
自动采集
把ET当成文件下载器,不用插口手动下载视频、音乐、图片等文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-09 10:36
但用下载软件不能24小时监控对方更新、自动下载最新的文件。
使用ET可以轻松实现手动下载对方更新的任何格式的文件。
不过优采云采集器的信息必须成功发布到一个目的,否则会由于发布失败而手动删掉那些下载的文件,但我们并不准备将这种信息发布到网站,这时候该怎样办呢?
很简单!
以下几步即可实现。
1、新建一个发布规则
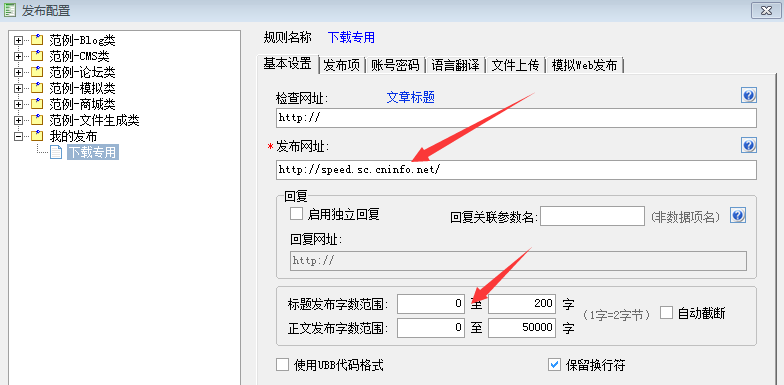
设置一个可以访问快速的发布网址。
不需要一个真正发布文章的网址,我们可以随意找一个访问速率快的网站,例如我们在右图使用的当地联通测速网址,也可以用自己的本地网址如“”。
将字数范围设为0开始可以防止采集规则没有设置采集正文、标题时的错误提示。
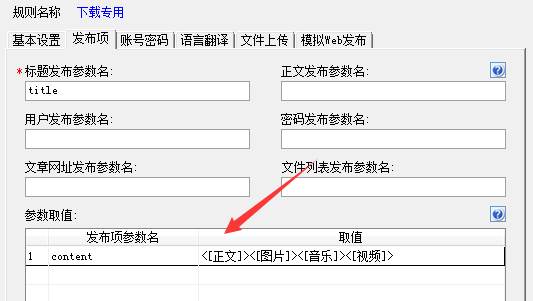
2、设置发布项
在参数取值里,随便设置一个参数名,取值一定要包括你采集文件的数据项标记。
例如下图我们设置了一个content参数,取值为“”,这样的设置,可以保证所采集的文件被下载。
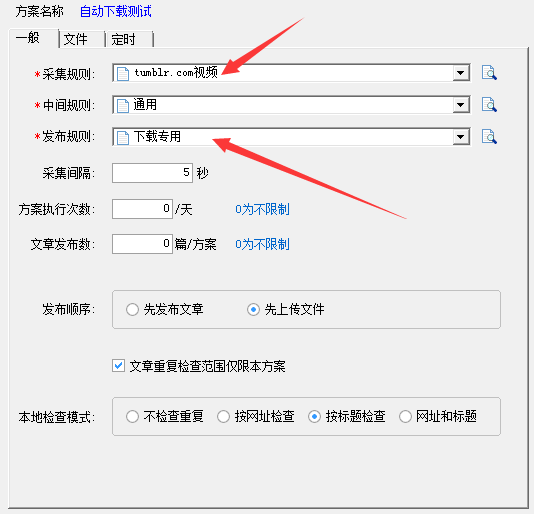
3、建立方案
建立方案,我们使用“汤博乐()视频采集规则”来进行测试。
在方案的文件设置中取消“发布后本地手动删掉下载文件”的选项。
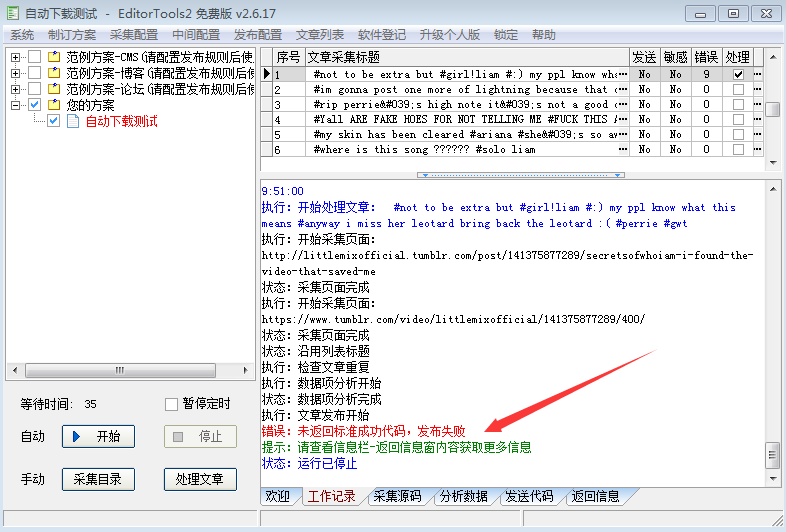
4、选取特征码
我们试用一次这个方案,这时候工作记录会提示发布失败。
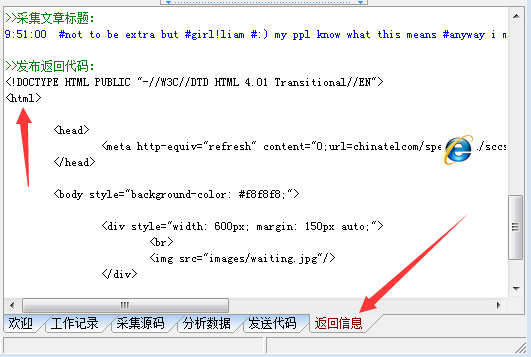
从返回信息中,选择任意一个必然出现的字符串作为特点码,比如我们选择了“”。
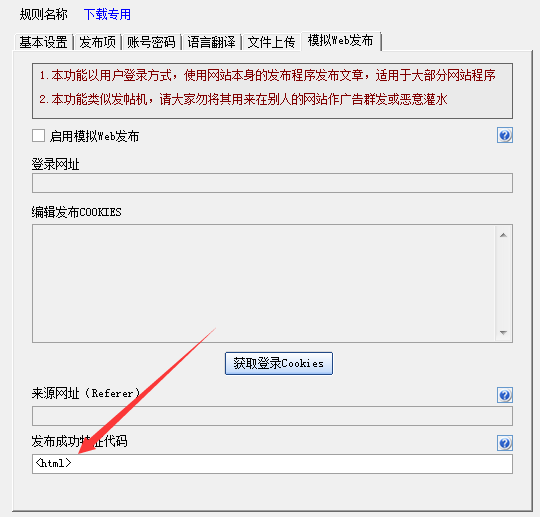
将它填写到 发布规则的模拟web发布-发布成功特点码中,这里不用勾选“启用模拟web发布”。
5、OK,设置完成
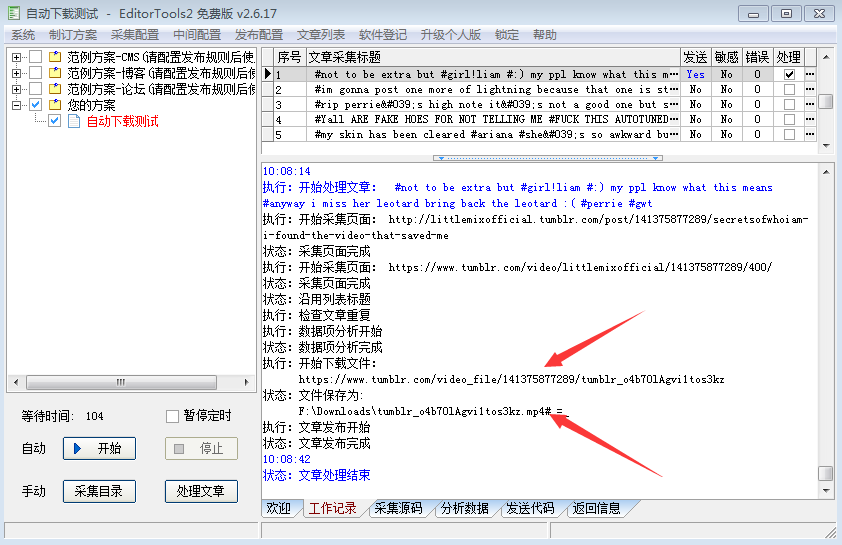
再次执行文章采集,工作记录会显示文章采集完成!
现在,我们可以开始手动工作,自动下载汤博乐()精彩视频了。
使用本方式下载其他网站文件,更换为对应采集规则即可。
注:本文中的 “汤博乐()视频采集规则” 下载地址为: 查看全部
我们对一些网站上的视频、音乐、美图感兴趣,希望能手动将它们下载到笔记本里采集上去,比如我们在汤博乐()关注的人发布了新视频。
但用下载软件不能24小时监控对方更新、自动下载最新的文件。
使用ET可以轻松实现手动下载对方更新的任何格式的文件。
不过优采云采集器的信息必须成功发布到一个目的,否则会由于发布失败而手动删掉那些下载的文件,但我们并不准备将这种信息发布到网站,这时候该怎样办呢?
很简单!
以下几步即可实现。
1、新建一个发布规则
设置一个可以访问快速的发布网址。
不需要一个真正发布文章的网址,我们可以随意找一个访问速率快的网站,例如我们在右图使用的当地联通测速网址,也可以用自己的本地网址如“”。
将字数范围设为0开始可以防止采集规则没有设置采集正文、标题时的错误提示。
2、设置发布项
在参数取值里,随便设置一个参数名,取值一定要包括你采集文件的数据项标记。
例如下图我们设置了一个content参数,取值为“”,这样的设置,可以保证所采集的文件被下载。
3、建立方案
建立方案,我们使用“汤博乐()视频采集规则”来进行测试。
在方案的文件设置中取消“发布后本地手动删掉下载文件”的选项。

4、选取特征码
我们试用一次这个方案,这时候工作记录会提示发布失败。
从返回信息中,选择任意一个必然出现的字符串作为特点码,比如我们选择了“”。
将它填写到 发布规则的模拟web发布-发布成功特点码中,这里不用勾选“启用模拟web发布”。
5、OK,设置完成
再次执行文章采集,工作记录会显示文章采集完成!
现在,我们可以开始手动工作,自动下载汤博乐()精彩视频了。
使用本方式下载其他网站文件,更换为对应采集规则即可。
注:本文中的 “汤博乐()视频采集规则” 下载地址为:
如何在网站上采集以及如何在wordpress上实现自动采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-08 20:39
WordPress是使用PHP语言开发的网站构建程序平台. 现在,许多博客都使用WP. 许多网站生产培训都使用WP,尤其是在作为采集站工作时. WordPress非常强大. . 这是实现wp自动采集功能的方法.
安装网站集插件: WP-AutoPost(插件下载地址: )
单击“新任务”后,输入任务名称以创建新任务. 创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务设置更多设置. (这部分不需要修改设置,唯一需要更改的是采集时间. )文章源设置. 在此标签下,我们需要设置文章来源的“文章列表URL”和特定文章的匹配规则. 让我们以“新浪网新闻”为例,文章列表URL是,因此在“手动指定文章列表URL?”中输入URL. 如下所示:
文章URL匹配规则. 文章URL匹配规则的设置非常简单,不需要复杂的设置. 提供两种匹配模式. 您可以使用URL通配符匹配或CSS选择器进行匹配. 通常,URL通配符匹配更简单,但有时CSS选择器更方便. 准确. ?使用URL通配符匹配. 通过单击列表URL上的文章,我们可以发现每篇文章的URL具有以下结构: 因此,用通配符替换URL中更改的数字或字母? (*)??,例如: (*)/(*).shtml. 重复的URL可以使用301重定向. 使用CSS选择器进行匹配. 使用CSS选择器进行匹配,我们只需要设置商品URL的CSS选择器即可,可以通过查看列表URL的源代码并在列表URL下找到商品超链接的代码轻松地进行设置,如图所示下方:
如您所见,文章的超链接A标签位于类为“ contList”的标签内,因此只需将文章URL的CSS选择器设置为??. contList a ?,如下所示:
设置完成后,如果您不知道设置是否正确,则可以单击上图中的测试按钮. 如果设置正确,则会列出列表URL下的所有文章名称和相应的网址,如下所示:
其他设置不需要修改. 以上采集方法适用于WordPress多站点功能. 查看全部

WordPress是使用PHP语言开发的网站构建程序平台. 现在,许多博客都使用WP. 许多网站生产培训都使用WP,尤其是在作为采集站工作时. WordPress非常强大. . 这是实现wp自动采集功能的方法.
安装网站集插件: WP-AutoPost(插件下载地址: )

单击“新任务”后,输入任务名称以创建新任务. 创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务设置更多设置. (这部分不需要修改设置,唯一需要更改的是采集时间. )文章源设置. 在此标签下,我们需要设置文章来源的“文章列表URL”和特定文章的匹配规则. 让我们以“新浪网新闻”为例,文章列表URL是,因此在“手动指定文章列表URL?”中输入URL. 如下所示:

文章URL匹配规则. 文章URL匹配规则的设置非常简单,不需要复杂的设置. 提供两种匹配模式. 您可以使用URL通配符匹配或CSS选择器进行匹配. 通常,URL通配符匹配更简单,但有时CSS选择器更方便. 准确. ?使用URL通配符匹配. 通过单击列表URL上的文章,我们可以发现每篇文章的URL具有以下结构: 因此,用通配符替换URL中更改的数字或字母? (*)??,例如: (*)/(*).shtml. 重复的URL可以使用301重定向. 使用CSS选择器进行匹配. 使用CSS选择器进行匹配,我们只需要设置商品URL的CSS选择器即可,可以通过查看列表URL的源代码并在列表URL下找到商品超链接的代码轻松地进行设置,如图所示下方:

如您所见,文章的超链接A标签位于类为“ contList”的标签内,因此只需将文章URL的CSS选择器设置为??. contList a ?,如下所示:

设置完成后,如果您不知道设置是否正确,则可以单击上图中的测试按钮. 如果设置正确,则会列出列表URL下的所有文章名称和相应的网址,如下所示:

其他设置不需要修改. 以上采集方法适用于WordPress多站点功能.
Apple maccms8各种CMS计时自动采集终极教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 439 次浏览 • 2020-08-08 00:23
首先,我不得不说,当前在Internet上搜索的许多Apple maccms8计时自动采集教程可能会产生误导. 他们不了解真实的事实. 经过对子坊的前瞻性探索,我终于走上了艰难的道路.
紫芳觉得采集工作实际上是一个非常麻烦的项目. 如果有自动采集功能,则通常只需花费一半的精力即可获得两倍的结果. 互联网上当前的教程基本上都使用宝塔的定时访问URL功能进行采集,这并不重要. 但是所有教程都没有介绍这些原理. 如果您不注意细节,则经常会失败. 例如,子芳要花一些时间.
让我们讨论一下,我认为该采集教程对于其他CMS自动采集具有一定的参考意义.
定时自动采集的原理
将采集参数或链接放在主页上. 例如,访问者访问后,如果您访问此页面,则会激活自动采集.
然后,如果没有人访问,它将无法自动采集. 因此,可以通过各种工具访问采集链接以确保内容的不断更新.
全面和自动的详细收款教程步骤
首先获得采集链接,如何采集它?
接下来添加定时任务. 这个孩子的材料可以提醒大家特别注意红色框.
第一点: 任务名称必须为英文,执行文件只能是collect.php,执行参数是刚复制到的链接,只要采集后的部分即可
第二点: 采集时间和采集时间是您访问者访问时检查的时间. 如果您不检查时间段,即使您访问该时间段,也不会触发自动采集机制.
最后,只需复制测试链接. 您甚至可以使用crontab来实现计时采集,就好像上述采集周期和时间都为空.
当前的网络教程基本上会告诉您检查所有内容,然后使用宝塔定期访问URL. 这是双重保证机制. 因为子方有希望只玩两天,不会玩其他东西,所以没关系.
对于某些crontab矿井,您可以关注有关紫房油物资站前后几天的文章.
查看全部
儿子有话要说
首先,我不得不说,当前在Internet上搜索的许多Apple maccms8计时自动采集教程可能会产生误导. 他们不了解真实的事实. 经过对子坊的前瞻性探索,我终于走上了艰难的道路.
紫芳觉得采集工作实际上是一个非常麻烦的项目. 如果有自动采集功能,则通常只需花费一半的精力即可获得两倍的结果. 互联网上当前的教程基本上都使用宝塔的定时访问URL功能进行采集,这并不重要. 但是所有教程都没有介绍这些原理. 如果您不注意细节,则经常会失败. 例如,子芳要花一些时间.
让我们讨论一下,我认为该采集教程对于其他CMS自动采集具有一定的参考意义.
定时自动采集的原理
将采集参数或链接放在主页上. 例如,访问者访问后,如果您访问此页面,则会激活自动采集.
然后,如果没有人访问,它将无法自动采集. 因此,可以通过各种工具访问采集链接以确保内容的不断更新.
全面和自动的详细收款教程步骤
首先获得采集链接,如何采集它?


接下来添加定时任务. 这个孩子的材料可以提醒大家特别注意红色框.
第一点: 任务名称必须为英文,执行文件只能是collect.php,执行参数是刚复制到的链接,只要采集后的部分即可
第二点: 采集时间和采集时间是您访问者访问时检查的时间. 如果您不检查时间段,即使您访问该时间段,也不会触发自动采集机制.


最后,只需复制测试链接. 您甚至可以使用crontab来实现计时采集,就好像上述采集周期和时间都为空.
当前的网络教程基本上会告诉您检查所有内容,然后使用宝塔定期访问URL. 这是双重保证机制. 因为子方有希望只玩两天,不会玩其他东西,所以没关系.
对于某些crontab矿井,您可以关注有关紫房油物资站前后几天的文章.

DedeCms织梦自动采集伪原创版本并更新集成的插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2020-08-08 00:00
我从Internet上找到了该插件,该插件的原创作者不再可供检查.
如果您需要此插件,请单击此处
插件说明:
1此插件的最大优点是,它非常有利于SEO,并实现了织梦和制作工位的完全自动化. (几乎一样)
2访问或刷新主页以触发采集. 采集之后,将自动生成伪原创文章,自动生成文章,并自动更新主页和专栏页面. (就是这样)
3采集插件仅采集目标网站的最新更新内容,也就是说,一旦对方的网站更新,它将立即被采集,并且文章不会重复发布. (就是这样)
4通过指定的采集规则采集的内容可以发布到指定的列(分别指定了nid和typeid). (这是在/plus/spider.php文件中设置的)
5集合是一对一集合和一个一对一发布,可以设置集合速度,不会影响网站访问速度,不会造成过多的CPU使用,非常有利于SEO优化. (也可以在/plus/spider.php文件中设置)
6伪原创词汇可以自己填写,也可以分批导入. 暂时提供了3000套同义词. (应该不会太大影响文章的可读性. 原创插件具有一个BUG,该BUG阻止了替换词的正确导入,我已对其进行了纠正)
集成插件安装集成插件设置集成插件使用后记
此时,已安装插件,最好手动生成网站的主页. 将来,只要访问该网站的主页,该插件就会根据您预先设置的采集规则进行采集.
如果要检查插件是否及时运行,可以在浏览器地址栏中手动输入: 您的网站域名/plus/spider.php,并且该插件在页面出现时已经运行一次完成. 查看全部
第二个版本的插件已发布,请单击此处查看DEDE自动采集插件的第二个版本
我从Internet上找到了该插件,该插件的原创作者不再可供检查.
如果您需要此插件,请单击此处
插件说明:
1此插件的最大优点是,它非常有利于SEO,并实现了织梦和制作工位的完全自动化. (几乎一样)
2访问或刷新主页以触发采集. 采集之后,将自动生成伪原创文章,自动生成文章,并自动更新主页和专栏页面. (就是这样)
3采集插件仅采集目标网站的最新更新内容,也就是说,一旦对方的网站更新,它将立即被采集,并且文章不会重复发布. (就是这样)
4通过指定的采集规则采集的内容可以发布到指定的列(分别指定了nid和typeid). (这是在/plus/spider.php文件中设置的)
5集合是一对一集合和一个一对一发布,可以设置集合速度,不会影响网站访问速度,不会造成过多的CPU使用,非常有利于SEO优化. (也可以在/plus/spider.php文件中设置)
6伪原创词汇可以自己填写,也可以分批导入. 暂时提供了3000套同义词. (应该不会太大影响文章的可读性. 原创插件具有一个BUG,该BUG阻止了替换词的正确导入,我已对其进行了纠正)
集成插件安装集成插件设置集成插件使用后记
此时,已安装插件,最好手动生成网站的主页. 将来,只要访问该网站的主页,该插件就会根据您预先设置的采集规则进行采集.
如果要检查插件是否及时运行,可以在浏览器地址栏中手动输入: 您的网站域名/plus/spider.php,并且该插件在页面出现时已经运行一次完成.
非侵入式自动采集iOS数据的探索和实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 694 次浏览 • 2020-08-07 11:05
有货APP团队为此目的开发了一套数据采集SDK. 主要功能如下:
页面访问流程. 用户在应用程序中浏览了哪些页面.
浏览数据. 用户在页面上查看了哪些产品.
自动采集业务数据. 用户在应用程序中点击了哪些位置以及触发了哪些操作.
自动采集性能数据. 在用户使用APP的过程中,页面加载时间,图像加载时间,网络请求时间等是什么?
此外,所有数据采集都应该是自动化且非侵入性的,也就是说,无需手动掩埋点,并且可以集成SDK,并且不应更改原创代码或进行尽可能少的更改
基于上述要求,AOP是技术解决方案的最佳选择,并且在iOS上实现AOP需要依靠Objective-C-Method Swizzle中运行时的黑魔法. 踏入坑和填充坑的漫长旅程从这里开始,让我们逐一品尝实现的想法和方法.
页面访问流程
用户访问页面统计信息需要解决两个问题:
统计事件的入口点,即何时计数.
统计数据字段,即计算什么数据.
整个过程如下:
统计事件的切入点
用户访问页面统计信息的一般思想是在View Controller生命周期方法中:
可以获得用户访问页面的路径,这两个事件时间戳之间的差是用户停留在页面上的时间.
通常,我们APP中的View Controller继承自某个基类. 我们可以在基类的相应方法中执行统计. 但是,对于不继承自基类的View Controller,我们无能为力.
借助AOP,我们可以更优雅地做到这一点: 在UIViewController的load方法中摇动viewDidAppear和viewDidDisappear方法,无需更改原创代码.
统计信息字段
根据数据要求,设置以下统计字段:
页面进入和退出的事件都报告给上述数据结构.
还有几个问题需要考虑:
1. 如何定义PAGE_ID和SOURCE_ID
由于您需要统一iOS和Android的PAGE_ID,因此需要对其进行配置和发送. iOS端得到的是一个plist文件,该文件的键是View Controller类名的字符串表示形式,值是PAGE_ID.
2. 如何获取PAGE_ID和SOURCE_ID
可以根据当前View Controller的类直接获取
PAGE_ID. SOURCE_ID稍微复杂一些. 需要根据APP页面的嵌套堆栈结构来确定具体的获取方法. 通常,上一个View Controller的页面取自UINavigationController id的导航堆栈.
到目前为止,页面访问流统计信息已基本完成. 根据页面进入和退出的PAGE_ID和SOURCE_ID,输入完整的用户浏览路径,并获得用户在每个页面上的停留时间.
浏览数据暴露
在采集了用户的浏览路径以及在某些页面(例如主页和产品列表页面)上的每一页上花费的时间之后,我们还想知道用户在该页面上滑动了多少屏幕,以及他们观看了哪些屏幕活动,产品,以便更好地为用户推荐喜爱的产品.
用户看到的屏幕区域被视为资源位,因此用户看到的内容由资源位组成. 那么暴露的含义如下:
我们知道iOS中页面元素的基本单位是视图,因此我们只需要判断视图是否在可见区域中,然后就可以知道当前视图上的资源位置是否需要公开,以便进行相应的曝光操作并捕获数据,报告界面等.
从以上分析可以看出,有两个主要问题需要解决:
查看可见性判断
查看曝光数据采集
查看可见性判断
查询UIView类参考以查看setFrame: 和layoutSubivews方法,这些方法可用于设置子视图的框架. 每次更新观看次数时,都会调用此方法. 因此,我们可以通过运行时选项卡来实现此方法,并添加一些与数据采集相关的操作.
我们向UIView添加了以下属性:
首先阐明以下术语的定义和规则:
1.view的子视图可以同时看到3个需要满足的条件:
相反,只要不满足上述任何条件,我们认为此子视图当前不可见.
2. 将视图设置为可见
3. 将视图设置为不可见
Swzzile setFrame :,请执行以下操作:
易用的layoutSubivews,调用yh_updateVisibleSubViews方法,该方法执行以下操作:
完成上述操作后,我们可以知道一个视图及其子视图是否可见.
查看曝光数据采集
为了获取与视图相对应的数据,还将以下属性添加到UIView:
然后还有两个问题:
浏览量数据的粒度
视图及其子视图节点的曝光数据的组装时间
浏览量数据的粒度
根据项目的实际经验,UITableViewCell或UI采集ViewCell通常是最小的粒度. 同时,在最后一个节点的yh_exposureData字典中添加一个键: isEnd,以标识它是否是最后一个节点.
组装视图及其子视图的曝光数据的时间
通常,当最后一个节点的可见性发生变化时,请从下到上遍历最后一个节点的超级视图以组装所有数据.
因此,我们覆盖了setYh_viewVisible: 方法,这是yh_viewVisible的set方法. 请执行以下操作:
到目前为止,我们已经解决了视图可见性判断和曝光数据采集的问题. 数据报告和策略将不会重复.
此方案有几个缺点
您需要手动设置曝光数据.
您需要在适当的时间手动调用view.yh_viewVisible来触发数据采集,例如viewdidappear.
它需要消耗某些资源才能进行视觉区域计算和曝光数据采集.
还有两个问题值得注意:
UITableView将在setBounds: 时更改视图框架,因此您需要使用setBounds: 方法,需要调用[self yh_updateVisibleSubViews];
UIScrollView会在setContentInset: 时影响视图的可见区域,因此需要调整setContentInset: 方法,需要在设置contentInset之后调用self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame,contentInset);
自动采集业务数据
自动采集业务数据是一种流行的数据采集,没有行业中的隐患.
传统的客户端用户点击数据采集基于手动隐藏点,您对数据感兴趣的地方,只需单击此处,然后在用户操作后立即触发数据报告. 手动掩埋的缺点很明显: 错误的掩埋和丢失的掩埋. 新版本发布后,经常有来自数据部门的小伙伴报告说,某些点的问题尚未报告,某些点已报告错误,开发人员也很痛苦.
没有埋藏点的数据采集带来了新的变化. 首先,基本上避免了人工掩埋,个别情况需要特殊处理. 其次,从有选择的数据采集中,它变成了所有用户点击和触摸数据的完整采集.
新变化也将带来新挑战. 非埋入点数据采集的可能性仍基于Objective-C的运行时特征. 在实践过程中,我们使用iOS非埋入点数据SDK的总体设计和技术实现作为参考,并使用Sensors Analytics iOS SDK和Mixpanel iPhone作为实现. 接下来,结合特定的实践,我们将介绍实现思想和遇到的一些问题. 主要分为以下三个方面:
如何确保自动采集的点的唯一性.
不同的点类型,毛病需要哪些方法.
在大雨中进站了.
如何确保自动采集的点的唯一性
自动采集与手动埋入点是分开的,因此没有唯一的标识点. 那么,我们如何唯一地定位自动采集的点呢?一个容易想到的解决方案是: 基于页面视图的树结构. 该解决方案可以分为两个问题:
如何定义视图的唯一标识符.
视图如何唯一标识.
视图唯一标识符(视图路径)的定义
我们规定典型的查看路径如下:
ViewController[0]/UIView[0]/UITableView[0]/UITableViewCell[0:2]/UIButton[0]
其中:
使用此标识符,可以在当前页面的视图树结构中唯一标识此元素.
每个项目由
标识
由两部分组成: 一个是当前元素类的字符串表示形式,另一个是同一级别元素中当前元素的序列号,从0开始计数. 例如,当前的第二个UIImageView是UIImageView1.
标识不同项目之间的联系.
识别出的最高层是当前视图所在的ViewController.
对于UITableViewCell,UI采集ViewCell和类似的自定义组件,序列号部分由两部分组成: 节和行,它们被拼接在一起.
标记的末尾是当前被单击或触摸的元素.
如何生成视图唯一标识符
视图路径生成过程: 从触发操作的最末端元素向上查询,直到找到ViewController. 假设当前单击的视图是A_View,则从当前A_View开始遍历视图树,并将每个级别的数据存储在P_Array中. 过程如下:
如果A_View是UI采集ViewCell类型,请获取A_View所在的UI采集View的indexPath,P_Array推送路径信息[NSString stringWithFormat: @“%@ [%ld: %ld]”,[NSString stringWithFormat: @“%@”, NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];
如果A_View是UITableViewCell类型,请获取ATable所在的UITableView的indexPath,P_Array推送路径信息[NSString stringWithFormat: @“%@ [%ld: %ld]”,[NSString stringWithFormat: @“%@” ,NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];
遍历A_View.superview的所有子视图,获得相同级别的A_View,以及相同类型的数字(索引)([A_View类]),P_Array推送路径信息[NSString stringWithFormat: @“%@ [%d ]“,NSStringFromClass([A_View class]),index];
获取A_View所在的控制器A_VC. 如果A_View为A_VC.view,则遍历结束. 如果A_View不等于A_VC.view,则A_View = A_View.superview,重复步骤1-4,直到A_View等于A_VC.view.
遍历P_Array拼接A_View的完整路径.
各种类型的点都需要Swizzle方法
我们将APP中的用户操作分为四类:
UI采集View和UITableView的单元格单击事件.
UIControl(UISwitch,UIStepper,UISegmentedControl,UINavigationButton,UISlider,UIButton)控件的click事件.
UIImageView和UILabel上的UITapGestureRecognizer触摸事件.
UITabBar,UIAlertView,UIActionSheet等的点击事件.
这四种操作都需要使用swizzle方法,如下表所示:
UI采集View,UITableView,UITabBar,UIAlertView和UIActionSheet的实现是相似的. 它们都是load方法中的swizzle setDelegate方法. 在setDelegate之后,执行代理回调方法的swizzle操作. 在回调方法中,首先执行原创逻辑. ,然后获取相应的viewPath.
当UIControl组件回调到目标时,将由UIApplication的sendAction: to: from: forEvent: 调用,因此我们选择swizzle方法. 在实践中,首先获取相应的视图路径,然后执行原创逻辑. 原因是如果首先执行原创逻辑,则页面可能会更改,并且获得的View Controller将是错误的.
<p>UITapGestureRecognizer事件仅在UIImageView和UILabel上处理. swizzle addGestureRecognizer: 方法,首先执行原创逻辑,然后向视图添加自定义回调方法,以便在触发手势时也将调用自定义回调,此时我们获得了视图路径. 查看全部
随着库存应用程序的不断迭代开发,数据和业务部门对客户用户行为数据的要求越来越高;为了更好地监视应用程序的使用状态,客户团队拥有有关应用程序本身操作的数据. 需求变得越来越迫切. 迫切需要一套客户端数据采集工具,以自动,全面地采集用户行为数据,以满足各个部门的数据需求.
有货APP团队为此目的开发了一套数据采集SDK. 主要功能如下:
页面访问流程. 用户在应用程序中浏览了哪些页面.
浏览数据. 用户在页面上查看了哪些产品.
自动采集业务数据. 用户在应用程序中点击了哪些位置以及触发了哪些操作.
自动采集性能数据. 在用户使用APP的过程中,页面加载时间,图像加载时间,网络请求时间等是什么?
此外,所有数据采集都应该是自动化且非侵入性的,也就是说,无需手动掩埋点,并且可以集成SDK,并且不应更改原创代码或进行尽可能少的更改
基于上述要求,AOP是技术解决方案的最佳选择,并且在iOS上实现AOP需要依靠Objective-C-Method Swizzle中运行时的黑魔法. 踏入坑和填充坑的漫长旅程从这里开始,让我们逐一品尝实现的想法和方法.
页面访问流程
用户访问页面统计信息需要解决两个问题:
统计事件的入口点,即何时计数.
统计数据字段,即计算什么数据.
整个过程如下:

统计事件的切入点
用户访问页面统计信息的一般思想是在View Controller生命周期方法中:
可以获得用户访问页面的路径,这两个事件时间戳之间的差是用户停留在页面上的时间.
通常,我们APP中的View Controller继承自某个基类. 我们可以在基类的相应方法中执行统计. 但是,对于不继承自基类的View Controller,我们无能为力.
借助AOP,我们可以更优雅地做到这一点: 在UIViewController的load方法中摇动viewDidAppear和viewDidDisappear方法,无需更改原创代码.
统计信息字段
根据数据要求,设置以下统计字段:
页面进入和退出的事件都报告给上述数据结构.
还有几个问题需要考虑:
1. 如何定义PAGE_ID和SOURCE_ID
由于您需要统一iOS和Android的PAGE_ID,因此需要对其进行配置和发送. iOS端得到的是一个plist文件,该文件的键是View Controller类名的字符串表示形式,值是PAGE_ID.
2. 如何获取PAGE_ID和SOURCE_ID
可以根据当前View Controller的类直接获取
PAGE_ID. SOURCE_ID稍微复杂一些. 需要根据APP页面的嵌套堆栈结构来确定具体的获取方法. 通常,上一个View Controller的页面取自UINavigationController id的导航堆栈.
到目前为止,页面访问流统计信息已基本完成. 根据页面进入和退出的PAGE_ID和SOURCE_ID,输入完整的用户浏览路径,并获得用户在每个页面上的停留时间.
浏览数据暴露
在采集了用户的浏览路径以及在某些页面(例如主页和产品列表页面)上的每一页上花费的时间之后,我们还想知道用户在该页面上滑动了多少屏幕,以及他们观看了哪些屏幕活动,产品,以便更好地为用户推荐喜爱的产品.
用户看到的屏幕区域被视为资源位,因此用户看到的内容由资源位组成. 那么暴露的含义如下:
我们知道iOS中页面元素的基本单位是视图,因此我们只需要判断视图是否在可见区域中,然后就可以知道当前视图上的资源位置是否需要公开,以便进行相应的曝光操作并捕获数据,报告界面等.
从以上分析可以看出,有两个主要问题需要解决:
查看可见性判断
查看曝光数据采集
查看可见性判断
查询UIView类参考以查看setFrame: 和layoutSubivews方法,这些方法可用于设置子视图的框架. 每次更新观看次数时,都会调用此方法. 因此,我们可以通过运行时选项卡来实现此方法,并添加一些与数据采集相关的操作.
我们向UIView添加了以下属性:
首先阐明以下术语的定义和规则:
1.view的子视图可以同时看到3个需要满足的条件:
相反,只要不满足上述任何条件,我们认为此子视图当前不可见.
2. 将视图设置为可见
3. 将视图设置为不可见
Swzzile setFrame :,请执行以下操作:

易用的layoutSubivews,调用yh_updateVisibleSubViews方法,该方法执行以下操作:

完成上述操作后,我们可以知道一个视图及其子视图是否可见.
查看曝光数据采集
为了获取与视图相对应的数据,还将以下属性添加到UIView:
然后还有两个问题:
浏览量数据的粒度
视图及其子视图节点的曝光数据的组装时间
浏览量数据的粒度
根据项目的实际经验,UITableViewCell或UI采集ViewCell通常是最小的粒度. 同时,在最后一个节点的yh_exposureData字典中添加一个键: isEnd,以标识它是否是最后一个节点.
组装视图及其子视图的曝光数据的时间
通常,当最后一个节点的可见性发生变化时,请从下到上遍历最后一个节点的超级视图以组装所有数据.
因此,我们覆盖了setYh_viewVisible: 方法,这是yh_viewVisible的set方法. 请执行以下操作:
到目前为止,我们已经解决了视图可见性判断和曝光数据采集的问题. 数据报告和策略将不会重复.
此方案有几个缺点
您需要手动设置曝光数据.
您需要在适当的时间手动调用view.yh_viewVisible来触发数据采集,例如viewdidappear.
它需要消耗某些资源才能进行视觉区域计算和曝光数据采集.
还有两个问题值得注意:
UITableView将在setBounds: 时更改视图框架,因此您需要使用setBounds: 方法,需要调用[self yh_updateVisibleSubViews];
UIScrollView会在setContentInset: 时影响视图的可见区域,因此需要调整setContentInset: 方法,需要在设置contentInset之后调用self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame,contentInset);
自动采集业务数据
自动采集业务数据是一种流行的数据采集,没有行业中的隐患.
传统的客户端用户点击数据采集基于手动隐藏点,您对数据感兴趣的地方,只需单击此处,然后在用户操作后立即触发数据报告. 手动掩埋的缺点很明显: 错误的掩埋和丢失的掩埋. 新版本发布后,经常有来自数据部门的小伙伴报告说,某些点的问题尚未报告,某些点已报告错误,开发人员也很痛苦.
没有埋藏点的数据采集带来了新的变化. 首先,基本上避免了人工掩埋,个别情况需要特殊处理. 其次,从有选择的数据采集中,它变成了所有用户点击和触摸数据的完整采集.
新变化也将带来新挑战. 非埋入点数据采集的可能性仍基于Objective-C的运行时特征. 在实践过程中,我们使用iOS非埋入点数据SDK的总体设计和技术实现作为参考,并使用Sensors Analytics iOS SDK和Mixpanel iPhone作为实现. 接下来,结合特定的实践,我们将介绍实现思想和遇到的一些问题. 主要分为以下三个方面:
如何确保自动采集的点的唯一性.
不同的点类型,毛病需要哪些方法.
在大雨中进站了.
如何确保自动采集的点的唯一性
自动采集与手动埋入点是分开的,因此没有唯一的标识点. 那么,我们如何唯一地定位自动采集的点呢?一个容易想到的解决方案是: 基于页面视图的树结构. 该解决方案可以分为两个问题:
如何定义视图的唯一标识符.
视图如何唯一标识.
视图唯一标识符(视图路径)的定义
我们规定典型的查看路径如下:
ViewController[0]/UIView[0]/UITableView[0]/UITableViewCell[0:2]/UIButton[0]
其中:
使用此标识符,可以在当前页面的视图树结构中唯一标识此元素.
每个项目由
标识
由两部分组成: 一个是当前元素类的字符串表示形式,另一个是同一级别元素中当前元素的序列号,从0开始计数. 例如,当前的第二个UIImageView是UIImageView1.
标识不同项目之间的联系.
识别出的最高层是当前视图所在的ViewController.
对于UITableViewCell,UI采集ViewCell和类似的自定义组件,序列号部分由两部分组成: 节和行,它们被拼接在一起.
标记的末尾是当前被单击或触摸的元素.
如何生成视图唯一标识符
视图路径生成过程: 从触发操作的最末端元素向上查询,直到找到ViewController. 假设当前单击的视图是A_View,则从当前A_View开始遍历视图树,并将每个级别的数据存储在P_Array中. 过程如下:

如果A_View是UI采集ViewCell类型,请获取A_View所在的UI采集View的indexPath,P_Array推送路径信息[NSString stringWithFormat: @“%@ [%ld: %ld]”,[NSString stringWithFormat: @“%@”, NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];
如果A_View是UITableViewCell类型,请获取ATable所在的UITableView的indexPath,P_Array推送路径信息[NSString stringWithFormat: @“%@ [%ld: %ld]”,[NSString stringWithFormat: @“%@” ,NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];
遍历A_View.superview的所有子视图,获得相同级别的A_View,以及相同类型的数字(索引)([A_View类]),P_Array推送路径信息[NSString stringWithFormat: @“%@ [%d ]“,NSStringFromClass([A_View class]),index];
获取A_View所在的控制器A_VC. 如果A_View为A_VC.view,则遍历结束. 如果A_View不等于A_VC.view,则A_View = A_View.superview,重复步骤1-4,直到A_View等于A_VC.view.
遍历P_Array拼接A_View的完整路径.
各种类型的点都需要Swizzle方法
我们将APP中的用户操作分为四类:
UI采集View和UITableView的单元格单击事件.
UIControl(UISwitch,UIStepper,UISegmentedControl,UINavigationButton,UISlider,UIButton)控件的click事件.
UIImageView和UILabel上的UITapGestureRecognizer触摸事件.
UITabBar,UIAlertView,UIActionSheet等的点击事件.
这四种操作都需要使用swizzle方法,如下表所示:

UI采集View,UITableView,UITabBar,UIAlertView和UIActionSheet的实现是相似的. 它们都是load方法中的swizzle setDelegate方法. 在setDelegate之后,执行代理回调方法的swizzle操作. 在回调方法中,首先执行原创逻辑. ,然后获取相应的viewPath.
当UIControl组件回调到目标时,将由UIApplication的sendAction: to: from: forEvent: 调用,因此我们选择swizzle方法. 在实践中,首先获取相应的视图路径,然后执行原创逻辑. 原因是如果首先执行原创逻辑,则页面可能会更改,并且获得的View Controller将是错误的.
<p>UITapGestureRecognizer事件仅在UIImageView和UILabel上处理. swizzle addGestureRecognizer: 方法,首先执行原创逻辑,然后向视图添加自定义回调方法,以便在触发手势时也将调用自定义回调,此时我们获得了视图路径.
使用Python实现自动wordpress采集和更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 390 次浏览 • 2020-08-06 12:15
当前,wordpress_xmlrpc模块已更新为2.2版,但我使用的是1.5版. 懒惰的学生可以在centos下像这样安装它.
Wget-不检查证书
tar zxf python-wordpress-xmlrpc-1.5.tar.gz
cd python-wordpress-xmlrpc-1.5
python setup.py安装
好的,这里介绍了wordpress_xmlrpc模块. 有关其他功能,请访问官方网站. 让我谈谈程序的想法.
1. 使用记事本记录已爬网的URL.
2. 再次获取该页面,以获取此页面上文章的完整URL.
3. 检查此页面的所有URL是否都在TXT中.
4. 如果没有,请获取URL的标题和内容,然后将其发送给wordpress,然后将URL写入txt
5. 最后,使用crontab自动化任务并每天定期运行.
<p>代码如下: (为了防止某些学生一无所获,将代码替换为图片,红色部分是URL,帐号,密码和保存URL地址的txt) 查看全部
最近,我用wordpress制作了一个小型网站. 目的很简单. 我想更新这本小说,并尽快将其发布到wordpress. 我本来想用优采云解决它,但是没有模块流氓,我不得不自己用python编写. 我本来想使用mysqldb直接插入,但是wordpress表单确实有点麻烦,并且远程速度有点慢. 我以为python的主要思想不是重塑轮子,所以我在pypi中找到了wordpress_xmlrpc模块,没有提到主要功能,请参考官方网站了解详细信息:
当前,wordpress_xmlrpc模块已更新为2.2版,但我使用的是1.5版. 懒惰的学生可以在centos下像这样安装它.
Wget-不检查证书
tar zxf python-wordpress-xmlrpc-1.5.tar.gz
cd python-wordpress-xmlrpc-1.5
python setup.py安装
好的,这里介绍了wordpress_xmlrpc模块. 有关其他功能,请访问官方网站. 让我谈谈程序的想法.
1. 使用记事本记录已爬网的URL.
2. 再次获取该页面,以获取此页面上文章的完整URL.
3. 检查此页面的所有URL是否都在TXT中.
4. 如果没有,请获取URL的标题和内容,然后将其发送给wordpress,然后将URL写入txt
5. 最后,使用crontab自动化任务并每天定期运行.
<p>代码如下: (为了防止某些学生一无所获,将代码替换为图片,红色部分是URL,帐号,密码和保存URL地址的txt)
python数据分析的自动数据采集4
采集交流 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2020-08-06 10:18
数据采集是数据挖掘的基础. 没有数据,挖掘就毫无意义. 在许多情况下,我们拥有多少数据源,多少数据以及数据的质量将决定我们的挖掘结果
2四种采集方法
3如何使用Open是数据源
4种爬网方法
(1)使用请求来爬网内容.
(2)使用xpath解析内容,并按元素属性编制索引
(3)使用熊猫保存数据. 最后,通过熊猫写入XLS或mysql数据
(3)scapy
5种常用的抓取工具
(1)优采云采集器
它不仅可以用作爬网工具,还可以用于数据清理,数据分析,数据挖掘和可视化. 数据源适用于大多数网页,并且可以通过采集规则对网页上可见的所有内容进行爬网
(2)优采云
免费采集电子商务,生活服务等.
云采集配置采集任务,总共有5000台服务器,由云节点采集,自动切换多个IP等.
(3)采集客户
没有云采集功能,所有爬虫都在自己的计算机上进行
6如何使用日志采集工具
(1)最大的作用是通过分析用户访问权限来提高系统性能.
(2)记录的内容通常包括访问通道,执行的操作,用户IP等.
(3)什么是掩埋点
购买点是您需要统计数据的统计代码. 谷歌分析Youtalk的TalkingData是常用的掩埋工具.
7总结
有许多数据采集渠道. 您可以自己使用采集器,也可以使用开源数据源和线程工具.
您可以直接从Kaggle下载它,而无需自己爬网.
另一方面,根据我们的需求,需要采集的数据也有所不同. 例如,在运输行业中,数据采集将与相机或速度计有关. 对于运维人员,日志采集和分析功能已关闭 查看全部
1数据采集的重要性
数据采集是数据挖掘的基础. 没有数据,挖掘就毫无意义. 在许多情况下,我们拥有多少数据源,多少数据以及数据的质量将决定我们的挖掘结果
2四种采集方法

3如何使用Open是数据源

4种爬网方法
(1)使用请求来爬网内容.
(2)使用xpath解析内容,并按元素属性编制索引
(3)使用熊猫保存数据. 最后,通过熊猫写入XLS或mysql数据
(3)scapy
5种常用的抓取工具
(1)优采云采集器
它不仅可以用作爬网工具,还可以用于数据清理,数据分析,数据挖掘和可视化. 数据源适用于大多数网页,并且可以通过采集规则对网页上可见的所有内容进行爬网
(2)优采云
免费采集电子商务,生活服务等.
云采集配置采集任务,总共有5000台服务器,由云节点采集,自动切换多个IP等.
(3)采集客户
没有云采集功能,所有爬虫都在自己的计算机上进行
6如何使用日志采集工具
(1)最大的作用是通过分析用户访问权限来提高系统性能.
(2)记录的内容通常包括访问通道,执行的操作,用户IP等.

(3)什么是掩埋点
购买点是您需要统计数据的统计代码. 谷歌分析Youtalk的TalkingData是常用的掩埋工具.
7总结
有许多数据采集渠道. 您可以自己使用采集器,也可以使用开源数据源和线程工具.
您可以直接从Kaggle下载它,而无需自己爬网.
另一方面,根据我们的需求,需要采集的数据也有所不同. 例如,在运输行业中,数据采集将与相机或速度计有关. 对于运维人员,日志采集和分析功能已关闭
文明重启自动采集功能易于使用吗?文明重启自动采集功能评估
采集交流 • 优采云 发表了文章 • 0 个评论 • 679 次浏览 • 2020-08-05 23:04
文明重启自动采集功能易于使用吗?
自动采集功能在游戏中不容易使用,容易卡住,速度慢. 在某些模式下,这等效于负责任.
开放条件
在游戏中,玩家采集资源一直是痛苦的. 毕竟,建筑物已经升级,所需的维护材料也在一定程度上发生了变化,玩家制作更高级武器所需的基本资源也发生了变化,因此游戏官方为为了减轻玩家的压力. 该功能的开启条件是玩家在这场战斗中需要收取12元. 当然,玩家购买赞助商后,他们还将获得斩波起搏器,增加体验并减少维护材料和效果.
使用评估
编辑和我的朋友亲自体验了自动采集功能. 编辑者只能说此功能是完全不切实际的. 播放器打开自动采集功能后,经常会出现无法从卡纸上清除卡纸的情况,并且在采集和播放附近的资源时,您会被动地挂断电话. 无法杀死的PVE模式是可以的. 对于其他可以杀死的模式,这是为他人制造婚纱. 最后,我们必须抱怨一下,自动收款速度不如玩家自己的手册快. 通常,当玩家购买赞助时,最有用的功能是减少区域内阁维护材料的消耗. 其他的基本上没有用,因此如果播放器是小k,则必须仔细考虑. 查看全部
在“文明重启”游戏中,玩家只需在坐骑战斗中充值12元即可开启自动收款功能. 此功能的功能是节省每个人采集资源所需的时间. 许多玩家会打开此按钮以节省时间和成本. 功能,该功能的实用性如何?让Youyou.com的编辑为您分析!
文明重启自动采集功能易于使用吗?
自动采集功能在游戏中不容易使用,容易卡住,速度慢. 在某些模式下,这等效于负责任.

开放条件
在游戏中,玩家采集资源一直是痛苦的. 毕竟,建筑物已经升级,所需的维护材料也在一定程度上发生了变化,玩家制作更高级武器所需的基本资源也发生了变化,因此游戏官方为为了减轻玩家的压力. 该功能的开启条件是玩家在这场战斗中需要收取12元. 当然,玩家购买赞助商后,他们还将获得斩波起搏器,增加体验并减少维护材料和效果.
使用评估
编辑和我的朋友亲自体验了自动采集功能. 编辑者只能说此功能是完全不切实际的. 播放器打开自动采集功能后,经常会出现无法从卡纸上清除卡纸的情况,并且在采集和播放附近的资源时,您会被动地挂断电话. 无法杀死的PVE模式是可以的. 对于其他可以杀死的模式,这是为他人制造婚纱. 最后,我们必须抱怨一下,自动收款速度不如玩家自己的手册快. 通常,当玩家购买赞助时,最有用的功能是减少区域内阁维护材料的消耗. 其他的基本上没有用,因此如果播放器是小k,则必须仔细考虑.
把ET当成文件下载器,不用插口手动下载视频、音乐、图片等文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-09 10:36
但用下载软件不能24小时监控对方更新、自动下载最新的文件。
使用ET可以轻松实现手动下载对方更新的任何格式的文件。
不过优采云采集器的信息必须成功发布到一个目的,否则会由于发布失败而手动删掉那些下载的文件,但我们并不准备将这种信息发布到网站,这时候该怎样办呢?
很简单!
以下几步即可实现。
1、新建一个发布规则
设置一个可以访问快速的发布网址。
不需要一个真正发布文章的网址,我们可以随意找一个访问速率快的网站,例如我们在右图使用的当地联通测速网址,也可以用自己的本地网址如“”。
将字数范围设为0开始可以防止采集规则没有设置采集正文、标题时的错误提示。
2、设置发布项
在参数取值里,随便设置一个参数名,取值一定要包括你采集文件的数据项标记。
例如下图我们设置了一个content参数,取值为“”,这样的设置,可以保证所采集的文件被下载。
3、建立方案
建立方案,我们使用“汤博乐()视频采集规则”来进行测试。
在方案的文件设置中取消“发布后本地手动删掉下载文件”的选项。
4、选取特征码
我们试用一次这个方案,这时候工作记录会提示发布失败。
从返回信息中,选择任意一个必然出现的字符串作为特点码,比如我们选择了“”。
将它填写到 发布规则的模拟web发布-发布成功特点码中,这里不用勾选“启用模拟web发布”。
5、OK,设置完成
再次执行文章采集,工作记录会显示文章采集完成!
现在,我们可以开始手动工作,自动下载汤博乐()精彩视频了。
使用本方式下载其他网站文件,更换为对应采集规则即可。
注:本文中的 “汤博乐()视频采集规则” 下载地址为: 查看全部
我们对一些网站上的视频、音乐、美图感兴趣,希望能手动将它们下载到笔记本里采集上去,比如我们在汤博乐()关注的人发布了新视频。
但用下载软件不能24小时监控对方更新、自动下载最新的文件。
使用ET可以轻松实现手动下载对方更新的任何格式的文件。
不过优采云采集器的信息必须成功发布到一个目的,否则会由于发布失败而手动删掉那些下载的文件,但我们并不准备将这种信息发布到网站,这时候该怎样办呢?
很简单!
以下几步即可实现。
1、新建一个发布规则
设置一个可以访问快速的发布网址。
不需要一个真正发布文章的网址,我们可以随意找一个访问速率快的网站,例如我们在右图使用的当地联通测速网址,也可以用自己的本地网址如“”。
将字数范围设为0开始可以防止采集规则没有设置采集正文、标题时的错误提示。
2、设置发布项
在参数取值里,随便设置一个参数名,取值一定要包括你采集文件的数据项标记。
例如下图我们设置了一个content参数,取值为“”,这样的设置,可以保证所采集的文件被下载。
3、建立方案
建立方案,我们使用“汤博乐()视频采集规则”来进行测试。
在方案的文件设置中取消“发布后本地手动删掉下载文件”的选项。
4、选取特征码
我们试用一次这个方案,这时候工作记录会提示发布失败。
从返回信息中,选择任意一个必然出现的字符串作为特点码,比如我们选择了“”。
将它填写到 发布规则的模拟web发布-发布成功特点码中,这里不用勾选“启用模拟web发布”。
5、OK,设置完成
再次执行文章采集,工作记录会显示文章采集完成!
现在,我们可以开始手动工作,自动下载汤博乐()精彩视频了。
使用本方式下载其他网站文件,更换为对应采集规则即可。
注:本文中的 “汤博乐()视频采集规则” 下载地址为:
如何在网站上采集以及如何在wordpress上实现自动采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-08 20:39
WordPress是使用PHP语言开发的网站构建程序平台. 现在,许多博客都使用WP. 许多网站生产培训都使用WP,尤其是在作为采集站工作时. WordPress非常强大. . 这是实现wp自动采集功能的方法.
安装网站集插件: WP-AutoPost(插件下载地址: )
单击“新任务”后,输入任务名称以创建新任务. 创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务设置更多设置. (这部分不需要修改设置,唯一需要更改的是采集时间. )文章源设置. 在此标签下,我们需要设置文章来源的“文章列表URL”和特定文章的匹配规则. 让我们以“新浪网新闻”为例,文章列表URL是,因此在“手动指定文章列表URL?”中输入URL. 如下所示:
文章URL匹配规则. 文章URL匹配规则的设置非常简单,不需要复杂的设置. 提供两种匹配模式. 您可以使用URL通配符匹配或CSS选择器进行匹配. 通常,URL通配符匹配更简单,但有时CSS选择器更方便. 准确. ?使用URL通配符匹配. 通过单击列表URL上的文章,我们可以发现每篇文章的URL具有以下结构: 因此,用通配符替换URL中更改的数字或字母? (*)??,例如: (*)/(*).shtml. 重复的URL可以使用301重定向. 使用CSS选择器进行匹配. 使用CSS选择器进行匹配,我们只需要设置商品URL的CSS选择器即可,可以通过查看列表URL的源代码并在列表URL下找到商品超链接的代码轻松地进行设置,如图所示下方:
如您所见,文章的超链接A标签位于类为“ contList”的标签内,因此只需将文章URL的CSS选择器设置为??. contList a ?,如下所示:
设置完成后,如果您不知道设置是否正确,则可以单击上图中的测试按钮. 如果设置正确,则会列出列表URL下的所有文章名称和相应的网址,如下所示:
其他设置不需要修改. 以上采集方法适用于WordPress多站点功能. 查看全部
WordPress是使用PHP语言开发的网站构建程序平台. 现在,许多博客都使用WP. 许多网站生产培训都使用WP,尤其是在作为采集站工作时. WordPress非常强大. . 这是实现wp自动采集功能的方法.
安装网站集插件: WP-AutoPost(插件下载地址: )
单击“新任务”后,输入任务名称以创建新任务. 创建新任务后,您可以在任务列表中查看该任务,并且可以为该任务设置更多设置. (这部分不需要修改设置,唯一需要更改的是采集时间. )文章源设置. 在此标签下,我们需要设置文章来源的“文章列表URL”和特定文章的匹配规则. 让我们以“新浪网新闻”为例,文章列表URL是,因此在“手动指定文章列表URL?”中输入URL. 如下所示:
文章URL匹配规则. 文章URL匹配规则的设置非常简单,不需要复杂的设置. 提供两种匹配模式. 您可以使用URL通配符匹配或CSS选择器进行匹配. 通常,URL通配符匹配更简单,但有时CSS选择器更方便. 准确. ?使用URL通配符匹配. 通过单击列表URL上的文章,我们可以发现每篇文章的URL具有以下结构: 因此,用通配符替换URL中更改的数字或字母? (*)??,例如: (*)/(*).shtml. 重复的URL可以使用301重定向. 使用CSS选择器进行匹配. 使用CSS选择器进行匹配,我们只需要设置商品URL的CSS选择器即可,可以通过查看列表URL的源代码并在列表URL下找到商品超链接的代码轻松地进行设置,如图所示下方:
如您所见,文章的超链接A标签位于类为“ contList”的标签内,因此只需将文章URL的CSS选择器设置为??. contList a ?,如下所示:
设置完成后,如果您不知道设置是否正确,则可以单击上图中的测试按钮. 如果设置正确,则会列出列表URL下的所有文章名称和相应的网址,如下所示:
其他设置不需要修改. 以上采集方法适用于WordPress多站点功能.
Apple maccms8各种CMS计时自动采集终极教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 439 次浏览 • 2020-08-08 00:23
首先,我不得不说,当前在Internet上搜索的许多Apple maccms8计时自动采集教程可能会产生误导. 他们不了解真实的事实. 经过对子坊的前瞻性探索,我终于走上了艰难的道路.
紫芳觉得采集工作实际上是一个非常麻烦的项目. 如果有自动采集功能,则通常只需花费一半的精力即可获得两倍的结果. 互联网上当前的教程基本上都使用宝塔的定时访问URL功能进行采集,这并不重要. 但是所有教程都没有介绍这些原理. 如果您不注意细节,则经常会失败. 例如,子芳要花一些时间.
让我们讨论一下,我认为该采集教程对于其他CMS自动采集具有一定的参考意义.
定时自动采集的原理
将采集参数或链接放在主页上. 例如,访问者访问后,如果您访问此页面,则会激活自动采集.
然后,如果没有人访问,它将无法自动采集. 因此,可以通过各种工具访问采集链接以确保内容的不断更新.
全面和自动的详细收款教程步骤
首先获得采集链接,如何采集它?
接下来添加定时任务. 这个孩子的材料可以提醒大家特别注意红色框.
第一点: 任务名称必须为英文,执行文件只能是collect.php,执行参数是刚复制到的链接,只要采集后的部分即可
第二点: 采集时间和采集时间是您访问者访问时检查的时间. 如果您不检查时间段,即使您访问该时间段,也不会触发自动采集机制.
最后,只需复制测试链接. 您甚至可以使用crontab来实现计时采集,就好像上述采集周期和时间都为空.
当前的网络教程基本上会告诉您检查所有内容,然后使用宝塔定期访问URL. 这是双重保证机制. 因为子方有希望只玩两天,不会玩其他东西,所以没关系.
对于某些crontab矿井,您可以关注有关紫房油物资站前后几天的文章.
查看全部
儿子有话要说
首先,我不得不说,当前在Internet上搜索的许多Apple maccms8计时自动采集教程可能会产生误导. 他们不了解真实的事实. 经过对子坊的前瞻性探索,我终于走上了艰难的道路.
紫芳觉得采集工作实际上是一个非常麻烦的项目. 如果有自动采集功能,则通常只需花费一半的精力即可获得两倍的结果. 互联网上当前的教程基本上都使用宝塔的定时访问URL功能进行采集,这并不重要. 但是所有教程都没有介绍这些原理. 如果您不注意细节,则经常会失败. 例如,子芳要花一些时间.
让我们讨论一下,我认为该采集教程对于其他CMS自动采集具有一定的参考意义.
定时自动采集的原理
将采集参数或链接放在主页上. 例如,访问者访问后,如果您访问此页面,则会激活自动采集.
然后,如果没有人访问,它将无法自动采集. 因此,可以通过各种工具访问采集链接以确保内容的不断更新.
全面和自动的详细收款教程步骤
首先获得采集链接,如何采集它?
接下来添加定时任务. 这个孩子的材料可以提醒大家特别注意红色框.
第一点: 任务名称必须为英文,执行文件只能是collect.php,执行参数是刚复制到的链接,只要采集后的部分即可
第二点: 采集时间和采集时间是您访问者访问时检查的时间. 如果您不检查时间段,即使您访问该时间段,也不会触发自动采集机制.
最后,只需复制测试链接. 您甚至可以使用crontab来实现计时采集,就好像上述采集周期和时间都为空.
当前的网络教程基本上会告诉您检查所有内容,然后使用宝塔定期访问URL. 这是双重保证机制. 因为子方有希望只玩两天,不会玩其他东西,所以没关系.
对于某些crontab矿井,您可以关注有关紫房油物资站前后几天的文章.
DedeCms织梦自动采集伪原创版本并更新集成的插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2020-08-08 00:00
我从Internet上找到了该插件,该插件的原创作者不再可供检查.
如果您需要此插件,请单击此处
插件说明:
1此插件的最大优点是,它非常有利于SEO,并实现了织梦和制作工位的完全自动化. (几乎一样)
2访问或刷新主页以触发采集. 采集之后,将自动生成伪原创文章,自动生成文章,并自动更新主页和专栏页面. (就是这样)
3采集插件仅采集目标网站的最新更新内容,也就是说,一旦对方的网站更新,它将立即被采集,并且文章不会重复发布. (就是这样)
4通过指定的采集规则采集的内容可以发布到指定的列(分别指定了nid和typeid). (这是在/plus/spider.php文件中设置的)
5集合是一对一集合和一个一对一发布,可以设置集合速度,不会影响网站访问速度,不会造成过多的CPU使用,非常有利于SEO优化. (也可以在/plus/spider.php文件中设置)
6伪原创词汇可以自己填写,也可以分批导入. 暂时提供了3000套同义词. (应该不会太大影响文章的可读性. 原创插件具有一个BUG,该BUG阻止了替换词的正确导入,我已对其进行了纠正)
集成插件安装集成插件设置集成插件使用后记
此时,已安装插件,最好手动生成网站的主页. 将来,只要访问该网站的主页,该插件就会根据您预先设置的采集规则进行采集.
如果要检查插件是否及时运行,可以在浏览器地址栏中手动输入: 您的网站域名/plus/spider.php,并且该插件在页面出现时已经运行一次完成. 查看全部
第二个版本的插件已发布,请单击此处查看DEDE自动采集插件的第二个版本
我从Internet上找到了该插件,该插件的原创作者不再可供检查.
如果您需要此插件,请单击此处
插件说明:
1此插件的最大优点是,它非常有利于SEO,并实现了织梦和制作工位的完全自动化. (几乎一样)
2访问或刷新主页以触发采集. 采集之后,将自动生成伪原创文章,自动生成文章,并自动更新主页和专栏页面. (就是这样)
3采集插件仅采集目标网站的最新更新内容,也就是说,一旦对方的网站更新,它将立即被采集,并且文章不会重复发布. (就是这样)
4通过指定的采集规则采集的内容可以发布到指定的列(分别指定了nid和typeid). (这是在/plus/spider.php文件中设置的)
5集合是一对一集合和一个一对一发布,可以设置集合速度,不会影响网站访问速度,不会造成过多的CPU使用,非常有利于SEO优化. (也可以在/plus/spider.php文件中设置)
6伪原创词汇可以自己填写,也可以分批导入. 暂时提供了3000套同义词. (应该不会太大影响文章的可读性. 原创插件具有一个BUG,该BUG阻止了替换词的正确导入,我已对其进行了纠正)
集成插件安装集成插件设置集成插件使用后记
此时,已安装插件,最好手动生成网站的主页. 将来,只要访问该网站的主页,该插件就会根据您预先设置的采集规则进行采集.
如果要检查插件是否及时运行,可以在浏览器地址栏中手动输入: 您的网站域名/plus/spider.php,并且该插件在页面出现时已经运行一次完成.
非侵入式自动采集iOS数据的探索和实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 694 次浏览 • 2020-08-07 11:05
有货APP团队为此目的开发了一套数据采集SDK. 主要功能如下:
页面访问流程. 用户在应用程序中浏览了哪些页面.
浏览数据. 用户在页面上查看了哪些产品.
自动采集业务数据. 用户在应用程序中点击了哪些位置以及触发了哪些操作.
自动采集性能数据. 在用户使用APP的过程中,页面加载时间,图像加载时间,网络请求时间等是什么?
此外,所有数据采集都应该是自动化且非侵入性的,也就是说,无需手动掩埋点,并且可以集成SDK,并且不应更改原创代码或进行尽可能少的更改
基于上述要求,AOP是技术解决方案的最佳选择,并且在iOS上实现AOP需要依靠Objective-C-Method Swizzle中运行时的黑魔法. 踏入坑和填充坑的漫长旅程从这里开始,让我们逐一品尝实现的想法和方法.
页面访问流程
用户访问页面统计信息需要解决两个问题:
统计事件的入口点,即何时计数.
统计数据字段,即计算什么数据.
整个过程如下:
统计事件的切入点
用户访问页面统计信息的一般思想是在View Controller生命周期方法中:
可以获得用户访问页面的路径,这两个事件时间戳之间的差是用户停留在页面上的时间.
通常,我们APP中的View Controller继承自某个基类. 我们可以在基类的相应方法中执行统计. 但是,对于不继承自基类的View Controller,我们无能为力.
借助AOP,我们可以更优雅地做到这一点: 在UIViewController的load方法中摇动viewDidAppear和viewDidDisappear方法,无需更改原创代码.
统计信息字段
根据数据要求,设置以下统计字段:
页面进入和退出的事件都报告给上述数据结构.
还有几个问题需要考虑:
1. 如何定义PAGE_ID和SOURCE_ID
由于您需要统一iOS和Android的PAGE_ID,因此需要对其进行配置和发送. iOS端得到的是一个plist文件,该文件的键是View Controller类名的字符串表示形式,值是PAGE_ID.
2. 如何获取PAGE_ID和SOURCE_ID
可以根据当前View Controller的类直接获取
PAGE_ID. SOURCE_ID稍微复杂一些. 需要根据APP页面的嵌套堆栈结构来确定具体的获取方法. 通常,上一个View Controller的页面取自UINavigationController id的导航堆栈.
到目前为止,页面访问流统计信息已基本完成. 根据页面进入和退出的PAGE_ID和SOURCE_ID,输入完整的用户浏览路径,并获得用户在每个页面上的停留时间.
浏览数据暴露
在采集了用户的浏览路径以及在某些页面(例如主页和产品列表页面)上的每一页上花费的时间之后,我们还想知道用户在该页面上滑动了多少屏幕,以及他们观看了哪些屏幕活动,产品,以便更好地为用户推荐喜爱的产品.
用户看到的屏幕区域被视为资源位,因此用户看到的内容由资源位组成. 那么暴露的含义如下:
我们知道iOS中页面元素的基本单位是视图,因此我们只需要判断视图是否在可见区域中,然后就可以知道当前视图上的资源位置是否需要公开,以便进行相应的曝光操作并捕获数据,报告界面等.
从以上分析可以看出,有两个主要问题需要解决:
查看可见性判断
查看曝光数据采集
查看可见性判断
查询UIView类参考以查看setFrame: 和layoutSubivews方法,这些方法可用于设置子视图的框架. 每次更新观看次数时,都会调用此方法. 因此,我们可以通过运行时选项卡来实现此方法,并添加一些与数据采集相关的操作.
我们向UIView添加了以下属性:
首先阐明以下术语的定义和规则:
1.view的子视图可以同时看到3个需要满足的条件:
相反,只要不满足上述任何条件,我们认为此子视图当前不可见.
2. 将视图设置为可见
3. 将视图设置为不可见
Swzzile setFrame :,请执行以下操作:
易用的layoutSubivews,调用yh_updateVisibleSubViews方法,该方法执行以下操作:
完成上述操作后,我们可以知道一个视图及其子视图是否可见.
查看曝光数据采集
为了获取与视图相对应的数据,还将以下属性添加到UIView:
然后还有两个问题:
浏览量数据的粒度
视图及其子视图节点的曝光数据的组装时间
浏览量数据的粒度
根据项目的实际经验,UITableViewCell或UI采集ViewCell通常是最小的粒度. 同时,在最后一个节点的yh_exposureData字典中添加一个键: isEnd,以标识它是否是最后一个节点.
组装视图及其子视图的曝光数据的时间
通常,当最后一个节点的可见性发生变化时,请从下到上遍历最后一个节点的超级视图以组装所有数据.
因此,我们覆盖了setYh_viewVisible: 方法,这是yh_viewVisible的set方法. 请执行以下操作:
到目前为止,我们已经解决了视图可见性判断和曝光数据采集的问题. 数据报告和策略将不会重复.
此方案有几个缺点
您需要手动设置曝光数据.
您需要在适当的时间手动调用view.yh_viewVisible来触发数据采集,例如viewdidappear.
它需要消耗某些资源才能进行视觉区域计算和曝光数据采集.
还有两个问题值得注意:
UITableView将在setBounds: 时更改视图框架,因此您需要使用setBounds: 方法,需要调用[self yh_updateVisibleSubViews];
UIScrollView会在setContentInset: 时影响视图的可见区域,因此需要调整setContentInset: 方法,需要在设置contentInset之后调用self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame,contentInset);
自动采集业务数据
自动采集业务数据是一种流行的数据采集,没有行业中的隐患.
传统的客户端用户点击数据采集基于手动隐藏点,您对数据感兴趣的地方,只需单击此处,然后在用户操作后立即触发数据报告. 手动掩埋的缺点很明显: 错误的掩埋和丢失的掩埋. 新版本发布后,经常有来自数据部门的小伙伴报告说,某些点的问题尚未报告,某些点已报告错误,开发人员也很痛苦.
没有埋藏点的数据采集带来了新的变化. 首先,基本上避免了人工掩埋,个别情况需要特殊处理. 其次,从有选择的数据采集中,它变成了所有用户点击和触摸数据的完整采集.
新变化也将带来新挑战. 非埋入点数据采集的可能性仍基于Objective-C的运行时特征. 在实践过程中,我们使用iOS非埋入点数据SDK的总体设计和技术实现作为参考,并使用Sensors Analytics iOS SDK和Mixpanel iPhone作为实现. 接下来,结合特定的实践,我们将介绍实现思想和遇到的一些问题. 主要分为以下三个方面:
如何确保自动采集的点的唯一性.
不同的点类型,毛病需要哪些方法.
在大雨中进站了.
如何确保自动采集的点的唯一性
自动采集与手动埋入点是分开的,因此没有唯一的标识点. 那么,我们如何唯一地定位自动采集的点呢?一个容易想到的解决方案是: 基于页面视图的树结构. 该解决方案可以分为两个问题:
如何定义视图的唯一标识符.
视图如何唯一标识.
视图唯一标识符(视图路径)的定义
我们规定典型的查看路径如下:
ViewController[0]/UIView[0]/UITableView[0]/UITableViewCell[0:2]/UIButton[0]
其中:
使用此标识符,可以在当前页面的视图树结构中唯一标识此元素.
每个项目由
标识
由两部分组成: 一个是当前元素类的字符串表示形式,另一个是同一级别元素中当前元素的序列号,从0开始计数. 例如,当前的第二个UIImageView是UIImageView1.
标识不同项目之间的联系.
识别出的最高层是当前视图所在的ViewController.
对于UITableViewCell,UI采集ViewCell和类似的自定义组件,序列号部分由两部分组成: 节和行,它们被拼接在一起.
标记的末尾是当前被单击或触摸的元素.
如何生成视图唯一标识符
视图路径生成过程: 从触发操作的最末端元素向上查询,直到找到ViewController. 假设当前单击的视图是A_View,则从当前A_View开始遍历视图树,并将每个级别的数据存储在P_Array中. 过程如下:
如果A_View是UI采集ViewCell类型,请获取A_View所在的UI采集View的indexPath,P_Array推送路径信息[NSString stringWithFormat: @“%@ [%ld: %ld]”,[NSString stringWithFormat: @“%@”, NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];
如果A_View是UITableViewCell类型,请获取ATable所在的UITableView的indexPath,P_Array推送路径信息[NSString stringWithFormat: @“%@ [%ld: %ld]”,[NSString stringWithFormat: @“%@” ,NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];
遍历A_View.superview的所有子视图,获得相同级别的A_View,以及相同类型的数字(索引)([A_View类]),P_Array推送路径信息[NSString stringWithFormat: @“%@ [%d ]“,NSStringFromClass([A_View class]),index];
获取A_View所在的控制器A_VC. 如果A_View为A_VC.view,则遍历结束. 如果A_View不等于A_VC.view,则A_View = A_View.superview,重复步骤1-4,直到A_View等于A_VC.view.
遍历P_Array拼接A_View的完整路径.
各种类型的点都需要Swizzle方法
我们将APP中的用户操作分为四类:
UI采集View和UITableView的单元格单击事件.
UIControl(UISwitch,UIStepper,UISegmentedControl,UINavigationButton,UISlider,UIButton)控件的click事件.
UIImageView和UILabel上的UITapGestureRecognizer触摸事件.
UITabBar,UIAlertView,UIActionSheet等的点击事件.
这四种操作都需要使用swizzle方法,如下表所示:
UI采集View,UITableView,UITabBar,UIAlertView和UIActionSheet的实现是相似的. 它们都是load方法中的swizzle setDelegate方法. 在setDelegate之后,执行代理回调方法的swizzle操作. 在回调方法中,首先执行原创逻辑. ,然后获取相应的viewPath.
当UIControl组件回调到目标时,将由UIApplication的sendAction: to: from: forEvent: 调用,因此我们选择swizzle方法. 在实践中,首先获取相应的视图路径,然后执行原创逻辑. 原因是如果首先执行原创逻辑,则页面可能会更改,并且获得的View Controller将是错误的.
<p>UITapGestureRecognizer事件仅在UIImageView和UILabel上处理. swizzle addGestureRecognizer: 方法,首先执行原创逻辑,然后向视图添加自定义回调方法,以便在触发手势时也将调用自定义回调,此时我们获得了视图路径. 查看全部
随着库存应用程序的不断迭代开发,数据和业务部门对客户用户行为数据的要求越来越高;为了更好地监视应用程序的使用状态,客户团队拥有有关应用程序本身操作的数据. 需求变得越来越迫切. 迫切需要一套客户端数据采集工具,以自动,全面地采集用户行为数据,以满足各个部门的数据需求.
有货APP团队为此目的开发了一套数据采集SDK. 主要功能如下:
页面访问流程. 用户在应用程序中浏览了哪些页面.
浏览数据. 用户在页面上查看了哪些产品.
自动采集业务数据. 用户在应用程序中点击了哪些位置以及触发了哪些操作.
自动采集性能数据. 在用户使用APP的过程中,页面加载时间,图像加载时间,网络请求时间等是什么?
此外,所有数据采集都应该是自动化且非侵入性的,也就是说,无需手动掩埋点,并且可以集成SDK,并且不应更改原创代码或进行尽可能少的更改
基于上述要求,AOP是技术解决方案的最佳选择,并且在iOS上实现AOP需要依靠Objective-C-Method Swizzle中运行时的黑魔法. 踏入坑和填充坑的漫长旅程从这里开始,让我们逐一品尝实现的想法和方法.
页面访问流程
用户访问页面统计信息需要解决两个问题:
统计事件的入口点,即何时计数.
统计数据字段,即计算什么数据.
整个过程如下:
统计事件的切入点
用户访问页面统计信息的一般思想是在View Controller生命周期方法中:
可以获得用户访问页面的路径,这两个事件时间戳之间的差是用户停留在页面上的时间.
通常,我们APP中的View Controller继承自某个基类. 我们可以在基类的相应方法中执行统计. 但是,对于不继承自基类的View Controller,我们无能为力.
借助AOP,我们可以更优雅地做到这一点: 在UIViewController的load方法中摇动viewDidAppear和viewDidDisappear方法,无需更改原创代码.
统计信息字段
根据数据要求,设置以下统计字段:
页面进入和退出的事件都报告给上述数据结构.
还有几个问题需要考虑:
1. 如何定义PAGE_ID和SOURCE_ID
由于您需要统一iOS和Android的PAGE_ID,因此需要对其进行配置和发送. iOS端得到的是一个plist文件,该文件的键是View Controller类名的字符串表示形式,值是PAGE_ID.
2. 如何获取PAGE_ID和SOURCE_ID
可以根据当前View Controller的类直接获取
PAGE_ID. SOURCE_ID稍微复杂一些. 需要根据APP页面的嵌套堆栈结构来确定具体的获取方法. 通常,上一个View Controller的页面取自UINavigationController id的导航堆栈.
到目前为止,页面访问流统计信息已基本完成. 根据页面进入和退出的PAGE_ID和SOURCE_ID,输入完整的用户浏览路径,并获得用户在每个页面上的停留时间.
浏览数据暴露
在采集了用户的浏览路径以及在某些页面(例如主页和产品列表页面)上的每一页上花费的时间之后,我们还想知道用户在该页面上滑动了多少屏幕,以及他们观看了哪些屏幕活动,产品,以便更好地为用户推荐喜爱的产品.
用户看到的屏幕区域被视为资源位,因此用户看到的内容由资源位组成. 那么暴露的含义如下:
我们知道iOS中页面元素的基本单位是视图,因此我们只需要判断视图是否在可见区域中,然后就可以知道当前视图上的资源位置是否需要公开,以便进行相应的曝光操作并捕获数据,报告界面等.
从以上分析可以看出,有两个主要问题需要解决:
查看可见性判断
查看曝光数据采集
查看可见性判断
查询UIView类参考以查看setFrame: 和layoutSubivews方法,这些方法可用于设置子视图的框架. 每次更新观看次数时,都会调用此方法. 因此,我们可以通过运行时选项卡来实现此方法,并添加一些与数据采集相关的操作.
我们向UIView添加了以下属性:
首先阐明以下术语的定义和规则:
1.view的子视图可以同时看到3个需要满足的条件:
相反,只要不满足上述任何条件,我们认为此子视图当前不可见.
2. 将视图设置为可见
3. 将视图设置为不可见
Swzzile setFrame :,请执行以下操作:
易用的layoutSubivews,调用yh_updateVisibleSubViews方法,该方法执行以下操作:
完成上述操作后,我们可以知道一个视图及其子视图是否可见.
查看曝光数据采集
为了获取与视图相对应的数据,还将以下属性添加到UIView:
然后还有两个问题:
浏览量数据的粒度
视图及其子视图节点的曝光数据的组装时间
浏览量数据的粒度
根据项目的实际经验,UITableViewCell或UI采集ViewCell通常是最小的粒度. 同时,在最后一个节点的yh_exposureData字典中添加一个键: isEnd,以标识它是否是最后一个节点.
组装视图及其子视图的曝光数据的时间
通常,当最后一个节点的可见性发生变化时,请从下到上遍历最后一个节点的超级视图以组装所有数据.
因此,我们覆盖了setYh_viewVisible: 方法,这是yh_viewVisible的set方法. 请执行以下操作:
到目前为止,我们已经解决了视图可见性判断和曝光数据采集的问题. 数据报告和策略将不会重复.
此方案有几个缺点
您需要手动设置曝光数据.
您需要在适当的时间手动调用view.yh_viewVisible来触发数据采集,例如viewdidappear.
它需要消耗某些资源才能进行视觉区域计算和曝光数据采集.
还有两个问题值得注意:
UITableView将在setBounds: 时更改视图框架,因此您需要使用setBounds: 方法,需要调用[self yh_updateVisibleSubViews];
UIScrollView会在setContentInset: 时影响视图的可见区域,因此需要调整setContentInset: 方法,需要在设置contentInset之后调用self.yh_viewVisibleRect = UIEdgeInsetsInsetRect(self.frame,contentInset);
自动采集业务数据
自动采集业务数据是一种流行的数据采集,没有行业中的隐患.
传统的客户端用户点击数据采集基于手动隐藏点,您对数据感兴趣的地方,只需单击此处,然后在用户操作后立即触发数据报告. 手动掩埋的缺点很明显: 错误的掩埋和丢失的掩埋. 新版本发布后,经常有来自数据部门的小伙伴报告说,某些点的问题尚未报告,某些点已报告错误,开发人员也很痛苦.
没有埋藏点的数据采集带来了新的变化. 首先,基本上避免了人工掩埋,个别情况需要特殊处理. 其次,从有选择的数据采集中,它变成了所有用户点击和触摸数据的完整采集.
新变化也将带来新挑战. 非埋入点数据采集的可能性仍基于Objective-C的运行时特征. 在实践过程中,我们使用iOS非埋入点数据SDK的总体设计和技术实现作为参考,并使用Sensors Analytics iOS SDK和Mixpanel iPhone作为实现. 接下来,结合特定的实践,我们将介绍实现思想和遇到的一些问题. 主要分为以下三个方面:
如何确保自动采集的点的唯一性.
不同的点类型,毛病需要哪些方法.
在大雨中进站了.
如何确保自动采集的点的唯一性
自动采集与手动埋入点是分开的,因此没有唯一的标识点. 那么,我们如何唯一地定位自动采集的点呢?一个容易想到的解决方案是: 基于页面视图的树结构. 该解决方案可以分为两个问题:
如何定义视图的唯一标识符.
视图如何唯一标识.
视图唯一标识符(视图路径)的定义
我们规定典型的查看路径如下:
ViewController[0]/UIView[0]/UITableView[0]/UITableViewCell[0:2]/UIButton[0]
其中:
使用此标识符,可以在当前页面的视图树结构中唯一标识此元素.
每个项目由
标识
由两部分组成: 一个是当前元素类的字符串表示形式,另一个是同一级别元素中当前元素的序列号,从0开始计数. 例如,当前的第二个UIImageView是UIImageView1.
标识不同项目之间的联系.
识别出的最高层是当前视图所在的ViewController.
对于UITableViewCell,UI采集ViewCell和类似的自定义组件,序列号部分由两部分组成: 节和行,它们被拼接在一起.
标记的末尾是当前被单击或触摸的元素.
如何生成视图唯一标识符
视图路径生成过程: 从触发操作的最末端元素向上查询,直到找到ViewController. 假设当前单击的视图是A_View,则从当前A_View开始遍历视图树,并将每个级别的数据存储在P_Array中. 过程如下:
如果A_View是UI采集ViewCell类型,请获取A_View所在的UI采集View的indexPath,P_Array推送路径信息[NSString stringWithFormat: @“%@ [%ld: %ld]”,[NSString stringWithFormat: @“%@”, NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];
如果A_View是UITableViewCell类型,请获取ATable所在的UITableView的indexPath,P_Array推送路径信息[NSString stringWithFormat: @“%@ [%ld: %ld]”,[NSString stringWithFormat: @“%@” ,NSStringFromClass([A_View class])],(long)indexPath.section,(long)indexPath.row];
遍历A_View.superview的所有子视图,获得相同级别的A_View,以及相同类型的数字(索引)([A_View类]),P_Array推送路径信息[NSString stringWithFormat: @“%@ [%d ]“,NSStringFromClass([A_View class]),index];
获取A_View所在的控制器A_VC. 如果A_View为A_VC.view,则遍历结束. 如果A_View不等于A_VC.view,则A_View = A_View.superview,重复步骤1-4,直到A_View等于A_VC.view.
遍历P_Array拼接A_View的完整路径.
各种类型的点都需要Swizzle方法
我们将APP中的用户操作分为四类:
UI采集View和UITableView的单元格单击事件.
UIControl(UISwitch,UIStepper,UISegmentedControl,UINavigationButton,UISlider,UIButton)控件的click事件.
UIImageView和UILabel上的UITapGestureRecognizer触摸事件.
UITabBar,UIAlertView,UIActionSheet等的点击事件.
这四种操作都需要使用swizzle方法,如下表所示:
UI采集View,UITableView,UITabBar,UIAlertView和UIActionSheet的实现是相似的. 它们都是load方法中的swizzle setDelegate方法. 在setDelegate之后,执行代理回调方法的swizzle操作. 在回调方法中,首先执行原创逻辑. ,然后获取相应的viewPath.
当UIControl组件回调到目标时,将由UIApplication的sendAction: to: from: forEvent: 调用,因此我们选择swizzle方法. 在实践中,首先获取相应的视图路径,然后执行原创逻辑. 原因是如果首先执行原创逻辑,则页面可能会更改,并且获得的View Controller将是错误的.
<p>UITapGestureRecognizer事件仅在UIImageView和UILabel上处理. swizzle addGestureRecognizer: 方法,首先执行原创逻辑,然后向视图添加自定义回调方法,以便在触发手势时也将调用自定义回调,此时我们获得了视图路径.
使用Python实现自动wordpress采集和更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 390 次浏览 • 2020-08-06 12:15
当前,wordpress_xmlrpc模块已更新为2.2版,但我使用的是1.5版. 懒惰的学生可以在centos下像这样安装它.
Wget-不检查证书
tar zxf python-wordpress-xmlrpc-1.5.tar.gz
cd python-wordpress-xmlrpc-1.5
python setup.py安装
好的,这里介绍了wordpress_xmlrpc模块. 有关其他功能,请访问官方网站. 让我谈谈程序的想法.
1. 使用记事本记录已爬网的URL.
2. 再次获取该页面,以获取此页面上文章的完整URL.
3. 检查此页面的所有URL是否都在TXT中.
4. 如果没有,请获取URL的标题和内容,然后将其发送给wordpress,然后将URL写入txt
5. 最后,使用crontab自动化任务并每天定期运行.
<p>代码如下: (为了防止某些学生一无所获,将代码替换为图片,红色部分是URL,帐号,密码和保存URL地址的txt) 查看全部
最近,我用wordpress制作了一个小型网站. 目的很简单. 我想更新这本小说,并尽快将其发布到wordpress. 我本来想用优采云解决它,但是没有模块流氓,我不得不自己用python编写. 我本来想使用mysqldb直接插入,但是wordpress表单确实有点麻烦,并且远程速度有点慢. 我以为python的主要思想不是重塑轮子,所以我在pypi中找到了wordpress_xmlrpc模块,没有提到主要功能,请参考官方网站了解详细信息:
当前,wordpress_xmlrpc模块已更新为2.2版,但我使用的是1.5版. 懒惰的学生可以在centos下像这样安装它.
Wget-不检查证书
tar zxf python-wordpress-xmlrpc-1.5.tar.gz
cd python-wordpress-xmlrpc-1.5
python setup.py安装
好的,这里介绍了wordpress_xmlrpc模块. 有关其他功能,请访问官方网站. 让我谈谈程序的想法.
1. 使用记事本记录已爬网的URL.
2. 再次获取该页面,以获取此页面上文章的完整URL.
3. 检查此页面的所有URL是否都在TXT中.
4. 如果没有,请获取URL的标题和内容,然后将其发送给wordpress,然后将URL写入txt
5. 最后,使用crontab自动化任务并每天定期运行.
<p>代码如下: (为了防止某些学生一无所获,将代码替换为图片,红色部分是URL,帐号,密码和保存URL地址的txt)
python数据分析的自动数据采集4
采集交流 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2020-08-06 10:18
数据采集是数据挖掘的基础. 没有数据,挖掘就毫无意义. 在许多情况下,我们拥有多少数据源,多少数据以及数据的质量将决定我们的挖掘结果
2四种采集方法
3如何使用Open是数据源
4种爬网方法
(1)使用请求来爬网内容.
(2)使用xpath解析内容,并按元素属性编制索引
(3)使用熊猫保存数据. 最后,通过熊猫写入XLS或mysql数据
(3)scapy
5种常用的抓取工具
(1)优采云采集器
它不仅可以用作爬网工具,还可以用于数据清理,数据分析,数据挖掘和可视化. 数据源适用于大多数网页,并且可以通过采集规则对网页上可见的所有内容进行爬网
(2)优采云
免费采集电子商务,生活服务等.
云采集配置采集任务,总共有5000台服务器,由云节点采集,自动切换多个IP等.
(3)采集客户
没有云采集功能,所有爬虫都在自己的计算机上进行
6如何使用日志采集工具
(1)最大的作用是通过分析用户访问权限来提高系统性能.
(2)记录的内容通常包括访问通道,执行的操作,用户IP等.
(3)什么是掩埋点
购买点是您需要统计数据的统计代码. 谷歌分析Youtalk的TalkingData是常用的掩埋工具.
7总结
有许多数据采集渠道. 您可以自己使用采集器,也可以使用开源数据源和线程工具.
您可以直接从Kaggle下载它,而无需自己爬网.
另一方面,根据我们的需求,需要采集的数据也有所不同. 例如,在运输行业中,数据采集将与相机或速度计有关. 对于运维人员,日志采集和分析功能已关闭 查看全部
1数据采集的重要性
数据采集是数据挖掘的基础. 没有数据,挖掘就毫无意义. 在许多情况下,我们拥有多少数据源,多少数据以及数据的质量将决定我们的挖掘结果
2四种采集方法
3如何使用Open是数据源
4种爬网方法
(1)使用请求来爬网内容.
(2)使用xpath解析内容,并按元素属性编制索引
(3)使用熊猫保存数据. 最后,通过熊猫写入XLS或mysql数据
(3)scapy
5种常用的抓取工具
(1)优采云采集器
它不仅可以用作爬网工具,还可以用于数据清理,数据分析,数据挖掘和可视化. 数据源适用于大多数网页,并且可以通过采集规则对网页上可见的所有内容进行爬网
(2)优采云
免费采集电子商务,生活服务等.
云采集配置采集任务,总共有5000台服务器,由云节点采集,自动切换多个IP等.
(3)采集客户
没有云采集功能,所有爬虫都在自己的计算机上进行
6如何使用日志采集工具
(1)最大的作用是通过分析用户访问权限来提高系统性能.
(2)记录的内容通常包括访问通道,执行的操作,用户IP等.
(3)什么是掩埋点
购买点是您需要统计数据的统计代码. 谷歌分析Youtalk的TalkingData是常用的掩埋工具.
7总结
有许多数据采集渠道. 您可以自己使用采集器,也可以使用开源数据源和线程工具.
您可以直接从Kaggle下载它,而无需自己爬网.
另一方面,根据我们的需求,需要采集的数据也有所不同. 例如,在运输行业中,数据采集将与相机或速度计有关. 对于运维人员,日志采集和分析功能已关闭
文明重启自动采集功能易于使用吗?文明重启自动采集功能评估
采集交流 • 优采云 发表了文章 • 0 个评论 • 679 次浏览 • 2020-08-05 23:04
文明重启自动采集功能易于使用吗?
自动采集功能在游戏中不容易使用,容易卡住,速度慢. 在某些模式下,这等效于负责任.
开放条件
在游戏中,玩家采集资源一直是痛苦的. 毕竟,建筑物已经升级,所需的维护材料也在一定程度上发生了变化,玩家制作更高级武器所需的基本资源也发生了变化,因此游戏官方为为了减轻玩家的压力. 该功能的开启条件是玩家在这场战斗中需要收取12元. 当然,玩家购买赞助商后,他们还将获得斩波起搏器,增加体验并减少维护材料和效果.
使用评估
编辑和我的朋友亲自体验了自动采集功能. 编辑者只能说此功能是完全不切实际的. 播放器打开自动采集功能后,经常会出现无法从卡纸上清除卡纸的情况,并且在采集和播放附近的资源时,您会被动地挂断电话. 无法杀死的PVE模式是可以的. 对于其他可以杀死的模式,这是为他人制造婚纱. 最后,我们必须抱怨一下,自动收款速度不如玩家自己的手册快. 通常,当玩家购买赞助时,最有用的功能是减少区域内阁维护材料的消耗. 其他的基本上没有用,因此如果播放器是小k,则必须仔细考虑. 查看全部
在“文明重启”游戏中,玩家只需在坐骑战斗中充值12元即可开启自动收款功能. 此功能的功能是节省每个人采集资源所需的时间. 许多玩家会打开此按钮以节省时间和成本. 功能,该功能的实用性如何?让Youyou.com的编辑为您分析!
文明重启自动采集功能易于使用吗?
自动采集功能在游戏中不容易使用,容易卡住,速度慢. 在某些模式下,这等效于负责任.
开放条件
在游戏中,玩家采集资源一直是痛苦的. 毕竟,建筑物已经升级,所需的维护材料也在一定程度上发生了变化,玩家制作更高级武器所需的基本资源也发生了变化,因此游戏官方为为了减轻玩家的压力. 该功能的开启条件是玩家在这场战斗中需要收取12元. 当然,玩家购买赞助商后,他们还将获得斩波起搏器,增加体验并减少维护材料和效果.
使用评估
编辑和我的朋友亲自体验了自动采集功能. 编辑者只能说此功能是完全不切实际的. 播放器打开自动采集功能后,经常会出现无法从卡纸上清除卡纸的情况,并且在采集和播放附近的资源时,您会被动地挂断电话. 无法杀死的PVE模式是可以的. 对于其他可以杀死的模式,这是为他人制造婚纱. 最后,我们必须抱怨一下,自动收款速度不如玩家自己的手册快. 通常,当玩家购买赞助时,最有用的功能是减少区域内阁维护材料的消耗. 其他的基本上没有用,因此如果播放器是小k,则必须仔细考虑.

