
采集器的自动识别算法
防采集 - 最讨厌采集,一点技术浓度都没有!
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-11 14:55
很多防采集方法在实行的时侯须要考虑是否影响搜索引擎对网站的抓取,所以先来剖析下通常采集器和搜索引擎爬虫采集有何不同。
相同点:a. 两者都须要直接抓取到网页源码能够有效工作,b. 两者单位时间内会多次大量抓取被访问的网站内容;c. 宏观上来讲二者IP就会变动;d. 两者多没耐心的去破解你对网页的一些加密(验证),比如网页内容通过js文件加密,比如须要输入验证码能够浏览内容,比如须要登陆能够访问内容等。
不同点:搜索引擎爬虫先忽视整个网页源码脚本和款式以及html标签代码,然后对剩下的文字部份进行切成语法复句剖析等一系列的复杂处理。而采集器通常是通过html标签特性来抓取须要的数据,在制做采集规则时须要填写目标内容的开始标志何结束标志,这样就定位了所须要的内容;或者采用对特定网页制做特定的正则表达式,来筛选出须要的内容。无论是借助开始结束标志还是正则表达式,都会涉及到html标签(网页结构剖析)。
然后再来提出一些防采集方法
1、限制IP地址单位时间的访问次数
分析:没有那个常人一秒钟内能访问相同网站5次,除非是程序访问,而有这些喜好的,就剩下搜索引擎爬虫和厌恶的采集器了。
弊端:一刀切,这同样会制止搜索引擎对网站的收录
适用网站:不太借助搜索引擎的网站
采集器会怎样做:减少单位时间的访问次数,减低采集效率
2、屏蔽ip
分析:通过后台计数器,记录来访者ip和访问频度,人为剖析来访记录,屏蔽可疑Ip。
弊端:似乎没哪些弊病,就是站长忙了点
适用网站:所有网站,且站长才能晓得什么是google或则百度的机器人
采集器会怎样做:打游击战呗!利用ip代理采集一次换一次,不过会增加采集器的效率和网速(用代理嘛)。
3、利用js加密网页内容
Note:这个方式我没接触过,只是从别处看来
分析:不用剖析了,搜索引擎爬虫和采集器通杀
适用网站:极度厌恶搜索引擎和采集器的网站
采集器会如此做:你这么牛,都豁出去了,他就不来采你了
4、网页里隐藏网站版权或则一些随机垃圾文字,这些文字风格写在css文件中
分析:虽然不能避免采集,但是会使采集后的内容饱含了你网站的版权说明或则一些垃圾文字,因为通常采集器不会同时采集你的css文件,那些文字没了风格,就显示下来了。
适用网站:所有网站
采集器会怎样做:对于版权文字,好办,替换掉。对于随机的垃圾文字,没办法,勤快点了。
5、用户登入能够访问网站内容
分析:搜索引擎爬虫不会对每位这样类型的网站设计登入程序。听说采集器可以针对某个网站设计模拟用户登入递交表单行为。
适用网站:极度厌恶搜索引擎,且想制止大部分采集器的网站
采集器会怎样做:制作拟用户登入递交表单行为的模块
6、利用脚本语言做分页(隐藏分页)
分析:还是那句,搜索引擎爬虫不会针对各类网站的隐藏分页进行剖析,这影响搜索引擎对其收录。但是,采集器在编撰采集规则时,要剖析目标网页代码,懂点脚本知识的人,就会晓得分页的真实链接地址。
适用网站:对搜索引擎依赖度不高的网站,还有,采集你的人不懂脚本知识
采集器会怎样做:应该说采集器会怎样做,他总之都要剖析你的网页代码,顺便剖析你的分页脚本,花不了多少额外时间。
7、防盗链举措(只容许通过本站页面联接查看,如:Request.ServerVariables(“HTTP_REFERER“) )
分析:ASP/' target='_blank'>asp和php可以通过读取恳求的HTTP_REFERER属性,来判定该恳求是否来自本网站,从而来限制采集器,同样也限制了搜索引擎爬虫,严重影响搜索引擎对网站部分防盗链内容的收录。
适用网站:不太考虑搜索引擎收录的网站
采集器会怎样做:伪装HTTP_REFERER嘛,不难。
8、全flash、图片或则pdf来呈现网站内容
分析:对搜索引擎爬虫和采集器支持性不好,这个好多懂点seo的人都晓得
适用网站:媒体设计类而且不在乎搜索引擎收录的网站
采集器会怎样做:不采了,走人
9、网站随机采用不同模版
分析:因为采集器是依照网页结构来定位所须要的内容,一旦先后两次模版更换,采集规则就失效,不错。而且这样对搜索引擎爬虫没影响。
适用网站:动态网站,并且不考虑用户体验。
采集器会怎样做:一个网站模版不可能少于10个吧,每个模版弄一个规则就行了,不同模版采用不同采集规则。如果少于10个模版了,既然目标网站都这么费力的更换模版,成全他,撤。
10、采用动态不规则的html标签
分析:这个比较变态。考虑到html标签内含空格和不含空格疗效是一样的,所以和对于页面显示疗效一样,但是作为采集器的标记就是两个不同标记了。如果每次页面的html标签内空格数随机,那么
采集规则就失效了。但是,这对搜索引擎爬虫没多大影响。
适合网站:所有动态且不想违背网页设计规范的网站。
采集器会怎样做:还是有对策的,现在html cleaner还是好多的,先清除了html标签,然后再写采集规则;应该用采集规则前先清除html标签,还是才能领到所需数据。
总结:
一旦要同时搜索引擎爬虫和采集器,这是太使人无奈的事情,因为搜索引擎第一步就是采集目标网页内容,这跟采集器原理一样,所以好多避免采集的方式同时也妨碍了搜索引擎对网站的收录,无奈,是吧?以上10条建议尽管不能百分之百防采集,但是几种方式一起适用早已拒绝了一大部分采集器了。
三、关于防采集的方式
优采云:下面讲一些主要的防采集方法。可以说是攻守对战吧。打开一个网页实际就是一个Http请求浏览器。百度蜘蛛,小到我们的采集器使用的都是一个原理,模拟http请求,所以我们同样能模拟出浏览器。百度蜘蛛下来所以绝对的防采集根本不存在,只是难度的高低。或者你觉得搜索引擎的搜录也无所谓了。你可以用一些特别强悍的activex,flash,全图片文字的方式,这个我们无能为力。
普通的防采集方法有
1、来源判定
2、登录信息判定 Cookie
3、请求次数判别。如一段时间内恳求多少,非常规操作则封IP
4、发送方法判定 POST GET 使用JS,Ajax等恳请内容
举例:
1.2不用说了,论坛,下载站等。。
3、一些大网站,需要配置服务器,单纯靠脚本判定资源消耗比较大
4、如一些急聘站,的分页,Web2.0站的ajax恳求内容
当然我们前面还发觉一些*****锏,今天第一次在这里给你们公布下来~~ 有优质内容须要防采集的同学可以考虑试下
1、网页默认deflate压缩输出(gzip容易一点,容易解压) 我们普通的浏览器和baidu支持辨识gzip,deflate输出内容
2、网页内容不定时 /0 内容手动截断,这两点基本可以防主大部分主流软件采集及web采集程序了~
今天主要想要抒发的一点,大家在做站时一定要注意技术的提升,比如我们上面有后期外部php及.net插口处理采集数据。或者干脆你自己做一个发布时的插口程序自己入库。我们伪原创做得再好,一样有特别多的会员使用,那样又不原创了,采集一样须要技术,只有你通过采集器获得了没有多少人有的数据,你才是惟一了。可能是我最为技术型人的一个弊病,谢谢你们!
互动环节
问:您刚刚谈到对采集有屏蔽,那对搜索引擎呢
答:采集和百度爬虫是一模一样的原理 还有浏览器也是一样的 所以没有绝对的屏蔽,相反都会影响客户体验,你可以做一些不影响客户体验和搜索引擎搜录而提升采集难度的尝试
问:你刚刚讲的是网页内容采集,有没有针对匹配关键词的指定数组的高速采集,比如采集所有带”IDC“的网页的邮箱和电话号码?用过一些,速度太慢,而且数据量显著很少。
答:我们不做这样批量的工具,其实例如做峰会发帖机之类的实现上去道理一样,也很容易,其实实现上去也是可以,只是有更多的一些人工操作,我们上面有 正则匹配。。也就是你要的这些单一工具把这些正则都集成在上面了。而我们须要用户自己去写
问:采集的复杂度应当就在这吧?页面规则的不规则性和多变性?
答:在软件上面设置才能匹配多种模板的正则表达式,一样可以采集到多模板的网站,所谓“道高一尺,魔高一丈”。
问:优采云,能不能说一下如何把phpcms的文章模块下的第一级栏目显示下来啊?
答:用的是 07 还是08版 07版有一个终极栏目的属性 如果是,就不显示。
问:优采云,你认为那个CMS比较好用,你给你们推荐一个你最钟意的CMS系统吧。
答:我如今是对phpcms更熟悉一些。选择一个适宜自己的就够了。研究透一个。
问:有个采集工具 海纳 号称不要编撰采集规则,不知道有没有同事研究过,想讨教其原理?
答:你说的这个是内容主体辨识的范畴了。也做过,但只对一些新闻网站识别得比较好 ,这是一个手动匹配方式的工具,就像百度新闻一样,能手动匹配到正文数据。对大数据量的提取有用处。但精度相对低点点,因为人工不可控。
问:2008 版本能平滑升级到 2009吗?我是免费用户,呵呵。
答:软件升级:请运行程序目录下的updateto2009.exe进行升级。支持3.2sp5及2008版到2009版的升级,支持所有用户
问:请问伪原创的问题如何处理呢?
答:我们伪原创做得再好,一样有特别多的会员使用,那样又不原创了,采集一样须要技术,只有你通过采集器获得了没有多少人有的数据,你才是惟一了。比如我们有同义词替换功能,这个词库就须要最好你自己去扩展一个属于自己的伪原创。使用同义词反义词替换,排除敏感词,不同的标签之间数据融合,指如标题内容之间数据的互相替换给标题。内容副词。为文章标题等生成拼音地址 给文章加上摘要。采集一些其他编码的网站,我们可以做到简简体转化,可以采集中文网站翻译成英文(虽然比较垃圾,但应当可以算是原创)网民,默认的我们能否手动辨识网页的编码。但可能也会有出错的时侯,这时候你须要在任务第四页手工定义一下,比如是gb2312还是utf8等等。 查看全部
笔者自己是写采集器的,所以对网站防采集有一些心得感悟。因为是在下班时间,各种方式只是简单的提到。
很多防采集方法在实行的时侯须要考虑是否影响搜索引擎对网站的抓取,所以先来剖析下通常采集器和搜索引擎爬虫采集有何不同。
相同点:a. 两者都须要直接抓取到网页源码能够有效工作,b. 两者单位时间内会多次大量抓取被访问的网站内容;c. 宏观上来讲二者IP就会变动;d. 两者多没耐心的去破解你对网页的一些加密(验证),比如网页内容通过js文件加密,比如须要输入验证码能够浏览内容,比如须要登陆能够访问内容等。
不同点:搜索引擎爬虫先忽视整个网页源码脚本和款式以及html标签代码,然后对剩下的文字部份进行切成语法复句剖析等一系列的复杂处理。而采集器通常是通过html标签特性来抓取须要的数据,在制做采集规则时须要填写目标内容的开始标志何结束标志,这样就定位了所须要的内容;或者采用对特定网页制做特定的正则表达式,来筛选出须要的内容。无论是借助开始结束标志还是正则表达式,都会涉及到html标签(网页结构剖析)。
然后再来提出一些防采集方法
1、限制IP地址单位时间的访问次数
分析:没有那个常人一秒钟内能访问相同网站5次,除非是程序访问,而有这些喜好的,就剩下搜索引擎爬虫和厌恶的采集器了。
弊端:一刀切,这同样会制止搜索引擎对网站的收录
适用网站:不太借助搜索引擎的网站
采集器会怎样做:减少单位时间的访问次数,减低采集效率
2、屏蔽ip
分析:通过后台计数器,记录来访者ip和访问频度,人为剖析来访记录,屏蔽可疑Ip。
弊端:似乎没哪些弊病,就是站长忙了点
适用网站:所有网站,且站长才能晓得什么是google或则百度的机器人
采集器会怎样做:打游击战呗!利用ip代理采集一次换一次,不过会增加采集器的效率和网速(用代理嘛)。
3、利用js加密网页内容
Note:这个方式我没接触过,只是从别处看来
分析:不用剖析了,搜索引擎爬虫和采集器通杀
适用网站:极度厌恶搜索引擎和采集器的网站
采集器会如此做:你这么牛,都豁出去了,他就不来采你了
4、网页里隐藏网站版权或则一些随机垃圾文字,这些文字风格写在css文件中
分析:虽然不能避免采集,但是会使采集后的内容饱含了你网站的版权说明或则一些垃圾文字,因为通常采集器不会同时采集你的css文件,那些文字没了风格,就显示下来了。
适用网站:所有网站
采集器会怎样做:对于版权文字,好办,替换掉。对于随机的垃圾文字,没办法,勤快点了。
5、用户登入能够访问网站内容
分析:搜索引擎爬虫不会对每位这样类型的网站设计登入程序。听说采集器可以针对某个网站设计模拟用户登入递交表单行为。
适用网站:极度厌恶搜索引擎,且想制止大部分采集器的网站
采集器会怎样做:制作拟用户登入递交表单行为的模块
6、利用脚本语言做分页(隐藏分页)
分析:还是那句,搜索引擎爬虫不会针对各类网站的隐藏分页进行剖析,这影响搜索引擎对其收录。但是,采集器在编撰采集规则时,要剖析目标网页代码,懂点脚本知识的人,就会晓得分页的真实链接地址。
适用网站:对搜索引擎依赖度不高的网站,还有,采集你的人不懂脚本知识
采集器会怎样做:应该说采集器会怎样做,他总之都要剖析你的网页代码,顺便剖析你的分页脚本,花不了多少额外时间。
7、防盗链举措(只容许通过本站页面联接查看,如:Request.ServerVariables(“HTTP_REFERER“) )
分析:ASP/' target='_blank'>asp和php可以通过读取恳求的HTTP_REFERER属性,来判定该恳求是否来自本网站,从而来限制采集器,同样也限制了搜索引擎爬虫,严重影响搜索引擎对网站部分防盗链内容的收录。
适用网站:不太考虑搜索引擎收录的网站
采集器会怎样做:伪装HTTP_REFERER嘛,不难。
8、全flash、图片或则pdf来呈现网站内容
分析:对搜索引擎爬虫和采集器支持性不好,这个好多懂点seo的人都晓得
适用网站:媒体设计类而且不在乎搜索引擎收录的网站
采集器会怎样做:不采了,走人
9、网站随机采用不同模版
分析:因为采集器是依照网页结构来定位所须要的内容,一旦先后两次模版更换,采集规则就失效,不错。而且这样对搜索引擎爬虫没影响。
适用网站:动态网站,并且不考虑用户体验。
采集器会怎样做:一个网站模版不可能少于10个吧,每个模版弄一个规则就行了,不同模版采用不同采集规则。如果少于10个模版了,既然目标网站都这么费力的更换模版,成全他,撤。
10、采用动态不规则的html标签
分析:这个比较变态。考虑到html标签内含空格和不含空格疗效是一样的,所以和对于页面显示疗效一样,但是作为采集器的标记就是两个不同标记了。如果每次页面的html标签内空格数随机,那么
采集规则就失效了。但是,这对搜索引擎爬虫没多大影响。
适合网站:所有动态且不想违背网页设计规范的网站。
采集器会怎样做:还是有对策的,现在html cleaner还是好多的,先清除了html标签,然后再写采集规则;应该用采集规则前先清除html标签,还是才能领到所需数据。
总结:
一旦要同时搜索引擎爬虫和采集器,这是太使人无奈的事情,因为搜索引擎第一步就是采集目标网页内容,这跟采集器原理一样,所以好多避免采集的方式同时也妨碍了搜索引擎对网站的收录,无奈,是吧?以上10条建议尽管不能百分之百防采集,但是几种方式一起适用早已拒绝了一大部分采集器了。
三、关于防采集的方式
优采云:下面讲一些主要的防采集方法。可以说是攻守对战吧。打开一个网页实际就是一个Http请求浏览器。百度蜘蛛,小到我们的采集器使用的都是一个原理,模拟http请求,所以我们同样能模拟出浏览器。百度蜘蛛下来所以绝对的防采集根本不存在,只是难度的高低。或者你觉得搜索引擎的搜录也无所谓了。你可以用一些特别强悍的activex,flash,全图片文字的方式,这个我们无能为力。
普通的防采集方法有
1、来源判定
2、登录信息判定 Cookie
3、请求次数判别。如一段时间内恳求多少,非常规操作则封IP
4、发送方法判定 POST GET 使用JS,Ajax等恳请内容
举例:
1.2不用说了,论坛,下载站等。。
3、一些大网站,需要配置服务器,单纯靠脚本判定资源消耗比较大
4、如一些急聘站,的分页,Web2.0站的ajax恳求内容
当然我们前面还发觉一些*****锏,今天第一次在这里给你们公布下来~~ 有优质内容须要防采集的同学可以考虑试下
1、网页默认deflate压缩输出(gzip容易一点,容易解压) 我们普通的浏览器和baidu支持辨识gzip,deflate输出内容
2、网页内容不定时 /0 内容手动截断,这两点基本可以防主大部分主流软件采集及web采集程序了~
今天主要想要抒发的一点,大家在做站时一定要注意技术的提升,比如我们上面有后期外部php及.net插口处理采集数据。或者干脆你自己做一个发布时的插口程序自己入库。我们伪原创做得再好,一样有特别多的会员使用,那样又不原创了,采集一样须要技术,只有你通过采集器获得了没有多少人有的数据,你才是惟一了。可能是我最为技术型人的一个弊病,谢谢你们!
互动环节
问:您刚刚谈到对采集有屏蔽,那对搜索引擎呢
答:采集和百度爬虫是一模一样的原理 还有浏览器也是一样的 所以没有绝对的屏蔽,相反都会影响客户体验,你可以做一些不影响客户体验和搜索引擎搜录而提升采集难度的尝试
问:你刚刚讲的是网页内容采集,有没有针对匹配关键词的指定数组的高速采集,比如采集所有带”IDC“的网页的邮箱和电话号码?用过一些,速度太慢,而且数据量显著很少。
答:我们不做这样批量的工具,其实例如做峰会发帖机之类的实现上去道理一样,也很容易,其实实现上去也是可以,只是有更多的一些人工操作,我们上面有 正则匹配。。也就是你要的这些单一工具把这些正则都集成在上面了。而我们须要用户自己去写
问:采集的复杂度应当就在这吧?页面规则的不规则性和多变性?
答:在软件上面设置才能匹配多种模板的正则表达式,一样可以采集到多模板的网站,所谓“道高一尺,魔高一丈”。
问:优采云,能不能说一下如何把phpcms的文章模块下的第一级栏目显示下来啊?
答:用的是 07 还是08版 07版有一个终极栏目的属性 如果是,就不显示。
问:优采云,你认为那个CMS比较好用,你给你们推荐一个你最钟意的CMS系统吧。
答:我如今是对phpcms更熟悉一些。选择一个适宜自己的就够了。研究透一个。
问:有个采集工具 海纳 号称不要编撰采集规则,不知道有没有同事研究过,想讨教其原理?
答:你说的这个是内容主体辨识的范畴了。也做过,但只对一些新闻网站识别得比较好 ,这是一个手动匹配方式的工具,就像百度新闻一样,能手动匹配到正文数据。对大数据量的提取有用处。但精度相对低点点,因为人工不可控。
问:2008 版本能平滑升级到 2009吗?我是免费用户,呵呵。
答:软件升级:请运行程序目录下的updateto2009.exe进行升级。支持3.2sp5及2008版到2009版的升级,支持所有用户
问:请问伪原创的问题如何处理呢?
答:我们伪原创做得再好,一样有特别多的会员使用,那样又不原创了,采集一样须要技术,只有你通过采集器获得了没有多少人有的数据,你才是惟一了。比如我们有同义词替换功能,这个词库就须要最好你自己去扩展一个属于自己的伪原创。使用同义词反义词替换,排除敏感词,不同的标签之间数据融合,指如标题内容之间数据的互相替换给标题。内容副词。为文章标题等生成拼音地址 给文章加上摘要。采集一些其他编码的网站,我们可以做到简简体转化,可以采集中文网站翻译成英文(虽然比较垃圾,但应当可以算是原创)网民,默认的我们能否手动辨识网页的编码。但可能也会有出错的时侯,这时候你须要在任务第四页手工定义一下,比如是gb2312还是utf8等等。
前嗅ForeSpider数据采集中采集列表界面介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-09 21:47
课程演示环境:Ubuntu须要学习Windows系统YOLOv4的朋友请抵达《Windows版YOLOv4目标测量实战:训练自己的数据集》,课程链接YOLOv4来了!速度和精度双提高!与 YOLOv3 相比,新版本的 AP(精度)和 FPS (每秒帧数)分别提升了 10% 和 12%。YOLO系列是基于深度学习的端到端实时目标测量方式。本课程将手把手地教你们使用labelImg标明和使用YOLOv4训练自己的数据集。课程实战分为两个项目:单目标测量(足球目标测量)和多目标测量(足球和梅西同时测量)。本课程的YOLOv4使用AlexAB/darknet,在Ubuntu系统上做项目演示。包括:安装YOLOv4、标注自己的数据集、整理自己的数据集、修改配置文件、训练自己的数据集、测试训练出的网路模型、性能统计(mAP估算和画出PR曲线)和先验框降维剖析。还将介绍改善YOLOv4目标训练性能的方法。除本课程《YOLOv4目标测量实战:训练自己的数据集》外,本人将推出有关YOLOv4目标测量的系列课程。请持续关注该系列的其它视频课程,包括:《YOLOv4目标测量实战:人脸口罩配戴辨识》《YOLOv4目标测量实战:中国交通标志辨识》《YOLOv4目标测量:原理与源码解析》
Jvm垃圾采集器和垃圾采集算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 280 次浏览 • 2020-08-07 09:11
目前,内存的动态分配和内存恢复技术已经相当成熟. 一切似乎都进入了“自动化”时代. 为什么我们需要了解GC和内存分配?原因很简单: 当有必要解决各种内存泄漏和内存溢出问题时,当垃圾采集器成为系统实现更高并发性的瓶颈时,我们需要对这些“自动化”技术进行必要的监视和调整.
上一个博客讨论了Java虚拟机的运行时内存的各个部分. 其中,程序计数器,虚拟机堆栈和本地方法堆栈由线程生成,并由线程终止. 堆栈中的堆栈框架遵循该方法. 进入和退出执行推入和弹出操作,因此当方法结束或线程结束时,内存自然会跟随恢复. Java堆与方法块不同. 我们只知道在运行时将创建哪些对象. 这部分内存和恢复是动态的,垃圾回收器也与此部分内存有关. 稍后提到的内存分配和恢复也仅涉及内存的这一部分.
1. 判断物体的生与死1.参考计数方法
许多教科书或开发人员回答了以下问题: “如何判断对象是否还活着?”大多数答案都是引用计数. 实现是这样的: 向该对象添加一个引用计数器;在某个地方被引用时,将添加+1;在引用变为无效时,将添加-1;并且在任何时候其计数器为0的对象将无法被引用.
客观地讲,引用计数方法易于实现并且判断效率很高,但是至少主流的Java虚拟机不使用引用计数方法来管理内存. 主要原因是很难解决对象之间的相互循环. 引用的问题.
2. 可达性分析算法
“可达性分析”是Java和C#当前的主流实现,用于确定对象是否存在. 主要思想是使用一些类作为成为“ GC根目录”的起点的对象,并从这些节点向下搜索. 搜索的路径称为参考链. 如果没有针对GC根目录的对象的引用链,则证明该对象不可用.
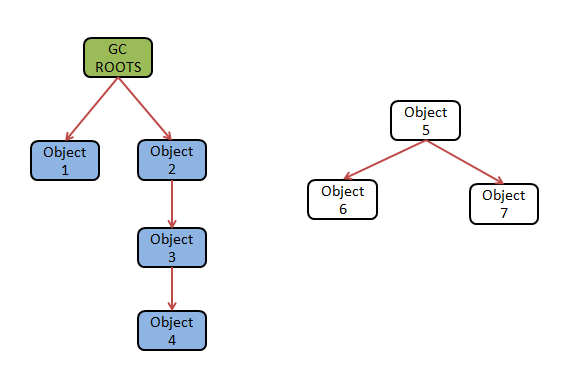
如下所示:
Object1-Object4的参考链连接到GC根,而Object5-Oject7没有通过参考链连接,因此被判断为可回收对象
在Java中,有四种类型可以用作GC根节点
3. 再谈报价
在JDK1.2之前,Java中的引用定义为: 如果将引用类型的数据存储为代表另一个内存块的起始地址的值,则可以说该内存块表示一个引用. 在JDK1.2之后,Java扩展了引用的概念,分为以下四种类型:
4. 生存还是死亡
即使在可达性分析算法中无法达到的对象也不是“必须死亡”的. 目前,他们处于“试用”阶段. 要声明一个对象已死亡,至少需要两个标记过程.
以下代码一次显示对象的自救:
1 //代码演示了两点
2 //1.对象可以实现自救
3 //2.这种自救只能一次,因为finalize方法只会被执行一次
4
5 public class jvmtest1 {
6 public static jvmtest1 obj = null;
7
8 public void isAlive() {
9 System.out.println("I am alive");
10 }
11
12 @Override
13 protected void finalize() throws Throwable {
14 super.finalize();
15 System.out.println("finalize method executed!");
16 obj = this;
17 }
18
19 public static void main(String[] args) throws Exception {
20 obj = new jvmtest1();
21
22 obj = null;
23 System.gc();
24 // 因为finalize方法优先级很低,所以暂停0.5s执行
25 Thread.sleep(500);
26 if (obj != null) {
27 obj.isAlive();
28 } else {
29 System.out.println("I am dead");
30 }
31
32 // 与上面的代码完全相同,但是自救失败了
33 obj = null;
34 System.gc();
35 // 因为finalize方法优先级很低,所以暂停0.5s执行
36 Thread.sleep(500);
37 if (obj != null) {
38 obj.isAlive();
39 } else {
40 System.out.println("I am dead");
41 }
42 }
43 }
程序输出为:
可以看出obj的finalize()方法确实是由GC触发的,并且成功地保存了一次. 应该注意的是,下部的代码与上部的代码相同,但是自助失败. 这是因为对象的finalize()方法只能被系统自动调用一次. 如果对象面临第二次恢复,则不会调用其finalize(The)方法,因此第二次自助操作将失败.
5. 恢复方法区域
方法区域中的垃圾回收具有“成本效益”. 在堆中,特别是在新一代中,常规应用程序的垃圾回收通常可以回收70%-95%的空间,而方法区域(在HatSport虚拟机中)永久生成的恢复效率远远低于这个.
永久代中有两种主要的垃圾采集类型: 过时的常量和无用的类
(1)此类的所有实例均已回收,也就是说,堆中没有此类的实例
(2)加载了此类的ClassLoader已被回收
(3)与此类对应的java.lang.Class对象在任何地方都没有引用,并且该类的方法无法在任何地方通过反射来访问.
满足以上三个条件的类也可以被回收,但不一定. 在经常使用ByteCode框架(例如反射,动态代理,CGLib等)并且经常定义ClassLoader(例如动态生成的JSP和OSGi)的场景中,虚拟机需要类卸载功能,以确保永久生成不会溢出.
2. 垃圾采集算法1.打标算法
标记扫描算法是最基本的采集算法. 首先标记需要回收的对象,并在标记完成后统一采集所有标记的对象.
主要缺点有两个:
过程如下:
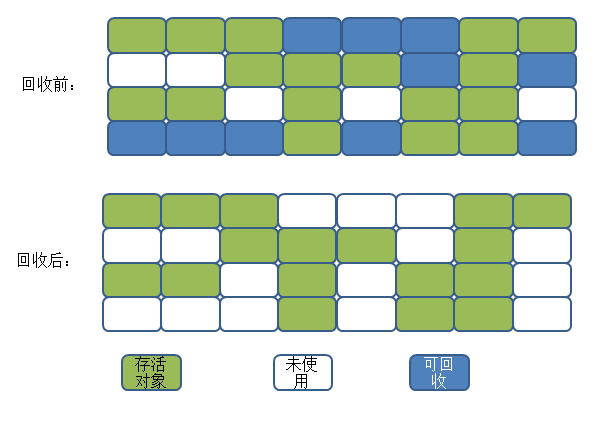
2. 复制算法
为了解决效率问题,出现了复制算法(Copying),他将内存分为相等大小的两块,一次只使用其中之一. 当该内存块用完时,会将尚存的对象复制到另一个块,然后清除该空间块. 这样,每次都可以在整个半个区域中回收内存,并且无需考虑在内存分配过程中内存碎片的复杂性. 您只需要移动指针并按顺序分配内存即可.
这种方法的代价是将内存分成两半,这太高了.
过程如下:
当前的商用虚拟机都使用此方法来回收新一代产品. IBM的特殊研究表明,新一代对象中有98%是“生死攸关的”,因此无需划分1: 1内存空间. 另一种方法是将内存块划分为Eden空间(80%)和两个Survivor空间(10%). 每次使用Eden空间和一个Survivor空间时,在回收过程中会将幸存的对象复制到另一个Survivor空间. ,因此每次仅“浪费”了10%的空间. 当Survivor空间不足时,它需要依赖其他内存(旧代)来进行分配保证(与旧代中的分配保证机制相同).
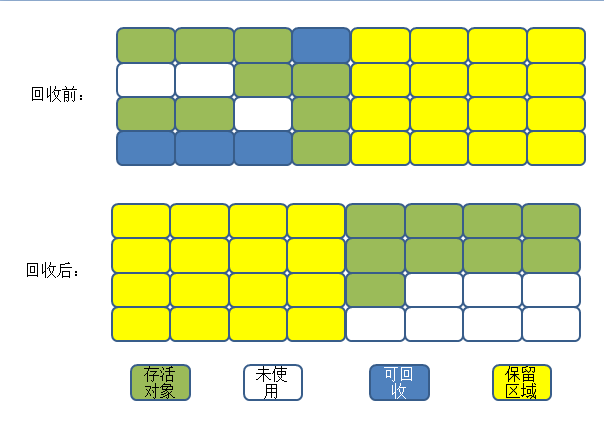
3. 标记排序算法
当副本采集算法的对象存活率较高时,它将执行更多的复制操作,并且效率会降低. 更重要的是,如果您不希望浪费50%的空间,则需要有额外的空间用于分配保证,以应对极端情况,即已用内存中的所有对象都处于100%活动状态,因此旧一代通常无法选择这种方法. 提出了Mark-Compact算法(Mark-Compact).
标记过程与“ mark-sweep”算法相同,但是后续步骤不是直接清理可回收部分,而是将所有活动对象移到一端,然后直接清理内存在末尾.
过程如下:
4. 分代采集算法
当前的商用虚拟机都使用Generational 采集算法. 通常,堆分为新一代和旧一代,并且根据每个时代的不同特性使用最合适的算法. 新一代一般采用复制算法,只需要支付少量复制幸存对象的费用即可. 在旧的一代中,由于对象生存率很高并且没有多余的空间来分配它,因此必须使用“标记清除”或“标记组织”算法来进行恢复.
概述:
目前,内存的动态分配和内存恢复技术已经相当成熟. 一切似乎都进入了“自动化”时代. 为什么我们需要了解GC和内存分配?原因很简单: 当有必要解决各种内存泄漏和内存溢出问题时,当垃圾采集器成为系统实现更高并发性的瓶颈时,我们需要对这些“自动化”技术进行必要的监视和调整.
上一个博客讨论了Java虚拟机的运行时内存的各个部分. 其中,程序计数器,虚拟机堆栈和本地方法堆栈由线程生成,并由线程终止. 堆栈中的堆栈框架遵循该方法. 进入和退出执行推入和弹出操作,因此当方法结束或线程结束时,内存自然会跟随恢复. Java堆与方法块不同. 我们只知道在运行时将创建哪些对象. 这部分内存和恢复是动态的,垃圾回收器也与此部分内存有关. 稍后提到的内存分配和恢复也仅涉及内存的这一部分.
1. 判断物体的生与死1.参考计数方法
许多教科书或开发人员回答了以下问题: “如何判断对象是否还活着?”大多数答案都是引用计数. 实现是这样的: 向该对象添加一个引用计数器;在某个地方被引用时,将添加+1;在引用变为无效时,将添加-1;并且在任何时候其计数器为0的对象将无法被引用.
客观地讲,引用计数方法易于实现并且判断效率很高,但是至少主流的Java虚拟机不使用引用计数方法来管理内存. 主要原因是很难解决对象之间的相互循环. 引用的问题.
2. 可达性分析算法
“可达性分析”是Java和C#当前的主流实现,用于确定对象是否存在. 主要思想是使用一些类作为成为“ GC根目录”的起点的对象,并从这些节点向下搜索. 搜索的路径称为参考链. 如果没有针对GC根目录的对象的引用链,则证明该对象不可用.
如下所示:
Object1-Object4的参考链连接到GC根,而Object5-Oject7没有通过参考链连接,因此被判断为可回收对象
在Java中,有四种类型可以用作GC根节点
3. 再谈报价
在JDK1.2之前,Java中的引用定义为: 如果将引用类型的数据存储为代表另一个内存块的起始地址的值,则可以说该内存块表示一个引用. 在JDK1.2之后,Java扩展了引用的概念,分为以下四种类型:
4. 生存还是死亡
即使在可达性分析算法中无法达到的对象也不是“必须死亡”的. 目前,他们处于“试用”阶段. 要声明一个对象已死亡,至少需要两个标记过程.
以下代码一次显示对象的自救:
1 //代码演示了两点
2 //1.对象可以实现自救
3 //2.这种自救只能一次,因为finalize方法只会被执行一次
4
5 public class jvmtest1 {
6 public static jvmtest1 obj = null;
7
8 public void isAlive() {
9 System.out.println("I am alive");
10 }
11
12 @Override
13 protected void finalize() throws Throwable {
14 super.finalize();
15 System.out.println("finalize method executed!");
16 obj = this;
17 }
18
19 public static void main(String[] args) throws Exception {
20 obj = new jvmtest1();
21
22 obj = null;
23 System.gc();
24 // 因为finalize方法优先级很低,所以暂停0.5s执行
25 Thread.sleep(500);
26 if (obj != null) {
27 obj.isAlive();
28 } else {
29 System.out.println("I am dead");
30 }
31
32 // 与上面的代码完全相同,但是自救失败了
33 obj = null;
34 System.gc();
35 // 因为finalize方法优先级很低,所以暂停0.5s执行
36 Thread.sleep(500);
37 if (obj != null) {
38 obj.isAlive();
39 } else {
40 System.out.println("I am dead");
41 }
42 }
43 }
程序输出为:
可以看出obj的finalize()方法确实是由GC触发的,并且成功地保存了一次. 应该注意的是,下部的代码与上部的代码相同,但是自助失败. 这是因为对象的finalize()方法只能被系统自动调用一次. 如果对象面临第二次恢复,则不会调用其finalize(The)方法,因此第二次自助操作将失败.
5. 恢复方法区域
方法区域中的垃圾回收具有“成本效益”. 在堆中,特别是在新一代中,常规应用程序的垃圾回收通常可以回收70%-95%的空间,而方法区域(在HatSport虚拟机中)永久生成的恢复效率远远低于这个.
永久代中有两种主要的垃圾采集类型: 过时的常量和无用的类
(1)此类的所有实例均已回收,也就是说,堆中没有此类的实例
(2)加载了此类的ClassLoader已被回收
(3)与此类对应的java.lang.Class对象在任何地方都没有引用,并且该类的方法无法在任何地方通过反射来访问.
满足以上三个条件的类也可以被回收,但不一定. 在经常使用ByteCode框架(例如反射,动态代理,CGLib等)并且经常定义ClassLoader(例如动态生成的JSP和OSGi)的场景中,虚拟机需要类卸载功能,以确保永久生成不会溢出.
2. 垃圾采集算法1.打标算法
标记扫描算法是最基本的采集算法. 首先标记需要回收的对象,并在标记完成后统一采集所有标记的对象.
主要缺点有两个:
过程如下:
2. 复制算法
为了解决效率问题,出现了复制算法(Copying),他将内存分为相等大小的两块,一次只使用其中之一. 当该内存块用完时,会将尚存的对象复制到另一个块,然后清除该空间块. 这样,每次都可以在整个半个区域中回收内存,并且无需考虑在内存分配过程中内存碎片的复杂性. 您只需要移动指针并按顺序分配内存即可.
这种方法的代价是将内存分成两半,这太高了.
过程如下:
当前的商用虚拟机都使用此方法来回收新一代产品. IBM的特殊研究表明,新一代对象中有98%是“生死攸关的”,因此无需划分1: 1内存空间. 另一种方法是将内存块划分为Eden空间(80%)和两个Survivor空间(10%). 每次使用Eden空间和一个Survivor空间时,在回收过程中会将幸存的对象复制到另一个Survivor空间. ,因此每次仅“浪费”了10%的空间. 当Survivor空间不足时,它需要依赖其他内存(旧代)来进行分配保证(与旧代中的分配保证机制相同).
3. 标记排序算法
当副本采集算法的对象存活率较高时,它将执行更多的复制操作,并且效率会降低. 更重要的是,如果您不希望浪费50%的空间,则需要有额外的空间用于分配保证,以应对极端情况,即已用内存中的所有对象都处于100%活动状态,因此旧一代通常无法选择这种方法. 提出了Mark-Compact算法(Mark-Compact).
标记过程与“标记清除”算法相同,但是后续步骤不是直接清理可回收部分,而是将所有活动对象移动到一端,然后直接清理内存在末尾.
过程如下:
4. 分代采集算法
当前的商用虚拟机都使用Generational 采集算法. 通常,堆分为新一代和旧一代,并且根据每个时代的不同特性使用最合适的算法. 新一代一般采用复制算法,只需要支付少量复制幸存对象的费用即可. 在旧的一代中,由于对象生存率很高并且没有多余的空间来分配它,因此必须使用“标记清除”或“标记组织”算法来进行恢复. 查看全部
概述:
目前,内存的动态分配和内存恢复技术已经相当成熟. 一切似乎都进入了“自动化”时代. 为什么我们需要了解GC和内存分配?原因很简单: 当有必要解决各种内存泄漏和内存溢出问题时,当垃圾采集器成为系统实现更高并发性的瓶颈时,我们需要对这些“自动化”技术进行必要的监视和调整.
上一个博客讨论了Java虚拟机的运行时内存的各个部分. 其中,程序计数器,虚拟机堆栈和本地方法堆栈由线程生成,并由线程终止. 堆栈中的堆栈框架遵循该方法. 进入和退出执行推入和弹出操作,因此当方法结束或线程结束时,内存自然会跟随恢复. Java堆与方法块不同. 我们只知道在运行时将创建哪些对象. 这部分内存和恢复是动态的,垃圾回收器也与此部分内存有关. 稍后提到的内存分配和恢复也仅涉及内存的这一部分.
1. 判断物体的生与死1.参考计数方法
许多教科书或开发人员回答了以下问题: “如何判断对象是否还活着?”大多数答案都是引用计数. 实现是这样的: 向该对象添加一个引用计数器;在某个地方被引用时,将添加+1;在引用变为无效时,将添加-1;并且在任何时候其计数器为0的对象将无法被引用.
客观地讲,引用计数方法易于实现并且判断效率很高,但是至少主流的Java虚拟机不使用引用计数方法来管理内存. 主要原因是很难解决对象之间的相互循环. 引用的问题.
2. 可达性分析算法
“可达性分析”是Java和C#当前的主流实现,用于确定对象是否存在. 主要思想是使用一些类作为成为“ GC根目录”的起点的对象,并从这些节点向下搜索. 搜索的路径称为参考链. 如果没有针对GC根目录的对象的引用链,则证明该对象不可用.
如下所示:
Object1-Object4的参考链连接到GC根,而Object5-Oject7没有通过参考链连接,因此被判断为可回收对象
在Java中,有四种类型可以用作GC根节点
3. 再谈报价
在JDK1.2之前,Java中的引用定义为: 如果将引用类型的数据存储为代表另一个内存块的起始地址的值,则可以说该内存块表示一个引用. 在JDK1.2之后,Java扩展了引用的概念,分为以下四种类型:
4. 生存还是死亡
即使在可达性分析算法中无法达到的对象也不是“必须死亡”的. 目前,他们处于“试用”阶段. 要声明一个对象已死亡,至少需要两个标记过程.
以下代码一次显示对象的自救:

1 //代码演示了两点
2 //1.对象可以实现自救
3 //2.这种自救只能一次,因为finalize方法只会被执行一次
4
5 public class jvmtest1 {
6 public static jvmtest1 obj = null;
7
8 public void isAlive() {
9 System.out.println("I am alive");
10 }
11
12 @Override
13 protected void finalize() throws Throwable {
14 super.finalize();
15 System.out.println("finalize method executed!");
16 obj = this;
17 }
18
19 public static void main(String[] args) throws Exception {
20 obj = new jvmtest1();
21
22 obj = null;
23 System.gc();
24 // 因为finalize方法优先级很低,所以暂停0.5s执行
25 Thread.sleep(500);
26 if (obj != null) {
27 obj.isAlive();
28 } else {
29 System.out.println("I am dead");
30 }
31
32 // 与上面的代码完全相同,但是自救失败了
33 obj = null;
34 System.gc();
35 // 因为finalize方法优先级很低,所以暂停0.5s执行
36 Thread.sleep(500);
37 if (obj != null) {
38 obj.isAlive();
39 } else {
40 System.out.println("I am dead");
41 }
42 }
43 }
程序输出为:

可以看出obj的finalize()方法确实是由GC触发的,并且成功地保存了一次. 应该注意的是,下部的代码与上部的代码相同,但是自助失败. 这是因为对象的finalize()方法只能被系统自动调用一次. 如果对象面临第二次恢复,则不会调用其finalize(The)方法,因此第二次自助操作将失败.
5. 恢复方法区域
方法区域中的垃圾回收具有“成本效益”. 在堆中,特别是在新一代中,常规应用程序的垃圾回收通常可以回收70%-95%的空间,而方法区域(在HatSport虚拟机中)永久生成的恢复效率远远低于这个.
永久代中有两种主要的垃圾采集类型: 过时的常量和无用的类
(1)此类的所有实例均已回收,也就是说,堆中没有此类的实例
(2)加载了此类的ClassLoader已被回收
(3)与此类对应的java.lang.Class对象在任何地方都没有引用,并且该类的方法无法在任何地方通过反射来访问.
满足以上三个条件的类也可以被回收,但不一定. 在经常使用ByteCode框架(例如反射,动态代理,CGLib等)并且经常定义ClassLoader(例如动态生成的JSP和OSGi)的场景中,虚拟机需要类卸载功能,以确保永久生成不会溢出.
2. 垃圾采集算法1.打标算法
标记扫描算法是最基本的采集算法. 首先标记需要回收的对象,并在标记完成后统一采集所有标记的对象.
主要缺点有两个:
过程如下:
2. 复制算法
为了解决效率问题,出现了复制算法(Copying),他将内存分为相等大小的两块,一次只使用其中之一. 当该内存块用完时,会将尚存的对象复制到另一个块,然后清除该空间块. 这样,每次都可以在整个半个区域中回收内存,并且无需考虑在内存分配过程中内存碎片的复杂性. 您只需要移动指针并按顺序分配内存即可.
这种方法的代价是将内存分成两半,这太高了.
过程如下:
当前的商用虚拟机都使用此方法来回收新一代产品. IBM的特殊研究表明,新一代对象中有98%是“生死攸关的”,因此无需划分1: 1内存空间. 另一种方法是将内存块划分为Eden空间(80%)和两个Survivor空间(10%). 每次使用Eden空间和一个Survivor空间时,在回收过程中会将幸存的对象复制到另一个Survivor空间. ,因此每次仅“浪费”了10%的空间. 当Survivor空间不足时,它需要依赖其他内存(旧代)来进行分配保证(与旧代中的分配保证机制相同).
3. 标记排序算法
当副本采集算法的对象存活率较高时,它将执行更多的复制操作,并且效率会降低. 更重要的是,如果您不希望浪费50%的空间,则需要有额外的空间用于分配保证,以应对极端情况,即已用内存中的所有对象都处于100%活动状态,因此旧一代通常无法选择这种方法. 提出了Mark-Compact算法(Mark-Compact).
标记过程与“ mark-sweep”算法相同,但是后续步骤不是直接清理可回收部分,而是将所有活动对象移到一端,然后直接清理内存在末尾.
过程如下:

4. 分代采集算法
当前的商用虚拟机都使用Generational 采集算法. 通常,堆分为新一代和旧一代,并且根据每个时代的不同特性使用最合适的算法. 新一代一般采用复制算法,只需要支付少量复制幸存对象的费用即可. 在旧的一代中,由于对象生存率很高并且没有多余的空间来分配它,因此必须使用“标记清除”或“标记组织”算法来进行恢复.
概述:
目前,内存的动态分配和内存恢复技术已经相当成熟. 一切似乎都进入了“自动化”时代. 为什么我们需要了解GC和内存分配?原因很简单: 当有必要解决各种内存泄漏和内存溢出问题时,当垃圾采集器成为系统实现更高并发性的瓶颈时,我们需要对这些“自动化”技术进行必要的监视和调整.
上一个博客讨论了Java虚拟机的运行时内存的各个部分. 其中,程序计数器,虚拟机堆栈和本地方法堆栈由线程生成,并由线程终止. 堆栈中的堆栈框架遵循该方法. 进入和退出执行推入和弹出操作,因此当方法结束或线程结束时,内存自然会跟随恢复. Java堆与方法块不同. 我们只知道在运行时将创建哪些对象. 这部分内存和恢复是动态的,垃圾回收器也与此部分内存有关. 稍后提到的内存分配和恢复也仅涉及内存的这一部分.
1. 判断物体的生与死1.参考计数方法
许多教科书或开发人员回答了以下问题: “如何判断对象是否还活着?”大多数答案都是引用计数. 实现是这样的: 向该对象添加一个引用计数器;在某个地方被引用时,将添加+1;在引用变为无效时,将添加-1;并且在任何时候其计数器为0的对象将无法被引用.
客观地讲,引用计数方法易于实现并且判断效率很高,但是至少主流的Java虚拟机不使用引用计数方法来管理内存. 主要原因是很难解决对象之间的相互循环. 引用的问题.
2. 可达性分析算法
“可达性分析”是Java和C#当前的主流实现,用于确定对象是否存在. 主要思想是使用一些类作为成为“ GC根目录”的起点的对象,并从这些节点向下搜索. 搜索的路径称为参考链. 如果没有针对GC根目录的对象的引用链,则证明该对象不可用.
如下所示:
Object1-Object4的参考链连接到GC根,而Object5-Oject7没有通过参考链连接,因此被判断为可回收对象
在Java中,有四种类型可以用作GC根节点
3. 再谈报价
在JDK1.2之前,Java中的引用定义为: 如果将引用类型的数据存储为代表另一个内存块的起始地址的值,则可以说该内存块表示一个引用. 在JDK1.2之后,Java扩展了引用的概念,分为以下四种类型:
4. 生存还是死亡
即使在可达性分析算法中无法达到的对象也不是“必须死亡”的. 目前,他们处于“试用”阶段. 要声明一个对象已死亡,至少需要两个标记过程.
以下代码一次显示对象的自救:
1 //代码演示了两点
2 //1.对象可以实现自救
3 //2.这种自救只能一次,因为finalize方法只会被执行一次
4
5 public class jvmtest1 {
6 public static jvmtest1 obj = null;
7
8 public void isAlive() {
9 System.out.println("I am alive");
10 }
11
12 @Override
13 protected void finalize() throws Throwable {
14 super.finalize();
15 System.out.println("finalize method executed!");
16 obj = this;
17 }
18
19 public static void main(String[] args) throws Exception {
20 obj = new jvmtest1();
21
22 obj = null;
23 System.gc();
24 // 因为finalize方法优先级很低,所以暂停0.5s执行
25 Thread.sleep(500);
26 if (obj != null) {
27 obj.isAlive();
28 } else {
29 System.out.println("I am dead");
30 }
31
32 // 与上面的代码完全相同,但是自救失败了
33 obj = null;
34 System.gc();
35 // 因为finalize方法优先级很低,所以暂停0.5s执行
36 Thread.sleep(500);
37 if (obj != null) {
38 obj.isAlive();
39 } else {
40 System.out.println("I am dead");
41 }
42 }
43 }
程序输出为:
可以看出obj的finalize()方法确实是由GC触发的,并且成功地保存了一次. 应该注意的是,下部的代码与上部的代码相同,但是自助失败. 这是因为对象的finalize()方法只能被系统自动调用一次. 如果对象面临第二次恢复,则不会调用其finalize(The)方法,因此第二次自助操作将失败.
5. 恢复方法区域
方法区域中的垃圾回收具有“成本效益”. 在堆中,特别是在新一代中,常规应用程序的垃圾回收通常可以回收70%-95%的空间,而方法区域(在HatSport虚拟机中)永久生成的恢复效率远远低于这个.
永久代中有两种主要的垃圾采集类型: 过时的常量和无用的类
(1)此类的所有实例均已回收,也就是说,堆中没有此类的实例
(2)加载了此类的ClassLoader已被回收
(3)与此类对应的java.lang.Class对象在任何地方都没有引用,并且该类的方法无法在任何地方通过反射来访问.
满足以上三个条件的类也可以被回收,但不一定. 在经常使用ByteCode框架(例如反射,动态代理,CGLib等)并且经常定义ClassLoader(例如动态生成的JSP和OSGi)的场景中,虚拟机需要类卸载功能,以确保永久生成不会溢出.
2. 垃圾采集算法1.打标算法
标记扫描算法是最基本的采集算法. 首先标记需要回收的对象,并在标记完成后统一采集所有标记的对象.
主要缺点有两个:
过程如下:
2. 复制算法
为了解决效率问题,出现了复制算法(Copying),他将内存分为相等大小的两块,一次只使用其中之一. 当该内存块用完时,会将尚存的对象复制到另一个块,然后清除该空间块. 这样,每次都可以在整个半个区域中回收内存,并且无需考虑在内存分配过程中内存碎片的复杂性. 您只需要移动指针并按顺序分配内存即可.
这种方法的代价是将内存分成两半,这太高了.
过程如下:
当前的商用虚拟机都使用此方法来回收新一代产品. IBM的特殊研究表明,新一代对象中有98%是“生死攸关的”,因此无需划分1: 1内存空间. 另一种方法是将内存块划分为Eden空间(80%)和两个Survivor空间(10%). 每次使用Eden空间和一个Survivor空间时,在回收过程中会将幸存的对象复制到另一个Survivor空间. ,因此每次仅“浪费”了10%的空间. 当Survivor空间不足时,它需要依赖其他内存(旧代)来进行分配保证(与旧代中的分配保证机制相同).
3. 标记排序算法
当副本采集算法的对象存活率较高时,它将执行更多的复制操作,并且效率会降低. 更重要的是,如果您不希望浪费50%的空间,则需要有额外的空间用于分配保证,以应对极端情况,即已用内存中的所有对象都处于100%活动状态,因此旧一代通常无法选择这种方法. 提出了Mark-Compact算法(Mark-Compact).
标记过程与“标记清除”算法相同,但是后续步骤不是直接清理可回收部分,而是将所有活动对象移动到一端,然后直接清理内存在末尾.
过程如下:
4. 分代采集算法
当前的商用虚拟机都使用Generational 采集算法. 通常,堆分为新一代和旧一代,并且根据每个时代的不同特性使用最合适的算法. 新一代一般采用复制算法,只需要支付少量复制幸存对象的费用即可. 在旧的一代中,由于对象生存率很高并且没有多余的空间来分配它,因此必须使用“标记清除”或“标记组织”算法来进行恢复.
垃圾采集器和内存分配策略-HotSpot算法实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2020-08-07 03:05
首先,让我们看一下图片: 该图片分析了在执行HotSpot算法和执行可达性分析算法时必须满足的要求
虚拟机algorithm.png
图像分析过程如下:
可达性分析算法从GC Roots节点搜索参考链,但是如果您在程序中一个接一个地检查参考,则会消耗大量时间,并且可达性分析算法对时间非常敏感,在分析过程中需要时间时间的一致性就像时间已经停止一样. 无法在此处分析引用链,并且那里的对象引用仍在变化. 因此,必须在GC进程中停止所有Java执行线程.
为了确保执行效率,在分析可达性分析算法时并不需要分析所有参考. 而是直接通过称为“ OopMap”的数据结构保存对象的引用,以便HotSpot可以快速而准确地完成GC根枚举. 但是,由于整个系统中的引用过多,因此无法将所有指令保存在OopMap中,否则会增加GC空间的成本. 实际上,HotSpot只会使用OopMap在某些特定位置记录信息.
哪些特定点与程序状态有关. 例如,当程序正常执行时,它将进入一个称为“安全点”的特定位置以保存参考信息. 相反,如果程序处于休眠或锁定状态,它将进入一个安全区域进行保存.
安全点的数量应适当. 选择标准是: 是否具有允许程序长时间执行的特征. 选择安全点之后,如何在发生GC时使所有线程(不包括JNI调用的线程)进入安全点?这里有两种方法
①抢先中断(PreeMptive Suspension): 不需要所有线程积极配合,而是直接中断所有线程. 如果在中断时发现线程不在安全点,则将还原该线程并使其安全运行. 单击然后中断.
②自愿暂停: 执行GC操作时,线程不会直接中断,而是会给该线程一个标志. 每个线程将自动检查该标志是否为true. 如果为真,则自行挂起. (查询标志的位置与安全点重合)
当前的虚拟机基本上使用第二种方法: 主动中断.
安全区域意味着在另一段代码中,引用关系将不再更改. 执行GC操作时,该线程在该区域中的任何位置都是安全的. 安全区域是安全点的升级版本. 进入安全区域的线程将带有一个标志,表明它们已进入安全区域,并且在发生GC时虚拟机将不会管理这些线程. 当这些线程要离开安全区域时,它们必须检查外部GC操作是否已完成. 如果GC已完成,则线程将继续执行. 如果GC未完成,则线程必须在安全区域中等待,以等待GC完成后再离开. 查看全部
以前,我们介绍了如何判断对象是否还活着并实现相关的垃圾采集算法. 在此基础上,我们将讨论在HotSpot中实现这些算法时必须满足的要求,以确保算法的有效执行.
首先,让我们看一下图片: 该图片分析了在执行HotSpot算法和执行可达性分析算法时必须满足的要求

虚拟机algorithm.png
图像分析过程如下:
可达性分析算法从GC Roots节点搜索参考链,但是如果您在程序中一个接一个地检查参考,则会消耗大量时间,并且可达性分析算法对时间非常敏感,在分析过程中需要时间时间的一致性就像时间已经停止一样. 无法在此处分析引用链,并且那里的对象引用仍在变化. 因此,必须在GC进程中停止所有Java执行线程.
为了确保执行效率,在分析可达性分析算法时并不需要分析所有参考. 而是直接通过称为“ OopMap”的数据结构保存对象的引用,以便HotSpot可以快速而准确地完成GC根枚举. 但是,由于整个系统中的引用过多,因此无法将所有指令保存在OopMap中,否则会增加GC空间的成本. 实际上,HotSpot只会使用OopMap在某些特定位置记录信息.
哪些特定点与程序状态有关. 例如,当程序正常执行时,它将进入一个称为“安全点”的特定位置以保存参考信息. 相反,如果程序处于休眠或锁定状态,它将进入一个安全区域进行保存.
安全点的数量应适当. 选择标准是: 是否具有允许程序长时间执行的特征. 选择安全点之后,如何在发生GC时使所有线程(不包括JNI调用的线程)进入安全点?这里有两种方法
①抢先中断(PreeMptive Suspension): 不需要所有线程积极配合,而是直接中断所有线程. 如果在中断时发现线程不在安全点,则将还原该线程并使其安全运行. 单击然后中断.
②自愿暂停: 执行GC操作时,线程不会直接中断,而是会给该线程一个标志. 每个线程将自动检查该标志是否为true. 如果为真,则自行挂起. (查询标志的位置与安全点重合)
当前的虚拟机基本上使用第二种方法: 主动中断.
安全区域意味着在另一段代码中,引用关系将不再更改. 执行GC操作时,该线程在该区域中的任何位置都是安全的. 安全区域是安全点的升级版本. 进入安全区域的线程将带有一个标志,表明它们已进入安全区域,并且在发生GC时虚拟机将不会管理这些线程. 当这些线程要离开安全区域时,它们必须检查外部GC操作是否已完成. 如果GC已完成,则线程将继续执行. 如果GC未完成,则线程必须在安全区域中等待,以等待GC完成后再离开.
声音检测异常
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-07 02:01
优秀论文:
1. 监督分级异常声音检测系统的设计与实现. 叶建杰撰写. 您可以浏览CNKI.
2. 智能监控前端系统中异常声音检测的实现张露露等.
顾名思义,异常声音检测是指检测现实生活中的异常声音,例如枪声,爆炸,哭声,尖叫声等,属于公共安全监控类别.
传统的公共安全监视使用摄像头,但是摄像头只能监视特定的固定场景,并且受到光线的很大影响. 因此,在电影中,犯罪分子只要知道相机的位置,就可以轻松避开相机. 或用布覆盖相机.
随着移动互联网的发展,各种可穿戴安全产品陆续出现,但它们都是主要的定位卡. 360°儿童手表可以录制,但是父母需要积极拨动手表进行录制. 这种应用场景是父母希望知道孩子何时拨动手表以使其记录10秒钟. 这段10秒的录音可以让父母知道孩子的环境吗?更不用说主动拨手表的父母了,何时打电话的问题. 父母只有在记住时才打电话,也许孩子已经处于危险之中. 360°儿童手表还可以让儿童在遇到危险时求助. 所谓的危险必须是孩子有意识并意识到需要寻求帮助. 因此,这种父母主动拨号或孩子主动寻求帮助的方法是被动的.
如果使用异常声音判断孩子是否安全,该怎么办?因为声音是全向的并且不受光线影响,所以理论上可以检测到异常声音. 但是,异常声音的类型太复杂. 更不用说哭,尖叫,枪声和其他不同的异常声音了,甚至枪声也可能是手枪,步枪等. 并且在现实生活中干扰太多,因此仍然很难准确确定异常声音.
该领域当前有两种解决方案,一种称为异常声音检测,另一种称为异常声音分类. 所谓的异常声音检测是指检测是否存在异常声音,但无法确定是哪种异常声音. 异常声音分类是对异常声音进行分类,从而知道检测到哪种异常声音. 显然,这种方法可以限制检测到的异常声音的类型.
异常声音检测的一般方法是对背景环境声音进行建模,所有与模型不匹配的异常声音均为异常声音. 异常声音分类是对异常声音进行建模,而与模型匹配的都是某些异常声音. . 这两种方法的原理实际上是从语音识别中得出的,实质上是训练分类器. 语音识别的关键在于分类器的辨别力,即模型的准确性,而准确性又取决于所选的声学特征和声音模型.
除MPEG-7外,常用的声学功能是MFCC. 我们听到的声音收录太多无用的信息. MFCC使用24维特征系数来表示声音帧. 当然,除了GMM等之外,常用的声音模型当然是HMM. 因此,使用这种方法的难度与语音识别的难度相同.
在实时检测中,准确检测异常声音的开始和结束也很重要. 因为如果起点和终点不准确,将不可避免地影响模型的准确性,从而影响识别率.
参考: 查看全部
最近,我们将为室内紧急情况提供遇险声音检测系统. 这是两篇好论文.
优秀论文:
1. 监督分级异常声音检测系统的设计与实现. 叶建杰撰写. 您可以浏览CNKI.
2. 智能监控前端系统中异常声音检测的实现张露露等.
顾名思义,异常声音检测是指检测现实生活中的异常声音,例如枪声,爆炸,哭声,尖叫声等,属于公共安全监控类别.
传统的公共安全监视使用摄像头,但是摄像头只能监视特定的固定场景,并且受到光线的很大影响. 因此,在电影中,犯罪分子只要知道相机的位置,就可以轻松避开相机. 或用布覆盖相机.
随着移动互联网的发展,各种可穿戴安全产品陆续出现,但它们都是主要的定位卡. 360°儿童手表可以录制,但是父母需要积极拨动手表进行录制. 这种应用场景是父母希望知道孩子何时拨动手表以使其记录10秒钟. 这段10秒的录音可以让父母知道孩子的环境吗?更不用说主动拨手表的父母了,何时打电话的问题. 父母只有在记住时才打电话,也许孩子已经处于危险之中. 360°儿童手表还可以让儿童在遇到危险时求助. 所谓的危险必须是孩子有意识并意识到需要寻求帮助. 因此,这种父母主动拨号或孩子主动寻求帮助的方法是被动的.
如果使用异常声音判断孩子是否安全,该怎么办?因为声音是全向的并且不受光线影响,所以理论上可以检测到异常声音. 但是,异常声音的类型太复杂. 更不用说哭,尖叫,枪声和其他不同的异常声音了,甚至枪声也可能是手枪,步枪等. 并且在现实生活中干扰太多,因此仍然很难准确确定异常声音.
该领域当前有两种解决方案,一种称为异常声音检测,另一种称为异常声音分类. 所谓的异常声音检测是指检测是否存在异常声音,但无法确定是哪种异常声音. 异常声音分类是对异常声音进行分类,从而知道检测到哪种异常声音. 显然,这种方法可以限制检测到的异常声音的类型.
异常声音检测的一般方法是对背景环境声音进行建模,所有与模型不匹配的异常声音均为异常声音. 异常声音分类是对异常声音进行建模,而与模型匹配的都是某些异常声音. . 这两种方法的原理实际上是从语音识别中得出的,实质上是训练分类器. 语音识别的关键在于分类器的辨别力,即模型的准确性,而准确性又取决于所选的声学特征和声音模型.
除MPEG-7外,常用的声学功能是MFCC. 我们听到的声音收录太多无用的信息. MFCC使用24维特征系数来表示声音帧. 当然,除了GMM等之外,常用的声音模型当然是HMM. 因此,使用这种方法的难度与语音识别的难度相同.
在实时检测中,准确检测异常声音的开始和结束也很重要. 因为如果起点和终点不准确,将不可避免地影响模型的准确性,从而影响识别率.
参考:
OpenCV3实现人脸识别(两个)-采集要识别的人脸数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 749 次浏览 • 2020-08-06 22:14
1. 上一篇博客文章演示了如何使用OpenCV内置的面部和眼睛级联分类器检测图像中的面部,此处将演示如何打开连接到计算机的相机并检测面部,然后保存照片. 接下来,它将用作面部识别的训练数据.
2. 我的编程环境是Windows 7 64位,IDE是VS2015,配置了OpenCV3.3和OpenCV_Contrib,其中Boost 1.66用于配置文件和目录,因此,如果配置上述环境,则可以阅读博客文章. 我以前写过.
I. 处理官方数据
1. 下载OpenCV的官方面孔数据. 官方人脸数据提供了总共40个人的面孔,这些面孔被分类到文件目录中. 每个人有10个面部数据,格式为pgm. ,无法通过PC上的查看软件打开Pgm格式,但是您可以使用OpenCV编写一个小程序来查看其中的内容. csdn的下载地址是: . 下载后,它看起来像这样:
每个文件夹收录10个面部数据,格式为pgm,大小为92X112.
2. 编写函数以查看每个类别的面部数据. 这里,boost库的文件操作类别用于递归遍历每个子目录中的图像数据并显示它.
(1)功能代码
/显示目标路径下的所有图像
void showImage(string image_path)
{
//判断是事为文件夹
if (!fs::is_directory(image_path))
{
Mat image = imread(image_path);
if (!image.empty())
{
imshow(image_path, image);
waitKey(0);
}
}
else if(fs::is_directory(image_path))
{
fs::recursive_directory_iterator begin_iter(image_path);
fs::recursive_directory_iterator end_iter;
for (; begin_iter != end_iter; begin_iter++)
{
string file_name = begin_iter->path().string();
if (!fs::is_directory(file_name))
{
Mat image = imread(file_name);
if (!image.empty())
{
imshow(file_name, image);
waitKey(30);
}
}
}
}
}
(2)打开一组数据,您可以看到其中的面部,并且正面具有各种角度,因此在输入要识别的面部时,我们可以从官方角度尽可能地学习.
二,采集要识别的人脸数据
采集要识别的面部数据. 您可以从图像集合中检测面部,也可以从USB相机或笔记本计算机随附的相机检测面部. 此处给出的代码是从相机检测面部,然后对其进行拦截,将其更改为与官方面部图像大小相同的数据,然后保存.
1. 使用OpenCV人脸检测级联分类器来检测人脸,如果它检测到当前视频中只有一个人脸,则使用眼睛分类器来检测该人脸是否可以完全检测到两只眼睛,如果可以同时检测到两只眼睛时间,按p键拍照并保存. 保存10张以上的面孔并退出.
<p>void photograph(string save_path,int _cap)
{
int image_number = 0;
if (!face_detector.load(face_path))
{
std::cout 查看全部
前言
1. 上一篇博客文章演示了如何使用OpenCV内置的面部和眼睛级联分类器检测图像中的面部,此处将演示如何打开连接到计算机的相机并检测面部,然后保存照片. 接下来,它将用作面部识别的训练数据.
2. 我的编程环境是Windows 7 64位,IDE是VS2015,配置了OpenCV3.3和OpenCV_Contrib,其中Boost 1.66用于配置文件和目录,因此,如果配置上述环境,则可以阅读博客文章. 我以前写过.
I. 处理官方数据
1. 下载OpenCV的官方面孔数据. 官方人脸数据提供了总共40个人的面孔,这些面孔被分类到文件目录中. 每个人有10个面部数据,格式为pgm. ,无法通过PC上的查看软件打开Pgm格式,但是您可以使用OpenCV编写一个小程序来查看其中的内容. csdn的下载地址是: . 下载后,它看起来像这样:
每个文件夹收录10个面部数据,格式为pgm,大小为92X112.
2. 编写函数以查看每个类别的面部数据. 这里,boost库的文件操作类别用于递归遍历每个子目录中的图像数据并显示它.
(1)功能代码
/显示目标路径下的所有图像
void showImage(string image_path)
{
//判断是事为文件夹
if (!fs::is_directory(image_path))
{
Mat image = imread(image_path);
if (!image.empty())
{
imshow(image_path, image);
waitKey(0);
}
}
else if(fs::is_directory(image_path))
{
fs::recursive_directory_iterator begin_iter(image_path);
fs::recursive_directory_iterator end_iter;
for (; begin_iter != end_iter; begin_iter++)
{
string file_name = begin_iter->path().string();
if (!fs::is_directory(file_name))
{
Mat image = imread(file_name);
if (!image.empty())
{
imshow(file_name, image);
waitKey(30);
}
}
}
}
}
(2)打开一组数据,您可以看到其中的面部,并且正面具有各种角度,因此在输入要识别的面部时,我们可以从官方角度尽可能地学习.

二,采集要识别的人脸数据
采集要识别的面部数据. 您可以从图像集合中检测面部,也可以从USB相机或笔记本计算机随附的相机检测面部. 此处给出的代码是从相机检测面部,然后对其进行拦截,将其更改为与官方面部图像大小相同的数据,然后保存.
1. 使用OpenCV人脸检测级联分类器来检测人脸,如果它检测到当前视频中只有一个人脸,则使用眼睛分类器来检测该人脸是否可以完全检测到两只眼睛,如果可以同时检测到两只眼睛时间,按p键拍照并保存. 保存10张以上的面孔并退出.
<p>void photograph(string save_path,int _cap)
{
int image_number = 0;
if (!face_detector.load(face_path))
{
std::cout
关于采集器和浏览器内核(完整版)的思考
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-08-06 04:07
当前采集技术的几个基本方面:
1. 可达性: 是否可以获取信息
2. 效率: 如何高效获得,有两种:
A. 一般效率问题:
a. SOCKET级别的效率
b. JS级效率问题
B. 目标效率问题
根据目标网站的逻辑特征,采用有针对性的采集算法. 包括目标重复检查算法和目标刷新算法,以避免重复采集和无效采集.
3. 系统集成
如何将采集系统集成在一起,以及如何与提取算法形成一个整体,以便系统可以确保采集率,正确的采集和提取率,实时性能和网站适应性. 达到整个系统的最佳状态.
4. 反托收问题
获取程序是交互式程序. 这不是纯粹的程序行为,而是一种社会行为.
采集技术的最重要特征是被动的后续开发. 随着Internet的发展,它继续面临着新的技术挑战.
基本过程总结如下:
1.Web1.0时代
在互联网发展的初期,以TCP和HTTP技术为核心技术,以信息发布为主要功能的网站是分开建立的.
相应的采集器技术基于Socket技术,而链接提取是核心.
在系统和分布式技术上合并URL重复检查.
相关研究集中于主题采集和刷新算法. 以最低的成本获得所需的东西.
2.web2.0时代
Web2.0更关注用户的交互. 用户不仅是网站内容的查看者,而且还是网站内容的创建者
随着新闻,论坛和博客的兴起,这些站点具有相同的结构.
主要挑战是如何及时获取新信息?如何适应和使用这些网站结构并开发相应的采集算法.
3. JS / AJAX / HTML5的兴起
丰富的JS技术(包括HTML5)的逐渐兴起为诸如Canvas之类的采集技术带来了新的挑战. 未来是否会成为网站开发技术的主流还不得而知.
获取的基本问题已从下载页面变为下载交互式程序,提供交互式操作,判断程序结束并获得程序结果.
由于JS技术与浏览器环境密切相关,因此浏览器技术已成为解决此类问题的最重要方法.
但是实际上,并非不可能与浏览器分离. JS技术被广泛应用后,如何理解浏览器和JS程序并根据集合问题对其进行优化将是一个需要解决的问题.
如果是这样,浏览器技术将成为未来捕获技术的核心. 查看全部
我已经从事采集工作很多年了,对此技术点我有了更多的见解. 让我与您分享. 欢迎批评和指正.
当前采集技术的几个基本方面:
1. 可达性: 是否可以获取信息
2. 效率: 如何高效获得,有两种:
A. 一般效率问题:
a. SOCKET级别的效率
b. JS级效率问题
B. 目标效率问题
根据目标网站的逻辑特征,采用有针对性的采集算法. 包括目标重复检查算法和目标刷新算法,以避免重复采集和无效采集.
3. 系统集成
如何将采集系统集成在一起,以及如何与提取算法形成一个整体,以便系统可以确保采集率,正确的采集和提取率,实时性能和网站适应性. 达到整个系统的最佳状态.
4. 反托收问题
获取程序是交互式程序. 这不是纯粹的程序行为,而是一种社会行为.
采集技术的最重要特征是被动的后续开发. 随着Internet的发展,它继续面临着新的技术挑战.
基本过程总结如下:
1.Web1.0时代
在互联网发展的初期,以TCP和HTTP技术为核心技术,以信息发布为主要功能的网站是分开建立的.
相应的采集器技术基于Socket技术,而链接提取是核心.
在系统和分布式技术上合并URL重复检查.
相关研究集中于主题采集和刷新算法. 以最低的成本获得所需的东西.
2.web2.0时代
Web2.0更关注用户的交互. 用户不仅是网站内容的查看者,而且还是网站内容的创建者
随着新闻,论坛和博客的兴起,这些站点具有相同的结构.
主要挑战是如何及时获取新信息?如何适应和使用这些网站结构并开发相应的采集算法.
3. JS / AJAX / HTML5的兴起
丰富的JS技术(包括HTML5)的逐渐兴起为诸如Canvas之类的采集技术带来了新的挑战. 未来是否会成为网站开发技术的主流还不得而知.
获取的基本问题已从下载页面变为下载交互式程序,提供交互式操作,判断程序结束并获得程序结果.
由于JS技术与浏览器环境密切相关,因此浏览器技术已成为解决此类问题的最重要方法.
但是实际上,并非不可能与浏览器分离. JS技术被广泛应用后,如何理解浏览器和JS程序并根据集合问题对其进行优化将是一个需要解决的问题.
如果是这样,浏览器技术将成为未来捕获技术的核心.
防采集 - 最讨厌采集,一点技术浓度都没有!
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-11 14:55
很多防采集方法在实行的时侯须要考虑是否影响搜索引擎对网站的抓取,所以先来剖析下通常采集器和搜索引擎爬虫采集有何不同。
相同点:a. 两者都须要直接抓取到网页源码能够有效工作,b. 两者单位时间内会多次大量抓取被访问的网站内容;c. 宏观上来讲二者IP就会变动;d. 两者多没耐心的去破解你对网页的一些加密(验证),比如网页内容通过js文件加密,比如须要输入验证码能够浏览内容,比如须要登陆能够访问内容等。
不同点:搜索引擎爬虫先忽视整个网页源码脚本和款式以及html标签代码,然后对剩下的文字部份进行切成语法复句剖析等一系列的复杂处理。而采集器通常是通过html标签特性来抓取须要的数据,在制做采集规则时须要填写目标内容的开始标志何结束标志,这样就定位了所须要的内容;或者采用对特定网页制做特定的正则表达式,来筛选出须要的内容。无论是借助开始结束标志还是正则表达式,都会涉及到html标签(网页结构剖析)。
然后再来提出一些防采集方法
1、限制IP地址单位时间的访问次数
分析:没有那个常人一秒钟内能访问相同网站5次,除非是程序访问,而有这些喜好的,就剩下搜索引擎爬虫和厌恶的采集器了。
弊端:一刀切,这同样会制止搜索引擎对网站的收录
适用网站:不太借助搜索引擎的网站
采集器会怎样做:减少单位时间的访问次数,减低采集效率
2、屏蔽ip
分析:通过后台计数器,记录来访者ip和访问频度,人为剖析来访记录,屏蔽可疑Ip。
弊端:似乎没哪些弊病,就是站长忙了点
适用网站:所有网站,且站长才能晓得什么是google或则百度的机器人
采集器会怎样做:打游击战呗!利用ip代理采集一次换一次,不过会增加采集器的效率和网速(用代理嘛)。
3、利用js加密网页内容
Note:这个方式我没接触过,只是从别处看来
分析:不用剖析了,搜索引擎爬虫和采集器通杀
适用网站:极度厌恶搜索引擎和采集器的网站
采集器会如此做:你这么牛,都豁出去了,他就不来采你了
4、网页里隐藏网站版权或则一些随机垃圾文字,这些文字风格写在css文件中
分析:虽然不能避免采集,但是会使采集后的内容饱含了你网站的版权说明或则一些垃圾文字,因为通常采集器不会同时采集你的css文件,那些文字没了风格,就显示下来了。
适用网站:所有网站
采集器会怎样做:对于版权文字,好办,替换掉。对于随机的垃圾文字,没办法,勤快点了。
5、用户登入能够访问网站内容
分析:搜索引擎爬虫不会对每位这样类型的网站设计登入程序。听说采集器可以针对某个网站设计模拟用户登入递交表单行为。
适用网站:极度厌恶搜索引擎,且想制止大部分采集器的网站
采集器会怎样做:制作拟用户登入递交表单行为的模块
6、利用脚本语言做分页(隐藏分页)
分析:还是那句,搜索引擎爬虫不会针对各类网站的隐藏分页进行剖析,这影响搜索引擎对其收录。但是,采集器在编撰采集规则时,要剖析目标网页代码,懂点脚本知识的人,就会晓得分页的真实链接地址。
适用网站:对搜索引擎依赖度不高的网站,还有,采集你的人不懂脚本知识
采集器会怎样做:应该说采集器会怎样做,他总之都要剖析你的网页代码,顺便剖析你的分页脚本,花不了多少额外时间。
7、防盗链举措(只容许通过本站页面联接查看,如:Request.ServerVariables(“HTTP_REFERER“) )
分析:ASP/' target='_blank'>asp和php可以通过读取恳求的HTTP_REFERER属性,来判定该恳求是否来自本网站,从而来限制采集器,同样也限制了搜索引擎爬虫,严重影响搜索引擎对网站部分防盗链内容的收录。
适用网站:不太考虑搜索引擎收录的网站
采集器会怎样做:伪装HTTP_REFERER嘛,不难。
8、全flash、图片或则pdf来呈现网站内容
分析:对搜索引擎爬虫和采集器支持性不好,这个好多懂点seo的人都晓得
适用网站:媒体设计类而且不在乎搜索引擎收录的网站
采集器会怎样做:不采了,走人
9、网站随机采用不同模版
分析:因为采集器是依照网页结构来定位所须要的内容,一旦先后两次模版更换,采集规则就失效,不错。而且这样对搜索引擎爬虫没影响。
适用网站:动态网站,并且不考虑用户体验。
采集器会怎样做:一个网站模版不可能少于10个吧,每个模版弄一个规则就行了,不同模版采用不同采集规则。如果少于10个模版了,既然目标网站都这么费力的更换模版,成全他,撤。
10、采用动态不规则的html标签
分析:这个比较变态。考虑到html标签内含空格和不含空格疗效是一样的,所以和对于页面显示疗效一样,但是作为采集器的标记就是两个不同标记了。如果每次页面的html标签内空格数随机,那么
采集规则就失效了。但是,这对搜索引擎爬虫没多大影响。
适合网站:所有动态且不想违背网页设计规范的网站。
采集器会怎样做:还是有对策的,现在html cleaner还是好多的,先清除了html标签,然后再写采集规则;应该用采集规则前先清除html标签,还是才能领到所需数据。
总结:
一旦要同时搜索引擎爬虫和采集器,这是太使人无奈的事情,因为搜索引擎第一步就是采集目标网页内容,这跟采集器原理一样,所以好多避免采集的方式同时也妨碍了搜索引擎对网站的收录,无奈,是吧?以上10条建议尽管不能百分之百防采集,但是几种方式一起适用早已拒绝了一大部分采集器了。
三、关于防采集的方式
优采云:下面讲一些主要的防采集方法。可以说是攻守对战吧。打开一个网页实际就是一个Http请求浏览器。百度蜘蛛,小到我们的采集器使用的都是一个原理,模拟http请求,所以我们同样能模拟出浏览器。百度蜘蛛下来所以绝对的防采集根本不存在,只是难度的高低。或者你觉得搜索引擎的搜录也无所谓了。你可以用一些特别强悍的activex,flash,全图片文字的方式,这个我们无能为力。
普通的防采集方法有
1、来源判定
2、登录信息判定 Cookie
3、请求次数判别。如一段时间内恳求多少,非常规操作则封IP
4、发送方法判定 POST GET 使用JS,Ajax等恳请内容
举例:
1.2不用说了,论坛,下载站等。。
3、一些大网站,需要配置服务器,单纯靠脚本判定资源消耗比较大
4、如一些急聘站,的分页,Web2.0站的ajax恳求内容
当然我们前面还发觉一些*****锏,今天第一次在这里给你们公布下来~~ 有优质内容须要防采集的同学可以考虑试下
1、网页默认deflate压缩输出(gzip容易一点,容易解压) 我们普通的浏览器和baidu支持辨识gzip,deflate输出内容
2、网页内容不定时 /0 内容手动截断,这两点基本可以防主大部分主流软件采集及web采集程序了~
今天主要想要抒发的一点,大家在做站时一定要注意技术的提升,比如我们上面有后期外部php及.net插口处理采集数据。或者干脆你自己做一个发布时的插口程序自己入库。我们伪原创做得再好,一样有特别多的会员使用,那样又不原创了,采集一样须要技术,只有你通过采集器获得了没有多少人有的数据,你才是惟一了。可能是我最为技术型人的一个弊病,谢谢你们!
互动环节
问:您刚刚谈到对采集有屏蔽,那对搜索引擎呢
答:采集和百度爬虫是一模一样的原理 还有浏览器也是一样的 所以没有绝对的屏蔽,相反都会影响客户体验,你可以做一些不影响客户体验和搜索引擎搜录而提升采集难度的尝试
问:你刚刚讲的是网页内容采集,有没有针对匹配关键词的指定数组的高速采集,比如采集所有带”IDC“的网页的邮箱和电话号码?用过一些,速度太慢,而且数据量显著很少。
答:我们不做这样批量的工具,其实例如做峰会发帖机之类的实现上去道理一样,也很容易,其实实现上去也是可以,只是有更多的一些人工操作,我们上面有 正则匹配。。也就是你要的这些单一工具把这些正则都集成在上面了。而我们须要用户自己去写
问:采集的复杂度应当就在这吧?页面规则的不规则性和多变性?
答:在软件上面设置才能匹配多种模板的正则表达式,一样可以采集到多模板的网站,所谓“道高一尺,魔高一丈”。
问:优采云,能不能说一下如何把phpcms的文章模块下的第一级栏目显示下来啊?
答:用的是 07 还是08版 07版有一个终极栏目的属性 如果是,就不显示。
问:优采云,你认为那个CMS比较好用,你给你们推荐一个你最钟意的CMS系统吧。
答:我如今是对phpcms更熟悉一些。选择一个适宜自己的就够了。研究透一个。
问:有个采集工具 海纳 号称不要编撰采集规则,不知道有没有同事研究过,想讨教其原理?
答:你说的这个是内容主体辨识的范畴了。也做过,但只对一些新闻网站识别得比较好 ,这是一个手动匹配方式的工具,就像百度新闻一样,能手动匹配到正文数据。对大数据量的提取有用处。但精度相对低点点,因为人工不可控。
问:2008 版本能平滑升级到 2009吗?我是免费用户,呵呵。
答:软件升级:请运行程序目录下的updateto2009.exe进行升级。支持3.2sp5及2008版到2009版的升级,支持所有用户
问:请问伪原创的问题如何处理呢?
答:我们伪原创做得再好,一样有特别多的会员使用,那样又不原创了,采集一样须要技术,只有你通过采集器获得了没有多少人有的数据,你才是惟一了。比如我们有同义词替换功能,这个词库就须要最好你自己去扩展一个属于自己的伪原创。使用同义词反义词替换,排除敏感词,不同的标签之间数据融合,指如标题内容之间数据的互相替换给标题。内容副词。为文章标题等生成拼音地址 给文章加上摘要。采集一些其他编码的网站,我们可以做到简简体转化,可以采集中文网站翻译成英文(虽然比较垃圾,但应当可以算是原创)网民,默认的我们能否手动辨识网页的编码。但可能也会有出错的时侯,这时候你须要在任务第四页手工定义一下,比如是gb2312还是utf8等等。 查看全部
笔者自己是写采集器的,所以对网站防采集有一些心得感悟。因为是在下班时间,各种方式只是简单的提到。
很多防采集方法在实行的时侯须要考虑是否影响搜索引擎对网站的抓取,所以先来剖析下通常采集器和搜索引擎爬虫采集有何不同。
相同点:a. 两者都须要直接抓取到网页源码能够有效工作,b. 两者单位时间内会多次大量抓取被访问的网站内容;c. 宏观上来讲二者IP就会变动;d. 两者多没耐心的去破解你对网页的一些加密(验证),比如网页内容通过js文件加密,比如须要输入验证码能够浏览内容,比如须要登陆能够访问内容等。
不同点:搜索引擎爬虫先忽视整个网页源码脚本和款式以及html标签代码,然后对剩下的文字部份进行切成语法复句剖析等一系列的复杂处理。而采集器通常是通过html标签特性来抓取须要的数据,在制做采集规则时须要填写目标内容的开始标志何结束标志,这样就定位了所须要的内容;或者采用对特定网页制做特定的正则表达式,来筛选出须要的内容。无论是借助开始结束标志还是正则表达式,都会涉及到html标签(网页结构剖析)。
然后再来提出一些防采集方法
1、限制IP地址单位时间的访问次数
分析:没有那个常人一秒钟内能访问相同网站5次,除非是程序访问,而有这些喜好的,就剩下搜索引擎爬虫和厌恶的采集器了。
弊端:一刀切,这同样会制止搜索引擎对网站的收录
适用网站:不太借助搜索引擎的网站
采集器会怎样做:减少单位时间的访问次数,减低采集效率
2、屏蔽ip
分析:通过后台计数器,记录来访者ip和访问频度,人为剖析来访记录,屏蔽可疑Ip。
弊端:似乎没哪些弊病,就是站长忙了点
适用网站:所有网站,且站长才能晓得什么是google或则百度的机器人
采集器会怎样做:打游击战呗!利用ip代理采集一次换一次,不过会增加采集器的效率和网速(用代理嘛)。
3、利用js加密网页内容
Note:这个方式我没接触过,只是从别处看来
分析:不用剖析了,搜索引擎爬虫和采集器通杀
适用网站:极度厌恶搜索引擎和采集器的网站
采集器会如此做:你这么牛,都豁出去了,他就不来采你了
4、网页里隐藏网站版权或则一些随机垃圾文字,这些文字风格写在css文件中
分析:虽然不能避免采集,但是会使采集后的内容饱含了你网站的版权说明或则一些垃圾文字,因为通常采集器不会同时采集你的css文件,那些文字没了风格,就显示下来了。
适用网站:所有网站
采集器会怎样做:对于版权文字,好办,替换掉。对于随机的垃圾文字,没办法,勤快点了。
5、用户登入能够访问网站内容
分析:搜索引擎爬虫不会对每位这样类型的网站设计登入程序。听说采集器可以针对某个网站设计模拟用户登入递交表单行为。
适用网站:极度厌恶搜索引擎,且想制止大部分采集器的网站
采集器会怎样做:制作拟用户登入递交表单行为的模块
6、利用脚本语言做分页(隐藏分页)
分析:还是那句,搜索引擎爬虫不会针对各类网站的隐藏分页进行剖析,这影响搜索引擎对其收录。但是,采集器在编撰采集规则时,要剖析目标网页代码,懂点脚本知识的人,就会晓得分页的真实链接地址。
适用网站:对搜索引擎依赖度不高的网站,还有,采集你的人不懂脚本知识
采集器会怎样做:应该说采集器会怎样做,他总之都要剖析你的网页代码,顺便剖析你的分页脚本,花不了多少额外时间。
7、防盗链举措(只容许通过本站页面联接查看,如:Request.ServerVariables(“HTTP_REFERER“) )
分析:ASP/' target='_blank'>asp和php可以通过读取恳求的HTTP_REFERER属性,来判定该恳求是否来自本网站,从而来限制采集器,同样也限制了搜索引擎爬虫,严重影响搜索引擎对网站部分防盗链内容的收录。
适用网站:不太考虑搜索引擎收录的网站
采集器会怎样做:伪装HTTP_REFERER嘛,不难。
8、全flash、图片或则pdf来呈现网站内容
分析:对搜索引擎爬虫和采集器支持性不好,这个好多懂点seo的人都晓得
适用网站:媒体设计类而且不在乎搜索引擎收录的网站
采集器会怎样做:不采了,走人
9、网站随机采用不同模版
分析:因为采集器是依照网页结构来定位所须要的内容,一旦先后两次模版更换,采集规则就失效,不错。而且这样对搜索引擎爬虫没影响。
适用网站:动态网站,并且不考虑用户体验。
采集器会怎样做:一个网站模版不可能少于10个吧,每个模版弄一个规则就行了,不同模版采用不同采集规则。如果少于10个模版了,既然目标网站都这么费力的更换模版,成全他,撤。
10、采用动态不规则的html标签
分析:这个比较变态。考虑到html标签内含空格和不含空格疗效是一样的,所以和对于页面显示疗效一样,但是作为采集器的标记就是两个不同标记了。如果每次页面的html标签内空格数随机,那么
采集规则就失效了。但是,这对搜索引擎爬虫没多大影响。
适合网站:所有动态且不想违背网页设计规范的网站。
采集器会怎样做:还是有对策的,现在html cleaner还是好多的,先清除了html标签,然后再写采集规则;应该用采集规则前先清除html标签,还是才能领到所需数据。
总结:
一旦要同时搜索引擎爬虫和采集器,这是太使人无奈的事情,因为搜索引擎第一步就是采集目标网页内容,这跟采集器原理一样,所以好多避免采集的方式同时也妨碍了搜索引擎对网站的收录,无奈,是吧?以上10条建议尽管不能百分之百防采集,但是几种方式一起适用早已拒绝了一大部分采集器了。
三、关于防采集的方式
优采云:下面讲一些主要的防采集方法。可以说是攻守对战吧。打开一个网页实际就是一个Http请求浏览器。百度蜘蛛,小到我们的采集器使用的都是一个原理,模拟http请求,所以我们同样能模拟出浏览器。百度蜘蛛下来所以绝对的防采集根本不存在,只是难度的高低。或者你觉得搜索引擎的搜录也无所谓了。你可以用一些特别强悍的activex,flash,全图片文字的方式,这个我们无能为力。
普通的防采集方法有
1、来源判定
2、登录信息判定 Cookie
3、请求次数判别。如一段时间内恳求多少,非常规操作则封IP
4、发送方法判定 POST GET 使用JS,Ajax等恳请内容
举例:
1.2不用说了,论坛,下载站等。。
3、一些大网站,需要配置服务器,单纯靠脚本判定资源消耗比较大
4、如一些急聘站,的分页,Web2.0站的ajax恳求内容
当然我们前面还发觉一些*****锏,今天第一次在这里给你们公布下来~~ 有优质内容须要防采集的同学可以考虑试下
1、网页默认deflate压缩输出(gzip容易一点,容易解压) 我们普通的浏览器和baidu支持辨识gzip,deflate输出内容
2、网页内容不定时 /0 内容手动截断,这两点基本可以防主大部分主流软件采集及web采集程序了~
今天主要想要抒发的一点,大家在做站时一定要注意技术的提升,比如我们上面有后期外部php及.net插口处理采集数据。或者干脆你自己做一个发布时的插口程序自己入库。我们伪原创做得再好,一样有特别多的会员使用,那样又不原创了,采集一样须要技术,只有你通过采集器获得了没有多少人有的数据,你才是惟一了。可能是我最为技术型人的一个弊病,谢谢你们!
互动环节
问:您刚刚谈到对采集有屏蔽,那对搜索引擎呢
答:采集和百度爬虫是一模一样的原理 还有浏览器也是一样的 所以没有绝对的屏蔽,相反都会影响客户体验,你可以做一些不影响客户体验和搜索引擎搜录而提升采集难度的尝试
问:你刚刚讲的是网页内容采集,有没有针对匹配关键词的指定数组的高速采集,比如采集所有带”IDC“的网页的邮箱和电话号码?用过一些,速度太慢,而且数据量显著很少。
答:我们不做这样批量的工具,其实例如做峰会发帖机之类的实现上去道理一样,也很容易,其实实现上去也是可以,只是有更多的一些人工操作,我们上面有 正则匹配。。也就是你要的这些单一工具把这些正则都集成在上面了。而我们须要用户自己去写
问:采集的复杂度应当就在这吧?页面规则的不规则性和多变性?
答:在软件上面设置才能匹配多种模板的正则表达式,一样可以采集到多模板的网站,所谓“道高一尺,魔高一丈”。
问:优采云,能不能说一下如何把phpcms的文章模块下的第一级栏目显示下来啊?
答:用的是 07 还是08版 07版有一个终极栏目的属性 如果是,就不显示。
问:优采云,你认为那个CMS比较好用,你给你们推荐一个你最钟意的CMS系统吧。
答:我如今是对phpcms更熟悉一些。选择一个适宜自己的就够了。研究透一个。
问:有个采集工具 海纳 号称不要编撰采集规则,不知道有没有同事研究过,想讨教其原理?
答:你说的这个是内容主体辨识的范畴了。也做过,但只对一些新闻网站识别得比较好 ,这是一个手动匹配方式的工具,就像百度新闻一样,能手动匹配到正文数据。对大数据量的提取有用处。但精度相对低点点,因为人工不可控。
问:2008 版本能平滑升级到 2009吗?我是免费用户,呵呵。
答:软件升级:请运行程序目录下的updateto2009.exe进行升级。支持3.2sp5及2008版到2009版的升级,支持所有用户
问:请问伪原创的问题如何处理呢?
答:我们伪原创做得再好,一样有特别多的会员使用,那样又不原创了,采集一样须要技术,只有你通过采集器获得了没有多少人有的数据,你才是惟一了。比如我们有同义词替换功能,这个词库就须要最好你自己去扩展一个属于自己的伪原创。使用同义词反义词替换,排除敏感词,不同的标签之间数据融合,指如标题内容之间数据的互相替换给标题。内容副词。为文章标题等生成拼音地址 给文章加上摘要。采集一些其他编码的网站,我们可以做到简简体转化,可以采集中文网站翻译成英文(虽然比较垃圾,但应当可以算是原创)网民,默认的我们能否手动辨识网页的编码。但可能也会有出错的时侯,这时候你须要在任务第四页手工定义一下,比如是gb2312还是utf8等等。
前嗅ForeSpider数据采集中采集列表界面介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2020-08-09 21:47
课程演示环境:Ubuntu须要学习Windows系统YOLOv4的朋友请抵达《Windows版YOLOv4目标测量实战:训练自己的数据集》,课程链接YOLOv4来了!速度和精度双提高!与 YOLOv3 相比,新版本的 AP(精度)和 FPS (每秒帧数)分别提升了 10% 和 12%。YOLO系列是基于深度学习的端到端实时目标测量方式。本课程将手把手地教你们使用labelImg标明和使用YOLOv4训练自己的数据集。课程实战分为两个项目:单目标测量(足球目标测量)和多目标测量(足球和梅西同时测量)。本课程的YOLOv4使用AlexAB/darknet,在Ubuntu系统上做项目演示。包括:安装YOLOv4、标注自己的数据集、整理自己的数据集、修改配置文件、训练自己的数据集、测试训练出的网路模型、性能统计(mAP估算和画出PR曲线)和先验框降维剖析。还将介绍改善YOLOv4目标训练性能的方法。除本课程《YOLOv4目标测量实战:训练自己的数据集》外,本人将推出有关YOLOv4目标测量的系列课程。请持续关注该系列的其它视频课程,包括:《YOLOv4目标测量实战:人脸口罩配戴辨识》《YOLOv4目标测量实战:中国交通标志辨识》《YOLOv4目标测量:原理与源码解析》
Jvm垃圾采集器和垃圾采集算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 280 次浏览 • 2020-08-07 09:11
目前,内存的动态分配和内存恢复技术已经相当成熟. 一切似乎都进入了“自动化”时代. 为什么我们需要了解GC和内存分配?原因很简单: 当有必要解决各种内存泄漏和内存溢出问题时,当垃圾采集器成为系统实现更高并发性的瓶颈时,我们需要对这些“自动化”技术进行必要的监视和调整.
上一个博客讨论了Java虚拟机的运行时内存的各个部分. 其中,程序计数器,虚拟机堆栈和本地方法堆栈由线程生成,并由线程终止. 堆栈中的堆栈框架遵循该方法. 进入和退出执行推入和弹出操作,因此当方法结束或线程结束时,内存自然会跟随恢复. Java堆与方法块不同. 我们只知道在运行时将创建哪些对象. 这部分内存和恢复是动态的,垃圾回收器也与此部分内存有关. 稍后提到的内存分配和恢复也仅涉及内存的这一部分.
1. 判断物体的生与死1.参考计数方法
许多教科书或开发人员回答了以下问题: “如何判断对象是否还活着?”大多数答案都是引用计数. 实现是这样的: 向该对象添加一个引用计数器;在某个地方被引用时,将添加+1;在引用变为无效时,将添加-1;并且在任何时候其计数器为0的对象将无法被引用.
客观地讲,引用计数方法易于实现并且判断效率很高,但是至少主流的Java虚拟机不使用引用计数方法来管理内存. 主要原因是很难解决对象之间的相互循环. 引用的问题.
2. 可达性分析算法
“可达性分析”是Java和C#当前的主流实现,用于确定对象是否存在. 主要思想是使用一些类作为成为“ GC根目录”的起点的对象,并从这些节点向下搜索. 搜索的路径称为参考链. 如果没有针对GC根目录的对象的引用链,则证明该对象不可用.
如下所示:
Object1-Object4的参考链连接到GC根,而Object5-Oject7没有通过参考链连接,因此被判断为可回收对象
在Java中,有四种类型可以用作GC根节点
3. 再谈报价
在JDK1.2之前,Java中的引用定义为: 如果将引用类型的数据存储为代表另一个内存块的起始地址的值,则可以说该内存块表示一个引用. 在JDK1.2之后,Java扩展了引用的概念,分为以下四种类型:
4. 生存还是死亡
即使在可达性分析算法中无法达到的对象也不是“必须死亡”的. 目前,他们处于“试用”阶段. 要声明一个对象已死亡,至少需要两个标记过程.
以下代码一次显示对象的自救:
1 //代码演示了两点
2 //1.对象可以实现自救
3 //2.这种自救只能一次,因为finalize方法只会被执行一次
4
5 public class jvmtest1 {
6 public static jvmtest1 obj = null;
7
8 public void isAlive() {
9 System.out.println("I am alive");
10 }
11
12 @Override
13 protected void finalize() throws Throwable {
14 super.finalize();
15 System.out.println("finalize method executed!");
16 obj = this;
17 }
18
19 public static void main(String[] args) throws Exception {
20 obj = new jvmtest1();
21
22 obj = null;
23 System.gc();
24 // 因为finalize方法优先级很低,所以暂停0.5s执行
25 Thread.sleep(500);
26 if (obj != null) {
27 obj.isAlive();
28 } else {
29 System.out.println("I am dead");
30 }
31
32 // 与上面的代码完全相同,但是自救失败了
33 obj = null;
34 System.gc();
35 // 因为finalize方法优先级很低,所以暂停0.5s执行
36 Thread.sleep(500);
37 if (obj != null) {
38 obj.isAlive();
39 } else {
40 System.out.println("I am dead");
41 }
42 }
43 }
程序输出为:
可以看出obj的finalize()方法确实是由GC触发的,并且成功地保存了一次. 应该注意的是,下部的代码与上部的代码相同,但是自助失败. 这是因为对象的finalize()方法只能被系统自动调用一次. 如果对象面临第二次恢复,则不会调用其finalize(The)方法,因此第二次自助操作将失败.
5. 恢复方法区域
方法区域中的垃圾回收具有“成本效益”. 在堆中,特别是在新一代中,常规应用程序的垃圾回收通常可以回收70%-95%的空间,而方法区域(在HatSport虚拟机中)永久生成的恢复效率远远低于这个.
永久代中有两种主要的垃圾采集类型: 过时的常量和无用的类
(1)此类的所有实例均已回收,也就是说,堆中没有此类的实例
(2)加载了此类的ClassLoader已被回收
(3)与此类对应的java.lang.Class对象在任何地方都没有引用,并且该类的方法无法在任何地方通过反射来访问.
满足以上三个条件的类也可以被回收,但不一定. 在经常使用ByteCode框架(例如反射,动态代理,CGLib等)并且经常定义ClassLoader(例如动态生成的JSP和OSGi)的场景中,虚拟机需要类卸载功能,以确保永久生成不会溢出.
2. 垃圾采集算法1.打标算法
标记扫描算法是最基本的采集算法. 首先标记需要回收的对象,并在标记完成后统一采集所有标记的对象.
主要缺点有两个:
过程如下:
2. 复制算法
为了解决效率问题,出现了复制算法(Copying),他将内存分为相等大小的两块,一次只使用其中之一. 当该内存块用完时,会将尚存的对象复制到另一个块,然后清除该空间块. 这样,每次都可以在整个半个区域中回收内存,并且无需考虑在内存分配过程中内存碎片的复杂性. 您只需要移动指针并按顺序分配内存即可.
这种方法的代价是将内存分成两半,这太高了.
过程如下:
当前的商用虚拟机都使用此方法来回收新一代产品. IBM的特殊研究表明,新一代对象中有98%是“生死攸关的”,因此无需划分1: 1内存空间. 另一种方法是将内存块划分为Eden空间(80%)和两个Survivor空间(10%). 每次使用Eden空间和一个Survivor空间时,在回收过程中会将幸存的对象复制到另一个Survivor空间. ,因此每次仅“浪费”了10%的空间. 当Survivor空间不足时,它需要依赖其他内存(旧代)来进行分配保证(与旧代中的分配保证机制相同).
3. 标记排序算法
当副本采集算法的对象存活率较高时,它将执行更多的复制操作,并且效率会降低. 更重要的是,如果您不希望浪费50%的空间,则需要有额外的空间用于分配保证,以应对极端情况,即已用内存中的所有对象都处于100%活动状态,因此旧一代通常无法选择这种方法. 提出了Mark-Compact算法(Mark-Compact).
标记过程与“ mark-sweep”算法相同,但是后续步骤不是直接清理可回收部分,而是将所有活动对象移到一端,然后直接清理内存在末尾.
过程如下:
4. 分代采集算法
当前的商用虚拟机都使用Generational 采集算法. 通常,堆分为新一代和旧一代,并且根据每个时代的不同特性使用最合适的算法. 新一代一般采用复制算法,只需要支付少量复制幸存对象的费用即可. 在旧的一代中,由于对象生存率很高并且没有多余的空间来分配它,因此必须使用“标记清除”或“标记组织”算法来进行恢复.
概述:
目前,内存的动态分配和内存恢复技术已经相当成熟. 一切似乎都进入了“自动化”时代. 为什么我们需要了解GC和内存分配?原因很简单: 当有必要解决各种内存泄漏和内存溢出问题时,当垃圾采集器成为系统实现更高并发性的瓶颈时,我们需要对这些“自动化”技术进行必要的监视和调整.
上一个博客讨论了Java虚拟机的运行时内存的各个部分. 其中,程序计数器,虚拟机堆栈和本地方法堆栈由线程生成,并由线程终止. 堆栈中的堆栈框架遵循该方法. 进入和退出执行推入和弹出操作,因此当方法结束或线程结束时,内存自然会跟随恢复. Java堆与方法块不同. 我们只知道在运行时将创建哪些对象. 这部分内存和恢复是动态的,垃圾回收器也与此部分内存有关. 稍后提到的内存分配和恢复也仅涉及内存的这一部分.
1. 判断物体的生与死1.参考计数方法
许多教科书或开发人员回答了以下问题: “如何判断对象是否还活着?”大多数答案都是引用计数. 实现是这样的: 向该对象添加一个引用计数器;在某个地方被引用时,将添加+1;在引用变为无效时,将添加-1;并且在任何时候其计数器为0的对象将无法被引用.
客观地讲,引用计数方法易于实现并且判断效率很高,但是至少主流的Java虚拟机不使用引用计数方法来管理内存. 主要原因是很难解决对象之间的相互循环. 引用的问题.
2. 可达性分析算法
“可达性分析”是Java和C#当前的主流实现,用于确定对象是否存在. 主要思想是使用一些类作为成为“ GC根目录”的起点的对象,并从这些节点向下搜索. 搜索的路径称为参考链. 如果没有针对GC根目录的对象的引用链,则证明该对象不可用.
如下所示:
Object1-Object4的参考链连接到GC根,而Object5-Oject7没有通过参考链连接,因此被判断为可回收对象
在Java中,有四种类型可以用作GC根节点
3. 再谈报价
在JDK1.2之前,Java中的引用定义为: 如果将引用类型的数据存储为代表另一个内存块的起始地址的值,则可以说该内存块表示一个引用. 在JDK1.2之后,Java扩展了引用的概念,分为以下四种类型:
4. 生存还是死亡
即使在可达性分析算法中无法达到的对象也不是“必须死亡”的. 目前,他们处于“试用”阶段. 要声明一个对象已死亡,至少需要两个标记过程.
以下代码一次显示对象的自救:
1 //代码演示了两点
2 //1.对象可以实现自救
3 //2.这种自救只能一次,因为finalize方法只会被执行一次
4
5 public class jvmtest1 {
6 public static jvmtest1 obj = null;
7
8 public void isAlive() {
9 System.out.println("I am alive");
10 }
11
12 @Override
13 protected void finalize() throws Throwable {
14 super.finalize();
15 System.out.println("finalize method executed!");
16 obj = this;
17 }
18
19 public static void main(String[] args) throws Exception {
20 obj = new jvmtest1();
21
22 obj = null;
23 System.gc();
24 // 因为finalize方法优先级很低,所以暂停0.5s执行
25 Thread.sleep(500);
26 if (obj != null) {
27 obj.isAlive();
28 } else {
29 System.out.println("I am dead");
30 }
31
32 // 与上面的代码完全相同,但是自救失败了
33 obj = null;
34 System.gc();
35 // 因为finalize方法优先级很低,所以暂停0.5s执行
36 Thread.sleep(500);
37 if (obj != null) {
38 obj.isAlive();
39 } else {
40 System.out.println("I am dead");
41 }
42 }
43 }
程序输出为:
可以看出obj的finalize()方法确实是由GC触发的,并且成功地保存了一次. 应该注意的是,下部的代码与上部的代码相同,但是自助失败. 这是因为对象的finalize()方法只能被系统自动调用一次. 如果对象面临第二次恢复,则不会调用其finalize(The)方法,因此第二次自助操作将失败.
5. 恢复方法区域
方法区域中的垃圾回收具有“成本效益”. 在堆中,特别是在新一代中,常规应用程序的垃圾回收通常可以回收70%-95%的空间,而方法区域(在HatSport虚拟机中)永久生成的恢复效率远远低于这个.
永久代中有两种主要的垃圾采集类型: 过时的常量和无用的类
(1)此类的所有实例均已回收,也就是说,堆中没有此类的实例
(2)加载了此类的ClassLoader已被回收
(3)与此类对应的java.lang.Class对象在任何地方都没有引用,并且该类的方法无法在任何地方通过反射来访问.
满足以上三个条件的类也可以被回收,但不一定. 在经常使用ByteCode框架(例如反射,动态代理,CGLib等)并且经常定义ClassLoader(例如动态生成的JSP和OSGi)的场景中,虚拟机需要类卸载功能,以确保永久生成不会溢出.
2. 垃圾采集算法1.打标算法
标记扫描算法是最基本的采集算法. 首先标记需要回收的对象,并在标记完成后统一采集所有标记的对象.
主要缺点有两个:
过程如下:
2. 复制算法
为了解决效率问题,出现了复制算法(Copying),他将内存分为相等大小的两块,一次只使用其中之一. 当该内存块用完时,会将尚存的对象复制到另一个块,然后清除该空间块. 这样,每次都可以在整个半个区域中回收内存,并且无需考虑在内存分配过程中内存碎片的复杂性. 您只需要移动指针并按顺序分配内存即可.
这种方法的代价是将内存分成两半,这太高了.
过程如下:
当前的商用虚拟机都使用此方法来回收新一代产品. IBM的特殊研究表明,新一代对象中有98%是“生死攸关的”,因此无需划分1: 1内存空间. 另一种方法是将内存块划分为Eden空间(80%)和两个Survivor空间(10%). 每次使用Eden空间和一个Survivor空间时,在回收过程中会将幸存的对象复制到另一个Survivor空间. ,因此每次仅“浪费”了10%的空间. 当Survivor空间不足时,它需要依赖其他内存(旧代)来进行分配保证(与旧代中的分配保证机制相同).
3. 标记排序算法
当副本采集算法的对象存活率较高时,它将执行更多的复制操作,并且效率会降低. 更重要的是,如果您不希望浪费50%的空间,则需要有额外的空间用于分配保证,以应对极端情况,即已用内存中的所有对象都处于100%活动状态,因此旧一代通常无法选择这种方法. 提出了Mark-Compact算法(Mark-Compact).
标记过程与“标记清除”算法相同,但是后续步骤不是直接清理可回收部分,而是将所有活动对象移动到一端,然后直接清理内存在末尾.
过程如下:
4. 分代采集算法
当前的商用虚拟机都使用Generational 采集算法. 通常,堆分为新一代和旧一代,并且根据每个时代的不同特性使用最合适的算法. 新一代一般采用复制算法,只需要支付少量复制幸存对象的费用即可. 在旧的一代中,由于对象生存率很高并且没有多余的空间来分配它,因此必须使用“标记清除”或“标记组织”算法来进行恢复. 查看全部
概述:
目前,内存的动态分配和内存恢复技术已经相当成熟. 一切似乎都进入了“自动化”时代. 为什么我们需要了解GC和内存分配?原因很简单: 当有必要解决各种内存泄漏和内存溢出问题时,当垃圾采集器成为系统实现更高并发性的瓶颈时,我们需要对这些“自动化”技术进行必要的监视和调整.
上一个博客讨论了Java虚拟机的运行时内存的各个部分. 其中,程序计数器,虚拟机堆栈和本地方法堆栈由线程生成,并由线程终止. 堆栈中的堆栈框架遵循该方法. 进入和退出执行推入和弹出操作,因此当方法结束或线程结束时,内存自然会跟随恢复. Java堆与方法块不同. 我们只知道在运行时将创建哪些对象. 这部分内存和恢复是动态的,垃圾回收器也与此部分内存有关. 稍后提到的内存分配和恢复也仅涉及内存的这一部分.
1. 判断物体的生与死1.参考计数方法
许多教科书或开发人员回答了以下问题: “如何判断对象是否还活着?”大多数答案都是引用计数. 实现是这样的: 向该对象添加一个引用计数器;在某个地方被引用时,将添加+1;在引用变为无效时,将添加-1;并且在任何时候其计数器为0的对象将无法被引用.
客观地讲,引用计数方法易于实现并且判断效率很高,但是至少主流的Java虚拟机不使用引用计数方法来管理内存. 主要原因是很难解决对象之间的相互循环. 引用的问题.
2. 可达性分析算法
“可达性分析”是Java和C#当前的主流实现,用于确定对象是否存在. 主要思想是使用一些类作为成为“ GC根目录”的起点的对象,并从这些节点向下搜索. 搜索的路径称为参考链. 如果没有针对GC根目录的对象的引用链,则证明该对象不可用.
如下所示:
Object1-Object4的参考链连接到GC根,而Object5-Oject7没有通过参考链连接,因此被判断为可回收对象
在Java中,有四种类型可以用作GC根节点
3. 再谈报价
在JDK1.2之前,Java中的引用定义为: 如果将引用类型的数据存储为代表另一个内存块的起始地址的值,则可以说该内存块表示一个引用. 在JDK1.2之后,Java扩展了引用的概念,分为以下四种类型:
4. 生存还是死亡
即使在可达性分析算法中无法达到的对象也不是“必须死亡”的. 目前,他们处于“试用”阶段. 要声明一个对象已死亡,至少需要两个标记过程.
以下代码一次显示对象的自救:
1 //代码演示了两点
2 //1.对象可以实现自救
3 //2.这种自救只能一次,因为finalize方法只会被执行一次
4
5 public class jvmtest1 {
6 public static jvmtest1 obj = null;
7
8 public void isAlive() {
9 System.out.println("I am alive");
10 }
11
12 @Override
13 protected void finalize() throws Throwable {
14 super.finalize();
15 System.out.println("finalize method executed!");
16 obj = this;
17 }
18
19 public static void main(String[] args) throws Exception {
20 obj = new jvmtest1();
21
22 obj = null;
23 System.gc();
24 // 因为finalize方法优先级很低,所以暂停0.5s执行
25 Thread.sleep(500);
26 if (obj != null) {
27 obj.isAlive();
28 } else {
29 System.out.println("I am dead");
30 }
31
32 // 与上面的代码完全相同,但是自救失败了
33 obj = null;
34 System.gc();
35 // 因为finalize方法优先级很低,所以暂停0.5s执行
36 Thread.sleep(500);
37 if (obj != null) {
38 obj.isAlive();
39 } else {
40 System.out.println("I am dead");
41 }
42 }
43 }
程序输出为:
可以看出obj的finalize()方法确实是由GC触发的,并且成功地保存了一次. 应该注意的是,下部的代码与上部的代码相同,但是自助失败. 这是因为对象的finalize()方法只能被系统自动调用一次. 如果对象面临第二次恢复,则不会调用其finalize(The)方法,因此第二次自助操作将失败.
5. 恢复方法区域
方法区域中的垃圾回收具有“成本效益”. 在堆中,特别是在新一代中,常规应用程序的垃圾回收通常可以回收70%-95%的空间,而方法区域(在HatSport虚拟机中)永久生成的恢复效率远远低于这个.
永久代中有两种主要的垃圾采集类型: 过时的常量和无用的类
(1)此类的所有实例均已回收,也就是说,堆中没有此类的实例
(2)加载了此类的ClassLoader已被回收
(3)与此类对应的java.lang.Class对象在任何地方都没有引用,并且该类的方法无法在任何地方通过反射来访问.
满足以上三个条件的类也可以被回收,但不一定. 在经常使用ByteCode框架(例如反射,动态代理,CGLib等)并且经常定义ClassLoader(例如动态生成的JSP和OSGi)的场景中,虚拟机需要类卸载功能,以确保永久生成不会溢出.
2. 垃圾采集算法1.打标算法
标记扫描算法是最基本的采集算法. 首先标记需要回收的对象,并在标记完成后统一采集所有标记的对象.
主要缺点有两个:
过程如下:
2. 复制算法
为了解决效率问题,出现了复制算法(Copying),他将内存分为相等大小的两块,一次只使用其中之一. 当该内存块用完时,会将尚存的对象复制到另一个块,然后清除该空间块. 这样,每次都可以在整个半个区域中回收内存,并且无需考虑在内存分配过程中内存碎片的复杂性. 您只需要移动指针并按顺序分配内存即可.
这种方法的代价是将内存分成两半,这太高了.
过程如下:
当前的商用虚拟机都使用此方法来回收新一代产品. IBM的特殊研究表明,新一代对象中有98%是“生死攸关的”,因此无需划分1: 1内存空间. 另一种方法是将内存块划分为Eden空间(80%)和两个Survivor空间(10%). 每次使用Eden空间和一个Survivor空间时,在回收过程中会将幸存的对象复制到另一个Survivor空间. ,因此每次仅“浪费”了10%的空间. 当Survivor空间不足时,它需要依赖其他内存(旧代)来进行分配保证(与旧代中的分配保证机制相同).
3. 标记排序算法
当副本采集算法的对象存活率较高时,它将执行更多的复制操作,并且效率会降低. 更重要的是,如果您不希望浪费50%的空间,则需要有额外的空间用于分配保证,以应对极端情况,即已用内存中的所有对象都处于100%活动状态,因此旧一代通常无法选择这种方法. 提出了Mark-Compact算法(Mark-Compact).
标记过程与“ mark-sweep”算法相同,但是后续步骤不是直接清理可回收部分,而是将所有活动对象移到一端,然后直接清理内存在末尾.
过程如下:
4. 分代采集算法
当前的商用虚拟机都使用Generational 采集算法. 通常,堆分为新一代和旧一代,并且根据每个时代的不同特性使用最合适的算法. 新一代一般采用复制算法,只需要支付少量复制幸存对象的费用即可. 在旧的一代中,由于对象生存率很高并且没有多余的空间来分配它,因此必须使用“标记清除”或“标记组织”算法来进行恢复.
概述:
目前,内存的动态分配和内存恢复技术已经相当成熟. 一切似乎都进入了“自动化”时代. 为什么我们需要了解GC和内存分配?原因很简单: 当有必要解决各种内存泄漏和内存溢出问题时,当垃圾采集器成为系统实现更高并发性的瓶颈时,我们需要对这些“自动化”技术进行必要的监视和调整.
上一个博客讨论了Java虚拟机的运行时内存的各个部分. 其中,程序计数器,虚拟机堆栈和本地方法堆栈由线程生成,并由线程终止. 堆栈中的堆栈框架遵循该方法. 进入和退出执行推入和弹出操作,因此当方法结束或线程结束时,内存自然会跟随恢复. Java堆与方法块不同. 我们只知道在运行时将创建哪些对象. 这部分内存和恢复是动态的,垃圾回收器也与此部分内存有关. 稍后提到的内存分配和恢复也仅涉及内存的这一部分.
1. 判断物体的生与死1.参考计数方法
许多教科书或开发人员回答了以下问题: “如何判断对象是否还活着?”大多数答案都是引用计数. 实现是这样的: 向该对象添加一个引用计数器;在某个地方被引用时,将添加+1;在引用变为无效时,将添加-1;并且在任何时候其计数器为0的对象将无法被引用.
客观地讲,引用计数方法易于实现并且判断效率很高,但是至少主流的Java虚拟机不使用引用计数方法来管理内存. 主要原因是很难解决对象之间的相互循环. 引用的问题.
2. 可达性分析算法
“可达性分析”是Java和C#当前的主流实现,用于确定对象是否存在. 主要思想是使用一些类作为成为“ GC根目录”的起点的对象,并从这些节点向下搜索. 搜索的路径称为参考链. 如果没有针对GC根目录的对象的引用链,则证明该对象不可用.
如下所示:
Object1-Object4的参考链连接到GC根,而Object5-Oject7没有通过参考链连接,因此被判断为可回收对象
在Java中,有四种类型可以用作GC根节点
3. 再谈报价
在JDK1.2之前,Java中的引用定义为: 如果将引用类型的数据存储为代表另一个内存块的起始地址的值,则可以说该内存块表示一个引用. 在JDK1.2之后,Java扩展了引用的概念,分为以下四种类型:
4. 生存还是死亡
即使在可达性分析算法中无法达到的对象也不是“必须死亡”的. 目前,他们处于“试用”阶段. 要声明一个对象已死亡,至少需要两个标记过程.
以下代码一次显示对象的自救:
1 //代码演示了两点
2 //1.对象可以实现自救
3 //2.这种自救只能一次,因为finalize方法只会被执行一次
4
5 public class jvmtest1 {
6 public static jvmtest1 obj = null;
7
8 public void isAlive() {
9 System.out.println("I am alive");
10 }
11
12 @Override
13 protected void finalize() throws Throwable {
14 super.finalize();
15 System.out.println("finalize method executed!");
16 obj = this;
17 }
18
19 public static void main(String[] args) throws Exception {
20 obj = new jvmtest1();
21
22 obj = null;
23 System.gc();
24 // 因为finalize方法优先级很低,所以暂停0.5s执行
25 Thread.sleep(500);
26 if (obj != null) {
27 obj.isAlive();
28 } else {
29 System.out.println("I am dead");
30 }
31
32 // 与上面的代码完全相同,但是自救失败了
33 obj = null;
34 System.gc();
35 // 因为finalize方法优先级很低,所以暂停0.5s执行
36 Thread.sleep(500);
37 if (obj != null) {
38 obj.isAlive();
39 } else {
40 System.out.println("I am dead");
41 }
42 }
43 }
程序输出为:
可以看出obj的finalize()方法确实是由GC触发的,并且成功地保存了一次. 应该注意的是,下部的代码与上部的代码相同,但是自助失败. 这是因为对象的finalize()方法只能被系统自动调用一次. 如果对象面临第二次恢复,则不会调用其finalize(The)方法,因此第二次自助操作将失败.
5. 恢复方法区域
方法区域中的垃圾回收具有“成本效益”. 在堆中,特别是在新一代中,常规应用程序的垃圾回收通常可以回收70%-95%的空间,而方法区域(在HatSport虚拟机中)永久生成的恢复效率远远低于这个.
永久代中有两种主要的垃圾采集类型: 过时的常量和无用的类
(1)此类的所有实例均已回收,也就是说,堆中没有此类的实例
(2)加载了此类的ClassLoader已被回收
(3)与此类对应的java.lang.Class对象在任何地方都没有引用,并且该类的方法无法在任何地方通过反射来访问.
满足以上三个条件的类也可以被回收,但不一定. 在经常使用ByteCode框架(例如反射,动态代理,CGLib等)并且经常定义ClassLoader(例如动态生成的JSP和OSGi)的场景中,虚拟机需要类卸载功能,以确保永久生成不会溢出.
2. 垃圾采集算法1.打标算法
标记扫描算法是最基本的采集算法. 首先标记需要回收的对象,并在标记完成后统一采集所有标记的对象.
主要缺点有两个:
过程如下:
2. 复制算法
为了解决效率问题,出现了复制算法(Copying),他将内存分为相等大小的两块,一次只使用其中之一. 当该内存块用完时,会将尚存的对象复制到另一个块,然后清除该空间块. 这样,每次都可以在整个半个区域中回收内存,并且无需考虑在内存分配过程中内存碎片的复杂性. 您只需要移动指针并按顺序分配内存即可.
这种方法的代价是将内存分成两半,这太高了.
过程如下:
当前的商用虚拟机都使用此方法来回收新一代产品. IBM的特殊研究表明,新一代对象中有98%是“生死攸关的”,因此无需划分1: 1内存空间. 另一种方法是将内存块划分为Eden空间(80%)和两个Survivor空间(10%). 每次使用Eden空间和一个Survivor空间时,在回收过程中会将幸存的对象复制到另一个Survivor空间. ,因此每次仅“浪费”了10%的空间. 当Survivor空间不足时,它需要依赖其他内存(旧代)来进行分配保证(与旧代中的分配保证机制相同).
3. 标记排序算法
当副本采集算法的对象存活率较高时,它将执行更多的复制操作,并且效率会降低. 更重要的是,如果您不希望浪费50%的空间,则需要有额外的空间用于分配保证,以应对极端情况,即已用内存中的所有对象都处于100%活动状态,因此旧一代通常无法选择这种方法. 提出了Mark-Compact算法(Mark-Compact).
标记过程与“标记清除”算法相同,但是后续步骤不是直接清理可回收部分,而是将所有活动对象移动到一端,然后直接清理内存在末尾.
过程如下:
4. 分代采集算法
当前的商用虚拟机都使用Generational 采集算法. 通常,堆分为新一代和旧一代,并且根据每个时代的不同特性使用最合适的算法. 新一代一般采用复制算法,只需要支付少量复制幸存对象的费用即可. 在旧的一代中,由于对象生存率很高并且没有多余的空间来分配它,因此必须使用“标记清除”或“标记组织”算法来进行恢复.
垃圾采集器和内存分配策略-HotSpot算法实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 364 次浏览 • 2020-08-07 03:05
首先,让我们看一下图片: 该图片分析了在执行HotSpot算法和执行可达性分析算法时必须满足的要求
虚拟机algorithm.png
图像分析过程如下:
可达性分析算法从GC Roots节点搜索参考链,但是如果您在程序中一个接一个地检查参考,则会消耗大量时间,并且可达性分析算法对时间非常敏感,在分析过程中需要时间时间的一致性就像时间已经停止一样. 无法在此处分析引用链,并且那里的对象引用仍在变化. 因此,必须在GC进程中停止所有Java执行线程.
为了确保执行效率,在分析可达性分析算法时并不需要分析所有参考. 而是直接通过称为“ OopMap”的数据结构保存对象的引用,以便HotSpot可以快速而准确地完成GC根枚举. 但是,由于整个系统中的引用过多,因此无法将所有指令保存在OopMap中,否则会增加GC空间的成本. 实际上,HotSpot只会使用OopMap在某些特定位置记录信息.
哪些特定点与程序状态有关. 例如,当程序正常执行时,它将进入一个称为“安全点”的特定位置以保存参考信息. 相反,如果程序处于休眠或锁定状态,它将进入一个安全区域进行保存.
安全点的数量应适当. 选择标准是: 是否具有允许程序长时间执行的特征. 选择安全点之后,如何在发生GC时使所有线程(不包括JNI调用的线程)进入安全点?这里有两种方法
①抢先中断(PreeMptive Suspension): 不需要所有线程积极配合,而是直接中断所有线程. 如果在中断时发现线程不在安全点,则将还原该线程并使其安全运行. 单击然后中断.
②自愿暂停: 执行GC操作时,线程不会直接中断,而是会给该线程一个标志. 每个线程将自动检查该标志是否为true. 如果为真,则自行挂起. (查询标志的位置与安全点重合)
当前的虚拟机基本上使用第二种方法: 主动中断.
安全区域意味着在另一段代码中,引用关系将不再更改. 执行GC操作时,该线程在该区域中的任何位置都是安全的. 安全区域是安全点的升级版本. 进入安全区域的线程将带有一个标志,表明它们已进入安全区域,并且在发生GC时虚拟机将不会管理这些线程. 当这些线程要离开安全区域时,它们必须检查外部GC操作是否已完成. 如果GC已完成,则线程将继续执行. 如果GC未完成,则线程必须在安全区域中等待,以等待GC完成后再离开. 查看全部
以前,我们介绍了如何判断对象是否还活着并实现相关的垃圾采集算法. 在此基础上,我们将讨论在HotSpot中实现这些算法时必须满足的要求,以确保算法的有效执行.
首先,让我们看一下图片: 该图片分析了在执行HotSpot算法和执行可达性分析算法时必须满足的要求
虚拟机algorithm.png
图像分析过程如下:
可达性分析算法从GC Roots节点搜索参考链,但是如果您在程序中一个接一个地检查参考,则会消耗大量时间,并且可达性分析算法对时间非常敏感,在分析过程中需要时间时间的一致性就像时间已经停止一样. 无法在此处分析引用链,并且那里的对象引用仍在变化. 因此,必须在GC进程中停止所有Java执行线程.
为了确保执行效率,在分析可达性分析算法时并不需要分析所有参考. 而是直接通过称为“ OopMap”的数据结构保存对象的引用,以便HotSpot可以快速而准确地完成GC根枚举. 但是,由于整个系统中的引用过多,因此无法将所有指令保存在OopMap中,否则会增加GC空间的成本. 实际上,HotSpot只会使用OopMap在某些特定位置记录信息.
哪些特定点与程序状态有关. 例如,当程序正常执行时,它将进入一个称为“安全点”的特定位置以保存参考信息. 相反,如果程序处于休眠或锁定状态,它将进入一个安全区域进行保存.
安全点的数量应适当. 选择标准是: 是否具有允许程序长时间执行的特征. 选择安全点之后,如何在发生GC时使所有线程(不包括JNI调用的线程)进入安全点?这里有两种方法
①抢先中断(PreeMptive Suspension): 不需要所有线程积极配合,而是直接中断所有线程. 如果在中断时发现线程不在安全点,则将还原该线程并使其安全运行. 单击然后中断.
②自愿暂停: 执行GC操作时,线程不会直接中断,而是会给该线程一个标志. 每个线程将自动检查该标志是否为true. 如果为真,则自行挂起. (查询标志的位置与安全点重合)
当前的虚拟机基本上使用第二种方法: 主动中断.
安全区域意味着在另一段代码中,引用关系将不再更改. 执行GC操作时,该线程在该区域中的任何位置都是安全的. 安全区域是安全点的升级版本. 进入安全区域的线程将带有一个标志,表明它们已进入安全区域,并且在发生GC时虚拟机将不会管理这些线程. 当这些线程要离开安全区域时,它们必须检查外部GC操作是否已完成. 如果GC已完成,则线程将继续执行. 如果GC未完成,则线程必须在安全区域中等待,以等待GC完成后再离开.
声音检测异常
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-07 02:01
优秀论文:
1. 监督分级异常声音检测系统的设计与实现. 叶建杰撰写. 您可以浏览CNKI.
2. 智能监控前端系统中异常声音检测的实现张露露等.
顾名思义,异常声音检测是指检测现实生活中的异常声音,例如枪声,爆炸,哭声,尖叫声等,属于公共安全监控类别.
传统的公共安全监视使用摄像头,但是摄像头只能监视特定的固定场景,并且受到光线的很大影响. 因此,在电影中,犯罪分子只要知道相机的位置,就可以轻松避开相机. 或用布覆盖相机.
随着移动互联网的发展,各种可穿戴安全产品陆续出现,但它们都是主要的定位卡. 360°儿童手表可以录制,但是父母需要积极拨动手表进行录制. 这种应用场景是父母希望知道孩子何时拨动手表以使其记录10秒钟. 这段10秒的录音可以让父母知道孩子的环境吗?更不用说主动拨手表的父母了,何时打电话的问题. 父母只有在记住时才打电话,也许孩子已经处于危险之中. 360°儿童手表还可以让儿童在遇到危险时求助. 所谓的危险必须是孩子有意识并意识到需要寻求帮助. 因此,这种父母主动拨号或孩子主动寻求帮助的方法是被动的.
如果使用异常声音判断孩子是否安全,该怎么办?因为声音是全向的并且不受光线影响,所以理论上可以检测到异常声音. 但是,异常声音的类型太复杂. 更不用说哭,尖叫,枪声和其他不同的异常声音了,甚至枪声也可能是手枪,步枪等. 并且在现实生活中干扰太多,因此仍然很难准确确定异常声音.
该领域当前有两种解决方案,一种称为异常声音检测,另一种称为异常声音分类. 所谓的异常声音检测是指检测是否存在异常声音,但无法确定是哪种异常声音. 异常声音分类是对异常声音进行分类,从而知道检测到哪种异常声音. 显然,这种方法可以限制检测到的异常声音的类型.
异常声音检测的一般方法是对背景环境声音进行建模,所有与模型不匹配的异常声音均为异常声音. 异常声音分类是对异常声音进行建模,而与模型匹配的都是某些异常声音. . 这两种方法的原理实际上是从语音识别中得出的,实质上是训练分类器. 语音识别的关键在于分类器的辨别力,即模型的准确性,而准确性又取决于所选的声学特征和声音模型.
除MPEG-7外,常用的声学功能是MFCC. 我们听到的声音收录太多无用的信息. MFCC使用24维特征系数来表示声音帧. 当然,除了GMM等之外,常用的声音模型当然是HMM. 因此,使用这种方法的难度与语音识别的难度相同.
在实时检测中,准确检测异常声音的开始和结束也很重要. 因为如果起点和终点不准确,将不可避免地影响模型的准确性,从而影响识别率.
参考: 查看全部
最近,我们将为室内紧急情况提供遇险声音检测系统. 这是两篇好论文.
优秀论文:
1. 监督分级异常声音检测系统的设计与实现. 叶建杰撰写. 您可以浏览CNKI.
2. 智能监控前端系统中异常声音检测的实现张露露等.
顾名思义,异常声音检测是指检测现实生活中的异常声音,例如枪声,爆炸,哭声,尖叫声等,属于公共安全监控类别.
传统的公共安全监视使用摄像头,但是摄像头只能监视特定的固定场景,并且受到光线的很大影响. 因此,在电影中,犯罪分子只要知道相机的位置,就可以轻松避开相机. 或用布覆盖相机.
随着移动互联网的发展,各种可穿戴安全产品陆续出现,但它们都是主要的定位卡. 360°儿童手表可以录制,但是父母需要积极拨动手表进行录制. 这种应用场景是父母希望知道孩子何时拨动手表以使其记录10秒钟. 这段10秒的录音可以让父母知道孩子的环境吗?更不用说主动拨手表的父母了,何时打电话的问题. 父母只有在记住时才打电话,也许孩子已经处于危险之中. 360°儿童手表还可以让儿童在遇到危险时求助. 所谓的危险必须是孩子有意识并意识到需要寻求帮助. 因此,这种父母主动拨号或孩子主动寻求帮助的方法是被动的.
如果使用异常声音判断孩子是否安全,该怎么办?因为声音是全向的并且不受光线影响,所以理论上可以检测到异常声音. 但是,异常声音的类型太复杂. 更不用说哭,尖叫,枪声和其他不同的异常声音了,甚至枪声也可能是手枪,步枪等. 并且在现实生活中干扰太多,因此仍然很难准确确定异常声音.
该领域当前有两种解决方案,一种称为异常声音检测,另一种称为异常声音分类. 所谓的异常声音检测是指检测是否存在异常声音,但无法确定是哪种异常声音. 异常声音分类是对异常声音进行分类,从而知道检测到哪种异常声音. 显然,这种方法可以限制检测到的异常声音的类型.
异常声音检测的一般方法是对背景环境声音进行建模,所有与模型不匹配的异常声音均为异常声音. 异常声音分类是对异常声音进行建模,而与模型匹配的都是某些异常声音. . 这两种方法的原理实际上是从语音识别中得出的,实质上是训练分类器. 语音识别的关键在于分类器的辨别力,即模型的准确性,而准确性又取决于所选的声学特征和声音模型.
除MPEG-7外,常用的声学功能是MFCC. 我们听到的声音收录太多无用的信息. MFCC使用24维特征系数来表示声音帧. 当然,除了GMM等之外,常用的声音模型当然是HMM. 因此,使用这种方法的难度与语音识别的难度相同.
在实时检测中,准确检测异常声音的开始和结束也很重要. 因为如果起点和终点不准确,将不可避免地影响模型的准确性,从而影响识别率.
参考:
OpenCV3实现人脸识别(两个)-采集要识别的人脸数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 749 次浏览 • 2020-08-06 22:14
1. 上一篇博客文章演示了如何使用OpenCV内置的面部和眼睛级联分类器检测图像中的面部,此处将演示如何打开连接到计算机的相机并检测面部,然后保存照片. 接下来,它将用作面部识别的训练数据.
2. 我的编程环境是Windows 7 64位,IDE是VS2015,配置了OpenCV3.3和OpenCV_Contrib,其中Boost 1.66用于配置文件和目录,因此,如果配置上述环境,则可以阅读博客文章. 我以前写过.
I. 处理官方数据
1. 下载OpenCV的官方面孔数据. 官方人脸数据提供了总共40个人的面孔,这些面孔被分类到文件目录中. 每个人有10个面部数据,格式为pgm. ,无法通过PC上的查看软件打开Pgm格式,但是您可以使用OpenCV编写一个小程序来查看其中的内容. csdn的下载地址是: . 下载后,它看起来像这样:
每个文件夹收录10个面部数据,格式为pgm,大小为92X112.
2. 编写函数以查看每个类别的面部数据. 这里,boost库的文件操作类别用于递归遍历每个子目录中的图像数据并显示它.
(1)功能代码
/显示目标路径下的所有图像
void showImage(string image_path)
{
//判断是事为文件夹
if (!fs::is_directory(image_path))
{
Mat image = imread(image_path);
if (!image.empty())
{
imshow(image_path, image);
waitKey(0);
}
}
else if(fs::is_directory(image_path))
{
fs::recursive_directory_iterator begin_iter(image_path);
fs::recursive_directory_iterator end_iter;
for (; begin_iter != end_iter; begin_iter++)
{
string file_name = begin_iter->path().string();
if (!fs::is_directory(file_name))
{
Mat image = imread(file_name);
if (!image.empty())
{
imshow(file_name, image);
waitKey(30);
}
}
}
}
}
(2)打开一组数据,您可以看到其中的面部,并且正面具有各种角度,因此在输入要识别的面部时,我们可以从官方角度尽可能地学习.
二,采集要识别的人脸数据
采集要识别的面部数据. 您可以从图像集合中检测面部,也可以从USB相机或笔记本计算机随附的相机检测面部. 此处给出的代码是从相机检测面部,然后对其进行拦截,将其更改为与官方面部图像大小相同的数据,然后保存.
1. 使用OpenCV人脸检测级联分类器来检测人脸,如果它检测到当前视频中只有一个人脸,则使用眼睛分类器来检测该人脸是否可以完全检测到两只眼睛,如果可以同时检测到两只眼睛时间,按p键拍照并保存. 保存10张以上的面孔并退出.
<p>void photograph(string save_path,int _cap)
{
int image_number = 0;
if (!face_detector.load(face_path))
{
std::cout 查看全部
前言
1. 上一篇博客文章演示了如何使用OpenCV内置的面部和眼睛级联分类器检测图像中的面部,此处将演示如何打开连接到计算机的相机并检测面部,然后保存照片. 接下来,它将用作面部识别的训练数据.
2. 我的编程环境是Windows 7 64位,IDE是VS2015,配置了OpenCV3.3和OpenCV_Contrib,其中Boost 1.66用于配置文件和目录,因此,如果配置上述环境,则可以阅读博客文章. 我以前写过.
I. 处理官方数据
1. 下载OpenCV的官方面孔数据. 官方人脸数据提供了总共40个人的面孔,这些面孔被分类到文件目录中. 每个人有10个面部数据,格式为pgm. ,无法通过PC上的查看软件打开Pgm格式,但是您可以使用OpenCV编写一个小程序来查看其中的内容. csdn的下载地址是: . 下载后,它看起来像这样:
每个文件夹收录10个面部数据,格式为pgm,大小为92X112.
2. 编写函数以查看每个类别的面部数据. 这里,boost库的文件操作类别用于递归遍历每个子目录中的图像数据并显示它.
(1)功能代码
/显示目标路径下的所有图像
void showImage(string image_path)
{
//判断是事为文件夹
if (!fs::is_directory(image_path))
{
Mat image = imread(image_path);
if (!image.empty())
{
imshow(image_path, image);
waitKey(0);
}
}
else if(fs::is_directory(image_path))
{
fs::recursive_directory_iterator begin_iter(image_path);
fs::recursive_directory_iterator end_iter;
for (; begin_iter != end_iter; begin_iter++)
{
string file_name = begin_iter->path().string();
if (!fs::is_directory(file_name))
{
Mat image = imread(file_name);
if (!image.empty())
{
imshow(file_name, image);
waitKey(30);
}
}
}
}
}
(2)打开一组数据,您可以看到其中的面部,并且正面具有各种角度,因此在输入要识别的面部时,我们可以从官方角度尽可能地学习.
二,采集要识别的人脸数据
采集要识别的面部数据. 您可以从图像集合中检测面部,也可以从USB相机或笔记本计算机随附的相机检测面部. 此处给出的代码是从相机检测面部,然后对其进行拦截,将其更改为与官方面部图像大小相同的数据,然后保存.
1. 使用OpenCV人脸检测级联分类器来检测人脸,如果它检测到当前视频中只有一个人脸,则使用眼睛分类器来检测该人脸是否可以完全检测到两只眼睛,如果可以同时检测到两只眼睛时间,按p键拍照并保存. 保存10张以上的面孔并退出.
<p>void photograph(string save_path,int _cap)
{
int image_number = 0;
if (!face_detector.load(face_path))
{
std::cout
关于采集器和浏览器内核(完整版)的思考
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-08-06 04:07
当前采集技术的几个基本方面:
1. 可达性: 是否可以获取信息
2. 效率: 如何高效获得,有两种:
A. 一般效率问题:
a. SOCKET级别的效率
b. JS级效率问题
B. 目标效率问题
根据目标网站的逻辑特征,采用有针对性的采集算法. 包括目标重复检查算法和目标刷新算法,以避免重复采集和无效采集.
3. 系统集成
如何将采集系统集成在一起,以及如何与提取算法形成一个整体,以便系统可以确保采集率,正确的采集和提取率,实时性能和网站适应性. 达到整个系统的最佳状态.
4. 反托收问题
获取程序是交互式程序. 这不是纯粹的程序行为,而是一种社会行为.
采集技术的最重要特征是被动的后续开发. 随着Internet的发展,它继续面临着新的技术挑战.
基本过程总结如下:
1.Web1.0时代
在互联网发展的初期,以TCP和HTTP技术为核心技术,以信息发布为主要功能的网站是分开建立的.
相应的采集器技术基于Socket技术,而链接提取是核心.
在系统和分布式技术上合并URL重复检查.
相关研究集中于主题采集和刷新算法. 以最低的成本获得所需的东西.
2.web2.0时代
Web2.0更关注用户的交互. 用户不仅是网站内容的查看者,而且还是网站内容的创建者
随着新闻,论坛和博客的兴起,这些站点具有相同的结构.
主要挑战是如何及时获取新信息?如何适应和使用这些网站结构并开发相应的采集算法.
3. JS / AJAX / HTML5的兴起
丰富的JS技术(包括HTML5)的逐渐兴起为诸如Canvas之类的采集技术带来了新的挑战. 未来是否会成为网站开发技术的主流还不得而知.
获取的基本问题已从下载页面变为下载交互式程序,提供交互式操作,判断程序结束并获得程序结果.
由于JS技术与浏览器环境密切相关,因此浏览器技术已成为解决此类问题的最重要方法.
但是实际上,并非不可能与浏览器分离. JS技术被广泛应用后,如何理解浏览器和JS程序并根据集合问题对其进行优化将是一个需要解决的问题.
如果是这样,浏览器技术将成为未来捕获技术的核心. 查看全部
我已经从事采集工作很多年了,对此技术点我有了更多的见解. 让我与您分享. 欢迎批评和指正.
当前采集技术的几个基本方面:
1. 可达性: 是否可以获取信息
2. 效率: 如何高效获得,有两种:
A. 一般效率问题:
a. SOCKET级别的效率
b. JS级效率问题
B. 目标效率问题
根据目标网站的逻辑特征,采用有针对性的采集算法. 包括目标重复检查算法和目标刷新算法,以避免重复采集和无效采集.
3. 系统集成
如何将采集系统集成在一起,以及如何与提取算法形成一个整体,以便系统可以确保采集率,正确的采集和提取率,实时性能和网站适应性. 达到整个系统的最佳状态.
4. 反托收问题
获取程序是交互式程序. 这不是纯粹的程序行为,而是一种社会行为.
采集技术的最重要特征是被动的后续开发. 随着Internet的发展,它继续面临着新的技术挑战.
基本过程总结如下:
1.Web1.0时代
在互联网发展的初期,以TCP和HTTP技术为核心技术,以信息发布为主要功能的网站是分开建立的.
相应的采集器技术基于Socket技术,而链接提取是核心.
在系统和分布式技术上合并URL重复检查.
相关研究集中于主题采集和刷新算法. 以最低的成本获得所需的东西.
2.web2.0时代
Web2.0更关注用户的交互. 用户不仅是网站内容的查看者,而且还是网站内容的创建者
随着新闻,论坛和博客的兴起,这些站点具有相同的结构.
主要挑战是如何及时获取新信息?如何适应和使用这些网站结构并开发相应的采集算法.
3. JS / AJAX / HTML5的兴起
丰富的JS技术(包括HTML5)的逐渐兴起为诸如Canvas之类的采集技术带来了新的挑战. 未来是否会成为网站开发技术的主流还不得而知.
获取的基本问题已从下载页面变为下载交互式程序,提供交互式操作,判断程序结束并获得程序结果.
由于JS技术与浏览器环境密切相关,因此浏览器技术已成为解决此类问题的最重要方法.
但是实际上,并非不可能与浏览器分离. JS技术被广泛应用后,如何理解浏览器和JS程序并根据集合问题对其进行优化将是一个需要解决的问题.
如果是这样,浏览器技术将成为未来捕获技术的核心.

