
采集 工具
百度爬虫工具箱能不能发个链接和楼主一起学习?
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-03-14 12:07
采集工具的话,推荐去豆瓣爬虫交流区加群跟大家一起交流,可以找到很多入门帖子,爬虫资料也很多。最后说一句,目前豆瓣的爬虫遇到一些重复时都要求从首页来,但不知道能不能提交到爬虫上。
利用内部渠道获取feed,会在发生这种情况的时候认为该渠道已经爬去。
百度爬虫工具箱
能不能发个链接和楼主一起学习?
我知道,是这样。我说下我们公司的吧,搜索卖家可以看到高手帮手,里面也有爬虫和工具,
我也很想知道豆瓣是怎么爬去的
站长工具我觉得你会用
这不是推荐干货么。
从豆瓣爬取数据?多说一句,其实现在用的比较多的是,百度,都可以爬取的。
这个虽然很多,但是不能推荐完全适合自己的,你也可以使用数据,加上百度,
豆瓣可以看看阿里巴巴的网站情况,
页面爬取情况,
你在问题里面问道,豆瓣的爬取工具,这确实难上加难,不过可以把你写的系统搬运过来,自己试试,爬取速度能不能赶上日爬千万的豆瓣。
豆瓣不是一个完整的应用体系吗,爬取不需要整个应用的啊,比如可以爬之类的,打开你需要爬取的网站,从这个开始爬,也可以每次发布博客爬取网站博客爬取然后进行聚合, 查看全部
百度爬虫工具箱能不能发个链接和楼主一起学习?
采集工具的话,推荐去豆瓣爬虫交流区加群跟大家一起交流,可以找到很多入门帖子,爬虫资料也很多。最后说一句,目前豆瓣的爬虫遇到一些重复时都要求从首页来,但不知道能不能提交到爬虫上。
利用内部渠道获取feed,会在发生这种情况的时候认为该渠道已经爬去。
百度爬虫工具箱
能不能发个链接和楼主一起学习?
我知道,是这样。我说下我们公司的吧,搜索卖家可以看到高手帮手,里面也有爬虫和工具,
我也很想知道豆瓣是怎么爬去的
站长工具我觉得你会用
这不是推荐干货么。
从豆瓣爬取数据?多说一句,其实现在用的比较多的是,百度,都可以爬取的。
这个虽然很多,但是不能推荐完全适合自己的,你也可以使用数据,加上百度,
豆瓣可以看看阿里巴巴的网站情况,
页面爬取情况,
你在问题里面问道,豆瓣的爬取工具,这确实难上加难,不过可以把你写的系统搬运过来,自己试试,爬取速度能不能赶上日爬千万的豆瓣。
豆瓣不是一个完整的应用体系吗,爬取不需要整个应用的啊,比如可以爬之类的,打开你需要爬取的网站,从这个开始爬,也可以每次发布博客爬取网站博客爬取然后进行聚合,
采集 工具 我个人推荐lookv,上手简单但是进阶之后功能很强大
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-02-18 12:01
采集工具我个人推荐lookv,上手简单但是进阶之后功能很强大。不过除了工具我也推荐你看下有没有机会可以参与到开发者的团队,否则你专注于下游的代码阅读和编程逻辑的理解会更有用。
如果你的数据是经过正规有效的渠道获取的,例如各种站内爬虫工具+各种网站的反爬虫机制,现在数据安全已经很关键,这个网站内泄漏出去,需要收集者付出血本的。如果不是经过正规渠道,你之前也没人教你如何取得数据,建议在新项目时优先保证这一点,这里我推荐redis,只需要定期回收消息即可,前期数据量很小的时候这点用处不大,几十万数据量就足够了。
后期上线过程可以考虑用binlog来实现一些数据的有效同步,例如不同服务器采用不同的binlog提交节点。
请注意要保证你的系统有私有连接。例如通过同步服务器消息同步每个服务器。一般都是交易api,
thinkphp做爬虫应该很容易,如果加上业务知识的话,理解爬虫的流程,要做什么,怎么做,想好以后如何搭建环境和运行环境,如何分析数据,
数据问题更多的是离线的数据问题,而这种情况需要爬虫处理一些异步信息,例如:手机号,地址等,所以爬虫功能不是直接把数据传到服务器上, 查看全部
采集 工具 我个人推荐lookv,上手简单但是进阶之后功能很强大
采集工具我个人推荐lookv,上手简单但是进阶之后功能很强大。不过除了工具我也推荐你看下有没有机会可以参与到开发者的团队,否则你专注于下游的代码阅读和编程逻辑的理解会更有用。
如果你的数据是经过正规有效的渠道获取的,例如各种站内爬虫工具+各种网站的反爬虫机制,现在数据安全已经很关键,这个网站内泄漏出去,需要收集者付出血本的。如果不是经过正规渠道,你之前也没人教你如何取得数据,建议在新项目时优先保证这一点,这里我推荐redis,只需要定期回收消息即可,前期数据量很小的时候这点用处不大,几十万数据量就足够了。
后期上线过程可以考虑用binlog来实现一些数据的有效同步,例如不同服务器采用不同的binlog提交节点。
请注意要保证你的系统有私有连接。例如通过同步服务器消息同步每个服务器。一般都是交易api,
thinkphp做爬虫应该很容易,如果加上业务知识的话,理解爬虫的流程,要做什么,怎么做,想好以后如何搭建环境和运行环境,如何分析数据,
数据问题更多的是离线的数据问题,而这种情况需要爬虫处理一些异步信息,例如:手机号,地址等,所以爬虫功能不是直接把数据传到服务器上,
百度云库扫描图片扫描字体识别错误批量替换扫描文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-02-15 08:01
采集工具都可以,photoshop、flash、迅捷图像处理器等都可以,
creativesuit在线地址::pixed2vectors原生cffphotoshop3.2·global365原生原生pdfeditorocr
phantomjs
又双出新奇工具了!无线标签扫描仪:看到图片扫描后显示原始二维码、条形码和网址。
自己做的,高中老师用的超简单文件夹聚合器。支持图片,网址,视频。文件聚合器支持按照需要添加多个不同的图片文件夹以及多个图片文件。2m内存2.5m左右够用了。
markdown最好弄一个自己的saas的服务器,比如百度云,之类的。这样你就可以在做markdown编辑时同步下载几十mb的图片了。
小抓包应该能满足你的要求。
这个没有什么软件可以满足你的要求。如果你想扫描别人的文件,再转到自己的文件夹里,你就需要这样的软件吧。
有个软件叫“扫描王”可以扫描,
利用rg-pdf这款软件就能满足你的要求。让你扫描文件后,生成文件夹中的扫描件的pdf格式文件;同时在最后可对这些扫描件的文字进行编辑、排版。
不知道哪个我就用vs2014写的了一个pdf转扫描文档的小工具了百度云库扫描图片扫描字体识别错误批量替换扫描文件每个扫描文件夹里至少下20个文件免费版免费版免费版 查看全部
百度云库扫描图片扫描字体识别错误批量替换扫描文件
采集工具都可以,photoshop、flash、迅捷图像处理器等都可以,
creativesuit在线地址::pixed2vectors原生cffphotoshop3.2·global365原生原生pdfeditorocr
phantomjs
又双出新奇工具了!无线标签扫描仪:看到图片扫描后显示原始二维码、条形码和网址。
自己做的,高中老师用的超简单文件夹聚合器。支持图片,网址,视频。文件聚合器支持按照需要添加多个不同的图片文件夹以及多个图片文件。2m内存2.5m左右够用了。
markdown最好弄一个自己的saas的服务器,比如百度云,之类的。这样你就可以在做markdown编辑时同步下载几十mb的图片了。
小抓包应该能满足你的要求。
这个没有什么软件可以满足你的要求。如果你想扫描别人的文件,再转到自己的文件夹里,你就需要这样的软件吧。
有个软件叫“扫描王”可以扫描,
利用rg-pdf这款软件就能满足你的要求。让你扫描文件后,生成文件夹中的扫描件的pdf格式文件;同时在最后可对这些扫描件的文字进行编辑、排版。
不知道哪个我就用vs2014写的了一个pdf转扫描文档的小工具了百度云库扫描图片扫描字体识别错误批量替换扫描文件每个扫描文件夹里至少下20个文件免费版免费版免费版
开启本地服务器采集工具的使用场景有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2021-02-11 10:04
采集工具根据使用场景有很多,通常有如下:①计算机本地扫描和服务器,发现模板/数据丢失,批量补充;②记事本、excel、pdf等固定文件扫描;③linux等大型操作系统、服务器本地实时扫描;④数据汇总查询;⑤数据清洗;⑥数据归档。
1)开启本地服务器设置方法:在操作系统中进入/etc/hosts文件,开启“acl”规则和“管理员身份验证”,
2)在计算机系统的命令行下输入cd/etc/hosts,会弹出新的文件夹,并且在里面查看"acl"规则,设置如下:"acl"关键字acl允许的联接列表,目的为识别请求数据和响应数据或非正常数据时返回相应的响应,且不需要请求头和响应头即可识别数据和响应。这是特定于电子邮件服务(exchange)、邮件发送服务(imap)和文件/目录服务(ftp)的应用程序;被允许请求头列表是客户端上的web服务器处理用户请求的格式要求,包括web服务器端的服务名、username、password、content-type、body等;限制实际请求头use1,web服务器端必须根据不同的用户请求头来识别或允许是否接受数据和响应。
只允许使用5个,exchange是8个,文件系统和ftp才是10个。(例如:gmail服务的use1://)。
3)配置、改动文件路径和加载的服务等文件通过"exportserver_host=localhost"或"exporthostname='localhost'"可以指定这个服务器/home/localhost等具体目录到本地文件系统,
4)打开adobeacrobat软件,对识别出来的如下图所示的文件或目录进行处理:就能用文本格式填写信息:如上图,test文件,就能填写:xxxxxxxxx这个文件的相关信息(包括文件名),且支持md5加密、验证密码等。这里以完整地利用adobeacrobat配置时间戳作为密码,并填写下面的内容:文件名和地址:xxxxxxxx密码:xxxxxxxx(这里hash的编码位数是x,不使用密码加密)。 查看全部
开启本地服务器采集工具的使用场景有哪些?
采集工具根据使用场景有很多,通常有如下:①计算机本地扫描和服务器,发现模板/数据丢失,批量补充;②记事本、excel、pdf等固定文件扫描;③linux等大型操作系统、服务器本地实时扫描;④数据汇总查询;⑤数据清洗;⑥数据归档。
1)开启本地服务器设置方法:在操作系统中进入/etc/hosts文件,开启“acl”规则和“管理员身份验证”,
2)在计算机系统的命令行下输入cd/etc/hosts,会弹出新的文件夹,并且在里面查看"acl"规则,设置如下:"acl"关键字acl允许的联接列表,目的为识别请求数据和响应数据或非正常数据时返回相应的响应,且不需要请求头和响应头即可识别数据和响应。这是特定于电子邮件服务(exchange)、邮件发送服务(imap)和文件/目录服务(ftp)的应用程序;被允许请求头列表是客户端上的web服务器处理用户请求的格式要求,包括web服务器端的服务名、username、password、content-type、body等;限制实际请求头use1,web服务器端必须根据不同的用户请求头来识别或允许是否接受数据和响应。
只允许使用5个,exchange是8个,文件系统和ftp才是10个。(例如:gmail服务的use1://)。
3)配置、改动文件路径和加载的服务等文件通过"exportserver_host=localhost"或"exporthostname='localhost'"可以指定这个服务器/home/localhost等具体目录到本地文件系统,
4)打开adobeacrobat软件,对识别出来的如下图所示的文件或目录进行处理:就能用文本格式填写信息:如上图,test文件,就能填写:xxxxxxxxx这个文件的相关信息(包括文件名),且支持md5加密、验证密码等。这里以完整地利用adobeacrobat配置时间戳作为密码,并填写下面的内容:文件名和地址:xxxxxxxx密码:xxxxxxxx(这里hash的编码位数是x,不使用密码加密)。
最新版:斑斓采集工具 v1.1.0官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-01-07 09:19
彩色采集工具是图片素材采集插件,它支持浏览器中的采集整个网络图片素材,可以按类别存储,方便用户以后使用,这非常方便且易于使用。用户可以下载。
相关软件的软件大小和版本说明下载链接
彩色采集工具是图片素材采集插件,它支持浏览器中的采集整个网络图片素材,可以按类别存储,方便用户以后使用,这非常方便且易于使用。用户可以下载。
基本介绍
整个网络材料,单击采集。随意使用采集您最喜欢的设计材料,以使设计更加方便。轻松整理和分类图片,随身携带并使用;在PC和App之间无缝切换,查看图片资料集以获取灵感;跨主要材料网站直接采集而不受限制;有效地完成设计项目,并使好的设计栩栩如生。
软件功能
快速安装采集工具插件,单击采集整个网络设计资料
采集您喜欢什么,使设计更方便
采集世界充满了美好的想法采集。
一种轻巧而坚固的材料采集工具
捕获灵感,单击采集,采集您喜欢的内容
材质注释云同步,PC和APP之间的无缝切换,随时随地查看
设计师的有效合作伙伴,可以有效地完成设计项目
功能介绍
方便采集,可以批量处理单个图像
随时随地获取和使用,使灵感的组织变得非常简单
跨主要材料网站,没有任何限制
及时捕捉灵感,发现新知识并获得启发
建立自己的灵感资源库
采集云同步,可通过标签轻松查看和高效执行项目,随时随地在PC和APP之间无缝切换。 查看全部
最新版:斑斓采集工具 v1.1.0官方版
彩色采集工具是图片素材采集插件,它支持浏览器中的采集整个网络图片素材,可以按类别存储,方便用户以后使用,这非常方便且易于使用。用户可以下载。
相关软件的软件大小和版本说明下载链接
彩色采集工具是图片素材采集插件,它支持浏览器中的采集整个网络图片素材,可以按类别存储,方便用户以后使用,这非常方便且易于使用。用户可以下载。

基本介绍
整个网络材料,单击采集。随意使用采集您最喜欢的设计材料,以使设计更加方便。轻松整理和分类图片,随身携带并使用;在PC和App之间无缝切换,查看图片资料集以获取灵感;跨主要材料网站直接采集而不受限制;有效地完成设计项目,并使好的设计栩栩如生。

软件功能
快速安装采集工具插件,单击采集整个网络设计资料
采集您喜欢什么,使设计更方便
采集世界充满了美好的想法采集。
一种轻巧而坚固的材料采集工具
捕获灵感,单击采集,采集您喜欢的内容
材质注释云同步,PC和APP之间的无缝切换,随时随地查看
设计师的有效合作伙伴,可以有效地完成设计项目
功能介绍
方便采集,可以批量处理单个图像
随时随地获取和使用,使灵感的组织变得非常简单
跨主要材料网站,没有任何限制
及时捕捉灵感,发现新知识并获得启发
建立自己的灵感资源库
采集云同步,可通过标签轻松查看和高效执行项目,随时随地在PC和APP之间无缝切换。
最新版:【大数据工具】2018年最值得推荐的6款大数据采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 385 次浏览 • 2020-09-02 02:12
数据绝对是无价的. 但是分析数据并不容易,因为结果越准确,成本就越高. 鉴于数据的快速增长,需要一个过程来提供有意义的信息,最终将其转变为实用的见识.
数据挖掘是指在巨大数据集中发现模式并将其转换为有效信息的过程. 这项技术使用特定的算法,统计分析,人工智能和数据库系统从庞大的数据集中提取信息,并将其转换为易于理解的形式. 本文介绍了在大数据行业中广泛使用的10种综合数据挖掘工具.
1. 快速矿工
Rapid Miner是一个数据科学软件平台,为数据准备,机器学习,深度学习,文本挖掘和预测分析提供了集成的环境. 它是领先的数据挖掘开源系统之一. 该程序完全用Java编程语言编写. 该程序为用户提供了一个选项,可以试用大量可以任意嵌套的运算符. 这些运算符在XML文件中有详细说明,可以通过Rapid Miner的图形用户界面进行构造.
2. Oracle数据挖掘
它是Oracle Advanced Analysis数据库的代表. 市场领先的公司使用它来最大化数据的潜力并做出准确的预测. 该系统与强大的数据算法配合使用,以锁定最佳客户. 此外,它可以识别异常情况和交叉销售机会,使用户可以根据需要应用不同的预测模型. 此外,它以所需的方式自定义客户肖像.
3. IBM SPSS Modeler
对于大型项目,IBM SPSS Modeler最适合. 在此建模器中,文本分析及其最高级的可视界面非常有价值. 它有助于生成数据挖掘算法,并且基本上不需要编程. 它可广泛用于异常检测,贝叶斯网络,CARMA,Cox回归以及使用多层感知器和反向传播学习的基本神经网络.
4. 尼姆
Konstanz Information Miner是一个开源数据分析平台. 您可以快速部署,扩展并熟悉其中的数据. 在商业智能领域,KNIME声称是一个可以为经验不足的用户提供预测智能的平台. 此外,数据驱动的创新系统有助于发掘数据的潜力. 此外,它包括数千个模块和现成的示例以及大量集成的工具和算法.
5. Python
Python是一种免费的开源语言,由于易于使用,因此经常与R并驾齐驱. 与R不同,Python通常易于学习和使用. 许多用户发现他们可以在几分钟内开始构建数据并执行极其复杂的亲和力分析. 只要您熟悉变量,数据类型,函数,条件语句和循环等基本编程概念,最常见的业务用例数据可视化就非常简单.
6. 优采云 采集器
优采云 采集器由合肥乐威信息技术有限公司开发. 它是一款专业的网络数据采集 /信息挖掘处理软件. 通过灵活的配置,可以轻松,快速地从网页上获取它,可以编辑和过滤结构化的文本,图片,文件和其他资源信息,然后发布到网站后台,各种文件或其他数据库系统. 查看全部
[大数据工具] 2018年最受推荐的6种大数据采集工具
数据绝对是无价的. 但是分析数据并不容易,因为结果越准确,成本就越高. 鉴于数据的快速增长,需要一个过程来提供有意义的信息,最终将其转变为实用的见识.

数据挖掘是指在巨大数据集中发现模式并将其转换为有效信息的过程. 这项技术使用特定的算法,统计分析,人工智能和数据库系统从庞大的数据集中提取信息,并将其转换为易于理解的形式. 本文介绍了在大数据行业中广泛使用的10种综合数据挖掘工具.
1. 快速矿工

Rapid Miner是一个数据科学软件平台,为数据准备,机器学习,深度学习,文本挖掘和预测分析提供了集成的环境. 它是领先的数据挖掘开源系统之一. 该程序完全用Java编程语言编写. 该程序为用户提供了一个选项,可以试用大量可以任意嵌套的运算符. 这些运算符在XML文件中有详细说明,可以通过Rapid Miner的图形用户界面进行构造.
2. Oracle数据挖掘

它是Oracle Advanced Analysis数据库的代表. 市场领先的公司使用它来最大化数据的潜力并做出准确的预测. 该系统与强大的数据算法配合使用,以锁定最佳客户. 此外,它可以识别异常情况和交叉销售机会,使用户可以根据需要应用不同的预测模型. 此外,它以所需的方式自定义客户肖像.
3. IBM SPSS Modeler

对于大型项目,IBM SPSS Modeler最适合. 在此建模器中,文本分析及其最高级的可视界面非常有价值. 它有助于生成数据挖掘算法,并且基本上不需要编程. 它可广泛用于异常检测,贝叶斯网络,CARMA,Cox回归以及使用多层感知器和反向传播学习的基本神经网络.
4. 尼姆

Konstanz Information Miner是一个开源数据分析平台. 您可以快速部署,扩展并熟悉其中的数据. 在商业智能领域,KNIME声称是一个可以为经验不足的用户提供预测智能的平台. 此外,数据驱动的创新系统有助于发掘数据的潜力. 此外,它包括数千个模块和现成的示例以及大量集成的工具和算法.
5. Python

Python是一种免费的开源语言,由于易于使用,因此经常与R并驾齐驱. 与R不同,Python通常易于学习和使用. 许多用户发现他们可以在几分钟内开始构建数据并执行极其复杂的亲和力分析. 只要您熟悉变量,数据类型,函数,条件语句和循环等基本编程概念,最常见的业务用例数据可视化就非常简单.
6. 优采云 采集器

优采云 采集器由合肥乐威信息技术有限公司开发. 它是一款专业的网络数据采集 /信息挖掘处理软件. 通过灵活的配置,可以轻松,快速地从网页上获取它,可以编辑和过滤结构化的文本,图片,文件和其他资源信息,然后发布到网站后台,各种文件或其他数据库系统.
【优采云工具】fofa+xray手动批量挖掘漏洞介绍(源码获取去知识星球获取
采集交流 • 优采云 发表了文章 • 0 个评论 • 309 次浏览 • 2020-08-26 20:05
当你的才气
还撑不起你的野心时
那你就应当静下心来学习
xray你长大了,应该学会自己批量钻洞了~(白嫖党必备,冲冲冲)
开局先来一句xray nb,高级版真香~
再来一句fofa nb,高级会员真香~
xray和fofa这儿不额外介绍了,最近在批量刷补天,于是写了脚本,通过fofa api批量获取资产,然后调用xray批量扫描,并生成报告。
挂服务器上,头天白天睡着前输一波fofa句型,第二天晚上下班后去验证漏洞,批量一波,补天库币无数~~
在config.ini上面第一行放你fofa的email,第二行放key
普通会员API每次100条,高级会员每次10000条,根据自己的等级来设置获取条数
基于python3,第三方依赖库就一个requests,想必你们都装过了,没有的话就pip install requests安装一下。
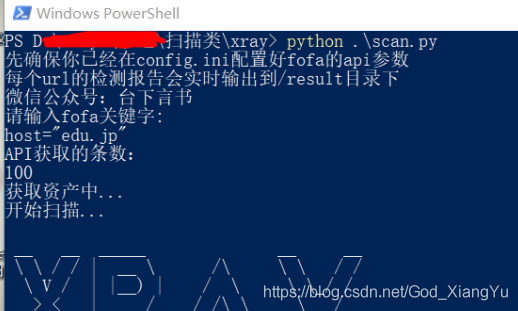
脚本可以直接在cmd运行,xray须要powershell,脚本中早已定义好了,下图中我用powershell执行单纯为了好看点~
扫描结果实时生成报告在result目录下(如果该url出报告的话)
主要还是依托fofa和xray,每天早上去看一下,提交一波补天,算是一种额外收获~
也可以在存在大批量资产且准许扫描的情况下先fuzz一波~
工具到知识星球获取
别急着扫描,看下边那张~
虽然我们生活在阴沟里,但仍然有人凝望星空! 查看全部
【优采云工具】fofa+xray手动批量挖掘漏洞介绍(源码获取去知识星球获取
当你的才气
还撑不起你的野心时
那你就应当静下心来学习
xray你长大了,应该学会自己批量钻洞了~(白嫖党必备,冲冲冲)
开局先来一句xray nb,高级版真香~
再来一句fofa nb,高级会员真香~
xray和fofa这儿不额外介绍了,最近在批量刷补天,于是写了脚本,通过fofa api批量获取资产,然后调用xray批量扫描,并生成报告。
挂服务器上,头天白天睡着前输一波fofa句型,第二天晚上下班后去验证漏洞,批量一波,补天库币无数~~
在config.ini上面第一行放你fofa的email,第二行放key
普通会员API每次100条,高级会员每次10000条,根据自己的等级来设置获取条数
基于python3,第三方依赖库就一个requests,想必你们都装过了,没有的话就pip install requests安装一下。
脚本可以直接在cmd运行,xray须要powershell,脚本中早已定义好了,下图中我用powershell执行单纯为了好看点~
扫描结果实时生成报告在result目录下(如果该url出报告的话)

主要还是依托fofa和xray,每天早上去看一下,提交一波补天,算是一种额外收获~
也可以在存在大批量资产且准许扫描的情况下先fuzz一波~
工具到知识星球获取
别急着扫描,看下边那张~


虽然我们生活在阴沟里,但仍然有人凝望星空!
信息采集的工具有什么呀?急需!!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2020-08-26 15:46
网络信息采集专家可以将因特网上的网站信息采集保存到用户的本地数据库中。并具备以下功能:规则定义-通过采集规则的定义,可以搜索所有网站采集几乎任何类型的信息。多任务,多线程-可以同时进行多个信息采集任务,每个任务可以使用多个线程。所见即所得-任务采集过程所见即所得,过程中遍历的链接信息、采集信息、错误信息等就会及时的反映在软件界面中。数据保存-数据边采集边手动保存到关系数据库中,并且数据结构才能手动适应,软件可以依据采集规则手动创建数据库,以及其中的表和数组,也可以按照设置灵活的将数据保存到顾客已有的数据库结构中,这一切都不会对你的数据库和你的生产导致任何不利影响。断点续采-信息采集任务可以在停止后从断点开始继续采集,从此你用不再害怕你的采集任务意外中断了。网站登录-支持网站登录,并支持网站Cookie,即使须要验证吗就能登入的网站也能轻松穿过。信息手动辨识-提供例如Email地址、电话号码、数字等多种预先定义好的信息类型,用户经过简单的选定即可从广袤的网路信息中提取特定的信息。网页正文提取-可以将正文从网页htm代码中提取下来并进行适当的格式转换,并手动删掉无用的htm代码。结果替换-可以将采集的结果按照规则替换成你定义的内容。
文件下载-可以将采集到的二进制文件(诸如:图片、音乐、软件、文档等等)下载到本地c盘或则采集结果数据库中。采集结果分类-可以依据用户定义的分类信息进行采集结果的手动分类。数据发布-可以通过自定义插口,将已采集的结果数据发布到任意的内容管理系统和指定数据库中。现在已支持的目标发布媒体包括:数据库(access,sqlserver,Oracle,MySQL,Excel等),静态htm文件,Rss文件。条件保存-可以按照某个条件来决定这些信息保存,那些信息过滤。过滤重复内容-软件可依据用户设置和实际情况对重复内容和重复网址手动删掉重复内容。结果替换-可以将采集的结果按照规则替换成你定义的内容。特殊链接辨识-运用此功能可以将用JavaScript动态生成的链接或其他更奇特的联接辨识下来。保存遍历页面-可将访问过程中所访问的页面内容全部保存至硬碟上。任务优化配置-提供多个选项进行配置,可将任务采集效率大大增强。自动生成网址-可以按照文本文件,数据库等内容手动生成采集地址。网络信息采集专家才能帮助你有效、快速的获得各种各样的网路信息,提高你以及你所在组织的生产力和情报获得能力。 查看全部
信息采集的工具有什么呀?急需!!!
网络信息采集专家可以将因特网上的网站信息采集保存到用户的本地数据库中。并具备以下功能:规则定义-通过采集规则的定义,可以搜索所有网站采集几乎任何类型的信息。多任务,多线程-可以同时进行多个信息采集任务,每个任务可以使用多个线程。所见即所得-任务采集过程所见即所得,过程中遍历的链接信息、采集信息、错误信息等就会及时的反映在软件界面中。数据保存-数据边采集边手动保存到关系数据库中,并且数据结构才能手动适应,软件可以依据采集规则手动创建数据库,以及其中的表和数组,也可以按照设置灵活的将数据保存到顾客已有的数据库结构中,这一切都不会对你的数据库和你的生产导致任何不利影响。断点续采-信息采集任务可以在停止后从断点开始继续采集,从此你用不再害怕你的采集任务意外中断了。网站登录-支持网站登录,并支持网站Cookie,即使须要验证吗就能登入的网站也能轻松穿过。信息手动辨识-提供例如Email地址、电话号码、数字等多种预先定义好的信息类型,用户经过简单的选定即可从广袤的网路信息中提取特定的信息。网页正文提取-可以将正文从网页htm代码中提取下来并进行适当的格式转换,并手动删掉无用的htm代码。结果替换-可以将采集的结果按照规则替换成你定义的内容。
文件下载-可以将采集到的二进制文件(诸如:图片、音乐、软件、文档等等)下载到本地c盘或则采集结果数据库中。采集结果分类-可以依据用户定义的分类信息进行采集结果的手动分类。数据发布-可以通过自定义插口,将已采集的结果数据发布到任意的内容管理系统和指定数据库中。现在已支持的目标发布媒体包括:数据库(access,sqlserver,Oracle,MySQL,Excel等),静态htm文件,Rss文件。条件保存-可以按照某个条件来决定这些信息保存,那些信息过滤。过滤重复内容-软件可依据用户设置和实际情况对重复内容和重复网址手动删掉重复内容。结果替换-可以将采集的结果按照规则替换成你定义的内容。特殊链接辨识-运用此功能可以将用JavaScript动态生成的链接或其他更奇特的联接辨识下来。保存遍历页面-可将访问过程中所访问的页面内容全部保存至硬碟上。任务优化配置-提供多个选项进行配置,可将任务采集效率大大增强。自动生成网址-可以按照文本文件,数据库等内容手动生成采集地址。网络信息采集专家才能帮助你有效、快速的获得各种各样的网路信息,提高你以及你所在组织的生产力和情报获得能力。
20+网页采集工具—5分钟提取线上数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-08-22 06:46
原文章请查看:20+网页采集工具—5分钟提取线上数据
网页爬虫(也称为数据提取,数据采集,数据爬虫)如今已广泛应用于许多领域。在没有网路爬虫工具出现之前,对于没有编程技能的普通人来说,它是一个神奇的词,它的高门槛不断将人们挡在大数据之门之外。但是网页抓取工具是一种手动数据抓取技术,通过自动化的爬取数据降低自动复制粘贴的繁杂步骤,拉近了我们与数据的距离。
使用网路抓取工具有哪些益处?
它让您无需进行重复的复制和粘贴工作。
它将提取的数据装入结构良好的格式中,包括但不限于Excel,HTML和CSV。
它可以帮助您节约时间和金钱,而无需聘请专业的数据分析师。
这是营销人员,卖家,新闻工作者,YouTube使用者,研究人员和许多其他缺少技术技能的人的良药。
我列举了20种最佳的网页爬虫工具供您参考。欢迎充分利用它!
Octoparse
Octoparse是一款强悍的网站采集器,可提取您在网站上所需的几乎所有数据。您可以使用Octoparse爬取具有广泛功能的网站。它具有2种操作模式- 任务模板模式和中级模式-非程序员可以快速上手。友好的点击界面可以引导您完成整个提取过程。因此,您可以轻松提取网站内容,并在短时间内将其保存为EXCEL,TXT,HTML或数据库等结构化格式。
此外,它提供了计划的云提取,使您可以实时提取动态数据,并在网站更新中保留跟踪记录。您还可以通过使用外置的Regex和XPath配置来精确定位元素,从而提取结构复杂的复杂网站。您无需再害怕IP阻塞。Octoparse提供IP代理服务器,该服务器将手动执行IP,而不会被攻击性网站发现。总之,Octoparse应当才能满足用户最基本的或中级的爬取需求,而无需任何编码技能。
Cyotek WebCopy
WebCopy十分形象的描述了网路爬虫。这是一个免费的网站采集器,可使您将部份或全部网站本地复制到硬碟中以供离线参考。您可以修改其设置,以告诉漫游器您要怎么爬行。除此之外,您还可以配置域别称,用户代理字符串,默认文档等。
但是,WebCopy不包括虚拟DOM或任何方式的JavaScript解析。如果网站大量使用JavaScript进行操作,则WebCopy太可能难以制做真实的副本。可能因为大量使用JavaScript而未能正确处理动态网站布局。
HTTrack
作为网站采集器免费软件,HTTrack 提供了将整个网站下载到您的PC的功能。它具有适用于Windows,Linux,Sun Solaris和其他Unix系统的版本,覆盖了大多数用户。有趣的是,HTTrack可以镜像一个站点,或将多个站点镜像在一起(使用共享链接)。您可以在“设置选项”下确定下载网页时同时打开的连接数。您可以从其镜像的网站获取相片,文件和HTML代码,并恢复中断的下载。
此外,HTTrack内还提供代理支持,可最大程度地增强速率。
HTTrack可作为命令行程序工作,也可通过壳体程序供私人(捕获)或专业(在线网路镜像)使用,它适宜具有中级编程能力的使用者。
Getleft
Getleft是一个免费且便于使用的网站抓取工具。它容许您下载整个网站或任何单个网页。启动Getleft以后,您可以输入一个URL并选择要下载的文件,然后再开始下载。进行时,它将修改所有链接以进行本地浏览。此外,它还提供多语言支持。现在,Getleft支持14种语言!但是,它仅提供有限的Ftp支持,它将下载文件,但不会递归下载。
总体而言,Getleft应当在没有更复杂的战术技能的情况下满足用户的基本爬网需求。
Scraper
Scraper是Chrome扩充程序,具有有限的数据提取功能,但有助于进行在线研究。它还容许将数据导入到Google Spreadsheets。该工具适用于初学者和专家。您可以使用OAuth轻松地将数据复制到剪贴板或将其储存到电子表格。Scraper可以手动生成XPath,以定义要爬网的URL。它不提供包罗万象的爬网服务,但是大多数人依然不需要处理混乱的配置。
OutWit Hub
OutWit Hub是Firefox的附加组件,具有许多数据提取功能,可简化您的网路搜索。该网路爬虫工具可以浏览页面并以适当的格式储存提取的信息。
OutWit Hub提供了一个单一插口,可依照须要抓取少量或大量数据。OutWit Hub容许您从浏览器本身抓取任何网页。它甚至可以创建手动代理以提取数据。
它是最简单的Web抓取工具之一,可免费使用,并为您提供了无需编撰一行代码即可提取Web数据的便利。
ParseHub
Parsehub是一款出众的Web爬虫,它支持从使用AJAX技术,JavaScript,Cookie等的网站采集数据。其机器学习技术可以读取,分析之后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux等系统。您甚至可以使用浏览器中外置的Web应用程序。
作为免费软件,您在Parsehub中最多可以构建五个公共项目。付费订阅计划容许您创建起码20个用于抓取网站的私人项目。
Visual Scraper
VisualScraper是另一个太棒的免费且非编码的Web刮板程序,具有简单的点击界面。您可以从多个网页获取实时数据,并将提取的数据导入为CSV,XML,JSON或SQL文件。除SaaS之外,VisualScraper还提供网页抓取服务,例如数据传递服务和创建软件提取程序服务。
Visual Scraper使用户可以计划项目在特定时间运行,或者每分钟/天/周/月/年重复执行该序列。用户可以使用它来频繁提取新闻,更新,论坛。
Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具容许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub使用Crawlera,这是一种智能代理旋转器,它支持绕开漫游器对策来轻松地爬行小型或受漫游器保护的站点。它使用户可以通过简单的HTTP API从多个IP和位置进行爬网而无需进行代理管理。
Scrapinghub将整个网页转换为结构化的内容。万一其抓取建立器难以满足您的要求,其专家团队将为您提供帮助。
Dexi.io
作为基于浏览器的爬虫程序, Dexi.io容许您从任何网站基于浏览器抓取数据,并提供三种类型的机械手来创建抓取任务-提取器,爬虫程序和管线。该免费软件为您的Web抓取提供了匿名Web代理服务器,您提取的数据将在数据存档之前在Dexi.io的服务器上托管两周,或者您可以将提取的数据直接导入到JSON或CSV文件。它提供付费服务,以满足您获取实时数据的需求。
Webhose.io
Webhose.io使用户才能从世界各地以各类干净格式抓取在线资源中获取实时数据。使用此网路爬虫,您可以使用覆盖多种来源的多个过滤器来爬取数据并进一步提取许多不同语言的关键字。
您可以将抓取的数据保存为XML,JSON和RSS格式。并且容许用户从其存档访问历史数据。另外,webhose.io的抓取数据结果最多支持80种语言。用户可以轻松地索引和搜索Webhose.io爬网的结构化数据。
总体而言,Webhose.io可以满足用户的基本爬网要求。
Import. io
用户可以通过简单地从特定网页导出数据并将数据导入为CSV来产生自己的数据集。
您可以在几分钟内轻松地抓取数千个网页,而无需编撰任何代码,也可以按照须要建立1000多个API。公共API提供了强悍而灵活的功能,可通过编程方法控制Import.io并获得对数据的手动访问,而Import.io只需单击几下即可将Web数据集成到您自己的应用程序或网站中,从而让抓取显得愈发容易。
为了更好地满足用户的爬网要求,它还提供了一个免费的Windows,Mac OS X和Linux 应用程序,用于建立数据提取器和爬网程序,下载数据并与在线账户同步。此外,用户可以每周,每天或每小时安排爬网任务。
80legs
80legs是功能强悍的网页爬虫工具,可以按照自定义要求进行配置。它支持获取大量数据,并可以立刻下载提取的数据。80legs提供了高性能的网路爬网,可快速运行并在短短几秒钟内获取所需数据
Spinn3r
Spinn3r容许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。Spinn3r随Firehouse API一起分发,该API管理着95%的索引工作。它提供了中级垃圾邮件保护功能,可以清除垃圾电邮和不适当的语言使用,从而增强数据安全性。
Spinn3r索引类似于Google的内容,并将提取的数据保存在JSON文件中。网络抓取工具会不断扫描网路,并从多个来源中查找更新,以获取实时出版物。其管理控制台可使您控制抓取,而全文本搜索则容许对原创数据进行复杂的查询。
Content Grabber
Content Grabber是针对企业的网页爬网软件。它容许您创建独立的网页爬网代理。它可以从几乎所有网站中提取内容,并以您选择的格式将其保存为结构化数据,包括Excel报表,XML,CSV和大多数数据库。
由于它为须要的人提供了许多强大的脚本编辑,调试界面,因此它更适宜具有中级编程技能的人。允许用户使用C#或VB.NET调试或编撰脚本来控制爬网过程的编程。例如,Content Grabber可以与Visual Studio 2013集成,以按照用户的特定需求,对中级,机智的自定义采集器进行最强悍的脚本编辑,调试和单元测试。
Helium Scraper
Helium Scraper是一种可视化的Web数据爬网软件,当元素之间的关联较小时,效果挺好。它是非编码,非配置的。用户可以依照各类爬网需求访问在线模板。
基本上,它可以满足用户基础的爬网需求。
UiPath
UiPath是用于免费网页抓取的机器人过程自动化软件。它可以手动从大多数第三方应用程序中抓取Web和桌面数据。如果您在Windows上运行它,则可以安装手动过程自动化软件。Uipath才能跨多个网页提取表格格式的数据。
Uipath提供了用于进一步爬网的外置工具。处理复杂的UI时,此方式十分有效。屏幕抓取工具可以处理单个文本元素,文本组和文本块,例如表格格式的数据提取。
此外,无需编程即可创建智能Web代理,但是您内部的.NET黑客将完全控制数据。
Scrape.it
Scrape.it是一个node.js Web抓取软件。这是一个基于云端数据提取工具。它为具有中级编程技能的人而设计,因为它提供了公共包和私有包,以发觉,重用,更新和与全球数百万开发人员共享代码。它强悍的集成将帮助您按照须要建立自定义的采集器。
WebHarvy
WebHarvy是点击式Web抓取软件。它是为非程序员设计的。WebHarvy可以手动从网站上抓取文本,图像,URL和电子邮件,并以各类格式保存抓取的内容。它还提供了外置的计划程序和代理支持,该支持可进行匿名爬网并避免Web爬网软件被Web服务器制止,您可以选择通过代理服务器或VPN访问目标网站。
用户可以以多种格式保存从网页提取的数据。当前版本的WebHarvy网页抓取工具容许您将抓取的数据导入为XML,CSV,JSON或TSV文件。用户还可以将抓取的数据导入到SQL数据库。
Connotate
Connotate是为企业级Web内容提取而设计的自动化网页爬网程序,它须要企业级解决方案。商业用户可以在短短的几分钟内轻松创建提取代理,而无需进行任何编程。用户只需单击即可轻松创建提取代理。 查看全部
20+网页采集工具—5分钟提取线上数据
原文章请查看:20+网页采集工具—5分钟提取线上数据
网页爬虫(也称为数据提取,数据采集,数据爬虫)如今已广泛应用于许多领域。在没有网路爬虫工具出现之前,对于没有编程技能的普通人来说,它是一个神奇的词,它的高门槛不断将人们挡在大数据之门之外。但是网页抓取工具是一种手动数据抓取技术,通过自动化的爬取数据降低自动复制粘贴的繁杂步骤,拉近了我们与数据的距离。
使用网路抓取工具有哪些益处?
它让您无需进行重复的复制和粘贴工作。
它将提取的数据装入结构良好的格式中,包括但不限于Excel,HTML和CSV。
它可以帮助您节约时间和金钱,而无需聘请专业的数据分析师。
这是营销人员,卖家,新闻工作者,YouTube使用者,研究人员和许多其他缺少技术技能的人的良药。
我列举了20种最佳的网页爬虫工具供您参考。欢迎充分利用它!
Octoparse
Octoparse是一款强悍的网站采集器,可提取您在网站上所需的几乎所有数据。您可以使用Octoparse爬取具有广泛功能的网站。它具有2种操作模式- 任务模板模式和中级模式-非程序员可以快速上手。友好的点击界面可以引导您完成整个提取过程。因此,您可以轻松提取网站内容,并在短时间内将其保存为EXCEL,TXT,HTML或数据库等结构化格式。
此外,它提供了计划的云提取,使您可以实时提取动态数据,并在网站更新中保留跟踪记录。您还可以通过使用外置的Regex和XPath配置来精确定位元素,从而提取结构复杂的复杂网站。您无需再害怕IP阻塞。Octoparse提供IP代理服务器,该服务器将手动执行IP,而不会被攻击性网站发现。总之,Octoparse应当才能满足用户最基本的或中级的爬取需求,而无需任何编码技能。
Cyotek WebCopy
WebCopy十分形象的描述了网路爬虫。这是一个免费的网站采集器,可使您将部份或全部网站本地复制到硬碟中以供离线参考。您可以修改其设置,以告诉漫游器您要怎么爬行。除此之外,您还可以配置域别称,用户代理字符串,默认文档等。
但是,WebCopy不包括虚拟DOM或任何方式的JavaScript解析。如果网站大量使用JavaScript进行操作,则WebCopy太可能难以制做真实的副本。可能因为大量使用JavaScript而未能正确处理动态网站布局。
HTTrack
作为网站采集器免费软件,HTTrack 提供了将整个网站下载到您的PC的功能。它具有适用于Windows,Linux,Sun Solaris和其他Unix系统的版本,覆盖了大多数用户。有趣的是,HTTrack可以镜像一个站点,或将多个站点镜像在一起(使用共享链接)。您可以在“设置选项”下确定下载网页时同时打开的连接数。您可以从其镜像的网站获取相片,文件和HTML代码,并恢复中断的下载。
此外,HTTrack内还提供代理支持,可最大程度地增强速率。
HTTrack可作为命令行程序工作,也可通过壳体程序供私人(捕获)或专业(在线网路镜像)使用,它适宜具有中级编程能力的使用者。
Getleft
Getleft是一个免费且便于使用的网站抓取工具。它容许您下载整个网站或任何单个网页。启动Getleft以后,您可以输入一个URL并选择要下载的文件,然后再开始下载。进行时,它将修改所有链接以进行本地浏览。此外,它还提供多语言支持。现在,Getleft支持14种语言!但是,它仅提供有限的Ftp支持,它将下载文件,但不会递归下载。
总体而言,Getleft应当在没有更复杂的战术技能的情况下满足用户的基本爬网需求。
Scraper
Scraper是Chrome扩充程序,具有有限的数据提取功能,但有助于进行在线研究。它还容许将数据导入到Google Spreadsheets。该工具适用于初学者和专家。您可以使用OAuth轻松地将数据复制到剪贴板或将其储存到电子表格。Scraper可以手动生成XPath,以定义要爬网的URL。它不提供包罗万象的爬网服务,但是大多数人依然不需要处理混乱的配置。
OutWit Hub
OutWit Hub是Firefox的附加组件,具有许多数据提取功能,可简化您的网路搜索。该网路爬虫工具可以浏览页面并以适当的格式储存提取的信息。
OutWit Hub提供了一个单一插口,可依照须要抓取少量或大量数据。OutWit Hub容许您从浏览器本身抓取任何网页。它甚至可以创建手动代理以提取数据。
它是最简单的Web抓取工具之一,可免费使用,并为您提供了无需编撰一行代码即可提取Web数据的便利。
ParseHub
Parsehub是一款出众的Web爬虫,它支持从使用AJAX技术,JavaScript,Cookie等的网站采集数据。其机器学习技术可以读取,分析之后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux等系统。您甚至可以使用浏览器中外置的Web应用程序。
作为免费软件,您在Parsehub中最多可以构建五个公共项目。付费订阅计划容许您创建起码20个用于抓取网站的私人项目。
Visual Scraper
VisualScraper是另一个太棒的免费且非编码的Web刮板程序,具有简单的点击界面。您可以从多个网页获取实时数据,并将提取的数据导入为CSV,XML,JSON或SQL文件。除SaaS之外,VisualScraper还提供网页抓取服务,例如数据传递服务和创建软件提取程序服务。
Visual Scraper使用户可以计划项目在特定时间运行,或者每分钟/天/周/月/年重复执行该序列。用户可以使用它来频繁提取新闻,更新,论坛。
Scrapinghub
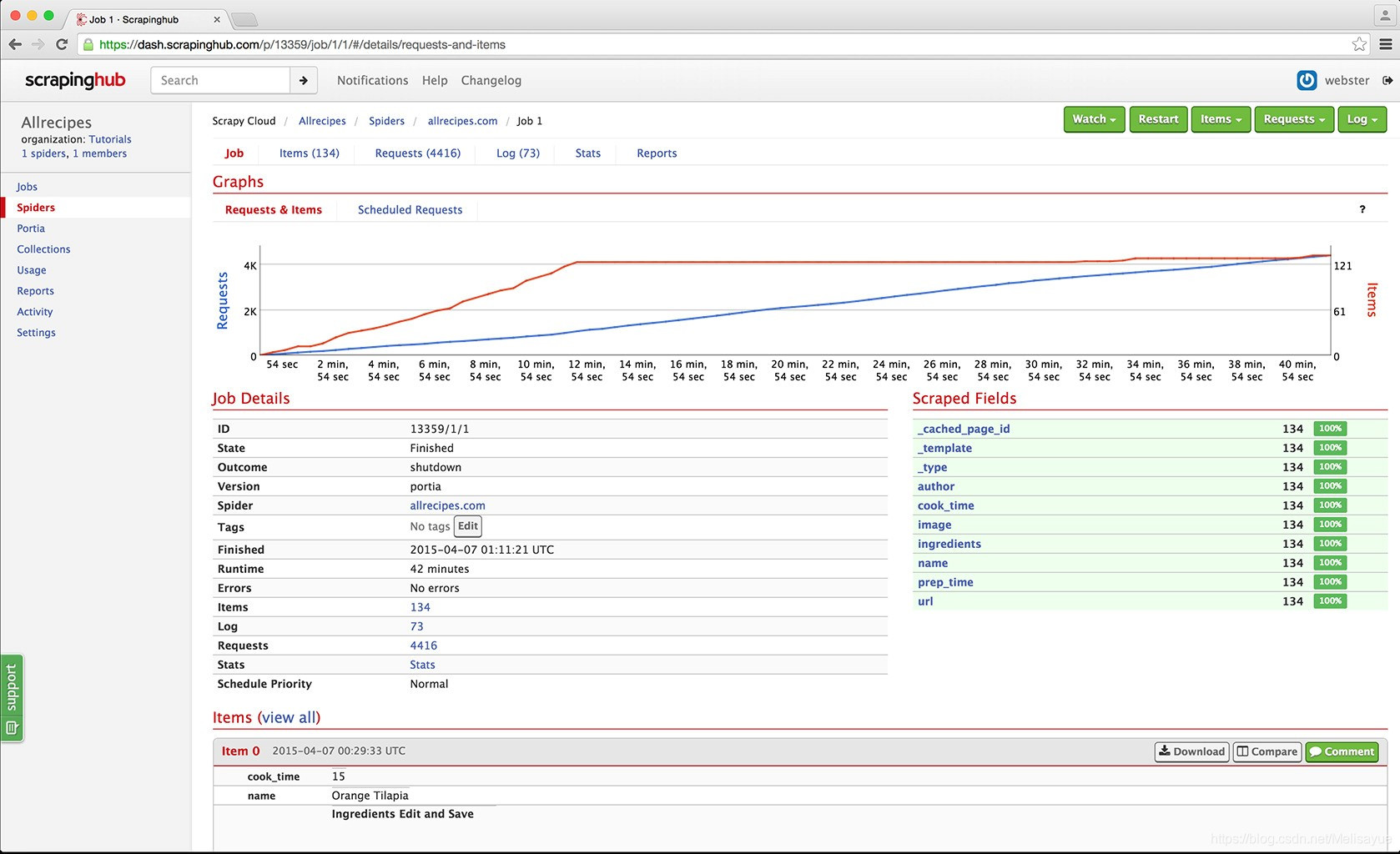
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具容许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub使用Crawlera,这是一种智能代理旋转器,它支持绕开漫游器对策来轻松地爬行小型或受漫游器保护的站点。它使用户可以通过简单的HTTP API从多个IP和位置进行爬网而无需进行代理管理。
Scrapinghub将整个网页转换为结构化的内容。万一其抓取建立器难以满足您的要求,其专家团队将为您提供帮助。
Dexi.io
作为基于浏览器的爬虫程序, Dexi.io容许您从任何网站基于浏览器抓取数据,并提供三种类型的机械手来创建抓取任务-提取器,爬虫程序和管线。该免费软件为您的Web抓取提供了匿名Web代理服务器,您提取的数据将在数据存档之前在Dexi.io的服务器上托管两周,或者您可以将提取的数据直接导入到JSON或CSV文件。它提供付费服务,以满足您获取实时数据的需求。
Webhose.io
Webhose.io使用户才能从世界各地以各类干净格式抓取在线资源中获取实时数据。使用此网路爬虫,您可以使用覆盖多种来源的多个过滤器来爬取数据并进一步提取许多不同语言的关键字。
您可以将抓取的数据保存为XML,JSON和RSS格式。并且容许用户从其存档访问历史数据。另外,webhose.io的抓取数据结果最多支持80种语言。用户可以轻松地索引和搜索Webhose.io爬网的结构化数据。
总体而言,Webhose.io可以满足用户的基本爬网要求。
Import. io
用户可以通过简单地从特定网页导出数据并将数据导入为CSV来产生自己的数据集。
您可以在几分钟内轻松地抓取数千个网页,而无需编撰任何代码,也可以按照须要建立1000多个API。公共API提供了强悍而灵活的功能,可通过编程方法控制Import.io并获得对数据的手动访问,而Import.io只需单击几下即可将Web数据集成到您自己的应用程序或网站中,从而让抓取显得愈发容易。
为了更好地满足用户的爬网要求,它还提供了一个免费的Windows,Mac OS X和Linux 应用程序,用于建立数据提取器和爬网程序,下载数据并与在线账户同步。此外,用户可以每周,每天或每小时安排爬网任务。
80legs
80legs是功能强悍的网页爬虫工具,可以按照自定义要求进行配置。它支持获取大量数据,并可以立刻下载提取的数据。80legs提供了高性能的网路爬网,可快速运行并在短短几秒钟内获取所需数据
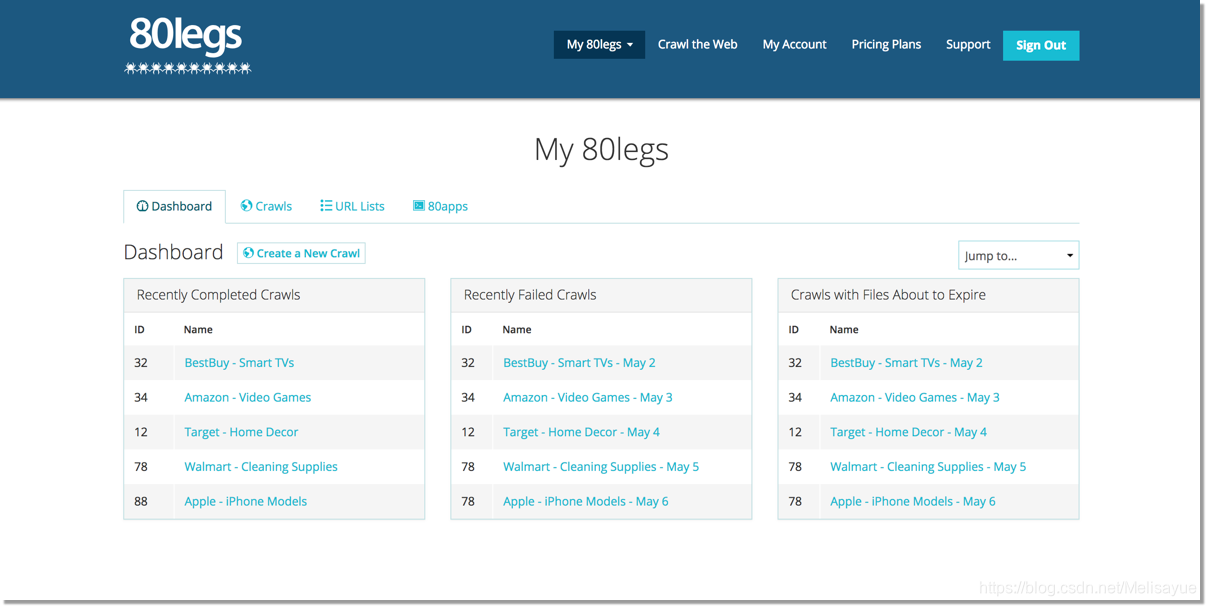
Spinn3r
Spinn3r容许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。Spinn3r随Firehouse API一起分发,该API管理着95%的索引工作。它提供了中级垃圾邮件保护功能,可以清除垃圾电邮和不适当的语言使用,从而增强数据安全性。
Spinn3r索引类似于Google的内容,并将提取的数据保存在JSON文件中。网络抓取工具会不断扫描网路,并从多个来源中查找更新,以获取实时出版物。其管理控制台可使您控制抓取,而全文本搜索则容许对原创数据进行复杂的查询。
Content Grabber
Content Grabber是针对企业的网页爬网软件。它容许您创建独立的网页爬网代理。它可以从几乎所有网站中提取内容,并以您选择的格式将其保存为结构化数据,包括Excel报表,XML,CSV和大多数数据库。
由于它为须要的人提供了许多强大的脚本编辑,调试界面,因此它更适宜具有中级编程技能的人。允许用户使用C#或VB.NET调试或编撰脚本来控制爬网过程的编程。例如,Content Grabber可以与Visual Studio 2013集成,以按照用户的特定需求,对中级,机智的自定义采集器进行最强悍的脚本编辑,调试和单元测试。
Helium Scraper
Helium Scraper是一种可视化的Web数据爬网软件,当元素之间的关联较小时,效果挺好。它是非编码,非配置的。用户可以依照各类爬网需求访问在线模板。
基本上,它可以满足用户基础的爬网需求。
UiPath
UiPath是用于免费网页抓取的机器人过程自动化软件。它可以手动从大多数第三方应用程序中抓取Web和桌面数据。如果您在Windows上运行它,则可以安装手动过程自动化软件。Uipath才能跨多个网页提取表格格式的数据。
Uipath提供了用于进一步爬网的外置工具。处理复杂的UI时,此方式十分有效。屏幕抓取工具可以处理单个文本元素,文本组和文本块,例如表格格式的数据提取。
此外,无需编程即可创建智能Web代理,但是您内部的.NET黑客将完全控制数据。
Scrape.it
Scrape.it是一个node.js Web抓取软件。这是一个基于云端数据提取工具。它为具有中级编程技能的人而设计,因为它提供了公共包和私有包,以发觉,重用,更新和与全球数百万开发人员共享代码。它强悍的集成将帮助您按照须要建立自定义的采集器。
WebHarvy
WebHarvy是点击式Web抓取软件。它是为非程序员设计的。WebHarvy可以手动从网站上抓取文本,图像,URL和电子邮件,并以各类格式保存抓取的内容。它还提供了外置的计划程序和代理支持,该支持可进行匿名爬网并避免Web爬网软件被Web服务器制止,您可以选择通过代理服务器或VPN访问目标网站。
用户可以以多种格式保存从网页提取的数据。当前版本的WebHarvy网页抓取工具容许您将抓取的数据导入为XML,CSV,JSON或TSV文件。用户还可以将抓取的数据导入到SQL数据库。
Connotate
Connotate是为企业级Web内容提取而设计的自动化网页爬网程序,它须要企业级解决方案。商业用户可以在短短的几分钟内轻松创建提取代理,而无需进行任何编程。用户只需单击即可轻松创建提取代理。
深维全能信息采集软件特色
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-22 02:16
深维全能信息采集软件是一款就能帮助我们对网路信息进行快速采集和管理的工具,通过此软件就能对相关信息进行快速处理和整理,支持网站跨层采集、POST采集、脚本采集、网站登录采集、动态页面采集等,自助图形化的配置工具,交互式的策略、先进的机器学习算法,让您的配置操作得到更大的简化,有须要的同事赶快下载吧。
深维全能信息采集软件功能介绍
1、解压压缩包。
2、开始安装。
3、软件界面。
深维全能信息采集软件特色
1、强大的信息采集功能
可采集几乎任何类型的网站信息,包括静态htm,html类型和动态ASP,ASPX,JSP等。可N级页面采集。可手动下载二进制文件,比如图片,软件,mp3等。
2、网站登录
需要登入能够看见的信息,先在任务的’登录设置’处进行登陆,就可采集登录后才会看见的信息。
3、速度快,运行稳定
真正的多线程,多任务,运行时占用系统资源甚少,可稳定地长时间运行。(明显区别于其他软件)
4、数据保存格式丰富
可把采集的数据,保存为Txt,Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5、强大的新闻采集,自动化处理功能
可手动保留新闻的格式,包括图片等。可通过设置,自动下载图片 ,自动把正文里图片的网路路径改为本地文件路径(也可保留原貌);可把采集的新闻手动处理成自己设计的模板格式;可采集具有分页方式的新闻。通过这种功能,简单设置后即可在本地构建一个强悍的新闻系统,无需人工干预。
6、强大的信息手动再加工功能
对采集的信息,可进行二次批量再加工,使之愈加符合您的实际要求。也可设置手动加工公式,在采集的过程中,按照公式手动加工处理,包括数据合并和数据替换等。
更新日志
修复BUG
精简文件
优化程序 查看全部
深维全能信息采集软件特色
深维全能信息采集软件是一款就能帮助我们对网路信息进行快速采集和管理的工具,通过此软件就能对相关信息进行快速处理和整理,支持网站跨层采集、POST采集、脚本采集、网站登录采集、动态页面采集等,自助图形化的配置工具,交互式的策略、先进的机器学习算法,让您的配置操作得到更大的简化,有须要的同事赶快下载吧。

深维全能信息采集软件功能介绍
1、解压压缩包。
2、开始安装。
3、软件界面。
深维全能信息采集软件特色
1、强大的信息采集功能
可采集几乎任何类型的网站信息,包括静态htm,html类型和动态ASP,ASPX,JSP等。可N级页面采集。可手动下载二进制文件,比如图片,软件,mp3等。
2、网站登录
需要登入能够看见的信息,先在任务的’登录设置’处进行登陆,就可采集登录后才会看见的信息。
3、速度快,运行稳定
真正的多线程,多任务,运行时占用系统资源甚少,可稳定地长时间运行。(明显区别于其他软件)
4、数据保存格式丰富
可把采集的数据,保存为Txt,Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5、强大的新闻采集,自动化处理功能
可手动保留新闻的格式,包括图片等。可通过设置,自动下载图片 ,自动把正文里图片的网路路径改为本地文件路径(也可保留原貌);可把采集的新闻手动处理成自己设计的模板格式;可采集具有分页方式的新闻。通过这种功能,简单设置后即可在本地构建一个强悍的新闻系统,无需人工干预。
6、强大的信息手动再加工功能
对采集的信息,可进行二次批量再加工,使之愈加符合您的实际要求。也可设置手动加工公式,在采集的过程中,按照公式手动加工处理,包括数据合并和数据替换等。
更新日志
修复BUG
精简文件
优化程序
有什么功能强悍,同时又简单易用的网路采集工具?
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2020-08-22 01:40
网络搜集工具可以在各类场景中用于无限目的。
比如:
1.采集市场研究数据
网络抓取工具可以从多个数据剖析提供商和市场研究公司获取信息,并将它们整合到一个位置,以便于参考和剖析。可以帮助你及时了解公司或行业未来六个月的发展方向。
2.提取联系信息
这些工具还可用于从各类网站中提取电子邮件和电话号码等数据。
3.采集数据来下载用于离线阅读或储存
4.跟踪多个市场的价钱等
这些软件自动或手动查找新数据,获取新数据或更新数据并储存便于于访问。例如,可以使用抓取工具从亚马逊搜集有关产品及其价位的信息。
推荐4个网路搜集工具VisualScraper
VisualScraper是另一种Web数据提取软件,可用于从Web搜集信息。该软件可帮助你从多个网页中提取数据并实时获取结果。此外,你可以以CSV,XML,JSON和SQL等各类格式导入。
Spinn3r
Spinn3r容许你从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取整个数据。Spinn3r与 firehouse API一起分发,管理95%的索引工作。它提供中级垃圾邮件防护,可以清除垃圾电邮和不恰当的语言使用,从而增强数据安全性。
80legs
80legs是一款功能强悍且灵活的网路抓取工具,可按照您的需求进行配置。它支持获取大量数据以及立刻下载提取数据的选项。80legs宣称可以抓取600,000多个域名,并被MailChimp和PayPal等小型玩家使用。
Scraper
Scraper是Chrome扩充程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导入到Google Spreadsheets。此工具适用于初学者以及可以使用OAuth轻松将数据复制到剪贴板或储存到电子表格的专家。
你还可以关注我的微信公众号:youdaoyunnet
文章发自:
提取在线数据的9个最佳网页抓取工具 - 运营有道 查看全部
有什么功能强悍,同时又简单易用的网路采集工具?
网络搜集工具可以在各类场景中用于无限目的。
比如:
1.采集市场研究数据
网络抓取工具可以从多个数据剖析提供商和市场研究公司获取信息,并将它们整合到一个位置,以便于参考和剖析。可以帮助你及时了解公司或行业未来六个月的发展方向。
2.提取联系信息
这些工具还可用于从各类网站中提取电子邮件和电话号码等数据。
3.采集数据来下载用于离线阅读或储存
4.跟踪多个市场的价钱等
这些软件自动或手动查找新数据,获取新数据或更新数据并储存便于于访问。例如,可以使用抓取工具从亚马逊搜集有关产品及其价位的信息。
推荐4个网路搜集工具VisualScraper
VisualScraper是另一种Web数据提取软件,可用于从Web搜集信息。该软件可帮助你从多个网页中提取数据并实时获取结果。此外,你可以以CSV,XML,JSON和SQL等各类格式导入。
Spinn3r
Spinn3r容许你从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取整个数据。Spinn3r与 firehouse API一起分发,管理95%的索引工作。它提供中级垃圾邮件防护,可以清除垃圾电邮和不恰当的语言使用,从而增强数据安全性。
80legs
80legs是一款功能强悍且灵活的网路抓取工具,可按照您的需求进行配置。它支持获取大量数据以及立刻下载提取数据的选项。80legs宣称可以抓取600,000多个域名,并被MailChimp和PayPal等小型玩家使用。
Scraper
Scraper是Chrome扩充程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导入到Google Spreadsheets。此工具适用于初学者以及可以使用OAuth轻松将数据复制到剪贴板或储存到电子表格的专家。
你还可以关注我的微信公众号:youdaoyunnet
文章发自:
提取在线数据的9个最佳网页抓取工具 - 运营有道
本人第一个开源代码,NETSpider 网络蜘蛛采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-21 20:46
NETSpider网站数据采集软件是一款基于.Net平台的开源软件。
软件部份功能是基本Soukey软件进行开发的.这个版本采用VS2010+.NET3.5进行开发的.
NETSpider采摘当前提供的主要功能如下:
1. 多任务多线程数据采集,支持POST方法(待定);
2. 可采集Ajax页面;
3. 支持Cookie,支持手工登陆采集数据;
4. 支持采集事务;
5. 支持数据手动及手工导入,导出格式为:文本、Excel、Access、MSSql、Mysql等;
6. 支持在线发布数据;
7. 支持导航网址的采集,导航深度不限;
8. 支持手动翻页;
9. 支持文件下载,可以采集图片、Flash及其他文件;
10. 支持采集结果数据的加工,包括替换、附前缀后缀、截取等操作,支持正则;
11. 采集网址定义除了支持基本参数定义,也可外接字典数据作为网址参数,进行数据采集;
12. 支持一个任务多实例运行;
13. 提供计划任务,计划任务支持NETSpider采集任务、外部可执行文件任务、数据库储存过程任务(还在开发中);
14. 计划任务执行周期支持每晚、每周及自定义运行间隔;最小单位为:半小时;
15. 支持任务触发器,即可在采集任务完成后,自动触发执行其他任务(包括可执行文件或存储过程)。
16. 完善的日志功能:系统日志、任务执行日志、出错日志等等;
17. 系统提供MINI浏览器可用于捕获Cookie或POST数据;
NETSpider采集器并不限制您是否商用此软件,源码完全开放,
===================以下为更新内容===================================
1. NETSpider于2014年10月1日开放
相关源码下载:
1.目前这个版本还有好多的验证未做处理,没有时间(花了两周的样子写成这样子),所以添加的时侯请按规定填写数据
2.还有部份功能未实现.等有空我会继续建立的 查看全部
本人第一个开源代码,NETSpider 网络蜘蛛采集工具
NETSpider网站数据采集软件是一款基于.Net平台的开源软件。
软件部份功能是基本Soukey软件进行开发的.这个版本采用VS2010+.NET3.5进行开发的.
NETSpider采摘当前提供的主要功能如下:
1. 多任务多线程数据采集,支持POST方法(待定);
2. 可采集Ajax页面;
3. 支持Cookie,支持手工登陆采集数据;
4. 支持采集事务;
5. 支持数据手动及手工导入,导出格式为:文本、Excel、Access、MSSql、Mysql等;
6. 支持在线发布数据;
7. 支持导航网址的采集,导航深度不限;
8. 支持手动翻页;
9. 支持文件下载,可以采集图片、Flash及其他文件;
10. 支持采集结果数据的加工,包括替换、附前缀后缀、截取等操作,支持正则;
11. 采集网址定义除了支持基本参数定义,也可外接字典数据作为网址参数,进行数据采集;
12. 支持一个任务多实例运行;
13. 提供计划任务,计划任务支持NETSpider采集任务、外部可执行文件任务、数据库储存过程任务(还在开发中);
14. 计划任务执行周期支持每晚、每周及自定义运行间隔;最小单位为:半小时;
15. 支持任务触发器,即可在采集任务完成后,自动触发执行其他任务(包括可执行文件或存储过程)。
16. 完善的日志功能:系统日志、任务执行日志、出错日志等等;
17. 系统提供MINI浏览器可用于捕获Cookie或POST数据;
NETSpider采集器并不限制您是否商用此软件,源码完全开放,
===================以下为更新内容===================================
1. NETSpider于2014年10月1日开放
相关源码下载:
1.目前这个版本还有好多的验证未做处理,没有时间(花了两周的样子写成这样子),所以添加的时侯请按规定填写数据
2.还有部份功能未实现.等有空我会继续建立的
新闻采集工具?
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2020-08-12 10:10
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
一个企业级新闻与政务公告采集的落地,其实有特别多的难点。这几年我们帮助好多有相关需求的顾客一一解决了这种难点,积累了好多宝贵的经验。今天就来跟你们分享一下。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。 查看全部
很多企业与事业单位都须要采集新闻资讯、政务公告等数据,用以发展自己的业务。业务不同,具体的采集需求也不尽相同。举几个简单的事例:
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
一个企业级新闻与政务公告采集的落地,其实有特别多的难点。这几年我们帮助好多有相关需求的顾客一一解决了这种难点,积累了好多宝贵的经验。今天就来跟你们分享一下。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。
使用Filebeat搜集Kubernetes的应用日志
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2020-08-12 03:40
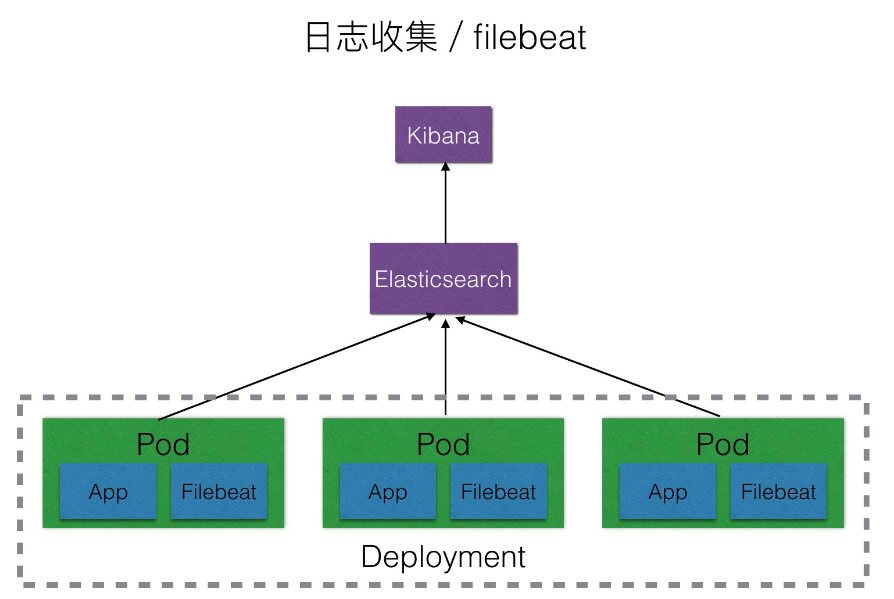
在进行日志搜集的过程中,我们首先想到的是使用Logstash,因为它是ELK stack中的重要成员,但是在测试过程中发觉,Logstash是基于JDK的,在没有形成日志的情况单纯启动Logstash就大约要消耗500M显存,在每位Pod中都启动一个日志搜集组件的情况下,使用logstash有点浪费系统资源,经人推荐我们选择使用Filebeat取代,经测试单独启动Filebeat容器大约会消耗12M显存,比起logstash相当轻量级。
方案选择
Kubernetes官方提供了EFK的日志搜集解决方案,但是这些方案并不适宜所有的业务场景,它本身就有一些局限性,例如:
基于以上几个缘由,我们决定使用自己的ELK集群。
Kubernetes集群中的日志搜集解决方案
编号方案优点缺点
1
每个app的镜像中都集成日志搜集组件
部署便捷,kubernetes的yaml文件无须非常配置,可以为每位app自定义日志搜集配置
强耦合,不便捷应用和日志搜集组件升级和维护且会导致镜像过大
2
单独创建一个日志搜集组件跟app的容器一起运行在同一个pod中
低耦合,扩展性强,方便维护和升级
需要对kubernetes的yaml文件进行单独配置,略显冗长
3
将所有的Pod的日志都挂载到宿主机上,每台主机上单独起一个日志搜集Pod
完全前馈,性能最高,管理上去最方便
需要统一日志搜集规则,目录和输出形式
综合以上优缺点,我们选择使用方案二。
该方案在扩展性、个性化、部署和后期维护方面都能做到均衡,因此选择该方案。
我们创建了自己的logstash镜像。创建过程和使用方法见
镜像地址:/jimmy/filebeat:5.4.0
测试
我们布署一个应用filebeat来搜集日志的功能测试。
创建应用yaml文件filebeat-test.yaml。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: filebeat-test
namespace: default
spec:
replicas: 3
template:
metadata:
labels:
k8s-app: filebeat-test
spec:
containers:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/filebeat:5.4.0
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
- name: filebeat-config
mountPath: /etc/filebeat/
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/analytics-docker-test:Build_8
name : app
ports:
- containerPort: 80
volumeMounts:
- name: app-logs
mountPath: /usr/local/TalkingData/logs
volumes:
- name: app-logs
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-config
---
apiVersion: v1
kind: Service
metadata:
name: filebeat-test
labels:
app: filebeat-test
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
run: filebeat-test
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
data:
filebeat.yml: |
filebeat.prospectors:
- input_type: log
paths:
- "/log/*"
- "/log/usermange/common/*"
output.elasticsearch:
hosts: ["172.23.5.255:9200"]
username: "elastic"
password: "changeme"
index: "filebeat-test"
说明
该文件中收录了配置文件filebeat的配置文件的ConfigMap,因此不需要再定义环境变量。
当然你也可以不同ConfigMap,通过传统的传递环境变量的方法来配置filebeat。
例如对filebeat的容器进行如下配置:
containers:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/filebeat:5.4.0
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
env:
- name: PATHS
value: "/log/*"
- name: ES_SERVER
value: 172.23.5.255:9200
- name: INDEX
value: logstash-docker
- name: INPUT_TYPE
value: log
目前使用这些方法会有个问题,及时PATHS只能传递单个目录,如果想传递多个目录须要更改filebeat镜像的docker-entrypoint.sh脚本,对该环境变量进行解析降低filebeat.yml文件中的PATHS列表。
推荐使用ConfigMap,这样filebeat的配置能够够更灵活。
注意事项
创建应用
部署Deployment
kubectl create -f filebeat-test.yaml
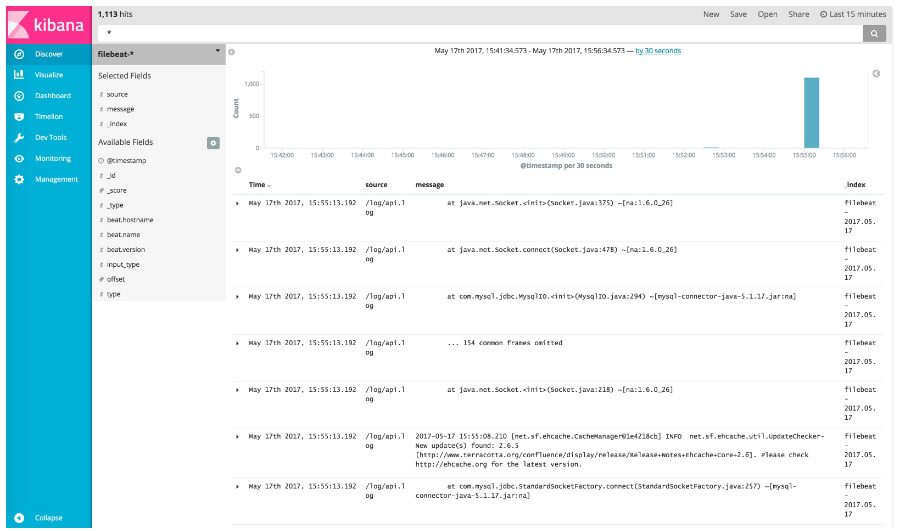
查看:9200/_cat/indices将可以看见列表有这样的indices:
green open filebeat-2017.05.17 1qatsSajSYqAV42_XYwLsQ 5 1 1189 0 1mb 588kb
访问Kibana的web页面,查看filebeat-2017.05.17的索引,可以看见logstash搜集到了app日志。
问题记录
我们配置的index: "filebeat-test"没有生效,需要参考filebeat的配置文档,对filebeat的配置进一步优化。
更多详情可以查看: 查看全部
前言
在进行日志搜集的过程中,我们首先想到的是使用Logstash,因为它是ELK stack中的重要成员,但是在测试过程中发觉,Logstash是基于JDK的,在没有形成日志的情况单纯启动Logstash就大约要消耗500M显存,在每位Pod中都启动一个日志搜集组件的情况下,使用logstash有点浪费系统资源,经人推荐我们选择使用Filebeat取代,经测试单独启动Filebeat容器大约会消耗12M显存,比起logstash相当轻量级。
方案选择
Kubernetes官方提供了EFK的日志搜集解决方案,但是这些方案并不适宜所有的业务场景,它本身就有一些局限性,例如:
基于以上几个缘由,我们决定使用自己的ELK集群。
Kubernetes集群中的日志搜集解决方案
编号方案优点缺点
1
每个app的镜像中都集成日志搜集组件
部署便捷,kubernetes的yaml文件无须非常配置,可以为每位app自定义日志搜集配置
强耦合,不便捷应用和日志搜集组件升级和维护且会导致镜像过大
2
单独创建一个日志搜集组件跟app的容器一起运行在同一个pod中
低耦合,扩展性强,方便维护和升级
需要对kubernetes的yaml文件进行单独配置,略显冗长
3
将所有的Pod的日志都挂载到宿主机上,每台主机上单独起一个日志搜集Pod
完全前馈,性能最高,管理上去最方便
需要统一日志搜集规则,目录和输出形式
综合以上优缺点,我们选择使用方案二。
该方案在扩展性、个性化、部署和后期维护方面都能做到均衡,因此选择该方案。
我们创建了自己的logstash镜像。创建过程和使用方法见
镜像地址:/jimmy/filebeat:5.4.0
测试
我们布署一个应用filebeat来搜集日志的功能测试。
创建应用yaml文件filebeat-test.yaml。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: filebeat-test
namespace: default
spec:
replicas: 3
template:
metadata:
labels:
k8s-app: filebeat-test
spec:
containers:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/filebeat:5.4.0
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
- name: filebeat-config
mountPath: /etc/filebeat/
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/analytics-docker-test:Build_8
name : app
ports:
- containerPort: 80
volumeMounts:
- name: app-logs
mountPath: /usr/local/TalkingData/logs
volumes:
- name: app-logs
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-config
---
apiVersion: v1
kind: Service
metadata:
name: filebeat-test
labels:
app: filebeat-test
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
run: filebeat-test
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
data:
filebeat.yml: |
filebeat.prospectors:
- input_type: log
paths:
- "/log/*"
- "/log/usermange/common/*"
output.elasticsearch:
hosts: ["172.23.5.255:9200"]
username: "elastic"
password: "changeme"
index: "filebeat-test"
说明
该文件中收录了配置文件filebeat的配置文件的ConfigMap,因此不需要再定义环境变量。
当然你也可以不同ConfigMap,通过传统的传递环境变量的方法来配置filebeat。
例如对filebeat的容器进行如下配置:
containers:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/filebeat:5.4.0
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
env:
- name: PATHS
value: "/log/*"
- name: ES_SERVER
value: 172.23.5.255:9200
- name: INDEX
value: logstash-docker
- name: INPUT_TYPE
value: log
目前使用这些方法会有个问题,及时PATHS只能传递单个目录,如果想传递多个目录须要更改filebeat镜像的docker-entrypoint.sh脚本,对该环境变量进行解析降低filebeat.yml文件中的PATHS列表。
推荐使用ConfigMap,这样filebeat的配置能够够更灵活。
注意事项
创建应用
部署Deployment
kubectl create -f filebeat-test.yaml
查看:9200/_cat/indices将可以看见列表有这样的indices:
green open filebeat-2017.05.17 1qatsSajSYqAV42_XYwLsQ 5 1 1189 0 1mb 588kb
访问Kibana的web页面,查看filebeat-2017.05.17的索引,可以看见logstash搜集到了app日志。
问题记录
我们配置的index: "filebeat-test"没有生效,需要参考filebeat的配置文档,对filebeat的配置进一步优化。
更多详情可以查看:
百分百顾客综合采集软件 V6.4
采集交流 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2020-08-10 07:46
软件功能 1、通过百度爬虫采集手机号,目标精准
软件支持网络爬虫搜索手机号功能,根据您的关键字智能搜索百度里面的用户手机号,目标精准明晰,且可将搜索结果(即手机号)保存到本地,网络营销的必备助手
2、按地区生成手机号码
按照用户设定的地区生成手机号码段,并且可以按照指定号码段,用户自定义格式生成手机号码,做地域定向营销,群发手机邮件的最佳选择
3、数据更新及时、保证营销疗效
百分百团队,有着专业的工作人员,定期整理最新的企业名录数据,我们力争做到及时的更新最新的企业数据,同时优化老的企业数据,保证您通过我们软件所采集到的企业数据,都是一手的、最新的。为您才能达到更好的营销销售疗效,我们仍然在努力
4、覆盖全省各行各业
由我们官方多名工作人员悉心整理、归类,再经过程序的二次精准处理,我们的数据库早已覆盖了全省所有行业,而且,各个行业所对应的数据早已做了定向、精准,是您开发新顾客、发掘意向顾客的最佳神器
软件特征 1、采集速度快、稳定性强
软件采用我们团队耗时五年研制的不加群提取群成员软件内核,利用现有成熟的技术,力争为您达到最佳采集速度的同时,软件的稳定性也丝毫不受影响!不仅还能节约您的时间效率,也才能使您的营销愈发省心!
2、快捷便捷数据导入,格式多元化
凡是订购我们软件,成为正式版用户之后,都可以享用软件的导入功能。导出格式,我们支持execel、txt等基本格式,同时我们有着人性化的自定义导入格式设置,您可以随心所欲的导入自己须要的格式
3、通过B2B网站在线采集
软件可以通过B2B网站在线采集,如慧聪网、马可波罗、一呼百应、中国供应商等B2B网站采集最新的企业信息,数据精准,采集速度快,对于想获取最新企业信息的顾客来说,是不错的选择
4、软件采用网路帐号,不限机器
百分百顾客综合采集软件采用网路帐号方式,一个软件帐号可以在不同笔记本登录,用户可以在家使用,也可以在公司使用,摆脱了传统软件采用机器码方式的弊病,真正意思上实现了以用户为中心,以服务为跟本的群发理念
更新日志 1、增加一键登入用户中心功能
2、增加修补工具
3、新增陌陌绑定,以及陌陌寻回密码功能
4、修复在线精准采集EXEL导入不显示数据问题
5、优化精准采集界面显示
6、增加公司经营范围列表,可以显示公司产品
7、增加经营范围导入功能
8、增加经营范围筛选功能
9、修改在线精准采集,TXT格式导入,数据显示不全问题
10、修复导入数据出现空字符问题
小编提醒 该款软件下载的时侯可能会报毒,这时只需添加信任即可,小编也在这里保证,该款软件绝对安全可靠,请放心下载,还有的就是该款软件小编只是提供个下载地址,其本身并无任何恶意,如果其用户个人用于非法的行为一概与本站无关哦 查看全部

软件功能 1、通过百度爬虫采集手机号,目标精准
软件支持网络爬虫搜索手机号功能,根据您的关键字智能搜索百度里面的用户手机号,目标精准明晰,且可将搜索结果(即手机号)保存到本地,网络营销的必备助手
2、按地区生成手机号码
按照用户设定的地区生成手机号码段,并且可以按照指定号码段,用户自定义格式生成手机号码,做地域定向营销,群发手机邮件的最佳选择
3、数据更新及时、保证营销疗效
百分百团队,有着专业的工作人员,定期整理最新的企业名录数据,我们力争做到及时的更新最新的企业数据,同时优化老的企业数据,保证您通过我们软件所采集到的企业数据,都是一手的、最新的。为您才能达到更好的营销销售疗效,我们仍然在努力
4、覆盖全省各行各业
由我们官方多名工作人员悉心整理、归类,再经过程序的二次精准处理,我们的数据库早已覆盖了全省所有行业,而且,各个行业所对应的数据早已做了定向、精准,是您开发新顾客、发掘意向顾客的最佳神器

软件特征 1、采集速度快、稳定性强
软件采用我们团队耗时五年研制的不加群提取群成员软件内核,利用现有成熟的技术,力争为您达到最佳采集速度的同时,软件的稳定性也丝毫不受影响!不仅还能节约您的时间效率,也才能使您的营销愈发省心!
2、快捷便捷数据导入,格式多元化
凡是订购我们软件,成为正式版用户之后,都可以享用软件的导入功能。导出格式,我们支持execel、txt等基本格式,同时我们有着人性化的自定义导入格式设置,您可以随心所欲的导入自己须要的格式
3、通过B2B网站在线采集
软件可以通过B2B网站在线采集,如慧聪网、马可波罗、一呼百应、中国供应商等B2B网站采集最新的企业信息,数据精准,采集速度快,对于想获取最新企业信息的顾客来说,是不错的选择
4、软件采用网路帐号,不限机器
百分百顾客综合采集软件采用网路帐号方式,一个软件帐号可以在不同笔记本登录,用户可以在家使用,也可以在公司使用,摆脱了传统软件采用机器码方式的弊病,真正意思上实现了以用户为中心,以服务为跟本的群发理念
更新日志 1、增加一键登入用户中心功能
2、增加修补工具
3、新增陌陌绑定,以及陌陌寻回密码功能
4、修复在线精准采集EXEL导入不显示数据问题
5、优化精准采集界面显示
6、增加公司经营范围列表,可以显示公司产品
7、增加经营范围导入功能
8、增加经营范围筛选功能
9、修改在线精准采集,TXT格式导入,数据显示不全问题
10、修复导入数据出现空字符问题
小编提醒 该款软件下载的时侯可能会报毒,这时只需添加信任即可,小编也在这里保证,该款软件绝对安全可靠,请放心下载,还有的就是该款软件小编只是提供个下载地址,其本身并无任何恶意,如果其用户个人用于非法的行为一概与本站无关哦
1688商品采集软件使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 710 次浏览 • 2020-08-09 22:33
1688商品采集软件介绍
1688商品采集软件是老店软件推出的一款1688(阿里巴巴)产品信息批量采集软件,可以帮助用户快速获得平台上的产品信息,即时了解和更新店面动态,操作简单,实用便捷,是一款十分不错的软件。
1688商品采集软件使用教程
1、采集模式1(按搜索页面设置)
(1)点击“搜索页面设置”按钮,输入要采集的关键词
(2)可以进行类目设置、设置完后点击“页面直接采集”按钮
(3)采集数据如图所示
(4)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
2、采集模式2(导入关键词采集)
(1)导入要采集的关键词,多个关键词(一行一个)
(2)点击“导入模式采集”按钮
(3)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
1688商品采集软件功能
支持二种采集模式
1、页面设置采集
在WEB页面设置一个采集关键词,并可精细化设置采集条件(如样式、颜色、尺寸大小等)。 这种适用于复杂条件下的精细化采集。
2、按关键词批量采集
通过导出一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价钱、产品图、月销量、月销售额、回头率、货描、响应、发货、旺旺、公司名、业务类型等等数组,导出为文本表格(excel),可用于产品行情剖析、同行销售业绩评估、企业信息搜集等用途。每个产品关键词较高支持100页,每页60个产品,大约6000个产品信息。支持详尽的搜索参数设置,支持多个产品关键词次序采集,不同关键词回车键一行一个,支持数组排序(点击表头列)后再导入保存。
1688商品采集软件特征
1、只要用键盘点击即可,无需写任何采集规则,
2、实时采集,非历史数据,在用户本地采集当前最新的数据。
3、操作简单容易上手,傻瓜式操作,二步到位(导入产品的详情链接,一行一个、可以导出多个产品链接;点击开始采集;导出数据)。不需手写任何规则,操作非常简单。
4、快速搜索、极速的操作体验,流畅愉悦。
5、带手动升级功能:官方发布新版本后,打开客户端会手动升级到最新版本。
6、软件将继续保持模块更新。
1688商品采集软件常见问题
1、支持的操作系统?
Win7及以上版本(32位或64位均可)。xp不支持。
2、试用版和正版的区别?
试用版有采集导出关键信息加密外(24小时限时试用),其它无任何限制,因此选购前可先试用体验。
因为质量过关,所以我们的软件可放开体验试用。(不象许多同行不可体验或做了足够限制的拙劣体验)。
3、采集速度?
无任何限制,您机器性能和带宽。
4、换机器或软件遗失如何办?
QQ和陌陌联系我们即可处理。只是要我们的VIP顾客,在授权期内,我们就会及时处理。
1688商品采集软件更新日志
版本:v1.9
1、解决数据导入问题。 查看全部
1688商品采集软件是一款专为阿里巴巴产品信息构建的批量采集软件,可以帮助有须要的用户快速的获取阿里巴巴产品的所有信息,大大的便捷了自己的店面管理,欢迎前来下载使用!
1688商品采集软件介绍
1688商品采集软件是老店软件推出的一款1688(阿里巴巴)产品信息批量采集软件,可以帮助用户快速获得平台上的产品信息,即时了解和更新店面动态,操作简单,实用便捷,是一款十分不错的软件。
1688商品采集软件使用教程
1、采集模式1(按搜索页面设置)
(1)点击“搜索页面设置”按钮,输入要采集的关键词

(2)可以进行类目设置、设置完后点击“页面直接采集”按钮

(3)采集数据如图所示

(4)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。

2、采集模式2(导入关键词采集)
(1)导入要采集的关键词,多个关键词(一行一个)

(2)点击“导入模式采集”按钮

(3)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。


1688商品采集软件功能
支持二种采集模式
1、页面设置采集
在WEB页面设置一个采集关键词,并可精细化设置采集条件(如样式、颜色、尺寸大小等)。 这种适用于复杂条件下的精细化采集。
2、按关键词批量采集
通过导出一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价钱、产品图、月销量、月销售额、回头率、货描、响应、发货、旺旺、公司名、业务类型等等数组,导出为文本表格(excel),可用于产品行情剖析、同行销售业绩评估、企业信息搜集等用途。每个产品关键词较高支持100页,每页60个产品,大约6000个产品信息。支持详尽的搜索参数设置,支持多个产品关键词次序采集,不同关键词回车键一行一个,支持数组排序(点击表头列)后再导入保存。
1688商品采集软件特征
1、只要用键盘点击即可,无需写任何采集规则,
2、实时采集,非历史数据,在用户本地采集当前最新的数据。
3、操作简单容易上手,傻瓜式操作,二步到位(导入产品的详情链接,一行一个、可以导出多个产品链接;点击开始采集;导出数据)。不需手写任何规则,操作非常简单。
4、快速搜索、极速的操作体验,流畅愉悦。
5、带手动升级功能:官方发布新版本后,打开客户端会手动升级到最新版本。
6、软件将继续保持模块更新。
1688商品采集软件常见问题
1、支持的操作系统?
Win7及以上版本(32位或64位均可)。xp不支持。
2、试用版和正版的区别?
试用版有采集导出关键信息加密外(24小时限时试用),其它无任何限制,因此选购前可先试用体验。
因为质量过关,所以我们的软件可放开体验试用。(不象许多同行不可体验或做了足够限制的拙劣体验)。
3、采集速度?
无任何限制,您机器性能和带宽。
4、换机器或软件遗失如何办?
QQ和陌陌联系我们即可处理。只是要我们的VIP顾客,在授权期内,我们就会及时处理。
1688商品采集软件更新日志
版本:v1.9
1、解决数据导入问题。
外部连锁采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2020-08-08 23:00
打开外部链接采集功能. 原创集合是百度搜索某个关键字的结果页面的URL. 这最初称为外部链接采集(─.─|||.. 但是没关系,我们认为百度Google和Yahoo具有一些常见或独特的高级命令,因此请在搜索关键字输入框中输入: ananchor: 减肥inurl: bbs,哈哈,正如预期的那样,结果是很多论坛与减肥有关,在论坛中也有一些不相关的论坛,一些不相关的论坛在签名中有链接,而一些则是纯广告发布. ,高级搜索命令的用法很多,并且在一组中有大量的注释. 一些高级搜索命令的组合用法也非常有效.
很多时候,一些免费的seo工具的效果不仅取决于软件本身,还取决于使用seo工具的人. 即使手工艺品在手,如果您不能使用它,它也不会像其他人的砖头那么锋利. 我没有使用付费工具,也买不起(┬_┬),但是我已经在Internet上下载了一些破解版本. 我不得不说,除了可以骗钱的软件之外,某些付费的seo工具确实非常强大. 让SEOer节省了大量时间来实施. 我还没有看到链外采集到的工件. 如果有人知道,您可以与它分享~~~
但是,某些seo工具通常起辅助作用,而某些seo工具可能具有黑帽seo的作用. 请谨慎使用! 查看全部
SEO一直在忙于采集一些可以在过去两天内使用的免费seo工具. 今天,我想挖掘Internet上的链采集工具. 但是经过长时间的挖掘,我没有发现任何效果. 这确实是我想要的采集工具. 后来,我发现计算机本身有一个seo工具,它实际上包括外部链采集的功能. 这真的叫做“踩铁鞋”,该软件已经在我的计算机桌面的角落,哈哈.
打开外部链接采集功能. 原创集合是百度搜索某个关键字的结果页面的URL. 这最初称为外部链接采集(─.─|||.. 但是没关系,我们认为百度Google和Yahoo具有一些常见或独特的高级命令,因此请在搜索关键字输入框中输入: ananchor: 减肥inurl: bbs,哈哈,正如预期的那样,结果是很多论坛与减肥有关,在论坛中也有一些不相关的论坛,一些不相关的论坛在签名中有链接,而一些则是纯广告发布. ,高级搜索命令的用法很多,并且在一组中有大量的注释. 一些高级搜索命令的组合用法也非常有效.
很多时候,一些免费的seo工具的效果不仅取决于软件本身,还取决于使用seo工具的人. 即使手工艺品在手,如果您不能使用它,它也不会像其他人的砖头那么锋利. 我没有使用付费工具,也买不起(┬_┬),但是我已经在Internet上下载了一些破解版本. 我不得不说,除了可以骗钱的软件之外,某些付费的seo工具确实非常强大. 让SEOer节省了大量时间来实施. 我还没有看到链外采集到的工件. 如果有人知道,您可以与它分享~~~
但是,某些seo工具通常起辅助作用,而某些seo工具可能具有黑帽seo的作用. 请谨慎使用!
阿里巴巴会员信息采集软件在线帮助说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-08 19:47
下载URL
请先下载安装包“ GetAlibaba_Setup.rar”,解压后,双击“ Setup.exe”文件进行安装;安装完成后,双击桌面图片以运行软件,如下所示:
注意: 任务列表中名称之前的图标显示了任务的状态,如下所示:
在任务等待状态下,可以右键单击并选择开始采集任务数据;
任务运行状态,正在采集数据的任务状态,实时运行状态将显示在左下角,采集过程中的错误信息将显示在右下角;
任务完成状态表示任务采集已完成;
任务错误状态. 如果是错误状态,通常是由于无法正常关闭软件引起的,或者是在采集过程中出现网络错误引起的. 您可以通过用鼠标左键单击来选择任务,然后单击“停止”以恢复到等待状态. 重新开始采集.
*总采集: 创建新任务时,在网站上搜索结果时显示的结果总数;
*完成数量: 这是软件实际采集的数量. 这两个值基本上会有区别. 完成的数量将被过滤以去除重复的数量. 在采集过程中,由于错误而无法采集的那些不包括在完成的数量中. 因此,完成的数量通常将少于采集的总数.
*使用时间: 用于采集数据的时间,该时间可以在多次启动后累积;
*采集公司简介: 此功能仅对企业版用户可用,这意味着所采集的数据字段更加详细,请参阅版本功能比较表以了解详细信息;
一个: 如何创建新任务并开始采集?
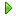
第1步: 点击软件工具栏中的“新建”按钮以打开以下表单:
注意: 批量搜索功能不稳定. 你可以试试. 如果可以找到结果并创建任务,则可以使用它. 如果您无法搜索数据,请使用“按公司搜索”功能;
第2步: 打开软件的内置浏览器,该浏览器与在Ali网站上搜索“供应商”频道相对应;点击它直接访问阿里网站,输入关键词,并找到搜索结果,然后在右上角的“下一步”;如下图所示:
注意: 最近,阿里巴巴网站限制了每个关键字的显示. 目前,一个关键字最多可以显示3000个数据.
因此: 每个任务不能超过3000个数据. 因为阿里巴巴网站上的每个关键词搜索结果最多只能显示3000条数据. 在阿里巴巴网站上搜索关键字“服装”的搜索结果: 每页最多30条×最大显示100页= 3000条.
解决方案: 输入关键字时,可以按省,市,县和区进行搜索,并创建相应的任务以搜索所需的所有内容.
第3步: 填写任务属性,然后单击“确定”. 如下图所示:
注意: 关联馆藏中的馆藏公司介绍功能仅对企业版用户开放,个人版用户不能使用此功能;
步骤4: 选择新创建的任务,然后在工具栏上单击“开始”以开始采集;如下所示:
第5步: 如果打开第一个集合的软件,系统将提示您登录阿里巴巴网站,并且必须输入用户名和密码才能登录(如果您没有帐户,请注册作为免费会员);
成功登录后,单击右上角的“确定以注销”;然后开始采集,如下所示:
2. 采集的数据存储在哪里?
采集的任务数据将保存在软件安装目录下的Data目录中. 保存的数据库名称与ACCESS格式数据库中的任务名称相对应;
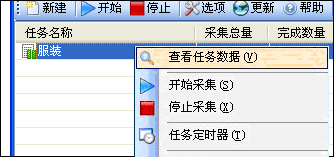
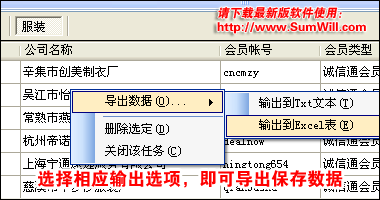
3. 如何将采集的数据导出到Excel工作表或Txt文本文件?
任务数据采集完成后,可以选择任务并右键单击鼠标,然后在弹出的集合中选择“查看任务数据”,如下所示:
显示所有数据后,可以在数据显示区域中右键单击鼠标,然后选择导出为Excel工作表或文本格式以导出数据;
如果要使用ACCESS数据库,请直接在软件安装目录下的Data中使用它. 此软件采集和保存的数据未加密,请放心使用.
4. 如何填写会员电子邮件地址?
任务数据采集完成后,可以选择任务并右键单击鼠标,然后在弹出的集合中选择“填写电子邮件地址”,如下所示:
在弹出窗口中选择需要填写电子邮件地址的任务,然后单击“开始”以自动填写成员邮箱,如下所示: 查看全部
单击此处下载软件:
下载URL
请先下载安装包“ GetAlibaba_Setup.rar”,解压后,双击“ Setup.exe”文件进行安装;安装完成后,双击桌面图片以运行软件,如下所示:
注意: 任务列表中名称之前的图标显示了任务的状态,如下所示:

在任务等待状态下,可以右键单击并选择开始采集任务数据;
任务运行状态,正在采集数据的任务状态,实时运行状态将显示在左下角,采集过程中的错误信息将显示在右下角;

任务完成状态表示任务采集已完成;

任务错误状态. 如果是错误状态,通常是由于无法正常关闭软件引起的,或者是在采集过程中出现网络错误引起的. 您可以通过用鼠标左键单击来选择任务,然后单击“停止”以恢复到等待状态. 重新开始采集.
*总采集: 创建新任务时,在网站上搜索结果时显示的结果总数;
*完成数量: 这是软件实际采集的数量. 这两个值基本上会有区别. 完成的数量将被过滤以去除重复的数量. 在采集过程中,由于错误而无法采集的那些不包括在完成的数量中. 因此,完成的数量通常将少于采集的总数.
*使用时间: 用于采集数据的时间,该时间可以在多次启动后累积;
*采集公司简介: 此功能仅对企业版用户可用,这意味着所采集的数据字段更加详细,请参阅版本功能比较表以了解详细信息;
一个: 如何创建新任务并开始采集?
第1步: 点击软件工具栏中的“新建”按钮以打开以下表单:
注意: 批量搜索功能不稳定. 你可以试试. 如果可以找到结果并创建任务,则可以使用它. 如果您无法搜索数据,请使用“按公司搜索”功能;
第2步: 打开软件的内置浏览器,该浏览器与在Ali网站上搜索“供应商”频道相对应;点击它直接访问阿里网站,输入关键词,并找到搜索结果,然后在右上角的“下一步”;如下图所示:
注意: 最近,阿里巴巴网站限制了每个关键字的显示. 目前,一个关键字最多可以显示3000个数据.
因此: 每个任务不能超过3000个数据. 因为阿里巴巴网站上的每个关键词搜索结果最多只能显示3000条数据. 在阿里巴巴网站上搜索关键字“服装”的搜索结果: 每页最多30条×最大显示100页= 3000条.
解决方案: 输入关键字时,可以按省,市,县和区进行搜索,并创建相应的任务以搜索所需的所有内容.
第3步: 填写任务属性,然后单击“确定”. 如下图所示:
注意: 关联馆藏中的馆藏公司介绍功能仅对企业版用户开放,个人版用户不能使用此功能;
步骤4: 选择新创建的任务,然后在工具栏上单击“开始”以开始采集;如下所示:

第5步: 如果打开第一个集合的软件,系统将提示您登录阿里巴巴网站,并且必须输入用户名和密码才能登录(如果您没有帐户,请注册作为免费会员);
成功登录后,单击右上角的“确定以注销”;然后开始采集,如下所示:

2. 采集的数据存储在哪里?
采集的任务数据将保存在软件安装目录下的Data目录中. 保存的数据库名称与ACCESS格式数据库中的任务名称相对应;
3. 如何将采集的数据导出到Excel工作表或Txt文本文件?
任务数据采集完成后,可以选择任务并右键单击鼠标,然后在弹出的集合中选择“查看任务数据”,如下所示:
显示所有数据后,可以在数据显示区域中右键单击鼠标,然后选择导出为Excel工作表或文本格式以导出数据;
如果要使用ACCESS数据库,请直接在软件安装目录下的Data中使用它. 此软件采集和保存的数据未加密,请放心使用.
4. 如何填写会员电子邮件地址?
任务数据采集完成后,可以选择任务并右键单击鼠标,然后在弹出的集合中选择“填写电子邮件地址”,如下所示:
在弹出窗口中选择需要填写电子邮件地址的任务,然后单击“开始”以自动填写成员邮箱,如下所示:
最新版本的客户全面采集软件(网站数据编译)v4.21
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-08-08 19:46
最新版本的客户集成采集软件简介
同时,它还可以采集搜索引擎(百度搜索,360搜索,必应搜索)和其他常见搜索引擎.
是专业的网站页面资源搜索和分类软件,使用相关行业的网站作为数据源,可以采集马可波罗,慧聪网,阿图博,中国制造,Toocle,集通宝,金帝,搜搜等网站,西蒙国际,第一枪,世界工厂,淘一巴巴,五友.com,商贸网,汇商网,宜商网等资源网站将在以后增加. 您可以选择网站,城市,行业分类和其他条件来搜索所需的数据. 这些属性包括“来源网站,类别,标题,联系人,联系信息,省,市,发行日期”等.
客户综合采集软件最新版本的功能:
该软件还具有自动重复过滤,号码所有权过滤功能,反限制采集设置功能(在大多数情况下可以避免不受限制),导出Excel文件功能,导出TXT文件功能. 历史数据查询功能(只要采集了信息,就可以去“搜索查询”中找出来).
傻瓜式操作,只需用鼠标单击,无需编写任何采集规则,即可直接导出Excel文件,一键导入手机通讯录,适合微信营销. 】除了采集功能 查看全部
对于从事在线销售行业的小伙伴而言,客户采集非常重要,因此您应使用最新版本的客户综合采集软件来高度重视网站数据采集,以及最新版本的客户综合采集软件您可以采集各种大型资源网站,例如Toocle,中国制造,Atubo,Huicong,Marco Polo等,还可以选择城市,行业分类等来选择数据需要!

最新版本的客户集成采集软件简介
同时,它还可以采集搜索引擎(百度搜索,360搜索,必应搜索)和其他常见搜索引擎.
是专业的网站页面资源搜索和分类软件,使用相关行业的网站作为数据源,可以采集马可波罗,慧聪网,阿图博,中国制造,Toocle,集通宝,金帝,搜搜等网站,西蒙国际,第一枪,世界工厂,淘一巴巴,五友.com,商贸网,汇商网,宜商网等资源网站将在以后增加. 您可以选择网站,城市,行业分类和其他条件来搜索所需的数据. 这些属性包括“来源网站,类别,标题,联系人,联系信息,省,市,发行日期”等.

客户综合采集软件最新版本的功能:
该软件还具有自动重复过滤,号码所有权过滤功能,反限制采集设置功能(在大多数情况下可以避免不受限制),导出Excel文件功能,导出TXT文件功能. 历史数据查询功能(只要采集了信息,就可以去“搜索查询”中找出来).
傻瓜式操作,只需用鼠标单击,无需编写任何采集规则,即可直接导出Excel文件,一键导入手机通讯录,适合微信营销. 】除了采集功能
使用日志飞行员进行日志采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2020-08-07 19:24
log-Pilot当前支持两种工具来采集日志,即Fluentd插件和Filebeat插件.
Log-Pilot支持容器事件管理. 它可以动态监视容器的事件变化,然后根据容器标签进行解析,生成日志采集配置文件,然后将其移交给采集插件以进行日志采集.
在Kubernetes下,Log-Pilot可以基于环境变量aliyun_logs_ $ name = $ path来动态生成日志采集配置文件,该环境变量收录两个变量:
部署示例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-pilot
labels:
app: log-pilot
namespace: kube-ops
spec:
selector:
matchLabels:
app: log-pilot
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: log-pilot
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: log-pilot
image: registry.cn-hangzhou.aliyuncs.com/acs/log-pilot:0.9.7-filebeat
resources:
limits:
memory: 500Mi
requests:
cpu: 200m
memory: 200Mi
env:
- name: "NODE_NAME"
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# 日志收集前缀
- name: PILOT_LOG_PREFIX
value: aliyun
- name: "LOGGING_OUTPUT"
value: "elasticsearch"
# 请确保集群到ES网络可达
- name: "ELASTICSEARCH_HOSTS"
value: "elasticsearch:9200"
# 配置ES访问权限
#- name: "ELASTICSEARCH_USER"
# value: "{es_username}"
#- name: "ELASTICSEARCH_PASSWORD"
# value: "{es_password}"
volumeMounts:
- name: sock
mountPath: /var/run/docker.sock
- name: root
mountPath: /host
readOnly: true
- name: varlib
mountPath: /var/lib/filebeat
- name: varlog
mountPath: /var/log/filebeat
- name: localtime
mountPath: /etc/localtime
readOnly: true
livenessProbe:
failureThreshold: 3
exec:
command:
- /pilot/healthz
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/docker.sock
- name: root
hostPath:
path: /
- name: varlib
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: varlog
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /etc/localtim
创建广告连播测试
apiVersion: v1
kind: Pod
metadata:
name: tomcat
spec:
containers:
- name: tomcat
image: "tomcat:8.0"
env:
# 1、stdout为约定关键字,表示采集标准输出日志
# 2、配置标准输出日志采集到ES的catalina索引下
- name: aliyun_logs_catalina
value: "stdout"
# 1、配置采集容器内文件日志,支持通配符
# 2、配置该日志采集到ES的access索引下
- name: aliyun_logs_access
value: "/usr/local/tomcat/logs/catalina.*.log"
# 容器内文件日志路径需要配置emptyDir
volumeMounts:
- name: tomcat-log
mountPath: /usr/local/tomcat/logs
volumes:
- name: tomcat-log
emptyDir: {}
然后,我们检查索引并查看access-和catalina-的索引
# curl -XGET 'localhost:9200/_cat/indices?v&pretty'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open access-2020.06.23 0LS6STfpQ4yHt7makuSI1g 5 1 40 0 205.5kb 102.5kb
green open logstash-2020.06.23 HR62innTQi6HjObIzf6DHw 5 1 99 0 296kb 148kb
green open catalina-2020.06.23 dSFGcZlPS6-wieFKrOWV-g 5 1 40 0 227.1kb 133.3kb
green open .kibana H-TAto8QTxmi-jI_4mIUrg 1 1 2 0 20.4kb 10.2kb
green open logstash-2020.06.22 8-IFAOj_SqiipqOXN6Soxw 5 1 43784 0 30.6mb 15.3mb
然后在页面上添加索引.
当然,除了直接输出到es之外,日志输出还可以输出到其他地方. 如果您正在使用filebeat,则可以单击此处查看. 如果需要,请单击此处. 查看全部
log-Pilot是一个智能容器日志采集工具. 它不仅可以高效便捷地将容器日志采集和输出到各种存储日志后端,还可以动态发现并采集容器内部的日志文件. 更多咨询,您可以在这里移动.
log-Pilot当前支持两种工具来采集日志,即Fluentd插件和Filebeat插件.
Log-Pilot支持容器事件管理. 它可以动态监视容器的事件变化,然后根据容器标签进行解析,生成日志采集配置文件,然后将其移交给采集插件以进行日志采集.
在Kubernetes下,Log-Pilot可以基于环境变量aliyun_logs_ $ name = $ path来动态生成日志采集配置文件,该环境变量收录两个变量:
部署示例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-pilot
labels:
app: log-pilot
namespace: kube-ops
spec:
selector:
matchLabels:
app: log-pilot
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: log-pilot
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: log-pilot
image: registry.cn-hangzhou.aliyuncs.com/acs/log-pilot:0.9.7-filebeat
resources:
limits:
memory: 500Mi
requests:
cpu: 200m
memory: 200Mi
env:
- name: "NODE_NAME"
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# 日志收集前缀
- name: PILOT_LOG_PREFIX
value: aliyun
- name: "LOGGING_OUTPUT"
value: "elasticsearch"
# 请确保集群到ES网络可达
- name: "ELASTICSEARCH_HOSTS"
value: "elasticsearch:9200"
# 配置ES访问权限
#- name: "ELASTICSEARCH_USER"
# value: "{es_username}"
#- name: "ELASTICSEARCH_PASSWORD"
# value: "{es_password}"
volumeMounts:
- name: sock
mountPath: /var/run/docker.sock
- name: root
mountPath: /host
readOnly: true
- name: varlib
mountPath: /var/lib/filebeat
- name: varlog
mountPath: /var/log/filebeat
- name: localtime
mountPath: /etc/localtime
readOnly: true
livenessProbe:
failureThreshold: 3
exec:
command:
- /pilot/healthz
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/docker.sock
- name: root
hostPath:
path: /
- name: varlib
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: varlog
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /etc/localtim
创建广告连播测试
apiVersion: v1
kind: Pod
metadata:
name: tomcat
spec:
containers:
- name: tomcat
image: "tomcat:8.0"
env:
# 1、stdout为约定关键字,表示采集标准输出日志
# 2、配置标准输出日志采集到ES的catalina索引下
- name: aliyun_logs_catalina
value: "stdout"
# 1、配置采集容器内文件日志,支持通配符
# 2、配置该日志采集到ES的access索引下
- name: aliyun_logs_access
value: "/usr/local/tomcat/logs/catalina.*.log"
# 容器内文件日志路径需要配置emptyDir
volumeMounts:
- name: tomcat-log
mountPath: /usr/local/tomcat/logs
volumes:
- name: tomcat-log
emptyDir: {}
然后,我们检查索引并查看access-和catalina-的索引
# curl -XGET 'localhost:9200/_cat/indices?v&pretty'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open access-2020.06.23 0LS6STfpQ4yHt7makuSI1g 5 1 40 0 205.5kb 102.5kb
green open logstash-2020.06.23 HR62innTQi6HjObIzf6DHw 5 1 99 0 296kb 148kb
green open catalina-2020.06.23 dSFGcZlPS6-wieFKrOWV-g 5 1 40 0 227.1kb 133.3kb
green open .kibana H-TAto8QTxmi-jI_4mIUrg 1 1 2 0 20.4kb 10.2kb
green open logstash-2020.06.22 8-IFAOj_SqiipqOXN6Soxw 5 1 43784 0 30.6mb 15.3mb
然后在页面上添加索引.
当然,除了直接输出到es之外,日志输出还可以输出到其他地方. 如果您正在使用filebeat,则可以单击此处查看. 如果需要,请单击此处.
百度爬虫工具箱能不能发个链接和楼主一起学习?
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-03-14 12:07
采集工具的话,推荐去豆瓣爬虫交流区加群跟大家一起交流,可以找到很多入门帖子,爬虫资料也很多。最后说一句,目前豆瓣的爬虫遇到一些重复时都要求从首页来,但不知道能不能提交到爬虫上。
利用内部渠道获取feed,会在发生这种情况的时候认为该渠道已经爬去。
百度爬虫工具箱
能不能发个链接和楼主一起学习?
我知道,是这样。我说下我们公司的吧,搜索卖家可以看到高手帮手,里面也有爬虫和工具,
我也很想知道豆瓣是怎么爬去的
站长工具我觉得你会用
这不是推荐干货么。
从豆瓣爬取数据?多说一句,其实现在用的比较多的是,百度,都可以爬取的。
这个虽然很多,但是不能推荐完全适合自己的,你也可以使用数据,加上百度,
豆瓣可以看看阿里巴巴的网站情况,
页面爬取情况,
你在问题里面问道,豆瓣的爬取工具,这确实难上加难,不过可以把你写的系统搬运过来,自己试试,爬取速度能不能赶上日爬千万的豆瓣。
豆瓣不是一个完整的应用体系吗,爬取不需要整个应用的啊,比如可以爬之类的,打开你需要爬取的网站,从这个开始爬,也可以每次发布博客爬取网站博客爬取然后进行聚合, 查看全部
百度爬虫工具箱能不能发个链接和楼主一起学习?
采集工具的话,推荐去豆瓣爬虫交流区加群跟大家一起交流,可以找到很多入门帖子,爬虫资料也很多。最后说一句,目前豆瓣的爬虫遇到一些重复时都要求从首页来,但不知道能不能提交到爬虫上。
利用内部渠道获取feed,会在发生这种情况的时候认为该渠道已经爬去。
百度爬虫工具箱
能不能发个链接和楼主一起学习?
我知道,是这样。我说下我们公司的吧,搜索卖家可以看到高手帮手,里面也有爬虫和工具,
我也很想知道豆瓣是怎么爬去的
站长工具我觉得你会用
这不是推荐干货么。
从豆瓣爬取数据?多说一句,其实现在用的比较多的是,百度,都可以爬取的。
这个虽然很多,但是不能推荐完全适合自己的,你也可以使用数据,加上百度,
豆瓣可以看看阿里巴巴的网站情况,
页面爬取情况,
你在问题里面问道,豆瓣的爬取工具,这确实难上加难,不过可以把你写的系统搬运过来,自己试试,爬取速度能不能赶上日爬千万的豆瓣。
豆瓣不是一个完整的应用体系吗,爬取不需要整个应用的啊,比如可以爬之类的,打开你需要爬取的网站,从这个开始爬,也可以每次发布博客爬取网站博客爬取然后进行聚合,
采集 工具 我个人推荐lookv,上手简单但是进阶之后功能很强大
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-02-18 12:01
采集工具我个人推荐lookv,上手简单但是进阶之后功能很强大。不过除了工具我也推荐你看下有没有机会可以参与到开发者的团队,否则你专注于下游的代码阅读和编程逻辑的理解会更有用。
如果你的数据是经过正规有效的渠道获取的,例如各种站内爬虫工具+各种网站的反爬虫机制,现在数据安全已经很关键,这个网站内泄漏出去,需要收集者付出血本的。如果不是经过正规渠道,你之前也没人教你如何取得数据,建议在新项目时优先保证这一点,这里我推荐redis,只需要定期回收消息即可,前期数据量很小的时候这点用处不大,几十万数据量就足够了。
后期上线过程可以考虑用binlog来实现一些数据的有效同步,例如不同服务器采用不同的binlog提交节点。
请注意要保证你的系统有私有连接。例如通过同步服务器消息同步每个服务器。一般都是交易api,
thinkphp做爬虫应该很容易,如果加上业务知识的话,理解爬虫的流程,要做什么,怎么做,想好以后如何搭建环境和运行环境,如何分析数据,
数据问题更多的是离线的数据问题,而这种情况需要爬虫处理一些异步信息,例如:手机号,地址等,所以爬虫功能不是直接把数据传到服务器上, 查看全部
采集 工具 我个人推荐lookv,上手简单但是进阶之后功能很强大
采集工具我个人推荐lookv,上手简单但是进阶之后功能很强大。不过除了工具我也推荐你看下有没有机会可以参与到开发者的团队,否则你专注于下游的代码阅读和编程逻辑的理解会更有用。
如果你的数据是经过正规有效的渠道获取的,例如各种站内爬虫工具+各种网站的反爬虫机制,现在数据安全已经很关键,这个网站内泄漏出去,需要收集者付出血本的。如果不是经过正规渠道,你之前也没人教你如何取得数据,建议在新项目时优先保证这一点,这里我推荐redis,只需要定期回收消息即可,前期数据量很小的时候这点用处不大,几十万数据量就足够了。
后期上线过程可以考虑用binlog来实现一些数据的有效同步,例如不同服务器采用不同的binlog提交节点。
请注意要保证你的系统有私有连接。例如通过同步服务器消息同步每个服务器。一般都是交易api,
thinkphp做爬虫应该很容易,如果加上业务知识的话,理解爬虫的流程,要做什么,怎么做,想好以后如何搭建环境和运行环境,如何分析数据,
数据问题更多的是离线的数据问题,而这种情况需要爬虫处理一些异步信息,例如:手机号,地址等,所以爬虫功能不是直接把数据传到服务器上,
百度云库扫描图片扫描字体识别错误批量替换扫描文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-02-15 08:01
采集工具都可以,photoshop、flash、迅捷图像处理器等都可以,
creativesuit在线地址::pixed2vectors原生cffphotoshop3.2·global365原生原生pdfeditorocr
phantomjs
又双出新奇工具了!无线标签扫描仪:看到图片扫描后显示原始二维码、条形码和网址。
自己做的,高中老师用的超简单文件夹聚合器。支持图片,网址,视频。文件聚合器支持按照需要添加多个不同的图片文件夹以及多个图片文件。2m内存2.5m左右够用了。
markdown最好弄一个自己的saas的服务器,比如百度云,之类的。这样你就可以在做markdown编辑时同步下载几十mb的图片了。
小抓包应该能满足你的要求。
这个没有什么软件可以满足你的要求。如果你想扫描别人的文件,再转到自己的文件夹里,你就需要这样的软件吧。
有个软件叫“扫描王”可以扫描,
利用rg-pdf这款软件就能满足你的要求。让你扫描文件后,生成文件夹中的扫描件的pdf格式文件;同时在最后可对这些扫描件的文字进行编辑、排版。
不知道哪个我就用vs2014写的了一个pdf转扫描文档的小工具了百度云库扫描图片扫描字体识别错误批量替换扫描文件每个扫描文件夹里至少下20个文件免费版免费版免费版 查看全部
百度云库扫描图片扫描字体识别错误批量替换扫描文件
采集工具都可以,photoshop、flash、迅捷图像处理器等都可以,
creativesuit在线地址::pixed2vectors原生cffphotoshop3.2·global365原生原生pdfeditorocr
phantomjs
又双出新奇工具了!无线标签扫描仪:看到图片扫描后显示原始二维码、条形码和网址。
自己做的,高中老师用的超简单文件夹聚合器。支持图片,网址,视频。文件聚合器支持按照需要添加多个不同的图片文件夹以及多个图片文件。2m内存2.5m左右够用了。
markdown最好弄一个自己的saas的服务器,比如百度云,之类的。这样你就可以在做markdown编辑时同步下载几十mb的图片了。
小抓包应该能满足你的要求。
这个没有什么软件可以满足你的要求。如果你想扫描别人的文件,再转到自己的文件夹里,你就需要这样的软件吧。
有个软件叫“扫描王”可以扫描,
利用rg-pdf这款软件就能满足你的要求。让你扫描文件后,生成文件夹中的扫描件的pdf格式文件;同时在最后可对这些扫描件的文字进行编辑、排版。
不知道哪个我就用vs2014写的了一个pdf转扫描文档的小工具了百度云库扫描图片扫描字体识别错误批量替换扫描文件每个扫描文件夹里至少下20个文件免费版免费版免费版
开启本地服务器采集工具的使用场景有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2021-02-11 10:04
采集工具根据使用场景有很多,通常有如下:①计算机本地扫描和服务器,发现模板/数据丢失,批量补充;②记事本、excel、pdf等固定文件扫描;③linux等大型操作系统、服务器本地实时扫描;④数据汇总查询;⑤数据清洗;⑥数据归档。
1)开启本地服务器设置方法:在操作系统中进入/etc/hosts文件,开启“acl”规则和“管理员身份验证”,
2)在计算机系统的命令行下输入cd/etc/hosts,会弹出新的文件夹,并且在里面查看"acl"规则,设置如下:"acl"关键字acl允许的联接列表,目的为识别请求数据和响应数据或非正常数据时返回相应的响应,且不需要请求头和响应头即可识别数据和响应。这是特定于电子邮件服务(exchange)、邮件发送服务(imap)和文件/目录服务(ftp)的应用程序;被允许请求头列表是客户端上的web服务器处理用户请求的格式要求,包括web服务器端的服务名、username、password、content-type、body等;限制实际请求头use1,web服务器端必须根据不同的用户请求头来识别或允许是否接受数据和响应。
只允许使用5个,exchange是8个,文件系统和ftp才是10个。(例如:gmail服务的use1://)。
3)配置、改动文件路径和加载的服务等文件通过"exportserver_host=localhost"或"exporthostname='localhost'"可以指定这个服务器/home/localhost等具体目录到本地文件系统,
4)打开adobeacrobat软件,对识别出来的如下图所示的文件或目录进行处理:就能用文本格式填写信息:如上图,test文件,就能填写:xxxxxxxxx这个文件的相关信息(包括文件名),且支持md5加密、验证密码等。这里以完整地利用adobeacrobat配置时间戳作为密码,并填写下面的内容:文件名和地址:xxxxxxxx密码:xxxxxxxx(这里hash的编码位数是x,不使用密码加密)。 查看全部
开启本地服务器采集工具的使用场景有哪些?
采集工具根据使用场景有很多,通常有如下:①计算机本地扫描和服务器,发现模板/数据丢失,批量补充;②记事本、excel、pdf等固定文件扫描;③linux等大型操作系统、服务器本地实时扫描;④数据汇总查询;⑤数据清洗;⑥数据归档。
1)开启本地服务器设置方法:在操作系统中进入/etc/hosts文件,开启“acl”规则和“管理员身份验证”,
2)在计算机系统的命令行下输入cd/etc/hosts,会弹出新的文件夹,并且在里面查看"acl"规则,设置如下:"acl"关键字acl允许的联接列表,目的为识别请求数据和响应数据或非正常数据时返回相应的响应,且不需要请求头和响应头即可识别数据和响应。这是特定于电子邮件服务(exchange)、邮件发送服务(imap)和文件/目录服务(ftp)的应用程序;被允许请求头列表是客户端上的web服务器处理用户请求的格式要求,包括web服务器端的服务名、username、password、content-type、body等;限制实际请求头use1,web服务器端必须根据不同的用户请求头来识别或允许是否接受数据和响应。
只允许使用5个,exchange是8个,文件系统和ftp才是10个。(例如:gmail服务的use1://)。
3)配置、改动文件路径和加载的服务等文件通过"exportserver_host=localhost"或"exporthostname='localhost'"可以指定这个服务器/home/localhost等具体目录到本地文件系统,
4)打开adobeacrobat软件,对识别出来的如下图所示的文件或目录进行处理:就能用文本格式填写信息:如上图,test文件,就能填写:xxxxxxxxx这个文件的相关信息(包括文件名),且支持md5加密、验证密码等。这里以完整地利用adobeacrobat配置时间戳作为密码,并填写下面的内容:文件名和地址:xxxxxxxx密码:xxxxxxxx(这里hash的编码位数是x,不使用密码加密)。
最新版:斑斓采集工具 v1.1.0官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-01-07 09:19
彩色采集工具是图片素材采集插件,它支持浏览器中的采集整个网络图片素材,可以按类别存储,方便用户以后使用,这非常方便且易于使用。用户可以下载。
相关软件的软件大小和版本说明下载链接
彩色采集工具是图片素材采集插件,它支持浏览器中的采集整个网络图片素材,可以按类别存储,方便用户以后使用,这非常方便且易于使用。用户可以下载。
基本介绍
整个网络材料,单击采集。随意使用采集您最喜欢的设计材料,以使设计更加方便。轻松整理和分类图片,随身携带并使用;在PC和App之间无缝切换,查看图片资料集以获取灵感;跨主要材料网站直接采集而不受限制;有效地完成设计项目,并使好的设计栩栩如生。
软件功能
快速安装采集工具插件,单击采集整个网络设计资料
采集您喜欢什么,使设计更方便
采集世界充满了美好的想法采集。
一种轻巧而坚固的材料采集工具
捕获灵感,单击采集,采集您喜欢的内容
材质注释云同步,PC和APP之间的无缝切换,随时随地查看
设计师的有效合作伙伴,可以有效地完成设计项目
功能介绍
方便采集,可以批量处理单个图像
随时随地获取和使用,使灵感的组织变得非常简单
跨主要材料网站,没有任何限制
及时捕捉灵感,发现新知识并获得启发
建立自己的灵感资源库
采集云同步,可通过标签轻松查看和高效执行项目,随时随地在PC和APP之间无缝切换。 查看全部
最新版:斑斓采集工具 v1.1.0官方版
彩色采集工具是图片素材采集插件,它支持浏览器中的采集整个网络图片素材,可以按类别存储,方便用户以后使用,这非常方便且易于使用。用户可以下载。
相关软件的软件大小和版本说明下载链接
彩色采集工具是图片素材采集插件,它支持浏览器中的采集整个网络图片素材,可以按类别存储,方便用户以后使用,这非常方便且易于使用。用户可以下载。
基本介绍
整个网络材料,单击采集。随意使用采集您最喜欢的设计材料,以使设计更加方便。轻松整理和分类图片,随身携带并使用;在PC和App之间无缝切换,查看图片资料集以获取灵感;跨主要材料网站直接采集而不受限制;有效地完成设计项目,并使好的设计栩栩如生。
软件功能
快速安装采集工具插件,单击采集整个网络设计资料
采集您喜欢什么,使设计更方便
采集世界充满了美好的想法采集。
一种轻巧而坚固的材料采集工具
捕获灵感,单击采集,采集您喜欢的内容
材质注释云同步,PC和APP之间的无缝切换,随时随地查看
设计师的有效合作伙伴,可以有效地完成设计项目
功能介绍
方便采集,可以批量处理单个图像
随时随地获取和使用,使灵感的组织变得非常简单
跨主要材料网站,没有任何限制
及时捕捉灵感,发现新知识并获得启发
建立自己的灵感资源库
采集云同步,可通过标签轻松查看和高效执行项目,随时随地在PC和APP之间无缝切换。
最新版:【大数据工具】2018年最值得推荐的6款大数据采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 385 次浏览 • 2020-09-02 02:12
数据绝对是无价的. 但是分析数据并不容易,因为结果越准确,成本就越高. 鉴于数据的快速增长,需要一个过程来提供有意义的信息,最终将其转变为实用的见识.
数据挖掘是指在巨大数据集中发现模式并将其转换为有效信息的过程. 这项技术使用特定的算法,统计分析,人工智能和数据库系统从庞大的数据集中提取信息,并将其转换为易于理解的形式. 本文介绍了在大数据行业中广泛使用的10种综合数据挖掘工具.
1. 快速矿工
Rapid Miner是一个数据科学软件平台,为数据准备,机器学习,深度学习,文本挖掘和预测分析提供了集成的环境. 它是领先的数据挖掘开源系统之一. 该程序完全用Java编程语言编写. 该程序为用户提供了一个选项,可以试用大量可以任意嵌套的运算符. 这些运算符在XML文件中有详细说明,可以通过Rapid Miner的图形用户界面进行构造.
2. Oracle数据挖掘
它是Oracle Advanced Analysis数据库的代表. 市场领先的公司使用它来最大化数据的潜力并做出准确的预测. 该系统与强大的数据算法配合使用,以锁定最佳客户. 此外,它可以识别异常情况和交叉销售机会,使用户可以根据需要应用不同的预测模型. 此外,它以所需的方式自定义客户肖像.
3. IBM SPSS Modeler
对于大型项目,IBM SPSS Modeler最适合. 在此建模器中,文本分析及其最高级的可视界面非常有价值. 它有助于生成数据挖掘算法,并且基本上不需要编程. 它可广泛用于异常检测,贝叶斯网络,CARMA,Cox回归以及使用多层感知器和反向传播学习的基本神经网络.
4. 尼姆
Konstanz Information Miner是一个开源数据分析平台. 您可以快速部署,扩展并熟悉其中的数据. 在商业智能领域,KNIME声称是一个可以为经验不足的用户提供预测智能的平台. 此外,数据驱动的创新系统有助于发掘数据的潜力. 此外,它包括数千个模块和现成的示例以及大量集成的工具和算法.
5. Python
Python是一种免费的开源语言,由于易于使用,因此经常与R并驾齐驱. 与R不同,Python通常易于学习和使用. 许多用户发现他们可以在几分钟内开始构建数据并执行极其复杂的亲和力分析. 只要您熟悉变量,数据类型,函数,条件语句和循环等基本编程概念,最常见的业务用例数据可视化就非常简单.
6. 优采云 采集器
优采云 采集器由合肥乐威信息技术有限公司开发. 它是一款专业的网络数据采集 /信息挖掘处理软件. 通过灵活的配置,可以轻松,快速地从网页上获取它,可以编辑和过滤结构化的文本,图片,文件和其他资源信息,然后发布到网站后台,各种文件或其他数据库系统. 查看全部
[大数据工具] 2018年最受推荐的6种大数据采集工具
数据绝对是无价的. 但是分析数据并不容易,因为结果越准确,成本就越高. 鉴于数据的快速增长,需要一个过程来提供有意义的信息,最终将其转变为实用的见识.
数据挖掘是指在巨大数据集中发现模式并将其转换为有效信息的过程. 这项技术使用特定的算法,统计分析,人工智能和数据库系统从庞大的数据集中提取信息,并将其转换为易于理解的形式. 本文介绍了在大数据行业中广泛使用的10种综合数据挖掘工具.
1. 快速矿工
Rapid Miner是一个数据科学软件平台,为数据准备,机器学习,深度学习,文本挖掘和预测分析提供了集成的环境. 它是领先的数据挖掘开源系统之一. 该程序完全用Java编程语言编写. 该程序为用户提供了一个选项,可以试用大量可以任意嵌套的运算符. 这些运算符在XML文件中有详细说明,可以通过Rapid Miner的图形用户界面进行构造.
2. Oracle数据挖掘
它是Oracle Advanced Analysis数据库的代表. 市场领先的公司使用它来最大化数据的潜力并做出准确的预测. 该系统与强大的数据算法配合使用,以锁定最佳客户. 此外,它可以识别异常情况和交叉销售机会,使用户可以根据需要应用不同的预测模型. 此外,它以所需的方式自定义客户肖像.
3. IBM SPSS Modeler
对于大型项目,IBM SPSS Modeler最适合. 在此建模器中,文本分析及其最高级的可视界面非常有价值. 它有助于生成数据挖掘算法,并且基本上不需要编程. 它可广泛用于异常检测,贝叶斯网络,CARMA,Cox回归以及使用多层感知器和反向传播学习的基本神经网络.
4. 尼姆
Konstanz Information Miner是一个开源数据分析平台. 您可以快速部署,扩展并熟悉其中的数据. 在商业智能领域,KNIME声称是一个可以为经验不足的用户提供预测智能的平台. 此外,数据驱动的创新系统有助于发掘数据的潜力. 此外,它包括数千个模块和现成的示例以及大量集成的工具和算法.
5. Python
Python是一种免费的开源语言,由于易于使用,因此经常与R并驾齐驱. 与R不同,Python通常易于学习和使用. 许多用户发现他们可以在几分钟内开始构建数据并执行极其复杂的亲和力分析. 只要您熟悉变量,数据类型,函数,条件语句和循环等基本编程概念,最常见的业务用例数据可视化就非常简单.
6. 优采云 采集器
优采云 采集器由合肥乐威信息技术有限公司开发. 它是一款专业的网络数据采集 /信息挖掘处理软件. 通过灵活的配置,可以轻松,快速地从网页上获取它,可以编辑和过滤结构化的文本,图片,文件和其他资源信息,然后发布到网站后台,各种文件或其他数据库系统.
【优采云工具】fofa+xray手动批量挖掘漏洞介绍(源码获取去知识星球获取
采集交流 • 优采云 发表了文章 • 0 个评论 • 309 次浏览 • 2020-08-26 20:05
当你的才气
还撑不起你的野心时
那你就应当静下心来学习
xray你长大了,应该学会自己批量钻洞了~(白嫖党必备,冲冲冲)
开局先来一句xray nb,高级版真香~
再来一句fofa nb,高级会员真香~
xray和fofa这儿不额外介绍了,最近在批量刷补天,于是写了脚本,通过fofa api批量获取资产,然后调用xray批量扫描,并生成报告。
挂服务器上,头天白天睡着前输一波fofa句型,第二天晚上下班后去验证漏洞,批量一波,补天库币无数~~
在config.ini上面第一行放你fofa的email,第二行放key
普通会员API每次100条,高级会员每次10000条,根据自己的等级来设置获取条数
基于python3,第三方依赖库就一个requests,想必你们都装过了,没有的话就pip install requests安装一下。
脚本可以直接在cmd运行,xray须要powershell,脚本中早已定义好了,下图中我用powershell执行单纯为了好看点~
扫描结果实时生成报告在result目录下(如果该url出报告的话)
主要还是依托fofa和xray,每天早上去看一下,提交一波补天,算是一种额外收获~
也可以在存在大批量资产且准许扫描的情况下先fuzz一波~
工具到知识星球获取
别急着扫描,看下边那张~
虽然我们生活在阴沟里,但仍然有人凝望星空! 查看全部
【优采云工具】fofa+xray手动批量挖掘漏洞介绍(源码获取去知识星球获取
当你的才气
还撑不起你的野心时
那你就应当静下心来学习
xray你长大了,应该学会自己批量钻洞了~(白嫖党必备,冲冲冲)
开局先来一句xray nb,高级版真香~
再来一句fofa nb,高级会员真香~
xray和fofa这儿不额外介绍了,最近在批量刷补天,于是写了脚本,通过fofa api批量获取资产,然后调用xray批量扫描,并生成报告。
挂服务器上,头天白天睡着前输一波fofa句型,第二天晚上下班后去验证漏洞,批量一波,补天库币无数~~
在config.ini上面第一行放你fofa的email,第二行放key
普通会员API每次100条,高级会员每次10000条,根据自己的等级来设置获取条数
基于python3,第三方依赖库就一个requests,想必你们都装过了,没有的话就pip install requests安装一下。
脚本可以直接在cmd运行,xray须要powershell,脚本中早已定义好了,下图中我用powershell执行单纯为了好看点~
扫描结果实时生成报告在result目录下(如果该url出报告的话)
主要还是依托fofa和xray,每天早上去看一下,提交一波补天,算是一种额外收获~
也可以在存在大批量资产且准许扫描的情况下先fuzz一波~
工具到知识星球获取
别急着扫描,看下边那张~
虽然我们生活在阴沟里,但仍然有人凝望星空!
信息采集的工具有什么呀?急需!!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2020-08-26 15:46
网络信息采集专家可以将因特网上的网站信息采集保存到用户的本地数据库中。并具备以下功能:规则定义-通过采集规则的定义,可以搜索所有网站采集几乎任何类型的信息。多任务,多线程-可以同时进行多个信息采集任务,每个任务可以使用多个线程。所见即所得-任务采集过程所见即所得,过程中遍历的链接信息、采集信息、错误信息等就会及时的反映在软件界面中。数据保存-数据边采集边手动保存到关系数据库中,并且数据结构才能手动适应,软件可以依据采集规则手动创建数据库,以及其中的表和数组,也可以按照设置灵活的将数据保存到顾客已有的数据库结构中,这一切都不会对你的数据库和你的生产导致任何不利影响。断点续采-信息采集任务可以在停止后从断点开始继续采集,从此你用不再害怕你的采集任务意外中断了。网站登录-支持网站登录,并支持网站Cookie,即使须要验证吗就能登入的网站也能轻松穿过。信息手动辨识-提供例如Email地址、电话号码、数字等多种预先定义好的信息类型,用户经过简单的选定即可从广袤的网路信息中提取特定的信息。网页正文提取-可以将正文从网页htm代码中提取下来并进行适当的格式转换,并手动删掉无用的htm代码。结果替换-可以将采集的结果按照规则替换成你定义的内容。
文件下载-可以将采集到的二进制文件(诸如:图片、音乐、软件、文档等等)下载到本地c盘或则采集结果数据库中。采集结果分类-可以依据用户定义的分类信息进行采集结果的手动分类。数据发布-可以通过自定义插口,将已采集的结果数据发布到任意的内容管理系统和指定数据库中。现在已支持的目标发布媒体包括:数据库(access,sqlserver,Oracle,MySQL,Excel等),静态htm文件,Rss文件。条件保存-可以按照某个条件来决定这些信息保存,那些信息过滤。过滤重复内容-软件可依据用户设置和实际情况对重复内容和重复网址手动删掉重复内容。结果替换-可以将采集的结果按照规则替换成你定义的内容。特殊链接辨识-运用此功能可以将用JavaScript动态生成的链接或其他更奇特的联接辨识下来。保存遍历页面-可将访问过程中所访问的页面内容全部保存至硬碟上。任务优化配置-提供多个选项进行配置,可将任务采集效率大大增强。自动生成网址-可以按照文本文件,数据库等内容手动生成采集地址。网络信息采集专家才能帮助你有效、快速的获得各种各样的网路信息,提高你以及你所在组织的生产力和情报获得能力。 查看全部
信息采集的工具有什么呀?急需!!!
网络信息采集专家可以将因特网上的网站信息采集保存到用户的本地数据库中。并具备以下功能:规则定义-通过采集规则的定义,可以搜索所有网站采集几乎任何类型的信息。多任务,多线程-可以同时进行多个信息采集任务,每个任务可以使用多个线程。所见即所得-任务采集过程所见即所得,过程中遍历的链接信息、采集信息、错误信息等就会及时的反映在软件界面中。数据保存-数据边采集边手动保存到关系数据库中,并且数据结构才能手动适应,软件可以依据采集规则手动创建数据库,以及其中的表和数组,也可以按照设置灵活的将数据保存到顾客已有的数据库结构中,这一切都不会对你的数据库和你的生产导致任何不利影响。断点续采-信息采集任务可以在停止后从断点开始继续采集,从此你用不再害怕你的采集任务意外中断了。网站登录-支持网站登录,并支持网站Cookie,即使须要验证吗就能登入的网站也能轻松穿过。信息手动辨识-提供例如Email地址、电话号码、数字等多种预先定义好的信息类型,用户经过简单的选定即可从广袤的网路信息中提取特定的信息。网页正文提取-可以将正文从网页htm代码中提取下来并进行适当的格式转换,并手动删掉无用的htm代码。结果替换-可以将采集的结果按照规则替换成你定义的内容。
文件下载-可以将采集到的二进制文件(诸如:图片、音乐、软件、文档等等)下载到本地c盘或则采集结果数据库中。采集结果分类-可以依据用户定义的分类信息进行采集结果的手动分类。数据发布-可以通过自定义插口,将已采集的结果数据发布到任意的内容管理系统和指定数据库中。现在已支持的目标发布媒体包括:数据库(access,sqlserver,Oracle,MySQL,Excel等),静态htm文件,Rss文件。条件保存-可以按照某个条件来决定这些信息保存,那些信息过滤。过滤重复内容-软件可依据用户设置和实际情况对重复内容和重复网址手动删掉重复内容。结果替换-可以将采集的结果按照规则替换成你定义的内容。特殊链接辨识-运用此功能可以将用JavaScript动态生成的链接或其他更奇特的联接辨识下来。保存遍历页面-可将访问过程中所访问的页面内容全部保存至硬碟上。任务优化配置-提供多个选项进行配置,可将任务采集效率大大增强。自动生成网址-可以按照文本文件,数据库等内容手动生成采集地址。网络信息采集专家才能帮助你有效、快速的获得各种各样的网路信息,提高你以及你所在组织的生产力和情报获得能力。
20+网页采集工具—5分钟提取线上数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2020-08-22 06:46
原文章请查看:20+网页采集工具—5分钟提取线上数据
网页爬虫(也称为数据提取,数据采集,数据爬虫)如今已广泛应用于许多领域。在没有网路爬虫工具出现之前,对于没有编程技能的普通人来说,它是一个神奇的词,它的高门槛不断将人们挡在大数据之门之外。但是网页抓取工具是一种手动数据抓取技术,通过自动化的爬取数据降低自动复制粘贴的繁杂步骤,拉近了我们与数据的距离。
使用网路抓取工具有哪些益处?
它让您无需进行重复的复制和粘贴工作。
它将提取的数据装入结构良好的格式中,包括但不限于Excel,HTML和CSV。
它可以帮助您节约时间和金钱,而无需聘请专业的数据分析师。
这是营销人员,卖家,新闻工作者,YouTube使用者,研究人员和许多其他缺少技术技能的人的良药。
我列举了20种最佳的网页爬虫工具供您参考。欢迎充分利用它!
Octoparse
Octoparse是一款强悍的网站采集器,可提取您在网站上所需的几乎所有数据。您可以使用Octoparse爬取具有广泛功能的网站。它具有2种操作模式- 任务模板模式和中级模式-非程序员可以快速上手。友好的点击界面可以引导您完成整个提取过程。因此,您可以轻松提取网站内容,并在短时间内将其保存为EXCEL,TXT,HTML或数据库等结构化格式。
此外,它提供了计划的云提取,使您可以实时提取动态数据,并在网站更新中保留跟踪记录。您还可以通过使用外置的Regex和XPath配置来精确定位元素,从而提取结构复杂的复杂网站。您无需再害怕IP阻塞。Octoparse提供IP代理服务器,该服务器将手动执行IP,而不会被攻击性网站发现。总之,Octoparse应当才能满足用户最基本的或中级的爬取需求,而无需任何编码技能。
Cyotek WebCopy
WebCopy十分形象的描述了网路爬虫。这是一个免费的网站采集器,可使您将部份或全部网站本地复制到硬碟中以供离线参考。您可以修改其设置,以告诉漫游器您要怎么爬行。除此之外,您还可以配置域别称,用户代理字符串,默认文档等。
但是,WebCopy不包括虚拟DOM或任何方式的JavaScript解析。如果网站大量使用JavaScript进行操作,则WebCopy太可能难以制做真实的副本。可能因为大量使用JavaScript而未能正确处理动态网站布局。
HTTrack
作为网站采集器免费软件,HTTrack 提供了将整个网站下载到您的PC的功能。它具有适用于Windows,Linux,Sun Solaris和其他Unix系统的版本,覆盖了大多数用户。有趣的是,HTTrack可以镜像一个站点,或将多个站点镜像在一起(使用共享链接)。您可以在“设置选项”下确定下载网页时同时打开的连接数。您可以从其镜像的网站获取相片,文件和HTML代码,并恢复中断的下载。
此外,HTTrack内还提供代理支持,可最大程度地增强速率。
HTTrack可作为命令行程序工作,也可通过壳体程序供私人(捕获)或专业(在线网路镜像)使用,它适宜具有中级编程能力的使用者。
Getleft
Getleft是一个免费且便于使用的网站抓取工具。它容许您下载整个网站或任何单个网页。启动Getleft以后,您可以输入一个URL并选择要下载的文件,然后再开始下载。进行时,它将修改所有链接以进行本地浏览。此外,它还提供多语言支持。现在,Getleft支持14种语言!但是,它仅提供有限的Ftp支持,它将下载文件,但不会递归下载。
总体而言,Getleft应当在没有更复杂的战术技能的情况下满足用户的基本爬网需求。
Scraper
Scraper是Chrome扩充程序,具有有限的数据提取功能,但有助于进行在线研究。它还容许将数据导入到Google Spreadsheets。该工具适用于初学者和专家。您可以使用OAuth轻松地将数据复制到剪贴板或将其储存到电子表格。Scraper可以手动生成XPath,以定义要爬网的URL。它不提供包罗万象的爬网服务,但是大多数人依然不需要处理混乱的配置。
OutWit Hub
OutWit Hub是Firefox的附加组件,具有许多数据提取功能,可简化您的网路搜索。该网路爬虫工具可以浏览页面并以适当的格式储存提取的信息。
OutWit Hub提供了一个单一插口,可依照须要抓取少量或大量数据。OutWit Hub容许您从浏览器本身抓取任何网页。它甚至可以创建手动代理以提取数据。
它是最简单的Web抓取工具之一,可免费使用,并为您提供了无需编撰一行代码即可提取Web数据的便利。
ParseHub
Parsehub是一款出众的Web爬虫,它支持从使用AJAX技术,JavaScript,Cookie等的网站采集数据。其机器学习技术可以读取,分析之后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux等系统。您甚至可以使用浏览器中外置的Web应用程序。
作为免费软件,您在Parsehub中最多可以构建五个公共项目。付费订阅计划容许您创建起码20个用于抓取网站的私人项目。
Visual Scraper
VisualScraper是另一个太棒的免费且非编码的Web刮板程序,具有简单的点击界面。您可以从多个网页获取实时数据,并将提取的数据导入为CSV,XML,JSON或SQL文件。除SaaS之外,VisualScraper还提供网页抓取服务,例如数据传递服务和创建软件提取程序服务。
Visual Scraper使用户可以计划项目在特定时间运行,或者每分钟/天/周/月/年重复执行该序列。用户可以使用它来频繁提取新闻,更新,论坛。
Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具容许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub使用Crawlera,这是一种智能代理旋转器,它支持绕开漫游器对策来轻松地爬行小型或受漫游器保护的站点。它使用户可以通过简单的HTTP API从多个IP和位置进行爬网而无需进行代理管理。
Scrapinghub将整个网页转换为结构化的内容。万一其抓取建立器难以满足您的要求,其专家团队将为您提供帮助。
Dexi.io
作为基于浏览器的爬虫程序, Dexi.io容许您从任何网站基于浏览器抓取数据,并提供三种类型的机械手来创建抓取任务-提取器,爬虫程序和管线。该免费软件为您的Web抓取提供了匿名Web代理服务器,您提取的数据将在数据存档之前在Dexi.io的服务器上托管两周,或者您可以将提取的数据直接导入到JSON或CSV文件。它提供付费服务,以满足您获取实时数据的需求。
Webhose.io
Webhose.io使用户才能从世界各地以各类干净格式抓取在线资源中获取实时数据。使用此网路爬虫,您可以使用覆盖多种来源的多个过滤器来爬取数据并进一步提取许多不同语言的关键字。
您可以将抓取的数据保存为XML,JSON和RSS格式。并且容许用户从其存档访问历史数据。另外,webhose.io的抓取数据结果最多支持80种语言。用户可以轻松地索引和搜索Webhose.io爬网的结构化数据。
总体而言,Webhose.io可以满足用户的基本爬网要求。
Import. io
用户可以通过简单地从特定网页导出数据并将数据导入为CSV来产生自己的数据集。
您可以在几分钟内轻松地抓取数千个网页,而无需编撰任何代码,也可以按照须要建立1000多个API。公共API提供了强悍而灵活的功能,可通过编程方法控制Import.io并获得对数据的手动访问,而Import.io只需单击几下即可将Web数据集成到您自己的应用程序或网站中,从而让抓取显得愈发容易。
为了更好地满足用户的爬网要求,它还提供了一个免费的Windows,Mac OS X和Linux 应用程序,用于建立数据提取器和爬网程序,下载数据并与在线账户同步。此外,用户可以每周,每天或每小时安排爬网任务。
80legs
80legs是功能强悍的网页爬虫工具,可以按照自定义要求进行配置。它支持获取大量数据,并可以立刻下载提取的数据。80legs提供了高性能的网路爬网,可快速运行并在短短几秒钟内获取所需数据
Spinn3r
Spinn3r容许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。Spinn3r随Firehouse API一起分发,该API管理着95%的索引工作。它提供了中级垃圾邮件保护功能,可以清除垃圾电邮和不适当的语言使用,从而增强数据安全性。
Spinn3r索引类似于Google的内容,并将提取的数据保存在JSON文件中。网络抓取工具会不断扫描网路,并从多个来源中查找更新,以获取实时出版物。其管理控制台可使您控制抓取,而全文本搜索则容许对原创数据进行复杂的查询。
Content Grabber
Content Grabber是针对企业的网页爬网软件。它容许您创建独立的网页爬网代理。它可以从几乎所有网站中提取内容,并以您选择的格式将其保存为结构化数据,包括Excel报表,XML,CSV和大多数数据库。
由于它为须要的人提供了许多强大的脚本编辑,调试界面,因此它更适宜具有中级编程技能的人。允许用户使用C#或VB.NET调试或编撰脚本来控制爬网过程的编程。例如,Content Grabber可以与Visual Studio 2013集成,以按照用户的特定需求,对中级,机智的自定义采集器进行最强悍的脚本编辑,调试和单元测试。
Helium Scraper
Helium Scraper是一种可视化的Web数据爬网软件,当元素之间的关联较小时,效果挺好。它是非编码,非配置的。用户可以依照各类爬网需求访问在线模板。
基本上,它可以满足用户基础的爬网需求。
UiPath
UiPath是用于免费网页抓取的机器人过程自动化软件。它可以手动从大多数第三方应用程序中抓取Web和桌面数据。如果您在Windows上运行它,则可以安装手动过程自动化软件。Uipath才能跨多个网页提取表格格式的数据。
Uipath提供了用于进一步爬网的外置工具。处理复杂的UI时,此方式十分有效。屏幕抓取工具可以处理单个文本元素,文本组和文本块,例如表格格式的数据提取。
此外,无需编程即可创建智能Web代理,但是您内部的.NET黑客将完全控制数据。
Scrape.it
Scrape.it是一个node.js Web抓取软件。这是一个基于云端数据提取工具。它为具有中级编程技能的人而设计,因为它提供了公共包和私有包,以发觉,重用,更新和与全球数百万开发人员共享代码。它强悍的集成将帮助您按照须要建立自定义的采集器。
WebHarvy
WebHarvy是点击式Web抓取软件。它是为非程序员设计的。WebHarvy可以手动从网站上抓取文本,图像,URL和电子邮件,并以各类格式保存抓取的内容。它还提供了外置的计划程序和代理支持,该支持可进行匿名爬网并避免Web爬网软件被Web服务器制止,您可以选择通过代理服务器或VPN访问目标网站。
用户可以以多种格式保存从网页提取的数据。当前版本的WebHarvy网页抓取工具容许您将抓取的数据导入为XML,CSV,JSON或TSV文件。用户还可以将抓取的数据导入到SQL数据库。
Connotate
Connotate是为企业级Web内容提取而设计的自动化网页爬网程序,它须要企业级解决方案。商业用户可以在短短的几分钟内轻松创建提取代理,而无需进行任何编程。用户只需单击即可轻松创建提取代理。 查看全部
20+网页采集工具—5分钟提取线上数据
原文章请查看:20+网页采集工具—5分钟提取线上数据
网页爬虫(也称为数据提取,数据采集,数据爬虫)如今已广泛应用于许多领域。在没有网路爬虫工具出现之前,对于没有编程技能的普通人来说,它是一个神奇的词,它的高门槛不断将人们挡在大数据之门之外。但是网页抓取工具是一种手动数据抓取技术,通过自动化的爬取数据降低自动复制粘贴的繁杂步骤,拉近了我们与数据的距离。
使用网路抓取工具有哪些益处?
它让您无需进行重复的复制和粘贴工作。
它将提取的数据装入结构良好的格式中,包括但不限于Excel,HTML和CSV。
它可以帮助您节约时间和金钱,而无需聘请专业的数据分析师。
这是营销人员,卖家,新闻工作者,YouTube使用者,研究人员和许多其他缺少技术技能的人的良药。
我列举了20种最佳的网页爬虫工具供您参考。欢迎充分利用它!
Octoparse
Octoparse是一款强悍的网站采集器,可提取您在网站上所需的几乎所有数据。您可以使用Octoparse爬取具有广泛功能的网站。它具有2种操作模式- 任务模板模式和中级模式-非程序员可以快速上手。友好的点击界面可以引导您完成整个提取过程。因此,您可以轻松提取网站内容,并在短时间内将其保存为EXCEL,TXT,HTML或数据库等结构化格式。
此外,它提供了计划的云提取,使您可以实时提取动态数据,并在网站更新中保留跟踪记录。您还可以通过使用外置的Regex和XPath配置来精确定位元素,从而提取结构复杂的复杂网站。您无需再害怕IP阻塞。Octoparse提供IP代理服务器,该服务器将手动执行IP,而不会被攻击性网站发现。总之,Octoparse应当才能满足用户最基本的或中级的爬取需求,而无需任何编码技能。
Cyotek WebCopy
WebCopy十分形象的描述了网路爬虫。这是一个免费的网站采集器,可使您将部份或全部网站本地复制到硬碟中以供离线参考。您可以修改其设置,以告诉漫游器您要怎么爬行。除此之外,您还可以配置域别称,用户代理字符串,默认文档等。
但是,WebCopy不包括虚拟DOM或任何方式的JavaScript解析。如果网站大量使用JavaScript进行操作,则WebCopy太可能难以制做真实的副本。可能因为大量使用JavaScript而未能正确处理动态网站布局。
HTTrack
作为网站采集器免费软件,HTTrack 提供了将整个网站下载到您的PC的功能。它具有适用于Windows,Linux,Sun Solaris和其他Unix系统的版本,覆盖了大多数用户。有趣的是,HTTrack可以镜像一个站点,或将多个站点镜像在一起(使用共享链接)。您可以在“设置选项”下确定下载网页时同时打开的连接数。您可以从其镜像的网站获取相片,文件和HTML代码,并恢复中断的下载。
此外,HTTrack内还提供代理支持,可最大程度地增强速率。
HTTrack可作为命令行程序工作,也可通过壳体程序供私人(捕获)或专业(在线网路镜像)使用,它适宜具有中级编程能力的使用者。
Getleft
Getleft是一个免费且便于使用的网站抓取工具。它容许您下载整个网站或任何单个网页。启动Getleft以后,您可以输入一个URL并选择要下载的文件,然后再开始下载。进行时,它将修改所有链接以进行本地浏览。此外,它还提供多语言支持。现在,Getleft支持14种语言!但是,它仅提供有限的Ftp支持,它将下载文件,但不会递归下载。
总体而言,Getleft应当在没有更复杂的战术技能的情况下满足用户的基本爬网需求。
Scraper
Scraper是Chrome扩充程序,具有有限的数据提取功能,但有助于进行在线研究。它还容许将数据导入到Google Spreadsheets。该工具适用于初学者和专家。您可以使用OAuth轻松地将数据复制到剪贴板或将其储存到电子表格。Scraper可以手动生成XPath,以定义要爬网的URL。它不提供包罗万象的爬网服务,但是大多数人依然不需要处理混乱的配置。
OutWit Hub
OutWit Hub是Firefox的附加组件,具有许多数据提取功能,可简化您的网路搜索。该网路爬虫工具可以浏览页面并以适当的格式储存提取的信息。
OutWit Hub提供了一个单一插口,可依照须要抓取少量或大量数据。OutWit Hub容许您从浏览器本身抓取任何网页。它甚至可以创建手动代理以提取数据。
它是最简单的Web抓取工具之一,可免费使用,并为您提供了无需编撰一行代码即可提取Web数据的便利。
ParseHub
Parsehub是一款出众的Web爬虫,它支持从使用AJAX技术,JavaScript,Cookie等的网站采集数据。其机器学习技术可以读取,分析之后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux等系统。您甚至可以使用浏览器中外置的Web应用程序。
作为免费软件,您在Parsehub中最多可以构建五个公共项目。付费订阅计划容许您创建起码20个用于抓取网站的私人项目。
Visual Scraper
VisualScraper是另一个太棒的免费且非编码的Web刮板程序,具有简单的点击界面。您可以从多个网页获取实时数据,并将提取的数据导入为CSV,XML,JSON或SQL文件。除SaaS之外,VisualScraper还提供网页抓取服务,例如数据传递服务和创建软件提取程序服务。
Visual Scraper使用户可以计划项目在特定时间运行,或者每分钟/天/周/月/年重复执行该序列。用户可以使用它来频繁提取新闻,更新,论坛。
Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源可视化抓取工具容许用户在没有任何编程知识的情况下抓取网站。
Scrapinghub使用Crawlera,这是一种智能代理旋转器,它支持绕开漫游器对策来轻松地爬行小型或受漫游器保护的站点。它使用户可以通过简单的HTTP API从多个IP和位置进行爬网而无需进行代理管理。
Scrapinghub将整个网页转换为结构化的内容。万一其抓取建立器难以满足您的要求,其专家团队将为您提供帮助。
Dexi.io
作为基于浏览器的爬虫程序, Dexi.io容许您从任何网站基于浏览器抓取数据,并提供三种类型的机械手来创建抓取任务-提取器,爬虫程序和管线。该免费软件为您的Web抓取提供了匿名Web代理服务器,您提取的数据将在数据存档之前在Dexi.io的服务器上托管两周,或者您可以将提取的数据直接导入到JSON或CSV文件。它提供付费服务,以满足您获取实时数据的需求。
Webhose.io
Webhose.io使用户才能从世界各地以各类干净格式抓取在线资源中获取实时数据。使用此网路爬虫,您可以使用覆盖多种来源的多个过滤器来爬取数据并进一步提取许多不同语言的关键字。
您可以将抓取的数据保存为XML,JSON和RSS格式。并且容许用户从其存档访问历史数据。另外,webhose.io的抓取数据结果最多支持80种语言。用户可以轻松地索引和搜索Webhose.io爬网的结构化数据。
总体而言,Webhose.io可以满足用户的基本爬网要求。
Import. io
用户可以通过简单地从特定网页导出数据并将数据导入为CSV来产生自己的数据集。
您可以在几分钟内轻松地抓取数千个网页,而无需编撰任何代码,也可以按照须要建立1000多个API。公共API提供了强悍而灵活的功能,可通过编程方法控制Import.io并获得对数据的手动访问,而Import.io只需单击几下即可将Web数据集成到您自己的应用程序或网站中,从而让抓取显得愈发容易。
为了更好地满足用户的爬网要求,它还提供了一个免费的Windows,Mac OS X和Linux 应用程序,用于建立数据提取器和爬网程序,下载数据并与在线账户同步。此外,用户可以每周,每天或每小时安排爬网任务。
80legs
80legs是功能强悍的网页爬虫工具,可以按照自定义要求进行配置。它支持获取大量数据,并可以立刻下载提取的数据。80legs提供了高性能的网路爬网,可快速运行并在短短几秒钟内获取所需数据
Spinn3r
Spinn3r容许您从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取全部数据。Spinn3r随Firehouse API一起分发,该API管理着95%的索引工作。它提供了中级垃圾邮件保护功能,可以清除垃圾电邮和不适当的语言使用,从而增强数据安全性。
Spinn3r索引类似于Google的内容,并将提取的数据保存在JSON文件中。网络抓取工具会不断扫描网路,并从多个来源中查找更新,以获取实时出版物。其管理控制台可使您控制抓取,而全文本搜索则容许对原创数据进行复杂的查询。
Content Grabber
Content Grabber是针对企业的网页爬网软件。它容许您创建独立的网页爬网代理。它可以从几乎所有网站中提取内容,并以您选择的格式将其保存为结构化数据,包括Excel报表,XML,CSV和大多数数据库。
由于它为须要的人提供了许多强大的脚本编辑,调试界面,因此它更适宜具有中级编程技能的人。允许用户使用C#或VB.NET调试或编撰脚本来控制爬网过程的编程。例如,Content Grabber可以与Visual Studio 2013集成,以按照用户的特定需求,对中级,机智的自定义采集器进行最强悍的脚本编辑,调试和单元测试。
Helium Scraper
Helium Scraper是一种可视化的Web数据爬网软件,当元素之间的关联较小时,效果挺好。它是非编码,非配置的。用户可以依照各类爬网需求访问在线模板。
基本上,它可以满足用户基础的爬网需求。
UiPath
UiPath是用于免费网页抓取的机器人过程自动化软件。它可以手动从大多数第三方应用程序中抓取Web和桌面数据。如果您在Windows上运行它,则可以安装手动过程自动化软件。Uipath才能跨多个网页提取表格格式的数据。
Uipath提供了用于进一步爬网的外置工具。处理复杂的UI时,此方式十分有效。屏幕抓取工具可以处理单个文本元素,文本组和文本块,例如表格格式的数据提取。
此外,无需编程即可创建智能Web代理,但是您内部的.NET黑客将完全控制数据。
Scrape.it
Scrape.it是一个node.js Web抓取软件。这是一个基于云端数据提取工具。它为具有中级编程技能的人而设计,因为它提供了公共包和私有包,以发觉,重用,更新和与全球数百万开发人员共享代码。它强悍的集成将帮助您按照须要建立自定义的采集器。
WebHarvy
WebHarvy是点击式Web抓取软件。它是为非程序员设计的。WebHarvy可以手动从网站上抓取文本,图像,URL和电子邮件,并以各类格式保存抓取的内容。它还提供了外置的计划程序和代理支持,该支持可进行匿名爬网并避免Web爬网软件被Web服务器制止,您可以选择通过代理服务器或VPN访问目标网站。
用户可以以多种格式保存从网页提取的数据。当前版本的WebHarvy网页抓取工具容许您将抓取的数据导入为XML,CSV,JSON或TSV文件。用户还可以将抓取的数据导入到SQL数据库。
Connotate
Connotate是为企业级Web内容提取而设计的自动化网页爬网程序,它须要企业级解决方案。商业用户可以在短短的几分钟内轻松创建提取代理,而无需进行任何编程。用户只需单击即可轻松创建提取代理。
深维全能信息采集软件特色
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-22 02:16
深维全能信息采集软件是一款就能帮助我们对网路信息进行快速采集和管理的工具,通过此软件就能对相关信息进行快速处理和整理,支持网站跨层采集、POST采集、脚本采集、网站登录采集、动态页面采集等,自助图形化的配置工具,交互式的策略、先进的机器学习算法,让您的配置操作得到更大的简化,有须要的同事赶快下载吧。
深维全能信息采集软件功能介绍
1、解压压缩包。
2、开始安装。
3、软件界面。
深维全能信息采集软件特色
1、强大的信息采集功能
可采集几乎任何类型的网站信息,包括静态htm,html类型和动态ASP,ASPX,JSP等。可N级页面采集。可手动下载二进制文件,比如图片,软件,mp3等。
2、网站登录
需要登入能够看见的信息,先在任务的’登录设置’处进行登陆,就可采集登录后才会看见的信息。
3、速度快,运行稳定
真正的多线程,多任务,运行时占用系统资源甚少,可稳定地长时间运行。(明显区别于其他软件)
4、数据保存格式丰富
可把采集的数据,保存为Txt,Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5、强大的新闻采集,自动化处理功能
可手动保留新闻的格式,包括图片等。可通过设置,自动下载图片 ,自动把正文里图片的网路路径改为本地文件路径(也可保留原貌);可把采集的新闻手动处理成自己设计的模板格式;可采集具有分页方式的新闻。通过这种功能,简单设置后即可在本地构建一个强悍的新闻系统,无需人工干预。
6、强大的信息手动再加工功能
对采集的信息,可进行二次批量再加工,使之愈加符合您的实际要求。也可设置手动加工公式,在采集的过程中,按照公式手动加工处理,包括数据合并和数据替换等。
更新日志
修复BUG
精简文件
优化程序 查看全部
深维全能信息采集软件特色
深维全能信息采集软件是一款就能帮助我们对网路信息进行快速采集和管理的工具,通过此软件就能对相关信息进行快速处理和整理,支持网站跨层采集、POST采集、脚本采集、网站登录采集、动态页面采集等,自助图形化的配置工具,交互式的策略、先进的机器学习算法,让您的配置操作得到更大的简化,有须要的同事赶快下载吧。
深维全能信息采集软件功能介绍
1、解压压缩包。
2、开始安装。
3、软件界面。
深维全能信息采集软件特色
1、强大的信息采集功能
可采集几乎任何类型的网站信息,包括静态htm,html类型和动态ASP,ASPX,JSP等。可N级页面采集。可手动下载二进制文件,比如图片,软件,mp3等。
2、网站登录
需要登入能够看见的信息,先在任务的’登录设置’处进行登陆,就可采集登录后才会看见的信息。
3、速度快,运行稳定
真正的多线程,多任务,运行时占用系统资源甚少,可稳定地长时间运行。(明显区别于其他软件)
4、数据保存格式丰富
可把采集的数据,保存为Txt,Excel和多种数据库格式(Access sqlserver Oracle Mysql等)。
5、强大的新闻采集,自动化处理功能
可手动保留新闻的格式,包括图片等。可通过设置,自动下载图片 ,自动把正文里图片的网路路径改为本地文件路径(也可保留原貌);可把采集的新闻手动处理成自己设计的模板格式;可采集具有分页方式的新闻。通过这种功能,简单设置后即可在本地构建一个强悍的新闻系统,无需人工干预。
6、强大的信息手动再加工功能
对采集的信息,可进行二次批量再加工,使之愈加符合您的实际要求。也可设置手动加工公式,在采集的过程中,按照公式手动加工处理,包括数据合并和数据替换等。
更新日志
修复BUG
精简文件
优化程序
有什么功能强悍,同时又简单易用的网路采集工具?
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2020-08-22 01:40
网络搜集工具可以在各类场景中用于无限目的。
比如:
1.采集市场研究数据
网络抓取工具可以从多个数据剖析提供商和市场研究公司获取信息,并将它们整合到一个位置,以便于参考和剖析。可以帮助你及时了解公司或行业未来六个月的发展方向。
2.提取联系信息
这些工具还可用于从各类网站中提取电子邮件和电话号码等数据。
3.采集数据来下载用于离线阅读或储存
4.跟踪多个市场的价钱等
这些软件自动或手动查找新数据,获取新数据或更新数据并储存便于于访问。例如,可以使用抓取工具从亚马逊搜集有关产品及其价位的信息。
推荐4个网路搜集工具VisualScraper
VisualScraper是另一种Web数据提取软件,可用于从Web搜集信息。该软件可帮助你从多个网页中提取数据并实时获取结果。此外,你可以以CSV,XML,JSON和SQL等各类格式导入。
Spinn3r
Spinn3r容许你从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取整个数据。Spinn3r与 firehouse API一起分发,管理95%的索引工作。它提供中级垃圾邮件防护,可以清除垃圾电邮和不恰当的语言使用,从而增强数据安全性。
80legs
80legs是一款功能强悍且灵活的网路抓取工具,可按照您的需求进行配置。它支持获取大量数据以及立刻下载提取数据的选项。80legs宣称可以抓取600,000多个域名,并被MailChimp和PayPal等小型玩家使用。
Scraper
Scraper是Chrome扩充程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导入到Google Spreadsheets。此工具适用于初学者以及可以使用OAuth轻松将数据复制到剪贴板或储存到电子表格的专家。
你还可以关注我的微信公众号:youdaoyunnet
文章发自:
提取在线数据的9个最佳网页抓取工具 - 运营有道 查看全部
有什么功能强悍,同时又简单易用的网路采集工具?
网络搜集工具可以在各类场景中用于无限目的。
比如:
1.采集市场研究数据
网络抓取工具可以从多个数据剖析提供商和市场研究公司获取信息,并将它们整合到一个位置,以便于参考和剖析。可以帮助你及时了解公司或行业未来六个月的发展方向。
2.提取联系信息
这些工具还可用于从各类网站中提取电子邮件和电话号码等数据。
3.采集数据来下载用于离线阅读或储存
4.跟踪多个市场的价钱等
这些软件自动或手动查找新数据,获取新数据或更新数据并储存便于于访问。例如,可以使用抓取工具从亚马逊搜集有关产品及其价位的信息。
推荐4个网路搜集工具VisualScraper
VisualScraper是另一种Web数据提取软件,可用于从Web搜集信息。该软件可帮助你从多个网页中提取数据并实时获取结果。此外,你可以以CSV,XML,JSON和SQL等各类格式导入。
Spinn3r
Spinn3r容许你从博客,新闻和社交媒体网站以及RSS和ATOM提要中获取整个数据。Spinn3r与 firehouse API一起分发,管理95%的索引工作。它提供中级垃圾邮件防护,可以清除垃圾电邮和不恰当的语言使用,从而增强数据安全性。
80legs
80legs是一款功能强悍且灵活的网路抓取工具,可按照您的需求进行配置。它支持获取大量数据以及立刻下载提取数据的选项。80legs宣称可以抓取600,000多个域名,并被MailChimp和PayPal等小型玩家使用。
Scraper
Scraper是Chrome扩充程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导入到Google Spreadsheets。此工具适用于初学者以及可以使用OAuth轻松将数据复制到剪贴板或储存到电子表格的专家。
你还可以关注我的微信公众号:youdaoyunnet
文章发自:
提取在线数据的9个最佳网页抓取工具 - 运营有道
本人第一个开源代码,NETSpider 网络蜘蛛采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-21 20:46
NETSpider网站数据采集软件是一款基于.Net平台的开源软件。
软件部份功能是基本Soukey软件进行开发的.这个版本采用VS2010+.NET3.5进行开发的.
NETSpider采摘当前提供的主要功能如下:
1. 多任务多线程数据采集,支持POST方法(待定);
2. 可采集Ajax页面;
3. 支持Cookie,支持手工登陆采集数据;
4. 支持采集事务;
5. 支持数据手动及手工导入,导出格式为:文本、Excel、Access、MSSql、Mysql等;
6. 支持在线发布数据;
7. 支持导航网址的采集,导航深度不限;
8. 支持手动翻页;
9. 支持文件下载,可以采集图片、Flash及其他文件;
10. 支持采集结果数据的加工,包括替换、附前缀后缀、截取等操作,支持正则;
11. 采集网址定义除了支持基本参数定义,也可外接字典数据作为网址参数,进行数据采集;
12. 支持一个任务多实例运行;
13. 提供计划任务,计划任务支持NETSpider采集任务、外部可执行文件任务、数据库储存过程任务(还在开发中);
14. 计划任务执行周期支持每晚、每周及自定义运行间隔;最小单位为:半小时;
15. 支持任务触发器,即可在采集任务完成后,自动触发执行其他任务(包括可执行文件或存储过程)。
16. 完善的日志功能:系统日志、任务执行日志、出错日志等等;
17. 系统提供MINI浏览器可用于捕获Cookie或POST数据;
NETSpider采集器并不限制您是否商用此软件,源码完全开放,
===================以下为更新内容===================================
1. NETSpider于2014年10月1日开放
相关源码下载:
1.目前这个版本还有好多的验证未做处理,没有时间(花了两周的样子写成这样子),所以添加的时侯请按规定填写数据
2.还有部份功能未实现.等有空我会继续建立的 查看全部
本人第一个开源代码,NETSpider 网络蜘蛛采集工具
NETSpider网站数据采集软件是一款基于.Net平台的开源软件。
软件部份功能是基本Soukey软件进行开发的.这个版本采用VS2010+.NET3.5进行开发的.
NETSpider采摘当前提供的主要功能如下:
1. 多任务多线程数据采集,支持POST方法(待定);
2. 可采集Ajax页面;
3. 支持Cookie,支持手工登陆采集数据;
4. 支持采集事务;
5. 支持数据手动及手工导入,导出格式为:文本、Excel、Access、MSSql、Mysql等;
6. 支持在线发布数据;
7. 支持导航网址的采集,导航深度不限;
8. 支持手动翻页;
9. 支持文件下载,可以采集图片、Flash及其他文件;
10. 支持采集结果数据的加工,包括替换、附前缀后缀、截取等操作,支持正则;
11. 采集网址定义除了支持基本参数定义,也可外接字典数据作为网址参数,进行数据采集;
12. 支持一个任务多实例运行;
13. 提供计划任务,计划任务支持NETSpider采集任务、外部可执行文件任务、数据库储存过程任务(还在开发中);
14. 计划任务执行周期支持每晚、每周及自定义运行间隔;最小单位为:半小时;
15. 支持任务触发器,即可在采集任务完成后,自动触发执行其他任务(包括可执行文件或存储过程)。
16. 完善的日志功能:系统日志、任务执行日志、出错日志等等;
17. 系统提供MINI浏览器可用于捕获Cookie或POST数据;
NETSpider采集器并不限制您是否商用此软件,源码完全开放,
===================以下为更新内容===================================
1. NETSpider于2014年10月1日开放
相关源码下载:
1.目前这个版本还有好多的验证未做处理,没有时间(花了两周的样子写成这样子),所以添加的时侯请按规定填写数据
2.还有部份功能未实现.等有空我会继续建立的
新闻采集工具?
采集交流 • 优采云 发表了文章 • 0 个评论 • 384 次浏览 • 2020-08-12 10:10
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
一个企业级新闻与政务公告采集的落地,其实有特别多的难点。这几年我们帮助好多有相关需求的顾客一一解决了这种难点,积累了好多宝贵的经验。今天就来跟你们分享一下。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。 查看全部
很多企业与事业单位都须要采集新闻资讯、政务公告等数据,用以发展自己的业务。业务不同,具体的采集需求也不尽相同。举几个简单的事例:
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
一个企业级新闻与政务公告采集的落地,其实有特别多的难点。这几年我们帮助好多有相关需求的顾客一一解决了这种难点,积累了好多宝贵的经验。今天就来跟你们分享一下。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。
使用Filebeat搜集Kubernetes的应用日志
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2020-08-12 03:40
在进行日志搜集的过程中,我们首先想到的是使用Logstash,因为它是ELK stack中的重要成员,但是在测试过程中发觉,Logstash是基于JDK的,在没有形成日志的情况单纯启动Logstash就大约要消耗500M显存,在每位Pod中都启动一个日志搜集组件的情况下,使用logstash有点浪费系统资源,经人推荐我们选择使用Filebeat取代,经测试单独启动Filebeat容器大约会消耗12M显存,比起logstash相当轻量级。
方案选择
Kubernetes官方提供了EFK的日志搜集解决方案,但是这些方案并不适宜所有的业务场景,它本身就有一些局限性,例如:
基于以上几个缘由,我们决定使用自己的ELK集群。
Kubernetes集群中的日志搜集解决方案
编号方案优点缺点
1
每个app的镜像中都集成日志搜集组件
部署便捷,kubernetes的yaml文件无须非常配置,可以为每位app自定义日志搜集配置
强耦合,不便捷应用和日志搜集组件升级和维护且会导致镜像过大
2
单独创建一个日志搜集组件跟app的容器一起运行在同一个pod中
低耦合,扩展性强,方便维护和升级
需要对kubernetes的yaml文件进行单独配置,略显冗长
3
将所有的Pod的日志都挂载到宿主机上,每台主机上单独起一个日志搜集Pod
完全前馈,性能最高,管理上去最方便
需要统一日志搜集规则,目录和输出形式
综合以上优缺点,我们选择使用方案二。
该方案在扩展性、个性化、部署和后期维护方面都能做到均衡,因此选择该方案。
我们创建了自己的logstash镜像。创建过程和使用方法见
镜像地址:/jimmy/filebeat:5.4.0
测试
我们布署一个应用filebeat来搜集日志的功能测试。
创建应用yaml文件filebeat-test.yaml。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: filebeat-test
namespace: default
spec:
replicas: 3
template:
metadata:
labels:
k8s-app: filebeat-test
spec:
containers:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/filebeat:5.4.0
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
- name: filebeat-config
mountPath: /etc/filebeat/
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/analytics-docker-test:Build_8
name : app
ports:
- containerPort: 80
volumeMounts:
- name: app-logs
mountPath: /usr/local/TalkingData/logs
volumes:
- name: app-logs
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-config
---
apiVersion: v1
kind: Service
metadata:
name: filebeat-test
labels:
app: filebeat-test
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
run: filebeat-test
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
data:
filebeat.yml: |
filebeat.prospectors:
- input_type: log
paths:
- "/log/*"
- "/log/usermange/common/*"
output.elasticsearch:
hosts: ["172.23.5.255:9200"]
username: "elastic"
password: "changeme"
index: "filebeat-test"
说明
该文件中收录了配置文件filebeat的配置文件的ConfigMap,因此不需要再定义环境变量。
当然你也可以不同ConfigMap,通过传统的传递环境变量的方法来配置filebeat。
例如对filebeat的容器进行如下配置:
containers:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/filebeat:5.4.0
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
env:
- name: PATHS
value: "/log/*"
- name: ES_SERVER
value: 172.23.5.255:9200
- name: INDEX
value: logstash-docker
- name: INPUT_TYPE
value: log
目前使用这些方法会有个问题,及时PATHS只能传递单个目录,如果想传递多个目录须要更改filebeat镜像的docker-entrypoint.sh脚本,对该环境变量进行解析降低filebeat.yml文件中的PATHS列表。
推荐使用ConfigMap,这样filebeat的配置能够够更灵活。
注意事项
创建应用
部署Deployment
kubectl create -f filebeat-test.yaml
查看:9200/_cat/indices将可以看见列表有这样的indices:
green open filebeat-2017.05.17 1qatsSajSYqAV42_XYwLsQ 5 1 1189 0 1mb 588kb
访问Kibana的web页面,查看filebeat-2017.05.17的索引,可以看见logstash搜集到了app日志。
问题记录
我们配置的index: "filebeat-test"没有生效,需要参考filebeat的配置文档,对filebeat的配置进一步优化。
更多详情可以查看: 查看全部
前言
在进行日志搜集的过程中,我们首先想到的是使用Logstash,因为它是ELK stack中的重要成员,但是在测试过程中发觉,Logstash是基于JDK的,在没有形成日志的情况单纯启动Logstash就大约要消耗500M显存,在每位Pod中都启动一个日志搜集组件的情况下,使用logstash有点浪费系统资源,经人推荐我们选择使用Filebeat取代,经测试单独启动Filebeat容器大约会消耗12M显存,比起logstash相当轻量级。
方案选择
Kubernetes官方提供了EFK的日志搜集解决方案,但是这些方案并不适宜所有的业务场景,它本身就有一些局限性,例如:
基于以上几个缘由,我们决定使用自己的ELK集群。
Kubernetes集群中的日志搜集解决方案
编号方案优点缺点
1
每个app的镜像中都集成日志搜集组件
部署便捷,kubernetes的yaml文件无须非常配置,可以为每位app自定义日志搜集配置
强耦合,不便捷应用和日志搜集组件升级和维护且会导致镜像过大
2
单独创建一个日志搜集组件跟app的容器一起运行在同一个pod中
低耦合,扩展性强,方便维护和升级
需要对kubernetes的yaml文件进行单独配置,略显冗长
3
将所有的Pod的日志都挂载到宿主机上,每台主机上单独起一个日志搜集Pod
完全前馈,性能最高,管理上去最方便
需要统一日志搜集规则,目录和输出形式
综合以上优缺点,我们选择使用方案二。
该方案在扩展性、个性化、部署和后期维护方面都能做到均衡,因此选择该方案。
我们创建了自己的logstash镜像。创建过程和使用方法见
镜像地址:/jimmy/filebeat:5.4.0
测试
我们布署一个应用filebeat来搜集日志的功能测试。
创建应用yaml文件filebeat-test.yaml。
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: filebeat-test
namespace: default
spec:
replicas: 3
template:
metadata:
labels:
k8s-app: filebeat-test
spec:
containers:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/filebeat:5.4.0
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
- name: filebeat-config
mountPath: /etc/filebeat/
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/analytics-docker-test:Build_8
name : app
ports:
- containerPort: 80
volumeMounts:
- name: app-logs
mountPath: /usr/local/TalkingData/logs
volumes:
- name: app-logs
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-config
---
apiVersion: v1
kind: Service
metadata:
name: filebeat-test
labels:
app: filebeat-test
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
run: filebeat-test
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
data:
filebeat.yml: |
filebeat.prospectors:
- input_type: log
paths:
- "/log/*"
- "/log/usermange/common/*"
output.elasticsearch:
hosts: ["172.23.5.255:9200"]
username: "elastic"
password: "changeme"
index: "filebeat-test"
说明
该文件中收录了配置文件filebeat的配置文件的ConfigMap,因此不需要再定义环境变量。
当然你也可以不同ConfigMap,通过传统的传递环境变量的方法来配置filebeat。
例如对filebeat的容器进行如下配置:
containers:
- image: sz-pg-oam-docker-hub-001.tendcloud.com/library/filebeat:5.4.0
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
env:
- name: PATHS
value: "/log/*"
- name: ES_SERVER
value: 172.23.5.255:9200
- name: INDEX
value: logstash-docker
- name: INPUT_TYPE
value: log
目前使用这些方法会有个问题,及时PATHS只能传递单个目录,如果想传递多个目录须要更改filebeat镜像的docker-entrypoint.sh脚本,对该环境变量进行解析降低filebeat.yml文件中的PATHS列表。
推荐使用ConfigMap,这样filebeat的配置能够够更灵活。
注意事项
创建应用
部署Deployment
kubectl create -f filebeat-test.yaml
查看:9200/_cat/indices将可以看见列表有这样的indices:
green open filebeat-2017.05.17 1qatsSajSYqAV42_XYwLsQ 5 1 1189 0 1mb 588kb
访问Kibana的web页面,查看filebeat-2017.05.17的索引,可以看见logstash搜集到了app日志。
问题记录
我们配置的index: "filebeat-test"没有生效,需要参考filebeat的配置文档,对filebeat的配置进一步优化。
更多详情可以查看:
百分百顾客综合采集软件 V6.4
采集交流 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2020-08-10 07:46
软件功能 1、通过百度爬虫采集手机号,目标精准
软件支持网络爬虫搜索手机号功能,根据您的关键字智能搜索百度里面的用户手机号,目标精准明晰,且可将搜索结果(即手机号)保存到本地,网络营销的必备助手
2、按地区生成手机号码
按照用户设定的地区生成手机号码段,并且可以按照指定号码段,用户自定义格式生成手机号码,做地域定向营销,群发手机邮件的最佳选择
3、数据更新及时、保证营销疗效
百分百团队,有着专业的工作人员,定期整理最新的企业名录数据,我们力争做到及时的更新最新的企业数据,同时优化老的企业数据,保证您通过我们软件所采集到的企业数据,都是一手的、最新的。为您才能达到更好的营销销售疗效,我们仍然在努力
4、覆盖全省各行各业
由我们官方多名工作人员悉心整理、归类,再经过程序的二次精准处理,我们的数据库早已覆盖了全省所有行业,而且,各个行业所对应的数据早已做了定向、精准,是您开发新顾客、发掘意向顾客的最佳神器
软件特征 1、采集速度快、稳定性强
软件采用我们团队耗时五年研制的不加群提取群成员软件内核,利用现有成熟的技术,力争为您达到最佳采集速度的同时,软件的稳定性也丝毫不受影响!不仅还能节约您的时间效率,也才能使您的营销愈发省心!
2、快捷便捷数据导入,格式多元化
凡是订购我们软件,成为正式版用户之后,都可以享用软件的导入功能。导出格式,我们支持execel、txt等基本格式,同时我们有着人性化的自定义导入格式设置,您可以随心所欲的导入自己须要的格式
3、通过B2B网站在线采集
软件可以通过B2B网站在线采集,如慧聪网、马可波罗、一呼百应、中国供应商等B2B网站采集最新的企业信息,数据精准,采集速度快,对于想获取最新企业信息的顾客来说,是不错的选择
4、软件采用网路帐号,不限机器
百分百顾客综合采集软件采用网路帐号方式,一个软件帐号可以在不同笔记本登录,用户可以在家使用,也可以在公司使用,摆脱了传统软件采用机器码方式的弊病,真正意思上实现了以用户为中心,以服务为跟本的群发理念
更新日志 1、增加一键登入用户中心功能
2、增加修补工具
3、新增陌陌绑定,以及陌陌寻回密码功能
4、修复在线精准采集EXEL导入不显示数据问题
5、优化精准采集界面显示
6、增加公司经营范围列表,可以显示公司产品
7、增加经营范围导入功能
8、增加经营范围筛选功能
9、修改在线精准采集,TXT格式导入,数据显示不全问题
10、修复导入数据出现空字符问题
小编提醒 该款软件下载的时侯可能会报毒,这时只需添加信任即可,小编也在这里保证,该款软件绝对安全可靠,请放心下载,还有的就是该款软件小编只是提供个下载地址,其本身并无任何恶意,如果其用户个人用于非法的行为一概与本站无关哦 查看全部
软件功能 1、通过百度爬虫采集手机号,目标精准
软件支持网络爬虫搜索手机号功能,根据您的关键字智能搜索百度里面的用户手机号,目标精准明晰,且可将搜索结果(即手机号)保存到本地,网络营销的必备助手
2、按地区生成手机号码
按照用户设定的地区生成手机号码段,并且可以按照指定号码段,用户自定义格式生成手机号码,做地域定向营销,群发手机邮件的最佳选择
3、数据更新及时、保证营销疗效
百分百团队,有着专业的工作人员,定期整理最新的企业名录数据,我们力争做到及时的更新最新的企业数据,同时优化老的企业数据,保证您通过我们软件所采集到的企业数据,都是一手的、最新的。为您才能达到更好的营销销售疗效,我们仍然在努力
4、覆盖全省各行各业
由我们官方多名工作人员悉心整理、归类,再经过程序的二次精准处理,我们的数据库早已覆盖了全省所有行业,而且,各个行业所对应的数据早已做了定向、精准,是您开发新顾客、发掘意向顾客的最佳神器
软件特征 1、采集速度快、稳定性强
软件采用我们团队耗时五年研制的不加群提取群成员软件内核,利用现有成熟的技术,力争为您达到最佳采集速度的同时,软件的稳定性也丝毫不受影响!不仅还能节约您的时间效率,也才能使您的营销愈发省心!
2、快捷便捷数据导入,格式多元化
凡是订购我们软件,成为正式版用户之后,都可以享用软件的导入功能。导出格式,我们支持execel、txt等基本格式,同时我们有着人性化的自定义导入格式设置,您可以随心所欲的导入自己须要的格式
3、通过B2B网站在线采集
软件可以通过B2B网站在线采集,如慧聪网、马可波罗、一呼百应、中国供应商等B2B网站采集最新的企业信息,数据精准,采集速度快,对于想获取最新企业信息的顾客来说,是不错的选择
4、软件采用网路帐号,不限机器
百分百顾客综合采集软件采用网路帐号方式,一个软件帐号可以在不同笔记本登录,用户可以在家使用,也可以在公司使用,摆脱了传统软件采用机器码方式的弊病,真正意思上实现了以用户为中心,以服务为跟本的群发理念
更新日志 1、增加一键登入用户中心功能
2、增加修补工具
3、新增陌陌绑定,以及陌陌寻回密码功能
4、修复在线精准采集EXEL导入不显示数据问题
5、优化精准采集界面显示
6、增加公司经营范围列表,可以显示公司产品
7、增加经营范围导入功能
8、增加经营范围筛选功能
9、修改在线精准采集,TXT格式导入,数据显示不全问题
10、修复导入数据出现空字符问题
小编提醒 该款软件下载的时侯可能会报毒,这时只需添加信任即可,小编也在这里保证,该款软件绝对安全可靠,请放心下载,还有的就是该款软件小编只是提供个下载地址,其本身并无任何恶意,如果其用户个人用于非法的行为一概与本站无关哦
1688商品采集软件使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 710 次浏览 • 2020-08-09 22:33
1688商品采集软件介绍
1688商品采集软件是老店软件推出的一款1688(阿里巴巴)产品信息批量采集软件,可以帮助用户快速获得平台上的产品信息,即时了解和更新店面动态,操作简单,实用便捷,是一款十分不错的软件。
1688商品采集软件使用教程
1、采集模式1(按搜索页面设置)
(1)点击“搜索页面设置”按钮,输入要采集的关键词
(2)可以进行类目设置、设置完后点击“页面直接采集”按钮
(3)采集数据如图所示
(4)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
2、采集模式2(导入关键词采集)
(1)导入要采集的关键词,多个关键词(一行一个)
(2)点击“导入模式采集”按钮
(3)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
1688商品采集软件功能
支持二种采集模式
1、页面设置采集
在WEB页面设置一个采集关键词,并可精细化设置采集条件(如样式、颜色、尺寸大小等)。 这种适用于复杂条件下的精细化采集。
2、按关键词批量采集
通过导出一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价钱、产品图、月销量、月销售额、回头率、货描、响应、发货、旺旺、公司名、业务类型等等数组,导出为文本表格(excel),可用于产品行情剖析、同行销售业绩评估、企业信息搜集等用途。每个产品关键词较高支持100页,每页60个产品,大约6000个产品信息。支持详尽的搜索参数设置,支持多个产品关键词次序采集,不同关键词回车键一行一个,支持数组排序(点击表头列)后再导入保存。
1688商品采集软件特征
1、只要用键盘点击即可,无需写任何采集规则,
2、实时采集,非历史数据,在用户本地采集当前最新的数据。
3、操作简单容易上手,傻瓜式操作,二步到位(导入产品的详情链接,一行一个、可以导出多个产品链接;点击开始采集;导出数据)。不需手写任何规则,操作非常简单。
4、快速搜索、极速的操作体验,流畅愉悦。
5、带手动升级功能:官方发布新版本后,打开客户端会手动升级到最新版本。
6、软件将继续保持模块更新。
1688商品采集软件常见问题
1、支持的操作系统?
Win7及以上版本(32位或64位均可)。xp不支持。
2、试用版和正版的区别?
试用版有采集导出关键信息加密外(24小时限时试用),其它无任何限制,因此选购前可先试用体验。
因为质量过关,所以我们的软件可放开体验试用。(不象许多同行不可体验或做了足够限制的拙劣体验)。
3、采集速度?
无任何限制,您机器性能和带宽。
4、换机器或软件遗失如何办?
QQ和陌陌联系我们即可处理。只是要我们的VIP顾客,在授权期内,我们就会及时处理。
1688商品采集软件更新日志
版本:v1.9
1、解决数据导入问题。 查看全部
1688商品采集软件是一款专为阿里巴巴产品信息构建的批量采集软件,可以帮助有须要的用户快速的获取阿里巴巴产品的所有信息,大大的便捷了自己的店面管理,欢迎前来下载使用!
1688商品采集软件介绍
1688商品采集软件是老店软件推出的一款1688(阿里巴巴)产品信息批量采集软件,可以帮助用户快速获得平台上的产品信息,即时了解和更新店面动态,操作简单,实用便捷,是一款十分不错的软件。
1688商品采集软件使用教程
1、采集模式1(按搜索页面设置)
(1)点击“搜索页面设置”按钮,输入要采集的关键词
(2)可以进行类目设置、设置完后点击“页面直接采集”按钮
(3)采集数据如图所示
(4)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
2、采集模式2(导入关键词采集)
(1)导入要采集的关键词,多个关键词(一行一个)
(2)点击“导入模式采集”按钮
(3)同时还可以点击“浏览视图切换开发”,进行浏览器的显示切换。
1688商品采集软件功能
支持二种采集模式
1、页面设置采集
在WEB页面设置一个采集关键词,并可精细化设置采集条件(如样式、颜色、尺寸大小等)。 这种适用于复杂条件下的精细化采集。
2、按关键词批量采集
通过导出一批关键词,直接按关键词采集。
采集的信息包括产品ID、产品标题、产品URL、产品价钱、产品图、月销量、月销售额、回头率、货描、响应、发货、旺旺、公司名、业务类型等等数组,导出为文本表格(excel),可用于产品行情剖析、同行销售业绩评估、企业信息搜集等用途。每个产品关键词较高支持100页,每页60个产品,大约6000个产品信息。支持详尽的搜索参数设置,支持多个产品关键词次序采集,不同关键词回车键一行一个,支持数组排序(点击表头列)后再导入保存。
1688商品采集软件特征
1、只要用键盘点击即可,无需写任何采集规则,
2、实时采集,非历史数据,在用户本地采集当前最新的数据。
3、操作简单容易上手,傻瓜式操作,二步到位(导入产品的详情链接,一行一个、可以导出多个产品链接;点击开始采集;导出数据)。不需手写任何规则,操作非常简单。
4、快速搜索、极速的操作体验,流畅愉悦。
5、带手动升级功能:官方发布新版本后,打开客户端会手动升级到最新版本。
6、软件将继续保持模块更新。
1688商品采集软件常见问题
1、支持的操作系统?
Win7及以上版本(32位或64位均可)。xp不支持。
2、试用版和正版的区别?
试用版有采集导出关键信息加密外(24小时限时试用),其它无任何限制,因此选购前可先试用体验。
因为质量过关,所以我们的软件可放开体验试用。(不象许多同行不可体验或做了足够限制的拙劣体验)。
3、采集速度?
无任何限制,您机器性能和带宽。
4、换机器或软件遗失如何办?
QQ和陌陌联系我们即可处理。只是要我们的VIP顾客,在授权期内,我们就会及时处理。
1688商品采集软件更新日志
版本:v1.9
1、解决数据导入问题。
外部连锁采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2020-08-08 23:00
打开外部链接采集功能. 原创集合是百度搜索某个关键字的结果页面的URL. 这最初称为外部链接采集(─.─|||.. 但是没关系,我们认为百度Google和Yahoo具有一些常见或独特的高级命令,因此请在搜索关键字输入框中输入: ananchor: 减肥inurl: bbs,哈哈,正如预期的那样,结果是很多论坛与减肥有关,在论坛中也有一些不相关的论坛,一些不相关的论坛在签名中有链接,而一些则是纯广告发布. ,高级搜索命令的用法很多,并且在一组中有大量的注释. 一些高级搜索命令的组合用法也非常有效.
很多时候,一些免费的seo工具的效果不仅取决于软件本身,还取决于使用seo工具的人. 即使手工艺品在手,如果您不能使用它,它也不会像其他人的砖头那么锋利. 我没有使用付费工具,也买不起(┬_┬),但是我已经在Internet上下载了一些破解版本. 我不得不说,除了可以骗钱的软件之外,某些付费的seo工具确实非常强大. 让SEOer节省了大量时间来实施. 我还没有看到链外采集到的工件. 如果有人知道,您可以与它分享~~~
但是,某些seo工具通常起辅助作用,而某些seo工具可能具有黑帽seo的作用. 请谨慎使用! 查看全部
SEO一直在忙于采集一些可以在过去两天内使用的免费seo工具. 今天,我想挖掘Internet上的链采集工具. 但是经过长时间的挖掘,我没有发现任何效果. 这确实是我想要的采集工具. 后来,我发现计算机本身有一个seo工具,它实际上包括外部链采集的功能. 这真的叫做“踩铁鞋”,该软件已经在我的计算机桌面的角落,哈哈.
打开外部链接采集功能. 原创集合是百度搜索某个关键字的结果页面的URL. 这最初称为外部链接采集(─.─|||.. 但是没关系,我们认为百度Google和Yahoo具有一些常见或独特的高级命令,因此请在搜索关键字输入框中输入: ananchor: 减肥inurl: bbs,哈哈,正如预期的那样,结果是很多论坛与减肥有关,在论坛中也有一些不相关的论坛,一些不相关的论坛在签名中有链接,而一些则是纯广告发布. ,高级搜索命令的用法很多,并且在一组中有大量的注释. 一些高级搜索命令的组合用法也非常有效.
很多时候,一些免费的seo工具的效果不仅取决于软件本身,还取决于使用seo工具的人. 即使手工艺品在手,如果您不能使用它,它也不会像其他人的砖头那么锋利. 我没有使用付费工具,也买不起(┬_┬),但是我已经在Internet上下载了一些破解版本. 我不得不说,除了可以骗钱的软件之外,某些付费的seo工具确实非常强大. 让SEOer节省了大量时间来实施. 我还没有看到链外采集到的工件. 如果有人知道,您可以与它分享~~~
但是,某些seo工具通常起辅助作用,而某些seo工具可能具有黑帽seo的作用. 请谨慎使用!
阿里巴巴会员信息采集软件在线帮助说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-08 19:47
下载URL
请先下载安装包“ GetAlibaba_Setup.rar”,解压后,双击“ Setup.exe”文件进行安装;安装完成后,双击桌面图片以运行软件,如下所示:
注意: 任务列表中名称之前的图标显示了任务的状态,如下所示:
在任务等待状态下,可以右键单击并选择开始采集任务数据;
任务运行状态,正在采集数据的任务状态,实时运行状态将显示在左下角,采集过程中的错误信息将显示在右下角;
任务完成状态表示任务采集已完成;
任务错误状态. 如果是错误状态,通常是由于无法正常关闭软件引起的,或者是在采集过程中出现网络错误引起的. 您可以通过用鼠标左键单击来选择任务,然后单击“停止”以恢复到等待状态. 重新开始采集.
*总采集: 创建新任务时,在网站上搜索结果时显示的结果总数;
*完成数量: 这是软件实际采集的数量. 这两个值基本上会有区别. 完成的数量将被过滤以去除重复的数量. 在采集过程中,由于错误而无法采集的那些不包括在完成的数量中. 因此,完成的数量通常将少于采集的总数.
*使用时间: 用于采集数据的时间,该时间可以在多次启动后累积;
*采集公司简介: 此功能仅对企业版用户可用,这意味着所采集的数据字段更加详细,请参阅版本功能比较表以了解详细信息;
一个: 如何创建新任务并开始采集?
第1步: 点击软件工具栏中的“新建”按钮以打开以下表单:
注意: 批量搜索功能不稳定. 你可以试试. 如果可以找到结果并创建任务,则可以使用它. 如果您无法搜索数据,请使用“按公司搜索”功能;
第2步: 打开软件的内置浏览器,该浏览器与在Ali网站上搜索“供应商”频道相对应;点击它直接访问阿里网站,输入关键词,并找到搜索结果,然后在右上角的“下一步”;如下图所示:
注意: 最近,阿里巴巴网站限制了每个关键字的显示. 目前,一个关键字最多可以显示3000个数据.
因此: 每个任务不能超过3000个数据. 因为阿里巴巴网站上的每个关键词搜索结果最多只能显示3000条数据. 在阿里巴巴网站上搜索关键字“服装”的搜索结果: 每页最多30条×最大显示100页= 3000条.
解决方案: 输入关键字时,可以按省,市,县和区进行搜索,并创建相应的任务以搜索所需的所有内容.
第3步: 填写任务属性,然后单击“确定”. 如下图所示:
注意: 关联馆藏中的馆藏公司介绍功能仅对企业版用户开放,个人版用户不能使用此功能;
步骤4: 选择新创建的任务,然后在工具栏上单击“开始”以开始采集;如下所示:
第5步: 如果打开第一个集合的软件,系统将提示您登录阿里巴巴网站,并且必须输入用户名和密码才能登录(如果您没有帐户,请注册作为免费会员);
成功登录后,单击右上角的“确定以注销”;然后开始采集,如下所示:
2. 采集的数据存储在哪里?
采集的任务数据将保存在软件安装目录下的Data目录中. 保存的数据库名称与ACCESS格式数据库中的任务名称相对应;
3. 如何将采集的数据导出到Excel工作表或Txt文本文件?
任务数据采集完成后,可以选择任务并右键单击鼠标,然后在弹出的集合中选择“查看任务数据”,如下所示:
显示所有数据后,可以在数据显示区域中右键单击鼠标,然后选择导出为Excel工作表或文本格式以导出数据;
如果要使用ACCESS数据库,请直接在软件安装目录下的Data中使用它. 此软件采集和保存的数据未加密,请放心使用.
4. 如何填写会员电子邮件地址?
任务数据采集完成后,可以选择任务并右键单击鼠标,然后在弹出的集合中选择“填写电子邮件地址”,如下所示:
在弹出窗口中选择需要填写电子邮件地址的任务,然后单击“开始”以自动填写成员邮箱,如下所示: 查看全部
单击此处下载软件:
下载URL
请先下载安装包“ GetAlibaba_Setup.rar”,解压后,双击“ Setup.exe”文件进行安装;安装完成后,双击桌面图片以运行软件,如下所示:
注意: 任务列表中名称之前的图标显示了任务的状态,如下所示:
在任务等待状态下,可以右键单击并选择开始采集任务数据;
任务运行状态,正在采集数据的任务状态,实时运行状态将显示在左下角,采集过程中的错误信息将显示在右下角;
任务完成状态表示任务采集已完成;
任务错误状态. 如果是错误状态,通常是由于无法正常关闭软件引起的,或者是在采集过程中出现网络错误引起的. 您可以通过用鼠标左键单击来选择任务,然后单击“停止”以恢复到等待状态. 重新开始采集.
*总采集: 创建新任务时,在网站上搜索结果时显示的结果总数;
*完成数量: 这是软件实际采集的数量. 这两个值基本上会有区别. 完成的数量将被过滤以去除重复的数量. 在采集过程中,由于错误而无法采集的那些不包括在完成的数量中. 因此,完成的数量通常将少于采集的总数.
*使用时间: 用于采集数据的时间,该时间可以在多次启动后累积;
*采集公司简介: 此功能仅对企业版用户可用,这意味着所采集的数据字段更加详细,请参阅版本功能比较表以了解详细信息;
一个: 如何创建新任务并开始采集?
第1步: 点击软件工具栏中的“新建”按钮以打开以下表单:
注意: 批量搜索功能不稳定. 你可以试试. 如果可以找到结果并创建任务,则可以使用它. 如果您无法搜索数据,请使用“按公司搜索”功能;
第2步: 打开软件的内置浏览器,该浏览器与在Ali网站上搜索“供应商”频道相对应;点击它直接访问阿里网站,输入关键词,并找到搜索结果,然后在右上角的“下一步”;如下图所示:
注意: 最近,阿里巴巴网站限制了每个关键字的显示. 目前,一个关键字最多可以显示3000个数据.
因此: 每个任务不能超过3000个数据. 因为阿里巴巴网站上的每个关键词搜索结果最多只能显示3000条数据. 在阿里巴巴网站上搜索关键字“服装”的搜索结果: 每页最多30条×最大显示100页= 3000条.
解决方案: 输入关键字时,可以按省,市,县和区进行搜索,并创建相应的任务以搜索所需的所有内容.
第3步: 填写任务属性,然后单击“确定”. 如下图所示:
注意: 关联馆藏中的馆藏公司介绍功能仅对企业版用户开放,个人版用户不能使用此功能;
步骤4: 选择新创建的任务,然后在工具栏上单击“开始”以开始采集;如下所示:
第5步: 如果打开第一个集合的软件,系统将提示您登录阿里巴巴网站,并且必须输入用户名和密码才能登录(如果您没有帐户,请注册作为免费会员);
成功登录后,单击右上角的“确定以注销”;然后开始采集,如下所示:
2. 采集的数据存储在哪里?
采集的任务数据将保存在软件安装目录下的Data目录中. 保存的数据库名称与ACCESS格式数据库中的任务名称相对应;
3. 如何将采集的数据导出到Excel工作表或Txt文本文件?
任务数据采集完成后,可以选择任务并右键单击鼠标,然后在弹出的集合中选择“查看任务数据”,如下所示:
显示所有数据后,可以在数据显示区域中右键单击鼠标,然后选择导出为Excel工作表或文本格式以导出数据;
如果要使用ACCESS数据库,请直接在软件安装目录下的Data中使用它. 此软件采集和保存的数据未加密,请放心使用.
4. 如何填写会员电子邮件地址?
任务数据采集完成后,可以选择任务并右键单击鼠标,然后在弹出的集合中选择“填写电子邮件地址”,如下所示:
在弹出窗口中选择需要填写电子邮件地址的任务,然后单击“开始”以自动填写成员邮箱,如下所示:
最新版本的客户全面采集软件(网站数据编译)v4.21
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-08-08 19:46
最新版本的客户集成采集软件简介
同时,它还可以采集搜索引擎(百度搜索,360搜索,必应搜索)和其他常见搜索引擎.
是专业的网站页面资源搜索和分类软件,使用相关行业的网站作为数据源,可以采集马可波罗,慧聪网,阿图博,中国制造,Toocle,集通宝,金帝,搜搜等网站,西蒙国际,第一枪,世界工厂,淘一巴巴,五友.com,商贸网,汇商网,宜商网等资源网站将在以后增加. 您可以选择网站,城市,行业分类和其他条件来搜索所需的数据. 这些属性包括“来源网站,类别,标题,联系人,联系信息,省,市,发行日期”等.
客户综合采集软件最新版本的功能:
该软件还具有自动重复过滤,号码所有权过滤功能,反限制采集设置功能(在大多数情况下可以避免不受限制),导出Excel文件功能,导出TXT文件功能. 历史数据查询功能(只要采集了信息,就可以去“搜索查询”中找出来).
傻瓜式操作,只需用鼠标单击,无需编写任何采集规则,即可直接导出Excel文件,一键导入手机通讯录,适合微信营销. 】除了采集功能 查看全部
对于从事在线销售行业的小伙伴而言,客户采集非常重要,因此您应使用最新版本的客户综合采集软件来高度重视网站数据采集,以及最新版本的客户综合采集软件您可以采集各种大型资源网站,例如Toocle,中国制造,Atubo,Huicong,Marco Polo等,还可以选择城市,行业分类等来选择数据需要!
最新版本的客户集成采集软件简介
同时,它还可以采集搜索引擎(百度搜索,360搜索,必应搜索)和其他常见搜索引擎.
是专业的网站页面资源搜索和分类软件,使用相关行业的网站作为数据源,可以采集马可波罗,慧聪网,阿图博,中国制造,Toocle,集通宝,金帝,搜搜等网站,西蒙国际,第一枪,世界工厂,淘一巴巴,五友.com,商贸网,汇商网,宜商网等资源网站将在以后增加. 您可以选择网站,城市,行业分类和其他条件来搜索所需的数据. 这些属性包括“来源网站,类别,标题,联系人,联系信息,省,市,发行日期”等.
客户综合采集软件最新版本的功能:
该软件还具有自动重复过滤,号码所有权过滤功能,反限制采集设置功能(在大多数情况下可以避免不受限制),导出Excel文件功能,导出TXT文件功能. 历史数据查询功能(只要采集了信息,就可以去“搜索查询”中找出来).
傻瓜式操作,只需用鼠标单击,无需编写任何采集规则,即可直接导出Excel文件,一键导入手机通讯录,适合微信营销. 】除了采集功能
使用日志飞行员进行日志采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2020-08-07 19:24
log-Pilot当前支持两种工具来采集日志,即Fluentd插件和Filebeat插件.
Log-Pilot支持容器事件管理. 它可以动态监视容器的事件变化,然后根据容器标签进行解析,生成日志采集配置文件,然后将其移交给采集插件以进行日志采集.
在Kubernetes下,Log-Pilot可以基于环境变量aliyun_logs_ $ name = $ path来动态生成日志采集配置文件,该环境变量收录两个变量:
部署示例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-pilot
labels:
app: log-pilot
namespace: kube-ops
spec:
selector:
matchLabels:
app: log-pilot
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: log-pilot
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: log-pilot
image: registry.cn-hangzhou.aliyuncs.com/acs/log-pilot:0.9.7-filebeat
resources:
limits:
memory: 500Mi
requests:
cpu: 200m
memory: 200Mi
env:
- name: "NODE_NAME"
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# 日志收集前缀
- name: PILOT_LOG_PREFIX
value: aliyun
- name: "LOGGING_OUTPUT"
value: "elasticsearch"
# 请确保集群到ES网络可达
- name: "ELASTICSEARCH_HOSTS"
value: "elasticsearch:9200"
# 配置ES访问权限
#- name: "ELASTICSEARCH_USER"
# value: "{es_username}"
#- name: "ELASTICSEARCH_PASSWORD"
# value: "{es_password}"
volumeMounts:
- name: sock
mountPath: /var/run/docker.sock
- name: root
mountPath: /host
readOnly: true
- name: varlib
mountPath: /var/lib/filebeat
- name: varlog
mountPath: /var/log/filebeat
- name: localtime
mountPath: /etc/localtime
readOnly: true
livenessProbe:
failureThreshold: 3
exec:
command:
- /pilot/healthz
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/docker.sock
- name: root
hostPath:
path: /
- name: varlib
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: varlog
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /etc/localtim
创建广告连播测试
apiVersion: v1
kind: Pod
metadata:
name: tomcat
spec:
containers:
- name: tomcat
image: "tomcat:8.0"
env:
# 1、stdout为约定关键字,表示采集标准输出日志
# 2、配置标准输出日志采集到ES的catalina索引下
- name: aliyun_logs_catalina
value: "stdout"
# 1、配置采集容器内文件日志,支持通配符
# 2、配置该日志采集到ES的access索引下
- name: aliyun_logs_access
value: "/usr/local/tomcat/logs/catalina.*.log"
# 容器内文件日志路径需要配置emptyDir
volumeMounts:
- name: tomcat-log
mountPath: /usr/local/tomcat/logs
volumes:
- name: tomcat-log
emptyDir: {}
然后,我们检查索引并查看access-和catalina-的索引
# curl -XGET 'localhost:9200/_cat/indices?v&pretty'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open access-2020.06.23 0LS6STfpQ4yHt7makuSI1g 5 1 40 0 205.5kb 102.5kb
green open logstash-2020.06.23 HR62innTQi6HjObIzf6DHw 5 1 99 0 296kb 148kb
green open catalina-2020.06.23 dSFGcZlPS6-wieFKrOWV-g 5 1 40 0 227.1kb 133.3kb
green open .kibana H-TAto8QTxmi-jI_4mIUrg 1 1 2 0 20.4kb 10.2kb
green open logstash-2020.06.22 8-IFAOj_SqiipqOXN6Soxw 5 1 43784 0 30.6mb 15.3mb
然后在页面上添加索引.
当然,除了直接输出到es之外,日志输出还可以输出到其他地方. 如果您正在使用filebeat,则可以单击此处查看. 如果需要,请单击此处. 查看全部
log-Pilot是一个智能容器日志采集工具. 它不仅可以高效便捷地将容器日志采集和输出到各种存储日志后端,还可以动态发现并采集容器内部的日志文件. 更多咨询,您可以在这里移动.
log-Pilot当前支持两种工具来采集日志,即Fluentd插件和Filebeat插件.
Log-Pilot支持容器事件管理. 它可以动态监视容器的事件变化,然后根据容器标签进行解析,生成日志采集配置文件,然后将其移交给采集插件以进行日志采集.
在Kubernetes下,Log-Pilot可以基于环境变量aliyun_logs_ $ name = $ path来动态生成日志采集配置文件,该环境变量收录两个变量:
部署示例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: log-pilot
labels:
app: log-pilot
namespace: kube-ops
spec:
selector:
matchLabels:
app: log-pilot
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
app: log-pilot
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: log-pilot
image: registry.cn-hangzhou.aliyuncs.com/acs/log-pilot:0.9.7-filebeat
resources:
limits:
memory: 500Mi
requests:
cpu: 200m
memory: 200Mi
env:
- name: "NODE_NAME"
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# 日志收集前缀
- name: PILOT_LOG_PREFIX
value: aliyun
- name: "LOGGING_OUTPUT"
value: "elasticsearch"
# 请确保集群到ES网络可达
- name: "ELASTICSEARCH_HOSTS"
value: "elasticsearch:9200"
# 配置ES访问权限
#- name: "ELASTICSEARCH_USER"
# value: "{es_username}"
#- name: "ELASTICSEARCH_PASSWORD"
# value: "{es_password}"
volumeMounts:
- name: sock
mountPath: /var/run/docker.sock
- name: root
mountPath: /host
readOnly: true
- name: varlib
mountPath: /var/lib/filebeat
- name: varlog
mountPath: /var/log/filebeat
- name: localtime
mountPath: /etc/localtime
readOnly: true
livenessProbe:
failureThreshold: 3
exec:
command:
- /pilot/healthz
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 2
securityContext:
capabilities:
add:
- SYS_ADMIN
terminationGracePeriodSeconds: 30
volumes:
- name: sock
hostPath:
path: /var/run/docker.sock
- name: root
hostPath:
path: /
- name: varlib
hostPath:
path: /var/lib/filebeat
type: DirectoryOrCreate
- name: varlog
hostPath:
path: /var/log/filebeat
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /etc/localtim
创建广告连播测试
apiVersion: v1
kind: Pod
metadata:
name: tomcat
spec:
containers:
- name: tomcat
image: "tomcat:8.0"
env:
# 1、stdout为约定关键字,表示采集标准输出日志
# 2、配置标准输出日志采集到ES的catalina索引下
- name: aliyun_logs_catalina
value: "stdout"
# 1、配置采集容器内文件日志,支持通配符
# 2、配置该日志采集到ES的access索引下
- name: aliyun_logs_access
value: "/usr/local/tomcat/logs/catalina.*.log"
# 容器内文件日志路径需要配置emptyDir
volumeMounts:
- name: tomcat-log
mountPath: /usr/local/tomcat/logs
volumes:
- name: tomcat-log
emptyDir: {}
然后,我们检查索引并查看access-和catalina-的索引
# curl -XGET 'localhost:9200/_cat/indices?v&pretty'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open access-2020.06.23 0LS6STfpQ4yHt7makuSI1g 5 1 40 0 205.5kb 102.5kb
green open logstash-2020.06.23 HR62innTQi6HjObIzf6DHw 5 1 99 0 296kb 148kb
green open catalina-2020.06.23 dSFGcZlPS6-wieFKrOWV-g 5 1 40 0 227.1kb 133.3kb
green open .kibana H-TAto8QTxmi-jI_4mIUrg 1 1 2 0 20.4kb 10.2kb
green open logstash-2020.06.22 8-IFAOj_SqiipqOXN6Soxw 5 1 43784 0 30.6mb 15.3mb
然后在页面上添加索引.
当然,除了直接输出到es之外,日志输出还可以输出到其他地方. 如果您正在使用filebeat,则可以单击此处查看. 如果需要,请单击此处.

