 调用extract方法提取所需内容
result = bbsExtra.extract(doc)
# 显示提取结果
print(str(result))
提取结果如下图所示:
5. 继续阅读
这篇文章已经解释了提取器的价值和用法,但是并没有说如何生成它。只有快速生成提取器,才能达到节省开发者时间的目的。为网页内容提取生成 xslt 模板"
6. GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史 查看全部
集搜客网页抓取软件(1.《1分钟快速生成用于网页内容提取的xslt模板》)
1.项目背景
在python即时网络爬虫项目启动说明中,我们讨论了一个数字:程序员在调试内容提取规则上浪费时间,所以我们推出这个项目是为了让程序员从繁琐的调试规则中解放出来,投入更多的高端数据处理工作。
2.解决方案
为了解决这个问题,我们将影响通用性和工作效率的提取器隔离出来,描述数据处理流程图如下:
图中的“可插拔提取器”一定是非常模块化的,所以关键接口是:
3. 提取器代码
可插拔提取器是即时网络爬虫项目的核心组件,定义为一个类:gsExtractor
请从 github 下载 python 源代码文件及其文档
使用模式是这样的:
下面是这个 gsExtractor 类的源代码
#!/usr/bin/python
# -*- coding: utf-8 -*-
# 模块名: gooseeker
# 类名: gsExtractor
# Version: 2.0
# 说明: html内容提取器
# 功能: 使用xslt作为模板,快速提取HTML DOM中的内容。
# released by 集搜客(http://www.gooseeker.com) on May 18, 2016
# github: https://github.com/FullerHua/j ... er.py
from urllib import request
from urllib.parse import quote
from lxml import etree
import time
class gsExtractor(object):
def _init_(self):
self.xslt = ""
# 从文件读取xslt
def setXsltFromFile(self , xsltFilePath):
file = open(xsltFilePath , 'r' , encoding='UTF-8')
try:
self.xslt = file.read()
finally:
file.close()
# 从字符串获得xslt
def setXsltFromMem(self , xsltStr):
self.xslt = xsltStr
# 通过GooSeeker API接口获得xslt
def setXsltFromAPI(self , APIKey , theme, middle=None, bname=None):
apiurl = "http://www.gooseeker.com/api/g ... 3B%2B APIKey +"&theme="+quote(theme)
if (middle):
apiurl = apiurl + "&middle="+quote(middle)
if (bname):
apiurl = apiurl + "&bname="+quote(bname)
apiconn = request.urlopen(apiurl)
self.xslt = apiconn.read()
# 返回当前xslt
def getXslt(self):
return self.xslt
# 提取方法,入参是一个HTML DOM对象,返回是提取结果
def extract(self , html):
xslt_root = etree.XML(self.xslt)
transform = etree.XSLT(xslt_root)
result_tree = transform(html)
return result_tree
4. 使用示例
下面是一个示例程序,演示如何使用 gsExtractor 类提取 GooSeeker 官网的 bbs 帖子列表。这个例子有以下特点
下面是源码,都可以从github下载
#-*_coding:utf8-*-
# 使用gsExtractor类的示例程序
# 访问集搜客论坛,以xslt为模板提取论坛内容
# xslt保存在xslt_bbs.xml中
from urllib import request
from lxml import etree
from gooseeker import gsExtractor
# 访问并读取网页内容
url = "http://www.gooseeker.com/cn/forum/7"
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
# 生成xsltExtractor对象
bbsExtra = gsExtractor()
# 调用set方法设置xslt内容
bbsExtra.setXsltFromFile("xslt_bbs.xml")
# 调用extract方法提取所需内容
result = bbsExtra.extract(doc)
# 显示提取结果
print(str(result))
提取结果如下图所示:
5. 继续阅读
这篇文章已经解释了提取器的价值和用法,但是并没有说如何生成它。只有快速生成提取器,才能达到节省开发者时间的目的。为网页内容提取生成 xslt 模板"
6. GooSeeker开源代码下载源
1.GooSeeker开源Python网络爬虫GitHub源码
7. 文档修改历史

