
采集系
使用Spark Streaming实施分布式采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 407 次浏览 • 2020-08-07 10:10
在我在微信矩中发布段落之前,解释了Spark Streaming不仅是流计算,而且是一种通用模型,使您可以专注于业务逻辑而无需关注分布式相关问题并快速解决业务问题.
前言
两天前,我刚刚在一篇文章中讲道,数据本质上是流式传输,并指出:
批处理计算一直在缓慢地退化,未来必须属于流计算. 数据流必须由数据本身驱动.
就高层概念而言,Spark Streaming完美地集成了批处理和流计算,使它们能够在您和我之间拥有我. 这种设计使Spark Streaming成为流计算的载体,并且还可以为需要分布式体系结构的其他问题提供解决方案.
Spark Streaming作为某些分布式任务系统的基础的优势
它自然是分布式的,因此无需担心实现分布式协调
基于任务的任务执行机制,任务数可以随意控制
无需关注机器,它是面向资源的,使得部署极其简单,声明资源,提交,结束
完全集成的输入和输出,包括HDFS / Kafka / ElasticSearch / HBase / MySQL / Redis等,
成熟而简单的运算符使您的数据处理变得极其简单
StreamingPro项目简化了声明性或复杂的Spark Streaming程序,同时,它还可以通过StreamingPro提供的Rest接口增强Spark Streaming Driver的交互功能.
现在以标题中的采集系统为例. 您只需要为整个事情实现采集逻辑. 至于特定的元数据读取,只要简单的配置或使用现成的组件,结果就可以存储在任何地方,并且最终部署只需要简单的声明即可. 可以将资源放置在可以灵活扩展的群集上.
有关此作品的概念,请参阅
开发采集系统的动机
当前,此采集系统主要用于监视. 每当公司或部门拥有大量开源系统时,每个开源组件将提供大约三种类型的输出:
标准指标输出,方便您集成到神经节等监控系统中
Spark,Storm,HBase等Web UI均提供自己的Web界面等.
Rest接口,主要是JSon,XML,字符串
但是对于监视来说,前两个是直观且易于使用的,但是它们也存在很大的问题:
度量标准直接输出到监视系统意味着无法自定义它. 如果我想将多个指标放在一起,这可能很难实现.
Web UI需要有人看到它
相反,Rest接口是最灵活的,但是您需要做自己的写逻辑,例如获取数据,处理然后做自己的演示. 问题是,如果我要获取数千个Rest接口数据,并且需要一种非常方便的方法来提取所需的值(或指标). 这涉及两个问题:
可能有很多采集接口. 如何使采集程序在水平方向上可扩展?
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,允许用户通过简单的配置提取内容?
系统处理结构
QQ20160529-1@2x.png
一般信息提取方案
回到上面的问题,
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,以便用户可以通过简单的配置提取内容
Rest接口返回的数据仅是四种类型:
HTML
JSON
XML
TEXT
对于1,我们暂不讨论. 对于JSON,XML,我们可以使用XPATH,对于TEXT,我们可以使用标准的常规或ETL进行提取.
当我们定义要采集的URL时,我们需要同时配置要采集的索引和相应索引的XPATH路径或规则性. 当然,逻辑也可以由后端的ETL完成. 但是,现在我们已经将Spark Streaming用作采集系统,我们自然可以使用其强大的数据处理功能来完成必要的格式化操作. 因此,我们建议直接在采集系统中进行此操作.
采集系统
数据源的可能数据结构:
appName 采集的应用名称,cluster1,cluster2
appType 采集的应用类型,storm/zookeeper/yarn 等
url 需要采集的接口
params 可能存在例如post请求之类的,需要额外的请求参数
method Get/POST/PUT 等请求方法体
key_search_qps : $.store.book[0].author 定义需要抽取的指标名称以及在Response 对应的XPATH 路径
key_..... 可以有更多的XPATH
key_..... 可以有更多的XPATH
extraParams 人工填写一些其他参数
获取系统通过我们打包的DInputStream获取这些数据,然后根据批处理(计划周期)获取这些数据,然后将其传递给特定的执行逻辑以进行执行. 使用StreamingPro,将像这样:
"RestCatch": { "desc": "RestCatch", "strategy": "....SparkStreamingStrategy", "algorithm": [], "ref": [], "compositor": [
{ "name": "....ESInputCompositor", "params": [
{ "es.nodes": "....", "es.resource": "monitor_rest/rest"
}
]
},
{ "name": ".....RestFetchCompositor",//发起http请求,获取response
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": "....JSonExtractCompositor",//根据XPath获取response里的指标
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": ".....ConsoleOutputCompositor",//输出结果
"params": []
}
], "configParams": {
}
}
通过上述配置文件,您可以很好地看到处理流程.
输入采集来源
采集结果
根据XPATH提取指标
输出结果
创建元数据管理系统
元数据管理系统是必需的,它可以帮助您添加新的URL监视项目. 使用StreamingPro,您可以将元数据管理页面添加到Spark Streaming的驱动程序,以实现元数据操作逻辑. 将来,我们将提供更好的教程,介绍如何通过StreamingPro将自定义的Rest界面/网页添加到Spark Streaming.
结束了吗?
以上实际上是采集系统的原型. 得益于Spark Streaming的自然分布和灵活的运算符,我们的系统足够灵活,可以水平缩放.
但是,您会发现
如果每个接口需要不同的采集期限怎么办?
如果我想获得更好的容错能力?
如何实现更好的动态扩展?
第一个问题很好地解决了. 我们在元数据中定义采集周期,并将Spark Streaming的调度周期设置为最小粒度.
第二个问题是业务级别的容错能力,但是如果任务失败,Spark Streaming将尝试重新计划并重试. 我们建议您自己做.
第三,只要打开动态资源分配,就可以根据情况扩展和利用资源.
作者: William Zhu
链接: 查看全部
前言
两天前,我刚刚在一篇文章中讲道,数据本质上是流式传输,并指出:
批处理计算一直在缓慢地退化,未来必须属于流计算. 数据流必须由数据本身驱动.
就高层概念而言,Spark Streaming完美地集成了批处理和流计算,使它们能够在您和我之间拥有我. 这种设计使Spark Streaming成为流计算的载体,并且还可以为需要分布式体系结构的其他问题提供解决方案.
Spark Streaming作为某些分布式任务系统的基础的优势
它自然是分布式的,因此无需担心实现分布式协调
基于任务的任务执行机制,任务数可以随意控制
无需关注机器,它是面向资源的,使得部署极其简单,声明资源,提交,结束
完全集成的输入和输出,包括HDFS / Kafka / ElasticSearch / HBase / MySQL / Redis等,
成熟而简单的运算符使您的数据处理变得极其简单
StreamingPro项目简化了声明性或复杂的Spark Streaming程序,同时,它还可以通过StreamingPro提供的Rest接口增强Spark Streaming Driver的交互功能.
现在以标题中的采集系统为例. 您只需要为整个事情实现采集逻辑. 至于特定的元数据读取,只要简单的配置或使用现成的组件,结果就可以存储在任何地方,并且最终部署只需要简单的声明即可. 可以将资源放置在可以灵活扩展的群集上.
有关此作品的概念,请参阅
开发采集系统的动机
当前,此采集系统主要用于监视. 每当公司或部门拥有大量开源系统时,每个开源组件将提供大约三种类型的输出:
标准指标输出,方便您集成到神经节等监控系统中
Spark,Storm,HBase等Web UI均提供自己的Web界面等.
Rest接口,主要是JSon,XML,字符串
但是对于监视来说,前两个是直观且易于使用的,但是它们也存在很大的问题:
度量标准直接输出到监视系统意味着无法自定义它. 如果我想将多个指标放在一起,这可能很难实现.
Web UI需要有人看到它
相反,Rest接口是最灵活的,但是您需要做自己的写逻辑,例如获取数据,处理然后做自己的演示. 问题是,如果我要获取数千个Rest接口数据,并且需要一种非常方便的方法来提取所需的值(或指标). 这涉及两个问题:
可能有很多采集接口. 如何使采集程序在水平方向上可扩展?
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,允许用户通过简单的配置提取内容?
系统处理结构
QQ20160529-1@2x.png
一般信息提取方案
回到上面的问题,
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,以便用户可以通过简单的配置提取内容
Rest接口返回的数据仅是四种类型:
HTML
JSON
XML
TEXT
对于1,我们暂不讨论. 对于JSON,XML,我们可以使用XPATH,对于TEXT,我们可以使用标准的常规或ETL进行提取.
当我们定义要采集的URL时,我们需要同时配置要采集的索引和相应索引的XPATH路径或规则性. 当然,逻辑也可以由后端的ETL完成. 但是,现在我们已经将Spark Streaming用作采集系统,我们自然可以使用其强大的数据处理功能来完成必要的格式化操作. 因此,我们建议直接在采集系统中进行此操作.
采集系统
数据源的可能数据结构:
appName 采集的应用名称,cluster1,cluster2
appType 采集的应用类型,storm/zookeeper/yarn 等
url 需要采集的接口
params 可能存在例如post请求之类的,需要额外的请求参数
method Get/POST/PUT 等请求方法体
key_search_qps : $.store.book[0].author 定义需要抽取的指标名称以及在Response 对应的XPATH 路径
key_..... 可以有更多的XPATH
key_..... 可以有更多的XPATH
extraParams 人工填写一些其他参数
获取系统通过我们打包的DInputStream获取这些数据,然后根据批处理(计划周期)获取这些数据,然后将其传递给特定的执行逻辑以进行执行. 使用StreamingPro,将像这样:
"RestCatch": { "desc": "RestCatch", "strategy": "....SparkStreamingStrategy", "algorithm": [], "ref": [], "compositor": [
{ "name": "....ESInputCompositor", "params": [
{ "es.nodes": "....", "es.resource": "monitor_rest/rest"
}
]
},
{ "name": ".....RestFetchCompositor",//发起http请求,获取response
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": "....JSonExtractCompositor",//根据XPath获取response里的指标
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": ".....ConsoleOutputCompositor",//输出结果
"params": []
}
], "configParams": {
}
}
通过上述配置文件,您可以很好地看到处理流程.
输入采集来源
采集结果
根据XPATH提取指标
输出结果
创建元数据管理系统
元数据管理系统是必需的,它可以帮助您添加新的URL监视项目. 使用StreamingPro,您可以将元数据管理页面添加到Spark Streaming的驱动程序,以实现元数据操作逻辑. 将来,我们将提供更好的教程,介绍如何通过StreamingPro将自定义的Rest界面/网页添加到Spark Streaming.
结束了吗?
以上实际上是采集系统的原型. 得益于Spark Streaming的自然分布和灵活的运算符,我们的系统足够灵活,可以水平缩放.
但是,您会发现
如果每个接口需要不同的采集期限怎么办?
如果我想获得更好的容错能力?
如何实现更好的动态扩展?
第一个问题很好地解决了. 我们在元数据中定义采集周期,并将Spark Streaming的调度周期设置为最小粒度.
第二个问题是业务级别的容错能力,但是如果任务失败,Spark Streaming将尝试重新计划并重试. 我们建议您自己做.
第三,只要打开动态资源分配,就可以根据情况扩展和利用资源.
作者: William Zhu
链接: 查看全部
在我在微信矩中发布段落之前,解释了Spark Streaming不仅是流计算,而且是一种通用模型,使您可以专注于业务逻辑而无需关注分布式相关问题并快速解决业务问题.
前言
两天前,我刚刚在一篇文章中讲道,数据本质上是流式传输,并指出:
批处理计算一直在缓慢地退化,未来必须属于流计算. 数据流必须由数据本身驱动.
就高层概念而言,Spark Streaming完美地集成了批处理和流计算,使它们能够在您和我之间拥有我. 这种设计使Spark Streaming成为流计算的载体,并且还可以为需要分布式体系结构的其他问题提供解决方案.
Spark Streaming作为某些分布式任务系统的基础的优势
它自然是分布式的,因此无需担心实现分布式协调
基于任务的任务执行机制,任务数可以随意控制
无需关注机器,它是面向资源的,使得部署极其简单,声明资源,提交,结束
完全集成的输入和输出,包括HDFS / Kafka / ElasticSearch / HBase / MySQL / Redis等,
成熟而简单的运算符使您的数据处理变得极其简单
StreamingPro项目简化了声明性或复杂的Spark Streaming程序,同时,它还可以通过StreamingPro提供的Rest接口增强Spark Streaming Driver的交互功能.
现在以标题中的采集系统为例. 您只需要为整个事情实现采集逻辑. 至于特定的元数据读取,只要简单的配置或使用现成的组件,结果就可以存储在任何地方,并且最终部署只需要简单的声明即可. 可以将资源放置在可以灵活扩展的群集上.
有关此作品的概念,请参阅
开发采集系统的动机
当前,此采集系统主要用于监视. 每当公司或部门拥有大量开源系统时,每个开源组件将提供大约三种类型的输出:
标准指标输出,方便您集成到神经节等监控系统中
Spark,Storm,HBase等Web UI均提供自己的Web界面等.
Rest接口,主要是JSon,XML,字符串
但是对于监视来说,前两个是直观且易于使用的,但是它们也存在很大的问题:
度量标准直接输出到监视系统意味着无法自定义它. 如果我想将多个指标放在一起,这可能很难实现.
Web UI需要有人看到它
相反,Rest接口是最灵活的,但是您需要做自己的写逻辑,例如获取数据,处理然后做自己的演示. 问题是,如果我要获取数千个Rest接口数据,并且需要一种非常方便的方法来提取所需的值(或指标). 这涉及两个问题:
可能有很多采集接口. 如何使采集程序在水平方向上可扩展?
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,允许用户通过简单的配置提取内容?
系统处理结构
QQ20160529-1@2x.png
一般信息提取方案
回到上面的问题,
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,以便用户可以通过简单的配置提取内容
Rest接口返回的数据仅是四种类型:
HTML
JSON
XML
TEXT
对于1,我们暂不讨论. 对于JSON,XML,我们可以使用XPATH,对于TEXT,我们可以使用标准的常规或ETL进行提取.
当我们定义要采集的URL时,我们需要同时配置要采集的索引和相应索引的XPATH路径或规则性. 当然,逻辑也可以由后端的ETL完成. 但是,现在我们已经将Spark Streaming用作采集系统,我们自然可以使用其强大的数据处理功能来完成必要的格式化操作. 因此,我们建议直接在采集系统中进行此操作.
采集系统
数据源的可能数据结构:
appName 采集的应用名称,cluster1,cluster2
appType 采集的应用类型,storm/zookeeper/yarn 等
url 需要采集的接口
params 可能存在例如post请求之类的,需要额外的请求参数
method Get/POST/PUT 等请求方法体
key_search_qps : $.store.book[0].author 定义需要抽取的指标名称以及在Response 对应的XPATH 路径
key_..... 可以有更多的XPATH
key_..... 可以有更多的XPATH
extraParams 人工填写一些其他参数
获取系统通过我们打包的DInputStream获取这些数据,然后根据批处理(计划周期)获取这些数据,然后将其传递给特定的执行逻辑以进行执行. 使用StreamingPro,将像这样:
"RestCatch": { "desc": "RestCatch", "strategy": "....SparkStreamingStrategy", "algorithm": [], "ref": [], "compositor": [
{ "name": "....ESInputCompositor", "params": [
{ "es.nodes": "....", "es.resource": "monitor_rest/rest"
}
]
},
{ "name": ".....RestFetchCompositor",//发起http请求,获取response
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": "....JSonExtractCompositor",//根据XPath获取response里的指标
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": ".....ConsoleOutputCompositor",//输出结果
"params": []
}
], "configParams": {
}
}
通过上述配置文件,您可以很好地看到处理流程.
输入采集来源
采集结果
根据XPATH提取指标
输出结果
创建元数据管理系统
元数据管理系统是必需的,它可以帮助您添加新的URL监视项目. 使用StreamingPro,您可以将元数据管理页面添加到Spark Streaming的驱动程序,以实现元数据操作逻辑. 将来,我们将提供更好的教程,介绍如何通过StreamingPro将自定义的Rest界面/网页添加到Spark Streaming.
结束了吗?
以上实际上是采集系统的原型. 得益于Spark Streaming的自然分布和灵活的运算符,我们的系统足够灵活,可以水平缩放.
但是,您会发现
如果每个接口需要不同的采集期限怎么办?
如果我想获得更好的容错能力?
如何实现更好的动态扩展?
第一个问题很好地解决了. 我们在元数据中定义采集周期,并将Spark Streaming的调度周期设置为最小粒度.
第二个问题是业务级别的容错能力,但是如果任务失败,Spark Streaming将尝试重新计划并重试. 我们建议您自己做.
第三,只要打开动态资源分配,就可以根据情况扩展和利用资源.
作者: William Zhu
链接:
[在线版]安徽省政府保险部门数据采集.doc 16页
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-06 08:12
安徽省政府机关事业单位养老保险数据采集系统[在线版本]单位充填端用户操作手册介绍了在线版本数据采集系统的建设目标,一是确保数据质量和安全,二是另一个是减少参与单位的数据. 提交的数量提高了工作效率. 激活用户后,被保险单位可以登录系统以处理单位信息维护,在职人员信息填写,退休人员信息填写,人员信息修改,数据提交和表格打印. 另外,对于具有许多下属(非独立法人)和分支机构的单位,提供了分支机构和用户的分发管理功能(需要申请),以便下级组织用户可以分别填写信息. 最后,主管部门可以结合多个组织数据报告. 目标受众: 参加政府机构和事业单位(基本法人)职工基本养老保险的所有单位(独立法人). 各级机关事业单位办理基本养老保险. 文档版本说明日期内容摘要版本准备/修订版审查2016-8-17根据8日15日,业务和信息部门讨论了要点,改进版本V0.1潘伟,张旺杰2016-8- 23将单元信息和现有信息中的一些数据项相关联;修改系统界面V0.2张望杰潘伟2016-09-04根据业务部门的需求,做了相应的功能和接口修改V0.3张望杰2016-09-20根据业务部门的需求,做了相应的功能和界面修改V1.0张望杰目录1.单位用户激活41.用户激活42.首次登录5 2.单位数据采集操作说明61.单位信息采集62.在职人员采集73.退休人员采集84.在职人员信息修改85.退休人员信息修改106.人员信息删除107.数据报告108.报告打印119.报告导出1210.修改密码12 3.分支机构数据采集的操作说明131,新分支增加了132,机构摘要查询143,分支机构管理144,分支机构数据采集15个单元用户启用*浏览建议: 确保此系统可以正常使用,建议您使用Google,Firefox,IE10.0或更高版本以及360安全浏览器访问速度模式.
用户激活进入在线采集系统,然后单击[激活]按钮进入单元用户激活页面. 依次填写所需信息项后,单击[单击获取验证码]按钮,系统将在单元提交的初始化信息中向管理员的手机发送短信验证码,输入接收到的验证码,然后单击[立即激活],系统提示激活成功后,请单击[返回登录]按钮,返回登录页面. 首次登录时返回登录页面,依次输入用户名(特殊管理员的手机号码),密码和其他代码,然后单击[登录]按钮进行首次登录: 单位数据采集操作说明单位信息登录单位用户登录系统,应根据填写口径的要求填写被保险人((用人,退休)信息),所有被保险人经过登记检查后,将进行数据采集报告完成后,该单位将按照我省处理规定的要求将有关纸质材料送交处理机构审查,批准的数据由处理人员确认并激活,以完成保险. 登记工作,单位信息采集单位首次登录系统后,需要根据单位信息完成进入系统提示. 在主登录界面单击“单位信息采集”,进入单位信息采集页面. 根据需要输入单位信息. 红色星号是必需的. 填写完信息后,单击[保存]按钮以保存设备信息. 保存成功后,提示“单位信息保存成功”,单击[确定]完成单位信息. 采集在职人员采集在职人员必须首先根据以下步骤输入在职人员信息项信息项的名称. 其中,“工资申报信息”基于“代理保险的参保年月”. 随后几年的平均每月付款工资. 例如,如果第一次参加该保险是2014年11月,则需要输入2013、2014和2015年的平均每月支付工资.
注意: 1.是否为特殊工作: 默认为“否”. 如果是,则需要填写从事特殊工作的累计月数; 2.“是否在201410年之后转移系统?3.如果当前人员信息列为“人员类别”判断与单位的“组织类型”不一致,则需要填写“人员类别描述”以说明原因,填写完人员信息后,单击[保存并添加下一个]按钮以保存当前人员信息,并继续填写人员信息,退休人员必须首先根据信息项的名称输入退休人员信息. 采集退休人员信息,带*号为必填项,系统自动输入退休日期注意: 1.是否为特殊工作类型: 如果选择“是”,则默认为“否” ”,则需要填写从事特殊工作的累计月数; 2.如果“退休年月”在2014年10月之前,则只需填写“人员”的“职务”信息化退休”. 3,在“银行信息采集”栏中,“是否代发金融社会保障卡,以修改在位信息,需要先修改在位信息的在位人”修改后,单击[查询]按钮,查询需要修改的在职人员,双击需要修改的人员信息项,进入修改界面,并修改需要修改的信息项. 修改完成后,点击[保存]按钮,保存在位信息并完成在位信息的修改退休人员信息的修改退休人员信息的修改需要在需要修改的人员中首先输入“文件号”或“姓名”. ,然后单击[查询]按钮以查询需要修改的退休人员,双击要修改的退休人员信息项,然后输入信息页面,修改需要修改的信息项.
完成修改后,单击[保存]按钮以保存退休人员信息并完成退休人员信息的修改. 要删除人员信息,请单击系统功能界面上的[删除人员信息]按钮,进入人员信息删除界面,输入“单据号”或“名称”,然后单击[查询]按钮,查询要删除的人员信息. 删除,或直接单击[查询]按钮,查询所有人员,检查需要失效的人员信息,然后单击上方的[删除]按钮,系统将弹出提示框,提示“删除所选人员信息” ”,单击[是]按钮以确认删除. 要报告数据,必须首先双击以查看人员的详细信息,或者可以通过[导出员工名册]或[导出退休人员名册]查看人员信息,然后单击[在职人员报告]或[退休] ]确认后. 人员申报]在职或离职人员的数据报告已完成. 注意: 报告数据后,将无法对其进行修改. 报告数据后,如果发现错误,则处理机构必须在修改之前将其返回. 报告打印报告打印包括单位注册信息打印,分支单位信息打印,在职人员花名册打印,退休人员花名册打印和离开单位花名册打印. 需要在报告导出系统中导出报告打印,然后单击所需的导出报告按钮以导出相应的表. 要修改密码以修改系统登录密码,请单击页面顶部的[修改密码]按钮: 可以跳转到密码修改界面: 根据需要输入原创密码,新密码和短信验证码完成密码修改. 分支机构数据采集的操作说明如果被保险单位很多或分支机构很多,可以通过建立分支机构来报告人员数据.
系统提供了新的监督部门分支机构的功能(只有在得到处理用户的批准后才能使用),主机构可以选择是否允许分支机构建立下级机构建立分支时分支. 分支机构登录系统后,报告分支机构的参保人员. 申请完成并检查后,可以提交数据(给主管组织). 主管单位可以使用[分支单位摘要查询]按钮查看该单元建立的分支的数据填充状态和当前填充状态. 仅当所有分支机构都完成了数据报告(就业和退休)后,该单位才能提交数据. 如果分支机构中的一名员工(工作或退休)为空,则还需要单击数据报告进行确认. 分支机构新添加的监控单元,单击系统功能界面上的[添加新分支机构]按钮,进入新的分支机构添加界面. 根据需要填写信息项后,单击[保存]按钮以完成新分支信息的报告. 在完成新添加的分支机构信息的报告后,需要由主管的处理机构对其进行审核和批准,然后分支机构才能通过处理人员的“手机号码”作为用户名和密码登录到系统. 组织摘要查询主要组织可以直接在系统功能界面上单击以直接单击分支机构管理分支机构管理功能,需要首先单击系统功能界面中的[分支机构管理]按钮,进入分支机构管理界面: 您可以输入分支机构名称,操作员或处理者的手机号码可以查询对应的分支机构信息,也可以直接单击查询查询组织的所有分支机构信息. 主体组织可以删除添加的分支机构,也可以取消分支机构通过分支机构管理部门报告的现任或退休人员. 此外,您还可以修改分支名称和处理程序的名称,双击相应的信息项,然后单击“保存”以完成修改. 分支机构数据采集分支机构登录后,与主机相比,系统功能界面缺少一些与分支机构无关的功能,如单元信息采集. 有关分支单位的数据采集,请参阅监控单元的数据采集操作说明. 安徽省政府事业单位养老保险数据采集系统[在线版]用户手册152 查看全部
用户激活进入在线采集系统,然后单击[激活]按钮进入单元用户激活页面. 依次填写所需信息项后,单击[单击获取验证码]按钮,系统将在单元提交的初始化信息中向管理员的手机发送短信验证码,输入接收到的验证码,然后单击[立即激活],系统提示激活成功后,请单击[返回登录]按钮,返回登录页面. 首次登录时返回登录页面,依次输入用户名(特殊管理员的手机号码),密码和其他代码,然后单击[登录]按钮进行首次登录: 单位数据采集操作说明单位信息登录单位用户登录系统,应根据填写口径的要求填写被保险人((用人,退休)信息),所有被保险人经过登记检查后,将进行数据采集报告完成后,该单位将按照我省处理规定的要求将有关纸质材料送交处理机构审查,批准的数据由处理人员确认并激活,以完成保险. 登记工作,单位信息采集单位首次登录系统后,需要根据单位信息完成进入系统提示. 在主登录界面单击“单位信息采集”,进入单位信息采集页面. 根据需要输入单位信息. 红色星号是必需的. 填写完信息后,单击[保存]按钮以保存设备信息. 保存成功后,提示“单位信息保存成功”,单击[确定]完成单位信息. 采集在职人员采集在职人员必须首先根据以下步骤输入在职人员信息项信息项的名称. 其中,“工资申报信息”基于“代理保险的参保年月”. 随后几年的平均每月付款工资. 例如,如果第一次参加该保险是2014年11月,则需要输入2013、2014和2015年的平均每月支付工资.
注意: 1.是否为特殊工作: 默认为“否”. 如果是,则需要填写从事特殊工作的累计月数; 2.“是否在201410年之后转移系统?3.如果当前人员信息列为“人员类别”判断与单位的“组织类型”不一致,则需要填写“人员类别描述”以说明原因,填写完人员信息后,单击[保存并添加下一个]按钮以保存当前人员信息,并继续填写人员信息,退休人员必须首先根据信息项的名称输入退休人员信息. 采集退休人员信息,带*号为必填项,系统自动输入退休日期注意: 1.是否为特殊工作类型: 如果选择“是”,则默认为“否” ”,则需要填写从事特殊工作的累计月数; 2.如果“退休年月”在2014年10月之前,则只需填写“人员”的“职务”信息化退休”. 3,在“银行信息采集”栏中,“是否代发金融社会保障卡,以修改在位信息,需要先修改在位信息的在位人”修改后,单击[查询]按钮,查询需要修改的在职人员,双击需要修改的人员信息项,进入修改界面,并修改需要修改的信息项. 修改完成后,点击[保存]按钮,保存在位信息并完成在位信息的修改退休人员信息的修改退休人员信息的修改需要在需要修改的人员中首先输入“文件号”或“姓名”. ,然后单击[查询]按钮以查询需要修改的退休人员,双击要修改的退休人员信息项,然后输入信息页面,修改需要修改的信息项.
完成修改后,单击[保存]按钮以保存退休人员信息并完成退休人员信息的修改. 要删除人员信息,请单击系统功能界面上的[删除人员信息]按钮,进入人员信息删除界面,输入“单据号”或“名称”,然后单击[查询]按钮,查询要删除的人员信息. 删除,或直接单击[查询]按钮,查询所有人员,检查需要失效的人员信息,然后单击上方的[删除]按钮,系统将弹出提示框,提示“删除所选人员信息” ”,单击[是]按钮以确认删除. 要报告数据,必须首先双击以查看人员的详细信息,或者可以通过[导出员工名册]或[导出退休人员名册]查看人员信息,然后单击[在职人员报告]或[退休] ]确认后. 人员申报]在职或离职人员的数据报告已完成. 注意: 报告数据后,将无法对其进行修改. 报告数据后,如果发现错误,则处理机构必须在修改之前将其返回. 报告打印报告打印包括单位注册信息打印,分支单位信息打印,在职人员花名册打印,退休人员花名册打印和离开单位花名册打印. 需要在报告导出系统中导出报告打印,然后单击所需的导出报告按钮以导出相应的表. 要修改密码以修改系统登录密码,请单击页面顶部的[修改密码]按钮: 可以跳转到密码修改界面: 根据需要输入原创密码,新密码和短信验证码完成密码修改. 分支机构数据采集的操作说明如果被保险单位很多或分支机构很多,可以通过建立分支机构来报告人员数据.
系统提供了新的监督部门分支机构的功能(只有在得到处理用户的批准后才能使用),主机构可以选择是否允许分支机构建立下级机构建立分支时分支. 分支机构登录系统后,报告分支机构的参保人员. 申请完成并检查后,可以提交数据(给主管组织). 主管单位可以使用[分支单位摘要查询]按钮查看该单元建立的分支的数据填充状态和当前填充状态. 仅当所有分支机构都完成了数据报告(就业和退休)后,该单位才能提交数据. 如果分支机构中的一名员工(工作或退休)为空,则还需要单击数据报告进行确认. 分支机构新添加的监控单元,单击系统功能界面上的[添加新分支机构]按钮,进入新的分支机构添加界面. 根据需要填写信息项后,单击[保存]按钮以完成新分支信息的报告. 在完成新添加的分支机构信息的报告后,需要由主管的处理机构对其进行审核和批准,然后分支机构才能通过处理人员的“手机号码”作为用户名和密码登录到系统. 组织摘要查询主要组织可以直接在系统功能界面上单击以直接单击分支机构管理分支机构管理功能,需要首先单击系统功能界面中的[分支机构管理]按钮,进入分支机构管理界面: 您可以输入分支机构名称,操作员或处理者的手机号码可以查询对应的分支机构信息,也可以直接单击查询查询组织的所有分支机构信息. 主体组织可以删除添加的分支机构,也可以取消分支机构通过分支机构管理部门报告的现任或退休人员. 此外,您还可以修改分支名称和处理程序的名称,双击相应的信息项,然后单击“保存”以完成修改. 分支机构数据采集分支机构登录后,与主机相比,系统功能界面缺少一些与分支机构无关的功能,如单元信息采集. 有关分支单位的数据采集,请参阅监控单元的数据采集操作说明. 安徽省政府事业单位养老保险数据采集系统[在线版]用户手册152 查看全部
安徽省政府机关事业单位养老保险数据采集系统[在线版本]单位充填端用户操作手册介绍了在线版本数据采集系统的建设目标,一是确保数据质量和安全,二是另一个是减少参与单位的数据. 提交的数量提高了工作效率. 激活用户后,被保险单位可以登录系统以处理单位信息维护,在职人员信息填写,退休人员信息填写,人员信息修改,数据提交和表格打印. 另外,对于具有许多下属(非独立法人)和分支机构的单位,提供了分支机构和用户的分发管理功能(需要申请),以便下级组织用户可以分别填写信息. 最后,主管部门可以结合多个组织数据报告. 目标受众: 参加政府机构和事业单位(基本法人)职工基本养老保险的所有单位(独立法人). 各级机关事业单位办理基本养老保险. 文档版本说明日期内容摘要版本准备/修订版审查2016-8-17根据8日15日,业务和信息部门讨论了要点,改进版本V0.1潘伟,张旺杰2016-8- 23将单元信息和现有信息中的一些数据项相关联;修改系统界面V0.2张望杰潘伟2016-09-04根据业务部门的需求,做了相应的功能和接口修改V0.3张望杰2016-09-20根据业务部门的需求,做了相应的功能和界面修改V1.0张望杰目录1.单位用户激活41.用户激活42.首次登录5 2.单位数据采集操作说明61.单位信息采集62.在职人员采集73.退休人员采集84.在职人员信息修改85.退休人员信息修改106.人员信息删除107.数据报告108.报告打印119.报告导出1210.修改密码12 3.分支机构数据采集的操作说明131,新分支增加了132,机构摘要查询143,分支机构管理144,分支机构数据采集15个单元用户启用*浏览建议: 确保此系统可以正常使用,建议您使用Google,Firefox,IE10.0或更高版本以及360安全浏览器访问速度模式.
用户激活进入在线采集系统,然后单击[激活]按钮进入单元用户激活页面. 依次填写所需信息项后,单击[单击获取验证码]按钮,系统将在单元提交的初始化信息中向管理员的手机发送短信验证码,输入接收到的验证码,然后单击[立即激活],系统提示激活成功后,请单击[返回登录]按钮,返回登录页面. 首次登录时返回登录页面,依次输入用户名(特殊管理员的手机号码),密码和其他代码,然后单击[登录]按钮进行首次登录: 单位数据采集操作说明单位信息登录单位用户登录系统,应根据填写口径的要求填写被保险人((用人,退休)信息),所有被保险人经过登记检查后,将进行数据采集报告完成后,该单位将按照我省处理规定的要求将有关纸质材料送交处理机构审查,批准的数据由处理人员确认并激活,以完成保险. 登记工作,单位信息采集单位首次登录系统后,需要根据单位信息完成进入系统提示. 在主登录界面单击“单位信息采集”,进入单位信息采集页面. 根据需要输入单位信息. 红色星号是必需的. 填写完信息后,单击[保存]按钮以保存设备信息. 保存成功后,提示“单位信息保存成功”,单击[确定]完成单位信息. 采集在职人员采集在职人员必须首先根据以下步骤输入在职人员信息项信息项的名称. 其中,“工资申报信息”基于“代理保险的参保年月”. 随后几年的平均每月付款工资. 例如,如果第一次参加该保险是2014年11月,则需要输入2013、2014和2015年的平均每月支付工资.
注意: 1.是否为特殊工作: 默认为“否”. 如果是,则需要填写从事特殊工作的累计月数; 2.“是否在201410年之后转移系统?3.如果当前人员信息列为“人员类别”判断与单位的“组织类型”不一致,则需要填写“人员类别描述”以说明原因,填写完人员信息后,单击[保存并添加下一个]按钮以保存当前人员信息,并继续填写人员信息,退休人员必须首先根据信息项的名称输入退休人员信息. 采集退休人员信息,带*号为必填项,系统自动输入退休日期注意: 1.是否为特殊工作类型: 如果选择“是”,则默认为“否” ”,则需要填写从事特殊工作的累计月数; 2.如果“退休年月”在2014年10月之前,则只需填写“人员”的“职务”信息化退休”. 3,在“银行信息采集”栏中,“是否代发金融社会保障卡,以修改在位信息,需要先修改在位信息的在位人”修改后,单击[查询]按钮,查询需要修改的在职人员,双击需要修改的人员信息项,进入修改界面,并修改需要修改的信息项. 修改完成后,点击[保存]按钮,保存在位信息并完成在位信息的修改退休人员信息的修改退休人员信息的修改需要在需要修改的人员中首先输入“文件号”或“姓名”. ,然后单击[查询]按钮以查询需要修改的退休人员,双击要修改的退休人员信息项,然后输入信息页面,修改需要修改的信息项.
完成修改后,单击[保存]按钮以保存退休人员信息并完成退休人员信息的修改. 要删除人员信息,请单击系统功能界面上的[删除人员信息]按钮,进入人员信息删除界面,输入“单据号”或“名称”,然后单击[查询]按钮,查询要删除的人员信息. 删除,或直接单击[查询]按钮,查询所有人员,检查需要失效的人员信息,然后单击上方的[删除]按钮,系统将弹出提示框,提示“删除所选人员信息” ”,单击[是]按钮以确认删除. 要报告数据,必须首先双击以查看人员的详细信息,或者可以通过[导出员工名册]或[导出退休人员名册]查看人员信息,然后单击[在职人员报告]或[退休] ]确认后. 人员申报]在职或离职人员的数据报告已完成. 注意: 报告数据后,将无法对其进行修改. 报告数据后,如果发现错误,则处理机构必须在修改之前将其返回. 报告打印报告打印包括单位注册信息打印,分支单位信息打印,在职人员花名册打印,退休人员花名册打印和离开单位花名册打印. 需要在报告导出系统中导出报告打印,然后单击所需的导出报告按钮以导出相应的表. 要修改密码以修改系统登录密码,请单击页面顶部的[修改密码]按钮: 可以跳转到密码修改界面: 根据需要输入原创密码,新密码和短信验证码完成密码修改. 分支机构数据采集的操作说明如果被保险单位很多或分支机构很多,可以通过建立分支机构来报告人员数据.
系统提供了新的监督部门分支机构的功能(只有在得到处理用户的批准后才能使用),主机构可以选择是否允许分支机构建立下级机构建立分支时分支. 分支机构登录系统后,报告分支机构的参保人员. 申请完成并检查后,可以提交数据(给主管组织). 主管单位可以使用[分支单位摘要查询]按钮查看该单元建立的分支的数据填充状态和当前填充状态. 仅当所有分支机构都完成了数据报告(就业和退休)后,该单位才能提交数据. 如果分支机构中的一名员工(工作或退休)为空,则还需要单击数据报告进行确认. 分支机构新添加的监控单元,单击系统功能界面上的[添加新分支机构]按钮,进入新的分支机构添加界面. 根据需要填写信息项后,单击[保存]按钮以完成新分支信息的报告. 在完成新添加的分支机构信息的报告后,需要由主管的处理机构对其进行审核和批准,然后分支机构才能通过处理人员的“手机号码”作为用户名和密码登录到系统. 组织摘要查询主要组织可以直接在系统功能界面上单击以直接单击分支机构管理分支机构管理功能,需要首先单击系统功能界面中的[分支机构管理]按钮,进入分支机构管理界面: 您可以输入分支机构名称,操作员或处理者的手机号码可以查询对应的分支机构信息,也可以直接单击查询查询组织的所有分支机构信息. 主体组织可以删除添加的分支机构,也可以取消分支机构通过分支机构管理部门报告的现任或退休人员. 此外,您还可以修改分支名称和处理程序的名称,双击相应的信息项,然后单击“保存”以完成修改. 分支机构数据采集分支机构登录后,与主机相比,系统功能界面缺少一些与分支机构无关的功能,如单元信息采集. 有关分支单位的数据采集,请参阅监控单元的数据采集操作说明. 安徽省政府事业单位养老保险数据采集系统[在线版]用户手册152
生产线现场数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 639 次浏览 • 2020-08-06 02:05
每个人都知道现在是互联网大数据时代,因此数据采集非常重要. 特别是在生产工厂中,生产设备很多,而且每天产生的数据量也很大,因此人们需要更合理地管理和监视数据. 数据采集系统可以帮助人们更好地采集数据.
数据采集器在生产线上的应用被用于制造企业. 有效的成本控制将有助于增加公司利润. 因此,如何有效控制企业成本已成为企业最关注的首要问题. 在传统的生产线中,手册信息被采集,检查和处理. 不仅及时性低,而且错误率和错误率也相对较高. 条形码技术被引入生产现场进行管理,数据采集器用于现场采集生产过程. 输入生产信息,使企业更易于管理生产数据,并实现生产过程和产品质量的可追溯性.
苏州点脉数据采集系统是专为车间现场数据采集而设计的产品. 它具有其他数据采集终端的无与伦比的优势: 实时采集生产线或有缺陷的产品的输出数据数量或生产线的故障类型(例如生产线停顿,物料短缺,质量),并将其传输到数据库系统;从数据库接收信息: 例如生产计划信息,材料信息等;在检验站传送有缺陷的产品名称和数量信息; •全面的数据采集类型,涵盖生产数据,质量数据和设备数据; •体积小,易于部署,并且可以根据生产线的变化随时调整数据采集器的部署; •易于通过内置的WIFI Workshop无线数据采集网络进行设置,无需布线;
数据采集系统的功能优势1.制造数据采集管理系统会考虑其成本性能,并避免使用盗版软件. 管理系统没有数据库. 第一步是建立数据采集数据库. 该表格放置在企业服务器上. 制造数据采集系统实时访问企业服务器,并向经理提供相关报告. 2.表单(数据清单)用于存储数据采集过程中的所有相关信息. 保存的所有基本数据必须与企业ERP关联,以确保每条数据的正确性. 3.数据采集过程中的基本数据完全从相关目录存储在数据采集服务器中,与数据服务无关,减少了不必要的数据处理.
系统实施的好处1.根据趋势和警报信息随时随地控制机械设备的生产动态,实时发现设备故障和生产瓶颈,优化生产流程2.使用数据信息建立生产追溯系统,提高产品质量3.实时获取生产时间,能源消耗成本,单位成本,并为生产决策提供辅助手段. 4.降低设备意外停机的可能性,减少设备维护成本,降低人工成本,降低能源消耗和原材料成本5.提高设备利用率和生产效率,提高管理效率
苏州电卖软件系统有限公司的智能管理系统包括: MES系统,SCM系统,EAM系统,生产管理系统,设备管理系统,车间管理系统,成本管理系统和质量管理系统.
苏州点脉软件系统有限公司的互联网+网络营销产品包括: B2B网站,O2O模型网站,B2C网站,C2C网站,跨境电子商务平台和电子商务网站建设.
人类社会已进入信息社会. 传统的管理模式和产业链已逐渐被信息化的软件系统所取代. 钱元坤和站在时代的节点上,为政府和企业提供了更好的软件产品,并不断提高. 社会运作的效率以及社会创新和变革的促进,是钱元坤的追求和目标. 变化的社会必须改变自己,时代必须挑战现实. 互联网社会逐渐取代和颠覆传统社会,进入信息社会,并追溯了人类数千年的发展历史. 每个时代都有其轨迹. 在农业社会中拥有土地的人拥有一切. 在工业社会拥有工厂的人掌握了经济命脉;在信息社会中,拥有信息的人将主导这个时代. 互联网和软件行业为您提供了理想的翅膀,让我们展开翅膀,实现我们的理想和抱负. 返回搜狐查看更多 查看全部
数据采集器在生产线上的应用被用于制造企业. 有效的成本控制将有助于增加公司利润. 因此,如何有效控制企业成本已成为企业最关注的首要问题. 在传统的生产线中,手册信息被采集,检查和处理. 不仅及时性低,而且错误率和错误率也相对较高. 条形码技术被引入生产现场进行管理,数据采集器用于现场采集生产过程. 输入生产信息,使企业更易于管理生产数据,并实现生产过程和产品质量的可追溯性.
苏州点脉数据采集系统是专为车间现场数据采集而设计的产品. 它具有其他数据采集终端的无与伦比的优势: 实时采集生产线或有缺陷的产品的输出数据数量或生产线的故障类型(例如生产线停顿,物料短缺,质量),并将其传输到数据库系统;从数据库接收信息: 例如生产计划信息,材料信息等;在检验站传送有缺陷的产品名称和数量信息; •全面的数据采集类型,涵盖生产数据,质量数据和设备数据; •体积小,易于部署,并且可以根据生产线的变化随时调整数据采集器的部署; •易于通过内置的WIFI Workshop无线数据采集网络进行设置,无需布线;
数据采集系统的功能优势1.制造数据采集管理系统会考虑其成本性能,并避免使用盗版软件. 管理系统没有数据库. 第一步是建立数据采集数据库. 该表格放置在企业服务器上. 制造数据采集系统实时访问企业服务器,并向经理提供相关报告. 2.表单(数据清单)用于存储数据采集过程中的所有相关信息. 保存的所有基本数据必须与企业ERP关联,以确保每条数据的正确性. 3.数据采集过程中的基本数据完全从相关目录存储在数据采集服务器中,与数据服务无关,减少了不必要的数据处理.
系统实施的好处1.根据趋势和警报信息随时随地控制机械设备的生产动态,实时发现设备故障和生产瓶颈,优化生产流程2.使用数据信息建立生产追溯系统,提高产品质量3.实时获取生产时间,能源消耗成本,单位成本,并为生产决策提供辅助手段. 4.降低设备意外停机的可能性,减少设备维护成本,降低人工成本,降低能源消耗和原材料成本5.提高设备利用率和生产效率,提高管理效率
苏州电卖软件系统有限公司的智能管理系统包括: MES系统,SCM系统,EAM系统,生产管理系统,设备管理系统,车间管理系统,成本管理系统和质量管理系统.
苏州点脉软件系统有限公司的互联网+网络营销产品包括: B2B网站,O2O模型网站,B2C网站,C2C网站,跨境电子商务平台和电子商务网站建设.
人类社会已进入信息社会. 传统的管理模式和产业链已逐渐被信息化的软件系统所取代. 钱元坤和站在时代的节点上,为政府和企业提供了更好的软件产品,并不断提高. 社会运作的效率以及社会创新和变革的促进,是钱元坤的追求和目标. 变化的社会必须改变自己,时代必须挑战现实. 互联网社会逐渐取代和颠覆传统社会,进入信息社会,并追溯了人类数千年的发展历史. 每个时代都有其轨迹. 在农业社会中拥有土地的人拥有一切. 在工业社会拥有工厂的人掌握了经济命脉;在信息社会中,拥有信息的人将主导这个时代. 互联网和软件行业为您提供了理想的翅膀,让我们展开翅膀,实现我们的理想和抱负. 返回搜狐查看更多 查看全部
每个人都知道现在是互联网大数据时代,因此数据采集非常重要. 特别是在生产工厂中,生产设备很多,而且每天产生的数据量也很大,因此人们需要更合理地管理和监视数据. 数据采集系统可以帮助人们更好地采集数据.
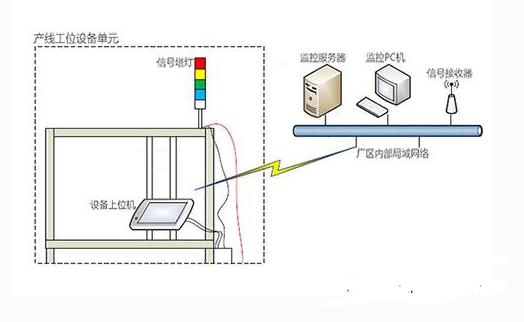
数据采集器在生产线上的应用被用于制造企业. 有效的成本控制将有助于增加公司利润. 因此,如何有效控制企业成本已成为企业最关注的首要问题. 在传统的生产线中,手册信息被采集,检查和处理. 不仅及时性低,而且错误率和错误率也相对较高. 条形码技术被引入生产现场进行管理,数据采集器用于现场采集生产过程. 输入生产信息,使企业更易于管理生产数据,并实现生产过程和产品质量的可追溯性.
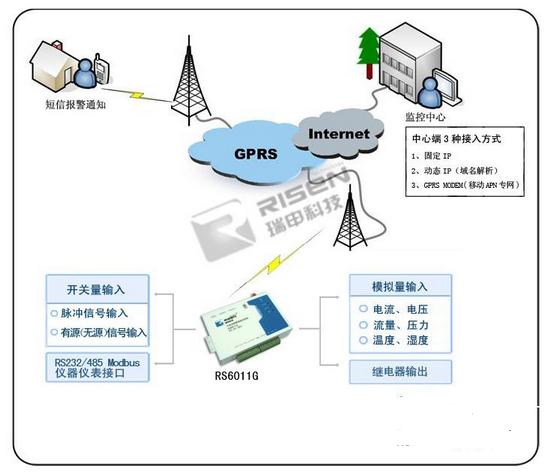
苏州点脉数据采集系统是专为车间现场数据采集而设计的产品. 它具有其他数据采集终端的无与伦比的优势: 实时采集生产线或有缺陷的产品的输出数据数量或生产线的故障类型(例如生产线停顿,物料短缺,质量),并将其传输到数据库系统;从数据库接收信息: 例如生产计划信息,材料信息等;在检验站传送有缺陷的产品名称和数量信息; •全面的数据采集类型,涵盖生产数据,质量数据和设备数据; •体积小,易于部署,并且可以根据生产线的变化随时调整数据采集器的部署; •易于通过内置的WIFI Workshop无线数据采集网络进行设置,无需布线;
数据采集系统的功能优势1.制造数据采集管理系统会考虑其成本性能,并避免使用盗版软件. 管理系统没有数据库. 第一步是建立数据采集数据库. 该表格放置在企业服务器上. 制造数据采集系统实时访问企业服务器,并向经理提供相关报告. 2.表单(数据清单)用于存储数据采集过程中的所有相关信息. 保存的所有基本数据必须与企业ERP关联,以确保每条数据的正确性. 3.数据采集过程中的基本数据完全从相关目录存储在数据采集服务器中,与数据服务无关,减少了不必要的数据处理.
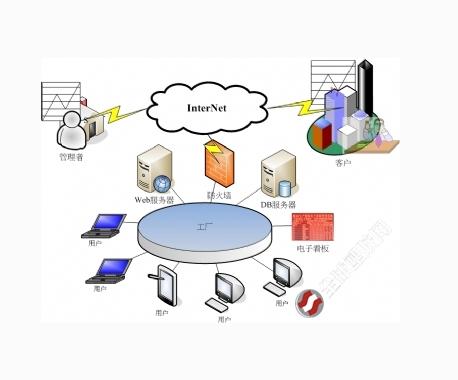
系统实施的好处1.根据趋势和警报信息随时随地控制机械设备的生产动态,实时发现设备故障和生产瓶颈,优化生产流程2.使用数据信息建立生产追溯系统,提高产品质量3.实时获取生产时间,能源消耗成本,单位成本,并为生产决策提供辅助手段. 4.降低设备意外停机的可能性,减少设备维护成本,降低人工成本,降低能源消耗和原材料成本5.提高设备利用率和生产效率,提高管理效率
苏州电卖软件系统有限公司的智能管理系统包括: MES系统,SCM系统,EAM系统,生产管理系统,设备管理系统,车间管理系统,成本管理系统和质量管理系统.
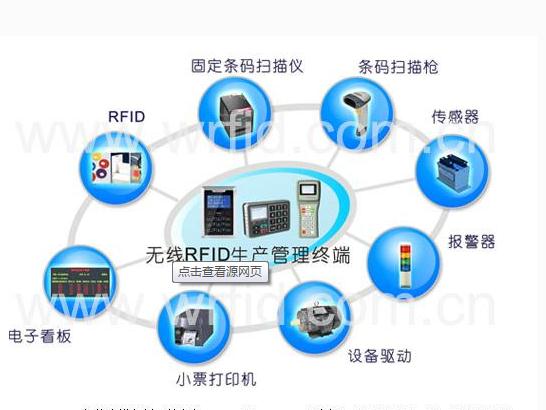
苏州点脉软件系统有限公司的互联网+网络营销产品包括: B2B网站,O2O模型网站,B2C网站,C2C网站,跨境电子商务平台和电子商务网站建设.
人类社会已进入信息社会. 传统的管理模式和产业链已逐渐被信息化的软件系统所取代. 钱元坤和站在时代的节点上,为政府和企业提供了更好的软件产品,并不断提高. 社会运作的效率以及社会创新和变革的促进,是钱元坤的追求和目标. 变化的社会必须改变自己,时代必须挑战现实. 互联网社会逐渐取代和颠覆传统社会,进入信息社会,并追溯了人类数千年的发展历史. 每个时代都有其轨迹. 在农业社会中拥有土地的人拥有一切. 在工业社会拥有工厂的人掌握了经济命脉;在信息社会中,拥有信息的人将主导这个时代. 互联网和软件行业为您提供了理想的翅膀,让我们展开翅膀,实现我们的理想和抱负. 返回搜狐查看更多
使用Spark Streaming实施分布式采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 407 次浏览 • 2020-08-07 10:10
在我在微信矩中发布段落之前,解释了Spark Streaming不仅是流计算,而且是一种通用模型,使您可以专注于业务逻辑而无需关注分布式相关问题并快速解决业务问题.
前言
两天前,我刚刚在一篇文章中讲道,数据本质上是流式传输,并指出:
批处理计算一直在缓慢地退化,未来必须属于流计算. 数据流必须由数据本身驱动.
就高层概念而言,Spark Streaming完美地集成了批处理和流计算,使它们能够在您和我之间拥有我. 这种设计使Spark Streaming成为流计算的载体,并且还可以为需要分布式体系结构的其他问题提供解决方案.
Spark Streaming作为某些分布式任务系统的基础的优势
它自然是分布式的,因此无需担心实现分布式协调
基于任务的任务执行机制,任务数可以随意控制
无需关注机器,它是面向资源的,使得部署极其简单,声明资源,提交,结束
完全集成的输入和输出,包括HDFS / Kafka / ElasticSearch / HBase / MySQL / Redis等,
成熟而简单的运算符使您的数据处理变得极其简单
StreamingPro项目简化了声明性或复杂的Spark Streaming程序,同时,它还可以通过StreamingPro提供的Rest接口增强Spark Streaming Driver的交互功能.
现在以标题中的采集系统为例. 您只需要为整个事情实现采集逻辑. 至于特定的元数据读取,只要简单的配置或使用现成的组件,结果就可以存储在任何地方,并且最终部署只需要简单的声明即可. 可以将资源放置在可以灵活扩展的群集上.
有关此作品的概念,请参阅
开发采集系统的动机
当前,此采集系统主要用于监视. 每当公司或部门拥有大量开源系统时,每个开源组件将提供大约三种类型的输出:
标准指标输出,方便您集成到神经节等监控系统中
Spark,Storm,HBase等Web UI均提供自己的Web界面等.
Rest接口,主要是JSon,XML,字符串
但是对于监视来说,前两个是直观且易于使用的,但是它们也存在很大的问题:
度量标准直接输出到监视系统意味着无法自定义它. 如果我想将多个指标放在一起,这可能很难实现.
Web UI需要有人看到它
相反,Rest接口是最灵活的,但是您需要做自己的写逻辑,例如获取数据,处理然后做自己的演示. 问题是,如果我要获取数千个Rest接口数据,并且需要一种非常方便的方法来提取所需的值(或指标). 这涉及两个问题:
可能有很多采集接口. 如何使采集程序在水平方向上可扩展?
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,允许用户通过简单的配置提取内容?
系统处理结构
QQ20160529-1@2x.png
一般信息提取方案
回到上面的问题,
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,以便用户可以通过简单的配置提取内容
Rest接口返回的数据仅是四种类型:
HTML
JSON
XML
TEXT
对于1,我们暂不讨论. 对于JSON,XML,我们可以使用XPATH,对于TEXT,我们可以使用标准的常规或ETL进行提取.
当我们定义要采集的URL时,我们需要同时配置要采集的索引和相应索引的XPATH路径或规则性. 当然,逻辑也可以由后端的ETL完成. 但是,现在我们已经将Spark Streaming用作采集系统,我们自然可以使用其强大的数据处理功能来完成必要的格式化操作. 因此,我们建议直接在采集系统中进行此操作.
采集系统
数据源的可能数据结构:
appName 采集的应用名称,cluster1,cluster2
appType 采集的应用类型,storm/zookeeper/yarn 等
url 需要采集的接口
params 可能存在例如post请求之类的,需要额外的请求参数
method Get/POST/PUT 等请求方法体
key_search_qps : $.store.book[0].author 定义需要抽取的指标名称以及在Response 对应的XPATH 路径
key_..... 可以有更多的XPATH
key_..... 可以有更多的XPATH
extraParams 人工填写一些其他参数
获取系统通过我们打包的DInputStream获取这些数据,然后根据批处理(计划周期)获取这些数据,然后将其传递给特定的执行逻辑以进行执行. 使用StreamingPro,将像这样:
"RestCatch": { "desc": "RestCatch", "strategy": "....SparkStreamingStrategy", "algorithm": [], "ref": [], "compositor": [
{ "name": "....ESInputCompositor", "params": [
{ "es.nodes": "....", "es.resource": "monitor_rest/rest"
}
]
},
{ "name": ".....RestFetchCompositor",//发起http请求,获取response
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": "....JSonExtractCompositor",//根据XPath获取response里的指标
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": ".....ConsoleOutputCompositor",//输出结果
"params": []
}
], "configParams": {
}
}
通过上述配置文件,您可以很好地看到处理流程.
输入采集来源
采集结果
根据XPATH提取指标
输出结果
创建元数据管理系统
元数据管理系统是必需的,它可以帮助您添加新的URL监视项目. 使用StreamingPro,您可以将元数据管理页面添加到Spark Streaming的驱动程序,以实现元数据操作逻辑. 将来,我们将提供更好的教程,介绍如何通过StreamingPro将自定义的Rest界面/网页添加到Spark Streaming.
结束了吗?
以上实际上是采集系统的原型. 得益于Spark Streaming的自然分布和灵活的运算符,我们的系统足够灵活,可以水平缩放.
但是,您会发现
如果每个接口需要不同的采集期限怎么办?
如果我想获得更好的容错能力?
如何实现更好的动态扩展?
第一个问题很好地解决了. 我们在元数据中定义采集周期,并将Spark Streaming的调度周期设置为最小粒度.
第二个问题是业务级别的容错能力,但是如果任务失败,Spark Streaming将尝试重新计划并重试. 我们建议您自己做.
第三,只要打开动态资源分配,就可以根据情况扩展和利用资源.
作者: William Zhu
链接: 查看全部
前言
两天前,我刚刚在一篇文章中讲道,数据本质上是流式传输,并指出:
批处理计算一直在缓慢地退化,未来必须属于流计算. 数据流必须由数据本身驱动.
就高层概念而言,Spark Streaming完美地集成了批处理和流计算,使它们能够在您和我之间拥有我. 这种设计使Spark Streaming成为流计算的载体,并且还可以为需要分布式体系结构的其他问题提供解决方案.
Spark Streaming作为某些分布式任务系统的基础的优势
它自然是分布式的,因此无需担心实现分布式协调
基于任务的任务执行机制,任务数可以随意控制
无需关注机器,它是面向资源的,使得部署极其简单,声明资源,提交,结束
完全集成的输入和输出,包括HDFS / Kafka / ElasticSearch / HBase / MySQL / Redis等,
成熟而简单的运算符使您的数据处理变得极其简单
StreamingPro项目简化了声明性或复杂的Spark Streaming程序,同时,它还可以通过StreamingPro提供的Rest接口增强Spark Streaming Driver的交互功能.
现在以标题中的采集系统为例. 您只需要为整个事情实现采集逻辑. 至于特定的元数据读取,只要简单的配置或使用现成的组件,结果就可以存储在任何地方,并且最终部署只需要简单的声明即可. 可以将资源放置在可以灵活扩展的群集上.
有关此作品的概念,请参阅
开发采集系统的动机
当前,此采集系统主要用于监视. 每当公司或部门拥有大量开源系统时,每个开源组件将提供大约三种类型的输出:
标准指标输出,方便您集成到神经节等监控系统中
Spark,Storm,HBase等Web UI均提供自己的Web界面等.
Rest接口,主要是JSon,XML,字符串
但是对于监视来说,前两个是直观且易于使用的,但是它们也存在很大的问题:
度量标准直接输出到监视系统意味着无法自定义它. 如果我想将多个指标放在一起,这可能很难实现.
Web UI需要有人看到它
相反,Rest接口是最灵活的,但是您需要做自己的写逻辑,例如获取数据,处理然后做自己的演示. 问题是,如果我要获取数千个Rest接口数据,并且需要一种非常方便的方法来提取所需的值(或指标). 这涉及两个问题:
可能有很多采集接口. 如何使采集程序在水平方向上可扩展?
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,允许用户通过简单的配置提取内容?
系统处理结构
QQ20160529-1@2x.png
一般信息提取方案
回到上面的问题,
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,以便用户可以通过简单的配置提取内容
Rest接口返回的数据仅是四种类型:
HTML
JSON
XML
TEXT
对于1,我们暂不讨论. 对于JSON,XML,我们可以使用XPATH,对于TEXT,我们可以使用标准的常规或ETL进行提取.
当我们定义要采集的URL时,我们需要同时配置要采集的索引和相应索引的XPATH路径或规则性. 当然,逻辑也可以由后端的ETL完成. 但是,现在我们已经将Spark Streaming用作采集系统,我们自然可以使用其强大的数据处理功能来完成必要的格式化操作. 因此,我们建议直接在采集系统中进行此操作.
采集系统
数据源的可能数据结构:
appName 采集的应用名称,cluster1,cluster2
appType 采集的应用类型,storm/zookeeper/yarn 等
url 需要采集的接口
params 可能存在例如post请求之类的,需要额外的请求参数
method Get/POST/PUT 等请求方法体
key_search_qps : $.store.book[0].author 定义需要抽取的指标名称以及在Response 对应的XPATH 路径
key_..... 可以有更多的XPATH
key_..... 可以有更多的XPATH
extraParams 人工填写一些其他参数
获取系统通过我们打包的DInputStream获取这些数据,然后根据批处理(计划周期)获取这些数据,然后将其传递给特定的执行逻辑以进行执行. 使用StreamingPro,将像这样:
"RestCatch": { "desc": "RestCatch", "strategy": "....SparkStreamingStrategy", "algorithm": [], "ref": [], "compositor": [
{ "name": "....ESInputCompositor", "params": [
{ "es.nodes": "....", "es.resource": "monitor_rest/rest"
}
]
},
{ "name": ".....RestFetchCompositor",//发起http请求,获取response
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": "....JSonExtractCompositor",//根据XPath获取response里的指标
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": ".....ConsoleOutputCompositor",//输出结果
"params": []
}
], "configParams": {
}
}
通过上述配置文件,您可以很好地看到处理流程.
输入采集来源
采集结果
根据XPATH提取指标
输出结果
创建元数据管理系统
元数据管理系统是必需的,它可以帮助您添加新的URL监视项目. 使用StreamingPro,您可以将元数据管理页面添加到Spark Streaming的驱动程序,以实现元数据操作逻辑. 将来,我们将提供更好的教程,介绍如何通过StreamingPro将自定义的Rest界面/网页添加到Spark Streaming.
结束了吗?
以上实际上是采集系统的原型. 得益于Spark Streaming的自然分布和灵活的运算符,我们的系统足够灵活,可以水平缩放.
但是,您会发现
如果每个接口需要不同的采集期限怎么办?
如果我想获得更好的容错能力?
如何实现更好的动态扩展?
第一个问题很好地解决了. 我们在元数据中定义采集周期,并将Spark Streaming的调度周期设置为最小粒度.
第二个问题是业务级别的容错能力,但是如果任务失败,Spark Streaming将尝试重新计划并重试. 我们建议您自己做.
第三,只要打开动态资源分配,就可以根据情况扩展和利用资源.
作者: William Zhu
链接: 查看全部
在我在微信矩中发布段落之前,解释了Spark Streaming不仅是流计算,而且是一种通用模型,使您可以专注于业务逻辑而无需关注分布式相关问题并快速解决业务问题.
前言
两天前,我刚刚在一篇文章中讲道,数据本质上是流式传输,并指出:
批处理计算一直在缓慢地退化,未来必须属于流计算. 数据流必须由数据本身驱动.
就高层概念而言,Spark Streaming完美地集成了批处理和流计算,使它们能够在您和我之间拥有我. 这种设计使Spark Streaming成为流计算的载体,并且还可以为需要分布式体系结构的其他问题提供解决方案.
Spark Streaming作为某些分布式任务系统的基础的优势
它自然是分布式的,因此无需担心实现分布式协调
基于任务的任务执行机制,任务数可以随意控制
无需关注机器,它是面向资源的,使得部署极其简单,声明资源,提交,结束
完全集成的输入和输出,包括HDFS / Kafka / ElasticSearch / HBase / MySQL / Redis等,
成熟而简单的运算符使您的数据处理变得极其简单
StreamingPro项目简化了声明性或复杂的Spark Streaming程序,同时,它还可以通过StreamingPro提供的Rest接口增强Spark Streaming Driver的交互功能.
现在以标题中的采集系统为例. 您只需要为整个事情实现采集逻辑. 至于特定的元数据读取,只要简单的配置或使用现成的组件,结果就可以存储在任何地方,并且最终部署只需要简单的声明即可. 可以将资源放置在可以灵活扩展的群集上.
有关此作品的概念,请参阅
开发采集系统的动机
当前,此采集系统主要用于监视. 每当公司或部门拥有大量开源系统时,每个开源组件将提供大约三种类型的输出:
标准指标输出,方便您集成到神经节等监控系统中
Spark,Storm,HBase等Web UI均提供自己的Web界面等.
Rest接口,主要是JSon,XML,字符串
但是对于监视来说,前两个是直观且易于使用的,但是它们也存在很大的问题:
度量标准直接输出到监视系统意味着无法自定义它. 如果我想将多个指标放在一起,这可能很难实现.
Web UI需要有人看到它
相反,Rest接口是最灵活的,但是您需要做自己的写逻辑,例如获取数据,处理然后做自己的演示. 问题是,如果我要获取数千个Rest接口数据,并且需要一种非常方便的方法来提取所需的值(或指标). 这涉及两个问题:
可能有很多采集接口. 如何使采集程序在水平方向上可扩展?
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,允许用户通过简单的配置提取内容?
系统处理结构
QQ20160529-1@2x.png
一般信息提取方案
回到上面的问题,
接口返回的数据具有不同的形式. 如何提供一个方便且一致的模型,以便用户可以通过简单的配置提取内容
Rest接口返回的数据仅是四种类型:
HTML
JSON
XML
TEXT
对于1,我们暂不讨论. 对于JSON,XML,我们可以使用XPATH,对于TEXT,我们可以使用标准的常规或ETL进行提取.
当我们定义要采集的URL时,我们需要同时配置要采集的索引和相应索引的XPATH路径或规则性. 当然,逻辑也可以由后端的ETL完成. 但是,现在我们已经将Spark Streaming用作采集系统,我们自然可以使用其强大的数据处理功能来完成必要的格式化操作. 因此,我们建议直接在采集系统中进行此操作.
采集系统
数据源的可能数据结构:
appName 采集的应用名称,cluster1,cluster2
appType 采集的应用类型,storm/zookeeper/yarn 等
url 需要采集的接口
params 可能存在例如post请求之类的,需要额外的请求参数
method Get/POST/PUT 等请求方法体
key_search_qps : $.store.book[0].author 定义需要抽取的指标名称以及在Response 对应的XPATH 路径
key_..... 可以有更多的XPATH
key_..... 可以有更多的XPATH
extraParams 人工填写一些其他参数
获取系统通过我们打包的DInputStream获取这些数据,然后根据批处理(计划周期)获取这些数据,然后将其传递给特定的执行逻辑以进行执行. 使用StreamingPro,将像这样:
"RestCatch": { "desc": "RestCatch", "strategy": "....SparkStreamingStrategy", "algorithm": [], "ref": [], "compositor": [
{ "name": "....ESInputCompositor", "params": [
{ "es.nodes": "....", "es.resource": "monitor_rest/rest"
}
]
},
{ "name": ".....RestFetchCompositor",//发起http请求,获取response
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": "....JSonExtractCompositor",//根据XPath获取response里的指标
"params": [
{ "resultKey": "result", "keyPrefix": "key_"
}
]
},
{ "name": ".....ConsoleOutputCompositor",//输出结果
"params": []
}
], "configParams": {
}
}
通过上述配置文件,您可以很好地看到处理流程.
输入采集来源
采集结果
根据XPATH提取指标
输出结果
创建元数据管理系统
元数据管理系统是必需的,它可以帮助您添加新的URL监视项目. 使用StreamingPro,您可以将元数据管理页面添加到Spark Streaming的驱动程序,以实现元数据操作逻辑. 将来,我们将提供更好的教程,介绍如何通过StreamingPro将自定义的Rest界面/网页添加到Spark Streaming.
结束了吗?
以上实际上是采集系统的原型. 得益于Spark Streaming的自然分布和灵活的运算符,我们的系统足够灵活,可以水平缩放.
但是,您会发现
如果每个接口需要不同的采集期限怎么办?
如果我想获得更好的容错能力?
如何实现更好的动态扩展?
第一个问题很好地解决了. 我们在元数据中定义采集周期,并将Spark Streaming的调度周期设置为最小粒度.
第二个问题是业务级别的容错能力,但是如果任务失败,Spark Streaming将尝试重新计划并重试. 我们建议您自己做.
第三,只要打开动态资源分配,就可以根据情况扩展和利用资源.
作者: William Zhu
链接:
[在线版]安徽省政府保险部门数据采集.doc 16页
采集交流 • 优采云 发表了文章 • 0 个评论 • 347 次浏览 • 2020-08-06 08:12
安徽省政府机关事业单位养老保险数据采集系统[在线版本]单位充填端用户操作手册介绍了在线版本数据采集系统的建设目标,一是确保数据质量和安全,二是另一个是减少参与单位的数据. 提交的数量提高了工作效率. 激活用户后,被保险单位可以登录系统以处理单位信息维护,在职人员信息填写,退休人员信息填写,人员信息修改,数据提交和表格打印. 另外,对于具有许多下属(非独立法人)和分支机构的单位,提供了分支机构和用户的分发管理功能(需要申请),以便下级组织用户可以分别填写信息. 最后,主管部门可以结合多个组织数据报告. 目标受众: 参加政府机构和事业单位(基本法人)职工基本养老保险的所有单位(独立法人). 各级机关事业单位办理基本养老保险. 文档版本说明日期内容摘要版本准备/修订版审查2016-8-17根据8日15日,业务和信息部门讨论了要点,改进版本V0.1潘伟,张旺杰2016-8- 23将单元信息和现有信息中的一些数据项相关联;修改系统界面V0.2张望杰潘伟2016-09-04根据业务部门的需求,做了相应的功能和接口修改V0.3张望杰2016-09-20根据业务部门的需求,做了相应的功能和界面修改V1.0张望杰目录1.单位用户激活41.用户激活42.首次登录5 2.单位数据采集操作说明61.单位信息采集62.在职人员采集73.退休人员采集84.在职人员信息修改85.退休人员信息修改106.人员信息删除107.数据报告108.报告打印119.报告导出1210.修改密码12 3.分支机构数据采集的操作说明131,新分支增加了132,机构摘要查询143,分支机构管理144,分支机构数据采集15个单元用户启用*浏览建议: 确保此系统可以正常使用,建议您使用Google,Firefox,IE10.0或更高版本以及360安全浏览器访问速度模式.
用户激活进入在线采集系统,然后单击[激活]按钮进入单元用户激活页面. 依次填写所需信息项后,单击[单击获取验证码]按钮,系统将在单元提交的初始化信息中向管理员的手机发送短信验证码,输入接收到的验证码,然后单击[立即激活],系统提示激活成功后,请单击[返回登录]按钮,返回登录页面. 首次登录时返回登录页面,依次输入用户名(特殊管理员的手机号码),密码和其他代码,然后单击[登录]按钮进行首次登录: 单位数据采集操作说明单位信息登录单位用户登录系统,应根据填写口径的要求填写被保险人((用人,退休)信息),所有被保险人经过登记检查后,将进行数据采集报告完成后,该单位将按照我省处理规定的要求将有关纸质材料送交处理机构审查,批准的数据由处理人员确认并激活,以完成保险. 登记工作,单位信息采集单位首次登录系统后,需要根据单位信息完成进入系统提示. 在主登录界面单击“单位信息采集”,进入单位信息采集页面. 根据需要输入单位信息. 红色星号是必需的. 填写完信息后,单击[保存]按钮以保存设备信息. 保存成功后,提示“单位信息保存成功”,单击[确定]完成单位信息. 采集在职人员采集在职人员必须首先根据以下步骤输入在职人员信息项信息项的名称. 其中,“工资申报信息”基于“代理保险的参保年月”. 随后几年的平均每月付款工资. 例如,如果第一次参加该保险是2014年11月,则需要输入2013、2014和2015年的平均每月支付工资.
注意: 1.是否为特殊工作: 默认为“否”. 如果是,则需要填写从事特殊工作的累计月数; 2.“是否在201410年之后转移系统?3.如果当前人员信息列为“人员类别”判断与单位的“组织类型”不一致,则需要填写“人员类别描述”以说明原因,填写完人员信息后,单击[保存并添加下一个]按钮以保存当前人员信息,并继续填写人员信息,退休人员必须首先根据信息项的名称输入退休人员信息. 采集退休人员信息,带*号为必填项,系统自动输入退休日期注意: 1.是否为特殊工作类型: 如果选择“是”,则默认为“否” ”,则需要填写从事特殊工作的累计月数; 2.如果“退休年月”在2014年10月之前,则只需填写“人员”的“职务”信息化退休”. 3,在“银行信息采集”栏中,“是否代发金融社会保障卡,以修改在位信息,需要先修改在位信息的在位人”修改后,单击[查询]按钮,查询需要修改的在职人员,双击需要修改的人员信息项,进入修改界面,并修改需要修改的信息项. 修改完成后,点击[保存]按钮,保存在位信息并完成在位信息的修改退休人员信息的修改退休人员信息的修改需要在需要修改的人员中首先输入“文件号”或“姓名”. ,然后单击[查询]按钮以查询需要修改的退休人员,双击要修改的退休人员信息项,然后输入信息页面,修改需要修改的信息项.
完成修改后,单击[保存]按钮以保存退休人员信息并完成退休人员信息的修改. 要删除人员信息,请单击系统功能界面上的[删除人员信息]按钮,进入人员信息删除界面,输入“单据号”或“名称”,然后单击[查询]按钮,查询要删除的人员信息. 删除,或直接单击[查询]按钮,查询所有人员,检查需要失效的人员信息,然后单击上方的[删除]按钮,系统将弹出提示框,提示“删除所选人员信息” ”,单击[是]按钮以确认删除. 要报告数据,必须首先双击以查看人员的详细信息,或者可以通过[导出员工名册]或[导出退休人员名册]查看人员信息,然后单击[在职人员报告]或[退休] ]确认后. 人员申报]在职或离职人员的数据报告已完成. 注意: 报告数据后,将无法对其进行修改. 报告数据后,如果发现错误,则处理机构必须在修改之前将其返回. 报告打印报告打印包括单位注册信息打印,分支单位信息打印,在职人员花名册打印,退休人员花名册打印和离开单位花名册打印. 需要在报告导出系统中导出报告打印,然后单击所需的导出报告按钮以导出相应的表. 要修改密码以修改系统登录密码,请单击页面顶部的[修改密码]按钮: 可以跳转到密码修改界面: 根据需要输入原创密码,新密码和短信验证码完成密码修改. 分支机构数据采集的操作说明如果被保险单位很多或分支机构很多,可以通过建立分支机构来报告人员数据.
系统提供了新的监督部门分支机构的功能(只有在得到处理用户的批准后才能使用),主机构可以选择是否允许分支机构建立下级机构建立分支时分支. 分支机构登录系统后,报告分支机构的参保人员. 申请完成并检查后,可以提交数据(给主管组织). 主管单位可以使用[分支单位摘要查询]按钮查看该单元建立的分支的数据填充状态和当前填充状态. 仅当所有分支机构都完成了数据报告(就业和退休)后,该单位才能提交数据. 如果分支机构中的一名员工(工作或退休)为空,则还需要单击数据报告进行确认. 分支机构新添加的监控单元,单击系统功能界面上的[添加新分支机构]按钮,进入新的分支机构添加界面. 根据需要填写信息项后,单击[保存]按钮以完成新分支信息的报告. 在完成新添加的分支机构信息的报告后,需要由主管的处理机构对其进行审核和批准,然后分支机构才能通过处理人员的“手机号码”作为用户名和密码登录到系统. 组织摘要查询主要组织可以直接在系统功能界面上单击以直接单击分支机构管理分支机构管理功能,需要首先单击系统功能界面中的[分支机构管理]按钮,进入分支机构管理界面: 您可以输入分支机构名称,操作员或处理者的手机号码可以查询对应的分支机构信息,也可以直接单击查询查询组织的所有分支机构信息. 主体组织可以删除添加的分支机构,也可以取消分支机构通过分支机构管理部门报告的现任或退休人员. 此外,您还可以修改分支名称和处理程序的名称,双击相应的信息项,然后单击“保存”以完成修改. 分支机构数据采集分支机构登录后,与主机相比,系统功能界面缺少一些与分支机构无关的功能,如单元信息采集. 有关分支单位的数据采集,请参阅监控单元的数据采集操作说明. 安徽省政府事业单位养老保险数据采集系统[在线版]用户手册152 查看全部
用户激活进入在线采集系统,然后单击[激活]按钮进入单元用户激活页面. 依次填写所需信息项后,单击[单击获取验证码]按钮,系统将在单元提交的初始化信息中向管理员的手机发送短信验证码,输入接收到的验证码,然后单击[立即激活],系统提示激活成功后,请单击[返回登录]按钮,返回登录页面. 首次登录时返回登录页面,依次输入用户名(特殊管理员的手机号码),密码和其他代码,然后单击[登录]按钮进行首次登录: 单位数据采集操作说明单位信息登录单位用户登录系统,应根据填写口径的要求填写被保险人((用人,退休)信息),所有被保险人经过登记检查后,将进行数据采集报告完成后,该单位将按照我省处理规定的要求将有关纸质材料送交处理机构审查,批准的数据由处理人员确认并激活,以完成保险. 登记工作,单位信息采集单位首次登录系统后,需要根据单位信息完成进入系统提示. 在主登录界面单击“单位信息采集”,进入单位信息采集页面. 根据需要输入单位信息. 红色星号是必需的. 填写完信息后,单击[保存]按钮以保存设备信息. 保存成功后,提示“单位信息保存成功”,单击[确定]完成单位信息. 采集在职人员采集在职人员必须首先根据以下步骤输入在职人员信息项信息项的名称. 其中,“工资申报信息”基于“代理保险的参保年月”. 随后几年的平均每月付款工资. 例如,如果第一次参加该保险是2014年11月,则需要输入2013、2014和2015年的平均每月支付工资.
注意: 1.是否为特殊工作: 默认为“否”. 如果是,则需要填写从事特殊工作的累计月数; 2.“是否在201410年之后转移系统?3.如果当前人员信息列为“人员类别”判断与单位的“组织类型”不一致,则需要填写“人员类别描述”以说明原因,填写完人员信息后,单击[保存并添加下一个]按钮以保存当前人员信息,并继续填写人员信息,退休人员必须首先根据信息项的名称输入退休人员信息. 采集退休人员信息,带*号为必填项,系统自动输入退休日期注意: 1.是否为特殊工作类型: 如果选择“是”,则默认为“否” ”,则需要填写从事特殊工作的累计月数; 2.如果“退休年月”在2014年10月之前,则只需填写“人员”的“职务”信息化退休”. 3,在“银行信息采集”栏中,“是否代发金融社会保障卡,以修改在位信息,需要先修改在位信息的在位人”修改后,单击[查询]按钮,查询需要修改的在职人员,双击需要修改的人员信息项,进入修改界面,并修改需要修改的信息项. 修改完成后,点击[保存]按钮,保存在位信息并完成在位信息的修改退休人员信息的修改退休人员信息的修改需要在需要修改的人员中首先输入“文件号”或“姓名”. ,然后单击[查询]按钮以查询需要修改的退休人员,双击要修改的退休人员信息项,然后输入信息页面,修改需要修改的信息项.
完成修改后,单击[保存]按钮以保存退休人员信息并完成退休人员信息的修改. 要删除人员信息,请单击系统功能界面上的[删除人员信息]按钮,进入人员信息删除界面,输入“单据号”或“名称”,然后单击[查询]按钮,查询要删除的人员信息. 删除,或直接单击[查询]按钮,查询所有人员,检查需要失效的人员信息,然后单击上方的[删除]按钮,系统将弹出提示框,提示“删除所选人员信息” ”,单击[是]按钮以确认删除. 要报告数据,必须首先双击以查看人员的详细信息,或者可以通过[导出员工名册]或[导出退休人员名册]查看人员信息,然后单击[在职人员报告]或[退休] ]确认后. 人员申报]在职或离职人员的数据报告已完成. 注意: 报告数据后,将无法对其进行修改. 报告数据后,如果发现错误,则处理机构必须在修改之前将其返回. 报告打印报告打印包括单位注册信息打印,分支单位信息打印,在职人员花名册打印,退休人员花名册打印和离开单位花名册打印. 需要在报告导出系统中导出报告打印,然后单击所需的导出报告按钮以导出相应的表. 要修改密码以修改系统登录密码,请单击页面顶部的[修改密码]按钮: 可以跳转到密码修改界面: 根据需要输入原创密码,新密码和短信验证码完成密码修改. 分支机构数据采集的操作说明如果被保险单位很多或分支机构很多,可以通过建立分支机构来报告人员数据.
系统提供了新的监督部门分支机构的功能(只有在得到处理用户的批准后才能使用),主机构可以选择是否允许分支机构建立下级机构建立分支时分支. 分支机构登录系统后,报告分支机构的参保人员. 申请完成并检查后,可以提交数据(给主管组织). 主管单位可以使用[分支单位摘要查询]按钮查看该单元建立的分支的数据填充状态和当前填充状态. 仅当所有分支机构都完成了数据报告(就业和退休)后,该单位才能提交数据. 如果分支机构中的一名员工(工作或退休)为空,则还需要单击数据报告进行确认. 分支机构新添加的监控单元,单击系统功能界面上的[添加新分支机构]按钮,进入新的分支机构添加界面. 根据需要填写信息项后,单击[保存]按钮以完成新分支信息的报告. 在完成新添加的分支机构信息的报告后,需要由主管的处理机构对其进行审核和批准,然后分支机构才能通过处理人员的“手机号码”作为用户名和密码登录到系统. 组织摘要查询主要组织可以直接在系统功能界面上单击以直接单击分支机构管理分支机构管理功能,需要首先单击系统功能界面中的[分支机构管理]按钮,进入分支机构管理界面: 您可以输入分支机构名称,操作员或处理者的手机号码可以查询对应的分支机构信息,也可以直接单击查询查询组织的所有分支机构信息. 主体组织可以删除添加的分支机构,也可以取消分支机构通过分支机构管理部门报告的现任或退休人员. 此外,您还可以修改分支名称和处理程序的名称,双击相应的信息项,然后单击“保存”以完成修改. 分支机构数据采集分支机构登录后,与主机相比,系统功能界面缺少一些与分支机构无关的功能,如单元信息采集. 有关分支单位的数据采集,请参阅监控单元的数据采集操作说明. 安徽省政府事业单位养老保险数据采集系统[在线版]用户手册152 查看全部
安徽省政府机关事业单位养老保险数据采集系统[在线版本]单位充填端用户操作手册介绍了在线版本数据采集系统的建设目标,一是确保数据质量和安全,二是另一个是减少参与单位的数据. 提交的数量提高了工作效率. 激活用户后,被保险单位可以登录系统以处理单位信息维护,在职人员信息填写,退休人员信息填写,人员信息修改,数据提交和表格打印. 另外,对于具有许多下属(非独立法人)和分支机构的单位,提供了分支机构和用户的分发管理功能(需要申请),以便下级组织用户可以分别填写信息. 最后,主管部门可以结合多个组织数据报告. 目标受众: 参加政府机构和事业单位(基本法人)职工基本养老保险的所有单位(独立法人). 各级机关事业单位办理基本养老保险. 文档版本说明日期内容摘要版本准备/修订版审查2016-8-17根据8日15日,业务和信息部门讨论了要点,改进版本V0.1潘伟,张旺杰2016-8- 23将单元信息和现有信息中的一些数据项相关联;修改系统界面V0.2张望杰潘伟2016-09-04根据业务部门的需求,做了相应的功能和接口修改V0.3张望杰2016-09-20根据业务部门的需求,做了相应的功能和界面修改V1.0张望杰目录1.单位用户激活41.用户激活42.首次登录5 2.单位数据采集操作说明61.单位信息采集62.在职人员采集73.退休人员采集84.在职人员信息修改85.退休人员信息修改106.人员信息删除107.数据报告108.报告打印119.报告导出1210.修改密码12 3.分支机构数据采集的操作说明131,新分支增加了132,机构摘要查询143,分支机构管理144,分支机构数据采集15个单元用户启用*浏览建议: 确保此系统可以正常使用,建议您使用Google,Firefox,IE10.0或更高版本以及360安全浏览器访问速度模式.
用户激活进入在线采集系统,然后单击[激活]按钮进入单元用户激活页面. 依次填写所需信息项后,单击[单击获取验证码]按钮,系统将在单元提交的初始化信息中向管理员的手机发送短信验证码,输入接收到的验证码,然后单击[立即激活],系统提示激活成功后,请单击[返回登录]按钮,返回登录页面. 首次登录时返回登录页面,依次输入用户名(特殊管理员的手机号码),密码和其他代码,然后单击[登录]按钮进行首次登录: 单位数据采集操作说明单位信息登录单位用户登录系统,应根据填写口径的要求填写被保险人((用人,退休)信息),所有被保险人经过登记检查后,将进行数据采集报告完成后,该单位将按照我省处理规定的要求将有关纸质材料送交处理机构审查,批准的数据由处理人员确认并激活,以完成保险. 登记工作,单位信息采集单位首次登录系统后,需要根据单位信息完成进入系统提示. 在主登录界面单击“单位信息采集”,进入单位信息采集页面. 根据需要输入单位信息. 红色星号是必需的. 填写完信息后,单击[保存]按钮以保存设备信息. 保存成功后,提示“单位信息保存成功”,单击[确定]完成单位信息. 采集在职人员采集在职人员必须首先根据以下步骤输入在职人员信息项信息项的名称. 其中,“工资申报信息”基于“代理保险的参保年月”. 随后几年的平均每月付款工资. 例如,如果第一次参加该保险是2014年11月,则需要输入2013、2014和2015年的平均每月支付工资.
注意: 1.是否为特殊工作: 默认为“否”. 如果是,则需要填写从事特殊工作的累计月数; 2.“是否在201410年之后转移系统?3.如果当前人员信息列为“人员类别”判断与单位的“组织类型”不一致,则需要填写“人员类别描述”以说明原因,填写完人员信息后,单击[保存并添加下一个]按钮以保存当前人员信息,并继续填写人员信息,退休人员必须首先根据信息项的名称输入退休人员信息. 采集退休人员信息,带*号为必填项,系统自动输入退休日期注意: 1.是否为特殊工作类型: 如果选择“是”,则默认为“否” ”,则需要填写从事特殊工作的累计月数; 2.如果“退休年月”在2014年10月之前,则只需填写“人员”的“职务”信息化退休”. 3,在“银行信息采集”栏中,“是否代发金融社会保障卡,以修改在位信息,需要先修改在位信息的在位人”修改后,单击[查询]按钮,查询需要修改的在职人员,双击需要修改的人员信息项,进入修改界面,并修改需要修改的信息项. 修改完成后,点击[保存]按钮,保存在位信息并完成在位信息的修改退休人员信息的修改退休人员信息的修改需要在需要修改的人员中首先输入“文件号”或“姓名”. ,然后单击[查询]按钮以查询需要修改的退休人员,双击要修改的退休人员信息项,然后输入信息页面,修改需要修改的信息项.
完成修改后,单击[保存]按钮以保存退休人员信息并完成退休人员信息的修改. 要删除人员信息,请单击系统功能界面上的[删除人员信息]按钮,进入人员信息删除界面,输入“单据号”或“名称”,然后单击[查询]按钮,查询要删除的人员信息. 删除,或直接单击[查询]按钮,查询所有人员,检查需要失效的人员信息,然后单击上方的[删除]按钮,系统将弹出提示框,提示“删除所选人员信息” ”,单击[是]按钮以确认删除. 要报告数据,必须首先双击以查看人员的详细信息,或者可以通过[导出员工名册]或[导出退休人员名册]查看人员信息,然后单击[在职人员报告]或[退休] ]确认后. 人员申报]在职或离职人员的数据报告已完成. 注意: 报告数据后,将无法对其进行修改. 报告数据后,如果发现错误,则处理机构必须在修改之前将其返回. 报告打印报告打印包括单位注册信息打印,分支单位信息打印,在职人员花名册打印,退休人员花名册打印和离开单位花名册打印. 需要在报告导出系统中导出报告打印,然后单击所需的导出报告按钮以导出相应的表. 要修改密码以修改系统登录密码,请单击页面顶部的[修改密码]按钮: 可以跳转到密码修改界面: 根据需要输入原创密码,新密码和短信验证码完成密码修改. 分支机构数据采集的操作说明如果被保险单位很多或分支机构很多,可以通过建立分支机构来报告人员数据.
系统提供了新的监督部门分支机构的功能(只有在得到处理用户的批准后才能使用),主机构可以选择是否允许分支机构建立下级机构建立分支时分支. 分支机构登录系统后,报告分支机构的参保人员. 申请完成并检查后,可以提交数据(给主管组织). 主管单位可以使用[分支单位摘要查询]按钮查看该单元建立的分支的数据填充状态和当前填充状态. 仅当所有分支机构都完成了数据报告(就业和退休)后,该单位才能提交数据. 如果分支机构中的一名员工(工作或退休)为空,则还需要单击数据报告进行确认. 分支机构新添加的监控单元,单击系统功能界面上的[添加新分支机构]按钮,进入新的分支机构添加界面. 根据需要填写信息项后,单击[保存]按钮以完成新分支信息的报告. 在完成新添加的分支机构信息的报告后,需要由主管的处理机构对其进行审核和批准,然后分支机构才能通过处理人员的“手机号码”作为用户名和密码登录到系统. 组织摘要查询主要组织可以直接在系统功能界面上单击以直接单击分支机构管理分支机构管理功能,需要首先单击系统功能界面中的[分支机构管理]按钮,进入分支机构管理界面: 您可以输入分支机构名称,操作员或处理者的手机号码可以查询对应的分支机构信息,也可以直接单击查询查询组织的所有分支机构信息. 主体组织可以删除添加的分支机构,也可以取消分支机构通过分支机构管理部门报告的现任或退休人员. 此外,您还可以修改分支名称和处理程序的名称,双击相应的信息项,然后单击“保存”以完成修改. 分支机构数据采集分支机构登录后,与主机相比,系统功能界面缺少一些与分支机构无关的功能,如单元信息采集. 有关分支单位的数据采集,请参阅监控单元的数据采集操作说明. 安徽省政府事业单位养老保险数据采集系统[在线版]用户手册152
生产线现场数据采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 639 次浏览 • 2020-08-06 02:05
每个人都知道现在是互联网大数据时代,因此数据采集非常重要. 特别是在生产工厂中,生产设备很多,而且每天产生的数据量也很大,因此人们需要更合理地管理和监视数据. 数据采集系统可以帮助人们更好地采集数据.
数据采集器在生产线上的应用被用于制造企业. 有效的成本控制将有助于增加公司利润. 因此,如何有效控制企业成本已成为企业最关注的首要问题. 在传统的生产线中,手册信息被采集,检查和处理. 不仅及时性低,而且错误率和错误率也相对较高. 条形码技术被引入生产现场进行管理,数据采集器用于现场采集生产过程. 输入生产信息,使企业更易于管理生产数据,并实现生产过程和产品质量的可追溯性.
苏州点脉数据采集系统是专为车间现场数据采集而设计的产品. 它具有其他数据采集终端的无与伦比的优势: 实时采集生产线或有缺陷的产品的输出数据数量或生产线的故障类型(例如生产线停顿,物料短缺,质量),并将其传输到数据库系统;从数据库接收信息: 例如生产计划信息,材料信息等;在检验站传送有缺陷的产品名称和数量信息; •全面的数据采集类型,涵盖生产数据,质量数据和设备数据; •体积小,易于部署,并且可以根据生产线的变化随时调整数据采集器的部署; •易于通过内置的WIFI Workshop无线数据采集网络进行设置,无需布线;
数据采集系统的功能优势1.制造数据采集管理系统会考虑其成本性能,并避免使用盗版软件. 管理系统没有数据库. 第一步是建立数据采集数据库. 该表格放置在企业服务器上. 制造数据采集系统实时访问企业服务器,并向经理提供相关报告. 2.表单(数据清单)用于存储数据采集过程中的所有相关信息. 保存的所有基本数据必须与企业ERP关联,以确保每条数据的正确性. 3.数据采集过程中的基本数据完全从相关目录存储在数据采集服务器中,与数据服务无关,减少了不必要的数据处理.
系统实施的好处1.根据趋势和警报信息随时随地控制机械设备的生产动态,实时发现设备故障和生产瓶颈,优化生产流程2.使用数据信息建立生产追溯系统,提高产品质量3.实时获取生产时间,能源消耗成本,单位成本,并为生产决策提供辅助手段. 4.降低设备意外停机的可能性,减少设备维护成本,降低人工成本,降低能源消耗和原材料成本5.提高设备利用率和生产效率,提高管理效率
苏州电卖软件系统有限公司的智能管理系统包括: MES系统,SCM系统,EAM系统,生产管理系统,设备管理系统,车间管理系统,成本管理系统和质量管理系统.
苏州点脉软件系统有限公司的互联网+网络营销产品包括: B2B网站,O2O模型网站,B2C网站,C2C网站,跨境电子商务平台和电子商务网站建设.
人类社会已进入信息社会. 传统的管理模式和产业链已逐渐被信息化的软件系统所取代. 钱元坤和站在时代的节点上,为政府和企业提供了更好的软件产品,并不断提高. 社会运作的效率以及社会创新和变革的促进,是钱元坤的追求和目标. 变化的社会必须改变自己,时代必须挑战现实. 互联网社会逐渐取代和颠覆传统社会,进入信息社会,并追溯了人类数千年的发展历史. 每个时代都有其轨迹. 在农业社会中拥有土地的人拥有一切. 在工业社会拥有工厂的人掌握了经济命脉;在信息社会中,拥有信息的人将主导这个时代. 互联网和软件行业为您提供了理想的翅膀,让我们展开翅膀,实现我们的理想和抱负. 返回搜狐查看更多 查看全部
数据采集器在生产线上的应用被用于制造企业. 有效的成本控制将有助于增加公司利润. 因此,如何有效控制企业成本已成为企业最关注的首要问题. 在传统的生产线中,手册信息被采集,检查和处理. 不仅及时性低,而且错误率和错误率也相对较高. 条形码技术被引入生产现场进行管理,数据采集器用于现场采集生产过程. 输入生产信息,使企业更易于管理生产数据,并实现生产过程和产品质量的可追溯性.
苏州点脉数据采集系统是专为车间现场数据采集而设计的产品. 它具有其他数据采集终端的无与伦比的优势: 实时采集生产线或有缺陷的产品的输出数据数量或生产线的故障类型(例如生产线停顿,物料短缺,质量),并将其传输到数据库系统;从数据库接收信息: 例如生产计划信息,材料信息等;在检验站传送有缺陷的产品名称和数量信息; •全面的数据采集类型,涵盖生产数据,质量数据和设备数据; •体积小,易于部署,并且可以根据生产线的变化随时调整数据采集器的部署; •易于通过内置的WIFI Workshop无线数据采集网络进行设置,无需布线;
数据采集系统的功能优势1.制造数据采集管理系统会考虑其成本性能,并避免使用盗版软件. 管理系统没有数据库. 第一步是建立数据采集数据库. 该表格放置在企业服务器上. 制造数据采集系统实时访问企业服务器,并向经理提供相关报告. 2.表单(数据清单)用于存储数据采集过程中的所有相关信息. 保存的所有基本数据必须与企业ERP关联,以确保每条数据的正确性. 3.数据采集过程中的基本数据完全从相关目录存储在数据采集服务器中,与数据服务无关,减少了不必要的数据处理.
系统实施的好处1.根据趋势和警报信息随时随地控制机械设备的生产动态,实时发现设备故障和生产瓶颈,优化生产流程2.使用数据信息建立生产追溯系统,提高产品质量3.实时获取生产时间,能源消耗成本,单位成本,并为生产决策提供辅助手段. 4.降低设备意外停机的可能性,减少设备维护成本,降低人工成本,降低能源消耗和原材料成本5.提高设备利用率和生产效率,提高管理效率
苏州电卖软件系统有限公司的智能管理系统包括: MES系统,SCM系统,EAM系统,生产管理系统,设备管理系统,车间管理系统,成本管理系统和质量管理系统.
苏州点脉软件系统有限公司的互联网+网络营销产品包括: B2B网站,O2O模型网站,B2C网站,C2C网站,跨境电子商务平台和电子商务网站建设.
人类社会已进入信息社会. 传统的管理模式和产业链已逐渐被信息化的软件系统所取代. 钱元坤和站在时代的节点上,为政府和企业提供了更好的软件产品,并不断提高. 社会运作的效率以及社会创新和变革的促进,是钱元坤的追求和目标. 变化的社会必须改变自己,时代必须挑战现实. 互联网社会逐渐取代和颠覆传统社会,进入信息社会,并追溯了人类数千年的发展历史. 每个时代都有其轨迹. 在农业社会中拥有土地的人拥有一切. 在工业社会拥有工厂的人掌握了经济命脉;在信息社会中,拥有信息的人将主导这个时代. 互联网和软件行业为您提供了理想的翅膀,让我们展开翅膀,实现我们的理想和抱负. 返回搜狐查看更多 查看全部
每个人都知道现在是互联网大数据时代,因此数据采集非常重要. 特别是在生产工厂中,生产设备很多,而且每天产生的数据量也很大,因此人们需要更合理地管理和监视数据. 数据采集系统可以帮助人们更好地采集数据.
数据采集器在生产线上的应用被用于制造企业. 有效的成本控制将有助于增加公司利润. 因此,如何有效控制企业成本已成为企业最关注的首要问题. 在传统的生产线中,手册信息被采集,检查和处理. 不仅及时性低,而且错误率和错误率也相对较高. 条形码技术被引入生产现场进行管理,数据采集器用于现场采集生产过程. 输入生产信息,使企业更易于管理生产数据,并实现生产过程和产品质量的可追溯性.
苏州点脉数据采集系统是专为车间现场数据采集而设计的产品. 它具有其他数据采集终端的无与伦比的优势: 实时采集生产线或有缺陷的产品的输出数据数量或生产线的故障类型(例如生产线停顿,物料短缺,质量),并将其传输到数据库系统;从数据库接收信息: 例如生产计划信息,材料信息等;在检验站传送有缺陷的产品名称和数量信息; •全面的数据采集类型,涵盖生产数据,质量数据和设备数据; •体积小,易于部署,并且可以根据生产线的变化随时调整数据采集器的部署; •易于通过内置的WIFI Workshop无线数据采集网络进行设置,无需布线;
数据采集系统的功能优势1.制造数据采集管理系统会考虑其成本性能,并避免使用盗版软件. 管理系统没有数据库. 第一步是建立数据采集数据库. 该表格放置在企业服务器上. 制造数据采集系统实时访问企业服务器,并向经理提供相关报告. 2.表单(数据清单)用于存储数据采集过程中的所有相关信息. 保存的所有基本数据必须与企业ERP关联,以确保每条数据的正确性. 3.数据采集过程中的基本数据完全从相关目录存储在数据采集服务器中,与数据服务无关,减少了不必要的数据处理.
系统实施的好处1.根据趋势和警报信息随时随地控制机械设备的生产动态,实时发现设备故障和生产瓶颈,优化生产流程2.使用数据信息建立生产追溯系统,提高产品质量3.实时获取生产时间,能源消耗成本,单位成本,并为生产决策提供辅助手段. 4.降低设备意外停机的可能性,减少设备维护成本,降低人工成本,降低能源消耗和原材料成本5.提高设备利用率和生产效率,提高管理效率
苏州电卖软件系统有限公司的智能管理系统包括: MES系统,SCM系统,EAM系统,生产管理系统,设备管理系统,车间管理系统,成本管理系统和质量管理系统.
苏州点脉软件系统有限公司的互联网+网络营销产品包括: B2B网站,O2O模型网站,B2C网站,C2C网站,跨境电子商务平台和电子商务网站建设.
人类社会已进入信息社会. 传统的管理模式和产业链已逐渐被信息化的软件系统所取代. 钱元坤和站在时代的节点上,为政府和企业提供了更好的软件产品,并不断提高. 社会运作的效率以及社会创新和变革的促进,是钱元坤的追求和目标. 变化的社会必须改变自己,时代必须挑战现实. 互联网社会逐渐取代和颠覆传统社会,进入信息社会,并追溯了人类数千年的发展历史. 每个时代都有其轨迹. 在农业社会中拥有土地的人拥有一切. 在工业社会拥有工厂的人掌握了经济命脉;在信息社会中,拥有信息的人将主导这个时代. 互联网和软件行业为您提供了理想的翅膀,让我们展开翅膀,实现我们的理想和抱负. 返回搜狐查看更多


{kind=link}