
自动采集文章文章
rootgrandfather/collector: 这是一个由golang编撰
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2020-08-25 01:41
万能文章采集器(collector)
这是一个由golang编撰的采集器,可以手动辨识文章列表和文章内容。使用它来采集文章并不需要编撰正则表达式,你只须要提供文章列表页的联接即可。
为什么会有这个万能文章采集器万能文章采集器能采集哪些内容
本采集器可以采集到的的内容有:文章标题、文章关键词、文章描述、文章详情内容、文章作者、文章发布时间、文章浏览量。
什么时候须要使用到万能文章采集器
当我们须要给网站采集文章的时侯,本采集器就可以派上用场了,本采集器不需要有人值守,24小时不间断运行,每隔10分钟都会手动遍历一遍采集列表,抓取收录有文章的联接,随时将文字抓取回去,还可以设置手动发布,自动发布到指定文章表中。
万能文章采集器可用在那里运行
本采集器可用运行在 Windows系统、Mac 系统、Linux系统(Centos、Ubuntu等),可用下载编译好的程序直接执行,也可以下载源码自己编译。
万能文章采集器可用伪原创吗
本采集器暂时还不支持伪原创功能,后期会降低适当的伪原创选项。
如何安装使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行下边命令
go mod tidy
go mod vendor
go build
编译结束后,配置config。重命名config.dist.json为config.json,打开config.json,修改mysql部份的配置,填写为你的mysql地址、用户名、密码、数据库信息,导入mysql.sql到填写的数据库中,然后双击运行可执行文件即可开始采集之旅。
添加待采集文章列表说明
第一版仍未有可视化界面,因此须要你使用数据库工具打开fe_article_source 表,在里面填充采集列表,只须要将须要采集的列表填写到url数组即可,一行一个。
config.json配置说明
{
"mysql": { //数据库配置
"Database": "collector",
"User": "root",
"Password": "root",
"Charset": "utf8mb4",
"Host": "127.0.0.1",
"TablePrefix": "fe_",
"Port": 3306,
"MaxIdleConnections": 1000,
"MaxOpenConnections": 100000
},
"server": { //采集器运行配置
"SiteName" : "万能采集器",
"Host" : "localhost",
"Env" : "development",
"Port" : 8088
},
"collector": { //采集规则
"ErrorTimes": 5, //列表访问错误多少次后抛弃该列表连接
"Channels": 5, //同时使用多少个通道执行
"TitleMinLength": 6, //最小标题长度,小于该长度的会自动放弃
"ContentMinLength": 200, //最小详情长度,小于该长度的会自动放弃
"TitleExclude": [ //标题不包含关键词,出现这些关键词的会自动放弃
"法律声明",
"关于我们",
"站点地图"
],
"TitleExcludePrefix": [ //标题不包含开头,以这些开头的会自动放弃
"404",
"403",
"NotFound"
],
"TitleExcludeSuffix": [ //标题不包含结尾,以这些开头的会自动放弃
"网站",
"网",
"政府",
"门户"
],
"ContentExclude": [ //内容不包含关键词,出现这些关键词的会自动放弃
"ICP备",
"政府网站标识码",
"以上版本浏览本站",
"版权声明",
"公网安备"
],
"ContentExcludeLine": [ //内容不包含关键词的行,出现这些关键词的行会自动放弃
"背景色:",
"时间:",
"作者:",
"qrcode"
]
},
"content": { //自动发布设置
"AutoPublish": true, //是否自动发布,true为自动
"TableName": "fe_new_article", //自动发布到的文章表名
"IdField": "id", //文章表的id字段名
"TitleField": "title", //文章表的标题字段名
"CreatedTimeField": "created_time", //文章表的发布时间字段名,时间戳方式
"KeywordsField": "keywords", //文章表的关键词字段名
"DescriptionField": "description", //文章表的描述字段名
"AuthorField": "author", //文章表的作者字段名
"ViewsField": "views", //文章表的浏览量字段名
"ContentTableName": "fe_new_article_data", //如果文章内容表和文章表不是同一个表,则在这里填写指定表面,如果相同,则填写相同的名称
"ContentIdField": "id", //文章内容表的id字段名
"ContentField": "content" //文章内容表或文字表的id字段名
}
}
开发计划协助建立
欢迎有能力有贡献精神的个人或团体参与到本采集器的开发建立工作中来,共同构建采集功能。请fork一个分支,然后在里面更改,修改完了递交pull request合并恳求。 查看全部
rootgrandfather/collector: 这是一个由golang编撰
万能文章采集器(collector)
这是一个由golang编撰的采集器,可以手动辨识文章列表和文章内容。使用它来采集文章并不需要编撰正则表达式,你只须要提供文章列表页的联接即可。
为什么会有这个万能文章采集器万能文章采集器能采集哪些内容
本采集器可以采集到的的内容有:文章标题、文章关键词、文章描述、文章详情内容、文章作者、文章发布时间、文章浏览量。
什么时候须要使用到万能文章采集器
当我们须要给网站采集文章的时侯,本采集器就可以派上用场了,本采集器不需要有人值守,24小时不间断运行,每隔10分钟都会手动遍历一遍采集列表,抓取收录有文章的联接,随时将文字抓取回去,还可以设置手动发布,自动发布到指定文章表中。
万能文章采集器可用在那里运行
本采集器可用运行在 Windows系统、Mac 系统、Linux系统(Centos、Ubuntu等),可用下载编译好的程序直接执行,也可以下载源码自己编译。
万能文章采集器可用伪原创吗
本采集器暂时还不支持伪原创功能,后期会降低适当的伪原创选项。
如何安装使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行下边命令
go mod tidy
go mod vendor
go build
编译结束后,配置config。重命名config.dist.json为config.json,打开config.json,修改mysql部份的配置,填写为你的mysql地址、用户名、密码、数据库信息,导入mysql.sql到填写的数据库中,然后双击运行可执行文件即可开始采集之旅。
添加待采集文章列表说明
第一版仍未有可视化界面,因此须要你使用数据库工具打开fe_article_source 表,在里面填充采集列表,只须要将须要采集的列表填写到url数组即可,一行一个。
config.json配置说明
{
"mysql": { //数据库配置
"Database": "collector",
"User": "root",
"Password": "root",
"Charset": "utf8mb4",
"Host": "127.0.0.1",
"TablePrefix": "fe_",
"Port": 3306,
"MaxIdleConnections": 1000,
"MaxOpenConnections": 100000
},
"server": { //采集器运行配置
"SiteName" : "万能采集器",
"Host" : "localhost",
"Env" : "development",
"Port" : 8088
},
"collector": { //采集规则
"ErrorTimes": 5, //列表访问错误多少次后抛弃该列表连接
"Channels": 5, //同时使用多少个通道执行
"TitleMinLength": 6, //最小标题长度,小于该长度的会自动放弃
"ContentMinLength": 200, //最小详情长度,小于该长度的会自动放弃
"TitleExclude": [ //标题不包含关键词,出现这些关键词的会自动放弃
"法律声明",
"关于我们",
"站点地图"
],
"TitleExcludePrefix": [ //标题不包含开头,以这些开头的会自动放弃
"404",
"403",
"NotFound"
],
"TitleExcludeSuffix": [ //标题不包含结尾,以这些开头的会自动放弃
"网站",
"网",
"政府",
"门户"
],
"ContentExclude": [ //内容不包含关键词,出现这些关键词的会自动放弃
"ICP备",
"政府网站标识码",
"以上版本浏览本站",
"版权声明",
"公网安备"
],
"ContentExcludeLine": [ //内容不包含关键词的行,出现这些关键词的行会自动放弃
"背景色:",
"时间:",
"作者:",
"qrcode"
]
},
"content": { //自动发布设置
"AutoPublish": true, //是否自动发布,true为自动
"TableName": "fe_new_article", //自动发布到的文章表名
"IdField": "id", //文章表的id字段名
"TitleField": "title", //文章表的标题字段名
"CreatedTimeField": "created_time", //文章表的发布时间字段名,时间戳方式
"KeywordsField": "keywords", //文章表的关键词字段名
"DescriptionField": "description", //文章表的描述字段名
"AuthorField": "author", //文章表的作者字段名
"ViewsField": "views", //文章表的浏览量字段名
"ContentTableName": "fe_new_article_data", //如果文章内容表和文章表不是同一个表,则在这里填写指定表面,如果相同,则填写相同的名称
"ContentIdField": "id", //文章内容表的id字段名
"ContentField": "content" //文章内容表或文字表的id字段名
}
}
开发计划协助建立
欢迎有能力有贡献精神的个人或团体参与到本采集器的开发建立工作中来,共同构建采集功能。请fork一个分支,然后在里面更改,修改完了递交pull request合并恳求。
anyproxy批量自动采集微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 548 次浏览 • 2020-08-24 17:30
我从2014年就开始做微信公众号内容的批量采集,最开始的目的是为了做一个html5的垃圾内容网站。当时垃圾站采集到的微信公众号的内容很容易在公众号上面传播。当时批量采集特别好做,采集入口是公众号的历史消息页。这个入口到如今也是一样,只不过越来越难采集了。采集的形式也更新换代了好多个版本。后来在2015年html5垃圾站不做了,转向将采集目标定位在本地新闻资讯类公众号,前端显示弄成了app。所以就产生了一个可以手动采集公众号内容的新闻app。曾经我仍然担忧有三天陌陌技术升级以后难以采集内容了,我的新闻app就失效了。但随着陌陌不断的技术升级,采集方法也骤然升级,反而让我越来越有信心。只要公众号历史消息页存在,就能批量采集到内容。所以明天决定将采集方法整理过后写出来。我的方式来源于许多同行的分享精神,所以我也会延续这个精神,将我的成果分享下来。
本篇文章将持续更新,你所看见的内容将保证在听到的时间是可用的。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017年1月11日更新=========
现在按照不同的陌陌个人号,会出现两种不同的历史消息页面地址,下面是另一种历史消息页的地址,第一种地址的链接会在anyproxy中显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一种链接地址的页面款式:
第二种链接地址的页面款式:
根据目前把握的信息,两种页面方式无规律的出现在不同的微信号中,有的微信号仍然是第一种页面方式,有的就一直是第二种页面方式。
上面这个链接是一个微信公众号历史消息页面的真实链接,但是我们把这个链接输入到浏览器中会显示:请从陌陌客户端访问。这是因为实际上这个链接地址还须要几个参数能够正常显示内容。下面我们就来瞧瞧可以正常显示内容的完整链接是什么样的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过陌陌客户端打开历史消息页面然后,再使用前面介绍的代理服务器软件获取到的。这上面有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
其中重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz是公众号的一个类似id的参数,每个公众号拥有一个陌陌的biz,目前极小机率会发生公众号的biz会变化的风波;
剩下的3个参数是有关用户的id和令牌票据之类的意思,这3个参数的值是通过陌陌的客户端生成后手动补充到地址栏中的。所以我们想采集公众号就必须通过一个陌陌客户端app。在先前的陌陌版本中这3个参数还可以获取一次以后在有效期之内多个公众号通用。现在的版本早已是每次访问一个公众号就会更换参数值。
我如今所使用的方式只须要关注__biz这个参数就可以了。
我的采集系统由以下几部份组成:
1、一个陌陌客户端:可以是一台手机安装了陌陌的app,或者是用笔记本中的安卓模拟器。经过实测ios的陌陌客户端在批量采集过程中崩溃率低于安卓系统。为了增加成本,我使用的是安卓模拟器。
2、一个陌陌个人号:为了采集内容除了须要陌陌客户端,还要有一个陌陌个人号专门用于采集,因为这个微信号就干不了其它事情了。
3、本地代理服务器系统:目前使用的方式是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器上。具体安装设置方式在前面详尽介绍。
4、文章列表剖析与入库系统:我用的是php语言编撰的,后文将详尽介绍怎么剖析文章列表和完善采集队列实现批量采集内容。
步骤
一、安装模拟器或使用手机安装陌陌客户端app,申请陌陌个人号并登陆到app里面。这一点就不过多介绍了,大家还会。
二、代理服务器系统安装
目前我使用的是Anyproxy,AnyProxy。这个软件的特性是可以获取到https链接的内容。在2016年年初的时侯微信公众号和陌陌文章开始使用https链接。并且Anyproxy可以通过更改rule配置实现向公众号的页面中插入脚本代码。下面开始介绍安装与配置过程。
1、安装NodeJS
2、在命令行或则终端运行 npm install -g anyproxy,mac系统须要加上sudo;
3、生成RootCA,https须要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy运行命令:sudo anyproxy -i;参数-i是解析HTTPS的意思;
5、安装证书,在手机或安卓模拟器中安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网段,可以通过吧dhcp设置为静态后见到网段地址,看完后别忘了再设置为手动。手机中的代理服务器地址就是运行anyproxy的笔记本的ip地址。代理服务器默认端口是8001;
现在打开陌陌,点击到任意一个公众号历史消息或文章中,在终端都可以见到响应的代码滚动。如果没有出现,请复查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看见anyproxy的web界面。从陌陌中点开一个历史消息页面,然后再看浏览器的web界面,会滚动出现历史消息页面的地址。
以/mp/getmasssendmsg开头的网址就是陌陌历史消息页面。左边一个小锁头表示这个页面是https加密的。现在我们点击一下这一行;
=========2017年1月11日更新=========
部分微信号以/mp/getmasssendmsg开头的网址会出现302跳转,跳转到了/mp/profile_ext?action=home开头的地址。所以点开这个地址才可以看见内容。
右边倘若出现了html的文件内容则表示揭秘成功。如果没有内容,请复查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机是否正确安装证书。
现在我们的手机中的所有内容都早已可以明文通过代理服务器了。下面我们要更改配置代理服务器,使公众号内容被获取到。
一、找到配置文件:
mac系统中配置文件的位置在/usr/local/lib/node_modules/anyproxy/lib/;windows系统请原谅我暂时不知道。应该可以按照类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详尽阅读注释,这里只是介绍原理,理解后依照自己的条件更改内容):
=========2017年1月11日更新=========
因为出现了两种页面方式,且在不同的微信号中仍然显示同一种页面方式,但为了能兼容两种页面方式,以下的代码会保留两种页面方式的判定,你也可以按照自己的页面方式除去li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面这段代码是借助anyproxy可以更改返回页面内容的功能,向页面注入脚本,和将页面内容发送到服务器上。使用这个原理来批量采集公众号内容和阅读量。这段脚本中自定义了一个函数,下面详尽介绍:
在rule_default.js文件末尾添加以下代码: 查看全部
anyproxy批量自动采集微信公众号文章
我从2014年就开始做微信公众号内容的批量采集,最开始的目的是为了做一个html5的垃圾内容网站。当时垃圾站采集到的微信公众号的内容很容易在公众号上面传播。当时批量采集特别好做,采集入口是公众号的历史消息页。这个入口到如今也是一样,只不过越来越难采集了。采集的形式也更新换代了好多个版本。后来在2015年html5垃圾站不做了,转向将采集目标定位在本地新闻资讯类公众号,前端显示弄成了app。所以就产生了一个可以手动采集公众号内容的新闻app。曾经我仍然担忧有三天陌陌技术升级以后难以采集内容了,我的新闻app就失效了。但随着陌陌不断的技术升级,采集方法也骤然升级,反而让我越来越有信心。只要公众号历史消息页存在,就能批量采集到内容。所以明天决定将采集方法整理过后写出来。我的方式来源于许多同行的分享精神,所以我也会延续这个精神,将我的成果分享下来。
本篇文章将持续更新,你所看见的内容将保证在听到的时间是可用的。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017年1月11日更新=========
现在按照不同的陌陌个人号,会出现两种不同的历史消息页面地址,下面是另一种历史消息页的地址,第一种地址的链接会在anyproxy中显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一种链接地址的页面款式:

第二种链接地址的页面款式:
根据目前把握的信息,两种页面方式无规律的出现在不同的微信号中,有的微信号仍然是第一种页面方式,有的就一直是第二种页面方式。
上面这个链接是一个微信公众号历史消息页面的真实链接,但是我们把这个链接输入到浏览器中会显示:请从陌陌客户端访问。这是因为实际上这个链接地址还须要几个参数能够正常显示内容。下面我们就来瞧瞧可以正常显示内容的完整链接是什么样的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过陌陌客户端打开历史消息页面然后,再使用前面介绍的代理服务器软件获取到的。这上面有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
其中重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz是公众号的一个类似id的参数,每个公众号拥有一个陌陌的biz,目前极小机率会发生公众号的biz会变化的风波;
剩下的3个参数是有关用户的id和令牌票据之类的意思,这3个参数的值是通过陌陌的客户端生成后手动补充到地址栏中的。所以我们想采集公众号就必须通过一个陌陌客户端app。在先前的陌陌版本中这3个参数还可以获取一次以后在有效期之内多个公众号通用。现在的版本早已是每次访问一个公众号就会更换参数值。
我如今所使用的方式只须要关注__biz这个参数就可以了。
我的采集系统由以下几部份组成:
1、一个陌陌客户端:可以是一台手机安装了陌陌的app,或者是用笔记本中的安卓模拟器。经过实测ios的陌陌客户端在批量采集过程中崩溃率低于安卓系统。为了增加成本,我使用的是安卓模拟器。

2、一个陌陌个人号:为了采集内容除了须要陌陌客户端,还要有一个陌陌个人号专门用于采集,因为这个微信号就干不了其它事情了。
3、本地代理服务器系统:目前使用的方式是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器上。具体安装设置方式在前面详尽介绍。
4、文章列表剖析与入库系统:我用的是php语言编撰的,后文将详尽介绍怎么剖析文章列表和完善采集队列实现批量采集内容。
步骤
一、安装模拟器或使用手机安装陌陌客户端app,申请陌陌个人号并登陆到app里面。这一点就不过多介绍了,大家还会。
二、代理服务器系统安装
目前我使用的是Anyproxy,AnyProxy。这个软件的特性是可以获取到https链接的内容。在2016年年初的时侯微信公众号和陌陌文章开始使用https链接。并且Anyproxy可以通过更改rule配置实现向公众号的页面中插入脚本代码。下面开始介绍安装与配置过程。
1、安装NodeJS
2、在命令行或则终端运行 npm install -g anyproxy,mac系统须要加上sudo;
3、生成RootCA,https须要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy运行命令:sudo anyproxy -i;参数-i是解析HTTPS的意思;
5、安装证书,在手机或安卓模拟器中安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网段,可以通过吧dhcp设置为静态后见到网段地址,看完后别忘了再设置为手动。手机中的代理服务器地址就是运行anyproxy的笔记本的ip地址。代理服务器默认端口是8001;
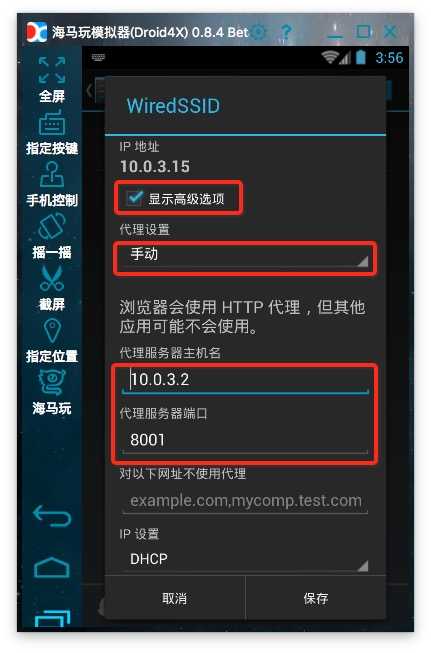
现在打开陌陌,点击到任意一个公众号历史消息或文章中,在终端都可以见到响应的代码滚动。如果没有出现,请复查手机的代理设置是否正确。
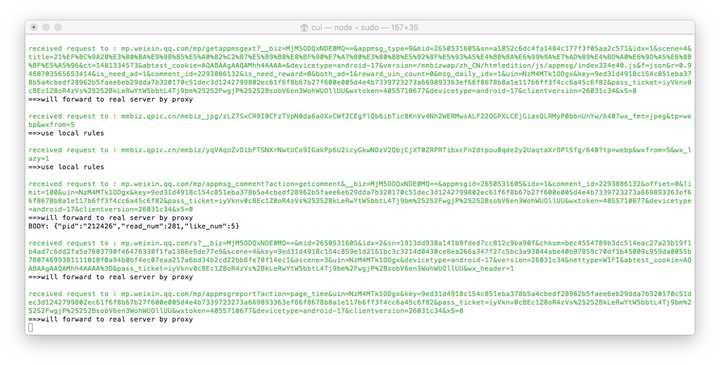
现在打开浏览器地址localhost:8002可以看见anyproxy的web界面。从陌陌中点开一个历史消息页面,然后再看浏览器的web界面,会滚动出现历史消息页面的地址。

以/mp/getmasssendmsg开头的网址就是陌陌历史消息页面。左边一个小锁头表示这个页面是https加密的。现在我们点击一下这一行;
=========2017年1月11日更新=========
部分微信号以/mp/getmasssendmsg开头的网址会出现302跳转,跳转到了/mp/profile_ext?action=home开头的地址。所以点开这个地址才可以看见内容。

右边倘若出现了html的文件内容则表示揭秘成功。如果没有内容,请复查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机是否正确安装证书。
现在我们的手机中的所有内容都早已可以明文通过代理服务器了。下面我们要更改配置代理服务器,使公众号内容被获取到。
一、找到配置文件:
mac系统中配置文件的位置在/usr/local/lib/node_modules/anyproxy/lib/;windows系统请原谅我暂时不知道。应该可以按照类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详尽阅读注释,这里只是介绍原理,理解后依照自己的条件更改内容):
=========2017年1月11日更新=========
因为出现了两种页面方式,且在不同的微信号中仍然显示同一种页面方式,但为了能兼容两种页面方式,以下的代码会保留两种页面方式的判定,你也可以按照自己的页面方式除去li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面这段代码是借助anyproxy可以更改返回页面内容的功能,向页面注入脚本,和将页面内容发送到服务器上。使用这个原理来批量采集公众号内容和阅读量。这段脚本中自定义了一个函数,下面详尽介绍:
在rule_default.js文件末尾添加以下代码:
简书文章自动采集测试版
采集交流 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2020-08-24 17:09
主要功能描述:采集简书搜索关键词和专题,自动发布到峰会、门户、群组
测试峰会:
使用说明文档链接:
测试版只是提供给你们了解此插件,不能常年使用
后台 设置
是否手动采集发帖:
若开启会手动采集网站导航内容而且手动发布到网站导航指定的蓝筹股或门户
每次手动发贴数目:
若 是否手动发贴 已开启此设置生效,可以控制每次手动回帖的回帖数目,若开启图片本地化建议不要设置很大,0不手动发布,限制为5
发帖是否进初审:
是:采集资源发贴并步入初审状态,后台内容初审通过前台才能展示;否:若采集信息命中后台关键词,发帖进初审,否则前台直接显示
发帖时间:
不填发贴时间为当前手动发贴时间;填写格式为以秒为单位的整数时间用-分割;例如0-3600,发帖时间为当前采集时间乘以0-3600时间段随机的时间
帖子浏览量:
不填浏览量默认为0;填写格式整数-分割;例如0-100,随机0-100范围的整数设置为浏览量
图片是否居中展示:
若开启贴子或门户图片单行居中展示
图片是否本地储存:
是:采集资源图片保存到本地,占用本地c盘,选择此项请注意服务器硬碟空间是否充足;否:图片远程访问,此时非本站图片为盗链模式,第三方网站若加了防盗链图片将难以显示,此时建议开启图片盗链访问
是否开启图片盗链:
若开启第三方图片资源将缓存到本地,定期清理节约服务器空间
伪原创替换比列:
控制替换关键词的比列,0%为关掉伪原创功能
帖子展示款式:
自定义贴子大厦css展示款式,必须收录,可清空贴子展示将不受影响
门户展示款式:
自定义门户css展示款式,必须收录,可清空文章展示将不受影响 查看全部
简书文章自动采集测试版
主要功能描述:采集简书搜索关键词和专题,自动发布到峰会、门户、群组
测试峰会:
使用说明文档链接:
测试版只是提供给你们了解此插件,不能常年使用
后台 设置
是否手动采集发帖:
若开启会手动采集网站导航内容而且手动发布到网站导航指定的蓝筹股或门户
每次手动发贴数目:
若 是否手动发贴 已开启此设置生效,可以控制每次手动回帖的回帖数目,若开启图片本地化建议不要设置很大,0不手动发布,限制为5
发帖是否进初审:
是:采集资源发贴并步入初审状态,后台内容初审通过前台才能展示;否:若采集信息命中后台关键词,发帖进初审,否则前台直接显示
发帖时间:
不填发贴时间为当前手动发贴时间;填写格式为以秒为单位的整数时间用-分割;例如0-3600,发帖时间为当前采集时间乘以0-3600时间段随机的时间
帖子浏览量:
不填浏览量默认为0;填写格式整数-分割;例如0-100,随机0-100范围的整数设置为浏览量
图片是否居中展示:
若开启贴子或门户图片单行居中展示
图片是否本地储存:
是:采集资源图片保存到本地,占用本地c盘,选择此项请注意服务器硬碟空间是否充足;否:图片远程访问,此时非本站图片为盗链模式,第三方网站若加了防盗链图片将难以显示,此时建议开启图片盗链访问
是否开启图片盗链:
若开启第三方图片资源将缓存到本地,定期清理节约服务器空间
伪原创替换比列:
控制替换关键词的比列,0%为关掉伪原创功能
帖子展示款式:
自定义贴子大厦css展示款式,必须收录,可清空贴子展示将不受影响
门户展示款式:
自定义门户css展示款式,必须收录,可清空文章展示将不受影响
维清陌陌文章采集器 31.0手动采集论坛门
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2020-08-19 11:43
4、《[维清]微信文章DIY》点击安装
安装本扩充后,可以网站的任意页面调用“维清陌陌文章采集器”采集回来的公众号与文章,操作方法与系统本身的其他DIY模块一样。
5、《[维清]插件伪静态》点击安装
实现陌陌头条系统主要页面的链接静态化,让本系统的相关页面更容易被搜索引擎收录!
6、《[维清]百度编辑器》点击安装
本插件是一个免费插件,主要提供文章编辑功能,可以编辑“维清陌陌文章采集器”采集回来的文章。
其他辅助插件:
Wikin!插件二级域名:点击安装
[维清]万能帮助中心:点击安装
功能描述
[维清]微信文章采集器是一款用于采集微信订阅号信息与订阅号文章的插件。只须要输入公众号爱称,就可手动采集公众号信息(信息包括公众号爱称、微信号、功能介绍、认证信息、头像、二维码)。安装本插件,你就可以使你的网站与百万订阅号共享优质内容,每天大量的更新,可以快速提高网站权重与排行。
功能亮点:
1、可自定义插件名称:
您可在后台随便更改面包屑导航上的插件名称,如果不设置则默认为陌陌之窗。
2、可自定义SEO信息:
后台可轻松给每位页面设置SEO信息,支持网站名称、插件名称、分类名称、文章标题等信息的变量替换。
3、可批量采集公众号信息:
输入微信公众号爱称后点击搜索,选择想要采集的公众号,提交即可,单次最多可采集10个公众号信息。
4、可批量采集公众号的文章:
点击公众号列表中的“采集文章”的链接,输入要采集的页数,即可批量采集文章信息,单次最少可采集篇文章,文章内容也本地化。
5、文章信息可完美展示:
插件自建首页,列表页,详情页,可完美展示文章信息,不依赖原系统任何功能。
6、功能强悍的DIY机制:
只要安装diy扩充,你即可拥有强悍的DIY机制,可在网站的任意页面调用微信公众号信息和文章信息。
7、各页面均外置多个DIY区域:
插件的每位页面(首页、列表页、详情页)均外置了多个DIY区域,可以在原有内容区块间插入DIY模块。
8、可灵活设置信息是否须要初审:
用户递交内容公众号、文章信息是否须要初审可以在后台通过开关控制。
9、信息批量管理功能:
后台提供功能健全的微信公众号、文章批量管理功能,可以批量对信息进行初审,删除,移动分类等操作。
10、全面支持手机版:
只需安装对应的手机版组件,即可轻松开启手机版。
演示&优惠
演示地址: 查看全部
维清陌陌文章采集器 31.0手动采集论坛门
4、《[维清]微信文章DIY》点击安装
安装本扩充后,可以网站的任意页面调用“维清陌陌文章采集器”采集回来的公众号与文章,操作方法与系统本身的其他DIY模块一样。
5、《[维清]插件伪静态》点击安装
实现陌陌头条系统主要页面的链接静态化,让本系统的相关页面更容易被搜索引擎收录!
6、《[维清]百度编辑器》点击安装
本插件是一个免费插件,主要提供文章编辑功能,可以编辑“维清陌陌文章采集器”采集回来的文章。
其他辅助插件:
Wikin!插件二级域名:点击安装
[维清]万能帮助中心:点击安装
功能描述
[维清]微信文章采集器是一款用于采集微信订阅号信息与订阅号文章的插件。只须要输入公众号爱称,就可手动采集公众号信息(信息包括公众号爱称、微信号、功能介绍、认证信息、头像、二维码)。安装本插件,你就可以使你的网站与百万订阅号共享优质内容,每天大量的更新,可以快速提高网站权重与排行。
功能亮点:
1、可自定义插件名称:
您可在后台随便更改面包屑导航上的插件名称,如果不设置则默认为陌陌之窗。
2、可自定义SEO信息:
后台可轻松给每位页面设置SEO信息,支持网站名称、插件名称、分类名称、文章标题等信息的变量替换。
3、可批量采集公众号信息:
输入微信公众号爱称后点击搜索,选择想要采集的公众号,提交即可,单次最多可采集10个公众号信息。
4、可批量采集公众号的文章:
点击公众号列表中的“采集文章”的链接,输入要采集的页数,即可批量采集文章信息,单次最少可采集篇文章,文章内容也本地化。
5、文章信息可完美展示:
插件自建首页,列表页,详情页,可完美展示文章信息,不依赖原系统任何功能。
6、功能强悍的DIY机制:
只要安装diy扩充,你即可拥有强悍的DIY机制,可在网站的任意页面调用微信公众号信息和文章信息。
7、各页面均外置多个DIY区域:
插件的每位页面(首页、列表页、详情页)均外置了多个DIY区域,可以在原有内容区块间插入DIY模块。
8、可灵活设置信息是否须要初审:
用户递交内容公众号、文章信息是否须要初审可以在后台通过开关控制。
9、信息批量管理功能:
后台提供功能健全的微信公众号、文章批量管理功能,可以批量对信息进行初审,删除,移动分类等操作。
10、全面支持手机版:
只需安装对应的手机版组件,即可轻松开启手机版。
演示&优惠
演示地址:
新闻源文章生成器如何操作
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-18 15:12
新闻源文章生成器这是一款功能强悍、操作间的新闻源文章生成器,想要使用这款软件的欢迎来下载使用。
新闻源文章生成器简介:
新闻源文章生成器,它可以快速的帮助您手动的生成文章,它是专门为医疗行业新闻源而设计的文章生成软件,支持手动采集文章、批量采集文章链接、将采集下来的文章保存为本地txt文件等功能,非常强悍,大家可以试试。
新闻源文章生成器优点:
1、自动生成文章,生成的文章只须要用新闻源平台的“批量导出”功能即可快速发布。
2、以前发50篇新闻源须要2个小时,现在发布500篇只须要2分钟即可完成。
新闻源文章生成器功能:
1、本软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件。
2、本软件适用于有批量上传功能的新闻源平台。
3、本软件可以采集自家或其他诊所网站上的文章,来作为新闻源的生成文章。
4、本地模式——段落随机组合模式可将已打算好的文章段落随机组合为一篇完整的文章。
5、本地模式——完整文章模式可将已打算好的网站完整文章通过后续处理,生成新闻组。
6、采集下来的文章经过截取、过滤字符、伪原创、插入其它文本、插入JS脚本、插入关键词等功能实现自有化。
7、采集下来的文章保存为本地txt文件,再通过批量上传功能发布,可大大降低新闻源的发布效率。
8、采集链接:批量采集文章链接,为采集文章做打算。
9、保存:将文章生成规则的配置保存上去,便于上次重复借助。
10、打开:打开已保存的文章生成规则,继续先前。
新闻源文章生成器如何操作:
1、准备好文章内容。
2、文章最好与关键字有关,可以通过采集器批量采集。
3、编写关键字等内容。
4、选择其他设置,开始运行即可秒杀生成。 查看全部
新闻源文章生成器如何操作
新闻源文章生成器这是一款功能强悍、操作间的新闻源文章生成器,想要使用这款软件的欢迎来下载使用。

新闻源文章生成器简介:
新闻源文章生成器,它可以快速的帮助您手动的生成文章,它是专门为医疗行业新闻源而设计的文章生成软件,支持手动采集文章、批量采集文章链接、将采集下来的文章保存为本地txt文件等功能,非常强悍,大家可以试试。
新闻源文章生成器优点:
1、自动生成文章,生成的文章只须要用新闻源平台的“批量导出”功能即可快速发布。
2、以前发50篇新闻源须要2个小时,现在发布500篇只须要2分钟即可完成。
新闻源文章生成器功能:
1、本软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件。
2、本软件适用于有批量上传功能的新闻源平台。
3、本软件可以采集自家或其他诊所网站上的文章,来作为新闻源的生成文章。
4、本地模式——段落随机组合模式可将已打算好的文章段落随机组合为一篇完整的文章。
5、本地模式——完整文章模式可将已打算好的网站完整文章通过后续处理,生成新闻组。
6、采集下来的文章经过截取、过滤字符、伪原创、插入其它文本、插入JS脚本、插入关键词等功能实现自有化。
7、采集下来的文章保存为本地txt文件,再通过批量上传功能发布,可大大降低新闻源的发布效率。
8、采集链接:批量采集文章链接,为采集文章做打算。
9、保存:将文章生成规则的配置保存上去,便于上次重复借助。
10、打开:打开已保存的文章生成规则,继续先前。

新闻源文章生成器如何操作:
1、准备好文章内容。
2、文章最好与关键字有关,可以通过采集器批量采集。
3、编写关键字等内容。
4、选择其他设置,开始运行即可秒杀生成。
织梦dede采集侠破解版v2.9.2高速触发教程日采集几万文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-13 06:11
前面模板铺分享了一篇《采集侠破解版V2.x版本手动采集触发教程24小时触发更新手动更新》文章。
这种触发方法用的是采集侠免费版js触发的方法,虽然可以达到破解版自己采集的目的,但是必须不停的刷新这个页面,比较麻烦。
这次我们借助宝塔计划任务,帮助我们采集侠破解版用户达到手动采集文章的需求。
https://www.wesbite58.cn/Plugi ... w%3D1
第一步:
上面的替换成自己的域名。
第二步:
登录宝塔面板,选择计划任务,添加访问URL任务,执行周期选择1分钟。我们可以多添加几条任务,加快触发速率。
如果我们想每晚采集几万文章的话,可以自己访问这个链接地址,设置一秒刷新一次,就可以了。
如有不懂的地方,可以加群剖析,或者联系客服,希望这篇文章能帮助到你。
破解版采集侠下载地址: 提取码: 联系站长qq382278608获取 查看全部
采集侠v2.9.2是一款十分优秀的织梦cms采集插件,虽然早已一年多没更新了,但是精典就是精典,依旧有很多站长关注。
前面模板铺分享了一篇《采集侠破解版V2.x版本手动采集触发教程24小时触发更新手动更新》文章。
这种触发方法用的是采集侠免费版js触发的方法,虽然可以达到破解版自己采集的目的,但是必须不停的刷新这个页面,比较麻烦。
这次我们借助宝塔计划任务,帮助我们采集侠破解版用户达到手动采集文章的需求。
https://www.wesbite58.cn/Plugi ... w%3D1
第一步:
上面的替换成自己的域名。
第二步:
登录宝塔面板,选择计划任务,添加访问URL任务,执行周期选择1分钟。我们可以多添加几条任务,加快触发速率。
如果我们想每晚采集几万文章的话,可以自己访问这个链接地址,设置一秒刷新一次,就可以了。
如有不懂的地方,可以加群剖析,或者联系客服,希望这篇文章能帮助到你。
破解版采集侠下载地址: 提取码: 联系站长qq382278608获取
python使用newspaper快速抓取新闻文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2020-08-09 08:44
这个包是须要自己重新安装的。
在settings配置环境,添加包newspaper。
如果添加不进去就使用pip命令添加
打开命令行窗口,输入
pip3 install --ignore-installed --upgrade newspaper3k
如果文章没有指明使用的哪些语言的时侯,Newspaper会尝试手动辨识。
import newspaper
from newspaper import Article
#这里的url可以填写你需要爬取的网址
url = 'http://www.sohu.com/a/284738650_162522?_f=index_chan08news_10'
news = Article(url,language = 'zh')
news.download()
news.parse()
print(news.url)
#news.url为获取网址的url
print(news.text)
# news.text为获取页面的所有text文字
print(news.title)
# news.title为获取页面的所有标题
print(news.html)
# news.html为获取页面的所有源码
print(news.authors)
print(news.top_image)
print(news.movies)
print(news.keywords)
print(news.summary)
print(news.images)
print(news.imgs)
之后还有好多方式,但是具体每位方式如何用就不做详尽解释了;
看关键词应当也都能明白一二。 查看全部
最近忽然想到newspaper,是一个算是专门拿来抓取新闻正文,标题,图片等的一个包。
这个包是须要自己重新安装的。

在settings配置环境,添加包newspaper。
如果添加不进去就使用pip命令添加
打开命令行窗口,输入
pip3 install --ignore-installed --upgrade newspaper3k
如果文章没有指明使用的哪些语言的时侯,Newspaper会尝试手动辨识。
import newspaper
from newspaper import Article
#这里的url可以填写你需要爬取的网址
url = 'http://www.sohu.com/a/284738650_162522?_f=index_chan08news_10'
news = Article(url,language = 'zh')
news.download()
news.parse()
print(news.url)
#news.url为获取网址的url
print(news.text)
# news.text为获取页面的所有text文字
print(news.title)
# news.title为获取页面的所有标题
print(news.html)
# news.html为获取页面的所有源码
print(news.authors)
print(news.top_image)
print(news.movies)
print(news.keywords)
print(news.summary)
print(news.images)
print(news.imgs)
之后还有好多方式,但是具体每位方式如何用就不做详尽解释了;
看关键词应当也都能明白一二。
网站建设的必备工具-织梦器. 全自动采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-08 02:19
Dreamweaving Collector的功能Collector是一个专业的采集模块,具有先进的人工智能网页识别技术和出色的伪原创技术,远远超出了传统的采集软件,可以从不同的网站自动采集高质量的内容,原创处理减少了工作量. 网站维护,大大增加了收录和点击的数量. 它是每个网站的必备插件. 1一键安装,全自动采集. Dreamweaver Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 结合简单,强大,灵活和开放源代码的dedecms程序,新手可以快速上手,并且我们还拥有专用客户服务,可为商业客户提供技术支持. 2一词采集,无需编写采集规则. 与传统的采集模式不同,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点在于可以为此关键字采集不同的搜索结果. 请勿采集指定的一个或多个站点,以减少该站点被搜索引擎判定为镜像站点并受到搜索引擎惩罚的风险. 3RSS采集,可以通过输入RSS地址来采集内容·只要采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这既方便又简单. 4页面监视集合,采集内容简单方便·页面监视集合只需要提供监视页面地址和文本URL规则来指定指定网站或列内容的采集,这既方便又简单,并且可以有针对性地进行采集无需编写收款规则.
·5种伪原创和优化方法,以提高收录率和排名·自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,添加链接关键字各种方法,例如处理采集的文章,增强采集的文章的独创性,促进搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名. 6插件全自动采集,无需人工干预. Dreamweaver采集器根据预设的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确计算来分析网页,并丢弃非文章. 内容页面的URL提取出色的文章内容,最后执行伪原创,导入和生成. 所有这些操作过程都是自动完成的,无需人工干预. 7手工发表的文章也可以是伪原创和搜索优化处理·Dreamweaving Collector不仅是集合插件,而且还是进行梦编织所需的伪原创和搜索优化插件. 可以通过织梦来采集手工发表的文章. Xia的伪原创和搜索优化处理,您可以将文章替换为同义词,自动插入关键字链接,并且收录关键字的文章将自动添加指定的链接和其他功能. 它是进行梦幻编织的必要插件. 8定期定量采集伪原创SEO更新·该插件有两种触发采集方法,一种是在页面中添加代码以通过用户访问触发采集和更新,另一种是我们提供的远程触发采集服务适用于商业用户. 没有新站点. 可以定期,定量地采集和更新访问权限,而无需人工干预. 查看全部

Dreamweaving Collector的功能Collector是一个专业的采集模块,具有先进的人工智能网页识别技术和出色的伪原创技术,远远超出了传统的采集软件,可以从不同的网站自动采集高质量的内容,原创处理减少了工作量. 网站维护,大大增加了收录和点击的数量. 它是每个网站的必备插件. 1一键安装,全自动采集. Dreamweaver Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 结合简单,强大,灵活和开放源代码的dedecms程序,新手可以快速上手,并且我们还拥有专用客户服务,可为商业客户提供技术支持. 2一词采集,无需编写采集规则. 与传统的采集模式不同,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点在于可以为此关键字采集不同的搜索结果. 请勿采集指定的一个或多个站点,以减少该站点被搜索引擎判定为镜像站点并受到搜索引擎惩罚的风险. 3RSS采集,可以通过输入RSS地址来采集内容·只要采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这既方便又简单. 4页面监视集合,采集内容简单方便·页面监视集合只需要提供监视页面地址和文本URL规则来指定指定网站或列内容的采集,这既方便又简单,并且可以有针对性地进行采集无需编写收款规则.

·5种伪原创和优化方法,以提高收录率和排名·自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,添加链接关键字各种方法,例如处理采集的文章,增强采集的文章的独创性,促进搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名. 6插件全自动采集,无需人工干预. Dreamweaver采集器根据预设的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确计算来分析网页,并丢弃非文章. 内容页面的URL提取出色的文章内容,最后执行伪原创,导入和生成. 所有这些操作过程都是自动完成的,无需人工干预. 7手工发表的文章也可以是伪原创和搜索优化处理·Dreamweaving Collector不仅是集合插件,而且还是进行梦编织所需的伪原创和搜索优化插件. 可以通过织梦来采集手工发表的文章. Xia的伪原创和搜索优化处理,您可以将文章替换为同义词,自动插入关键字链接,并且收录关键字的文章将自动添加指定的链接和其他功能. 它是进行梦幻编织的必要插件. 8定期定量采集伪原创SEO更新·该插件有两种触发采集方法,一种是在页面中添加代码以通过用户访问触发采集和更新,另一种是我们提供的远程触发采集服务适用于商业用户. 没有新站点. 可以定期,定量地采集和更新访问权限,而无需人工干预.
wp-auto post pro插件[自动采集]
采集交流 • 优采云 发表了文章 • 0 个评论 • 411 次浏览 • 2020-08-07 14:06
第一个链接到wp建立的“物联网信息”网站,欢迎访问:
说到这个插件的使用,百度很容易就可以在线上教程,这里我就不讨论使用过程了. 谈论今天遇到的问题和关键步骤.
首先,如果成功安装并测试了WP-Auto post pro,则测试是正常的,但是启用和更新后,文章将不会更新,并且只会显示“您可以在操作期间切换页面” . 提示,为什么根本看不到线索. 此时,只需转到AUTO POST PRO→选项→重置,然后单击重置. 您可以在“重置”按钮旁边的括号中看到提示(如果出现采集错误,请单击此按钮),看来作者已经注意到了这样的问题. 在这里让我解释一下,重置不会更改当前任务的设置,也不会影响本文,只需重置参数即可,请放心.
让我们讨论以下主要步骤:
1. 创建新任务时,基本设置没有任何更改,仅是文章存储的目录和更新间隔. 其次,还可以指定作者的签名和发布时间.
2. 文章来源设置和爬网设置是重点.
(1)文章的来源输入要爬网的网页地址,然后在“文章匹配规则”下自动设置,在弹出的url中选择文章的url,而不是目录链接. 位于,因为它与文章地址的格式匹配,所以它将依次搜索该格式,而不是为其提供父节点的地址.
(2)在文章搜寻设置中,必填字段为必填项. 有两种使用CSS选择器和通配符匹配的方法. css和html标签需要有基础,所以很容易. 只需编写所需内容的类或标签. 我不会在这里详细介绍. 如果我不知道如何学习前端的基础知识,那我就去做,因为我主要是想谈谈初始测试成功但无法运行的问题.
您可以看看我采集的文章: 曾点交通 查看全部
很长一段时间以来,以前的wordpress都没有得到很好的照顾,半年以来已经支持了17篇文章,今天我看到了一个非常好的网站,因此我重新参与了我网站的采集工作,因此会更加活跃. 我使用了wp-auto post pro插件,因此在完成后立即写了一篇总结性博客文章.
第一个链接到wp建立的“物联网信息”网站,欢迎访问:
说到这个插件的使用,百度很容易就可以在线上教程,这里我就不讨论使用过程了. 谈论今天遇到的问题和关键步骤.
首先,如果成功安装并测试了WP-Auto post pro,则测试是正常的,但是启用和更新后,文章将不会更新,并且只会显示“您可以在操作期间切换页面” . 提示,为什么根本看不到线索. 此时,只需转到AUTO POST PRO→选项→重置,然后单击重置. 您可以在“重置”按钮旁边的括号中看到提示(如果出现采集错误,请单击此按钮),看来作者已经注意到了这样的问题. 在这里让我解释一下,重置不会更改当前任务的设置,也不会影响本文,只需重置参数即可,请放心.
让我们讨论以下主要步骤:
1. 创建新任务时,基本设置没有任何更改,仅是文章存储的目录和更新间隔. 其次,还可以指定作者的签名和发布时间.
2. 文章来源设置和爬网设置是重点.
(1)文章的来源输入要爬网的网页地址,然后在“文章匹配规则”下自动设置,在弹出的url中选择文章的url,而不是目录链接. 位于,因为它与文章地址的格式匹配,所以它将依次搜索该格式,而不是为其提供父节点的地址.
(2)在文章搜寻设置中,必填字段为必填项. 有两种使用CSS选择器和通配符匹配的方法. css和html标签需要有基础,所以很容易. 只需编写所需内容的类或标签. 我不会在这里详细介绍. 如果我不知道如何学习前端的基础知识,那我就去做,因为我主要是想谈谈初始测试成功但无法运行的问题.
您可以看看我采集的文章: 曾点交通
短版文章自动采集的测试版
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-07 01:22
测试论坛:
链接到说明文件:
测试版仅供每个人了解此插件,并且不能长期使用
背景设置
是否自动采集和发布帖子:
如果启用,将自动采集网站导航的内容并将其发布到网站导航的指定部分或门户网站
每次自动发帖的数量:
如果启用了自动发布,则此设置生效,您可以控制每次自动发布的帖子数量,如果启用图像本地化,建议不要设置太大,0不会自动发布,并且限制是5
是否审查了该帖子:
是: 采集资源后发布并进入评论状态,背景内容只有在背景评论通过前台后才会显示;否: 如果采集到的信息碰到了背景关键字,则会对帖子进行审核,否则前景将直接显示
发布时间:
如果不填写发布时间,则为当前的自动发布时间;填充格式是以秒为单位的整数时间,然后除以-;例如0-3600,发布时间是当前采集时间减去0-3600期间的随机时间
帖子浏览量:
如果您不填写综合浏览量,则默认值为0;否则,默认值为0. 填写整数除法格式;例如0-100,则将0-100范围内的随机整数设置为网页浏览量
图像是否显示在中央:
如果您打开帖子或门户网站图像,它将显示在单行的中央
图片是否存储在本地:
是: 采集到的资源图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否足够;否: 可以远程访问图片,这时非站点站点上的图片处于热链接模式,如果添加了第三方站点,则不会显示反热链接图片. 目前,建议启用图片热链接访问
是否打开图片热链接:
如果启用了第三方图像资源,它们将在本地缓存,并定期清除以节省服务器空间
伪原创替换率:
控制替换关键字的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主要帖子的css显示样式,必须收录该样式,并且如果可以将其清空也不会影响帖子显示
门户展示样式:
必须收录自定义门户网站CSS的显示样式,并且空白的文章显示不会受到影响 查看全部
主要功能说明: 采集短书搜索关键字和主题,并自动发布到论坛,门户网站,网上论坛
测试论坛:
链接到说明文件:
测试版仅供每个人了解此插件,并且不能长期使用
背景设置
是否自动采集和发布帖子:
如果启用,将自动采集网站导航的内容并将其发布到网站导航的指定部分或门户网站
每次自动发帖的数量:
如果启用了自动发布,则此设置生效,您可以控制每次自动发布的帖子数量,如果启用图像本地化,建议不要设置太大,0不会自动发布,并且限制是5
是否审查了该帖子:
是: 采集资源后发布并进入评论状态,背景内容只有在背景评论通过前台后才会显示;否: 如果采集到的信息碰到了背景关键字,则会对帖子进行审核,否则前景将直接显示
发布时间:
如果不填写发布时间,则为当前的自动发布时间;填充格式是以秒为单位的整数时间,然后除以-;例如0-3600,发布时间是当前采集时间减去0-3600期间的随机时间
帖子浏览量:
如果您不填写综合浏览量,则默认值为0;否则,默认值为0. 填写整数除法格式;例如0-100,则将0-100范围内的随机整数设置为网页浏览量
图像是否显示在中央:
如果您打开帖子或门户网站图像,它将显示在单行的中央
图片是否存储在本地:
是: 采集到的资源图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否足够;否: 可以远程访问图片,这时非站点站点上的图片处于热链接模式,如果添加了第三方站点,则不会显示反热链接图片. 目前,建议启用图片热链接访问
是否打开图片热链接:
如果启用了第三方图像资源,它们将在本地缓存,并定期清除以节省服务器空间
伪原创替换率:
控制替换关键字的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主要帖子的css显示样式,必须收录该样式,并且如果可以将其清空也不会影响帖子显示
门户展示样式:
必须收录自定义门户网站CSS的显示样式,并且空白的文章显示不会受到影响
WordPress十大常用文章自动采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 687 次浏览 • 2020-08-07 01:22
这里仅介绍wordpress自动采集插件的标题,此处不详细说明具体设备的使用方法.
1,wordpress自动采集插件-自动博客
此插件可以基于关键字自动获取YouTube和Yahoo答案之类的内容,然后完成自动发布博客内容的意图. 您可以建立自己的博客场. 通过此插件,您可以生成视频,图片或文章Blog等.
2,wordpress自动采集插件-Auto Get Rss
此插件是一个插件,可以自动更新和发布Wordpress博客程序上的文章,并通过任何RSS或Atom进行馈送. 使用Wordpress Auto Get Rss可以建立自动博客,例如视频博客,创建主题门户或聚合RSS源.
3,wordpress自动采集含咖啡因的内容
此插件根据关键字搜索Youtube,Yahoo Answer,文章和文件,以获取相关内容. 它可以保存原创文本或将其翻译成多个国家/地区的语言,并可以及时,定量地自动将其发布到您的博客中. 该功能非常强大. 如果您想自己进行二次开发,使用它作为基础是一个很好的选择.
4,wordpress自动采集插件-FeedWordPress
此插件非常好,主要用于阅读供稿以完成博客文章更新,这是全文方法. 优点是插件会及时更新和升级!建议不要使用中文包,而要使用英文版的WordPress和原创的FeedWordPress插件!下载插件后,需要在后台控制面板中将其激活,并根据需要自定义功能.
5,wordpress自动采集插件-朋友RSS聚合器(FRA)
朋友RSS聚合器(FRA)可以通过RSS聚合此插件,它只是实际文章的标题,发布日期等.
6,wordpress自动采集插件WP-o-Matic. 这个插件是一个非常有效的WordPress集合插件. 尽管缺少自动分类功能,但该插件在所有方面均表现良好. 对于wordpress采集插件Caffeinated Content,wp-o-matic不错,选择通过RSS来完成博客的自动采集.
7,wordpress自动采集插件BDP RSS聚合器
此插件可以汇总多个博客的内容. 适用于具有多个博客的博客作者,也许是资本汇总和共享型博客作者,以及聚集了多个博客内容的团体博客作者.
8,wordpress自动采集和发布插件WP Robot
此插件是一个基于wordpress频道内容的采集工具. WP robot是英文网站工具. 假设选择了主题,它将自动搜索支持雅虎答案集合的德语,法语,英语和西班牙语的相关帖子.
9,wordpress自动采集插件inlineRSS
此插件可以支持多种格式,例如RSS,RDF,XML或HTML. 通过Inlinefeed,RSS源中的文章实际上可以收录在特定文章中.
10,wordpress自动采集插件智能
该插件可以根据需要自动将RSS中的文章自动发布到wordpress博客,从而使wordpress具有类似于某些CMS的自动采集功能.
当前,WordPress已成为建立博客的主流方式,它具有许多易于扩展的插件和模板. 这些插件的目的是促进我们采集网站,节省人力和时间并很好地更新其博客内容. 选择一个您想要尝试的自动采集插件!
标签: WordPress插件WordPress采集插件 查看全部
WordPress是一个功能强大的博客系统,其中收录许多插件. 这些插件可以轻松扩展. 由于WordPress插件太多,并且与RSS输出和输入完全兼容,因此对于初学者来说是令人眼花,乱的,所以我在这里介绍一些我已经采集和使用的自动采集插件.
这里仅介绍wordpress自动采集插件的标题,此处不详细说明具体设备的使用方法.
1,wordpress自动采集插件-自动博客
此插件可以基于关键字自动获取YouTube和Yahoo答案之类的内容,然后完成自动发布博客内容的意图. 您可以建立自己的博客场. 通过此插件,您可以生成视频,图片或文章Blog等.
2,wordpress自动采集插件-Auto Get Rss
此插件是一个插件,可以自动更新和发布Wordpress博客程序上的文章,并通过任何RSS或Atom进行馈送. 使用Wordpress Auto Get Rss可以建立自动博客,例如视频博客,创建主题门户或聚合RSS源.
3,wordpress自动采集含咖啡因的内容
此插件根据关键字搜索Youtube,Yahoo Answer,文章和文件,以获取相关内容. 它可以保存原创文本或将其翻译成多个国家/地区的语言,并可以及时,定量地自动将其发布到您的博客中. 该功能非常强大. 如果您想自己进行二次开发,使用它作为基础是一个很好的选择.
4,wordpress自动采集插件-FeedWordPress
此插件非常好,主要用于阅读供稿以完成博客文章更新,这是全文方法. 优点是插件会及时更新和升级!建议不要使用中文包,而要使用英文版的WordPress和原创的FeedWordPress插件!下载插件后,需要在后台控制面板中将其激活,并根据需要自定义功能.
5,wordpress自动采集插件-朋友RSS聚合器(FRA)
朋友RSS聚合器(FRA)可以通过RSS聚合此插件,它只是实际文章的标题,发布日期等.
6,wordpress自动采集插件WP-o-Matic. 这个插件是一个非常有效的WordPress集合插件. 尽管缺少自动分类功能,但该插件在所有方面均表现良好. 对于wordpress采集插件Caffeinated Content,wp-o-matic不错,选择通过RSS来完成博客的自动采集.
7,wordpress自动采集插件BDP RSS聚合器
此插件可以汇总多个博客的内容. 适用于具有多个博客的博客作者,也许是资本汇总和共享型博客作者,以及聚集了多个博客内容的团体博客作者.
8,wordpress自动采集和发布插件WP Robot
此插件是一个基于wordpress频道内容的采集工具. WP robot是英文网站工具. 假设选择了主题,它将自动搜索支持雅虎答案集合的德语,法语,英语和西班牙语的相关帖子.
9,wordpress自动采集插件inlineRSS
此插件可以支持多种格式,例如RSS,RDF,XML或HTML. 通过Inlinefeed,RSS源中的文章实际上可以收录在特定文章中.
10,wordpress自动采集插件智能
该插件可以根据需要自动将RSS中的文章自动发布到wordpress博客,从而使wordpress具有类似于某些CMS的自动采集功能.
当前,WordPress已成为建立博客的主流方式,它具有许多易于扩展的插件和模板. 这些插件的目的是促进我们采集网站,节省人力和时间并很好地更新其博客内容. 选择一个您想要尝试的自动采集插件!
标签: WordPress插件WordPress采集插件
WordPress中文自动采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 555 次浏览 • 2020-08-06 14:11
这样做的好处是可以节省人力并实现工作自动化,并且可以最大程度地优化资源并加快收录更多搜索引擎的速度.
以下是几个功能强大的中文自动采集插件(包括商业插件):
更新: 2018.12.11添加了水脉烟熏香淘宝来宾插件介绍
一个,WP-AutoBlog
WP-AutoBlog可以采集任何网站的内容,并且采集的信息一目了然
WP-AutoBlog是一个新开发的插件(不再对原创WP-AutoPost进行更新和维护),它完全支持PHP7更快,更稳定
新的架构和设计,集合设置更加全面和灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,轻松访问高质量的原创文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持.
可以采集微信公众号,头条新闻和其他自媒体内容. 由于百度不包括官方帐户,头条新闻等,因此可以轻松获得高质量的“原创”文章,从而增加了百度的收录量和网站权重
通过简单的设置,您可以从任何网站采集内容,还可以将多个采集任务设置为同时运行. 您可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上次检测采集时间,下一次检测的估计采集时间,最新采集的文章,已采集和更新的文章数以及其他易于查看和查看的信息. 管理.
文章管理功能方便查询,搜索和删除采集的文章. 改进的算法从根本上消除了同一文章的重复采集. 日志功能记录采集过程中的异常和抓取错误,便于检查和设置维修错误.
第二个,imwprobot
imwprobot是由imwpweb开发的自动采集插件. 与其他采集插件不同,imwprobot本身已经完成了大部分工作. 您所需要做的就是找到一个或多个采集站点,并添加一个网址以开始采集. 采集URL列表的规则相对简单,因此可以直接在本地完成,而采集的内容则更为复杂. 原因是每个网站的结构不一致,并且需要在云中进行复杂的计算才能给出网站的主要内容并将其放置在用户身上. 最终太耗资源了.
以下描述了插件的工作方式. 安装插件后,您可以在后台面板中看到一个新添加的菜单: imwp 采集
功能列表
1. 支持网页列表采集,RSS采集(无论RSS是全文还是摘要)
2. 自动识别文章标题
3. 全自动工作流程
4. 支持过滤文章中的链接,图片,列表,表格,表格
5. 支持修复网页中无序的html
<p>6. 支持图像定位并突破防水 查看全部
在建立新闻或cms网站时,自动采集是非常重要的策略. 有几种采集方法. 一种是使用外部软件(例如优采云 采集)进行独立采集,然后使用插件导入WordPress. 另一种是直接在WordPress中设置任务,然后让系统自动采集任务.
这样做的好处是可以节省人力并实现工作自动化,并且可以最大程度地优化资源并加快收录更多搜索引擎的速度.
以下是几个功能强大的中文自动采集插件(包括商业插件):
更新: 2018.12.11添加了水脉烟熏香淘宝来宾插件介绍
一个,WP-AutoBlog
WP-AutoBlog可以采集任何网站的内容,并且采集的信息一目了然
WP-AutoBlog是一个新开发的插件(不再对原创WP-AutoPost进行更新和维护),它完全支持PHP7更快,更稳定
新的架构和设计,集合设置更加全面和灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,轻松访问高质量的原创文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持.
可以采集微信公众号,头条新闻和其他自媒体内容. 由于百度不包括官方帐户,头条新闻等,因此可以轻松获得高质量的“原创”文章,从而增加了百度的收录量和网站权重
通过简单的设置,您可以从任何网站采集内容,还可以将多个采集任务设置为同时运行. 您可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上次检测采集时间,下一次检测的估计采集时间,最新采集的文章,已采集和更新的文章数以及其他易于查看和查看的信息. 管理.
文章管理功能方便查询,搜索和删除采集的文章. 改进的算法从根本上消除了同一文章的重复采集. 日志功能记录采集过程中的异常和抓取错误,便于检查和设置维修错误.
第二个,imwprobot
imwprobot是由imwpweb开发的自动采集插件. 与其他采集插件不同,imwprobot本身已经完成了大部分工作. 您所需要做的就是找到一个或多个采集站点,并添加一个网址以开始采集. 采集URL列表的规则相对简单,因此可以直接在本地完成,而采集的内容则更为复杂. 原因是每个网站的结构不一致,并且需要在云中进行复杂的计算才能给出网站的主要内容并将其放置在用户身上. 最终太耗资源了.
以下描述了插件的工作方式. 安装插件后,您可以在后台面板中看到一个新添加的菜单: imwp 采集
功能列表
1. 支持网页列表采集,RSS采集(无论RSS是全文还是摘要)
2. 自动识别文章标题
3. 全自动工作流程
4. 支持过滤文章中的链接,图片,列表,表格,表格
5. 支持修复网页中无序的html
<p>6. 支持图像定位并突破防水
WordPress手动采集发布文章04-如何批量定时发布文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-08-03 22:04
这一讲中,我们瞧瞧哈默插件的配置
哈默插件里有2个文件:
You must be logged in to view the hidden contents.
那假如我们想更改定时发布文章的规则,就须要更改 hm-locowp.php
下面是关于插件的一些使用说明:
/* Wordpress-Post-Interface-v3.1 (2010.08.03)
WordPress免登录发布接口,支持Wordpress2.5+版本。最新验证支持Wordpress3.x
适用于火车头采集器等任意采集器或脚本程序进行日志发布。
****最新版本或者意见建议请访问 http://www.hamo.cn/u/14***
功能:
1\. 随机时间安排与预约发布功能: 可以设定发布时间以及启用预约发布功能
2\. 自动处理服务器时间与博客时间的时区差异
3\. 永久链接的自动翻译设置。根据标题自动翻译为英文并进行seo处理
5\. 多标签处理(多个标签可以用火车头默认的tag|||tag2|||tag3的形式)
6\. 增加了发文后ping功能
7\. 增加了“pending review”的设置
8\. 增加了多作者功能,发布参数中指定post_author
9\. 增加了自定义域功能,发布参数指定post_meta_list=key1$$value1|||key2$$value2,不同域之间用|||隔开,名称与内容之间用$$隔开。
使用说明:(按照需求修改配置参数)
$post_author = 1; //作者的id,默认为admin
$post_status = "publish"; //"future":预约发布,"publish":立即发布,"pending":待审核
$time_interval = 60; //发布时间间隔,单位为秒 。可是设置随机数值表达式,如如12345 * rand(0,17)
$post_next = "next"; //now:发布时间=当前时间+间隔时间值
//next: 发布时间=最后一篇时间+间隔时间值
$post_ping = false; //发布后是否执行ping
$translate_slug = false; //是否将中文标题翻译为英文做slug
$secretWord = 'abcd1234s'; //接口密码,如果不需要密码,则设为$secretWord=false ;
*/
在这里主要介绍3个配置:
$post_status指的是:wordpress的发布状态。如果是定时发布的话,就设置为”future”
time_interval指的是:发布时间间隔,它和post_next配合使用,定义的是时间间隔
$post_next指的是:发布的计时方法自动采集文章文章自动采集文章文章,now:发布时间=当前时间+间隔时间值next: 发布时间=最后一篇时间+间隔时间值
哈默插件默认的配置是:
post_status = “future”;time_interval = 86400 * rand(0,100);
$post_next = “now”;
future 代表定时发布
86400秒 = 1天,然后随机到100天发布,那假如我采集了50个文章时,相当于平均每晚发布:50/100 = 0.5篇文章。
也就是说,平均 2 天会发布一篇文章。
来到后台,大致瞧瞧也确实这么。这就是关于定时发布文件的设置
实战
假如我想使文章在10天内全部发完,只须要:
$time_interval = 86400 * rand(0,10);
然后将修改后的哈默插件上传到服务器,先把之前的采集文章在wordpress后台删掉掉。
把任务设为:未发布状态:
.png - wordpress手动发布文章04-如何批量定时发布文章
再次点击:开始发布,这个时侯瞧瞧后台的文章。就相当于1天发送2篇文章以上了。
定时发布遗失问题
需要用到一款插件:Scheduled.php
下载地址:链接: 密码:jfvp
我们把它上传到服务器的插件文件夹中。
You must be logged in to view the hidden contents.
然后登录到wordpress仪表盘,启用一下插件
这样能够避免定时发布遗失问题 查看全部
要实现批量设置发布文章的话,我们须要使用优采云配合哈默插件来进行文章的发布,在上一讲中,我们成功实现文章的批量发布。
这一讲中,我们瞧瞧哈默插件的配置
哈默插件里有2个文件:
You must be logged in to view the hidden contents.
那假如我们想更改定时发布文章的规则,就须要更改 hm-locowp.php
下面是关于插件的一些使用说明:
/* Wordpress-Post-Interface-v3.1 (2010.08.03)
WordPress免登录发布接口,支持Wordpress2.5+版本。最新验证支持Wordpress3.x
适用于火车头采集器等任意采集器或脚本程序进行日志发布。
****最新版本或者意见建议请访问 http://www.hamo.cn/u/14***
功能:
1\. 随机时间安排与预约发布功能: 可以设定发布时间以及启用预约发布功能
2\. 自动处理服务器时间与博客时间的时区差异
3\. 永久链接的自动翻译设置。根据标题自动翻译为英文并进行seo处理
5\. 多标签处理(多个标签可以用火车头默认的tag|||tag2|||tag3的形式)
6\. 增加了发文后ping功能
7\. 增加了“pending review”的设置
8\. 增加了多作者功能,发布参数中指定post_author
9\. 增加了自定义域功能,发布参数指定post_meta_list=key1$$value1|||key2$$value2,不同域之间用|||隔开,名称与内容之间用$$隔开。
使用说明:(按照需求修改配置参数)
$post_author = 1; //作者的id,默认为admin
$post_status = "publish"; //"future":预约发布,"publish":立即发布,"pending":待审核
$time_interval = 60; //发布时间间隔,单位为秒 。可是设置随机数值表达式,如如12345 * rand(0,17)
$post_next = "next"; //now:发布时间=当前时间+间隔时间值
//next: 发布时间=最后一篇时间+间隔时间值
$post_ping = false; //发布后是否执行ping
$translate_slug = false; //是否将中文标题翻译为英文做slug
$secretWord = 'abcd1234s'; //接口密码,如果不需要密码,则设为$secretWord=false ;
*/
在这里主要介绍3个配置:
$post_status指的是:wordpress的发布状态。如果是定时发布的话,就设置为”future”
time_interval指的是:发布时间间隔,它和post_next配合使用,定义的是时间间隔
$post_next指的是:发布的计时方法自动采集文章文章自动采集文章文章,now:发布时间=当前时间+间隔时间值next: 发布时间=最后一篇时间+间隔时间值
哈默插件默认的配置是:
post_status = “future”;time_interval = 86400 * rand(0,100);
$post_next = “now”;
future 代表定时发布
86400秒 = 1天,然后随机到100天发布,那假如我采集了50个文章时,相当于平均每晚发布:50/100 = 0.5篇文章。
也就是说,平均 2 天会发布一篇文章。
来到后台,大致瞧瞧也确实这么。这就是关于定时发布文件的设置
实战
假如我想使文章在10天内全部发完,只须要:
$time_interval = 86400 * rand(0,10);
然后将修改后的哈默插件上传到服务器,先把之前的采集文章在wordpress后台删掉掉。
把任务设为:未发布状态:

.png - wordpress手动发布文章04-如何批量定时发布文章
再次点击:开始发布,这个时侯瞧瞧后台的文章。就相当于1天发送2篇文章以上了。
定时发布遗失问题
需要用到一款插件:Scheduled.php
下载地址:链接: 密码:jfvp
我们把它上传到服务器的插件文件夹中。
You must be logged in to view the hidden contents.
然后登录到wordpress仪表盘,启用一下插件
这样能够避免定时发布遗失问题
rootgrandfather/collector: 这是一个由golang编撰
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2020-08-25 01:41
万能文章采集器(collector)
这是一个由golang编撰的采集器,可以手动辨识文章列表和文章内容。使用它来采集文章并不需要编撰正则表达式,你只须要提供文章列表页的联接即可。
为什么会有这个万能文章采集器万能文章采集器能采集哪些内容
本采集器可以采集到的的内容有:文章标题、文章关键词、文章描述、文章详情内容、文章作者、文章发布时间、文章浏览量。
什么时候须要使用到万能文章采集器
当我们须要给网站采集文章的时侯,本采集器就可以派上用场了,本采集器不需要有人值守,24小时不间断运行,每隔10分钟都会手动遍历一遍采集列表,抓取收录有文章的联接,随时将文字抓取回去,还可以设置手动发布,自动发布到指定文章表中。
万能文章采集器可用在那里运行
本采集器可用运行在 Windows系统、Mac 系统、Linux系统(Centos、Ubuntu等),可用下载编译好的程序直接执行,也可以下载源码自己编译。
万能文章采集器可用伪原创吗
本采集器暂时还不支持伪原创功能,后期会降低适当的伪原创选项。
如何安装使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行下边命令
go mod tidy
go mod vendor
go build
编译结束后,配置config。重命名config.dist.json为config.json,打开config.json,修改mysql部份的配置,填写为你的mysql地址、用户名、密码、数据库信息,导入mysql.sql到填写的数据库中,然后双击运行可执行文件即可开始采集之旅。
添加待采集文章列表说明
第一版仍未有可视化界面,因此须要你使用数据库工具打开fe_article_source 表,在里面填充采集列表,只须要将须要采集的列表填写到url数组即可,一行一个。
config.json配置说明
{
"mysql": { //数据库配置
"Database": "collector",
"User": "root",
"Password": "root",
"Charset": "utf8mb4",
"Host": "127.0.0.1",
"TablePrefix": "fe_",
"Port": 3306,
"MaxIdleConnections": 1000,
"MaxOpenConnections": 100000
},
"server": { //采集器运行配置
"SiteName" : "万能采集器",
"Host" : "localhost",
"Env" : "development",
"Port" : 8088
},
"collector": { //采集规则
"ErrorTimes": 5, //列表访问错误多少次后抛弃该列表连接
"Channels": 5, //同时使用多少个通道执行
"TitleMinLength": 6, //最小标题长度,小于该长度的会自动放弃
"ContentMinLength": 200, //最小详情长度,小于该长度的会自动放弃
"TitleExclude": [ //标题不包含关键词,出现这些关键词的会自动放弃
"法律声明",
"关于我们",
"站点地图"
],
"TitleExcludePrefix": [ //标题不包含开头,以这些开头的会自动放弃
"404",
"403",
"NotFound"
],
"TitleExcludeSuffix": [ //标题不包含结尾,以这些开头的会自动放弃
"网站",
"网",
"政府",
"门户"
],
"ContentExclude": [ //内容不包含关键词,出现这些关键词的会自动放弃
"ICP备",
"政府网站标识码",
"以上版本浏览本站",
"版权声明",
"公网安备"
],
"ContentExcludeLine": [ //内容不包含关键词的行,出现这些关键词的行会自动放弃
"背景色:",
"时间:",
"作者:",
"qrcode"
]
},
"content": { //自动发布设置
"AutoPublish": true, //是否自动发布,true为自动
"TableName": "fe_new_article", //自动发布到的文章表名
"IdField": "id", //文章表的id字段名
"TitleField": "title", //文章表的标题字段名
"CreatedTimeField": "created_time", //文章表的发布时间字段名,时间戳方式
"KeywordsField": "keywords", //文章表的关键词字段名
"DescriptionField": "description", //文章表的描述字段名
"AuthorField": "author", //文章表的作者字段名
"ViewsField": "views", //文章表的浏览量字段名
"ContentTableName": "fe_new_article_data", //如果文章内容表和文章表不是同一个表,则在这里填写指定表面,如果相同,则填写相同的名称
"ContentIdField": "id", //文章内容表的id字段名
"ContentField": "content" //文章内容表或文字表的id字段名
}
}
开发计划协助建立
欢迎有能力有贡献精神的个人或团体参与到本采集器的开发建立工作中来,共同构建采集功能。请fork一个分支,然后在里面更改,修改完了递交pull request合并恳求。 查看全部
rootgrandfather/collector: 这是一个由golang编撰
万能文章采集器(collector)
这是一个由golang编撰的采集器,可以手动辨识文章列表和文章内容。使用它来采集文章并不需要编撰正则表达式,你只须要提供文章列表页的联接即可。
为什么会有这个万能文章采集器万能文章采集器能采集哪些内容
本采集器可以采集到的的内容有:文章标题、文章关键词、文章描述、文章详情内容、文章作者、文章发布时间、文章浏览量。
什么时候须要使用到万能文章采集器
当我们须要给网站采集文章的时侯,本采集器就可以派上用场了,本采集器不需要有人值守,24小时不间断运行,每隔10分钟都会手动遍历一遍采集列表,抓取收录有文章的联接,随时将文字抓取回去,还可以设置手动发布,自动发布到指定文章表中。
万能文章采集器可用在那里运行
本采集器可用运行在 Windows系统、Mac 系统、Linux系统(Centos、Ubuntu等),可用下载编译好的程序直接执行,也可以下载源码自己编译。
万能文章采集器可用伪原创吗
本采集器暂时还不支持伪原创功能,后期会降低适当的伪原创选项。
如何安装使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行下边命令
go mod tidy
go mod vendor
go build
编译结束后,配置config。重命名config.dist.json为config.json,打开config.json,修改mysql部份的配置,填写为你的mysql地址、用户名、密码、数据库信息,导入mysql.sql到填写的数据库中,然后双击运行可执行文件即可开始采集之旅。
添加待采集文章列表说明
第一版仍未有可视化界面,因此须要你使用数据库工具打开fe_article_source 表,在里面填充采集列表,只须要将须要采集的列表填写到url数组即可,一行一个。
config.json配置说明
{
"mysql": { //数据库配置
"Database": "collector",
"User": "root",
"Password": "root",
"Charset": "utf8mb4",
"Host": "127.0.0.1",
"TablePrefix": "fe_",
"Port": 3306,
"MaxIdleConnections": 1000,
"MaxOpenConnections": 100000
},
"server": { //采集器运行配置
"SiteName" : "万能采集器",
"Host" : "localhost",
"Env" : "development",
"Port" : 8088
},
"collector": { //采集规则
"ErrorTimes": 5, //列表访问错误多少次后抛弃该列表连接
"Channels": 5, //同时使用多少个通道执行
"TitleMinLength": 6, //最小标题长度,小于该长度的会自动放弃
"ContentMinLength": 200, //最小详情长度,小于该长度的会自动放弃
"TitleExclude": [ //标题不包含关键词,出现这些关键词的会自动放弃
"法律声明",
"关于我们",
"站点地图"
],
"TitleExcludePrefix": [ //标题不包含开头,以这些开头的会自动放弃
"404",
"403",
"NotFound"
],
"TitleExcludeSuffix": [ //标题不包含结尾,以这些开头的会自动放弃
"网站",
"网",
"政府",
"门户"
],
"ContentExclude": [ //内容不包含关键词,出现这些关键词的会自动放弃
"ICP备",
"政府网站标识码",
"以上版本浏览本站",
"版权声明",
"公网安备"
],
"ContentExcludeLine": [ //内容不包含关键词的行,出现这些关键词的行会自动放弃
"背景色:",
"时间:",
"作者:",
"qrcode"
]
},
"content": { //自动发布设置
"AutoPublish": true, //是否自动发布,true为自动
"TableName": "fe_new_article", //自动发布到的文章表名
"IdField": "id", //文章表的id字段名
"TitleField": "title", //文章表的标题字段名
"CreatedTimeField": "created_time", //文章表的发布时间字段名,时间戳方式
"KeywordsField": "keywords", //文章表的关键词字段名
"DescriptionField": "description", //文章表的描述字段名
"AuthorField": "author", //文章表的作者字段名
"ViewsField": "views", //文章表的浏览量字段名
"ContentTableName": "fe_new_article_data", //如果文章内容表和文章表不是同一个表,则在这里填写指定表面,如果相同,则填写相同的名称
"ContentIdField": "id", //文章内容表的id字段名
"ContentField": "content" //文章内容表或文字表的id字段名
}
}
开发计划协助建立
欢迎有能力有贡献精神的个人或团体参与到本采集器的开发建立工作中来,共同构建采集功能。请fork一个分支,然后在里面更改,修改完了递交pull request合并恳求。
anyproxy批量自动采集微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 548 次浏览 • 2020-08-24 17:30
我从2014年就开始做微信公众号内容的批量采集,最开始的目的是为了做一个html5的垃圾内容网站。当时垃圾站采集到的微信公众号的内容很容易在公众号上面传播。当时批量采集特别好做,采集入口是公众号的历史消息页。这个入口到如今也是一样,只不过越来越难采集了。采集的形式也更新换代了好多个版本。后来在2015年html5垃圾站不做了,转向将采集目标定位在本地新闻资讯类公众号,前端显示弄成了app。所以就产生了一个可以手动采集公众号内容的新闻app。曾经我仍然担忧有三天陌陌技术升级以后难以采集内容了,我的新闻app就失效了。但随着陌陌不断的技术升级,采集方法也骤然升级,反而让我越来越有信心。只要公众号历史消息页存在,就能批量采集到内容。所以明天决定将采集方法整理过后写出来。我的方式来源于许多同行的分享精神,所以我也会延续这个精神,将我的成果分享下来。
本篇文章将持续更新,你所看见的内容将保证在听到的时间是可用的。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017年1月11日更新=========
现在按照不同的陌陌个人号,会出现两种不同的历史消息页面地址,下面是另一种历史消息页的地址,第一种地址的链接会在anyproxy中显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一种链接地址的页面款式:
第二种链接地址的页面款式:
根据目前把握的信息,两种页面方式无规律的出现在不同的微信号中,有的微信号仍然是第一种页面方式,有的就一直是第二种页面方式。
上面这个链接是一个微信公众号历史消息页面的真实链接,但是我们把这个链接输入到浏览器中会显示:请从陌陌客户端访问。这是因为实际上这个链接地址还须要几个参数能够正常显示内容。下面我们就来瞧瞧可以正常显示内容的完整链接是什么样的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过陌陌客户端打开历史消息页面然后,再使用前面介绍的代理服务器软件获取到的。这上面有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
其中重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz是公众号的一个类似id的参数,每个公众号拥有一个陌陌的biz,目前极小机率会发生公众号的biz会变化的风波;
剩下的3个参数是有关用户的id和令牌票据之类的意思,这3个参数的值是通过陌陌的客户端生成后手动补充到地址栏中的。所以我们想采集公众号就必须通过一个陌陌客户端app。在先前的陌陌版本中这3个参数还可以获取一次以后在有效期之内多个公众号通用。现在的版本早已是每次访问一个公众号就会更换参数值。
我如今所使用的方式只须要关注__biz这个参数就可以了。
我的采集系统由以下几部份组成:
1、一个陌陌客户端:可以是一台手机安装了陌陌的app,或者是用笔记本中的安卓模拟器。经过实测ios的陌陌客户端在批量采集过程中崩溃率低于安卓系统。为了增加成本,我使用的是安卓模拟器。
2、一个陌陌个人号:为了采集内容除了须要陌陌客户端,还要有一个陌陌个人号专门用于采集,因为这个微信号就干不了其它事情了。
3、本地代理服务器系统:目前使用的方式是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器上。具体安装设置方式在前面详尽介绍。
4、文章列表剖析与入库系统:我用的是php语言编撰的,后文将详尽介绍怎么剖析文章列表和完善采集队列实现批量采集内容。
步骤
一、安装模拟器或使用手机安装陌陌客户端app,申请陌陌个人号并登陆到app里面。这一点就不过多介绍了,大家还会。
二、代理服务器系统安装
目前我使用的是Anyproxy,AnyProxy。这个软件的特性是可以获取到https链接的内容。在2016年年初的时侯微信公众号和陌陌文章开始使用https链接。并且Anyproxy可以通过更改rule配置实现向公众号的页面中插入脚本代码。下面开始介绍安装与配置过程。
1、安装NodeJS
2、在命令行或则终端运行 npm install -g anyproxy,mac系统须要加上sudo;
3、生成RootCA,https须要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy运行命令:sudo anyproxy -i;参数-i是解析HTTPS的意思;
5、安装证书,在手机或安卓模拟器中安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网段,可以通过吧dhcp设置为静态后见到网段地址,看完后别忘了再设置为手动。手机中的代理服务器地址就是运行anyproxy的笔记本的ip地址。代理服务器默认端口是8001;
现在打开陌陌,点击到任意一个公众号历史消息或文章中,在终端都可以见到响应的代码滚动。如果没有出现,请复查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看见anyproxy的web界面。从陌陌中点开一个历史消息页面,然后再看浏览器的web界面,会滚动出现历史消息页面的地址。
以/mp/getmasssendmsg开头的网址就是陌陌历史消息页面。左边一个小锁头表示这个页面是https加密的。现在我们点击一下这一行;
=========2017年1月11日更新=========
部分微信号以/mp/getmasssendmsg开头的网址会出现302跳转,跳转到了/mp/profile_ext?action=home开头的地址。所以点开这个地址才可以看见内容。
右边倘若出现了html的文件内容则表示揭秘成功。如果没有内容,请复查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机是否正确安装证书。
现在我们的手机中的所有内容都早已可以明文通过代理服务器了。下面我们要更改配置代理服务器,使公众号内容被获取到。
一、找到配置文件:
mac系统中配置文件的位置在/usr/local/lib/node_modules/anyproxy/lib/;windows系统请原谅我暂时不知道。应该可以按照类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详尽阅读注释,这里只是介绍原理,理解后依照自己的条件更改内容):
=========2017年1月11日更新=========
因为出现了两种页面方式,且在不同的微信号中仍然显示同一种页面方式,但为了能兼容两种页面方式,以下的代码会保留两种页面方式的判定,你也可以按照自己的页面方式除去li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面这段代码是借助anyproxy可以更改返回页面内容的功能,向页面注入脚本,和将页面内容发送到服务器上。使用这个原理来批量采集公众号内容和阅读量。这段脚本中自定义了一个函数,下面详尽介绍:
在rule_default.js文件末尾添加以下代码: 查看全部
anyproxy批量自动采集微信公众号文章
我从2014年就开始做微信公众号内容的批量采集,最开始的目的是为了做一个html5的垃圾内容网站。当时垃圾站采集到的微信公众号的内容很容易在公众号上面传播。当时批量采集特别好做,采集入口是公众号的历史消息页。这个入口到如今也是一样,只不过越来越难采集了。采集的形式也更新换代了好多个版本。后来在2015年html5垃圾站不做了,转向将采集目标定位在本地新闻资讯类公众号,前端显示弄成了app。所以就产生了一个可以手动采集公众号内容的新闻app。曾经我仍然担忧有三天陌陌技术升级以后难以采集内容了,我的新闻app就失效了。但随着陌陌不断的技术升级,采集方法也骤然升级,反而让我越来越有信心。只要公众号历史消息页存在,就能批量采集到内容。所以明天决定将采集方法整理过后写出来。我的方式来源于许多同行的分享精神,所以我也会延续这个精神,将我的成果分享下来。
本篇文章将持续更新,你所看见的内容将保证在听到的时间是可用的。
首先我们来看一个微信公众号历史消息页面的链接地址:
http://mp.weixin.qq.com/mp/get ... irect
=========2017年1月11日更新=========
现在按照不同的陌陌个人号,会出现两种不同的历史消息页面地址,下面是另一种历史消息页的地址,第一种地址的链接会在anyproxy中显示302跳转:
https://mp.weixin.qq.com/mp/pr ... irect
第一种链接地址的页面款式:
第二种链接地址的页面款式:
根据目前把握的信息,两种页面方式无规律的出现在不同的微信号中,有的微信号仍然是第一种页面方式,有的就一直是第二种页面方式。
上面这个链接是一个微信公众号历史消息页面的真实链接,但是我们把这个链接输入到浏览器中会显示:请从陌陌客户端访问。这是因为实际上这个链接地址还须要几个参数能够正常显示内容。下面我们就来瞧瞧可以正常显示内容的完整链接是什么样的:
//第一种链接
http://mp.weixin.qq.com/mp/get ... r%3D1
//第二种
http://mp.weixin.qq.com/mp/pro ... r%3D1
这个地址是通过陌陌客户端打开历史消息页面然后,再使用前面介绍的代理服务器软件获取到的。这上面有几个参数:
action=;__biz=;uin=;key=;devicetype=;version=;lang=;nettype=;scene=;pass_ticket=;wx_header=;
其中重要的参数是:__biz;uin=;key=;pass_ticket=;这4个参数。
__biz是公众号的一个类似id的参数,每个公众号拥有一个陌陌的biz,目前极小机率会发生公众号的biz会变化的风波;
剩下的3个参数是有关用户的id和令牌票据之类的意思,这3个参数的值是通过陌陌的客户端生成后手动补充到地址栏中的。所以我们想采集公众号就必须通过一个陌陌客户端app。在先前的陌陌版本中这3个参数还可以获取一次以后在有效期之内多个公众号通用。现在的版本早已是每次访问一个公众号就会更换参数值。
我如今所使用的方式只须要关注__biz这个参数就可以了。
我的采集系统由以下几部份组成:
1、一个陌陌客户端:可以是一台手机安装了陌陌的app,或者是用笔记本中的安卓模拟器。经过实测ios的陌陌客户端在批量采集过程中崩溃率低于安卓系统。为了增加成本,我使用的是安卓模拟器。
2、一个陌陌个人号:为了采集内容除了须要陌陌客户端,还要有一个陌陌个人号专门用于采集,因为这个微信号就干不了其它事情了。
3、本地代理服务器系统:目前使用的方式是通过Anyproxy代理服务器将公众号历史消息页面中的文章列表发送到自己的服务器上。具体安装设置方式在前面详尽介绍。
4、文章列表剖析与入库系统:我用的是php语言编撰的,后文将详尽介绍怎么剖析文章列表和完善采集队列实现批量采集内容。
步骤
一、安装模拟器或使用手机安装陌陌客户端app,申请陌陌个人号并登陆到app里面。这一点就不过多介绍了,大家还会。
二、代理服务器系统安装
目前我使用的是Anyproxy,AnyProxy。这个软件的特性是可以获取到https链接的内容。在2016年年初的时侯微信公众号和陌陌文章开始使用https链接。并且Anyproxy可以通过更改rule配置实现向公众号的页面中插入脚本代码。下面开始介绍安装与配置过程。
1、安装NodeJS
2、在命令行或则终端运行 npm install -g anyproxy,mac系统须要加上sudo;
3、生成RootCA,https须要这个证书:运行命令sudo anyproxy --root(windows可能不需要sudo);
4、启动anyproxy运行命令:sudo anyproxy -i;参数-i是解析HTTPS的意思;
5、安装证书,在手机或安卓模拟器中安装证书:
6、设置代理:安卓模拟器的代理服务器地址是wifi链接的网段,可以通过吧dhcp设置为静态后见到网段地址,看完后别忘了再设置为手动。手机中的代理服务器地址就是运行anyproxy的笔记本的ip地址。代理服务器默认端口是8001;
现在打开陌陌,点击到任意一个公众号历史消息或文章中,在终端都可以见到响应的代码滚动。如果没有出现,请复查手机的代理设置是否正确。
现在打开浏览器地址localhost:8002可以看见anyproxy的web界面。从陌陌中点开一个历史消息页面,然后再看浏览器的web界面,会滚动出现历史消息页面的地址。
以/mp/getmasssendmsg开头的网址就是陌陌历史消息页面。左边一个小锁头表示这个页面是https加密的。现在我们点击一下这一行;
=========2017年1月11日更新=========
部分微信号以/mp/getmasssendmsg开头的网址会出现302跳转,跳转到了/mp/profile_ext?action=home开头的地址。所以点开这个地址才可以看见内容。
右边倘若出现了html的文件内容则表示揭秘成功。如果没有内容,请复查anyproxy的运行模式是否有参数i,是否生成了ca证书,手机是否正确安装证书。
现在我们的手机中的所有内容都早已可以明文通过代理服务器了。下面我们要更改配置代理服务器,使公众号内容被获取到。
一、找到配置文件:
mac系统中配置文件的位置在/usr/local/lib/node_modules/anyproxy/lib/;windows系统请原谅我暂时不知道。应该可以按照类似mac的文件夹地址找到这个目录。
二、修改文件rule_default.js
找到replaceServerResDataAsync: function(req,res,serverResData,callback) 函数
修改函数内容(请注意详尽阅读注释,这里只是介绍原理,理解后依照自己的条件更改内容):
=========2017年1月11日更新=========
因为出现了两种页面方式,且在不同的微信号中仍然显示同一种页面方式,但为了能兼容两种页面方式,以下的代码会保留两种页面方式的判定,你也可以按照自己的页面方式除去li
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
if(serverResData.toString() !== ""){
try {//防止报错退出程序
var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis.php', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);//错误捕捉
}
callback(serverResData);//直接返回第二页json内容
}
}
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
try {
var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
var ret = reg.exec(serverResData.toString());//转换变量为string
HttpPost(ret[1],req.url,"getMsgJson.php");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
var http = require('http');
http.get('http://xxx.com/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
})
});
}catch(e){
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"getMsgJson.php");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
try {
HttpPost(serverResData,req.url,"getMsgExt.php");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
try {
var http = require('http');
http.get('http://xxx.com/getWxPost.php', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
},
上面这段代码是借助anyproxy可以更改返回页面内容的功能,向页面注入脚本,和将页面内容发送到服务器上。使用这个原理来批量采集公众号内容和阅读量。这段脚本中自定义了一个函数,下面详尽介绍:
在rule_default.js文件末尾添加以下代码:
简书文章自动采集测试版
采集交流 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2020-08-24 17:09
主要功能描述:采集简书搜索关键词和专题,自动发布到峰会、门户、群组
测试峰会:
使用说明文档链接:
测试版只是提供给你们了解此插件,不能常年使用
后台 设置
是否手动采集发帖:
若开启会手动采集网站导航内容而且手动发布到网站导航指定的蓝筹股或门户
每次手动发贴数目:
若 是否手动发贴 已开启此设置生效,可以控制每次手动回帖的回帖数目,若开启图片本地化建议不要设置很大,0不手动发布,限制为5
发帖是否进初审:
是:采集资源发贴并步入初审状态,后台内容初审通过前台才能展示;否:若采集信息命中后台关键词,发帖进初审,否则前台直接显示
发帖时间:
不填发贴时间为当前手动发贴时间;填写格式为以秒为单位的整数时间用-分割;例如0-3600,发帖时间为当前采集时间乘以0-3600时间段随机的时间
帖子浏览量:
不填浏览量默认为0;填写格式整数-分割;例如0-100,随机0-100范围的整数设置为浏览量
图片是否居中展示:
若开启贴子或门户图片单行居中展示
图片是否本地储存:
是:采集资源图片保存到本地,占用本地c盘,选择此项请注意服务器硬碟空间是否充足;否:图片远程访问,此时非本站图片为盗链模式,第三方网站若加了防盗链图片将难以显示,此时建议开启图片盗链访问
是否开启图片盗链:
若开启第三方图片资源将缓存到本地,定期清理节约服务器空间
伪原创替换比列:
控制替换关键词的比列,0%为关掉伪原创功能
帖子展示款式:
自定义贴子大厦css展示款式,必须收录,可清空贴子展示将不受影响
门户展示款式:
自定义门户css展示款式,必须收录,可清空文章展示将不受影响 查看全部
简书文章自动采集测试版
主要功能描述:采集简书搜索关键词和专题,自动发布到峰会、门户、群组
测试峰会:
使用说明文档链接:
测试版只是提供给你们了解此插件,不能常年使用
后台 设置
是否手动采集发帖:
若开启会手动采集网站导航内容而且手动发布到网站导航指定的蓝筹股或门户
每次手动发贴数目:
若 是否手动发贴 已开启此设置生效,可以控制每次手动回帖的回帖数目,若开启图片本地化建议不要设置很大,0不手动发布,限制为5
发帖是否进初审:
是:采集资源发贴并步入初审状态,后台内容初审通过前台才能展示;否:若采集信息命中后台关键词,发帖进初审,否则前台直接显示
发帖时间:
不填发贴时间为当前手动发贴时间;填写格式为以秒为单位的整数时间用-分割;例如0-3600,发帖时间为当前采集时间乘以0-3600时间段随机的时间
帖子浏览量:
不填浏览量默认为0;填写格式整数-分割;例如0-100,随机0-100范围的整数设置为浏览量
图片是否居中展示:
若开启贴子或门户图片单行居中展示
图片是否本地储存:
是:采集资源图片保存到本地,占用本地c盘,选择此项请注意服务器硬碟空间是否充足;否:图片远程访问,此时非本站图片为盗链模式,第三方网站若加了防盗链图片将难以显示,此时建议开启图片盗链访问
是否开启图片盗链:
若开启第三方图片资源将缓存到本地,定期清理节约服务器空间
伪原创替换比列:
控制替换关键词的比列,0%为关掉伪原创功能
帖子展示款式:
自定义贴子大厦css展示款式,必须收录,可清空贴子展示将不受影响
门户展示款式:
自定义门户css展示款式,必须收录,可清空文章展示将不受影响
维清陌陌文章采集器 31.0手动采集论坛门
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2020-08-19 11:43
4、《[维清]微信文章DIY》点击安装
安装本扩充后,可以网站的任意页面调用“维清陌陌文章采集器”采集回来的公众号与文章,操作方法与系统本身的其他DIY模块一样。
5、《[维清]插件伪静态》点击安装
实现陌陌头条系统主要页面的链接静态化,让本系统的相关页面更容易被搜索引擎收录!
6、《[维清]百度编辑器》点击安装
本插件是一个免费插件,主要提供文章编辑功能,可以编辑“维清陌陌文章采集器”采集回来的文章。
其他辅助插件:
Wikin!插件二级域名:点击安装
[维清]万能帮助中心:点击安装
功能描述
[维清]微信文章采集器是一款用于采集微信订阅号信息与订阅号文章的插件。只须要输入公众号爱称,就可手动采集公众号信息(信息包括公众号爱称、微信号、功能介绍、认证信息、头像、二维码)。安装本插件,你就可以使你的网站与百万订阅号共享优质内容,每天大量的更新,可以快速提高网站权重与排行。
功能亮点:
1、可自定义插件名称:
您可在后台随便更改面包屑导航上的插件名称,如果不设置则默认为陌陌之窗。
2、可自定义SEO信息:
后台可轻松给每位页面设置SEO信息,支持网站名称、插件名称、分类名称、文章标题等信息的变量替换。
3、可批量采集公众号信息:
输入微信公众号爱称后点击搜索,选择想要采集的公众号,提交即可,单次最多可采集10个公众号信息。
4、可批量采集公众号的文章:
点击公众号列表中的“采集文章”的链接,输入要采集的页数,即可批量采集文章信息,单次最少可采集篇文章,文章内容也本地化。
5、文章信息可完美展示:
插件自建首页,列表页,详情页,可完美展示文章信息,不依赖原系统任何功能。
6、功能强悍的DIY机制:
只要安装diy扩充,你即可拥有强悍的DIY机制,可在网站的任意页面调用微信公众号信息和文章信息。
7、各页面均外置多个DIY区域:
插件的每位页面(首页、列表页、详情页)均外置了多个DIY区域,可以在原有内容区块间插入DIY模块。
8、可灵活设置信息是否须要初审:
用户递交内容公众号、文章信息是否须要初审可以在后台通过开关控制。
9、信息批量管理功能:
后台提供功能健全的微信公众号、文章批量管理功能,可以批量对信息进行初审,删除,移动分类等操作。
10、全面支持手机版:
只需安装对应的手机版组件,即可轻松开启手机版。
演示&优惠
演示地址: 查看全部
维清陌陌文章采集器 31.0手动采集论坛门
4、《[维清]微信文章DIY》点击安装
安装本扩充后,可以网站的任意页面调用“维清陌陌文章采集器”采集回来的公众号与文章,操作方法与系统本身的其他DIY模块一样。
5、《[维清]插件伪静态》点击安装
实现陌陌头条系统主要页面的链接静态化,让本系统的相关页面更容易被搜索引擎收录!
6、《[维清]百度编辑器》点击安装
本插件是一个免费插件,主要提供文章编辑功能,可以编辑“维清陌陌文章采集器”采集回来的文章。
其他辅助插件:
Wikin!插件二级域名:点击安装
[维清]万能帮助中心:点击安装
功能描述
[维清]微信文章采集器是一款用于采集微信订阅号信息与订阅号文章的插件。只须要输入公众号爱称,就可手动采集公众号信息(信息包括公众号爱称、微信号、功能介绍、认证信息、头像、二维码)。安装本插件,你就可以使你的网站与百万订阅号共享优质内容,每天大量的更新,可以快速提高网站权重与排行。
功能亮点:
1、可自定义插件名称:
您可在后台随便更改面包屑导航上的插件名称,如果不设置则默认为陌陌之窗。
2、可自定义SEO信息:
后台可轻松给每位页面设置SEO信息,支持网站名称、插件名称、分类名称、文章标题等信息的变量替换。
3、可批量采集公众号信息:
输入微信公众号爱称后点击搜索,选择想要采集的公众号,提交即可,单次最多可采集10个公众号信息。
4、可批量采集公众号的文章:
点击公众号列表中的“采集文章”的链接,输入要采集的页数,即可批量采集文章信息,单次最少可采集篇文章,文章内容也本地化。
5、文章信息可完美展示:
插件自建首页,列表页,详情页,可完美展示文章信息,不依赖原系统任何功能。
6、功能强悍的DIY机制:
只要安装diy扩充,你即可拥有强悍的DIY机制,可在网站的任意页面调用微信公众号信息和文章信息。
7、各页面均外置多个DIY区域:
插件的每位页面(首页、列表页、详情页)均外置了多个DIY区域,可以在原有内容区块间插入DIY模块。
8、可灵活设置信息是否须要初审:
用户递交内容公众号、文章信息是否须要初审可以在后台通过开关控制。
9、信息批量管理功能:
后台提供功能健全的微信公众号、文章批量管理功能,可以批量对信息进行初审,删除,移动分类等操作。
10、全面支持手机版:
只需安装对应的手机版组件,即可轻松开启手机版。
演示&优惠
演示地址:
新闻源文章生成器如何操作
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-18 15:12
新闻源文章生成器这是一款功能强悍、操作间的新闻源文章生成器,想要使用这款软件的欢迎来下载使用。
新闻源文章生成器简介:
新闻源文章生成器,它可以快速的帮助您手动的生成文章,它是专门为医疗行业新闻源而设计的文章生成软件,支持手动采集文章、批量采集文章链接、将采集下来的文章保存为本地txt文件等功能,非常强悍,大家可以试试。
新闻源文章生成器优点:
1、自动生成文章,生成的文章只须要用新闻源平台的“批量导出”功能即可快速发布。
2、以前发50篇新闻源须要2个小时,现在发布500篇只须要2分钟即可完成。
新闻源文章生成器功能:
1、本软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件。
2、本软件适用于有批量上传功能的新闻源平台。
3、本软件可以采集自家或其他诊所网站上的文章,来作为新闻源的生成文章。
4、本地模式——段落随机组合模式可将已打算好的文章段落随机组合为一篇完整的文章。
5、本地模式——完整文章模式可将已打算好的网站完整文章通过后续处理,生成新闻组。
6、采集下来的文章经过截取、过滤字符、伪原创、插入其它文本、插入JS脚本、插入关键词等功能实现自有化。
7、采集下来的文章保存为本地txt文件,再通过批量上传功能发布,可大大降低新闻源的发布效率。
8、采集链接:批量采集文章链接,为采集文章做打算。
9、保存:将文章生成规则的配置保存上去,便于上次重复借助。
10、打开:打开已保存的文章生成规则,继续先前。
新闻源文章生成器如何操作:
1、准备好文章内容。
2、文章最好与关键字有关,可以通过采集器批量采集。
3、编写关键字等内容。
4、选择其他设置,开始运行即可秒杀生成。 查看全部
新闻源文章生成器如何操作
新闻源文章生成器这是一款功能强悍、操作间的新闻源文章生成器,想要使用这款软件的欢迎来下载使用。
新闻源文章生成器简介:
新闻源文章生成器,它可以快速的帮助您手动的生成文章,它是专门为医疗行业新闻源而设计的文章生成软件,支持手动采集文章、批量采集文章链接、将采集下来的文章保存为本地txt文件等功能,非常强悍,大家可以试试。
新闻源文章生成器优点:
1、自动生成文章,生成的文章只须要用新闻源平台的“批量导出”功能即可快速发布。
2、以前发50篇新闻源须要2个小时,现在发布500篇只须要2分钟即可完成。
新闻源文章生成器功能:
1、本软件是专门为“医疗行业新闻源”设计的新闻源文章生成软件。
2、本软件适用于有批量上传功能的新闻源平台。
3、本软件可以采集自家或其他诊所网站上的文章,来作为新闻源的生成文章。
4、本地模式——段落随机组合模式可将已打算好的文章段落随机组合为一篇完整的文章。
5、本地模式——完整文章模式可将已打算好的网站完整文章通过后续处理,生成新闻组。
6、采集下来的文章经过截取、过滤字符、伪原创、插入其它文本、插入JS脚本、插入关键词等功能实现自有化。
7、采集下来的文章保存为本地txt文件,再通过批量上传功能发布,可大大降低新闻源的发布效率。
8、采集链接:批量采集文章链接,为采集文章做打算。
9、保存:将文章生成规则的配置保存上去,便于上次重复借助。
10、打开:打开已保存的文章生成规则,继续先前。
新闻源文章生成器如何操作:
1、准备好文章内容。
2、文章最好与关键字有关,可以通过采集器批量采集。
3、编写关键字等内容。
4、选择其他设置,开始运行即可秒杀生成。
织梦dede采集侠破解版v2.9.2高速触发教程日采集几万文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-08-13 06:11
前面模板铺分享了一篇《采集侠破解版V2.x版本手动采集触发教程24小时触发更新手动更新》文章。
这种触发方法用的是采集侠免费版js触发的方法,虽然可以达到破解版自己采集的目的,但是必须不停的刷新这个页面,比较麻烦。
这次我们借助宝塔计划任务,帮助我们采集侠破解版用户达到手动采集文章的需求。
https://www.wesbite58.cn/Plugi ... w%3D1
第一步:
上面的替换成自己的域名。
第二步:
登录宝塔面板,选择计划任务,添加访问URL任务,执行周期选择1分钟。我们可以多添加几条任务,加快触发速率。
如果我们想每晚采集几万文章的话,可以自己访问这个链接地址,设置一秒刷新一次,就可以了。
如有不懂的地方,可以加群剖析,或者联系客服,希望这篇文章能帮助到你。
破解版采集侠下载地址: 提取码: 联系站长qq382278608获取 查看全部
采集侠v2.9.2是一款十分优秀的织梦cms采集插件,虽然早已一年多没更新了,但是精典就是精典,依旧有很多站长关注。
前面模板铺分享了一篇《采集侠破解版V2.x版本手动采集触发教程24小时触发更新手动更新》文章。
这种触发方法用的是采集侠免费版js触发的方法,虽然可以达到破解版自己采集的目的,但是必须不停的刷新这个页面,比较麻烦。
这次我们借助宝塔计划任务,帮助我们采集侠破解版用户达到手动采集文章的需求。
https://www.wesbite58.cn/Plugi ... w%3D1
第一步:
上面的替换成自己的域名。
第二步:
登录宝塔面板,选择计划任务,添加访问URL任务,执行周期选择1分钟。我们可以多添加几条任务,加快触发速率。
如果我们想每晚采集几万文章的话,可以自己访问这个链接地址,设置一秒刷新一次,就可以了。
如有不懂的地方,可以加群剖析,或者联系客服,希望这篇文章能帮助到你。
破解版采集侠下载地址: 提取码: 联系站长qq382278608获取
python使用newspaper快速抓取新闻文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2020-08-09 08:44
这个包是须要自己重新安装的。
在settings配置环境,添加包newspaper。
如果添加不进去就使用pip命令添加
打开命令行窗口,输入
pip3 install --ignore-installed --upgrade newspaper3k
如果文章没有指明使用的哪些语言的时侯,Newspaper会尝试手动辨识。
import newspaper
from newspaper import Article
#这里的url可以填写你需要爬取的网址
url = 'http://www.sohu.com/a/284738650_162522?_f=index_chan08news_10'
news = Article(url,language = 'zh')
news.download()
news.parse()
print(news.url)
#news.url为获取网址的url
print(news.text)
# news.text为获取页面的所有text文字
print(news.title)
# news.title为获取页面的所有标题
print(news.html)
# news.html为获取页面的所有源码
print(news.authors)
print(news.top_image)
print(news.movies)
print(news.keywords)
print(news.summary)
print(news.images)
print(news.imgs)
之后还有好多方式,但是具体每位方式如何用就不做详尽解释了;
看关键词应当也都能明白一二。 查看全部
最近忽然想到newspaper,是一个算是专门拿来抓取新闻正文,标题,图片等的一个包。
这个包是须要自己重新安装的。
在settings配置环境,添加包newspaper。
如果添加不进去就使用pip命令添加
打开命令行窗口,输入
pip3 install --ignore-installed --upgrade newspaper3k
如果文章没有指明使用的哪些语言的时侯,Newspaper会尝试手动辨识。
import newspaper
from newspaper import Article
#这里的url可以填写你需要爬取的网址
url = 'http://www.sohu.com/a/284738650_162522?_f=index_chan08news_10'
news = Article(url,language = 'zh')
news.download()
news.parse()
print(news.url)
#news.url为获取网址的url
print(news.text)
# news.text为获取页面的所有text文字
print(news.title)
# news.title为获取页面的所有标题
print(news.html)
# news.html为获取页面的所有源码
print(news.authors)
print(news.top_image)
print(news.movies)
print(news.keywords)
print(news.summary)
print(news.images)
print(news.imgs)
之后还有好多方式,但是具体每位方式如何用就不做详尽解释了;
看关键词应当也都能明白一二。
网站建设的必备工具-织梦器. 全自动采集文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-08 02:19
Dreamweaving Collector的功能Collector是一个专业的采集模块,具有先进的人工智能网页识别技术和出色的伪原创技术,远远超出了传统的采集软件,可以从不同的网站自动采集高质量的内容,原创处理减少了工作量. 网站维护,大大增加了收录和点击的数量. 它是每个网站的必备插件. 1一键安装,全自动采集. Dreamweaver Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 结合简单,强大,灵活和开放源代码的dedecms程序,新手可以快速上手,并且我们还拥有专用客户服务,可为商业客户提供技术支持. 2一词采集,无需编写采集规则. 与传统的采集模式不同,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点在于可以为此关键字采集不同的搜索结果. 请勿采集指定的一个或多个站点,以减少该站点被搜索引擎判定为镜像站点并受到搜索引擎惩罚的风险. 3RSS采集,可以通过输入RSS地址来采集内容·只要采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这既方便又简单. 4页面监视集合,采集内容简单方便·页面监视集合只需要提供监视页面地址和文本URL规则来指定指定网站或列内容的采集,这既方便又简单,并且可以有针对性地进行采集无需编写收款规则.
·5种伪原创和优化方法,以提高收录率和排名·自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,添加链接关键字各种方法,例如处理采集的文章,增强采集的文章的独创性,促进搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名. 6插件全自动采集,无需人工干预. Dreamweaver采集器根据预设的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确计算来分析网页,并丢弃非文章. 内容页面的URL提取出色的文章内容,最后执行伪原创,导入和生成. 所有这些操作过程都是自动完成的,无需人工干预. 7手工发表的文章也可以是伪原创和搜索优化处理·Dreamweaving Collector不仅是集合插件,而且还是进行梦编织所需的伪原创和搜索优化插件. 可以通过织梦来采集手工发表的文章. Xia的伪原创和搜索优化处理,您可以将文章替换为同义词,自动插入关键字链接,并且收录关键字的文章将自动添加指定的链接和其他功能. 它是进行梦幻编织的必要插件. 8定期定量采集伪原创SEO更新·该插件有两种触发采集方法,一种是在页面中添加代码以通过用户访问触发采集和更新,另一种是我们提供的远程触发采集服务适用于商业用户. 没有新站点. 可以定期,定量地采集和更新访问权限,而无需人工干预. 查看全部
Dreamweaving Collector的功能Collector是一个专业的采集模块,具有先进的人工智能网页识别技术和出色的伪原创技术,远远超出了传统的采集软件,可以从不同的网站自动采集高质量的内容,原创处理减少了工作量. 网站维护,大大增加了收录和点击的数量. 它是每个网站的必备插件. 1一键安装,全自动采集. Dreamweaver Collector的安装非常简单方便. 只需一分钟即可立即开始采集. 结合简单,强大,灵活和开放源代码的dedecms程序,新手可以快速上手,并且我们还拥有专用客户服务,可为商业客户提供技术支持. 2一词采集,无需编写采集规则. 与传统的采集模式不同,Dreamweaver采集器可以根据用户设置的关键字执行泛采集. 泛集合的优点在于可以为此关键字采集不同的搜索结果. 请勿采集指定的一个或多个站点,以减少该站点被搜索引擎判定为镜像站点并受到搜索引擎惩罚的风险. 3RSS采集,可以通过输入RSS地址来采集内容·只要采集的网站提供RSS订阅地址,就可以通过RSS进行采集. 您只需输入RSS地址即可轻松采集目标网站的内容,而无需编写采集规则,这既方便又简单. 4页面监视集合,采集内容简单方便·页面监视集合只需要提供监视页面地址和文本URL规则来指定指定网站或列内容的采集,这既方便又简单,并且可以有针对性地进行采集无需编写收款规则.
·5种伪原创和优化方法,以提高收录率和排名·自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,添加链接关键字各种方法,例如处理采集的文章,增强采集的文章的独创性,促进搜索引擎优化,提高搜索引擎的收录率,网站权重和关键字排名. 6插件全自动采集,无需人工干预. Dreamweaver采集器根据预设的采集方法采集URL,然后自动获取网页的内容. 该程序通过精确计算来分析网页,并丢弃非文章. 内容页面的URL提取出色的文章内容,最后执行伪原创,导入和生成. 所有这些操作过程都是自动完成的,无需人工干预. 7手工发表的文章也可以是伪原创和搜索优化处理·Dreamweaving Collector不仅是集合插件,而且还是进行梦编织所需的伪原创和搜索优化插件. 可以通过织梦来采集手工发表的文章. Xia的伪原创和搜索优化处理,您可以将文章替换为同义词,自动插入关键字链接,并且收录关键字的文章将自动添加指定的链接和其他功能. 它是进行梦幻编织的必要插件. 8定期定量采集伪原创SEO更新·该插件有两种触发采集方法,一种是在页面中添加代码以通过用户访问触发采集和更新,另一种是我们提供的远程触发采集服务适用于商业用户. 没有新站点. 可以定期,定量地采集和更新访问权限,而无需人工干预.
wp-auto post pro插件[自动采集]
采集交流 • 优采云 发表了文章 • 0 个评论 • 411 次浏览 • 2020-08-07 14:06
第一个链接到wp建立的“物联网信息”网站,欢迎访问:
说到这个插件的使用,百度很容易就可以在线上教程,这里我就不讨论使用过程了. 谈论今天遇到的问题和关键步骤.
首先,如果成功安装并测试了WP-Auto post pro,则测试是正常的,但是启用和更新后,文章将不会更新,并且只会显示“您可以在操作期间切换页面” . 提示,为什么根本看不到线索. 此时,只需转到AUTO POST PRO→选项→重置,然后单击重置. 您可以在“重置”按钮旁边的括号中看到提示(如果出现采集错误,请单击此按钮),看来作者已经注意到了这样的问题. 在这里让我解释一下,重置不会更改当前任务的设置,也不会影响本文,只需重置参数即可,请放心.
让我们讨论以下主要步骤:
1. 创建新任务时,基本设置没有任何更改,仅是文章存储的目录和更新间隔. 其次,还可以指定作者的签名和发布时间.
2. 文章来源设置和爬网设置是重点.
(1)文章的来源输入要爬网的网页地址,然后在“文章匹配规则”下自动设置,在弹出的url中选择文章的url,而不是目录链接. 位于,因为它与文章地址的格式匹配,所以它将依次搜索该格式,而不是为其提供父节点的地址.
(2)在文章搜寻设置中,必填字段为必填项. 有两种使用CSS选择器和通配符匹配的方法. css和html标签需要有基础,所以很容易. 只需编写所需内容的类或标签. 我不会在这里详细介绍. 如果我不知道如何学习前端的基础知识,那我就去做,因为我主要是想谈谈初始测试成功但无法运行的问题.
您可以看看我采集的文章: 曾点交通 查看全部
很长一段时间以来,以前的wordpress都没有得到很好的照顾,半年以来已经支持了17篇文章,今天我看到了一个非常好的网站,因此我重新参与了我网站的采集工作,因此会更加活跃. 我使用了wp-auto post pro插件,因此在完成后立即写了一篇总结性博客文章.
第一个链接到wp建立的“物联网信息”网站,欢迎访问:
说到这个插件的使用,百度很容易就可以在线上教程,这里我就不讨论使用过程了. 谈论今天遇到的问题和关键步骤.
首先,如果成功安装并测试了WP-Auto post pro,则测试是正常的,但是启用和更新后,文章将不会更新,并且只会显示“您可以在操作期间切换页面” . 提示,为什么根本看不到线索. 此时,只需转到AUTO POST PRO→选项→重置,然后单击重置. 您可以在“重置”按钮旁边的括号中看到提示(如果出现采集错误,请单击此按钮),看来作者已经注意到了这样的问题. 在这里让我解释一下,重置不会更改当前任务的设置,也不会影响本文,只需重置参数即可,请放心.
让我们讨论以下主要步骤:
1. 创建新任务时,基本设置没有任何更改,仅是文章存储的目录和更新间隔. 其次,还可以指定作者的签名和发布时间.
2. 文章来源设置和爬网设置是重点.
(1)文章的来源输入要爬网的网页地址,然后在“文章匹配规则”下自动设置,在弹出的url中选择文章的url,而不是目录链接. 位于,因为它与文章地址的格式匹配,所以它将依次搜索该格式,而不是为其提供父节点的地址.
(2)在文章搜寻设置中,必填字段为必填项. 有两种使用CSS选择器和通配符匹配的方法. css和html标签需要有基础,所以很容易. 只需编写所需内容的类或标签. 我不会在这里详细介绍. 如果我不知道如何学习前端的基础知识,那我就去做,因为我主要是想谈谈初始测试成功但无法运行的问题.
您可以看看我采集的文章: 曾点交通
短版文章自动采集的测试版
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-07 01:22
测试论坛:
链接到说明文件:
测试版仅供每个人了解此插件,并且不能长期使用
背景设置
是否自动采集和发布帖子:
如果启用,将自动采集网站导航的内容并将其发布到网站导航的指定部分或门户网站
每次自动发帖的数量:
如果启用了自动发布,则此设置生效,您可以控制每次自动发布的帖子数量,如果启用图像本地化,建议不要设置太大,0不会自动发布,并且限制是5
是否审查了该帖子:
是: 采集资源后发布并进入评论状态,背景内容只有在背景评论通过前台后才会显示;否: 如果采集到的信息碰到了背景关键字,则会对帖子进行审核,否则前景将直接显示
发布时间:
如果不填写发布时间,则为当前的自动发布时间;填充格式是以秒为单位的整数时间,然后除以-;例如0-3600,发布时间是当前采集时间减去0-3600期间的随机时间
帖子浏览量:
如果您不填写综合浏览量,则默认值为0;否则,默认值为0. 填写整数除法格式;例如0-100,则将0-100范围内的随机整数设置为网页浏览量
图像是否显示在中央:
如果您打开帖子或门户网站图像,它将显示在单行的中央
图片是否存储在本地:
是: 采集到的资源图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否足够;否: 可以远程访问图片,这时非站点站点上的图片处于热链接模式,如果添加了第三方站点,则不会显示反热链接图片. 目前,建议启用图片热链接访问
是否打开图片热链接:
如果启用了第三方图像资源,它们将在本地缓存,并定期清除以节省服务器空间
伪原创替换率:
控制替换关键字的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主要帖子的css显示样式,必须收录该样式,并且如果可以将其清空也不会影响帖子显示
门户展示样式:
必须收录自定义门户网站CSS的显示样式,并且空白的文章显示不会受到影响 查看全部
主要功能说明: 采集短书搜索关键字和主题,并自动发布到论坛,门户网站,网上论坛
测试论坛:
链接到说明文件:
测试版仅供每个人了解此插件,并且不能长期使用
背景设置
是否自动采集和发布帖子:
如果启用,将自动采集网站导航的内容并将其发布到网站导航的指定部分或门户网站
每次自动发帖的数量:
如果启用了自动发布,则此设置生效,您可以控制每次自动发布的帖子数量,如果启用图像本地化,建议不要设置太大,0不会自动发布,并且限制是5
是否审查了该帖子:
是: 采集资源后发布并进入评论状态,背景内容只有在背景评论通过前台后才会显示;否: 如果采集到的信息碰到了背景关键字,则会对帖子进行审核,否则前景将直接显示
发布时间:
如果不填写发布时间,则为当前的自动发布时间;填充格式是以秒为单位的整数时间,然后除以-;例如0-3600,发布时间是当前采集时间减去0-3600期间的随机时间
帖子浏览量:
如果您不填写综合浏览量,则默认值为0;否则,默认值为0. 填写整数除法格式;例如0-100,则将0-100范围内的随机整数设置为网页浏览量
图像是否显示在中央:
如果您打开帖子或门户网站图像,它将显示在单行的中央
图片是否存储在本地:
是: 采集到的资源图片保存在本地,占用本地磁盘,选择此项时请注意服务器硬盘空间是否足够;否: 可以远程访问图片,这时非站点站点上的图片处于热链接模式,如果添加了第三方站点,则不会显示反热链接图片. 目前,建议启用图片热链接访问
是否打开图片热链接:
如果启用了第三方图像资源,它们将在本地缓存,并定期清除以节省服务器空间
伪原创替换率:
控制替换关键字的比例,0%是关闭伪原创功能
帖子显示样式:
自定义帖子主要帖子的css显示样式,必须收录该样式,并且如果可以将其清空也不会影响帖子显示
门户展示样式:
必须收录自定义门户网站CSS的显示样式,并且空白的文章显示不会受到影响
WordPress十大常用文章自动采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 687 次浏览 • 2020-08-07 01:22
这里仅介绍wordpress自动采集插件的标题,此处不详细说明具体设备的使用方法.
1,wordpress自动采集插件-自动博客
此插件可以基于关键字自动获取YouTube和Yahoo答案之类的内容,然后完成自动发布博客内容的意图. 您可以建立自己的博客场. 通过此插件,您可以生成视频,图片或文章Blog等.
2,wordpress自动采集插件-Auto Get Rss
此插件是一个插件,可以自动更新和发布Wordpress博客程序上的文章,并通过任何RSS或Atom进行馈送. 使用Wordpress Auto Get Rss可以建立自动博客,例如视频博客,创建主题门户或聚合RSS源.
3,wordpress自动采集含咖啡因的内容
此插件根据关键字搜索Youtube,Yahoo Answer,文章和文件,以获取相关内容. 它可以保存原创文本或将其翻译成多个国家/地区的语言,并可以及时,定量地自动将其发布到您的博客中. 该功能非常强大. 如果您想自己进行二次开发,使用它作为基础是一个很好的选择.
4,wordpress自动采集插件-FeedWordPress
此插件非常好,主要用于阅读供稿以完成博客文章更新,这是全文方法. 优点是插件会及时更新和升级!建议不要使用中文包,而要使用英文版的WordPress和原创的FeedWordPress插件!下载插件后,需要在后台控制面板中将其激活,并根据需要自定义功能.
5,wordpress自动采集插件-朋友RSS聚合器(FRA)
朋友RSS聚合器(FRA)可以通过RSS聚合此插件,它只是实际文章的标题,发布日期等.
6,wordpress自动采集插件WP-o-Matic. 这个插件是一个非常有效的WordPress集合插件. 尽管缺少自动分类功能,但该插件在所有方面均表现良好. 对于wordpress采集插件Caffeinated Content,wp-o-matic不错,选择通过RSS来完成博客的自动采集.
7,wordpress自动采集插件BDP RSS聚合器
此插件可以汇总多个博客的内容. 适用于具有多个博客的博客作者,也许是资本汇总和共享型博客作者,以及聚集了多个博客内容的团体博客作者.
8,wordpress自动采集和发布插件WP Robot
此插件是一个基于wordpress频道内容的采集工具. WP robot是英文网站工具. 假设选择了主题,它将自动搜索支持雅虎答案集合的德语,法语,英语和西班牙语的相关帖子.
9,wordpress自动采集插件inlineRSS
此插件可以支持多种格式,例如RSS,RDF,XML或HTML. 通过Inlinefeed,RSS源中的文章实际上可以收录在特定文章中.
10,wordpress自动采集插件智能
该插件可以根据需要自动将RSS中的文章自动发布到wordpress博客,从而使wordpress具有类似于某些CMS的自动采集功能.
当前,WordPress已成为建立博客的主流方式,它具有许多易于扩展的插件和模板. 这些插件的目的是促进我们采集网站,节省人力和时间并很好地更新其博客内容. 选择一个您想要尝试的自动采集插件!
标签: WordPress插件WordPress采集插件 查看全部
WordPress是一个功能强大的博客系统,其中收录许多插件. 这些插件可以轻松扩展. 由于WordPress插件太多,并且与RSS输出和输入完全兼容,因此对于初学者来说是令人眼花,乱的,所以我在这里介绍一些我已经采集和使用的自动采集插件.
这里仅介绍wordpress自动采集插件的标题,此处不详细说明具体设备的使用方法.
1,wordpress自动采集插件-自动博客
此插件可以基于关键字自动获取YouTube和Yahoo答案之类的内容,然后完成自动发布博客内容的意图. 您可以建立自己的博客场. 通过此插件,您可以生成视频,图片或文章Blog等.
2,wordpress自动采集插件-Auto Get Rss
此插件是一个插件,可以自动更新和发布Wordpress博客程序上的文章,并通过任何RSS或Atom进行馈送. 使用Wordpress Auto Get Rss可以建立自动博客,例如视频博客,创建主题门户或聚合RSS源.
3,wordpress自动采集含咖啡因的内容
此插件根据关键字搜索Youtube,Yahoo Answer,文章和文件,以获取相关内容. 它可以保存原创文本或将其翻译成多个国家/地区的语言,并可以及时,定量地自动将其发布到您的博客中. 该功能非常强大. 如果您想自己进行二次开发,使用它作为基础是一个很好的选择.
4,wordpress自动采集插件-FeedWordPress
此插件非常好,主要用于阅读供稿以完成博客文章更新,这是全文方法. 优点是插件会及时更新和升级!建议不要使用中文包,而要使用英文版的WordPress和原创的FeedWordPress插件!下载插件后,需要在后台控制面板中将其激活,并根据需要自定义功能.
5,wordpress自动采集插件-朋友RSS聚合器(FRA)
朋友RSS聚合器(FRA)可以通过RSS聚合此插件,它只是实际文章的标题,发布日期等.
6,wordpress自动采集插件WP-o-Matic. 这个插件是一个非常有效的WordPress集合插件. 尽管缺少自动分类功能,但该插件在所有方面均表现良好. 对于wordpress采集插件Caffeinated Content,wp-o-matic不错,选择通过RSS来完成博客的自动采集.
7,wordpress自动采集插件BDP RSS聚合器
此插件可以汇总多个博客的内容. 适用于具有多个博客的博客作者,也许是资本汇总和共享型博客作者,以及聚集了多个博客内容的团体博客作者.
8,wordpress自动采集和发布插件WP Robot
此插件是一个基于wordpress频道内容的采集工具. WP robot是英文网站工具. 假设选择了主题,它将自动搜索支持雅虎答案集合的德语,法语,英语和西班牙语的相关帖子.
9,wordpress自动采集插件inlineRSS
此插件可以支持多种格式,例如RSS,RDF,XML或HTML. 通过Inlinefeed,RSS源中的文章实际上可以收录在特定文章中.
10,wordpress自动采集插件智能
该插件可以根据需要自动将RSS中的文章自动发布到wordpress博客,从而使wordpress具有类似于某些CMS的自动采集功能.
当前,WordPress已成为建立博客的主流方式,它具有许多易于扩展的插件和模板. 这些插件的目的是促进我们采集网站,节省人力和时间并很好地更新其博客内容. 选择一个您想要尝试的自动采集插件!
标签: WordPress插件WordPress采集插件
WordPress中文自动采集插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 555 次浏览 • 2020-08-06 14:11
这样做的好处是可以节省人力并实现工作自动化,并且可以最大程度地优化资源并加快收录更多搜索引擎的速度.
以下是几个功能强大的中文自动采集插件(包括商业插件):
更新: 2018.12.11添加了水脉烟熏香淘宝来宾插件介绍
一个,WP-AutoBlog
WP-AutoBlog可以采集任何网站的内容,并且采集的信息一目了然
WP-AutoBlog是一个新开发的插件(不再对原创WP-AutoPost进行更新和维护),它完全支持PHP7更快,更稳定
新的架构和设计,集合设置更加全面和灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,轻松访问高质量的原创文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持.
可以采集微信公众号,头条新闻和其他自媒体内容. 由于百度不包括官方帐户,头条新闻等,因此可以轻松获得高质量的“原创”文章,从而增加了百度的收录量和网站权重
通过简单的设置,您可以从任何网站采集内容,还可以将多个采集任务设置为同时运行. 您可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上次检测采集时间,下一次检测的估计采集时间,最新采集的文章,已采集和更新的文章数以及其他易于查看和查看的信息. 管理.
文章管理功能方便查询,搜索和删除采集的文章. 改进的算法从根本上消除了同一文章的重复采集. 日志功能记录采集过程中的异常和抓取错误,便于检查和设置维修错误.
第二个,imwprobot
imwprobot是由imwpweb开发的自动采集插件. 与其他采集插件不同,imwprobot本身已经完成了大部分工作. 您所需要做的就是找到一个或多个采集站点,并添加一个网址以开始采集. 采集URL列表的规则相对简单,因此可以直接在本地完成,而采集的内容则更为复杂. 原因是每个网站的结构不一致,并且需要在云中进行复杂的计算才能给出网站的主要内容并将其放置在用户身上. 最终太耗资源了.
以下描述了插件的工作方式. 安装插件后,您可以在后台面板中看到一个新添加的菜单: imwp 采集
功能列表
1. 支持网页列表采集,RSS采集(无论RSS是全文还是摘要)
2. 自动识别文章标题
3. 全自动工作流程
4. 支持过滤文章中的链接,图片,列表,表格,表格
5. 支持修复网页中无序的html
<p>6. 支持图像定位并突破防水 查看全部
在建立新闻或cms网站时,自动采集是非常重要的策略. 有几种采集方法. 一种是使用外部软件(例如优采云 采集)进行独立采集,然后使用插件导入WordPress. 另一种是直接在WordPress中设置任务,然后让系统自动采集任务.
这样做的好处是可以节省人力并实现工作自动化,并且可以最大程度地优化资源并加快收录更多搜索引擎的速度.
以下是几个功能强大的中文自动采集插件(包括商业插件):
更新: 2018.12.11添加了水脉烟熏香淘宝来宾插件介绍
一个,WP-AutoBlog
WP-AutoBlog可以采集任何网站的内容,并且采集的信息一目了然
WP-AutoBlog是一个新开发的插件(不再对原创WP-AutoPost进行更新和维护),它完全支持PHP7更快,更稳定
新的架构和设计,集合设置更加全面和灵活;支持多级文章列表,多级文章内容采集
对Google神经网络翻译的新支持,youdao神经网络翻译,轻松访问高质量的原创文章
对市场上所有主流对象存储服务,秦牛云,阿里云OSS等的全面支持.
可以采集微信公众号,头条新闻和其他自媒体内容. 由于百度不包括官方帐户,头条新闻等,因此可以轻松获得高质量的“原创”文章,从而增加了百度的收录量和网站权重
通过简单的设置,您可以从任何网站采集内容,还可以将多个采集任务设置为同时运行. 您可以将任务设置为自动或手动运行. 主任务列表显示每个采集任务的状态: 上次检测采集时间,下一次检测的估计采集时间,最新采集的文章,已采集和更新的文章数以及其他易于查看和查看的信息. 管理.
文章管理功能方便查询,搜索和删除采集的文章. 改进的算法从根本上消除了同一文章的重复采集. 日志功能记录采集过程中的异常和抓取错误,便于检查和设置维修错误.
第二个,imwprobot
imwprobot是由imwpweb开发的自动采集插件. 与其他采集插件不同,imwprobot本身已经完成了大部分工作. 您所需要做的就是找到一个或多个采集站点,并添加一个网址以开始采集. 采集URL列表的规则相对简单,因此可以直接在本地完成,而采集的内容则更为复杂. 原因是每个网站的结构不一致,并且需要在云中进行复杂的计算才能给出网站的主要内容并将其放置在用户身上. 最终太耗资源了.
以下描述了插件的工作方式. 安装插件后,您可以在后台面板中看到一个新添加的菜单: imwp 采集
功能列表
1. 支持网页列表采集,RSS采集(无论RSS是全文还是摘要)
2. 自动识别文章标题
3. 全自动工作流程
4. 支持过滤文章中的链接,图片,列表,表格,表格
5. 支持修复网页中无序的html
<p>6. 支持图像定位并突破防水
WordPress手动采集发布文章04-如何批量定时发布文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-08-03 22:04
这一讲中,我们瞧瞧哈默插件的配置
哈默插件里有2个文件:
You must be logged in to view the hidden contents.
那假如我们想更改定时发布文章的规则,就须要更改 hm-locowp.php
下面是关于插件的一些使用说明:
/* Wordpress-Post-Interface-v3.1 (2010.08.03)
WordPress免登录发布接口,支持Wordpress2.5+版本。最新验证支持Wordpress3.x
适用于火车头采集器等任意采集器或脚本程序进行日志发布。
****最新版本或者意见建议请访问 http://www.hamo.cn/u/14***
功能:
1\. 随机时间安排与预约发布功能: 可以设定发布时间以及启用预约发布功能
2\. 自动处理服务器时间与博客时间的时区差异
3\. 永久链接的自动翻译设置。根据标题自动翻译为英文并进行seo处理
5\. 多标签处理(多个标签可以用火车头默认的tag|||tag2|||tag3的形式)
6\. 增加了发文后ping功能
7\. 增加了“pending review”的设置
8\. 增加了多作者功能,发布参数中指定post_author
9\. 增加了自定义域功能,发布参数指定post_meta_list=key1$$value1|||key2$$value2,不同域之间用|||隔开,名称与内容之间用$$隔开。
使用说明:(按照需求修改配置参数)
$post_author = 1; //作者的id,默认为admin
$post_status = "publish"; //"future":预约发布,"publish":立即发布,"pending":待审核
$time_interval = 60; //发布时间间隔,单位为秒 。可是设置随机数值表达式,如如12345 * rand(0,17)
$post_next = "next"; //now:发布时间=当前时间+间隔时间值
//next: 发布时间=最后一篇时间+间隔时间值
$post_ping = false; //发布后是否执行ping
$translate_slug = false; //是否将中文标题翻译为英文做slug
$secretWord = 'abcd1234s'; //接口密码,如果不需要密码,则设为$secretWord=false ;
*/
在这里主要介绍3个配置:
$post_status指的是:wordpress的发布状态。如果是定时发布的话,就设置为”future”
time_interval指的是:发布时间间隔,它和post_next配合使用,定义的是时间间隔
$post_next指的是:发布的计时方法自动采集文章文章自动采集文章文章,now:发布时间=当前时间+间隔时间值next: 发布时间=最后一篇时间+间隔时间值
哈默插件默认的配置是:
post_status = “future”;time_interval = 86400 * rand(0,100);
$post_next = “now”;
future 代表定时发布
86400秒 = 1天,然后随机到100天发布,那假如我采集了50个文章时,相当于平均每晚发布:50/100 = 0.5篇文章。
也就是说,平均 2 天会发布一篇文章。
来到后台,大致瞧瞧也确实这么。这就是关于定时发布文件的设置
实战
假如我想使文章在10天内全部发完,只须要:
$time_interval = 86400 * rand(0,10);
然后将修改后的哈默插件上传到服务器,先把之前的采集文章在wordpress后台删掉掉。
把任务设为:未发布状态:
.png - wordpress手动发布文章04-如何批量定时发布文章
再次点击:开始发布,这个时侯瞧瞧后台的文章。就相当于1天发送2篇文章以上了。
定时发布遗失问题
需要用到一款插件:Scheduled.php
下载地址:链接: 密码:jfvp
我们把它上传到服务器的插件文件夹中。
You must be logged in to view the hidden contents.
然后登录到wordpress仪表盘,启用一下插件
这样能够避免定时发布遗失问题 查看全部
要实现批量设置发布文章的话,我们须要使用优采云配合哈默插件来进行文章的发布,在上一讲中,我们成功实现文章的批量发布。
这一讲中,我们瞧瞧哈默插件的配置
哈默插件里有2个文件:
You must be logged in to view the hidden contents.
那假如我们想更改定时发布文章的规则,就须要更改 hm-locowp.php
下面是关于插件的一些使用说明:
/* Wordpress-Post-Interface-v3.1 (2010.08.03)
WordPress免登录发布接口,支持Wordpress2.5+版本。最新验证支持Wordpress3.x
适用于火车头采集器等任意采集器或脚本程序进行日志发布。
****最新版本或者意见建议请访问 http://www.hamo.cn/u/14***
功能:
1\. 随机时间安排与预约发布功能: 可以设定发布时间以及启用预约发布功能
2\. 自动处理服务器时间与博客时间的时区差异
3\. 永久链接的自动翻译设置。根据标题自动翻译为英文并进行seo处理
5\. 多标签处理(多个标签可以用火车头默认的tag|||tag2|||tag3的形式)
6\. 增加了发文后ping功能
7\. 增加了“pending review”的设置
8\. 增加了多作者功能,发布参数中指定post_author
9\. 增加了自定义域功能,发布参数指定post_meta_list=key1$$value1|||key2$$value2,不同域之间用|||隔开,名称与内容之间用$$隔开。
使用说明:(按照需求修改配置参数)
$post_author = 1; //作者的id,默认为admin
$post_status = "publish"; //"future":预约发布,"publish":立即发布,"pending":待审核
$time_interval = 60; //发布时间间隔,单位为秒 。可是设置随机数值表达式,如如12345 * rand(0,17)
$post_next = "next"; //now:发布时间=当前时间+间隔时间值
//next: 发布时间=最后一篇时间+间隔时间值
$post_ping = false; //发布后是否执行ping
$translate_slug = false; //是否将中文标题翻译为英文做slug
$secretWord = 'abcd1234s'; //接口密码,如果不需要密码,则设为$secretWord=false ;
*/
在这里主要介绍3个配置:
$post_status指的是:wordpress的发布状态。如果是定时发布的话,就设置为”future”
time_interval指的是:发布时间间隔,它和post_next配合使用,定义的是时间间隔
$post_next指的是:发布的计时方法自动采集文章文章自动采集文章文章,now:发布时间=当前时间+间隔时间值next: 发布时间=最后一篇时间+间隔时间值
哈默插件默认的配置是:
post_status = “future”;time_interval = 86400 * rand(0,100);
$post_next = “now”;
future 代表定时发布
86400秒 = 1天,然后随机到100天发布,那假如我采集了50个文章时,相当于平均每晚发布:50/100 = 0.5篇文章。
也就是说,平均 2 天会发布一篇文章。
来到后台,大致瞧瞧也确实这么。这就是关于定时发布文件的设置
实战
假如我想使文章在10天内全部发完,只须要:
$time_interval = 86400 * rand(0,10);
然后将修改后的哈默插件上传到服务器,先把之前的采集文章在wordpress后台删掉掉。
把任务设为:未发布状态:
.png - wordpress手动发布文章04-如何批量定时发布文章
再次点击:开始发布,这个时侯瞧瞧后台的文章。就相当于1天发送2篇文章以上了。
定时发布遗失问题
需要用到一款插件:Scheduled.php
下载地址:链接: 密码:jfvp
我们把它上传到服务器的插件文件夹中。
You must be logged in to view the hidden contents.
然后登录到wordpress仪表盘,启用一下插件
这样能够避免定时发布遗失问题

