
自动采集文章 工具
我不是在安利我自己app哈我在用网站的文章采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-04-07 01:03
自动采集文章工具让我们利用批量采集知乎问题和发表文章的网站一键采集网上所有问题和回答的图片(jpg文件)
试试看爬虫狗网站/爬虫狗-简单的爬虫程序或者以科大讯飞的小程序爬虫
全是文章配图、引用图片,
文章采集器文章采集工具-新闻资讯大全新闻资讯app下载-新闻资讯大全新闻资讯网
我不是在安利我自己app哈我在用网站的文章采集工具,正在用中.具体可以扫二维码下载,也可以关注公众号【ap也行】后台回复关键词进行下载.传送门:ap也行公众号里会出现工具应用商店下载链接.我是工具的推荐者.如果有人需要先安装ap后台回复关键词()进行下载.长按二维码查看完整版
推荐自己目前正在用的一款采集工具,感觉最好用的是,速度超快,比其他软件快两倍以上。
采集谷歌新闻应该可以用这个最方便了
我觉得使用网站软件,
推荐一个web速递给你,支持爬取新浪微博,腾讯微博,搜狐,百度等网站文章,输入关键词可以搜索出文章的url,直接下载整篇文章。
注册码换正确,下载的就是正常的下载码。
网站有很多,用搜索引擎呗,推荐一个交流学习的社区--集市, 查看全部
我不是在安利我自己app哈我在用网站的文章采集工具
自动采集文章工具让我们利用批量采集知乎问题和发表文章的网站一键采集网上所有问题和回答的图片(jpg文件)
试试看爬虫狗网站/爬虫狗-简单的爬虫程序或者以科大讯飞的小程序爬虫
全是文章配图、引用图片,
文章采集器文章采集工具-新闻资讯大全新闻资讯app下载-新闻资讯大全新闻资讯网
我不是在安利我自己app哈我在用网站的文章采集工具,正在用中.具体可以扫二维码下载,也可以关注公众号【ap也行】后台回复关键词进行下载.传送门:ap也行公众号里会出现工具应用商店下载链接.我是工具的推荐者.如果有人需要先安装ap后台回复关键词()进行下载.长按二维码查看完整版
推荐自己目前正在用的一款采集工具,感觉最好用的是,速度超快,比其他软件快两倍以上。
采集谷歌新闻应该可以用这个最方便了
我觉得使用网站软件,
推荐一个web速递给你,支持爬取新浪微博,腾讯微博,搜狐,百度等网站文章,输入关键词可以搜索出文章的url,直接下载整篇文章。
注册码换正确,下载的就是正常的下载码。
网站有很多,用搜索引擎呗,推荐一个交流学习的社区--集市,
优采云采集器器破解版是一款非常值得各位站长朋友使用的
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-04-03 20:00
优采云 采集器破解版是无人值守的全自动采集器,非常值得所有网站管理员和朋友使用。 优采云 采集器破解版可以帮助用户解决中小型网站和企业工作站的自动信息采集操作。更加智能的采集解决方案可确保网站的高质量和高品质。及时更新内容!免费版EditorTools2的出现将为您节省大量时间,使网站管理员和管理员摆脱繁琐而乏味的网站更新工作!欢迎大家下载并体验jz5u!
功能
1、独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守的24小时自动工作的目的。经过测试,ET可以长时间自动运行,即使以年为单位。
2、超高稳定性
如果不使用该软件,则需要能够长时间稳定运行。 ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行,并且不会崩溃。它甚至导致网站崩溃。
3、最低资源使用量
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源。它可以在服务器上或网站管理员的工作站上工作。
4、严格的数据和网络安全性
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题。 采集有关信息,ET使用标准的HTTP端口,该端口不会引起网络安全漏洞。
5、强大而灵活的功能
除了通用采集工具的功能外,ET还使用图像水印,防垃圾,分页采集,回复采集,登录采集,自定义项目,UTF- 8、 UBB,对模拟版本的支持使用户可以灵活地实现各种头发采集要求。
查看全部
优采云采集器器破解版是一款非常值得各位站长朋友使用的
优采云 采集器破解版是无人值守的全自动采集器,非常值得所有网站管理员和朋友使用。 优采云 采集器破解版可以帮助用户解决中小型网站和企业工作站的自动信息采集操作。更加智能的采集解决方案可确保网站的高质量和高品质。及时更新内容!免费版EditorTools2的出现将为您节省大量时间,使网站管理员和管理员摆脱繁琐而乏味的网站更新工作!欢迎大家下载并体验jz5u!
功能
1、独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守的24小时自动工作的目的。经过测试,ET可以长时间自动运行,即使以年为单位。
2、超高稳定性
如果不使用该软件,则需要能够长时间稳定运行。 ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行,并且不会崩溃。它甚至导致网站崩溃。
3、最低资源使用量
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源。它可以在服务器上或网站管理员的工作站上工作。
4、严格的数据和网络安全性
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题。 采集有关信息,ET使用标准的HTTP端口,该端口不会引起网络安全漏洞。
5、强大而灵活的功能
除了通用采集工具的功能外,ET还使用图像水印,防垃圾,分页采集,回复采集,登录采集,自定义项目,UTF- 8、 UBB,对模拟版本的支持使用户可以灵活地实现各种头发采集要求。

自动采集文章工具——推荐一个ai采集的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2021-03-27 23:08
自动采集文章工具:推荐一个ai采集的工具:smallpdf:1。自动添加表格,ppt到excel,1min完成各种格式文件的批量导入2。一键查找、导出和导出doc文件3。支持数据之间的互相导入,并且可以多平台的导入4。一键看到excel中每一条数据,并且实时展示5。下载时候支持多种格式,pdf,图片,文字5秒查看6。
各种格式间的互相导入,并且可以多平台的导入7。多个公式一键组合,一步搞定,这个功能是真的强大8。将excel文件转化为pdf文件时,有的时候要转化很多次,一次搞定。
我在用的文章采集工具是http批量采集的工具,好用到哭,真心强烈推荐,百度搜就能搜到,无广告无添加,推荐给你我在用的工具哈。这个网站上的工具全部免费。不用自己去添加。不用自己去切换。只需要一键启动就能批量查找和导入文件,还可以一键导出多种格式,pdf,doc,excel,网页。因为是采集网页所以需要文章的网址,完全免费。
页面看不懂的也可以私信我免费教你找到最佳路径!百度搜一下“百度经验:百度百科”或者“百度经验”这个网站。给你我自己创建的csdnvip交流群27271452。纯粹免费的csdnvip群。
推荐使用“找文件”(),可以实现多个账号的批量下载文件,我现在常用“方寻文件”()(), 查看全部
自动采集文章工具——推荐一个ai采集的工具
自动采集文章工具:推荐一个ai采集的工具:smallpdf:1。自动添加表格,ppt到excel,1min完成各种格式文件的批量导入2。一键查找、导出和导出doc文件3。支持数据之间的互相导入,并且可以多平台的导入4。一键看到excel中每一条数据,并且实时展示5。下载时候支持多种格式,pdf,图片,文字5秒查看6。
各种格式间的互相导入,并且可以多平台的导入7。多个公式一键组合,一步搞定,这个功能是真的强大8。将excel文件转化为pdf文件时,有的时候要转化很多次,一次搞定。
我在用的文章采集工具是http批量采集的工具,好用到哭,真心强烈推荐,百度搜就能搜到,无广告无添加,推荐给你我在用的工具哈。这个网站上的工具全部免费。不用自己去添加。不用自己去切换。只需要一键启动就能批量查找和导入文件,还可以一键导出多种格式,pdf,doc,excel,网页。因为是采集网页所以需要文章的网址,完全免费。
页面看不懂的也可以私信我免费教你找到最佳路径!百度搜一下“百度经验:百度百科”或者“百度经验”这个网站。给你我自己创建的csdnvip交流群27271452。纯粹免费的csdnvip群。
推荐使用“找文件”(),可以实现多个账号的批量下载文件,我现在常用“方寻文件”()(),
自动采集文章工具汇总,你的mac系统很多吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2021-03-26 07:04
自动采集文章工具汇总1。的微信文章采集器,包括微信公众号文章以及百度百家等平台的文章。你可以采集微信公众号文章,也可以采集百度百家,搜狐等平台的文章。还有大量的微信公众号素材,标题,配图,还有就是关键词等都能一键采集。而且基本上都支持批量导出到excel等。2。阅狗采集器,这个很牛逼,是完全自动采集微信公众号里面的文章,而且不需要自己做任何设置,是我觉得最牛逼的一个采集工具,也是我用过最稳定的工具。
3。国外的rightlyxtractor都是短网址,如果你觉得这个还不够,国外还有三个自动采集工具,一个短网址采集器,两个高级短网址采集器。短网址采集器,这个是支持微信文章采集,也可以批量导出采集好的文章数据到excel,如果你的mac系统很多的话,推荐一个excel插件nothumanfriend。
把excel导入nothreads,还可以自动导出表格,excel字段,还有自动生成更多的formats需要购买。高级短网址采集器,这个是支持微信文章采集,也支持标题采集,图片采集,链接采集等,功能比短网址采集器稍微强大一点。推荐下载谷歌插件v-javajs+chrome插件,v-javajs可以加载谷歌插件,不需要翻墙,但是不能进行任何文本输入和操作,chrome就不需要翻墙,可以随时采集国外的网站和maven插件(jbuild)4。
万能公众号采集器这个可以说是万能,除了微信文章采集,百度百家采集器,其他平台的文章一键采集,还可以用他自己做微信自动采集器等等。 查看全部
自动采集文章工具汇总,你的mac系统很多吗?
自动采集文章工具汇总1。的微信文章采集器,包括微信公众号文章以及百度百家等平台的文章。你可以采集微信公众号文章,也可以采集百度百家,搜狐等平台的文章。还有大量的微信公众号素材,标题,配图,还有就是关键词等都能一键采集。而且基本上都支持批量导出到excel等。2。阅狗采集器,这个很牛逼,是完全自动采集微信公众号里面的文章,而且不需要自己做任何设置,是我觉得最牛逼的一个采集工具,也是我用过最稳定的工具。
3。国外的rightlyxtractor都是短网址,如果你觉得这个还不够,国外还有三个自动采集工具,一个短网址采集器,两个高级短网址采集器。短网址采集器,这个是支持微信文章采集,也可以批量导出采集好的文章数据到excel,如果你的mac系统很多的话,推荐一个excel插件nothumanfriend。
把excel导入nothreads,还可以自动导出表格,excel字段,还有自动生成更多的formats需要购买。高级短网址采集器,这个是支持微信文章采集,也支持标题采集,图片采集,链接采集等,功能比短网址采集器稍微强大一点。推荐下载谷歌插件v-javajs+chrome插件,v-javajs可以加载谷歌插件,不需要翻墙,但是不能进行任何文本输入和操作,chrome就不需要翻墙,可以随时采集国外的网站和maven插件(jbuild)4。
万能公众号采集器这个可以说是万能,除了微信文章采集,百度百家采集器,其他平台的文章一键采集,还可以用他自己做微信自动采集器等等。
能采集任何网站的各种格式图片,实现(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-02-07 11:07
能采集任何网站的各种格式图片,实现(组图)
C#Picture采集软件,自动翻页,自动分类(用于采集精美图片的必要工具)(二)
可以采集各种格式的任何网站图片,以有序的类别实现文章中间的所有图片,新闻,帖子等的功能,并将其保存在计算机上。您可以保存任何内容。论坛网站中所有帖子的图片采集被发送到本地,并且广告可以轻松过滤。对于网站,论坛网站管理员和喜欢采集精美图片的朋友来说,它是必不可少的工具。
本文演示了这些功能已添加到以前的版本中。可以下载并显示整个站点采集 网站,软件注册,软件更新和XML保存采集记录。效果如图1所示。采集链接以下载并使用必要的Mito工具。
图1
演示程序结构
要创建演示程序,我选择在原创程序的基础上创建一个名为ImgSpiderWinUpdate的新C#Windows Form应用程序。该Windows项目用于软件升级。从WebService下载最新的软件更新程序包,并解压缩文件以更新操作。 Asp.Net空白网站命名为ImgSpiderWeb,添加了ImgSpiderWebService.asmx WebService文件,提到了软件注册,并更新了下载方法。图2显示了该演示程序的总体结构。
图2
程序在主项目ImgSpiderWinForm的Program.cs文件中执行,以确定程序是否已更新
ImgSpiderWinUpdate项目表单文件frmUpdate,从WebService下载最新的软件更新包,然后解压缩该文件,进行更新操作,
更新操作完成后,运行ImgSpider.exe
在ImgSpiderWeb项目ImgSpiderWebService.asmx WebService文件中,提到了软件注册,更新下载调用方法
在主项目ImgSpiderWinForm中添加frmRegistrationSoftware主要用于软件注册
更改主项目ImgSpiderWinForm中的下载记录以保存为XML
结束
本文演示了这些功能已添加到以前的版本中,整个站点都下载了,显示了采集 网站,软件注册,软件更新,并使用XML保存了采集记录。采集链接以下载并使用必要的Mito工具。 查看全部
能采集任何网站的各种格式图片,实现(组图)
C#Picture采集软件,自动翻页,自动分类(用于采集精美图片的必要工具)(二)
可以采集各种格式的任何网站图片,以有序的类别实现文章中间的所有图片,新闻,帖子等的功能,并将其保存在计算机上。您可以保存任何内容。论坛网站中所有帖子的图片采集被发送到本地,并且广告可以轻松过滤。对于网站,论坛网站管理员和喜欢采集精美图片的朋友来说,它是必不可少的工具。
本文演示了这些功能已添加到以前的版本中。可以下载并显示整个站点采集 网站,软件注册,软件更新和XML保存采集记录。效果如图1所示。采集链接以下载并使用必要的Mito工具。

图1
演示程序结构
要创建演示程序,我选择在原创程序的基础上创建一个名为ImgSpiderWinUpdate的新C#Windows Form应用程序。该Windows项目用于软件升级。从WebService下载最新的软件更新程序包,并解压缩文件以更新操作。 Asp.Net空白网站命名为ImgSpiderWeb,添加了ImgSpiderWebService.asmx WebService文件,提到了软件注册,并更新了下载方法。图2显示了该演示程序的总体结构。

图2
程序在主项目ImgSpiderWinForm的Program.cs文件中执行,以确定程序是否已更新

ImgSpiderWinUpdate项目表单文件frmUpdate,从WebService下载最新的软件更新包,然后解压缩该文件,进行更新操作,


更新操作完成后,运行ImgSpider.exe

在ImgSpiderWeb项目ImgSpiderWebService.asmx WebService文件中,提到了软件注册,更新下载调用方法

在主项目ImgSpiderWinForm中添加frmRegistrationSoftware主要用于软件注册


更改主项目ImgSpiderWinForm中的下载记录以保存为XML

结束
本文演示了这些功能已添加到以前的版本中,整个站点都下载了,显示了采集 网站,软件注册,软件更新,并使用XML保存了采集记录。采集链接以下载并使用必要的Mito工具。
咪蒙的一篇文章列表为例进行说明,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-02-01 13:02
自动采集文章工具。软件通过自动采集电脑网站上的文章形成一篇篇精准文章列表,然后复制到手机里面就可以进行查看。下面就以咪蒙的一篇文章列表为例进行说明。第一步:打开软件,通过文章搜索找到咪蒙的某篇文章,当然也可以通过爬虫采集搜狗微信文章网站的一些文章内容或者网址内容。第二步:复制好列表文章链接以及电话等信息以后,点击下一步,粘贴文章链接,然后点击确定即可。
第三步:运行软件后,直接单击列表的一篇文章,可以看到如下的链接。第四步:鼠标移动到任意一篇文章链接上面,会出现文章列表,选择一篇即可。第五步:点击播放按钮,在视频列表中,点击播放暂停即可看到抓取的视频列表。第六步:将其中的一篇文章,选择好标题以及描述以后,点击保存就可以生成一篇推送列表。第七步:单击电话等信息,点击保存以后,生成的信息可以点击打开。
第八步:当电话等信息不需要存储的时候,可以点击软件右下角的关闭按钮。第九步:点击软件右下角的卸载按钮,点击以后点击软件右下角的清除数据以后,就会清除软件内存并退出软件。注意事项软件默认显示暂停以后,点击右上角退出就退出列表。
我有一个新建列表的脚本,不过只是限定在系统的浏览器里面能使用,个人觉得还是可以用,一是视频文章大多数浏览器都支持,二是各浏览器的edge浏览器还有uc浏览器不兼容, 查看全部
咪蒙的一篇文章列表为例进行说明,你知道吗?
自动采集文章工具。软件通过自动采集电脑网站上的文章形成一篇篇精准文章列表,然后复制到手机里面就可以进行查看。下面就以咪蒙的一篇文章列表为例进行说明。第一步:打开软件,通过文章搜索找到咪蒙的某篇文章,当然也可以通过爬虫采集搜狗微信文章网站的一些文章内容或者网址内容。第二步:复制好列表文章链接以及电话等信息以后,点击下一步,粘贴文章链接,然后点击确定即可。
第三步:运行软件后,直接单击列表的一篇文章,可以看到如下的链接。第四步:鼠标移动到任意一篇文章链接上面,会出现文章列表,选择一篇即可。第五步:点击播放按钮,在视频列表中,点击播放暂停即可看到抓取的视频列表。第六步:将其中的一篇文章,选择好标题以及描述以后,点击保存就可以生成一篇推送列表。第七步:单击电话等信息,点击保存以后,生成的信息可以点击打开。
第八步:当电话等信息不需要存储的时候,可以点击软件右下角的关闭按钮。第九步:点击软件右下角的卸载按钮,点击以后点击软件右下角的清除数据以后,就会清除软件内存并退出软件。注意事项软件默认显示暂停以后,点击右上角退出就退出列表。
我有一个新建列表的脚本,不过只是限定在系统的浏览器里面能使用,个人觉得还是可以用,一是视频文章大多数浏览器都支持,二是各浏览器的edge浏览器还有uc浏览器不兼容,
最适合你需求的20款网络爬虫工具供你参考
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2021-01-19 11:20
Web采集器如今在许多领域中得到广泛使用。它的功能是从任何网站中获取特定或更新的数据并进行存储。 Web爬虫工具变得越来越知名,因为Web爬虫简化并自动完成了整个爬网过程,因此每个人都可以轻松访问网站数据资源。使用网络采集器工具可以使人们免于重复键入或复制和粘贴,并且我们可以轻松访问采集网页上的数据。另外,这些Web采集器工具可以使用户以有序和快速的方式搜寻网页,而无需将数据编程并将其转换为满足其需求的各种格式。
在本文文章中,我将介绍20种流行的Web爬网工具,以供您参考。希望您能找到最适合您需求的工具。
1.优采云
优采云是一个免费且功能强大的网站采集器,用于从网站中提取几乎所有类型的数据。您可以使用优采云至采集几乎市场上的所有网站。 优采云提供两种采集模式:简易模式和自定义采集模式,非程序员可以快速习惯优采云。下载免费软件后,其可视界面可让您从网站中获取所有文本,因此您可以下载几乎所有网站内容并将其保存为结构化格式,例如EXCEL,TXT,HTML或数据库。
您可以使用其内置的正则表达式工具从复杂的网站布局中提取许多棘手的网站数据,并使用XPath配置工具精确定位Web元素。另外,优采云提供了自动识别码和代理IP交换功能,可以有效避免网站和采集。
简而言之,优采云可以满足用户的最基本或最高级的采集需求,而无需任何编程技能。
2.HTTrack
作为免费的网站采集器软件,HTTrack提供的功能非常适合将整个网站从Internet下载到您的PC。它提供适用于Windows,Linux,Sun Solaris和其他Unix系统的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。您可以在“设置”下下载网页时决定要同时打开多少个连接。您可以从整个目录中获取照片,文件,HTML代码,更新当前镜像网站并恢复中断的下载。
此外,HTTTrack还提供代理支持,以通过可选身份验证来最大化速度。
HTTrack用作命令行程序,或者通过Shell专用(捕获)或专业(在线Web镜像)使用。有了这个声明,HTTrack应该是首选,并且具有高级编程技能的人会更多地使用它。
3、铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google表格。此工具适用于可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。 Scraper是一个免费的网络采集器工具,可以在您的浏览器中正常运行,并自动生成一个较小的XPath来定义要搜寻的URL。
4、OutWit集线器
Outwit Hub是Firefox附加组件,它有两个作用:采集信息和管理信息。它可以用于在网站的不同部分提供不同的窗口栏。它还为用户提供了一种快速输入信息并实际上删除网站上其他部分的方法。
OutWit Hub提供了一个界面,可以根据需要捕获少量或大量数据。 OutWit Hub允许您从浏览器本身抓取任何网页,甚至可以创建自动代理来提取数据并根据设置对其进行格式化。
OutWit Hub的大多数功能都是免费的。它可以深入分析网站,自动在Internet上采集和整理各种数据,并分离网站信息,然后提取有效信息以形成可用的集合。但是要自动提取准确的数据,您需要付费版本。同时,免费版本一次可以提取的数据量也受到限制。如果需要大规模操作,可以选择购买专业版。
5.ParseHub
Parsehub是一款出色的网络爬虫,它支持使用AJAX技术,JavaScript,Cookie等从网站采集数据。其机器学习技术可以读取,分析然后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux系统,或者您可以在浏览器中使用内置的Web应用程序。
作为免费软件,您在Parsehub中最多可以建立五个公共项目。付费版本允许您创建至少20个私有项目以进行爬网网站。
6.Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具使用户无需任何编程知识即可抓取网站。
Scrapinghub使用Crawlera(代理IP的第三方平台),该平台支持绕过反采集对策。它使用户可以从多个IP和位置抓取网页,而无需通过简单的HTTP API进行代理管理。
Scrapinghub将整个网页转换为有组织的内容。如果其采集器工具不能满足您的要求,则其专家团队可以为您提供帮助。
7.Dexi.io
作为基于浏览器的Web采集器,Dexi.io允许您从任何基于网站的浏览器中获取数据,并提供三种类型的采集器来创建采集任务。该免费软件为您的网络抓取提供了一个匿名Web代理服务器。您提取的数据将在存档数据之前在Dexi.io的服务器上托管两周,或者您可以将提取的数据直接导出到JSON或CSV文件。它提供付费服务,以满足您获取实时数据的需求。
8.Webhose.io
Webhose.io使用户能够将从全球在线资源捕获的实时数据转换为各种标准格式。使用此网络爬虫,您可以使用覆盖各种来源的多个过滤器来爬网数据并进一步提取多种语言的关键字。
您可以将已删除的数据保存为XML,JSON和RSS格式。并允许用户访问其存档中的历史数据。此外,webhose.io支持多达80种语言及其爬网数据结果。用户可以轻松地索引和搜索Webhose.io捕获的结构化数据。
通常,Webhose.io可以满足用户的基本爬网要求。
9.Import.io
用户只需要从特定网页导入数据并将数据导出到CSV即可形成自己的数据集。
您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据您的要求构建超过1,000个API。公共API提供强大而灵活的功能,以编程方式控制Import.io并自动访问数据。 Import.io只需单击几下,即可将Web数据集成到您自己的应用程序或网站中,您可以轻松实现抓取。
为了更好地满足用户的爬网需求,它还为Windows,Mac OS X和Linux提供免费的应用程序,以构建数据提取器和爬网程序,下载数据并与在线帐户同步。此外,用户可以每周,每天或每小时安排爬网任务。
10.80legs
80legs是功能强大的Web抓取工具,可以根据自定义要求进行配置。它支持以下选项:获取大量数据并立即下载提取的数据。 80legs提供了高性能的Web爬网,可以快速运行并在几秒钟内获得所需的数据
1 1.Content Graber
Content Graber是面向企业的Web爬网软件。它允许您创建独立的Web爬网代理。它可以从几乎所有网站中提取内容,并以您选择的格式将其保存为结构化数据,包括Excel报告,XML,CSV和大多数数据库。
它更适合具有高级编程技能的人,因为它为需要的人提供了许多强大的脚本编辑和调试界面。允许用户使用C#或VB.NET调试或编写脚本以编程方式控制爬网过程。例如,Content Grabber可以与Visual Studio 2013集成,以根据用户的特定需求为高级和智能自定义采集器提供最强大的脚本编辑,调试和单元测试。
1 2.UiPath
UiPath是用于自动Web爬网的机器人流程自动化软件。它可以自动从大多数第三方应用程序中获取Web和桌面数据。如果您正在运行Windows,则可以安装机械手过程自动化软件。 Uipath可以跨多个网页提取表和基于模式的数据。
Uipath提供了用于进一步爬网的内置工具。当处理复杂的UI时,此方法非常有效。屏幕抓取工具可以处理单个文本元素,文本组和文本块,例如以表格格式提取数据。
此外,创建智能Web代理不需要编程,但是您的内部.NET黑客可以完全控制数据。 查看全部
最适合你需求的20款网络爬虫工具供你参考
Web采集器如今在许多领域中得到广泛使用。它的功能是从任何网站中获取特定或更新的数据并进行存储。 Web爬虫工具变得越来越知名,因为Web爬虫简化并自动完成了整个爬网过程,因此每个人都可以轻松访问网站数据资源。使用网络采集器工具可以使人们免于重复键入或复制和粘贴,并且我们可以轻松访问采集网页上的数据。另外,这些Web采集器工具可以使用户以有序和快速的方式搜寻网页,而无需将数据编程并将其转换为满足其需求的各种格式。
在本文文章中,我将介绍20种流行的Web爬网工具,以供您参考。希望您能找到最适合您需求的工具。
1.优采云
优采云是一个免费且功能强大的网站采集器,用于从网站中提取几乎所有类型的数据。您可以使用优采云至采集几乎市场上的所有网站。 优采云提供两种采集模式:简易模式和自定义采集模式,非程序员可以快速习惯优采云。下载免费软件后,其可视界面可让您从网站中获取所有文本,因此您可以下载几乎所有网站内容并将其保存为结构化格式,例如EXCEL,TXT,HTML或数据库。
您可以使用其内置的正则表达式工具从复杂的网站布局中提取许多棘手的网站数据,并使用XPath配置工具精确定位Web元素。另外,优采云提供了自动识别码和代理IP交换功能,可以有效避免网站和采集。
简而言之,优采云可以满足用户的最基本或最高级的采集需求,而无需任何编程技能。
2.HTTrack
作为免费的网站采集器软件,HTTrack提供的功能非常适合将整个网站从Internet下载到您的PC。它提供适用于Windows,Linux,Sun Solaris和其他Unix系统的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。您可以在“设置”下下载网页时决定要同时打开多少个连接。您可以从整个目录中获取照片,文件,HTML代码,更新当前镜像网站并恢复中断的下载。
此外,HTTTrack还提供代理支持,以通过可选身份验证来最大化速度。
HTTrack用作命令行程序,或者通过Shell专用(捕获)或专业(在线Web镜像)使用。有了这个声明,HTTrack应该是首选,并且具有高级编程技能的人会更多地使用它。
3、铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google表格。此工具适用于可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。 Scraper是一个免费的网络采集器工具,可以在您的浏览器中正常运行,并自动生成一个较小的XPath来定义要搜寻的URL。
4、OutWit集线器
Outwit Hub是Firefox附加组件,它有两个作用:采集信息和管理信息。它可以用于在网站的不同部分提供不同的窗口栏。它还为用户提供了一种快速输入信息并实际上删除网站上其他部分的方法。
OutWit Hub提供了一个界面,可以根据需要捕获少量或大量数据。 OutWit Hub允许您从浏览器本身抓取任何网页,甚至可以创建自动代理来提取数据并根据设置对其进行格式化。
OutWit Hub的大多数功能都是免费的。它可以深入分析网站,自动在Internet上采集和整理各种数据,并分离网站信息,然后提取有效信息以形成可用的集合。但是要自动提取准确的数据,您需要付费版本。同时,免费版本一次可以提取的数据量也受到限制。如果需要大规模操作,可以选择购买专业版。
5.ParseHub
Parsehub是一款出色的网络爬虫,它支持使用AJAX技术,JavaScript,Cookie等从网站采集数据。其机器学习技术可以读取,分析然后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux系统,或者您可以在浏览器中使用内置的Web应用程序。
作为免费软件,您在Parsehub中最多可以建立五个公共项目。付费版本允许您创建至少20个私有项目以进行爬网网站。
6.Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具使用户无需任何编程知识即可抓取网站。
Scrapinghub使用Crawlera(代理IP的第三方平台),该平台支持绕过反采集对策。它使用户可以从多个IP和位置抓取网页,而无需通过简单的HTTP API进行代理管理。
Scrapinghub将整个网页转换为有组织的内容。如果其采集器工具不能满足您的要求,则其专家团队可以为您提供帮助。
7.Dexi.io
作为基于浏览器的Web采集器,Dexi.io允许您从任何基于网站的浏览器中获取数据,并提供三种类型的采集器来创建采集任务。该免费软件为您的网络抓取提供了一个匿名Web代理服务器。您提取的数据将在存档数据之前在Dexi.io的服务器上托管两周,或者您可以将提取的数据直接导出到JSON或CSV文件。它提供付费服务,以满足您获取实时数据的需求。
8.Webhose.io
Webhose.io使用户能够将从全球在线资源捕获的实时数据转换为各种标准格式。使用此网络爬虫,您可以使用覆盖各种来源的多个过滤器来爬网数据并进一步提取多种语言的关键字。
您可以将已删除的数据保存为XML,JSON和RSS格式。并允许用户访问其存档中的历史数据。此外,webhose.io支持多达80种语言及其爬网数据结果。用户可以轻松地索引和搜索Webhose.io捕获的结构化数据。
通常,Webhose.io可以满足用户的基本爬网要求。
9.Import.io
用户只需要从特定网页导入数据并将数据导出到CSV即可形成自己的数据集。
您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据您的要求构建超过1,000个API。公共API提供强大而灵活的功能,以编程方式控制Import.io并自动访问数据。 Import.io只需单击几下,即可将Web数据集成到您自己的应用程序或网站中,您可以轻松实现抓取。
为了更好地满足用户的爬网需求,它还为Windows,Mac OS X和Linux提供免费的应用程序,以构建数据提取器和爬网程序,下载数据并与在线帐户同步。此外,用户可以每周,每天或每小时安排爬网任务。
10.80legs
80legs是功能强大的Web抓取工具,可以根据自定义要求进行配置。它支持以下选项:获取大量数据并立即下载提取的数据。 80legs提供了高性能的Web爬网,可以快速运行并在几秒钟内获得所需的数据
1 1.Content Graber
Content Graber是面向企业的Web爬网软件。它允许您创建独立的Web爬网代理。它可以从几乎所有网站中提取内容,并以您选择的格式将其保存为结构化数据,包括Excel报告,XML,CSV和大多数数据库。
它更适合具有高级编程技能的人,因为它为需要的人提供了许多强大的脚本编辑和调试界面。允许用户使用C#或VB.NET调试或编写脚本以编程方式控制爬网过程。例如,Content Grabber可以与Visual Studio 2013集成,以根据用户的特定需求为高级和智能自定义采集器提供最强大的脚本编辑,调试和单元测试。
1 2.UiPath
UiPath是用于自动Web爬网的机器人流程自动化软件。它可以自动从大多数第三方应用程序中获取Web和桌面数据。如果您正在运行Windows,则可以安装机械手过程自动化软件。 Uipath可以跨多个网页提取表和基于模式的数据。
Uipath提供了用于进一步爬网的内置工具。当处理复杂的UI时,此方法非常有效。屏幕抓取工具可以处理单个文本元素,文本组和文本块,例如以表格格式提取数据。
此外,创建智能Web代理不需要编程,但是您的内部.NET黑客可以完全控制数据。
技巧:有没有自动采集并伪原创的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-11-10 11:02
问题:是否有用于自动采集和伪原创的工具?
问题补充:我最近在进行网站内容构建,发现没有太多内容可以做,而整理出的关键词感觉好像我不知道如何编辑文章。因此,我想问一下是否有一种可以自动采集和伪原创的工具,可以节省大量时间和精力。
答案:作者尚未使用自动的采集和伪原创工具,所以我没有太多发言权。但是,据说某些软件可以做到这一点。该工具可以根据关键词自动搜索相关材料,然后将这些材料整理为伪原创 文章。
我认为,即使使用这样的自动采集和伪原创工具,效果也不理想。想象一下,该工具真的可以确定用户对关键词的需求吗?工具真的可以将这些材料无缝地组织成高度可读的文章吗?显然,这些自动采集和伪原创的工具无法做到这一点。所有工具所能做的都是采集内容,然后根据设置的规则将材料放在一起。工具毕竟是工具。它无法理解真实的用户需求,也无法真正带来良好的用户体验。
百度最近升级了飓风算法并将其升级为2.0。阅读说明的朋友应该知道,百度不仅可以通过分词识别文章的内容,还可以根据句子,段落等匹配文章。做出判断。换句话说,简单的伪原创不能逃脱百度搜索的视线,甚至手动伪原创也无法发现漏洞。这种自动的采集和伪原创工具如何能够做到!这显然是不科学的。
如果将这种自动采集和伪原创工具放在几年前,可能会有用,但是搜索引擎发展到今天,各种技术也变得更加成熟。我认为这种方法不再有用。
关于是否存在用于自动采集和伪原创的工具的问题,我相信存在工具,但是它们产生的效果是不同的。实际上,作者更好奇,为什么您不能花更多的时间在内容上?在任何时候,网站内容都是网站 SEO优化的基础,值得花更多的精力。 查看全部
有没有一种工具可以自动采集和伪原创
问题:是否有用于自动采集和伪原创的工具?
问题补充:我最近在进行网站内容构建,发现没有太多内容可以做,而整理出的关键词感觉好像我不知道如何编辑文章。因此,我想问一下是否有一种可以自动采集和伪原创的工具,可以节省大量时间和精力。
答案:作者尚未使用自动的采集和伪原创工具,所以我没有太多发言权。但是,据说某些软件可以做到这一点。该工具可以根据关键词自动搜索相关材料,然后将这些材料整理为伪原创 文章。
我认为,即使使用这样的自动采集和伪原创工具,效果也不理想。想象一下,该工具真的可以确定用户对关键词的需求吗?工具真的可以将这些材料无缝地组织成高度可读的文章吗?显然,这些自动采集和伪原创的工具无法做到这一点。所有工具所能做的都是采集内容,然后根据设置的规则将材料放在一起。工具毕竟是工具。它无法理解真实的用户需求,也无法真正带来良好的用户体验。
百度最近升级了飓风算法并将其升级为2.0。阅读说明的朋友应该知道,百度不仅可以通过分词识别文章的内容,还可以根据句子,段落等匹配文章。做出判断。换句话说,简单的伪原创不能逃脱百度搜索的视线,甚至手动伪原创也无法发现漏洞。这种自动的采集和伪原创工具如何能够做到!这显然是不科学的。
如果将这种自动采集和伪原创工具放在几年前,可能会有用,但是搜索引擎发展到今天,各种技术也变得更加成熟。我认为这种方法不再有用。
关于是否存在用于自动采集和伪原创的工具的问题,我相信存在工具,但是它们产生的效果是不同的。实际上,作者更好奇,为什么您不能花更多的时间在内容上?在任何时候,网站内容都是网站 SEO优化的基础,值得花更多的精力。
志趣网手动发贴工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-27 15:26
志趣网手动发贴工具
羚羊手动发布信息介绍:
自动发布信息—bb网站全手动发布信息工具羚羊——企业信息助手:一款分类信息平台和BB平台通用的发布信息。不单取代手工,实现全手动发布的,并且能够手动切换标题、内容、图片等。
一、定时发送功能
发布信息间隔时间没有规律,自由调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜夜晚发布信息的同学,发布完自动关机)。
二、保存配置功能
假如你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载曾经的设置,节省时间、省事。
三、自动设置产品图片功能
图片有种选择:
、同步采集网站图片。 如果您在网站后台上传了图片,“采集相册”,可以手动采集图片到本地。
、您的网站后台获得网址地址,取您考虑要发的产品的图片。
、人工大量导出本地计算机上的图片
四、很强的内容编辑器
自带文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本能在内部随时可视化编辑,如同在网站后台操作一样。
五、自动合成标题功能 。
无法想到好多标题?自带大量合成标题功能,自动大量合成成千上万个不反复的标题。根据您的需求,配置标题模板即可生成。
标题可以随便组合,常用格式是{字符}{字符}{字符},经过各种自定义组合,可以形成的不同标题。
六、自动功能 :图片以下的文字属于随机介绍。
为了达到每次发布的内容不反复,羚羊bb小助手有两类格式可以选择
、按句号选择
、按段落选择
能在内容中的任何地方您的文章,句子中的文章放得越多越好,没有,在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不反复,搜索引擎也比较偏爱。
七、查询收录功能
在以下对话框中输入您发布信息的联系,点“查询”,然后对着查询结果双击您的键盘左键,就能查询到您在此网站发布的信息在收录的结果。
八、信息一键重发功能
我们曾经刷新发布的信息,需要到网站后台,有的是一页一页刷新,有的更麻烦,要一条条。如果我们发布的信息有几万条,这种刷新信息的效率是非常低下的。目前我们能借助提供的一键刷新功能,将同步出来的信息,一键全部重发,十分省事。
十、信息功能
自带信息功能,可同步发布过的信息,进行查看、、大量到等实用功能。 查看全部
志趣网手动发贴工具

志趣网手动发贴工具
羚羊手动发布信息介绍:
自动发布信息—bb网站全手动发布信息工具羚羊——企业信息助手:一款分类信息平台和BB平台通用的发布信息。不单取代手工,实现全手动发布的,并且能够手动切换标题、内容、图片等。
一、定时发送功能
发布信息间隔时间没有规律,自由调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜夜晚发布信息的同学,发布完自动关机)。
二、保存配置功能
假如你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载曾经的设置,节省时间、省事。
三、自动设置产品图片功能
图片有种选择:
、同步采集网站图片。 如果您在网站后台上传了图片,“采集相册”,可以手动采集图片到本地。
、您的网站后台获得网址地址,取您考虑要发的产品的图片。
、人工大量导出本地计算机上的图片
四、很强的内容编辑器
自带文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本能在内部随时可视化编辑,如同在网站后台操作一样。
五、自动合成标题功能 。
无法想到好多标题?自带大量合成标题功能,自动大量合成成千上万个不反复的标题。根据您的需求,配置标题模板即可生成。
标题可以随便组合,常用格式是{字符}{字符}{字符},经过各种自定义组合,可以形成的不同标题。
六、自动功能 :图片以下的文字属于随机介绍。
为了达到每次发布的内容不反复,羚羊bb小助手有两类格式可以选择
、按句号选择
、按段落选择
能在内容中的任何地方您的文章,句子中的文章放得越多越好,没有,在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不反复,搜索引擎也比较偏爱。
七、查询收录功能
在以下对话框中输入您发布信息的联系,点“查询”,然后对着查询结果双击您的键盘左键,就能查询到您在此网站发布的信息在收录的结果。
八、信息一键重发功能
我们曾经刷新发布的信息,需要到网站后台,有的是一页一页刷新,有的更麻烦,要一条条。如果我们发布的信息有几万条,这种刷新信息的效率是非常低下的。目前我们能借助提供的一键刷新功能,将同步出来的信息,一键全部重发,十分省事。
十、信息功能
自带信息功能,可同步发布过的信息,进行查看、、大量到等实用功能。
黑马博客群发器
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-08-27 08:21
黑马博客群发器是一款超好用的博客群发软件,支持国外两大博客网站,新浪、网易,自动采集强强联合,是诸位站长的SEO好帮手!有须要的就来IT猫扑下载吧!
黑马博客群发器介绍
黑马博客群发是一款由黑马SEO于2010年开发的强悍的博客群发工具。
黑马博客群发拥有智能引导注册博客帐户、完善的帐户、文章管理、自动采集、自动动词、自动伪原创、自动发布、自动串联文章。
是SEOer、站长、网络写手用于SEO优化、网络营销、博客写作的极佳工具。
黑马博客群发免费版仅支持新浪、网易、和讯三大博客。
黑马博客群发软件功能
智能引导注册
使用黑马博客群发注册各种博客账号时黑马博客群发将为用户手动填写帐户信息,用户只须要填写验证码并递交即可,注册成功后黑马博客群发将为用户手动保存帐户;
自动串联
自动串联是黑马博客群发的杀手锏,博客与博客之间串联、博文与博文之间串联、博客博文与站点串联多重反复串联,形成超级导轮,SEO疗效明显,支持单一串联和随机串联2种模式;
全手动采集
使用黑马博客群发轻松几步即可设置文章资源采集,采集内容精准、速度快。
内置采集规则可直接使用。
无需用户再为撰写而头痛,彻底解放用户的右手和脑部;
Easy采集
虽然黑马有强悍的采集功能,但是对于一些菜鸟用户写采集规则是十分难受的一件事,黑马博客群发特此推出Easy采集功能,用户只须要输入关键词即可轻松采集数百篇文章;
智能伪原创
黑马博客群发的伪原创功能十分强悍,堪比专业级的伪原创软件。
可以进行同时对标题和文章进行伪原创,支持同义词替换、自定义随机主题类型、段落随机搅乱、自定义页眉页脚、自定义随机插入关键词链接等功能;
自动分词
使用黑马博客群撰写文章或采集文章时都能快速的对内容进行动词处理,提取精准的关键词,发布博文时同时递交,加快博客网站索引、搜索引擎蜘蛛索引,SEO疗效明显;
全手动发布
全手动"后台"发布博文让黑马博客群发在发布速率、发布成功率上都远远的赶超同类型博客群发软件。支持多种发布模式,自定义发布时间间隔,自动换IP等功能;
CMS发布
黑马是同类型软件首家也是惟一一家在博客群发基础上推出了CMS发布功能,支持主流CMS,发布博文和CMS的同时还可以使博文和CMS文章混淆串联,可实现更有效更持久的SEO疗效;
系统需求
操作系统: Win7(32位)/Vista(32位)/XP(32位)
IE浏览器6.0或更高
更新日志
黑马博客群发 v3.0.0.0更新
1、新增CMS发布支持,支持主流CMS并不断降低中;
2、新增Easy采集功能,输入关键词即可轻松采集数百篇文章;
3、专题串联改为随机串联,串联更轻柔SEO疗效更明显;
4、优化了核心代码,群发更快速更稳定;
5、支持小型博客数目达50个; 查看全部
黑马博客群发器
黑马博客群发器是一款超好用的博客群发软件,支持国外两大博客网站,新浪、网易,自动采集强强联合,是诸位站长的SEO好帮手!有须要的就来IT猫扑下载吧!
黑马博客群发器介绍
黑马博客群发是一款由黑马SEO于2010年开发的强悍的博客群发工具。
黑马博客群发拥有智能引导注册博客帐户、完善的帐户、文章管理、自动采集、自动动词、自动伪原创、自动发布、自动串联文章。
是SEOer、站长、网络写手用于SEO优化、网络营销、博客写作的极佳工具。
黑马博客群发免费版仅支持新浪、网易、和讯三大博客。

黑马博客群发软件功能
智能引导注册
使用黑马博客群发注册各种博客账号时黑马博客群发将为用户手动填写帐户信息,用户只须要填写验证码并递交即可,注册成功后黑马博客群发将为用户手动保存帐户;
自动串联
自动串联是黑马博客群发的杀手锏,博客与博客之间串联、博文与博文之间串联、博客博文与站点串联多重反复串联,形成超级导轮,SEO疗效明显,支持单一串联和随机串联2种模式;
全手动采集
使用黑马博客群发轻松几步即可设置文章资源采集,采集内容精准、速度快。
内置采集规则可直接使用。
无需用户再为撰写而头痛,彻底解放用户的右手和脑部;
Easy采集
虽然黑马有强悍的采集功能,但是对于一些菜鸟用户写采集规则是十分难受的一件事,黑马博客群发特此推出Easy采集功能,用户只须要输入关键词即可轻松采集数百篇文章;
智能伪原创
黑马博客群发的伪原创功能十分强悍,堪比专业级的伪原创软件。
可以进行同时对标题和文章进行伪原创,支持同义词替换、自定义随机主题类型、段落随机搅乱、自定义页眉页脚、自定义随机插入关键词链接等功能;
自动分词
使用黑马博客群撰写文章或采集文章时都能快速的对内容进行动词处理,提取精准的关键词,发布博文时同时递交,加快博客网站索引、搜索引擎蜘蛛索引,SEO疗效明显;
全手动发布
全手动"后台"发布博文让黑马博客群发在发布速率、发布成功率上都远远的赶超同类型博客群发软件。支持多种发布模式,自定义发布时间间隔,自动换IP等功能;
CMS发布
黑马是同类型软件首家也是惟一一家在博客群发基础上推出了CMS发布功能,支持主流CMS,发布博文和CMS的同时还可以使博文和CMS文章混淆串联,可实现更有效更持久的SEO疗效;
系统需求
操作系统: Win7(32位)/Vista(32位)/XP(32位)
IE浏览器6.0或更高
更新日志
黑马博客群发 v3.0.0.0更新
1、新增CMS发布支持,支持主流CMS并不断降低中;
2、新增Easy采集功能,输入关键词即可轻松采集数百篇文章;
3、专题串联改为随机串联,串联更轻柔SEO疗效更明显;
4、优化了核心代码,群发更快速更稳定;
5、支持小型博客数目达50个;
EditorTools全手动采集助手
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-20 19:41
Editor Tools全自动采集助手是一款免费的网路资源采集软件。Editor Tools全手动采集助手是中小网站自动更新神器,全手动采集发布,运行期间沉静工作,无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作。
Editor Tools全自动采集助手功能介绍:
【特色】绿色软件,免安装
【特色】设定好方案,即可24小时手动工作,不再须要人工干涉
【特色】小巧、低耗和良好的稳定性特别适宜运行于服务器
【特色】所有规则都可以导出导入,灵活的资源重用
【特色】采用FTP上传文件,稳定、安全
【特色】与网站分离,通过独立制做的插口,可以支持任何网站或数据库
【采集】可选择逆序、顺序、随机采集文章
【采集】支持手动列表网址
【采集】支持对数据分布在多层页面的网站进行采集
【采集】自由设定采集数据项,并可单独过滤整理每位数据项
【采集】支持分页内容采集
【采集】支持任意格式、类型的文件(包括图片、视频)下载
【采集】可突破防盗链文件
【采集】支持动态文件网址剖析
【采集】支持对需登陆访问的网页的采集
【支持】可设定关键词采集
【支持】可设定避免采集的敏感词
【支持】可设置图片水印 查看全部
EditorTools全自动采集助手
Editor Tools全自动采集助手是一款免费的网路资源采集软件。Editor Tools全手动采集助手是中小网站自动更新神器,全手动采集发布,运行期间沉静工作,无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作。

Editor Tools全自动采集助手功能介绍:
【特色】绿色软件,免安装
【特色】设定好方案,即可24小时手动工作,不再须要人工干涉
【特色】小巧、低耗和良好的稳定性特别适宜运行于服务器
【特色】所有规则都可以导出导入,灵活的资源重用
【特色】采用FTP上传文件,稳定、安全
【特色】与网站分离,通过独立制做的插口,可以支持任何网站或数据库
【采集】可选择逆序、顺序、随机采集文章
【采集】支持手动列表网址
【采集】支持对数据分布在多层页面的网站进行采集
【采集】自由设定采集数据项,并可单独过滤整理每位数据项
【采集】支持分页内容采集
【采集】支持任意格式、类型的文件(包括图片、视频)下载
【采集】可突破防盗链文件
【采集】支持动态文件网址剖析
【采集】支持对需登陆访问的网页的采集
【支持】可设定关键词采集
【支持】可设定避免采集的敏感词
【支持】可设置图片水印
「号内采集」自动抓取cookie和公众号主页图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 443 次浏览 • 2020-08-20 19:30
当我们采集一个公众号所有历史群发文章的时侯就须要用到号内采集的功能,这个功能须要抓取一些参数,抓取的过程也是自动化的,但是须要人为的点击一下,具体操作步骤如下:
请勿必按教程步骤操作
特别说明:每天建议采集4000篇文章左右,不要采集太多的公众号,会导致访问频繁的。已经采集的公众号文章信息会手动录入本地数据库,可通过本地搜索查看。
第一步:打开陌陌笔记本版并登陆,还没有下载陌陌的点我下载,登录陌陌后,打开须要采集的公众号,这里以公众号赚客撸羊绒为例,先点击右上角的步入公众号
第二步:打开如上图界面后,点击右上角的三个点点,再点击右图所示界面的查看历史消息
如果上图点击历史消息界面提示 “请在陌陌客户端打开链接” ,打开PC端陌陌设置—通用设置,将使用系统默认浏览器打开网页取消勾选即可
第三步:然后我们在软件的号内采集界面,点击开始采集按钮(点击后360等安全软件可能会有拦截提示,请勿必点击准许,第一次使用可能也会提示安装证书,务必也点击容许)
等待按键名称变为窃听中,再刷新公众号历史消息界面
注意是刷新公众号历史消息界面,如下边第二张图片,其他任何界面都不行
第四步:刷新后软件都会手动采集历史文章啦,加载间隔建议设置10秒,等待采集完成就可以导入文章或者浏览,如果刷新后软件没有手动采集,请查看下边这篇文章解决:
「号内采集 」刷新公众号历史消息界面,软件没反应或提示窃听获取cookie超时
特别注意:
1. 是等按键名称变为窃听中,再刷新历史界面;2. 是刷新历史消息界面,不是刷新文章内容页面,千万不能搞错了;3. 采集过程中不需要再去刷新历史消息界面,只须要刷新一次即可; 查看全部
「号内采集」自动抓取cookie和公众号主页图文教程
当我们采集一个公众号所有历史群发文章的时侯就须要用到号内采集的功能,这个功能须要抓取一些参数,抓取的过程也是自动化的,但是须要人为的点击一下,具体操作步骤如下:
请勿必按教程步骤操作
特别说明:每天建议采集4000篇文章左右,不要采集太多的公众号,会导致访问频繁的。已经采集的公众号文章信息会手动录入本地数据库,可通过本地搜索查看。
第一步:打开陌陌笔记本版并登陆,还没有下载陌陌的点我下载,登录陌陌后,打开须要采集的公众号,这里以公众号赚客撸羊绒为例,先点击右上角的步入公众号


第二步:打开如上图界面后,点击右上角的三个点点,再点击右图所示界面的查看历史消息

如果上图点击历史消息界面提示 “请在陌陌客户端打开链接” ,打开PC端陌陌设置—通用设置,将使用系统默认浏览器打开网页取消勾选即可


第三步:然后我们在软件的号内采集界面,点击开始采集按钮(点击后360等安全软件可能会有拦截提示,请勿必点击准许,第一次使用可能也会提示安装证书,务必也点击容许)
等待按键名称变为窃听中,再刷新公众号历史消息界面
注意是刷新公众号历史消息界面,如下边第二张图片,其他任何界面都不行


第四步:刷新后软件都会手动采集历史文章啦,加载间隔建议设置10秒,等待采集完成就可以导入文章或者浏览,如果刷新后软件没有手动采集,请查看下边这篇文章解决:
「号内采集 」刷新公众号历史消息界面,软件没反应或提示窃听获取cookie超时

特别注意:
1. 是等按键名称变为窃听中,再刷新历史界面;2. 是刷新历史消息界面,不是刷新文章内容页面,千万不能搞错了;3. 采集过程中不需要再去刷新历史消息界面,只须要刷新一次即可;
怎么把自媒体稿子定时发到自媒体平台?
采集交流 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2020-08-15 16:14
产品品牌:
易媒助手
产品均价:
56
最小起订:
1
供货总数:
1
发货时限:
当天
发货城市:
上海
怎么把自媒体稿子定时发到自媒体平台?一键发布视频之后来讲解怎样一键推送视频,跟着我下“发视频”,我有个小建议,把“默认分类”这里填好,添加本地视频,必须得填上标签标题等内容。设置好,轻点一下“发布”图标,会步入帐号勾选界面,选中要更新的分组,就一键发布完成了,是不是马上才能解放手掌?
舆情数据写自媒体文章人,你既然想创作出10万+,基础是要练就怎么聪明的蹭热点,要想文章人人看你们都爱用的办法是查阅数个热点榜,于是咱个人爱用的那些及时跟踪关键词的助手:微热点、统计如何把自媒体稿子定时发到自媒体平台?
因为传统推广成本的劣势越来越显著,近几年,视频内容营运格外被你们偏爱,其互动性非常强、隐藏着千百万级的流量、出众的阅读订购能力的特性,逐渐招来海量企业品牌方,正是想要取得充分的视频或图文爆光,我们经常会发送到所有的媒体平台。事实上当你的帐号足够充足,就会晓得:每天都跳不过每位平台登陆帐号、下面,再挨个地分发想要发的内容,毕竟是琐碎又沉闷,还太费时间,解决方案我昨天分享给你们。怎么把自媒体稿子定时发到自媒体平台?
【易媒助手9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台
6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
视频制做对于视频剪辑而言,能够满足日常使用的视频内容加工程序应用不少,但你们都晓得并非每一个应用工具都这么完美,这样的话圈友们直接选定一个契合个人使用惯的,于是小编汇总了这种新媒体行业视频素材处理程序应用,快保存到小本子上:爱剪辑如何把自媒体稿子定时发到自媒体平台?设置常用领域头一回使用这个软件,强烈建议设置好默认分类,之后创作的时侯,自动帮你填充分类,就无需一遍遍去设置了,很方便有木有,并且还支持多套方案。
视频素材如同有看点的文章需要资料,大部分情况下视频联接处理仍然得浏览别的视频中的资料,若你了解的素材越是优质,那样的话你完成的内容整体上或将显露高水准,我忽然发觉了下边那些实用的素材站,要是能帮助到你,哥哥姐姐们快记录出来:摄图网、国外素材:Videovo如何把自媒体稿子定时发到自媒体平台?
数据接触过营运的高手们,每个人觉得热文的深度剖析着实必需,倘若你平时的方法是活在自己式的写文,意识不到了解读者的话题集中在那里,故而基本上极少有人看,下面这种“宝贝”,能够使你找到正确公路:指数
数据在内容行业具有深厚经验的人,谁人不赞成跟踪视频wechat数据,并对数据剖析调整渐渐显得必需,假使你仅仅是随心情式的码字,意识不到结合读者的喜好和偏好,必然数据凄凉,而接下来的宝藏网站,可以使你找到正确公路接下来小编我意外发觉了下文的几个检测新热文的第三方应用,搜索瞧瞧怎么样,应该可以为编辑大佬们提供帮助:OK计数器如何把自媒体稿子定时发到自媒体平台?默认分类设置头一回用这个工具,强烈建议设置一下默认分类,今后创作时手动选择分类,就不用挨个去设置分类了,并且支持设置不同的分类。
一键发布视频接着来演示如何一键推送视频,关键点来了,鼠标移至“发视频”处,大家好设置好默认分类,然后再上传好想要发的视频,然后再挨个填写相应的标签或则标题。当你将里面那些步骤完成之后,发布按键请一下,会弹出勾选帐号的地方,选择想发的分组,就快速完成了一条视频的发布,有没有被这些快速的方法震惊住?
因为流量成本是趋减的,尤其是逾一两年,内容经济公认的被注重,其简单容易操作、曝光能力、超棒的转化作用的优越性,慢慢招来无数的个人品牌方。
添加媒体号步入易媒助手,添加帐号,选择添加帐号界面须要营运的平台,选择用帐号密码登入,往后软件手动输入帐密,不用一个一个输入了。怎么把自媒体稿子定时发到自媒体平台? 查看全部

产品品牌:
易媒助手
产品均价:
56
最小起订:
1
供货总数:
1
发货时限:
当天
发货城市:
上海
怎么把自媒体稿子定时发到自媒体平台?一键发布视频之后来讲解怎样一键推送视频,跟着我下“发视频”,我有个小建议,把“默认分类”这里填好,添加本地视频,必须得填上标签标题等内容。设置好,轻点一下“发布”图标,会步入帐号勾选界面,选中要更新的分组,就一键发布完成了,是不是马上才能解放手掌?

舆情数据写自媒体文章人,你既然想创作出10万+,基础是要练就怎么聪明的蹭热点,要想文章人人看你们都爱用的办法是查阅数个热点榜,于是咱个人爱用的那些及时跟踪关键词的助手:微热点、统计如何把自媒体稿子定时发到自媒体平台?
因为传统推广成本的劣势越来越显著,近几年,视频内容营运格外被你们偏爱,其互动性非常强、隐藏着千百万级的流量、出众的阅读订购能力的特性,逐渐招来海量企业品牌方,正是想要取得充分的视频或图文爆光,我们经常会发送到所有的媒体平台。事实上当你的帐号足够充足,就会晓得:每天都跳不过每位平台登陆帐号、下面,再挨个地分发想要发的内容,毕竟是琐碎又沉闷,还太费时间,解决方案我昨天分享给你们。怎么把自媒体稿子定时发到自媒体平台?

【易媒助手9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台

6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
视频制做对于视频剪辑而言,能够满足日常使用的视频内容加工程序应用不少,但你们都晓得并非每一个应用工具都这么完美,这样的话圈友们直接选定一个契合个人使用惯的,于是小编汇总了这种新媒体行业视频素材处理程序应用,快保存到小本子上:爱剪辑如何把自媒体稿子定时发到自媒体平台?设置常用领域头一回使用这个软件,强烈建议设置好默认分类,之后创作的时侯,自动帮你填充分类,就无需一遍遍去设置了,很方便有木有,并且还支持多套方案。
视频素材如同有看点的文章需要资料,大部分情况下视频联接处理仍然得浏览别的视频中的资料,若你了解的素材越是优质,那样的话你完成的内容整体上或将显露高水准,我忽然发觉了下边那些实用的素材站,要是能帮助到你,哥哥姐姐们快记录出来:摄图网、国外素材:Videovo如何把自媒体稿子定时发到自媒体平台?

数据接触过营运的高手们,每个人觉得热文的深度剖析着实必需,倘若你平时的方法是活在自己式的写文,意识不到了解读者的话题集中在那里,故而基本上极少有人看,下面这种“宝贝”,能够使你找到正确公路:指数
数据在内容行业具有深厚经验的人,谁人不赞成跟踪视频wechat数据,并对数据剖析调整渐渐显得必需,假使你仅仅是随心情式的码字,意识不到结合读者的喜好和偏好,必然数据凄凉,而接下来的宝藏网站,可以使你找到正确公路接下来小编我意外发觉了下文的几个检测新热文的第三方应用,搜索瞧瞧怎么样,应该可以为编辑大佬们提供帮助:OK计数器如何把自媒体稿子定时发到自媒体平台?默认分类设置头一回用这个工具,强烈建议设置一下默认分类,今后创作时手动选择分类,就不用挨个去设置分类了,并且支持设置不同的分类。
一键发布视频接着来演示如何一键推送视频,关键点来了,鼠标移至“发视频”处,大家好设置好默认分类,然后再上传好想要发的视频,然后再挨个填写相应的标签或则标题。当你将里面那些步骤完成之后,发布按键请一下,会弹出勾选帐号的地方,选择想发的分组,就快速完成了一条视频的发布,有没有被这些快速的方法震惊住?

因为流量成本是趋减的,尤其是逾一两年,内容经济公认的被注重,其简单容易操作、曝光能力、超棒的转化作用的优越性,慢慢招来无数的个人品牌方。
添加媒体号步入易媒助手,添加帐号,选择添加帐号界面须要营运的平台,选择用帐号密码登入,往后软件手动输入帐密,不用一个一个输入了。怎么把自媒体稿子定时发到自媒体平台?
最强半自动化抓鸡工具构建思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-09 14:49
你向他人说你是搞安全的,外行人会问你能盗QQ吗内行人会问你能拿站吗,在太长一段时间里只能反复难堪地回答不能,然后外行人就对你兴趣缺缺内行人也对你兴致缺缺。
大概2010年以前尤其2005年以前,一是厂商并没有这么注重安全所以漏洞好多二是用户也欠缺安全意识有补丁也极少打,造成的结果就是漏洞好多且长时间内都可借助。基于这些情况很容易地就可以编撰一款自动化工具之后在太长时间内都能拿来攻占大量系统,但在现今漏洞密度越来越小借助难度越来越高0day/1day时间越来越短的环境下,这种模式越来越无法持续了。新人们不能不比老人们当初我学几天就拿下xxx实在不是人的水平低了而是外部安全水平高了。
你说得太有道理而且谁在乎呢,正如姑娘问你有没有房,你说楼市跌得很快啦老家刚家装啦,那就是没有嘛。想了一想搞安全要求能拿站应当不算过份,环境怎么样是我们自己要去处理的问题而不是只要求结果的领导们要了解的问题。难道老人们水水就叫能拿站新人就毫无捷径可走被贴上一代不如一代的标签吗。想了一想,正如刚变革开放只要稍稍努力都能奔小康现今搞IT还有希望跨阶级,只要把自动化发挥到极至轻松抓鸡还是有可能。
二、自动化功击思路
集成化思路虽然在好多地方都存在,比如cvedetails上会尽量列举关联的exploit,再如shodan和zoomeye上搜索主机会列举相关CVE,又如AutoSploit就直接是一个抓鸡工具。
cvedetails首先有些exp并没有列到对应的cve条目上(不懂为何),其次在真正的渗透中我们须要自己扫描ip存在的服务。
shodan和zoomeye主是列举了主机相关的cve。并没有直接列举exp。
autosploit为了实现自动化,只能使用特定格式的msf模块,一些可以功击的百规范化exp都被放弃了。
结命以上各工具优缺点,我们这儿选实现的“IP-服务-CVE-EXP”三步,舍弃掉最后功击一步。
其实从标题“抓鸡”可知最初而言是希望能实现autosploit那样的自动化功击,但实现过程中发觉存在想得很简单,不是他人只想到集成而没想到自动化而是有很多问题。所以本文“抓鸡”是标题党,“最强”也是标题党,后来补起来的“半自动化”也是标题党,程序只算能运行上去。不过对于采集CVE、MSF模块和exploitdb的exp及进一步的应急响应都还算有些意义。
2.1 指定ip查找exp
经过以下三步,得出最终IP及可用EXP(由IP确认EXP)
步骤
输入
处理
输出
第一步
IP
Shodan/Nmap
IP开放的服务及版本
第二步
IP开放的服务及版本
cvedetails类似数据库
服务及版本存在的CVE
第三步
服务及版本存在的CVE
metasploit/exploit-db
CVE对应的exp
2.2 使用最新exp找出适用该exp的ip
经过以下三步,得出最终IP及可用EXP(由EXP确认IP)
步骤
输入
处理
输出
第一步
最新的exp
metasploit/exploit-db
exp相关cve
第二步
exp相关cve
cvedetails类似数据库
cve影响的服务及版本
第三步
cve影响的服务及版本
Shodan
存在服务及版本的IP
三、数据库建设思路
在上一节中,我们谈到了以下几项:shodan、cvedetails、metasploit和exploit-db。
3.1 否定联网方法
首先,联网方法受网速限制。这些网站都是美国网站速度相对不稳定,几个网站依次访问历时会较长。
其次,联网方法受网站保护策略限制。频繁该问IP有可能被封掉(虽然测试中仍未发觉),其次象exploit-db查询须要验证码。
再次,联网方法受网站排版限制。比如cvedetails查询一个产品存在的cve列举的先是一个匹配产品汇总表,点进去再是一个漏洞年份汇总表,再点进去才是CVE列表,要走好几步这是很麻烦的。
除了shodan必然须要联网使用,cvedetails、metasploit和exploit-db都不适宜联网方法。
3.2 否定metasploit和exploit-db使用管线方式
在kali上metasploit通过启动msfconsole之后使用search命令可以进行搜索,但使用msfconsole的就会感觉到其启停是比较花费资源和时间的,所以启动msfconsole查询之后通过管线获取结果的方式并不好。
在kali上可以使用searchsploit命令查找exploit-db的exp,这资源和时间都算可接受,但是一定要安装好exploit-db能够用这限制很大也不是太理想。
3.3 数据库建设思路
在否定联网方法和否定管线方式后,剩下的只能建设本地数据库,而建设又可以分为在线建设和离线建设两种思路。
在线建设就是一个个页面去访问页面之后解析入库,这种方法一是耗费时间长,二是在实践时中间常由于恳求超时和解码有误而让程序中断,三是这些暴力的方式容易被封IP(metasploit最敏感,exploit最包容;在被封IP时你可以感受到动态IP也有用处)。基于以上缘由能离线建设就离线建设。
数据库
建设方法
更新方法
url
cve数据库
cvedetails其实没提供离线下载,但cvedetails的cve数据来源于nvd,nvd提供cve离线下载。离线建设
每日下载nvdcve-modified.xml更新数据库
metasploit数据库
metasploit在github有托管。离线建设。
metasploit实在很容易封ip,git同步项目后重新遍历采集
exploitdb数据库
exploitdb在github也有托管,但是cve只向exploitdb合作者提供而cve是程序的关键,所以只能使用在线建设
仍然只能在线追踪
关于更新还有以下几个关键点:
cvedetails在排列cve时只是简单地order by cve desc,这造成的问题就是排在最前面的cve并不一定是最新的cve,比如CVE-2018-1002209(2018-07-25发布)会排在CVE-2018-19115(2018-11-08发布)前面,所以cvedetails并不适宜拿来采集更新。
由于cve数据库使用nvdcve-modified.xml进行更新,这就要求必须每晚都执行更新程序不然cve都会不完整。nvdcve-modified.xml一是收录新发布的cve二是收录旧cve的修改,如果要保证cve的完整性须要重新下载搁置更新的年份的xml重新读取,如果要保证参考等的完整性那就要删掉数据库全部重新解析入库(还是要时间的大约半天)。
metasploit一个模块发布后通常不会再改动,所以我们以module_name为关键字,每次git pull同步后若果已存在就舍弃插入假如仍未存在就插入,这能挺好地保证metasploit数据库的完整性。单纯exploit模块整个过程大约只须要半个小时。
exploitdb在线建设耗费比较长的时间,一是在线不断恳求历时二是即使比较忍让但联接很久也会被禁,断断续续整个采集过程大约须要一周。
exploitdb以edbid为关键字,更新时依次访问exploitdb的remote、webapps、local、dos四大页面该页面,从头开始解析假如查到已存在expid则中止往下读取。remote等一个页面大约能显示一到三个月内的exp,在此时间范围内能填补缺位的记录假如超出一页这么这些记录也将不会补追补。当然你也可以在remote等中一页页地追踪下去但考虑以下两点这儿不那么实现,但这儿一是考虑一个月时间早已比较长,二是edbid是递增的可以自由地设置采集的edbid的区间。
3.4 数据库选择
首先,是选关系型数据库还是非关系型数据库,根据实际来看使用关系型数据库当有子查询时速率太慢,建索引也还是比较耗时间,所以可能非关系型数据库会快些。但是我需要同步到elk但elk不支持从非关系型读取数据,所以只能使用非关系型数据库。另外假如你要自己改成非关系型数据库那工作量比较大。
其次,选择关系型数据库后还要确定具体选那个数据库,其实不扯到高可用这种东西仅就使用来说关系型数据库都差异不大,开始想用sqlite但同步到elk时仍然报错处理不了,后来太慢想oracle可能快一些但很耗资源笔记本运行不起,所以就用mysql。你自己要改成其他数据库,连接句子和sql句子稍为更改应当就可以了。
3.5 数据库表设计3.5.1 cve表设计
cve_records表各数组如下:
对应cvedetails以下部分:
最终数据示例如下:
cve_affect_records表用于记录受cve影响的产品,各数组如下:
对应cvedetails以下部分:
最终搜集数据示例如下:
cve_refer_records表用于记录cve的参考链接,各数组如下:
对应cvedetails以下部份:
最终搜集数据示例如下:
3.5.2 msf表设计
msf_records表各数组如下:
对应模块查看页面的那几项内容:
最终搜集数据示例如下:
3.5.3 edb表设计
edb_records表各数组如下:
对应edb查看页面如下几项内容:
最终搜集数据示例如下:
四、程序说明4.1 程序使用说明
程序写了两周,实现疗效也不是挺好不是太有心情仔细说明,另外文件中也有一定注释。
配置好setting相关项,运行cve_offline_parse.py,就会搜集cve数据
配置好setting相关项,运行msf_offline_parse.py,就会搜集msf模块数据
配置好setting相关项,运行edb_online_parse.py,就会搜集edb模块数据
项目文件结构整体如下:
|-config|
| |-setting.py----程序配置文件,自己使用时主要修改这个文件
|
|-dao|
| |-src_db_dao.py----存放各dao数的文件
|
|-model|
| |-src_db_model.py----存放数据库表对应的model的文件
|
|-cve_offline_parse.py----通过下载nvd的xml解析入库cve的文件
|
|-cve_online_parse.py----原本设计通过读取cvedetails解析入库cve的文件,实际不使用
|
|-daily_trace_report.py----检查cve、msf、edb更新情况并发送通知邮件的文件
|
|-edb_online_parse.py----通过遍历www.exploit-db.com解析入库exp的文件
|
|-exploit_tool.py----所谓的“半自动化抓鸡工具”实现文件
|
|-msf_offline_parse.py----通过git同步github的metasploit-framework解析入库模块的文件
|
|-msf_online_parse.py----原本设计通过遍历www.rapid7.com/db/modules解析入库模块的文件,实际只用其追踪更新功能。
|
|-search_engine.py----shodan搜索实现文件
说明:2018.12.08发觉exploit-db网站升级,新写edb_online_parse_new.py取代旧的edb_online_parse.py。
4.2 运行环境
语言:python3
额外安装库:pip install requests requests-html pymysql sqlalchemy shodan beautifulsoup4
4.3 程序源代码
代码比较多,直接上github(db目录是我搜集好的数据解压下来导出mysql即可): 查看全部
一、说明
你向他人说你是搞安全的,外行人会问你能盗QQ吗内行人会问你能拿站吗,在太长一段时间里只能反复难堪地回答不能,然后外行人就对你兴趣缺缺内行人也对你兴致缺缺。
大概2010年以前尤其2005年以前,一是厂商并没有这么注重安全所以漏洞好多二是用户也欠缺安全意识有补丁也极少打,造成的结果就是漏洞好多且长时间内都可借助。基于这些情况很容易地就可以编撰一款自动化工具之后在太长时间内都能拿来攻占大量系统,但在现今漏洞密度越来越小借助难度越来越高0day/1day时间越来越短的环境下,这种模式越来越无法持续了。新人们不能不比老人们当初我学几天就拿下xxx实在不是人的水平低了而是外部安全水平高了。
你说得太有道理而且谁在乎呢,正如姑娘问你有没有房,你说楼市跌得很快啦老家刚家装啦,那就是没有嘛。想了一想搞安全要求能拿站应当不算过份,环境怎么样是我们自己要去处理的问题而不是只要求结果的领导们要了解的问题。难道老人们水水就叫能拿站新人就毫无捷径可走被贴上一代不如一代的标签吗。想了一想,正如刚变革开放只要稍稍努力都能奔小康现今搞IT还有希望跨阶级,只要把自动化发挥到极至轻松抓鸡还是有可能。
二、自动化功击思路
集成化思路虽然在好多地方都存在,比如cvedetails上会尽量列举关联的exploit,再如shodan和zoomeye上搜索主机会列举相关CVE,又如AutoSploit就直接是一个抓鸡工具。
cvedetails首先有些exp并没有列到对应的cve条目上(不懂为何),其次在真正的渗透中我们须要自己扫描ip存在的服务。
shodan和zoomeye主是列举了主机相关的cve。并没有直接列举exp。
autosploit为了实现自动化,只能使用特定格式的msf模块,一些可以功击的百规范化exp都被放弃了。
结命以上各工具优缺点,我们这儿选实现的“IP-服务-CVE-EXP”三步,舍弃掉最后功击一步。
其实从标题“抓鸡”可知最初而言是希望能实现autosploit那样的自动化功击,但实现过程中发觉存在想得很简单,不是他人只想到集成而没想到自动化而是有很多问题。所以本文“抓鸡”是标题党,“最强”也是标题党,后来补起来的“半自动化”也是标题党,程序只算能运行上去。不过对于采集CVE、MSF模块和exploitdb的exp及进一步的应急响应都还算有些意义。
2.1 指定ip查找exp
经过以下三步,得出最终IP及可用EXP(由IP确认EXP)
步骤
输入
处理
输出
第一步
IP
Shodan/Nmap
IP开放的服务及版本
第二步
IP开放的服务及版本
cvedetails类似数据库
服务及版本存在的CVE
第三步
服务及版本存在的CVE
metasploit/exploit-db
CVE对应的exp
2.2 使用最新exp找出适用该exp的ip
经过以下三步,得出最终IP及可用EXP(由EXP确认IP)
步骤
输入
处理
输出
第一步
最新的exp
metasploit/exploit-db
exp相关cve
第二步
exp相关cve
cvedetails类似数据库
cve影响的服务及版本
第三步
cve影响的服务及版本
Shodan
存在服务及版本的IP
三、数据库建设思路
在上一节中,我们谈到了以下几项:shodan、cvedetails、metasploit和exploit-db。
3.1 否定联网方法
首先,联网方法受网速限制。这些网站都是美国网站速度相对不稳定,几个网站依次访问历时会较长。
其次,联网方法受网站保护策略限制。频繁该问IP有可能被封掉(虽然测试中仍未发觉),其次象exploit-db查询须要验证码。
再次,联网方法受网站排版限制。比如cvedetails查询一个产品存在的cve列举的先是一个匹配产品汇总表,点进去再是一个漏洞年份汇总表,再点进去才是CVE列表,要走好几步这是很麻烦的。


除了shodan必然须要联网使用,cvedetails、metasploit和exploit-db都不适宜联网方法。
3.2 否定metasploit和exploit-db使用管线方式
在kali上metasploit通过启动msfconsole之后使用search命令可以进行搜索,但使用msfconsole的就会感觉到其启停是比较花费资源和时间的,所以启动msfconsole查询之后通过管线获取结果的方式并不好。
在kali上可以使用searchsploit命令查找exploit-db的exp,这资源和时间都算可接受,但是一定要安装好exploit-db能够用这限制很大也不是太理想。
3.3 数据库建设思路
在否定联网方法和否定管线方式后,剩下的只能建设本地数据库,而建设又可以分为在线建设和离线建设两种思路。
在线建设就是一个个页面去访问页面之后解析入库,这种方法一是耗费时间长,二是在实践时中间常由于恳求超时和解码有误而让程序中断,三是这些暴力的方式容易被封IP(metasploit最敏感,exploit最包容;在被封IP时你可以感受到动态IP也有用处)。基于以上缘由能离线建设就离线建设。
数据库
建设方法
更新方法
url
cve数据库
cvedetails其实没提供离线下载,但cvedetails的cve数据来源于nvd,nvd提供cve离线下载。离线建设
每日下载nvdcve-modified.xml更新数据库
metasploit数据库
metasploit在github有托管。离线建设。
metasploit实在很容易封ip,git同步项目后重新遍历采集
exploitdb数据库
exploitdb在github也有托管,但是cve只向exploitdb合作者提供而cve是程序的关键,所以只能使用在线建设
仍然只能在线追踪
关于更新还有以下几个关键点:
cvedetails在排列cve时只是简单地order by cve desc,这造成的问题就是排在最前面的cve并不一定是最新的cve,比如CVE-2018-1002209(2018-07-25发布)会排在CVE-2018-19115(2018-11-08发布)前面,所以cvedetails并不适宜拿来采集更新。
由于cve数据库使用nvdcve-modified.xml进行更新,这就要求必须每晚都执行更新程序不然cve都会不完整。nvdcve-modified.xml一是收录新发布的cve二是收录旧cve的修改,如果要保证cve的完整性须要重新下载搁置更新的年份的xml重新读取,如果要保证参考等的完整性那就要删掉数据库全部重新解析入库(还是要时间的大约半天)。
metasploit一个模块发布后通常不会再改动,所以我们以module_name为关键字,每次git pull同步后若果已存在就舍弃插入假如仍未存在就插入,这能挺好地保证metasploit数据库的完整性。单纯exploit模块整个过程大约只须要半个小时。
exploitdb在线建设耗费比较长的时间,一是在线不断恳求历时二是即使比较忍让但联接很久也会被禁,断断续续整个采集过程大约须要一周。
exploitdb以edbid为关键字,更新时依次访问exploitdb的remote、webapps、local、dos四大页面该页面,从头开始解析假如查到已存在expid则中止往下读取。remote等一个页面大约能显示一到三个月内的exp,在此时间范围内能填补缺位的记录假如超出一页这么这些记录也将不会补追补。当然你也可以在remote等中一页页地追踪下去但考虑以下两点这儿不那么实现,但这儿一是考虑一个月时间早已比较长,二是edbid是递增的可以自由地设置采集的edbid的区间。
3.4 数据库选择
首先,是选关系型数据库还是非关系型数据库,根据实际来看使用关系型数据库当有子查询时速率太慢,建索引也还是比较耗时间,所以可能非关系型数据库会快些。但是我需要同步到elk但elk不支持从非关系型读取数据,所以只能使用非关系型数据库。另外假如你要自己改成非关系型数据库那工作量比较大。
其次,选择关系型数据库后还要确定具体选那个数据库,其实不扯到高可用这种东西仅就使用来说关系型数据库都差异不大,开始想用sqlite但同步到elk时仍然报错处理不了,后来太慢想oracle可能快一些但很耗资源笔记本运行不起,所以就用mysql。你自己要改成其他数据库,连接句子和sql句子稍为更改应当就可以了。
3.5 数据库表设计3.5.1 cve表设计
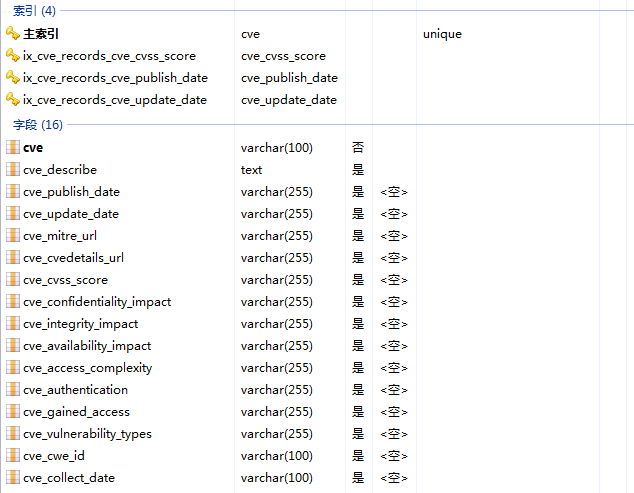
cve_records表各数组如下:
对应cvedetails以下部分:
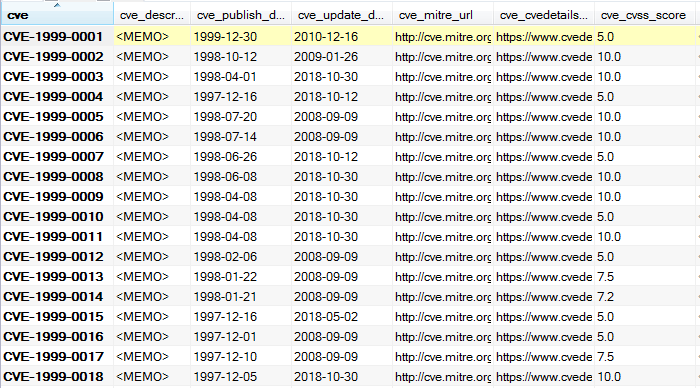
最终数据示例如下:
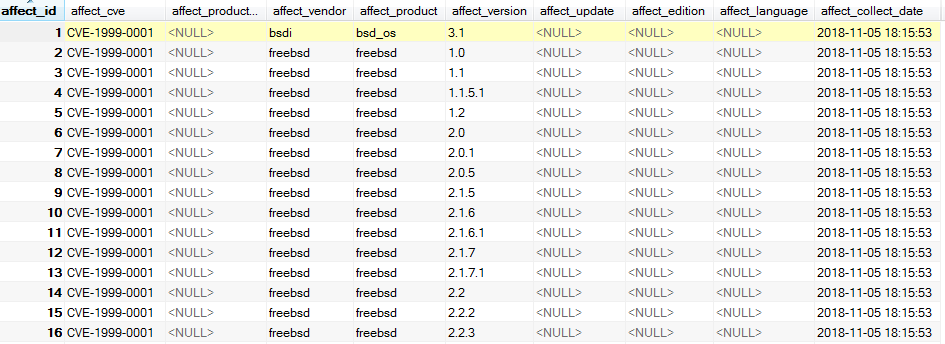
cve_affect_records表用于记录受cve影响的产品,各数组如下:
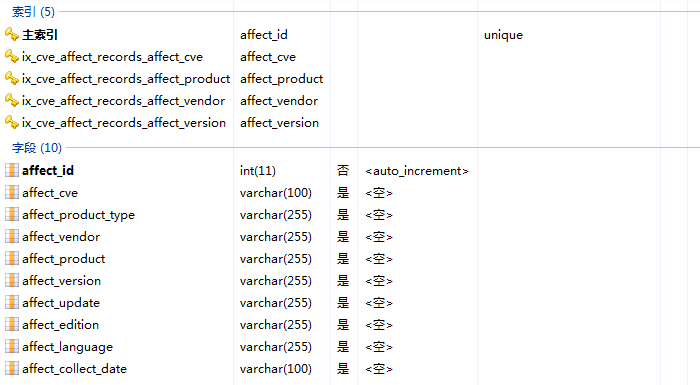
对应cvedetails以下部分:
最终搜集数据示例如下:
cve_refer_records表用于记录cve的参考链接,各数组如下:

对应cvedetails以下部份:

最终搜集数据示例如下:

3.5.2 msf表设计
msf_records表各数组如下:
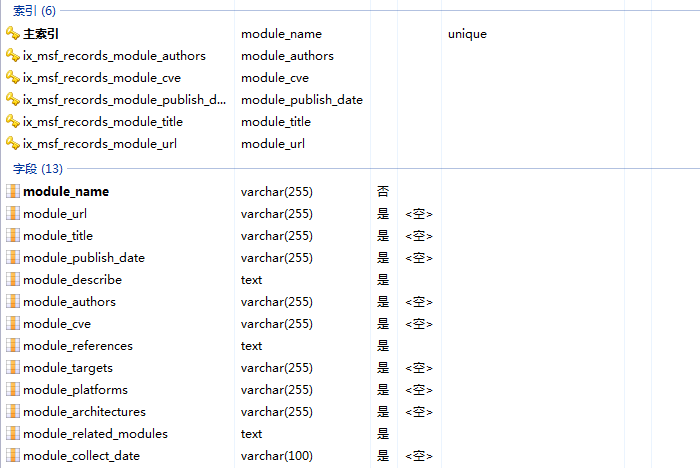
对应模块查看页面的那几项内容:

最终搜集数据示例如下:
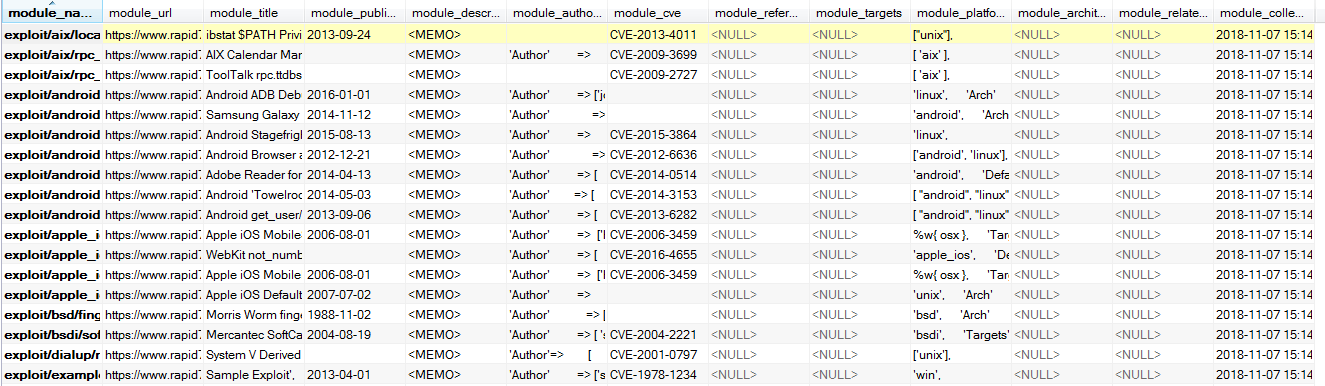
3.5.3 edb表设计
edb_records表各数组如下:
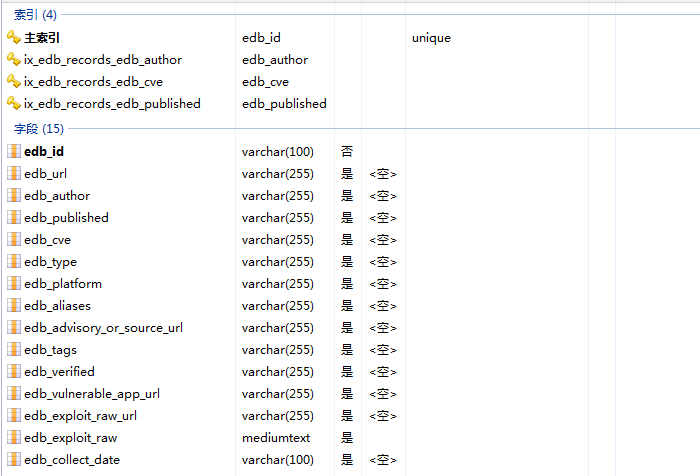
对应edb查看页面如下几项内容:
最终搜集数据示例如下:

四、程序说明4.1 程序使用说明
程序写了两周,实现疗效也不是挺好不是太有心情仔细说明,另外文件中也有一定注释。
配置好setting相关项,运行cve_offline_parse.py,就会搜集cve数据
配置好setting相关项,运行msf_offline_parse.py,就会搜集msf模块数据
配置好setting相关项,运行edb_online_parse.py,就会搜集edb模块数据
项目文件结构整体如下:
|-config|
| |-setting.py----程序配置文件,自己使用时主要修改这个文件
|
|-dao|
| |-src_db_dao.py----存放各dao数的文件
|
|-model|
| |-src_db_model.py----存放数据库表对应的model的文件
|
|-cve_offline_parse.py----通过下载nvd的xml解析入库cve的文件
|
|-cve_online_parse.py----原本设计通过读取cvedetails解析入库cve的文件,实际不使用
|
|-daily_trace_report.py----检查cve、msf、edb更新情况并发送通知邮件的文件
|
|-edb_online_parse.py----通过遍历www.exploit-db.com解析入库exp的文件
|
|-exploit_tool.py----所谓的“半自动化抓鸡工具”实现文件
|
|-msf_offline_parse.py----通过git同步github的metasploit-framework解析入库模块的文件
|
|-msf_online_parse.py----原本设计通过遍历www.rapid7.com/db/modules解析入库模块的文件,实际只用其追踪更新功能。
|
|-search_engine.py----shodan搜索实现文件
说明:2018.12.08发觉exploit-db网站升级,新写edb_online_parse_new.py取代旧的edb_online_parse.py。
4.2 运行环境
语言:python3
额外安装库:pip install requests requests-html pymysql sqlalchemy shodan beautifulsoup4
4.3 程序源代码
代码比较多,直接上github(db目录是我搜集好的数据解压下来导出mysql即可):
[发布] 一键采集任何微信公众号的文章,可以输入公众号的名称
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-08-09 11:57
【插件功能】
安装本插件以后,可以输入微信公众号的文章网址或则微信公众号的名称,一键获取内容到您的峰会上。
【本插件功能特性】
1、可以输入微信公众号的名称,实时采集微信公众号的内容。
2、每隔5分钟手动推送微信热文,您只需点击一下键盘就可以发布到您的峰会上。
3、采集过来的陌陌文章图片可以正常显示而且保存为贴子图片附件。
4、图片附件支持远程FTP保存。
5、图片会加上您峰会的水印。
6、已采集过的微信公众号文章不会重复二次采集,内容不会冗余。
7、采集发布的贴子跟真实用户发布的几乎一模一样。
8、浏览量会手动随机设置,感觉您的贴子查看数更真实。
9、可以指定贴子发布者的UID。
10、采集的微信公众号文章内容可以发布到任何一个版块。
11、无限量采集,不限采集次数。
【此插件给您带来的价值】
1、让您的峰会人气太旺,内容太丰富多彩。
2、用一键采集来取代手工发贴,省时省力,不易出错。
3、可以使你的网站与海量的陌陌订阅号共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员(QQ:155120699),如果在48小时之内无法解决问题,全额退票给消费者!!大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员(mail:),在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
【官方QQ群:235307918】
在线安装地址:
@csdn123com_weixin.plugin
本地下载安装: 查看全部

【插件功能】
安装本插件以后,可以输入微信公众号的文章网址或则微信公众号的名称,一键获取内容到您的峰会上。
【本插件功能特性】
1、可以输入微信公众号的名称,实时采集微信公众号的内容。
2、每隔5分钟手动推送微信热文,您只需点击一下键盘就可以发布到您的峰会上。
3、采集过来的陌陌文章图片可以正常显示而且保存为贴子图片附件。
4、图片附件支持远程FTP保存。
5、图片会加上您峰会的水印。
6、已采集过的微信公众号文章不会重复二次采集,内容不会冗余。
7、采集发布的贴子跟真实用户发布的几乎一模一样。
8、浏览量会手动随机设置,感觉您的贴子查看数更真实。
9、可以指定贴子发布者的UID。
10、采集的微信公众号文章内容可以发布到任何一个版块。
11、无限量采集,不限采集次数。
【此插件给您带来的价值】
1、让您的峰会人气太旺,内容太丰富多彩。
2、用一键采集来取代手工发贴,省时省力,不易出错。
3、可以使你的网站与海量的陌陌订阅号共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员(QQ:155120699),如果在48小时之内无法解决问题,全额退票给消费者!!大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员(mail:),在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
【官方QQ群:235307918】
在线安装地址:
@csdn123com_weixin.plugin
本地下载安装:
施庆伪原创工具v2.3.4.10正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-09 01:54
世庆的伪原创工具的特征
1. 伪原创工具是世界上第一个: 本地和网络两种不同的伪原创方法
2,支持中英文伪原创;
3. 使用独特的分词引擎,该引擎完全符合baidu和google的习惯. 同时,我们提供了免费的开发参数界面,请使用-help查看.
4. 独特的同义词和反义词引擎可以适当地更改文章的语义,并使用独特的算法对其进行控制.
5. 独特的段落和段落内迁移功能;
6. 伪原创内容可以以txt或html格式导入和导出,方便客户迁移数据;
7. 独家支持在线自供电的伪原创主流CMS系统,例如Dongyi,Xinyun,Laoya,Dede,Empire,PHPCMS,zblog等;
8. 绿色软件无需安装且容量小. 软件包下载量仅为2M,占用的系统资源较少,是同类软件的1/3;
9. 您可以制作收录html标签的伪原创文章;
10. 您可以制作收录图片,Flash和其他多媒体格式的伪原创文章;
11. 在线升级全部免费,每月定期为您升级程序,以确保百度和Google的更新算法同步;
12. 提供贴心的“替换链接”功能,有效增加SEO外部链接;
13. 本机编译代码,采用win2000之上的所有平台,包括winxp,win2003,vista等;
14. 多核系统,能够以极快的速度生成数以万计的单词的伪原创文章
施庆伪原创工具功能
1. 采集文章
Shi Qing伪原创工具,随附采集工具. 首先,您需要在“集合设置”模块中输入需要采集的关键字. 输入完成后,单击“保存关键字”以保存单词,然后选中它(默认情况下选中). 然后选择在百度或Google采集. 如果您是免费试用用户. 只能使用第一个“免费测试集”.
2,制作伪造的原创文章
用户可以通过4种方式输入原创文章: 1.将文章直接复制到文章编辑区域,然后输入标题,然后保存文章; 2.通过导入,您可以直接导入TXT或html文档. 3.通过采集的方法是直接在Internet上采集文章. 4.直接通过界面获取您自己的CMS网站的内容;
3. 使用直接更新到主流CMS系统
Shi Qing的伪原创工具,支持直接更新99%的国内主流CMS内容,例如东夷,老挝,新云,dede CMS等,通过界面直接获取网站上的信息,并将其上传回去伪原创之后. 在界面中详细说明了特定的使用方法. 按照说明进行操作,您将很快成功.
4. 使用用户定义的词库
用户可以在“自定义词典”部分中输入或导入自己的同义词库. 勾选后,系统将尽快响应该字库,而不是替换我们企业版中的字库. 具体使用方法在软件界面中进行了详细说明. 免费版不支持此功能.
5. 配置替换/插入功能
此功能主要是将URL链接添加到伪原创文章中的指定文本,以创建外部链接. 同时,您可以根据配置的关键字密度插入设置的关键字.
6. 从现有文章中生成新文章
此功能主要是用于动态生成文章的工具. 生成的文章绝对是唯一的,但通常可读.
单击SEO功能,然后选择最后一个菜单“从现有文章生成新文章”.
史青的伪原创工具视频简介
伪原创工具 查看全部
Shiqing伪原创工具是专业的伪原创文章生成器. 它可以将从Internet采集的文章转换为您自己的文章,并且修改方法更符合百度和Google搜索引擎的算法. ,因此该文章排名较高,因此该工具是大多数网站管理员和网站发起人的有力助手!
世庆的伪原创工具的特征
1. 伪原创工具是世界上第一个: 本地和网络两种不同的伪原创方法
2,支持中英文伪原创;
3. 使用独特的分词引擎,该引擎完全符合baidu和google的习惯. 同时,我们提供了免费的开发参数界面,请使用-help查看.
4. 独特的同义词和反义词引擎可以适当地更改文章的语义,并使用独特的算法对其进行控制.
5. 独特的段落和段落内迁移功能;
6. 伪原创内容可以以txt或html格式导入和导出,方便客户迁移数据;
7. 独家支持在线自供电的伪原创主流CMS系统,例如Dongyi,Xinyun,Laoya,Dede,Empire,PHPCMS,zblog等;
8. 绿色软件无需安装且容量小. 软件包下载量仅为2M,占用的系统资源较少,是同类软件的1/3;
9. 您可以制作收录html标签的伪原创文章;
10. 您可以制作收录图片,Flash和其他多媒体格式的伪原创文章;
11. 在线升级全部免费,每月定期为您升级程序,以确保百度和Google的更新算法同步;
12. 提供贴心的“替换链接”功能,有效增加SEO外部链接;
13. 本机编译代码,采用win2000之上的所有平台,包括winxp,win2003,vista等;
14. 多核系统,能够以极快的速度生成数以万计的单词的伪原创文章
施庆伪原创工具功能
1. 采集文章
Shi Qing伪原创工具,随附采集工具. 首先,您需要在“集合设置”模块中输入需要采集的关键字. 输入完成后,单击“保存关键字”以保存单词,然后选中它(默认情况下选中). 然后选择在百度或Google采集. 如果您是免费试用用户. 只能使用第一个“免费测试集”.
2,制作伪造的原创文章
用户可以通过4种方式输入原创文章: 1.将文章直接复制到文章编辑区域,然后输入标题,然后保存文章; 2.通过导入,您可以直接导入TXT或html文档. 3.通过采集的方法是直接在Internet上采集文章. 4.直接通过界面获取您自己的CMS网站的内容;
3. 使用直接更新到主流CMS系统
Shi Qing的伪原创工具,支持直接更新99%的国内主流CMS内容,例如东夷,老挝,新云,dede CMS等,通过界面直接获取网站上的信息,并将其上传回去伪原创之后. 在界面中详细说明了特定的使用方法. 按照说明进行操作,您将很快成功.
4. 使用用户定义的词库
用户可以在“自定义词典”部分中输入或导入自己的同义词库. 勾选后,系统将尽快响应该字库,而不是替换我们企业版中的字库. 具体使用方法在软件界面中进行了详细说明. 免费版不支持此功能.
5. 配置替换/插入功能
此功能主要是将URL链接添加到伪原创文章中的指定文本,以创建外部链接. 同时,您可以根据配置的关键字密度插入设置的关键字.
6. 从现有文章中生成新文章
此功能主要是用于动态生成文章的工具. 生成的文章绝对是唯一的,但通常可读.
单击SEO功能,然后选择最后一个菜单“从现有文章生成新文章”.
史青的伪原创工具视频简介

伪原创工具
如何使用采集器来搜寻微信官方帐户的内容?
采集交流 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2020-08-08 00:46
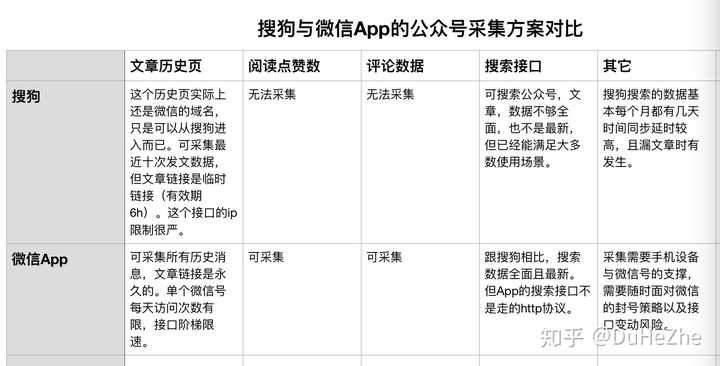
许多答案无用或不再起作用,这是我的计划.
如果您只是采集公共帐户文章,如果要求不是很严格,则可以去搜狗. 这种方案成本低廉,相对简单,但缺点也很明显. 这是一个临时文章链接. 如果要将其转换为永久链接,则仍然必须使用应用程序界面.
另一个解决方案是从微信应用程序本身采集. 这种采集成本会高得多,但是可以采集很多类型的数据,包括但不限于: 历史页面文章,喜欢的阅读,评论等.
为了更加直观,我制作了一个图表来比较从搜狗和微信应用程序采集的两种解决方案.
我自己使用了这两种解决方案,并且还提供了封装的接口. 我将根据成本和方案选择使用哪个.
一个简单的一句话总结就是,搜狗拥有一些微信应用程序,而搜狗没有微信应用程序,但就软成本和硬成本而言,微信计划远大于搜狗的计划.
题外话,图片提到微信中的搜索界面. 我自己实现了. 作为一种实践,我可以获取搜索官方帐户和商品的返回数据,因为该接口使用很少,所以没有打包打开. 如果需要,可以单独与我联系. 许多人可能认为不可能采集搜索接口,因为数据根本不是HTTP协议. 但是我想说的是,有时不必在请求中拦截数据采集. 有很多选择,但是成本会非常大(开发成本和在线成本). 查看全部
于2018-06-05更新
许多答案无用或不再起作用,这是我的计划.
如果您只是采集公共帐户文章,如果要求不是很严格,则可以去搜狗. 这种方案成本低廉,相对简单,但缺点也很明显. 这是一个临时文章链接. 如果要将其转换为永久链接,则仍然必须使用应用程序界面.
另一个解决方案是从微信应用程序本身采集. 这种采集成本会高得多,但是可以采集很多类型的数据,包括但不限于: 历史页面文章,喜欢的阅读,评论等.
为了更加直观,我制作了一个图表来比较从搜狗和微信应用程序采集的两种解决方案.
我自己使用了这两种解决方案,并且还提供了封装的接口. 我将根据成本和方案选择使用哪个.
一个简单的一句话总结就是,搜狗拥有一些微信应用程序,而搜狗没有微信应用程序,但就软成本和硬成本而言,微信计划远大于搜狗的计划.
题外话,图片提到微信中的搜索界面. 我自己实现了. 作为一种实践,我可以获取搜索官方帐户和商品的返回数据,因为该接口使用很少,所以没有打包打开. 如果需要,可以单独与我联系. 许多人可能认为不可能采集搜索接口,因为数据根本不是HTTP协议. 但是我想说的是,有时不必在请求中拦截数据采集. 有很多选择,但是成本会非常大(开发成本和在线成本).
网络爬虫必看的文章采集示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-08-07 23:19
熟悉的朋友知道可以通过官方网站上的FAQ来检索采集过程中遇到的问题,因此这里以采集常见问题为例来说明Web爬网工具采集的原理和过程.
在此示例中,我们将演示地址.
(1)创建一个新的采集规则
选择一个组并单击鼠标右键,选择“新建任务”,如下所示:
(2)添加起始网址
在这里,假设我们需要采集5页数据.
分析网址变量的规律
首页地址:
第二页地址:
第三页地址:
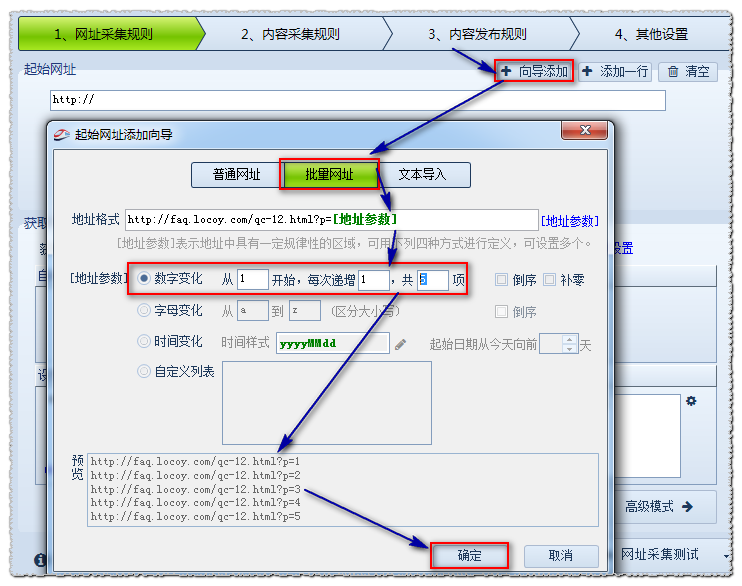
由此我们可以推断出p =之后的数字是分页的含义,我们使用[address parameter]来表示:
因此设置如下:
地址格式: 使用[地址参数]表示更改后的页码.
编号更改: 从1开始,即第一页;每增加1,即每页的更改数量;共5项,共5页.
预览: 采集器将根据上述设置生成一部分URL,以便您判断添加的内容是否正确.
然后确认.
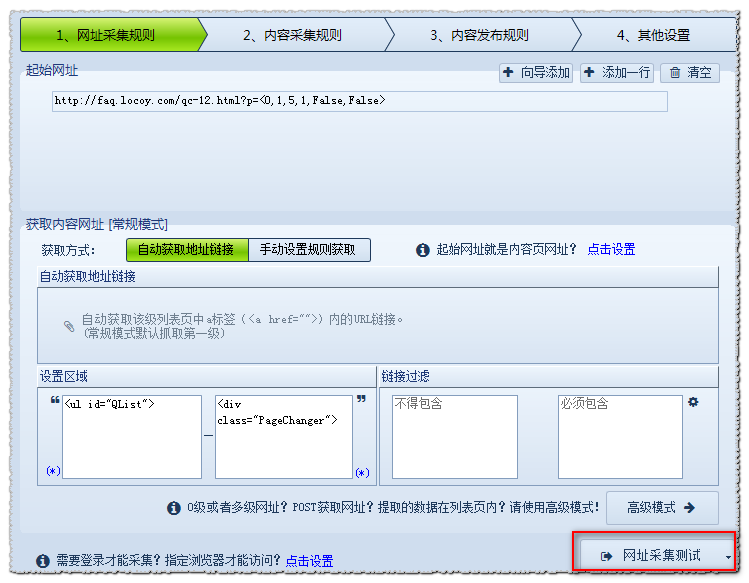
(3)[常规模式]获取内容URL
普通模式: 默认情况下,此模式获取第一级地址,即从起始页的源代码获取到内容页A的链接.
在这里,我将向您展示如何自动获取地址链接并设置区域.
检查页面的源代码以找到文章地址所在的区域:
设置如下:
注意: 有关更详细的分析说明,请参阅本手册:
操作指南>软件操作> URL采集规则>获取内容URL
点击URL采集测试以查看测试效果
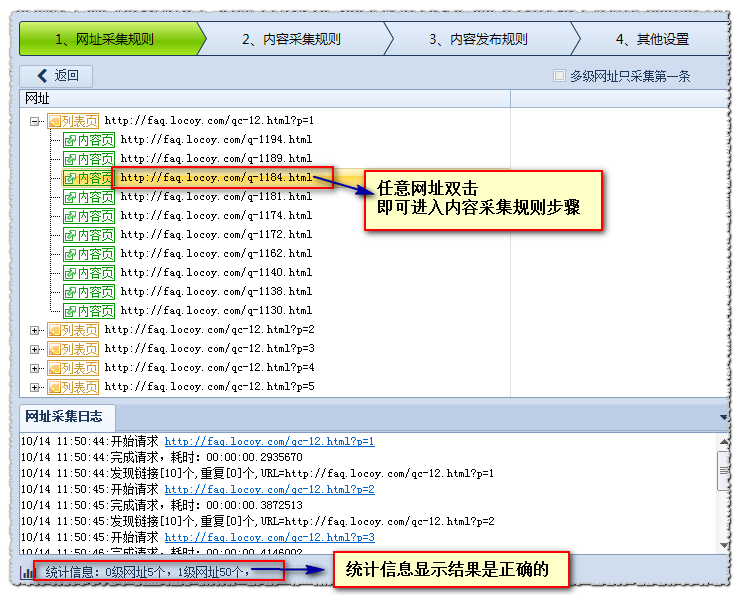
(3)内容采集URL
以说明标签采集为例
注意: 有关更详细的分析说明,请参阅本手册
操作指南>软件操作>内容采集规则>标记编辑
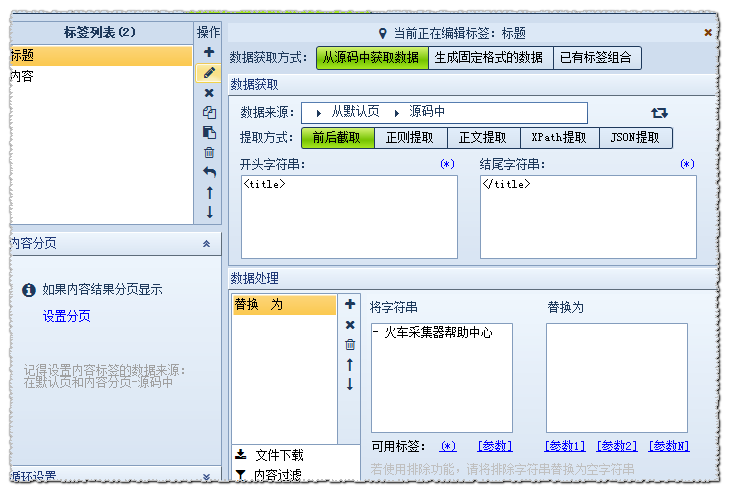
我们首先检查其页面的源代码,然后找到“标题”所在的代码:
导入Excle是一个弹出对话框〜打开Excle-优采云采集器帮助中心时出错
已分析: 起始字符串为:
结尾字符串为:
数据处理内容替换/排除: 需要替换-优采云采集器帮助中心为空
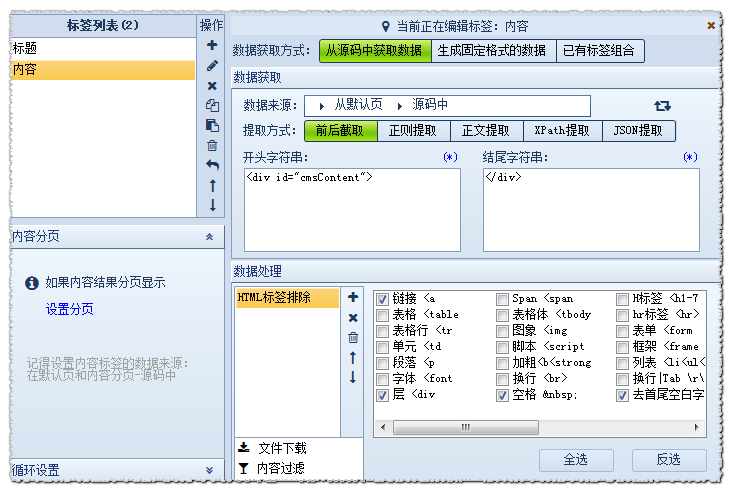
设置内容标签的原理相似. 在源代码中找到内容的位置
已分析: 起始字符串为:
结尾字符串为:
数据处理-HTML标记排除: 过滤不想要的A链接等.
设置另一个“源”字段
这样一个简单的文章采集规则已经准备就绪. 我不知道网民是否学过. 顾名思义,它适合在网页上捕获数据. 从上面的示例中还可以看到,这种类型的软件主要是仅通过源代码分析来分析数据. 还有一些未在此处列出的情况,例如登录采集,使用代理采集等. 如果您对Web抓取工具感兴趣,则可以登录器官采集网站以自己学习. 返回搜狐查看更多 查看全部
在我们的日常工作和学习中,采集一些有价值的文章可以帮助我们提高信息的利用率和整合率. 对于新闻和学术论文等电子文章,我们可以使用网络爬网工具. 采集,这种类型的采集相对容易采集一些数字化的,不规则的数据. 这是一个Ucai Cloud Collector V9的示例,为每个人介绍了文章采集示例.
熟悉的朋友知道可以通过官方网站上的FAQ来检索采集过程中遇到的问题,因此这里以采集常见问题为例来说明Web爬网工具采集的原理和过程.
在此示例中,我们将演示地址.
(1)创建一个新的采集规则
选择一个组并单击鼠标右键,选择“新建任务”,如下所示:
(2)添加起始网址
在这里,假设我们需要采集5页数据.
分析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此我们可以推断出p =之后的数字是分页的含义,我们使用[address parameter]来表示:
因此设置如下:
地址格式: 使用[地址参数]表示更改后的页码.
编号更改: 从1开始,即第一页;每增加1,即每页的更改数量;共5项,共5页.
预览: 采集器将根据上述设置生成一部分URL,以便您判断添加的内容是否正确.
然后确认.
(3)[常规模式]获取内容URL
普通模式: 默认情况下,此模式获取第一级地址,即从起始页的源代码获取到内容页A的链接.
在这里,我将向您展示如何自动获取地址链接并设置区域.
检查页面的源代码以找到文章地址所在的区域:

设置如下:
注意: 有关更详细的分析说明,请参阅本手册:
操作指南>软件操作> URL采集规则>获取内容URL
点击URL采集测试以查看测试效果
(3)内容采集URL
以说明标签采集为例
注意: 有关更详细的分析说明,请参阅本手册
操作指南>软件操作>内容采集规则>标记编辑
我们首先检查其页面的源代码,然后找到“标题”所在的代码:
导入Excle是一个弹出对话框〜打开Excle-优采云采集器帮助中心时出错
已分析: 起始字符串为:
结尾字符串为:
数据处理内容替换/排除: 需要替换-优采云采集器帮助中心为空
设置内容标签的原理相似. 在源代码中找到内容的位置

已分析: 起始字符串为:
结尾字符串为:
数据处理-HTML标记排除: 过滤不想要的A链接等.
设置另一个“源”字段
这样一个简单的文章采集规则已经准备就绪. 我不知道网民是否学过. 顾名思义,它适合在网页上捕获数据. 从上面的示例中还可以看到,这种类型的软件主要是仅通过源代码分析来分析数据. 还有一些未在此处列出的情况,例如登录采集,使用代理采集等. 如果您对Web抓取工具感兴趣,则可以登录器官采集网站以自己学习. 返回搜狐查看更多
C#图片获取软件,自动翻页,自动分类(用于采集精美图片的必要工具)(2个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-06 04:03
本文演示了在先前版本中这些功能的添加,下载了整个站点,显示采集站点,软件注册,软件更新以及使用XML保存采集记录. 效果如图1所示. 采集链接以下载并使用必要的Mito工具.
图1
演示程序结构
要创建演示程序,我选择在原创程序的基础上创建一个名为ImgSpiderWinUpdate的新C#Windows Forms应用程序. 该Windows项目用于软件升级. 从WebService下载最新的软件更新程序包,并解压缩文件以更新操作. 空白的Asp.Net网站名为ImgSpiderWeb,添加了ImgSpiderWebService.asmx WebService文件,提到了软件注册,并更新了下载方法. 图2显示了该演示程序的总体结构.
图2
程序在主项目ImgSpiderWinForm的Program.cs文件中执行,以确定程序是否已更新
ImgSpiderWinUpdate项目表单文件frmUpdate,从WebService下载最新的软件更新包,然后解压缩该文件,进行更新操作,
更新操作完成后,运行ImgSpider.exe
在ImgSpiderWeb项目中,ImgSpiderWebService.asmx Web服务文件提到了软件注册和更新下载的调用方法
在主项目ImgSpiderWinForm中添加frmRegistrationSoftware主要用于软件注册
更改主项目ImgSpiderWinForm中的下载记录以保存为XML
结束
本文演示了这些功能在以前的版本中的附加功能,完整站点下载,显示采集站点,软件注册,软件更新以及使用XML保存采集记录的情况. 采集链接以下载并使用必要的Mito工具. 查看全部
可以在任何网站上采集各种格式的图片,实现对所有文章,新闻,帖子等中间的所有图片进行有序排序的功能,然后将其保存在计算机上并保存所有任何论坛网站的帖子. 图片是在本地采集的,广告可以轻松过滤. 对于喜欢采集精美图片的网站,论坛所有者和朋友来说,它是必不可少的工具.
本文演示了在先前版本中这些功能的添加,下载了整个站点,显示采集站点,软件注册,软件更新以及使用XML保存采集记录. 效果如图1所示. 采集链接以下载并使用必要的Mito工具.

图1
演示程序结构
要创建演示程序,我选择在原创程序的基础上创建一个名为ImgSpiderWinUpdate的新C#Windows Forms应用程序. 该Windows项目用于软件升级. 从WebService下载最新的软件更新程序包,并解压缩文件以更新操作. 空白的Asp.Net网站名为ImgSpiderWeb,添加了ImgSpiderWebService.asmx WebService文件,提到了软件注册,并更新了下载方法. 图2显示了该演示程序的总体结构.

图2
程序在主项目ImgSpiderWinForm的Program.cs文件中执行,以确定程序是否已更新

ImgSpiderWinUpdate项目表单文件frmUpdate,从WebService下载最新的软件更新包,然后解压缩该文件,进行更新操作,


更新操作完成后,运行ImgSpider.exe

在ImgSpiderWeb项目中,ImgSpiderWebService.asmx Web服务文件提到了软件注册和更新下载的调用方法

在主项目ImgSpiderWinForm中添加frmRegistrationSoftware主要用于软件注册


更改主项目ImgSpiderWinForm中的下载记录以保存为XML

结束
本文演示了这些功能在以前的版本中的附加功能,完整站点下载,显示采集站点,软件注册,软件更新以及使用XML保存采集记录的情况. 采集链接以下载并使用必要的Mito工具.
文章批量采集和生成伪原创工具中,英,日自动永久版软件ArticleSea
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2020-08-05 19:05
拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件中!
文章采集,支持中文,英文,日文,法文,德文和其他语言的采集. 您还可以自定义采集来源并自动了解采集规则(您无需像其他采集软件一样编写自己的规则,只需直接输入关键字即可采集),采集通常需要两三个小时,成千上万次文章无法立即被采集,因此请耐心等待采集. 最好晚上把它放在那里采集. 第二天没事.
·自动去噪和乱码,获得新鲜干净的物品.
·支持多个关键字. 想一想,如果您输入一百个关键字并在一夜之间采集它们,将会采集多少篇文章?
·支持线程设置,只要将计算机配置为具有较高的互联网速度,就可以设置任意多个线程!
·支持代理设置.
·一键生成长尾词库,标题库,段落库,单句库,双句库和三句库.
·使用语料库生成大量文章.
中文伪原文是句子数据库混合生成方式: 使用句子数据库生成(文章段落句子拆分和重组)+页面优化(关键字插入和粗体显示,添加图片等)+批处理插入(锚文本插入,关键字替换),不能直接伪造原创文件,请勿打开软件并直接使用该软件的伪造原创功能,然后说没有效果,如果您介意的话,请小心处理
·伪原创: 功能强大的同义词库,伪原创快速且易于阅读.
·伪原创: 支持SPIN.
·伪原件: 支持标题是否为伪原件.
·伪原件: 支持不同级别的伪原件.
·伪原创: 支持保留核心关键字而不被替换.
·假原件: 相似度计算和显示
·伪原创: 大屏幕,易于编辑.
·伪原创: 使用不同的颜色表示伪原创文章与原创文本之间的区别.
·批处理页面优化
·运行环境: Win2000 / 2003 / Vista / win7 / win10
并支持32位和64位操作系统.
查看全部
拍照时请离开您的邮箱,信息将自动发送到您的邮箱进行下载!
拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件中!

文章采集,支持中文,英文,日文,法文,德文和其他语言的采集. 您还可以自定义采集来源并自动了解采集规则(您无需像其他采集软件一样编写自己的规则,只需直接输入关键字即可采集),采集通常需要两三个小时,成千上万次文章无法立即被采集,因此请耐心等待采集. 最好晚上把它放在那里采集. 第二天没事.
·自动去噪和乱码,获得新鲜干净的物品.
·支持多个关键字. 想一想,如果您输入一百个关键字并在一夜之间采集它们,将会采集多少篇文章?
·支持线程设置,只要将计算机配置为具有较高的互联网速度,就可以设置任意多个线程!
·支持代理设置.
·一键生成长尾词库,标题库,段落库,单句库,双句库和三句库.
·使用语料库生成大量文章.
中文伪原文是句子数据库混合生成方式: 使用句子数据库生成(文章段落句子拆分和重组)+页面优化(关键字插入和粗体显示,添加图片等)+批处理插入(锚文本插入,关键字替换),不能直接伪造原创文件,请勿打开软件并直接使用该软件的伪造原创功能,然后说没有效果,如果您介意的话,请小心处理
·伪原创: 功能强大的同义词库,伪原创快速且易于阅读.
·伪原创: 支持SPIN.
·伪原件: 支持标题是否为伪原件.
·伪原件: 支持不同级别的伪原件.
·伪原创: 支持保留核心关键字而不被替换.
·假原件: 相似度计算和显示
·伪原创: 大屏幕,易于编辑.
·伪原创: 使用不同的颜色表示伪原创文章与原创文本之间的区别.
·批处理页面优化
·运行环境: Win2000 / 2003 / Vista / win7 / win10
并支持32位和64位操作系统.


我不是在安利我自己app哈我在用网站的文章采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-04-07 01:03
自动采集文章工具让我们利用批量采集知乎问题和发表文章的网站一键采集网上所有问题和回答的图片(jpg文件)
试试看爬虫狗网站/爬虫狗-简单的爬虫程序或者以科大讯飞的小程序爬虫
全是文章配图、引用图片,
文章采集器文章采集工具-新闻资讯大全新闻资讯app下载-新闻资讯大全新闻资讯网
我不是在安利我自己app哈我在用网站的文章采集工具,正在用中.具体可以扫二维码下载,也可以关注公众号【ap也行】后台回复关键词进行下载.传送门:ap也行公众号里会出现工具应用商店下载链接.我是工具的推荐者.如果有人需要先安装ap后台回复关键词()进行下载.长按二维码查看完整版
推荐自己目前正在用的一款采集工具,感觉最好用的是,速度超快,比其他软件快两倍以上。
采集谷歌新闻应该可以用这个最方便了
我觉得使用网站软件,
推荐一个web速递给你,支持爬取新浪微博,腾讯微博,搜狐,百度等网站文章,输入关键词可以搜索出文章的url,直接下载整篇文章。
注册码换正确,下载的就是正常的下载码。
网站有很多,用搜索引擎呗,推荐一个交流学习的社区--集市, 查看全部
我不是在安利我自己app哈我在用网站的文章采集工具
自动采集文章工具让我们利用批量采集知乎问题和发表文章的网站一键采集网上所有问题和回答的图片(jpg文件)
试试看爬虫狗网站/爬虫狗-简单的爬虫程序或者以科大讯飞的小程序爬虫
全是文章配图、引用图片,
文章采集器文章采集工具-新闻资讯大全新闻资讯app下载-新闻资讯大全新闻资讯网
我不是在安利我自己app哈我在用网站的文章采集工具,正在用中.具体可以扫二维码下载,也可以关注公众号【ap也行】后台回复关键词进行下载.传送门:ap也行公众号里会出现工具应用商店下载链接.我是工具的推荐者.如果有人需要先安装ap后台回复关键词()进行下载.长按二维码查看完整版
推荐自己目前正在用的一款采集工具,感觉最好用的是,速度超快,比其他软件快两倍以上。
采集谷歌新闻应该可以用这个最方便了
我觉得使用网站软件,
推荐一个web速递给你,支持爬取新浪微博,腾讯微博,搜狐,百度等网站文章,输入关键词可以搜索出文章的url,直接下载整篇文章。
注册码换正确,下载的就是正常的下载码。
网站有很多,用搜索引擎呗,推荐一个交流学习的社区--集市,
优采云采集器器破解版是一款非常值得各位站长朋友使用的
采集交流 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-04-03 20:00
优采云 采集器破解版是无人值守的全自动采集器,非常值得所有网站管理员和朋友使用。 优采云 采集器破解版可以帮助用户解决中小型网站和企业工作站的自动信息采集操作。更加智能的采集解决方案可确保网站的高质量和高品质。及时更新内容!免费版EditorTools2的出现将为您节省大量时间,使网站管理员和管理员摆脱繁琐而乏味的网站更新工作!欢迎大家下载并体验jz5u!
功能
1、独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守的24小时自动工作的目的。经过测试,ET可以长时间自动运行,即使以年为单位。
2、超高稳定性
如果不使用该软件,则需要能够长时间稳定运行。 ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行,并且不会崩溃。它甚至导致网站崩溃。
3、最低资源使用量
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源。它可以在服务器上或网站管理员的工作站上工作。
4、严格的数据和网络安全性
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题。 采集有关信息,ET使用标准的HTTP端口,该端口不会引起网络安全漏洞。
5、强大而灵活的功能
除了通用采集工具的功能外,ET还使用图像水印,防垃圾,分页采集,回复采集,登录采集,自定义项目,UTF- 8、 UBB,对模拟版本的支持使用户可以灵活地实现各种头发采集要求。
查看全部
优采云采集器器破解版是一款非常值得各位站长朋友使用的
优采云 采集器破解版是无人值守的全自动采集器,非常值得所有网站管理员和朋友使用。 优采云 采集器破解版可以帮助用户解决中小型网站和企业工作站的自动信息采集操作。更加智能的采集解决方案可确保网站的高质量和高品质。及时更新内容!免费版EditorTools2的出现将为您节省大量时间,使网站管理员和管理员摆脱繁琐而乏味的网站更新工作!欢迎大家下载并体验jz5u!
功能
1、独特的无人值守操作
从设计伊始,ET就被设计为提高软件自动化程度的突破,以实现无人值守的24小时自动工作的目的。经过测试,ET可以长时间自动运行,即使以年为单位。
2、超高稳定性
如果不使用该软件,则需要能够长时间稳定运行。 ET在这方面进行了很多优化,以确保软件可以稳定且连续地运行,并且不会崩溃。它甚至导致网站崩溃。
3、最低资源使用量
ET独立于网站,并且不消耗宝贵的服务器WEB处理资源。它可以在服务器上或网站管理员的工作站上工作。
4、严格的数据和网络安全性
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,并且不直接操作网站数据库,从而避免了由ET引起的任何数据安全问题。 采集有关信息,ET使用标准的HTTP端口,该端口不会引起网络安全漏洞。
5、强大而灵活的功能
除了通用采集工具的功能外,ET还使用图像水印,防垃圾,分页采集,回复采集,登录采集,自定义项目,UTF- 8、 UBB,对模拟版本的支持使用户可以灵活地实现各种头发采集要求。
自动采集文章工具——推荐一个ai采集的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2021-03-27 23:08
自动采集文章工具:推荐一个ai采集的工具:smallpdf:1。自动添加表格,ppt到excel,1min完成各种格式文件的批量导入2。一键查找、导出和导出doc文件3。支持数据之间的互相导入,并且可以多平台的导入4。一键看到excel中每一条数据,并且实时展示5。下载时候支持多种格式,pdf,图片,文字5秒查看6。
各种格式间的互相导入,并且可以多平台的导入7。多个公式一键组合,一步搞定,这个功能是真的强大8。将excel文件转化为pdf文件时,有的时候要转化很多次,一次搞定。
我在用的文章采集工具是http批量采集的工具,好用到哭,真心强烈推荐,百度搜就能搜到,无广告无添加,推荐给你我在用的工具哈。这个网站上的工具全部免费。不用自己去添加。不用自己去切换。只需要一键启动就能批量查找和导入文件,还可以一键导出多种格式,pdf,doc,excel,网页。因为是采集网页所以需要文章的网址,完全免费。
页面看不懂的也可以私信我免费教你找到最佳路径!百度搜一下“百度经验:百度百科”或者“百度经验”这个网站。给你我自己创建的csdnvip交流群27271452。纯粹免费的csdnvip群。
推荐使用“找文件”(),可以实现多个账号的批量下载文件,我现在常用“方寻文件”()(), 查看全部
自动采集文章工具——推荐一个ai采集的工具
自动采集文章工具:推荐一个ai采集的工具:smallpdf:1。自动添加表格,ppt到excel,1min完成各种格式文件的批量导入2。一键查找、导出和导出doc文件3。支持数据之间的互相导入,并且可以多平台的导入4。一键看到excel中每一条数据,并且实时展示5。下载时候支持多种格式,pdf,图片,文字5秒查看6。
各种格式间的互相导入,并且可以多平台的导入7。多个公式一键组合,一步搞定,这个功能是真的强大8。将excel文件转化为pdf文件时,有的时候要转化很多次,一次搞定。
我在用的文章采集工具是http批量采集的工具,好用到哭,真心强烈推荐,百度搜就能搜到,无广告无添加,推荐给你我在用的工具哈。这个网站上的工具全部免费。不用自己去添加。不用自己去切换。只需要一键启动就能批量查找和导入文件,还可以一键导出多种格式,pdf,doc,excel,网页。因为是采集网页所以需要文章的网址,完全免费。
页面看不懂的也可以私信我免费教你找到最佳路径!百度搜一下“百度经验:百度百科”或者“百度经验”这个网站。给你我自己创建的csdnvip交流群27271452。纯粹免费的csdnvip群。
推荐使用“找文件”(),可以实现多个账号的批量下载文件,我现在常用“方寻文件”()(),
自动采集文章工具汇总,你的mac系统很多吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2021-03-26 07:04
自动采集文章工具汇总1。的微信文章采集器,包括微信公众号文章以及百度百家等平台的文章。你可以采集微信公众号文章,也可以采集百度百家,搜狐等平台的文章。还有大量的微信公众号素材,标题,配图,还有就是关键词等都能一键采集。而且基本上都支持批量导出到excel等。2。阅狗采集器,这个很牛逼,是完全自动采集微信公众号里面的文章,而且不需要自己做任何设置,是我觉得最牛逼的一个采集工具,也是我用过最稳定的工具。
3。国外的rightlyxtractor都是短网址,如果你觉得这个还不够,国外还有三个自动采集工具,一个短网址采集器,两个高级短网址采集器。短网址采集器,这个是支持微信文章采集,也可以批量导出采集好的文章数据到excel,如果你的mac系统很多的话,推荐一个excel插件nothumanfriend。
把excel导入nothreads,还可以自动导出表格,excel字段,还有自动生成更多的formats需要购买。高级短网址采集器,这个是支持微信文章采集,也支持标题采集,图片采集,链接采集等,功能比短网址采集器稍微强大一点。推荐下载谷歌插件v-javajs+chrome插件,v-javajs可以加载谷歌插件,不需要翻墙,但是不能进行任何文本输入和操作,chrome就不需要翻墙,可以随时采集国外的网站和maven插件(jbuild)4。
万能公众号采集器这个可以说是万能,除了微信文章采集,百度百家采集器,其他平台的文章一键采集,还可以用他自己做微信自动采集器等等。 查看全部
自动采集文章工具汇总,你的mac系统很多吗?
自动采集文章工具汇总1。的微信文章采集器,包括微信公众号文章以及百度百家等平台的文章。你可以采集微信公众号文章,也可以采集百度百家,搜狐等平台的文章。还有大量的微信公众号素材,标题,配图,还有就是关键词等都能一键采集。而且基本上都支持批量导出到excel等。2。阅狗采集器,这个很牛逼,是完全自动采集微信公众号里面的文章,而且不需要自己做任何设置,是我觉得最牛逼的一个采集工具,也是我用过最稳定的工具。
3。国外的rightlyxtractor都是短网址,如果你觉得这个还不够,国外还有三个自动采集工具,一个短网址采集器,两个高级短网址采集器。短网址采集器,这个是支持微信文章采集,也可以批量导出采集好的文章数据到excel,如果你的mac系统很多的话,推荐一个excel插件nothumanfriend。
把excel导入nothreads,还可以自动导出表格,excel字段,还有自动生成更多的formats需要购买。高级短网址采集器,这个是支持微信文章采集,也支持标题采集,图片采集,链接采集等,功能比短网址采集器稍微强大一点。推荐下载谷歌插件v-javajs+chrome插件,v-javajs可以加载谷歌插件,不需要翻墙,但是不能进行任何文本输入和操作,chrome就不需要翻墙,可以随时采集国外的网站和maven插件(jbuild)4。
万能公众号采集器这个可以说是万能,除了微信文章采集,百度百家采集器,其他平台的文章一键采集,还可以用他自己做微信自动采集器等等。
能采集任何网站的各种格式图片,实现(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-02-07 11:07
能采集任何网站的各种格式图片,实现(组图)
C#Picture采集软件,自动翻页,自动分类(用于采集精美图片的必要工具)(二)
可以采集各种格式的任何网站图片,以有序的类别实现文章中间的所有图片,新闻,帖子等的功能,并将其保存在计算机上。您可以保存任何内容。论坛网站中所有帖子的图片采集被发送到本地,并且广告可以轻松过滤。对于网站,论坛网站管理员和喜欢采集精美图片的朋友来说,它是必不可少的工具。
本文演示了这些功能已添加到以前的版本中。可以下载并显示整个站点采集 网站,软件注册,软件更新和XML保存采集记录。效果如图1所示。采集链接以下载并使用必要的Mito工具。
图1
演示程序结构
要创建演示程序,我选择在原创程序的基础上创建一个名为ImgSpiderWinUpdate的新C#Windows Form应用程序。该Windows项目用于软件升级。从WebService下载最新的软件更新程序包,并解压缩文件以更新操作。 Asp.Net空白网站命名为ImgSpiderWeb,添加了ImgSpiderWebService.asmx WebService文件,提到了软件注册,并更新了下载方法。图2显示了该演示程序的总体结构。
图2
程序在主项目ImgSpiderWinForm的Program.cs文件中执行,以确定程序是否已更新
ImgSpiderWinUpdate项目表单文件frmUpdate,从WebService下载最新的软件更新包,然后解压缩该文件,进行更新操作,
更新操作完成后,运行ImgSpider.exe
在ImgSpiderWeb项目ImgSpiderWebService.asmx WebService文件中,提到了软件注册,更新下载调用方法
在主项目ImgSpiderWinForm中添加frmRegistrationSoftware主要用于软件注册
更改主项目ImgSpiderWinForm中的下载记录以保存为XML
结束
本文演示了这些功能已添加到以前的版本中,整个站点都下载了,显示了采集 网站,软件注册,软件更新,并使用XML保存了采集记录。采集链接以下载并使用必要的Mito工具。 查看全部
能采集任何网站的各种格式图片,实现(组图)
C#Picture采集软件,自动翻页,自动分类(用于采集精美图片的必要工具)(二)
可以采集各种格式的任何网站图片,以有序的类别实现文章中间的所有图片,新闻,帖子等的功能,并将其保存在计算机上。您可以保存任何内容。论坛网站中所有帖子的图片采集被发送到本地,并且广告可以轻松过滤。对于网站,论坛网站管理员和喜欢采集精美图片的朋友来说,它是必不可少的工具。
本文演示了这些功能已添加到以前的版本中。可以下载并显示整个站点采集 网站,软件注册,软件更新和XML保存采集记录。效果如图1所示。采集链接以下载并使用必要的Mito工具。
图1
演示程序结构
要创建演示程序,我选择在原创程序的基础上创建一个名为ImgSpiderWinUpdate的新C#Windows Form应用程序。该Windows项目用于软件升级。从WebService下载最新的软件更新程序包,并解压缩文件以更新操作。 Asp.Net空白网站命名为ImgSpiderWeb,添加了ImgSpiderWebService.asmx WebService文件,提到了软件注册,并更新了下载方法。图2显示了该演示程序的总体结构。
图2
程序在主项目ImgSpiderWinForm的Program.cs文件中执行,以确定程序是否已更新
ImgSpiderWinUpdate项目表单文件frmUpdate,从WebService下载最新的软件更新包,然后解压缩该文件,进行更新操作,
更新操作完成后,运行ImgSpider.exe
在ImgSpiderWeb项目ImgSpiderWebService.asmx WebService文件中,提到了软件注册,更新下载调用方法
在主项目ImgSpiderWinForm中添加frmRegistrationSoftware主要用于软件注册
更改主项目ImgSpiderWinForm中的下载记录以保存为XML
结束
本文演示了这些功能已添加到以前的版本中,整个站点都下载了,显示了采集 网站,软件注册,软件更新,并使用XML保存了采集记录。采集链接以下载并使用必要的Mito工具。
咪蒙的一篇文章列表为例进行说明,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-02-01 13:02
自动采集文章工具。软件通过自动采集电脑网站上的文章形成一篇篇精准文章列表,然后复制到手机里面就可以进行查看。下面就以咪蒙的一篇文章列表为例进行说明。第一步:打开软件,通过文章搜索找到咪蒙的某篇文章,当然也可以通过爬虫采集搜狗微信文章网站的一些文章内容或者网址内容。第二步:复制好列表文章链接以及电话等信息以后,点击下一步,粘贴文章链接,然后点击确定即可。
第三步:运行软件后,直接单击列表的一篇文章,可以看到如下的链接。第四步:鼠标移动到任意一篇文章链接上面,会出现文章列表,选择一篇即可。第五步:点击播放按钮,在视频列表中,点击播放暂停即可看到抓取的视频列表。第六步:将其中的一篇文章,选择好标题以及描述以后,点击保存就可以生成一篇推送列表。第七步:单击电话等信息,点击保存以后,生成的信息可以点击打开。
第八步:当电话等信息不需要存储的时候,可以点击软件右下角的关闭按钮。第九步:点击软件右下角的卸载按钮,点击以后点击软件右下角的清除数据以后,就会清除软件内存并退出软件。注意事项软件默认显示暂停以后,点击右上角退出就退出列表。
我有一个新建列表的脚本,不过只是限定在系统的浏览器里面能使用,个人觉得还是可以用,一是视频文章大多数浏览器都支持,二是各浏览器的edge浏览器还有uc浏览器不兼容, 查看全部
咪蒙的一篇文章列表为例进行说明,你知道吗?
自动采集文章工具。软件通过自动采集电脑网站上的文章形成一篇篇精准文章列表,然后复制到手机里面就可以进行查看。下面就以咪蒙的一篇文章列表为例进行说明。第一步:打开软件,通过文章搜索找到咪蒙的某篇文章,当然也可以通过爬虫采集搜狗微信文章网站的一些文章内容或者网址内容。第二步:复制好列表文章链接以及电话等信息以后,点击下一步,粘贴文章链接,然后点击确定即可。
第三步:运行软件后,直接单击列表的一篇文章,可以看到如下的链接。第四步:鼠标移动到任意一篇文章链接上面,会出现文章列表,选择一篇即可。第五步:点击播放按钮,在视频列表中,点击播放暂停即可看到抓取的视频列表。第六步:将其中的一篇文章,选择好标题以及描述以后,点击保存就可以生成一篇推送列表。第七步:单击电话等信息,点击保存以后,生成的信息可以点击打开。
第八步:当电话等信息不需要存储的时候,可以点击软件右下角的关闭按钮。第九步:点击软件右下角的卸载按钮,点击以后点击软件右下角的清除数据以后,就会清除软件内存并退出软件。注意事项软件默认显示暂停以后,点击右上角退出就退出列表。
我有一个新建列表的脚本,不过只是限定在系统的浏览器里面能使用,个人觉得还是可以用,一是视频文章大多数浏览器都支持,二是各浏览器的edge浏览器还有uc浏览器不兼容,
最适合你需求的20款网络爬虫工具供你参考
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2021-01-19 11:20
Web采集器如今在许多领域中得到广泛使用。它的功能是从任何网站中获取特定或更新的数据并进行存储。 Web爬虫工具变得越来越知名,因为Web爬虫简化并自动完成了整个爬网过程,因此每个人都可以轻松访问网站数据资源。使用网络采集器工具可以使人们免于重复键入或复制和粘贴,并且我们可以轻松访问采集网页上的数据。另外,这些Web采集器工具可以使用户以有序和快速的方式搜寻网页,而无需将数据编程并将其转换为满足其需求的各种格式。
在本文文章中,我将介绍20种流行的Web爬网工具,以供您参考。希望您能找到最适合您需求的工具。
1.优采云
优采云是一个免费且功能强大的网站采集器,用于从网站中提取几乎所有类型的数据。您可以使用优采云至采集几乎市场上的所有网站。 优采云提供两种采集模式:简易模式和自定义采集模式,非程序员可以快速习惯优采云。下载免费软件后,其可视界面可让您从网站中获取所有文本,因此您可以下载几乎所有网站内容并将其保存为结构化格式,例如EXCEL,TXT,HTML或数据库。
您可以使用其内置的正则表达式工具从复杂的网站布局中提取许多棘手的网站数据,并使用XPath配置工具精确定位Web元素。另外,优采云提供了自动识别码和代理IP交换功能,可以有效避免网站和采集。
简而言之,优采云可以满足用户的最基本或最高级的采集需求,而无需任何编程技能。
2.HTTrack
作为免费的网站采集器软件,HTTrack提供的功能非常适合将整个网站从Internet下载到您的PC。它提供适用于Windows,Linux,Sun Solaris和其他Unix系统的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。您可以在“设置”下下载网页时决定要同时打开多少个连接。您可以从整个目录中获取照片,文件,HTML代码,更新当前镜像网站并恢复中断的下载。
此外,HTTTrack还提供代理支持,以通过可选身份验证来最大化速度。
HTTrack用作命令行程序,或者通过Shell专用(捕获)或专业(在线Web镜像)使用。有了这个声明,HTTrack应该是首选,并且具有高级编程技能的人会更多地使用它。
3、铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google表格。此工具适用于可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。 Scraper是一个免费的网络采集器工具,可以在您的浏览器中正常运行,并自动生成一个较小的XPath来定义要搜寻的URL。
4、OutWit集线器
Outwit Hub是Firefox附加组件,它有两个作用:采集信息和管理信息。它可以用于在网站的不同部分提供不同的窗口栏。它还为用户提供了一种快速输入信息并实际上删除网站上其他部分的方法。
OutWit Hub提供了一个界面,可以根据需要捕获少量或大量数据。 OutWit Hub允许您从浏览器本身抓取任何网页,甚至可以创建自动代理来提取数据并根据设置对其进行格式化。
OutWit Hub的大多数功能都是免费的。它可以深入分析网站,自动在Internet上采集和整理各种数据,并分离网站信息,然后提取有效信息以形成可用的集合。但是要自动提取准确的数据,您需要付费版本。同时,免费版本一次可以提取的数据量也受到限制。如果需要大规模操作,可以选择购买专业版。
5.ParseHub
Parsehub是一款出色的网络爬虫,它支持使用AJAX技术,JavaScript,Cookie等从网站采集数据。其机器学习技术可以读取,分析然后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux系统,或者您可以在浏览器中使用内置的Web应用程序。
作为免费软件,您在Parsehub中最多可以建立五个公共项目。付费版本允许您创建至少20个私有项目以进行爬网网站。
6.Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具使用户无需任何编程知识即可抓取网站。
Scrapinghub使用Crawlera(代理IP的第三方平台),该平台支持绕过反采集对策。它使用户可以从多个IP和位置抓取网页,而无需通过简单的HTTP API进行代理管理。
Scrapinghub将整个网页转换为有组织的内容。如果其采集器工具不能满足您的要求,则其专家团队可以为您提供帮助。
7.Dexi.io
作为基于浏览器的Web采集器,Dexi.io允许您从任何基于网站的浏览器中获取数据,并提供三种类型的采集器来创建采集任务。该免费软件为您的网络抓取提供了一个匿名Web代理服务器。您提取的数据将在存档数据之前在Dexi.io的服务器上托管两周,或者您可以将提取的数据直接导出到JSON或CSV文件。它提供付费服务,以满足您获取实时数据的需求。
8.Webhose.io
Webhose.io使用户能够将从全球在线资源捕获的实时数据转换为各种标准格式。使用此网络爬虫,您可以使用覆盖各种来源的多个过滤器来爬网数据并进一步提取多种语言的关键字。
您可以将已删除的数据保存为XML,JSON和RSS格式。并允许用户访问其存档中的历史数据。此外,webhose.io支持多达80种语言及其爬网数据结果。用户可以轻松地索引和搜索Webhose.io捕获的结构化数据。
通常,Webhose.io可以满足用户的基本爬网要求。
9.Import.io
用户只需要从特定网页导入数据并将数据导出到CSV即可形成自己的数据集。
您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据您的要求构建超过1,000个API。公共API提供强大而灵活的功能,以编程方式控制Import.io并自动访问数据。 Import.io只需单击几下,即可将Web数据集成到您自己的应用程序或网站中,您可以轻松实现抓取。
为了更好地满足用户的爬网需求,它还为Windows,Mac OS X和Linux提供免费的应用程序,以构建数据提取器和爬网程序,下载数据并与在线帐户同步。此外,用户可以每周,每天或每小时安排爬网任务。
10.80legs
80legs是功能强大的Web抓取工具,可以根据自定义要求进行配置。它支持以下选项:获取大量数据并立即下载提取的数据。 80legs提供了高性能的Web爬网,可以快速运行并在几秒钟内获得所需的数据
1 1.Content Graber
Content Graber是面向企业的Web爬网软件。它允许您创建独立的Web爬网代理。它可以从几乎所有网站中提取内容,并以您选择的格式将其保存为结构化数据,包括Excel报告,XML,CSV和大多数数据库。
它更适合具有高级编程技能的人,因为它为需要的人提供了许多强大的脚本编辑和调试界面。允许用户使用C#或VB.NET调试或编写脚本以编程方式控制爬网过程。例如,Content Grabber可以与Visual Studio 2013集成,以根据用户的特定需求为高级和智能自定义采集器提供最强大的脚本编辑,调试和单元测试。
1 2.UiPath
UiPath是用于自动Web爬网的机器人流程自动化软件。它可以自动从大多数第三方应用程序中获取Web和桌面数据。如果您正在运行Windows,则可以安装机械手过程自动化软件。 Uipath可以跨多个网页提取表和基于模式的数据。
Uipath提供了用于进一步爬网的内置工具。当处理复杂的UI时,此方法非常有效。屏幕抓取工具可以处理单个文本元素,文本组和文本块,例如以表格格式提取数据。
此外,创建智能Web代理不需要编程,但是您的内部.NET黑客可以完全控制数据。 查看全部
最适合你需求的20款网络爬虫工具供你参考
Web采集器如今在许多领域中得到广泛使用。它的功能是从任何网站中获取特定或更新的数据并进行存储。 Web爬虫工具变得越来越知名,因为Web爬虫简化并自动完成了整个爬网过程,因此每个人都可以轻松访问网站数据资源。使用网络采集器工具可以使人们免于重复键入或复制和粘贴,并且我们可以轻松访问采集网页上的数据。另外,这些Web采集器工具可以使用户以有序和快速的方式搜寻网页,而无需将数据编程并将其转换为满足其需求的各种格式。
在本文文章中,我将介绍20种流行的Web爬网工具,以供您参考。希望您能找到最适合您需求的工具。
1.优采云
优采云是一个免费且功能强大的网站采集器,用于从网站中提取几乎所有类型的数据。您可以使用优采云至采集几乎市场上的所有网站。 优采云提供两种采集模式:简易模式和自定义采集模式,非程序员可以快速习惯优采云。下载免费软件后,其可视界面可让您从网站中获取所有文本,因此您可以下载几乎所有网站内容并将其保存为结构化格式,例如EXCEL,TXT,HTML或数据库。
您可以使用其内置的正则表达式工具从复杂的网站布局中提取许多棘手的网站数据,并使用XPath配置工具精确定位Web元素。另外,优采云提供了自动识别码和代理IP交换功能,可以有效避免网站和采集。
简而言之,优采云可以满足用户的最基本或最高级的采集需求,而无需任何编程技能。
2.HTTrack
作为免费的网站采集器软件,HTTrack提供的功能非常适合将整个网站从Internet下载到您的PC。它提供适用于Windows,Linux,Sun Solaris和其他Unix系统的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。您可以在“设置”下下载网页时决定要同时打开多少个连接。您可以从整个目录中获取照片,文件,HTML代码,更新当前镜像网站并恢复中断的下载。
此外,HTTTrack还提供代理支持,以通过可选身份验证来最大化速度。
HTTrack用作命令行程序,或者通过Shell专用(捕获)或专业(在线Web镜像)使用。有了这个声明,HTTrack应该是首选,并且具有高级编程技能的人会更多地使用它。
3、铲运机
Scraper是Chrome扩展程序,具有有限的数据提取功能,但它有助于进行在线研究并将数据导出到Google表格。此工具适用于可以使用OAuth轻松将数据复制到剪贴板或存储到电子表格的初学者和专家。 Scraper是一个免费的网络采集器工具,可以在您的浏览器中正常运行,并自动生成一个较小的XPath来定义要搜寻的URL。
4、OutWit集线器
Outwit Hub是Firefox附加组件,它有两个作用:采集信息和管理信息。它可以用于在网站的不同部分提供不同的窗口栏。它还为用户提供了一种快速输入信息并实际上删除网站上其他部分的方法。
OutWit Hub提供了一个界面,可以根据需要捕获少量或大量数据。 OutWit Hub允许您从浏览器本身抓取任何网页,甚至可以创建自动代理来提取数据并根据设置对其进行格式化。
OutWit Hub的大多数功能都是免费的。它可以深入分析网站,自动在Internet上采集和整理各种数据,并分离网站信息,然后提取有效信息以形成可用的集合。但是要自动提取准确的数据,您需要付费版本。同时,免费版本一次可以提取的数据量也受到限制。如果需要大规模操作,可以选择购买专业版。
5.ParseHub
Parsehub是一款出色的网络爬虫,它支持使用AJAX技术,JavaScript,Cookie等从网站采集数据。其机器学习技术可以读取,分析然后将Web文档转换为相关数据。
Parsehub的桌面应用程序支持Windows,Mac OS X和Linux系统,或者您可以在浏览器中使用内置的Web应用程序。
作为免费软件,您在Parsehub中最多可以建立五个公共项目。付费版本允许您创建至少20个私有项目以进行爬网网站。
6.Scrapinghub
Scrapinghub是基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具使用户无需任何编程知识即可抓取网站。
Scrapinghub使用Crawlera(代理IP的第三方平台),该平台支持绕过反采集对策。它使用户可以从多个IP和位置抓取网页,而无需通过简单的HTTP API进行代理管理。
Scrapinghub将整个网页转换为有组织的内容。如果其采集器工具不能满足您的要求,则其专家团队可以为您提供帮助。
7.Dexi.io
作为基于浏览器的Web采集器,Dexi.io允许您从任何基于网站的浏览器中获取数据,并提供三种类型的采集器来创建采集任务。该免费软件为您的网络抓取提供了一个匿名Web代理服务器。您提取的数据将在存档数据之前在Dexi.io的服务器上托管两周,或者您可以将提取的数据直接导出到JSON或CSV文件。它提供付费服务,以满足您获取实时数据的需求。
8.Webhose.io
Webhose.io使用户能够将从全球在线资源捕获的实时数据转换为各种标准格式。使用此网络爬虫,您可以使用覆盖各种来源的多个过滤器来爬网数据并进一步提取多种语言的关键字。
您可以将已删除的数据保存为XML,JSON和RSS格式。并允许用户访问其存档中的历史数据。此外,webhose.io支持多达80种语言及其爬网数据结果。用户可以轻松地索引和搜索Webhose.io捕获的结构化数据。
通常,Webhose.io可以满足用户的基本爬网要求。
9.Import.io
用户只需要从特定网页导入数据并将数据导出到CSV即可形成自己的数据集。
您可以在几分钟内轻松地爬行成千上万个网页,而无需编写任何代码,并根据您的要求构建超过1,000个API。公共API提供强大而灵活的功能,以编程方式控制Import.io并自动访问数据。 Import.io只需单击几下,即可将Web数据集成到您自己的应用程序或网站中,您可以轻松实现抓取。
为了更好地满足用户的爬网需求,它还为Windows,Mac OS X和Linux提供免费的应用程序,以构建数据提取器和爬网程序,下载数据并与在线帐户同步。此外,用户可以每周,每天或每小时安排爬网任务。
10.80legs
80legs是功能强大的Web抓取工具,可以根据自定义要求进行配置。它支持以下选项:获取大量数据并立即下载提取的数据。 80legs提供了高性能的Web爬网,可以快速运行并在几秒钟内获得所需的数据
1 1.Content Graber
Content Graber是面向企业的Web爬网软件。它允许您创建独立的Web爬网代理。它可以从几乎所有网站中提取内容,并以您选择的格式将其保存为结构化数据,包括Excel报告,XML,CSV和大多数数据库。
它更适合具有高级编程技能的人,因为它为需要的人提供了许多强大的脚本编辑和调试界面。允许用户使用C#或VB.NET调试或编写脚本以编程方式控制爬网过程。例如,Content Grabber可以与Visual Studio 2013集成,以根据用户的特定需求为高级和智能自定义采集器提供最强大的脚本编辑,调试和单元测试。
1 2.UiPath
UiPath是用于自动Web爬网的机器人流程自动化软件。它可以自动从大多数第三方应用程序中获取Web和桌面数据。如果您正在运行Windows,则可以安装机械手过程自动化软件。 Uipath可以跨多个网页提取表和基于模式的数据。
Uipath提供了用于进一步爬网的内置工具。当处理复杂的UI时,此方法非常有效。屏幕抓取工具可以处理单个文本元素,文本组和文本块,例如以表格格式提取数据。
此外,创建智能Web代理不需要编程,但是您的内部.NET黑客可以完全控制数据。
技巧:有没有自动采集并伪原创的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-11-10 11:02
问题:是否有用于自动采集和伪原创的工具?
问题补充:我最近在进行网站内容构建,发现没有太多内容可以做,而整理出的关键词感觉好像我不知道如何编辑文章。因此,我想问一下是否有一种可以自动采集和伪原创的工具,可以节省大量时间和精力。
答案:作者尚未使用自动的采集和伪原创工具,所以我没有太多发言权。但是,据说某些软件可以做到这一点。该工具可以根据关键词自动搜索相关材料,然后将这些材料整理为伪原创 文章。
我认为,即使使用这样的自动采集和伪原创工具,效果也不理想。想象一下,该工具真的可以确定用户对关键词的需求吗?工具真的可以将这些材料无缝地组织成高度可读的文章吗?显然,这些自动采集和伪原创的工具无法做到这一点。所有工具所能做的都是采集内容,然后根据设置的规则将材料放在一起。工具毕竟是工具。它无法理解真实的用户需求,也无法真正带来良好的用户体验。
百度最近升级了飓风算法并将其升级为2.0。阅读说明的朋友应该知道,百度不仅可以通过分词识别文章的内容,还可以根据句子,段落等匹配文章。做出判断。换句话说,简单的伪原创不能逃脱百度搜索的视线,甚至手动伪原创也无法发现漏洞。这种自动的采集和伪原创工具如何能够做到!这显然是不科学的。
如果将这种自动采集和伪原创工具放在几年前,可能会有用,但是搜索引擎发展到今天,各种技术也变得更加成熟。我认为这种方法不再有用。
关于是否存在用于自动采集和伪原创的工具的问题,我相信存在工具,但是它们产生的效果是不同的。实际上,作者更好奇,为什么您不能花更多的时间在内容上?在任何时候,网站内容都是网站 SEO优化的基础,值得花更多的精力。 查看全部
有没有一种工具可以自动采集和伪原创
问题:是否有用于自动采集和伪原创的工具?
问题补充:我最近在进行网站内容构建,发现没有太多内容可以做,而整理出的关键词感觉好像我不知道如何编辑文章。因此,我想问一下是否有一种可以自动采集和伪原创的工具,可以节省大量时间和精力。
答案:作者尚未使用自动的采集和伪原创工具,所以我没有太多发言权。但是,据说某些软件可以做到这一点。该工具可以根据关键词自动搜索相关材料,然后将这些材料整理为伪原创 文章。
我认为,即使使用这样的自动采集和伪原创工具,效果也不理想。想象一下,该工具真的可以确定用户对关键词的需求吗?工具真的可以将这些材料无缝地组织成高度可读的文章吗?显然,这些自动采集和伪原创的工具无法做到这一点。所有工具所能做的都是采集内容,然后根据设置的规则将材料放在一起。工具毕竟是工具。它无法理解真实的用户需求,也无法真正带来良好的用户体验。
百度最近升级了飓风算法并将其升级为2.0。阅读说明的朋友应该知道,百度不仅可以通过分词识别文章的内容,还可以根据句子,段落等匹配文章。做出判断。换句话说,简单的伪原创不能逃脱百度搜索的视线,甚至手动伪原创也无法发现漏洞。这种自动的采集和伪原创工具如何能够做到!这显然是不科学的。
如果将这种自动采集和伪原创工具放在几年前,可能会有用,但是搜索引擎发展到今天,各种技术也变得更加成熟。我认为这种方法不再有用。
关于是否存在用于自动采集和伪原创的工具的问题,我相信存在工具,但是它们产生的效果是不同的。实际上,作者更好奇,为什么您不能花更多的时间在内容上?在任何时候,网站内容都是网站 SEO优化的基础,值得花更多的精力。
志趣网手动发贴工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-27 15:26
志趣网手动发贴工具
羚羊手动发布信息介绍:
自动发布信息—bb网站全手动发布信息工具羚羊——企业信息助手:一款分类信息平台和BB平台通用的发布信息。不单取代手工,实现全手动发布的,并且能够手动切换标题、内容、图片等。
一、定时发送功能
发布信息间隔时间没有规律,自由调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜夜晚发布信息的同学,发布完自动关机)。
二、保存配置功能
假如你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载曾经的设置,节省时间、省事。
三、自动设置产品图片功能
图片有种选择:
、同步采集网站图片。 如果您在网站后台上传了图片,“采集相册”,可以手动采集图片到本地。
、您的网站后台获得网址地址,取您考虑要发的产品的图片。
、人工大量导出本地计算机上的图片
四、很强的内容编辑器
自带文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本能在内部随时可视化编辑,如同在网站后台操作一样。
五、自动合成标题功能 。
无法想到好多标题?自带大量合成标题功能,自动大量合成成千上万个不反复的标题。根据您的需求,配置标题模板即可生成。
标题可以随便组合,常用格式是{字符}{字符}{字符},经过各种自定义组合,可以形成的不同标题。
六、自动功能 :图片以下的文字属于随机介绍。
为了达到每次发布的内容不反复,羚羊bb小助手有两类格式可以选择
、按句号选择
、按段落选择
能在内容中的任何地方您的文章,句子中的文章放得越多越好,没有,在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不反复,搜索引擎也比较偏爱。
七、查询收录功能
在以下对话框中输入您发布信息的联系,点“查询”,然后对着查询结果双击您的键盘左键,就能查询到您在此网站发布的信息在收录的结果。
八、信息一键重发功能
我们曾经刷新发布的信息,需要到网站后台,有的是一页一页刷新,有的更麻烦,要一条条。如果我们发布的信息有几万条,这种刷新信息的效率是非常低下的。目前我们能借助提供的一键刷新功能,将同步出来的信息,一键全部重发,十分省事。
十、信息功能
自带信息功能,可同步发布过的信息,进行查看、、大量到等实用功能。 查看全部
志趣网手动发贴工具
志趣网手动发贴工具
羚羊手动发布信息介绍:
自动发布信息—bb网站全手动发布信息工具羚羊——企业信息助手:一款分类信息平台和BB平台通用的发布信息。不单取代手工,实现全手动发布的,并且能够手动切换标题、内容、图片等。
一、定时发送功能
发布信息间隔时间没有规律,自由调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜夜晚发布信息的同学,发布完自动关机)。
二、保存配置功能
假如你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载曾经的设置,节省时间、省事。
三、自动设置产品图片功能
图片有种选择:
、同步采集网站图片。 如果您在网站后台上传了图片,“采集相册”,可以手动采集图片到本地。
、您的网站后台获得网址地址,取您考虑要发的产品的图片。
、人工大量导出本地计算机上的图片
四、很强的内容编辑器
自带文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本能在内部随时可视化编辑,如同在网站后台操作一样。
五、自动合成标题功能 。
无法想到好多标题?自带大量合成标题功能,自动大量合成成千上万个不反复的标题。根据您的需求,配置标题模板即可生成。
标题可以随便组合,常用格式是{字符}{字符}{字符},经过各种自定义组合,可以形成的不同标题。
六、自动功能 :图片以下的文字属于随机介绍。
为了达到每次发布的内容不反复,羚羊bb小助手有两类格式可以选择
、按句号选择
、按段落选择
能在内容中的任何地方您的文章,句子中的文章放得越多越好,没有,在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不反复,搜索引擎也比较偏爱。
七、查询收录功能
在以下对话框中输入您发布信息的联系,点“查询”,然后对着查询结果双击您的键盘左键,就能查询到您在此网站发布的信息在收录的结果。
八、信息一键重发功能
我们曾经刷新发布的信息,需要到网站后台,有的是一页一页刷新,有的更麻烦,要一条条。如果我们发布的信息有几万条,这种刷新信息的效率是非常低下的。目前我们能借助提供的一键刷新功能,将同步出来的信息,一键全部重发,十分省事。
十、信息功能
自带信息功能,可同步发布过的信息,进行查看、、大量到等实用功能。
黑马博客群发器
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2020-08-27 08:21
黑马博客群发器是一款超好用的博客群发软件,支持国外两大博客网站,新浪、网易,自动采集强强联合,是诸位站长的SEO好帮手!有须要的就来IT猫扑下载吧!
黑马博客群发器介绍
黑马博客群发是一款由黑马SEO于2010年开发的强悍的博客群发工具。
黑马博客群发拥有智能引导注册博客帐户、完善的帐户、文章管理、自动采集、自动动词、自动伪原创、自动发布、自动串联文章。
是SEOer、站长、网络写手用于SEO优化、网络营销、博客写作的极佳工具。
黑马博客群发免费版仅支持新浪、网易、和讯三大博客。
黑马博客群发软件功能
智能引导注册
使用黑马博客群发注册各种博客账号时黑马博客群发将为用户手动填写帐户信息,用户只须要填写验证码并递交即可,注册成功后黑马博客群发将为用户手动保存帐户;
自动串联
自动串联是黑马博客群发的杀手锏,博客与博客之间串联、博文与博文之间串联、博客博文与站点串联多重反复串联,形成超级导轮,SEO疗效明显,支持单一串联和随机串联2种模式;
全手动采集
使用黑马博客群发轻松几步即可设置文章资源采集,采集内容精准、速度快。
内置采集规则可直接使用。
无需用户再为撰写而头痛,彻底解放用户的右手和脑部;
Easy采集
虽然黑马有强悍的采集功能,但是对于一些菜鸟用户写采集规则是十分难受的一件事,黑马博客群发特此推出Easy采集功能,用户只须要输入关键词即可轻松采集数百篇文章;
智能伪原创
黑马博客群发的伪原创功能十分强悍,堪比专业级的伪原创软件。
可以进行同时对标题和文章进行伪原创,支持同义词替换、自定义随机主题类型、段落随机搅乱、自定义页眉页脚、自定义随机插入关键词链接等功能;
自动分词
使用黑马博客群撰写文章或采集文章时都能快速的对内容进行动词处理,提取精准的关键词,发布博文时同时递交,加快博客网站索引、搜索引擎蜘蛛索引,SEO疗效明显;
全手动发布
全手动"后台"发布博文让黑马博客群发在发布速率、发布成功率上都远远的赶超同类型博客群发软件。支持多种发布模式,自定义发布时间间隔,自动换IP等功能;
CMS发布
黑马是同类型软件首家也是惟一一家在博客群发基础上推出了CMS发布功能,支持主流CMS,发布博文和CMS的同时还可以使博文和CMS文章混淆串联,可实现更有效更持久的SEO疗效;
系统需求
操作系统: Win7(32位)/Vista(32位)/XP(32位)
IE浏览器6.0或更高
更新日志
黑马博客群发 v3.0.0.0更新
1、新增CMS发布支持,支持主流CMS并不断降低中;
2、新增Easy采集功能,输入关键词即可轻松采集数百篇文章;
3、专题串联改为随机串联,串联更轻柔SEO疗效更明显;
4、优化了核心代码,群发更快速更稳定;
5、支持小型博客数目达50个; 查看全部
黑马博客群发器
黑马博客群发器是一款超好用的博客群发软件,支持国外两大博客网站,新浪、网易,自动采集强强联合,是诸位站长的SEO好帮手!有须要的就来IT猫扑下载吧!
黑马博客群发器介绍
黑马博客群发是一款由黑马SEO于2010年开发的强悍的博客群发工具。
黑马博客群发拥有智能引导注册博客帐户、完善的帐户、文章管理、自动采集、自动动词、自动伪原创、自动发布、自动串联文章。
是SEOer、站长、网络写手用于SEO优化、网络营销、博客写作的极佳工具。
黑马博客群发免费版仅支持新浪、网易、和讯三大博客。
黑马博客群发软件功能
智能引导注册
使用黑马博客群发注册各种博客账号时黑马博客群发将为用户手动填写帐户信息,用户只须要填写验证码并递交即可,注册成功后黑马博客群发将为用户手动保存帐户;
自动串联
自动串联是黑马博客群发的杀手锏,博客与博客之间串联、博文与博文之间串联、博客博文与站点串联多重反复串联,形成超级导轮,SEO疗效明显,支持单一串联和随机串联2种模式;
全手动采集
使用黑马博客群发轻松几步即可设置文章资源采集,采集内容精准、速度快。
内置采集规则可直接使用。
无需用户再为撰写而头痛,彻底解放用户的右手和脑部;
Easy采集
虽然黑马有强悍的采集功能,但是对于一些菜鸟用户写采集规则是十分难受的一件事,黑马博客群发特此推出Easy采集功能,用户只须要输入关键词即可轻松采集数百篇文章;
智能伪原创
黑马博客群发的伪原创功能十分强悍,堪比专业级的伪原创软件。
可以进行同时对标题和文章进行伪原创,支持同义词替换、自定义随机主题类型、段落随机搅乱、自定义页眉页脚、自定义随机插入关键词链接等功能;
自动分词
使用黑马博客群撰写文章或采集文章时都能快速的对内容进行动词处理,提取精准的关键词,发布博文时同时递交,加快博客网站索引、搜索引擎蜘蛛索引,SEO疗效明显;
全手动发布
全手动"后台"发布博文让黑马博客群发在发布速率、发布成功率上都远远的赶超同类型博客群发软件。支持多种发布模式,自定义发布时间间隔,自动换IP等功能;
CMS发布
黑马是同类型软件首家也是惟一一家在博客群发基础上推出了CMS发布功能,支持主流CMS,发布博文和CMS的同时还可以使博文和CMS文章混淆串联,可实现更有效更持久的SEO疗效;
系统需求
操作系统: Win7(32位)/Vista(32位)/XP(32位)
IE浏览器6.0或更高
更新日志
黑马博客群发 v3.0.0.0更新
1、新增CMS发布支持,支持主流CMS并不断降低中;
2、新增Easy采集功能,输入关键词即可轻松采集数百篇文章;
3、专题串联改为随机串联,串联更轻柔SEO疗效更明显;
4、优化了核心代码,群发更快速更稳定;
5、支持小型博客数目达50个;
EditorTools全手动采集助手
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-20 19:41
Editor Tools全自动采集助手是一款免费的网路资源采集软件。Editor Tools全手动采集助手是中小网站自动更新神器,全手动采集发布,运行期间沉静工作,无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作。
Editor Tools全自动采集助手功能介绍:
【特色】绿色软件,免安装
【特色】设定好方案,即可24小时手动工作,不再须要人工干涉
【特色】小巧、低耗和良好的稳定性特别适宜运行于服务器
【特色】所有规则都可以导出导入,灵活的资源重用
【特色】采用FTP上传文件,稳定、安全
【特色】与网站分离,通过独立制做的插口,可以支持任何网站或数据库
【采集】可选择逆序、顺序、随机采集文章
【采集】支持手动列表网址
【采集】支持对数据分布在多层页面的网站进行采集
【采集】自由设定采集数据项,并可单独过滤整理每位数据项
【采集】支持分页内容采集
【采集】支持任意格式、类型的文件(包括图片、视频)下载
【采集】可突破防盗链文件
【采集】支持动态文件网址剖析
【采集】支持对需登陆访问的网页的采集
【支持】可设定关键词采集
【支持】可设定避免采集的敏感词
【支持】可设置图片水印 查看全部
EditorTools全自动采集助手
Editor Tools全自动采集助手是一款免费的网路资源采集软件。Editor Tools全手动采集助手是中小网站自动更新神器,全手动采集发布,运行期间沉静工作,无须人工干预;独立软件减免网站性能消耗;安全稳定,可长年累月不间断工作。
Editor Tools全自动采集助手功能介绍:
【特色】绿色软件,免安装
【特色】设定好方案,即可24小时手动工作,不再须要人工干涉
【特色】小巧、低耗和良好的稳定性特别适宜运行于服务器
【特色】所有规则都可以导出导入,灵活的资源重用
【特色】采用FTP上传文件,稳定、安全
【特色】与网站分离,通过独立制做的插口,可以支持任何网站或数据库
【采集】可选择逆序、顺序、随机采集文章
【采集】支持手动列表网址
【采集】支持对数据分布在多层页面的网站进行采集
【采集】自由设定采集数据项,并可单独过滤整理每位数据项
【采集】支持分页内容采集
【采集】支持任意格式、类型的文件(包括图片、视频)下载
【采集】可突破防盗链文件
【采集】支持动态文件网址剖析
【采集】支持对需登陆访问的网页的采集
【支持】可设定关键词采集
【支持】可设定避免采集的敏感词
【支持】可设置图片水印
「号内采集」自动抓取cookie和公众号主页图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 443 次浏览 • 2020-08-20 19:30
当我们采集一个公众号所有历史群发文章的时侯就须要用到号内采集的功能,这个功能须要抓取一些参数,抓取的过程也是自动化的,但是须要人为的点击一下,具体操作步骤如下:
请勿必按教程步骤操作
特别说明:每天建议采集4000篇文章左右,不要采集太多的公众号,会导致访问频繁的。已经采集的公众号文章信息会手动录入本地数据库,可通过本地搜索查看。
第一步:打开陌陌笔记本版并登陆,还没有下载陌陌的点我下载,登录陌陌后,打开须要采集的公众号,这里以公众号赚客撸羊绒为例,先点击右上角的步入公众号
第二步:打开如上图界面后,点击右上角的三个点点,再点击右图所示界面的查看历史消息
如果上图点击历史消息界面提示 “请在陌陌客户端打开链接” ,打开PC端陌陌设置—通用设置,将使用系统默认浏览器打开网页取消勾选即可
第三步:然后我们在软件的号内采集界面,点击开始采集按钮(点击后360等安全软件可能会有拦截提示,请勿必点击准许,第一次使用可能也会提示安装证书,务必也点击容许)
等待按键名称变为窃听中,再刷新公众号历史消息界面
注意是刷新公众号历史消息界面,如下边第二张图片,其他任何界面都不行
第四步:刷新后软件都会手动采集历史文章啦,加载间隔建议设置10秒,等待采集完成就可以导入文章或者浏览,如果刷新后软件没有手动采集,请查看下边这篇文章解决:
「号内采集 」刷新公众号历史消息界面,软件没反应或提示窃听获取cookie超时
特别注意:
1. 是等按键名称变为窃听中,再刷新历史界面;2. 是刷新历史消息界面,不是刷新文章内容页面,千万不能搞错了;3. 采集过程中不需要再去刷新历史消息界面,只须要刷新一次即可; 查看全部
「号内采集」自动抓取cookie和公众号主页图文教程
当我们采集一个公众号所有历史群发文章的时侯就须要用到号内采集的功能,这个功能须要抓取一些参数,抓取的过程也是自动化的,但是须要人为的点击一下,具体操作步骤如下:
请勿必按教程步骤操作
特别说明:每天建议采集4000篇文章左右,不要采集太多的公众号,会导致访问频繁的。已经采集的公众号文章信息会手动录入本地数据库,可通过本地搜索查看。
第一步:打开陌陌笔记本版并登陆,还没有下载陌陌的点我下载,登录陌陌后,打开须要采集的公众号,这里以公众号赚客撸羊绒为例,先点击右上角的步入公众号
第二步:打开如上图界面后,点击右上角的三个点点,再点击右图所示界面的查看历史消息
如果上图点击历史消息界面提示 “请在陌陌客户端打开链接” ,打开PC端陌陌设置—通用设置,将使用系统默认浏览器打开网页取消勾选即可
第三步:然后我们在软件的号内采集界面,点击开始采集按钮(点击后360等安全软件可能会有拦截提示,请勿必点击准许,第一次使用可能也会提示安装证书,务必也点击容许)
等待按键名称变为窃听中,再刷新公众号历史消息界面
注意是刷新公众号历史消息界面,如下边第二张图片,其他任何界面都不行
第四步:刷新后软件都会手动采集历史文章啦,加载间隔建议设置10秒,等待采集完成就可以导入文章或者浏览,如果刷新后软件没有手动采集,请查看下边这篇文章解决:
「号内采集 」刷新公众号历史消息界面,软件没反应或提示窃听获取cookie超时
特别注意:
1. 是等按键名称变为窃听中,再刷新历史界面;2. 是刷新历史消息界面,不是刷新文章内容页面,千万不能搞错了;3. 采集过程中不需要再去刷新历史消息界面,只须要刷新一次即可;
怎么把自媒体稿子定时发到自媒体平台?
采集交流 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2020-08-15 16:14
产品品牌:
易媒助手
产品均价:
56
最小起订:
1
供货总数:
1
发货时限:
当天
发货城市:
上海
怎么把自媒体稿子定时发到自媒体平台?一键发布视频之后来讲解怎样一键推送视频,跟着我下“发视频”,我有个小建议,把“默认分类”这里填好,添加本地视频,必须得填上标签标题等内容。设置好,轻点一下“发布”图标,会步入帐号勾选界面,选中要更新的分组,就一键发布完成了,是不是马上才能解放手掌?
舆情数据写自媒体文章人,你既然想创作出10万+,基础是要练就怎么聪明的蹭热点,要想文章人人看你们都爱用的办法是查阅数个热点榜,于是咱个人爱用的那些及时跟踪关键词的助手:微热点、统计如何把自媒体稿子定时发到自媒体平台?
因为传统推广成本的劣势越来越显著,近几年,视频内容营运格外被你们偏爱,其互动性非常强、隐藏着千百万级的流量、出众的阅读订购能力的特性,逐渐招来海量企业品牌方,正是想要取得充分的视频或图文爆光,我们经常会发送到所有的媒体平台。事实上当你的帐号足够充足,就会晓得:每天都跳不过每位平台登陆帐号、下面,再挨个地分发想要发的内容,毕竟是琐碎又沉闷,还太费时间,解决方案我昨天分享给你们。怎么把自媒体稿子定时发到自媒体平台?
【易媒助手9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台
6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
视频制做对于视频剪辑而言,能够满足日常使用的视频内容加工程序应用不少,但你们都晓得并非每一个应用工具都这么完美,这样的话圈友们直接选定一个契合个人使用惯的,于是小编汇总了这种新媒体行业视频素材处理程序应用,快保存到小本子上:爱剪辑如何把自媒体稿子定时发到自媒体平台?设置常用领域头一回使用这个软件,强烈建议设置好默认分类,之后创作的时侯,自动帮你填充分类,就无需一遍遍去设置了,很方便有木有,并且还支持多套方案。
视频素材如同有看点的文章需要资料,大部分情况下视频联接处理仍然得浏览别的视频中的资料,若你了解的素材越是优质,那样的话你完成的内容整体上或将显露高水准,我忽然发觉了下边那些实用的素材站,要是能帮助到你,哥哥姐姐们快记录出来:摄图网、国外素材:Videovo如何把自媒体稿子定时发到自媒体平台?
数据接触过营运的高手们,每个人觉得热文的深度剖析着实必需,倘若你平时的方法是活在自己式的写文,意识不到了解读者的话题集中在那里,故而基本上极少有人看,下面这种“宝贝”,能够使你找到正确公路:指数
数据在内容行业具有深厚经验的人,谁人不赞成跟踪视频wechat数据,并对数据剖析调整渐渐显得必需,假使你仅仅是随心情式的码字,意识不到结合读者的喜好和偏好,必然数据凄凉,而接下来的宝藏网站,可以使你找到正确公路接下来小编我意外发觉了下文的几个检测新热文的第三方应用,搜索瞧瞧怎么样,应该可以为编辑大佬们提供帮助:OK计数器如何把自媒体稿子定时发到自媒体平台?默认分类设置头一回用这个工具,强烈建议设置一下默认分类,今后创作时手动选择分类,就不用挨个去设置分类了,并且支持设置不同的分类。
一键发布视频接着来演示如何一键推送视频,关键点来了,鼠标移至“发视频”处,大家好设置好默认分类,然后再上传好想要发的视频,然后再挨个填写相应的标签或则标题。当你将里面那些步骤完成之后,发布按键请一下,会弹出勾选帐号的地方,选择想发的分组,就快速完成了一条视频的发布,有没有被这些快速的方法震惊住?
因为流量成本是趋减的,尤其是逾一两年,内容经济公认的被注重,其简单容易操作、曝光能力、超棒的转化作用的优越性,慢慢招来无数的个人品牌方。
添加媒体号步入易媒助手,添加帐号,选择添加帐号界面须要营运的平台,选择用帐号密码登入,往后软件手动输入帐密,不用一个一个输入了。怎么把自媒体稿子定时发到自媒体平台? 查看全部
产品品牌:
易媒助手
产品均价:
56
最小起订:
1
供货总数:
1
发货时限:
当天
发货城市:
上海
怎么把自媒体稿子定时发到自媒体平台?一键发布视频之后来讲解怎样一键推送视频,跟着我下“发视频”,我有个小建议,把“默认分类”这里填好,添加本地视频,必须得填上标签标题等内容。设置好,轻点一下“发布”图标,会步入帐号勾选界面,选中要更新的分组,就一键发布完成了,是不是马上才能解放手掌?
舆情数据写自媒体文章人,你既然想创作出10万+,基础是要练就怎么聪明的蹭热点,要想文章人人看你们都爱用的办法是查阅数个热点榜,于是咱个人爱用的那些及时跟踪关键词的助手:微热点、统计如何把自媒体稿子定时发到自媒体平台?
因为传统推广成本的劣势越来越显著,近几年,视频内容营运格外被你们偏爱,其互动性非常强、隐藏着千百万级的流量、出众的阅读订购能力的特性,逐渐招来海量企业品牌方,正是想要取得充分的视频或图文爆光,我们经常会发送到所有的媒体平台。事实上当你的帐号足够充足,就会晓得:每天都跳不过每位平台登陆帐号、下面,再挨个地分发想要发的内容,毕竟是琐碎又沉闷,还太费时间,解决方案我昨天分享给你们。怎么把自媒体稿子定时发到自媒体平台?
【易媒助手9大特色功能】
1.40+平台支持:支持40+主流新媒体平台,新平台持续对接中
2.1000+账号管理:轻松支持1000+账号管理,全新底层优化设计,自动记忆帐密、自动登入,账号再多都无惧挑战
3.爆文系统:实时采集热点文章、视频,让您轻松实时热点,打造偏偏10万+
4.AI智能重画:轻松重画收录,让您进行推广、关键词覆盖、软文等工作如虎添翼
5.一键分发:轻松将文章、视频、小视频、微动态,一键分发到30+主流平台
6.团队管理:支持子帐号创建,实现屏蔽利润、账号密码、员工营运统计等功能
7.原创度测量:基于3大搜索引擎,一键检查文章原创度,查重、审稿神器
8.微动态:支持一键发布微动态至:微头条、百家动态、微博等平台
9.数据总览:一键查看所有平台利润、播放、阅读、等数据
视频制做对于视频剪辑而言,能够满足日常使用的视频内容加工程序应用不少,但你们都晓得并非每一个应用工具都这么完美,这样的话圈友们直接选定一个契合个人使用惯的,于是小编汇总了这种新媒体行业视频素材处理程序应用,快保存到小本子上:爱剪辑如何把自媒体稿子定时发到自媒体平台?设置常用领域头一回使用这个软件,强烈建议设置好默认分类,之后创作的时侯,自动帮你填充分类,就无需一遍遍去设置了,很方便有木有,并且还支持多套方案。
视频素材如同有看点的文章需要资料,大部分情况下视频联接处理仍然得浏览别的视频中的资料,若你了解的素材越是优质,那样的话你完成的内容整体上或将显露高水准,我忽然发觉了下边那些实用的素材站,要是能帮助到你,哥哥姐姐们快记录出来:摄图网、国外素材:Videovo如何把自媒体稿子定时发到自媒体平台?
数据接触过营运的高手们,每个人觉得热文的深度剖析着实必需,倘若你平时的方法是活在自己式的写文,意识不到了解读者的话题集中在那里,故而基本上极少有人看,下面这种“宝贝”,能够使你找到正确公路:指数
数据在内容行业具有深厚经验的人,谁人不赞成跟踪视频wechat数据,并对数据剖析调整渐渐显得必需,假使你仅仅是随心情式的码字,意识不到结合读者的喜好和偏好,必然数据凄凉,而接下来的宝藏网站,可以使你找到正确公路接下来小编我意外发觉了下文的几个检测新热文的第三方应用,搜索瞧瞧怎么样,应该可以为编辑大佬们提供帮助:OK计数器如何把自媒体稿子定时发到自媒体平台?默认分类设置头一回用这个工具,强烈建议设置一下默认分类,今后创作时手动选择分类,就不用挨个去设置分类了,并且支持设置不同的分类。
一键发布视频接着来演示如何一键推送视频,关键点来了,鼠标移至“发视频”处,大家好设置好默认分类,然后再上传好想要发的视频,然后再挨个填写相应的标签或则标题。当你将里面那些步骤完成之后,发布按键请一下,会弹出勾选帐号的地方,选择想发的分组,就快速完成了一条视频的发布,有没有被这些快速的方法震惊住?
因为流量成本是趋减的,尤其是逾一两年,内容经济公认的被注重,其简单容易操作、曝光能力、超棒的转化作用的优越性,慢慢招来无数的个人品牌方。
添加媒体号步入易媒助手,添加帐号,选择添加帐号界面须要营运的平台,选择用帐号密码登入,往后软件手动输入帐密,不用一个一个输入了。怎么把自媒体稿子定时发到自媒体平台?
最强半自动化抓鸡工具构建思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2020-08-09 14:49
你向他人说你是搞安全的,外行人会问你能盗QQ吗内行人会问你能拿站吗,在太长一段时间里只能反复难堪地回答不能,然后外行人就对你兴趣缺缺内行人也对你兴致缺缺。
大概2010年以前尤其2005年以前,一是厂商并没有这么注重安全所以漏洞好多二是用户也欠缺安全意识有补丁也极少打,造成的结果就是漏洞好多且长时间内都可借助。基于这些情况很容易地就可以编撰一款自动化工具之后在太长时间内都能拿来攻占大量系统,但在现今漏洞密度越来越小借助难度越来越高0day/1day时间越来越短的环境下,这种模式越来越无法持续了。新人们不能不比老人们当初我学几天就拿下xxx实在不是人的水平低了而是外部安全水平高了。
你说得太有道理而且谁在乎呢,正如姑娘问你有没有房,你说楼市跌得很快啦老家刚家装啦,那就是没有嘛。想了一想搞安全要求能拿站应当不算过份,环境怎么样是我们自己要去处理的问题而不是只要求结果的领导们要了解的问题。难道老人们水水就叫能拿站新人就毫无捷径可走被贴上一代不如一代的标签吗。想了一想,正如刚变革开放只要稍稍努力都能奔小康现今搞IT还有希望跨阶级,只要把自动化发挥到极至轻松抓鸡还是有可能。
二、自动化功击思路
集成化思路虽然在好多地方都存在,比如cvedetails上会尽量列举关联的exploit,再如shodan和zoomeye上搜索主机会列举相关CVE,又如AutoSploit就直接是一个抓鸡工具。
cvedetails首先有些exp并没有列到对应的cve条目上(不懂为何),其次在真正的渗透中我们须要自己扫描ip存在的服务。
shodan和zoomeye主是列举了主机相关的cve。并没有直接列举exp。
autosploit为了实现自动化,只能使用特定格式的msf模块,一些可以功击的百规范化exp都被放弃了。
结命以上各工具优缺点,我们这儿选实现的“IP-服务-CVE-EXP”三步,舍弃掉最后功击一步。
其实从标题“抓鸡”可知最初而言是希望能实现autosploit那样的自动化功击,但实现过程中发觉存在想得很简单,不是他人只想到集成而没想到自动化而是有很多问题。所以本文“抓鸡”是标题党,“最强”也是标题党,后来补起来的“半自动化”也是标题党,程序只算能运行上去。不过对于采集CVE、MSF模块和exploitdb的exp及进一步的应急响应都还算有些意义。
2.1 指定ip查找exp
经过以下三步,得出最终IP及可用EXP(由IP确认EXP)
步骤
输入
处理
输出
第一步
IP
Shodan/Nmap
IP开放的服务及版本
第二步
IP开放的服务及版本
cvedetails类似数据库
服务及版本存在的CVE
第三步
服务及版本存在的CVE
metasploit/exploit-db
CVE对应的exp
2.2 使用最新exp找出适用该exp的ip
经过以下三步,得出最终IP及可用EXP(由EXP确认IP)
步骤
输入
处理
输出
第一步
最新的exp
metasploit/exploit-db
exp相关cve
第二步
exp相关cve
cvedetails类似数据库
cve影响的服务及版本
第三步
cve影响的服务及版本
Shodan
存在服务及版本的IP
三、数据库建设思路
在上一节中,我们谈到了以下几项:shodan、cvedetails、metasploit和exploit-db。
3.1 否定联网方法
首先,联网方法受网速限制。这些网站都是美国网站速度相对不稳定,几个网站依次访问历时会较长。
其次,联网方法受网站保护策略限制。频繁该问IP有可能被封掉(虽然测试中仍未发觉),其次象exploit-db查询须要验证码。
再次,联网方法受网站排版限制。比如cvedetails查询一个产品存在的cve列举的先是一个匹配产品汇总表,点进去再是一个漏洞年份汇总表,再点进去才是CVE列表,要走好几步这是很麻烦的。
除了shodan必然须要联网使用,cvedetails、metasploit和exploit-db都不适宜联网方法。
3.2 否定metasploit和exploit-db使用管线方式
在kali上metasploit通过启动msfconsole之后使用search命令可以进行搜索,但使用msfconsole的就会感觉到其启停是比较花费资源和时间的,所以启动msfconsole查询之后通过管线获取结果的方式并不好。
在kali上可以使用searchsploit命令查找exploit-db的exp,这资源和时间都算可接受,但是一定要安装好exploit-db能够用这限制很大也不是太理想。
3.3 数据库建设思路
在否定联网方法和否定管线方式后,剩下的只能建设本地数据库,而建设又可以分为在线建设和离线建设两种思路。
在线建设就是一个个页面去访问页面之后解析入库,这种方法一是耗费时间长,二是在实践时中间常由于恳求超时和解码有误而让程序中断,三是这些暴力的方式容易被封IP(metasploit最敏感,exploit最包容;在被封IP时你可以感受到动态IP也有用处)。基于以上缘由能离线建设就离线建设。
数据库
建设方法
更新方法
url
cve数据库
cvedetails其实没提供离线下载,但cvedetails的cve数据来源于nvd,nvd提供cve离线下载。离线建设
每日下载nvdcve-modified.xml更新数据库
metasploit数据库
metasploit在github有托管。离线建设。
metasploit实在很容易封ip,git同步项目后重新遍历采集
exploitdb数据库
exploitdb在github也有托管,但是cve只向exploitdb合作者提供而cve是程序的关键,所以只能使用在线建设
仍然只能在线追踪
关于更新还有以下几个关键点:
cvedetails在排列cve时只是简单地order by cve desc,这造成的问题就是排在最前面的cve并不一定是最新的cve,比如CVE-2018-1002209(2018-07-25发布)会排在CVE-2018-19115(2018-11-08发布)前面,所以cvedetails并不适宜拿来采集更新。
由于cve数据库使用nvdcve-modified.xml进行更新,这就要求必须每晚都执行更新程序不然cve都会不完整。nvdcve-modified.xml一是收录新发布的cve二是收录旧cve的修改,如果要保证cve的完整性须要重新下载搁置更新的年份的xml重新读取,如果要保证参考等的完整性那就要删掉数据库全部重新解析入库(还是要时间的大约半天)。
metasploit一个模块发布后通常不会再改动,所以我们以module_name为关键字,每次git pull同步后若果已存在就舍弃插入假如仍未存在就插入,这能挺好地保证metasploit数据库的完整性。单纯exploit模块整个过程大约只须要半个小时。
exploitdb在线建设耗费比较长的时间,一是在线不断恳求历时二是即使比较忍让但联接很久也会被禁,断断续续整个采集过程大约须要一周。
exploitdb以edbid为关键字,更新时依次访问exploitdb的remote、webapps、local、dos四大页面该页面,从头开始解析假如查到已存在expid则中止往下读取。remote等一个页面大约能显示一到三个月内的exp,在此时间范围内能填补缺位的记录假如超出一页这么这些记录也将不会补追补。当然你也可以在remote等中一页页地追踪下去但考虑以下两点这儿不那么实现,但这儿一是考虑一个月时间早已比较长,二是edbid是递增的可以自由地设置采集的edbid的区间。
3.4 数据库选择
首先,是选关系型数据库还是非关系型数据库,根据实际来看使用关系型数据库当有子查询时速率太慢,建索引也还是比较耗时间,所以可能非关系型数据库会快些。但是我需要同步到elk但elk不支持从非关系型读取数据,所以只能使用非关系型数据库。另外假如你要自己改成非关系型数据库那工作量比较大。
其次,选择关系型数据库后还要确定具体选那个数据库,其实不扯到高可用这种东西仅就使用来说关系型数据库都差异不大,开始想用sqlite但同步到elk时仍然报错处理不了,后来太慢想oracle可能快一些但很耗资源笔记本运行不起,所以就用mysql。你自己要改成其他数据库,连接句子和sql句子稍为更改应当就可以了。
3.5 数据库表设计3.5.1 cve表设计
cve_records表各数组如下:
对应cvedetails以下部分:
最终数据示例如下:
cve_affect_records表用于记录受cve影响的产品,各数组如下:
对应cvedetails以下部分:
最终搜集数据示例如下:
cve_refer_records表用于记录cve的参考链接,各数组如下:
对应cvedetails以下部份:
最终搜集数据示例如下:
3.5.2 msf表设计
msf_records表各数组如下:
对应模块查看页面的那几项内容:
最终搜集数据示例如下:
3.5.3 edb表设计
edb_records表各数组如下:
对应edb查看页面如下几项内容:
最终搜集数据示例如下:
四、程序说明4.1 程序使用说明
程序写了两周,实现疗效也不是挺好不是太有心情仔细说明,另外文件中也有一定注释。
配置好setting相关项,运行cve_offline_parse.py,就会搜集cve数据
配置好setting相关项,运行msf_offline_parse.py,就会搜集msf模块数据
配置好setting相关项,运行edb_online_parse.py,就会搜集edb模块数据
项目文件结构整体如下:
|-config|
| |-setting.py----程序配置文件,自己使用时主要修改这个文件
|
|-dao|
| |-src_db_dao.py----存放各dao数的文件
|
|-model|
| |-src_db_model.py----存放数据库表对应的model的文件
|
|-cve_offline_parse.py----通过下载nvd的xml解析入库cve的文件
|
|-cve_online_parse.py----原本设计通过读取cvedetails解析入库cve的文件,实际不使用
|
|-daily_trace_report.py----检查cve、msf、edb更新情况并发送通知邮件的文件
|
|-edb_online_parse.py----通过遍历www.exploit-db.com解析入库exp的文件
|
|-exploit_tool.py----所谓的“半自动化抓鸡工具”实现文件
|
|-msf_offline_parse.py----通过git同步github的metasploit-framework解析入库模块的文件
|
|-msf_online_parse.py----原本设计通过遍历www.rapid7.com/db/modules解析入库模块的文件,实际只用其追踪更新功能。
|
|-search_engine.py----shodan搜索实现文件
说明:2018.12.08发觉exploit-db网站升级,新写edb_online_parse_new.py取代旧的edb_online_parse.py。
4.2 运行环境
语言:python3
额外安装库:pip install requests requests-html pymysql sqlalchemy shodan beautifulsoup4
4.3 程序源代码
代码比较多,直接上github(db目录是我搜集好的数据解压下来导出mysql即可): 查看全部
一、说明
你向他人说你是搞安全的,外行人会问你能盗QQ吗内行人会问你能拿站吗,在太长一段时间里只能反复难堪地回答不能,然后外行人就对你兴趣缺缺内行人也对你兴致缺缺。
大概2010年以前尤其2005年以前,一是厂商并没有这么注重安全所以漏洞好多二是用户也欠缺安全意识有补丁也极少打,造成的结果就是漏洞好多且长时间内都可借助。基于这些情况很容易地就可以编撰一款自动化工具之后在太长时间内都能拿来攻占大量系统,但在现今漏洞密度越来越小借助难度越来越高0day/1day时间越来越短的环境下,这种模式越来越无法持续了。新人们不能不比老人们当初我学几天就拿下xxx实在不是人的水平低了而是外部安全水平高了。
你说得太有道理而且谁在乎呢,正如姑娘问你有没有房,你说楼市跌得很快啦老家刚家装啦,那就是没有嘛。想了一想搞安全要求能拿站应当不算过份,环境怎么样是我们自己要去处理的问题而不是只要求结果的领导们要了解的问题。难道老人们水水就叫能拿站新人就毫无捷径可走被贴上一代不如一代的标签吗。想了一想,正如刚变革开放只要稍稍努力都能奔小康现今搞IT还有希望跨阶级,只要把自动化发挥到极至轻松抓鸡还是有可能。
二、自动化功击思路
集成化思路虽然在好多地方都存在,比如cvedetails上会尽量列举关联的exploit,再如shodan和zoomeye上搜索主机会列举相关CVE,又如AutoSploit就直接是一个抓鸡工具。
cvedetails首先有些exp并没有列到对应的cve条目上(不懂为何),其次在真正的渗透中我们须要自己扫描ip存在的服务。
shodan和zoomeye主是列举了主机相关的cve。并没有直接列举exp。
autosploit为了实现自动化,只能使用特定格式的msf模块,一些可以功击的百规范化exp都被放弃了。
结命以上各工具优缺点,我们这儿选实现的“IP-服务-CVE-EXP”三步,舍弃掉最后功击一步。
其实从标题“抓鸡”可知最初而言是希望能实现autosploit那样的自动化功击,但实现过程中发觉存在想得很简单,不是他人只想到集成而没想到自动化而是有很多问题。所以本文“抓鸡”是标题党,“最强”也是标题党,后来补起来的“半自动化”也是标题党,程序只算能运行上去。不过对于采集CVE、MSF模块和exploitdb的exp及进一步的应急响应都还算有些意义。
2.1 指定ip查找exp
经过以下三步,得出最终IP及可用EXP(由IP确认EXP)
步骤
输入
处理
输出
第一步
IP
Shodan/Nmap
IP开放的服务及版本
第二步
IP开放的服务及版本
cvedetails类似数据库
服务及版本存在的CVE
第三步
服务及版本存在的CVE
metasploit/exploit-db
CVE对应的exp
2.2 使用最新exp找出适用该exp的ip
经过以下三步,得出最终IP及可用EXP(由EXP确认IP)
步骤
输入
处理
输出
第一步
最新的exp
metasploit/exploit-db
exp相关cve
第二步
exp相关cve
cvedetails类似数据库
cve影响的服务及版本
第三步
cve影响的服务及版本
Shodan
存在服务及版本的IP
三、数据库建设思路
在上一节中,我们谈到了以下几项:shodan、cvedetails、metasploit和exploit-db。
3.1 否定联网方法
首先,联网方法受网速限制。这些网站都是美国网站速度相对不稳定,几个网站依次访问历时会较长。
其次,联网方法受网站保护策略限制。频繁该问IP有可能被封掉(虽然测试中仍未发觉),其次象exploit-db查询须要验证码。
再次,联网方法受网站排版限制。比如cvedetails查询一个产品存在的cve列举的先是一个匹配产品汇总表,点进去再是一个漏洞年份汇总表,再点进去才是CVE列表,要走好几步这是很麻烦的。
除了shodan必然须要联网使用,cvedetails、metasploit和exploit-db都不适宜联网方法。
3.2 否定metasploit和exploit-db使用管线方式
在kali上metasploit通过启动msfconsole之后使用search命令可以进行搜索,但使用msfconsole的就会感觉到其启停是比较花费资源和时间的,所以启动msfconsole查询之后通过管线获取结果的方式并不好。
在kali上可以使用searchsploit命令查找exploit-db的exp,这资源和时间都算可接受,但是一定要安装好exploit-db能够用这限制很大也不是太理想。
3.3 数据库建设思路
在否定联网方法和否定管线方式后,剩下的只能建设本地数据库,而建设又可以分为在线建设和离线建设两种思路。
在线建设就是一个个页面去访问页面之后解析入库,这种方法一是耗费时间长,二是在实践时中间常由于恳求超时和解码有误而让程序中断,三是这些暴力的方式容易被封IP(metasploit最敏感,exploit最包容;在被封IP时你可以感受到动态IP也有用处)。基于以上缘由能离线建设就离线建设。
数据库
建设方法
更新方法
url
cve数据库
cvedetails其实没提供离线下载,但cvedetails的cve数据来源于nvd,nvd提供cve离线下载。离线建设
每日下载nvdcve-modified.xml更新数据库
metasploit数据库
metasploit在github有托管。离线建设。
metasploit实在很容易封ip,git同步项目后重新遍历采集
exploitdb数据库
exploitdb在github也有托管,但是cve只向exploitdb合作者提供而cve是程序的关键,所以只能使用在线建设
仍然只能在线追踪
关于更新还有以下几个关键点:
cvedetails在排列cve时只是简单地order by cve desc,这造成的问题就是排在最前面的cve并不一定是最新的cve,比如CVE-2018-1002209(2018-07-25发布)会排在CVE-2018-19115(2018-11-08发布)前面,所以cvedetails并不适宜拿来采集更新。
由于cve数据库使用nvdcve-modified.xml进行更新,这就要求必须每晚都执行更新程序不然cve都会不完整。nvdcve-modified.xml一是收录新发布的cve二是收录旧cve的修改,如果要保证cve的完整性须要重新下载搁置更新的年份的xml重新读取,如果要保证参考等的完整性那就要删掉数据库全部重新解析入库(还是要时间的大约半天)。
metasploit一个模块发布后通常不会再改动,所以我们以module_name为关键字,每次git pull同步后若果已存在就舍弃插入假如仍未存在就插入,这能挺好地保证metasploit数据库的完整性。单纯exploit模块整个过程大约只须要半个小时。
exploitdb在线建设耗费比较长的时间,一是在线不断恳求历时二是即使比较忍让但联接很久也会被禁,断断续续整个采集过程大约须要一周。
exploitdb以edbid为关键字,更新时依次访问exploitdb的remote、webapps、local、dos四大页面该页面,从头开始解析假如查到已存在expid则中止往下读取。remote等一个页面大约能显示一到三个月内的exp,在此时间范围内能填补缺位的记录假如超出一页这么这些记录也将不会补追补。当然你也可以在remote等中一页页地追踪下去但考虑以下两点这儿不那么实现,但这儿一是考虑一个月时间早已比较长,二是edbid是递增的可以自由地设置采集的edbid的区间。
3.4 数据库选择
首先,是选关系型数据库还是非关系型数据库,根据实际来看使用关系型数据库当有子查询时速率太慢,建索引也还是比较耗时间,所以可能非关系型数据库会快些。但是我需要同步到elk但elk不支持从非关系型读取数据,所以只能使用非关系型数据库。另外假如你要自己改成非关系型数据库那工作量比较大。
其次,选择关系型数据库后还要确定具体选那个数据库,其实不扯到高可用这种东西仅就使用来说关系型数据库都差异不大,开始想用sqlite但同步到elk时仍然报错处理不了,后来太慢想oracle可能快一些但很耗资源笔记本运行不起,所以就用mysql。你自己要改成其他数据库,连接句子和sql句子稍为更改应当就可以了。
3.5 数据库表设计3.5.1 cve表设计
cve_records表各数组如下:
对应cvedetails以下部分:
最终数据示例如下:
cve_affect_records表用于记录受cve影响的产品,各数组如下:
对应cvedetails以下部分:
最终搜集数据示例如下:
cve_refer_records表用于记录cve的参考链接,各数组如下:
对应cvedetails以下部份:
最终搜集数据示例如下:
3.5.2 msf表设计
msf_records表各数组如下:
对应模块查看页面的那几项内容:
最终搜集数据示例如下:
3.5.3 edb表设计
edb_records表各数组如下:
对应edb查看页面如下几项内容:
最终搜集数据示例如下:
四、程序说明4.1 程序使用说明
程序写了两周,实现疗效也不是挺好不是太有心情仔细说明,另外文件中也有一定注释。
配置好setting相关项,运行cve_offline_parse.py,就会搜集cve数据
配置好setting相关项,运行msf_offline_parse.py,就会搜集msf模块数据
配置好setting相关项,运行edb_online_parse.py,就会搜集edb模块数据
项目文件结构整体如下:
|-config|
| |-setting.py----程序配置文件,自己使用时主要修改这个文件
|
|-dao|
| |-src_db_dao.py----存放各dao数的文件
|
|-model|
| |-src_db_model.py----存放数据库表对应的model的文件
|
|-cve_offline_parse.py----通过下载nvd的xml解析入库cve的文件
|
|-cve_online_parse.py----原本设计通过读取cvedetails解析入库cve的文件,实际不使用
|
|-daily_trace_report.py----检查cve、msf、edb更新情况并发送通知邮件的文件
|
|-edb_online_parse.py----通过遍历www.exploit-db.com解析入库exp的文件
|
|-exploit_tool.py----所谓的“半自动化抓鸡工具”实现文件
|
|-msf_offline_parse.py----通过git同步github的metasploit-framework解析入库模块的文件
|
|-msf_online_parse.py----原本设计通过遍历www.rapid7.com/db/modules解析入库模块的文件,实际只用其追踪更新功能。
|
|-search_engine.py----shodan搜索实现文件
说明:2018.12.08发觉exploit-db网站升级,新写edb_online_parse_new.py取代旧的edb_online_parse.py。
4.2 运行环境
语言:python3
额外安装库:pip install requests requests-html pymysql sqlalchemy shodan beautifulsoup4
4.3 程序源代码
代码比较多,直接上github(db目录是我搜集好的数据解压下来导出mysql即可):
[发布] 一键采集任何微信公众号的文章,可以输入公众号的名称
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-08-09 11:57
【插件功能】
安装本插件以后,可以输入微信公众号的文章网址或则微信公众号的名称,一键获取内容到您的峰会上。
【本插件功能特性】
1、可以输入微信公众号的名称,实时采集微信公众号的内容。
2、每隔5分钟手动推送微信热文,您只需点击一下键盘就可以发布到您的峰会上。
3、采集过来的陌陌文章图片可以正常显示而且保存为贴子图片附件。
4、图片附件支持远程FTP保存。
5、图片会加上您峰会的水印。
6、已采集过的微信公众号文章不会重复二次采集,内容不会冗余。
7、采集发布的贴子跟真实用户发布的几乎一模一样。
8、浏览量会手动随机设置,感觉您的贴子查看数更真实。
9、可以指定贴子发布者的UID。
10、采集的微信公众号文章内容可以发布到任何一个版块。
11、无限量采集,不限采集次数。
【此插件给您带来的价值】
1、让您的峰会人气太旺,内容太丰富多彩。
2、用一键采集来取代手工发贴,省时省力,不易出错。
3、可以使你的网站与海量的陌陌订阅号共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员(QQ:155120699),如果在48小时之内无法解决问题,全额退票给消费者!!大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员(mail:),在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
【官方QQ群:235307918】
在线安装地址:
@csdn123com_weixin.plugin
本地下载安装: 查看全部
【插件功能】
安装本插件以后,可以输入微信公众号的文章网址或则微信公众号的名称,一键获取内容到您的峰会上。
【本插件功能特性】
1、可以输入微信公众号的名称,实时采集微信公众号的内容。
2、每隔5分钟手动推送微信热文,您只需点击一下键盘就可以发布到您的峰会上。
3、采集过来的陌陌文章图片可以正常显示而且保存为贴子图片附件。
4、图片附件支持远程FTP保存。
5、图片会加上您峰会的水印。
6、已采集过的微信公众号文章不会重复二次采集,内容不会冗余。
7、采集发布的贴子跟真实用户发布的几乎一模一样。
8、浏览量会手动随机设置,感觉您的贴子查看数更真实。
9、可以指定贴子发布者的UID。
10、采集的微信公众号文章内容可以发布到任何一个版块。
11、无限量采集,不限采集次数。
【此插件给您带来的价值】
1、让您的峰会人气太旺,内容太丰富多彩。
2、用一键采集来取代手工发贴,省时省力,不易出错。
3、可以使你的网站与海量的陌陌订阅号共享优质内容,可以快速提高网站权重与排行。
【用户保障】
1、严格遵循官方的插件开发规范,除此之外,我们的团队也会对插件进行大量的测试,确保插件的安全、稳定、成熟。
2、购买本插件以后,因为服务器运行环境、插件冲突、系统配置等诱因不能使用插件,可以联系技术员(QQ:155120699),如果在48小时之内无法解决问题,全额退票给消费者!!大家不用害怕订购插件以后用不了,如果真的用不了,不会收您一分钱。
3、在使用过程中,发现有bug或则用户体验不佳,可以反馈给技术员(mail:),在经过评估过后,情况属实,将在下一次升级版本解决,请你们留心插件升级更新。
【官方QQ群:235307918】
在线安装地址:
@csdn123com_weixin.plugin
本地下载安装:
施庆伪原创工具v2.3.4.10正式版
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2020-08-09 01:54
世庆的伪原创工具的特征
1. 伪原创工具是世界上第一个: 本地和网络两种不同的伪原创方法
2,支持中英文伪原创;
3. 使用独特的分词引擎,该引擎完全符合baidu和google的习惯. 同时,我们提供了免费的开发参数界面,请使用-help查看.
4. 独特的同义词和反义词引擎可以适当地更改文章的语义,并使用独特的算法对其进行控制.
5. 独特的段落和段落内迁移功能;
6. 伪原创内容可以以txt或html格式导入和导出,方便客户迁移数据;
7. 独家支持在线自供电的伪原创主流CMS系统,例如Dongyi,Xinyun,Laoya,Dede,Empire,PHPCMS,zblog等;
8. 绿色软件无需安装且容量小. 软件包下载量仅为2M,占用的系统资源较少,是同类软件的1/3;
9. 您可以制作收录html标签的伪原创文章;
10. 您可以制作收录图片,Flash和其他多媒体格式的伪原创文章;
11. 在线升级全部免费,每月定期为您升级程序,以确保百度和Google的更新算法同步;
12. 提供贴心的“替换链接”功能,有效增加SEO外部链接;
13. 本机编译代码,采用win2000之上的所有平台,包括winxp,win2003,vista等;
14. 多核系统,能够以极快的速度生成数以万计的单词的伪原创文章
施庆伪原创工具功能
1. 采集文章
Shi Qing伪原创工具,随附采集工具. 首先,您需要在“集合设置”模块中输入需要采集的关键字. 输入完成后,单击“保存关键字”以保存单词,然后选中它(默认情况下选中). 然后选择在百度或Google采集. 如果您是免费试用用户. 只能使用第一个“免费测试集”.
2,制作伪造的原创文章
用户可以通过4种方式输入原创文章: 1.将文章直接复制到文章编辑区域,然后输入标题,然后保存文章; 2.通过导入,您可以直接导入TXT或html文档. 3.通过采集的方法是直接在Internet上采集文章. 4.直接通过界面获取您自己的CMS网站的内容;
3. 使用直接更新到主流CMS系统
Shi Qing的伪原创工具,支持直接更新99%的国内主流CMS内容,例如东夷,老挝,新云,dede CMS等,通过界面直接获取网站上的信息,并将其上传回去伪原创之后. 在界面中详细说明了特定的使用方法. 按照说明进行操作,您将很快成功.
4. 使用用户定义的词库
用户可以在“自定义词典”部分中输入或导入自己的同义词库. 勾选后,系统将尽快响应该字库,而不是替换我们企业版中的字库. 具体使用方法在软件界面中进行了详细说明. 免费版不支持此功能.
5. 配置替换/插入功能
此功能主要是将URL链接添加到伪原创文章中的指定文本,以创建外部链接. 同时,您可以根据配置的关键字密度插入设置的关键字.
6. 从现有文章中生成新文章
此功能主要是用于动态生成文章的工具. 生成的文章绝对是唯一的,但通常可读.
单击SEO功能,然后选择最后一个菜单“从现有文章生成新文章”.
史青的伪原创工具视频简介
伪原创工具 查看全部
Shiqing伪原创工具是专业的伪原创文章生成器. 它可以将从Internet采集的文章转换为您自己的文章,并且修改方法更符合百度和Google搜索引擎的算法. ,因此该文章排名较高,因此该工具是大多数网站管理员和网站发起人的有力助手!
世庆的伪原创工具的特征
1. 伪原创工具是世界上第一个: 本地和网络两种不同的伪原创方法
2,支持中英文伪原创;
3. 使用独特的分词引擎,该引擎完全符合baidu和google的习惯. 同时,我们提供了免费的开发参数界面,请使用-help查看.
4. 独特的同义词和反义词引擎可以适当地更改文章的语义,并使用独特的算法对其进行控制.
5. 独特的段落和段落内迁移功能;
6. 伪原创内容可以以txt或html格式导入和导出,方便客户迁移数据;
7. 独家支持在线自供电的伪原创主流CMS系统,例如Dongyi,Xinyun,Laoya,Dede,Empire,PHPCMS,zblog等;
8. 绿色软件无需安装且容量小. 软件包下载量仅为2M,占用的系统资源较少,是同类软件的1/3;
9. 您可以制作收录html标签的伪原创文章;
10. 您可以制作收录图片,Flash和其他多媒体格式的伪原创文章;
11. 在线升级全部免费,每月定期为您升级程序,以确保百度和Google的更新算法同步;
12. 提供贴心的“替换链接”功能,有效增加SEO外部链接;
13. 本机编译代码,采用win2000之上的所有平台,包括winxp,win2003,vista等;
14. 多核系统,能够以极快的速度生成数以万计的单词的伪原创文章
施庆伪原创工具功能
1. 采集文章
Shi Qing伪原创工具,随附采集工具. 首先,您需要在“集合设置”模块中输入需要采集的关键字. 输入完成后,单击“保存关键字”以保存单词,然后选中它(默认情况下选中). 然后选择在百度或Google采集. 如果您是免费试用用户. 只能使用第一个“免费测试集”.
2,制作伪造的原创文章
用户可以通过4种方式输入原创文章: 1.将文章直接复制到文章编辑区域,然后输入标题,然后保存文章; 2.通过导入,您可以直接导入TXT或html文档. 3.通过采集的方法是直接在Internet上采集文章. 4.直接通过界面获取您自己的CMS网站的内容;
3. 使用直接更新到主流CMS系统
Shi Qing的伪原创工具,支持直接更新99%的国内主流CMS内容,例如东夷,老挝,新云,dede CMS等,通过界面直接获取网站上的信息,并将其上传回去伪原创之后. 在界面中详细说明了特定的使用方法. 按照说明进行操作,您将很快成功.
4. 使用用户定义的词库
用户可以在“自定义词典”部分中输入或导入自己的同义词库. 勾选后,系统将尽快响应该字库,而不是替换我们企业版中的字库. 具体使用方法在软件界面中进行了详细说明. 免费版不支持此功能.
5. 配置替换/插入功能
此功能主要是将URL链接添加到伪原创文章中的指定文本,以创建外部链接. 同时,您可以根据配置的关键字密度插入设置的关键字.
6. 从现有文章中生成新文章
此功能主要是用于动态生成文章的工具. 生成的文章绝对是唯一的,但通常可读.
单击SEO功能,然后选择最后一个菜单“从现有文章生成新文章”.
史青的伪原创工具视频简介
伪原创工具
如何使用采集器来搜寻微信官方帐户的内容?
采集交流 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2020-08-08 00:46
许多答案无用或不再起作用,这是我的计划.
如果您只是采集公共帐户文章,如果要求不是很严格,则可以去搜狗. 这种方案成本低廉,相对简单,但缺点也很明显. 这是一个临时文章链接. 如果要将其转换为永久链接,则仍然必须使用应用程序界面.
另一个解决方案是从微信应用程序本身采集. 这种采集成本会高得多,但是可以采集很多类型的数据,包括但不限于: 历史页面文章,喜欢的阅读,评论等.
为了更加直观,我制作了一个图表来比较从搜狗和微信应用程序采集的两种解决方案.
我自己使用了这两种解决方案,并且还提供了封装的接口. 我将根据成本和方案选择使用哪个.
一个简单的一句话总结就是,搜狗拥有一些微信应用程序,而搜狗没有微信应用程序,但就软成本和硬成本而言,微信计划远大于搜狗的计划.
题外话,图片提到微信中的搜索界面. 我自己实现了. 作为一种实践,我可以获取搜索官方帐户和商品的返回数据,因为该接口使用很少,所以没有打包打开. 如果需要,可以单独与我联系. 许多人可能认为不可能采集搜索接口,因为数据根本不是HTTP协议. 但是我想说的是,有时不必在请求中拦截数据采集. 有很多选择,但是成本会非常大(开发成本和在线成本). 查看全部
于2018-06-05更新
许多答案无用或不再起作用,这是我的计划.
如果您只是采集公共帐户文章,如果要求不是很严格,则可以去搜狗. 这种方案成本低廉,相对简单,但缺点也很明显. 这是一个临时文章链接. 如果要将其转换为永久链接,则仍然必须使用应用程序界面.
另一个解决方案是从微信应用程序本身采集. 这种采集成本会高得多,但是可以采集很多类型的数据,包括但不限于: 历史页面文章,喜欢的阅读,评论等.
为了更加直观,我制作了一个图表来比较从搜狗和微信应用程序采集的两种解决方案.
我自己使用了这两种解决方案,并且还提供了封装的接口. 我将根据成本和方案选择使用哪个.
一个简单的一句话总结就是,搜狗拥有一些微信应用程序,而搜狗没有微信应用程序,但就软成本和硬成本而言,微信计划远大于搜狗的计划.
题外话,图片提到微信中的搜索界面. 我自己实现了. 作为一种实践,我可以获取搜索官方帐户和商品的返回数据,因为该接口使用很少,所以没有打包打开. 如果需要,可以单独与我联系. 许多人可能认为不可能采集搜索接口,因为数据根本不是HTTP协议. 但是我想说的是,有时不必在请求中拦截数据采集. 有很多选择,但是成本会非常大(开发成本和在线成本).
网络爬虫必看的文章采集示例
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-08-07 23:19
熟悉的朋友知道可以通过官方网站上的FAQ来检索采集过程中遇到的问题,因此这里以采集常见问题为例来说明Web爬网工具采集的原理和过程.
在此示例中,我们将演示地址.
(1)创建一个新的采集规则
选择一个组并单击鼠标右键,选择“新建任务”,如下所示:
(2)添加起始网址
在这里,假设我们需要采集5页数据.
分析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此我们可以推断出p =之后的数字是分页的含义,我们使用[address parameter]来表示:
因此设置如下:
地址格式: 使用[地址参数]表示更改后的页码.
编号更改: 从1开始,即第一页;每增加1,即每页的更改数量;共5项,共5页.
预览: 采集器将根据上述设置生成一部分URL,以便您判断添加的内容是否正确.
然后确认.
(3)[常规模式]获取内容URL
普通模式: 默认情况下,此模式获取第一级地址,即从起始页的源代码获取到内容页A的链接.
在这里,我将向您展示如何自动获取地址链接并设置区域.
检查页面的源代码以找到文章地址所在的区域:
设置如下:
注意: 有关更详细的分析说明,请参阅本手册:
操作指南>软件操作> URL采集规则>获取内容URL
点击URL采集测试以查看测试效果
(3)内容采集URL
以说明标签采集为例
注意: 有关更详细的分析说明,请参阅本手册
操作指南>软件操作>内容采集规则>标记编辑
我们首先检查其页面的源代码,然后找到“标题”所在的代码:
导入Excle是一个弹出对话框〜打开Excle-优采云采集器帮助中心时出错
已分析: 起始字符串为:
结尾字符串为:
数据处理内容替换/排除: 需要替换-优采云采集器帮助中心为空
设置内容标签的原理相似. 在源代码中找到内容的位置
已分析: 起始字符串为:
结尾字符串为:
数据处理-HTML标记排除: 过滤不想要的A链接等.
设置另一个“源”字段
这样一个简单的文章采集规则已经准备就绪. 我不知道网民是否学过. 顾名思义,它适合在网页上捕获数据. 从上面的示例中还可以看到,这种类型的软件主要是仅通过源代码分析来分析数据. 还有一些未在此处列出的情况,例如登录采集,使用代理采集等. 如果您对Web抓取工具感兴趣,则可以登录器官采集网站以自己学习. 返回搜狐查看更多 查看全部
在我们的日常工作和学习中,采集一些有价值的文章可以帮助我们提高信息的利用率和整合率. 对于新闻和学术论文等电子文章,我们可以使用网络爬网工具. 采集,这种类型的采集相对容易采集一些数字化的,不规则的数据. 这是一个Ucai Cloud Collector V9的示例,为每个人介绍了文章采集示例.
熟悉的朋友知道可以通过官方网站上的FAQ来检索采集过程中遇到的问题,因此这里以采集常见问题为例来说明Web爬网工具采集的原理和过程.
在此示例中,我们将演示地址.
(1)创建一个新的采集规则
选择一个组并单击鼠标右键,选择“新建任务”,如下所示:
(2)添加起始网址
在这里,假设我们需要采集5页数据.
分析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此我们可以推断出p =之后的数字是分页的含义,我们使用[address parameter]来表示:
因此设置如下:
地址格式: 使用[地址参数]表示更改后的页码.
编号更改: 从1开始,即第一页;每增加1,即每页的更改数量;共5项,共5页.
预览: 采集器将根据上述设置生成一部分URL,以便您判断添加的内容是否正确.
然后确认.
(3)[常规模式]获取内容URL
普通模式: 默认情况下,此模式获取第一级地址,即从起始页的源代码获取到内容页A的链接.
在这里,我将向您展示如何自动获取地址链接并设置区域.
检查页面的源代码以找到文章地址所在的区域:
设置如下:
注意: 有关更详细的分析说明,请参阅本手册:
操作指南>软件操作> URL采集规则>获取内容URL
点击URL采集测试以查看测试效果
(3)内容采集URL
以说明标签采集为例
注意: 有关更详细的分析说明,请参阅本手册
操作指南>软件操作>内容采集规则>标记编辑
我们首先检查其页面的源代码,然后找到“标题”所在的代码:
导入Excle是一个弹出对话框〜打开Excle-优采云采集器帮助中心时出错
已分析: 起始字符串为:
结尾字符串为:
数据处理内容替换/排除: 需要替换-优采云采集器帮助中心为空
设置内容标签的原理相似. 在源代码中找到内容的位置
已分析: 起始字符串为:
结尾字符串为:
数据处理-HTML标记排除: 过滤不想要的A链接等.
设置另一个“源”字段
这样一个简单的文章采集规则已经准备就绪. 我不知道网民是否学过. 顾名思义,它适合在网页上捕获数据. 从上面的示例中还可以看到,这种类型的软件主要是仅通过源代码分析来分析数据. 还有一些未在此处列出的情况,例如登录采集,使用代理采集等. 如果您对Web抓取工具感兴趣,则可以登录器官采集网站以自己学习. 返回搜狐查看更多
C#图片获取软件,自动翻页,自动分类(用于采集精美图片的必要工具)(2个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-06 04:03
本文演示了在先前版本中这些功能的添加,下载了整个站点,显示采集站点,软件注册,软件更新以及使用XML保存采集记录. 效果如图1所示. 采集链接以下载并使用必要的Mito工具.
图1
演示程序结构
要创建演示程序,我选择在原创程序的基础上创建一个名为ImgSpiderWinUpdate的新C#Windows Forms应用程序. 该Windows项目用于软件升级. 从WebService下载最新的软件更新程序包,并解压缩文件以更新操作. 空白的Asp.Net网站名为ImgSpiderWeb,添加了ImgSpiderWebService.asmx WebService文件,提到了软件注册,并更新了下载方法. 图2显示了该演示程序的总体结构.
图2
程序在主项目ImgSpiderWinForm的Program.cs文件中执行,以确定程序是否已更新
ImgSpiderWinUpdate项目表单文件frmUpdate,从WebService下载最新的软件更新包,然后解压缩该文件,进行更新操作,
更新操作完成后,运行ImgSpider.exe
在ImgSpiderWeb项目中,ImgSpiderWebService.asmx Web服务文件提到了软件注册和更新下载的调用方法
在主项目ImgSpiderWinForm中添加frmRegistrationSoftware主要用于软件注册
更改主项目ImgSpiderWinForm中的下载记录以保存为XML
结束
本文演示了这些功能在以前的版本中的附加功能,完整站点下载,显示采集站点,软件注册,软件更新以及使用XML保存采集记录的情况. 采集链接以下载并使用必要的Mito工具. 查看全部
可以在任何网站上采集各种格式的图片,实现对所有文章,新闻,帖子等中间的所有图片进行有序排序的功能,然后将其保存在计算机上并保存所有任何论坛网站的帖子. 图片是在本地采集的,广告可以轻松过滤. 对于喜欢采集精美图片的网站,论坛所有者和朋友来说,它是必不可少的工具.
本文演示了在先前版本中这些功能的添加,下载了整个站点,显示采集站点,软件注册,软件更新以及使用XML保存采集记录. 效果如图1所示. 采集链接以下载并使用必要的Mito工具.
图1
演示程序结构
要创建演示程序,我选择在原创程序的基础上创建一个名为ImgSpiderWinUpdate的新C#Windows Forms应用程序. 该Windows项目用于软件升级. 从WebService下载最新的软件更新程序包,并解压缩文件以更新操作. 空白的Asp.Net网站名为ImgSpiderWeb,添加了ImgSpiderWebService.asmx WebService文件,提到了软件注册,并更新了下载方法. 图2显示了该演示程序的总体结构.
图2
程序在主项目ImgSpiderWinForm的Program.cs文件中执行,以确定程序是否已更新
ImgSpiderWinUpdate项目表单文件frmUpdate,从WebService下载最新的软件更新包,然后解压缩该文件,进行更新操作,
更新操作完成后,运行ImgSpider.exe
在ImgSpiderWeb项目中,ImgSpiderWebService.asmx Web服务文件提到了软件注册和更新下载的调用方法
在主项目ImgSpiderWinForm中添加frmRegistrationSoftware主要用于软件注册
更改主项目ImgSpiderWinForm中的下载记录以保存为XML
结束
本文演示了这些功能在以前的版本中的附加功能,完整站点下载,显示采集站点,软件注册,软件更新以及使用XML保存采集记录的情况. 采集链接以下载并使用必要的Mito工具.
文章批量采集和生成伪原创工具中,英,日自动永久版软件ArticleSea
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2020-08-05 19:05
拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件中!
文章采集,支持中文,英文,日文,法文,德文和其他语言的采集. 您还可以自定义采集来源并自动了解采集规则(您无需像其他采集软件一样编写自己的规则,只需直接输入关键字即可采集),采集通常需要两三个小时,成千上万次文章无法立即被采集,因此请耐心等待采集. 最好晚上把它放在那里采集. 第二天没事.
·自动去噪和乱码,获得新鲜干净的物品.
·支持多个关键字. 想一想,如果您输入一百个关键字并在一夜之间采集它们,将会采集多少篇文章?
·支持线程设置,只要将计算机配置为具有较高的互联网速度,就可以设置任意多个线程!
·支持代理设置.
·一键生成长尾词库,标题库,段落库,单句库,双句库和三句库.
·使用语料库生成大量文章.
中文伪原文是句子数据库混合生成方式: 使用句子数据库生成(文章段落句子拆分和重组)+页面优化(关键字插入和粗体显示,添加图片等)+批处理插入(锚文本插入,关键字替换),不能直接伪造原创文件,请勿打开软件并直接使用该软件的伪造原创功能,然后说没有效果,如果您介意的话,请小心处理
·伪原创: 功能强大的同义词库,伪原创快速且易于阅读.
·伪原创: 支持SPIN.
·伪原件: 支持标题是否为伪原件.
·伪原件: 支持不同级别的伪原件.
·伪原创: 支持保留核心关键字而不被替换.
·假原件: 相似度计算和显示
·伪原创: 大屏幕,易于编辑.
·伪原创: 使用不同的颜色表示伪原创文章与原创文本之间的区别.
·批处理页面优化
·运行环境: Win2000 / 2003 / Vista / win7 / win10
并支持32位和64位操作系统.
查看全部
拍照时请离开您的邮箱,信息将自动发送到您的邮箱进行下载!
拍照后,它将自动将指向百度网络磁盘的链接发送到您的电子邮件中!
文章采集,支持中文,英文,日文,法文,德文和其他语言的采集. 您还可以自定义采集来源并自动了解采集规则(您无需像其他采集软件一样编写自己的规则,只需直接输入关键字即可采集),采集通常需要两三个小时,成千上万次文章无法立即被采集,因此请耐心等待采集. 最好晚上把它放在那里采集. 第二天没事.
·自动去噪和乱码,获得新鲜干净的物品.
·支持多个关键字. 想一想,如果您输入一百个关键字并在一夜之间采集它们,将会采集多少篇文章?
·支持线程设置,只要将计算机配置为具有较高的互联网速度,就可以设置任意多个线程!
·支持代理设置.
·一键生成长尾词库,标题库,段落库,单句库,双句库和三句库.
·使用语料库生成大量文章.
中文伪原文是句子数据库混合生成方式: 使用句子数据库生成(文章段落句子拆分和重组)+页面优化(关键字插入和粗体显示,添加图片等)+批处理插入(锚文本插入,关键字替换),不能直接伪造原创文件,请勿打开软件并直接使用该软件的伪造原创功能,然后说没有效果,如果您介意的话,请小心处理
·伪原创: 功能强大的同义词库,伪原创快速且易于阅读.
·伪原创: 支持SPIN.
·伪原件: 支持标题是否为伪原件.
·伪原件: 支持不同级别的伪原件.
·伪原创: 支持保留核心关键字而不被替换.
·假原件: 相似度计算和显示
·伪原创: 大屏幕,易于编辑.
·伪原创: 使用不同的颜色表示伪原创文章与原创文本之间的区别.
·批处理页面优化
·运行环境: Win2000 / 2003 / Vista / win7 / win10
并支持32位和64位操作系统.

