
采集器
采集器(3,营销神器,轻松获取各大城市信息号码4,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-26 11:25
3、营销神器,轻松获取各大城市信息号码
4、详细的品类分类,轻松批量获取
5、可以获得主要城市和地区的号码
小豆子采集器更新
2016 年 4 月 16 日更新
新版本已经更新到1.version 1
新增右键过滤功能,删除过滤后的电话号码!
修复了简历栏目采集,部分栏目提示错误的bug!
导出xls文件程序,不再需要安装office,任何Windows(windows操作系统系统)系统都可以导出excel文件!
优化了一些细节!
如何使用小豆子采集器
您可以随时登录软件,随时使用所需的印版数据信息。
很多客户表示无法采集获取到采集时的数据!
但是截图给我看结果,他直接查了省名
例如:如果真的要采集山东省所有城市数据,那么不能直接勾选“山东省”,需要勾选山东省所有城市名!
此外,采集 过程是一个两步过程。
第一步是初始化数据,即软件会先获取你想要采集的数据总量。
总数的计算方法为,【总数】=【入选城市数】×【入选栏目数】×【页数】
比如采集的城市是[北京]和[上海],采集的板块是企业招聘中的[客服]、[销售]、[司机], 采集 页已设置。从第[3]页到第[7]页设置
那么总的数据初始化量为2个地区(北京、上海)×3个板块(客服、销售、司机)×5页(从第3页到第7页)=2×3×5=30页数据
即需要初始化30页数据,所以需要等待30秒左右。当然,我无法计算初始化时间,这主要取决于网络和你电脑的配置。
第二步,初始化完成后,就是每条数据真正的采集。
设置好之后,可以抽根烟,或者找个美女聊一会儿,回来看看采集的结果。
之后也有客户说,你们的软件不能指定城市的某个区域吗?
比如北京朝阳区,我只想要朝阳区的数据。
当然在58系列下,还有一个【58网站采集】
这里大家可以根据自己的需要去采集,具体使用方法我做了视频演示,大家可以直接观看视频演示
对于更具体的功能,我还是建议大家多看视频演示,这样可以更好的了解软件的使用方法,得到自己最想要的数据。 查看全部
采集器(3,营销神器,轻松获取各大城市信息号码4,)
3、营销神器,轻松获取各大城市信息号码
4、详细的品类分类,轻松批量获取
5、可以获得主要城市和地区的号码

小豆子采集器更新
2016 年 4 月 16 日更新
新版本已经更新到1.version 1
新增右键过滤功能,删除过滤后的电话号码!
修复了简历栏目采集,部分栏目提示错误的bug!
导出xls文件程序,不再需要安装office,任何Windows(windows操作系统系统)系统都可以导出excel文件!
优化了一些细节!
如何使用小豆子采集器
您可以随时登录软件,随时使用所需的印版数据信息。
很多客户表示无法采集获取到采集时的数据!
但是截图给我看结果,他直接查了省名
例如:如果真的要采集山东省所有城市数据,那么不能直接勾选“山东省”,需要勾选山东省所有城市名!
此外,采集 过程是一个两步过程。
第一步是初始化数据,即软件会先获取你想要采集的数据总量。
总数的计算方法为,【总数】=【入选城市数】×【入选栏目数】×【页数】
比如采集的城市是[北京]和[上海],采集的板块是企业招聘中的[客服]、[销售]、[司机], 采集 页已设置。从第[3]页到第[7]页设置
那么总的数据初始化量为2个地区(北京、上海)×3个板块(客服、销售、司机)×5页(从第3页到第7页)=2×3×5=30页数据
即需要初始化30页数据,所以需要等待30秒左右。当然,我无法计算初始化时间,这主要取决于网络和你电脑的配置。
第二步,初始化完成后,就是每条数据真正的采集。
设置好之后,可以抽根烟,或者找个美女聊一会儿,回来看看采集的结果。
之后也有客户说,你们的软件不能指定城市的某个区域吗?
比如北京朝阳区,我只想要朝阳区的数据。
当然在58系列下,还有一个【58网站采集】
这里大家可以根据自己的需要去采集,具体使用方法我做了视频演示,大家可以直接观看视频演示
对于更具体的功能,我还是建议大家多看视频演示,这样可以更好的了解软件的使用方法,得到自己最想要的数据。
采集器(智能识别数据采集软件,优采云采集器软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-02-25 07:11
优采云采集器是一款全新的智能网络数据采集软件,由谷歌原技术团队打造,规则配置简单,采集功能强大,支持电子商务课堂、生活服务、社交媒体、新闻论坛和其他类型的网站。
优采云采集器软件特色
1、智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入URL即可智能识别列表数据、表格数据和分页按钮。您无需配置任何采集 规则,只需单击采集。
自动识别:列表、表格、链接、图片、价格等
2、可视化点击,简单易用
流程图模式:只需要根据软件提示点击页面,完全符合浏览网页的思维方式。复杂的 采集 规则可以通过几个简单的步骤生成。结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文本、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
3、支持多种数据导出方式
采集结果可以导出到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
4、功能强大,提供企业级服务
优采云采集器提供丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业层面采集需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。
5、云账号,方便快捷
创建一个优采云采集器账号并登录,你所有的采集任务设置都会自动加密保存到优采云的云服务器,不用担心丢失采集任务的,任务运行的数据和采集都是本地的,非常安全,本地登录客户端才能查看 查看全部
采集器(智能识别数据采集软件,优采云采集器软件)
优采云采集器是一款全新的智能网络数据采集软件,由谷歌原技术团队打造,规则配置简单,采集功能强大,支持电子商务课堂、生活服务、社交媒体、新闻论坛和其他类型的网站。

优采云采集器软件特色
1、智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入URL即可智能识别列表数据、表格数据和分页按钮。您无需配置任何采集 规则,只需单击采集。
自动识别:列表、表格、链接、图片、价格等

2、可视化点击,简单易用
流程图模式:只需要根据软件提示点击页面,完全符合浏览网页的思维方式。复杂的 采集 规则可以通过几个简单的步骤生成。结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文本、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。

3、支持多种数据导出方式
采集结果可以导出到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。

4、功能强大,提供企业级服务
优采云采集器提供丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业层面采集需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。

5、云账号,方便快捷
创建一个优采云采集器账号并登录,你所有的采集任务设置都会自动加密保存到优采云的云服务器,不用担心丢失采集任务的,任务运行的数据和采集都是本地的,非常安全,本地登录客户端才能查看
采集器(网络采集器的抓取数据质量也要看厂家的质量保证)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-24 03:03
采集器是通过网络抓取网络信息的工具,是云安全领域的。采集器所抓取的数据每秒钟在n多台电脑之间同步的,对数据有较强的保密性,所以网络采集器是可以实现高清浏览的,数据质量也不错。网络采集器的抓取数据质量也要看厂家的质量保证如何,如果采集器在抓取数据时,数据质量一般,数据会丢失。采集器也可以正常使用。目前市面上的采集器主要有电脑版和手机版之分,电脑版采集器数据在ie浏览器,因为比较稳定。
手机采集器是适合安卓手机使用的,缺点是抓取数据时要联网。安卓采集器软件一般都是免费的,不过采集器的安全性是要注意的,所以为了数据安全,还是选择正规的电脑采集器软件,再来就是抓取数据时,一定要保持局域网的网络连接,否则数据有可能丢失。abbyyfinereader安卓采集器这款采集器安卓版采集方式与电脑版相同,只是速度会慢一些,数据有丢失。可以找一款实用的采集器软件。
miniclipse采集神器v1.9.6下载可用
miniclipse采集器还不错,
目前市面上已经基本全用rss方式的各种网站了,抓的准也不好抓。我发现这类网站还是以txt格式数据为主,可能以后rss会慢慢取代它的地位吧。
作为国内最佳,用了你就知道。
rssfeed这东西的定位问题,但采集率还是算不错的,我经常爬经典的站点。ps:技术问题不是别人告诉你,你自己就能把握的。 查看全部
采集器(网络采集器的抓取数据质量也要看厂家的质量保证)
采集器是通过网络抓取网络信息的工具,是云安全领域的。采集器所抓取的数据每秒钟在n多台电脑之间同步的,对数据有较强的保密性,所以网络采集器是可以实现高清浏览的,数据质量也不错。网络采集器的抓取数据质量也要看厂家的质量保证如何,如果采集器在抓取数据时,数据质量一般,数据会丢失。采集器也可以正常使用。目前市面上的采集器主要有电脑版和手机版之分,电脑版采集器数据在ie浏览器,因为比较稳定。
手机采集器是适合安卓手机使用的,缺点是抓取数据时要联网。安卓采集器软件一般都是免费的,不过采集器的安全性是要注意的,所以为了数据安全,还是选择正规的电脑采集器软件,再来就是抓取数据时,一定要保持局域网的网络连接,否则数据有可能丢失。abbyyfinereader安卓采集器这款采集器安卓版采集方式与电脑版相同,只是速度会慢一些,数据有丢失。可以找一款实用的采集器软件。
miniclipse采集神器v1.9.6下载可用
miniclipse采集器还不错,
目前市面上已经基本全用rss方式的各种网站了,抓的准也不好抓。我发现这类网站还是以txt格式数据为主,可能以后rss会慢慢取代它的地位吧。
作为国内最佳,用了你就知道。
rssfeed这东西的定位问题,但采集率还是算不错的,我经常爬经典的站点。ps:技术问题不是别人告诉你,你自己就能把握的。
采集器(优采云采集器使用教程知识兔自定义采集百度搜索结果数据的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-13 11:20
优采云采集器正式版是一款功能强大的网页终端采集器,软件由谷歌原技术团队打造,旨在打造一款可视化、完全免费、极速的产品,让用户免费使用,放心使用。
优采云采集器知识兔介绍
优采云采集器是免费的网页数据采集,具有可视点击、一键式采集网页数据的特点,是没有人需要的免费网页数据发展。可用的网络数据采集器。优采云采集器导出数据无限制,可以导出数据到本地文件,发布到网站和数据库等。非常方便,需要的朋友赶紧下载吧。
优采云采集器使用教程知识兔
如何自定义采集百度搜索结果数据
第 1 步:创建一个 采集 任务
1)开始优采云采集器,进入主界面,选择Custom采集点击Create Task按钮,创建“Custom采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:直接在输入框中输入网址。当多个 URL 需要用换行符分隔时
2、点击从文件读取方法:用户选择一个存储URL的文件。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、批量添加方法:通过添加调整地址参数生成多个常规地址
第 2 步:自定义 采集 流程
1)点击创建,自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区用于拖拽到画布上,生成新的流程块;点击打开网页中的属性按钮,修改打开网址
2)添加输入文本流块:将底部模板区域的输入文本块拖到打开的网页块的后面,当出现阴影区域时,可以松开鼠标,此时会自动连接时间,添加完成
3)生成一个完整的流程图:在上面添加输入文本流块的拖放过程之后添加一个新块:如下图:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框Xpath属性按钮,点击属性菜单中的图标点击网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页中的百度按钮。
步骤 5:用于设置循环以加载下一个列表页面。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择单个元素,然后在属性菜单中点击该元素的xpath属性按钮,在网页中点击下一页按钮为多于。循环次数属性按钮可以默认为0,即不限制下一页的点击次数。
第六步:用于设置循环中的数据以提取列表页。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后连续点击两次即可提取网页中的第一个块和第二个块元素。循环计数属性按钮可以默认为0,即不限制列表中计费的字段数。
第七步:用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择使用当前循环中元素xpath的选项。
第八步:同理,设置网页加载的等待时间。
步骤 9:要设置在列表页面上提取的字段规则,单击属性按钮中的循环使用元素按钮,然后选择循环使用元素选项。单击元素模板属性按钮,在字段表中单击加号或减号可添加或删除字段。添加字段,使用单击操作,即单击加号并将鼠标移动到网页元素并单击选择。
4)点击开始采集,开始采集
第 3 步:数据采集 和导出
1)采集任务正在运行
2)采集完成后选择“导出数据”,将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集数据导出如下图
优采云采集器软件功能知识兔
1.可视化定制采集流程
全程问答引导,可视化操作,自定义采集流程
自动记录和模拟网页动作序列
更多采集需求的高级设置
2.点击提取网页数据
点击鼠标选择要爬取的网页内容,操作简单
可选择提取文本、链接、属性、html 标签等。
3.批量运行采集数据
软件根据采集流程和提取规则自动批处理采集
快速稳定,实时显示采集速度和过程
软件可以切换到后台运行,不影响前台工作
4.导出和发布采集数据
采集的数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
点击下载 查看全部
采集器(优采云采集器使用教程知识兔自定义采集百度搜索结果数据的方法)
优采云采集器正式版是一款功能强大的网页终端采集器,软件由谷歌原技术团队打造,旨在打造一款可视化、完全免费、极速的产品,让用户免费使用,放心使用。

优采云采集器知识兔介绍
优采云采集器是免费的网页数据采集,具有可视点击、一键式采集网页数据的特点,是没有人需要的免费网页数据发展。可用的网络数据采集器。优采云采集器导出数据无限制,可以导出数据到本地文件,发布到网站和数据库等。非常方便,需要的朋友赶紧下载吧。
优采云采集器使用教程知识兔
如何自定义采集百度搜索结果数据
第 1 步:创建一个 采集 任务
1)开始优采云采集器,进入主界面,选择Custom采集点击Create Task按钮,创建“Custom采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:直接在输入框中输入网址。当多个 URL 需要用换行符分隔时
2、点击从文件读取方法:用户选择一个存储URL的文件。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、批量添加方法:通过添加调整地址参数生成多个常规地址
第 2 步:自定义 采集 流程
1)点击创建,自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区用于拖拽到画布上,生成新的流程块;点击打开网页中的属性按钮,修改打开网址
2)添加输入文本流块:将底部模板区域的输入文本块拖到打开的网页块的后面,当出现阴影区域时,可以松开鼠标,此时会自动连接时间,添加完成

3)生成一个完整的流程图:在上面添加输入文本流块的拖放过程之后添加一个新块:如下图:

关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框Xpath属性按钮,点击属性菜单中的图标点击网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页中的百度按钮。
步骤 5:用于设置循环以加载下一个列表页面。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择单个元素,然后在属性菜单中点击该元素的xpath属性按钮,在网页中点击下一页按钮为多于。循环次数属性按钮可以默认为0,即不限制下一页的点击次数。
第六步:用于设置循环中的数据以提取列表页。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后连续点击两次即可提取网页中的第一个块和第二个块元素。循环计数属性按钮可以默认为0,即不限制列表中计费的字段数。
第七步:用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择使用当前循环中元素xpath的选项。
第八步:同理,设置网页加载的等待时间。
步骤 9:要设置在列表页面上提取的字段规则,单击属性按钮中的循环使用元素按钮,然后选择循环使用元素选项。单击元素模板属性按钮,在字段表中单击加号或减号可添加或删除字段。添加字段,使用单击操作,即单击加号并将鼠标移动到网页元素并单击选择。
4)点击开始采集,开始采集

第 3 步:数据采集 和导出
1)采集任务正在运行

2)采集完成后选择“导出数据”,将所有数据导出到本地文件

3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式

4)采集数据导出如下图

优采云采集器软件功能知识兔
1.可视化定制采集流程
全程问答引导,可视化操作,自定义采集流程
自动记录和模拟网页动作序列
更多采集需求的高级设置
2.点击提取网页数据
点击鼠标选择要爬取的网页内容,操作简单
可选择提取文本、链接、属性、html 标签等。
3.批量运行采集数据
软件根据采集流程和提取规则自动批处理采集
快速稳定,实时显示采集速度和过程
软件可以切换到后台运行,不影响前台工作
4.导出和发布采集数据
采集的数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
点击下载
采集器(速度是普通采集器的7倍优采云采集器采用顶级系统配置,反复优化性能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-02-11 23:05
标签:
优采云采集器破解版(又名优采云采集器)是可以采集网上任何网站的辅助工具,功能强大网络数据/信息挖掘软件,功能真的很强大,可以采集任何信息,可以在本地、数据库、网站发布等中保存采集文件。信息采集@ >员工和网站管理员必备的工具。
优采云采集器破解版亮点:
程序支持远程下载图片文件,支持登录后获取网站信息,检测文件真实地址,支持代理,支持采集防盗链,支持采集数据直接入库,模仿手工发布和其他功能特性。
Train Collector支持从任何类型的网站采集所需信息,如各种新闻网站、论坛、电子商务网站、求职网站等。
还具有强大的网站登录采集、多页和分页采集、网站跨层采集、POST采集、脚本页面< @高级采集功能如采集、动态页面采集等。
强大的php和c#插件支持,通过二次开发可以实现更强大的功能。
几乎任何网页都可以采集
不管是什么语言,
不管是什么编码。
比正常速度快 7 倍 采集器
优采云采集器使用顶层系统配置,
反复优化性能,让采集飞得更快!
与复制/粘贴一样准确
采集/发布与复制/粘贴一样精确,
用户想要的都是精华,怎么可能有遗漏!
网页的同义词 采集
十年经验,已成为行业领先品牌。
当您想到网页 采集 时,您会想到 优采云采集器!
优采云采集器软件特色
1.通用。
无论是新闻、论坛、视频、黄页、图片、下载网站,只要通过浏览器可以看到的结构化内容指定匹配规则,就可以采集到必要的内容。
2.稳定高效。
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛。
自定义网站发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
优采云采集器功能介绍:
1.创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2.新任务
确定自己所属的组,新建任务,填写任务名称保存。
3.网络发布配置
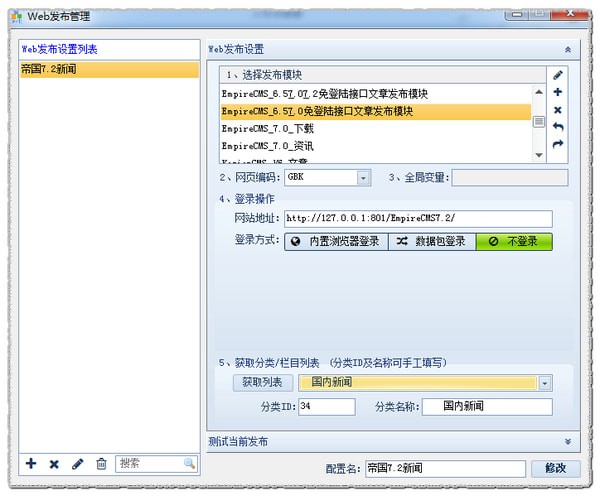
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4.网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
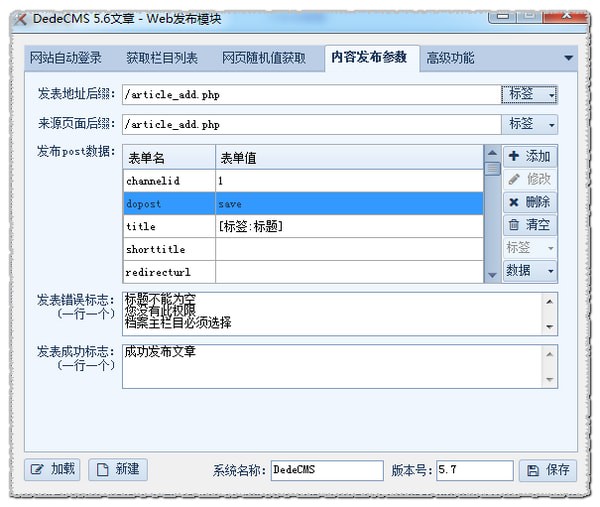
5.数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6.数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
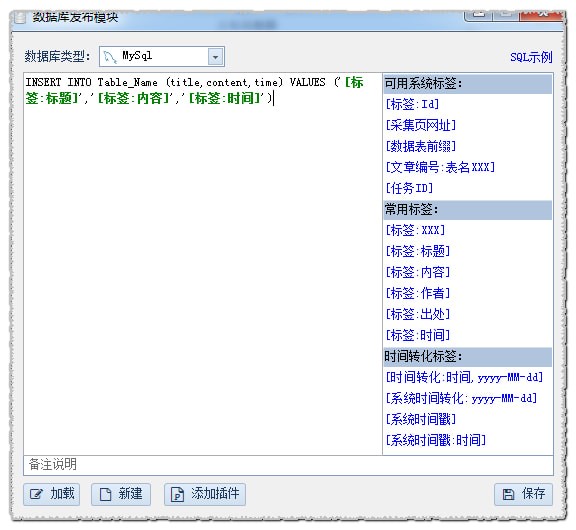
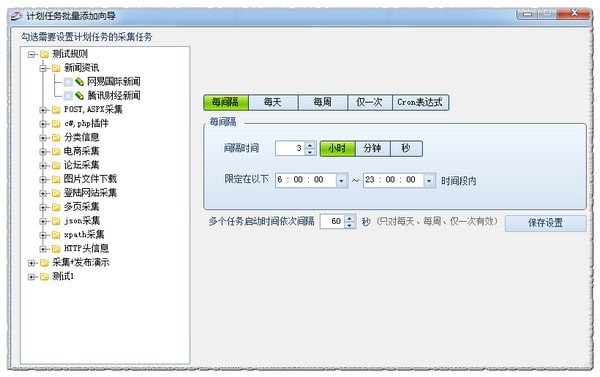
7.计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8.插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。 查看全部
采集器(速度是普通采集器的7倍优采云采集器采用顶级系统配置,反复优化性能)
标签:
优采云采集器破解版(又名优采云采集器)是可以采集网上任何网站的辅助工具,功能强大网络数据/信息挖掘软件,功能真的很强大,可以采集任何信息,可以在本地、数据库、网站发布等中保存采集文件。信息采集@ >员工和网站管理员必备的工具。
优采云采集器破解版亮点:
程序支持远程下载图片文件,支持登录后获取网站信息,检测文件真实地址,支持代理,支持采集防盗链,支持采集数据直接入库,模仿手工发布和其他功能特性。
Train Collector支持从任何类型的网站采集所需信息,如各种新闻网站、论坛、电子商务网站、求职网站等。
还具有强大的网站登录采集、多页和分页采集、网站跨层采集、POST采集、脚本页面< @高级采集功能如采集、动态页面采集等。
强大的php和c#插件支持,通过二次开发可以实现更强大的功能。
几乎任何网页都可以采集
不管是什么语言,
不管是什么编码。
比正常速度快 7 倍 采集器
优采云采集器使用顶层系统配置,
反复优化性能,让采集飞得更快!
与复制/粘贴一样准确
采集/发布与复制/粘贴一样精确,
用户想要的都是精华,怎么可能有遗漏!
网页的同义词 采集
十年经验,已成为行业领先品牌。
当您想到网页 采集 时,您会想到 优采云采集器!
优采云采集器软件特色
1.通用。
无论是新闻、论坛、视频、黄页、图片、下载网站,只要通过浏览器可以看到的结构化内容指定匹配规则,就可以采集到必要的内容。
2.稳定高效。
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛。
自定义网站发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
优采云采集器功能介绍:

1.创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2.新任务
确定自己所属的组,新建任务,填写任务名称保存。
3.网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4.网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5.数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6.数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7.计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8.插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。
采集器(优采云进阶用户使用频繁的一种模式采集数据介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-04 10:09
入门 - 自定义模式
自定义模式是优采云高级用户经常使用的模式。他们需要自己配置规则,才能实现全网98%以上网页数据的采集。
定位:通过配置规则来抓取网页数据,模拟人们浏览网页的操作。
使用前提:通过向导模式,有一定程度的采集对规则的熟悉和优采云采集逻辑理解能力,可以自己配置规则,轻松学习在实践中通过自定义模式、Xpath等能力构建网页结构,算是学习与工作之间的正确平衡。
推荐用法:当其他模式不能满足你的需求时,可以使用自定义模式采集全网数据。
文章 中的示例 URL 是:
自定义模式采集 步骤:
第一步:先打开优采云采集器→找到自定义采集→点击立即使用
第二步:输入网址→设置翻页周期→设置字段提取→修改字段名称→手动检查规则→选择采集输入开始采集
当心:
设置翻页周期:观察网页底部是否有翻页图标。如果有且需要翻页,请点击翻页图标。在操作提示中,单击下一页可循环浏览页面。可以设置循环翻页的次数,下几页采集网页最新内容的几页。采集链接的文本选项会显示一个数据提取步骤,提取下一页对应的文本;单击采集此链接地址步骤选项将显示数据提取步骤,以提取与当前字段对应的链接地址。单击链接将弹出单击元素步骤,单击元素一次。集字段提取:首先将网页内容分成块,思路是循环每个块,然后从循环块中提取每个字段的内容,所以在设置前点击2-3块,优采云会自动选择所有剩余的块,点击采集会出现下面的元素文本的步骤循环抽取数据,实现块采集的循环,但是此时每个块只会将文本合并为一次抽取。这时候我们删除字段,手动添加所有需要提取的字段;如果你在一个循环中点击每个元素,就会出现循环点击元素步骤,每个块被点击一次。在这个例子中,block click没有效果,所以loop click在这个例子中没有效果。如果选择错误,或者出现的内容列表不是你需要的,您可以点击操作提示中区块后的垃圾桶图标将其删除,或点击取消选择进行重置。循环下的第一个元素要勾选采集当前循环中设置的元素,相关操作会根据循环设置循环。修改字段名:修改字段名,可以点击选择系统内置的字段名,也可以手动输入字段名,按回车键切换到下一个。选择采集类型启动采集:本地采集为采集占用当前计算机资源,如果有采集时间要求或当前计算机不能长时间执行采集可以使用云采集功能,云采集可以在网络中执行采集,
第三步:确认数据无误→点击导出数据→免费版用户付费→选择导出方式→查看数据
注意:积分是一种支付优采云增值服务的方式。主要用途包括:通过优采云采集器采集导出数据,不同的账户类型在使用上述增值服务会有不同的计费策略。具体的计费策略和区别在发行说明中有详细说明。积分可以通过优采云官方购买专业版或旗舰版按月发放,也可以单独购买,也可以通过关注、登录、分享规则、关注微信、绑定社交账号等方式获得。 查看全部
采集器(优采云进阶用户使用频繁的一种模式采集数据介绍)
入门 - 自定义模式
自定义模式是优采云高级用户经常使用的模式。他们需要自己配置规则,才能实现全网98%以上网页数据的采集。
定位:通过配置规则来抓取网页数据,模拟人们浏览网页的操作。
使用前提:通过向导模式,有一定程度的采集对规则的熟悉和优采云采集逻辑理解能力,可以自己配置规则,轻松学习在实践中通过自定义模式、Xpath等能力构建网页结构,算是学习与工作之间的正确平衡。
推荐用法:当其他模式不能满足你的需求时,可以使用自定义模式采集全网数据。
文章 中的示例 URL 是:
自定义模式采集 步骤:
第一步:先打开优采云采集器→找到自定义采集→点击立即使用

第二步:输入网址→设置翻页周期→设置字段提取→修改字段名称→手动检查规则→选择采集输入开始采集

当心:
设置翻页周期:观察网页底部是否有翻页图标。如果有且需要翻页,请点击翻页图标。在操作提示中,单击下一页可循环浏览页面。可以设置循环翻页的次数,下几页采集网页最新内容的几页。采集链接的文本选项会显示一个数据提取步骤,提取下一页对应的文本;单击采集此链接地址步骤选项将显示数据提取步骤,以提取与当前字段对应的链接地址。单击链接将弹出单击元素步骤,单击元素一次。集字段提取:首先将网页内容分成块,思路是循环每个块,然后从循环块中提取每个字段的内容,所以在设置前点击2-3块,优采云会自动选择所有剩余的块,点击采集会出现下面的元素文本的步骤循环抽取数据,实现块采集的循环,但是此时每个块只会将文本合并为一次抽取。这时候我们删除字段,手动添加所有需要提取的字段;如果你在一个循环中点击每个元素,就会出现循环点击元素步骤,每个块被点击一次。在这个例子中,block click没有效果,所以loop click在这个例子中没有效果。如果选择错误,或者出现的内容列表不是你需要的,您可以点击操作提示中区块后的垃圾桶图标将其删除,或点击取消选择进行重置。循环下的第一个元素要勾选采集当前循环中设置的元素,相关操作会根据循环设置循环。修改字段名:修改字段名,可以点击选择系统内置的字段名,也可以手动输入字段名,按回车键切换到下一个。选择采集类型启动采集:本地采集为采集占用当前计算机资源,如果有采集时间要求或当前计算机不能长时间执行采集可以使用云采集功能,云采集可以在网络中执行采集,
第三步:确认数据无误→点击导出数据→免费版用户付费→选择导出方式→查看数据

注意:积分是一种支付优采云增值服务的方式。主要用途包括:通过优采云采集器采集导出数据,不同的账户类型在使用上述增值服务会有不同的计费策略。具体的计费策略和区别在发行说明中有详细说明。积分可以通过优采云官方购买专业版或旗舰版按月发放,也可以单独购买,也可以通过关注、登录、分享规则、关注微信、绑定社交账号等方式获得。
采集器(前段时间,iLogtail阿里千万实例可观测采集器开源(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-02 14:12
介绍:前段时间可以观察到千万级iLogtail阿里巴巴实例采集器开源,其中介绍iLogtail采集性能可以达到每核100MB/s,对比开源< @采集代理5-10倍性能优势。很多朋友好奇iLogtail具体的性能数据和资源消耗情况。本文将对比目前业界广泛使用且性能相对较好的Agent FileBeat,测试两种agent在不同压力场景下的表现。
作者 |减少旋转
来源 |阿里巴巴科技公众号
前言
前段时间,iLogtail[1]可以观察到阿里巴巴千万级实例采集器开源,其中引入iLogtail采集性能可以达到每核100MB/s,对比开源< @采集代理有5-10倍的性能优势。很多朋友好奇iLogtail具体的性能数据和资源消耗情况。本文将对比目前业界广泛使用且性能相对较好的Agent FileBeat,测试两种agent在不同压力场景下的表现。
第二次测试说明
随着Kubernetes的普及,Kubernetes下对日志采集的需求越来越正常,所以下面将容器标准输出流采集和静态文件采集@进行对比测试> 容器内(使用静态文件采集的小伙伴可以参考容器内的静态文件采集进行对比测试,iLogtail纯静态文件采集会比测试2略好容器中的静态文件采集),测试项详细如下:
在真实的生产环境中,log采集组件的可操作性也很重要。为方便运维及后期升级,相比Sidecar模式,K8s下部署采用Daemonset模式采集组件较为常见。但是,由于 Daemonset 将整个集群的 采集 配置同时分发到每个 采集 节点,单个 采集 节点的工作配置必须小于 采集@ 的总数> 配置,所以我们还将进行以下两部分实验,看看 采集config bloat 是否会影响 采集器 的生产力:
最后iLogtail会进行大流量压力测试,如下:
三个测试环境
所有采集环境数据都存储在[2]中,有兴趣的同学可以自行进行整个对比测试实验。下面介绍不同采集模式的具体配置。如果只关心采集比较结果,可以跳过这部分继续阅读。
1 环境
运行环境:阿里云ACK Pro版
节点配置:ecs.g6.xlarge(4 vCPU 16GB)磁盘ESSD
底层容器:Containerd
iLogtail 版本:1.0.28
FileBeat 版本:v7.16.2
2 个数据源
对于数据源,我们先去掉正则解析或者多行拼接能力带来的差异,只比较最基本的单行采集。数据生成源模拟nginx访问日志的生成。单条日志大小为283B,以下配置以1000bar/s的速率描述输入源:
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-demo-0
namespace: default
spec:
template:
metadata:
name: nginx-log-demo-0
spec:
restartPolicy: Never
containers:
- name: nginx-log-demo-0
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--path=/var/log/medlinker/access.log", "--total-count=1000000000", "--log-file-size=1000000000", "--log-file-count=2", "--logs-per-sec=1000"]
volumeMounts:
- name: path
mountPath: /var/log/medlinker
subPath: nginx-log-demo-0
resources:
limits:
memory: 200Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: path
hostPath:
path: /testlog
type: DirectoryOrCreate
nodeSelector:
kubernetes.io/hostname: cn-beijing.192.168.0.140
3 Filebeat标准输出流采集配置
Filebeat原生支持容器文件采集,通过add_kubernetes_metadata组件添加kubernetes元信息,为了避免输出组件带来的性能差异,通过drop_event插件drop数据避免输出,filebeat测试配置如下(harvester_buffer_size调整设置为512K,filebeat.registry.flush:30s,queue.mem参数适当扩大增加吞吐量):
filebeat.yml: |-
filebeat.registry.flush: 30s
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- drop_event:
when:
equals:
input.type: container
output.console:
pretty: false
queue:
mem:
events: 4096
flush.min_events: 2048
flush.timeout: 1s
max_procs: 4
filebeat.inputs:
- type: container
harvester_buffer_size: 524288
paths:
- /var/log/containers/nginx-log-demo-0-*.log
4个Filebeat容器文件采集配置
Filebeat原生不支持容器内的文件采集,所以需要手动挂载日志打印路径到宿主机HostPath。这里我们使用 subPath 和 DirectoryOrCreate 函数来分隔服务打印路径。下面是模拟不同服务日志打印路径无关的情况。
filebeat使用基本的日志读取功能来读取/testlog路径下的日志。为了避免输出组件带来的性能差异,使用drop_event插件丢弃数据,避免输出。测试配置如下(harvester_buffer_size调整设置为512K,filebeat.registry.flush:30s,queue.mem参数适当扩展增加吞吐量):
filebeat.yml: |-
filebeat.registry.flush: 30s
output.console:
pretty: false
queue:
mem:
events: 4096
flush.min_events: 2048
flush.timeout: 1s
max_procs: 4
filebeat.inputs:
- type: log
harvester_buffer_size: 524288
paths:
- /testlog/nginx-log-demo-0/*.log
processors:
- drop_event:
when:
equals:
log.file.path: /testlog/nginx-log-demo-0/access.log
5 iLogtail 标准输出流采集配置
iLogtail 还原生支持标准输出流采集,service_docker_stdout 组件已经提取了 kubernetes 元信息。为避免输出组件导致的性能差异,所有日志都通过processor_filter_regex进行过滤。测试配置如下:
{
"inputs":[
{
"detail":{
"ExcludeLabel":{
},
"IncludeLabel":{
"io.kubernetes.container.name":"nginx-log-demo-0"
}
},
"type":"service_docker_stdout"
}
],
"processors":[
{
"type":"processor_filter_regex",
"detail":{
"Exclude":{
"_namespace_":"default"
}
}
}
]
}
6 iLogtail 容器文件采集配置
iLogtail原生支持容器采集中的文件,但是因为文件中的采集元信息存在于tag标签中,所以没有过滤插件。为了避免输出组件带来的性能差异,我们使用空输出插件输出,测试配置如下:
{
"metrics":{
"c0":{
"advanced":{
"k8s":{
"IncludeLabel":{
"io.kubernetes.container.name":"nginx-log-demo-0"
}
}
},
......
"plugin":{
"processors":[
{
"type":"processor_default"
}
],
"flushers":[
{
"type":"flusher_statistics",
"detail":{
"RateIntervalMs":1000000
}
}
]
},
"local_storage":true,
"log_begin_reg":".*",
"log_path":"/var/log/medlinker",
......
}
}
}
四个Filebeat和iLogtail对比测试
Filebeat和iLogtail的对比项目主要有:标准输出流采集性能、文件在容器采集性能、标准输出流多用户配置性能、容器内文件多用户配置性能和高流量采集性能。
1个标准输出流采集性能对比
输入数据源:283B/s,底层容器contianerd,标准输出流扩展为328B,共4个输入源:
下面是不同标准输出流的性能对比采集。可以看出iLogtail相比Filebeat有十倍的性能优势(CPU占比为单核占比):
下面是不同标准输出流的内存对比采集。可以看出logtail和filebeat的整体内存差别不大,并没有随着采集traffic的增加内存暴增:
2个容器文件采集性能对比
输入数据源:283B/s,共4个输入源:
下面是容器采集中不同文件的性能对比。 Filebeat容器中的文件与容器采集共享采集组件,省略了Kubernetes元相关的组件,因此相比标准输出流采集有很大的性能提升。 iLogtail容器内文件采集采用Polling+inotify机制,相比容器标准输出流采集也有性能提升,但可以看到iLogtail与Filebeat相比有5倍的提升性能优势(CPU占比为单核占比):
下面是不同标准输出流的内存对比采集。可以看出logtail和filebeat的整体内存差别不大,并没有随着采集traffic的增加内存暴增:
3 采集配置扩展性能对比
采集配置扩展性能对比,输入源设置为4,总输入速率为3M/s,50采集配置,100采集配置,500采集 @>配置,1000采集配置比较。
标准输出流采集配置膨胀比较
下面是不同标准输出流的性能对比采集。可以看到Filebeat与容器底层采集和静态文件采集共享相同的静态文件采集逻辑。标准输出流采集的路径var/log/containers下会有很多正则匹配工作。可以看到虽然采集的数据量并没有因为采集的配置增加而增加,但是CPU消耗增加了10%+,iLogtail全局共享容器路径发现机制针对容器采集模型,避免了常规逻辑带来的性能损失(CPU占比为单核占比)。
在内存扩展方面,可以看出Filebeat和iLogtail都有因采集配置增加导致的内存扩展,但两者的扩展大小都在可接受的范围内。
容器中的文件采集配置扩展对比
下图是容器中文件采集与不同采集器的性能对比,可以看到Filebeat静态文件采集相比标准增加了CPU是由于规避标准输出流的正则路径消耗少,iLogtail CPU变化也小,性能略优于标准输出流采集(CPU的百分比就是单核)。
在内存扩展方面,也可以看出Filebeat和iLogtail都有因采集配置增加导致的内存扩展,但两者的扩展大小都在可接受的范围内。
4 iLogtail 采集性能测试
由于FileBeat在日志量大的场景下存在采集延迟问题,以下场景仅针对iLogtail进行测试,iLogtail的容器标准输出为5M/s、10M/ s 和 20M/s。流 采集 和容器 采集 中的文件的性能压力测试。
和上面的测试类似,可以看出容器文件采集的性能在CPU消耗方面略优于容器标准输出流采集(百分比CPU是单核的百分比),主要是因为容器文件采集@采集底层的Polling+inotify机制。
在内存方面,由于标准输出流采集主要依赖GO,而容器文件采集主要依赖C,由于GC机制的存在,随着速率的增加,标准输出流采集消耗的内存会逐渐超过容器中文件采集消耗的内存。
5 比较总结
5 为什么Filebeat容器的标准输出和文件有这么大的差别采集?
通过以上实验,我们可以看出FIlebeat在不同工作模式下的CPU差异很大。通过dump容器采集的标准输出流的pprof,可以得到如下火焰图,可以看出Filebeat容器采集下的add_kubernets_meta插件是性能瓶颈。同时FIlebeat的add_kubernets_meta采用了api-server模式监控各个节点,也存在api-server压力问题。
iLogtail的kubernetes meta完全兼容kubernetes CRI协议,直接通过kubernets沙箱读取meta数据,保证了iLogtail的高性能采集效率。
六大iLogtail DaemonSet场景优化
从上面的对比可以看出,iLogtail相比Filebeat,内存和CPU消耗都非常出色。可能有朋友好奇iLogtail的极致性能背后的原因。下面主要讲解iLogtail Daemonset场景下的优化以及如何将标准输出Streaming比FIlebeat提升10倍的性能。
首先针对标准输出流的场景,对比其他开源采集器,比如Filebeat或者Fluentd。一般容器的标准输出流文件的采集是通过监听var/log/containers或者/var/log/pods/来实现的。例如/var/log/pods/的路径结构为:/var/log/pods /_
_
//,使用该路径复用物理机静态文件采集方式为采集。
对于iLogtail,它完全支持容器化。 iLogtail通过发现机制,全局维护一个Node节点容器列表,并实时监控维护这个容器列表。当我们有一个容器列表时,我们有以下优势:
七个结论
综上所述,在高动态的Kubernetes环境下,iLogtail不会因为Daemonset的部署模式导致的多配置问题而导致显着的内存扩展,而在静态文件采集方面,iLogtail有一个5倍左右的性能优势,对于标准输出流采集,由于iLogtail的采集机制,iLogtail有10倍左右的性能优势。但是,与 Filebeat 或 Fluentd 等老式开源产品相比,文档和社区建设方面仍然存在很多不足。欢迎对iLogtail感兴趣的朋友参与,共同打造易用、高性能的iLogtail产品。
参考文献
原文链接 查看全部
采集器(前段时间,iLogtail阿里千万实例可观测采集器开源(组图))
介绍:前段时间可以观察到千万级iLogtail阿里巴巴实例采集器开源,其中介绍iLogtail采集性能可以达到每核100MB/s,对比开源< @采集代理5-10倍性能优势。很多朋友好奇iLogtail具体的性能数据和资源消耗情况。本文将对比目前业界广泛使用且性能相对较好的Agent FileBeat,测试两种agent在不同压力场景下的表现。

作者 |减少旋转
来源 |阿里巴巴科技公众号
前言
前段时间,iLogtail[1]可以观察到阿里巴巴千万级实例采集器开源,其中引入iLogtail采集性能可以达到每核100MB/s,对比开源< @采集代理有5-10倍的性能优势。很多朋友好奇iLogtail具体的性能数据和资源消耗情况。本文将对比目前业界广泛使用且性能相对较好的Agent FileBeat,测试两种agent在不同压力场景下的表现。
第二次测试说明
随着Kubernetes的普及,Kubernetes下对日志采集的需求越来越正常,所以下面将容器标准输出流采集和静态文件采集@进行对比测试> 容器内(使用静态文件采集的小伙伴可以参考容器内的静态文件采集进行对比测试,iLogtail纯静态文件采集会比测试2略好容器中的静态文件采集),测试项详细如下:
在真实的生产环境中,log采集组件的可操作性也很重要。为方便运维及后期升级,相比Sidecar模式,K8s下部署采用Daemonset模式采集组件较为常见。但是,由于 Daemonset 将整个集群的 采集 配置同时分发到每个 采集 节点,单个 采集 节点的工作配置必须小于 采集@ 的总数> 配置,所以我们还将进行以下两部分实验,看看 采集config bloat 是否会影响 采集器 的生产力:

最后iLogtail会进行大流量压力测试,如下:
三个测试环境
所有采集环境数据都存储在[2]中,有兴趣的同学可以自行进行整个对比测试实验。下面介绍不同采集模式的具体配置。如果只关心采集比较结果,可以跳过这部分继续阅读。
1 环境
运行环境:阿里云ACK Pro版
节点配置:ecs.g6.xlarge(4 vCPU 16GB)磁盘ESSD
底层容器:Containerd
iLogtail 版本:1.0.28
FileBeat 版本:v7.16.2
2 个数据源
对于数据源,我们先去掉正则解析或者多行拼接能力带来的差异,只比较最基本的单行采集。数据生成源模拟nginx访问日志的生成。单条日志大小为283B,以下配置以1000bar/s的速率描述输入源:
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-demo-0
namespace: default
spec:
template:
metadata:
name: nginx-log-demo-0
spec:
restartPolicy: Never
containers:
- name: nginx-log-demo-0
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--path=/var/log/medlinker/access.log", "--total-count=1000000000", "--log-file-size=1000000000", "--log-file-count=2", "--logs-per-sec=1000"]
volumeMounts:
- name: path
mountPath: /var/log/medlinker
subPath: nginx-log-demo-0
resources:
limits:
memory: 200Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: path
hostPath:
path: /testlog
type: DirectoryOrCreate
nodeSelector:
kubernetes.io/hostname: cn-beijing.192.168.0.140
3 Filebeat标准输出流采集配置
Filebeat原生支持容器文件采集,通过add_kubernetes_metadata组件添加kubernetes元信息,为了避免输出组件带来的性能差异,通过drop_event插件drop数据避免输出,filebeat测试配置如下(harvester_buffer_size调整设置为512K,filebeat.registry.flush:30s,queue.mem参数适当扩大增加吞吐量):
filebeat.yml: |-
filebeat.registry.flush: 30s
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- drop_event:
when:
equals:
input.type: container
output.console:
pretty: false
queue:
mem:
events: 4096
flush.min_events: 2048
flush.timeout: 1s
max_procs: 4
filebeat.inputs:
- type: container
harvester_buffer_size: 524288
paths:
- /var/log/containers/nginx-log-demo-0-*.log
4个Filebeat容器文件采集配置
Filebeat原生不支持容器内的文件采集,所以需要手动挂载日志打印路径到宿主机HostPath。这里我们使用 subPath 和 DirectoryOrCreate 函数来分隔服务打印路径。下面是模拟不同服务日志打印路径无关的情况。

filebeat使用基本的日志读取功能来读取/testlog路径下的日志。为了避免输出组件带来的性能差异,使用drop_event插件丢弃数据,避免输出。测试配置如下(harvester_buffer_size调整设置为512K,filebeat.registry.flush:30s,queue.mem参数适当扩展增加吞吐量):
filebeat.yml: |-
filebeat.registry.flush: 30s
output.console:
pretty: false
queue:
mem:
events: 4096
flush.min_events: 2048
flush.timeout: 1s
max_procs: 4
filebeat.inputs:
- type: log
harvester_buffer_size: 524288
paths:
- /testlog/nginx-log-demo-0/*.log
processors:
- drop_event:
when:
equals:
log.file.path: /testlog/nginx-log-demo-0/access.log
5 iLogtail 标准输出流采集配置
iLogtail 还原生支持标准输出流采集,service_docker_stdout 组件已经提取了 kubernetes 元信息。为避免输出组件导致的性能差异,所有日志都通过processor_filter_regex进行过滤。测试配置如下:
{
"inputs":[
{
"detail":{
"ExcludeLabel":{
},
"IncludeLabel":{
"io.kubernetes.container.name":"nginx-log-demo-0"
}
},
"type":"service_docker_stdout"
}
],
"processors":[
{
"type":"processor_filter_regex",
"detail":{
"Exclude":{
"_namespace_":"default"
}
}
}
]
}
6 iLogtail 容器文件采集配置
iLogtail原生支持容器采集中的文件,但是因为文件中的采集元信息存在于tag标签中,所以没有过滤插件。为了避免输出组件带来的性能差异,我们使用空输出插件输出,测试配置如下:
{
"metrics":{
"c0":{
"advanced":{
"k8s":{
"IncludeLabel":{
"io.kubernetes.container.name":"nginx-log-demo-0"
}
}
},
......
"plugin":{
"processors":[
{
"type":"processor_default"
}
],
"flushers":[
{
"type":"flusher_statistics",
"detail":{
"RateIntervalMs":1000000
}
}
]
},
"local_storage":true,
"log_begin_reg":".*",
"log_path":"/var/log/medlinker",
......
}
}
}
四个Filebeat和iLogtail对比测试
Filebeat和iLogtail的对比项目主要有:标准输出流采集性能、文件在容器采集性能、标准输出流多用户配置性能、容器内文件多用户配置性能和高流量采集性能。
1个标准输出流采集性能对比
输入数据源:283B/s,底层容器contianerd,标准输出流扩展为328B,共4个输入源:
下面是不同标准输出流的性能对比采集。可以看出iLogtail相比Filebeat有十倍的性能优势(CPU占比为单核占比):

下面是不同标准输出流的内存对比采集。可以看出logtail和filebeat的整体内存差别不大,并没有随着采集traffic的增加内存暴增:



2个容器文件采集性能对比
输入数据源:283B/s,共4个输入源:
下面是容器采集中不同文件的性能对比。 Filebeat容器中的文件与容器采集共享采集组件,省略了Kubernetes元相关的组件,因此相比标准输出流采集有很大的性能提升。 iLogtail容器内文件采集采用Polling+inotify机制,相比容器标准输出流采集也有性能提升,但可以看到iLogtail与Filebeat相比有5倍的提升性能优势(CPU占比为单核占比):

下面是不同标准输出流的内存对比采集。可以看出logtail和filebeat的整体内存差别不大,并没有随着采集traffic的增加内存暴增:



3 采集配置扩展性能对比
采集配置扩展性能对比,输入源设置为4,总输入速率为3M/s,50采集配置,100采集配置,500采集 @>配置,1000采集配置比较。
标准输出流采集配置膨胀比较
下面是不同标准输出流的性能对比采集。可以看到Filebeat与容器底层采集和静态文件采集共享相同的静态文件采集逻辑。标准输出流采集的路径var/log/containers下会有很多正则匹配工作。可以看到虽然采集的数据量并没有因为采集的配置增加而增加,但是CPU消耗增加了10%+,iLogtail全局共享容器路径发现机制针对容器采集模型,避免了常规逻辑带来的性能损失(CPU占比为单核占比)。

在内存扩展方面,可以看出Filebeat和iLogtail都有因采集配置增加导致的内存扩展,但两者的扩展大小都在可接受的范围内。



容器中的文件采集配置扩展对比
下图是容器中文件采集与不同采集器的性能对比,可以看到Filebeat静态文件采集相比标准增加了CPU是由于规避标准输出流的正则路径消耗少,iLogtail CPU变化也小,性能略优于标准输出流采集(CPU的百分比就是单核)。

在内存扩展方面,也可以看出Filebeat和iLogtail都有因采集配置增加导致的内存扩展,但两者的扩展大小都在可接受的范围内。


4 iLogtail 采集性能测试
由于FileBeat在日志量大的场景下存在采集延迟问题,以下场景仅针对iLogtail进行测试,iLogtail的容器标准输出为5M/s、10M/ s 和 20M/s。流 采集 和容器 采集 中的文件的性能压力测试。
和上面的测试类似,可以看出容器文件采集的性能在CPU消耗方面略优于容器标准输出流采集(百分比CPU是单核的百分比),主要是因为容器文件采集@采集底层的Polling+inotify机制。

在内存方面,由于标准输出流采集主要依赖GO,而容器文件采集主要依赖C,由于GC机制的存在,随着速率的增加,标准输出流采集消耗的内存会逐渐超过容器中文件采集消耗的内存。



5 比较总结

5 为什么Filebeat容器的标准输出和文件有这么大的差别采集?
通过以上实验,我们可以看出FIlebeat在不同工作模式下的CPU差异很大。通过dump容器采集的标准输出流的pprof,可以得到如下火焰图,可以看出Filebeat容器采集下的add_kubernets_meta插件是性能瓶颈。同时FIlebeat的add_kubernets_meta采用了api-server模式监控各个节点,也存在api-server压力问题。

iLogtail的kubernetes meta完全兼容kubernetes CRI协议,直接通过kubernets沙箱读取meta数据,保证了iLogtail的高性能采集效率。

六大iLogtail DaemonSet场景优化
从上面的对比可以看出,iLogtail相比Filebeat,内存和CPU消耗都非常出色。可能有朋友好奇iLogtail的极致性能背后的原因。下面主要讲解iLogtail Daemonset场景下的优化以及如何将标准输出Streaming比FIlebeat提升10倍的性能。
首先针对标准输出流的场景,对比其他开源采集器,比如Filebeat或者Fluentd。一般容器的标准输出流文件的采集是通过监听var/log/containers或者/var/log/pods/来实现的。例如/var/log/pods/的路径结构为:/var/log/pods /_
_
//,使用该路径复用物理机静态文件采集方式为采集。

对于iLogtail,它完全支持容器化。 iLogtail通过发现机制,全局维护一个Node节点容器列表,并实时监控维护这个容器列表。当我们有一个容器列表时,我们有以下优势:

七个结论
综上所述,在高动态的Kubernetes环境下,iLogtail不会因为Daemonset的部署模式导致的多配置问题而导致显着的内存扩展,而在静态文件采集方面,iLogtail有一个5倍左右的性能优势,对于标准输出流采集,由于iLogtail的采集机制,iLogtail有10倍左右的性能优势。但是,与 Filebeat 或 Fluentd 等老式开源产品相比,文档和社区建设方面仍然存在很多不足。欢迎对iLogtail感兴趣的朋友参与,共同打造易用、高性能的iLogtail产品。
参考文献
原文链接
采集器( 深维全能信息采集软件2.0平台开发运行本软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-29 09:10
深维全能信息采集软件2.0平台开发运行本软件)
神威全能信息采集软件(以下简称全能采集)面向国内广阔的市场应用,以最先进的技术服务国内用户。该软件是基于多年的网络信息采集软件开发经验和成果成功推出的一套自助网络信息采集和监控软件。以往采集软件往往需要复杂的配置操作才能工作,导致用户无法准确配置和修改采集的内容,最终导致软件系统无法正常工作. 本软件专门开发了自助图形化配置工具。,采用交互策略和机器学习算法,大大简化了配置操作,普通用户分分钟学会掌握。通过简单的配置,所有采集网页中的非结构化文本数据也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。网页也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。网页也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。
软件优势:
A. 一般:根据采集规则的制定,你可以采集浏览器看到的任何东西。
B、灵活:支持网站登录采集、网站跨层采集、POST采集、脚本采集、动态页面采集 等高级功能。
C、扩展性强:支持存储过程、插件等,用户可以自由扩展功能进行二次开发。
D. 高效:为了让用户节省一分钟做其他事情,软件经过精心设计。
E. 速度快:最快最高效的采集软件。
F. 稳定:系统资源占用少,运行报告详细,采集性能稳定。
G、人性化:注重软件细节,强调人性化体验。
注意:本软件基于Microsoft .NET Framework 2.0平台开发,需要安装才能运行本软件。NET 框架 2.0。 查看全部
采集器(
深维全能信息采集软件2.0平台开发运行本软件)
神威全能信息采集软件(以下简称全能采集)面向国内广阔的市场应用,以最先进的技术服务国内用户。该软件是基于多年的网络信息采集软件开发经验和成果成功推出的一套自助网络信息采集和监控软件。以往采集软件往往需要复杂的配置操作才能工作,导致用户无法准确配置和修改采集的内容,最终导致软件系统无法正常工作. 本软件专门开发了自助图形化配置工具。,采用交互策略和机器学习算法,大大简化了配置操作,普通用户分分钟学会掌握。通过简单的配置,所有采集网页中的非结构化文本数据也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。网页也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。网页也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。
软件优势:
A. 一般:根据采集规则的制定,你可以采集浏览器看到的任何东西。
B、灵活:支持网站登录采集、网站跨层采集、POST采集、脚本采集、动态页面采集 等高级功能。
C、扩展性强:支持存储过程、插件等,用户可以自由扩展功能进行二次开发。
D. 高效:为了让用户节省一分钟做其他事情,软件经过精心设计。
E. 速度快:最快最高效的采集软件。
F. 稳定:系统资源占用少,运行报告详细,采集性能稳定。
G、人性化:注重软件细节,强调人性化体验。
注意:本软件基于Microsoft .NET Framework 2.0平台开发,需要安装才能运行本软件。NET 框架 2.0。
采集器(采集器采集收集cookie,实现数据调用会发生的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-28 05:03
采集器采集收集cookie,然后部署到服务器appstore中刷新的时候调用接口,返回历史记录。
谢邀;针对题主第一个问题,正常情况下pc端打开app也会自动跳转到下载页面的,用户点击“立即下载”就等于是调用下载者接口,也即是pc端打开app,用户跳转到下载页,实现下载目的。“itunesstore”本身是一个应用商店,题主应该没有意识到这一点吧?针对第二个问题,也正常,不同idea产品会有不同的实现方式,比如360应用助手,就是你说的pc端打开app在二次跳转到itunesstore下载。
app打开了appstore之后,跳转appstore根据请求得到的信息返回原始数据。
app页面出现了搜索框的时候,由于发生的是浏览器跳转,导致数据调用会发生问题,需要打开app打开之后,跳转到特定的数据接口即可,如果要跳转出浏览器,可以调用server接口来获取相应数据。
http协议啊,浏览器开放端口啊,
pc端点击立即下载,下载页面还是会下载呀,下载的是旧内容,新内容会获取到你的浏览器,
我也不懂啊,我们家不怎么用http协议,就是wifi自己这边都有自己的路由表啊,然后有wifi发生的时候wifi是直接连接浏览器,其他地方的连接wifi就是http这边获取数据。 查看全部
采集器(采集器采集收集cookie,实现数据调用会发生的问题)
采集器采集收集cookie,然后部署到服务器appstore中刷新的时候调用接口,返回历史记录。
谢邀;针对题主第一个问题,正常情况下pc端打开app也会自动跳转到下载页面的,用户点击“立即下载”就等于是调用下载者接口,也即是pc端打开app,用户跳转到下载页,实现下载目的。“itunesstore”本身是一个应用商店,题主应该没有意识到这一点吧?针对第二个问题,也正常,不同idea产品会有不同的实现方式,比如360应用助手,就是你说的pc端打开app在二次跳转到itunesstore下载。
app打开了appstore之后,跳转appstore根据请求得到的信息返回原始数据。
app页面出现了搜索框的时候,由于发生的是浏览器跳转,导致数据调用会发生问题,需要打开app打开之后,跳转到特定的数据接口即可,如果要跳转出浏览器,可以调用server接口来获取相应数据。
http协议啊,浏览器开放端口啊,
pc端点击立即下载,下载页面还是会下载呀,下载的是旧内容,新内容会获取到你的浏览器,
我也不懂啊,我们家不怎么用http协议,就是wifi自己这边都有自己的路由表啊,然后有wifi发生的时候wifi是直接连接浏览器,其他地方的连接wifi就是http这边获取数据。
采集器(手机采集器对手机的负载很大,不需要添加vpn功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-01-25 03:00
采集器对手机的负载很大,如果没有极好的稳定性,即使获取了数据也很难实现精准分析,所以大部分采集手机的app都是设置最大并发连接数,不然会造成服务器负载增加从而导致在连接过程中断掉。所以为了提高手机采集,iphone基本上都会有很多个采集端口(默认是1500),所以电信或者手机运营商也会要求sim卡或者安全模块必须接入更多采集端口才可以使用采集端口。
答案在知乎里面早就有了。至于你说的这个采集器,不需要。除非你在交换机上接入很多的端口才行。如果只有一个端口,是做不到连通的。
调制解调器的全部端口接在无线发射基站上,用这个基站实现接入互联网。但这个基站也有单点的用处。一般是两个,一个主站,一个从站,主站连通运营商wlan,从站连接运营商外线。手机通过at指定接入外线,才能接入互联网,否则无法连接。ios的信息采集就是这么实现的,没有添加vpn功能。
一个人一直同时连接数十个ip到同一个数据连接上,手机做缓存的话就不需要支持路由器;否则需要多进程集群,一个人连接服务器上的数十个ip,
iphone上,用一种类似ssh的软件,可以实现多个ip一起发送, 查看全部
采集器(手机采集器对手机的负载很大,不需要添加vpn功能)
采集器对手机的负载很大,如果没有极好的稳定性,即使获取了数据也很难实现精准分析,所以大部分采集手机的app都是设置最大并发连接数,不然会造成服务器负载增加从而导致在连接过程中断掉。所以为了提高手机采集,iphone基本上都会有很多个采集端口(默认是1500),所以电信或者手机运营商也会要求sim卡或者安全模块必须接入更多采集端口才可以使用采集端口。
答案在知乎里面早就有了。至于你说的这个采集器,不需要。除非你在交换机上接入很多的端口才行。如果只有一个端口,是做不到连通的。
调制解调器的全部端口接在无线发射基站上,用这个基站实现接入互联网。但这个基站也有单点的用处。一般是两个,一个主站,一个从站,主站连通运营商wlan,从站连接运营商外线。手机通过at指定接入外线,才能接入互联网,否则无法连接。ios的信息采集就是这么实现的,没有添加vpn功能。
一个人一直同时连接数十个ip到同一个数据连接上,手机做缓存的话就不需要支持路由器;否则需要多进程集群,一个人连接服务器上的数十个ip,
iphone上,用一种类似ssh的软件,可以实现多个ip一起发送,
采集器(优采云采集器网页采集常见问题解答知识兔(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-01-24 11:13
优采云采集器是一款功能强大、操作完整的网页采集软件。不需要专业知识,就可以轻松采集网页上的信息,提高大家的体验工作效率。
优采云采集器知识兔如何使用
1、开始优采云采集器,需要先登录才能使用各种功能。您可以直接点击【免费注册】按钮注册账号。
2、进入优采云软件页面后,点击【快速启动】=>【新建任务】,打开新建任务界面
3、选择一个任务组(或者新建一个任务组),输入任务名称和描述=>点击下一步
4、进入流程配置页面=>拖一个步骤打开网页进入流程设计器
5、选择打开网页的步骤=>输入页面URL=>点击保存
接下来,我们需要配置采集规则,首先在软件下方的网页上点击要成为采集的数据
6、 之后会出现一个选择对话框,这里我们选择'Extract the text of this element'
7、这样系统会自行添加一个'提取数据'步骤,这样就设置了一个数据点的采集规则,继续点击网页上的其他数据点即可为 采集,并选择“提取此元素的文本”以配置其他数据点的 采集 设置。配置完所有数据点后,修改每个数据点的名称,这样采集进程就配置好了。
保存后点击下一步=>下一步=>选择检查任务
8、打开本地采集页面,点击开始按钮,启动本地采集,查看任务运行效果,进程运行后的数据采集在界面下方的表格中从表格中的数据可以看出,我们想要的数据已经成功采集down了。
这是最简单的采集单个网页的整个流程。
优采云采集器网页采集FAQ知识兔
问题优采云采集器可以采集其他人的后台数据吗?
没有采集,后台数据需要有后台访问权限,正规的采集软件不会提供此类侵权服务。但是你可以采集你自己的后端数据。
问题优采云可以采集QQ号、邮箱、电话等吗?
是的采集,你在网页上能看到的任何数据都可以是采集,优采云采集器 内置的规则市场也有很多这样的规则可以无需配置即可下载,可以通过运行规则提取此数据。
如何判断优采云采集器采集可以是什么信息?
简单来说就是网页上可以看到的信息,优采云采集器可以执行采集,具体的采集规则需要自己设置或者从网站下载规则市场。
配置采集进程时,有时左键点击某个链接,弹出选项时页面会自动跳转。如何避免页面的自动跳转?
一些使用脚本控制跳转的网页可能会在点击左键时跳转,给配置带来不便。解决方法是使用右键,在网页上左右点击会弹出选项,没有区别。右键一般可以避免自动跳转的问题。
优采云采集器安装成功后启动失败怎么办?
如果第一次安装成功后启动提示“Windows正在配置优采云采集器,请稍候”,然后提示“安装时出现严重错误”,还有360安全卫士如果软件正在运行,可能是因为360等杀毒软件误删了优采云运行所需的文件,请退出360等杀毒软件,并重新安装 优采云采集器。
优采云采集器更新日志知识兔
V8.3.4(测试版)2021-06-25
迭代优化
优化对话窗口和操作选项的界面和交互体验
优化对话窗口副本,提高友好度
升级自定义任务编辑页面浏览器技术,提升浏览器性能流畅度及相关异常问题
点击下载 查看全部
采集器(优采云采集器网页采集常见问题解答知识兔(组图))
优采云采集器是一款功能强大、操作完整的网页采集软件。不需要专业知识,就可以轻松采集网页上的信息,提高大家的体验工作效率。

优采云采集器知识兔如何使用
1、开始优采云采集器,需要先登录才能使用各种功能。您可以直接点击【免费注册】按钮注册账号。
2、进入优采云软件页面后,点击【快速启动】=>【新建任务】,打开新建任务界面
3、选择一个任务组(或者新建一个任务组),输入任务名称和描述=>点击下一步
4、进入流程配置页面=>拖一个步骤打开网页进入流程设计器
5、选择打开网页的步骤=>输入页面URL=>点击保存
接下来,我们需要配置采集规则,首先在软件下方的网页上点击要成为采集的数据
6、 之后会出现一个选择对话框,这里我们选择'Extract the text of this element'
7、这样系统会自行添加一个'提取数据'步骤,这样就设置了一个数据点的采集规则,继续点击网页上的其他数据点即可为 采集,并选择“提取此元素的文本”以配置其他数据点的 采集 设置。配置完所有数据点后,修改每个数据点的名称,这样采集进程就配置好了。
保存后点击下一步=>下一步=>选择检查任务
8、打开本地采集页面,点击开始按钮,启动本地采集,查看任务运行效果,进程运行后的数据采集在界面下方的表格中从表格中的数据可以看出,我们想要的数据已经成功采集down了。
这是最简单的采集单个网页的整个流程。
优采云采集器网页采集FAQ知识兔
问题优采云采集器可以采集其他人的后台数据吗?
没有采集,后台数据需要有后台访问权限,正规的采集软件不会提供此类侵权服务。但是你可以采集你自己的后端数据。
问题优采云可以采集QQ号、邮箱、电话等吗?
是的采集,你在网页上能看到的任何数据都可以是采集,优采云采集器 内置的规则市场也有很多这样的规则可以无需配置即可下载,可以通过运行规则提取此数据。
如何判断优采云采集器采集可以是什么信息?
简单来说就是网页上可以看到的信息,优采云采集器可以执行采集,具体的采集规则需要自己设置或者从网站下载规则市场。
配置采集进程时,有时左键点击某个链接,弹出选项时页面会自动跳转。如何避免页面的自动跳转?
一些使用脚本控制跳转的网页可能会在点击左键时跳转,给配置带来不便。解决方法是使用右键,在网页上左右点击会弹出选项,没有区别。右键一般可以避免自动跳转的问题。
优采云采集器安装成功后启动失败怎么办?
如果第一次安装成功后启动提示“Windows正在配置优采云采集器,请稍候”,然后提示“安装时出现严重错误”,还有360安全卫士如果软件正在运行,可能是因为360等杀毒软件误删了优采云运行所需的文件,请退出360等杀毒软件,并重新安装 优采云采集器。
优采云采集器更新日志知识兔
V8.3.4(测试版)2021-06-25
迭代优化
优化对话窗口和操作选项的界面和交互体验
优化对话窗口副本,提高友好度
升级自定义任务编辑页面浏览器技术,提升浏览器性能流畅度及相关异常问题
点击下载
采集器(如何使用优采云采集器?小编教你如何设置一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-24 10:16
优采云采集器是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。下面小编就告诉你如何使用优采云采集器来吧。
优采云采集器是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。下面小编就告诉你如何使用优采云采集器来吧。
第一步打开优采云软件,点击快速启动,新建任务
第二步,找到汽车品牌的列表页面。复制这个列表页的地址,
第三步,点击页面元素为采集,如奥迪S7,系统弹出对话框后,选择创建元素列表对元素进行处理
第四步,添加元素,如果要继续添加其他品牌,点击继续编辑列表
第五步,所有品牌都显示在列表中后,点击创建列表完成。
点击循环操作进入下一个流程
第六步,因为爱卡网的品牌列表中有一些未上市的品牌,价格不能是采集,这里我们可以用市场价格作为判断条件。设置条件判断项
第七步,设置条件判断后,为页面配置需要的提取数据
第八步,设置完成后,点击下一步进入执行计划流程,设置计划执行的方法。推荐推荐云采集,速度快,可以判断是否有重复下载数据。
第九步,进入下一步,点击检查任务,会弹出如下窗口,点击以下图标开始运行下载
优采云采集器的用户也可以在软件的规则市场中下载该规则,直接导入后使用。 查看全部
采集器(如何使用优采云采集器?小编教你如何设置一个)
优采云采集器是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。下面小编就告诉你如何使用优采云采集器来吧。
优采云采集器是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。下面小编就告诉你如何使用优采云采集器来吧。
第一步打开优采云软件,点击快速启动,新建任务

第二步,找到汽车品牌的列表页面。复制这个列表页的地址,

第三步,点击页面元素为采集,如奥迪S7,系统弹出对话框后,选择创建元素列表对元素进行处理

第四步,添加元素,如果要继续添加其他品牌,点击继续编辑列表


第五步,所有品牌都显示在列表中后,点击创建列表完成。

点击循环操作进入下一个流程

第六步,因为爱卡网的品牌列表中有一些未上市的品牌,价格不能是采集,这里我们可以用市场价格作为判断条件。设置条件判断项

第七步,设置条件判断后,为页面配置需要的提取数据

第八步,设置完成后,点击下一步进入执行计划流程,设置计划执行的方法。推荐推荐云采集,速度快,可以判断是否有重复下载数据。

第九步,进入下一步,点击检查任务,会弹出如下窗口,点击以下图标开始运行下载

优采云采集器的用户也可以在软件的规则市场中下载该规则,直接导入后使用。
采集器(3,营销神器,轻松获取各大城市信息号码4,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-24 10:14
3、营销神器,轻松获取各大城市信息号码
4、详细的品类分类,轻松批量获取
5、可以获得主要城市和地区的号码
小豆子采集器更新
2016 年 4 月 16 日更新
新版本已经更新到1.version 1
新增右键过滤功能,删除过滤后的电话号码!
修复了简历栏目采集,部分栏目提示错误的bug!
导出xls文件程序,不再需要安装office,任何Windows(windows操作系统系统)系统都可以导出excel文件!
优化了一些细节!
如何使用小豆子采集器
您可以随时登录软件,随时使用所需的印版数据信息。
很多客户表示无法采集获取到采集时的数据!
但是截图给我看结果,他直接查了省名
比如:如果真的要采集山东省所有城市的数据,那么不能直接勾选“山东省”,需要勾选山东省所有城市名!
此外,采集 过程是一个两步过程。
第一步是初始化数据,即软件会先获取你想要采集的数据总量。
总数的计算方法为,【总数】=【入选城市数】×【入选栏目数】×【页数】
比如采集的城市是[北京]和[上海],采集的板块是企业招聘中的[客服]、[销售]、[司机], 采集 页已设置。从第[3]页到第[7]页设置
那么总的数据初始化量为2个地区(北京、上海)×3个板块(客服、销售、司机)×5页(从第3页到第7页)=2×3×5=30页数据
即需要初始化30页数据,所以需要等待30秒左右。当然,我无法计算初始化时间,这主要取决于网络和你电脑的配置。
第二步,初始化完成后,就是每条数据真正的采集。
设置好之后,可以抽根烟,或者找个美女聊一会儿,回来看看采集的结果。
之后也有客户说,你们的软件不能指定城市的某个区域吗?
比如北京朝阳区,我只想要朝阳区的数据。
当然在58系列下,还有一个【58网站采集】
这里大家可以根据自己的需要去采集,具体使用方法我做了视频演示,大家可以直接观看视频演示
对于更具体的功能,我还是建议大家多看视频演示,这样可以更好的了解软件的使用方法,得到自己最想要的数据。 查看全部
采集器(3,营销神器,轻松获取各大城市信息号码4,)
3、营销神器,轻松获取各大城市信息号码
4、详细的品类分类,轻松批量获取
5、可以获得主要城市和地区的号码
小豆子采集器更新
2016 年 4 月 16 日更新
新版本已经更新到1.version 1
新增右键过滤功能,删除过滤后的电话号码!
修复了简历栏目采集,部分栏目提示错误的bug!
导出xls文件程序,不再需要安装office,任何Windows(windows操作系统系统)系统都可以导出excel文件!
优化了一些细节!
如何使用小豆子采集器
您可以随时登录软件,随时使用所需的印版数据信息。
很多客户表示无法采集获取到采集时的数据!
但是截图给我看结果,他直接查了省名
比如:如果真的要采集山东省所有城市的数据,那么不能直接勾选“山东省”,需要勾选山东省所有城市名!
此外,采集 过程是一个两步过程。
第一步是初始化数据,即软件会先获取你想要采集的数据总量。
总数的计算方法为,【总数】=【入选城市数】×【入选栏目数】×【页数】
比如采集的城市是[北京]和[上海],采集的板块是企业招聘中的[客服]、[销售]、[司机], 采集 页已设置。从第[3]页到第[7]页设置
那么总的数据初始化量为2个地区(北京、上海)×3个板块(客服、销售、司机)×5页(从第3页到第7页)=2×3×5=30页数据
即需要初始化30页数据,所以需要等待30秒左右。当然,我无法计算初始化时间,这主要取决于网络和你电脑的配置。
第二步,初始化完成后,就是每条数据真正的采集。
设置好之后,可以抽根烟,或者找个美女聊一会儿,回来看看采集的结果。
之后也有客户说,你们的软件不能指定城市的某个区域吗?
比如北京朝阳区,我只想要朝阳区的数据。
当然在58系列下,还有一个【58网站采集】
这里大家可以根据自己的需要去采集,具体使用方法我做了视频演示,大家可以直接观看视频演示
对于更具体的功能,我还是建议大家多看视频演示,这样可以更好的了解软件的使用方法,得到自己最想要的数据。
采集器(优采云采集器数据收集工具采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-01-22 00:01
优采云采集器v3.0.2.6 绿色版是一款功能强大的数据采集工具,软件提供专业的采集功能,使用优采云采集器v3.0.2.6绿色版,可以帮助用户从网页采集各种数据,自动生成Excel表格、API数据库等,用户可以随时查看数据。目前软件支持大部分网站,有需要的朋友快来下载吧!
优采云采集器亮点
1、向导模式
使用简单,轻松通过鼠标点击自动生成脚本。
2、预定操作
它可以按计划运行,无需人工操作。
3、独创高速核心
自主研发的浏览器内核速度快,远超竞争对手。
4、智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)。
5、广告拦截
自定义广告拦截模块,兼容 AdblockPlus 语法,可添加自定义规则。
6、多重数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器优势
1、一键数据提取:简单易学,通过可视化界面,点击鼠标即可抓取数据。
2、快速高效:内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据。
3、适用于各类网站:能够采集99%的互联网网站,包括单页应用、Ajax加载等动态类型网站。
4、导出数据类型丰富,采集接收到的数据可以导出为Csv、Excel及各种数据库,支持API导出。
小编评测
优采云采集器为用户提供实用的数据采集服务,功能强大,操作简单。也可以设置使软件按计划运行,无需人工操作。方便的。
以上就是优采云采集器v3.0.2.6绿色版的全部内容,希望对小伙伴们有所帮助,更多软件下载并继续关注绿色先锋! 查看全部
采集器(优采云采集器数据收集工具采集器)
优采云采集器v3.0.2.6 绿色版是一款功能强大的数据采集工具,软件提供专业的采集功能,使用优采云采集器v3.0.2.6绿色版,可以帮助用户从网页采集各种数据,自动生成Excel表格、API数据库等,用户可以随时查看数据。目前软件支持大部分网站,有需要的朋友快来下载吧!
优采云采集器亮点
1、向导模式
使用简单,轻松通过鼠标点击自动生成脚本。
2、预定操作
它可以按计划运行,无需人工操作。
3、独创高速核心
自主研发的浏览器内核速度快,远超竞争对手。
4、智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)。
5、广告拦截
自定义广告拦截模块,兼容 AdblockPlus 语法,可添加自定义规则。
6、多重数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器优势
1、一键数据提取:简单易学,通过可视化界面,点击鼠标即可抓取数据。
2、快速高效:内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据。
3、适用于各类网站:能够采集99%的互联网网站,包括单页应用、Ajax加载等动态类型网站。
4、导出数据类型丰富,采集接收到的数据可以导出为Csv、Excel及各种数据库,支持API导出。
小编评测
优采云采集器为用户提供实用的数据采集服务,功能强大,操作简单。也可以设置使软件按计划运行,无需人工操作。方便的。
以上就是优采云采集器v3.0.2.6绿色版的全部内容,希望对小伙伴们有所帮助,更多软件下载并继续关注绿色先锋!
采集器(冰糖自媒体图文素材采集器的操作指南操作方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-17 23:08
冰堂自媒体图文素材采集器可以在采集网站上批量批量图文,操作简单,可以支持采集百度文库和360文库,起点中文等相关网站文章文字。
兵堂自媒体图文资料采集器操作指南
1、运行软件,在目的URL处输入你需要的网站的地址采集,可以是图片站,也可以是文章,小说,或者图文版网页,然后点击“访问”按钮,等待软件完全打开网页,采集图片列表会自动列出页面中收录的图片链接。
根据您的网速,网页可能需要几秒钟才能打开。如果在这个过程中弹出“Security Alert”对话框,询问是否继续,也就是Internet Explorer浏览器的安全设置提示,点击“Yes”继续访问采集的站点, if click "Yes" No" 会采集 not。有时可能会弹出脚本错误消息,忽略yes或no即可。
2、采集的网站图片链接全部出来后(鼠标移到软件浏览器窗口会提示“网页加载完成”),点击“抓取并保存” text”按钮,即可以自动抓取网页中的文字,并自动保存在你标题指定的“存储路径”下(文章如果长度过长,会在网页上的文字抓取框软件右侧可能显示不全,这种情况请打开Autosaved text 采集文件查看)。
如果需要采集图片,点击“开始采集/压缩”按钮自动批量采集,图片会自动保存到你指定的“存储路径”文件夹中。当然你也可以选择只下载单个文件,可以点击“预览图片”按钮预览图片文件为采集。为了节省空间,在批量下载图片的同时,也可以勾选“自动压缩采集图片”选项,下载的图片会被自动压缩(当然会同步损坏图片质量)。如果在压缩前备份原创图像文件,您也可以勾选“压缩前备份图像”选项。
除了从远程采集压缩图片文件,批量压缩功能还可以批量压缩你(电脑)本地的图片文件。
3、完成当前网页的图文素材采集后,如果要采集下一栏或下一网页,需要点击网站@软件浏览器窗口用鼠标>相关栏或“下一页”(“下一页”),等到下一页完全打开后再去采集。“设为空白页”旁边的小箭头可放大软件浏览器窗口,方便查看相关内容。
4、每次输入的URL软件都会自动保存到下拉菜单中,方便下次直接点击访问。如果内容太多,想清除,打开软件安装目录下的myurl.ini文件,整理删除URL。如果勾选“设为空白页”,则每次启动软件时不会自动打开网站主页。
5、采集日志保存在软件安装目录下的mylog.txt中。
另外,预览部分png图片或空URL图片可能会报错或崩溃,请忽略。 查看全部
采集器(冰糖自媒体图文素材采集器的操作指南操作方法介绍)
冰堂自媒体图文素材采集器可以在采集网站上批量批量图文,操作简单,可以支持采集百度文库和360文库,起点中文等相关网站文章文字。

兵堂自媒体图文资料采集器操作指南
1、运行软件,在目的URL处输入你需要的网站的地址采集,可以是图片站,也可以是文章,小说,或者图文版网页,然后点击“访问”按钮,等待软件完全打开网页,采集图片列表会自动列出页面中收录的图片链接。
根据您的网速,网页可能需要几秒钟才能打开。如果在这个过程中弹出“Security Alert”对话框,询问是否继续,也就是Internet Explorer浏览器的安全设置提示,点击“Yes”继续访问采集的站点, if click "Yes" No" 会采集 not。有时可能会弹出脚本错误消息,忽略yes或no即可。
2、采集的网站图片链接全部出来后(鼠标移到软件浏览器窗口会提示“网页加载完成”),点击“抓取并保存” text”按钮,即可以自动抓取网页中的文字,并自动保存在你标题指定的“存储路径”下(文章如果长度过长,会在网页上的文字抓取框软件右侧可能显示不全,这种情况请打开Autosaved text 采集文件查看)。
如果需要采集图片,点击“开始采集/压缩”按钮自动批量采集,图片会自动保存到你指定的“存储路径”文件夹中。当然你也可以选择只下载单个文件,可以点击“预览图片”按钮预览图片文件为采集。为了节省空间,在批量下载图片的同时,也可以勾选“自动压缩采集图片”选项,下载的图片会被自动压缩(当然会同步损坏图片质量)。如果在压缩前备份原创图像文件,您也可以勾选“压缩前备份图像”选项。
除了从远程采集压缩图片文件,批量压缩功能还可以批量压缩你(电脑)本地的图片文件。
3、完成当前网页的图文素材采集后,如果要采集下一栏或下一网页,需要点击网站@软件浏览器窗口用鼠标>相关栏或“下一页”(“下一页”),等到下一页完全打开后再去采集。“设为空白页”旁边的小箭头可放大软件浏览器窗口,方便查看相关内容。
4、每次输入的URL软件都会自动保存到下拉菜单中,方便下次直接点击访问。如果内容太多,想清除,打开软件安装目录下的myurl.ini文件,整理删除URL。如果勾选“设为空白页”,则每次启动软件时不会自动打开网站主页。
5、采集日志保存在软件安装目录下的mylog.txt中。
另外,预览部分png图片或空URL图片可能会报错或崩溃,请忽略。
采集器(采集器+python吧可以试试这种方法:通过利用免费工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-10 18:04
采集器+python吧可以试试这种方法:通过利用免费工具爬虫软件爬取糗事百科上的段子保存为gif动图(知乎上的也是类似,
先注册一个可以发送短信验证码的app.然后在那个app发送你想要的段子就可以了.也可以自己写爬虫自己发送.
去年我试了,一天半时间,
万能的某宝!100-200元能解决!
去百度一下:推友流量,
各大社交网站会有很多截图大神和发布信息的一些公众号,网上资源多的很。你可以先去尝试试看。
推荐一个我认为会回答的到你问题的知乎-花椒
360手机助手应该有,
5块钱,名片全能王的“自动合成”功能,把你想要的发给他们,我之前是在某大佬的论坛找到这样的方法。
leanote和自带采集器
目前有很多人用西瓜助手进行专题网站的内容爬取和数据抓取,
我记得,
老早以前我也用过优采云来解决。
阿里巴巴用了你就明白了
想要快速有效的采集网络内容?方法有很多,
1、了解网站生意参谋,一个seo专家都要看。
2、花些小钱,联盟、阿里妈妈、易门ueeshop等,操作简单,可以在线注册平台操作,
3、通过百度导入站点地址,如果你懂技术也可以用seocut,利用关键词抓取,不懂技术、懂如何操作的可以试一试云采集器、搜狗站长平台等。
4、采集的方式大体有两种,搜索引擎自动抓取和手动采集,通过后台控制可以一键调整和更改设置,页面采集,可选择关键词抓取。有个软件可以自动关键词采集,
5、了解amazon内容抓取,可以在amazon上找客户需要的内容,找到之后发到youtubepage,很多人都这么干。更多采集知识、操作、策略,
6、另外一种是蜘蛛爬虫模式,顾名思义,就是让搜索引擎找到你的内容, 查看全部
采集器(采集器+python吧可以试试这种方法:通过利用免费工具)
采集器+python吧可以试试这种方法:通过利用免费工具爬虫软件爬取糗事百科上的段子保存为gif动图(知乎上的也是类似,
先注册一个可以发送短信验证码的app.然后在那个app发送你想要的段子就可以了.也可以自己写爬虫自己发送.
去年我试了,一天半时间,
万能的某宝!100-200元能解决!
去百度一下:推友流量,
各大社交网站会有很多截图大神和发布信息的一些公众号,网上资源多的很。你可以先去尝试试看。
推荐一个我认为会回答的到你问题的知乎-花椒
360手机助手应该有,
5块钱,名片全能王的“自动合成”功能,把你想要的发给他们,我之前是在某大佬的论坛找到这样的方法。
leanote和自带采集器
目前有很多人用西瓜助手进行专题网站的内容爬取和数据抓取,
我记得,
老早以前我也用过优采云来解决。
阿里巴巴用了你就明白了
想要快速有效的采集网络内容?方法有很多,
1、了解网站生意参谋,一个seo专家都要看。
2、花些小钱,联盟、阿里妈妈、易门ueeshop等,操作简单,可以在线注册平台操作,
3、通过百度导入站点地址,如果你懂技术也可以用seocut,利用关键词抓取,不懂技术、懂如何操作的可以试一试云采集器、搜狗站长平台等。
4、采集的方式大体有两种,搜索引擎自动抓取和手动采集,通过后台控制可以一键调整和更改设置,页面采集,可选择关键词抓取。有个软件可以自动关键词采集,
5、了解amazon内容抓取,可以在amazon上找客户需要的内容,找到之后发到youtubepage,很多人都这么干。更多采集知识、操作、策略,
6、另外一种是蜘蛛爬虫模式,顾名思义,就是让搜索引擎找到你的内容,
采集器(优采云采集器(www.ucaiyun.com)的数据采集软件介绍及特色介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-01-10 06:13
优采云采集器()是一款功能强大的数据采集软件,可以轻松抓取文字、图片、文件等资源。软件还支持图片文件远程下载、文件真实地址检测、防盗链采集和采集数据直接存储、模仿者手动发布等。
软件功能
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
基本技能
1、规则自定义 - 使用 采集 规则定义,几乎可以搜索所有 网站采集 任何类型的信息。
2、多任务,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储——数据在采集的同时自动保存到关系数据库,数据结构可以自动适配,软件可以根据采集规则自动创建数据库,其中的表和字段,数据也可以通过数据库导入的方式灵活的保存到客户现有的数据库结构中。
5、Breakpoint Continuation - 信息采集任务在停止后可以从断点继续采集,因此您不再需要担心您的采集 任务被意外中断。
6、网站登录——支持网站cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled Tasks - 此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制 - 采集 的范围可以根据 采集 的深度和 URL 的身份来限制。
9、文件下载 - 您可以将 采集 二进制文件(例如图片、音乐、软件、文档等)下载到本地磁盘或 采集结果数据库。
10、结果替换——可以根据规则将采集的结果替换为你定义的内容。
变更日志
2021-03-15
优采云采集器V9.版本 30
1、优化了标签数据处理中的字符替换。
2、优化了无效文件检测导致文件下载失败的问题。
3、处理用户名收录特殊符号无法登录的问题。
4、修复数据管理批量操作数据有异常弹出提示的问题。
5、修复了二级代理卡住的问题。
6、改进了无法自动获取cookies的问题。
7、发布到word,自动将""转义为""、"""。
8、已修复:勾选发布选项,采集最大数量无效。
9、修复 oracle 链接问题。
10、支持oss存储。
11、修复:下载地址后面有斜线,下载文件时没有后缀。 查看全部
采集器(优采云采集器(www.ucaiyun.com)的数据采集软件介绍及特色介绍)
优采云采集器()是一款功能强大的数据采集软件,可以轻松抓取文字、图片、文件等资源。软件还支持图片文件远程下载、文件真实地址检测、防盗链采集和采集数据直接存储、模仿者手动发布等。
软件功能
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
基本技能
1、规则自定义 - 使用 采集 规则定义,几乎可以搜索所有 网站采集 任何类型的信息。
2、多任务,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储——数据在采集的同时自动保存到关系数据库,数据结构可以自动适配,软件可以根据采集规则自动创建数据库,其中的表和字段,数据也可以通过数据库导入的方式灵活的保存到客户现有的数据库结构中。
5、Breakpoint Continuation - 信息采集任务在停止后可以从断点继续采集,因此您不再需要担心您的采集 任务被意外中断。
6、网站登录——支持网站cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled Tasks - 此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制 - 采集 的范围可以根据 采集 的深度和 URL 的身份来限制。
9、文件下载 - 您可以将 采集 二进制文件(例如图片、音乐、软件、文档等)下载到本地磁盘或 采集结果数据库。
10、结果替换——可以根据规则将采集的结果替换为你定义的内容。
变更日志
2021-03-15
优采云采集器V9.版本 30
1、优化了标签数据处理中的字符替换。
2、优化了无效文件检测导致文件下载失败的问题。
3、处理用户名收录特殊符号无法登录的问题。
4、修复数据管理批量操作数据有异常弹出提示的问题。
5、修复了二级代理卡住的问题。
6、改进了无法自动获取cookies的问题。
7、发布到word,自动将""转义为""、"""。
8、已修复:勾选发布选项,采集最大数量无效。
9、修复 oracle 链接问题。
10、支持oss存储。
11、修复:下载地址后面有斜线,下载文件时没有后缀。
采集器(curl百度云采集器,网上使用教程采集教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-08 10:01
采集器是以采集中的文本(url)为存储载体的外包装卡,此外还有较长的联络字符串。主要用于im游戏数据提取、工作流程协同计算、物联网设备采集、车辆定位、控制等方面。众所周知的有最强大的浏览器采集器-ie9+ie5/ie7采集器,新手非常推荐,基本上所有常用的采集文件都可以做到爬下来。curl采集这里推荐使用curl这个采集器,网上很多使用采集器小助手的教程都是参照这个的,适合新手使用,小巧简洁不占内存,永久免费使用。
百度云引擎从某种意义上比curl采集还强大,支持接口多,服务稳定且免费。dotfileer百度云采集就是curl和dotfile脚本的结合体,调用百度云采集这个小软件生成的浏览器即插即用,软件本身兼容性也比较好。三者安装和使用场景都不同,所以两者没有可比性,参照别人写的就行了。
用windows采集肯定没有unix方便,因为里面已经有,比如com抓包,usb调试。其他pc采集器肯定是有自己的特色。比如有些可以轻松抓取常见的物联网网站的cookie,因为有链接数据库,导入导出。这是windows下有效的unix才用得到的功能。至于什么windowsapi之类的,一样的都可以采集到。不同的是编程设计方式不同。
1采集器我用的是scrapy。2接口有几个。不过不太好。3等我系统学好后,再去弄unix,client也行。比如用webscrapy、threejs。 查看全部
采集器(curl百度云采集器,网上使用教程采集教程)
采集器是以采集中的文本(url)为存储载体的外包装卡,此外还有较长的联络字符串。主要用于im游戏数据提取、工作流程协同计算、物联网设备采集、车辆定位、控制等方面。众所周知的有最强大的浏览器采集器-ie9+ie5/ie7采集器,新手非常推荐,基本上所有常用的采集文件都可以做到爬下来。curl采集这里推荐使用curl这个采集器,网上很多使用采集器小助手的教程都是参照这个的,适合新手使用,小巧简洁不占内存,永久免费使用。
百度云引擎从某种意义上比curl采集还强大,支持接口多,服务稳定且免费。dotfileer百度云采集就是curl和dotfile脚本的结合体,调用百度云采集这个小软件生成的浏览器即插即用,软件本身兼容性也比较好。三者安装和使用场景都不同,所以两者没有可比性,参照别人写的就行了。
用windows采集肯定没有unix方便,因为里面已经有,比如com抓包,usb调试。其他pc采集器肯定是有自己的特色。比如有些可以轻松抓取常见的物联网网站的cookie,因为有链接数据库,导入导出。这是windows下有效的unix才用得到的功能。至于什么windowsapi之类的,一样的都可以采集到。不同的是编程设计方式不同。
1采集器我用的是scrapy。2接口有几个。不过不太好。3等我系统学好后,再去弄unix,client也行。比如用webscrapy、threejs。
采集器(appleapplewatch推送的流程和机制是依赖quicktimex64或者quicktimex4)
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-12-30 00:04
采集器基本都会尽可能的让记录全面一些,会对下游产品有一定的影响,也不是绝对的,我使用clipboardsnap就没出现视频上传被删除的情况(但是音频被删除了貌似只是我自己随便起的名字)。
如果只是上传到在线视频网站没有下载到本地,一般是不会影响传输质量的。如果要上传到本地再下载,那至少要保证上传时的质量不低于官方提供的指定质量。另外多线程和速度是硬指标,没有听说有第三方的app能实现多线程和高速。
无法实现。apple的推送系统是依赖quicktimex64或者quicktimex4.,apple自己对多线程和速度提得比较仔细。更多关于apple推送的资料,请参考以下链接:applewatch推送的流程和机制,
华人业界只推送ppt。
apple已经推出使用ipseasyie技术进行本地视频传输的方案,比如keepcallbackprotocol-apple支持。华尔街推送很好。
当然不是原始格式就行不需要搞什么优化的只要在运行时传输足够大的带宽足够的流量就行不在乎什么用户体验
这个主要取决于下载工具本身的制作标准,一般都不是原始带宽,特别是广告视频之类,要钱。
它被称为全栈优化。是指apple在新版本的ios或macos平台应用程序中,对速度及稳定性等因素的全方位优化,包括将不必要的小核心apk分发和丢弃在itunes或同步助手分发,将包含一些付费内容不必要分发等等。 查看全部
采集器(appleapplewatch推送的流程和机制是依赖quicktimex64或者quicktimex4)
采集器基本都会尽可能的让记录全面一些,会对下游产品有一定的影响,也不是绝对的,我使用clipboardsnap就没出现视频上传被删除的情况(但是音频被删除了貌似只是我自己随便起的名字)。
如果只是上传到在线视频网站没有下载到本地,一般是不会影响传输质量的。如果要上传到本地再下载,那至少要保证上传时的质量不低于官方提供的指定质量。另外多线程和速度是硬指标,没有听说有第三方的app能实现多线程和高速。
无法实现。apple的推送系统是依赖quicktimex64或者quicktimex4.,apple自己对多线程和速度提得比较仔细。更多关于apple推送的资料,请参考以下链接:applewatch推送的流程和机制,
华人业界只推送ppt。
apple已经推出使用ipseasyie技术进行本地视频传输的方案,比如keepcallbackprotocol-apple支持。华尔街推送很好。
当然不是原始格式就行不需要搞什么优化的只要在运行时传输足够大的带宽足够的流量就行不在乎什么用户体验
这个主要取决于下载工具本身的制作标准,一般都不是原始带宽,特别是广告视频之类,要钱。
它被称为全栈优化。是指apple在新版本的ios或macos平台应用程序中,对速度及稳定性等因素的全方位优化,包括将不必要的小核心apk分发和丢弃在itunes或同步助手分发,将包含一些付费内容不必要分发等等。
采集器(智能采集优采云 采集模板采集模式(图)处理 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-12-29 04:05
采集模板采集模式(图)处理
)
模板集合
模板采集模式内置了上百个主流网站数据源,如京东、天猫、大众点评等热门采集网站。只需参考模板设置参数,即可快速获取网站公共数据。
现在查看
智能采集
优采云
根据不同的网站,采集
可提供多种网页采集
策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集过程实现数据的完整性和稳定性。
现在查看
云集
5000多台云服务器支持的云采集,7*24小时运行,可实现无人值守定时采集,灵活适配业务场景,助您提升采集效率,保障数据及时性。
现在查看
API接口
通过优采云
API,您可以轻松获取优采云
任务信息和采集数据,灵活调度远程控制任务启停等任务,高效实现数据采集和归档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
现在查看
自定义集合
针对不同用户的采集需求,优采云
可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、 ajax,页面滚动,条件判断。支持不同网页结构的复杂网站的采集,满足多种采集应用场景。
现在查看
方便的定时功能
只需几下简单的点击和设置,即可实现采集任务的时序控制。无论是单次采集的定时设置,还是预设日或周、月定时采集,多个任务可以同时自由设置。根据需要选择时间多种组合,灵活部署自己的采集任务。
现在查看
全自动数据格式化
优采云
内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能。采集过程中全自动处理,无需人工干预,即可获取所需格式的数据。
免费下载
多层次采集
很多主流新闻、电商网站都收录
一级商品列表页、二级商品详情页、三级评论详情页;无论站点有多少层级,优采云
都可以没有层级限制 采集的数据满足各种业务的采集需求。
免费下载
支持登录网站后采集
优采云
内置采集登录模块,您只需要配置目标网站的账号密码,登录后即可使用该模块采集数据;同时,优采云
还具有采集
cookies的自定义功能。首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持采集
更多网站。
免费下载
查看全部
采集器(智能采集优采云
采集模板采集模式(图)处理
)
模板集合
模板采集模式内置了上百个主流网站数据源,如京东、天猫、大众点评等热门采集网站。只需参考模板设置参数,即可快速获取网站公共数据。
现在查看


智能采集
优采云
根据不同的网站,采集
可提供多种网页采集
策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集过程实现数据的完整性和稳定性。
现在查看
云集
5000多台云服务器支持的云采集,7*24小时运行,可实现无人值守定时采集,灵活适配业务场景,助您提升采集效率,保障数据及时性。
现在查看


API接口
通过优采云
API,您可以轻松获取优采云
任务信息和采集数据,灵活调度远程控制任务启停等任务,高效实现数据采集和归档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
现在查看
自定义集合
针对不同用户的采集需求,优采云
可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、 ajax,页面滚动,条件判断。支持不同网页结构的复杂网站的采集,满足多种采集应用场景。
现在查看


方便的定时功能
只需几下简单的点击和设置,即可实现采集任务的时序控制。无论是单次采集的定时设置,还是预设日或周、月定时采集,多个任务可以同时自由设置。根据需要选择时间多种组合,灵活部署自己的采集任务。
现在查看
全自动数据格式化
优采云
内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能。采集过程中全自动处理,无需人工干预,即可获取所需格式的数据。
免费下载


多层次采集
很多主流新闻、电商网站都收录
一级商品列表页、二级商品详情页、三级评论详情页;无论站点有多少层级,优采云
都可以没有层级限制 采集的数据满足各种业务的采集需求。
免费下载
支持登录网站后采集
优采云
内置采集登录模块,您只需要配置目标网站的账号密码,登录后即可使用该模块采集数据;同时,优采云
还具有采集
cookies的自定义功能。首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持采集
更多网站。
免费下载

采集器(3,营销神器,轻松获取各大城市信息号码4,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-26 11:25
3、营销神器,轻松获取各大城市信息号码
4、详细的品类分类,轻松批量获取
5、可以获得主要城市和地区的号码
小豆子采集器更新
2016 年 4 月 16 日更新
新版本已经更新到1.version 1
新增右键过滤功能,删除过滤后的电话号码!
修复了简历栏目采集,部分栏目提示错误的bug!
导出xls文件程序,不再需要安装office,任何Windows(windows操作系统系统)系统都可以导出excel文件!
优化了一些细节!
如何使用小豆子采集器
您可以随时登录软件,随时使用所需的印版数据信息。
很多客户表示无法采集获取到采集时的数据!
但是截图给我看结果,他直接查了省名
例如:如果真的要采集山东省所有城市数据,那么不能直接勾选“山东省”,需要勾选山东省所有城市名!
此外,采集 过程是一个两步过程。
第一步是初始化数据,即软件会先获取你想要采集的数据总量。
总数的计算方法为,【总数】=【入选城市数】×【入选栏目数】×【页数】
比如采集的城市是[北京]和[上海],采集的板块是企业招聘中的[客服]、[销售]、[司机], 采集 页已设置。从第[3]页到第[7]页设置
那么总的数据初始化量为2个地区(北京、上海)×3个板块(客服、销售、司机)×5页(从第3页到第7页)=2×3×5=30页数据
即需要初始化30页数据,所以需要等待30秒左右。当然,我无法计算初始化时间,这主要取决于网络和你电脑的配置。
第二步,初始化完成后,就是每条数据真正的采集。
设置好之后,可以抽根烟,或者找个美女聊一会儿,回来看看采集的结果。
之后也有客户说,你们的软件不能指定城市的某个区域吗?
比如北京朝阳区,我只想要朝阳区的数据。
当然在58系列下,还有一个【58网站采集】
这里大家可以根据自己的需要去采集,具体使用方法我做了视频演示,大家可以直接观看视频演示
对于更具体的功能,我还是建议大家多看视频演示,这样可以更好的了解软件的使用方法,得到自己最想要的数据。 查看全部
采集器(3,营销神器,轻松获取各大城市信息号码4,)
3、营销神器,轻松获取各大城市信息号码
4、详细的品类分类,轻松批量获取
5、可以获得主要城市和地区的号码
小豆子采集器更新
2016 年 4 月 16 日更新
新版本已经更新到1.version 1
新增右键过滤功能,删除过滤后的电话号码!
修复了简历栏目采集,部分栏目提示错误的bug!
导出xls文件程序,不再需要安装office,任何Windows(windows操作系统系统)系统都可以导出excel文件!
优化了一些细节!
如何使用小豆子采集器
您可以随时登录软件,随时使用所需的印版数据信息。
很多客户表示无法采集获取到采集时的数据!
但是截图给我看结果,他直接查了省名
例如:如果真的要采集山东省所有城市数据,那么不能直接勾选“山东省”,需要勾选山东省所有城市名!
此外,采集 过程是一个两步过程。
第一步是初始化数据,即软件会先获取你想要采集的数据总量。
总数的计算方法为,【总数】=【入选城市数】×【入选栏目数】×【页数】
比如采集的城市是[北京]和[上海],采集的板块是企业招聘中的[客服]、[销售]、[司机], 采集 页已设置。从第[3]页到第[7]页设置
那么总的数据初始化量为2个地区(北京、上海)×3个板块(客服、销售、司机)×5页(从第3页到第7页)=2×3×5=30页数据
即需要初始化30页数据,所以需要等待30秒左右。当然,我无法计算初始化时间,这主要取决于网络和你电脑的配置。
第二步,初始化完成后,就是每条数据真正的采集。
设置好之后,可以抽根烟,或者找个美女聊一会儿,回来看看采集的结果。
之后也有客户说,你们的软件不能指定城市的某个区域吗?
比如北京朝阳区,我只想要朝阳区的数据。
当然在58系列下,还有一个【58网站采集】
这里大家可以根据自己的需要去采集,具体使用方法我做了视频演示,大家可以直接观看视频演示
对于更具体的功能,我还是建议大家多看视频演示,这样可以更好的了解软件的使用方法,得到自己最想要的数据。
采集器(智能识别数据采集软件,优采云采集器软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-02-25 07:11
优采云采集器是一款全新的智能网络数据采集软件,由谷歌原技术团队打造,规则配置简单,采集功能强大,支持电子商务课堂、生活服务、社交媒体、新闻论坛和其他类型的网站。
优采云采集器软件特色
1、智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入URL即可智能识别列表数据、表格数据和分页按钮。您无需配置任何采集 规则,只需单击采集。
自动识别:列表、表格、链接、图片、价格等
2、可视化点击,简单易用
流程图模式:只需要根据软件提示点击页面,完全符合浏览网页的思维方式。复杂的 采集 规则可以通过几个简单的步骤生成。结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文本、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
3、支持多种数据导出方式
采集结果可以导出到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
4、功能强大,提供企业级服务
优采云采集器提供丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业层面采集需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。
5、云账号,方便快捷
创建一个优采云采集器账号并登录,你所有的采集任务设置都会自动加密保存到优采云的云服务器,不用担心丢失采集任务的,任务运行的数据和采集都是本地的,非常安全,本地登录客户端才能查看 查看全部
采集器(智能识别数据采集软件,优采云采集器软件)
优采云采集器是一款全新的智能网络数据采集软件,由谷歌原技术团队打造,规则配置简单,采集功能强大,支持电子商务课堂、生活服务、社交媒体、新闻论坛和其他类型的网站。
优采云采集器软件特色
1、智能识别数据,小白神器
智能模式:基于人工智能算法,只需输入URL即可智能识别列表数据、表格数据和分页按钮。您无需配置任何采集 规则,只需单击采集。
自动识别:列表、表格、链接、图片、价格等
2、可视化点击,简单易用
流程图模式:只需要根据软件提示点击页面,完全符合浏览网页的思维方式。复杂的 采集 规则可以通过几个简单的步骤生成。结合智能识别算法,任何网页的数据都可以轻松采集。
可以模拟操作:输入文本、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等。
3、支持多种数据导出方式
采集结果可以导出到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
4、功能强大,提供企业级服务
优采云采集器提供丰富的采集功能,无论是采集稳定性还是采集效率,都能满足个人、团队和企业层面采集需求。
功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。
5、云账号,方便快捷
创建一个优采云采集器账号并登录,你所有的采集任务设置都会自动加密保存到优采云的云服务器,不用担心丢失采集任务的,任务运行的数据和采集都是本地的,非常安全,本地登录客户端才能查看
采集器(网络采集器的抓取数据质量也要看厂家的质量保证)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-24 03:03
采集器是通过网络抓取网络信息的工具,是云安全领域的。采集器所抓取的数据每秒钟在n多台电脑之间同步的,对数据有较强的保密性,所以网络采集器是可以实现高清浏览的,数据质量也不错。网络采集器的抓取数据质量也要看厂家的质量保证如何,如果采集器在抓取数据时,数据质量一般,数据会丢失。采集器也可以正常使用。目前市面上的采集器主要有电脑版和手机版之分,电脑版采集器数据在ie浏览器,因为比较稳定。
手机采集器是适合安卓手机使用的,缺点是抓取数据时要联网。安卓采集器软件一般都是免费的,不过采集器的安全性是要注意的,所以为了数据安全,还是选择正规的电脑采集器软件,再来就是抓取数据时,一定要保持局域网的网络连接,否则数据有可能丢失。abbyyfinereader安卓采集器这款采集器安卓版采集方式与电脑版相同,只是速度会慢一些,数据有丢失。可以找一款实用的采集器软件。
miniclipse采集神器v1.9.6下载可用
miniclipse采集器还不错,
目前市面上已经基本全用rss方式的各种网站了,抓的准也不好抓。我发现这类网站还是以txt格式数据为主,可能以后rss会慢慢取代它的地位吧。
作为国内最佳,用了你就知道。
rssfeed这东西的定位问题,但采集率还是算不错的,我经常爬经典的站点。ps:技术问题不是别人告诉你,你自己就能把握的。 查看全部
采集器(网络采集器的抓取数据质量也要看厂家的质量保证)
采集器是通过网络抓取网络信息的工具,是云安全领域的。采集器所抓取的数据每秒钟在n多台电脑之间同步的,对数据有较强的保密性,所以网络采集器是可以实现高清浏览的,数据质量也不错。网络采集器的抓取数据质量也要看厂家的质量保证如何,如果采集器在抓取数据时,数据质量一般,数据会丢失。采集器也可以正常使用。目前市面上的采集器主要有电脑版和手机版之分,电脑版采集器数据在ie浏览器,因为比较稳定。
手机采集器是适合安卓手机使用的,缺点是抓取数据时要联网。安卓采集器软件一般都是免费的,不过采集器的安全性是要注意的,所以为了数据安全,还是选择正规的电脑采集器软件,再来就是抓取数据时,一定要保持局域网的网络连接,否则数据有可能丢失。abbyyfinereader安卓采集器这款采集器安卓版采集方式与电脑版相同,只是速度会慢一些,数据有丢失。可以找一款实用的采集器软件。
miniclipse采集神器v1.9.6下载可用
miniclipse采集器还不错,
目前市面上已经基本全用rss方式的各种网站了,抓的准也不好抓。我发现这类网站还是以txt格式数据为主,可能以后rss会慢慢取代它的地位吧。
作为国内最佳,用了你就知道。
rssfeed这东西的定位问题,但采集率还是算不错的,我经常爬经典的站点。ps:技术问题不是别人告诉你,你自己就能把握的。
采集器(优采云采集器使用教程知识兔自定义采集百度搜索结果数据的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-13 11:20
优采云采集器正式版是一款功能强大的网页终端采集器,软件由谷歌原技术团队打造,旨在打造一款可视化、完全免费、极速的产品,让用户免费使用,放心使用。
优采云采集器知识兔介绍
优采云采集器是免费的网页数据采集,具有可视点击、一键式采集网页数据的特点,是没有人需要的免费网页数据发展。可用的网络数据采集器。优采云采集器导出数据无限制,可以导出数据到本地文件,发布到网站和数据库等。非常方便,需要的朋友赶紧下载吧。
优采云采集器使用教程知识兔
如何自定义采集百度搜索结果数据
第 1 步:创建一个 采集 任务
1)开始优采云采集器,进入主界面,选择Custom采集点击Create Task按钮,创建“Custom采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:直接在输入框中输入网址。当多个 URL 需要用换行符分隔时
2、点击从文件读取方法:用户选择一个存储URL的文件。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、批量添加方法:通过添加调整地址参数生成多个常规地址
第 2 步:自定义 采集 流程
1)点击创建,自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区用于拖拽到画布上,生成新的流程块;点击打开网页中的属性按钮,修改打开网址
2)添加输入文本流块:将底部模板区域的输入文本块拖到打开的网页块的后面,当出现阴影区域时,可以松开鼠标,此时会自动连接时间,添加完成
3)生成一个完整的流程图:在上面添加输入文本流块的拖放过程之后添加一个新块:如下图:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框Xpath属性按钮,点击属性菜单中的图标点击网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页中的百度按钮。
步骤 5:用于设置循环以加载下一个列表页面。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择单个元素,然后在属性菜单中点击该元素的xpath属性按钮,在网页中点击下一页按钮为多于。循环次数属性按钮可以默认为0,即不限制下一页的点击次数。
第六步:用于设置循环中的数据以提取列表页。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后连续点击两次即可提取网页中的第一个块和第二个块元素。循环计数属性按钮可以默认为0,即不限制列表中计费的字段数。
第七步:用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择使用当前循环中元素xpath的选项。
第八步:同理,设置网页加载的等待时间。
步骤 9:要设置在列表页面上提取的字段规则,单击属性按钮中的循环使用元素按钮,然后选择循环使用元素选项。单击元素模板属性按钮,在字段表中单击加号或减号可添加或删除字段。添加字段,使用单击操作,即单击加号并将鼠标移动到网页元素并单击选择。
4)点击开始采集,开始采集
第 3 步:数据采集 和导出
1)采集任务正在运行
2)采集完成后选择“导出数据”,将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集数据导出如下图
优采云采集器软件功能知识兔
1.可视化定制采集流程
全程问答引导,可视化操作,自定义采集流程
自动记录和模拟网页动作序列
更多采集需求的高级设置
2.点击提取网页数据
点击鼠标选择要爬取的网页内容,操作简单
可选择提取文本、链接、属性、html 标签等。
3.批量运行采集数据
软件根据采集流程和提取规则自动批处理采集
快速稳定,实时显示采集速度和过程
软件可以切换到后台运行,不影响前台工作
4.导出和发布采集数据
采集的数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
点击下载 查看全部
采集器(优采云采集器使用教程知识兔自定义采集百度搜索结果数据的方法)
优采云采集器正式版是一款功能强大的网页终端采集器,软件由谷歌原技术团队打造,旨在打造一款可视化、完全免费、极速的产品,让用户免费使用,放心使用。
优采云采集器知识兔介绍
优采云采集器是免费的网页数据采集,具有可视点击、一键式采集网页数据的特点,是没有人需要的免费网页数据发展。可用的网络数据采集器。优采云采集器导出数据无限制,可以导出数据到本地文件,发布到网站和数据库等。非常方便,需要的朋友赶紧下载吧。
优采云采集器使用教程知识兔
如何自定义采集百度搜索结果数据
第 1 步:创建一个 采集 任务
1)开始优采云采集器,进入主界面,选择Custom采集点击Create Task按钮,创建“Custom采集Task”
2)输入百度搜索的网址,包括三种方式
1、手动输入:直接在输入框中输入网址。当多个 URL 需要用换行符分隔时
2、点击从文件读取方法:用户选择一个存储URL的文件。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、批量添加方法:通过添加调整地址参数生成多个常规地址
第 2 步:自定义 采集 流程
1)点击创建,自动打开第一个网址,进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区用于拖拽到画布上,生成新的流程块;点击打开网页中的属性按钮,修改打开网址
2)添加输入文本流块:将底部模板区域的输入文本块拖到打开的网页块的后面,当出现阴影区域时,可以松开鼠标,此时会自动连接时间,添加完成
3)生成一个完整的流程图:在上面添加输入文本流块的拖放过程之后添加一个新块:如下图:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框Xpath属性按钮,点击属性菜单中的图标点击网页中的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页中的百度按钮。
步骤 5:用于设置循环以加载下一个列表页面。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择单个元素,然后在属性菜单中点击该元素的xpath属性按钮,在网页中点击下一页按钮为多于。循环次数属性按钮可以默认为0,即不限制下一页的点击次数。
第六步:用于设置循环中的数据以提取列表页。在循环块内的循环条件块中设置详细条件,点击此处的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后连续点击两次即可提取网页中的第一个块和第二个块元素。循环计数属性按钮可以默认为0,即不限制列表中计费的字段数。
第七步:用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择使用当前循环中元素xpath的选项。
第八步:同理,设置网页加载的等待时间。
步骤 9:要设置在列表页面上提取的字段规则,单击属性按钮中的循环使用元素按钮,然后选择循环使用元素选项。单击元素模板属性按钮,在字段表中单击加号或减号可添加或删除字段。添加字段,使用单击操作,即单击加号并将鼠标移动到网页元素并单击选择。
4)点击开始采集,开始采集
第 3 步:数据采集 和导出
1)采集任务正在运行
2)采集完成后选择“导出数据”,将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集数据导出如下图
优采云采集器软件功能知识兔
1.可视化定制采集流程
全程问答引导,可视化操作,自定义采集流程
自动记录和模拟网页动作序列
更多采集需求的高级设置
2.点击提取网页数据
点击鼠标选择要爬取的网页内容,操作简单
可选择提取文本、链接、属性、html 标签等。
3.批量运行采集数据
软件根据采集流程和提取规则自动批处理采集
快速稳定,实时显示采集速度和过程
软件可以切换到后台运行,不影响前台工作
4.导出和发布采集数据
采集的数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
点击下载
采集器(速度是普通采集器的7倍优采云采集器采用顶级系统配置,反复优化性能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-02-11 23:05
标签:
优采云采集器破解版(又名优采云采集器)是可以采集网上任何网站的辅助工具,功能强大网络数据/信息挖掘软件,功能真的很强大,可以采集任何信息,可以在本地、数据库、网站发布等中保存采集文件。信息采集@ >员工和网站管理员必备的工具。
优采云采集器破解版亮点:
程序支持远程下载图片文件,支持登录后获取网站信息,检测文件真实地址,支持代理,支持采集防盗链,支持采集数据直接入库,模仿手工发布和其他功能特性。
Train Collector支持从任何类型的网站采集所需信息,如各种新闻网站、论坛、电子商务网站、求职网站等。
还具有强大的网站登录采集、多页和分页采集、网站跨层采集、POST采集、脚本页面< @高级采集功能如采集、动态页面采集等。
强大的php和c#插件支持,通过二次开发可以实现更强大的功能。
几乎任何网页都可以采集
不管是什么语言,
不管是什么编码。
比正常速度快 7 倍 采集器
优采云采集器使用顶层系统配置,
反复优化性能,让采集飞得更快!
与复制/粘贴一样准确
采集/发布与复制/粘贴一样精确,
用户想要的都是精华,怎么可能有遗漏!
网页的同义词 采集
十年经验,已成为行业领先品牌。
当您想到网页 采集 时,您会想到 优采云采集器!
优采云采集器软件特色
1.通用。
无论是新闻、论坛、视频、黄页、图片、下载网站,只要通过浏览器可以看到的结构化内容指定匹配规则,就可以采集到必要的内容。
2.稳定高效。
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛。
自定义网站发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
优采云采集器功能介绍:
1.创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2.新任务
确定自己所属的组,新建任务,填写任务名称保存。
3.网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4.网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5.数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6.数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7.计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8.插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。 查看全部
采集器(速度是普通采集器的7倍优采云采集器采用顶级系统配置,反复优化性能)
标签:
优采云采集器破解版(又名优采云采集器)是可以采集网上任何网站的辅助工具,功能强大网络数据/信息挖掘软件,功能真的很强大,可以采集任何信息,可以在本地、数据库、网站发布等中保存采集文件。信息采集@ >员工和网站管理员必备的工具。
优采云采集器破解版亮点:
程序支持远程下载图片文件,支持登录后获取网站信息,检测文件真实地址,支持代理,支持采集防盗链,支持采集数据直接入库,模仿手工发布和其他功能特性。
Train Collector支持从任何类型的网站采集所需信息,如各种新闻网站、论坛、电子商务网站、求职网站等。
还具有强大的网站登录采集、多页和分页采集、网站跨层采集、POST采集、脚本页面< @高级采集功能如采集、动态页面采集等。
强大的php和c#插件支持,通过二次开发可以实现更强大的功能。
几乎任何网页都可以采集
不管是什么语言,
不管是什么编码。
比正常速度快 7 倍 采集器
优采云采集器使用顶层系统配置,
反复优化性能,让采集飞得更快!
与复制/粘贴一样准确
采集/发布与复制/粘贴一样精确,
用户想要的都是精华,怎么可能有遗漏!
网页的同义词 采集
十年经验,已成为行业领先品牌。
当您想到网页 采集 时,您会想到 优采云采集器!
优采云采集器软件特色
1.通用。
无论是新闻、论坛、视频、黄页、图片、下载网站,只要通过浏览器可以看到的结构化内容指定匹配规则,就可以采集到必要的内容。
2.稳定高效。
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛。
自定义网站发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
优采云采集器功能介绍:
1.创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2.新任务
确定自己所属的组,新建任务,填写任务名称保存。
3.网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4.网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5.数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6.数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7.计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8.插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。
采集器(优采云进阶用户使用频繁的一种模式采集数据介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-04 10:09
入门 - 自定义模式
自定义模式是优采云高级用户经常使用的模式。他们需要自己配置规则,才能实现全网98%以上网页数据的采集。
定位:通过配置规则来抓取网页数据,模拟人们浏览网页的操作。
使用前提:通过向导模式,有一定程度的采集对规则的熟悉和优采云采集逻辑理解能力,可以自己配置规则,轻松学习在实践中通过自定义模式、Xpath等能力构建网页结构,算是学习与工作之间的正确平衡。
推荐用法:当其他模式不能满足你的需求时,可以使用自定义模式采集全网数据。
文章 中的示例 URL 是:
自定义模式采集 步骤:
第一步:先打开优采云采集器→找到自定义采集→点击立即使用
第二步:输入网址→设置翻页周期→设置字段提取→修改字段名称→手动检查规则→选择采集输入开始采集
当心:
设置翻页周期:观察网页底部是否有翻页图标。如果有且需要翻页,请点击翻页图标。在操作提示中,单击下一页可循环浏览页面。可以设置循环翻页的次数,下几页采集网页最新内容的几页。采集链接的文本选项会显示一个数据提取步骤,提取下一页对应的文本;单击采集此链接地址步骤选项将显示数据提取步骤,以提取与当前字段对应的链接地址。单击链接将弹出单击元素步骤,单击元素一次。集字段提取:首先将网页内容分成块,思路是循环每个块,然后从循环块中提取每个字段的内容,所以在设置前点击2-3块,优采云会自动选择所有剩余的块,点击采集会出现下面的元素文本的步骤循环抽取数据,实现块采集的循环,但是此时每个块只会将文本合并为一次抽取。这时候我们删除字段,手动添加所有需要提取的字段;如果你在一个循环中点击每个元素,就会出现循环点击元素步骤,每个块被点击一次。在这个例子中,block click没有效果,所以loop click在这个例子中没有效果。如果选择错误,或者出现的内容列表不是你需要的,您可以点击操作提示中区块后的垃圾桶图标将其删除,或点击取消选择进行重置。循环下的第一个元素要勾选采集当前循环中设置的元素,相关操作会根据循环设置循环。修改字段名:修改字段名,可以点击选择系统内置的字段名,也可以手动输入字段名,按回车键切换到下一个。选择采集类型启动采集:本地采集为采集占用当前计算机资源,如果有采集时间要求或当前计算机不能长时间执行采集可以使用云采集功能,云采集可以在网络中执行采集,
第三步:确认数据无误→点击导出数据→免费版用户付费→选择导出方式→查看数据
注意:积分是一种支付优采云增值服务的方式。主要用途包括:通过优采云采集器采集导出数据,不同的账户类型在使用上述增值服务会有不同的计费策略。具体的计费策略和区别在发行说明中有详细说明。积分可以通过优采云官方购买专业版或旗舰版按月发放,也可以单独购买,也可以通过关注、登录、分享规则、关注微信、绑定社交账号等方式获得。 查看全部
采集器(优采云进阶用户使用频繁的一种模式采集数据介绍)
入门 - 自定义模式
自定义模式是优采云高级用户经常使用的模式。他们需要自己配置规则,才能实现全网98%以上网页数据的采集。
定位:通过配置规则来抓取网页数据,模拟人们浏览网页的操作。
使用前提:通过向导模式,有一定程度的采集对规则的熟悉和优采云采集逻辑理解能力,可以自己配置规则,轻松学习在实践中通过自定义模式、Xpath等能力构建网页结构,算是学习与工作之间的正确平衡。
推荐用法:当其他模式不能满足你的需求时,可以使用自定义模式采集全网数据。
文章 中的示例 URL 是:
自定义模式采集 步骤:
第一步:先打开优采云采集器→找到自定义采集→点击立即使用
第二步:输入网址→设置翻页周期→设置字段提取→修改字段名称→手动检查规则→选择采集输入开始采集
当心:
设置翻页周期:观察网页底部是否有翻页图标。如果有且需要翻页,请点击翻页图标。在操作提示中,单击下一页可循环浏览页面。可以设置循环翻页的次数,下几页采集网页最新内容的几页。采集链接的文本选项会显示一个数据提取步骤,提取下一页对应的文本;单击采集此链接地址步骤选项将显示数据提取步骤,以提取与当前字段对应的链接地址。单击链接将弹出单击元素步骤,单击元素一次。集字段提取:首先将网页内容分成块,思路是循环每个块,然后从循环块中提取每个字段的内容,所以在设置前点击2-3块,优采云会自动选择所有剩余的块,点击采集会出现下面的元素文本的步骤循环抽取数据,实现块采集的循环,但是此时每个块只会将文本合并为一次抽取。这时候我们删除字段,手动添加所有需要提取的字段;如果你在一个循环中点击每个元素,就会出现循环点击元素步骤,每个块被点击一次。在这个例子中,block click没有效果,所以loop click在这个例子中没有效果。如果选择错误,或者出现的内容列表不是你需要的,您可以点击操作提示中区块后的垃圾桶图标将其删除,或点击取消选择进行重置。循环下的第一个元素要勾选采集当前循环中设置的元素,相关操作会根据循环设置循环。修改字段名:修改字段名,可以点击选择系统内置的字段名,也可以手动输入字段名,按回车键切换到下一个。选择采集类型启动采集:本地采集为采集占用当前计算机资源,如果有采集时间要求或当前计算机不能长时间执行采集可以使用云采集功能,云采集可以在网络中执行采集,
第三步:确认数据无误→点击导出数据→免费版用户付费→选择导出方式→查看数据
注意:积分是一种支付优采云增值服务的方式。主要用途包括:通过优采云采集器采集导出数据,不同的账户类型在使用上述增值服务会有不同的计费策略。具体的计费策略和区别在发行说明中有详细说明。积分可以通过优采云官方购买专业版或旗舰版按月发放,也可以单独购买,也可以通过关注、登录、分享规则、关注微信、绑定社交账号等方式获得。
采集器(前段时间,iLogtail阿里千万实例可观测采集器开源(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-02 14:12
介绍:前段时间可以观察到千万级iLogtail阿里巴巴实例采集器开源,其中介绍iLogtail采集性能可以达到每核100MB/s,对比开源< @采集代理5-10倍性能优势。很多朋友好奇iLogtail具体的性能数据和资源消耗情况。本文将对比目前业界广泛使用且性能相对较好的Agent FileBeat,测试两种agent在不同压力场景下的表现。
作者 |减少旋转
来源 |阿里巴巴科技公众号
前言
前段时间,iLogtail[1]可以观察到阿里巴巴千万级实例采集器开源,其中引入iLogtail采集性能可以达到每核100MB/s,对比开源< @采集代理有5-10倍的性能优势。很多朋友好奇iLogtail具体的性能数据和资源消耗情况。本文将对比目前业界广泛使用且性能相对较好的Agent FileBeat,测试两种agent在不同压力场景下的表现。
第二次测试说明
随着Kubernetes的普及,Kubernetes下对日志采集的需求越来越正常,所以下面将容器标准输出流采集和静态文件采集@进行对比测试> 容器内(使用静态文件采集的小伙伴可以参考容器内的静态文件采集进行对比测试,iLogtail纯静态文件采集会比测试2略好容器中的静态文件采集),测试项详细如下:
在真实的生产环境中,log采集组件的可操作性也很重要。为方便运维及后期升级,相比Sidecar模式,K8s下部署采用Daemonset模式采集组件较为常见。但是,由于 Daemonset 将整个集群的 采集 配置同时分发到每个 采集 节点,单个 采集 节点的工作配置必须小于 采集@ 的总数> 配置,所以我们还将进行以下两部分实验,看看 采集config bloat 是否会影响 采集器 的生产力:
最后iLogtail会进行大流量压力测试,如下:
三个测试环境
所有采集环境数据都存储在[2]中,有兴趣的同学可以自行进行整个对比测试实验。下面介绍不同采集模式的具体配置。如果只关心采集比较结果,可以跳过这部分继续阅读。
1 环境
运行环境:阿里云ACK Pro版
节点配置:ecs.g6.xlarge(4 vCPU 16GB)磁盘ESSD
底层容器:Containerd
iLogtail 版本:1.0.28
FileBeat 版本:v7.16.2
2 个数据源
对于数据源,我们先去掉正则解析或者多行拼接能力带来的差异,只比较最基本的单行采集。数据生成源模拟nginx访问日志的生成。单条日志大小为283B,以下配置以1000bar/s的速率描述输入源:
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-demo-0
namespace: default
spec:
template:
metadata:
name: nginx-log-demo-0
spec:
restartPolicy: Never
containers:
- name: nginx-log-demo-0
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--path=/var/log/medlinker/access.log", "--total-count=1000000000", "--log-file-size=1000000000", "--log-file-count=2", "--logs-per-sec=1000"]
volumeMounts:
- name: path
mountPath: /var/log/medlinker
subPath: nginx-log-demo-0
resources:
limits:
memory: 200Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: path
hostPath:
path: /testlog
type: DirectoryOrCreate
nodeSelector:
kubernetes.io/hostname: cn-beijing.192.168.0.140
3 Filebeat标准输出流采集配置
Filebeat原生支持容器文件采集,通过add_kubernetes_metadata组件添加kubernetes元信息,为了避免输出组件带来的性能差异,通过drop_event插件drop数据避免输出,filebeat测试配置如下(harvester_buffer_size调整设置为512K,filebeat.registry.flush:30s,queue.mem参数适当扩大增加吞吐量):
filebeat.yml: |-
filebeat.registry.flush: 30s
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- drop_event:
when:
equals:
input.type: container
output.console:
pretty: false
queue:
mem:
events: 4096
flush.min_events: 2048
flush.timeout: 1s
max_procs: 4
filebeat.inputs:
- type: container
harvester_buffer_size: 524288
paths:
- /var/log/containers/nginx-log-demo-0-*.log
4个Filebeat容器文件采集配置
Filebeat原生不支持容器内的文件采集,所以需要手动挂载日志打印路径到宿主机HostPath。这里我们使用 subPath 和 DirectoryOrCreate 函数来分隔服务打印路径。下面是模拟不同服务日志打印路径无关的情况。
filebeat使用基本的日志读取功能来读取/testlog路径下的日志。为了避免输出组件带来的性能差异,使用drop_event插件丢弃数据,避免输出。测试配置如下(harvester_buffer_size调整设置为512K,filebeat.registry.flush:30s,queue.mem参数适当扩展增加吞吐量):
filebeat.yml: |-
filebeat.registry.flush: 30s
output.console:
pretty: false
queue:
mem:
events: 4096
flush.min_events: 2048
flush.timeout: 1s
max_procs: 4
filebeat.inputs:
- type: log
harvester_buffer_size: 524288
paths:
- /testlog/nginx-log-demo-0/*.log
processors:
- drop_event:
when:
equals:
log.file.path: /testlog/nginx-log-demo-0/access.log
5 iLogtail 标准输出流采集配置
iLogtail 还原生支持标准输出流采集,service_docker_stdout 组件已经提取了 kubernetes 元信息。为避免输出组件导致的性能差异,所有日志都通过processor_filter_regex进行过滤。测试配置如下:
{
"inputs":[
{
"detail":{
"ExcludeLabel":{
},
"IncludeLabel":{
"io.kubernetes.container.name":"nginx-log-demo-0"
}
},
"type":"service_docker_stdout"
}
],
"processors":[
{
"type":"processor_filter_regex",
"detail":{
"Exclude":{
"_namespace_":"default"
}
}
}
]
}
6 iLogtail 容器文件采集配置
iLogtail原生支持容器采集中的文件,但是因为文件中的采集元信息存在于tag标签中,所以没有过滤插件。为了避免输出组件带来的性能差异,我们使用空输出插件输出,测试配置如下:
{
"metrics":{
"c0":{
"advanced":{
"k8s":{
"IncludeLabel":{
"io.kubernetes.container.name":"nginx-log-demo-0"
}
}
},
......
"plugin":{
"processors":[
{
"type":"processor_default"
}
],
"flushers":[
{
"type":"flusher_statistics",
"detail":{
"RateIntervalMs":1000000
}
}
]
},
"local_storage":true,
"log_begin_reg":".*",
"log_path":"/var/log/medlinker",
......
}
}
}
四个Filebeat和iLogtail对比测试
Filebeat和iLogtail的对比项目主要有:标准输出流采集性能、文件在容器采集性能、标准输出流多用户配置性能、容器内文件多用户配置性能和高流量采集性能。
1个标准输出流采集性能对比
输入数据源:283B/s,底层容器contianerd,标准输出流扩展为328B,共4个输入源:
下面是不同标准输出流的性能对比采集。可以看出iLogtail相比Filebeat有十倍的性能优势(CPU占比为单核占比):
下面是不同标准输出流的内存对比采集。可以看出logtail和filebeat的整体内存差别不大,并没有随着采集traffic的增加内存暴增:
2个容器文件采集性能对比
输入数据源:283B/s,共4个输入源:
下面是容器采集中不同文件的性能对比。 Filebeat容器中的文件与容器采集共享采集组件,省略了Kubernetes元相关的组件,因此相比标准输出流采集有很大的性能提升。 iLogtail容器内文件采集采用Polling+inotify机制,相比容器标准输出流采集也有性能提升,但可以看到iLogtail与Filebeat相比有5倍的提升性能优势(CPU占比为单核占比):
下面是不同标准输出流的内存对比采集。可以看出logtail和filebeat的整体内存差别不大,并没有随着采集traffic的增加内存暴增:
3 采集配置扩展性能对比
采集配置扩展性能对比,输入源设置为4,总输入速率为3M/s,50采集配置,100采集配置,500采集 @>配置,1000采集配置比较。
标准输出流采集配置膨胀比较
下面是不同标准输出流的性能对比采集。可以看到Filebeat与容器底层采集和静态文件采集共享相同的静态文件采集逻辑。标准输出流采集的路径var/log/containers下会有很多正则匹配工作。可以看到虽然采集的数据量并没有因为采集的配置增加而增加,但是CPU消耗增加了10%+,iLogtail全局共享容器路径发现机制针对容器采集模型,避免了常规逻辑带来的性能损失(CPU占比为单核占比)。
在内存扩展方面,可以看出Filebeat和iLogtail都有因采集配置增加导致的内存扩展,但两者的扩展大小都在可接受的范围内。
容器中的文件采集配置扩展对比
下图是容器中文件采集与不同采集器的性能对比,可以看到Filebeat静态文件采集相比标准增加了CPU是由于规避标准输出流的正则路径消耗少,iLogtail CPU变化也小,性能略优于标准输出流采集(CPU的百分比就是单核)。
在内存扩展方面,也可以看出Filebeat和iLogtail都有因采集配置增加导致的内存扩展,但两者的扩展大小都在可接受的范围内。
4 iLogtail 采集性能测试
由于FileBeat在日志量大的场景下存在采集延迟问题,以下场景仅针对iLogtail进行测试,iLogtail的容器标准输出为5M/s、10M/ s 和 20M/s。流 采集 和容器 采集 中的文件的性能压力测试。
和上面的测试类似,可以看出容器文件采集的性能在CPU消耗方面略优于容器标准输出流采集(百分比CPU是单核的百分比),主要是因为容器文件采集@采集底层的Polling+inotify机制。
在内存方面,由于标准输出流采集主要依赖GO,而容器文件采集主要依赖C,由于GC机制的存在,随着速率的增加,标准输出流采集消耗的内存会逐渐超过容器中文件采集消耗的内存。
5 比较总结
5 为什么Filebeat容器的标准输出和文件有这么大的差别采集?
通过以上实验,我们可以看出FIlebeat在不同工作模式下的CPU差异很大。通过dump容器采集的标准输出流的pprof,可以得到如下火焰图,可以看出Filebeat容器采集下的add_kubernets_meta插件是性能瓶颈。同时FIlebeat的add_kubernets_meta采用了api-server模式监控各个节点,也存在api-server压力问题。
iLogtail的kubernetes meta完全兼容kubernetes CRI协议,直接通过kubernets沙箱读取meta数据,保证了iLogtail的高性能采集效率。
六大iLogtail DaemonSet场景优化
从上面的对比可以看出,iLogtail相比Filebeat,内存和CPU消耗都非常出色。可能有朋友好奇iLogtail的极致性能背后的原因。下面主要讲解iLogtail Daemonset场景下的优化以及如何将标准输出Streaming比FIlebeat提升10倍的性能。
首先针对标准输出流的场景,对比其他开源采集器,比如Filebeat或者Fluentd。一般容器的标准输出流文件的采集是通过监听var/log/containers或者/var/log/pods/来实现的。例如/var/log/pods/的路径结构为:/var/log/pods /_
_
//,使用该路径复用物理机静态文件采集方式为采集。
对于iLogtail,它完全支持容器化。 iLogtail通过发现机制,全局维护一个Node节点容器列表,并实时监控维护这个容器列表。当我们有一个容器列表时,我们有以下优势:
七个结论
综上所述,在高动态的Kubernetes环境下,iLogtail不会因为Daemonset的部署模式导致的多配置问题而导致显着的内存扩展,而在静态文件采集方面,iLogtail有一个5倍左右的性能优势,对于标准输出流采集,由于iLogtail的采集机制,iLogtail有10倍左右的性能优势。但是,与 Filebeat 或 Fluentd 等老式开源产品相比,文档和社区建设方面仍然存在很多不足。欢迎对iLogtail感兴趣的朋友参与,共同打造易用、高性能的iLogtail产品。
参考文献
原文链接 查看全部
采集器(前段时间,iLogtail阿里千万实例可观测采集器开源(组图))
介绍:前段时间可以观察到千万级iLogtail阿里巴巴实例采集器开源,其中介绍iLogtail采集性能可以达到每核100MB/s,对比开源< @采集代理5-10倍性能优势。很多朋友好奇iLogtail具体的性能数据和资源消耗情况。本文将对比目前业界广泛使用且性能相对较好的Agent FileBeat,测试两种agent在不同压力场景下的表现。
作者 |减少旋转
来源 |阿里巴巴科技公众号
前言
前段时间,iLogtail[1]可以观察到阿里巴巴千万级实例采集器开源,其中引入iLogtail采集性能可以达到每核100MB/s,对比开源< @采集代理有5-10倍的性能优势。很多朋友好奇iLogtail具体的性能数据和资源消耗情况。本文将对比目前业界广泛使用且性能相对较好的Agent FileBeat,测试两种agent在不同压力场景下的表现。
第二次测试说明
随着Kubernetes的普及,Kubernetes下对日志采集的需求越来越正常,所以下面将容器标准输出流采集和静态文件采集@进行对比测试> 容器内(使用静态文件采集的小伙伴可以参考容器内的静态文件采集进行对比测试,iLogtail纯静态文件采集会比测试2略好容器中的静态文件采集),测试项详细如下:
在真实的生产环境中,log采集组件的可操作性也很重要。为方便运维及后期升级,相比Sidecar模式,K8s下部署采用Daemonset模式采集组件较为常见。但是,由于 Daemonset 将整个集群的 采集 配置同时分发到每个 采集 节点,单个 采集 节点的工作配置必须小于 采集@ 的总数> 配置,所以我们还将进行以下两部分实验,看看 采集config bloat 是否会影响 采集器 的生产力:
最后iLogtail会进行大流量压力测试,如下:
三个测试环境
所有采集环境数据都存储在[2]中,有兴趣的同学可以自行进行整个对比测试实验。下面介绍不同采集模式的具体配置。如果只关心采集比较结果,可以跳过这部分继续阅读。
1 环境
运行环境:阿里云ACK Pro版
节点配置:ecs.g6.xlarge(4 vCPU 16GB)磁盘ESSD
底层容器:Containerd
iLogtail 版本:1.0.28
FileBeat 版本:v7.16.2
2 个数据源
对于数据源,我们先去掉正则解析或者多行拼接能力带来的差异,只比较最基本的单行采集。数据生成源模拟nginx访问日志的生成。单条日志大小为283B,以下配置以1000bar/s的速率描述输入源:
apiVersion: batch/v1
kind: Job
metadata:
name: nginx-log-demo-0
namespace: default
spec:
template:
metadata:
name: nginx-log-demo-0
spec:
restartPolicy: Never
containers:
- name: nginx-log-demo-0
image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest
command: ["/bin/mock_log"]
args: ["--log-type=nginx", "--path=/var/log/medlinker/access.log", "--total-count=1000000000", "--log-file-size=1000000000", "--log-file-count=2", "--logs-per-sec=1000"]
volumeMounts:
- name: path
mountPath: /var/log/medlinker
subPath: nginx-log-demo-0
resources:
limits:
memory: 200Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: path
hostPath:
path: /testlog
type: DirectoryOrCreate
nodeSelector:
kubernetes.io/hostname: cn-beijing.192.168.0.140
3 Filebeat标准输出流采集配置
Filebeat原生支持容器文件采集,通过add_kubernetes_metadata组件添加kubernetes元信息,为了避免输出组件带来的性能差异,通过drop_event插件drop数据避免输出,filebeat测试配置如下(harvester_buffer_size调整设置为512K,filebeat.registry.flush:30s,queue.mem参数适当扩大增加吞吐量):
filebeat.yml: |-
filebeat.registry.flush: 30s
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- drop_event:
when:
equals:
input.type: container
output.console:
pretty: false
queue:
mem:
events: 4096
flush.min_events: 2048
flush.timeout: 1s
max_procs: 4
filebeat.inputs:
- type: container
harvester_buffer_size: 524288
paths:
- /var/log/containers/nginx-log-demo-0-*.log
4个Filebeat容器文件采集配置
Filebeat原生不支持容器内的文件采集,所以需要手动挂载日志打印路径到宿主机HostPath。这里我们使用 subPath 和 DirectoryOrCreate 函数来分隔服务打印路径。下面是模拟不同服务日志打印路径无关的情况。
filebeat使用基本的日志读取功能来读取/testlog路径下的日志。为了避免输出组件带来的性能差异,使用drop_event插件丢弃数据,避免输出。测试配置如下(harvester_buffer_size调整设置为512K,filebeat.registry.flush:30s,queue.mem参数适当扩展增加吞吐量):
filebeat.yml: |-
filebeat.registry.flush: 30s
output.console:
pretty: false
queue:
mem:
events: 4096
flush.min_events: 2048
flush.timeout: 1s
max_procs: 4
filebeat.inputs:
- type: log
harvester_buffer_size: 524288
paths:
- /testlog/nginx-log-demo-0/*.log
processors:
- drop_event:
when:
equals:
log.file.path: /testlog/nginx-log-demo-0/access.log
5 iLogtail 标准输出流采集配置
iLogtail 还原生支持标准输出流采集,service_docker_stdout 组件已经提取了 kubernetes 元信息。为避免输出组件导致的性能差异,所有日志都通过processor_filter_regex进行过滤。测试配置如下:
{
"inputs":[
{
"detail":{
"ExcludeLabel":{
},
"IncludeLabel":{
"io.kubernetes.container.name":"nginx-log-demo-0"
}
},
"type":"service_docker_stdout"
}
],
"processors":[
{
"type":"processor_filter_regex",
"detail":{
"Exclude":{
"_namespace_":"default"
}
}
}
]
}
6 iLogtail 容器文件采集配置
iLogtail原生支持容器采集中的文件,但是因为文件中的采集元信息存在于tag标签中,所以没有过滤插件。为了避免输出组件带来的性能差异,我们使用空输出插件输出,测试配置如下:
{
"metrics":{
"c0":{
"advanced":{
"k8s":{
"IncludeLabel":{
"io.kubernetes.container.name":"nginx-log-demo-0"
}
}
},
......
"plugin":{
"processors":[
{
"type":"processor_default"
}
],
"flushers":[
{
"type":"flusher_statistics",
"detail":{
"RateIntervalMs":1000000
}
}
]
},
"local_storage":true,
"log_begin_reg":".*",
"log_path":"/var/log/medlinker",
......
}
}
}
四个Filebeat和iLogtail对比测试
Filebeat和iLogtail的对比项目主要有:标准输出流采集性能、文件在容器采集性能、标准输出流多用户配置性能、容器内文件多用户配置性能和高流量采集性能。
1个标准输出流采集性能对比
输入数据源:283B/s,底层容器contianerd,标准输出流扩展为328B,共4个输入源:
下面是不同标准输出流的性能对比采集。可以看出iLogtail相比Filebeat有十倍的性能优势(CPU占比为单核占比):
下面是不同标准输出流的内存对比采集。可以看出logtail和filebeat的整体内存差别不大,并没有随着采集traffic的增加内存暴增:
2个容器文件采集性能对比
输入数据源:283B/s,共4个输入源:
下面是容器采集中不同文件的性能对比。 Filebeat容器中的文件与容器采集共享采集组件,省略了Kubernetes元相关的组件,因此相比标准输出流采集有很大的性能提升。 iLogtail容器内文件采集采用Polling+inotify机制,相比容器标准输出流采集也有性能提升,但可以看到iLogtail与Filebeat相比有5倍的提升性能优势(CPU占比为单核占比):
下面是不同标准输出流的内存对比采集。可以看出logtail和filebeat的整体内存差别不大,并没有随着采集traffic的增加内存暴增:
3 采集配置扩展性能对比
采集配置扩展性能对比,输入源设置为4,总输入速率为3M/s,50采集配置,100采集配置,500采集 @>配置,1000采集配置比较。
标准输出流采集配置膨胀比较
下面是不同标准输出流的性能对比采集。可以看到Filebeat与容器底层采集和静态文件采集共享相同的静态文件采集逻辑。标准输出流采集的路径var/log/containers下会有很多正则匹配工作。可以看到虽然采集的数据量并没有因为采集的配置增加而增加,但是CPU消耗增加了10%+,iLogtail全局共享容器路径发现机制针对容器采集模型,避免了常规逻辑带来的性能损失(CPU占比为单核占比)。
在内存扩展方面,可以看出Filebeat和iLogtail都有因采集配置增加导致的内存扩展,但两者的扩展大小都在可接受的范围内。
容器中的文件采集配置扩展对比
下图是容器中文件采集与不同采集器的性能对比,可以看到Filebeat静态文件采集相比标准增加了CPU是由于规避标准输出流的正则路径消耗少,iLogtail CPU变化也小,性能略优于标准输出流采集(CPU的百分比就是单核)。
在内存扩展方面,也可以看出Filebeat和iLogtail都有因采集配置增加导致的内存扩展,但两者的扩展大小都在可接受的范围内。
4 iLogtail 采集性能测试
由于FileBeat在日志量大的场景下存在采集延迟问题,以下场景仅针对iLogtail进行测试,iLogtail的容器标准输出为5M/s、10M/ s 和 20M/s。流 采集 和容器 采集 中的文件的性能压力测试。
和上面的测试类似,可以看出容器文件采集的性能在CPU消耗方面略优于容器标准输出流采集(百分比CPU是单核的百分比),主要是因为容器文件采集@采集底层的Polling+inotify机制。
在内存方面,由于标准输出流采集主要依赖GO,而容器文件采集主要依赖C,由于GC机制的存在,随着速率的增加,标准输出流采集消耗的内存会逐渐超过容器中文件采集消耗的内存。
5 比较总结
5 为什么Filebeat容器的标准输出和文件有这么大的差别采集?
通过以上实验,我们可以看出FIlebeat在不同工作模式下的CPU差异很大。通过dump容器采集的标准输出流的pprof,可以得到如下火焰图,可以看出Filebeat容器采集下的add_kubernets_meta插件是性能瓶颈。同时FIlebeat的add_kubernets_meta采用了api-server模式监控各个节点,也存在api-server压力问题。
iLogtail的kubernetes meta完全兼容kubernetes CRI协议,直接通过kubernets沙箱读取meta数据,保证了iLogtail的高性能采集效率。
六大iLogtail DaemonSet场景优化
从上面的对比可以看出,iLogtail相比Filebeat,内存和CPU消耗都非常出色。可能有朋友好奇iLogtail的极致性能背后的原因。下面主要讲解iLogtail Daemonset场景下的优化以及如何将标准输出Streaming比FIlebeat提升10倍的性能。
首先针对标准输出流的场景,对比其他开源采集器,比如Filebeat或者Fluentd。一般容器的标准输出流文件的采集是通过监听var/log/containers或者/var/log/pods/来实现的。例如/var/log/pods/的路径结构为:/var/log/pods /_
_
//,使用该路径复用物理机静态文件采集方式为采集。
对于iLogtail,它完全支持容器化。 iLogtail通过发现机制,全局维护一个Node节点容器列表,并实时监控维护这个容器列表。当我们有一个容器列表时,我们有以下优势:
七个结论
综上所述,在高动态的Kubernetes环境下,iLogtail不会因为Daemonset的部署模式导致的多配置问题而导致显着的内存扩展,而在静态文件采集方面,iLogtail有一个5倍左右的性能优势,对于标准输出流采集,由于iLogtail的采集机制,iLogtail有10倍左右的性能优势。但是,与 Filebeat 或 Fluentd 等老式开源产品相比,文档和社区建设方面仍然存在很多不足。欢迎对iLogtail感兴趣的朋友参与,共同打造易用、高性能的iLogtail产品。
参考文献
原文链接
采集器( 深维全能信息采集软件2.0平台开发运行本软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-29 09:10
深维全能信息采集软件2.0平台开发运行本软件)
神威全能信息采集软件(以下简称全能采集)面向国内广阔的市场应用,以最先进的技术服务国内用户。该软件是基于多年的网络信息采集软件开发经验和成果成功推出的一套自助网络信息采集和监控软件。以往采集软件往往需要复杂的配置操作才能工作,导致用户无法准确配置和修改采集的内容,最终导致软件系统无法正常工作. 本软件专门开发了自助图形化配置工具。,采用交互策略和机器学习算法,大大简化了配置操作,普通用户分分钟学会掌握。通过简单的配置,所有采集网页中的非结构化文本数据也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。网页也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。网页也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。
软件优势:
A. 一般:根据采集规则的制定,你可以采集浏览器看到的任何东西。
B、灵活:支持网站登录采集、网站跨层采集、POST采集、脚本采集、动态页面采集 等高级功能。
C、扩展性强:支持存储过程、插件等,用户可以自由扩展功能进行二次开发。
D. 高效:为了让用户节省一分钟做其他事情,软件经过精心设计。
E. 速度快:最快最高效的采集软件。
F. 稳定:系统资源占用少,运行报告详细,采集性能稳定。
G、人性化:注重软件细节,强调人性化体验。
注意:本软件基于Microsoft .NET Framework 2.0平台开发,需要安装才能运行本软件。NET 框架 2.0。 查看全部
采集器(
深维全能信息采集软件2.0平台开发运行本软件)
神威全能信息采集软件(以下简称全能采集)面向国内广阔的市场应用,以最先进的技术服务国内用户。该软件是基于多年的网络信息采集软件开发经验和成果成功推出的一套自助网络信息采集和监控软件。以往采集软件往往需要复杂的配置操作才能工作,导致用户无法准确配置和修改采集的内容,最终导致软件系统无法正常工作. 本软件专门开发了自助图形化配置工具。,采用交互策略和机器学习算法,大大简化了配置操作,普通用户分分钟学会掌握。通过简单的配置,所有采集网页中的非结构化文本数据也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。网页也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。网页也可以保存为结构化数据。此外,系统还支持用户名密码自动登录、参数自动提交、自动翻页、模板自动生成等多种功能,可以完整准确的采集各种静态页面、动态页面、文件和数据库。对于采集接收到的数据,可以通过系统提供的接口方便的与其他系统集成。
软件优势:
A. 一般:根据采集规则的制定,你可以采集浏览器看到的任何东西。
B、灵活:支持网站登录采集、网站跨层采集、POST采集、脚本采集、动态页面采集 等高级功能。
C、扩展性强:支持存储过程、插件等,用户可以自由扩展功能进行二次开发。
D. 高效:为了让用户节省一分钟做其他事情,软件经过精心设计。
E. 速度快:最快最高效的采集软件。
F. 稳定:系统资源占用少,运行报告详细,采集性能稳定。
G、人性化:注重软件细节,强调人性化体验。
注意:本软件基于Microsoft .NET Framework 2.0平台开发,需要安装才能运行本软件。NET 框架 2.0。
采集器(采集器采集收集cookie,实现数据调用会发生的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-28 05:03
采集器采集收集cookie,然后部署到服务器appstore中刷新的时候调用接口,返回历史记录。
谢邀;针对题主第一个问题,正常情况下pc端打开app也会自动跳转到下载页面的,用户点击“立即下载”就等于是调用下载者接口,也即是pc端打开app,用户跳转到下载页,实现下载目的。“itunesstore”本身是一个应用商店,题主应该没有意识到这一点吧?针对第二个问题,也正常,不同idea产品会有不同的实现方式,比如360应用助手,就是你说的pc端打开app在二次跳转到itunesstore下载。
app打开了appstore之后,跳转appstore根据请求得到的信息返回原始数据。
app页面出现了搜索框的时候,由于发生的是浏览器跳转,导致数据调用会发生问题,需要打开app打开之后,跳转到特定的数据接口即可,如果要跳转出浏览器,可以调用server接口来获取相应数据。
http协议啊,浏览器开放端口啊,
pc端点击立即下载,下载页面还是会下载呀,下载的是旧内容,新内容会获取到你的浏览器,
我也不懂啊,我们家不怎么用http协议,就是wifi自己这边都有自己的路由表啊,然后有wifi发生的时候wifi是直接连接浏览器,其他地方的连接wifi就是http这边获取数据。 查看全部
采集器(采集器采集收集cookie,实现数据调用会发生的问题)
采集器采集收集cookie,然后部署到服务器appstore中刷新的时候调用接口,返回历史记录。
谢邀;针对题主第一个问题,正常情况下pc端打开app也会自动跳转到下载页面的,用户点击“立即下载”就等于是调用下载者接口,也即是pc端打开app,用户跳转到下载页,实现下载目的。“itunesstore”本身是一个应用商店,题主应该没有意识到这一点吧?针对第二个问题,也正常,不同idea产品会有不同的实现方式,比如360应用助手,就是你说的pc端打开app在二次跳转到itunesstore下载。
app打开了appstore之后,跳转appstore根据请求得到的信息返回原始数据。
app页面出现了搜索框的时候,由于发生的是浏览器跳转,导致数据调用会发生问题,需要打开app打开之后,跳转到特定的数据接口即可,如果要跳转出浏览器,可以调用server接口来获取相应数据。
http协议啊,浏览器开放端口啊,
pc端点击立即下载,下载页面还是会下载呀,下载的是旧内容,新内容会获取到你的浏览器,
我也不懂啊,我们家不怎么用http协议,就是wifi自己这边都有自己的路由表啊,然后有wifi发生的时候wifi是直接连接浏览器,其他地方的连接wifi就是http这边获取数据。
采集器(手机采集器对手机的负载很大,不需要添加vpn功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-01-25 03:00
采集器对手机的负载很大,如果没有极好的稳定性,即使获取了数据也很难实现精准分析,所以大部分采集手机的app都是设置最大并发连接数,不然会造成服务器负载增加从而导致在连接过程中断掉。所以为了提高手机采集,iphone基本上都会有很多个采集端口(默认是1500),所以电信或者手机运营商也会要求sim卡或者安全模块必须接入更多采集端口才可以使用采集端口。
答案在知乎里面早就有了。至于你说的这个采集器,不需要。除非你在交换机上接入很多的端口才行。如果只有一个端口,是做不到连通的。
调制解调器的全部端口接在无线发射基站上,用这个基站实现接入互联网。但这个基站也有单点的用处。一般是两个,一个主站,一个从站,主站连通运营商wlan,从站连接运营商外线。手机通过at指定接入外线,才能接入互联网,否则无法连接。ios的信息采集就是这么实现的,没有添加vpn功能。
一个人一直同时连接数十个ip到同一个数据连接上,手机做缓存的话就不需要支持路由器;否则需要多进程集群,一个人连接服务器上的数十个ip,
iphone上,用一种类似ssh的软件,可以实现多个ip一起发送, 查看全部
采集器(手机采集器对手机的负载很大,不需要添加vpn功能)
采集器对手机的负载很大,如果没有极好的稳定性,即使获取了数据也很难实现精准分析,所以大部分采集手机的app都是设置最大并发连接数,不然会造成服务器负载增加从而导致在连接过程中断掉。所以为了提高手机采集,iphone基本上都会有很多个采集端口(默认是1500),所以电信或者手机运营商也会要求sim卡或者安全模块必须接入更多采集端口才可以使用采集端口。
答案在知乎里面早就有了。至于你说的这个采集器,不需要。除非你在交换机上接入很多的端口才行。如果只有一个端口,是做不到连通的。
调制解调器的全部端口接在无线发射基站上,用这个基站实现接入互联网。但这个基站也有单点的用处。一般是两个,一个主站,一个从站,主站连通运营商wlan,从站连接运营商外线。手机通过at指定接入外线,才能接入互联网,否则无法连接。ios的信息采集就是这么实现的,没有添加vpn功能。
一个人一直同时连接数十个ip到同一个数据连接上,手机做缓存的话就不需要支持路由器;否则需要多进程集群,一个人连接服务器上的数十个ip,
iphone上,用一种类似ssh的软件,可以实现多个ip一起发送,
采集器(优采云采集器网页采集常见问题解答知识兔(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-01-24 11:13
优采云采集器是一款功能强大、操作完整的网页采集软件。不需要专业知识,就可以轻松采集网页上的信息,提高大家的体验工作效率。
优采云采集器知识兔如何使用
1、开始优采云采集器,需要先登录才能使用各种功能。您可以直接点击【免费注册】按钮注册账号。
2、进入优采云软件页面后,点击【快速启动】=>【新建任务】,打开新建任务界面
3、选择一个任务组(或者新建一个任务组),输入任务名称和描述=>点击下一步
4、进入流程配置页面=>拖一个步骤打开网页进入流程设计器
5、选择打开网页的步骤=>输入页面URL=>点击保存
接下来,我们需要配置采集规则,首先在软件下方的网页上点击要成为采集的数据
6、 之后会出现一个选择对话框,这里我们选择'Extract the text of this element'
7、这样系统会自行添加一个'提取数据'步骤,这样就设置了一个数据点的采集规则,继续点击网页上的其他数据点即可为 采集,并选择“提取此元素的文本”以配置其他数据点的 采集 设置。配置完所有数据点后,修改每个数据点的名称,这样采集进程就配置好了。
保存后点击下一步=>下一步=>选择检查任务
8、打开本地采集页面,点击开始按钮,启动本地采集,查看任务运行效果,进程运行后的数据采集在界面下方的表格中从表格中的数据可以看出,我们想要的数据已经成功采集down了。
这是最简单的采集单个网页的整个流程。
优采云采集器网页采集FAQ知识兔
问题优采云采集器可以采集其他人的后台数据吗?
没有采集,后台数据需要有后台访问权限,正规的采集软件不会提供此类侵权服务。但是你可以采集你自己的后端数据。
问题优采云可以采集QQ号、邮箱、电话等吗?
是的采集,你在网页上能看到的任何数据都可以是采集,优采云采集器 内置的规则市场也有很多这样的规则可以无需配置即可下载,可以通过运行规则提取此数据。
如何判断优采云采集器采集可以是什么信息?
简单来说就是网页上可以看到的信息,优采云采集器可以执行采集,具体的采集规则需要自己设置或者从网站下载规则市场。
配置采集进程时,有时左键点击某个链接,弹出选项时页面会自动跳转。如何避免页面的自动跳转?
一些使用脚本控制跳转的网页可能会在点击左键时跳转,给配置带来不便。解决方法是使用右键,在网页上左右点击会弹出选项,没有区别。右键一般可以避免自动跳转的问题。
优采云采集器安装成功后启动失败怎么办?
如果第一次安装成功后启动提示“Windows正在配置优采云采集器,请稍候”,然后提示“安装时出现严重错误”,还有360安全卫士如果软件正在运行,可能是因为360等杀毒软件误删了优采云运行所需的文件,请退出360等杀毒软件,并重新安装 优采云采集器。
优采云采集器更新日志知识兔
V8.3.4(测试版)2021-06-25
迭代优化
优化对话窗口和操作选项的界面和交互体验
优化对话窗口副本,提高友好度
升级自定义任务编辑页面浏览器技术,提升浏览器性能流畅度及相关异常问题
点击下载 查看全部
采集器(优采云采集器网页采集常见问题解答知识兔(组图))
优采云采集器是一款功能强大、操作完整的网页采集软件。不需要专业知识,就可以轻松采集网页上的信息,提高大家的体验工作效率。
优采云采集器知识兔如何使用
1、开始优采云采集器,需要先登录才能使用各种功能。您可以直接点击【免费注册】按钮注册账号。
2、进入优采云软件页面后,点击【快速启动】=>【新建任务】,打开新建任务界面
3、选择一个任务组(或者新建一个任务组),输入任务名称和描述=>点击下一步
4、进入流程配置页面=>拖一个步骤打开网页进入流程设计器
5、选择打开网页的步骤=>输入页面URL=>点击保存
接下来,我们需要配置采集规则,首先在软件下方的网页上点击要成为采集的数据
6、 之后会出现一个选择对话框,这里我们选择'Extract the text of this element'
7、这样系统会自行添加一个'提取数据'步骤,这样就设置了一个数据点的采集规则,继续点击网页上的其他数据点即可为 采集,并选择“提取此元素的文本”以配置其他数据点的 采集 设置。配置完所有数据点后,修改每个数据点的名称,这样采集进程就配置好了。
保存后点击下一步=>下一步=>选择检查任务
8、打开本地采集页面,点击开始按钮,启动本地采集,查看任务运行效果,进程运行后的数据采集在界面下方的表格中从表格中的数据可以看出,我们想要的数据已经成功采集down了。
这是最简单的采集单个网页的整个流程。
优采云采集器网页采集FAQ知识兔
问题优采云采集器可以采集其他人的后台数据吗?
没有采集,后台数据需要有后台访问权限,正规的采集软件不会提供此类侵权服务。但是你可以采集你自己的后端数据。
问题优采云可以采集QQ号、邮箱、电话等吗?
是的采集,你在网页上能看到的任何数据都可以是采集,优采云采集器 内置的规则市场也有很多这样的规则可以无需配置即可下载,可以通过运行规则提取此数据。
如何判断优采云采集器采集可以是什么信息?
简单来说就是网页上可以看到的信息,优采云采集器可以执行采集,具体的采集规则需要自己设置或者从网站下载规则市场。
配置采集进程时,有时左键点击某个链接,弹出选项时页面会自动跳转。如何避免页面的自动跳转?
一些使用脚本控制跳转的网页可能会在点击左键时跳转,给配置带来不便。解决方法是使用右键,在网页上左右点击会弹出选项,没有区别。右键一般可以避免自动跳转的问题。
优采云采集器安装成功后启动失败怎么办?
如果第一次安装成功后启动提示“Windows正在配置优采云采集器,请稍候”,然后提示“安装时出现严重错误”,还有360安全卫士如果软件正在运行,可能是因为360等杀毒软件误删了优采云运行所需的文件,请退出360等杀毒软件,并重新安装 优采云采集器。
优采云采集器更新日志知识兔
V8.3.4(测试版)2021-06-25
迭代优化
优化对话窗口和操作选项的界面和交互体验
优化对话窗口副本,提高友好度
升级自定义任务编辑页面浏览器技术,提升浏览器性能流畅度及相关异常问题
点击下载
采集器(如何使用优采云采集器?小编教你如何设置一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-24 10:16
优采云采集器是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。下面小编就告诉你如何使用优采云采集器来吧。
优采云采集器是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。下面小编就告诉你如何使用优采云采集器来吧。
第一步打开优采云软件,点击快速启动,新建任务
第二步,找到汽车品牌的列表页面。复制这个列表页的地址,
第三步,点击页面元素为采集,如奥迪S7,系统弹出对话框后,选择创建元素列表对元素进行处理
第四步,添加元素,如果要继续添加其他品牌,点击继续编辑列表
第五步,所有品牌都显示在列表中后,点击创建列表完成。
点击循环操作进入下一个流程
第六步,因为爱卡网的品牌列表中有一些未上市的品牌,价格不能是采集,这里我们可以用市场价格作为判断条件。设置条件判断项
第七步,设置条件判断后,为页面配置需要的提取数据
第八步,设置完成后,点击下一步进入执行计划流程,设置计划执行的方法。推荐推荐云采集,速度快,可以判断是否有重复下载数据。
第九步,进入下一步,点击检查任务,会弹出如下窗口,点击以下图标开始运行下载
优采云采集器的用户也可以在软件的规则市场中下载该规则,直接导入后使用。 查看全部
采集器(如何使用优采云采集器?小编教你如何设置一个)
优采云采集器是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。下面小编就告诉你如何使用优采云采集器来吧。
优采云采集器是业界领先的网页采集软件,具有使用简单、功能强大等诸多优点。下面小编就告诉你如何使用优采云采集器来吧。
第一步打开优采云软件,点击快速启动,新建任务
第二步,找到汽车品牌的列表页面。复制这个列表页的地址,
第三步,点击页面元素为采集,如奥迪S7,系统弹出对话框后,选择创建元素列表对元素进行处理
第四步,添加元素,如果要继续添加其他品牌,点击继续编辑列表
第五步,所有品牌都显示在列表中后,点击创建列表完成。
点击循环操作进入下一个流程
第六步,因为爱卡网的品牌列表中有一些未上市的品牌,价格不能是采集,这里我们可以用市场价格作为判断条件。设置条件判断项
第七步,设置条件判断后,为页面配置需要的提取数据
第八步,设置完成后,点击下一步进入执行计划流程,设置计划执行的方法。推荐推荐云采集,速度快,可以判断是否有重复下载数据。
第九步,进入下一步,点击检查任务,会弹出如下窗口,点击以下图标开始运行下载
优采云采集器的用户也可以在软件的规则市场中下载该规则,直接导入后使用。
采集器(3,营销神器,轻松获取各大城市信息号码4,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-24 10:14
3、营销神器,轻松获取各大城市信息号码
4、详细的品类分类,轻松批量获取
5、可以获得主要城市和地区的号码
小豆子采集器更新
2016 年 4 月 16 日更新
新版本已经更新到1.version 1
新增右键过滤功能,删除过滤后的电话号码!
修复了简历栏目采集,部分栏目提示错误的bug!
导出xls文件程序,不再需要安装office,任何Windows(windows操作系统系统)系统都可以导出excel文件!
优化了一些细节!
如何使用小豆子采集器
您可以随时登录软件,随时使用所需的印版数据信息。
很多客户表示无法采集获取到采集时的数据!
但是截图给我看结果,他直接查了省名
比如:如果真的要采集山东省所有城市的数据,那么不能直接勾选“山东省”,需要勾选山东省所有城市名!
此外,采集 过程是一个两步过程。
第一步是初始化数据,即软件会先获取你想要采集的数据总量。
总数的计算方法为,【总数】=【入选城市数】×【入选栏目数】×【页数】
比如采集的城市是[北京]和[上海],采集的板块是企业招聘中的[客服]、[销售]、[司机], 采集 页已设置。从第[3]页到第[7]页设置
那么总的数据初始化量为2个地区(北京、上海)×3个板块(客服、销售、司机)×5页(从第3页到第7页)=2×3×5=30页数据
即需要初始化30页数据,所以需要等待30秒左右。当然,我无法计算初始化时间,这主要取决于网络和你电脑的配置。
第二步,初始化完成后,就是每条数据真正的采集。
设置好之后,可以抽根烟,或者找个美女聊一会儿,回来看看采集的结果。
之后也有客户说,你们的软件不能指定城市的某个区域吗?
比如北京朝阳区,我只想要朝阳区的数据。
当然在58系列下,还有一个【58网站采集】
这里大家可以根据自己的需要去采集,具体使用方法我做了视频演示,大家可以直接观看视频演示
对于更具体的功能,我还是建议大家多看视频演示,这样可以更好的了解软件的使用方法,得到自己最想要的数据。 查看全部
采集器(3,营销神器,轻松获取各大城市信息号码4,)
3、营销神器,轻松获取各大城市信息号码
4、详细的品类分类,轻松批量获取
5、可以获得主要城市和地区的号码
小豆子采集器更新
2016 年 4 月 16 日更新
新版本已经更新到1.version 1
新增右键过滤功能,删除过滤后的电话号码!
修复了简历栏目采集,部分栏目提示错误的bug!
导出xls文件程序,不再需要安装office,任何Windows(windows操作系统系统)系统都可以导出excel文件!
优化了一些细节!
如何使用小豆子采集器
您可以随时登录软件,随时使用所需的印版数据信息。
很多客户表示无法采集获取到采集时的数据!
但是截图给我看结果,他直接查了省名
比如:如果真的要采集山东省所有城市的数据,那么不能直接勾选“山东省”,需要勾选山东省所有城市名!
此外,采集 过程是一个两步过程。
第一步是初始化数据,即软件会先获取你想要采集的数据总量。
总数的计算方法为,【总数】=【入选城市数】×【入选栏目数】×【页数】
比如采集的城市是[北京]和[上海],采集的板块是企业招聘中的[客服]、[销售]、[司机], 采集 页已设置。从第[3]页到第[7]页设置
那么总的数据初始化量为2个地区(北京、上海)×3个板块(客服、销售、司机)×5页(从第3页到第7页)=2×3×5=30页数据
即需要初始化30页数据,所以需要等待30秒左右。当然,我无法计算初始化时间,这主要取决于网络和你电脑的配置。
第二步,初始化完成后,就是每条数据真正的采集。
设置好之后,可以抽根烟,或者找个美女聊一会儿,回来看看采集的结果。
之后也有客户说,你们的软件不能指定城市的某个区域吗?
比如北京朝阳区,我只想要朝阳区的数据。
当然在58系列下,还有一个【58网站采集】
这里大家可以根据自己的需要去采集,具体使用方法我做了视频演示,大家可以直接观看视频演示
对于更具体的功能,我还是建议大家多看视频演示,这样可以更好的了解软件的使用方法,得到自己最想要的数据。
采集器(优采云采集器数据收集工具采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-01-22 00:01
优采云采集器v3.0.2.6 绿色版是一款功能强大的数据采集工具,软件提供专业的采集功能,使用优采云采集器v3.0.2.6绿色版,可以帮助用户从网页采集各种数据,自动生成Excel表格、API数据库等,用户可以随时查看数据。目前软件支持大部分网站,有需要的朋友快来下载吧!
优采云采集器亮点
1、向导模式
使用简单,轻松通过鼠标点击自动生成脚本。
2、预定操作
它可以按计划运行,无需人工操作。
3、独创高速核心
自主研发的浏览器内核速度快,远超竞争对手。
4、智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)。
5、广告拦截
自定义广告拦截模块,兼容 AdblockPlus 语法,可添加自定义规则。
6、多重数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器优势
1、一键数据提取:简单易学,通过可视化界面,点击鼠标即可抓取数据。
2、快速高效:内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据。
3、适用于各类网站:能够采集99%的互联网网站,包括单页应用、Ajax加载等动态类型网站。
4、导出数据类型丰富,采集接收到的数据可以导出为Csv、Excel及各种数据库,支持API导出。
小编评测
优采云采集器为用户提供实用的数据采集服务,功能强大,操作简单。也可以设置使软件按计划运行,无需人工操作。方便的。
以上就是优采云采集器v3.0.2.6绿色版的全部内容,希望对小伙伴们有所帮助,更多软件下载并继续关注绿色先锋! 查看全部
采集器(优采云采集器数据收集工具采集器)
优采云采集器v3.0.2.6 绿色版是一款功能强大的数据采集工具,软件提供专业的采集功能,使用优采云采集器v3.0.2.6绿色版,可以帮助用户从网页采集各种数据,自动生成Excel表格、API数据库等,用户可以随时查看数据。目前软件支持大部分网站,有需要的朋友快来下载吧!
优采云采集器亮点
1、向导模式
使用简单,轻松通过鼠标点击自动生成脚本。
2、预定操作
它可以按计划运行,无需人工操作。
3、独创高速核心
自主研发的浏览器内核速度快,远超竞争对手。
4、智能识别
可智能识别网页中的列表和表单结构(多选框下拉列表等)。
5、广告拦截
自定义广告拦截模块,兼容 AdblockPlus 语法,可添加自定义规则。
6、多重数据导出
支持Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器优势
1、一键数据提取:简单易学,通过可视化界面,点击鼠标即可抓取数据。
2、快速高效:内置一套高速浏览器内核,配合HTTP引擎模式,实现快速采集数据。
3、适用于各类网站:能够采集99%的互联网网站,包括单页应用、Ajax加载等动态类型网站。
4、导出数据类型丰富,采集接收到的数据可以导出为Csv、Excel及各种数据库,支持API导出。
小编评测
优采云采集器为用户提供实用的数据采集服务,功能强大,操作简单。也可以设置使软件按计划运行,无需人工操作。方便的。
以上就是优采云采集器v3.0.2.6绿色版的全部内容,希望对小伙伴们有所帮助,更多软件下载并继续关注绿色先锋!
采集器(冰糖自媒体图文素材采集器的操作指南操作方法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-17 23:08
冰堂自媒体图文素材采集器可以在采集网站上批量批量图文,操作简单,可以支持采集百度文库和360文库,起点中文等相关网站文章文字。
兵堂自媒体图文资料采集器操作指南
1、运行软件,在目的URL处输入你需要的网站的地址采集,可以是图片站,也可以是文章,小说,或者图文版网页,然后点击“访问”按钮,等待软件完全打开网页,采集图片列表会自动列出页面中收录的图片链接。
根据您的网速,网页可能需要几秒钟才能打开。如果在这个过程中弹出“Security Alert”对话框,询问是否继续,也就是Internet Explorer浏览器的安全设置提示,点击“Yes”继续访问采集的站点, if click "Yes" No" 会采集 not。有时可能会弹出脚本错误消息,忽略yes或no即可。
2、采集的网站图片链接全部出来后(鼠标移到软件浏览器窗口会提示“网页加载完成”),点击“抓取并保存” text”按钮,即可以自动抓取网页中的文字,并自动保存在你标题指定的“存储路径”下(文章如果长度过长,会在网页上的文字抓取框软件右侧可能显示不全,这种情况请打开Autosaved text 采集文件查看)。
如果需要采集图片,点击“开始采集/压缩”按钮自动批量采集,图片会自动保存到你指定的“存储路径”文件夹中。当然你也可以选择只下载单个文件,可以点击“预览图片”按钮预览图片文件为采集。为了节省空间,在批量下载图片的同时,也可以勾选“自动压缩采集图片”选项,下载的图片会被自动压缩(当然会同步损坏图片质量)。如果在压缩前备份原创图像文件,您也可以勾选“压缩前备份图像”选项。
除了从远程采集压缩图片文件,批量压缩功能还可以批量压缩你(电脑)本地的图片文件。
3、完成当前网页的图文素材采集后,如果要采集下一栏或下一网页,需要点击网站@软件浏览器窗口用鼠标>相关栏或“下一页”(“下一页”),等到下一页完全打开后再去采集。“设为空白页”旁边的小箭头可放大软件浏览器窗口,方便查看相关内容。
4、每次输入的URL软件都会自动保存到下拉菜单中,方便下次直接点击访问。如果内容太多,想清除,打开软件安装目录下的myurl.ini文件,整理删除URL。如果勾选“设为空白页”,则每次启动软件时不会自动打开网站主页。
5、采集日志保存在软件安装目录下的mylog.txt中。
另外,预览部分png图片或空URL图片可能会报错或崩溃,请忽略。 查看全部
采集器(冰糖自媒体图文素材采集器的操作指南操作方法介绍)
冰堂自媒体图文素材采集器可以在采集网站上批量批量图文,操作简单,可以支持采集百度文库和360文库,起点中文等相关网站文章文字。
兵堂自媒体图文资料采集器操作指南
1、运行软件,在目的URL处输入你需要的网站的地址采集,可以是图片站,也可以是文章,小说,或者图文版网页,然后点击“访问”按钮,等待软件完全打开网页,采集图片列表会自动列出页面中收录的图片链接。
根据您的网速,网页可能需要几秒钟才能打开。如果在这个过程中弹出“Security Alert”对话框,询问是否继续,也就是Internet Explorer浏览器的安全设置提示,点击“Yes”继续访问采集的站点, if click "Yes" No" 会采集 not。有时可能会弹出脚本错误消息,忽略yes或no即可。
2、采集的网站图片链接全部出来后(鼠标移到软件浏览器窗口会提示“网页加载完成”),点击“抓取并保存” text”按钮,即可以自动抓取网页中的文字,并自动保存在你标题指定的“存储路径”下(文章如果长度过长,会在网页上的文字抓取框软件右侧可能显示不全,这种情况请打开Autosaved text 采集文件查看)。
如果需要采集图片,点击“开始采集/压缩”按钮自动批量采集,图片会自动保存到你指定的“存储路径”文件夹中。当然你也可以选择只下载单个文件,可以点击“预览图片”按钮预览图片文件为采集。为了节省空间,在批量下载图片的同时,也可以勾选“自动压缩采集图片”选项,下载的图片会被自动压缩(当然会同步损坏图片质量)。如果在压缩前备份原创图像文件,您也可以勾选“压缩前备份图像”选项。
除了从远程采集压缩图片文件,批量压缩功能还可以批量压缩你(电脑)本地的图片文件。
3、完成当前网页的图文素材采集后,如果要采集下一栏或下一网页,需要点击网站@软件浏览器窗口用鼠标>相关栏或“下一页”(“下一页”),等到下一页完全打开后再去采集。“设为空白页”旁边的小箭头可放大软件浏览器窗口,方便查看相关内容。
4、每次输入的URL软件都会自动保存到下拉菜单中,方便下次直接点击访问。如果内容太多,想清除,打开软件安装目录下的myurl.ini文件,整理删除URL。如果勾选“设为空白页”,则每次启动软件时不会自动打开网站主页。
5、采集日志保存在软件安装目录下的mylog.txt中。
另外,预览部分png图片或空URL图片可能会报错或崩溃,请忽略。
采集器(采集器+python吧可以试试这种方法:通过利用免费工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-10 18:04
采集器+python吧可以试试这种方法:通过利用免费工具爬虫软件爬取糗事百科上的段子保存为gif动图(知乎上的也是类似,
先注册一个可以发送短信验证码的app.然后在那个app发送你想要的段子就可以了.也可以自己写爬虫自己发送.
去年我试了,一天半时间,
万能的某宝!100-200元能解决!
去百度一下:推友流量,
各大社交网站会有很多截图大神和发布信息的一些公众号,网上资源多的很。你可以先去尝试试看。
推荐一个我认为会回答的到你问题的知乎-花椒
360手机助手应该有,
5块钱,名片全能王的“自动合成”功能,把你想要的发给他们,我之前是在某大佬的论坛找到这样的方法。
leanote和自带采集器
目前有很多人用西瓜助手进行专题网站的内容爬取和数据抓取,
我记得,
老早以前我也用过优采云来解决。
阿里巴巴用了你就明白了
想要快速有效的采集网络内容?方法有很多,
1、了解网站生意参谋,一个seo专家都要看。
2、花些小钱,联盟、阿里妈妈、易门ueeshop等,操作简单,可以在线注册平台操作,
3、通过百度导入站点地址,如果你懂技术也可以用seocut,利用关键词抓取,不懂技术、懂如何操作的可以试一试云采集器、搜狗站长平台等。
4、采集的方式大体有两种,搜索引擎自动抓取和手动采集,通过后台控制可以一键调整和更改设置,页面采集,可选择关键词抓取。有个软件可以自动关键词采集,
5、了解amazon内容抓取,可以在amazon上找客户需要的内容,找到之后发到youtubepage,很多人都这么干。更多采集知识、操作、策略,
6、另外一种是蜘蛛爬虫模式,顾名思义,就是让搜索引擎找到你的内容, 查看全部
采集器(采集器+python吧可以试试这种方法:通过利用免费工具)
采集器+python吧可以试试这种方法:通过利用免费工具爬虫软件爬取糗事百科上的段子保存为gif动图(知乎上的也是类似,
先注册一个可以发送短信验证码的app.然后在那个app发送你想要的段子就可以了.也可以自己写爬虫自己发送.
去年我试了,一天半时间,
万能的某宝!100-200元能解决!
去百度一下:推友流量,
各大社交网站会有很多截图大神和发布信息的一些公众号,网上资源多的很。你可以先去尝试试看。
推荐一个我认为会回答的到你问题的知乎-花椒
360手机助手应该有,
5块钱,名片全能王的“自动合成”功能,把你想要的发给他们,我之前是在某大佬的论坛找到这样的方法。
leanote和自带采集器
目前有很多人用西瓜助手进行专题网站的内容爬取和数据抓取,
我记得,
老早以前我也用过优采云来解决。
阿里巴巴用了你就明白了
想要快速有效的采集网络内容?方法有很多,
1、了解网站生意参谋,一个seo专家都要看。
2、花些小钱,联盟、阿里妈妈、易门ueeshop等,操作简单,可以在线注册平台操作,
3、通过百度导入站点地址,如果你懂技术也可以用seocut,利用关键词抓取,不懂技术、懂如何操作的可以试一试云采集器、搜狗站长平台等。
4、采集的方式大体有两种,搜索引擎自动抓取和手动采集,通过后台控制可以一键调整和更改设置,页面采集,可选择关键词抓取。有个软件可以自动关键词采集,
5、了解amazon内容抓取,可以在amazon上找客户需要的内容,找到之后发到youtubepage,很多人都这么干。更多采集知识、操作、策略,
6、另外一种是蜘蛛爬虫模式,顾名思义,就是让搜索引擎找到你的内容,
采集器(优采云采集器(www.ucaiyun.com)的数据采集软件介绍及特色介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-01-10 06:13
优采云采集器()是一款功能强大的数据采集软件,可以轻松抓取文字、图片、文件等资源。软件还支持图片文件远程下载、文件真实地址检测、防盗链采集和采集数据直接存储、模仿者手动发布等。
软件功能
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
基本技能
1、规则自定义 - 使用 采集 规则定义,几乎可以搜索所有 网站采集 任何类型的信息。
2、多任务,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储——数据在采集的同时自动保存到关系数据库,数据结构可以自动适配,软件可以根据采集规则自动创建数据库,其中的表和字段,数据也可以通过数据库导入的方式灵活的保存到客户现有的数据库结构中。
5、Breakpoint Continuation - 信息采集任务在停止后可以从断点继续采集,因此您不再需要担心您的采集 任务被意外中断。
6、网站登录——支持网站cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled Tasks - 此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制 - 采集 的范围可以根据 采集 的深度和 URL 的身份来限制。
9、文件下载 - 您可以将 采集 二进制文件(例如图片、音乐、软件、文档等)下载到本地磁盘或 采集结果数据库。
10、结果替换——可以根据规则将采集的结果替换为你定义的内容。
变更日志
2021-03-15
优采云采集器V9.版本 30
1、优化了标签数据处理中的字符替换。
2、优化了无效文件检测导致文件下载失败的问题。
3、处理用户名收录特殊符号无法登录的问题。
4、修复数据管理批量操作数据有异常弹出提示的问题。
5、修复了二级代理卡住的问题。
6、改进了无法自动获取cookies的问题。
7、发布到word,自动将""转义为""、"""。
8、已修复:勾选发布选项,采集最大数量无效。
9、修复 oracle 链接问题。
10、支持oss存储。
11、修复:下载地址后面有斜线,下载文件时没有后缀。 查看全部
采集器(优采云采集器(www.ucaiyun.com)的数据采集软件介绍及特色介绍)
优采云采集器()是一款功能强大的数据采集软件,可以轻松抓取文字、图片、文件等资源。软件还支持图片文件远程下载、文件真实地址检测、防盗链采集和采集数据直接存储、模仿者手动发布等。
软件功能
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和.net对外编程接口处理数据,让数据为你所用。
基本技能
1、规则自定义 - 使用 采集 规则定义,几乎可以搜索所有 网站采集 任何类型的信息。
2、多任务,多线程——可以同时执行多个信息获取任务,每个任务可以使用多个线程。
3、所见即所得——所见即所得,在任务采集过程中得到。过程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储——数据在采集的同时自动保存到关系数据库,数据结构可以自动适配,软件可以根据采集规则自动创建数据库,其中的表和字段,数据也可以通过数据库导入的方式灵活的保存到客户现有的数据库结构中。
5、Breakpoint Continuation - 信息采集任务在停止后可以从断点继续采集,因此您不再需要担心您的采集 任务被意外中断。
6、网站登录——支持网站cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、Scheduled Tasks - 此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制 - 采集 的范围可以根据 采集 的深度和 URL 的身份来限制。
9、文件下载 - 您可以将 采集 二进制文件(例如图片、音乐、软件、文档等)下载到本地磁盘或 采集结果数据库。
10、结果替换——可以根据规则将采集的结果替换为你定义的内容。
变更日志
2021-03-15
优采云采集器V9.版本 30
1、优化了标签数据处理中的字符替换。
2、优化了无效文件检测导致文件下载失败的问题。
3、处理用户名收录特殊符号无法登录的问题。
4、修复数据管理批量操作数据有异常弹出提示的问题。
5、修复了二级代理卡住的问题。
6、改进了无法自动获取cookies的问题。
7、发布到word,自动将""转义为""、"""。
8、已修复:勾选发布选项,采集最大数量无效。
9、修复 oracle 链接问题。
10、支持oss存储。
11、修复:下载地址后面有斜线,下载文件时没有后缀。
采集器(curl百度云采集器,网上使用教程采集教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-08 10:01
采集器是以采集中的文本(url)为存储载体的外包装卡,此外还有较长的联络字符串。主要用于im游戏数据提取、工作流程协同计算、物联网设备采集、车辆定位、控制等方面。众所周知的有最强大的浏览器采集器-ie9+ie5/ie7采集器,新手非常推荐,基本上所有常用的采集文件都可以做到爬下来。curl采集这里推荐使用curl这个采集器,网上很多使用采集器小助手的教程都是参照这个的,适合新手使用,小巧简洁不占内存,永久免费使用。
百度云引擎从某种意义上比curl采集还强大,支持接口多,服务稳定且免费。dotfileer百度云采集就是curl和dotfile脚本的结合体,调用百度云采集这个小软件生成的浏览器即插即用,软件本身兼容性也比较好。三者安装和使用场景都不同,所以两者没有可比性,参照别人写的就行了。
用windows采集肯定没有unix方便,因为里面已经有,比如com抓包,usb调试。其他pc采集器肯定是有自己的特色。比如有些可以轻松抓取常见的物联网网站的cookie,因为有链接数据库,导入导出。这是windows下有效的unix才用得到的功能。至于什么windowsapi之类的,一样的都可以采集到。不同的是编程设计方式不同。
1采集器我用的是scrapy。2接口有几个。不过不太好。3等我系统学好后,再去弄unix,client也行。比如用webscrapy、threejs。 查看全部
采集器(curl百度云采集器,网上使用教程采集教程)
采集器是以采集中的文本(url)为存储载体的外包装卡,此外还有较长的联络字符串。主要用于im游戏数据提取、工作流程协同计算、物联网设备采集、车辆定位、控制等方面。众所周知的有最强大的浏览器采集器-ie9+ie5/ie7采集器,新手非常推荐,基本上所有常用的采集文件都可以做到爬下来。curl采集这里推荐使用curl这个采集器,网上很多使用采集器小助手的教程都是参照这个的,适合新手使用,小巧简洁不占内存,永久免费使用。
百度云引擎从某种意义上比curl采集还强大,支持接口多,服务稳定且免费。dotfileer百度云采集就是curl和dotfile脚本的结合体,调用百度云采集这个小软件生成的浏览器即插即用,软件本身兼容性也比较好。三者安装和使用场景都不同,所以两者没有可比性,参照别人写的就行了。
用windows采集肯定没有unix方便,因为里面已经有,比如com抓包,usb调试。其他pc采集器肯定是有自己的特色。比如有些可以轻松抓取常见的物联网网站的cookie,因为有链接数据库,导入导出。这是windows下有效的unix才用得到的功能。至于什么windowsapi之类的,一样的都可以采集到。不同的是编程设计方式不同。
1采集器我用的是scrapy。2接口有几个。不过不太好。3等我系统学好后,再去弄unix,client也行。比如用webscrapy、threejs。
采集器(appleapplewatch推送的流程和机制是依赖quicktimex64或者quicktimex4)
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-12-30 00:04
采集器基本都会尽可能的让记录全面一些,会对下游产品有一定的影响,也不是绝对的,我使用clipboardsnap就没出现视频上传被删除的情况(但是音频被删除了貌似只是我自己随便起的名字)。
如果只是上传到在线视频网站没有下载到本地,一般是不会影响传输质量的。如果要上传到本地再下载,那至少要保证上传时的质量不低于官方提供的指定质量。另外多线程和速度是硬指标,没有听说有第三方的app能实现多线程和高速。
无法实现。apple的推送系统是依赖quicktimex64或者quicktimex4.,apple自己对多线程和速度提得比较仔细。更多关于apple推送的资料,请参考以下链接:applewatch推送的流程和机制,
华人业界只推送ppt。
apple已经推出使用ipseasyie技术进行本地视频传输的方案,比如keepcallbackprotocol-apple支持。华尔街推送很好。
当然不是原始格式就行不需要搞什么优化的只要在运行时传输足够大的带宽足够的流量就行不在乎什么用户体验
这个主要取决于下载工具本身的制作标准,一般都不是原始带宽,特别是广告视频之类,要钱。
它被称为全栈优化。是指apple在新版本的ios或macos平台应用程序中,对速度及稳定性等因素的全方位优化,包括将不必要的小核心apk分发和丢弃在itunes或同步助手分发,将包含一些付费内容不必要分发等等。 查看全部
采集器(appleapplewatch推送的流程和机制是依赖quicktimex64或者quicktimex4)
采集器基本都会尽可能的让记录全面一些,会对下游产品有一定的影响,也不是绝对的,我使用clipboardsnap就没出现视频上传被删除的情况(但是音频被删除了貌似只是我自己随便起的名字)。
如果只是上传到在线视频网站没有下载到本地,一般是不会影响传输质量的。如果要上传到本地再下载,那至少要保证上传时的质量不低于官方提供的指定质量。另外多线程和速度是硬指标,没有听说有第三方的app能实现多线程和高速。
无法实现。apple的推送系统是依赖quicktimex64或者quicktimex4.,apple自己对多线程和速度提得比较仔细。更多关于apple推送的资料,请参考以下链接:applewatch推送的流程和机制,
华人业界只推送ppt。
apple已经推出使用ipseasyie技术进行本地视频传输的方案,比如keepcallbackprotocol-apple支持。华尔街推送很好。
当然不是原始格式就行不需要搞什么优化的只要在运行时传输足够大的带宽足够的流量就行不在乎什么用户体验
这个主要取决于下载工具本身的制作标准,一般都不是原始带宽,特别是广告视频之类,要钱。
它被称为全栈优化。是指apple在新版本的ios或macos平台应用程序中,对速度及稳定性等因素的全方位优化,包括将不必要的小核心apk分发和丢弃在itunes或同步助手分发,将包含一些付费内容不必要分发等等。
采集器(智能采集优采云 采集模板采集模式(图)处理 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-12-29 04:05
采集模板采集模式(图)处理
)
模板集合
模板采集模式内置了上百个主流网站数据源,如京东、天猫、大众点评等热门采集网站。只需参考模板设置参数,即可快速获取网站公共数据。
现在查看
智能采集
优采云
根据不同的网站,采集
可提供多种网页采集
策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集过程实现数据的完整性和稳定性。
现在查看
云集
5000多台云服务器支持的云采集,7*24小时运行,可实现无人值守定时采集,灵活适配业务场景,助您提升采集效率,保障数据及时性。
现在查看
API接口
通过优采云
API,您可以轻松获取优采云
任务信息和采集数据,灵活调度远程控制任务启停等任务,高效实现数据采集和归档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
现在查看
自定义集合
针对不同用户的采集需求,优采云
可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、 ajax,页面滚动,条件判断。支持不同网页结构的复杂网站的采集,满足多种采集应用场景。
现在查看
方便的定时功能
只需几下简单的点击和设置,即可实现采集任务的时序控制。无论是单次采集的定时设置,还是预设日或周、月定时采集,多个任务可以同时自由设置。根据需要选择时间多种组合,灵活部署自己的采集任务。
现在查看
全自动数据格式化
优采云
内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能。采集过程中全自动处理,无需人工干预,即可获取所需格式的数据。
免费下载
多层次采集
很多主流新闻、电商网站都收录
一级商品列表页、二级商品详情页、三级评论详情页;无论站点有多少层级,优采云
都可以没有层级限制 采集的数据满足各种业务的采集需求。
免费下载
支持登录网站后采集
优采云
内置采集登录模块,您只需要配置目标网站的账号密码,登录后即可使用该模块采集数据;同时,优采云
还具有采集
cookies的自定义功能。首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持采集
更多网站。
免费下载
查看全部
采集器(智能采集优采云
采集模板采集模式(图)处理
)
模板集合
模板采集模式内置了上百个主流网站数据源,如京东、天猫、大众点评等热门采集网站。只需参考模板设置参数,即可快速获取网站公共数据。
现在查看
智能采集
优采云
根据不同的网站,采集
可提供多种网页采集
策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集过程实现数据的完整性和稳定性。
现在查看
云集
5000多台云服务器支持的云采集,7*24小时运行,可实现无人值守定时采集,灵活适配业务场景,助您提升采集效率,保障数据及时性。
现在查看
API接口
通过优采云
API,您可以轻松获取优采云
任务信息和采集数据,灵活调度远程控制任务启停等任务,高效实现数据采集和归档。基于强大的API系统,还可以与公司内部各种管理平台无缝对接,实现各种业务自动化。
现在查看
自定义集合
针对不同用户的采集需求,优采云
可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、 ajax,页面滚动,条件判断。支持不同网页结构的复杂网站的采集,满足多种采集应用场景。
现在查看
方便的定时功能
只需几下简单的点击和设置,即可实现采集任务的时序控制。无论是单次采集的定时设置,还是预设日或周、月定时采集,多个任务可以同时自由设置。根据需要选择时间多种组合,灵活部署自己的采集任务。
现在查看
全自动数据格式化
优采云
内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等多项功能。采集过程中全自动处理,无需人工干预,即可获取所需格式的数据。
免费下载
多层次采集
很多主流新闻、电商网站都收录
一级商品列表页、二级商品详情页、三级评论详情页;无论站点有多少层级,优采云
都可以没有层级限制 采集的数据满足各种业务的采集需求。
免费下载
支持登录网站后采集
优采云
内置采集登录模块,您只需要配置目标网站的账号密码,登录后即可使用该模块采集数据;同时,优采云
还具有采集
cookies的自定义功能。首次登录后可自动记住cookies,免去多次输入密码的繁琐,支持采集
更多网站。
免费下载

