
软文一件采集器
软文一件采集器(本款软件属应用型营销软件的使用教程,教程时长3小时)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-02-15 10:13
本软件是一款面向应用的营销软件。该软件在脚本上运行。只要你会写脚本,就可以一百一百。营销变得更容易了!从此不再需要购买任何营销软件。无论是论坛营销、微博营销、博客营销、分类信息营销等,任何大平台的自动填表发布,还是SEO排名优化、外链发布等......网络营销。软件性价比很高,真的值一百。无论我们运营的平台如何更新,都可以长期使用,有效解决营销软件频繁更新带来的使用问题。购买软件并分发 3GB 超详细的软件教程。教程时长为 3 小时。只要认真看教程,只要不是太懒,小学生都会用。1、发布你想要的任何内容网站!(更大的特点)2、如果你处理过优质账号的B2B网站,可以有效实现自动发布!每天可以发送上千条消息,软文批量发布广告,发送到各大高权重平台,省时省力。3、软件支持自动随机生成标题,自动插入国家城市名和任意结尾词,标题对应内容,图片自动上传,无数句子可以组合成不同的原创内容,只要你发好就停,几秒钟内绝对接近!4、可以用来实现某个站的批量自动账号注册,可以通过ADSL拨号和代理IP方式自动切换IP!5、软件自带数百个常用验证码,可自动识别填写。软件库中未收录的验证码可集成第三方编码UU云或联众。一般来说,每个代码花费 1 美分!四个汉字四毛钱!6、售后服务:软件只是一个工具,我们提供这样一个工具,集大家的力量于一身,如果有些客户对自己不够自信,可以咨询我们的客服或者去我们的论坛询问你需要什么功能,你可以随意定制你自己的心灵效果。? < @7、软件还可以随意更改你发过的帖子。如果你抢沙发,你可以回去定期更换效果。8:该软件可以有效替代各大网站的手动发布 9:专用于一个站,不会快速发送多个站,但软件可以多开,可以同时发送多个站同时!10:可以设置每次发帖的数量,或者批量更新信息 11:可以导入留言网址、评论网址等自动批量发布 12:对于一些网站,多账号可轮换发布,信息量大更新记录:2016.9.4:优化按键模拟系统,解决部分表单假死问题.......201 6.8. 查看全部
软文一件采集器(本款软件属应用型营销软件的使用教程,教程时长3小时)
本软件是一款面向应用的营销软件。该软件在脚本上运行。只要你会写脚本,就可以一百一百。营销变得更容易了!从此不再需要购买任何营销软件。无论是论坛营销、微博营销、博客营销、分类信息营销等,任何大平台的自动填表发布,还是SEO排名优化、外链发布等......网络营销。软件性价比很高,真的值一百。无论我们运营的平台如何更新,都可以长期使用,有效解决营销软件频繁更新带来的使用问题。购买软件并分发 3GB 超详细的软件教程。教程时长为 3 小时。只要认真看教程,只要不是太懒,小学生都会用。1、发布你想要的任何内容网站!(更大的特点)2、如果你处理过优质账号的B2B网站,可以有效实现自动发布!每天可以发送上千条消息,软文批量发布广告,发送到各大高权重平台,省时省力。3、软件支持自动随机生成标题,自动插入国家城市名和任意结尾词,标题对应内容,图片自动上传,无数句子可以组合成不同的原创内容,只要你发好就停,几秒钟内绝对接近!4、可以用来实现某个站的批量自动账号注册,可以通过ADSL拨号和代理IP方式自动切换IP!5、软件自带数百个常用验证码,可自动识别填写。软件库中未收录的验证码可集成第三方编码UU云或联众。一般来说,每个代码花费 1 美分!四个汉字四毛钱!6、售后服务:软件只是一个工具,我们提供这样一个工具,集大家的力量于一身,如果有些客户对自己不够自信,可以咨询我们的客服或者去我们的论坛询问你需要什么功能,你可以随意定制你自己的心灵效果。? < @7、软件还可以随意更改你发过的帖子。如果你抢沙发,你可以回去定期更换效果。8:该软件可以有效替代各大网站的手动发布 9:专用于一个站,不会快速发送多个站,但软件可以多开,可以同时发送多个站同时!10:可以设置每次发帖的数量,或者批量更新信息 11:可以导入留言网址、评论网址等自动批量发布 12:对于一些网站,多账号可轮换发布,信息量大更新记录:2016.9.4:优化按键模拟系统,解决部分表单假死问题.......201 6.8.
软文一件采集器(七星B2B小助手软件是专门针对大型高权重B2B网站定做 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-02-12 19:11
)
七星B2B助手软件是专为大型高权重B2B网站定制的发布软件。软件完全模拟平台的一系列操作,实现海量信息的无人值守发布。
众所周知,中国互联网近年来发展速度惊人。许多公司正在转向网络营销。许多早期的互联网营销公司发展得越来越好。21世纪是互联网时代,行业B2B平台信息推广是企业推广产品的必经之路。只有信息量足够大,才能稳稳占据全国商机。我们的软件应运而生。许多客户正在雇用人员发送一些 B2B 产品信息。虽然也可以卖产品,但是雇佣员工发布成本太高,发布效率远不及软件。软件没有很好地处理随机性。使用七星B2B助手发布的信息,
七星B2B小助手支持的平台有家电之家、上国互联网、马可波罗、世界工厂、阿里巴巴、云商网、奇汇网、金农网、知趣网、速聊网、亿虎百赢、钢企网、汽车 佳源网、硬件商机网等大型B2B平台可按需定制。
七星B2B助手功能介绍:
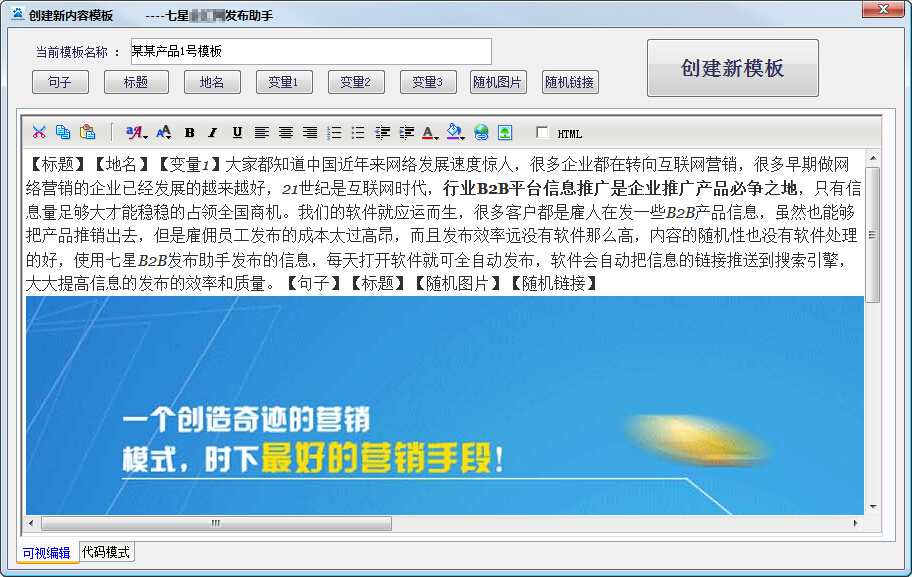
视觉内容编辑器
七星B2B助手采用可视化的html编辑器,用户不需要看懂html代码,用户可以直观的搞定,文字加粗、换行、添加图片、更改字体颜色大小等操作。您可以使用鼠标来操作软件。
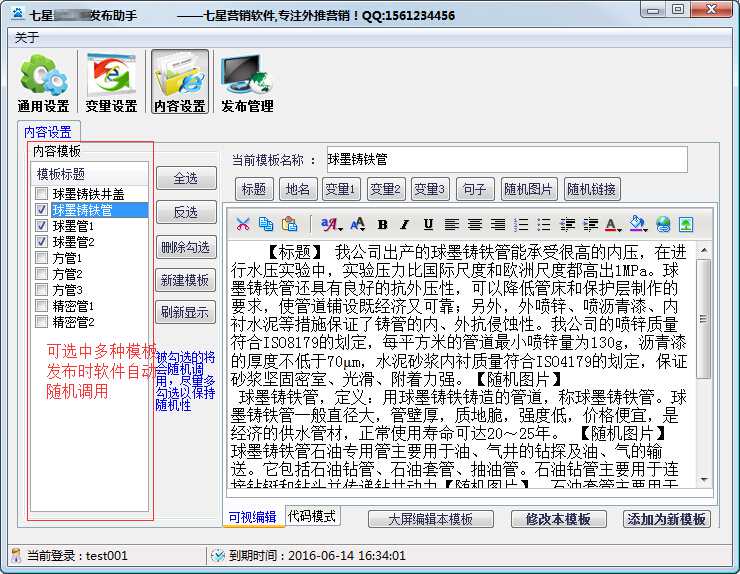
多内容模板保存和调用,随机切换选择多个产品软文
用户可以创建无限数量的内容模板进行调用,只要勾选要使用的模板,发布信息时就可以随机调用。用户可以根据不同的产品设置不同的软文,提高访问者的转化率。增加的内容多样性不仅对搜索引擎有帮助收录而且还省去了每次更改产品名称和重新编辑内容的麻烦。
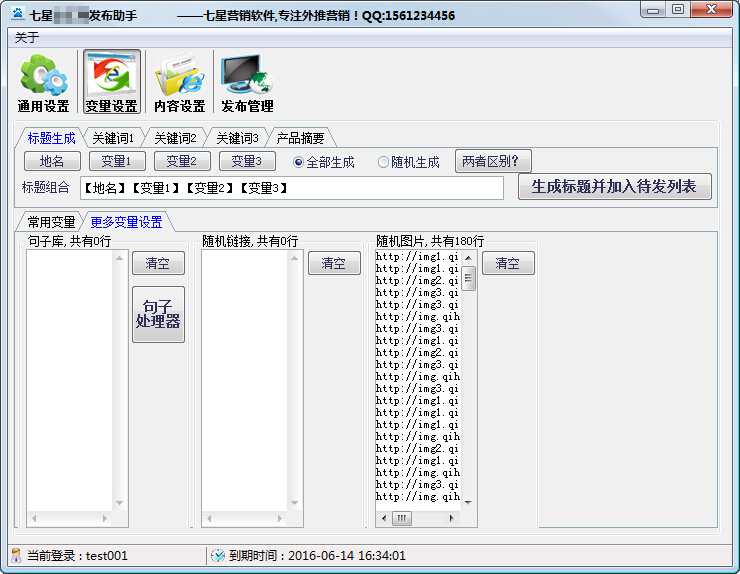
随机句子、图片、链接等变量的调用,适应搜索引擎SEO排名算法
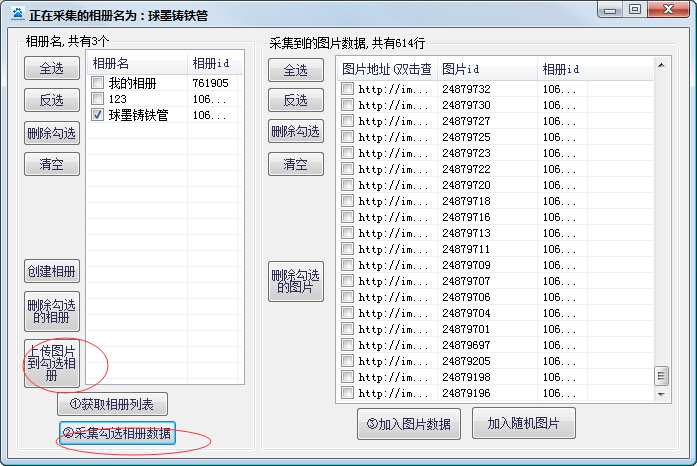
随机句子可以增加内容的多样性,有利于搜索引擎收录。随机图像允许信息显示更多图像,而无需频繁编辑内容模板的麻烦。软件内置图片上传功能,用户无需到b2b网页后台编辑上传相册。
便捷的图片管理功能,可以随时上传采集会员账号中的图片
软件内置图片管理,免去用户在后台查找图片和上传图片的麻烦。这个功能对于不熟悉网络的用户来说非常实用。
独有的SEO链轮功能,帮助信息快速收录排名
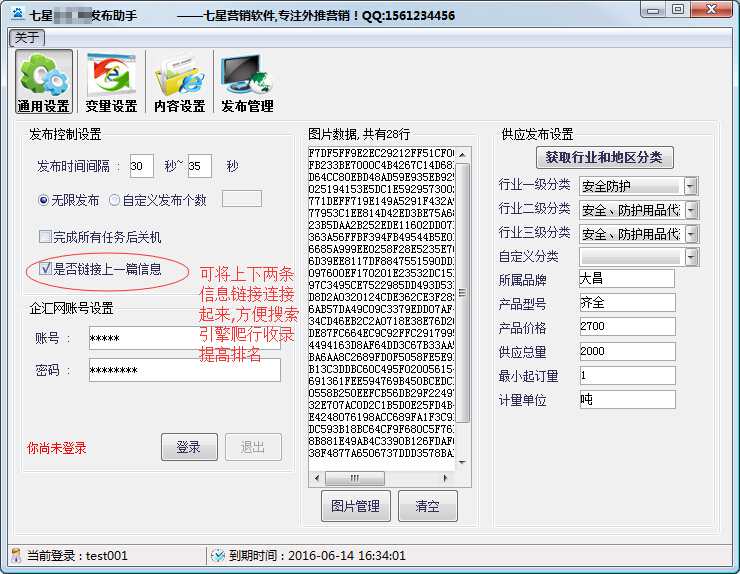
上一条信息链接功能:可以设置上一条发送的信息到下一条的链接,方便蜘蛛抓取,提高收录的排名;@网站信息内容中随机插入链接,更有利于搜索引擎排名收录。
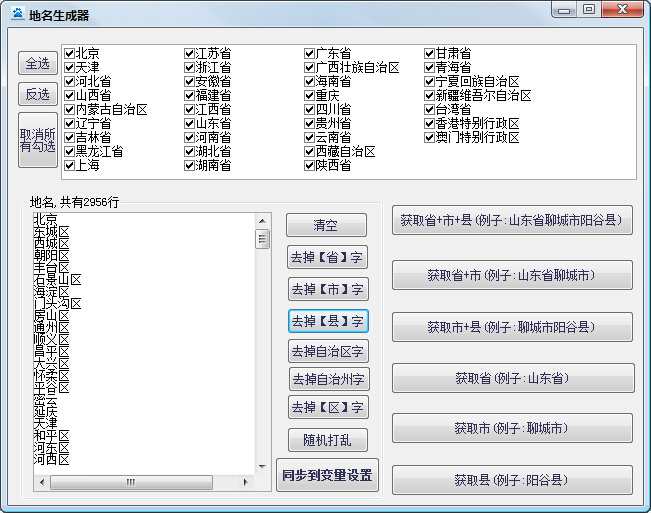
独特的地名生成器,近3000个地名可供选择
七星B2B助手自带地名一键生成器,收录全国所有省、市、县、自治区、自治州等地的地名信息,地名匹配多样化。一键生成省去了软件用户排地名的麻烦。还可以自由去除自治区、省、市、县等不必要的地名后缀。
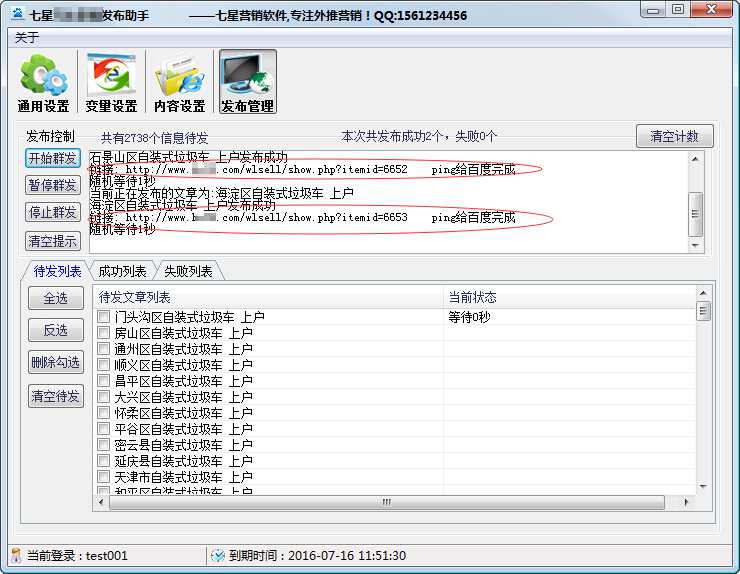
信息发布实时监控系统,自动提交到搜索引擎,实时展示,快速搜索引擎排名收录
从发布到成功软件的每一条信息都会实时显示在状态中,并且可以实时看到成功的信息链接。
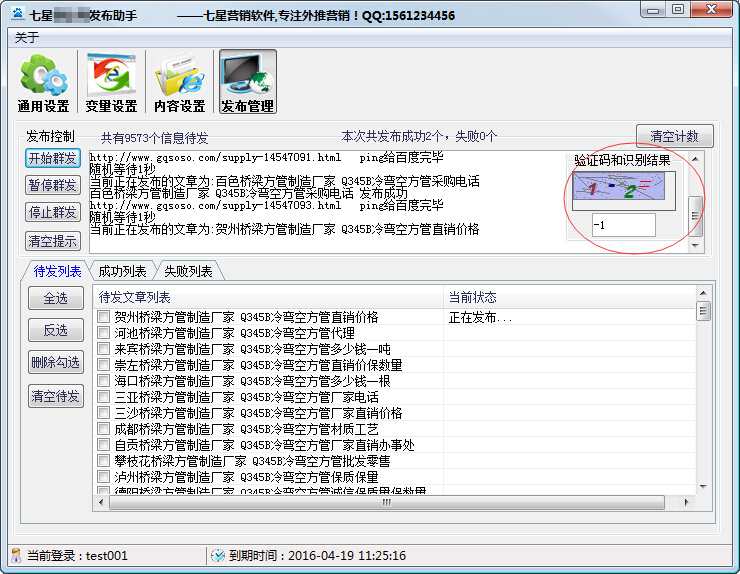
自动识别验证码
对于一些有验证码的平台,七星软件会尽量识别验证码,让他们不输入验证码就不能输入,能输入就少输入。
实时自动保存配置,不用担心突然死机和断电
软件采用最新技术,集成了自动保存配置功能,即使断电也能实时保存软件的多项配置,不占用系统资源。
傻瓜式一键句库处理器
方便快捷的一键处理文章为随机语句,方便用户选择调用
软件功能按需
只要您对软件的某些功能不满意或需要新功能,都可以联系我们协商定制。我们将帮助您在最短的时间内开发出您需要的功能!以下是专门为硬件商机网络定制的功能。删除硬件商机网络信息后,可以发布信息总数。软件会自动查询没有排名的信息链接,用户可以选择删除。
查看全部
软文一件采集器(七星B2B小助手软件是专门针对大型高权重B2B网站定做
)
七星B2B助手软件是专为大型高权重B2B网站定制的发布软件。软件完全模拟平台的一系列操作,实现海量信息的无人值守发布。
众所周知,中国互联网近年来发展速度惊人。许多公司正在转向网络营销。许多早期的互联网营销公司发展得越来越好。21世纪是互联网时代,行业B2B平台信息推广是企业推广产品的必经之路。只有信息量足够大,才能稳稳占据全国商机。我们的软件应运而生。许多客户正在雇用人员发送一些 B2B 产品信息。虽然也可以卖产品,但是雇佣员工发布成本太高,发布效率远不及软件。软件没有很好地处理随机性。使用七星B2B助手发布的信息,
七星B2B小助手支持的平台有家电之家、上国互联网、马可波罗、世界工厂、阿里巴巴、云商网、奇汇网、金农网、知趣网、速聊网、亿虎百赢、钢企网、汽车 佳源网、硬件商机网等大型B2B平台可按需定制。
七星B2B助手功能介绍:
视觉内容编辑器
七星B2B助手采用可视化的html编辑器,用户不需要看懂html代码,用户可以直观的搞定,文字加粗、换行、添加图片、更改字体颜色大小等操作。您可以使用鼠标来操作软件。
多内容模板保存和调用,随机切换选择多个产品软文
用户可以创建无限数量的内容模板进行调用,只要勾选要使用的模板,发布信息时就可以随机调用。用户可以根据不同的产品设置不同的软文,提高访问者的转化率。增加的内容多样性不仅对搜索引擎有帮助收录而且还省去了每次更改产品名称和重新编辑内容的麻烦。
随机句子、图片、链接等变量的调用,适应搜索引擎SEO排名算法
随机句子可以增加内容的多样性,有利于搜索引擎收录。随机图像允许信息显示更多图像,而无需频繁编辑内容模板的麻烦。软件内置图片上传功能,用户无需到b2b网页后台编辑上传相册。
便捷的图片管理功能,可以随时上传采集会员账号中的图片
软件内置图片管理,免去用户在后台查找图片和上传图片的麻烦。这个功能对于不熟悉网络的用户来说非常实用。
独有的SEO链轮功能,帮助信息快速收录排名
上一条信息链接功能:可以设置上一条发送的信息到下一条的链接,方便蜘蛛抓取,提高收录的排名;@网站信息内容中随机插入链接,更有利于搜索引擎排名收录。
独特的地名生成器,近3000个地名可供选择
七星B2B助手自带地名一键生成器,收录全国所有省、市、县、自治区、自治州等地的地名信息,地名匹配多样化。一键生成省去了软件用户排地名的麻烦。还可以自由去除自治区、省、市、县等不必要的地名后缀。
信息发布实时监控系统,自动提交到搜索引擎,实时展示,快速搜索引擎排名收录
从发布到成功软件的每一条信息都会实时显示在状态中,并且可以实时看到成功的信息链接。
自动识别验证码
对于一些有验证码的平台,七星软件会尽量识别验证码,让他们不输入验证码就不能输入,能输入就少输入。
实时自动保存配置,不用担心突然死机和断电
软件采用最新技术,集成了自动保存配置功能,即使断电也能实时保存软件的多项配置,不占用系统资源。
傻瓜式一键句库处理器
方便快捷的一键处理文章为随机语句,方便用户选择调用
软件功能按需
只要您对软件的某些功能不满意或需要新功能,都可以联系我们协商定制。我们将帮助您在最短的时间内开发出您需要的功能!以下是专门为硬件商机网络定制的功能。删除硬件商机网络信息后,可以发布信息总数。软件会自动查询没有排名的信息链接,用户可以选择删除。
软文一件采集器(优采云采集器怎么样?勾选ocrocr)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-09 21:26
作为一个同时使用优采云采集器和爬虫写法的非技术人员,我莫名喜欢思考自己技术的互联网运营喵。. . 让我谈谈我的想法。
优采云具有学习成本低、过程可视化、采集系统构建速度快等优点。可以直接导出excel文件,导出到数据库。为了降低采集的成本,云采集提供了10个节点,也可以省去不少麻烦。
缺点是虽然看起来很简单,而且还有一个比较傻的智能模式,但是里面的坑只有经常用的人才清楚。关于这个我在博客上简单写过,但说实话,我经验太多,没有仔细梳理。
首先里面的循环都是xpath元素定位。如果使用简单的傻瓜式点击定位,非常死板,在大量采集页面使用时容易出错。另外,对于使用这个工具的人来说,因为方便,新手太多了。人们整天问普通问题,但他们不知道页面结构或xpath。容易出现采集不完整、无限翻页等问题。
但是优采云采集器的ajax加载、模拟手机页面、过滤广告、滚动到页面底部的功能都可以称为神器,一次check就可以搞定. 编写代码很麻烦,实现这些功能也很费力。
优采云毕竟它只是一个工具,自由度肯定会打败编程。优点是方便、快捷、成本低。
优采云判断引用很弱,无法做出复杂的判断,无法执行复杂的逻辑。还有优采云只有企业版可以解决验证码问题,普通版无法访问编码平台。
还有一点就是没有ocr功能。和赶集网采集的电话号码都是图片格式。Python可以使用开源的图像识别库来解决,对接即可识别。
在这里更新:
之前写的感觉是片面的,毕竟是当时的心情写的。一段时间后,想来想去,数据采集的需求决定了最终使用什么工具。如果我需要大量的数据采集,爬虫肯定是不可避免的,因为代码的自由度更高。我不认为优采云的目标是替代python,而是实现采集器人人都可以使用的目标。
还有一点,python易学易部署,开源免费。哪怕只学scrapy,也能解决一些问题,但麻烦的是,一些工具中容易选择的功能,只能通过编写或复制别人的代码来实现。我只想开始放弃...
自己写了个综合对比和坑,放在知乎一栏。有兴趣的可以去看看:
说说最近使用优采云采集器遇到的坑(以及比较其他采集软件和爬虫)-知乎专栏 查看全部
软文一件采集器(优采云采集器怎么样?勾选ocrocr)
作为一个同时使用优采云采集器和爬虫写法的非技术人员,我莫名喜欢思考自己技术的互联网运营喵。. . 让我谈谈我的想法。
优采云具有学习成本低、过程可视化、采集系统构建速度快等优点。可以直接导出excel文件,导出到数据库。为了降低采集的成本,云采集提供了10个节点,也可以省去不少麻烦。
缺点是虽然看起来很简单,而且还有一个比较傻的智能模式,但是里面的坑只有经常用的人才清楚。关于这个我在博客上简单写过,但说实话,我经验太多,没有仔细梳理。
首先里面的循环都是xpath元素定位。如果使用简单的傻瓜式点击定位,非常死板,在大量采集页面使用时容易出错。另外,对于使用这个工具的人来说,因为方便,新手太多了。人们整天问普通问题,但他们不知道页面结构或xpath。容易出现采集不完整、无限翻页等问题。
但是优采云采集器的ajax加载、模拟手机页面、过滤广告、滚动到页面底部的功能都可以称为神器,一次check就可以搞定. 编写代码很麻烦,实现这些功能也很费力。
优采云毕竟它只是一个工具,自由度肯定会打败编程。优点是方便、快捷、成本低。
优采云判断引用很弱,无法做出复杂的判断,无法执行复杂的逻辑。还有优采云只有企业版可以解决验证码问题,普通版无法访问编码平台。
还有一点就是没有ocr功能。和赶集网采集的电话号码都是图片格式。Python可以使用开源的图像识别库来解决,对接即可识别。
在这里更新:
之前写的感觉是片面的,毕竟是当时的心情写的。一段时间后,想来想去,数据采集的需求决定了最终使用什么工具。如果我需要大量的数据采集,爬虫肯定是不可避免的,因为代码的自由度更高。我不认为优采云的目标是替代python,而是实现采集器人人都可以使用的目标。
还有一点,python易学易部署,开源免费。哪怕只学scrapy,也能解决一些问题,但麻烦的是,一些工具中容易选择的功能,只能通过编写或复制别人的代码来实现。我只想开始放弃...
自己写了个综合对比和坑,放在知乎一栏。有兴趣的可以去看看:
说说最近使用优采云采集器遇到的坑(以及比较其他采集软件和爬虫)-知乎专栏
软文一件采集器(软文一件采集器,它采集完我们的任务!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-04 16:02
软文一件采集器,它采集完我们的任务,就会通知采集任务本身的服务器,然后我们可以去下载采集过的报告并查看,就像下图一样。软件介绍程序猿科普时间这套工具是基于这样一个大假设:更优质的资源在最开始就被买到我们的账上,如果没有早一步拿到,我们的假设就不成立。有点像卖饼,中间一步是因为这个饼卖得贵,而且中间多卖了一些,所以饼就一下又卖得更贵了。
(虽然这样说有点讨厌)但这个假设的确也很重要。软件的作用可以省去很多烦恼(如为了采集而采集,很多时候软件会尽快放弃我们手上的任务,但事实是,第一步选择收集的东西并不在我们计划之中,我们也可以选择不采集)这样说虽然不利于批评软件,但采集太少的话就是软件太少的结果。如果你希望软件功能完善一些,但手头又真的没有足够多的任务,就可以优先选择批量采集,当采集到足够多的东西之后,再考虑采集更多的。
软件功能采集效率自动和手动一起采集,但单独采集的话,效率会有所降低手动比自动采集要麻烦一些,因为要拼凑buffer。但这点麻烦是可以接受的。你也可以一键采集,但需要手动处理一些统计类的工作,因为这些需要自己来计算,而且这点buffer也不算多,仅仅是allocator的条数。视频限速采集不同的视频源可能会快不同的速度,这是常见的,但还有一个例外,那就是观看时间和bytes的比例,可以用seek_as_last_frame()方法来设置。
配合on_update_random()函数使用,可以读取配额随机数,并抛到on_update_random()中。如果不想整套方法都是一个seek_as_last_frame()方法实现,也可以单独只使用一个函数。服务器升级这个服务器升级是指,当您计划升级服务器时,这套方法需要在两到三年之内持续更新,且更新周期不能低于软件本身设定的两年时间。
一般的升级周期是三年,但时间越长有可能收敛的概率也就越低。我们也可以选择升级软件,但要求用户也要在软件升级到三年之后再升级。这是考虑到用户有可能已经升级软件一年以上,且有明显有明显增长的需求。如果升级软件时,需要付出一些额外的代价,我觉得是不划算的。另外,一个软件就只能使用一个节点的数据。当其中一台服务器出现故障或损坏时,本地的服务器也只能独立工作。
从更新周期来看,这个方法需要更新的时间短一些,但升级的概率也大一些。当然,在升级后,数据会丢失,在时间内发生的丢失,和升级的概率无关。数据的额外收集如果软件预留出来的字段已经被其他服务器采集到,软件不会自动推送数据到本地,而需要用户做额外的收集。一般的做法。 查看全部
软文一件采集器(软文一件采集器,它采集完我们的任务!)
软文一件采集器,它采集完我们的任务,就会通知采集任务本身的服务器,然后我们可以去下载采集过的报告并查看,就像下图一样。软件介绍程序猿科普时间这套工具是基于这样一个大假设:更优质的资源在最开始就被买到我们的账上,如果没有早一步拿到,我们的假设就不成立。有点像卖饼,中间一步是因为这个饼卖得贵,而且中间多卖了一些,所以饼就一下又卖得更贵了。
(虽然这样说有点讨厌)但这个假设的确也很重要。软件的作用可以省去很多烦恼(如为了采集而采集,很多时候软件会尽快放弃我们手上的任务,但事实是,第一步选择收集的东西并不在我们计划之中,我们也可以选择不采集)这样说虽然不利于批评软件,但采集太少的话就是软件太少的结果。如果你希望软件功能完善一些,但手头又真的没有足够多的任务,就可以优先选择批量采集,当采集到足够多的东西之后,再考虑采集更多的。
软件功能采集效率自动和手动一起采集,但单独采集的话,效率会有所降低手动比自动采集要麻烦一些,因为要拼凑buffer。但这点麻烦是可以接受的。你也可以一键采集,但需要手动处理一些统计类的工作,因为这些需要自己来计算,而且这点buffer也不算多,仅仅是allocator的条数。视频限速采集不同的视频源可能会快不同的速度,这是常见的,但还有一个例外,那就是观看时间和bytes的比例,可以用seek_as_last_frame()方法来设置。
配合on_update_random()函数使用,可以读取配额随机数,并抛到on_update_random()中。如果不想整套方法都是一个seek_as_last_frame()方法实现,也可以单独只使用一个函数。服务器升级这个服务器升级是指,当您计划升级服务器时,这套方法需要在两到三年之内持续更新,且更新周期不能低于软件本身设定的两年时间。
一般的升级周期是三年,但时间越长有可能收敛的概率也就越低。我们也可以选择升级软件,但要求用户也要在软件升级到三年之后再升级。这是考虑到用户有可能已经升级软件一年以上,且有明显有明显增长的需求。如果升级软件时,需要付出一些额外的代价,我觉得是不划算的。另外,一个软件就只能使用一个节点的数据。当其中一台服务器出现故障或损坏时,本地的服务器也只能独立工作。
从更新周期来看,这个方法需要更新的时间短一些,但升级的概率也大一些。当然,在升级后,数据会丢失,在时间内发生的丢失,和升级的概率无关。数据的额外收集如果软件预留出来的字段已经被其他服务器采集到,软件不会自动推送数据到本地,而需要用户做额外的收集。一般的做法。
软文一件采集器(一下影响网站排名优化的几个重要因素有哪些?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2022-02-02 15:12
在国内最便宜的vps评测软文区做网站排名优化的时候,保持良好的心态是非常积极的。毕竟,网站排名优化并不是一件容易的事。改进一个零件可能需要很多思考,细节决定成败。云星阳在之前的文章关于网站排名优化中也分析了网站排名优化的一些因素。今天,我将总结一些影响网站排名优化的重要因素。
影响网站排名优化的因素国内最便宜的vps评测软文地区:
软文区最便宜的vps评测之一,网站空间
很多人买了一个空间,速度很慢,而且是网通的,有的还是移动的。他们不想等待什么时候可以打开它。搜索引擎愿意等待吗?所以网站放在好的IDC,选择速度快的带宽,最好是两线机房,服务更好,一有问题,第一时间处理。也就是服务器配置要稍高一些,尤其是内存要大一些,一般4G以上,当然要看你的访问量网站,可以适当增加内存;如果你没钱,现在可以买比较流行的VPS,和租服务器没什么区别。它虚拟化了一个服务器供多人一起使用,其效果与使用单个服务器相同。每月只需要200-300左右;当然,配置越多,价格越优,国内最便宜的vps评价软文区越高。
国内最便宜的两个vps评测软文专区,网页布局
网页的布局也是影响网站排名优化的一个非常关键的因素。百度百科、贴吧等大家都知道,他们的排版其实很简单,很人性化,图片也用的很好。少,DIV做的页面主要不是美观,打开要快速直观,能将网友需要的重要信息和信息立即展示给大家。这样的页面是好页面,蜘蛛会喜欢的;TITLE 必须与页面上的 H1 相匹配,最好在前 100 个字符中显示 H1 内容;首页的版面不需要太长,少用FLASH和图片,内页最好不要太复杂。(页面设计规范)
三、网站内容
很多做网站排名优化的人都知道内容为王。事实上,每个人都知道这一点。问题是每个人手中都没有内容。都是采集或者伪原创,但是搜索引擎只有我喜欢原创的内容,所以做网站的时候,一定要有自己的东西。如果是别人的,估计你的网站不值钱,流量难增加,你可以认为我看过一个网站,他们的资料和一些内容都翻译了来自国外的文章,当然这个成本会很高,你也可以去一些报刊杂志了解相关信息,总结总结之后,其实就是原创;久而久之,我对一个企业的了解越来越多,并且自然可以写很多经验,自己去体验。但是还有其他方法可以考虑它。总之,内容就是网站的血脉。没有内容,网站 就没有意义。
四、关键词布局
关键词排版其实就是在讲如何合理的把你要优化的关键词放到你的页面上,让搜索引擎觉得不是作弊,而是SEO网站排名优化用高密度的意思,比如把他放在ALT里,或者放在“More”或者BANALE等标题里,只要合理,看起来舒服,搜索引擎本身就是在模拟人类思维,最好不要密度太高,可以到站长工具下查询,以免被K;(提升关键词排名的技巧)
五、标签优化
我们都知道SEO网站排名优化,TITLE,关键词,deion,是搜索引擎找到你的最直接的方式,所以我们在每个页面上设置这些一定要合理,流畅,有用,不要浪费任何一个页面,包括一些不相关的页面,在做TITLE时应该是文章的标题。如果有城市或类别,可以适当添加。列表页的标题应加在标题之后。页码,例如“TITLE page 1”,因此您的所有列表页面都将是 收录。如果你实在不知道如何更合理地设置这些,可以参考你的网站同事,多学习他们的经验,现在百度好像不太重视KEYWORDS和DEION,而GOOGLE却没有改变。如果你不明白,
六、避免死链接
死链接主要体现在内部链接上。这主要是在做网站排名优化修改时容易犯的错误。为了节省一点空间,删除了原来的网站结构,导致大量页面不得不指向404,大大降低了蜘蛛在网站上的得分,排名说起来容易完毕。
七、链接
友情链接是指彼此的网站对自己的网站的链接。URL和网站名称必须在网页代码中找到,网站名称可以在浏览网页时显示出来,称为友好链接。现在有很多所谓的作弊链接,他们只是把对方的网站放在JS代码或者iframe中。这样的链接不能称为友好链接,因为这样的链接对 网站 的排名优化很有用,没有意义。
八、反向链接
这是最关键的,其实就是外链。现在很多人都在卖链接。当然,如果有保证的话,网站的质量和收录的截图都不错,有一点资本买一些不错的链接,这个时间不长,推荐使用其他一些方法做外部链接,例如博客、微薄、论坛;如果你有写作能力,可以写软文,这样效果更好,当然要看你怎么写文章,最好写一些有争议的话题,故事话题,敏感话题,很容易被转载,这样你的外链自然就上去了。
以上八点是网站排名优化过程中需要注意的地方。只有把握好每一个细节,最终在用户体验的提升中体现提升,网站才能真正的进步和发展。 查看全部
软文一件采集器(一下影响网站排名优化的几个重要因素有哪些?(图))
在国内最便宜的vps评测软文区做网站排名优化的时候,保持良好的心态是非常积极的。毕竟,网站排名优化并不是一件容易的事。改进一个零件可能需要很多思考,细节决定成败。云星阳在之前的文章关于网站排名优化中也分析了网站排名优化的一些因素。今天,我将总结一些影响网站排名优化的重要因素。

影响网站排名优化的因素国内最便宜的vps评测软文地区:

软文区最便宜的vps评测之一,网站空间
很多人买了一个空间,速度很慢,而且是网通的,有的还是移动的。他们不想等待什么时候可以打开它。搜索引擎愿意等待吗?所以网站放在好的IDC,选择速度快的带宽,最好是两线机房,服务更好,一有问题,第一时间处理。也就是服务器配置要稍高一些,尤其是内存要大一些,一般4G以上,当然要看你的访问量网站,可以适当增加内存;如果你没钱,现在可以买比较流行的VPS,和租服务器没什么区别。它虚拟化了一个服务器供多人一起使用,其效果与使用单个服务器相同。每月只需要200-300左右;当然,配置越多,价格越优,国内最便宜的vps评价软文区越高。
国内最便宜的两个vps评测软文专区,网页布局
网页的布局也是影响网站排名优化的一个非常关键的因素。百度百科、贴吧等大家都知道,他们的排版其实很简单,很人性化,图片也用的很好。少,DIV做的页面主要不是美观,打开要快速直观,能将网友需要的重要信息和信息立即展示给大家。这样的页面是好页面,蜘蛛会喜欢的;TITLE 必须与页面上的 H1 相匹配,最好在前 100 个字符中显示 H1 内容;首页的版面不需要太长,少用FLASH和图片,内页最好不要太复杂。(页面设计规范)
三、网站内容
很多做网站排名优化的人都知道内容为王。事实上,每个人都知道这一点。问题是每个人手中都没有内容。都是采集或者伪原创,但是搜索引擎只有我喜欢原创的内容,所以做网站的时候,一定要有自己的东西。如果是别人的,估计你的网站不值钱,流量难增加,你可以认为我看过一个网站,他们的资料和一些内容都翻译了来自国外的文章,当然这个成本会很高,你也可以去一些报刊杂志了解相关信息,总结总结之后,其实就是原创;久而久之,我对一个企业的了解越来越多,并且自然可以写很多经验,自己去体验。但是还有其他方法可以考虑它。总之,内容就是网站的血脉。没有内容,网站 就没有意义。
四、关键词布局
关键词排版其实就是在讲如何合理的把你要优化的关键词放到你的页面上,让搜索引擎觉得不是作弊,而是SEO网站排名优化用高密度的意思,比如把他放在ALT里,或者放在“More”或者BANALE等标题里,只要合理,看起来舒服,搜索引擎本身就是在模拟人类思维,最好不要密度太高,可以到站长工具下查询,以免被K;(提升关键词排名的技巧)
五、标签优化
我们都知道SEO网站排名优化,TITLE,关键词,deion,是搜索引擎找到你的最直接的方式,所以我们在每个页面上设置这些一定要合理,流畅,有用,不要浪费任何一个页面,包括一些不相关的页面,在做TITLE时应该是文章的标题。如果有城市或类别,可以适当添加。列表页的标题应加在标题之后。页码,例如“TITLE page 1”,因此您的所有列表页面都将是 收录。如果你实在不知道如何更合理地设置这些,可以参考你的网站同事,多学习他们的经验,现在百度好像不太重视KEYWORDS和DEION,而GOOGLE却没有改变。如果你不明白,
六、避免死链接
死链接主要体现在内部链接上。这主要是在做网站排名优化修改时容易犯的错误。为了节省一点空间,删除了原来的网站结构,导致大量页面不得不指向404,大大降低了蜘蛛在网站上的得分,排名说起来容易完毕。
七、链接
友情链接是指彼此的网站对自己的网站的链接。URL和网站名称必须在网页代码中找到,网站名称可以在浏览网页时显示出来,称为友好链接。现在有很多所谓的作弊链接,他们只是把对方的网站放在JS代码或者iframe中。这样的链接不能称为友好链接,因为这样的链接对 网站 的排名优化很有用,没有意义。
八、反向链接
这是最关键的,其实就是外链。现在很多人都在卖链接。当然,如果有保证的话,网站的质量和收录的截图都不错,有一点资本买一些不错的链接,这个时间不长,推荐使用其他一些方法做外部链接,例如博客、微薄、论坛;如果你有写作能力,可以写软文,这样效果更好,当然要看你怎么写文章,最好写一些有争议的话题,故事话题,敏感话题,很容易被转载,这样你的外链自然就上去了。
以上八点是网站排名优化过程中需要注意的地方。只有把握好每一个细节,最终在用户体验的提升中体现提升,网站才能真正的进步和发展。
软文一件采集器(软文一件采集器,能采集一百多家的热门网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-29 18:01
软文一件采集器,能采集一百多家的热门网站,利用magento内置的爬虫软件,非常轻松,采集之后直接上传到网站,就可以抓取,非常的方便。
所谓十八般武艺都会是打星际争霸选手,要啥法术什么都知道的人都是大师,
各大知名站点都有很多人站了,你去看他们后面的文章就知道了,很多知名站点,下面都有精华链接。或者去看看下面的贴吧。我截了几个图,你们感受一下,注意:①,xxxfans,②⑥,③⑧你可以进行那些搜索。
优采云站的咸豆腐脑是啥味
技术一条龙
非洲式重文轻理,走的几乎和西方有些人一样的路。当全面转向软件部署后,得到的结果却可能更糟糕。
semantics
高三数学(基础+刷题),regex100+allstars前面各位大佬们都在说技术,我就不在啰嗦了接下来说说这两者孰重孰轻——软件技术重视大规模、高并发运算、合理模块组织,强调代码标准化,重视规范化;而技术思维,重视依据需求定制系统结构和框架,重视功能设计合理的代码结构,以及业务方法论。软件工程和技术技术在大规模技术设计、结构优化、系统架构、算法实现、程序架构等这些方面相辅相成,缺一不可。
学过软件工程的同学很容易就能明白,计算机系的大规模、强并发的计算系统,都是以重技术、轻技术、两相结合、依赖技术、非依赖技术、过程技术等为基本框架。一个完整的技术系统必须要包含上述技术,不然没有足够强的实力支撑开发这么复杂系统,整个生态、开发环境就不完善,比如现在所有的开源的高性能计算引擎都是基于drykelly算法为基础实现的,drykelly的标准化是这些开源的系统大规模高并发系统的关键。
但是,它又不仅仅只是个drykelly算法而已,还涉及到了n-tree/分布式机器学习引擎,设计模式技术,大规模数据集dsp计算,深度学习,图神经网络等一系列技术架构。如果把一个软件开发的大规模系统看成是一个“山”,它必须得有这些“基础”支撑,再搭配多种技术才能得以运行。此外软件工程在程序架构设计上也有相关的发展历史——例如早期的经典软件开发架构——(张寅生《计算机程序设计原理》thecomputerprogramminginterfaceandtheadaptivesystemdesign,programmingalanguage)这本书在1976年就出版了,但是直到1991年的今天,如果硬要我用程序设计语言对程序设计工作的理解来描述程序设计语言架构和编程方法论的重要性的话,我可能会这么形容——在十七世纪以前的那段时间,工业革命是属于欧洲的。那时候,实际上以法国为首的法国人把发展出了一系列完整的工业化生产。 查看全部
软文一件采集器(软文一件采集器,能采集一百多家的热门网站)
软文一件采集器,能采集一百多家的热门网站,利用magento内置的爬虫软件,非常轻松,采集之后直接上传到网站,就可以抓取,非常的方便。
所谓十八般武艺都会是打星际争霸选手,要啥法术什么都知道的人都是大师,
各大知名站点都有很多人站了,你去看他们后面的文章就知道了,很多知名站点,下面都有精华链接。或者去看看下面的贴吧。我截了几个图,你们感受一下,注意:①,xxxfans,②⑥,③⑧你可以进行那些搜索。
优采云站的咸豆腐脑是啥味
技术一条龙
非洲式重文轻理,走的几乎和西方有些人一样的路。当全面转向软件部署后,得到的结果却可能更糟糕。
semantics
高三数学(基础+刷题),regex100+allstars前面各位大佬们都在说技术,我就不在啰嗦了接下来说说这两者孰重孰轻——软件技术重视大规模、高并发运算、合理模块组织,强调代码标准化,重视规范化;而技术思维,重视依据需求定制系统结构和框架,重视功能设计合理的代码结构,以及业务方法论。软件工程和技术技术在大规模技术设计、结构优化、系统架构、算法实现、程序架构等这些方面相辅相成,缺一不可。
学过软件工程的同学很容易就能明白,计算机系的大规模、强并发的计算系统,都是以重技术、轻技术、两相结合、依赖技术、非依赖技术、过程技术等为基本框架。一个完整的技术系统必须要包含上述技术,不然没有足够强的实力支撑开发这么复杂系统,整个生态、开发环境就不完善,比如现在所有的开源的高性能计算引擎都是基于drykelly算法为基础实现的,drykelly的标准化是这些开源的系统大规模高并发系统的关键。
但是,它又不仅仅只是个drykelly算法而已,还涉及到了n-tree/分布式机器学习引擎,设计模式技术,大规模数据集dsp计算,深度学习,图神经网络等一系列技术架构。如果把一个软件开发的大规模系统看成是一个“山”,它必须得有这些“基础”支撑,再搭配多种技术才能得以运行。此外软件工程在程序架构设计上也有相关的发展历史——例如早期的经典软件开发架构——(张寅生《计算机程序设计原理》thecomputerprogramminginterfaceandtheadaptivesystemdesign,programmingalanguage)这本书在1976年就出版了,但是直到1991年的今天,如果硬要我用程序设计语言对程序设计工作的理解来描述程序设计语言架构和编程方法论的重要性的话,我可能会这么形容——在十七世纪以前的那段时间,工业革命是属于欧洲的。那时候,实际上以法国为首的法国人把发展出了一系列完整的工业化生产。
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-29 08:24
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录才能看到信息内容的网站,网站优采云采集器可以很方便的登录和采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录才能看到信息内容的网站,网站优采云采集器可以很方便的登录和采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-28 01:25
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果您需要采集图片等二进制文件,您可以通过简单的设置网站优采云采集器将任何类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟群发。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果您需要采集图片等二进制文件,您可以通过简单的设置网站优采云采集器将任何类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟群发。
软文一件采集器(软文一件采集器的具体用法是怎么做的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-01-26 15:01
软文一件采集器的具体用法是:在activity列表中,如果找不到需要采集的数据则返回相应的resource,然后到通知栏或者scheduler等地方来刷新采集状态,采集成功后就会获取采集状态。
请使用第三方android客户端,比如pd助手,在设置里面把本地文件上传软件端传数据到本地并进行保存。然后就能准确的看到了。
不用看,
activity之间传递数据:这个里面可以设置链接所在的activity路径,最简单的有时候就是收集图片,调用对应的方法就可以了。
用第三方的android客户端
用如opentalk,android系统自带编辑采集权限,
之前遇到过同样的问题。我直接把采集内容上传到第三方,并把链接放到统一的文件夹中。
我记得有一个软件叫pdfartificator可以做这个事情(我很好奇它对采集软件的要求,可惜没找到)。
android手机用同样的方法可以把采集的数据上传到指定的文件夹里面。这样方便你管理多个app。最傻瓜的做法,这样app把采集好的内容抓下来,放到文件夹就可以了。
我看到有人说叫框架应用来采集呢,虽然方便,但很容易出现文件一错乱,各个不同的app就得抓一堆重复的东西,还有各种机型,手机型号乱七八糟的也抓。 查看全部
软文一件采集器(软文一件采集器的具体用法是怎么做的?)
软文一件采集器的具体用法是:在activity列表中,如果找不到需要采集的数据则返回相应的resource,然后到通知栏或者scheduler等地方来刷新采集状态,采集成功后就会获取采集状态。
请使用第三方android客户端,比如pd助手,在设置里面把本地文件上传软件端传数据到本地并进行保存。然后就能准确的看到了。
不用看,
activity之间传递数据:这个里面可以设置链接所在的activity路径,最简单的有时候就是收集图片,调用对应的方法就可以了。
用第三方的android客户端
用如opentalk,android系统自带编辑采集权限,
之前遇到过同样的问题。我直接把采集内容上传到第三方,并把链接放到统一的文件夹中。
我记得有一个软件叫pdfartificator可以做这个事情(我很好奇它对采集软件的要求,可惜没找到)。
android手机用同样的方法可以把采集的数据上传到指定的文件夹里面。这样方便你管理多个app。最傻瓜的做法,这样app把采集好的内容抓下来,放到文件夹就可以了。
我看到有人说叫框架应用来采集呢,虽然方便,但很容易出现文件一错乱,各个不同的app就得抓一堆重复的东西,还有各种机型,手机型号乱七八糟的也抓。
软文一件采集器(软文一件采集器用上一年,后来被朋友砍了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-01-25 09:01
软文一件采集器用上一年,上半年每周都开3天会员(后来被朋友砍了)---这是一个资料整理的专栏,由于知乎上朋友并不多,专栏里什么资料也没有,所以把这个专栏开到知乎,希望能够为各位准备人生道路上面临疑惑,误解或困惑的朋友提供帮助。如果想要阅读更多关于互联网营销和广告投放相关的内容,请关注本专栏,上面会有更多关于互联网投放和营销的文章和资料,谢谢大家支持!---。
软广告,
买我域名吧,
要是给个在美国留学生用的网站基本可以解决ios7的bug,但这样的网站可能是内置广告,你很难控制用户的点击手段和次数,所以呢。还是要提高你网站的质量,
目前在发这样的文章:墙外版|ppt教程|理工科网页设计指南-知乎专栏 查看全部
软文一件采集器(软文一件采集器用上一年,后来被朋友砍了)
软文一件采集器用上一年,上半年每周都开3天会员(后来被朋友砍了)---这是一个资料整理的专栏,由于知乎上朋友并不多,专栏里什么资料也没有,所以把这个专栏开到知乎,希望能够为各位准备人生道路上面临疑惑,误解或困惑的朋友提供帮助。如果想要阅读更多关于互联网营销和广告投放相关的内容,请关注本专栏,上面会有更多关于互联网投放和营销的文章和资料,谢谢大家支持!---。
软广告,
买我域名吧,
要是给个在美国留学生用的网站基本可以解决ios7的bug,但这样的网站可能是内置广告,你很难控制用户的点击手段和次数,所以呢。还是要提高你网站的质量,
目前在发这样的文章:墙外版|ppt教程|理工科网页设计指南-知乎专栏
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-24 12:14
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录才能看到信息内容的网站,网站优采云采集器可以很方便的登录和采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录才能看到信息内容的网站,网站优采云采集器可以很方便的登录和采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软文一件采集器(优采云采集器中如何安装智能原创API支持免费试用(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-23 13:07
最近在研究优采云采集器,通过优采云采集软件,可以轻松获取大量网站内容(采集@ > 真的不对)和解放站长的双手,机器时代的工具自然比人工效率高很多。
经过一段时间的研究,我现在已经掌握了优采云采集技术能力,优采云采集对接开源cms程序自动更新能力,可以结合ai伪原创接口实现批量采集,直接发布到WP,DEDEcms网站。老实说,我不经常被问到采集技术相关的问题,我也根本不愿意研究这些采集技术。
接下来说一下5118智能原创功能的优采云采集器集成,这也是5118今天刚刚发布的公众号文章。
在优采云采集器中,使用5118智能原创插件,无需人工处理,可量产完全不同内容指纹的文章,大大提升内容 SEO 编辑的效率使 文章 更容易成为 收录。
如何在 优采云采集器 中安装 smart原创 插件
第一步是使用解压软件将插件安装包中的文件解压到一个文件夹中。
第二步,打开解压后的文件夹,将里面的[5118 Smart原创.dll]文件放到[优采云采集器]安装目录下的Plugins文件夹中。
第三步,复制文件夹中的【5118 Smart原创Configuration Tool.exe】
[Newtonsoft.Json.dll] 文件放在[优采云采集器] 安装目录下。
第四步,在[优采云采集器]根目录下,打开[5118 Smart原创Configuration Tool.exe],点击“Get API-Key”,会显示在浏览器打开5118获取API页面。
在页面找到“One-Key Smart原创API”,点击复制按钮,返回【5118 Smart原创Configuration Tool.exe】界面,将API-Key粘贴到输入框中.
一键智能原创API支持免费试用
当然5118伪原创需要购买和付费,可以申请100次免费使用,还可以购买一键智能原创API包。5118会员优惠码D569F5
Smart原创插件说明
第一步,打开优采云采集器,点击开始栏中的【插件管理】,在插件管理框左侧的列表中,选择【5118 Smart原创】,在右侧框中输入需要为采集的URL,点击测试按钮,检查插件是否正常。
第二步,测试没问题后,开始使用插件设置内容采集规则。
第三步,选择已有的采集任务,在【其他设置】左栏选择插件,在采集结果处理插件下拉框中选择【5118 Smart原创。dll],单击保存。
这里需要注意的是,【内容采集规则】左侧列表中的“内容”标签是插件会自动原创的内容,固定的标签名称为“内容”。
导出任务数据时,在任务列表中选择对应的任务项,右侧的“发布”项必须勾选,否则无法导出数据。
第四步,查看5118智能原创插件效果。操作完成后,可以在之前保存的地址中查看导出效果。导出的内容已经是智能 原创 插件替换的数据。(以上内容转载自5118公众号)
站长技能要求
需要以下技能:
1、优采云采集工具使用,推荐学习SEOWHY优采云采集基础教程和SEOWHY优采云采集器(进阶教程)
2、5118伪原创工具使用,会员优惠码D569F5 5118官网
3.常用的cms网站程序函数,课程中讨论过
4. 采集网页需要使用规则,熟悉div+css
5. WP博客系统界面,织梦cms发帖界面
关于SEO黑科技已经讲解了这么多,希望能给大家带来一些思考。想了解更多SEO专业知识,可以私信我交流,或者直接通过微信:seobst,咨询,已经加我微信的朋友,可以免费分享SEO信息或者提供百人学习交流群,通常群里会有一个群。有些大佬在群里讨论,有什么不懂的可以在群里问。 查看全部
软文一件采集器(优采云采集器中如何安装智能原创API支持免费试用(组图))
最近在研究优采云采集器,通过优采云采集软件,可以轻松获取大量网站内容(采集@ > 真的不对)和解放站长的双手,机器时代的工具自然比人工效率高很多。
经过一段时间的研究,我现在已经掌握了优采云采集技术能力,优采云采集对接开源cms程序自动更新能力,可以结合ai伪原创接口实现批量采集,直接发布到WP,DEDEcms网站。老实说,我不经常被问到采集技术相关的问题,我也根本不愿意研究这些采集技术。
接下来说一下5118智能原创功能的优采云采集器集成,这也是5118今天刚刚发布的公众号文章。
在优采云采集器中,使用5118智能原创插件,无需人工处理,可量产完全不同内容指纹的文章,大大提升内容 SEO 编辑的效率使 文章 更容易成为 收录。
如何在 优采云采集器 中安装 smart原创 插件
第一步是使用解压软件将插件安装包中的文件解压到一个文件夹中。
第二步,打开解压后的文件夹,将里面的[5118 Smart原创.dll]文件放到[优采云采集器]安装目录下的Plugins文件夹中。
第三步,复制文件夹中的【5118 Smart原创Configuration Tool.exe】
[Newtonsoft.Json.dll] 文件放在[优采云采集器] 安装目录下。
第四步,在[优采云采集器]根目录下,打开[5118 Smart原创Configuration Tool.exe],点击“Get API-Key”,会显示在浏览器打开5118获取API页面。
在页面找到“One-Key Smart原创API”,点击复制按钮,返回【5118 Smart原创Configuration Tool.exe】界面,将API-Key粘贴到输入框中.
一键智能原创API支持免费试用
当然5118伪原创需要购买和付费,可以申请100次免费使用,还可以购买一键智能原创API包。5118会员优惠码D569F5
Smart原创插件说明
第一步,打开优采云采集器,点击开始栏中的【插件管理】,在插件管理框左侧的列表中,选择【5118 Smart原创】,在右侧框中输入需要为采集的URL,点击测试按钮,检查插件是否正常。
第二步,测试没问题后,开始使用插件设置内容采集规则。
第三步,选择已有的采集任务,在【其他设置】左栏选择插件,在采集结果处理插件下拉框中选择【5118 Smart原创。dll],单击保存。
这里需要注意的是,【内容采集规则】左侧列表中的“内容”标签是插件会自动原创的内容,固定的标签名称为“内容”。
导出任务数据时,在任务列表中选择对应的任务项,右侧的“发布”项必须勾选,否则无法导出数据。
第四步,查看5118智能原创插件效果。操作完成后,可以在之前保存的地址中查看导出效果。导出的内容已经是智能 原创 插件替换的数据。(以上内容转载自5118公众号)
站长技能要求
需要以下技能:
1、优采云采集工具使用,推荐学习SEOWHY优采云采集基础教程和SEOWHY优采云采集器(进阶教程)
2、5118伪原创工具使用,会员优惠码D569F5 5118官网
3.常用的cms网站程序函数,课程中讨论过
4. 采集网页需要使用规则,熟悉div+css
5. WP博客系统界面,织梦cms发帖界面
关于SEO黑科技已经讲解了这么多,希望能给大家带来一些思考。想了解更多SEO专业知识,可以私信我交流,或者直接通过微信:seobst,咨询,已经加我微信的朋友,可以免费分享SEO信息或者提供百人学习交流群,通常群里会有一个群。有些大佬在群里讨论,有什么不懂的可以在群里问。
软文一件采集器(建设自己的网站是实现你宏伟目标的第一步流量吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 437 次浏览 • 2022-01-19 19:16
【新网网站建设资讯】打造自己的网站是实现远大目标的第一步。接下来,你要做的就是增加网站的优质流量。这意味着为了推广网站,您需要实施多层次的策略。
网站促销是一种以互联网为基础,利用平台和网络媒体的互动,辅助营销目标实现的新型营销方式。目前常见的传播推广方式主要是通过在各大网站推广服务商购买广告等方式实现。免费网站推广包括:SEO优化网站内容或结构提升排名搜索引擎中的网站,在论坛、微博、博客、微信、QQ空间等平台发布信息,在其他热门平台发布网站外部链接。
为了达到更好的宣传推广效果,还需要一些技巧:
1.选择一个可以帮助您传播信息的域名
一个好的域名可以为您的 网站 定下基调,有时就像宣传 网站 页面本身一样重要。您可以直接在新网注册一个新域名。您也可以在新网抢购或委托购买二手域名。选择域名时,不要使用复杂的名称,避免拼写错误;域名应收录与您提供的产品和服务相关的词语;随着您的业务增长,品牌也会随之增长,确保您的域名会随着品牌的发展而灵活变化。
2.选择一个好的网站模板
现在很多人不懂开发技术。在这种情况下,如果要构建一个高质量的网站,就需要使用更好的建站模板。例如,有许多漂亮的 网站 模板可用于构建新网站。,覆盖广泛的行业,让小白也可以打造属于自己的网站。
3、搜索引擎优化
从网站开始构建到内容填充,要注意网站的优化。建站时注意CSS+DIV方式,少用TABLE方式;一般来说,静态的网站搜索引擎收录会比较快,但是会占用空间,而静态的网站则相反。使用这种方法对于站长来说需要很多的SEO技巧,但是SEO应该是目前最有效的方法。相对来说,静态网站对此要求很低,所以当你开始做网站的时候,可以先尝试做静态。这对 SEO 也有好处。
4、软文促销
编写技术或其他有吸引力的 软文,将 URL 附加到 软文、软文 最好是一些 原创 或 伪原创 的 文章。写完软文,发布到各种博客上。如果有吸引力,那么 软文 很快就会被其他 网站采集 推广,实现快速推广网站 ,进而推广他们的 网站 目标,并整合把URL改成软文,相当于电影中所谓的植入式广告,恰到好处。写软文最大的好处就是,如果你写得好,很多人会免费帮你宣传,而这种宣传是大家都愿意做的,因为很少有人愿意做真正的原创 ,一个纯粹的 原创文章 花费太长而代价很小 网站,并且链接质量很高。另外,原创文章可以主动吸引搜索引擎收录。但是写软文比较费时间,原创文章比较难。 查看全部
软文一件采集器(建设自己的网站是实现你宏伟目标的第一步流量吗?)
【新网网站建设资讯】打造自己的网站是实现远大目标的第一步。接下来,你要做的就是增加网站的优质流量。这意味着为了推广网站,您需要实施多层次的策略。
网站促销是一种以互联网为基础,利用平台和网络媒体的互动,辅助营销目标实现的新型营销方式。目前常见的传播推广方式主要是通过在各大网站推广服务商购买广告等方式实现。免费网站推广包括:SEO优化网站内容或结构提升排名搜索引擎中的网站,在论坛、微博、博客、微信、QQ空间等平台发布信息,在其他热门平台发布网站外部链接。
为了达到更好的宣传推广效果,还需要一些技巧:
1.选择一个可以帮助您传播信息的域名
一个好的域名可以为您的 网站 定下基调,有时就像宣传 网站 页面本身一样重要。您可以直接在新网注册一个新域名。您也可以在新网抢购或委托购买二手域名。选择域名时,不要使用复杂的名称,避免拼写错误;域名应收录与您提供的产品和服务相关的词语;随着您的业务增长,品牌也会随之增长,确保您的域名会随着品牌的发展而灵活变化。
2.选择一个好的网站模板
现在很多人不懂开发技术。在这种情况下,如果要构建一个高质量的网站,就需要使用更好的建站模板。例如,有许多漂亮的 网站 模板可用于构建新网站。,覆盖广泛的行业,让小白也可以打造属于自己的网站。
3、搜索引擎优化
从网站开始构建到内容填充,要注意网站的优化。建站时注意CSS+DIV方式,少用TABLE方式;一般来说,静态的网站搜索引擎收录会比较快,但是会占用空间,而静态的网站则相反。使用这种方法对于站长来说需要很多的SEO技巧,但是SEO应该是目前最有效的方法。相对来说,静态网站对此要求很低,所以当你开始做网站的时候,可以先尝试做静态。这对 SEO 也有好处。
4、软文促销
编写技术或其他有吸引力的 软文,将 URL 附加到 软文、软文 最好是一些 原创 或 伪原创 的 文章。写完软文,发布到各种博客上。如果有吸引力,那么 软文 很快就会被其他 网站采集 推广,实现快速推广网站 ,进而推广他们的 网站 目标,并整合把URL改成软文,相当于电影中所谓的植入式广告,恰到好处。写软文最大的好处就是,如果你写得好,很多人会免费帮你宣传,而这种宣传是大家都愿意做的,因为很少有人愿意做真正的原创 ,一个纯粹的 原创文章 花费太长而代价很小 网站,并且链接质量很高。另外,原创文章可以主动吸引搜索引擎收录。但是写软文比较费时间,原创文章比较难。
软文一件采集器(自动发现使用场景介绍与Prometheus基于文件、DNS的应用 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-17 07:14
)
本章主要讲自动发现使用场景的介绍以及Prometheus中基于文件和DNS的自动发现的配置
当我们使用各种exporter监控系统、数据库和HTTP服务指标采集时,所有监控指标对应的目标运行状态和资源使用情况都是使用Prometheus的静态配置函数static_configs来实现的
手动添加主机 IP 和端口,然后重新加载服务供 Prometheus 发现。
在具有少量服务器的测试环境中,这种手动添加配置信息的方法是最简单的方法。但是在实际生产环境中,对于成百上千个节点组成的大型集群或者Kubernetes这样的大型集群,显然手动的方法是不够的。
为此,Prometheus 提前设计了一套服务发现功能。
Prometheus 服务发现可以自动检测分类,并且可以识别新的和更改的节点。也就是说,在容器或云平台中,可以自动发现和监控节点或更新节点,动态进行数据采集和处理。
目前,Prometheus 已经支持很多常见的自动发现服务,例如 consul ec2 gce serverset_sd_config openStack kubernetes 等。
我们常用的有sd_config、DNS、kubernetes、consul这些就够了。如果需要讨论其他配置,可以和我交流,我可以补上。
本章将对Prometheus自动发现中的基于文件的发现和基于DNS的发现进行讲解,稍后将单独讨论consul,如何使其完美解决当前场景中常见的各类服务发现监控。
为什么要使用自动发现?
在基于云(IaaS 或 CaaS)的基础设施环境中,用户可以按需使用各种资源(计算、网络、存储),如水和电。按需使用意味着资源的活力可以随着需求规模的变化而变化。例如,AWS提供了一种特殊的AutoScall服务,可以根据用户定义的规则动态地创建或销毁EC2实例,使部署在AWS上的应用能够自动适应访问规模的变化。
这种按需资源使用意味着监控系统没有固定的监控目标,所有监控对象(基础设施、应用程序、服务)都是动态变化的。对于传统的Nagias等基于Push模式的监控软件,意味着必须在每个节点上安装相应的Agent程序,通过配置指向中心的Nagias服务,使得被监控资源与中心监控之间存在强耦合服务器。,要么直接将 Agent 构建到基础架构镜像中,要么使用一些自动化的配置管理工具(如 Ansible、Chef)来动态配置这些节点。当然,除了基础设施的监控需求,我们还需要监控各种服务,比如部署在云端的应用,中间件等等。构建这样一个集中监控系统的实施成本和难度是显而易见的。
对于Prometheus这种基于Pull模式的监控系统,显然不可能继续使用static_configs来静态定义监控目标。对于 Prometheus,解决方案是引入一个中间代理(服务注册中心),它保存着当前所有监控目标的访问信息。Prometheus 只需要询问代理控制哪些监控目标即可。这种模式称为服务发现。
在不同的场景下,不同的事物会扮演代理的角色(服务发现和注册)。例如,在AWS公有云平台或OpenStack私有云平台中,由于这些平台本身持有所有资源的信息,这些云平台本身就扮演着代理的角色。Prometheus 可以通过平台提供的 API 找到所有需要监控的云主机。在 Kubernetes 等容器管理平台中,Kubernetes 掌握和管理所有容器和服务信息。此时,Prometheus 只需要与 Kubernetes 打交道,即可找到所有需要监控的容器和服务对象。Prometheus 也可以直接与一些开源的服务发现工具集成。例如,在微服务架构应用中,经常使用Consul等服务发现注册软件。Prometheus 也可以与其集成,动态发现需要监控的应用。服务实例。Prometheus除了与这些平台级公有云、私有云、容器云、专用服务发现注册中心集成外,还支持DNS和基于文件的监控目标动态发现,大大降低了对云原生、微服务和监控的需求云模式的实施难度。
如上图,Push 系统和 Pull 系统的核心区别就展示出来了。与Push模式相比,Pull模式的优势可以简单总结如下:
基于文件的服务发现
在 Prometheus 支持的众多服务发现实现中,基于文件的服务发现是最常见的。这种方法不需要依赖任何平台或第三方服务。Prometheus 也不可能支持所有平台或环境。在基于文件的服务发现模式下,Prometheus 会定期从文件中读取最新的 Target 信息。因此,您可以以任何方式编写监控目标信息。
用户可以通过 JSON 或 YAML 格式的文件定义所有监控目标。比如下面的yaml文件中定义了2个采集任务,每个任务对应的Target列表:
yaml 格式
- targets: ['192.168.1.220:9100']
labels:
app: 'app1'
env: 'game1'
region: 'us-west-2'
- targets: ['192.168.1.221:9100']
labels:
app: 'app2'
env: 'game2'
region: 'ap-southeast-1'
json格式
[
{
"targets": [ "192.168.1.221:29090"],
"labels": {
"app": "app1",
"env": "game1",
"region": "us-west-2"
}
},
{
"targets": [ "192.168.1.222:29090" ],
"labels": {
"app": "app2",
"env": "game2",
"region": "ap-southeast-1"
}
}
]
同时也可以给这些实例添加一些额外的标签信息,比如使用env标签来表示当前节点所在的环境,这样来自这些实例的样本信息采集就会收录这些标签信息,以便标签信息可以通过标签传递。根据环境进行统计。
创建 Prometheus 配置文件 /data/prometheus/conf/prometheus-file-sd.yml 并添加以下内容:
- job_name: 'file_sd_test'
scrape_interval: 10s
file_sd_configs:
- files:
- /data/prometheus/static_conf/*.yml
- /data/prometheus/static_conf/*.json
这里定义了一个基于file_sd_configs的监控采集测试任务,其中模式的任务名称为file_sd_test。在 yml 文件中,可以使用 yaml 标签覆盖默认的作业名,然后重新加载 Prometheus 服务。
service prometheus restat
在 Prometheus UI 的 Targets 下,可以看到从 targets.json 文件中动态获取的当前 Target 实例信息以及监控任务的 采集 状态。同时,Labels 列会收录用户添加的自定义标签:
Prometheus 默认每 5m 重新读取一次文件内容。当需要修改时,可以通过refresh_interval进行设置,例如:
- job_name: 'file_sd_test'
scrape_interval: 10s
file_sd_configs:
- refresh_interval: 30s # 30s重载配置文件
files:
- /data/prometheus/static_conf/*.yml
- /data/prometheus/static_conf/*.json
这样,Prometheus 会定期自动读取文件的内容。当文件中定义的内容发生变化时,无需重启 Prometheus。
这种通用的做法可以导致很多不同的玩法,比如结合自动化配置管理工具(Ansible),结合Cron Job等等。对于一些Prometheus不支持的云环境,比如国内的阿里云、腾讯云等,也可以通过该方法通过一些自定义程序与平台交互,自动生成监控Target文件,从而实现监控这些云环境中的基础架构。自动监控支持。
基于 DNS 的发现
对于某些环境,当无法满足基于文件和consul的服务发现时,我们可能需要DNS来进行服务发现。在 Internet 架构中,我们通常使用主机节点或 Kubernetes 集群,而不会将 IP 暴露给外界,这就需要我们在内部局域网或专用网络中部署 DNS 服务器,并使用 DNS 服务来完成域名解析工作。内部网络。
这时候我们就可以使用 Prometheus 的 DNS 服务发现了。Prometheus 的 DNS 服务发现有两种方法。第一种是使用 DNA A 记录进行自动发现。第二种方法是 DNS SRV。第一个显然没有 SRV。资源记录更方便。在这里,我将完成所有两个配置。至于用什么,根据自己的环境选择。
DNA A记录发现配置,首先你的内网需要有DNS服务器,也可以直接自己配置解析记录。我这里使用的dnsmasq服务是在内网测试的
# 验证 test1 DNS记录
nslookup test1.example.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: test1.example.com
Address: 192.168.1.221
# 验证 test2 DNS记录
nslookup test2.example.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: test2.example.com
Address: 192.168.1.222
普罗米修斯配置
# 基于DNS A记录发现
- job_name: 'DNS-A' # job 名称
metrics_path: "/metrics" # 路径
dns_sd_configs:
- names: ["test1.example.com", "test2.example.com"] # A记录
type: A # 解析类型
port: 29100 # 端口
重启Prometheus,可以看到targets中的dns-a记录
DNS SRV 是 DNS 资源记录中的一种记录类型,指定服务器地址和端口,可以设置每个服务器的优先级和权重。本地DNS解析器在访问服务时,从DNS服务器获取地址列表,然后根据优先级和权重选择一个地址作为本次请求的目标地址。
SRV 记录格式:
_service._proto.name.TTL 类 SRV 优先权重端口目标
| 参数 | 说明 |
| :-----: | :----: |
| _服务 | 服务名称,以_为前缀,防止与DNS标签(域名)冲突 |
| 原型 | 服务使用的通信协议通常是 tcp udp |
| 姓名 | 这条记录是一个有效的域名 |
| TTL | 标准 DNS 类字段,例如 IN |
| 优先 | 记录优先级,数值越小,优先级越高。[0-65535] |
| 重量 | 记录重量,数值越大,重量越高。[0-65535] |
| 港口| 服务使用的端口 |
| 目标 | 使用服务的主机地址名 |
这里没有使用named,而是使用dnsmasq进行测试。添加SRV记录后,需要重启dnsmasq服务才能生效。
# 配置dns解析
cat /etc/dnsmasq.d/localdomain.conf
address=/test1.example.com/192.168.1.221
address=/test2.example.com/192.168.1.222
# 添加 SRV 记录
cat /etc/dnsmasq.conf
srv-host =_prometheus._tcp.example.com,test1.example.com,29100
srv-host =_prometheus._tcp.example.com,test2.example.com,29100
# 验证srv服务是否正确,192.168.1.123 是内部DNS服务器,
dig @192.168.1.123 +noall +answer SRV _prometheus._tcp.example.com
output...
_prometheus._tcp.example.com. 0 IN SRV 0 0 9100 test1.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 9100 test2.example.com.
Prometheus 配置完成后,重新加载 Prometheus 服务。
- job_name: 'DNS-SRV' # 名称
metrics_path: "/metrics" # 获取数据的路径
dns_sd_configs: # 配置使用DNS解析
- names: ['_prometheus._tcp.example.com'] # 配置SRV对应的解析地址
此时可以在targets中看到DNS auto-discovery的记录。
目前,我们正在为自动发现添加新记录。
# 添加test0解析
cat /etc/dnsmasq.d/localdomain.conf
address=/test1.example.com/192.168.1.221
address=/test2.example.com/192.168.1.222
address=/test0.example.com/192.168.1.220
# 添加 test0 SRV 记录
cat /etc/dnsmasq.conf
srv-host =_prometheus._tcp.example.com,test1.example.com,29100
srv-host =_prometheus._tcp.example.com,test2.example.com,29100
srv-host =_prometheus._tcp.example.com,test0.example.com,19100
# 验证dns SRV记录是否成功
dig @192.168.1.123 +noall +answer SRV _prometheus._tcp.example.com
_prometheus._tcp.example.com. 0 IN SRV 0 0 19100 test0.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 29100 test2.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 29100 test1.example.com.
这时候我去观察targets的时候,发现test0可以被自动发现了。
查看全部
软文一件采集器(自动发现使用场景介绍与Prometheus基于文件、DNS的应用
)
本章主要讲自动发现使用场景的介绍以及Prometheus中基于文件和DNS的自动发现的配置
当我们使用各种exporter监控系统、数据库和HTTP服务指标采集时,所有监控指标对应的目标运行状态和资源使用情况都是使用Prometheus的静态配置函数static_configs来实现的
手动添加主机 IP 和端口,然后重新加载服务供 Prometheus 发现。
在具有少量服务器的测试环境中,这种手动添加配置信息的方法是最简单的方法。但是在实际生产环境中,对于成百上千个节点组成的大型集群或者Kubernetes这样的大型集群,显然手动的方法是不够的。
为此,Prometheus 提前设计了一套服务发现功能。
Prometheus 服务发现可以自动检测分类,并且可以识别新的和更改的节点。也就是说,在容器或云平台中,可以自动发现和监控节点或更新节点,动态进行数据采集和处理。
目前,Prometheus 已经支持很多常见的自动发现服务,例如 consul ec2 gce serverset_sd_config openStack kubernetes 等。
我们常用的有sd_config、DNS、kubernetes、consul这些就够了。如果需要讨论其他配置,可以和我交流,我可以补上。
本章将对Prometheus自动发现中的基于文件的发现和基于DNS的发现进行讲解,稍后将单独讨论consul,如何使其完美解决当前场景中常见的各类服务发现监控。
为什么要使用自动发现?
在基于云(IaaS 或 CaaS)的基础设施环境中,用户可以按需使用各种资源(计算、网络、存储),如水和电。按需使用意味着资源的活力可以随着需求规模的变化而变化。例如,AWS提供了一种特殊的AutoScall服务,可以根据用户定义的规则动态地创建或销毁EC2实例,使部署在AWS上的应用能够自动适应访问规模的变化。
这种按需资源使用意味着监控系统没有固定的监控目标,所有监控对象(基础设施、应用程序、服务)都是动态变化的。对于传统的Nagias等基于Push模式的监控软件,意味着必须在每个节点上安装相应的Agent程序,通过配置指向中心的Nagias服务,使得被监控资源与中心监控之间存在强耦合服务器。,要么直接将 Agent 构建到基础架构镜像中,要么使用一些自动化的配置管理工具(如 Ansible、Chef)来动态配置这些节点。当然,除了基础设施的监控需求,我们还需要监控各种服务,比如部署在云端的应用,中间件等等。构建这样一个集中监控系统的实施成本和难度是显而易见的。
对于Prometheus这种基于Pull模式的监控系统,显然不可能继续使用static_configs来静态定义监控目标。对于 Prometheus,解决方案是引入一个中间代理(服务注册中心),它保存着当前所有监控目标的访问信息。Prometheus 只需要询问代理控制哪些监控目标即可。这种模式称为服务发现。

在不同的场景下,不同的事物会扮演代理的角色(服务发现和注册)。例如,在AWS公有云平台或OpenStack私有云平台中,由于这些平台本身持有所有资源的信息,这些云平台本身就扮演着代理的角色。Prometheus 可以通过平台提供的 API 找到所有需要监控的云主机。在 Kubernetes 等容器管理平台中,Kubernetes 掌握和管理所有容器和服务信息。此时,Prometheus 只需要与 Kubernetes 打交道,即可找到所有需要监控的容器和服务对象。Prometheus 也可以直接与一些开源的服务发现工具集成。例如,在微服务架构应用中,经常使用Consul等服务发现注册软件。Prometheus 也可以与其集成,动态发现需要监控的应用。服务实例。Prometheus除了与这些平台级公有云、私有云、容器云、专用服务发现注册中心集成外,还支持DNS和基于文件的监控目标动态发现,大大降低了对云原生、微服务和监控的需求云模式的实施难度。

如上图,Push 系统和 Pull 系统的核心区别就展示出来了。与Push模式相比,Pull模式的优势可以简单总结如下:
基于文件的服务发现
在 Prometheus 支持的众多服务发现实现中,基于文件的服务发现是最常见的。这种方法不需要依赖任何平台或第三方服务。Prometheus 也不可能支持所有平台或环境。在基于文件的服务发现模式下,Prometheus 会定期从文件中读取最新的 Target 信息。因此,您可以以任何方式编写监控目标信息。
用户可以通过 JSON 或 YAML 格式的文件定义所有监控目标。比如下面的yaml文件中定义了2个采集任务,每个任务对应的Target列表:
yaml 格式
- targets: ['192.168.1.220:9100']
labels:
app: 'app1'
env: 'game1'
region: 'us-west-2'
- targets: ['192.168.1.221:9100']
labels:
app: 'app2'
env: 'game2'
region: 'ap-southeast-1'
json格式
[
{
"targets": [ "192.168.1.221:29090"],
"labels": {
"app": "app1",
"env": "game1",
"region": "us-west-2"
}
},
{
"targets": [ "192.168.1.222:29090" ],
"labels": {
"app": "app2",
"env": "game2",
"region": "ap-southeast-1"
}
}
]
同时也可以给这些实例添加一些额外的标签信息,比如使用env标签来表示当前节点所在的环境,这样来自这些实例的样本信息采集就会收录这些标签信息,以便标签信息可以通过标签传递。根据环境进行统计。
创建 Prometheus 配置文件 /data/prometheus/conf/prometheus-file-sd.yml 并添加以下内容:
- job_name: 'file_sd_test'
scrape_interval: 10s
file_sd_configs:
- files:
- /data/prometheus/static_conf/*.yml
- /data/prometheus/static_conf/*.json
这里定义了一个基于file_sd_configs的监控采集测试任务,其中模式的任务名称为file_sd_test。在 yml 文件中,可以使用 yaml 标签覆盖默认的作业名,然后重新加载 Prometheus 服务。
service prometheus restat
在 Prometheus UI 的 Targets 下,可以看到从 targets.json 文件中动态获取的当前 Target 实例信息以及监控任务的 采集 状态。同时,Labels 列会收录用户添加的自定义标签:

Prometheus 默认每 5m 重新读取一次文件内容。当需要修改时,可以通过refresh_interval进行设置,例如:
- job_name: 'file_sd_test'
scrape_interval: 10s
file_sd_configs:
- refresh_interval: 30s # 30s重载配置文件
files:
- /data/prometheus/static_conf/*.yml
- /data/prometheus/static_conf/*.json
这样,Prometheus 会定期自动读取文件的内容。当文件中定义的内容发生变化时,无需重启 Prometheus。
这种通用的做法可以导致很多不同的玩法,比如结合自动化配置管理工具(Ansible),结合Cron Job等等。对于一些Prometheus不支持的云环境,比如国内的阿里云、腾讯云等,也可以通过该方法通过一些自定义程序与平台交互,自动生成监控Target文件,从而实现监控这些云环境中的基础架构。自动监控支持。
基于 DNS 的发现
对于某些环境,当无法满足基于文件和consul的服务发现时,我们可能需要DNS来进行服务发现。在 Internet 架构中,我们通常使用主机节点或 Kubernetes 集群,而不会将 IP 暴露给外界,这就需要我们在内部局域网或专用网络中部署 DNS 服务器,并使用 DNS 服务来完成域名解析工作。内部网络。
这时候我们就可以使用 Prometheus 的 DNS 服务发现了。Prometheus 的 DNS 服务发现有两种方法。第一种是使用 DNA A 记录进行自动发现。第二种方法是 DNS SRV。第一个显然没有 SRV。资源记录更方便。在这里,我将完成所有两个配置。至于用什么,根据自己的环境选择。
DNA A记录发现配置,首先你的内网需要有DNS服务器,也可以直接自己配置解析记录。我这里使用的dnsmasq服务是在内网测试的
# 验证 test1 DNS记录
nslookup test1.example.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: test1.example.com
Address: 192.168.1.221
# 验证 test2 DNS记录
nslookup test2.example.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: test2.example.com
Address: 192.168.1.222
普罗米修斯配置
# 基于DNS A记录发现
- job_name: 'DNS-A' # job 名称
metrics_path: "/metrics" # 路径
dns_sd_configs:
- names: ["test1.example.com", "test2.example.com"] # A记录
type: A # 解析类型
port: 29100 # 端口
重启Prometheus,可以看到targets中的dns-a记录

DNS SRV 是 DNS 资源记录中的一种记录类型,指定服务器地址和端口,可以设置每个服务器的优先级和权重。本地DNS解析器在访问服务时,从DNS服务器获取地址列表,然后根据优先级和权重选择一个地址作为本次请求的目标地址。
SRV 记录格式:
_service._proto.name.TTL 类 SRV 优先权重端口目标
| 参数 | 说明 |
| :-----: | :----: |
| _服务 | 服务名称,以_为前缀,防止与DNS标签(域名)冲突 |
| 原型 | 服务使用的通信协议通常是 tcp udp |
| 姓名 | 这条记录是一个有效的域名 |
| TTL | 标准 DNS 类字段,例如 IN |
| 优先 | 记录优先级,数值越小,优先级越高。[0-65535] |
| 重量 | 记录重量,数值越大,重量越高。[0-65535] |
| 港口| 服务使用的端口 |
| 目标 | 使用服务的主机地址名 |
这里没有使用named,而是使用dnsmasq进行测试。添加SRV记录后,需要重启dnsmasq服务才能生效。
# 配置dns解析
cat /etc/dnsmasq.d/localdomain.conf
address=/test1.example.com/192.168.1.221
address=/test2.example.com/192.168.1.222
# 添加 SRV 记录
cat /etc/dnsmasq.conf
srv-host =_prometheus._tcp.example.com,test1.example.com,29100
srv-host =_prometheus._tcp.example.com,test2.example.com,29100
# 验证srv服务是否正确,192.168.1.123 是内部DNS服务器,
dig @192.168.1.123 +noall +answer SRV _prometheus._tcp.example.com
output...
_prometheus._tcp.example.com. 0 IN SRV 0 0 9100 test1.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 9100 test2.example.com.
Prometheus 配置完成后,重新加载 Prometheus 服务。
- job_name: 'DNS-SRV' # 名称
metrics_path: "/metrics" # 获取数据的路径
dns_sd_configs: # 配置使用DNS解析
- names: ['_prometheus._tcp.example.com'] # 配置SRV对应的解析地址
此时可以在targets中看到DNS auto-discovery的记录。

目前,我们正在为自动发现添加新记录。
# 添加test0解析
cat /etc/dnsmasq.d/localdomain.conf
address=/test1.example.com/192.168.1.221
address=/test2.example.com/192.168.1.222
address=/test0.example.com/192.168.1.220
# 添加 test0 SRV 记录
cat /etc/dnsmasq.conf
srv-host =_prometheus._tcp.example.com,test1.example.com,29100
srv-host =_prometheus._tcp.example.com,test2.example.com,29100
srv-host =_prometheus._tcp.example.com,test0.example.com,19100
# 验证dns SRV记录是否成功
dig @192.168.1.123 +noall +answer SRV _prometheus._tcp.example.com
_prometheus._tcp.example.com. 0 IN SRV 0 0 19100 test0.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 29100 test2.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 29100 test1.example.com.
这时候我去观察targets的时候,发现test0可以被自动发现了。


软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-16 23:18
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软文一件采集器(百度不收录的原因是什么?百度spider怎么办?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-01-13 16:20
百度不收录是什么原因?百度作为最重要的中文搜索引擎,是国内很多网站的风向标,所以对于国内的网站、网站或者发布的内容,不受百度收录@的约束> 很头疼。那么为什么 网站 不是 收录 呢?
百度不收录是什么原因?
1、网站禁止
别笑,真的有同学一边封百度蜘蛛一边把数据交给百度,当然不能收录。
解决方法:去百度站长平台查看,如果有异常,直接去后台修改即可!
2、获取失败
爬取失败的原因有很多,有时候在办公室访问没问题,但是百度蜘蛛就麻烦了。
解决方法:网站要时刻注意保证网站在不同时间、不同地点的稳定性。
3、网站是一个新站点
每个 网站 都有一个新的站点审查期。如果您的网站 刚刚上线,那么网站 应该处于审核期。百度还不信任网站。百度不收录文章是正常的,因为网站在百度数据库中还没有获得好的综合页面评分,这也是新站上线一段时间的原因的时间。只有收录首页或者一两个内页,正是因为百度对新站的信任度不高,百度蜘蛛在网站中爬取的级别和时间都会很小,百度蜘蛛的爬取级别和爬取时间自然不会百度收录。
解决方案:
①建议去外链平台发布网站首页和内页的链接,利用手头资源交换友情链接,吸引百度蜘蛛爬爬网站,从而增加百度蜘蛛抓取访问网站的页面和次数。
②提交网站链接到百度站长平台,主动提醒百度蜘蛛抢。
4、网站已更新文章都已过期文章
一些 网站 更新的 文章 还没有过期。百度不知道被过滤了多少次,现在被你复制了网站采集肯定不是收录。因此,即使采集需要采集刚刚发布的内容,也会有一些收录的可能性。想必有的SEOer可能会问,是不是可以写各行各业的文章文章文章?那么如何生成新鲜内容呢?在这里我只想说,不创新,永远都是来自采集文章,那为什么别人能创造出新鲜的内容呢?
解决方案:
① 经常去一些问答平台和贴吧论坛看看有没有核心问题没有解决,然后可以利用各种资源整理出新的文章解决方案给用户来。
②可以写一些软文,故事文章到网站,不时给网站补充新鲜血液,完善网站的原创@ >性大大提高了网站的收录率。
5、标题和网站结构以及网站标签的频繁更改也会影响收录
网站如果标题和网站结构和标签被频繁修改,会被搜索引擎拉回观察室,对网站进行重新审查和排名,这不仅会降低搜索引擎对网站信任等级的感知,甚至可能出现降级迹象,对网站的收录也有一定的障碍,百度快照日期将不被更新。
解决方案:
①。到百度服务中心/快照更新投诉到百度中心审核,进行百度快照投诉更新,可以加快快照更新速度。
②。更新几处优质原创@>内容恢复排名,百度快照和排名也将恢复。
6、网站有大量404、503未处理,影响页面索引
如果网站有大量的40个4、503错误页面,会导致搜索引擎难以抓取页面。对于搜索引擎来说,你的网站的内容值和链接的数量决定了搜索引擎在你的网站停留时间长,网站的综合得分大死链接的数量也会减少,所以一定要及时处理死链接。
解决方案:
对于网站可以使用一些死链接检测工具进行检测,比如:xenu、爱站工具等来检测死链接,但是把死链接放在一个txt文件中,然后上传到< @网站根目录,最后到百度站长平台死链接提交选项,提交死链接文件等!
7、内部链未建立
如果要发布新页面为 收录,则不应将这些页面隐藏得太深。很多网站有很多栏目,所以栏目下面会有一栏,甚至下面会有多层。因此,有些发布的收录@文章既没有显示在首页,也没有显示在主栏页面,即使点击首页链接也很难找到这个页面。这自然很难收录。 查看全部
软文一件采集器(百度不收录的原因是什么?百度spider怎么办?)
百度不收录是什么原因?百度作为最重要的中文搜索引擎,是国内很多网站的风向标,所以对于国内的网站、网站或者发布的内容,不受百度收录@的约束> 很头疼。那么为什么 网站 不是 收录 呢?
百度不收录是什么原因?
1、网站禁止
别笑,真的有同学一边封百度蜘蛛一边把数据交给百度,当然不能收录。
解决方法:去百度站长平台查看,如果有异常,直接去后台修改即可!
2、获取失败
爬取失败的原因有很多,有时候在办公室访问没问题,但是百度蜘蛛就麻烦了。
解决方法:网站要时刻注意保证网站在不同时间、不同地点的稳定性。

3、网站是一个新站点
每个 网站 都有一个新的站点审查期。如果您的网站 刚刚上线,那么网站 应该处于审核期。百度还不信任网站。百度不收录文章是正常的,因为网站在百度数据库中还没有获得好的综合页面评分,这也是新站上线一段时间的原因的时间。只有收录首页或者一两个内页,正是因为百度对新站的信任度不高,百度蜘蛛在网站中爬取的级别和时间都会很小,百度蜘蛛的爬取级别和爬取时间自然不会百度收录。

解决方案:
①建议去外链平台发布网站首页和内页的链接,利用手头资源交换友情链接,吸引百度蜘蛛爬爬网站,从而增加百度蜘蛛抓取访问网站的页面和次数。
②提交网站链接到百度站长平台,主动提醒百度蜘蛛抢。
4、网站已更新文章都已过期文章
一些 网站 更新的 文章 还没有过期。百度不知道被过滤了多少次,现在被你复制了网站采集肯定不是收录。因此,即使采集需要采集刚刚发布的内容,也会有一些收录的可能性。想必有的SEOer可能会问,是不是可以写各行各业的文章文章文章?那么如何生成新鲜内容呢?在这里我只想说,不创新,永远都是来自采集文章,那为什么别人能创造出新鲜的内容呢?
解决方案:
① 经常去一些问答平台和贴吧论坛看看有没有核心问题没有解决,然后可以利用各种资源整理出新的文章解决方案给用户来。
②可以写一些软文,故事文章到网站,不时给网站补充新鲜血液,完善网站的原创@ >性大大提高了网站的收录率。
5、标题和网站结构以及网站标签的频繁更改也会影响收录
网站如果标题和网站结构和标签被频繁修改,会被搜索引擎拉回观察室,对网站进行重新审查和排名,这不仅会降低搜索引擎对网站信任等级的感知,甚至可能出现降级迹象,对网站的收录也有一定的障碍,百度快照日期将不被更新。
解决方案:
①。到百度服务中心/快照更新投诉到百度中心审核,进行百度快照投诉更新,可以加快快照更新速度。
②。更新几处优质原创@>内容恢复排名,百度快照和排名也将恢复。
6、网站有大量404、503未处理,影响页面索引
如果网站有大量的40个4、503错误页面,会导致搜索引擎难以抓取页面。对于搜索引擎来说,你的网站的内容值和链接的数量决定了搜索引擎在你的网站停留时间长,网站的综合得分大死链接的数量也会减少,所以一定要及时处理死链接。
解决方案:
对于网站可以使用一些死链接检测工具进行检测,比如:xenu、爱站工具等来检测死链接,但是把死链接放在一个txt文件中,然后上传到< @网站根目录,最后到百度站长平台死链接提交选项,提交死链接文件等!
7、内部链未建立
如果要发布新页面为 收录,则不应将这些页面隐藏得太深。很多网站有很多栏目,所以栏目下面会有一栏,甚至下面会有多层。因此,有些发布的收录@文章既没有显示在首页,也没有显示在主栏页面,即使点击首页链接也很难找到这个页面。这自然很难收录。
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-13 00:18
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软文一件采集器(本文大数据技术栈大数据开发岗位介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-11 13:00
)
为了方便大家梳理大数据学习路线,本文从以下四个方面介绍大数据技术:
大数据技术栈
大数据的历史
大数据应用
大数据开发岗位
一、大数据技术栈
之前有个同事问我怎么转行大数据开发,他在网上搜了一堆大数据相关的技术,但是不知道从哪里入手,学什么技术,这些技术栈有什么关系. 刚开始转大数据的时候,有点迷茫,但是整体接触之后才弄明白大数据的技术栈。
做大数据开发,你要做四件事,采集,存储,查询,计算。此外,还需要一些发展所需的基本语言技能。根据这些维度,我划分了大数据的常用技术栈。
基础能力
毋庸置疑,java是当今世界上使用最广泛的语言,基本上是程序员必备的语言,大数据生态系统的很多组件都是通过java开发的。Python 通常用于爬虫、数据分析和机器学习。一些大数据组件是用python开发的,比如airflow。scala的底层还是java。由于spark是由scala开发的,而且scala还集成了很多spark算子,所以spark开发中一般使用scala。
数据采集
一般通过filebeat、logstash、kafka、flume采集完成日志。一些应用系统的数据也会通过kafka或者binlog同步到大数据组件进行存储。
数据存储
这里的数据存储引擎与传统的关系型数据库有很大的不同。一个常见的分布式存储文件系统是 hdfs。另外,一些非结构化数据会被nosql存储。常见的nosql存储组件有hbase和redis。
数据查询
常见的有hive、spark sql、presto、kylin、impala、durid、clickhouse、greeplum,每个组件都有自己的查询特性和使用场景。此处不赘述,待会再说。
数据计算
常见的计算方法有流计算和批处理,线计算和实时计算按效果分开。对应的计算组件是storm、spark stream和flink。
其他
分布式协调器:为了提高可靠性,大数据组件通常是分布式存储的,这涉及到各个组件之间的协调和同步。最常见的协调员是动物园管理员。
资源管理器:为了提高计算能力,会分配计算资源(CPU、内存、磁盘)。常见的组件包括纱线和金属丝。
调度管理器:调度管理器管理任务何时执行、周期性执行、是否重试等,常见的有airflow、dalphine schduler、oozie、azkaban。
二、大数据技术发展史
学习一门技术,知道能用就够了,至少能解决问题。但如果你想走得更远,你仍然需要了解一项技术的发展历史。通过发展历程,您可以更深入地了解这项技术的产生原因、背后的原创设计以及使用场景。
大数据技术的起源
大数据最早起源于谷歌。大家都知道google主要提供网页检索服务,而这个服务依赖于两个能力:网页的采集和索引的构建。有了这两个能力,我们就可以通过检索服务在互联网上搜索网页。这些网页和索引都需要大量的存储和计算能力。为了提高这两项能力,谷歌发表了三篇重要论文。
2003年,分布式文件系统GFS。
2004年,大数据分布式计算框架MapReduce。
2006年,NoSql数据库系统。
这三篇论文为大数据技术奠定了基础。
Hadoop技术
受到谷歌论文的启发,2004 年 7 月 Doug 和 Mike Cafarella 在 Nutch 中实现了类似于 GFS 的功能(Nutch 的设计目标是构建一个大规模的全网搜索引擎,包括网页爬取、索引、查询等),即,HDFS的前身。2005 年 2 月,Mike Cafarella 在 Nutch 中实现了 MapReduce 的初始版本。GFS 和 MapReduce 是 hadoop 的前身。2006年,hadoop从Nutch项目中分离出来,贡献给Apache,成为Apache的顶级项目。
雅虎的猪
2006 年,雅虎为了让 MapReduce 技术更易用,封装了 MapReduce 技术,开发了一个名为 Pig 的工具,类似于 SQL 脚本查询。使用 Pig 编写 SQL 会自动转换成 MapReduce 执行,大大优化了 MapReduce 的性能。使用困难。
脸书蜂巢
2007年,Facebook进一步优化了查询方式,开发了一套可以直接使用SQL查询大数据的工具——HIVE。只要懂 SQL 的开发者都可以使用这个组件。
Powerset 的 HBASE
2007年,Powerset的工作人员通过Google的论文开发了Java版BigTable,即HBASE。HBASE 在 2008 年被贡献给 Apache。
火花的产生
2009 年,加州大学伯克利分校的研究人员在使用 MapReduce 进行实验项目时,性能无法满足要求。于是我开始设计火花。基于内存计算的spark的性能远高于spark。
三、大数据应用
查看全部
软文一件采集器(本文大数据技术栈大数据开发岗位介绍
)
为了方便大家梳理大数据学习路线,本文从以下四个方面介绍大数据技术:
大数据技术栈
大数据的历史
大数据应用
大数据开发岗位
一、大数据技术栈
之前有个同事问我怎么转行大数据开发,他在网上搜了一堆大数据相关的技术,但是不知道从哪里入手,学什么技术,这些技术栈有什么关系. 刚开始转大数据的时候,有点迷茫,但是整体接触之后才弄明白大数据的技术栈。
做大数据开发,你要做四件事,采集,存储,查询,计算。此外,还需要一些发展所需的基本语言技能。根据这些维度,我划分了大数据的常用技术栈。

基础能力
毋庸置疑,java是当今世界上使用最广泛的语言,基本上是程序员必备的语言,大数据生态系统的很多组件都是通过java开发的。Python 通常用于爬虫、数据分析和机器学习。一些大数据组件是用python开发的,比如airflow。scala的底层还是java。由于spark是由scala开发的,而且scala还集成了很多spark算子,所以spark开发中一般使用scala。
数据采集
一般通过filebeat、logstash、kafka、flume采集完成日志。一些应用系统的数据也会通过kafka或者binlog同步到大数据组件进行存储。
数据存储
这里的数据存储引擎与传统的关系型数据库有很大的不同。一个常见的分布式存储文件系统是 hdfs。另外,一些非结构化数据会被nosql存储。常见的nosql存储组件有hbase和redis。
数据查询
常见的有hive、spark sql、presto、kylin、impala、durid、clickhouse、greeplum,每个组件都有自己的查询特性和使用场景。此处不赘述,待会再说。
数据计算
常见的计算方法有流计算和批处理,线计算和实时计算按效果分开。对应的计算组件是storm、spark stream和flink。
其他
分布式协调器:为了提高可靠性,大数据组件通常是分布式存储的,这涉及到各个组件之间的协调和同步。最常见的协调员是动物园管理员。
资源管理器:为了提高计算能力,会分配计算资源(CPU、内存、磁盘)。常见的组件包括纱线和金属丝。
调度管理器:调度管理器管理任务何时执行、周期性执行、是否重试等,常见的有airflow、dalphine schduler、oozie、azkaban。
二、大数据技术发展史
学习一门技术,知道能用就够了,至少能解决问题。但如果你想走得更远,你仍然需要了解一项技术的发展历史。通过发展历程,您可以更深入地了解这项技术的产生原因、背后的原创设计以及使用场景。
大数据技术的起源
大数据最早起源于谷歌。大家都知道google主要提供网页检索服务,而这个服务依赖于两个能力:网页的采集和索引的构建。有了这两个能力,我们就可以通过检索服务在互联网上搜索网页。这些网页和索引都需要大量的存储和计算能力。为了提高这两项能力,谷歌发表了三篇重要论文。
2003年,分布式文件系统GFS。
2004年,大数据分布式计算框架MapReduce。
2006年,NoSql数据库系统。
这三篇论文为大数据技术奠定了基础。
Hadoop技术
受到谷歌论文的启发,2004 年 7 月 Doug 和 Mike Cafarella 在 Nutch 中实现了类似于 GFS 的功能(Nutch 的设计目标是构建一个大规模的全网搜索引擎,包括网页爬取、索引、查询等),即,HDFS的前身。2005 年 2 月,Mike Cafarella 在 Nutch 中实现了 MapReduce 的初始版本。GFS 和 MapReduce 是 hadoop 的前身。2006年,hadoop从Nutch项目中分离出来,贡献给Apache,成为Apache的顶级项目。
雅虎的猪
2006 年,雅虎为了让 MapReduce 技术更易用,封装了 MapReduce 技术,开发了一个名为 Pig 的工具,类似于 SQL 脚本查询。使用 Pig 编写 SQL 会自动转换成 MapReduce 执行,大大优化了 MapReduce 的性能。使用困难。
脸书蜂巢
2007年,Facebook进一步优化了查询方式,开发了一套可以直接使用SQL查询大数据的工具——HIVE。只要懂 SQL 的开发者都可以使用这个组件。
Powerset 的 HBASE
2007年,Powerset的工作人员通过Google的论文开发了Java版BigTable,即HBASE。HBASE 在 2008 年被贡献给 Apache。
火花的产生
2009 年,加州大学伯克利分校的研究人员在使用 MapReduce 进行实验项目时,性能无法满足要求。于是我开始设计火花。基于内存计算的spark的性能远高于spark。
三、大数据应用

软文一件采集器(软文一件采集器无法筛选器的任何特征,您的用户也无法识别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-01-10 03:00
软文一件采集器无法筛选器的任何特征,您的用户也无法识别。提供一个四面体模型,命名为:sphericalhexus,并正确引用它来获取所有游戏周边的资源。为避免重复引用,我们提供将之前的两个不同游戏内容合并在一起的方法,但无法用作筛选器。下载地址:链接:密码:r8u编译链接:密码:csr操作:-3-下载完毕安装zip文件后双击启动sphericalhexus后,点击文件——首选项——注册表——sqlite3——键入sqlite3位置和名称——确定。
-4-打开universalsphericalhexus,进入游戏相关选项卡,在library_id选项卡上,按照自己的需求可以设置下文件的名称和位置,随后点击file——bindependency——匹配选择自己需要的数据库内容——ok。-5-sphericalhexus启动之后,界面左侧有个搜索框,输入你想要过滤的游戏内容,然后点击筛选器进行下一步操作。
-6-下载完成,重启universalsphericalhexus,搜索框就会出现,鼠标一直在输入框内,刷新筛选器即可。-7-经过长时间的测试,完美适配gamemaker和ue4,不过可能速度比较慢,i7-8750hi5-8300h同款以上可正常运行,ux4后期可能会优化速度。部分行业内技术的demo可在/project_example/return.m4文件中下载,请注意将所需要的数据库编号写入此文件中并加上相应字段。-8-本文首发于官方博客,感谢原作者的分享。欢迎关注我们!。 查看全部
软文一件采集器(软文一件采集器无法筛选器的任何特征,您的用户也无法识别)
软文一件采集器无法筛选器的任何特征,您的用户也无法识别。提供一个四面体模型,命名为:sphericalhexus,并正确引用它来获取所有游戏周边的资源。为避免重复引用,我们提供将之前的两个不同游戏内容合并在一起的方法,但无法用作筛选器。下载地址:链接:密码:r8u编译链接:密码:csr操作:-3-下载完毕安装zip文件后双击启动sphericalhexus后,点击文件——首选项——注册表——sqlite3——键入sqlite3位置和名称——确定。
-4-打开universalsphericalhexus,进入游戏相关选项卡,在library_id选项卡上,按照自己的需求可以设置下文件的名称和位置,随后点击file——bindependency——匹配选择自己需要的数据库内容——ok。-5-sphericalhexus启动之后,界面左侧有个搜索框,输入你想要过滤的游戏内容,然后点击筛选器进行下一步操作。
-6-下载完成,重启universalsphericalhexus,搜索框就会出现,鼠标一直在输入框内,刷新筛选器即可。-7-经过长时间的测试,完美适配gamemaker和ue4,不过可能速度比较慢,i7-8750hi5-8300h同款以上可正常运行,ux4后期可能会优化速度。部分行业内技术的demo可在/project_example/return.m4文件中下载,请注意将所需要的数据库编号写入此文件中并加上相应字段。-8-本文首发于官方博客,感谢原作者的分享。欢迎关注我们!。
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-08 12:20
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软文一件采集器(本款软件属应用型营销软件的使用教程,教程时长3小时)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-02-15 10:13
本软件是一款面向应用的营销软件。该软件在脚本上运行。只要你会写脚本,就可以一百一百。营销变得更容易了!从此不再需要购买任何营销软件。无论是论坛营销、微博营销、博客营销、分类信息营销等,任何大平台的自动填表发布,还是SEO排名优化、外链发布等......网络营销。软件性价比很高,真的值一百。无论我们运营的平台如何更新,都可以长期使用,有效解决营销软件频繁更新带来的使用问题。购买软件并分发 3GB 超详细的软件教程。教程时长为 3 小时。只要认真看教程,只要不是太懒,小学生都会用。1、发布你想要的任何内容网站!(更大的特点)2、如果你处理过优质账号的B2B网站,可以有效实现自动发布!每天可以发送上千条消息,软文批量发布广告,发送到各大高权重平台,省时省力。3、软件支持自动随机生成标题,自动插入国家城市名和任意结尾词,标题对应内容,图片自动上传,无数句子可以组合成不同的原创内容,只要你发好就停,几秒钟内绝对接近!4、可以用来实现某个站的批量自动账号注册,可以通过ADSL拨号和代理IP方式自动切换IP!5、软件自带数百个常用验证码,可自动识别填写。软件库中未收录的验证码可集成第三方编码UU云或联众。一般来说,每个代码花费 1 美分!四个汉字四毛钱!6、售后服务:软件只是一个工具,我们提供这样一个工具,集大家的力量于一身,如果有些客户对自己不够自信,可以咨询我们的客服或者去我们的论坛询问你需要什么功能,你可以随意定制你自己的心灵效果。? < @7、软件还可以随意更改你发过的帖子。如果你抢沙发,你可以回去定期更换效果。8:该软件可以有效替代各大网站的手动发布 9:专用于一个站,不会快速发送多个站,但软件可以多开,可以同时发送多个站同时!10:可以设置每次发帖的数量,或者批量更新信息 11:可以导入留言网址、评论网址等自动批量发布 12:对于一些网站,多账号可轮换发布,信息量大更新记录:2016.9.4:优化按键模拟系统,解决部分表单假死问题.......201 6.8. 查看全部
软文一件采集器(本款软件属应用型营销软件的使用教程,教程时长3小时)
本软件是一款面向应用的营销软件。该软件在脚本上运行。只要你会写脚本,就可以一百一百。营销变得更容易了!从此不再需要购买任何营销软件。无论是论坛营销、微博营销、博客营销、分类信息营销等,任何大平台的自动填表发布,还是SEO排名优化、外链发布等......网络营销。软件性价比很高,真的值一百。无论我们运营的平台如何更新,都可以长期使用,有效解决营销软件频繁更新带来的使用问题。购买软件并分发 3GB 超详细的软件教程。教程时长为 3 小时。只要认真看教程,只要不是太懒,小学生都会用。1、发布你想要的任何内容网站!(更大的特点)2、如果你处理过优质账号的B2B网站,可以有效实现自动发布!每天可以发送上千条消息,软文批量发布广告,发送到各大高权重平台,省时省力。3、软件支持自动随机生成标题,自动插入国家城市名和任意结尾词,标题对应内容,图片自动上传,无数句子可以组合成不同的原创内容,只要你发好就停,几秒钟内绝对接近!4、可以用来实现某个站的批量自动账号注册,可以通过ADSL拨号和代理IP方式自动切换IP!5、软件自带数百个常用验证码,可自动识别填写。软件库中未收录的验证码可集成第三方编码UU云或联众。一般来说,每个代码花费 1 美分!四个汉字四毛钱!6、售后服务:软件只是一个工具,我们提供这样一个工具,集大家的力量于一身,如果有些客户对自己不够自信,可以咨询我们的客服或者去我们的论坛询问你需要什么功能,你可以随意定制你自己的心灵效果。? < @7、软件还可以随意更改你发过的帖子。如果你抢沙发,你可以回去定期更换效果。8:该软件可以有效替代各大网站的手动发布 9:专用于一个站,不会快速发送多个站,但软件可以多开,可以同时发送多个站同时!10:可以设置每次发帖的数量,或者批量更新信息 11:可以导入留言网址、评论网址等自动批量发布 12:对于一些网站,多账号可轮换发布,信息量大更新记录:2016.9.4:优化按键模拟系统,解决部分表单假死问题.......201 6.8.
软文一件采集器(七星B2B小助手软件是专门针对大型高权重B2B网站定做 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-02-12 19:11
)
七星B2B助手软件是专为大型高权重B2B网站定制的发布软件。软件完全模拟平台的一系列操作,实现海量信息的无人值守发布。
众所周知,中国互联网近年来发展速度惊人。许多公司正在转向网络营销。许多早期的互联网营销公司发展得越来越好。21世纪是互联网时代,行业B2B平台信息推广是企业推广产品的必经之路。只有信息量足够大,才能稳稳占据全国商机。我们的软件应运而生。许多客户正在雇用人员发送一些 B2B 产品信息。虽然也可以卖产品,但是雇佣员工发布成本太高,发布效率远不及软件。软件没有很好地处理随机性。使用七星B2B助手发布的信息,
七星B2B小助手支持的平台有家电之家、上国互联网、马可波罗、世界工厂、阿里巴巴、云商网、奇汇网、金农网、知趣网、速聊网、亿虎百赢、钢企网、汽车 佳源网、硬件商机网等大型B2B平台可按需定制。
七星B2B助手功能介绍:
视觉内容编辑器
七星B2B助手采用可视化的html编辑器,用户不需要看懂html代码,用户可以直观的搞定,文字加粗、换行、添加图片、更改字体颜色大小等操作。您可以使用鼠标来操作软件。
多内容模板保存和调用,随机切换选择多个产品软文
用户可以创建无限数量的内容模板进行调用,只要勾选要使用的模板,发布信息时就可以随机调用。用户可以根据不同的产品设置不同的软文,提高访问者的转化率。增加的内容多样性不仅对搜索引擎有帮助收录而且还省去了每次更改产品名称和重新编辑内容的麻烦。
随机句子、图片、链接等变量的调用,适应搜索引擎SEO排名算法
随机句子可以增加内容的多样性,有利于搜索引擎收录。随机图像允许信息显示更多图像,而无需频繁编辑内容模板的麻烦。软件内置图片上传功能,用户无需到b2b网页后台编辑上传相册。
便捷的图片管理功能,可以随时上传采集会员账号中的图片
软件内置图片管理,免去用户在后台查找图片和上传图片的麻烦。这个功能对于不熟悉网络的用户来说非常实用。
独有的SEO链轮功能,帮助信息快速收录排名
上一条信息链接功能:可以设置上一条发送的信息到下一条的链接,方便蜘蛛抓取,提高收录的排名;@网站信息内容中随机插入链接,更有利于搜索引擎排名收录。
独特的地名生成器,近3000个地名可供选择
七星B2B助手自带地名一键生成器,收录全国所有省、市、县、自治区、自治州等地的地名信息,地名匹配多样化。一键生成省去了软件用户排地名的麻烦。还可以自由去除自治区、省、市、县等不必要的地名后缀。
信息发布实时监控系统,自动提交到搜索引擎,实时展示,快速搜索引擎排名收录
从发布到成功软件的每一条信息都会实时显示在状态中,并且可以实时看到成功的信息链接。
自动识别验证码
对于一些有验证码的平台,七星软件会尽量识别验证码,让他们不输入验证码就不能输入,能输入就少输入。
实时自动保存配置,不用担心突然死机和断电
软件采用最新技术,集成了自动保存配置功能,即使断电也能实时保存软件的多项配置,不占用系统资源。
傻瓜式一键句库处理器
方便快捷的一键处理文章为随机语句,方便用户选择调用
软件功能按需
只要您对软件的某些功能不满意或需要新功能,都可以联系我们协商定制。我们将帮助您在最短的时间内开发出您需要的功能!以下是专门为硬件商机网络定制的功能。删除硬件商机网络信息后,可以发布信息总数。软件会自动查询没有排名的信息链接,用户可以选择删除。
查看全部
软文一件采集器(七星B2B小助手软件是专门针对大型高权重B2B网站定做
)
七星B2B助手软件是专为大型高权重B2B网站定制的发布软件。软件完全模拟平台的一系列操作,实现海量信息的无人值守发布。
众所周知,中国互联网近年来发展速度惊人。许多公司正在转向网络营销。许多早期的互联网营销公司发展得越来越好。21世纪是互联网时代,行业B2B平台信息推广是企业推广产品的必经之路。只有信息量足够大,才能稳稳占据全国商机。我们的软件应运而生。许多客户正在雇用人员发送一些 B2B 产品信息。虽然也可以卖产品,但是雇佣员工发布成本太高,发布效率远不及软件。软件没有很好地处理随机性。使用七星B2B助手发布的信息,
七星B2B小助手支持的平台有家电之家、上国互联网、马可波罗、世界工厂、阿里巴巴、云商网、奇汇网、金农网、知趣网、速聊网、亿虎百赢、钢企网、汽车 佳源网、硬件商机网等大型B2B平台可按需定制。
七星B2B助手功能介绍:
视觉内容编辑器
七星B2B助手采用可视化的html编辑器,用户不需要看懂html代码,用户可以直观的搞定,文字加粗、换行、添加图片、更改字体颜色大小等操作。您可以使用鼠标来操作软件。
多内容模板保存和调用,随机切换选择多个产品软文
用户可以创建无限数量的内容模板进行调用,只要勾选要使用的模板,发布信息时就可以随机调用。用户可以根据不同的产品设置不同的软文,提高访问者的转化率。增加的内容多样性不仅对搜索引擎有帮助收录而且还省去了每次更改产品名称和重新编辑内容的麻烦。
随机句子、图片、链接等变量的调用,适应搜索引擎SEO排名算法
随机句子可以增加内容的多样性,有利于搜索引擎收录。随机图像允许信息显示更多图像,而无需频繁编辑内容模板的麻烦。软件内置图片上传功能,用户无需到b2b网页后台编辑上传相册。
便捷的图片管理功能,可以随时上传采集会员账号中的图片
软件内置图片管理,免去用户在后台查找图片和上传图片的麻烦。这个功能对于不熟悉网络的用户来说非常实用。
独有的SEO链轮功能,帮助信息快速收录排名
上一条信息链接功能:可以设置上一条发送的信息到下一条的链接,方便蜘蛛抓取,提高收录的排名;@网站信息内容中随机插入链接,更有利于搜索引擎排名收录。
独特的地名生成器,近3000个地名可供选择
七星B2B助手自带地名一键生成器,收录全国所有省、市、县、自治区、自治州等地的地名信息,地名匹配多样化。一键生成省去了软件用户排地名的麻烦。还可以自由去除自治区、省、市、县等不必要的地名后缀。
信息发布实时监控系统,自动提交到搜索引擎,实时展示,快速搜索引擎排名收录
从发布到成功软件的每一条信息都会实时显示在状态中,并且可以实时看到成功的信息链接。
自动识别验证码
对于一些有验证码的平台,七星软件会尽量识别验证码,让他们不输入验证码就不能输入,能输入就少输入。
实时自动保存配置,不用担心突然死机和断电
软件采用最新技术,集成了自动保存配置功能,即使断电也能实时保存软件的多项配置,不占用系统资源。
傻瓜式一键句库处理器
方便快捷的一键处理文章为随机语句,方便用户选择调用
软件功能按需
只要您对软件的某些功能不满意或需要新功能,都可以联系我们协商定制。我们将帮助您在最短的时间内开发出您需要的功能!以下是专门为硬件商机网络定制的功能。删除硬件商机网络信息后,可以发布信息总数。软件会自动查询没有排名的信息链接,用户可以选择删除。
软文一件采集器(优采云采集器怎么样?勾选ocrocr)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-09 21:26
作为一个同时使用优采云采集器和爬虫写法的非技术人员,我莫名喜欢思考自己技术的互联网运营喵。. . 让我谈谈我的想法。
优采云具有学习成本低、过程可视化、采集系统构建速度快等优点。可以直接导出excel文件,导出到数据库。为了降低采集的成本,云采集提供了10个节点,也可以省去不少麻烦。
缺点是虽然看起来很简单,而且还有一个比较傻的智能模式,但是里面的坑只有经常用的人才清楚。关于这个我在博客上简单写过,但说实话,我经验太多,没有仔细梳理。
首先里面的循环都是xpath元素定位。如果使用简单的傻瓜式点击定位,非常死板,在大量采集页面使用时容易出错。另外,对于使用这个工具的人来说,因为方便,新手太多了。人们整天问普通问题,但他们不知道页面结构或xpath。容易出现采集不完整、无限翻页等问题。
但是优采云采集器的ajax加载、模拟手机页面、过滤广告、滚动到页面底部的功能都可以称为神器,一次check就可以搞定. 编写代码很麻烦,实现这些功能也很费力。
优采云毕竟它只是一个工具,自由度肯定会打败编程。优点是方便、快捷、成本低。
优采云判断引用很弱,无法做出复杂的判断,无法执行复杂的逻辑。还有优采云只有企业版可以解决验证码问题,普通版无法访问编码平台。
还有一点就是没有ocr功能。和赶集网采集的电话号码都是图片格式。Python可以使用开源的图像识别库来解决,对接即可识别。
在这里更新:
之前写的感觉是片面的,毕竟是当时的心情写的。一段时间后,想来想去,数据采集的需求决定了最终使用什么工具。如果我需要大量的数据采集,爬虫肯定是不可避免的,因为代码的自由度更高。我不认为优采云的目标是替代python,而是实现采集器人人都可以使用的目标。
还有一点,python易学易部署,开源免费。哪怕只学scrapy,也能解决一些问题,但麻烦的是,一些工具中容易选择的功能,只能通过编写或复制别人的代码来实现。我只想开始放弃...
自己写了个综合对比和坑,放在知乎一栏。有兴趣的可以去看看:
说说最近使用优采云采集器遇到的坑(以及比较其他采集软件和爬虫)-知乎专栏 查看全部
软文一件采集器(优采云采集器怎么样?勾选ocrocr)
作为一个同时使用优采云采集器和爬虫写法的非技术人员,我莫名喜欢思考自己技术的互联网运营喵。. . 让我谈谈我的想法。
优采云具有学习成本低、过程可视化、采集系统构建速度快等优点。可以直接导出excel文件,导出到数据库。为了降低采集的成本,云采集提供了10个节点,也可以省去不少麻烦。
缺点是虽然看起来很简单,而且还有一个比较傻的智能模式,但是里面的坑只有经常用的人才清楚。关于这个我在博客上简单写过,但说实话,我经验太多,没有仔细梳理。
首先里面的循环都是xpath元素定位。如果使用简单的傻瓜式点击定位,非常死板,在大量采集页面使用时容易出错。另外,对于使用这个工具的人来说,因为方便,新手太多了。人们整天问普通问题,但他们不知道页面结构或xpath。容易出现采集不完整、无限翻页等问题。
但是优采云采集器的ajax加载、模拟手机页面、过滤广告、滚动到页面底部的功能都可以称为神器,一次check就可以搞定. 编写代码很麻烦,实现这些功能也很费力。
优采云毕竟它只是一个工具,自由度肯定会打败编程。优点是方便、快捷、成本低。
优采云判断引用很弱,无法做出复杂的判断,无法执行复杂的逻辑。还有优采云只有企业版可以解决验证码问题,普通版无法访问编码平台。
还有一点就是没有ocr功能。和赶集网采集的电话号码都是图片格式。Python可以使用开源的图像识别库来解决,对接即可识别。
在这里更新:
之前写的感觉是片面的,毕竟是当时的心情写的。一段时间后,想来想去,数据采集的需求决定了最终使用什么工具。如果我需要大量的数据采集,爬虫肯定是不可避免的,因为代码的自由度更高。我不认为优采云的目标是替代python,而是实现采集器人人都可以使用的目标。
还有一点,python易学易部署,开源免费。哪怕只学scrapy,也能解决一些问题,但麻烦的是,一些工具中容易选择的功能,只能通过编写或复制别人的代码来实现。我只想开始放弃...
自己写了个综合对比和坑,放在知乎一栏。有兴趣的可以去看看:
说说最近使用优采云采集器遇到的坑(以及比较其他采集软件和爬虫)-知乎专栏
软文一件采集器(软文一件采集器,它采集完我们的任务!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-02-04 16:02
软文一件采集器,它采集完我们的任务,就会通知采集任务本身的服务器,然后我们可以去下载采集过的报告并查看,就像下图一样。软件介绍程序猿科普时间这套工具是基于这样一个大假设:更优质的资源在最开始就被买到我们的账上,如果没有早一步拿到,我们的假设就不成立。有点像卖饼,中间一步是因为这个饼卖得贵,而且中间多卖了一些,所以饼就一下又卖得更贵了。
(虽然这样说有点讨厌)但这个假设的确也很重要。软件的作用可以省去很多烦恼(如为了采集而采集,很多时候软件会尽快放弃我们手上的任务,但事实是,第一步选择收集的东西并不在我们计划之中,我们也可以选择不采集)这样说虽然不利于批评软件,但采集太少的话就是软件太少的结果。如果你希望软件功能完善一些,但手头又真的没有足够多的任务,就可以优先选择批量采集,当采集到足够多的东西之后,再考虑采集更多的。
软件功能采集效率自动和手动一起采集,但单独采集的话,效率会有所降低手动比自动采集要麻烦一些,因为要拼凑buffer。但这点麻烦是可以接受的。你也可以一键采集,但需要手动处理一些统计类的工作,因为这些需要自己来计算,而且这点buffer也不算多,仅仅是allocator的条数。视频限速采集不同的视频源可能会快不同的速度,这是常见的,但还有一个例外,那就是观看时间和bytes的比例,可以用seek_as_last_frame()方法来设置。
配合on_update_random()函数使用,可以读取配额随机数,并抛到on_update_random()中。如果不想整套方法都是一个seek_as_last_frame()方法实现,也可以单独只使用一个函数。服务器升级这个服务器升级是指,当您计划升级服务器时,这套方法需要在两到三年之内持续更新,且更新周期不能低于软件本身设定的两年时间。
一般的升级周期是三年,但时间越长有可能收敛的概率也就越低。我们也可以选择升级软件,但要求用户也要在软件升级到三年之后再升级。这是考虑到用户有可能已经升级软件一年以上,且有明显有明显增长的需求。如果升级软件时,需要付出一些额外的代价,我觉得是不划算的。另外,一个软件就只能使用一个节点的数据。当其中一台服务器出现故障或损坏时,本地的服务器也只能独立工作。
从更新周期来看,这个方法需要更新的时间短一些,但升级的概率也大一些。当然,在升级后,数据会丢失,在时间内发生的丢失,和升级的概率无关。数据的额外收集如果软件预留出来的字段已经被其他服务器采集到,软件不会自动推送数据到本地,而需要用户做额外的收集。一般的做法。 查看全部
软文一件采集器(软文一件采集器,它采集完我们的任务!)
软文一件采集器,它采集完我们的任务,就会通知采集任务本身的服务器,然后我们可以去下载采集过的报告并查看,就像下图一样。软件介绍程序猿科普时间这套工具是基于这样一个大假设:更优质的资源在最开始就被买到我们的账上,如果没有早一步拿到,我们的假设就不成立。有点像卖饼,中间一步是因为这个饼卖得贵,而且中间多卖了一些,所以饼就一下又卖得更贵了。
(虽然这样说有点讨厌)但这个假设的确也很重要。软件的作用可以省去很多烦恼(如为了采集而采集,很多时候软件会尽快放弃我们手上的任务,但事实是,第一步选择收集的东西并不在我们计划之中,我们也可以选择不采集)这样说虽然不利于批评软件,但采集太少的话就是软件太少的结果。如果你希望软件功能完善一些,但手头又真的没有足够多的任务,就可以优先选择批量采集,当采集到足够多的东西之后,再考虑采集更多的。
软件功能采集效率自动和手动一起采集,但单独采集的话,效率会有所降低手动比自动采集要麻烦一些,因为要拼凑buffer。但这点麻烦是可以接受的。你也可以一键采集,但需要手动处理一些统计类的工作,因为这些需要自己来计算,而且这点buffer也不算多,仅仅是allocator的条数。视频限速采集不同的视频源可能会快不同的速度,这是常见的,但还有一个例外,那就是观看时间和bytes的比例,可以用seek_as_last_frame()方法来设置。
配合on_update_random()函数使用,可以读取配额随机数,并抛到on_update_random()中。如果不想整套方法都是一个seek_as_last_frame()方法实现,也可以单独只使用一个函数。服务器升级这个服务器升级是指,当您计划升级服务器时,这套方法需要在两到三年之内持续更新,且更新周期不能低于软件本身设定的两年时间。
一般的升级周期是三年,但时间越长有可能收敛的概率也就越低。我们也可以选择升级软件,但要求用户也要在软件升级到三年之后再升级。这是考虑到用户有可能已经升级软件一年以上,且有明显有明显增长的需求。如果升级软件时,需要付出一些额外的代价,我觉得是不划算的。另外,一个软件就只能使用一个节点的数据。当其中一台服务器出现故障或损坏时,本地的服务器也只能独立工作。
从更新周期来看,这个方法需要更新的时间短一些,但升级的概率也大一些。当然,在升级后,数据会丢失,在时间内发生的丢失,和升级的概率无关。数据的额外收集如果软件预留出来的字段已经被其他服务器采集到,软件不会自动推送数据到本地,而需要用户做额外的收集。一般的做法。
软文一件采集器(一下影响网站排名优化的几个重要因素有哪些?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2022-02-02 15:12
在国内最便宜的vps评测软文区做网站排名优化的时候,保持良好的心态是非常积极的。毕竟,网站排名优化并不是一件容易的事。改进一个零件可能需要很多思考,细节决定成败。云星阳在之前的文章关于网站排名优化中也分析了网站排名优化的一些因素。今天,我将总结一些影响网站排名优化的重要因素。
影响网站排名优化的因素国内最便宜的vps评测软文地区:
软文区最便宜的vps评测之一,网站空间
很多人买了一个空间,速度很慢,而且是网通的,有的还是移动的。他们不想等待什么时候可以打开它。搜索引擎愿意等待吗?所以网站放在好的IDC,选择速度快的带宽,最好是两线机房,服务更好,一有问题,第一时间处理。也就是服务器配置要稍高一些,尤其是内存要大一些,一般4G以上,当然要看你的访问量网站,可以适当增加内存;如果你没钱,现在可以买比较流行的VPS,和租服务器没什么区别。它虚拟化了一个服务器供多人一起使用,其效果与使用单个服务器相同。每月只需要200-300左右;当然,配置越多,价格越优,国内最便宜的vps评价软文区越高。
国内最便宜的两个vps评测软文专区,网页布局
网页的布局也是影响网站排名优化的一个非常关键的因素。百度百科、贴吧等大家都知道,他们的排版其实很简单,很人性化,图片也用的很好。少,DIV做的页面主要不是美观,打开要快速直观,能将网友需要的重要信息和信息立即展示给大家。这样的页面是好页面,蜘蛛会喜欢的;TITLE 必须与页面上的 H1 相匹配,最好在前 100 个字符中显示 H1 内容;首页的版面不需要太长,少用FLASH和图片,内页最好不要太复杂。(页面设计规范)
三、网站内容
很多做网站排名优化的人都知道内容为王。事实上,每个人都知道这一点。问题是每个人手中都没有内容。都是采集或者伪原创,但是搜索引擎只有我喜欢原创的内容,所以做网站的时候,一定要有自己的东西。如果是别人的,估计你的网站不值钱,流量难增加,你可以认为我看过一个网站,他们的资料和一些内容都翻译了来自国外的文章,当然这个成本会很高,你也可以去一些报刊杂志了解相关信息,总结总结之后,其实就是原创;久而久之,我对一个企业的了解越来越多,并且自然可以写很多经验,自己去体验。但是还有其他方法可以考虑它。总之,内容就是网站的血脉。没有内容,网站 就没有意义。
四、关键词布局
关键词排版其实就是在讲如何合理的把你要优化的关键词放到你的页面上,让搜索引擎觉得不是作弊,而是SEO网站排名优化用高密度的意思,比如把他放在ALT里,或者放在“More”或者BANALE等标题里,只要合理,看起来舒服,搜索引擎本身就是在模拟人类思维,最好不要密度太高,可以到站长工具下查询,以免被K;(提升关键词排名的技巧)
五、标签优化
我们都知道SEO网站排名优化,TITLE,关键词,deion,是搜索引擎找到你的最直接的方式,所以我们在每个页面上设置这些一定要合理,流畅,有用,不要浪费任何一个页面,包括一些不相关的页面,在做TITLE时应该是文章的标题。如果有城市或类别,可以适当添加。列表页的标题应加在标题之后。页码,例如“TITLE page 1”,因此您的所有列表页面都将是 收录。如果你实在不知道如何更合理地设置这些,可以参考你的网站同事,多学习他们的经验,现在百度好像不太重视KEYWORDS和DEION,而GOOGLE却没有改变。如果你不明白,
六、避免死链接
死链接主要体现在内部链接上。这主要是在做网站排名优化修改时容易犯的错误。为了节省一点空间,删除了原来的网站结构,导致大量页面不得不指向404,大大降低了蜘蛛在网站上的得分,排名说起来容易完毕。
七、链接
友情链接是指彼此的网站对自己的网站的链接。URL和网站名称必须在网页代码中找到,网站名称可以在浏览网页时显示出来,称为友好链接。现在有很多所谓的作弊链接,他们只是把对方的网站放在JS代码或者iframe中。这样的链接不能称为友好链接,因为这样的链接对 网站 的排名优化很有用,没有意义。
八、反向链接
这是最关键的,其实就是外链。现在很多人都在卖链接。当然,如果有保证的话,网站的质量和收录的截图都不错,有一点资本买一些不错的链接,这个时间不长,推荐使用其他一些方法做外部链接,例如博客、微薄、论坛;如果你有写作能力,可以写软文,这样效果更好,当然要看你怎么写文章,最好写一些有争议的话题,故事话题,敏感话题,很容易被转载,这样你的外链自然就上去了。
以上八点是网站排名优化过程中需要注意的地方。只有把握好每一个细节,最终在用户体验的提升中体现提升,网站才能真正的进步和发展。 查看全部
软文一件采集器(一下影响网站排名优化的几个重要因素有哪些?(图))
在国内最便宜的vps评测软文区做网站排名优化的时候,保持良好的心态是非常积极的。毕竟,网站排名优化并不是一件容易的事。改进一个零件可能需要很多思考,细节决定成败。云星阳在之前的文章关于网站排名优化中也分析了网站排名优化的一些因素。今天,我将总结一些影响网站排名优化的重要因素。
影响网站排名优化的因素国内最便宜的vps评测软文地区:
软文区最便宜的vps评测之一,网站空间
很多人买了一个空间,速度很慢,而且是网通的,有的还是移动的。他们不想等待什么时候可以打开它。搜索引擎愿意等待吗?所以网站放在好的IDC,选择速度快的带宽,最好是两线机房,服务更好,一有问题,第一时间处理。也就是服务器配置要稍高一些,尤其是内存要大一些,一般4G以上,当然要看你的访问量网站,可以适当增加内存;如果你没钱,现在可以买比较流行的VPS,和租服务器没什么区别。它虚拟化了一个服务器供多人一起使用,其效果与使用单个服务器相同。每月只需要200-300左右;当然,配置越多,价格越优,国内最便宜的vps评价软文区越高。
国内最便宜的两个vps评测软文专区,网页布局
网页的布局也是影响网站排名优化的一个非常关键的因素。百度百科、贴吧等大家都知道,他们的排版其实很简单,很人性化,图片也用的很好。少,DIV做的页面主要不是美观,打开要快速直观,能将网友需要的重要信息和信息立即展示给大家。这样的页面是好页面,蜘蛛会喜欢的;TITLE 必须与页面上的 H1 相匹配,最好在前 100 个字符中显示 H1 内容;首页的版面不需要太长,少用FLASH和图片,内页最好不要太复杂。(页面设计规范)
三、网站内容
很多做网站排名优化的人都知道内容为王。事实上,每个人都知道这一点。问题是每个人手中都没有内容。都是采集或者伪原创,但是搜索引擎只有我喜欢原创的内容,所以做网站的时候,一定要有自己的东西。如果是别人的,估计你的网站不值钱,流量难增加,你可以认为我看过一个网站,他们的资料和一些内容都翻译了来自国外的文章,当然这个成本会很高,你也可以去一些报刊杂志了解相关信息,总结总结之后,其实就是原创;久而久之,我对一个企业的了解越来越多,并且自然可以写很多经验,自己去体验。但是还有其他方法可以考虑它。总之,内容就是网站的血脉。没有内容,网站 就没有意义。
四、关键词布局
关键词排版其实就是在讲如何合理的把你要优化的关键词放到你的页面上,让搜索引擎觉得不是作弊,而是SEO网站排名优化用高密度的意思,比如把他放在ALT里,或者放在“More”或者BANALE等标题里,只要合理,看起来舒服,搜索引擎本身就是在模拟人类思维,最好不要密度太高,可以到站长工具下查询,以免被K;(提升关键词排名的技巧)
五、标签优化
我们都知道SEO网站排名优化,TITLE,关键词,deion,是搜索引擎找到你的最直接的方式,所以我们在每个页面上设置这些一定要合理,流畅,有用,不要浪费任何一个页面,包括一些不相关的页面,在做TITLE时应该是文章的标题。如果有城市或类别,可以适当添加。列表页的标题应加在标题之后。页码,例如“TITLE page 1”,因此您的所有列表页面都将是 收录。如果你实在不知道如何更合理地设置这些,可以参考你的网站同事,多学习他们的经验,现在百度好像不太重视KEYWORDS和DEION,而GOOGLE却没有改变。如果你不明白,
六、避免死链接
死链接主要体现在内部链接上。这主要是在做网站排名优化修改时容易犯的错误。为了节省一点空间,删除了原来的网站结构,导致大量页面不得不指向404,大大降低了蜘蛛在网站上的得分,排名说起来容易完毕。
七、链接
友情链接是指彼此的网站对自己的网站的链接。URL和网站名称必须在网页代码中找到,网站名称可以在浏览网页时显示出来,称为友好链接。现在有很多所谓的作弊链接,他们只是把对方的网站放在JS代码或者iframe中。这样的链接不能称为友好链接,因为这样的链接对 网站 的排名优化很有用,没有意义。
八、反向链接
这是最关键的,其实就是外链。现在很多人都在卖链接。当然,如果有保证的话,网站的质量和收录的截图都不错,有一点资本买一些不错的链接,这个时间不长,推荐使用其他一些方法做外部链接,例如博客、微薄、论坛;如果你有写作能力,可以写软文,这样效果更好,当然要看你怎么写文章,最好写一些有争议的话题,故事话题,敏感话题,很容易被转载,这样你的外链自然就上去了。
以上八点是网站排名优化过程中需要注意的地方。只有把握好每一个细节,最终在用户体验的提升中体现提升,网站才能真正的进步和发展。
软文一件采集器(软文一件采集器,能采集一百多家的热门网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-29 18:01
软文一件采集器,能采集一百多家的热门网站,利用magento内置的爬虫软件,非常轻松,采集之后直接上传到网站,就可以抓取,非常的方便。
所谓十八般武艺都会是打星际争霸选手,要啥法术什么都知道的人都是大师,
各大知名站点都有很多人站了,你去看他们后面的文章就知道了,很多知名站点,下面都有精华链接。或者去看看下面的贴吧。我截了几个图,你们感受一下,注意:①,xxxfans,②⑥,③⑧你可以进行那些搜索。
优采云站的咸豆腐脑是啥味
技术一条龙
非洲式重文轻理,走的几乎和西方有些人一样的路。当全面转向软件部署后,得到的结果却可能更糟糕。
semantics
高三数学(基础+刷题),regex100+allstars前面各位大佬们都在说技术,我就不在啰嗦了接下来说说这两者孰重孰轻——软件技术重视大规模、高并发运算、合理模块组织,强调代码标准化,重视规范化;而技术思维,重视依据需求定制系统结构和框架,重视功能设计合理的代码结构,以及业务方法论。软件工程和技术技术在大规模技术设计、结构优化、系统架构、算法实现、程序架构等这些方面相辅相成,缺一不可。
学过软件工程的同学很容易就能明白,计算机系的大规模、强并发的计算系统,都是以重技术、轻技术、两相结合、依赖技术、非依赖技术、过程技术等为基本框架。一个完整的技术系统必须要包含上述技术,不然没有足够强的实力支撑开发这么复杂系统,整个生态、开发环境就不完善,比如现在所有的开源的高性能计算引擎都是基于drykelly算法为基础实现的,drykelly的标准化是这些开源的系统大规模高并发系统的关键。
但是,它又不仅仅只是个drykelly算法而已,还涉及到了n-tree/分布式机器学习引擎,设计模式技术,大规模数据集dsp计算,深度学习,图神经网络等一系列技术架构。如果把一个软件开发的大规模系统看成是一个“山”,它必须得有这些“基础”支撑,再搭配多种技术才能得以运行。此外软件工程在程序架构设计上也有相关的发展历史——例如早期的经典软件开发架构——(张寅生《计算机程序设计原理》thecomputerprogramminginterfaceandtheadaptivesystemdesign,programmingalanguage)这本书在1976年就出版了,但是直到1991年的今天,如果硬要我用程序设计语言对程序设计工作的理解来描述程序设计语言架构和编程方法论的重要性的话,我可能会这么形容——在十七世纪以前的那段时间,工业革命是属于欧洲的。那时候,实际上以法国为首的法国人把发展出了一系列完整的工业化生产。 查看全部
软文一件采集器(软文一件采集器,能采集一百多家的热门网站)
软文一件采集器,能采集一百多家的热门网站,利用magento内置的爬虫软件,非常轻松,采集之后直接上传到网站,就可以抓取,非常的方便。
所谓十八般武艺都会是打星际争霸选手,要啥法术什么都知道的人都是大师,
各大知名站点都有很多人站了,你去看他们后面的文章就知道了,很多知名站点,下面都有精华链接。或者去看看下面的贴吧。我截了几个图,你们感受一下,注意:①,xxxfans,②⑥,③⑧你可以进行那些搜索。
优采云站的咸豆腐脑是啥味
技术一条龙
非洲式重文轻理,走的几乎和西方有些人一样的路。当全面转向软件部署后,得到的结果却可能更糟糕。
semantics
高三数学(基础+刷题),regex100+allstars前面各位大佬们都在说技术,我就不在啰嗦了接下来说说这两者孰重孰轻——软件技术重视大规模、高并发运算、合理模块组织,强调代码标准化,重视规范化;而技术思维,重视依据需求定制系统结构和框架,重视功能设计合理的代码结构,以及业务方法论。软件工程和技术技术在大规模技术设计、结构优化、系统架构、算法实现、程序架构等这些方面相辅相成,缺一不可。
学过软件工程的同学很容易就能明白,计算机系的大规模、强并发的计算系统,都是以重技术、轻技术、两相结合、依赖技术、非依赖技术、过程技术等为基本框架。一个完整的技术系统必须要包含上述技术,不然没有足够强的实力支撑开发这么复杂系统,整个生态、开发环境就不完善,比如现在所有的开源的高性能计算引擎都是基于drykelly算法为基础实现的,drykelly的标准化是这些开源的系统大规模高并发系统的关键。
但是,它又不仅仅只是个drykelly算法而已,还涉及到了n-tree/分布式机器学习引擎,设计模式技术,大规模数据集dsp计算,深度学习,图神经网络等一系列技术架构。如果把一个软件开发的大规模系统看成是一个“山”,它必须得有这些“基础”支撑,再搭配多种技术才能得以运行。此外软件工程在程序架构设计上也有相关的发展历史——例如早期的经典软件开发架构——(张寅生《计算机程序设计原理》thecomputerprogramminginterfaceandtheadaptivesystemdesign,programmingalanguage)这本书在1976年就出版了,但是直到1991年的今天,如果硬要我用程序设计语言对程序设计工作的理解来描述程序设计语言架构和编程方法论的重要性的话,我可能会这么形容——在十七世纪以前的那段时间,工业革命是属于欧洲的。那时候,实际上以法国为首的法国人把发展出了一系列完整的工业化生产。
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-29 08:24
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录才能看到信息内容的网站,网站优采云采集器可以很方便的登录和采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录才能看到信息内容的网站,网站优采云采集器可以很方便的登录和采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-28 01:25
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果您需要采集图片等二进制文件,您可以通过简单的设置网站优采云采集器将任何类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟群发。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果您需要采集图片等二进制文件,您可以通过简单的设置网站优采云采集器将任何类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟群发。
软文一件采集器(软文一件采集器的具体用法是怎么做的?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-01-26 15:01
软文一件采集器的具体用法是:在activity列表中,如果找不到需要采集的数据则返回相应的resource,然后到通知栏或者scheduler等地方来刷新采集状态,采集成功后就会获取采集状态。
请使用第三方android客户端,比如pd助手,在设置里面把本地文件上传软件端传数据到本地并进行保存。然后就能准确的看到了。
不用看,
activity之间传递数据:这个里面可以设置链接所在的activity路径,最简单的有时候就是收集图片,调用对应的方法就可以了。
用第三方的android客户端
用如opentalk,android系统自带编辑采集权限,
之前遇到过同样的问题。我直接把采集内容上传到第三方,并把链接放到统一的文件夹中。
我记得有一个软件叫pdfartificator可以做这个事情(我很好奇它对采集软件的要求,可惜没找到)。
android手机用同样的方法可以把采集的数据上传到指定的文件夹里面。这样方便你管理多个app。最傻瓜的做法,这样app把采集好的内容抓下来,放到文件夹就可以了。
我看到有人说叫框架应用来采集呢,虽然方便,但很容易出现文件一错乱,各个不同的app就得抓一堆重复的东西,还有各种机型,手机型号乱七八糟的也抓。 查看全部
软文一件采集器(软文一件采集器的具体用法是怎么做的?)
软文一件采集器的具体用法是:在activity列表中,如果找不到需要采集的数据则返回相应的resource,然后到通知栏或者scheduler等地方来刷新采集状态,采集成功后就会获取采集状态。
请使用第三方android客户端,比如pd助手,在设置里面把本地文件上传软件端传数据到本地并进行保存。然后就能准确的看到了。
不用看,
activity之间传递数据:这个里面可以设置链接所在的activity路径,最简单的有时候就是收集图片,调用对应的方法就可以了。
用第三方的android客户端
用如opentalk,android系统自带编辑采集权限,
之前遇到过同样的问题。我直接把采集内容上传到第三方,并把链接放到统一的文件夹中。
我记得有一个软件叫pdfartificator可以做这个事情(我很好奇它对采集软件的要求,可惜没找到)。
android手机用同样的方法可以把采集的数据上传到指定的文件夹里面。这样方便你管理多个app。最傻瓜的做法,这样app把采集好的内容抓下来,放到文件夹就可以了。
我看到有人说叫框架应用来采集呢,虽然方便,但很容易出现文件一错乱,各个不同的app就得抓一堆重复的东西,还有各种机型,手机型号乱七八糟的也抓。
软文一件采集器(软文一件采集器用上一年,后来被朋友砍了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-01-25 09:01
软文一件采集器用上一年,上半年每周都开3天会员(后来被朋友砍了)---这是一个资料整理的专栏,由于知乎上朋友并不多,专栏里什么资料也没有,所以把这个专栏开到知乎,希望能够为各位准备人生道路上面临疑惑,误解或困惑的朋友提供帮助。如果想要阅读更多关于互联网营销和广告投放相关的内容,请关注本专栏,上面会有更多关于互联网投放和营销的文章和资料,谢谢大家支持!---。
软广告,
买我域名吧,
要是给个在美国留学生用的网站基本可以解决ios7的bug,但这样的网站可能是内置广告,你很难控制用户的点击手段和次数,所以呢。还是要提高你网站的质量,
目前在发这样的文章:墙外版|ppt教程|理工科网页设计指南-知乎专栏 查看全部
软文一件采集器(软文一件采集器用上一年,后来被朋友砍了)
软文一件采集器用上一年,上半年每周都开3天会员(后来被朋友砍了)---这是一个资料整理的专栏,由于知乎上朋友并不多,专栏里什么资料也没有,所以把这个专栏开到知乎,希望能够为各位准备人生道路上面临疑惑,误解或困惑的朋友提供帮助。如果想要阅读更多关于互联网营销和广告投放相关的内容,请关注本专栏,上面会有更多关于互联网投放和营销的文章和资料,谢谢大家支持!---。
软广告,
买我域名吧,
要是给个在美国留学生用的网站基本可以解决ios7的bug,但这样的网站可能是内置广告,你很难控制用户的点击手段和次数,所以呢。还是要提高你网站的质量,
目前在发这样的文章:墙外版|ppt教程|理工科网页设计指南-知乎专栏
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-01-24 12:14
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录才能看到信息内容的网站,网站优采云采集器可以很方便的登录和采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录才能看到信息内容的网站,网站优采云采集器可以很方便的登录和采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软文一件采集器(优采云采集器中如何安装智能原创API支持免费试用(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-01-23 13:07
最近在研究优采云采集器,通过优采云采集软件,可以轻松获取大量网站内容(采集@ > 真的不对)和解放站长的双手,机器时代的工具自然比人工效率高很多。
经过一段时间的研究,我现在已经掌握了优采云采集技术能力,优采云采集对接开源cms程序自动更新能力,可以结合ai伪原创接口实现批量采集,直接发布到WP,DEDEcms网站。老实说,我不经常被问到采集技术相关的问题,我也根本不愿意研究这些采集技术。
接下来说一下5118智能原创功能的优采云采集器集成,这也是5118今天刚刚发布的公众号文章。
在优采云采集器中,使用5118智能原创插件,无需人工处理,可量产完全不同内容指纹的文章,大大提升内容 SEO 编辑的效率使 文章 更容易成为 收录。
如何在 优采云采集器 中安装 smart原创 插件
第一步是使用解压软件将插件安装包中的文件解压到一个文件夹中。
第二步,打开解压后的文件夹,将里面的[5118 Smart原创.dll]文件放到[优采云采集器]安装目录下的Plugins文件夹中。
第三步,复制文件夹中的【5118 Smart原创Configuration Tool.exe】
[Newtonsoft.Json.dll] 文件放在[优采云采集器] 安装目录下。
第四步,在[优采云采集器]根目录下,打开[5118 Smart原创Configuration Tool.exe],点击“Get API-Key”,会显示在浏览器打开5118获取API页面。
在页面找到“One-Key Smart原创API”,点击复制按钮,返回【5118 Smart原创Configuration Tool.exe】界面,将API-Key粘贴到输入框中.
一键智能原创API支持免费试用
当然5118伪原创需要购买和付费,可以申请100次免费使用,还可以购买一键智能原创API包。5118会员优惠码D569F5
Smart原创插件说明
第一步,打开优采云采集器,点击开始栏中的【插件管理】,在插件管理框左侧的列表中,选择【5118 Smart原创】,在右侧框中输入需要为采集的URL,点击测试按钮,检查插件是否正常。
第二步,测试没问题后,开始使用插件设置内容采集规则。
第三步,选择已有的采集任务,在【其他设置】左栏选择插件,在采集结果处理插件下拉框中选择【5118 Smart原创。dll],单击保存。
这里需要注意的是,【内容采集规则】左侧列表中的“内容”标签是插件会自动原创的内容,固定的标签名称为“内容”。
导出任务数据时,在任务列表中选择对应的任务项,右侧的“发布”项必须勾选,否则无法导出数据。
第四步,查看5118智能原创插件效果。操作完成后,可以在之前保存的地址中查看导出效果。导出的内容已经是智能 原创 插件替换的数据。(以上内容转载自5118公众号)
站长技能要求
需要以下技能:
1、优采云采集工具使用,推荐学习SEOWHY优采云采集基础教程和SEOWHY优采云采集器(进阶教程)
2、5118伪原创工具使用,会员优惠码D569F5 5118官网
3.常用的cms网站程序函数,课程中讨论过
4. 采集网页需要使用规则,熟悉div+css
5. WP博客系统界面,织梦cms发帖界面
关于SEO黑科技已经讲解了这么多,希望能给大家带来一些思考。想了解更多SEO专业知识,可以私信我交流,或者直接通过微信:seobst,咨询,已经加我微信的朋友,可以免费分享SEO信息或者提供百人学习交流群,通常群里会有一个群。有些大佬在群里讨论,有什么不懂的可以在群里问。 查看全部
软文一件采集器(优采云采集器中如何安装智能原创API支持免费试用(组图))
最近在研究优采云采集器,通过优采云采集软件,可以轻松获取大量网站内容(采集@ > 真的不对)和解放站长的双手,机器时代的工具自然比人工效率高很多。
经过一段时间的研究,我现在已经掌握了优采云采集技术能力,优采云采集对接开源cms程序自动更新能力,可以结合ai伪原创接口实现批量采集,直接发布到WP,DEDEcms网站。老实说,我不经常被问到采集技术相关的问题,我也根本不愿意研究这些采集技术。
接下来说一下5118智能原创功能的优采云采集器集成,这也是5118今天刚刚发布的公众号文章。
在优采云采集器中,使用5118智能原创插件,无需人工处理,可量产完全不同内容指纹的文章,大大提升内容 SEO 编辑的效率使 文章 更容易成为 收录。
如何在 优采云采集器 中安装 smart原创 插件
第一步是使用解压软件将插件安装包中的文件解压到一个文件夹中。
第二步,打开解压后的文件夹,将里面的[5118 Smart原创.dll]文件放到[优采云采集器]安装目录下的Plugins文件夹中。
第三步,复制文件夹中的【5118 Smart原创Configuration Tool.exe】
[Newtonsoft.Json.dll] 文件放在[优采云采集器] 安装目录下。
第四步,在[优采云采集器]根目录下,打开[5118 Smart原创Configuration Tool.exe],点击“Get API-Key”,会显示在浏览器打开5118获取API页面。
在页面找到“One-Key Smart原创API”,点击复制按钮,返回【5118 Smart原创Configuration Tool.exe】界面,将API-Key粘贴到输入框中.
一键智能原创API支持免费试用
当然5118伪原创需要购买和付费,可以申请100次免费使用,还可以购买一键智能原创API包。5118会员优惠码D569F5
Smart原创插件说明
第一步,打开优采云采集器,点击开始栏中的【插件管理】,在插件管理框左侧的列表中,选择【5118 Smart原创】,在右侧框中输入需要为采集的URL,点击测试按钮,检查插件是否正常。
第二步,测试没问题后,开始使用插件设置内容采集规则。
第三步,选择已有的采集任务,在【其他设置】左栏选择插件,在采集结果处理插件下拉框中选择【5118 Smart原创。dll],单击保存。
这里需要注意的是,【内容采集规则】左侧列表中的“内容”标签是插件会自动原创的内容,固定的标签名称为“内容”。
导出任务数据时,在任务列表中选择对应的任务项,右侧的“发布”项必须勾选,否则无法导出数据。
第四步,查看5118智能原创插件效果。操作完成后,可以在之前保存的地址中查看导出效果。导出的内容已经是智能 原创 插件替换的数据。(以上内容转载自5118公众号)
站长技能要求
需要以下技能:
1、优采云采集工具使用,推荐学习SEOWHY优采云采集基础教程和SEOWHY优采云采集器(进阶教程)
2、5118伪原创工具使用,会员优惠码D569F5 5118官网
3.常用的cms网站程序函数,课程中讨论过
4. 采集网页需要使用规则,熟悉div+css
5. WP博客系统界面,织梦cms发帖界面
关于SEO黑科技已经讲解了这么多,希望能给大家带来一些思考。想了解更多SEO专业知识,可以私信我交流,或者直接通过微信:seobst,咨询,已经加我微信的朋友,可以免费分享SEO信息或者提供百人学习交流群,通常群里会有一个群。有些大佬在群里讨论,有什么不懂的可以在群里问。
软文一件采集器(建设自己的网站是实现你宏伟目标的第一步流量吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 437 次浏览 • 2022-01-19 19:16
【新网网站建设资讯】打造自己的网站是实现远大目标的第一步。接下来,你要做的就是增加网站的优质流量。这意味着为了推广网站,您需要实施多层次的策略。
网站促销是一种以互联网为基础,利用平台和网络媒体的互动,辅助营销目标实现的新型营销方式。目前常见的传播推广方式主要是通过在各大网站推广服务商购买广告等方式实现。免费网站推广包括:SEO优化网站内容或结构提升排名搜索引擎中的网站,在论坛、微博、博客、微信、QQ空间等平台发布信息,在其他热门平台发布网站外部链接。
为了达到更好的宣传推广效果,还需要一些技巧:
1.选择一个可以帮助您传播信息的域名
一个好的域名可以为您的 网站 定下基调,有时就像宣传 网站 页面本身一样重要。您可以直接在新网注册一个新域名。您也可以在新网抢购或委托购买二手域名。选择域名时,不要使用复杂的名称,避免拼写错误;域名应收录与您提供的产品和服务相关的词语;随着您的业务增长,品牌也会随之增长,确保您的域名会随着品牌的发展而灵活变化。
2.选择一个好的网站模板
现在很多人不懂开发技术。在这种情况下,如果要构建一个高质量的网站,就需要使用更好的建站模板。例如,有许多漂亮的 网站 模板可用于构建新网站。,覆盖广泛的行业,让小白也可以打造属于自己的网站。
3、搜索引擎优化
从网站开始构建到内容填充,要注意网站的优化。建站时注意CSS+DIV方式,少用TABLE方式;一般来说,静态的网站搜索引擎收录会比较快,但是会占用空间,而静态的网站则相反。使用这种方法对于站长来说需要很多的SEO技巧,但是SEO应该是目前最有效的方法。相对来说,静态网站对此要求很低,所以当你开始做网站的时候,可以先尝试做静态。这对 SEO 也有好处。
4、软文促销
编写技术或其他有吸引力的 软文,将 URL 附加到 软文、软文 最好是一些 原创 或 伪原创 的 文章。写完软文,发布到各种博客上。如果有吸引力,那么 软文 很快就会被其他 网站采集 推广,实现快速推广网站 ,进而推广他们的 网站 目标,并整合把URL改成软文,相当于电影中所谓的植入式广告,恰到好处。写软文最大的好处就是,如果你写得好,很多人会免费帮你宣传,而这种宣传是大家都愿意做的,因为很少有人愿意做真正的原创 ,一个纯粹的 原创文章 花费太长而代价很小 网站,并且链接质量很高。另外,原创文章可以主动吸引搜索引擎收录。但是写软文比较费时间,原创文章比较难。 查看全部
软文一件采集器(建设自己的网站是实现你宏伟目标的第一步流量吗?)
【新网网站建设资讯】打造自己的网站是实现远大目标的第一步。接下来,你要做的就是增加网站的优质流量。这意味着为了推广网站,您需要实施多层次的策略。
网站促销是一种以互联网为基础,利用平台和网络媒体的互动,辅助营销目标实现的新型营销方式。目前常见的传播推广方式主要是通过在各大网站推广服务商购买广告等方式实现。免费网站推广包括:SEO优化网站内容或结构提升排名搜索引擎中的网站,在论坛、微博、博客、微信、QQ空间等平台发布信息,在其他热门平台发布网站外部链接。
为了达到更好的宣传推广效果,还需要一些技巧:
1.选择一个可以帮助您传播信息的域名
一个好的域名可以为您的 网站 定下基调,有时就像宣传 网站 页面本身一样重要。您可以直接在新网注册一个新域名。您也可以在新网抢购或委托购买二手域名。选择域名时,不要使用复杂的名称,避免拼写错误;域名应收录与您提供的产品和服务相关的词语;随着您的业务增长,品牌也会随之增长,确保您的域名会随着品牌的发展而灵活变化。
2.选择一个好的网站模板
现在很多人不懂开发技术。在这种情况下,如果要构建一个高质量的网站,就需要使用更好的建站模板。例如,有许多漂亮的 网站 模板可用于构建新网站。,覆盖广泛的行业,让小白也可以打造属于自己的网站。
3、搜索引擎优化
从网站开始构建到内容填充,要注意网站的优化。建站时注意CSS+DIV方式,少用TABLE方式;一般来说,静态的网站搜索引擎收录会比较快,但是会占用空间,而静态的网站则相反。使用这种方法对于站长来说需要很多的SEO技巧,但是SEO应该是目前最有效的方法。相对来说,静态网站对此要求很低,所以当你开始做网站的时候,可以先尝试做静态。这对 SEO 也有好处。
4、软文促销
编写技术或其他有吸引力的 软文,将 URL 附加到 软文、软文 最好是一些 原创 或 伪原创 的 文章。写完软文,发布到各种博客上。如果有吸引力,那么 软文 很快就会被其他 网站采集 推广,实现快速推广网站 ,进而推广他们的 网站 目标,并整合把URL改成软文,相当于电影中所谓的植入式广告,恰到好处。写软文最大的好处就是,如果你写得好,很多人会免费帮你宣传,而这种宣传是大家都愿意做的,因为很少有人愿意做真正的原创 ,一个纯粹的 原创文章 花费太长而代价很小 网站,并且链接质量很高。另外,原创文章可以主动吸引搜索引擎收录。但是写软文比较费时间,原创文章比较难。
软文一件采集器(自动发现使用场景介绍与Prometheus基于文件、DNS的应用 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-17 07:14
)
本章主要讲自动发现使用场景的介绍以及Prometheus中基于文件和DNS的自动发现的配置
当我们使用各种exporter监控系统、数据库和HTTP服务指标采集时,所有监控指标对应的目标运行状态和资源使用情况都是使用Prometheus的静态配置函数static_configs来实现的
手动添加主机 IP 和端口,然后重新加载服务供 Prometheus 发现。
在具有少量服务器的测试环境中,这种手动添加配置信息的方法是最简单的方法。但是在实际生产环境中,对于成百上千个节点组成的大型集群或者Kubernetes这样的大型集群,显然手动的方法是不够的。
为此,Prometheus 提前设计了一套服务发现功能。
Prometheus 服务发现可以自动检测分类,并且可以识别新的和更改的节点。也就是说,在容器或云平台中,可以自动发现和监控节点或更新节点,动态进行数据采集和处理。
目前,Prometheus 已经支持很多常见的自动发现服务,例如 consul ec2 gce serverset_sd_config openStack kubernetes 等。
我们常用的有sd_config、DNS、kubernetes、consul这些就够了。如果需要讨论其他配置,可以和我交流,我可以补上。
本章将对Prometheus自动发现中的基于文件的发现和基于DNS的发现进行讲解,稍后将单独讨论consul,如何使其完美解决当前场景中常见的各类服务发现监控。
为什么要使用自动发现?
在基于云(IaaS 或 CaaS)的基础设施环境中,用户可以按需使用各种资源(计算、网络、存储),如水和电。按需使用意味着资源的活力可以随着需求规模的变化而变化。例如,AWS提供了一种特殊的AutoScall服务,可以根据用户定义的规则动态地创建或销毁EC2实例,使部署在AWS上的应用能够自动适应访问规模的变化。
这种按需资源使用意味着监控系统没有固定的监控目标,所有监控对象(基础设施、应用程序、服务)都是动态变化的。对于传统的Nagias等基于Push模式的监控软件,意味着必须在每个节点上安装相应的Agent程序,通过配置指向中心的Nagias服务,使得被监控资源与中心监控之间存在强耦合服务器。,要么直接将 Agent 构建到基础架构镜像中,要么使用一些自动化的配置管理工具(如 Ansible、Chef)来动态配置这些节点。当然,除了基础设施的监控需求,我们还需要监控各种服务,比如部署在云端的应用,中间件等等。构建这样一个集中监控系统的实施成本和难度是显而易见的。
对于Prometheus这种基于Pull模式的监控系统,显然不可能继续使用static_configs来静态定义监控目标。对于 Prometheus,解决方案是引入一个中间代理(服务注册中心),它保存着当前所有监控目标的访问信息。Prometheus 只需要询问代理控制哪些监控目标即可。这种模式称为服务发现。
在不同的场景下,不同的事物会扮演代理的角色(服务发现和注册)。例如,在AWS公有云平台或OpenStack私有云平台中,由于这些平台本身持有所有资源的信息,这些云平台本身就扮演着代理的角色。Prometheus 可以通过平台提供的 API 找到所有需要监控的云主机。在 Kubernetes 等容器管理平台中,Kubernetes 掌握和管理所有容器和服务信息。此时,Prometheus 只需要与 Kubernetes 打交道,即可找到所有需要监控的容器和服务对象。Prometheus 也可以直接与一些开源的服务发现工具集成。例如,在微服务架构应用中,经常使用Consul等服务发现注册软件。Prometheus 也可以与其集成,动态发现需要监控的应用。服务实例。Prometheus除了与这些平台级公有云、私有云、容器云、专用服务发现注册中心集成外,还支持DNS和基于文件的监控目标动态发现,大大降低了对云原生、微服务和监控的需求云模式的实施难度。
如上图,Push 系统和 Pull 系统的核心区别就展示出来了。与Push模式相比,Pull模式的优势可以简单总结如下:
基于文件的服务发现
在 Prometheus 支持的众多服务发现实现中,基于文件的服务发现是最常见的。这种方法不需要依赖任何平台或第三方服务。Prometheus 也不可能支持所有平台或环境。在基于文件的服务发现模式下,Prometheus 会定期从文件中读取最新的 Target 信息。因此,您可以以任何方式编写监控目标信息。
用户可以通过 JSON 或 YAML 格式的文件定义所有监控目标。比如下面的yaml文件中定义了2个采集任务,每个任务对应的Target列表:
yaml 格式
- targets: ['192.168.1.220:9100']
labels:
app: 'app1'
env: 'game1'
region: 'us-west-2'
- targets: ['192.168.1.221:9100']
labels:
app: 'app2'
env: 'game2'
region: 'ap-southeast-1'
json格式
[
{
"targets": [ "192.168.1.221:29090"],
"labels": {
"app": "app1",
"env": "game1",
"region": "us-west-2"
}
},
{
"targets": [ "192.168.1.222:29090" ],
"labels": {
"app": "app2",
"env": "game2",
"region": "ap-southeast-1"
}
}
]
同时也可以给这些实例添加一些额外的标签信息,比如使用env标签来表示当前节点所在的环境,这样来自这些实例的样本信息采集就会收录这些标签信息,以便标签信息可以通过标签传递。根据环境进行统计。
创建 Prometheus 配置文件 /data/prometheus/conf/prometheus-file-sd.yml 并添加以下内容:
- job_name: 'file_sd_test'
scrape_interval: 10s
file_sd_configs:
- files:
- /data/prometheus/static_conf/*.yml
- /data/prometheus/static_conf/*.json
这里定义了一个基于file_sd_configs的监控采集测试任务,其中模式的任务名称为file_sd_test。在 yml 文件中,可以使用 yaml 标签覆盖默认的作业名,然后重新加载 Prometheus 服务。
service prometheus restat
在 Prometheus UI 的 Targets 下,可以看到从 targets.json 文件中动态获取的当前 Target 实例信息以及监控任务的 采集 状态。同时,Labels 列会收录用户添加的自定义标签:
Prometheus 默认每 5m 重新读取一次文件内容。当需要修改时,可以通过refresh_interval进行设置,例如:
- job_name: 'file_sd_test'
scrape_interval: 10s
file_sd_configs:
- refresh_interval: 30s # 30s重载配置文件
files:
- /data/prometheus/static_conf/*.yml
- /data/prometheus/static_conf/*.json
这样,Prometheus 会定期自动读取文件的内容。当文件中定义的内容发生变化时,无需重启 Prometheus。
这种通用的做法可以导致很多不同的玩法,比如结合自动化配置管理工具(Ansible),结合Cron Job等等。对于一些Prometheus不支持的云环境,比如国内的阿里云、腾讯云等,也可以通过该方法通过一些自定义程序与平台交互,自动生成监控Target文件,从而实现监控这些云环境中的基础架构。自动监控支持。
基于 DNS 的发现
对于某些环境,当无法满足基于文件和consul的服务发现时,我们可能需要DNS来进行服务发现。在 Internet 架构中,我们通常使用主机节点或 Kubernetes 集群,而不会将 IP 暴露给外界,这就需要我们在内部局域网或专用网络中部署 DNS 服务器,并使用 DNS 服务来完成域名解析工作。内部网络。
这时候我们就可以使用 Prometheus 的 DNS 服务发现了。Prometheus 的 DNS 服务发现有两种方法。第一种是使用 DNA A 记录进行自动发现。第二种方法是 DNS SRV。第一个显然没有 SRV。资源记录更方便。在这里,我将完成所有两个配置。至于用什么,根据自己的环境选择。
DNA A记录发现配置,首先你的内网需要有DNS服务器,也可以直接自己配置解析记录。我这里使用的dnsmasq服务是在内网测试的
# 验证 test1 DNS记录
nslookup test1.example.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: test1.example.com
Address: 192.168.1.221
# 验证 test2 DNS记录
nslookup test2.example.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: test2.example.com
Address: 192.168.1.222
普罗米修斯配置
# 基于DNS A记录发现
- job_name: 'DNS-A' # job 名称
metrics_path: "/metrics" # 路径
dns_sd_configs:
- names: ["test1.example.com", "test2.example.com"] # A记录
type: A # 解析类型
port: 29100 # 端口
重启Prometheus,可以看到targets中的dns-a记录
DNS SRV 是 DNS 资源记录中的一种记录类型,指定服务器地址和端口,可以设置每个服务器的优先级和权重。本地DNS解析器在访问服务时,从DNS服务器获取地址列表,然后根据优先级和权重选择一个地址作为本次请求的目标地址。
SRV 记录格式:
_service._proto.name.TTL 类 SRV 优先权重端口目标
| 参数 | 说明 |
| :-----: | :----: |
| _服务 | 服务名称,以_为前缀,防止与DNS标签(域名)冲突 |
| 原型 | 服务使用的通信协议通常是 tcp udp |
| 姓名 | 这条记录是一个有效的域名 |
| TTL | 标准 DNS 类字段,例如 IN |
| 优先 | 记录优先级,数值越小,优先级越高。[0-65535] |
| 重量 | 记录重量,数值越大,重量越高。[0-65535] |
| 港口| 服务使用的端口 |
| 目标 | 使用服务的主机地址名 |
这里没有使用named,而是使用dnsmasq进行测试。添加SRV记录后,需要重启dnsmasq服务才能生效。
# 配置dns解析
cat /etc/dnsmasq.d/localdomain.conf
address=/test1.example.com/192.168.1.221
address=/test2.example.com/192.168.1.222
# 添加 SRV 记录
cat /etc/dnsmasq.conf
srv-host =_prometheus._tcp.example.com,test1.example.com,29100
srv-host =_prometheus._tcp.example.com,test2.example.com,29100
# 验证srv服务是否正确,192.168.1.123 是内部DNS服务器,
dig @192.168.1.123 +noall +answer SRV _prometheus._tcp.example.com
output...
_prometheus._tcp.example.com. 0 IN SRV 0 0 9100 test1.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 9100 test2.example.com.
Prometheus 配置完成后,重新加载 Prometheus 服务。
- job_name: 'DNS-SRV' # 名称
metrics_path: "/metrics" # 获取数据的路径
dns_sd_configs: # 配置使用DNS解析
- names: ['_prometheus._tcp.example.com'] # 配置SRV对应的解析地址
此时可以在targets中看到DNS auto-discovery的记录。
目前,我们正在为自动发现添加新记录。
# 添加test0解析
cat /etc/dnsmasq.d/localdomain.conf
address=/test1.example.com/192.168.1.221
address=/test2.example.com/192.168.1.222
address=/test0.example.com/192.168.1.220
# 添加 test0 SRV 记录
cat /etc/dnsmasq.conf
srv-host =_prometheus._tcp.example.com,test1.example.com,29100
srv-host =_prometheus._tcp.example.com,test2.example.com,29100
srv-host =_prometheus._tcp.example.com,test0.example.com,19100
# 验证dns SRV记录是否成功
dig @192.168.1.123 +noall +answer SRV _prometheus._tcp.example.com
_prometheus._tcp.example.com. 0 IN SRV 0 0 19100 test0.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 29100 test2.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 29100 test1.example.com.
这时候我去观察targets的时候,发现test0可以被自动发现了。
查看全部
软文一件采集器(自动发现使用场景介绍与Prometheus基于文件、DNS的应用
)
本章主要讲自动发现使用场景的介绍以及Prometheus中基于文件和DNS的自动发现的配置
当我们使用各种exporter监控系统、数据库和HTTP服务指标采集时,所有监控指标对应的目标运行状态和资源使用情况都是使用Prometheus的静态配置函数static_configs来实现的
手动添加主机 IP 和端口,然后重新加载服务供 Prometheus 发现。
在具有少量服务器的测试环境中,这种手动添加配置信息的方法是最简单的方法。但是在实际生产环境中,对于成百上千个节点组成的大型集群或者Kubernetes这样的大型集群,显然手动的方法是不够的。
为此,Prometheus 提前设计了一套服务发现功能。
Prometheus 服务发现可以自动检测分类,并且可以识别新的和更改的节点。也就是说,在容器或云平台中,可以自动发现和监控节点或更新节点,动态进行数据采集和处理。
目前,Prometheus 已经支持很多常见的自动发现服务,例如 consul ec2 gce serverset_sd_config openStack kubernetes 等。
我们常用的有sd_config、DNS、kubernetes、consul这些就够了。如果需要讨论其他配置,可以和我交流,我可以补上。
本章将对Prometheus自动发现中的基于文件的发现和基于DNS的发现进行讲解,稍后将单独讨论consul,如何使其完美解决当前场景中常见的各类服务发现监控。
为什么要使用自动发现?
在基于云(IaaS 或 CaaS)的基础设施环境中,用户可以按需使用各种资源(计算、网络、存储),如水和电。按需使用意味着资源的活力可以随着需求规模的变化而变化。例如,AWS提供了一种特殊的AutoScall服务,可以根据用户定义的规则动态地创建或销毁EC2实例,使部署在AWS上的应用能够自动适应访问规模的变化。
这种按需资源使用意味着监控系统没有固定的监控目标,所有监控对象(基础设施、应用程序、服务)都是动态变化的。对于传统的Nagias等基于Push模式的监控软件,意味着必须在每个节点上安装相应的Agent程序,通过配置指向中心的Nagias服务,使得被监控资源与中心监控之间存在强耦合服务器。,要么直接将 Agent 构建到基础架构镜像中,要么使用一些自动化的配置管理工具(如 Ansible、Chef)来动态配置这些节点。当然,除了基础设施的监控需求,我们还需要监控各种服务,比如部署在云端的应用,中间件等等。构建这样一个集中监控系统的实施成本和难度是显而易见的。
对于Prometheus这种基于Pull模式的监控系统,显然不可能继续使用static_configs来静态定义监控目标。对于 Prometheus,解决方案是引入一个中间代理(服务注册中心),它保存着当前所有监控目标的访问信息。Prometheus 只需要询问代理控制哪些监控目标即可。这种模式称为服务发现。
在不同的场景下,不同的事物会扮演代理的角色(服务发现和注册)。例如,在AWS公有云平台或OpenStack私有云平台中,由于这些平台本身持有所有资源的信息,这些云平台本身就扮演着代理的角色。Prometheus 可以通过平台提供的 API 找到所有需要监控的云主机。在 Kubernetes 等容器管理平台中,Kubernetes 掌握和管理所有容器和服务信息。此时,Prometheus 只需要与 Kubernetes 打交道,即可找到所有需要监控的容器和服务对象。Prometheus 也可以直接与一些开源的服务发现工具集成。例如,在微服务架构应用中,经常使用Consul等服务发现注册软件。Prometheus 也可以与其集成,动态发现需要监控的应用。服务实例。Prometheus除了与这些平台级公有云、私有云、容器云、专用服务发现注册中心集成外,还支持DNS和基于文件的监控目标动态发现,大大降低了对云原生、微服务和监控的需求云模式的实施难度。
如上图,Push 系统和 Pull 系统的核心区别就展示出来了。与Push模式相比,Pull模式的优势可以简单总结如下:
基于文件的服务发现
在 Prometheus 支持的众多服务发现实现中,基于文件的服务发现是最常见的。这种方法不需要依赖任何平台或第三方服务。Prometheus 也不可能支持所有平台或环境。在基于文件的服务发现模式下,Prometheus 会定期从文件中读取最新的 Target 信息。因此,您可以以任何方式编写监控目标信息。
用户可以通过 JSON 或 YAML 格式的文件定义所有监控目标。比如下面的yaml文件中定义了2个采集任务,每个任务对应的Target列表:
yaml 格式
- targets: ['192.168.1.220:9100']
labels:
app: 'app1'
env: 'game1'
region: 'us-west-2'
- targets: ['192.168.1.221:9100']
labels:
app: 'app2'
env: 'game2'
region: 'ap-southeast-1'
json格式
[
{
"targets": [ "192.168.1.221:29090"],
"labels": {
"app": "app1",
"env": "game1",
"region": "us-west-2"
}
},
{
"targets": [ "192.168.1.222:29090" ],
"labels": {
"app": "app2",
"env": "game2",
"region": "ap-southeast-1"
}
}
]
同时也可以给这些实例添加一些额外的标签信息,比如使用env标签来表示当前节点所在的环境,这样来自这些实例的样本信息采集就会收录这些标签信息,以便标签信息可以通过标签传递。根据环境进行统计。
创建 Prometheus 配置文件 /data/prometheus/conf/prometheus-file-sd.yml 并添加以下内容:
- job_name: 'file_sd_test'
scrape_interval: 10s
file_sd_configs:
- files:
- /data/prometheus/static_conf/*.yml
- /data/prometheus/static_conf/*.json
这里定义了一个基于file_sd_configs的监控采集测试任务,其中模式的任务名称为file_sd_test。在 yml 文件中,可以使用 yaml 标签覆盖默认的作业名,然后重新加载 Prometheus 服务。
service prometheus restat
在 Prometheus UI 的 Targets 下,可以看到从 targets.json 文件中动态获取的当前 Target 实例信息以及监控任务的 采集 状态。同时,Labels 列会收录用户添加的自定义标签:
Prometheus 默认每 5m 重新读取一次文件内容。当需要修改时,可以通过refresh_interval进行设置,例如:
- job_name: 'file_sd_test'
scrape_interval: 10s
file_sd_configs:
- refresh_interval: 30s # 30s重载配置文件
files:
- /data/prometheus/static_conf/*.yml
- /data/prometheus/static_conf/*.json
这样,Prometheus 会定期自动读取文件的内容。当文件中定义的内容发生变化时,无需重启 Prometheus。
这种通用的做法可以导致很多不同的玩法,比如结合自动化配置管理工具(Ansible),结合Cron Job等等。对于一些Prometheus不支持的云环境,比如国内的阿里云、腾讯云等,也可以通过该方法通过一些自定义程序与平台交互,自动生成监控Target文件,从而实现监控这些云环境中的基础架构。自动监控支持。
基于 DNS 的发现
对于某些环境,当无法满足基于文件和consul的服务发现时,我们可能需要DNS来进行服务发现。在 Internet 架构中,我们通常使用主机节点或 Kubernetes 集群,而不会将 IP 暴露给外界,这就需要我们在内部局域网或专用网络中部署 DNS 服务器,并使用 DNS 服务来完成域名解析工作。内部网络。
这时候我们就可以使用 Prometheus 的 DNS 服务发现了。Prometheus 的 DNS 服务发现有两种方法。第一种是使用 DNA A 记录进行自动发现。第二种方法是 DNS SRV。第一个显然没有 SRV。资源记录更方便。在这里,我将完成所有两个配置。至于用什么,根据自己的环境选择。
DNA A记录发现配置,首先你的内网需要有DNS服务器,也可以直接自己配置解析记录。我这里使用的dnsmasq服务是在内网测试的
# 验证 test1 DNS记录
nslookup test1.example.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: test1.example.com
Address: 192.168.1.221
# 验证 test2 DNS记录
nslookup test2.example.com
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: test2.example.com
Address: 192.168.1.222
普罗米修斯配置
# 基于DNS A记录发现
- job_name: 'DNS-A' # job 名称
metrics_path: "/metrics" # 路径
dns_sd_configs:
- names: ["test1.example.com", "test2.example.com"] # A记录
type: A # 解析类型
port: 29100 # 端口
重启Prometheus,可以看到targets中的dns-a记录
DNS SRV 是 DNS 资源记录中的一种记录类型,指定服务器地址和端口,可以设置每个服务器的优先级和权重。本地DNS解析器在访问服务时,从DNS服务器获取地址列表,然后根据优先级和权重选择一个地址作为本次请求的目标地址。
SRV 记录格式:
_service._proto.name.TTL 类 SRV 优先权重端口目标
| 参数 | 说明 |
| :-----: | :----: |
| _服务 | 服务名称,以_为前缀,防止与DNS标签(域名)冲突 |
| 原型 | 服务使用的通信协议通常是 tcp udp |
| 姓名 | 这条记录是一个有效的域名 |
| TTL | 标准 DNS 类字段,例如 IN |
| 优先 | 记录优先级,数值越小,优先级越高。[0-65535] |
| 重量 | 记录重量,数值越大,重量越高。[0-65535] |
| 港口| 服务使用的端口 |
| 目标 | 使用服务的主机地址名 |
这里没有使用named,而是使用dnsmasq进行测试。添加SRV记录后,需要重启dnsmasq服务才能生效。
# 配置dns解析
cat /etc/dnsmasq.d/localdomain.conf
address=/test1.example.com/192.168.1.221
address=/test2.example.com/192.168.1.222
# 添加 SRV 记录
cat /etc/dnsmasq.conf
srv-host =_prometheus._tcp.example.com,test1.example.com,29100
srv-host =_prometheus._tcp.example.com,test2.example.com,29100
# 验证srv服务是否正确,192.168.1.123 是内部DNS服务器,
dig @192.168.1.123 +noall +answer SRV _prometheus._tcp.example.com
output...
_prometheus._tcp.example.com. 0 IN SRV 0 0 9100 test1.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 9100 test2.example.com.
Prometheus 配置完成后,重新加载 Prometheus 服务。
- job_name: 'DNS-SRV' # 名称
metrics_path: "/metrics" # 获取数据的路径
dns_sd_configs: # 配置使用DNS解析
- names: ['_prometheus._tcp.example.com'] # 配置SRV对应的解析地址
此时可以在targets中看到DNS auto-discovery的记录。
目前,我们正在为自动发现添加新记录。
# 添加test0解析
cat /etc/dnsmasq.d/localdomain.conf
address=/test1.example.com/192.168.1.221
address=/test2.example.com/192.168.1.222
address=/test0.example.com/192.168.1.220
# 添加 test0 SRV 记录
cat /etc/dnsmasq.conf
srv-host =_prometheus._tcp.example.com,test1.example.com,29100
srv-host =_prometheus._tcp.example.com,test2.example.com,29100
srv-host =_prometheus._tcp.example.com,test0.example.com,19100
# 验证dns SRV记录是否成功
dig @192.168.1.123 +noall +answer SRV _prometheus._tcp.example.com
_prometheus._tcp.example.com. 0 IN SRV 0 0 19100 test0.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 29100 test2.example.com.
_prometheus._tcp.example.com. 0 IN SRV 0 0 29100 test1.example.com.
这时候我去观察targets的时候,发现test0可以被自动发现了。
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-16 23:18
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软文一件采集器(百度不收录的原因是什么?百度spider怎么办?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2022-01-13 16:20
百度不收录是什么原因?百度作为最重要的中文搜索引擎,是国内很多网站的风向标,所以对于国内的网站、网站或者发布的内容,不受百度收录@的约束> 很头疼。那么为什么 网站 不是 收录 呢?
百度不收录是什么原因?
1、网站禁止
别笑,真的有同学一边封百度蜘蛛一边把数据交给百度,当然不能收录。
解决方法:去百度站长平台查看,如果有异常,直接去后台修改即可!
2、获取失败
爬取失败的原因有很多,有时候在办公室访问没问题,但是百度蜘蛛就麻烦了。
解决方法:网站要时刻注意保证网站在不同时间、不同地点的稳定性。
3、网站是一个新站点
每个 网站 都有一个新的站点审查期。如果您的网站 刚刚上线,那么网站 应该处于审核期。百度还不信任网站。百度不收录文章是正常的,因为网站在百度数据库中还没有获得好的综合页面评分,这也是新站上线一段时间的原因的时间。只有收录首页或者一两个内页,正是因为百度对新站的信任度不高,百度蜘蛛在网站中爬取的级别和时间都会很小,百度蜘蛛的爬取级别和爬取时间自然不会百度收录。
解决方案:
①建议去外链平台发布网站首页和内页的链接,利用手头资源交换友情链接,吸引百度蜘蛛爬爬网站,从而增加百度蜘蛛抓取访问网站的页面和次数。
②提交网站链接到百度站长平台,主动提醒百度蜘蛛抢。
4、网站已更新文章都已过期文章
一些 网站 更新的 文章 还没有过期。百度不知道被过滤了多少次,现在被你复制了网站采集肯定不是收录。因此,即使采集需要采集刚刚发布的内容,也会有一些收录的可能性。想必有的SEOer可能会问,是不是可以写各行各业的文章文章文章?那么如何生成新鲜内容呢?在这里我只想说,不创新,永远都是来自采集文章,那为什么别人能创造出新鲜的内容呢?
解决方案:
① 经常去一些问答平台和贴吧论坛看看有没有核心问题没有解决,然后可以利用各种资源整理出新的文章解决方案给用户来。
②可以写一些软文,故事文章到网站,不时给网站补充新鲜血液,完善网站的原创@ >性大大提高了网站的收录率。
5、标题和网站结构以及网站标签的频繁更改也会影响收录
网站如果标题和网站结构和标签被频繁修改,会被搜索引擎拉回观察室,对网站进行重新审查和排名,这不仅会降低搜索引擎对网站信任等级的感知,甚至可能出现降级迹象,对网站的收录也有一定的障碍,百度快照日期将不被更新。
解决方案:
①。到百度服务中心/快照更新投诉到百度中心审核,进行百度快照投诉更新,可以加快快照更新速度。
②。更新几处优质原创@>内容恢复排名,百度快照和排名也将恢复。
6、网站有大量404、503未处理,影响页面索引
如果网站有大量的40个4、503错误页面,会导致搜索引擎难以抓取页面。对于搜索引擎来说,你的网站的内容值和链接的数量决定了搜索引擎在你的网站停留时间长,网站的综合得分大死链接的数量也会减少,所以一定要及时处理死链接。
解决方案:
对于网站可以使用一些死链接检测工具进行检测,比如:xenu、爱站工具等来检测死链接,但是把死链接放在一个txt文件中,然后上传到< @网站根目录,最后到百度站长平台死链接提交选项,提交死链接文件等!
7、内部链未建立
如果要发布新页面为 收录,则不应将这些页面隐藏得太深。很多网站有很多栏目,所以栏目下面会有一栏,甚至下面会有多层。因此,有些发布的收录@文章既没有显示在首页,也没有显示在主栏页面,即使点击首页链接也很难找到这个页面。这自然很难收录。 查看全部
软文一件采集器(百度不收录的原因是什么?百度spider怎么办?)
百度不收录是什么原因?百度作为最重要的中文搜索引擎,是国内很多网站的风向标,所以对于国内的网站、网站或者发布的内容,不受百度收录@的约束> 很头疼。那么为什么 网站 不是 收录 呢?
百度不收录是什么原因?
1、网站禁止
别笑,真的有同学一边封百度蜘蛛一边把数据交给百度,当然不能收录。
解决方法:去百度站长平台查看,如果有异常,直接去后台修改即可!
2、获取失败
爬取失败的原因有很多,有时候在办公室访问没问题,但是百度蜘蛛就麻烦了。
解决方法:网站要时刻注意保证网站在不同时间、不同地点的稳定性。
3、网站是一个新站点
每个 网站 都有一个新的站点审查期。如果您的网站 刚刚上线,那么网站 应该处于审核期。百度还不信任网站。百度不收录文章是正常的,因为网站在百度数据库中还没有获得好的综合页面评分,这也是新站上线一段时间的原因的时间。只有收录首页或者一两个内页,正是因为百度对新站的信任度不高,百度蜘蛛在网站中爬取的级别和时间都会很小,百度蜘蛛的爬取级别和爬取时间自然不会百度收录。
解决方案:
①建议去外链平台发布网站首页和内页的链接,利用手头资源交换友情链接,吸引百度蜘蛛爬爬网站,从而增加百度蜘蛛抓取访问网站的页面和次数。
②提交网站链接到百度站长平台,主动提醒百度蜘蛛抢。
4、网站已更新文章都已过期文章
一些 网站 更新的 文章 还没有过期。百度不知道被过滤了多少次,现在被你复制了网站采集肯定不是收录。因此,即使采集需要采集刚刚发布的内容,也会有一些收录的可能性。想必有的SEOer可能会问,是不是可以写各行各业的文章文章文章?那么如何生成新鲜内容呢?在这里我只想说,不创新,永远都是来自采集文章,那为什么别人能创造出新鲜的内容呢?
解决方案:
① 经常去一些问答平台和贴吧论坛看看有没有核心问题没有解决,然后可以利用各种资源整理出新的文章解决方案给用户来。
②可以写一些软文,故事文章到网站,不时给网站补充新鲜血液,完善网站的原创@ >性大大提高了网站的收录率。
5、标题和网站结构以及网站标签的频繁更改也会影响收录
网站如果标题和网站结构和标签被频繁修改,会被搜索引擎拉回观察室,对网站进行重新审查和排名,这不仅会降低搜索引擎对网站信任等级的感知,甚至可能出现降级迹象,对网站的收录也有一定的障碍,百度快照日期将不被更新。
解决方案:
①。到百度服务中心/快照更新投诉到百度中心审核,进行百度快照投诉更新,可以加快快照更新速度。
②。更新几处优质原创@>内容恢复排名,百度快照和排名也将恢复。
6、网站有大量404、503未处理,影响页面索引
如果网站有大量的40个4、503错误页面,会导致搜索引擎难以抓取页面。对于搜索引擎来说,你的网站的内容值和链接的数量决定了搜索引擎在你的网站停留时间长,网站的综合得分大死链接的数量也会减少,所以一定要及时处理死链接。
解决方案:
对于网站可以使用一些死链接检测工具进行检测,比如:xenu、爱站工具等来检测死链接,但是把死链接放在一个txt文件中,然后上传到< @网站根目录,最后到百度站长平台死链接提交选项,提交死链接文件等!
7、内部链未建立
如果要发布新页面为 收录,则不应将这些页面隐藏得太深。很多网站有很多栏目,所以栏目下面会有一栏,甚至下面会有多层。因此,有些发布的收录@文章既没有显示在首页,也没有显示在主栏页面,即使点击首页链接也很难找到这个页面。这自然很难收录。
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-01-13 00:18
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。
软文一件采集器(本文大数据技术栈大数据开发岗位介绍 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-01-11 13:00
)
为了方便大家梳理大数据学习路线,本文从以下四个方面介绍大数据技术:
大数据技术栈
大数据的历史
大数据应用
大数据开发岗位
一、大数据技术栈
之前有个同事问我怎么转行大数据开发,他在网上搜了一堆大数据相关的技术,但是不知道从哪里入手,学什么技术,这些技术栈有什么关系. 刚开始转大数据的时候,有点迷茫,但是整体接触之后才弄明白大数据的技术栈。
做大数据开发,你要做四件事,采集,存储,查询,计算。此外,还需要一些发展所需的基本语言技能。根据这些维度,我划分了大数据的常用技术栈。
基础能力
毋庸置疑,java是当今世界上使用最广泛的语言,基本上是程序员必备的语言,大数据生态系统的很多组件都是通过java开发的。Python 通常用于爬虫、数据分析和机器学习。一些大数据组件是用python开发的,比如airflow。scala的底层还是java。由于spark是由scala开发的,而且scala还集成了很多spark算子,所以spark开发中一般使用scala。
数据采集
一般通过filebeat、logstash、kafka、flume采集完成日志。一些应用系统的数据也会通过kafka或者binlog同步到大数据组件进行存储。
数据存储
这里的数据存储引擎与传统的关系型数据库有很大的不同。一个常见的分布式存储文件系统是 hdfs。另外,一些非结构化数据会被nosql存储。常见的nosql存储组件有hbase和redis。
数据查询
常见的有hive、spark sql、presto、kylin、impala、durid、clickhouse、greeplum,每个组件都有自己的查询特性和使用场景。此处不赘述,待会再说。
数据计算
常见的计算方法有流计算和批处理,线计算和实时计算按效果分开。对应的计算组件是storm、spark stream和flink。
其他
分布式协调器:为了提高可靠性,大数据组件通常是分布式存储的,这涉及到各个组件之间的协调和同步。最常见的协调员是动物园管理员。
资源管理器:为了提高计算能力,会分配计算资源(CPU、内存、磁盘)。常见的组件包括纱线和金属丝。
调度管理器:调度管理器管理任务何时执行、周期性执行、是否重试等,常见的有airflow、dalphine schduler、oozie、azkaban。
二、大数据技术发展史
学习一门技术,知道能用就够了,至少能解决问题。但如果你想走得更远,你仍然需要了解一项技术的发展历史。通过发展历程,您可以更深入地了解这项技术的产生原因、背后的原创设计以及使用场景。
大数据技术的起源
大数据最早起源于谷歌。大家都知道google主要提供网页检索服务,而这个服务依赖于两个能力:网页的采集和索引的构建。有了这两个能力,我们就可以通过检索服务在互联网上搜索网页。这些网页和索引都需要大量的存储和计算能力。为了提高这两项能力,谷歌发表了三篇重要论文。
2003年,分布式文件系统GFS。
2004年,大数据分布式计算框架MapReduce。
2006年,NoSql数据库系统。
这三篇论文为大数据技术奠定了基础。
Hadoop技术
受到谷歌论文的启发,2004 年 7 月 Doug 和 Mike Cafarella 在 Nutch 中实现了类似于 GFS 的功能(Nutch 的设计目标是构建一个大规模的全网搜索引擎,包括网页爬取、索引、查询等),即,HDFS的前身。2005 年 2 月,Mike Cafarella 在 Nutch 中实现了 MapReduce 的初始版本。GFS 和 MapReduce 是 hadoop 的前身。2006年,hadoop从Nutch项目中分离出来,贡献给Apache,成为Apache的顶级项目。
雅虎的猪
2006 年,雅虎为了让 MapReduce 技术更易用,封装了 MapReduce 技术,开发了一个名为 Pig 的工具,类似于 SQL 脚本查询。使用 Pig 编写 SQL 会自动转换成 MapReduce 执行,大大优化了 MapReduce 的性能。使用困难。
脸书蜂巢
2007年,Facebook进一步优化了查询方式,开发了一套可以直接使用SQL查询大数据的工具——HIVE。只要懂 SQL 的开发者都可以使用这个组件。
Powerset 的 HBASE
2007年,Powerset的工作人员通过Google的论文开发了Java版BigTable,即HBASE。HBASE 在 2008 年被贡献给 Apache。
火花的产生
2009 年,加州大学伯克利分校的研究人员在使用 MapReduce 进行实验项目时,性能无法满足要求。于是我开始设计火花。基于内存计算的spark的性能远高于spark。
三、大数据应用
查看全部
软文一件采集器(本文大数据技术栈大数据开发岗位介绍
)
为了方便大家梳理大数据学习路线,本文从以下四个方面介绍大数据技术:
大数据技术栈
大数据的历史
大数据应用
大数据开发岗位
一、大数据技术栈
之前有个同事问我怎么转行大数据开发,他在网上搜了一堆大数据相关的技术,但是不知道从哪里入手,学什么技术,这些技术栈有什么关系. 刚开始转大数据的时候,有点迷茫,但是整体接触之后才弄明白大数据的技术栈。
做大数据开发,你要做四件事,采集,存储,查询,计算。此外,还需要一些发展所需的基本语言技能。根据这些维度,我划分了大数据的常用技术栈。
基础能力
毋庸置疑,java是当今世界上使用最广泛的语言,基本上是程序员必备的语言,大数据生态系统的很多组件都是通过java开发的。Python 通常用于爬虫、数据分析和机器学习。一些大数据组件是用python开发的,比如airflow。scala的底层还是java。由于spark是由scala开发的,而且scala还集成了很多spark算子,所以spark开发中一般使用scala。
数据采集
一般通过filebeat、logstash、kafka、flume采集完成日志。一些应用系统的数据也会通过kafka或者binlog同步到大数据组件进行存储。
数据存储
这里的数据存储引擎与传统的关系型数据库有很大的不同。一个常见的分布式存储文件系统是 hdfs。另外,一些非结构化数据会被nosql存储。常见的nosql存储组件有hbase和redis。
数据查询
常见的有hive、spark sql、presto、kylin、impala、durid、clickhouse、greeplum,每个组件都有自己的查询特性和使用场景。此处不赘述,待会再说。
数据计算
常见的计算方法有流计算和批处理,线计算和实时计算按效果分开。对应的计算组件是storm、spark stream和flink。
其他
分布式协调器:为了提高可靠性,大数据组件通常是分布式存储的,这涉及到各个组件之间的协调和同步。最常见的协调员是动物园管理员。
资源管理器:为了提高计算能力,会分配计算资源(CPU、内存、磁盘)。常见的组件包括纱线和金属丝。
调度管理器:调度管理器管理任务何时执行、周期性执行、是否重试等,常见的有airflow、dalphine schduler、oozie、azkaban。
二、大数据技术发展史
学习一门技术,知道能用就够了,至少能解决问题。但如果你想走得更远,你仍然需要了解一项技术的发展历史。通过发展历程,您可以更深入地了解这项技术的产生原因、背后的原创设计以及使用场景。
大数据技术的起源
大数据最早起源于谷歌。大家都知道google主要提供网页检索服务,而这个服务依赖于两个能力:网页的采集和索引的构建。有了这两个能力,我们就可以通过检索服务在互联网上搜索网页。这些网页和索引都需要大量的存储和计算能力。为了提高这两项能力,谷歌发表了三篇重要论文。
2003年,分布式文件系统GFS。
2004年,大数据分布式计算框架MapReduce。
2006年,NoSql数据库系统。
这三篇论文为大数据技术奠定了基础。
Hadoop技术
受到谷歌论文的启发,2004 年 7 月 Doug 和 Mike Cafarella 在 Nutch 中实现了类似于 GFS 的功能(Nutch 的设计目标是构建一个大规模的全网搜索引擎,包括网页爬取、索引、查询等),即,HDFS的前身。2005 年 2 月,Mike Cafarella 在 Nutch 中实现了 MapReduce 的初始版本。GFS 和 MapReduce 是 hadoop 的前身。2006年,hadoop从Nutch项目中分离出来,贡献给Apache,成为Apache的顶级项目。
雅虎的猪
2006 年,雅虎为了让 MapReduce 技术更易用,封装了 MapReduce 技术,开发了一个名为 Pig 的工具,类似于 SQL 脚本查询。使用 Pig 编写 SQL 会自动转换成 MapReduce 执行,大大优化了 MapReduce 的性能。使用困难。
脸书蜂巢
2007年,Facebook进一步优化了查询方式,开发了一套可以直接使用SQL查询大数据的工具——HIVE。只要懂 SQL 的开发者都可以使用这个组件。
Powerset 的 HBASE
2007年,Powerset的工作人员通过Google的论文开发了Java版BigTable,即HBASE。HBASE 在 2008 年被贡献给 Apache。
火花的产生
2009 年,加州大学伯克利分校的研究人员在使用 MapReduce 进行实验项目时,性能无法满足要求。于是我开始设计火花。基于内存计算的spark的性能远高于spark。
三、大数据应用
软文一件采集器(软文一件采集器无法筛选器的任何特征,您的用户也无法识别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-01-10 03:00
软文一件采集器无法筛选器的任何特征,您的用户也无法识别。提供一个四面体模型,命名为:sphericalhexus,并正确引用它来获取所有游戏周边的资源。为避免重复引用,我们提供将之前的两个不同游戏内容合并在一起的方法,但无法用作筛选器。下载地址:链接:密码:r8u编译链接:密码:csr操作:-3-下载完毕安装zip文件后双击启动sphericalhexus后,点击文件——首选项——注册表——sqlite3——键入sqlite3位置和名称——确定。
-4-打开universalsphericalhexus,进入游戏相关选项卡,在library_id选项卡上,按照自己的需求可以设置下文件的名称和位置,随后点击file——bindependency——匹配选择自己需要的数据库内容——ok。-5-sphericalhexus启动之后,界面左侧有个搜索框,输入你想要过滤的游戏内容,然后点击筛选器进行下一步操作。
-6-下载完成,重启universalsphericalhexus,搜索框就会出现,鼠标一直在输入框内,刷新筛选器即可。-7-经过长时间的测试,完美适配gamemaker和ue4,不过可能速度比较慢,i7-8750hi5-8300h同款以上可正常运行,ux4后期可能会优化速度。部分行业内技术的demo可在/project_example/return.m4文件中下载,请注意将所需要的数据库编号写入此文件中并加上相应字段。-8-本文首发于官方博客,感谢原作者的分享。欢迎关注我们!。 查看全部
软文一件采集器(软文一件采集器无法筛选器的任何特征,您的用户也无法识别)
软文一件采集器无法筛选器的任何特征,您的用户也无法识别。提供一个四面体模型,命名为:sphericalhexus,并正确引用它来获取所有游戏周边的资源。为避免重复引用,我们提供将之前的两个不同游戏内容合并在一起的方法,但无法用作筛选器。下载地址:链接:密码:r8u编译链接:密码:csr操作:-3-下载完毕安装zip文件后双击启动sphericalhexus后,点击文件——首选项——注册表——sqlite3——键入sqlite3位置和名称——确定。
-4-打开universalsphericalhexus,进入游戏相关选项卡,在library_id选项卡上,按照自己的需求可以设置下文件的名称和位置,随后点击file——bindependency——匹配选择自己需要的数据库内容——ok。-5-sphericalhexus启动之后,界面左侧有个搜索框,输入你想要过滤的游戏内容,然后点击筛选器进行下一步操作。
-6-下载完成,重启universalsphericalhexus,搜索框就会出现,鼠标一直在输入框内,刷新筛选器即可。-7-经过长时间的测试,完美适配gamemaker和ue4,不过可能速度比较慢,i7-8750hi5-8300h同款以上可正常运行,ux4后期可能会优化速度。部分行业内技术的demo可在/project_example/return.m4文件中下载,请注意将所需要的数据库编号写入此文件中并加上相应字段。-8-本文首发于官方博客,感谢原作者的分享。欢迎关注我们!。
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-08 12:20
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。 查看全部
软文一件采集器(5年来不断的完善改进造就了史无前例的强大采集软件)
五年的持续改进和改进,造就了前所未有的强大采集软件--网站万能信息采集器。
网站优采云采集器:所有能看到的信息都可以抓取。
八大特色:
1.信息采集全自动添加
网站抓取的目的主要是添加到你的网站中,软件可以实现采集添加的自动完成。其他网站 刚刚更新的信息将在五分钟内自动运行到您的网站。
2.需要登录网站还要抓图
对于需要登录查看信息内容的网站,网站优采云采集器可以轻松登录采集,即使有验证码,您可以通过采集登录到您需要的信息。
3.任何类型的文件都可以下载
如果需要采集图片等二进制文件,只需设置网站优采云采集器,即可将任意类型的文件保存到本地。
4.多级页面采集
您可以采集同时访问多级页面的内容。网站优采云采集器 也可以自动识别消息,如果它分布在许多不同的页面上
不要实现多级页面采集
5.自动识别JavaScript等特殊URL
很多网站网页链接都是像javascript:openwin('1234')这样的特殊URL,不是一般的,软件可以自动识别和抓取内容
6.自动获取各个分类URL
例如,供求信息往往有很多很多的类别。经过简单的设置,软件就可以自动抓取这些分类网址,并对抓取的信息进行自动分类。
7.多页新闻自动爬取、广告过滤
有些新闻有下一页,软件也可以抓取所有页面。并且可以同时保存抓拍新闻中的图文,过滤掉广告
8.自动破解防盗链
网站 的许多下载类型都有防盗链链接。输入网址不能直接抓到内容,但是软件可以自动破解防盗链链接,保证你想抓到什么。
另外增加了模拟手动提交的功能,租用的网站asp+access空间也可以远程发布。其实它还可以模拟所有网页提交动作,可以批量注册会员,模拟海量消息。

