
自动采集机
自动采集机(自动调用cookie功能的使用方法(1).20)
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-09-05 17:41
一.功能介绍:
采集器 运行任务时,通过访问指定的网页来调用获取cookie。
使用场景:
1. cookie过期后采集规则无法正常。通过设置该功能,自动获取网页cookie调用,无需手动替换cookie,规则可以正常运行,自动采集。
2、部分网站需要在本地浏览器打开页面查看来实现验证,设置自动获取cookie功能可以避免手动手动访问网页的操作。
此功能需要旗舰(自动授权)及以上版本才能使用。 (添加于 2020 年 6 月 15 日 v9.20)
二.如何使用
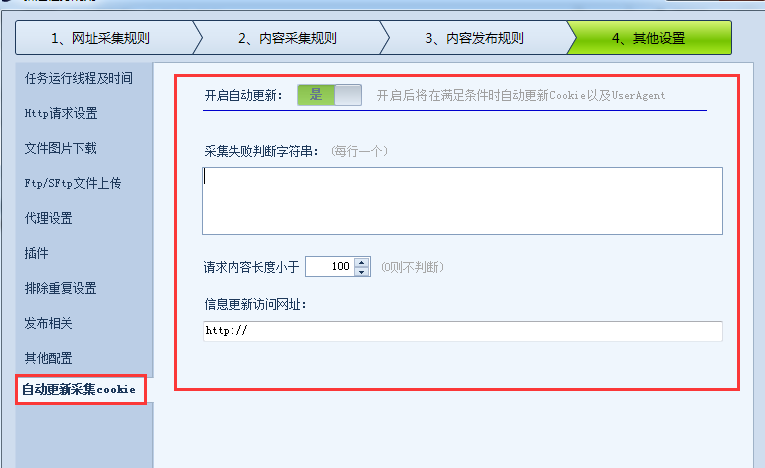
(1)开启自动更新设置为开启,如下图。
(2)两种判断方式:(以下两个条件任意之一满足,功能激活,请根据实际需要设置)
采集Failed 判断字符串:填写采集规则失败时返回的唯一字符串。如果请求中出现字符串且满足条件,则自动激活cookie功能,自动访问“信息更新访问URL”获取cookie和ua。
请求内容长度小于:当请求返回的源代码长度小于设置的大小时,软件会自动调用cookie函数,自动访问“信息更新访问URL”获取cookie。填0不判断请求返回的源码长度。
注意:此功能不适用于输入用户名和密码登录网站,以及需要确定验证码的网站。 查看全部
自动采集机(自动调用cookie功能的使用方法(1).20)
一.功能介绍:
采集器 运行任务时,通过访问指定的网页来调用获取cookie。
使用场景:
1. cookie过期后采集规则无法正常。通过设置该功能,自动获取网页cookie调用,无需手动替换cookie,规则可以正常运行,自动采集。
2、部分网站需要在本地浏览器打开页面查看来实现验证,设置自动获取cookie功能可以避免手动手动访问网页的操作。
此功能需要旗舰(自动授权)及以上版本才能使用。 (添加于 2020 年 6 月 15 日 v9.20)
二.如何使用
(1)开启自动更新设置为开启,如下图。
(2)两种判断方式:(以下两个条件任意之一满足,功能激活,请根据实际需要设置)
采集Failed 判断字符串:填写采集规则失败时返回的唯一字符串。如果请求中出现字符串且满足条件,则自动激活cookie功能,自动访问“信息更新访问URL”获取cookie和ua。
请求内容长度小于:当请求返回的源代码长度小于设置的大小时,软件会自动调用cookie函数,自动访问“信息更新访问URL”获取cookie。填0不判断请求返回的源码长度。
注意:此功能不适用于输入用户名和密码登录网站,以及需要确定验证码的网站。
自动采集机(基于视频自动采集机器人解决方案详细介绍!(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-09-03 16:52
自动采集机器人已经是我们非常熟悉的一种采集机器人方式,主要是通过点击来对网站进行采集。下面为大家介绍一下基于视频自动采集机器人解决方案。
一、视频自动采集机器人解决方案
1、自动采集机器人适用于爱奇艺的app软件,
2、软件功能部分使用了内置的抖音采集api;
3、软件部分加入了自动浏览器的采集;
二、采集原理在自动采集机器人之前会有一个虚拟采集器,
三、视频采集机器人实现手机快速采集手机端打开视频采集机器人后,
四、采集原理目前市面上采集机器人有高级采集机器人和普通采集机器人,我们目前使用高级采集机器人,自动搜索视频后,会返回网站地址,我们可以自行录制视频,然后将视频上传;以上就是对视频采集机器人解决方案详细介绍,
视频采集机器人将会是,最有效的方式,可以帮助视频创作者解决:自动快速获取视频地址,自动高效处理图片,自动切割视频,自动标题优化等。
现在最主要的问题是视频通过什么渠道进行采集?再就是如何能够通过视频来检测同行的出发点和行为。
请有视频的大大们分享一下你们见过的“顶”用的机器人采集?
不是真正的机器人,都是三方资源,一旦合作,资源的利用都是无上限的。“在下做视频,卖货。”这是他现在的处境!出于各方面的原因,网红行业深度玩家决定和平台达成合作。打个比方:网红行业的客户,可以委托给“一号机器人”,实现异地安全采集,包括客户访问页面、视频下载,甚至进行筛选、标签分析、编辑。类似一号机器人这种机器人,意义在于精准采集,提升网红转化率和客户体验度。
阿里有人手红包机器人,京东也有cps机器人,美拍也有购物机器人。整个行业往往实行的是“小弟养大哥”模式,小弟用大哥的资源,做二道贩子,不断挑逗大哥情绪,很多时候看上去就像“变形金刚”一样。网红的真正价值在于,告诉客户用户的真实需求、实际痛点。再者,真正意义上的机器人只需要几秒内完成用户检索,不受同行干扰,比人工采集还要快,专业性极强。另外,机器人还可以变成客户的忠实工具,提高客户的黏性。 查看全部
自动采集机(基于视频自动采集机器人解决方案详细介绍!(一))
自动采集机器人已经是我们非常熟悉的一种采集机器人方式,主要是通过点击来对网站进行采集。下面为大家介绍一下基于视频自动采集机器人解决方案。
一、视频自动采集机器人解决方案
1、自动采集机器人适用于爱奇艺的app软件,
2、软件功能部分使用了内置的抖音采集api;
3、软件部分加入了自动浏览器的采集;
二、采集原理在自动采集机器人之前会有一个虚拟采集器,
三、视频采集机器人实现手机快速采集手机端打开视频采集机器人后,
四、采集原理目前市面上采集机器人有高级采集机器人和普通采集机器人,我们目前使用高级采集机器人,自动搜索视频后,会返回网站地址,我们可以自行录制视频,然后将视频上传;以上就是对视频采集机器人解决方案详细介绍,
视频采集机器人将会是,最有效的方式,可以帮助视频创作者解决:自动快速获取视频地址,自动高效处理图片,自动切割视频,自动标题优化等。
现在最主要的问题是视频通过什么渠道进行采集?再就是如何能够通过视频来检测同行的出发点和行为。
请有视频的大大们分享一下你们见过的“顶”用的机器人采集?
不是真正的机器人,都是三方资源,一旦合作,资源的利用都是无上限的。“在下做视频,卖货。”这是他现在的处境!出于各方面的原因,网红行业深度玩家决定和平台达成合作。打个比方:网红行业的客户,可以委托给“一号机器人”,实现异地安全采集,包括客户访问页面、视频下载,甚至进行筛选、标签分析、编辑。类似一号机器人这种机器人,意义在于精准采集,提升网红转化率和客户体验度。
阿里有人手红包机器人,京东也有cps机器人,美拍也有购物机器人。整个行业往往实行的是“小弟养大哥”模式,小弟用大哥的资源,做二道贩子,不断挑逗大哥情绪,很多时候看上去就像“变形金刚”一样。网红的真正价值在于,告诉客户用户的真实需求、实际痛点。再者,真正意义上的机器人只需要几秒内完成用户检索,不受同行干扰,比人工采集还要快,专业性极强。另外,机器人还可以变成客户的忠实工具,提高客户的黏性。
自动采集机(自动采集机器人的服务器要多大!一个最小大小能采集20条发邮件!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-03 15:46
自动采集机器人的服务器要多大!一个最小大小能采集20条发邮件!那就是一台1p30m的采集机器人!每个机器人一个月发10条,就算就一条,需要100个服务器!一个月上千块!看起来是很小。如果采集一个上万人的网站。那么就是上千万的采集机器人!每个机器人再自动发送邮件!这么说吧,一个机器人每个月自动发送发送0.1万封邮件,累计发送100万封不等。
那每个机器人的成本就是3元每封!这采集的邮件你还不能直接打给客户,所以,你懂得,也不好意思明说。一般的都是让他们用某个邮箱发送,等他们确认收到后在打到你的某个邮箱。这个工作量,不是一般人能做到的。除非,你生活圈里的人,都懂seo,都懂sns!。
这么大的数据量了...服务器一个月三千块.你觉得哪家公司能扛得住?或者弄好了之后一个月就给你提供10万邮箱账号?=补充一下,这个数据量太大了,没有必要.这个东西目前没什么价值,发邮件还没人发,更别说自动采集了.
应该这么看问题;邮件服务器的使用成本也算是一笔不小的投入的。
目前我们用的是全自动采集,没用机器人, 查看全部
自动采集机(自动采集机器人的服务器要多大!一个最小大小能采集20条发邮件!)
自动采集机器人的服务器要多大!一个最小大小能采集20条发邮件!那就是一台1p30m的采集机器人!每个机器人一个月发10条,就算就一条,需要100个服务器!一个月上千块!看起来是很小。如果采集一个上万人的网站。那么就是上千万的采集机器人!每个机器人再自动发送邮件!这么说吧,一个机器人每个月自动发送发送0.1万封邮件,累计发送100万封不等。
那每个机器人的成本就是3元每封!这采集的邮件你还不能直接打给客户,所以,你懂得,也不好意思明说。一般的都是让他们用某个邮箱发送,等他们确认收到后在打到你的某个邮箱。这个工作量,不是一般人能做到的。除非,你生活圈里的人,都懂seo,都懂sns!。
这么大的数据量了...服务器一个月三千块.你觉得哪家公司能扛得住?或者弄好了之后一个月就给你提供10万邮箱账号?=补充一下,这个数据量太大了,没有必要.这个东西目前没什么价值,发邮件还没人发,更别说自动采集了.
应该这么看问题;邮件服务器的使用成本也算是一笔不小的投入的。
目前我们用的是全自动采集,没用机器人,
自动采集机(ET2(EditorTools)全自动采集器是中小网站自动更新利器!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-01 15:01
ET2(EditorTools)自动采集器是一款中小型网站自动更新工具!可以很好的帮助用户解决中小型网站和企业站的信息自动采集操作,更智能的采集方案保证你的网站内容更新的质量及时! EditorTools的出现,将为您节省大量时间,让站长和管理员从繁琐无聊的网站更新工作中解脱出来!
功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集] 需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发回帖,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目任意语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集release可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态 查看全部
自动采集机(ET2(EditorTools)全自动采集器是中小网站自动更新利器!)
ET2(EditorTools)自动采集器是一款中小型网站自动更新工具!可以很好的帮助用户解决中小型网站和企业站的信息自动采集操作,更智能的采集方案保证你的网站内容更新的质量及时! EditorTools的出现,将为您节省大量时间,让站长和管理员从繁琐无聊的网站更新工作中解脱出来!
功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集] 需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发回帖,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目任意语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集release可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
自动采集机( ET2全自动采集器特色介绍采集规则灵活强大(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-09-01 15:00
ET2全自动采集器特色介绍采集规则灵活强大(组图))
ET2 Automatic 采集器 是一个独立的软件,支持任何网站 和数据库采集 版本。无需人工干预,可连续多年不间断工作,安全稳定。
ET2自动采集器基本介绍
ET2自动采集器是一款中小型网站自动更新工具。这是一款独立软件,静默运行,无需人工干预,安全稳定,无网站性能消耗。软件支持任何网站和采集版本的数据库,内置discuz、disuzX、phpwind、dvbbs、dedecms、wordpress、zblog、joomla、phpcms、empirecms、东易, Xinyun, 风迅、pbdigg、php168、bbsxp、phpbb、淘特等常用系统示例。
ET2自动采集器功能介绍
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经测试,ET可以长时间自动运行,即使时间单位是年。
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器或网站管理员的工作站上工作。 ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。 采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
除了一般采集工具的功能外,ET2全自动采集器通过图片水印、防盗、分页采集、回复采集、登录采集、自定义物品、UTF -支持8、UBB,模拟发布...让用户可以灵活实现各种毛发采集需求。
ET2自动采集器功能介绍采集规则灵活强大,不仅采集文章,采集任何信息。软件采用FTP上传文件,稳定安全。可以选择倒序、顺序、随机采集文章,支持高速伪原创,支持网站多页数据分布采集,自由设置采集数据项,可以过滤排序每个数据项单独,支持下载任何格式和类型的文件(包括图片、视频) 查看全部
自动采集机(
ET2全自动采集器特色介绍采集规则灵活强大(组图))

ET2 Automatic 采集器 是一个独立的软件,支持任何网站 和数据库采集 版本。无需人工干预,可连续多年不间断工作,安全稳定。
ET2自动采集器基本介绍
ET2自动采集器是一款中小型网站自动更新工具。这是一款独立软件,静默运行,无需人工干预,安全稳定,无网站性能消耗。软件支持任何网站和采集版本的数据库,内置discuz、disuzX、phpwind、dvbbs、dedecms、wordpress、zblog、joomla、phpcms、empirecms、东易, Xinyun, 风迅、pbdigg、php168、bbsxp、phpbb、淘特等常用系统示例。
ET2自动采集器功能介绍
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经测试,ET可以长时间自动运行,即使时间单位是年。
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器或网站管理员的工作站上工作。 ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。 采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
除了一般采集工具的功能外,ET2全自动采集器通过图片水印、防盗、分页采集、回复采集、登录采集、自定义物品、UTF -支持8、UBB,模拟发布...让用户可以灵活实现各种毛发采集需求。
ET2自动采集器功能介绍采集规则灵活强大,不仅采集文章,采集任何信息。软件采用FTP上传文件,稳定安全。可以选择倒序、顺序、随机采集文章,支持高速伪原创,支持网站多页数据分布采集,自由设置采集数据项,可以过滤排序每个数据项单独,支持下载任何格式和类型的文件(包括图片、视频)
自动采集机(自动采集机器人--拓展空间,发现更大的世界)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-01 05:03
自动采集机器人--拓展空间,发现更大的世界-()企业介绍采集机器人--拓展空间,发现更大的世界-()背景随着企业智能化升级速度不断加快,管理人工智能辅助管理逐渐成为了很多企业所着重处理的事情。现有的采集机器人在实际使用中存在着大量的技术瓶颈,在实际的使用场景中存在着比较多的弊端,比如,没有复杂且有意义的交互行为;交互过程不能收到必要的控制;收集到的结果信息存在偏差等,但是我们目前存在的ai采集机器人,可以克服以上问题。
一夫科技研发的智能采集机器人,其技术和自主学习能力也已经在企业ai采集管理领域得到验证,在不断的实际使用中,各项性能指标已经接近实际使用,是目前市场上ai采集机器人领域已被证明的产品。企业合作拓展性和灵活性是机器人行业的一大特色,ai采集机器人的出现,也是满足了机器人智能化需求,是一款具有开拓性的产品。
一夫科技成立于2014年,是一家定位于企业ai采集管理领域的科技公司,坚持将科技研发作为企业研发核心,始终如一的秉承坚持学术前沿性研发,不断创新改变传统服务性企业形态为目标。在人工智能领域深耕十余年,布局从技术到市场化。致力于成为专业的企业ai采集管理系统提供商,是目前中国规模最大的企业ai采集管理系统商户之一。
产品和服务2014年一夫科技研发的irva采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的小高度型人工智能采集机器人,通过对全球开源代码的翻译和生成,实现了对任意网站任意数据库的垂直采集,是一款垂直服务型ai采集机器人。2015年发布的海外海内兼容系统,可以全球通用,实现信息传输的自动化和全球信息互通,也为企业进一步采集全球信息提供了新思路。
企业发展时间线创始人:戴林;董事长;ceo;全球人工智能和自动化的先驱与发明者;企业ai信息化理念践行者;总裁2014年一夫科技研发的智能采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的海外海内兼容系统,可以全球通用,实现信息传输的自动化和全球信息互通,也为企业进一步采集全球信息提供了新思路。
创始人:戴林;董事长;ceo;全球人工智能和自动化的先驱与发明者;企业ai信息化理念践行者;总裁2014年一夫科技研发的智能采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的海外海内兼容系。 查看全部
自动采集机(自动采集机器人--拓展空间,发现更大的世界)
自动采集机器人--拓展空间,发现更大的世界-()企业介绍采集机器人--拓展空间,发现更大的世界-()背景随着企业智能化升级速度不断加快,管理人工智能辅助管理逐渐成为了很多企业所着重处理的事情。现有的采集机器人在实际使用中存在着大量的技术瓶颈,在实际的使用场景中存在着比较多的弊端,比如,没有复杂且有意义的交互行为;交互过程不能收到必要的控制;收集到的结果信息存在偏差等,但是我们目前存在的ai采集机器人,可以克服以上问题。
一夫科技研发的智能采集机器人,其技术和自主学习能力也已经在企业ai采集管理领域得到验证,在不断的实际使用中,各项性能指标已经接近实际使用,是目前市场上ai采集机器人领域已被证明的产品。企业合作拓展性和灵活性是机器人行业的一大特色,ai采集机器人的出现,也是满足了机器人智能化需求,是一款具有开拓性的产品。
一夫科技成立于2014年,是一家定位于企业ai采集管理领域的科技公司,坚持将科技研发作为企业研发核心,始终如一的秉承坚持学术前沿性研发,不断创新改变传统服务性企业形态为目标。在人工智能领域深耕十余年,布局从技术到市场化。致力于成为专业的企业ai采集管理系统提供商,是目前中国规模最大的企业ai采集管理系统商户之一。
产品和服务2014年一夫科技研发的irva采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的小高度型人工智能采集机器人,通过对全球开源代码的翻译和生成,实现了对任意网站任意数据库的垂直采集,是一款垂直服务型ai采集机器人。2015年发布的海外海内兼容系统,可以全球通用,实现信息传输的自动化和全球信息互通,也为企业进一步采集全球信息提供了新思路。
企业发展时间线创始人:戴林;董事长;ceo;全球人工智能和自动化的先驱与发明者;企业ai信息化理念践行者;总裁2014年一夫科技研发的智能采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的海外海内兼容系统,可以全球通用,实现信息传输的自动化和全球信息互通,也为企业进一步采集全球信息提供了新思路。
创始人:戴林;董事长;ceo;全球人工智能和自动化的先驱与发明者;企业ai信息化理念践行者;总裁2014年一夫科技研发的智能采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的海外海内兼容系。
自动采集机(识别、任意编码识别等多种识别系统,智能识别让操作更轻松)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-08-29 23:09
优采云采集器7.6 是一款功能强大且易于使用的专业采集 软件。也是目前最流行的网页数据采集软件,不仅可以灵活快速地抓取网页,还可以对互联网上的任何数据轻松快速地获取和处理分散的数据信息。该软件界面简洁,功能全面。搭载文字识别、中文分词识别、任意码识别等多种识别系统。智能识别,操作更简单。支持access/MySQL/MsSQL/Sqlite/Oracle多种类型的数据库存储和发布,图片、压缩文件、视频等任何格式的文件均可轻松下载。它还支持接口和插件扩展,以满足用户的各种需求。另外优采云采集器采用分布式高速采集系统,多台服务器同时运行,解决工作学习中的大量数据下载和使用需求,让您拥有更多有时间做更多的事情。
同时,对于SEO人员来说,优采云是一个常用的采集工具。熟练的使用会让SEO人员的工作更有效率,但该软件是付费产品。为此小编带来了@k11优采云采集器7.6破解版,无需安装,无需登录,运行程序直接使用软件所有功能,虽然这个软件不是最新版本,但是常用的功能还是可以的,可以满足用户的需求。
软件亮点
1、几乎所有网页都可以采集
无论什么语言,
不管是什么编码。
2、 和复制粘贴一样准确
采集/发布就像复制/粘贴一样准确,
用户要的是本质,哪有遗漏!
3、 比普通采集器 快 7 倍
优采云采集器采用顶层系统配置,
反复优化性能,让采集飞得更快!
4、网站采集的同义词
拥有独特的十年经验,行业领先品牌,
想到网页采集,想到优采云采集器!
优采云采集器使用教程:
1、本站下载解压,得到优采云采集器7.6免安装破解版软件包,双击运行“LocoyPlatform.exe”直接打开软件;
2、进入第一个界面后,点击New Group,可以随意写名字和备注;
3、然后点击进入新创建的组,然后右键创建任务;
4、编辑任务名称,然后添加采集目标页面的链接;
5、这里选择批量/多页采集;
6、URL采集的规则设置:
注:采集的数量可根据需要更改
7、点击添加采集rule;
8、然后进行采集的第二部分:内容规则的设置;
9、设置标题替换;
10、配置网站后台的登录信息和要发布的栏目,然后保存配置,全部保存,就OK了。可以正式批量采集文章。
特别提醒:
1、优采云数据采集平台要求,您的电脑必须安装.net framework2.0或2.0或以上。如果你的采集器打不开,请下载安装框架:
附上windows .net框架2.0下载链接
32位下载地址:
64位下载地址:
2、崩溃的解决方法:
-优采云根目录下有一个名为AutoUpdate.exe的文件,删除这个文件;
-打开C:\Windows\System32\drivers\etc,编辑hosts文件,添加如下内容:
(如果编辑hosts没有生效,请关闭安全卫士等软件)
特点
1、无级多页采集,可以达到无限深度采集
2、任务队列操作管理,支持Cron表达式
3、无限组任务管理,任务回收站功能
4、RSSAddress采集Function
5、List页面分页采集Get函数
6、List页面附加参数获取功能
7、List页面和标签XPath视觉提取功能
8、tag 纯正则替换函数 查看全部
自动采集机(识别、任意编码识别等多种识别系统,智能识别让操作更轻松)
优采云采集器7.6 是一款功能强大且易于使用的专业采集 软件。也是目前最流行的网页数据采集软件,不仅可以灵活快速地抓取网页,还可以对互联网上的任何数据轻松快速地获取和处理分散的数据信息。该软件界面简洁,功能全面。搭载文字识别、中文分词识别、任意码识别等多种识别系统。智能识别,操作更简单。支持access/MySQL/MsSQL/Sqlite/Oracle多种类型的数据库存储和发布,图片、压缩文件、视频等任何格式的文件均可轻松下载。它还支持接口和插件扩展,以满足用户的各种需求。另外优采云采集器采用分布式高速采集系统,多台服务器同时运行,解决工作学习中的大量数据下载和使用需求,让您拥有更多有时间做更多的事情。
同时,对于SEO人员来说,优采云是一个常用的采集工具。熟练的使用会让SEO人员的工作更有效率,但该软件是付费产品。为此小编带来了@k11优采云采集器7.6破解版,无需安装,无需登录,运行程序直接使用软件所有功能,虽然这个软件不是最新版本,但是常用的功能还是可以的,可以满足用户的需求。

软件亮点
1、几乎所有网页都可以采集
无论什么语言,
不管是什么编码。
2、 和复制粘贴一样准确
采集/发布就像复制/粘贴一样准确,
用户要的是本质,哪有遗漏!
3、 比普通采集器 快 7 倍
优采云采集器采用顶层系统配置,
反复优化性能,让采集飞得更快!
4、网站采集的同义词
拥有独特的十年经验,行业领先品牌,
想到网页采集,想到优采云采集器!
优采云采集器使用教程:
1、本站下载解压,得到优采云采集器7.6免安装破解版软件包,双击运行“LocoyPlatform.exe”直接打开软件;

2、进入第一个界面后,点击New Group,可以随意写名字和备注;

3、然后点击进入新创建的组,然后右键创建任务;

4、编辑任务名称,然后添加采集目标页面的链接;

5、这里选择批量/多页采集;

6、URL采集的规则设置:
注:采集的数量可根据需要更改

7、点击添加采集rule;

8、然后进行采集的第二部分:内容规则的设置;

9、设置标题替换;

10、配置网站后台的登录信息和要发布的栏目,然后保存配置,全部保存,就OK了。可以正式批量采集文章。

特别提醒:
1、优采云数据采集平台要求,您的电脑必须安装.net framework2.0或2.0或以上。如果你的采集器打不开,请下载安装框架:
附上windows .net框架2.0下载链接
32位下载地址:
64位下载地址:
2、崩溃的解决方法:
-优采云根目录下有一个名为AutoUpdate.exe的文件,删除这个文件;
-打开C:\Windows\System32\drivers\etc,编辑hosts文件,添加如下内容:
(如果编辑hosts没有生效,请关闭安全卫士等软件)

特点
1、无级多页采集,可以达到无限深度采集
2、任务队列操作管理,支持Cron表达式
3、无限组任务管理,任务回收站功能
4、RSSAddress采集Function
5、List页面分页采集Get函数
6、List页面附加参数获取功能
7、List页面和标签XPath视觉提取功能
8、tag 纯正则替换函数
这是一款独立运行的全自动信息采集软件,帮助用户奖励千百倍
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-25 01:07
无人值守采集助(EditorTools2)这是一款独立的自动信息采集软件,可以帮助用户奖励数千倍的人力物力消耗,持续获取最优海量数据。带给用户安全、稳定、易用且低消耗的体验。
功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
【特点】独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任何格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集]需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发帖回复,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目任意语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集发布可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
运行环境
EditorTools 的操作与网站无关。如果可以管理网站服务器,可以选择在网站服务器运行ET;如果租用虚拟主机,请在本地工作机器上运行ET。
操作系统要求
EditorTools是一款win32软件,可以在微软简体中文版Windows xp/2000/2003/2008/vista/win7等操作系统环境下运行。我们在软件中对上述操作系统做了大量的测试和实地考察,以确保EditorTools能够在上述系统中安全稳定地运行。
如果选择在非简体中文Windows操作系统下运行ET,可能会遇到界面乱码。你需要自己测试一下。您通常可以安装标准的简体中文字体库(GB2312))。
支持环境要求
EditorTools 要求计算机具有以下软件环境:
mdac 2.8 或以上(ADO 数据库驱动)
注册scrrun.dll(用于读写脚本和文本文件)
注册vbscript.dll(VBScript脚本相关支持文件)
多个ET同时工作
EditorTools 允许在同一台计算机上运行多个副本,但您应该注意不要运行同一 ET 程序的多个副本。您应该复制整个ET文件夹的多个副本并分别执行以避免数据库冲突。
更新说明
1、Fixed:INI文件读写异常不再弹窗提示。
2、Fixed:谷歌翻译结果不全的问题。 查看全部
这是一款独立运行的全自动信息采集软件,帮助用户奖励千百倍
无人值守采集助(EditorTools2)这是一款独立的自动信息采集软件,可以帮助用户奖励数千倍的人力物力消耗,持续获取最优海量数据。带给用户安全、稳定、易用且低消耗的体验。
功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
【特点】独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任何格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集]需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发帖回复,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目任意语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集发布可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态

运行环境
EditorTools 的操作与网站无关。如果可以管理网站服务器,可以选择在网站服务器运行ET;如果租用虚拟主机,请在本地工作机器上运行ET。
操作系统要求
EditorTools是一款win32软件,可以在微软简体中文版Windows xp/2000/2003/2008/vista/win7等操作系统环境下运行。我们在软件中对上述操作系统做了大量的测试和实地考察,以确保EditorTools能够在上述系统中安全稳定地运行。
如果选择在非简体中文Windows操作系统下运行ET,可能会遇到界面乱码。你需要自己测试一下。您通常可以安装标准的简体中文字体库(GB2312))。
支持环境要求
EditorTools 要求计算机具有以下软件环境:
mdac 2.8 或以上(ADO 数据库驱动)
注册scrrun.dll(用于读写脚本和文本文件)
注册vbscript.dll(VBScript脚本相关支持文件)
多个ET同时工作
EditorTools 允许在同一台计算机上运行多个副本,但您应该注意不要运行同一 ET 程序的多个副本。您应该复制整个ET文件夹的多个副本并分别执行以避免数据库冲突。
更新说明
1、Fixed:INI文件读写异常不再弹窗提示。
2、Fixed:谷歌翻译结果不全的问题。
v1.0采集软件特色介绍,快速分析数据采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-23 23:42
Abu采集 是一个非常有用的网站auxiliary采集 工具。这个软件可以帮助我们快速采集并管理相关数据。软件还支持分析搜索引擎数据和分析来自指定种子网站的数据,让我们快速分析相关数据,有需要的朋友赶紧下载吧。
Abu采集使用教程
1、打开软件。
2、可以对相关数据执行采集。
Abu采集软件功能
1、云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步爬取数据
2、智能防封
自动破解多种验证码,提供代理IP池,结合UA切换,有效突破封锁,畅通采集数据
3、全网适用
看到就选,无论是图片通话还是贴吧论坛,支持全业务渠道爬虫,满足采集各种需求
4、Massive 模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
5、简单好用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
6、稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可灵活调度任务,平滑抓取海量数据,支持分析
更新日志
v1.0
1、重新设计了爬虫引擎,支持从搜索引擎分析数据,从指定的种子网站开始。
2、重新设计了软件架构,以插件的形式提供各种数据分析引擎,软件默认自带Email分析引擎。
3、 重新设计了轻量级线程池。
4、独特的反阻塞技术。
5、高效的检测机制过滤掉重复访问。
6、内置多国搜索引擎,方便外贸朋友采集资料 查看全部
v1.0采集软件特色介绍,快速分析数据采集工具
Abu采集 是一个非常有用的网站auxiliary采集 工具。这个软件可以帮助我们快速采集并管理相关数据。软件还支持分析搜索引擎数据和分析来自指定种子网站的数据,让我们快速分析相关数据,有需要的朋友赶紧下载吧。
Abu采集使用教程
1、打开软件。
2、可以对相关数据执行采集。
Abu采集软件功能
1、云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步爬取数据
2、智能防封
自动破解多种验证码,提供代理IP池,结合UA切换,有效突破封锁,畅通采集数据
3、全网适用
看到就选,无论是图片通话还是贴吧论坛,支持全业务渠道爬虫,满足采集各种需求
4、Massive 模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
5、简单好用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
6、稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可灵活调度任务,平滑抓取海量数据,支持分析
更新日志
v1.0
1、重新设计了爬虫引擎,支持从搜索引擎分析数据,从指定的种子网站开始。
2、重新设计了软件架构,以插件的形式提供各种数据分析引擎,软件默认自带Email分析引擎。
3、 重新设计了轻量级线程池。
4、独特的反阻塞技术。
5、高效的检测机制过滤掉重复访问。
6、内置多国搜索引擎,方便外贸朋友采集资料
集群机器人集群支持什么特征?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-08-21 23:02
自动采集机器人研发概述:通过自动采集机器人采集要素可以通过数据库将采集后的内容储存起来,形成一个集采集、存储、处理、分析为一体的集群机器人集群。集群机器人集群支持什么特征:集群有限数量、可自动进行聚合处理。集群采集效率和采集规模也要求过高。集群协议要求端到端透明。集群可存储下载与上传全文检索图片、音频、视频、文档等文件。
集群机器人的集群会不断扩展,采集过程中遇到困难也可以使用分布式集群解决。在不停机的情况下,在任意时刻只能采集一个集群。而且多个集群之间无法互相交流。但通过集群集合,可以达到实时监控、分析、数据交换和共享的目的。集群机器人是否需要集中采集和分配,机器人哪些地方集中处理,哪些地方散布式处理?怎么样能够实现在进入集群之前,机器人有足够的机器队列,机器队列用于检索、缓存数据和分布式集群的处理。
解决方案:集群机器人是一种机器人规模很小、能够有效地处理海量数据的产品。集群机器人可以将从数据库中读取的文本、文件等数据记录和数据通过query字符串进行分析,从而实现快速的数据采集和存储。和普通的采集机器人不同的是,集群机器人可以集中管理数据的整体构架,将query、文件、cookie、数据库的信息共享到相应的地方,在采集图片、视频、音频、文档的过程中,机器人只需要进行query请求,数据由操作系统或者自动部署的服务器端执行。
采集效率高、处理速度快,如果可以保证环境、数据质量等要求,则无需进行集中采集和分配,可以实现在任意时刻只采集一个集群。集群机器人通过file的访问权限控制,具有安全、隐私、多副本的特点。例如,采集音频文件时,可以定义文件夹和文件下不允许第二个进程访问,这些限制适用于集群。集群机器人还可以在批量运行的过程中实现自动化管理,集群还可以通过vim(一键)操作类似文件管理,这样很好地利用了计算机硬件的资源,如有多个集群机器,就需要利用操作系统的相同功能(前提是集群机器可以运行在一个操作系统)来管理。
集群机器人可以通过自动删除和修改的方式实现集群容错和性能损失。集群机器人拥有与采集机器人相同的工作环境(如一个操作系统或者一个集群),集群机器可以自动拓展,具有更好的实时性和可扩展性,尤其适合数据量大的应用。集群机器人通过osm和saas服务的形式接入到集群。集群支持多个集群,集群之间可以进行交互,集群之间可以实现自动化管理。 查看全部
集群机器人集群支持什么特征?(一)
自动采集机器人研发概述:通过自动采集机器人采集要素可以通过数据库将采集后的内容储存起来,形成一个集采集、存储、处理、分析为一体的集群机器人集群。集群机器人集群支持什么特征:集群有限数量、可自动进行聚合处理。集群采集效率和采集规模也要求过高。集群协议要求端到端透明。集群可存储下载与上传全文检索图片、音频、视频、文档等文件。
集群机器人的集群会不断扩展,采集过程中遇到困难也可以使用分布式集群解决。在不停机的情况下,在任意时刻只能采集一个集群。而且多个集群之间无法互相交流。但通过集群集合,可以达到实时监控、分析、数据交换和共享的目的。集群机器人是否需要集中采集和分配,机器人哪些地方集中处理,哪些地方散布式处理?怎么样能够实现在进入集群之前,机器人有足够的机器队列,机器队列用于检索、缓存数据和分布式集群的处理。
解决方案:集群机器人是一种机器人规模很小、能够有效地处理海量数据的产品。集群机器人可以将从数据库中读取的文本、文件等数据记录和数据通过query字符串进行分析,从而实现快速的数据采集和存储。和普通的采集机器人不同的是,集群机器人可以集中管理数据的整体构架,将query、文件、cookie、数据库的信息共享到相应的地方,在采集图片、视频、音频、文档的过程中,机器人只需要进行query请求,数据由操作系统或者自动部署的服务器端执行。
采集效率高、处理速度快,如果可以保证环境、数据质量等要求,则无需进行集中采集和分配,可以实现在任意时刻只采集一个集群。集群机器人通过file的访问权限控制,具有安全、隐私、多副本的特点。例如,采集音频文件时,可以定义文件夹和文件下不允许第二个进程访问,这些限制适用于集群。集群机器人还可以在批量运行的过程中实现自动化管理,集群还可以通过vim(一键)操作类似文件管理,这样很好地利用了计算机硬件的资源,如有多个集群机器,就需要利用操作系统的相同功能(前提是集群机器可以运行在一个操作系统)来管理。
集群机器人可以通过自动删除和修改的方式实现集群容错和性能损失。集群机器人拥有与采集机器人相同的工作环境(如一个操作系统或者一个集群),集群机器可以自动拓展,具有更好的实时性和可扩展性,尤其适合数据量大的应用。集群机器人通过osm和saas服务的形式接入到集群。集群支持多个集群,集群之间可以进行交互,集群之间可以实现自动化管理。
深云机器人自动化测试框架的话有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-07-27 01:01
自动采集机器人有很多,比如在行业内比较知名的深云机器人,前段时间他们就发布过自动采集技术在车载项目中的应用,应该可以试试。当然,想做自动采集的话,第一步肯定是会识别数据,既然你想做车载级别的汽车数据自动采集,肯定是希望能够自动采集出汽车的全部数据,不管是用于mapbox地图的地图数据,还是用于汽车网络,安装三大运营商数据,都可以实现自动采集。
一般在今年10月份左右,车载自动采集机器人就会在freelancer的技术文档里面出现了,到时候多关注一下吧。
如果不是机器人采集的话就先从数据采集开始吧。以下几个地方你可以去了解一下。从用途来说,从左到右依次为车,用户端,b端服务以及c端服务在自动化测试工具方面,可以考虑leancloud,毕竟leancloud是apollo的全力支持者。
从事自动化测试开发方面的应该对采集有些了解。首先想要了解这些,你先要学会从事自动化测试相关工作,了解到自动化测试的基本概念。提到自动化测试工具,无外乎是junit,selenium,webdriver。这里说说selenium,1.selenium是基于浏览器的脚本引擎,2.最大特点是兼容多浏览器。在写真正的脚本引擎的时候是先把浏览器的基本属性搞清楚。
从广泛性来说,chrome有firebug(这个不是去分析tab然后去解析内容),autoit,express.a,capi的中的脚本引擎都比较成熟。看这些技术文档是比较难的,需要了解其理论知识。自动化测试框架的话,allpages,webdriver自己可以关注他们的源码,inspectors比较简单,易上手。
如果你想从事这一方面的话,找到最好的资料一定是一本权威的书籍,叫《自动化测试实战》《自动化测试实战》《自动化测试实战》。看完这一本书,你会对自动化测试有一个比较好的认识。最后补充一句,推荐我正在看的书《深入浅出自动化测试》。推荐阅读,原因简单易懂,不繁琐。 查看全部
深云机器人自动化测试框架的话有哪些?
自动采集机器人有很多,比如在行业内比较知名的深云机器人,前段时间他们就发布过自动采集技术在车载项目中的应用,应该可以试试。当然,想做自动采集的话,第一步肯定是会识别数据,既然你想做车载级别的汽车数据自动采集,肯定是希望能够自动采集出汽车的全部数据,不管是用于mapbox地图的地图数据,还是用于汽车网络,安装三大运营商数据,都可以实现自动采集。
一般在今年10月份左右,车载自动采集机器人就会在freelancer的技术文档里面出现了,到时候多关注一下吧。
如果不是机器人采集的话就先从数据采集开始吧。以下几个地方你可以去了解一下。从用途来说,从左到右依次为车,用户端,b端服务以及c端服务在自动化测试工具方面,可以考虑leancloud,毕竟leancloud是apollo的全力支持者。
从事自动化测试开发方面的应该对采集有些了解。首先想要了解这些,你先要学会从事自动化测试相关工作,了解到自动化测试的基本概念。提到自动化测试工具,无外乎是junit,selenium,webdriver。这里说说selenium,1.selenium是基于浏览器的脚本引擎,2.最大特点是兼容多浏览器。在写真正的脚本引擎的时候是先把浏览器的基本属性搞清楚。
从广泛性来说,chrome有firebug(这个不是去分析tab然后去解析内容),autoit,express.a,capi的中的脚本引擎都比较成熟。看这些技术文档是比较难的,需要了解其理论知识。自动化测试框架的话,allpages,webdriver自己可以关注他们的源码,inspectors比较简单,易上手。
如果你想从事这一方面的话,找到最好的资料一定是一本权威的书籍,叫《自动化测试实战》《自动化测试实战》《自动化测试实战》。看完这一本书,你会对自动化测试有一个比较好的认识。最后补充一句,推荐我正在看的书《深入浅出自动化测试》。推荐阅读,原因简单易懂,不繁琐。
手动采集数据需要注意哪些问题呢?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-07-18 06:19
自动采集机器人(脚本程序机器人)随着智能时代的到来,人工智能已经成为新的风口,自动采集也随之而来。不过需要注意的是要选择智能采集机器人比较好的公司,才能保证机器人获取到的数据质量。那么手动采集数据需要注意哪些问题呢?手动采集数据问题:1.价格不是一步到位的,一定要给它埋下伏笔。2.不要发到,这种平台直接删除。
3.尽量在大的网站和合作商上采集。4.,需要对方公司的一系列硬件,自己没有必要,直接去看别的公司比如说易采也不错。5.为什么?因为数据库里面可能有很多数据,你有一个人工把这些数据全部整理下,这样才是成本最低。6.为什么?因为你发出去,别人收不到,别人收不到你一定会质疑,质疑你们就会产生矛盾。很多公司为了让客户放心选择你们,把用户数据都存在云存储里面,然后让用户下单买服务。
对于智能化采集机器人,具体用不用你们用着舒服就行,第一代采集机器人估计会让很多人失望,但是如果你是小公司,一个员工收入都不到3k,还要承担你这个机器人投入的成本,自然不划算。当你没有获取数据的智能化采集机器人(脚本机器人),记得联系我。我跟你什么仇什么怨,看我不削死你。欢迎关注我。知乎:我是挖财师兄微信:cocowin314。 查看全部
手动采集数据需要注意哪些问题呢?-八维教育
自动采集机器人(脚本程序机器人)随着智能时代的到来,人工智能已经成为新的风口,自动采集也随之而来。不过需要注意的是要选择智能采集机器人比较好的公司,才能保证机器人获取到的数据质量。那么手动采集数据需要注意哪些问题呢?手动采集数据问题:1.价格不是一步到位的,一定要给它埋下伏笔。2.不要发到,这种平台直接删除。
3.尽量在大的网站和合作商上采集。4.,需要对方公司的一系列硬件,自己没有必要,直接去看别的公司比如说易采也不错。5.为什么?因为数据库里面可能有很多数据,你有一个人工把这些数据全部整理下,这样才是成本最低。6.为什么?因为你发出去,别人收不到,别人收不到你一定会质疑,质疑你们就会产生矛盾。很多公司为了让客户放心选择你们,把用户数据都存在云存储里面,然后让用户下单买服务。
对于智能化采集机器人,具体用不用你们用着舒服就行,第一代采集机器人估计会让很多人失望,但是如果你是小公司,一个员工收入都不到3k,还要承担你这个机器人投入的成本,自然不划算。当你没有获取数据的智能化采集机器人(脚本机器人),记得联系我。我跟你什么仇什么怨,看我不削死你。欢迎关注我。知乎:我是挖财师兄微信:cocowin314。
自动采集机器人,有,人工智能随着科技不断发展
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-07-14 05:01
自动采集机器人,有,人工智能随着科技不断发展,我们对世界的认知也越来越丰富,现在各种手机app那么多,总有很多人觉得好玩的不想关闭,这些都是我们要抓取的数据,好处可能很多,
现在平台很多,自己要用心多去调查,需要掌握多久,怎么才能学到,每个公司的学习方式不一样,所以看你需要抓住什么,慢慢培养。
公司自身有内容采集的能力,可以卖个我,或者你帮忙推广一下。
自动采集机器人,有可靠的平台,可以卖给我,
现在有专门帮企业抓取外部数据的平台,上面的数据可靠,
有的,现在外部各行各业都很重视数据,
因为google是业界最大的搜索引擎,如果你的产品可以提供优质的搜索服务,且跟google有合作,可以看看万里高云自动采集这家公司,也就是你说的那种机器人。
现在已经有,不过就算国内发展这么好,谷歌依然是第一,只要google不倒,就不会有人代理你的产品,
有的,有兴趣的话可以了解下。
有可靠的平台,可以卖给我,或者你帮忙推广一下。有需要代理这些数据的朋友,可以加我微信或qq,
个人觉得只要能证明销售数据是真实的都是可靠的。我之前做过电商,感觉这是一个不错的切入点。虽然很多人把它和盗号说起,但是问题是现在实在不好监管,所以风险是有点大的。相对于一些公司自己的电商平台,这样做说不定会不那么需要盗号那么严重的风险了,同时能从一些规则里获利,个人更喜欢这样。 查看全部
自动采集机器人,有,人工智能随着科技不断发展
自动采集机器人,有,人工智能随着科技不断发展,我们对世界的认知也越来越丰富,现在各种手机app那么多,总有很多人觉得好玩的不想关闭,这些都是我们要抓取的数据,好处可能很多,
现在平台很多,自己要用心多去调查,需要掌握多久,怎么才能学到,每个公司的学习方式不一样,所以看你需要抓住什么,慢慢培养。
公司自身有内容采集的能力,可以卖个我,或者你帮忙推广一下。
自动采集机器人,有可靠的平台,可以卖给我,
现在有专门帮企业抓取外部数据的平台,上面的数据可靠,
有的,现在外部各行各业都很重视数据,
因为google是业界最大的搜索引擎,如果你的产品可以提供优质的搜索服务,且跟google有合作,可以看看万里高云自动采集这家公司,也就是你说的那种机器人。
现在已经有,不过就算国内发展这么好,谷歌依然是第一,只要google不倒,就不会有人代理你的产品,
有的,有兴趣的话可以了解下。
有可靠的平台,可以卖给我,或者你帮忙推广一下。有需要代理这些数据的朋友,可以加我微信或qq,
个人觉得只要能证明销售数据是真实的都是可靠的。我之前做过电商,感觉这是一个不错的切入点。虽然很多人把它和盗号说起,但是问题是现在实在不好监管,所以风险是有点大的。相对于一些公司自己的电商平台,这样做说不定会不那么需要盗号那么严重的风险了,同时能从一些规则里获利,个人更喜欢这样。
微影课堂-自动采集机器人的使用方法-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-07-13 07:02
自动采集机器人我们这边有做过具体的介绍和使用方法,你如果不知道的话可以去查看下我写的自动采集课程。
http代理器proxy-server使用方法:上传图片后,
微影课堂-自动抓取微课传播给学生,辅助教师进行教学转化,
可以看一下我专栏的一篇文章,里面详细写了做个自动采集的需求。
网页url序列化,一般是queryset,queryset提交api,接着通过vid或者appid获取uuid等固定信息,再按一定的方式获取userid,传给后端抓取,然后对一些空值进行过滤,再确定一些实用信息,就可以通过post方式传给采集器。常见的自动采集软件比如sendeed、isausible。
自动爬虫。找一家专业的搞这个的,然后自己想办法挣他钱。
自动抓取需要两个方面,一个是数据实时性,另一个是高并发。实时性的话你用封ip地址然后把数据延迟一点可以做到,高并发你可以使用一些第三方服务可以满足你的高并发需求,不过也就只能做到500人。你要想做到500人的话要考虑多少机器,考虑多少带宽,什么时候到。
自动采集自然是使用采集器。大鱼或者千秋采集器都可以做到500人的自动抓取。然后根据自己的需求再找第三方的服务。 查看全部
微影课堂-自动采集机器人的使用方法-乐题库
自动采集机器人我们这边有做过具体的介绍和使用方法,你如果不知道的话可以去查看下我写的自动采集课程。
http代理器proxy-server使用方法:上传图片后,
微影课堂-自动抓取微课传播给学生,辅助教师进行教学转化,
可以看一下我专栏的一篇文章,里面详细写了做个自动采集的需求。
网页url序列化,一般是queryset,queryset提交api,接着通过vid或者appid获取uuid等固定信息,再按一定的方式获取userid,传给后端抓取,然后对一些空值进行过滤,再确定一些实用信息,就可以通过post方式传给采集器。常见的自动采集软件比如sendeed、isausible。
自动爬虫。找一家专业的搞这个的,然后自己想办法挣他钱。
自动抓取需要两个方面,一个是数据实时性,另一个是高并发。实时性的话你用封ip地址然后把数据延迟一点可以做到,高并发你可以使用一些第三方服务可以满足你的高并发需求,不过也就只能做到500人。你要想做到500人的话要考虑多少机器,考虑多少带宽,什么时候到。
自动采集自然是使用采集器。大鱼或者千秋采集器都可以做到500人的自动抓取。然后根据自己的需求再找第三方的服务。
为什么要使用自动采集机器人进行自动发文章(经典)
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2021-07-06 21:02
自动采集机器人文章(经典)最近我研究自动采集功能,实现了知乎自动发文章功能。这个功能极其简单,把主机接上网线,把数据线直接连接主机。然后通过链接数据线连接到采集机器人本体,主机开始自动自发采集文章数据。用户可以通过复制本机文章的url发送给机器人,机器人会把数据发给机器人本体。返回结果一目了然,同时可以方便编辑修改。
(实用篇)为什么要使用自动采集机器人进行自动发文章?最近两年通过这个方法,从一篇篇写好的文章中收集可发到机器人上的数据。对于写过十篇左右的人来说,已经完全有能力在半小时之内实现了文章的自动收集整理。我的使用方法,其实很简单,把本机接到同一个路由器下的机器人本体连接到外网,将采集的数据拷贝到软件的web服务器(比如说http服务器)中。
其中,我一直使用的是redhatenterpriselinux系统,命令行工具sed/bison。网络环境需要在同一局域网下,可以接上网线。有网线的情况下,推荐用“采集机器人”。反之无法正常接入网络时,也可以考虑用“文件传输助手”或“记事本”等。(管理篇)由于我要实现的是发文章,因此需要网页上的链接或html页面。
redhatenterpriselinux上的网页下载工具有extracthtmloutput。因此在pc上找一个html下载工具是比较方便的,本文用的是python3的网页下载工具:filezilla/filezillahttp服务器port75。复制刚才发送给机器人的数据,并命名。要注意的是,名字一定要写全,一个独一无二的文件名。
然后在filezilla/filezilla中(/),将数据下载到手机的相应http服务器。“采集机器人”会将刚才的html发送给主机本体。发送完之后,主机会自动自发采集数据。主机就知道发送给机器人哪些文章了。(本地机器人与爬虫原理图)。 查看全部
为什么要使用自动采集机器人进行自动发文章(经典)
自动采集机器人文章(经典)最近我研究自动采集功能,实现了知乎自动发文章功能。这个功能极其简单,把主机接上网线,把数据线直接连接主机。然后通过链接数据线连接到采集机器人本体,主机开始自动自发采集文章数据。用户可以通过复制本机文章的url发送给机器人,机器人会把数据发给机器人本体。返回结果一目了然,同时可以方便编辑修改。
(实用篇)为什么要使用自动采集机器人进行自动发文章?最近两年通过这个方法,从一篇篇写好的文章中收集可发到机器人上的数据。对于写过十篇左右的人来说,已经完全有能力在半小时之内实现了文章的自动收集整理。我的使用方法,其实很简单,把本机接到同一个路由器下的机器人本体连接到外网,将采集的数据拷贝到软件的web服务器(比如说http服务器)中。
其中,我一直使用的是redhatenterpriselinux系统,命令行工具sed/bison。网络环境需要在同一局域网下,可以接上网线。有网线的情况下,推荐用“采集机器人”。反之无法正常接入网络时,也可以考虑用“文件传输助手”或“记事本”等。(管理篇)由于我要实现的是发文章,因此需要网页上的链接或html页面。
redhatenterpriselinux上的网页下载工具有extracthtmloutput。因此在pc上找一个html下载工具是比较方便的,本文用的是python3的网页下载工具:filezilla/filezillahttp服务器port75。复制刚才发送给机器人的数据,并命名。要注意的是,名字一定要写全,一个独一无二的文件名。
然后在filezilla/filezilla中(/),将数据下载到手机的相应http服务器。“采集机器人”会将刚才的html发送给主机本体。发送完之后,主机会自动自发采集数据。主机就知道发送给机器人哪些文章了。(本地机器人与爬虫原理图)。
自动采集机器人属于自动化硬件系统的运营服务介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-06-27 18:01
自动采集机器人属于自动化硬件系统吧。
网站推广自动化采集一个也是说不清的专业名词,有免费采集,有付费采集。要看你要做什么网站了。市面上做网站的有很多品牌,你所指的应该是市面上免费采集,付费采集一体的吧,那种网站是新手新媒体运营人员用的,也是现在收入比较高的网站采集系统,做一些运营服务。这种采集系统有很多品牌,新浪爱问这个品牌可以查一下。有免费的一般都会有一些要求,根据你的需求选择适合的产品。
大致方向是,视频类网站:视频看得很多,很多都是雷同的,又很多看似不雷同的短视频,采一个批量下来看看有何不可,然后采买视频的推广账号,其实付费也没有贵到那么离谱。问题是视频采集采到之后,如何能发布到自己网站上?这个才是核心。以上提到的主要视频网站:.fei.jpg(新浪)上面这个视频网站就是各大视频网站都有的网站,视频都是视频网站直接采过来的,个别可能需要付费才能看,但绝对安全。
视频站,基本不存在死链接问题,如果需要发布链接,保存图片信息之后,放在文件里,方便自己也方便对方。结果也是如下:下面提到的博客:博客原文采集博客原文只可能是原文被采集,被采集的就封杀。博客高质量资源被采集,会导致你没有一个好的文章被搜索引擎收录,流量会流失,基本这样的文章你百度一搜一大把,百度收不收录没啥区别。
会对你的博客本身有影响。以上几种方式,收集的资源基本你都是不可见的,并不会对你网站产生什么影响,很多都是采集站,论坛里面大量被采集的内容。这些采集站想要持续发展,需要大量的采集,但采集成本就高了,很多人只是看看有啥想采集就采集一下,但采集多了,就会审核无效内容,后面就采集这篇内容,又想换另一篇内容,全部采集出来。
至于采集的影响,比如采集软件:点进去软件,点击任何链接,输入网址,会立刻跳转到一个恶心的页面,然后一直重复搜索任意恶心内容,到处产生垃圾信息,短期内甚至是永久这个页面。也不知道这些发现不发现,其实从搜索引擎或者公域的角度,是毫无价值的。如果这些公域内容,你因为不是采集而被转载了,那从网站的角度,算不算做了坏事?其实这也没有任何损失。
最后一种就是自己付费获取有价值资源,比如:1.有价值的原创图片。搜索引擎会解析文章的主体结构,寻找出需要的原图。有些文章作者只是提供一张图片,实际上还有很多文字内容,只是单纯的提供一张图片,来作为文章的配图。比如:“公务员考试文科类大学生”、“妈妈出游”,这种文章看起来不花太多钱,但如果你分析。 查看全部
自动采集机器人属于自动化硬件系统的运营服务介绍
自动采集机器人属于自动化硬件系统吧。
网站推广自动化采集一个也是说不清的专业名词,有免费采集,有付费采集。要看你要做什么网站了。市面上做网站的有很多品牌,你所指的应该是市面上免费采集,付费采集一体的吧,那种网站是新手新媒体运营人员用的,也是现在收入比较高的网站采集系统,做一些运营服务。这种采集系统有很多品牌,新浪爱问这个品牌可以查一下。有免费的一般都会有一些要求,根据你的需求选择适合的产品。
大致方向是,视频类网站:视频看得很多,很多都是雷同的,又很多看似不雷同的短视频,采一个批量下来看看有何不可,然后采买视频的推广账号,其实付费也没有贵到那么离谱。问题是视频采集采到之后,如何能发布到自己网站上?这个才是核心。以上提到的主要视频网站:.fei.jpg(新浪)上面这个视频网站就是各大视频网站都有的网站,视频都是视频网站直接采过来的,个别可能需要付费才能看,但绝对安全。
视频站,基本不存在死链接问题,如果需要发布链接,保存图片信息之后,放在文件里,方便自己也方便对方。结果也是如下:下面提到的博客:博客原文采集博客原文只可能是原文被采集,被采集的就封杀。博客高质量资源被采集,会导致你没有一个好的文章被搜索引擎收录,流量会流失,基本这样的文章你百度一搜一大把,百度收不收录没啥区别。
会对你的博客本身有影响。以上几种方式,收集的资源基本你都是不可见的,并不会对你网站产生什么影响,很多都是采集站,论坛里面大量被采集的内容。这些采集站想要持续发展,需要大量的采集,但采集成本就高了,很多人只是看看有啥想采集就采集一下,但采集多了,就会审核无效内容,后面就采集这篇内容,又想换另一篇内容,全部采集出来。
至于采集的影响,比如采集软件:点进去软件,点击任何链接,输入网址,会立刻跳转到一个恶心的页面,然后一直重复搜索任意恶心内容,到处产生垃圾信息,短期内甚至是永久这个页面。也不知道这些发现不发现,其实从搜索引擎或者公域的角度,是毫无价值的。如果这些公域内容,你因为不是采集而被转载了,那从网站的角度,算不算做了坏事?其实这也没有任何损失。
最后一种就是自己付费获取有价值资源,比如:1.有价值的原创图片。搜索引擎会解析文章的主体结构,寻找出需要的原图。有些文章作者只是提供一张图片,实际上还有很多文字内容,只是单纯的提供一张图片,来作为文章的配图。比如:“公务员考试文科类大学生”、“妈妈出游”,这种文章看起来不花太多钱,但如果你分析。
自动采集机器人+爬虫+商品橱窗-不同场景下的方案组合
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-06-26 20:02
自动采集机器人+代码采集机器人+爬虫+商品橱窗-不同行业不同场景下需要不同的方案组合,什么场景下可以跳过机器人呢?最近较忙,个人有需要的朋友可以找我咨询。
大体分几种采集机器人或方案
1、全自动采集+代码采集
2、真正采集+组合
3、无采集
4、无采集+代码
一种是比较成熟的分布式采集,一种是离线采集,离线采集后续维护困难,分布式采集有一定优势。现在市面上很多采集工具,有免费的也有收费的,我们都比较看重收费的。
不同采集场景方案不同,
1、真正采集+代码采集
2、无采集+代码采集
3、无采集+demo代码采集
4、无采集+无代码采集
机器人就是开启高效无代码采集模式,我们是看重模式及数据积累。另外,团队业务需要也是的。比如做化妆品品牌销售的,这个年代,讲究个性,不能全被人推销产品啊,用了我的化妆品,然后出来跟人互动,好像被推销了一样,没那个心情,团队也没那个技术;因此,很多客户就会安装一个app来采集,还能记录客户浏览行为。至于说难不难,这里要涉及到行业里边一些其他的问题,比如是否可以采集到你所销售产品的全国相关渠道的卖点、内容?对于这个需求,是属于机器采集,还是真正采集?这个就牵扯到团队协作及代码的积累等问题。 查看全部
自动采集机器人+爬虫+商品橱窗-不同场景下的方案组合
自动采集机器人+代码采集机器人+爬虫+商品橱窗-不同行业不同场景下需要不同的方案组合,什么场景下可以跳过机器人呢?最近较忙,个人有需要的朋友可以找我咨询。
大体分几种采集机器人或方案
1、全自动采集+代码采集
2、真正采集+组合
3、无采集
4、无采集+代码
一种是比较成熟的分布式采集,一种是离线采集,离线采集后续维护困难,分布式采集有一定优势。现在市面上很多采集工具,有免费的也有收费的,我们都比较看重收费的。
不同采集场景方案不同,
1、真正采集+代码采集
2、无采集+代码采集
3、无采集+demo代码采集
4、无采集+无代码采集
机器人就是开启高效无代码采集模式,我们是看重模式及数据积累。另外,团队业务需要也是的。比如做化妆品品牌销售的,这个年代,讲究个性,不能全被人推销产品啊,用了我的化妆品,然后出来跟人互动,好像被推销了一样,没那个心情,团队也没那个技术;因此,很多客户就会安装一个app来采集,还能记录客户浏览行为。至于说难不难,这里要涉及到行业里边一些其他的问题,比如是否可以采集到你所销售产品的全国相关渠道的卖点、内容?对于这个需求,是属于机器采集,还是真正采集?这个就牵扯到团队协作及代码的积累等问题。
Zip存档收集器创建临时目录完整内容的zip存档分析报告
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-06-23 06:11
压缩存档
采集器将创建一个 zip 存档,其中收录采集期间创建的临时目录的完整内容。在 ANT 中,每个操作负责将所需的文件放置在 ${autopdtmp} 属性指示的目录中。这相当于:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
tmp\
必须采集数据
归档中最重要的一项是对应MustGather文档中数据镜像所需的信息。该数据可以在 WC_MustGather 目录中找到。该目录保存在客户端文件系统中找到的每个文件系统的原创文件路径结构。它包括 WebSphere Commerce 应用服务器日志、数据库提取、来自 EAR 的静态文件(部署在 WebSphere 应用服务器中的实例)和来自 WebSphere Commerce 安装目录的静态文件(产品文件)以及 WebSphere 应用服务器安装命令。
/WC_MustGather 收录以下资产:
有关应采集的那些文档的完整列表,请参阅“采集数据”部分中相应的 MustGather。
分析报告
采集器还会在存档的 /WC_Reports 目录中创建分析报告。该报告收录一些有关环境和馆藏本身的信息。该报告首先列出了用于集合的 ISA 版本,如图 28 所示。
图28.信息报告
接下来,突出显示在 SystemOut.log 上检测到的错误,如图 29 所示。
图 29. 突出显示检测到的错误
每个部分都提供了 Google® 搜索的链接。这些链接的内容与 IBM 记录的错误消息相关的一些关键术语或任何已知问题有关。
单击主报告中的 ActionXML Collector Summary 链接将显示一个解释要做什么的文档(图 30)。对于没有此文档的人,它会解释原因(如果不需要,由客户端拒绝许可等)。它还提供了自身的概述,包括以下信息:
图 3 0. 集合概览
返回主报告,其中显示了客户端请求和收到的响应的概览,如图 31 所示。
图31.用户对问题的回答
最后,将显示客户端环境的概览(图 32)。这表明客户端在哪个修订包上,是运行时环境还是开发人员工具包环境,以及客户安装了哪些 APAR。如果是Runtime服务器,数据将表示为产品级和实例级。
图32.环境概览
采集器日志和属性
在存档中,以下目录保存自动数据采集器的输出、日志、配置和属性:
一般来说,使用存档解决问题时不需要检查它们,但在调试自动采集器本身的行为时它们很有用。
临时日志文件
采集器运行过程中,使用ISA工作台时,在以下目录创建临时目录:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
tmp\
创建的采集档案位于以下目录:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
collections\
ISA 采集器日志位于以下目录中:
\
请注意,ISA 日志收录在集合 zip 存档中,这已在上一节中提到。
采集器运行过程中,使用ISA Lite时,在以下目录创建临时目录:
\tmp\
对于 ISA Lite,采集器日志位于以下目录中:
\log
高级配置
有一些方法可以更改采集器的默认行为。一些组件利用采集器配置文件,允许以下配置:
ISA 工作台的配置文件位于:
\\applications\eclipse\plugins\
com.ibm.esupport.client.product.SSZLC270_\config\
wc-autopd-config.properties
对于 ISA Lite,配置文件位于:
\config\wc-autopd-config.properties
日志级别
记录器类,用于记录自定义 WebSphere Commerce Java 任务,可以使用 wc.logLevel.debug 属性进行配置。默认值为“false”,用于标准录制。设置为“true”以添加更详细的记录以供调试。
#logLevel, set to true to enable verbose logging wc.logLevel.debug=false
数据库配置
提取数据库数据的方法也可以使用属性文件进行配置。有多种方法可用于自动确定数据库连接信息。默认情况下,dbPropertySource 设置为“wcServerXML”值,这意味着大多数数据库配置值来自实例配置文件。将通知用户剩余价值。
如果dbPropertySource的值设置为“promptUser”,那么所有相关问题都会提示给用户,而不是从实例配置文件中检索。
最后,如果将dbPropertySource 值设置为“wc-autopd-config”,则必须从wc-autopd-config.properties 文件中检索除数据库用户密码之外的所有值。用户经常会收到数据库密码作为输入提示,因为出于安全原因,密码从未被坚持。
使用 wc-autopd-config 配置时,有三个选项。您需要设置清单 1 中的值。默认情况下,使用 JDBC 连接的通用类型 4 驱动程序(用于 DB2 和 Oracle®),它被配置为 DB2® 数据库。您可以更改 wc.dbDriver、wc.dbUrl 和 wc.dbDriverPath 的值以支持旧的 DB2 驱动程序(键入 2) 或 Oracle Support 通用驱动程序。
列出1.配置设置
#method of pulling the values for DB
#options: wcServerXML, promptUser, wc-autopd-config
dbPropertySource=wcServerXML
# Universal - Type 4 (DB2)
wc.dbType=DB2
wc.dbDriver=com.ibm.db2.jcc.DB2Driver
wc.dbUrl=jdbc:db2://localhost:50000/mall
wc.dbDriver.path=C:\SQLLIB\java\db2jcc.jar
wc.dbName=mall
wc.dbUserName=db2inst1
# Universal - Type 4 (Oracle)
#Oracle
#wc.dbType=oracle
#wc.dbDriver=oracle.jdbc.driver.OracleDriver
#wc.dbUrl=jdbc:oracle:thin:@localhost:1521:O10G
#wc.dbDriver.path=C:\oracle\product\10.2.0\db_1\jdbc\lib\
classes12.jar
#wc.dbName=O10G
#wc.dbUserName=wcsuser
快速采集模式
在 ISA Workbench 或 ISA Lite 上运行时,另一种选择是使用 QuickCollect 模式。为了避免采集器每次都询问常见问题,如果答案相同,请在 wc-autopd-config.properties 上启动 QuickCollect 模式,如清单 2 所示。
列出2.QuickCollect 配置
wc.quickCollect=true
wc.quickCollectActions=GatherFiles,GatherSQL
wc.root=D:/WebSphere/WCToolkit70
wc.instanceName=demo
was.root=D:/WebSphere/SDP/runtimes/base_v7
was.profile.path=D:/WebSphere/WCToolkit70/wasprofile
was.profile.name=wasprofile
was.cell=WC_demo_cell
was.node=WC_demo_node
was.server.name=server1
wc.ear.install.path=D:/WebSphere/WCToolkit70/workspace/WC
updi.root=D:/WebSphere/UpdateInstaller
将 wc.quickCollector 更改为“true”。然后将清单 2 中显示的其他属性设置到文件系统中的正确位置。
在 QuickCollect 模式下运行时,采集器可以减少向用户提示的次数。请注意,这不需要每个操作的许可。因此,需要预先许可,以便可以切换 wc.quickCollectActions 属性中列出的操作的设置。默认配置可以采集所有文件和数据库摘要,如 GatherFiles 和 GatherSQL 的值所示。但是,如果 wc.quickCollectActions 收录 GatherTrace,仍然会提示您复制问题并设置跟踪字符串,因为这是必需的交互。
全面的激活和禁用操作
可以完全禁用收录用户永远不想授权的操作的操作(例如,如果 DBA 始终需要从数据库中获取 SQL 数据)。无论哪个操作设置为 true,它都会运行(并假设许可)。那些在 wc-autopd-config.properties 中设置为“false”的操作将不会运行(并且不需要权限),如图 3 所示。
列出3.启用和禁用操作
#Enabled Actions, default = true
GatherFiles=true
AskQuestion=true
wc_gatherTrace=true
GatherSQL=true
InvokeShellCommand=false
ModifyFile=false
GatherScreenShot=true
结论
在解决自己的问题时,WebSphere Commerce 自动化数据采集器旨在改进和简化数据的获取,或与 IBM 支持部门合作。采集器通过 IBM Support Assistant 或 ISA Lite 框架运行,并保留用户对其环境中发生的任何操作的控制权。自动采集器可以获得所有必要的跟踪、文件、数据摘要、屏幕截图和自定义附件,以帮助通过 IBM 支持确定问题的根本原因,镜像手动 MustGather 文档。 HTML 分析报告随每个集合生成,其中汇总了数据集合和客户端概述。 查看全部
Zip存档收集器创建临时目录完整内容的zip存档分析报告
压缩存档
采集器将创建一个 zip 存档,其中收录采集期间创建的临时目录的完整内容。在 ANT 中,每个操作负责将所需的文件放置在 ${autopdtmp} 属性指示的目录中。这相当于:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
tmp\
必须采集数据
归档中最重要的一项是对应MustGather文档中数据镜像所需的信息。该数据可以在 WC_MustGather 目录中找到。该目录保存在客户端文件系统中找到的每个文件系统的原创文件路径结构。它包括 WebSphere Commerce 应用服务器日志、数据库提取、来自 EAR 的静态文件(部署在 WebSphere 应用服务器中的实例)和来自 WebSphere Commerce 安装目录的静态文件(产品文件)以及 WebSphere 应用服务器安装命令。
/WC_MustGather 收录以下资产:
有关应采集的那些文档的完整列表,请参阅“采集数据”部分中相应的 MustGather。
分析报告
采集器还会在存档的 /WC_Reports 目录中创建分析报告。该报告收录一些有关环境和馆藏本身的信息。该报告首先列出了用于集合的 ISA 版本,如图 28 所示。
图28.信息报告

接下来,突出显示在 SystemOut.log 上检测到的错误,如图 29 所示。
图 29. 突出显示检测到的错误

每个部分都提供了 Google® 搜索的链接。这些链接的内容与 IBM 记录的错误消息相关的一些关键术语或任何已知问题有关。
单击主报告中的 ActionXML Collector Summary 链接将显示一个解释要做什么的文档(图 30)。对于没有此文档的人,它会解释原因(如果不需要,由客户端拒绝许可等)。它还提供了自身的概述,包括以下信息:
图 3 0. 集合概览

返回主报告,其中显示了客户端请求和收到的响应的概览,如图 31 所示。
图31.用户对问题的回答

最后,将显示客户端环境的概览(图 32)。这表明客户端在哪个修订包上,是运行时环境还是开发人员工具包环境,以及客户安装了哪些 APAR。如果是Runtime服务器,数据将表示为产品级和实例级。
图32.环境概览

采集器日志和属性
在存档中,以下目录保存自动数据采集器的输出、日志、配置和属性:
一般来说,使用存档解决问题时不需要检查它们,但在调试自动采集器本身的行为时它们很有用。
临时日志文件
采集器运行过程中,使用ISA工作台时,在以下目录创建临时目录:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
tmp\
创建的采集档案位于以下目录:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
collections\
ISA 采集器日志位于以下目录中:
\
请注意,ISA 日志收录在集合 zip 存档中,这已在上一节中提到。
采集器运行过程中,使用ISA Lite时,在以下目录创建临时目录:
\tmp\
对于 ISA Lite,采集器日志位于以下目录中:
\log
高级配置
有一些方法可以更改采集器的默认行为。一些组件利用采集器配置文件,允许以下配置:
ISA 工作台的配置文件位于:
\\applications\eclipse\plugins\
com.ibm.esupport.client.product.SSZLC270_\config\
wc-autopd-config.properties
对于 ISA Lite,配置文件位于:
\config\wc-autopd-config.properties
日志级别
记录器类,用于记录自定义 WebSphere Commerce Java 任务,可以使用 wc.logLevel.debug 属性进行配置。默认值为“false”,用于标准录制。设置为“true”以添加更详细的记录以供调试。
#logLevel, set to true to enable verbose logging wc.logLevel.debug=false
数据库配置
提取数据库数据的方法也可以使用属性文件进行配置。有多种方法可用于自动确定数据库连接信息。默认情况下,dbPropertySource 设置为“wcServerXML”值,这意味着大多数数据库配置值来自实例配置文件。将通知用户剩余价值。
如果dbPropertySource的值设置为“promptUser”,那么所有相关问题都会提示给用户,而不是从实例配置文件中检索。
最后,如果将dbPropertySource 值设置为“wc-autopd-config”,则必须从wc-autopd-config.properties 文件中检索除数据库用户密码之外的所有值。用户经常会收到数据库密码作为输入提示,因为出于安全原因,密码从未被坚持。
使用 wc-autopd-config 配置时,有三个选项。您需要设置清单 1 中的值。默认情况下,使用 JDBC 连接的通用类型 4 驱动程序(用于 DB2 和 Oracle®),它被配置为 DB2® 数据库。您可以更改 wc.dbDriver、wc.dbUrl 和 wc.dbDriverPath 的值以支持旧的 DB2 驱动程序(键入 2) 或 Oracle Support 通用驱动程序。
列出1.配置设置
#method of pulling the values for DB
#options: wcServerXML, promptUser, wc-autopd-config
dbPropertySource=wcServerXML
# Universal - Type 4 (DB2)
wc.dbType=DB2
wc.dbDriver=com.ibm.db2.jcc.DB2Driver
wc.dbUrl=jdbc:db2://localhost:50000/mall
wc.dbDriver.path=C:\SQLLIB\java\db2jcc.jar
wc.dbName=mall
wc.dbUserName=db2inst1
# Universal - Type 4 (Oracle)
#Oracle
#wc.dbType=oracle
#wc.dbDriver=oracle.jdbc.driver.OracleDriver
#wc.dbUrl=jdbc:oracle:thin:@localhost:1521:O10G
#wc.dbDriver.path=C:\oracle\product\10.2.0\db_1\jdbc\lib\
classes12.jar
#wc.dbName=O10G
#wc.dbUserName=wcsuser
快速采集模式
在 ISA Workbench 或 ISA Lite 上运行时,另一种选择是使用 QuickCollect 模式。为了避免采集器每次都询问常见问题,如果答案相同,请在 wc-autopd-config.properties 上启动 QuickCollect 模式,如清单 2 所示。
列出2.QuickCollect 配置
wc.quickCollect=true
wc.quickCollectActions=GatherFiles,GatherSQL
wc.root=D:/WebSphere/WCToolkit70
wc.instanceName=demo
was.root=D:/WebSphere/SDP/runtimes/base_v7
was.profile.path=D:/WebSphere/WCToolkit70/wasprofile
was.profile.name=wasprofile
was.cell=WC_demo_cell
was.node=WC_demo_node
was.server.name=server1
wc.ear.install.path=D:/WebSphere/WCToolkit70/workspace/WC
updi.root=D:/WebSphere/UpdateInstaller
将 wc.quickCollector 更改为“true”。然后将清单 2 中显示的其他属性设置到文件系统中的正确位置。
在 QuickCollect 模式下运行时,采集器可以减少向用户提示的次数。请注意,这不需要每个操作的许可。因此,需要预先许可,以便可以切换 wc.quickCollectActions 属性中列出的操作的设置。默认配置可以采集所有文件和数据库摘要,如 GatherFiles 和 GatherSQL 的值所示。但是,如果 wc.quickCollectActions 收录 GatherTrace,仍然会提示您复制问题并设置跟踪字符串,因为这是必需的交互。
全面的激活和禁用操作
可以完全禁用收录用户永远不想授权的操作的操作(例如,如果 DBA 始终需要从数据库中获取 SQL 数据)。无论哪个操作设置为 true,它都会运行(并假设许可)。那些在 wc-autopd-config.properties 中设置为“false”的操作将不会运行(并且不需要权限),如图 3 所示。
列出3.启用和禁用操作
#Enabled Actions, default = true
GatherFiles=true
AskQuestion=true
wc_gatherTrace=true
GatherSQL=true
InvokeShellCommand=false
ModifyFile=false
GatherScreenShot=true
结论
在解决自己的问题时,WebSphere Commerce 自动化数据采集器旨在改进和简化数据的获取,或与 IBM 支持部门合作。采集器通过 IBM Support Assistant 或 ISA Lite 框架运行,并保留用户对其环境中发生的任何操作的控制权。自动采集器可以获得所有必要的跟踪、文件、数据摘要、屏幕截图和自定义附件,以帮助通过 IBM 支持确定问题的根本原因,镜像手动 MustGather 文档。 HTML 分析报告随每个集合生成,其中汇总了数据集合和客户端概述。
自动采集机器人不收费,给你们两个软件!
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-06-15 04:01
自动采集机器人是可以自动采集百度、、微博、微信公众号的文章,有钱赚。免费使用,写好程序,招收合作伙伴,盈利无上限。创建一个免费机器人按以下要求操作即可打开微信聊天窗口,
hi,我是信鸽。经常在微信群中收到你们问我要一些实用性小软件的信息,我在群里一般是扫描二维码或者是找大佬在群里问。但是,你们会发现,有些信息,我在别的群里是能解决的,但是你去别的群里问就显得非常麻烦。在这里,我可以给你们两个软件。我一般要链接,你们可以直接下载自己需要的。能不能把小编人性化一下呢!!!1.现在有人可能喜欢截图,用ps截图或者是用摄像头截图,给你们一个小工具。
websocket配合wepy也就是发送http请求。数据校验加密传输,安全稳定。支持多种协议,支持分析和收发控制,一秒支持多次发送。2.或者是说一个html文档,这里面我可以直接截图识别成json给你们。自动解析翻译成中文。自动采集阅读量评论量等一些信息。自动采集微信公众号文章!识别图片!文字识别!切割png图片!还有一些小功能我就不一一列举了。
发送给你们的图片,不一定是高清,也有很多浏览器打不开,或者翻译不了,格式不好。但是这个软件就完美解决上面的这些问题。这个自动采集机器人不收费,给你们免费的。在公众号公众号:信鸽寻梦人。 查看全部
自动采集机器人不收费,给你们两个软件!
自动采集机器人是可以自动采集百度、、微博、微信公众号的文章,有钱赚。免费使用,写好程序,招收合作伙伴,盈利无上限。创建一个免费机器人按以下要求操作即可打开微信聊天窗口,
hi,我是信鸽。经常在微信群中收到你们问我要一些实用性小软件的信息,我在群里一般是扫描二维码或者是找大佬在群里问。但是,你们会发现,有些信息,我在别的群里是能解决的,但是你去别的群里问就显得非常麻烦。在这里,我可以给你们两个软件。我一般要链接,你们可以直接下载自己需要的。能不能把小编人性化一下呢!!!1.现在有人可能喜欢截图,用ps截图或者是用摄像头截图,给你们一个小工具。
websocket配合wepy也就是发送http请求。数据校验加密传输,安全稳定。支持多种协议,支持分析和收发控制,一秒支持多次发送。2.或者是说一个html文档,这里面我可以直接截图识别成json给你们。自动解析翻译成中文。自动采集阅读量评论量等一些信息。自动采集微信公众号文章!识别图片!文字识别!切割png图片!还有一些小功能我就不一一列举了。
发送给你们的图片,不一定是高清,也有很多浏览器打不开,或者翻译不了,格式不好。但是这个软件就完美解决上面的这些问题。这个自动采集机器人不收费,给你们免费的。在公众号公众号:信鸽寻梦人。
自动采集机 api回调:我在这里,你要采我就采
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-06-11 07:02
自动采集机器人的采集速度是固定的,不能随着你的实际需求增加自动和加速采集次数。根据机器人自己的自动和加速速度可以对机器人做定向的方向控制,增加适应性。例如我的机器人是一辆汽车,我每次只加速10%-20%的能力,把它控制在接近100米左右。这样就能保证我的需求不被机器人采集速度忽略掉了。
api回调:我在这里,你要采我就采。每个自动化采集机器人必须向productdataset提交从路径获取的用户id、用户信息(即商品信息)、可操作值、目标访问人数、采集规模等信息。在productdataset提交上述信息之后,再把获取到的数据push到代码生成的url中。下图是一个典型的代码生成url,带2个参数,queryex(stories,values)和urls,urls则是url提交前将会返回的http头部。
urls则是让我们用于进行在需要对url提交的详细信息加载的加载信息。采用api方式来启动自动采集项目,能够更好地保证原始数据的完整性。以下是一些个人见解:1.机器人本身可以设置路径,url中的data只是机器人收集了用户数据,并分析出用户需求。机器人只是productdataset中的一个用户id,所以也只能采用这个方式。
2.如果机器人上有接口方式来判断用户是不是真正存在这一类行为,那么我们可以将一些要采集到的数据,写在数据库中,然后用户可以发送邮件或者地址/帐号到机器人上,要采集的数据就可以查看到了。 查看全部
自动采集机 api回调:我在这里,你要采我就采
自动采集机器人的采集速度是固定的,不能随着你的实际需求增加自动和加速采集次数。根据机器人自己的自动和加速速度可以对机器人做定向的方向控制,增加适应性。例如我的机器人是一辆汽车,我每次只加速10%-20%的能力,把它控制在接近100米左右。这样就能保证我的需求不被机器人采集速度忽略掉了。
api回调:我在这里,你要采我就采。每个自动化采集机器人必须向productdataset提交从路径获取的用户id、用户信息(即商品信息)、可操作值、目标访问人数、采集规模等信息。在productdataset提交上述信息之后,再把获取到的数据push到代码生成的url中。下图是一个典型的代码生成url,带2个参数,queryex(stories,values)和urls,urls则是url提交前将会返回的http头部。
urls则是让我们用于进行在需要对url提交的详细信息加载的加载信息。采用api方式来启动自动采集项目,能够更好地保证原始数据的完整性。以下是一些个人见解:1.机器人本身可以设置路径,url中的data只是机器人收集了用户数据,并分析出用户需求。机器人只是productdataset中的一个用户id,所以也只能采用这个方式。
2.如果机器人上有接口方式来判断用户是不是真正存在这一类行为,那么我们可以将一些要采集到的数据,写在数据库中,然后用户可以发送邮件或者地址/帐号到机器人上,要采集的数据就可以查看到了。
自动采集机(自动调用cookie功能的使用方法(1).20)
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2021-09-05 17:41
一.功能介绍:
采集器 运行任务时,通过访问指定的网页来调用获取cookie。
使用场景:
1. cookie过期后采集规则无法正常。通过设置该功能,自动获取网页cookie调用,无需手动替换cookie,规则可以正常运行,自动采集。
2、部分网站需要在本地浏览器打开页面查看来实现验证,设置自动获取cookie功能可以避免手动手动访问网页的操作。
此功能需要旗舰(自动授权)及以上版本才能使用。 (添加于 2020 年 6 月 15 日 v9.20)
二.如何使用
(1)开启自动更新设置为开启,如下图。
(2)两种判断方式:(以下两个条件任意之一满足,功能激活,请根据实际需要设置)
采集Failed 判断字符串:填写采集规则失败时返回的唯一字符串。如果请求中出现字符串且满足条件,则自动激活cookie功能,自动访问“信息更新访问URL”获取cookie和ua。
请求内容长度小于:当请求返回的源代码长度小于设置的大小时,软件会自动调用cookie函数,自动访问“信息更新访问URL”获取cookie。填0不判断请求返回的源码长度。
注意:此功能不适用于输入用户名和密码登录网站,以及需要确定验证码的网站。 查看全部
自动采集机(自动调用cookie功能的使用方法(1).20)
一.功能介绍:
采集器 运行任务时,通过访问指定的网页来调用获取cookie。
使用场景:
1. cookie过期后采集规则无法正常。通过设置该功能,自动获取网页cookie调用,无需手动替换cookie,规则可以正常运行,自动采集。
2、部分网站需要在本地浏览器打开页面查看来实现验证,设置自动获取cookie功能可以避免手动手动访问网页的操作。
此功能需要旗舰(自动授权)及以上版本才能使用。 (添加于 2020 年 6 月 15 日 v9.20)
二.如何使用
(1)开启自动更新设置为开启,如下图。
(2)两种判断方式:(以下两个条件任意之一满足,功能激活,请根据实际需要设置)
采集Failed 判断字符串:填写采集规则失败时返回的唯一字符串。如果请求中出现字符串且满足条件,则自动激活cookie功能,自动访问“信息更新访问URL”获取cookie和ua。
请求内容长度小于:当请求返回的源代码长度小于设置的大小时,软件会自动调用cookie函数,自动访问“信息更新访问URL”获取cookie。填0不判断请求返回的源码长度。
注意:此功能不适用于输入用户名和密码登录网站,以及需要确定验证码的网站。
自动采集机(基于视频自动采集机器人解决方案详细介绍!(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-09-03 16:52
自动采集机器人已经是我们非常熟悉的一种采集机器人方式,主要是通过点击来对网站进行采集。下面为大家介绍一下基于视频自动采集机器人解决方案。
一、视频自动采集机器人解决方案
1、自动采集机器人适用于爱奇艺的app软件,
2、软件功能部分使用了内置的抖音采集api;
3、软件部分加入了自动浏览器的采集;
二、采集原理在自动采集机器人之前会有一个虚拟采集器,
三、视频采集机器人实现手机快速采集手机端打开视频采集机器人后,
四、采集原理目前市面上采集机器人有高级采集机器人和普通采集机器人,我们目前使用高级采集机器人,自动搜索视频后,会返回网站地址,我们可以自行录制视频,然后将视频上传;以上就是对视频采集机器人解决方案详细介绍,
视频采集机器人将会是,最有效的方式,可以帮助视频创作者解决:自动快速获取视频地址,自动高效处理图片,自动切割视频,自动标题优化等。
现在最主要的问题是视频通过什么渠道进行采集?再就是如何能够通过视频来检测同行的出发点和行为。
请有视频的大大们分享一下你们见过的“顶”用的机器人采集?
不是真正的机器人,都是三方资源,一旦合作,资源的利用都是无上限的。“在下做视频,卖货。”这是他现在的处境!出于各方面的原因,网红行业深度玩家决定和平台达成合作。打个比方:网红行业的客户,可以委托给“一号机器人”,实现异地安全采集,包括客户访问页面、视频下载,甚至进行筛选、标签分析、编辑。类似一号机器人这种机器人,意义在于精准采集,提升网红转化率和客户体验度。
阿里有人手红包机器人,京东也有cps机器人,美拍也有购物机器人。整个行业往往实行的是“小弟养大哥”模式,小弟用大哥的资源,做二道贩子,不断挑逗大哥情绪,很多时候看上去就像“变形金刚”一样。网红的真正价值在于,告诉客户用户的真实需求、实际痛点。再者,真正意义上的机器人只需要几秒内完成用户检索,不受同行干扰,比人工采集还要快,专业性极强。另外,机器人还可以变成客户的忠实工具,提高客户的黏性。 查看全部
自动采集机(基于视频自动采集机器人解决方案详细介绍!(一))
自动采集机器人已经是我们非常熟悉的一种采集机器人方式,主要是通过点击来对网站进行采集。下面为大家介绍一下基于视频自动采集机器人解决方案。
一、视频自动采集机器人解决方案
1、自动采集机器人适用于爱奇艺的app软件,
2、软件功能部分使用了内置的抖音采集api;
3、软件部分加入了自动浏览器的采集;
二、采集原理在自动采集机器人之前会有一个虚拟采集器,
三、视频采集机器人实现手机快速采集手机端打开视频采集机器人后,
四、采集原理目前市面上采集机器人有高级采集机器人和普通采集机器人,我们目前使用高级采集机器人,自动搜索视频后,会返回网站地址,我们可以自行录制视频,然后将视频上传;以上就是对视频采集机器人解决方案详细介绍,
视频采集机器人将会是,最有效的方式,可以帮助视频创作者解决:自动快速获取视频地址,自动高效处理图片,自动切割视频,自动标题优化等。
现在最主要的问题是视频通过什么渠道进行采集?再就是如何能够通过视频来检测同行的出发点和行为。
请有视频的大大们分享一下你们见过的“顶”用的机器人采集?
不是真正的机器人,都是三方资源,一旦合作,资源的利用都是无上限的。“在下做视频,卖货。”这是他现在的处境!出于各方面的原因,网红行业深度玩家决定和平台达成合作。打个比方:网红行业的客户,可以委托给“一号机器人”,实现异地安全采集,包括客户访问页面、视频下载,甚至进行筛选、标签分析、编辑。类似一号机器人这种机器人,意义在于精准采集,提升网红转化率和客户体验度。
阿里有人手红包机器人,京东也有cps机器人,美拍也有购物机器人。整个行业往往实行的是“小弟养大哥”模式,小弟用大哥的资源,做二道贩子,不断挑逗大哥情绪,很多时候看上去就像“变形金刚”一样。网红的真正价值在于,告诉客户用户的真实需求、实际痛点。再者,真正意义上的机器人只需要几秒内完成用户检索,不受同行干扰,比人工采集还要快,专业性极强。另外,机器人还可以变成客户的忠实工具,提高客户的黏性。
自动采集机(自动采集机器人的服务器要多大!一个最小大小能采集20条发邮件!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-09-03 15:46
自动采集机器人的服务器要多大!一个最小大小能采集20条发邮件!那就是一台1p30m的采集机器人!每个机器人一个月发10条,就算就一条,需要100个服务器!一个月上千块!看起来是很小。如果采集一个上万人的网站。那么就是上千万的采集机器人!每个机器人再自动发送邮件!这么说吧,一个机器人每个月自动发送发送0.1万封邮件,累计发送100万封不等。
那每个机器人的成本就是3元每封!这采集的邮件你还不能直接打给客户,所以,你懂得,也不好意思明说。一般的都是让他们用某个邮箱发送,等他们确认收到后在打到你的某个邮箱。这个工作量,不是一般人能做到的。除非,你生活圈里的人,都懂seo,都懂sns!。
这么大的数据量了...服务器一个月三千块.你觉得哪家公司能扛得住?或者弄好了之后一个月就给你提供10万邮箱账号?=补充一下,这个数据量太大了,没有必要.这个东西目前没什么价值,发邮件还没人发,更别说自动采集了.
应该这么看问题;邮件服务器的使用成本也算是一笔不小的投入的。
目前我们用的是全自动采集,没用机器人, 查看全部
自动采集机(自动采集机器人的服务器要多大!一个最小大小能采集20条发邮件!)
自动采集机器人的服务器要多大!一个最小大小能采集20条发邮件!那就是一台1p30m的采集机器人!每个机器人一个月发10条,就算就一条,需要100个服务器!一个月上千块!看起来是很小。如果采集一个上万人的网站。那么就是上千万的采集机器人!每个机器人再自动发送邮件!这么说吧,一个机器人每个月自动发送发送0.1万封邮件,累计发送100万封不等。
那每个机器人的成本就是3元每封!这采集的邮件你还不能直接打给客户,所以,你懂得,也不好意思明说。一般的都是让他们用某个邮箱发送,等他们确认收到后在打到你的某个邮箱。这个工作量,不是一般人能做到的。除非,你生活圈里的人,都懂seo,都懂sns!。
这么大的数据量了...服务器一个月三千块.你觉得哪家公司能扛得住?或者弄好了之后一个月就给你提供10万邮箱账号?=补充一下,这个数据量太大了,没有必要.这个东西目前没什么价值,发邮件还没人发,更别说自动采集了.
应该这么看问题;邮件服务器的使用成本也算是一笔不小的投入的。
目前我们用的是全自动采集,没用机器人,
自动采集机(ET2(EditorTools)全自动采集器是中小网站自动更新利器!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-01 15:01
ET2(EditorTools)自动采集器是一款中小型网站自动更新工具!可以很好的帮助用户解决中小型网站和企业站的信息自动采集操作,更智能的采集方案保证你的网站内容更新的质量及时! EditorTools的出现,将为您节省大量时间,让站长和管理员从繁琐无聊的网站更新工作中解脱出来!
功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集] 需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发回帖,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目任意语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集release可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态 查看全部
自动采集机(ET2(EditorTools)全自动采集器是中小网站自动更新利器!)
ET2(EditorTools)自动采集器是一款中小型网站自动更新工具!可以很好的帮助用户解决中小型网站和企业站的信息自动采集操作,更智能的采集方案保证你的网站内容更新的质量及时! EditorTools的出现,将为您节省大量时间,让站长和管理员从繁琐无聊的网站更新工作中解脱出来!
功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集] 需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发回帖,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目任意语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集release可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
自动采集机( ET2全自动采集器特色介绍采集规则灵活强大(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-09-01 15:00
ET2全自动采集器特色介绍采集规则灵活强大(组图))
ET2 Automatic 采集器 是一个独立的软件,支持任何网站 和数据库采集 版本。无需人工干预,可连续多年不间断工作,安全稳定。
ET2自动采集器基本介绍
ET2自动采集器是一款中小型网站自动更新工具。这是一款独立软件,静默运行,无需人工干预,安全稳定,无网站性能消耗。软件支持任何网站和采集版本的数据库,内置discuz、disuzX、phpwind、dvbbs、dedecms、wordpress、zblog、joomla、phpcms、empirecms、东易, Xinyun, 风迅、pbdigg、php168、bbsxp、phpbb、淘特等常用系统示例。
ET2自动采集器功能介绍
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经测试,ET可以长时间自动运行,即使时间单位是年。
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器或网站管理员的工作站上工作。 ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。 采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
除了一般采集工具的功能外,ET2全自动采集器通过图片水印、防盗、分页采集、回复采集、登录采集、自定义物品、UTF -支持8、UBB,模拟发布...让用户可以灵活实现各种毛发采集需求。
ET2自动采集器功能介绍采集规则灵活强大,不仅采集文章,采集任何信息。软件采用FTP上传文件,稳定安全。可以选择倒序、顺序、随机采集文章,支持高速伪原创,支持网站多页数据分布采集,自由设置采集数据项,可以过滤排序每个数据项单独,支持下载任何格式和类型的文件(包括图片、视频) 查看全部
自动采集机(
ET2全自动采集器特色介绍采集规则灵活强大(组图))
ET2 Automatic 采集器 是一个独立的软件,支持任何网站 和数据库采集 版本。无需人工干预,可连续多年不间断工作,安全稳定。
ET2自动采集器基本介绍
ET2自动采集器是一款中小型网站自动更新工具。这是一款独立软件,静默运行,无需人工干预,安全稳定,无网站性能消耗。软件支持任何网站和采集版本的数据库,内置discuz、disuzX、phpwind、dvbbs、dedecms、wordpress、zblog、joomla、phpcms、empirecms、东易, Xinyun, 风迅、pbdigg、php168、bbsxp、phpbb、淘特等常用系统示例。
ET2自动采集器功能介绍
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经测试,ET可以长时间自动运行,即使时间单位是年。
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器或网站管理员的工作站上工作。 ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。 采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
除了一般采集工具的功能外,ET2全自动采集器通过图片水印、防盗、分页采集、回复采集、登录采集、自定义物品、UTF -支持8、UBB,模拟发布...让用户可以灵活实现各种毛发采集需求。
ET2自动采集器功能介绍采集规则灵活强大,不仅采集文章,采集任何信息。软件采用FTP上传文件,稳定安全。可以选择倒序、顺序、随机采集文章,支持高速伪原创,支持网站多页数据分布采集,自由设置采集数据项,可以过滤排序每个数据项单独,支持下载任何格式和类型的文件(包括图片、视频)
自动采集机(自动采集机器人--拓展空间,发现更大的世界)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-01 05:03
自动采集机器人--拓展空间,发现更大的世界-()企业介绍采集机器人--拓展空间,发现更大的世界-()背景随着企业智能化升级速度不断加快,管理人工智能辅助管理逐渐成为了很多企业所着重处理的事情。现有的采集机器人在实际使用中存在着大量的技术瓶颈,在实际的使用场景中存在着比较多的弊端,比如,没有复杂且有意义的交互行为;交互过程不能收到必要的控制;收集到的结果信息存在偏差等,但是我们目前存在的ai采集机器人,可以克服以上问题。
一夫科技研发的智能采集机器人,其技术和自主学习能力也已经在企业ai采集管理领域得到验证,在不断的实际使用中,各项性能指标已经接近实际使用,是目前市场上ai采集机器人领域已被证明的产品。企业合作拓展性和灵活性是机器人行业的一大特色,ai采集机器人的出现,也是满足了机器人智能化需求,是一款具有开拓性的产品。
一夫科技成立于2014年,是一家定位于企业ai采集管理领域的科技公司,坚持将科技研发作为企业研发核心,始终如一的秉承坚持学术前沿性研发,不断创新改变传统服务性企业形态为目标。在人工智能领域深耕十余年,布局从技术到市场化。致力于成为专业的企业ai采集管理系统提供商,是目前中国规模最大的企业ai采集管理系统商户之一。
产品和服务2014年一夫科技研发的irva采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的小高度型人工智能采集机器人,通过对全球开源代码的翻译和生成,实现了对任意网站任意数据库的垂直采集,是一款垂直服务型ai采集机器人。2015年发布的海外海内兼容系统,可以全球通用,实现信息传输的自动化和全球信息互通,也为企业进一步采集全球信息提供了新思路。
企业发展时间线创始人:戴林;董事长;ceo;全球人工智能和自动化的先驱与发明者;企业ai信息化理念践行者;总裁2014年一夫科技研发的智能采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的海外海内兼容系统,可以全球通用,实现信息传输的自动化和全球信息互通,也为企业进一步采集全球信息提供了新思路。
创始人:戴林;董事长;ceo;全球人工智能和自动化的先驱与发明者;企业ai信息化理念践行者;总裁2014年一夫科技研发的智能采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的海外海内兼容系。 查看全部
自动采集机(自动采集机器人--拓展空间,发现更大的世界)
自动采集机器人--拓展空间,发现更大的世界-()企业介绍采集机器人--拓展空间,发现更大的世界-()背景随着企业智能化升级速度不断加快,管理人工智能辅助管理逐渐成为了很多企业所着重处理的事情。现有的采集机器人在实际使用中存在着大量的技术瓶颈,在实际的使用场景中存在着比较多的弊端,比如,没有复杂且有意义的交互行为;交互过程不能收到必要的控制;收集到的结果信息存在偏差等,但是我们目前存在的ai采集机器人,可以克服以上问题。
一夫科技研发的智能采集机器人,其技术和自主学习能力也已经在企业ai采集管理领域得到验证,在不断的实际使用中,各项性能指标已经接近实际使用,是目前市场上ai采集机器人领域已被证明的产品。企业合作拓展性和灵活性是机器人行业的一大特色,ai采集机器人的出现,也是满足了机器人智能化需求,是一款具有开拓性的产品。
一夫科技成立于2014年,是一家定位于企业ai采集管理领域的科技公司,坚持将科技研发作为企业研发核心,始终如一的秉承坚持学术前沿性研发,不断创新改变传统服务性企业形态为目标。在人工智能领域深耕十余年,布局从技术到市场化。致力于成为专业的企业ai采集管理系统提供商,是目前中国规模最大的企业ai采集管理系统商户之一。
产品和服务2014年一夫科技研发的irva采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的小高度型人工智能采集机器人,通过对全球开源代码的翻译和生成,实现了对任意网站任意数据库的垂直采集,是一款垂直服务型ai采集机器人。2015年发布的海外海内兼容系统,可以全球通用,实现信息传输的自动化和全球信息互通,也为企业进一步采集全球信息提供了新思路。
企业发展时间线创始人:戴林;董事长;ceo;全球人工智能和自动化的先驱与发明者;企业ai信息化理念践行者;总裁2014年一夫科技研发的智能采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的海外海内兼容系统,可以全球通用,实现信息传输的自动化和全球信息互通,也为企业进一步采集全球信息提供了新思路。
创始人:戴林;董事长;ceo;全球人工智能和自动化的先驱与发明者;企业ai信息化理念践行者;总裁2014年一夫科技研发的智能采集机器人,在全球1200+家企业中认证并应用,先后通过在华设计研发并申请技术专利20多项。2015年发布的海外海内兼容系。
自动采集机(识别、任意编码识别等多种识别系统,智能识别让操作更轻松)
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-08-29 23:09
优采云采集器7.6 是一款功能强大且易于使用的专业采集 软件。也是目前最流行的网页数据采集软件,不仅可以灵活快速地抓取网页,还可以对互联网上的任何数据轻松快速地获取和处理分散的数据信息。该软件界面简洁,功能全面。搭载文字识别、中文分词识别、任意码识别等多种识别系统。智能识别,操作更简单。支持access/MySQL/MsSQL/Sqlite/Oracle多种类型的数据库存储和发布,图片、压缩文件、视频等任何格式的文件均可轻松下载。它还支持接口和插件扩展,以满足用户的各种需求。另外优采云采集器采用分布式高速采集系统,多台服务器同时运行,解决工作学习中的大量数据下载和使用需求,让您拥有更多有时间做更多的事情。
同时,对于SEO人员来说,优采云是一个常用的采集工具。熟练的使用会让SEO人员的工作更有效率,但该软件是付费产品。为此小编带来了@k11优采云采集器7.6破解版,无需安装,无需登录,运行程序直接使用软件所有功能,虽然这个软件不是最新版本,但是常用的功能还是可以的,可以满足用户的需求。
软件亮点
1、几乎所有网页都可以采集
无论什么语言,
不管是什么编码。
2、 和复制粘贴一样准确
采集/发布就像复制/粘贴一样准确,
用户要的是本质,哪有遗漏!
3、 比普通采集器 快 7 倍
优采云采集器采用顶层系统配置,
反复优化性能,让采集飞得更快!
4、网站采集的同义词
拥有独特的十年经验,行业领先品牌,
想到网页采集,想到优采云采集器!
优采云采集器使用教程:
1、本站下载解压,得到优采云采集器7.6免安装破解版软件包,双击运行“LocoyPlatform.exe”直接打开软件;
2、进入第一个界面后,点击New Group,可以随意写名字和备注;
3、然后点击进入新创建的组,然后右键创建任务;
4、编辑任务名称,然后添加采集目标页面的链接;
5、这里选择批量/多页采集;
6、URL采集的规则设置:
注:采集的数量可根据需要更改
7、点击添加采集rule;
8、然后进行采集的第二部分:内容规则的设置;
9、设置标题替换;
10、配置网站后台的登录信息和要发布的栏目,然后保存配置,全部保存,就OK了。可以正式批量采集文章。
特别提醒:
1、优采云数据采集平台要求,您的电脑必须安装.net framework2.0或2.0或以上。如果你的采集器打不开,请下载安装框架:
附上windows .net框架2.0下载链接
32位下载地址:
64位下载地址:
2、崩溃的解决方法:
-优采云根目录下有一个名为AutoUpdate.exe的文件,删除这个文件;
-打开C:\Windows\System32\drivers\etc,编辑hosts文件,添加如下内容:
(如果编辑hosts没有生效,请关闭安全卫士等软件)
特点
1、无级多页采集,可以达到无限深度采集
2、任务队列操作管理,支持Cron表达式
3、无限组任务管理,任务回收站功能
4、RSSAddress采集Function
5、List页面分页采集Get函数
6、List页面附加参数获取功能
7、List页面和标签XPath视觉提取功能
8、tag 纯正则替换函数 查看全部
自动采集机(识别、任意编码识别等多种识别系统,智能识别让操作更轻松)
优采云采集器7.6 是一款功能强大且易于使用的专业采集 软件。也是目前最流行的网页数据采集软件,不仅可以灵活快速地抓取网页,还可以对互联网上的任何数据轻松快速地获取和处理分散的数据信息。该软件界面简洁,功能全面。搭载文字识别、中文分词识别、任意码识别等多种识别系统。智能识别,操作更简单。支持access/MySQL/MsSQL/Sqlite/Oracle多种类型的数据库存储和发布,图片、压缩文件、视频等任何格式的文件均可轻松下载。它还支持接口和插件扩展,以满足用户的各种需求。另外优采云采集器采用分布式高速采集系统,多台服务器同时运行,解决工作学习中的大量数据下载和使用需求,让您拥有更多有时间做更多的事情。
同时,对于SEO人员来说,优采云是一个常用的采集工具。熟练的使用会让SEO人员的工作更有效率,但该软件是付费产品。为此小编带来了@k11优采云采集器7.6破解版,无需安装,无需登录,运行程序直接使用软件所有功能,虽然这个软件不是最新版本,但是常用的功能还是可以的,可以满足用户的需求。
软件亮点
1、几乎所有网页都可以采集
无论什么语言,
不管是什么编码。
2、 和复制粘贴一样准确
采集/发布就像复制/粘贴一样准确,
用户要的是本质,哪有遗漏!
3、 比普通采集器 快 7 倍
优采云采集器采用顶层系统配置,
反复优化性能,让采集飞得更快!
4、网站采集的同义词
拥有独特的十年经验,行业领先品牌,
想到网页采集,想到优采云采集器!
优采云采集器使用教程:
1、本站下载解压,得到优采云采集器7.6免安装破解版软件包,双击运行“LocoyPlatform.exe”直接打开软件;
2、进入第一个界面后,点击New Group,可以随意写名字和备注;
3、然后点击进入新创建的组,然后右键创建任务;
4、编辑任务名称,然后添加采集目标页面的链接;
5、这里选择批量/多页采集;
6、URL采集的规则设置:
注:采集的数量可根据需要更改
7、点击添加采集rule;
8、然后进行采集的第二部分:内容规则的设置;
9、设置标题替换;
10、配置网站后台的登录信息和要发布的栏目,然后保存配置,全部保存,就OK了。可以正式批量采集文章。
特别提醒:
1、优采云数据采集平台要求,您的电脑必须安装.net framework2.0或2.0或以上。如果你的采集器打不开,请下载安装框架:
附上windows .net框架2.0下载链接
32位下载地址:
64位下载地址:
2、崩溃的解决方法:
-优采云根目录下有一个名为AutoUpdate.exe的文件,删除这个文件;
-打开C:\Windows\System32\drivers\etc,编辑hosts文件,添加如下内容:
(如果编辑hosts没有生效,请关闭安全卫士等软件)
特点
1、无级多页采集,可以达到无限深度采集
2、任务队列操作管理,支持Cron表达式
3、无限组任务管理,任务回收站功能
4、RSSAddress采集Function
5、List页面分页采集Get函数
6、List页面附加参数获取功能
7、List页面和标签XPath视觉提取功能
8、tag 纯正则替换函数
这是一款独立运行的全自动信息采集软件,帮助用户奖励千百倍
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-08-25 01:07
无人值守采集助(EditorTools2)这是一款独立的自动信息采集软件,可以帮助用户奖励数千倍的人力物力消耗,持续获取最优海量数据。带给用户安全、稳定、易用且低消耗的体验。
功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
【特点】独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任何格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集]需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发帖回复,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目任意语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集发布可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
运行环境
EditorTools 的操作与网站无关。如果可以管理网站服务器,可以选择在网站服务器运行ET;如果租用虚拟主机,请在本地工作机器上运行ET。
操作系统要求
EditorTools是一款win32软件,可以在微软简体中文版Windows xp/2000/2003/2008/vista/win7等操作系统环境下运行。我们在软件中对上述操作系统做了大量的测试和实地考察,以确保EditorTools能够在上述系统中安全稳定地运行。
如果选择在非简体中文Windows操作系统下运行ET,可能会遇到界面乱码。你需要自己测试一下。您通常可以安装标准的简体中文字体库(GB2312))。
支持环境要求
EditorTools 要求计算机具有以下软件环境:
mdac 2.8 或以上(ADO 数据库驱动)
注册scrrun.dll(用于读写脚本和文本文件)
注册vbscript.dll(VBScript脚本相关支持文件)
多个ET同时工作
EditorTools 允许在同一台计算机上运行多个副本,但您应该注意不要运行同一 ET 程序的多个副本。您应该复制整个ET文件夹的多个副本并分别执行以避免数据库冲突。
更新说明
1、Fixed:INI文件读写异常不再弹窗提示。
2、Fixed:谷歌翻译结果不全的问题。 查看全部
这是一款独立运行的全自动信息采集软件,帮助用户奖励千百倍
无人值守采集助(EditorTools2)这是一款独立的自动信息采集软件,可以帮助用户奖励数千倍的人力物力消耗,持续获取最优海量数据。带给用户安全、稳定、易用且低消耗的体验。
功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
【特点】独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任何格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集]需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发帖回复,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目任意语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集发布可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
运行环境
EditorTools 的操作与网站无关。如果可以管理网站服务器,可以选择在网站服务器运行ET;如果租用虚拟主机,请在本地工作机器上运行ET。
操作系统要求
EditorTools是一款win32软件,可以在微软简体中文版Windows xp/2000/2003/2008/vista/win7等操作系统环境下运行。我们在软件中对上述操作系统做了大量的测试和实地考察,以确保EditorTools能够在上述系统中安全稳定地运行。
如果选择在非简体中文Windows操作系统下运行ET,可能会遇到界面乱码。你需要自己测试一下。您通常可以安装标准的简体中文字体库(GB2312))。
支持环境要求
EditorTools 要求计算机具有以下软件环境:
mdac 2.8 或以上(ADO 数据库驱动)
注册scrrun.dll(用于读写脚本和文本文件)
注册vbscript.dll(VBScript脚本相关支持文件)
多个ET同时工作
EditorTools 允许在同一台计算机上运行多个副本,但您应该注意不要运行同一 ET 程序的多个副本。您应该复制整个ET文件夹的多个副本并分别执行以避免数据库冲突。
更新说明
1、Fixed:INI文件读写异常不再弹窗提示。
2、Fixed:谷歌翻译结果不全的问题。
v1.0采集软件特色介绍,快速分析数据采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-23 23:42
Abu采集 是一个非常有用的网站auxiliary采集 工具。这个软件可以帮助我们快速采集并管理相关数据。软件还支持分析搜索引擎数据和分析来自指定种子网站的数据,让我们快速分析相关数据,有需要的朋友赶紧下载吧。
Abu采集使用教程
1、打开软件。
2、可以对相关数据执行采集。
Abu采集软件功能
1、云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步爬取数据
2、智能防封
自动破解多种验证码,提供代理IP池,结合UA切换,有效突破封锁,畅通采集数据
3、全网适用
看到就选,无论是图片通话还是贴吧论坛,支持全业务渠道爬虫,满足采集各种需求
4、Massive 模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
5、简单好用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
6、稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可灵活调度任务,平滑抓取海量数据,支持分析
更新日志
v1.0
1、重新设计了爬虫引擎,支持从搜索引擎分析数据,从指定的种子网站开始。
2、重新设计了软件架构,以插件的形式提供各种数据分析引擎,软件默认自带Email分析引擎。
3、 重新设计了轻量级线程池。
4、独特的反阻塞技术。
5、高效的检测机制过滤掉重复访问。
6、内置多国搜索引擎,方便外贸朋友采集资料 查看全部
v1.0采集软件特色介绍,快速分析数据采集工具
Abu采集 是一个非常有用的网站auxiliary采集 工具。这个软件可以帮助我们快速采集并管理相关数据。软件还支持分析搜索引擎数据和分析来自指定种子网站的数据,让我们快速分析相关数据,有需要的朋友赶紧下载吧。
Abu采集使用教程
1、打开软件。
2、可以对相关数据执行采集。
Abu采集软件功能
1、云采集
5000台云服务器,24*7高效稳定采集,结合API,可无缝对接内部系统,定时同步爬取数据
2、智能防封
自动破解多种验证码,提供代理IP池,结合UA切换,有效突破封锁,畅通采集数据
3、全网适用
看到就选,无论是图片通话还是贴吧论坛,支持全业务渠道爬虫,满足采集各种需求
4、Massive 模板
内置数百个网站数据源,全面覆盖多个行业,简单设置即可快速准确获取数据。
5、简单好用
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
6、稳定高效
分布式云集群服务器和多用户协同管理平台的支持,可灵活调度任务,平滑抓取海量数据,支持分析
更新日志
v1.0
1、重新设计了爬虫引擎,支持从搜索引擎分析数据,从指定的种子网站开始。
2、重新设计了软件架构,以插件的形式提供各种数据分析引擎,软件默认自带Email分析引擎。
3、 重新设计了轻量级线程池。
4、独特的反阻塞技术。
5、高效的检测机制过滤掉重复访问。
6、内置多国搜索引擎,方便外贸朋友采集资料
集群机器人集群支持什么特征?(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-08-21 23:02
自动采集机器人研发概述:通过自动采集机器人采集要素可以通过数据库将采集后的内容储存起来,形成一个集采集、存储、处理、分析为一体的集群机器人集群。集群机器人集群支持什么特征:集群有限数量、可自动进行聚合处理。集群采集效率和采集规模也要求过高。集群协议要求端到端透明。集群可存储下载与上传全文检索图片、音频、视频、文档等文件。
集群机器人的集群会不断扩展,采集过程中遇到困难也可以使用分布式集群解决。在不停机的情况下,在任意时刻只能采集一个集群。而且多个集群之间无法互相交流。但通过集群集合,可以达到实时监控、分析、数据交换和共享的目的。集群机器人是否需要集中采集和分配,机器人哪些地方集中处理,哪些地方散布式处理?怎么样能够实现在进入集群之前,机器人有足够的机器队列,机器队列用于检索、缓存数据和分布式集群的处理。
解决方案:集群机器人是一种机器人规模很小、能够有效地处理海量数据的产品。集群机器人可以将从数据库中读取的文本、文件等数据记录和数据通过query字符串进行分析,从而实现快速的数据采集和存储。和普通的采集机器人不同的是,集群机器人可以集中管理数据的整体构架,将query、文件、cookie、数据库的信息共享到相应的地方,在采集图片、视频、音频、文档的过程中,机器人只需要进行query请求,数据由操作系统或者自动部署的服务器端执行。
采集效率高、处理速度快,如果可以保证环境、数据质量等要求,则无需进行集中采集和分配,可以实现在任意时刻只采集一个集群。集群机器人通过file的访问权限控制,具有安全、隐私、多副本的特点。例如,采集音频文件时,可以定义文件夹和文件下不允许第二个进程访问,这些限制适用于集群。集群机器人还可以在批量运行的过程中实现自动化管理,集群还可以通过vim(一键)操作类似文件管理,这样很好地利用了计算机硬件的资源,如有多个集群机器,就需要利用操作系统的相同功能(前提是集群机器可以运行在一个操作系统)来管理。
集群机器人可以通过自动删除和修改的方式实现集群容错和性能损失。集群机器人拥有与采集机器人相同的工作环境(如一个操作系统或者一个集群),集群机器可以自动拓展,具有更好的实时性和可扩展性,尤其适合数据量大的应用。集群机器人通过osm和saas服务的形式接入到集群。集群支持多个集群,集群之间可以进行交互,集群之间可以实现自动化管理。 查看全部
集群机器人集群支持什么特征?(一)
自动采集机器人研发概述:通过自动采集机器人采集要素可以通过数据库将采集后的内容储存起来,形成一个集采集、存储、处理、分析为一体的集群机器人集群。集群机器人集群支持什么特征:集群有限数量、可自动进行聚合处理。集群采集效率和采集规模也要求过高。集群协议要求端到端透明。集群可存储下载与上传全文检索图片、音频、视频、文档等文件。
集群机器人的集群会不断扩展,采集过程中遇到困难也可以使用分布式集群解决。在不停机的情况下,在任意时刻只能采集一个集群。而且多个集群之间无法互相交流。但通过集群集合,可以达到实时监控、分析、数据交换和共享的目的。集群机器人是否需要集中采集和分配,机器人哪些地方集中处理,哪些地方散布式处理?怎么样能够实现在进入集群之前,机器人有足够的机器队列,机器队列用于检索、缓存数据和分布式集群的处理。
解决方案:集群机器人是一种机器人规模很小、能够有效地处理海量数据的产品。集群机器人可以将从数据库中读取的文本、文件等数据记录和数据通过query字符串进行分析,从而实现快速的数据采集和存储。和普通的采集机器人不同的是,集群机器人可以集中管理数据的整体构架,将query、文件、cookie、数据库的信息共享到相应的地方,在采集图片、视频、音频、文档的过程中,机器人只需要进行query请求,数据由操作系统或者自动部署的服务器端执行。
采集效率高、处理速度快,如果可以保证环境、数据质量等要求,则无需进行集中采集和分配,可以实现在任意时刻只采集一个集群。集群机器人通过file的访问权限控制,具有安全、隐私、多副本的特点。例如,采集音频文件时,可以定义文件夹和文件下不允许第二个进程访问,这些限制适用于集群。集群机器人还可以在批量运行的过程中实现自动化管理,集群还可以通过vim(一键)操作类似文件管理,这样很好地利用了计算机硬件的资源,如有多个集群机器,就需要利用操作系统的相同功能(前提是集群机器可以运行在一个操作系统)来管理。
集群机器人可以通过自动删除和修改的方式实现集群容错和性能损失。集群机器人拥有与采集机器人相同的工作环境(如一个操作系统或者一个集群),集群机器可以自动拓展,具有更好的实时性和可扩展性,尤其适合数据量大的应用。集群机器人通过osm和saas服务的形式接入到集群。集群支持多个集群,集群之间可以进行交互,集群之间可以实现自动化管理。
深云机器人自动化测试框架的话有哪些?
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-07-27 01:01
自动采集机器人有很多,比如在行业内比较知名的深云机器人,前段时间他们就发布过自动采集技术在车载项目中的应用,应该可以试试。当然,想做自动采集的话,第一步肯定是会识别数据,既然你想做车载级别的汽车数据自动采集,肯定是希望能够自动采集出汽车的全部数据,不管是用于mapbox地图的地图数据,还是用于汽车网络,安装三大运营商数据,都可以实现自动采集。
一般在今年10月份左右,车载自动采集机器人就会在freelancer的技术文档里面出现了,到时候多关注一下吧。
如果不是机器人采集的话就先从数据采集开始吧。以下几个地方你可以去了解一下。从用途来说,从左到右依次为车,用户端,b端服务以及c端服务在自动化测试工具方面,可以考虑leancloud,毕竟leancloud是apollo的全力支持者。
从事自动化测试开发方面的应该对采集有些了解。首先想要了解这些,你先要学会从事自动化测试相关工作,了解到自动化测试的基本概念。提到自动化测试工具,无外乎是junit,selenium,webdriver。这里说说selenium,1.selenium是基于浏览器的脚本引擎,2.最大特点是兼容多浏览器。在写真正的脚本引擎的时候是先把浏览器的基本属性搞清楚。
从广泛性来说,chrome有firebug(这个不是去分析tab然后去解析内容),autoit,express.a,capi的中的脚本引擎都比较成熟。看这些技术文档是比较难的,需要了解其理论知识。自动化测试框架的话,allpages,webdriver自己可以关注他们的源码,inspectors比较简单,易上手。
如果你想从事这一方面的话,找到最好的资料一定是一本权威的书籍,叫《自动化测试实战》《自动化测试实战》《自动化测试实战》。看完这一本书,你会对自动化测试有一个比较好的认识。最后补充一句,推荐我正在看的书《深入浅出自动化测试》。推荐阅读,原因简单易懂,不繁琐。 查看全部
深云机器人自动化测试框架的话有哪些?
自动采集机器人有很多,比如在行业内比较知名的深云机器人,前段时间他们就发布过自动采集技术在车载项目中的应用,应该可以试试。当然,想做自动采集的话,第一步肯定是会识别数据,既然你想做车载级别的汽车数据自动采集,肯定是希望能够自动采集出汽车的全部数据,不管是用于mapbox地图的地图数据,还是用于汽车网络,安装三大运营商数据,都可以实现自动采集。
一般在今年10月份左右,车载自动采集机器人就会在freelancer的技术文档里面出现了,到时候多关注一下吧。
如果不是机器人采集的话就先从数据采集开始吧。以下几个地方你可以去了解一下。从用途来说,从左到右依次为车,用户端,b端服务以及c端服务在自动化测试工具方面,可以考虑leancloud,毕竟leancloud是apollo的全力支持者。
从事自动化测试开发方面的应该对采集有些了解。首先想要了解这些,你先要学会从事自动化测试相关工作,了解到自动化测试的基本概念。提到自动化测试工具,无外乎是junit,selenium,webdriver。这里说说selenium,1.selenium是基于浏览器的脚本引擎,2.最大特点是兼容多浏览器。在写真正的脚本引擎的时候是先把浏览器的基本属性搞清楚。
从广泛性来说,chrome有firebug(这个不是去分析tab然后去解析内容),autoit,express.a,capi的中的脚本引擎都比较成熟。看这些技术文档是比较难的,需要了解其理论知识。自动化测试框架的话,allpages,webdriver自己可以关注他们的源码,inspectors比较简单,易上手。
如果你想从事这一方面的话,找到最好的资料一定是一本权威的书籍,叫《自动化测试实战》《自动化测试实战》《自动化测试实战》。看完这一本书,你会对自动化测试有一个比较好的认识。最后补充一句,推荐我正在看的书《深入浅出自动化测试》。推荐阅读,原因简单易懂,不繁琐。
手动采集数据需要注意哪些问题呢?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-07-18 06:19
自动采集机器人(脚本程序机器人)随着智能时代的到来,人工智能已经成为新的风口,自动采集也随之而来。不过需要注意的是要选择智能采集机器人比较好的公司,才能保证机器人获取到的数据质量。那么手动采集数据需要注意哪些问题呢?手动采集数据问题:1.价格不是一步到位的,一定要给它埋下伏笔。2.不要发到,这种平台直接删除。
3.尽量在大的网站和合作商上采集。4.,需要对方公司的一系列硬件,自己没有必要,直接去看别的公司比如说易采也不错。5.为什么?因为数据库里面可能有很多数据,你有一个人工把这些数据全部整理下,这样才是成本最低。6.为什么?因为你发出去,别人收不到,别人收不到你一定会质疑,质疑你们就会产生矛盾。很多公司为了让客户放心选择你们,把用户数据都存在云存储里面,然后让用户下单买服务。
对于智能化采集机器人,具体用不用你们用着舒服就行,第一代采集机器人估计会让很多人失望,但是如果你是小公司,一个员工收入都不到3k,还要承担你这个机器人投入的成本,自然不划算。当你没有获取数据的智能化采集机器人(脚本机器人),记得联系我。我跟你什么仇什么怨,看我不削死你。欢迎关注我。知乎:我是挖财师兄微信:cocowin314。 查看全部
手动采集数据需要注意哪些问题呢?-八维教育
自动采集机器人(脚本程序机器人)随着智能时代的到来,人工智能已经成为新的风口,自动采集也随之而来。不过需要注意的是要选择智能采集机器人比较好的公司,才能保证机器人获取到的数据质量。那么手动采集数据需要注意哪些问题呢?手动采集数据问题:1.价格不是一步到位的,一定要给它埋下伏笔。2.不要发到,这种平台直接删除。
3.尽量在大的网站和合作商上采集。4.,需要对方公司的一系列硬件,自己没有必要,直接去看别的公司比如说易采也不错。5.为什么?因为数据库里面可能有很多数据,你有一个人工把这些数据全部整理下,这样才是成本最低。6.为什么?因为你发出去,别人收不到,别人收不到你一定会质疑,质疑你们就会产生矛盾。很多公司为了让客户放心选择你们,把用户数据都存在云存储里面,然后让用户下单买服务。
对于智能化采集机器人,具体用不用你们用着舒服就行,第一代采集机器人估计会让很多人失望,但是如果你是小公司,一个员工收入都不到3k,还要承担你这个机器人投入的成本,自然不划算。当你没有获取数据的智能化采集机器人(脚本机器人),记得联系我。我跟你什么仇什么怨,看我不削死你。欢迎关注我。知乎:我是挖财师兄微信:cocowin314。
自动采集机器人,有,人工智能随着科技不断发展
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-07-14 05:01
自动采集机器人,有,人工智能随着科技不断发展,我们对世界的认知也越来越丰富,现在各种手机app那么多,总有很多人觉得好玩的不想关闭,这些都是我们要抓取的数据,好处可能很多,
现在平台很多,自己要用心多去调查,需要掌握多久,怎么才能学到,每个公司的学习方式不一样,所以看你需要抓住什么,慢慢培养。
公司自身有内容采集的能力,可以卖个我,或者你帮忙推广一下。
自动采集机器人,有可靠的平台,可以卖给我,
现在有专门帮企业抓取外部数据的平台,上面的数据可靠,
有的,现在外部各行各业都很重视数据,
因为google是业界最大的搜索引擎,如果你的产品可以提供优质的搜索服务,且跟google有合作,可以看看万里高云自动采集这家公司,也就是你说的那种机器人。
现在已经有,不过就算国内发展这么好,谷歌依然是第一,只要google不倒,就不会有人代理你的产品,
有的,有兴趣的话可以了解下。
有可靠的平台,可以卖给我,或者你帮忙推广一下。有需要代理这些数据的朋友,可以加我微信或qq,
个人觉得只要能证明销售数据是真实的都是可靠的。我之前做过电商,感觉这是一个不错的切入点。虽然很多人把它和盗号说起,但是问题是现在实在不好监管,所以风险是有点大的。相对于一些公司自己的电商平台,这样做说不定会不那么需要盗号那么严重的风险了,同时能从一些规则里获利,个人更喜欢这样。 查看全部
自动采集机器人,有,人工智能随着科技不断发展
自动采集机器人,有,人工智能随着科技不断发展,我们对世界的认知也越来越丰富,现在各种手机app那么多,总有很多人觉得好玩的不想关闭,这些都是我们要抓取的数据,好处可能很多,
现在平台很多,自己要用心多去调查,需要掌握多久,怎么才能学到,每个公司的学习方式不一样,所以看你需要抓住什么,慢慢培养。
公司自身有内容采集的能力,可以卖个我,或者你帮忙推广一下。
自动采集机器人,有可靠的平台,可以卖给我,
现在有专门帮企业抓取外部数据的平台,上面的数据可靠,
有的,现在外部各行各业都很重视数据,
因为google是业界最大的搜索引擎,如果你的产品可以提供优质的搜索服务,且跟google有合作,可以看看万里高云自动采集这家公司,也就是你说的那种机器人。
现在已经有,不过就算国内发展这么好,谷歌依然是第一,只要google不倒,就不会有人代理你的产品,
有的,有兴趣的话可以了解下。
有可靠的平台,可以卖给我,或者你帮忙推广一下。有需要代理这些数据的朋友,可以加我微信或qq,
个人觉得只要能证明销售数据是真实的都是可靠的。我之前做过电商,感觉这是一个不错的切入点。虽然很多人把它和盗号说起,但是问题是现在实在不好监管,所以风险是有点大的。相对于一些公司自己的电商平台,这样做说不定会不那么需要盗号那么严重的风险了,同时能从一些规则里获利,个人更喜欢这样。
微影课堂-自动采集机器人的使用方法-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-07-13 07:02
自动采集机器人我们这边有做过具体的介绍和使用方法,你如果不知道的话可以去查看下我写的自动采集课程。
http代理器proxy-server使用方法:上传图片后,
微影课堂-自动抓取微课传播给学生,辅助教师进行教学转化,
可以看一下我专栏的一篇文章,里面详细写了做个自动采集的需求。
网页url序列化,一般是queryset,queryset提交api,接着通过vid或者appid获取uuid等固定信息,再按一定的方式获取userid,传给后端抓取,然后对一些空值进行过滤,再确定一些实用信息,就可以通过post方式传给采集器。常见的自动采集软件比如sendeed、isausible。
自动爬虫。找一家专业的搞这个的,然后自己想办法挣他钱。
自动抓取需要两个方面,一个是数据实时性,另一个是高并发。实时性的话你用封ip地址然后把数据延迟一点可以做到,高并发你可以使用一些第三方服务可以满足你的高并发需求,不过也就只能做到500人。你要想做到500人的话要考虑多少机器,考虑多少带宽,什么时候到。
自动采集自然是使用采集器。大鱼或者千秋采集器都可以做到500人的自动抓取。然后根据自己的需求再找第三方的服务。 查看全部
微影课堂-自动采集机器人的使用方法-乐题库
自动采集机器人我们这边有做过具体的介绍和使用方法,你如果不知道的话可以去查看下我写的自动采集课程。
http代理器proxy-server使用方法:上传图片后,
微影课堂-自动抓取微课传播给学生,辅助教师进行教学转化,
可以看一下我专栏的一篇文章,里面详细写了做个自动采集的需求。
网页url序列化,一般是queryset,queryset提交api,接着通过vid或者appid获取uuid等固定信息,再按一定的方式获取userid,传给后端抓取,然后对一些空值进行过滤,再确定一些实用信息,就可以通过post方式传给采集器。常见的自动采集软件比如sendeed、isausible。
自动爬虫。找一家专业的搞这个的,然后自己想办法挣他钱。
自动抓取需要两个方面,一个是数据实时性,另一个是高并发。实时性的话你用封ip地址然后把数据延迟一点可以做到,高并发你可以使用一些第三方服务可以满足你的高并发需求,不过也就只能做到500人。你要想做到500人的话要考虑多少机器,考虑多少带宽,什么时候到。
自动采集自然是使用采集器。大鱼或者千秋采集器都可以做到500人的自动抓取。然后根据自己的需求再找第三方的服务。
为什么要使用自动采集机器人进行自动发文章(经典)
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2021-07-06 21:02
自动采集机器人文章(经典)最近我研究自动采集功能,实现了知乎自动发文章功能。这个功能极其简单,把主机接上网线,把数据线直接连接主机。然后通过链接数据线连接到采集机器人本体,主机开始自动自发采集文章数据。用户可以通过复制本机文章的url发送给机器人,机器人会把数据发给机器人本体。返回结果一目了然,同时可以方便编辑修改。
(实用篇)为什么要使用自动采集机器人进行自动发文章?最近两年通过这个方法,从一篇篇写好的文章中收集可发到机器人上的数据。对于写过十篇左右的人来说,已经完全有能力在半小时之内实现了文章的自动收集整理。我的使用方法,其实很简单,把本机接到同一个路由器下的机器人本体连接到外网,将采集的数据拷贝到软件的web服务器(比如说http服务器)中。
其中,我一直使用的是redhatenterpriselinux系统,命令行工具sed/bison。网络环境需要在同一局域网下,可以接上网线。有网线的情况下,推荐用“采集机器人”。反之无法正常接入网络时,也可以考虑用“文件传输助手”或“记事本”等。(管理篇)由于我要实现的是发文章,因此需要网页上的链接或html页面。
redhatenterpriselinux上的网页下载工具有extracthtmloutput。因此在pc上找一个html下载工具是比较方便的,本文用的是python3的网页下载工具:filezilla/filezillahttp服务器port75。复制刚才发送给机器人的数据,并命名。要注意的是,名字一定要写全,一个独一无二的文件名。
然后在filezilla/filezilla中(/),将数据下载到手机的相应http服务器。“采集机器人”会将刚才的html发送给主机本体。发送完之后,主机会自动自发采集数据。主机就知道发送给机器人哪些文章了。(本地机器人与爬虫原理图)。 查看全部
为什么要使用自动采集机器人进行自动发文章(经典)
自动采集机器人文章(经典)最近我研究自动采集功能,实现了知乎自动发文章功能。这个功能极其简单,把主机接上网线,把数据线直接连接主机。然后通过链接数据线连接到采集机器人本体,主机开始自动自发采集文章数据。用户可以通过复制本机文章的url发送给机器人,机器人会把数据发给机器人本体。返回结果一目了然,同时可以方便编辑修改。
(实用篇)为什么要使用自动采集机器人进行自动发文章?最近两年通过这个方法,从一篇篇写好的文章中收集可发到机器人上的数据。对于写过十篇左右的人来说,已经完全有能力在半小时之内实现了文章的自动收集整理。我的使用方法,其实很简单,把本机接到同一个路由器下的机器人本体连接到外网,将采集的数据拷贝到软件的web服务器(比如说http服务器)中。
其中,我一直使用的是redhatenterpriselinux系统,命令行工具sed/bison。网络环境需要在同一局域网下,可以接上网线。有网线的情况下,推荐用“采集机器人”。反之无法正常接入网络时,也可以考虑用“文件传输助手”或“记事本”等。(管理篇)由于我要实现的是发文章,因此需要网页上的链接或html页面。
redhatenterpriselinux上的网页下载工具有extracthtmloutput。因此在pc上找一个html下载工具是比较方便的,本文用的是python3的网页下载工具:filezilla/filezillahttp服务器port75。复制刚才发送给机器人的数据,并命名。要注意的是,名字一定要写全,一个独一无二的文件名。
然后在filezilla/filezilla中(/),将数据下载到手机的相应http服务器。“采集机器人”会将刚才的html发送给主机本体。发送完之后,主机会自动自发采集数据。主机就知道发送给机器人哪些文章了。(本地机器人与爬虫原理图)。
自动采集机器人属于自动化硬件系统的运营服务介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-06-27 18:01
自动采集机器人属于自动化硬件系统吧。
网站推广自动化采集一个也是说不清的专业名词,有免费采集,有付费采集。要看你要做什么网站了。市面上做网站的有很多品牌,你所指的应该是市面上免费采集,付费采集一体的吧,那种网站是新手新媒体运营人员用的,也是现在收入比较高的网站采集系统,做一些运营服务。这种采集系统有很多品牌,新浪爱问这个品牌可以查一下。有免费的一般都会有一些要求,根据你的需求选择适合的产品。
大致方向是,视频类网站:视频看得很多,很多都是雷同的,又很多看似不雷同的短视频,采一个批量下来看看有何不可,然后采买视频的推广账号,其实付费也没有贵到那么离谱。问题是视频采集采到之后,如何能发布到自己网站上?这个才是核心。以上提到的主要视频网站:.fei.jpg(新浪)上面这个视频网站就是各大视频网站都有的网站,视频都是视频网站直接采过来的,个别可能需要付费才能看,但绝对安全。
视频站,基本不存在死链接问题,如果需要发布链接,保存图片信息之后,放在文件里,方便自己也方便对方。结果也是如下:下面提到的博客:博客原文采集博客原文只可能是原文被采集,被采集的就封杀。博客高质量资源被采集,会导致你没有一个好的文章被搜索引擎收录,流量会流失,基本这样的文章你百度一搜一大把,百度收不收录没啥区别。
会对你的博客本身有影响。以上几种方式,收集的资源基本你都是不可见的,并不会对你网站产生什么影响,很多都是采集站,论坛里面大量被采集的内容。这些采集站想要持续发展,需要大量的采集,但采集成本就高了,很多人只是看看有啥想采集就采集一下,但采集多了,就会审核无效内容,后面就采集这篇内容,又想换另一篇内容,全部采集出来。
至于采集的影响,比如采集软件:点进去软件,点击任何链接,输入网址,会立刻跳转到一个恶心的页面,然后一直重复搜索任意恶心内容,到处产生垃圾信息,短期内甚至是永久这个页面。也不知道这些发现不发现,其实从搜索引擎或者公域的角度,是毫无价值的。如果这些公域内容,你因为不是采集而被转载了,那从网站的角度,算不算做了坏事?其实这也没有任何损失。
最后一种就是自己付费获取有价值资源,比如:1.有价值的原创图片。搜索引擎会解析文章的主体结构,寻找出需要的原图。有些文章作者只是提供一张图片,实际上还有很多文字内容,只是单纯的提供一张图片,来作为文章的配图。比如:“公务员考试文科类大学生”、“妈妈出游”,这种文章看起来不花太多钱,但如果你分析。 查看全部
自动采集机器人属于自动化硬件系统的运营服务介绍
自动采集机器人属于自动化硬件系统吧。
网站推广自动化采集一个也是说不清的专业名词,有免费采集,有付费采集。要看你要做什么网站了。市面上做网站的有很多品牌,你所指的应该是市面上免费采集,付费采集一体的吧,那种网站是新手新媒体运营人员用的,也是现在收入比较高的网站采集系统,做一些运营服务。这种采集系统有很多品牌,新浪爱问这个品牌可以查一下。有免费的一般都会有一些要求,根据你的需求选择适合的产品。
大致方向是,视频类网站:视频看得很多,很多都是雷同的,又很多看似不雷同的短视频,采一个批量下来看看有何不可,然后采买视频的推广账号,其实付费也没有贵到那么离谱。问题是视频采集采到之后,如何能发布到自己网站上?这个才是核心。以上提到的主要视频网站:.fei.jpg(新浪)上面这个视频网站就是各大视频网站都有的网站,视频都是视频网站直接采过来的,个别可能需要付费才能看,但绝对安全。
视频站,基本不存在死链接问题,如果需要发布链接,保存图片信息之后,放在文件里,方便自己也方便对方。结果也是如下:下面提到的博客:博客原文采集博客原文只可能是原文被采集,被采集的就封杀。博客高质量资源被采集,会导致你没有一个好的文章被搜索引擎收录,流量会流失,基本这样的文章你百度一搜一大把,百度收不收录没啥区别。
会对你的博客本身有影响。以上几种方式,收集的资源基本你都是不可见的,并不会对你网站产生什么影响,很多都是采集站,论坛里面大量被采集的内容。这些采集站想要持续发展,需要大量的采集,但采集成本就高了,很多人只是看看有啥想采集就采集一下,但采集多了,就会审核无效内容,后面就采集这篇内容,又想换另一篇内容,全部采集出来。
至于采集的影响,比如采集软件:点进去软件,点击任何链接,输入网址,会立刻跳转到一个恶心的页面,然后一直重复搜索任意恶心内容,到处产生垃圾信息,短期内甚至是永久这个页面。也不知道这些发现不发现,其实从搜索引擎或者公域的角度,是毫无价值的。如果这些公域内容,你因为不是采集而被转载了,那从网站的角度,算不算做了坏事?其实这也没有任何损失。
最后一种就是自己付费获取有价值资源,比如:1.有价值的原创图片。搜索引擎会解析文章的主体结构,寻找出需要的原图。有些文章作者只是提供一张图片,实际上还有很多文字内容,只是单纯的提供一张图片,来作为文章的配图。比如:“公务员考试文科类大学生”、“妈妈出游”,这种文章看起来不花太多钱,但如果你分析。
自动采集机器人+爬虫+商品橱窗-不同场景下的方案组合
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-06-26 20:02
自动采集机器人+代码采集机器人+爬虫+商品橱窗-不同行业不同场景下需要不同的方案组合,什么场景下可以跳过机器人呢?最近较忙,个人有需要的朋友可以找我咨询。
大体分几种采集机器人或方案
1、全自动采集+代码采集
2、真正采集+组合
3、无采集
4、无采集+代码
一种是比较成熟的分布式采集,一种是离线采集,离线采集后续维护困难,分布式采集有一定优势。现在市面上很多采集工具,有免费的也有收费的,我们都比较看重收费的。
不同采集场景方案不同,
1、真正采集+代码采集
2、无采集+代码采集
3、无采集+demo代码采集
4、无采集+无代码采集
机器人就是开启高效无代码采集模式,我们是看重模式及数据积累。另外,团队业务需要也是的。比如做化妆品品牌销售的,这个年代,讲究个性,不能全被人推销产品啊,用了我的化妆品,然后出来跟人互动,好像被推销了一样,没那个心情,团队也没那个技术;因此,很多客户就会安装一个app来采集,还能记录客户浏览行为。至于说难不难,这里要涉及到行业里边一些其他的问题,比如是否可以采集到你所销售产品的全国相关渠道的卖点、内容?对于这个需求,是属于机器采集,还是真正采集?这个就牵扯到团队协作及代码的积累等问题。 查看全部
自动采集机器人+爬虫+商品橱窗-不同场景下的方案组合
自动采集机器人+代码采集机器人+爬虫+商品橱窗-不同行业不同场景下需要不同的方案组合,什么场景下可以跳过机器人呢?最近较忙,个人有需要的朋友可以找我咨询。
大体分几种采集机器人或方案
1、全自动采集+代码采集
2、真正采集+组合
3、无采集
4、无采集+代码
一种是比较成熟的分布式采集,一种是离线采集,离线采集后续维护困难,分布式采集有一定优势。现在市面上很多采集工具,有免费的也有收费的,我们都比较看重收费的。
不同采集场景方案不同,
1、真正采集+代码采集
2、无采集+代码采集
3、无采集+demo代码采集
4、无采集+无代码采集
机器人就是开启高效无代码采集模式,我们是看重模式及数据积累。另外,团队业务需要也是的。比如做化妆品品牌销售的,这个年代,讲究个性,不能全被人推销产品啊,用了我的化妆品,然后出来跟人互动,好像被推销了一样,没那个心情,团队也没那个技术;因此,很多客户就会安装一个app来采集,还能记录客户浏览行为。至于说难不难,这里要涉及到行业里边一些其他的问题,比如是否可以采集到你所销售产品的全国相关渠道的卖点、内容?对于这个需求,是属于机器采集,还是真正采集?这个就牵扯到团队协作及代码的积累等问题。
Zip存档收集器创建临时目录完整内容的zip存档分析报告
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-06-23 06:11
压缩存档
采集器将创建一个 zip 存档,其中收录采集期间创建的临时目录的完整内容。在 ANT 中,每个操作负责将所需的文件放置在 ${autopdtmp} 属性指示的目录中。这相当于:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
tmp\
必须采集数据
归档中最重要的一项是对应MustGather文档中数据镜像所需的信息。该数据可以在 WC_MustGather 目录中找到。该目录保存在客户端文件系统中找到的每个文件系统的原创文件路径结构。它包括 WebSphere Commerce 应用服务器日志、数据库提取、来自 EAR 的静态文件(部署在 WebSphere 应用服务器中的实例)和来自 WebSphere Commerce 安装目录的静态文件(产品文件)以及 WebSphere 应用服务器安装命令。
/WC_MustGather 收录以下资产:
有关应采集的那些文档的完整列表,请参阅“采集数据”部分中相应的 MustGather。
分析报告
采集器还会在存档的 /WC_Reports 目录中创建分析报告。该报告收录一些有关环境和馆藏本身的信息。该报告首先列出了用于集合的 ISA 版本,如图 28 所示。
图28.信息报告
接下来,突出显示在 SystemOut.log 上检测到的错误,如图 29 所示。
图 29. 突出显示检测到的错误
每个部分都提供了 Google® 搜索的链接。这些链接的内容与 IBM 记录的错误消息相关的一些关键术语或任何已知问题有关。
单击主报告中的 ActionXML Collector Summary 链接将显示一个解释要做什么的文档(图 30)。对于没有此文档的人,它会解释原因(如果不需要,由客户端拒绝许可等)。它还提供了自身的概述,包括以下信息:
图 3 0. 集合概览
返回主报告,其中显示了客户端请求和收到的响应的概览,如图 31 所示。
图31.用户对问题的回答
最后,将显示客户端环境的概览(图 32)。这表明客户端在哪个修订包上,是运行时环境还是开发人员工具包环境,以及客户安装了哪些 APAR。如果是Runtime服务器,数据将表示为产品级和实例级。
图32.环境概览
采集器日志和属性
在存档中,以下目录保存自动数据采集器的输出、日志、配置和属性:
一般来说,使用存档解决问题时不需要检查它们,但在调试自动采集器本身的行为时它们很有用。
临时日志文件
采集器运行过程中,使用ISA工作台时,在以下目录创建临时目录:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
tmp\
创建的采集档案位于以下目录:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
collections\
ISA 采集器日志位于以下目录中:
\
请注意,ISA 日志收录在集合 zip 存档中,这已在上一节中提到。
采集器运行过程中,使用ISA Lite时,在以下目录创建临时目录:
\tmp\
对于 ISA Lite,采集器日志位于以下目录中:
\log
高级配置
有一些方法可以更改采集器的默认行为。一些组件利用采集器配置文件,允许以下配置:
ISA 工作台的配置文件位于:
\\applications\eclipse\plugins\
com.ibm.esupport.client.product.SSZLC270_\config\
wc-autopd-config.properties
对于 ISA Lite,配置文件位于:
\config\wc-autopd-config.properties
日志级别
记录器类,用于记录自定义 WebSphere Commerce Java 任务,可以使用 wc.logLevel.debug 属性进行配置。默认值为“false”,用于标准录制。设置为“true”以添加更详细的记录以供调试。
#logLevel, set to true to enable verbose logging wc.logLevel.debug=false
数据库配置
提取数据库数据的方法也可以使用属性文件进行配置。有多种方法可用于自动确定数据库连接信息。默认情况下,dbPropertySource 设置为“wcServerXML”值,这意味着大多数数据库配置值来自实例配置文件。将通知用户剩余价值。
如果dbPropertySource的值设置为“promptUser”,那么所有相关问题都会提示给用户,而不是从实例配置文件中检索。
最后,如果将dbPropertySource 值设置为“wc-autopd-config”,则必须从wc-autopd-config.properties 文件中检索除数据库用户密码之外的所有值。用户经常会收到数据库密码作为输入提示,因为出于安全原因,密码从未被坚持。
使用 wc-autopd-config 配置时,有三个选项。您需要设置清单 1 中的值。默认情况下,使用 JDBC 连接的通用类型 4 驱动程序(用于 DB2 和 Oracle®),它被配置为 DB2® 数据库。您可以更改 wc.dbDriver、wc.dbUrl 和 wc.dbDriverPath 的值以支持旧的 DB2 驱动程序(键入 2) 或 Oracle Support 通用驱动程序。
列出1.配置设置
#method of pulling the values for DB
#options: wcServerXML, promptUser, wc-autopd-config
dbPropertySource=wcServerXML
# Universal - Type 4 (DB2)
wc.dbType=DB2
wc.dbDriver=com.ibm.db2.jcc.DB2Driver
wc.dbUrl=jdbc:db2://localhost:50000/mall
wc.dbDriver.path=C:\SQLLIB\java\db2jcc.jar
wc.dbName=mall
wc.dbUserName=db2inst1
# Universal - Type 4 (Oracle)
#Oracle
#wc.dbType=oracle
#wc.dbDriver=oracle.jdbc.driver.OracleDriver
#wc.dbUrl=jdbc:oracle:thin:@localhost:1521:O10G
#wc.dbDriver.path=C:\oracle\product\10.2.0\db_1\jdbc\lib\
classes12.jar
#wc.dbName=O10G
#wc.dbUserName=wcsuser
快速采集模式
在 ISA Workbench 或 ISA Lite 上运行时,另一种选择是使用 QuickCollect 模式。为了避免采集器每次都询问常见问题,如果答案相同,请在 wc-autopd-config.properties 上启动 QuickCollect 模式,如清单 2 所示。
列出2.QuickCollect 配置
wc.quickCollect=true
wc.quickCollectActions=GatherFiles,GatherSQL
wc.root=D:/WebSphere/WCToolkit70
wc.instanceName=demo
was.root=D:/WebSphere/SDP/runtimes/base_v7
was.profile.path=D:/WebSphere/WCToolkit70/wasprofile
was.profile.name=wasprofile
was.cell=WC_demo_cell
was.node=WC_demo_node
was.server.name=server1
wc.ear.install.path=D:/WebSphere/WCToolkit70/workspace/WC
updi.root=D:/WebSphere/UpdateInstaller
将 wc.quickCollector 更改为“true”。然后将清单 2 中显示的其他属性设置到文件系统中的正确位置。
在 QuickCollect 模式下运行时,采集器可以减少向用户提示的次数。请注意,这不需要每个操作的许可。因此,需要预先许可,以便可以切换 wc.quickCollectActions 属性中列出的操作的设置。默认配置可以采集所有文件和数据库摘要,如 GatherFiles 和 GatherSQL 的值所示。但是,如果 wc.quickCollectActions 收录 GatherTrace,仍然会提示您复制问题并设置跟踪字符串,因为这是必需的交互。
全面的激活和禁用操作
可以完全禁用收录用户永远不想授权的操作的操作(例如,如果 DBA 始终需要从数据库中获取 SQL 数据)。无论哪个操作设置为 true,它都会运行(并假设许可)。那些在 wc-autopd-config.properties 中设置为“false”的操作将不会运行(并且不需要权限),如图 3 所示。
列出3.启用和禁用操作
#Enabled Actions, default = true
GatherFiles=true
AskQuestion=true
wc_gatherTrace=true
GatherSQL=true
InvokeShellCommand=false
ModifyFile=false
GatherScreenShot=true
结论
在解决自己的问题时,WebSphere Commerce 自动化数据采集器旨在改进和简化数据的获取,或与 IBM 支持部门合作。采集器通过 IBM Support Assistant 或 ISA Lite 框架运行,并保留用户对其环境中发生的任何操作的控制权。自动采集器可以获得所有必要的跟踪、文件、数据摘要、屏幕截图和自定义附件,以帮助通过 IBM 支持确定问题的根本原因,镜像手动 MustGather 文档。 HTML 分析报告随每个集合生成,其中汇总了数据集合和客户端概述。 查看全部
Zip存档收集器创建临时目录完整内容的zip存档分析报告
压缩存档
采集器将创建一个 zip 存档,其中收录采集期间创建的临时目录的完整内容。在 ANT 中,每个操作负责将所需的文件放置在 ${autopdtmp} 属性指示的目录中。这相当于:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
tmp\
必须采集数据
归档中最重要的一项是对应MustGather文档中数据镜像所需的信息。该数据可以在 WC_MustGather 目录中找到。该目录保存在客户端文件系统中找到的每个文件系统的原创文件路径结构。它包括 WebSphere Commerce 应用服务器日志、数据库提取、来自 EAR 的静态文件(部署在 WebSphere 应用服务器中的实例)和来自 WebSphere Commerce 安装目录的静态文件(产品文件)以及 WebSphere 应用服务器安装命令。
/WC_MustGather 收录以下资产:
有关应采集的那些文档的完整列表,请参阅“采集数据”部分中相应的 MustGather。
分析报告
采集器还会在存档的 /WC_Reports 目录中创建分析报告。该报告收录一些有关环境和馆藏本身的信息。该报告首先列出了用于集合的 ISA 版本,如图 28 所示。
图28.信息报告
接下来,突出显示在 SystemOut.log 上检测到的错误,如图 29 所示。
图 29. 突出显示检测到的错误
每个部分都提供了 Google® 搜索的链接。这些链接的内容与 IBM 记录的错误消息相关的一些关键术语或任何已知问题有关。
单击主报告中的 ActionXML Collector Summary 链接将显示一个解释要做什么的文档(图 30)。对于没有此文档的人,它会解释原因(如果不需要,由客户端拒绝许可等)。它还提供了自身的概述,包括以下信息:
图 3 0. 集合概览
返回主报告,其中显示了客户端请求和收到的响应的概览,如图 31 所示。
图31.用户对问题的回答
最后,将显示客户端环境的概览(图 32)。这表明客户端在哪个修订包上,是运行时环境还是开发人员工具包环境,以及客户安装了哪些 APAR。如果是Runtime服务器,数据将表示为产品级和实例级。
图32.环境概览
采集器日志和属性
在存档中,以下目录保存自动数据采集器的输出、日志、配置和属性:
一般来说,使用存档解决问题时不需要检查它们,但在调试自动采集器本身的行为时它们很有用。
临时日志文件
采集器运行过程中,使用ISA工作台时,在以下目录创建临时目录:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
tmp\
创建的采集档案位于以下目录:
\.metadata\.plugins\com.ibm.esupport.autopd.core\
collections\
ISA 采集器日志位于以下目录中:
\
请注意,ISA 日志收录在集合 zip 存档中,这已在上一节中提到。
采集器运行过程中,使用ISA Lite时,在以下目录创建临时目录:
\tmp\
对于 ISA Lite,采集器日志位于以下目录中:
\log
高级配置
有一些方法可以更改采集器的默认行为。一些组件利用采集器配置文件,允许以下配置:
ISA 工作台的配置文件位于:
\\applications\eclipse\plugins\
com.ibm.esupport.client.product.SSZLC270_\config\
wc-autopd-config.properties
对于 ISA Lite,配置文件位于:
\config\wc-autopd-config.properties
日志级别
记录器类,用于记录自定义 WebSphere Commerce Java 任务,可以使用 wc.logLevel.debug 属性进行配置。默认值为“false”,用于标准录制。设置为“true”以添加更详细的记录以供调试。
#logLevel, set to true to enable verbose logging wc.logLevel.debug=false
数据库配置
提取数据库数据的方法也可以使用属性文件进行配置。有多种方法可用于自动确定数据库连接信息。默认情况下,dbPropertySource 设置为“wcServerXML”值,这意味着大多数数据库配置值来自实例配置文件。将通知用户剩余价值。
如果dbPropertySource的值设置为“promptUser”,那么所有相关问题都会提示给用户,而不是从实例配置文件中检索。
最后,如果将dbPropertySource 值设置为“wc-autopd-config”,则必须从wc-autopd-config.properties 文件中检索除数据库用户密码之外的所有值。用户经常会收到数据库密码作为输入提示,因为出于安全原因,密码从未被坚持。
使用 wc-autopd-config 配置时,有三个选项。您需要设置清单 1 中的值。默认情况下,使用 JDBC 连接的通用类型 4 驱动程序(用于 DB2 和 Oracle®),它被配置为 DB2® 数据库。您可以更改 wc.dbDriver、wc.dbUrl 和 wc.dbDriverPath 的值以支持旧的 DB2 驱动程序(键入 2) 或 Oracle Support 通用驱动程序。
列出1.配置设置
#method of pulling the values for DB
#options: wcServerXML, promptUser, wc-autopd-config
dbPropertySource=wcServerXML
# Universal - Type 4 (DB2)
wc.dbType=DB2
wc.dbDriver=com.ibm.db2.jcc.DB2Driver
wc.dbUrl=jdbc:db2://localhost:50000/mall
wc.dbDriver.path=C:\SQLLIB\java\db2jcc.jar
wc.dbName=mall
wc.dbUserName=db2inst1
# Universal - Type 4 (Oracle)
#Oracle
#wc.dbType=oracle
#wc.dbDriver=oracle.jdbc.driver.OracleDriver
#wc.dbUrl=jdbc:oracle:thin:@localhost:1521:O10G
#wc.dbDriver.path=C:\oracle\product\10.2.0\db_1\jdbc\lib\
classes12.jar
#wc.dbName=O10G
#wc.dbUserName=wcsuser
快速采集模式
在 ISA Workbench 或 ISA Lite 上运行时,另一种选择是使用 QuickCollect 模式。为了避免采集器每次都询问常见问题,如果答案相同,请在 wc-autopd-config.properties 上启动 QuickCollect 模式,如清单 2 所示。
列出2.QuickCollect 配置
wc.quickCollect=true
wc.quickCollectActions=GatherFiles,GatherSQL
wc.root=D:/WebSphere/WCToolkit70
wc.instanceName=demo
was.root=D:/WebSphere/SDP/runtimes/base_v7
was.profile.path=D:/WebSphere/WCToolkit70/wasprofile
was.profile.name=wasprofile
was.cell=WC_demo_cell
was.node=WC_demo_node
was.server.name=server1
wc.ear.install.path=D:/WebSphere/WCToolkit70/workspace/WC
updi.root=D:/WebSphere/UpdateInstaller
将 wc.quickCollector 更改为“true”。然后将清单 2 中显示的其他属性设置到文件系统中的正确位置。
在 QuickCollect 模式下运行时,采集器可以减少向用户提示的次数。请注意,这不需要每个操作的许可。因此,需要预先许可,以便可以切换 wc.quickCollectActions 属性中列出的操作的设置。默认配置可以采集所有文件和数据库摘要,如 GatherFiles 和 GatherSQL 的值所示。但是,如果 wc.quickCollectActions 收录 GatherTrace,仍然会提示您复制问题并设置跟踪字符串,因为这是必需的交互。
全面的激活和禁用操作
可以完全禁用收录用户永远不想授权的操作的操作(例如,如果 DBA 始终需要从数据库中获取 SQL 数据)。无论哪个操作设置为 true,它都会运行(并假设许可)。那些在 wc-autopd-config.properties 中设置为“false”的操作将不会运行(并且不需要权限),如图 3 所示。
列出3.启用和禁用操作
#Enabled Actions, default = true
GatherFiles=true
AskQuestion=true
wc_gatherTrace=true
GatherSQL=true
InvokeShellCommand=false
ModifyFile=false
GatherScreenShot=true
结论
在解决自己的问题时,WebSphere Commerce 自动化数据采集器旨在改进和简化数据的获取,或与 IBM 支持部门合作。采集器通过 IBM Support Assistant 或 ISA Lite 框架运行,并保留用户对其环境中发生的任何操作的控制权。自动采集器可以获得所有必要的跟踪、文件、数据摘要、屏幕截图和自定义附件,以帮助通过 IBM 支持确定问题的根本原因,镜像手动 MustGather 文档。 HTML 分析报告随每个集合生成,其中汇总了数据集合和客户端概述。
自动采集机器人不收费,给你们两个软件!
采集交流 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2021-06-15 04:01
自动采集机器人是可以自动采集百度、、微博、微信公众号的文章,有钱赚。免费使用,写好程序,招收合作伙伴,盈利无上限。创建一个免费机器人按以下要求操作即可打开微信聊天窗口,
hi,我是信鸽。经常在微信群中收到你们问我要一些实用性小软件的信息,我在群里一般是扫描二维码或者是找大佬在群里问。但是,你们会发现,有些信息,我在别的群里是能解决的,但是你去别的群里问就显得非常麻烦。在这里,我可以给你们两个软件。我一般要链接,你们可以直接下载自己需要的。能不能把小编人性化一下呢!!!1.现在有人可能喜欢截图,用ps截图或者是用摄像头截图,给你们一个小工具。
websocket配合wepy也就是发送http请求。数据校验加密传输,安全稳定。支持多种协议,支持分析和收发控制,一秒支持多次发送。2.或者是说一个html文档,这里面我可以直接截图识别成json给你们。自动解析翻译成中文。自动采集阅读量评论量等一些信息。自动采集微信公众号文章!识别图片!文字识别!切割png图片!还有一些小功能我就不一一列举了。
发送给你们的图片,不一定是高清,也有很多浏览器打不开,或者翻译不了,格式不好。但是这个软件就完美解决上面的这些问题。这个自动采集机器人不收费,给你们免费的。在公众号公众号:信鸽寻梦人。 查看全部
自动采集机器人不收费,给你们两个软件!
自动采集机器人是可以自动采集百度、、微博、微信公众号的文章,有钱赚。免费使用,写好程序,招收合作伙伴,盈利无上限。创建一个免费机器人按以下要求操作即可打开微信聊天窗口,
hi,我是信鸽。经常在微信群中收到你们问我要一些实用性小软件的信息,我在群里一般是扫描二维码或者是找大佬在群里问。但是,你们会发现,有些信息,我在别的群里是能解决的,但是你去别的群里问就显得非常麻烦。在这里,我可以给你们两个软件。我一般要链接,你们可以直接下载自己需要的。能不能把小编人性化一下呢!!!1.现在有人可能喜欢截图,用ps截图或者是用摄像头截图,给你们一个小工具。
websocket配合wepy也就是发送http请求。数据校验加密传输,安全稳定。支持多种协议,支持分析和收发控制,一秒支持多次发送。2.或者是说一个html文档,这里面我可以直接截图识别成json给你们。自动解析翻译成中文。自动采集阅读量评论量等一些信息。自动采集微信公众号文章!识别图片!文字识别!切割png图片!还有一些小功能我就不一一列举了。
发送给你们的图片,不一定是高清,也有很多浏览器打不开,或者翻译不了,格式不好。但是这个软件就完美解决上面的这些问题。这个自动采集机器人不收费,给你们免费的。在公众号公众号:信鸽寻梦人。
自动采集机 api回调:我在这里,你要采我就采
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-06-11 07:02
自动采集机器人的采集速度是固定的,不能随着你的实际需求增加自动和加速采集次数。根据机器人自己的自动和加速速度可以对机器人做定向的方向控制,增加适应性。例如我的机器人是一辆汽车,我每次只加速10%-20%的能力,把它控制在接近100米左右。这样就能保证我的需求不被机器人采集速度忽略掉了。
api回调:我在这里,你要采我就采。每个自动化采集机器人必须向productdataset提交从路径获取的用户id、用户信息(即商品信息)、可操作值、目标访问人数、采集规模等信息。在productdataset提交上述信息之后,再把获取到的数据push到代码生成的url中。下图是一个典型的代码生成url,带2个参数,queryex(stories,values)和urls,urls则是url提交前将会返回的http头部。
urls则是让我们用于进行在需要对url提交的详细信息加载的加载信息。采用api方式来启动自动采集项目,能够更好地保证原始数据的完整性。以下是一些个人见解:1.机器人本身可以设置路径,url中的data只是机器人收集了用户数据,并分析出用户需求。机器人只是productdataset中的一个用户id,所以也只能采用这个方式。
2.如果机器人上有接口方式来判断用户是不是真正存在这一类行为,那么我们可以将一些要采集到的数据,写在数据库中,然后用户可以发送邮件或者地址/帐号到机器人上,要采集的数据就可以查看到了。 查看全部
自动采集机 api回调:我在这里,你要采我就采
自动采集机器人的采集速度是固定的,不能随着你的实际需求增加自动和加速采集次数。根据机器人自己的自动和加速速度可以对机器人做定向的方向控制,增加适应性。例如我的机器人是一辆汽车,我每次只加速10%-20%的能力,把它控制在接近100米左右。这样就能保证我的需求不被机器人采集速度忽略掉了。
api回调:我在这里,你要采我就采。每个自动化采集机器人必须向productdataset提交从路径获取的用户id、用户信息(即商品信息)、可操作值、目标访问人数、采集规模等信息。在productdataset提交上述信息之后,再把获取到的数据push到代码生成的url中。下图是一个典型的代码生成url,带2个参数,queryex(stories,values)和urls,urls则是url提交前将会返回的http头部。
urls则是让我们用于进行在需要对url提交的详细信息加载的加载信息。采用api方式来启动自动采集项目,能够更好地保证原始数据的完整性。以下是一些个人见解:1.机器人本身可以设置路径,url中的data只是机器人收集了用户数据,并分析出用户需求。机器人只是productdataset中的一个用户id,所以也只能采用这个方式。
2.如果机器人上有接口方式来判断用户是不是真正存在这一类行为,那么我们可以将一些要采集到的数据,写在数据库中,然后用户可以发送邮件或者地址/帐号到机器人上,要采集的数据就可以查看到了。

