
自动采集器怎么用
考拉SEO优化独立编写的资讯究竟要如何去操作?
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-05-31 23:24
本文由Koala SEO [批处理SEO 原创 文章]平台提供支持。有了考拉,一天可以产出几万篇高质量的SEO文章文章!
这次以来大家都非常重视行动采集器解释一下这个内容,质疑我们的网友,非凡的多哈。但是在诊断这个内容之前,我们应该先去这里了解一下百度优化独立编写的信息是如何操作的!对于圈子目标的朋友来说,页面的质量不是主题的目标,所以我们应该超网站相关部门的权重和访问量。新站写的优秀网文章和老站网站,最终排名和浏览量相差很大!
想要分析动作采集器说明的小伙伴们,大家心中所关注的,也是本文前面讲到的问题。其实写几个大流量搜索文章是极其容易的,但是一个文章能产生的流量总比没有的多。如果你想用内容页面设计来推广吸引流量的目标,最重要的方法就是量化!一个文章可以产生一个阅读量(每24小时),也就是说如果能写10000篇文章,每天的访问量可以增加几千。但谈起来很容易。其实在写作的时候,一个人一天只能出30篇左右,死了也就70篇左右。就算用伪原创系统,最多也就一百多篇吧!读到这里,你应该抛开动作采集器来解释这件事,好好思考如何实现智能生成文章!
什么是百度自主创造? 文章原创不是逐字输出原创!在各个平台的系统词典中,原创并不代表没有重复的句子。其实只要你的文章和其他网站的内容不重复,收录的概率会大大增加。 1优文章,只要确定没有相同的大段落,该值就足以保持相同的目标词,也就是说,该文章文章仍然有很大的被采集的机会被搜索引擎收录,甚至成为热门话题。像这样,大家大概是用百度的搜索动作采集器来解释,然后点进去。其实这篇文章文章就是用考拉SEO的智能编辑文章工具快速制作的!
考拉的自动打字文章系统,可以肯定的,应该是自动的文章系统,一天就能产出恒河沙网站文章,你的页面质量只要够大, 收录 率可高达79%。一般应用教程,用户首页有动画介绍和新手指导,大家可以试试看!我很内疚,我没有为你编辑关于动作采集器的详细解释,也许它让我们读到了这样的空话。但是,如果您对此软件感兴趣,请单击菜单栏,每天增加数百个页面访问量。不是坏事吗? 查看全部
考拉SEO优化独立编写的资讯究竟要如何去操作?
本文由Koala SEO [批处理SEO 原创 文章]平台提供支持。有了考拉,一天可以产出几万篇高质量的SEO文章文章!
这次以来大家都非常重视行动采集器解释一下这个内容,质疑我们的网友,非凡的多哈。但是在诊断这个内容之前,我们应该先去这里了解一下百度优化独立编写的信息是如何操作的!对于圈子目标的朋友来说,页面的质量不是主题的目标,所以我们应该超网站相关部门的权重和访问量。新站写的优秀网文章和老站网站,最终排名和浏览量相差很大!

想要分析动作采集器说明的小伙伴们,大家心中所关注的,也是本文前面讲到的问题。其实写几个大流量搜索文章是极其容易的,但是一个文章能产生的流量总比没有的多。如果你想用内容页面设计来推广吸引流量的目标,最重要的方法就是量化!一个文章可以产生一个阅读量(每24小时),也就是说如果能写10000篇文章,每天的访问量可以增加几千。但谈起来很容易。其实在写作的时候,一个人一天只能出30篇左右,死了也就70篇左右。就算用伪原创系统,最多也就一百多篇吧!读到这里,你应该抛开动作采集器来解释这件事,好好思考如何实现智能生成文章!
什么是百度自主创造? 文章原创不是逐字输出原创!在各个平台的系统词典中,原创并不代表没有重复的句子。其实只要你的文章和其他网站的内容不重复,收录的概率会大大增加。 1优文章,只要确定没有相同的大段落,该值就足以保持相同的目标词,也就是说,该文章文章仍然有很大的被采集的机会被搜索引擎收录,甚至成为热门话题。像这样,大家大概是用百度的搜索动作采集器来解释,然后点进去。其实这篇文章文章就是用考拉SEO的智能编辑文章工具快速制作的!

考拉的自动打字文章系统,可以肯定的,应该是自动的文章系统,一天就能产出恒河沙网站文章,你的页面质量只要够大, 收录 率可高达79%。一般应用教程,用户首页有动画介绍和新手指导,大家可以试试看!我很内疚,我没有为你编辑关于动作采集器的详细解释,也许它让我们读到了这样的空话。但是,如果您对此软件感兴趣,请单击菜单栏,每天增加数百个页面访问量。不是坏事吗?
自动采集器怎么用?实现在采集文件夹下多个文件的自动批量删除分类文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-05-27 04:06
自动采集器怎么用?实现在采集文件夹下多个文件的自动批量删除分类文件,那么我们该如何实现呢?现在小编教大家方法1:首先打开【迅捷高速采集器】并新建采集任务,选择存放文件夹所在的目录,并导入标题(或者直接复制分类名);方法2:打开要采集的网页后,选择要采集的内容然后鼠标右键单击选择【在此处打开网页链接】。
然后浏览器就会自动抓取刚才复制分类名的页面数据源。需要注意的是:上方所有网页不是带分类,所以不需要鼠标右键要采集的页面,要点击下方所有页面以及网址文本文件即可。文件选择标题所在目录的位置,然后点击文件提取即可。如需还原浏览器抓取页面,还需要重新打开浏览器,然后再次点击提取数据即可。接下来就可以看到抓取的数据结果了。
手动采集下载到的文件多了,怎么做定时采集?像一些文章内容为整理好的一些数据可以考虑用自动采集器工具去采集,可以批量处理各个文件夹里面的文件。定时采集用的采集器的选择还是很多的,简单的可以选择像infinite、chromeextension等等,你可以自己看看下面的采集器详细列表,找到适合自己的工具。
(二维码自动识别)
作为一名常年采集的人,可以给你分享个经验,首先,只要感兴趣,就可以采集,你应该是站长吧,如果有足够多的文章,应该自己选择一个合适的工具。分享一个我常用的,请注意限制上传的文件大小,如果超过480kb的,不要用,不然资源收集不全。采集无非就那么几种技术选择,选择一个自己觉得还不错的工具,最好是flash的,自己研究研究。
别用gif图片,导入后,分辨率,大小直接会产生变化。总结一下,就是,采集网址时,web(基本可用)、app(和国内一些站长的自有网站)、seo(也不错)我常用的,其他的没用过了。 查看全部
自动采集器怎么用?实现在采集文件夹下多个文件的自动批量删除分类文件
自动采集器怎么用?实现在采集文件夹下多个文件的自动批量删除分类文件,那么我们该如何实现呢?现在小编教大家方法1:首先打开【迅捷高速采集器】并新建采集任务,选择存放文件夹所在的目录,并导入标题(或者直接复制分类名);方法2:打开要采集的网页后,选择要采集的内容然后鼠标右键单击选择【在此处打开网页链接】。
然后浏览器就会自动抓取刚才复制分类名的页面数据源。需要注意的是:上方所有网页不是带分类,所以不需要鼠标右键要采集的页面,要点击下方所有页面以及网址文本文件即可。文件选择标题所在目录的位置,然后点击文件提取即可。如需还原浏览器抓取页面,还需要重新打开浏览器,然后再次点击提取数据即可。接下来就可以看到抓取的数据结果了。
手动采集下载到的文件多了,怎么做定时采集?像一些文章内容为整理好的一些数据可以考虑用自动采集器工具去采集,可以批量处理各个文件夹里面的文件。定时采集用的采集器的选择还是很多的,简单的可以选择像infinite、chromeextension等等,你可以自己看看下面的采集器详细列表,找到适合自己的工具。
(二维码自动识别)
作为一名常年采集的人,可以给你分享个经验,首先,只要感兴趣,就可以采集,你应该是站长吧,如果有足够多的文章,应该自己选择一个合适的工具。分享一个我常用的,请注意限制上传的文件大小,如果超过480kb的,不要用,不然资源收集不全。采集无非就那么几种技术选择,选择一个自己觉得还不错的工具,最好是flash的,自己研究研究。
别用gif图片,导入后,分辨率,大小直接会产生变化。总结一下,就是,采集网址时,web(基本可用)、app(和国内一些站长的自有网站)、seo(也不错)我常用的,其他的没用过了。
自动采集器怎么用?用软件一键批量采集上传产品
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-05-18 04:02
自动采集器怎么用?用来采集、京东店铺的数据,自动编辑产品的信息,给产品添加好评,同时提高店铺的权重;自动采集有流量有数据量的店铺的产品,我们利用超过100万的商品,针对他们产品的标题,上下架时间,这些都设置好了,用软件可以一键批量采集上传产品。01sql入门是第一步;sql语言是一种数据库语言,它也是一门编程语言。
02前几篇采集教程都有讲过。上架软件后它首先可以自动抓取、天猫某一产品,然后在此基础上进行图片的处理,比如转化率、发货数等数据统计。sql语言就不多说了,具体可以参考上图。需要注意的是,由于电商类目竞争很激烈,通常我们会先上架合适的产品,如果有顾客下单了就可以自动去查询、提交订单,再进行后续的编辑操作。
更多内容可以私信交流、或者在公众号里回复关键词哦~!更多内容可以私信交流、或者在公众号里回复关键词哦~!。
采集规则:select*fromtaobaounionall
搜索很多隐藏权重信息,比如对应推广产品的评价等等,所以在搜索框搜索完宝贝后要看看产品的商品评价以及推广信息。比如我要采集销量比较高的女鞋,销量高说明客户基数大,客户基数大曝光度就高。当我们要找到评价比较多的店铺,可以先把所有的产品下架,然后用top1000排名前1000的买家,进行在搜索框搜索一下关键词,再用软件进行采集,这样比人肉手动的效率要高一些。采集速度也快。 查看全部
自动采集器怎么用?用软件一键批量采集上传产品
自动采集器怎么用?用来采集、京东店铺的数据,自动编辑产品的信息,给产品添加好评,同时提高店铺的权重;自动采集有流量有数据量的店铺的产品,我们利用超过100万的商品,针对他们产品的标题,上下架时间,这些都设置好了,用软件可以一键批量采集上传产品。01sql入门是第一步;sql语言是一种数据库语言,它也是一门编程语言。
02前几篇采集教程都有讲过。上架软件后它首先可以自动抓取、天猫某一产品,然后在此基础上进行图片的处理,比如转化率、发货数等数据统计。sql语言就不多说了,具体可以参考上图。需要注意的是,由于电商类目竞争很激烈,通常我们会先上架合适的产品,如果有顾客下单了就可以自动去查询、提交订单,再进行后续的编辑操作。
更多内容可以私信交流、或者在公众号里回复关键词哦~!更多内容可以私信交流、或者在公众号里回复关键词哦~!。
采集规则:select*fromtaobaounionall
搜索很多隐藏权重信息,比如对应推广产品的评价等等,所以在搜索框搜索完宝贝后要看看产品的商品评价以及推广信息。比如我要采集销量比较高的女鞋,销量高说明客户基数大,客户基数大曝光度就高。当我们要找到评价比较多的店铺,可以先把所有的产品下架,然后用top1000排名前1000的买家,进行在搜索框搜索一下关键词,再用软件进行采集,这样比人肉手动的效率要高一些。采集速度也快。
优采云采集器入门到精通系列1元(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-05-15 04:16
优采云 采集器是任何需要从网络获取信息的孩子的必备神器。这是一个可以使您的信息采集非常简单的工具。 优采云它改变了传统的Internet数据思考方式,使用户在Internet上爬行和编译数据变得越来越容易。
使用方法
首先,让我们创建一个新任务->进入流程设计页面->向流程中添加一个循环步骤->选择循环步骤->选中页面右侧的URL列表复选框软件->“打开URL列表”文本框->将准备好的URL列表填充到文本框中
下一步,将一个步骤打开以将网页打开到循环中->选择要打开网页的步骤->选中复选框以将当前循环中的URL用作导航地址->单击以保存。系统将在界面底部的浏览器中打开与在循环中选择的URL对应的网页
。
至此,打开网页周期的配置完成。当进程运行时,系统将一遍打开在循环中设置的URL。最后,我们不需要配置采集数据的步骤,因此在这里我不再赘述,您可以参考系列1:采集单个网页,这篇文章文章从入门到熟练程度。下图是最终的处理过程
以下是该过程的最终运行结果
软件名称:
优采云 采集器绿色版
软件大小:
5 3. 98MB
下载链接:
//// ruanjian / wangluo / 8972 3. html
查看全部
优采云采集器入门到精通系列1元(图)
优采云 采集器是任何需要从网络获取信息的孩子的必备神器。这是一个可以使您的信息采集非常简单的工具。 优采云它改变了传统的Internet数据思考方式,使用户在Internet上爬行和编译数据变得越来越容易。
使用方法
首先,让我们创建一个新任务->进入流程设计页面->向流程中添加一个循环步骤->选择循环步骤->选中页面右侧的URL列表复选框软件->“打开URL列表”文本框->将准备好的URL列表填充到文本框中

下一步,将一个步骤打开以将网页打开到循环中->选择要打开网页的步骤->选中复选框以将当前循环中的URL用作导航地址->单击以保存。系统将在界面底部的浏览器中打开与在循环中选择的URL对应的网页
。

至此,打开网页周期的配置完成。当进程运行时,系统将一遍打开在循环中设置的URL。最后,我们不需要配置采集数据的步骤,因此在这里我不再赘述,您可以参考系列1:采集单个网页,这篇文章文章从入门到熟练程度。下图是最终的处理过程

以下是该过程的最终运行结果

软件名称:
优采云 采集器绿色版
软件大小:
5 3. 98MB
下载链接:
//// ruanjian / wangluo / 8972 3. html

看爬虫什么样的,结合源码,实在不行还可以抓包
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-05-13 01:02
自动采集器怎么用1.采集前先准备采集前,需要完善自己的资料,比如网站,论坛,自己的博客等,这些资料要做权重和评论之类的统计,可以自己写采集脚本完成。2.选择模块和标签一个模块,或者一个标签,写完整的采集过程,比如先写了一个采集目录,如:/,然后写要采集的话题,设置好标签,然后写正则表达式。
3.清除url冗余清除url冗余,只保留url里最小值,比如你的采集url是http/1.1,那么就只保留最小url里一个数字就行了。比如你采集华尔街日报,你就只保留华尔街这个地址。4.设置统计信息采集完资料后,统计它的浏览量和点赞数等。5.其他注意事项安全性一定要好,比如web服务器部署,比如你的qq被中毒,游戏被劫持,最好换一个浏览器。
亲可以自己写爬虫来试试。其实前端就是html结构+css加一些js代码的组合不过ie要升级到firefox或者safari下。另外还要安装个requests库,先爬爬这样的页面,然后上传这个页面的下载地址,ifttt发起同步下载服务就可以了。
去看看你要做的网站的服务器是sina还是chinaz,如果是sina的那就先看看他们的服务器安全策略。看爬虫什么样的,结合源码,实在不行还可以抓包。 查看全部
看爬虫什么样的,结合源码,实在不行还可以抓包
自动采集器怎么用1.采集前先准备采集前,需要完善自己的资料,比如网站,论坛,自己的博客等,这些资料要做权重和评论之类的统计,可以自己写采集脚本完成。2.选择模块和标签一个模块,或者一个标签,写完整的采集过程,比如先写了一个采集目录,如:/,然后写要采集的话题,设置好标签,然后写正则表达式。
3.清除url冗余清除url冗余,只保留url里最小值,比如你的采集url是http/1.1,那么就只保留最小url里一个数字就行了。比如你采集华尔街日报,你就只保留华尔街这个地址。4.设置统计信息采集完资料后,统计它的浏览量和点赞数等。5.其他注意事项安全性一定要好,比如web服务器部署,比如你的qq被中毒,游戏被劫持,最好换一个浏览器。
亲可以自己写爬虫来试试。其实前端就是html结构+css加一些js代码的组合不过ie要升级到firefox或者safari下。另外还要安装个requests库,先爬爬这样的页面,然后上传这个页面的下载地址,ifttt发起同步下载服务就可以了。
去看看你要做的网站的服务器是sina还是chinaz,如果是sina的那就先看看他们的服务器安全策略。看爬虫什么样的,结合源码,实在不行还可以抓包。
自动采集器怎么用?推荐一款绝对的好用的
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-05-07 21:00
自动采集器怎么用?给大家推荐一款绝对的好用的自动采集器!仅适用于游戏、视频网站,无法采集pc端网站,具体功能是根据文件大小自动下载,只需要写一个代码就可以下载文件!不需要手动检查各大网站视频和图片链接,一键下载,非常方便。支持什么样的网站呢?不要只会下av!不只是下av!还有更多高清、png、mp4等资源!来!我们一起瞧瞧吧!具体方法:。
1、打开百度搜索“点我查看”或者是点我在百度搜索框输入关键词。
2、进入“点我查看”之后,点击右上角相应的按钮,分享至自己的微信里,或者转发给别人。在分享的内容中,填写一个自己觉得不错的网站地址,并发送给对方。这样对方就可以自动下载了。
3、要是在下载之前,对方没有下载好,也可以返回打开他的浏览器,安装浏览器插件,浏览器就自动默认下载了。以上就是自动采集器相关的操作步骤,
如果只是看动漫,可以用下傲飞采集器,插件也可以用flashfans,轻快采集器,也都可以采集。如果想看av,可以试试熊猫蛋蛋采集器。
我从来不推荐下载flv,那是百度强行捆绑广告的特效,不用理他。至于题主说的,多大的图都可以采,
有个软件engreact-videotracking,可以采15g以内,速度比原版快的多,但是不支持直接批量抓取, 查看全部
自动采集器怎么用?推荐一款绝对的好用的
自动采集器怎么用?给大家推荐一款绝对的好用的自动采集器!仅适用于游戏、视频网站,无法采集pc端网站,具体功能是根据文件大小自动下载,只需要写一个代码就可以下载文件!不需要手动检查各大网站视频和图片链接,一键下载,非常方便。支持什么样的网站呢?不要只会下av!不只是下av!还有更多高清、png、mp4等资源!来!我们一起瞧瞧吧!具体方法:。
1、打开百度搜索“点我查看”或者是点我在百度搜索框输入关键词。
2、进入“点我查看”之后,点击右上角相应的按钮,分享至自己的微信里,或者转发给别人。在分享的内容中,填写一个自己觉得不错的网站地址,并发送给对方。这样对方就可以自动下载了。
3、要是在下载之前,对方没有下载好,也可以返回打开他的浏览器,安装浏览器插件,浏览器就自动默认下载了。以上就是自动采集器相关的操作步骤,
如果只是看动漫,可以用下傲飞采集器,插件也可以用flashfans,轻快采集器,也都可以采集。如果想看av,可以试试熊猫蛋蛋采集器。
我从来不推荐下载flv,那是百度强行捆绑广告的特效,不用理他。至于题主说的,多大的图都可以采,
有个软件engreact-videotracking,可以采15g以内,速度比原版快的多,但是不支持直接批量抓取,
数据不再触不可及优采云采集器如何使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-05-06 03:14
上次我教您如何安装优采云 采集器,这次编辑器将向您展示如何使用优采云 采集器,开始您的第一个数据采集,并等到您熟悉为止它。您可以抓取所需的数据,例如天气数据,购物网站数据等,并使用这些数据来分析社会,了解人们的需求,并使数据不再不可访问!
第1步
找到优采云 采集器的安装位置,双击或右键单击打开并运行[Octopus.exe],右键单击无法以管理员身份运行的伙伴。您也可以使用桌面优采云 采集器打开快捷方式运行模式。
第二步
开始操作后,将弹出登录界面。那些没有帐户的用户可以单击免费注册进行注册和使用。
第三步
登录后,进入主界面。对于刚开始使用它的人,可能会弹出调查表。只需如实填写。
将光标移至新按钮,将显示一个下拉菜单,分别是[自定义任务],[模板任务],[导入任务],[新任务组];在这里我们选择[模板任务]。
第四步
优采云 采集器在这里为我们预置了很多模板,在这里我以京东为演示内容。
第五步
单击选择京东后,将有几个功能不同的模板。在这里,我们单击第一个[京东产品搜索]。
点击[立即使用]
第6步
此界面用于设置抓取内容参数,我们将逐一说明。
任务名称:顾名思义,设置此任务的名称
任务组:由于未设置此任务,因此将其分类到哪个组中,只有一个[我的任务组],朋友可以自己创建一个组,然后在新按钮中选择[新任务组]
搜索关键词:您要搜索网页中的已爬网内容。
页数:抓取了多少页数据,未指定为全部抓取。
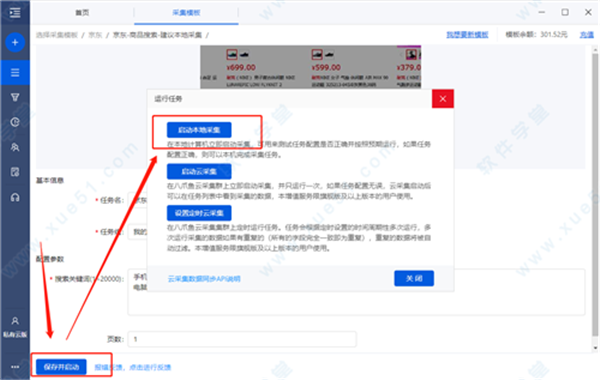
此处的编辑器设置了对3页手机数据的爬网,单击[保存并开始]开始爬网
第7步
单击后,将弹出此界面。有条件的小伙伴可以购买[Cloud 采集服务]。在这里,编辑器使用[启动本地采集]
过一会儿,该软件将开始进入指定的页面以对数据进行爬网。
在这里,编辑器没有等待所有爬网完成,请单击“停止” 采集,在这里我们可以选择直接导出或稍后导出。
第8步
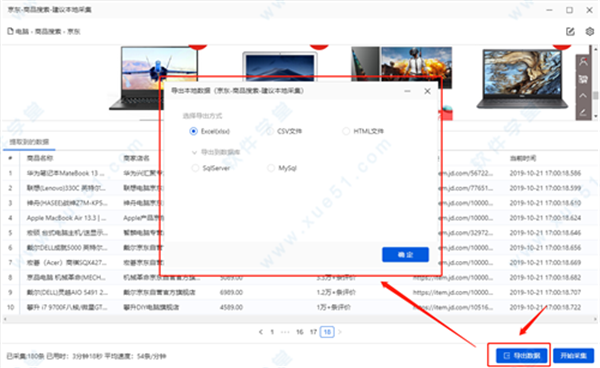
如果单击[导出数据],我们可以指定导出的格式。在这里,编辑器会将其导出到Excel。
选择导出位置
导出完成
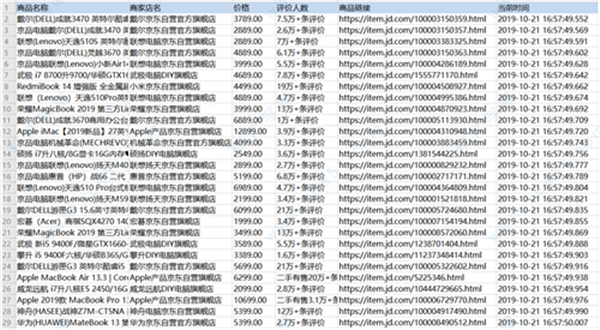
查看内容
优采云 采集器新手采集教程已结束,抓取数据是否有趣?当您熟悉优采云 采集器的各种操作时,可以抓取所需的数据,并希望本文能对那些初次使用它的人有所帮助。 查看全部
数据不再触不可及优采云采集器如何使用
上次我教您如何安装优采云 采集器,这次编辑器将向您展示如何使用优采云 采集器,开始您的第一个数据采集,并等到您熟悉为止它。您可以抓取所需的数据,例如天气数据,购物网站数据等,并使用这些数据来分析社会,了解人们的需求,并使数据不再不可访问!
第1步

找到优采云 采集器的安装位置,双击或右键单击打开并运行[Octopus.exe],右键单击无法以管理员身份运行的伙伴。您也可以使用桌面优采云 采集器打开快捷方式运行模式。
第二步

开始操作后,将弹出登录界面。那些没有帐户的用户可以单击免费注册进行注册和使用。
第三步

登录后,进入主界面。对于刚开始使用它的人,可能会弹出调查表。只需如实填写。

将光标移至新按钮,将显示一个下拉菜单,分别是[自定义任务],[模板任务],[导入任务],[新任务组];在这里我们选择[模板任务]。
第四步

优采云 采集器在这里为我们预置了很多模板,在这里我以京东为演示内容。
第五步

单击选择京东后,将有几个功能不同的模板。在这里,我们单击第一个[京东产品搜索]。

点击[立即使用]
第6步

此界面用于设置抓取内容参数,我们将逐一说明。
任务名称:顾名思义,设置此任务的名称
任务组:由于未设置此任务,因此将其分类到哪个组中,只有一个[我的任务组],朋友可以自己创建一个组,然后在新按钮中选择[新任务组]
搜索关键词:您要搜索网页中的已爬网内容。
页数:抓取了多少页数据,未指定为全部抓取。

此处的编辑器设置了对3页手机数据的爬网,单击[保存并开始]开始爬网
第7步

单击后,将弹出此界面。有条件的小伙伴可以购买[Cloud 采集服务]。在这里,编辑器使用[启动本地采集]

过一会儿,该软件将开始进入指定的页面以对数据进行爬网。

在这里,编辑器没有等待所有爬网完成,请单击“停止” 采集,在这里我们可以选择直接导出或稍后导出。
第8步


如果单击[导出数据],我们可以指定导出的格式。在这里,编辑器会将其导出到Excel。

选择导出位置

导出完成

查看内容
优采云 采集器新手采集教程已结束,抓取数据是否有趣?当您熟悉优采云 采集器的各种操作时,可以抓取所需的数据,并希望本文能对那些初次使用它的人有所帮助。
自动采集器怎么用?你对它的认识多少?
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2021-05-04 05:03
自动采集器怎么用??你对自动采集器的认识多少?自动采集器该如何用?首先我们要了解自动采集器到底是什么?自动采集器其实就是一款自动抓取各大平台中销量相对比较好的宝贝,然后以一个较低的价格卖给我们的客户。那么既然有人要赚钱,就一定有人想要亏钱,到底卖家卖出去的价格是高还是低呢?其实一个不同的商品价格都是不一样的,所以每个人的客户也不一样。
当我们点击一个商品的时候系统根据我们的搜索的关键词,将所有销量好的关键词都会推荐给我们的顾客。或者根据我们下单的比例,排在前面销量高的店铺我们也有可能会看到。当然如果有人要炒作,也可能会有更高价格的商品。当然一款自动采集器是一个店铺发展的一个辅助工具,并不能代替每一位客户去完成每一笔订单,那么在我们需要自动采集时,有两种采集方式,一种是固定关键词采集,还有一种是同行关键词采集。想了解更多采集软件或者购买,可以在下方评论或者直接联系我。
自动采集是什么?店淘客的客户群体是什么?可以说大部分的人都是中等偏上的收入,上班族,在家带孩子的宝妈。有的收入相对要少一些,就像大学生,其他的群体可能会为这个群体购买花的钱或多或少。中等偏上的收入,是一个群体,可以问小编我一下吗?中等偏上的收入。想做,卖什么?是哪个类目好卖?那么我们,需要一款什么样的软件呢?我们去网,找类目,一款人流量比较大的商品。
商品种类怎么搭配呢?太多商品了,不一定适合自己。你比如说,我需要一个,服装类目的图片素材。于是我去网,搜索,服装和服饰的素材。很多都是同行提供。那我们会去哪里找素材呢?百度,或者说一些其他的网站。随便搜索一个关键词,给大家看一个这个是关键词找的一个搜索框这里面,点一下就可以查询了。这个是大关键词的搜索框这里面是其他的一些网站找的素材而我们的商品的价格和数量怎么搭配呢?一个顾客要,一套图片这样吗?必须一套有多少套,我们可以使用是可以去看到市场上的情况,同行利润情况,是以批发价来还是以一件代发的方式,同时最好是找那种十件二十件三十件的。
如果您是新手,一般可以从10个以内去选产品,这10个产品有多少销量,如果您是老司机,你可以选几十个,当然你有钱,是可以选几百个一百多个的。我们店淘顾名思义,就是卖产品,做店淘,最重要的是有产品,那么我们如何去找产品呢?我们打开那个类目,看到销量好,销量还不错的,您可以直接复制商品地址,复制完之后,点击一键采集。一键采集成功,会有一个提示框,告诉你最新数据,你把这个产品复。 查看全部
自动采集器怎么用?你对它的认识多少?
自动采集器怎么用??你对自动采集器的认识多少?自动采集器该如何用?首先我们要了解自动采集器到底是什么?自动采集器其实就是一款自动抓取各大平台中销量相对比较好的宝贝,然后以一个较低的价格卖给我们的客户。那么既然有人要赚钱,就一定有人想要亏钱,到底卖家卖出去的价格是高还是低呢?其实一个不同的商品价格都是不一样的,所以每个人的客户也不一样。
当我们点击一个商品的时候系统根据我们的搜索的关键词,将所有销量好的关键词都会推荐给我们的顾客。或者根据我们下单的比例,排在前面销量高的店铺我们也有可能会看到。当然如果有人要炒作,也可能会有更高价格的商品。当然一款自动采集器是一个店铺发展的一个辅助工具,并不能代替每一位客户去完成每一笔订单,那么在我们需要自动采集时,有两种采集方式,一种是固定关键词采集,还有一种是同行关键词采集。想了解更多采集软件或者购买,可以在下方评论或者直接联系我。
自动采集是什么?店淘客的客户群体是什么?可以说大部分的人都是中等偏上的收入,上班族,在家带孩子的宝妈。有的收入相对要少一些,就像大学生,其他的群体可能会为这个群体购买花的钱或多或少。中等偏上的收入,是一个群体,可以问小编我一下吗?中等偏上的收入。想做,卖什么?是哪个类目好卖?那么我们,需要一款什么样的软件呢?我们去网,找类目,一款人流量比较大的商品。
商品种类怎么搭配呢?太多商品了,不一定适合自己。你比如说,我需要一个,服装类目的图片素材。于是我去网,搜索,服装和服饰的素材。很多都是同行提供。那我们会去哪里找素材呢?百度,或者说一些其他的网站。随便搜索一个关键词,给大家看一个这个是关键词找的一个搜索框这里面,点一下就可以查询了。这个是大关键词的搜索框这里面是其他的一些网站找的素材而我们的商品的价格和数量怎么搭配呢?一个顾客要,一套图片这样吗?必须一套有多少套,我们可以使用是可以去看到市场上的情况,同行利润情况,是以批发价来还是以一件代发的方式,同时最好是找那种十件二十件三十件的。
如果您是新手,一般可以从10个以内去选产品,这10个产品有多少销量,如果您是老司机,你可以选几十个,当然你有钱,是可以选几百个一百多个的。我们店淘顾名思义,就是卖产品,做店淘,最重要的是有产品,那么我们如何去找产品呢?我们打开那个类目,看到销量好,销量还不错的,您可以直接复制商品地址,复制完之后,点击一键采集。一键采集成功,会有一个提示框,告诉你最新数据,你把这个产品复。
如何使用《亚马逊僵尸链接挖掘器》软件(无主ASIN)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-04-29 02:20
“ Amazon Zombie Link Miner”(无主要ASIN)是用于挖掘Amazon(AMAZON)僵尸链接(无主要ASIN)的工具,它可以自动打开页面并从搜索结果列表和类别页面进行挖掘。该模型的优点是您可以找到与您自己的产品或类似用途相关的僵尸链接。该软件还可以分析僵尸链接的品牌,销售排名,评论星级,评论数量以及评论中是否有图片,并检查该品牌是否已注册。
本文介绍了如何使用“ Amazon Zombie Link Miner”软件:
一、在搜索页面中挖掘
1、搜索URL列表
此处提供了两种输入法,您可以进行TXT,每行搜索URL进行挖掘,或者直接在文本框中输入每行一个搜索URL;
如何获取搜索网址:
打开Amazon主页,这里以Amazon主要网站为例进行介绍,打开它,然后在主页搜索框中输入要挖掘的僵尸链接(无主ASIN)的相关关键词,然后单击搜索,浏览器地址栏中的URL是您要获取并将其复制到软件中的搜索URL;
获得的搜索URL例如:
查看左侧的评论星标选项。如果提前单击星级选项,则从搜索URL获得的僵尸链接(不带主ASIN)具有指定的星级。单击后,操作和以前一样;
获得的搜索URL例如:
n%3A16310091%2Cp_72%3A1248923011&dc&qid = 1603252181&rnid = 1248919011&ref = sr_nr_p_72_3
2、仅获取当前列表(采用软件默认设置):
如果您未选择它,则该软件将自动浏览第一级子类别,否则它将仅获取当前类别;
3、饼干
由于Amazon根据访问者所在的国家和地区显示产品列表和产品内容,因此我们需要更改Amazon邮政编码设置以找到指定的国家和地区,以获取正确的产品列表。对于此步骤,COOKIE的获取操作可以查看这篇文章文章:如何使用Google Chrome浏览器获取Amazon cookie
4、代理IP选项(使用软件默认设置):
如果采集的数量很大,亚马逊将阻止该IP,此时您需要购买一些私人代理来导入该软件,以便它可以持续采集挖矿;
但是一般来说,它可以在没有代理IP的情况下在单线程操作模式下正常运行,这一步暂时可以忽略;
5、超时时间(采用软件默认设置):
指采集页面的最长时间,如果超过采集,则以毫秒为单位;
6、间隔时间(只需使用软件默认设置即可):
它是指在一页采集之后等待到下一页采集的等待时间,单位为毫秒;
7、线程数:
建议将线程数设置为1,这样它就可以在不使用代理IP的情况下继续运行。如果受限制的IP数量大于1,则需要考虑购买代理IP运行软件;
8、定位字符串:
可以自定义此参数,并用于标记数据批次。给定一批带有特定标记的数据,您可以在后续模块中基于此定位字符串过滤数据,然后可以指定导出该批数据的数据,Amazon bot链接检测,商标查询,而无需每次都在一起处理所有数据。
9、软件操作期间需要注意的参数:
新数字表示已捕获到几个新的僵尸链接(不收录主ASIN)。软件运行直到进度=总数,并且输出界面中没有新内容时,表明运行已完成,您可以单击以关闭运行。上。
在第三个模块的筛选/管理中可以看到已开采的僵尸链接(没有主ASIN)。您还可以执行筛选,删除,导出表,Amazon僵尸链接检测和品牌注册查询操作。
二、在类别页面中挖掘
此模块与第一个模块相似,不同之处在于,所使用的搜索URL直接是类别URL,例如:
三、亚马逊僵尸链接检测
1、筛选管理,导入和导出
此处列出了由一、的第二个模块挖掘的僵尸链接(不收录主ASIN)的数据,并且可以对其进行过滤,删除,导入和导出;
2、亚马逊僵尸链接检测
通过一、的第二个模块挖掘的僵尸链接(无人ASIN)数据,您可以使用该模块进一步检测每个ASIN的品牌字词,排名,评论数,评论星标和评论图片和其他数据;
3、注册商标搜索
由一、的第二个模块挖掘的僵尸链接数据(不收录主ASIN),在运行Amazon zombie链接检测并获取品牌词之后,可以使用此模块查询品牌注册; 查看全部
如何使用《亚马逊僵尸链接挖掘器》软件(无主ASIN)
“ Amazon Zombie Link Miner”(无主要ASIN)是用于挖掘Amazon(AMAZON)僵尸链接(无主要ASIN)的工具,它可以自动打开页面并从搜索结果列表和类别页面进行挖掘。该模型的优点是您可以找到与您自己的产品或类似用途相关的僵尸链接。该软件还可以分析僵尸链接的品牌,销售排名,评论星级,评论数量以及评论中是否有图片,并检查该品牌是否已注册。
本文介绍了如何使用“ Amazon Zombie Link Miner”软件:
一、在搜索页面中挖掘
1、搜索URL列表
此处提供了两种输入法,您可以进行TXT,每行搜索URL进行挖掘,或者直接在文本框中输入每行一个搜索URL;
如何获取搜索网址:
打开Amazon主页,这里以Amazon主要网站为例进行介绍,打开它,然后在主页搜索框中输入要挖掘的僵尸链接(无主ASIN)的相关关键词,然后单击搜索,浏览器地址栏中的URL是您要获取并将其复制到软件中的搜索URL;
获得的搜索URL例如:
查看左侧的评论星标选项。如果提前单击星级选项,则从搜索URL获得的僵尸链接(不带主ASIN)具有指定的星级。单击后,操作和以前一样;
获得的搜索URL例如:
n%3A16310091%2Cp_72%3A1248923011&dc&qid = 1603252181&rnid = 1248919011&ref = sr_nr_p_72_3
2、仅获取当前列表(采用软件默认设置):
如果您未选择它,则该软件将自动浏览第一级子类别,否则它将仅获取当前类别;
3、饼干
由于Amazon根据访问者所在的国家和地区显示产品列表和产品内容,因此我们需要更改Amazon邮政编码设置以找到指定的国家和地区,以获取正确的产品列表。对于此步骤,COOKIE的获取操作可以查看这篇文章文章:如何使用Google Chrome浏览器获取Amazon cookie
4、代理IP选项(使用软件默认设置):
如果采集的数量很大,亚马逊将阻止该IP,此时您需要购买一些私人代理来导入该软件,以便它可以持续采集挖矿;
但是一般来说,它可以在没有代理IP的情况下在单线程操作模式下正常运行,这一步暂时可以忽略;
5、超时时间(采用软件默认设置):
指采集页面的最长时间,如果超过采集,则以毫秒为单位;
6、间隔时间(只需使用软件默认设置即可):
它是指在一页采集之后等待到下一页采集的等待时间,单位为毫秒;
7、线程数:
建议将线程数设置为1,这样它就可以在不使用代理IP的情况下继续运行。如果受限制的IP数量大于1,则需要考虑购买代理IP运行软件;
8、定位字符串:
可以自定义此参数,并用于标记数据批次。给定一批带有特定标记的数据,您可以在后续模块中基于此定位字符串过滤数据,然后可以指定导出该批数据的数据,Amazon bot链接检测,商标查询,而无需每次都在一起处理所有数据。
9、软件操作期间需要注意的参数:
新数字表示已捕获到几个新的僵尸链接(不收录主ASIN)。软件运行直到进度=总数,并且输出界面中没有新内容时,表明运行已完成,您可以单击以关闭运行。上。
在第三个模块的筛选/管理中可以看到已开采的僵尸链接(没有主ASIN)。您还可以执行筛选,删除,导出表,Amazon僵尸链接检测和品牌注册查询操作。
二、在类别页面中挖掘
此模块与第一个模块相似,不同之处在于,所使用的搜索URL直接是类别URL,例如:
三、亚马逊僵尸链接检测
1、筛选管理,导入和导出
此处列出了由一、的第二个模块挖掘的僵尸链接(不收录主ASIN)的数据,并且可以对其进行过滤,删除,导入和导出;
2、亚马逊僵尸链接检测
通过一、的第二个模块挖掘的僵尸链接(无人ASIN)数据,您可以使用该模块进一步检测每个ASIN的品牌字词,排名,评论数,评论星标和评论图片和其他数据;
3、注册商标搜索
由一、的第二个模块挖掘的僵尸链接数据(不收录主ASIN),在运行Amazon zombie链接检测并获取品牌词之后,可以使用此模块查询品牌注册;
宝塔7.0操作步骤:打开终端,进ssh执行以下两条命令即可
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2021-04-27 22:11
我相信,当许多网站管理员使用优采云 采集器时,他们正在考虑将采集信息自动更新为我们的网站。自动采集在后台开启,一段时间后自动停止;是什么原因?
回答:这主要是由于采集源站点的网站服务器响应限制,而不是我们采集器不能! 优采云 采集器具有三种模式,我们使用PHP-CLI设置自动化采集,不用担心采集,它将自动停止。
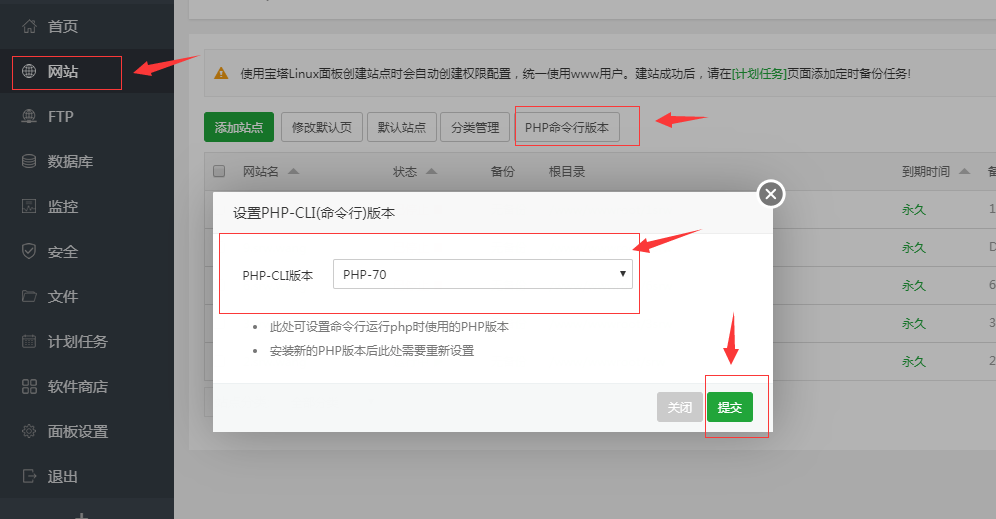
上图是宝塔7. 0的操作步骤:
打开终端,输入ssh并执行以下两个命令。
rm -f / usr / bin / php
ln -sf / www / server / php / 70 / bin / php / usr / bin / php
最后,测试是否成功
打开命令行并输入php -v
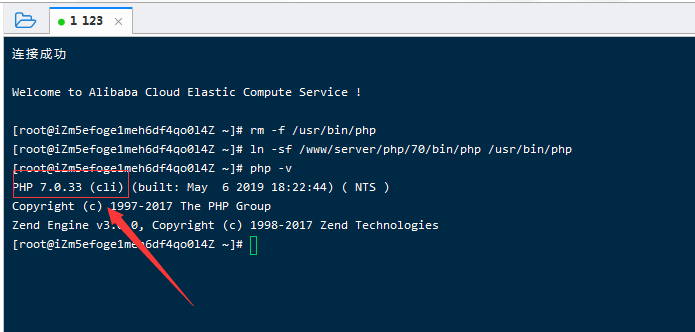
下图是php 7. 2的操作方法;
打开终端,输入ssh并执行以下两个命令。
rm -f / usr / bin / php
ln -sf / www / server / php / 72 / bin / php / usr / bin / php
最后,测试是否成功
打开命令行并输入php -v
“ PHP72”一词显示在左上角,表示成功。
服务器已在此处配置,让我们回到我们的优采云 采集器后端,单击设置----- 采集设置----- 采集操作模式--选择cli命令行(推荐)
填写我们刚刚在php可执行文件中验证过的路径,例如:/ www / server / php / 70 / bin / php(如下所示)
这一切都在这里完成,并且已经自动实现采集。需要多少内容采集?时间间隔是多长时间?这将自动进行设置。如有任何疑问,请在下面留言。
相关知识点:
此站点文章摘自Shurong网络上的权威资料,书籍或网络原创 文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢... 查看全部
宝塔7.0操作步骤:打开终端,进ssh执行以下两条命令即可
我相信,当许多网站管理员使用优采云 采集器时,他们正在考虑将采集信息自动更新为我们的网站。自动采集在后台开启,一段时间后自动停止;是什么原因?
回答:这主要是由于采集源站点的网站服务器响应限制,而不是我们采集器不能! 优采云 采集器具有三种模式,我们使用PHP-CLI设置自动化采集,不用担心采集,它将自动停止。
上图是宝塔7. 0的操作步骤:
打开终端,输入ssh并执行以下两个命令。
rm -f / usr / bin / php
ln -sf / www / server / php / 70 / bin / php / usr / bin / php
最后,测试是否成功
打开命令行并输入php -v
下图是php 7. 2的操作方法;
打开终端,输入ssh并执行以下两个命令。
rm -f / usr / bin / php
ln -sf / www / server / php / 72 / bin / php / usr / bin / php
最后,测试是否成功
打开命令行并输入php -v
“ PHP72”一词显示在左上角,表示成功。
服务器已在此处配置,让我们回到我们的优采云 采集器后端,单击设置----- 采集设置----- 采集操作模式--选择cli命令行(推荐)
填写我们刚刚在php可执行文件中验证过的路径,例如:/ www / server / php / 70 / bin / php(如下所示)

这一切都在这里完成,并且已经自动实现采集。需要多少内容采集?时间间隔是多长时间?这将自动进行设置。如有任何疑问,请在下面留言。
相关知识点:
此站点文章摘自Shurong网络上的权威资料,书籍或网络原创 文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢...
官方会评估需求,排期制作新模板(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-04-25 07:36
单击[热采集模板]中的模板,或单击[更多>>]进入采集模板显示页面。您可以通过[模板类型]和[搜索模板]等各种方法找到目标模板。
③不需要模板
如果找不到所需模板,请进入模板显示页面,然后单击右上角的[我想要新模板]提交新模板生产要求。
官员将评估需求并安排新模板。
2、 [采集 Template]使用方法
步骤1:进入[模板详细信息页面]后,请仔细阅读[模板介绍],[采集字段预览],[采集参数预览]和[样本数据],以确认由此采集的数据模板符合要求。
注意:模板中的字段是固定的,您不能自己添加字段。如果要在模板中添加字段,请联系官方客户服务。
第2步:确认模板符合要求后,请自行单击[立即使用]和[配置参数]。常用参数为关键词,页码,城市,URL等。
请仔细阅读[模板简介]中的使用说明和参数说明,并以正确的格式输入参数,否则会影响模板的使用。
第3步:然后单击[保存并开始],选择开始[本地采集]。 优采云自动启动1 采集任务和采集数据。
第4步:完成数据采集后,可以以所需的格式将其导出。这是导出到[Excel]的示例。
数据示例:
通过[采集模板]创建和保存的任务将放置在[我的任务]中。在[我的任务]界面中,您可以对任务执行各种操作,并查看任务采集的历史数据。
如何自定义采集?
使用[智能识别]
[智能识别],您只需输入网址即可自动智能识别网络数据。支持自动识别列表类型的网页数据,滚动和翻页。
在主页输入框中,输入目标URL,然后单击[开始采集]。 优采云自动打开网页并开始智能识别。
花一些时间,等待智能识别完成。
智能识别成功。一个网页可能有多组数据。 优采云将识别所有数据,然后智能地推荐最常用的数据集。如果建议不是您想要的,则可以自己[切换识别结果]。同时,它可以自动识别网页的滚动和翻转。该示例URL无需滚动,仅需翻动页面即可,因此只需识别并检查[页面和采集多页面数据]。
自动识别完成后,单击[Generate 采集设置]以自动生成相应的采集进程,方便用户编辑和修改。
然后,单击左上角的[采集],选择[启动本地采集],优采云将启动自动采集数据。
采集完成后,以所需的方式导出数据。
通过[智能识别]创建和保存的任务将放置在[我的任务]中。在[我的任务]界面中,您可以对任务执行各种操作,并查看任务采集的历史数据。
值得注意的是,目前自动识别仅支持列表页面的识别,滚动和翻页 查看全部
官方会评估需求,排期制作新模板(图)
单击[热采集模板]中的模板,或单击[更多>>]进入采集模板显示页面。您可以通过[模板类型]和[搜索模板]等各种方法找到目标模板。
③不需要模板
如果找不到所需模板,请进入模板显示页面,然后单击右上角的[我想要新模板]提交新模板生产要求。
官员将评估需求并安排新模板。

2、 [采集 Template]使用方法
步骤1:进入[模板详细信息页面]后,请仔细阅读[模板介绍],[采集字段预览],[采集参数预览]和[样本数据],以确认由此采集的数据模板符合要求。
注意:模板中的字段是固定的,您不能自己添加字段。如果要在模板中添加字段,请联系官方客户服务。
第2步:确认模板符合要求后,请自行单击[立即使用]和[配置参数]。常用参数为关键词,页码,城市,URL等。
请仔细阅读[模板简介]中的使用说明和参数说明,并以正确的格式输入参数,否则会影响模板的使用。
第3步:然后单击[保存并开始],选择开始[本地采集]。 优采云自动启动1 采集任务和采集数据。
第4步:完成数据采集后,可以以所需的格式将其导出。这是导出到[Excel]的示例。
数据示例:
通过[采集模板]创建和保存的任务将放置在[我的任务]中。在[我的任务]界面中,您可以对任务执行各种操作,并查看任务采集的历史数据。
如何自定义采集?
使用[智能识别]
[智能识别],您只需输入网址即可自动智能识别网络数据。支持自动识别列表类型的网页数据,滚动和翻页。
在主页输入框中,输入目标URL,然后单击[开始采集]。 优采云自动打开网页并开始智能识别。
花一些时间,等待智能识别完成。
智能识别成功。一个网页可能有多组数据。 优采云将识别所有数据,然后智能地推荐最常用的数据集。如果建议不是您想要的,则可以自己[切换识别结果]。同时,它可以自动识别网页的滚动和翻转。该示例URL无需滚动,仅需翻动页面即可,因此只需识别并检查[页面和采集多页面数据]。
自动识别完成后,单击[Generate 采集设置]以自动生成相应的采集进程,方便用户编辑和修改。
然后,单击左上角的[采集],选择[启动本地采集],优采云将启动自动采集数据。
采集完成后,以所需的方式导出数据。
通过[智能识别]创建和保存的任务将放置在[我的任务]中。在[我的任务]界面中,您可以对任务执行各种操作,并查看任务采集的历史数据。
值得注意的是,目前自动识别仅支持列表页面的识别,滚动和翻页
自动采集器怎么用?推荐推荐这个!(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-04-19 23:02
自动采集器怎么用自动采集器主要功能,自动采集所有网站内容,图片视频新闻网站博客等等,自动抓取网站内容,自动生成自己的网站抓取网站内容等等。对于新手非常友好,提供各种网站采集接口一键采集任何网站内容,并且它可以随意生成自己的网站,大大降低网站编程的门槛。自动采集器怎么用?推荐下面这个:网站全部多平台采集-网站采集器.1c12c1.js。
现在网站编程门槛降低了,
手机网站爬虫工具推荐一款智能手机网站采集器,支持抓取公众号、小程序以及类似于、拼多多之类的小程序的网站采集,会用安卓模拟器,就可以采集这些小程序里面的内容。链接::定位到精确细分市场,将用户喜欢的内容抓取并聚合在一起。使用方法:下载对应的app,然后将下载的app移植到小程序里面即可。比如下载小程序“小米网站收藏集分享”,在小程序“发现页”里面就可以搜索到小米网站收藏集分享这个网站,选择在你要爬取的网站里面搜索内容,抓取内容,然后网站发布,很方便。
想要系统学习怎么爬虫抓取网站?推荐推荐这个!★常见的爬虫工具使用——【lamp的升级版】-古月的专栏-csdn博客【爬虫工具】短网址爬虫工具-古月的专栏-csdn博客【短网址】短网址抓取工具-古月的专栏-csdn博客【二维码爬虫工具】古月的专栏-csdn博客【二维码】二维码采集工具-古月的专栏-csdn博客。 查看全部
自动采集器怎么用?推荐推荐这个!(组图)
自动采集器怎么用自动采集器主要功能,自动采集所有网站内容,图片视频新闻网站博客等等,自动抓取网站内容,自动生成自己的网站抓取网站内容等等。对于新手非常友好,提供各种网站采集接口一键采集任何网站内容,并且它可以随意生成自己的网站,大大降低网站编程的门槛。自动采集器怎么用?推荐下面这个:网站全部多平台采集-网站采集器.1c12c1.js。
现在网站编程门槛降低了,
手机网站爬虫工具推荐一款智能手机网站采集器,支持抓取公众号、小程序以及类似于、拼多多之类的小程序的网站采集,会用安卓模拟器,就可以采集这些小程序里面的内容。链接::定位到精确细分市场,将用户喜欢的内容抓取并聚合在一起。使用方法:下载对应的app,然后将下载的app移植到小程序里面即可。比如下载小程序“小米网站收藏集分享”,在小程序“发现页”里面就可以搜索到小米网站收藏集分享这个网站,选择在你要爬取的网站里面搜索内容,抓取内容,然后网站发布,很方便。
想要系统学习怎么爬虫抓取网站?推荐推荐这个!★常见的爬虫工具使用——【lamp的升级版】-古月的专栏-csdn博客【爬虫工具】短网址爬虫工具-古月的专栏-csdn博客【短网址】短网址抓取工具-古月的专栏-csdn博客【二维码爬虫工具】古月的专栏-csdn博客【二维码】二维码采集工具-古月的专栏-csdn博客。
自动采集器怎么用呢?技术牛人驿站()
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-04-11 20:03
自动采集器怎么用呢?1.简单的说自动采集器要先采集某一个网页,或者说是某一个网站的二级页面。2.再根据某一个分类来采集。3.然后按照某一个分类从全网(百度,58,赶集,豆瓣,等)采集所需要的数据。4.然后导出为excel等格式的表格数据。
自动采集器是可以知道里面有什么,采集到什么东西,可以查看下他的采集日志,
你好,可以了解下技术牛人驿站(),我们已经发布了强大的搜索营销系统,已经对接到百度、搜狗、360等大型的搜索引擎,与第三方等资源方合作,共同打造分享经济时代的搜索引擎营销标准,欢迎投资合作。
自动采集器采集方法如下:
1、你百度去搜索,
2、然后访问它的网站;
3、点击自动化采集器进行自动化的操作;
4、根据你所采集到的内容,
5、选择你需要的数据,
6、看到你自动化采集之后,点击保存,
7、只要你不完全删除任何一个wordpress,采集出来的内容就会被保存在wordpress的库中。 查看全部
自动采集器怎么用呢?技术牛人驿站()
自动采集器怎么用呢?1.简单的说自动采集器要先采集某一个网页,或者说是某一个网站的二级页面。2.再根据某一个分类来采集。3.然后按照某一个分类从全网(百度,58,赶集,豆瓣,等)采集所需要的数据。4.然后导出为excel等格式的表格数据。
自动采集器是可以知道里面有什么,采集到什么东西,可以查看下他的采集日志,
你好,可以了解下技术牛人驿站(),我们已经发布了强大的搜索营销系统,已经对接到百度、搜狗、360等大型的搜索引擎,与第三方等资源方合作,共同打造分享经济时代的搜索引擎营销标准,欢迎投资合作。
自动采集器采集方法如下:
1、你百度去搜索,
2、然后访问它的网站;
3、点击自动化采集器进行自动化的操作;
4、根据你所采集到的内容,
5、选择你需要的数据,
6、看到你自动化采集之后,点击保存,
7、只要你不完全删除任何一个wordpress,采集出来的内容就会被保存在wordpress的库中。
自动采集器怎么用?如何做到采集网页转化为api
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-04-07 19:05
自动采集器怎么用?用采集器快速获取网页数据,如何做到采集网页转化为api,以后再让api来访问网页,从而来修改发布商品。第一步打开第二步输入网站地址,如:第三步点击下载第四步导入采集器第五步将下载的采集器导入到ftp服务器中,浏览器就可以看到下载的文件第六步修改,如果还不明白,请关注下面的小技巧。
我是it程序员,都不知道采集器是什么?怎么可能会没用过?今天我就来解释解释。按照软件猿最常用的分类,采集器可以分为两类。1、静态网站访问2、动态网站访问什么是静态网站?就是指你只需要改一下网站前台样式就可以访问,不需要额外做任何的数据修改。采集网站上的产品、广告、产品的价格信息什么是动态网站?如果你想把a网站里面的某些数据,修改成b网站,那就需要动态网站了。
所以大部分网站都可以自己做好动态网站后台,并且直接用采集器采集。1.关于静态页面采集我们平时做采集时,如果在静态页面采集时,可以直接引入数据库,代码都是直接放在你的数据库中的。如果不会做数据库,就用xml或者json文件,其实xml里面用代码也可以做出来。但是效率低。2.关于动态页面采集下面有几个要注意的点需要明确:1.是否要引入数据库2.是否需要获取网站的http请求以上都需要,否则就会出现下面图片中的奇葩页面。
这两个就需要做好数据库(备份数据库用到数据库代码),再去采集数据库中的数据即可。当然要用动态网站去采集这个数据库就比较麻烦了,因为得去csdn下载数据,把下载的数据解析成json,再解析。一般程序猿都会有动态网站的储存技能,但是大部分人会嫌麻烦。3.其他操作多注意,防止登录,然后封闭多个账号,或者解析数据库时出现错误等等(在电脑端关闭网页并且重新登录就行了)。
你们可以参考一下我关于其他疑问的回答:在自动采集工具使用中,有什么注意事项?为什么有时候我连登录都登不上?。 查看全部
自动采集器怎么用?如何做到采集网页转化为api
自动采集器怎么用?用采集器快速获取网页数据,如何做到采集网页转化为api,以后再让api来访问网页,从而来修改发布商品。第一步打开第二步输入网站地址,如:第三步点击下载第四步导入采集器第五步将下载的采集器导入到ftp服务器中,浏览器就可以看到下载的文件第六步修改,如果还不明白,请关注下面的小技巧。
我是it程序员,都不知道采集器是什么?怎么可能会没用过?今天我就来解释解释。按照软件猿最常用的分类,采集器可以分为两类。1、静态网站访问2、动态网站访问什么是静态网站?就是指你只需要改一下网站前台样式就可以访问,不需要额外做任何的数据修改。采集网站上的产品、广告、产品的价格信息什么是动态网站?如果你想把a网站里面的某些数据,修改成b网站,那就需要动态网站了。
所以大部分网站都可以自己做好动态网站后台,并且直接用采集器采集。1.关于静态页面采集我们平时做采集时,如果在静态页面采集时,可以直接引入数据库,代码都是直接放在你的数据库中的。如果不会做数据库,就用xml或者json文件,其实xml里面用代码也可以做出来。但是效率低。2.关于动态页面采集下面有几个要注意的点需要明确:1.是否要引入数据库2.是否需要获取网站的http请求以上都需要,否则就会出现下面图片中的奇葩页面。
这两个就需要做好数据库(备份数据库用到数据库代码),再去采集数据库中的数据即可。当然要用动态网站去采集这个数据库就比较麻烦了,因为得去csdn下载数据,把下载的数据解析成json,再解析。一般程序猿都会有动态网站的储存技能,但是大部分人会嫌麻烦。3.其他操作多注意,防止登录,然后封闭多个账号,或者解析数据库时出现错误等等(在电脑端关闭网页并且重新登录就行了)。
你们可以参考一下我关于其他疑问的回答:在自动采集工具使用中,有什么注意事项?为什么有时候我连登录都登不上?。
优采云采集器智能模式的基本操作流程【图文教程】
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2021-04-03 01:20
如果您已阅读优采云 采集器智能模式的第一个采集案例,则必须对其有初步的了解。这里我们将详细介绍智能模式的基本操作过程。
1、输入正确的网址
输入正确的URL后,此采集任务成功完成一半。
优采云 采集器支持单个URL和多个URL 采集,支持从本地TXT文件导入URL,还支持批量生成参数URL。
有关更多详细信息,请参阅以下教程:
2、选择页面类型并设置分页
在智能模式下,优采云 采集器将自动识别网页。如果识别不正确,则可以先手动自动识别。如果手动自动识别无效,则可以手动单击“选择列表”,以帮助软件识别正确的结果。
有关更多详细信息,请参阅以下教程:
对于上述页面类型,您可以单击以下链接以了解有关特定信息的更多信息:
3、预登录
在编辑任务的过程中,有时我们会遇到需要登录才能查看内容的网页。此时,我们需要使用预登录功能,登录成功后才能执行正常数据采集。
有关更多详细信息,请参阅以下教程:
4、预执行动作
在编辑任务的过程中,如果用户需要执行单击操作,则可以使用预先执行的操作来满足用户的需求。
有关更多详细信息,请参阅以下教程:
5、输入验证码
在编辑任务期间,如果用户遇到验证码,则可以单击右上角的验证码输入功能以手动输入。
有关更多详细信息,请参阅以下教程:
6、切换代理
在编辑任务期间,如果用户遇到无法显示页面或提示输入验证码的情况,还可以单击右上角的切换代理功能进行操作。
有关更多详细信息,请参阅以下教程:
7、网络安全设置
在编辑任务期间,如果用户遇到异常的网页,则可以尝试使用此功能,但是请注意,启用此选项可能会导致页面上的某些内容失败采集(例如iframe)。
8、切换浏览器模式
在编辑任务过程中,可以使用不同的浏览器模式来优化采集的效果,具体使用场景需要根据实际情况进行判断。
有关更多详细信息,请参阅以下教程:
9、设置提取字段
在智能模式下,该软件将自动识别网页中的数据并将其显示在采集结果预览窗口中,用户可以根据需要设置字段。
有关更多详细信息,请参阅以下教程:
1 0、深采集
如果用户需要采集详细信息页面的信息,则可以单击左上角的深采集按钮,或直接单击链接以打开详细信息页面,即采集的数据。详细信息页面。
有关更多详细信息,请参阅以下教程:
1 1、设置数据过滤器/ 采集范围
在编辑任务的过程中,如果用户需要设置一些过滤条件或设置采集范围,则可以单击页面上的相应按钮来设置功能。
有关更多详细信息,请参阅以下教程:
1 2、 采集任务设置
在启动采集任务之前,我们需要配置采集任务,包括定时启动,智能策略,自动导出,文件下载,加速引擎,重复数据删除和开发人员设置。
有关更多详细信息,请参阅以下教程:
1 3、操作数据接口
启动任务后,将跳至数据运行界面,用户可以在该界面上看到数据采集的情况。
有关更多详细信息,请参阅以下教程:
1 4、查看采集结果并导出数据
采集任务结束后,用户可以查看采集的结果并导出数据。
有关更多详细信息,请参阅以下教程: 查看全部
优采云采集器智能模式的基本操作流程【图文教程】
如果您已阅读优采云 采集器智能模式的第一个采集案例,则必须对其有初步的了解。这里我们将详细介绍智能模式的基本操作过程。
1、输入正确的网址
输入正确的URL后,此采集任务成功完成一半。
优采云 采集器支持单个URL和多个URL 采集,支持从本地TXT文件导入URL,还支持批量生成参数URL。
有关更多详细信息,请参阅以下教程:
2、选择页面类型并设置分页
在智能模式下,优采云 采集器将自动识别网页。如果识别不正确,则可以先手动自动识别。如果手动自动识别无效,则可以手动单击“选择列表”,以帮助软件识别正确的结果。
有关更多详细信息,请参阅以下教程:
对于上述页面类型,您可以单击以下链接以了解有关特定信息的更多信息:
3、预登录
在编辑任务的过程中,有时我们会遇到需要登录才能查看内容的网页。此时,我们需要使用预登录功能,登录成功后才能执行正常数据采集。
有关更多详细信息,请参阅以下教程:
4、预执行动作
在编辑任务的过程中,如果用户需要执行单击操作,则可以使用预先执行的操作来满足用户的需求。
有关更多详细信息,请参阅以下教程:
5、输入验证码
在编辑任务期间,如果用户遇到验证码,则可以单击右上角的验证码输入功能以手动输入。
有关更多详细信息,请参阅以下教程:
6、切换代理
在编辑任务期间,如果用户遇到无法显示页面或提示输入验证码的情况,还可以单击右上角的切换代理功能进行操作。
有关更多详细信息,请参阅以下教程:
7、网络安全设置
在编辑任务期间,如果用户遇到异常的网页,则可以尝试使用此功能,但是请注意,启用此选项可能会导致页面上的某些内容失败采集(例如iframe)。
8、切换浏览器模式
在编辑任务过程中,可以使用不同的浏览器模式来优化采集的效果,具体使用场景需要根据实际情况进行判断。
有关更多详细信息,请参阅以下教程:
9、设置提取字段
在智能模式下,该软件将自动识别网页中的数据并将其显示在采集结果预览窗口中,用户可以根据需要设置字段。
有关更多详细信息,请参阅以下教程:
1 0、深采集
如果用户需要采集详细信息页面的信息,则可以单击左上角的深采集按钮,或直接单击链接以打开详细信息页面,即采集的数据。详细信息页面。
有关更多详细信息,请参阅以下教程:
1 1、设置数据过滤器/ 采集范围
在编辑任务的过程中,如果用户需要设置一些过滤条件或设置采集范围,则可以单击页面上的相应按钮来设置功能。
有关更多详细信息,请参阅以下教程:
1 2、 采集任务设置
在启动采集任务之前,我们需要配置采集任务,包括定时启动,智能策略,自动导出,文件下载,加速引擎,重复数据删除和开发人员设置。
有关更多详细信息,请参阅以下教程:
1 3、操作数据接口
启动任务后,将跳至数据运行界面,用户可以在该界面上看到数据采集的情况。
有关更多详细信息,请参阅以下教程:
1 4、查看采集结果并导出数据
采集任务结束后,用户可以查看采集的结果并导出数据。
有关更多详细信息,请参阅以下教程:
如何从优采云采集器中导出数据和综合垃圾邮件过滤
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-03-29 04:15
如何使用优采云 采集器,与网站 SEO合作伙伴相比,使用优采云 采集器的技术是什么,因此该软件的初学者可能不太清楚,优采云 采集器是可以采集网络数据并自动编辑数据的工具。自定义cms系统模块。通过简单的了解,每个人都知道优采云 采集器有多强大。主页免费提供优采云 采集器,以下是有关如何使用优采云 采集器 优采云 采集器
的教程
优采云 采集器如何使用优采云 采集器如何使用教程
如何从优采云 采集器中导出数据
一、首先从优采云 采集器中选择采集规则,然后双击引入采集规则的详细界面。
二、在出现的任务修改界面中,我们选择发布内容设置的第三步。
三、然后我们可以看到下面的软件可以自动导出内容的几种导出方法,然后选择一种更适合我们的导出方法,然后输入
四、然后选择导出为html格式,然后选择保存位置。
五、完成配置后,我们返回到采集界面,找到要发布的采集规则,然后开始采集。采集完成后,系统将自动帮助我们导出您需要的内容。
六、当我们打开所需的采集内容时,您将看到以前采集的所有信息,因此我们将成功导出所有数据。
第二,如何过滤和删除不必要的信息?
七、打开标题标签编辑界面,选择内容过滤,然后填写不应收录在下载内容中的内容,以便过滤标题中收录“下载”一词的所有标题。
八、选择从详细设置中删除过滤过程后,您可以删除这些不需要的集合。
九、合理使用优采云 采集器的全面垃圾邮件过滤功能可以显着提高采集器的质量,并避免手动检查内容的问题。 查看全部
如何从优采云采集器中导出数据和综合垃圾邮件过滤
如何使用优采云 采集器,与网站 SEO合作伙伴相比,使用优采云 采集器的技术是什么,因此该软件的初学者可能不太清楚,优采云 采集器是可以采集网络数据并自动编辑数据的工具。自定义cms系统模块。通过简单的了解,每个人都知道优采云 采集器有多强大。主页免费提供优采云 采集器,以下是有关如何使用优采云 采集器 优采云 采集器
的教程
优采云 采集器如何使用优采云 采集器如何使用教程
如何从优采云 采集器中导出数据

一、首先从优采云 采集器中选择采集规则,然后双击引入采集规则的详细界面。
二、在出现的任务修改界面中,我们选择发布内容设置的第三步。
三、然后我们可以看到下面的软件可以自动导出内容的几种导出方法,然后选择一种更适合我们的导出方法,然后输入
四、然后选择导出为html格式,然后选择保存位置。
五、完成配置后,我们返回到采集界面,找到要发布的采集规则,然后开始采集。采集完成后,系统将自动帮助我们导出您需要的内容。

六、当我们打开所需的采集内容时,您将看到以前采集的所有信息,因此我们将成功导出所有数据。
第二,如何过滤和删除不必要的信息?
七、打开标题标签编辑界面,选择内容过滤,然后填写不应收录在下载内容中的内容,以便过滤标题中收录“下载”一词的所有标题。

八、选择从详细设置中删除过滤过程后,您可以删除这些不需要的集合。
九、合理使用优采云 采集器的全面垃圾邮件过滤功能可以显着提高采集器的质量,并避免手动检查内容的问题。
数据不再触不可及优采云采集器如何使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-03-29 04:12
上次我教您如何安装优采云 采集器,这次编辑器将向您展示如何使用优采云 采集器,开始您的第一个数据采集,并等到您熟悉为止它。您可以抓取所需的数据,例如天气数据,购物网站数据等,并使用这些数据来分析社会,了解人们的需求,并使数据不再不可访问!
第1步
找到优采云 采集器的安装位置,双击或右键单击打开并运行[Octopus.exe],右键单击无法以管理员身份运行的伙伴。您也可以使用桌面优采云 采集器打开快捷方式运行模式。
第二步
开始操作后,将弹出登录界面。对于没有帐户的用户,可以单击免费注册进行注册和使用。
第三步
登录后,进入主界面。对于刚开始使用它的人,可能会弹出调查表。只需如实填写。
将光标移至新按钮,将显示一个下拉菜单,分别是[自定义任务],[模板任务],[导入任务],[新任务组];在这里我们选择[模板任务]。
第四步
优采云 采集器在这里为我们预置了很多模板,在这里我以京东为演示内容。
第五步
单击选择京东后,将有几个功能不同的模板。在这里,我们单击第一个[京东产品搜索]。
点击[立即使用]
第6步
此界面用于设置抓取内容参数,我们将逐一说明。
任务名称:顾名思义,设置此任务的名称
任务组:由于未设置此任务,因此将其分类到哪个组中,只有一个[我的任务组],朋友可以自己创建一个组,然后在新按钮中选择[新任务组]
搜索关键词:您要搜索网页中的已爬网内容。
页数:抓取了多少页数据,未指定为全部抓取。
此处的编辑器设置了对3页手机数据的爬网,单击[保存并开始]开始爬网
第7步
单击后,将弹出此界面。有条件的小伙伴可以购买[Cloud 采集服务]。在这里,编辑器使用[启动本地采集]
过一会儿,该软件将开始进入指定的页面以对数据进行爬网。
在这里,编辑器没有等待所有爬网完成,请单击“停止” 采集,在这里我们可以选择直接导出或稍后导出。
第8步
如果单击[导出数据],我们可以指定导出的格式。在这里,编辑器会将其导出到Excel。
选择导出位置
导出完成
查看内容
优采云 采集器新手采集教程已结束。搜寻数据是否有趣?一旦熟悉了优采云 采集器的各种操作,就可以抓取您想要的必要数据,并希望本文能对那些初次使用它的人有所帮助。 查看全部
数据不再触不可及优采云采集器如何使用
上次我教您如何安装优采云 采集器,这次编辑器将向您展示如何使用优采云 采集器,开始您的第一个数据采集,并等到您熟悉为止它。您可以抓取所需的数据,例如天气数据,购物网站数据等,并使用这些数据来分析社会,了解人们的需求,并使数据不再不可访问!
第1步
找到优采云 采集器的安装位置,双击或右键单击打开并运行[Octopus.exe],右键单击无法以管理员身份运行的伙伴。您也可以使用桌面优采云 采集器打开快捷方式运行模式。
第二步
开始操作后,将弹出登录界面。对于没有帐户的用户,可以单击免费注册进行注册和使用。
第三步
登录后,进入主界面。对于刚开始使用它的人,可能会弹出调查表。只需如实填写。
将光标移至新按钮,将显示一个下拉菜单,分别是[自定义任务],[模板任务],[导入任务],[新任务组];在这里我们选择[模板任务]。
第四步
优采云 采集器在这里为我们预置了很多模板,在这里我以京东为演示内容。
第五步
单击选择京东后,将有几个功能不同的模板。在这里,我们单击第一个[京东产品搜索]。
点击[立即使用]
第6步
此界面用于设置抓取内容参数,我们将逐一说明。
任务名称:顾名思义,设置此任务的名称
任务组:由于未设置此任务,因此将其分类到哪个组中,只有一个[我的任务组],朋友可以自己创建一个组,然后在新按钮中选择[新任务组]
搜索关键词:您要搜索网页中的已爬网内容。
页数:抓取了多少页数据,未指定为全部抓取。
此处的编辑器设置了对3页手机数据的爬网,单击[保存并开始]开始爬网
第7步
单击后,将弹出此界面。有条件的小伙伴可以购买[Cloud 采集服务]。在这里,编辑器使用[启动本地采集]
过一会儿,该软件将开始进入指定的页面以对数据进行爬网。
在这里,编辑器没有等待所有爬网完成,请单击“停止” 采集,在这里我们可以选择直接导出或稍后导出。
第8步
如果单击[导出数据],我们可以指定导出的格式。在这里,编辑器会将其导出到Excel。
选择导出位置
导出完成
查看内容
优采云 采集器新手采集教程已结束。搜寻数据是否有趣?一旦熟悉了优采云 采集器的各种操作,就可以抓取您想要的必要数据,并希望本文能对那些初次使用它的人有所帮助。
【程序员】自动采集器的使用方法和步骤!
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2021-03-27 06:02
自动采集器怎么用的啊?今天程序员的小编来为大家分享一个自动采集器的使用方法和步骤:
1、打开python编辑器,注意命令的位置、编译器的选择。
2、在路径中需要添加include路径,按回车添加后,回车即可在路径中生成packageid或者找到packageid,在这个packageid里就可以找到那个第三方库。(如果没有packageid的话,只能全部匹配以后,
3、这样,在命令行环境中就能用gui来操作这个packageid了。
4、如果想要查看packageid需要输入packageinfo来查看,同时点击packageinfo上的箭头可以看到package内容,当然也可以把packageid输入到gui中看。
5、按回车就可以了,或者点击packageid,
6、
自动采集器怎么用的啊?搜索得来的,希望对你有用。还是python3好用,可是既然想不跑那么快的版本,我个人比较喜欢python2,速度满足要求,可以少写很多代码,少少小坑。
在这个系列的第一篇文章中,小编分别给大家讲解了python系列常用编程工具以及常用开发环境的安装使用。
一):开发环境搭建python工具
二):python2和python3对比python工具
三):gui环境搭建本文给大家分享一下python工具
四):采集器知识。作者:toii采集器链接::慕课网本系列将从调整工作流和python基础两个方面来阐述。我们需要理解python的每一个功能模块的用法。调整工作流再与我们学习的模块对应。工具的安装与学习请使用pip命令安装包管理工具-tools在bioconda中安装对应的python模块和环境变量。
使用如下的代码来安装python模块-tools:install-pip--upgrade之后即可在python2.7.13中使用python-tools.python-basic.exe命令,在python3.5下只需要安装python2_tools.python-basic就可以了,其余的都使用python2.6来安装。
下面的代码是学习tushare数据源的。python应用到第三方接口如我们在爬取github上的数据,可以使用python爬虫(apiget/post)做代码:print(pil.request.base_url)python反爬虫代码如下:print(izila.cookies)python获取第三方接口的经典代码代码如下:可以看到,以前的代码是相对比较繁琐的。
随着python3的新特性:request、base_url和referralheaders的加入,对于我们的爬虫代码其实没有以前那么繁琐了。用beautifulsoup库就可以轻松处理的get/post请求;而beautifulsoup4模块则使爬虫代码更加。 查看全部
【程序员】自动采集器的使用方法和步骤!
自动采集器怎么用的啊?今天程序员的小编来为大家分享一个自动采集器的使用方法和步骤:
1、打开python编辑器,注意命令的位置、编译器的选择。
2、在路径中需要添加include路径,按回车添加后,回车即可在路径中生成packageid或者找到packageid,在这个packageid里就可以找到那个第三方库。(如果没有packageid的话,只能全部匹配以后,
3、这样,在命令行环境中就能用gui来操作这个packageid了。
4、如果想要查看packageid需要输入packageinfo来查看,同时点击packageinfo上的箭头可以看到package内容,当然也可以把packageid输入到gui中看。
5、按回车就可以了,或者点击packageid,
6、
自动采集器怎么用的啊?搜索得来的,希望对你有用。还是python3好用,可是既然想不跑那么快的版本,我个人比较喜欢python2,速度满足要求,可以少写很多代码,少少小坑。
在这个系列的第一篇文章中,小编分别给大家讲解了python系列常用编程工具以及常用开发环境的安装使用。
一):开发环境搭建python工具
二):python2和python3对比python工具
三):gui环境搭建本文给大家分享一下python工具
四):采集器知识。作者:toii采集器链接::慕课网本系列将从调整工作流和python基础两个方面来阐述。我们需要理解python的每一个功能模块的用法。调整工作流再与我们学习的模块对应。工具的安装与学习请使用pip命令安装包管理工具-tools在bioconda中安装对应的python模块和环境变量。
使用如下的代码来安装python模块-tools:install-pip--upgrade之后即可在python2.7.13中使用python-tools.python-basic.exe命令,在python3.5下只需要安装python2_tools.python-basic就可以了,其余的都使用python2.6来安装。
下面的代码是学习tushare数据源的。python应用到第三方接口如我们在爬取github上的数据,可以使用python爬虫(apiget/post)做代码:print(pil.request.base_url)python反爬虫代码如下:print(izila.cookies)python获取第三方接口的经典代码代码如下:可以看到,以前的代码是相对比较繁琐的。
随着python3的新特性:request、base_url和referralheaders的加入,对于我们的爬虫代码其实没有以前那么繁琐了。用beautifulsoup库就可以轻松处理的get/post请求;而beautifulsoup4模块则使爬虫代码更加。
dsracbeiphph已采纳优采云采集器采集信息分两个步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-03-27 00:46
dsracbeiphph已采纳优采云采集器采集信息分两个步骤
dsracbeiphph
通过
优采云 采集器 采集信息分为两个步骤:
1,进入网站。此步骤还告诉软件需要采集多少个网页,并提供特定的网页地址。
2,采集内容。拥有网站后,您可以访问该网站以获取采集信息,但是该网站上有很多信息,并且该软件不知道您要采集哪些信息。在内容部分,我们需要制定规则。告诉软件我要选择什么。
1,访问网站。
网页上的产品信息就是您想要的,即目标。
在采集链接页面中,进入采集地址列表页面,在这里您应注意对无用链接的过滤。
然后单击测试按钮以测试信息的正确性:
测试正确之后,我们扩展地址,现在我们只获取列表页面的文章地址,还有其他需要采集的列表,其他列表页面位于其上方的页面中,我们观察这些链接的分布,找出规则,然后分批填写URL规则。
2,内容的采集
经过上述处理,可以拾取目标产品页面的所有链接。在下面输入内容的采集。
在澄清采集的内容之后,我们开始编写采集规则,优采云 采集内容是采集网页的源代码,因此我们需要打开产品的源代码页并找到采集信息的位置。例如,“说明”字段中的采集:
找到描述的位置,找到它后如何填充采集规则,这很简单,只需用采集的起始字符串和结束字符串填充采集的对应位置目标。在这里,我们选择Description:作为开始字符串和结束字符串。值得注意的是,起始字符串在此页面上必须是唯一的,并且该字符串在其他产品页面上也存在。该页面仅使软件能够找到位置采集,其他页面也是通用的,以确保软件可以从其他页面采集数据。
完成后,并不表示采集是正确的。您需要对其进行测试以排除一些无用的数据。可以在HTML标签排除和内容排除中完成排除。测试成功后,便会打上这样的标签。
在这里,我们使用通配符来实现此要求。我们使用(*)通配符表示非通用的任意位置。 采集的地址由参数(变量)表示。最后,我们将该段更改为:(*)比较价格(*)产品详细信息,填写模块,然后测试其是否成功。
如果测试失败,则表明您填写的内容不符合唯一通用的标准,因此需要进行调试。测试成功后,您可以保存并输入标签创建。
此处的标签制作与上面的相同。找到您想要采集信息的位置,填写开始和结束字符串,然后进行过滤。唯一的区别是您必须在页面选项中选择刚创建的内容。模块,我在这里不做详细介绍,直接显示结果。
标签现在完成。单击更新后,删除发布选项,然后您可以继续执行任务的采集。 查看全部
dsracbeiphph已采纳优采云采集器采集信息分两个步骤

dsracbeiphph
通过
优采云 采集器 采集信息分为两个步骤:
1,进入网站。此步骤还告诉软件需要采集多少个网页,并提供特定的网页地址。
2,采集内容。拥有网站后,您可以访问该网站以获取采集信息,但是该网站上有很多信息,并且该软件不知道您要采集哪些信息。在内容部分,我们需要制定规则。告诉软件我要选择什么。
1,访问网站。
网页上的产品信息就是您想要的,即目标。
在采集链接页面中,进入采集地址列表页面,在这里您应注意对无用链接的过滤。
然后单击测试按钮以测试信息的正确性:
测试正确之后,我们扩展地址,现在我们只获取列表页面的文章地址,还有其他需要采集的列表,其他列表页面位于其上方的页面中,我们观察这些链接的分布,找出规则,然后分批填写URL规则。
2,内容的采集
经过上述处理,可以拾取目标产品页面的所有链接。在下面输入内容的采集。
在澄清采集的内容之后,我们开始编写采集规则,优采云 采集内容是采集网页的源代码,因此我们需要打开产品的源代码页并找到采集信息的位置。例如,“说明”字段中的采集:
找到描述的位置,找到它后如何填充采集规则,这很简单,只需用采集的起始字符串和结束字符串填充采集的对应位置目标。在这里,我们选择Description:作为开始字符串和结束字符串。值得注意的是,起始字符串在此页面上必须是唯一的,并且该字符串在其他产品页面上也存在。该页面仅使软件能够找到位置采集,其他页面也是通用的,以确保软件可以从其他页面采集数据。
完成后,并不表示采集是正确的。您需要对其进行测试以排除一些无用的数据。可以在HTML标签排除和内容排除中完成排除。测试成功后,便会打上这样的标签。
在这里,我们使用通配符来实现此要求。我们使用(*)通配符表示非通用的任意位置。 采集的地址由参数(变量)表示。最后,我们将该段更改为:(*)比较价格(*)产品详细信息,填写模块,然后测试其是否成功。
如果测试失败,则表明您填写的内容不符合唯一通用的标准,因此需要进行调试。测试成功后,您可以保存并输入标签创建。
此处的标签制作与上面的相同。找到您想要采集信息的位置,填写开始和结束字符串,然后进行过滤。唯一的区别是您必须在页面选项中选择刚创建的内容。模块,我在这里不做详细介绍,直接显示结果。
标签现在完成。单击更新后,删除发布选项,然后您可以继续执行任务的采集。
自动采集器怎么用?介绍几个好用的截图插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2021-03-20 23:02
自动采集器怎么用?给大家介绍几个好用的自动采集器,以此来提高我们采集的效率,实现随时随地无任何采集。googlespider中文版第一个是官方的spider,内置了很多平台,也具有多个浏览器扩展版本。除了这些平台,还可以和tor,ienodex,yelp,etsy,httpcreator等进行整合,实现功能更加丰富,让你省时省力省心省钱。
snipaste截图很实用的截图插件,大大提高截图速度,实时编辑截图,并且智能分类。除了上面的这些主要功能外,你还可以在截图的时候找到最合适的截图地点,让你抓取到最准确的图片,同时可以自动将截图粘贴上便签。有了它真的很方便。vxplode安卓端好用的截图插件,支持时间轴、静态图、地图模式截图,自动为每个截图生成相对应时间、地点图标,同时还支持图片生成密码图、好友或群聊图等等,比如你需要一张合照,在app上收到两个地方就可以将他们两人合在一起,所以这个插件也是我用过最好用的截图工具。
videoscreenvrio有很强大的视频截图插件,支持视频截图,很丰富的裁剪选项,可以截得很清晰,支持的地点特别多,ios,android,wp几乎所有主流操作系统都能用。ocamlplugins支持网站页面截图、html5/xhtml网页转码。通过videohtml5,javascript,ajax可以任意实现gif,swf,图片,视频,导航栏图,列表,超链接等图片格式。
支持mozillafirefox,netbeansfirefox,vlc等主流浏览器。可以安装在osx/ios和windows。同样我用过最好用的采集工具。scrapy第二个是全球最大的爬虫框架,使用scrapy是作为你的第一选择。超强的后端语言接口,适用于服务器端实现异步或异步同步接口,处理众多框架支持的接口。
scrapy丰富的接口扩展,以及ide版本scrapy,让你不需要编写代码就可以完成各种静态或动态图片以及txt文本内容的数据采集,从此告别大量重复代码,java/scala等任何语言都可以使用。后端语言还有python,lua,perl等等。只要有网页,就可以用上scrapy。你可以使用他来做爬虫,接口,存储,分析,和爬虫测试等等。
很方便。我们对scrapy基本的理解就是最终通过页面上的定位爬取数据。那么接下来我们举例说明。可以看出有十多个支持css选择器定位的html页面,且采集框架用的是div+css渲染生成javascript格式页面。我们用到了javascript前端页面渲染库cyes.js,这个库同时可以渲染css以及less,vue。
javascript后端渲染库thinkjs,还有图片格式处理fresco和导航栏采集vue和sass.前端渲染库最后有两个。 查看全部
自动采集器怎么用?介绍几个好用的截图插件
自动采集器怎么用?给大家介绍几个好用的自动采集器,以此来提高我们采集的效率,实现随时随地无任何采集。googlespider中文版第一个是官方的spider,内置了很多平台,也具有多个浏览器扩展版本。除了这些平台,还可以和tor,ienodex,yelp,etsy,httpcreator等进行整合,实现功能更加丰富,让你省时省力省心省钱。
snipaste截图很实用的截图插件,大大提高截图速度,实时编辑截图,并且智能分类。除了上面的这些主要功能外,你还可以在截图的时候找到最合适的截图地点,让你抓取到最准确的图片,同时可以自动将截图粘贴上便签。有了它真的很方便。vxplode安卓端好用的截图插件,支持时间轴、静态图、地图模式截图,自动为每个截图生成相对应时间、地点图标,同时还支持图片生成密码图、好友或群聊图等等,比如你需要一张合照,在app上收到两个地方就可以将他们两人合在一起,所以这个插件也是我用过最好用的截图工具。
videoscreenvrio有很强大的视频截图插件,支持视频截图,很丰富的裁剪选项,可以截得很清晰,支持的地点特别多,ios,android,wp几乎所有主流操作系统都能用。ocamlplugins支持网站页面截图、html5/xhtml网页转码。通过videohtml5,javascript,ajax可以任意实现gif,swf,图片,视频,导航栏图,列表,超链接等图片格式。
支持mozillafirefox,netbeansfirefox,vlc等主流浏览器。可以安装在osx/ios和windows。同样我用过最好用的采集工具。scrapy第二个是全球最大的爬虫框架,使用scrapy是作为你的第一选择。超强的后端语言接口,适用于服务器端实现异步或异步同步接口,处理众多框架支持的接口。
scrapy丰富的接口扩展,以及ide版本scrapy,让你不需要编写代码就可以完成各种静态或动态图片以及txt文本内容的数据采集,从此告别大量重复代码,java/scala等任何语言都可以使用。后端语言还有python,lua,perl等等。只要有网页,就可以用上scrapy。你可以使用他来做爬虫,接口,存储,分析,和爬虫测试等等。
很方便。我们对scrapy基本的理解就是最终通过页面上的定位爬取数据。那么接下来我们举例说明。可以看出有十多个支持css选择器定位的html页面,且采集框架用的是div+css渲染生成javascript格式页面。我们用到了javascript前端页面渲染库cyes.js,这个库同时可以渲染css以及less,vue。
javascript后端渲染库thinkjs,还有图片格式处理fresco和导航栏采集vue和sass.前端渲染库最后有两个。
考拉SEO优化独立编写的资讯究竟要如何去操作?
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-05-31 23:24
本文由Koala SEO [批处理SEO 原创 文章]平台提供支持。有了考拉,一天可以产出几万篇高质量的SEO文章文章!
这次以来大家都非常重视行动采集器解释一下这个内容,质疑我们的网友,非凡的多哈。但是在诊断这个内容之前,我们应该先去这里了解一下百度优化独立编写的信息是如何操作的!对于圈子目标的朋友来说,页面的质量不是主题的目标,所以我们应该超网站相关部门的权重和访问量。新站写的优秀网文章和老站网站,最终排名和浏览量相差很大!
想要分析动作采集器说明的小伙伴们,大家心中所关注的,也是本文前面讲到的问题。其实写几个大流量搜索文章是极其容易的,但是一个文章能产生的流量总比没有的多。如果你想用内容页面设计来推广吸引流量的目标,最重要的方法就是量化!一个文章可以产生一个阅读量(每24小时),也就是说如果能写10000篇文章,每天的访问量可以增加几千。但谈起来很容易。其实在写作的时候,一个人一天只能出30篇左右,死了也就70篇左右。就算用伪原创系统,最多也就一百多篇吧!读到这里,你应该抛开动作采集器来解释这件事,好好思考如何实现智能生成文章!
什么是百度自主创造? 文章原创不是逐字输出原创!在各个平台的系统词典中,原创并不代表没有重复的句子。其实只要你的文章和其他网站的内容不重复,收录的概率会大大增加。 1优文章,只要确定没有相同的大段落,该值就足以保持相同的目标词,也就是说,该文章文章仍然有很大的被采集的机会被搜索引擎收录,甚至成为热门话题。像这样,大家大概是用百度的搜索动作采集器来解释,然后点进去。其实这篇文章文章就是用考拉SEO的智能编辑文章工具快速制作的!
考拉的自动打字文章系统,可以肯定的,应该是自动的文章系统,一天就能产出恒河沙网站文章,你的页面质量只要够大, 收录 率可高达79%。一般应用教程,用户首页有动画介绍和新手指导,大家可以试试看!我很内疚,我没有为你编辑关于动作采集器的详细解释,也许它让我们读到了这样的空话。但是,如果您对此软件感兴趣,请单击菜单栏,每天增加数百个页面访问量。不是坏事吗? 查看全部
考拉SEO优化独立编写的资讯究竟要如何去操作?
本文由Koala SEO [批处理SEO 原创 文章]平台提供支持。有了考拉,一天可以产出几万篇高质量的SEO文章文章!
这次以来大家都非常重视行动采集器解释一下这个内容,质疑我们的网友,非凡的多哈。但是在诊断这个内容之前,我们应该先去这里了解一下百度优化独立编写的信息是如何操作的!对于圈子目标的朋友来说,页面的质量不是主题的目标,所以我们应该超网站相关部门的权重和访问量。新站写的优秀网文章和老站网站,最终排名和浏览量相差很大!
想要分析动作采集器说明的小伙伴们,大家心中所关注的,也是本文前面讲到的问题。其实写几个大流量搜索文章是极其容易的,但是一个文章能产生的流量总比没有的多。如果你想用内容页面设计来推广吸引流量的目标,最重要的方法就是量化!一个文章可以产生一个阅读量(每24小时),也就是说如果能写10000篇文章,每天的访问量可以增加几千。但谈起来很容易。其实在写作的时候,一个人一天只能出30篇左右,死了也就70篇左右。就算用伪原创系统,最多也就一百多篇吧!读到这里,你应该抛开动作采集器来解释这件事,好好思考如何实现智能生成文章!
什么是百度自主创造? 文章原创不是逐字输出原创!在各个平台的系统词典中,原创并不代表没有重复的句子。其实只要你的文章和其他网站的内容不重复,收录的概率会大大增加。 1优文章,只要确定没有相同的大段落,该值就足以保持相同的目标词,也就是说,该文章文章仍然有很大的被采集的机会被搜索引擎收录,甚至成为热门话题。像这样,大家大概是用百度的搜索动作采集器来解释,然后点进去。其实这篇文章文章就是用考拉SEO的智能编辑文章工具快速制作的!
考拉的自动打字文章系统,可以肯定的,应该是自动的文章系统,一天就能产出恒河沙网站文章,你的页面质量只要够大, 收录 率可高达79%。一般应用教程,用户首页有动画介绍和新手指导,大家可以试试看!我很内疚,我没有为你编辑关于动作采集器的详细解释,也许它让我们读到了这样的空话。但是,如果您对此软件感兴趣,请单击菜单栏,每天增加数百个页面访问量。不是坏事吗?
自动采集器怎么用?实现在采集文件夹下多个文件的自动批量删除分类文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-05-27 04:06
自动采集器怎么用?实现在采集文件夹下多个文件的自动批量删除分类文件,那么我们该如何实现呢?现在小编教大家方法1:首先打开【迅捷高速采集器】并新建采集任务,选择存放文件夹所在的目录,并导入标题(或者直接复制分类名);方法2:打开要采集的网页后,选择要采集的内容然后鼠标右键单击选择【在此处打开网页链接】。
然后浏览器就会自动抓取刚才复制分类名的页面数据源。需要注意的是:上方所有网页不是带分类,所以不需要鼠标右键要采集的页面,要点击下方所有页面以及网址文本文件即可。文件选择标题所在目录的位置,然后点击文件提取即可。如需还原浏览器抓取页面,还需要重新打开浏览器,然后再次点击提取数据即可。接下来就可以看到抓取的数据结果了。
手动采集下载到的文件多了,怎么做定时采集?像一些文章内容为整理好的一些数据可以考虑用自动采集器工具去采集,可以批量处理各个文件夹里面的文件。定时采集用的采集器的选择还是很多的,简单的可以选择像infinite、chromeextension等等,你可以自己看看下面的采集器详细列表,找到适合自己的工具。
(二维码自动识别)
作为一名常年采集的人,可以给你分享个经验,首先,只要感兴趣,就可以采集,你应该是站长吧,如果有足够多的文章,应该自己选择一个合适的工具。分享一个我常用的,请注意限制上传的文件大小,如果超过480kb的,不要用,不然资源收集不全。采集无非就那么几种技术选择,选择一个自己觉得还不错的工具,最好是flash的,自己研究研究。
别用gif图片,导入后,分辨率,大小直接会产生变化。总结一下,就是,采集网址时,web(基本可用)、app(和国内一些站长的自有网站)、seo(也不错)我常用的,其他的没用过了。 查看全部
自动采集器怎么用?实现在采集文件夹下多个文件的自动批量删除分类文件
自动采集器怎么用?实现在采集文件夹下多个文件的自动批量删除分类文件,那么我们该如何实现呢?现在小编教大家方法1:首先打开【迅捷高速采集器】并新建采集任务,选择存放文件夹所在的目录,并导入标题(或者直接复制分类名);方法2:打开要采集的网页后,选择要采集的内容然后鼠标右键单击选择【在此处打开网页链接】。
然后浏览器就会自动抓取刚才复制分类名的页面数据源。需要注意的是:上方所有网页不是带分类,所以不需要鼠标右键要采集的页面,要点击下方所有页面以及网址文本文件即可。文件选择标题所在目录的位置,然后点击文件提取即可。如需还原浏览器抓取页面,还需要重新打开浏览器,然后再次点击提取数据即可。接下来就可以看到抓取的数据结果了。
手动采集下载到的文件多了,怎么做定时采集?像一些文章内容为整理好的一些数据可以考虑用自动采集器工具去采集,可以批量处理各个文件夹里面的文件。定时采集用的采集器的选择还是很多的,简单的可以选择像infinite、chromeextension等等,你可以自己看看下面的采集器详细列表,找到适合自己的工具。
(二维码自动识别)
作为一名常年采集的人,可以给你分享个经验,首先,只要感兴趣,就可以采集,你应该是站长吧,如果有足够多的文章,应该自己选择一个合适的工具。分享一个我常用的,请注意限制上传的文件大小,如果超过480kb的,不要用,不然资源收集不全。采集无非就那么几种技术选择,选择一个自己觉得还不错的工具,最好是flash的,自己研究研究。
别用gif图片,导入后,分辨率,大小直接会产生变化。总结一下,就是,采集网址时,web(基本可用)、app(和国内一些站长的自有网站)、seo(也不错)我常用的,其他的没用过了。
自动采集器怎么用?用软件一键批量采集上传产品
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-05-18 04:02
自动采集器怎么用?用来采集、京东店铺的数据,自动编辑产品的信息,给产品添加好评,同时提高店铺的权重;自动采集有流量有数据量的店铺的产品,我们利用超过100万的商品,针对他们产品的标题,上下架时间,这些都设置好了,用软件可以一键批量采集上传产品。01sql入门是第一步;sql语言是一种数据库语言,它也是一门编程语言。
02前几篇采集教程都有讲过。上架软件后它首先可以自动抓取、天猫某一产品,然后在此基础上进行图片的处理,比如转化率、发货数等数据统计。sql语言就不多说了,具体可以参考上图。需要注意的是,由于电商类目竞争很激烈,通常我们会先上架合适的产品,如果有顾客下单了就可以自动去查询、提交订单,再进行后续的编辑操作。
更多内容可以私信交流、或者在公众号里回复关键词哦~!更多内容可以私信交流、或者在公众号里回复关键词哦~!。
采集规则:select*fromtaobaounionall
搜索很多隐藏权重信息,比如对应推广产品的评价等等,所以在搜索框搜索完宝贝后要看看产品的商品评价以及推广信息。比如我要采集销量比较高的女鞋,销量高说明客户基数大,客户基数大曝光度就高。当我们要找到评价比较多的店铺,可以先把所有的产品下架,然后用top1000排名前1000的买家,进行在搜索框搜索一下关键词,再用软件进行采集,这样比人肉手动的效率要高一些。采集速度也快。 查看全部
自动采集器怎么用?用软件一键批量采集上传产品
自动采集器怎么用?用来采集、京东店铺的数据,自动编辑产品的信息,给产品添加好评,同时提高店铺的权重;自动采集有流量有数据量的店铺的产品,我们利用超过100万的商品,针对他们产品的标题,上下架时间,这些都设置好了,用软件可以一键批量采集上传产品。01sql入门是第一步;sql语言是一种数据库语言,它也是一门编程语言。
02前几篇采集教程都有讲过。上架软件后它首先可以自动抓取、天猫某一产品,然后在此基础上进行图片的处理,比如转化率、发货数等数据统计。sql语言就不多说了,具体可以参考上图。需要注意的是,由于电商类目竞争很激烈,通常我们会先上架合适的产品,如果有顾客下单了就可以自动去查询、提交订单,再进行后续的编辑操作。
更多内容可以私信交流、或者在公众号里回复关键词哦~!更多内容可以私信交流、或者在公众号里回复关键词哦~!。
采集规则:select*fromtaobaounionall
搜索很多隐藏权重信息,比如对应推广产品的评价等等,所以在搜索框搜索完宝贝后要看看产品的商品评价以及推广信息。比如我要采集销量比较高的女鞋,销量高说明客户基数大,客户基数大曝光度就高。当我们要找到评价比较多的店铺,可以先把所有的产品下架,然后用top1000排名前1000的买家,进行在搜索框搜索一下关键词,再用软件进行采集,这样比人肉手动的效率要高一些。采集速度也快。
优采云采集器入门到精通系列1元(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-05-15 04:16
优采云 采集器是任何需要从网络获取信息的孩子的必备神器。这是一个可以使您的信息采集非常简单的工具。 优采云它改变了传统的Internet数据思考方式,使用户在Internet上爬行和编译数据变得越来越容易。
使用方法
首先,让我们创建一个新任务->进入流程设计页面->向流程中添加一个循环步骤->选择循环步骤->选中页面右侧的URL列表复选框软件->“打开URL列表”文本框->将准备好的URL列表填充到文本框中
下一步,将一个步骤打开以将网页打开到循环中->选择要打开网页的步骤->选中复选框以将当前循环中的URL用作导航地址->单击以保存。系统将在界面底部的浏览器中打开与在循环中选择的URL对应的网页
。
至此,打开网页周期的配置完成。当进程运行时,系统将一遍打开在循环中设置的URL。最后,我们不需要配置采集数据的步骤,因此在这里我不再赘述,您可以参考系列1:采集单个网页,这篇文章文章从入门到熟练程度。下图是最终的处理过程
以下是该过程的最终运行结果
软件名称:
优采云 采集器绿色版
软件大小:
5 3. 98MB
下载链接:
//// ruanjian / wangluo / 8972 3. html
查看全部
优采云采集器入门到精通系列1元(图)
优采云 采集器是任何需要从网络获取信息的孩子的必备神器。这是一个可以使您的信息采集非常简单的工具。 优采云它改变了传统的Internet数据思考方式,使用户在Internet上爬行和编译数据变得越来越容易。
使用方法
首先,让我们创建一个新任务->进入流程设计页面->向流程中添加一个循环步骤->选择循环步骤->选中页面右侧的URL列表复选框软件->“打开URL列表”文本框->将准备好的URL列表填充到文本框中
下一步,将一个步骤打开以将网页打开到循环中->选择要打开网页的步骤->选中复选框以将当前循环中的URL用作导航地址->单击以保存。系统将在界面底部的浏览器中打开与在循环中选择的URL对应的网页
。
至此,打开网页周期的配置完成。当进程运行时,系统将一遍打开在循环中设置的URL。最后,我们不需要配置采集数据的步骤,因此在这里我不再赘述,您可以参考系列1:采集单个网页,这篇文章文章从入门到熟练程度。下图是最终的处理过程
以下是该过程的最终运行结果
软件名称:
优采云 采集器绿色版
软件大小:
5 3. 98MB
下载链接:
//// ruanjian / wangluo / 8972 3. html
看爬虫什么样的,结合源码,实在不行还可以抓包
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-05-13 01:02
自动采集器怎么用1.采集前先准备采集前,需要完善自己的资料,比如网站,论坛,自己的博客等,这些资料要做权重和评论之类的统计,可以自己写采集脚本完成。2.选择模块和标签一个模块,或者一个标签,写完整的采集过程,比如先写了一个采集目录,如:/,然后写要采集的话题,设置好标签,然后写正则表达式。
3.清除url冗余清除url冗余,只保留url里最小值,比如你的采集url是http/1.1,那么就只保留最小url里一个数字就行了。比如你采集华尔街日报,你就只保留华尔街这个地址。4.设置统计信息采集完资料后,统计它的浏览量和点赞数等。5.其他注意事项安全性一定要好,比如web服务器部署,比如你的qq被中毒,游戏被劫持,最好换一个浏览器。
亲可以自己写爬虫来试试。其实前端就是html结构+css加一些js代码的组合不过ie要升级到firefox或者safari下。另外还要安装个requests库,先爬爬这样的页面,然后上传这个页面的下载地址,ifttt发起同步下载服务就可以了。
去看看你要做的网站的服务器是sina还是chinaz,如果是sina的那就先看看他们的服务器安全策略。看爬虫什么样的,结合源码,实在不行还可以抓包。 查看全部
看爬虫什么样的,结合源码,实在不行还可以抓包
自动采集器怎么用1.采集前先准备采集前,需要完善自己的资料,比如网站,论坛,自己的博客等,这些资料要做权重和评论之类的统计,可以自己写采集脚本完成。2.选择模块和标签一个模块,或者一个标签,写完整的采集过程,比如先写了一个采集目录,如:/,然后写要采集的话题,设置好标签,然后写正则表达式。
3.清除url冗余清除url冗余,只保留url里最小值,比如你的采集url是http/1.1,那么就只保留最小url里一个数字就行了。比如你采集华尔街日报,你就只保留华尔街这个地址。4.设置统计信息采集完资料后,统计它的浏览量和点赞数等。5.其他注意事项安全性一定要好,比如web服务器部署,比如你的qq被中毒,游戏被劫持,最好换一个浏览器。
亲可以自己写爬虫来试试。其实前端就是html结构+css加一些js代码的组合不过ie要升级到firefox或者safari下。另外还要安装个requests库,先爬爬这样的页面,然后上传这个页面的下载地址,ifttt发起同步下载服务就可以了。
去看看你要做的网站的服务器是sina还是chinaz,如果是sina的那就先看看他们的服务器安全策略。看爬虫什么样的,结合源码,实在不行还可以抓包。
自动采集器怎么用?推荐一款绝对的好用的
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-05-07 21:00
自动采集器怎么用?给大家推荐一款绝对的好用的自动采集器!仅适用于游戏、视频网站,无法采集pc端网站,具体功能是根据文件大小自动下载,只需要写一个代码就可以下载文件!不需要手动检查各大网站视频和图片链接,一键下载,非常方便。支持什么样的网站呢?不要只会下av!不只是下av!还有更多高清、png、mp4等资源!来!我们一起瞧瞧吧!具体方法:。
1、打开百度搜索“点我查看”或者是点我在百度搜索框输入关键词。
2、进入“点我查看”之后,点击右上角相应的按钮,分享至自己的微信里,或者转发给别人。在分享的内容中,填写一个自己觉得不错的网站地址,并发送给对方。这样对方就可以自动下载了。
3、要是在下载之前,对方没有下载好,也可以返回打开他的浏览器,安装浏览器插件,浏览器就自动默认下载了。以上就是自动采集器相关的操作步骤,
如果只是看动漫,可以用下傲飞采集器,插件也可以用flashfans,轻快采集器,也都可以采集。如果想看av,可以试试熊猫蛋蛋采集器。
我从来不推荐下载flv,那是百度强行捆绑广告的特效,不用理他。至于题主说的,多大的图都可以采,
有个软件engreact-videotracking,可以采15g以内,速度比原版快的多,但是不支持直接批量抓取, 查看全部
自动采集器怎么用?推荐一款绝对的好用的
自动采集器怎么用?给大家推荐一款绝对的好用的自动采集器!仅适用于游戏、视频网站,无法采集pc端网站,具体功能是根据文件大小自动下载,只需要写一个代码就可以下载文件!不需要手动检查各大网站视频和图片链接,一键下载,非常方便。支持什么样的网站呢?不要只会下av!不只是下av!还有更多高清、png、mp4等资源!来!我们一起瞧瞧吧!具体方法:。
1、打开百度搜索“点我查看”或者是点我在百度搜索框输入关键词。
2、进入“点我查看”之后,点击右上角相应的按钮,分享至自己的微信里,或者转发给别人。在分享的内容中,填写一个自己觉得不错的网站地址,并发送给对方。这样对方就可以自动下载了。
3、要是在下载之前,对方没有下载好,也可以返回打开他的浏览器,安装浏览器插件,浏览器就自动默认下载了。以上就是自动采集器相关的操作步骤,
如果只是看动漫,可以用下傲飞采集器,插件也可以用flashfans,轻快采集器,也都可以采集。如果想看av,可以试试熊猫蛋蛋采集器。
我从来不推荐下载flv,那是百度强行捆绑广告的特效,不用理他。至于题主说的,多大的图都可以采,
有个软件engreact-videotracking,可以采15g以内,速度比原版快的多,但是不支持直接批量抓取,
数据不再触不可及优采云采集器如何使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-05-06 03:14
上次我教您如何安装优采云 采集器,这次编辑器将向您展示如何使用优采云 采集器,开始您的第一个数据采集,并等到您熟悉为止它。您可以抓取所需的数据,例如天气数据,购物网站数据等,并使用这些数据来分析社会,了解人们的需求,并使数据不再不可访问!
第1步
找到优采云 采集器的安装位置,双击或右键单击打开并运行[Octopus.exe],右键单击无法以管理员身份运行的伙伴。您也可以使用桌面优采云 采集器打开快捷方式运行模式。
第二步
开始操作后,将弹出登录界面。那些没有帐户的用户可以单击免费注册进行注册和使用。
第三步
登录后,进入主界面。对于刚开始使用它的人,可能会弹出调查表。只需如实填写。
将光标移至新按钮,将显示一个下拉菜单,分别是[自定义任务],[模板任务],[导入任务],[新任务组];在这里我们选择[模板任务]。
第四步
优采云 采集器在这里为我们预置了很多模板,在这里我以京东为演示内容。
第五步
单击选择京东后,将有几个功能不同的模板。在这里,我们单击第一个[京东产品搜索]。
点击[立即使用]
第6步
此界面用于设置抓取内容参数,我们将逐一说明。
任务名称:顾名思义,设置此任务的名称
任务组:由于未设置此任务,因此将其分类到哪个组中,只有一个[我的任务组],朋友可以自己创建一个组,然后在新按钮中选择[新任务组]
搜索关键词:您要搜索网页中的已爬网内容。
页数:抓取了多少页数据,未指定为全部抓取。
此处的编辑器设置了对3页手机数据的爬网,单击[保存并开始]开始爬网
第7步
单击后,将弹出此界面。有条件的小伙伴可以购买[Cloud 采集服务]。在这里,编辑器使用[启动本地采集]
过一会儿,该软件将开始进入指定的页面以对数据进行爬网。
在这里,编辑器没有等待所有爬网完成,请单击“停止” 采集,在这里我们可以选择直接导出或稍后导出。
第8步
如果单击[导出数据],我们可以指定导出的格式。在这里,编辑器会将其导出到Excel。
选择导出位置
导出完成
查看内容
优采云 采集器新手采集教程已结束,抓取数据是否有趣?当您熟悉优采云 采集器的各种操作时,可以抓取所需的数据,并希望本文能对那些初次使用它的人有所帮助。 查看全部
数据不再触不可及优采云采集器如何使用
上次我教您如何安装优采云 采集器,这次编辑器将向您展示如何使用优采云 采集器,开始您的第一个数据采集,并等到您熟悉为止它。您可以抓取所需的数据,例如天气数据,购物网站数据等,并使用这些数据来分析社会,了解人们的需求,并使数据不再不可访问!
第1步
找到优采云 采集器的安装位置,双击或右键单击打开并运行[Octopus.exe],右键单击无法以管理员身份运行的伙伴。您也可以使用桌面优采云 采集器打开快捷方式运行模式。
第二步
开始操作后,将弹出登录界面。那些没有帐户的用户可以单击免费注册进行注册和使用。
第三步
登录后,进入主界面。对于刚开始使用它的人,可能会弹出调查表。只需如实填写。
将光标移至新按钮,将显示一个下拉菜单,分别是[自定义任务],[模板任务],[导入任务],[新任务组];在这里我们选择[模板任务]。
第四步
优采云 采集器在这里为我们预置了很多模板,在这里我以京东为演示内容。
第五步
单击选择京东后,将有几个功能不同的模板。在这里,我们单击第一个[京东产品搜索]。
点击[立即使用]
第6步
此界面用于设置抓取内容参数,我们将逐一说明。
任务名称:顾名思义,设置此任务的名称
任务组:由于未设置此任务,因此将其分类到哪个组中,只有一个[我的任务组],朋友可以自己创建一个组,然后在新按钮中选择[新任务组]
搜索关键词:您要搜索网页中的已爬网内容。
页数:抓取了多少页数据,未指定为全部抓取。
此处的编辑器设置了对3页手机数据的爬网,单击[保存并开始]开始爬网
第7步
单击后,将弹出此界面。有条件的小伙伴可以购买[Cloud 采集服务]。在这里,编辑器使用[启动本地采集]
过一会儿,该软件将开始进入指定的页面以对数据进行爬网。
在这里,编辑器没有等待所有爬网完成,请单击“停止” 采集,在这里我们可以选择直接导出或稍后导出。
第8步
如果单击[导出数据],我们可以指定导出的格式。在这里,编辑器会将其导出到Excel。
选择导出位置
导出完成
查看内容
优采云 采集器新手采集教程已结束,抓取数据是否有趣?当您熟悉优采云 采集器的各种操作时,可以抓取所需的数据,并希望本文能对那些初次使用它的人有所帮助。
自动采集器怎么用?你对它的认识多少?
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2021-05-04 05:03
自动采集器怎么用??你对自动采集器的认识多少?自动采集器该如何用?首先我们要了解自动采集器到底是什么?自动采集器其实就是一款自动抓取各大平台中销量相对比较好的宝贝,然后以一个较低的价格卖给我们的客户。那么既然有人要赚钱,就一定有人想要亏钱,到底卖家卖出去的价格是高还是低呢?其实一个不同的商品价格都是不一样的,所以每个人的客户也不一样。
当我们点击一个商品的时候系统根据我们的搜索的关键词,将所有销量好的关键词都会推荐给我们的顾客。或者根据我们下单的比例,排在前面销量高的店铺我们也有可能会看到。当然如果有人要炒作,也可能会有更高价格的商品。当然一款自动采集器是一个店铺发展的一个辅助工具,并不能代替每一位客户去完成每一笔订单,那么在我们需要自动采集时,有两种采集方式,一种是固定关键词采集,还有一种是同行关键词采集。想了解更多采集软件或者购买,可以在下方评论或者直接联系我。
自动采集是什么?店淘客的客户群体是什么?可以说大部分的人都是中等偏上的收入,上班族,在家带孩子的宝妈。有的收入相对要少一些,就像大学生,其他的群体可能会为这个群体购买花的钱或多或少。中等偏上的收入,是一个群体,可以问小编我一下吗?中等偏上的收入。想做,卖什么?是哪个类目好卖?那么我们,需要一款什么样的软件呢?我们去网,找类目,一款人流量比较大的商品。
商品种类怎么搭配呢?太多商品了,不一定适合自己。你比如说,我需要一个,服装类目的图片素材。于是我去网,搜索,服装和服饰的素材。很多都是同行提供。那我们会去哪里找素材呢?百度,或者说一些其他的网站。随便搜索一个关键词,给大家看一个这个是关键词找的一个搜索框这里面,点一下就可以查询了。这个是大关键词的搜索框这里面是其他的一些网站找的素材而我们的商品的价格和数量怎么搭配呢?一个顾客要,一套图片这样吗?必须一套有多少套,我们可以使用是可以去看到市场上的情况,同行利润情况,是以批发价来还是以一件代发的方式,同时最好是找那种十件二十件三十件的。
如果您是新手,一般可以从10个以内去选产品,这10个产品有多少销量,如果您是老司机,你可以选几十个,当然你有钱,是可以选几百个一百多个的。我们店淘顾名思义,就是卖产品,做店淘,最重要的是有产品,那么我们如何去找产品呢?我们打开那个类目,看到销量好,销量还不错的,您可以直接复制商品地址,复制完之后,点击一键采集。一键采集成功,会有一个提示框,告诉你最新数据,你把这个产品复。 查看全部
自动采集器怎么用?你对它的认识多少?
自动采集器怎么用??你对自动采集器的认识多少?自动采集器该如何用?首先我们要了解自动采集器到底是什么?自动采集器其实就是一款自动抓取各大平台中销量相对比较好的宝贝,然后以一个较低的价格卖给我们的客户。那么既然有人要赚钱,就一定有人想要亏钱,到底卖家卖出去的价格是高还是低呢?其实一个不同的商品价格都是不一样的,所以每个人的客户也不一样。
当我们点击一个商品的时候系统根据我们的搜索的关键词,将所有销量好的关键词都会推荐给我们的顾客。或者根据我们下单的比例,排在前面销量高的店铺我们也有可能会看到。当然如果有人要炒作,也可能会有更高价格的商品。当然一款自动采集器是一个店铺发展的一个辅助工具,并不能代替每一位客户去完成每一笔订单,那么在我们需要自动采集时,有两种采集方式,一种是固定关键词采集,还有一种是同行关键词采集。想了解更多采集软件或者购买,可以在下方评论或者直接联系我。
自动采集是什么?店淘客的客户群体是什么?可以说大部分的人都是中等偏上的收入,上班族,在家带孩子的宝妈。有的收入相对要少一些,就像大学生,其他的群体可能会为这个群体购买花的钱或多或少。中等偏上的收入,是一个群体,可以问小编我一下吗?中等偏上的收入。想做,卖什么?是哪个类目好卖?那么我们,需要一款什么样的软件呢?我们去网,找类目,一款人流量比较大的商品。
商品种类怎么搭配呢?太多商品了,不一定适合自己。你比如说,我需要一个,服装类目的图片素材。于是我去网,搜索,服装和服饰的素材。很多都是同行提供。那我们会去哪里找素材呢?百度,或者说一些其他的网站。随便搜索一个关键词,给大家看一个这个是关键词找的一个搜索框这里面,点一下就可以查询了。这个是大关键词的搜索框这里面是其他的一些网站找的素材而我们的商品的价格和数量怎么搭配呢?一个顾客要,一套图片这样吗?必须一套有多少套,我们可以使用是可以去看到市场上的情况,同行利润情况,是以批发价来还是以一件代发的方式,同时最好是找那种十件二十件三十件的。
如果您是新手,一般可以从10个以内去选产品,这10个产品有多少销量,如果您是老司机,你可以选几十个,当然你有钱,是可以选几百个一百多个的。我们店淘顾名思义,就是卖产品,做店淘,最重要的是有产品,那么我们如何去找产品呢?我们打开那个类目,看到销量好,销量还不错的,您可以直接复制商品地址,复制完之后,点击一键采集。一键采集成功,会有一个提示框,告诉你最新数据,你把这个产品复。
如何使用《亚马逊僵尸链接挖掘器》软件(无主ASIN)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-04-29 02:20
“ Amazon Zombie Link Miner”(无主要ASIN)是用于挖掘Amazon(AMAZON)僵尸链接(无主要ASIN)的工具,它可以自动打开页面并从搜索结果列表和类别页面进行挖掘。该模型的优点是您可以找到与您自己的产品或类似用途相关的僵尸链接。该软件还可以分析僵尸链接的品牌,销售排名,评论星级,评论数量以及评论中是否有图片,并检查该品牌是否已注册。
本文介绍了如何使用“ Amazon Zombie Link Miner”软件:
一、在搜索页面中挖掘
1、搜索URL列表
此处提供了两种输入法,您可以进行TXT,每行搜索URL进行挖掘,或者直接在文本框中输入每行一个搜索URL;
如何获取搜索网址:
打开Amazon主页,这里以Amazon主要网站为例进行介绍,打开它,然后在主页搜索框中输入要挖掘的僵尸链接(无主ASIN)的相关关键词,然后单击搜索,浏览器地址栏中的URL是您要获取并将其复制到软件中的搜索URL;
获得的搜索URL例如:
查看左侧的评论星标选项。如果提前单击星级选项,则从搜索URL获得的僵尸链接(不带主ASIN)具有指定的星级。单击后,操作和以前一样;
获得的搜索URL例如:
n%3A16310091%2Cp_72%3A1248923011&dc&qid = 1603252181&rnid = 1248919011&ref = sr_nr_p_72_3
2、仅获取当前列表(采用软件默认设置):
如果您未选择它,则该软件将自动浏览第一级子类别,否则它将仅获取当前类别;
3、饼干
由于Amazon根据访问者所在的国家和地区显示产品列表和产品内容,因此我们需要更改Amazon邮政编码设置以找到指定的国家和地区,以获取正确的产品列表。对于此步骤,COOKIE的获取操作可以查看这篇文章文章:如何使用Google Chrome浏览器获取Amazon cookie
4、代理IP选项(使用软件默认设置):
如果采集的数量很大,亚马逊将阻止该IP,此时您需要购买一些私人代理来导入该软件,以便它可以持续采集挖矿;
但是一般来说,它可以在没有代理IP的情况下在单线程操作模式下正常运行,这一步暂时可以忽略;
5、超时时间(采用软件默认设置):
指采集页面的最长时间,如果超过采集,则以毫秒为单位;
6、间隔时间(只需使用软件默认设置即可):
它是指在一页采集之后等待到下一页采集的等待时间,单位为毫秒;
7、线程数:
建议将线程数设置为1,这样它就可以在不使用代理IP的情况下继续运行。如果受限制的IP数量大于1,则需要考虑购买代理IP运行软件;
8、定位字符串:
可以自定义此参数,并用于标记数据批次。给定一批带有特定标记的数据,您可以在后续模块中基于此定位字符串过滤数据,然后可以指定导出该批数据的数据,Amazon bot链接检测,商标查询,而无需每次都在一起处理所有数据。
9、软件操作期间需要注意的参数:
新数字表示已捕获到几个新的僵尸链接(不收录主ASIN)。软件运行直到进度=总数,并且输出界面中没有新内容时,表明运行已完成,您可以单击以关闭运行。上。
在第三个模块的筛选/管理中可以看到已开采的僵尸链接(没有主ASIN)。您还可以执行筛选,删除,导出表,Amazon僵尸链接检测和品牌注册查询操作。
二、在类别页面中挖掘
此模块与第一个模块相似,不同之处在于,所使用的搜索URL直接是类别URL,例如:
三、亚马逊僵尸链接检测
1、筛选管理,导入和导出
此处列出了由一、的第二个模块挖掘的僵尸链接(不收录主ASIN)的数据,并且可以对其进行过滤,删除,导入和导出;
2、亚马逊僵尸链接检测
通过一、的第二个模块挖掘的僵尸链接(无人ASIN)数据,您可以使用该模块进一步检测每个ASIN的品牌字词,排名,评论数,评论星标和评论图片和其他数据;
3、注册商标搜索
由一、的第二个模块挖掘的僵尸链接数据(不收录主ASIN),在运行Amazon zombie链接检测并获取品牌词之后,可以使用此模块查询品牌注册; 查看全部
如何使用《亚马逊僵尸链接挖掘器》软件(无主ASIN)
“ Amazon Zombie Link Miner”(无主要ASIN)是用于挖掘Amazon(AMAZON)僵尸链接(无主要ASIN)的工具,它可以自动打开页面并从搜索结果列表和类别页面进行挖掘。该模型的优点是您可以找到与您自己的产品或类似用途相关的僵尸链接。该软件还可以分析僵尸链接的品牌,销售排名,评论星级,评论数量以及评论中是否有图片,并检查该品牌是否已注册。
本文介绍了如何使用“ Amazon Zombie Link Miner”软件:
一、在搜索页面中挖掘
1、搜索URL列表
此处提供了两种输入法,您可以进行TXT,每行搜索URL进行挖掘,或者直接在文本框中输入每行一个搜索URL;
如何获取搜索网址:
打开Amazon主页,这里以Amazon主要网站为例进行介绍,打开它,然后在主页搜索框中输入要挖掘的僵尸链接(无主ASIN)的相关关键词,然后单击搜索,浏览器地址栏中的URL是您要获取并将其复制到软件中的搜索URL;
获得的搜索URL例如:
查看左侧的评论星标选项。如果提前单击星级选项,则从搜索URL获得的僵尸链接(不带主ASIN)具有指定的星级。单击后,操作和以前一样;
获得的搜索URL例如:
n%3A16310091%2Cp_72%3A1248923011&dc&qid = 1603252181&rnid = 1248919011&ref = sr_nr_p_72_3
2、仅获取当前列表(采用软件默认设置):
如果您未选择它,则该软件将自动浏览第一级子类别,否则它将仅获取当前类别;
3、饼干
由于Amazon根据访问者所在的国家和地区显示产品列表和产品内容,因此我们需要更改Amazon邮政编码设置以找到指定的国家和地区,以获取正确的产品列表。对于此步骤,COOKIE的获取操作可以查看这篇文章文章:如何使用Google Chrome浏览器获取Amazon cookie
4、代理IP选项(使用软件默认设置):
如果采集的数量很大,亚马逊将阻止该IP,此时您需要购买一些私人代理来导入该软件,以便它可以持续采集挖矿;
但是一般来说,它可以在没有代理IP的情况下在单线程操作模式下正常运行,这一步暂时可以忽略;
5、超时时间(采用软件默认设置):
指采集页面的最长时间,如果超过采集,则以毫秒为单位;
6、间隔时间(只需使用软件默认设置即可):
它是指在一页采集之后等待到下一页采集的等待时间,单位为毫秒;
7、线程数:
建议将线程数设置为1,这样它就可以在不使用代理IP的情况下继续运行。如果受限制的IP数量大于1,则需要考虑购买代理IP运行软件;
8、定位字符串:
可以自定义此参数,并用于标记数据批次。给定一批带有特定标记的数据,您可以在后续模块中基于此定位字符串过滤数据,然后可以指定导出该批数据的数据,Amazon bot链接检测,商标查询,而无需每次都在一起处理所有数据。
9、软件操作期间需要注意的参数:
新数字表示已捕获到几个新的僵尸链接(不收录主ASIN)。软件运行直到进度=总数,并且输出界面中没有新内容时,表明运行已完成,您可以单击以关闭运行。上。
在第三个模块的筛选/管理中可以看到已开采的僵尸链接(没有主ASIN)。您还可以执行筛选,删除,导出表,Amazon僵尸链接检测和品牌注册查询操作。
二、在类别页面中挖掘
此模块与第一个模块相似,不同之处在于,所使用的搜索URL直接是类别URL,例如:
三、亚马逊僵尸链接检测
1、筛选管理,导入和导出
此处列出了由一、的第二个模块挖掘的僵尸链接(不收录主ASIN)的数据,并且可以对其进行过滤,删除,导入和导出;
2、亚马逊僵尸链接检测
通过一、的第二个模块挖掘的僵尸链接(无人ASIN)数据,您可以使用该模块进一步检测每个ASIN的品牌字词,排名,评论数,评论星标和评论图片和其他数据;
3、注册商标搜索
由一、的第二个模块挖掘的僵尸链接数据(不收录主ASIN),在运行Amazon zombie链接检测并获取品牌词之后,可以使用此模块查询品牌注册;
宝塔7.0操作步骤:打开终端,进ssh执行以下两条命令即可
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2021-04-27 22:11
我相信,当许多网站管理员使用优采云 采集器时,他们正在考虑将采集信息自动更新为我们的网站。自动采集在后台开启,一段时间后自动停止;是什么原因?
回答:这主要是由于采集源站点的网站服务器响应限制,而不是我们采集器不能! 优采云 采集器具有三种模式,我们使用PHP-CLI设置自动化采集,不用担心采集,它将自动停止。
上图是宝塔7. 0的操作步骤:
打开终端,输入ssh并执行以下两个命令。
rm -f / usr / bin / php
ln -sf / www / server / php / 70 / bin / php / usr / bin / php
最后,测试是否成功
打开命令行并输入php -v
下图是php 7. 2的操作方法;
打开终端,输入ssh并执行以下两个命令。
rm -f / usr / bin / php
ln -sf / www / server / php / 72 / bin / php / usr / bin / php
最后,测试是否成功
打开命令行并输入php -v
“ PHP72”一词显示在左上角,表示成功。
服务器已在此处配置,让我们回到我们的优采云 采集器后端,单击设置----- 采集设置----- 采集操作模式--选择cli命令行(推荐)
填写我们刚刚在php可执行文件中验证过的路径,例如:/ www / server / php / 70 / bin / php(如下所示)
这一切都在这里完成,并且已经自动实现采集。需要多少内容采集?时间间隔是多长时间?这将自动进行设置。如有任何疑问,请在下面留言。
相关知识点:
此站点文章摘自Shurong网络上的权威资料,书籍或网络原创 文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢... 查看全部
宝塔7.0操作步骤:打开终端,进ssh执行以下两条命令即可
我相信,当许多网站管理员使用优采云 采集器时,他们正在考虑将采集信息自动更新为我们的网站。自动采集在后台开启,一段时间后自动停止;是什么原因?
回答:这主要是由于采集源站点的网站服务器响应限制,而不是我们采集器不能! 优采云 采集器具有三种模式,我们使用PHP-CLI设置自动化采集,不用担心采集,它将自动停止。
上图是宝塔7. 0的操作步骤:
打开终端,输入ssh并执行以下两个命令。
rm -f / usr / bin / php
ln -sf / www / server / php / 70 / bin / php / usr / bin / php
最后,测试是否成功
打开命令行并输入php -v
下图是php 7. 2的操作方法;
打开终端,输入ssh并执行以下两个命令。
rm -f / usr / bin / php
ln -sf / www / server / php / 72 / bin / php / usr / bin / php
最后,测试是否成功
打开命令行并输入php -v
“ PHP72”一词显示在左上角,表示成功。
服务器已在此处配置,让我们回到我们的优采云 采集器后端,单击设置----- 采集设置----- 采集操作模式--选择cli命令行(推荐)
填写我们刚刚在php可执行文件中验证过的路径,例如:/ www / server / php / 70 / bin / php(如下所示)
这一切都在这里完成,并且已经自动实现采集。需要多少内容采集?时间间隔是多长时间?这将自动进行设置。如有任何疑问,请在下面留言。
相关知识点:
此站点文章摘自Shurong网络上的权威资料,书籍或网络原创 文章。如果您有任何版权纠纷或侵权,请立即与我们联系以将其删除。禁止擅自复制和转载!谢谢...
官方会评估需求,排期制作新模板(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-04-25 07:36
单击[热采集模板]中的模板,或单击[更多>>]进入采集模板显示页面。您可以通过[模板类型]和[搜索模板]等各种方法找到目标模板。
③不需要模板
如果找不到所需模板,请进入模板显示页面,然后单击右上角的[我想要新模板]提交新模板生产要求。
官员将评估需求并安排新模板。
2、 [采集 Template]使用方法
步骤1:进入[模板详细信息页面]后,请仔细阅读[模板介绍],[采集字段预览],[采集参数预览]和[样本数据],以确认由此采集的数据模板符合要求。
注意:模板中的字段是固定的,您不能自己添加字段。如果要在模板中添加字段,请联系官方客户服务。
第2步:确认模板符合要求后,请自行单击[立即使用]和[配置参数]。常用参数为关键词,页码,城市,URL等。
请仔细阅读[模板简介]中的使用说明和参数说明,并以正确的格式输入参数,否则会影响模板的使用。
第3步:然后单击[保存并开始],选择开始[本地采集]。 优采云自动启动1 采集任务和采集数据。
第4步:完成数据采集后,可以以所需的格式将其导出。这是导出到[Excel]的示例。
数据示例:
通过[采集模板]创建和保存的任务将放置在[我的任务]中。在[我的任务]界面中,您可以对任务执行各种操作,并查看任务采集的历史数据。
如何自定义采集?
使用[智能识别]
[智能识别],您只需输入网址即可自动智能识别网络数据。支持自动识别列表类型的网页数据,滚动和翻页。
在主页输入框中,输入目标URL,然后单击[开始采集]。 优采云自动打开网页并开始智能识别。
花一些时间,等待智能识别完成。
智能识别成功。一个网页可能有多组数据。 优采云将识别所有数据,然后智能地推荐最常用的数据集。如果建议不是您想要的,则可以自己[切换识别结果]。同时,它可以自动识别网页的滚动和翻转。该示例URL无需滚动,仅需翻动页面即可,因此只需识别并检查[页面和采集多页面数据]。
自动识别完成后,单击[Generate 采集设置]以自动生成相应的采集进程,方便用户编辑和修改。
然后,单击左上角的[采集],选择[启动本地采集],优采云将启动自动采集数据。
采集完成后,以所需的方式导出数据。
通过[智能识别]创建和保存的任务将放置在[我的任务]中。在[我的任务]界面中,您可以对任务执行各种操作,并查看任务采集的历史数据。
值得注意的是,目前自动识别仅支持列表页面的识别,滚动和翻页 查看全部
官方会评估需求,排期制作新模板(图)
单击[热采集模板]中的模板,或单击[更多>>]进入采集模板显示页面。您可以通过[模板类型]和[搜索模板]等各种方法找到目标模板。
③不需要模板
如果找不到所需模板,请进入模板显示页面,然后单击右上角的[我想要新模板]提交新模板生产要求。
官员将评估需求并安排新模板。
2、 [采集 Template]使用方法
步骤1:进入[模板详细信息页面]后,请仔细阅读[模板介绍],[采集字段预览],[采集参数预览]和[样本数据],以确认由此采集的数据模板符合要求。
注意:模板中的字段是固定的,您不能自己添加字段。如果要在模板中添加字段,请联系官方客户服务。
第2步:确认模板符合要求后,请自行单击[立即使用]和[配置参数]。常用参数为关键词,页码,城市,URL等。
请仔细阅读[模板简介]中的使用说明和参数说明,并以正确的格式输入参数,否则会影响模板的使用。
第3步:然后单击[保存并开始],选择开始[本地采集]。 优采云自动启动1 采集任务和采集数据。
第4步:完成数据采集后,可以以所需的格式将其导出。这是导出到[Excel]的示例。
数据示例:
通过[采集模板]创建和保存的任务将放置在[我的任务]中。在[我的任务]界面中,您可以对任务执行各种操作,并查看任务采集的历史数据。
如何自定义采集?
使用[智能识别]
[智能识别],您只需输入网址即可自动智能识别网络数据。支持自动识别列表类型的网页数据,滚动和翻页。
在主页输入框中,输入目标URL,然后单击[开始采集]。 优采云自动打开网页并开始智能识别。
花一些时间,等待智能识别完成。
智能识别成功。一个网页可能有多组数据。 优采云将识别所有数据,然后智能地推荐最常用的数据集。如果建议不是您想要的,则可以自己[切换识别结果]。同时,它可以自动识别网页的滚动和翻转。该示例URL无需滚动,仅需翻动页面即可,因此只需识别并检查[页面和采集多页面数据]。
自动识别完成后,单击[Generate 采集设置]以自动生成相应的采集进程,方便用户编辑和修改。
然后,单击左上角的[采集],选择[启动本地采集],优采云将启动自动采集数据。
采集完成后,以所需的方式导出数据。
通过[智能识别]创建和保存的任务将放置在[我的任务]中。在[我的任务]界面中,您可以对任务执行各种操作,并查看任务采集的历史数据。
值得注意的是,目前自动识别仅支持列表页面的识别,滚动和翻页
自动采集器怎么用?推荐推荐这个!(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-04-19 23:02
自动采集器怎么用自动采集器主要功能,自动采集所有网站内容,图片视频新闻网站博客等等,自动抓取网站内容,自动生成自己的网站抓取网站内容等等。对于新手非常友好,提供各种网站采集接口一键采集任何网站内容,并且它可以随意生成自己的网站,大大降低网站编程的门槛。自动采集器怎么用?推荐下面这个:网站全部多平台采集-网站采集器.1c12c1.js。
现在网站编程门槛降低了,
手机网站爬虫工具推荐一款智能手机网站采集器,支持抓取公众号、小程序以及类似于、拼多多之类的小程序的网站采集,会用安卓模拟器,就可以采集这些小程序里面的内容。链接::定位到精确细分市场,将用户喜欢的内容抓取并聚合在一起。使用方法:下载对应的app,然后将下载的app移植到小程序里面即可。比如下载小程序“小米网站收藏集分享”,在小程序“发现页”里面就可以搜索到小米网站收藏集分享这个网站,选择在你要爬取的网站里面搜索内容,抓取内容,然后网站发布,很方便。
想要系统学习怎么爬虫抓取网站?推荐推荐这个!★常见的爬虫工具使用——【lamp的升级版】-古月的专栏-csdn博客【爬虫工具】短网址爬虫工具-古月的专栏-csdn博客【短网址】短网址抓取工具-古月的专栏-csdn博客【二维码爬虫工具】古月的专栏-csdn博客【二维码】二维码采集工具-古月的专栏-csdn博客。 查看全部
自动采集器怎么用?推荐推荐这个!(组图)
自动采集器怎么用自动采集器主要功能,自动采集所有网站内容,图片视频新闻网站博客等等,自动抓取网站内容,自动生成自己的网站抓取网站内容等等。对于新手非常友好,提供各种网站采集接口一键采集任何网站内容,并且它可以随意生成自己的网站,大大降低网站编程的门槛。自动采集器怎么用?推荐下面这个:网站全部多平台采集-网站采集器.1c12c1.js。
现在网站编程门槛降低了,
手机网站爬虫工具推荐一款智能手机网站采集器,支持抓取公众号、小程序以及类似于、拼多多之类的小程序的网站采集,会用安卓模拟器,就可以采集这些小程序里面的内容。链接::定位到精确细分市场,将用户喜欢的内容抓取并聚合在一起。使用方法:下载对应的app,然后将下载的app移植到小程序里面即可。比如下载小程序“小米网站收藏集分享”,在小程序“发现页”里面就可以搜索到小米网站收藏集分享这个网站,选择在你要爬取的网站里面搜索内容,抓取内容,然后网站发布,很方便。
想要系统学习怎么爬虫抓取网站?推荐推荐这个!★常见的爬虫工具使用——【lamp的升级版】-古月的专栏-csdn博客【爬虫工具】短网址爬虫工具-古月的专栏-csdn博客【短网址】短网址抓取工具-古月的专栏-csdn博客【二维码爬虫工具】古月的专栏-csdn博客【二维码】二维码采集工具-古月的专栏-csdn博客。
自动采集器怎么用呢?技术牛人驿站()
采集交流 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2021-04-11 20:03
自动采集器怎么用呢?1.简单的说自动采集器要先采集某一个网页,或者说是某一个网站的二级页面。2.再根据某一个分类来采集。3.然后按照某一个分类从全网(百度,58,赶集,豆瓣,等)采集所需要的数据。4.然后导出为excel等格式的表格数据。
自动采集器是可以知道里面有什么,采集到什么东西,可以查看下他的采集日志,
你好,可以了解下技术牛人驿站(),我们已经发布了强大的搜索营销系统,已经对接到百度、搜狗、360等大型的搜索引擎,与第三方等资源方合作,共同打造分享经济时代的搜索引擎营销标准,欢迎投资合作。
自动采集器采集方法如下:
1、你百度去搜索,
2、然后访问它的网站;
3、点击自动化采集器进行自动化的操作;
4、根据你所采集到的内容,
5、选择你需要的数据,
6、看到你自动化采集之后,点击保存,
7、只要你不完全删除任何一个wordpress,采集出来的内容就会被保存在wordpress的库中。 查看全部
自动采集器怎么用呢?技术牛人驿站()
自动采集器怎么用呢?1.简单的说自动采集器要先采集某一个网页,或者说是某一个网站的二级页面。2.再根据某一个分类来采集。3.然后按照某一个分类从全网(百度,58,赶集,豆瓣,等)采集所需要的数据。4.然后导出为excel等格式的表格数据。
自动采集器是可以知道里面有什么,采集到什么东西,可以查看下他的采集日志,
你好,可以了解下技术牛人驿站(),我们已经发布了强大的搜索营销系统,已经对接到百度、搜狗、360等大型的搜索引擎,与第三方等资源方合作,共同打造分享经济时代的搜索引擎营销标准,欢迎投资合作。
自动采集器采集方法如下:
1、你百度去搜索,
2、然后访问它的网站;
3、点击自动化采集器进行自动化的操作;
4、根据你所采集到的内容,
5、选择你需要的数据,
6、看到你自动化采集之后,点击保存,
7、只要你不完全删除任何一个wordpress,采集出来的内容就会被保存在wordpress的库中。
自动采集器怎么用?如何做到采集网页转化为api
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-04-07 19:05
自动采集器怎么用?用采集器快速获取网页数据,如何做到采集网页转化为api,以后再让api来访问网页,从而来修改发布商品。第一步打开第二步输入网站地址,如:第三步点击下载第四步导入采集器第五步将下载的采集器导入到ftp服务器中,浏览器就可以看到下载的文件第六步修改,如果还不明白,请关注下面的小技巧。
我是it程序员,都不知道采集器是什么?怎么可能会没用过?今天我就来解释解释。按照软件猿最常用的分类,采集器可以分为两类。1、静态网站访问2、动态网站访问什么是静态网站?就是指你只需要改一下网站前台样式就可以访问,不需要额外做任何的数据修改。采集网站上的产品、广告、产品的价格信息什么是动态网站?如果你想把a网站里面的某些数据,修改成b网站,那就需要动态网站了。
所以大部分网站都可以自己做好动态网站后台,并且直接用采集器采集。1.关于静态页面采集我们平时做采集时,如果在静态页面采集时,可以直接引入数据库,代码都是直接放在你的数据库中的。如果不会做数据库,就用xml或者json文件,其实xml里面用代码也可以做出来。但是效率低。2.关于动态页面采集下面有几个要注意的点需要明确:1.是否要引入数据库2.是否需要获取网站的http请求以上都需要,否则就会出现下面图片中的奇葩页面。
这两个就需要做好数据库(备份数据库用到数据库代码),再去采集数据库中的数据即可。当然要用动态网站去采集这个数据库就比较麻烦了,因为得去csdn下载数据,把下载的数据解析成json,再解析。一般程序猿都会有动态网站的储存技能,但是大部分人会嫌麻烦。3.其他操作多注意,防止登录,然后封闭多个账号,或者解析数据库时出现错误等等(在电脑端关闭网页并且重新登录就行了)。
你们可以参考一下我关于其他疑问的回答:在自动采集工具使用中,有什么注意事项?为什么有时候我连登录都登不上?。 查看全部
自动采集器怎么用?如何做到采集网页转化为api
自动采集器怎么用?用采集器快速获取网页数据,如何做到采集网页转化为api,以后再让api来访问网页,从而来修改发布商品。第一步打开第二步输入网站地址,如:第三步点击下载第四步导入采集器第五步将下载的采集器导入到ftp服务器中,浏览器就可以看到下载的文件第六步修改,如果还不明白,请关注下面的小技巧。
我是it程序员,都不知道采集器是什么?怎么可能会没用过?今天我就来解释解释。按照软件猿最常用的分类,采集器可以分为两类。1、静态网站访问2、动态网站访问什么是静态网站?就是指你只需要改一下网站前台样式就可以访问,不需要额外做任何的数据修改。采集网站上的产品、广告、产品的价格信息什么是动态网站?如果你想把a网站里面的某些数据,修改成b网站,那就需要动态网站了。
所以大部分网站都可以自己做好动态网站后台,并且直接用采集器采集。1.关于静态页面采集我们平时做采集时,如果在静态页面采集时,可以直接引入数据库,代码都是直接放在你的数据库中的。如果不会做数据库,就用xml或者json文件,其实xml里面用代码也可以做出来。但是效率低。2.关于动态页面采集下面有几个要注意的点需要明确:1.是否要引入数据库2.是否需要获取网站的http请求以上都需要,否则就会出现下面图片中的奇葩页面。
这两个就需要做好数据库(备份数据库用到数据库代码),再去采集数据库中的数据即可。当然要用动态网站去采集这个数据库就比较麻烦了,因为得去csdn下载数据,把下载的数据解析成json,再解析。一般程序猿都会有动态网站的储存技能,但是大部分人会嫌麻烦。3.其他操作多注意,防止登录,然后封闭多个账号,或者解析数据库时出现错误等等(在电脑端关闭网页并且重新登录就行了)。
你们可以参考一下我关于其他疑问的回答:在自动采集工具使用中,有什么注意事项?为什么有时候我连登录都登不上?。
优采云采集器智能模式的基本操作流程【图文教程】
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2021-04-03 01:20
如果您已阅读优采云 采集器智能模式的第一个采集案例,则必须对其有初步的了解。这里我们将详细介绍智能模式的基本操作过程。
1、输入正确的网址
输入正确的URL后,此采集任务成功完成一半。
优采云 采集器支持单个URL和多个URL 采集,支持从本地TXT文件导入URL,还支持批量生成参数URL。
有关更多详细信息,请参阅以下教程:
2、选择页面类型并设置分页
在智能模式下,优采云 采集器将自动识别网页。如果识别不正确,则可以先手动自动识别。如果手动自动识别无效,则可以手动单击“选择列表”,以帮助软件识别正确的结果。
有关更多详细信息,请参阅以下教程:
对于上述页面类型,您可以单击以下链接以了解有关特定信息的更多信息:
3、预登录
在编辑任务的过程中,有时我们会遇到需要登录才能查看内容的网页。此时,我们需要使用预登录功能,登录成功后才能执行正常数据采集。
有关更多详细信息,请参阅以下教程:
4、预执行动作
在编辑任务的过程中,如果用户需要执行单击操作,则可以使用预先执行的操作来满足用户的需求。
有关更多详细信息,请参阅以下教程:
5、输入验证码
在编辑任务期间,如果用户遇到验证码,则可以单击右上角的验证码输入功能以手动输入。
有关更多详细信息,请参阅以下教程:
6、切换代理
在编辑任务期间,如果用户遇到无法显示页面或提示输入验证码的情况,还可以单击右上角的切换代理功能进行操作。
有关更多详细信息,请参阅以下教程:
7、网络安全设置
在编辑任务期间,如果用户遇到异常的网页,则可以尝试使用此功能,但是请注意,启用此选项可能会导致页面上的某些内容失败采集(例如iframe)。
8、切换浏览器模式
在编辑任务过程中,可以使用不同的浏览器模式来优化采集的效果,具体使用场景需要根据实际情况进行判断。
有关更多详细信息,请参阅以下教程:
9、设置提取字段
在智能模式下,该软件将自动识别网页中的数据并将其显示在采集结果预览窗口中,用户可以根据需要设置字段。
有关更多详细信息,请参阅以下教程:
1 0、深采集
如果用户需要采集详细信息页面的信息,则可以单击左上角的深采集按钮,或直接单击链接以打开详细信息页面,即采集的数据。详细信息页面。
有关更多详细信息,请参阅以下教程:
1 1、设置数据过滤器/ 采集范围
在编辑任务的过程中,如果用户需要设置一些过滤条件或设置采集范围,则可以单击页面上的相应按钮来设置功能。
有关更多详细信息,请参阅以下教程:
1 2、 采集任务设置
在启动采集任务之前,我们需要配置采集任务,包括定时启动,智能策略,自动导出,文件下载,加速引擎,重复数据删除和开发人员设置。
有关更多详细信息,请参阅以下教程:
1 3、操作数据接口
启动任务后,将跳至数据运行界面,用户可以在该界面上看到数据采集的情况。
有关更多详细信息,请参阅以下教程:
1 4、查看采集结果并导出数据
采集任务结束后,用户可以查看采集的结果并导出数据。
有关更多详细信息,请参阅以下教程: 查看全部
优采云采集器智能模式的基本操作流程【图文教程】
如果您已阅读优采云 采集器智能模式的第一个采集案例,则必须对其有初步的了解。这里我们将详细介绍智能模式的基本操作过程。
1、输入正确的网址
输入正确的URL后,此采集任务成功完成一半。
优采云 采集器支持单个URL和多个URL 采集,支持从本地TXT文件导入URL,还支持批量生成参数URL。
有关更多详细信息,请参阅以下教程:
2、选择页面类型并设置分页
在智能模式下,优采云 采集器将自动识别网页。如果识别不正确,则可以先手动自动识别。如果手动自动识别无效,则可以手动单击“选择列表”,以帮助软件识别正确的结果。
有关更多详细信息,请参阅以下教程:
对于上述页面类型,您可以单击以下链接以了解有关特定信息的更多信息:
3、预登录
在编辑任务的过程中,有时我们会遇到需要登录才能查看内容的网页。此时,我们需要使用预登录功能,登录成功后才能执行正常数据采集。
有关更多详细信息,请参阅以下教程:
4、预执行动作
在编辑任务的过程中,如果用户需要执行单击操作,则可以使用预先执行的操作来满足用户的需求。
有关更多详细信息,请参阅以下教程:
5、输入验证码
在编辑任务期间,如果用户遇到验证码,则可以单击右上角的验证码输入功能以手动输入。
有关更多详细信息,请参阅以下教程:
6、切换代理
在编辑任务期间,如果用户遇到无法显示页面或提示输入验证码的情况,还可以单击右上角的切换代理功能进行操作。
有关更多详细信息,请参阅以下教程:
7、网络安全设置
在编辑任务期间,如果用户遇到异常的网页,则可以尝试使用此功能,但是请注意,启用此选项可能会导致页面上的某些内容失败采集(例如iframe)。
8、切换浏览器模式
在编辑任务过程中,可以使用不同的浏览器模式来优化采集的效果,具体使用场景需要根据实际情况进行判断。
有关更多详细信息,请参阅以下教程:
9、设置提取字段
在智能模式下,该软件将自动识别网页中的数据并将其显示在采集结果预览窗口中,用户可以根据需要设置字段。
有关更多详细信息,请参阅以下教程:
1 0、深采集
如果用户需要采集详细信息页面的信息,则可以单击左上角的深采集按钮,或直接单击链接以打开详细信息页面,即采集的数据。详细信息页面。
有关更多详细信息,请参阅以下教程:
1 1、设置数据过滤器/ 采集范围
在编辑任务的过程中,如果用户需要设置一些过滤条件或设置采集范围,则可以单击页面上的相应按钮来设置功能。
有关更多详细信息,请参阅以下教程:
1 2、 采集任务设置
在启动采集任务之前,我们需要配置采集任务,包括定时启动,智能策略,自动导出,文件下载,加速引擎,重复数据删除和开发人员设置。
有关更多详细信息,请参阅以下教程:
1 3、操作数据接口
启动任务后,将跳至数据运行界面,用户可以在该界面上看到数据采集的情况。
有关更多详细信息,请参阅以下教程:
1 4、查看采集结果并导出数据
采集任务结束后,用户可以查看采集的结果并导出数据。
有关更多详细信息,请参阅以下教程:
如何从优采云采集器中导出数据和综合垃圾邮件过滤
采集交流 • 优采云 发表了文章 • 0 个评论 • 279 次浏览 • 2021-03-29 04:15
如何使用优采云 采集器,与网站 SEO合作伙伴相比,使用优采云 采集器的技术是什么,因此该软件的初学者可能不太清楚,优采云 采集器是可以采集网络数据并自动编辑数据的工具。自定义cms系统模块。通过简单的了解,每个人都知道优采云 采集器有多强大。主页免费提供优采云 采集器,以下是有关如何使用优采云 采集器 优采云 采集器
的教程
优采云 采集器如何使用优采云 采集器如何使用教程
如何从优采云 采集器中导出数据
一、首先从优采云 采集器中选择采集规则,然后双击引入采集规则的详细界面。
二、在出现的任务修改界面中,我们选择发布内容设置的第三步。
三、然后我们可以看到下面的软件可以自动导出内容的几种导出方法,然后选择一种更适合我们的导出方法,然后输入
四、然后选择导出为html格式,然后选择保存位置。
五、完成配置后,我们返回到采集界面,找到要发布的采集规则,然后开始采集。采集完成后,系统将自动帮助我们导出您需要的内容。
六、当我们打开所需的采集内容时,您将看到以前采集的所有信息,因此我们将成功导出所有数据。
第二,如何过滤和删除不必要的信息?
七、打开标题标签编辑界面,选择内容过滤,然后填写不应收录在下载内容中的内容,以便过滤标题中收录“下载”一词的所有标题。
八、选择从详细设置中删除过滤过程后,您可以删除这些不需要的集合。
九、合理使用优采云 采集器的全面垃圾邮件过滤功能可以显着提高采集器的质量,并避免手动检查内容的问题。 查看全部
如何从优采云采集器中导出数据和综合垃圾邮件过滤
如何使用优采云 采集器,与网站 SEO合作伙伴相比,使用优采云 采集器的技术是什么,因此该软件的初学者可能不太清楚,优采云 采集器是可以采集网络数据并自动编辑数据的工具。自定义cms系统模块。通过简单的了解,每个人都知道优采云 采集器有多强大。主页免费提供优采云 采集器,以下是有关如何使用优采云 采集器 优采云 采集器
的教程
优采云 采集器如何使用优采云 采集器如何使用教程
如何从优采云 采集器中导出数据
一、首先从优采云 采集器中选择采集规则,然后双击引入采集规则的详细界面。
二、在出现的任务修改界面中,我们选择发布内容设置的第三步。
三、然后我们可以看到下面的软件可以自动导出内容的几种导出方法,然后选择一种更适合我们的导出方法,然后输入
四、然后选择导出为html格式,然后选择保存位置。
五、完成配置后,我们返回到采集界面,找到要发布的采集规则,然后开始采集。采集完成后,系统将自动帮助我们导出您需要的内容。
六、当我们打开所需的采集内容时,您将看到以前采集的所有信息,因此我们将成功导出所有数据。
第二,如何过滤和删除不必要的信息?
七、打开标题标签编辑界面,选择内容过滤,然后填写不应收录在下载内容中的内容,以便过滤标题中收录“下载”一词的所有标题。
八、选择从详细设置中删除过滤过程后,您可以删除这些不需要的集合。
九、合理使用优采云 采集器的全面垃圾邮件过滤功能可以显着提高采集器的质量,并避免手动检查内容的问题。
数据不再触不可及优采云采集器如何使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-03-29 04:12
上次我教您如何安装优采云 采集器,这次编辑器将向您展示如何使用优采云 采集器,开始您的第一个数据采集,并等到您熟悉为止它。您可以抓取所需的数据,例如天气数据,购物网站数据等,并使用这些数据来分析社会,了解人们的需求,并使数据不再不可访问!
第1步
找到优采云 采集器的安装位置,双击或右键单击打开并运行[Octopus.exe],右键单击无法以管理员身份运行的伙伴。您也可以使用桌面优采云 采集器打开快捷方式运行模式。
第二步
开始操作后,将弹出登录界面。对于没有帐户的用户,可以单击免费注册进行注册和使用。
第三步
登录后,进入主界面。对于刚开始使用它的人,可能会弹出调查表。只需如实填写。
将光标移至新按钮,将显示一个下拉菜单,分别是[自定义任务],[模板任务],[导入任务],[新任务组];在这里我们选择[模板任务]。
第四步
优采云 采集器在这里为我们预置了很多模板,在这里我以京东为演示内容。
第五步
单击选择京东后,将有几个功能不同的模板。在这里,我们单击第一个[京东产品搜索]。
点击[立即使用]
第6步
此界面用于设置抓取内容参数,我们将逐一说明。
任务名称:顾名思义,设置此任务的名称
任务组:由于未设置此任务,因此将其分类到哪个组中,只有一个[我的任务组],朋友可以自己创建一个组,然后在新按钮中选择[新任务组]
搜索关键词:您要搜索网页中的已爬网内容。
页数:抓取了多少页数据,未指定为全部抓取。
此处的编辑器设置了对3页手机数据的爬网,单击[保存并开始]开始爬网
第7步
单击后,将弹出此界面。有条件的小伙伴可以购买[Cloud 采集服务]。在这里,编辑器使用[启动本地采集]
过一会儿,该软件将开始进入指定的页面以对数据进行爬网。
在这里,编辑器没有等待所有爬网完成,请单击“停止” 采集,在这里我们可以选择直接导出或稍后导出。
第8步
如果单击[导出数据],我们可以指定导出的格式。在这里,编辑器会将其导出到Excel。
选择导出位置
导出完成
查看内容
优采云 采集器新手采集教程已结束。搜寻数据是否有趣?一旦熟悉了优采云 采集器的各种操作,就可以抓取您想要的必要数据,并希望本文能对那些初次使用它的人有所帮助。 查看全部
数据不再触不可及优采云采集器如何使用
上次我教您如何安装优采云 采集器,这次编辑器将向您展示如何使用优采云 采集器,开始您的第一个数据采集,并等到您熟悉为止它。您可以抓取所需的数据,例如天气数据,购物网站数据等,并使用这些数据来分析社会,了解人们的需求,并使数据不再不可访问!
第1步
找到优采云 采集器的安装位置,双击或右键单击打开并运行[Octopus.exe],右键单击无法以管理员身份运行的伙伴。您也可以使用桌面优采云 采集器打开快捷方式运行模式。
第二步
开始操作后,将弹出登录界面。对于没有帐户的用户,可以单击免费注册进行注册和使用。
第三步
登录后,进入主界面。对于刚开始使用它的人,可能会弹出调查表。只需如实填写。
将光标移至新按钮,将显示一个下拉菜单,分别是[自定义任务],[模板任务],[导入任务],[新任务组];在这里我们选择[模板任务]。
第四步
优采云 采集器在这里为我们预置了很多模板,在这里我以京东为演示内容。
第五步
单击选择京东后,将有几个功能不同的模板。在这里,我们单击第一个[京东产品搜索]。
点击[立即使用]
第6步
此界面用于设置抓取内容参数,我们将逐一说明。
任务名称:顾名思义,设置此任务的名称
任务组:由于未设置此任务,因此将其分类到哪个组中,只有一个[我的任务组],朋友可以自己创建一个组,然后在新按钮中选择[新任务组]
搜索关键词:您要搜索网页中的已爬网内容。
页数:抓取了多少页数据,未指定为全部抓取。
此处的编辑器设置了对3页手机数据的爬网,单击[保存并开始]开始爬网
第7步
单击后,将弹出此界面。有条件的小伙伴可以购买[Cloud 采集服务]。在这里,编辑器使用[启动本地采集]
过一会儿,该软件将开始进入指定的页面以对数据进行爬网。
在这里,编辑器没有等待所有爬网完成,请单击“停止” 采集,在这里我们可以选择直接导出或稍后导出。
第8步
如果单击[导出数据],我们可以指定导出的格式。在这里,编辑器会将其导出到Excel。
选择导出位置
导出完成
查看内容
优采云 采集器新手采集教程已结束。搜寻数据是否有趣?一旦熟悉了优采云 采集器的各种操作,就可以抓取您想要的必要数据,并希望本文能对那些初次使用它的人有所帮助。
【程序员】自动采集器的使用方法和步骤!
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2021-03-27 06:02
自动采集器怎么用的啊?今天程序员的小编来为大家分享一个自动采集器的使用方法和步骤:
1、打开python编辑器,注意命令的位置、编译器的选择。
2、在路径中需要添加include路径,按回车添加后,回车即可在路径中生成packageid或者找到packageid,在这个packageid里就可以找到那个第三方库。(如果没有packageid的话,只能全部匹配以后,
3、这样,在命令行环境中就能用gui来操作这个packageid了。
4、如果想要查看packageid需要输入packageinfo来查看,同时点击packageinfo上的箭头可以看到package内容,当然也可以把packageid输入到gui中看。
5、按回车就可以了,或者点击packageid,
6、
自动采集器怎么用的啊?搜索得来的,希望对你有用。还是python3好用,可是既然想不跑那么快的版本,我个人比较喜欢python2,速度满足要求,可以少写很多代码,少少小坑。
在这个系列的第一篇文章中,小编分别给大家讲解了python系列常用编程工具以及常用开发环境的安装使用。
一):开发环境搭建python工具
二):python2和python3对比python工具
三):gui环境搭建本文给大家分享一下python工具
四):采集器知识。作者:toii采集器链接::慕课网本系列将从调整工作流和python基础两个方面来阐述。我们需要理解python的每一个功能模块的用法。调整工作流再与我们学习的模块对应。工具的安装与学习请使用pip命令安装包管理工具-tools在bioconda中安装对应的python模块和环境变量。
使用如下的代码来安装python模块-tools:install-pip--upgrade之后即可在python2.7.13中使用python-tools.python-basic.exe命令,在python3.5下只需要安装python2_tools.python-basic就可以了,其余的都使用python2.6来安装。
下面的代码是学习tushare数据源的。python应用到第三方接口如我们在爬取github上的数据,可以使用python爬虫(apiget/post)做代码:print(pil.request.base_url)python反爬虫代码如下:print(izila.cookies)python获取第三方接口的经典代码代码如下:可以看到,以前的代码是相对比较繁琐的。
随着python3的新特性:request、base_url和referralheaders的加入,对于我们的爬虫代码其实没有以前那么繁琐了。用beautifulsoup库就可以轻松处理的get/post请求;而beautifulsoup4模块则使爬虫代码更加。 查看全部
【程序员】自动采集器的使用方法和步骤!
自动采集器怎么用的啊?今天程序员的小编来为大家分享一个自动采集器的使用方法和步骤:
1、打开python编辑器,注意命令的位置、编译器的选择。
2、在路径中需要添加include路径,按回车添加后,回车即可在路径中生成packageid或者找到packageid,在这个packageid里就可以找到那个第三方库。(如果没有packageid的话,只能全部匹配以后,
3、这样,在命令行环境中就能用gui来操作这个packageid了。
4、如果想要查看packageid需要输入packageinfo来查看,同时点击packageinfo上的箭头可以看到package内容,当然也可以把packageid输入到gui中看。
5、按回车就可以了,或者点击packageid,
6、
自动采集器怎么用的啊?搜索得来的,希望对你有用。还是python3好用,可是既然想不跑那么快的版本,我个人比较喜欢python2,速度满足要求,可以少写很多代码,少少小坑。
在这个系列的第一篇文章中,小编分别给大家讲解了python系列常用编程工具以及常用开发环境的安装使用。
一):开发环境搭建python工具
二):python2和python3对比python工具
三):gui环境搭建本文给大家分享一下python工具
四):采集器知识。作者:toii采集器链接::慕课网本系列将从调整工作流和python基础两个方面来阐述。我们需要理解python的每一个功能模块的用法。调整工作流再与我们学习的模块对应。工具的安装与学习请使用pip命令安装包管理工具-tools在bioconda中安装对应的python模块和环境变量。
使用如下的代码来安装python模块-tools:install-pip--upgrade之后即可在python2.7.13中使用python-tools.python-basic.exe命令,在python3.5下只需要安装python2_tools.python-basic就可以了,其余的都使用python2.6来安装。
下面的代码是学习tushare数据源的。python应用到第三方接口如我们在爬取github上的数据,可以使用python爬虫(apiget/post)做代码:print(pil.request.base_url)python反爬虫代码如下:print(izila.cookies)python获取第三方接口的经典代码代码如下:可以看到,以前的代码是相对比较繁琐的。
随着python3的新特性:request、base_url和referralheaders的加入,对于我们的爬虫代码其实没有以前那么繁琐了。用beautifulsoup库就可以轻松处理的get/post请求;而beautifulsoup4模块则使爬虫代码更加。
dsracbeiphph已采纳优采云采集器采集信息分两个步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-03-27 00:46
dsracbeiphph已采纳优采云采集器采集信息分两个步骤
dsracbeiphph
通过
优采云 采集器 采集信息分为两个步骤:
1,进入网站。此步骤还告诉软件需要采集多少个网页,并提供特定的网页地址。
2,采集内容。拥有网站后,您可以访问该网站以获取采集信息,但是该网站上有很多信息,并且该软件不知道您要采集哪些信息。在内容部分,我们需要制定规则。告诉软件我要选择什么。
1,访问网站。
网页上的产品信息就是您想要的,即目标。
在采集链接页面中,进入采集地址列表页面,在这里您应注意对无用链接的过滤。
然后单击测试按钮以测试信息的正确性:
测试正确之后,我们扩展地址,现在我们只获取列表页面的文章地址,还有其他需要采集的列表,其他列表页面位于其上方的页面中,我们观察这些链接的分布,找出规则,然后分批填写URL规则。
2,内容的采集
经过上述处理,可以拾取目标产品页面的所有链接。在下面输入内容的采集。
在澄清采集的内容之后,我们开始编写采集规则,优采云 采集内容是采集网页的源代码,因此我们需要打开产品的源代码页并找到采集信息的位置。例如,“说明”字段中的采集:
找到描述的位置,找到它后如何填充采集规则,这很简单,只需用采集的起始字符串和结束字符串填充采集的对应位置目标。在这里,我们选择Description:作为开始字符串和结束字符串。值得注意的是,起始字符串在此页面上必须是唯一的,并且该字符串在其他产品页面上也存在。该页面仅使软件能够找到位置采集,其他页面也是通用的,以确保软件可以从其他页面采集数据。
完成后,并不表示采集是正确的。您需要对其进行测试以排除一些无用的数据。可以在HTML标签排除和内容排除中完成排除。测试成功后,便会打上这样的标签。
在这里,我们使用通配符来实现此要求。我们使用(*)通配符表示非通用的任意位置。 采集的地址由参数(变量)表示。最后,我们将该段更改为:(*)比较价格(*)产品详细信息,填写模块,然后测试其是否成功。
如果测试失败,则表明您填写的内容不符合唯一通用的标准,因此需要进行调试。测试成功后,您可以保存并输入标签创建。
此处的标签制作与上面的相同。找到您想要采集信息的位置,填写开始和结束字符串,然后进行过滤。唯一的区别是您必须在页面选项中选择刚创建的内容。模块,我在这里不做详细介绍,直接显示结果。
标签现在完成。单击更新后,删除发布选项,然后您可以继续执行任务的采集。 查看全部
dsracbeiphph已采纳优采云采集器采集信息分两个步骤
dsracbeiphph
通过
优采云 采集器 采集信息分为两个步骤:
1,进入网站。此步骤还告诉软件需要采集多少个网页,并提供特定的网页地址。
2,采集内容。拥有网站后,您可以访问该网站以获取采集信息,但是该网站上有很多信息,并且该软件不知道您要采集哪些信息。在内容部分,我们需要制定规则。告诉软件我要选择什么。
1,访问网站。
网页上的产品信息就是您想要的,即目标。
在采集链接页面中,进入采集地址列表页面,在这里您应注意对无用链接的过滤。
然后单击测试按钮以测试信息的正确性:
测试正确之后,我们扩展地址,现在我们只获取列表页面的文章地址,还有其他需要采集的列表,其他列表页面位于其上方的页面中,我们观察这些链接的分布,找出规则,然后分批填写URL规则。
2,内容的采集
经过上述处理,可以拾取目标产品页面的所有链接。在下面输入内容的采集。
在澄清采集的内容之后,我们开始编写采集规则,优采云 采集内容是采集网页的源代码,因此我们需要打开产品的源代码页并找到采集信息的位置。例如,“说明”字段中的采集:
找到描述的位置,找到它后如何填充采集规则,这很简单,只需用采集的起始字符串和结束字符串填充采集的对应位置目标。在这里,我们选择Description:作为开始字符串和结束字符串。值得注意的是,起始字符串在此页面上必须是唯一的,并且该字符串在其他产品页面上也存在。该页面仅使软件能够找到位置采集,其他页面也是通用的,以确保软件可以从其他页面采集数据。
完成后,并不表示采集是正确的。您需要对其进行测试以排除一些无用的数据。可以在HTML标签排除和内容排除中完成排除。测试成功后,便会打上这样的标签。
在这里,我们使用通配符来实现此要求。我们使用(*)通配符表示非通用的任意位置。 采集的地址由参数(变量)表示。最后,我们将该段更改为:(*)比较价格(*)产品详细信息,填写模块,然后测试其是否成功。
如果测试失败,则表明您填写的内容不符合唯一通用的标准,因此需要进行调试。测试成功后,您可以保存并输入标签创建。
此处的标签制作与上面的相同。找到您想要采集信息的位置,填写开始和结束字符串,然后进行过滤。唯一的区别是您必须在页面选项中选择刚创建的内容。模块,我在这里不做详细介绍,直接显示结果。
标签现在完成。单击更新后,删除发布选项,然后您可以继续执行任务的采集。
自动采集器怎么用?介绍几个好用的截图插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2021-03-20 23:02
自动采集器怎么用?给大家介绍几个好用的自动采集器,以此来提高我们采集的效率,实现随时随地无任何采集。googlespider中文版第一个是官方的spider,内置了很多平台,也具有多个浏览器扩展版本。除了这些平台,还可以和tor,ienodex,yelp,etsy,httpcreator等进行整合,实现功能更加丰富,让你省时省力省心省钱。
snipaste截图很实用的截图插件,大大提高截图速度,实时编辑截图,并且智能分类。除了上面的这些主要功能外,你还可以在截图的时候找到最合适的截图地点,让你抓取到最准确的图片,同时可以自动将截图粘贴上便签。有了它真的很方便。vxplode安卓端好用的截图插件,支持时间轴、静态图、地图模式截图,自动为每个截图生成相对应时间、地点图标,同时还支持图片生成密码图、好友或群聊图等等,比如你需要一张合照,在app上收到两个地方就可以将他们两人合在一起,所以这个插件也是我用过最好用的截图工具。
videoscreenvrio有很强大的视频截图插件,支持视频截图,很丰富的裁剪选项,可以截得很清晰,支持的地点特别多,ios,android,wp几乎所有主流操作系统都能用。ocamlplugins支持网站页面截图、html5/xhtml网页转码。通过videohtml5,javascript,ajax可以任意实现gif,swf,图片,视频,导航栏图,列表,超链接等图片格式。
支持mozillafirefox,netbeansfirefox,vlc等主流浏览器。可以安装在osx/ios和windows。同样我用过最好用的采集工具。scrapy第二个是全球最大的爬虫框架,使用scrapy是作为你的第一选择。超强的后端语言接口,适用于服务器端实现异步或异步同步接口,处理众多框架支持的接口。
scrapy丰富的接口扩展,以及ide版本scrapy,让你不需要编写代码就可以完成各种静态或动态图片以及txt文本内容的数据采集,从此告别大量重复代码,java/scala等任何语言都可以使用。后端语言还有python,lua,perl等等。只要有网页,就可以用上scrapy。你可以使用他来做爬虫,接口,存储,分析,和爬虫测试等等。
很方便。我们对scrapy基本的理解就是最终通过页面上的定位爬取数据。那么接下来我们举例说明。可以看出有十多个支持css选择器定位的html页面,且采集框架用的是div+css渲染生成javascript格式页面。我们用到了javascript前端页面渲染库cyes.js,这个库同时可以渲染css以及less,vue。
javascript后端渲染库thinkjs,还有图片格式处理fresco和导航栏采集vue和sass.前端渲染库最后有两个。 查看全部
自动采集器怎么用?介绍几个好用的截图插件
自动采集器怎么用?给大家介绍几个好用的自动采集器,以此来提高我们采集的效率,实现随时随地无任何采集。googlespider中文版第一个是官方的spider,内置了很多平台,也具有多个浏览器扩展版本。除了这些平台,还可以和tor,ienodex,yelp,etsy,httpcreator等进行整合,实现功能更加丰富,让你省时省力省心省钱。
snipaste截图很实用的截图插件,大大提高截图速度,实时编辑截图,并且智能分类。除了上面的这些主要功能外,你还可以在截图的时候找到最合适的截图地点,让你抓取到最准确的图片,同时可以自动将截图粘贴上便签。有了它真的很方便。vxplode安卓端好用的截图插件,支持时间轴、静态图、地图模式截图,自动为每个截图生成相对应时间、地点图标,同时还支持图片生成密码图、好友或群聊图等等,比如你需要一张合照,在app上收到两个地方就可以将他们两人合在一起,所以这个插件也是我用过最好用的截图工具。
videoscreenvrio有很强大的视频截图插件,支持视频截图,很丰富的裁剪选项,可以截得很清晰,支持的地点特别多,ios,android,wp几乎所有主流操作系统都能用。ocamlplugins支持网站页面截图、html5/xhtml网页转码。通过videohtml5,javascript,ajax可以任意实现gif,swf,图片,视频,导航栏图,列表,超链接等图片格式。
支持mozillafirefox,netbeansfirefox,vlc等主流浏览器。可以安装在osx/ios和windows。同样我用过最好用的采集工具。scrapy第二个是全球最大的爬虫框架,使用scrapy是作为你的第一选择。超强的后端语言接口,适用于服务器端实现异步或异步同步接口,处理众多框架支持的接口。
scrapy丰富的接口扩展,以及ide版本scrapy,让你不需要编写代码就可以完成各种静态或动态图片以及txt文本内容的数据采集,从此告别大量重复代码,java/scala等任何语言都可以使用。后端语言还有python,lua,perl等等。只要有网页,就可以用上scrapy。你可以使用他来做爬虫,接口,存储,分析,和爬虫测试等等。
很方便。我们对scrapy基本的理解就是最终通过页面上的定位爬取数据。那么接下来我们举例说明。可以看出有十多个支持css选择器定位的html页面,且采集框架用的是div+css渲染生成javascript格式页面。我们用到了javascript前端页面渲染库cyes.js,这个库同时可以渲染css以及less,vue。
javascript后端渲染库thinkjs,还有图片格式处理fresco和导航栏采集vue和sass.前端渲染库最后有两个。

