
遍历
开源JAVA单机爬虫框架简介,优缺点剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-06-06 08:01
互联网营销时代,获取海量数据成为营销推广的关键。而获得数据的最佳方法就是借助爬虫去抓取。但是爬虫的使用少不了代理ip太阳HTTP的支撑。当然网路上现今有很多开源爬虫,大大便捷了你们使用。但是开源网路爬虫也是有优点也有缺点,清晰认知这一点能够达成自己的目标。
对于爬虫的功能来说。用户比较关心的问题常常是:
1)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取那些数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我早已可以生成我所须要的ajax恳求(列表),如何用这种爬虫来对那些恳求进行爬取?
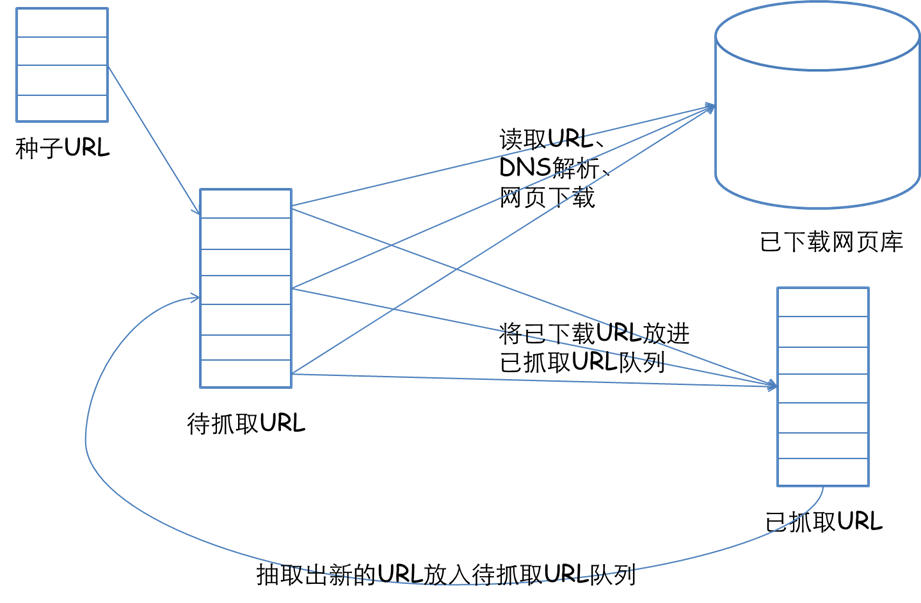
爬虫常常都是设计成广度遍历或则深度遍历的模式爬虫框架,去遍历静态或则动态页面。爬取ajax信息属于deep web(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
2)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
能不能爬js生成的信息和爬虫本身没有很大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往须要花费好多的时间来处理一个页面。所以一种策略就是,使用这种爬虫来遍历网站,遇到须要解析的页面,就将网页的相关信息递交给模拟浏览器,来完成JS生成信息的抽取。
3)爬虫如何保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加递交数据库的操作。至于使用pipeline这些模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
4)爬虫如何爬取要登录的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
5)爬虫如何抽取网页的信息?
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSS SELECTOR和XPATH。至于那个好,这里不评价。
6)明明代码写对了,爬不到数据爬虫框架,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这些情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
7)哪个爬虫的设计模式和架构比较好?
设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会促使爬虫的设计愈发臃肿。
至于架构,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些你们都能控制好。
8)哪个爬虫可以判定网站是否爬完、那个爬虫可以依照主题进行爬取?
爬虫难以判定网站是否爬完,只能尽可能覆盖。
至于依照主题爬取,爬虫然后把内容爬出来才晓得是哪些主题。所以通常都是整个爬出来,然后再去筛选内容。如果嫌爬的很泛,可以通过限制URL正则等方法,来缩小一下范围。
9)爬虫速率怎么样?
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。
10)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
11)爬虫被网站封了如何办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这种开源爬虫通常没有直接支持随机代理ip的切换。 查看全部
互联网营销时代,获取海量数据成为营销推广的关键。而获得数据的最佳方法就是借助爬虫去抓取。但是爬虫的使用少不了代理ip太阳HTTP的支撑。当然网路上现今有很多开源爬虫,大大便捷了你们使用。但是开源网路爬虫也是有优点也有缺点,清晰认知这一点能够达成自己的目标。
对于爬虫的功能来说。用户比较关心的问题常常是:
1)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取那些数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我早已可以生成我所须要的ajax恳求(列表),如何用这种爬虫来对那些恳求进行爬取?
爬虫常常都是设计成广度遍历或则深度遍历的模式爬虫框架,去遍历静态或则动态页面。爬取ajax信息属于deep web(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
2)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
能不能爬js生成的信息和爬虫本身没有很大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往须要花费好多的时间来处理一个页面。所以一种策略就是,使用这种爬虫来遍历网站,遇到须要解析的页面,就将网页的相关信息递交给模拟浏览器,来完成JS生成信息的抽取。
3)爬虫如何保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加递交数据库的操作。至于使用pipeline这些模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
4)爬虫如何爬取要登录的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
5)爬虫如何抽取网页的信息?
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSS SELECTOR和XPATH。至于那个好,这里不评价。
6)明明代码写对了,爬不到数据爬虫框架,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这些情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
7)哪个爬虫的设计模式和架构比较好?
设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会促使爬虫的设计愈发臃肿。
至于架构,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些你们都能控制好。
8)哪个爬虫可以判定网站是否爬完、那个爬虫可以依照主题进行爬取?
爬虫难以判定网站是否爬完,只能尽可能覆盖。
至于依照主题爬取,爬虫然后把内容爬出来才晓得是哪些主题。所以通常都是整个爬出来,然后再去筛选内容。如果嫌爬的很泛,可以通过限制URL正则等方法,来缩小一下范围。
9)爬虫速率怎么样?
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。
10)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
11)爬虫被网站封了如何办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这种开源爬虫通常没有直接支持随机代理ip的切换。
红叶文章采集器3.6绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 445 次浏览 • 2020-04-18 09:52
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章文章采集,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题文章采集软件下载,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路文章采集软件下载,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。 查看全部

超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章文章采集,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题文章采集软件下载,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路文章采集软件下载,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
开源JAVA单机爬虫框架简介,优缺点剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-06-06 08:01
互联网营销时代,获取海量数据成为营销推广的关键。而获得数据的最佳方法就是借助爬虫去抓取。但是爬虫的使用少不了代理ip太阳HTTP的支撑。当然网路上现今有很多开源爬虫,大大便捷了你们使用。但是开源网路爬虫也是有优点也有缺点,清晰认知这一点能够达成自己的目标。
对于爬虫的功能来说。用户比较关心的问题常常是:
1)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取那些数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我早已可以生成我所须要的ajax恳求(列表),如何用这种爬虫来对那些恳求进行爬取?
爬虫常常都是设计成广度遍历或则深度遍历的模式爬虫框架,去遍历静态或则动态页面。爬取ajax信息属于deep web(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
2)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
能不能爬js生成的信息和爬虫本身没有很大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往须要花费好多的时间来处理一个页面。所以一种策略就是,使用这种爬虫来遍历网站,遇到须要解析的页面,就将网页的相关信息递交给模拟浏览器,来完成JS生成信息的抽取。
3)爬虫如何保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加递交数据库的操作。至于使用pipeline这些模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
4)爬虫如何爬取要登录的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
5)爬虫如何抽取网页的信息?
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSS SELECTOR和XPATH。至于那个好,这里不评价。
6)明明代码写对了,爬不到数据爬虫框架,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这些情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
7)哪个爬虫的设计模式和架构比较好?
设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会促使爬虫的设计愈发臃肿。
至于架构,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些你们都能控制好。
8)哪个爬虫可以判定网站是否爬完、那个爬虫可以依照主题进行爬取?
爬虫难以判定网站是否爬完,只能尽可能覆盖。
至于依照主题爬取,爬虫然后把内容爬出来才晓得是哪些主题。所以通常都是整个爬出来,然后再去筛选内容。如果嫌爬的很泛,可以通过限制URL正则等方法,来缩小一下范围。
9)爬虫速率怎么样?
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。
10)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
11)爬虫被网站封了如何办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这种开源爬虫通常没有直接支持随机代理ip的切换。 查看全部
互联网营销时代,获取海量数据成为营销推广的关键。而获得数据的最佳方法就是借助爬虫去抓取。但是爬虫的使用少不了代理ip太阳HTTP的支撑。当然网路上现今有很多开源爬虫,大大便捷了你们使用。但是开源网路爬虫也是有优点也有缺点,清晰认知这一点能够达成自己的目标。
对于爬虫的功能来说。用户比较关心的问题常常是:
1)爬虫可以爬取ajax信息么?
网页上有一些异步加载的数据,爬取那些数据有两种方式:使用模拟浏览器(问题1中描述过了),或者剖析ajax的http请求,自己生成ajax恳求的url,获取返回的数据。如果是自己生成ajax恳求,使用开源爬虫的意义在那里?其实是要用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我早已可以生成我所须要的ajax恳求(列表),如何用这种爬虫来对那些恳求进行爬取?
爬虫常常都是设计成广度遍历或则深度遍历的模式爬虫框架,去遍历静态或则动态页面。爬取ajax信息属于deep web(深网)的范畴,虽然大多数爬虫都不直接支持。但是也可以通过一些方式来完成。比如WebCollector使用广度遍历来遍历网站。爬虫的第一轮爬取就是爬取种子集合(seeds)中的所有url。简单来说,就是将生成的ajax恳求作为种子,放入爬虫。用爬虫对那些种子,进行深度为1的广度遍历(默认就是广度遍历)。
2)爬虫支持多线程么、爬虫能用代理么、爬虫会爬取重复数据么、爬虫能爬取JS生成的信息么?
能不能爬js生成的信息和爬虫本身没有很大关系。爬虫主要是负责遍历网站和下载页面。爬js生成的信息和网页信息抽取模块有关,往往须要通过模拟浏览器(htmlunit,selenium)来完成。这些模拟浏览器,往往须要花费好多的时间来处理一个页面。所以一种策略就是,使用这种爬虫来遍历网站,遇到须要解析的页面,就将网页的相关信息递交给模拟浏览器,来完成JS生成信息的抽取。
3)爬虫如何保存网页的信息?
有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加递交数据库的操作。至于使用pipeline这些模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
4)爬虫如何爬取要登录的网站?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要是靠cookies。至于cookies如何获取,不是爬虫管的事情。你可以自动获取、用http请求模拟登录或则用模拟浏览器手动登入获取cookie。
5)爬虫如何抽取网页的信息?
开源爬虫通常还会集成网页抽取工具。主要支持两种规范:CSS SELECTOR和XPATH。至于那个好,这里不评价。
6)明明代码写对了,爬不到数据爬虫框架,是不是爬虫有问题,换个爬虫能解决么?
如果代码写对了,又爬不到数据,换其他爬虫也是一样爬不到。遇到这些情况,要么是网站把你封了,要么是你爬的数据是javascript生成的。爬不到数据通过换爬虫是不能解决的。
7)哪个爬虫的设计模式和架构比较好?
设计模式对软件开发没有指导性作用。用设计模式来设计爬虫,只会促使爬虫的设计愈发臃肿。
至于架构,开源爬虫目前主要是细节的数据结构的设计,比如爬取线程池、任务队列,这些你们都能控制好。
8)哪个爬虫可以判定网站是否爬完、那个爬虫可以依照主题进行爬取?
爬虫难以判定网站是否爬完,只能尽可能覆盖。
至于依照主题爬取,爬虫然后把内容爬出来才晓得是哪些主题。所以通常都是整个爬出来,然后再去筛选内容。如果嫌爬的很泛,可以通过限制URL正则等方法,来缩小一下范围。
9)爬虫速率怎么样?
单机开源爬虫的速率,基本都可以讲本机的网速用到极限。爬虫的速率慢,往往是由于用户把线程数开少了、网速慢,或者在数据持久化时,和数据库的交互速率慢。而这种东西,往往都是用户的机器和二次开发的代码决定的。
10)网页可以调用爬虫么?
爬虫的调用是在Web的服务端调用的,平时如何用就如何用,这些爬虫都可以使用。
11)爬虫被网站封了如何办?
爬虫被网站封了,一般用多代理(随机代理)就可以解决。但是这种开源爬虫通常没有直接支持随机代理ip的切换。
红叶文章采集器3.6绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 445 次浏览 • 2020-04-18 09:52
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章文章采集,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题文章采集软件下载,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路文章采集软件下载,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。 查看全部
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章文章采集,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题文章采集软件下载,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路文章采集软件下载,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。

