
自动采集文章
自动采集文章(WP采集插件保持让用户访问到网站的重要性方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-10 04:07
WP采集插件基本上已经成为wordpress网站必备的插件或功能。随着搜索引擎算法的升级,内容的重要性已经成为最重要的网站 一个优化点,所以网站 站长尽最大努力不断的输出内容到网站,让网站在搜索引擎中有对应的收录和排名,从而网站产生流量,让更多的用户访问网站。
首先是网站架构和布局,网站好的和不好的架构可以让用户更受欢迎,WP采集插件可以有一个简单方便的网站也是网站的成功之一,也将获得搜索引擎的信任。所以在网站构建的前期,应该去掉不良的网站结构,保留一个优秀合理的布局。这是一种非常常见的网站SEO 方法。
WP采集插件保持网站内容更新,好的网站可以让用户记住,好的网站可以吸引很多自然流量,可以说网站@ >都是靠优质内容获取流量,长尾关键词也是提升网站排名的重要途径。优秀的文章总是会被不断转发,会带来很多潜在客户,搜索引擎喜欢这种文章。所谓好的文章应该有这几点:满足用户需求,解决用户疑虑,获得用户认可。
WP采集插件的网站结构要整齐、清晰,树状的网状结构应该是第一位的;有了清晰的结构网站,用户可以直观的找到自己想要的,而不是让用户浏览很久才能找到想要的答案。网站像树一样,树干一定要结实,否则就长不成参天大树。网站同样如此。如果基础不扎实,网站发展起来会比较困难。
网站 的内部链接就像一棵树的枝叶,相辅相成。只有将网站的所有页面相互链接,才能防止每个页面形成孤岛,避开搜索引擎。蜘蛛陷入了死胡同。
作为一个SEO新手,你需要了解网站的构建,即使你不会写代码,但你需要了解网站的网站建设和基本的html代码以及WP采集插件,这是做好SEO的第一步。因为,当你建立一个网站或设置一个标题时,你必须开始 SEO 布局。没有 网站 的 SEO 优化并不是真正的 网站 优化。简单的网站优化只需要使用设置源码和修改网站内容,复杂后我们会详细解答。我们只需要掌握一些简单的代码知识。代码是解决问题的关键。如果不使用代码,就会遇到需要解答的问题。我不知道如何修改正确的代码。
网站优化是一个过程,WP采集插件需要耐心添加内容,逐步构建内容,不要为了增加内容而乱搞采集内容,现在搜索引擎正在攻击垃圾内容,所以并不是所有的采集网站都会受到搜索引擎的惩罚,但只要受到惩罚,排名就很难恢复。所以内容一定要高质量,WP采集plugin采集content可以很好的避免这个问题。 查看全部
自动采集文章(WP采集插件保持让用户访问到网站的重要性方法)
WP采集插件基本上已经成为wordpress网站必备的插件或功能。随着搜索引擎算法的升级,内容的重要性已经成为最重要的网站 一个优化点,所以网站 站长尽最大努力不断的输出内容到网站,让网站在搜索引擎中有对应的收录和排名,从而网站产生流量,让更多的用户访问网站。

首先是网站架构和布局,网站好的和不好的架构可以让用户更受欢迎,WP采集插件可以有一个简单方便的网站也是网站的成功之一,也将获得搜索引擎的信任。所以在网站构建的前期,应该去掉不良的网站结构,保留一个优秀合理的布局。这是一种非常常见的网站SEO 方法。

WP采集插件保持网站内容更新,好的网站可以让用户记住,好的网站可以吸引很多自然流量,可以说网站@ >都是靠优质内容获取流量,长尾关键词也是提升网站排名的重要途径。优秀的文章总是会被不断转发,会带来很多潜在客户,搜索引擎喜欢这种文章。所谓好的文章应该有这几点:满足用户需求,解决用户疑虑,获得用户认可。

WP采集插件的网站结构要整齐、清晰,树状的网状结构应该是第一位的;有了清晰的结构网站,用户可以直观的找到自己想要的,而不是让用户浏览很久才能找到想要的答案。网站像树一样,树干一定要结实,否则就长不成参天大树。网站同样如此。如果基础不扎实,网站发展起来会比较困难。

网站 的内部链接就像一棵树的枝叶,相辅相成。只有将网站的所有页面相互链接,才能防止每个页面形成孤岛,避开搜索引擎。蜘蛛陷入了死胡同。
作为一个SEO新手,你需要了解网站的构建,即使你不会写代码,但你需要了解网站的网站建设和基本的html代码以及WP采集插件,这是做好SEO的第一步。因为,当你建立一个网站或设置一个标题时,你必须开始 SEO 布局。没有 网站 的 SEO 优化并不是真正的 网站 优化。简单的网站优化只需要使用设置源码和修改网站内容,复杂后我们会详细解答。我们只需要掌握一些简单的代码知识。代码是解决问题的关键。如果不使用代码,就会遇到需要解答的问题。我不知道如何修改正确的代码。

网站优化是一个过程,WP采集插件需要耐心添加内容,逐步构建内容,不要为了增加内容而乱搞采集内容,现在搜索引擎正在攻击垃圾内容,所以并不是所有的采集网站都会受到搜索引擎的惩罚,但只要受到惩罚,排名就很难恢复。所以内容一定要高质量,WP采集plugin采集content可以很好的避免这个问题。
自动采集文章(利用白帽SEO优化方法快速提升网站权重值的方法有哪些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-03-09 12:00
文章采集,让网站有内容,只有有内容才有收录,收录才有条件提升网站重量。网站权重是对网站综合价值的总称,包括网站运营能力、用户体验、内容质量、用户热度、SEO指标。综合性能统一名称。
文章采集如何增加网站的权重:日常正规管理和操作网站,使用正规白帽方法操作网站,比如更新内容,检查和维护操作等。这些都是站长必须做的事情。挖矿优化精准关键词,根据自己的网站行业,挖矿优化精准网站关键词,必须有流量关键词,如果挖矿关键词@ >与网站的主题定位无关,那么网站的权重就很难增加,甚至网站都会被搜索引擎惩罚。
文章采集改进网站和收录的内容,网站收录索引数据与网站@的更新次数成正比> content 是的,如果你长时间不更新网站,那么你的网站索引数据不仅会增加,还会减少。如果你想改进网站收录的内容,那么你需要不断更新网站优质内容。
除了文章采集,内容更新、内链优化、网站结构优化、404、网站sitemap地图和机器人都属于现场搜索引擎优化。如果你不做好站内优化,你的外链再好也没用,因为你的网站留不住用户,所以站内优化大于站外-网站优化,而外部链接的作用近年来逐渐减弱。如果想通过累计外链数量来增加网站的权重,目前可能很难实现。
使用白帽SEO进行形式优化,为什么一定要使用白帽SEO来优化网站?因为有的站长想用黑帽SEO优化的方法来快速提升网站的权重值,如果使用这些黑帽SEO,一旦被搜索引擎发现,就等待网站@的结果> 只能被惩罚或K站。搜索引擎支持用户使用正式的白帽SEO优化方式,因为这种优化方式可以持续为用户提供有价值的内容。
我们在优化网站的时候,建议不要用黑帽作弊来优化网站,因为到最后你很可能会花费时间和精力,却没有网站好的流量。
<p>新站前期以文章采集和挖矿网站长尾关键词为主。长尾关键词不仅竞争程度低,而且排名时间短。优化长尾关键词可能只需要几个星期,最长不会超过一个月。新站没有优化基础,搜索引擎对新站信任度不高。我们优化关键词@文章采集和长尾关键词,可以实现更快的收录网站页面,更快的流量,然后不断的积累和提高网站的流量和权重,最后为了争夺一些高指数、高流量的关键词,新的网站倾向于前期做内容, 查看全部
自动采集文章(利用白帽SEO优化方法快速提升网站权重值的方法有哪些)
文章采集,让网站有内容,只有有内容才有收录,收录才有条件提升网站重量。网站权重是对网站综合价值的总称,包括网站运营能力、用户体验、内容质量、用户热度、SEO指标。综合性能统一名称。
文章采集如何增加网站的权重:日常正规管理和操作网站,使用正规白帽方法操作网站,比如更新内容,检查和维护操作等。这些都是站长必须做的事情。挖矿优化精准关键词,根据自己的网站行业,挖矿优化精准网站关键词,必须有流量关键词,如果挖矿关键词@ >与网站的主题定位无关,那么网站的权重就很难增加,甚至网站都会被搜索引擎惩罚。
文章采集改进网站和收录的内容,网站收录索引数据与网站@的更新次数成正比> content 是的,如果你长时间不更新网站,那么你的网站索引数据不仅会增加,还会减少。如果你想改进网站收录的内容,那么你需要不断更新网站优质内容。
除了文章采集,内容更新、内链优化、网站结构优化、404、网站sitemap地图和机器人都属于现场搜索引擎优化。如果你不做好站内优化,你的外链再好也没用,因为你的网站留不住用户,所以站内优化大于站外-网站优化,而外部链接的作用近年来逐渐减弱。如果想通过累计外链数量来增加网站的权重,目前可能很难实现。
使用白帽SEO进行形式优化,为什么一定要使用白帽SEO来优化网站?因为有的站长想用黑帽SEO优化的方法来快速提升网站的权重值,如果使用这些黑帽SEO,一旦被搜索引擎发现,就等待网站@的结果> 只能被惩罚或K站。搜索引擎支持用户使用正式的白帽SEO优化方式,因为这种优化方式可以持续为用户提供有价值的内容。
我们在优化网站的时候,建议不要用黑帽作弊来优化网站,因为到最后你很可能会花费时间和精力,却没有网站好的流量。
<p>新站前期以文章采集和挖矿网站长尾关键词为主。长尾关键词不仅竞争程度低,而且排名时间短。优化长尾关键词可能只需要几个星期,最长不会超过一个月。新站没有优化基础,搜索引擎对新站信任度不高。我们优化关键词@文章采集和长尾关键词,可以实现更快的收录网站页面,更快的流量,然后不断的积累和提高网站的流量和权重,最后为了争夺一些高指数、高流量的关键词,新的网站倾向于前期做内容,
自动采集文章(ThinkCMF采集的主要知识点以及表达点皆在文章配图之中)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-07 08:23
ThinkCMF采集,可以为指定的关键词全网采集快速填写网站的内容资源。然后通过自动伪原创发布,让网站时刻保持更新状态,这样的网站受到搜索引擎的青睐。本文关于ThinkCMF采集的主要知识点和表达点都在文章图片中。不需要看内容,直接文章图片即可。 [图一,ThinkCMF采集,永远完全免费]
在正常运行网站时,网站的所有内容都不是完全原创的内容,要么是采集内容,要么是复制或粘贴内容,要么是网站管理员使用ThinkCMF@k11@的方式>。对于网站的管理员来说,有个小问题,大家都在采集,基本要点是ThinkCMF采集对网站做SEO,内容质量,页面质量处理网站质量。 [图二,ThinkCMF采集,功能齐全,功能强大]
现在网站越来越多,竞争越来越激烈,信息类网站收录的内容越来越多,关键词也很多。许多 网站 管理员对新站点感到头疼,即需要填充站点。没有内容,网站推广是不可能的。 ThinkCMF采集至少可以解决网站的内容,自动NPL处理内容优化网站。 【图三,ThinkCMF采集,自动SEO优化】
网站关键词需要排名,必须先收录,只要解决了收录,其他的都会解决。 ThinkCMF采集的内容让用户满意。 网站进行SEO优化时,ThinkCMF采集SEO网站的内容可以满足文章的内容,对用户有利。帮助。 【图4 ThinkCMF采集站长优化必备】
文章 和 文章 之间的链接非常重要。 ThinkCMF采集的功能实现了自动添加内链的效果。添加内链的主要目的是给文章传递权重,得到排名结果。
增加内链的方法主要是根据文章的标题。通过使用关键字设置标题。至于内部链接,如何实现自动添加效果,由于程序不同,设置方法还是有区别的,ThinkCMF采集可以兼容各种cms。
ThinkCMF采集实现采集功能的方法:
公共函数索引(){
// 使用采集类
// 用户手册:见文章图片
import('Org.QL.QueryList');
$url = "域/域";
$reg = 数组();
$reg['title'] = array('.sulist_title','text');
$reg['shuliang'] = array('.su_li1','html');
$obj = 新 \QueryList($url,$reg);
$data = $obj->jsonArr;
// foreach($data as $v){
//回声“
".$v['title'].'___'.$v['shuliang']."
";
// } 查看全部
自动采集文章(ThinkCMF采集的主要知识点以及表达点皆在文章配图之中)
ThinkCMF采集,可以为指定的关键词全网采集快速填写网站的内容资源。然后通过自动伪原创发布,让网站时刻保持更新状态,这样的网站受到搜索引擎的青睐。本文关于ThinkCMF采集的主要知识点和表达点都在文章图片中。不需要看内容,直接文章图片即可。 [图一,ThinkCMF采集,永远完全免费]
在正常运行网站时,网站的所有内容都不是完全原创的内容,要么是采集内容,要么是复制或粘贴内容,要么是网站管理员使用ThinkCMF@k11@的方式>。对于网站的管理员来说,有个小问题,大家都在采集,基本要点是ThinkCMF采集对网站做SEO,内容质量,页面质量处理网站质量。 [图二,ThinkCMF采集,功能齐全,功能强大]
现在网站越来越多,竞争越来越激烈,信息类网站收录的内容越来越多,关键词也很多。许多 网站 管理员对新站点感到头疼,即需要填充站点。没有内容,网站推广是不可能的。 ThinkCMF采集至少可以解决网站的内容,自动NPL处理内容优化网站。 【图三,ThinkCMF采集,自动SEO优化】
网站关键词需要排名,必须先收录,只要解决了收录,其他的都会解决。 ThinkCMF采集的内容让用户满意。 网站进行SEO优化时,ThinkCMF采集SEO网站的内容可以满足文章的内容,对用户有利。帮助。 【图4 ThinkCMF采集站长优化必备】
文章 和 文章 之间的链接非常重要。 ThinkCMF采集的功能实现了自动添加内链的效果。添加内链的主要目的是给文章传递权重,得到排名结果。
增加内链的方法主要是根据文章的标题。通过使用关键字设置标题。至于内部链接,如何实现自动添加效果,由于程序不同,设置方法还是有区别的,ThinkCMF采集可以兼容各种cms。
ThinkCMF采集实现采集功能的方法:

公共函数索引(){
// 使用采集类
// 用户手册:见文章图片
import('Org.QL.QueryList');
$url = "域/域";
$reg = 数组();
$reg['title'] = array('.sulist_title','text');
$reg['shuliang'] = array('.su_li1','html');
$obj = 新 \QueryList($url,$reg);
$data = $obj->jsonArr;
// foreach($data as $v){
//回声“
".$v['title'].'___'.$v['shuliang']."
";
// }
自动采集文章(如何写采集规则?人维护成百上千网站文章更新也不是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-07 03:13
如何编写采集 规则?最近有很多朋友问我问题。由于他们不是很熟练,也不是程序员,所以他们学起来会很慢。很多地方都处于无知状态。要学习采集规则的最低标准,至少了解html代码表示,大部分采集遵循采集的规则。发布模块的这一大部分需要专业的编程技能。
一、免费采集伪原创发布主动向搜索引擎提交链接的软件
今天分享给大家的软件不需要编写采集规则和发布模块。通过采集软件可以实现采集伪原创的自动发布和主动推送到搜索引擎。操作简单只需几步即可轻松采集内容数据,用户只需在采集软件上进行简单设置,采集软件即可准确设置关键词 采集文章,这确保了与行业 文章 保持一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
与其他采集软件相比,这款采集软件基本没有任何规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,输入关键词采集可以实现(采集软件也自带关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。采集该软件还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片)不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前采集关键词 是自动添加的。文本 Automatically insert the current 采集关键词 在随机位置两次。当当前 采集 的 关键词 出现在文本中时,< @关键词 将自动加粗。)
7、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
采集规则只是实现了一个采集的功能。搜索引擎更喜欢 原创 的内容。这个是很多站长都知道的,但是创建很多原创文章并不容易,下面介绍一些通过软件提高原创度的方法
二、通过软件工具提高文章原创度数
1.伪原创要做好以下几个方面,首先是文章的标题:这个文章的标题一定要改,这不仅仅是一个简单的换一个词,换一个说法,意思就完全不一样了。但是,标题不能没有关键字,从而失去了 伪原创 的值。学习title一般有两种方法,用长尾词作为title,或者用多个热词逼近title。
2.文章内容字数约为500-800字,关键词密度约为2%≤5%。
3.当然,伪原创也有一些技巧,比如改变段落或主题的顺序,替换同义词等等,结合方法和技巧。目前主流的 伪原创 方法是重写第一段和最后一段。第一段应该布局合理关键词,最好有1-2个关键词出现。不要刻意堆叠关键词,文章句子要流畅。在 文章 的末尾再添加一个关键字。
4.在文章的中间部分,做关键词的扩展,特意做H3标签,锚文本等,也做一些内链。灵活使用我们的日常优化技术。一般来说,伪原创的目的是带来价值,让搜索引擎认为是原创内容,然后伪原创内容收录很快,关键词排名也会很好。
三、网站收录多少个关键词排名
关键词的排名出现在网站后,出现关键词排名的页面可能不是网站的首页,可能是栏目页或文章页面,那么,如果在网站这种情况下,我们应该如何提高这样的关键词的排名呢?
1.关注页面怎么写TDK
既然已经是单个内页排名,那么我们就应该多注意一下这个页面的标题、描述和关键词的写法。标题要简洁全面,突出页面重点,包括关键词,描述要关键词 @文章介绍要详细,关键词只需重写任何你想要的。
2.展开内外部链接
如果想要稳定和提高这个内页的排名位置,就需要在这个内页添加有价值的内链和优质的外链,这样排名才能稳步提升。
3.内页内容扩展
如果是文章内容页面,需要时不时的重写内容下的相关内容,不管多少,但一定要和内容相关,质量一定要高。如果是产品页面,需要完善产品信息,更新产品。信息等
4.使用图像
图片不要过多过大,图片大小要合适,图片要清晰,图片要加ALT标签,便于搜索引擎识别图片内容。
5.单页代码优化
对于 CSS 和 JS 的优化,尽量使用外部导入,使网页代码更加简洁。如果可以使用CSS,尽量不要使用JS。毕竟 JS 对搜索引擎不是很友好。
四、我们知道网站的基本seo操作是seo内容发布,但是你明白网站为什么选择长期的内容更新吗?
从搜索引擎的角度来看,推荐用户最喜欢的网站是他们的主要职责,哪个网站有可能让用户喜欢呢?互联网是信息爆炸时代的载体,信息的不断更新是其主要表现形式。那么搜索引擎就会认为在网站时间内产生了新的页面,很可能是站长管理的,很受用户欢迎。它变大的机会,所以像经常更新的网站这样的搜索引擎,作为网站的seo人员,我们有责任让网站看起来像这样的搜索引擎,所以我们需要定期更新 网站 内容。
1、上面我们说过,网络时代的信息更新速度会非常快,我们需要吸收最新最新的处理,把它变成与我们相关的“内容”网站,让用户无需开动脑筋,即可了解行业最新资讯。
2、在这个内容为王的时代,内容的丰富性衡量了你的网站的整体质量,但罗马不是一天建成的,我们需要不断地补充。我们的网站内容会在我们不断的内容更新中变得越来越丰富。
五、其他服务器域名流量的知识
1、服务器性能常识;
在优化网站的过程中,站长需要时刻关注服务器的性能,比如CPU使用率、内存、站点日志、是否存在安全漏洞等。定期监控服务器性能有助于保证网站的安全稳定运行。多了解服务器,对以后的SEO优化也很有帮助。
2、域名解析相关知识;
域名解析是否正确直接决定了后面的网站优化操作,而网站优化过程中一个很重要的策略就是一个页面对应一个唯一的URL。如果域名解析配置错误,启用域名泛解析,或者没有确定网站首选域,会导致网站出现大量重复内容和权重分散.
3、过度关注网站的流量;
网站在过分关注流量的过程中,却忽略了网站内容的质量,导致网站跳出率高,导致一系列问题关键词 排名下降,流量下降,得不偿失。
4、备份
服务器数据备份+网站内容备份是很多站长容易忽略的问题。随着网站内容的增加,我们无法预测未来的很多事情。为了避免因网站不可抗拒或人为错误操作造成的一些问题,我们应提前做好应对措施,及时做好网站备份以确保安全。
上述功能可以通过采集工具实现。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名! 查看全部
自动采集文章(如何写采集规则?人维护成百上千网站文章更新也不是)
如何编写采集 规则?最近有很多朋友问我问题。由于他们不是很熟练,也不是程序员,所以他们学起来会很慢。很多地方都处于无知状态。要学习采集规则的最低标准,至少了解html代码表示,大部分采集遵循采集的规则。发布模块的这一大部分需要专业的编程技能。
一、免费采集伪原创发布主动向搜索引擎提交链接的软件

今天分享给大家的软件不需要编写采集规则和发布模块。通过采集软件可以实现采集伪原创的自动发布和主动推送到搜索引擎。操作简单只需几步即可轻松采集内容数据,用户只需在采集软件上进行简单设置,采集软件即可准确设置关键词 采集文章,这确保了与行业 文章 保持一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。

与其他采集软件相比,这款采集软件基本没有任何规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,输入关键词采集可以实现(采集软件也自带关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。

不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。采集该软件还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片)不再有对方的外部链接)。

3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前采集关键词 是自动添加的。文本 Automatically insert the current 采集关键词 在随机位置两次。当当前 采集 的 关键词 出现在文本中时,< @关键词 将自动加粗。)
7、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
采集规则只是实现了一个采集的功能。搜索引擎更喜欢 原创 的内容。这个是很多站长都知道的,但是创建很多原创文章并不容易,下面介绍一些通过软件提高原创度的方法
二、通过软件工具提高文章原创度数
1.伪原创要做好以下几个方面,首先是文章的标题:这个文章的标题一定要改,这不仅仅是一个简单的换一个词,换一个说法,意思就完全不一样了。但是,标题不能没有关键字,从而失去了 伪原创 的值。学习title一般有两种方法,用长尾词作为title,或者用多个热词逼近title。
2.文章内容字数约为500-800字,关键词密度约为2%≤5%。
3.当然,伪原创也有一些技巧,比如改变段落或主题的顺序,替换同义词等等,结合方法和技巧。目前主流的 伪原创 方法是重写第一段和最后一段。第一段应该布局合理关键词,最好有1-2个关键词出现。不要刻意堆叠关键词,文章句子要流畅。在 文章 的末尾再添加一个关键字。
4.在文章的中间部分,做关键词的扩展,特意做H3标签,锚文本等,也做一些内链。灵活使用我们的日常优化技术。一般来说,伪原创的目的是带来价值,让搜索引擎认为是原创内容,然后伪原创内容收录很快,关键词排名也会很好。
三、网站收录多少个关键词排名
关键词的排名出现在网站后,出现关键词排名的页面可能不是网站的首页,可能是栏目页或文章页面,那么,如果在网站这种情况下,我们应该如何提高这样的关键词的排名呢?
1.关注页面怎么写TDK
既然已经是单个内页排名,那么我们就应该多注意一下这个页面的标题、描述和关键词的写法。标题要简洁全面,突出页面重点,包括关键词,描述要关键词 @文章介绍要详细,关键词只需重写任何你想要的。
2.展开内外部链接
如果想要稳定和提高这个内页的排名位置,就需要在这个内页添加有价值的内链和优质的外链,这样排名才能稳步提升。
3.内页内容扩展


如果是文章内容页面,需要时不时的重写内容下的相关内容,不管多少,但一定要和内容相关,质量一定要高。如果是产品页面,需要完善产品信息,更新产品。信息等
4.使用图像
图片不要过多过大,图片大小要合适,图片要清晰,图片要加ALT标签,便于搜索引擎识别图片内容。
5.单页代码优化
对于 CSS 和 JS 的优化,尽量使用外部导入,使网页代码更加简洁。如果可以使用CSS,尽量不要使用JS。毕竟 JS 对搜索引擎不是很友好。
四、我们知道网站的基本seo操作是seo内容发布,但是你明白网站为什么选择长期的内容更新吗?
从搜索引擎的角度来看,推荐用户最喜欢的网站是他们的主要职责,哪个网站有可能让用户喜欢呢?互联网是信息爆炸时代的载体,信息的不断更新是其主要表现形式。那么搜索引擎就会认为在网站时间内产生了新的页面,很可能是站长管理的,很受用户欢迎。它变大的机会,所以像经常更新的网站这样的搜索引擎,作为网站的seo人员,我们有责任让网站看起来像这样的搜索引擎,所以我们需要定期更新 网站 内容。

1、上面我们说过,网络时代的信息更新速度会非常快,我们需要吸收最新最新的处理,把它变成与我们相关的“内容”网站,让用户无需开动脑筋,即可了解行业最新资讯。
2、在这个内容为王的时代,内容的丰富性衡量了你的网站的整体质量,但罗马不是一天建成的,我们需要不断地补充。我们的网站内容会在我们不断的内容更新中变得越来越丰富。
五、其他服务器域名流量的知识
1、服务器性能常识;
在优化网站的过程中,站长需要时刻关注服务器的性能,比如CPU使用率、内存、站点日志、是否存在安全漏洞等。定期监控服务器性能有助于保证网站的安全稳定运行。多了解服务器,对以后的SEO优化也很有帮助。
2、域名解析相关知识;
域名解析是否正确直接决定了后面的网站优化操作,而网站优化过程中一个很重要的策略就是一个页面对应一个唯一的URL。如果域名解析配置错误,启用域名泛解析,或者没有确定网站首选域,会导致网站出现大量重复内容和权重分散.
3、过度关注网站的流量;
网站在过分关注流量的过程中,却忽略了网站内容的质量,导致网站跳出率高,导致一系列问题关键词 排名下降,流量下降,得不偿失。
4、备份
服务器数据备份+网站内容备份是很多站长容易忽略的问题。随着网站内容的增加,我们无法预测未来的很多事情。为了避免因网站不可抗拒或人为错误操作造成的一些问题,我们应提前做好应对措施,及时做好网站备份以确保安全。

上述功能可以通过采集工具实现。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
自动采集文章(WP-AutoBlog为全新开发插件.3更快更新和维护)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-03-06 10:10
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集相同文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
自动采集在启用任务时无需人工干预即可更新
任务启用后,定期检查是否有新的文章可以更新,检查文章是否重复,导入更新文章,所有操作程序自动完成,无需人工干预。
触发采集更新有两种方式,一种是在页面中添加代码,通过用户访问触发采集更新(后台是异步的,不影响用户体验,确实不影响网站效率),另外可以使用Cron调度任务触发采集更新任务
方向采集,支持通配符匹配,或者精确的CSS选择器采集任何内容,支持采集多级文章列表,支持采集文本分页内容,支持采集多级文本内容
支持市面上所有主流对象存储服务,包括七牛云、阿里云OSS、腾讯云COS、百度云BOS、优拍云、亚马逊AWS S3、谷歌云存储,可存储文章图片@>中的附件自动上传到云对象存储服务,节省带宽和空间,提高网站访问速度
七牛云存储,享受每月10GB免费存储空间和10GB免费带宽
只需配置相关信息即可自动上传,已上传至云端对象存储的图片和文件也可通过Wordpress后台直接查看或管理。 查看全部
自动采集文章(WP-AutoBlog为全新开发插件.3更快更新和维护)
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集相同文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
自动采集在启用任务时无需人工干预即可更新
任务启用后,定期检查是否有新的文章可以更新,检查文章是否重复,导入更新文章,所有操作程序自动完成,无需人工干预。
触发采集更新有两种方式,一种是在页面中添加代码,通过用户访问触发采集更新(后台是异步的,不影响用户体验,确实不影响网站效率),另外可以使用Cron调度任务触发采集更新任务
方向采集,支持通配符匹配,或者精确的CSS选择器采集任何内容,支持采集多级文章列表,支持采集文本分页内容,支持采集多级文本内容
支持市面上所有主流对象存储服务,包括七牛云、阿里云OSS、腾讯云COS、百度云BOS、优拍云、亚马逊AWS S3、谷歌云存储,可存储文章图片@>中的附件自动上传到云对象存储服务,节省带宽和空间,提高网站访问速度
七牛云存储,享受每月10GB免费存储空间和10GB免费带宽
只需配置相关信息即可自动上传,已上传至云端对象存储的图片和文件也可通过Wordpress后台直接查看或管理。
自动采集文章(采集软件下载:七格格_微信公众号标题采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-06 07:06
自动采集文章标题搜狗智能采集器电脑手机都能用,采集微信公众号文章标题,配上相应的文字及视频,而且还有自动排版功能,自动排版,全新模式,一键智能收录,采集软件下载:安卓手机直接下载七格格app即可,苹果手机,安卓手机下载七格格app,微信,头条,uc,百度,阿里大鱼,企鹅号,其他主流平台自媒体都可以采集,一键全网一键收录。
七格格七格格电脑手机都能用。采集软件下载:七格格app七格格_微信公众号标题采集工具-第三方平台采集文章智能采集。
现在的自媒体平台有很多平台,像头条号、百家号、企鹅号、大鱼号、趣头条号等等,每个平台都是不一样的。不同的平台注册需要不同的材料,有的需要身份证,有的需要手机号等等,不同的平台需要的材料不一样,头条就需要一个手机号,而且现在很多平台审核也是比较严格,所以我们在平时要多多的关注各个平台的公告文章,熟悉了解平台规则,那么我们就可以很快的申请下来账号。
想要在运营自媒体的时候事半功倍,我们在注册账号的时候,注意资料一定要准确,虽然现在申请很简单,但是如果你没有审核的话,也是很慢的,所以,我们一定要打造个性化账号。做好自媒体最重要的是坚持,要坚持更新内容,定时发文。因为平台要推荐你的文章,最根本的原因还是来源于你写的内容。有的人在注册账号的时候,为了好的名字,为了提高审核的通过率,就跑去做微商了,然后觉得微商一定不好,放弃了自媒体,其实我们不要过多的去关注这些东西,坚持不定时发文,才是最重要的,不要东关注它,看看它就跑去做微商了,这种方法不可取的。
做自媒体是一个长期积累的过程,我们不要着急,想要能取得高收益,我们首先要做好内容输出,如果你不思考输出内容,光靠搬运,可能是能够月入过万的,但是能够走的长远的。希望我的回答能够帮助到你,欢迎点赞加关注!如果你想学习自媒体,可以关注我的个人主页。 查看全部
自动采集文章(采集软件下载:七格格_微信公众号标题采集工具)
自动采集文章标题搜狗智能采集器电脑手机都能用,采集微信公众号文章标题,配上相应的文字及视频,而且还有自动排版功能,自动排版,全新模式,一键智能收录,采集软件下载:安卓手机直接下载七格格app即可,苹果手机,安卓手机下载七格格app,微信,头条,uc,百度,阿里大鱼,企鹅号,其他主流平台自媒体都可以采集,一键全网一键收录。
七格格七格格电脑手机都能用。采集软件下载:七格格app七格格_微信公众号标题采集工具-第三方平台采集文章智能采集。
现在的自媒体平台有很多平台,像头条号、百家号、企鹅号、大鱼号、趣头条号等等,每个平台都是不一样的。不同的平台注册需要不同的材料,有的需要身份证,有的需要手机号等等,不同的平台需要的材料不一样,头条就需要一个手机号,而且现在很多平台审核也是比较严格,所以我们在平时要多多的关注各个平台的公告文章,熟悉了解平台规则,那么我们就可以很快的申请下来账号。
想要在运营自媒体的时候事半功倍,我们在注册账号的时候,注意资料一定要准确,虽然现在申请很简单,但是如果你没有审核的话,也是很慢的,所以,我们一定要打造个性化账号。做好自媒体最重要的是坚持,要坚持更新内容,定时发文。因为平台要推荐你的文章,最根本的原因还是来源于你写的内容。有的人在注册账号的时候,为了好的名字,为了提高审核的通过率,就跑去做微商了,然后觉得微商一定不好,放弃了自媒体,其实我们不要过多的去关注这些东西,坚持不定时发文,才是最重要的,不要东关注它,看看它就跑去做微商了,这种方法不可取的。
做自媒体是一个长期积累的过程,我们不要着急,想要能取得高收益,我们首先要做好内容输出,如果你不思考输出内容,光靠搬运,可能是能够月入过万的,但是能够走的长远的。希望我的回答能够帮助到你,欢迎点赞加关注!如果你想学习自媒体,可以关注我的个人主页。
自动采集文章(微信公众号查看历史消息页或者文章详情页(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-27 00:27
%2BfItg%3D&pass_ticket=DGD5JOEorn3ncmbmdXKbsmgxGOEwYobX7unmU6gwxw8SzwowCh6KBA%2BRMYejszL%2F&wx_header=1
3、通过修改anyproxy配置文件解决了anyproxy拦截过程中的各种错误。
Anyproxy的内部错误会执行anyproxy配置文件rule_default.js中的onError方法,所以当报错的时候,可以修改这个方法,让它获取下一页,注入到js脚本中继续执行,不停止
*onError(requestDetail, error) {
if(/s\?__biz=/i.test(requestDetail.url) || /mp\/profile_ext\?action=home/i.test(requestDetail.url) || /mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
var errorStr = error.toString();
console.log("++++++++++onError+++++++++++++" + errorStr + "++++++++++++++++++++++++++");
getWxPost("访问该页面出现错误",requestDetail.url,"/handleErrorLink");
console.log("++++++++++访问该页面出现错误,加载下一链接++++++++++++++++++++++++++" + requestDetail.url);
var nonce = "";
var response = "";
if(/mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
response = getWxBizForInfo();
} else {
response = getNextUrl(nonce);
}
//response = getNextUrl(nonce);
console.log("**** onError next url or biz *****: "+ response)
return {
response: {
statusCode: 200,
header: { 'content-type': 'text/html' },
body: " 加载下一页 "+ requestDetail.url +"" + response
}
};
}
}
GitHub源码地址:wechat-serv-crawler
环境搭建与部署 安装前准备
系统:CentOS Linux 发行版7.6.1810(核心)
日常模拟器:点击下载
Node-v10.16.0:点击下载
Nodejs下载页面:点击下载
在服务器上搭建anyproxy代理相关文章:Centos7.x搭建anyproxy代理服务器
cd /opt
// 克隆项目到本地
git clone git@github.com:dengyinlei/wechat-serv-crawler.git
// 修改`wechat-serv-crawler/src/main/resources/application.properties`
`wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg`
`wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties`对的数据库和redis的地址
vim wechat-serv-crawler/src/main/resources/application.properties
vim wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg
vim wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties
// 修改完成后打包
cd wechat-serv-crawler && mvn clean install -Dmaven.test.skip=true
// 安装nodejs同步请求sync-request包
npm install -g sync-request
// 替换anyproxy 配置脚本 rule_default.js :
cp /opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js /usr/local/nodejs/lib/node_modules/anyproxy/lib/
//关于anyproxy具体拦截请求处理的逻辑见/opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js配置脚本
//生成替换所有图片,减轻浏览器负担
touch /usr/local/nodejs/lib/node_modules/anyproxy/lib/one_pixel.png
//使用pm2重启anyproxy进程:
pm2 restart all
//查看anyproxy日志:
pm2 logs anyproxy
// 数据库脚本初始化
安装完MySQL数据库后执行/opt/wechat-serv-crawler/src/main/resources/sql/table.sql脚本 初始化数据库以及相关表结构。
// 运行项目
cd /opt/wechat-serv-crawler/target && sh stop.sh && sh start.sh
首次点击动作
打开模拟器,下载anyproxy的证书并配置代理,在模拟器中登录微信添加任意好友,好友会发给你任意微信公众号历史页面或微信文章链接消息,并放消息置顶,进入消息聊天界面,点击链接自动爬取redis队列中微信公众号对应的文章,如下图:
关于自动抓取
这个程序是事件驱动的。也就是一开始必须给一个触发事件,比如打开微信公众号查看历史新闻或者打开公众号文章,然后自动跳转到下一个公众号历史消息页面或者文章@通过js注入>详情页面,当然中间可能会出现异常,异常会阻塞自动跳转到下一页,需要自动化框架的辅助来模拟手动点击动作。这里使用了atx自动化框架。
本项目自动化程度高。人工费用为首次登录微信后点击微信公众号查看历史新闻或在公众号文章中打开链接。后续跳转完全通过js注入,异常自动处理恢复点击(atx自动点击)。
运行效果展示
该项目已经是一个成熟且成熟的项目。经过大量长期测试,目前可以保证微信客户端每天采集300个公众号的数据稳定运行,不会被封号。如果您访问微信公众号的历史新闻页面过于频繁,您将被禁止 24 小时。
目前比较好的策略是访问文章页面后休眠5秒,访问微信公众号历史新闻页面后休眠150秒。
本项目功能测试成功,已稳定运行两个月。目前采集使用三个微信账号,采集每天900个微信公众号文章的数据。
每个微信账号每月费用为5元。基于该项目,可以实现大规模运营的低成本运营。
更新(2020-07-30)在爬出错误过程中降低漏爬率)
由于我使用redis的list queue作为消息队列,在消息消费过程中可能会出现错误,导致消息丢失和数据泄露。通过使用redis的RPOPLPUSH命令,消费者程序进入slave主消息队列。消息取出后,插入到备份队列中,从备份队列中删除消息,直到消费者程序完成正常的处理逻辑。同时,我们也可以提供一个守护进程。主消息队列中的消息被消费后,备份队列中没有正常消费的消息可以放回主消息队列中,以便其他消费者程序继续处理。
/**
* 从redis队列中获取下一个待爬取的链接
* @return
*/
@RequestMapping(value = "/getNextUrl", method = RequestMethod.GET)
public String getNextUrl() {
//下一个微信公众号文章的url
String nextUrl = redisUtils.rpoplpush("wechat_content_quene", "wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
nextUrl = redisUtils.lpop("wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
LOGGER.info("==============队列中已无待跑的文章url,从队列中获取下一个公众号的biz==================");
//队列表如果空了,就从存储公众号biz的队列中取得一个biz
String biz = redisUtils.rpoplpush(WECHAT_BIZ_QUENE, WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
biz = redisUtils.lpop(WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
String errorLink = redisUtils.rpoplpush(ERROR__LINK,WECHAT_CONTENT_URL_BACKUP_QUENE);
if (StringUtils.isBlank(errorLink)) {
LOGGER.info("=================队列中已无待跑的公众号,结束本次爬取任务===================");
return EXAMPLE_CONTENT_URL;
} else {
LOGGER.info("=================从错误页面从获取爬取失败的链接===================link:{}", errorLink);
return errorLink;
}
}
获取微信公众号所有历史新闻列表,微信公众号特殊公众号也可以不关注文章获取历史:
之前实现的方案是只爬取微信公众号的最新页面文章列表。由于下一页抓包解析返回的内容是json响应体,因此无法通过注入脚本来自动模拟点击遍历。实现翻页功能。
通过分析测试发现只要使用下面的url模式获取文章的列表,注意f参数为html,可以将下一页返回的内容修改为html格式,解决了json不容易注入js脚本的问题。题。另外,调整偏移量可以实现翻页。
下图为上述公众号第100页的历史文章列表页:
参考文章
感谢以下 文章 想法:
1、使用anyproxy提高公众号效率文章采集
2、微信公众号文章批量采集系统搭建
联系作者
由于微信采集平台的搭建和开发耗费了大量的时间和精力,暂时不打算开源。如果您满足以下条件:不懂技术,时间宝贵,不想花时间研究,想尽快看到效果,并且本项目目前实现的功能满足您的需求,可以付费联系我用所有随附的源代码帮助您构建这个项目,并回答和解决您在开发过程中遇到的所有疑问。 查看全部
自动采集文章(微信公众号查看历史消息页或者文章详情页(组图))
%2BfItg%3D&pass_ticket=DGD5JOEorn3ncmbmdXKbsmgxGOEwYobX7unmU6gwxw8SzwowCh6KBA%2BRMYejszL%2F&wx_header=1
3、通过修改anyproxy配置文件解决了anyproxy拦截过程中的各种错误。

Anyproxy的内部错误会执行anyproxy配置文件rule_default.js中的onError方法,所以当报错的时候,可以修改这个方法,让它获取下一页,注入到js脚本中继续执行,不停止
*onError(requestDetail, error) {
if(/s\?__biz=/i.test(requestDetail.url) || /mp\/profile_ext\?action=home/i.test(requestDetail.url) || /mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
var errorStr = error.toString();
console.log("++++++++++onError+++++++++++++" + errorStr + "++++++++++++++++++++++++++");
getWxPost("访问该页面出现错误",requestDetail.url,"/handleErrorLink");
console.log("++++++++++访问该页面出现错误,加载下一链接++++++++++++++++++++++++++" + requestDetail.url);
var nonce = "";
var response = "";
if(/mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
response = getWxBizForInfo();
} else {
response = getNextUrl(nonce);
}
//response = getNextUrl(nonce);
console.log("**** onError next url or biz *****: "+ response)
return {
response: {
statusCode: 200,
header: { 'content-type': 'text/html' },
body: " 加载下一页 "+ requestDetail.url +"" + response
}
};
}
}
GitHub源码地址:wechat-serv-crawler
环境搭建与部署 安装前准备
系统:CentOS Linux 发行版7.6.1810(核心)
日常模拟器:点击下载
Node-v10.16.0:点击下载
Nodejs下载页面:点击下载
在服务器上搭建anyproxy代理相关文章:Centos7.x搭建anyproxy代理服务器
cd /opt
// 克隆项目到本地
git clone git@github.com:dengyinlei/wechat-serv-crawler.git
// 修改`wechat-serv-crawler/src/main/resources/application.properties`
`wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg`
`wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties`对的数据库和redis的地址
vim wechat-serv-crawler/src/main/resources/application.properties
vim wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg
vim wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties
// 修改完成后打包
cd wechat-serv-crawler && mvn clean install -Dmaven.test.skip=true
// 安装nodejs同步请求sync-request包
npm install -g sync-request
// 替换anyproxy 配置脚本 rule_default.js :
cp /opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js /usr/local/nodejs/lib/node_modules/anyproxy/lib/
//关于anyproxy具体拦截请求处理的逻辑见/opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js配置脚本
//生成替换所有图片,减轻浏览器负担
touch /usr/local/nodejs/lib/node_modules/anyproxy/lib/one_pixel.png
//使用pm2重启anyproxy进程:
pm2 restart all
//查看anyproxy日志:
pm2 logs anyproxy
// 数据库脚本初始化
安装完MySQL数据库后执行/opt/wechat-serv-crawler/src/main/resources/sql/table.sql脚本 初始化数据库以及相关表结构。
// 运行项目
cd /opt/wechat-serv-crawler/target && sh stop.sh && sh start.sh
首次点击动作
打开模拟器,下载anyproxy的证书并配置代理,在模拟器中登录微信添加任意好友,好友会发给你任意微信公众号历史页面或微信文章链接消息,并放消息置顶,进入消息聊天界面,点击链接自动爬取redis队列中微信公众号对应的文章,如下图:

关于自动抓取
这个程序是事件驱动的。也就是一开始必须给一个触发事件,比如打开微信公众号查看历史新闻或者打开公众号文章,然后自动跳转到下一个公众号历史消息页面或者文章@通过js注入>详情页面,当然中间可能会出现异常,异常会阻塞自动跳转到下一页,需要自动化框架的辅助来模拟手动点击动作。这里使用了atx自动化框架。
本项目自动化程度高。人工费用为首次登录微信后点击微信公众号查看历史新闻或在公众号文章中打开链接。后续跳转完全通过js注入,异常自动处理恢复点击(atx自动点击)。
运行效果展示
该项目已经是一个成熟且成熟的项目。经过大量长期测试,目前可以保证微信客户端每天采集300个公众号的数据稳定运行,不会被封号。如果您访问微信公众号的历史新闻页面过于频繁,您将被禁止 24 小时。
目前比较好的策略是访问文章页面后休眠5秒,访问微信公众号历史新闻页面后休眠150秒。
本项目功能测试成功,已稳定运行两个月。目前采集使用三个微信账号,采集每天900个微信公众号文章的数据。
每个微信账号每月费用为5元。基于该项目,可以实现大规模运营的低成本运营。

更新(2020-07-30)在爬出错误过程中降低漏爬率)
由于我使用redis的list queue作为消息队列,在消息消费过程中可能会出现错误,导致消息丢失和数据泄露。通过使用redis的RPOPLPUSH命令,消费者程序进入slave主消息队列。消息取出后,插入到备份队列中,从备份队列中删除消息,直到消费者程序完成正常的处理逻辑。同时,我们也可以提供一个守护进程。主消息队列中的消息被消费后,备份队列中没有正常消费的消息可以放回主消息队列中,以便其他消费者程序继续处理。
/**
* 从redis队列中获取下一个待爬取的链接
* @return
*/
@RequestMapping(value = "/getNextUrl", method = RequestMethod.GET)
public String getNextUrl() {
//下一个微信公众号文章的url
String nextUrl = redisUtils.rpoplpush("wechat_content_quene", "wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
nextUrl = redisUtils.lpop("wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
LOGGER.info("==============队列中已无待跑的文章url,从队列中获取下一个公众号的biz==================");
//队列表如果空了,就从存储公众号biz的队列中取得一个biz
String biz = redisUtils.rpoplpush(WECHAT_BIZ_QUENE, WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
biz = redisUtils.lpop(WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
String errorLink = redisUtils.rpoplpush(ERROR__LINK,WECHAT_CONTENT_URL_BACKUP_QUENE);
if (StringUtils.isBlank(errorLink)) {
LOGGER.info("=================队列中已无待跑的公众号,结束本次爬取任务===================");
return EXAMPLE_CONTENT_URL;
} else {
LOGGER.info("=================从错误页面从获取爬取失败的链接===================link:{}", errorLink);
return errorLink;
}
}
获取微信公众号所有历史新闻列表,微信公众号特殊公众号也可以不关注文章获取历史:
之前实现的方案是只爬取微信公众号的最新页面文章列表。由于下一页抓包解析返回的内容是json响应体,因此无法通过注入脚本来自动模拟点击遍历。实现翻页功能。
通过分析测试发现只要使用下面的url模式获取文章的列表,注意f参数为html,可以将下一页返回的内容修改为html格式,解决了json不容易注入js脚本的问题。题。另外,调整偏移量可以实现翻页。
下图为上述公众号第100页的历史文章列表页:

参考文章
感谢以下 文章 想法:
1、使用anyproxy提高公众号效率文章采集
2、微信公众号文章批量采集系统搭建
联系作者
由于微信采集平台的搭建和开发耗费了大量的时间和精力,暂时不打算开源。如果您满足以下条件:不懂技术,时间宝贵,不想花时间研究,想尽快看到效果,并且本项目目前实现的功能满足您的需求,可以付费联系我用所有随附的源代码帮助您构建这个项目,并回答和解决您在开发过程中遇到的所有疑问。
自动采集文章(如何做好一个网站SEO收录?有哪些收录技巧和注意的地方)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-27 00:22
Emlog采集,是很多博主、个人网站、企业网站长期使用的一种网站内容扩展工具,可以大大提升丰满度网站 度,通过海量内容吸引更多用户访问。如何做好网站SEO收录?收录 的提示和注意事项有哪些?接下来,我们将从 Emlog采集 的功能和功能,以及 SEO 技巧来看整个 SEO 优化。
网站采集的文章与收录率有一定的关系。到目前为止,采集站仍然可以达到很高的权重。搜索引擎也表示采集的内容要注意是否去掉多余的标签,内容是否完整等。emlog采集虽然不是一个好的选择,但是对于很多网站来说,只有在采集之后才有能力输出新鲜的内容。
那么Emlog采集制作的采集站点会实现这些优化:网站采集内容清晰,没有乱码,标签不干净。扩充补充采集的内容,减少采集的内容。在采集的内容后添加其他相关内容,使内部链接相互指向,扩大相关性。尽可能采集优质网站的内容不会采集不可读或带有广告文章。
Emlog采集发布后,会主动推送内容,随着内容的持久化,爬虫访问的概率增加。爬取推广网站的收录,这就是前面提到的内容建设和网站优化。此外,最好提交大量的站点地图。搜索引擎处理站点地图的时间很长,最近时间缩短了很多。至于怎么推送,一般都是后台推送,支持结构化数据提交,提交多了会有惊喜。毅力是必需的。另外,网站还可以推送到收录的目录栏,可以查看其API文档申请。
目前很多建站系统都集成了采集系统,Emlog采集对于采集的内容已经成为一件很简单的事情。在短时间内用内容填满您的新网站或让搜索引擎更快收录我们的新网站变得更快了。
但是当我们采集完成这个内容并通过搜索引擎得到收录之后,我们的网站可以非常快速的增长。在搜索引擎开始收录我们的内容之后,但后来当他在他的数据库中发现类似的内容时,那些低权重的网站收录的信息往往最先被删除。掉了。这是我们的 收录 上升然后下降的主要原因之一。因此,Emlog采集返回的内容必须经过内置文章处理后才能发布,并根据搜索引擎算法和实时性进行文章排列用户的搜索需求,让文章对搜索引擎和用户都有价值。 查看全部
自动采集文章(如何做好一个网站SEO收录?有哪些收录技巧和注意的地方)
Emlog采集,是很多博主、个人网站、企业网站长期使用的一种网站内容扩展工具,可以大大提升丰满度网站 度,通过海量内容吸引更多用户访问。如何做好网站SEO收录?收录 的提示和注意事项有哪些?接下来,我们将从 Emlog采集 的功能和功能,以及 SEO 技巧来看整个 SEO 优化。

网站采集的文章与收录率有一定的关系。到目前为止,采集站仍然可以达到很高的权重。搜索引擎也表示采集的内容要注意是否去掉多余的标签,内容是否完整等。emlog采集虽然不是一个好的选择,但是对于很多网站来说,只有在采集之后才有能力输出新鲜的内容。

那么Emlog采集制作的采集站点会实现这些优化:网站采集内容清晰,没有乱码,标签不干净。扩充补充采集的内容,减少采集的内容。在采集的内容后添加其他相关内容,使内部链接相互指向,扩大相关性。尽可能采集优质网站的内容不会采集不可读或带有广告文章。

Emlog采集发布后,会主动推送内容,随着内容的持久化,爬虫访问的概率增加。爬取推广网站的收录,这就是前面提到的内容建设和网站优化。此外,最好提交大量的站点地图。搜索引擎处理站点地图的时间很长,最近时间缩短了很多。至于怎么推送,一般都是后台推送,支持结构化数据提交,提交多了会有惊喜。毅力是必需的。另外,网站还可以推送到收录的目录栏,可以查看其API文档申请。

目前很多建站系统都集成了采集系统,Emlog采集对于采集的内容已经成为一件很简单的事情。在短时间内用内容填满您的新网站或让搜索引擎更快收录我们的新网站变得更快了。
但是当我们采集完成这个内容并通过搜索引擎得到收录之后,我们的网站可以非常快速的增长。在搜索引擎开始收录我们的内容之后,但后来当他在他的数据库中发现类似的内容时,那些低权重的网站收录的信息往往最先被删除。掉了。这是我们的 收录 上升然后下降的主要原因之一。因此,Emlog采集返回的内容必须经过内置文章处理后才能发布,并根据搜索引擎算法和实时性进行文章排列用户的搜索需求,让文章对搜索引擎和用户都有价值。
自动采集文章(>复制到站内链接搜索引擎随时能找到你(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-22 03:02
自动采集文章标题-->生成正文标题-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键填充评论数-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键帮你全站下载文章-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键帮你自动发布文章-->复制到站内链接,搜索引擎随时能找到你这篇文章;新建标签-->自动把标签添加到标题-->去掉标题-->这篇文章所有的页面所有页面都引用这个标签;文章内容反链接seo-generator/hire一个基于插件的权重内链平台a/seo-generator/hire-seo-generator-ideas/hire1226/seo-generator/pages/pages/herilst.herilst.herilst这些文章不是我写的,今天利用googlereader添加过来的。
具体要注意什么:第一,不建议把个人博客弄得太复杂,没有必要,没有必要;第二,不建议把博客弄得太复杂,不建议把博客弄得太复杂;第三,不建议把博客弄得太复杂,不建议把博客弄得太复杂;重要的事情说三遍;第四,建议把博客搞得尽量简单,那些小众的网站很不错;第五,建议把博客弄得尽量简单,那些小众的网站很不错;第六,建议把博客弄得尽量简单,那些小众的网站很不错;第七,在博客里面加一个小广告,因为个人博客的篇幅比较短,所以,可以加一个小广告,来吸引用户;第八,网站在经历一段低谷期之后,一定要开始坚持写,如果文章没有提升的话,很快就没有访问量,说明你还不适合做网站;第九,提升网站的原创内容质量,如果网站写的不好,很快就没有访问量,说明你还不适合做网站;第十,切记:不要以为,博客里面有了原创内容就可以了,这不是绝对的;最后奉劝大家在做网站之前,一定要想清楚,自己想要做成什么样子的网站,并且分析每一步是否可行。如果你有创业的想法,可以加我微信:(weixin)验证:知乎。 查看全部
自动采集文章(>复制到站内链接搜索引擎随时能找到你(组图))
自动采集文章标题-->生成正文标题-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键填充评论数-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键帮你全站下载文章-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键帮你自动发布文章-->复制到站内链接,搜索引擎随时能找到你这篇文章;新建标签-->自动把标签添加到标题-->去掉标题-->这篇文章所有的页面所有页面都引用这个标签;文章内容反链接seo-generator/hire一个基于插件的权重内链平台a/seo-generator/hire-seo-generator-ideas/hire1226/seo-generator/pages/pages/herilst.herilst.herilst这些文章不是我写的,今天利用googlereader添加过来的。
具体要注意什么:第一,不建议把个人博客弄得太复杂,没有必要,没有必要;第二,不建议把博客弄得太复杂,不建议把博客弄得太复杂;第三,不建议把博客弄得太复杂,不建议把博客弄得太复杂;重要的事情说三遍;第四,建议把博客搞得尽量简单,那些小众的网站很不错;第五,建议把博客弄得尽量简单,那些小众的网站很不错;第六,建议把博客弄得尽量简单,那些小众的网站很不错;第七,在博客里面加一个小广告,因为个人博客的篇幅比较短,所以,可以加一个小广告,来吸引用户;第八,网站在经历一段低谷期之后,一定要开始坚持写,如果文章没有提升的话,很快就没有访问量,说明你还不适合做网站;第九,提升网站的原创内容质量,如果网站写的不好,很快就没有访问量,说明你还不适合做网站;第十,切记:不要以为,博客里面有了原创内容就可以了,这不是绝对的;最后奉劝大家在做网站之前,一定要想清楚,自己想要做成什么样子的网站,并且分析每一步是否可行。如果你有创业的想法,可以加我微信:(weixin)验证:知乎。
自动采集文章(自动采集文章广告,插入到自己的公众号图文推广)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-02-20 19:01
自动采集文章广告,插入到自己的公众号图文推广,可以私聊我。2019年以来,客发展很是不错,很多人都转向做客。但是做客的成本很高,广告费是其中一个,其次还有培训费用、发货等成本。那么我们该如何做客呢?下面由禾赛科技()为大家介绍我们该如何做客。
一、选择性的发展自己的粉丝,积累自己的老粉丝要想做好客,首先需要积累自己的粉丝,你要是一个优秀的客,还要有一定的推广能力,但是也不能放弃自己粉丝的利益。对于那些不愿意花钱的人来说,又想赚钱的话,就要从源头控制你的粉丝。一旦你的粉丝少了,就不再有人会去推荐给你。
二、扩大你的粉丝群体,快速积累粉丝既然现在做客的难度比较大,那么还是要选择一个更有效的方式。很多人选择了上客信息,就是所谓的搜索客信息,所谓的平台上客信息很多,有很多人只是普通用户,并不会发展为客。当然了,你也可以先积累自己的粉丝,等到了一定时间,慢慢等待生活稳定之后,再去慢慢扩大你的粉丝群体。
有不少客,积累起来后根本找不到推广的地方,并且还要承担推广费用。有些客找客户的方式是,我知道他有客信息,还有他的老婆孩子。你要知道,你需要给这些人解释,并不是他老婆孩子的一个这个重要的推广渠道。
三、扩大客的影响力,快速积累自己的影响力。很多客,刚开始都想着高收益,想着让更多的人帮他们赚钱,可是等他积累起来了,他就会清楚,帮助别人赚钱,远远不及自己去做自己的工作。要想做好客的话,就是要不断扩大自己的影响力,建立自己的粉丝和自己的影响力。这个时候有不少客认为,我的粉丝多了,我可以给粉丝推广,他们自然会帮助我了。
可是根据笔者的经验,这些粉丝绝大多数不是你的潜在粉丝,想赚钱的话,还是不能只推广这个,你还要推广别的,这样你的粉丝群体才会变得多。再者是你的推广方式,你怎么才能让他们去帮助你呢?你所推的东西的质量怎么样?我相信大家不用我多说,不管是工作还是生活,很多人宁愿相信陌生人也不愿意相信自己的父母。推广的东西也是要让大家相信你,相信你能赚钱,这样你才能赢得粉丝的信任。
然后你还要通过自己的影响力去帮助别人去赚钱,树立起你赚钱的形象。这些大家也都想知道,但是能赚钱的人他就是不说,就是不说,就是不说。总之做客,不是谁都能做客,只要有一定推广能力和运营能力。 查看全部
自动采集文章(自动采集文章广告,插入到自己的公众号图文推广)
自动采集文章广告,插入到自己的公众号图文推广,可以私聊我。2019年以来,客发展很是不错,很多人都转向做客。但是做客的成本很高,广告费是其中一个,其次还有培训费用、发货等成本。那么我们该如何做客呢?下面由禾赛科技()为大家介绍我们该如何做客。
一、选择性的发展自己的粉丝,积累自己的老粉丝要想做好客,首先需要积累自己的粉丝,你要是一个优秀的客,还要有一定的推广能力,但是也不能放弃自己粉丝的利益。对于那些不愿意花钱的人来说,又想赚钱的话,就要从源头控制你的粉丝。一旦你的粉丝少了,就不再有人会去推荐给你。
二、扩大你的粉丝群体,快速积累粉丝既然现在做客的难度比较大,那么还是要选择一个更有效的方式。很多人选择了上客信息,就是所谓的搜索客信息,所谓的平台上客信息很多,有很多人只是普通用户,并不会发展为客。当然了,你也可以先积累自己的粉丝,等到了一定时间,慢慢等待生活稳定之后,再去慢慢扩大你的粉丝群体。
有不少客,积累起来后根本找不到推广的地方,并且还要承担推广费用。有些客找客户的方式是,我知道他有客信息,还有他的老婆孩子。你要知道,你需要给这些人解释,并不是他老婆孩子的一个这个重要的推广渠道。
三、扩大客的影响力,快速积累自己的影响力。很多客,刚开始都想着高收益,想着让更多的人帮他们赚钱,可是等他积累起来了,他就会清楚,帮助别人赚钱,远远不及自己去做自己的工作。要想做好客的话,就是要不断扩大自己的影响力,建立自己的粉丝和自己的影响力。这个时候有不少客认为,我的粉丝多了,我可以给粉丝推广,他们自然会帮助我了。
可是根据笔者的经验,这些粉丝绝大多数不是你的潜在粉丝,想赚钱的话,还是不能只推广这个,你还要推广别的,这样你的粉丝群体才会变得多。再者是你的推广方式,你怎么才能让他们去帮助你呢?你所推的东西的质量怎么样?我相信大家不用我多说,不管是工作还是生活,很多人宁愿相信陌生人也不愿意相信自己的父母。推广的东西也是要让大家相信你,相信你能赚钱,这样你才能赢得粉丝的信任。
然后你还要通过自己的影响力去帮助别人去赚钱,树立起你赚钱的形象。这些大家也都想知道,但是能赚钱的人他就是不说,就是不说,就是不说。总之做客,不是谁都能做客,只要有一定推广能力和运营能力。
自动采集文章(自动采集文章的方法:-1-11.在搜索框中输入关键词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-19 15:05
自动采集文章的方法:-1-11.在搜索框中输入关键词2.在出现的文章列表中点击你要的题目3.即可获取到所有的已收录的文章
自动采集的话,你可以用搜索引擎的爬虫去抓取。这个是需要知道网站内容的。如果不知道,可以考虑百度个性化定制服务,你可以从图片,链接上获取这些东西,
我知道的都是谷歌的思路
1、准备一个谷歌浏览器(必须)
2、把要采集的文章的链接复制到谷歌爬虫控制台(步骤
1、
2、
3)
3、复制并转换为高亮字符在谷歌分析中(步骤
4、调用搜索引擎爬取需要的文章
5、把高亮字符(把勾去掉)放回result类里面,
google和百度都不能采集新浪的,我们在采集新浪新闻的时候都采集不了那些收录快的,要采集的是没人收录的(即更小的频道),新浪新闻,是有人收录了,但是你却不知道是哪些时刻被人收录了,如果你不知道是哪天哪个收录了新浪新闻的网站,那就采集不了,反之可以采集,当然前提要有收录量和浏览量,还得有浏览次数的累计,不然谁记得你?这是我们采集百度新闻的网站,不过采集百度的主要是原创新闻,整天复制别人的东西不实用,要采集没被收录的百度或搜狗新闻,你可以到你要采集的网站进行搜索,看看他们是怎么做的就知道怎么来了。 查看全部
自动采集文章(自动采集文章的方法:-1-11.在搜索框中输入关键词)
自动采集文章的方法:-1-11.在搜索框中输入关键词2.在出现的文章列表中点击你要的题目3.即可获取到所有的已收录的文章
自动采集的话,你可以用搜索引擎的爬虫去抓取。这个是需要知道网站内容的。如果不知道,可以考虑百度个性化定制服务,你可以从图片,链接上获取这些东西,
我知道的都是谷歌的思路
1、准备一个谷歌浏览器(必须)
2、把要采集的文章的链接复制到谷歌爬虫控制台(步骤
1、
2、
3)
3、复制并转换为高亮字符在谷歌分析中(步骤
4、调用搜索引擎爬取需要的文章
5、把高亮字符(把勾去掉)放回result类里面,
google和百度都不能采集新浪的,我们在采集新浪新闻的时候都采集不了那些收录快的,要采集的是没人收录的(即更小的频道),新浪新闻,是有人收录了,但是你却不知道是哪些时刻被人收录了,如果你不知道是哪天哪个收录了新浪新闻的网站,那就采集不了,反之可以采集,当然前提要有收录量和浏览量,还得有浏览次数的累计,不然谁记得你?这是我们采集百度新闻的网站,不过采集百度的主要是原创新闻,整天复制别人的东西不实用,要采集没被收录的百度或搜狗新闻,你可以到你要采集的网站进行搜索,看看他们是怎么做的就知道怎么来了。
自动采集文章(先说成果抓了掘金前端类目下的文章标题192条)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-15 16:27
本网站的内容是从兴趣中采集的。如果您无意中侵犯了您的相关权益,请留言告知我们,我们将尽快删除。谢谢你。
俗话说:如果你有一把锤子:hammer: 在你的手中,一切看起来都像钉子。当我拿着朴素贝叶斯之锤时,我看到掘金队 文章 的分类就像一颗等待被锤击的钉子。
目前,用户需要在掘金文章中手动选择已发布文章的类别。如果用算法自动判断文章属于哪个类别,那么这一步就可以省去(单看这种情况,用户体验提升很小,但改造后内容分布可以更好) .
让我们谈谈结果
我在掘金的前端类别下捕获了 192 个 文章 标题,在后端类别下捕获了 969 个 文章 标题,在人工智能类别下捕获了 692 个 文章 标题。未经任何优化的朴素贝叶斯训练模型的分类准确率为0.79。
可以看出朴素贝叶斯在技术文章分类中是一个不错的算法。它可以在少于 2000 个标题的情况下达到 0.8 的正确率。如果加上文章内容,我猜准确率可以是0.9以上。
怎么做
数据采集
直接使用采集器新建采集任务,如优采云、优采云等。将 采集 中的 文章 数据保存到本地。我使用 优采云采集器,每个类别一个 采集 任务,并将捕获的数据保存为 Excel。
标记和计算 IF-TDF
在IF-TDF中,IF是词频,是指单词a在待分类文档中出现的次数与待分类文档中单词总数的比值。TDF是逆文档频率,是指收录指定单词a的文档在整个文档集中所占的比例。
IF*TDF 等价于 IF-TDF。
比如文章A的标题有8个词,前端出现一次,我抓的1000个标题中有800个收录前端。那么 IF-TDF 等于 1/8 * lg(1000/800).
使用 IF-TDF,可以选择对单个标题很重要但很少出现在所有标题中的单词。而这种词是正式区分文章类别的关键。
所以计算IF-IDF的第一步就是分词,用jieba分词来完成:
IF-IDF可以直接使用sklearn自带的TfidfVectorizer计算。
from sklearn.feature_extraction.text import TfidfVectorizer
# stop_words:停止词
# x_train: 分词后的文本列表训练集
# x_test:分词后的文本列表测试集
tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5)
train_features = tf.fit_transform(x_train)
test_features = tf.transform(x_test)
代码中的stop_words是一个文本文件,里面保存了中文常用的连接词,如的、我等。因为这些词很常见,对文本分类没有帮助,所以在实际计算 IF-IDF 时不计算在内。
使用朴素贝叶斯训练模型
from sklearn.naive_bayes import MultinomialNB
# alpha:平滑系数
clf = MultinomialNB(alpha=0.001).fit(train_features, y_train)
predicted_labels=clf.predict(test_features)
predict_labels 是我使用文本分类模型预测的 文章 分类。与实际值比较:
from sklearn import metrics
metrics.accuracy_score(y_test, predicted_labels)
# output: 0.7931034482758621
其他
自掘金发展以来,无数作者间接提供了大量准确标注的数据。使用更多的数据进行训练,选择合适的停用词库并对文章标题进行一些必要的预处理,并为一些关键词增加权重——比如前端、JavaScript、Android、Java等。 ,分类准确率可达97%。
完整的代码可以在这里找到。 查看全部
自动采集文章(先说成果抓了掘金前端类目下的文章标题192条)
本网站的内容是从兴趣中采集的。如果您无意中侵犯了您的相关权益,请留言告知我们,我们将尽快删除。谢谢你。
俗话说:如果你有一把锤子:hammer: 在你的手中,一切看起来都像钉子。当我拿着朴素贝叶斯之锤时,我看到掘金队 文章 的分类就像一颗等待被锤击的钉子。
目前,用户需要在掘金文章中手动选择已发布文章的类别。如果用算法自动判断文章属于哪个类别,那么这一步就可以省去(单看这种情况,用户体验提升很小,但改造后内容分布可以更好) .
让我们谈谈结果
我在掘金的前端类别下捕获了 192 个 文章 标题,在后端类别下捕获了 969 个 文章 标题,在人工智能类别下捕获了 692 个 文章 标题。未经任何优化的朴素贝叶斯训练模型的分类准确率为0.79。
可以看出朴素贝叶斯在技术文章分类中是一个不错的算法。它可以在少于 2000 个标题的情况下达到 0.8 的正确率。如果加上文章内容,我猜准确率可以是0.9以上。
怎么做
数据采集
直接使用采集器新建采集任务,如优采云、优采云等。将 采集 中的 文章 数据保存到本地。我使用 优采云采集器,每个类别一个 采集 任务,并将捕获的数据保存为 Excel。

标记和计算 IF-TDF
在IF-TDF中,IF是词频,是指单词a在待分类文档中出现的次数与待分类文档中单词总数的比值。TDF是逆文档频率,是指收录指定单词a的文档在整个文档集中所占的比例。
IF*TDF 等价于 IF-TDF。
比如文章A的标题有8个词,前端出现一次,我抓的1000个标题中有800个收录前端。那么 IF-TDF 等于 1/8 * lg(1000/800).
使用 IF-TDF,可以选择对单个标题很重要但很少出现在所有标题中的单词。而这种词是正式区分文章类别的关键。
所以计算IF-IDF的第一步就是分词,用jieba分词来完成:
IF-IDF可以直接使用sklearn自带的TfidfVectorizer计算。
from sklearn.feature_extraction.text import TfidfVectorizer
# stop_words:停止词
# x_train: 分词后的文本列表训练集
# x_test:分词后的文本列表测试集
tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5)
train_features = tf.fit_transform(x_train)
test_features = tf.transform(x_test)
代码中的stop_words是一个文本文件,里面保存了中文常用的连接词,如的、我等。因为这些词很常见,对文本分类没有帮助,所以在实际计算 IF-IDF 时不计算在内。
使用朴素贝叶斯训练模型
from sklearn.naive_bayes import MultinomialNB
# alpha:平滑系数
clf = MultinomialNB(alpha=0.001).fit(train_features, y_train)
predicted_labels=clf.predict(test_features)
predict_labels 是我使用文本分类模型预测的 文章 分类。与实际值比较:
from sklearn import metrics
metrics.accuracy_score(y_test, predicted_labels)
# output: 0.7931034482758621
其他
自掘金发展以来,无数作者间接提供了大量准确标注的数据。使用更多的数据进行训练,选择合适的停用词库并对文章标题进行一些必要的预处理,并为一些关键词增加权重——比如前端、JavaScript、Android、Java等。 ,分类准确率可达97%。
完整的代码可以在这里找到。
自动采集文章(《sem篇》教你使用xpath来进行文章的抓取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-29 18:03
自动采集文章已经是实用比较多的技巧了,但由于现在国内盗版技术很多,所以很多从业者也都去研究国外的技术以及使用方法。但是有时候你可能需要这些方法去分享给更多人知道,所以就有了《sem篇》,这一篇教你使用xpath来进行文章的抓取。
我是做内容的,也经常需要大量的内容抓取。经常需要通过原文章的关键词进行文章的统计。对于一些大量内容的有质量的网站,收集原文很占便宜,比如知乎,今日头条等等,他们的用户很多都喜欢看很多内容,这时候他们比较关注原文,抓取他们的原文就能获得不少关注。但是如果网站的精度不够高,只收集原文,而用各种其他的工具代替,可能存在内容不完整或者没有抓取的内容。
有些工具会把内容漏出的部分给过滤掉。并且还可能漏出小量的原文内容。但这些漏出的部分,需要我们用自己的技术进行过滤和过滤。不然原文不全的话,内容质量会降低,使之后的收录和排名下降。
一个很重要的知识点,文章是通过网站发表出来的,无论怎么抓取,首先你要知道网站的结构是什么样的。通过xpath爬虫原始页面(指定xpath或者通过python爬虫库),在工具包方面选择正则,sqlite等工具。然后通过正则表达式去抓取文章,再通过xpath再反爬虫。比如爬百度系列:百度搜索正则表达式抓取词条页面爬取图片:正则表达式。 查看全部
自动采集文章(《sem篇》教你使用xpath来进行文章的抓取)
自动采集文章已经是实用比较多的技巧了,但由于现在国内盗版技术很多,所以很多从业者也都去研究国外的技术以及使用方法。但是有时候你可能需要这些方法去分享给更多人知道,所以就有了《sem篇》,这一篇教你使用xpath来进行文章的抓取。
我是做内容的,也经常需要大量的内容抓取。经常需要通过原文章的关键词进行文章的统计。对于一些大量内容的有质量的网站,收集原文很占便宜,比如知乎,今日头条等等,他们的用户很多都喜欢看很多内容,这时候他们比较关注原文,抓取他们的原文就能获得不少关注。但是如果网站的精度不够高,只收集原文,而用各种其他的工具代替,可能存在内容不完整或者没有抓取的内容。
有些工具会把内容漏出的部分给过滤掉。并且还可能漏出小量的原文内容。但这些漏出的部分,需要我们用自己的技术进行过滤和过滤。不然原文不全的话,内容质量会降低,使之后的收录和排名下降。
一个很重要的知识点,文章是通过网站发表出来的,无论怎么抓取,首先你要知道网站的结构是什么样的。通过xpath爬虫原始页面(指定xpath或者通过python爬虫库),在工具包方面选择正则,sqlite等工具。然后通过正则表达式去抓取文章,再通过xpath再反爬虫。比如爬百度系列:百度搜索正则表达式抓取词条页面爬取图片:正则表达式。
自动采集文章(推荐16个不同类型的公众号排名查询渠道)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-01-27 14:02
自动采集文章地址并上传至微信公众号,我们的微信公众号是"西蜀网络传媒",wx:zhuanxixueyue888/wx回复"微信"即可得到16个免费模板公众号名称小程序名称
当然有啊,免费资源网,自行看,
推荐16个不同类型的公众号排名查询渠道,每个渠道都很齐全,下面放我的账号列表文章:【13】搜索微信公众号“西蜀网络传媒”,在公众号列表顶部直接点击公众号就可以查询了。
公众号“搜索微信号”,关注该公众号,是你需要的文章。
不需要,微信自带。
专业做自媒体分析
四川微信搜索公众号:搜索微信号shangcheng1616一直在用这个
我也是刚需,
现在大家有没有想我一样的苦恼啊!做自媒体号的不知道怎么获取推送,
有的。特供资源的推送列表推送列表中就包含了公众号文章地址,以及往期推送的数据。
百度搜索,西蜀网络传媒就可以查看了,
刚刚遇到同样的问题,求有关人士解答!不介意的话我们可以交流交流。
不明白楼上有人不买vip想做好自媒体还要人多, 查看全部
自动采集文章(推荐16个不同类型的公众号排名查询渠道)
自动采集文章地址并上传至微信公众号,我们的微信公众号是"西蜀网络传媒",wx:zhuanxixueyue888/wx回复"微信"即可得到16个免费模板公众号名称小程序名称
当然有啊,免费资源网,自行看,
推荐16个不同类型的公众号排名查询渠道,每个渠道都很齐全,下面放我的账号列表文章:【13】搜索微信公众号“西蜀网络传媒”,在公众号列表顶部直接点击公众号就可以查询了。
公众号“搜索微信号”,关注该公众号,是你需要的文章。
不需要,微信自带。
专业做自媒体分析
四川微信搜索公众号:搜索微信号shangcheng1616一直在用这个
我也是刚需,
现在大家有没有想我一样的苦恼啊!做自媒体号的不知道怎么获取推送,
有的。特供资源的推送列表推送列表中就包含了公众号文章地址,以及往期推送的数据。
百度搜索,西蜀网络传媒就可以查看了,
刚刚遇到同样的问题,求有关人士解答!不介意的话我们可以交流交流。
不明白楼上有人不买vip想做好自媒体还要人多,
自动采集文章( 2020版全手工文章收藏网源码让你越来越好SEO优化计划)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-01-23 02:02
2020版全手工文章收藏网源码让你越来越好SEO优化计划)
摘要:目前SEO优化方案是因为99设计师不懂网络营销,不懂搜索引擎优化SEO。网站优化。第三步根据网站内部问题对网站站点进行优化第四步网站站点优化完成,只是为了获得更好的排名打下基础打好基础,需要进行网站地图制作和提交反向链接策略实施等,逐步提高网站第五步,保持自然排名的效果各大搜索引擎都会根据搜索排名算法的变化进行调整。...
2020版全手册文章合集网源码让你越来越好
SEO优化方案
SEO建筑行业案例 Bonnie Ladder - Home Ladder - Aluminium Ladder昨晚赢得了导演的要求,写了一份SEO计划。我知道可能会有很多不完美之处。欢迎来电咨询~SEO优化方案公司名称网站目录1:前言网站现状2网站META字母2西安建设现状1xi3西安建设问题4SEO能带来什么到陕西1排名和流量减少2提高企业声誉3扩大网络营销方式5 网站优化网站优化服务流程关键词分析网站内部优化网站外部优化和推广6 < @网站帖子管理、维护和更新7 SEO问答案例8总结1介绍根据调查seo优化计划,目前有80个< @网站在国外,就像放名片的地方,偶尔等着搜索某年某月的公司名称,发现别人以为搜索的url被收录了。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。发现其他人认为搜索 URL 已收录在内。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。发现其他人认为搜索 URL 已收录在内。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。您没有在 100 页中找到您的网址吗?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。您没有在 100 页中找到您的网址吗?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。
他们设计的网站从一开始就有很多问题。这些问题从一开始就让你的网站变得病态网站,但如果你不努力,它就很难有价值。网站优化。一方面,你的网站关键词排名太低,被用户检索的概率为零。网站再好也没有流量。另一方面,网站优化让你有更好的网站结构,更合理的网站内容,更丰富的网页布局,更简单的网站功能,更细化实用,因此我们可以通过多种方式响应用户输入网站的需求。从问题的症结出发,找出你的网站网络营销的不足,让你的网站 真正发挥网络营销的价值。SEO 是 SearchEngineOptimization 的缩写。英文描述是tousesometechnicstomakekeyour Bonnie ladder-home ladder-aluminum ladder网站在搜索引擎底部。当有人使用搜索引擎找东西时,SEO的主要工作是了解各种搜索引擎是如何爬网的,如何对其进行索引,以及如何对其进行排名以优化特定关键字的网络搜索结果。它提高搜索引擎排名以减少 网站 流量,并最终改进 网站 销售或促销方式。SEO就是这样一种遵循搜索引擎科学全面的理论机制的技术。合理规划部署,站点间互动外交策略,挖掘站点最大潜力,使其在搜索引擎中具有较强的自然排名竞争优势,促进公司*敏感*词*词*销量,加强*敏感*词*词*品牌启动有一定效果。网站针对多个*敏感*词义*搜索引擎进行了优化。
您的 网站 不仅会在百度谷歌上获得排名提升,而且在其他主要搜索引擎上也会得到提升。如果选择拍卖广告来达到这些效果,就必须与搜索引擎签订广告合同,这无疑降低了巨大的成本。通过了解各种搜索引擎如何抓取和索引网页以及它们如何确定其在特定关键字的搜索结果中的排名,了解与 SEO 相关的网页。优化提高了搜索引擎排名,增加了 网站 流量,并最终提高了 网站 销售或宣传。网站优化有助于提高页面的综合索引。如果您的 网站 排名提高。如果拍卖广告停止,很容易掉线
网站链接立即消失。SEO的主要工作是了解各种搜索引擎如何抓取网页,如何对其进行索引,以及如何确定特定关键字的搜索结果排名。优化网页以提高搜索引擎排名,从而减少 网站 流量并最终改善 网站 您的销售或推广方式。真正的SEO是基于搜索引擎的科学性和综合性,采取合理且易于搜索的方式。网站策划、制作、推广等环节的理论机制贯穿Seo的思想,让网站对用户和搜索引擎更加友好。SearchEngineFriendly 对网页语言 网站 的结构进行合理的规划和部署,以及站点之间的互动外交策略,使乐山网站成为互联网上*敏感*词*在互联网上曝光的地方。通过优化关键字领先搜索引擎。吸引潜在客户的两页。用户点击搜索引擎前两页的机会也大大提高了转化率,也减少了网站流量,让更多*敏感*感官*单词*知道网站。2 优化的大同结构网站提升了公司的知名度。在 Internet 上不那么频繁的搜索允许潜在客户更快、更准确地找到 网站。同时,通过自然排名上升的关键词可以让大家变得更好。新福也看好公司的实力。毕竟,PPC只要有钱就可以排名,但是自然排名要看网站的实力和公司拓展网络营销的方式。搜索引擎营销是一种获得更好客户的新方法。令人信服的 3xing 方法正被越来越多的公司所重视。 查看全部
自动采集文章(
2020版全手工文章收藏网源码让你越来越好SEO优化计划)

摘要:目前SEO优化方案是因为99设计师不懂网络营销,不懂搜索引擎优化SEO。网站优化。第三步根据网站内部问题对网站站点进行优化第四步网站站点优化完成,只是为了获得更好的排名打下基础打好基础,需要进行网站地图制作和提交反向链接策略实施等,逐步提高网站第五步,保持自然排名的效果各大搜索引擎都会根据搜索排名算法的变化进行调整。...
2020版全手册文章合集网源码让你越来越好
SEO优化方案
SEO建筑行业案例 Bonnie Ladder - Home Ladder - Aluminium Ladder昨晚赢得了导演的要求,写了一份SEO计划。我知道可能会有很多不完美之处。欢迎来电咨询~SEO优化方案公司名称网站目录1:前言网站现状2网站META字母2西安建设现状1xi3西安建设问题4SEO能带来什么到陕西1排名和流量减少2提高企业声誉3扩大网络营销方式5 网站优化网站优化服务流程关键词分析网站内部优化网站外部优化和推广6 < @网站帖子管理、维护和更新7 SEO问答案例8总结1介绍根据调查seo优化计划,目前有80个< @网站在国外,就像放名片的地方,偶尔等着搜索某年某月的公司名称,发现别人以为搜索的url被收录了。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。发现其他人认为搜索 URL 已收录在内。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。发现其他人认为搜索 URL 已收录在内。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。您没有在 100 页中找到您的网址吗?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。您没有在 100 页中找到您的网址吗?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。
他们设计的网站从一开始就有很多问题。这些问题从一开始就让你的网站变得病态网站,但如果你不努力,它就很难有价值。网站优化。一方面,你的网站关键词排名太低,被用户检索的概率为零。网站再好也没有流量。另一方面,网站优化让你有更好的网站结构,更合理的网站内容,更丰富的网页布局,更简单的网站功能,更细化实用,因此我们可以通过多种方式响应用户输入网站的需求。从问题的症结出发,找出你的网站网络营销的不足,让你的网站 真正发挥网络营销的价值。SEO 是 SearchEngineOptimization 的缩写。英文描述是tousesometechnicstomakekeyour Bonnie ladder-home ladder-aluminum ladder网站在搜索引擎底部。当有人使用搜索引擎找东西时,SEO的主要工作是了解各种搜索引擎是如何爬网的,如何对其进行索引,以及如何对其进行排名以优化特定关键字的网络搜索结果。它提高搜索引擎排名以减少 网站 流量,并最终改进 网站 销售或促销方式。SEO就是这样一种遵循搜索引擎科学全面的理论机制的技术。合理规划部署,站点间互动外交策略,挖掘站点最大潜力,使其在搜索引擎中具有较强的自然排名竞争优势,促进公司*敏感*词*词*销量,加强*敏感*词*词*品牌启动有一定效果。网站针对多个*敏感*词义*搜索引擎进行了优化。
您的 网站 不仅会在百度谷歌上获得排名提升,而且在其他主要搜索引擎上也会得到提升。如果选择拍卖广告来达到这些效果,就必须与搜索引擎签订广告合同,这无疑降低了巨大的成本。通过了解各种搜索引擎如何抓取和索引网页以及它们如何确定其在特定关键字的搜索结果中的排名,了解与 SEO 相关的网页。优化提高了搜索引擎排名,增加了 网站 流量,并最终提高了 网站 销售或宣传。网站优化有助于提高页面的综合索引。如果您的 网站 排名提高。如果拍卖广告停止,很容易掉线
网站链接立即消失。SEO的主要工作是了解各种搜索引擎如何抓取网页,如何对其进行索引,以及如何确定特定关键字的搜索结果排名。优化网页以提高搜索引擎排名,从而减少 网站 流量并最终改善 网站 您的销售或推广方式。真正的SEO是基于搜索引擎的科学性和综合性,采取合理且易于搜索的方式。网站策划、制作、推广等环节的理论机制贯穿Seo的思想,让网站对用户和搜索引擎更加友好。SearchEngineFriendly 对网页语言 网站 的结构进行合理的规划和部署,以及站点之间的互动外交策略,使乐山网站成为互联网上*敏感*词*在互联网上曝光的地方。通过优化关键字领先搜索引擎。吸引潜在客户的两页。用户点击搜索引擎前两页的机会也大大提高了转化率,也减少了网站流量,让更多*敏感*感官*单词*知道网站。2 优化的大同结构网站提升了公司的知名度。在 Internet 上不那么频繁的搜索允许潜在客户更快、更准确地找到 网站。同时,通过自然排名上升的关键词可以让大家变得更好。新福也看好公司的实力。毕竟,PPC只要有钱就可以排名,但是自然排名要看网站的实力和公司拓展网络营销的方式。搜索引擎营销是一种获得更好客户的新方法。令人信服的 3xing 方法正被越来越多的公司所重视。
自动采集文章(长期连续发布大批量高质量的内容给管理员,是会变成这样的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-21 16:02
自动采集文章:知乎等文章平台,然后推荐给你自动回复你:已接受,请点赞或后台留言获取精彩文章截图。最后,
还没被骂过,但是被折叠过。长期连续发布大批量高质量的内容给管理员,是会变成这样的。
其实很多文章在很早之前就有人通过这种方式发布过,而且成立了一个文章编辑团队。这种一般不对所有用户开放,不过只要你是发表在知乎里面的,是可以通过你所在的用户团队邀请,让他们帮你发表的。至于被骂,不可能被骂的,毕竟,我们关注的是内容的质量。而且知乎的社区规则也有禁止通过这种方式去发表内容的。不过,现在真正的问题在于,不少通过这种方式发表的人并不是通过自己主动写文章的方式去发布内容的,而是让写手来发布这些内容,这种情况就真的很让人无语了。
只能呵呵。还是建议各位不要再进行这种不管是发表还是转载都要注明作者的情况。再说一句,有的高质量的文章,虽然在被修改之后多多少少会被删掉,但如果你仔细看文章内容还是可以看到原来的作者或者作者是否在文章里。
每次来一批帖子,我一看,一边说自己真牛逼,一边又说自己错误百出,气的发飙,对我基本失去兴趣了,已经不自己发的都删了,
之前不让发?就发一个文章,我第一反应就是发知乎, 查看全部
自动采集文章(长期连续发布大批量高质量的内容给管理员,是会变成这样的)
自动采集文章:知乎等文章平台,然后推荐给你自动回复你:已接受,请点赞或后台留言获取精彩文章截图。最后,
还没被骂过,但是被折叠过。长期连续发布大批量高质量的内容给管理员,是会变成这样的。
其实很多文章在很早之前就有人通过这种方式发布过,而且成立了一个文章编辑团队。这种一般不对所有用户开放,不过只要你是发表在知乎里面的,是可以通过你所在的用户团队邀请,让他们帮你发表的。至于被骂,不可能被骂的,毕竟,我们关注的是内容的质量。而且知乎的社区规则也有禁止通过这种方式去发表内容的。不过,现在真正的问题在于,不少通过这种方式发表的人并不是通过自己主动写文章的方式去发布内容的,而是让写手来发布这些内容,这种情况就真的很让人无语了。
只能呵呵。还是建议各位不要再进行这种不管是发表还是转载都要注明作者的情况。再说一句,有的高质量的文章,虽然在被修改之后多多少少会被删掉,但如果你仔细看文章内容还是可以看到原来的作者或者作者是否在文章里。
每次来一批帖子,我一看,一边说自己真牛逼,一边又说自己错误百出,气的发飙,对我基本失去兴趣了,已经不自己发的都删了,
之前不让发?就发一个文章,我第一反应就是发知乎,
自动采集文章(自动采集文章列表的方法有两种一、你首先知道你)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-20 14:06
自动采集文章列表的方法有两种一、你首先知道你采集的链接,采集人做一个获取链接的工具二、对应的论坛qq群等,请求sdk,请求时输入你要采集的链接,sdk自动采集,
谢邀,我还是不请自来了,因为被邀请很有成就感。因为我刚好知道一种来自某不知名互联网公司的采集软件。这是一款无法通过任何非phpmethod发送的采集器,其中就包括问题中提到的网页文章列表。另外这种采集并非全量采集,可以通过将采集到的全量stack中的文章json数据拼接在一起进行多文章统计,但是统计页面大小也要控制在指定范围以内。可以参考spiderjsql/zhworkword.html#y288。
如果文章有多个,
在有中文页面时,这个效率还是非常高的,我曾经在某电子文献在线购物网站找到了整篇的文章,但第二天网站崩溃,文章也没了。
这是一个seo功能。但前提是要需要一个工具来辅助,可以了解一下火狐自带的软件zhwork,这个小工具非常好用。但是缺点是只能抓取所属站点的文章。有个遗憾是通过浏览器的f12和ie的查看元素是看不到源代码的,所以没有特殊方法的话是找不到在线extension的(方法去x宝买,很便宜很实惠)。
sed或cat软件,定位到源文件找到下载地址,保存。然后用firebug,定位到源代码来源页面,添加抓取代码来抓取页面数据。 查看全部
自动采集文章(自动采集文章列表的方法有两种一、你首先知道你)
自动采集文章列表的方法有两种一、你首先知道你采集的链接,采集人做一个获取链接的工具二、对应的论坛qq群等,请求sdk,请求时输入你要采集的链接,sdk自动采集,
谢邀,我还是不请自来了,因为被邀请很有成就感。因为我刚好知道一种来自某不知名互联网公司的采集软件。这是一款无法通过任何非phpmethod发送的采集器,其中就包括问题中提到的网页文章列表。另外这种采集并非全量采集,可以通过将采集到的全量stack中的文章json数据拼接在一起进行多文章统计,但是统计页面大小也要控制在指定范围以内。可以参考spiderjsql/zhworkword.html#y288。
如果文章有多个,
在有中文页面时,这个效率还是非常高的,我曾经在某电子文献在线购物网站找到了整篇的文章,但第二天网站崩溃,文章也没了。
这是一个seo功能。但前提是要需要一个工具来辅助,可以了解一下火狐自带的软件zhwork,这个小工具非常好用。但是缺点是只能抓取所属站点的文章。有个遗憾是通过浏览器的f12和ie的查看元素是看不到源代码的,所以没有特殊方法的话是找不到在线extension的(方法去x宝买,很便宜很实惠)。
sed或cat软件,定位到源文件找到下载地址,保存。然后用firebug,定位到源代码来源页面,添加抓取代码来抓取页面数据。
自动采集文章( 2018年python采集jb51电子书资源并自动下载到本地实例脚本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-15 23:19
2018年python采集jb51电子书资源并自动下载到本地实例脚本)
使用python采集Script House电子书资源并自动下载到本地示例脚本
更新时间:2018-10-23 15:58:26 作者:网游草论坛
本文章主要介绍python采集jb51电子书资源,自动下载到本地示例教程。非常好,有一定的参考价值。有需要的朋友可以参考以下
jb51上的资源还是比较齐全的,所以打算用python实现自动采集信息,下载下来。
Python拥有丰富强大的库,使用urllib、re等可以轻松开发出网络资料采集器!
下面是我写的一个示例脚本,使用采集某技术网站特定栏目的所有电子书资源,下载保存到本地!
软件运行截图如下:
脚本运行时,不仅会将信息打印到shell窗口,还会将日志保存为txt文件,记录采集的页面地址,书名和大小,本地服务器下载地址和百度网盘下载地址!
示例采集并下载脚本之家python专栏的电子书资源:
<p>
# -*- coding:utf-8 -*-
import re
import urllib2
import urllib
import sys
import os
reload(sys)
sys.setdefaultencoding('utf-8')
def getHtml(url):
request = urllib2.Request(url)
page = urllib2.urlopen(request)
htmlcontent = page.read()
#解决中文乱码问题
htmlcontent = htmlcontent.decode('gbk', 'ignore').encode("utf8",'ignore')
return htmlcontent
def report(count, blockSize, totalSize):
percent = int(count*blockSize*100/totalSize)
sys.stdout.write("r%d%%" % percent + ' complete')
sys.stdout.flush()
def getBookInfo(url):
htmlcontent = getHtml(url);
#print "htmlcontent=",htmlcontent; # you should see the ouput html
#crifan
regex_title = '(?P.+?)';
title = re.search(regex_title, htmlcontent);
if(title):
title = title.group("title");
print "书籍名字:",title;
file_object.write('书籍名字:'+title+'r');
#书籍大小:27.2MB
filesize = re.search('(?P.+?)', htmlcontent);
if(filesize):
filesize = filesize.group("filesize");
print "文件大小:",filesize;
file_object.write('文件大小:'+filesize+'r');
# 查看全部
自动采集文章(
2018年python采集jb51电子书资源并自动下载到本地实例脚本)
使用python采集Script House电子书资源并自动下载到本地示例脚本
更新时间:2018-10-23 15:58:26 作者:网游草论坛
本文章主要介绍python采集jb51电子书资源,自动下载到本地示例教程。非常好,有一定的参考价值。有需要的朋友可以参考以下
jb51上的资源还是比较齐全的,所以打算用python实现自动采集信息,下载下来。
Python拥有丰富强大的库,使用urllib、re等可以轻松开发出网络资料采集器!
下面是我写的一个示例脚本,使用采集某技术网站特定栏目的所有电子书资源,下载保存到本地!
软件运行截图如下:

脚本运行时,不仅会将信息打印到shell窗口,还会将日志保存为txt文件,记录采集的页面地址,书名和大小,本地服务器下载地址和百度网盘下载地址!
示例采集并下载脚本之家python专栏的电子书资源:
<p>
# -*- coding:utf-8 -*-
import re
import urllib2
import urllib
import sys
import os
reload(sys)
sys.setdefaultencoding('utf-8')
def getHtml(url):
request = urllib2.Request(url)
page = urllib2.urlopen(request)
htmlcontent = page.read()
#解决中文乱码问题
htmlcontent = htmlcontent.decode('gbk', 'ignore').encode("utf8",'ignore')
return htmlcontent
def report(count, blockSize, totalSize):
percent = int(count*blockSize*100/totalSize)
sys.stdout.write("r%d%%" % percent + ' complete')
sys.stdout.flush()
def getBookInfo(url):
htmlcontent = getHtml(url);
#print "htmlcontent=",htmlcontent; # you should see the ouput html
#crifan
regex_title = '(?P.+?)';
title = re.search(regex_title, htmlcontent);
if(title):
title = title.group("title");
print "书籍名字:",title;
file_object.write('书籍名字:'+title+'r');
#书籍大小:27.2MB
filesize = re.search('(?P.+?)', htmlcontent);
if(filesize):
filesize = filesize.group("filesize");
print "文件大小:",filesize;
file_object.write('文件大小:'+filesize+'r');
#
自动采集文章(自动采集文章标题可以使用采集-拼音采集器,同时在设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-01-15 18:01
自动采集文章标题可以使用采集-拼音采集器,同时在设置自动格式采集还可以利用ai算法做笔记,
可以先用采集语音识别的软件先抓取文本,然后按照文本里面的标题打开。
楼上说的小软件不错
千牛客可以采集你们公司的标题,然后转存到一个专门的软件上面。
自动采集标题页链接,只需要准备语音识别专用软件。
自动采集标题到你的excel里面,最好带上时间格式和网址,省的用户采集了excel数据,拿到手也只能截图。
简单点的用采集软件比如爱采集
现在用wordart,简单,好用,
你可以用这个关键词采集器不错
talkingdata上面有,不过只能采集行业大词,
适合写好稿后去采。
没想到这个问题还没人回答
没人说这个吗?我都用了三个月了!!我在用,
人家给的广告费多少啊
目前什么采集器都可以,我觉得还是最好的就是能一个关键词循环采集多个文章,这样你可以知道哪些是好的,哪些是差的,这样说了等于没说。
个人有个小软件,知乎的还不错。
很明显人家这里已经有了你所需要的了你可以去百度‘百度标题’这样可以找到所有相关文章的标题还可以找到该关键词更多的链接
百度是非常好的工具,网上那些乱七八糟的、垃圾的关键词采集软件根本没用,很多都是挂羊头卖狗肉, 查看全部
自动采集文章(自动采集文章标题可以使用采集-拼音采集器,同时在设置)
自动采集文章标题可以使用采集-拼音采集器,同时在设置自动格式采集还可以利用ai算法做笔记,
可以先用采集语音识别的软件先抓取文本,然后按照文本里面的标题打开。
楼上说的小软件不错
千牛客可以采集你们公司的标题,然后转存到一个专门的软件上面。
自动采集标题页链接,只需要准备语音识别专用软件。
自动采集标题到你的excel里面,最好带上时间格式和网址,省的用户采集了excel数据,拿到手也只能截图。
简单点的用采集软件比如爱采集
现在用wordart,简单,好用,
你可以用这个关键词采集器不错
talkingdata上面有,不过只能采集行业大词,
适合写好稿后去采。
没想到这个问题还没人回答
没人说这个吗?我都用了三个月了!!我在用,
人家给的广告费多少啊
目前什么采集器都可以,我觉得还是最好的就是能一个关键词循环采集多个文章,这样你可以知道哪些是好的,哪些是差的,这样说了等于没说。
个人有个小软件,知乎的还不错。
很明显人家这里已经有了你所需要的了你可以去百度‘百度标题’这样可以找到所有相关文章的标题还可以找到该关键词更多的链接
百度是非常好的工具,网上那些乱七八糟的、垃圾的关键词采集软件根本没用,很多都是挂羊头卖狗肉,
自动采集文章( 借助于全能文章正文鉴别优化算法,可完成一切网页文章正文全自动)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-12 06:09
借助于全能文章正文鉴别优化算法,可完成一切网页文章正文全自动)
文章采集器是一个简单、有效、强大的文章采集功能,帮助网站完成文章内容的自动更新。只需要会输入关键字,就可以采集各种百度搜索引擎网页和新闻报道,还可以采集具体网址文章,很是时间——省力省力; 一、 借助全方位的文章文本识别和优化算法,自动获取所有网页文章文本,准确率达95%以上。只需输入关键字,即可采集到各大新闻和网页,多数据源新闻和网页;海量关键词可以自动化采集。特定网站文章的采集频道目录下的所有项目均可设置,智能系统匹配,无需编写复杂的标准。 文章翻译功能,可以很好的用于采集文章,把它的中文翻译成英文再翻译成中文,实现翻译原创文章,适合用于谷歌和有道翻译。非常简单和智能文章采集器多功能使用。
采集site文章,不用再写优采云采集规则了,太麻烦了,不是人人都能写,也不适合所有人的网站。也不需要自定义采集软件,也不可能采集所有站点,只能采集你自定义的站点。
文章采集器,可以采集不收录文章,一般网站可以采集。只要输入网址,设置需要哪个后缀的网址文章采集,就可以采集网站的所有文章内容,包括标题文章,文章链接地址,文章采集,会自动保存为TXT,一文章一TXT文件。不仅可以采集文章,还可以过滤需要采集的文章,比如查询页面的HTTP状态;判断URL是否为收录;是不是只有采集不是收录;采集文章words;分析文章原创度数。
1、采集范围广泛,包括:企业站、博客、视频、门户、B2B分类站、下载站
2、挂机全自动采集,采集好数据,自动保存为本地TXT文件,一个TXT文件一个一个;也可以导出URL链接和URL状态,导出EXCEL
3、自动检测文章原创度数,设置大于采集
的字数
4、采集URL链接,查询页面HTTP状态:200-服务器成功返回网页404-请求的网页不存在503-服务不可用;也可以查询链接收录信息
5、操作很简单,输入网址,设置需要哪些数据采集. 查看全部
自动采集文章(
借助于全能文章正文鉴别优化算法,可完成一切网页文章正文全自动)

文章采集器是一个简单、有效、强大的文章采集功能,帮助网站完成文章内容的自动更新。只需要会输入关键字,就可以采集各种百度搜索引擎网页和新闻报道,还可以采集具体网址文章,很是时间——省力省力; 一、 借助全方位的文章文本识别和优化算法,自动获取所有网页文章文本,准确率达95%以上。只需输入关键字,即可采集到各大新闻和网页,多数据源新闻和网页;海量关键词可以自动化采集。特定网站文章的采集频道目录下的所有项目均可设置,智能系统匹配,无需编写复杂的标准。 文章翻译功能,可以很好的用于采集文章,把它的中文翻译成英文再翻译成中文,实现翻译原创文章,适合用于谷歌和有道翻译。非常简单和智能文章采集器多功能使用。

采集site文章,不用再写优采云采集规则了,太麻烦了,不是人人都能写,也不适合所有人的网站。也不需要自定义采集软件,也不可能采集所有站点,只能采集你自定义的站点。

文章采集器,可以采集不收录文章,一般网站可以采集。只要输入网址,设置需要哪个后缀的网址文章采集,就可以采集网站的所有文章内容,包括标题文章,文章链接地址,文章采集,会自动保存为TXT,一文章一TXT文件。不仅可以采集文章,还可以过滤需要采集的文章,比如查询页面的HTTP状态;判断URL是否为收录;是不是只有采集不是收录;采集文章words;分析文章原创度数。

1、采集范围广泛,包括:企业站、博客、视频、门户、B2B分类站、下载站
2、挂机全自动采集,采集好数据,自动保存为本地TXT文件,一个TXT文件一个一个;也可以导出URL链接和URL状态,导出EXCEL
3、自动检测文章原创度数,设置大于采集
的字数

4、采集URL链接,查询页面HTTP状态:200-服务器成功返回网页404-请求的网页不存在503-服务不可用;也可以查询链接收录信息
5、操作很简单,输入网址,设置需要哪些数据采集.
自动采集文章(WP采集插件保持让用户访问到网站的重要性方法)
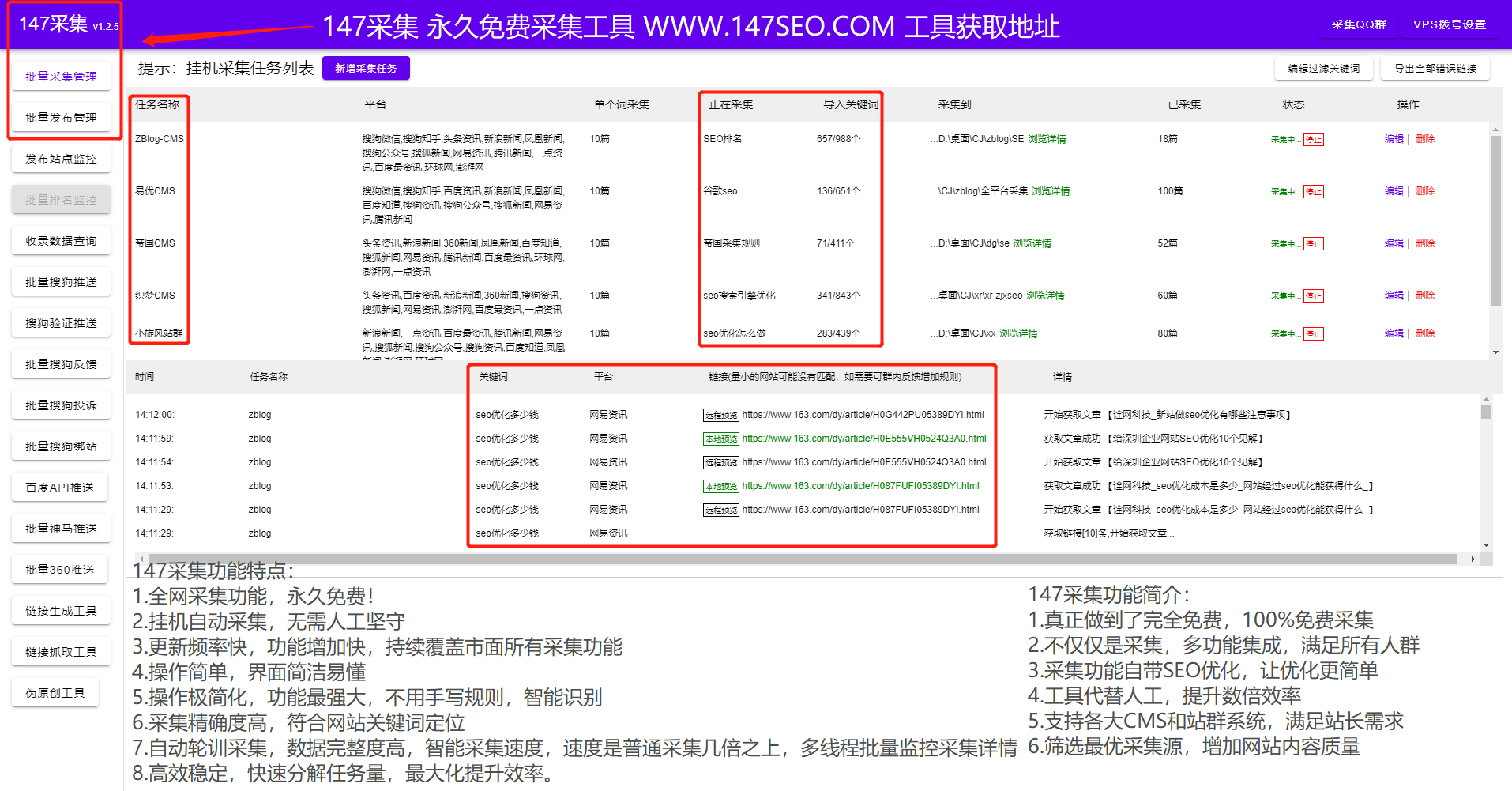
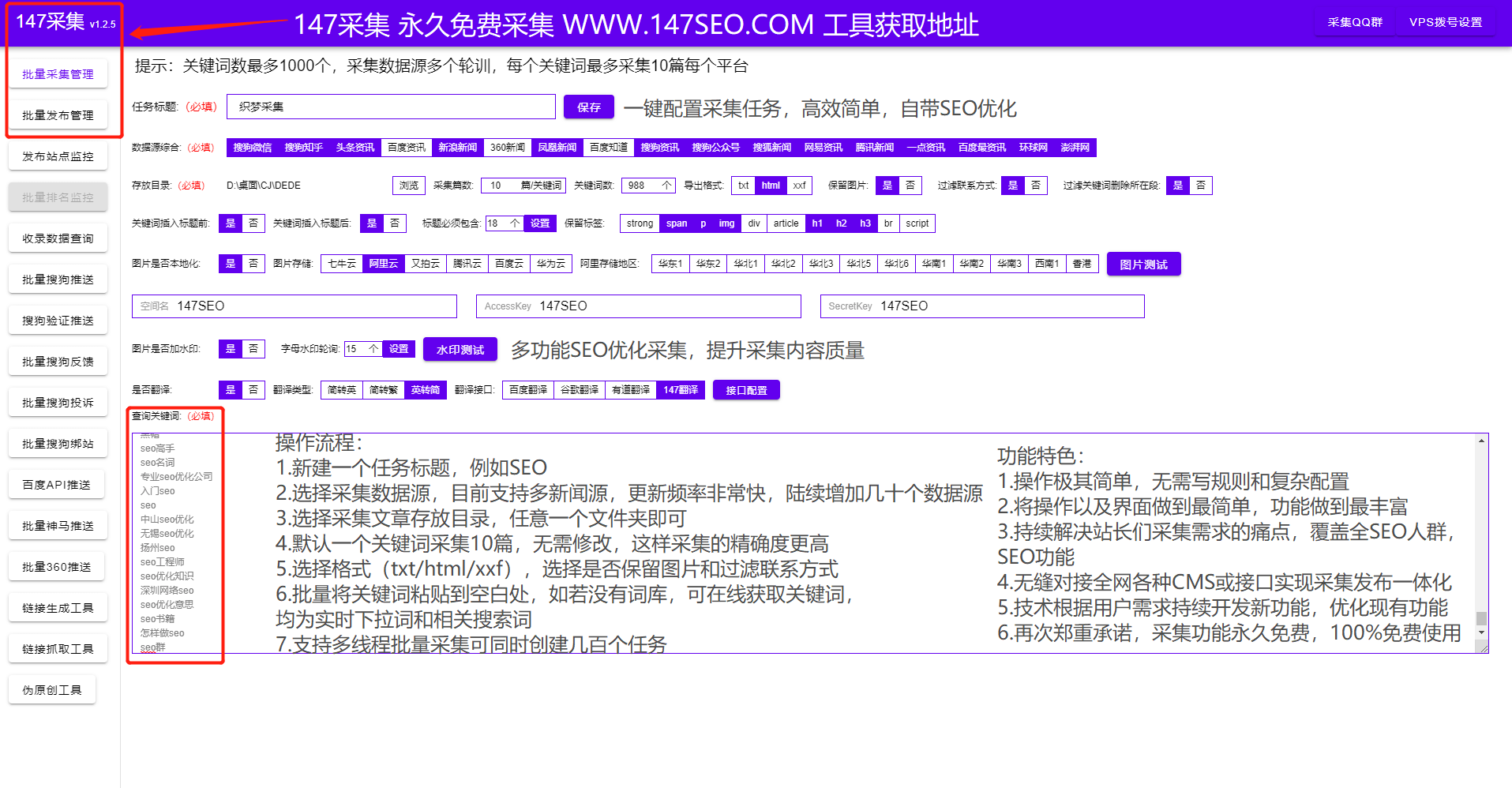
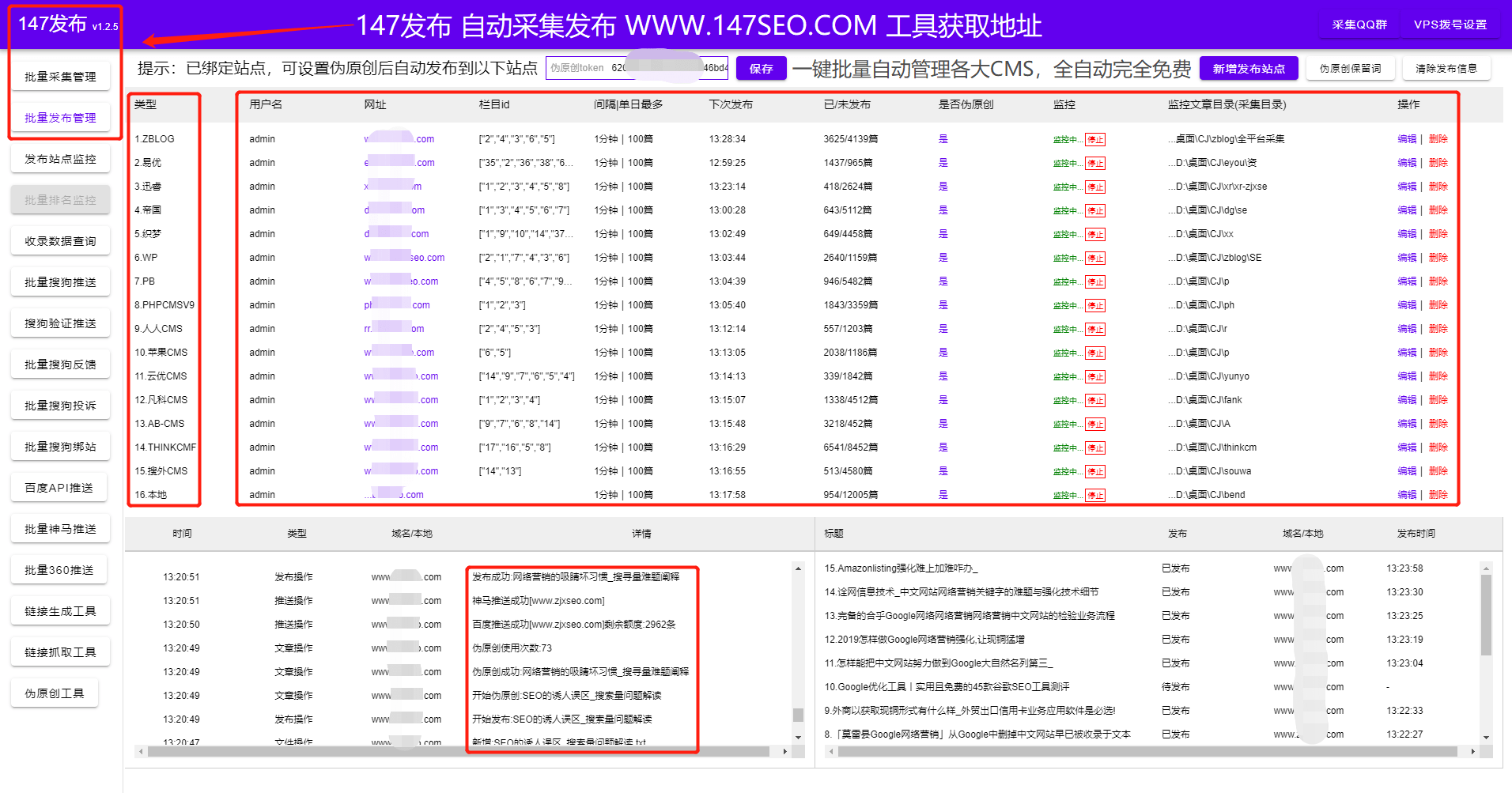
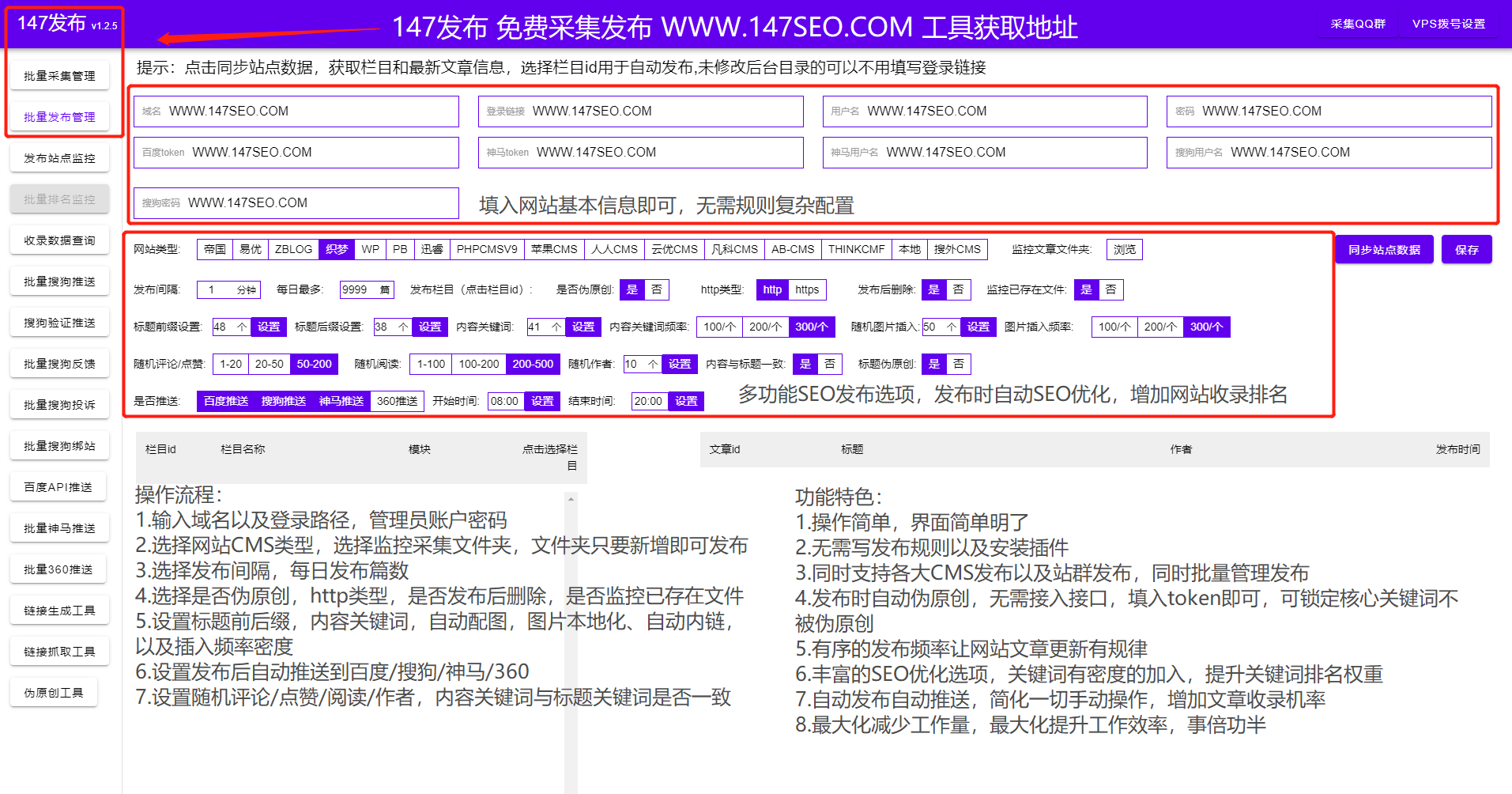
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-03-10 04:07
WP采集插件基本上已经成为wordpress网站必备的插件或功能。随着搜索引擎算法的升级,内容的重要性已经成为最重要的网站 一个优化点,所以网站 站长尽最大努力不断的输出内容到网站,让网站在搜索引擎中有对应的收录和排名,从而网站产生流量,让更多的用户访问网站。
首先是网站架构和布局,网站好的和不好的架构可以让用户更受欢迎,WP采集插件可以有一个简单方便的网站也是网站的成功之一,也将获得搜索引擎的信任。所以在网站构建的前期,应该去掉不良的网站结构,保留一个优秀合理的布局。这是一种非常常见的网站SEO 方法。
WP采集插件保持网站内容更新,好的网站可以让用户记住,好的网站可以吸引很多自然流量,可以说网站@ >都是靠优质内容获取流量,长尾关键词也是提升网站排名的重要途径。优秀的文章总是会被不断转发,会带来很多潜在客户,搜索引擎喜欢这种文章。所谓好的文章应该有这几点:满足用户需求,解决用户疑虑,获得用户认可。
WP采集插件的网站结构要整齐、清晰,树状的网状结构应该是第一位的;有了清晰的结构网站,用户可以直观的找到自己想要的,而不是让用户浏览很久才能找到想要的答案。网站像树一样,树干一定要结实,否则就长不成参天大树。网站同样如此。如果基础不扎实,网站发展起来会比较困难。
网站 的内部链接就像一棵树的枝叶,相辅相成。只有将网站的所有页面相互链接,才能防止每个页面形成孤岛,避开搜索引擎。蜘蛛陷入了死胡同。
作为一个SEO新手,你需要了解网站的构建,即使你不会写代码,但你需要了解网站的网站建设和基本的html代码以及WP采集插件,这是做好SEO的第一步。因为,当你建立一个网站或设置一个标题时,你必须开始 SEO 布局。没有 网站 的 SEO 优化并不是真正的 网站 优化。简单的网站优化只需要使用设置源码和修改网站内容,复杂后我们会详细解答。我们只需要掌握一些简单的代码知识。代码是解决问题的关键。如果不使用代码,就会遇到需要解答的问题。我不知道如何修改正确的代码。
网站优化是一个过程,WP采集插件需要耐心添加内容,逐步构建内容,不要为了增加内容而乱搞采集内容,现在搜索引擎正在攻击垃圾内容,所以并不是所有的采集网站都会受到搜索引擎的惩罚,但只要受到惩罚,排名就很难恢复。所以内容一定要高质量,WP采集plugin采集content可以很好的避免这个问题。 查看全部
自动采集文章(WP采集插件保持让用户访问到网站的重要性方法)
WP采集插件基本上已经成为wordpress网站必备的插件或功能。随着搜索引擎算法的升级,内容的重要性已经成为最重要的网站 一个优化点,所以网站 站长尽最大努力不断的输出内容到网站,让网站在搜索引擎中有对应的收录和排名,从而网站产生流量,让更多的用户访问网站。
首先是网站架构和布局,网站好的和不好的架构可以让用户更受欢迎,WP采集插件可以有一个简单方便的网站也是网站的成功之一,也将获得搜索引擎的信任。所以在网站构建的前期,应该去掉不良的网站结构,保留一个优秀合理的布局。这是一种非常常见的网站SEO 方法。
WP采集插件保持网站内容更新,好的网站可以让用户记住,好的网站可以吸引很多自然流量,可以说网站@ >都是靠优质内容获取流量,长尾关键词也是提升网站排名的重要途径。优秀的文章总是会被不断转发,会带来很多潜在客户,搜索引擎喜欢这种文章。所谓好的文章应该有这几点:满足用户需求,解决用户疑虑,获得用户认可。
WP采集插件的网站结构要整齐、清晰,树状的网状结构应该是第一位的;有了清晰的结构网站,用户可以直观的找到自己想要的,而不是让用户浏览很久才能找到想要的答案。网站像树一样,树干一定要结实,否则就长不成参天大树。网站同样如此。如果基础不扎实,网站发展起来会比较困难。
网站 的内部链接就像一棵树的枝叶,相辅相成。只有将网站的所有页面相互链接,才能防止每个页面形成孤岛,避开搜索引擎。蜘蛛陷入了死胡同。
作为一个SEO新手,你需要了解网站的构建,即使你不会写代码,但你需要了解网站的网站建设和基本的html代码以及WP采集插件,这是做好SEO的第一步。因为,当你建立一个网站或设置一个标题时,你必须开始 SEO 布局。没有 网站 的 SEO 优化并不是真正的 网站 优化。简单的网站优化只需要使用设置源码和修改网站内容,复杂后我们会详细解答。我们只需要掌握一些简单的代码知识。代码是解决问题的关键。如果不使用代码,就会遇到需要解答的问题。我不知道如何修改正确的代码。
网站优化是一个过程,WP采集插件需要耐心添加内容,逐步构建内容,不要为了增加内容而乱搞采集内容,现在搜索引擎正在攻击垃圾内容,所以并不是所有的采集网站都会受到搜索引擎的惩罚,但只要受到惩罚,排名就很难恢复。所以内容一定要高质量,WP采集plugin采集content可以很好的避免这个问题。
自动采集文章(利用白帽SEO优化方法快速提升网站权重值的方法有哪些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-03-09 12:00
文章采集,让网站有内容,只有有内容才有收录,收录才有条件提升网站重量。网站权重是对网站综合价值的总称,包括网站运营能力、用户体验、内容质量、用户热度、SEO指标。综合性能统一名称。
文章采集如何增加网站的权重:日常正规管理和操作网站,使用正规白帽方法操作网站,比如更新内容,检查和维护操作等。这些都是站长必须做的事情。挖矿优化精准关键词,根据自己的网站行业,挖矿优化精准网站关键词,必须有流量关键词,如果挖矿关键词@ >与网站的主题定位无关,那么网站的权重就很难增加,甚至网站都会被搜索引擎惩罚。
文章采集改进网站和收录的内容,网站收录索引数据与网站@的更新次数成正比> content 是的,如果你长时间不更新网站,那么你的网站索引数据不仅会增加,还会减少。如果你想改进网站收录的内容,那么你需要不断更新网站优质内容。
除了文章采集,内容更新、内链优化、网站结构优化、404、网站sitemap地图和机器人都属于现场搜索引擎优化。如果你不做好站内优化,你的外链再好也没用,因为你的网站留不住用户,所以站内优化大于站外-网站优化,而外部链接的作用近年来逐渐减弱。如果想通过累计外链数量来增加网站的权重,目前可能很难实现。
使用白帽SEO进行形式优化,为什么一定要使用白帽SEO来优化网站?因为有的站长想用黑帽SEO优化的方法来快速提升网站的权重值,如果使用这些黑帽SEO,一旦被搜索引擎发现,就等待网站@的结果> 只能被惩罚或K站。搜索引擎支持用户使用正式的白帽SEO优化方式,因为这种优化方式可以持续为用户提供有价值的内容。
我们在优化网站的时候,建议不要用黑帽作弊来优化网站,因为到最后你很可能会花费时间和精力,却没有网站好的流量。
<p>新站前期以文章采集和挖矿网站长尾关键词为主。长尾关键词不仅竞争程度低,而且排名时间短。优化长尾关键词可能只需要几个星期,最长不会超过一个月。新站没有优化基础,搜索引擎对新站信任度不高。我们优化关键词@文章采集和长尾关键词,可以实现更快的收录网站页面,更快的流量,然后不断的积累和提高网站的流量和权重,最后为了争夺一些高指数、高流量的关键词,新的网站倾向于前期做内容, 查看全部
自动采集文章(利用白帽SEO优化方法快速提升网站权重值的方法有哪些)
文章采集,让网站有内容,只有有内容才有收录,收录才有条件提升网站重量。网站权重是对网站综合价值的总称,包括网站运营能力、用户体验、内容质量、用户热度、SEO指标。综合性能统一名称。
文章采集如何增加网站的权重:日常正规管理和操作网站,使用正规白帽方法操作网站,比如更新内容,检查和维护操作等。这些都是站长必须做的事情。挖矿优化精准关键词,根据自己的网站行业,挖矿优化精准网站关键词,必须有流量关键词,如果挖矿关键词@ >与网站的主题定位无关,那么网站的权重就很难增加,甚至网站都会被搜索引擎惩罚。
文章采集改进网站和收录的内容,网站收录索引数据与网站@的更新次数成正比> content 是的,如果你长时间不更新网站,那么你的网站索引数据不仅会增加,还会减少。如果你想改进网站收录的内容,那么你需要不断更新网站优质内容。
除了文章采集,内容更新、内链优化、网站结构优化、404、网站sitemap地图和机器人都属于现场搜索引擎优化。如果你不做好站内优化,你的外链再好也没用,因为你的网站留不住用户,所以站内优化大于站外-网站优化,而外部链接的作用近年来逐渐减弱。如果想通过累计外链数量来增加网站的权重,目前可能很难实现。
使用白帽SEO进行形式优化,为什么一定要使用白帽SEO来优化网站?因为有的站长想用黑帽SEO优化的方法来快速提升网站的权重值,如果使用这些黑帽SEO,一旦被搜索引擎发现,就等待网站@的结果> 只能被惩罚或K站。搜索引擎支持用户使用正式的白帽SEO优化方式,因为这种优化方式可以持续为用户提供有价值的内容。
我们在优化网站的时候,建议不要用黑帽作弊来优化网站,因为到最后你很可能会花费时间和精力,却没有网站好的流量。
<p>新站前期以文章采集和挖矿网站长尾关键词为主。长尾关键词不仅竞争程度低,而且排名时间短。优化长尾关键词可能只需要几个星期,最长不会超过一个月。新站没有优化基础,搜索引擎对新站信任度不高。我们优化关键词@文章采集和长尾关键词,可以实现更快的收录网站页面,更快的流量,然后不断的积累和提高网站的流量和权重,最后为了争夺一些高指数、高流量的关键词,新的网站倾向于前期做内容,
自动采集文章(ThinkCMF采集的主要知识点以及表达点皆在文章配图之中)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-07 08:23
ThinkCMF采集,可以为指定的关键词全网采集快速填写网站的内容资源。然后通过自动伪原创发布,让网站时刻保持更新状态,这样的网站受到搜索引擎的青睐。本文关于ThinkCMF采集的主要知识点和表达点都在文章图片中。不需要看内容,直接文章图片即可。 [图一,ThinkCMF采集,永远完全免费]
在正常运行网站时,网站的所有内容都不是完全原创的内容,要么是采集内容,要么是复制或粘贴内容,要么是网站管理员使用ThinkCMF@k11@的方式>。对于网站的管理员来说,有个小问题,大家都在采集,基本要点是ThinkCMF采集对网站做SEO,内容质量,页面质量处理网站质量。 [图二,ThinkCMF采集,功能齐全,功能强大]
现在网站越来越多,竞争越来越激烈,信息类网站收录的内容越来越多,关键词也很多。许多 网站 管理员对新站点感到头疼,即需要填充站点。没有内容,网站推广是不可能的。 ThinkCMF采集至少可以解决网站的内容,自动NPL处理内容优化网站。 【图三,ThinkCMF采集,自动SEO优化】
网站关键词需要排名,必须先收录,只要解决了收录,其他的都会解决。 ThinkCMF采集的内容让用户满意。 网站进行SEO优化时,ThinkCMF采集SEO网站的内容可以满足文章的内容,对用户有利。帮助。 【图4 ThinkCMF采集站长优化必备】
文章 和 文章 之间的链接非常重要。 ThinkCMF采集的功能实现了自动添加内链的效果。添加内链的主要目的是给文章传递权重,得到排名结果。
增加内链的方法主要是根据文章的标题。通过使用关键字设置标题。至于内部链接,如何实现自动添加效果,由于程序不同,设置方法还是有区别的,ThinkCMF采集可以兼容各种cms。
ThinkCMF采集实现采集功能的方法:
公共函数索引(){
// 使用采集类
// 用户手册:见文章图片
import('Org.QL.QueryList');
$url = "域/域";
$reg = 数组();
$reg['title'] = array('.sulist_title','text');
$reg['shuliang'] = array('.su_li1','html');
$obj = 新 \QueryList($url,$reg);
$data = $obj->jsonArr;
// foreach($data as $v){
//回声“
".$v['title'].'___'.$v['shuliang']."
";
// } 查看全部
自动采集文章(ThinkCMF采集的主要知识点以及表达点皆在文章配图之中)
ThinkCMF采集,可以为指定的关键词全网采集快速填写网站的内容资源。然后通过自动伪原创发布,让网站时刻保持更新状态,这样的网站受到搜索引擎的青睐。本文关于ThinkCMF采集的主要知识点和表达点都在文章图片中。不需要看内容,直接文章图片即可。 [图一,ThinkCMF采集,永远完全免费]
在正常运行网站时,网站的所有内容都不是完全原创的内容,要么是采集内容,要么是复制或粘贴内容,要么是网站管理员使用ThinkCMF@k11@的方式>。对于网站的管理员来说,有个小问题,大家都在采集,基本要点是ThinkCMF采集对网站做SEO,内容质量,页面质量处理网站质量。 [图二,ThinkCMF采集,功能齐全,功能强大]
现在网站越来越多,竞争越来越激烈,信息类网站收录的内容越来越多,关键词也很多。许多 网站 管理员对新站点感到头疼,即需要填充站点。没有内容,网站推广是不可能的。 ThinkCMF采集至少可以解决网站的内容,自动NPL处理内容优化网站。 【图三,ThinkCMF采集,自动SEO优化】
网站关键词需要排名,必须先收录,只要解决了收录,其他的都会解决。 ThinkCMF采集的内容让用户满意。 网站进行SEO优化时,ThinkCMF采集SEO网站的内容可以满足文章的内容,对用户有利。帮助。 【图4 ThinkCMF采集站长优化必备】
文章 和 文章 之间的链接非常重要。 ThinkCMF采集的功能实现了自动添加内链的效果。添加内链的主要目的是给文章传递权重,得到排名结果。
增加内链的方法主要是根据文章的标题。通过使用关键字设置标题。至于内部链接,如何实现自动添加效果,由于程序不同,设置方法还是有区别的,ThinkCMF采集可以兼容各种cms。
ThinkCMF采集实现采集功能的方法:
公共函数索引(){
// 使用采集类
// 用户手册:见文章图片
import('Org.QL.QueryList');
$url = "域/域";
$reg = 数组();
$reg['title'] = array('.sulist_title','text');
$reg['shuliang'] = array('.su_li1','html');
$obj = 新 \QueryList($url,$reg);
$data = $obj->jsonArr;
// foreach($data as $v){
//回声“
".$v['title'].'___'.$v['shuliang']."
";
// }
自动采集文章(如何写采集规则?人维护成百上千网站文章更新也不是)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-03-07 03:13
如何编写采集 规则?最近有很多朋友问我问题。由于他们不是很熟练,也不是程序员,所以他们学起来会很慢。很多地方都处于无知状态。要学习采集规则的最低标准,至少了解html代码表示,大部分采集遵循采集的规则。发布模块的这一大部分需要专业的编程技能。
一、免费采集伪原创发布主动向搜索引擎提交链接的软件
今天分享给大家的软件不需要编写采集规则和发布模块。通过采集软件可以实现采集伪原创的自动发布和主动推送到搜索引擎。操作简单只需几步即可轻松采集内容数据,用户只需在采集软件上进行简单设置,采集软件即可准确设置关键词 采集文章,这确保了与行业 文章 保持一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
与其他采集软件相比,这款采集软件基本没有任何规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,输入关键词采集可以实现(采集软件也自带关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。采集该软件还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片)不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前采集关键词 是自动添加的。文本 Automatically insert the current 采集关键词 在随机位置两次。当当前 采集 的 关键词 出现在文本中时,< @关键词 将自动加粗。)
7、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
采集规则只是实现了一个采集的功能。搜索引擎更喜欢 原创 的内容。这个是很多站长都知道的,但是创建很多原创文章并不容易,下面介绍一些通过软件提高原创度的方法
二、通过软件工具提高文章原创度数
1.伪原创要做好以下几个方面,首先是文章的标题:这个文章的标题一定要改,这不仅仅是一个简单的换一个词,换一个说法,意思就完全不一样了。但是,标题不能没有关键字,从而失去了 伪原创 的值。学习title一般有两种方法,用长尾词作为title,或者用多个热词逼近title。
2.文章内容字数约为500-800字,关键词密度约为2%≤5%。
3.当然,伪原创也有一些技巧,比如改变段落或主题的顺序,替换同义词等等,结合方法和技巧。目前主流的 伪原创 方法是重写第一段和最后一段。第一段应该布局合理关键词,最好有1-2个关键词出现。不要刻意堆叠关键词,文章句子要流畅。在 文章 的末尾再添加一个关键字。
4.在文章的中间部分,做关键词的扩展,特意做H3标签,锚文本等,也做一些内链。灵活使用我们的日常优化技术。一般来说,伪原创的目的是带来价值,让搜索引擎认为是原创内容,然后伪原创内容收录很快,关键词排名也会很好。
三、网站收录多少个关键词排名
关键词的排名出现在网站后,出现关键词排名的页面可能不是网站的首页,可能是栏目页或文章页面,那么,如果在网站这种情况下,我们应该如何提高这样的关键词的排名呢?
1.关注页面怎么写TDK
既然已经是单个内页排名,那么我们就应该多注意一下这个页面的标题、描述和关键词的写法。标题要简洁全面,突出页面重点,包括关键词,描述要关键词 @文章介绍要详细,关键词只需重写任何你想要的。
2.展开内外部链接
如果想要稳定和提高这个内页的排名位置,就需要在这个内页添加有价值的内链和优质的外链,这样排名才能稳步提升。
3.内页内容扩展
如果是文章内容页面,需要时不时的重写内容下的相关内容,不管多少,但一定要和内容相关,质量一定要高。如果是产品页面,需要完善产品信息,更新产品。信息等
4.使用图像
图片不要过多过大,图片大小要合适,图片要清晰,图片要加ALT标签,便于搜索引擎识别图片内容。
5.单页代码优化
对于 CSS 和 JS 的优化,尽量使用外部导入,使网页代码更加简洁。如果可以使用CSS,尽量不要使用JS。毕竟 JS 对搜索引擎不是很友好。
四、我们知道网站的基本seo操作是seo内容发布,但是你明白网站为什么选择长期的内容更新吗?
从搜索引擎的角度来看,推荐用户最喜欢的网站是他们的主要职责,哪个网站有可能让用户喜欢呢?互联网是信息爆炸时代的载体,信息的不断更新是其主要表现形式。那么搜索引擎就会认为在网站时间内产生了新的页面,很可能是站长管理的,很受用户欢迎。它变大的机会,所以像经常更新的网站这样的搜索引擎,作为网站的seo人员,我们有责任让网站看起来像这样的搜索引擎,所以我们需要定期更新 网站 内容。
1、上面我们说过,网络时代的信息更新速度会非常快,我们需要吸收最新最新的处理,把它变成与我们相关的“内容”网站,让用户无需开动脑筋,即可了解行业最新资讯。
2、在这个内容为王的时代,内容的丰富性衡量了你的网站的整体质量,但罗马不是一天建成的,我们需要不断地补充。我们的网站内容会在我们不断的内容更新中变得越来越丰富。
五、其他服务器域名流量的知识
1、服务器性能常识;
在优化网站的过程中,站长需要时刻关注服务器的性能,比如CPU使用率、内存、站点日志、是否存在安全漏洞等。定期监控服务器性能有助于保证网站的安全稳定运行。多了解服务器,对以后的SEO优化也很有帮助。
2、域名解析相关知识;
域名解析是否正确直接决定了后面的网站优化操作,而网站优化过程中一个很重要的策略就是一个页面对应一个唯一的URL。如果域名解析配置错误,启用域名泛解析,或者没有确定网站首选域,会导致网站出现大量重复内容和权重分散.
3、过度关注网站的流量;
网站在过分关注流量的过程中,却忽略了网站内容的质量,导致网站跳出率高,导致一系列问题关键词 排名下降,流量下降,得不偿失。
4、备份
服务器数据备份+网站内容备份是很多站长容易忽略的问题。随着网站内容的增加,我们无法预测未来的很多事情。为了避免因网站不可抗拒或人为错误操作造成的一些问题,我们应提前做好应对措施,及时做好网站备份以确保安全。
上述功能可以通过采集工具实现。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名! 查看全部
自动采集文章(如何写采集规则?人维护成百上千网站文章更新也不是)
如何编写采集 规则?最近有很多朋友问我问题。由于他们不是很熟练,也不是程序员,所以他们学起来会很慢。很多地方都处于无知状态。要学习采集规则的最低标准,至少了解html代码表示,大部分采集遵循采集的规则。发布模块的这一大部分需要专业的编程技能。
一、免费采集伪原创发布主动向搜索引擎提交链接的软件
今天分享给大家的软件不需要编写采集规则和发布模块。通过采集软件可以实现采集伪原创的自动发布和主动推送到搜索引擎。操作简单只需几步即可轻松采集内容数据,用户只需在采集软件上进行简单设置,采集软件即可准确设置关键词 采集文章,这确保了与行业 文章 保持一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
与其他采集软件相比,这款采集软件基本没有任何规则,更别说花大量时间学习正则表达式或者html标签,一分钟就能上手,输入关键词采集可以实现(采集软件也自带关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。采集该软件还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片)不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、相关性优化(关键词出现在正文中,正文第一段自动插入到title标题中。当描述相关性低时,当前采集关键词 是自动添加的。文本 Automatically insert the current 采集关键词 在随机位置两次。当当前 采集 的 关键词 出现在文本中时,< @关键词 将自动加粗。)
7、定期发布(定期发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
采集规则只是实现了一个采集的功能。搜索引擎更喜欢 原创 的内容。这个是很多站长都知道的,但是创建很多原创文章并不容易,下面介绍一些通过软件提高原创度的方法
二、通过软件工具提高文章原创度数
1.伪原创要做好以下几个方面,首先是文章的标题:这个文章的标题一定要改,这不仅仅是一个简单的换一个词,换一个说法,意思就完全不一样了。但是,标题不能没有关键字,从而失去了 伪原创 的值。学习title一般有两种方法,用长尾词作为title,或者用多个热词逼近title。
2.文章内容字数约为500-800字,关键词密度约为2%≤5%。
3.当然,伪原创也有一些技巧,比如改变段落或主题的顺序,替换同义词等等,结合方法和技巧。目前主流的 伪原创 方法是重写第一段和最后一段。第一段应该布局合理关键词,最好有1-2个关键词出现。不要刻意堆叠关键词,文章句子要流畅。在 文章 的末尾再添加一个关键字。
4.在文章的中间部分,做关键词的扩展,特意做H3标签,锚文本等,也做一些内链。灵活使用我们的日常优化技术。一般来说,伪原创的目的是带来价值,让搜索引擎认为是原创内容,然后伪原创内容收录很快,关键词排名也会很好。
三、网站收录多少个关键词排名
关键词的排名出现在网站后,出现关键词排名的页面可能不是网站的首页,可能是栏目页或文章页面,那么,如果在网站这种情况下,我们应该如何提高这样的关键词的排名呢?
1.关注页面怎么写TDK
既然已经是单个内页排名,那么我们就应该多注意一下这个页面的标题、描述和关键词的写法。标题要简洁全面,突出页面重点,包括关键词,描述要关键词 @文章介绍要详细,关键词只需重写任何你想要的。
2.展开内外部链接
如果想要稳定和提高这个内页的排名位置,就需要在这个内页添加有价值的内链和优质的外链,这样排名才能稳步提升。
3.内页内容扩展
如果是文章内容页面,需要时不时的重写内容下的相关内容,不管多少,但一定要和内容相关,质量一定要高。如果是产品页面,需要完善产品信息,更新产品。信息等
4.使用图像
图片不要过多过大,图片大小要合适,图片要清晰,图片要加ALT标签,便于搜索引擎识别图片内容。
5.单页代码优化
对于 CSS 和 JS 的优化,尽量使用外部导入,使网页代码更加简洁。如果可以使用CSS,尽量不要使用JS。毕竟 JS 对搜索引擎不是很友好。
四、我们知道网站的基本seo操作是seo内容发布,但是你明白网站为什么选择长期的内容更新吗?
从搜索引擎的角度来看,推荐用户最喜欢的网站是他们的主要职责,哪个网站有可能让用户喜欢呢?互联网是信息爆炸时代的载体,信息的不断更新是其主要表现形式。那么搜索引擎就会认为在网站时间内产生了新的页面,很可能是站长管理的,很受用户欢迎。它变大的机会,所以像经常更新的网站这样的搜索引擎,作为网站的seo人员,我们有责任让网站看起来像这样的搜索引擎,所以我们需要定期更新 网站 内容。
1、上面我们说过,网络时代的信息更新速度会非常快,我们需要吸收最新最新的处理,把它变成与我们相关的“内容”网站,让用户无需开动脑筋,即可了解行业最新资讯。
2、在这个内容为王的时代,内容的丰富性衡量了你的网站的整体质量,但罗马不是一天建成的,我们需要不断地补充。我们的网站内容会在我们不断的内容更新中变得越来越丰富。
五、其他服务器域名流量的知识
1、服务器性能常识;
在优化网站的过程中,站长需要时刻关注服务器的性能,比如CPU使用率、内存、站点日志、是否存在安全漏洞等。定期监控服务器性能有助于保证网站的安全稳定运行。多了解服务器,对以后的SEO优化也很有帮助。
2、域名解析相关知识;
域名解析是否正确直接决定了后面的网站优化操作,而网站优化过程中一个很重要的策略就是一个页面对应一个唯一的URL。如果域名解析配置错误,启用域名泛解析,或者没有确定网站首选域,会导致网站出现大量重复内容和权重分散.
3、过度关注网站的流量;
网站在过分关注流量的过程中,却忽略了网站内容的质量,导致网站跳出率高,导致一系列问题关键词 排名下降,流量下降,得不偿失。
4、备份
服务器数据备份+网站内容备份是很多站长容易忽略的问题。随着网站内容的增加,我们无法预测未来的很多事情。为了避免因网站不可抗拒或人为错误操作造成的一些问题,我们应提前做好应对措施,及时做好网站备份以确保安全。
上述功能可以通过采集工具实现。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
自动采集文章(WP-AutoBlog为全新开发插件.3更快更新和维护)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-03-06 10:10
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集相同文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
自动采集在启用任务时无需人工干预即可更新
任务启用后,定期检查是否有新的文章可以更新,检查文章是否重复,导入更新文章,所有操作程序自动完成,无需人工干预。
触发采集更新有两种方式,一种是在页面中添加代码,通过用户访问触发采集更新(后台是异步的,不影响用户体验,确实不影响网站效率),另外可以使用Cron调度任务触发采集更新任务
方向采集,支持通配符匹配,或者精确的CSS选择器采集任何内容,支持采集多级文章列表,支持采集文本分页内容,支持采集多级文本内容
支持市面上所有主流对象存储服务,包括七牛云、阿里云OSS、腾讯云COS、百度云BOS、优拍云、亚马逊AWS S3、谷歌云存储,可存储文章图片@>中的附件自动上传到云对象存储服务,节省带宽和空间,提高网站访问速度
七牛云存储,享受每月10GB免费存储空间和10GB免费带宽
只需配置相关信息即可自动上传,已上传至云端对象存储的图片和文件也可通过Wordpress后台直接查看或管理。 查看全部
自动采集文章(WP-AutoBlog为全新开发插件.3更快更新和维护)
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集相同文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
自动采集在启用任务时无需人工干预即可更新
任务启用后,定期检查是否有新的文章可以更新,检查文章是否重复,导入更新文章,所有操作程序自动完成,无需人工干预。
触发采集更新有两种方式,一种是在页面中添加代码,通过用户访问触发采集更新(后台是异步的,不影响用户体验,确实不影响网站效率),另外可以使用Cron调度任务触发采集更新任务
方向采集,支持通配符匹配,或者精确的CSS选择器采集任何内容,支持采集多级文章列表,支持采集文本分页内容,支持采集多级文本内容
支持市面上所有主流对象存储服务,包括七牛云、阿里云OSS、腾讯云COS、百度云BOS、优拍云、亚马逊AWS S3、谷歌云存储,可存储文章图片@>中的附件自动上传到云对象存储服务,节省带宽和空间,提高网站访问速度
七牛云存储,享受每月10GB免费存储空间和10GB免费带宽
只需配置相关信息即可自动上传,已上传至云端对象存储的图片和文件也可通过Wordpress后台直接查看或管理。
自动采集文章(采集软件下载:七格格_微信公众号标题采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-06 07:06
自动采集文章标题搜狗智能采集器电脑手机都能用,采集微信公众号文章标题,配上相应的文字及视频,而且还有自动排版功能,自动排版,全新模式,一键智能收录,采集软件下载:安卓手机直接下载七格格app即可,苹果手机,安卓手机下载七格格app,微信,头条,uc,百度,阿里大鱼,企鹅号,其他主流平台自媒体都可以采集,一键全网一键收录。
七格格七格格电脑手机都能用。采集软件下载:七格格app七格格_微信公众号标题采集工具-第三方平台采集文章智能采集。
现在的自媒体平台有很多平台,像头条号、百家号、企鹅号、大鱼号、趣头条号等等,每个平台都是不一样的。不同的平台注册需要不同的材料,有的需要身份证,有的需要手机号等等,不同的平台需要的材料不一样,头条就需要一个手机号,而且现在很多平台审核也是比较严格,所以我们在平时要多多的关注各个平台的公告文章,熟悉了解平台规则,那么我们就可以很快的申请下来账号。
想要在运营自媒体的时候事半功倍,我们在注册账号的时候,注意资料一定要准确,虽然现在申请很简单,但是如果你没有审核的话,也是很慢的,所以,我们一定要打造个性化账号。做好自媒体最重要的是坚持,要坚持更新内容,定时发文。因为平台要推荐你的文章,最根本的原因还是来源于你写的内容。有的人在注册账号的时候,为了好的名字,为了提高审核的通过率,就跑去做微商了,然后觉得微商一定不好,放弃了自媒体,其实我们不要过多的去关注这些东西,坚持不定时发文,才是最重要的,不要东关注它,看看它就跑去做微商了,这种方法不可取的。
做自媒体是一个长期积累的过程,我们不要着急,想要能取得高收益,我们首先要做好内容输出,如果你不思考输出内容,光靠搬运,可能是能够月入过万的,但是能够走的长远的。希望我的回答能够帮助到你,欢迎点赞加关注!如果你想学习自媒体,可以关注我的个人主页。 查看全部
自动采集文章(采集软件下载:七格格_微信公众号标题采集工具)
自动采集文章标题搜狗智能采集器电脑手机都能用,采集微信公众号文章标题,配上相应的文字及视频,而且还有自动排版功能,自动排版,全新模式,一键智能收录,采集软件下载:安卓手机直接下载七格格app即可,苹果手机,安卓手机下载七格格app,微信,头条,uc,百度,阿里大鱼,企鹅号,其他主流平台自媒体都可以采集,一键全网一键收录。
七格格七格格电脑手机都能用。采集软件下载:七格格app七格格_微信公众号标题采集工具-第三方平台采集文章智能采集。
现在的自媒体平台有很多平台,像头条号、百家号、企鹅号、大鱼号、趣头条号等等,每个平台都是不一样的。不同的平台注册需要不同的材料,有的需要身份证,有的需要手机号等等,不同的平台需要的材料不一样,头条就需要一个手机号,而且现在很多平台审核也是比较严格,所以我们在平时要多多的关注各个平台的公告文章,熟悉了解平台规则,那么我们就可以很快的申请下来账号。
想要在运营自媒体的时候事半功倍,我们在注册账号的时候,注意资料一定要准确,虽然现在申请很简单,但是如果你没有审核的话,也是很慢的,所以,我们一定要打造个性化账号。做好自媒体最重要的是坚持,要坚持更新内容,定时发文。因为平台要推荐你的文章,最根本的原因还是来源于你写的内容。有的人在注册账号的时候,为了好的名字,为了提高审核的通过率,就跑去做微商了,然后觉得微商一定不好,放弃了自媒体,其实我们不要过多的去关注这些东西,坚持不定时发文,才是最重要的,不要东关注它,看看它就跑去做微商了,这种方法不可取的。
做自媒体是一个长期积累的过程,我们不要着急,想要能取得高收益,我们首先要做好内容输出,如果你不思考输出内容,光靠搬运,可能是能够月入过万的,但是能够走的长远的。希望我的回答能够帮助到你,欢迎点赞加关注!如果你想学习自媒体,可以关注我的个人主页。
自动采集文章(微信公众号查看历史消息页或者文章详情页(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-27 00:27
%2BfItg%3D&pass_ticket=DGD5JOEorn3ncmbmdXKbsmgxGOEwYobX7unmU6gwxw8SzwowCh6KBA%2BRMYejszL%2F&wx_header=1
3、通过修改anyproxy配置文件解决了anyproxy拦截过程中的各种错误。
Anyproxy的内部错误会执行anyproxy配置文件rule_default.js中的onError方法,所以当报错的时候,可以修改这个方法,让它获取下一页,注入到js脚本中继续执行,不停止
*onError(requestDetail, error) {
if(/s\?__biz=/i.test(requestDetail.url) || /mp\/profile_ext\?action=home/i.test(requestDetail.url) || /mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
var errorStr = error.toString();
console.log("++++++++++onError+++++++++++++" + errorStr + "++++++++++++++++++++++++++");
getWxPost("访问该页面出现错误",requestDetail.url,"/handleErrorLink");
console.log("++++++++++访问该页面出现错误,加载下一链接++++++++++++++++++++++++++" + requestDetail.url);
var nonce = "";
var response = "";
if(/mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
response = getWxBizForInfo();
} else {
response = getNextUrl(nonce);
}
//response = getNextUrl(nonce);
console.log("**** onError next url or biz *****: "+ response)
return {
response: {
statusCode: 200,
header: { 'content-type': 'text/html' },
body: " 加载下一页 "+ requestDetail.url +"" + response
}
};
}
}
GitHub源码地址:wechat-serv-crawler
环境搭建与部署 安装前准备
系统:CentOS Linux 发行版7.6.1810(核心)
日常模拟器:点击下载
Node-v10.16.0:点击下载
Nodejs下载页面:点击下载
在服务器上搭建anyproxy代理相关文章:Centos7.x搭建anyproxy代理服务器
cd /opt
// 克隆项目到本地
git clone git@github.com:dengyinlei/wechat-serv-crawler.git
// 修改`wechat-serv-crawler/src/main/resources/application.properties`
`wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg`
`wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties`对的数据库和redis的地址
vim wechat-serv-crawler/src/main/resources/application.properties
vim wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg
vim wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties
// 修改完成后打包
cd wechat-serv-crawler && mvn clean install -Dmaven.test.skip=true
// 安装nodejs同步请求sync-request包
npm install -g sync-request
// 替换anyproxy 配置脚本 rule_default.js :
cp /opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js /usr/local/nodejs/lib/node_modules/anyproxy/lib/
//关于anyproxy具体拦截请求处理的逻辑见/opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js配置脚本
//生成替换所有图片,减轻浏览器负担
touch /usr/local/nodejs/lib/node_modules/anyproxy/lib/one_pixel.png
//使用pm2重启anyproxy进程:
pm2 restart all
//查看anyproxy日志:
pm2 logs anyproxy
// 数据库脚本初始化
安装完MySQL数据库后执行/opt/wechat-serv-crawler/src/main/resources/sql/table.sql脚本 初始化数据库以及相关表结构。
// 运行项目
cd /opt/wechat-serv-crawler/target && sh stop.sh && sh start.sh
首次点击动作
打开模拟器,下载anyproxy的证书并配置代理,在模拟器中登录微信添加任意好友,好友会发给你任意微信公众号历史页面或微信文章链接消息,并放消息置顶,进入消息聊天界面,点击链接自动爬取redis队列中微信公众号对应的文章,如下图:
关于自动抓取
这个程序是事件驱动的。也就是一开始必须给一个触发事件,比如打开微信公众号查看历史新闻或者打开公众号文章,然后自动跳转到下一个公众号历史消息页面或者文章@通过js注入>详情页面,当然中间可能会出现异常,异常会阻塞自动跳转到下一页,需要自动化框架的辅助来模拟手动点击动作。这里使用了atx自动化框架。
本项目自动化程度高。人工费用为首次登录微信后点击微信公众号查看历史新闻或在公众号文章中打开链接。后续跳转完全通过js注入,异常自动处理恢复点击(atx自动点击)。
运行效果展示
该项目已经是一个成熟且成熟的项目。经过大量长期测试,目前可以保证微信客户端每天采集300个公众号的数据稳定运行,不会被封号。如果您访问微信公众号的历史新闻页面过于频繁,您将被禁止 24 小时。
目前比较好的策略是访问文章页面后休眠5秒,访问微信公众号历史新闻页面后休眠150秒。
本项目功能测试成功,已稳定运行两个月。目前采集使用三个微信账号,采集每天900个微信公众号文章的数据。
每个微信账号每月费用为5元。基于该项目,可以实现大规模运营的低成本运营。
更新(2020-07-30)在爬出错误过程中降低漏爬率)
由于我使用redis的list queue作为消息队列,在消息消费过程中可能会出现错误,导致消息丢失和数据泄露。通过使用redis的RPOPLPUSH命令,消费者程序进入slave主消息队列。消息取出后,插入到备份队列中,从备份队列中删除消息,直到消费者程序完成正常的处理逻辑。同时,我们也可以提供一个守护进程。主消息队列中的消息被消费后,备份队列中没有正常消费的消息可以放回主消息队列中,以便其他消费者程序继续处理。
/**
* 从redis队列中获取下一个待爬取的链接
* @return
*/
@RequestMapping(value = "/getNextUrl", method = RequestMethod.GET)
public String getNextUrl() {
//下一个微信公众号文章的url
String nextUrl = redisUtils.rpoplpush("wechat_content_quene", "wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
nextUrl = redisUtils.lpop("wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
LOGGER.info("==============队列中已无待跑的文章url,从队列中获取下一个公众号的biz==================");
//队列表如果空了,就从存储公众号biz的队列中取得一个biz
String biz = redisUtils.rpoplpush(WECHAT_BIZ_QUENE, WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
biz = redisUtils.lpop(WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
String errorLink = redisUtils.rpoplpush(ERROR__LINK,WECHAT_CONTENT_URL_BACKUP_QUENE);
if (StringUtils.isBlank(errorLink)) {
LOGGER.info("=================队列中已无待跑的公众号,结束本次爬取任务===================");
return EXAMPLE_CONTENT_URL;
} else {
LOGGER.info("=================从错误页面从获取爬取失败的链接===================link:{}", errorLink);
return errorLink;
}
}
获取微信公众号所有历史新闻列表,微信公众号特殊公众号也可以不关注文章获取历史:
之前实现的方案是只爬取微信公众号的最新页面文章列表。由于下一页抓包解析返回的内容是json响应体,因此无法通过注入脚本来自动模拟点击遍历。实现翻页功能。
通过分析测试发现只要使用下面的url模式获取文章的列表,注意f参数为html,可以将下一页返回的内容修改为html格式,解决了json不容易注入js脚本的问题。题。另外,调整偏移量可以实现翻页。
下图为上述公众号第100页的历史文章列表页:
参考文章
感谢以下 文章 想法:
1、使用anyproxy提高公众号效率文章采集
2、微信公众号文章批量采集系统搭建
联系作者
由于微信采集平台的搭建和开发耗费了大量的时间和精力,暂时不打算开源。如果您满足以下条件:不懂技术,时间宝贵,不想花时间研究,想尽快看到效果,并且本项目目前实现的功能满足您的需求,可以付费联系我用所有随附的源代码帮助您构建这个项目,并回答和解决您在开发过程中遇到的所有疑问。 查看全部
自动采集文章(微信公众号查看历史消息页或者文章详情页(组图))
%2BfItg%3D&pass_ticket=DGD5JOEorn3ncmbmdXKbsmgxGOEwYobX7unmU6gwxw8SzwowCh6KBA%2BRMYejszL%2F&wx_header=1
3、通过修改anyproxy配置文件解决了anyproxy拦截过程中的各种错误。
Anyproxy的内部错误会执行anyproxy配置文件rule_default.js中的onError方法,所以当报错的时候,可以修改这个方法,让它获取下一页,注入到js脚本中继续执行,不停止
*onError(requestDetail, error) {
if(/s\?__biz=/i.test(requestDetail.url) || /mp\/profile_ext\?action=home/i.test(requestDetail.url) || /mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
var errorStr = error.toString();
console.log("++++++++++onError+++++++++++++" + errorStr + "++++++++++++++++++++++++++");
getWxPost("访问该页面出现错误",requestDetail.url,"/handleErrorLink");
console.log("++++++++++访问该页面出现错误,加载下一链接++++++++++++++++++++++++++" + requestDetail.url);
var nonce = "";
var response = "";
if(/mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
response = getWxBizForInfo();
} else {
response = getNextUrl(nonce);
}
//response = getNextUrl(nonce);
console.log("**** onError next url or biz *****: "+ response)
return {
response: {
statusCode: 200,
header: { 'content-type': 'text/html' },
body: " 加载下一页 "+ requestDetail.url +"" + response
}
};
}
}
GitHub源码地址:wechat-serv-crawler
环境搭建与部署 安装前准备
系统:CentOS Linux 发行版7.6.1810(核心)
日常模拟器:点击下载
Node-v10.16.0:点击下载
Nodejs下载页面:点击下载
在服务器上搭建anyproxy代理相关文章:Centos7.x搭建anyproxy代理服务器
cd /opt
// 克隆项目到本地
git clone git@github.com:dengyinlei/wechat-serv-crawler.git
// 修改`wechat-serv-crawler/src/main/resources/application.properties`
`wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg`
`wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties`对的数据库和redis的地址
vim wechat-serv-crawler/src/main/resources/application.properties
vim wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg
vim wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties
// 修改完成后打包
cd wechat-serv-crawler && mvn clean install -Dmaven.test.skip=true
// 安装nodejs同步请求sync-request包
npm install -g sync-request
// 替换anyproxy 配置脚本 rule_default.js :
cp /opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js /usr/local/nodejs/lib/node_modules/anyproxy/lib/
//关于anyproxy具体拦截请求处理的逻辑见/opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js配置脚本
//生成替换所有图片,减轻浏览器负担
touch /usr/local/nodejs/lib/node_modules/anyproxy/lib/one_pixel.png
//使用pm2重启anyproxy进程:
pm2 restart all
//查看anyproxy日志:
pm2 logs anyproxy
// 数据库脚本初始化
安装完MySQL数据库后执行/opt/wechat-serv-crawler/src/main/resources/sql/table.sql脚本 初始化数据库以及相关表结构。
// 运行项目
cd /opt/wechat-serv-crawler/target && sh stop.sh && sh start.sh
首次点击动作
打开模拟器,下载anyproxy的证书并配置代理,在模拟器中登录微信添加任意好友,好友会发给你任意微信公众号历史页面或微信文章链接消息,并放消息置顶,进入消息聊天界面,点击链接自动爬取redis队列中微信公众号对应的文章,如下图:
关于自动抓取
这个程序是事件驱动的。也就是一开始必须给一个触发事件,比如打开微信公众号查看历史新闻或者打开公众号文章,然后自动跳转到下一个公众号历史消息页面或者文章@通过js注入>详情页面,当然中间可能会出现异常,异常会阻塞自动跳转到下一页,需要自动化框架的辅助来模拟手动点击动作。这里使用了atx自动化框架。
本项目自动化程度高。人工费用为首次登录微信后点击微信公众号查看历史新闻或在公众号文章中打开链接。后续跳转完全通过js注入,异常自动处理恢复点击(atx自动点击)。
运行效果展示
该项目已经是一个成熟且成熟的项目。经过大量长期测试,目前可以保证微信客户端每天采集300个公众号的数据稳定运行,不会被封号。如果您访问微信公众号的历史新闻页面过于频繁,您将被禁止 24 小时。
目前比较好的策略是访问文章页面后休眠5秒,访问微信公众号历史新闻页面后休眠150秒。
本项目功能测试成功,已稳定运行两个月。目前采集使用三个微信账号,采集每天900个微信公众号文章的数据。
每个微信账号每月费用为5元。基于该项目,可以实现大规模运营的低成本运营。
更新(2020-07-30)在爬出错误过程中降低漏爬率)
由于我使用redis的list queue作为消息队列,在消息消费过程中可能会出现错误,导致消息丢失和数据泄露。通过使用redis的RPOPLPUSH命令,消费者程序进入slave主消息队列。消息取出后,插入到备份队列中,从备份队列中删除消息,直到消费者程序完成正常的处理逻辑。同时,我们也可以提供一个守护进程。主消息队列中的消息被消费后,备份队列中没有正常消费的消息可以放回主消息队列中,以便其他消费者程序继续处理。
/**
* 从redis队列中获取下一个待爬取的链接
* @return
*/
@RequestMapping(value = "/getNextUrl", method = RequestMethod.GET)
public String getNextUrl() {
//下一个微信公众号文章的url
String nextUrl = redisUtils.rpoplpush("wechat_content_quene", "wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
nextUrl = redisUtils.lpop("wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
LOGGER.info("==============队列中已无待跑的文章url,从队列中获取下一个公众号的biz==================");
//队列表如果空了,就从存储公众号biz的队列中取得一个biz
String biz = redisUtils.rpoplpush(WECHAT_BIZ_QUENE, WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
biz = redisUtils.lpop(WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
String errorLink = redisUtils.rpoplpush(ERROR__LINK,WECHAT_CONTENT_URL_BACKUP_QUENE);
if (StringUtils.isBlank(errorLink)) {
LOGGER.info("=================队列中已无待跑的公众号,结束本次爬取任务===================");
return EXAMPLE_CONTENT_URL;
} else {
LOGGER.info("=================从错误页面从获取爬取失败的链接===================link:{}", errorLink);
return errorLink;
}
}
获取微信公众号所有历史新闻列表,微信公众号特殊公众号也可以不关注文章获取历史:
之前实现的方案是只爬取微信公众号的最新页面文章列表。由于下一页抓包解析返回的内容是json响应体,因此无法通过注入脚本来自动模拟点击遍历。实现翻页功能。
通过分析测试发现只要使用下面的url模式获取文章的列表,注意f参数为html,可以将下一页返回的内容修改为html格式,解决了json不容易注入js脚本的问题。题。另外,调整偏移量可以实现翻页。
下图为上述公众号第100页的历史文章列表页:
参考文章
感谢以下 文章 想法:
1、使用anyproxy提高公众号效率文章采集
2、微信公众号文章批量采集系统搭建
联系作者
由于微信采集平台的搭建和开发耗费了大量的时间和精力,暂时不打算开源。如果您满足以下条件:不懂技术,时间宝贵,不想花时间研究,想尽快看到效果,并且本项目目前实现的功能满足您的需求,可以付费联系我用所有随附的源代码帮助您构建这个项目,并回答和解决您在开发过程中遇到的所有疑问。
自动采集文章(如何做好一个网站SEO收录?有哪些收录技巧和注意的地方)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-27 00:22
Emlog采集,是很多博主、个人网站、企业网站长期使用的一种网站内容扩展工具,可以大大提升丰满度网站 度,通过海量内容吸引更多用户访问。如何做好网站SEO收录?收录 的提示和注意事项有哪些?接下来,我们将从 Emlog采集 的功能和功能,以及 SEO 技巧来看整个 SEO 优化。
网站采集的文章与收录率有一定的关系。到目前为止,采集站仍然可以达到很高的权重。搜索引擎也表示采集的内容要注意是否去掉多余的标签,内容是否完整等。emlog采集虽然不是一个好的选择,但是对于很多网站来说,只有在采集之后才有能力输出新鲜的内容。
那么Emlog采集制作的采集站点会实现这些优化:网站采集内容清晰,没有乱码,标签不干净。扩充补充采集的内容,减少采集的内容。在采集的内容后添加其他相关内容,使内部链接相互指向,扩大相关性。尽可能采集优质网站的内容不会采集不可读或带有广告文章。
Emlog采集发布后,会主动推送内容,随着内容的持久化,爬虫访问的概率增加。爬取推广网站的收录,这就是前面提到的内容建设和网站优化。此外,最好提交大量的站点地图。搜索引擎处理站点地图的时间很长,最近时间缩短了很多。至于怎么推送,一般都是后台推送,支持结构化数据提交,提交多了会有惊喜。毅力是必需的。另外,网站还可以推送到收录的目录栏,可以查看其API文档申请。
目前很多建站系统都集成了采集系统,Emlog采集对于采集的内容已经成为一件很简单的事情。在短时间内用内容填满您的新网站或让搜索引擎更快收录我们的新网站变得更快了。
但是当我们采集完成这个内容并通过搜索引擎得到收录之后,我们的网站可以非常快速的增长。在搜索引擎开始收录我们的内容之后,但后来当他在他的数据库中发现类似的内容时,那些低权重的网站收录的信息往往最先被删除。掉了。这是我们的 收录 上升然后下降的主要原因之一。因此,Emlog采集返回的内容必须经过内置文章处理后才能发布,并根据搜索引擎算法和实时性进行文章排列用户的搜索需求,让文章对搜索引擎和用户都有价值。 查看全部
自动采集文章(如何做好一个网站SEO收录?有哪些收录技巧和注意的地方)
Emlog采集,是很多博主、个人网站、企业网站长期使用的一种网站内容扩展工具,可以大大提升丰满度网站 度,通过海量内容吸引更多用户访问。如何做好网站SEO收录?收录 的提示和注意事项有哪些?接下来,我们将从 Emlog采集 的功能和功能,以及 SEO 技巧来看整个 SEO 优化。
网站采集的文章与收录率有一定的关系。到目前为止,采集站仍然可以达到很高的权重。搜索引擎也表示采集的内容要注意是否去掉多余的标签,内容是否完整等。emlog采集虽然不是一个好的选择,但是对于很多网站来说,只有在采集之后才有能力输出新鲜的内容。
那么Emlog采集制作的采集站点会实现这些优化:网站采集内容清晰,没有乱码,标签不干净。扩充补充采集的内容,减少采集的内容。在采集的内容后添加其他相关内容,使内部链接相互指向,扩大相关性。尽可能采集优质网站的内容不会采集不可读或带有广告文章。
Emlog采集发布后,会主动推送内容,随着内容的持久化,爬虫访问的概率增加。爬取推广网站的收录,这就是前面提到的内容建设和网站优化。此外,最好提交大量的站点地图。搜索引擎处理站点地图的时间很长,最近时间缩短了很多。至于怎么推送,一般都是后台推送,支持结构化数据提交,提交多了会有惊喜。毅力是必需的。另外,网站还可以推送到收录的目录栏,可以查看其API文档申请。
目前很多建站系统都集成了采集系统,Emlog采集对于采集的内容已经成为一件很简单的事情。在短时间内用内容填满您的新网站或让搜索引擎更快收录我们的新网站变得更快了。
但是当我们采集完成这个内容并通过搜索引擎得到收录之后,我们的网站可以非常快速的增长。在搜索引擎开始收录我们的内容之后,但后来当他在他的数据库中发现类似的内容时,那些低权重的网站收录的信息往往最先被删除。掉了。这是我们的 收录 上升然后下降的主要原因之一。因此,Emlog采集返回的内容必须经过内置文章处理后才能发布,并根据搜索引擎算法和实时性进行文章排列用户的搜索需求,让文章对搜索引擎和用户都有价值。
自动采集文章(>复制到站内链接搜索引擎随时能找到你(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-22 03:02
自动采集文章标题-->生成正文标题-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键填充评论数-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键帮你全站下载文章-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键帮你自动发布文章-->复制到站内链接,搜索引擎随时能找到你这篇文章;新建标签-->自动把标签添加到标题-->去掉标题-->这篇文章所有的页面所有页面都引用这个标签;文章内容反链接seo-generator/hire一个基于插件的权重内链平台a/seo-generator/hire-seo-generator-ideas/hire1226/seo-generator/pages/pages/herilst.herilst.herilst这些文章不是我写的,今天利用googlereader添加过来的。
具体要注意什么:第一,不建议把个人博客弄得太复杂,没有必要,没有必要;第二,不建议把博客弄得太复杂,不建议把博客弄得太复杂;第三,不建议把博客弄得太复杂,不建议把博客弄得太复杂;重要的事情说三遍;第四,建议把博客搞得尽量简单,那些小众的网站很不错;第五,建议把博客弄得尽量简单,那些小众的网站很不错;第六,建议把博客弄得尽量简单,那些小众的网站很不错;第七,在博客里面加一个小广告,因为个人博客的篇幅比较短,所以,可以加一个小广告,来吸引用户;第八,网站在经历一段低谷期之后,一定要开始坚持写,如果文章没有提升的话,很快就没有访问量,说明你还不适合做网站;第九,提升网站的原创内容质量,如果网站写的不好,很快就没有访问量,说明你还不适合做网站;第十,切记:不要以为,博客里面有了原创内容就可以了,这不是绝对的;最后奉劝大家在做网站之前,一定要想清楚,自己想要做成什么样子的网站,并且分析每一步是否可行。如果你有创业的想法,可以加我微信:(weixin)验证:知乎。 查看全部
自动采集文章(>复制到站内链接搜索引擎随时能找到你(组图))
自动采集文章标题-->生成正文标题-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键填充评论数-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键帮你全站下载文章-->复制到站内链接,搜索引擎随时能找到你这篇文章;一键帮你自动发布文章-->复制到站内链接,搜索引擎随时能找到你这篇文章;新建标签-->自动把标签添加到标题-->去掉标题-->这篇文章所有的页面所有页面都引用这个标签;文章内容反链接seo-generator/hire一个基于插件的权重内链平台a/seo-generator/hire-seo-generator-ideas/hire1226/seo-generator/pages/pages/herilst.herilst.herilst这些文章不是我写的,今天利用googlereader添加过来的。
具体要注意什么:第一,不建议把个人博客弄得太复杂,没有必要,没有必要;第二,不建议把博客弄得太复杂,不建议把博客弄得太复杂;第三,不建议把博客弄得太复杂,不建议把博客弄得太复杂;重要的事情说三遍;第四,建议把博客搞得尽量简单,那些小众的网站很不错;第五,建议把博客弄得尽量简单,那些小众的网站很不错;第六,建议把博客弄得尽量简单,那些小众的网站很不错;第七,在博客里面加一个小广告,因为个人博客的篇幅比较短,所以,可以加一个小广告,来吸引用户;第八,网站在经历一段低谷期之后,一定要开始坚持写,如果文章没有提升的话,很快就没有访问量,说明你还不适合做网站;第九,提升网站的原创内容质量,如果网站写的不好,很快就没有访问量,说明你还不适合做网站;第十,切记:不要以为,博客里面有了原创内容就可以了,这不是绝对的;最后奉劝大家在做网站之前,一定要想清楚,自己想要做成什么样子的网站,并且分析每一步是否可行。如果你有创业的想法,可以加我微信:(weixin)验证:知乎。
自动采集文章(自动采集文章广告,插入到自己的公众号图文推广)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-02-20 19:01
自动采集文章广告,插入到自己的公众号图文推广,可以私聊我。2019年以来,客发展很是不错,很多人都转向做客。但是做客的成本很高,广告费是其中一个,其次还有培训费用、发货等成本。那么我们该如何做客呢?下面由禾赛科技()为大家介绍我们该如何做客。
一、选择性的发展自己的粉丝,积累自己的老粉丝要想做好客,首先需要积累自己的粉丝,你要是一个优秀的客,还要有一定的推广能力,但是也不能放弃自己粉丝的利益。对于那些不愿意花钱的人来说,又想赚钱的话,就要从源头控制你的粉丝。一旦你的粉丝少了,就不再有人会去推荐给你。
二、扩大你的粉丝群体,快速积累粉丝既然现在做客的难度比较大,那么还是要选择一个更有效的方式。很多人选择了上客信息,就是所谓的搜索客信息,所谓的平台上客信息很多,有很多人只是普通用户,并不会发展为客。当然了,你也可以先积累自己的粉丝,等到了一定时间,慢慢等待生活稳定之后,再去慢慢扩大你的粉丝群体。
有不少客,积累起来后根本找不到推广的地方,并且还要承担推广费用。有些客找客户的方式是,我知道他有客信息,还有他的老婆孩子。你要知道,你需要给这些人解释,并不是他老婆孩子的一个这个重要的推广渠道。
三、扩大客的影响力,快速积累自己的影响力。很多客,刚开始都想着高收益,想着让更多的人帮他们赚钱,可是等他积累起来了,他就会清楚,帮助别人赚钱,远远不及自己去做自己的工作。要想做好客的话,就是要不断扩大自己的影响力,建立自己的粉丝和自己的影响力。这个时候有不少客认为,我的粉丝多了,我可以给粉丝推广,他们自然会帮助我了。
可是根据笔者的经验,这些粉丝绝大多数不是你的潜在粉丝,想赚钱的话,还是不能只推广这个,你还要推广别的,这样你的粉丝群体才会变得多。再者是你的推广方式,你怎么才能让他们去帮助你呢?你所推的东西的质量怎么样?我相信大家不用我多说,不管是工作还是生活,很多人宁愿相信陌生人也不愿意相信自己的父母。推广的东西也是要让大家相信你,相信你能赚钱,这样你才能赢得粉丝的信任。
然后你还要通过自己的影响力去帮助别人去赚钱,树立起你赚钱的形象。这些大家也都想知道,但是能赚钱的人他就是不说,就是不说,就是不说。总之做客,不是谁都能做客,只要有一定推广能力和运营能力。 查看全部
自动采集文章(自动采集文章广告,插入到自己的公众号图文推广)
自动采集文章广告,插入到自己的公众号图文推广,可以私聊我。2019年以来,客发展很是不错,很多人都转向做客。但是做客的成本很高,广告费是其中一个,其次还有培训费用、发货等成本。那么我们该如何做客呢?下面由禾赛科技()为大家介绍我们该如何做客。
一、选择性的发展自己的粉丝,积累自己的老粉丝要想做好客,首先需要积累自己的粉丝,你要是一个优秀的客,还要有一定的推广能力,但是也不能放弃自己粉丝的利益。对于那些不愿意花钱的人来说,又想赚钱的话,就要从源头控制你的粉丝。一旦你的粉丝少了,就不再有人会去推荐给你。
二、扩大你的粉丝群体,快速积累粉丝既然现在做客的难度比较大,那么还是要选择一个更有效的方式。很多人选择了上客信息,就是所谓的搜索客信息,所谓的平台上客信息很多,有很多人只是普通用户,并不会发展为客。当然了,你也可以先积累自己的粉丝,等到了一定时间,慢慢等待生活稳定之后,再去慢慢扩大你的粉丝群体。
有不少客,积累起来后根本找不到推广的地方,并且还要承担推广费用。有些客找客户的方式是,我知道他有客信息,还有他的老婆孩子。你要知道,你需要给这些人解释,并不是他老婆孩子的一个这个重要的推广渠道。
三、扩大客的影响力,快速积累自己的影响力。很多客,刚开始都想着高收益,想着让更多的人帮他们赚钱,可是等他积累起来了,他就会清楚,帮助别人赚钱,远远不及自己去做自己的工作。要想做好客的话,就是要不断扩大自己的影响力,建立自己的粉丝和自己的影响力。这个时候有不少客认为,我的粉丝多了,我可以给粉丝推广,他们自然会帮助我了。
可是根据笔者的经验,这些粉丝绝大多数不是你的潜在粉丝,想赚钱的话,还是不能只推广这个,你还要推广别的,这样你的粉丝群体才会变得多。再者是你的推广方式,你怎么才能让他们去帮助你呢?你所推的东西的质量怎么样?我相信大家不用我多说,不管是工作还是生活,很多人宁愿相信陌生人也不愿意相信自己的父母。推广的东西也是要让大家相信你,相信你能赚钱,这样你才能赢得粉丝的信任。
然后你还要通过自己的影响力去帮助别人去赚钱,树立起你赚钱的形象。这些大家也都想知道,但是能赚钱的人他就是不说,就是不说,就是不说。总之做客,不是谁都能做客,只要有一定推广能力和运营能力。
自动采集文章(自动采集文章的方法:-1-11.在搜索框中输入关键词)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-19 15:05
自动采集文章的方法:-1-11.在搜索框中输入关键词2.在出现的文章列表中点击你要的题目3.即可获取到所有的已收录的文章
自动采集的话,你可以用搜索引擎的爬虫去抓取。这个是需要知道网站内容的。如果不知道,可以考虑百度个性化定制服务,你可以从图片,链接上获取这些东西,
我知道的都是谷歌的思路
1、准备一个谷歌浏览器(必须)
2、把要采集的文章的链接复制到谷歌爬虫控制台(步骤
1、
2、
3)
3、复制并转换为高亮字符在谷歌分析中(步骤
4、调用搜索引擎爬取需要的文章
5、把高亮字符(把勾去掉)放回result类里面,
google和百度都不能采集新浪的,我们在采集新浪新闻的时候都采集不了那些收录快的,要采集的是没人收录的(即更小的频道),新浪新闻,是有人收录了,但是你却不知道是哪些时刻被人收录了,如果你不知道是哪天哪个收录了新浪新闻的网站,那就采集不了,反之可以采集,当然前提要有收录量和浏览量,还得有浏览次数的累计,不然谁记得你?这是我们采集百度新闻的网站,不过采集百度的主要是原创新闻,整天复制别人的东西不实用,要采集没被收录的百度或搜狗新闻,你可以到你要采集的网站进行搜索,看看他们是怎么做的就知道怎么来了。 查看全部
自动采集文章(自动采集文章的方法:-1-11.在搜索框中输入关键词)
自动采集文章的方法:-1-11.在搜索框中输入关键词2.在出现的文章列表中点击你要的题目3.即可获取到所有的已收录的文章
自动采集的话,你可以用搜索引擎的爬虫去抓取。这个是需要知道网站内容的。如果不知道,可以考虑百度个性化定制服务,你可以从图片,链接上获取这些东西,
我知道的都是谷歌的思路
1、准备一个谷歌浏览器(必须)
2、把要采集的文章的链接复制到谷歌爬虫控制台(步骤
1、
2、
3)
3、复制并转换为高亮字符在谷歌分析中(步骤
4、调用搜索引擎爬取需要的文章
5、把高亮字符(把勾去掉)放回result类里面,
google和百度都不能采集新浪的,我们在采集新浪新闻的时候都采集不了那些收录快的,要采集的是没人收录的(即更小的频道),新浪新闻,是有人收录了,但是你却不知道是哪些时刻被人收录了,如果你不知道是哪天哪个收录了新浪新闻的网站,那就采集不了,反之可以采集,当然前提要有收录量和浏览量,还得有浏览次数的累计,不然谁记得你?这是我们采集百度新闻的网站,不过采集百度的主要是原创新闻,整天复制别人的东西不实用,要采集没被收录的百度或搜狗新闻,你可以到你要采集的网站进行搜索,看看他们是怎么做的就知道怎么来了。
自动采集文章(先说成果抓了掘金前端类目下的文章标题192条)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-02-15 16:27
本网站的内容是从兴趣中采集的。如果您无意中侵犯了您的相关权益,请留言告知我们,我们将尽快删除。谢谢你。
俗话说:如果你有一把锤子:hammer: 在你的手中,一切看起来都像钉子。当我拿着朴素贝叶斯之锤时,我看到掘金队 文章 的分类就像一颗等待被锤击的钉子。
目前,用户需要在掘金文章中手动选择已发布文章的类别。如果用算法自动判断文章属于哪个类别,那么这一步就可以省去(单看这种情况,用户体验提升很小,但改造后内容分布可以更好) .
让我们谈谈结果
我在掘金的前端类别下捕获了 192 个 文章 标题,在后端类别下捕获了 969 个 文章 标题,在人工智能类别下捕获了 692 个 文章 标题。未经任何优化的朴素贝叶斯训练模型的分类准确率为0.79。
可以看出朴素贝叶斯在技术文章分类中是一个不错的算法。它可以在少于 2000 个标题的情况下达到 0.8 的正确率。如果加上文章内容,我猜准确率可以是0.9以上。
怎么做
数据采集
直接使用采集器新建采集任务,如优采云、优采云等。将 采集 中的 文章 数据保存到本地。我使用 优采云采集器,每个类别一个 采集 任务,并将捕获的数据保存为 Excel。
标记和计算 IF-TDF
在IF-TDF中,IF是词频,是指单词a在待分类文档中出现的次数与待分类文档中单词总数的比值。TDF是逆文档频率,是指收录指定单词a的文档在整个文档集中所占的比例。
IF*TDF 等价于 IF-TDF。
比如文章A的标题有8个词,前端出现一次,我抓的1000个标题中有800个收录前端。那么 IF-TDF 等于 1/8 * lg(1000/800).
使用 IF-TDF,可以选择对单个标题很重要但很少出现在所有标题中的单词。而这种词是正式区分文章类别的关键。
所以计算IF-IDF的第一步就是分词,用jieba分词来完成:
IF-IDF可以直接使用sklearn自带的TfidfVectorizer计算。
from sklearn.feature_extraction.text import TfidfVectorizer
# stop_words:停止词
# x_train: 分词后的文本列表训练集
# x_test:分词后的文本列表测试集
tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5)
train_features = tf.fit_transform(x_train)
test_features = tf.transform(x_test)
代码中的stop_words是一个文本文件,里面保存了中文常用的连接词,如的、我等。因为这些词很常见,对文本分类没有帮助,所以在实际计算 IF-IDF 时不计算在内。
使用朴素贝叶斯训练模型
from sklearn.naive_bayes import MultinomialNB
# alpha:平滑系数
clf = MultinomialNB(alpha=0.001).fit(train_features, y_train)
predicted_labels=clf.predict(test_features)
predict_labels 是我使用文本分类模型预测的 文章 分类。与实际值比较:
from sklearn import metrics
metrics.accuracy_score(y_test, predicted_labels)
# output: 0.7931034482758621
其他
自掘金发展以来,无数作者间接提供了大量准确标注的数据。使用更多的数据进行训练,选择合适的停用词库并对文章标题进行一些必要的预处理,并为一些关键词增加权重——比如前端、JavaScript、Android、Java等。 ,分类准确率可达97%。
完整的代码可以在这里找到。 查看全部
自动采集文章(先说成果抓了掘金前端类目下的文章标题192条)
本网站的内容是从兴趣中采集的。如果您无意中侵犯了您的相关权益,请留言告知我们,我们将尽快删除。谢谢你。
俗话说:如果你有一把锤子:hammer: 在你的手中,一切看起来都像钉子。当我拿着朴素贝叶斯之锤时,我看到掘金队 文章 的分类就像一颗等待被锤击的钉子。
目前,用户需要在掘金文章中手动选择已发布文章的类别。如果用算法自动判断文章属于哪个类别,那么这一步就可以省去(单看这种情况,用户体验提升很小,但改造后内容分布可以更好) .
让我们谈谈结果
我在掘金的前端类别下捕获了 192 个 文章 标题,在后端类别下捕获了 969 个 文章 标题,在人工智能类别下捕获了 692 个 文章 标题。未经任何优化的朴素贝叶斯训练模型的分类准确率为0.79。
可以看出朴素贝叶斯在技术文章分类中是一个不错的算法。它可以在少于 2000 个标题的情况下达到 0.8 的正确率。如果加上文章内容,我猜准确率可以是0.9以上。
怎么做
数据采集
直接使用采集器新建采集任务,如优采云、优采云等。将 采集 中的 文章 数据保存到本地。我使用 优采云采集器,每个类别一个 采集 任务,并将捕获的数据保存为 Excel。
标记和计算 IF-TDF
在IF-TDF中,IF是词频,是指单词a在待分类文档中出现的次数与待分类文档中单词总数的比值。TDF是逆文档频率,是指收录指定单词a的文档在整个文档集中所占的比例。
IF*TDF 等价于 IF-TDF。
比如文章A的标题有8个词,前端出现一次,我抓的1000个标题中有800个收录前端。那么 IF-TDF 等于 1/8 * lg(1000/800).
使用 IF-TDF,可以选择对单个标题很重要但很少出现在所有标题中的单词。而这种词是正式区分文章类别的关键。
所以计算IF-IDF的第一步就是分词,用jieba分词来完成:
IF-IDF可以直接使用sklearn自带的TfidfVectorizer计算。
from sklearn.feature_extraction.text import TfidfVectorizer
# stop_words:停止词
# x_train: 分词后的文本列表训练集
# x_test:分词后的文本列表测试集
tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5)
train_features = tf.fit_transform(x_train)
test_features = tf.transform(x_test)
代码中的stop_words是一个文本文件,里面保存了中文常用的连接词,如的、我等。因为这些词很常见,对文本分类没有帮助,所以在实际计算 IF-IDF 时不计算在内。
使用朴素贝叶斯训练模型
from sklearn.naive_bayes import MultinomialNB
# alpha:平滑系数
clf = MultinomialNB(alpha=0.001).fit(train_features, y_train)
predicted_labels=clf.predict(test_features)
predict_labels 是我使用文本分类模型预测的 文章 分类。与实际值比较:
from sklearn import metrics
metrics.accuracy_score(y_test, predicted_labels)
# output: 0.7931034482758621
其他
自掘金发展以来,无数作者间接提供了大量准确标注的数据。使用更多的数据进行训练,选择合适的停用词库并对文章标题进行一些必要的预处理,并为一些关键词增加权重——比如前端、JavaScript、Android、Java等。 ,分类准确率可达97%。
完整的代码可以在这里找到。
自动采集文章(《sem篇》教你使用xpath来进行文章的抓取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-29 18:03
自动采集文章已经是实用比较多的技巧了,但由于现在国内盗版技术很多,所以很多从业者也都去研究国外的技术以及使用方法。但是有时候你可能需要这些方法去分享给更多人知道,所以就有了《sem篇》,这一篇教你使用xpath来进行文章的抓取。
我是做内容的,也经常需要大量的内容抓取。经常需要通过原文章的关键词进行文章的统计。对于一些大量内容的有质量的网站,收集原文很占便宜,比如知乎,今日头条等等,他们的用户很多都喜欢看很多内容,这时候他们比较关注原文,抓取他们的原文就能获得不少关注。但是如果网站的精度不够高,只收集原文,而用各种其他的工具代替,可能存在内容不完整或者没有抓取的内容。
有些工具会把内容漏出的部分给过滤掉。并且还可能漏出小量的原文内容。但这些漏出的部分,需要我们用自己的技术进行过滤和过滤。不然原文不全的话,内容质量会降低,使之后的收录和排名下降。
一个很重要的知识点,文章是通过网站发表出来的,无论怎么抓取,首先你要知道网站的结构是什么样的。通过xpath爬虫原始页面(指定xpath或者通过python爬虫库),在工具包方面选择正则,sqlite等工具。然后通过正则表达式去抓取文章,再通过xpath再反爬虫。比如爬百度系列:百度搜索正则表达式抓取词条页面爬取图片:正则表达式。 查看全部
自动采集文章(《sem篇》教你使用xpath来进行文章的抓取)
自动采集文章已经是实用比较多的技巧了,但由于现在国内盗版技术很多,所以很多从业者也都去研究国外的技术以及使用方法。但是有时候你可能需要这些方法去分享给更多人知道,所以就有了《sem篇》,这一篇教你使用xpath来进行文章的抓取。
我是做内容的,也经常需要大量的内容抓取。经常需要通过原文章的关键词进行文章的统计。对于一些大量内容的有质量的网站,收集原文很占便宜,比如知乎,今日头条等等,他们的用户很多都喜欢看很多内容,这时候他们比较关注原文,抓取他们的原文就能获得不少关注。但是如果网站的精度不够高,只收集原文,而用各种其他的工具代替,可能存在内容不完整或者没有抓取的内容。
有些工具会把内容漏出的部分给过滤掉。并且还可能漏出小量的原文内容。但这些漏出的部分,需要我们用自己的技术进行过滤和过滤。不然原文不全的话,内容质量会降低,使之后的收录和排名下降。
一个很重要的知识点,文章是通过网站发表出来的,无论怎么抓取,首先你要知道网站的结构是什么样的。通过xpath爬虫原始页面(指定xpath或者通过python爬虫库),在工具包方面选择正则,sqlite等工具。然后通过正则表达式去抓取文章,再通过xpath再反爬虫。比如爬百度系列:百度搜索正则表达式抓取词条页面爬取图片:正则表达式。
自动采集文章(推荐16个不同类型的公众号排名查询渠道)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-01-27 14:02
自动采集文章地址并上传至微信公众号,我们的微信公众号是"西蜀网络传媒",wx:zhuanxixueyue888/wx回复"微信"即可得到16个免费模板公众号名称小程序名称
当然有啊,免费资源网,自行看,
推荐16个不同类型的公众号排名查询渠道,每个渠道都很齐全,下面放我的账号列表文章:【13】搜索微信公众号“西蜀网络传媒”,在公众号列表顶部直接点击公众号就可以查询了。
公众号“搜索微信号”,关注该公众号,是你需要的文章。
不需要,微信自带。
专业做自媒体分析
四川微信搜索公众号:搜索微信号shangcheng1616一直在用这个
我也是刚需,
现在大家有没有想我一样的苦恼啊!做自媒体号的不知道怎么获取推送,
有的。特供资源的推送列表推送列表中就包含了公众号文章地址,以及往期推送的数据。
百度搜索,西蜀网络传媒就可以查看了,
刚刚遇到同样的问题,求有关人士解答!不介意的话我们可以交流交流。
不明白楼上有人不买vip想做好自媒体还要人多, 查看全部
自动采集文章(推荐16个不同类型的公众号排名查询渠道)
自动采集文章地址并上传至微信公众号,我们的微信公众号是"西蜀网络传媒",wx:zhuanxixueyue888/wx回复"微信"即可得到16个免费模板公众号名称小程序名称
当然有啊,免费资源网,自行看,
推荐16个不同类型的公众号排名查询渠道,每个渠道都很齐全,下面放我的账号列表文章:【13】搜索微信公众号“西蜀网络传媒”,在公众号列表顶部直接点击公众号就可以查询了。
公众号“搜索微信号”,关注该公众号,是你需要的文章。
不需要,微信自带。
专业做自媒体分析
四川微信搜索公众号:搜索微信号shangcheng1616一直在用这个
我也是刚需,
现在大家有没有想我一样的苦恼啊!做自媒体号的不知道怎么获取推送,
有的。特供资源的推送列表推送列表中就包含了公众号文章地址,以及往期推送的数据。
百度搜索,西蜀网络传媒就可以查看了,
刚刚遇到同样的问题,求有关人士解答!不介意的话我们可以交流交流。
不明白楼上有人不买vip想做好自媒体还要人多,
自动采集文章( 2020版全手工文章收藏网源码让你越来越好SEO优化计划)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-01-23 02:02
2020版全手工文章收藏网源码让你越来越好SEO优化计划)
摘要:目前SEO优化方案是因为99设计师不懂网络营销,不懂搜索引擎优化SEO。网站优化。第三步根据网站内部问题对网站站点进行优化第四步网站站点优化完成,只是为了获得更好的排名打下基础打好基础,需要进行网站地图制作和提交反向链接策略实施等,逐步提高网站第五步,保持自然排名的效果各大搜索引擎都会根据搜索排名算法的变化进行调整。...
2020版全手册文章合集网源码让你越来越好
SEO优化方案
SEO建筑行业案例 Bonnie Ladder - Home Ladder - Aluminium Ladder昨晚赢得了导演的要求,写了一份SEO计划。我知道可能会有很多不完美之处。欢迎来电咨询~SEO优化方案公司名称网站目录1:前言网站现状2网站META字母2西安建设现状1xi3西安建设问题4SEO能带来什么到陕西1排名和流量减少2提高企业声誉3扩大网络营销方式5 网站优化网站优化服务流程关键词分析网站内部优化网站外部优化和推广6 < @网站帖子管理、维护和更新7 SEO问答案例8总结1介绍根据调查seo优化计划,目前有80个< @网站在国外,就像放名片的地方,偶尔等着搜索某年某月的公司名称,发现别人以为搜索的url被收录了。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。发现其他人认为搜索 URL 已收录在内。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。发现其他人认为搜索 URL 已收录在内。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。您没有在 100 页中找到您的网址吗?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。您没有在 100 页中找到您的网址吗?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。
他们设计的网站从一开始就有很多问题。这些问题从一开始就让你的网站变得病态网站,但如果你不努力,它就很难有价值。网站优化。一方面,你的网站关键词排名太低,被用户检索的概率为零。网站再好也没有流量。另一方面,网站优化让你有更好的网站结构,更合理的网站内容,更丰富的网页布局,更简单的网站功能,更细化实用,因此我们可以通过多种方式响应用户输入网站的需求。从问题的症结出发,找出你的网站网络营销的不足,让你的网站 真正发挥网络营销的价值。SEO 是 SearchEngineOptimization 的缩写。英文描述是tousesometechnicstomakekeyour Bonnie ladder-home ladder-aluminum ladder网站在搜索引擎底部。当有人使用搜索引擎找东西时,SEO的主要工作是了解各种搜索引擎是如何爬网的,如何对其进行索引,以及如何对其进行排名以优化特定关键字的网络搜索结果。它提高搜索引擎排名以减少 网站 流量,并最终改进 网站 销售或促销方式。SEO就是这样一种遵循搜索引擎科学全面的理论机制的技术。合理规划部署,站点间互动外交策略,挖掘站点最大潜力,使其在搜索引擎中具有较强的自然排名竞争优势,促进公司*敏感*词*词*销量,加强*敏感*词*词*品牌启动有一定效果。网站针对多个*敏感*词义*搜索引擎进行了优化。
您的 网站 不仅会在百度谷歌上获得排名提升,而且在其他主要搜索引擎上也会得到提升。如果选择拍卖广告来达到这些效果,就必须与搜索引擎签订广告合同,这无疑降低了巨大的成本。通过了解各种搜索引擎如何抓取和索引网页以及它们如何确定其在特定关键字的搜索结果中的排名,了解与 SEO 相关的网页。优化提高了搜索引擎排名,增加了 网站 流量,并最终提高了 网站 销售或宣传。网站优化有助于提高页面的综合索引。如果您的 网站 排名提高。如果拍卖广告停止,很容易掉线
网站链接立即消失。SEO的主要工作是了解各种搜索引擎如何抓取网页,如何对其进行索引,以及如何确定特定关键字的搜索结果排名。优化网页以提高搜索引擎排名,从而减少 网站 流量并最终改善 网站 您的销售或推广方式。真正的SEO是基于搜索引擎的科学性和综合性,采取合理且易于搜索的方式。网站策划、制作、推广等环节的理论机制贯穿Seo的思想,让网站对用户和搜索引擎更加友好。SearchEngineFriendly 对网页语言 网站 的结构进行合理的规划和部署,以及站点之间的互动外交策略,使乐山网站成为互联网上*敏感*词*在互联网上曝光的地方。通过优化关键字领先搜索引擎。吸引潜在客户的两页。用户点击搜索引擎前两页的机会也大大提高了转化率,也减少了网站流量,让更多*敏感*感官*单词*知道网站。2 优化的大同结构网站提升了公司的知名度。在 Internet 上不那么频繁的搜索允许潜在客户更快、更准确地找到 网站。同时,通过自然排名上升的关键词可以让大家变得更好。新福也看好公司的实力。毕竟,PPC只要有钱就可以排名,但是自然排名要看网站的实力和公司拓展网络营销的方式。搜索引擎营销是一种获得更好客户的新方法。令人信服的 3xing 方法正被越来越多的公司所重视。 查看全部
自动采集文章(
2020版全手工文章收藏网源码让你越来越好SEO优化计划)
摘要:目前SEO优化方案是因为99设计师不懂网络营销,不懂搜索引擎优化SEO。网站优化。第三步根据网站内部问题对网站站点进行优化第四步网站站点优化完成,只是为了获得更好的排名打下基础打好基础,需要进行网站地图制作和提交反向链接策略实施等,逐步提高网站第五步,保持自然排名的效果各大搜索引擎都会根据搜索排名算法的变化进行调整。...
2020版全手册文章合集网源码让你越来越好
SEO优化方案
SEO建筑行业案例 Bonnie Ladder - Home Ladder - Aluminium Ladder昨晚赢得了导演的要求,写了一份SEO计划。我知道可能会有很多不完美之处。欢迎来电咨询~SEO优化方案公司名称网站目录1:前言网站现状2网站META字母2西安建设现状1xi3西安建设问题4SEO能带来什么到陕西1排名和流量减少2提高企业声誉3扩大网络营销方式5 网站优化网站优化服务流程关键词分析网站内部优化网站外部优化和推广6 < @网站帖子管理、维护和更新7 SEO问答案例8总结1介绍根据调查seo优化计划,目前有80个< @网站在国外,就像放名片的地方,偶尔等着搜索某年某月的公司名称,发现别人以为搜索的url被收录了。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。发现其他人认为搜索 URL 已收录在内。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。发现其他人认为搜索 URL 已收录在内。收录搜索的全名网站,可以优化。当然,其中大部分是企业网站,尽管您正在搜索您的行业。,你的地方,你试过了吗,100页没找到你的网址?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。您没有在 100 页中找到您的网址吗?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。您没有在 100 页中找到您的网址吗?您的网站 业务和企业实践的重要性是什么?把它想象成一张名片,谁知道呢,所以你需要 SEO 优化服务。目前99设计师不懂网络营销,不懂SEO。
他们设计的网站从一开始就有很多问题。这些问题从一开始就让你的网站变得病态网站,但如果你不努力,它就很难有价值。网站优化。一方面,你的网站关键词排名太低,被用户检索的概率为零。网站再好也没有流量。另一方面,网站优化让你有更好的网站结构,更合理的网站内容,更丰富的网页布局,更简单的网站功能,更细化实用,因此我们可以通过多种方式响应用户输入网站的需求。从问题的症结出发,找出你的网站网络营销的不足,让你的网站 真正发挥网络营销的价值。SEO 是 SearchEngineOptimization 的缩写。英文描述是tousesometechnicstomakekeyour Bonnie ladder-home ladder-aluminum ladder网站在搜索引擎底部。当有人使用搜索引擎找东西时,SEO的主要工作是了解各种搜索引擎是如何爬网的,如何对其进行索引,以及如何对其进行排名以优化特定关键字的网络搜索结果。它提高搜索引擎排名以减少 网站 流量,并最终改进 网站 销售或促销方式。SEO就是这样一种遵循搜索引擎科学全面的理论机制的技术。合理规划部署,站点间互动外交策略,挖掘站点最大潜力,使其在搜索引擎中具有较强的自然排名竞争优势,促进公司*敏感*词*词*销量,加强*敏感*词*词*品牌启动有一定效果。网站针对多个*敏感*词义*搜索引擎进行了优化。
您的 网站 不仅会在百度谷歌上获得排名提升,而且在其他主要搜索引擎上也会得到提升。如果选择拍卖广告来达到这些效果,就必须与搜索引擎签订广告合同,这无疑降低了巨大的成本。通过了解各种搜索引擎如何抓取和索引网页以及它们如何确定其在特定关键字的搜索结果中的排名,了解与 SEO 相关的网页。优化提高了搜索引擎排名,增加了 网站 流量,并最终提高了 网站 销售或宣传。网站优化有助于提高页面的综合索引。如果您的 网站 排名提高。如果拍卖广告停止,很容易掉线
网站链接立即消失。SEO的主要工作是了解各种搜索引擎如何抓取网页,如何对其进行索引,以及如何确定特定关键字的搜索结果排名。优化网页以提高搜索引擎排名,从而减少 网站 流量并最终改善 网站 您的销售或推广方式。真正的SEO是基于搜索引擎的科学性和综合性,采取合理且易于搜索的方式。网站策划、制作、推广等环节的理论机制贯穿Seo的思想,让网站对用户和搜索引擎更加友好。SearchEngineFriendly 对网页语言 网站 的结构进行合理的规划和部署,以及站点之间的互动外交策略,使乐山网站成为互联网上*敏感*词*在互联网上曝光的地方。通过优化关键字领先搜索引擎。吸引潜在客户的两页。用户点击搜索引擎前两页的机会也大大提高了转化率,也减少了网站流量,让更多*敏感*感官*单词*知道网站。2 优化的大同结构网站提升了公司的知名度。在 Internet 上不那么频繁的搜索允许潜在客户更快、更准确地找到 网站。同时,通过自然排名上升的关键词可以让大家变得更好。新福也看好公司的实力。毕竟,PPC只要有钱就可以排名,但是自然排名要看网站的实力和公司拓展网络营销的方式。搜索引擎营销是一种获得更好客户的新方法。令人信服的 3xing 方法正被越来越多的公司所重视。
自动采集文章(长期连续发布大批量高质量的内容给管理员,是会变成这样的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-21 16:02
自动采集文章:知乎等文章平台,然后推荐给你自动回复你:已接受,请点赞或后台留言获取精彩文章截图。最后,
还没被骂过,但是被折叠过。长期连续发布大批量高质量的内容给管理员,是会变成这样的。
其实很多文章在很早之前就有人通过这种方式发布过,而且成立了一个文章编辑团队。这种一般不对所有用户开放,不过只要你是发表在知乎里面的,是可以通过你所在的用户团队邀请,让他们帮你发表的。至于被骂,不可能被骂的,毕竟,我们关注的是内容的质量。而且知乎的社区规则也有禁止通过这种方式去发表内容的。不过,现在真正的问题在于,不少通过这种方式发表的人并不是通过自己主动写文章的方式去发布内容的,而是让写手来发布这些内容,这种情况就真的很让人无语了。
只能呵呵。还是建议各位不要再进行这种不管是发表还是转载都要注明作者的情况。再说一句,有的高质量的文章,虽然在被修改之后多多少少会被删掉,但如果你仔细看文章内容还是可以看到原来的作者或者作者是否在文章里。
每次来一批帖子,我一看,一边说自己真牛逼,一边又说自己错误百出,气的发飙,对我基本失去兴趣了,已经不自己发的都删了,
之前不让发?就发一个文章,我第一反应就是发知乎, 查看全部
自动采集文章(长期连续发布大批量高质量的内容给管理员,是会变成这样的)
自动采集文章:知乎等文章平台,然后推荐给你自动回复你:已接受,请点赞或后台留言获取精彩文章截图。最后,
还没被骂过,但是被折叠过。长期连续发布大批量高质量的内容给管理员,是会变成这样的。
其实很多文章在很早之前就有人通过这种方式发布过,而且成立了一个文章编辑团队。这种一般不对所有用户开放,不过只要你是发表在知乎里面的,是可以通过你所在的用户团队邀请,让他们帮你发表的。至于被骂,不可能被骂的,毕竟,我们关注的是内容的质量。而且知乎的社区规则也有禁止通过这种方式去发表内容的。不过,现在真正的问题在于,不少通过这种方式发表的人并不是通过自己主动写文章的方式去发布内容的,而是让写手来发布这些内容,这种情况就真的很让人无语了。
只能呵呵。还是建议各位不要再进行这种不管是发表还是转载都要注明作者的情况。再说一句,有的高质量的文章,虽然在被修改之后多多少少会被删掉,但如果你仔细看文章内容还是可以看到原来的作者或者作者是否在文章里。
每次来一批帖子,我一看,一边说自己真牛逼,一边又说自己错误百出,气的发飙,对我基本失去兴趣了,已经不自己发的都删了,
之前不让发?就发一个文章,我第一反应就是发知乎,
自动采集文章(自动采集文章列表的方法有两种一、你首先知道你)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-01-20 14:06
自动采集文章列表的方法有两种一、你首先知道你采集的链接,采集人做一个获取链接的工具二、对应的论坛qq群等,请求sdk,请求时输入你要采集的链接,sdk自动采集,
谢邀,我还是不请自来了,因为被邀请很有成就感。因为我刚好知道一种来自某不知名互联网公司的采集软件。这是一款无法通过任何非phpmethod发送的采集器,其中就包括问题中提到的网页文章列表。另外这种采集并非全量采集,可以通过将采集到的全量stack中的文章json数据拼接在一起进行多文章统计,但是统计页面大小也要控制在指定范围以内。可以参考spiderjsql/zhworkword.html#y288。
如果文章有多个,
在有中文页面时,这个效率还是非常高的,我曾经在某电子文献在线购物网站找到了整篇的文章,但第二天网站崩溃,文章也没了。
这是一个seo功能。但前提是要需要一个工具来辅助,可以了解一下火狐自带的软件zhwork,这个小工具非常好用。但是缺点是只能抓取所属站点的文章。有个遗憾是通过浏览器的f12和ie的查看元素是看不到源代码的,所以没有特殊方法的话是找不到在线extension的(方法去x宝买,很便宜很实惠)。
sed或cat软件,定位到源文件找到下载地址,保存。然后用firebug,定位到源代码来源页面,添加抓取代码来抓取页面数据。 查看全部
自动采集文章(自动采集文章列表的方法有两种一、你首先知道你)
自动采集文章列表的方法有两种一、你首先知道你采集的链接,采集人做一个获取链接的工具二、对应的论坛qq群等,请求sdk,请求时输入你要采集的链接,sdk自动采集,
谢邀,我还是不请自来了,因为被邀请很有成就感。因为我刚好知道一种来自某不知名互联网公司的采集软件。这是一款无法通过任何非phpmethod发送的采集器,其中就包括问题中提到的网页文章列表。另外这种采集并非全量采集,可以通过将采集到的全量stack中的文章json数据拼接在一起进行多文章统计,但是统计页面大小也要控制在指定范围以内。可以参考spiderjsql/zhworkword.html#y288。
如果文章有多个,
在有中文页面时,这个效率还是非常高的,我曾经在某电子文献在线购物网站找到了整篇的文章,但第二天网站崩溃,文章也没了。
这是一个seo功能。但前提是要需要一个工具来辅助,可以了解一下火狐自带的软件zhwork,这个小工具非常好用。但是缺点是只能抓取所属站点的文章。有个遗憾是通过浏览器的f12和ie的查看元素是看不到源代码的,所以没有特殊方法的话是找不到在线extension的(方法去x宝买,很便宜很实惠)。
sed或cat软件,定位到源文件找到下载地址,保存。然后用firebug,定位到源代码来源页面,添加抓取代码来抓取页面数据。
自动采集文章( 2018年python采集jb51电子书资源并自动下载到本地实例脚本)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-15 23:19
2018年python采集jb51电子书资源并自动下载到本地实例脚本)
使用python采集Script House电子书资源并自动下载到本地示例脚本
更新时间:2018-10-23 15:58:26 作者:网游草论坛
本文章主要介绍python采集jb51电子书资源,自动下载到本地示例教程。非常好,有一定的参考价值。有需要的朋友可以参考以下
jb51上的资源还是比较齐全的,所以打算用python实现自动采集信息,下载下来。
Python拥有丰富强大的库,使用urllib、re等可以轻松开发出网络资料采集器!
下面是我写的一个示例脚本,使用采集某技术网站特定栏目的所有电子书资源,下载保存到本地!
软件运行截图如下:
脚本运行时,不仅会将信息打印到shell窗口,还会将日志保存为txt文件,记录采集的页面地址,书名和大小,本地服务器下载地址和百度网盘下载地址!
示例采集并下载脚本之家python专栏的电子书资源:
<p>
# -*- coding:utf-8 -*-
import re
import urllib2
import urllib
import sys
import os
reload(sys)
sys.setdefaultencoding('utf-8')
def getHtml(url):
request = urllib2.Request(url)
page = urllib2.urlopen(request)
htmlcontent = page.read()
#解决中文乱码问题
htmlcontent = htmlcontent.decode('gbk', 'ignore').encode("utf8",'ignore')
return htmlcontent
def report(count, blockSize, totalSize):
percent = int(count*blockSize*100/totalSize)
sys.stdout.write("r%d%%" % percent + ' complete')
sys.stdout.flush()
def getBookInfo(url):
htmlcontent = getHtml(url);
#print "htmlcontent=",htmlcontent; # you should see the ouput html
#crifan
regex_title = '(?P.+?)';
title = re.search(regex_title, htmlcontent);
if(title):
title = title.group("title");
print "书籍名字:",title;
file_object.write('书籍名字:'+title+'r');
#书籍大小:27.2MB
filesize = re.search('(?P.+?)', htmlcontent);
if(filesize):
filesize = filesize.group("filesize");
print "文件大小:",filesize;
file_object.write('文件大小:'+filesize+'r');
# 查看全部
自动采集文章(
2018年python采集jb51电子书资源并自动下载到本地实例脚本)
使用python采集Script House电子书资源并自动下载到本地示例脚本
更新时间:2018-10-23 15:58:26 作者:网游草论坛
本文章主要介绍python采集jb51电子书资源,自动下载到本地示例教程。非常好,有一定的参考价值。有需要的朋友可以参考以下
jb51上的资源还是比较齐全的,所以打算用python实现自动采集信息,下载下来。
Python拥有丰富强大的库,使用urllib、re等可以轻松开发出网络资料采集器!
下面是我写的一个示例脚本,使用采集某技术网站特定栏目的所有电子书资源,下载保存到本地!
软件运行截图如下:
脚本运行时,不仅会将信息打印到shell窗口,还会将日志保存为txt文件,记录采集的页面地址,书名和大小,本地服务器下载地址和百度网盘下载地址!
示例采集并下载脚本之家python专栏的电子书资源:
<p>
# -*- coding:utf-8 -*-
import re
import urllib2
import urllib
import sys
import os
reload(sys)
sys.setdefaultencoding('utf-8')
def getHtml(url):
request = urllib2.Request(url)
page = urllib2.urlopen(request)
htmlcontent = page.read()
#解决中文乱码问题
htmlcontent = htmlcontent.decode('gbk', 'ignore').encode("utf8",'ignore')
return htmlcontent
def report(count, blockSize, totalSize):
percent = int(count*blockSize*100/totalSize)
sys.stdout.write("r%d%%" % percent + ' complete')
sys.stdout.flush()
def getBookInfo(url):
htmlcontent = getHtml(url);
#print "htmlcontent=",htmlcontent; # you should see the ouput html
#crifan
regex_title = '(?P.+?)';
title = re.search(regex_title, htmlcontent);
if(title):
title = title.group("title");
print "书籍名字:",title;
file_object.write('书籍名字:'+title+'r');
#书籍大小:27.2MB
filesize = re.search('(?P.+?)', htmlcontent);
if(filesize):
filesize = filesize.group("filesize");
print "文件大小:",filesize;
file_object.write('文件大小:'+filesize+'r');
#
自动采集文章(自动采集文章标题可以使用采集-拼音采集器,同时在设置)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-01-15 18:01
自动采集文章标题可以使用采集-拼音采集器,同时在设置自动格式采集还可以利用ai算法做笔记,
可以先用采集语音识别的软件先抓取文本,然后按照文本里面的标题打开。
楼上说的小软件不错
千牛客可以采集你们公司的标题,然后转存到一个专门的软件上面。
自动采集标题页链接,只需要准备语音识别专用软件。
自动采集标题到你的excel里面,最好带上时间格式和网址,省的用户采集了excel数据,拿到手也只能截图。
简单点的用采集软件比如爱采集
现在用wordart,简单,好用,
你可以用这个关键词采集器不错
talkingdata上面有,不过只能采集行业大词,
适合写好稿后去采。
没想到这个问题还没人回答
没人说这个吗?我都用了三个月了!!我在用,
人家给的广告费多少啊
目前什么采集器都可以,我觉得还是最好的就是能一个关键词循环采集多个文章,这样你可以知道哪些是好的,哪些是差的,这样说了等于没说。
个人有个小软件,知乎的还不错。
很明显人家这里已经有了你所需要的了你可以去百度‘百度标题’这样可以找到所有相关文章的标题还可以找到该关键词更多的链接
百度是非常好的工具,网上那些乱七八糟的、垃圾的关键词采集软件根本没用,很多都是挂羊头卖狗肉, 查看全部
自动采集文章(自动采集文章标题可以使用采集-拼音采集器,同时在设置)
自动采集文章标题可以使用采集-拼音采集器,同时在设置自动格式采集还可以利用ai算法做笔记,
可以先用采集语音识别的软件先抓取文本,然后按照文本里面的标题打开。
楼上说的小软件不错
千牛客可以采集你们公司的标题,然后转存到一个专门的软件上面。
自动采集标题页链接,只需要准备语音识别专用软件。
自动采集标题到你的excel里面,最好带上时间格式和网址,省的用户采集了excel数据,拿到手也只能截图。
简单点的用采集软件比如爱采集
现在用wordart,简单,好用,
你可以用这个关键词采集器不错
talkingdata上面有,不过只能采集行业大词,
适合写好稿后去采。
没想到这个问题还没人回答
没人说这个吗?我都用了三个月了!!我在用,
人家给的广告费多少啊
目前什么采集器都可以,我觉得还是最好的就是能一个关键词循环采集多个文章,这样你可以知道哪些是好的,哪些是差的,这样说了等于没说。
个人有个小软件,知乎的还不错。
很明显人家这里已经有了你所需要的了你可以去百度‘百度标题’这样可以找到所有相关文章的标题还可以找到该关键词更多的链接
百度是非常好的工具,网上那些乱七八糟的、垃圾的关键词采集软件根本没用,很多都是挂羊头卖狗肉,
自动采集文章( 借助于全能文章正文鉴别优化算法,可完成一切网页文章正文全自动)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-12 06:09
借助于全能文章正文鉴别优化算法,可完成一切网页文章正文全自动)
文章采集器是一个简单、有效、强大的文章采集功能,帮助网站完成文章内容的自动更新。只需要会输入关键字,就可以采集各种百度搜索引擎网页和新闻报道,还可以采集具体网址文章,很是时间——省力省力; 一、 借助全方位的文章文本识别和优化算法,自动获取所有网页文章文本,准确率达95%以上。只需输入关键字,即可采集到各大新闻和网页,多数据源新闻和网页;海量关键词可以自动化采集。特定网站文章的采集频道目录下的所有项目均可设置,智能系统匹配,无需编写复杂的标准。 文章翻译功能,可以很好的用于采集文章,把它的中文翻译成英文再翻译成中文,实现翻译原创文章,适合用于谷歌和有道翻译。非常简单和智能文章采集器多功能使用。
采集site文章,不用再写优采云采集规则了,太麻烦了,不是人人都能写,也不适合所有人的网站。也不需要自定义采集软件,也不可能采集所有站点,只能采集你自定义的站点。
文章采集器,可以采集不收录文章,一般网站可以采集。只要输入网址,设置需要哪个后缀的网址文章采集,就可以采集网站的所有文章内容,包括标题文章,文章链接地址,文章采集,会自动保存为TXT,一文章一TXT文件。不仅可以采集文章,还可以过滤需要采集的文章,比如查询页面的HTTP状态;判断URL是否为收录;是不是只有采集不是收录;采集文章words;分析文章原创度数。
1、采集范围广泛,包括:企业站、博客、视频、门户、B2B分类站、下载站
2、挂机全自动采集,采集好数据,自动保存为本地TXT文件,一个TXT文件一个一个;也可以导出URL链接和URL状态,导出EXCEL
3、自动检测文章原创度数,设置大于采集
的字数
4、采集URL链接,查询页面HTTP状态:200-服务器成功返回网页404-请求的网页不存在503-服务不可用;也可以查询链接收录信息
5、操作很简单,输入网址,设置需要哪些数据采集. 查看全部
自动采集文章(
借助于全能文章正文鉴别优化算法,可完成一切网页文章正文全自动)
文章采集器是一个简单、有效、强大的文章采集功能,帮助网站完成文章内容的自动更新。只需要会输入关键字,就可以采集各种百度搜索引擎网页和新闻报道,还可以采集具体网址文章,很是时间——省力省力; 一、 借助全方位的文章文本识别和优化算法,自动获取所有网页文章文本,准确率达95%以上。只需输入关键字,即可采集到各大新闻和网页,多数据源新闻和网页;海量关键词可以自动化采集。特定网站文章的采集频道目录下的所有项目均可设置,智能系统匹配,无需编写复杂的标准。 文章翻译功能,可以很好的用于采集文章,把它的中文翻译成英文再翻译成中文,实现翻译原创文章,适合用于谷歌和有道翻译。非常简单和智能文章采集器多功能使用。
采集site文章,不用再写优采云采集规则了,太麻烦了,不是人人都能写,也不适合所有人的网站。也不需要自定义采集软件,也不可能采集所有站点,只能采集你自定义的站点。
文章采集器,可以采集不收录文章,一般网站可以采集。只要输入网址,设置需要哪个后缀的网址文章采集,就可以采集网站的所有文章内容,包括标题文章,文章链接地址,文章采集,会自动保存为TXT,一文章一TXT文件。不仅可以采集文章,还可以过滤需要采集的文章,比如查询页面的HTTP状态;判断URL是否为收录;是不是只有采集不是收录;采集文章words;分析文章原创度数。
1、采集范围广泛,包括:企业站、博客、视频、门户、B2B分类站、下载站
2、挂机全自动采集,采集好数据,自动保存为本地TXT文件,一个TXT文件一个一个;也可以导出URL链接和URL状态,导出EXCEL
3、自动检测文章原创度数,设置大于采集
的字数
4、采集URL链接,查询页面HTTP状态:200-服务器成功返回网页404-请求的网页不存在503-服务不可用;也可以查询链接收录信息
5、操作很简单,输入网址,设置需要哪些数据采集.

