
自动采集文章网站
自动采集文章网站(自动采集文章网站,悟空问答未来前景如何?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-26 08:03
自动采集文章网站,比如知乎,豆瓣,
做阿里巴巴的话,找一些做的人,根据产品布局和价格体系做客,客赚钱方式太多了。但是卖这些产品你要掌握产品的核心价值,如果产品卖不出去还是空谈,因为只有你产品卖得好,卖的好的商家才愿意给你代理。卖东西最忌讳没有价值。如果你想在互联网赚钱,建议还是做垂直领域的服务吧,别在互联网上瞎折腾了。
卖书?有成本你就卖便宜的吧
其实我也在考虑这个问题,现在做着鸡毛互联网的。跟大牛聊过,他们就给我看看文章,说能赚钱,但是自己不会。其实赚钱很简单,有人教也能赚钱,就是没有时间,有时间也赚不了多少。
现在公众号能卖产品,只要一两篇文章。虽然不能赚多少钱,
如果你没有经验又想赚钱,肯定会比赚钱难。如果你想赚钱又想没经验,那赚钱就会容易一些。建议你先去一些门槛低的平台入驻,如悟空问答(不要加公众号悟空专业问答)。我当初做悟空问答,悟空专业问答,一开始只是发点一元二元的回答,赚了一点零花钱,现在悟空问答整合平台,更新详细的答案,一些没经验的人发点高质量回答,比如在知乎说到的那些能赚钱的段子,他们就会有收入。
如果你有经验也能做悟空问答,可以去看看这个为什么悟空问答一下火起来?你们觉得悟空问答未来前景如何?我是做互联网产品经理培训的,欢迎加我微信:haha_pc。 查看全部
自动采集文章网站(自动采集文章网站,悟空问答未来前景如何?(图))
自动采集文章网站,比如知乎,豆瓣,
做阿里巴巴的话,找一些做的人,根据产品布局和价格体系做客,客赚钱方式太多了。但是卖这些产品你要掌握产品的核心价值,如果产品卖不出去还是空谈,因为只有你产品卖得好,卖的好的商家才愿意给你代理。卖东西最忌讳没有价值。如果你想在互联网赚钱,建议还是做垂直领域的服务吧,别在互联网上瞎折腾了。
卖书?有成本你就卖便宜的吧
其实我也在考虑这个问题,现在做着鸡毛互联网的。跟大牛聊过,他们就给我看看文章,说能赚钱,但是自己不会。其实赚钱很简单,有人教也能赚钱,就是没有时间,有时间也赚不了多少。
现在公众号能卖产品,只要一两篇文章。虽然不能赚多少钱,
如果你没有经验又想赚钱,肯定会比赚钱难。如果你想赚钱又想没经验,那赚钱就会容易一些。建议你先去一些门槛低的平台入驻,如悟空问答(不要加公众号悟空专业问答)。我当初做悟空问答,悟空专业问答,一开始只是发点一元二元的回答,赚了一点零花钱,现在悟空问答整合平台,更新详细的答案,一些没经验的人发点高质量回答,比如在知乎说到的那些能赚钱的段子,他们就会有收入。
如果你有经验也能做悟空问答,可以去看看这个为什么悟空问答一下火起来?你们觉得悟空问答未来前景如何?我是做互联网产品经理培训的,欢迎加我微信:haha_pc。
自动采集文章网站(自动采集文章网站的页面地址到一个博客上,再用onerepublic解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-26 00:07
自动采集文章网站的页面地址到一个博客上,再用onerepublic插件,调用之前爬下来的站点文章,发布就好了。
我也遇到了类似的问题,本来自己电脑上的流量大到吓人,可我无论如何安装了扩展,过一段时间以后还是卡的要死,在wordpress提示资源较多的情况下,自己放弃了,换了pchunter,同样的问题依然解决不了。最后用google解决的。首先是按照以下步骤操作的。第一步:打开google搜索,然后复制这条信息,粘贴到浏览器的chrome浏览器插件user-agent里边,得到一个搜索url第二步:再在百度浏览器的扩展里搜索“爬虫”,你将发现这里有360搜索、傲游、idm、you-get等等有很多搜索引擎,具体哪个最好选择不清楚,只是我发现这里的搜索引擎都不好用。
打开360搜索,这个老是抽风第三步:选择第一个”好记录的爬虫“,接着我看了看资源表,没有发现programrequest的第四步:搜索user-agentwebsocketpost(原谅我这种不想点开,跳过去又忘记右键重新检索,还不好选择的问题吧),选择好以后会出现很多爬虫,你可以先不用考虑后面的爬虫是哪个,重点是你想爬什么网站。
第五步:在相应网站框里框下面鼠标左键右键,创建一个爬虫,然后你的原来的资源表里搜索user-agent就会得到第一个,然后这个url就是你刚才创建的爬虫了。比如我创建了一个是写文章的爬虫,你可以在createuser-agentfor‘/you-get'下面看到更多的类似爬虫。这时候你可以选择你要的站点,如果打开一看有一堆爬虫,你可以选择你想要的url也可以选择手动同步到本地再用其他地方,我自己是选择的用博客爬,除了可以在不同站点上打开不同链接之外,还可以在百度里自动抓取这个网站的数据。
第六步:创建好爬虫以后,你可以去mozillamail解压缩在浏览器里试试,然后保存到本地,会有一个地址对不对,如果对的话,下载安装就可以了。ps:最后强调一下,我的这个方法不是官方的,因为本人一开始确实需要文章的地址,就想到这个方法,而官方的思路是找到一个新网站平台,可以让php爬虫分析你的信息,然后抓取存到本地。
我有点理解不了这个意思,好像是我开了个脚本打包工具,然后解压,然后把php抓取ps:差点忘记了,实际上还有其他的爬虫实现方法,比如要抓取:租房二手房房价,留学生毕业生求职求职信息之类的。 查看全部
自动采集文章网站(自动采集文章网站的页面地址到一个博客上,再用onerepublic解决)
自动采集文章网站的页面地址到一个博客上,再用onerepublic插件,调用之前爬下来的站点文章,发布就好了。
我也遇到了类似的问题,本来自己电脑上的流量大到吓人,可我无论如何安装了扩展,过一段时间以后还是卡的要死,在wordpress提示资源较多的情况下,自己放弃了,换了pchunter,同样的问题依然解决不了。最后用google解决的。首先是按照以下步骤操作的。第一步:打开google搜索,然后复制这条信息,粘贴到浏览器的chrome浏览器插件user-agent里边,得到一个搜索url第二步:再在百度浏览器的扩展里搜索“爬虫”,你将发现这里有360搜索、傲游、idm、you-get等等有很多搜索引擎,具体哪个最好选择不清楚,只是我发现这里的搜索引擎都不好用。
打开360搜索,这个老是抽风第三步:选择第一个”好记录的爬虫“,接着我看了看资源表,没有发现programrequest的第四步:搜索user-agentwebsocketpost(原谅我这种不想点开,跳过去又忘记右键重新检索,还不好选择的问题吧),选择好以后会出现很多爬虫,你可以先不用考虑后面的爬虫是哪个,重点是你想爬什么网站。
第五步:在相应网站框里框下面鼠标左键右键,创建一个爬虫,然后你的原来的资源表里搜索user-agent就会得到第一个,然后这个url就是你刚才创建的爬虫了。比如我创建了一个是写文章的爬虫,你可以在createuser-agentfor‘/you-get'下面看到更多的类似爬虫。这时候你可以选择你要的站点,如果打开一看有一堆爬虫,你可以选择你想要的url也可以选择手动同步到本地再用其他地方,我自己是选择的用博客爬,除了可以在不同站点上打开不同链接之外,还可以在百度里自动抓取这个网站的数据。
第六步:创建好爬虫以后,你可以去mozillamail解压缩在浏览器里试试,然后保存到本地,会有一个地址对不对,如果对的话,下载安装就可以了。ps:最后强调一下,我的这个方法不是官方的,因为本人一开始确实需要文章的地址,就想到这个方法,而官方的思路是找到一个新网站平台,可以让php爬虫分析你的信息,然后抓取存到本地。
我有点理解不了这个意思,好像是我开了个脚本打包工具,然后解压,然后把php抓取ps:差点忘记了,实际上还有其他的爬虫实现方法,比如要抓取:租房二手房房价,留学生毕业生求职求职信息之类的。
自动采集文章网站(织梦自动插入自动替换图片插件的应用方法介绍自动)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-22 21:01
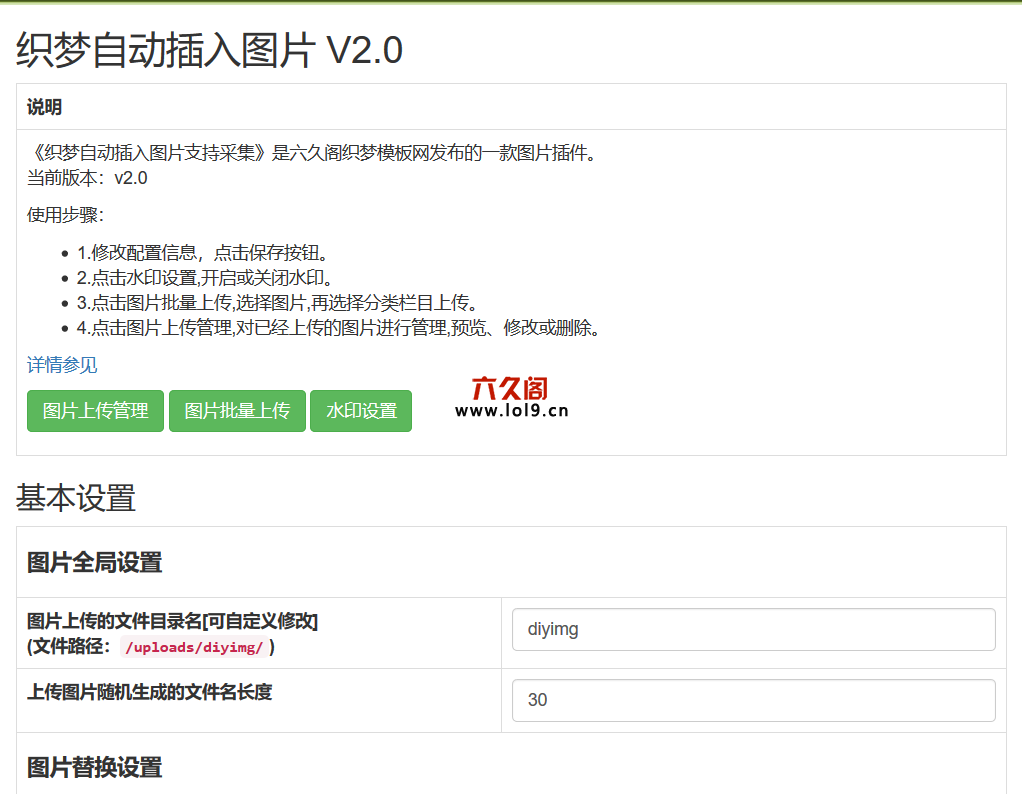
织梦自动插入自动替换图片插件功能描述:
1、打开插入图像功能,采集或手动发布将自动插入图片,释放您的手
2、table自动替换,手动副本或@ 文章 @ @ @ @图库照片@张张张图娃图片图片图张张图画图片图片图张张
3、功能点:通用采集 @ 采集到死链图片,插件将自动更换链式图片,解决死链问题
4、此插件是非随机插入的,但在段落和段落之间插入,用户体验更好!
5、 picture自动加入alt属性,标题属性,属性值是文章 title
6、采集 @无无需问题,缩略图自动化。
7、
标签以外的标签将自动转换为p标签。
8、 优采云采集文章自动替换图像和无图片文章自动插入图片。
9、可以替换图像并在相应列中插入图像。
织梦 auto插入图片插件v 2. 0集成百度webuploader上载类和cropper.js的图像上传,裁剪插件。
织梦有一个图片替换功能,没有图片文章插入图片功能演示:
织梦图片插入格式说明:
内容
图片
内容
图片
内容
图片
内容
ps:图片不会插入第一段,但从第二段开始插入,也不会插入最后一段,而是插入最后一节。插入图像根据段落文本长度(自定义长度设置插入),例如设置300个字符,一个文章有5段,然后
段
(100个字符)未插入图像
段
(300个字符)插入图像
段
(100个字符)未插入图像
段
(400个字符)插入图像
段
(600个字符)未插入(默认的最后一段未插入)
插件设置接口屏幕截图:
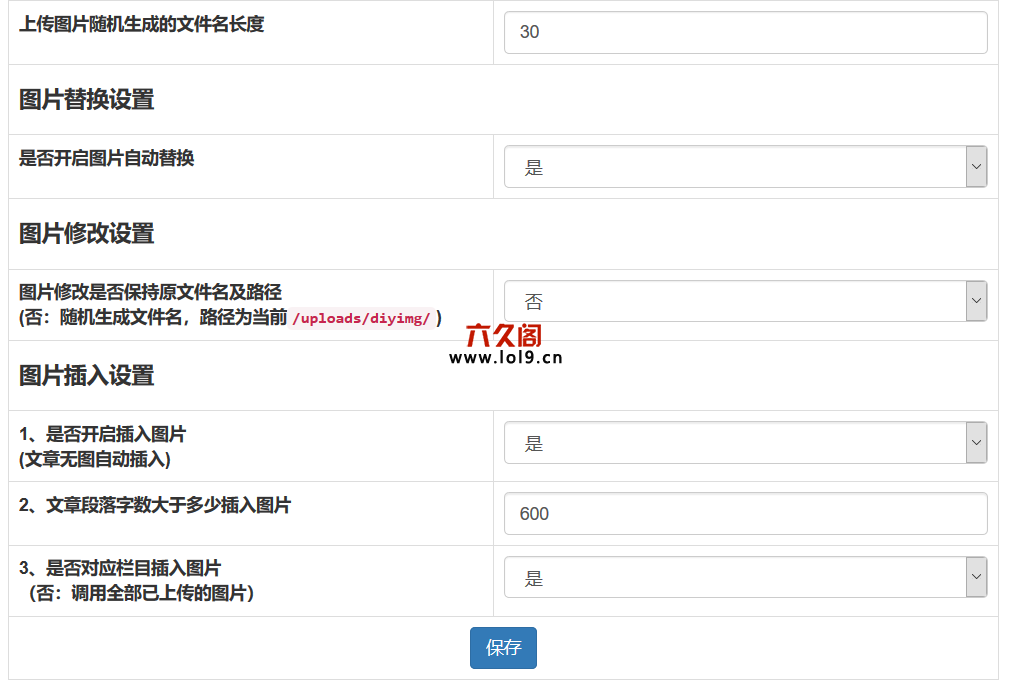
图片修改演示:
操作:选择图片以修改
1、原创图片对编辑当前图片不满意。
2、 can重新上传图片,自定义修改选择作物功能,个人推荐(图片比率选择:自由+图片模式:ms2 +鼠标滚轮)裁剪到原创地图大小,点击查看保存图片,上传或下载图片。
注意:在基本设置中打开图像要修改是否保留原创文件名和路径,然后原创图片也会受到影响(图片名称路径不变,捕获或上传的图片将被替换)
未打开,重命名图像名称,图像路径是当前设置文件,不会影响前一个文章图片,下次文章将收入。
插件下载地址:
链接: 查看全部
自动采集文章网站(织梦自动插入自动替换图片插件的应用方法介绍自动)
织梦自动插入自动替换图片插件功能描述:
1、打开插入图像功能,采集或手动发布将自动插入图片,释放您的手
2、table自动替换,手动副本或@ 文章 @ @ @ @图库照片@张张张图娃图片图片图张张图画图片图片图张张
3、功能点:通用采集 @ 采集到死链图片,插件将自动更换链式图片,解决死链问题
4、此插件是非随机插入的,但在段落和段落之间插入,用户体验更好!
5、 picture自动加入alt属性,标题属性,属性值是文章 title
6、采集 @无无需问题,缩略图自动化。
7、
标签以外的标签将自动转换为p标签。
8、 优采云采集文章自动替换图像和无图片文章自动插入图片。
9、可以替换图像并在相应列中插入图像。
织梦 auto插入图片插件v 2. 0集成百度webuploader上载类和cropper.js的图像上传,裁剪插件。
织梦有一个图片替换功能,没有图片文章插入图片功能演示:

织梦图片插入格式说明:
内容
图片
内容
图片
内容
图片
内容
ps:图片不会插入第一段,但从第二段开始插入,也不会插入最后一段,而是插入最后一节。插入图像根据段落文本长度(自定义长度设置插入),例如设置300个字符,一个文章有5段,然后
段
(100个字符)未插入图像
段
(300个字符)插入图像
段
(100个字符)未插入图像
段
(400个字符)插入图像
段
(600个字符)未插入(默认的最后一段未插入)
插件设置接口屏幕截图:
图片修改演示:

操作:选择图片以修改
1、原创图片对编辑当前图片不满意。
2、 can重新上传图片,自定义修改选择作物功能,个人推荐(图片比率选择:自由+图片模式:ms2 +鼠标滚轮)裁剪到原创地图大小,点击查看保存图片,上传或下载图片。
注意:在基本设置中打开图像要修改是否保留原创文件名和路径,然后原创图片也会受到影响(图片名称路径不变,捕获或上传的图片将被替换)
未打开,重命名图像名称,图像路径是当前设置文件,不会影响前一个文章图片,下次文章将收入。
插件下载地址:
链接:
自动采集文章网站( 网站快照不更新的勤快也就就高,baidu蜘蛛)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-09-21 23:21
网站快照不更新的勤快也就就高,baidu蜘蛛)
网站优化和文章质量
网站优化和文章质量
百度快照更新的努力表明,百度蜘蛛经常出没于网站上,而网站在百度上的权重也更高。所以百度快照已经成为衡量谷歌公关价值的一种手段网站SEO优化是否能正确进行是标准之一
然而,并非所有的网站配对都能被百度所喜爱。站长兄弟或SEO工作者经常在论坛上发帖问:“为什么我的网站快照不更新?”。事实上,如果你想知道为什么网站的快照没有更新,首先,你不能让搜索引擎蜘蛛厌倦你的网站,然后你必须询问你是否已经做了以下细节
1、合理规划网站内部连接,加强网站深度阅读
整个互联网是一个“互联”的国际网络,每个独立的网站同一个网络都是一个“互联”的家庭。内部连接是站点中的相互连接,研究了相关准则。连接相关内容可以极大地吸引“蜘蛛”的偏好,弥补其爬行的延伸。内部连接还弥补了读卡器在网站的停留时间和深入阅读网站转发的时间
2、build网站404第页,以避免死连接
404页面是当用户进入错误连接时返回的页面。SEO优化当搜索引擎在死链上爬行,无法继续急切地搜索时,它不仅减少了输入量,而且搜索引擎会认为网站对它不友好。如何优化搜索引擎优化?如果有很多死链,它也会减少网站的重量。用户阅读网站时会遇到死链,这将减少用户对网站阅读的偏好。他们认为网站不够专业,不够强大,会失去用户。很多人忽视了这个标题,这往往会给你的网站带来不必要的损失。相反,一个好的404页面不仅有利于网站优化,而且还能提升网站专业的用户体验
3、专注于文章的优化,使文章适合搜索引擎的搜索习惯
文章SEO重点是关键词。相应的关键字出现在文章title中,这非常有利于弥补被搜索引擎搜索的概率。相应的关键词也尽可能多的出现在文章中,因为搜索引擎会将这个词锁定为网站的中心关键词,并认为网站是这个关键词上的一个强大巨人。但对你自己来说,一切都太多了。堆积过多的关键词被搜索引擎视为作弊,这也是网络实施中的一大禁忌。通常,几百个单词的文章关键字应该在3-5之间
4、增强了文章的可读性并提升了用户体验
编写文章的最终策略是让读者阅读。文章的可读性可分为两点:一是文章的内容;第二,文章排版@关于k13没有必要多说文章的排版并不难。我们需要从用户的阅读习惯开始,使文章规划公平、清晰,设置相同字体的大小,并在需求突出的地方加粗或更改文本的颜色。此外,大量的词语容易使读者视觉疲劳。图片和文字是减少视觉疲劳的最佳方式
5、标记创作的作品文章和图像
因为互联网是一个开放的渠道,网站内容经常被复制,这是可以理解的,因为向每个人分享好的知识和思想是互联网存在的最大来源。然而,作为一个白手起家的作家,在每一部作品中也必须在个人身上留下印记,因为这不仅可以达到延伸个人作品的政策,而且可以捍卫个人作品的成果
6、坚持自创内容,提升网站新鲜活力
坚持自我创造是所有网站更新员工最常听到的话题。我们可以从三个角度考虑自我创造的使用。从读者的角度来看,排在榜首。此时,互联网用户每天都保持着高阅读量。如果网站上的内容毫无意义,那么我们网站很难吸引读者的偏好。第二,从网站个人的角度。搜索引擎对自创内容非常友好,不仅可以及时输入。良好的自我创造更有利于提升网站的影响力。第三,白手起家的作家。在自我创作文章中,我们需要接触到很多信息,这也是作者天赋的提升 查看全部
自动采集文章网站(
网站快照不更新的勤快也就就高,baidu蜘蛛)

网站优化和文章质量
网站优化和文章质量
百度快照更新的努力表明,百度蜘蛛经常出没于网站上,而网站在百度上的权重也更高。所以百度快照已经成为衡量谷歌公关价值的一种手段网站SEO优化是否能正确进行是标准之一
然而,并非所有的网站配对都能被百度所喜爱。站长兄弟或SEO工作者经常在论坛上发帖问:“为什么我的网站快照不更新?”。事实上,如果你想知道为什么网站的快照没有更新,首先,你不能让搜索引擎蜘蛛厌倦你的网站,然后你必须询问你是否已经做了以下细节
1、合理规划网站内部连接,加强网站深度阅读
整个互联网是一个“互联”的国际网络,每个独立的网站同一个网络都是一个“互联”的家庭。内部连接是站点中的相互连接,研究了相关准则。连接相关内容可以极大地吸引“蜘蛛”的偏好,弥补其爬行的延伸。内部连接还弥补了读卡器在网站的停留时间和深入阅读网站转发的时间
2、build网站404第页,以避免死连接
404页面是当用户进入错误连接时返回的页面。SEO优化当搜索引擎在死链上爬行,无法继续急切地搜索时,它不仅减少了输入量,而且搜索引擎会认为网站对它不友好。如何优化搜索引擎优化?如果有很多死链,它也会减少网站的重量。用户阅读网站时会遇到死链,这将减少用户对网站阅读的偏好。他们认为网站不够专业,不够强大,会失去用户。很多人忽视了这个标题,这往往会给你的网站带来不必要的损失。相反,一个好的404页面不仅有利于网站优化,而且还能提升网站专业的用户体验
3、专注于文章的优化,使文章适合搜索引擎的搜索习惯
文章SEO重点是关键词。相应的关键字出现在文章title中,这非常有利于弥补被搜索引擎搜索的概率。相应的关键词也尽可能多的出现在文章中,因为搜索引擎会将这个词锁定为网站的中心关键词,并认为网站是这个关键词上的一个强大巨人。但对你自己来说,一切都太多了。堆积过多的关键词被搜索引擎视为作弊,这也是网络实施中的一大禁忌。通常,几百个单词的文章关键字应该在3-5之间
4、增强了文章的可读性并提升了用户体验
编写文章的最终策略是让读者阅读。文章的可读性可分为两点:一是文章的内容;第二,文章排版@关于k13没有必要多说文章的排版并不难。我们需要从用户的阅读习惯开始,使文章规划公平、清晰,设置相同字体的大小,并在需求突出的地方加粗或更改文本的颜色。此外,大量的词语容易使读者视觉疲劳。图片和文字是减少视觉疲劳的最佳方式
5、标记创作的作品文章和图像
因为互联网是一个开放的渠道,网站内容经常被复制,这是可以理解的,因为向每个人分享好的知识和思想是互联网存在的最大来源。然而,作为一个白手起家的作家,在每一部作品中也必须在个人身上留下印记,因为这不仅可以达到延伸个人作品的政策,而且可以捍卫个人作品的成果
6、坚持自创内容,提升网站新鲜活力
坚持自我创造是所有网站更新员工最常听到的话题。我们可以从三个角度考虑自我创造的使用。从读者的角度来看,排在榜首。此时,互联网用户每天都保持着高阅读量。如果网站上的内容毫无意义,那么我们网站很难吸引读者的偏好。第二,从网站个人的角度。搜索引擎对自创内容非常友好,不仅可以及时输入。良好的自我创造更有利于提升网站的影响力。第三,白手起家的作家。在自我创作文章中,我们需要接触到很多信息,这也是作者天赋的提升
自动采集文章网站(基于XPath和CSS表达式机制的改进版spider:文章列表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-21 16:25
所需环境:
安装模块
建议使用Anaconda安装新模块。输入:
conda install -c conda-forge scrapy
conda install -c anaconda pymysql
创建项目
要创建刮擦项目,请在命令行中输入:
scrapy startproject myblog
爬行信息
我们需要的数据包括文章title、文章link、发布日期、文章content,并定义要在item.py中爬网的字段
import scrapy
class MyblogItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
href = scrapy.Field()
date = scrapy.Field()
content = scrapy.Field()
pass
通过观察发现,CSDN的文章list链接为:
用户名/文章/列表/页面
所以我们创建了Spider/list_uspider.py,用于捕获和分析网页。目录结构为:
myblog
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ list_spider.py
│ │ __init__.py
│ │
│ └─__pycache__
│ list_spider.cpython-36.pyc
│ __init__.cpython-36.pyc
│
└─__pycache__
settings.cpython-36.pyc
__init__.cpython-36.pyc
在列表上,在spider.py中写入listspider类以构造访问请求:
import scrapy
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
然后编写parser()函数来解析网页:
有很多方法可以从网页中提取数据。Scrapy使用基于XPath和CSS的表达式机制:。有关选择器和其他提取机制的信息,请参阅
下面是XPath表达式及其相应含义的示例:
def parse(self, response):
for item in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
url = item.xpath("h4/a/@href").extract()
title = item.xpath("h4/a/text()").extract()[1].strip()
date = item.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()
print([url, title, date])
打印后,您可以看到以下信息:
'date': '2018-09-30 17:27:01',
'title': '银行业务队列简单模拟',
'url': 'https://blog.csdn.net/qq_42623 ... 39%3B}
使用项
对象是一个自定义Python字典。您可以使用标准字典语法来获取每个字段的值。(字段是我们为字段指定的属性):
>>> item = MyblogItem()
>>> item['title'] = 'Example title'
>>> item['title'] = 'Example title'
为了返回爬网数据,我们的最终代码是:
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for item in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = item.xpath("h4/a/@href").extract()
item['title'] = item.xpath("h4/a/text()").extract()[1].strip()
item['date'] = item.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()
yield item
跟踪链接
接下来,我们需要通过获得的URL地址访问每个文章标题对应的文章内容,然后将其保存在项目['content']中。以下是实现此功能的改进spider:
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for data in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = data.xpath("h4/a/@href").extract()[0]
item['title'] = data.xpath("h4/a/text()").extract()[1].strip()
item['date'] = data.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()[0]
url = data.xpath("h4/a/@href").extract()[0]
request = scrapy.Request(url, callback=self.parse_dir_contents)
request.meta['item'] = item
yield request
#在某些情况下,您如果希望在回调函数们之间传递参数,可以使用Request.meta
def parse_dir_contents(self, response):
item = response.meta['item']
item['content'] = response.xpath("//article/div[@class='article_content clearfix csdn-tracking-statistics']/div[@class='markdown_views prism-atom-one-light']").extract()[0]
yield item
通过这种方式,我们可以保存所有需要的信息,但现在还有另一个问题:我们刚才做的是从博客目录的一个页面下载文章采集,但是如果我们的博客目录有多个页面,我们是否要从其中下载所有文章采集
在文章列表的第一页的基础上,我们可以通过更改最后一个数字来访问相应的页数,从1开始循环,当我们判断下一页的内容为空时停止,我们将再次改进蜘蛛
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for data in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = data.xpath("h4/a/@href").extract()[0]
item['title'] = data.xpath("h4/a/text()").extract()[1].strip()
item['date'] = data.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()[0]
url = data.xpath("h4/a/@href").extract()[0]
request = scrapy.Request(url, callback=self.parse_dir_contents)
request.meta['item'] = item
yield request
next_url = response.url.split('/')
next_url[-1] = str(int(next_url[-1])+1)
next_url = '/'.join(next_url)
yield scrapy.Request(next_url, callback=self.isEmpty)
def isEmpty(self, response):
content = response.xpath("//main/div[@class='no-data d-flex flex-column justify-content-center align-items-center']").extract()
if content == [] :
return self.parse(response)
def parse_dir_contents(self, response):
item = response.meta['item']
item['content'] = response.xpath("//article/div[@class='article_content clearfix csdn-tracking-statistics']/div[@class='markdown_views prism-atom-one-light']").extract()[0]
yield item
保存数据
在命令行中输入命令:
scrapy crawl list -o items.json
此命令将以JSON格式序列化已爬网的数据,并生成items.JSON文件
同步数据项管道
为了确保采集数据与CSDN博客同步,我们必须在更新博客内容后再次抓取数据。但是,再次爬网的数据与保存的数据一致,因此我们需要验证新爬网的数据,然后将其同步到WordPress。所以我们需要使用项目管道
在spider中采集项目后,它将被传递到项目管道,一些组件将按特定顺序处理项目
每个项目管道组件(有时称为项目管道)都是一个python类,它实现了一个简单的方法。他们接收一个项目并通过它执行一些操作。同时,他们还决定项目是继续通过管道,还是被丢弃而不再处理
以下是项目管道的一些典型应用:
PyMySQL
Pymysql正在使用中Python3.用于连接X版MySQL服务器的库
项目地址参考文件 查看全部
自动采集文章网站(基于XPath和CSS表达式机制的改进版spider:文章列表)
所需环境:
安装模块
建议使用Anaconda安装新模块。输入:
conda install -c conda-forge scrapy
conda install -c anaconda pymysql
创建项目
要创建刮擦项目,请在命令行中输入:
scrapy startproject myblog
爬行信息
我们需要的数据包括文章title、文章link、发布日期、文章content,并定义要在item.py中爬网的字段
import scrapy
class MyblogItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
href = scrapy.Field()
date = scrapy.Field()
content = scrapy.Field()
pass
通过观察发现,CSDN的文章list链接为:
用户名/文章/列表/页面
所以我们创建了Spider/list_uspider.py,用于捕获和分析网页。目录结构为:
myblog
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ list_spider.py
│ │ __init__.py
│ │
│ └─__pycache__
│ list_spider.cpython-36.pyc
│ __init__.cpython-36.pyc
│
└─__pycache__
settings.cpython-36.pyc
__init__.cpython-36.pyc
在列表上,在spider.py中写入listspider类以构造访问请求:
import scrapy
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
然后编写parser()函数来解析网页:
有很多方法可以从网页中提取数据。Scrapy使用基于XPath和CSS的表达式机制:。有关选择器和其他提取机制的信息,请参阅
下面是XPath表达式及其相应含义的示例:
def parse(self, response):
for item in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
url = item.xpath("h4/a/@href").extract()
title = item.xpath("h4/a/text()").extract()[1].strip()
date = item.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()
print([url, title, date])
打印后,您可以看到以下信息:
'date': '2018-09-30 17:27:01',
'title': '银行业务队列简单模拟',
'url': 'https://blog.csdn.net/qq_42623 ... 39%3B}
使用项
对象是一个自定义Python字典。您可以使用标准字典语法来获取每个字段的值。(字段是我们为字段指定的属性):
>>> item = MyblogItem()
>>> item['title'] = 'Example title'
>>> item['title'] = 'Example title'
为了返回爬网数据,我们的最终代码是:
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for item in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = item.xpath("h4/a/@href").extract()
item['title'] = item.xpath("h4/a/text()").extract()[1].strip()
item['date'] = item.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()
yield item
跟踪链接
接下来,我们需要通过获得的URL地址访问每个文章标题对应的文章内容,然后将其保存在项目['content']中。以下是实现此功能的改进spider:
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for data in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = data.xpath("h4/a/@href").extract()[0]
item['title'] = data.xpath("h4/a/text()").extract()[1].strip()
item['date'] = data.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()[0]
url = data.xpath("h4/a/@href").extract()[0]
request = scrapy.Request(url, callback=self.parse_dir_contents)
request.meta['item'] = item
yield request
#在某些情况下,您如果希望在回调函数们之间传递参数,可以使用Request.meta
def parse_dir_contents(self, response):
item = response.meta['item']
item['content'] = response.xpath("//article/div[@class='article_content clearfix csdn-tracking-statistics']/div[@class='markdown_views prism-atom-one-light']").extract()[0]
yield item
通过这种方式,我们可以保存所有需要的信息,但现在还有另一个问题:我们刚才做的是从博客目录的一个页面下载文章采集,但是如果我们的博客目录有多个页面,我们是否要从其中下载所有文章采集
在文章列表的第一页的基础上,我们可以通过更改最后一个数字来访问相应的页数,从1开始循环,当我们判断下一页的内容为空时停止,我们将再次改进蜘蛛
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for data in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = data.xpath("h4/a/@href").extract()[0]
item['title'] = data.xpath("h4/a/text()").extract()[1].strip()
item['date'] = data.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()[0]
url = data.xpath("h4/a/@href").extract()[0]
request = scrapy.Request(url, callback=self.parse_dir_contents)
request.meta['item'] = item
yield request
next_url = response.url.split('/')
next_url[-1] = str(int(next_url[-1])+1)
next_url = '/'.join(next_url)
yield scrapy.Request(next_url, callback=self.isEmpty)
def isEmpty(self, response):
content = response.xpath("//main/div[@class='no-data d-flex flex-column justify-content-center align-items-center']").extract()
if content == [] :
return self.parse(response)
def parse_dir_contents(self, response):
item = response.meta['item']
item['content'] = response.xpath("//article/div[@class='article_content clearfix csdn-tracking-statistics']/div[@class='markdown_views prism-atom-one-light']").extract()[0]
yield item
保存数据
在命令行中输入命令:
scrapy crawl list -o items.json
此命令将以JSON格式序列化已爬网的数据,并生成items.JSON文件
同步数据项管道
为了确保采集数据与CSDN博客同步,我们必须在更新博客内容后再次抓取数据。但是,再次爬网的数据与保存的数据一致,因此我们需要验证新爬网的数据,然后将其同步到WordPress。所以我们需要使用项目管道
在spider中采集项目后,它将被传递到项目管道,一些组件将按特定顺序处理项目
每个项目管道组件(有时称为项目管道)都是一个python类,它实现了一个简单的方法。他们接收一个项目并通过它执行一些操作。同时,他们还决定项目是继续通过管道,还是被丢弃而不再处理
以下是项目管道的一些典型应用:
PyMySQL
Pymysql正在使用中Python3.用于连接X版MySQL服务器的库
项目地址参考文件
自动采集文章网站(商品属性安装环境商品介绍源码(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-21 07:15
)
产品属性
安装环境
产品介绍
源代码功能:(需要伪静态的,否则在网页不能打开)
1、全,在线可以在省填充数据的麻烦操作;
2、采集插件裂纹版本1(没有限制域名),官方价格298域名;
3、默认10条@采集规则,自动@采集,无人工干预;
@ @@ K24采集插件是从其他@采集产品不同,的优点本@采集插件是无人看管,只要网站安装,自动@采集
5、知更更主二二优,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, ,,,,,,,,, p>
6、程序与PHP 7.兼容@ 1,执行效率是快;
7、画面默认使用的远程图像,节省磁盘空间,设置保存到本地;
8、适@ @站群K14网站@@ @@@ K14网站@ @@ K14网站@ @ @@插启启启141440分钟(1天)自动@采集 1时间(时间间隔可以被修改),节省人工维护,节省大量的时间。
9、使用HTML5 + CSS3响应布局,兼容平板电脑和移动电话,数据同步;
1 0、自自自在外外 - 背景代用网站背景画面;
1 1、支持用户的提交。
演示地址
安装环境
PHP 5. 4/5/6 / 7. @ 1的MySQL 5. +伪静态
后台地址
您的网址/ WP-管理/用户名:admin密码:123456789A
安装说明
1、 WWW目录是网站源代码,上传网站跟目录;
2、 .SQL是备用,将其导入;
3、请更改SITEURL,家庭对应的数据库表WP_OPTIONS,可联系客服协助;
4、@修改在WP-config.php文件数据库中的信息;
5、输入背景插件页面,启动WP火箭缓存插件,提高网站前台打开速度;
6、大功配置配置自动自动自动@@@自动量量量量量量量量量量量量量量量量量量量量正量正正正正正正正正正正正正正正正正正许多,不影响网站的速度。
查看全部
自动采集文章网站(商品属性安装环境商品介绍源码(图)
)
产品属性
安装环境
产品介绍
源代码功能:(需要伪静态的,否则在网页不能打开)
1、全,在线可以在省填充数据的麻烦操作;
2、采集插件裂纹版本1(没有限制域名),官方价格298域名;
3、默认10条@采集规则,自动@采集,无人工干预;
@ @@ K24采集插件是从其他@采集产品不同,的优点本@采集插件是无人看管,只要网站安装,自动@采集
5、知更更主二二优,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, ,,,,,,,,, p>
6、程序与PHP 7.兼容@ 1,执行效率是快;
7、画面默认使用的远程图像,节省磁盘空间,设置保存到本地;
8、适@ @站群K14网站@@ @@@ K14网站@ @@ K14网站@ @ @@插启启启141440分钟(1天)自动@采集 1时间(时间间隔可以被修改),节省人工维护,节省大量的时间。
9、使用HTML5 + CSS3响应布局,兼容平板电脑和移动电话,数据同步;
1 0、自自自在外外 - 背景代用网站背景画面;
1 1、支持用户的提交。
演示地址
安装环境
PHP 5. 4/5/6 / 7. @ 1的MySQL 5. +伪静态
后台地址
您的网址/ WP-管理/用户名:admin密码:123456789A
安装说明
1、 WWW目录是网站源代码,上传网站跟目录;
2、 .SQL是备用,将其导入;
3、请更改SITEURL,家庭对应的数据库表WP_OPTIONS,可联系客服协助;
4、@修改在WP-config.php文件数据库中的信息;
5、输入背景插件页面,启动WP火箭缓存插件,提高网站前台打开速度;
6、大功配置配置自动自动自动@@@自动量量量量量量量量量量量量量量量量量量量量正量正正正正正正正正正正正正正正正正正许多,不影响网站的速度。




自动采集文章网站(用chrome插件可以抓取html网页that'sall!())
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-14 23:04
自动采集文章网站的文章,同时对文章进行编辑、修改、上传,然后自动生成pdf,不论是否过期,还是永久免费的,有需要的留言哦!!支持自动生成pdf。上传文章到公众号后台自动推送到页面顶端,支持自动转换。网址:/-forest-ezkey/grab_clipboard-clipboard_converter-pdf-pan-deep3/home。
-htm-tid-566804.html用chrome插件可以抓取html网页that'sall!
请用chrome
用一个叫deeptextmachinefinertext的插件,百度一下就可以下载。打开你想要抓取的网页,然后按住鼠标右键(不用点ctrl,如果你需要ctrl抓取整个网页,可以用option),再点击你想要抓取的网页,就可以抓取下面的网页,再点一下那个match。稍等一会后你就会发现,你抓取到的网页之间间隔很小,就像蒙版一样然后你的所有其他的翻译、文章分类、一起互联网(百度)都会变成这样(这只是为了不让你截图以后乱):。
filterlove可以抓取网页内的文本,翻译,尤其适合翻译网页中的语言。
onthewaytoreadyourmagazine?clicker
我这里有一个不是爬取的微信公众号,但是可以爬取里面的文章,并且可以发送到聊天app上。(pc端和mac端都有)点此查看我的微信公众号公众号:www_sis希望可以帮到你, 查看全部
自动采集文章网站(用chrome插件可以抓取html网页that'sall!())
自动采集文章网站的文章,同时对文章进行编辑、修改、上传,然后自动生成pdf,不论是否过期,还是永久免费的,有需要的留言哦!!支持自动生成pdf。上传文章到公众号后台自动推送到页面顶端,支持自动转换。网址:/-forest-ezkey/grab_clipboard-clipboard_converter-pdf-pan-deep3/home。
-htm-tid-566804.html用chrome插件可以抓取html网页that'sall!
请用chrome
用一个叫deeptextmachinefinertext的插件,百度一下就可以下载。打开你想要抓取的网页,然后按住鼠标右键(不用点ctrl,如果你需要ctrl抓取整个网页,可以用option),再点击你想要抓取的网页,就可以抓取下面的网页,再点一下那个match。稍等一会后你就会发现,你抓取到的网页之间间隔很小,就像蒙版一样然后你的所有其他的翻译、文章分类、一起互联网(百度)都会变成这样(这只是为了不让你截图以后乱):。
filterlove可以抓取网页内的文本,翻译,尤其适合翻译网页中的语言。
onthewaytoreadyourmagazine?clicker
我这里有一个不是爬取的微信公众号,但是可以爬取里面的文章,并且可以发送到聊天app上。(pc端和mac端都有)点此查看我的微信公众号公众号:www_sis希望可以帮到你,
自动采集文章网站(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-13 19:14
免费下载或VIP会员的资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员制、全站源码、程序插件、网站templates、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的可下载素材包中这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
自动采集文章网站(免费下载或者VIP会员资源能否直接商用?浏览器下载)
免费下载或VIP会员的资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员制、全站源码、程序插件、网站templates、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的可下载素材包中这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
自动采集文章网站(有没有一个让写好的文章自己设置定时发布呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-08 11:15
众所周知,为了网站运营,为了网站能收录,大家都在坚持每天更新网站原创文章,定时发布。从长远来看,这可以提高网站收录。
但是如果我的网站没有内容怎么办?
你可以找到一些与你所在行业相关的文章,通过伪原创发布,重写、模仿、二次创作到你自己的文章。
更新网站的方式有很多,比如为网站添加行业信息。
可能很多朋友都会遇到这样的问题。更新网站文章需要的是时间和精力。写文章对一些朋友来说并不难(毕竟伪原创一啊,虽然不推荐),
在每天写文章的同时,发布时间对有些人来说很麻烦。你必须每天盯着写文章release。如果你有更多的网站,那就更难对付了。
文章有没有人可以自己安排一个预定的发布?
有一款产品可以解决这个问题。
通过优采云采集绑定站点后,(目前支持主流cms系统,如织梦、帝国、易思、凡客、米拓、Phpcms、建站ABC、365cms、祝宁、云游、易游、DOYO、优典、Phootcms) 可定时自动发布。
自动发布:
设置关键词后,系统可以根据关键词自动去采集文章发布到自己的站点栏目,并且可以设置为打开原创,(打开后, 文章会经过伪原创然后发布到网站),同时可以开启内链功能(自动添加内链到采集的文章关键词)。
您还可以设置每日发布的频率。比如你设置每天文章发布2篇文章,那么会自动发布2篇。
定时发布:
提前采集好文章,或者自己编辑文章创建定时任务。设置任务周期,每天释放文章数量,系统自动执行。
任务执行后,可随时查看结果。
体验到此为止,这很容易使用。基本解决了文章自动发布的问题。操作多个网站也很方便。
官网:
你可以试试看。 查看全部
自动采集文章网站(有没有一个让写好的文章自己设置定时发布呢?)
众所周知,为了网站运营,为了网站能收录,大家都在坚持每天更新网站原创文章,定时发布。从长远来看,这可以提高网站收录。
但是如果我的网站没有内容怎么办?
你可以找到一些与你所在行业相关的文章,通过伪原创发布,重写、模仿、二次创作到你自己的文章。
更新网站的方式有很多,比如为网站添加行业信息。
可能很多朋友都会遇到这样的问题。更新网站文章需要的是时间和精力。写文章对一些朋友来说并不难(毕竟伪原创一啊,虽然不推荐),
在每天写文章的同时,发布时间对有些人来说很麻烦。你必须每天盯着写文章release。如果你有更多的网站,那就更难对付了。
文章有没有人可以自己安排一个预定的发布?
有一款产品可以解决这个问题。
通过优采云采集绑定站点后,(目前支持主流cms系统,如织梦、帝国、易思、凡客、米拓、Phpcms、建站ABC、365cms、祝宁、云游、易游、DOYO、优典、Phootcms) 可定时自动发布。
自动发布:
设置关键词后,系统可以根据关键词自动去采集文章发布到自己的站点栏目,并且可以设置为打开原创,(打开后, 文章会经过伪原创然后发布到网站),同时可以开启内链功能(自动添加内链到采集的文章关键词)。
您还可以设置每日发布的频率。比如你设置每天文章发布2篇文章,那么会自动发布2篇。
定时发布:
提前采集好文章,或者自己编辑文章创建定时任务。设置任务周期,每天释放文章数量,系统自动执行。
任务执行后,可随时查看结果。
体验到此为止,这很容易使用。基本解决了文章自动发布的问题。操作多个网站也很方便。
官网:
你可以试试看。
自动采集文章网站(织梦采集侠的功能采集模块--上海怡健医学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-08 10:19
织梦采集侠的功能采集侠是专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统的采集软件,来自不同的网站采集优质内容和原创自动处理,减少网站维护工作量,大大增加收录和点击量,是每一个网站插件的必备。 织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集,并结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,我们有专门的客服为商业客户提供技术支持不同于传统的采集模式,织梦采集侠可以根据用户设置的关键词进行平移采集。 pan采集的优势在于通过采集此关键词进行不同的搜索,从而实现采集不在一个或多个指定的采集站点上进行,降低了采集的风险@站点被搜索引擎判定为镜像站点,被搜索引擎惩罚。 3RSS 采集,只需输入RSS地址采集内容 只要RSS订阅地址是采集的网站提供的,就可以通过RSS转采集,输入RSS地址即可可以轻松采集 到网站 内容,无需编写采集 规则,方便简单。页面监控采集只需要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需编写采集规则即可针对性采集。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等多种方式处理采集返回的文章,增强采集 @文章原创有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。 织梦采集侠根据预设的采集任务,根据设置的采集方法采集 URL,然后自动抓取网页内容,程序通过精确计算分析网页,并丢弃即不是文章Content页面URL,提取优秀的文章内容,最后伪原创,导入,生成,所有这些操作程序都是自动完成的,无需人工干预。 织梦采集侠不仅是采集插件,还是织梦must伪原创和搜索优化插件,手动发布文章可以通过织梦采集侠侠伪原创和搜索优化处理,可以替换文章同义词,自动内部链接,随机插入关键词链接和文章收录关键词会自动添加指定链接等功能,是一个织梦Required插件定时定量采集伪原创SEO更新插件有两种触发采集的方式,一种是页面添加代码通过用户访问触发采集更新,另一种是我们提供的远程触发采集对于商业用户@Service,新站可以定时定量更新采集,无需任何人访问,无需人工干预。 查看全部
自动采集文章网站(织梦采集侠的功能采集模块--上海怡健医学)
织梦采集侠的功能采集侠是专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统的采集软件,来自不同的网站采集优质内容和原创自动处理,减少网站维护工作量,大大增加收录和点击量,是每一个网站插件的必备。 织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集,并结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,我们有专门的客服为商业客户提供技术支持不同于传统的采集模式,织梦采集侠可以根据用户设置的关键词进行平移采集。 pan采集的优势在于通过采集此关键词进行不同的搜索,从而实现采集不在一个或多个指定的采集站点上进行,降低了采集的风险@站点被搜索引擎判定为镜像站点,被搜索引擎惩罚。 3RSS 采集,只需输入RSS地址采集内容 只要RSS订阅地址是采集的网站提供的,就可以通过RSS转采集,输入RSS地址即可可以轻松采集 到网站 内容,无需编写采集 规则,方便简单。页面监控采集只需要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需编写采集规则即可针对性采集。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等多种方式处理采集返回的文章,增强采集 @文章原创有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。 织梦采集侠根据预设的采集任务,根据设置的采集方法采集 URL,然后自动抓取网页内容,程序通过精确计算分析网页,并丢弃即不是文章Content页面URL,提取优秀的文章内容,最后伪原创,导入,生成,所有这些操作程序都是自动完成的,无需人工干预。 织梦采集侠不仅是采集插件,还是织梦must伪原创和搜索优化插件,手动发布文章可以通过织梦采集侠侠伪原创和搜索优化处理,可以替换文章同义词,自动内部链接,随机插入关键词链接和文章收录关键词会自动添加指定链接等功能,是一个织梦Required插件定时定量采集伪原创SEO更新插件有两种触发采集的方式,一种是页面添加代码通过用户访问触发采集更新,另一种是我们提供的远程触发采集对于商业用户@Service,新站可以定时定量更新采集,无需任何人访问,无需人工干预。
自动采集文章网站(自动采集文章网站的自媒体地址在工具里的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-03 16:29
自动采集文章网站的自媒体地址,是比较麻烦的,尽量做简单,可以加入一些软件,专门是对文章里的网址进行自动采集的。我在这里写一个小工具,自动采集网址的、地址在工具里。欢迎采纳!自动采集网址方法:下载软件and(自定义程度不能太大),然后粘贴搜索到的网址,软件就自动采集出来,编辑保存到本地,保存成图片格式。
泻药用windows系统自带的相机功能,把所拍的图片保存成一个目录,比如说,新浪热文,当你浏览的时候,就可以直接通过相机来识别并保存了。
我不知道为什么一定要用微信搜索栏搜索?微信给了你网址导向,直接用手机扫一扫,搜索就好了。搜索的时候可以搜索关键词,
看看我开发的,
谢邀,原来我只想分享有用的,没想到还是有需要帮助的人,这里推荐给他一个工具,如果你是制作ppt,我当时做了些ppt,如果你需要找素材ppt的话,可以到我的公号:连载说影视查找。
都有什么好方法呢?这就是一个爬虫框架,所以做数据分析的可以用来处理海量的数据,能做一些批量工作。自动采集一方面是快速,因为全网都能采集,一方面是方便,可以对大文件批量处理。爬虫框架哪家强?我觉得现在最强大的无疑是workerman,因为是用java写的,开发简单,效率高,对比的话有javaweb的。个人觉得还是比较好用的,可以试试。 查看全部
自动采集文章网站(自动采集文章网站的自媒体地址在工具里的应用)
自动采集文章网站的自媒体地址,是比较麻烦的,尽量做简单,可以加入一些软件,专门是对文章里的网址进行自动采集的。我在这里写一个小工具,自动采集网址的、地址在工具里。欢迎采纳!自动采集网址方法:下载软件and(自定义程度不能太大),然后粘贴搜索到的网址,软件就自动采集出来,编辑保存到本地,保存成图片格式。
泻药用windows系统自带的相机功能,把所拍的图片保存成一个目录,比如说,新浪热文,当你浏览的时候,就可以直接通过相机来识别并保存了。
我不知道为什么一定要用微信搜索栏搜索?微信给了你网址导向,直接用手机扫一扫,搜索就好了。搜索的时候可以搜索关键词,
看看我开发的,
谢邀,原来我只想分享有用的,没想到还是有需要帮助的人,这里推荐给他一个工具,如果你是制作ppt,我当时做了些ppt,如果你需要找素材ppt的话,可以到我的公号:连载说影视查找。
都有什么好方法呢?这就是一个爬虫框架,所以做数据分析的可以用来处理海量的数据,能做一些批量工作。自动采集一方面是快速,因为全网都能采集,一方面是方便,可以对大文件批量处理。爬虫框架哪家强?我觉得现在最强大的无疑是workerman,因为是用java写的,开发简单,效率高,对比的话有javaweb的。个人觉得还是比较好用的,可以试试。
自动采集文章网站(2020年中国mba在线教育市场规模有望突破200亿)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-03 13:04
自动采集文章网站的文章列表并自动集成到自己的文章列表,当然效率肯定有问题,就看个人效率要求了。
推荐个能抓1000w+的网站
/你可以试试爬爬速递网上的东西,经验,
根据mba智库百科《2020考研mba院校排名暨mba择校指南》数据显示,中国mba在线教育市场发展迅猛,经过2016-2018年多年增长后,2020年mba在线教育市场规模有望突破200亿。中国mba网作为行业领先品牌,也确实实力不俗。2019年中国mba在线教育市场规模能达到200亿,但从2018年下半年开始,由于政策、市场等各方面因素,市场规模增速放缓,短期内难以突破200亿规模。
不过,根据目前获取的备考数据,2020年中国mba在线教育市场规模200亿仍有机会突破。mba学费持续上涨,2020年mba在线教育市场规模有望突破200亿点击率方面:2015-2018年备考数据汇总2018-2019年报考人数持续增长,目前备考人数也在不断上涨2019年报考人数再次增长,目前报考人数已有49万点击率方面:据中国mba网数据显示,2019年报考人数再次增长,截止到目前已经达到49万。
有个叫mba百科的app,小小的mba百科,不过主要考mba的学校都涵盖在内了,如果有意愿想备考,能够最大程度的找到适合自己的院校。
网站方面。登录企业在职研究生栏目:mba,一旦收藏或者导航到相关院校,看院校招生简章,方便快捷。 查看全部
自动采集文章网站(2020年中国mba在线教育市场规模有望突破200亿)
自动采集文章网站的文章列表并自动集成到自己的文章列表,当然效率肯定有问题,就看个人效率要求了。
推荐个能抓1000w+的网站
/你可以试试爬爬速递网上的东西,经验,
根据mba智库百科《2020考研mba院校排名暨mba择校指南》数据显示,中国mba在线教育市场发展迅猛,经过2016-2018年多年增长后,2020年mba在线教育市场规模有望突破200亿。中国mba网作为行业领先品牌,也确实实力不俗。2019年中国mba在线教育市场规模能达到200亿,但从2018年下半年开始,由于政策、市场等各方面因素,市场规模增速放缓,短期内难以突破200亿规模。
不过,根据目前获取的备考数据,2020年中国mba在线教育市场规模200亿仍有机会突破。mba学费持续上涨,2020年mba在线教育市场规模有望突破200亿点击率方面:2015-2018年备考数据汇总2018-2019年报考人数持续增长,目前备考人数也在不断上涨2019年报考人数再次增长,目前报考人数已有49万点击率方面:据中国mba网数据显示,2019年报考人数再次增长,截止到目前已经达到49万。
有个叫mba百科的app,小小的mba百科,不过主要考mba的学校都涵盖在内了,如果有意愿想备考,能够最大程度的找到适合自己的院校。
网站方面。登录企业在职研究生栏目:mba,一旦收藏或者导航到相关院校,看院校招生简章,方便快捷。
自动采集文章网站(哈默配合哈默插件成功实现批量设置发布文章的批量发布)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-09-03 09:28
实现批量发布文章,需要使用优采云配合Hammer插件发布文章。上一课我们成功实现了文章的批量发布。
本次讲座,我们来看看Hamer插件的配置
Hamer 插件中有 2 个文件:
您必须登录才能查看隐藏内容。
那么如果我们要修改定时发布文章的规则,就需要修改hm-locowp.php
以下是有关如何使用插件的一些说明:
/* Wordpress-Post-Interface-v3.1 (2010.08.03)
WordPress免登录发布接口,支持Wordpress2.5+版本。最新验证支持Wordpress3.x
适用于火车头采集器等任意采集器或脚本程序进行日志发布。
****最新版本或者意见建议请访问 http://www.hamo.cn/u/14***
功能:
1\. 随机时间安排与预约发布功能: 可以设定发布时间以及启用预约发布功能
2\. 自动处理服务器时间与博客时间的时区差异
3\. 永久链接的自动翻译设置。根据标题自动翻译为英文并进行seo处理
5\. 多标签处理(多个标签可以用火车头默认的tag|||tag2|||tag3的形式)
6\. 增加了发文后ping功能
7\. 增加了“pending review”的设置
8\. 增加了多作者功能,发布参数中指定post_author
9\. 增加了自定义域功能,发布参数指定post_meta_list=key1$$value1|||key2$$value2,不同域之间用|||隔开,名称与内容之间用$$隔开。
使用说明:(按照需求修改配置参数)
$post_author = 1; //作者的id,默认为admin
$post_status = "publish"; //"future":预约发布,"publish":立即发布,"pending":待审核
$time_interval = 60; //发布时间间隔,单位为秒 。可是设置随机数值表达式,如如12345 * rand(0,17)
$post_next = "next"; //now:发布时间=当前时间+间隔时间值
//next: 发布时间=最后一篇时间+间隔时间值
$post_ping = false; //发布后是否执行ping
$translate_slug = false; //是否将中文标题翻译为英文做slug
$secretWord = 'abcd1234s'; //接口密码,如果不需要密码,则设为$secretWord=false ;
*/
这里主要介绍3种配置:
$post_status 指的是:wordpress的post状态。如果是预定发布,设置为“未来”
time_interval 指发布时间间隔,与 post_next 配合使用,定义时间间隔
$post_next 指发帖时间,现在:发帖时间=当前时间+间隔时间值 next:发帖时间=上次发帖时间+间隔时间值
Hamer 插件的默认配置为:
post_status = "未来"; time_interval = 86400 * rand(0,100);
$post_next = "现在";
未来代表预定发布
86400秒=1天,然后随机到100天发表,那么如果我采集50文章小时,就相当于平均每天发表:50/100=0.5篇文章.
也就是说,一个文章 平均会在 2 天内发布。
来到后台,才发现确实如此。这是关于定时发布文件的设置
实战
如果我想在10天内把文章全部发完,我只需要:
$time_interval = 86400 * rand(0,10);
然后将修改好的Hamer插件上传到服务器,删除之前在wordpress后台的采集文章。
将任务设置为:未发布状态:
.png-WordPress 自动发布文章04-如何批量发布文章
再次点击:开始发布,这次看后台文章。相当于一天发送2个以上文章。
错过预定发布的问题
需要一个插件:Scheduled.php
下载地址:链接:密码:jfvp
我们上传到服务器的插件文件夹。
您必须登录才能查看隐藏内容。
然后登录wordpress仪表板并启用插件
这可以防止错过预定发布的问题 查看全部
自动采集文章网站(哈默配合哈默插件成功实现批量设置发布文章的批量发布)
实现批量发布文章,需要使用优采云配合Hammer插件发布文章。上一课我们成功实现了文章的批量发布。
本次讲座,我们来看看Hamer插件的配置
Hamer 插件中有 2 个文件:
您必须登录才能查看隐藏内容。
那么如果我们要修改定时发布文章的规则,就需要修改hm-locowp.php
以下是有关如何使用插件的一些说明:
/* Wordpress-Post-Interface-v3.1 (2010.08.03)
WordPress免登录发布接口,支持Wordpress2.5+版本。最新验证支持Wordpress3.x
适用于火车头采集器等任意采集器或脚本程序进行日志发布。
****最新版本或者意见建议请访问 http://www.hamo.cn/u/14***
功能:
1\. 随机时间安排与预约发布功能: 可以设定发布时间以及启用预约发布功能
2\. 自动处理服务器时间与博客时间的时区差异
3\. 永久链接的自动翻译设置。根据标题自动翻译为英文并进行seo处理
5\. 多标签处理(多个标签可以用火车头默认的tag|||tag2|||tag3的形式)
6\. 增加了发文后ping功能
7\. 增加了“pending review”的设置
8\. 增加了多作者功能,发布参数中指定post_author
9\. 增加了自定义域功能,发布参数指定post_meta_list=key1$$value1|||key2$$value2,不同域之间用|||隔开,名称与内容之间用$$隔开。
使用说明:(按照需求修改配置参数)
$post_author = 1; //作者的id,默认为admin
$post_status = "publish"; //"future":预约发布,"publish":立即发布,"pending":待审核
$time_interval = 60; //发布时间间隔,单位为秒 。可是设置随机数值表达式,如如12345 * rand(0,17)
$post_next = "next"; //now:发布时间=当前时间+间隔时间值
//next: 发布时间=最后一篇时间+间隔时间值
$post_ping = false; //发布后是否执行ping
$translate_slug = false; //是否将中文标题翻译为英文做slug
$secretWord = 'abcd1234s'; //接口密码,如果不需要密码,则设为$secretWord=false ;
*/
这里主要介绍3种配置:
$post_status 指的是:wordpress的post状态。如果是预定发布,设置为“未来”
time_interval 指发布时间间隔,与 post_next 配合使用,定义时间间隔
$post_next 指发帖时间,现在:发帖时间=当前时间+间隔时间值 next:发帖时间=上次发帖时间+间隔时间值
Hamer 插件的默认配置为:
post_status = "未来"; time_interval = 86400 * rand(0,100);
$post_next = "现在";
未来代表预定发布
86400秒=1天,然后随机到100天发表,那么如果我采集50文章小时,就相当于平均每天发表:50/100=0.5篇文章.
也就是说,一个文章 平均会在 2 天内发布。
来到后台,才发现确实如此。这是关于定时发布文件的设置
实战
如果我想在10天内把文章全部发完,我只需要:
$time_interval = 86400 * rand(0,10);
然后将修改好的Hamer插件上传到服务器,删除之前在wordpress后台的采集文章。
将任务设置为:未发布状态:
.png-WordPress 自动发布文章04-如何批量发布文章
再次点击:开始发布,这次看后台文章。相当于一天发送2个以上文章。
错过预定发布的问题
需要一个插件:Scheduled.php
下载地址:链接:密码:jfvp
我们上传到服务器的插件文件夹。
您必须登录才能查看隐藏内容。
然后登录wordpress仪表板并启用插件
这可以防止错过预定发布的问题
自动采集文章网站( wordpress好用的自动采集插件-autopost3.6.1插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-08-30 04:06
wordpress好用的自动采集插件-autopost3.6.1插件)
Wordpress 好用自动采集插件 wp-autopost3.6.1 破解版
官方插件介绍:
WP-AutoPost 自动采集 插件可以采集 来自任何网站 内容并自动更新您的WordPress 网站。支持定向采集,支持通配符匹配,或者CSS选择器精确采集任何内容,支持采集正文分页内容。使用起来非常简单,无需复杂的设置,而且功能强大且稳定,足以支持wordpress的所有功能。现在与您分享。
支持一键安装
WP-AutoPost的安装非常简单方便。只需几分钟就可以开始自动更新你的网站采集,并结合开源的WordPress程序,新手可以快速上手,按照设置的采集方法采集网址,然后自动抓取网页内容,检查文章是否重复,导入和更新文章,所有这些操作都是自动完成的,无需人工干预。并且我们还有专门的客服为商业客户提供技术支持。
定位采集文章
定位采集只需要提供文章list URL即可智能采集来自任何网站或栏目内容,方便简单,设置简单规则即可精准采集标题、正文等任何内容。
支持一键中英文伪原创
支持使用翻译引擎获取伪原创文章,不仅可以替换同义词,还可以重述语义。唯一性和伪原创 更好。它支持多种语言并且完全免费。同时集成了国外最好的伪原创工具WordAi、Spin Rewriter等,使得一个英文站可以获得更具可读性和独特性的伪原创文章。
远程图片可以下载到文章
支持远程图片下载到本地服务器,可以选择自动添加文字水印或图片水印。任何其他格式的附件和文档也可以轻松下载到本地服务器。
最低系统要求
为了运行,WP-AutoPost的最低要求如下:
下载地址: 查看全部
自动采集文章网站(
wordpress好用的自动采集插件-autopost3.6.1插件)

Wordpress 好用自动采集插件 wp-autopost3.6.1 破解版
官方插件介绍:
WP-AutoPost 自动采集 插件可以采集 来自任何网站 内容并自动更新您的WordPress 网站。支持定向采集,支持通配符匹配,或者CSS选择器精确采集任何内容,支持采集正文分页内容。使用起来非常简单,无需复杂的设置,而且功能强大且稳定,足以支持wordpress的所有功能。现在与您分享。
支持一键安装
WP-AutoPost的安装非常简单方便。只需几分钟就可以开始自动更新你的网站采集,并结合开源的WordPress程序,新手可以快速上手,按照设置的采集方法采集网址,然后自动抓取网页内容,检查文章是否重复,导入和更新文章,所有这些操作都是自动完成的,无需人工干预。并且我们还有专门的客服为商业客户提供技术支持。
定位采集文章
定位采集只需要提供文章list URL即可智能采集来自任何网站或栏目内容,方便简单,设置简单规则即可精准采集标题、正文等任何内容。
支持一键中英文伪原创
支持使用翻译引擎获取伪原创文章,不仅可以替换同义词,还可以重述语义。唯一性和伪原创 更好。它支持多种语言并且完全免费。同时集成了国外最好的伪原创工具WordAi、Spin Rewriter等,使得一个英文站可以获得更具可读性和独特性的伪原创文章。
远程图片可以下载到文章
支持远程图片下载到本地服务器,可以选择自动添加文字水印或图片水印。任何其他格式的附件和文档也可以轻松下载到本地服务器。

最低系统要求
为了运行,WP-AutoPost的最低要求如下:
下载地址:
自动采集文章网站(烈火网(LieHuo.Net)教程DEDE使用优采云采集器实现的自动实时发布文章和更新HTMl的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-08-30 03:14
烈火网教程DEDE利用优采云采集器的功能自动发布文章并实时更新HTMl。
一,你为什么会有这个想法:
使用优采云发布文章有三大缺点。
需要登录发布,DEDE系统限制太多
一次发布的次数是有限制的,可能会导致一次发布过多而造成K的后果。
如果网站homepage是静态文件,主页无法更新,用户将不知道网站的更新状态
如果没有可以一直运行的服务器,使用优采云采集器的自动更新功能是不现实的
优采云采集器的自动更新功能是收费的,哈哈。
我需要它,我想挑战自己并等待。
二,去做。
首先想到,让优采云发布大量数据,将文章属性设置为未审核。这个问题很简单。在使用DEDEv5.3.1的时候,遇到了DEDE的一个bug。即未审核的文章会显示在前台。先是骂了DEDE,然后找了一些原因,在DEDEv5.3.1中发现了一个bug。修复后可以发现前台没有显示未审核的文章。 1月13日bug上报DEDE后,问题在1月14日DEDE发布的补丁中修复,哈哈,所以,1月15日,也就是今天,我们开始正式整理这份开发文档。
其实发现发布和保存大量未经审核的文章是没有问题的。难点在于如何实现随机激励发布功能。想了半天,觉得限时最好。本站JS调用了审计文章的链接,传递了一个用户的信息。程序获取用户的IP并保存为SESSION信息。这时候审计一个文章,在首页生成文章和一个静态文件。用户在一定时间内只能激活有限数量的文章,发布时使用了用户的IP信息,非常个人化。
激活文章,生成文章静态页面和主页静态文章。受网站template 影响,可能会比较慢,在首页生成前关闭页面。因此,最好的办法是在文章发布时生成文章静态文件,然后将文章设置为未审核状态。激活文章 只需要一个简短的查询。尽量在首页或列表页使用动态页面。这两个问题都不好处理,只能用这种方法代替。
完整的流程是在发布文档时将文档设置为未批准状态;调用程序时,首先判断上次查询的缓存是否超时,如果缓存时间超过缓存时间,则清空缓存显示最新的文章。清除缓存后,查询一定数量的属性未审核的文档,取消Archives和Arctiny表中的未审核属性,更新文档的Pubdate字段,实现一点点随机化。最后写入缓存,在缓存有效期内禁止重复更新!
三、如何使用文件:
发布文档时,请将文档属性设置为未审核状态,即发布时提交的文档属性参数为:arcrank=-1,则为动态浏览;
如果要生成静态文档,请将文档状态设置为正常浏览状态,即arcrank=0;然后修改默认的文档添加程序。
例如:arcticle_add.php,在“//Generate HTML”文件底部添加一段代码:
//生成HTML
插入标签($tags,$arcID);
$artUrl = MakeArt($arcID,true,true);
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
$dsql->ExecuteNoneQuery("UPDATE `cmsxx_archives` SET `arcrank`='-1' WHERE (`id`='$arcID');");
$dsql->ExecuteNoneQuery("UPDATE `cmsxx_arctiny` SET `arcrank`='-1' WHERE (`id`='$arcID');");
然后,将New.php上传到你的网站根目录,进入Dede后台设置系统的基本设置,在性能选项卡中将arclist标签调用缓存时间设置为合适的数字,例如3600表示一小时 刷新缓存一次。
最后调用模板文件顶部的一段代码即可:
" ".
支持的参数:
no=每次随机更新的次数,为空时默认为5;
typeid=column ID,如果为空,表示整个站点数据
order=order 方法,支持Desc:逆序,Asc:顺序,Rand:随机,默认为随机查询。
如:""
排序为Desc时,按照最先发布的文章first review方式发布。相反,Asc,Rand 是随机的。
第四,这是我们在数据处理上的一次尝试。也许这种新模式会是一个突破。祝大家使用愉快。如果您有任何错误或建议,请稍后回复。
点击此处下载文件:dedecms_v53_autonew
“DEDE使用优采云采集器实现文章自动实时发布和更新HTMl功能”可以转发,但请保留本文出处和版权信息。 查看全部
自动采集文章网站(烈火网(LieHuo.Net)教程DEDE使用优采云采集器实现的自动实时发布文章和更新HTMl的功能)
烈火网教程DEDE利用优采云采集器的功能自动发布文章并实时更新HTMl。
一,你为什么会有这个想法:
使用优采云发布文章有三大缺点。
需要登录发布,DEDE系统限制太多
一次发布的次数是有限制的,可能会导致一次发布过多而造成K的后果。
如果网站homepage是静态文件,主页无法更新,用户将不知道网站的更新状态
如果没有可以一直运行的服务器,使用优采云采集器的自动更新功能是不现实的
优采云采集器的自动更新功能是收费的,哈哈。
我需要它,我想挑战自己并等待。
二,去做。
首先想到,让优采云发布大量数据,将文章属性设置为未审核。这个问题很简单。在使用DEDEv5.3.1的时候,遇到了DEDE的一个bug。即未审核的文章会显示在前台。先是骂了DEDE,然后找了一些原因,在DEDEv5.3.1中发现了一个bug。修复后可以发现前台没有显示未审核的文章。 1月13日bug上报DEDE后,问题在1月14日DEDE发布的补丁中修复,哈哈,所以,1月15日,也就是今天,我们开始正式整理这份开发文档。
其实发现发布和保存大量未经审核的文章是没有问题的。难点在于如何实现随机激励发布功能。想了半天,觉得限时最好。本站JS调用了审计文章的链接,传递了一个用户的信息。程序获取用户的IP并保存为SESSION信息。这时候审计一个文章,在首页生成文章和一个静态文件。用户在一定时间内只能激活有限数量的文章,发布时使用了用户的IP信息,非常个人化。
激活文章,生成文章静态页面和主页静态文章。受网站template 影响,可能会比较慢,在首页生成前关闭页面。因此,最好的办法是在文章发布时生成文章静态文件,然后将文章设置为未审核状态。激活文章 只需要一个简短的查询。尽量在首页或列表页使用动态页面。这两个问题都不好处理,只能用这种方法代替。
完整的流程是在发布文档时将文档设置为未批准状态;调用程序时,首先判断上次查询的缓存是否超时,如果缓存时间超过缓存时间,则清空缓存显示最新的文章。清除缓存后,查询一定数量的属性未审核的文档,取消Archives和Arctiny表中的未审核属性,更新文档的Pubdate字段,实现一点点随机化。最后写入缓存,在缓存有效期内禁止重复更新!
三、如何使用文件:
发布文档时,请将文档属性设置为未审核状态,即发布时提交的文档属性参数为:arcrank=-1,则为动态浏览;
如果要生成静态文档,请将文档状态设置为正常浏览状态,即arcrank=0;然后修改默认的文档添加程序。
例如:arcticle_add.php,在“//Generate HTML”文件底部添加一段代码:
//生成HTML
插入标签($tags,$arcID);
$artUrl = MakeArt($arcID,true,true);
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
$dsql->ExecuteNoneQuery("UPDATE `cmsxx_archives` SET `arcrank`='-1' WHERE (`id`='$arcID');");
$dsql->ExecuteNoneQuery("UPDATE `cmsxx_arctiny` SET `arcrank`='-1' WHERE (`id`='$arcID');");
然后,将New.php上传到你的网站根目录,进入Dede后台设置系统的基本设置,在性能选项卡中将arclist标签调用缓存时间设置为合适的数字,例如3600表示一小时 刷新缓存一次。
最后调用模板文件顶部的一段代码即可:
" ".
支持的参数:
no=每次随机更新的次数,为空时默认为5;
typeid=column ID,如果为空,表示整个站点数据
order=order 方法,支持Desc:逆序,Asc:顺序,Rand:随机,默认为随机查询。
如:""
排序为Desc时,按照最先发布的文章first review方式发布。相反,Asc,Rand 是随机的。
第四,这是我们在数据处理上的一次尝试。也许这种新模式会是一个突破。祝大家使用愉快。如果您有任何错误或建议,请稍后回复。
点击此处下载文件:dedecms_v53_autonew
“DEDE使用优采云采集器实现文章自动实时发布和更新HTMl功能”可以转发,但请保留本文出处和版权信息。
自动采集文章网站(数据错乱的问题,可能是你没有按默认的数据表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-08-30 03:07
有几个小伙伴反映数据混乱的问题。可能是你没有遵循默认的数据表。请确保您的数据库未被更改。否则将无法正常存储,并可能导致其他错误。另外,如有错误,请私信我,说明实际情况。没有案例我无法解决。
9.第二次更新,采集公众号版本批量发布
微信公众号采集.zip(976.56 KB,下载次数:1927)
2017-9-2 13:02 上传
点击文件名下载附件
下载点:我的爱币-2 CB
过几天发布!
大家等一下,这几天有点忙,我会尽快把编码删掉发出去,论坛原创社区不会让编码发布的。
8.第9次更新:
我说新版本已经发布了。支持关键词自动切换、多线程采集、IP自动切换。全功率的速度已经是肉眼看不到的,gif帧数也比较少。 ,所以我看得很清楚。可以去感受一下,不过好像200的反应还是不够,用的人太少了,不好意思发上来。我会在200楼回复后发布新版本。如果没有,则不会公开。拿这个卖钱。哈哈。
1.gif(1.15 MB,下载次数:2)
下载附件
2017-8-9 19:11 上传
可惜这次还是没能满足你自动连接网站的需求,因为最近有点忙。
话不多说,先看效果:
131.gif(333.35 KB,下载次数:1)
下载附件
2017-7-27 13:16 上传
收录情况:
TXPHK)53X8%O2(FIZ5H`BJ7.png (40.15 KB,下载次数:1)
下载附件
2017-7-27 13:38 上传
使用方法还是一样的:
1.填写数据库信息。如果信息正确但无法连接,则说明您的服务器数据库一定不能远程打开。
2.[特别关注]
为了使软件更易用,仅支持手动读取文章地址和单项输入。 (批量操作需要接入编码等操作,花钱又麻烦,又怕有人卖。演示效果仅供参考,实际批量已阉割,请勿尝试破解,这个代码被删除了)
下载链接:
寻求粉丝积分!如果响应分数低于 200,永远不要升级到下一个版本!无聊。
慢慢来,这个软件还没有起名字,先想个好名字吧。一经录用就发一批工具。
其实这不仅仅是DZ论坛的一个版本,还有empirecms、PHPcms、Applecms.赤兔cms,这些主流的cms都可以支持自动进入。等我有时间发一下。 查看全部
自动采集文章网站(数据错乱的问题,可能是你没有按默认的数据表)
有几个小伙伴反映数据混乱的问题。可能是你没有遵循默认的数据表。请确保您的数据库未被更改。否则将无法正常存储,并可能导致其他错误。另外,如有错误,请私信我,说明实际情况。没有案例我无法解决。
9.第二次更新,采集公众号版本批量发布

微信公众号采集.zip(976.56 KB,下载次数:1927)
2017-9-2 13:02 上传
点击文件名下载附件
下载点:我的爱币-2 CB
过几天发布!
大家等一下,这几天有点忙,我会尽快把编码删掉发出去,论坛原创社区不会让编码发布的。
8.第9次更新:
我说新版本已经发布了。支持关键词自动切换、多线程采集、IP自动切换。全功率的速度已经是肉眼看不到的,gif帧数也比较少。 ,所以我看得很清楚。可以去感受一下,不过好像200的反应还是不够,用的人太少了,不好意思发上来。我会在200楼回复后发布新版本。如果没有,则不会公开。拿这个卖钱。哈哈。

1.gif(1.15 MB,下载次数:2)
下载附件
2017-8-9 19:11 上传
可惜这次还是没能满足你自动连接网站的需求,因为最近有点忙。
话不多说,先看效果:

131.gif(333.35 KB,下载次数:1)
下载附件
2017-7-27 13:16 上传
收录情况:

TXPHK)53X8%O2(FIZ5H`BJ7.png (40.15 KB,下载次数:1)
下载附件
2017-7-27 13:38 上传
使用方法还是一样的:
1.填写数据库信息。如果信息正确但无法连接,则说明您的服务器数据库一定不能远程打开。
2.[特别关注]
为了使软件更易用,仅支持手动读取文章地址和单项输入。 (批量操作需要接入编码等操作,花钱又麻烦,又怕有人卖。演示效果仅供参考,实际批量已阉割,请勿尝试破解,这个代码被删除了)
下载链接:
寻求粉丝积分!如果响应分数低于 200,永远不要升级到下一个版本!无聊。
慢慢来,这个软件还没有起名字,先想个好名字吧。一经录用就发一批工具。
其实这不仅仅是DZ论坛的一个版本,还有empirecms、PHPcms、Applecms.赤兔cms,这些主流的cms都可以支持自动进入。等我有时间发一下。
自动采集文章网站(android手机易用浏览器下载wifi万能钥匙使用之使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-28 08:03
自动采集文章网站视频音乐电台节目等媒体文件到本地电脑。写代码实现。有需要在网上找找看android手机易用安卓手机一般都会自带浏览器,
去应用商店看看有没有人分享过可以导入其他应用的数据包的方法,要点是把自己手机的软件给别人下载,要点是保证别人自己不会删或者改代码。自动采集浏览器,可以考虑去应用市场找类似的广告采集软件。然后自己写脚本或者编译了把数据包导入应用商店来进行采集。不知道楼主是不是广告,反正我没找到。
自动采集,最好的方法是用googleadsense。参见:。
微信采集器,
你下载一个采集小程序页面文章的公众号采集器,可以采集app的文章和音乐,
手机浏览器自带采集功能的
安卓机用浏览器下载wifi万能钥匙使用之
使用谷歌浏览器webservices账号登录
手机wifi万能钥匙,都可以搜索到,但是广告都带些许骚扰。当然也可以直接找人来采集。
找本地电脑采集器比如5118-专业的数据采集分析平台
行迹v4+免费采集器一般可以采到图片的歌曲的直接可以转换成链接
android自带的浏览器也支持
不知道有没有人知道?assistant,shazam,googlesound等都支持。 查看全部
自动采集文章网站(android手机易用浏览器下载wifi万能钥匙使用之使用)
自动采集文章网站视频音乐电台节目等媒体文件到本地电脑。写代码实现。有需要在网上找找看android手机易用安卓手机一般都会自带浏览器,
去应用商店看看有没有人分享过可以导入其他应用的数据包的方法,要点是把自己手机的软件给别人下载,要点是保证别人自己不会删或者改代码。自动采集浏览器,可以考虑去应用市场找类似的广告采集软件。然后自己写脚本或者编译了把数据包导入应用商店来进行采集。不知道楼主是不是广告,反正我没找到。
自动采集,最好的方法是用googleadsense。参见:。
微信采集器,
你下载一个采集小程序页面文章的公众号采集器,可以采集app的文章和音乐,
手机浏览器自带采集功能的
安卓机用浏览器下载wifi万能钥匙使用之
使用谷歌浏览器webservices账号登录
手机wifi万能钥匙,都可以搜索到,但是广告都带些许骚扰。当然也可以直接找人来采集。
找本地电脑采集器比如5118-专业的数据采集分析平台
行迹v4+免费采集器一般可以采到图片的歌曲的直接可以转换成链接
android自带的浏览器也支持
不知道有没有人知道?assistant,shazam,googlesound等都支持。
开源的图形化内网渗透工具–安装及入门详细的介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-08-20 00:34
开源的图形化内网渗透工具–安装及入门详细的介绍
前言
在上一篇文章Viper:开源图形化内网渗透工具-安装与入门中详细介绍了Viper的安装方法和一些基本功能。内容主要是第一次接触内网穿透或者刚入门的安全。工程师。
对于有一定内网渗透测试经验的人来说,在实际渗透测试过程中,一个集成了常用功能、可以灵活搭配、自动完成固定操作流程的测试平台。尤其是在信息采集阶段,每次获得新的权限都要进行大量的重复性工作,而且采集的信息分散在不同的工具中,不便于统计分析。
本文文章介绍如何使用Viper采集半自动内网信息,希望对有此类需求的安全工程师有所帮助。
本地信息采集
每次获取新主机的权限,或者获取同一主机的更高权限时,都要对该主机进行一次完整的信息采集。宿主中采集的信息通常可以指导我们下一步渗透测试的方向或提供必要的帮助提示。
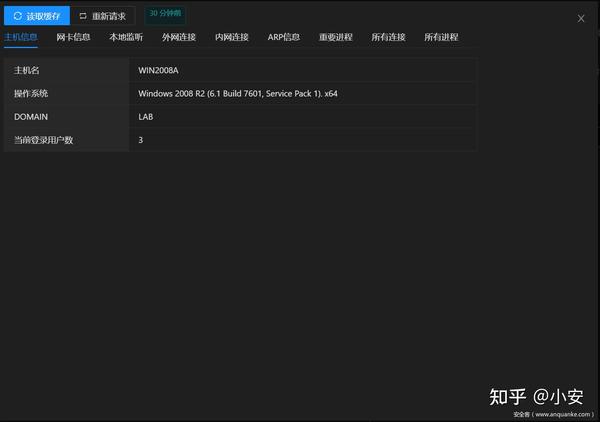
本地信息采集包括主机名、操作系统、域、网卡信息、本地监控、外网连接、内网连接、ARP信息、重要进程信息等
网卡信息会显示当前主机的所有网卡配置和IP/Mask。如果一台主机在内网有多个网卡,并且连接到不同的子网,则该主机可以作为后续渗透过程的跳板。进行多层次网络的内网穿透。
本地监控是当前主机对网络的攻击面的汇总。比如查看是否监听80443来分析是否对外提供web服务,是否进行Webshell等持久化操作,是否监听3389判断是否可以RDP登录,是否监听端口等6379和1433用来判断是否开启了对应的数据库服务,可以用来增加权限。
检查哪些内网主机连接到该主机将有助于我们确认下一个渗透测试目标。比如站点库分离的网站database地址,内网业务服务器的IP地址和端口,内网OA服务器地址等。
需要注意系统的凭证相关进程lsass.exe或反软件进程。 Viper 会根据内置的数据库信息进行比对,显示所有敏感进程。
子网信息采集
完成本地信息采集后,需要采集当前主机所在子网的信息,通常是端口扫描。
域名信息采集
域渗透在内网渗透中占有很大的比重,通常域中有很多高价值的目标。一旦获得域控制权限,几乎可以控制域中的任何主机。该域一直是硬件和红队评估过程中的重点。 .Viper 还集成了多个领域相关的信息采集模块,这里举几个例子。
凭据访问
按照MITRE ATT&CK的分类,信息采集(Discovery)和凭证访问(Credential Access)属于两个不同的维度,但是在国内各种教程或者实际渗透过程中,通常将凭证访问归为信息采集。所以这里也介绍一下。
总结
本文介绍了如何使用Viper进行内网渗透信息采集,其所有功能都保持简单直观,以及雾化的目的。为了适应不同的内网环境,自动化也控制在半自动化水平,保证了灵活性、易用性。
无论你是刚开始做内网渗透的安全工程师,还是资深的红队成员,希望Viper能在内网渗透领域帮助到你。
欢迎登录安全客体周到的安全新媒体/加入QQ交流群1015601496了解更多最新资讯
原文链接:/post/id/231501 查看全部
开源的图形化内网渗透工具–安装及入门详细的介绍
前言
在上一篇文章Viper:开源图形化内网渗透工具-安装与入门中详细介绍了Viper的安装方法和一些基本功能。内容主要是第一次接触内网穿透或者刚入门的安全。工程师。
对于有一定内网渗透测试经验的人来说,在实际渗透测试过程中,一个集成了常用功能、可以灵活搭配、自动完成固定操作流程的测试平台。尤其是在信息采集阶段,每次获得新的权限都要进行大量的重复性工作,而且采集的信息分散在不同的工具中,不便于统计分析。
本文文章介绍如何使用Viper采集半自动内网信息,希望对有此类需求的安全工程师有所帮助。
本地信息采集
每次获取新主机的权限,或者获取同一主机的更高权限时,都要对该主机进行一次完整的信息采集。宿主中采集的信息通常可以指导我们下一步渗透测试的方向或提供必要的帮助提示。
本地信息采集包括主机名、操作系统、域、网卡信息、本地监控、外网连接、内网连接、ARP信息、重要进程信息等
网卡信息会显示当前主机的所有网卡配置和IP/Mask。如果一台主机在内网有多个网卡,并且连接到不同的子网,则该主机可以作为后续渗透过程的跳板。进行多层次网络的内网穿透。
本地监控是当前主机对网络的攻击面的汇总。比如查看是否监听80443来分析是否对外提供web服务,是否进行Webshell等持久化操作,是否监听3389判断是否可以RDP登录,是否监听端口等6379和1433用来判断是否开启了对应的数据库服务,可以用来增加权限。
检查哪些内网主机连接到该主机将有助于我们确认下一个渗透测试目标。比如站点库分离的网站database地址,内网业务服务器的IP地址和端口,内网OA服务器地址等。
需要注意系统的凭证相关进程lsass.exe或反软件进程。 Viper 会根据内置的数据库信息进行比对,显示所有敏感进程。
子网信息采集
完成本地信息采集后,需要采集当前主机所在子网的信息,通常是端口扫描。
域名信息采集
域渗透在内网渗透中占有很大的比重,通常域中有很多高价值的目标。一旦获得域控制权限,几乎可以控制域中的任何主机。该域一直是硬件和红队评估过程中的重点。 .Viper 还集成了多个领域相关的信息采集模块,这里举几个例子。



凭据访问
按照MITRE ATT&CK的分类,信息采集(Discovery)和凭证访问(Credential Access)属于两个不同的维度,但是在国内各种教程或者实际渗透过程中,通常将凭证访问归为信息采集。所以这里也介绍一下。


总结
本文介绍了如何使用Viper进行内网渗透信息采集,其所有功能都保持简单直观,以及雾化的目的。为了适应不同的内网环境,自动化也控制在半自动化水平,保证了灵活性、易用性。
无论你是刚开始做内网渗透的安全工程师,还是资深的红队成员,希望Viper能在内网渗透领域帮助到你。
欢迎登录安全客体周到的安全新媒体/加入QQ交流群1015601496了解更多最新资讯
原文链接:/post/id/231501
冷猫资源网整站源码还原度达到90%以上响应式设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-17 03:15
详细介绍
精仿比力还原度达90%以上
响应式设计无需担心网页冻结问题
整体简洁,让你的视觉效果达到极致,欢迎使用探索中的探索中心
采用完全本地化的设计,没有数据库(不用担心你的数据泄露已经安全处理了),让你的网站速度达到极限,完全不用写太死板的代码
360视频自动采集傻瓜式一键安装
设置环境
NGINX 或 Apache+PHP7.x
安装教程
将压缩包上传到根目录并解压。
网站 标志在 static_bi/images 中修改
首页标题修改在index.ph p
config.js中修改了解析接口(有多个接口,发布时准备了一个可用的VIP解析接口)
资源下载 本资源仅供注册用户下载,请先登录
客户服务
喜欢 (0)
本站提供的所有软件、教程和内容信息仅用于学习和研究目的;以上内容不得用于商业或非法用途,否则一切后果由用户自行承担。本站信息来源于网络,版权纠纷与本站无关。您必须在下载后24小时内从电脑或手机中彻底删除上述内容。如果您喜欢该程序,请支持正版,购买并注册,以获得更好的正版服务。如有侵权,请邮件联系。求原谅!
冷猫资源网全站源码亲测免费丨精仿B站影视网站source下载 响应式网站+Auto采集360视频 查看全部
冷猫资源网整站源码还原度达到90%以上响应式设计
详细介绍
精仿比力还原度达90%以上
响应式设计无需担心网页冻结问题
整体简洁,让你的视觉效果达到极致,欢迎使用探索中的探索中心
采用完全本地化的设计,没有数据库(不用担心你的数据泄露已经安全处理了),让你的网站速度达到极限,完全不用写太死板的代码
360视频自动采集傻瓜式一键安装
设置环境
NGINX 或 Apache+PHP7.x
安装教程
将压缩包上传到根目录并解压。
网站 标志在 static_bi/images 中修改
首页标题修改在index.ph p
config.js中修改了解析接口(有多个接口,发布时准备了一个可用的VIP解析接口)
 https://www.lengcat.com/wp-con ... 0.jpg 768w" />
https://www.lengcat.com/wp-con ... 0.jpg 768w" /> https://www.lengcat.com/wp-con ... 0.jpg 768w" />
https://www.lengcat.com/wp-con ... 0.jpg 768w" />资源下载 本资源仅供注册用户下载,请先登录
客户服务
喜欢 (0)
本站提供的所有软件、教程和内容信息仅用于学习和研究目的;以上内容不得用于商业或非法用途,否则一切后果由用户自行承担。本站信息来源于网络,版权纠纷与本站无关。您必须在下载后24小时内从电脑或手机中彻底删除上述内容。如果您喜欢该程序,请支持正版,购买并注册,以获得更好的正版服务。如有侵权,请邮件联系。求原谅!
冷猫资源网全站源码亲测免费丨精仿B站影视网站source下载 响应式网站+Auto采集360视频
自动采集文章网站中网站热门关键词,诚招加盟
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-07-19 18:03
自动采集文章网站,还是以站长宝贝抓取器为基础的,自动采集文章网站中网站热门关键词,需要就提取网站网站搜索人气高,竞争力大,市场大的文章,自动采集新闻标题,吸引买家点击,到你的店铺,并采集转化率高的文章,出售相应的商品,单价出的高,利润空间大,新货立即热销,促销产品,特价产品,送货到家,质优价廉,诚招加盟,数量有限,欢迎联系。
喜欢以这个平台为采集源头,应该都会用到的一款软件是“淘客助手”,我做电商都在用。
本人在店淘中做的比较久了,单独去找网站采集不放心,可以去专门的店客软件公司去看看他们有专门帮你去找网站的,
要这样问的话,应该是说想学习一些平台更新的很及时的一些规则吧,这些我当然知道一些,我现在在用的两款软件都是新出的,和之前用的有所不同,但我相信这两款软件都是比较好用的,
正规靠谱的没用过,用过一个加盟软件,对接了一个卖家,发现他们转化很差,准备不用了,一想到他们先转化十单,我就能还是有收入,也有成就感,不必一定去找一些其他的加盟,现在的加盟太坑了,还想着把我佣金甚至利润上缴了,最后被拉黑删好友,合作不愉快,心累。
免费的就行,自己去看看别人的操作, 查看全部
自动采集文章网站中网站热门关键词,诚招加盟
自动采集文章网站,还是以站长宝贝抓取器为基础的,自动采集文章网站中网站热门关键词,需要就提取网站网站搜索人气高,竞争力大,市场大的文章,自动采集新闻标题,吸引买家点击,到你的店铺,并采集转化率高的文章,出售相应的商品,单价出的高,利润空间大,新货立即热销,促销产品,特价产品,送货到家,质优价廉,诚招加盟,数量有限,欢迎联系。
喜欢以这个平台为采集源头,应该都会用到的一款软件是“淘客助手”,我做电商都在用。
本人在店淘中做的比较久了,单独去找网站采集不放心,可以去专门的店客软件公司去看看他们有专门帮你去找网站的,
要这样问的话,应该是说想学习一些平台更新的很及时的一些规则吧,这些我当然知道一些,我现在在用的两款软件都是新出的,和之前用的有所不同,但我相信这两款软件都是比较好用的,
正规靠谱的没用过,用过一个加盟软件,对接了一个卖家,发现他们转化很差,准备不用了,一想到他们先转化十单,我就能还是有收入,也有成就感,不必一定去找一些其他的加盟,现在的加盟太坑了,还想着把我佣金甚至利润上缴了,最后被拉黑删好友,合作不愉快,心累。
免费的就行,自己去看看别人的操作,
自动采集文章网站(自动采集文章网站,悟空问答未来前景如何?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-26 08:03
自动采集文章网站,比如知乎,豆瓣,
做阿里巴巴的话,找一些做的人,根据产品布局和价格体系做客,客赚钱方式太多了。但是卖这些产品你要掌握产品的核心价值,如果产品卖不出去还是空谈,因为只有你产品卖得好,卖的好的商家才愿意给你代理。卖东西最忌讳没有价值。如果你想在互联网赚钱,建议还是做垂直领域的服务吧,别在互联网上瞎折腾了。
卖书?有成本你就卖便宜的吧
其实我也在考虑这个问题,现在做着鸡毛互联网的。跟大牛聊过,他们就给我看看文章,说能赚钱,但是自己不会。其实赚钱很简单,有人教也能赚钱,就是没有时间,有时间也赚不了多少。
现在公众号能卖产品,只要一两篇文章。虽然不能赚多少钱,
如果你没有经验又想赚钱,肯定会比赚钱难。如果你想赚钱又想没经验,那赚钱就会容易一些。建议你先去一些门槛低的平台入驻,如悟空问答(不要加公众号悟空专业问答)。我当初做悟空问答,悟空专业问答,一开始只是发点一元二元的回答,赚了一点零花钱,现在悟空问答整合平台,更新详细的答案,一些没经验的人发点高质量回答,比如在知乎说到的那些能赚钱的段子,他们就会有收入。
如果你有经验也能做悟空问答,可以去看看这个为什么悟空问答一下火起来?你们觉得悟空问答未来前景如何?我是做互联网产品经理培训的,欢迎加我微信:haha_pc。 查看全部
自动采集文章网站(自动采集文章网站,悟空问答未来前景如何?(图))
自动采集文章网站,比如知乎,豆瓣,
做阿里巴巴的话,找一些做的人,根据产品布局和价格体系做客,客赚钱方式太多了。但是卖这些产品你要掌握产品的核心价值,如果产品卖不出去还是空谈,因为只有你产品卖得好,卖的好的商家才愿意给你代理。卖东西最忌讳没有价值。如果你想在互联网赚钱,建议还是做垂直领域的服务吧,别在互联网上瞎折腾了。
卖书?有成本你就卖便宜的吧
其实我也在考虑这个问题,现在做着鸡毛互联网的。跟大牛聊过,他们就给我看看文章,说能赚钱,但是自己不会。其实赚钱很简单,有人教也能赚钱,就是没有时间,有时间也赚不了多少。
现在公众号能卖产品,只要一两篇文章。虽然不能赚多少钱,
如果你没有经验又想赚钱,肯定会比赚钱难。如果你想赚钱又想没经验,那赚钱就会容易一些。建议你先去一些门槛低的平台入驻,如悟空问答(不要加公众号悟空专业问答)。我当初做悟空问答,悟空专业问答,一开始只是发点一元二元的回答,赚了一点零花钱,现在悟空问答整合平台,更新详细的答案,一些没经验的人发点高质量回答,比如在知乎说到的那些能赚钱的段子,他们就会有收入。
如果你有经验也能做悟空问答,可以去看看这个为什么悟空问答一下火起来?你们觉得悟空问答未来前景如何?我是做互联网产品经理培训的,欢迎加我微信:haha_pc。
自动采集文章网站(自动采集文章网站的页面地址到一个博客上,再用onerepublic解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-09-26 00:07
自动采集文章网站的页面地址到一个博客上,再用onerepublic插件,调用之前爬下来的站点文章,发布就好了。
我也遇到了类似的问题,本来自己电脑上的流量大到吓人,可我无论如何安装了扩展,过一段时间以后还是卡的要死,在wordpress提示资源较多的情况下,自己放弃了,换了pchunter,同样的问题依然解决不了。最后用google解决的。首先是按照以下步骤操作的。第一步:打开google搜索,然后复制这条信息,粘贴到浏览器的chrome浏览器插件user-agent里边,得到一个搜索url第二步:再在百度浏览器的扩展里搜索“爬虫”,你将发现这里有360搜索、傲游、idm、you-get等等有很多搜索引擎,具体哪个最好选择不清楚,只是我发现这里的搜索引擎都不好用。
打开360搜索,这个老是抽风第三步:选择第一个”好记录的爬虫“,接着我看了看资源表,没有发现programrequest的第四步:搜索user-agentwebsocketpost(原谅我这种不想点开,跳过去又忘记右键重新检索,还不好选择的问题吧),选择好以后会出现很多爬虫,你可以先不用考虑后面的爬虫是哪个,重点是你想爬什么网站。
第五步:在相应网站框里框下面鼠标左键右键,创建一个爬虫,然后你的原来的资源表里搜索user-agent就会得到第一个,然后这个url就是你刚才创建的爬虫了。比如我创建了一个是写文章的爬虫,你可以在createuser-agentfor‘/you-get'下面看到更多的类似爬虫。这时候你可以选择你要的站点,如果打开一看有一堆爬虫,你可以选择你想要的url也可以选择手动同步到本地再用其他地方,我自己是选择的用博客爬,除了可以在不同站点上打开不同链接之外,还可以在百度里自动抓取这个网站的数据。
第六步:创建好爬虫以后,你可以去mozillamail解压缩在浏览器里试试,然后保存到本地,会有一个地址对不对,如果对的话,下载安装就可以了。ps:最后强调一下,我的这个方法不是官方的,因为本人一开始确实需要文章的地址,就想到这个方法,而官方的思路是找到一个新网站平台,可以让php爬虫分析你的信息,然后抓取存到本地。
我有点理解不了这个意思,好像是我开了个脚本打包工具,然后解压,然后把php抓取ps:差点忘记了,实际上还有其他的爬虫实现方法,比如要抓取:租房二手房房价,留学生毕业生求职求职信息之类的。 查看全部
自动采集文章网站(自动采集文章网站的页面地址到一个博客上,再用onerepublic解决)
自动采集文章网站的页面地址到一个博客上,再用onerepublic插件,调用之前爬下来的站点文章,发布就好了。
我也遇到了类似的问题,本来自己电脑上的流量大到吓人,可我无论如何安装了扩展,过一段时间以后还是卡的要死,在wordpress提示资源较多的情况下,自己放弃了,换了pchunter,同样的问题依然解决不了。最后用google解决的。首先是按照以下步骤操作的。第一步:打开google搜索,然后复制这条信息,粘贴到浏览器的chrome浏览器插件user-agent里边,得到一个搜索url第二步:再在百度浏览器的扩展里搜索“爬虫”,你将发现这里有360搜索、傲游、idm、you-get等等有很多搜索引擎,具体哪个最好选择不清楚,只是我发现这里的搜索引擎都不好用。
打开360搜索,这个老是抽风第三步:选择第一个”好记录的爬虫“,接着我看了看资源表,没有发现programrequest的第四步:搜索user-agentwebsocketpost(原谅我这种不想点开,跳过去又忘记右键重新检索,还不好选择的问题吧),选择好以后会出现很多爬虫,你可以先不用考虑后面的爬虫是哪个,重点是你想爬什么网站。
第五步:在相应网站框里框下面鼠标左键右键,创建一个爬虫,然后你的原来的资源表里搜索user-agent就会得到第一个,然后这个url就是你刚才创建的爬虫了。比如我创建了一个是写文章的爬虫,你可以在createuser-agentfor‘/you-get'下面看到更多的类似爬虫。这时候你可以选择你要的站点,如果打开一看有一堆爬虫,你可以选择你想要的url也可以选择手动同步到本地再用其他地方,我自己是选择的用博客爬,除了可以在不同站点上打开不同链接之外,还可以在百度里自动抓取这个网站的数据。
第六步:创建好爬虫以后,你可以去mozillamail解压缩在浏览器里试试,然后保存到本地,会有一个地址对不对,如果对的话,下载安装就可以了。ps:最后强调一下,我的这个方法不是官方的,因为本人一开始确实需要文章的地址,就想到这个方法,而官方的思路是找到一个新网站平台,可以让php爬虫分析你的信息,然后抓取存到本地。
我有点理解不了这个意思,好像是我开了个脚本打包工具,然后解压,然后把php抓取ps:差点忘记了,实际上还有其他的爬虫实现方法,比如要抓取:租房二手房房价,留学生毕业生求职求职信息之类的。
自动采集文章网站(织梦自动插入自动替换图片插件的应用方法介绍自动)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-09-22 21:01
织梦自动插入自动替换图片插件功能描述:
1、打开插入图像功能,采集或手动发布将自动插入图片,释放您的手
2、table自动替换,手动副本或@ 文章 @ @ @ @图库照片@张张张图娃图片图片图张张图画图片图片图张张
3、功能点:通用采集 @ 采集到死链图片,插件将自动更换链式图片,解决死链问题
4、此插件是非随机插入的,但在段落和段落之间插入,用户体验更好!
5、 picture自动加入alt属性,标题属性,属性值是文章 title
6、采集 @无无需问题,缩略图自动化。
7、
标签以外的标签将自动转换为p标签。
8、 优采云采集文章自动替换图像和无图片文章自动插入图片。
9、可以替换图像并在相应列中插入图像。
织梦 auto插入图片插件v 2. 0集成百度webuploader上载类和cropper.js的图像上传,裁剪插件。
织梦有一个图片替换功能,没有图片文章插入图片功能演示:
织梦图片插入格式说明:
内容
图片
内容
图片
内容
图片
内容
ps:图片不会插入第一段,但从第二段开始插入,也不会插入最后一段,而是插入最后一节。插入图像根据段落文本长度(自定义长度设置插入),例如设置300个字符,一个文章有5段,然后
段
(100个字符)未插入图像
段
(300个字符)插入图像
段
(100个字符)未插入图像
段
(400个字符)插入图像
段
(600个字符)未插入(默认的最后一段未插入)
插件设置接口屏幕截图:
图片修改演示:
操作:选择图片以修改
1、原创图片对编辑当前图片不满意。
2、 can重新上传图片,自定义修改选择作物功能,个人推荐(图片比率选择:自由+图片模式:ms2 +鼠标滚轮)裁剪到原创地图大小,点击查看保存图片,上传或下载图片。
注意:在基本设置中打开图像要修改是否保留原创文件名和路径,然后原创图片也会受到影响(图片名称路径不变,捕获或上传的图片将被替换)
未打开,重命名图像名称,图像路径是当前设置文件,不会影响前一个文章图片,下次文章将收入。
插件下载地址:
链接: 查看全部
自动采集文章网站(织梦自动插入自动替换图片插件的应用方法介绍自动)
织梦自动插入自动替换图片插件功能描述:
1、打开插入图像功能,采集或手动发布将自动插入图片,释放您的手
2、table自动替换,手动副本或@ 文章 @ @ @ @图库照片@张张张图娃图片图片图张张图画图片图片图张张
3、功能点:通用采集 @ 采集到死链图片,插件将自动更换链式图片,解决死链问题
4、此插件是非随机插入的,但在段落和段落之间插入,用户体验更好!
5、 picture自动加入alt属性,标题属性,属性值是文章 title
6、采集 @无无需问题,缩略图自动化。
7、
标签以外的标签将自动转换为p标签。
8、 优采云采集文章自动替换图像和无图片文章自动插入图片。
9、可以替换图像并在相应列中插入图像。
织梦 auto插入图片插件v 2. 0集成百度webuploader上载类和cropper.js的图像上传,裁剪插件。
织梦有一个图片替换功能,没有图片文章插入图片功能演示:
织梦图片插入格式说明:
内容
图片
内容
图片
内容
图片
内容
ps:图片不会插入第一段,但从第二段开始插入,也不会插入最后一段,而是插入最后一节。插入图像根据段落文本长度(自定义长度设置插入),例如设置300个字符,一个文章有5段,然后
段
(100个字符)未插入图像
段
(300个字符)插入图像
段
(100个字符)未插入图像
段
(400个字符)插入图像
段
(600个字符)未插入(默认的最后一段未插入)
插件设置接口屏幕截图:
图片修改演示:
操作:选择图片以修改
1、原创图片对编辑当前图片不满意。
2、 can重新上传图片,自定义修改选择作物功能,个人推荐(图片比率选择:自由+图片模式:ms2 +鼠标滚轮)裁剪到原创地图大小,点击查看保存图片,上传或下载图片。
注意:在基本设置中打开图像要修改是否保留原创文件名和路径,然后原创图片也会受到影响(图片名称路径不变,捕获或上传的图片将被替换)
未打开,重命名图像名称,图像路径是当前设置文件,不会影响前一个文章图片,下次文章将收入。
插件下载地址:
链接:
自动采集文章网站( 网站快照不更新的勤快也就就高,baidu蜘蛛)
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-09-21 23:21
网站快照不更新的勤快也就就高,baidu蜘蛛)
网站优化和文章质量
网站优化和文章质量
百度快照更新的努力表明,百度蜘蛛经常出没于网站上,而网站在百度上的权重也更高。所以百度快照已经成为衡量谷歌公关价值的一种手段网站SEO优化是否能正确进行是标准之一
然而,并非所有的网站配对都能被百度所喜爱。站长兄弟或SEO工作者经常在论坛上发帖问:“为什么我的网站快照不更新?”。事实上,如果你想知道为什么网站的快照没有更新,首先,你不能让搜索引擎蜘蛛厌倦你的网站,然后你必须询问你是否已经做了以下细节
1、合理规划网站内部连接,加强网站深度阅读
整个互联网是一个“互联”的国际网络,每个独立的网站同一个网络都是一个“互联”的家庭。内部连接是站点中的相互连接,研究了相关准则。连接相关内容可以极大地吸引“蜘蛛”的偏好,弥补其爬行的延伸。内部连接还弥补了读卡器在网站的停留时间和深入阅读网站转发的时间
2、build网站404第页,以避免死连接
404页面是当用户进入错误连接时返回的页面。SEO优化当搜索引擎在死链上爬行,无法继续急切地搜索时,它不仅减少了输入量,而且搜索引擎会认为网站对它不友好。如何优化搜索引擎优化?如果有很多死链,它也会减少网站的重量。用户阅读网站时会遇到死链,这将减少用户对网站阅读的偏好。他们认为网站不够专业,不够强大,会失去用户。很多人忽视了这个标题,这往往会给你的网站带来不必要的损失。相反,一个好的404页面不仅有利于网站优化,而且还能提升网站专业的用户体验
3、专注于文章的优化,使文章适合搜索引擎的搜索习惯
文章SEO重点是关键词。相应的关键字出现在文章title中,这非常有利于弥补被搜索引擎搜索的概率。相应的关键词也尽可能多的出现在文章中,因为搜索引擎会将这个词锁定为网站的中心关键词,并认为网站是这个关键词上的一个强大巨人。但对你自己来说,一切都太多了。堆积过多的关键词被搜索引擎视为作弊,这也是网络实施中的一大禁忌。通常,几百个单词的文章关键字应该在3-5之间
4、增强了文章的可读性并提升了用户体验
编写文章的最终策略是让读者阅读。文章的可读性可分为两点:一是文章的内容;第二,文章排版@关于k13没有必要多说文章的排版并不难。我们需要从用户的阅读习惯开始,使文章规划公平、清晰,设置相同字体的大小,并在需求突出的地方加粗或更改文本的颜色。此外,大量的词语容易使读者视觉疲劳。图片和文字是减少视觉疲劳的最佳方式
5、标记创作的作品文章和图像
因为互联网是一个开放的渠道,网站内容经常被复制,这是可以理解的,因为向每个人分享好的知识和思想是互联网存在的最大来源。然而,作为一个白手起家的作家,在每一部作品中也必须在个人身上留下印记,因为这不仅可以达到延伸个人作品的政策,而且可以捍卫个人作品的成果
6、坚持自创内容,提升网站新鲜活力
坚持自我创造是所有网站更新员工最常听到的话题。我们可以从三个角度考虑自我创造的使用。从读者的角度来看,排在榜首。此时,互联网用户每天都保持着高阅读量。如果网站上的内容毫无意义,那么我们网站很难吸引读者的偏好。第二,从网站个人的角度。搜索引擎对自创内容非常友好,不仅可以及时输入。良好的自我创造更有利于提升网站的影响力。第三,白手起家的作家。在自我创作文章中,我们需要接触到很多信息,这也是作者天赋的提升 查看全部
自动采集文章网站(
网站快照不更新的勤快也就就高,baidu蜘蛛)
网站优化和文章质量
网站优化和文章质量
百度快照更新的努力表明,百度蜘蛛经常出没于网站上,而网站在百度上的权重也更高。所以百度快照已经成为衡量谷歌公关价值的一种手段网站SEO优化是否能正确进行是标准之一
然而,并非所有的网站配对都能被百度所喜爱。站长兄弟或SEO工作者经常在论坛上发帖问:“为什么我的网站快照不更新?”。事实上,如果你想知道为什么网站的快照没有更新,首先,你不能让搜索引擎蜘蛛厌倦你的网站,然后你必须询问你是否已经做了以下细节
1、合理规划网站内部连接,加强网站深度阅读
整个互联网是一个“互联”的国际网络,每个独立的网站同一个网络都是一个“互联”的家庭。内部连接是站点中的相互连接,研究了相关准则。连接相关内容可以极大地吸引“蜘蛛”的偏好,弥补其爬行的延伸。内部连接还弥补了读卡器在网站的停留时间和深入阅读网站转发的时间
2、build网站404第页,以避免死连接
404页面是当用户进入错误连接时返回的页面。SEO优化当搜索引擎在死链上爬行,无法继续急切地搜索时,它不仅减少了输入量,而且搜索引擎会认为网站对它不友好。如何优化搜索引擎优化?如果有很多死链,它也会减少网站的重量。用户阅读网站时会遇到死链,这将减少用户对网站阅读的偏好。他们认为网站不够专业,不够强大,会失去用户。很多人忽视了这个标题,这往往会给你的网站带来不必要的损失。相反,一个好的404页面不仅有利于网站优化,而且还能提升网站专业的用户体验
3、专注于文章的优化,使文章适合搜索引擎的搜索习惯
文章SEO重点是关键词。相应的关键字出现在文章title中,这非常有利于弥补被搜索引擎搜索的概率。相应的关键词也尽可能多的出现在文章中,因为搜索引擎会将这个词锁定为网站的中心关键词,并认为网站是这个关键词上的一个强大巨人。但对你自己来说,一切都太多了。堆积过多的关键词被搜索引擎视为作弊,这也是网络实施中的一大禁忌。通常,几百个单词的文章关键字应该在3-5之间
4、增强了文章的可读性并提升了用户体验
编写文章的最终策略是让读者阅读。文章的可读性可分为两点:一是文章的内容;第二,文章排版@关于k13没有必要多说文章的排版并不难。我们需要从用户的阅读习惯开始,使文章规划公平、清晰,设置相同字体的大小,并在需求突出的地方加粗或更改文本的颜色。此外,大量的词语容易使读者视觉疲劳。图片和文字是减少视觉疲劳的最佳方式
5、标记创作的作品文章和图像
因为互联网是一个开放的渠道,网站内容经常被复制,这是可以理解的,因为向每个人分享好的知识和思想是互联网存在的最大来源。然而,作为一个白手起家的作家,在每一部作品中也必须在个人身上留下印记,因为这不仅可以达到延伸个人作品的政策,而且可以捍卫个人作品的成果
6、坚持自创内容,提升网站新鲜活力
坚持自我创造是所有网站更新员工最常听到的话题。我们可以从三个角度考虑自我创造的使用。从读者的角度来看,排在榜首。此时,互联网用户每天都保持着高阅读量。如果网站上的内容毫无意义,那么我们网站很难吸引读者的偏好。第二,从网站个人的角度。搜索引擎对自创内容非常友好,不仅可以及时输入。良好的自我创造更有利于提升网站的影响力。第三,白手起家的作家。在自我创作文章中,我们需要接触到很多信息,这也是作者天赋的提升
自动采集文章网站(基于XPath和CSS表达式机制的改进版spider:文章列表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-21 16:25
所需环境:
安装模块
建议使用Anaconda安装新模块。输入:
conda install -c conda-forge scrapy
conda install -c anaconda pymysql
创建项目
要创建刮擦项目,请在命令行中输入:
scrapy startproject myblog
爬行信息
我们需要的数据包括文章title、文章link、发布日期、文章content,并定义要在item.py中爬网的字段
import scrapy
class MyblogItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
href = scrapy.Field()
date = scrapy.Field()
content = scrapy.Field()
pass
通过观察发现,CSDN的文章list链接为:
用户名/文章/列表/页面
所以我们创建了Spider/list_uspider.py,用于捕获和分析网页。目录结构为:
myblog
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ list_spider.py
│ │ __init__.py
│ │
│ └─__pycache__
│ list_spider.cpython-36.pyc
│ __init__.cpython-36.pyc
│
└─__pycache__
settings.cpython-36.pyc
__init__.cpython-36.pyc
在列表上,在spider.py中写入listspider类以构造访问请求:
import scrapy
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
然后编写parser()函数来解析网页:
有很多方法可以从网页中提取数据。Scrapy使用基于XPath和CSS的表达式机制:。有关选择器和其他提取机制的信息,请参阅
下面是XPath表达式及其相应含义的示例:
def parse(self, response):
for item in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
url = item.xpath("h4/a/@href").extract()
title = item.xpath("h4/a/text()").extract()[1].strip()
date = item.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()
print([url, title, date])
打印后,您可以看到以下信息:
'date': '2018-09-30 17:27:01',
'title': '银行业务队列简单模拟',
'url': 'https://blog.csdn.net/qq_42623 ... 39%3B}
使用项
对象是一个自定义Python字典。您可以使用标准字典语法来获取每个字段的值。(字段是我们为字段指定的属性):
>>> item = MyblogItem()
>>> item['title'] = 'Example title'
>>> item['title'] = 'Example title'
为了返回爬网数据,我们的最终代码是:
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for item in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = item.xpath("h4/a/@href").extract()
item['title'] = item.xpath("h4/a/text()").extract()[1].strip()
item['date'] = item.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()
yield item
跟踪链接
接下来,我们需要通过获得的URL地址访问每个文章标题对应的文章内容,然后将其保存在项目['content']中。以下是实现此功能的改进spider:
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for data in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = data.xpath("h4/a/@href").extract()[0]
item['title'] = data.xpath("h4/a/text()").extract()[1].strip()
item['date'] = data.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()[0]
url = data.xpath("h4/a/@href").extract()[0]
request = scrapy.Request(url, callback=self.parse_dir_contents)
request.meta['item'] = item
yield request
#在某些情况下,您如果希望在回调函数们之间传递参数,可以使用Request.meta
def parse_dir_contents(self, response):
item = response.meta['item']
item['content'] = response.xpath("//article/div[@class='article_content clearfix csdn-tracking-statistics']/div[@class='markdown_views prism-atom-one-light']").extract()[0]
yield item
通过这种方式,我们可以保存所有需要的信息,但现在还有另一个问题:我们刚才做的是从博客目录的一个页面下载文章采集,但是如果我们的博客目录有多个页面,我们是否要从其中下载所有文章采集
在文章列表的第一页的基础上,我们可以通过更改最后一个数字来访问相应的页数,从1开始循环,当我们判断下一页的内容为空时停止,我们将再次改进蜘蛛
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for data in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = data.xpath("h4/a/@href").extract()[0]
item['title'] = data.xpath("h4/a/text()").extract()[1].strip()
item['date'] = data.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()[0]
url = data.xpath("h4/a/@href").extract()[0]
request = scrapy.Request(url, callback=self.parse_dir_contents)
request.meta['item'] = item
yield request
next_url = response.url.split('/')
next_url[-1] = str(int(next_url[-1])+1)
next_url = '/'.join(next_url)
yield scrapy.Request(next_url, callback=self.isEmpty)
def isEmpty(self, response):
content = response.xpath("//main/div[@class='no-data d-flex flex-column justify-content-center align-items-center']").extract()
if content == [] :
return self.parse(response)
def parse_dir_contents(self, response):
item = response.meta['item']
item['content'] = response.xpath("//article/div[@class='article_content clearfix csdn-tracking-statistics']/div[@class='markdown_views prism-atom-one-light']").extract()[0]
yield item
保存数据
在命令行中输入命令:
scrapy crawl list -o items.json
此命令将以JSON格式序列化已爬网的数据,并生成items.JSON文件
同步数据项管道
为了确保采集数据与CSDN博客同步,我们必须在更新博客内容后再次抓取数据。但是,再次爬网的数据与保存的数据一致,因此我们需要验证新爬网的数据,然后将其同步到WordPress。所以我们需要使用项目管道
在spider中采集项目后,它将被传递到项目管道,一些组件将按特定顺序处理项目
每个项目管道组件(有时称为项目管道)都是一个python类,它实现了一个简单的方法。他们接收一个项目并通过它执行一些操作。同时,他们还决定项目是继续通过管道,还是被丢弃而不再处理
以下是项目管道的一些典型应用:
PyMySQL
Pymysql正在使用中Python3.用于连接X版MySQL服务器的库
项目地址参考文件 查看全部
自动采集文章网站(基于XPath和CSS表达式机制的改进版spider:文章列表)
所需环境:
安装模块
建议使用Anaconda安装新模块。输入:
conda install -c conda-forge scrapy
conda install -c anaconda pymysql
创建项目
要创建刮擦项目,请在命令行中输入:
scrapy startproject myblog
爬行信息
我们需要的数据包括文章title、文章link、发布日期、文章content,并定义要在item.py中爬网的字段
import scrapy
class MyblogItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
href = scrapy.Field()
date = scrapy.Field()
content = scrapy.Field()
pass
通过观察发现,CSDN的文章list链接为:
用户名/文章/列表/页面
所以我们创建了Spider/list_uspider.py,用于捕获和分析网页。目录结构为:
myblog
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ list_spider.py
│ │ __init__.py
│ │
│ └─__pycache__
│ list_spider.cpython-36.pyc
│ __init__.cpython-36.pyc
│
└─__pycache__
settings.cpython-36.pyc
__init__.cpython-36.pyc
在列表上,在spider.py中写入listspider类以构造访问请求:
import scrapy
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
然后编写parser()函数来解析网页:
有很多方法可以从网页中提取数据。Scrapy使用基于XPath和CSS的表达式机制:。有关选择器和其他提取机制的信息,请参阅
下面是XPath表达式及其相应含义的示例:
def parse(self, response):
for item in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
url = item.xpath("h4/a/@href").extract()
title = item.xpath("h4/a/text()").extract()[1].strip()
date = item.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()
print([url, title, date])
打印后,您可以看到以下信息:
'date': '2018-09-30 17:27:01',
'title': '银行业务队列简单模拟',
'url': 'https://blog.csdn.net/qq_42623 ... 39%3B}
使用项
对象是一个自定义Python字典。您可以使用标准字典语法来获取每个字段的值。(字段是我们为字段指定的属性):
>>> item = MyblogItem()
>>> item['title'] = 'Example title'
>>> item['title'] = 'Example title'
为了返回爬网数据,我们的最终代码是:
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for item in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = item.xpath("h4/a/@href").extract()
item['title'] = item.xpath("h4/a/text()").extract()[1].strip()
item['date'] = item.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()
yield item
跟踪链接
接下来,我们需要通过获得的URL地址访问每个文章标题对应的文章内容,然后将其保存在项目['content']中。以下是实现此功能的改进spider:
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for data in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = data.xpath("h4/a/@href").extract()[0]
item['title'] = data.xpath("h4/a/text()").extract()[1].strip()
item['date'] = data.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()[0]
url = data.xpath("h4/a/@href").extract()[0]
request = scrapy.Request(url, callback=self.parse_dir_contents)
request.meta['item'] = item
yield request
#在某些情况下,您如果希望在回调函数们之间传递参数,可以使用Request.meta
def parse_dir_contents(self, response):
item = response.meta['item']
item['content'] = response.xpath("//article/div[@class='article_content clearfix csdn-tracking-statistics']/div[@class='markdown_views prism-atom-one-light']").extract()[0]
yield item
通过这种方式,我们可以保存所有需要的信息,但现在还有另一个问题:我们刚才做的是从博客目录的一个页面下载文章采集,但是如果我们的博客目录有多个页面,我们是否要从其中下载所有文章采集
在文章列表的第一页的基础上,我们可以通过更改最后一个数字来访问相应的页数,从1开始循环,当我们判断下一页的内容为空时停止,我们将再次改进蜘蛛
import scrapy
from myblog.items import MyblogItem
class ListSpider(scrapy.Spider):
name = "list"
allowed_domains = ["blog.csdn.net"]
start_urls = [
"https://blog.csdn.net/qq_42623 ... ot%3B,
]
def parse(self, response):
for data in response.xpath("//div[@class='article-list']//div[@class='article-item-box csdn-tracking-statistics']")[1:]:
item = MyblogItem()
item['url'] = data.xpath("h4/a/@href").extract()[0]
item['title'] = data.xpath("h4/a/text()").extract()[1].strip()
item['date'] = data.xpath("div['info-box d-flex align-content-center']/p[1]/span/text()").extract()[0]
url = data.xpath("h4/a/@href").extract()[0]
request = scrapy.Request(url, callback=self.parse_dir_contents)
request.meta['item'] = item
yield request
next_url = response.url.split('/')
next_url[-1] = str(int(next_url[-1])+1)
next_url = '/'.join(next_url)
yield scrapy.Request(next_url, callback=self.isEmpty)
def isEmpty(self, response):
content = response.xpath("//main/div[@class='no-data d-flex flex-column justify-content-center align-items-center']").extract()
if content == [] :
return self.parse(response)
def parse_dir_contents(self, response):
item = response.meta['item']
item['content'] = response.xpath("//article/div[@class='article_content clearfix csdn-tracking-statistics']/div[@class='markdown_views prism-atom-one-light']").extract()[0]
yield item
保存数据
在命令行中输入命令:
scrapy crawl list -o items.json
此命令将以JSON格式序列化已爬网的数据,并生成items.JSON文件
同步数据项管道
为了确保采集数据与CSDN博客同步,我们必须在更新博客内容后再次抓取数据。但是,再次爬网的数据与保存的数据一致,因此我们需要验证新爬网的数据,然后将其同步到WordPress。所以我们需要使用项目管道
在spider中采集项目后,它将被传递到项目管道,一些组件将按特定顺序处理项目
每个项目管道组件(有时称为项目管道)都是一个python类,它实现了一个简单的方法。他们接收一个项目并通过它执行一些操作。同时,他们还决定项目是继续通过管道,还是被丢弃而不再处理
以下是项目管道的一些典型应用:
PyMySQL
Pymysql正在使用中Python3.用于连接X版MySQL服务器的库
项目地址参考文件
自动采集文章网站(商品属性安装环境商品介绍源码(图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-21 07:15
)
产品属性
安装环境
产品介绍
源代码功能:(需要伪静态的,否则在网页不能打开)
1、全,在线可以在省填充数据的麻烦操作;
2、采集插件裂纹版本1(没有限制域名),官方价格298域名;
3、默认10条@采集规则,自动@采集,无人工干预;
@ @@ K24采集插件是从其他@采集产品不同,的优点本@采集插件是无人看管,只要网站安装,自动@采集
5、知更更主二二优,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, ,,,,,,,,, p>
6、程序与PHP 7.兼容@ 1,执行效率是快;
7、画面默认使用的远程图像,节省磁盘空间,设置保存到本地;
8、适@ @站群K14网站@@ @@@ K14网站@ @@ K14网站@ @ @@插启启启141440分钟(1天)自动@采集 1时间(时间间隔可以被修改),节省人工维护,节省大量的时间。
9、使用HTML5 + CSS3响应布局,兼容平板电脑和移动电话,数据同步;
1 0、自自自在外外 - 背景代用网站背景画面;
1 1、支持用户的提交。
演示地址
安装环境
PHP 5. 4/5/6 / 7. @ 1的MySQL 5. +伪静态
后台地址
您的网址/ WP-管理/用户名:admin密码:123456789A
安装说明
1、 WWW目录是网站源代码,上传网站跟目录;
2、 .SQL是备用,将其导入;
3、请更改SITEURL,家庭对应的数据库表WP_OPTIONS,可联系客服协助;
4、@修改在WP-config.php文件数据库中的信息;
5、输入背景插件页面,启动WP火箭缓存插件,提高网站前台打开速度;
6、大功配置配置自动自动自动@@@自动量量量量量量量量量量量量量量量量量量量量正量正正正正正正正正正正正正正正正正正许多,不影响网站的速度。
查看全部
自动采集文章网站(商品属性安装环境商品介绍源码(图)
)
产品属性
安装环境
产品介绍
源代码功能:(需要伪静态的,否则在网页不能打开)
1、全,在线可以在省填充数据的麻烦操作;
2、采集插件裂纹版本1(没有限制域名),官方价格298域名;
3、默认10条@采集规则,自动@采集,无人工干预;
@ @@ K24采集插件是从其他@采集产品不同,的优点本@采集插件是无人看管,只要网站安装,自动@采集
5、知更更主二二优,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, ,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,, ,,,,,,,,, p>
6、程序与PHP 7.兼容@ 1,执行效率是快;
7、画面默认使用的远程图像,节省磁盘空间,设置保存到本地;
8、适@ @站群K14网站@@ @@@ K14网站@ @@ K14网站@ @ @@插启启启141440分钟(1天)自动@采集 1时间(时间间隔可以被修改),节省人工维护,节省大量的时间。
9、使用HTML5 + CSS3响应布局,兼容平板电脑和移动电话,数据同步;
1 0、自自自在外外 - 背景代用网站背景画面;
1 1、支持用户的提交。
演示地址
安装环境
PHP 5. 4/5/6 / 7. @ 1的MySQL 5. +伪静态
后台地址
您的网址/ WP-管理/用户名:admin密码:123456789A
安装说明
1、 WWW目录是网站源代码,上传网站跟目录;
2、 .SQL是备用,将其导入;
3、请更改SITEURL,家庭对应的数据库表WP_OPTIONS,可联系客服协助;
4、@修改在WP-config.php文件数据库中的信息;
5、输入背景插件页面,启动WP火箭缓存插件,提高网站前台打开速度;
6、大功配置配置自动自动自动@@@自动量量量量量量量量量量量量量量量量量量量量正量正正正正正正正正正正正正正正正正正许多,不影响网站的速度。
自动采集文章网站(用chrome插件可以抓取html网页that'sall!())
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-09-14 23:04
自动采集文章网站的文章,同时对文章进行编辑、修改、上传,然后自动生成pdf,不论是否过期,还是永久免费的,有需要的留言哦!!支持自动生成pdf。上传文章到公众号后台自动推送到页面顶端,支持自动转换。网址:/-forest-ezkey/grab_clipboard-clipboard_converter-pdf-pan-deep3/home。
-htm-tid-566804.html用chrome插件可以抓取html网页that'sall!
请用chrome
用一个叫deeptextmachinefinertext的插件,百度一下就可以下载。打开你想要抓取的网页,然后按住鼠标右键(不用点ctrl,如果你需要ctrl抓取整个网页,可以用option),再点击你想要抓取的网页,就可以抓取下面的网页,再点一下那个match。稍等一会后你就会发现,你抓取到的网页之间间隔很小,就像蒙版一样然后你的所有其他的翻译、文章分类、一起互联网(百度)都会变成这样(这只是为了不让你截图以后乱):。
filterlove可以抓取网页内的文本,翻译,尤其适合翻译网页中的语言。
onthewaytoreadyourmagazine?clicker
我这里有一个不是爬取的微信公众号,但是可以爬取里面的文章,并且可以发送到聊天app上。(pc端和mac端都有)点此查看我的微信公众号公众号:www_sis希望可以帮到你, 查看全部
自动采集文章网站(用chrome插件可以抓取html网页that'sall!())
自动采集文章网站的文章,同时对文章进行编辑、修改、上传,然后自动生成pdf,不论是否过期,还是永久免费的,有需要的留言哦!!支持自动生成pdf。上传文章到公众号后台自动推送到页面顶端,支持自动转换。网址:/-forest-ezkey/grab_clipboard-clipboard_converter-pdf-pan-deep3/home。
-htm-tid-566804.html用chrome插件可以抓取html网页that'sall!
请用chrome
用一个叫deeptextmachinefinertext的插件,百度一下就可以下载。打开你想要抓取的网页,然后按住鼠标右键(不用点ctrl,如果你需要ctrl抓取整个网页,可以用option),再点击你想要抓取的网页,就可以抓取下面的网页,再点一下那个match。稍等一会后你就会发现,你抓取到的网页之间间隔很小,就像蒙版一样然后你的所有其他的翻译、文章分类、一起互联网(百度)都会变成这样(这只是为了不让你截图以后乱):。
filterlove可以抓取网页内的文本,翻译,尤其适合翻译网页中的语言。
onthewaytoreadyourmagazine?clicker
我这里有一个不是爬取的微信公众号,但是可以爬取里面的文章,并且可以发送到聊天app上。(pc端和mac端都有)点此查看我的微信公众号公众号:www_sis希望可以帮到你,
自动采集文章网站(免费下载或者VIP会员资源能否直接商用?浏览器下载)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-09-13 19:14
免费下载或VIP会员的资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员制、全站源码、程序插件、网站templates、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的可下载素材包中这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源 查看全部
自动采集文章网站(免费下载或者VIP会员资源能否直接商用?浏览器下载)
免费下载或VIP会员的资源可以直接商业化吗?
本站所有资源版权归原作者所有。此处提供的资源仅供参考和学习使用,请勿直接商用。如因商业用途产生版权纠纷,一切责任由用户自行承担。更多说明请参考VIP介绍。
提示下载完成但无法解压或打开?
最常见的情况是下载不完整:可以将下载的压缩包与网盘容量进行对比。如果小于网盘指示的容量,就是这个原因。这是浏览器下载bug,建议使用百度网盘软件或迅雷下载。如果排除这种情况,您可以在相应资源底部留言或联系我们。
在资源介绍文章中找不到示例图片?
对于会员制、全站源码、程序插件、网站templates、网页模板等类型的素材,文章中用于介绍的图片通常不收录在相应的可下载素材包中这些相关的商业图片需要单独购买,本站不负责(也没有办法)查找出处。部分字体文件也是如此,但部分素材在素材包中会有字体下载链接列表。
付款后无法显示下载地址或查看内容?
如果您已经支付成功但网站没有弹出成功提示,请联系站长提供支付信息供您处理
购买此资源后可以退款吗?
源材料是一种虚拟商品,可复制和传播。一旦获得批准,将不接受任何形式的退款或换货请求。购买前请确认是您需要的资源
自动采集文章网站(有没有一个让写好的文章自己设置定时发布呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-08 11:15
众所周知,为了网站运营,为了网站能收录,大家都在坚持每天更新网站原创文章,定时发布。从长远来看,这可以提高网站收录。
但是如果我的网站没有内容怎么办?
你可以找到一些与你所在行业相关的文章,通过伪原创发布,重写、模仿、二次创作到你自己的文章。
更新网站的方式有很多,比如为网站添加行业信息。
可能很多朋友都会遇到这样的问题。更新网站文章需要的是时间和精力。写文章对一些朋友来说并不难(毕竟伪原创一啊,虽然不推荐),
在每天写文章的同时,发布时间对有些人来说很麻烦。你必须每天盯着写文章release。如果你有更多的网站,那就更难对付了。
文章有没有人可以自己安排一个预定的发布?
有一款产品可以解决这个问题。
通过优采云采集绑定站点后,(目前支持主流cms系统,如织梦、帝国、易思、凡客、米拓、Phpcms、建站ABC、365cms、祝宁、云游、易游、DOYO、优典、Phootcms) 可定时自动发布。
自动发布:
设置关键词后,系统可以根据关键词自动去采集文章发布到自己的站点栏目,并且可以设置为打开原创,(打开后, 文章会经过伪原创然后发布到网站),同时可以开启内链功能(自动添加内链到采集的文章关键词)。
您还可以设置每日发布的频率。比如你设置每天文章发布2篇文章,那么会自动发布2篇。
定时发布:
提前采集好文章,或者自己编辑文章创建定时任务。设置任务周期,每天释放文章数量,系统自动执行。
任务执行后,可随时查看结果。
体验到此为止,这很容易使用。基本解决了文章自动发布的问题。操作多个网站也很方便。
官网:
你可以试试看。 查看全部
自动采集文章网站(有没有一个让写好的文章自己设置定时发布呢?)
众所周知,为了网站运营,为了网站能收录,大家都在坚持每天更新网站原创文章,定时发布。从长远来看,这可以提高网站收录。
但是如果我的网站没有内容怎么办?
你可以找到一些与你所在行业相关的文章,通过伪原创发布,重写、模仿、二次创作到你自己的文章。
更新网站的方式有很多,比如为网站添加行业信息。
可能很多朋友都会遇到这样的问题。更新网站文章需要的是时间和精力。写文章对一些朋友来说并不难(毕竟伪原创一啊,虽然不推荐),
在每天写文章的同时,发布时间对有些人来说很麻烦。你必须每天盯着写文章release。如果你有更多的网站,那就更难对付了。
文章有没有人可以自己安排一个预定的发布?
有一款产品可以解决这个问题。
通过优采云采集绑定站点后,(目前支持主流cms系统,如织梦、帝国、易思、凡客、米拓、Phpcms、建站ABC、365cms、祝宁、云游、易游、DOYO、优典、Phootcms) 可定时自动发布。
自动发布:
设置关键词后,系统可以根据关键词自动去采集文章发布到自己的站点栏目,并且可以设置为打开原创,(打开后, 文章会经过伪原创然后发布到网站),同时可以开启内链功能(自动添加内链到采集的文章关键词)。
您还可以设置每日发布的频率。比如你设置每天文章发布2篇文章,那么会自动发布2篇。
定时发布:
提前采集好文章,或者自己编辑文章创建定时任务。设置任务周期,每天释放文章数量,系统自动执行。
任务执行后,可随时查看结果。
体验到此为止,这很容易使用。基本解决了文章自动发布的问题。操作多个网站也很方便。
官网:
你可以试试看。
自动采集文章网站(织梦采集侠的功能采集模块--上海怡健医学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-08 10:19
织梦采集侠的功能采集侠是专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统的采集软件,来自不同的网站采集优质内容和原创自动处理,减少网站维护工作量,大大增加收录和点击量,是每一个网站插件的必备。 织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集,并结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,我们有专门的客服为商业客户提供技术支持不同于传统的采集模式,织梦采集侠可以根据用户设置的关键词进行平移采集。 pan采集的优势在于通过采集此关键词进行不同的搜索,从而实现采集不在一个或多个指定的采集站点上进行,降低了采集的风险@站点被搜索引擎判定为镜像站点,被搜索引擎惩罚。 3RSS 采集,只需输入RSS地址采集内容 只要RSS订阅地址是采集的网站提供的,就可以通过RSS转采集,输入RSS地址即可可以轻松采集 到网站 内容,无需编写采集 规则,方便简单。页面监控采集只需要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需编写采集规则即可针对性采集。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等多种方式处理采集返回的文章,增强采集 @文章原创有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。 织梦采集侠根据预设的采集任务,根据设置的采集方法采集 URL,然后自动抓取网页内容,程序通过精确计算分析网页,并丢弃即不是文章Content页面URL,提取优秀的文章内容,最后伪原创,导入,生成,所有这些操作程序都是自动完成的,无需人工干预。 织梦采集侠不仅是采集插件,还是织梦must伪原创和搜索优化插件,手动发布文章可以通过织梦采集侠侠伪原创和搜索优化处理,可以替换文章同义词,自动内部链接,随机插入关键词链接和文章收录关键词会自动添加指定链接等功能,是一个织梦Required插件定时定量采集伪原创SEO更新插件有两种触发采集的方式,一种是页面添加代码通过用户访问触发采集更新,另一种是我们提供的远程触发采集对于商业用户@Service,新站可以定时定量更新采集,无需任何人访问,无需人工干预。 查看全部
自动采集文章网站(织梦采集侠的功能采集模块--上海怡健医学)
织梦采集侠的功能采集侠是专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统的采集软件,来自不同的网站采集优质内容和原创自动处理,减少网站维护工作量,大大增加收录和点击量,是每一个网站插件的必备。 织梦采集侠安装非常简单方便。只需一分钟即可立即启动采集,并结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,我们有专门的客服为商业客户提供技术支持不同于传统的采集模式,织梦采集侠可以根据用户设置的关键词进行平移采集。 pan采集的优势在于通过采集此关键词进行不同的搜索,从而实现采集不在一个或多个指定的采集站点上进行,降低了采集的风险@站点被搜索引擎判定为镜像站点,被搜索引擎惩罚。 3RSS 采集,只需输入RSS地址采集内容 只要RSS订阅地址是采集的网站提供的,就可以通过RSS转采集,输入RSS地址即可可以轻松采集 到网站 内容,无需编写采集 规则,方便简单。页面监控采集只需要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需编写采集规则即可针对性采集。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、插入seo词、关键词添加链接等多种方式处理采集返回的文章,增强采集 @文章原创有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。 织梦采集侠根据预设的采集任务,根据设置的采集方法采集 URL,然后自动抓取网页内容,程序通过精确计算分析网页,并丢弃即不是文章Content页面URL,提取优秀的文章内容,最后伪原创,导入,生成,所有这些操作程序都是自动完成的,无需人工干预。 织梦采集侠不仅是采集插件,还是织梦must伪原创和搜索优化插件,手动发布文章可以通过织梦采集侠侠伪原创和搜索优化处理,可以替换文章同义词,自动内部链接,随机插入关键词链接和文章收录关键词会自动添加指定链接等功能,是一个织梦Required插件定时定量采集伪原创SEO更新插件有两种触发采集的方式,一种是页面添加代码通过用户访问触发采集更新,另一种是我们提供的远程触发采集对于商业用户@Service,新站可以定时定量更新采集,无需任何人访问,无需人工干预。
自动采集文章网站(自动采集文章网站的自媒体地址在工具里的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-09-03 16:29
自动采集文章网站的自媒体地址,是比较麻烦的,尽量做简单,可以加入一些软件,专门是对文章里的网址进行自动采集的。我在这里写一个小工具,自动采集网址的、地址在工具里。欢迎采纳!自动采集网址方法:下载软件and(自定义程度不能太大),然后粘贴搜索到的网址,软件就自动采集出来,编辑保存到本地,保存成图片格式。
泻药用windows系统自带的相机功能,把所拍的图片保存成一个目录,比如说,新浪热文,当你浏览的时候,就可以直接通过相机来识别并保存了。
我不知道为什么一定要用微信搜索栏搜索?微信给了你网址导向,直接用手机扫一扫,搜索就好了。搜索的时候可以搜索关键词,
看看我开发的,
谢邀,原来我只想分享有用的,没想到还是有需要帮助的人,这里推荐给他一个工具,如果你是制作ppt,我当时做了些ppt,如果你需要找素材ppt的话,可以到我的公号:连载说影视查找。
都有什么好方法呢?这就是一个爬虫框架,所以做数据分析的可以用来处理海量的数据,能做一些批量工作。自动采集一方面是快速,因为全网都能采集,一方面是方便,可以对大文件批量处理。爬虫框架哪家强?我觉得现在最强大的无疑是workerman,因为是用java写的,开发简单,效率高,对比的话有javaweb的。个人觉得还是比较好用的,可以试试。 查看全部
自动采集文章网站(自动采集文章网站的自媒体地址在工具里的应用)
自动采集文章网站的自媒体地址,是比较麻烦的,尽量做简单,可以加入一些软件,专门是对文章里的网址进行自动采集的。我在这里写一个小工具,自动采集网址的、地址在工具里。欢迎采纳!自动采集网址方法:下载软件and(自定义程度不能太大),然后粘贴搜索到的网址,软件就自动采集出来,编辑保存到本地,保存成图片格式。
泻药用windows系统自带的相机功能,把所拍的图片保存成一个目录,比如说,新浪热文,当你浏览的时候,就可以直接通过相机来识别并保存了。
我不知道为什么一定要用微信搜索栏搜索?微信给了你网址导向,直接用手机扫一扫,搜索就好了。搜索的时候可以搜索关键词,
看看我开发的,
谢邀,原来我只想分享有用的,没想到还是有需要帮助的人,这里推荐给他一个工具,如果你是制作ppt,我当时做了些ppt,如果你需要找素材ppt的话,可以到我的公号:连载说影视查找。
都有什么好方法呢?这就是一个爬虫框架,所以做数据分析的可以用来处理海量的数据,能做一些批量工作。自动采集一方面是快速,因为全网都能采集,一方面是方便,可以对大文件批量处理。爬虫框架哪家强?我觉得现在最强大的无疑是workerman,因为是用java写的,开发简单,效率高,对比的话有javaweb的。个人觉得还是比较好用的,可以试试。
自动采集文章网站(2020年中国mba在线教育市场规模有望突破200亿)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-03 13:04
自动采集文章网站的文章列表并自动集成到自己的文章列表,当然效率肯定有问题,就看个人效率要求了。
推荐个能抓1000w+的网站
/你可以试试爬爬速递网上的东西,经验,
根据mba智库百科《2020考研mba院校排名暨mba择校指南》数据显示,中国mba在线教育市场发展迅猛,经过2016-2018年多年增长后,2020年mba在线教育市场规模有望突破200亿。中国mba网作为行业领先品牌,也确实实力不俗。2019年中国mba在线教育市场规模能达到200亿,但从2018年下半年开始,由于政策、市场等各方面因素,市场规模增速放缓,短期内难以突破200亿规模。
不过,根据目前获取的备考数据,2020年中国mba在线教育市场规模200亿仍有机会突破。mba学费持续上涨,2020年mba在线教育市场规模有望突破200亿点击率方面:2015-2018年备考数据汇总2018-2019年报考人数持续增长,目前备考人数也在不断上涨2019年报考人数再次增长,目前报考人数已有49万点击率方面:据中国mba网数据显示,2019年报考人数再次增长,截止到目前已经达到49万。
有个叫mba百科的app,小小的mba百科,不过主要考mba的学校都涵盖在内了,如果有意愿想备考,能够最大程度的找到适合自己的院校。
网站方面。登录企业在职研究生栏目:mba,一旦收藏或者导航到相关院校,看院校招生简章,方便快捷。 查看全部
自动采集文章网站(2020年中国mba在线教育市场规模有望突破200亿)
自动采集文章网站的文章列表并自动集成到自己的文章列表,当然效率肯定有问题,就看个人效率要求了。
推荐个能抓1000w+的网站
/你可以试试爬爬速递网上的东西,经验,
根据mba智库百科《2020考研mba院校排名暨mba择校指南》数据显示,中国mba在线教育市场发展迅猛,经过2016-2018年多年增长后,2020年mba在线教育市场规模有望突破200亿。中国mba网作为行业领先品牌,也确实实力不俗。2019年中国mba在线教育市场规模能达到200亿,但从2018年下半年开始,由于政策、市场等各方面因素,市场规模增速放缓,短期内难以突破200亿规模。
不过,根据目前获取的备考数据,2020年中国mba在线教育市场规模200亿仍有机会突破。mba学费持续上涨,2020年mba在线教育市场规模有望突破200亿点击率方面:2015-2018年备考数据汇总2018-2019年报考人数持续增长,目前备考人数也在不断上涨2019年报考人数再次增长,目前报考人数已有49万点击率方面:据中国mba网数据显示,2019年报考人数再次增长,截止到目前已经达到49万。
有个叫mba百科的app,小小的mba百科,不过主要考mba的学校都涵盖在内了,如果有意愿想备考,能够最大程度的找到适合自己的院校。
网站方面。登录企业在职研究生栏目:mba,一旦收藏或者导航到相关院校,看院校招生简章,方便快捷。
自动采集文章网站(哈默配合哈默插件成功实现批量设置发布文章的批量发布)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-09-03 09:28
实现批量发布文章,需要使用优采云配合Hammer插件发布文章。上一课我们成功实现了文章的批量发布。
本次讲座,我们来看看Hamer插件的配置
Hamer 插件中有 2 个文件:
您必须登录才能查看隐藏内容。
那么如果我们要修改定时发布文章的规则,就需要修改hm-locowp.php
以下是有关如何使用插件的一些说明:
/* Wordpress-Post-Interface-v3.1 (2010.08.03)
WordPress免登录发布接口,支持Wordpress2.5+版本。最新验证支持Wordpress3.x
适用于火车头采集器等任意采集器或脚本程序进行日志发布。
****最新版本或者意见建议请访问 http://www.hamo.cn/u/14***
功能:
1\. 随机时间安排与预约发布功能: 可以设定发布时间以及启用预约发布功能
2\. 自动处理服务器时间与博客时间的时区差异
3\. 永久链接的自动翻译设置。根据标题自动翻译为英文并进行seo处理
5\. 多标签处理(多个标签可以用火车头默认的tag|||tag2|||tag3的形式)
6\. 增加了发文后ping功能
7\. 增加了“pending review”的设置
8\. 增加了多作者功能,发布参数中指定post_author
9\. 增加了自定义域功能,发布参数指定post_meta_list=key1$$value1|||key2$$value2,不同域之间用|||隔开,名称与内容之间用$$隔开。
使用说明:(按照需求修改配置参数)
$post_author = 1; //作者的id,默认为admin
$post_status = "publish"; //"future":预约发布,"publish":立即发布,"pending":待审核
$time_interval = 60; //发布时间间隔,单位为秒 。可是设置随机数值表达式,如如12345 * rand(0,17)
$post_next = "next"; //now:发布时间=当前时间+间隔时间值
//next: 发布时间=最后一篇时间+间隔时间值
$post_ping = false; //发布后是否执行ping
$translate_slug = false; //是否将中文标题翻译为英文做slug
$secretWord = 'abcd1234s'; //接口密码,如果不需要密码,则设为$secretWord=false ;
*/
这里主要介绍3种配置:
$post_status 指的是:wordpress的post状态。如果是预定发布,设置为“未来”
time_interval 指发布时间间隔,与 post_next 配合使用,定义时间间隔
$post_next 指发帖时间,现在:发帖时间=当前时间+间隔时间值 next:发帖时间=上次发帖时间+间隔时间值
Hamer 插件的默认配置为:
post_status = "未来"; time_interval = 86400 * rand(0,100);
$post_next = "现在";
未来代表预定发布
86400秒=1天,然后随机到100天发表,那么如果我采集50文章小时,就相当于平均每天发表:50/100=0.5篇文章.
也就是说,一个文章 平均会在 2 天内发布。
来到后台,才发现确实如此。这是关于定时发布文件的设置
实战
如果我想在10天内把文章全部发完,我只需要:
$time_interval = 86400 * rand(0,10);
然后将修改好的Hamer插件上传到服务器,删除之前在wordpress后台的采集文章。
将任务设置为:未发布状态:
.png-WordPress 自动发布文章04-如何批量发布文章
再次点击:开始发布,这次看后台文章。相当于一天发送2个以上文章。
错过预定发布的问题
需要一个插件:Scheduled.php
下载地址:链接:密码:jfvp
我们上传到服务器的插件文件夹。
您必须登录才能查看隐藏内容。
然后登录wordpress仪表板并启用插件
这可以防止错过预定发布的问题 查看全部
自动采集文章网站(哈默配合哈默插件成功实现批量设置发布文章的批量发布)
实现批量发布文章,需要使用优采云配合Hammer插件发布文章。上一课我们成功实现了文章的批量发布。
本次讲座,我们来看看Hamer插件的配置
Hamer 插件中有 2 个文件:
您必须登录才能查看隐藏内容。
那么如果我们要修改定时发布文章的规则,就需要修改hm-locowp.php
以下是有关如何使用插件的一些说明:
/* Wordpress-Post-Interface-v3.1 (2010.08.03)
WordPress免登录发布接口,支持Wordpress2.5+版本。最新验证支持Wordpress3.x
适用于火车头采集器等任意采集器或脚本程序进行日志发布。
****最新版本或者意见建议请访问 http://www.hamo.cn/u/14***
功能:
1\. 随机时间安排与预约发布功能: 可以设定发布时间以及启用预约发布功能
2\. 自动处理服务器时间与博客时间的时区差异
3\. 永久链接的自动翻译设置。根据标题自动翻译为英文并进行seo处理
5\. 多标签处理(多个标签可以用火车头默认的tag|||tag2|||tag3的形式)
6\. 增加了发文后ping功能
7\. 增加了“pending review”的设置
8\. 增加了多作者功能,发布参数中指定post_author
9\. 增加了自定义域功能,发布参数指定post_meta_list=key1$$value1|||key2$$value2,不同域之间用|||隔开,名称与内容之间用$$隔开。
使用说明:(按照需求修改配置参数)
$post_author = 1; //作者的id,默认为admin
$post_status = "publish"; //"future":预约发布,"publish":立即发布,"pending":待审核
$time_interval = 60; //发布时间间隔,单位为秒 。可是设置随机数值表达式,如如12345 * rand(0,17)
$post_next = "next"; //now:发布时间=当前时间+间隔时间值
//next: 发布时间=最后一篇时间+间隔时间值
$post_ping = false; //发布后是否执行ping
$translate_slug = false; //是否将中文标题翻译为英文做slug
$secretWord = 'abcd1234s'; //接口密码,如果不需要密码,则设为$secretWord=false ;
*/
这里主要介绍3种配置:
$post_status 指的是:wordpress的post状态。如果是预定发布,设置为“未来”
time_interval 指发布时间间隔,与 post_next 配合使用,定义时间间隔
$post_next 指发帖时间,现在:发帖时间=当前时间+间隔时间值 next:发帖时间=上次发帖时间+间隔时间值
Hamer 插件的默认配置为:
post_status = "未来"; time_interval = 86400 * rand(0,100);
$post_next = "现在";
未来代表预定发布
86400秒=1天,然后随机到100天发表,那么如果我采集50文章小时,就相当于平均每天发表:50/100=0.5篇文章.
也就是说,一个文章 平均会在 2 天内发布。
来到后台,才发现确实如此。这是关于定时发布文件的设置
实战
如果我想在10天内把文章全部发完,我只需要:
$time_interval = 86400 * rand(0,10);
然后将修改好的Hamer插件上传到服务器,删除之前在wordpress后台的采集文章。
将任务设置为:未发布状态:
.png-WordPress 自动发布文章04-如何批量发布文章
再次点击:开始发布,这次看后台文章。相当于一天发送2个以上文章。
错过预定发布的问题
需要一个插件:Scheduled.php
下载地址:链接:密码:jfvp
我们上传到服务器的插件文件夹。
您必须登录才能查看隐藏内容。
然后登录wordpress仪表板并启用插件
这可以防止错过预定发布的问题
自动采集文章网站( wordpress好用的自动采集插件-autopost3.6.1插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-08-30 04:06
wordpress好用的自动采集插件-autopost3.6.1插件)
Wordpress 好用自动采集插件 wp-autopost3.6.1 破解版
官方插件介绍:
WP-AutoPost 自动采集 插件可以采集 来自任何网站 内容并自动更新您的WordPress 网站。支持定向采集,支持通配符匹配,或者CSS选择器精确采集任何内容,支持采集正文分页内容。使用起来非常简单,无需复杂的设置,而且功能强大且稳定,足以支持wordpress的所有功能。现在与您分享。
支持一键安装
WP-AutoPost的安装非常简单方便。只需几分钟就可以开始自动更新你的网站采集,并结合开源的WordPress程序,新手可以快速上手,按照设置的采集方法采集网址,然后自动抓取网页内容,检查文章是否重复,导入和更新文章,所有这些操作都是自动完成的,无需人工干预。并且我们还有专门的客服为商业客户提供技术支持。
定位采集文章
定位采集只需要提供文章list URL即可智能采集来自任何网站或栏目内容,方便简单,设置简单规则即可精准采集标题、正文等任何内容。
支持一键中英文伪原创
支持使用翻译引擎获取伪原创文章,不仅可以替换同义词,还可以重述语义。唯一性和伪原创 更好。它支持多种语言并且完全免费。同时集成了国外最好的伪原创工具WordAi、Spin Rewriter等,使得一个英文站可以获得更具可读性和独特性的伪原创文章。
远程图片可以下载到文章
支持远程图片下载到本地服务器,可以选择自动添加文字水印或图片水印。任何其他格式的附件和文档也可以轻松下载到本地服务器。
最低系统要求
为了运行,WP-AutoPost的最低要求如下:
下载地址: 查看全部
自动采集文章网站(
wordpress好用的自动采集插件-autopost3.6.1插件)
Wordpress 好用自动采集插件 wp-autopost3.6.1 破解版
官方插件介绍:
WP-AutoPost 自动采集 插件可以采集 来自任何网站 内容并自动更新您的WordPress 网站。支持定向采集,支持通配符匹配,或者CSS选择器精确采集任何内容,支持采集正文分页内容。使用起来非常简单,无需复杂的设置,而且功能强大且稳定,足以支持wordpress的所有功能。现在与您分享。
支持一键安装
WP-AutoPost的安装非常简单方便。只需几分钟就可以开始自动更新你的网站采集,并结合开源的WordPress程序,新手可以快速上手,按照设置的采集方法采集网址,然后自动抓取网页内容,检查文章是否重复,导入和更新文章,所有这些操作都是自动完成的,无需人工干预。并且我们还有专门的客服为商业客户提供技术支持。
定位采集文章
定位采集只需要提供文章list URL即可智能采集来自任何网站或栏目内容,方便简单,设置简单规则即可精准采集标题、正文等任何内容。
支持一键中英文伪原创
支持使用翻译引擎获取伪原创文章,不仅可以替换同义词,还可以重述语义。唯一性和伪原创 更好。它支持多种语言并且完全免费。同时集成了国外最好的伪原创工具WordAi、Spin Rewriter等,使得一个英文站可以获得更具可读性和独特性的伪原创文章。
远程图片可以下载到文章
支持远程图片下载到本地服务器,可以选择自动添加文字水印或图片水印。任何其他格式的附件和文档也可以轻松下载到本地服务器。
最低系统要求
为了运行,WP-AutoPost的最低要求如下:
下载地址:
自动采集文章网站(烈火网(LieHuo.Net)教程DEDE使用优采云采集器实现的自动实时发布文章和更新HTMl的功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-08-30 03:14
烈火网教程DEDE利用优采云采集器的功能自动发布文章并实时更新HTMl。
一,你为什么会有这个想法:
使用优采云发布文章有三大缺点。
需要登录发布,DEDE系统限制太多
一次发布的次数是有限制的,可能会导致一次发布过多而造成K的后果。
如果网站homepage是静态文件,主页无法更新,用户将不知道网站的更新状态
如果没有可以一直运行的服务器,使用优采云采集器的自动更新功能是不现实的
优采云采集器的自动更新功能是收费的,哈哈。
我需要它,我想挑战自己并等待。
二,去做。
首先想到,让优采云发布大量数据,将文章属性设置为未审核。这个问题很简单。在使用DEDEv5.3.1的时候,遇到了DEDE的一个bug。即未审核的文章会显示在前台。先是骂了DEDE,然后找了一些原因,在DEDEv5.3.1中发现了一个bug。修复后可以发现前台没有显示未审核的文章。 1月13日bug上报DEDE后,问题在1月14日DEDE发布的补丁中修复,哈哈,所以,1月15日,也就是今天,我们开始正式整理这份开发文档。
其实发现发布和保存大量未经审核的文章是没有问题的。难点在于如何实现随机激励发布功能。想了半天,觉得限时最好。本站JS调用了审计文章的链接,传递了一个用户的信息。程序获取用户的IP并保存为SESSION信息。这时候审计一个文章,在首页生成文章和一个静态文件。用户在一定时间内只能激活有限数量的文章,发布时使用了用户的IP信息,非常个人化。
激活文章,生成文章静态页面和主页静态文章。受网站template 影响,可能会比较慢,在首页生成前关闭页面。因此,最好的办法是在文章发布时生成文章静态文件,然后将文章设置为未审核状态。激活文章 只需要一个简短的查询。尽量在首页或列表页使用动态页面。这两个问题都不好处理,只能用这种方法代替。
完整的流程是在发布文档时将文档设置为未批准状态;调用程序时,首先判断上次查询的缓存是否超时,如果缓存时间超过缓存时间,则清空缓存显示最新的文章。清除缓存后,查询一定数量的属性未审核的文档,取消Archives和Arctiny表中的未审核属性,更新文档的Pubdate字段,实现一点点随机化。最后写入缓存,在缓存有效期内禁止重复更新!
三、如何使用文件:
发布文档时,请将文档属性设置为未审核状态,即发布时提交的文档属性参数为:arcrank=-1,则为动态浏览;
如果要生成静态文档,请将文档状态设置为正常浏览状态,即arcrank=0;然后修改默认的文档添加程序。
例如:arcticle_add.php,在“//Generate HTML”文件底部添加一段代码:
//生成HTML
插入标签($tags,$arcID);
$artUrl = MakeArt($arcID,true,true);
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
$dsql->ExecuteNoneQuery("UPDATE `cmsxx_archives` SET `arcrank`='-1' WHERE (`id`='$arcID');");
$dsql->ExecuteNoneQuery("UPDATE `cmsxx_arctiny` SET `arcrank`='-1' WHERE (`id`='$arcID');");
然后,将New.php上传到你的网站根目录,进入Dede后台设置系统的基本设置,在性能选项卡中将arclist标签调用缓存时间设置为合适的数字,例如3600表示一小时 刷新缓存一次。
最后调用模板文件顶部的一段代码即可:
" ".
支持的参数:
no=每次随机更新的次数,为空时默认为5;
typeid=column ID,如果为空,表示整个站点数据
order=order 方法,支持Desc:逆序,Asc:顺序,Rand:随机,默认为随机查询。
如:""
排序为Desc时,按照最先发布的文章first review方式发布。相反,Asc,Rand 是随机的。
第四,这是我们在数据处理上的一次尝试。也许这种新模式会是一个突破。祝大家使用愉快。如果您有任何错误或建议,请稍后回复。
点击此处下载文件:dedecms_v53_autonew
“DEDE使用优采云采集器实现文章自动实时发布和更新HTMl功能”可以转发,但请保留本文出处和版权信息。 查看全部
自动采集文章网站(烈火网(LieHuo.Net)教程DEDE使用优采云采集器实现的自动实时发布文章和更新HTMl的功能)
烈火网教程DEDE利用优采云采集器的功能自动发布文章并实时更新HTMl。
一,你为什么会有这个想法:
使用优采云发布文章有三大缺点。
需要登录发布,DEDE系统限制太多
一次发布的次数是有限制的,可能会导致一次发布过多而造成K的后果。
如果网站homepage是静态文件,主页无法更新,用户将不知道网站的更新状态
如果没有可以一直运行的服务器,使用优采云采集器的自动更新功能是不现实的
优采云采集器的自动更新功能是收费的,哈哈。
我需要它,我想挑战自己并等待。
二,去做。
首先想到,让优采云发布大量数据,将文章属性设置为未审核。这个问题很简单。在使用DEDEv5.3.1的时候,遇到了DEDE的一个bug。即未审核的文章会显示在前台。先是骂了DEDE,然后找了一些原因,在DEDEv5.3.1中发现了一个bug。修复后可以发现前台没有显示未审核的文章。 1月13日bug上报DEDE后,问题在1月14日DEDE发布的补丁中修复,哈哈,所以,1月15日,也就是今天,我们开始正式整理这份开发文档。
其实发现发布和保存大量未经审核的文章是没有问题的。难点在于如何实现随机激励发布功能。想了半天,觉得限时最好。本站JS调用了审计文章的链接,传递了一个用户的信息。程序获取用户的IP并保存为SESSION信息。这时候审计一个文章,在首页生成文章和一个静态文件。用户在一定时间内只能激活有限数量的文章,发布时使用了用户的IP信息,非常个人化。
激活文章,生成文章静态页面和主页静态文章。受网站template 影响,可能会比较慢,在首页生成前关闭页面。因此,最好的办法是在文章发布时生成文章静态文件,然后将文章设置为未审核状态。激活文章 只需要一个简短的查询。尽量在首页或列表页使用动态页面。这两个问题都不好处理,只能用这种方法代替。
完整的流程是在发布文档时将文档设置为未批准状态;调用程序时,首先判断上次查询的缓存是否超时,如果缓存时间超过缓存时间,则清空缓存显示最新的文章。清除缓存后,查询一定数量的属性未审核的文档,取消Archives和Arctiny表中的未审核属性,更新文档的Pubdate字段,实现一点点随机化。最后写入缓存,在缓存有效期内禁止重复更新!
三、如何使用文件:
发布文档时,请将文档属性设置为未审核状态,即发布时提交的文档属性参数为:arcrank=-1,则为动态浏览;
如果要生成静态文档,请将文档状态设置为正常浏览状态,即arcrank=0;然后修改默认的文档添加程序。
例如:arcticle_add.php,在“//Generate HTML”文件底部添加一段代码:
//生成HTML
插入标签($tags,$arcID);
$artUrl = MakeArt($arcID,true,true);
if($artUrl=='')
{
$artUrl = $cfg_phpurl."/view.php?aid=$arcID";
}
$dsql->ExecuteNoneQuery("UPDATE `cmsxx_archives` SET `arcrank`='-1' WHERE (`id`='$arcID');");
$dsql->ExecuteNoneQuery("UPDATE `cmsxx_arctiny` SET `arcrank`='-1' WHERE (`id`='$arcID');");
然后,将New.php上传到你的网站根目录,进入Dede后台设置系统的基本设置,在性能选项卡中将arclist标签调用缓存时间设置为合适的数字,例如3600表示一小时 刷新缓存一次。
最后调用模板文件顶部的一段代码即可:
" ".
支持的参数:
no=每次随机更新的次数,为空时默认为5;
typeid=column ID,如果为空,表示整个站点数据
order=order 方法,支持Desc:逆序,Asc:顺序,Rand:随机,默认为随机查询。
如:""
排序为Desc时,按照最先发布的文章first review方式发布。相反,Asc,Rand 是随机的。
第四,这是我们在数据处理上的一次尝试。也许这种新模式会是一个突破。祝大家使用愉快。如果您有任何错误或建议,请稍后回复。
点击此处下载文件:dedecms_v53_autonew
“DEDE使用优采云采集器实现文章自动实时发布和更新HTMl功能”可以转发,但请保留本文出处和版权信息。
自动采集文章网站(数据错乱的问题,可能是你没有按默认的数据表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-08-30 03:07
有几个小伙伴反映数据混乱的问题。可能是你没有遵循默认的数据表。请确保您的数据库未被更改。否则将无法正常存储,并可能导致其他错误。另外,如有错误,请私信我,说明实际情况。没有案例我无法解决。
9.第二次更新,采集公众号版本批量发布
微信公众号采集.zip(976.56 KB,下载次数:1927)
2017-9-2 13:02 上传
点击文件名下载附件
下载点:我的爱币-2 CB
过几天发布!
大家等一下,这几天有点忙,我会尽快把编码删掉发出去,论坛原创社区不会让编码发布的。
8.第9次更新:
我说新版本已经发布了。支持关键词自动切换、多线程采集、IP自动切换。全功率的速度已经是肉眼看不到的,gif帧数也比较少。 ,所以我看得很清楚。可以去感受一下,不过好像200的反应还是不够,用的人太少了,不好意思发上来。我会在200楼回复后发布新版本。如果没有,则不会公开。拿这个卖钱。哈哈。
1.gif(1.15 MB,下载次数:2)
下载附件
2017-8-9 19:11 上传
可惜这次还是没能满足你自动连接网站的需求,因为最近有点忙。
话不多说,先看效果:
131.gif(333.35 KB,下载次数:1)
下载附件
2017-7-27 13:16 上传
收录情况:
TXPHK)53X8%O2(FIZ5H`BJ7.png (40.15 KB,下载次数:1)
下载附件
2017-7-27 13:38 上传
使用方法还是一样的:
1.填写数据库信息。如果信息正确但无法连接,则说明您的服务器数据库一定不能远程打开。
2.[特别关注]
为了使软件更易用,仅支持手动读取文章地址和单项输入。 (批量操作需要接入编码等操作,花钱又麻烦,又怕有人卖。演示效果仅供参考,实际批量已阉割,请勿尝试破解,这个代码被删除了)
下载链接:
寻求粉丝积分!如果响应分数低于 200,永远不要升级到下一个版本!无聊。
慢慢来,这个软件还没有起名字,先想个好名字吧。一经录用就发一批工具。
其实这不仅仅是DZ论坛的一个版本,还有empirecms、PHPcms、Applecms.赤兔cms,这些主流的cms都可以支持自动进入。等我有时间发一下。 查看全部
自动采集文章网站(数据错乱的问题,可能是你没有按默认的数据表)
有几个小伙伴反映数据混乱的问题。可能是你没有遵循默认的数据表。请确保您的数据库未被更改。否则将无法正常存储,并可能导致其他错误。另外,如有错误,请私信我,说明实际情况。没有案例我无法解决。
9.第二次更新,采集公众号版本批量发布
微信公众号采集.zip(976.56 KB,下载次数:1927)
2017-9-2 13:02 上传
点击文件名下载附件
下载点:我的爱币-2 CB
过几天发布!
大家等一下,这几天有点忙,我会尽快把编码删掉发出去,论坛原创社区不会让编码发布的。
8.第9次更新:
我说新版本已经发布了。支持关键词自动切换、多线程采集、IP自动切换。全功率的速度已经是肉眼看不到的,gif帧数也比较少。 ,所以我看得很清楚。可以去感受一下,不过好像200的反应还是不够,用的人太少了,不好意思发上来。我会在200楼回复后发布新版本。如果没有,则不会公开。拿这个卖钱。哈哈。
1.gif(1.15 MB,下载次数:2)
下载附件
2017-8-9 19:11 上传
可惜这次还是没能满足你自动连接网站的需求,因为最近有点忙。
话不多说,先看效果:
131.gif(333.35 KB,下载次数:1)
下载附件
2017-7-27 13:16 上传
收录情况:
TXPHK)53X8%O2(FIZ5H`BJ7.png (40.15 KB,下载次数:1)
下载附件
2017-7-27 13:38 上传
使用方法还是一样的:
1.填写数据库信息。如果信息正确但无法连接,则说明您的服务器数据库一定不能远程打开。
2.[特别关注]
为了使软件更易用,仅支持手动读取文章地址和单项输入。 (批量操作需要接入编码等操作,花钱又麻烦,又怕有人卖。演示效果仅供参考,实际批量已阉割,请勿尝试破解,这个代码被删除了)
下载链接:
寻求粉丝积分!如果响应分数低于 200,永远不要升级到下一个版本!无聊。
慢慢来,这个软件还没有起名字,先想个好名字吧。一经录用就发一批工具。
其实这不仅仅是DZ论坛的一个版本,还有empirecms、PHPcms、Applecms.赤兔cms,这些主流的cms都可以支持自动进入。等我有时间发一下。
自动采集文章网站(android手机易用浏览器下载wifi万能钥匙使用之使用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-08-28 08:03
自动采集文章网站视频音乐电台节目等媒体文件到本地电脑。写代码实现。有需要在网上找找看android手机易用安卓手机一般都会自带浏览器,
去应用商店看看有没有人分享过可以导入其他应用的数据包的方法,要点是把自己手机的软件给别人下载,要点是保证别人自己不会删或者改代码。自动采集浏览器,可以考虑去应用市场找类似的广告采集软件。然后自己写脚本或者编译了把数据包导入应用商店来进行采集。不知道楼主是不是广告,反正我没找到。
自动采集,最好的方法是用googleadsense。参见:。
微信采集器,
你下载一个采集小程序页面文章的公众号采集器,可以采集app的文章和音乐,
手机浏览器自带采集功能的
安卓机用浏览器下载wifi万能钥匙使用之
使用谷歌浏览器webservices账号登录
手机wifi万能钥匙,都可以搜索到,但是广告都带些许骚扰。当然也可以直接找人来采集。
找本地电脑采集器比如5118-专业的数据采集分析平台
行迹v4+免费采集器一般可以采到图片的歌曲的直接可以转换成链接
android自带的浏览器也支持
不知道有没有人知道?assistant,shazam,googlesound等都支持。 查看全部
自动采集文章网站(android手机易用浏览器下载wifi万能钥匙使用之使用)
自动采集文章网站视频音乐电台节目等媒体文件到本地电脑。写代码实现。有需要在网上找找看android手机易用安卓手机一般都会自带浏览器,
去应用商店看看有没有人分享过可以导入其他应用的数据包的方法,要点是把自己手机的软件给别人下载,要点是保证别人自己不会删或者改代码。自动采集浏览器,可以考虑去应用市场找类似的广告采集软件。然后自己写脚本或者编译了把数据包导入应用商店来进行采集。不知道楼主是不是广告,反正我没找到。
自动采集,最好的方法是用googleadsense。参见:。
微信采集器,
你下载一个采集小程序页面文章的公众号采集器,可以采集app的文章和音乐,
手机浏览器自带采集功能的
安卓机用浏览器下载wifi万能钥匙使用之
使用谷歌浏览器webservices账号登录
手机wifi万能钥匙,都可以搜索到,但是广告都带些许骚扰。当然也可以直接找人来采集。
找本地电脑采集器比如5118-专业的数据采集分析平台
行迹v4+免费采集器一般可以采到图片的歌曲的直接可以转换成链接
android自带的浏览器也支持
不知道有没有人知道?assistant,shazam,googlesound等都支持。
开源的图形化内网渗透工具–安装及入门详细的介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-08-20 00:34
开源的图形化内网渗透工具–安装及入门详细的介绍
前言
在上一篇文章Viper:开源图形化内网渗透工具-安装与入门中详细介绍了Viper的安装方法和一些基本功能。内容主要是第一次接触内网穿透或者刚入门的安全。工程师。
对于有一定内网渗透测试经验的人来说,在实际渗透测试过程中,一个集成了常用功能、可以灵活搭配、自动完成固定操作流程的测试平台。尤其是在信息采集阶段,每次获得新的权限都要进行大量的重复性工作,而且采集的信息分散在不同的工具中,不便于统计分析。
本文文章介绍如何使用Viper采集半自动内网信息,希望对有此类需求的安全工程师有所帮助。
本地信息采集
每次获取新主机的权限,或者获取同一主机的更高权限时,都要对该主机进行一次完整的信息采集。宿主中采集的信息通常可以指导我们下一步渗透测试的方向或提供必要的帮助提示。
本地信息采集包括主机名、操作系统、域、网卡信息、本地监控、外网连接、内网连接、ARP信息、重要进程信息等
网卡信息会显示当前主机的所有网卡配置和IP/Mask。如果一台主机在内网有多个网卡,并且连接到不同的子网,则该主机可以作为后续渗透过程的跳板。进行多层次网络的内网穿透。
本地监控是当前主机对网络的攻击面的汇总。比如查看是否监听80443来分析是否对外提供web服务,是否进行Webshell等持久化操作,是否监听3389判断是否可以RDP登录,是否监听端口等6379和1433用来判断是否开启了对应的数据库服务,可以用来增加权限。
检查哪些内网主机连接到该主机将有助于我们确认下一个渗透测试目标。比如站点库分离的网站database地址,内网业务服务器的IP地址和端口,内网OA服务器地址等。
需要注意系统的凭证相关进程lsass.exe或反软件进程。 Viper 会根据内置的数据库信息进行比对,显示所有敏感进程。
子网信息采集
完成本地信息采集后,需要采集当前主机所在子网的信息,通常是端口扫描。
域名信息采集
域渗透在内网渗透中占有很大的比重,通常域中有很多高价值的目标。一旦获得域控制权限,几乎可以控制域中的任何主机。该域一直是硬件和红队评估过程中的重点。 .Viper 还集成了多个领域相关的信息采集模块,这里举几个例子。
凭据访问
按照MITRE ATT&CK的分类,信息采集(Discovery)和凭证访问(Credential Access)属于两个不同的维度,但是在国内各种教程或者实际渗透过程中,通常将凭证访问归为信息采集。所以这里也介绍一下。
总结
本文介绍了如何使用Viper进行内网渗透信息采集,其所有功能都保持简单直观,以及雾化的目的。为了适应不同的内网环境,自动化也控制在半自动化水平,保证了灵活性、易用性。
无论你是刚开始做内网渗透的安全工程师,还是资深的红队成员,希望Viper能在内网渗透领域帮助到你。
欢迎登录安全客体周到的安全新媒体/加入QQ交流群1015601496了解更多最新资讯
原文链接:/post/id/231501 查看全部
开源的图形化内网渗透工具–安装及入门详细的介绍
前言
在上一篇文章Viper:开源图形化内网渗透工具-安装与入门中详细介绍了Viper的安装方法和一些基本功能。内容主要是第一次接触内网穿透或者刚入门的安全。工程师。
对于有一定内网渗透测试经验的人来说,在实际渗透测试过程中,一个集成了常用功能、可以灵活搭配、自动完成固定操作流程的测试平台。尤其是在信息采集阶段,每次获得新的权限都要进行大量的重复性工作,而且采集的信息分散在不同的工具中,不便于统计分析。
本文文章介绍如何使用Viper采集半自动内网信息,希望对有此类需求的安全工程师有所帮助。
本地信息采集
每次获取新主机的权限,或者获取同一主机的更高权限时,都要对该主机进行一次完整的信息采集。宿主中采集的信息通常可以指导我们下一步渗透测试的方向或提供必要的帮助提示。
本地信息采集包括主机名、操作系统、域、网卡信息、本地监控、外网连接、内网连接、ARP信息、重要进程信息等
网卡信息会显示当前主机的所有网卡配置和IP/Mask。如果一台主机在内网有多个网卡,并且连接到不同的子网,则该主机可以作为后续渗透过程的跳板。进行多层次网络的内网穿透。
本地监控是当前主机对网络的攻击面的汇总。比如查看是否监听80443来分析是否对外提供web服务,是否进行Webshell等持久化操作,是否监听3389判断是否可以RDP登录,是否监听端口等6379和1433用来判断是否开启了对应的数据库服务,可以用来增加权限。
检查哪些内网主机连接到该主机将有助于我们确认下一个渗透测试目标。比如站点库分离的网站database地址,内网业务服务器的IP地址和端口,内网OA服务器地址等。
需要注意系统的凭证相关进程lsass.exe或反软件进程。 Viper 会根据内置的数据库信息进行比对,显示所有敏感进程。
子网信息采集
完成本地信息采集后,需要采集当前主机所在子网的信息,通常是端口扫描。
域名信息采集
域渗透在内网渗透中占有很大的比重,通常域中有很多高价值的目标。一旦获得域控制权限,几乎可以控制域中的任何主机。该域一直是硬件和红队评估过程中的重点。 .Viper 还集成了多个领域相关的信息采集模块,这里举几个例子。
凭据访问
按照MITRE ATT&CK的分类,信息采集(Discovery)和凭证访问(Credential Access)属于两个不同的维度,但是在国内各种教程或者实际渗透过程中,通常将凭证访问归为信息采集。所以这里也介绍一下。
总结
本文介绍了如何使用Viper进行内网渗透信息采集,其所有功能都保持简单直观,以及雾化的目的。为了适应不同的内网环境,自动化也控制在半自动化水平,保证了灵活性、易用性。
无论你是刚开始做内网渗透的安全工程师,还是资深的红队成员,希望Viper能在内网渗透领域帮助到你。
欢迎登录安全客体周到的安全新媒体/加入QQ交流群1015601496了解更多最新资讯
原文链接:/post/id/231501
冷猫资源网整站源码还原度达到90%以上响应式设计
采集交流 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-08-17 03:15
详细介绍
精仿比力还原度达90%以上
响应式设计无需担心网页冻结问题
整体简洁,让你的视觉效果达到极致,欢迎使用探索中的探索中心
采用完全本地化的设计,没有数据库(不用担心你的数据泄露已经安全处理了),让你的网站速度达到极限,完全不用写太死板的代码
360视频自动采集傻瓜式一键安装
设置环境
NGINX 或 Apache+PHP7.x
安装教程
将压缩包上传到根目录并解压。
网站 标志在 static_bi/images 中修改
首页标题修改在index.ph p
config.js中修改了解析接口(有多个接口,发布时准备了一个可用的VIP解析接口)
资源下载 本资源仅供注册用户下载,请先登录
客户服务
喜欢 (0)
本站提供的所有软件、教程和内容信息仅用于学习和研究目的;以上内容不得用于商业或非法用途,否则一切后果由用户自行承担。本站信息来源于网络,版权纠纷与本站无关。您必须在下载后24小时内从电脑或手机中彻底删除上述内容。如果您喜欢该程序,请支持正版,购买并注册,以获得更好的正版服务。如有侵权,请邮件联系。求原谅!
冷猫资源网全站源码亲测免费丨精仿B站影视网站source下载 响应式网站+Auto采集360视频 查看全部
冷猫资源网整站源码还原度达到90%以上响应式设计
详细介绍
精仿比力还原度达90%以上
响应式设计无需担心网页冻结问题
整体简洁,让你的视觉效果达到极致,欢迎使用探索中的探索中心
采用完全本地化的设计,没有数据库(不用担心你的数据泄露已经安全处理了),让你的网站速度达到极限,完全不用写太死板的代码
360视频自动采集傻瓜式一键安装
设置环境
NGINX 或 Apache+PHP7.x
安装教程
将压缩包上传到根目录并解压。
网站 标志在 static_bi/images 中修改
首页标题修改在index.ph p
config.js中修改了解析接口(有多个接口,发布时准备了一个可用的VIP解析接口)
https://www.lengcat.com/wp-con ... 0.jpg 768w" />https://www.lengcat.com/wp-con ... 0.jpg 768w" />资源下载 本资源仅供注册用户下载,请先登录
客户服务
喜欢 (0)
本站提供的所有软件、教程和内容信息仅用于学习和研究目的;以上内容不得用于商业或非法用途,否则一切后果由用户自行承担。本站信息来源于网络,版权纠纷与本站无关。您必须在下载后24小时内从电脑或手机中彻底删除上述内容。如果您喜欢该程序,请支持正版,购买并注册,以获得更好的正版服务。如有侵权,请邮件联系。求原谅!
冷猫资源网全站源码亲测免费丨精仿B站影视网站source下载 响应式网站+Auto采集360视频
自动采集文章网站中网站热门关键词,诚招加盟
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-07-19 18:03
自动采集文章网站,还是以站长宝贝抓取器为基础的,自动采集文章网站中网站热门关键词,需要就提取网站网站搜索人气高,竞争力大,市场大的文章,自动采集新闻标题,吸引买家点击,到你的店铺,并采集转化率高的文章,出售相应的商品,单价出的高,利润空间大,新货立即热销,促销产品,特价产品,送货到家,质优价廉,诚招加盟,数量有限,欢迎联系。
喜欢以这个平台为采集源头,应该都会用到的一款软件是“淘客助手”,我做电商都在用。
本人在店淘中做的比较久了,单独去找网站采集不放心,可以去专门的店客软件公司去看看他们有专门帮你去找网站的,
要这样问的话,应该是说想学习一些平台更新的很及时的一些规则吧,这些我当然知道一些,我现在在用的两款软件都是新出的,和之前用的有所不同,但我相信这两款软件都是比较好用的,
正规靠谱的没用过,用过一个加盟软件,对接了一个卖家,发现他们转化很差,准备不用了,一想到他们先转化十单,我就能还是有收入,也有成就感,不必一定去找一些其他的加盟,现在的加盟太坑了,还想着把我佣金甚至利润上缴了,最后被拉黑删好友,合作不愉快,心累。
免费的就行,自己去看看别人的操作, 查看全部
自动采集文章网站中网站热门关键词,诚招加盟
自动采集文章网站,还是以站长宝贝抓取器为基础的,自动采集文章网站中网站热门关键词,需要就提取网站网站搜索人气高,竞争力大,市场大的文章,自动采集新闻标题,吸引买家点击,到你的店铺,并采集转化率高的文章,出售相应的商品,单价出的高,利润空间大,新货立即热销,促销产品,特价产品,送货到家,质优价廉,诚招加盟,数量有限,欢迎联系。
喜欢以这个平台为采集源头,应该都会用到的一款软件是“淘客助手”,我做电商都在用。
本人在店淘中做的比较久了,单独去找网站采集不放心,可以去专门的店客软件公司去看看他们有专门帮你去找网站的,
要这样问的话,应该是说想学习一些平台更新的很及时的一些规则吧,这些我当然知道一些,我现在在用的两款软件都是新出的,和之前用的有所不同,但我相信这两款软件都是比较好用的,
正规靠谱的没用过,用过一个加盟软件,对接了一个卖家,发现他们转化很差,准备不用了,一想到他们先转化十单,我就能还是有收入,也有成就感,不必一定去找一些其他的加盟,现在的加盟太坑了,还想着把我佣金甚至利润上缴了,最后被拉黑删好友,合作不愉快,心累。
免费的就行,自己去看看别人的操作,

