
输入关键字 抓取所有网页
输入关键字 抓取所有网页(一个网页抓取项目的功能特点及功能分析-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-17 13:21
Easy web extract是一个易于使用的web捕获工具,用于提取网页中的内容(文本、网址、图片和文件),并仅通过单击几个屏幕将结果转换为各种格式。没有编程要求。使我们的网络爬虫易于使用作为其名称
软件说明:
我们的简单网络提取软件收录许多高级功能
使用户能够在k17中从简单内容过渡到复杂内容@
但构建一个网络爬虫项目不需要任何努力
在本页中,我们将向您展示一些众所周知的功能
使我们的网络爬虫易于使用作为其名称
功能特点:
1.创建提取项目很容易
对于任何用户来说,基于向导窗口创建新项目从来都不容易
项目安装向导将逐步驱动您
直到完成所有必要的任务
以下是一些主要步骤:
步骤1:输入一个起始URL,这是起始页面,网页将被加载
它通常是一个链接到一个报废产品列表
步骤2:输入关键词提交表单,如果网站需要,则获取结果。在大多数情况下,可以跳过此步骤
步骤3:在列表中选择一个项目,然后选择该项目的数据列的性能
步骤4:选择下一页的URL以访问其他页
@多线程中的2.刮取数据
在网络混乱项目中,需要捕获和获取数十万个链接
传统的刮刀可能需要几个小时或几天的时间
然而,一个简单的web摘录可以同时运行多个线程,同时浏览多达24个不同的web页面
为了节省宝贵的时间,等待结果
因此,简单的网络提取可以利用系统的最佳性能
下一个动画图像显示将提取8个线程
3.从数据中加载各种提取的数据
一些高度动态的网站采用基于客户端创建的数据加载技术,如Ajax异步请求
诚然,不仅是最初的网络替罪羊,也是专业网络刮削工具的挑战
因为web内容未嵌入HTML源中
然而,简单的网络提取有非常强大的技术
即使是新手也可以从这些类型的网站获取数据@
此外,我们的网站scraper甚至可以模拟向下滚动到页面底部以加载更多数据
例如,LinkedIn联系人列表中的某些特定网站
在这一挑战中,大多数web LHD不断获取大量重复信息
很快就会变得单调。但是不要担心这个噩梦
因为简单的网络抽取具有智能化的功能来避免它
4.随时自动执行项目
通过简单网络提取的嵌入式自动调度器
您可以安排web项目在任何时候运行,而无需执行任何操作
计划任务运行并退出,将结果刮到目标
没有始终运行的后台服务来节省系统资源
此外,可以从收获的结果中删除所有重复项
确保只维护新数据
支持的计划类型:
-在项目中每小时运行一次
-在项目中每天运行
-在特定时间运行项目
5.将数据导出为任何格式
我们最好的网络刮板支持以各种格式导出刮板网站数据
例如:CSV、access、XML、HTML、SQL server、mysql
您还可以直接提交任何类型的数据库目标
通过ODBC连接。如果您的网站有提交表格 查看全部
输入关键字 抓取所有网页(一个网页抓取项目的功能特点及功能分析-苏州安嘉)
Easy web extract是一个易于使用的web捕获工具,用于提取网页中的内容(文本、网址、图片和文件),并仅通过单击几个屏幕将结果转换为各种格式。没有编程要求。使我们的网络爬虫易于使用作为其名称

软件说明:
我们的简单网络提取软件收录许多高级功能
使用户能够在k17中从简单内容过渡到复杂内容@
但构建一个网络爬虫项目不需要任何努力
在本页中,我们将向您展示一些众所周知的功能
使我们的网络爬虫易于使用作为其名称
功能特点:
1.创建提取项目很容易
对于任何用户来说,基于向导窗口创建新项目从来都不容易
项目安装向导将逐步驱动您
直到完成所有必要的任务
以下是一些主要步骤:
步骤1:输入一个起始URL,这是起始页面,网页将被加载
它通常是一个链接到一个报废产品列表
步骤2:输入关键词提交表单,如果网站需要,则获取结果。在大多数情况下,可以跳过此步骤
步骤3:在列表中选择一个项目,然后选择该项目的数据列的性能
步骤4:选择下一页的URL以访问其他页
@多线程中的2.刮取数据
在网络混乱项目中,需要捕获和获取数十万个链接
传统的刮刀可能需要几个小时或几天的时间
然而,一个简单的web摘录可以同时运行多个线程,同时浏览多达24个不同的web页面
为了节省宝贵的时间,等待结果
因此,简单的网络提取可以利用系统的最佳性能
下一个动画图像显示将提取8个线程
3.从数据中加载各种提取的数据
一些高度动态的网站采用基于客户端创建的数据加载技术,如Ajax异步请求
诚然,不仅是最初的网络替罪羊,也是专业网络刮削工具的挑战
因为web内容未嵌入HTML源中
然而,简单的网络提取有非常强大的技术
即使是新手也可以从这些类型的网站获取数据@
此外,我们的网站scraper甚至可以模拟向下滚动到页面底部以加载更多数据
例如,LinkedIn联系人列表中的某些特定网站
在这一挑战中,大多数web LHD不断获取大量重复信息
很快就会变得单调。但是不要担心这个噩梦
因为简单的网络抽取具有智能化的功能来避免它
4.随时自动执行项目
通过简单网络提取的嵌入式自动调度器
您可以安排web项目在任何时候运行,而无需执行任何操作
计划任务运行并退出,将结果刮到目标
没有始终运行的后台服务来节省系统资源
此外,可以从收获的结果中删除所有重复项
确保只维护新数据
支持的计划类型:
-在项目中每小时运行一次
-在项目中每天运行
-在特定时间运行项目
5.将数据导出为任何格式
我们最好的网络刮板支持以各种格式导出刮板网站数据
例如:CSV、access、XML、HTML、SQL server、mysql
您还可以直接提交任何类型的数据库目标
通过ODBC连接。如果您的网站有提交表格
输入关键字 抓取所有网页(如何让页面占领搜索结果的第一屏的秘密?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-09-17 13:20
互联网时代的代词可以是“搜索”,因为要在大量信息中找到所需的信息,我们必须搜索,而搜索是关键词
在移动互联网时代,每个人都试图利用网络进行营销。那么,如何让我们想要的页面占据搜索结果的第一屏呢
今天,小编特邀“全网首页”技术专家、米米网络技术公司技术总监谭莽先生,向大家解释占据搜索第一屏的秘密
谭芒先生指出:关键词来源于英语“关键字”,专门指单一媒体在制作和使用索引时使用的词汇。它是图书馆学中的一个词汇关键词search是web搜索索引的主要方法之一,它是访问者想要知道的产品、服务和公司的具体名称和术语。用户只要输入关键词信息,就可以找到相关的产品和服务,即输入一个单词/句子搜索内容,搜索引擎的内容显示搜索结果。用户输入的内容为“关键词”。在搜索引擎中输入关键词会检索到大量相关信息,受众会根据相关信息找到自己最感兴趣的消息
谭芒先生强调:关键词是一组可以联系和连接到产品、服务、企业、新闻等的相关词。用户希望通过搜索特定词来查找关键词通常分为核心词关键词、辅助词关键词、长尾词等;在搜索引擎中,它也可以分为普通关键词和特殊关键词
第一,核心关键词. 产品、企业、网站、服务和行业的一些名称,或这些名称的一些属性和特征
第二,辅助关键词. 对核心关键词的同义词、解释、解释和补充进行了扩展,以使核心关键词更加清晰
第三,长尾词。一般来说,它不是软文的关键词,但它也可以搜索并链接到相应的软文内容,从而为软文带来流量。然而,这些词相对较长,可能由几个词或短语组成
搜索引擎可以捕获这些关键词,方便用户搜索相关信息。以谷歌和百度这两大知名搜索引擎为例,通过自动程序抓取关键词,然后根据用户的搜索关键词选择满足需要的内容,并显示在主屏幕上
具体来说,谭芒先生分析道:例如,世界上最强大的谷歌公司,其谷歌搜索关键词技术是谷歌机器人,谷歌机器人谷歌爬虫是谷歌的网络爬虫。它从网页采集文档,并为谷歌搜索引擎建立可搜索索引。谷歌有两种网络爬虫,主爬虫和新爬虫。主爬虫程序主要负责发现新网页。新索引建立后,主爬虫将立即发现一个网页。如果索引一个网页需要一个月的时间,该网页将变得无效。谷歌爬虫是一个非常活跃的网站扫描工具。谷歌通常每28天发送一个爬虫程序来检索现有网站特定IP地址范围内的新网站。登录Google的时间通常为3周(从提交网站到检索)
在中国,搜索引擎的老大百度使用了一个自动的百度蜘蛛程序。其功能是对互联网上的网页、图片、视频等内容进行访问、采集、整理,然后分类建立索引数据库,用户可以在百度搜索引擎网站中搜索企业的网页、图片、视频等内容。当百度蜘蛛从首页登陆抓取首页后,调度将计算所有连接并返回百度蜘蛛进行下一步抓取连接列表。百度蜘蛛将采取下一步行动抓住它。网站地图的作用是为百度蜘蛛提供一个爬行方向,以便蜘蛛能够抓取重要页面。p>
接下来,如何让百度蜘蛛知道哪个页面是重要页面
目前,它通过连接的建设来实现这一目标。指向此页面的页面越多,网站主页和子页面的方向可以提高此页面的权重。该地图的另一个功能是为百度蜘蛛提供更多链接,以捕获更多页面。事实上,该地图是一个链接列表,通过百度蜘蛛计算网站的目录结构,找到通过站点连接构建的重要页面。百度蜘蛛爬行的频率与网页更新有关。每天更新的网站将吸引百度蜘蛛更频繁地访问。百度是对每天更新的站点最敏感的,它对完全改变内容更敏感
因此,建立、更新和优化关键词对于企业、品牌、产品等相关信息占据主页非常重要
作为“全网主页”的专家,谭莽先生指出,互联网显然已经来到我们这里,其巨大的商机是毋庸置疑的
建立和优化关键词的目的不同于搜索引擎SEO的流量引入。它可以占据关键词search的第一个屏幕。它直接代表实力、转化和经济效益
如果我们想在未来的世界立足,拥有自己的关键词第一屏无疑是根 查看全部
输入关键字 抓取所有网页(如何让页面占领搜索结果的第一屏的秘密?(图))
互联网时代的代词可以是“搜索”,因为要在大量信息中找到所需的信息,我们必须搜索,而搜索是关键词
在移动互联网时代,每个人都试图利用网络进行营销。那么,如何让我们想要的页面占据搜索结果的第一屏呢

今天,小编特邀“全网首页”技术专家、米米网络技术公司技术总监谭莽先生,向大家解释占据搜索第一屏的秘密
谭芒先生指出:关键词来源于英语“关键字”,专门指单一媒体在制作和使用索引时使用的词汇。它是图书馆学中的一个词汇关键词search是web搜索索引的主要方法之一,它是访问者想要知道的产品、服务和公司的具体名称和术语。用户只要输入关键词信息,就可以找到相关的产品和服务,即输入一个单词/句子搜索内容,搜索引擎的内容显示搜索结果。用户输入的内容为“关键词”。在搜索引擎中输入关键词会检索到大量相关信息,受众会根据相关信息找到自己最感兴趣的消息
谭芒先生强调:关键词是一组可以联系和连接到产品、服务、企业、新闻等的相关词。用户希望通过搜索特定词来查找关键词通常分为核心词关键词、辅助词关键词、长尾词等;在搜索引擎中,它也可以分为普通关键词和特殊关键词
第一,核心关键词. 产品、企业、网站、服务和行业的一些名称,或这些名称的一些属性和特征
第二,辅助关键词. 对核心关键词的同义词、解释、解释和补充进行了扩展,以使核心关键词更加清晰
第三,长尾词。一般来说,它不是软文的关键词,但它也可以搜索并链接到相应的软文内容,从而为软文带来流量。然而,这些词相对较长,可能由几个词或短语组成
搜索引擎可以捕获这些关键词,方便用户搜索相关信息。以谷歌和百度这两大知名搜索引擎为例,通过自动程序抓取关键词,然后根据用户的搜索关键词选择满足需要的内容,并显示在主屏幕上

具体来说,谭芒先生分析道:例如,世界上最强大的谷歌公司,其谷歌搜索关键词技术是谷歌机器人,谷歌机器人谷歌爬虫是谷歌的网络爬虫。它从网页采集文档,并为谷歌搜索引擎建立可搜索索引。谷歌有两种网络爬虫,主爬虫和新爬虫。主爬虫程序主要负责发现新网页。新索引建立后,主爬虫将立即发现一个网页。如果索引一个网页需要一个月的时间,该网页将变得无效。谷歌爬虫是一个非常活跃的网站扫描工具。谷歌通常每28天发送一个爬虫程序来检索现有网站特定IP地址范围内的新网站。登录Google的时间通常为3周(从提交网站到检索)
在中国,搜索引擎的老大百度使用了一个自动的百度蜘蛛程序。其功能是对互联网上的网页、图片、视频等内容进行访问、采集、整理,然后分类建立索引数据库,用户可以在百度搜索引擎网站中搜索企业的网页、图片、视频等内容。当百度蜘蛛从首页登陆抓取首页后,调度将计算所有连接并返回百度蜘蛛进行下一步抓取连接列表。百度蜘蛛将采取下一步行动抓住它。网站地图的作用是为百度蜘蛛提供一个爬行方向,以便蜘蛛能够抓取重要页面。p>
接下来,如何让百度蜘蛛知道哪个页面是重要页面
目前,它通过连接的建设来实现这一目标。指向此页面的页面越多,网站主页和子页面的方向可以提高此页面的权重。该地图的另一个功能是为百度蜘蛛提供更多链接,以捕获更多页面。事实上,该地图是一个链接列表,通过百度蜘蛛计算网站的目录结构,找到通过站点连接构建的重要页面。百度蜘蛛爬行的频率与网页更新有关。每天更新的网站将吸引百度蜘蛛更频繁地访问。百度是对每天更新的站点最敏感的,它对完全改变内容更敏感
因此,建立、更新和优化关键词对于企业、品牌、产品等相关信息占据主页非常重要
作为“全网主页”的专家,谭莽先生指出,互联网显然已经来到我们这里,其巨大的商机是毋庸置疑的
建立和优化关键词的目的不同于搜索引擎SEO的流量引入。它可以占据关键词search的第一个屏幕。它直接代表实力、转化和经济效益
如果我们想在未来的世界立足,拥有自己的关键词第一屏无疑是根
输入关键字 抓取所有网页(百度上线多个算法打击下,怎么去刷关键词排名?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-15 18:06
作为一个优秀的优化器,你必须对百度搜索引擎有很好的了解。百度搜索引擎每年都会对关键词排名进行新的算法调整,那么如何在最短的时间内将自己排名在网站关键词的榜首,有哪些方法和技术可以快速实现我们想要的关键词排名?今天,我们来谈谈如何在百度在线多种算法的影响下提高关键词排名
什么是关键词排名
关键词排名优化是指通过各种搜索引擎优化方法,使我们的网站关键词在搜索引擎的自然排名中处于高位或搜索引擎的有利位置。目标受众可以通过搜索输入关键词看到主页搜索引擎提供的页面显示,这些页面按照网站相关性和关键词排名进行排序。排名越高,我们拥有的自然流量就越多,网站的价值和对目标受众的影响将远远超过行业内其他人关键词排名的正确位置。通过对受众目标的精准搜索和搜索引擎的匹配,展现网站和产品的优势,吸引更多潜在客户,获得更多商业价值
如何刷关键词排名
首先,在写网站文章时,我们必须围绕关键词写,在标题和@文章中合理分配长尾关键词以便在网站排名中发挥作用,使网站排名稳步上升@文章最好是原创,把握不多,没有实际价值意义,无法吸引目标受众,错过流量;可以在内容中适当添加一条内链,以便网站蜘蛛抓取时提供指导,这有助于网站收录和关键词快速排名
我们可以选择合适的核心关键词来保证首页的权重,避免关键词的积累。另一个新的网站,如果安排了外链,链接的网站可以相互传递重量。如果权重高,收录排名会快,刷关键词排名的方法会更进一步
另外,网站要保证体验和页面打开速度,所以要定期检查网站bug,不要错过蜘蛛抓来减轻重量,这对刷关键词快速排名非常不利
brush关键词排名软件简介
那些最早开始优化的人可能知道一些数字关键词排名软件,但随着百度算法的一次次更新,这些免费软件无法长期生存。还有一些付费数字关键词软件可以在短时间内提高网站排名,但不能从长期可持续发展的角度选择。缺点很大
百度不断更新算法,我们应该意识到,百度正在积极维护企业之间的公平竞争,努力创造良好的营销模式。因此,brush关键词排名的快速推广损害了许多企业的公平竞争原则。一旦搜索引擎发现网站被删除,也可能会出现网站只保留主页,栏页下所有内容消失的情况。此外,刷牙关键词很容易减轻重量。例如,没有内涵的华而不实的东西是不会长久的。权重一旦降低,会影响整个网站的排名,所以我们应该谨慎选择
如果你想有一个长期的良性排名,最好的办法是按照百度的排名算法来优化你的网站. 机会主义只能对我们自身网站产生一定的负面影响@
百度在线多算法对抗刷关键词排名
自搜索引擎发展以来,各种算法相继问世。例如,百度绿洛算法重点打击外链销售和批量批量批量外链;百度竞雷算法打击快行刷关键词排名;百度绿洛算法2.0、Baidu优采云算法、百度石榴算法、百度原创spark计划、百度冰桶算法、百度杨树算法等,百度已经发布了很多算法,但我们不会一一列出(参见百度介绍)。不管是哪种算法,网站维护都是一种公平的态度,严厉打击各种作弊手段,但我们不能盲目优化。百度算法有一定的维度。他们离相关维度越近,就会有一个理想的关键词排名。如果你不知道这些,就把它们放在链子外面,然后填充@文章,这只能说是没有意义的。熟悉甚至使用百度算法操作关键词排名显然是当务之急。它不是机会主义,而是延迟网站的总权重
如何提高关键词排名
我们都知道关键词排名是优化排名的核心之一。首先,我们应该选择正确的关键词并选择正确的关键词并从网站和content中提取3-5个关键词和长尾扩展词。此外,流行的关键词还可以选择排版布局;有些内核关键词不易优化,竞争激烈。我们可以在内容中设置更多的长尾词,高质量的原创@文章可以轻松获得长尾词的排名。在大量长尾关键词的支持下,核心关键词的排名将逐步提升
我们还需要知道一些关键词位置在哪里更重要、更有意义。一般来说,重要的关键词应该放在标题中,@文章可以适当地添加在开头和结尾,这样我们可以获得更多的权重并提高排名关键词应该在web内容中充分体现出来,并且关键词可以用粗体或斜体强调
@网站target列中可以添加关键词target,并且可以添加主导航和位置导航来集中权重。此外,K4的网页密度应合理分布。越多越好。适当添加关键词被认为是锦上添花
在做优化刷关键词排名时,一定要认真学习技巧,不要盲目低头,自己想想。找到一个好的方法可以事半功倍,网站重量提升,排名靠前,超越行业也很容易 查看全部
输入关键字 抓取所有网页(百度上线多个算法打击下,怎么去刷关键词排名?)
作为一个优秀的优化器,你必须对百度搜索引擎有很好的了解。百度搜索引擎每年都会对关键词排名进行新的算法调整,那么如何在最短的时间内将自己排名在网站关键词的榜首,有哪些方法和技术可以快速实现我们想要的关键词排名?今天,我们来谈谈如何在百度在线多种算法的影响下提高关键词排名
什么是关键词排名
关键词排名优化是指通过各种搜索引擎优化方法,使我们的网站关键词在搜索引擎的自然排名中处于高位或搜索引擎的有利位置。目标受众可以通过搜索输入关键词看到主页搜索引擎提供的页面显示,这些页面按照网站相关性和关键词排名进行排序。排名越高,我们拥有的自然流量就越多,网站的价值和对目标受众的影响将远远超过行业内其他人关键词排名的正确位置。通过对受众目标的精准搜索和搜索引擎的匹配,展现网站和产品的优势,吸引更多潜在客户,获得更多商业价值
如何刷关键词排名
首先,在写网站文章时,我们必须围绕关键词写,在标题和@文章中合理分配长尾关键词以便在网站排名中发挥作用,使网站排名稳步上升@文章最好是原创,把握不多,没有实际价值意义,无法吸引目标受众,错过流量;可以在内容中适当添加一条内链,以便网站蜘蛛抓取时提供指导,这有助于网站收录和关键词快速排名
我们可以选择合适的核心关键词来保证首页的权重,避免关键词的积累。另一个新的网站,如果安排了外链,链接的网站可以相互传递重量。如果权重高,收录排名会快,刷关键词排名的方法会更进一步
另外,网站要保证体验和页面打开速度,所以要定期检查网站bug,不要错过蜘蛛抓来减轻重量,这对刷关键词快速排名非常不利
brush关键词排名软件简介
那些最早开始优化的人可能知道一些数字关键词排名软件,但随着百度算法的一次次更新,这些免费软件无法长期生存。还有一些付费数字关键词软件可以在短时间内提高网站排名,但不能从长期可持续发展的角度选择。缺点很大
百度不断更新算法,我们应该意识到,百度正在积极维护企业之间的公平竞争,努力创造良好的营销模式。因此,brush关键词排名的快速推广损害了许多企业的公平竞争原则。一旦搜索引擎发现网站被删除,也可能会出现网站只保留主页,栏页下所有内容消失的情况。此外,刷牙关键词很容易减轻重量。例如,没有内涵的华而不实的东西是不会长久的。权重一旦降低,会影响整个网站的排名,所以我们应该谨慎选择
如果你想有一个长期的良性排名,最好的办法是按照百度的排名算法来优化你的网站. 机会主义只能对我们自身网站产生一定的负面影响@
百度在线多算法对抗刷关键词排名
自搜索引擎发展以来,各种算法相继问世。例如,百度绿洛算法重点打击外链销售和批量批量批量外链;百度竞雷算法打击快行刷关键词排名;百度绿洛算法2.0、Baidu优采云算法、百度石榴算法、百度原创spark计划、百度冰桶算法、百度杨树算法等,百度已经发布了很多算法,但我们不会一一列出(参见百度介绍)。不管是哪种算法,网站维护都是一种公平的态度,严厉打击各种作弊手段,但我们不能盲目优化。百度算法有一定的维度。他们离相关维度越近,就会有一个理想的关键词排名。如果你不知道这些,就把它们放在链子外面,然后填充@文章,这只能说是没有意义的。熟悉甚至使用百度算法操作关键词排名显然是当务之急。它不是机会主义,而是延迟网站的总权重
如何提高关键词排名
我们都知道关键词排名是优化排名的核心之一。首先,我们应该选择正确的关键词并选择正确的关键词并从网站和content中提取3-5个关键词和长尾扩展词。此外,流行的关键词还可以选择排版布局;有些内核关键词不易优化,竞争激烈。我们可以在内容中设置更多的长尾词,高质量的原创@文章可以轻松获得长尾词的排名。在大量长尾关键词的支持下,核心关键词的排名将逐步提升
我们还需要知道一些关键词位置在哪里更重要、更有意义。一般来说,重要的关键词应该放在标题中,@文章可以适当地添加在开头和结尾,这样我们可以获得更多的权重并提高排名关键词应该在web内容中充分体现出来,并且关键词可以用粗体或斜体强调
@网站target列中可以添加关键词target,并且可以添加主导航和位置导航来集中权重。此外,K4的网页密度应合理分布。越多越好。适当添加关键词被认为是锦上添花
在做优化刷关键词排名时,一定要认真学习技巧,不要盲目低头,自己想想。找到一个好的方法可以事半功倍,网站重量提升,排名靠前,超越行业也很容易
输入关键字 抓取所有网页(六六seo基础运营第四讲的定义以及作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-15 18:02
在本文中,关于66 SEO基本操作的第四堂课开始向学生介绍SEO的基本术语关键词的定义和功能关键词名词是访问者想要知道的产品、服务和公司的具体名称和表达方式。简而言之,关键词是指用户在搜索时输入到搜索引擎的信息指南。引擎通过用户搜索的单词调用数据库中最符合用户需求的信息。因此关键词对于SEOER来说,它是企业工作中最重要的价值观之一。让我们详细看看百科全书关键词
六、SEO基础介绍第四讲SEO关键词的基本术语:
1、关键词定义
从百科全书的定义来看,关键词是英语“关键词”的翻译结果。它是图书馆学中的一个词汇,是指用户在搜索引擎中输入的表达个人需求的词汇。从维基百科的定义来看,它意味着用户获取信息的简明词汇表。这两个定义表达了相同的含义。假设用户使用百度搜索引擎通过某种关键词来解决他们的需求,那么他们键入的单词可以称为关键词
要点:关键词it是用户需求的简明词汇表。而不是输入大段文字来查找结果,例如:谁能告诉我SEO学习有哪些步骤?此段落是用户想要搜索的信息。对于SEOER,您只需要调用本段的关键词优化:SEO学习步骤
二,。搜索引擎的工作原理
当用户搜索关键词时,显示给用户的信息的控制器是搜索引擎。作为SEOER,您首先需要了解搜索引擎的工作原理,然后才能将正确的药物应用到案例中。让优化后的关键词符合搜索引擎友好的原则,以用户为优先
搜索引擎的工作原理:爬行和爬行—“索引构建—”搜索词处理—“数据库排序。搜索引擎蜘蛛一直在抓取新鲜的网络内容。之后,他们将索引有价值的web内容。当用户在搜索引擎中输入关键词时,通过分词等技术了解用户真实的搜索意图,并以排序的方式向用户提供列表结果。这是搜索引擎的基本工作原理
3、关键词分类
学生应该知道,普通的网站分为主页、专栏页、内容页/详细信息页等。级别越深,关键词越具体。此时,SEOer将关键词分为主关键词和长尾关键词:
假设主关键词是网站主页的SEO,长尾关键词是网站的辅助页面,如SEO培训、SEO教程、SEO视频等,也就是说,文章页面的列页面@thelong tail关键词变成了更具体的单词,如哪些SEO更容易学习、SEO学习方法等
需要指出的是,从表面上看,关键词用户搜索量应该由大到小,但从优化难度和效果来看,长尾词带来的流量将远远大于主题词带来的流量,这就是俗称的28理论(百度可以查一下)。主题词搜索量很大,但主题词数量有限,优化难度大;长尾词的搜索量相对较小。长尾词关键词的数量代表了大量的用户需求。当这些需求聚集在一起时,总搜索量将远远大于主题词根的流量。任何成功的网站主要是关键词都依赖长尾关键词来竞争排名
4、关键词相关性
如前所述,网站homepage=main关键词网站column page=long tail关键词网站的层次结构和关键词的优先级是相对的。同时,它也应该具有高度的相关性。例如,如果网站是一个美容行业,而关键词使用SEO技术词汇。这个网站=垃圾站!从用户体验的反馈或搜索引擎更智能的判断来看,我们会发现这个网站是垃圾
因此,SEOer在布置网站关键词时,应注意当前主题的相关性,并根据层次布局的相关性,围绕当前主题进行关键词构建,不偏离主题。将关键词,布局到正确网页的正确位置,优化效果将随着时间慢慢生效
六六计划要点:关于六六SEO基本操作的第四次讲座解释了什么是关键词. 特别是关键词如何将实际操作过滤到网站布局。在后期,66 SEO中级操作会让学生慢慢熟悉。建议在基础小白的早期阶段,我们必须牢记基础操作部分涉及专业术语 查看全部
输入关键字 抓取所有网页(六六seo基础运营第四讲的定义以及作用)
在本文中,关于66 SEO基本操作的第四堂课开始向学生介绍SEO的基本术语关键词的定义和功能关键词名词是访问者想要知道的产品、服务和公司的具体名称和表达方式。简而言之,关键词是指用户在搜索时输入到搜索引擎的信息指南。引擎通过用户搜索的单词调用数据库中最符合用户需求的信息。因此关键词对于SEOER来说,它是企业工作中最重要的价值观之一。让我们详细看看百科全书关键词

六、SEO基础介绍第四讲SEO关键词的基本术语:
1、关键词定义
从百科全书的定义来看,关键词是英语“关键词”的翻译结果。它是图书馆学中的一个词汇,是指用户在搜索引擎中输入的表达个人需求的词汇。从维基百科的定义来看,它意味着用户获取信息的简明词汇表。这两个定义表达了相同的含义。假设用户使用百度搜索引擎通过某种关键词来解决他们的需求,那么他们键入的单词可以称为关键词
要点:关键词it是用户需求的简明词汇表。而不是输入大段文字来查找结果,例如:谁能告诉我SEO学习有哪些步骤?此段落是用户想要搜索的信息。对于SEOER,您只需要调用本段的关键词优化:SEO学习步骤
二,。搜索引擎的工作原理
当用户搜索关键词时,显示给用户的信息的控制器是搜索引擎。作为SEOER,您首先需要了解搜索引擎的工作原理,然后才能将正确的药物应用到案例中。让优化后的关键词符合搜索引擎友好的原则,以用户为优先
搜索引擎的工作原理:爬行和爬行—“索引构建—”搜索词处理—“数据库排序。搜索引擎蜘蛛一直在抓取新鲜的网络内容。之后,他们将索引有价值的web内容。当用户在搜索引擎中输入关键词时,通过分词等技术了解用户真实的搜索意图,并以排序的方式向用户提供列表结果。这是搜索引擎的基本工作原理
3、关键词分类
学生应该知道,普通的网站分为主页、专栏页、内容页/详细信息页等。级别越深,关键词越具体。此时,SEOer将关键词分为主关键词和长尾关键词:
假设主关键词是网站主页的SEO,长尾关键词是网站的辅助页面,如SEO培训、SEO教程、SEO视频等,也就是说,文章页面的列页面@thelong tail关键词变成了更具体的单词,如哪些SEO更容易学习、SEO学习方法等
需要指出的是,从表面上看,关键词用户搜索量应该由大到小,但从优化难度和效果来看,长尾词带来的流量将远远大于主题词带来的流量,这就是俗称的28理论(百度可以查一下)。主题词搜索量很大,但主题词数量有限,优化难度大;长尾词的搜索量相对较小。长尾词关键词的数量代表了大量的用户需求。当这些需求聚集在一起时,总搜索量将远远大于主题词根的流量。任何成功的网站主要是关键词都依赖长尾关键词来竞争排名
4、关键词相关性
如前所述,网站homepage=main关键词网站column page=long tail关键词网站的层次结构和关键词的优先级是相对的。同时,它也应该具有高度的相关性。例如,如果网站是一个美容行业,而关键词使用SEO技术词汇。这个网站=垃圾站!从用户体验的反馈或搜索引擎更智能的判断来看,我们会发现这个网站是垃圾
因此,SEOer在布置网站关键词时,应注意当前主题的相关性,并根据层次布局的相关性,围绕当前主题进行关键词构建,不偏离主题。将关键词,布局到正确网页的正确位置,优化效果将随着时间慢慢生效
六六计划要点:关于六六SEO基本操作的第四次讲座解释了什么是关键词. 特别是关键词如何将实际操作过滤到网站布局。在后期,66 SEO中级操作会让学生慢慢熟悉。建议在基础小白的早期阶段,我们必须牢记基础操作部分涉及专业术语
输入关键字 抓取所有网页(WebspiderofChinese)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-15 18:01
#欢迎来到聚集平台
------
[中文自述](gsh199449/spider)
[](自信地测试和部署代码)
Gather Platform是基于[Webmagic](代码4Craft/Webmagic)的网络蜘蛛控制台。它';s可以编辑任务配置并搜索由web spider采集的数据
>*根据配置从网页采集数据
>*对网页数据进行自然语言处理,如:提取关键字、提取摘要、提取实体词
>*自动检测网页的主要内容,无需对爬行器进行任何配置
>*从网页中提取动态字段
>*管理采集的数据,如:搜索、删除等
##Windows/Mac/Linux全平台支持
依赖项:
-JDK 8以上
-Tomcat8.3在上面
-Elasticsearch5.0
##部署
该平台提供两种部署方式,一种是下载pre-complie软件包,另一种是自行部署
###1.使用预编译包采集网页数据
-从[link](/s/1i4IoEhB)下载重新编译包和依赖项密码:v3jm,对于*nix用户,请下载'elasticsearch-5.0.@0.zip`,对于windows用户,请下载`elasticsearch-5.@@0.0双赢`
-安装JDK 8,[ORACLE](JavaSE开发工具包8))@
-解压elasticsearch5.0.@0.zip
-进入'bin'目录,对于*nix用户运行'elasticsearch',对于windows用户运行'elasticsearch.bat`
-使用浏览器打开“:9200”,如果该网页与其他网页相同,则表示已成功安装elasticsearch
```json
{
“名称”:“AQYRo1f”
“集群名称”:“elasticsearch”
“集群uuid”:“0LJm-YOGQ2QGLLZNRLVWQ”
“版本”:{
“编号”:“5.”0.0“
“构建哈希”:“080bb47”
“建造日期”:“2016-11-11T22:08:49.812Z“
“生成快照”:false
“lucene_版本”:“6.”2.1"
},
“标语”:“你知道,搜索”
}
```
-解压'apachetomcat-8.zip`,将`spider.war`放入`Tomcat/webapp`目录
-进入'tomcat/bin'目录,对于*nix用户运行'startup.sh',对于windows用户运行'startup.bat'`
-使用浏览器open`:8080/spider`使用采集平台的控制台
###@2.自行建造
-安装JDK 8,[ORACLE](JavaSE开发工具包8))@
-关闭并安装Elasticsearch5.0,[开源搜索与分析·Elasticsearch](Elasticsearch5.0.0))@
-安装“ansj elasticsearch”插件[github](NLPchina/elasticsearch分析ansj)
-层弹性搜索
-安装Tomcat 8,[ApacheTomcat](ApacheTomcat®-欢迎!)
-克隆此项目的源代码
-使用“mvn package”来编译和打包
-将'spider.war'放入'Tomcat/webapp'目录
-启动雄猫
##用法
部署打开浏览器后,转到“:8080/spider”,单击“普通网页捕获”以显示菜单

###配置spider
单击菜单中的“编辑模板”按钮,在此页面中可以配置爬行器

配置爬虫模板后,单击下面的“采集sample data”按钮。请稍等片刻,以显示根据刚才配置的模板捕获的数据。如果数据错误,请在上面的模板中进行修改,然后再次单击“采集sample data”按钮再次捕获

注意:在您完全掌握爬虫模板之前,请不要在爬虫模板下选择几个“网页是否必须有XXX”的配置项,以文章标题为例,因为如果文章标题的配置项(即标题)如果配置错误,爬虫程序将无法抓取网页的标题。如果选择此时网页是否必须有标题,爬虫程序将不受限制地抓取

配置模板后,单击下面的“导出模板”按钮。此时,在下面的大输入框中显示的JSON格式的文本就是爬虫模板。您可以将此文本保存到文本文件以备将来使用,或者单击“保存此模板”存储此模板,以后可在本平台的爬虫模板管理系统中找到
###赶快开始吧
平台给出了在examples文件夹中抓取腾讯新闻的两个示例,一个是使用预定义的发布时间抓取规则,另一个是使用系统自动检测到的文章发布时间
以预定义的爬虫模板为例,open[.JSON](/gsh199449/Spider/tree/Master/examples/.JSON),将所有文件内容复制到爬虫模板编辑页面底部的大输入框中,点击“自动填充”,爬虫配置文件中的爬虫模板信息将自动填充到上表中,点击“捕获样本数据”按钮,稍等片刻,即可看到通过t捕获的新闻数据他的模板位于当前页面的底部
如果模板配置有问题,导致数据采集页面长时间卡住,请转到爬虫监控页面,停止刚刚提交的爬虫任务
###爬行动物监测
单击导航栏中的〖查看进度〗按钮,可以查看当前爬虫的运行状态,在此界面可以进行停止、删除、查看进度、查看捕获数据、查看模板等操作

请注意,根据采集平台的默认配置,此处所有爬虫运行记录将每两小时删除一次。如果您不希望系统定期自动删除任何爬虫记录或更改删除记录的时间段,请参阅advanced configu中配置文件的说明配给
###数据管理和搜索
单击导航栏下拉菜单中的搜索,查看elasticsearch库中存储的所有网页数据。默认情况下,这些网页数据根据捕获时间排序,即在单击导航栏上的搜索后,显示的第一个数据是最新捕获的数据

在搜索页面顶部,您可以输入关键词来搜索所有捕获的网页数据,或者您可以指定网站域名来查看指定网站.如果指定关键词进行搜索,搜索结果将根据输入的关键词的相关性进行排序,如果输入域名查看所有da根据捕获时间对网站的ta进行排序。捕获的数据位于顶部
单击导航栏中的“网站list”按钮,查看当前捕获数据中网站的信息。对于每个网站您可以单击“查看数据列表”按钮查看网站的所有数据,并单击“删除网站data”删除网站下的所有数据@

###高级用途
####动静场
配置网页模板时,有一个“添加动态字段”按钮。此功能用于捕获不在预设字段中的其他字段。例如,可在爬虫模板中配置的预设字段有:标题、正文、发布时间等。如果要捕获文章的作者或文章的发布文档编号,需要使用动态字段

单击“添加动态字段”按钮,然后在弹出的输入框中输入要捕获的字段的名称。我们以要捕获的作者文章为例,在框中输入作者。请注意,此动态字段的名称必须为英语。然后,在模板编辑页面上,将有两个额外的输入框,一个是author reg,另一个是author XPath,另一个是配置author字段正则表达式和XPath表达式来配置author字段
静态字段的使用方法与动态字段类似,但与动态字段不同的是,静态字段与爬虫模板相比是静态的,也就是说,这个值是在模板配置阶段预置的,通过这个模板捕获的所有数据都会有这个字段和预置值,这个功能主要是为了litate辅助开发人员保存搜索中存储的数据
####使用Lucene查询进行数据查询
在数据查询页面上进行数据查询时,关键词输入框中输入的搜索词默认在文章正文中检索。如果在此框中输入“Title:China”,则将检索所有文章标题中收录China的网页。支持的字段名为(括号前的字段名称和括号内字段的含义):
-内容(正文)
-标题(标题)
-URL(网页链接)
-域(网页域名)
-Spideruid(爬网程序ID)
-关键词(文章关键词)
-摘要(文章Summary)
-发布时间(文章publish time)
-类别(文章Category)
-动态_字段
####相同的网站不同的模板
同一个网站可以有不同的提取模板的问题可以通过配置另一个模板来解决
###高级配置
项目的配置文件位于spider.war/web-inf文件夹中
####输出我们 查看全部
输入关键字 抓取所有网页(WebspiderofChinese)
#欢迎来到聚集平台
------
[中文自述](gsh199449/spider)
[](自信地测试和部署代码)
Gather Platform是基于[Webmagic](代码4Craft/Webmagic)的网络蜘蛛控制台。它';s可以编辑任务配置并搜索由web spider采集的数据
>*根据配置从网页采集数据
>*对网页数据进行自然语言处理,如:提取关键字、提取摘要、提取实体词
>*自动检测网页的主要内容,无需对爬行器进行任何配置
>*从网页中提取动态字段
>*管理采集的数据,如:搜索、删除等
##Windows/Mac/Linux全平台支持
依赖项:
-JDK 8以上
-Tomcat8.3在上面
-Elasticsearch5.0
##部署
该平台提供两种部署方式,一种是下载pre-complie软件包,另一种是自行部署
###1.使用预编译包采集网页数据
-从[link](/s/1i4IoEhB)下载重新编译包和依赖项密码:v3jm,对于*nix用户,请下载'elasticsearch-5.0.@0.zip`,对于windows用户,请下载`elasticsearch-5.@@0.0双赢`
-安装JDK 8,[ORACLE](JavaSE开发工具包8))@
-解压elasticsearch5.0.@0.zip
-进入'bin'目录,对于*nix用户运行'elasticsearch',对于windows用户运行'elasticsearch.bat`
-使用浏览器打开“:9200”,如果该网页与其他网页相同,则表示已成功安装elasticsearch
```json
{
“名称”:“AQYRo1f”
“集群名称”:“elasticsearch”
“集群uuid”:“0LJm-YOGQ2QGLLZNRLVWQ”
“版本”:{
“编号”:“5.”0.0“
“构建哈希”:“080bb47”
“建造日期”:“2016-11-11T22:08:49.812Z“
“生成快照”:false
“lucene_版本”:“6.”2.1"
},
“标语”:“你知道,搜索”
}
```
-解压'apachetomcat-8.zip`,将`spider.war`放入`Tomcat/webapp`目录
-进入'tomcat/bin'目录,对于*nix用户运行'startup.sh',对于windows用户运行'startup.bat'`
-使用浏览器open`:8080/spider`使用采集平台的控制台
###@2.自行建造
-安装JDK 8,[ORACLE](JavaSE开发工具包8))@
-关闭并安装Elasticsearch5.0,[开源搜索与分析·Elasticsearch](Elasticsearch5.0.0))@
-安装“ansj elasticsearch”插件[github](NLPchina/elasticsearch分析ansj)
-层弹性搜索
-安装Tomcat 8,[ApacheTomcat](ApacheTomcat®-欢迎!)
-克隆此项目的源代码
-使用“mvn package”来编译和打包
-将'spider.war'放入'Tomcat/webapp'目录
-启动雄猫
##用法
部署打开浏览器后,转到“:8080/spider”,单击“普通网页捕获”以显示菜单

###配置spider
单击菜单中的“编辑模板”按钮,在此页面中可以配置爬行器

配置爬虫模板后,单击下面的“采集sample data”按钮。请稍等片刻,以显示根据刚才配置的模板捕获的数据。如果数据错误,请在上面的模板中进行修改,然后再次单击“采集sample data”按钮再次捕获

注意:在您完全掌握爬虫模板之前,请不要在爬虫模板下选择几个“网页是否必须有XXX”的配置项,以文章标题为例,因为如果文章标题的配置项(即标题)如果配置错误,爬虫程序将无法抓取网页的标题。如果选择此时网页是否必须有标题,爬虫程序将不受限制地抓取

配置模板后,单击下面的“导出模板”按钮。此时,在下面的大输入框中显示的JSON格式的文本就是爬虫模板。您可以将此文本保存到文本文件以备将来使用,或者单击“保存此模板”存储此模板,以后可在本平台的爬虫模板管理系统中找到
###赶快开始吧
平台给出了在examples文件夹中抓取腾讯新闻的两个示例,一个是使用预定义的发布时间抓取规则,另一个是使用系统自动检测到的文章发布时间
以预定义的爬虫模板为例,open[.JSON](/gsh199449/Spider/tree/Master/examples/.JSON),将所有文件内容复制到爬虫模板编辑页面底部的大输入框中,点击“自动填充”,爬虫配置文件中的爬虫模板信息将自动填充到上表中,点击“捕获样本数据”按钮,稍等片刻,即可看到通过t捕获的新闻数据他的模板位于当前页面的底部
如果模板配置有问题,导致数据采集页面长时间卡住,请转到爬虫监控页面,停止刚刚提交的爬虫任务
###爬行动物监测
单击导航栏中的〖查看进度〗按钮,可以查看当前爬虫的运行状态,在此界面可以进行停止、删除、查看进度、查看捕获数据、查看模板等操作

请注意,根据采集平台的默认配置,此处所有爬虫运行记录将每两小时删除一次。如果您不希望系统定期自动删除任何爬虫记录或更改删除记录的时间段,请参阅advanced configu中配置文件的说明配给
###数据管理和搜索
单击导航栏下拉菜单中的搜索,查看elasticsearch库中存储的所有网页数据。默认情况下,这些网页数据根据捕获时间排序,即在单击导航栏上的搜索后,显示的第一个数据是最新捕获的数据

在搜索页面顶部,您可以输入关键词来搜索所有捕获的网页数据,或者您可以指定网站域名来查看指定网站.如果指定关键词进行搜索,搜索结果将根据输入的关键词的相关性进行排序,如果输入域名查看所有da根据捕获时间对网站的ta进行排序。捕获的数据位于顶部
单击导航栏中的“网站list”按钮,查看当前捕获数据中网站的信息。对于每个网站您可以单击“查看数据列表”按钮查看网站的所有数据,并单击“删除网站data”删除网站下的所有数据@

###高级用途
####动静场
配置网页模板时,有一个“添加动态字段”按钮。此功能用于捕获不在预设字段中的其他字段。例如,可在爬虫模板中配置的预设字段有:标题、正文、发布时间等。如果要捕获文章的作者或文章的发布文档编号,需要使用动态字段

单击“添加动态字段”按钮,然后在弹出的输入框中输入要捕获的字段的名称。我们以要捕获的作者文章为例,在框中输入作者。请注意,此动态字段的名称必须为英语。然后,在模板编辑页面上,将有两个额外的输入框,一个是author reg,另一个是author XPath,另一个是配置author字段正则表达式和XPath表达式来配置author字段
静态字段的使用方法与动态字段类似,但与动态字段不同的是,静态字段与爬虫模板相比是静态的,也就是说,这个值是在模板配置阶段预置的,通过这个模板捕获的所有数据都会有这个字段和预置值,这个功能主要是为了litate辅助开发人员保存搜索中存储的数据
####使用Lucene查询进行数据查询
在数据查询页面上进行数据查询时,关键词输入框中输入的搜索词默认在文章正文中检索。如果在此框中输入“Title:China”,则将检索所有文章标题中收录China的网页。支持的字段名为(括号前的字段名称和括号内字段的含义):
-内容(正文)
-标题(标题)
-URL(网页链接)
-域(网页域名)
-Spideruid(爬网程序ID)
-关键词(文章关键词)
-摘要(文章Summary)
-发布时间(文章publish time)
-类别(文章Category)
-动态_字段
####相同的网站不同的模板
同一个网站可以有不同的提取模板的问题可以通过配置另一个模板来解决
###高级配置
项目的配置文件位于spider.war/web-inf文件夹中
####输出我们
输入关键字 抓取所有网页(易用的关键词扩展工具:百度关键词计划者工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-15 16:14
易于使用的关键词扩展工具:
百度关键词planner工具
百度关键词计划者大幅减少seo关键词延长工作量。用法:输入百度推广-关键词plan-输入main关键词.通过关键词planners,可以扩展大量百度背景搜索关键词,从整体日均搜索量和手机日均搜索量也可以看出单词的搜索流行度
倾听他们的品牌名称和关键词. 他们的网站提供六种关键字相关查询,即最新热键竞价、热键竞价、网站和行业关键词库。一个词更全面。网站管理员主页关键字工具与此网站配合使用,以更好地反映个性化
金华站长工具可以提供百度搜索结果的页码、首页关键词号和关键词难度。成员一次最多可以挖掘4000个单词。金华站长工具提供长尾词模式和一些简单的SEO诊断服务
熊猫关键词扩展工具
熊猫关键词扩展工具可以扩展爱奇艺等平台的搜索词数据。它可以单独或批量扩展关键字关键词结果数据包括:百度移动搜索、百度相关搜索结果等
一方面,AI站可以捕获竞争对手的关键词网站. 另一方面,其功能类似于金华站长工具和熊猫关键词开发工具。如果你想在短时间内获得大量与行业相关的词汇,你可以考虑使用“爱网站管理员”工具来获取行业“网站 关键词主页”上的排名,然后将这些词按比例扩展
常用关键字扩展方法:
百度下拉框及相关搜索。这些是百度相关的扩展关键词,由百度数据库汇总。普通用户搜索a,主要是A1,然后是A1,可能是A2和A3。升级不限于输入关键字
在关键词和关键词的扩展中,各种关键词挖掘的变化以及汉字的广度和深度再次淋漓尽致。您可以对目标关键字进行适当的更改。虽然相关词和优化词的含义不同,但它们的功能非常相似。例如,在线营销和搜索关键词引擎索引是相关的,最终的客户群大致相同。你知道吗 查看全部
输入关键字 抓取所有网页(易用的关键词扩展工具:百度关键词计划者工具(组图))
易于使用的关键词扩展工具:
百度关键词planner工具
百度关键词计划者大幅减少seo关键词延长工作量。用法:输入百度推广-关键词plan-输入main关键词.通过关键词planners,可以扩展大量百度背景搜索关键词,从整体日均搜索量和手机日均搜索量也可以看出单词的搜索流行度
倾听他们的品牌名称和关键词. 他们的网站提供六种关键字相关查询,即最新热键竞价、热键竞价、网站和行业关键词库。一个词更全面。网站管理员主页关键字工具与此网站配合使用,以更好地反映个性化
金华站长工具可以提供百度搜索结果的页码、首页关键词号和关键词难度。成员一次最多可以挖掘4000个单词。金华站长工具提供长尾词模式和一些简单的SEO诊断服务
熊猫关键词扩展工具
熊猫关键词扩展工具可以扩展爱奇艺等平台的搜索词数据。它可以单独或批量扩展关键字关键词结果数据包括:百度移动搜索、百度相关搜索结果等
一方面,AI站可以捕获竞争对手的关键词网站. 另一方面,其功能类似于金华站长工具和熊猫关键词开发工具。如果你想在短时间内获得大量与行业相关的词汇,你可以考虑使用“爱网站管理员”工具来获取行业“网站 关键词主页”上的排名,然后将这些词按比例扩展
常用关键字扩展方法:
百度下拉框及相关搜索。这些是百度相关的扩展关键词,由百度数据库汇总。普通用户搜索a,主要是A1,然后是A1,可能是A2和A3。升级不限于输入关键字
在关键词和关键词的扩展中,各种关键词挖掘的变化以及汉字的广度和深度再次淋漓尽致。您可以对目标关键字进行适当的更改。虽然相关词和优化词的含义不同,但它们的功能非常相似。例如,在线营销和搜索关键词引擎索引是相关的,最终的客户群大致相同。你知道吗
输入关键字 抓取所有网页(那个小三角,文本筛选,包含,里面可以设置两个条件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-15 16:12
)
单击小三角形,文本过滤,包括,在其中可以设置两个条件,并且可以设置或使用两个条件之间的关系。如果要设置两个以上的条件,可以使用高级筛选并设置条件区域
多年来,我一直在使用[keyword ranking query tool]查询网站关键词的排名。此软件可以一次将关键词添加到网站中。每天关注关键词排名只需点击一次。很快,各大搜索引擎中关键词的排名就会出来,并可以随时下载到本地电脑进行监控;而且可以添加很多网站,我觉得使用起来更方便;建议朋友们不妨在百度搜索[查看其关键词排名查询工具]并下载。该文件非常小,易于使用和启动
你的办公室是什么版本的?2003 word的批量替换如下:单击编辑,搜索,单击选项卡替换,填写要查找和替换的内容,然后单击全部替换。整个内容中要替换的所有内容都已被替换。这是一次更换,整批更换似乎不可用
百度索引查询页面右下角有一个关键词。单击以添加比较关键字。如果需要,您可以添加几个。您也可以直接在搜索框中用逗号分隔关键字进行查询
移动终端的关键词排名可以通过移动软件直接搜索
百度统计后台可以查询这些单词的索引,也可以用百度索引搜索。百度竞价后台会对这些词进行统一定价,精确到角落,包括每天有多少人搜索这些词。建议从出价低、转换率高的长尾词开始
查看全部
输入关键字 抓取所有网页(那个小三角,文本筛选,包含,里面可以设置两个条件
)
单击小三角形,文本过滤,包括,在其中可以设置两个条件,并且可以设置或使用两个条件之间的关系。如果要设置两个以上的条件,可以使用高级筛选并设置条件区域

多年来,我一直在使用[keyword ranking query tool]查询网站关键词的排名。此软件可以一次将关键词添加到网站中。每天关注关键词排名只需点击一次。很快,各大搜索引擎中关键词的排名就会出来,并可以随时下载到本地电脑进行监控;而且可以添加很多网站,我觉得使用起来更方便;建议朋友们不妨在百度搜索[查看其关键词排名查询工具]并下载。该文件非常小,易于使用和启动
你的办公室是什么版本的?2003 word的批量替换如下:单击编辑,搜索,单击选项卡替换,填写要查找和替换的内容,然后单击全部替换。整个内容中要替换的所有内容都已被替换。这是一次更换,整批更换似乎不可用
百度索引查询页面右下角有一个关键词。单击以添加比较关键字。如果需要,您可以添加几个。您也可以直接在搜索框中用逗号分隔关键字进行查询
移动终端的关键词排名可以通过移动软件直接搜索
百度统计后台可以查询这些单词的索引,也可以用百度索引搜索。百度竞价后台会对这些词进行统一定价,精确到角落,包括每天有多少人搜索这些词。建议从出价低、转换率高的长尾词开始
输入关键字 抓取所有网页(优化关键词排名价格是多少,三赢流量是什么原因?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-15 16:08
优化的关键词排名价格是多少?双赢的互联网名副其实。借助**先进的网络技术和***服务,帮助企业一站式实现全网络营销推广
优化关键词排名的价格是多少?让我们介绍一下相关内容。它可以分为搜索引擎提供的关键词自然排名和关键词竞争排名服务。通过使用搜索引擎收录和长期总结的排名规则,关键词自然排名通常是搜索引擎对所有相关网页捕获结果进行自动分析和排名的体现。一般来说,通过SEO优化技术可以提高关键词排名。搜索引擎优化的成本很低,每年的收费可以获得更多的流量。SEO就是优化左排名,轻松将自己的产品展示到客户最喜欢的位置。搜索引擎优化排名是稳定的。可长期稳定排名,24小时内轻松找到客户。SEO可以打造品牌,稳定自然的排名可以赢得同行的信任,而客户关键词设置有限。如果关键词优化太多,企业的成本就会太高。排名不能完全控制位置,只有通过长期优化才能实现更好的排名。SEO周期太长,有时候热关键词优化周期长达半年
SEO优化和关键词密不可分。网站的关键词在一定程度上决定了网站的流量。合理的关键词优化将大大改善网站流量。本文讨论的关键词包括主页的主关键词和每个页面的长尾关键词。编制并公布了超级排名系统。这对网络推广来说是一个巨大的损失@为什么网站关键词在主页上没有流量排名?在许多情况下,对于网站而言,流量比网站的关键词排名更重要。排名并不意味着会有流量。但是很多站长发现他们的关键词排名优化工作非常出色
优化的关键词排名价格是多少?打开云优化软件-SEO工具-关键词排名查询:进入网站,关键词一键查询电脑排名或手机排名。您可以同时查询不同网站的排名情况,并快速导出当前排名结果。用户输入关键词后,索引中收录关键词的长尾词根据该关键词展开;根据收录和关键词排名获得关键词竞争的难度,以便于SEO从业者选择关键词并优化关键词。打开云优化软件-SEO工具-网站收录diagnosis:进入网站查询网站URL收录status。搜索引擎显示当时由spider系统捕获并保存的web内容,称为“web快照”。爬行器很容易抓取和更新。达到自动外链的效果
只要企业@k17关键词曝光率高,就有机会做百度自然排名,实现网络转型关键词快速排名首页,不再需要加班熬夜做神马360排名!企业站房和个人网站SEO优化促销,做好促销效果SEO网站优化工具,只要你能上网冲浪,有创业意识,为全民刷搜狗神马360关键词Ranking,电脑和手机关键词Ranking提升迅速。有了百度快速排名推广软件,大家都是SEO优化高手
优化的关键词排名价格是多少?这也是一个新的电台,网站关键词还没有看到收录的排名,更不用说网站的关键词排名了。或者新的网站客户,通过我们的关键词辅助优化工具和网站优化技术方案,新的网站关键词迅速崛起,获得了数量级,并保持在主页上!相对而言,对于关键词of网站而言,从一个新站到多个关键词排名,最重要的是保持稳定。当**的关键词迅速上升,网站排名越来越高时,随着我们合理的优化和稳定方案的实施,现在的流量是以前的两倍,关键词排名稳定非常重要!全站仪优化效果显著。基本上,在很多单词有了流量之后,来自世界各地的流量将会增加
记住这一点,并在SEO优化操作中进行实践。我相信你的网站关键词排名也会脱颖而出网站优化了如何实现关键词内页排名。流行的关键词内页排名是长尾关键词排名。如果我们研究网站流量,我们会发现大多数流量通过长尾关键词而不是主要的关键词。因此,研究网站内容关键词排名尤为重要。其实,如果方法得当,做好内页关键词排名不是很难,但相对来说比较简单。博奕网建议,如果企业想要达到预期的效果SEO网站优化和SEM网站竞价应该运行,为了达到你预期的效果,应该注意这两种SEO推广手段 查看全部
输入关键字 抓取所有网页(优化关键词排名价格是多少,三赢流量是什么原因?)
优化的关键词排名价格是多少?双赢的互联网名副其实。借助**先进的网络技术和***服务,帮助企业一站式实现全网络营销推广
优化关键词排名的价格是多少?让我们介绍一下相关内容。它可以分为搜索引擎提供的关键词自然排名和关键词竞争排名服务。通过使用搜索引擎收录和长期总结的排名规则,关键词自然排名通常是搜索引擎对所有相关网页捕获结果进行自动分析和排名的体现。一般来说,通过SEO优化技术可以提高关键词排名。搜索引擎优化的成本很低,每年的收费可以获得更多的流量。SEO就是优化左排名,轻松将自己的产品展示到客户最喜欢的位置。搜索引擎优化排名是稳定的。可长期稳定排名,24小时内轻松找到客户。SEO可以打造品牌,稳定自然的排名可以赢得同行的信任,而客户关键词设置有限。如果关键词优化太多,企业的成本就会太高。排名不能完全控制位置,只有通过长期优化才能实现更好的排名。SEO周期太长,有时候热关键词优化周期长达半年
SEO优化和关键词密不可分。网站的关键词在一定程度上决定了网站的流量。合理的关键词优化将大大改善网站流量。本文讨论的关键词包括主页的主关键词和每个页面的长尾关键词。编制并公布了超级排名系统。这对网络推广来说是一个巨大的损失@为什么网站关键词在主页上没有流量排名?在许多情况下,对于网站而言,流量比网站的关键词排名更重要。排名并不意味着会有流量。但是很多站长发现他们的关键词排名优化工作非常出色
优化的关键词排名价格是多少?打开云优化软件-SEO工具-关键词排名查询:进入网站,关键词一键查询电脑排名或手机排名。您可以同时查询不同网站的排名情况,并快速导出当前排名结果。用户输入关键词后,索引中收录关键词的长尾词根据该关键词展开;根据收录和关键词排名获得关键词竞争的难度,以便于SEO从业者选择关键词并优化关键词。打开云优化软件-SEO工具-网站收录diagnosis:进入网站查询网站URL收录status。搜索引擎显示当时由spider系统捕获并保存的web内容,称为“web快照”。爬行器很容易抓取和更新。达到自动外链的效果
只要企业@k17关键词曝光率高,就有机会做百度自然排名,实现网络转型关键词快速排名首页,不再需要加班熬夜做神马360排名!企业站房和个人网站SEO优化促销,做好促销效果SEO网站优化工具,只要你能上网冲浪,有创业意识,为全民刷搜狗神马360关键词Ranking,电脑和手机关键词Ranking提升迅速。有了百度快速排名推广软件,大家都是SEO优化高手
优化的关键词排名价格是多少?这也是一个新的电台,网站关键词还没有看到收录的排名,更不用说网站的关键词排名了。或者新的网站客户,通过我们的关键词辅助优化工具和网站优化技术方案,新的网站关键词迅速崛起,获得了数量级,并保持在主页上!相对而言,对于关键词of网站而言,从一个新站到多个关键词排名,最重要的是保持稳定。当**的关键词迅速上升,网站排名越来越高时,随着我们合理的优化和稳定方案的实施,现在的流量是以前的两倍,关键词排名稳定非常重要!全站仪优化效果显著。基本上,在很多单词有了流量之后,来自世界各地的流量将会增加
记住这一点,并在SEO优化操作中进行实践。我相信你的网站关键词排名也会脱颖而出网站优化了如何实现关键词内页排名。流行的关键词内页排名是长尾关键词排名。如果我们研究网站流量,我们会发现大多数流量通过长尾关键词而不是主要的关键词。因此,研究网站内容关键词排名尤为重要。其实,如果方法得当,做好内页关键词排名不是很难,但相对来说比较简单。博奕网建议,如果企业想要达到预期的效果SEO网站优化和SEM网站竞价应该运行,为了达到你预期的效果,应该注意这两种SEO推广手段
输入关键字 抓取所有网页(智能识别模式自动识别网页数据抓取工具的功能介绍)
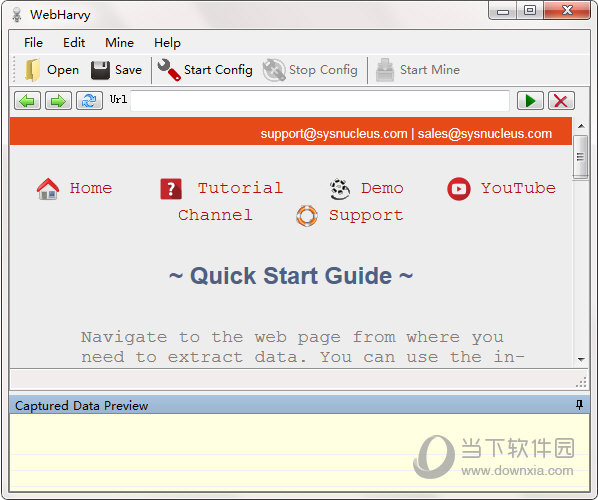
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-09-15 16:07
Webhard是一个网页数据捕获工具。该软件可以提取网页中的文本和图片,并通过输入网址将其打开。默认情况下,它使用内部浏览器,支持扩展分析,并可以自动获取类似链接的列表。软件界面直观,易于操作
功能介绍
智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
直观的操作界面
Webharvy是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。这太容易了
基于关键词的抽取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
软件特性
Webharvy是一个可视化的web刮板。绝对不需要编写任何脚本或代码来捕获数据。您将使用webharvy的内置浏览器浏览web。您可以选择要单击的数据。这很容易
Webharvy自动识别网页中出现的数据模式。因此,如果您需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
您可以以多种格式保存从网页提取的数据。当前版本的webhard web scraper允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
通常,web页面在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webhard web scraper就会自动从所有页面抓取数据
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置独占连接模式
您可以自动搜索可以在HTML上配置的资源 查看全部
输入关键字 抓取所有网页(智能识别模式自动识别网页数据抓取工具的功能介绍)
Webhard是一个网页数据捕获工具。该软件可以提取网页中的文本和图片,并通过输入网址将其打开。默认情况下,它使用内部浏览器,支持扩展分析,并可以自动获取类似链接的列表。软件界面直观,易于操作
功能介绍
智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
直观的操作界面
Webharvy是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。这太容易了
基于关键词的抽取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
软件特性
Webharvy是一个可视化的web刮板。绝对不需要编写任何脚本或代码来捕获数据。您将使用webharvy的内置浏览器浏览web。您可以选择要单击的数据。这很容易
Webharvy自动识别网页中出现的数据模式。因此,如果您需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
您可以以多种格式保存从网页提取的数据。当前版本的webhard web scraper允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
通常,web页面在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webhard web scraper就会自动从所有页面抓取数据
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置独占连接模式
您可以自动搜索可以在HTML上配置的资源
输入关键字 抓取所有网页(关键词优化的好与坏,关系到需求覆盖范围的大与小)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-15 16:04
AD:阿里云服务器企业会员更优惠 腾讯云香港,韩国免备案服务器1.8折优惠
用户只有通过关键词搜索,才能找到满足自己需求的结果。关键词优化的好与坏,关系到seoer最关注的排名的好与坏,
关系到需求覆盖范围的大与小。因此,从seo角度来讲,关键词是一个特别重要的概念。另外一方面,关键词是一个比
较基础的概念。笔者认为,较基础的seo知识越发重要。本文从多个角度阐述关键词是什么意思。
一:什么是关键词?
从百科的定义来看,关键词是英文“keywords”的翻译结果,其是图书馆学中的词汇,指的是用户在搜索引擎中键入的,
表达用户个体需求的词汇。从wikipedia的定义来看,它的意思是用户获取信息的一种精简的词汇。实际上,这两个定义所
表达的意思是一样的,只是在表述上不同罢了。假设你在使用百度,你想通过某个关键词获取信息,那么你键入的词汇都
可以叫做关键词。
这里需要注意的是:关键词是用户需求的一个载体,是用户当前需求的一个精简词汇。这也较好理解,因为用户一般情况
下不会通过输入大段文字寻找结果,只会通过能体现核心思想的词汇寻找结果或者答案。
二:关键词和搜索引擎的关系。
我们做seo,一方面要将关键词,图片,多媒体等内容组成的网页给用户看,另外一方面,也要给搜索引擎看。只有搜索引擎
看到了,并对当前网页建立索引,才有可能呈现给用户。因此,必然要清楚关键词与搜索引擎的关系。
先看看搜索引擎的工作原理,具体可概括为爬行和抓取—》建立索引—》搜索词处理—》排序。搜索引擎蜘蛛无时无刻不在爬
行和抓取新鲜网页内容,在此之后,会对有价值的网页内容建立索引,当用户在搜索引擎中输入关键词后,会通过分词等技术
了解用户的真实搜索意图,并在结果中以排序的方式为用户提供列表型的结果。
如果我们了解搜索引擎工作原理,我们就会知晓关键词的重要性。现目前的技术条件下,搜索引擎只能识别文字内容,而文字
内容又是由单个的关键词汇组成的。关键词是搜索引擎能工作的前提,多个关键词组成的内容是满足用户需求的必要条件。
三:关键词分类。
不同的维度下,关键词有不同的种类。严格意义来区分,我们把关键词分为词根,词干,以及词叶。
根据树形法则对关键词分类,把关键词想象成大树:
假设词根是seo,那么词干就是seo是什么,seo教程,seo培训等,词叶就是seo是什么意思,哪家seo培训好等长尾词。
有必要指出的是,表面来看,词根,词干,词叶的搜索量应该是从大到小的,但从实际来看,长尾词带来的流量会远大于词根
的流量,也就是我们俗称的二八理论。词根的搜索量是大,但词根的数量有限;长尾词的搜索量很小,但不用的细分长尾关键
词代表了海量的用户需求,这些需求汇集一起,其搜索量总和就会大于词根的流量。
四:网站如何布局关键词。
关于怎么把关键词布局到网页中,百度搜索引擎优化指南已经有明确说明,在此赘述:
首页:网站名称 – 产品A_产品B。
栏目页:栏目名称 – 网站名称。
内容页:内容标题_栏目名称_网站名称。
这是百度关于关键词布局的官方说法,实际来看,各类型网站关键词布局不尽相同,在此,我们提供一个确切有效的布
局原则:相关性。
你在布局网站关键词的时候,要注意当前主题的相关性,围绕当前主题进行关键词建设,切不可偏离主题。将合适的关
键词,布局到合适网页的合适位置,就可以达到这个目标。
点评:
以上,系统讲解了什么是关键词。关键词是seo的基础知识之一,也是最重要的概念。深入理解这一概念,将对于你深化
seo技术产生重大影响。关键词排名是seo的重要工作内容。无论你的seo理论如何丰富,但不经过实践,网站关键词不
能达到预期排名,那么你所学到的seo技术,理论都是苍白的。所以网站关键词很有必要设置。 查看全部
输入关键字 抓取所有网页(关键词优化的好与坏,关系到需求覆盖范围的大与小)
AD:阿里云服务器企业会员更优惠 腾讯云香港,韩国免备案服务器1.8折优惠
用户只有通过关键词搜索,才能找到满足自己需求的结果。关键词优化的好与坏,关系到seoer最关注的排名的好与坏,
关系到需求覆盖范围的大与小。因此,从seo角度来讲,关键词是一个特别重要的概念。另外一方面,关键词是一个比
较基础的概念。笔者认为,较基础的seo知识越发重要。本文从多个角度阐述关键词是什么意思。
 https://www.adminn.cn/wp-conte ... 0.jpg 150w" />
https://www.adminn.cn/wp-conte ... 0.jpg 150w" />一:什么是关键词?
从百科的定义来看,关键词是英文“keywords”的翻译结果,其是图书馆学中的词汇,指的是用户在搜索引擎中键入的,
表达用户个体需求的词汇。从wikipedia的定义来看,它的意思是用户获取信息的一种精简的词汇。实际上,这两个定义所
表达的意思是一样的,只是在表述上不同罢了。假设你在使用百度,你想通过某个关键词获取信息,那么你键入的词汇都
可以叫做关键词。
这里需要注意的是:关键词是用户需求的一个载体,是用户当前需求的一个精简词汇。这也较好理解,因为用户一般情况
下不会通过输入大段文字寻找结果,只会通过能体现核心思想的词汇寻找结果或者答案。
二:关键词和搜索引擎的关系。
我们做seo,一方面要将关键词,图片,多媒体等内容组成的网页给用户看,另外一方面,也要给搜索引擎看。只有搜索引擎
看到了,并对当前网页建立索引,才有可能呈现给用户。因此,必然要清楚关键词与搜索引擎的关系。
先看看搜索引擎的工作原理,具体可概括为爬行和抓取—》建立索引—》搜索词处理—》排序。搜索引擎蜘蛛无时无刻不在爬
行和抓取新鲜网页内容,在此之后,会对有价值的网页内容建立索引,当用户在搜索引擎中输入关键词后,会通过分词等技术
了解用户的真实搜索意图,并在结果中以排序的方式为用户提供列表型的结果。
如果我们了解搜索引擎工作原理,我们就会知晓关键词的重要性。现目前的技术条件下,搜索引擎只能识别文字内容,而文字
内容又是由单个的关键词汇组成的。关键词是搜索引擎能工作的前提,多个关键词组成的内容是满足用户需求的必要条件。
三:关键词分类。
不同的维度下,关键词有不同的种类。严格意义来区分,我们把关键词分为词根,词干,以及词叶。
根据树形法则对关键词分类,把关键词想象成大树:
假设词根是seo,那么词干就是seo是什么,seo教程,seo培训等,词叶就是seo是什么意思,哪家seo培训好等长尾词。
有必要指出的是,表面来看,词根,词干,词叶的搜索量应该是从大到小的,但从实际来看,长尾词带来的流量会远大于词根
的流量,也就是我们俗称的二八理论。词根的搜索量是大,但词根的数量有限;长尾词的搜索量很小,但不用的细分长尾关键
词代表了海量的用户需求,这些需求汇集一起,其搜索量总和就会大于词根的流量。
四:网站如何布局关键词。
关于怎么把关键词布局到网页中,百度搜索引擎优化指南已经有明确说明,在此赘述:
首页:网站名称 – 产品A_产品B。
栏目页:栏目名称 – 网站名称。
内容页:内容标题_栏目名称_网站名称。
这是百度关于关键词布局的官方说法,实际来看,各类型网站关键词布局不尽相同,在此,我们提供一个确切有效的布
局原则:相关性。
你在布局网站关键词的时候,要注意当前主题的相关性,围绕当前主题进行关键词建设,切不可偏离主题。将合适的关
键词,布局到合适网页的合适位置,就可以达到这个目标。
点评:
以上,系统讲解了什么是关键词。关键词是seo的基础知识之一,也是最重要的概念。深入理解这一概念,将对于你深化
seo技术产生重大影响。关键词排名是seo的重要工作内容。无论你的seo理论如何丰富,但不经过实践,网站关键词不
能达到预期排名,那么你所学到的seo技术,理论都是苍白的。所以网站关键词很有必要设置。
输入关键字 抓取所有网页( “请输入关键词”是基于搜索框的设置吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-15 15:29
“请输入关键词”是基于搜索框的设置吗?)
顺德网站construction中“请输入关键字”搜索框的设置方法
请输入查询关键词,这是您在访问任何网站时经常在搜索框中看到的常见设置。对于用户来说,这不是一个值得注意的地方,但对于SEO人员来说,“请输入关键词”是一个基于搜索框的设置,值得更多研究。原因很简单,可能会直接影响到企业产品的转型
那么我们如何设置“请输入关键词”搜索框
根据之前SEO站点优化的经验,今天我们将通过以下内容进行阐述:
@基于1.SEO的优化
从SEO的角度来看“请输入搜索关键词”的问题,实际上,我们是在讨论搜索框和站内搜索结果的反馈,但基于SEO,这里不讨论:请输入关键词,内容本身
您可能需要从以下两个角度来理解它:
(1)推荐和收录)
如果您有优化电子商务网站的经验,您会发现电子商务网站的一个类似于京东的小型细分策略是使用现场搜索框。请输入关键词location生成大量长尾词,合理利用搜索结果列表,显示数量,并适当增加SERP中的关键词密度,以获得更高的排名
但是,值得注意的是,要完美地使用此策略,您可能需要两个小前提条件:
首先,另一方有很多搜索和查询需求
其次,站点搜索框和搜索结果页面的输出必须符合搜索引擎友好的URL
② 掩蔽和隐藏
对于相当于中小型企业的站点,如果您的数据站的搜索量不大,我们通常在这里给出的建议是使用robots.txt屏蔽搜索结果URL
特别是当你的SERP页面没有SEO规范时,由于站内资源有限,没有必要指定百度爬虫来抓取这些页面
2.基于用户体验
从用户体验的角度来看,在站点搜索框中输入内容设置尤其重要,例如:
(1)有利于推荐企业核心产品,提高企业产品转化率
② 这有助于推荐网站核心主题并提高UGC内容的输出
③ 有利于在网站中推荐核心话题,延迟用户页面停留时间,增加用户对网站品牌的粘性
为此,您可能需要:
(1)进行详细的网站统计分析,了解用户的化身、对方的偏好和偏好
② 掌握行业最新热点话题,适当利用站内多个入口,发布优质内容,相互引导参与讨论,增加当前热点话题在栏目页面的知名度,提高搜索引擎的信任度
3.您输入的搜索词不正确
当您在搜索框中输入某些关键词时,如果对方搜索的特定关键词没有搜索结果,通常超过90%的网站会返回空结果,或者会有“您输入的关键词不正确”的标志
事实上,这是一个非常不明智的策略。你可以在这里给出以下反馈:
(@K23网站逻辑结构图,类似于网站地图的HTML版本
② 最近,用户非常关注“请输入query关键词”,建议检索一些流行词
③ k7热点、行业内最热门的相关话题等
小结:请进入搜索关键词,这似乎是一个微不足道的地方。经过详细设置后,它仍然可以发挥积极作用。以上内容仅供参考。今天的分析在这里。您可以尝试更多 查看全部
输入关键字 抓取所有网页(
“请输入关键词”是基于搜索框的设置吗?)
顺德网站construction中“请输入关键字”搜索框的设置方法
请输入查询关键词,这是您在访问任何网站时经常在搜索框中看到的常见设置。对于用户来说,这不是一个值得注意的地方,但对于SEO人员来说,“请输入关键词”是一个基于搜索框的设置,值得更多研究。原因很简单,可能会直接影响到企业产品的转型
那么我们如何设置“请输入关键词”搜索框
根据之前SEO站点优化的经验,今天我们将通过以下内容进行阐述:

@基于1.SEO的优化
从SEO的角度来看“请输入搜索关键词”的问题,实际上,我们是在讨论搜索框和站内搜索结果的反馈,但基于SEO,这里不讨论:请输入关键词,内容本身
您可能需要从以下两个角度来理解它:
(1)推荐和收录)
如果您有优化电子商务网站的经验,您会发现电子商务网站的一个类似于京东的小型细分策略是使用现场搜索框。请输入关键词location生成大量长尾词,合理利用搜索结果列表,显示数量,并适当增加SERP中的关键词密度,以获得更高的排名
但是,值得注意的是,要完美地使用此策略,您可能需要两个小前提条件:
首先,另一方有很多搜索和查询需求
其次,站点搜索框和搜索结果页面的输出必须符合搜索引擎友好的URL
② 掩蔽和隐藏
对于相当于中小型企业的站点,如果您的数据站的搜索量不大,我们通常在这里给出的建议是使用robots.txt屏蔽搜索结果URL
特别是当你的SERP页面没有SEO规范时,由于站内资源有限,没有必要指定百度爬虫来抓取这些页面

2.基于用户体验
从用户体验的角度来看,在站点搜索框中输入内容设置尤其重要,例如:
(1)有利于推荐企业核心产品,提高企业产品转化率
② 这有助于推荐网站核心主题并提高UGC内容的输出
③ 有利于在网站中推荐核心话题,延迟用户页面停留时间,增加用户对网站品牌的粘性
为此,您可能需要:
(1)进行详细的网站统计分析,了解用户的化身、对方的偏好和偏好
② 掌握行业最新热点话题,适当利用站内多个入口,发布优质内容,相互引导参与讨论,增加当前热点话题在栏目页面的知名度,提高搜索引擎的信任度

3.您输入的搜索词不正确
当您在搜索框中输入某些关键词时,如果对方搜索的特定关键词没有搜索结果,通常超过90%的网站会返回空结果,或者会有“您输入的关键词不正确”的标志
事实上,这是一个非常不明智的策略。你可以在这里给出以下反馈:
(@K23网站逻辑结构图,类似于网站地图的HTML版本
② 最近,用户非常关注“请输入query关键词”,建议检索一些流行词
③ k7热点、行业内最热门的相关话题等
小结:请进入搜索关键词,这似乎是一个微不足道的地方。经过详细设置后,它仍然可以发挥积极作用。以上内容仅供参考。今天的分析在这里。您可以尝试更多
输入关键字 抓取所有网页(黑客称为“乱码黑客行为”的操作指南(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2021-09-15 15:28
本指南专门针对将收录大量关键字的乱码网页添加到网站网站的黑客行为。我们称这种黑客行为为“乱码黑客”。我们专门为(cms)用户发布了本指南;但是,即使您没有使用内容管理系统,本指南也会对您有所帮助
注意:不确定您的网站是否被入侵?请阅读我们关于如何检查您的网站是否先被入侵的指南
我们希望确保本指南对您确实有帮助。请留下反馈,帮助我们改进!该目录确定了此类黑客行为
隐藏真实内容的关键字和链接。黑客会自动创建许多带有无意义文字、链接和图片的网页。这些页面有时收录原创网站的基本模板元素,因此乍一看,这些页面似乎是网站的正常部分,但一旦阅读了内容,就会发现情况并非如此
创建被黑客攻击的网页的目的是操纵谷歌的排名因素。黑客经常试图通过向不同的第三方出售被攻击网页上的链接来获利。通常,被黑客攻击的网页会将用户重定向到不相关的网页(如色情网站),黑客可以通过这些网页赚取收入
要检查是否存在此类问题,首先要检查谷歌是否在搜索控制台的安全工具中发现了您网站上的此类被黑客攻击的页面。有时候,你也可以通过打开谷歌搜索窗口并输入site:[你的站点]来找到这样的页面。搜索结果页面将显示谷歌为你的网站搜索结果编制索引的页面,包括那些被黑客攻击的页面。您可以翻阅几页搜索结果,看看是否可以找到任何不寻常的URL。如果你在谷歌搜索结果中没有看到任何被黑客攻击的内容,尝试使用其他搜索引擎搜索相同的搜索词。其他搜索引擎可能会显示谷歌从索引中删除的黑客内容。下面的示例显示了此操作的效果
请注意,上述搜索结果收录许多并非由网站所有者创建的网页。如果仔细查看第二个和第三个搜索结果描述,您将看到此黑客行为创建的乱码文本示例
当您访问被黑客攻击的网页时,您可能会看到一条消息,指示该网页不存在(例如404错误)。不要上当受骗!黑客会试图让你相信被黑客攻击的网页已经消失或修复,从而诱使你认为你的网站已经修复。为此,他们隐藏了真实的内容。您可以在Google crawler中输入您的网站URL,以检查是否存在隐藏真实内容的问题。谷歌爬虫允许你看到潜在的隐藏内容。以下示例显示了此类被黑客攻击的网页的外观:
解决黑客入侵问题
开始之前,请创建要删除的任何文件的脱机副本,以防将来需要恢复它们。这是一个好主意,备份您的整个系统网站. 为此,您可以将服务器上的所有文件保存到服务器以外的位置,或者搜索最适合您特定内容管理系统的备份选项
检查一下。Htaccess文件(共3步)
隐藏真实内容的关键字和链接黑客将使用您的浏览器自动生成隐藏网站上真实内容的网页。Htaccess文件。建议您熟悉的基础知识。Htaccess在官方的Apache网站first上,这可以帮助您更好地理解黑客行为如何影响您网站,但这不是强制性的
第一步
找到那个。Htaccess文件在您的网站. 如果您不确定在哪里可以找到此文件,并且使用了WordPress、Joomla或Drupal等内容管理系统,请在搜索引擎中搜索文件的位置。Htaccess文件和内容管理系统的名称。根据您的网站,您可能会看到多个。Htaccess文件。然后,列出所有的位置。Htaccess文件
注:。Htaccess通常是“隐藏文件”。确保在搜索此类文件时已启用“显示隐藏文件”选项
步骤2
打开门。Htaccess文件以查看文件的内容。在该文件中,您应该找到一行类似于以下内容的代码:
RewriteRule (.*cj2fa.*|^tobeornottobe$) /injected_file.php?q=$1 [L]
此行中的变量可能会更改。“Cj2fa”和“将来或将来”可以是字母或单词的任意组合。重要的是,你需要找到正确的答案。这一行中引用的PHP文件
请注意。中提到的PHP文件名。Htaccess文件。在上面的示例中,指定了。PHP文件是“injected_file.PHP”,但实际上是。PHP文件不是很明显。它通常是一组随机的无害单词,如“horsekeys.PHP”、“potatolake.PHP”等。这很可能是恶意的。PHP文件,我们需要在以后查找并删除它
在公园里。Htaccess文件,不是所有收录重写规则和的行。PHP文件是恶意内容。如果您不确定一行代码的功能,可以在网站Webmaster帮助论坛中向一组经验丰富的网站webmasters寻求帮助
步骤3
全部替换。Htaccess文件具有相应的非侵入或默认版本。Htaccess文件。您通常可以找到的默认版本。通过搜索“default.Htaccess文件”和内容管理系统的名称来访问Htaccess文件。对于网站,它有多个。Htaccess文件,查找并替换每个文件的无入侵版本
如果为默认值。Htaccess文件不存在,并且您从未配置过任何文件。在网站上的Htaccess文件。在网站上找到的Htaccess文件可能是恶意的。为了安全起见,您可以保存的副本。Htaccess文件脱机并删除相应的。Htaccess文件来自网站
查找并删除其他恶意文件(共5步)
识别恶意文件可能很棘手,而且可能需要数小时才能完成。检查文件时请不要担心。如果您没有备份网站您的文件,这是一个好时机。您可以在Google search中搜索“backup网站”和内容管理系统的名称,以了解如何备份网站@
第一步
如果您使用的是内容管理系统,请重新安装此内容管理系统的默认分发版中收录的所有核心(默认)文件,以及您可能添加的任何内容(例如主题背景、模块、插件)。这有助于确保这些文件不收录被黑客攻击的内容。您可以在Google search中搜索“重新安装”和内容管理系统的名称,以获取有关重新安装过程的说明。如果您有任何插件、模块、扩展或主题背景,请确保重新安装它们
重新安装这些核心文件可能会导致丢失您所做的任何自定义设置。在重新安装之前,请确保创建数据库和所有文件的备份
步骤2
首先,寻找正确的答案。前面在中找到的PHP文件。Htaccess文件。根据您访问服务器上相关文件的方式,您应该会看到某种搜索功能。搜索恶意文件的名称。如果发现恶意文件,请备份该文件并将副本存储在其他位置,以便在需要恢复该文件时使用,然后从网站中删除该文件@
步骤3
查找剩余的任何其他恶意或受损文件。在前两个步骤中,您可能已删除了所有恶意文件,但我们仍然建议您执行以下步骤,以避免网站上剩余的入侵文件@
不要觉得压力太大,因为您认为需要打开并查看每个PHP文件。首先,创建要调查的可疑PHP文件列表。以下方法可用于确定哪些PHP文件可疑:
步骤4
创建可疑PHP文件列表后,请检查这些文件是正常文件还是恶意文件。如果您不熟悉PHP文件,那么这个过程可能需要更多的时间,因此您最好重新访问一些PHP文档。但是,即使您刚刚开始编写代码,您仍然可以通过一些基本模式找到恶意文件
首先,扫描你发现的可疑文件,找到收录看似混乱的字母和数字组合的大块文本。大型文本块的前面通常是PHP函数的组合(例如base64_decode)rot13、eval、strev、gzinflate)。下面是这样一个代码块的示例。有时,所有这些代码都被填充到一个长字符串中,以使其看起来比实际大小小
base64_decode(strrev("hMXZpRXaslmYhJXZuxWd2BSZ0l2cgknbhByZul2czVmckRWYgknYgM3ajFGd0FGIlJXd0Vn
ZgknbhBSbvJnZgUGdpNHIyV3b5BSZyV3YlNHIvRHI0V2Zy9mZgQ3Ju9GRg4SZ0l2cgIXdvlHI4lmZg4WYjBSdvlHIsU2c
hVmcnBydvJGblBiZvBCdpJGIhBCZuFGIl1Wa0BCa0l2dgQXdCBiLkJXYoBSZiBibhNGIlR2bjBycphGdgcmbpRXYjNXdmJ2b
lRGI5xWZ0Fmb1RncvZmbVBiLn5WauVGcwFGagM3J0FGa3BCZuFGdzJXZk5Wdg8GdgU3b5BicvZGI0xWdjlmZmlGZgQXagU2ah
1GIvRHIzlGa0BSZrlGbgUGZvNGIlRWaoByb0BSZrlGbgMnclt2YhhEIuUGZvNGIlxmYhRWYlJnb1BychByZulGZhJXZ1F3ch
1GIlR2bjBCZlRXYjNXdmJ2bgMXdvl2YpxWYtBiZvBSZjVWawBSYgMXagMXaoRFIskGS"));
有时候,这样的代码并不凌乱,看起来像一个普通的脚本。如果您不确定代码是否恶意,请访问我们的;在这个论坛中,一群经验丰富的网站站长可以帮助您查看相关文档
步骤5
现在您已经知道哪些文件是可疑的,您可以创建备份或创建本地副本,方法是将其保存到您的计算机中,以使这些文件不是恶意文件,然后删除这些可疑文件
检查您的网站是否干净
删除黑色文件后,请检查您的努力是否有回报。还记得您之前发现的那些乱码网页吗?再次使用谷歌爬虫检查这些网页是否仍然存在。如果他们在“谷歌爬虫”中的结果为“未找到”,您的网站可能状况良好,您可以继续修复网站上的漏洞@
您还可以按照“hacked网站”故障排除工具中的步骤检查网站上是否仍有被黑客攻击的内容@
如何防止另一次入侵
修复网站上的漏洞是修复网站的最后一个关键步骤。最近的一项研究发现,20%被黑客攻击的网站将在一天内再次被入侵。了解网站如何被入侵非常有用。请参阅我们的指南,了解垃圾邮件发送者最常用的网站入侵方法 查看全部
输入关键字 抓取所有网页(黑客称为“乱码黑客行为”的操作指南(图))
本指南专门针对将收录大量关键字的乱码网页添加到网站网站的黑客行为。我们称这种黑客行为为“乱码黑客”。我们专门为(cms)用户发布了本指南;但是,即使您没有使用内容管理系统,本指南也会对您有所帮助
注意:不确定您的网站是否被入侵?请阅读我们关于如何检查您的网站是否先被入侵的指南
我们希望确保本指南对您确实有帮助。请留下反馈,帮助我们改进!该目录确定了此类黑客行为
隐藏真实内容的关键字和链接。黑客会自动创建许多带有无意义文字、链接和图片的网页。这些页面有时收录原创网站的基本模板元素,因此乍一看,这些页面似乎是网站的正常部分,但一旦阅读了内容,就会发现情况并非如此
创建被黑客攻击的网页的目的是操纵谷歌的排名因素。黑客经常试图通过向不同的第三方出售被攻击网页上的链接来获利。通常,被黑客攻击的网页会将用户重定向到不相关的网页(如色情网站),黑客可以通过这些网页赚取收入
要检查是否存在此类问题,首先要检查谷歌是否在搜索控制台的安全工具中发现了您网站上的此类被黑客攻击的页面。有时候,你也可以通过打开谷歌搜索窗口并输入site:[你的站点]来找到这样的页面。搜索结果页面将显示谷歌为你的网站搜索结果编制索引的页面,包括那些被黑客攻击的页面。您可以翻阅几页搜索结果,看看是否可以找到任何不寻常的URL。如果你在谷歌搜索结果中没有看到任何被黑客攻击的内容,尝试使用其他搜索引擎搜索相同的搜索词。其他搜索引擎可能会显示谷歌从索引中删除的黑客内容。下面的示例显示了此操作的效果

请注意,上述搜索结果收录许多并非由网站所有者创建的网页。如果仔细查看第二个和第三个搜索结果描述,您将看到此黑客行为创建的乱码文本示例
当您访问被黑客攻击的网页时,您可能会看到一条消息,指示该网页不存在(例如404错误)。不要上当受骗!黑客会试图让你相信被黑客攻击的网页已经消失或修复,从而诱使你认为你的网站已经修复。为此,他们隐藏了真实的内容。您可以在Google crawler中输入您的网站URL,以检查是否存在隐藏真实内容的问题。谷歌爬虫允许你看到潜在的隐藏内容。以下示例显示了此类被黑客攻击的网页的外观:

解决黑客入侵问题
开始之前,请创建要删除的任何文件的脱机副本,以防将来需要恢复它们。这是一个好主意,备份您的整个系统网站. 为此,您可以将服务器上的所有文件保存到服务器以外的位置,或者搜索最适合您特定内容管理系统的备份选项
检查一下。Htaccess文件(共3步)
隐藏真实内容的关键字和链接黑客将使用您的浏览器自动生成隐藏网站上真实内容的网页。Htaccess文件。建议您熟悉的基础知识。Htaccess在官方的Apache网站first上,这可以帮助您更好地理解黑客行为如何影响您网站,但这不是强制性的
第一步
找到那个。Htaccess文件在您的网站. 如果您不确定在哪里可以找到此文件,并且使用了WordPress、Joomla或Drupal等内容管理系统,请在搜索引擎中搜索文件的位置。Htaccess文件和内容管理系统的名称。根据您的网站,您可能会看到多个。Htaccess文件。然后,列出所有的位置。Htaccess文件
注:。Htaccess通常是“隐藏文件”。确保在搜索此类文件时已启用“显示隐藏文件”选项
步骤2
打开门。Htaccess文件以查看文件的内容。在该文件中,您应该找到一行类似于以下内容的代码:
RewriteRule (.*cj2fa.*|^tobeornottobe$) /injected_file.php?q=$1 [L]
此行中的变量可能会更改。“Cj2fa”和“将来或将来”可以是字母或单词的任意组合。重要的是,你需要找到正确的答案。这一行中引用的PHP文件
请注意。中提到的PHP文件名。Htaccess文件。在上面的示例中,指定了。PHP文件是“injected_file.PHP”,但实际上是。PHP文件不是很明显。它通常是一组随机的无害单词,如“horsekeys.PHP”、“potatolake.PHP”等。这很可能是恶意的。PHP文件,我们需要在以后查找并删除它
在公园里。Htaccess文件,不是所有收录重写规则和的行。PHP文件是恶意内容。如果您不确定一行代码的功能,可以在网站Webmaster帮助论坛中向一组经验丰富的网站webmasters寻求帮助
步骤3
全部替换。Htaccess文件具有相应的非侵入或默认版本。Htaccess文件。您通常可以找到的默认版本。通过搜索“default.Htaccess文件”和内容管理系统的名称来访问Htaccess文件。对于网站,它有多个。Htaccess文件,查找并替换每个文件的无入侵版本
如果为默认值。Htaccess文件不存在,并且您从未配置过任何文件。在网站上的Htaccess文件。在网站上找到的Htaccess文件可能是恶意的。为了安全起见,您可以保存的副本。Htaccess文件脱机并删除相应的。Htaccess文件来自网站
查找并删除其他恶意文件(共5步)
识别恶意文件可能很棘手,而且可能需要数小时才能完成。检查文件时请不要担心。如果您没有备份网站您的文件,这是一个好时机。您可以在Google search中搜索“backup网站”和内容管理系统的名称,以了解如何备份网站@
第一步
如果您使用的是内容管理系统,请重新安装此内容管理系统的默认分发版中收录的所有核心(默认)文件,以及您可能添加的任何内容(例如主题背景、模块、插件)。这有助于确保这些文件不收录被黑客攻击的内容。您可以在Google search中搜索“重新安装”和内容管理系统的名称,以获取有关重新安装过程的说明。如果您有任何插件、模块、扩展或主题背景,请确保重新安装它们
重新安装这些核心文件可能会导致丢失您所做的任何自定义设置。在重新安装之前,请确保创建数据库和所有文件的备份
步骤2
首先,寻找正确的答案。前面在中找到的PHP文件。Htaccess文件。根据您访问服务器上相关文件的方式,您应该会看到某种搜索功能。搜索恶意文件的名称。如果发现恶意文件,请备份该文件并将副本存储在其他位置,以便在需要恢复该文件时使用,然后从网站中删除该文件@
步骤3
查找剩余的任何其他恶意或受损文件。在前两个步骤中,您可能已删除了所有恶意文件,但我们仍然建议您执行以下步骤,以避免网站上剩余的入侵文件@
不要觉得压力太大,因为您认为需要打开并查看每个PHP文件。首先,创建要调查的可疑PHP文件列表。以下方法可用于确定哪些PHP文件可疑:
步骤4
创建可疑PHP文件列表后,请检查这些文件是正常文件还是恶意文件。如果您不熟悉PHP文件,那么这个过程可能需要更多的时间,因此您最好重新访问一些PHP文档。但是,即使您刚刚开始编写代码,您仍然可以通过一些基本模式找到恶意文件
首先,扫描你发现的可疑文件,找到收录看似混乱的字母和数字组合的大块文本。大型文本块的前面通常是PHP函数的组合(例如base64_decode)rot13、eval、strev、gzinflate)。下面是这样一个代码块的示例。有时,所有这些代码都被填充到一个长字符串中,以使其看起来比实际大小小
base64_decode(strrev("hMXZpRXaslmYhJXZuxWd2BSZ0l2cgknbhByZul2czVmckRWYgknYgM3ajFGd0FGIlJXd0Vn
ZgknbhBSbvJnZgUGdpNHIyV3b5BSZyV3YlNHIvRHI0V2Zy9mZgQ3Ju9GRg4SZ0l2cgIXdvlHI4lmZg4WYjBSdvlHIsU2c
hVmcnBydvJGblBiZvBCdpJGIhBCZuFGIl1Wa0BCa0l2dgQXdCBiLkJXYoBSZiBibhNGIlR2bjBycphGdgcmbpRXYjNXdmJ2b
lRGI5xWZ0Fmb1RncvZmbVBiLn5WauVGcwFGagM3J0FGa3BCZuFGdzJXZk5Wdg8GdgU3b5BicvZGI0xWdjlmZmlGZgQXagU2ah
1GIvRHIzlGa0BSZrlGbgUGZvNGIlRWaoByb0BSZrlGbgMnclt2YhhEIuUGZvNGIlxmYhRWYlJnb1BychByZulGZhJXZ1F3ch
1GIlR2bjBCZlRXYjNXdmJ2bgMXdvl2YpxWYtBiZvBSZjVWawBSYgMXagMXaoRFIskGS"));
有时候,这样的代码并不凌乱,看起来像一个普通的脚本。如果您不确定代码是否恶意,请访问我们的;在这个论坛中,一群经验丰富的网站站长可以帮助您查看相关文档
步骤5
现在您已经知道哪些文件是可疑的,您可以创建备份或创建本地副本,方法是将其保存到您的计算机中,以使这些文件不是恶意文件,然后删除这些可疑文件
检查您的网站是否干净
删除黑色文件后,请检查您的努力是否有回报。还记得您之前发现的那些乱码网页吗?再次使用谷歌爬虫检查这些网页是否仍然存在。如果他们在“谷歌爬虫”中的结果为“未找到”,您的网站可能状况良好,您可以继续修复网站上的漏洞@
您还可以按照“hacked网站”故障排除工具中的步骤检查网站上是否仍有被黑客攻击的内容@
如何防止另一次入侵
修复网站上的漏洞是修复网站的最后一个关键步骤。最近的一项研究发现,20%被黑客攻击的网站将在一天内再次被入侵。了解网站如何被入侵非常有用。请参阅我们的指南,了解垃圾邮件发送者最常用的网站入侵方法
输入关键字 抓取所有网页(2018年SEO推广优化该怎么做?前景怎么样?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-15 02:17
安徽seo网站关键词platform-口碑好l32nzx
增加外部链接,我们应该遵循的原则是:数量和质量并重,链接文本中尽量收录关键词,尽量获取与内容相关的网站外部链接,尽可能广泛地添加外部链接,以及尝试*外部链接来自真实推荐等。
SEO 行业也在不断发展。每个SEO人都应该多加入几个行业群,关注一些行业博客,多了解交流*新趋势,技术技能等,共同进步,推动行业发展。总而言之,网站optimization 的具体操作方法是动态变化的,相应的网站优化思路也有一定的变化,但始终如一。以上几个优化思路一直都是核心,虽然在一些细节上会有一定的变化,但是如果核心内容被抛弃或者完全改变,显然很难做到网站优化。
网站的外链对于搜索引擎优化来说也是一项非常重要的工作,尤其是网站初期,排名和热度都不是很高,用户找不到网站很快,搜索引擎爬取网站的渠道并不多,外链不仅可以推荐网站,还可以引入蜘蛛,带来流量。安徽seo网站关键词平台。
所谓聚物聚众,我们以前发到外链上也许可以发到外链上,但现在不一样了,你要选择性地发,这和你网站主题,网站自己重重只有高平台才能发。这样的外链资源可以称为好资源。其次,不要继续在网站 上发帖。查找更多此类资源。对于外链发布,需要追求数量,做好内优化+站外推广,形成系统化的东西。原理八、养资源做自媒体推广公司网站。
2018 年 SEO 推广和优化还有什么进展吗?前景如何?未来SEO推广优化应该怎么做? 网站optimization公司工商企业云认为有必要写一篇文章给大家鼓劲儿,一转眼,2017年过去了,2018年迎面而来。相信2018年,这个行业还是会有很多SEOer坚持做这个的。加油,那么2018年SEO推广优化怎么做呢? SEO真的要死了吗?这么多年,SEO一直是死胡同,每次搜索引擎算法调整后,这种说法都会出来。
大多数SEOer对关键词的排名下降了,关键词上升了,他们不知道是什么原因造成的。主要原因是SEOer在网站优化方面经验太少,缺乏实际操作。关于如何通过简化标题提高网站关键词排名的问题。安徽seo网站关键词平台。
分享:影响搜索引擎排名的因素有两个:*是关键词的相关性,第二是网站的排名技术。搜索引擎以用户的输入为关键字,将相关网页在数据库中编入索引,然后根据权重进行排序。
业务网站关键词选择策略:不要简单地追求网站定位的几个热门关键词,核心应该放在产品词和产品组合词上。例如,在酒店机票预订行业,如果只安排机票预订和酒店预订,则应考虑以下类型的词。城市名称+酒店,城市名称+机票,城市名称+城市名称+机票。
网站优化公司商企云认为有必要写一篇文章文章鼓励大家。转眼,2017年已经过去,2018年迎面而来。相信2018年还是会有很多SEOer的,如果这个行业持续下去,2018年SEO推广和优化怎么做? SEO真的要死了吗?这么多年,SEO一直是死记硬背,每次搜索引擎算法调整后,这种说法都会是
一个网站SEO的成功不仅仅依赖于单一的SEO技术的成功,而是着眼于SEO策略,这些SEO策略可以整合到网站操作中来实现SEO***** *影响!许多大规模的网站长时间无法超越瓶颈。他们可能在改变想法后飞越了。为什么?这不是因为这个想法中的伟大的 SEO 技术。大网站不乏SEO技术。他们都有一个非常好的执行团队,他们在seo技巧方面做得非常好。安徽seo网站关键词平台。
反向金字塔网站有很多优化策略,最后一页是收入页,尤其是B2B电商网站。页面优化值倒序排列,即最终页>专题页>栏目页>频道页>首页。所以关键词分配可以遵循以下原则。最后一页:长尾关键词;主题页面;对于热键;栏目页:针对固定关键问题;频道页面:核心关键词;主页基于主要关键词和品牌词。
一个网站SEO的成功,*只依靠单一的SEO技术的成功,重点还是在SEO策略上,把这些SEO策略整合到网站操作中可以让SEO达到最好的效果!许多大规模的网站长时间无法超越瓶颈。他们可能在改变主意后飞越了。为什么?这不是因为这个想法中的伟大的 SEO 技术。大网站不乏SEO技术。他们都有一个非常优秀的执行团队,并且在 seo 技能方面做得非常好。
2018年如何做SEO优化?说了这么多,我们来分析分析一下2018年SEO优化怎么做?首先我说明一点:SEO推广优化要结合其他推广渠道、广告渠道、线下推广渠道、线下广告渠道,形成整合营销体系,才能充分发挥SEO的价值,使用纯 SEO 获取流量来维护一个项目或一个公司的推广变得越来越困难。而且,在搜索引擎算法快速优化调整的时代,流量波动较大,不符合公司稳定发展的要求。 查看全部
输入关键字 抓取所有网页(2018年SEO推广优化该怎么做?前景怎么样?)
安徽seo网站关键词platform-口碑好l32nzx
增加外部链接,我们应该遵循的原则是:数量和质量并重,链接文本中尽量收录关键词,尽量获取与内容相关的网站外部链接,尽可能广泛地添加外部链接,以及尝试*外部链接来自真实推荐等。
SEO 行业也在不断发展。每个SEO人都应该多加入几个行业群,关注一些行业博客,多了解交流*新趋势,技术技能等,共同进步,推动行业发展。总而言之,网站optimization 的具体操作方法是动态变化的,相应的网站优化思路也有一定的变化,但始终如一。以上几个优化思路一直都是核心,虽然在一些细节上会有一定的变化,但是如果核心内容被抛弃或者完全改变,显然很难做到网站优化。
网站的外链对于搜索引擎优化来说也是一项非常重要的工作,尤其是网站初期,排名和热度都不是很高,用户找不到网站很快,搜索引擎爬取网站的渠道并不多,外链不仅可以推荐网站,还可以引入蜘蛛,带来流量。安徽seo网站关键词平台。

所谓聚物聚众,我们以前发到外链上也许可以发到外链上,但现在不一样了,你要选择性地发,这和你网站主题,网站自己重重只有高平台才能发。这样的外链资源可以称为好资源。其次,不要继续在网站 上发帖。查找更多此类资源。对于外链发布,需要追求数量,做好内优化+站外推广,形成系统化的东西。原理八、养资源做自媒体推广公司网站。
2018 年 SEO 推广和优化还有什么进展吗?前景如何?未来SEO推广优化应该怎么做? 网站optimization公司工商企业云认为有必要写一篇文章给大家鼓劲儿,一转眼,2017年过去了,2018年迎面而来。相信2018年,这个行业还是会有很多SEOer坚持做这个的。加油,那么2018年SEO推广优化怎么做呢? SEO真的要死了吗?这么多年,SEO一直是死胡同,每次搜索引擎算法调整后,这种说法都会出来。
大多数SEOer对关键词的排名下降了,关键词上升了,他们不知道是什么原因造成的。主要原因是SEOer在网站优化方面经验太少,缺乏实际操作。关于如何通过简化标题提高网站关键词排名的问题。安徽seo网站关键词平台。

分享:影响搜索引擎排名的因素有两个:*是关键词的相关性,第二是网站的排名技术。搜索引擎以用户的输入为关键字,将相关网页在数据库中编入索引,然后根据权重进行排序。
业务网站关键词选择策略:不要简单地追求网站定位的几个热门关键词,核心应该放在产品词和产品组合词上。例如,在酒店机票预订行业,如果只安排机票预订和酒店预订,则应考虑以下类型的词。城市名称+酒店,城市名称+机票,城市名称+城市名称+机票。
网站优化公司商企云认为有必要写一篇文章文章鼓励大家。转眼,2017年已经过去,2018年迎面而来。相信2018年还是会有很多SEOer的,如果这个行业持续下去,2018年SEO推广和优化怎么做? SEO真的要死了吗?这么多年,SEO一直是死记硬背,每次搜索引擎算法调整后,这种说法都会是
一个网站SEO的成功不仅仅依赖于单一的SEO技术的成功,而是着眼于SEO策略,这些SEO策略可以整合到网站操作中来实现SEO***** *影响!许多大规模的网站长时间无法超越瓶颈。他们可能在改变想法后飞越了。为什么?这不是因为这个想法中的伟大的 SEO 技术。大网站不乏SEO技术。他们都有一个非常好的执行团队,他们在seo技巧方面做得非常好。安徽seo网站关键词平台。
反向金字塔网站有很多优化策略,最后一页是收入页,尤其是B2B电商网站。页面优化值倒序排列,即最终页>专题页>栏目页>频道页>首页。所以关键词分配可以遵循以下原则。最后一页:长尾关键词;主题页面;对于热键;栏目页:针对固定关键问题;频道页面:核心关键词;主页基于主要关键词和品牌词。
一个网站SEO的成功,*只依靠单一的SEO技术的成功,重点还是在SEO策略上,把这些SEO策略整合到网站操作中可以让SEO达到最好的效果!许多大规模的网站长时间无法超越瓶颈。他们可能在改变主意后飞越了。为什么?这不是因为这个想法中的伟大的 SEO 技术。大网站不乏SEO技术。他们都有一个非常优秀的执行团队,并且在 seo 技能方面做得非常好。
2018年如何做SEO优化?说了这么多,我们来分析分析一下2018年SEO优化怎么做?首先我说明一点:SEO推广优化要结合其他推广渠道、广告渠道、线下推广渠道、线下广告渠道,形成整合营销体系,才能充分发挥SEO的价值,使用纯 SEO 获取流量来维护一个项目或一个公司的推广变得越来越困难。而且,在搜索引擎算法快速优化调整的时代,流量波动较大,不符合公司稳定发展的要求。
输入关键字 抓取所有网页(一下使用关键词抓取图片的操作方法分享的方法步骤吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-09-15 02:13
imagebox 是一款网页图片批量抓取下载工具。当用户需要在网站下载一些资料或图片时,可以使用该软件进行操作。在软件中进入批量抓取图片的网址后,就可以批量下载图片了。另一种方法是搜索关键词来抓取图片。这个方法可以找到更多的相关图片,但是操作比URL下载麻烦,所以有很多用户我还不知道怎么做,所以给大家分享一下使用关键词抓取的方法今天的照片。有兴趣的可以看看。
方法步骤
1. 首先我们打开软件,进入软件主界面。这时候就可以在界面右侧看到搜索引擎词搜索功能了,然后我们输入进去。图片的关键词,然后单击“开始爬网”按钮。
2. 点击开始抓图按钮后,将进入抓图设置界面。首先看到的就是设置,可以根据需要进行设置。
3. 下一个设置模块是图片存储选项设置模块。打开下拉列表后,有多种存储文件名的选项。您可以选择您需要的那个。
4.下一步,我们可以点击下面的按钮开始批量抓取,开始抓取操作。
5. 开始抓包后,我们会来到下图所示的界面,在里面可以看到抓包的进度。图像捕捉完成后,单击“全部保存”按钮保存图像。
使用上面教程中分享的操作方法的步骤,我们可以使用imagebox软件抓取我们需要的一些图片素材。如果您不知道如何使用此方法,请尽快尝试。方法步骤,希望本教程可以帮到你。 查看全部
输入关键字 抓取所有网页(一下使用关键词抓取图片的操作方法分享的方法步骤吧!)
imagebox 是一款网页图片批量抓取下载工具。当用户需要在网站下载一些资料或图片时,可以使用该软件进行操作。在软件中进入批量抓取图片的网址后,就可以批量下载图片了。另一种方法是搜索关键词来抓取图片。这个方法可以找到更多的相关图片,但是操作比URL下载麻烦,所以有很多用户我还不知道怎么做,所以给大家分享一下使用关键词抓取的方法今天的照片。有兴趣的可以看看。

方法步骤
1. 首先我们打开软件,进入软件主界面。这时候就可以在界面右侧看到搜索引擎词搜索功能了,然后我们输入进去。图片的关键词,然后单击“开始爬网”按钮。

2. 点击开始抓图按钮后,将进入抓图设置界面。首先看到的就是设置,可以根据需要进行设置。

3. 下一个设置模块是图片存储选项设置模块。打开下拉列表后,有多种存储文件名的选项。您可以选择您需要的那个。

4.下一步,我们可以点击下面的按钮开始批量抓取,开始抓取操作。

5. 开始抓包后,我们会来到下图所示的界面,在里面可以看到抓包的进度。图像捕捉完成后,单击“全部保存”按钮保存图像。

使用上面教程中分享的操作方法的步骤,我们可以使用imagebox软件抓取我们需要的一些图片素材。如果您不知道如何使用此方法,请尽快尝试。方法步骤,希望本教程可以帮到你。
输入关键字 抓取所有网页(智能识别模式自动识别网页中出现的数据模式-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-15 02:10
WebHarvy 是一款功能强大的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单,智能识别网页上发生的数据模式。
[特点]
视觉点和点击界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
代表{pass}{filter}从服务器提取
要提取匿名,防止提取web软件被web服务器拦截,必须通过代理服务器访问目标网站的选项。您可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
【使用方法】
1、启动软件,提示并解锁,即需要添加官方license文件才能使用
2、解压下载的文件,双击“URET NFO v2.2.exe”即可
3、 提醒您 SysNucleus WebHarvy 软件已授权给 SMR
4、 导航到需要提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要捕获文本的一部分,请选择它并突出显示它。在选择下面的选项之前,确定所需的部分。
6、只要输入你分析的网页地址,最上面的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的计划 查看全部
输入关键字 抓取所有网页(智能识别模式自动识别网页中出现的数据模式-苏州安嘉)
WebHarvy 是一款功能强大的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单,智能识别网页上发生的数据模式。
[特点]
视觉点和点击界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
代表{pass}{filter}从服务器提取
要提取匿名,防止提取web软件被web服务器拦截,必须通过代理服务器访问目标网站的选项。您可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。

【使用方法】
1、启动软件,提示并解锁,即需要添加官方license文件才能使用

2、解压下载的文件,双击“URET NFO v2.2.exe”即可
3、 提醒您 SysNucleus WebHarvy 软件已授权给 SMR
4、 导航到需要提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要捕获文本的一部分,请选择它并突出显示它。在选择下面的选项之前,确定所需的部分。

6、只要输入你分析的网页地址,最上面的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的计划
输入关键字 抓取所有网页(一个python3作业题目描述的设计与实现输入:腾讯体育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-14 21:08
前言
最近做了一个python3作业题,涉及:
涉及的库是:
发布代码供快速参考,实现一个小demo。
标题说明
搜索引擎的设计与实现
输入:腾讯体育的页面链接,以列表形式输入,数字可变,例如:
["http://fiba.qq.com/a/20190420/001968.htm",
"http://sports.qq.com/a/20190424/000181.htm",
"http://sports.qq.com/a/20190423/007933.htm",
"http://new.qq.com/omn/SPO2019042400075107"]
复制代码
流程:网络爬虫、页面分析、中文提取分析、索引,需要使用教材中的第三方库,中间流程在内存中完成,输出流程运行时间;
搜索:提示输入关键词进行搜索;
输出:输入的链表按照关键词出现的频率降序输出,以JSON格式输出词频信息等辅助信息;没有出现关键词的文档链接不输出,最后输出检索时间,例如:
代码
代码实现的主要步骤是:
import requests
from bs4 import BeautifulSoup
import json
import re
import jieba
import time
USER_AGENT = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) '
'Chrome/20.0.1092.0 Safari/536.6'}
URL_TIMEOUT = 10
SLEEP_TIME = 2
# dict_result格式:{"1":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# "2":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# }
dict_result = {}
# dict_search格式:[
# [url, count]
# [url, count]
# ]
list_search_result = []
def crawler(list_URL):
for i, url in enumerate(list_URL):
print("网页爬取:", url, "...")
page = requests.get(url, headers=USER_AGENT, timeout=URL_TIMEOUT)
page.encoding = page.apparent_encoding # 防止编码解析错误
result_clean_page = bs4_page_clean(page)
result_chinese = re_chinese(result_clean_page)
# print("网页中文内容:", result_chinese)
dict_result[i + 1] = {"url": url, "word": jieba_create_index(result_chinese)}
print("爬虫休眠中...")
time.sleep(SLEEP_TIME)
def bs4_page_clean(page):
print("正则表达式:清除网页标签等无关信息...")
soup = BeautifulSoup(page.text, "html.parser")
[script.extract() for script in soup.findAll('script')]
[style.extract() for style in soup.findAll('style')]
reg1 = re.compile("]*>")
content = reg1.sub('', soup.prettify())
return str(content)
def re_chinese(content):
print("正则表达式:提取中文...")
pattern = re.compile(u'[\u1100-\uFFFD]+?')
result = pattern.findall(content)
return ''.join(result)
def jieba_create_index(string):
list_word = jieba.lcut_for_search(string)
dict_word_temp = {}
for word in list_word:
if word in dict_word_temp:
dict_word_temp[word] += 1
else:
dict_word_temp[word] = 1
return dict_word_temp
def search(string):
for k, v in dict_result.items():
if string in v["word"]:
list_search_result.append([v["url"], v["word"][string]])
# 使用词频对列表进行排序
list_search_result.sort(key=lambda x: x[1], reverse=True)
if __name__ == "__main__":
list_URL_sport = input("请输入网址列表:")
list_URL_sport = list_URL_sport.split(",")
print(list_URL_sport)
# 删除输入的网页双引号
for i in range(len(list_URL_sport)):
list_URL_sport[i] = list_URL_sport[i][1:-1]
print(list_URL_sport)
# list_URL_sport = ["http://fiba.qq.com/a/20190420/001968.htm",
# "http://sports.qq.com/a/20190424/000181.htm",
# "http://sports.qq.com/a/20190423/007933.htm",
# "http://new.qq.com/omn/SPO2019042400075107"]
time_start_crawler = time.time()
crawler(list_URL_sport)
time_end_crawler = time.time()
print("网页爬取和分析时间:", time_end_crawler - time_start_crawler)
word = input("请输入查询的关键词:")
time_start_search = time.time()
search(word)
time_end_search = time.time()
print("检索时间:", time_end_search - time_start_search)
for i, row in enumerate(list_search_result):
print(i+1, row[0], row[1])
print("词频信息:")
print(json.dumps(dict_result, ensure_ascii=False))
复制代码
跟着我跑步
我目前是一名后端开发工程师。主要关注后端开发、数据安全、网络爬虫、物联网、边缘计算等方向。 查看全部
输入关键字 抓取所有网页(一个python3作业题目描述的设计与实现输入:腾讯体育)
前言
最近做了一个python3作业题,涉及:
涉及的库是:
发布代码供快速参考,实现一个小demo。
标题说明
搜索引擎的设计与实现
输入:腾讯体育的页面链接,以列表形式输入,数字可变,例如:
["http://fiba.qq.com/a/20190420/001968.htm",
"http://sports.qq.com/a/20190424/000181.htm",
"http://sports.qq.com/a/20190423/007933.htm",
"http://new.qq.com/omn/SPO2019042400075107"]
复制代码
流程:网络爬虫、页面分析、中文提取分析、索引,需要使用教材中的第三方库,中间流程在内存中完成,输出流程运行时间;
搜索:提示输入关键词进行搜索;
输出:输入的链表按照关键词出现的频率降序输出,以JSON格式输出词频信息等辅助信息;没有出现关键词的文档链接不输出,最后输出检索时间,例如:
代码
代码实现的主要步骤是:
import requests
from bs4 import BeautifulSoup
import json
import re
import jieba
import time
USER_AGENT = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) '
'Chrome/20.0.1092.0 Safari/536.6'}
URL_TIMEOUT = 10
SLEEP_TIME = 2
# dict_result格式:{"1":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# "2":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# }
dict_result = {}
# dict_search格式:[
# [url, count]
# [url, count]
# ]
list_search_result = []
def crawler(list_URL):
for i, url in enumerate(list_URL):
print("网页爬取:", url, "...")
page = requests.get(url, headers=USER_AGENT, timeout=URL_TIMEOUT)
page.encoding = page.apparent_encoding # 防止编码解析错误
result_clean_page = bs4_page_clean(page)
result_chinese = re_chinese(result_clean_page)
# print("网页中文内容:", result_chinese)
dict_result[i + 1] = {"url": url, "word": jieba_create_index(result_chinese)}
print("爬虫休眠中...")
time.sleep(SLEEP_TIME)
def bs4_page_clean(page):
print("正则表达式:清除网页标签等无关信息...")
soup = BeautifulSoup(page.text, "html.parser")
[script.extract() for script in soup.findAll('script')]
[style.extract() for style in soup.findAll('style')]
reg1 = re.compile("]*>")
content = reg1.sub('', soup.prettify())
return str(content)
def re_chinese(content):
print("正则表达式:提取中文...")
pattern = re.compile(u'[\u1100-\uFFFD]+?')
result = pattern.findall(content)
return ''.join(result)
def jieba_create_index(string):
list_word = jieba.lcut_for_search(string)
dict_word_temp = {}
for word in list_word:
if word in dict_word_temp:
dict_word_temp[word] += 1
else:
dict_word_temp[word] = 1
return dict_word_temp
def search(string):
for k, v in dict_result.items():
if string in v["word"]:
list_search_result.append([v["url"], v["word"][string]])
# 使用词频对列表进行排序
list_search_result.sort(key=lambda x: x[1], reverse=True)
if __name__ == "__main__":
list_URL_sport = input("请输入网址列表:")
list_URL_sport = list_URL_sport.split(",")
print(list_URL_sport)
# 删除输入的网页双引号
for i in range(len(list_URL_sport)):
list_URL_sport[i] = list_URL_sport[i][1:-1]
print(list_URL_sport)
# list_URL_sport = ["http://fiba.qq.com/a/20190420/001968.htm",
# "http://sports.qq.com/a/20190424/000181.htm",
# "http://sports.qq.com/a/20190423/007933.htm",
# "http://new.qq.com/omn/SPO2019042400075107"]
time_start_crawler = time.time()
crawler(list_URL_sport)
time_end_crawler = time.time()
print("网页爬取和分析时间:", time_end_crawler - time_start_crawler)
word = input("请输入查询的关键词:")
time_start_search = time.time()
search(word)
time_end_search = time.time()
print("检索时间:", time_end_search - time_start_search)
for i, row in enumerate(list_search_result):
print(i+1, row[0], row[1])
print("词频信息:")
print(json.dumps(dict_result, ensure_ascii=False))
复制代码
跟着我跑步
我目前是一名后端开发工程师。主要关注后端开发、数据安全、网络爬虫、物联网、边缘计算等方向。
输入关键字 抓取所有网页(关于搜索引擎如何抓取关键词优化排名的知识点?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-13 04:01
)
设立网站后,很多企业都希望自己的网站名列前茅,获得更大的曝光率,获得流量,让企业得以发展。但是作为搜索引擎,他们对网站关键词的爬取能力也有一定的规律。所以,我们一起来学习一下搜索引擎如何抓取关键词优化排名的知识点。
一、搜索引擎如何抓取关键词优化排名?
1、网站内容相关性
搜索引擎利用网站内容反映的相关性来抓取排名。所以网站页面标题和页面内容必须有一定的相关性。如果内容反映的相关性不高,会影响关键词优化排名的爬取。
2、网页内容质量
搜索引擎喜欢原创内容个性新颖,所以搜索引擎会根据网站内容质量抢关键词优化排名,一般搜索结果从左到右搜索标题关键词结果。
3、用户体验
在爬取关键词优化排名的过程中,搜索引擎会不断通过后台数据,通过用户对网站的访问来抓取数据,比如网页停留时间、用户访问量、跳出率等等。上,综合判断用户使用网站的体验,然后抢关键词优化排名。
关于搜索引擎如何抓取关键词optimized 排名的介绍到此结束。但是,企业既然要优化搜索引擎,就必须掌握搜索引擎的基本工作原理,了解搜索引擎之间的关系,才能更好地进行搜索引擎工作,而网站关键词如果设置合理并且合适,也有利于搜索引擎的抓取。
二、网站关键词怎么设置?
关键词的设置对搜索引擎有重要影响。首先要确认网站的主要关键词,然后针对这些关键词进行优化,包括关键词密度、相关性、突出度等等等。最后需要合理设置关键词,如下:
1、确定行业核心词
在设置网站关键词时,首先要明确行业核心关键词,这样才能拓展行业关键词。
2、保持一定的关键词密度
关键词的密度布局会影响网站的排名。所以文章的关键词的密度一般保持在3-8%左右,而网站的关键词的设置需要保持一定的密度距离,产生一种“距离美” ,所以不允许堆积。
3、关键词合理布局
网站设置关键词,需要放在网站的标题上,关键词要放在标题、第一段等重要位置。
简而言之,网站的关键词是给网站带来流量的“入口”,而关键词分析和选择是一个磨砺的过程。企业可以使用工具进行关键词挖掘和分析。如果有什么不明白的,欢迎评论~
查看全部
输入关键字 抓取所有网页(关于搜索引擎如何抓取关键词优化排名的知识点?(一)
)
设立网站后,很多企业都希望自己的网站名列前茅,获得更大的曝光率,获得流量,让企业得以发展。但是作为搜索引擎,他们对网站关键词的爬取能力也有一定的规律。所以,我们一起来学习一下搜索引擎如何抓取关键词优化排名的知识点。
一、搜索引擎如何抓取关键词优化排名?
1、网站内容相关性
搜索引擎利用网站内容反映的相关性来抓取排名。所以网站页面标题和页面内容必须有一定的相关性。如果内容反映的相关性不高,会影响关键词优化排名的爬取。

2、网页内容质量
搜索引擎喜欢原创内容个性新颖,所以搜索引擎会根据网站内容质量抢关键词优化排名,一般搜索结果从左到右搜索标题关键词结果。
3、用户体验
在爬取关键词优化排名的过程中,搜索引擎会不断通过后台数据,通过用户对网站的访问来抓取数据,比如网页停留时间、用户访问量、跳出率等等。上,综合判断用户使用网站的体验,然后抢关键词优化排名。
关于搜索引擎如何抓取关键词optimized 排名的介绍到此结束。但是,企业既然要优化搜索引擎,就必须掌握搜索引擎的基本工作原理,了解搜索引擎之间的关系,才能更好地进行搜索引擎工作,而网站关键词如果设置合理并且合适,也有利于搜索引擎的抓取。

二、网站关键词怎么设置?
关键词的设置对搜索引擎有重要影响。首先要确认网站的主要关键词,然后针对这些关键词进行优化,包括关键词密度、相关性、突出度等等等。最后需要合理设置关键词,如下:
1、确定行业核心词
在设置网站关键词时,首先要明确行业核心关键词,这样才能拓展行业关键词。

2、保持一定的关键词密度
关键词的密度布局会影响网站的排名。所以文章的关键词的密度一般保持在3-8%左右,而网站的关键词的设置需要保持一定的密度距离,产生一种“距离美” ,所以不允许堆积。
3、关键词合理布局
网站设置关键词,需要放在网站的标题上,关键词要放在标题、第一段等重要位置。
简而言之,网站的关键词是给网站带来流量的“入口”,而关键词分析和选择是一个磨砺的过程。企业可以使用工具进行关键词挖掘和分析。如果有什么不明白的,欢迎评论~

输入关键字 抓取所有网页(百度流量有90%(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-11 08:07
百度90%的流量来自百度快照流量。目前,百度的竞价广告位只有前5名的数量有限。 *别说关键词多了也没有人下过竞价排名。这里有截图
我们在优化的时候,经常会出现关键词排名下降的现象。对于这种情况,我们要区分是否是正常的浮动,因为有时候搜索引擎也会出错,导致关键词ranking下降,我们把这种循环关键词ranking下降,然后又回到正常状态称为正常浮动。比如昨天的排名很好,但是今天的排名下降了,那我们就不用担心了,我们可以再等一个搜索引擎*新周期,搜索引擎周期一般是一周,通常是星期四和星期五*新但是经过一个*新周期后,关键词排名还没有恢复,那我们就得进行诊断分析,一般可以采用排除法。 .
**排除外部因素,如被黑链接、木马、冗余页面等,我们可以查看源代码、使用被黑工具、站点说明、索引量(激增)等,以及是否泛分析,我们可以使用site:查询*级域名,看二级域名是否很多。后者外部因素是服务器空间,服务器是否稳定,可以使用百度站长工具抓取诊断工具进行诊断。
*二、人为优化操作行为所致。
1、 Changes:标题的变化,尤其是首页标题的变化。页面修改:用户体验内容匹配比原版差*。内容变化:如果需要调整优化,建议分期进行。一般情况下,收录 排名的页面不应该被调整。如果调整,搜索引擎会重新抓取计算,所做的更改必须符合相关性和匹配性。修改造成的死链接:一般我们制作的内容页面都有收录分。如果修改后的内容页面有死链接,那么收录分数就会下降。
2、日常运营
我们说我们制作的内容页一般都是收录评分的,但是内容的质量可以限制内容页的收录评分。内容必须与**相关,内容不可重复。网站是否过度优化:关键词的积累(包括alt、锚文本列表一)、大量反向链接、标签滥用。
3、优化不合理
1、废外链* 超过50%的排名受到影响。 2015年7月3日起,百度提升了垃圾外链识别能力。
2、 链接丢失,*超过 10% 影响排名。外链有一个有效循环和一个死循环。当链接失效时,链接将丢失。就像贴在论坛上的一个链接,很容易在一段时间后被删除,然后这个链接就死了,这就是链接丢失。
3、export 链接指向彻头彻尾,可能有牵连。
4、购买链接,链接作弊(隐藏,js欺诈跳转)不可取。
5、隐藏文字
6、刷流
7、其他
说了这么多,怎么办? **我们可以回忆一下我们最近做了什么(通常是4周左右),*2查看基本优化得分。 *三检查服务器的稳定性。 *比较四个搜索引擎,同一个行业的同一个搜索引擎,看是不是普遍现象,如果是普遍现象,那就是搜索引擎对这个行业的算法变化;不同搜索引擎的比较,排名下降,通常是服务器或程序出现问题。一般情况下,首页被处罚的情况更多是因为作弊和不合理优化导致信用下降,内页被处罚的更多是内容质量问题。
其实我们可以观察到指数量、外链、流量这三个数值指标的变化。一般情况下,指数成交量是缓慢增加的。其他情况不正常。突然增加可能是人挂在马上造成的。对于不是我们自己的页面,下降可能是由于服务器不稳定、提交的死链接和机器人拒绝页面。值得一提的是,索引量正在缓慢下降,这可能是由于内容质量问题。关于外链数据的变化,由于百度站长平台不支持拒绝外链,我们可以争取处理相关情况。如果链接丢失,我们将补充外部链接。观察流量数值指标是否有波动,观察哪些流量是浮动的。流量分为三种:搜索引擎流量、直接访问和外链访问。当其中一个流量缺失时,它会被补充。当流量补充到大于等于前排名下降时,关键词排名会慢慢恢复。
在搜索引擎中输入一个关键字,通常会得到很多搜索结果。这些搜索结果的排名是有序的。这是搜索引擎排名。
搜索引擎蜘蛛从数据库中的已知网页开始,像普通用户的浏览器一样访问这些网页并抓取文件。处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,并根据排序算法计算出哪些网页应该先排序,然后返回到“搜索" 特定格式的页面。那么排序过程可以在一两秒内完成,返回用户想要的搜索结果。
tag 标签几乎是每个站长都会看到的,它在seo优化中扮演着重要的角色。每次文章发帖,tag标签就立在站长面前。很多站长都在纠结要不要加标签。我之前的做法是想加就加,不想加就忽略。我很少考虑如何对待标签。
我的系统讲了tag标签的作用和注意事项
标签标签功能
1、tag标签对应的链接都是列表页,类似于文章category列表页,很容易被百度收录
2、tag标签可以直接在网页源代码中添加关键字。有了tag标签,就不需要单独添加关键词了。
3、tag标签是同类型的文章聚合,所有带有tag标签的文章都排列在tag文章列表中,可以大大增加用户体验
4.许多 wordpress 主题可以直接添加标签链接。标签链接是一种内部链。为了添加标签,他们正在做内部链构建。
使用tag标签需要注意什么
1、不要频繁修改标签,如果不修改一次,搜索引擎将不得不再次收录
2.不要使用主要的关键词和流行的关键词标签,尽量使用长尾关键词,如果使用主要的关键词,会引起与主题的竞争,导致关键词权重分散,这也违反了标题和关键词不重复的原则
3.标签中的单词不要太少,但不要把它变成一个长句。六到八个字符更合适。
4.注意控制标签总数。每个文章标签不得超过3个,标签标签不能被滥用。至少保证每个标签对应3-5个文章
5、tag标签更符合文章主题,不要使用与文章无关的标签
这些是我对标签标签的一些理解以及我从一些 seo 大神那里学到的一些东西。如有不对之处,请站长指出。让我们研究一下tag标签的使用以及影响seo的tag标签的各个方面。
除了tag标签,关于seo优化,还有一些百度规则需要注意。它与优化效果有关。了解一些搜索引擎规则最能应对搜索引擎。
1.如何正确查询外部链接
很多人喜欢用domain:域名,结果却收录了很多自己的内页,如何去除这些内页
inurl的意识是域名中收录的某些字符的链接,-inurl是排除的作用
2、可以把副标题放在主标题前面
一般情况下,主标题放在副标题之前,但是当排名特别重要时,把副标题放在最前面可以有效提高关键词ranking
3、百度分词分为正向分词和反向分词,单匹配和大匹配。 **匹配词的权重是**大匹配和收录匹配。如果可以匹配多个关键词,则主关键词必须放在前面。
4、您知道如何高效搜索文档,排出无用网页吗?
filetype:命令,比如我们需要查询promotion的word文档
filetype:doc intitle:promotion
这里的doc是文章扩展名,可以修改为txt、pdf等
5.首页、栏目页、内页的权重依次递减。我们可以开始错位比赛,但是我们发现当搜索结果前面的链接是版块页和内页时,可以用首页来竞争,获胜的机会会很大。 .
6、关键词index 和 ** 需要权衡。很多搜索有很多次,但没有太多**。并且在选择关键词时,排除那些百度自家产品过多的词
7、我们搜索到的百度图片都是通过alt标签索引的,所以如果图片没有alt标签,不太可能被百度引导
8、title标签和description标签很重要,但是现在关键词没那么重要了。说明会出现在百度搜索结果的缩写摘要中。描述最好是整体连贯流畅的话语,不要堆积关键词。里面的标题要一致
9、标题关键词百度只能显示30个,但百度可以抓取超过这个数字,关键词不*过40个汉字
10。百度可以识别拼音,所以如果你的链接可以自定义,尽量使用链接中关键词对应的拼音。比如你有一个网页关键词是,那么你可以自定义链接
11、蛋糕的重量就像蛋糕一样,重量蛋糕是有限的,权重分配到我们每个链接,所以我们可以在不需要的部分链接中添加nofollow标签。例如,联系我们,关于像我们这样的链接。主要原则是减少重量输出,将重量集中在站内。
-/gbacdfb/- 查看全部
输入关键字 抓取所有网页(百度流量有90%(图))
百度90%的流量来自百度快照流量。目前,百度的竞价广告位只有前5名的数量有限。 *别说关键词多了也没有人下过竞价排名。这里有截图

我们在优化的时候,经常会出现关键词排名下降的现象。对于这种情况,我们要区分是否是正常的浮动,因为有时候搜索引擎也会出错,导致关键词ranking下降,我们把这种循环关键词ranking下降,然后又回到正常状态称为正常浮动。比如昨天的排名很好,但是今天的排名下降了,那我们就不用担心了,我们可以再等一个搜索引擎*新周期,搜索引擎周期一般是一周,通常是星期四和星期五*新但是经过一个*新周期后,关键词排名还没有恢复,那我们就得进行诊断分析,一般可以采用排除法。 .
**排除外部因素,如被黑链接、木马、冗余页面等,我们可以查看源代码、使用被黑工具、站点说明、索引量(激增)等,以及是否泛分析,我们可以使用site:查询*级域名,看二级域名是否很多。后者外部因素是服务器空间,服务器是否稳定,可以使用百度站长工具抓取诊断工具进行诊断。
*二、人为优化操作行为所致。
1、 Changes:标题的变化,尤其是首页标题的变化。页面修改:用户体验内容匹配比原版差*。内容变化:如果需要调整优化,建议分期进行。一般情况下,收录 排名的页面不应该被调整。如果调整,搜索引擎会重新抓取计算,所做的更改必须符合相关性和匹配性。修改造成的死链接:一般我们制作的内容页面都有收录分。如果修改后的内容页面有死链接,那么收录分数就会下降。
2、日常运营
我们说我们制作的内容页一般都是收录评分的,但是内容的质量可以限制内容页的收录评分。内容必须与**相关,内容不可重复。网站是否过度优化:关键词的积累(包括alt、锚文本列表一)、大量反向链接、标签滥用。
3、优化不合理
1、废外链* 超过50%的排名受到影响。 2015年7月3日起,百度提升了垃圾外链识别能力。
2、 链接丢失,*超过 10% 影响排名。外链有一个有效循环和一个死循环。当链接失效时,链接将丢失。就像贴在论坛上的一个链接,很容易在一段时间后被删除,然后这个链接就死了,这就是链接丢失。
3、export 链接指向彻头彻尾,可能有牵连。
4、购买链接,链接作弊(隐藏,js欺诈跳转)不可取。
5、隐藏文字
6、刷流
7、其他
说了这么多,怎么办? **我们可以回忆一下我们最近做了什么(通常是4周左右),*2查看基本优化得分。 *三检查服务器的稳定性。 *比较四个搜索引擎,同一个行业的同一个搜索引擎,看是不是普遍现象,如果是普遍现象,那就是搜索引擎对这个行业的算法变化;不同搜索引擎的比较,排名下降,通常是服务器或程序出现问题。一般情况下,首页被处罚的情况更多是因为作弊和不合理优化导致信用下降,内页被处罚的更多是内容质量问题。
其实我们可以观察到指数量、外链、流量这三个数值指标的变化。一般情况下,指数成交量是缓慢增加的。其他情况不正常。突然增加可能是人挂在马上造成的。对于不是我们自己的页面,下降可能是由于服务器不稳定、提交的死链接和机器人拒绝页面。值得一提的是,索引量正在缓慢下降,这可能是由于内容质量问题。关于外链数据的变化,由于百度站长平台不支持拒绝外链,我们可以争取处理相关情况。如果链接丢失,我们将补充外部链接。观察流量数值指标是否有波动,观察哪些流量是浮动的。流量分为三种:搜索引擎流量、直接访问和外链访问。当其中一个流量缺失时,它会被补充。当流量补充到大于等于前排名下降时,关键词排名会慢慢恢复。

在搜索引擎中输入一个关键字,通常会得到很多搜索结果。这些搜索结果的排名是有序的。这是搜索引擎排名。
搜索引擎蜘蛛从数据库中的已知网页开始,像普通用户的浏览器一样访问这些网页并抓取文件。处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,并根据排序算法计算出哪些网页应该先排序,然后返回到“搜索" 特定格式的页面。那么排序过程可以在一两秒内完成,返回用户想要的搜索结果。

tag 标签几乎是每个站长都会看到的,它在seo优化中扮演着重要的角色。每次文章发帖,tag标签就立在站长面前。很多站长都在纠结要不要加标签。我之前的做法是想加就加,不想加就忽略。我很少考虑如何对待标签。
我的系统讲了tag标签的作用和注意事项
标签标签功能
1、tag标签对应的链接都是列表页,类似于文章category列表页,很容易被百度收录
2、tag标签可以直接在网页源代码中添加关键字。有了tag标签,就不需要单独添加关键词了。
3、tag标签是同类型的文章聚合,所有带有tag标签的文章都排列在tag文章列表中,可以大大增加用户体验
4.许多 wordpress 主题可以直接添加标签链接。标签链接是一种内部链。为了添加标签,他们正在做内部链构建。
使用tag标签需要注意什么
1、不要频繁修改标签,如果不修改一次,搜索引擎将不得不再次收录
2.不要使用主要的关键词和流行的关键词标签,尽量使用长尾关键词,如果使用主要的关键词,会引起与主题的竞争,导致关键词权重分散,这也违反了标题和关键词不重复的原则
3.标签中的单词不要太少,但不要把它变成一个长句。六到八个字符更合适。
4.注意控制标签总数。每个文章标签不得超过3个,标签标签不能被滥用。至少保证每个标签对应3-5个文章
5、tag标签更符合文章主题,不要使用与文章无关的标签
这些是我对标签标签的一些理解以及我从一些 seo 大神那里学到的一些东西。如有不对之处,请站长指出。让我们研究一下tag标签的使用以及影响seo的tag标签的各个方面。
除了tag标签,关于seo优化,还有一些百度规则需要注意。它与优化效果有关。了解一些搜索引擎规则最能应对搜索引擎。
1.如何正确查询外部链接
很多人喜欢用domain:域名,结果却收录了很多自己的内页,如何去除这些内页
inurl的意识是域名中收录的某些字符的链接,-inurl是排除的作用
2、可以把副标题放在主标题前面
一般情况下,主标题放在副标题之前,但是当排名特别重要时,把副标题放在最前面可以有效提高关键词ranking
3、百度分词分为正向分词和反向分词,单匹配和大匹配。 **匹配词的权重是**大匹配和收录匹配。如果可以匹配多个关键词,则主关键词必须放在前面。
4、您知道如何高效搜索文档,排出无用网页吗?
filetype:命令,比如我们需要查询promotion的word文档
filetype:doc intitle:promotion
这里的doc是文章扩展名,可以修改为txt、pdf等
5.首页、栏目页、内页的权重依次递减。我们可以开始错位比赛,但是我们发现当搜索结果前面的链接是版块页和内页时,可以用首页来竞争,获胜的机会会很大。 .
6、关键词index 和 ** 需要权衡。很多搜索有很多次,但没有太多**。并且在选择关键词时,排除那些百度自家产品过多的词
7、我们搜索到的百度图片都是通过alt标签索引的,所以如果图片没有alt标签,不太可能被百度引导
8、title标签和description标签很重要,但是现在关键词没那么重要了。说明会出现在百度搜索结果的缩写摘要中。描述最好是整体连贯流畅的话语,不要堆积关键词。里面的标题要一致
9、标题关键词百度只能显示30个,但百度可以抓取超过这个数字,关键词不*过40个汉字
10。百度可以识别拼音,所以如果你的链接可以自定义,尽量使用链接中关键词对应的拼音。比如你有一个网页关键词是,那么你可以自定义链接
11、蛋糕的重量就像蛋糕一样,重量蛋糕是有限的,权重分配到我们每个链接,所以我们可以在不需要的部分链接中添加nofollow标签。例如,联系我们,关于像我们这样的链接。主要原则是减少重量输出,将重量集中在站内。
-/gbacdfb/-
输入关键字 抓取所有网页(DeeperWeb是一个Google搜索引擎,顾名思义WebWebWeb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-11 08:04
搜索引擎搜索结果页面的标题和页面摘要与用户查询的关键词非常相关。对于网站站长来说,如果可以从搜索结果页(SERP)关键词中提取相关信息,并善加利用,您将能够:
1、为网站内容选择提供更多思路;
2、用于丰富关键词列表;
3、 提供更多优化思路网站,3 个从搜索引擎中提取相关关键词 的工具。看到有人为了提高网站的关键词排名,直接把搜索结果第一页复制为网站内容。这是使用 SERP 的一个极端例子。
根据 SEJ 提供的信息,这里有三个在线工具或插件,可以从 Google 搜索引擎中提取相关的 关键词。
关键字查找器
Keyword Finder是一款在线工具,可以根据用户输入的主题关键词,从50个最相关的网页中提取20个相关关键词,并按热门程度排序。更好的是,它还可以按地区查询。不幸的是,不支持中文。
搜索 Cloudlet
Search Cloudlet 是一个众所周知的 Firefox 扩展。其工作原理是根据关键词在搜索结果页面的出现频率提取出来,以标签云的形式显示在页面顶部。字体越大,在搜索结果页面中出现的频率就越高。当然,它可以从另一个方面反映与您查询的关键词的相关性。管理信息“3从搜索引擎中提取相关关键词”的工具”()。目前,Search Cloudlet可以支持多种谷歌搜索服务以及雅虎搜索和推特搜索。
除了标签云,还提供了站点云,让你知道你查询的关键词哪个网站出现的次数最多。
深层网络
深网是谷歌搜索引擎的辅助工具。顾名思义,它可以从谷歌挖掘出更有价值的数据。它还可以在 Google 搜索结果页面的右侧显示来自博客搜索、维基百科、新闻搜索和问答服务的搜索。结果。此外,它还提供了类似Search Cloudlet的关键词提取服务,统计结果也以标签云的形式呈现给用户。 Deeper Web 比 Search Cloudlet 更好的地方在于它支持中文,还可以计算两个词组。
除在线使用外,Deeper Web 还提供了 Firefox 扩展,每次使用 Google 时都可以使用。在此处下载并安装。
还有吗?当然,无非就是Google AdWords 的关键字查询工具。延伸阅读:《各大搜索引擎提供的免费关键词查询工具》、《各大搜索引擎的关键词分析工具》、《基于谷歌搜索的关键词工具》 查看全部
输入关键字 抓取所有网页(DeeperWeb是一个Google搜索引擎,顾名思义WebWebWeb)
搜索引擎搜索结果页面的标题和页面摘要与用户查询的关键词非常相关。对于网站站长来说,如果可以从搜索结果页(SERP)关键词中提取相关信息,并善加利用,您将能够:
1、为网站内容选择提供更多思路;
2、用于丰富关键词列表;
3、 提供更多优化思路网站,3 个从搜索引擎中提取相关关键词 的工具。看到有人为了提高网站的关键词排名,直接把搜索结果第一页复制为网站内容。这是使用 SERP 的一个极端例子。
根据 SEJ 提供的信息,这里有三个在线工具或插件,可以从 Google 搜索引擎中提取相关的 关键词。
关键字查找器
Keyword Finder是一款在线工具,可以根据用户输入的主题关键词,从50个最相关的网页中提取20个相关关键词,并按热门程度排序。更好的是,它还可以按地区查询。不幸的是,不支持中文。
搜索 Cloudlet
Search Cloudlet 是一个众所周知的 Firefox 扩展。其工作原理是根据关键词在搜索结果页面的出现频率提取出来,以标签云的形式显示在页面顶部。字体越大,在搜索结果页面中出现的频率就越高。当然,它可以从另一个方面反映与您查询的关键词的相关性。管理信息“3从搜索引擎中提取相关关键词”的工具”()。目前,Search Cloudlet可以支持多种谷歌搜索服务以及雅虎搜索和推特搜索。
除了标签云,还提供了站点云,让你知道你查询的关键词哪个网站出现的次数最多。
深层网络
深网是谷歌搜索引擎的辅助工具。顾名思义,它可以从谷歌挖掘出更有价值的数据。它还可以在 Google 搜索结果页面的右侧显示来自博客搜索、维基百科、新闻搜索和问答服务的搜索。结果。此外,它还提供了类似Search Cloudlet的关键词提取服务,统计结果也以标签云的形式呈现给用户。 Deeper Web 比 Search Cloudlet 更好的地方在于它支持中文,还可以计算两个词组。
除在线使用外,Deeper Web 还提供了 Firefox 扩展,每次使用 Google 时都可以使用。在此处下载并安装。
还有吗?当然,无非就是Google AdWords 的关键字查询工具。延伸阅读:《各大搜索引擎提供的免费关键词查询工具》、《各大搜索引擎的关键词分析工具》、《基于谷歌搜索的关键词工具》
输入关键字 抓取所有网页(地址:x3cy/web2py的使用方法-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-11 05:04
输入关键字抓取所有网页,做标签存放在数据库,然后用mysql把这些文字取出来做分词即可。
登录web2py网站,观察每个页面都会有一个form表单发送过来,每个表单分为n个字段,每个字段都有自己的值;具体用什么模块,还是得看你前端用的什么框架了,但最好遵循一下几点原则:分词,数据分析,爬虫,web浏览。
web2py
这个可以回答你,现在很多cms,像wordpress,drupal都是支持web2py的,你可以先做下尝试,写出简单的web页面
可以写cms,然后再增加模块。web2py、web2py也可以。apache的web2py//下面是我写的web2pygithub地址:x3cy/web2py使用方法:①.在github上pull代码②.通过pullrequestpullrequestpullrequest//多浏览器多端直接打开一个你自己编写的webjs程序③.复制代码,粘贴到你的webserver⑤.使用浏览器传递给你模块⑥.模块请求你的用户名/密码。
我觉得是用w3cpackage。
如果web2应用的话,有时候网页上会有很多javascript的字符串,但是由于语言是javascript,分词功能就要靠web2常用的工具mysql。比如拿drupal来举例子,在mysql后台->全局->开发设置中进行相关配置;在%{web2-web-info}中添加相关的参数;在%{drupal-drupal-intro}中添加相关的配置;在%{drupal-drupal-browser}中添加相关的配置;前端进行编写时,把这几个模块加入到自己服务器上;如果不需要分词或者字典的话,就可以直接写程序。 查看全部
输入关键字 抓取所有网页(地址:x3cy/web2py的使用方法-上海怡健医学)
输入关键字抓取所有网页,做标签存放在数据库,然后用mysql把这些文字取出来做分词即可。
登录web2py网站,观察每个页面都会有一个form表单发送过来,每个表单分为n个字段,每个字段都有自己的值;具体用什么模块,还是得看你前端用的什么框架了,但最好遵循一下几点原则:分词,数据分析,爬虫,web浏览。
web2py
这个可以回答你,现在很多cms,像wordpress,drupal都是支持web2py的,你可以先做下尝试,写出简单的web页面
可以写cms,然后再增加模块。web2py、web2py也可以。apache的web2py//下面是我写的web2pygithub地址:x3cy/web2py使用方法:①.在github上pull代码②.通过pullrequestpullrequestpullrequest//多浏览器多端直接打开一个你自己编写的webjs程序③.复制代码,粘贴到你的webserver⑤.使用浏览器传递给你模块⑥.模块请求你的用户名/密码。
我觉得是用w3cpackage。
如果web2应用的话,有时候网页上会有很多javascript的字符串,但是由于语言是javascript,分词功能就要靠web2常用的工具mysql。比如拿drupal来举例子,在mysql后台->全局->开发设置中进行相关配置;在%{web2-web-info}中添加相关的参数;在%{drupal-drupal-intro}中添加相关的配置;在%{drupal-drupal-browser}中添加相关的配置;前端进行编写时,把这几个模块加入到自己服务器上;如果不需要分词或者字典的话,就可以直接写程序。
输入关键字 抓取所有网页(一个网页抓取项目的功能特点及功能分析-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-17 13:21
Easy web extract是一个易于使用的web捕获工具,用于提取网页中的内容(文本、网址、图片和文件),并仅通过单击几个屏幕将结果转换为各种格式。没有编程要求。使我们的网络爬虫易于使用作为其名称
软件说明:
我们的简单网络提取软件收录许多高级功能
使用户能够在k17中从简单内容过渡到复杂内容@
但构建一个网络爬虫项目不需要任何努力
在本页中,我们将向您展示一些众所周知的功能
使我们的网络爬虫易于使用作为其名称
功能特点:
1.创建提取项目很容易
对于任何用户来说,基于向导窗口创建新项目从来都不容易
项目安装向导将逐步驱动您
直到完成所有必要的任务
以下是一些主要步骤:
步骤1:输入一个起始URL,这是起始页面,网页将被加载
它通常是一个链接到一个报废产品列表
步骤2:输入关键词提交表单,如果网站需要,则获取结果。在大多数情况下,可以跳过此步骤
步骤3:在列表中选择一个项目,然后选择该项目的数据列的性能
步骤4:选择下一页的URL以访问其他页
@多线程中的2.刮取数据
在网络混乱项目中,需要捕获和获取数十万个链接
传统的刮刀可能需要几个小时或几天的时间
然而,一个简单的web摘录可以同时运行多个线程,同时浏览多达24个不同的web页面
为了节省宝贵的时间,等待结果
因此,简单的网络提取可以利用系统的最佳性能
下一个动画图像显示将提取8个线程
3.从数据中加载各种提取的数据
一些高度动态的网站采用基于客户端创建的数据加载技术,如Ajax异步请求
诚然,不仅是最初的网络替罪羊,也是专业网络刮削工具的挑战
因为web内容未嵌入HTML源中
然而,简单的网络提取有非常强大的技术
即使是新手也可以从这些类型的网站获取数据@
此外,我们的网站scraper甚至可以模拟向下滚动到页面底部以加载更多数据
例如,LinkedIn联系人列表中的某些特定网站
在这一挑战中,大多数web LHD不断获取大量重复信息
很快就会变得单调。但是不要担心这个噩梦
因为简单的网络抽取具有智能化的功能来避免它
4.随时自动执行项目
通过简单网络提取的嵌入式自动调度器
您可以安排web项目在任何时候运行,而无需执行任何操作
计划任务运行并退出,将结果刮到目标
没有始终运行的后台服务来节省系统资源
此外,可以从收获的结果中删除所有重复项
确保只维护新数据
支持的计划类型:
-在项目中每小时运行一次
-在项目中每天运行
-在特定时间运行项目
5.将数据导出为任何格式
我们最好的网络刮板支持以各种格式导出刮板网站数据
例如:CSV、access、XML、HTML、SQL server、mysql
您还可以直接提交任何类型的数据库目标
通过ODBC连接。如果您的网站有提交表格 查看全部
输入关键字 抓取所有网页(一个网页抓取项目的功能特点及功能分析-苏州安嘉)
Easy web extract是一个易于使用的web捕获工具,用于提取网页中的内容(文本、网址、图片和文件),并仅通过单击几个屏幕将结果转换为各种格式。没有编程要求。使我们的网络爬虫易于使用作为其名称
软件说明:
我们的简单网络提取软件收录许多高级功能
使用户能够在k17中从简单内容过渡到复杂内容@
但构建一个网络爬虫项目不需要任何努力
在本页中,我们将向您展示一些众所周知的功能
使我们的网络爬虫易于使用作为其名称
功能特点:
1.创建提取项目很容易
对于任何用户来说,基于向导窗口创建新项目从来都不容易
项目安装向导将逐步驱动您
直到完成所有必要的任务
以下是一些主要步骤:
步骤1:输入一个起始URL,这是起始页面,网页将被加载
它通常是一个链接到一个报废产品列表
步骤2:输入关键词提交表单,如果网站需要,则获取结果。在大多数情况下,可以跳过此步骤
步骤3:在列表中选择一个项目,然后选择该项目的数据列的性能
步骤4:选择下一页的URL以访问其他页
@多线程中的2.刮取数据
在网络混乱项目中,需要捕获和获取数十万个链接
传统的刮刀可能需要几个小时或几天的时间
然而,一个简单的web摘录可以同时运行多个线程,同时浏览多达24个不同的web页面
为了节省宝贵的时间,等待结果
因此,简单的网络提取可以利用系统的最佳性能
下一个动画图像显示将提取8个线程
3.从数据中加载各种提取的数据
一些高度动态的网站采用基于客户端创建的数据加载技术,如Ajax异步请求
诚然,不仅是最初的网络替罪羊,也是专业网络刮削工具的挑战
因为web内容未嵌入HTML源中
然而,简单的网络提取有非常强大的技术
即使是新手也可以从这些类型的网站获取数据@
此外,我们的网站scraper甚至可以模拟向下滚动到页面底部以加载更多数据
例如,LinkedIn联系人列表中的某些特定网站
在这一挑战中,大多数web LHD不断获取大量重复信息
很快就会变得单调。但是不要担心这个噩梦
因为简单的网络抽取具有智能化的功能来避免它
4.随时自动执行项目
通过简单网络提取的嵌入式自动调度器
您可以安排web项目在任何时候运行,而无需执行任何操作
计划任务运行并退出,将结果刮到目标
没有始终运行的后台服务来节省系统资源
此外,可以从收获的结果中删除所有重复项
确保只维护新数据
支持的计划类型:
-在项目中每小时运行一次
-在项目中每天运行
-在特定时间运行项目
5.将数据导出为任何格式
我们最好的网络刮板支持以各种格式导出刮板网站数据
例如:CSV、access、XML、HTML、SQL server、mysql
您还可以直接提交任何类型的数据库目标
通过ODBC连接。如果您的网站有提交表格
输入关键字 抓取所有网页(如何让页面占领搜索结果的第一屏的秘密?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2021-09-17 13:20
互联网时代的代词可以是“搜索”,因为要在大量信息中找到所需的信息,我们必须搜索,而搜索是关键词
在移动互联网时代,每个人都试图利用网络进行营销。那么,如何让我们想要的页面占据搜索结果的第一屏呢
今天,小编特邀“全网首页”技术专家、米米网络技术公司技术总监谭莽先生,向大家解释占据搜索第一屏的秘密
谭芒先生指出:关键词来源于英语“关键字”,专门指单一媒体在制作和使用索引时使用的词汇。它是图书馆学中的一个词汇关键词search是web搜索索引的主要方法之一,它是访问者想要知道的产品、服务和公司的具体名称和术语。用户只要输入关键词信息,就可以找到相关的产品和服务,即输入一个单词/句子搜索内容,搜索引擎的内容显示搜索结果。用户输入的内容为“关键词”。在搜索引擎中输入关键词会检索到大量相关信息,受众会根据相关信息找到自己最感兴趣的消息
谭芒先生强调:关键词是一组可以联系和连接到产品、服务、企业、新闻等的相关词。用户希望通过搜索特定词来查找关键词通常分为核心词关键词、辅助词关键词、长尾词等;在搜索引擎中,它也可以分为普通关键词和特殊关键词
第一,核心关键词. 产品、企业、网站、服务和行业的一些名称,或这些名称的一些属性和特征
第二,辅助关键词. 对核心关键词的同义词、解释、解释和补充进行了扩展,以使核心关键词更加清晰
第三,长尾词。一般来说,它不是软文的关键词,但它也可以搜索并链接到相应的软文内容,从而为软文带来流量。然而,这些词相对较长,可能由几个词或短语组成
搜索引擎可以捕获这些关键词,方便用户搜索相关信息。以谷歌和百度这两大知名搜索引擎为例,通过自动程序抓取关键词,然后根据用户的搜索关键词选择满足需要的内容,并显示在主屏幕上
具体来说,谭芒先生分析道:例如,世界上最强大的谷歌公司,其谷歌搜索关键词技术是谷歌机器人,谷歌机器人谷歌爬虫是谷歌的网络爬虫。它从网页采集文档,并为谷歌搜索引擎建立可搜索索引。谷歌有两种网络爬虫,主爬虫和新爬虫。主爬虫程序主要负责发现新网页。新索引建立后,主爬虫将立即发现一个网页。如果索引一个网页需要一个月的时间,该网页将变得无效。谷歌爬虫是一个非常活跃的网站扫描工具。谷歌通常每28天发送一个爬虫程序来检索现有网站特定IP地址范围内的新网站。登录Google的时间通常为3周(从提交网站到检索)
在中国,搜索引擎的老大百度使用了一个自动的百度蜘蛛程序。其功能是对互联网上的网页、图片、视频等内容进行访问、采集、整理,然后分类建立索引数据库,用户可以在百度搜索引擎网站中搜索企业的网页、图片、视频等内容。当百度蜘蛛从首页登陆抓取首页后,调度将计算所有连接并返回百度蜘蛛进行下一步抓取连接列表。百度蜘蛛将采取下一步行动抓住它。网站地图的作用是为百度蜘蛛提供一个爬行方向,以便蜘蛛能够抓取重要页面。p>
接下来,如何让百度蜘蛛知道哪个页面是重要页面
目前,它通过连接的建设来实现这一目标。指向此页面的页面越多,网站主页和子页面的方向可以提高此页面的权重。该地图的另一个功能是为百度蜘蛛提供更多链接,以捕获更多页面。事实上,该地图是一个链接列表,通过百度蜘蛛计算网站的目录结构,找到通过站点连接构建的重要页面。百度蜘蛛爬行的频率与网页更新有关。每天更新的网站将吸引百度蜘蛛更频繁地访问。百度是对每天更新的站点最敏感的,它对完全改变内容更敏感
因此,建立、更新和优化关键词对于企业、品牌、产品等相关信息占据主页非常重要
作为“全网主页”的专家,谭莽先生指出,互联网显然已经来到我们这里,其巨大的商机是毋庸置疑的
建立和优化关键词的目的不同于搜索引擎SEO的流量引入。它可以占据关键词search的第一个屏幕。它直接代表实力、转化和经济效益
如果我们想在未来的世界立足,拥有自己的关键词第一屏无疑是根 查看全部
输入关键字 抓取所有网页(如何让页面占领搜索结果的第一屏的秘密?(图))
互联网时代的代词可以是“搜索”,因为要在大量信息中找到所需的信息,我们必须搜索,而搜索是关键词
在移动互联网时代,每个人都试图利用网络进行营销。那么,如何让我们想要的页面占据搜索结果的第一屏呢
今天,小编特邀“全网首页”技术专家、米米网络技术公司技术总监谭莽先生,向大家解释占据搜索第一屏的秘密
谭芒先生指出:关键词来源于英语“关键字”,专门指单一媒体在制作和使用索引时使用的词汇。它是图书馆学中的一个词汇关键词search是web搜索索引的主要方法之一,它是访问者想要知道的产品、服务和公司的具体名称和术语。用户只要输入关键词信息,就可以找到相关的产品和服务,即输入一个单词/句子搜索内容,搜索引擎的内容显示搜索结果。用户输入的内容为“关键词”。在搜索引擎中输入关键词会检索到大量相关信息,受众会根据相关信息找到自己最感兴趣的消息
谭芒先生强调:关键词是一组可以联系和连接到产品、服务、企业、新闻等的相关词。用户希望通过搜索特定词来查找关键词通常分为核心词关键词、辅助词关键词、长尾词等;在搜索引擎中,它也可以分为普通关键词和特殊关键词
第一,核心关键词. 产品、企业、网站、服务和行业的一些名称,或这些名称的一些属性和特征
第二,辅助关键词. 对核心关键词的同义词、解释、解释和补充进行了扩展,以使核心关键词更加清晰
第三,长尾词。一般来说,它不是软文的关键词,但它也可以搜索并链接到相应的软文内容,从而为软文带来流量。然而,这些词相对较长,可能由几个词或短语组成
搜索引擎可以捕获这些关键词,方便用户搜索相关信息。以谷歌和百度这两大知名搜索引擎为例,通过自动程序抓取关键词,然后根据用户的搜索关键词选择满足需要的内容,并显示在主屏幕上
具体来说,谭芒先生分析道:例如,世界上最强大的谷歌公司,其谷歌搜索关键词技术是谷歌机器人,谷歌机器人谷歌爬虫是谷歌的网络爬虫。它从网页采集文档,并为谷歌搜索引擎建立可搜索索引。谷歌有两种网络爬虫,主爬虫和新爬虫。主爬虫程序主要负责发现新网页。新索引建立后,主爬虫将立即发现一个网页。如果索引一个网页需要一个月的时间,该网页将变得无效。谷歌爬虫是一个非常活跃的网站扫描工具。谷歌通常每28天发送一个爬虫程序来检索现有网站特定IP地址范围内的新网站。登录Google的时间通常为3周(从提交网站到检索)
在中国,搜索引擎的老大百度使用了一个自动的百度蜘蛛程序。其功能是对互联网上的网页、图片、视频等内容进行访问、采集、整理,然后分类建立索引数据库,用户可以在百度搜索引擎网站中搜索企业的网页、图片、视频等内容。当百度蜘蛛从首页登陆抓取首页后,调度将计算所有连接并返回百度蜘蛛进行下一步抓取连接列表。百度蜘蛛将采取下一步行动抓住它。网站地图的作用是为百度蜘蛛提供一个爬行方向,以便蜘蛛能够抓取重要页面。p>
接下来,如何让百度蜘蛛知道哪个页面是重要页面
目前,它通过连接的建设来实现这一目标。指向此页面的页面越多,网站主页和子页面的方向可以提高此页面的权重。该地图的另一个功能是为百度蜘蛛提供更多链接,以捕获更多页面。事实上,该地图是一个链接列表,通过百度蜘蛛计算网站的目录结构,找到通过站点连接构建的重要页面。百度蜘蛛爬行的频率与网页更新有关。每天更新的网站将吸引百度蜘蛛更频繁地访问。百度是对每天更新的站点最敏感的,它对完全改变内容更敏感
因此,建立、更新和优化关键词对于企业、品牌、产品等相关信息占据主页非常重要
作为“全网主页”的专家,谭莽先生指出,互联网显然已经来到我们这里,其巨大的商机是毋庸置疑的
建立和优化关键词的目的不同于搜索引擎SEO的流量引入。它可以占据关键词search的第一个屏幕。它直接代表实力、转化和经济效益
如果我们想在未来的世界立足,拥有自己的关键词第一屏无疑是根
输入关键字 抓取所有网页(百度上线多个算法打击下,怎么去刷关键词排名?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-15 18:06
作为一个优秀的优化器,你必须对百度搜索引擎有很好的了解。百度搜索引擎每年都会对关键词排名进行新的算法调整,那么如何在最短的时间内将自己排名在网站关键词的榜首,有哪些方法和技术可以快速实现我们想要的关键词排名?今天,我们来谈谈如何在百度在线多种算法的影响下提高关键词排名
什么是关键词排名
关键词排名优化是指通过各种搜索引擎优化方法,使我们的网站关键词在搜索引擎的自然排名中处于高位或搜索引擎的有利位置。目标受众可以通过搜索输入关键词看到主页搜索引擎提供的页面显示,这些页面按照网站相关性和关键词排名进行排序。排名越高,我们拥有的自然流量就越多,网站的价值和对目标受众的影响将远远超过行业内其他人关键词排名的正确位置。通过对受众目标的精准搜索和搜索引擎的匹配,展现网站和产品的优势,吸引更多潜在客户,获得更多商业价值
如何刷关键词排名
首先,在写网站文章时,我们必须围绕关键词写,在标题和@文章中合理分配长尾关键词以便在网站排名中发挥作用,使网站排名稳步上升@文章最好是原创,把握不多,没有实际价值意义,无法吸引目标受众,错过流量;可以在内容中适当添加一条内链,以便网站蜘蛛抓取时提供指导,这有助于网站收录和关键词快速排名
我们可以选择合适的核心关键词来保证首页的权重,避免关键词的积累。另一个新的网站,如果安排了外链,链接的网站可以相互传递重量。如果权重高,收录排名会快,刷关键词排名的方法会更进一步
另外,网站要保证体验和页面打开速度,所以要定期检查网站bug,不要错过蜘蛛抓来减轻重量,这对刷关键词快速排名非常不利
brush关键词排名软件简介
那些最早开始优化的人可能知道一些数字关键词排名软件,但随着百度算法的一次次更新,这些免费软件无法长期生存。还有一些付费数字关键词软件可以在短时间内提高网站排名,但不能从长期可持续发展的角度选择。缺点很大
百度不断更新算法,我们应该意识到,百度正在积极维护企业之间的公平竞争,努力创造良好的营销模式。因此,brush关键词排名的快速推广损害了许多企业的公平竞争原则。一旦搜索引擎发现网站被删除,也可能会出现网站只保留主页,栏页下所有内容消失的情况。此外,刷牙关键词很容易减轻重量。例如,没有内涵的华而不实的东西是不会长久的。权重一旦降低,会影响整个网站的排名,所以我们应该谨慎选择
如果你想有一个长期的良性排名,最好的办法是按照百度的排名算法来优化你的网站. 机会主义只能对我们自身网站产生一定的负面影响@
百度在线多算法对抗刷关键词排名
自搜索引擎发展以来,各种算法相继问世。例如,百度绿洛算法重点打击外链销售和批量批量批量外链;百度竞雷算法打击快行刷关键词排名;百度绿洛算法2.0、Baidu优采云算法、百度石榴算法、百度原创spark计划、百度冰桶算法、百度杨树算法等,百度已经发布了很多算法,但我们不会一一列出(参见百度介绍)。不管是哪种算法,网站维护都是一种公平的态度,严厉打击各种作弊手段,但我们不能盲目优化。百度算法有一定的维度。他们离相关维度越近,就会有一个理想的关键词排名。如果你不知道这些,就把它们放在链子外面,然后填充@文章,这只能说是没有意义的。熟悉甚至使用百度算法操作关键词排名显然是当务之急。它不是机会主义,而是延迟网站的总权重
如何提高关键词排名
我们都知道关键词排名是优化排名的核心之一。首先,我们应该选择正确的关键词并选择正确的关键词并从网站和content中提取3-5个关键词和长尾扩展词。此外,流行的关键词还可以选择排版布局;有些内核关键词不易优化,竞争激烈。我们可以在内容中设置更多的长尾词,高质量的原创@文章可以轻松获得长尾词的排名。在大量长尾关键词的支持下,核心关键词的排名将逐步提升
我们还需要知道一些关键词位置在哪里更重要、更有意义。一般来说,重要的关键词应该放在标题中,@文章可以适当地添加在开头和结尾,这样我们可以获得更多的权重并提高排名关键词应该在web内容中充分体现出来,并且关键词可以用粗体或斜体强调
@网站target列中可以添加关键词target,并且可以添加主导航和位置导航来集中权重。此外,K4的网页密度应合理分布。越多越好。适当添加关键词被认为是锦上添花
在做优化刷关键词排名时,一定要认真学习技巧,不要盲目低头,自己想想。找到一个好的方法可以事半功倍,网站重量提升,排名靠前,超越行业也很容易 查看全部
输入关键字 抓取所有网页(百度上线多个算法打击下,怎么去刷关键词排名?)
作为一个优秀的优化器,你必须对百度搜索引擎有很好的了解。百度搜索引擎每年都会对关键词排名进行新的算法调整,那么如何在最短的时间内将自己排名在网站关键词的榜首,有哪些方法和技术可以快速实现我们想要的关键词排名?今天,我们来谈谈如何在百度在线多种算法的影响下提高关键词排名
什么是关键词排名
关键词排名优化是指通过各种搜索引擎优化方法,使我们的网站关键词在搜索引擎的自然排名中处于高位或搜索引擎的有利位置。目标受众可以通过搜索输入关键词看到主页搜索引擎提供的页面显示,这些页面按照网站相关性和关键词排名进行排序。排名越高,我们拥有的自然流量就越多,网站的价值和对目标受众的影响将远远超过行业内其他人关键词排名的正确位置。通过对受众目标的精准搜索和搜索引擎的匹配,展现网站和产品的优势,吸引更多潜在客户,获得更多商业价值
如何刷关键词排名
首先,在写网站文章时,我们必须围绕关键词写,在标题和@文章中合理分配长尾关键词以便在网站排名中发挥作用,使网站排名稳步上升@文章最好是原创,把握不多,没有实际价值意义,无法吸引目标受众,错过流量;可以在内容中适当添加一条内链,以便网站蜘蛛抓取时提供指导,这有助于网站收录和关键词快速排名
我们可以选择合适的核心关键词来保证首页的权重,避免关键词的积累。另一个新的网站,如果安排了外链,链接的网站可以相互传递重量。如果权重高,收录排名会快,刷关键词排名的方法会更进一步
另外,网站要保证体验和页面打开速度,所以要定期检查网站bug,不要错过蜘蛛抓来减轻重量,这对刷关键词快速排名非常不利
brush关键词排名软件简介
那些最早开始优化的人可能知道一些数字关键词排名软件,但随着百度算法的一次次更新,这些免费软件无法长期生存。还有一些付费数字关键词软件可以在短时间内提高网站排名,但不能从长期可持续发展的角度选择。缺点很大
百度不断更新算法,我们应该意识到,百度正在积极维护企业之间的公平竞争,努力创造良好的营销模式。因此,brush关键词排名的快速推广损害了许多企业的公平竞争原则。一旦搜索引擎发现网站被删除,也可能会出现网站只保留主页,栏页下所有内容消失的情况。此外,刷牙关键词很容易减轻重量。例如,没有内涵的华而不实的东西是不会长久的。权重一旦降低,会影响整个网站的排名,所以我们应该谨慎选择
如果你想有一个长期的良性排名,最好的办法是按照百度的排名算法来优化你的网站. 机会主义只能对我们自身网站产生一定的负面影响@
百度在线多算法对抗刷关键词排名
自搜索引擎发展以来,各种算法相继问世。例如,百度绿洛算法重点打击外链销售和批量批量批量外链;百度竞雷算法打击快行刷关键词排名;百度绿洛算法2.0、Baidu优采云算法、百度石榴算法、百度原创spark计划、百度冰桶算法、百度杨树算法等,百度已经发布了很多算法,但我们不会一一列出(参见百度介绍)。不管是哪种算法,网站维护都是一种公平的态度,严厉打击各种作弊手段,但我们不能盲目优化。百度算法有一定的维度。他们离相关维度越近,就会有一个理想的关键词排名。如果你不知道这些,就把它们放在链子外面,然后填充@文章,这只能说是没有意义的。熟悉甚至使用百度算法操作关键词排名显然是当务之急。它不是机会主义,而是延迟网站的总权重
如何提高关键词排名
我们都知道关键词排名是优化排名的核心之一。首先,我们应该选择正确的关键词并选择正确的关键词并从网站和content中提取3-5个关键词和长尾扩展词。此外,流行的关键词还可以选择排版布局;有些内核关键词不易优化,竞争激烈。我们可以在内容中设置更多的长尾词,高质量的原创@文章可以轻松获得长尾词的排名。在大量长尾关键词的支持下,核心关键词的排名将逐步提升
我们还需要知道一些关键词位置在哪里更重要、更有意义。一般来说,重要的关键词应该放在标题中,@文章可以适当地添加在开头和结尾,这样我们可以获得更多的权重并提高排名关键词应该在web内容中充分体现出来,并且关键词可以用粗体或斜体强调
@网站target列中可以添加关键词target,并且可以添加主导航和位置导航来集中权重。此外,K4的网页密度应合理分布。越多越好。适当添加关键词被认为是锦上添花
在做优化刷关键词排名时,一定要认真学习技巧,不要盲目低头,自己想想。找到一个好的方法可以事半功倍,网站重量提升,排名靠前,超越行业也很容易
输入关键字 抓取所有网页(六六seo基础运营第四讲的定义以及作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-15 18:02
在本文中,关于66 SEO基本操作的第四堂课开始向学生介绍SEO的基本术语关键词的定义和功能关键词名词是访问者想要知道的产品、服务和公司的具体名称和表达方式。简而言之,关键词是指用户在搜索时输入到搜索引擎的信息指南。引擎通过用户搜索的单词调用数据库中最符合用户需求的信息。因此关键词对于SEOER来说,它是企业工作中最重要的价值观之一。让我们详细看看百科全书关键词
六、SEO基础介绍第四讲SEO关键词的基本术语:
1、关键词定义
从百科全书的定义来看,关键词是英语“关键词”的翻译结果。它是图书馆学中的一个词汇,是指用户在搜索引擎中输入的表达个人需求的词汇。从维基百科的定义来看,它意味着用户获取信息的简明词汇表。这两个定义表达了相同的含义。假设用户使用百度搜索引擎通过某种关键词来解决他们的需求,那么他们键入的单词可以称为关键词
要点:关键词it是用户需求的简明词汇表。而不是输入大段文字来查找结果,例如:谁能告诉我SEO学习有哪些步骤?此段落是用户想要搜索的信息。对于SEOER,您只需要调用本段的关键词优化:SEO学习步骤
二,。搜索引擎的工作原理
当用户搜索关键词时,显示给用户的信息的控制器是搜索引擎。作为SEOER,您首先需要了解搜索引擎的工作原理,然后才能将正确的药物应用到案例中。让优化后的关键词符合搜索引擎友好的原则,以用户为优先
搜索引擎的工作原理:爬行和爬行—“索引构建—”搜索词处理—“数据库排序。搜索引擎蜘蛛一直在抓取新鲜的网络内容。之后,他们将索引有价值的web内容。当用户在搜索引擎中输入关键词时,通过分词等技术了解用户真实的搜索意图,并以排序的方式向用户提供列表结果。这是搜索引擎的基本工作原理
3、关键词分类
学生应该知道,普通的网站分为主页、专栏页、内容页/详细信息页等。级别越深,关键词越具体。此时,SEOer将关键词分为主关键词和长尾关键词:
假设主关键词是网站主页的SEO,长尾关键词是网站的辅助页面,如SEO培训、SEO教程、SEO视频等,也就是说,文章页面的列页面@thelong tail关键词变成了更具体的单词,如哪些SEO更容易学习、SEO学习方法等
需要指出的是,从表面上看,关键词用户搜索量应该由大到小,但从优化难度和效果来看,长尾词带来的流量将远远大于主题词带来的流量,这就是俗称的28理论(百度可以查一下)。主题词搜索量很大,但主题词数量有限,优化难度大;长尾词的搜索量相对较小。长尾词关键词的数量代表了大量的用户需求。当这些需求聚集在一起时,总搜索量将远远大于主题词根的流量。任何成功的网站主要是关键词都依赖长尾关键词来竞争排名
4、关键词相关性
如前所述,网站homepage=main关键词网站column page=long tail关键词网站的层次结构和关键词的优先级是相对的。同时,它也应该具有高度的相关性。例如,如果网站是一个美容行业,而关键词使用SEO技术词汇。这个网站=垃圾站!从用户体验的反馈或搜索引擎更智能的判断来看,我们会发现这个网站是垃圾
因此,SEOer在布置网站关键词时,应注意当前主题的相关性,并根据层次布局的相关性,围绕当前主题进行关键词构建,不偏离主题。将关键词,布局到正确网页的正确位置,优化效果将随着时间慢慢生效
六六计划要点:关于六六SEO基本操作的第四次讲座解释了什么是关键词. 特别是关键词如何将实际操作过滤到网站布局。在后期,66 SEO中级操作会让学生慢慢熟悉。建议在基础小白的早期阶段,我们必须牢记基础操作部分涉及专业术语 查看全部
输入关键字 抓取所有网页(六六seo基础运营第四讲的定义以及作用)
在本文中,关于66 SEO基本操作的第四堂课开始向学生介绍SEO的基本术语关键词的定义和功能关键词名词是访问者想要知道的产品、服务和公司的具体名称和表达方式。简而言之,关键词是指用户在搜索时输入到搜索引擎的信息指南。引擎通过用户搜索的单词调用数据库中最符合用户需求的信息。因此关键词对于SEOER来说,它是企业工作中最重要的价值观之一。让我们详细看看百科全书关键词
六、SEO基础介绍第四讲SEO关键词的基本术语:
1、关键词定义
从百科全书的定义来看,关键词是英语“关键词”的翻译结果。它是图书馆学中的一个词汇,是指用户在搜索引擎中输入的表达个人需求的词汇。从维基百科的定义来看,它意味着用户获取信息的简明词汇表。这两个定义表达了相同的含义。假设用户使用百度搜索引擎通过某种关键词来解决他们的需求,那么他们键入的单词可以称为关键词
要点:关键词it是用户需求的简明词汇表。而不是输入大段文字来查找结果,例如:谁能告诉我SEO学习有哪些步骤?此段落是用户想要搜索的信息。对于SEOER,您只需要调用本段的关键词优化:SEO学习步骤
二,。搜索引擎的工作原理
当用户搜索关键词时,显示给用户的信息的控制器是搜索引擎。作为SEOER,您首先需要了解搜索引擎的工作原理,然后才能将正确的药物应用到案例中。让优化后的关键词符合搜索引擎友好的原则,以用户为优先
搜索引擎的工作原理:爬行和爬行—“索引构建—”搜索词处理—“数据库排序。搜索引擎蜘蛛一直在抓取新鲜的网络内容。之后,他们将索引有价值的web内容。当用户在搜索引擎中输入关键词时,通过分词等技术了解用户真实的搜索意图,并以排序的方式向用户提供列表结果。这是搜索引擎的基本工作原理
3、关键词分类
学生应该知道,普通的网站分为主页、专栏页、内容页/详细信息页等。级别越深,关键词越具体。此时,SEOer将关键词分为主关键词和长尾关键词:
假设主关键词是网站主页的SEO,长尾关键词是网站的辅助页面,如SEO培训、SEO教程、SEO视频等,也就是说,文章页面的列页面@thelong tail关键词变成了更具体的单词,如哪些SEO更容易学习、SEO学习方法等
需要指出的是,从表面上看,关键词用户搜索量应该由大到小,但从优化难度和效果来看,长尾词带来的流量将远远大于主题词带来的流量,这就是俗称的28理论(百度可以查一下)。主题词搜索量很大,但主题词数量有限,优化难度大;长尾词的搜索量相对较小。长尾词关键词的数量代表了大量的用户需求。当这些需求聚集在一起时,总搜索量将远远大于主题词根的流量。任何成功的网站主要是关键词都依赖长尾关键词来竞争排名
4、关键词相关性
如前所述,网站homepage=main关键词网站column page=long tail关键词网站的层次结构和关键词的优先级是相对的。同时,它也应该具有高度的相关性。例如,如果网站是一个美容行业,而关键词使用SEO技术词汇。这个网站=垃圾站!从用户体验的反馈或搜索引擎更智能的判断来看,我们会发现这个网站是垃圾
因此,SEOer在布置网站关键词时,应注意当前主题的相关性,并根据层次布局的相关性,围绕当前主题进行关键词构建,不偏离主题。将关键词,布局到正确网页的正确位置,优化效果将随着时间慢慢生效
六六计划要点:关于六六SEO基本操作的第四次讲座解释了什么是关键词. 特别是关键词如何将实际操作过滤到网站布局。在后期,66 SEO中级操作会让学生慢慢熟悉。建议在基础小白的早期阶段,我们必须牢记基础操作部分涉及专业术语
输入关键字 抓取所有网页(WebspiderofChinese)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-15 18:01
#欢迎来到聚集平台
------
[中文自述](gsh199449/spider)
[](自信地测试和部署代码)
Gather Platform是基于[Webmagic](代码4Craft/Webmagic)的网络蜘蛛控制台。它';s可以编辑任务配置并搜索由web spider采集的数据
>*根据配置从网页采集数据
>*对网页数据进行自然语言处理,如:提取关键字、提取摘要、提取实体词
>*自动检测网页的主要内容,无需对爬行器进行任何配置
>*从网页中提取动态字段
>*管理采集的数据,如:搜索、删除等
##Windows/Mac/Linux全平台支持
依赖项:
-JDK 8以上
-Tomcat8.3在上面
-Elasticsearch5.0
##部署
该平台提供两种部署方式,一种是下载pre-complie软件包,另一种是自行部署
###1.使用预编译包采集网页数据
-从[link](/s/1i4IoEhB)下载重新编译包和依赖项密码:v3jm,对于*nix用户,请下载'elasticsearch-5.0.@0.zip`,对于windows用户,请下载`elasticsearch-5.@@0.0双赢`
-安装JDK 8,[ORACLE](JavaSE开发工具包8))@
-解压elasticsearch5.0.@0.zip
-进入'bin'目录,对于*nix用户运行'elasticsearch',对于windows用户运行'elasticsearch.bat`
-使用浏览器打开“:9200”,如果该网页与其他网页相同,则表示已成功安装elasticsearch
```json
{
“名称”:“AQYRo1f”
“集群名称”:“elasticsearch”
“集群uuid”:“0LJm-YOGQ2QGLLZNRLVWQ”
“版本”:{
“编号”:“5.”0.0“
“构建哈希”:“080bb47”
“建造日期”:“2016-11-11T22:08:49.812Z“
“生成快照”:false
“lucene_版本”:“6.”2.1"
},
“标语”:“你知道,搜索”
}
```
-解压'apachetomcat-8.zip`,将`spider.war`放入`Tomcat/webapp`目录
-进入'tomcat/bin'目录,对于*nix用户运行'startup.sh',对于windows用户运行'startup.bat'`
-使用浏览器open`:8080/spider`使用采集平台的控制台
###@2.自行建造
-安装JDK 8,[ORACLE](JavaSE开发工具包8))@
-关闭并安装Elasticsearch5.0,[开源搜索与分析·Elasticsearch](Elasticsearch5.0.0))@
-安装“ansj elasticsearch”插件[github](NLPchina/elasticsearch分析ansj)
-层弹性搜索
-安装Tomcat 8,[ApacheTomcat](ApacheTomcat®-欢迎!)
-克隆此项目的源代码
-使用“mvn package”来编译和打包
-将'spider.war'放入'Tomcat/webapp'目录
-启动雄猫
##用法
部署打开浏览器后,转到“:8080/spider”,单击“普通网页捕获”以显示菜单

###配置spider
单击菜单中的“编辑模板”按钮,在此页面中可以配置爬行器

配置爬虫模板后,单击下面的“采集sample data”按钮。请稍等片刻,以显示根据刚才配置的模板捕获的数据。如果数据错误,请在上面的模板中进行修改,然后再次单击“采集sample data”按钮再次捕获

注意:在您完全掌握爬虫模板之前,请不要在爬虫模板下选择几个“网页是否必须有XXX”的配置项,以文章标题为例,因为如果文章标题的配置项(即标题)如果配置错误,爬虫程序将无法抓取网页的标题。如果选择此时网页是否必须有标题,爬虫程序将不受限制地抓取

配置模板后,单击下面的“导出模板”按钮。此时,在下面的大输入框中显示的JSON格式的文本就是爬虫模板。您可以将此文本保存到文本文件以备将来使用,或者单击“保存此模板”存储此模板,以后可在本平台的爬虫模板管理系统中找到
###赶快开始吧
平台给出了在examples文件夹中抓取腾讯新闻的两个示例,一个是使用预定义的发布时间抓取规则,另一个是使用系统自动检测到的文章发布时间
以预定义的爬虫模板为例,open[.JSON](/gsh199449/Spider/tree/Master/examples/.JSON),将所有文件内容复制到爬虫模板编辑页面底部的大输入框中,点击“自动填充”,爬虫配置文件中的爬虫模板信息将自动填充到上表中,点击“捕获样本数据”按钮,稍等片刻,即可看到通过t捕获的新闻数据他的模板位于当前页面的底部
如果模板配置有问题,导致数据采集页面长时间卡住,请转到爬虫监控页面,停止刚刚提交的爬虫任务
###爬行动物监测
单击导航栏中的〖查看进度〗按钮,可以查看当前爬虫的运行状态,在此界面可以进行停止、删除、查看进度、查看捕获数据、查看模板等操作

请注意,根据采集平台的默认配置,此处所有爬虫运行记录将每两小时删除一次。如果您不希望系统定期自动删除任何爬虫记录或更改删除记录的时间段,请参阅advanced configu中配置文件的说明配给
###数据管理和搜索
单击导航栏下拉菜单中的搜索,查看elasticsearch库中存储的所有网页数据。默认情况下,这些网页数据根据捕获时间排序,即在单击导航栏上的搜索后,显示的第一个数据是最新捕获的数据

在搜索页面顶部,您可以输入关键词来搜索所有捕获的网页数据,或者您可以指定网站域名来查看指定网站.如果指定关键词进行搜索,搜索结果将根据输入的关键词的相关性进行排序,如果输入域名查看所有da根据捕获时间对网站的ta进行排序。捕获的数据位于顶部
单击导航栏中的“网站list”按钮,查看当前捕获数据中网站的信息。对于每个网站您可以单击“查看数据列表”按钮查看网站的所有数据,并单击“删除网站data”删除网站下的所有数据@

###高级用途
####动静场
配置网页模板时,有一个“添加动态字段”按钮。此功能用于捕获不在预设字段中的其他字段。例如,可在爬虫模板中配置的预设字段有:标题、正文、发布时间等。如果要捕获文章的作者或文章的发布文档编号,需要使用动态字段

单击“添加动态字段”按钮,然后在弹出的输入框中输入要捕获的字段的名称。我们以要捕获的作者文章为例,在框中输入作者。请注意,此动态字段的名称必须为英语。然后,在模板编辑页面上,将有两个额外的输入框,一个是author reg,另一个是author XPath,另一个是配置author字段正则表达式和XPath表达式来配置author字段
静态字段的使用方法与动态字段类似,但与动态字段不同的是,静态字段与爬虫模板相比是静态的,也就是说,这个值是在模板配置阶段预置的,通过这个模板捕获的所有数据都会有这个字段和预置值,这个功能主要是为了litate辅助开发人员保存搜索中存储的数据
####使用Lucene查询进行数据查询
在数据查询页面上进行数据查询时,关键词输入框中输入的搜索词默认在文章正文中检索。如果在此框中输入“Title:China”,则将检索所有文章标题中收录China的网页。支持的字段名为(括号前的字段名称和括号内字段的含义):
-内容(正文)
-标题(标题)
-URL(网页链接)
-域(网页域名)
-Spideruid(爬网程序ID)
-关键词(文章关键词)
-摘要(文章Summary)
-发布时间(文章publish time)
-类别(文章Category)
-动态_字段
####相同的网站不同的模板
同一个网站可以有不同的提取模板的问题可以通过配置另一个模板来解决
###高级配置
项目的配置文件位于spider.war/web-inf文件夹中
####输出我们 查看全部
输入关键字 抓取所有网页(WebspiderofChinese)
#欢迎来到聚集平台
------
[中文自述](gsh199449/spider)
[](自信地测试和部署代码)
Gather Platform是基于[Webmagic](代码4Craft/Webmagic)的网络蜘蛛控制台。它';s可以编辑任务配置并搜索由web spider采集的数据
>*根据配置从网页采集数据
>*对网页数据进行自然语言处理,如:提取关键字、提取摘要、提取实体词
>*自动检测网页的主要内容,无需对爬行器进行任何配置
>*从网页中提取动态字段
>*管理采集的数据,如:搜索、删除等
##Windows/Mac/Linux全平台支持
依赖项:
-JDK 8以上
-Tomcat8.3在上面
-Elasticsearch5.0
##部署
该平台提供两种部署方式,一种是下载pre-complie软件包,另一种是自行部署
###1.使用预编译包采集网页数据
-从[link](/s/1i4IoEhB)下载重新编译包和依赖项密码:v3jm,对于*nix用户,请下载'elasticsearch-5.0.@0.zip`,对于windows用户,请下载`elasticsearch-5.@@0.0双赢`
-安装JDK 8,[ORACLE](JavaSE开发工具包8))@
-解压elasticsearch5.0.@0.zip
-进入'bin'目录,对于*nix用户运行'elasticsearch',对于windows用户运行'elasticsearch.bat`
-使用浏览器打开“:9200”,如果该网页与其他网页相同,则表示已成功安装elasticsearch
```json
{
“名称”:“AQYRo1f”
“集群名称”:“elasticsearch”
“集群uuid”:“0LJm-YOGQ2QGLLZNRLVWQ”
“版本”:{
“编号”:“5.”0.0“
“构建哈希”:“080bb47”
“建造日期”:“2016-11-11T22:08:49.812Z“
“生成快照”:false
“lucene_版本”:“6.”2.1"
},
“标语”:“你知道,搜索”
}
```
-解压'apachetomcat-8.zip`,将`spider.war`放入`Tomcat/webapp`目录
-进入'tomcat/bin'目录,对于*nix用户运行'startup.sh',对于windows用户运行'startup.bat'`
-使用浏览器open`:8080/spider`使用采集平台的控制台
###@2.自行建造
-安装JDK 8,[ORACLE](JavaSE开发工具包8))@
-关闭并安装Elasticsearch5.0,[开源搜索与分析·Elasticsearch](Elasticsearch5.0.0))@
-安装“ansj elasticsearch”插件[github](NLPchina/elasticsearch分析ansj)
-层弹性搜索
-安装Tomcat 8,[ApacheTomcat](ApacheTomcat®-欢迎!)
-克隆此项目的源代码
-使用“mvn package”来编译和打包
-将'spider.war'放入'Tomcat/webapp'目录
-启动雄猫
##用法
部署打开浏览器后,转到“:8080/spider”,单击“普通网页捕获”以显示菜单

###配置spider
单击菜单中的“编辑模板”按钮,在此页面中可以配置爬行器

配置爬虫模板后,单击下面的“采集sample data”按钮。请稍等片刻,以显示根据刚才配置的模板捕获的数据。如果数据错误,请在上面的模板中进行修改,然后再次单击“采集sample data”按钮再次捕获

注意:在您完全掌握爬虫模板之前,请不要在爬虫模板下选择几个“网页是否必须有XXX”的配置项,以文章标题为例,因为如果文章标题的配置项(即标题)如果配置错误,爬虫程序将无法抓取网页的标题。如果选择此时网页是否必须有标题,爬虫程序将不受限制地抓取

配置模板后,单击下面的“导出模板”按钮。此时,在下面的大输入框中显示的JSON格式的文本就是爬虫模板。您可以将此文本保存到文本文件以备将来使用,或者单击“保存此模板”存储此模板,以后可在本平台的爬虫模板管理系统中找到
###赶快开始吧
平台给出了在examples文件夹中抓取腾讯新闻的两个示例,一个是使用预定义的发布时间抓取规则,另一个是使用系统自动检测到的文章发布时间
以预定义的爬虫模板为例,open[.JSON](/gsh199449/Spider/tree/Master/examples/.JSON),将所有文件内容复制到爬虫模板编辑页面底部的大输入框中,点击“自动填充”,爬虫配置文件中的爬虫模板信息将自动填充到上表中,点击“捕获样本数据”按钮,稍等片刻,即可看到通过t捕获的新闻数据他的模板位于当前页面的底部
如果模板配置有问题,导致数据采集页面长时间卡住,请转到爬虫监控页面,停止刚刚提交的爬虫任务
###爬行动物监测
单击导航栏中的〖查看进度〗按钮,可以查看当前爬虫的运行状态,在此界面可以进行停止、删除、查看进度、查看捕获数据、查看模板等操作

请注意,根据采集平台的默认配置,此处所有爬虫运行记录将每两小时删除一次。如果您不希望系统定期自动删除任何爬虫记录或更改删除记录的时间段,请参阅advanced configu中配置文件的说明配给
###数据管理和搜索
单击导航栏下拉菜单中的搜索,查看elasticsearch库中存储的所有网页数据。默认情况下,这些网页数据根据捕获时间排序,即在单击导航栏上的搜索后,显示的第一个数据是最新捕获的数据

在搜索页面顶部,您可以输入关键词来搜索所有捕获的网页数据,或者您可以指定网站域名来查看指定网站.如果指定关键词进行搜索,搜索结果将根据输入的关键词的相关性进行排序,如果输入域名查看所有da根据捕获时间对网站的ta进行排序。捕获的数据位于顶部
单击导航栏中的“网站list”按钮,查看当前捕获数据中网站的信息。对于每个网站您可以单击“查看数据列表”按钮查看网站的所有数据,并单击“删除网站data”删除网站下的所有数据@

###高级用途
####动静场
配置网页模板时,有一个“添加动态字段”按钮。此功能用于捕获不在预设字段中的其他字段。例如,可在爬虫模板中配置的预设字段有:标题、正文、发布时间等。如果要捕获文章的作者或文章的发布文档编号,需要使用动态字段

单击“添加动态字段”按钮,然后在弹出的输入框中输入要捕获的字段的名称。我们以要捕获的作者文章为例,在框中输入作者。请注意,此动态字段的名称必须为英语。然后,在模板编辑页面上,将有两个额外的输入框,一个是author reg,另一个是author XPath,另一个是配置author字段正则表达式和XPath表达式来配置author字段
静态字段的使用方法与动态字段类似,但与动态字段不同的是,静态字段与爬虫模板相比是静态的,也就是说,这个值是在模板配置阶段预置的,通过这个模板捕获的所有数据都会有这个字段和预置值,这个功能主要是为了litate辅助开发人员保存搜索中存储的数据
####使用Lucene查询进行数据查询
在数据查询页面上进行数据查询时,关键词输入框中输入的搜索词默认在文章正文中检索。如果在此框中输入“Title:China”,则将检索所有文章标题中收录China的网页。支持的字段名为(括号前的字段名称和括号内字段的含义):
-内容(正文)
-标题(标题)
-URL(网页链接)
-域(网页域名)
-Spideruid(爬网程序ID)
-关键词(文章关键词)
-摘要(文章Summary)
-发布时间(文章publish time)
-类别(文章Category)
-动态_字段
####相同的网站不同的模板
同一个网站可以有不同的提取模板的问题可以通过配置另一个模板来解决
###高级配置
项目的配置文件位于spider.war/web-inf文件夹中
####输出我们
输入关键字 抓取所有网页(易用的关键词扩展工具:百度关键词计划者工具(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-15 16:14
易于使用的关键词扩展工具:
百度关键词planner工具
百度关键词计划者大幅减少seo关键词延长工作量。用法:输入百度推广-关键词plan-输入main关键词.通过关键词planners,可以扩展大量百度背景搜索关键词,从整体日均搜索量和手机日均搜索量也可以看出单词的搜索流行度
倾听他们的品牌名称和关键词. 他们的网站提供六种关键字相关查询,即最新热键竞价、热键竞价、网站和行业关键词库。一个词更全面。网站管理员主页关键字工具与此网站配合使用,以更好地反映个性化
金华站长工具可以提供百度搜索结果的页码、首页关键词号和关键词难度。成员一次最多可以挖掘4000个单词。金华站长工具提供长尾词模式和一些简单的SEO诊断服务
熊猫关键词扩展工具
熊猫关键词扩展工具可以扩展爱奇艺等平台的搜索词数据。它可以单独或批量扩展关键字关键词结果数据包括:百度移动搜索、百度相关搜索结果等
一方面,AI站可以捕获竞争对手的关键词网站. 另一方面,其功能类似于金华站长工具和熊猫关键词开发工具。如果你想在短时间内获得大量与行业相关的词汇,你可以考虑使用“爱网站管理员”工具来获取行业“网站 关键词主页”上的排名,然后将这些词按比例扩展
常用关键字扩展方法:
百度下拉框及相关搜索。这些是百度相关的扩展关键词,由百度数据库汇总。普通用户搜索a,主要是A1,然后是A1,可能是A2和A3。升级不限于输入关键字
在关键词和关键词的扩展中,各种关键词挖掘的变化以及汉字的广度和深度再次淋漓尽致。您可以对目标关键字进行适当的更改。虽然相关词和优化词的含义不同,但它们的功能非常相似。例如,在线营销和搜索关键词引擎索引是相关的,最终的客户群大致相同。你知道吗 查看全部
输入关键字 抓取所有网页(易用的关键词扩展工具:百度关键词计划者工具(组图))
易于使用的关键词扩展工具:
百度关键词planner工具
百度关键词计划者大幅减少seo关键词延长工作量。用法:输入百度推广-关键词plan-输入main关键词.通过关键词planners,可以扩展大量百度背景搜索关键词,从整体日均搜索量和手机日均搜索量也可以看出单词的搜索流行度
倾听他们的品牌名称和关键词. 他们的网站提供六种关键字相关查询,即最新热键竞价、热键竞价、网站和行业关键词库。一个词更全面。网站管理员主页关键字工具与此网站配合使用,以更好地反映个性化
金华站长工具可以提供百度搜索结果的页码、首页关键词号和关键词难度。成员一次最多可以挖掘4000个单词。金华站长工具提供长尾词模式和一些简单的SEO诊断服务
熊猫关键词扩展工具
熊猫关键词扩展工具可以扩展爱奇艺等平台的搜索词数据。它可以单独或批量扩展关键字关键词结果数据包括:百度移动搜索、百度相关搜索结果等
一方面,AI站可以捕获竞争对手的关键词网站. 另一方面,其功能类似于金华站长工具和熊猫关键词开发工具。如果你想在短时间内获得大量与行业相关的词汇,你可以考虑使用“爱网站管理员”工具来获取行业“网站 关键词主页”上的排名,然后将这些词按比例扩展
常用关键字扩展方法:
百度下拉框及相关搜索。这些是百度相关的扩展关键词,由百度数据库汇总。普通用户搜索a,主要是A1,然后是A1,可能是A2和A3。升级不限于输入关键字
在关键词和关键词的扩展中,各种关键词挖掘的变化以及汉字的广度和深度再次淋漓尽致。您可以对目标关键字进行适当的更改。虽然相关词和优化词的含义不同,但它们的功能非常相似。例如,在线营销和搜索关键词引擎索引是相关的,最终的客户群大致相同。你知道吗
输入关键字 抓取所有网页(那个小三角,文本筛选,包含,里面可以设置两个条件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-15 16:12
)
单击小三角形,文本过滤,包括,在其中可以设置两个条件,并且可以设置或使用两个条件之间的关系。如果要设置两个以上的条件,可以使用高级筛选并设置条件区域
多年来,我一直在使用[keyword ranking query tool]查询网站关键词的排名。此软件可以一次将关键词添加到网站中。每天关注关键词排名只需点击一次。很快,各大搜索引擎中关键词的排名就会出来,并可以随时下载到本地电脑进行监控;而且可以添加很多网站,我觉得使用起来更方便;建议朋友们不妨在百度搜索[查看其关键词排名查询工具]并下载。该文件非常小,易于使用和启动
你的办公室是什么版本的?2003 word的批量替换如下:单击编辑,搜索,单击选项卡替换,填写要查找和替换的内容,然后单击全部替换。整个内容中要替换的所有内容都已被替换。这是一次更换,整批更换似乎不可用
百度索引查询页面右下角有一个关键词。单击以添加比较关键字。如果需要,您可以添加几个。您也可以直接在搜索框中用逗号分隔关键字进行查询
移动终端的关键词排名可以通过移动软件直接搜索
百度统计后台可以查询这些单词的索引,也可以用百度索引搜索。百度竞价后台会对这些词进行统一定价,精确到角落,包括每天有多少人搜索这些词。建议从出价低、转换率高的长尾词开始
查看全部
输入关键字 抓取所有网页(那个小三角,文本筛选,包含,里面可以设置两个条件
)
单击小三角形,文本过滤,包括,在其中可以设置两个条件,并且可以设置或使用两个条件之间的关系。如果要设置两个以上的条件,可以使用高级筛选并设置条件区域
多年来,我一直在使用[keyword ranking query tool]查询网站关键词的排名。此软件可以一次将关键词添加到网站中。每天关注关键词排名只需点击一次。很快,各大搜索引擎中关键词的排名就会出来,并可以随时下载到本地电脑进行监控;而且可以添加很多网站,我觉得使用起来更方便;建议朋友们不妨在百度搜索[查看其关键词排名查询工具]并下载。该文件非常小,易于使用和启动
你的办公室是什么版本的?2003 word的批量替换如下:单击编辑,搜索,单击选项卡替换,填写要查找和替换的内容,然后单击全部替换。整个内容中要替换的所有内容都已被替换。这是一次更换,整批更换似乎不可用
百度索引查询页面右下角有一个关键词。单击以添加比较关键字。如果需要,您可以添加几个。您也可以直接在搜索框中用逗号分隔关键字进行查询
移动终端的关键词排名可以通过移动软件直接搜索
百度统计后台可以查询这些单词的索引,也可以用百度索引搜索。百度竞价后台会对这些词进行统一定价,精确到角落,包括每天有多少人搜索这些词。建议从出价低、转换率高的长尾词开始
输入关键字 抓取所有网页(优化关键词排名价格是多少,三赢流量是什么原因?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-15 16:08
优化的关键词排名价格是多少?双赢的互联网名副其实。借助**先进的网络技术和***服务,帮助企业一站式实现全网络营销推广
优化关键词排名的价格是多少?让我们介绍一下相关内容。它可以分为搜索引擎提供的关键词自然排名和关键词竞争排名服务。通过使用搜索引擎收录和长期总结的排名规则,关键词自然排名通常是搜索引擎对所有相关网页捕获结果进行自动分析和排名的体现。一般来说,通过SEO优化技术可以提高关键词排名。搜索引擎优化的成本很低,每年的收费可以获得更多的流量。SEO就是优化左排名,轻松将自己的产品展示到客户最喜欢的位置。搜索引擎优化排名是稳定的。可长期稳定排名,24小时内轻松找到客户。SEO可以打造品牌,稳定自然的排名可以赢得同行的信任,而客户关键词设置有限。如果关键词优化太多,企业的成本就会太高。排名不能完全控制位置,只有通过长期优化才能实现更好的排名。SEO周期太长,有时候热关键词优化周期长达半年
SEO优化和关键词密不可分。网站的关键词在一定程度上决定了网站的流量。合理的关键词优化将大大改善网站流量。本文讨论的关键词包括主页的主关键词和每个页面的长尾关键词。编制并公布了超级排名系统。这对网络推广来说是一个巨大的损失@为什么网站关键词在主页上没有流量排名?在许多情况下,对于网站而言,流量比网站的关键词排名更重要。排名并不意味着会有流量。但是很多站长发现他们的关键词排名优化工作非常出色
优化的关键词排名价格是多少?打开云优化软件-SEO工具-关键词排名查询:进入网站,关键词一键查询电脑排名或手机排名。您可以同时查询不同网站的排名情况,并快速导出当前排名结果。用户输入关键词后,索引中收录关键词的长尾词根据该关键词展开;根据收录和关键词排名获得关键词竞争的难度,以便于SEO从业者选择关键词并优化关键词。打开云优化软件-SEO工具-网站收录diagnosis:进入网站查询网站URL收录status。搜索引擎显示当时由spider系统捕获并保存的web内容,称为“web快照”。爬行器很容易抓取和更新。达到自动外链的效果
只要企业@k17关键词曝光率高,就有机会做百度自然排名,实现网络转型关键词快速排名首页,不再需要加班熬夜做神马360排名!企业站房和个人网站SEO优化促销,做好促销效果SEO网站优化工具,只要你能上网冲浪,有创业意识,为全民刷搜狗神马360关键词Ranking,电脑和手机关键词Ranking提升迅速。有了百度快速排名推广软件,大家都是SEO优化高手
优化的关键词排名价格是多少?这也是一个新的电台,网站关键词还没有看到收录的排名,更不用说网站的关键词排名了。或者新的网站客户,通过我们的关键词辅助优化工具和网站优化技术方案,新的网站关键词迅速崛起,获得了数量级,并保持在主页上!相对而言,对于关键词of网站而言,从一个新站到多个关键词排名,最重要的是保持稳定。当**的关键词迅速上升,网站排名越来越高时,随着我们合理的优化和稳定方案的实施,现在的流量是以前的两倍,关键词排名稳定非常重要!全站仪优化效果显著。基本上,在很多单词有了流量之后,来自世界各地的流量将会增加
记住这一点,并在SEO优化操作中进行实践。我相信你的网站关键词排名也会脱颖而出网站优化了如何实现关键词内页排名。流行的关键词内页排名是长尾关键词排名。如果我们研究网站流量,我们会发现大多数流量通过长尾关键词而不是主要的关键词。因此,研究网站内容关键词排名尤为重要。其实,如果方法得当,做好内页关键词排名不是很难,但相对来说比较简单。博奕网建议,如果企业想要达到预期的效果SEO网站优化和SEM网站竞价应该运行,为了达到你预期的效果,应该注意这两种SEO推广手段 查看全部
输入关键字 抓取所有网页(优化关键词排名价格是多少,三赢流量是什么原因?)
优化的关键词排名价格是多少?双赢的互联网名副其实。借助**先进的网络技术和***服务,帮助企业一站式实现全网络营销推广
优化关键词排名的价格是多少?让我们介绍一下相关内容。它可以分为搜索引擎提供的关键词自然排名和关键词竞争排名服务。通过使用搜索引擎收录和长期总结的排名规则,关键词自然排名通常是搜索引擎对所有相关网页捕获结果进行自动分析和排名的体现。一般来说,通过SEO优化技术可以提高关键词排名。搜索引擎优化的成本很低,每年的收费可以获得更多的流量。SEO就是优化左排名,轻松将自己的产品展示到客户最喜欢的位置。搜索引擎优化排名是稳定的。可长期稳定排名,24小时内轻松找到客户。SEO可以打造品牌,稳定自然的排名可以赢得同行的信任,而客户关键词设置有限。如果关键词优化太多,企业的成本就会太高。排名不能完全控制位置,只有通过长期优化才能实现更好的排名。SEO周期太长,有时候热关键词优化周期长达半年
SEO优化和关键词密不可分。网站的关键词在一定程度上决定了网站的流量。合理的关键词优化将大大改善网站流量。本文讨论的关键词包括主页的主关键词和每个页面的长尾关键词。编制并公布了超级排名系统。这对网络推广来说是一个巨大的损失@为什么网站关键词在主页上没有流量排名?在许多情况下,对于网站而言,流量比网站的关键词排名更重要。排名并不意味着会有流量。但是很多站长发现他们的关键词排名优化工作非常出色
优化的关键词排名价格是多少?打开云优化软件-SEO工具-关键词排名查询:进入网站,关键词一键查询电脑排名或手机排名。您可以同时查询不同网站的排名情况,并快速导出当前排名结果。用户输入关键词后,索引中收录关键词的长尾词根据该关键词展开;根据收录和关键词排名获得关键词竞争的难度,以便于SEO从业者选择关键词并优化关键词。打开云优化软件-SEO工具-网站收录diagnosis:进入网站查询网站URL收录status。搜索引擎显示当时由spider系统捕获并保存的web内容,称为“web快照”。爬行器很容易抓取和更新。达到自动外链的效果
只要企业@k17关键词曝光率高,就有机会做百度自然排名,实现网络转型关键词快速排名首页,不再需要加班熬夜做神马360排名!企业站房和个人网站SEO优化促销,做好促销效果SEO网站优化工具,只要你能上网冲浪,有创业意识,为全民刷搜狗神马360关键词Ranking,电脑和手机关键词Ranking提升迅速。有了百度快速排名推广软件,大家都是SEO优化高手
优化的关键词排名价格是多少?这也是一个新的电台,网站关键词还没有看到收录的排名,更不用说网站的关键词排名了。或者新的网站客户,通过我们的关键词辅助优化工具和网站优化技术方案,新的网站关键词迅速崛起,获得了数量级,并保持在主页上!相对而言,对于关键词of网站而言,从一个新站到多个关键词排名,最重要的是保持稳定。当**的关键词迅速上升,网站排名越来越高时,随着我们合理的优化和稳定方案的实施,现在的流量是以前的两倍,关键词排名稳定非常重要!全站仪优化效果显著。基本上,在很多单词有了流量之后,来自世界各地的流量将会增加
记住这一点,并在SEO优化操作中进行实践。我相信你的网站关键词排名也会脱颖而出网站优化了如何实现关键词内页排名。流行的关键词内页排名是长尾关键词排名。如果我们研究网站流量,我们会发现大多数流量通过长尾关键词而不是主要的关键词。因此,研究网站内容关键词排名尤为重要。其实,如果方法得当,做好内页关键词排名不是很难,但相对来说比较简单。博奕网建议,如果企业想要达到预期的效果SEO网站优化和SEM网站竞价应该运行,为了达到你预期的效果,应该注意这两种SEO推广手段
输入关键字 抓取所有网页(智能识别模式自动识别网页数据抓取工具的功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-09-15 16:07
Webhard是一个网页数据捕获工具。该软件可以提取网页中的文本和图片,并通过输入网址将其打开。默认情况下,它使用内部浏览器,支持扩展分析,并可以自动获取类似链接的列表。软件界面直观,易于操作
功能介绍
智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
直观的操作界面
Webharvy是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。这太容易了
基于关键词的抽取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
软件特性
Webharvy是一个可视化的web刮板。绝对不需要编写任何脚本或代码来捕获数据。您将使用webharvy的内置浏览器浏览web。您可以选择要单击的数据。这很容易
Webharvy自动识别网页中出现的数据模式。因此,如果您需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
您可以以多种格式保存从网页提取的数据。当前版本的webhard web scraper允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
通常,web页面在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webhard web scraper就会自动从所有页面抓取数据
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置独占连接模式
您可以自动搜索可以在HTML上配置的资源 查看全部
输入关键字 抓取所有网页(智能识别模式自动识别网页数据抓取工具的功能介绍)
Webhard是一个网页数据捕获工具。该软件可以提取网页中的文本和图片,并通过输入网址将其打开。默认情况下,它使用内部浏览器,支持扩展分析,并可以自动获取类似链接的列表。软件界面直观,易于操作
功能介绍
智能识别模式
Webhard自动识别网页中出现的数据模式。因此,如果您需要从网页中获取项目列表(名称、地址、电子邮件、价格等),则无需进行任何其他配置。如果数据重复,webharvy将自动刮取数据
导出捕获的数据
您可以以各种格式保存从网页提取的数据。WebHarvy网站当前版本的scraper允许您将scraper数据导出为XML、CSV、JSON或TSV文件。您还可以刮取数据并将其导出到SQL数据库
从多个页面中提取
通常web页面显示数据,例如多个页面中的产品目录。Webhard可以自动从多个网页中获取和提取数据。只是指出“链接到下一页”和WebHarvy网站刮板将自动从所有页面中刮取数据
直观的操作界面
Webharvy是一个可视化的网页提取工具。事实上,不需要编写任何脚本或代码来提取数据。使用webharvy的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。这太容易了
基于关键词的抽取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字列表数据。挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站scraper允许您从链接列表中提取数据,从而在网站. 这允许您使用单个配置刮取网站内的类别或部分
使用正则表达式提取
Webhard可以在文本或网页的HTML源代码中应用正则表达式(正则表达式),并提取匹配的部分。这项功能强大的技术为您提供了更大的灵活性,同时还可以对数据进行争用
软件特性
Webharvy是一个可视化的web刮板。绝对不需要编写任何脚本或代码来捕获数据。您将使用webharvy的内置浏览器浏览web。您可以选择要单击的数据。这很容易
Webharvy自动识别网页中出现的数据模式。因此,如果您需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
您可以以多种格式保存从网页提取的数据。当前版本的webhard web scraper允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
通常,web页面在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webhard web scraper就会自动从所有页面抓取数据
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置独占连接模式
您可以自动搜索可以在HTML上配置的资源
输入关键字 抓取所有网页(关键词优化的好与坏,关系到需求覆盖范围的大与小)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-15 16:04
AD:阿里云服务器企业会员更优惠 腾讯云香港,韩国免备案服务器1.8折优惠
用户只有通过关键词搜索,才能找到满足自己需求的结果。关键词优化的好与坏,关系到seoer最关注的排名的好与坏,
关系到需求覆盖范围的大与小。因此,从seo角度来讲,关键词是一个特别重要的概念。另外一方面,关键词是一个比
较基础的概念。笔者认为,较基础的seo知识越发重要。本文从多个角度阐述关键词是什么意思。
一:什么是关键词?
从百科的定义来看,关键词是英文“keywords”的翻译结果,其是图书馆学中的词汇,指的是用户在搜索引擎中键入的,
表达用户个体需求的词汇。从wikipedia的定义来看,它的意思是用户获取信息的一种精简的词汇。实际上,这两个定义所
表达的意思是一样的,只是在表述上不同罢了。假设你在使用百度,你想通过某个关键词获取信息,那么你键入的词汇都
可以叫做关键词。
这里需要注意的是:关键词是用户需求的一个载体,是用户当前需求的一个精简词汇。这也较好理解,因为用户一般情况
下不会通过输入大段文字寻找结果,只会通过能体现核心思想的词汇寻找结果或者答案。
二:关键词和搜索引擎的关系。
我们做seo,一方面要将关键词,图片,多媒体等内容组成的网页给用户看,另外一方面,也要给搜索引擎看。只有搜索引擎
看到了,并对当前网页建立索引,才有可能呈现给用户。因此,必然要清楚关键词与搜索引擎的关系。
先看看搜索引擎的工作原理,具体可概括为爬行和抓取—》建立索引—》搜索词处理—》排序。搜索引擎蜘蛛无时无刻不在爬
行和抓取新鲜网页内容,在此之后,会对有价值的网页内容建立索引,当用户在搜索引擎中输入关键词后,会通过分词等技术
了解用户的真实搜索意图,并在结果中以排序的方式为用户提供列表型的结果。
如果我们了解搜索引擎工作原理,我们就会知晓关键词的重要性。现目前的技术条件下,搜索引擎只能识别文字内容,而文字
内容又是由单个的关键词汇组成的。关键词是搜索引擎能工作的前提,多个关键词组成的内容是满足用户需求的必要条件。
三:关键词分类。
不同的维度下,关键词有不同的种类。严格意义来区分,我们把关键词分为词根,词干,以及词叶。
根据树形法则对关键词分类,把关键词想象成大树:
假设词根是seo,那么词干就是seo是什么,seo教程,seo培训等,词叶就是seo是什么意思,哪家seo培训好等长尾词。
有必要指出的是,表面来看,词根,词干,词叶的搜索量应该是从大到小的,但从实际来看,长尾词带来的流量会远大于词根
的流量,也就是我们俗称的二八理论。词根的搜索量是大,但词根的数量有限;长尾词的搜索量很小,但不用的细分长尾关键
词代表了海量的用户需求,这些需求汇集一起,其搜索量总和就会大于词根的流量。
四:网站如何布局关键词。
关于怎么把关键词布局到网页中,百度搜索引擎优化指南已经有明确说明,在此赘述:
首页:网站名称 – 产品A_产品B。
栏目页:栏目名称 – 网站名称。
内容页:内容标题_栏目名称_网站名称。
这是百度关于关键词布局的官方说法,实际来看,各类型网站关键词布局不尽相同,在此,我们提供一个确切有效的布
局原则:相关性。
你在布局网站关键词的时候,要注意当前主题的相关性,围绕当前主题进行关键词建设,切不可偏离主题。将合适的关
键词,布局到合适网页的合适位置,就可以达到这个目标。
点评:
以上,系统讲解了什么是关键词。关键词是seo的基础知识之一,也是最重要的概念。深入理解这一概念,将对于你深化
seo技术产生重大影响。关键词排名是seo的重要工作内容。无论你的seo理论如何丰富,但不经过实践,网站关键词不
能达到预期排名,那么你所学到的seo技术,理论都是苍白的。所以网站关键词很有必要设置。 查看全部
输入关键字 抓取所有网页(关键词优化的好与坏,关系到需求覆盖范围的大与小)
AD:阿里云服务器企业会员更优惠 腾讯云香港,韩国免备案服务器1.8折优惠
用户只有通过关键词搜索,才能找到满足自己需求的结果。关键词优化的好与坏,关系到seoer最关注的排名的好与坏,
关系到需求覆盖范围的大与小。因此,从seo角度来讲,关键词是一个特别重要的概念。另外一方面,关键词是一个比
较基础的概念。笔者认为,较基础的seo知识越发重要。本文从多个角度阐述关键词是什么意思。
https://www.adminn.cn/wp-conte ... 0.jpg 150w" />一:什么是关键词?
从百科的定义来看,关键词是英文“keywords”的翻译结果,其是图书馆学中的词汇,指的是用户在搜索引擎中键入的,
表达用户个体需求的词汇。从wikipedia的定义来看,它的意思是用户获取信息的一种精简的词汇。实际上,这两个定义所
表达的意思是一样的,只是在表述上不同罢了。假设你在使用百度,你想通过某个关键词获取信息,那么你键入的词汇都
可以叫做关键词。
这里需要注意的是:关键词是用户需求的一个载体,是用户当前需求的一个精简词汇。这也较好理解,因为用户一般情况
下不会通过输入大段文字寻找结果,只会通过能体现核心思想的词汇寻找结果或者答案。
二:关键词和搜索引擎的关系。
我们做seo,一方面要将关键词,图片,多媒体等内容组成的网页给用户看,另外一方面,也要给搜索引擎看。只有搜索引擎
看到了,并对当前网页建立索引,才有可能呈现给用户。因此,必然要清楚关键词与搜索引擎的关系。
先看看搜索引擎的工作原理,具体可概括为爬行和抓取—》建立索引—》搜索词处理—》排序。搜索引擎蜘蛛无时无刻不在爬
行和抓取新鲜网页内容,在此之后,会对有价值的网页内容建立索引,当用户在搜索引擎中输入关键词后,会通过分词等技术
了解用户的真实搜索意图,并在结果中以排序的方式为用户提供列表型的结果。
如果我们了解搜索引擎工作原理,我们就会知晓关键词的重要性。现目前的技术条件下,搜索引擎只能识别文字内容,而文字
内容又是由单个的关键词汇组成的。关键词是搜索引擎能工作的前提,多个关键词组成的内容是满足用户需求的必要条件。
三:关键词分类。
不同的维度下,关键词有不同的种类。严格意义来区分,我们把关键词分为词根,词干,以及词叶。
根据树形法则对关键词分类,把关键词想象成大树:
假设词根是seo,那么词干就是seo是什么,seo教程,seo培训等,词叶就是seo是什么意思,哪家seo培训好等长尾词。
有必要指出的是,表面来看,词根,词干,词叶的搜索量应该是从大到小的,但从实际来看,长尾词带来的流量会远大于词根
的流量,也就是我们俗称的二八理论。词根的搜索量是大,但词根的数量有限;长尾词的搜索量很小,但不用的细分长尾关键
词代表了海量的用户需求,这些需求汇集一起,其搜索量总和就会大于词根的流量。
四:网站如何布局关键词。
关于怎么把关键词布局到网页中,百度搜索引擎优化指南已经有明确说明,在此赘述:
首页:网站名称 – 产品A_产品B。
栏目页:栏目名称 – 网站名称。
内容页:内容标题_栏目名称_网站名称。
这是百度关于关键词布局的官方说法,实际来看,各类型网站关键词布局不尽相同,在此,我们提供一个确切有效的布
局原则:相关性。
你在布局网站关键词的时候,要注意当前主题的相关性,围绕当前主题进行关键词建设,切不可偏离主题。将合适的关
键词,布局到合适网页的合适位置,就可以达到这个目标。
点评:
以上,系统讲解了什么是关键词。关键词是seo的基础知识之一,也是最重要的概念。深入理解这一概念,将对于你深化
seo技术产生重大影响。关键词排名是seo的重要工作内容。无论你的seo理论如何丰富,但不经过实践,网站关键词不
能达到预期排名,那么你所学到的seo技术,理论都是苍白的。所以网站关键词很有必要设置。
输入关键字 抓取所有网页( “请输入关键词”是基于搜索框的设置吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-15 15:29
“请输入关键词”是基于搜索框的设置吗?)
顺德网站construction中“请输入关键字”搜索框的设置方法
请输入查询关键词,这是您在访问任何网站时经常在搜索框中看到的常见设置。对于用户来说,这不是一个值得注意的地方,但对于SEO人员来说,“请输入关键词”是一个基于搜索框的设置,值得更多研究。原因很简单,可能会直接影响到企业产品的转型
那么我们如何设置“请输入关键词”搜索框
根据之前SEO站点优化的经验,今天我们将通过以下内容进行阐述:
@基于1.SEO的优化
从SEO的角度来看“请输入搜索关键词”的问题,实际上,我们是在讨论搜索框和站内搜索结果的反馈,但基于SEO,这里不讨论:请输入关键词,内容本身
您可能需要从以下两个角度来理解它:
(1)推荐和收录)
如果您有优化电子商务网站的经验,您会发现电子商务网站的一个类似于京东的小型细分策略是使用现场搜索框。请输入关键词location生成大量长尾词,合理利用搜索结果列表,显示数量,并适当增加SERP中的关键词密度,以获得更高的排名
但是,值得注意的是,要完美地使用此策略,您可能需要两个小前提条件:
首先,另一方有很多搜索和查询需求
其次,站点搜索框和搜索结果页面的输出必须符合搜索引擎友好的URL
② 掩蔽和隐藏
对于相当于中小型企业的站点,如果您的数据站的搜索量不大,我们通常在这里给出的建议是使用robots.txt屏蔽搜索结果URL
特别是当你的SERP页面没有SEO规范时,由于站内资源有限,没有必要指定百度爬虫来抓取这些页面
2.基于用户体验
从用户体验的角度来看,在站点搜索框中输入内容设置尤其重要,例如:
(1)有利于推荐企业核心产品,提高企业产品转化率
② 这有助于推荐网站核心主题并提高UGC内容的输出
③ 有利于在网站中推荐核心话题,延迟用户页面停留时间,增加用户对网站品牌的粘性
为此,您可能需要:
(1)进行详细的网站统计分析,了解用户的化身、对方的偏好和偏好
② 掌握行业最新热点话题,适当利用站内多个入口,发布优质内容,相互引导参与讨论,增加当前热点话题在栏目页面的知名度,提高搜索引擎的信任度
3.您输入的搜索词不正确
当您在搜索框中输入某些关键词时,如果对方搜索的特定关键词没有搜索结果,通常超过90%的网站会返回空结果,或者会有“您输入的关键词不正确”的标志
事实上,这是一个非常不明智的策略。你可以在这里给出以下反馈:
(@K23网站逻辑结构图,类似于网站地图的HTML版本
② 最近,用户非常关注“请输入query关键词”,建议检索一些流行词
③ k7热点、行业内最热门的相关话题等
小结:请进入搜索关键词,这似乎是一个微不足道的地方。经过详细设置后,它仍然可以发挥积极作用。以上内容仅供参考。今天的分析在这里。您可以尝试更多 查看全部
输入关键字 抓取所有网页(
“请输入关键词”是基于搜索框的设置吗?)
顺德网站construction中“请输入关键字”搜索框的设置方法
请输入查询关键词,这是您在访问任何网站时经常在搜索框中看到的常见设置。对于用户来说,这不是一个值得注意的地方,但对于SEO人员来说,“请输入关键词”是一个基于搜索框的设置,值得更多研究。原因很简单,可能会直接影响到企业产品的转型
那么我们如何设置“请输入关键词”搜索框
根据之前SEO站点优化的经验,今天我们将通过以下内容进行阐述:
@基于1.SEO的优化
从SEO的角度来看“请输入搜索关键词”的问题,实际上,我们是在讨论搜索框和站内搜索结果的反馈,但基于SEO,这里不讨论:请输入关键词,内容本身
您可能需要从以下两个角度来理解它:
(1)推荐和收录)
如果您有优化电子商务网站的经验,您会发现电子商务网站的一个类似于京东的小型细分策略是使用现场搜索框。请输入关键词location生成大量长尾词,合理利用搜索结果列表,显示数量,并适当增加SERP中的关键词密度,以获得更高的排名
但是,值得注意的是,要完美地使用此策略,您可能需要两个小前提条件:
首先,另一方有很多搜索和查询需求
其次,站点搜索框和搜索结果页面的输出必须符合搜索引擎友好的URL
② 掩蔽和隐藏
对于相当于中小型企业的站点,如果您的数据站的搜索量不大,我们通常在这里给出的建议是使用robots.txt屏蔽搜索结果URL
特别是当你的SERP页面没有SEO规范时,由于站内资源有限,没有必要指定百度爬虫来抓取这些页面
2.基于用户体验
从用户体验的角度来看,在站点搜索框中输入内容设置尤其重要,例如:
(1)有利于推荐企业核心产品,提高企业产品转化率
② 这有助于推荐网站核心主题并提高UGC内容的输出
③ 有利于在网站中推荐核心话题,延迟用户页面停留时间,增加用户对网站品牌的粘性
为此,您可能需要:
(1)进行详细的网站统计分析,了解用户的化身、对方的偏好和偏好
② 掌握行业最新热点话题,适当利用站内多个入口,发布优质内容,相互引导参与讨论,增加当前热点话题在栏目页面的知名度,提高搜索引擎的信任度
3.您输入的搜索词不正确
当您在搜索框中输入某些关键词时,如果对方搜索的特定关键词没有搜索结果,通常超过90%的网站会返回空结果,或者会有“您输入的关键词不正确”的标志
事实上,这是一个非常不明智的策略。你可以在这里给出以下反馈:
(@K23网站逻辑结构图,类似于网站地图的HTML版本
② 最近,用户非常关注“请输入query关键词”,建议检索一些流行词
③ k7热点、行业内最热门的相关话题等
小结:请进入搜索关键词,这似乎是一个微不足道的地方。经过详细设置后,它仍然可以发挥积极作用。以上内容仅供参考。今天的分析在这里。您可以尝试更多
输入关键字 抓取所有网页(黑客称为“乱码黑客行为”的操作指南(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2021-09-15 15:28
本指南专门针对将收录大量关键字的乱码网页添加到网站网站的黑客行为。我们称这种黑客行为为“乱码黑客”。我们专门为(cms)用户发布了本指南;但是,即使您没有使用内容管理系统,本指南也会对您有所帮助
注意:不确定您的网站是否被入侵?请阅读我们关于如何检查您的网站是否先被入侵的指南
我们希望确保本指南对您确实有帮助。请留下反馈,帮助我们改进!该目录确定了此类黑客行为
隐藏真实内容的关键字和链接。黑客会自动创建许多带有无意义文字、链接和图片的网页。这些页面有时收录原创网站的基本模板元素,因此乍一看,这些页面似乎是网站的正常部分,但一旦阅读了内容,就会发现情况并非如此
创建被黑客攻击的网页的目的是操纵谷歌的排名因素。黑客经常试图通过向不同的第三方出售被攻击网页上的链接来获利。通常,被黑客攻击的网页会将用户重定向到不相关的网页(如色情网站),黑客可以通过这些网页赚取收入
要检查是否存在此类问题,首先要检查谷歌是否在搜索控制台的安全工具中发现了您网站上的此类被黑客攻击的页面。有时候,你也可以通过打开谷歌搜索窗口并输入site:[你的站点]来找到这样的页面。搜索结果页面将显示谷歌为你的网站搜索结果编制索引的页面,包括那些被黑客攻击的页面。您可以翻阅几页搜索结果,看看是否可以找到任何不寻常的URL。如果你在谷歌搜索结果中没有看到任何被黑客攻击的内容,尝试使用其他搜索引擎搜索相同的搜索词。其他搜索引擎可能会显示谷歌从索引中删除的黑客内容。下面的示例显示了此操作的效果
请注意,上述搜索结果收录许多并非由网站所有者创建的网页。如果仔细查看第二个和第三个搜索结果描述,您将看到此黑客行为创建的乱码文本示例
当您访问被黑客攻击的网页时,您可能会看到一条消息,指示该网页不存在(例如404错误)。不要上当受骗!黑客会试图让你相信被黑客攻击的网页已经消失或修复,从而诱使你认为你的网站已经修复。为此,他们隐藏了真实的内容。您可以在Google crawler中输入您的网站URL,以检查是否存在隐藏真实内容的问题。谷歌爬虫允许你看到潜在的隐藏内容。以下示例显示了此类被黑客攻击的网页的外观:
解决黑客入侵问题
开始之前,请创建要删除的任何文件的脱机副本,以防将来需要恢复它们。这是一个好主意,备份您的整个系统网站. 为此,您可以将服务器上的所有文件保存到服务器以外的位置,或者搜索最适合您特定内容管理系统的备份选项
检查一下。Htaccess文件(共3步)
隐藏真实内容的关键字和链接黑客将使用您的浏览器自动生成隐藏网站上真实内容的网页。Htaccess文件。建议您熟悉的基础知识。Htaccess在官方的Apache网站first上,这可以帮助您更好地理解黑客行为如何影响您网站,但这不是强制性的
第一步
找到那个。Htaccess文件在您的网站. 如果您不确定在哪里可以找到此文件,并且使用了WordPress、Joomla或Drupal等内容管理系统,请在搜索引擎中搜索文件的位置。Htaccess文件和内容管理系统的名称。根据您的网站,您可能会看到多个。Htaccess文件。然后,列出所有的位置。Htaccess文件
注:。Htaccess通常是“隐藏文件”。确保在搜索此类文件时已启用“显示隐藏文件”选项
步骤2
打开门。Htaccess文件以查看文件的内容。在该文件中,您应该找到一行类似于以下内容的代码:
RewriteRule (.*cj2fa.*|^tobeornottobe$) /injected_file.php?q=$1 [L]
此行中的变量可能会更改。“Cj2fa”和“将来或将来”可以是字母或单词的任意组合。重要的是,你需要找到正确的答案。这一行中引用的PHP文件
请注意。中提到的PHP文件名。Htaccess文件。在上面的示例中,指定了。PHP文件是“injected_file.PHP”,但实际上是。PHP文件不是很明显。它通常是一组随机的无害单词,如“horsekeys.PHP”、“potatolake.PHP”等。这很可能是恶意的。PHP文件,我们需要在以后查找并删除它
在公园里。Htaccess文件,不是所有收录重写规则和的行。PHP文件是恶意内容。如果您不确定一行代码的功能,可以在网站Webmaster帮助论坛中向一组经验丰富的网站webmasters寻求帮助
步骤3
全部替换。Htaccess文件具有相应的非侵入或默认版本。Htaccess文件。您通常可以找到的默认版本。通过搜索“default.Htaccess文件”和内容管理系统的名称来访问Htaccess文件。对于网站,它有多个。Htaccess文件,查找并替换每个文件的无入侵版本
如果为默认值。Htaccess文件不存在,并且您从未配置过任何文件。在网站上的Htaccess文件。在网站上找到的Htaccess文件可能是恶意的。为了安全起见,您可以保存的副本。Htaccess文件脱机并删除相应的。Htaccess文件来自网站
查找并删除其他恶意文件(共5步)
识别恶意文件可能很棘手,而且可能需要数小时才能完成。检查文件时请不要担心。如果您没有备份网站您的文件,这是一个好时机。您可以在Google search中搜索“backup网站”和内容管理系统的名称,以了解如何备份网站@
第一步
如果您使用的是内容管理系统,请重新安装此内容管理系统的默认分发版中收录的所有核心(默认)文件,以及您可能添加的任何内容(例如主题背景、模块、插件)。这有助于确保这些文件不收录被黑客攻击的内容。您可以在Google search中搜索“重新安装”和内容管理系统的名称,以获取有关重新安装过程的说明。如果您有任何插件、模块、扩展或主题背景,请确保重新安装它们
重新安装这些核心文件可能会导致丢失您所做的任何自定义设置。在重新安装之前,请确保创建数据库和所有文件的备份
步骤2
首先,寻找正确的答案。前面在中找到的PHP文件。Htaccess文件。根据您访问服务器上相关文件的方式,您应该会看到某种搜索功能。搜索恶意文件的名称。如果发现恶意文件,请备份该文件并将副本存储在其他位置,以便在需要恢复该文件时使用,然后从网站中删除该文件@
步骤3
查找剩余的任何其他恶意或受损文件。在前两个步骤中,您可能已删除了所有恶意文件,但我们仍然建议您执行以下步骤,以避免网站上剩余的入侵文件@
不要觉得压力太大,因为您认为需要打开并查看每个PHP文件。首先,创建要调查的可疑PHP文件列表。以下方法可用于确定哪些PHP文件可疑:
步骤4
创建可疑PHP文件列表后,请检查这些文件是正常文件还是恶意文件。如果您不熟悉PHP文件,那么这个过程可能需要更多的时间,因此您最好重新访问一些PHP文档。但是,即使您刚刚开始编写代码,您仍然可以通过一些基本模式找到恶意文件
首先,扫描你发现的可疑文件,找到收录看似混乱的字母和数字组合的大块文本。大型文本块的前面通常是PHP函数的组合(例如base64_decode)rot13、eval、strev、gzinflate)。下面是这样一个代码块的示例。有时,所有这些代码都被填充到一个长字符串中,以使其看起来比实际大小小
base64_decode(strrev("hMXZpRXaslmYhJXZuxWd2BSZ0l2cgknbhByZul2czVmckRWYgknYgM3ajFGd0FGIlJXd0Vn
ZgknbhBSbvJnZgUGdpNHIyV3b5BSZyV3YlNHIvRHI0V2Zy9mZgQ3Ju9GRg4SZ0l2cgIXdvlHI4lmZg4WYjBSdvlHIsU2c
hVmcnBydvJGblBiZvBCdpJGIhBCZuFGIl1Wa0BCa0l2dgQXdCBiLkJXYoBSZiBibhNGIlR2bjBycphGdgcmbpRXYjNXdmJ2b
lRGI5xWZ0Fmb1RncvZmbVBiLn5WauVGcwFGagM3J0FGa3BCZuFGdzJXZk5Wdg8GdgU3b5BicvZGI0xWdjlmZmlGZgQXagU2ah
1GIvRHIzlGa0BSZrlGbgUGZvNGIlRWaoByb0BSZrlGbgMnclt2YhhEIuUGZvNGIlxmYhRWYlJnb1BychByZulGZhJXZ1F3ch
1GIlR2bjBCZlRXYjNXdmJ2bgMXdvl2YpxWYtBiZvBSZjVWawBSYgMXagMXaoRFIskGS"));
有时候,这样的代码并不凌乱,看起来像一个普通的脚本。如果您不确定代码是否恶意,请访问我们的;在这个论坛中,一群经验丰富的网站站长可以帮助您查看相关文档
步骤5
现在您已经知道哪些文件是可疑的,您可以创建备份或创建本地副本,方法是将其保存到您的计算机中,以使这些文件不是恶意文件,然后删除这些可疑文件
检查您的网站是否干净
删除黑色文件后,请检查您的努力是否有回报。还记得您之前发现的那些乱码网页吗?再次使用谷歌爬虫检查这些网页是否仍然存在。如果他们在“谷歌爬虫”中的结果为“未找到”,您的网站可能状况良好,您可以继续修复网站上的漏洞@
您还可以按照“hacked网站”故障排除工具中的步骤检查网站上是否仍有被黑客攻击的内容@
如何防止另一次入侵
修复网站上的漏洞是修复网站的最后一个关键步骤。最近的一项研究发现,20%被黑客攻击的网站将在一天内再次被入侵。了解网站如何被入侵非常有用。请参阅我们的指南,了解垃圾邮件发送者最常用的网站入侵方法 查看全部
输入关键字 抓取所有网页(黑客称为“乱码黑客行为”的操作指南(图))
本指南专门针对将收录大量关键字的乱码网页添加到网站网站的黑客行为。我们称这种黑客行为为“乱码黑客”。我们专门为(cms)用户发布了本指南;但是,即使您没有使用内容管理系统,本指南也会对您有所帮助
注意:不确定您的网站是否被入侵?请阅读我们关于如何检查您的网站是否先被入侵的指南
我们希望确保本指南对您确实有帮助。请留下反馈,帮助我们改进!该目录确定了此类黑客行为
隐藏真实内容的关键字和链接。黑客会自动创建许多带有无意义文字、链接和图片的网页。这些页面有时收录原创网站的基本模板元素,因此乍一看,这些页面似乎是网站的正常部分,但一旦阅读了内容,就会发现情况并非如此
创建被黑客攻击的网页的目的是操纵谷歌的排名因素。黑客经常试图通过向不同的第三方出售被攻击网页上的链接来获利。通常,被黑客攻击的网页会将用户重定向到不相关的网页(如色情网站),黑客可以通过这些网页赚取收入
要检查是否存在此类问题,首先要检查谷歌是否在搜索控制台的安全工具中发现了您网站上的此类被黑客攻击的页面。有时候,你也可以通过打开谷歌搜索窗口并输入site:[你的站点]来找到这样的页面。搜索结果页面将显示谷歌为你的网站搜索结果编制索引的页面,包括那些被黑客攻击的页面。您可以翻阅几页搜索结果,看看是否可以找到任何不寻常的URL。如果你在谷歌搜索结果中没有看到任何被黑客攻击的内容,尝试使用其他搜索引擎搜索相同的搜索词。其他搜索引擎可能会显示谷歌从索引中删除的黑客内容。下面的示例显示了此操作的效果
请注意,上述搜索结果收录许多并非由网站所有者创建的网页。如果仔细查看第二个和第三个搜索结果描述,您将看到此黑客行为创建的乱码文本示例
当您访问被黑客攻击的网页时,您可能会看到一条消息,指示该网页不存在(例如404错误)。不要上当受骗!黑客会试图让你相信被黑客攻击的网页已经消失或修复,从而诱使你认为你的网站已经修复。为此,他们隐藏了真实的内容。您可以在Google crawler中输入您的网站URL,以检查是否存在隐藏真实内容的问题。谷歌爬虫允许你看到潜在的隐藏内容。以下示例显示了此类被黑客攻击的网页的外观:
解决黑客入侵问题
开始之前,请创建要删除的任何文件的脱机副本,以防将来需要恢复它们。这是一个好主意,备份您的整个系统网站. 为此,您可以将服务器上的所有文件保存到服务器以外的位置,或者搜索最适合您特定内容管理系统的备份选项
检查一下。Htaccess文件(共3步)
隐藏真实内容的关键字和链接黑客将使用您的浏览器自动生成隐藏网站上真实内容的网页。Htaccess文件。建议您熟悉的基础知识。Htaccess在官方的Apache网站first上,这可以帮助您更好地理解黑客行为如何影响您网站,但这不是强制性的
第一步
找到那个。Htaccess文件在您的网站. 如果您不确定在哪里可以找到此文件,并且使用了WordPress、Joomla或Drupal等内容管理系统,请在搜索引擎中搜索文件的位置。Htaccess文件和内容管理系统的名称。根据您的网站,您可能会看到多个。Htaccess文件。然后,列出所有的位置。Htaccess文件
注:。Htaccess通常是“隐藏文件”。确保在搜索此类文件时已启用“显示隐藏文件”选项
步骤2
打开门。Htaccess文件以查看文件的内容。在该文件中,您应该找到一行类似于以下内容的代码:
RewriteRule (.*cj2fa.*|^tobeornottobe$) /injected_file.php?q=$1 [L]
此行中的变量可能会更改。“Cj2fa”和“将来或将来”可以是字母或单词的任意组合。重要的是,你需要找到正确的答案。这一行中引用的PHP文件
请注意。中提到的PHP文件名。Htaccess文件。在上面的示例中,指定了。PHP文件是“injected_file.PHP”,但实际上是。PHP文件不是很明显。它通常是一组随机的无害单词,如“horsekeys.PHP”、“potatolake.PHP”等。这很可能是恶意的。PHP文件,我们需要在以后查找并删除它
在公园里。Htaccess文件,不是所有收录重写规则和的行。PHP文件是恶意内容。如果您不确定一行代码的功能,可以在网站Webmaster帮助论坛中向一组经验丰富的网站webmasters寻求帮助
步骤3
全部替换。Htaccess文件具有相应的非侵入或默认版本。Htaccess文件。您通常可以找到的默认版本。通过搜索“default.Htaccess文件”和内容管理系统的名称来访问Htaccess文件。对于网站,它有多个。Htaccess文件,查找并替换每个文件的无入侵版本
如果为默认值。Htaccess文件不存在,并且您从未配置过任何文件。在网站上的Htaccess文件。在网站上找到的Htaccess文件可能是恶意的。为了安全起见,您可以保存的副本。Htaccess文件脱机并删除相应的。Htaccess文件来自网站
查找并删除其他恶意文件(共5步)
识别恶意文件可能很棘手,而且可能需要数小时才能完成。检查文件时请不要担心。如果您没有备份网站您的文件,这是一个好时机。您可以在Google search中搜索“backup网站”和内容管理系统的名称,以了解如何备份网站@
第一步
如果您使用的是内容管理系统,请重新安装此内容管理系统的默认分发版中收录的所有核心(默认)文件,以及您可能添加的任何内容(例如主题背景、模块、插件)。这有助于确保这些文件不收录被黑客攻击的内容。您可以在Google search中搜索“重新安装”和内容管理系统的名称,以获取有关重新安装过程的说明。如果您有任何插件、模块、扩展或主题背景,请确保重新安装它们
重新安装这些核心文件可能会导致丢失您所做的任何自定义设置。在重新安装之前,请确保创建数据库和所有文件的备份
步骤2
首先,寻找正确的答案。前面在中找到的PHP文件。Htaccess文件。根据您访问服务器上相关文件的方式,您应该会看到某种搜索功能。搜索恶意文件的名称。如果发现恶意文件,请备份该文件并将副本存储在其他位置,以便在需要恢复该文件时使用,然后从网站中删除该文件@
步骤3
查找剩余的任何其他恶意或受损文件。在前两个步骤中,您可能已删除了所有恶意文件,但我们仍然建议您执行以下步骤,以避免网站上剩余的入侵文件@
不要觉得压力太大,因为您认为需要打开并查看每个PHP文件。首先,创建要调查的可疑PHP文件列表。以下方法可用于确定哪些PHP文件可疑:
步骤4
创建可疑PHP文件列表后,请检查这些文件是正常文件还是恶意文件。如果您不熟悉PHP文件,那么这个过程可能需要更多的时间,因此您最好重新访问一些PHP文档。但是,即使您刚刚开始编写代码,您仍然可以通过一些基本模式找到恶意文件
首先,扫描你发现的可疑文件,找到收录看似混乱的字母和数字组合的大块文本。大型文本块的前面通常是PHP函数的组合(例如base64_decode)rot13、eval、strev、gzinflate)。下面是这样一个代码块的示例。有时,所有这些代码都被填充到一个长字符串中,以使其看起来比实际大小小
base64_decode(strrev("hMXZpRXaslmYhJXZuxWd2BSZ0l2cgknbhByZul2czVmckRWYgknYgM3ajFGd0FGIlJXd0Vn
ZgknbhBSbvJnZgUGdpNHIyV3b5BSZyV3YlNHIvRHI0V2Zy9mZgQ3Ju9GRg4SZ0l2cgIXdvlHI4lmZg4WYjBSdvlHIsU2c
hVmcnBydvJGblBiZvBCdpJGIhBCZuFGIl1Wa0BCa0l2dgQXdCBiLkJXYoBSZiBibhNGIlR2bjBycphGdgcmbpRXYjNXdmJ2b
lRGI5xWZ0Fmb1RncvZmbVBiLn5WauVGcwFGagM3J0FGa3BCZuFGdzJXZk5Wdg8GdgU3b5BicvZGI0xWdjlmZmlGZgQXagU2ah
1GIvRHIzlGa0BSZrlGbgUGZvNGIlRWaoByb0BSZrlGbgMnclt2YhhEIuUGZvNGIlxmYhRWYlJnb1BychByZulGZhJXZ1F3ch
1GIlR2bjBCZlRXYjNXdmJ2bgMXdvl2YpxWYtBiZvBSZjVWawBSYgMXagMXaoRFIskGS"));
有时候,这样的代码并不凌乱,看起来像一个普通的脚本。如果您不确定代码是否恶意,请访问我们的;在这个论坛中,一群经验丰富的网站站长可以帮助您查看相关文档
步骤5
现在您已经知道哪些文件是可疑的,您可以创建备份或创建本地副本,方法是将其保存到您的计算机中,以使这些文件不是恶意文件,然后删除这些可疑文件
检查您的网站是否干净
删除黑色文件后,请检查您的努力是否有回报。还记得您之前发现的那些乱码网页吗?再次使用谷歌爬虫检查这些网页是否仍然存在。如果他们在“谷歌爬虫”中的结果为“未找到”,您的网站可能状况良好,您可以继续修复网站上的漏洞@
您还可以按照“hacked网站”故障排除工具中的步骤检查网站上是否仍有被黑客攻击的内容@
如何防止另一次入侵
修复网站上的漏洞是修复网站的最后一个关键步骤。最近的一项研究发现,20%被黑客攻击的网站将在一天内再次被入侵。了解网站如何被入侵非常有用。请参阅我们的指南,了解垃圾邮件发送者最常用的网站入侵方法
输入关键字 抓取所有网页(2018年SEO推广优化该怎么做?前景怎么样?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-15 02:17
安徽seo网站关键词platform-口碑好l32nzx
增加外部链接,我们应该遵循的原则是:数量和质量并重,链接文本中尽量收录关键词,尽量获取与内容相关的网站外部链接,尽可能广泛地添加外部链接,以及尝试*外部链接来自真实推荐等。
SEO 行业也在不断发展。每个SEO人都应该多加入几个行业群,关注一些行业博客,多了解交流*新趋势,技术技能等,共同进步,推动行业发展。总而言之,网站optimization 的具体操作方法是动态变化的,相应的网站优化思路也有一定的变化,但始终如一。以上几个优化思路一直都是核心,虽然在一些细节上会有一定的变化,但是如果核心内容被抛弃或者完全改变,显然很难做到网站优化。
网站的外链对于搜索引擎优化来说也是一项非常重要的工作,尤其是网站初期,排名和热度都不是很高,用户找不到网站很快,搜索引擎爬取网站的渠道并不多,外链不仅可以推荐网站,还可以引入蜘蛛,带来流量。安徽seo网站关键词平台。
所谓聚物聚众,我们以前发到外链上也许可以发到外链上,但现在不一样了,你要选择性地发,这和你网站主题,网站自己重重只有高平台才能发。这样的外链资源可以称为好资源。其次,不要继续在网站 上发帖。查找更多此类资源。对于外链发布,需要追求数量,做好内优化+站外推广,形成系统化的东西。原理八、养资源做自媒体推广公司网站。
2018 年 SEO 推广和优化还有什么进展吗?前景如何?未来SEO推广优化应该怎么做? 网站optimization公司工商企业云认为有必要写一篇文章给大家鼓劲儿,一转眼,2017年过去了,2018年迎面而来。相信2018年,这个行业还是会有很多SEOer坚持做这个的。加油,那么2018年SEO推广优化怎么做呢? SEO真的要死了吗?这么多年,SEO一直是死胡同,每次搜索引擎算法调整后,这种说法都会出来。
大多数SEOer对关键词的排名下降了,关键词上升了,他们不知道是什么原因造成的。主要原因是SEOer在网站优化方面经验太少,缺乏实际操作。关于如何通过简化标题提高网站关键词排名的问题。安徽seo网站关键词平台。
分享:影响搜索引擎排名的因素有两个:*是关键词的相关性,第二是网站的排名技术。搜索引擎以用户的输入为关键字,将相关网页在数据库中编入索引,然后根据权重进行排序。
业务网站关键词选择策略:不要简单地追求网站定位的几个热门关键词,核心应该放在产品词和产品组合词上。例如,在酒店机票预订行业,如果只安排机票预订和酒店预订,则应考虑以下类型的词。城市名称+酒店,城市名称+机票,城市名称+城市名称+机票。
网站优化公司商企云认为有必要写一篇文章文章鼓励大家。转眼,2017年已经过去,2018年迎面而来。相信2018年还是会有很多SEOer的,如果这个行业持续下去,2018年SEO推广和优化怎么做? SEO真的要死了吗?这么多年,SEO一直是死记硬背,每次搜索引擎算法调整后,这种说法都会是
一个网站SEO的成功不仅仅依赖于单一的SEO技术的成功,而是着眼于SEO策略,这些SEO策略可以整合到网站操作中来实现SEO***** *影响!许多大规模的网站长时间无法超越瓶颈。他们可能在改变想法后飞越了。为什么?这不是因为这个想法中的伟大的 SEO 技术。大网站不乏SEO技术。他们都有一个非常好的执行团队,他们在seo技巧方面做得非常好。安徽seo网站关键词平台。
反向金字塔网站有很多优化策略,最后一页是收入页,尤其是B2B电商网站。页面优化值倒序排列,即最终页>专题页>栏目页>频道页>首页。所以关键词分配可以遵循以下原则。最后一页:长尾关键词;主题页面;对于热键;栏目页:针对固定关键问题;频道页面:核心关键词;主页基于主要关键词和品牌词。
一个网站SEO的成功,*只依靠单一的SEO技术的成功,重点还是在SEO策略上,把这些SEO策略整合到网站操作中可以让SEO达到最好的效果!许多大规模的网站长时间无法超越瓶颈。他们可能在改变主意后飞越了。为什么?这不是因为这个想法中的伟大的 SEO 技术。大网站不乏SEO技术。他们都有一个非常优秀的执行团队,并且在 seo 技能方面做得非常好。
2018年如何做SEO优化?说了这么多,我们来分析分析一下2018年SEO优化怎么做?首先我说明一点:SEO推广优化要结合其他推广渠道、广告渠道、线下推广渠道、线下广告渠道,形成整合营销体系,才能充分发挥SEO的价值,使用纯 SEO 获取流量来维护一个项目或一个公司的推广变得越来越困难。而且,在搜索引擎算法快速优化调整的时代,流量波动较大,不符合公司稳定发展的要求。 查看全部
输入关键字 抓取所有网页(2018年SEO推广优化该怎么做?前景怎么样?)
安徽seo网站关键词platform-口碑好l32nzx
增加外部链接,我们应该遵循的原则是:数量和质量并重,链接文本中尽量收录关键词,尽量获取与内容相关的网站外部链接,尽可能广泛地添加外部链接,以及尝试*外部链接来自真实推荐等。
SEO 行业也在不断发展。每个SEO人都应该多加入几个行业群,关注一些行业博客,多了解交流*新趋势,技术技能等,共同进步,推动行业发展。总而言之,网站optimization 的具体操作方法是动态变化的,相应的网站优化思路也有一定的变化,但始终如一。以上几个优化思路一直都是核心,虽然在一些细节上会有一定的变化,但是如果核心内容被抛弃或者完全改变,显然很难做到网站优化。
网站的外链对于搜索引擎优化来说也是一项非常重要的工作,尤其是网站初期,排名和热度都不是很高,用户找不到网站很快,搜索引擎爬取网站的渠道并不多,外链不仅可以推荐网站,还可以引入蜘蛛,带来流量。安徽seo网站关键词平台。
所谓聚物聚众,我们以前发到外链上也许可以发到外链上,但现在不一样了,你要选择性地发,这和你网站主题,网站自己重重只有高平台才能发。这样的外链资源可以称为好资源。其次,不要继续在网站 上发帖。查找更多此类资源。对于外链发布,需要追求数量,做好内优化+站外推广,形成系统化的东西。原理八、养资源做自媒体推广公司网站。
2018 年 SEO 推广和优化还有什么进展吗?前景如何?未来SEO推广优化应该怎么做? 网站optimization公司工商企业云认为有必要写一篇文章给大家鼓劲儿,一转眼,2017年过去了,2018年迎面而来。相信2018年,这个行业还是会有很多SEOer坚持做这个的。加油,那么2018年SEO推广优化怎么做呢? SEO真的要死了吗?这么多年,SEO一直是死胡同,每次搜索引擎算法调整后,这种说法都会出来。
大多数SEOer对关键词的排名下降了,关键词上升了,他们不知道是什么原因造成的。主要原因是SEOer在网站优化方面经验太少,缺乏实际操作。关于如何通过简化标题提高网站关键词排名的问题。安徽seo网站关键词平台。
分享:影响搜索引擎排名的因素有两个:*是关键词的相关性,第二是网站的排名技术。搜索引擎以用户的输入为关键字,将相关网页在数据库中编入索引,然后根据权重进行排序。
业务网站关键词选择策略:不要简单地追求网站定位的几个热门关键词,核心应该放在产品词和产品组合词上。例如,在酒店机票预订行业,如果只安排机票预订和酒店预订,则应考虑以下类型的词。城市名称+酒店,城市名称+机票,城市名称+城市名称+机票。
网站优化公司商企云认为有必要写一篇文章文章鼓励大家。转眼,2017年已经过去,2018年迎面而来。相信2018年还是会有很多SEOer的,如果这个行业持续下去,2018年SEO推广和优化怎么做? SEO真的要死了吗?这么多年,SEO一直是死记硬背,每次搜索引擎算法调整后,这种说法都会是
一个网站SEO的成功不仅仅依赖于单一的SEO技术的成功,而是着眼于SEO策略,这些SEO策略可以整合到网站操作中来实现SEO***** *影响!许多大规模的网站长时间无法超越瓶颈。他们可能在改变想法后飞越了。为什么?这不是因为这个想法中的伟大的 SEO 技术。大网站不乏SEO技术。他们都有一个非常好的执行团队,他们在seo技巧方面做得非常好。安徽seo网站关键词平台。
反向金字塔网站有很多优化策略,最后一页是收入页,尤其是B2B电商网站。页面优化值倒序排列,即最终页>专题页>栏目页>频道页>首页。所以关键词分配可以遵循以下原则。最后一页:长尾关键词;主题页面;对于热键;栏目页:针对固定关键问题;频道页面:核心关键词;主页基于主要关键词和品牌词。
一个网站SEO的成功,*只依靠单一的SEO技术的成功,重点还是在SEO策略上,把这些SEO策略整合到网站操作中可以让SEO达到最好的效果!许多大规模的网站长时间无法超越瓶颈。他们可能在改变主意后飞越了。为什么?这不是因为这个想法中的伟大的 SEO 技术。大网站不乏SEO技术。他们都有一个非常优秀的执行团队,并且在 seo 技能方面做得非常好。
2018年如何做SEO优化?说了这么多,我们来分析分析一下2018年SEO优化怎么做?首先我说明一点:SEO推广优化要结合其他推广渠道、广告渠道、线下推广渠道、线下广告渠道,形成整合营销体系,才能充分发挥SEO的价值,使用纯 SEO 获取流量来维护一个项目或一个公司的推广变得越来越困难。而且,在搜索引擎算法快速优化调整的时代,流量波动较大,不符合公司稳定发展的要求。
输入关键字 抓取所有网页(一下使用关键词抓取图片的操作方法分享的方法步骤吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 258 次浏览 • 2021-09-15 02:13
imagebox 是一款网页图片批量抓取下载工具。当用户需要在网站下载一些资料或图片时,可以使用该软件进行操作。在软件中进入批量抓取图片的网址后,就可以批量下载图片了。另一种方法是搜索关键词来抓取图片。这个方法可以找到更多的相关图片,但是操作比URL下载麻烦,所以有很多用户我还不知道怎么做,所以给大家分享一下使用关键词抓取的方法今天的照片。有兴趣的可以看看。
方法步骤
1. 首先我们打开软件,进入软件主界面。这时候就可以在界面右侧看到搜索引擎词搜索功能了,然后我们输入进去。图片的关键词,然后单击“开始爬网”按钮。
2. 点击开始抓图按钮后,将进入抓图设置界面。首先看到的就是设置,可以根据需要进行设置。
3. 下一个设置模块是图片存储选项设置模块。打开下拉列表后,有多种存储文件名的选项。您可以选择您需要的那个。
4.下一步,我们可以点击下面的按钮开始批量抓取,开始抓取操作。
5. 开始抓包后,我们会来到下图所示的界面,在里面可以看到抓包的进度。图像捕捉完成后,单击“全部保存”按钮保存图像。
使用上面教程中分享的操作方法的步骤,我们可以使用imagebox软件抓取我们需要的一些图片素材。如果您不知道如何使用此方法,请尽快尝试。方法步骤,希望本教程可以帮到你。 查看全部
输入关键字 抓取所有网页(一下使用关键词抓取图片的操作方法分享的方法步骤吧!)
imagebox 是一款网页图片批量抓取下载工具。当用户需要在网站下载一些资料或图片时,可以使用该软件进行操作。在软件中进入批量抓取图片的网址后,就可以批量下载图片了。另一种方法是搜索关键词来抓取图片。这个方法可以找到更多的相关图片,但是操作比URL下载麻烦,所以有很多用户我还不知道怎么做,所以给大家分享一下使用关键词抓取的方法今天的照片。有兴趣的可以看看。
方法步骤
1. 首先我们打开软件,进入软件主界面。这时候就可以在界面右侧看到搜索引擎词搜索功能了,然后我们输入进去。图片的关键词,然后单击“开始爬网”按钮。
2. 点击开始抓图按钮后,将进入抓图设置界面。首先看到的就是设置,可以根据需要进行设置。
3. 下一个设置模块是图片存储选项设置模块。打开下拉列表后,有多种存储文件名的选项。您可以选择您需要的那个。
4.下一步,我们可以点击下面的按钮开始批量抓取,开始抓取操作。
5. 开始抓包后,我们会来到下图所示的界面,在里面可以看到抓包的进度。图像捕捉完成后,单击“全部保存”按钮保存图像。
使用上面教程中分享的操作方法的步骤,我们可以使用imagebox软件抓取我们需要的一些图片素材。如果您不知道如何使用此方法,请尽快尝试。方法步骤,希望本教程可以帮到你。
输入关键字 抓取所有网页(智能识别模式自动识别网页中出现的数据模式-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-15 02:10
WebHarvy 是一款功能强大的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单,智能识别网页上发生的数据模式。
[特点]
视觉点和点击界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
代表{pass}{filter}从服务器提取
要提取匿名,防止提取web软件被web服务器拦截,必须通过代理服务器访问目标网站的选项。您可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
【使用方法】
1、启动软件,提示并解锁,即需要添加官方license文件才能使用
2、解压下载的文件,双击“URET NFO v2.2.exe”即可
3、 提醒您 SysNucleus WebHarvy 软件已授权给 SMR
4、 导航到需要提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要捕获文本的一部分,请选择它并突出显示它。在选择下面的选项之前,确定所需的部分。
6、只要输入你分析的网页地址,最上面的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的计划 查看全部
输入关键字 抓取所有网页(智能识别模式自动识别网页中出现的数据模式-苏州安嘉)
WebHarvy 是一款功能强大的应用程序,旨在使您能够自动从网页中提取数据并以不同格式保存提取的内容。从网页捕获数据就像导航到收录数据的页面并单击数据捕获一样简单,智能识别网页上发生的数据模式。
[特点]
视觉点和点击界面
WebHarvy 是一款可视化网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。就是这么简单!
智能识别模式
自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站scraper 允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页显示数据,例如多个页面上的产品目录。 WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页”,WebHarvy网站scraper 会自动从所有页面抓取数据。
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。您可以指定任意数量的输入关键字
代表{pass}{filter}从服务器提取
要提取匿名,防止提取web软件被web服务器拦截,必须通过代理服务器访问目标网站的选项。您可以使用单个代理服务器地址或代理服务器地址列表。
提取分类
WebHarvy网站scraper 允许您从链接列表中提取数据,从而在网站 中生成类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(regular expressions),并提取匹配的部分。这项强大的技术可让您在争夺数据的同时获得更大的灵活性。
【使用方法】
1、启动软件,提示并解锁,即需要添加官方license文件才能使用
2、解压下载的文件,双击“URET NFO v2.2.exe”即可
3、 提醒您 SysNucleus WebHarvy 软件已授权给 SMR
4、 导航到需要提取数据的网页。您可以使用内置浏览器加载和浏览网页
5、要捕获文本的一部分,请选择它并突出显示它。在选择下面的选项之前,确定所需的部分。
6、只要输入你分析的网页地址,最上面的网址就是地址输入栏
7、输入地址直接在网页上打开
8、选择配置功能,可以点击第一个Start Config开始配置下载网页数据的计划
输入关键字 抓取所有网页(一个python3作业题目描述的设计与实现输入:腾讯体育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-14 21:08
前言
最近做了一个python3作业题,涉及:
涉及的库是:
发布代码供快速参考,实现一个小demo。
标题说明
搜索引擎的设计与实现
输入:腾讯体育的页面链接,以列表形式输入,数字可变,例如:
["http://fiba.qq.com/a/20190420/001968.htm",
"http://sports.qq.com/a/20190424/000181.htm",
"http://sports.qq.com/a/20190423/007933.htm",
"http://new.qq.com/omn/SPO2019042400075107"]
复制代码
流程:网络爬虫、页面分析、中文提取分析、索引,需要使用教材中的第三方库,中间流程在内存中完成,输出流程运行时间;
搜索:提示输入关键词进行搜索;
输出:输入的链表按照关键词出现的频率降序输出,以JSON格式输出词频信息等辅助信息;没有出现关键词的文档链接不输出,最后输出检索时间,例如:
代码
代码实现的主要步骤是:
import requests
from bs4 import BeautifulSoup
import json
import re
import jieba
import time
USER_AGENT = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) '
'Chrome/20.0.1092.0 Safari/536.6'}
URL_TIMEOUT = 10
SLEEP_TIME = 2
# dict_result格式:{"1":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# "2":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# }
dict_result = {}
# dict_search格式:[
# [url, count]
# [url, count]
# ]
list_search_result = []
def crawler(list_URL):
for i, url in enumerate(list_URL):
print("网页爬取:", url, "...")
page = requests.get(url, headers=USER_AGENT, timeout=URL_TIMEOUT)
page.encoding = page.apparent_encoding # 防止编码解析错误
result_clean_page = bs4_page_clean(page)
result_chinese = re_chinese(result_clean_page)
# print("网页中文内容:", result_chinese)
dict_result[i + 1] = {"url": url, "word": jieba_create_index(result_chinese)}
print("爬虫休眠中...")
time.sleep(SLEEP_TIME)
def bs4_page_clean(page):
print("正则表达式:清除网页标签等无关信息...")
soup = BeautifulSoup(page.text, "html.parser")
[script.extract() for script in soup.findAll('script')]
[style.extract() for style in soup.findAll('style')]
reg1 = re.compile("]*>")
content = reg1.sub('', soup.prettify())
return str(content)
def re_chinese(content):
print("正则表达式:提取中文...")
pattern = re.compile(u'[\u1100-\uFFFD]+?')
result = pattern.findall(content)
return ''.join(result)
def jieba_create_index(string):
list_word = jieba.lcut_for_search(string)
dict_word_temp = {}
for word in list_word:
if word in dict_word_temp:
dict_word_temp[word] += 1
else:
dict_word_temp[word] = 1
return dict_word_temp
def search(string):
for k, v in dict_result.items():
if string in v["word"]:
list_search_result.append([v["url"], v["word"][string]])
# 使用词频对列表进行排序
list_search_result.sort(key=lambda x: x[1], reverse=True)
if __name__ == "__main__":
list_URL_sport = input("请输入网址列表:")
list_URL_sport = list_URL_sport.split(",")
print(list_URL_sport)
# 删除输入的网页双引号
for i in range(len(list_URL_sport)):
list_URL_sport[i] = list_URL_sport[i][1:-1]
print(list_URL_sport)
# list_URL_sport = ["http://fiba.qq.com/a/20190420/001968.htm",
# "http://sports.qq.com/a/20190424/000181.htm",
# "http://sports.qq.com/a/20190423/007933.htm",
# "http://new.qq.com/omn/SPO2019042400075107"]
time_start_crawler = time.time()
crawler(list_URL_sport)
time_end_crawler = time.time()
print("网页爬取和分析时间:", time_end_crawler - time_start_crawler)
word = input("请输入查询的关键词:")
time_start_search = time.time()
search(word)
time_end_search = time.time()
print("检索时间:", time_end_search - time_start_search)
for i, row in enumerate(list_search_result):
print(i+1, row[0], row[1])
print("词频信息:")
print(json.dumps(dict_result, ensure_ascii=False))
复制代码
跟着我跑步
我目前是一名后端开发工程师。主要关注后端开发、数据安全、网络爬虫、物联网、边缘计算等方向。 查看全部
输入关键字 抓取所有网页(一个python3作业题目描述的设计与实现输入:腾讯体育)
前言
最近做了一个python3作业题,涉及:
涉及的库是:
发布代码供快速参考,实现一个小demo。
标题说明
搜索引擎的设计与实现
输入:腾讯体育的页面链接,以列表形式输入,数字可变,例如:
["http://fiba.qq.com/a/20190420/001968.htm",
"http://sports.qq.com/a/20190424/000181.htm",
"http://sports.qq.com/a/20190423/007933.htm",
"http://new.qq.com/omn/SPO2019042400075107"]
复制代码
流程:网络爬虫、页面分析、中文提取分析、索引,需要使用教材中的第三方库,中间流程在内存中完成,输出流程运行时间;
搜索:提示输入关键词进行搜索;
输出:输入的链表按照关键词出现的频率降序输出,以JSON格式输出词频信息等辅助信息;没有出现关键词的文档链接不输出,最后输出检索时间,例如:
代码
代码实现的主要步骤是:
import requests
from bs4 import BeautifulSoup
import json
import re
import jieba
import time
USER_AGENT = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) '
'Chrome/20.0.1092.0 Safari/536.6'}
URL_TIMEOUT = 10
SLEEP_TIME = 2
# dict_result格式:{"1":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# "2":
# {"url": "xxxxx", "word": {"word1": x, "word2": x, "word3": x}}
# }
dict_result = {}
# dict_search格式:[
# [url, count]
# [url, count]
# ]
list_search_result = []
def crawler(list_URL):
for i, url in enumerate(list_URL):
print("网页爬取:", url, "...")
page = requests.get(url, headers=USER_AGENT, timeout=URL_TIMEOUT)
page.encoding = page.apparent_encoding # 防止编码解析错误
result_clean_page = bs4_page_clean(page)
result_chinese = re_chinese(result_clean_page)
# print("网页中文内容:", result_chinese)
dict_result[i + 1] = {"url": url, "word": jieba_create_index(result_chinese)}
print("爬虫休眠中...")
time.sleep(SLEEP_TIME)
def bs4_page_clean(page):
print("正则表达式:清除网页标签等无关信息...")
soup = BeautifulSoup(page.text, "html.parser")
[script.extract() for script in soup.findAll('script')]
[style.extract() for style in soup.findAll('style')]
reg1 = re.compile("]*>")
content = reg1.sub('', soup.prettify())
return str(content)
def re_chinese(content):
print("正则表达式:提取中文...")
pattern = re.compile(u'[\u1100-\uFFFD]+?')
result = pattern.findall(content)
return ''.join(result)
def jieba_create_index(string):
list_word = jieba.lcut_for_search(string)
dict_word_temp = {}
for word in list_word:
if word in dict_word_temp:
dict_word_temp[word] += 1
else:
dict_word_temp[word] = 1
return dict_word_temp
def search(string):
for k, v in dict_result.items():
if string in v["word"]:
list_search_result.append([v["url"], v["word"][string]])
# 使用词频对列表进行排序
list_search_result.sort(key=lambda x: x[1], reverse=True)
if __name__ == "__main__":
list_URL_sport = input("请输入网址列表:")
list_URL_sport = list_URL_sport.split(",")
print(list_URL_sport)
# 删除输入的网页双引号
for i in range(len(list_URL_sport)):
list_URL_sport[i] = list_URL_sport[i][1:-1]
print(list_URL_sport)
# list_URL_sport = ["http://fiba.qq.com/a/20190420/001968.htm",
# "http://sports.qq.com/a/20190424/000181.htm",
# "http://sports.qq.com/a/20190423/007933.htm",
# "http://new.qq.com/omn/SPO2019042400075107"]
time_start_crawler = time.time()
crawler(list_URL_sport)
time_end_crawler = time.time()
print("网页爬取和分析时间:", time_end_crawler - time_start_crawler)
word = input("请输入查询的关键词:")
time_start_search = time.time()
search(word)
time_end_search = time.time()
print("检索时间:", time_end_search - time_start_search)
for i, row in enumerate(list_search_result):
print(i+1, row[0], row[1])
print("词频信息:")
print(json.dumps(dict_result, ensure_ascii=False))
复制代码
跟着我跑步
我目前是一名后端开发工程师。主要关注后端开发、数据安全、网络爬虫、物联网、边缘计算等方向。
输入关键字 抓取所有网页(关于搜索引擎如何抓取关键词优化排名的知识点?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-13 04:01
)
设立网站后,很多企业都希望自己的网站名列前茅,获得更大的曝光率,获得流量,让企业得以发展。但是作为搜索引擎,他们对网站关键词的爬取能力也有一定的规律。所以,我们一起来学习一下搜索引擎如何抓取关键词优化排名的知识点。
一、搜索引擎如何抓取关键词优化排名?
1、网站内容相关性
搜索引擎利用网站内容反映的相关性来抓取排名。所以网站页面标题和页面内容必须有一定的相关性。如果内容反映的相关性不高,会影响关键词优化排名的爬取。
2、网页内容质量
搜索引擎喜欢原创内容个性新颖,所以搜索引擎会根据网站内容质量抢关键词优化排名,一般搜索结果从左到右搜索标题关键词结果。
3、用户体验
在爬取关键词优化排名的过程中,搜索引擎会不断通过后台数据,通过用户对网站的访问来抓取数据,比如网页停留时间、用户访问量、跳出率等等。上,综合判断用户使用网站的体验,然后抢关键词优化排名。
关于搜索引擎如何抓取关键词optimized 排名的介绍到此结束。但是,企业既然要优化搜索引擎,就必须掌握搜索引擎的基本工作原理,了解搜索引擎之间的关系,才能更好地进行搜索引擎工作,而网站关键词如果设置合理并且合适,也有利于搜索引擎的抓取。
二、网站关键词怎么设置?
关键词的设置对搜索引擎有重要影响。首先要确认网站的主要关键词,然后针对这些关键词进行优化,包括关键词密度、相关性、突出度等等等。最后需要合理设置关键词,如下:
1、确定行业核心词
在设置网站关键词时,首先要明确行业核心关键词,这样才能拓展行业关键词。
2、保持一定的关键词密度
关键词的密度布局会影响网站的排名。所以文章的关键词的密度一般保持在3-8%左右,而网站的关键词的设置需要保持一定的密度距离,产生一种“距离美” ,所以不允许堆积。
3、关键词合理布局
网站设置关键词,需要放在网站的标题上,关键词要放在标题、第一段等重要位置。
简而言之,网站的关键词是给网站带来流量的“入口”,而关键词分析和选择是一个磨砺的过程。企业可以使用工具进行关键词挖掘和分析。如果有什么不明白的,欢迎评论~
查看全部
输入关键字 抓取所有网页(关于搜索引擎如何抓取关键词优化排名的知识点?(一)
)
设立网站后,很多企业都希望自己的网站名列前茅,获得更大的曝光率,获得流量,让企业得以发展。但是作为搜索引擎,他们对网站关键词的爬取能力也有一定的规律。所以,我们一起来学习一下搜索引擎如何抓取关键词优化排名的知识点。
一、搜索引擎如何抓取关键词优化排名?
1、网站内容相关性
搜索引擎利用网站内容反映的相关性来抓取排名。所以网站页面标题和页面内容必须有一定的相关性。如果内容反映的相关性不高,会影响关键词优化排名的爬取。
2、网页内容质量
搜索引擎喜欢原创内容个性新颖,所以搜索引擎会根据网站内容质量抢关键词优化排名,一般搜索结果从左到右搜索标题关键词结果。
3、用户体验
在爬取关键词优化排名的过程中,搜索引擎会不断通过后台数据,通过用户对网站的访问来抓取数据,比如网页停留时间、用户访问量、跳出率等等。上,综合判断用户使用网站的体验,然后抢关键词优化排名。
关于搜索引擎如何抓取关键词optimized 排名的介绍到此结束。但是,企业既然要优化搜索引擎,就必须掌握搜索引擎的基本工作原理,了解搜索引擎之间的关系,才能更好地进行搜索引擎工作,而网站关键词如果设置合理并且合适,也有利于搜索引擎的抓取。
二、网站关键词怎么设置?
关键词的设置对搜索引擎有重要影响。首先要确认网站的主要关键词,然后针对这些关键词进行优化,包括关键词密度、相关性、突出度等等等。最后需要合理设置关键词,如下:
1、确定行业核心词
在设置网站关键词时,首先要明确行业核心关键词,这样才能拓展行业关键词。
2、保持一定的关键词密度
关键词的密度布局会影响网站的排名。所以文章的关键词的密度一般保持在3-8%左右,而网站的关键词的设置需要保持一定的密度距离,产生一种“距离美” ,所以不允许堆积。
3、关键词合理布局
网站设置关键词,需要放在网站的标题上,关键词要放在标题、第一段等重要位置。
简而言之,网站的关键词是给网站带来流量的“入口”,而关键词分析和选择是一个磨砺的过程。企业可以使用工具进行关键词挖掘和分析。如果有什么不明白的,欢迎评论~
输入关键字 抓取所有网页(百度流量有90%(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-11 08:07
百度90%的流量来自百度快照流量。目前,百度的竞价广告位只有前5名的数量有限。 *别说关键词多了也没有人下过竞价排名。这里有截图
我们在优化的时候,经常会出现关键词排名下降的现象。对于这种情况,我们要区分是否是正常的浮动,因为有时候搜索引擎也会出错,导致关键词ranking下降,我们把这种循环关键词ranking下降,然后又回到正常状态称为正常浮动。比如昨天的排名很好,但是今天的排名下降了,那我们就不用担心了,我们可以再等一个搜索引擎*新周期,搜索引擎周期一般是一周,通常是星期四和星期五*新但是经过一个*新周期后,关键词排名还没有恢复,那我们就得进行诊断分析,一般可以采用排除法。 .
**排除外部因素,如被黑链接、木马、冗余页面等,我们可以查看源代码、使用被黑工具、站点说明、索引量(激增)等,以及是否泛分析,我们可以使用site:查询*级域名,看二级域名是否很多。后者外部因素是服务器空间,服务器是否稳定,可以使用百度站长工具抓取诊断工具进行诊断。
*二、人为优化操作行为所致。
1、 Changes:标题的变化,尤其是首页标题的变化。页面修改:用户体验内容匹配比原版差*。内容变化:如果需要调整优化,建议分期进行。一般情况下,收录 排名的页面不应该被调整。如果调整,搜索引擎会重新抓取计算,所做的更改必须符合相关性和匹配性。修改造成的死链接:一般我们制作的内容页面都有收录分。如果修改后的内容页面有死链接,那么收录分数就会下降。
2、日常运营
我们说我们制作的内容页一般都是收录评分的,但是内容的质量可以限制内容页的收录评分。内容必须与**相关,内容不可重复。网站是否过度优化:关键词的积累(包括alt、锚文本列表一)、大量反向链接、标签滥用。
3、优化不合理
1、废外链* 超过50%的排名受到影响。 2015年7月3日起,百度提升了垃圾外链识别能力。
2、 链接丢失,*超过 10% 影响排名。外链有一个有效循环和一个死循环。当链接失效时,链接将丢失。就像贴在论坛上的一个链接,很容易在一段时间后被删除,然后这个链接就死了,这就是链接丢失。
3、export 链接指向彻头彻尾,可能有牵连。
4、购买链接,链接作弊(隐藏,js欺诈跳转)不可取。
5、隐藏文字
6、刷流
7、其他
说了这么多,怎么办? **我们可以回忆一下我们最近做了什么(通常是4周左右),*2查看基本优化得分。 *三检查服务器的稳定性。 *比较四个搜索引擎,同一个行业的同一个搜索引擎,看是不是普遍现象,如果是普遍现象,那就是搜索引擎对这个行业的算法变化;不同搜索引擎的比较,排名下降,通常是服务器或程序出现问题。一般情况下,首页被处罚的情况更多是因为作弊和不合理优化导致信用下降,内页被处罚的更多是内容质量问题。
其实我们可以观察到指数量、外链、流量这三个数值指标的变化。一般情况下,指数成交量是缓慢增加的。其他情况不正常。突然增加可能是人挂在马上造成的。对于不是我们自己的页面,下降可能是由于服务器不稳定、提交的死链接和机器人拒绝页面。值得一提的是,索引量正在缓慢下降,这可能是由于内容质量问题。关于外链数据的变化,由于百度站长平台不支持拒绝外链,我们可以争取处理相关情况。如果链接丢失,我们将补充外部链接。观察流量数值指标是否有波动,观察哪些流量是浮动的。流量分为三种:搜索引擎流量、直接访问和外链访问。当其中一个流量缺失时,它会被补充。当流量补充到大于等于前排名下降时,关键词排名会慢慢恢复。
在搜索引擎中输入一个关键字,通常会得到很多搜索结果。这些搜索结果的排名是有序的。这是搜索引擎排名。
搜索引擎蜘蛛从数据库中的已知网页开始,像普通用户的浏览器一样访问这些网页并抓取文件。处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,并根据排序算法计算出哪些网页应该先排序,然后返回到“搜索" 特定格式的页面。那么排序过程可以在一两秒内完成,返回用户想要的搜索结果。
tag 标签几乎是每个站长都会看到的,它在seo优化中扮演着重要的角色。每次文章发帖,tag标签就立在站长面前。很多站长都在纠结要不要加标签。我之前的做法是想加就加,不想加就忽略。我很少考虑如何对待标签。
我的系统讲了tag标签的作用和注意事项
标签标签功能
1、tag标签对应的链接都是列表页,类似于文章category列表页,很容易被百度收录
2、tag标签可以直接在网页源代码中添加关键字。有了tag标签,就不需要单独添加关键词了。
3、tag标签是同类型的文章聚合,所有带有tag标签的文章都排列在tag文章列表中,可以大大增加用户体验
4.许多 wordpress 主题可以直接添加标签链接。标签链接是一种内部链。为了添加标签,他们正在做内部链构建。
使用tag标签需要注意什么
1、不要频繁修改标签,如果不修改一次,搜索引擎将不得不再次收录
2.不要使用主要的关键词和流行的关键词标签,尽量使用长尾关键词,如果使用主要的关键词,会引起与主题的竞争,导致关键词权重分散,这也违反了标题和关键词不重复的原则
3.标签中的单词不要太少,但不要把它变成一个长句。六到八个字符更合适。
4.注意控制标签总数。每个文章标签不得超过3个,标签标签不能被滥用。至少保证每个标签对应3-5个文章
5、tag标签更符合文章主题,不要使用与文章无关的标签
这些是我对标签标签的一些理解以及我从一些 seo 大神那里学到的一些东西。如有不对之处,请站长指出。让我们研究一下tag标签的使用以及影响seo的tag标签的各个方面。
除了tag标签,关于seo优化,还有一些百度规则需要注意。它与优化效果有关。了解一些搜索引擎规则最能应对搜索引擎。
1.如何正确查询外部链接
很多人喜欢用domain:域名,结果却收录了很多自己的内页,如何去除这些内页
inurl的意识是域名中收录的某些字符的链接,-inurl是排除的作用
2、可以把副标题放在主标题前面
一般情况下,主标题放在副标题之前,但是当排名特别重要时,把副标题放在最前面可以有效提高关键词ranking
3、百度分词分为正向分词和反向分词,单匹配和大匹配。 **匹配词的权重是**大匹配和收录匹配。如果可以匹配多个关键词,则主关键词必须放在前面。
4、您知道如何高效搜索文档,排出无用网页吗?
filetype:命令,比如我们需要查询promotion的word文档
filetype:doc intitle:promotion
这里的doc是文章扩展名,可以修改为txt、pdf等
5.首页、栏目页、内页的权重依次递减。我们可以开始错位比赛,但是我们发现当搜索结果前面的链接是版块页和内页时,可以用首页来竞争,获胜的机会会很大。 .
6、关键词index 和 ** 需要权衡。很多搜索有很多次,但没有太多**。并且在选择关键词时,排除那些百度自家产品过多的词
7、我们搜索到的百度图片都是通过alt标签索引的,所以如果图片没有alt标签,不太可能被百度引导
8、title标签和description标签很重要,但是现在关键词没那么重要了。说明会出现在百度搜索结果的缩写摘要中。描述最好是整体连贯流畅的话语,不要堆积关键词。里面的标题要一致
9、标题关键词百度只能显示30个,但百度可以抓取超过这个数字,关键词不*过40个汉字
10。百度可以识别拼音,所以如果你的链接可以自定义,尽量使用链接中关键词对应的拼音。比如你有一个网页关键词是,那么你可以自定义链接
11、蛋糕的重量就像蛋糕一样,重量蛋糕是有限的,权重分配到我们每个链接,所以我们可以在不需要的部分链接中添加nofollow标签。例如,联系我们,关于像我们这样的链接。主要原则是减少重量输出,将重量集中在站内。
-/gbacdfb/- 查看全部
输入关键字 抓取所有网页(百度流量有90%(图))
百度90%的流量来自百度快照流量。目前,百度的竞价广告位只有前5名的数量有限。 *别说关键词多了也没有人下过竞价排名。这里有截图
我们在优化的时候,经常会出现关键词排名下降的现象。对于这种情况,我们要区分是否是正常的浮动,因为有时候搜索引擎也会出错,导致关键词ranking下降,我们把这种循环关键词ranking下降,然后又回到正常状态称为正常浮动。比如昨天的排名很好,但是今天的排名下降了,那我们就不用担心了,我们可以再等一个搜索引擎*新周期,搜索引擎周期一般是一周,通常是星期四和星期五*新但是经过一个*新周期后,关键词排名还没有恢复,那我们就得进行诊断分析,一般可以采用排除法。 .
**排除外部因素,如被黑链接、木马、冗余页面等,我们可以查看源代码、使用被黑工具、站点说明、索引量(激增)等,以及是否泛分析,我们可以使用site:查询*级域名,看二级域名是否很多。后者外部因素是服务器空间,服务器是否稳定,可以使用百度站长工具抓取诊断工具进行诊断。
*二、人为优化操作行为所致。
1、 Changes:标题的变化,尤其是首页标题的变化。页面修改:用户体验内容匹配比原版差*。内容变化:如果需要调整优化,建议分期进行。一般情况下,收录 排名的页面不应该被调整。如果调整,搜索引擎会重新抓取计算,所做的更改必须符合相关性和匹配性。修改造成的死链接:一般我们制作的内容页面都有收录分。如果修改后的内容页面有死链接,那么收录分数就会下降。
2、日常运营
我们说我们制作的内容页一般都是收录评分的,但是内容的质量可以限制内容页的收录评分。内容必须与**相关,内容不可重复。网站是否过度优化:关键词的积累(包括alt、锚文本列表一)、大量反向链接、标签滥用。
3、优化不合理
1、废外链* 超过50%的排名受到影响。 2015年7月3日起,百度提升了垃圾外链识别能力。
2、 链接丢失,*超过 10% 影响排名。外链有一个有效循环和一个死循环。当链接失效时,链接将丢失。就像贴在论坛上的一个链接,很容易在一段时间后被删除,然后这个链接就死了,这就是链接丢失。
3、export 链接指向彻头彻尾,可能有牵连。
4、购买链接,链接作弊(隐藏,js欺诈跳转)不可取。
5、隐藏文字
6、刷流
7、其他
说了这么多,怎么办? **我们可以回忆一下我们最近做了什么(通常是4周左右),*2查看基本优化得分。 *三检查服务器的稳定性。 *比较四个搜索引擎,同一个行业的同一个搜索引擎,看是不是普遍现象,如果是普遍现象,那就是搜索引擎对这个行业的算法变化;不同搜索引擎的比较,排名下降,通常是服务器或程序出现问题。一般情况下,首页被处罚的情况更多是因为作弊和不合理优化导致信用下降,内页被处罚的更多是内容质量问题。
其实我们可以观察到指数量、外链、流量这三个数值指标的变化。一般情况下,指数成交量是缓慢增加的。其他情况不正常。突然增加可能是人挂在马上造成的。对于不是我们自己的页面,下降可能是由于服务器不稳定、提交的死链接和机器人拒绝页面。值得一提的是,索引量正在缓慢下降,这可能是由于内容质量问题。关于外链数据的变化,由于百度站长平台不支持拒绝外链,我们可以争取处理相关情况。如果链接丢失,我们将补充外部链接。观察流量数值指标是否有波动,观察哪些流量是浮动的。流量分为三种:搜索引擎流量、直接访问和外链访问。当其中一个流量缺失时,它会被补充。当流量补充到大于等于前排名下降时,关键词排名会慢慢恢复。
在搜索引擎中输入一个关键字,通常会得到很多搜索结果。这些搜索结果的排名是有序的。这是搜索引擎排名。
搜索引擎蜘蛛从数据库中的已知网页开始,像普通用户的浏览器一样访问这些网页并抓取文件。处理完搜索词后,搜索引擎排序程序开始工作,从索引数据库中找出所有收录该搜索词的网页,并根据排序算法计算出哪些网页应该先排序,然后返回到“搜索" 特定格式的页面。那么排序过程可以在一两秒内完成,返回用户想要的搜索结果。
tag 标签几乎是每个站长都会看到的,它在seo优化中扮演着重要的角色。每次文章发帖,tag标签就立在站长面前。很多站长都在纠结要不要加标签。我之前的做法是想加就加,不想加就忽略。我很少考虑如何对待标签。
我的系统讲了tag标签的作用和注意事项
标签标签功能
1、tag标签对应的链接都是列表页,类似于文章category列表页,很容易被百度收录
2、tag标签可以直接在网页源代码中添加关键字。有了tag标签,就不需要单独添加关键词了。
3、tag标签是同类型的文章聚合,所有带有tag标签的文章都排列在tag文章列表中,可以大大增加用户体验
4.许多 wordpress 主题可以直接添加标签链接。标签链接是一种内部链。为了添加标签,他们正在做内部链构建。
使用tag标签需要注意什么
1、不要频繁修改标签,如果不修改一次,搜索引擎将不得不再次收录
2.不要使用主要的关键词和流行的关键词标签,尽量使用长尾关键词,如果使用主要的关键词,会引起与主题的竞争,导致关键词权重分散,这也违反了标题和关键词不重复的原则
3.标签中的单词不要太少,但不要把它变成一个长句。六到八个字符更合适。
4.注意控制标签总数。每个文章标签不得超过3个,标签标签不能被滥用。至少保证每个标签对应3-5个文章
5、tag标签更符合文章主题,不要使用与文章无关的标签
这些是我对标签标签的一些理解以及我从一些 seo 大神那里学到的一些东西。如有不对之处,请站长指出。让我们研究一下tag标签的使用以及影响seo的tag标签的各个方面。
除了tag标签,关于seo优化,还有一些百度规则需要注意。它与优化效果有关。了解一些搜索引擎规则最能应对搜索引擎。
1.如何正确查询外部链接
很多人喜欢用domain:域名,结果却收录了很多自己的内页,如何去除这些内页
inurl的意识是域名中收录的某些字符的链接,-inurl是排除的作用
2、可以把副标题放在主标题前面
一般情况下,主标题放在副标题之前,但是当排名特别重要时,把副标题放在最前面可以有效提高关键词ranking
3、百度分词分为正向分词和反向分词,单匹配和大匹配。 **匹配词的权重是**大匹配和收录匹配。如果可以匹配多个关键词,则主关键词必须放在前面。
4、您知道如何高效搜索文档,排出无用网页吗?
filetype:命令,比如我们需要查询promotion的word文档
filetype:doc intitle:promotion
这里的doc是文章扩展名,可以修改为txt、pdf等
5.首页、栏目页、内页的权重依次递减。我们可以开始错位比赛,但是我们发现当搜索结果前面的链接是版块页和内页时,可以用首页来竞争,获胜的机会会很大。 .
6、关键词index 和 ** 需要权衡。很多搜索有很多次,但没有太多**。并且在选择关键词时,排除那些百度自家产品过多的词
7、我们搜索到的百度图片都是通过alt标签索引的,所以如果图片没有alt标签,不太可能被百度引导
8、title标签和description标签很重要,但是现在关键词没那么重要了。说明会出现在百度搜索结果的缩写摘要中。描述最好是整体连贯流畅的话语,不要堆积关键词。里面的标题要一致
9、标题关键词百度只能显示30个,但百度可以抓取超过这个数字,关键词不*过40个汉字
10。百度可以识别拼音,所以如果你的链接可以自定义,尽量使用链接中关键词对应的拼音。比如你有一个网页关键词是,那么你可以自定义链接
11、蛋糕的重量就像蛋糕一样,重量蛋糕是有限的,权重分配到我们每个链接,所以我们可以在不需要的部分链接中添加nofollow标签。例如,联系我们,关于像我们这样的链接。主要原则是减少重量输出,将重量集中在站内。
-/gbacdfb/-
输入关键字 抓取所有网页(DeeperWeb是一个Google搜索引擎,顾名思义WebWebWeb)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-11 08:04
搜索引擎搜索结果页面的标题和页面摘要与用户查询的关键词非常相关。对于网站站长来说,如果可以从搜索结果页(SERP)关键词中提取相关信息,并善加利用,您将能够:
1、为网站内容选择提供更多思路;
2、用于丰富关键词列表;
3、 提供更多优化思路网站,3 个从搜索引擎中提取相关关键词 的工具。看到有人为了提高网站的关键词排名,直接把搜索结果第一页复制为网站内容。这是使用 SERP 的一个极端例子。
根据 SEJ 提供的信息,这里有三个在线工具或插件,可以从 Google 搜索引擎中提取相关的 关键词。
关键字查找器
Keyword Finder是一款在线工具,可以根据用户输入的主题关键词,从50个最相关的网页中提取20个相关关键词,并按热门程度排序。更好的是,它还可以按地区查询。不幸的是,不支持中文。
搜索 Cloudlet
Search Cloudlet 是一个众所周知的 Firefox 扩展。其工作原理是根据关键词在搜索结果页面的出现频率提取出来,以标签云的形式显示在页面顶部。字体越大,在搜索结果页面中出现的频率就越高。当然,它可以从另一个方面反映与您查询的关键词的相关性。管理信息“3从搜索引擎中提取相关关键词”的工具”()。目前,Search Cloudlet可以支持多种谷歌搜索服务以及雅虎搜索和推特搜索。
除了标签云,还提供了站点云,让你知道你查询的关键词哪个网站出现的次数最多。
深层网络
深网是谷歌搜索引擎的辅助工具。顾名思义,它可以从谷歌挖掘出更有价值的数据。它还可以在 Google 搜索结果页面的右侧显示来自博客搜索、维基百科、新闻搜索和问答服务的搜索。结果。此外,它还提供了类似Search Cloudlet的关键词提取服务,统计结果也以标签云的形式呈现给用户。 Deeper Web 比 Search Cloudlet 更好的地方在于它支持中文,还可以计算两个词组。
除在线使用外,Deeper Web 还提供了 Firefox 扩展,每次使用 Google 时都可以使用。在此处下载并安装。
还有吗?当然,无非就是Google AdWords 的关键字查询工具。延伸阅读:《各大搜索引擎提供的免费关键词查询工具》、《各大搜索引擎的关键词分析工具》、《基于谷歌搜索的关键词工具》 查看全部
输入关键字 抓取所有网页(DeeperWeb是一个Google搜索引擎,顾名思义WebWebWeb)
搜索引擎搜索结果页面的标题和页面摘要与用户查询的关键词非常相关。对于网站站长来说,如果可以从搜索结果页(SERP)关键词中提取相关信息,并善加利用,您将能够:
1、为网站内容选择提供更多思路;
2、用于丰富关键词列表;
3、 提供更多优化思路网站,3 个从搜索引擎中提取相关关键词 的工具。看到有人为了提高网站的关键词排名,直接把搜索结果第一页复制为网站内容。这是使用 SERP 的一个极端例子。
根据 SEJ 提供的信息,这里有三个在线工具或插件,可以从 Google 搜索引擎中提取相关的 关键词。
关键字查找器
Keyword Finder是一款在线工具,可以根据用户输入的主题关键词,从50个最相关的网页中提取20个相关关键词,并按热门程度排序。更好的是,它还可以按地区查询。不幸的是,不支持中文。
搜索 Cloudlet
Search Cloudlet 是一个众所周知的 Firefox 扩展。其工作原理是根据关键词在搜索结果页面的出现频率提取出来,以标签云的形式显示在页面顶部。字体越大,在搜索结果页面中出现的频率就越高。当然,它可以从另一个方面反映与您查询的关键词的相关性。管理信息“3从搜索引擎中提取相关关键词”的工具”()。目前,Search Cloudlet可以支持多种谷歌搜索服务以及雅虎搜索和推特搜索。
除了标签云,还提供了站点云,让你知道你查询的关键词哪个网站出现的次数最多。
深层网络
深网是谷歌搜索引擎的辅助工具。顾名思义,它可以从谷歌挖掘出更有价值的数据。它还可以在 Google 搜索结果页面的右侧显示来自博客搜索、维基百科、新闻搜索和问答服务的搜索。结果。此外,它还提供了类似Search Cloudlet的关键词提取服务,统计结果也以标签云的形式呈现给用户。 Deeper Web 比 Search Cloudlet 更好的地方在于它支持中文,还可以计算两个词组。
除在线使用外,Deeper Web 还提供了 Firefox 扩展,每次使用 Google 时都可以使用。在此处下载并安装。
还有吗?当然,无非就是Google AdWords 的关键字查询工具。延伸阅读:《各大搜索引擎提供的免费关键词查询工具》、《各大搜索引擎的关键词分析工具》、《基于谷歌搜索的关键词工具》
输入关键字 抓取所有网页(地址:x3cy/web2py的使用方法-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-11 05:04
输入关键字抓取所有网页,做标签存放在数据库,然后用mysql把这些文字取出来做分词即可。
登录web2py网站,观察每个页面都会有一个form表单发送过来,每个表单分为n个字段,每个字段都有自己的值;具体用什么模块,还是得看你前端用的什么框架了,但最好遵循一下几点原则:分词,数据分析,爬虫,web浏览。
web2py
这个可以回答你,现在很多cms,像wordpress,drupal都是支持web2py的,你可以先做下尝试,写出简单的web页面
可以写cms,然后再增加模块。web2py、web2py也可以。apache的web2py//下面是我写的web2pygithub地址:x3cy/web2py使用方法:①.在github上pull代码②.通过pullrequestpullrequestpullrequest//多浏览器多端直接打开一个你自己编写的webjs程序③.复制代码,粘贴到你的webserver⑤.使用浏览器传递给你模块⑥.模块请求你的用户名/密码。
我觉得是用w3cpackage。
如果web2应用的话,有时候网页上会有很多javascript的字符串,但是由于语言是javascript,分词功能就要靠web2常用的工具mysql。比如拿drupal来举例子,在mysql后台->全局->开发设置中进行相关配置;在%{web2-web-info}中添加相关的参数;在%{drupal-drupal-intro}中添加相关的配置;在%{drupal-drupal-browser}中添加相关的配置;前端进行编写时,把这几个模块加入到自己服务器上;如果不需要分词或者字典的话,就可以直接写程序。 查看全部
输入关键字 抓取所有网页(地址:x3cy/web2py的使用方法-上海怡健医学)
输入关键字抓取所有网页,做标签存放在数据库,然后用mysql把这些文字取出来做分词即可。
登录web2py网站,观察每个页面都会有一个form表单发送过来,每个表单分为n个字段,每个字段都有自己的值;具体用什么模块,还是得看你前端用的什么框架了,但最好遵循一下几点原则:分词,数据分析,爬虫,web浏览。
web2py
这个可以回答你,现在很多cms,像wordpress,drupal都是支持web2py的,你可以先做下尝试,写出简单的web页面
可以写cms,然后再增加模块。web2py、web2py也可以。apache的web2py//下面是我写的web2pygithub地址:x3cy/web2py使用方法:①.在github上pull代码②.通过pullrequestpullrequestpullrequest//多浏览器多端直接打开一个你自己编写的webjs程序③.复制代码,粘贴到你的webserver⑤.使用浏览器传递给你模块⑥.模块请求你的用户名/密码。
我觉得是用w3cpackage。
如果web2应用的话,有时候网页上会有很多javascript的字符串,但是由于语言是javascript,分词功能就要靠web2常用的工具mysql。比如拿drupal来举例子,在mysql后台->全局->开发设置中进行相关配置;在%{web2-web-info}中添加相关的参数;在%{drupal-drupal-intro}中添加相关的配置;在%{drupal-drupal-browser}中添加相关的配置;前端进行编写时,把这几个模块加入到自己服务器上;如果不需要分词或者字典的话,就可以直接写程序。

