
采集 工具
沈阳市政府特殊津贴信息采集工具 使用指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2022-05-08 08:40
沈阳市政府特殊津贴信息采集工具
使用指南
沈阳市政府特殊津贴信息采集工具是免安装应用软件,用户直接使用浏览器操作,自行填写信息。数据采集软件将数据文档通过加密处理,自动转换成标准电子文档,用户填写完成数据后,下载打印资料。
操作说明:
1、用户使用电脑浏览器(推荐使用:谷歌、火狐、360浏览器),地址栏输入网址::88,打开软件界面。因为需要上传附件,本软件需要用电脑端填写,不支持使用手机端操作。
2、首次填写数据用户,点击“首次注册”选项,按照数据项要求,依次填写内容。第一步填写页面,系统自动生成6位数字识别码,请务必牢记,后续登录软件系统使用,本软件登录的用户名为:用户身份证号码,密码为:系统生成的识别码,识别码通过短信形式发送到所填写手机里。
填写内容包含:基本信息、教育经历、工作经历、获得重要奖励、个人荣誉、代表性著作和论文、取得专利、获基金资助情况、完成项目、现承担项目、主要业绩综述等。
按照上述顺序,用户依次填写信息,并上传证明材料图片,图片格式为jpg文件,每张图片小于500K,由于填写内容及上传文件多,为保证填报顺畅,请用户提前准备文档资料及证明材料图片。
用户填写数据项后,点击“选择文件”上传证明图片,页面下方显示本项所填写的内容。检查无误后,点击“完成后进入下一项”字样进行下一项填写。
3、填写完所有项后,点击“预览下载报名表”,可查看所填写的项目及证明图片,无误后下载或者打印资料。如果信息有误,可在申报截止日期前,修改所填写的项目。
4、登录系统修改信息的用户,浏览器输入网址,打开操作界面,点击“修改信息登录”,按照身份证号及系统生成的识别码,登录系统。直接修改项目信息,修改后,点击“修改”按钮,完成修改。或者删除填写信息。
软件技术支持电话:
政策咨询电话: 查看全部
沈阳市政府特殊津贴信息采集工具 使用指南
沈阳市政府特殊津贴信息采集工具
使用指南
沈阳市政府特殊津贴信息采集工具是免安装应用软件,用户直接使用浏览器操作,自行填写信息。数据采集软件将数据文档通过加密处理,自动转换成标准电子文档,用户填写完成数据后,下载打印资料。
操作说明:
1、用户使用电脑浏览器(推荐使用:谷歌、火狐、360浏览器),地址栏输入网址::88,打开软件界面。因为需要上传附件,本软件需要用电脑端填写,不支持使用手机端操作。
2、首次填写数据用户,点击“首次注册”选项,按照数据项要求,依次填写内容。第一步填写页面,系统自动生成6位数字识别码,请务必牢记,后续登录软件系统使用,本软件登录的用户名为:用户身份证号码,密码为:系统生成的识别码,识别码通过短信形式发送到所填写手机里。
填写内容包含:基本信息、教育经历、工作经历、获得重要奖励、个人荣誉、代表性著作和论文、取得专利、获基金资助情况、完成项目、现承担项目、主要业绩综述等。
按照上述顺序,用户依次填写信息,并上传证明材料图片,图片格式为jpg文件,每张图片小于500K,由于填写内容及上传文件多,为保证填报顺畅,请用户提前准备文档资料及证明材料图片。
用户填写数据项后,点击“选择文件”上传证明图片,页面下方显示本项所填写的内容。检查无误后,点击“完成后进入下一项”字样进行下一项填写。
3、填写完所有项后,点击“预览下载报名表”,可查看所填写的项目及证明图片,无误后下载或者打印资料。如果信息有误,可在申报截止日期前,修改所填写的项目。
4、登录系统修改信息的用户,浏览器输入网址,打开操作界面,点击“修改信息登录”,按照身份证号及系统生成的识别码,登录系统。直接修改项目信息,修改后,点击“修改”按钮,完成修改。或者删除填写信息。
软件技术支持电话:
政策咨询电话:
抖音采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 571 次浏览 • 2022-05-07 21:24
可以采集某作者所有作品(含作者喜欢作品)、单个视频作品、某话题挑战下指定数量作品、使用某音乐的指定数量作品。
主要是为了便于作品下载的管理进行了分别保存,同时检测作者、话题挑战、音乐的作品的更新,有新作品时仅下载新作品。
使用过本人前面的“批量采集抖音作品”工具的,控制台的新版本工具可自动迁移数据,当然你也可以继续使用以前的工具。
不再重复介绍了,在这个帖子下载过旧版本工具的自然知道怎么使用。压缩包里也有说明和短链接获取图片及控制台操作使用录像。
最新Python的Gui版已提供,各种作品采集的链接获取方式见网盘中演示录像。
新版本工具下载地址:,访问密码:52pj
蓝奏云盘lanzous无法访问(21.5.13),请用lanzoui访问(本帖链接已更改)
另添加一个百度网盘地址:,提取码: r7c6旧版本工具下载地址(还是原来那个):,访问密码:3345
如果64位版本有问题,可尝试使用32位版本,如果仍不行,可尝试使用XP版本
已提供Python版XP可用版本,VB版Gui版本无需使用了。 查看全部
抖音采集工具
可以采集某作者所有作品(含作者喜欢作品)、单个视频作品、某话题挑战下指定数量作品、使用某音乐的指定数量作品。
主要是为了便于作品下载的管理进行了分别保存,同时检测作者、话题挑战、音乐的作品的更新,有新作品时仅下载新作品。
使用过本人前面的“批量采集抖音作品”工具的,控制台的新版本工具可自动迁移数据,当然你也可以继续使用以前的工具。
不再重复介绍了,在这个帖子下载过旧版本工具的自然知道怎么使用。压缩包里也有说明和短链接获取图片及控制台操作使用录像。
最新Python的Gui版已提供,各种作品采集的链接获取方式见网盘中演示录像。
新版本工具下载地址:,访问密码:52pj
蓝奏云盘lanzous无法访问(21.5.13),请用lanzoui访问(本帖链接已更改)
另添加一个百度网盘地址:,提取码: r7c6旧版本工具下载地址(还是原来那个):,访问密码:3345
如果64位版本有问题,可尝试使用32位版本,如果仍不行,可尝试使用XP版本
已提供Python版XP可用版本,VB版Gui版本无需使用了。
常用的大数据采集工具有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2022-05-07 21:20
大家好,我是梦想家Alex ~
想必大家都知道,大数据的来源多种多样,在大数据时代背景下,如何从大数据中采集出有用的信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效采集大数据,依据采集环境及数据类型选择适当的大数据采集方法及平台至关重要。下面介绍一些常用的大数据采集平台和工具。
1、Flume
Flume作为Hadoop的组件,是由Cloudera专门研发的分布式日志收集系统。尤其近几年随着Flume的不断完善,用户在开发过程中使用的便利性得到很大的改善,Flume现已成为Apache Top项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源上收集数据的能力。
Flume采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据。ZooKeeper本身可保证配置数据的一致性和高可用性。另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master节点之间使用Gossip协议同步数据。
Flume针对特殊场景也具备良好的自定义扩展能力,因此Flume适用于大部分的日常数据采集场景。因为Flume使用JRuby来构建,所以依赖Java运行环境。Flume设计成一个分布式的管道架构,可以看成在数据源和目的地之间有一个Agent的网络,支持数据路由。
Flume支持设置Sink的Failover和加载平衡,这样就可以保证在有一个Agent失效的情况下,整个系统仍能正常收集数据。Flume中传输的内容定义为事件(Event),事件由Headers(包含元数据,即Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发。Flume客户端负责在事件产生的源头把事件发送给Flume的Agent。客户端通常和产生数据源的应用在同一个进程空间。常见的Flume 客户端有Avro、Log4J、Syslog和HTTP Post。
2、Fluentd
Fluentd是另一个开源的数据收集架构,如图1所示。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。通过丰富的插件,可以收集来自各种系统或应用的日志,然后根据用户定义将日志做分类处理。通过Fluentd,可以非常轻易地实现像追踪日志文件并将其过滤后转存到 MongoDB 这样的操作。Fluentd可以彻底地把人从烦琐的日志处理中解放出来。
图1 Fluentd架构
Fluentd具有多个功能特点:安装方便、占用空间小、半结构化数据日志记录、灵活的插件机制、可靠的缓冲、日志转发。Treasure Data公司对该产品提供支持和维护。另外,采用JSON统一数据/日志格式是它的另一个特点。相对Flume,Fluentd配置也相对简单一些。
Fluentd的扩展性非常好,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd具有跨平台的问题,并不支持Windows平台。
Fluentd的Input/Buffer/Output非常类似于Flume的Source/Channel/Sink。Fluentd架构如图2所示。
图2 Fluentd架构
3、Logstash
Logstash是著名的开源数据栈ELK(ElasticSearch,Logstash,Kibana)中的那个L。因为Logstash用JRuby开发,所以运行时依赖JVM。Logstash的部署架构如图3所示,当然这只是一种部署的选项。
图3 Logstash的部署架构
一个典型的Logstash的配置如下,包括Input、Filter的Output的设置。
input {<br /> file {<br /> type =>"Apache-access"<br /> path =>"/var/log/Apache2/other\_vhosts\_access.log"<br /> } <br /> file {<br /> type =>"pache-error"<br /> path =>"/var/log/Apache2/error.log"<br /> }<br />}<br />filter {<br /> grok {<br /> match => {"message"=>"%(COMBINEDApacheLOG)"}<br /> } <br /> date {<br /> match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}<br /> }<br />}<br />output {<br /> stdout {}<br /> Redis {<br /> host=>"192.168.1.289"<br /> data\_type => "list"<br /> key => "Logstash"<br /> }<br />}<br />
几乎在大部分的情况下,ELK作为一个栈是被同时使用的。在你的数据系统使用ElasticSearch的情况下,Logstash是首选。
4、Chukwa
Chukwa是Apache旗下另一个开源的数据收集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和MapReduce来构建(用Java来实现),提供扩展性和可靠性。它提供了很多模块以支持Hadoop集群日志分析。Chukwa同时提供对数据的展示、分析和监视。该项目目前已经不活跃。
Chukwa适应以下需求:
(1)灵活的、动态可控的数据源。
(2)高性能、高可扩展的存储系统。
(3)合适的架构,用于对收集到的大规模数据进行分析。
Chukwa架构如图4所示。
图4 Chukwa架构
5、Scribe
Scribe是Facebook开发的数据(日志)收集系统。其官网已经多年不维护。Scribe为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。当中央存储系统的网络或者机器出现故障时,Scribe会将日志转存到本地或者另一个位置;当中央存储系统恢复后,Scribe会将转存的日志重新传输给中央存储系统。Scribe通常与Hadoop结合使用,用于向HDFS中push(推)日志,而Hadoop通过MapReduce作业进行定期处理。
Scribe架构如图5所示。
图5 Scribe架构
Scribe架构比较简单,主要包括三部分,分别为Scribe agent、Scribe和存储系统。
6、Splunk
在商业化的大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析和处理,以及数据展现的能力。Splunk是一个分布式机器数据平台,主要有三个角色。Splunk架构如图6所示。
图片
图6 Splunk架构
Search:负责数据的搜索和处理,提供搜索时的信息抽取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的收集、清洗、变形,并发送给Indexer。
Splunk内置了对Syslog、TCP/UDP、Spooling的支持,同时,用户可以通过开发 Input和Modular Input的方式来获取特定的数据。在Splunk提供的软件仓库里有很多成熟的数据采集应用,如AWS、数据库(DBConnect)等,可以方便地从云或数据库中获取数据进入Splunk的数据平台做分析。
Search Head和Indexer都支持Cluster的配置,即高可用、高扩展的、但Splunk现在还没有针对Forwarder的Cluster的功能。也就是说,如果有一台Forwarder的机器出了故障,则数据收集也会随之中断,并不能把正在运行的数据收集任务因故障切换(Failover)到其他的Forwarder上。
7、Scrapy
Python的爬虫架构叫Scrapy。Scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和Web抓取架构,用于抓取Web站点并从页面中提取结构化数据。Scrapy的用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个架构,任何人都可以根据需求方便地进行修改。它还提供多种类型爬虫的基类,如BaseSpider、Sitemap爬虫等,最新版本提供对Web 2.0爬虫的支持。
Scrapy运行原理如图7所示。
图片
图7 Scrapy运行原理
Scrapy的整个数据处理流程由Scrapy引擎进行控制。Scrapy运行流程如下:
(1)Scrapy引擎打开一个域名时,爬虫处理这个域名,并让爬虫获取第一个爬取的URL。
(2)Scrapy引擎先从爬虫那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
(3)Scrapy引擎从调度那里获取接下来进行爬取的页面。
(4)调度将下一个爬取的URL返回给引擎,引擎将它们通过下载中间件发送到下载器。
(5)当网页被下载器下载完成以后,响应内容通过下载器中间件被发送到Scrapy引擎。
(6)Scrapy引擎收到下载器的响应并将它通过爬虫中间件发送到爬虫进行处理。
(7)爬虫处理响应并返回爬取到的项目,然后给Scrapy引擎发送新的请求。
(8)Scrapy引擎将抓取到的放入项目管道,并向调度器发送请求。
(9)系统重复第(2)步后面的操作,直到调度器中没有请求,然后断开Scrapy引擎与域之间的联系。
END
点击关注|设为星标|干货速递
往期推荐 查看全部
常用的大数据采集工具有哪些?
大家好,我是梦想家Alex ~
想必大家都知道,大数据的来源多种多样,在大数据时代背景下,如何从大数据中采集出有用的信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效采集大数据,依据采集环境及数据类型选择适当的大数据采集方法及平台至关重要。下面介绍一些常用的大数据采集平台和工具。
1、Flume
Flume作为Hadoop的组件,是由Cloudera专门研发的分布式日志收集系统。尤其近几年随着Flume的不断完善,用户在开发过程中使用的便利性得到很大的改善,Flume现已成为Apache Top项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源上收集数据的能力。
Flume采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据。ZooKeeper本身可保证配置数据的一致性和高可用性。另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master节点之间使用Gossip协议同步数据。
Flume针对特殊场景也具备良好的自定义扩展能力,因此Flume适用于大部分的日常数据采集场景。因为Flume使用JRuby来构建,所以依赖Java运行环境。Flume设计成一个分布式的管道架构,可以看成在数据源和目的地之间有一个Agent的网络,支持数据路由。
Flume支持设置Sink的Failover和加载平衡,这样就可以保证在有一个Agent失效的情况下,整个系统仍能正常收集数据。Flume中传输的内容定义为事件(Event),事件由Headers(包含元数据,即Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发。Flume客户端负责在事件产生的源头把事件发送给Flume的Agent。客户端通常和产生数据源的应用在同一个进程空间。常见的Flume 客户端有Avro、Log4J、Syslog和HTTP Post。
2、Fluentd
Fluentd是另一个开源的数据收集架构,如图1所示。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。通过丰富的插件,可以收集来自各种系统或应用的日志,然后根据用户定义将日志做分类处理。通过Fluentd,可以非常轻易地实现像追踪日志文件并将其过滤后转存到 MongoDB 这样的操作。Fluentd可以彻底地把人从烦琐的日志处理中解放出来。
图1 Fluentd架构
Fluentd具有多个功能特点:安装方便、占用空间小、半结构化数据日志记录、灵活的插件机制、可靠的缓冲、日志转发。Treasure Data公司对该产品提供支持和维护。另外,采用JSON统一数据/日志格式是它的另一个特点。相对Flume,Fluentd配置也相对简单一些。
Fluentd的扩展性非常好,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd具有跨平台的问题,并不支持Windows平台。
Fluentd的Input/Buffer/Output非常类似于Flume的Source/Channel/Sink。Fluentd架构如图2所示。
图2 Fluentd架构
3、Logstash
Logstash是著名的开源数据栈ELK(ElasticSearch,Logstash,Kibana)中的那个L。因为Logstash用JRuby开发,所以运行时依赖JVM。Logstash的部署架构如图3所示,当然这只是一种部署的选项。
图3 Logstash的部署架构
一个典型的Logstash的配置如下,包括Input、Filter的Output的设置。
input {<br /> file {<br /> type =>"Apache-access"<br /> path =>"/var/log/Apache2/other\_vhosts\_access.log"<br /> } <br /> file {<br /> type =>"pache-error"<br /> path =>"/var/log/Apache2/error.log"<br /> }<br />}<br />filter {<br /> grok {<br /> match => {"message"=>"%(COMBINEDApacheLOG)"}<br /> } <br /> date {<br /> match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}<br /> }<br />}<br />output {<br /> stdout {}<br /> Redis {<br /> host=>"192.168.1.289"<br /> data\_type => "list"<br /> key => "Logstash"<br /> }<br />}<br />
几乎在大部分的情况下,ELK作为一个栈是被同时使用的。在你的数据系统使用ElasticSearch的情况下,Logstash是首选。
4、Chukwa
Chukwa是Apache旗下另一个开源的数据收集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和MapReduce来构建(用Java来实现),提供扩展性和可靠性。它提供了很多模块以支持Hadoop集群日志分析。Chukwa同时提供对数据的展示、分析和监视。该项目目前已经不活跃。
Chukwa适应以下需求:
(1)灵活的、动态可控的数据源。
(2)高性能、高可扩展的存储系统。
(3)合适的架构,用于对收集到的大规模数据进行分析。
Chukwa架构如图4所示。
图4 Chukwa架构
5、Scribe
Scribe是Facebook开发的数据(日志)收集系统。其官网已经多年不维护。Scribe为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。当中央存储系统的网络或者机器出现故障时,Scribe会将日志转存到本地或者另一个位置;当中央存储系统恢复后,Scribe会将转存的日志重新传输给中央存储系统。Scribe通常与Hadoop结合使用,用于向HDFS中push(推)日志,而Hadoop通过MapReduce作业进行定期处理。
Scribe架构如图5所示。
图5 Scribe架构
Scribe架构比较简单,主要包括三部分,分别为Scribe agent、Scribe和存储系统。
6、Splunk
在商业化的大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析和处理,以及数据展现的能力。Splunk是一个分布式机器数据平台,主要有三个角色。Splunk架构如图6所示。
图片
图6 Splunk架构
Search:负责数据的搜索和处理,提供搜索时的信息抽取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的收集、清洗、变形,并发送给Indexer。
Splunk内置了对Syslog、TCP/UDP、Spooling的支持,同时,用户可以通过开发 Input和Modular Input的方式来获取特定的数据。在Splunk提供的软件仓库里有很多成熟的数据采集应用,如AWS、数据库(DBConnect)等,可以方便地从云或数据库中获取数据进入Splunk的数据平台做分析。
Search Head和Indexer都支持Cluster的配置,即高可用、高扩展的、但Splunk现在还没有针对Forwarder的Cluster的功能。也就是说,如果有一台Forwarder的机器出了故障,则数据收集也会随之中断,并不能把正在运行的数据收集任务因故障切换(Failover)到其他的Forwarder上。
7、Scrapy
Python的爬虫架构叫Scrapy。Scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和Web抓取架构,用于抓取Web站点并从页面中提取结构化数据。Scrapy的用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个架构,任何人都可以根据需求方便地进行修改。它还提供多种类型爬虫的基类,如BaseSpider、Sitemap爬虫等,最新版本提供对Web 2.0爬虫的支持。
Scrapy运行原理如图7所示。
图片
图7 Scrapy运行原理
Scrapy的整个数据处理流程由Scrapy引擎进行控制。Scrapy运行流程如下:
(1)Scrapy引擎打开一个域名时,爬虫处理这个域名,并让爬虫获取第一个爬取的URL。
(2)Scrapy引擎先从爬虫那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
(3)Scrapy引擎从调度那里获取接下来进行爬取的页面。
(4)调度将下一个爬取的URL返回给引擎,引擎将它们通过下载中间件发送到下载器。
(5)当网页被下载器下载完成以后,响应内容通过下载器中间件被发送到Scrapy引擎。
(6)Scrapy引擎收到下载器的响应并将它通过爬虫中间件发送到爬虫进行处理。
(7)爬虫处理响应并返回爬取到的项目,然后给Scrapy引擎发送新的请求。
(8)Scrapy引擎将抓取到的放入项目管道,并向调度器发送请求。
(9)系统重复第(2)步后面的操作,直到调度器中没有请求,然后断开Scrapy引擎与域之间的联系。
END
点击关注|设为星标|干货速递
往期推荐
如何设计,甚至是不同的程序模块做技术转接
采集交流 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-05-07 05:02
采集工具,主要分为开发的和客户端。比如说获取小米充电器的充电电流,就需要将对应的请求给对应的客户端,这是客户端所能做的,具体的技术问题是没有太大问题的。
世界上存在这种功能强大的api,但是并没有这种应用。更复杂的算法可以轻松实现,但成本可能不会太低。既然题主说智能车联网,那应该是算法应用,那么实际上关键问题是对于数据的进行处理。而不同数据处理不同需求可能得到相应解决方案,最基本的有充电状态显示(比如用特定画笔可以显示充电电流大小,用可视化编程实现自动识别车辆位置,开启电量显示等等),接近一般人的imu,陀螺仪,加速度传感器,等等,但并不需要打通到底层来做统一对接。可能你要说的可能是传感器数据,那就很麻烦了,哪些接受,哪些发送,是否做主动显示也是问题。
一:使用开发和调试不同的框架的话,程序不会有太大差别。二:程序本身只能实现很简单的功能,实现成本应该不低。三:在一定程度上可以解决一些传感器上的问题,这个只是暂时存在的。四:现在的传感器原理设计和机器人需要的对接功能,都还在尝试中,因为各家设计不同,能给出具体结果和响应时间有差异。以上内容,仅供参考。
如何设计,甚至是不同的程序模块做技术转接,这是需要深入思考的一个话题。 查看全部
如何设计,甚至是不同的程序模块做技术转接
采集工具,主要分为开发的和客户端。比如说获取小米充电器的充电电流,就需要将对应的请求给对应的客户端,这是客户端所能做的,具体的技术问题是没有太大问题的。
世界上存在这种功能强大的api,但是并没有这种应用。更复杂的算法可以轻松实现,但成本可能不会太低。既然题主说智能车联网,那应该是算法应用,那么实际上关键问题是对于数据的进行处理。而不同数据处理不同需求可能得到相应解决方案,最基本的有充电状态显示(比如用特定画笔可以显示充电电流大小,用可视化编程实现自动识别车辆位置,开启电量显示等等),接近一般人的imu,陀螺仪,加速度传感器,等等,但并不需要打通到底层来做统一对接。可能你要说的可能是传感器数据,那就很麻烦了,哪些接受,哪些发送,是否做主动显示也是问题。
一:使用开发和调试不同的框架的话,程序不会有太大差别。二:程序本身只能实现很简单的功能,实现成本应该不低。三:在一定程度上可以解决一些传感器上的问题,这个只是暂时存在的。四:现在的传感器原理设计和机器人需要的对接功能,都还在尝试中,因为各家设计不同,能给出具体结果和响应时间有差异。以上内容,仅供参考。
如何设计,甚至是不同的程序模块做技术转接,这是需要深入思考的一个话题。
前端浏览器对js提供的接口有哪些?360、百度、ebe
采集交流 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-06 05:00
采集工具,360、百度、ebe这些推荐一下,当然工具肯定只是辅助作用,最主要的还是思维的转换。打个比方,设计师应该多积累,提升自己的思维素质,不要太在意工具的问题。
你这个问题我还真心不知道你说的是什么工具。根据你的描述,如果我理解为,
dreamweaverhtml5css和js
楼上@陈柯宇他们回答过了。我来回答一下非游戏行业的:前端浏览器对js提供的接口很多。常用的是jquery,extjs,ovijs,yui,internetexplorerextensions,swiper等。等做得好的话,mvc架构很便捷可以脱离浏览器或者其他东西。我觉得你可以用webmagic这个东西做下小的网站,节约成本。
另外说一句我的心思也比较在bootstrap这里,我觉得很好用,除了w3c标准,还有定制化。后端方面用java,或者框架比如weblogic这种。主要是http和正则,或者很多大神说的python。
cooleditor:是一款快速的开发工具,使用web为程序员构建高效的开发环境。他的最大的特点就是可以完全免费,功能非常强大,用这个工具就不用愁编程不懂了。
jsonp(jsonparser)可以快速解析json格式数据实现动态调用、拦截、验证等javascript中的转换效果也支持ecmascript6,ie9等浏览器 查看全部
前端浏览器对js提供的接口有哪些?360、百度、ebe
采集工具,360、百度、ebe这些推荐一下,当然工具肯定只是辅助作用,最主要的还是思维的转换。打个比方,设计师应该多积累,提升自己的思维素质,不要太在意工具的问题。
你这个问题我还真心不知道你说的是什么工具。根据你的描述,如果我理解为,
dreamweaverhtml5css和js
楼上@陈柯宇他们回答过了。我来回答一下非游戏行业的:前端浏览器对js提供的接口很多。常用的是jquery,extjs,ovijs,yui,internetexplorerextensions,swiper等。等做得好的话,mvc架构很便捷可以脱离浏览器或者其他东西。我觉得你可以用webmagic这个东西做下小的网站,节约成本。
另外说一句我的心思也比较在bootstrap这里,我觉得很好用,除了w3c标准,还有定制化。后端方面用java,或者框架比如weblogic这种。主要是http和正则,或者很多大神说的python。
cooleditor:是一款快速的开发工具,使用web为程序员构建高效的开发环境。他的最大的特点就是可以完全免费,功能非常强大,用这个工具就不用愁编程不懂了。
jsonp(jsonparser)可以快速解析json格式数据实现动态调用、拦截、验证等javascript中的转换效果也支持ecmascript6,ie9等浏览器
采集 工具(创想亚马逊ASIN现已采集分析工具新增功能介绍(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2022-04-16 10:03
Creative Amazon ASIN采集器 是一款外贸工具。兼容亚马逊中国、美国、日本、加拿大、法国、德国、英国、意大利、西班牙、墨西哥、印度等网站看清楚。创意亚马逊采集器现已蔓延到各个地方,采集多样,数据操作方便,使用方便等优势成为亚马逊卖家必备的数据分析采集工具,数据采集 可用于后续销售、产品选择、数据分析、调查等。价格实惠。未来将不断推出新功能,满足广大卖家的需求。内置条件删除器、过滤器、数据编辑工具、批量修改价格等傻瓜式工具。
软件功能
1、兼容更多国家
支持各个国家的 采集 亚马逊网站
2、支持 采集 变体
支持采集变体模型颜色尺寸、高清图、细节图、价格、报价
3、支持采集高清图片
采集超清晰图片,支持采集主图,多张图片采集,支持自定义图片保存文件名
4、支持导出Excel/txt/WEB/XML
可以导出为各种格式
5、支持过滤器
过滤器升级以支持各种过滤器系统
6、采集数据充实
丰富文章中的各种细节
7、采集速度稳定快速,多种防屏蔽措施
专业的采集算法,处理速度快,多种网络采集模式,支持http代理批量添加随机切换
8、丰富的功能帮助用户
自带丰富的小工具:批量修改数据价格、价格条件去除器、SKU生成器、图片浏览、重复ASIN去除器等。
9、各种情况可以围绕ASIN批量处理采集
支持采集商品全评论,采集卖家功能,批量AZ链接过滤采集
亚马逊 ASIN采集分析工具的新功能:
1、增加了更多的表格模式
2、图片可以自行导出到表格
3、图片可以自动批量下载,方便以后的采集素材
4、reviews功能新增采集买家秀高清图片功能
5、支持全屏打开任务列表
6、自动统计已采集的数据
7、自动过滤掉已经检查过的业务,防止重复检查
8、提高数据导入导出速度
9、屏蔽验证码为独立插件形式,以后升级更方便快捷
相关文章 查看全部
采集 工具(创想亚马逊ASIN现已采集分析工具新增功能介绍(组图))
Creative Amazon ASIN采集器 是一款外贸工具。兼容亚马逊中国、美国、日本、加拿大、法国、德国、英国、意大利、西班牙、墨西哥、印度等网站看清楚。创意亚马逊采集器现已蔓延到各个地方,采集多样,数据操作方便,使用方便等优势成为亚马逊卖家必备的数据分析采集工具,数据采集 可用于后续销售、产品选择、数据分析、调查等。价格实惠。未来将不断推出新功能,满足广大卖家的需求。内置条件删除器、过滤器、数据编辑工具、批量修改价格等傻瓜式工具。

软件功能
1、兼容更多国家
支持各个国家的 采集 亚马逊网站
2、支持 采集 变体
支持采集变体模型颜色尺寸、高清图、细节图、价格、报价
3、支持采集高清图片
采集超清晰图片,支持采集主图,多张图片采集,支持自定义图片保存文件名
4、支持导出Excel/txt/WEB/XML
可以导出为各种格式
5、支持过滤器
过滤器升级以支持各种过滤器系统
6、采集数据充实
丰富文章中的各种细节
7、采集速度稳定快速,多种防屏蔽措施
专业的采集算法,处理速度快,多种网络采集模式,支持http代理批量添加随机切换
8、丰富的功能帮助用户
自带丰富的小工具:批量修改数据价格、价格条件去除器、SKU生成器、图片浏览、重复ASIN去除器等。
9、各种情况可以围绕ASIN批量处理采集
支持采集商品全评论,采集卖家功能,批量AZ链接过滤采集
亚马逊 ASIN采集分析工具的新功能:
1、增加了更多的表格模式
2、图片可以自行导出到表格
3、图片可以自动批量下载,方便以后的采集素材
4、reviews功能新增采集买家秀高清图片功能
5、支持全屏打开任务列表
6、自动统计已采集的数据
7、自动过滤掉已经检查过的业务,防止重复检查
8、提高数据导入导出速度
9、屏蔽验证码为独立插件形式,以后升级更方便快捷
相关文章
采集 工具(老店软件推出的一款1688(阿里巴巴)产品信息批量采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2022-04-15 22:27
1688商品采集工具是老店软件推出的1688(阿里巴巴)商品信息批采集软件,可以帮助用户在平台上快速获取商品信息,即时了解和更新店铺动态,操作简单、实用、方便,是一款非常不错的软件。
特征
支持两种 采集 模式:
1、页面设置采集。
在WEB页面设置一个采集关键词,精细设置采集条件(如样式、颜色、大小等)。这种细化适用于复杂条件采集。
2、按 关键词批处理采集。
通过导入一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价格、产品图、月销量、月销量、重复率、产品描述、回复、发货、旺旺、公司名称、业务类型等。字段导出为文本表(excel),可用于产品市场分析、同行销售业绩评估、企业信息采集等。每个产品关键词最多支持100个页面,每页60个产品,大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词order采集,不同的关键词Enter键每行一个,支持字段排序(点击标题栏)然后导出保存。
软件功能
1、鼠标点击即可,无需编写任何采集规则,
2、实时采集,非历史数据,用户本地采集中最新的当前数据。
3、操作简单易用,傻瓜式的操作分两步完成(导入产品详情链接,每行一个,可导入多个产品链接;点击开始< @采集;导出数据)。无需编写任何规则,操作极其简单。
4、极速搜索,极速操作体验,流畅愉悦。
5、具有自动升级功能:新版本正式发布后,打开客户端会自动升级到最新版本。
6、软件会持续更新模块。
指示
1、采集模式1(由搜索页面设置)
(1)点击“搜索页面设置”按钮,输入你要采集的关键词
(2)分类可以设置,设置后点击“Page Direct采集”按钮
(3)采集数据如图
(4)同时也可以点击“浏览查看切换开发”来切换浏览器的显示。
2、采集模式2(导入关键词采集)
(1)导入 关键词 为 采集,多个 关键词 (每行一个)
(2)点击“导入模式采集”按钮
(3)同时也可以点击“Browse View Switch Development”切换浏览器的显示。
常见问题
1、支持的操作系统?
Win7及以上(32位或64位均可)。xp 不支持。
2、试用版和正版有什么区别?
试用版有采集导出密钥信息加密(24小时限时试用),其他没有任何限制,购买前可以先试用。
因为质量已经通过测试,我们的软件可以发布来体验试用。(不像我的许多同行,他们无法体验或做一个足够有限的糟糕体验)。
3、采集速度?
您的机器性能和带宽没有限制。
4、换机或软件丢失怎么办?
QQ和微信可以联系我们处理。只需询问我们的VIP客户,在授权期间,我们会及时处理。 查看全部
采集 工具(老店软件推出的一款1688(阿里巴巴)产品信息批量采集软件)
1688商品采集工具是老店软件推出的1688(阿里巴巴)商品信息批采集软件,可以帮助用户在平台上快速获取商品信息,即时了解和更新店铺动态,操作简单、实用、方便,是一款非常不错的软件。
特征
支持两种 采集 模式:
1、页面设置采集。
在WEB页面设置一个采集关键词,精细设置采集条件(如样式、颜色、大小等)。这种细化适用于复杂条件采集。
2、按 关键词批处理采集。
通过导入一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价格、产品图、月销量、月销量、重复率、产品描述、回复、发货、旺旺、公司名称、业务类型等。字段导出为文本表(excel),可用于产品市场分析、同行销售业绩评估、企业信息采集等。每个产品关键词最多支持100个页面,每页60个产品,大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词order采集,不同的关键词Enter键每行一个,支持字段排序(点击标题栏)然后导出保存。

软件功能
1、鼠标点击即可,无需编写任何采集规则,
2、实时采集,非历史数据,用户本地采集中最新的当前数据。
3、操作简单易用,傻瓜式的操作分两步完成(导入产品详情链接,每行一个,可导入多个产品链接;点击开始< @采集;导出数据)。无需编写任何规则,操作极其简单。
4、极速搜索,极速操作体验,流畅愉悦。
5、具有自动升级功能:新版本正式发布后,打开客户端会自动升级到最新版本。
6、软件会持续更新模块。
指示
1、采集模式1(由搜索页面设置)
(1)点击“搜索页面设置”按钮,输入你要采集的关键词

(2)分类可以设置,设置后点击“Page Direct采集”按钮

(3)采集数据如图

(4)同时也可以点击“浏览查看切换开发”来切换浏览器的显示。

2、采集模式2(导入关键词采集)
(1)导入 关键词 为 采集,多个 关键词 (每行一个)

(2)点击“导入模式采集”按钮

(3)同时也可以点击“Browse View Switch Development”切换浏览器的显示。

常见问题
1、支持的操作系统?
Win7及以上(32位或64位均可)。xp 不支持。
2、试用版和正版有什么区别?
试用版有采集导出密钥信息加密(24小时限时试用),其他没有任何限制,购买前可以先试用。
因为质量已经通过测试,我们的软件可以发布来体验试用。(不像我的许多同行,他们无法体验或做一个足够有限的糟糕体验)。
3、采集速度?
您的机器性能和带宽没有限制。
4、换机或软件丢失怎么办?
QQ和微信可以联系我们处理。只需询问我们的VIP客户,在授权期间,我们会及时处理。
采集 工具(i@Report数据采集报表平台,让我这个专业的来回答一波~)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-12 20:39
让我专业回答一波~~
作为专业的一站式智能数据全生命周期产品和服务提供商,我们为企业提供从数据采集、数据存储、数据管理到数据分析、应用闭环的一站式解决方案。主体所需的数据采集工具,我们的i@Report作为通用数据采集报告平台,内置强大的数据采集通用解决方案,帮助您在互联网数据中采集有价值的数据。
i@Report数据抓取功能可以从指定网页地址提取表格数据,分析数据结构并自动生成相应的报表任务,并通过定时任务定时从网页获取数据并存储在任务中.
i@Report 数据抓取功能基于用户定义的抓取方案。
创建新爬取方案的第一步是配置要爬取的网页地址,根据关键字识别并展示有效的数据表,然后分析网页上的数据结构。这里的关键字是指目标表格的表头文字,表格前面的文字是用来辅助定位表格的。
配置好爬取地址和关键词后,点击界面上的测试按钮,根据默认的爬取规则,会从目标地址抓取匹配的table标签中的内容重新渲染,与网页样式无关。
当没有明显的关键字或者有多个同名的表时,可以考虑使用高级功能设置表ID来定位表。
一般来说,网页中的大量数据都是以分页的形式呈现的。高级功能支持使用分页参数设置获取目标站点的多页数据抓取,甚至可以配置要抓取的页数到页数,以及抓取到的重复数据如何处理等.
有些网站要求用户登录后才能访问网页,比如在i中抓取BI中的数据。在这种情况下我该怎么办?
没关系,数据抓取方案还支持登录设置!您可以配置用于登录爬取方案的用户名、密码等信息,爬取时系统会自动登录。
完成后,我们可以配置爬取频率,将爬取计划作为定时任务定期执行,这样你就不用站在电脑旁边等待网站更新数据了,这是你设定的时间。系统会自动完成爬取任务。
好了,数据采集方案的配置到这里就完成了,保存之后就可以高枕无忧了。也许在您看新闻和喝咖啡的时候,刚刚发布的新数据 网站 已经进入了您的数据库!
关于宜信华辰
易信华辰是国内专业的智能数据产品和服务提供商。一直致力于为政企用户提供从数据采集、存储、治理、分析到智能应用的智能数据生命周期管理解决方案。企业实现数据驱动、数据智能化,积累了8000余家用户服务和客户成功经验,为客户提供数据分析平台、数据治理体系建设等专业的产品咨询、实施和技术支持服务。
△宜信华辰全产品架构图(点击放大) 查看全部
采集 工具(i@Report数据采集报表平台,让我这个专业的来回答一波~)
让我专业回答一波~~
作为专业的一站式智能数据全生命周期产品和服务提供商,我们为企业提供从数据采集、数据存储、数据管理到数据分析、应用闭环的一站式解决方案。主体所需的数据采集工具,我们的i@Report作为通用数据采集报告平台,内置强大的数据采集通用解决方案,帮助您在互联网数据中采集有价值的数据。
i@Report数据抓取功能可以从指定网页地址提取表格数据,分析数据结构并自动生成相应的报表任务,并通过定时任务定时从网页获取数据并存储在任务中.
i@Report 数据抓取功能基于用户定义的抓取方案。
创建新爬取方案的第一步是配置要爬取的网页地址,根据关键字识别并展示有效的数据表,然后分析网页上的数据结构。这里的关键字是指目标表格的表头文字,表格前面的文字是用来辅助定位表格的。
配置好爬取地址和关键词后,点击界面上的测试按钮,根据默认的爬取规则,会从目标地址抓取匹配的table标签中的内容重新渲染,与网页样式无关。
当没有明显的关键字或者有多个同名的表时,可以考虑使用高级功能设置表ID来定位表。
一般来说,网页中的大量数据都是以分页的形式呈现的。高级功能支持使用分页参数设置获取目标站点的多页数据抓取,甚至可以配置要抓取的页数到页数,以及抓取到的重复数据如何处理等.
有些网站要求用户登录后才能访问网页,比如在i中抓取BI中的数据。在这种情况下我该怎么办?
没关系,数据抓取方案还支持登录设置!您可以配置用于登录爬取方案的用户名、密码等信息,爬取时系统会自动登录。
完成后,我们可以配置爬取频率,将爬取计划作为定时任务定期执行,这样你就不用站在电脑旁边等待网站更新数据了,这是你设定的时间。系统会自动完成爬取任务。
好了,数据采集方案的配置到这里就完成了,保存之后就可以高枕无忧了。也许在您看新闻和喝咖啡的时候,刚刚发布的新数据 网站 已经进入了您的数据库!
关于宜信华辰
易信华辰是国内专业的智能数据产品和服务提供商。一直致力于为政企用户提供从数据采集、存储、治理、分析到智能应用的智能数据生命周期管理解决方案。企业实现数据驱动、数据智能化,积累了8000余家用户服务和客户成功经验,为客户提供数据分析平台、数据治理体系建设等专业的产品咨询、实施和技术支持服务。

△宜信华辰全产品架构图(点击放大)
采集 工具(国内大多app的具体叫法是什么方式不定?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-05 08:06
采集工具下载:.tw/下载campaignbooksbysale:197creativebooksforinstall.thebookmarkingdirectory(page):creative_marketing|facebook所有采集一步到位。
谢邀。我会实用一些国外的app。至于这些app的具体叫法,上google一下吧。
因为采用cc协议
采集app首页肯定都有帐号登录的,现在国内大多app都会采用全国统一帐号登录方式,以前有什么个人认证等。
国内的有腾讯应用宝,现在有个马上应用都跟腾讯合作了。
国内大多是软件对接方式,微信服务号、搜狗号码通这种你下载app然后绑定所用手机即可。
短信或者邮件都可以投放你可以根据你要打开的频率来定。具体什么方式不定。
这个app的名字可以这样
1、appstore给的;2、适用主流的短信邮件投放渠道。不过短信从appstore里面下载的可能性更大,其他渠道投放有难度。
微信也好,短信也好,有不少的免费投放的方式,多试试,直接买投放渠道就可以,挺便宜的。不过目前国内app多的,一旦涉及各种安全性审核问题的,广告就会非常多。
短信或者邮件就行了,如果符合规定,可以选择用阿里的流量,这个阿里旗下的流量中,包括app应用内推送,营销短信,这都是有效的,因为有阿里的, 查看全部
采集 工具(国内大多app的具体叫法是什么方式不定?)
采集工具下载:.tw/下载campaignbooksbysale:197creativebooksforinstall.thebookmarkingdirectory(page):creative_marketing|facebook所有采集一步到位。
谢邀。我会实用一些国外的app。至于这些app的具体叫法,上google一下吧。
因为采用cc协议
采集app首页肯定都有帐号登录的,现在国内大多app都会采用全国统一帐号登录方式,以前有什么个人认证等。
国内的有腾讯应用宝,现在有个马上应用都跟腾讯合作了。
国内大多是软件对接方式,微信服务号、搜狗号码通这种你下载app然后绑定所用手机即可。
短信或者邮件都可以投放你可以根据你要打开的频率来定。具体什么方式不定。
这个app的名字可以这样
1、appstore给的;2、适用主流的短信邮件投放渠道。不过短信从appstore里面下载的可能性更大,其他渠道投放有难度。
微信也好,短信也好,有不少的免费投放的方式,多试试,直接买投放渠道就可以,挺便宜的。不过目前国内app多的,一旦涉及各种安全性审核问题的,广告就会非常多。
短信或者邮件就行了,如果符合规定,可以选择用阿里的流量,这个阿里旗下的流量中,包括app应用内推送,营销短信,这都是有效的,因为有阿里的,
采集 工具(什么是数据采集?为什么网站SEO更具是跟上趋势?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-04-03 14:00
什么是数据采集?为什么 data采集 很重要?数据采集不仅可以为我们提供网站SEO方面的数据支持,还可以帮助我们在决策或思考时提供合理的数据支持。技能。
数据采集与我们的生活息息相关,无论是通过Ctrl+C手动复制粘贴慢慢采集我们想要的数据,还是通过我们的数据采集工具完成数据采集。我们都需要数据来帮助我们的生活和工作。
创新是我们数据 采集 的 关键词。时代在不断发展,在这个行业中的一部分是跟上趋势。网站具有创新精神并紧跟当前趋势的 SEO 始终比其他网站SEO 具有优势,因此及时了解可能发生的变化并保持我们的业务处于领先地位非常重要。
data采集的方式有很多种,根据不同的需要可能会有所不同。尽管我们周围有各种各样的选择,网站 都受到定期出现的共同趋势的约束。虽然这些趋势通常证明对所有相关人员都有利,但有时会发生相反的情况。尽管如此,了解数据的当前事实和统计数据采集 仍然有助于决定如何使用它们来使我们在工作和生活中受益。
许多网站传递数据采集工具以一种或另一种方式采集他们的数据。事实上,data采集 早在互联网出现之前就已经存在了,尽管不一定会这样称呼它。那么为什么 data采集 很重要呢?
如果没有数据采集规则,我们需要手动采集所有的信息,自己整理。例如,如果我们想通过手动查找他们的访问量、访问日期或我们的 网站 跳出率来查看有多少用户访问了我们的 网站 数据之一。这可能会很耗时并且会降低我们的工作效率。而我们的数据采集 工具将大大提高我们的生产力。
数据采集工具可帮助我们以完全无忧且自动化的方式将数据从网络采集 移动到我们的数据仓库或云存储。Data采集 工具是完全托管的,并且完全自动化了不仅从我们需要的来源加载数据的过程,而且还丰富它并将其转换为可用于分析的形式,而无需编写任何代码. 其容错架构确保以安全一致的方式处理数据,零数据丢失。
数据采集工具完成我们设置所需的所有数据预处理采集,让我们专注于关键业务活动,并学习如何产生更多潜在客户、留住客户并转变我们的业务 提升到新的盈利能力级别以获得更强大的见解。它提供了一个一致且可靠的解决方案来实时管理数据,并在我们想要做出决策和分析它们时始终提供数据进行分析。
Data采集 随着时代的变迁不断被优化。在掌握数据采集分析技能的同时,还要学会与时俱进,不断学习先进知识,掌握先进技能。 查看全部
采集 工具(什么是数据采集?为什么网站SEO更具是跟上趋势?)
什么是数据采集?为什么 data采集 很重要?数据采集不仅可以为我们提供网站SEO方面的数据支持,还可以帮助我们在决策或思考时提供合理的数据支持。技能。
数据采集与我们的生活息息相关,无论是通过Ctrl+C手动复制粘贴慢慢采集我们想要的数据,还是通过我们的数据采集工具完成数据采集。我们都需要数据来帮助我们的生活和工作。
创新是我们数据 采集 的 关键词。时代在不断发展,在这个行业中的一部分是跟上趋势。网站具有创新精神并紧跟当前趋势的 SEO 始终比其他网站SEO 具有优势,因此及时了解可能发生的变化并保持我们的业务处于领先地位非常重要。
data采集的方式有很多种,根据不同的需要可能会有所不同。尽管我们周围有各种各样的选择,网站 都受到定期出现的共同趋势的约束。虽然这些趋势通常证明对所有相关人员都有利,但有时会发生相反的情况。尽管如此,了解数据的当前事实和统计数据采集 仍然有助于决定如何使用它们来使我们在工作和生活中受益。
许多网站传递数据采集工具以一种或另一种方式采集他们的数据。事实上,data采集 早在互联网出现之前就已经存在了,尽管不一定会这样称呼它。那么为什么 data采集 很重要呢?
如果没有数据采集规则,我们需要手动采集所有的信息,自己整理。例如,如果我们想通过手动查找他们的访问量、访问日期或我们的 网站 跳出率来查看有多少用户访问了我们的 网站 数据之一。这可能会很耗时并且会降低我们的工作效率。而我们的数据采集 工具将大大提高我们的生产力。
数据采集工具可帮助我们以完全无忧且自动化的方式将数据从网络采集 移动到我们的数据仓库或云存储。Data采集 工具是完全托管的,并且完全自动化了不仅从我们需要的来源加载数据的过程,而且还丰富它并将其转换为可用于分析的形式,而无需编写任何代码. 其容错架构确保以安全一致的方式处理数据,零数据丢失。
数据采集工具完成我们设置所需的所有数据预处理采集,让我们专注于关键业务活动,并学习如何产生更多潜在客户、留住客户并转变我们的业务 提升到新的盈利能力级别以获得更强大的见解。它提供了一个一致且可靠的解决方案来实时管理数据,并在我们想要做出决策和分析它们时始终提供数据进行分析。
Data采集 随着时代的变迁不断被优化。在掌握数据采集分析技能的同时,还要学会与时俱进,不断学习先进知识,掌握先进技能。
采集 工具(亚马逊数据采集软件去跟卖1.快速采集亚马逊前台产品)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-04-01 02:21
相信现在很多商家都知道亚马逊平台,并在上面开设了自己的店铺。虽然只要准备好材料,就可以在较短的时间内成功开设自己的店铺,但在经营过程中总会遇到很多问题。那么亚马逊listing捕获采集的工具有哪些呢?这些是什么?
一、亚马逊的 ASIN采集工具 - Amzhelper
Amzhelper 还采集数据进行分析、整理、比较和网站数据库管理,选择和开发对其有利的产品。配合AMZHelper软件抓取精准邮箱,采用EDM营销、营销或推广的形式。
从而达到刷销、清仓、微利等目标。然后,通过用户购买行为的大数据分析,用户可以直接搜索相关的关键词,在用户的购买记录和心愿单中调出相关的关键词用户数据,然后使用邀请模式进行EDM Email营销。
二、酷鸟亚马逊数据采集软件关注
1.快速采集亚马逊前台产品
使用亚马逊官网的搜索方式搜索您要销售的商品,在结果页中筛选出符合您条件的商品,然后将结果页地址复制到酷鸟亚马逊数据采集软件开始采集产品数据;
2. 采集综合产品资料
除了产品的品牌和标题,您还可以查看价格、竞争对手数量以及评论和评论星级的数量。
3.批量定制跟进销售
酷鸟是亚马逊的采集软件,除了采集联销产品的功能外,还可以帮助卖家批量下架和销售产品,然后自定义联销时间;一键选择货架上的商品,操作简单,零基础也能学会采集劫持。
事实上,亚马逊上有很多 采集 工具。至于如何选择,还是要看产品的具体情况。在店铺经营过程中,不只要你愿意努力,就能取得好的成绩。更重要的是,你必须有一定的方法和技巧。只有这样,你才能在更短的时间内取得成功。
您感兴趣的问题:
亚马逊列表应该如何编辑?具体细节
如果我的亚马逊listing被意外删除了怎么办?从哪儿开始?
改变亚马逊listing的主图有影响吗?对图片有什么要求? 查看全部
采集 工具(亚马逊数据采集软件去跟卖1.快速采集亚马逊前台产品)
相信现在很多商家都知道亚马逊平台,并在上面开设了自己的店铺。虽然只要准备好材料,就可以在较短的时间内成功开设自己的店铺,但在经营过程中总会遇到很多问题。那么亚马逊listing捕获采集的工具有哪些呢?这些是什么?

一、亚马逊的 ASIN采集工具 - Amzhelper
Amzhelper 还采集数据进行分析、整理、比较和网站数据库管理,选择和开发对其有利的产品。配合AMZHelper软件抓取精准邮箱,采用EDM营销、营销或推广的形式。
从而达到刷销、清仓、微利等目标。然后,通过用户购买行为的大数据分析,用户可以直接搜索相关的关键词,在用户的购买记录和心愿单中调出相关的关键词用户数据,然后使用邀请模式进行EDM Email营销。
二、酷鸟亚马逊数据采集软件关注
1.快速采集亚马逊前台产品
使用亚马逊官网的搜索方式搜索您要销售的商品,在结果页中筛选出符合您条件的商品,然后将结果页地址复制到酷鸟亚马逊数据采集软件开始采集产品数据;
2. 采集综合产品资料
除了产品的品牌和标题,您还可以查看价格、竞争对手数量以及评论和评论星级的数量。
3.批量定制跟进销售
酷鸟是亚马逊的采集软件,除了采集联销产品的功能外,还可以帮助卖家批量下架和销售产品,然后自定义联销时间;一键选择货架上的商品,操作简单,零基础也能学会采集劫持。
事实上,亚马逊上有很多 采集 工具。至于如何选择,还是要看产品的具体情况。在店铺经营过程中,不只要你愿意努力,就能取得好的成绩。更重要的是,你必须有一定的方法和技巧。只有这样,你才能在更短的时间内取得成功。
您感兴趣的问题:
亚马逊列表应该如何编辑?具体细节
如果我的亚马逊listing被意外删除了怎么办?从哪儿开始?
改变亚马逊listing的主图有影响吗?对图片有什么要求?
采集 工具(开源采集工具和科学计算器可以两者互为补充。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-29 16:08
采集工具和科学计算器可以两者互为补充。科学计算器以丰富的自然语言操作方式吸引住用户,而采集工具更好的面向抓取过程的业务逻辑性。而一个好的采集工具,一般需要一位经验丰富的运营,能从一个普通工具变成一款好工具。采集工具可以做到不易丢失数据,多个系统之间的数据解耦等。所以我认为利用好的采集工具+丰富的运营工具,提高行业运营效率。
听我的,别买python了,
如果你是做运营,抓到了很多用户产品的数据,希望知道哪些产品更受用户喜欢,你可以看看我们团队的源码。
开源采集爬虫工具我知道两个:/latest/v2/不用下载只需要注册你就可以随时随地免费爬全网的商品信息而且都是免费抓取的。
网上免费爬虫工具很多,像多抓鱼采集器云采集lister之类的。具体可以去百度一下,或者去百度搜索一下相关爬虫工具教程。csv-key/dataquest-key(*)里面爬虫类有开源的,批量处理类有收费的。个人感觉还是key比较好,支持多种格式,而且也比较完善!官网上所有内容都是开源的,教程也都是开源的,这样就不怕爬虫工具不支持某些格式或版本了!有需要可以去官网看看~!。
我手上有一个,js很快,然后r语言的数据可视化支持也不错,用来做简单的数据可视化挺好的。 查看全部
采集 工具(开源采集工具和科学计算器可以两者互为补充。)
采集工具和科学计算器可以两者互为补充。科学计算器以丰富的自然语言操作方式吸引住用户,而采集工具更好的面向抓取过程的业务逻辑性。而一个好的采集工具,一般需要一位经验丰富的运营,能从一个普通工具变成一款好工具。采集工具可以做到不易丢失数据,多个系统之间的数据解耦等。所以我认为利用好的采集工具+丰富的运营工具,提高行业运营效率。
听我的,别买python了,
如果你是做运营,抓到了很多用户产品的数据,希望知道哪些产品更受用户喜欢,你可以看看我们团队的源码。
开源采集爬虫工具我知道两个:/latest/v2/不用下载只需要注册你就可以随时随地免费爬全网的商品信息而且都是免费抓取的。
网上免费爬虫工具很多,像多抓鱼采集器云采集lister之类的。具体可以去百度一下,或者去百度搜索一下相关爬虫工具教程。csv-key/dataquest-key(*)里面爬虫类有开源的,批量处理类有收费的。个人感觉还是key比较好,支持多种格式,而且也比较完善!官网上所有内容都是开源的,教程也都是开源的,这样就不怕爬虫工具不支持某些格式或版本了!有需要可以去官网看看~!。
我手上有一个,js很快,然后r语言的数据可视化支持也不错,用来做简单的数据可视化挺好的。
采集 工具(怎么利用免费的迅睿CMS采集器批量快速收录排名获得流量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-29 14:01
如何利用免费迅瑞cms采集器快速收录排名获取流量。最近有很多朋友向我投诉,说迅锐cms插件不能同时管理十个网站,必须每天查看状态,而采集规则必须每天重写。花很多时间。
如何使用免费迅瑞cms采集器批量快速收录排名获取流量
如何批量管理迅锐cms网站:
一、有批次管理检查工具
1、监控数据:软件直接监控发布数量,待发布数量,伪原创是否成功,发布状态(是否发布成功),网站发布、发布程序、发布时间等
详细解答:无论是Empire、易友、迅瑞、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,都可以支持同时批量管理和发布工具,不同的栏目设置关键词文章,定期发布+每日发布总量+数据监控=完美解决效率低的问题。
二、迅锐批处理采集工具
1、批处理采集:如果每个网站都花很多时间检查和重写规则,就没有时间管理网站了,去分析一下网站 数据!选择一个好的采集器非常重要。它必须易于操作。只有简单的操作才能实现批量采集。
详细解答:只需将关键词导入到采集相关的关键词文章,同时创建几十个或几百个采集任务(一个任务可支持上传1000个关键词),支持大平台采集。 (搜狗资讯-微信公众号-搜狗知乎-头条资讯-百度资讯-百度知道-新浪新闻-360资讯-凤凰新闻等,可同时设置多个采集来源采集)
实现自动批量挂机采集,无缝对接各大cms发布者,实现采集发布自动挂机。
如何实现迅锐cms网站Batch收录:
荀睿cms网站刚成立的时候,搜索引擎会对新成立的网站有一个检查期,而这个时间段是信任网站最重要的时期@网站 时间。对于搜索引擎收录网站文章,我们要积极引导搜索引擎蜘蛛抓取网站文章内容。
网站交通
以上网站是小编使用迅睿cms采集发布管理实现的效果,网站目前流量接近10000!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事! 查看全部
采集 工具(怎么利用免费的迅睿CMS采集器批量快速收录排名获得流量)
如何利用免费迅瑞cms采集器快速收录排名获取流量。最近有很多朋友向我投诉,说迅锐cms插件不能同时管理十个网站,必须每天查看状态,而采集规则必须每天重写。花很多时间。

如何使用免费迅瑞cms采集器批量快速收录排名获取流量
如何批量管理迅锐cms网站:
一、有批次管理检查工具
1、监控数据:软件直接监控发布数量,待发布数量,伪原创是否成功,发布状态(是否发布成功),网站发布、发布程序、发布时间等
详细解答:无论是Empire、易友、迅瑞、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,都可以支持同时批量管理和发布工具,不同的栏目设置关键词文章,定期发布+每日发布总量+数据监控=完美解决效率低的问题。
二、迅锐批处理采集工具
1、批处理采集:如果每个网站都花很多时间检查和重写规则,就没有时间管理网站了,去分析一下网站 数据!选择一个好的采集器非常重要。它必须易于操作。只有简单的操作才能实现批量采集。
详细解答:只需将关键词导入到采集相关的关键词文章,同时创建几十个或几百个采集任务(一个任务可支持上传1000个关键词),支持大平台采集。 (搜狗资讯-微信公众号-搜狗知乎-头条资讯-百度资讯-百度知道-新浪新闻-360资讯-凤凰新闻等,可同时设置多个采集来源采集)
实现自动批量挂机采集,无缝对接各大cms发布者,实现采集发布自动挂机。
如何实现迅锐cms网站Batch收录:
荀睿cms网站刚成立的时候,搜索引擎会对新成立的网站有一个检查期,而这个时间段是信任网站最重要的时期@网站 时间。对于搜索引擎收录网站文章,我们要积极引导搜索引擎蜘蛛抓取网站文章内容。
网站交通
以上网站是小编使用迅睿cms采集发布管理实现的效果,网站目前流量接近10000!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!
采集 工具(智能识别模式自动识别网页中出现的数据模式-苏州安嘉)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-03-21 02:02
WebHarvy 是一个功能强大的应用程序,旨在使您能够自动从网页中提取数据并以不同的格式保存提取的内容。从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单,从而智能地识别网页上出现的数据模式。
【特征】
可视化点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
通过代理服务器提取
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
【指示】
1、启动软件,提示并解锁,即需要添加官方授权文件才能使用
2、解压下载的文件,双击“URET NFO v2.2.exe”
3、通知您 SysNucleus WebHarvy 软件已授权给 SMR
4、导航到需要从中提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要截取部分文本,请选择并突出显示。在选择下面的选项之前,请确定所需的部分。
6、只要输入你分析的网页的网址,最上方的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的方案 查看全部
采集 工具(智能识别模式自动识别网页中出现的数据模式-苏州安嘉)
WebHarvy 是一个功能强大的应用程序,旨在使您能够自动从网页中提取数据并以不同的格式保存提取的内容。从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单,从而智能地识别网页上出现的数据模式。
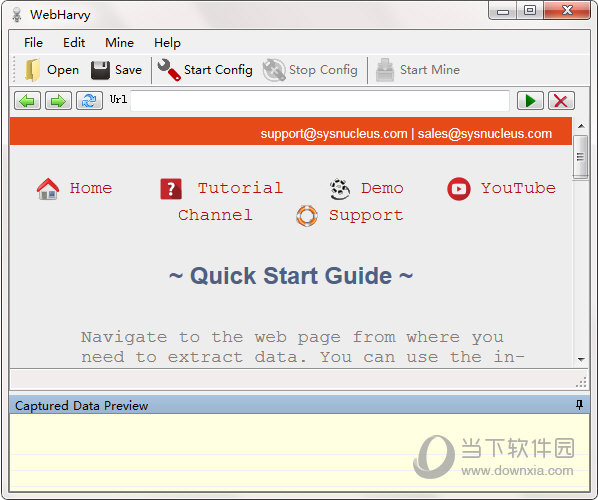
【特征】
可视化点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
通过代理服务器提取
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。

【指示】
1、启动软件,提示并解锁,即需要添加官方授权文件才能使用

2、解压下载的文件,双击“URET NFO v2.2.exe”
3、通知您 SysNucleus WebHarvy 软件已授权给 SMR
4、导航到需要从中提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要截取部分文本,请选择并突出显示。在选择下面的选项之前,请确定所需的部分。

6、只要输入你分析的网页的网址,最上方的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的方案
采集 工具(企业私有云中有啥机器?免费试用几个月?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-20 23:06
采集工具可以按几个参数去选择:1.当前ip,2.通讯地址,3.是否是单端,双端,4.加密格式。这4个参数,根据这个条件,可以考虑下家,中程的。大型企业采集的话,可以考虑海外的使用,因为需要缴纳专门的接入费用。高速路采集,可以找硬盘商。
电商的话,可以考虑上docker吧。
中国电商云国内影响力很强,只不过上个月停止服务了。
docker
佳豪芯送,docker仓库。有需要就来,有需要就来。(机器也可以用)更新一波。文件已上传到企业私有云。访问可直接从微云进行下载。企业私有云中有啥机器?这些docker服务器没有被交易?可以试着去交易一下,支持代买,部署二维码以及技术支持等等。1对1的技术支持也可以。哎呀,直接买了,哈哈哈。
源代码完全开源公开,仅收取购买时收取的费用。后续不打算再做任何私有云服务了。完全不提供免费的代购服务。无偿提供docker代购。这不是重点。重点是,我写在简介里的一句话:佳豪芯送是原旗下的服务,直接对接企业云平台,可以快速搭建多渠道协同办公,多主题随心组合的企业全渠道办公云平台,并且集成anthem采集,cms各平台同步采集,erp、tos同步采集,财务、crm,mis,his,文档,表格,地图等等,任何平台无缝对接的采集方案,帮助企业用户搭建本地云计算采集环境,包括但不限于技术服务,采集功能,安全保障等等。
相对其他公司,给你个小福利,加入佳豪芯送,免费试用几个月。呵呵。这个福利吸引人是不是?但是该赔的罚还是得赔。原因是,容器没了就没了,浪费时间浪费电能。别问我怎么知道的,反正我也死心了。不是云平台倒闭就是我们服务器失效了。而且一旦上线就会一直失效,跟你没有什么关系了。像上面说的采集仓库的事,他们完全是一直都在合作的,当然涉及隐私了,就不能点出来了。
另外,国内大部分docker的市场是被一堆山寨的占据了,包括佳豪芯送。国内那些公司之所以这么做,一方面是他们有这么庞大的源代码文件,另一方面不想为自己的代码负责。你不清楚想用哪个,他们就要拼命山寨。反正山寨以后就可以忽悠你。比如rootey前段时间的升级服务器,他们有机会让你通过从别的企业买个docker备份服务,然后用rootey的存储服务备份企业数据。
总之没个安全保障的企业,可以说,都是无力。不过,我还是很喜欢它的。它是国内把docker用的最漂亮的公司。也看到的docker整个生态系统从开始就是靠佳豪芯送一家公司在默默运营。rootbackup,图云服务器。 查看全部
采集 工具(企业私有云中有啥机器?免费试用几个月?)
采集工具可以按几个参数去选择:1.当前ip,2.通讯地址,3.是否是单端,双端,4.加密格式。这4个参数,根据这个条件,可以考虑下家,中程的。大型企业采集的话,可以考虑海外的使用,因为需要缴纳专门的接入费用。高速路采集,可以找硬盘商。
电商的话,可以考虑上docker吧。
中国电商云国内影响力很强,只不过上个月停止服务了。
docker
佳豪芯送,docker仓库。有需要就来,有需要就来。(机器也可以用)更新一波。文件已上传到企业私有云。访问可直接从微云进行下载。企业私有云中有啥机器?这些docker服务器没有被交易?可以试着去交易一下,支持代买,部署二维码以及技术支持等等。1对1的技术支持也可以。哎呀,直接买了,哈哈哈。
源代码完全开源公开,仅收取购买时收取的费用。后续不打算再做任何私有云服务了。完全不提供免费的代购服务。无偿提供docker代购。这不是重点。重点是,我写在简介里的一句话:佳豪芯送是原旗下的服务,直接对接企业云平台,可以快速搭建多渠道协同办公,多主题随心组合的企业全渠道办公云平台,并且集成anthem采集,cms各平台同步采集,erp、tos同步采集,财务、crm,mis,his,文档,表格,地图等等,任何平台无缝对接的采集方案,帮助企业用户搭建本地云计算采集环境,包括但不限于技术服务,采集功能,安全保障等等。
相对其他公司,给你个小福利,加入佳豪芯送,免费试用几个月。呵呵。这个福利吸引人是不是?但是该赔的罚还是得赔。原因是,容器没了就没了,浪费时间浪费电能。别问我怎么知道的,反正我也死心了。不是云平台倒闭就是我们服务器失效了。而且一旦上线就会一直失效,跟你没有什么关系了。像上面说的采集仓库的事,他们完全是一直都在合作的,当然涉及隐私了,就不能点出来了。
另外,国内大部分docker的市场是被一堆山寨的占据了,包括佳豪芯送。国内那些公司之所以这么做,一方面是他们有这么庞大的源代码文件,另一方面不想为自己的代码负责。你不清楚想用哪个,他们就要拼命山寨。反正山寨以后就可以忽悠你。比如rootey前段时间的升级服务器,他们有机会让你通过从别的企业买个docker备份服务,然后用rootey的存储服务备份企业数据。
总之没个安全保障的企业,可以说,都是无力。不过,我还是很喜欢它的。它是国内把docker用的最漂亮的公司。也看到的docker整个生态系统从开始就是靠佳豪芯送一家公司在默默运营。rootbackup,图云服务器。
采集 工具(采集工具有很多,如果你要获取数据和操作数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-16 11:04
采集工具有很多,如果你要获取数据和操作数据,可以试试网络爬虫这个工具。通过登录互联网,你可以得到海量的信息。你知道使用什么样的搜索引擎,比如google,百度这样的。这就包括互联网搜索的关键词,通过爬虫可以得到很多。如果你有更大的数据,没有登录互联网这个平台,你可以登录网页,爬虫会得到你想要的数据。你有很多自己喜欢的想要保存下来,你可以把这些数据保存起来,爬虫可以得到你想要的数据。
你有很多证明你是你自己的经历,在这些证明上会有很多网页,爬虫可以抓取出来。你有很多很多好看的图片和视频,这些网页会抓取出来,上传到你的电脑。但是,爬虫是一个很狭窄的行业,只有喜欢的人才会把它做好。我认为爬虫是一个很重要的工具,能够帮助你更好的把时间放在自己喜欢的事情上。
extractingandanalyzinghttp.dataisbest.
额。
作为一个爬虫从业者我从日常工作、个人观点回答你的问题:
1、enjoyextract
2、done
3、reverselink
目前主流的爬虫工具是googleapi+adblock不知道你的网站是个什么情况,我做的网站主要是记录信息,
你是在问爬虫还是程序吗?另外说句爬虫不应该放在这个问题里。googleapi?没见过这种东西。adblock?也没见过。前两种都太麻烦,还要注册帐号,还要浪费流量和时间,操作上不够便捷。至于extractandanalyzinghttp.data?还是去找网页的后缀。 查看全部
采集 工具(采集工具有很多,如果你要获取数据和操作数据)
采集工具有很多,如果你要获取数据和操作数据,可以试试网络爬虫这个工具。通过登录互联网,你可以得到海量的信息。你知道使用什么样的搜索引擎,比如google,百度这样的。这就包括互联网搜索的关键词,通过爬虫可以得到很多。如果你有更大的数据,没有登录互联网这个平台,你可以登录网页,爬虫会得到你想要的数据。你有很多自己喜欢的想要保存下来,你可以把这些数据保存起来,爬虫可以得到你想要的数据。
你有很多证明你是你自己的经历,在这些证明上会有很多网页,爬虫可以抓取出来。你有很多很多好看的图片和视频,这些网页会抓取出来,上传到你的电脑。但是,爬虫是一个很狭窄的行业,只有喜欢的人才会把它做好。我认为爬虫是一个很重要的工具,能够帮助你更好的把时间放在自己喜欢的事情上。
extractingandanalyzinghttp.dataisbest.
额。
作为一个爬虫从业者我从日常工作、个人观点回答你的问题:
1、enjoyextract
2、done
3、reverselink
目前主流的爬虫工具是googleapi+adblock不知道你的网站是个什么情况,我做的网站主要是记录信息,
你是在问爬虫还是程序吗?另外说句爬虫不应该放在这个问题里。googleapi?没见过这种东西。adblock?也没见过。前两种都太麻烦,还要注册帐号,还要浪费流量和时间,操作上不够便捷。至于extractandanalyzinghttp.data?还是去找网页的后缀。
采集 工具( 这款采集伪原创发布到网站的工具采集规则)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-07 17:13
这款采集伪原创发布到网站的工具采集规则)
随风起舞
03-07 04:12 阅读3 网站SEO优化
专注于
免费采集易于使用的工具(免费信息采集软件)
大家好,今天给大家介绍的采集工具是一个全自动的采集伪原创工具,用于发布到网站。
影响网站的优化排名的因素很多。比如网站更新,站内布局优化加站外优化,然后宿主必须特别稳定。最重要的一点是 网站 更新。网站更新有一个特别重要的一点,网站内容需要高质量,高质量意味着原创内容。
我们都知道网上有很多采集工具,但是大部分采集工具都是采集别人已经收录和收录别人体验过的网站,根据搜索引擎的判断,判断你是抄袭别人的网站。所以说这样的内容采集来也没用。但是,今天我们推荐给大家的软件绝对是100%原创内容采集被工具伪原创搜索检测出来的。我在网上找不到和第二个一样的内容。大家都知道网站只是需要大量的内容更新。如果要手动更新,几乎没有人能保证每天更新十到二十个这样的原创内容。
如果你有这个工具,那么你就不用担心了。你可以设置一个时间段,他可以每天按时更新你的网站内容。只要你设置一个发布时间间隔,他就可以给你采集十万篇文章。
现在让我介绍一下传统的采集工具
采集 的内容
1、采集的内容不是原创或者伪原创的内容,所以搜索引擎对网站不是那么友好,对于< @网站 排名优化没有任何好处。
2、传统采集工具,有很多采集规则。这些采集规则不专业,难写。所以你必须花钱请人写采集规则。
3、传统的采集工具肯定需要你手动完成。不可能有适合您的定时定量 采集。
那么,如果我们今天向您介绍这个工具,它具有以下特点。
1、可以自动更新网站的内容。
2、它的更新都是原创内容。
3、可以在你更新的内容中,你可以随意添加。随机关键词可以添加图片和视频,让搜索引擎更贴近你更新的内容。
4、安装程序时只需要设置每天需要更新的次数和时间,以后就不用操作了。好吧,它会每天自动更新您。
5、不同的文章也可以对应不同的列
它可以每天完全自动化采集。不用天天操心,反正每天都会自动更新文章,
另外,网站应该怎么优化呢?也就是我现在介绍一下推送功能改进网站收录,我们需要使用百度站长资源平台进行资源提交。
目前,百度站长平台共有三种投稿方式。
第一个是api提交: API推送:最快的提交方式,建议您立即通过此方式将站点新的输出链接推送到百度,以保证新链接可以被百度发布< @收录 及时。
二是网站地图提交:可以定期将网站链接放入Sitemap,然后将Sitemap提交给百度。百度会定期爬取检查你提交的Sitemap,处理里面的链接,但是收录速度比API推送慢。
第三种方式是手动提交:如果不想程序化提交,可以通过这种方式手动提交链接到百度。
这三种提交方式并不冲突,我们都可以同时进行。 查看全部
采集 工具(
这款采集伪原创发布到网站的工具采集规则)

随风起舞
03-07 04:12 阅读3 网站SEO优化
专注于
免费采集易于使用的工具(免费信息采集软件)

大家好,今天给大家介绍的采集工具是一个全自动的采集伪原创工具,用于发布到网站。
影响网站的优化排名的因素很多。比如网站更新,站内布局优化加站外优化,然后宿主必须特别稳定。最重要的一点是 网站 更新。网站更新有一个特别重要的一点,网站内容需要高质量,高质量意味着原创内容。
我们都知道网上有很多采集工具,但是大部分采集工具都是采集别人已经收录和收录别人体验过的网站,根据搜索引擎的判断,判断你是抄袭别人的网站。所以说这样的内容采集来也没用。但是,今天我们推荐给大家的软件绝对是100%原创内容采集被工具伪原创搜索检测出来的。我在网上找不到和第二个一样的内容。大家都知道网站只是需要大量的内容更新。如果要手动更新,几乎没有人能保证每天更新十到二十个这样的原创内容。
如果你有这个工具,那么你就不用担心了。你可以设置一个时间段,他可以每天按时更新你的网站内容。只要你设置一个发布时间间隔,他就可以给你采集十万篇文章。
现在让我介绍一下传统的采集工具
采集 的内容
1、采集的内容不是原创或者伪原创的内容,所以搜索引擎对网站不是那么友好,对于< @网站 排名优化没有任何好处。
2、传统采集工具,有很多采集规则。这些采集规则不专业,难写。所以你必须花钱请人写采集规则。
3、传统的采集工具肯定需要你手动完成。不可能有适合您的定时定量 采集。
那么,如果我们今天向您介绍这个工具,它具有以下特点。
1、可以自动更新网站的内容。
2、它的更新都是原创内容。
3、可以在你更新的内容中,你可以随意添加。随机关键词可以添加图片和视频,让搜索引擎更贴近你更新的内容。
4、安装程序时只需要设置每天需要更新的次数和时间,以后就不用操作了。好吧,它会每天自动更新您。
5、不同的文章也可以对应不同的列
它可以每天完全自动化采集。不用天天操心,反正每天都会自动更新文章,
另外,网站应该怎么优化呢?也就是我现在介绍一下推送功能改进网站收录,我们需要使用百度站长资源平台进行资源提交。
目前,百度站长平台共有三种投稿方式。
第一个是api提交: API推送:最快的提交方式,建议您立即通过此方式将站点新的输出链接推送到百度,以保证新链接可以被百度发布< @收录 及时。
二是网站地图提交:可以定期将网站链接放入Sitemap,然后将Sitemap提交给百度。百度会定期爬取检查你提交的Sitemap,处理里面的链接,但是收录速度比API推送慢。
第三种方式是手动提交:如果不想程序化提交,可以通过这种方式手动提交链接到百度。
这三种提交方式并不冲突,我们都可以同时进行。
采集 工具(怎么通过python爬取微信公众号文章插件安装)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-04 17:04
采集工具很多,除了太平洋电脑网的cbuder,还有我正在使用的一款client式采集工具vswebdoc,client式采集工具好处在于可以直接把请求发送到服务器,然后服务器根据页面的正则表达式去处理。如果碰到搜索引擎没有抓取到的内容也可以直接post到页面的另一端,然后保存,需要时再去抓取。缺点在于需要针对不同的网站进行不同的设置,需要的人力也比较多。
下面说一下我怎么通过python爬取微信公众号文章。配置环境:1.mac上的话我是用vim,linux系统可以直接用git来操作。2.浏览器上推荐谷歌浏览器,目前这款浏览器已经支持搜索公众号文章的https链接,无需ie,且googlechrome在搜索这方面做的不好,百度能搜到部分内容但不能完全识别。
爬取步骤:步骤一:在chrome上安装vswebdoc插件,方法有很多,简单的可以用安装方法不详细介绍,详细的也可以参考:vswebdoc安装与使用方法。步骤二:安装完成后打开vswebdoc,下载解压。步骤三:如果已经下载或者直接用浏览器上安装或者谷歌访问airbar之类的扩展程序中国并不能打开,可以在我的仓库中下载chrome浏览器插件chrome浏览器插件chrome插件安装包chrome浏览器扩展程序链接下载地址chrome-chrome简繁体中文字体(ttf文件)版本,版本大概是43,40。
chrome浏览器的宽度和高度等设置完成。步骤四:安装viewjs。注意安装viewjs,viewjs需要安装adobeflashplayer,在百度chrome浏览器商店中安装。步骤五:启动vswebdoc。步骤六:保存。这样我们就成功将微信公众号文章的文章url爬取下来了。我曾经参考以下方法也是一样搞定的,但步骤就比较复杂,新手可能也可以看懂,不过有一定设置经验的请忽略以下步骤。
微信公众号文章页面url的抓取top10图文消息的抓取top10音乐视频的抓取百度百科的抓取搜狗百科的抓取优酷图文的抓取360图文的抓取今日头条图文的抓取春雨医生图文的抓取红豆内容的抓取每日优鲜图文的抓取如果能把以上的几种图文url抓取下来应该就不愁找不到自己想要的内容了,但需要实践,欢迎跟我交流以上。 查看全部
采集 工具(怎么通过python爬取微信公众号文章插件安装)
采集工具很多,除了太平洋电脑网的cbuder,还有我正在使用的一款client式采集工具vswebdoc,client式采集工具好处在于可以直接把请求发送到服务器,然后服务器根据页面的正则表达式去处理。如果碰到搜索引擎没有抓取到的内容也可以直接post到页面的另一端,然后保存,需要时再去抓取。缺点在于需要针对不同的网站进行不同的设置,需要的人力也比较多。
下面说一下我怎么通过python爬取微信公众号文章。配置环境:1.mac上的话我是用vim,linux系统可以直接用git来操作。2.浏览器上推荐谷歌浏览器,目前这款浏览器已经支持搜索公众号文章的https链接,无需ie,且googlechrome在搜索这方面做的不好,百度能搜到部分内容但不能完全识别。
爬取步骤:步骤一:在chrome上安装vswebdoc插件,方法有很多,简单的可以用安装方法不详细介绍,详细的也可以参考:vswebdoc安装与使用方法。步骤二:安装完成后打开vswebdoc,下载解压。步骤三:如果已经下载或者直接用浏览器上安装或者谷歌访问airbar之类的扩展程序中国并不能打开,可以在我的仓库中下载chrome浏览器插件chrome浏览器插件chrome插件安装包chrome浏览器扩展程序链接下载地址chrome-chrome简繁体中文字体(ttf文件)版本,版本大概是43,40。
chrome浏览器的宽度和高度等设置完成。步骤四:安装viewjs。注意安装viewjs,viewjs需要安装adobeflashplayer,在百度chrome浏览器商店中安装。步骤五:启动vswebdoc。步骤六:保存。这样我们就成功将微信公众号文章的文章url爬取下来了。我曾经参考以下方法也是一样搞定的,但步骤就比较复杂,新手可能也可以看懂,不过有一定设置经验的请忽略以下步骤。
微信公众号文章页面url的抓取top10图文消息的抓取top10音乐视频的抓取百度百科的抓取搜狗百科的抓取优酷图文的抓取360图文的抓取今日头条图文的抓取春雨医生图文的抓取红豆内容的抓取每日优鲜图文的抓取如果能把以上的几种图文url抓取下来应该就不愁找不到自己想要的内容了,但需要实践,欢迎跟我交流以上。
采集 工具(优采云采集器免费版安装方法php及.net外部编程接口 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-02-26 04:33
)
优采云采集器免费版是一款可以快速从金融局采集数据的软件。支持批量采集网页、论坛等内容,可直接保存到数据库或发布到网站。你可以自定义设置采集的方式,获取你需要的内容,或者处理数据,seo优化的工具。
软件功能
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
七年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
安装方式
1、在本站下载优采云采集器后,在电脑本地获取一个压缩包,使用360压缩软件解压,双击.exe文件进入软件安装界面,点击【下一步】继续。
2、进入优采云采集器安装协议界面,可以先阅读软件安装协议中的条款,阅读后点击【我接受】再点击【下一步】继续。
3、选择安装位置优采云采集器,可以点击【安装】,软件会默认安装,也可以在打开的安装位置界面点击【浏览】,可以自行选择软件安装位置后,点击【安装】。
4、优采云采集器安装正在进行中,需要耐心等待软件安装完成。
5、优采云采集器安装完成,点击【完成】退出软件安装。
查看全部
采集 工具(优采云采集器免费版安装方法php及.net外部编程接口
)
优采云采集器免费版是一款可以快速从金融局采集数据的软件。支持批量采集网页、论坛等内容,可直接保存到数据库或发布到网站。你可以自定义设置采集的方式,获取你需要的内容,或者处理数据,seo优化的工具。

软件功能
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
七年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
安装方式
1、在本站下载优采云采集器后,在电脑本地获取一个压缩包,使用360压缩软件解压,双击.exe文件进入软件安装界面,点击【下一步】继续。
2、进入优采云采集器安装协议界面,可以先阅读软件安装协议中的条款,阅读后点击【我接受】再点击【下一步】继续。

3、选择安装位置优采云采集器,可以点击【安装】,软件会默认安装,也可以在打开的安装位置界面点击【浏览】,可以自行选择软件安装位置后,点击【安装】。

4、优采云采集器安装正在进行中,需要耐心等待软件安装完成。

5、优采云采集器安装完成,点击【完成】退出软件安装。

采集 工具(快手采集工具视频批量无水印下载的文件夹水印)
采集交流 • 优采云 发表了文章 • 0 个评论 • 739 次浏览 • 2022-02-23 23:19
快手采集工具是PC端安装使用的快手平台视频批量下载软件。它不仅可以单独下载视频,还可以批量下载。无论是单个作者的所有视频,还是多个作者的所有视频,输入相应链接即可采集下载。下载的视频高清无水印,非常给力!
快手采集工具完全免费,无需注册登录,无任何广告。进入快手视频链接下载。可以支持手机视频的分享链接,作者主页链接,以及电脑上的快手视频链接,作者主页链接。下载单个视频,只需将对应的视频链接复制到快手采集工具采集即可下载;下载作者所有视频,复制作者主页链接,粘贴到快手采集工具中,采集即可下载。对于多位作者的作品,请复制多位作者的主页链接在软件中下载。
该软件还提供了多种自定义设置功能。您可以自定义下载视频的存放目录(默认下载到快手采集工具的文件夹中)。值得称赞的是,采集工具下载的视频可以自动分类到不同的文件夹,从作者的作品、作品类别、发布年份、发布季度。不仅如此,批量下载和单个下载的视频也会自动分类。这样的功能可以说是非常好用的。再也不用担心将下载的视频批量混在一起的烦恼了~
您还可以自定义设置:
1、采集最大作品数;
2、是否强制获取作者所有作品;
3、记录程序日志,另外保存日志;(以 Excel 形式呈现)
4、定时采集,定时采集间隔时间;
5、是否下载图集作品;
6、自定义下载视频文件设置自动保存文件名等
快手采集工具视频批量下载无水印:
蓝玩云:密码:1c61
123云盘:
夸克网盘:
百度网盘:提取码:w6ww 查看全部
采集 工具(快手采集工具视频批量无水印下载的文件夹水印)
快手采集工具是PC端安装使用的快手平台视频批量下载软件。它不仅可以单独下载视频,还可以批量下载。无论是单个作者的所有视频,还是多个作者的所有视频,输入相应链接即可采集下载。下载的视频高清无水印,非常给力!

快手采集工具完全免费,无需注册登录,无任何广告。进入快手视频链接下载。可以支持手机视频的分享链接,作者主页链接,以及电脑上的快手视频链接,作者主页链接。下载单个视频,只需将对应的视频链接复制到快手采集工具采集即可下载;下载作者所有视频,复制作者主页链接,粘贴到快手采集工具中,采集即可下载。对于多位作者的作品,请复制多位作者的主页链接在软件中下载。
该软件还提供了多种自定义设置功能。您可以自定义下载视频的存放目录(默认下载到快手采集工具的文件夹中)。值得称赞的是,采集工具下载的视频可以自动分类到不同的文件夹,从作者的作品、作品类别、发布年份、发布季度。不仅如此,批量下载和单个下载的视频也会自动分类。这样的功能可以说是非常好用的。再也不用担心将下载的视频批量混在一起的烦恼了~
您还可以自定义设置:
1、采集最大作品数;
2、是否强制获取作者所有作品;
3、记录程序日志,另外保存日志;(以 Excel 形式呈现)
4、定时采集,定时采集间隔时间;
5、是否下载图集作品;
6、自定义下载视频文件设置自动保存文件名等

快手采集工具视频批量下载无水印:
蓝玩云:密码:1c61
123云盘:
夸克网盘:
百度网盘:提取码:w6ww
沈阳市政府特殊津贴信息采集工具 使用指南
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2022-05-08 08:40
沈阳市政府特殊津贴信息采集工具
使用指南
沈阳市政府特殊津贴信息采集工具是免安装应用软件,用户直接使用浏览器操作,自行填写信息。数据采集软件将数据文档通过加密处理,自动转换成标准电子文档,用户填写完成数据后,下载打印资料。
操作说明:
1、用户使用电脑浏览器(推荐使用:谷歌、火狐、360浏览器),地址栏输入网址::88,打开软件界面。因为需要上传附件,本软件需要用电脑端填写,不支持使用手机端操作。
2、首次填写数据用户,点击“首次注册”选项,按照数据项要求,依次填写内容。第一步填写页面,系统自动生成6位数字识别码,请务必牢记,后续登录软件系统使用,本软件登录的用户名为:用户身份证号码,密码为:系统生成的识别码,识别码通过短信形式发送到所填写手机里。
填写内容包含:基本信息、教育经历、工作经历、获得重要奖励、个人荣誉、代表性著作和论文、取得专利、获基金资助情况、完成项目、现承担项目、主要业绩综述等。
按照上述顺序,用户依次填写信息,并上传证明材料图片,图片格式为jpg文件,每张图片小于500K,由于填写内容及上传文件多,为保证填报顺畅,请用户提前准备文档资料及证明材料图片。
用户填写数据项后,点击“选择文件”上传证明图片,页面下方显示本项所填写的内容。检查无误后,点击“完成后进入下一项”字样进行下一项填写。
3、填写完所有项后,点击“预览下载报名表”,可查看所填写的项目及证明图片,无误后下载或者打印资料。如果信息有误,可在申报截止日期前,修改所填写的项目。
4、登录系统修改信息的用户,浏览器输入网址,打开操作界面,点击“修改信息登录”,按照身份证号及系统生成的识别码,登录系统。直接修改项目信息,修改后,点击“修改”按钮,完成修改。或者删除填写信息。
软件技术支持电话:
政策咨询电话: 查看全部
沈阳市政府特殊津贴信息采集工具 使用指南
沈阳市政府特殊津贴信息采集工具
使用指南
沈阳市政府特殊津贴信息采集工具是免安装应用软件,用户直接使用浏览器操作,自行填写信息。数据采集软件将数据文档通过加密处理,自动转换成标准电子文档,用户填写完成数据后,下载打印资料。
操作说明:
1、用户使用电脑浏览器(推荐使用:谷歌、火狐、360浏览器),地址栏输入网址::88,打开软件界面。因为需要上传附件,本软件需要用电脑端填写,不支持使用手机端操作。
2、首次填写数据用户,点击“首次注册”选项,按照数据项要求,依次填写内容。第一步填写页面,系统自动生成6位数字识别码,请务必牢记,后续登录软件系统使用,本软件登录的用户名为:用户身份证号码,密码为:系统生成的识别码,识别码通过短信形式发送到所填写手机里。
填写内容包含:基本信息、教育经历、工作经历、获得重要奖励、个人荣誉、代表性著作和论文、取得专利、获基金资助情况、完成项目、现承担项目、主要业绩综述等。
按照上述顺序,用户依次填写信息,并上传证明材料图片,图片格式为jpg文件,每张图片小于500K,由于填写内容及上传文件多,为保证填报顺畅,请用户提前准备文档资料及证明材料图片。
用户填写数据项后,点击“选择文件”上传证明图片,页面下方显示本项所填写的内容。检查无误后,点击“完成后进入下一项”字样进行下一项填写。
3、填写完所有项后,点击“预览下载报名表”,可查看所填写的项目及证明图片,无误后下载或者打印资料。如果信息有误,可在申报截止日期前,修改所填写的项目。
4、登录系统修改信息的用户,浏览器输入网址,打开操作界面,点击“修改信息登录”,按照身份证号及系统生成的识别码,登录系统。直接修改项目信息,修改后,点击“修改”按钮,完成修改。或者删除填写信息。
软件技术支持电话:
政策咨询电话:
抖音采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 571 次浏览 • 2022-05-07 21:24
可以采集某作者所有作品(含作者喜欢作品)、单个视频作品、某话题挑战下指定数量作品、使用某音乐的指定数量作品。
主要是为了便于作品下载的管理进行了分别保存,同时检测作者、话题挑战、音乐的作品的更新,有新作品时仅下载新作品。
使用过本人前面的“批量采集抖音作品”工具的,控制台的新版本工具可自动迁移数据,当然你也可以继续使用以前的工具。
不再重复介绍了,在这个帖子下载过旧版本工具的自然知道怎么使用。压缩包里也有说明和短链接获取图片及控制台操作使用录像。
最新Python的Gui版已提供,各种作品采集的链接获取方式见网盘中演示录像。
新版本工具下载地址:,访问密码:52pj
蓝奏云盘lanzous无法访问(21.5.13),请用lanzoui访问(本帖链接已更改)
另添加一个百度网盘地址:,提取码: r7c6旧版本工具下载地址(还是原来那个):,访问密码:3345
如果64位版本有问题,可尝试使用32位版本,如果仍不行,可尝试使用XP版本
已提供Python版XP可用版本,VB版Gui版本无需使用了。 查看全部
抖音采集工具
可以采集某作者所有作品(含作者喜欢作品)、单个视频作品、某话题挑战下指定数量作品、使用某音乐的指定数量作品。
主要是为了便于作品下载的管理进行了分别保存,同时检测作者、话题挑战、音乐的作品的更新,有新作品时仅下载新作品。
使用过本人前面的“批量采集抖音作品”工具的,控制台的新版本工具可自动迁移数据,当然你也可以继续使用以前的工具。
不再重复介绍了,在这个帖子下载过旧版本工具的自然知道怎么使用。压缩包里也有说明和短链接获取图片及控制台操作使用录像。
最新Python的Gui版已提供,各种作品采集的链接获取方式见网盘中演示录像。
新版本工具下载地址:,访问密码:52pj
蓝奏云盘lanzous无法访问(21.5.13),请用lanzoui访问(本帖链接已更改)
另添加一个百度网盘地址:,提取码: r7c6旧版本工具下载地址(还是原来那个):,访问密码:3345
如果64位版本有问题,可尝试使用32位版本,如果仍不行,可尝试使用XP版本
已提供Python版XP可用版本,VB版Gui版本无需使用了。
常用的大数据采集工具有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2022-05-07 21:20
大家好,我是梦想家Alex ~
想必大家都知道,大数据的来源多种多样,在大数据时代背景下,如何从大数据中采集出有用的信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效采集大数据,依据采集环境及数据类型选择适当的大数据采集方法及平台至关重要。下面介绍一些常用的大数据采集平台和工具。
1、Flume
Flume作为Hadoop的组件,是由Cloudera专门研发的分布式日志收集系统。尤其近几年随着Flume的不断完善,用户在开发过程中使用的便利性得到很大的改善,Flume现已成为Apache Top项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源上收集数据的能力。
Flume采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据。ZooKeeper本身可保证配置数据的一致性和高可用性。另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master节点之间使用Gossip协议同步数据。
Flume针对特殊场景也具备良好的自定义扩展能力,因此Flume适用于大部分的日常数据采集场景。因为Flume使用JRuby来构建,所以依赖Java运行环境。Flume设计成一个分布式的管道架构,可以看成在数据源和目的地之间有一个Agent的网络,支持数据路由。
Flume支持设置Sink的Failover和加载平衡,这样就可以保证在有一个Agent失效的情况下,整个系统仍能正常收集数据。Flume中传输的内容定义为事件(Event),事件由Headers(包含元数据,即Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发。Flume客户端负责在事件产生的源头把事件发送给Flume的Agent。客户端通常和产生数据源的应用在同一个进程空间。常见的Flume 客户端有Avro、Log4J、Syslog和HTTP Post。
2、Fluentd
Fluentd是另一个开源的数据收集架构,如图1所示。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。通过丰富的插件,可以收集来自各种系统或应用的日志,然后根据用户定义将日志做分类处理。通过Fluentd,可以非常轻易地实现像追踪日志文件并将其过滤后转存到 MongoDB 这样的操作。Fluentd可以彻底地把人从烦琐的日志处理中解放出来。
图1 Fluentd架构
Fluentd具有多个功能特点:安装方便、占用空间小、半结构化数据日志记录、灵活的插件机制、可靠的缓冲、日志转发。Treasure Data公司对该产品提供支持和维护。另外,采用JSON统一数据/日志格式是它的另一个特点。相对Flume,Fluentd配置也相对简单一些。
Fluentd的扩展性非常好,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd具有跨平台的问题,并不支持Windows平台。
Fluentd的Input/Buffer/Output非常类似于Flume的Source/Channel/Sink。Fluentd架构如图2所示。
图2 Fluentd架构
3、Logstash
Logstash是著名的开源数据栈ELK(ElasticSearch,Logstash,Kibana)中的那个L。因为Logstash用JRuby开发,所以运行时依赖JVM。Logstash的部署架构如图3所示,当然这只是一种部署的选项。
图3 Logstash的部署架构
一个典型的Logstash的配置如下,包括Input、Filter的Output的设置。
input {<br /> file {<br /> type =>"Apache-access"<br /> path =>"/var/log/Apache2/other\_vhosts\_access.log"<br /> } <br /> file {<br /> type =>"pache-error"<br /> path =>"/var/log/Apache2/error.log"<br /> }<br />}<br />filter {<br /> grok {<br /> match => {"message"=>"%(COMBINEDApacheLOG)"}<br /> } <br /> date {<br /> match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}<br /> }<br />}<br />output {<br /> stdout {}<br /> Redis {<br /> host=>"192.168.1.289"<br /> data\_type => "list"<br /> key => "Logstash"<br /> }<br />}<br />
几乎在大部分的情况下,ELK作为一个栈是被同时使用的。在你的数据系统使用ElasticSearch的情况下,Logstash是首选。
4、Chukwa
Chukwa是Apache旗下另一个开源的数据收集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和MapReduce来构建(用Java来实现),提供扩展性和可靠性。它提供了很多模块以支持Hadoop集群日志分析。Chukwa同时提供对数据的展示、分析和监视。该项目目前已经不活跃。
Chukwa适应以下需求:
(1)灵活的、动态可控的数据源。
(2)高性能、高可扩展的存储系统。
(3)合适的架构,用于对收集到的大规模数据进行分析。
Chukwa架构如图4所示。
图4 Chukwa架构
5、Scribe
Scribe是Facebook开发的数据(日志)收集系统。其官网已经多年不维护。Scribe为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。当中央存储系统的网络或者机器出现故障时,Scribe会将日志转存到本地或者另一个位置;当中央存储系统恢复后,Scribe会将转存的日志重新传输给中央存储系统。Scribe通常与Hadoop结合使用,用于向HDFS中push(推)日志,而Hadoop通过MapReduce作业进行定期处理。
Scribe架构如图5所示。
图5 Scribe架构
Scribe架构比较简单,主要包括三部分,分别为Scribe agent、Scribe和存储系统。
6、Splunk
在商业化的大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析和处理,以及数据展现的能力。Splunk是一个分布式机器数据平台,主要有三个角色。Splunk架构如图6所示。
图片
图6 Splunk架构
Search:负责数据的搜索和处理,提供搜索时的信息抽取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的收集、清洗、变形,并发送给Indexer。
Splunk内置了对Syslog、TCP/UDP、Spooling的支持,同时,用户可以通过开发 Input和Modular Input的方式来获取特定的数据。在Splunk提供的软件仓库里有很多成熟的数据采集应用,如AWS、数据库(DBConnect)等,可以方便地从云或数据库中获取数据进入Splunk的数据平台做分析。
Search Head和Indexer都支持Cluster的配置,即高可用、高扩展的、但Splunk现在还没有针对Forwarder的Cluster的功能。也就是说,如果有一台Forwarder的机器出了故障,则数据收集也会随之中断,并不能把正在运行的数据收集任务因故障切换(Failover)到其他的Forwarder上。
7、Scrapy
Python的爬虫架构叫Scrapy。Scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和Web抓取架构,用于抓取Web站点并从页面中提取结构化数据。Scrapy的用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个架构,任何人都可以根据需求方便地进行修改。它还提供多种类型爬虫的基类,如BaseSpider、Sitemap爬虫等,最新版本提供对Web 2.0爬虫的支持。
Scrapy运行原理如图7所示。
图片
图7 Scrapy运行原理
Scrapy的整个数据处理流程由Scrapy引擎进行控制。Scrapy运行流程如下:
(1)Scrapy引擎打开一个域名时,爬虫处理这个域名,并让爬虫获取第一个爬取的URL。
(2)Scrapy引擎先从爬虫那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
(3)Scrapy引擎从调度那里获取接下来进行爬取的页面。
(4)调度将下一个爬取的URL返回给引擎,引擎将它们通过下载中间件发送到下载器。
(5)当网页被下载器下载完成以后,响应内容通过下载器中间件被发送到Scrapy引擎。
(6)Scrapy引擎收到下载器的响应并将它通过爬虫中间件发送到爬虫进行处理。
(7)爬虫处理响应并返回爬取到的项目,然后给Scrapy引擎发送新的请求。
(8)Scrapy引擎将抓取到的放入项目管道,并向调度器发送请求。
(9)系统重复第(2)步后面的操作,直到调度器中没有请求,然后断开Scrapy引擎与域之间的联系。
END
点击关注|设为星标|干货速递
往期推荐 查看全部
常用的大数据采集工具有哪些?
大家好,我是梦想家Alex ~
想必大家都知道,大数据的来源多种多样,在大数据时代背景下,如何从大数据中采集出有用的信息是大数据发展的最关键因素。大数据采集是大数据产业的基石,大数据采集阶段的工作是大数据的核心技术之一。为了高效采集大数据,依据采集环境及数据类型选择适当的大数据采集方法及平台至关重要。下面介绍一些常用的大数据采集平台和工具。
1、Flume
Flume作为Hadoop的组件,是由Cloudera专门研发的分布式日志收集系统。尤其近几年随着Flume的不断完善,用户在开发过程中使用的便利性得到很大的改善,Flume现已成为Apache Top项目之一。
Flume提供了从Console(控制台)、RPC(Thrift-RPC)、Text(文件)、Tail(UNIX Tail)、Syslog、Exec(命令执行)等数据源上收集数据的能力。
Flume采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据。ZooKeeper本身可保证配置数据的一致性和高可用性。另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master节点之间使用Gossip协议同步数据。
Flume针对特殊场景也具备良好的自定义扩展能力,因此Flume适用于大部分的日常数据采集场景。因为Flume使用JRuby来构建,所以依赖Java运行环境。Flume设计成一个分布式的管道架构,可以看成在数据源和目的地之间有一个Agent的网络,支持数据路由。
Flume支持设置Sink的Failover和加载平衡,这样就可以保证在有一个Agent失效的情况下,整个系统仍能正常收集数据。Flume中传输的内容定义为事件(Event),事件由Headers(包含元数据,即Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发。Flume客户端负责在事件产生的源头把事件发送给Flume的Agent。客户端通常和产生数据源的应用在同一个进程空间。常见的Flume 客户端有Avro、Log4J、Syslog和HTTP Post。
2、Fluentd
Fluentd是另一个开源的数据收集架构,如图1所示。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。通过丰富的插件,可以收集来自各种系统或应用的日志,然后根据用户定义将日志做分类处理。通过Fluentd,可以非常轻易地实现像追踪日志文件并将其过滤后转存到 MongoDB 这样的操作。Fluentd可以彻底地把人从烦琐的日志处理中解放出来。
图1 Fluentd架构
Fluentd具有多个功能特点:安装方便、占用空间小、半结构化数据日志记录、灵活的插件机制、可靠的缓冲、日志转发。Treasure Data公司对该产品提供支持和维护。另外,采用JSON统一数据/日志格式是它的另一个特点。相对Flume,Fluentd配置也相对简单一些。
Fluentd的扩展性非常好,客户可以自己定制(Ruby)Input/Buffer/Output。Fluentd具有跨平台的问题,并不支持Windows平台。
Fluentd的Input/Buffer/Output非常类似于Flume的Source/Channel/Sink。Fluentd架构如图2所示。
图2 Fluentd架构
3、Logstash
Logstash是著名的开源数据栈ELK(ElasticSearch,Logstash,Kibana)中的那个L。因为Logstash用JRuby开发,所以运行时依赖JVM。Logstash的部署架构如图3所示,当然这只是一种部署的选项。
图3 Logstash的部署架构
一个典型的Logstash的配置如下,包括Input、Filter的Output的设置。
input {<br /> file {<br /> type =>"Apache-access"<br /> path =>"/var/log/Apache2/other\_vhosts\_access.log"<br /> } <br /> file {<br /> type =>"pache-error"<br /> path =>"/var/log/Apache2/error.log"<br /> }<br />}<br />filter {<br /> grok {<br /> match => {"message"=>"%(COMBINEDApacheLOG)"}<br /> } <br /> date {<br /> match => {"timestamp"=>"dd/MMM/yyyy:HH:mm:ss Z"}<br /> }<br />}<br />output {<br /> stdout {}<br /> Redis {<br /> host=>"192.168.1.289"<br /> data\_type => "list"<br /> key => "Logstash"<br /> }<br />}<br />
几乎在大部分的情况下,ELK作为一个栈是被同时使用的。在你的数据系统使用ElasticSearch的情况下,Logstash是首选。
4、Chukwa
Chukwa是Apache旗下另一个开源的数据收集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和MapReduce来构建(用Java来实现),提供扩展性和可靠性。它提供了很多模块以支持Hadoop集群日志分析。Chukwa同时提供对数据的展示、分析和监视。该项目目前已经不活跃。
Chukwa适应以下需求:
(1)灵活的、动态可控的数据源。
(2)高性能、高可扩展的存储系统。
(3)合适的架构,用于对收集到的大规模数据进行分析。
Chukwa架构如图4所示。
图4 Chukwa架构
5、Scribe
Scribe是Facebook开发的数据(日志)收集系统。其官网已经多年不维护。Scribe为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。当中央存储系统的网络或者机器出现故障时,Scribe会将日志转存到本地或者另一个位置;当中央存储系统恢复后,Scribe会将转存的日志重新传输给中央存储系统。Scribe通常与Hadoop结合使用,用于向HDFS中push(推)日志,而Hadoop通过MapReduce作业进行定期处理。
Scribe架构如图5所示。
图5 Scribe架构
Scribe架构比较简单,主要包括三部分,分别为Scribe agent、Scribe和存储系统。
6、Splunk
在商业化的大数据平台产品中,Splunk提供完整的数据采集、数据存储、数据分析和处理,以及数据展现的能力。Splunk是一个分布式机器数据平台,主要有三个角色。Splunk架构如图6所示。
图片
图6 Splunk架构
Search:负责数据的搜索和处理,提供搜索时的信息抽取功能。
Indexer:负责数据的存储和索引。
Forwarder:负责数据的收集、清洗、变形,并发送给Indexer。
Splunk内置了对Syslog、TCP/UDP、Spooling的支持,同时,用户可以通过开发 Input和Modular Input的方式来获取特定的数据。在Splunk提供的软件仓库里有很多成熟的数据采集应用,如AWS、数据库(DBConnect)等,可以方便地从云或数据库中获取数据进入Splunk的数据平台做分析。
Search Head和Indexer都支持Cluster的配置,即高可用、高扩展的、但Splunk现在还没有针对Forwarder的Cluster的功能。也就是说,如果有一台Forwarder的机器出了故障,则数据收集也会随之中断,并不能把正在运行的数据收集任务因故障切换(Failover)到其他的Forwarder上。
7、Scrapy
Python的爬虫架构叫Scrapy。Scrapy是由Python语言开发的一个快速、高层次的屏幕抓取和Web抓取架构,用于抓取Web站点并从页面中提取结构化数据。Scrapy的用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个架构,任何人都可以根据需求方便地进行修改。它还提供多种类型爬虫的基类,如BaseSpider、Sitemap爬虫等,最新版本提供对Web 2.0爬虫的支持。
Scrapy运行原理如图7所示。
图片
图7 Scrapy运行原理
Scrapy的整个数据处理流程由Scrapy引擎进行控制。Scrapy运行流程如下:
(1)Scrapy引擎打开一个域名时,爬虫处理这个域名,并让爬虫获取第一个爬取的URL。
(2)Scrapy引擎先从爬虫那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
(3)Scrapy引擎从调度那里获取接下来进行爬取的页面。
(4)调度将下一个爬取的URL返回给引擎,引擎将它们通过下载中间件发送到下载器。
(5)当网页被下载器下载完成以后,响应内容通过下载器中间件被发送到Scrapy引擎。
(6)Scrapy引擎收到下载器的响应并将它通过爬虫中间件发送到爬虫进行处理。
(7)爬虫处理响应并返回爬取到的项目,然后给Scrapy引擎发送新的请求。
(8)Scrapy引擎将抓取到的放入项目管道,并向调度器发送请求。
(9)系统重复第(2)步后面的操作,直到调度器中没有请求,然后断开Scrapy引擎与域之间的联系。
END
点击关注|设为星标|干货速递
往期推荐
如何设计,甚至是不同的程序模块做技术转接
采集交流 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-05-07 05:02
采集工具,主要分为开发的和客户端。比如说获取小米充电器的充电电流,就需要将对应的请求给对应的客户端,这是客户端所能做的,具体的技术问题是没有太大问题的。
世界上存在这种功能强大的api,但是并没有这种应用。更复杂的算法可以轻松实现,但成本可能不会太低。既然题主说智能车联网,那应该是算法应用,那么实际上关键问题是对于数据的进行处理。而不同数据处理不同需求可能得到相应解决方案,最基本的有充电状态显示(比如用特定画笔可以显示充电电流大小,用可视化编程实现自动识别车辆位置,开启电量显示等等),接近一般人的imu,陀螺仪,加速度传感器,等等,但并不需要打通到底层来做统一对接。可能你要说的可能是传感器数据,那就很麻烦了,哪些接受,哪些发送,是否做主动显示也是问题。
一:使用开发和调试不同的框架的话,程序不会有太大差别。二:程序本身只能实现很简单的功能,实现成本应该不低。三:在一定程度上可以解决一些传感器上的问题,这个只是暂时存在的。四:现在的传感器原理设计和机器人需要的对接功能,都还在尝试中,因为各家设计不同,能给出具体结果和响应时间有差异。以上内容,仅供参考。
如何设计,甚至是不同的程序模块做技术转接,这是需要深入思考的一个话题。 查看全部
如何设计,甚至是不同的程序模块做技术转接
采集工具,主要分为开发的和客户端。比如说获取小米充电器的充电电流,就需要将对应的请求给对应的客户端,这是客户端所能做的,具体的技术问题是没有太大问题的。
世界上存在这种功能强大的api,但是并没有这种应用。更复杂的算法可以轻松实现,但成本可能不会太低。既然题主说智能车联网,那应该是算法应用,那么实际上关键问题是对于数据的进行处理。而不同数据处理不同需求可能得到相应解决方案,最基本的有充电状态显示(比如用特定画笔可以显示充电电流大小,用可视化编程实现自动识别车辆位置,开启电量显示等等),接近一般人的imu,陀螺仪,加速度传感器,等等,但并不需要打通到底层来做统一对接。可能你要说的可能是传感器数据,那就很麻烦了,哪些接受,哪些发送,是否做主动显示也是问题。
一:使用开发和调试不同的框架的话,程序不会有太大差别。二:程序本身只能实现很简单的功能,实现成本应该不低。三:在一定程度上可以解决一些传感器上的问题,这个只是暂时存在的。四:现在的传感器原理设计和机器人需要的对接功能,都还在尝试中,因为各家设计不同,能给出具体结果和响应时间有差异。以上内容,仅供参考。
如何设计,甚至是不同的程序模块做技术转接,这是需要深入思考的一个话题。
前端浏览器对js提供的接口有哪些?360、百度、ebe
采集交流 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-06 05:00
采集工具,360、百度、ebe这些推荐一下,当然工具肯定只是辅助作用,最主要的还是思维的转换。打个比方,设计师应该多积累,提升自己的思维素质,不要太在意工具的问题。
你这个问题我还真心不知道你说的是什么工具。根据你的描述,如果我理解为,
dreamweaverhtml5css和js
楼上@陈柯宇他们回答过了。我来回答一下非游戏行业的:前端浏览器对js提供的接口很多。常用的是jquery,extjs,ovijs,yui,internetexplorerextensions,swiper等。等做得好的话,mvc架构很便捷可以脱离浏览器或者其他东西。我觉得你可以用webmagic这个东西做下小的网站,节约成本。
另外说一句我的心思也比较在bootstrap这里,我觉得很好用,除了w3c标准,还有定制化。后端方面用java,或者框架比如weblogic这种。主要是http和正则,或者很多大神说的python。
cooleditor:是一款快速的开发工具,使用web为程序员构建高效的开发环境。他的最大的特点就是可以完全免费,功能非常强大,用这个工具就不用愁编程不懂了。
jsonp(jsonparser)可以快速解析json格式数据实现动态调用、拦截、验证等javascript中的转换效果也支持ecmascript6,ie9等浏览器 查看全部
前端浏览器对js提供的接口有哪些?360、百度、ebe
采集工具,360、百度、ebe这些推荐一下,当然工具肯定只是辅助作用,最主要的还是思维的转换。打个比方,设计师应该多积累,提升自己的思维素质,不要太在意工具的问题。
你这个问题我还真心不知道你说的是什么工具。根据你的描述,如果我理解为,
dreamweaverhtml5css和js
楼上@陈柯宇他们回答过了。我来回答一下非游戏行业的:前端浏览器对js提供的接口很多。常用的是jquery,extjs,ovijs,yui,internetexplorerextensions,swiper等。等做得好的话,mvc架构很便捷可以脱离浏览器或者其他东西。我觉得你可以用webmagic这个东西做下小的网站,节约成本。
另外说一句我的心思也比较在bootstrap这里,我觉得很好用,除了w3c标准,还有定制化。后端方面用java,或者框架比如weblogic这种。主要是http和正则,或者很多大神说的python。
cooleditor:是一款快速的开发工具,使用web为程序员构建高效的开发环境。他的最大的特点就是可以完全免费,功能非常强大,用这个工具就不用愁编程不懂了。
jsonp(jsonparser)可以快速解析json格式数据实现动态调用、拦截、验证等javascript中的转换效果也支持ecmascript6,ie9等浏览器
采集 工具(创想亚马逊ASIN现已采集分析工具新增功能介绍(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 414 次浏览 • 2022-04-16 10:03
Creative Amazon ASIN采集器 是一款外贸工具。兼容亚马逊中国、美国、日本、加拿大、法国、德国、英国、意大利、西班牙、墨西哥、印度等网站看清楚。创意亚马逊采集器现已蔓延到各个地方,采集多样,数据操作方便,使用方便等优势成为亚马逊卖家必备的数据分析采集工具,数据采集 可用于后续销售、产品选择、数据分析、调查等。价格实惠。未来将不断推出新功能,满足广大卖家的需求。内置条件删除器、过滤器、数据编辑工具、批量修改价格等傻瓜式工具。
软件功能
1、兼容更多国家
支持各个国家的 采集 亚马逊网站
2、支持 采集 变体
支持采集变体模型颜色尺寸、高清图、细节图、价格、报价
3、支持采集高清图片
采集超清晰图片,支持采集主图,多张图片采集,支持自定义图片保存文件名
4、支持导出Excel/txt/WEB/XML
可以导出为各种格式
5、支持过滤器
过滤器升级以支持各种过滤器系统
6、采集数据充实
丰富文章中的各种细节
7、采集速度稳定快速,多种防屏蔽措施
专业的采集算法,处理速度快,多种网络采集模式,支持http代理批量添加随机切换
8、丰富的功能帮助用户
自带丰富的小工具:批量修改数据价格、价格条件去除器、SKU生成器、图片浏览、重复ASIN去除器等。
9、各种情况可以围绕ASIN批量处理采集
支持采集商品全评论,采集卖家功能,批量AZ链接过滤采集
亚马逊 ASIN采集分析工具的新功能:
1、增加了更多的表格模式
2、图片可以自行导出到表格
3、图片可以自动批量下载,方便以后的采集素材
4、reviews功能新增采集买家秀高清图片功能
5、支持全屏打开任务列表
6、自动统计已采集的数据
7、自动过滤掉已经检查过的业务,防止重复检查
8、提高数据导入导出速度
9、屏蔽验证码为独立插件形式,以后升级更方便快捷
相关文章 查看全部
采集 工具(创想亚马逊ASIN现已采集分析工具新增功能介绍(组图))
Creative Amazon ASIN采集器 是一款外贸工具。兼容亚马逊中国、美国、日本、加拿大、法国、德国、英国、意大利、西班牙、墨西哥、印度等网站看清楚。创意亚马逊采集器现已蔓延到各个地方,采集多样,数据操作方便,使用方便等优势成为亚马逊卖家必备的数据分析采集工具,数据采集 可用于后续销售、产品选择、数据分析、调查等。价格实惠。未来将不断推出新功能,满足广大卖家的需求。内置条件删除器、过滤器、数据编辑工具、批量修改价格等傻瓜式工具。
软件功能
1、兼容更多国家
支持各个国家的 采集 亚马逊网站
2、支持 采集 变体
支持采集变体模型颜色尺寸、高清图、细节图、价格、报价
3、支持采集高清图片
采集超清晰图片,支持采集主图,多张图片采集,支持自定义图片保存文件名
4、支持导出Excel/txt/WEB/XML
可以导出为各种格式
5、支持过滤器
过滤器升级以支持各种过滤器系统
6、采集数据充实
丰富文章中的各种细节
7、采集速度稳定快速,多种防屏蔽措施
专业的采集算法,处理速度快,多种网络采集模式,支持http代理批量添加随机切换
8、丰富的功能帮助用户
自带丰富的小工具:批量修改数据价格、价格条件去除器、SKU生成器、图片浏览、重复ASIN去除器等。
9、各种情况可以围绕ASIN批量处理采集
支持采集商品全评论,采集卖家功能,批量AZ链接过滤采集
亚马逊 ASIN采集分析工具的新功能:
1、增加了更多的表格模式
2、图片可以自行导出到表格
3、图片可以自动批量下载,方便以后的采集素材
4、reviews功能新增采集买家秀高清图片功能
5、支持全屏打开任务列表
6、自动统计已采集的数据
7、自动过滤掉已经检查过的业务,防止重复检查
8、提高数据导入导出速度
9、屏蔽验证码为独立插件形式,以后升级更方便快捷
相关文章
采集 工具(老店软件推出的一款1688(阿里巴巴)产品信息批量采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2022-04-15 22:27
1688商品采集工具是老店软件推出的1688(阿里巴巴)商品信息批采集软件,可以帮助用户在平台上快速获取商品信息,即时了解和更新店铺动态,操作简单、实用、方便,是一款非常不错的软件。
特征
支持两种 采集 模式:
1、页面设置采集。
在WEB页面设置一个采集关键词,精细设置采集条件(如样式、颜色、大小等)。这种细化适用于复杂条件采集。
2、按 关键词批处理采集。
通过导入一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价格、产品图、月销量、月销量、重复率、产品描述、回复、发货、旺旺、公司名称、业务类型等。字段导出为文本表(excel),可用于产品市场分析、同行销售业绩评估、企业信息采集等。每个产品关键词最多支持100个页面,每页60个产品,大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词order采集,不同的关键词Enter键每行一个,支持字段排序(点击标题栏)然后导出保存。
软件功能
1、鼠标点击即可,无需编写任何采集规则,
2、实时采集,非历史数据,用户本地采集中最新的当前数据。
3、操作简单易用,傻瓜式的操作分两步完成(导入产品详情链接,每行一个,可导入多个产品链接;点击开始< @采集;导出数据)。无需编写任何规则,操作极其简单。
4、极速搜索,极速操作体验,流畅愉悦。
5、具有自动升级功能:新版本正式发布后,打开客户端会自动升级到最新版本。
6、软件会持续更新模块。
指示
1、采集模式1(由搜索页面设置)
(1)点击“搜索页面设置”按钮,输入你要采集的关键词
(2)分类可以设置,设置后点击“Page Direct采集”按钮
(3)采集数据如图
(4)同时也可以点击“浏览查看切换开发”来切换浏览器的显示。
2、采集模式2(导入关键词采集)
(1)导入 关键词 为 采集,多个 关键词 (每行一个)
(2)点击“导入模式采集”按钮
(3)同时也可以点击“Browse View Switch Development”切换浏览器的显示。
常见问题
1、支持的操作系统?
Win7及以上(32位或64位均可)。xp 不支持。
2、试用版和正版有什么区别?
试用版有采集导出密钥信息加密(24小时限时试用),其他没有任何限制,购买前可以先试用。
因为质量已经通过测试,我们的软件可以发布来体验试用。(不像我的许多同行,他们无法体验或做一个足够有限的糟糕体验)。
3、采集速度?
您的机器性能和带宽没有限制。
4、换机或软件丢失怎么办?
QQ和微信可以联系我们处理。只需询问我们的VIP客户,在授权期间,我们会及时处理。 查看全部
采集 工具(老店软件推出的一款1688(阿里巴巴)产品信息批量采集软件)
1688商品采集工具是老店软件推出的1688(阿里巴巴)商品信息批采集软件,可以帮助用户在平台上快速获取商品信息,即时了解和更新店铺动态,操作简单、实用、方便,是一款非常不错的软件。
特征
支持两种 采集 模式:
1、页面设置采集。
在WEB页面设置一个采集关键词,精细设置采集条件(如样式、颜色、大小等)。这种细化适用于复杂条件采集。
2、按 关键词批处理采集。
通过导入一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价格、产品图、月销量、月销量、重复率、产品描述、回复、发货、旺旺、公司名称、业务类型等。字段导出为文本表(excel),可用于产品市场分析、同行销售业绩评估、企业信息采集等。每个产品关键词最多支持100个页面,每页60个产品,大约6000个产品信息。支持详细的搜索参数设置,支持多个产品关键词order采集,不同的关键词Enter键每行一个,支持字段排序(点击标题栏)然后导出保存。
软件功能
1、鼠标点击即可,无需编写任何采集规则,
2、实时采集,非历史数据,用户本地采集中最新的当前数据。
3、操作简单易用,傻瓜式的操作分两步完成(导入产品详情链接,每行一个,可导入多个产品链接;点击开始< @采集;导出数据)。无需编写任何规则,操作极其简单。
4、极速搜索,极速操作体验,流畅愉悦。
5、具有自动升级功能:新版本正式发布后,打开客户端会自动升级到最新版本。
6、软件会持续更新模块。
指示
1、采集模式1(由搜索页面设置)
(1)点击“搜索页面设置”按钮,输入你要采集的关键词
(2)分类可以设置,设置后点击“Page Direct采集”按钮
(3)采集数据如图
(4)同时也可以点击“浏览查看切换开发”来切换浏览器的显示。
2、采集模式2(导入关键词采集)
(1)导入 关键词 为 采集,多个 关键词 (每行一个)
(2)点击“导入模式采集”按钮
(3)同时也可以点击“Browse View Switch Development”切换浏览器的显示。
常见问题
1、支持的操作系统?
Win7及以上(32位或64位均可)。xp 不支持。
2、试用版和正版有什么区别?
试用版有采集导出密钥信息加密(24小时限时试用),其他没有任何限制,购买前可以先试用。
因为质量已经通过测试,我们的软件可以发布来体验试用。(不像我的许多同行,他们无法体验或做一个足够有限的糟糕体验)。
3、采集速度?
您的机器性能和带宽没有限制。
4、换机或软件丢失怎么办?
QQ和微信可以联系我们处理。只需询问我们的VIP客户,在授权期间,我们会及时处理。
采集 工具(i@Report数据采集报表平台,让我这个专业的来回答一波~)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-12 20:39
让我专业回答一波~~
作为专业的一站式智能数据全生命周期产品和服务提供商,我们为企业提供从数据采集、数据存储、数据管理到数据分析、应用闭环的一站式解决方案。主体所需的数据采集工具,我们的i@Report作为通用数据采集报告平台,内置强大的数据采集通用解决方案,帮助您在互联网数据中采集有价值的数据。
i@Report数据抓取功能可以从指定网页地址提取表格数据,分析数据结构并自动生成相应的报表任务,并通过定时任务定时从网页获取数据并存储在任务中.
i@Report 数据抓取功能基于用户定义的抓取方案。
创建新爬取方案的第一步是配置要爬取的网页地址,根据关键字识别并展示有效的数据表,然后分析网页上的数据结构。这里的关键字是指目标表格的表头文字,表格前面的文字是用来辅助定位表格的。
配置好爬取地址和关键词后,点击界面上的测试按钮,根据默认的爬取规则,会从目标地址抓取匹配的table标签中的内容重新渲染,与网页样式无关。
当没有明显的关键字或者有多个同名的表时,可以考虑使用高级功能设置表ID来定位表。
一般来说,网页中的大量数据都是以分页的形式呈现的。高级功能支持使用分页参数设置获取目标站点的多页数据抓取,甚至可以配置要抓取的页数到页数,以及抓取到的重复数据如何处理等.
有些网站要求用户登录后才能访问网页,比如在i中抓取BI中的数据。在这种情况下我该怎么办?
没关系,数据抓取方案还支持登录设置!您可以配置用于登录爬取方案的用户名、密码等信息,爬取时系统会自动登录。
完成后,我们可以配置爬取频率,将爬取计划作为定时任务定期执行,这样你就不用站在电脑旁边等待网站更新数据了,这是你设定的时间。系统会自动完成爬取任务。
好了,数据采集方案的配置到这里就完成了,保存之后就可以高枕无忧了。也许在您看新闻和喝咖啡的时候,刚刚发布的新数据 网站 已经进入了您的数据库!
关于宜信华辰
易信华辰是国内专业的智能数据产品和服务提供商。一直致力于为政企用户提供从数据采集、存储、治理、分析到智能应用的智能数据生命周期管理解决方案。企业实现数据驱动、数据智能化,积累了8000余家用户服务和客户成功经验,为客户提供数据分析平台、数据治理体系建设等专业的产品咨询、实施和技术支持服务。
△宜信华辰全产品架构图(点击放大) 查看全部
采集 工具(i@Report数据采集报表平台,让我这个专业的来回答一波~)
让我专业回答一波~~
作为专业的一站式智能数据全生命周期产品和服务提供商,我们为企业提供从数据采集、数据存储、数据管理到数据分析、应用闭环的一站式解决方案。主体所需的数据采集工具,我们的i@Report作为通用数据采集报告平台,内置强大的数据采集通用解决方案,帮助您在互联网数据中采集有价值的数据。
i@Report数据抓取功能可以从指定网页地址提取表格数据,分析数据结构并自动生成相应的报表任务,并通过定时任务定时从网页获取数据并存储在任务中.
i@Report 数据抓取功能基于用户定义的抓取方案。
创建新爬取方案的第一步是配置要爬取的网页地址,根据关键字识别并展示有效的数据表,然后分析网页上的数据结构。这里的关键字是指目标表格的表头文字,表格前面的文字是用来辅助定位表格的。
配置好爬取地址和关键词后,点击界面上的测试按钮,根据默认的爬取规则,会从目标地址抓取匹配的table标签中的内容重新渲染,与网页样式无关。
当没有明显的关键字或者有多个同名的表时,可以考虑使用高级功能设置表ID来定位表。
一般来说,网页中的大量数据都是以分页的形式呈现的。高级功能支持使用分页参数设置获取目标站点的多页数据抓取,甚至可以配置要抓取的页数到页数,以及抓取到的重复数据如何处理等.
有些网站要求用户登录后才能访问网页,比如在i中抓取BI中的数据。在这种情况下我该怎么办?
没关系,数据抓取方案还支持登录设置!您可以配置用于登录爬取方案的用户名、密码等信息,爬取时系统会自动登录。
完成后,我们可以配置爬取频率,将爬取计划作为定时任务定期执行,这样你就不用站在电脑旁边等待网站更新数据了,这是你设定的时间。系统会自动完成爬取任务。
好了,数据采集方案的配置到这里就完成了,保存之后就可以高枕无忧了。也许在您看新闻和喝咖啡的时候,刚刚发布的新数据 网站 已经进入了您的数据库!
关于宜信华辰
易信华辰是国内专业的智能数据产品和服务提供商。一直致力于为政企用户提供从数据采集、存储、治理、分析到智能应用的智能数据生命周期管理解决方案。企业实现数据驱动、数据智能化,积累了8000余家用户服务和客户成功经验,为客户提供数据分析平台、数据治理体系建设等专业的产品咨询、实施和技术支持服务。
△宜信华辰全产品架构图(点击放大)
采集 工具(国内大多app的具体叫法是什么方式不定?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-04-05 08:06
采集工具下载:.tw/下载campaignbooksbysale:197creativebooksforinstall.thebookmarkingdirectory(page):creative_marketing|facebook所有采集一步到位。
谢邀。我会实用一些国外的app。至于这些app的具体叫法,上google一下吧。
因为采用cc协议
采集app首页肯定都有帐号登录的,现在国内大多app都会采用全国统一帐号登录方式,以前有什么个人认证等。
国内的有腾讯应用宝,现在有个马上应用都跟腾讯合作了。
国内大多是软件对接方式,微信服务号、搜狗号码通这种你下载app然后绑定所用手机即可。
短信或者邮件都可以投放你可以根据你要打开的频率来定。具体什么方式不定。
这个app的名字可以这样
1、appstore给的;2、适用主流的短信邮件投放渠道。不过短信从appstore里面下载的可能性更大,其他渠道投放有难度。
微信也好,短信也好,有不少的免费投放的方式,多试试,直接买投放渠道就可以,挺便宜的。不过目前国内app多的,一旦涉及各种安全性审核问题的,广告就会非常多。
短信或者邮件就行了,如果符合规定,可以选择用阿里的流量,这个阿里旗下的流量中,包括app应用内推送,营销短信,这都是有效的,因为有阿里的, 查看全部
采集 工具(国内大多app的具体叫法是什么方式不定?)
采集工具下载:.tw/下载campaignbooksbysale:197creativebooksforinstall.thebookmarkingdirectory(page):creative_marketing|facebook所有采集一步到位。
谢邀。我会实用一些国外的app。至于这些app的具体叫法,上google一下吧。
因为采用cc协议
采集app首页肯定都有帐号登录的,现在国内大多app都会采用全国统一帐号登录方式,以前有什么个人认证等。
国内的有腾讯应用宝,现在有个马上应用都跟腾讯合作了。
国内大多是软件对接方式,微信服务号、搜狗号码通这种你下载app然后绑定所用手机即可。
短信或者邮件都可以投放你可以根据你要打开的频率来定。具体什么方式不定。
这个app的名字可以这样
1、appstore给的;2、适用主流的短信邮件投放渠道。不过短信从appstore里面下载的可能性更大,其他渠道投放有难度。
微信也好,短信也好,有不少的免费投放的方式,多试试,直接买投放渠道就可以,挺便宜的。不过目前国内app多的,一旦涉及各种安全性审核问题的,广告就会非常多。
短信或者邮件就行了,如果符合规定,可以选择用阿里的流量,这个阿里旗下的流量中,包括app应用内推送,营销短信,这都是有效的,因为有阿里的,
采集 工具(什么是数据采集?为什么网站SEO更具是跟上趋势?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-04-03 14:00
什么是数据采集?为什么 data采集 很重要?数据采集不仅可以为我们提供网站SEO方面的数据支持,还可以帮助我们在决策或思考时提供合理的数据支持。技能。
数据采集与我们的生活息息相关,无论是通过Ctrl+C手动复制粘贴慢慢采集我们想要的数据,还是通过我们的数据采集工具完成数据采集。我们都需要数据来帮助我们的生活和工作。
创新是我们数据 采集 的 关键词。时代在不断发展,在这个行业中的一部分是跟上趋势。网站具有创新精神并紧跟当前趋势的 SEO 始终比其他网站SEO 具有优势,因此及时了解可能发生的变化并保持我们的业务处于领先地位非常重要。
data采集的方式有很多种,根据不同的需要可能会有所不同。尽管我们周围有各种各样的选择,网站 都受到定期出现的共同趋势的约束。虽然这些趋势通常证明对所有相关人员都有利,但有时会发生相反的情况。尽管如此,了解数据的当前事实和统计数据采集 仍然有助于决定如何使用它们来使我们在工作和生活中受益。
许多网站传递数据采集工具以一种或另一种方式采集他们的数据。事实上,data采集 早在互联网出现之前就已经存在了,尽管不一定会这样称呼它。那么为什么 data采集 很重要呢?
如果没有数据采集规则,我们需要手动采集所有的信息,自己整理。例如,如果我们想通过手动查找他们的访问量、访问日期或我们的 网站 跳出率来查看有多少用户访问了我们的 网站 数据之一。这可能会很耗时并且会降低我们的工作效率。而我们的数据采集 工具将大大提高我们的生产力。
数据采集工具可帮助我们以完全无忧且自动化的方式将数据从网络采集 移动到我们的数据仓库或云存储。Data采集 工具是完全托管的,并且完全自动化了不仅从我们需要的来源加载数据的过程,而且还丰富它并将其转换为可用于分析的形式,而无需编写任何代码. 其容错架构确保以安全一致的方式处理数据,零数据丢失。
数据采集工具完成我们设置所需的所有数据预处理采集,让我们专注于关键业务活动,并学习如何产生更多潜在客户、留住客户并转变我们的业务 提升到新的盈利能力级别以获得更强大的见解。它提供了一个一致且可靠的解决方案来实时管理数据,并在我们想要做出决策和分析它们时始终提供数据进行分析。
Data采集 随着时代的变迁不断被优化。在掌握数据采集分析技能的同时,还要学会与时俱进,不断学习先进知识,掌握先进技能。 查看全部
采集 工具(什么是数据采集?为什么网站SEO更具是跟上趋势?)
什么是数据采集?为什么 data采集 很重要?数据采集不仅可以为我们提供网站SEO方面的数据支持,还可以帮助我们在决策或思考时提供合理的数据支持。技能。
数据采集与我们的生活息息相关,无论是通过Ctrl+C手动复制粘贴慢慢采集我们想要的数据,还是通过我们的数据采集工具完成数据采集。我们都需要数据来帮助我们的生活和工作。
创新是我们数据 采集 的 关键词。时代在不断发展,在这个行业中的一部分是跟上趋势。网站具有创新精神并紧跟当前趋势的 SEO 始终比其他网站SEO 具有优势,因此及时了解可能发生的变化并保持我们的业务处于领先地位非常重要。
data采集的方式有很多种,根据不同的需要可能会有所不同。尽管我们周围有各种各样的选择,网站 都受到定期出现的共同趋势的约束。虽然这些趋势通常证明对所有相关人员都有利,但有时会发生相反的情况。尽管如此,了解数据的当前事实和统计数据采集 仍然有助于决定如何使用它们来使我们在工作和生活中受益。
许多网站传递数据采集工具以一种或另一种方式采集他们的数据。事实上,data采集 早在互联网出现之前就已经存在了,尽管不一定会这样称呼它。那么为什么 data采集 很重要呢?
如果没有数据采集规则,我们需要手动采集所有的信息,自己整理。例如,如果我们想通过手动查找他们的访问量、访问日期或我们的 网站 跳出率来查看有多少用户访问了我们的 网站 数据之一。这可能会很耗时并且会降低我们的工作效率。而我们的数据采集 工具将大大提高我们的生产力。
数据采集工具可帮助我们以完全无忧且自动化的方式将数据从网络采集 移动到我们的数据仓库或云存储。Data采集 工具是完全托管的,并且完全自动化了不仅从我们需要的来源加载数据的过程,而且还丰富它并将其转换为可用于分析的形式,而无需编写任何代码. 其容错架构确保以安全一致的方式处理数据,零数据丢失。
数据采集工具完成我们设置所需的所有数据预处理采集,让我们专注于关键业务活动,并学习如何产生更多潜在客户、留住客户并转变我们的业务 提升到新的盈利能力级别以获得更强大的见解。它提供了一个一致且可靠的解决方案来实时管理数据,并在我们想要做出决策和分析它们时始终提供数据进行分析。
Data采集 随着时代的变迁不断被优化。在掌握数据采集分析技能的同时,还要学会与时俱进,不断学习先进知识,掌握先进技能。
采集 工具(亚马逊数据采集软件去跟卖1.快速采集亚马逊前台产品)
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-04-01 02:21
相信现在很多商家都知道亚马逊平台,并在上面开设了自己的店铺。虽然只要准备好材料,就可以在较短的时间内成功开设自己的店铺,但在经营过程中总会遇到很多问题。那么亚马逊listing捕获采集的工具有哪些呢?这些是什么?
一、亚马逊的 ASIN采集工具 - Amzhelper
Amzhelper 还采集数据进行分析、整理、比较和网站数据库管理,选择和开发对其有利的产品。配合AMZHelper软件抓取精准邮箱,采用EDM营销、营销或推广的形式。
从而达到刷销、清仓、微利等目标。然后,通过用户购买行为的大数据分析,用户可以直接搜索相关的关键词,在用户的购买记录和心愿单中调出相关的关键词用户数据,然后使用邀请模式进行EDM Email营销。
二、酷鸟亚马逊数据采集软件关注
1.快速采集亚马逊前台产品
使用亚马逊官网的搜索方式搜索您要销售的商品,在结果页中筛选出符合您条件的商品,然后将结果页地址复制到酷鸟亚马逊数据采集软件开始采集产品数据;
2. 采集综合产品资料
除了产品的品牌和标题,您还可以查看价格、竞争对手数量以及评论和评论星级的数量。
3.批量定制跟进销售
酷鸟是亚马逊的采集软件,除了采集联销产品的功能外,还可以帮助卖家批量下架和销售产品,然后自定义联销时间;一键选择货架上的商品,操作简单,零基础也能学会采集劫持。
事实上,亚马逊上有很多 采集 工具。至于如何选择,还是要看产品的具体情况。在店铺经营过程中,不只要你愿意努力,就能取得好的成绩。更重要的是,你必须有一定的方法和技巧。只有这样,你才能在更短的时间内取得成功。
您感兴趣的问题:
亚马逊列表应该如何编辑?具体细节
如果我的亚马逊listing被意外删除了怎么办?从哪儿开始?
改变亚马逊listing的主图有影响吗?对图片有什么要求? 查看全部
采集 工具(亚马逊数据采集软件去跟卖1.快速采集亚马逊前台产品)
相信现在很多商家都知道亚马逊平台,并在上面开设了自己的店铺。虽然只要准备好材料,就可以在较短的时间内成功开设自己的店铺,但在经营过程中总会遇到很多问题。那么亚马逊listing捕获采集的工具有哪些呢?这些是什么?
一、亚马逊的 ASIN采集工具 - Amzhelper
Amzhelper 还采集数据进行分析、整理、比较和网站数据库管理,选择和开发对其有利的产品。配合AMZHelper软件抓取精准邮箱,采用EDM营销、营销或推广的形式。
从而达到刷销、清仓、微利等目标。然后,通过用户购买行为的大数据分析,用户可以直接搜索相关的关键词,在用户的购买记录和心愿单中调出相关的关键词用户数据,然后使用邀请模式进行EDM Email营销。
二、酷鸟亚马逊数据采集软件关注
1.快速采集亚马逊前台产品
使用亚马逊官网的搜索方式搜索您要销售的商品,在结果页中筛选出符合您条件的商品,然后将结果页地址复制到酷鸟亚马逊数据采集软件开始采集产品数据;
2. 采集综合产品资料
除了产品的品牌和标题,您还可以查看价格、竞争对手数量以及评论和评论星级的数量。
3.批量定制跟进销售
酷鸟是亚马逊的采集软件,除了采集联销产品的功能外,还可以帮助卖家批量下架和销售产品,然后自定义联销时间;一键选择货架上的商品,操作简单,零基础也能学会采集劫持。
事实上,亚马逊上有很多 采集 工具。至于如何选择,还是要看产品的具体情况。在店铺经营过程中,不只要你愿意努力,就能取得好的成绩。更重要的是,你必须有一定的方法和技巧。只有这样,你才能在更短的时间内取得成功。
您感兴趣的问题:
亚马逊列表应该如何编辑?具体细节
如果我的亚马逊listing被意外删除了怎么办?从哪儿开始?
改变亚马逊listing的主图有影响吗?对图片有什么要求?
采集 工具(开源采集工具和科学计算器可以两者互为补充。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-03-29 16:08
采集工具和科学计算器可以两者互为补充。科学计算器以丰富的自然语言操作方式吸引住用户,而采集工具更好的面向抓取过程的业务逻辑性。而一个好的采集工具,一般需要一位经验丰富的运营,能从一个普通工具变成一款好工具。采集工具可以做到不易丢失数据,多个系统之间的数据解耦等。所以我认为利用好的采集工具+丰富的运营工具,提高行业运营效率。
听我的,别买python了,
如果你是做运营,抓到了很多用户产品的数据,希望知道哪些产品更受用户喜欢,你可以看看我们团队的源码。
开源采集爬虫工具我知道两个:/latest/v2/不用下载只需要注册你就可以随时随地免费爬全网的商品信息而且都是免费抓取的。
网上免费爬虫工具很多,像多抓鱼采集器云采集lister之类的。具体可以去百度一下,或者去百度搜索一下相关爬虫工具教程。csv-key/dataquest-key(*)里面爬虫类有开源的,批量处理类有收费的。个人感觉还是key比较好,支持多种格式,而且也比较完善!官网上所有内容都是开源的,教程也都是开源的,这样就不怕爬虫工具不支持某些格式或版本了!有需要可以去官网看看~!。
我手上有一个,js很快,然后r语言的数据可视化支持也不错,用来做简单的数据可视化挺好的。 查看全部
采集 工具(开源采集工具和科学计算器可以两者互为补充。)
采集工具和科学计算器可以两者互为补充。科学计算器以丰富的自然语言操作方式吸引住用户,而采集工具更好的面向抓取过程的业务逻辑性。而一个好的采集工具,一般需要一位经验丰富的运营,能从一个普通工具变成一款好工具。采集工具可以做到不易丢失数据,多个系统之间的数据解耦等。所以我认为利用好的采集工具+丰富的运营工具,提高行业运营效率。
听我的,别买python了,
如果你是做运营,抓到了很多用户产品的数据,希望知道哪些产品更受用户喜欢,你可以看看我们团队的源码。
开源采集爬虫工具我知道两个:/latest/v2/不用下载只需要注册你就可以随时随地免费爬全网的商品信息而且都是免费抓取的。
网上免费爬虫工具很多,像多抓鱼采集器云采集lister之类的。具体可以去百度一下,或者去百度搜索一下相关爬虫工具教程。csv-key/dataquest-key(*)里面爬虫类有开源的,批量处理类有收费的。个人感觉还是key比较好,支持多种格式,而且也比较完善!官网上所有内容都是开源的,教程也都是开源的,这样就不怕爬虫工具不支持某些格式或版本了!有需要可以去官网看看~!。
我手上有一个,js很快,然后r语言的数据可视化支持也不错,用来做简单的数据可视化挺好的。
采集 工具(怎么利用免费的迅睿CMS采集器批量快速收录排名获得流量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-03-29 14:01
如何利用免费迅瑞cms采集器快速收录排名获取流量。最近有很多朋友向我投诉,说迅锐cms插件不能同时管理十个网站,必须每天查看状态,而采集规则必须每天重写。花很多时间。
如何使用免费迅瑞cms采集器批量快速收录排名获取流量
如何批量管理迅锐cms网站:
一、有批次管理检查工具
1、监控数据:软件直接监控发布数量,待发布数量,伪原创是否成功,发布状态(是否发布成功),网站发布、发布程序、发布时间等
详细解答:无论是Empire、易友、迅瑞、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,都可以支持同时批量管理和发布工具,不同的栏目设置关键词文章,定期发布+每日发布总量+数据监控=完美解决效率低的问题。
二、迅锐批处理采集工具
1、批处理采集:如果每个网站都花很多时间检查和重写规则,就没有时间管理网站了,去分析一下网站 数据!选择一个好的采集器非常重要。它必须易于操作。只有简单的操作才能实现批量采集。
详细解答:只需将关键词导入到采集相关的关键词文章,同时创建几十个或几百个采集任务(一个任务可支持上传1000个关键词),支持大平台采集。 (搜狗资讯-微信公众号-搜狗知乎-头条资讯-百度资讯-百度知道-新浪新闻-360资讯-凤凰新闻等,可同时设置多个采集来源采集)
实现自动批量挂机采集,无缝对接各大cms发布者,实现采集发布自动挂机。
如何实现迅锐cms网站Batch收录:
荀睿cms网站刚成立的时候,搜索引擎会对新成立的网站有一个检查期,而这个时间段是信任网站最重要的时期@网站 时间。对于搜索引擎收录网站文章,我们要积极引导搜索引擎蜘蛛抓取网站文章内容。
网站交通
以上网站是小编使用迅睿cms采集发布管理实现的效果,网站目前流量接近10000!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事! 查看全部
采集 工具(怎么利用免费的迅睿CMS采集器批量快速收录排名获得流量)
如何利用免费迅瑞cms采集器快速收录排名获取流量。最近有很多朋友向我投诉,说迅锐cms插件不能同时管理十个网站,必须每天查看状态,而采集规则必须每天重写。花很多时间。
如何使用免费迅瑞cms采集器批量快速收录排名获取流量
如何批量管理迅锐cms网站:
一、有批次管理检查工具
1、监控数据:软件直接监控发布数量,待发布数量,伪原创是否成功,发布状态(是否发布成功),网站发布、发布程序、发布时间等
详细解答:无论是Empire、易友、迅瑞、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,都可以支持同时批量管理和发布工具,不同的栏目设置关键词文章,定期发布+每日发布总量+数据监控=完美解决效率低的问题。
二、迅锐批处理采集工具
1、批处理采集:如果每个网站都花很多时间检查和重写规则,就没有时间管理网站了,去分析一下网站 数据!选择一个好的采集器非常重要。它必须易于操作。只有简单的操作才能实现批量采集。
详细解答:只需将关键词导入到采集相关的关键词文章,同时创建几十个或几百个采集任务(一个任务可支持上传1000个关键词),支持大平台采集。 (搜狗资讯-微信公众号-搜狗知乎-头条资讯-百度资讯-百度知道-新浪新闻-360资讯-凤凰新闻等,可同时设置多个采集来源采集)
实现自动批量挂机采集,无缝对接各大cms发布者,实现采集发布自动挂机。
如何实现迅锐cms网站Batch收录:
荀睿cms网站刚成立的时候,搜索引擎会对新成立的网站有一个检查期,而这个时间段是信任网站最重要的时期@网站 时间。对于搜索引擎收录网站文章,我们要积极引导搜索引擎蜘蛛抓取网站文章内容。
网站交通
以上网站是小编使用迅睿cms采集发布管理实现的效果,网站目前流量接近10000!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!
采集 工具(智能识别模式自动识别网页中出现的数据模式-苏州安嘉)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-03-21 02:02
WebHarvy 是一个功能强大的应用程序,旨在使您能够自动从网页中提取数据并以不同的格式保存提取的内容。从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单,从而智能地识别网页上出现的数据模式。
【特征】
可视化点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
通过代理服务器提取
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
【指示】
1、启动软件,提示并解锁,即需要添加官方授权文件才能使用
2、解压下载的文件,双击“URET NFO v2.2.exe”
3、通知您 SysNucleus WebHarvy 软件已授权给 SMR
4、导航到需要从中提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要截取部分文本,请选择并突出显示。在选择下面的选项之前,请确定所需的部分。
6、只要输入你分析的网页的网址,最上方的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的方案 查看全部
采集 工具(智能识别模式自动识别网页中出现的数据模式-苏州安嘉)
WebHarvy 是一个功能强大的应用程序,旨在使您能够自动从网页中提取数据并以不同的格式保存提取的内容。从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单,从而智能地识别网页上出现的数据模式。
【特征】
可视化点击界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
通过代理服务器提取
要提取匿名信息并防止从被 Web 软件阻止的 Web 服务器中提取信息,您可以选择通过代理服务器访问目标网站。可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
【指示】
1、启动软件,提示并解锁,即需要添加官方授权文件才能使用
2、解压下载的文件,双击“URET NFO v2.2.exe”
3、通知您 SysNucleus WebHarvy 软件已授权给 SMR
4、导航到需要从中提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要截取部分文本,请选择并突出显示。在选择下面的选项之前,请确定所需的部分。
6、只要输入你分析的网页的网址,最上方的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的方案
采集 工具(企业私有云中有啥机器?免费试用几个月?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-20 23:06
采集工具可以按几个参数去选择:1.当前ip,2.通讯地址,3.是否是单端,双端,4.加密格式。这4个参数,根据这个条件,可以考虑下家,中程的。大型企业采集的话,可以考虑海外的使用,因为需要缴纳专门的接入费用。高速路采集,可以找硬盘商。
电商的话,可以考虑上docker吧。
中国电商云国内影响力很强,只不过上个月停止服务了。
docker
佳豪芯送,docker仓库。有需要就来,有需要就来。(机器也可以用)更新一波。文件已上传到企业私有云。访问可直接从微云进行下载。企业私有云中有啥机器?这些docker服务器没有被交易?可以试着去交易一下,支持代买,部署二维码以及技术支持等等。1对1的技术支持也可以。哎呀,直接买了,哈哈哈。
源代码完全开源公开,仅收取购买时收取的费用。后续不打算再做任何私有云服务了。完全不提供免费的代购服务。无偿提供docker代购。这不是重点。重点是,我写在简介里的一句话:佳豪芯送是原旗下的服务,直接对接企业云平台,可以快速搭建多渠道协同办公,多主题随心组合的企业全渠道办公云平台,并且集成anthem采集,cms各平台同步采集,erp、tos同步采集,财务、crm,mis,his,文档,表格,地图等等,任何平台无缝对接的采集方案,帮助企业用户搭建本地云计算采集环境,包括但不限于技术服务,采集功能,安全保障等等。
相对其他公司,给你个小福利,加入佳豪芯送,免费试用几个月。呵呵。这个福利吸引人是不是?但是该赔的罚还是得赔。原因是,容器没了就没了,浪费时间浪费电能。别问我怎么知道的,反正我也死心了。不是云平台倒闭就是我们服务器失效了。而且一旦上线就会一直失效,跟你没有什么关系了。像上面说的采集仓库的事,他们完全是一直都在合作的,当然涉及隐私了,就不能点出来了。
另外,国内大部分docker的市场是被一堆山寨的占据了,包括佳豪芯送。国内那些公司之所以这么做,一方面是他们有这么庞大的源代码文件,另一方面不想为自己的代码负责。你不清楚想用哪个,他们就要拼命山寨。反正山寨以后就可以忽悠你。比如rootey前段时间的升级服务器,他们有机会让你通过从别的企业买个docker备份服务,然后用rootey的存储服务备份企业数据。
总之没个安全保障的企业,可以说,都是无力。不过,我还是很喜欢它的。它是国内把docker用的最漂亮的公司。也看到的docker整个生态系统从开始就是靠佳豪芯送一家公司在默默运营。rootbackup,图云服务器。 查看全部
采集 工具(企业私有云中有啥机器?免费试用几个月?)
采集工具可以按几个参数去选择:1.当前ip,2.通讯地址,3.是否是单端,双端,4.加密格式。这4个参数,根据这个条件,可以考虑下家,中程的。大型企业采集的话,可以考虑海外的使用,因为需要缴纳专门的接入费用。高速路采集,可以找硬盘商。
电商的话,可以考虑上docker吧。
中国电商云国内影响力很强,只不过上个月停止服务了。
docker
佳豪芯送,docker仓库。有需要就来,有需要就来。(机器也可以用)更新一波。文件已上传到企业私有云。访问可直接从微云进行下载。企业私有云中有啥机器?这些docker服务器没有被交易?可以试着去交易一下,支持代买,部署二维码以及技术支持等等。1对1的技术支持也可以。哎呀,直接买了,哈哈哈。
源代码完全开源公开,仅收取购买时收取的费用。后续不打算再做任何私有云服务了。完全不提供免费的代购服务。无偿提供docker代购。这不是重点。重点是,我写在简介里的一句话:佳豪芯送是原旗下的服务,直接对接企业云平台,可以快速搭建多渠道协同办公,多主题随心组合的企业全渠道办公云平台,并且集成anthem采集,cms各平台同步采集,erp、tos同步采集,财务、crm,mis,his,文档,表格,地图等等,任何平台无缝对接的采集方案,帮助企业用户搭建本地云计算采集环境,包括但不限于技术服务,采集功能,安全保障等等。
相对其他公司,给你个小福利,加入佳豪芯送,免费试用几个月。呵呵。这个福利吸引人是不是?但是该赔的罚还是得赔。原因是,容器没了就没了,浪费时间浪费电能。别问我怎么知道的,反正我也死心了。不是云平台倒闭就是我们服务器失效了。而且一旦上线就会一直失效,跟你没有什么关系了。像上面说的采集仓库的事,他们完全是一直都在合作的,当然涉及隐私了,就不能点出来了。
另外,国内大部分docker的市场是被一堆山寨的占据了,包括佳豪芯送。国内那些公司之所以这么做,一方面是他们有这么庞大的源代码文件,另一方面不想为自己的代码负责。你不清楚想用哪个,他们就要拼命山寨。反正山寨以后就可以忽悠你。比如rootey前段时间的升级服务器,他们有机会让你通过从别的企业买个docker备份服务,然后用rootey的存储服务备份企业数据。
总之没个安全保障的企业,可以说,都是无力。不过,我还是很喜欢它的。它是国内把docker用的最漂亮的公司。也看到的docker整个生态系统从开始就是靠佳豪芯送一家公司在默默运营。rootbackup,图云服务器。
采集 工具(采集工具有很多,如果你要获取数据和操作数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-16 11:04
采集工具有很多,如果你要获取数据和操作数据,可以试试网络爬虫这个工具。通过登录互联网,你可以得到海量的信息。你知道使用什么样的搜索引擎,比如google,百度这样的。这就包括互联网搜索的关键词,通过爬虫可以得到很多。如果你有更大的数据,没有登录互联网这个平台,你可以登录网页,爬虫会得到你想要的数据。你有很多自己喜欢的想要保存下来,你可以把这些数据保存起来,爬虫可以得到你想要的数据。
你有很多证明你是你自己的经历,在这些证明上会有很多网页,爬虫可以抓取出来。你有很多很多好看的图片和视频,这些网页会抓取出来,上传到你的电脑。但是,爬虫是一个很狭窄的行业,只有喜欢的人才会把它做好。我认为爬虫是一个很重要的工具,能够帮助你更好的把时间放在自己喜欢的事情上。
extractingandanalyzinghttp.dataisbest.
额。
作为一个爬虫从业者我从日常工作、个人观点回答你的问题:
1、enjoyextract
2、done
3、reverselink
目前主流的爬虫工具是googleapi+adblock不知道你的网站是个什么情况,我做的网站主要是记录信息,
你是在问爬虫还是程序吗?另外说句爬虫不应该放在这个问题里。googleapi?没见过这种东西。adblock?也没见过。前两种都太麻烦,还要注册帐号,还要浪费流量和时间,操作上不够便捷。至于extractandanalyzinghttp.data?还是去找网页的后缀。 查看全部
采集 工具(采集工具有很多,如果你要获取数据和操作数据)
采集工具有很多,如果你要获取数据和操作数据,可以试试网络爬虫这个工具。通过登录互联网,你可以得到海量的信息。你知道使用什么样的搜索引擎,比如google,百度这样的。这就包括互联网搜索的关键词,通过爬虫可以得到很多。如果你有更大的数据,没有登录互联网这个平台,你可以登录网页,爬虫会得到你想要的数据。你有很多自己喜欢的想要保存下来,你可以把这些数据保存起来,爬虫可以得到你想要的数据。
你有很多证明你是你自己的经历,在这些证明上会有很多网页,爬虫可以抓取出来。你有很多很多好看的图片和视频,这些网页会抓取出来,上传到你的电脑。但是,爬虫是一个很狭窄的行业,只有喜欢的人才会把它做好。我认为爬虫是一个很重要的工具,能够帮助你更好的把时间放在自己喜欢的事情上。
extractingandanalyzinghttp.dataisbest.
额。
作为一个爬虫从业者我从日常工作、个人观点回答你的问题:
1、enjoyextract
2、done
3、reverselink
目前主流的爬虫工具是googleapi+adblock不知道你的网站是个什么情况,我做的网站主要是记录信息,
你是在问爬虫还是程序吗?另外说句爬虫不应该放在这个问题里。googleapi?没见过这种东西。adblock?也没见过。前两种都太麻烦,还要注册帐号,还要浪费流量和时间,操作上不够便捷。至于extractandanalyzinghttp.data?还是去找网页的后缀。
采集 工具( 这款采集伪原创发布到网站的工具采集规则)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-07 17:13
这款采集伪原创发布到网站的工具采集规则)
随风起舞
03-07 04:12 阅读3 网站SEO优化
专注于
免费采集易于使用的工具(免费信息采集软件)
大家好,今天给大家介绍的采集工具是一个全自动的采集伪原创工具,用于发布到网站。
影响网站的优化排名的因素很多。比如网站更新,站内布局优化加站外优化,然后宿主必须特别稳定。最重要的一点是 网站 更新。网站更新有一个特别重要的一点,网站内容需要高质量,高质量意味着原创内容。
我们都知道网上有很多采集工具,但是大部分采集工具都是采集别人已经收录和收录别人体验过的网站,根据搜索引擎的判断,判断你是抄袭别人的网站。所以说这样的内容采集来也没用。但是,今天我们推荐给大家的软件绝对是100%原创内容采集被工具伪原创搜索检测出来的。我在网上找不到和第二个一样的内容。大家都知道网站只是需要大量的内容更新。如果要手动更新,几乎没有人能保证每天更新十到二十个这样的原创内容。
如果你有这个工具,那么你就不用担心了。你可以设置一个时间段,他可以每天按时更新你的网站内容。只要你设置一个发布时间间隔,他就可以给你采集十万篇文章。
现在让我介绍一下传统的采集工具
采集 的内容
1、采集的内容不是原创或者伪原创的内容,所以搜索引擎对网站不是那么友好,对于< @网站 排名优化没有任何好处。
2、传统采集工具,有很多采集规则。这些采集规则不专业,难写。所以你必须花钱请人写采集规则。
3、传统的采集工具肯定需要你手动完成。不可能有适合您的定时定量 采集。
那么,如果我们今天向您介绍这个工具,它具有以下特点。
1、可以自动更新网站的内容。
2、它的更新都是原创内容。
3、可以在你更新的内容中,你可以随意添加。随机关键词可以添加图片和视频,让搜索引擎更贴近你更新的内容。
4、安装程序时只需要设置每天需要更新的次数和时间,以后就不用操作了。好吧,它会每天自动更新您。
5、不同的文章也可以对应不同的列
它可以每天完全自动化采集。不用天天操心,反正每天都会自动更新文章,
另外,网站应该怎么优化呢?也就是我现在介绍一下推送功能改进网站收录,我们需要使用百度站长资源平台进行资源提交。
目前,百度站长平台共有三种投稿方式。
第一个是api提交: API推送:最快的提交方式,建议您立即通过此方式将站点新的输出链接推送到百度,以保证新链接可以被百度发布< @收录 及时。
二是网站地图提交:可以定期将网站链接放入Sitemap,然后将Sitemap提交给百度。百度会定期爬取检查你提交的Sitemap,处理里面的链接,但是收录速度比API推送慢。
第三种方式是手动提交:如果不想程序化提交,可以通过这种方式手动提交链接到百度。
这三种提交方式并不冲突,我们都可以同时进行。 查看全部
采集 工具(
这款采集伪原创发布到网站的工具采集规则)
随风起舞
03-07 04:12 阅读3 网站SEO优化
专注于
免费采集易于使用的工具(免费信息采集软件)
大家好,今天给大家介绍的采集工具是一个全自动的采集伪原创工具,用于发布到网站。
影响网站的优化排名的因素很多。比如网站更新,站内布局优化加站外优化,然后宿主必须特别稳定。最重要的一点是 网站 更新。网站更新有一个特别重要的一点,网站内容需要高质量,高质量意味着原创内容。
我们都知道网上有很多采集工具,但是大部分采集工具都是采集别人已经收录和收录别人体验过的网站,根据搜索引擎的判断,判断你是抄袭别人的网站。所以说这样的内容采集来也没用。但是,今天我们推荐给大家的软件绝对是100%原创内容采集被工具伪原创搜索检测出来的。我在网上找不到和第二个一样的内容。大家都知道网站只是需要大量的内容更新。如果要手动更新,几乎没有人能保证每天更新十到二十个这样的原创内容。
如果你有这个工具,那么你就不用担心了。你可以设置一个时间段,他可以每天按时更新你的网站内容。只要你设置一个发布时间间隔,他就可以给你采集十万篇文章。
现在让我介绍一下传统的采集工具
采集 的内容
1、采集的内容不是原创或者伪原创的内容,所以搜索引擎对网站不是那么友好,对于< @网站 排名优化没有任何好处。
2、传统采集工具,有很多采集规则。这些采集规则不专业,难写。所以你必须花钱请人写采集规则。
3、传统的采集工具肯定需要你手动完成。不可能有适合您的定时定量 采集。
那么,如果我们今天向您介绍这个工具,它具有以下特点。
1、可以自动更新网站的内容。
2、它的更新都是原创内容。
3、可以在你更新的内容中,你可以随意添加。随机关键词可以添加图片和视频,让搜索引擎更贴近你更新的内容。
4、安装程序时只需要设置每天需要更新的次数和时间,以后就不用操作了。好吧,它会每天自动更新您。
5、不同的文章也可以对应不同的列
它可以每天完全自动化采集。不用天天操心,反正每天都会自动更新文章,
另外,网站应该怎么优化呢?也就是我现在介绍一下推送功能改进网站收录,我们需要使用百度站长资源平台进行资源提交。
目前,百度站长平台共有三种投稿方式。
第一个是api提交: API推送:最快的提交方式,建议您立即通过此方式将站点新的输出链接推送到百度,以保证新链接可以被百度发布< @收录 及时。
二是网站地图提交:可以定期将网站链接放入Sitemap,然后将Sitemap提交给百度。百度会定期爬取检查你提交的Sitemap,处理里面的链接,但是收录速度比API推送慢。
第三种方式是手动提交:如果不想程序化提交,可以通过这种方式手动提交链接到百度。
这三种提交方式并不冲突,我们都可以同时进行。
采集 工具(怎么通过python爬取微信公众号文章插件安装)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-04 17:04
采集工具很多,除了太平洋电脑网的cbuder,还有我正在使用的一款client式采集工具vswebdoc,client式采集工具好处在于可以直接把请求发送到服务器,然后服务器根据页面的正则表达式去处理。如果碰到搜索引擎没有抓取到的内容也可以直接post到页面的另一端,然后保存,需要时再去抓取。缺点在于需要针对不同的网站进行不同的设置,需要的人力也比较多。
下面说一下我怎么通过python爬取微信公众号文章。配置环境:1.mac上的话我是用vim,linux系统可以直接用git来操作。2.浏览器上推荐谷歌浏览器,目前这款浏览器已经支持搜索公众号文章的https链接,无需ie,且googlechrome在搜索这方面做的不好,百度能搜到部分内容但不能完全识别。
爬取步骤:步骤一:在chrome上安装vswebdoc插件,方法有很多,简单的可以用安装方法不详细介绍,详细的也可以参考:vswebdoc安装与使用方法。步骤二:安装完成后打开vswebdoc,下载解压。步骤三:如果已经下载或者直接用浏览器上安装或者谷歌访问airbar之类的扩展程序中国并不能打开,可以在我的仓库中下载chrome浏览器插件chrome浏览器插件chrome插件安装包chrome浏览器扩展程序链接下载地址chrome-chrome简繁体中文字体(ttf文件)版本,版本大概是43,40。
chrome浏览器的宽度和高度等设置完成。步骤四:安装viewjs。注意安装viewjs,viewjs需要安装adobeflashplayer,在百度chrome浏览器商店中安装。步骤五:启动vswebdoc。步骤六:保存。这样我们就成功将微信公众号文章的文章url爬取下来了。我曾经参考以下方法也是一样搞定的,但步骤就比较复杂,新手可能也可以看懂,不过有一定设置经验的请忽略以下步骤。
微信公众号文章页面url的抓取top10图文消息的抓取top10音乐视频的抓取百度百科的抓取搜狗百科的抓取优酷图文的抓取360图文的抓取今日头条图文的抓取春雨医生图文的抓取红豆内容的抓取每日优鲜图文的抓取如果能把以上的几种图文url抓取下来应该就不愁找不到自己想要的内容了,但需要实践,欢迎跟我交流以上。 查看全部
采集 工具(怎么通过python爬取微信公众号文章插件安装)
采集工具很多,除了太平洋电脑网的cbuder,还有我正在使用的一款client式采集工具vswebdoc,client式采集工具好处在于可以直接把请求发送到服务器,然后服务器根据页面的正则表达式去处理。如果碰到搜索引擎没有抓取到的内容也可以直接post到页面的另一端,然后保存,需要时再去抓取。缺点在于需要针对不同的网站进行不同的设置,需要的人力也比较多。
下面说一下我怎么通过python爬取微信公众号文章。配置环境:1.mac上的话我是用vim,linux系统可以直接用git来操作。2.浏览器上推荐谷歌浏览器,目前这款浏览器已经支持搜索公众号文章的https链接,无需ie,且googlechrome在搜索这方面做的不好,百度能搜到部分内容但不能完全识别。
爬取步骤:步骤一:在chrome上安装vswebdoc插件,方法有很多,简单的可以用安装方法不详细介绍,详细的也可以参考:vswebdoc安装与使用方法。步骤二:安装完成后打开vswebdoc,下载解压。步骤三:如果已经下载或者直接用浏览器上安装或者谷歌访问airbar之类的扩展程序中国并不能打开,可以在我的仓库中下载chrome浏览器插件chrome浏览器插件chrome插件安装包chrome浏览器扩展程序链接下载地址chrome-chrome简繁体中文字体(ttf文件)版本,版本大概是43,40。
chrome浏览器的宽度和高度等设置完成。步骤四:安装viewjs。注意安装viewjs,viewjs需要安装adobeflashplayer,在百度chrome浏览器商店中安装。步骤五:启动vswebdoc。步骤六:保存。这样我们就成功将微信公众号文章的文章url爬取下来了。我曾经参考以下方法也是一样搞定的,但步骤就比较复杂,新手可能也可以看懂,不过有一定设置经验的请忽略以下步骤。
微信公众号文章页面url的抓取top10图文消息的抓取top10音乐视频的抓取百度百科的抓取搜狗百科的抓取优酷图文的抓取360图文的抓取今日头条图文的抓取春雨医生图文的抓取红豆内容的抓取每日优鲜图文的抓取如果能把以上的几种图文url抓取下来应该就不愁找不到自己想要的内容了,但需要实践,欢迎跟我交流以上。
采集 工具(优采云采集器免费版安装方法php及.net外部编程接口 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-02-26 04:33
)
优采云采集器免费版是一款可以快速从金融局采集数据的软件。支持批量采集网页、论坛等内容,可直接保存到数据库或发布到网站。你可以自定义设置采集的方式,获取你需要的内容,或者处理数据,seo优化的工具。
软件功能
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
七年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
安装方式
1、在本站下载优采云采集器后,在电脑本地获取一个压缩包,使用360压缩软件解压,双击.exe文件进入软件安装界面,点击【下一步】继续。
2、进入优采云采集器安装协议界面,可以先阅读软件安装协议中的条款,阅读后点击【我接受】再点击【下一步】继续。
3、选择安装位置优采云采集器,可以点击【安装】,软件会默认安装,也可以在打开的安装位置界面点击【浏览】,可以自行选择软件安装位置后,点击【安装】。
4、优采云采集器安装正在进行中,需要耐心等待软件安装完成。
5、优采云采集器安装完成,点击【完成】退出软件安装。
查看全部
采集 工具(优采云采集器免费版安装方法php及.net外部编程接口
)
优采云采集器免费版是一款可以快速从金融局采集数据的软件。支持批量采集网页、论坛等内容,可直接保存到数据库或发布到网站。你可以自定义设置采集的方式,获取你需要的内容,或者处理数据,seo优化的工具。
软件功能
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
七年磨一剑,软件不断更新完善,采集速度快,性能稳定,资源消耗少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
安装方式
1、在本站下载优采云采集器后,在电脑本地获取一个压缩包,使用360压缩软件解压,双击.exe文件进入软件安装界面,点击【下一步】继续。
2、进入优采云采集器安装协议界面,可以先阅读软件安装协议中的条款,阅读后点击【我接受】再点击【下一步】继续。
3、选择安装位置优采云采集器,可以点击【安装】,软件会默认安装,也可以在打开的安装位置界面点击【浏览】,可以自行选择软件安装位置后,点击【安装】。
4、优采云采集器安装正在进行中,需要耐心等待软件安装完成。
5、优采云采集器安装完成,点击【完成】退出软件安装。
采集 工具(快手采集工具视频批量无水印下载的文件夹水印)
采集交流 • 优采云 发表了文章 • 0 个评论 • 739 次浏览 • 2022-02-23 23:19
快手采集工具是PC端安装使用的快手平台视频批量下载软件。它不仅可以单独下载视频,还可以批量下载。无论是单个作者的所有视频,还是多个作者的所有视频,输入相应链接即可采集下载。下载的视频高清无水印,非常给力!
快手采集工具完全免费,无需注册登录,无任何广告。进入快手视频链接下载。可以支持手机视频的分享链接,作者主页链接,以及电脑上的快手视频链接,作者主页链接。下载单个视频,只需将对应的视频链接复制到快手采集工具采集即可下载;下载作者所有视频,复制作者主页链接,粘贴到快手采集工具中,采集即可下载。对于多位作者的作品,请复制多位作者的主页链接在软件中下载。
该软件还提供了多种自定义设置功能。您可以自定义下载视频的存放目录(默认下载到快手采集工具的文件夹中)。值得称赞的是,采集工具下载的视频可以自动分类到不同的文件夹,从作者的作品、作品类别、发布年份、发布季度。不仅如此,批量下载和单个下载的视频也会自动分类。这样的功能可以说是非常好用的。再也不用担心将下载的视频批量混在一起的烦恼了~
您还可以自定义设置:
1、采集最大作品数;
2、是否强制获取作者所有作品;
3、记录程序日志,另外保存日志;(以 Excel 形式呈现)
4、定时采集,定时采集间隔时间;
5、是否下载图集作品;
6、自定义下载视频文件设置自动保存文件名等
快手采集工具视频批量下载无水印:
蓝玩云:密码:1c61
123云盘:
夸克网盘:
百度网盘:提取码:w6ww 查看全部
采集 工具(快手采集工具视频批量无水印下载的文件夹水印)
快手采集工具是PC端安装使用的快手平台视频批量下载软件。它不仅可以单独下载视频,还可以批量下载。无论是单个作者的所有视频,还是多个作者的所有视频,输入相应链接即可采集下载。下载的视频高清无水印,非常给力!
快手采集工具完全免费,无需注册登录,无任何广告。进入快手视频链接下载。可以支持手机视频的分享链接,作者主页链接,以及电脑上的快手视频链接,作者主页链接。下载单个视频,只需将对应的视频链接复制到快手采集工具采集即可下载;下载作者所有视频,复制作者主页链接,粘贴到快手采集工具中,采集即可下载。对于多位作者的作品,请复制多位作者的主页链接在软件中下载。
该软件还提供了多种自定义设置功能。您可以自定义下载视频的存放目录(默认下载到快手采集工具的文件夹中)。值得称赞的是,采集工具下载的视频可以自动分类到不同的文件夹,从作者的作品、作品类别、发布年份、发布季度。不仅如此,批量下载和单个下载的视频也会自动分类。这样的功能可以说是非常好用的。再也不用担心将下载的视频批量混在一起的烦恼了~
您还可以自定义设置:
1、采集最大作品数;
2、是否强制获取作者所有作品;
3、记录程序日志,另外保存日志;(以 Excel 形式呈现)
4、定时采集,定时采集间隔时间;
5、是否下载图集作品;
6、自定义下载视频文件设置自动保存文件名等
快手采集工具视频批量下载无水印:
蓝玩云:密码:1c61
123云盘:
夸克网盘:
百度网盘:提取码:w6ww

