
蜘蛛
WordPress手动采集插件:WP-CTspider(长腿蜘蛛)
站长必读 • 优采云 发表了文章 • 0 个评论 • 549 次浏览 • 2020-07-18 08:09
WP-CTspider(长腿蜘蛛)是一款基于php开发的Wordpress全手动采集插件,设置轻而易举,只须要设置定向采集网址,通过CSS选择器精准辨识采集区域,包括(内容,摘要,TAG,缩略图,自定义数组等…)然后手动检查抓取网页内容,文章去重,更新发布,这个过程全手动完成,无需人工干预。
WP-CTspider(长腿蜘蛛)采用php爬虫设计wordpress采集插件,只须要依照DIV标签进行简单地几步操作即可完成手动采集。只要的主机性能足够强劲,WP-CTspider还为你提供了多线程分离式采集,每个线程相互之间不干扰,独立运行。完美支持WordPress各类功能、标签,摘要,特色图片wordpress采集插件,自定义栏目等。其还拥有SEO全功能优化内容,支持内容的过滤,增加,修缮。
使用教程开发者写得十分详尽,我就不做过多赘言,请看官网文档。
点击采集后显示没有任何数据只有两种可能
采集规则没有设置好。 如果确定采集规则没问题,请查看当前采集的网址是否是Ajax动态渲染加载(PS:目前性感蜘蛛-CTspider不支持动态渲染加载采集
WP-CTspider(长腿蜘蛛)开发者字2017年上线以来始终在不断更新构建这款插件工具,如果你在使用中遇见哪些bug可以在官网上及时反馈。
下载信息 WP-CTSPIDER(长腿蜘蛛采集插件) WordPress 下载地址 查看全部
WP-CTspider(长腿蜘蛛)是一款基于php开发的Wordpress全手动采集插件,设置轻而易举,只须要设置定向采集网址,通过CSS选择器精准辨识采集区域,包括(内容,摘要,TAG,缩略图,自定义数组等…)然后手动检查抓取网页内容,文章去重,更新发布,这个过程全手动完成,无需人工干预。

WP-CTspider(长腿蜘蛛)采用php爬虫设计wordpress采集插件,只须要依照DIV标签进行简单地几步操作即可完成手动采集。只要的主机性能足够强劲,WP-CTspider还为你提供了多线程分离式采集,每个线程相互之间不干扰,独立运行。完美支持WordPress各类功能、标签,摘要,特色图片wordpress采集插件,自定义栏目等。其还拥有SEO全功能优化内容,支持内容的过滤,增加,修缮。
使用教程开发者写得十分详尽,我就不做过多赘言,请看官网文档。
点击采集后显示没有任何数据只有两种可能
采集规则没有设置好。 如果确定采集规则没问题,请查看当前采集的网址是否是Ajax动态渲染加载(PS:目前性感蜘蛛-CTspider不支持动态渲染加载采集
WP-CTspider(长腿蜘蛛)开发者字2017年上线以来始终在不断更新构建这款插件工具,如果你在使用中遇见哪些bug可以在官网上及时反馈。
下载信息 WP-CTSPIDER(长腿蜘蛛采集插件) WordPress 下载地址
百度蜘蛛(百度爬虫、网络蜘蛛)是哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-06-08 08:01
百度蜘蛛也叫百度爬虫、百度网路蜘蛛,其实不是真实蜘蛛,而是一个自动程序,该程序的抓取路径象蜘蛛丝一样,该程序通过网页上的锚链接进行爬行,类似蜘蛛爬行,因此叫百度蜘蛛、百度爬虫、网络蜘蛛等多种别称,其实就是一个搜索引擎抓取程序。
百度蜘蛛的作用:百度搜索引擎通过百度蜘蛛这个手动程序,访问其他网站,百度蜘蛛首先判定该网页是否符合搜索引擎的收录条件,如果符合收录条件,百度蜘蛛就下载该网页,然后保存到百度数据里,建立百度快照,当用户搜索某一个关键词时,搜索通过自身的排序机制,把快照进行索引排序,然后把排序结果诠释给读者。如果网页内容不符合搜索引擎的收录规则,那么百度蜘蛛不收录,并通过锚链接访问其他页面,进而重新进行判定是否收录。
提高百度蜘蛛抓取效率的方式
1、网站建立健全的网站内部链接,合理的网站导航、网站架构,必要时还可以通过网站地图增强百度蜘蛛抓取效率。
2、网站外链就好比百度蜘蛛的路径,网站外链越多,百度蜘蛛来网站的机会越大。
3、网站内容时常保持更新,百度蜘蛛喜欢新东西百度网络爬虫,如果你的网站经常更新,那么百度蜘蛛会时常光临。
通过网站日志可以判定百度蜘蛛是否光临。
产品名称 对应user-agent
网页搜索 Baiduspider
无线搜索 Baiduspider-mobile
图片搜索 Baiduspider-image
视频搜索 Baiduspider-video
新闻搜索 Baiduspider-news
百度搜藏 Baiduspider-favo
百度联盟Baiduspider-cpro
移动搜索 baidu+Transcoder
网上有很多百度蜘蛛模拟程序,你可以通过该程序,了解百度蜘蛛展示的结果,有的服务器或则程序对百度蜘蛛进行了屏蔽,因此可以通过该软件查询百度蜘蛛抓取的结果。同时若果你不希望百度蜘蛛收录网站的某个栏目,你可以通过设置robots.txt来告诉搜索引擎,哪些页面可以收录百度网络爬虫,哪些页面不可以收录,这样可以解决隐私内容被百度收录。 查看全部

百度蜘蛛也叫百度爬虫、百度网路蜘蛛,其实不是真实蜘蛛,而是一个自动程序,该程序的抓取路径象蜘蛛丝一样,该程序通过网页上的锚链接进行爬行,类似蜘蛛爬行,因此叫百度蜘蛛、百度爬虫、网络蜘蛛等多种别称,其实就是一个搜索引擎抓取程序。
百度蜘蛛的作用:百度搜索引擎通过百度蜘蛛这个手动程序,访问其他网站,百度蜘蛛首先判定该网页是否符合搜索引擎的收录条件,如果符合收录条件,百度蜘蛛就下载该网页,然后保存到百度数据里,建立百度快照,当用户搜索某一个关键词时,搜索通过自身的排序机制,把快照进行索引排序,然后把排序结果诠释给读者。如果网页内容不符合搜索引擎的收录规则,那么百度蜘蛛不收录,并通过锚链接访问其他页面,进而重新进行判定是否收录。
提高百度蜘蛛抓取效率的方式
1、网站建立健全的网站内部链接,合理的网站导航、网站架构,必要时还可以通过网站地图增强百度蜘蛛抓取效率。
2、网站外链就好比百度蜘蛛的路径,网站外链越多,百度蜘蛛来网站的机会越大。
3、网站内容时常保持更新,百度蜘蛛喜欢新东西百度网络爬虫,如果你的网站经常更新,那么百度蜘蛛会时常光临。
通过网站日志可以判定百度蜘蛛是否光临。
产品名称 对应user-agent
网页搜索 Baiduspider
无线搜索 Baiduspider-mobile
图片搜索 Baiduspider-image
视频搜索 Baiduspider-video
新闻搜索 Baiduspider-news
百度搜藏 Baiduspider-favo
百度联盟Baiduspider-cpro
移动搜索 baidu+Transcoder
网上有很多百度蜘蛛模拟程序,你可以通过该程序,了解百度蜘蛛展示的结果,有的服务器或则程序对百度蜘蛛进行了屏蔽,因此可以通过该软件查询百度蜘蛛抓取的结果。同时若果你不希望百度蜘蛛收录网站的某个栏目,你可以通过设置robots.txt来告诉搜索引擎,哪些页面可以收录百度网络爬虫,哪些页面不可以收录,这样可以解决隐私内容被百度收录。
百度蜘蛛爬虫的工作原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-05-11 08:02
我们可以从下边这张图片来详尽了解百度蜘蛛爬取网页的一整套流程和体系
第一步:抓取网页
百度蜘蛛先从索引市出发抓取网路上的网页链接,初步蜘蛛抓取的是全网的链接,没有针对性和目的性
第二步:筛选过滤(收录)
百度蜘蛛将抓取到的网页装入索引库来进行筛选和过滤,将符合百度算法和规则的内容进行索引,将不符合的内容进行剔除,还有一部分的心法储存,进行二次的筛选过滤百度爬虫攻击,这样不断的进行循环
第三步:进行索引
很多站长就会发觉,自己的网站收录和索引不相等,也有好多站长觉得收录=索引,其实不然,一般而言,收录是小于索引的。因为只有收录的文章才有资格被索引,被百度知道抓取到的符合推荐的文章,百度会进行索引。并不是所有的收录的文章都会被百度索引百度爬虫攻击,这一点是很重要的,也是好多站长所不知道的,裘哥在这里为你们重点来强调!
第四步:排名诠释
这是我们做网站优化人员最想见到的结果,也是蜘蛛抓取网页流程的最后一步,在索引区的文章,百度会统一的来进行分类,归档,排序,然后将内容反馈给搜索的用户。而我们SEO人员要做的就是将百度算法推荐给用户的文章索引排到相对较好的位置,从而至实现我们的流量转化和彰显我们SEO人员的价值。 查看全部
百度是中国目前的第一大搜索引擎,拥有健全的一套爬虫算法,了解百度蜘蛛的爬虫原理,对我们SEO优化工作有着举足轻重的作用。
我们可以从下边这张图片来详尽了解百度蜘蛛爬取网页的一整套流程和体系
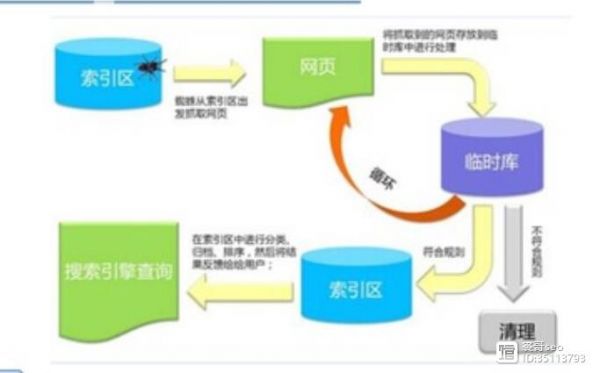
第一步:抓取网页
百度蜘蛛先从索引市出发抓取网路上的网页链接,初步蜘蛛抓取的是全网的链接,没有针对性和目的性
第二步:筛选过滤(收录)
百度蜘蛛将抓取到的网页装入索引库来进行筛选和过滤,将符合百度算法和规则的内容进行索引,将不符合的内容进行剔除,还有一部分的心法储存,进行二次的筛选过滤百度爬虫攻击,这样不断的进行循环
第三步:进行索引
很多站长就会发觉,自己的网站收录和索引不相等,也有好多站长觉得收录=索引,其实不然,一般而言,收录是小于索引的。因为只有收录的文章才有资格被索引,被百度知道抓取到的符合推荐的文章,百度会进行索引。并不是所有的收录的文章都会被百度索引百度爬虫攻击,这一点是很重要的,也是好多站长所不知道的,裘哥在这里为你们重点来强调!
第四步:排名诠释
这是我们做网站优化人员最想见到的结果,也是蜘蛛抓取网页流程的最后一步,在索引区的文章,百度会统一的来进行分类,归档,排序,然后将内容反馈给搜索的用户。而我们SEO人员要做的就是将百度算法推荐给用户的文章索引排到相对较好的位置,从而至实现我们的流量转化和彰显我们SEO人员的价值。
百度爬虫是哪些?百度蜘蛛有什么问题?
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-05-04 08:02
一般来说,搜索引擎爬行原则主要包括:抓取数据库,过滤,存储和显示结果。这四个过程与网站管理员常常讨论的百度蜘蛛爬行规则直接相关。
什么是百度蜘蛛?常见的百度抓取工具有问题?
什么是百度蜘蛛?
简单的理解,百度蜘蛛又称百度爬虫,主要的工作功能是捕获互联网上现有的URL,并评估页面质量,给出基本判别。
通常百度蜘蛛爬行规则是:
种子URL – >待定页面 – >提取URL – >筛选重复URL – >解析Web链接功能 – >输入链接总库 – >等待提取。
1.如何辨识百度蜘蛛
有两种方式可以快速辨识百度蜘蛛:
1网站蜘蛛日志剖析,你可以通过辨识百度蜘蛛UA辨识蜘蛛访问记录,比较便捷的方式是使用SEO软件手动辨识。有关百度UA的辨识,您还可以查看官方文档:https://ziyuan.baidu.com/college/articleinfo?id = 1002
2个CMS程序插件,自动嵌入辨识百度爬虫,当蜘蛛访问时,会记录相关的访问轨迹。
2.百度蜘蛛的规则是哪些?
并非每位网站蜘蛛就会抓取并抓取,它将被包含在内,这将构成搜索引擎的主要流程。这个过程主要分为:爬行,过滤,对比,索引,最后发布,并且还显示技术。页。
抓取:根据网站的网址抓取抓取工具。其主要目的是抓取网站上的文本链接,并逐层搜索视口。
筛选:爬行完成后,筛选步骤主要是过滤垃圾文章,如翻译,同义词替换,伪原创文章等,搜索引擎可以辨识它们,但通过此步骤辨识它们。
对比:比较主要是施行百度的Spark程序并保持文章的原创性。通常,在比较步骤过后,搜索引擎会下载您的网站,进行比较并创建快照,因此搜索引擎蜘蛛早已访问过您的网站,因此网站日志中会有百度的IP。
索引:通过确定您的网站没有问题,它将在您的网站上创建索引。如果您创建索引,则表示您的网站已包含在内。有时我们一直不在百度搜索。原因可能是它仍未发布,需要等待。
3.关于百度抓取工具的一些常见问题:
1怎么提升百度爬行的频度,暴涨频度的缘由是哪些?
在初期,由于包含相对困难,每个人都十分注重百度的爬行频度。但是,随着百度战略方向的调整,从目前来看,我们不需要刻意追求爬行频度的降低。当然,影响抓取频度的诱因主要包括:网站速度,安全性,内容质量,社会影响力等。
如果您发觉网站的抓取速率猛然上升,可能是因为存在链接圈套,蜘蛛难以抓取页面,或者内容质量很低,您须要抓取它,或者网站不稳定,遇到负面的SEO功击。
2怎样判别百度蜘蛛是否正常爬行
许多网站管理员都在线百度爬虫是什么意思,并且总是发布未包含的文章。所以我害怕百度抓取工具可以正常抓取。这是两个简单的工具:
百度爬行确诊:https://ziyuan.baidu.com/crawltools/index
百度Robots.txt测量:https://ziyuan.baidu.com/robots/index
您可以按照这两个页面检测页面的连接性,以及是否制止了百度蜘蛛爬行。
3百度爬虫继续爬行,为什么百度快照没有更新
快照不会长时间更新,也不代表任何问题。你只须要注意网站流量是否忽然升高。如果指标的各个方面都正常,蜘蛛时常访问,只代表您的页面质量很高,外部链接是理想的。
4网站防止侵权,禁止右键点击,百度蜘蛛是否可以辨识内容
如果您正在查看网页的源代码,您可以挺好地查看页面的内容。从理论上讲百度爬虫是什么意思,百度蜘蛛可以正常抓取页面。您也可以使用百度来瞧瞧。
5百度蜘蛛,真的有一个降权蜘蛛吗?
在初期,许多SEO人员喜欢剖析百度蜘蛛的IP段。 事实上,该高官已明晰表示,它并未表明什么蜘蛛正在爬行以代表权利,因此这个问题并没有被打破。
6抵挡百度蜘蛛,它会被包括在内吗?
一般来说,没有办法制止百度蜘蛛。 虽然主页会被收录,但内页不能包含在内,它如同“淘宝”基本上屏蔽了百度蜘蛛。 只有主页一直排行挺好。
总结:许多词组在市场中出现,就像蜘蛛池一样。 这是一种实现它的不切实际的形式。 不建议每位人使用。 以上仅供参考。
原创文章,作者:柴叔seo,如若转载,请标明出处: 查看全部
每个人的搜索引擎每晚基本上都有数百亿的爬行。无论是个人还是SEO网站推广团队,他们都习惯了解百度搜索引擎的爬行原则。但是,百度是十分自己的算法。值得的是,这须要SEO工作人员密切关注官方文档,并深入了解文档的真实涵义。
一般来说,搜索引擎爬行原则主要包括:抓取数据库,过滤,存储和显示结果。这四个过程与网站管理员常常讨论的百度蜘蛛爬行规则直接相关。

什么是百度蜘蛛?常见的百度抓取工具有问题?
什么是百度蜘蛛?
简单的理解,百度蜘蛛又称百度爬虫,主要的工作功能是捕获互联网上现有的URL,并评估页面质量,给出基本判别。
通常百度蜘蛛爬行规则是:
种子URL – >待定页面 – >提取URL – >筛选重复URL – >解析Web链接功能 – >输入链接总库 – >等待提取。
1.如何辨识百度蜘蛛
有两种方式可以快速辨识百度蜘蛛:
1网站蜘蛛日志剖析,你可以通过辨识百度蜘蛛UA辨识蜘蛛访问记录,比较便捷的方式是使用SEO软件手动辨识。有关百度UA的辨识,您还可以查看官方文档:https://ziyuan.baidu.com/college/articleinfo?id = 1002
2个CMS程序插件,自动嵌入辨识百度爬虫,当蜘蛛访问时,会记录相关的访问轨迹。
2.百度蜘蛛的规则是哪些?
并非每位网站蜘蛛就会抓取并抓取,它将被包含在内,这将构成搜索引擎的主要流程。这个过程主要分为:爬行,过滤,对比,索引,最后发布,并且还显示技术。页。
抓取:根据网站的网址抓取抓取工具。其主要目的是抓取网站上的文本链接,并逐层搜索视口。
筛选:爬行完成后,筛选步骤主要是过滤垃圾文章,如翻译,同义词替换,伪原创文章等,搜索引擎可以辨识它们,但通过此步骤辨识它们。
对比:比较主要是施行百度的Spark程序并保持文章的原创性。通常,在比较步骤过后,搜索引擎会下载您的网站,进行比较并创建快照,因此搜索引擎蜘蛛早已访问过您的网站,因此网站日志中会有百度的IP。
索引:通过确定您的网站没有问题,它将在您的网站上创建索引。如果您创建索引,则表示您的网站已包含在内。有时我们一直不在百度搜索。原因可能是它仍未发布,需要等待。

3.关于百度抓取工具的一些常见问题:
1怎么提升百度爬行的频度,暴涨频度的缘由是哪些?
在初期,由于包含相对困难,每个人都十分注重百度的爬行频度。但是,随着百度战略方向的调整,从目前来看,我们不需要刻意追求爬行频度的降低。当然,影响抓取频度的诱因主要包括:网站速度,安全性,内容质量,社会影响力等。
如果您发觉网站的抓取速率猛然上升,可能是因为存在链接圈套,蜘蛛难以抓取页面,或者内容质量很低,您须要抓取它,或者网站不稳定,遇到负面的SEO功击。
2怎样判别百度蜘蛛是否正常爬行
许多网站管理员都在线百度爬虫是什么意思,并且总是发布未包含的文章。所以我害怕百度抓取工具可以正常抓取。这是两个简单的工具:
百度爬行确诊:https://ziyuan.baidu.com/crawltools/index
百度Robots.txt测量:https://ziyuan.baidu.com/robots/index
您可以按照这两个页面检测页面的连接性,以及是否制止了百度蜘蛛爬行。
3百度爬虫继续爬行,为什么百度快照没有更新
快照不会长时间更新,也不代表任何问题。你只须要注意网站流量是否忽然升高。如果指标的各个方面都正常,蜘蛛时常访问,只代表您的页面质量很高,外部链接是理想的。
4网站防止侵权,禁止右键点击,百度蜘蛛是否可以辨识内容
如果您正在查看网页的源代码,您可以挺好地查看页面的内容。从理论上讲百度爬虫是什么意思,百度蜘蛛可以正常抓取页面。您也可以使用百度来瞧瞧。
5百度蜘蛛,真的有一个降权蜘蛛吗?
在初期,许多SEO人员喜欢剖析百度蜘蛛的IP段。 事实上,该高官已明晰表示,它并未表明什么蜘蛛正在爬行以代表权利,因此这个问题并没有被打破。
6抵挡百度蜘蛛,它会被包括在内吗?
一般来说,没有办法制止百度蜘蛛。 虽然主页会被收录,但内页不能包含在内,它如同“淘宝”基本上屏蔽了百度蜘蛛。 只有主页一直排行挺好。
总结:许多词组在市场中出现,就像蜘蛛池一样。 这是一种实现它的不切实际的形式。 不建议每位人使用。 以上仅供参考。
原创文章,作者:柴叔seo,如若转载,请标明出处:
红叶文章采集器3.6绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 451 次浏览 • 2020-04-18 09:52
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章文章采集,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题文章采集软件下载,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路文章采集软件下载,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。 查看全部

超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章文章采集,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题文章采集软件下载,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路文章采集软件下载,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
WordPress手动采集插件:WP-CTspider(长腿蜘蛛)
站长必读 • 优采云 发表了文章 • 0 个评论 • 549 次浏览 • 2020-07-18 08:09
WP-CTspider(长腿蜘蛛)是一款基于php开发的Wordpress全手动采集插件,设置轻而易举,只须要设置定向采集网址,通过CSS选择器精准辨识采集区域,包括(内容,摘要,TAG,缩略图,自定义数组等…)然后手动检查抓取网页内容,文章去重,更新发布,这个过程全手动完成,无需人工干预。
WP-CTspider(长腿蜘蛛)采用php爬虫设计wordpress采集插件,只须要依照DIV标签进行简单地几步操作即可完成手动采集。只要的主机性能足够强劲,WP-CTspider还为你提供了多线程分离式采集,每个线程相互之间不干扰,独立运行。完美支持WordPress各类功能、标签,摘要,特色图片wordpress采集插件,自定义栏目等。其还拥有SEO全功能优化内容,支持内容的过滤,增加,修缮。
使用教程开发者写得十分详尽,我就不做过多赘言,请看官网文档。
点击采集后显示没有任何数据只有两种可能
采集规则没有设置好。 如果确定采集规则没问题,请查看当前采集的网址是否是Ajax动态渲染加载(PS:目前性感蜘蛛-CTspider不支持动态渲染加载采集
WP-CTspider(长腿蜘蛛)开发者字2017年上线以来始终在不断更新构建这款插件工具,如果你在使用中遇见哪些bug可以在官网上及时反馈。
下载信息 WP-CTSPIDER(长腿蜘蛛采集插件) WordPress 下载地址 查看全部
WP-CTspider(长腿蜘蛛)是一款基于php开发的Wordpress全手动采集插件,设置轻而易举,只须要设置定向采集网址,通过CSS选择器精准辨识采集区域,包括(内容,摘要,TAG,缩略图,自定义数组等…)然后手动检查抓取网页内容,文章去重,更新发布,这个过程全手动完成,无需人工干预。
WP-CTspider(长腿蜘蛛)采用php爬虫设计wordpress采集插件,只须要依照DIV标签进行简单地几步操作即可完成手动采集。只要的主机性能足够强劲,WP-CTspider还为你提供了多线程分离式采集,每个线程相互之间不干扰,独立运行。完美支持WordPress各类功能、标签,摘要,特色图片wordpress采集插件,自定义栏目等。其还拥有SEO全功能优化内容,支持内容的过滤,增加,修缮。
使用教程开发者写得十分详尽,我就不做过多赘言,请看官网文档。
点击采集后显示没有任何数据只有两种可能
采集规则没有设置好。 如果确定采集规则没问题,请查看当前采集的网址是否是Ajax动态渲染加载(PS:目前性感蜘蛛-CTspider不支持动态渲染加载采集
WP-CTspider(长腿蜘蛛)开发者字2017年上线以来始终在不断更新构建这款插件工具,如果你在使用中遇见哪些bug可以在官网上及时反馈。
下载信息 WP-CTSPIDER(长腿蜘蛛采集插件) WordPress 下载地址
百度蜘蛛(百度爬虫、网络蜘蛛)是哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-06-08 08:01
百度蜘蛛也叫百度爬虫、百度网路蜘蛛,其实不是真实蜘蛛,而是一个自动程序,该程序的抓取路径象蜘蛛丝一样,该程序通过网页上的锚链接进行爬行,类似蜘蛛爬行,因此叫百度蜘蛛、百度爬虫、网络蜘蛛等多种别称,其实就是一个搜索引擎抓取程序。
百度蜘蛛的作用:百度搜索引擎通过百度蜘蛛这个手动程序,访问其他网站,百度蜘蛛首先判定该网页是否符合搜索引擎的收录条件,如果符合收录条件,百度蜘蛛就下载该网页,然后保存到百度数据里,建立百度快照,当用户搜索某一个关键词时,搜索通过自身的排序机制,把快照进行索引排序,然后把排序结果诠释给读者。如果网页内容不符合搜索引擎的收录规则,那么百度蜘蛛不收录,并通过锚链接访问其他页面,进而重新进行判定是否收录。
提高百度蜘蛛抓取效率的方式
1、网站建立健全的网站内部链接,合理的网站导航、网站架构,必要时还可以通过网站地图增强百度蜘蛛抓取效率。
2、网站外链就好比百度蜘蛛的路径,网站外链越多,百度蜘蛛来网站的机会越大。
3、网站内容时常保持更新,百度蜘蛛喜欢新东西百度网络爬虫,如果你的网站经常更新,那么百度蜘蛛会时常光临。
通过网站日志可以判定百度蜘蛛是否光临。
产品名称 对应user-agent
网页搜索 Baiduspider
无线搜索 Baiduspider-mobile
图片搜索 Baiduspider-image
视频搜索 Baiduspider-video
新闻搜索 Baiduspider-news
百度搜藏 Baiduspider-favo
百度联盟Baiduspider-cpro
移动搜索 baidu+Transcoder
网上有很多百度蜘蛛模拟程序,你可以通过该程序,了解百度蜘蛛展示的结果,有的服务器或则程序对百度蜘蛛进行了屏蔽,因此可以通过该软件查询百度蜘蛛抓取的结果。同时若果你不希望百度蜘蛛收录网站的某个栏目,你可以通过设置robots.txt来告诉搜索引擎,哪些页面可以收录百度网络爬虫,哪些页面不可以收录,这样可以解决隐私内容被百度收录。 查看全部
百度蜘蛛也叫百度爬虫、百度网路蜘蛛,其实不是真实蜘蛛,而是一个自动程序,该程序的抓取路径象蜘蛛丝一样,该程序通过网页上的锚链接进行爬行,类似蜘蛛爬行,因此叫百度蜘蛛、百度爬虫、网络蜘蛛等多种别称,其实就是一个搜索引擎抓取程序。
百度蜘蛛的作用:百度搜索引擎通过百度蜘蛛这个手动程序,访问其他网站,百度蜘蛛首先判定该网页是否符合搜索引擎的收录条件,如果符合收录条件,百度蜘蛛就下载该网页,然后保存到百度数据里,建立百度快照,当用户搜索某一个关键词时,搜索通过自身的排序机制,把快照进行索引排序,然后把排序结果诠释给读者。如果网页内容不符合搜索引擎的收录规则,那么百度蜘蛛不收录,并通过锚链接访问其他页面,进而重新进行判定是否收录。
提高百度蜘蛛抓取效率的方式
1、网站建立健全的网站内部链接,合理的网站导航、网站架构,必要时还可以通过网站地图增强百度蜘蛛抓取效率。
2、网站外链就好比百度蜘蛛的路径,网站外链越多,百度蜘蛛来网站的机会越大。
3、网站内容时常保持更新,百度蜘蛛喜欢新东西百度网络爬虫,如果你的网站经常更新,那么百度蜘蛛会时常光临。
通过网站日志可以判定百度蜘蛛是否光临。
产品名称 对应user-agent
网页搜索 Baiduspider
无线搜索 Baiduspider-mobile
图片搜索 Baiduspider-image
视频搜索 Baiduspider-video
新闻搜索 Baiduspider-news
百度搜藏 Baiduspider-favo
百度联盟Baiduspider-cpro
移动搜索 baidu+Transcoder
网上有很多百度蜘蛛模拟程序,你可以通过该程序,了解百度蜘蛛展示的结果,有的服务器或则程序对百度蜘蛛进行了屏蔽,因此可以通过该软件查询百度蜘蛛抓取的结果。同时若果你不希望百度蜘蛛收录网站的某个栏目,你可以通过设置robots.txt来告诉搜索引擎,哪些页面可以收录百度网络爬虫,哪些页面不可以收录,这样可以解决隐私内容被百度收录。
百度蜘蛛爬虫的工作原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-05-11 08:02
我们可以从下边这张图片来详尽了解百度蜘蛛爬取网页的一整套流程和体系
第一步:抓取网页
百度蜘蛛先从索引市出发抓取网路上的网页链接,初步蜘蛛抓取的是全网的链接,没有针对性和目的性
第二步:筛选过滤(收录)
百度蜘蛛将抓取到的网页装入索引库来进行筛选和过滤,将符合百度算法和规则的内容进行索引,将不符合的内容进行剔除,还有一部分的心法储存,进行二次的筛选过滤百度爬虫攻击,这样不断的进行循环
第三步:进行索引
很多站长就会发觉,自己的网站收录和索引不相等,也有好多站长觉得收录=索引,其实不然,一般而言,收录是小于索引的。因为只有收录的文章才有资格被索引,被百度知道抓取到的符合推荐的文章,百度会进行索引。并不是所有的收录的文章都会被百度索引百度爬虫攻击,这一点是很重要的,也是好多站长所不知道的,裘哥在这里为你们重点来强调!
第四步:排名诠释
这是我们做网站优化人员最想见到的结果,也是蜘蛛抓取网页流程的最后一步,在索引区的文章,百度会统一的来进行分类,归档,排序,然后将内容反馈给搜索的用户。而我们SEO人员要做的就是将百度算法推荐给用户的文章索引排到相对较好的位置,从而至实现我们的流量转化和彰显我们SEO人员的价值。 查看全部
百度是中国目前的第一大搜索引擎,拥有健全的一套爬虫算法,了解百度蜘蛛的爬虫原理,对我们SEO优化工作有着举足轻重的作用。
我们可以从下边这张图片来详尽了解百度蜘蛛爬取网页的一整套流程和体系
第一步:抓取网页
百度蜘蛛先从索引市出发抓取网路上的网页链接,初步蜘蛛抓取的是全网的链接,没有针对性和目的性
第二步:筛选过滤(收录)
百度蜘蛛将抓取到的网页装入索引库来进行筛选和过滤,将符合百度算法和规则的内容进行索引,将不符合的内容进行剔除,还有一部分的心法储存,进行二次的筛选过滤百度爬虫攻击,这样不断的进行循环
第三步:进行索引
很多站长就会发觉,自己的网站收录和索引不相等,也有好多站长觉得收录=索引,其实不然,一般而言,收录是小于索引的。因为只有收录的文章才有资格被索引,被百度知道抓取到的符合推荐的文章,百度会进行索引。并不是所有的收录的文章都会被百度索引百度爬虫攻击,这一点是很重要的,也是好多站长所不知道的,裘哥在这里为你们重点来强调!
第四步:排名诠释
这是我们做网站优化人员最想见到的结果,也是蜘蛛抓取网页流程的最后一步,在索引区的文章,百度会统一的来进行分类,归档,排序,然后将内容反馈给搜索的用户。而我们SEO人员要做的就是将百度算法推荐给用户的文章索引排到相对较好的位置,从而至实现我们的流量转化和彰显我们SEO人员的价值。
百度爬虫是哪些?百度蜘蛛有什么问题?
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-05-04 08:02
一般来说,搜索引擎爬行原则主要包括:抓取数据库,过滤,存储和显示结果。这四个过程与网站管理员常常讨论的百度蜘蛛爬行规则直接相关。
什么是百度蜘蛛?常见的百度抓取工具有问题?
什么是百度蜘蛛?
简单的理解,百度蜘蛛又称百度爬虫,主要的工作功能是捕获互联网上现有的URL,并评估页面质量,给出基本判别。
通常百度蜘蛛爬行规则是:
种子URL – >待定页面 – >提取URL – >筛选重复URL – >解析Web链接功能 – >输入链接总库 – >等待提取。
1.如何辨识百度蜘蛛
有两种方式可以快速辨识百度蜘蛛:
1网站蜘蛛日志剖析,你可以通过辨识百度蜘蛛UA辨识蜘蛛访问记录,比较便捷的方式是使用SEO软件手动辨识。有关百度UA的辨识,您还可以查看官方文档:https://ziyuan.baidu.com/college/articleinfo?id = 1002
2个CMS程序插件,自动嵌入辨识百度爬虫,当蜘蛛访问时,会记录相关的访问轨迹。
2.百度蜘蛛的规则是哪些?
并非每位网站蜘蛛就会抓取并抓取,它将被包含在内,这将构成搜索引擎的主要流程。这个过程主要分为:爬行,过滤,对比,索引,最后发布,并且还显示技术。页。
抓取:根据网站的网址抓取抓取工具。其主要目的是抓取网站上的文本链接,并逐层搜索视口。
筛选:爬行完成后,筛选步骤主要是过滤垃圾文章,如翻译,同义词替换,伪原创文章等,搜索引擎可以辨识它们,但通过此步骤辨识它们。
对比:比较主要是施行百度的Spark程序并保持文章的原创性。通常,在比较步骤过后,搜索引擎会下载您的网站,进行比较并创建快照,因此搜索引擎蜘蛛早已访问过您的网站,因此网站日志中会有百度的IP。
索引:通过确定您的网站没有问题,它将在您的网站上创建索引。如果您创建索引,则表示您的网站已包含在内。有时我们一直不在百度搜索。原因可能是它仍未发布,需要等待。
3.关于百度抓取工具的一些常见问题:
1怎么提升百度爬行的频度,暴涨频度的缘由是哪些?
在初期,由于包含相对困难,每个人都十分注重百度的爬行频度。但是,随着百度战略方向的调整,从目前来看,我们不需要刻意追求爬行频度的降低。当然,影响抓取频度的诱因主要包括:网站速度,安全性,内容质量,社会影响力等。
如果您发觉网站的抓取速率猛然上升,可能是因为存在链接圈套,蜘蛛难以抓取页面,或者内容质量很低,您须要抓取它,或者网站不稳定,遇到负面的SEO功击。
2怎样判别百度蜘蛛是否正常爬行
许多网站管理员都在线百度爬虫是什么意思,并且总是发布未包含的文章。所以我害怕百度抓取工具可以正常抓取。这是两个简单的工具:
百度爬行确诊:https://ziyuan.baidu.com/crawltools/index
百度Robots.txt测量:https://ziyuan.baidu.com/robots/index
您可以按照这两个页面检测页面的连接性,以及是否制止了百度蜘蛛爬行。
3百度爬虫继续爬行,为什么百度快照没有更新
快照不会长时间更新,也不代表任何问题。你只须要注意网站流量是否忽然升高。如果指标的各个方面都正常,蜘蛛时常访问,只代表您的页面质量很高,外部链接是理想的。
4网站防止侵权,禁止右键点击,百度蜘蛛是否可以辨识内容
如果您正在查看网页的源代码,您可以挺好地查看页面的内容。从理论上讲百度爬虫是什么意思,百度蜘蛛可以正常抓取页面。您也可以使用百度来瞧瞧。
5百度蜘蛛,真的有一个降权蜘蛛吗?
在初期,许多SEO人员喜欢剖析百度蜘蛛的IP段。 事实上,该高官已明晰表示,它并未表明什么蜘蛛正在爬行以代表权利,因此这个问题并没有被打破。
6抵挡百度蜘蛛,它会被包括在内吗?
一般来说,没有办法制止百度蜘蛛。 虽然主页会被收录,但内页不能包含在内,它如同“淘宝”基本上屏蔽了百度蜘蛛。 只有主页一直排行挺好。
总结:许多词组在市场中出现,就像蜘蛛池一样。 这是一种实现它的不切实际的形式。 不建议每位人使用。 以上仅供参考。
原创文章,作者:柴叔seo,如若转载,请标明出处: 查看全部
每个人的搜索引擎每晚基本上都有数百亿的爬行。无论是个人还是SEO网站推广团队,他们都习惯了解百度搜索引擎的爬行原则。但是,百度是十分自己的算法。值得的是,这须要SEO工作人员密切关注官方文档,并深入了解文档的真实涵义。
一般来说,搜索引擎爬行原则主要包括:抓取数据库,过滤,存储和显示结果。这四个过程与网站管理员常常讨论的百度蜘蛛爬行规则直接相关。
什么是百度蜘蛛?常见的百度抓取工具有问题?
什么是百度蜘蛛?
简单的理解,百度蜘蛛又称百度爬虫,主要的工作功能是捕获互联网上现有的URL,并评估页面质量,给出基本判别。
通常百度蜘蛛爬行规则是:
种子URL – >待定页面 – >提取URL – >筛选重复URL – >解析Web链接功能 – >输入链接总库 – >等待提取。
1.如何辨识百度蜘蛛
有两种方式可以快速辨识百度蜘蛛:
1网站蜘蛛日志剖析,你可以通过辨识百度蜘蛛UA辨识蜘蛛访问记录,比较便捷的方式是使用SEO软件手动辨识。有关百度UA的辨识,您还可以查看官方文档:https://ziyuan.baidu.com/college/articleinfo?id = 1002
2个CMS程序插件,自动嵌入辨识百度爬虫,当蜘蛛访问时,会记录相关的访问轨迹。
2.百度蜘蛛的规则是哪些?
并非每位网站蜘蛛就会抓取并抓取,它将被包含在内,这将构成搜索引擎的主要流程。这个过程主要分为:爬行,过滤,对比,索引,最后发布,并且还显示技术。页。
抓取:根据网站的网址抓取抓取工具。其主要目的是抓取网站上的文本链接,并逐层搜索视口。
筛选:爬行完成后,筛选步骤主要是过滤垃圾文章,如翻译,同义词替换,伪原创文章等,搜索引擎可以辨识它们,但通过此步骤辨识它们。
对比:比较主要是施行百度的Spark程序并保持文章的原创性。通常,在比较步骤过后,搜索引擎会下载您的网站,进行比较并创建快照,因此搜索引擎蜘蛛早已访问过您的网站,因此网站日志中会有百度的IP。
索引:通过确定您的网站没有问题,它将在您的网站上创建索引。如果您创建索引,则表示您的网站已包含在内。有时我们一直不在百度搜索。原因可能是它仍未发布,需要等待。
3.关于百度抓取工具的一些常见问题:
1怎么提升百度爬行的频度,暴涨频度的缘由是哪些?
在初期,由于包含相对困难,每个人都十分注重百度的爬行频度。但是,随着百度战略方向的调整,从目前来看,我们不需要刻意追求爬行频度的降低。当然,影响抓取频度的诱因主要包括:网站速度,安全性,内容质量,社会影响力等。
如果您发觉网站的抓取速率猛然上升,可能是因为存在链接圈套,蜘蛛难以抓取页面,或者内容质量很低,您须要抓取它,或者网站不稳定,遇到负面的SEO功击。
2怎样判别百度蜘蛛是否正常爬行
许多网站管理员都在线百度爬虫是什么意思,并且总是发布未包含的文章。所以我害怕百度抓取工具可以正常抓取。这是两个简单的工具:
百度爬行确诊:https://ziyuan.baidu.com/crawltools/index
百度Robots.txt测量:https://ziyuan.baidu.com/robots/index
您可以按照这两个页面检测页面的连接性,以及是否制止了百度蜘蛛爬行。
3百度爬虫继续爬行,为什么百度快照没有更新
快照不会长时间更新,也不代表任何问题。你只须要注意网站流量是否忽然升高。如果指标的各个方面都正常,蜘蛛时常访问,只代表您的页面质量很高,外部链接是理想的。
4网站防止侵权,禁止右键点击,百度蜘蛛是否可以辨识内容
如果您正在查看网页的源代码,您可以挺好地查看页面的内容。从理论上讲百度爬虫是什么意思,百度蜘蛛可以正常抓取页面。您也可以使用百度来瞧瞧。
5百度蜘蛛,真的有一个降权蜘蛛吗?
在初期,许多SEO人员喜欢剖析百度蜘蛛的IP段。 事实上,该高官已明晰表示,它并未表明什么蜘蛛正在爬行以代表权利,因此这个问题并没有被打破。
6抵挡百度蜘蛛,它会被包括在内吗?
一般来说,没有办法制止百度蜘蛛。 虽然主页会被收录,但内页不能包含在内,它如同“淘宝”基本上屏蔽了百度蜘蛛。 只有主页一直排行挺好。
总结:许多词组在市场中出现,就像蜘蛛池一样。 这是一种实现它的不切实际的形式。 不建议每位人使用。 以上仅供参考。
原创文章,作者:柴叔seo,如若转载,请标明出处:
红叶文章采集器3.6绿色版
采集交流 • 优采云 发表了文章 • 0 个评论 • 451 次浏览 • 2020-04-18 09:52
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章文章采集,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题文章采集软件下载,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路文章采集软件下载,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。 查看全部
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。
超级强悍的网站文章采集器,本软件全名为红叶文章采集器,英文名称Fast_Spider,属于蜘蛛爬虫类程序,用于从指定网站采集海量精华文章文章采集,将直接扔掉其中的垃圾网页信息,仅保存具备阅读价值和浏览价值的精华文章,自动执行HTM-TXT转换。本软件为红色软件解压即可使用!
软件特色
(1)本软件采用清华天网MD5指纹排重算法,对于相像相同的网页信息,不再重复保存。
(2)采集信息涵义:[[HT]]表示网页标题,[[HA]]表示文章标题文章采集软件下载,[[HC]]表示10个权重关键字,[[UR]]表示网页中的图片链接,[[TXT]]之后为正文。
(3)蜘蛛性能:本软件开启300个线程来保证采集效率。通过采集100万精华文章来执行压力测试,以普通网民的联网计算机为参考标准,单台计算机可以在一天内遍历200万网页、采集20万精华文章,100万精华文章仅需5天就可采集完毕。
(4) 正式版与免费版的区别在于:正式版准许将采集的精华文章数据手动保存为ACCESS数据库。购买正式版请联系QQ(970093569)。
操作方法
(1)使用前,必须确保你的计算机可以连通网路文章采集软件下载,且防火墙不要拦截本软件。
(2)运行SETUP.EXE和setup2.exe,以安装操作系统system32支持库。
(3)运行spider.exe,输入网址入口,先点"人工添加"按钮,再点"启动"按钮,将开始执行采集。
注意事项
(1)抓取深度:填写0表示不限制抓取深度;填写3表示抓到第3层。
(2)通用蜘蛛模式与分类蜘蛛模式的区别:假定网址入口为“;,若选择通用蜘蛛模式,将遍历“baidu.com”里面的每一个网页;若选择分类蜘蛛模式,则只遍历“youxi.baidu.com”里面的每一个网页。
(3) 按钮“从MDB导出”:网址入口从TASK.MDB中批量导出。
(4)本软件采集的原则是不越站,例如给的入口是“;,就只在百度站点内部抓取。
(5)本软件采集过程中,偶尔会弹出一个或数个“错误对话框”,请不予理会,倘若关掉“错误对话框”,采集软件都会死掉。
(6)使用者怎么选择采集题材:例如你若果采集 “股票类”文章,只需把这些“股票类”站点作为网址入口即可。

