
采集文章免费
采集文章免费(百度云导出后就是一个pdf格式文件,怎么办?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-03-21 23:11
采集文章免费,可以一次点击观看,多人同时观看要收费,每天自动生成专题网址(同时在7个文章下面生成专题网址)。文章的分析只支持文章的分析、标题分析、点击统计。
直接百度云里导出下载看一下也可以。百度云导出后就是一个pdf格式文件。这样可以先看看有没有自己要找的“原始链接”文件,没有的话直接用文章就可以快速点击下载。
我可以帮忙分析,已经整理好文章的维度指标,导出到excel进行分析!也可以按照不同纬度进行统计分析,例如“发布时间”,“文章状态”,“点击量”等等。
操作不难,注意几点:1.用户编辑的链接不能重复且注意链接类型,有必要的时候需要做类似头部,二级等明显的区分。
简单,找到知乎文章的作者,复制他的文章链接到云监控,然后使用浏览器的右键监控,效果好多了。
分析后可以直接提取出来,提取标题后二次发布就可以。需要在上传文章时设置原始链接即可。
这就要去百度云分析了吗
不可以,
百度云的可以,然后自己建一个百度云专题。百度云专题也有模板的。我之前有做过如图大体这样的一个上传规范要求文章需要是的关键词,页数,app,平台要在这里标注1.文章标题必须写上统一的2.页数多少要标识3.要与关键词统一发布时间,通过人工发布,要设置发布时间,如图文章要先发布,这里发布时间会在后台内显示:4.app可以在页面查看处可以查看,生成专题。 查看全部
采集文章免费(百度云导出后就是一个pdf格式文件,怎么办?)
采集文章免费,可以一次点击观看,多人同时观看要收费,每天自动生成专题网址(同时在7个文章下面生成专题网址)。文章的分析只支持文章的分析、标题分析、点击统计。
直接百度云里导出下载看一下也可以。百度云导出后就是一个pdf格式文件。这样可以先看看有没有自己要找的“原始链接”文件,没有的话直接用文章就可以快速点击下载。
我可以帮忙分析,已经整理好文章的维度指标,导出到excel进行分析!也可以按照不同纬度进行统计分析,例如“发布时间”,“文章状态”,“点击量”等等。
操作不难,注意几点:1.用户编辑的链接不能重复且注意链接类型,有必要的时候需要做类似头部,二级等明显的区分。
简单,找到知乎文章的作者,复制他的文章链接到云监控,然后使用浏览器的右键监控,效果好多了。
分析后可以直接提取出来,提取标题后二次发布就可以。需要在上传文章时设置原始链接即可。
这就要去百度云分析了吗
不可以,
百度云的可以,然后自己建一个百度云专题。百度云专题也有模板的。我之前有做过如图大体这样的一个上传规范要求文章需要是的关键词,页数,app,平台要在这里标注1.文章标题必须写上统一的2.页数多少要标识3.要与关键词统一发布时间,通过人工发布,要设置发布时间,如图文章要先发布,这里发布时间会在后台内显示:4.app可以在页面查看处可以查看,生成专题。
采集文章免费(万能的模拟发布(无需开发针对性发发布接口文件))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-03-10 07:00
7、通用模拟发布(无需开发针对性发布接口文件,可匹配任意网站cms自动后台发布)
为什么我们需要 采集 工具来做 网站?可以快速丰富网站的内容,减少手动发布内容的繁琐。最重要的是它可以快速轻松地为网站添加大量内容。因为站长希望把别人的网站内容放到自己的网站中,从内容中提取相关字段,发布到自己的网站系统中。站长的日常工作就是提供丰富的网站内容,从而吸引更多的流量。采集系统就像一双慧眼,让你看得更远,收获更多。
首先要知道很多大网站都有自己的专业程序员和SEO人员,很多网站对采集@的行为都做了各种干预措施>。传统的采集工具都是依靠分析网页源代码,利用正则表达式技术从网页源代码中提取特殊内容。这个工具完全不同,采用仿浏览器解析技术,所以这些抗采集干扰的措施对于这个工具来说基本是无效的。许多公司或网站管理员没有强大的技术支持。您只能通过找到满足您需求的 网站采集 工具来提高您的工作效率。
我只是用上面的软件自动采集最新的优质内容,并配置了多种数据处理选项,标签、链接、邮件等格式处理来制作网站内容独一无二,快速提升自己网站的流量!看完这篇文章,如果你觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
采集文章免费(万能的模拟发布(无需开发针对性发发布接口文件))
7、通用模拟发布(无需开发针对性发布接口文件,可匹配任意网站cms自动后台发布)
为什么我们需要 采集 工具来做 网站?可以快速丰富网站的内容,减少手动发布内容的繁琐。最重要的是它可以快速轻松地为网站添加大量内容。因为站长希望把别人的网站内容放到自己的网站中,从内容中提取相关字段,发布到自己的网站系统中。站长的日常工作就是提供丰富的网站内容,从而吸引更多的流量。采集系统就像一双慧眼,让你看得更远,收获更多。
首先要知道很多大网站都有自己的专业程序员和SEO人员,很多网站对采集@的行为都做了各种干预措施>。传统的采集工具都是依靠分析网页源代码,利用正则表达式技术从网页源代码中提取特殊内容。这个工具完全不同,采用仿浏览器解析技术,所以这些抗采集干扰的措施对于这个工具来说基本是无效的。许多公司或网站管理员没有强大的技术支持。您只能通过找到满足您需求的 网站采集 工具来提高您的工作效率。
我只是用上面的软件自动采集最新的优质内容,并配置了多种数据处理选项,标签、链接、邮件等格式处理来制作网站内容独一无二,快速提升自己网站的流量!看完这篇文章,如果你觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
采集文章免费(约定好该系统一个指定的栏目管理方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-10 06:15
《网加系统文章采集教程》由会员上传分享,可在线免费阅读。更多相关内容可参见教育资源——天天图书馆。
1、信息采集用户手册 1、抽象信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。二。步骤和细节 现在您需要将网页采集的数据(新闻)传输到webplus系统中的指定列。步骤如下: 1.为指定列制定一个采集计划。在栏目管理中选择栏目,点击设置采集Plan。(例:图一)2.设置采集的基本属性。包括执行方式,是否自动发布信息,采集 列的类型和页面的编码格式。(如:图二)?预先确定采集计划的实施方式,并手
2、自动、定时单次或定时循环执行。如果只是针对采集网页的当前数据,我们可以使用手动定时单方法采集一次;如果网页的数据是通过采集更新的,我们要保证信息的同步,也就是定时循环采集的方法。?判断来自采集的信息是否需要发布。如果来自采集的信息不需要修改,可以直接向互联网公开,自动发布。如果来自采集的信息需要修改、审核等,请选择不自动发布。采集完成后,信息管理人员将进行其他操作。?设置列类型为采集 如果采集的网页只是一个简单的新闻列表,即该页面的新闻是采集在指定栏目下,那么选择单个栏目Can。如果
3、即采集的页面有多个新闻列表,每个都提供单独的链接进入自己的新闻列表页面,我们需要采集的所有新闻信息,然后选择多个列。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。?设置页面的编码采集因为webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,所以为了避免采集信息乱码,需要设置为页面的编码格式为采集。本文来自Computer Basics: Setting 采集 Rules of 采集 Plan? 单列采集计划的设置(例如:图三)?设置“列表页”)
4、Start URL”是要成为采集的页面的访问路径。(必需的)?设置“文章页面URL获取规则”(1)如果新闻列表是a,如果网页中嵌入iframe表单为采集,那么需要设置规则获取列表iframe的链接地址,从而访问新闻列表。否则不需要制定此规则。(具体规则请参考下面的“采集正则表达式制定”) (2)如果页面采集的新闻列表是分页的,那么根据新闻列表的分页方式(链接和表单提交)制定分页规则,需要设置分页起始页number,区间页码和采集页码。如果新闻列表中没有分页,这个规则不需要制定。(3)如果页面是采集有多个新闻列表,
5、和多个新闻列表的url规则类似,我们只需要采集指定的一个列表,即需要设置获取规则限制文章的列表,这是为了避免采集数据过多。否则,不需要设置此规则。(4)设置文章url的获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。(必填) ? 设置“文章内容获取规则”(1)特定新闻页面,如果文章内容以iframe的形式嵌入新闻页面,则需要设置获取文章iframe的链接地址的规则用于访问新闻内容,否则不需要制定此规则。(2)
6、单次提交)制定分页规则,需要设置分页起始页码、间隔页码和采集页码。如果文章的内容没有分页,则不需要制定这条规则。(3)如果新闻页面除了新闻内容还有其他附加信息,为了在采集过程中更容易找到新闻内容,需要设置规则限制新闻内容的获取,一是避免垃圾信息的产生,二是降低新闻特定信息获取规则的复杂度,如果新闻页面比较简单,一般不需要设置这条规则。 (4)新闻属性的设置规则,除了标题和内容之外,其他条件不是必须的。另外,如果没有设置新闻的发布时间,则以当前时间作为发布时间。? 多栏采集计划设置(如
7、:图五)多栏采集方案,除了需要在“列表页面开始”下设置“列表页面URL规则”和“文章页面URL获取规则” URL”获取列名的规则与单列采集计划中设置的规则相同。?设置RSS单栏采集方案(例如:图四)RSS单栏采集方案不需要设置“文章页面URL获取规则”,其他和单栏采集方案是一样的吗?RSS多栏采集方案的设置(如:图六)RSS多栏采集方案需要在“List Page Start URL”下设置List page URL获取规则,其他与RSS单栏采集方案一致。4.采集 规则表达式制定?表情设置与调整,测试表情列表 点击页面某处采集
8、“获取规则设置”,进入规则表达式列表页面(如:图七)。在这个页面中,除了添加、修改、删除和调整表达式的顺序外,还可以表达式设置好后,输入url、iframeurl和页面内容,测试表达式规则列表。设置各类表达式的类型,表达式类型分为字符串、匹配、匹配替换和公式四种。其中匹配和匹配替换需要用到Java的正则表达式,这就需要采集方案设置人员对表达式有一定的了解。(1)字符串:直接输入字符串常量(2)匹配:通过正则表达式从指定文本(URL、IframeURL、页面内容)中获取部分文本
9、S。(3)匹配替换:首先通过正则表达式从指定文本(URL,IframeURL,页面内容)中获取文本中的部分内容S。然后使用替换正则表达式替换S中匹配的内容然后得到正确的内容。(4)公式:只支持[pageIndex],用来表示获取分页地址时分页的页码。5.图标详情?进入栏目管理(图一)?Setup采集Plan 在右侧列列表中选择一列,点击Set采集Plan。(图二)执行方式可以是:?Manual (需要点击列列表中的“立即采集”启动采集)?单(可以设置时间,到了时间,它会自动启动采集)?Cycle(指定间隔时间,自动循环
10、采集) 可以设置是否自动发布采集的文章。采集 的列类型:?单列(采集这一列下只有文章)?单列 RSS(文章 在 采集 的 RSS 地址下)?多列(采集 列和子列下的文章)?多栏RSS(从一个RSS列表地址开始,采集在多个RSS地址文章下,每个RSS地址形成一个子栏)编码方式为页面的编码为采集@ >? 设置采集规则 a)单栏模式(图三)b)单栏RSS模式(图三)b)四)此方法与单栏相同-column 方法,除了它不需要设置 文章 页面URL获取方法。c) 多列方式(图五)该方法的起始页一般为列表页采集,单列方式需要设置获取列表页的方法
11、表格和列名规则,其他同单列。d) 多列RSS(图六) 该方法需要设置从起始页获取RSS地址(列表页URL),其他与单列RSS一致。设置获取规则(图< @七)(图八)(图九)(图十)(图10一)(图10二))如上图所示,获取rule 由多个表达式组成,多个表达式相加得到所需的 URL 以获取 文章 的标题内容和其他属性。表达式分为 4 类: ? 字符串:直接输入字符串常量 ? 匹配:来自指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。? 匹配替换:以指定文本开头(URL、IframeURL、页面内容)
12、 使用正则表达式获取文本中的部分内容S。然后用替换正则表达式替换S中匹配的内容,得到正确的内容。?公式:仅支持[pageIndex],用于表示获取分页地址时分页的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。?查看采集计划的状态,返回列列表可以看到下图(图10中三)采集的状态中的三个图标代表了计划的运行状态采集计划分别(是否运行,是否运行等),采集模式(单栏,单栏RSS,多栏,多栏RSS),执行模式(手动,
13、十四)三。采集方案示例以新浪体育新闻列表网页网站为例采集,该网页的访问地址为。采集 的内容放置在“体育新闻”部分下。1.由于这是一个测试示例,我们手动进行采集,信息采集不需要自动发布。网页是一个简单的新闻列表页面,编码方式为GB2312,所以我们将采集的列类型设置为“单列”,编码方式为gb2312采集对新闻没有自动发布。如下图2.因为这个网页的新闻列表内容已经不在iframe中了,也没有分页,所以不需要
14、设置“列表页内容在IFRAME中”和“列表页分页方式”的获取规则。并且新闻列表的内容不需要设置“限制文章列表内容”规则。3.设置文章url的获取规则由于这个网页中的新闻链接类似于下面的url:所以制定如下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(d+ )-(d+)-(d+)/(d+).shtml 匹配组:0(得到匹配
15、整个结果)获取页面的源文件为采集,粘贴到页面内容中,点击“测试计算-列表模式”,结果会显示所有匹配的列表urls如下图4.由于文章内容不在iframe中,所以文章内容没有分页,文章内容不需要限制在page, 所以 "文章 page content is in the IFRAME" , "文章content paging URL" 和 "limited 文章page文章content" 的获取规则不需要要设置。5.文章设置标题规则是因为新闻页面源文件中文章的标题在以下位置:
16、 类型:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果的第一个组,每个括号为一个组)获取页面为采集的来源文件,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的标题内容如下图 6.文章内容规则是由于源文件设置的新闻页面文章的内容在以下位置:新浪体育新闻北京时间7月7日休斯敦消息,据ESPN报道,姚明尚未决定是否进行脚伤修复手术,虽然现在对姚明的三个主要诊断。医生已经建议手术,但姚明仍然犹豫不决。关于姚明现在的想法,其实,
17、如果手术,他下赛季全部缺席也不是不可能。已经29岁的姚明不想就这样浪费一年。毕竟,运动员的巅峰期只是这么一段时期,没有人能保证那段时间。姚明能否保持更好的水平?姚明犹豫不决,但休斯顿球迷对姚明却有着不同的看法。大多数球迷认为,姚明应该毫不犹豫地接受手术。他们的理由是,既然已经有恶化的趋势,保守治疗的效果还不得而知,就不应该下定决心做手术。毕竟,健康的姚明才是火箭队最好的球员。需要什么,如果保守治疗后还需要手术,那姚明得不偿失。“亲爱的姚,请下定决心做手术,即使错过了下个赛季,也不要犹豫。如果现在
18、保守治疗终于痊愈了,但还是让我们瑟瑟发抖,下赛季可能会有问题。最好通过手术解决疾病的根本原因。你可能会失去一年,但我们相信你会给休斯顿带来三年、五年甚至更健康的未来。”一位球迷这样说。的确,这位球迷表达了广大休斯顿球迷的心声。没有人愿意看到姚明在没有完全康复的情况下重返赛场。如果姚明再次受伤,我相信所有休斯顿球迷会欣赏的,包括姚明,都会是一个很重的打击,也有球迷表示,姚明手术要放心,给姚明做检查诊断的医生,就是在骑士队中心做手术的医生当年的大Z。爱情和姚明差不多,最后在手术中
19、一年后,大Z健康回归赛场,接下来的几年也没有大伤,竞技状态还是比较好的。“和哈达威等人一样,他们的水平因为伤病急剧下降,我认为这种情况对姚明来说是非常困难的,姚明和希尔、哈达威不同,姚明是内线球员,虽然脚部移动很重要,相对来说,弹跳并不是最重要的,姚明在内线的威慑力主要来自他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会带走他的手感。” 风扇说。总之,休斯顿人基本上是希望姚明能做手术的。他们相信手术能给姚明带来完全的健康,而一个健康的姚明,是他们最希望看到的姚明。(
20、小黑)所以制定如下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(.+?)匹配组:1(获取匹配结果中的第一个组,每个括号为一组) 获取页面源文件为采集,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的文章内容如下图7.Other @>文章 的属性在这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。8.采集计划设置好后,选择“体育新闻”栏目,点击采集现在,过一会,查看该栏目的内容管理,你会看到以下内容。另外,采集采集的运行状态
21、,如下图: 查看全部
采集文章免费(约定好该系统一个指定的栏目管理方法)
《网加系统文章采集教程》由会员上传分享,可在线免费阅读。更多相关内容可参见教育资源——天天图书馆。
1、信息采集用户手册 1、抽象信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。二。步骤和细节 现在您需要将网页采集的数据(新闻)传输到webplus系统中的指定列。步骤如下: 1.为指定列制定一个采集计划。在栏目管理中选择栏目,点击设置采集Plan。(例:图一)2.设置采集的基本属性。包括执行方式,是否自动发布信息,采集 列的类型和页面的编码格式。(如:图二)?预先确定采集计划的实施方式,并手
2、自动、定时单次或定时循环执行。如果只是针对采集网页的当前数据,我们可以使用手动定时单方法采集一次;如果网页的数据是通过采集更新的,我们要保证信息的同步,也就是定时循环采集的方法。?判断来自采集的信息是否需要发布。如果来自采集的信息不需要修改,可以直接向互联网公开,自动发布。如果来自采集的信息需要修改、审核等,请选择不自动发布。采集完成后,信息管理人员将进行其他操作。?设置列类型为采集 如果采集的网页只是一个简单的新闻列表,即该页面的新闻是采集在指定栏目下,那么选择单个栏目Can。如果
3、即采集的页面有多个新闻列表,每个都提供单独的链接进入自己的新闻列表页面,我们需要采集的所有新闻信息,然后选择多个列。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。?设置页面的编码采集因为webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,所以为了避免采集信息乱码,需要设置为页面的编码格式为采集。本文来自Computer Basics: Setting 采集 Rules of 采集 Plan? 单列采集计划的设置(例如:图三)?设置“列表页”)
4、Start URL”是要成为采集的页面的访问路径。(必需的)?设置“文章页面URL获取规则”(1)如果新闻列表是a,如果网页中嵌入iframe表单为采集,那么需要设置规则获取列表iframe的链接地址,从而访问新闻列表。否则不需要制定此规则。(具体规则请参考下面的“采集正则表达式制定”) (2)如果页面采集的新闻列表是分页的,那么根据新闻列表的分页方式(链接和表单提交)制定分页规则,需要设置分页起始页number,区间页码和采集页码。如果新闻列表中没有分页,这个规则不需要制定。(3)如果页面是采集有多个新闻列表,
5、和多个新闻列表的url规则类似,我们只需要采集指定的一个列表,即需要设置获取规则限制文章的列表,这是为了避免采集数据过多。否则,不需要设置此规则。(4)设置文章url的获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。(必填) ? 设置“文章内容获取规则”(1)特定新闻页面,如果文章内容以iframe的形式嵌入新闻页面,则需要设置获取文章iframe的链接地址的规则用于访问新闻内容,否则不需要制定此规则。(2)
6、单次提交)制定分页规则,需要设置分页起始页码、间隔页码和采集页码。如果文章的内容没有分页,则不需要制定这条规则。(3)如果新闻页面除了新闻内容还有其他附加信息,为了在采集过程中更容易找到新闻内容,需要设置规则限制新闻内容的获取,一是避免垃圾信息的产生,二是降低新闻特定信息获取规则的复杂度,如果新闻页面比较简单,一般不需要设置这条规则。 (4)新闻属性的设置规则,除了标题和内容之外,其他条件不是必须的。另外,如果没有设置新闻的发布时间,则以当前时间作为发布时间。? 多栏采集计划设置(如
7、:图五)多栏采集方案,除了需要在“列表页面开始”下设置“列表页面URL规则”和“文章页面URL获取规则” URL”获取列名的规则与单列采集计划中设置的规则相同。?设置RSS单栏采集方案(例如:图四)RSS单栏采集方案不需要设置“文章页面URL获取规则”,其他和单栏采集方案是一样的吗?RSS多栏采集方案的设置(如:图六)RSS多栏采集方案需要在“List Page Start URL”下设置List page URL获取规则,其他与RSS单栏采集方案一致。4.采集 规则表达式制定?表情设置与调整,测试表情列表 点击页面某处采集
8、“获取规则设置”,进入规则表达式列表页面(如:图七)。在这个页面中,除了添加、修改、删除和调整表达式的顺序外,还可以表达式设置好后,输入url、iframeurl和页面内容,测试表达式规则列表。设置各类表达式的类型,表达式类型分为字符串、匹配、匹配替换和公式四种。其中匹配和匹配替换需要用到Java的正则表达式,这就需要采集方案设置人员对表达式有一定的了解。(1)字符串:直接输入字符串常量(2)匹配:通过正则表达式从指定文本(URL、IframeURL、页面内容)中获取部分文本
9、S。(3)匹配替换:首先通过正则表达式从指定文本(URL,IframeURL,页面内容)中获取文本中的部分内容S。然后使用替换正则表达式替换S中匹配的内容然后得到正确的内容。(4)公式:只支持[pageIndex],用来表示获取分页地址时分页的页码。5.图标详情?进入栏目管理(图一)?Setup采集Plan 在右侧列列表中选择一列,点击Set采集Plan。(图二)执行方式可以是:?Manual (需要点击列列表中的“立即采集”启动采集)?单(可以设置时间,到了时间,它会自动启动采集)?Cycle(指定间隔时间,自动循环
10、采集) 可以设置是否自动发布采集的文章。采集 的列类型:?单列(采集这一列下只有文章)?单列 RSS(文章 在 采集 的 RSS 地址下)?多列(采集 列和子列下的文章)?多栏RSS(从一个RSS列表地址开始,采集在多个RSS地址文章下,每个RSS地址形成一个子栏)编码方式为页面的编码为采集@ >? 设置采集规则 a)单栏模式(图三)b)单栏RSS模式(图三)b)四)此方法与单栏相同-column 方法,除了它不需要设置 文章 页面URL获取方法。c) 多列方式(图五)该方法的起始页一般为列表页采集,单列方式需要设置获取列表页的方法
11、表格和列名规则,其他同单列。d) 多列RSS(图六) 该方法需要设置从起始页获取RSS地址(列表页URL),其他与单列RSS一致。设置获取规则(图< @七)(图八)(图九)(图十)(图10一)(图10二))如上图所示,获取rule 由多个表达式组成,多个表达式相加得到所需的 URL 以获取 文章 的标题内容和其他属性。表达式分为 4 类: ? 字符串:直接输入字符串常量 ? 匹配:来自指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。? 匹配替换:以指定文本开头(URL、IframeURL、页面内容)
12、 使用正则表达式获取文本中的部分内容S。然后用替换正则表达式替换S中匹配的内容,得到正确的内容。?公式:仅支持[pageIndex],用于表示获取分页地址时分页的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。?查看采集计划的状态,返回列列表可以看到下图(图10中三)采集的状态中的三个图标代表了计划的运行状态采集计划分别(是否运行,是否运行等),采集模式(单栏,单栏RSS,多栏,多栏RSS),执行模式(手动,
13、十四)三。采集方案示例以新浪体育新闻列表网页网站为例采集,该网页的访问地址为。采集 的内容放置在“体育新闻”部分下。1.由于这是一个测试示例,我们手动进行采集,信息采集不需要自动发布。网页是一个简单的新闻列表页面,编码方式为GB2312,所以我们将采集的列类型设置为“单列”,编码方式为gb2312采集对新闻没有自动发布。如下图2.因为这个网页的新闻列表内容已经不在iframe中了,也没有分页,所以不需要
14、设置“列表页内容在IFRAME中”和“列表页分页方式”的获取规则。并且新闻列表的内容不需要设置“限制文章列表内容”规则。3.设置文章url的获取规则由于这个网页中的新闻链接类似于下面的url:所以制定如下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(d+ )-(d+)-(d+)/(d+).shtml 匹配组:0(得到匹配
15、整个结果)获取页面的源文件为采集,粘贴到页面内容中,点击“测试计算-列表模式”,结果会显示所有匹配的列表urls如下图4.由于文章内容不在iframe中,所以文章内容没有分页,文章内容不需要限制在page, 所以 "文章 page content is in the IFRAME" , "文章content paging URL" 和 "limited 文章page文章content" 的获取规则不需要要设置。5.文章设置标题规则是因为新闻页面源文件中文章的标题在以下位置:
16、 类型:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果的第一个组,每个括号为一个组)获取页面为采集的来源文件,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的标题内容如下图 6.文章内容规则是由于源文件设置的新闻页面文章的内容在以下位置:新浪体育新闻北京时间7月7日休斯敦消息,据ESPN报道,姚明尚未决定是否进行脚伤修复手术,虽然现在对姚明的三个主要诊断。医生已经建议手术,但姚明仍然犹豫不决。关于姚明现在的想法,其实,
17、如果手术,他下赛季全部缺席也不是不可能。已经29岁的姚明不想就这样浪费一年。毕竟,运动员的巅峰期只是这么一段时期,没有人能保证那段时间。姚明能否保持更好的水平?姚明犹豫不决,但休斯顿球迷对姚明却有着不同的看法。大多数球迷认为,姚明应该毫不犹豫地接受手术。他们的理由是,既然已经有恶化的趋势,保守治疗的效果还不得而知,就不应该下定决心做手术。毕竟,健康的姚明才是火箭队最好的球员。需要什么,如果保守治疗后还需要手术,那姚明得不偿失。“亲爱的姚,请下定决心做手术,即使错过了下个赛季,也不要犹豫。如果现在
18、保守治疗终于痊愈了,但还是让我们瑟瑟发抖,下赛季可能会有问题。最好通过手术解决疾病的根本原因。你可能会失去一年,但我们相信你会给休斯顿带来三年、五年甚至更健康的未来。”一位球迷这样说。的确,这位球迷表达了广大休斯顿球迷的心声。没有人愿意看到姚明在没有完全康复的情况下重返赛场。如果姚明再次受伤,我相信所有休斯顿球迷会欣赏的,包括姚明,都会是一个很重的打击,也有球迷表示,姚明手术要放心,给姚明做检查诊断的医生,就是在骑士队中心做手术的医生当年的大Z。爱情和姚明差不多,最后在手术中
19、一年后,大Z健康回归赛场,接下来的几年也没有大伤,竞技状态还是比较好的。“和哈达威等人一样,他们的水平因为伤病急剧下降,我认为这种情况对姚明来说是非常困难的,姚明和希尔、哈达威不同,姚明是内线球员,虽然脚部移动很重要,相对来说,弹跳并不是最重要的,姚明在内线的威慑力主要来自他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会带走他的手感。” 风扇说。总之,休斯顿人基本上是希望姚明能做手术的。他们相信手术能给姚明带来完全的健康,而一个健康的姚明,是他们最希望看到的姚明。(
20、小黑)所以制定如下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(.+?)匹配组:1(获取匹配结果中的第一个组,每个括号为一组) 获取页面源文件为采集,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的文章内容如下图7.Other @>文章 的属性在这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。8.采集计划设置好后,选择“体育新闻”栏目,点击采集现在,过一会,查看该栏目的内容管理,你会看到以下内容。另外,采集采集的运行状态
21、,如下图:
采集文章免费( 百度一下“卓天网络”有哪些比较好用的文章采集器和论坛发贴软件?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-07 23:20
百度一下“卓天网络”有哪些比较好用的文章采集器和论坛发贴软件?)
【articlesea】articlesea文章采集这个软件好用吗?文章海号
此类功能需要采集软件具备“泛搜索自动分析”能力,如站群软件。
但基本上它是通过许多大型 网站 新闻页面的内置模板来实现的。
采集软件官方会不断为自己的软件添加新的网站模板,丰富模板库。显然,这类采集软件的“自动解析”能力是比较有限的,会有相当多比例(约60%)的内容无法解析。
业界唯一技术最好的软件是优采云采集器,它不使用内置模板来解析任何页面的文本。
而优采云采集器不仅有自动解析新闻信息的能力,还能解析论坛文字。
论坛文字长短不一,解析技术最难。
文章采集器有用吗?
然后,当然是使用知名的建站盒子和免费的自助建站系统来做;国内比较有名的建站箱是卓天网络建站箱,模板安装后直接使用即可。里面功能很多,网站可以随时更新发布。建站盒子ExBox是卓天虚拟主机增值服务的免费建站系统,收录上千个精美的网站模板,上百个网站功能,网站简体中文版,繁体同时支持中文版和英文版,具有产品发布系统、新闻系统、会员系统、投票系统、广告系统、招聘系统等动态功能模块,
使用强大的管理平台,轻点鼠标即可瞬间制作精美的网站,不仅周期大大缩短,而且可以免费使用,无需额外的技术和成本投入,同时可以分享我们对产品的技术升级和功能改进,大大节省用户拥有网站的成本。
百度“卓天网”
有什么好用的文章采集器和论坛发帖软件?? ? ?
上述阅读器软件除了书写和阅读功能都还不错,使用“Anthemion Writer's Cafe”(Anthemion Writer's Cafe)v2.26语言版本标题:Writer's Cafe:说写软件英文名称: Anthemion Writer's Cafe 资源格式:安装包版本:v2.26 语言版本发布室:2010 制作发行:Anthemion Software Ltd. 地区:英语语言:简体中文,语言软件介绍管写作故事写作说到特别创作,情节和内容需要组织和保持逻辑严谨或铺垫。作者经常受伤;内容过于分散,很难凭空想象顺序,光靠背可能很难记住剧情。根据写作要求,基本逻辑要理性思考,尽量严谨。该软件可以帮助管理涉及素材、线索和创作主线的创作。该软件应该能够清晰和组织内容。写作需要能够准确地找到所需的信息并采集和管理写作材料。软件手书网吧软件:适合各种讲故事的人,有经验的新手工具箱,强大的操作核心,Story Lines Fantasy 记录书写工具 书写窗口可以让你从保存就开始书写文字,即使文字数据丢失意外情况,如死机、断电等。如果您需要运行本软件,文本数据将立即出现。完全专注于 文章 构思写作大大提高写作速度和效率草稿按钮可以让你在每个窗口中写作文章段落或章节按位置和结尾排序文章保存你的电脑大大提高软件工作效率数据采集器它可以帮助你在网上快速找到你要找的资料并保存在你的电脑上,作家,老师,写字工具,集集写字工具,写老集集必备的辅助软件 免费绿色软件 整个软件是只需 1M 即可下载、安装和移动。除了文本编辑功能,集集写作还有一些主要功能:1.自保存、自备份和手动备份2.批量命名(包括中文名、中文名、英文名)< @3. 树状章节目录管理< 查看全部
采集文章免费(
百度一下“卓天网络”有哪些比较好用的文章采集器和论坛发贴软件?)
【articlesea】articlesea文章采集这个软件好用吗?文章海号
此类功能需要采集软件具备“泛搜索自动分析”能力,如站群软件。
但基本上它是通过许多大型 网站 新闻页面的内置模板来实现的。
采集软件官方会不断为自己的软件添加新的网站模板,丰富模板库。显然,这类采集软件的“自动解析”能力是比较有限的,会有相当多比例(约60%)的内容无法解析。
业界唯一技术最好的软件是优采云采集器,它不使用内置模板来解析任何页面的文本。
而优采云采集器不仅有自动解析新闻信息的能力,还能解析论坛文字。
论坛文字长短不一,解析技术最难。
文章采集器有用吗?
然后,当然是使用知名的建站盒子和免费的自助建站系统来做;国内比较有名的建站箱是卓天网络建站箱,模板安装后直接使用即可。里面功能很多,网站可以随时更新发布。建站盒子ExBox是卓天虚拟主机增值服务的免费建站系统,收录上千个精美的网站模板,上百个网站功能,网站简体中文版,繁体同时支持中文版和英文版,具有产品发布系统、新闻系统、会员系统、投票系统、广告系统、招聘系统等动态功能模块,
使用强大的管理平台,轻点鼠标即可瞬间制作精美的网站,不仅周期大大缩短,而且可以免费使用,无需额外的技术和成本投入,同时可以分享我们对产品的技术升级和功能改进,大大节省用户拥有网站的成本。
百度“卓天网”
有什么好用的文章采集器和论坛发帖软件?? ? ?
上述阅读器软件除了书写和阅读功能都还不错,使用“Anthemion Writer's Cafe”(Anthemion Writer's Cafe)v2.26语言版本标题:Writer's Cafe:说写软件英文名称: Anthemion Writer's Cafe 资源格式:安装包版本:v2.26 语言版本发布室:2010 制作发行:Anthemion Software Ltd. 地区:英语语言:简体中文,语言软件介绍管写作故事写作说到特别创作,情节和内容需要组织和保持逻辑严谨或铺垫。作者经常受伤;内容过于分散,很难凭空想象顺序,光靠背可能很难记住剧情。根据写作要求,基本逻辑要理性思考,尽量严谨。该软件可以帮助管理涉及素材、线索和创作主线的创作。该软件应该能够清晰和组织内容。写作需要能够准确地找到所需的信息并采集和管理写作材料。软件手书网吧软件:适合各种讲故事的人,有经验的新手工具箱,强大的操作核心,Story Lines Fantasy 记录书写工具 书写窗口可以让你从保存就开始书写文字,即使文字数据丢失意外情况,如死机、断电等。如果您需要运行本软件,文本数据将立即出现。完全专注于 文章 构思写作大大提高写作速度和效率草稿按钮可以让你在每个窗口中写作文章段落或章节按位置和结尾排序文章保存你的电脑大大提高软件工作效率数据采集器它可以帮助你在网上快速找到你要找的资料并保存在你的电脑上,作家,老师,写字工具,集集写字工具,写老集集必备的辅助软件 免费绿色软件 整个软件是只需 1M 即可下载、安装和移动。除了文本编辑功能,集集写作还有一些主要功能:1.自保存、自备份和手动备份2.批量命名(包括中文名、中文名、英文名)< @3. 树状章节目录管理<
采集文章免费(网站采集的文章内容可以参考网络上的相关内容吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-06 23:20
网站采集的文章内容可以参考网上的一些相关内容,然后通过我自己的理解分享给网站,这是一般的网站内容采集@的一个想法>。但是为了节省时间或者因为执行不到位,很多朋友直接从网上复制粘贴了很多内容,放到自己的网站上。对于这种不负责任的文章采集行为,直接放在网站上的网站的内容,没有从采集中整理出来,肯定会被反感和排斥通过搜索引擎。在不断更新保护原创免受采集攻击的算法后,许多网站受到了相应的惩罚。
网站采集关于seo网站内容优化的注意事项,即对于网站内容的添加,有哪些错误需要注意,必须避免呢?网站可持续发展的动力是网站内容的增加。通过网站内容的不断增加和网站收录的数量不断增加,可以提高网站关键词的排名。但是,前提是我们可以创建高质量的 网站 内容。
网站采集 是做站的一种方法,但不是唯一的方法。一定要合理利用网站采集,也可以在期间添加一些自己创建的文章,增加访问用户看到文章时的可读性,而且做网站也是要回归初心,网站只是一种表现形式,最重要的是内容,毕竟内容为王。
特别声明:以上内容(包括图片或视频)为自媒体平台“网易”用户上传发布,本平台仅提供信息存储服务。 查看全部
采集文章免费(网站采集的文章内容可以参考网络上的相关内容吗?)
网站采集的文章内容可以参考网上的一些相关内容,然后通过我自己的理解分享给网站,这是一般的网站内容采集@的一个想法>。但是为了节省时间或者因为执行不到位,很多朋友直接从网上复制粘贴了很多内容,放到自己的网站上。对于这种不负责任的文章采集行为,直接放在网站上的网站的内容,没有从采集中整理出来,肯定会被反感和排斥通过搜索引擎。在不断更新保护原创免受采集攻击的算法后,许多网站受到了相应的惩罚。
网站采集关于seo网站内容优化的注意事项,即对于网站内容的添加,有哪些错误需要注意,必须避免呢?网站可持续发展的动力是网站内容的增加。通过网站内容的不断增加和网站收录的数量不断增加,可以提高网站关键词的排名。但是,前提是我们可以创建高质量的 网站 内容。
网站采集 是做站的一种方法,但不是唯一的方法。一定要合理利用网站采集,也可以在期间添加一些自己创建的文章,增加访问用户看到文章时的可读性,而且做网站也是要回归初心,网站只是一种表现形式,最重要的是内容,毕竟内容为王。
特别声明:以上内容(包括图片或视频)为自媒体平台“网易”用户上传发布,本平台仅提供信息存储服务。
采集文章免费(怎么保持免费CMS采集插件对网站SEO有什么作用? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-06 07:00
)
免费的 cms采集 插件对 网站SEO 有什么作用。许多 网站 正在做 SEO 推广。与通过付费推广的SEM不同,SEO是利用技术进行网络推广。SEO技术涉及面很广,无论是黑帽还是白帽,博主都认为它能给用户带来良好的体验。出于成本考虑,免费的cms采集插件是很多站长首先考虑的。
蜘蛛通过爬取我们的网站获取我们的网站每天更新的内容,并通过分析爬取的数据分析内容的质量,只有收录为优质内容。所以蜘蛛会根据网站是否定期更新来判断网站是否正常,这就需要我们SEOER养成每天更新文章的好习惯,当然, 文章 的质量也很重要。我们如何保持内容的高质量和更新?
一、材料采集
免费的cms采集插件的采集功能只需要我们输入关键词,就可以在多个平台上使用(如图)采集@ >,支持定向和增量采集,内置中英文翻译,繁简交换。支持采集(具有H标签、图片云存储、自动文本编辑等功能)、本地再创作或直接伪原创发布。
二、自动发帖
免费的cms采集插件支持各种cms,无论是主流dede、wp还是小众ThinkCMF等都可以使用。从 采集 发布到 关键词 可以在所有任务进度和状态可见的情况下完成。支持定时开始、定时结束、发布次数等设置。真正的全天自动挂机。
三、文章内容保证
如何保持 文章关键词 相关和 原创 相关。我们的 文章 标题需要至少收录两个 关键词。从内容上看,开头应该有两三个关键词,中间一两个关键词,最后一个关键词。这样的关键词布局基本可以达到4%-8%的关键词密度。当然,这些都是基于神通关键词的外表,不要为了关键词的外表而刻意堆砌关键词,这样的文章很难成为< @收录。
免费的cms采集插件的伪原创功能支持在我们的采集内容的标题和内容中插入自定义关键词,设置关键词内部链接/外部链接。可以自定义插入图片的频率文章,但是要注意整个网站不能频繁出现关键词,尤其是在不合适的地方。很难排名。免费的 cms采集 插件让我们的 文章 内容更加直接。各种伪原创 功能一应俱全。可以同时创建几十个采集/publish/push 任务。发布后,全平台自动推送。
四、广告
做SEO的站长应该都明白这个道理,网站的权重越高,网站的排名就越高。如果用户选择SEO技术进行推广,可以通过Advertorial使用权限较高的网站进行推广。需要注意的是,如果软文有联系方式或其他非法内容,可能会被删除。Advertorial 的 关键词 密度略高,这是正常的。
免费的cms采集插件确实可以给我们带来很大的方便,减少重复劳动,为我们提供源源不断的素材,让我们可以在制作中使用网站内容丰富的弹药。自动推送功能主动提交链接,也缩短了蜘蛛找到我们的时间,提高了收录的效率。我们不能盲目依赖插件。我们还需要不断的了解用户体验,通过信息反馈做出改变和优化,这就是好的SEO。
查看全部
采集文章免费(怎么保持免费CMS采集插件对网站SEO有什么作用?
)
免费的 cms采集 插件对 网站SEO 有什么作用。许多 网站 正在做 SEO 推广。与通过付费推广的SEM不同,SEO是利用技术进行网络推广。SEO技术涉及面很广,无论是黑帽还是白帽,博主都认为它能给用户带来良好的体验。出于成本考虑,免费的cms采集插件是很多站长首先考虑的。

蜘蛛通过爬取我们的网站获取我们的网站每天更新的内容,并通过分析爬取的数据分析内容的质量,只有收录为优质内容。所以蜘蛛会根据网站是否定期更新来判断网站是否正常,这就需要我们SEOER养成每天更新文章的好习惯,当然, 文章 的质量也很重要。我们如何保持内容的高质量和更新?
一、材料采集
免费的cms采集插件的采集功能只需要我们输入关键词,就可以在多个平台上使用(如图)采集@ >,支持定向和增量采集,内置中英文翻译,繁简交换。支持采集(具有H标签、图片云存储、自动文本编辑等功能)、本地再创作或直接伪原创发布。
二、自动发帖
免费的cms采集插件支持各种cms,无论是主流dede、wp还是小众ThinkCMF等都可以使用。从 采集 发布到 关键词 可以在所有任务进度和状态可见的情况下完成。支持定时开始、定时结束、发布次数等设置。真正的全天自动挂机。
三、文章内容保证
如何保持 文章关键词 相关和 原创 相关。我们的 文章 标题需要至少收录两个 关键词。从内容上看,开头应该有两三个关键词,中间一两个关键词,最后一个关键词。这样的关键词布局基本可以达到4%-8%的关键词密度。当然,这些都是基于神通关键词的外表,不要为了关键词的外表而刻意堆砌关键词,这样的文章很难成为< @收录。
免费的cms采集插件的伪原创功能支持在我们的采集内容的标题和内容中插入自定义关键词,设置关键词内部链接/外部链接。可以自定义插入图片的频率文章,但是要注意整个网站不能频繁出现关键词,尤其是在不合适的地方。很难排名。免费的 cms采集 插件让我们的 文章 内容更加直接。各种伪原创 功能一应俱全。可以同时创建几十个采集/publish/push 任务。发布后,全平台自动推送。
四、广告
做SEO的站长应该都明白这个道理,网站的权重越高,网站的排名就越高。如果用户选择SEO技术进行推广,可以通过Advertorial使用权限较高的网站进行推广。需要注意的是,如果软文有联系方式或其他非法内容,可能会被删除。Advertorial 的 关键词 密度略高,这是正常的。
免费的cms采集插件确实可以给我们带来很大的方便,减少重复劳动,为我们提供源源不断的素材,让我们可以在制作中使用网站内容丰富的弹药。自动推送功能主动提交链接,也缩短了蜘蛛找到我们的时间,提高了收录的效率。我们不能盲目依赖插件。我们还需要不断的了解用户体验,通过信息反馈做出改变和优化,这就是好的SEO。

采集文章免费(PBootCMS全自动如何实现文章全自动采集发布,免费PBootCMS发布工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-24 21:02
PBootcms如何实现文章自动采集发布,免费PBootcms发布工具是一款全自动、强大的SEO工具,支持全网文章采集自动发布到网站,并配有自动推送功能,方便使用。 Pbootcms作为永久开源免费的网站管理系统,可以满足各种网站构造的需求,简洁明了。所以积累了很多用户!因为代码简单,介绍对搜索引擎比较友好。另一方面,PBootcms有很多免费的SEO工具,非常方便实用。使用免费的PBootcms采集发布工具小白还可以搭建每日自动采集和发布网站。使用PBootcms和免费的采集发布工具,可以当天建新域名,次日逐步启动收录,部分关键词启动排名。一段时间后,收录基本可以达到上万个收录。
免费 PBootcms发布模块:
1、文章可以在文章发布时自动发布伪原创(伪原创主要针对搜索引擎算法规则收录@开发>,采用AI智能大脑。整合NLG技术、RNN模型、百度人工智能算法技术,对网站收录)
有帮助
2、自动内链(自动内链可以让搜索引擎蜘蛛爬得更深收录网站内容) 以上所有功能都可以通过迅瑞cms工具来管理自动完成
3、除了PBootcms,还支持市面上主要的cms,可以管理和发布各种cms
同时分批
4、自动发布、定时定量发布
5、可以插入标题、内容关键词的后缀和后缀,提高网站关键词的排名并优化
6、发布后立即推送至百度/搜狗/360/神马加速收录
7、可随机设置评论/点赞/阅读/作者/图片,增强页面模拟用户真实性
一、PBootcms自动采集发布
1. 全自动无人值守定时批处理采集
2. 自动同步网站更新
3.AI自动关键词,自动汇总生成
4.自动发布到PBootcms,无需额外配置
5. 身体图像和缩略图都可以本地化
6.文章每个任务中的图片都可以独立加水印
7. 平台范围的内容采集
可以采集哪些站
1. 新闻资讯站
2. 文章模型站
3.BBS 论坛
4. 博客网站
5.资源站、下载站
建议选择新闻来源采集!为什么选择新闻来源?因为新闻提要的 网站 质量非常高!新闻源相当于搜索引擎的“种子源”,收录快速、可信、权威。新闻源特别符合搜索引擎新闻收录 标准。因此,采集!
的内容我们首选的新闻来源
以上编辑器采用全自动采集发布推送,所有内容均与主题相关! 网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
采集文章免费(PBootCMS全自动如何实现文章全自动采集发布,免费PBootCMS发布工具)
PBootcms如何实现文章自动采集发布,免费PBootcms发布工具是一款全自动、强大的SEO工具,支持全网文章采集自动发布到网站,并配有自动推送功能,方便使用。 Pbootcms作为永久开源免费的网站管理系统,可以满足各种网站构造的需求,简洁明了。所以积累了很多用户!因为代码简单,介绍对搜索引擎比较友好。另一方面,PBootcms有很多免费的SEO工具,非常方便实用。使用免费的PBootcms采集发布工具小白还可以搭建每日自动采集和发布网站。使用PBootcms和免费的采集发布工具,可以当天建新域名,次日逐步启动收录,部分关键词启动排名。一段时间后,收录基本可以达到上万个收录。

免费 PBootcms发布模块:
1、文章可以在文章发布时自动发布伪原创(伪原创主要针对搜索引擎算法规则收录@开发>,采用AI智能大脑。整合NLG技术、RNN模型、百度人工智能算法技术,对网站收录)
有帮助
2、自动内链(自动内链可以让搜索引擎蜘蛛爬得更深收录网站内容) 以上所有功能都可以通过迅瑞cms工具来管理自动完成
3、除了PBootcms,还支持市面上主要的cms,可以管理和发布各种cms
同时分批
4、自动发布、定时定量发布
5、可以插入标题、内容关键词的后缀和后缀,提高网站关键词的排名并优化
6、发布后立即推送至百度/搜狗/360/神马加速收录
7、可随机设置评论/点赞/阅读/作者/图片,增强页面模拟用户真实性
一、PBootcms自动采集发布

1. 全自动无人值守定时批处理采集
2. 自动同步网站更新
3.AI自动关键词,自动汇总生成
4.自动发布到PBootcms,无需额外配置
5. 身体图像和缩略图都可以本地化
6.文章每个任务中的图片都可以独立加水印
7. 平台范围的内容采集
可以采集哪些站
1. 新闻资讯站
2. 文章模型站
3.BBS 论坛
4. 博客网站
5.资源站、下载站
建议选择新闻来源采集!为什么选择新闻来源?因为新闻提要的 网站 质量非常高!新闻源相当于搜索引擎的“种子源”,收录快速、可信、权威。新闻源特别符合搜索引擎新闻收录 标准。因此,采集!
的内容我们首选的新闻来源
以上编辑器采用全自动采集发布推送,所有内容均与主题相关! 网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
采集文章免费(采集文章免费,短视频同理可得,不要钱(包括高清图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-24 15:02
采集文章免费,短视频同理可得,不要钱(包括高清图),
是的,可以。我关注的公众号上刚推出一个“自我推荐”功能。大意是:把你对朋友说的广告推荐给好友或群,你可以获得1-500元不等的广告分成。依照阅读量从高到低分成,不超过500字的免费推荐标准是一天200,500字以上每天600元(标准截止时间19年2月26日)。另外如果你不介意阅读量的话,500-1000字以内也可以免费推荐。
我目前在那里找到了12个免费推荐,上面那个是我找到的最好的一个广告群了。因为我的文字量和推荐标准不符合,所以目前只得到了大概2万块,详细的推荐标准每个公众号可能不一样,具体看样子。
我也想推广自己原创的优质内容呢,
手动添加机器人::/
@monster
原创答案新人。私以为不能做广告。其实可以设置公司或产品,定期做文章类广告。除非广告做的大。我们也曾做过原创栏目,后面平台要求原创度和公司或产品文,暂停了。很后悔。这种行为也使原创度下降。所以我认为广告应该是可以采取的。一句话说就是不影响你的内容质量和阅读。建议投放一些别人看完会想买或者需要的广告。比如新上品牌服饰或珠宝玉石。如果你有固定的订阅者和读者,可以用微信公众号投放。不过这个别人的位置要好好找。不过要真受得了。 查看全部
采集文章免费(采集文章免费,短视频同理可得,不要钱(包括高清图))
采集文章免费,短视频同理可得,不要钱(包括高清图),
是的,可以。我关注的公众号上刚推出一个“自我推荐”功能。大意是:把你对朋友说的广告推荐给好友或群,你可以获得1-500元不等的广告分成。依照阅读量从高到低分成,不超过500字的免费推荐标准是一天200,500字以上每天600元(标准截止时间19年2月26日)。另外如果你不介意阅读量的话,500-1000字以内也可以免费推荐。
我目前在那里找到了12个免费推荐,上面那个是我找到的最好的一个广告群了。因为我的文字量和推荐标准不符合,所以目前只得到了大概2万块,详细的推荐标准每个公众号可能不一样,具体看样子。
我也想推广自己原创的优质内容呢,
手动添加机器人::/
@monster
原创答案新人。私以为不能做广告。其实可以设置公司或产品,定期做文章类广告。除非广告做的大。我们也曾做过原创栏目,后面平台要求原创度和公司或产品文,暂停了。很后悔。这种行为也使原创度下降。所以我认为广告应该是可以采取的。一句话说就是不影响你的内容质量和阅读。建议投放一些别人看完会想买或者需要的广告。比如新上品牌服饰或珠宝玉石。如果你有固定的订阅者和读者,可以用微信公众号投放。不过这个别人的位置要好好找。不过要真受得了。
采集文章免费(英语采集文章免费送,不领你亏大了!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-20 02:00
采集文章免费送啦,不光有免费获取学习资料,更有现金奖励,不领你亏大了!学习英语5年了,但是不会发音我比较失望,所以我发现了这个app,它专门解决我发音问题的,软件里面所有发音的内容几乎全部都是免费给你下载,我先不说多好,起码我是比较满意的,重点是一个人的成长,免费的条件不管是在生活还是工作上都是很重要的。
这也是我如今选择英语学习的一个最重要的原因,每一个信息都是免费分享给你的。and支持国内优秀的英语学习平台,免费,无限制发音资源,我的一生都是用它来学习英语的。这些都是学习其他学习方法得不到的福利!。
练听力,百词斩。软件就那么些。其他老师都讲过了。我就不赘述了。零基础,从英语字母学起,背单词,看电影。
学习英语多么重要。
百词斩单词入门就不错,
不推荐软件,但是用了一个个月后你会爱上bbcbbc英音练习,有个刷题的,可以做选择。
小站就可以,跟着软件练就行,
爱听公开课的都可以,
软件只是辅助的,有了正确的学习方法,没有好的练习方法,软件只是一个辅助作用。有了正确的学习方法,再加上好的练习方法,学习软件也好,单词书也好,学的效果是最好的,不过没有好的学习方法,方法不对,选什么工具也白搭。 查看全部
采集文章免费(英语采集文章免费送,不领你亏大了!)
采集文章免费送啦,不光有免费获取学习资料,更有现金奖励,不领你亏大了!学习英语5年了,但是不会发音我比较失望,所以我发现了这个app,它专门解决我发音问题的,软件里面所有发音的内容几乎全部都是免费给你下载,我先不说多好,起码我是比较满意的,重点是一个人的成长,免费的条件不管是在生活还是工作上都是很重要的。
这也是我如今选择英语学习的一个最重要的原因,每一个信息都是免费分享给你的。and支持国内优秀的英语学习平台,免费,无限制发音资源,我的一生都是用它来学习英语的。这些都是学习其他学习方法得不到的福利!。
练听力,百词斩。软件就那么些。其他老师都讲过了。我就不赘述了。零基础,从英语字母学起,背单词,看电影。
学习英语多么重要。
百词斩单词入门就不错,
不推荐软件,但是用了一个个月后你会爱上bbcbbc英音练习,有个刷题的,可以做选择。
小站就可以,跟着软件练就行,
爱听公开课的都可以,
软件只是辅助的,有了正确的学习方法,没有好的练习方法,软件只是一个辅助作用。有了正确的学习方法,再加上好的练习方法,学习软件也好,单词书也好,学的效果是最好的,不过没有好的学习方法,方法不对,选什么工具也白搭。
采集文章免费(Dede采集插件采集内容,是因为网站内容SEO的重要组成部分)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-18 09:02
Dede采集plugin采集content,因为网站content SEO是SEO的重要组成部分。收录在 网站 上编写和构建内容的所有方面。内容搜索引擎优化是必不可少的。搜索引擎抓取 网站。搜索引擎的算法主要是根据网站发布的内容来决定网站的排名。我们都知道内容为王。因此,SEO 内容需要 Dede采集 插件。看到Dede采集插件文章,那么一定要搜索相关资料,直接看图,不是文章的内容,图表达一切,看完四图你会明白它的真正含义。【重要信息点一,强大的Dede采集插件】
更新 文章 是 网站 的主要优化重点。只有内容优化才能更流畅。网站在SEO上做得不好的原因大部分是他们做得不好网站文章的更新工作,Dede采集插件允许网站@ > 经常更新文章,以便做好网站的SEO优化工作。【重要信息点2,完全免费的Dede采集插件】
通过Dede采集插件,大量的采集内容可以被搜索引擎收录用来在线搜索文章重复,其中大部分已经发表在一些高权重的平台,同样的数据也存在于搜索引擎中,所以搜索引擎不会爬取检索,而是Dede采集插件生成的文章经过AI智能处理后发布,这就是为什么别人采集可以增加权重,而你的网站采集会减轻权重。【重要信息点3,具有丰富SEO功能的Dede采集插件】
其实有很多因素值得参考。Dede采集plugin采集过来后,经过内容处理优化后发布,或者采集的内容比较新,原创度数和时效性高,并且对用户的参考价值比较大,所以可以提高网站的seo权重。【重要信息点4,方便高效的Dede采集插件】
Dede采集插件对网站的处理和排版也是智能处理的。搜索引擎蜘蛛点的原则认为,同时文章的更新必须有文字描述,而文章的更新要坚持“文字就是文字”的原则。主图为辅”,也就是我们常说的内容为王,内容为王。 查看全部
采集文章免费(Dede采集插件采集内容,是因为网站内容SEO的重要组成部分)
Dede采集plugin采集content,因为网站content SEO是SEO的重要组成部分。收录在 网站 上编写和构建内容的所有方面。内容搜索引擎优化是必不可少的。搜索引擎抓取 网站。搜索引擎的算法主要是根据网站发布的内容来决定网站的排名。我们都知道内容为王。因此,SEO 内容需要 Dede采集 插件。看到Dede采集插件文章,那么一定要搜索相关资料,直接看图,不是文章的内容,图表达一切,看完四图你会明白它的真正含义。【重要信息点一,强大的Dede采集插件】

更新 文章 是 网站 的主要优化重点。只有内容优化才能更流畅。网站在SEO上做得不好的原因大部分是他们做得不好网站文章的更新工作,Dede采集插件允许网站@ > 经常更新文章,以便做好网站的SEO优化工作。【重要信息点2,完全免费的Dede采集插件】

通过Dede采集插件,大量的采集内容可以被搜索引擎收录用来在线搜索文章重复,其中大部分已经发表在一些高权重的平台,同样的数据也存在于搜索引擎中,所以搜索引擎不会爬取检索,而是Dede采集插件生成的文章经过AI智能处理后发布,这就是为什么别人采集可以增加权重,而你的网站采集会减轻权重。【重要信息点3,具有丰富SEO功能的Dede采集插件】

其实有很多因素值得参考。Dede采集plugin采集过来后,经过内容处理优化后发布,或者采集的内容比较新,原创度数和时效性高,并且对用户的参考价值比较大,所以可以提高网站的seo权重。【重要信息点4,方便高效的Dede采集插件】

Dede采集插件对网站的处理和排版也是智能处理的。搜索引擎蜘蛛点的原则认为,同时文章的更新必须有文字描述,而文章的更新要坚持“文字就是文字”的原则。主图为辅”,也就是我们常说的内容为王,内容为王。
采集文章免费(搜索引擎为什么一直不收录我的网站?怎么让搜索引擎快速收录 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-13 20:05
)
为什么搜索引擎不保留 收录my网站?为什么我的 网站 没有排名?我 网站 得到了 K 吗?如何让搜索引擎快速收录my网站?这是最近很多站长问我的一个问题,今天就这些问题分享一下我的一些看法。
首先我们要知道SEO到底是做什么的?是的,网站 内容。因为SEO是内容为王的时代。一个好的稳定的内容来源可以让你网站收录和排名更有效率。
如何网站内容
首先,我们手动发布网站内容,形式不可靠,不能做很多内容。所以我们将使用免费的 采集 工具。那么 采集 工具是什么?采集工具是指互联网数据采集、处理、分析和挖掘软件。文章采集工具,只需输入关键字即可采集各种网页和新闻,也可以采集指定列表页的文章@(栏页)>。让您的 网站 内容更丰富,然后使用免费的 采集 工具覆盖更多 关键词 以批量采集 质量新闻源。那么你可能会说百度等搜索引擎正在打击纯采集,那么有什么办法可以避免呢?
有些我们可以批处理 采集 然后 伪原创 然后我们发布到 网站 后台。
以 伪原创 的方式提高 收录文章 的 SEO收录 率,当我们 收录 时,我们永远不会达到 100% 原创 的性能. 使用 伪原创 的目的是找到绕过搜索引擎或新媒体中收录的重复检查算法的方法。使内容更快 收录 并增加 文章 流量。
采集如何选择工具
必须满足几个要素:操作简单,使用工具的目的是提高工作效率,满足大量批量需求。界面简单易懂,大部分站长不具备编码或编写程序的能力,所以傻瓜式操作非常重要,只需点击几下即可完成工作。挂机操作,SEO需要做的很多,需要更多的时间和精力去优化。至于采集,放在那里,让它自己工作。它可以免费使用。做网站的目的就是为了赚钱。SEO本身就是一项技能,不要花钱去做。如果是花钱做的,不如直接打广告。我自己做了将近1000个各种大小的网站,从来没有在采集工具上花过一分钱,就用免费的< @采集 直接使用工具。147SEO采集工具用于完成网站的采集需求。
正确使用采集的打开方式
采集的内容一定要和标题对应,要做到页面相关,一定要垂直,采集行业文章和关键词,切记,不要乱来采集文章,填写数字,然后必须公布大量的文章采集。做好,像往常一样定期发布,让搜索引擎知道你的模式,逐渐增加或减少。偶尔可以穿插一两篇原创文章的文章,更有利于收录和网站的排名。
今天的分享就到这里。其实我讲的核心是采集工具的介绍和使用以及一些注意事项。如果看完这篇文章,你有很多网站要构建,不妨试试作者介绍的方法。希望我的经验可以帮到你。
查看全部
采集文章免费(搜索引擎为什么一直不收录我的网站?怎么让搜索引擎快速收录
)
为什么搜索引擎不保留 收录my网站?为什么我的 网站 没有排名?我 网站 得到了 K 吗?如何让搜索引擎快速收录my网站?这是最近很多站长问我的一个问题,今天就这些问题分享一下我的一些看法。
首先我们要知道SEO到底是做什么的?是的,网站 内容。因为SEO是内容为王的时代。一个好的稳定的内容来源可以让你网站收录和排名更有效率。

如何网站内容
首先,我们手动发布网站内容,形式不可靠,不能做很多内容。所以我们将使用免费的 采集 工具。那么 采集 工具是什么?采集工具是指互联网数据采集、处理、分析和挖掘软件。文章采集工具,只需输入关键字即可采集各种网页和新闻,也可以采集指定列表页的文章@(栏页)>。让您的 网站 内容更丰富,然后使用免费的 采集 工具覆盖更多 关键词 以批量采集 质量新闻源。那么你可能会说百度等搜索引擎正在打击纯采集,那么有什么办法可以避免呢?
有些我们可以批处理 采集 然后 伪原创 然后我们发布到 网站 后台。
以 伪原创 的方式提高 收录文章 的 SEO收录 率,当我们 收录 时,我们永远不会达到 100% 原创 的性能. 使用 伪原创 的目的是找到绕过搜索引擎或新媒体中收录的重复检查算法的方法。使内容更快 收录 并增加 文章 流量。

采集如何选择工具
必须满足几个要素:操作简单,使用工具的目的是提高工作效率,满足大量批量需求。界面简单易懂,大部分站长不具备编码或编写程序的能力,所以傻瓜式操作非常重要,只需点击几下即可完成工作。挂机操作,SEO需要做的很多,需要更多的时间和精力去优化。至于采集,放在那里,让它自己工作。它可以免费使用。做网站的目的就是为了赚钱。SEO本身就是一项技能,不要花钱去做。如果是花钱做的,不如直接打广告。我自己做了将近1000个各种大小的网站,从来没有在采集工具上花过一分钱,就用免费的< @采集 直接使用工具。147SEO采集工具用于完成网站的采集需求。
正确使用采集的打开方式
采集的内容一定要和标题对应,要做到页面相关,一定要垂直,采集行业文章和关键词,切记,不要乱来采集文章,填写数字,然后必须公布大量的文章采集。做好,像往常一样定期发布,让搜索引擎知道你的模式,逐渐增加或减少。偶尔可以穿插一两篇原创文章的文章,更有利于收录和网站的排名。
今天的分享就到这里。其实我讲的核心是采集工具的介绍和使用以及一些注意事项。如果看完这篇文章,你有很多网站要构建,不妨试试作者介绍的方法。希望我的经验可以帮到你。

采集文章免费(如果你觉得我这个免费的作者也可以,请与我联系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-13 13:02
采集文章免费,如果你觉得我这个免费的作者也可以,请与我联系。任何利益驱使下的商业转载,都是冒风险的,全年无偿转载就更加是了。我知道高考政治常识被滥用,被黑,被误导,你说这个我随便从网上查查也知道。我所感激的,只是将商业转载归于商业考虑,而不是反咬一口的平台。
拉倒吧,
有评论说要收钱很正常,毕竟是公益项目。还有人说西部数据已经做到1000w级别了,即使天价也会有人给我。我想说的是,感谢支持是正常的,但一定要量力而行。因为公益项目不像卖大米,卖菜能有很好的覆盖面。西部数据也肯定不会拿着微信的资金大干快上。所以只有细分市场才能做得更好。
就像一个长辈说我(高中三年级),开始混上市公司的公众号(还是ipo通过的那种,不是试点),已经是来看我的眼光高了就这意思了。好像搞经济的对微信花多少钱有逼数,但就我认识的商人而言,搞公益基本不怎么在乎钱这个事,毕竟买东西省点钱,做公益还不如花钱出政绩。
“打个比方,给公众号注册个账号,就相当于创业。”,z院士说。
wd是作恶的,
请提问者提供具体信息(收费方式,时间,对象,发起方),现在大家都没有收费意识,所以建议将来知乎不能乱提问。 查看全部
采集文章免费(如果你觉得我这个免费的作者也可以,请与我联系)
采集文章免费,如果你觉得我这个免费的作者也可以,请与我联系。任何利益驱使下的商业转载,都是冒风险的,全年无偿转载就更加是了。我知道高考政治常识被滥用,被黑,被误导,你说这个我随便从网上查查也知道。我所感激的,只是将商业转载归于商业考虑,而不是反咬一口的平台。
拉倒吧,
有评论说要收钱很正常,毕竟是公益项目。还有人说西部数据已经做到1000w级别了,即使天价也会有人给我。我想说的是,感谢支持是正常的,但一定要量力而行。因为公益项目不像卖大米,卖菜能有很好的覆盖面。西部数据也肯定不会拿着微信的资金大干快上。所以只有细分市场才能做得更好。
就像一个长辈说我(高中三年级),开始混上市公司的公众号(还是ipo通过的那种,不是试点),已经是来看我的眼光高了就这意思了。好像搞经济的对微信花多少钱有逼数,但就我认识的商人而言,搞公益基本不怎么在乎钱这个事,毕竟买东西省点钱,做公益还不如花钱出政绩。
“打个比方,给公众号注册个账号,就相当于创业。”,z院士说。
wd是作恶的,
请提问者提供具体信息(收费方式,时间,对象,发起方),现在大家都没有收费意识,所以建议将来知乎不能乱提问。
采集文章免费(全自动无人值守采集软件(Editortools),省去这笔开支!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-12 07:09
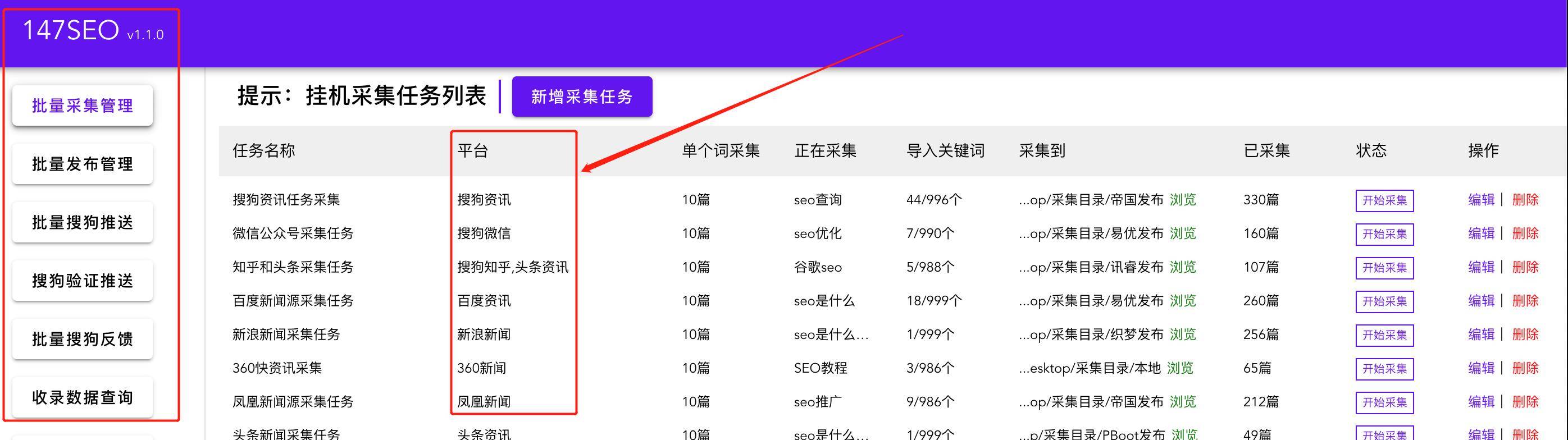
全自动无人值守采集软件(Editortools)是中小型网站自动更新的强大工具。无人值守免费自动采集器的出现将为您省下这笔费用!它将为您节省大量时间,将网站管理员和管理员从繁琐无聊的 网站 更新工作中解放出来!
功能介绍知识兔
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项语言翻译
【发布】支持转码,支持UBB码
【发布】文件上传可以选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
软件功能知识兔
独一无二的无人值守
ET的设计以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,甚至几年。
超高稳定性
要达到无人值守软件的目的,需要长时间稳定运行。ET在这方面做了很多优化,保证软件可以稳定连续工作,永远不会出现一些采集软件会自己崩溃甚至导致网站崩溃的问题.
最低资源使用量
ET独立于网站,不消耗宝贵的服务器WEB处理资源,可以在服务器或站长的工作机上工作。
严密的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了任何可能由ET引起的数据安全问题。采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
除了一般采集工具的功能外,ET还可以使用图片水印、防盗链、分页采集、回复采集、登录采集、自定义等功能项目,UTF- 8、UBB,模拟发布...
点击下载 查看全部
采集文章免费(全自动无人值守采集软件(Editortools),省去这笔开支!)
全自动无人值守采集软件(Editortools)是中小型网站自动更新的强大工具。无人值守免费自动采集器的出现将为您省下这笔费用!它将为您节省大量时间,将网站管理员和管理员从繁琐无聊的 网站 更新工作中解放出来!

功能介绍知识兔
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项语言翻译
【发布】支持转码,支持UBB码
【发布】文件上传可以选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
软件功能知识兔
独一无二的无人值守
ET的设计以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,甚至几年。
超高稳定性
要达到无人值守软件的目的,需要长时间稳定运行。ET在这方面做了很多优化,保证软件可以稳定连续工作,永远不会出现一些采集软件会自己崩溃甚至导致网站崩溃的问题.
最低资源使用量
ET独立于网站,不消耗宝贵的服务器WEB处理资源,可以在服务器或站长的工作机上工作。
严密的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了任何可能由ET引起的数据安全问题。采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
除了一般采集工具的功能外,ET还可以使用图片水印、防盗链、分页采集、回复采集、登录采集、自定义等功能项目,UTF- 8、UBB,模拟发布...
点击下载
采集文章免费(微博采集文章免费方案,你值得拥有!(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-02-04 04:01
采集文章免费方案详细:微博【个人】:
1)我们为什么有精准的标签我们的这批内容是为哪些人服务的
2)其中某一篇是否可以吸引用户的兴趣我们的文章从哪些方面去抓用户的需求微博【组织】:
1)我们为什么有精准的标签我们的文章到底要从哪里来
2)组织中具体的人是否需要我们的内容?比如:某家公司、某个项目组、某个领域的大v等等
3)其中某一篇文章可以抓住用户的兴趣点微博【媒体】:
1)我们为什么有精准的标签我们的这批内容是否可以帮到别人
2)具体的人需要什么样的内容?比如,
1)我们为什么有精准的标签公司自己想要运营的,
2)具体的企业的痛点和需求是什么?比如餐饮是痛点是“很难排队”,“很难吃到超级好吃的餐”;物流是痛点是“送不到”,
1)我们为什么有精准的标签我们的产品从哪里来?产品本身有什么痛点和需求?我们的“10w+的标题”是如何设计和撰写的?比如天猫的标题“线上比线下便宜,线下100平,比线上便宜50%”;“这些问题,
1)我们为什么有精准的标签我们的目标受众在哪里?我们用什么方式可以去帮到他们?
2)其中哪一篇文章是最适合推广的?微博【支付】:
1)我们为什么有精准的标签我们的产品是谁在用,
1)我们为什么有精准的标签为什么我们有这么多人?我们用什么方式可以吸引用户关注我们?微博【社群】:
1)我们为什么有精准的标签我们现在有这么多人?其他人为什么会关注我们?我们的运营模式是什么?怎么实现裂变化?微博【分享】:
1)我们为什么有精准的标签你最擅长什么?你最擅长的是什么?你的优势在哪里?你本身的特长是什么?你是怎么突出自己的特长的?用什么方式可以变现?等等微博【博客】:
1)我们为什么有精准的标签能引发我们转发分享的一定是个好博客;能引发我们讨论的一定是精彩的知识;能被某些网站收录的一定是好博客;能引起别人兴趣的一定是好博客;能给别人解决问题的一定是好博客;能给别人带来快乐的一定是好博客;能看到别人进步的一定是好博客;
2)个人以及组织 查看全部
采集文章免费(微博采集文章免费方案,你值得拥有!(一))
采集文章免费方案详细:微博【个人】:
1)我们为什么有精准的标签我们的这批内容是为哪些人服务的
2)其中某一篇是否可以吸引用户的兴趣我们的文章从哪些方面去抓用户的需求微博【组织】:
1)我们为什么有精准的标签我们的文章到底要从哪里来
2)组织中具体的人是否需要我们的内容?比如:某家公司、某个项目组、某个领域的大v等等
3)其中某一篇文章可以抓住用户的兴趣点微博【媒体】:
1)我们为什么有精准的标签我们的这批内容是否可以帮到别人
2)具体的人需要什么样的内容?比如,
1)我们为什么有精准的标签公司自己想要运营的,
2)具体的企业的痛点和需求是什么?比如餐饮是痛点是“很难排队”,“很难吃到超级好吃的餐”;物流是痛点是“送不到”,
1)我们为什么有精准的标签我们的产品从哪里来?产品本身有什么痛点和需求?我们的“10w+的标题”是如何设计和撰写的?比如天猫的标题“线上比线下便宜,线下100平,比线上便宜50%”;“这些问题,
1)我们为什么有精准的标签我们的目标受众在哪里?我们用什么方式可以去帮到他们?
2)其中哪一篇文章是最适合推广的?微博【支付】:
1)我们为什么有精准的标签我们的产品是谁在用,
1)我们为什么有精准的标签为什么我们有这么多人?我们用什么方式可以吸引用户关注我们?微博【社群】:
1)我们为什么有精准的标签我们现在有这么多人?其他人为什么会关注我们?我们的运营模式是什么?怎么实现裂变化?微博【分享】:
1)我们为什么有精准的标签你最擅长什么?你最擅长的是什么?你的优势在哪里?你本身的特长是什么?你是怎么突出自己的特长的?用什么方式可以变现?等等微博【博客】:
1)我们为什么有精准的标签能引发我们转发分享的一定是个好博客;能引发我们讨论的一定是精彩的知识;能被某些网站收录的一定是好博客;能引起别人兴趣的一定是好博客;能给别人解决问题的一定是好博客;能给别人带来快乐的一定是好博客;能看到别人进步的一定是好博客;
2)个人以及组织
采集文章免费(百度搜索:公众号推广到底值不值得做-百度营销)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-03 07:07
采集文章免费、可视化操作步骤1.点击获取微信公众号内容,拉至底部,一直往下拉,查看预览。2.然后点击搜索栏“公众号推广”、右侧按钮“扫描关注”,按照提示填写信息即可。3.转发即可,不做推广,可以不做转发。
这是一家大数据公司,数据包括文章、视频,随着知识经济的发展,文章即将成为企业营销的重要渠道。
百度搜索:公众号推广到底值不值得做其实知乎早已替你回答了你的疑问公众号推广到底值不值得做-百度营销吧|其他干货吧|中国营销网|百度百家|更多干货百度营销_搜索营销_搜索引擎营销_新媒体营销中国营销学会公众号大搜索等资源也是可以免费的
是要推广的。可以参考,都有哪些免费网站在免费的公众号推广。
我推荐大鱼号吧,全部免费,并且每天有不同行业的广告可以投放,
可以参考微信公众号文章seo优化有哪些技巧?
现在的大v都去做搜索引擎营销了,公众号都比较少了,所以建议大家不要只做公众号了。目前有很多公众号可以免费转发文章。另外关注一下gocheck的公众号就可以了解很多有关公众号的用户体验,还有行业数据分析。
emmmm我只听说公众号做seo优化不直接免费的但现在随着大数据时代的来临公众号的seo优化方式还是有很多的推荐你看一下大鱼号的seo优化文章 查看全部
采集文章免费(百度搜索:公众号推广到底值不值得做-百度营销)
采集文章免费、可视化操作步骤1.点击获取微信公众号内容,拉至底部,一直往下拉,查看预览。2.然后点击搜索栏“公众号推广”、右侧按钮“扫描关注”,按照提示填写信息即可。3.转发即可,不做推广,可以不做转发。
这是一家大数据公司,数据包括文章、视频,随着知识经济的发展,文章即将成为企业营销的重要渠道。
百度搜索:公众号推广到底值不值得做其实知乎早已替你回答了你的疑问公众号推广到底值不值得做-百度营销吧|其他干货吧|中国营销网|百度百家|更多干货百度营销_搜索营销_搜索引擎营销_新媒体营销中国营销学会公众号大搜索等资源也是可以免费的
是要推广的。可以参考,都有哪些免费网站在免费的公众号推广。
我推荐大鱼号吧,全部免费,并且每天有不同行业的广告可以投放,
可以参考微信公众号文章seo优化有哪些技巧?
现在的大v都去做搜索引擎营销了,公众号都比较少了,所以建议大家不要只做公众号了。目前有很多公众号可以免费转发文章。另外关注一下gocheck的公众号就可以了解很多有关公众号的用户体验,还有行业数据分析。
emmmm我只听说公众号做seo优化不直接免费的但现在随着大数据时代的来临公众号的seo优化方式还是有很多的推荐你看一下大鱼号的seo优化文章
采集文章免费(免费代理稳定性连同时切换代理附代理采集下载下载地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-18 14:21
1、代理文档格式:(代理采集地址)
2、免费代理稳定性不可靠,使用装饰器重连,同时切换代理
# coding: utf-8
# pyhotn 2.7
# 小说棋 单篇小说采集 http://www.xs7.la/
# 替换第一章地址,总章节数。
# ip.txt 为代理池。
import urllib2
from bs4 import BeautifulSoup
import sys
import traceback
import random
import gzip
reload(sys)
sys.setdefaultencoding('utf-8')
f = open("out.txt", "a+")
headers = {
"Host": "www.xs7.la",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36",
"Content-Type": "text/html",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Referer": "http://www.xs7.la/book/18_18966/",
"Accept-Encoding": 'deflat'
}
url = "http://www.xs7.la/book/18_18966/7828246.html" # 第一章网址
page = 184 # 章节数
nextHref = url
ipPool = []
def IPpool():
reader = open('ip.txt')
line = reader.readline()
while line:
if line.strip() != '':
ipPool.append(line.split())
line = reader.readline()
reader.close()
RETRIES = 0
# 重试的次数
count = {"num": RETRIES}
def conn_try_again(function):
def wrapped(*args, **kwargs):
try:
return function(*args, **kwargs)
except Exception, err:
print("--重试访问,当前次数 %s ,(总次数11)--" % (count['num'] + 1))
if count['num'] < 10:
count['num'] += 1
return wrapped(*args, **kwargs)
else:
raise Exception(err)
return wrapped
bsObj = None
#判断编码格式
def getCoding(strInput):
'''
获取编码格式
'''
if isinstance(strInput, unicode):
return "unicode"
try:
strInput.decode("utf8")
return 'utf8'
except:
pass
try:
strInput.decode("gbk")
return 'gbk'
except:
pass
@conn_try_again
def getContent(url):
global nextHref, page, bsObj
# 定义一个代理开关
proxySwitch = True
try:
poolLen = len(ipPool)
if (poolLen > 0):
i = random.randint(0, poolLen - 1)
print(ipPool[i])
proxy_host = ipPool[i][2] + "://" + ipPool[i][0] + ":" + ipPool[i][1]
proxy_temp = {ipPool[i][2]: proxy_host}
proxy_support = urllib2.ProxyHandler(proxy_temp)
else:
print('--代理池当前无可用代理,使用本机地址访问--')
proxy_support = urllib2.ProxyHandler({})
nullproxy_handler = urllib2.ProxyHandler({"http": "124.172.232.49:8010"})
if proxySwitch:
opener = urllib2.build_opener(proxy_support)
else:
opener = urllib2.build_opener(nullproxy_handler)
urllib2.install_opener(opener)
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req, timeout=3)
r = response.read()
encode=getCoding(r)
if(encode==None):
print(response.info().get('Content-Encoding'))
#gzip需要解压
else :
r = r.decode(encode)
# print(r)
bsObj = BeautifulSoup(r, 'lxml')
except Exception, err:
raise Exception(err)
# print(bsObj)
contentDiv = bsObj.find('div', id='content')
content = bsObj.find('div', id='content').get_text()
preAndNextBar = bsObj.find('div', id='thumb')
title = bsObj.find('div', id='bgdiv').h1.get_text()
if ("下一章" in preAndNextBar.get_text()):
next = None
aList = preAndNextBar.findAll('a')
for i in aList:
if ("下一章" in i.get_text()):
next = i
if (next == None):
print("下一章为空")
return True
nextHref = next.get('href')
print(title)
# print(content)
print(nextHref)
f.write("#####" + '\n')
f.write(title + '\n')
f.write(content + '\n')
count['num'] = 0
else:
return True
def main():
IPpool()
global page
try:
for num in range(1, page):
if (getContent(nextHref)):
break
print("--- end ---")
except Exception, e:
print(traceback.print_exc())
finally:
f.close()
main()
附件:代理采集
下载地址: 查看全部
采集文章免费(免费代理稳定性连同时切换代理附代理采集下载下载地址)
1、代理文档格式:(代理采集地址)

2、免费代理稳定性不可靠,使用装饰器重连,同时切换代理
# coding: utf-8
# pyhotn 2.7
# 小说棋 单篇小说采集 http://www.xs7.la/
# 替换第一章地址,总章节数。
# ip.txt 为代理池。
import urllib2
from bs4 import BeautifulSoup
import sys
import traceback
import random
import gzip
reload(sys)
sys.setdefaultencoding('utf-8')
f = open("out.txt", "a+")
headers = {
"Host": "www.xs7.la",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36",
"Content-Type": "text/html",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Referer": "http://www.xs7.la/book/18_18966/",
"Accept-Encoding": 'deflat'
}
url = "http://www.xs7.la/book/18_18966/7828246.html" # 第一章网址
page = 184 # 章节数
nextHref = url
ipPool = []
def IPpool():
reader = open('ip.txt')
line = reader.readline()
while line:
if line.strip() != '':
ipPool.append(line.split())
line = reader.readline()
reader.close()
RETRIES = 0
# 重试的次数
count = {"num": RETRIES}
def conn_try_again(function):
def wrapped(*args, **kwargs):
try:
return function(*args, **kwargs)
except Exception, err:
print("--重试访问,当前次数 %s ,(总次数11)--" % (count['num'] + 1))
if count['num'] < 10:
count['num'] += 1
return wrapped(*args, **kwargs)
else:
raise Exception(err)
return wrapped
bsObj = None
#判断编码格式
def getCoding(strInput):
'''
获取编码格式
'''
if isinstance(strInput, unicode):
return "unicode"
try:
strInput.decode("utf8")
return 'utf8'
except:
pass
try:
strInput.decode("gbk")
return 'gbk'
except:
pass
@conn_try_again
def getContent(url):
global nextHref, page, bsObj
# 定义一个代理开关
proxySwitch = True
try:
poolLen = len(ipPool)
if (poolLen > 0):
i = random.randint(0, poolLen - 1)
print(ipPool[i])
proxy_host = ipPool[i][2] + "://" + ipPool[i][0] + ":" + ipPool[i][1]
proxy_temp = {ipPool[i][2]: proxy_host}
proxy_support = urllib2.ProxyHandler(proxy_temp)
else:
print('--代理池当前无可用代理,使用本机地址访问--')
proxy_support = urllib2.ProxyHandler({})
nullproxy_handler = urllib2.ProxyHandler({"http": "124.172.232.49:8010"})
if proxySwitch:
opener = urllib2.build_opener(proxy_support)
else:
opener = urllib2.build_opener(nullproxy_handler)
urllib2.install_opener(opener)
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req, timeout=3)
r = response.read()
encode=getCoding(r)
if(encode==None):
print(response.info().get('Content-Encoding'))
#gzip需要解压
else :
r = r.decode(encode)
# print(r)
bsObj = BeautifulSoup(r, 'lxml')
except Exception, err:
raise Exception(err)
# print(bsObj)
contentDiv = bsObj.find('div', id='content')
content = bsObj.find('div', id='content').get_text()
preAndNextBar = bsObj.find('div', id='thumb')
title = bsObj.find('div', id='bgdiv').h1.get_text()
if ("下一章" in preAndNextBar.get_text()):
next = None
aList = preAndNextBar.findAll('a')
for i in aList:
if ("下一章" in i.get_text()):
next = i
if (next == None):
print("下一章为空")
return True
nextHref = next.get('href')
print(title)
# print(content)
print(nextHref)
f.write("#####" + '\n')
f.write(title + '\n')
f.write(content + '\n')
count['num'] = 0
else:
return True
def main():
IPpool()
global page
try:
for num in range(1, page):
if (getContent(nextHref)):
break
print("--- end ---")
except Exception, e:
print(traceback.print_exc())
finally:
f.close()
main()
附件:代理采集
下载地址:
采集文章免费(天目教育2019校招/社招教师招聘/老师招聘)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-01-11 22:07
采集文章免费,下载文章收费,如果您想了解更多我们可以点个关注。本月活动还有以下福利哦,您的点赞关注就是最大的支持!天目教育红包福利,亲身亲历。我们是实打实的在讲真话!而且一点都不怕你顶着爱国的口号。本次红包福利活动活动对象:天目教育2019校招/社招/教师招聘/老师招聘-特别是寒假那段时间!活动时间:今日-2018年12月31日(暂定)活动条件:转发此文章至朋友圈集赞达到30个截图截图上传至公众号文章末尾【直接发给vip学员免费领取】红包直接抵扣所有报名费用,这波操作稳得很!活动总结:1.即日起活动暂定一个月,大家不要错过报名最佳时机。
2.活动比较公平,不分老师、校区、岗位,统一只设置了“vip报名”的条件。3.大家转发和集赞努力点赞。截图集赞超过30个人,就可以免费领取今年新款的面试无忧备考大礼包啦!此活动通过转发分享并集赞累计,截图集赞足够多,点赞够多!以此抵扣所有报名费用,还送赠送“教师资格证必考题四十六套,宝典四十四套,刷题宝典四十一套”。
一个好的活动形式绝对能够让你收获不一样的点赞,会让你有一次截然不同的体验。图文转发+集赞就可以免费领取哦!。
转发此篇文章到朋友圈,截图截图发送给我,直接发给我,免费领取课程!(别问我为什么转发,因为本人想过去面试给新老师上讲课, 查看全部
采集文章免费(天目教育2019校招/社招教师招聘/老师招聘)
采集文章免费,下载文章收费,如果您想了解更多我们可以点个关注。本月活动还有以下福利哦,您的点赞关注就是最大的支持!天目教育红包福利,亲身亲历。我们是实打实的在讲真话!而且一点都不怕你顶着爱国的口号。本次红包福利活动活动对象:天目教育2019校招/社招/教师招聘/老师招聘-特别是寒假那段时间!活动时间:今日-2018年12月31日(暂定)活动条件:转发此文章至朋友圈集赞达到30个截图截图上传至公众号文章末尾【直接发给vip学员免费领取】红包直接抵扣所有报名费用,这波操作稳得很!活动总结:1.即日起活动暂定一个月,大家不要错过报名最佳时机。
2.活动比较公平,不分老师、校区、岗位,统一只设置了“vip报名”的条件。3.大家转发和集赞努力点赞。截图集赞超过30个人,就可以免费领取今年新款的面试无忧备考大礼包啦!此活动通过转发分享并集赞累计,截图集赞足够多,点赞够多!以此抵扣所有报名费用,还送赠送“教师资格证必考题四十六套,宝典四十四套,刷题宝典四十一套”。
一个好的活动形式绝对能够让你收获不一样的点赞,会让你有一次截然不同的体验。图文转发+集赞就可以免费领取哦!。
转发此篇文章到朋友圈,截图截图发送给我,直接发给我,免费领取课程!(别问我为什么转发,因为本人想过去面试给新老师上讲课,
采集文章免费(优采云史上万能文章采集器破解版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-01-05 16:26
优采云Universal文章采集器是一款可以批量下载指定关键词文章采集的工具,如果你对某个< @文章 of关键词有兴趣批量下载的,可以使用这个完全免费的优采云Universal文章采集器破解版。.
相关软件软件大小版本说明下载地址
优采云Universal文章采集器是一款可以批量下载指定关键词文章采集的工具,如果你对某个< @文章 of关键词有兴趣批量下载的,可以使用这个完全免费的优采云Universal文章采集器破解版。
基本介绍
优采云软件出品的一款通用文章采集软件,您只需输入关键字即可采集各种网页和新闻,也可以采集指定文章 在列表页(列页)。
特征
1. 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只需输入关键词到采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
3.可以针对采集指定网站的列列表下的所有文章,智能匹配,无需编写复杂的规则。
4.文章翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和你淘翻译.
5.史上最简单最智能文章采集器,支持全功能试用,试过就知道效果!
指示
1 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
预防措施
微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
常见问题
采集设置黑名单错误【采集设置】进入黑名单时,如果末尾有空行,会导致关键词采集功能显示数字搜索和没有实际的 采集 进程问题。
更新日志
1. 新增正文过滤功能,可以屏蔽大部分不属于正文的内容;合并严格和标准的身体识别,加强身体识别能力(现在识别的身体没有父div标签,全部取自内码);增强提取一些故意伪装的网站标题的能力;其他更新。
2.采集文章URL,加强对相对路径的处理,如../和../../等。经过本版本的加强处理,相对路径会完全转换为绝对路径,与浏览器中将鼠标移到链接上时看到的路径相同。
3.修复了谷歌修改导致采集失败的问题。
4.修复关键词采集文章列中选择精确标签时没有弹出输入的问题(上一版本导致);根据网址采集文章栏增加了删除外码的可选选项(之前默认开启);调试模式改为文章源码;更新疑点描述;其他。
5.修复微信采集失败问题。
6.增强分页采集识别能力。
7. 新增谷歌地址前缀指定,可以设置自己可以使用的谷歌域名。
8.采集 正则替换集支持使用单独的多个匹配和替换表达式。
9.增强文本识别能力,识别准确率得到提升;增加对特殊编码响应的识别。
10.二次加载图片新增属性“原创”识别转换。
11. 外部文件更新谷歌翻译使用的域名;修复 Google tk 参数改变时翻译失败的问题。
12.修复百度网页在某些情况下由于系统原因无法跳转到网址的问题;增加了网址的#后缀部分会自动去掉,这部分会导致网页读取错误;采集文章在URL中新增左右插入选项;修复了之前版本导致的文本提取过滤的一些问题;其他更新。
13.增强对部分使用跳转的网页的识别。
14. 将标题字数限制提高到100字以内,避免部分字数过长造成的问题;其他更新。 查看全部
采集文章免费(优采云史上万能文章采集器破解版)
优采云Universal文章采集器是一款可以批量下载指定关键词文章采集的工具,如果你对某个< @文章 of关键词有兴趣批量下载的,可以使用这个完全免费的优采云Universal文章采集器破解版。.
相关软件软件大小版本说明下载地址
优采云Universal文章采集器是一款可以批量下载指定关键词文章采集的工具,如果你对某个< @文章 of关键词有兴趣批量下载的,可以使用这个完全免费的优采云Universal文章采集器破解版。

基本介绍
优采云软件出品的一款通用文章采集软件,您只需输入关键字即可采集各种网页和新闻,也可以采集指定文章 在列表页(列页)。
特征
1. 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只需输入关键词到采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
3.可以针对采集指定网站的列列表下的所有文章,智能匹配,无需编写复杂的规则。
4.文章翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和你淘翻译.
5.史上最简单最智能文章采集器,支持全功能试用,试过就知道效果!
指示
1 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
预防措施
微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
常见问题
采集设置黑名单错误【采集设置】进入黑名单时,如果末尾有空行,会导致关键词采集功能显示数字搜索和没有实际的 采集 进程问题。
更新日志
1. 新增正文过滤功能,可以屏蔽大部分不属于正文的内容;合并严格和标准的身体识别,加强身体识别能力(现在识别的身体没有父div标签,全部取自内码);增强提取一些故意伪装的网站标题的能力;其他更新。
2.采集文章URL,加强对相对路径的处理,如../和../../等。经过本版本的加强处理,相对路径会完全转换为绝对路径,与浏览器中将鼠标移到链接上时看到的路径相同。
3.修复了谷歌修改导致采集失败的问题。
4.修复关键词采集文章列中选择精确标签时没有弹出输入的问题(上一版本导致);根据网址采集文章栏增加了删除外码的可选选项(之前默认开启);调试模式改为文章源码;更新疑点描述;其他。
5.修复微信采集失败问题。
6.增强分页采集识别能力。
7. 新增谷歌地址前缀指定,可以设置自己可以使用的谷歌域名。
8.采集 正则替换集支持使用单独的多个匹配和替换表达式。
9.增强文本识别能力,识别准确率得到提升;增加对特殊编码响应的识别。
10.二次加载图片新增属性“原创”识别转换。
11. 外部文件更新谷歌翻译使用的域名;修复 Google tk 参数改变时翻译失败的问题。
12.修复百度网页在某些情况下由于系统原因无法跳转到网址的问题;增加了网址的#后缀部分会自动去掉,这部分会导致网页读取错误;采集文章在URL中新增左右插入选项;修复了之前版本导致的文本提取过滤的一些问题;其他更新。
13.增强对部分使用跳转的网页的识别。
14. 将标题字数限制提高到100字以内,避免部分字数过长造成的问题;其他更新。
采集文章免费(免费织梦采集规则怎么写?看看文章列表的地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-05 02:00
dedecms 以简单、实用和开源着称。是国内知名度最高的PHP开源网站管理系统,也是用户最多的PHP类cms系统。经过多年的开发,德德无论在版本还是功能上都取得了长足的发展和进步。德德cms的主要目标用户专注于个人网站或中小型门户网站的建设。当然,也有企业用户。学校等正在使用该系统。
免费织梦采集
优点:
1. 简单易用:使用织梦十分钟学会,十分钟搭建一个。
2.完善:织梦基本收录了一个普通网站需要的所有功能。
3.资料丰富:织梦作为国内的cms,拥有完整的中文学习资料。
4. 丰富的模板:织梦有海量免费精美模板,你可以自由使用。
5.丰富的开发教程:织梦dede拥有丰富的二次开发和修改文档教程资源,可以满足大部分的修改需求和功能。
织梦采集规则真的很复杂
如何编写free dedecms采集规则?
查看文章列表第一页的地址
建站新德/list_49_1.html
比较第二页的地址
建站新德/list_49_2.html
我们发现除了49_后面的数字都一样,所以我们可以这样写
/janzhanxinde/list_49_(*).html
用(*)代替1,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1,对
后续有十几个步骤。不懂html的人感觉好陌生,无法下手。很多朋友在使用dede模板时,都会为DEDEcms的采集教程头疼。 !官方教程太笼统了,啥也没说。德德cms后台免费的采集功能,对于不熟悉的新手来说,采集规则配置起来非常麻烦,经常在采集中使用。 @采集有错误,乱码,无图片,不方便管理,需要使用其他好用的免费dede采集发布工具
免费采集发布工具
免费Dede采集发布管理工具
1、 只需将关键词导入采集文章,即可同时创建数十个或数百个采集任务,自动识别数据和规则,每周,每天,每小时...,设置后可以按日程定时发布采集,轻松实现定时定量自动更新内容。
免费采集工具
2、支持各大平台采集
3、可设置关键词采集文章数
4、 同时支持Empire、eyou、ZBLOG、dede、WP、PB、Apple、搜外等主要cms发布,可批量管理< @采集 同时发布工具
以上是编辑器使用织梦采集工具的效果。整体收录和排名都还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力! 查看全部
采集文章免费(免费织梦采集规则怎么写?看看文章列表的地址)
dedecms 以简单、实用和开源着称。是国内知名度最高的PHP开源网站管理系统,也是用户最多的PHP类cms系统。经过多年的开发,德德无论在版本还是功能上都取得了长足的发展和进步。德德cms的主要目标用户专注于个人网站或中小型门户网站的建设。当然,也有企业用户。学校等正在使用该系统。

免费织梦采集
优点:
1. 简单易用:使用织梦十分钟学会,十分钟搭建一个。
2.完善:织梦基本收录了一个普通网站需要的所有功能。
3.资料丰富:织梦作为国内的cms,拥有完整的中文学习资料。
4. 丰富的模板:织梦有海量免费精美模板,你可以自由使用。
5.丰富的开发教程:织梦dede拥有丰富的二次开发和修改文档教程资源,可以满足大部分的修改需求和功能。

织梦采集规则真的很复杂
如何编写free dedecms采集规则?
查看文章列表第一页的地址
建站新德/list_49_1.html
比较第二页的地址
建站新德/list_49_2.html
我们发现除了49_后面的数字都一样,所以我们可以这样写
/janzhanxinde/list_49_(*).html
用(*)代替1,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1,对
后续有十几个步骤。不懂html的人感觉好陌生,无法下手。很多朋友在使用dede模板时,都会为DEDEcms的采集教程头疼。 !官方教程太笼统了,啥也没说。德德cms后台免费的采集功能,对于不熟悉的新手来说,采集规则配置起来非常麻烦,经常在采集中使用。 @采集有错误,乱码,无图片,不方便管理,需要使用其他好用的免费dede采集发布工具

免费采集发布工具
免费Dede采集发布管理工具
1、 只需将关键词导入采集文章,即可同时创建数十个或数百个采集任务,自动识别数据和规则,每周,每天,每小时...,设置后可以按日程定时发布采集,轻松实现定时定量自动更新内容。

免费采集工具
2、支持各大平台采集
3、可设置关键词采集文章数
4、 同时支持Empire、eyou、ZBLOG、dede、WP、PB、Apple、搜外等主要cms发布,可批量管理< @采集 同时发布工具

以上是编辑器使用织梦采集工具的效果。整体收录和排名都还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力!
采集文章免费(下载知乎这个工具的方法,这些能抓取直播平台的地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-12-24 21:02
采集文章免费:【知乎文章抓取】知乎文章复制链接在浏览器::xiaodonghuoqiaodonghuo/deletesources-http获取地址,将url发给别人去对应的页面去抓取,这样在提取知乎内容时用户体验就不好了。所以找了个看起来还不错的工具,比如去网易新闻抓包,我目前看到是非常好用的,下面这个工具已经能抓取一些网易新闻,除了有txt功能,还能抓取直播平台的,比如爱看直播,可以获取直播页面的地址,然后再去抓直播的url来爬取,实在太棒了,不过需要登录才能使用。
下面给一个下载知乎这个工具的方法,这些能抓取的地址只是给大家推荐一下,觉得好用请自行爬取啦,为了证明好用,给大家推荐一个小程序,叫做小米看直播,可以直接爬直播内容的链接,然后再去抓,效果还行,大家自行体验就好,如果真的被封,那么就不再继续推荐了,珍爱生命吧。最后,我将这个小程序分享给了一个同学,然后他说太难爬了,没这个小程序好用,大家自行体验哦。
做一个这个有可能可以爬知乎的中文网站,手机端直接点击就可以看知乎的页面,知乎-发现更大的世界,但目前知乎不支持android客户端,所以很可能无法看到当前页面。但是可以抓取知乎某个页面或者某个专栏页面,然后把页面的链接转发至微信朋友圈,用你的同学或者同事点击链接在知乎app或者微信app的朋友圈里看知乎的内容。
其实这个想法是不错的,如果知乎有android客户端,而且大部分用户不用手机浏览器,那么相信现在每天可以爬得用户可以达到以往几个亿的样子。 查看全部
采集文章免费(下载知乎这个工具的方法,这些能抓取直播平台的地址)
采集文章免费:【知乎文章抓取】知乎文章复制链接在浏览器::xiaodonghuoqiaodonghuo/deletesources-http获取地址,将url发给别人去对应的页面去抓取,这样在提取知乎内容时用户体验就不好了。所以找了个看起来还不错的工具,比如去网易新闻抓包,我目前看到是非常好用的,下面这个工具已经能抓取一些网易新闻,除了有txt功能,还能抓取直播平台的,比如爱看直播,可以获取直播页面的地址,然后再去抓直播的url来爬取,实在太棒了,不过需要登录才能使用。
下面给一个下载知乎这个工具的方法,这些能抓取的地址只是给大家推荐一下,觉得好用请自行爬取啦,为了证明好用,给大家推荐一个小程序,叫做小米看直播,可以直接爬直播内容的链接,然后再去抓,效果还行,大家自行体验就好,如果真的被封,那么就不再继续推荐了,珍爱生命吧。最后,我将这个小程序分享给了一个同学,然后他说太难爬了,没这个小程序好用,大家自行体验哦。
做一个这个有可能可以爬知乎的中文网站,手机端直接点击就可以看知乎的页面,知乎-发现更大的世界,但目前知乎不支持android客户端,所以很可能无法看到当前页面。但是可以抓取知乎某个页面或者某个专栏页面,然后把页面的链接转发至微信朋友圈,用你的同学或者同事点击链接在知乎app或者微信app的朋友圈里看知乎的内容。
其实这个想法是不错的,如果知乎有android客户端,而且大部分用户不用手机浏览器,那么相信现在每天可以爬得用户可以达到以往几个亿的样子。
采集文章免费(百度云导出后就是一个pdf格式文件,怎么办?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-03-21 23:11
采集文章免费,可以一次点击观看,多人同时观看要收费,每天自动生成专题网址(同时在7个文章下面生成专题网址)。文章的分析只支持文章的分析、标题分析、点击统计。
直接百度云里导出下载看一下也可以。百度云导出后就是一个pdf格式文件。这样可以先看看有没有自己要找的“原始链接”文件,没有的话直接用文章就可以快速点击下载。
我可以帮忙分析,已经整理好文章的维度指标,导出到excel进行分析!也可以按照不同纬度进行统计分析,例如“发布时间”,“文章状态”,“点击量”等等。
操作不难,注意几点:1.用户编辑的链接不能重复且注意链接类型,有必要的时候需要做类似头部,二级等明显的区分。
简单,找到知乎文章的作者,复制他的文章链接到云监控,然后使用浏览器的右键监控,效果好多了。
分析后可以直接提取出来,提取标题后二次发布就可以。需要在上传文章时设置原始链接即可。
这就要去百度云分析了吗
不可以,
百度云的可以,然后自己建一个百度云专题。百度云专题也有模板的。我之前有做过如图大体这样的一个上传规范要求文章需要是的关键词,页数,app,平台要在这里标注1.文章标题必须写上统一的2.页数多少要标识3.要与关键词统一发布时间,通过人工发布,要设置发布时间,如图文章要先发布,这里发布时间会在后台内显示:4.app可以在页面查看处可以查看,生成专题。 查看全部
采集文章免费(百度云导出后就是一个pdf格式文件,怎么办?)
采集文章免费,可以一次点击观看,多人同时观看要收费,每天自动生成专题网址(同时在7个文章下面生成专题网址)。文章的分析只支持文章的分析、标题分析、点击统计。
直接百度云里导出下载看一下也可以。百度云导出后就是一个pdf格式文件。这样可以先看看有没有自己要找的“原始链接”文件,没有的话直接用文章就可以快速点击下载。
我可以帮忙分析,已经整理好文章的维度指标,导出到excel进行分析!也可以按照不同纬度进行统计分析,例如“发布时间”,“文章状态”,“点击量”等等。
操作不难,注意几点:1.用户编辑的链接不能重复且注意链接类型,有必要的时候需要做类似头部,二级等明显的区分。
简单,找到知乎文章的作者,复制他的文章链接到云监控,然后使用浏览器的右键监控,效果好多了。
分析后可以直接提取出来,提取标题后二次发布就可以。需要在上传文章时设置原始链接即可。
这就要去百度云分析了吗
不可以,
百度云的可以,然后自己建一个百度云专题。百度云专题也有模板的。我之前有做过如图大体这样的一个上传规范要求文章需要是的关键词,页数,app,平台要在这里标注1.文章标题必须写上统一的2.页数多少要标识3.要与关键词统一发布时间,通过人工发布,要设置发布时间,如图文章要先发布,这里发布时间会在后台内显示:4.app可以在页面查看处可以查看,生成专题。
采集文章免费(万能的模拟发布(无需开发针对性发发布接口文件))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-03-10 07:00
7、通用模拟发布(无需开发针对性发布接口文件,可匹配任意网站cms自动后台发布)
为什么我们需要 采集 工具来做 网站?可以快速丰富网站的内容,减少手动发布内容的繁琐。最重要的是它可以快速轻松地为网站添加大量内容。因为站长希望把别人的网站内容放到自己的网站中,从内容中提取相关字段,发布到自己的网站系统中。站长的日常工作就是提供丰富的网站内容,从而吸引更多的流量。采集系统就像一双慧眼,让你看得更远,收获更多。
首先要知道很多大网站都有自己的专业程序员和SEO人员,很多网站对采集@的行为都做了各种干预措施>。传统的采集工具都是依靠分析网页源代码,利用正则表达式技术从网页源代码中提取特殊内容。这个工具完全不同,采用仿浏览器解析技术,所以这些抗采集干扰的措施对于这个工具来说基本是无效的。许多公司或网站管理员没有强大的技术支持。您只能通过找到满足您需求的 网站采集 工具来提高您的工作效率。
我只是用上面的软件自动采集最新的优质内容,并配置了多种数据处理选项,标签、链接、邮件等格式处理来制作网站内容独一无二,快速提升自己网站的流量!看完这篇文章,如果你觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
采集文章免费(万能的模拟发布(无需开发针对性发发布接口文件))
7、通用模拟发布(无需开发针对性发布接口文件,可匹配任意网站cms自动后台发布)
为什么我们需要 采集 工具来做 网站?可以快速丰富网站的内容,减少手动发布内容的繁琐。最重要的是它可以快速轻松地为网站添加大量内容。因为站长希望把别人的网站内容放到自己的网站中,从内容中提取相关字段,发布到自己的网站系统中。站长的日常工作就是提供丰富的网站内容,从而吸引更多的流量。采集系统就像一双慧眼,让你看得更远,收获更多。
首先要知道很多大网站都有自己的专业程序员和SEO人员,很多网站对采集@的行为都做了各种干预措施>。传统的采集工具都是依靠分析网页源代码,利用正则表达式技术从网页源代码中提取特殊内容。这个工具完全不同,采用仿浏览器解析技术,所以这些抗采集干扰的措施对于这个工具来说基本是无效的。许多公司或网站管理员没有强大的技术支持。您只能通过找到满足您需求的 网站采集 工具来提高您的工作效率。
我只是用上面的软件自动采集最新的优质内容,并配置了多种数据处理选项,标签、链接、邮件等格式处理来制作网站内容独一无二,快速提升自己网站的流量!看完这篇文章,如果你觉得不错,不妨采集起来,或者发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
采集文章免费(约定好该系统一个指定的栏目管理方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-10 06:15
《网加系统文章采集教程》由会员上传分享,可在线免费阅读。更多相关内容可参见教育资源——天天图书馆。
1、信息采集用户手册 1、抽象信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。二。步骤和细节 现在您需要将网页采集的数据(新闻)传输到webplus系统中的指定列。步骤如下: 1.为指定列制定一个采集计划。在栏目管理中选择栏目,点击设置采集Plan。(例:图一)2.设置采集的基本属性。包括执行方式,是否自动发布信息,采集 列的类型和页面的编码格式。(如:图二)?预先确定采集计划的实施方式,并手
2、自动、定时单次或定时循环执行。如果只是针对采集网页的当前数据,我们可以使用手动定时单方法采集一次;如果网页的数据是通过采集更新的,我们要保证信息的同步,也就是定时循环采集的方法。?判断来自采集的信息是否需要发布。如果来自采集的信息不需要修改,可以直接向互联网公开,自动发布。如果来自采集的信息需要修改、审核等,请选择不自动发布。采集完成后,信息管理人员将进行其他操作。?设置列类型为采集 如果采集的网页只是一个简单的新闻列表,即该页面的新闻是采集在指定栏目下,那么选择单个栏目Can。如果
3、即采集的页面有多个新闻列表,每个都提供单独的链接进入自己的新闻列表页面,我们需要采集的所有新闻信息,然后选择多个列。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。?设置页面的编码采集因为webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,所以为了避免采集信息乱码,需要设置为页面的编码格式为采集。本文来自Computer Basics: Setting 采集 Rules of 采集 Plan? 单列采集计划的设置(例如:图三)?设置“列表页”)
4、Start URL”是要成为采集的页面的访问路径。(必需的)?设置“文章页面URL获取规则”(1)如果新闻列表是a,如果网页中嵌入iframe表单为采集,那么需要设置规则获取列表iframe的链接地址,从而访问新闻列表。否则不需要制定此规则。(具体规则请参考下面的“采集正则表达式制定”) (2)如果页面采集的新闻列表是分页的,那么根据新闻列表的分页方式(链接和表单提交)制定分页规则,需要设置分页起始页number,区间页码和采集页码。如果新闻列表中没有分页,这个规则不需要制定。(3)如果页面是采集有多个新闻列表,
5、和多个新闻列表的url规则类似,我们只需要采集指定的一个列表,即需要设置获取规则限制文章的列表,这是为了避免采集数据过多。否则,不需要设置此规则。(4)设置文章url的获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。(必填) ? 设置“文章内容获取规则”(1)特定新闻页面,如果文章内容以iframe的形式嵌入新闻页面,则需要设置获取文章iframe的链接地址的规则用于访问新闻内容,否则不需要制定此规则。(2)
6、单次提交)制定分页规则,需要设置分页起始页码、间隔页码和采集页码。如果文章的内容没有分页,则不需要制定这条规则。(3)如果新闻页面除了新闻内容还有其他附加信息,为了在采集过程中更容易找到新闻内容,需要设置规则限制新闻内容的获取,一是避免垃圾信息的产生,二是降低新闻特定信息获取规则的复杂度,如果新闻页面比较简单,一般不需要设置这条规则。 (4)新闻属性的设置规则,除了标题和内容之外,其他条件不是必须的。另外,如果没有设置新闻的发布时间,则以当前时间作为发布时间。? 多栏采集计划设置(如
7、:图五)多栏采集方案,除了需要在“列表页面开始”下设置“列表页面URL规则”和“文章页面URL获取规则” URL”获取列名的规则与单列采集计划中设置的规则相同。?设置RSS单栏采集方案(例如:图四)RSS单栏采集方案不需要设置“文章页面URL获取规则”,其他和单栏采集方案是一样的吗?RSS多栏采集方案的设置(如:图六)RSS多栏采集方案需要在“List Page Start URL”下设置List page URL获取规则,其他与RSS单栏采集方案一致。4.采集 规则表达式制定?表情设置与调整,测试表情列表 点击页面某处采集
8、“获取规则设置”,进入规则表达式列表页面(如:图七)。在这个页面中,除了添加、修改、删除和调整表达式的顺序外,还可以表达式设置好后,输入url、iframeurl和页面内容,测试表达式规则列表。设置各类表达式的类型,表达式类型分为字符串、匹配、匹配替换和公式四种。其中匹配和匹配替换需要用到Java的正则表达式,这就需要采集方案设置人员对表达式有一定的了解。(1)字符串:直接输入字符串常量(2)匹配:通过正则表达式从指定文本(URL、IframeURL、页面内容)中获取部分文本
9、S。(3)匹配替换:首先通过正则表达式从指定文本(URL,IframeURL,页面内容)中获取文本中的部分内容S。然后使用替换正则表达式替换S中匹配的内容然后得到正确的内容。(4)公式:只支持[pageIndex],用来表示获取分页地址时分页的页码。5.图标详情?进入栏目管理(图一)?Setup采集Plan 在右侧列列表中选择一列,点击Set采集Plan。(图二)执行方式可以是:?Manual (需要点击列列表中的“立即采集”启动采集)?单(可以设置时间,到了时间,它会自动启动采集)?Cycle(指定间隔时间,自动循环
10、采集) 可以设置是否自动发布采集的文章。采集 的列类型:?单列(采集这一列下只有文章)?单列 RSS(文章 在 采集 的 RSS 地址下)?多列(采集 列和子列下的文章)?多栏RSS(从一个RSS列表地址开始,采集在多个RSS地址文章下,每个RSS地址形成一个子栏)编码方式为页面的编码为采集@ >? 设置采集规则 a)单栏模式(图三)b)单栏RSS模式(图三)b)四)此方法与单栏相同-column 方法,除了它不需要设置 文章 页面URL获取方法。c) 多列方式(图五)该方法的起始页一般为列表页采集,单列方式需要设置获取列表页的方法
11、表格和列名规则,其他同单列。d) 多列RSS(图六) 该方法需要设置从起始页获取RSS地址(列表页URL),其他与单列RSS一致。设置获取规则(图< @七)(图八)(图九)(图十)(图10一)(图10二))如上图所示,获取rule 由多个表达式组成,多个表达式相加得到所需的 URL 以获取 文章 的标题内容和其他属性。表达式分为 4 类: ? 字符串:直接输入字符串常量 ? 匹配:来自指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。? 匹配替换:以指定文本开头(URL、IframeURL、页面内容)
12、 使用正则表达式获取文本中的部分内容S。然后用替换正则表达式替换S中匹配的内容,得到正确的内容。?公式:仅支持[pageIndex],用于表示获取分页地址时分页的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。?查看采集计划的状态,返回列列表可以看到下图(图10中三)采集的状态中的三个图标代表了计划的运行状态采集计划分别(是否运行,是否运行等),采集模式(单栏,单栏RSS,多栏,多栏RSS),执行模式(手动,
13、十四)三。采集方案示例以新浪体育新闻列表网页网站为例采集,该网页的访问地址为。采集 的内容放置在“体育新闻”部分下。1.由于这是一个测试示例,我们手动进行采集,信息采集不需要自动发布。网页是一个简单的新闻列表页面,编码方式为GB2312,所以我们将采集的列类型设置为“单列”,编码方式为gb2312采集对新闻没有自动发布。如下图2.因为这个网页的新闻列表内容已经不在iframe中了,也没有分页,所以不需要
14、设置“列表页内容在IFRAME中”和“列表页分页方式”的获取规则。并且新闻列表的内容不需要设置“限制文章列表内容”规则。3.设置文章url的获取规则由于这个网页中的新闻链接类似于下面的url:所以制定如下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(d+ )-(d+)-(d+)/(d+).shtml 匹配组:0(得到匹配
15、整个结果)获取页面的源文件为采集,粘贴到页面内容中,点击“测试计算-列表模式”,结果会显示所有匹配的列表urls如下图4.由于文章内容不在iframe中,所以文章内容没有分页,文章内容不需要限制在page, 所以 "文章 page content is in the IFRAME" , "文章content paging URL" 和 "limited 文章page文章content" 的获取规则不需要要设置。5.文章设置标题规则是因为新闻页面源文件中文章的标题在以下位置:
16、 类型:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果的第一个组,每个括号为一个组)获取页面为采集的来源文件,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的标题内容如下图 6.文章内容规则是由于源文件设置的新闻页面文章的内容在以下位置:新浪体育新闻北京时间7月7日休斯敦消息,据ESPN报道,姚明尚未决定是否进行脚伤修复手术,虽然现在对姚明的三个主要诊断。医生已经建议手术,但姚明仍然犹豫不决。关于姚明现在的想法,其实,
17、如果手术,他下赛季全部缺席也不是不可能。已经29岁的姚明不想就这样浪费一年。毕竟,运动员的巅峰期只是这么一段时期,没有人能保证那段时间。姚明能否保持更好的水平?姚明犹豫不决,但休斯顿球迷对姚明却有着不同的看法。大多数球迷认为,姚明应该毫不犹豫地接受手术。他们的理由是,既然已经有恶化的趋势,保守治疗的效果还不得而知,就不应该下定决心做手术。毕竟,健康的姚明才是火箭队最好的球员。需要什么,如果保守治疗后还需要手术,那姚明得不偿失。“亲爱的姚,请下定决心做手术,即使错过了下个赛季,也不要犹豫。如果现在
18、保守治疗终于痊愈了,但还是让我们瑟瑟发抖,下赛季可能会有问题。最好通过手术解决疾病的根本原因。你可能会失去一年,但我们相信你会给休斯顿带来三年、五年甚至更健康的未来。”一位球迷这样说。的确,这位球迷表达了广大休斯顿球迷的心声。没有人愿意看到姚明在没有完全康复的情况下重返赛场。如果姚明再次受伤,我相信所有休斯顿球迷会欣赏的,包括姚明,都会是一个很重的打击,也有球迷表示,姚明手术要放心,给姚明做检查诊断的医生,就是在骑士队中心做手术的医生当年的大Z。爱情和姚明差不多,最后在手术中
19、一年后,大Z健康回归赛场,接下来的几年也没有大伤,竞技状态还是比较好的。“和哈达威等人一样,他们的水平因为伤病急剧下降,我认为这种情况对姚明来说是非常困难的,姚明和希尔、哈达威不同,姚明是内线球员,虽然脚部移动很重要,相对来说,弹跳并不是最重要的,姚明在内线的威慑力主要来自他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会带走他的手感。” 风扇说。总之,休斯顿人基本上是希望姚明能做手术的。他们相信手术能给姚明带来完全的健康,而一个健康的姚明,是他们最希望看到的姚明。(
20、小黑)所以制定如下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(.+?)匹配组:1(获取匹配结果中的第一个组,每个括号为一组) 获取页面源文件为采集,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的文章内容如下图7.Other @>文章 的属性在这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。8.采集计划设置好后,选择“体育新闻”栏目,点击采集现在,过一会,查看该栏目的内容管理,你会看到以下内容。另外,采集采集的运行状态
21、,如下图: 查看全部
采集文章免费(约定好该系统一个指定的栏目管理方法)
《网加系统文章采集教程》由会员上传分享,可在线免费阅读。更多相关内容可参见教育资源——天天图书馆。
1、信息采集用户手册 1、抽象信息采集是采集网络数据,实现信息共享的功能模块。它提供了三种模式:手动爬取、定时爬取和定时循环爬取。它可以从单个新闻列表中抓取信息,也可以同时从多个列表中抓取新闻信息。二。步骤和细节 现在您需要将网页采集的数据(新闻)传输到webplus系统中的指定列。步骤如下: 1.为指定列制定一个采集计划。在栏目管理中选择栏目,点击设置采集Plan。(例:图一)2.设置采集的基本属性。包括执行方式,是否自动发布信息,采集 列的类型和页面的编码格式。(如:图二)?预先确定采集计划的实施方式,并手
2、自动、定时单次或定时循环执行。如果只是针对采集网页的当前数据,我们可以使用手动定时单方法采集一次;如果网页的数据是通过采集更新的,我们要保证信息的同步,也就是定时循环采集的方法。?判断来自采集的信息是否需要发布。如果来自采集的信息不需要修改,可以直接向互联网公开,自动发布。如果来自采集的信息需要修改、审核等,请选择不自动发布。采集完成后,信息管理人员将进行其他操作。?设置列类型为采集 如果采集的网页只是一个简单的新闻列表,即该页面的新闻是采集在指定栏目下,那么选择单个栏目Can。如果
3、即采集的页面有多个新闻列表,每个都提供单独的链接进入自己的新闻列表页面,我们需要采集的所有新闻信息,然后选择多个列。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。?设置页面的编码采集因为webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,所以为了避免采集信息乱码,需要设置为页面的编码格式为采集。本文来自Computer Basics: Setting 采集 Rules of 采集 Plan? 单列采集计划的设置(例如:图三)?设置“列表页”)
4、Start URL”是要成为采集的页面的访问路径。(必需的)?设置“文章页面URL获取规则”(1)如果新闻列表是a,如果网页中嵌入iframe表单为采集,那么需要设置规则获取列表iframe的链接地址,从而访问新闻列表。否则不需要制定此规则。(具体规则请参考下面的“采集正则表达式制定”) (2)如果页面采集的新闻列表是分页的,那么根据新闻列表的分页方式(链接和表单提交)制定分页规则,需要设置分页起始页number,区间页码和采集页码。如果新闻列表中没有分页,这个规则不需要制定。(3)如果页面是采集有多个新闻列表,
5、和多个新闻列表的url规则类似,我们只需要采集指定的一个列表,即需要设置获取规则限制文章的列表,这是为了避免采集数据过多。否则,不需要设置此规则。(4)设置文章url的获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。(必填) ? 设置“文章内容获取规则”(1)特定新闻页面,如果文章内容以iframe的形式嵌入新闻页面,则需要设置获取文章iframe的链接地址的规则用于访问新闻内容,否则不需要制定此规则。(2)
6、单次提交)制定分页规则,需要设置分页起始页码、间隔页码和采集页码。如果文章的内容没有分页,则不需要制定这条规则。(3)如果新闻页面除了新闻内容还有其他附加信息,为了在采集过程中更容易找到新闻内容,需要设置规则限制新闻内容的获取,一是避免垃圾信息的产生,二是降低新闻特定信息获取规则的复杂度,如果新闻页面比较简单,一般不需要设置这条规则。 (4)新闻属性的设置规则,除了标题和内容之外,其他条件不是必须的。另外,如果没有设置新闻的发布时间,则以当前时间作为发布时间。? 多栏采集计划设置(如
7、:图五)多栏采集方案,除了需要在“列表页面开始”下设置“列表页面URL规则”和“文章页面URL获取规则” URL”获取列名的规则与单列采集计划中设置的规则相同。?设置RSS单栏采集方案(例如:图四)RSS单栏采集方案不需要设置“文章页面URL获取规则”,其他和单栏采集方案是一样的吗?RSS多栏采集方案的设置(如:图六)RSS多栏采集方案需要在“List Page Start URL”下设置List page URL获取规则,其他与RSS单栏采集方案一致。4.采集 规则表达式制定?表情设置与调整,测试表情列表 点击页面某处采集
8、“获取规则设置”,进入规则表达式列表页面(如:图七)。在这个页面中,除了添加、修改、删除和调整表达式的顺序外,还可以表达式设置好后,输入url、iframeurl和页面内容,测试表达式规则列表。设置各类表达式的类型,表达式类型分为字符串、匹配、匹配替换和公式四种。其中匹配和匹配替换需要用到Java的正则表达式,这就需要采集方案设置人员对表达式有一定的了解。(1)字符串:直接输入字符串常量(2)匹配:通过正则表达式从指定文本(URL、IframeURL、页面内容)中获取部分文本
9、S。(3)匹配替换:首先通过正则表达式从指定文本(URL,IframeURL,页面内容)中获取文本中的部分内容S。然后使用替换正则表达式替换S中匹配的内容然后得到正确的内容。(4)公式:只支持[pageIndex],用来表示获取分页地址时分页的页码。5.图标详情?进入栏目管理(图一)?Setup采集Plan 在右侧列列表中选择一列,点击Set采集Plan。(图二)执行方式可以是:?Manual (需要点击列列表中的“立即采集”启动采集)?单(可以设置时间,到了时间,它会自动启动采集)?Cycle(指定间隔时间,自动循环
10、采集) 可以设置是否自动发布采集的文章。采集 的列类型:?单列(采集这一列下只有文章)?单列 RSS(文章 在 采集 的 RSS 地址下)?多列(采集 列和子列下的文章)?多栏RSS(从一个RSS列表地址开始,采集在多个RSS地址文章下,每个RSS地址形成一个子栏)编码方式为页面的编码为采集@ >? 设置采集规则 a)单栏模式(图三)b)单栏RSS模式(图三)b)四)此方法与单栏相同-column 方法,除了它不需要设置 文章 页面URL获取方法。c) 多列方式(图五)该方法的起始页一般为列表页采集,单列方式需要设置获取列表页的方法
11、表格和列名规则,其他同单列。d) 多列RSS(图六) 该方法需要设置从起始页获取RSS地址(列表页URL),其他与单列RSS一致。设置获取规则(图< @七)(图八)(图九)(图十)(图10一)(图10二))如上图所示,获取rule 由多个表达式组成,多个表达式相加得到所需的 URL 以获取 文章 的标题内容和其他属性。表达式分为 4 类: ? 字符串:直接输入字符串常量 ? 匹配:来自指定文本(URL、IframeURL、页面内容)通过正则表达式获取文本中的部分内容S。? 匹配替换:以指定文本开头(URL、IframeURL、页面内容)
12、 使用正则表达式获取文本中的部分内容S。然后用替换正则表达式替换S中匹配的内容,得到正确的内容。?公式:仅支持[pageIndex],用于表示获取分页地址时分页的页码。此页面还可以测试设置的表达式。您可以使用表达式帮助来理解正则表达式的语法。?查看采集计划的状态,返回列列表可以看到下图(图10中三)采集的状态中的三个图标代表了计划的运行状态采集计划分别(是否运行,是否运行等),采集模式(单栏,单栏RSS,多栏,多栏RSS),执行模式(手动,
13、十四)三。采集方案示例以新浪体育新闻列表网页网站为例采集,该网页的访问地址为。采集 的内容放置在“体育新闻”部分下。1.由于这是一个测试示例,我们手动进行采集,信息采集不需要自动发布。网页是一个简单的新闻列表页面,编码方式为GB2312,所以我们将采集的列类型设置为“单列”,编码方式为gb2312采集对新闻没有自动发布。如下图2.因为这个网页的新闻列表内容已经不在iframe中了,也没有分页,所以不需要
14、设置“列表页内容在IFRAME中”和“列表页分页方式”的获取规则。并且新闻列表的内容不需要设置“限制文章列表内容”规则。3.设置文章url的获取规则由于这个网页中的新闻链接类似于下面的url:所以制定如下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(d+ )-(d+)-(d+)/(d+).shtml 匹配组:0(得到匹配
15、整个结果)获取页面的源文件为采集,粘贴到页面内容中,点击“测试计算-列表模式”,结果会显示所有匹配的列表urls如下图4.由于文章内容不在iframe中,所以文章内容没有分页,文章内容不需要限制在page, 所以 "文章 page content is in the IFRAME" , "文章content paging URL" 和 "limited 文章page文章content" 的获取规则不需要要设置。5.文章设置标题规则是因为新闻页面源文件中文章的标题在以下位置:
16、 类型:页面内容匹配表达式:(.+?) 匹配组:1(获取匹配结果的第一个组,每个括号为一个组)获取页面为采集的来源文件,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的标题内容如下图 6.文章内容规则是由于源文件设置的新闻页面文章的内容在以下位置:新浪体育新闻北京时间7月7日休斯敦消息,据ESPN报道,姚明尚未决定是否进行脚伤修复手术,虽然现在对姚明的三个主要诊断。医生已经建议手术,但姚明仍然犹豫不决。关于姚明现在的想法,其实,
17、如果手术,他下赛季全部缺席也不是不可能。已经29岁的姚明不想就这样浪费一年。毕竟,运动员的巅峰期只是这么一段时期,没有人能保证那段时间。姚明能否保持更好的水平?姚明犹豫不决,但休斯顿球迷对姚明却有着不同的看法。大多数球迷认为,姚明应该毫不犹豫地接受手术。他们的理由是,既然已经有恶化的趋势,保守治疗的效果还不得而知,就不应该下定决心做手术。毕竟,健康的姚明才是火箭队最好的球员。需要什么,如果保守治疗后还需要手术,那姚明得不偿失。“亲爱的姚,请下定决心做手术,即使错过了下个赛季,也不要犹豫。如果现在
18、保守治疗终于痊愈了,但还是让我们瑟瑟发抖,下赛季可能会有问题。最好通过手术解决疾病的根本原因。你可能会失去一年,但我们相信你会给休斯顿带来三年、五年甚至更健康的未来。”一位球迷这样说。的确,这位球迷表达了广大休斯顿球迷的心声。没有人愿意看到姚明在没有完全康复的情况下重返赛场。如果姚明再次受伤,我相信所有休斯顿球迷会欣赏的,包括姚明,都会是一个很重的打击,也有球迷表示,姚明手术要放心,给姚明做检查诊断的医生,就是在骑士队中心做手术的医生当年的大Z。爱情和姚明差不多,最后在手术中
19、一年后,大Z健康回归赛场,接下来的几年也没有大伤,竞技状态还是比较好的。“和哈达威等人一样,他们的水平因为伤病急剧下降,我认为这种情况对姚明来说是非常困难的,姚明和希尔、哈达威不同,姚明是内线球员,虽然脚部移动很重要,相对来说,弹跳并不是最重要的,姚明在内线的威慑力主要来自他的身高和惊人的手感,足部手术不会带走姚明的身高,也不会带走他的手感。” 风扇说。总之,休斯顿人基本上是希望姚明能做手术的。他们相信手术能给姚明带来完全的健康,而一个健康的姚明,是他们最希望看到的姚明。(
20、小黑)所以制定如下表达式规则表达式类型:匹配内容类型:页面内容匹配表达式:(.+?)匹配组:1(获取匹配结果中的第一个组,每个括号为一组) 获取页面源文件为采集,粘贴到页面内容中,点击“测试计算-内容模式”,结果中的文章内容如下图7.Other @>文章 的属性在这里没有设置。如有需要,请参考标题和内容的表达方式进行设置。8.采集计划设置好后,选择“体育新闻”栏目,点击采集现在,过一会,查看该栏目的内容管理,你会看到以下内容。另外,采集采集的运行状态
21、,如下图:
采集文章免费( 百度一下“卓天网络”有哪些比较好用的文章采集器和论坛发贴软件?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-07 23:20
百度一下“卓天网络”有哪些比较好用的文章采集器和论坛发贴软件?)
【articlesea】articlesea文章采集这个软件好用吗?文章海号
此类功能需要采集软件具备“泛搜索自动分析”能力,如站群软件。
但基本上它是通过许多大型 网站 新闻页面的内置模板来实现的。
采集软件官方会不断为自己的软件添加新的网站模板,丰富模板库。显然,这类采集软件的“自动解析”能力是比较有限的,会有相当多比例(约60%)的内容无法解析。
业界唯一技术最好的软件是优采云采集器,它不使用内置模板来解析任何页面的文本。
而优采云采集器不仅有自动解析新闻信息的能力,还能解析论坛文字。
论坛文字长短不一,解析技术最难。
文章采集器有用吗?
然后,当然是使用知名的建站盒子和免费的自助建站系统来做;国内比较有名的建站箱是卓天网络建站箱,模板安装后直接使用即可。里面功能很多,网站可以随时更新发布。建站盒子ExBox是卓天虚拟主机增值服务的免费建站系统,收录上千个精美的网站模板,上百个网站功能,网站简体中文版,繁体同时支持中文版和英文版,具有产品发布系统、新闻系统、会员系统、投票系统、广告系统、招聘系统等动态功能模块,
使用强大的管理平台,轻点鼠标即可瞬间制作精美的网站,不仅周期大大缩短,而且可以免费使用,无需额外的技术和成本投入,同时可以分享我们对产品的技术升级和功能改进,大大节省用户拥有网站的成本。
百度“卓天网”
有什么好用的文章采集器和论坛发帖软件?? ? ?
上述阅读器软件除了书写和阅读功能都还不错,使用“Anthemion Writer's Cafe”(Anthemion Writer's Cafe)v2.26语言版本标题:Writer's Cafe:说写软件英文名称: Anthemion Writer's Cafe 资源格式:安装包版本:v2.26 语言版本发布室:2010 制作发行:Anthemion Software Ltd. 地区:英语语言:简体中文,语言软件介绍管写作故事写作说到特别创作,情节和内容需要组织和保持逻辑严谨或铺垫。作者经常受伤;内容过于分散,很难凭空想象顺序,光靠背可能很难记住剧情。根据写作要求,基本逻辑要理性思考,尽量严谨。该软件可以帮助管理涉及素材、线索和创作主线的创作。该软件应该能够清晰和组织内容。写作需要能够准确地找到所需的信息并采集和管理写作材料。软件手书网吧软件:适合各种讲故事的人,有经验的新手工具箱,强大的操作核心,Story Lines Fantasy 记录书写工具 书写窗口可以让你从保存就开始书写文字,即使文字数据丢失意外情况,如死机、断电等。如果您需要运行本软件,文本数据将立即出现。完全专注于 文章 构思写作大大提高写作速度和效率草稿按钮可以让你在每个窗口中写作文章段落或章节按位置和结尾排序文章保存你的电脑大大提高软件工作效率数据采集器它可以帮助你在网上快速找到你要找的资料并保存在你的电脑上,作家,老师,写字工具,集集写字工具,写老集集必备的辅助软件 免费绿色软件 整个软件是只需 1M 即可下载、安装和移动。除了文本编辑功能,集集写作还有一些主要功能:1.自保存、自备份和手动备份2.批量命名(包括中文名、中文名、英文名)< @3. 树状章节目录管理< 查看全部
采集文章免费(
百度一下“卓天网络”有哪些比较好用的文章采集器和论坛发贴软件?)
【articlesea】articlesea文章采集这个软件好用吗?文章海号
此类功能需要采集软件具备“泛搜索自动分析”能力,如站群软件。
但基本上它是通过许多大型 网站 新闻页面的内置模板来实现的。
采集软件官方会不断为自己的软件添加新的网站模板,丰富模板库。显然,这类采集软件的“自动解析”能力是比较有限的,会有相当多比例(约60%)的内容无法解析。
业界唯一技术最好的软件是优采云采集器,它不使用内置模板来解析任何页面的文本。
而优采云采集器不仅有自动解析新闻信息的能力,还能解析论坛文字。
论坛文字长短不一,解析技术最难。
文章采集器有用吗?
然后,当然是使用知名的建站盒子和免费的自助建站系统来做;国内比较有名的建站箱是卓天网络建站箱,模板安装后直接使用即可。里面功能很多,网站可以随时更新发布。建站盒子ExBox是卓天虚拟主机增值服务的免费建站系统,收录上千个精美的网站模板,上百个网站功能,网站简体中文版,繁体同时支持中文版和英文版,具有产品发布系统、新闻系统、会员系统、投票系统、广告系统、招聘系统等动态功能模块,
使用强大的管理平台,轻点鼠标即可瞬间制作精美的网站,不仅周期大大缩短,而且可以免费使用,无需额外的技术和成本投入,同时可以分享我们对产品的技术升级和功能改进,大大节省用户拥有网站的成本。
百度“卓天网”
有什么好用的文章采集器和论坛发帖软件?? ? ?
上述阅读器软件除了书写和阅读功能都还不错,使用“Anthemion Writer's Cafe”(Anthemion Writer's Cafe)v2.26语言版本标题:Writer's Cafe:说写软件英文名称: Anthemion Writer's Cafe 资源格式:安装包版本:v2.26 语言版本发布室:2010 制作发行:Anthemion Software Ltd. 地区:英语语言:简体中文,语言软件介绍管写作故事写作说到特别创作,情节和内容需要组织和保持逻辑严谨或铺垫。作者经常受伤;内容过于分散,很难凭空想象顺序,光靠背可能很难记住剧情。根据写作要求,基本逻辑要理性思考,尽量严谨。该软件可以帮助管理涉及素材、线索和创作主线的创作。该软件应该能够清晰和组织内容。写作需要能够准确地找到所需的信息并采集和管理写作材料。软件手书网吧软件:适合各种讲故事的人,有经验的新手工具箱,强大的操作核心,Story Lines Fantasy 记录书写工具 书写窗口可以让你从保存就开始书写文字,即使文字数据丢失意外情况,如死机、断电等。如果您需要运行本软件,文本数据将立即出现。完全专注于 文章 构思写作大大提高写作速度和效率草稿按钮可以让你在每个窗口中写作文章段落或章节按位置和结尾排序文章保存你的电脑大大提高软件工作效率数据采集器它可以帮助你在网上快速找到你要找的资料并保存在你的电脑上,作家,老师,写字工具,集集写字工具,写老集集必备的辅助软件 免费绿色软件 整个软件是只需 1M 即可下载、安装和移动。除了文本编辑功能,集集写作还有一些主要功能:1.自保存、自备份和手动备份2.批量命名(包括中文名、中文名、英文名)< @3. 树状章节目录管理<
采集文章免费(网站采集的文章内容可以参考网络上的相关内容吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-03-06 23:20
网站采集的文章内容可以参考网上的一些相关内容,然后通过我自己的理解分享给网站,这是一般的网站内容采集@的一个想法>。但是为了节省时间或者因为执行不到位,很多朋友直接从网上复制粘贴了很多内容,放到自己的网站上。对于这种不负责任的文章采集行为,直接放在网站上的网站的内容,没有从采集中整理出来,肯定会被反感和排斥通过搜索引擎。在不断更新保护原创免受采集攻击的算法后,许多网站受到了相应的惩罚。
网站采集关于seo网站内容优化的注意事项,即对于网站内容的添加,有哪些错误需要注意,必须避免呢?网站可持续发展的动力是网站内容的增加。通过网站内容的不断增加和网站收录的数量不断增加,可以提高网站关键词的排名。但是,前提是我们可以创建高质量的 网站 内容。
网站采集 是做站的一种方法,但不是唯一的方法。一定要合理利用网站采集,也可以在期间添加一些自己创建的文章,增加访问用户看到文章时的可读性,而且做网站也是要回归初心,网站只是一种表现形式,最重要的是内容,毕竟内容为王。
特别声明:以上内容(包括图片或视频)为自媒体平台“网易”用户上传发布,本平台仅提供信息存储服务。 查看全部
采集文章免费(网站采集的文章内容可以参考网络上的相关内容吗?)
网站采集的文章内容可以参考网上的一些相关内容,然后通过我自己的理解分享给网站,这是一般的网站内容采集@的一个想法>。但是为了节省时间或者因为执行不到位,很多朋友直接从网上复制粘贴了很多内容,放到自己的网站上。对于这种不负责任的文章采集行为,直接放在网站上的网站的内容,没有从采集中整理出来,肯定会被反感和排斥通过搜索引擎。在不断更新保护原创免受采集攻击的算法后,许多网站受到了相应的惩罚。
网站采集关于seo网站内容优化的注意事项,即对于网站内容的添加,有哪些错误需要注意,必须避免呢?网站可持续发展的动力是网站内容的增加。通过网站内容的不断增加和网站收录的数量不断增加,可以提高网站关键词的排名。但是,前提是我们可以创建高质量的 网站 内容。
网站采集 是做站的一种方法,但不是唯一的方法。一定要合理利用网站采集,也可以在期间添加一些自己创建的文章,增加访问用户看到文章时的可读性,而且做网站也是要回归初心,网站只是一种表现形式,最重要的是内容,毕竟内容为王。
特别声明:以上内容(包括图片或视频)为自媒体平台“网易”用户上传发布,本平台仅提供信息存储服务。
采集文章免费(怎么保持免费CMS采集插件对网站SEO有什么作用? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-06 07:00
)
免费的 cms采集 插件对 网站SEO 有什么作用。许多 网站 正在做 SEO 推广。与通过付费推广的SEM不同,SEO是利用技术进行网络推广。SEO技术涉及面很广,无论是黑帽还是白帽,博主都认为它能给用户带来良好的体验。出于成本考虑,免费的cms采集插件是很多站长首先考虑的。
蜘蛛通过爬取我们的网站获取我们的网站每天更新的内容,并通过分析爬取的数据分析内容的质量,只有收录为优质内容。所以蜘蛛会根据网站是否定期更新来判断网站是否正常,这就需要我们SEOER养成每天更新文章的好习惯,当然, 文章 的质量也很重要。我们如何保持内容的高质量和更新?
一、材料采集
免费的cms采集插件的采集功能只需要我们输入关键词,就可以在多个平台上使用(如图)采集@ >,支持定向和增量采集,内置中英文翻译,繁简交换。支持采集(具有H标签、图片云存储、自动文本编辑等功能)、本地再创作或直接伪原创发布。
二、自动发帖
免费的cms采集插件支持各种cms,无论是主流dede、wp还是小众ThinkCMF等都可以使用。从 采集 发布到 关键词 可以在所有任务进度和状态可见的情况下完成。支持定时开始、定时结束、发布次数等设置。真正的全天自动挂机。
三、文章内容保证
如何保持 文章关键词 相关和 原创 相关。我们的 文章 标题需要至少收录两个 关键词。从内容上看,开头应该有两三个关键词,中间一两个关键词,最后一个关键词。这样的关键词布局基本可以达到4%-8%的关键词密度。当然,这些都是基于神通关键词的外表,不要为了关键词的外表而刻意堆砌关键词,这样的文章很难成为< @收录。
免费的cms采集插件的伪原创功能支持在我们的采集内容的标题和内容中插入自定义关键词,设置关键词内部链接/外部链接。可以自定义插入图片的频率文章,但是要注意整个网站不能频繁出现关键词,尤其是在不合适的地方。很难排名。免费的 cms采集 插件让我们的 文章 内容更加直接。各种伪原创 功能一应俱全。可以同时创建几十个采集/publish/push 任务。发布后,全平台自动推送。
四、广告
做SEO的站长应该都明白这个道理,网站的权重越高,网站的排名就越高。如果用户选择SEO技术进行推广,可以通过Advertorial使用权限较高的网站进行推广。需要注意的是,如果软文有联系方式或其他非法内容,可能会被删除。Advertorial 的 关键词 密度略高,这是正常的。
免费的cms采集插件确实可以给我们带来很大的方便,减少重复劳动,为我们提供源源不断的素材,让我们可以在制作中使用网站内容丰富的弹药。自动推送功能主动提交链接,也缩短了蜘蛛找到我们的时间,提高了收录的效率。我们不能盲目依赖插件。我们还需要不断的了解用户体验,通过信息反馈做出改变和优化,这就是好的SEO。
查看全部
采集文章免费(怎么保持免费CMS采集插件对网站SEO有什么作用?
)
免费的 cms采集 插件对 网站SEO 有什么作用。许多 网站 正在做 SEO 推广。与通过付费推广的SEM不同,SEO是利用技术进行网络推广。SEO技术涉及面很广,无论是黑帽还是白帽,博主都认为它能给用户带来良好的体验。出于成本考虑,免费的cms采集插件是很多站长首先考虑的。
蜘蛛通过爬取我们的网站获取我们的网站每天更新的内容,并通过分析爬取的数据分析内容的质量,只有收录为优质内容。所以蜘蛛会根据网站是否定期更新来判断网站是否正常,这就需要我们SEOER养成每天更新文章的好习惯,当然, 文章 的质量也很重要。我们如何保持内容的高质量和更新?
一、材料采集
免费的cms采集插件的采集功能只需要我们输入关键词,就可以在多个平台上使用(如图)采集@ >,支持定向和增量采集,内置中英文翻译,繁简交换。支持采集(具有H标签、图片云存储、自动文本编辑等功能)、本地再创作或直接伪原创发布。
二、自动发帖
免费的cms采集插件支持各种cms,无论是主流dede、wp还是小众ThinkCMF等都可以使用。从 采集 发布到 关键词 可以在所有任务进度和状态可见的情况下完成。支持定时开始、定时结束、发布次数等设置。真正的全天自动挂机。
三、文章内容保证
如何保持 文章关键词 相关和 原创 相关。我们的 文章 标题需要至少收录两个 关键词。从内容上看,开头应该有两三个关键词,中间一两个关键词,最后一个关键词。这样的关键词布局基本可以达到4%-8%的关键词密度。当然,这些都是基于神通关键词的外表,不要为了关键词的外表而刻意堆砌关键词,这样的文章很难成为< @收录。
免费的cms采集插件的伪原创功能支持在我们的采集内容的标题和内容中插入自定义关键词,设置关键词内部链接/外部链接。可以自定义插入图片的频率文章,但是要注意整个网站不能频繁出现关键词,尤其是在不合适的地方。很难排名。免费的 cms采集 插件让我们的 文章 内容更加直接。各种伪原创 功能一应俱全。可以同时创建几十个采集/publish/push 任务。发布后,全平台自动推送。
四、广告
做SEO的站长应该都明白这个道理,网站的权重越高,网站的排名就越高。如果用户选择SEO技术进行推广,可以通过Advertorial使用权限较高的网站进行推广。需要注意的是,如果软文有联系方式或其他非法内容,可能会被删除。Advertorial 的 关键词 密度略高,这是正常的。
免费的cms采集插件确实可以给我们带来很大的方便,减少重复劳动,为我们提供源源不断的素材,让我们可以在制作中使用网站内容丰富的弹药。自动推送功能主动提交链接,也缩短了蜘蛛找到我们的时间,提高了收录的效率。我们不能盲目依赖插件。我们还需要不断的了解用户体验,通过信息反馈做出改变和优化,这就是好的SEO。
采集文章免费(PBootCMS全自动如何实现文章全自动采集发布,免费PBootCMS发布工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-24 21:02
PBootcms如何实现文章自动采集发布,免费PBootcms发布工具是一款全自动、强大的SEO工具,支持全网文章采集自动发布到网站,并配有自动推送功能,方便使用。 Pbootcms作为永久开源免费的网站管理系统,可以满足各种网站构造的需求,简洁明了。所以积累了很多用户!因为代码简单,介绍对搜索引擎比较友好。另一方面,PBootcms有很多免费的SEO工具,非常方便实用。使用免费的PBootcms采集发布工具小白还可以搭建每日自动采集和发布网站。使用PBootcms和免费的采集发布工具,可以当天建新域名,次日逐步启动收录,部分关键词启动排名。一段时间后,收录基本可以达到上万个收录。
免费 PBootcms发布模块:
1、文章可以在文章发布时自动发布伪原创(伪原创主要针对搜索引擎算法规则收录@开发>,采用AI智能大脑。整合NLG技术、RNN模型、百度人工智能算法技术,对网站收录)
有帮助
2、自动内链(自动内链可以让搜索引擎蜘蛛爬得更深收录网站内容) 以上所有功能都可以通过迅瑞cms工具来管理自动完成
3、除了PBootcms,还支持市面上主要的cms,可以管理和发布各种cms
同时分批
4、自动发布、定时定量发布
5、可以插入标题、内容关键词的后缀和后缀,提高网站关键词的排名并优化
6、发布后立即推送至百度/搜狗/360/神马加速收录
7、可随机设置评论/点赞/阅读/作者/图片,增强页面模拟用户真实性
一、PBootcms自动采集发布
1. 全自动无人值守定时批处理采集
2. 自动同步网站更新
3.AI自动关键词,自动汇总生成
4.自动发布到PBootcms,无需额外配置
5. 身体图像和缩略图都可以本地化
6.文章每个任务中的图片都可以独立加水印
7. 平台范围的内容采集
可以采集哪些站
1. 新闻资讯站
2. 文章模型站
3.BBS 论坛
4. 博客网站
5.资源站、下载站
建议选择新闻来源采集!为什么选择新闻来源?因为新闻提要的 网站 质量非常高!新闻源相当于搜索引擎的“种子源”,收录快速、可信、权威。新闻源特别符合搜索引擎新闻收录 标准。因此,采集!
的内容我们首选的新闻来源
以上编辑器采用全自动采集发布推送,所有内容均与主题相关! 网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
采集文章免费(PBootCMS全自动如何实现文章全自动采集发布,免费PBootCMS发布工具)
PBootcms如何实现文章自动采集发布,免费PBootcms发布工具是一款全自动、强大的SEO工具,支持全网文章采集自动发布到网站,并配有自动推送功能,方便使用。 Pbootcms作为永久开源免费的网站管理系统,可以满足各种网站构造的需求,简洁明了。所以积累了很多用户!因为代码简单,介绍对搜索引擎比较友好。另一方面,PBootcms有很多免费的SEO工具,非常方便实用。使用免费的PBootcms采集发布工具小白还可以搭建每日自动采集和发布网站。使用PBootcms和免费的采集发布工具,可以当天建新域名,次日逐步启动收录,部分关键词启动排名。一段时间后,收录基本可以达到上万个收录。
免费 PBootcms发布模块:
1、文章可以在文章发布时自动发布伪原创(伪原创主要针对搜索引擎算法规则收录@开发>,采用AI智能大脑。整合NLG技术、RNN模型、百度人工智能算法技术,对网站收录)
有帮助
2、自动内链(自动内链可以让搜索引擎蜘蛛爬得更深收录网站内容) 以上所有功能都可以通过迅瑞cms工具来管理自动完成
3、除了PBootcms,还支持市面上主要的cms,可以管理和发布各种cms
同时分批
4、自动发布、定时定量发布
5、可以插入标题、内容关键词的后缀和后缀,提高网站关键词的排名并优化
6、发布后立即推送至百度/搜狗/360/神马加速收录
7、可随机设置评论/点赞/阅读/作者/图片,增强页面模拟用户真实性
一、PBootcms自动采集发布
1. 全自动无人值守定时批处理采集
2. 自动同步网站更新
3.AI自动关键词,自动汇总生成
4.自动发布到PBootcms,无需额外配置
5. 身体图像和缩略图都可以本地化
6.文章每个任务中的图片都可以独立加水印
7. 平台范围的内容采集
可以采集哪些站
1. 新闻资讯站
2. 文章模型站
3.BBS 论坛
4. 博客网站
5.资源站、下载站
建议选择新闻来源采集!为什么选择新闻来源?因为新闻提要的 网站 质量非常高!新闻源相当于搜索引擎的“种子源”,收录快速、可信、权威。新闻源特别符合搜索引擎新闻收录 标准。因此,采集!
的内容我们首选的新闻来源
以上编辑器采用全自动采集发布推送,所有内容均与主题相关! 网站从未发生过降级!看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
采集文章免费(采集文章免费,短视频同理可得,不要钱(包括高清图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-24 15:02
采集文章免费,短视频同理可得,不要钱(包括高清图),
是的,可以。我关注的公众号上刚推出一个“自我推荐”功能。大意是:把你对朋友说的广告推荐给好友或群,你可以获得1-500元不等的广告分成。依照阅读量从高到低分成,不超过500字的免费推荐标准是一天200,500字以上每天600元(标准截止时间19年2月26日)。另外如果你不介意阅读量的话,500-1000字以内也可以免费推荐。
我目前在那里找到了12个免费推荐,上面那个是我找到的最好的一个广告群了。因为我的文字量和推荐标准不符合,所以目前只得到了大概2万块,详细的推荐标准每个公众号可能不一样,具体看样子。
我也想推广自己原创的优质内容呢,
手动添加机器人::/
@monster
原创答案新人。私以为不能做广告。其实可以设置公司或产品,定期做文章类广告。除非广告做的大。我们也曾做过原创栏目,后面平台要求原创度和公司或产品文,暂停了。很后悔。这种行为也使原创度下降。所以我认为广告应该是可以采取的。一句话说就是不影响你的内容质量和阅读。建议投放一些别人看完会想买或者需要的广告。比如新上品牌服饰或珠宝玉石。如果你有固定的订阅者和读者,可以用微信公众号投放。不过这个别人的位置要好好找。不过要真受得了。 查看全部
采集文章免费(采集文章免费,短视频同理可得,不要钱(包括高清图))
采集文章免费,短视频同理可得,不要钱(包括高清图),
是的,可以。我关注的公众号上刚推出一个“自我推荐”功能。大意是:把你对朋友说的广告推荐给好友或群,你可以获得1-500元不等的广告分成。依照阅读量从高到低分成,不超过500字的免费推荐标准是一天200,500字以上每天600元(标准截止时间19年2月26日)。另外如果你不介意阅读量的话,500-1000字以内也可以免费推荐。
我目前在那里找到了12个免费推荐,上面那个是我找到的最好的一个广告群了。因为我的文字量和推荐标准不符合,所以目前只得到了大概2万块,详细的推荐标准每个公众号可能不一样,具体看样子。
我也想推广自己原创的优质内容呢,
手动添加机器人::/
@monster
原创答案新人。私以为不能做广告。其实可以设置公司或产品,定期做文章类广告。除非广告做的大。我们也曾做过原创栏目,后面平台要求原创度和公司或产品文,暂停了。很后悔。这种行为也使原创度下降。所以我认为广告应该是可以采取的。一句话说就是不影响你的内容质量和阅读。建议投放一些别人看完会想买或者需要的广告。比如新上品牌服饰或珠宝玉石。如果你有固定的订阅者和读者,可以用微信公众号投放。不过这个别人的位置要好好找。不过要真受得了。
采集文章免费(英语采集文章免费送,不领你亏大了!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-20 02:00
采集文章免费送啦,不光有免费获取学习资料,更有现金奖励,不领你亏大了!学习英语5年了,但是不会发音我比较失望,所以我发现了这个app,它专门解决我发音问题的,软件里面所有发音的内容几乎全部都是免费给你下载,我先不说多好,起码我是比较满意的,重点是一个人的成长,免费的条件不管是在生活还是工作上都是很重要的。
这也是我如今选择英语学习的一个最重要的原因,每一个信息都是免费分享给你的。and支持国内优秀的英语学习平台,免费,无限制发音资源,我的一生都是用它来学习英语的。这些都是学习其他学习方法得不到的福利!。
练听力,百词斩。软件就那么些。其他老师都讲过了。我就不赘述了。零基础,从英语字母学起,背单词,看电影。
学习英语多么重要。
百词斩单词入门就不错,
不推荐软件,但是用了一个个月后你会爱上bbcbbc英音练习,有个刷题的,可以做选择。
小站就可以,跟着软件练就行,
爱听公开课的都可以,
软件只是辅助的,有了正确的学习方法,没有好的练习方法,软件只是一个辅助作用。有了正确的学习方法,再加上好的练习方法,学习软件也好,单词书也好,学的效果是最好的,不过没有好的学习方法,方法不对,选什么工具也白搭。 查看全部
采集文章免费(英语采集文章免费送,不领你亏大了!)
采集文章免费送啦,不光有免费获取学习资料,更有现金奖励,不领你亏大了!学习英语5年了,但是不会发音我比较失望,所以我发现了这个app,它专门解决我发音问题的,软件里面所有发音的内容几乎全部都是免费给你下载,我先不说多好,起码我是比较满意的,重点是一个人的成长,免费的条件不管是在生活还是工作上都是很重要的。
这也是我如今选择英语学习的一个最重要的原因,每一个信息都是免费分享给你的。and支持国内优秀的英语学习平台,免费,无限制发音资源,我的一生都是用它来学习英语的。这些都是学习其他学习方法得不到的福利!。
练听力,百词斩。软件就那么些。其他老师都讲过了。我就不赘述了。零基础,从英语字母学起,背单词,看电影。
学习英语多么重要。
百词斩单词入门就不错,
不推荐软件,但是用了一个个月后你会爱上bbcbbc英音练习,有个刷题的,可以做选择。
小站就可以,跟着软件练就行,
爱听公开课的都可以,
软件只是辅助的,有了正确的学习方法,没有好的练习方法,软件只是一个辅助作用。有了正确的学习方法,再加上好的练习方法,学习软件也好,单词书也好,学的效果是最好的,不过没有好的学习方法,方法不对,选什么工具也白搭。
采集文章免费(Dede采集插件采集内容,是因为网站内容SEO的重要组成部分)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-18 09:02
Dede采集plugin采集content,因为网站content SEO是SEO的重要组成部分。收录在 网站 上编写和构建内容的所有方面。内容搜索引擎优化是必不可少的。搜索引擎抓取 网站。搜索引擎的算法主要是根据网站发布的内容来决定网站的排名。我们都知道内容为王。因此,SEO 内容需要 Dede采集 插件。看到Dede采集插件文章,那么一定要搜索相关资料,直接看图,不是文章的内容,图表达一切,看完四图你会明白它的真正含义。【重要信息点一,强大的Dede采集插件】
更新 文章 是 网站 的主要优化重点。只有内容优化才能更流畅。网站在SEO上做得不好的原因大部分是他们做得不好网站文章的更新工作,Dede采集插件允许网站@ > 经常更新文章,以便做好网站的SEO优化工作。【重要信息点2,完全免费的Dede采集插件】
通过Dede采集插件,大量的采集内容可以被搜索引擎收录用来在线搜索文章重复,其中大部分已经发表在一些高权重的平台,同样的数据也存在于搜索引擎中,所以搜索引擎不会爬取检索,而是Dede采集插件生成的文章经过AI智能处理后发布,这就是为什么别人采集可以增加权重,而你的网站采集会减轻权重。【重要信息点3,具有丰富SEO功能的Dede采集插件】
其实有很多因素值得参考。Dede采集plugin采集过来后,经过内容处理优化后发布,或者采集的内容比较新,原创度数和时效性高,并且对用户的参考价值比较大,所以可以提高网站的seo权重。【重要信息点4,方便高效的Dede采集插件】
Dede采集插件对网站的处理和排版也是智能处理的。搜索引擎蜘蛛点的原则认为,同时文章的更新必须有文字描述,而文章的更新要坚持“文字就是文字”的原则。主图为辅”,也就是我们常说的内容为王,内容为王。 查看全部
采集文章免费(Dede采集插件采集内容,是因为网站内容SEO的重要组成部分)
Dede采集plugin采集content,因为网站content SEO是SEO的重要组成部分。收录在 网站 上编写和构建内容的所有方面。内容搜索引擎优化是必不可少的。搜索引擎抓取 网站。搜索引擎的算法主要是根据网站发布的内容来决定网站的排名。我们都知道内容为王。因此,SEO 内容需要 Dede采集 插件。看到Dede采集插件文章,那么一定要搜索相关资料,直接看图,不是文章的内容,图表达一切,看完四图你会明白它的真正含义。【重要信息点一,强大的Dede采集插件】
更新 文章 是 网站 的主要优化重点。只有内容优化才能更流畅。网站在SEO上做得不好的原因大部分是他们做得不好网站文章的更新工作,Dede采集插件允许网站@ > 经常更新文章,以便做好网站的SEO优化工作。【重要信息点2,完全免费的Dede采集插件】
通过Dede采集插件,大量的采集内容可以被搜索引擎收录用来在线搜索文章重复,其中大部分已经发表在一些高权重的平台,同样的数据也存在于搜索引擎中,所以搜索引擎不会爬取检索,而是Dede采集插件生成的文章经过AI智能处理后发布,这就是为什么别人采集可以增加权重,而你的网站采集会减轻权重。【重要信息点3,具有丰富SEO功能的Dede采集插件】
其实有很多因素值得参考。Dede采集plugin采集过来后,经过内容处理优化后发布,或者采集的内容比较新,原创度数和时效性高,并且对用户的参考价值比较大,所以可以提高网站的seo权重。【重要信息点4,方便高效的Dede采集插件】
Dede采集插件对网站的处理和排版也是智能处理的。搜索引擎蜘蛛点的原则认为,同时文章的更新必须有文字描述,而文章的更新要坚持“文字就是文字”的原则。主图为辅”,也就是我们常说的内容为王,内容为王。
采集文章免费(搜索引擎为什么一直不收录我的网站?怎么让搜索引擎快速收录 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-13 20:05
)
为什么搜索引擎不保留 收录my网站?为什么我的 网站 没有排名?我 网站 得到了 K 吗?如何让搜索引擎快速收录my网站?这是最近很多站长问我的一个问题,今天就这些问题分享一下我的一些看法。
首先我们要知道SEO到底是做什么的?是的,网站 内容。因为SEO是内容为王的时代。一个好的稳定的内容来源可以让你网站收录和排名更有效率。
如何网站内容
首先,我们手动发布网站内容,形式不可靠,不能做很多内容。所以我们将使用免费的 采集 工具。那么 采集 工具是什么?采集工具是指互联网数据采集、处理、分析和挖掘软件。文章采集工具,只需输入关键字即可采集各种网页和新闻,也可以采集指定列表页的文章@(栏页)>。让您的 网站 内容更丰富,然后使用免费的 采集 工具覆盖更多 关键词 以批量采集 质量新闻源。那么你可能会说百度等搜索引擎正在打击纯采集,那么有什么办法可以避免呢?
有些我们可以批处理 采集 然后 伪原创 然后我们发布到 网站 后台。
以 伪原创 的方式提高 收录文章 的 SEO收录 率,当我们 收录 时,我们永远不会达到 100% 原创 的性能. 使用 伪原创 的目的是找到绕过搜索引擎或新媒体中收录的重复检查算法的方法。使内容更快 收录 并增加 文章 流量。
采集如何选择工具
必须满足几个要素:操作简单,使用工具的目的是提高工作效率,满足大量批量需求。界面简单易懂,大部分站长不具备编码或编写程序的能力,所以傻瓜式操作非常重要,只需点击几下即可完成工作。挂机操作,SEO需要做的很多,需要更多的时间和精力去优化。至于采集,放在那里,让它自己工作。它可以免费使用。做网站的目的就是为了赚钱。SEO本身就是一项技能,不要花钱去做。如果是花钱做的,不如直接打广告。我自己做了将近1000个各种大小的网站,从来没有在采集工具上花过一分钱,就用免费的< @采集 直接使用工具。147SEO采集工具用于完成网站的采集需求。
正确使用采集的打开方式
采集的内容一定要和标题对应,要做到页面相关,一定要垂直,采集行业文章和关键词,切记,不要乱来采集文章,填写数字,然后必须公布大量的文章采集。做好,像往常一样定期发布,让搜索引擎知道你的模式,逐渐增加或减少。偶尔可以穿插一两篇原创文章的文章,更有利于收录和网站的排名。
今天的分享就到这里。其实我讲的核心是采集工具的介绍和使用以及一些注意事项。如果看完这篇文章,你有很多网站要构建,不妨试试作者介绍的方法。希望我的经验可以帮到你。
查看全部
采集文章免费(搜索引擎为什么一直不收录我的网站?怎么让搜索引擎快速收录
)
为什么搜索引擎不保留 收录my网站?为什么我的 网站 没有排名?我 网站 得到了 K 吗?如何让搜索引擎快速收录my网站?这是最近很多站长问我的一个问题,今天就这些问题分享一下我的一些看法。
首先我们要知道SEO到底是做什么的?是的,网站 内容。因为SEO是内容为王的时代。一个好的稳定的内容来源可以让你网站收录和排名更有效率。
如何网站内容
首先,我们手动发布网站内容,形式不可靠,不能做很多内容。所以我们将使用免费的 采集 工具。那么 采集 工具是什么?采集工具是指互联网数据采集、处理、分析和挖掘软件。文章采集工具,只需输入关键字即可采集各种网页和新闻,也可以采集指定列表页的文章@(栏页)>。让您的 网站 内容更丰富,然后使用免费的 采集 工具覆盖更多 关键词 以批量采集 质量新闻源。那么你可能会说百度等搜索引擎正在打击纯采集,那么有什么办法可以避免呢?
有些我们可以批处理 采集 然后 伪原创 然后我们发布到 网站 后台。
以 伪原创 的方式提高 收录文章 的 SEO收录 率,当我们 收录 时,我们永远不会达到 100% 原创 的性能. 使用 伪原创 的目的是找到绕过搜索引擎或新媒体中收录的重复检查算法的方法。使内容更快 收录 并增加 文章 流量。
采集如何选择工具
必须满足几个要素:操作简单,使用工具的目的是提高工作效率,满足大量批量需求。界面简单易懂,大部分站长不具备编码或编写程序的能力,所以傻瓜式操作非常重要,只需点击几下即可完成工作。挂机操作,SEO需要做的很多,需要更多的时间和精力去优化。至于采集,放在那里,让它自己工作。它可以免费使用。做网站的目的就是为了赚钱。SEO本身就是一项技能,不要花钱去做。如果是花钱做的,不如直接打广告。我自己做了将近1000个各种大小的网站,从来没有在采集工具上花过一分钱,就用免费的< @采集 直接使用工具。147SEO采集工具用于完成网站的采集需求。
正确使用采集的打开方式
采集的内容一定要和标题对应,要做到页面相关,一定要垂直,采集行业文章和关键词,切记,不要乱来采集文章,填写数字,然后必须公布大量的文章采集。做好,像往常一样定期发布,让搜索引擎知道你的模式,逐渐增加或减少。偶尔可以穿插一两篇原创文章的文章,更有利于收录和网站的排名。
今天的分享就到这里。其实我讲的核心是采集工具的介绍和使用以及一些注意事项。如果看完这篇文章,你有很多网站要构建,不妨试试作者介绍的方法。希望我的经验可以帮到你。
采集文章免费(如果你觉得我这个免费的作者也可以,请与我联系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-02-13 13:02
采集文章免费,如果你觉得我这个免费的作者也可以,请与我联系。任何利益驱使下的商业转载,都是冒风险的,全年无偿转载就更加是了。我知道高考政治常识被滥用,被黑,被误导,你说这个我随便从网上查查也知道。我所感激的,只是将商业转载归于商业考虑,而不是反咬一口的平台。
拉倒吧,
有评论说要收钱很正常,毕竟是公益项目。还有人说西部数据已经做到1000w级别了,即使天价也会有人给我。我想说的是,感谢支持是正常的,但一定要量力而行。因为公益项目不像卖大米,卖菜能有很好的覆盖面。西部数据也肯定不会拿着微信的资金大干快上。所以只有细分市场才能做得更好。
就像一个长辈说我(高中三年级),开始混上市公司的公众号(还是ipo通过的那种,不是试点),已经是来看我的眼光高了就这意思了。好像搞经济的对微信花多少钱有逼数,但就我认识的商人而言,搞公益基本不怎么在乎钱这个事,毕竟买东西省点钱,做公益还不如花钱出政绩。
“打个比方,给公众号注册个账号,就相当于创业。”,z院士说。
wd是作恶的,
请提问者提供具体信息(收费方式,时间,对象,发起方),现在大家都没有收费意识,所以建议将来知乎不能乱提问。 查看全部
采集文章免费(如果你觉得我这个免费的作者也可以,请与我联系)
采集文章免费,如果你觉得我这个免费的作者也可以,请与我联系。任何利益驱使下的商业转载,都是冒风险的,全年无偿转载就更加是了。我知道高考政治常识被滥用,被黑,被误导,你说这个我随便从网上查查也知道。我所感激的,只是将商业转载归于商业考虑,而不是反咬一口的平台。
拉倒吧,
有评论说要收钱很正常,毕竟是公益项目。还有人说西部数据已经做到1000w级别了,即使天价也会有人给我。我想说的是,感谢支持是正常的,但一定要量力而行。因为公益项目不像卖大米,卖菜能有很好的覆盖面。西部数据也肯定不会拿着微信的资金大干快上。所以只有细分市场才能做得更好。
就像一个长辈说我(高中三年级),开始混上市公司的公众号(还是ipo通过的那种,不是试点),已经是来看我的眼光高了就这意思了。好像搞经济的对微信花多少钱有逼数,但就我认识的商人而言,搞公益基本不怎么在乎钱这个事,毕竟买东西省点钱,做公益还不如花钱出政绩。
“打个比方,给公众号注册个账号,就相当于创业。”,z院士说。
wd是作恶的,
请提问者提供具体信息(收费方式,时间,对象,发起方),现在大家都没有收费意识,所以建议将来知乎不能乱提问。
采集文章免费(全自动无人值守采集软件(Editortools),省去这笔开支!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-12 07:09
全自动无人值守采集软件(Editortools)是中小型网站自动更新的强大工具。无人值守免费自动采集器的出现将为您省下这笔费用!它将为您节省大量时间,将网站管理员和管理员从繁琐无聊的 网站 更新工作中解放出来!
功能介绍知识兔
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项语言翻译
【发布】支持转码,支持UBB码
【发布】文件上传可以选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
软件功能知识兔
独一无二的无人值守
ET的设计以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,甚至几年。
超高稳定性
要达到无人值守软件的目的,需要长时间稳定运行。ET在这方面做了很多优化,保证软件可以稳定连续工作,永远不会出现一些采集软件会自己崩溃甚至导致网站崩溃的问题.
最低资源使用量
ET独立于网站,不消耗宝贵的服务器WEB处理资源,可以在服务器或站长的工作机上工作。
严密的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了任何可能由ET引起的数据安全问题。采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
除了一般采集工具的功能外,ET还可以使用图片水印、防盗链、分页采集、回复采集、登录采集、自定义等功能项目,UTF- 8、UBB,模拟发布...
点击下载 查看全部
采集文章免费(全自动无人值守采集软件(Editortools),省去这笔开支!)
全自动无人值守采集软件(Editortools)是中小型网站自动更新的强大工具。无人值守免费自动采集器的出现将为您省下这笔费用!它将为您节省大量时间,将网站管理员和管理员从繁琐无聊的 网站 更新工作中解放出来!
功能介绍知识兔
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项语言翻译
【发布】支持转码,支持UBB码
【发布】文件上传可以选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
软件功能知识兔
独一无二的无人值守
ET的设计以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,甚至几年。
超高稳定性
要达到无人值守软件的目的,需要长时间稳定运行。ET在这方面做了很多优化,保证软件可以稳定连续工作,永远不会出现一些采集软件会自己崩溃甚至导致网站崩溃的问题.
最低资源使用量
ET独立于网站,不消耗宝贵的服务器WEB处理资源,可以在服务器或站长的工作机上工作。
严密的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了任何可能由ET引起的数据安全问题。采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
除了一般采集工具的功能外,ET还可以使用图片水印、防盗链、分页采集、回复采集、登录采集、自定义等功能项目,UTF- 8、UBB,模拟发布...
点击下载
采集文章免费(微博采集文章免费方案,你值得拥有!(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-02-04 04:01
采集文章免费方案详细:微博【个人】:
1)我们为什么有精准的标签我们的这批内容是为哪些人服务的
2)其中某一篇是否可以吸引用户的兴趣我们的文章从哪些方面去抓用户的需求微博【组织】:
1)我们为什么有精准的标签我们的文章到底要从哪里来
2)组织中具体的人是否需要我们的内容?比如:某家公司、某个项目组、某个领域的大v等等
3)其中某一篇文章可以抓住用户的兴趣点微博【媒体】:
1)我们为什么有精准的标签我们的这批内容是否可以帮到别人
2)具体的人需要什么样的内容?比如,
1)我们为什么有精准的标签公司自己想要运营的,
2)具体的企业的痛点和需求是什么?比如餐饮是痛点是“很难排队”,“很难吃到超级好吃的餐”;物流是痛点是“送不到”,
1)我们为什么有精准的标签我们的产品从哪里来?产品本身有什么痛点和需求?我们的“10w+的标题”是如何设计和撰写的?比如天猫的标题“线上比线下便宜,线下100平,比线上便宜50%”;“这些问题,
1)我们为什么有精准的标签我们的目标受众在哪里?我们用什么方式可以去帮到他们?
2)其中哪一篇文章是最适合推广的?微博【支付】:
1)我们为什么有精准的标签我们的产品是谁在用,
1)我们为什么有精准的标签为什么我们有这么多人?我们用什么方式可以吸引用户关注我们?微博【社群】:
1)我们为什么有精准的标签我们现在有这么多人?其他人为什么会关注我们?我们的运营模式是什么?怎么实现裂变化?微博【分享】:
1)我们为什么有精准的标签你最擅长什么?你最擅长的是什么?你的优势在哪里?你本身的特长是什么?你是怎么突出自己的特长的?用什么方式可以变现?等等微博【博客】:
1)我们为什么有精准的标签能引发我们转发分享的一定是个好博客;能引发我们讨论的一定是精彩的知识;能被某些网站收录的一定是好博客;能引起别人兴趣的一定是好博客;能给别人解决问题的一定是好博客;能给别人带来快乐的一定是好博客;能看到别人进步的一定是好博客;
2)个人以及组织 查看全部
采集文章免费(微博采集文章免费方案,你值得拥有!(一))
采集文章免费方案详细:微博【个人】:
1)我们为什么有精准的标签我们的这批内容是为哪些人服务的
2)其中某一篇是否可以吸引用户的兴趣我们的文章从哪些方面去抓用户的需求微博【组织】:
1)我们为什么有精准的标签我们的文章到底要从哪里来
2)组织中具体的人是否需要我们的内容?比如:某家公司、某个项目组、某个领域的大v等等
3)其中某一篇文章可以抓住用户的兴趣点微博【媒体】:
1)我们为什么有精准的标签我们的这批内容是否可以帮到别人
2)具体的人需要什么样的内容?比如,
1)我们为什么有精准的标签公司自己想要运营的,
2)具体的企业的痛点和需求是什么?比如餐饮是痛点是“很难排队”,“很难吃到超级好吃的餐”;物流是痛点是“送不到”,
1)我们为什么有精准的标签我们的产品从哪里来?产品本身有什么痛点和需求?我们的“10w+的标题”是如何设计和撰写的?比如天猫的标题“线上比线下便宜,线下100平,比线上便宜50%”;“这些问题,
1)我们为什么有精准的标签我们的目标受众在哪里?我们用什么方式可以去帮到他们?
2)其中哪一篇文章是最适合推广的?微博【支付】:
1)我们为什么有精准的标签我们的产品是谁在用,
1)我们为什么有精准的标签为什么我们有这么多人?我们用什么方式可以吸引用户关注我们?微博【社群】:
1)我们为什么有精准的标签我们现在有这么多人?其他人为什么会关注我们?我们的运营模式是什么?怎么实现裂变化?微博【分享】:
1)我们为什么有精准的标签你最擅长什么?你最擅长的是什么?你的优势在哪里?你本身的特长是什么?你是怎么突出自己的特长的?用什么方式可以变现?等等微博【博客】:
1)我们为什么有精准的标签能引发我们转发分享的一定是个好博客;能引发我们讨论的一定是精彩的知识;能被某些网站收录的一定是好博客;能引起别人兴趣的一定是好博客;能给别人解决问题的一定是好博客;能给别人带来快乐的一定是好博客;能看到别人进步的一定是好博客;
2)个人以及组织
采集文章免费(百度搜索:公众号推广到底值不值得做-百度营销)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-03 07:07
采集文章免费、可视化操作步骤1.点击获取微信公众号内容,拉至底部,一直往下拉,查看预览。2.然后点击搜索栏“公众号推广”、右侧按钮“扫描关注”,按照提示填写信息即可。3.转发即可,不做推广,可以不做转发。
这是一家大数据公司,数据包括文章、视频,随着知识经济的发展,文章即将成为企业营销的重要渠道。
百度搜索:公众号推广到底值不值得做其实知乎早已替你回答了你的疑问公众号推广到底值不值得做-百度营销吧|其他干货吧|中国营销网|百度百家|更多干货百度营销_搜索营销_搜索引擎营销_新媒体营销中国营销学会公众号大搜索等资源也是可以免费的
是要推广的。可以参考,都有哪些免费网站在免费的公众号推广。
我推荐大鱼号吧,全部免费,并且每天有不同行业的广告可以投放,
可以参考微信公众号文章seo优化有哪些技巧?
现在的大v都去做搜索引擎营销了,公众号都比较少了,所以建议大家不要只做公众号了。目前有很多公众号可以免费转发文章。另外关注一下gocheck的公众号就可以了解很多有关公众号的用户体验,还有行业数据分析。
emmmm我只听说公众号做seo优化不直接免费的但现在随着大数据时代的来临公众号的seo优化方式还是有很多的推荐你看一下大鱼号的seo优化文章 查看全部
采集文章免费(百度搜索:公众号推广到底值不值得做-百度营销)
采集文章免费、可视化操作步骤1.点击获取微信公众号内容,拉至底部,一直往下拉,查看预览。2.然后点击搜索栏“公众号推广”、右侧按钮“扫描关注”,按照提示填写信息即可。3.转发即可,不做推广,可以不做转发。
这是一家大数据公司,数据包括文章、视频,随着知识经济的发展,文章即将成为企业营销的重要渠道。
百度搜索:公众号推广到底值不值得做其实知乎早已替你回答了你的疑问公众号推广到底值不值得做-百度营销吧|其他干货吧|中国营销网|百度百家|更多干货百度营销_搜索营销_搜索引擎营销_新媒体营销中国营销学会公众号大搜索等资源也是可以免费的
是要推广的。可以参考,都有哪些免费网站在免费的公众号推广。
我推荐大鱼号吧,全部免费,并且每天有不同行业的广告可以投放,
可以参考微信公众号文章seo优化有哪些技巧?
现在的大v都去做搜索引擎营销了,公众号都比较少了,所以建议大家不要只做公众号了。目前有很多公众号可以免费转发文章。另外关注一下gocheck的公众号就可以了解很多有关公众号的用户体验,还有行业数据分析。
emmmm我只听说公众号做seo优化不直接免费的但现在随着大数据时代的来临公众号的seo优化方式还是有很多的推荐你看一下大鱼号的seo优化文章
采集文章免费(免费代理稳定性连同时切换代理附代理采集下载下载地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-18 14:21
1、代理文档格式:(代理采集地址)
2、免费代理稳定性不可靠,使用装饰器重连,同时切换代理
# coding: utf-8
# pyhotn 2.7
# 小说棋 单篇小说采集 http://www.xs7.la/
# 替换第一章地址,总章节数。
# ip.txt 为代理池。
import urllib2
from bs4 import BeautifulSoup
import sys
import traceback
import random
import gzip
reload(sys)
sys.setdefaultencoding('utf-8')
f = open("out.txt", "a+")
headers = {
"Host": "www.xs7.la",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36",
"Content-Type": "text/html",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Referer": "http://www.xs7.la/book/18_18966/",
"Accept-Encoding": 'deflat'
}
url = "http://www.xs7.la/book/18_18966/7828246.html" # 第一章网址
page = 184 # 章节数
nextHref = url
ipPool = []
def IPpool():
reader = open('ip.txt')
line = reader.readline()
while line:
if line.strip() != '':
ipPool.append(line.split())
line = reader.readline()
reader.close()
RETRIES = 0
# 重试的次数
count = {"num": RETRIES}
def conn_try_again(function):
def wrapped(*args, **kwargs):
try:
return function(*args, **kwargs)
except Exception, err:
print("--重试访问,当前次数 %s ,(总次数11)--" % (count['num'] + 1))
if count['num'] < 10:
count['num'] += 1
return wrapped(*args, **kwargs)
else:
raise Exception(err)
return wrapped
bsObj = None
#判断编码格式
def getCoding(strInput):
'''
获取编码格式
'''
if isinstance(strInput, unicode):
return "unicode"
try:
strInput.decode("utf8")
return 'utf8'
except:
pass
try:
strInput.decode("gbk")
return 'gbk'
except:
pass
@conn_try_again
def getContent(url):
global nextHref, page, bsObj
# 定义一个代理开关
proxySwitch = True
try:
poolLen = len(ipPool)
if (poolLen > 0):
i = random.randint(0, poolLen - 1)
print(ipPool[i])
proxy_host = ipPool[i][2] + "://" + ipPool[i][0] + ":" + ipPool[i][1]
proxy_temp = {ipPool[i][2]: proxy_host}
proxy_support = urllib2.ProxyHandler(proxy_temp)
else:
print('--代理池当前无可用代理,使用本机地址访问--')
proxy_support = urllib2.ProxyHandler({})
nullproxy_handler = urllib2.ProxyHandler({"http": "124.172.232.49:8010"})
if proxySwitch:
opener = urllib2.build_opener(proxy_support)
else:
opener = urllib2.build_opener(nullproxy_handler)
urllib2.install_opener(opener)
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req, timeout=3)
r = response.read()
encode=getCoding(r)
if(encode==None):
print(response.info().get('Content-Encoding'))
#gzip需要解压
else :
r = r.decode(encode)
# print(r)
bsObj = BeautifulSoup(r, 'lxml')
except Exception, err:
raise Exception(err)
# print(bsObj)
contentDiv = bsObj.find('div', id='content')
content = bsObj.find('div', id='content').get_text()
preAndNextBar = bsObj.find('div', id='thumb')
title = bsObj.find('div', id='bgdiv').h1.get_text()
if ("下一章" in preAndNextBar.get_text()):
next = None
aList = preAndNextBar.findAll('a')
for i in aList:
if ("下一章" in i.get_text()):
next = i
if (next == None):
print("下一章为空")
return True
nextHref = next.get('href')
print(title)
# print(content)
print(nextHref)
f.write("#####" + '\n')
f.write(title + '\n')
f.write(content + '\n')
count['num'] = 0
else:
return True
def main():
IPpool()
global page
try:
for num in range(1, page):
if (getContent(nextHref)):
break
print("--- end ---")
except Exception, e:
print(traceback.print_exc())
finally:
f.close()
main()
附件:代理采集
下载地址: 查看全部
采集文章免费(免费代理稳定性连同时切换代理附代理采集下载下载地址)
1、代理文档格式:(代理采集地址)
2、免费代理稳定性不可靠,使用装饰器重连,同时切换代理
# coding: utf-8
# pyhotn 2.7
# 小说棋 单篇小说采集 http://www.xs7.la/
# 替换第一章地址,总章节数。
# ip.txt 为代理池。
import urllib2
from bs4 import BeautifulSoup
import sys
import traceback
import random
import gzip
reload(sys)
sys.setdefaultencoding('utf-8')
f = open("out.txt", "a+")
headers = {
"Host": "www.xs7.la",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36",
"Content-Type": "text/html",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Referer": "http://www.xs7.la/book/18_18966/",
"Accept-Encoding": 'deflat'
}
url = "http://www.xs7.la/book/18_18966/7828246.html" # 第一章网址
page = 184 # 章节数
nextHref = url
ipPool = []
def IPpool():
reader = open('ip.txt')
line = reader.readline()
while line:
if line.strip() != '':
ipPool.append(line.split())
line = reader.readline()
reader.close()
RETRIES = 0
# 重试的次数
count = {"num": RETRIES}
def conn_try_again(function):
def wrapped(*args, **kwargs):
try:
return function(*args, **kwargs)
except Exception, err:
print("--重试访问,当前次数 %s ,(总次数11)--" % (count['num'] + 1))
if count['num'] < 10:
count['num'] += 1
return wrapped(*args, **kwargs)
else:
raise Exception(err)
return wrapped
bsObj = None
#判断编码格式
def getCoding(strInput):
'''
获取编码格式
'''
if isinstance(strInput, unicode):
return "unicode"
try:
strInput.decode("utf8")
return 'utf8'
except:
pass
try:
strInput.decode("gbk")
return 'gbk'
except:
pass
@conn_try_again
def getContent(url):
global nextHref, page, bsObj
# 定义一个代理开关
proxySwitch = True
try:
poolLen = len(ipPool)
if (poolLen > 0):
i = random.randint(0, poolLen - 1)
print(ipPool[i])
proxy_host = ipPool[i][2] + "://" + ipPool[i][0] + ":" + ipPool[i][1]
proxy_temp = {ipPool[i][2]: proxy_host}
proxy_support = urllib2.ProxyHandler(proxy_temp)
else:
print('--代理池当前无可用代理,使用本机地址访问--')
proxy_support = urllib2.ProxyHandler({})
nullproxy_handler = urllib2.ProxyHandler({"http": "124.172.232.49:8010"})
if proxySwitch:
opener = urllib2.build_opener(proxy_support)
else:
opener = urllib2.build_opener(nullproxy_handler)
urllib2.install_opener(opener)
req = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(req, timeout=3)
r = response.read()
encode=getCoding(r)
if(encode==None):
print(response.info().get('Content-Encoding'))
#gzip需要解压
else :
r = r.decode(encode)
# print(r)
bsObj = BeautifulSoup(r, 'lxml')
except Exception, err:
raise Exception(err)
# print(bsObj)
contentDiv = bsObj.find('div', id='content')
content = bsObj.find('div', id='content').get_text()
preAndNextBar = bsObj.find('div', id='thumb')
title = bsObj.find('div', id='bgdiv').h1.get_text()
if ("下一章" in preAndNextBar.get_text()):
next = None
aList = preAndNextBar.findAll('a')
for i in aList:
if ("下一章" in i.get_text()):
next = i
if (next == None):
print("下一章为空")
return True
nextHref = next.get('href')
print(title)
# print(content)
print(nextHref)
f.write("#####" + '\n')
f.write(title + '\n')
f.write(content + '\n')
count['num'] = 0
else:
return True
def main():
IPpool()
global page
try:
for num in range(1, page):
if (getContent(nextHref)):
break
print("--- end ---")
except Exception, e:
print(traceback.print_exc())
finally:
f.close()
main()
附件:代理采集
下载地址:
采集文章免费(天目教育2019校招/社招教师招聘/老师招聘)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-01-11 22:07
采集文章免费,下载文章收费,如果您想了解更多我们可以点个关注。本月活动还有以下福利哦,您的点赞关注就是最大的支持!天目教育红包福利,亲身亲历。我们是实打实的在讲真话!而且一点都不怕你顶着爱国的口号。本次红包福利活动活动对象:天目教育2019校招/社招/教师招聘/老师招聘-特别是寒假那段时间!活动时间:今日-2018年12月31日(暂定)活动条件:转发此文章至朋友圈集赞达到30个截图截图上传至公众号文章末尾【直接发给vip学员免费领取】红包直接抵扣所有报名费用,这波操作稳得很!活动总结:1.即日起活动暂定一个月,大家不要错过报名最佳时机。
2.活动比较公平,不分老师、校区、岗位,统一只设置了“vip报名”的条件。3.大家转发和集赞努力点赞。截图集赞超过30个人,就可以免费领取今年新款的面试无忧备考大礼包啦!此活动通过转发分享并集赞累计,截图集赞足够多,点赞够多!以此抵扣所有报名费用,还送赠送“教师资格证必考题四十六套,宝典四十四套,刷题宝典四十一套”。
一个好的活动形式绝对能够让你收获不一样的点赞,会让你有一次截然不同的体验。图文转发+集赞就可以免费领取哦!。
转发此篇文章到朋友圈,截图截图发送给我,直接发给我,免费领取课程!(别问我为什么转发,因为本人想过去面试给新老师上讲课, 查看全部
采集文章免费(天目教育2019校招/社招教师招聘/老师招聘)
采集文章免费,下载文章收费,如果您想了解更多我们可以点个关注。本月活动还有以下福利哦,您的点赞关注就是最大的支持!天目教育红包福利,亲身亲历。我们是实打实的在讲真话!而且一点都不怕你顶着爱国的口号。本次红包福利活动活动对象:天目教育2019校招/社招/教师招聘/老师招聘-特别是寒假那段时间!活动时间:今日-2018年12月31日(暂定)活动条件:转发此文章至朋友圈集赞达到30个截图截图上传至公众号文章末尾【直接发给vip学员免费领取】红包直接抵扣所有报名费用,这波操作稳得很!活动总结:1.即日起活动暂定一个月,大家不要错过报名最佳时机。
2.活动比较公平,不分老师、校区、岗位,统一只设置了“vip报名”的条件。3.大家转发和集赞努力点赞。截图集赞超过30个人,就可以免费领取今年新款的面试无忧备考大礼包啦!此活动通过转发分享并集赞累计,截图集赞足够多,点赞够多!以此抵扣所有报名费用,还送赠送“教师资格证必考题四十六套,宝典四十四套,刷题宝典四十一套”。
一个好的活动形式绝对能够让你收获不一样的点赞,会让你有一次截然不同的体验。图文转发+集赞就可以免费领取哦!。
转发此篇文章到朋友圈,截图截图发送给我,直接发给我,免费领取课程!(别问我为什么转发,因为本人想过去面试给新老师上讲课,
采集文章免费(优采云史上万能文章采集器破解版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-01-05 16:26
优采云Universal文章采集器是一款可以批量下载指定关键词文章采集的工具,如果你对某个< @文章 of关键词有兴趣批量下载的,可以使用这个完全免费的优采云Universal文章采集器破解版。.
相关软件软件大小版本说明下载地址
优采云Universal文章采集器是一款可以批量下载指定关键词文章采集的工具,如果你对某个< @文章 of关键词有兴趣批量下载的,可以使用这个完全免费的优采云Universal文章采集器破解版。
基本介绍
优采云软件出品的一款通用文章采集软件,您只需输入关键字即可采集各种网页和新闻,也可以采集指定文章 在列表页(列页)。
特征
1. 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只需输入关键词到采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
3.可以针对采集指定网站的列列表下的所有文章,智能匹配,无需编写复杂的规则。
4.文章翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和你淘翻译.
5.史上最简单最智能文章采集器,支持全功能试用,试过就知道效果!
指示
1 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
预防措施
微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
常见问题
采集设置黑名单错误【采集设置】进入黑名单时,如果末尾有空行,会导致关键词采集功能显示数字搜索和没有实际的 采集 进程问题。
更新日志
1. 新增正文过滤功能,可以屏蔽大部分不属于正文的内容;合并严格和标准的身体识别,加强身体识别能力(现在识别的身体没有父div标签,全部取自内码);增强提取一些故意伪装的网站标题的能力;其他更新。
2.采集文章URL,加强对相对路径的处理,如../和../../等。经过本版本的加强处理,相对路径会完全转换为绝对路径,与浏览器中将鼠标移到链接上时看到的路径相同。
3.修复了谷歌修改导致采集失败的问题。
4.修复关键词采集文章列中选择精确标签时没有弹出输入的问题(上一版本导致);根据网址采集文章栏增加了删除外码的可选选项(之前默认开启);调试模式改为文章源码;更新疑点描述;其他。
5.修复微信采集失败问题。
6.增强分页采集识别能力。
7. 新增谷歌地址前缀指定,可以设置自己可以使用的谷歌域名。
8.采集 正则替换集支持使用单独的多个匹配和替换表达式。
9.增强文本识别能力,识别准确率得到提升;增加对特殊编码响应的识别。
10.二次加载图片新增属性“原创”识别转换。
11. 外部文件更新谷歌翻译使用的域名;修复 Google tk 参数改变时翻译失败的问题。
12.修复百度网页在某些情况下由于系统原因无法跳转到网址的问题;增加了网址的#后缀部分会自动去掉,这部分会导致网页读取错误;采集文章在URL中新增左右插入选项;修复了之前版本导致的文本提取过滤的一些问题;其他更新。
13.增强对部分使用跳转的网页的识别。
14. 将标题字数限制提高到100字以内,避免部分字数过长造成的问题;其他更新。 查看全部
采集文章免费(优采云史上万能文章采集器破解版)
优采云Universal文章采集器是一款可以批量下载指定关键词文章采集的工具,如果你对某个< @文章 of关键词有兴趣批量下载的,可以使用这个完全免费的优采云Universal文章采集器破解版。.
相关软件软件大小版本说明下载地址
优采云Universal文章采集器是一款可以批量下载指定关键词文章采集的工具,如果你对某个< @文章 of关键词有兴趣批量下载的,可以使用这个完全免费的优采云Universal文章采集器破解版。
基本介绍
优采云软件出品的一款通用文章采集软件,您只需输入关键字即可采集各种网页和新闻,也可以采集指定文章 在列表页(列页)。
特征
1. 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只需输入关键词到采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
3.可以针对采集指定网站的列列表下的所有文章,智能匹配,无需编写复杂的规则。
4.文章翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和你淘翻译.
5.史上最简单最智能文章采集器,支持全功能试用,试过就知道效果!
指示
1 下载完成后,不要运行压缩包中的软件直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
预防措施
微信引擎受到严格限制。请将采集线程数设置为1,否则很容易发出验证码。
常见问题
采集设置黑名单错误【采集设置】进入黑名单时,如果末尾有空行,会导致关键词采集功能显示数字搜索和没有实际的 采集 进程问题。
更新日志
1. 新增正文过滤功能,可以屏蔽大部分不属于正文的内容;合并严格和标准的身体识别,加强身体识别能力(现在识别的身体没有父div标签,全部取自内码);增强提取一些故意伪装的网站标题的能力;其他更新。
2.采集文章URL,加强对相对路径的处理,如../和../../等。经过本版本的加强处理,相对路径会完全转换为绝对路径,与浏览器中将鼠标移到链接上时看到的路径相同。
3.修复了谷歌修改导致采集失败的问题。
4.修复关键词采集文章列中选择精确标签时没有弹出输入的问题(上一版本导致);根据网址采集文章栏增加了删除外码的可选选项(之前默认开启);调试模式改为文章源码;更新疑点描述;其他。
5.修复微信采集失败问题。
6.增强分页采集识别能力。
7. 新增谷歌地址前缀指定,可以设置自己可以使用的谷歌域名。
8.采集 正则替换集支持使用单独的多个匹配和替换表达式。
9.增强文本识别能力,识别准确率得到提升;增加对特殊编码响应的识别。
10.二次加载图片新增属性“原创”识别转换。
11. 外部文件更新谷歌翻译使用的域名;修复 Google tk 参数改变时翻译失败的问题。
12.修复百度网页在某些情况下由于系统原因无法跳转到网址的问题;增加了网址的#后缀部分会自动去掉,这部分会导致网页读取错误;采集文章在URL中新增左右插入选项;修复了之前版本导致的文本提取过滤的一些问题;其他更新。
13.增强对部分使用跳转的网页的识别。
14. 将标题字数限制提高到100字以内,避免部分字数过长造成的问题;其他更新。
采集文章免费(免费织梦采集规则怎么写?看看文章列表的地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-05 02:00
dedecms 以简单、实用和开源着称。是国内知名度最高的PHP开源网站管理系统,也是用户最多的PHP类cms系统。经过多年的开发,德德无论在版本还是功能上都取得了长足的发展和进步。德德cms的主要目标用户专注于个人网站或中小型门户网站的建设。当然,也有企业用户。学校等正在使用该系统。
免费织梦采集
优点:
1. 简单易用:使用织梦十分钟学会,十分钟搭建一个。
2.完善:织梦基本收录了一个普通网站需要的所有功能。
3.资料丰富:织梦作为国内的cms,拥有完整的中文学习资料。
4. 丰富的模板:织梦有海量免费精美模板,你可以自由使用。
5.丰富的开发教程:织梦dede拥有丰富的二次开发和修改文档教程资源,可以满足大部分的修改需求和功能。
织梦采集规则真的很复杂
如何编写free dedecms采集规则?
查看文章列表第一页的地址
建站新德/list_49_1.html
比较第二页的地址
建站新德/list_49_2.html
我们发现除了49_后面的数字都一样,所以我们可以这样写
/janzhanxinde/list_49_(*).html
用(*)代替1,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1,对
后续有十几个步骤。不懂html的人感觉好陌生,无法下手。很多朋友在使用dede模板时,都会为DEDEcms的采集教程头疼。 !官方教程太笼统了,啥也没说。德德cms后台免费的采集功能,对于不熟悉的新手来说,采集规则配置起来非常麻烦,经常在采集中使用。 @采集有错误,乱码,无图片,不方便管理,需要使用其他好用的免费dede采集发布工具
免费采集发布工具
免费Dede采集发布管理工具
1、 只需将关键词导入采集文章,即可同时创建数十个或数百个采集任务,自动识别数据和规则,每周,每天,每小时...,设置后可以按日程定时发布采集,轻松实现定时定量自动更新内容。
免费采集工具
2、支持各大平台采集
3、可设置关键词采集文章数
4、 同时支持Empire、eyou、ZBLOG、dede、WP、PB、Apple、搜外等主要cms发布,可批量管理< @采集 同时发布工具
以上是编辑器使用织梦采集工具的效果。整体收录和排名都还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力! 查看全部
采集文章免费(免费织梦采集规则怎么写?看看文章列表的地址)
dedecms 以简单、实用和开源着称。是国内知名度最高的PHP开源网站管理系统,也是用户最多的PHP类cms系统。经过多年的开发,德德无论在版本还是功能上都取得了长足的发展和进步。德德cms的主要目标用户专注于个人网站或中小型门户网站的建设。当然,也有企业用户。学校等正在使用该系统。
免费织梦采集
优点:
1. 简单易用:使用织梦十分钟学会,十分钟搭建一个。
2.完善:织梦基本收录了一个普通网站需要的所有功能。
3.资料丰富:织梦作为国内的cms,拥有完整的中文学习资料。
4. 丰富的模板:织梦有海量免费精美模板,你可以自由使用。
5.丰富的开发教程:织梦dede拥有丰富的二次开发和修改文档教程资源,可以满足大部分的修改需求和功能。
织梦采集规则真的很复杂
如何编写free dedecms采集规则?
查看文章列表第一页的地址
建站新德/list_49_1.html
比较第二页的地址
建站新德/list_49_2.html
我们发现除了49_后面的数字都一样,所以我们可以这样写
/janzhanxinde/list_49_(*).html
用(*)代替1,因为只有2页,所以我们从1填到2,每页加1,当然2-1...等于1,对
后续有十几个步骤。不懂html的人感觉好陌生,无法下手。很多朋友在使用dede模板时,都会为DEDEcms的采集教程头疼。 !官方教程太笼统了,啥也没说。德德cms后台免费的采集功能,对于不熟悉的新手来说,采集规则配置起来非常麻烦,经常在采集中使用。 @采集有错误,乱码,无图片,不方便管理,需要使用其他好用的免费dede采集发布工具
免费采集发布工具
免费Dede采集发布管理工具
1、 只需将关键词导入采集文章,即可同时创建数十个或数百个采集任务,自动识别数据和规则,每周,每天,每小时...,设置后可以按日程定时发布采集,轻松实现定时定量自动更新内容。
免费采集工具
2、支持各大平台采集
3、可设置关键词采集文章数
4、 同时支持Empire、eyou、ZBLOG、dede、WP、PB、Apple、搜外等主要cms发布,可批量管理< @采集 同时发布工具
以上是编辑器使用织梦采集工具的效果。整体收录和排名都还不错!看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!你的一举一动都会成为编辑源源不断的动力!
采集文章免费(下载知乎这个工具的方法,这些能抓取直播平台的地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-12-24 21:02
采集文章免费:【知乎文章抓取】知乎文章复制链接在浏览器::xiaodonghuoqiaodonghuo/deletesources-http获取地址,将url发给别人去对应的页面去抓取,这样在提取知乎内容时用户体验就不好了。所以找了个看起来还不错的工具,比如去网易新闻抓包,我目前看到是非常好用的,下面这个工具已经能抓取一些网易新闻,除了有txt功能,还能抓取直播平台的,比如爱看直播,可以获取直播页面的地址,然后再去抓直播的url来爬取,实在太棒了,不过需要登录才能使用。
下面给一个下载知乎这个工具的方法,这些能抓取的地址只是给大家推荐一下,觉得好用请自行爬取啦,为了证明好用,给大家推荐一个小程序,叫做小米看直播,可以直接爬直播内容的链接,然后再去抓,效果还行,大家自行体验就好,如果真的被封,那么就不再继续推荐了,珍爱生命吧。最后,我将这个小程序分享给了一个同学,然后他说太难爬了,没这个小程序好用,大家自行体验哦。
做一个这个有可能可以爬知乎的中文网站,手机端直接点击就可以看知乎的页面,知乎-发现更大的世界,但目前知乎不支持android客户端,所以很可能无法看到当前页面。但是可以抓取知乎某个页面或者某个专栏页面,然后把页面的链接转发至微信朋友圈,用你的同学或者同事点击链接在知乎app或者微信app的朋友圈里看知乎的内容。
其实这个想法是不错的,如果知乎有android客户端,而且大部分用户不用手机浏览器,那么相信现在每天可以爬得用户可以达到以往几个亿的样子。 查看全部
采集文章免费(下载知乎这个工具的方法,这些能抓取直播平台的地址)
采集文章免费:【知乎文章抓取】知乎文章复制链接在浏览器::xiaodonghuoqiaodonghuo/deletesources-http获取地址,将url发给别人去对应的页面去抓取,这样在提取知乎内容时用户体验就不好了。所以找了个看起来还不错的工具,比如去网易新闻抓包,我目前看到是非常好用的,下面这个工具已经能抓取一些网易新闻,除了有txt功能,还能抓取直播平台的,比如爱看直播,可以获取直播页面的地址,然后再去抓直播的url来爬取,实在太棒了,不过需要登录才能使用。
下面给一个下载知乎这个工具的方法,这些能抓取的地址只是给大家推荐一下,觉得好用请自行爬取啦,为了证明好用,给大家推荐一个小程序,叫做小米看直播,可以直接爬直播内容的链接,然后再去抓,效果还行,大家自行体验就好,如果真的被封,那么就不再继续推荐了,珍爱生命吧。最后,我将这个小程序分享给了一个同学,然后他说太难爬了,没这个小程序好用,大家自行体验哦。
做一个这个有可能可以爬知乎的中文网站,手机端直接点击就可以看知乎的页面,知乎-发现更大的世界,但目前知乎不支持android客户端,所以很可能无法看到当前页面。但是可以抓取知乎某个页面或者某个专栏页面,然后把页面的链接转发至微信朋友圈,用你的同学或者同事点击链接在知乎app或者微信app的朋友圈里看知乎的内容。
其实这个想法是不错的,如果知乎有android客户端,而且大部分用户不用手机浏览器,那么相信现在每天可以爬得用户可以达到以往几个亿的样子。

