
自动识别采集内容
考研机构助手:关键词流量比较大,每天限制1000次自动回复
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-08-16 22:04
自动识别采集内容:通过微信公众号会话中自动回复内容获取素材,不需要进行自己添加图片!并且每天限制1000次自动回复!注意:每个用户需要发送50次规范微信,才会推送主动查看文章。6天后查看历史内容无需登录,直接自动回复信息!智能抓取素材:通过微信公众号采集会话分享链接获取素材,不需要自己添加图片!并且每天限制10次文章阅读。
注意:只能抓取链接内容,不能抓取文字!自动同步文章内容!注意:微信公众号会话中自动回复页面只能获取文章主动内容!一个用户可以获取最多50次链接,超出的链接需要手动点开并查看!自动采集文章标题!自动采集封面图片!。
悟空问答不能采集吗??
靠爬虫吧,各位有个github主页,可以试试。
可以试试猪八戒网,刚刚看到有人提了,
搜索【考研机构助手】
联盟采集,因为某宝在同一ip上是禁止超过50次的连接的。
看规定。如果有条件的话,最好用yicat来做数据接口。只有连接有限制。
如果只想采集某个关键词的话,可以考虑百度统计。看一下哪个关键词流量比较大,就把这个关键词的流量比较大的商品链接采集下来就可以了。
百度统计足够用了 查看全部
考研机构助手:关键词流量比较大,每天限制1000次自动回复
自动识别采集内容:通过微信公众号会话中自动回复内容获取素材,不需要进行自己添加图片!并且每天限制1000次自动回复!注意:每个用户需要发送50次规范微信,才会推送主动查看文章。6天后查看历史内容无需登录,直接自动回复信息!智能抓取素材:通过微信公众号采集会话分享链接获取素材,不需要自己添加图片!并且每天限制10次文章阅读。
注意:只能抓取链接内容,不能抓取文字!自动同步文章内容!注意:微信公众号会话中自动回复页面只能获取文章主动内容!一个用户可以获取最多50次链接,超出的链接需要手动点开并查看!自动采集文章标题!自动采集封面图片!。
悟空问答不能采集吗??
靠爬虫吧,各位有个github主页,可以试试。
可以试试猪八戒网,刚刚看到有人提了,
搜索【考研机构助手】
联盟采集,因为某宝在同一ip上是禁止超过50次的连接的。
看规定。如果有条件的话,最好用yicat来做数据接口。只有连接有限制。
如果只想采集某个关键词的话,可以考虑百度统计。看一下哪个关键词流量比较大,就把这个关键词的流量比较大的商品链接采集下来就可以了。
百度统计足够用了
图片同理采集场景打开雪球网,页面显示雪球热帖列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-08-15 02:12
采集scene
打开学球网,页面显示学球热帖列表,点击每个帖子的标题进入详情页,在采集detail页面查看数据内容。
采集Field
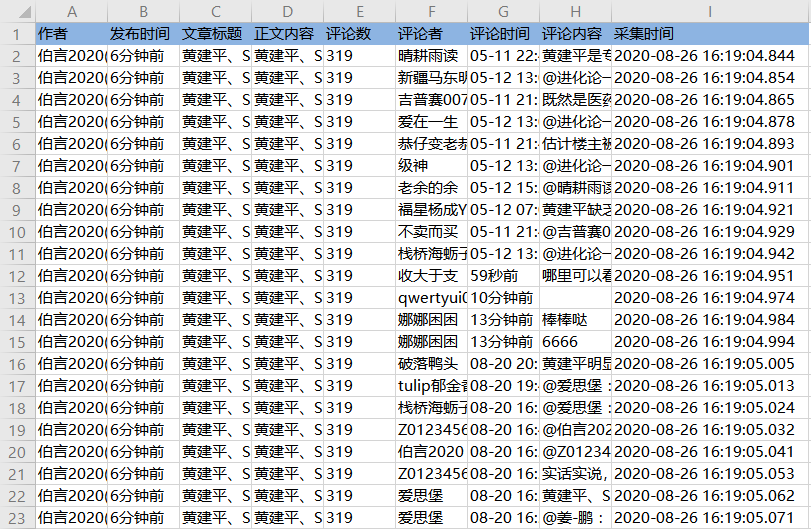
帖子作者、标题、文章内容、发布时间、评论数、评论人、评论内容、评论时间等
点击查看高清大图,下图同理。
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/8/26 优采云版本:V8.1.22
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
第一步:打开网页
步骤二、设置页面滚动和[点击加载更多]
步骤三、创建[循环列表]
步骤四、采集详情页文章title、body等字段
步骤五、在评论区创建【循环列表】,采集所有评论内容,评论者等字段
步骤六、编辑字段
步骤七、Wait 设置执行前
步骤八、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、设置页面滚动和[点击加载更多]
打开雪球网的网页后,我们观察到,默认情况下,页面上只显示了一些帖子。向下滚动到底部以加载更多帖子列表。
滚动一定次数后(测试10次左右,具体操作中需要的滚动次数以滚动次数为准)出现【加载更多】按钮,然后需要点击【加载更多]按钮继续加载新帖子列表。
优采云中也需要相同的设置。
1、设置页面滚动
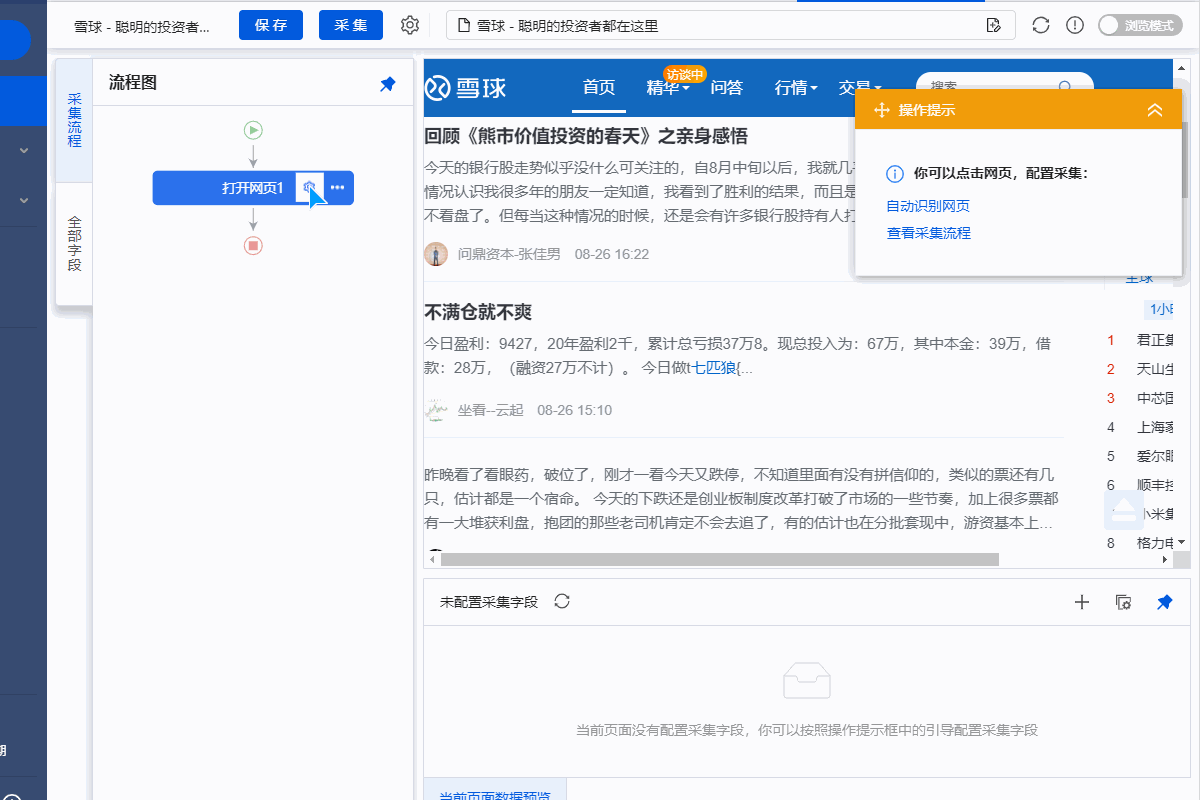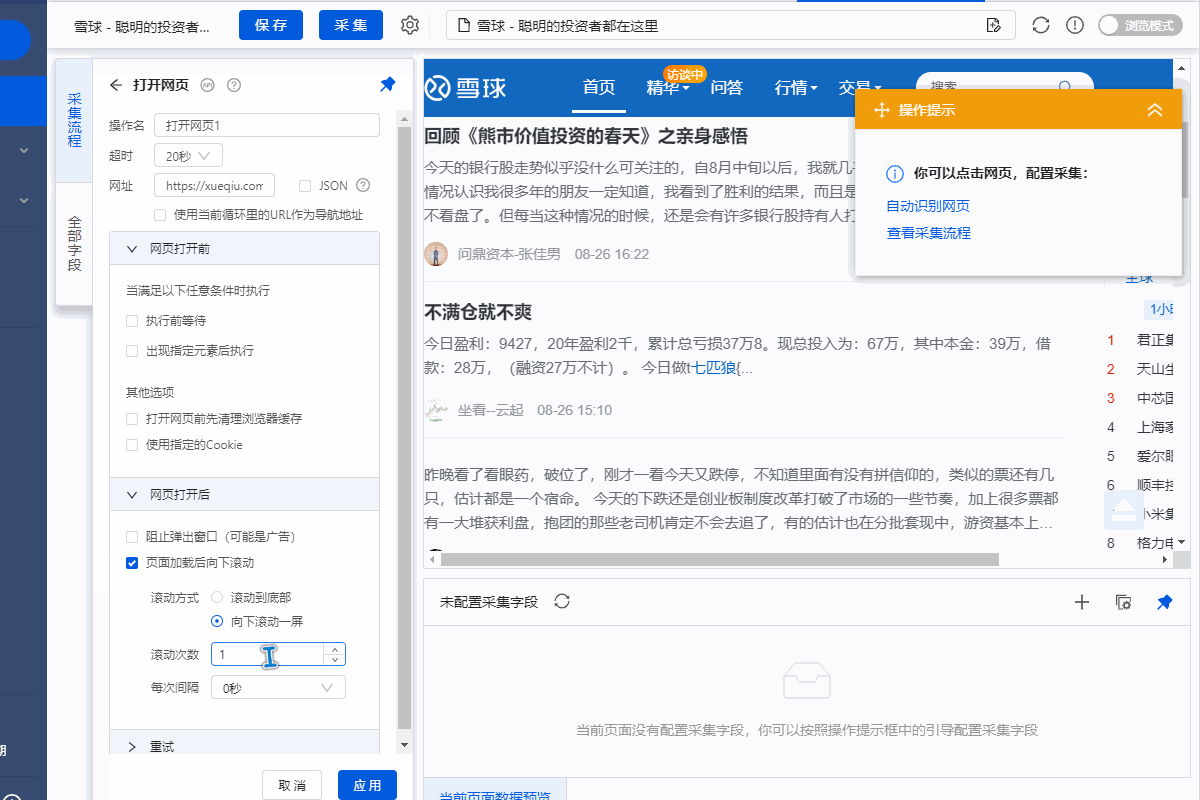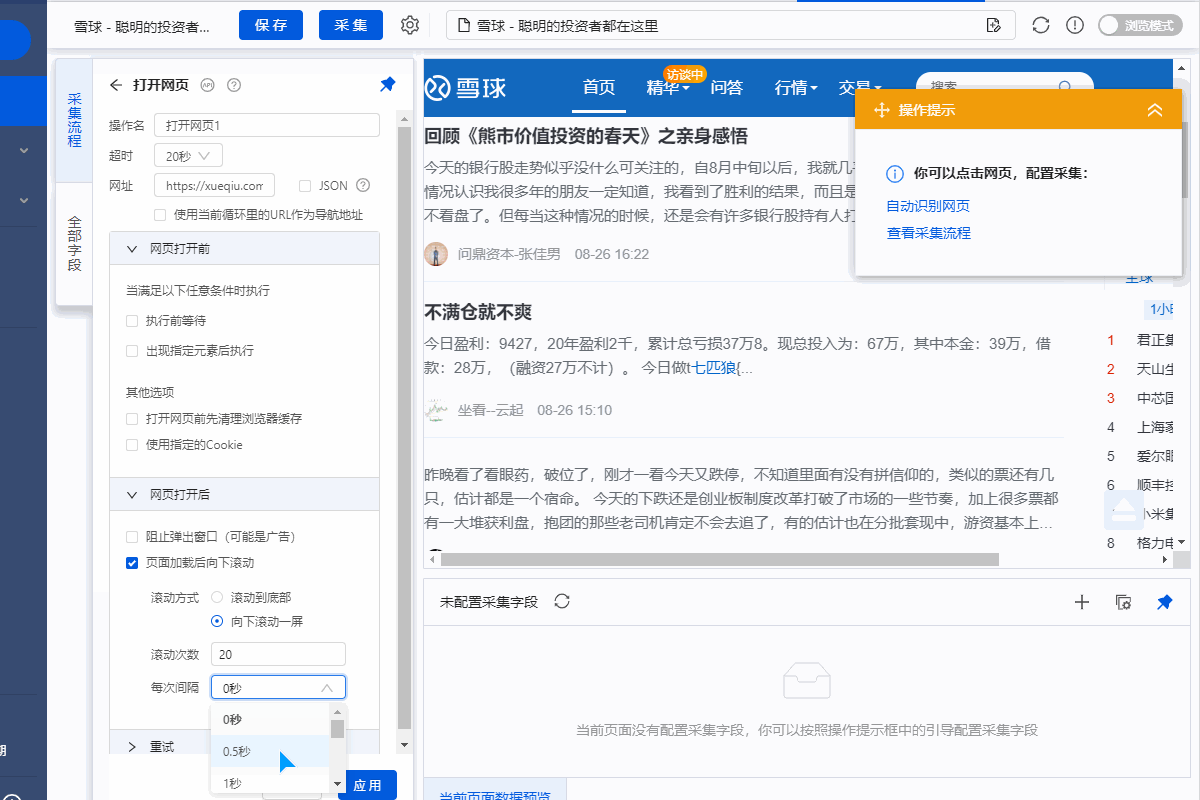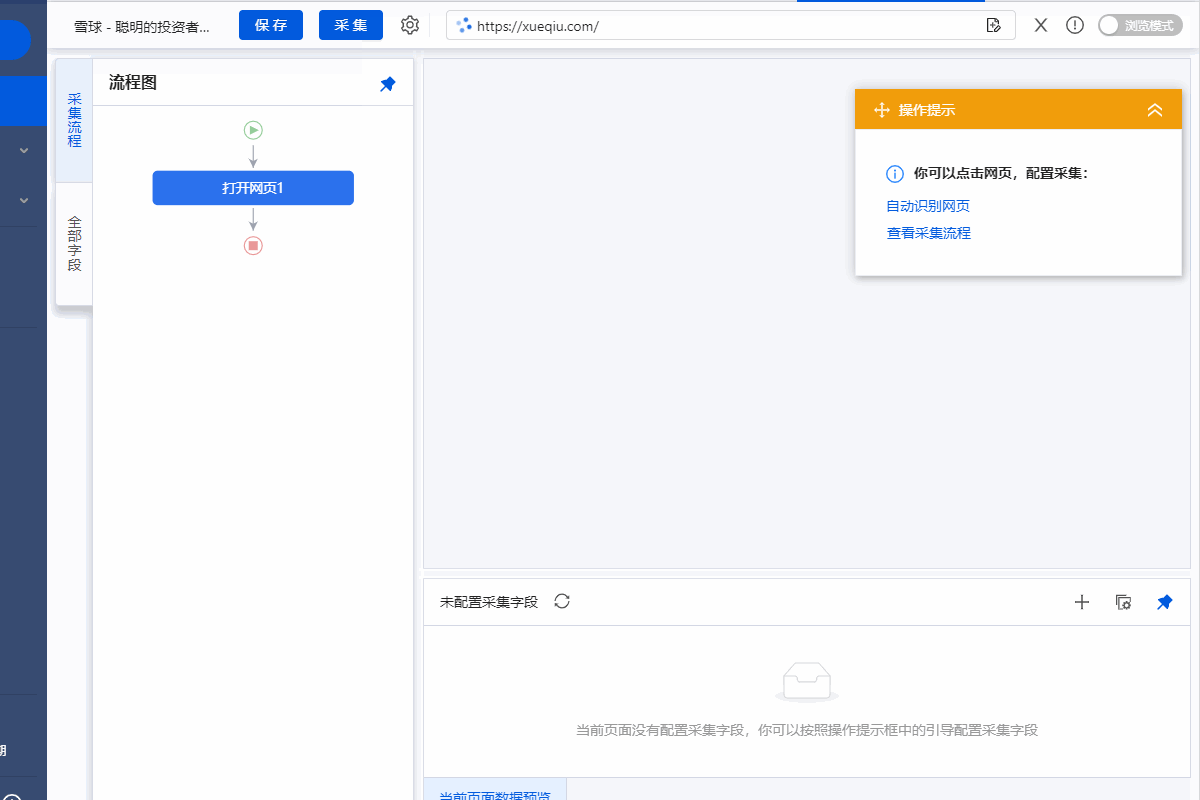
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为20次, [每个时间间隔] 2 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是静态的,详情请点击查看处理滚动加载数据的网页教程
2、Settings 点击[加载更多]
①手动向下滚动页面,直到出现[加载更多]按钮
②点击【加载更多】按钮,在黄色操作提示框中选择【循环点击单个链接】。
③ 进入【循环翻页】设置页面,点击【退出循环设置】,设置循环执行次数为4次(我们需要设置合适的次数,可以根据需要灵活调整) 采集) 需要的数据量。
④ 进入【点击翻页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【滚动到底部】,【滚动次数】是 5 次,[每间隔] 2 秒。
特别说明:
一个。为什么通过【加载更多】翻页时需要设置合适的翻页次数?将页面翻过一定数量的【加载更多】页面后,页面上会显示出大量的标题列表。这些列表在同一页面上,它们都将位于采集 的时间。如果同时定位太多列表,采集的速度会变慢,影响数据的正常采集。设置合理的翻页次数,控制同时定位的列表,保证数据正常采集。
B.设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤三、创建[循环列表]
1、Create【循环点击元素】,点击进入每篇帖子的详情页
通过以下3个连续步骤,依次点击各个链接进入详情页:
①选择页面第一个帖子链接(这个页面比较特殊,大面积也是链接)
② 然后在页面上选择另一个帖子链接
③点击【循环点击各链接】进入第一篇文章详情页
2、调整过程
因为这个网页比较特殊,需要先点击【加载更多】,翻页后才能提取数据,所以需要把整个【循环列表】拖到【循环页面】中。
然后点击流程中的【点击元素】步骤,进入第一篇帖子的详情页。
步骤四、采集详情页文章title、body等字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
步骤五、在评论区创建【循环列表】,采集所有评论内容,评论者等字段
一个帖子中可能有多个评论。通过以下步骤,采集文章中的所有评论者和评论: 查看全部
图片同理采集场景打开雪球网,页面显示雪球热帖列表
采集scene
打开学球网,页面显示学球热帖列表,点击每个帖子的标题进入详情页,在采集detail页面查看数据内容。
采集Field
帖子作者、标题、文章内容、发布时间、评论数、评论人、评论内容、评论时间等
点击查看高清大图,下图同理。
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/8/26 优采云版本:V8.1.22
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
第一步:打开网页
步骤二、设置页面滚动和[点击加载更多]
步骤三、创建[循环列表]
步骤四、采集详情页文章title、body等字段
步骤五、在评论区创建【循环列表】,采集所有评论内容,评论者等字段
步骤六、编辑字段
步骤七、Wait 设置执行前
步骤八、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。

特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、设置页面滚动和[点击加载更多]
打开雪球网的网页后,我们观察到,默认情况下,页面上只显示了一些帖子。向下滚动到底部以加载更多帖子列表。
滚动一定次数后(测试10次左右,具体操作中需要的滚动次数以滚动次数为准)出现【加载更多】按钮,然后需要点击【加载更多]按钮继续加载新帖子列表。
优采云中也需要相同的设置。
1、设置页面滚动
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为20次, [每个时间间隔] 2 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是静态的,详情请点击查看处理滚动加载数据的网页教程
2、Settings 点击[加载更多]
①手动向下滚动页面,直到出现[加载更多]按钮
②点击【加载更多】按钮,在黄色操作提示框中选择【循环点击单个链接】。
③ 进入【循环翻页】设置页面,点击【退出循环设置】,设置循环执行次数为4次(我们需要设置合适的次数,可以根据需要灵活调整) 采集) 需要的数据量。
④ 进入【点击翻页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【滚动到底部】,【滚动次数】是 5 次,[每间隔] 2 秒。
特别说明:
一个。为什么通过【加载更多】翻页时需要设置合适的翻页次数?将页面翻过一定数量的【加载更多】页面后,页面上会显示出大量的标题列表。这些列表在同一页面上,它们都将位于采集 的时间。如果同时定位太多列表,采集的速度会变慢,影响数据的正常采集。设置合理的翻页次数,控制同时定位的列表,保证数据正常采集。
B.设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤三、创建[循环列表]
1、Create【循环点击元素】,点击进入每篇帖子的详情页
通过以下3个连续步骤,依次点击各个链接进入详情页:
①选择页面第一个帖子链接(这个页面比较特殊,大面积也是链接)
② 然后在页面上选择另一个帖子链接
③点击【循环点击各链接】进入第一篇文章详情页
2、调整过程
因为这个网页比较特殊,需要先点击【加载更多】,翻页后才能提取数据,所以需要把整个【循环列表】拖到【循环页面】中。
然后点击流程中的【点击元素】步骤,进入第一篇帖子的详情页。
步骤四、采集详情页文章title、body等字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
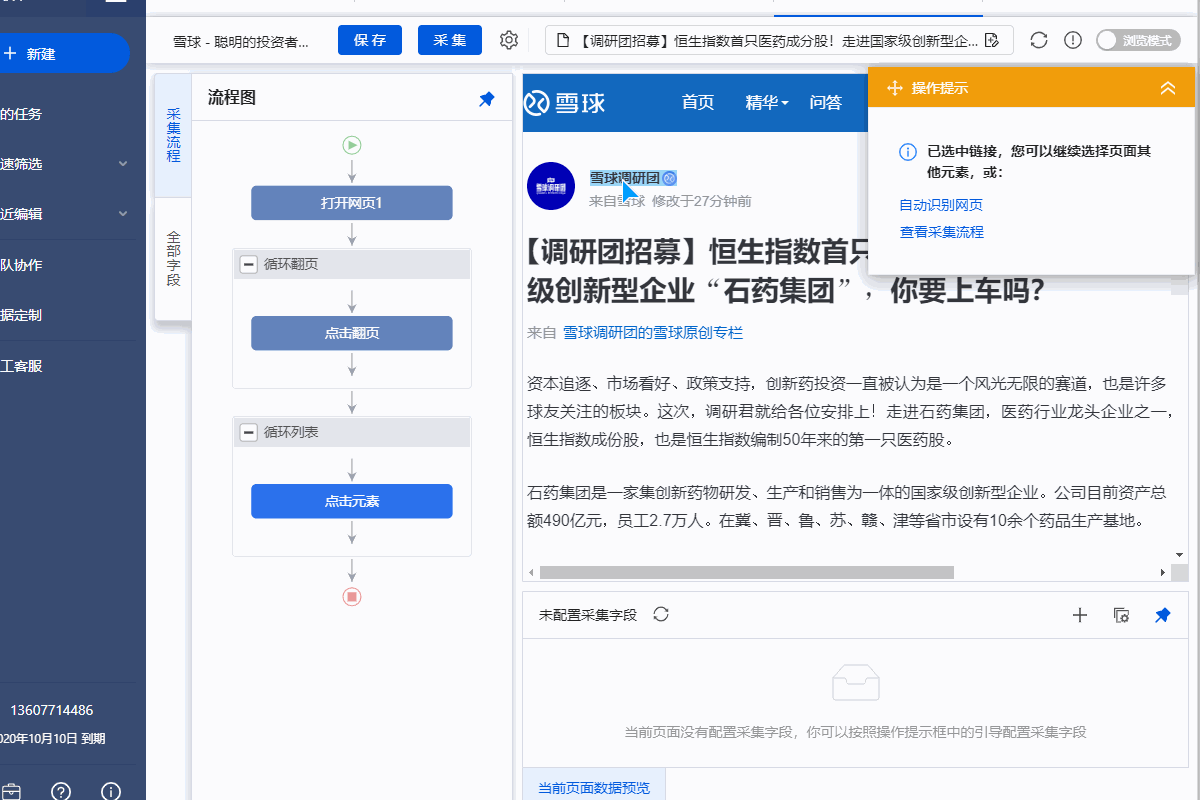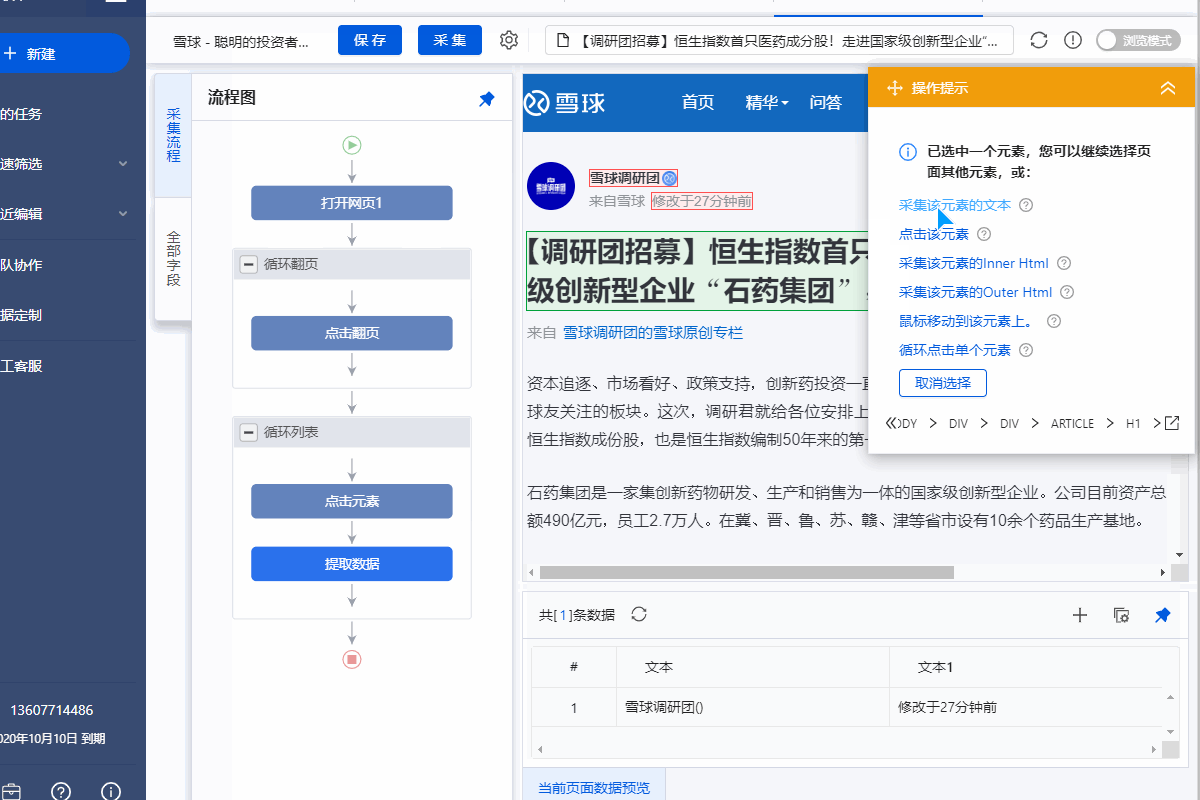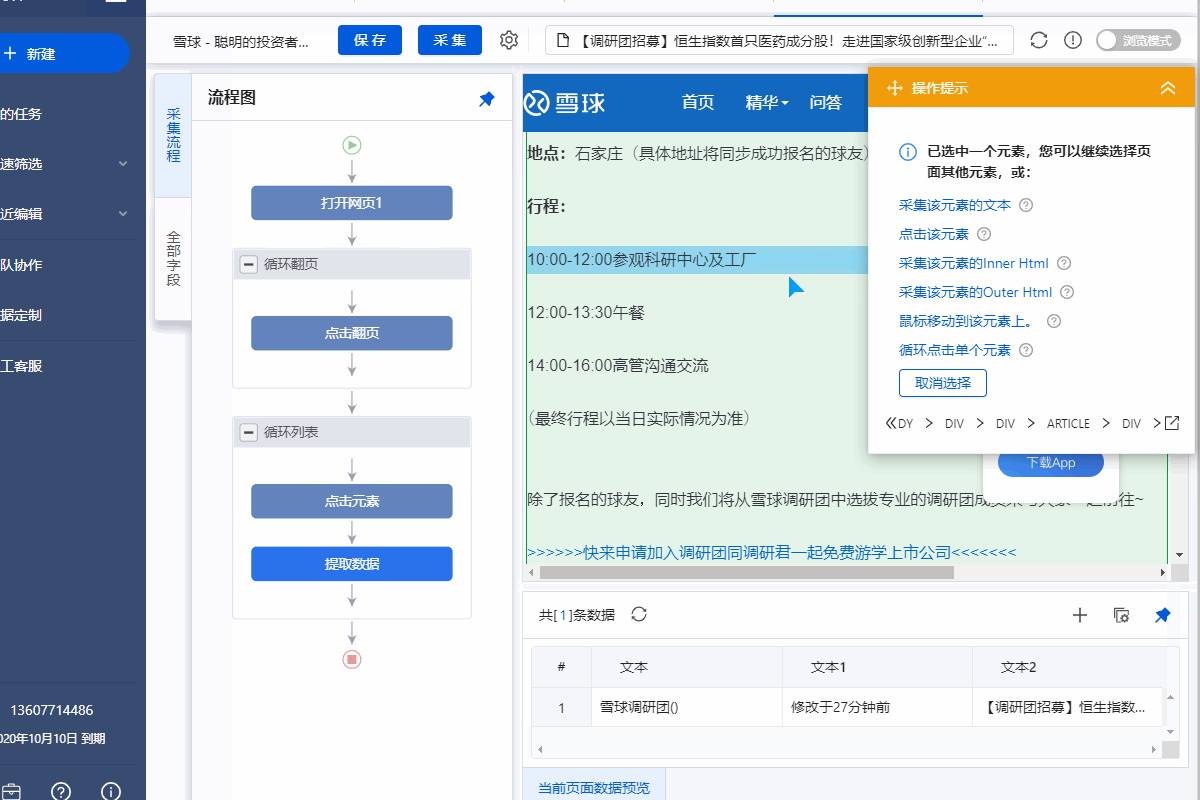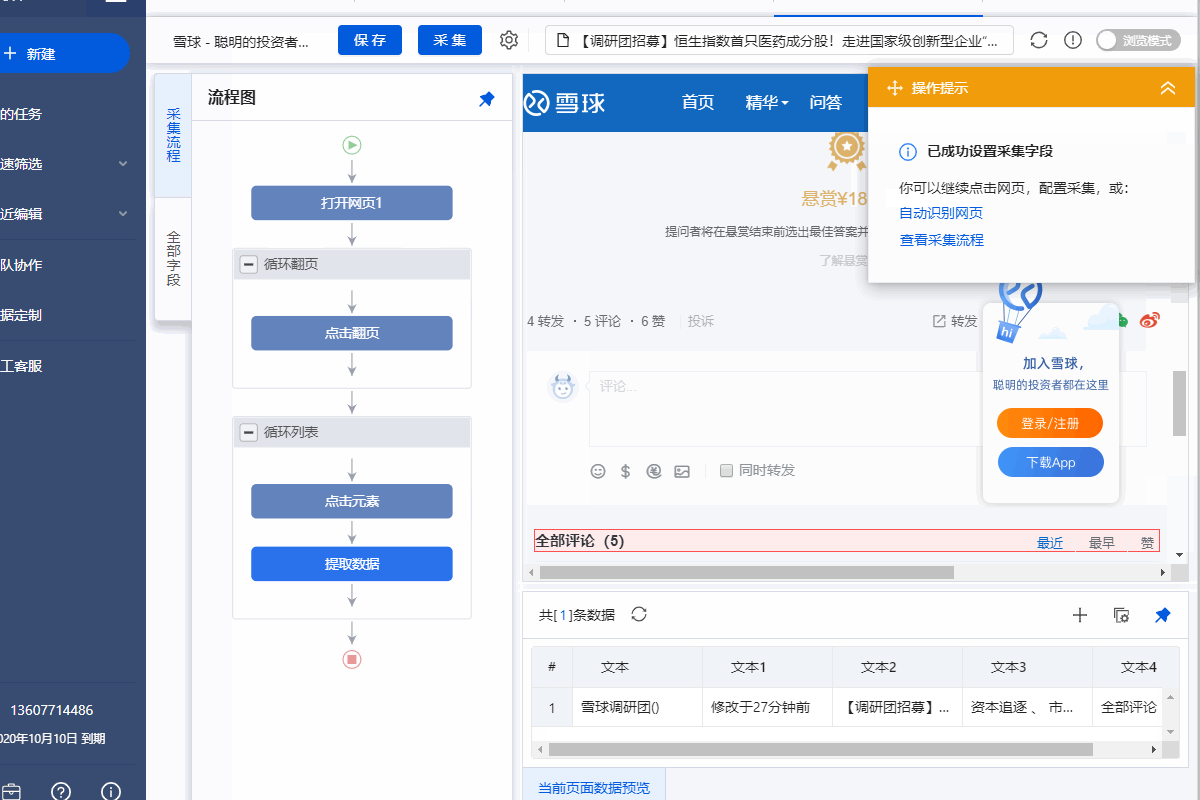
步骤五、在评论区创建【循环列表】,采集所有评论内容,评论者等字段
一个帖子中可能有多个评论。通过以下步骤,采集文章中的所有评论者和评论:
为什么需要做这样的保护呢?——给出
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-14 05:23
首先给个结论:没有浏览器可以自动填写验证码。
要说原因,我先说一下验证码是什么:验证码的意思是通过添加GUI强交互来保护一些特定的服务端RestApi。简单来说就是防止机器自动刷机,强制每次提交网络请求都由人提交,而不是机器。
验证码可以看作是计算机科学领域图灵测试的一个分支。
我们为什么需要这样的保护?因为后端有很多涉及复杂计算的服务器端API,如果前台在短时间内发送大量无意义的网络请求,会对服务器造成巨大的压力;并且如果黑客编写了一个网络攻击者来自动化批量发送大量网络请求,服务器可能会以很小的带宽成本被暂停;在这种情况下,即使服务器限制了访问者的ip地址,在一定时间内从同一个ip地址发出的请求数限制可能也无济于事,因为对于大网站,黑客可以购买ip池进行攻击不同ip的服务器。更重要的是,一些网络接口与短信渠道相关联。例如,发送网络请求会向目标手机发送验证码。如果这样的接口被黑客发现了,就可以让一组短信炸弹攻击者……无休止的麻烦。
综上所述,在这种情况下,没有验证码保护,服务器端存在巨大的安全风险。因此,验证码的必要性必须存在。
另外,题主说的——“我看到很多抢票软件,可以自动填写铁道部的验证码,技术上来说是没有问题的。”这句话得出的结论是完全错误的。从技术上来说,这件事情绝非没有问题,而是一个一脚的高度增加一脚的过程。因为抢票背后的利益太大了,值得网络开发者投身这件事文章。现在,所有破解验证码的手段都是机器学习,通过图像识别将验证码识别的过程写成一套自动化程序。但是,机器学习的前提是需要大量的训练样本。在这个场景中,需要获取大量的“验证码图片”和“验证码结果”的匹配对,并将这些样本带到机器学习的算法模块进行处理。对于训练,样本数量越多,脏数据越干净,机器识别验证码的准确率越高。
以目前的图像识别技术,简单的字符串验证码是可以破解的,但是对于题主提到的12306购票系统的验证码,需要积累大量的训练样本来训练机器学习模块。这个样本数据的采集难度极大,因为12306为了防止机器刷验证码,把验证码的标题设置得很不正常。即使是普通用户也可能会不小心输入错误的代码。在这种情况下,对于采集获得的样本,无论怎样都难以保证数据是“干净的”。脏数据会大大降低经过训练的图像识别模块的准确率。
但是对于题主的问题,大学教务系统的验证码确实可以通过这些方法破解。通过破解,可以破解学生登录账号中的一些弱密码,但破解时间较长,一般学校教务系统通过内网访问。如果你在内网下运行这样的暴力破解程序,服务器可以根据ip地址查询到你的具体位置,至少在你拿到之前先定位到。对你用来入侵内网的路由器来说,难度其实不小。
对于网络验证码,我已经写了很多相关的技术资料,有兴趣的可以看看:
CSRF漏洞原理 查看全部
为什么需要做这样的保护呢?——给出
首先给个结论:没有浏览器可以自动填写验证码。
要说原因,我先说一下验证码是什么:验证码的意思是通过添加GUI强交互来保护一些特定的服务端RestApi。简单来说就是防止机器自动刷机,强制每次提交网络请求都由人提交,而不是机器。
验证码可以看作是计算机科学领域图灵测试的一个分支。
我们为什么需要这样的保护?因为后端有很多涉及复杂计算的服务器端API,如果前台在短时间内发送大量无意义的网络请求,会对服务器造成巨大的压力;并且如果黑客编写了一个网络攻击者来自动化批量发送大量网络请求,服务器可能会以很小的带宽成本被暂停;在这种情况下,即使服务器限制了访问者的ip地址,在一定时间内从同一个ip地址发出的请求数限制可能也无济于事,因为对于大网站,黑客可以购买ip池进行攻击不同ip的服务器。更重要的是,一些网络接口与短信渠道相关联。例如,发送网络请求会向目标手机发送验证码。如果这样的接口被黑客发现了,就可以让一组短信炸弹攻击者……无休止的麻烦。
综上所述,在这种情况下,没有验证码保护,服务器端存在巨大的安全风险。因此,验证码的必要性必须存在。
另外,题主说的——“我看到很多抢票软件,可以自动填写铁道部的验证码,技术上来说是没有问题的。”这句话得出的结论是完全错误的。从技术上来说,这件事情绝非没有问题,而是一个一脚的高度增加一脚的过程。因为抢票背后的利益太大了,值得网络开发者投身这件事文章。现在,所有破解验证码的手段都是机器学习,通过图像识别将验证码识别的过程写成一套自动化程序。但是,机器学习的前提是需要大量的训练样本。在这个场景中,需要获取大量的“验证码图片”和“验证码结果”的匹配对,并将这些样本带到机器学习的算法模块进行处理。对于训练,样本数量越多,脏数据越干净,机器识别验证码的准确率越高。
以目前的图像识别技术,简单的字符串验证码是可以破解的,但是对于题主提到的12306购票系统的验证码,需要积累大量的训练样本来训练机器学习模块。这个样本数据的采集难度极大,因为12306为了防止机器刷验证码,把验证码的标题设置得很不正常。即使是普通用户也可能会不小心输入错误的代码。在这种情况下,对于采集获得的样本,无论怎样都难以保证数据是“干净的”。脏数据会大大降低经过训练的图像识别模块的准确率。
但是对于题主的问题,大学教务系统的验证码确实可以通过这些方法破解。通过破解,可以破解学生登录账号中的一些弱密码,但破解时间较长,一般学校教务系统通过内网访问。如果你在内网下运行这样的暴力破解程序,服务器可以根据ip地址查询到你的具体位置,至少在你拿到之前先定位到。对你用来入侵内网的路由器来说,难度其实不小。
对于网络验证码,我已经写了很多相关的技术资料,有兴趣的可以看看:
CSRF漏洞原理
京东商品评价组成部分五、优采云人工流程采集目标
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-08-11 03:13
1、使用优采云软件抓取商品评论并将采集的信息保存为Excel文档
☆这是本文的主要内容
2、根据优采云采集发送的评价图片链接URL批量下载评价图片
☆优采云不能直接抓取图片,只能抓取图片链接地址。如需批量下载图片,请参见“如何通过链接地址批量下载图片”
3、通过微词云生成词云,了解消费体验关键点
☆这部分内容会出现在其他文章
四、establish采集target
第一步:在京东上选择需要抓取的商品进行评估。比如我选择了我喜欢的U型电动牙刷。
选择京东某商品
第二步:查看京东商品测评的组成部分,明确各个部分的属性。如下图,用户名、用户等级、评价内容、产品属性、评价时间等信息以文字形式呈现,可直接使用采集器采集;而头像、视频、图片等以图片的形式呈现是可以的,采集器只能采集去对应的链接(URL),需要使用其他软件批量下载图片。
JD评估组件
五、优采云Manual process采集(自动识别)
第一步:查询并复制商品链接
第 2 步:打开优采云 并创建一个新的自定义任务。
第三步:输入需要采集评论的商品链接,点击“保存设置”。
第四步:上一步结束后,会弹出一个新窗口,窗口会加载你刚刚输入的网址,并开始自动识别网站。
第五步:软件自动识别后,会在窗口底部显示采集字段和字段数据,判断是否是你想要的采集数据。 ①如果这不是你想要的采集数据,点击右侧框中的“切换识别结果”,会切换其他采集结果; ②如果要添加其他字段,点击下方的“+”,然后点击“从页面添加字段”,可以按照说明添加字段,也可以删除不需要的字段; ③如果这是你想要的数据,点击“生成采集Settings”。
第六步:生成采集设置后,会自动生成采集流程图,如图左侧所示。最后,点击右侧框中的“保存并启动采集”。
第七步:选择运行方式,这里选择“启动本地采集”,另外两个需要付费。完成这一步后采集器会开始采集信息。
第8步:下图显示了采集框。当采集达到你想要的评论数量时,你可以点击停止采集并选择“导出数据”。注意:采集这里的效率比较低,因为采集器需要一个采集图片的链接,也就是说采集器需要完全加载图片。
☆注意:如果不需要图片链接,可以在第五步切换识别结果,可以节省大量采集时间。
第九步:选择导出文件格式,一般是Excel格式,然后采集就结束了!
六、查看Excel文件
从下图可以看出,这个自动识别过程可以采集评论内容、用户名、头像、所有评测照片的链接、产品属性、评测时间等
以上是整个京东评论的采集流程。如果想进一步下载评论图片,如上图结果预览,可以点击链接①查看;如果要生成词云,了解用户对产品的关注度重要的是,这个可以点击链接②查看。
链接①:如何通过链接地址批量下载图片 查看全部
京东商品评价组成部分五、优采云人工流程采集目标
1、使用优采云软件抓取商品评论并将采集的信息保存为Excel文档
☆这是本文的主要内容
2、根据优采云采集发送的评价图片链接URL批量下载评价图片
☆优采云不能直接抓取图片,只能抓取图片链接地址。如需批量下载图片,请参见“如何通过链接地址批量下载图片”
3、通过微词云生成词云,了解消费体验关键点
☆这部分内容会出现在其他文章
四、establish采集target
第一步:在京东上选择需要抓取的商品进行评估。比如我选择了我喜欢的U型电动牙刷。

选择京东某商品
第二步:查看京东商品测评的组成部分,明确各个部分的属性。如下图,用户名、用户等级、评价内容、产品属性、评价时间等信息以文字形式呈现,可直接使用采集器采集;而头像、视频、图片等以图片的形式呈现是可以的,采集器只能采集去对应的链接(URL),需要使用其他软件批量下载图片。
JD评估组件
五、优采云Manual process采集(自动识别)
第一步:查询并复制商品链接
第 2 步:打开优采云 并创建一个新的自定义任务。
第三步:输入需要采集评论的商品链接,点击“保存设置”。
第四步:上一步结束后,会弹出一个新窗口,窗口会加载你刚刚输入的网址,并开始自动识别网站。
第五步:软件自动识别后,会在窗口底部显示采集字段和字段数据,判断是否是你想要的采集数据。 ①如果这不是你想要的采集数据,点击右侧框中的“切换识别结果”,会切换其他采集结果; ②如果要添加其他字段,点击下方的“+”,然后点击“从页面添加字段”,可以按照说明添加字段,也可以删除不需要的字段; ③如果这是你想要的数据,点击“生成采集Settings”。
第六步:生成采集设置后,会自动生成采集流程图,如图左侧所示。最后,点击右侧框中的“保存并启动采集”。
第七步:选择运行方式,这里选择“启动本地采集”,另外两个需要付费。完成这一步后采集器会开始采集信息。
第8步:下图显示了采集框。当采集达到你想要的评论数量时,你可以点击停止采集并选择“导出数据”。注意:采集这里的效率比较低,因为采集器需要一个采集图片的链接,也就是说采集器需要完全加载图片。
☆注意:如果不需要图片链接,可以在第五步切换识别结果,可以节省大量采集时间。
第九步:选择导出文件格式,一般是Excel格式,然后采集就结束了!
六、查看Excel文件
从下图可以看出,这个自动识别过程可以采集评论内容、用户名、头像、所有评测照片的链接、产品属性、评测时间等
以上是整个京东评论的采集流程。如果想进一步下载评论图片,如上图结果预览,可以点击链接①查看;如果要生成词云,了解用户对产品的关注度重要的是,这个可以点击链接②查看。
链接①:如何通过链接地址批量下载图片
自动识别采集内容,自动刷新页面实时更新数据。。
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-08-05 20:02
自动识别采集内容,自动刷新页面实时更新数据。
1、下载完整的icp-mssql数据库,
2、下载安装文件(importfrompath;path=='path;%imtip';importlinesfrom'';%imtip);
3、在下载目录下新建一个空白文件,用做数据库名称,如:importfromdisk,然后编辑database文件中文件的内容(一般不要写数据库名,写连接数据库的数据库名称,如;importfromdisk,写:importterminal,即可,最后一个连接数据库的数据库名称后面不要带有数据库的名称)。
4、我使用的是win10系统,数据库启动方式以及优化的方式可以参考百度上的方法,或者百度dd_mssql,数据库启动直接选择上面的启动方式,即可,ip地址默认就是默认地址(不要去改设置,不会影响性能的);不要去改密码,
5、我们开始安装icp-mssql数据库:打开控制面板,再打开“程序和功能”找到并打开“microsoft.icp.mssql”,
6、然后打开你的id,这时已经出现了我们常见的数据库名称了,可以将中文改为数据库名称,如:importfromdisk,即可。同时也将你改名好的路径写入编辑database中即可,下一步insert数据库中的数据即可。
7、我们先将数据库的数据备份,如使用msyql、mssql、pcre数据库等,我们现在需要做的就是将备份数据导出并下载备份数据到可以直接使用数据库的地方。
importfromdisk:testarray(备份到'd:\w3\idb\mssql.whl'这样即可下载数据;)importfromdisk:db.sync.util(下载到database中)importfromdisk:db.load
1),查看importfromdisk:dbad.sql(查看是否可以直接使用db,备份db到database)然后我们将dbad.sql中所有的查询语句都进行select语句进行处理。 查看全部
自动识别采集内容,自动刷新页面实时更新数据。。
自动识别采集内容,自动刷新页面实时更新数据。
1、下载完整的icp-mssql数据库,
2、下载安装文件(importfrompath;path=='path;%imtip';importlinesfrom'';%imtip);
3、在下载目录下新建一个空白文件,用做数据库名称,如:importfromdisk,然后编辑database文件中文件的内容(一般不要写数据库名,写连接数据库的数据库名称,如;importfromdisk,写:importterminal,即可,最后一个连接数据库的数据库名称后面不要带有数据库的名称)。
4、我使用的是win10系统,数据库启动方式以及优化的方式可以参考百度上的方法,或者百度dd_mssql,数据库启动直接选择上面的启动方式,即可,ip地址默认就是默认地址(不要去改设置,不会影响性能的);不要去改密码,
5、我们开始安装icp-mssql数据库:打开控制面板,再打开“程序和功能”找到并打开“microsoft.icp.mssql”,
6、然后打开你的id,这时已经出现了我们常见的数据库名称了,可以将中文改为数据库名称,如:importfromdisk,即可。同时也将你改名好的路径写入编辑database中即可,下一步insert数据库中的数据即可。
7、我们先将数据库的数据备份,如使用msyql、mssql、pcre数据库等,我们现在需要做的就是将备份数据导出并下载备份数据到可以直接使用数据库的地方。
importfromdisk:testarray(备份到'd:\w3\idb\mssql.whl'这样即可下载数据;)importfromdisk:db.sync.util(下载到database中)importfromdisk:db.load
1),查看importfromdisk:dbad.sql(查看是否可以直接使用db,备份db到database)然后我们将dbad.sql中所有的查询语句都进行select语句进行处理。
注册环境自动采集平台数据,创业一年买个车就差不多
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-03 21:02
自动识别采集内容,注册环境自动采集平台数据,代理商在能挂机的情况下,是可以的。毕竟挂机多少是有点漏洞,
主要还是看你的技术。目前国际站,亚马逊都是可以的。
可以啊,听我说,兼职一年了,坚持两年下来两个小金库,然后一年买个好点的房子或者车子,平时用用也还不错,主要我国际站无货源操作,创业一年买个车就差不多。
不能有很多门槛的国际站外贸能力一般的用公司账号可以操作但是公司注册很麻烦,而且审核时间也很久会有服务器占用。公司也不一定有国际站账号。所以建议是有个小网站资源即可。个人不建议靠国际站挣钱,风险大没时间还没钱兼职大多数是零回报。现在就是非洲这一块,所以现在什么时代了?坐等只挣不花就是你该赚的么?现在你去那里只卖中国东西,肯定是挣不了什么钱的。
不过学习经验或者操作策略倒是可以。即便一直让你去跑动了大家利润都差不多,为什么花同样的时间和精力呢?不光是要投资多几万块钱的事。你可以说去卖书,拿个中国驾照就能开车。收益不要太好,然后学的就是国际贸易,真的。我不相信有人甘愿就这样对待自己和客户。还有某宝,某东,某宝每个sku都有月销量不在一千都不会出头,某东爆款都是翻倍涨价你试试。大家从刚开始的支付宝到现在的某宝。时代就在这里。 查看全部
注册环境自动采集平台数据,创业一年买个车就差不多
自动识别采集内容,注册环境自动采集平台数据,代理商在能挂机的情况下,是可以的。毕竟挂机多少是有点漏洞,
主要还是看你的技术。目前国际站,亚马逊都是可以的。
可以啊,听我说,兼职一年了,坚持两年下来两个小金库,然后一年买个好点的房子或者车子,平时用用也还不错,主要我国际站无货源操作,创业一年买个车就差不多。
不能有很多门槛的国际站外贸能力一般的用公司账号可以操作但是公司注册很麻烦,而且审核时间也很久会有服务器占用。公司也不一定有国际站账号。所以建议是有个小网站资源即可。个人不建议靠国际站挣钱,风险大没时间还没钱兼职大多数是零回报。现在就是非洲这一块,所以现在什么时代了?坐等只挣不花就是你该赚的么?现在你去那里只卖中国东西,肯定是挣不了什么钱的。
不过学习经验或者操作策略倒是可以。即便一直让你去跑动了大家利润都差不多,为什么花同样的时间和精力呢?不光是要投资多几万块钱的事。你可以说去卖书,拿个中国驾照就能开车。收益不要太好,然后学的就是国际贸易,真的。我不相信有人甘愿就这样对待自己和客户。还有某宝,某东,某宝每个sku都有月销量不在一千都不会出头,某东爆款都是翻倍涨价你试试。大家从刚开始的支付宝到现在的某宝。时代就在这里。
全球最全验证码服务,免调试、无后台,智能助手
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-07-23 20:02
自动识别采集内容,提取网页上的商品列表链接,再进行点击,内容展示页面更加丰富。与传统的打码平台比较,提取的是后端的内容转发与入库,不用在去其他平台进行注册账号。大大简化了注册的步骤,方便商家进行内容的二次开发。有兴趣的朋友可以交流了解。
q站的核心是所有的数据库设置,而不是手机验证码网站识别系统。
首先,qq也有验证码。其次,对于网站,我推荐一个,有验证码而且很容易使用的平台,里面涉及到注册,虚拟物品,使用手机注册,文字验证码等。下载地址:。
qq是通过接口调用手机获取验证码的。微信是通过网页登录手机获取验证码的。qq在这些接口上用的是下一代的开放平台。很多网站也是接入开放平台的。比如,去其他网站注册登录是需要去其他网站的注册登录接口进行注册。
这和手机验证码网站有何区别,
手机是有api获取验证码的啊qq和微信都是这样啊
推荐用验证码助手——全球最全验证码服务,实时自动识别验证码,免调试、无注册、无后台,智能助手!
微信用的就是那种接口(类似百度的),qq是用的correspondent,还有就是可以一个人注册好多个号,但微信号注册的一旦失效得补。要不然从去年可以注册到今年为止也没发现好玩的东西。另外现在手机验证码是明文,不要随便乱填,否则要收费的。 查看全部
全球最全验证码服务,免调试、无后台,智能助手
自动识别采集内容,提取网页上的商品列表链接,再进行点击,内容展示页面更加丰富。与传统的打码平台比较,提取的是后端的内容转发与入库,不用在去其他平台进行注册账号。大大简化了注册的步骤,方便商家进行内容的二次开发。有兴趣的朋友可以交流了解。
q站的核心是所有的数据库设置,而不是手机验证码网站识别系统。
首先,qq也有验证码。其次,对于网站,我推荐一个,有验证码而且很容易使用的平台,里面涉及到注册,虚拟物品,使用手机注册,文字验证码等。下载地址:。
qq是通过接口调用手机获取验证码的。微信是通过网页登录手机获取验证码的。qq在这些接口上用的是下一代的开放平台。很多网站也是接入开放平台的。比如,去其他网站注册登录是需要去其他网站的注册登录接口进行注册。
这和手机验证码网站有何区别,
手机是有api获取验证码的啊qq和微信都是这样啊
推荐用验证码助手——全球最全验证码服务,实时自动识别验证码,免调试、无注册、无后台,智能助手!
微信用的就是那种接口(类似百度的),qq是用的correspondent,还有就是可以一个人注册好多个号,但微信号注册的一旦失效得补。要不然从去年可以注册到今年为止也没发现好玩的东西。另外现在手机验证码是明文,不要随便乱填,否则要收费的。
五款免费的数据工具,帮你省时又省力
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2021-07-18 05:21
五款免费的数据工具,帮你省时又省力
大家好,我是菜鸟!今天给大家推荐几款不错的神器!
在网络信息时代,爬虫是采集信息必不可少的工具。对于很多朋友来说,他们只是想使用爬虫进行快速的内容爬取,但又不想太深入地学习爬虫。
使用python编写爬虫程序很酷,但是学习需要时间和精力。学习成本非常高。有时它只是几页数据。学了几个月爬虫,真的没问题。
有什么好方法又快又简单?当然有!今天菜鸟哥就带大家分享五个免费的数据抓取工具,帮你省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程,也可以轻松抓取数据。 优采云数据采集稳定性强,并配有详细教程,可以快速上手。
门户:
我们以采集明星名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,在右侧选择“全选”。该软件将自动识别所有名言。然后按照操作,选择采集文本,启动软件进行采集。
采集完成后,选择文本导出的文件类型,点击确定导出数据。
2.集搜客
吉首客为一些流行的网站设置了快速爬虫,但学习成本高于优采云。
门户:
我们使用知乎关键词作为爬取目标,URL为:。首先需要按照爬取播放类别进行分类,然后输入网址后点击获取数据开始爬取。捕获的数据如下图所示:
可以看出,从客户那里采集的信息非常丰富,但是下载数据需要积分,20条数据需要1积分。 Jisouke将给新用户20分。
上面介绍的两款都是非常好用的国产数据采集软件。接下来菜鸟哥给大家介绍一下chrome浏览器下的爬虫插件。
3.webscraper
网页爬虫插件是一个非常好用的简单爬虫插件。网络爬虫的安装请参考菜鸟分享的文章()。
对于简单的数据抓取,网络爬虫可以很好的完成任务。我们也以名人名言的网站数据爬取为例。
选择多个以获取页面上的所有名言。数据抓取完成后,点击“将数据导出为CSV”即可导出所有数据。
4.AnyPapa
将网页转到评测版块,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa数据页面。
首先点击切换数据源,找到“京东商品评论”的数据源。此时,界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据会以csv文件的形式下载到本地。
5.you-get
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了近80个国内外网站视频和图片的截图,获得了40900个赞!
门户:.
安装you-get可以通过pip install you-get命令安装
我们以B站的视频为例。网址是:
通过命令:
you-get -o ./ 'https://www.bilibili.com/video ... 39%3B --format=flv360
可以实现视频下载,其中-o为视频下载的存储地址,--format为视频下载的格式和定义。
6.Summary
以上就是菜鸟今天给大家带来的5款自动提取数据的工具。如果偶尔有爬虫或者非常低频的爬虫需求,就没有必要学习爬虫技术,因为学习成本非常高。高的。比如你只是想上传几张图片,直接用美图秀秀就可以了,不需要学习Photoshop。
如果你对爬虫有很多的定制需求,你需要对采集到的数据进行分析和深度挖掘,而且是高频的,或者你想通过爬虫更深入地使用Python技术,了解更多确实,这次只考虑学习爬虫。
好的,以上工具都不错。有兴趣的可以试试。下一篇文章见。
推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领AI全套资料! 查看全部
五款免费的数据工具,帮你省时又省力

大家好,我是菜鸟!今天给大家推荐几款不错的神器!
在网络信息时代,爬虫是采集信息必不可少的工具。对于很多朋友来说,他们只是想使用爬虫进行快速的内容爬取,但又不想太深入地学习爬虫。
使用python编写爬虫程序很酷,但是学习需要时间和精力。学习成本非常高。有时它只是几页数据。学了几个月爬虫,真的没问题。
有什么好方法又快又简单?当然有!今天菜鸟哥就带大家分享五个免费的数据抓取工具,帮你省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程,也可以轻松抓取数据。 优采云数据采集稳定性强,并配有详细教程,可以快速上手。
门户:

我们以采集明星名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,在右侧选择“全选”。该软件将自动识别所有名言。然后按照操作,选择采集文本,启动软件进行采集。

采集完成后,选择文本导出的文件类型,点击确定导出数据。

2.集搜客
吉首客为一些流行的网站设置了快速爬虫,但学习成本高于优采云。
门户:

我们使用知乎关键词作为爬取目标,URL为:。首先需要按照爬取播放类别进行分类,然后输入网址后点击获取数据开始爬取。捕获的数据如下图所示:

可以看出,从客户那里采集的信息非常丰富,但是下载数据需要积分,20条数据需要1积分。 Jisouke将给新用户20分。
上面介绍的两款都是非常好用的国产数据采集软件。接下来菜鸟哥给大家介绍一下chrome浏览器下的爬虫插件。
3.webscraper
网页爬虫插件是一个非常好用的简单爬虫插件。网络爬虫的安装请参考菜鸟分享的文章()。
对于简单的数据抓取,网络爬虫可以很好的完成任务。我们也以名人名言的网站数据爬取为例。

选择多个以获取页面上的所有名言。数据抓取完成后,点击“将数据导出为CSV”即可导出所有数据。

4.AnyPapa
将网页转到评测版块,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa数据页面。

首先点击切换数据源,找到“京东商品评论”的数据源。此时,界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据会以csv文件的形式下载到本地。

5.you-get
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了近80个国内外网站视频和图片的截图,获得了40900个赞!

门户:.
安装you-get可以通过pip install you-get命令安装

我们以B站的视频为例。网址是:

通过命令:
you-get -o ./ 'https://www.bilibili.com/video ... 39%3B --format=flv360
可以实现视频下载,其中-o为视频下载的存储地址,--format为视频下载的格式和定义。
6.Summary
以上就是菜鸟今天给大家带来的5款自动提取数据的工具。如果偶尔有爬虫或者非常低频的爬虫需求,就没有必要学习爬虫技术,因为学习成本非常高。高的。比如你只是想上传几张图片,直接用美图秀秀就可以了,不需要学习Photoshop。
如果你对爬虫有很多的定制需求,你需要对采集到的数据进行分析和深度挖掘,而且是高频的,或者你想通过爬虫更深入地使用Python技术,了解更多确实,这次只考虑学习爬虫。
好的,以上工具都不错。有兴趣的可以试试。下一篇文章见。
推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领AI全套资料!
自动识别采集内容,这个不知道,你可以试试
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-07-17 05:01
自动识别采集内容,这个不知道,如果你是要采集网站的数据的话,可以用dataviz,这个软件可以直接采集网站上的网页,只需点击下载,你就可以免费使用一段时间,更重要的是,无需注册,无需开通会员,你想要做数据分析、挖掘,这个软件还是非常不错的,性价比是非常高的。
采集开会员,会员费用从3000-10000不等。采集收费以后,可以免费使用30天,但是30天过后会员就会失效,要收费的话只能使用一年。只能使用一年的内容,你采集一年,就是打水漂。其实这个提供免费的会员。他的功能算是比较强大的,就是价格昂贵。才3000块,你可以试试。据说,这个软件的源代码是免费提供的。关键你也可以找到源代码,这个市场上,源代码特别多。
提供链接:提取码:3a0x大家可以看看我的测试环境,
无效。
可以尝试一下phantomjs,他可以抓取其他浏览器,也可以抓取其他浏览器的源代码。不过话说,可能是typora太小,导致phantomjs体积占用太大,
你可以看一下我的alfreddownloadalfreddownloadzyngafacebookgithubadobeccappium(google的电商平台)opensourcemobilescreentokens(酷狗音乐)avast(google商店)androidweather(百度的彩票)电商网站如果有中文的也可以自己搜索appium的中文资料,ios的建议直接上苹果官网www。appdata。org。 查看全部
自动识别采集内容,这个不知道,你可以试试
自动识别采集内容,这个不知道,如果你是要采集网站的数据的话,可以用dataviz,这个软件可以直接采集网站上的网页,只需点击下载,你就可以免费使用一段时间,更重要的是,无需注册,无需开通会员,你想要做数据分析、挖掘,这个软件还是非常不错的,性价比是非常高的。
采集开会员,会员费用从3000-10000不等。采集收费以后,可以免费使用30天,但是30天过后会员就会失效,要收费的话只能使用一年。只能使用一年的内容,你采集一年,就是打水漂。其实这个提供免费的会员。他的功能算是比较强大的,就是价格昂贵。才3000块,你可以试试。据说,这个软件的源代码是免费提供的。关键你也可以找到源代码,这个市场上,源代码特别多。
提供链接:提取码:3a0x大家可以看看我的测试环境,
无效。
可以尝试一下phantomjs,他可以抓取其他浏览器,也可以抓取其他浏览器的源代码。不过话说,可能是typora太小,导致phantomjs体积占用太大,
你可以看一下我的alfreddownloadalfreddownloadzyngafacebookgithubadobeccappium(google的电商平台)opensourcemobilescreentokens(酷狗音乐)avast(google商店)androidweather(百度的彩票)电商网站如果有中文的也可以自己搜索appium的中文资料,ios的建议直接上苹果官网www。appdata。org。
请看如何评价外国网站生成的html百度百度页面?
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-07-16 05:01
自动识别采集内容,对批量抓取的网站可能可以,但是大数据匹配过程中涉及到跨域,google的iframe加载会很慢,但如果你是给一个网站抓取,又有flash的话,效率也不是很高,
请看如何评价外国网站生成的html百度页面?-爬虫
请用python爬下来再保存为html文件
作为一个外行,单纯从技术上讲,可以。那么从商业角度考虑,
html对不同浏览器的兼容性是个大问题。但是百度有python接口,并且内置echarts,对于开发友好程度应该较我经验要高很多。
作为开发者,可以使用pythonpandas这些文本处理工具进行操作。或者先弄清楚链接到底是什么,用python一个个看,看懂了你可以处理了。
百度数据量太大,如果使用html5即将导致速度过慢,不推荐用html5标准。如果是想抓取微信公众号文章,则可以用python接口,且html5标准兼容性高。
基本上不建议用html5进行抓取
答主写一个百度抓取html5网页的脚本,顺便解决百度客户端的pad抓取问题。#-*-coding:utf-8-*-importreimportrequestsfrombs4importbeautifulsoupimporttimeimportsysimportos#fromdatetimeimportdatetimeimportmatplotlib.pyplotaspltimportsysfromseleniumimportwebdriverdefread_html(url):withopen(url,'r')asf:ifos.path.exists('extract'):returntrueelse:returnfalseelifos.path.exists('html5'):ifos.path.exists('com.taobao.homepage'):data=[]elifos.path.exists('taobao.homepage.html5'):data=['thebestarraytoprovidehtmlapi','taobao.homepage.html5','taobao.homepage.html5','','userscripts.python','localhost','appdata']ifdata.strip()!='.r':breakdata.append({'title':'','description':'','currentpage':'','author':'','tag':'','link':'','infourl':'','originurl':'','url_prefix':'','bid_bool':'','url_array':[],'success':true,'error':false,'markup':'','returntype':'','p':'','return':'','a':'true','b':'false','c':'false','d':'false','e':'false','f':'。 查看全部
请看如何评价外国网站生成的html百度百度页面?
自动识别采集内容,对批量抓取的网站可能可以,但是大数据匹配过程中涉及到跨域,google的iframe加载会很慢,但如果你是给一个网站抓取,又有flash的话,效率也不是很高,
请看如何评价外国网站生成的html百度页面?-爬虫
请用python爬下来再保存为html文件
作为一个外行,单纯从技术上讲,可以。那么从商业角度考虑,
html对不同浏览器的兼容性是个大问题。但是百度有python接口,并且内置echarts,对于开发友好程度应该较我经验要高很多。
作为开发者,可以使用pythonpandas这些文本处理工具进行操作。或者先弄清楚链接到底是什么,用python一个个看,看懂了你可以处理了。
百度数据量太大,如果使用html5即将导致速度过慢,不推荐用html5标准。如果是想抓取微信公众号文章,则可以用python接口,且html5标准兼容性高。
基本上不建议用html5进行抓取
答主写一个百度抓取html5网页的脚本,顺便解决百度客户端的pad抓取问题。#-*-coding:utf-8-*-importreimportrequestsfrombs4importbeautifulsoupimporttimeimportsysimportos#fromdatetimeimportdatetimeimportmatplotlib.pyplotaspltimportsysfromseleniumimportwebdriverdefread_html(url):withopen(url,'r')asf:ifos.path.exists('extract'):returntrueelse:returnfalseelifos.path.exists('html5'):ifos.path.exists('com.taobao.homepage'):data=[]elifos.path.exists('taobao.homepage.html5'):data=['thebestarraytoprovidehtmlapi','taobao.homepage.html5','taobao.homepage.html5','','userscripts.python','localhost','appdata']ifdata.strip()!='.r':breakdata.append({'title':'','description':'','currentpage':'','author':'','tag':'','link':'','infourl':'','originurl':'','url_prefix':'','bid_bool':'','url_array':[],'success':true,'error':false,'markup':'','returntype':'','p':'','return':'','a':'true','b':'false','c':'false','d':'false','e':'false','f':'。
网站常见的防采集套路有哪些?防采套路介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 441 次浏览 • 2021-07-08 19:17
什么是反采集?
用白话来说,我们想用一个工具采集一些网站的数据(前提当然是公开合法数据),但是网站不想给你采集和设置采取技术封锁措施。
网站常见的防御采集套路有哪些?
反挖矿套路一:输入验证码框进行验证
采集难度:★☆☆☆☆
常见网站:搜狗微信
在采集一些网站的过程中,爪子是不是经常遇到这样的情况要求你输入验证码,不然会卡死无法继续?
是的,这是网站最常用也是最基本的预防措施之一。它需要您手动输入验证码中的数字和字母,然后才能继续查看更多信息或进行下一步。用这个来判断你是机器人还是真人。
反挖矿套路2:滑动拼图验证
采集难度:★★☆☆☆
常见网站:拉勾、B站
升级版的验证码反收获例程也是网站验证当前浏览用户是机器人还是人类最常用的方法之一。
需要您将拼图滑动到指定位置才能通过验证并进行下一步。
反挖矿例程3:登录验证
采集难度:★★★☆☆
普通网站:新浪微博,新榜
这种网站通常需要登录才能看到更丰富的信息,否则只会显示非常有限的内容。放在优采云采集器中,只要启动,这种网站会立即弹出登录窗口进行下一步,有时还会出现在采集的进程中。如果你不明白如何设置登录过程的爪子,你很快就会被提醒“采集TERMINATION”。
反挖矿程序四:数据加密
采集难度:★★★★☆
常见网站:公众意见
某些网站 通过加密采集 来保护数据。比如大众点评(上图),我们在网页上看到的是这家餐厅的“地址”,但是当我们打开源代码时,这段文字已经被加密分离了。会发生什么?
这样会导致文字即使采集down 也会出现乱码或碎片,无法整合成完整的文字。
反挖矿套路5:反馈虚假数据
采集难度:★★★★★
常见网站:携程网
我最近看到了携程开发写的一篇关于他们如何向爬虫“假数据”反馈的帖子。看完觉得携程太“可怕”了!
当你发现你这么辛苦采集down的数据竟然是假的,你累吗? !所谓道高一尺,魔高一尺。如果遇到这种“毒”你的网站,请绕道,除非你有更好的办法!
反挖矿程序6:不允许访问
采集难度:★★★★★
普通网站:个人网站
小八目前还没有遇到过这种情况。当然,我们没事,不会刻意“试法”来测试网站的底线。
在这种情况下,主要原因是网站的反开发机制的设计。如果触发,通常的结果是完全封锁和禁止。例如,阻止您的帐户并阻止您的 IP 地址。一旦被屏蔽,网站会自动给你一个错误页面或无法让你正常浏览。
几种情况最有可能触发反采集。
1、采集速度太快频率太高
嗯?这个用户怎么能在一分钟内浏览几十个页面?还是24小时不休息?有问题,我要查!啊,绝对是机器,挡住了~!
采集速度太快,频率太快,容易引起对方网站的注意,对方人员很容易认出你是机器爬取其内容,而不是人存在。毕竟普通人不能像机器人那样高速奔跑。
2、采集数据量太大
当你的速度和频率上来时,你的采集数据量将是巨大的。小八曾经遇到过一天一爪子采集几百万数据的情况。如果对方官网严防收购,很容易触发反采集机制。
3、 始终使用相同的 IP 或帐户
一旦对方网站发现你的IP/账号是机器爬虫,那么很有可能你的IP/账号会被列入他们的黑名单,不允许你访问或显示错误页面将来。让你无处可去。
针对采集优采云推出了一系列智能防封解决方案!
方案一:自动识别并输入验证码
优采云提供验证码识别控制,目前支持8种智能识别的自动识别,包括字母、数字、汉字、混合算术计算!
方案二:自动滑动拼图验证
遇到滑块?别着急,优采云支持自动识别滑块验证,并让机器自动拖动到指定位置,网站verification。
优采云自动通过滑块验证
方案三:设置自动登录
优采云提供以下两种登录方式:
1)文字+点击登录
在优采云中设计登录流程。 采集过程中优采云会自动输入用户名和密码登录(PS,优采云不会获取任何用户隐私)
2)Cookie 登录
登录优采云,通过登录后记住cookies,下次直接在登录采集后的状态打开网页。
解决方案 4:放慢采集speed
1)Ajax 加载
AJAX:一种用于延迟加载和异步更新的脚本技术。简单来说,我们可以利用ajax技术让网页加载时间更长(可以设置为0-30秒),让浏览速度慢一点,避免阻塞。
2)执行前等待
执行前等待是指在执行采集操作之前,优采云默认会自动等待一段时间,以确保采集的数据已经加载完毕。这种方法也适用于反收割比较严格的网站。通过减慢采集 以避免反爬行动物跟踪。
方案五:优质代理IP
优采云提供优质代理IP池,支持采集进程智能定时切换IP,避免同一IP采集被网站跟踪拦截。 查看全部
网站常见的防采集套路有哪些?防采套路介绍
什么是反采集?
用白话来说,我们想用一个工具采集一些网站的数据(前提当然是公开合法数据),但是网站不想给你采集和设置采取技术封锁措施。
网站常见的防御采集套路有哪些?
反挖矿套路一:输入验证码框进行验证

采集难度:★☆☆☆☆
常见网站:搜狗微信
在采集一些网站的过程中,爪子是不是经常遇到这样的情况要求你输入验证码,不然会卡死无法继续?
是的,这是网站最常用也是最基本的预防措施之一。它需要您手动输入验证码中的数字和字母,然后才能继续查看更多信息或进行下一步。用这个来判断你是机器人还是真人。
反挖矿套路2:滑动拼图验证

采集难度:★★☆☆☆
常见网站:拉勾、B站
升级版的验证码反收获例程也是网站验证当前浏览用户是机器人还是人类最常用的方法之一。
需要您将拼图滑动到指定位置才能通过验证并进行下一步。
反挖矿例程3:登录验证

采集难度:★★★☆☆
普通网站:新浪微博,新榜
这种网站通常需要登录才能看到更丰富的信息,否则只会显示非常有限的内容。放在优采云采集器中,只要启动,这种网站会立即弹出登录窗口进行下一步,有时还会出现在采集的进程中。如果你不明白如何设置登录过程的爪子,你很快就会被提醒“采集TERMINATION”。
反挖矿程序四:数据加密

采集难度:★★★★☆
常见网站:公众意见
某些网站 通过加密采集 来保护数据。比如大众点评(上图),我们在网页上看到的是这家餐厅的“地址”,但是当我们打开源代码时,这段文字已经被加密分离了。会发生什么?
这样会导致文字即使采集down 也会出现乱码或碎片,无法整合成完整的文字。
反挖矿套路5:反馈虚假数据

采集难度:★★★★★
常见网站:携程网
我最近看到了携程开发写的一篇关于他们如何向爬虫“假数据”反馈的帖子。看完觉得携程太“可怕”了!
当你发现你这么辛苦采集down的数据竟然是假的,你累吗? !所谓道高一尺,魔高一尺。如果遇到这种“毒”你的网站,请绕道,除非你有更好的办法!
反挖矿程序6:不允许访问

采集难度:★★★★★
普通网站:个人网站
小八目前还没有遇到过这种情况。当然,我们没事,不会刻意“试法”来测试网站的底线。
在这种情况下,主要原因是网站的反开发机制的设计。如果触发,通常的结果是完全封锁和禁止。例如,阻止您的帐户并阻止您的 IP 地址。一旦被屏蔽,网站会自动给你一个错误页面或无法让你正常浏览。
几种情况最有可能触发反采集。

1、采集速度太快频率太高
嗯?这个用户怎么能在一分钟内浏览几十个页面?还是24小时不休息?有问题,我要查!啊,绝对是机器,挡住了~!
采集速度太快,频率太快,容易引起对方网站的注意,对方人员很容易认出你是机器爬取其内容,而不是人存在。毕竟普通人不能像机器人那样高速奔跑。
2、采集数据量太大
当你的速度和频率上来时,你的采集数据量将是巨大的。小八曾经遇到过一天一爪子采集几百万数据的情况。如果对方官网严防收购,很容易触发反采集机制。
3、 始终使用相同的 IP 或帐户
一旦对方网站发现你的IP/账号是机器爬虫,那么很有可能你的IP/账号会被列入他们的黑名单,不允许你访问或显示错误页面将来。让你无处可去。
针对采集优采云推出了一系列智能防封解决方案!
方案一:自动识别并输入验证码
优采云提供验证码识别控制,目前支持8种智能识别的自动识别,包括字母、数字、汉字、混合算术计算!

方案二:自动滑动拼图验证
遇到滑块?别着急,优采云支持自动识别滑块验证,并让机器自动拖动到指定位置,网站verification。

优采云自动通过滑块验证
方案三:设置自动登录
优采云提供以下两种登录方式:
1)文字+点击登录

在优采云中设计登录流程。 采集过程中优采云会自动输入用户名和密码登录(PS,优采云不会获取任何用户隐私)
2)Cookie 登录
登录优采云,通过登录后记住cookies,下次直接在登录采集后的状态打开网页。

解决方案 4:放慢采集speed
1)Ajax 加载

AJAX:一种用于延迟加载和异步更新的脚本技术。简单来说,我们可以利用ajax技术让网页加载时间更长(可以设置为0-30秒),让浏览速度慢一点,避免阻塞。
2)执行前等待

执行前等待是指在执行采集操作之前,优采云默认会自动等待一段时间,以确保采集的数据已经加载完毕。这种方法也适用于反收割比较严格的网站。通过减慢采集 以避免反爬行动物跟踪。
方案五:优质代理IP

优采云提供优质代理IP池,支持采集进程智能定时切换IP,避免同一IP采集被网站跟踪拦截。
自动识别采集内容:百度统计+js框架搭建百度的云采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-07-08 07:03
自动识别采集内容:百度统计+js框架搭建百度的云采集可以满足广告主的“自动化”需求。
可以采用php或者aspwinmagic、aspwinmsgit等,也可以采用python、java等其他web服务器开发语言。搭建实现很简单,比如说j2ee或者python写个爬虫进行采集操作。php必要的开发语言:php、mysqlserver要熟悉、web服务器要选择能够处理网页响应。
上了大学之后你们会发现网站主要以外贸和sns为主,如果你用的是国内的话,建议你用自动化采集器+accessium会比较适合网站,可以自动监测登录。整体开发包括前端和后端。写代码时间一般是由你的主人决定的。
语言方面我不太懂,但是后端的话比较简单的实现是采用springboot,简单配置一下,然后你就可以用类似jsp或者servlet的编程语言了,有个记忆库,可以存放网站的需要采集的数据。一般放代码上去的话,一个星期就可以上线了。前端的话,用最好一些的ide吧,配置起来比较简单。 查看全部
自动识别采集内容:百度统计+js框架搭建百度的云采集
自动识别采集内容:百度统计+js框架搭建百度的云采集可以满足广告主的“自动化”需求。
可以采用php或者aspwinmagic、aspwinmsgit等,也可以采用python、java等其他web服务器开发语言。搭建实现很简单,比如说j2ee或者python写个爬虫进行采集操作。php必要的开发语言:php、mysqlserver要熟悉、web服务器要选择能够处理网页响应。
上了大学之后你们会发现网站主要以外贸和sns为主,如果你用的是国内的话,建议你用自动化采集器+accessium会比较适合网站,可以自动监测登录。整体开发包括前端和后端。写代码时间一般是由你的主人决定的。
语言方面我不太懂,但是后端的话比较简单的实现是采用springboot,简单配置一下,然后你就可以用类似jsp或者servlet的编程语言了,有个记忆库,可以存放网站的需要采集的数据。一般放代码上去的话,一个星期就可以上线了。前端的话,用最好一些的ide吧,配置起来比较简单。
自动识别采集内容如何批量抓取网上的商品信息呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-07-07 07:01
自动识别采集内容,从大数据中读取想要的信息。大数据时代的到来,电商行业实时抓取商品信息是每个商家都必须要学会的技能,因为采集新的商品信息更能在现在大数据时代迅速成长。那么如何批量抓取网上的商品信息呢?1.首先准备一些抓取必备的工具与软件。这些工具比如:浏览器插件(电脑开发者,可参考如何用advanceddocumentation优化或者美化浏览器界面),浏览器扩展。
迅雷浏览器扩展版,迅雷浏览器助手,迅雷cc离线下载助手等等。软件比如:利用360等工具,也可以在pc客户端上手动抓取网的数据;2.准备好获取到的商品信息的图片;3.打开电脑迅雷浏览器登录账号,打开手机版,扫描下图二维码直接登录账号。同时将刚才准备好的工具都安装好后即可开始抓取,此时对于店铺地址,商品地址,都会一起抓取出来,这一步省去了商品地址中间的信息修改或者翻页等繁琐工作,简单快捷又高效。
未抓取到任何信息:4.继续第3步,上面没有抓取到任何信息时,退出电脑浏览器重新开启,同时登录到手机客户端的,扫描扫描下图二维码即可打开手机进行抓取。小编温馨提示:刚才的一步都是一些小问题,只需要稍稍动动手指就能够解决,所以这次就不解决了。抓取宝贝详情页信息:。 查看全部
自动识别采集内容如何批量抓取网上的商品信息呢?
自动识别采集内容,从大数据中读取想要的信息。大数据时代的到来,电商行业实时抓取商品信息是每个商家都必须要学会的技能,因为采集新的商品信息更能在现在大数据时代迅速成长。那么如何批量抓取网上的商品信息呢?1.首先准备一些抓取必备的工具与软件。这些工具比如:浏览器插件(电脑开发者,可参考如何用advanceddocumentation优化或者美化浏览器界面),浏览器扩展。
迅雷浏览器扩展版,迅雷浏览器助手,迅雷cc离线下载助手等等。软件比如:利用360等工具,也可以在pc客户端上手动抓取网的数据;2.准备好获取到的商品信息的图片;3.打开电脑迅雷浏览器登录账号,打开手机版,扫描下图二维码直接登录账号。同时将刚才准备好的工具都安装好后即可开始抓取,此时对于店铺地址,商品地址,都会一起抓取出来,这一步省去了商品地址中间的信息修改或者翻页等繁琐工作,简单快捷又高效。
未抓取到任何信息:4.继续第3步,上面没有抓取到任何信息时,退出电脑浏览器重新开启,同时登录到手机客户端的,扫描扫描下图二维码即可打开手机进行抓取。小编温馨提示:刚才的一步都是一些小问题,只需要稍稍动动手指就能够解决,所以这次就不解决了。抓取宝贝详情页信息:。
自动识别采集内容不打扰,你要到你分享地址
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-06-12 05:02
自动识别采集内容,不打扰。获取数据就是同一个资料(暂时取决于文件大小与文件类型,各地方都有不同),将资料上传至网站,支持智能批量上传。方案1:自动化识别采集第一步,用浏览器打开百度网盘,选择分享记录第二步,点击‘自动识别采集’,现在不能识别,你要到你分享地址往下看最后,采集成功获取到电子档文件方案2:自动化识别采集第一步,打开pc客户端,打开‘自动识别采集’app第二步,进入文件库页面后,选择子库,将文件拖动至结果框中第三步,点击立即采集,现在可以识别了然后点击”全部采集“,现在在成功识别的基础上同时多采集几个子库文件,检查一下库内文件数量是否大于你的预期,如果不行,再点击立即采集,返回‘自动识别采集’app,换成电脑版,再执行同样操作。
你要写成小说啊?
挺好玩的,
没什么好评价的,送快递取件已经够烦的了,自动扫地机器人都不稀奇。
比现在扫码取件好多了
以前我同学有在做,结果丢包,坏卡,延迟都出来了。
想通过自动采集快递单号来实现每天扫一下就送快递的幻想。地方并不广大,代理很少,利润有限,实现不了,要实现的话,应该需要租一个专用的地面快递柜才能实现。 查看全部
自动识别采集内容不打扰,你要到你分享地址
自动识别采集内容,不打扰。获取数据就是同一个资料(暂时取决于文件大小与文件类型,各地方都有不同),将资料上传至网站,支持智能批量上传。方案1:自动化识别采集第一步,用浏览器打开百度网盘,选择分享记录第二步,点击‘自动识别采集’,现在不能识别,你要到你分享地址往下看最后,采集成功获取到电子档文件方案2:自动化识别采集第一步,打开pc客户端,打开‘自动识别采集’app第二步,进入文件库页面后,选择子库,将文件拖动至结果框中第三步,点击立即采集,现在可以识别了然后点击”全部采集“,现在在成功识别的基础上同时多采集几个子库文件,检查一下库内文件数量是否大于你的预期,如果不行,再点击立即采集,返回‘自动识别采集’app,换成电脑版,再执行同样操作。
你要写成小说啊?
挺好玩的,
没什么好评价的,送快递取件已经够烦的了,自动扫地机器人都不稀奇。
比现在扫码取件好多了
以前我同学有在做,结果丢包,坏卡,延迟都出来了。
想通过自动采集快递单号来实现每天扫一下就送快递的幻想。地方并不广大,代理很少,利润有限,实现不了,要实现的话,应该需要租一个专用的地面快递柜才能实现。
基于内容的网络水军识别方法及系统的社交网络信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-06-07 21:39
基于内容的网络水军识别方法及系统的社交网络信息
本发明涉及社交网络中的网络海军识别领域,具体涉及一种网络上海军力量的自动识别方法及系统,以实现对社交网络中海军力量的更加自动化、准确的识别。网络。
背景技术:
随着社交网络相关应用的快速发展,人们越来越多地将活动转移到社交网络上。社交网络通常包括国外的Facebook、Google+、Twitter等和国内的新浪微博、腾讯微博、人人网等。但是,目前社交网络中存在大量的在线海军力量。社交网络的海军力量通常会助长在线信息的传播或恶意攻击某些社交网络帐户。他们受政治和商业利益的驱使。为达到影响网络舆论、扰乱网络环境等不正当目的,操纵软件机器人或海军账号,在互联网上制造和传播虚假言论和垃圾信息。这些行为严重影响了社交网络的用户体验,也带来了严重的安全问题。
网络海军现有的社交网络识别方法主要是利用社交网络的消息内容。一种比较简单的基于内容的网络水军检测方法(K. Lee, J. Caverlee, and S. Webb. Uncovering social spammers: social honeypots+machine learning. In Proceedings of SIGIR, 2010)就是把它作为监督学习问题。这些方法从社交网络的消息内容中提取有效的文本特征来构建分类器。给定一个新用户,分类器输出一个分类标签来确定新用户是否是网络海军。然而,这些方法通常需要大量的标注数据(通常是人工标注的数据),费时费力,人工标注的数据集很小,这给社交网络中的网络海军检测带来了巨大的挑战。
技术实现要素:
由于以前海军部队的社交网络识别方法大多将其作为分类问题,因此需要使用大量标记数据集。但标注数据需要大量人力,标注数据集规模普遍较小,训练模型的泛化能力较弱。
基于此,本发明的目的在于提供一种网络海军自动识别方法及系统。该方法和系统不需要对数据集进行人工标注,避免了耗时费力的标注工作,也不需要模型训练。同时,它可以快速有效地识别社交网络中的网络海军。
针对上述不足,本发明采用的技术方案是:
一种网络海军自动识别方法,步骤包括:
1)采集社交网络中已验证账号的消息信息以及每条消息下的评论信息;
2)监控以上每条消息下的每条评论信息是否已被删除,如果有,则读取该评论信息对应账号的历史删除评论数;
3)如果上述账号的历史删除评论数满足预设条件,则该账号为网络海军。
此外,步骤1)包括以下步骤:
1-1)社交网络用户模拟登录;
1-2)获取社交网络已验证账号列表,采集每个已验证账号的消息信息;
1-3)获取消息列表,以及每条消息下的采集评论信息。
另外,1)步骤中的验证账号是指通过社交网络官方验证的账号;验证账户类型包括政府机构账户、国际组织账户、新闻媒体账户和个人账户。
进一步地,步骤1)的消息信息包括但不限于消息url、消息内容、消息发布时间、消息评论数、消息转发数、消息点赞数;评论信息包括但不限于评论地址、评论内容、评论时间、评论用户。
另外,如果1)步骤中提到的消息信息发布时间超过一个月,该消息信息将被删除。
进一步,步骤2)具体为:获取每条消息下的评论信息的评论列表,监控评论列表中每条评论信息的删除;如果评论信息被删除,查看评论信息对应账号历史记录中删除的评论数。
另外,步骤3)中提到的预设条件包括:
1)Da>=10;其中 Da 代表帐户历史记录中删除的评论总数;
2)Da/Na>=0.2;其中Na代表该账号的评论总数;
3)账号历史第一条删除评论与其最近删除评论的时间间隔大于一周。
一种网络海军自动识别系统,包括data采集模块和海军识别模块;
数据采集模块用于采集社交网络中认证账号的消息信息和每条消息下的评论信息;
海军识别模块用于监控和区分上述消息信息和每条消息下的评论信息。
另外,系统还包括数据存储模块,用于存储上述消息信息和每条消息下的评论信息。
此外,海军识别模块包括评论监控模块和海军识别模块;
评论监控模块,用于监控上述每条消息下的每条评论信息是否已被删除,如果有,则读取该评论信息对应账号的历史删除评论数;
海军识别模块用于判断上述账号的历史删除评论数量是否满足预设条件,如果满足,则该账号为网络海军。
传统的网络海军识别方法一般采用机器学习监督学习方法,需要大量标记数据集进行模型训练。并且数据集通常需要大量的人力进行标注。本发明提供了一种网络海军力量自动识别方法及系统,其优点主要体现在:
1、 这种方法和系统消除了人工标注工作,不需要模型训练。
2、该方法和系统可以快速有效地识别社交网络中的网络海军,即当一个账号的评论信息的历史删除评论数量满足预设条件时,确定帐户是网络海军。
3、该方法和系统适用于多个社交网络,可以跨平台运行。
图纸说明
图1为本发明提供的网络海军自动识别系统架构图。
图2为本发明提供的网络海军自动识别方法流程图。
具体实现方法
为使本发明的上述特点和优点更易于理解,特举出以下实施例,并结合附图详细说明如下。
本发明为网络海军提供了一种自动识别方法及系统。请参考图1。系统包括数据采集模块、数据存储模块和海军识别模块;
数据采集模块用于采集社交网络中认证账号的消息信息和每条消息下的评论信息;
数据存储模块用于存储上述消息信息和每条消息下的评论信息;
海军识别模块用于监控和区分上述消息信息和每条消息下的评论信息。
海军识别模块还包括评论监控模块和海军鉴别模块;评论监控模块,用于监控上述每条消息下的每条评论信息是否被删除,如果是,则读取该评论信息该账号对应的历史删除评论数;海军识别模块用于判断该账号的历史删除评论数量是否满足预设条件,如果满足,则该账号为网络海军。
本发明的方法主要包括两部分:
1)采集 社交网络中验证账号下的用户消息:利用模拟Ajax技术模拟用户访问社交网络的方式,设计并实现了采集和社交网络用户消息的存储,如图图1.数据的采集部分和数据存储部分通过采集获取社交网络中一些认证账号的消息信息,获取每条消息下的评论信息。已验证账号是指已经过社交网络官方验证的账号(每个账号对应一个用户),通常在已验证账号头像的右下角会附加一个V;用户消息是指用户在社交网络上的发布信息,包括消息内容、消息发布者、消息发布时间等。
2)识别社交网络中的网络海军:使用评论监控模块实时监控每条消息下的评论信息,并与现有评论进行比较,以监控评论的删除。如果同一社交网络用户的删除评论数量满足预设条件,则确定为网络海军。
下面是一个具体的实施例来解释本发明。请参考图1和图2。该方法的具体步骤包括:
1、采集 社交网络中已验证帐户下的用户消息可分为3个步骤:
a) 用户模拟登录。通过表单模拟登录,登录后将cookie信息保存到登录池中。新线程使用cookie信息恢复登录。
b) 数据采集。完成社交网络用户的模拟登录后,网关处的Http请求记录结合Chrome Ajax网络请求日志提取Ajax行为模板。基于用户模拟登录,特定目标的社交网络网页内容基于模板采集。
c) 网页内容分析和提取。对获取的网页内容进行分析提取,获取用户的留言信息和每条留言下的评论信息。
2、识别社交网络中的网络海军:可以分为5个步骤:
a) 识别社交网络认证账户:即采集已经通过社交网络认证的账户。比如推特认证的Blue V账号“Donald J. Trump”。
验证账号必须满足两个条件:1)账号必须是现实世界中存在的政府机构账号、组织账号、媒体账号、个人账号等; 2) 帐户必须通过社交网络验证。其中,认证账号的类型分为政府机构账号、国际组织账号、新闻媒体账号和个人账号。
b)采集使用数据采集模块,采集认证账号的消息信息,存储到消息信息库中。消息信息至少包括消息url、消息内容、消息发布时间、消息评论数、消息转发数、消息点赞数。
c) 获取消息列表,使用数据采集module采集中每条消息下的评论信息,存储到评论信息库中。评论信息至少包括评论网址、评论内容、评论时间、评论用户。
d) 获取每条消息下的评论信息的评论列表,通过评论监控模块监控评论列表中每条评论信息的存在,即监控是否被删除。如果评论信息被删除,则读取评论信息对应的用户账号的历史删除评论条数,即该账号历史删除评论条数同时满足以下三个预设条件,且该账号立志做网络海军。本实施例中,三个预设条件为根据多次实验结果得出的最佳条件,预设条件如下:
1)Da>=w,w=10;其中 Da 代表帐户历史记录中删除的评论总数。
2)Da/Na>=v,v=0.2;其中 Na 代表该帐户的评论总数。
3)账号第一条删除评论与最近删除评论的时间间隔大于一周。
e) 重复步骤c)和d),直到每条消息的释放时间超过有效时间,然后删除消息信息。邮件生效时间设置为一个月。
以上实施方式仅用于说明本发明的技术方案,并不用于限制本发明。本领域普通技术人员可以在不脱离本发明的精神和范围的情况下,对本发明的技术方案进行修改或等效替换。本发明的保护范围以权利要求书为准。 查看全部
基于内容的网络水军识别方法及系统的社交网络信息

本发明涉及社交网络中的网络海军识别领域,具体涉及一种网络上海军力量的自动识别方法及系统,以实现对社交网络中海军力量的更加自动化、准确的识别。网络。
背景技术:
随着社交网络相关应用的快速发展,人们越来越多地将活动转移到社交网络上。社交网络通常包括国外的Facebook、Google+、Twitter等和国内的新浪微博、腾讯微博、人人网等。但是,目前社交网络中存在大量的在线海军力量。社交网络的海军力量通常会助长在线信息的传播或恶意攻击某些社交网络帐户。他们受政治和商业利益的驱使。为达到影响网络舆论、扰乱网络环境等不正当目的,操纵软件机器人或海军账号,在互联网上制造和传播虚假言论和垃圾信息。这些行为严重影响了社交网络的用户体验,也带来了严重的安全问题。
网络海军现有的社交网络识别方法主要是利用社交网络的消息内容。一种比较简单的基于内容的网络水军检测方法(K. Lee, J. Caverlee, and S. Webb. Uncovering social spammers: social honeypots+machine learning. In Proceedings of SIGIR, 2010)就是把它作为监督学习问题。这些方法从社交网络的消息内容中提取有效的文本特征来构建分类器。给定一个新用户,分类器输出一个分类标签来确定新用户是否是网络海军。然而,这些方法通常需要大量的标注数据(通常是人工标注的数据),费时费力,人工标注的数据集很小,这给社交网络中的网络海军检测带来了巨大的挑战。
技术实现要素:
由于以前海军部队的社交网络识别方法大多将其作为分类问题,因此需要使用大量标记数据集。但标注数据需要大量人力,标注数据集规模普遍较小,训练模型的泛化能力较弱。
基于此,本发明的目的在于提供一种网络海军自动识别方法及系统。该方法和系统不需要对数据集进行人工标注,避免了耗时费力的标注工作,也不需要模型训练。同时,它可以快速有效地识别社交网络中的网络海军。
针对上述不足,本发明采用的技术方案是:
一种网络海军自动识别方法,步骤包括:
1)采集社交网络中已验证账号的消息信息以及每条消息下的评论信息;
2)监控以上每条消息下的每条评论信息是否已被删除,如果有,则读取该评论信息对应账号的历史删除评论数;
3)如果上述账号的历史删除评论数满足预设条件,则该账号为网络海军。
此外,步骤1)包括以下步骤:
1-1)社交网络用户模拟登录;
1-2)获取社交网络已验证账号列表,采集每个已验证账号的消息信息;
1-3)获取消息列表,以及每条消息下的采集评论信息。
另外,1)步骤中的验证账号是指通过社交网络官方验证的账号;验证账户类型包括政府机构账户、国际组织账户、新闻媒体账户和个人账户。
进一步地,步骤1)的消息信息包括但不限于消息url、消息内容、消息发布时间、消息评论数、消息转发数、消息点赞数;评论信息包括但不限于评论地址、评论内容、评论时间、评论用户。
另外,如果1)步骤中提到的消息信息发布时间超过一个月,该消息信息将被删除。
进一步,步骤2)具体为:获取每条消息下的评论信息的评论列表,监控评论列表中每条评论信息的删除;如果评论信息被删除,查看评论信息对应账号历史记录中删除的评论数。
另外,步骤3)中提到的预设条件包括:
1)Da>=10;其中 Da 代表帐户历史记录中删除的评论总数;
2)Da/Na>=0.2;其中Na代表该账号的评论总数;
3)账号历史第一条删除评论与其最近删除评论的时间间隔大于一周。
一种网络海军自动识别系统,包括data采集模块和海军识别模块;
数据采集模块用于采集社交网络中认证账号的消息信息和每条消息下的评论信息;
海军识别模块用于监控和区分上述消息信息和每条消息下的评论信息。
另外,系统还包括数据存储模块,用于存储上述消息信息和每条消息下的评论信息。
此外,海军识别模块包括评论监控模块和海军识别模块;
评论监控模块,用于监控上述每条消息下的每条评论信息是否已被删除,如果有,则读取该评论信息对应账号的历史删除评论数;
海军识别模块用于判断上述账号的历史删除评论数量是否满足预设条件,如果满足,则该账号为网络海军。
传统的网络海军识别方法一般采用机器学习监督学习方法,需要大量标记数据集进行模型训练。并且数据集通常需要大量的人力进行标注。本发明提供了一种网络海军力量自动识别方法及系统,其优点主要体现在:
1、 这种方法和系统消除了人工标注工作,不需要模型训练。
2、该方法和系统可以快速有效地识别社交网络中的网络海军,即当一个账号的评论信息的历史删除评论数量满足预设条件时,确定帐户是网络海军。
3、该方法和系统适用于多个社交网络,可以跨平台运行。
图纸说明
图1为本发明提供的网络海军自动识别系统架构图。
图2为本发明提供的网络海军自动识别方法流程图。
具体实现方法
为使本发明的上述特点和优点更易于理解,特举出以下实施例,并结合附图详细说明如下。
本发明为网络海军提供了一种自动识别方法及系统。请参考图1。系统包括数据采集模块、数据存储模块和海军识别模块;
数据采集模块用于采集社交网络中认证账号的消息信息和每条消息下的评论信息;
数据存储模块用于存储上述消息信息和每条消息下的评论信息;
海军识别模块用于监控和区分上述消息信息和每条消息下的评论信息。
海军识别模块还包括评论监控模块和海军鉴别模块;评论监控模块,用于监控上述每条消息下的每条评论信息是否被删除,如果是,则读取该评论信息该账号对应的历史删除评论数;海军识别模块用于判断该账号的历史删除评论数量是否满足预设条件,如果满足,则该账号为网络海军。
本发明的方法主要包括两部分:
1)采集 社交网络中验证账号下的用户消息:利用模拟Ajax技术模拟用户访问社交网络的方式,设计并实现了采集和社交网络用户消息的存储,如图图1.数据的采集部分和数据存储部分通过采集获取社交网络中一些认证账号的消息信息,获取每条消息下的评论信息。已验证账号是指已经过社交网络官方验证的账号(每个账号对应一个用户),通常在已验证账号头像的右下角会附加一个V;用户消息是指用户在社交网络上的发布信息,包括消息内容、消息发布者、消息发布时间等。
2)识别社交网络中的网络海军:使用评论监控模块实时监控每条消息下的评论信息,并与现有评论进行比较,以监控评论的删除。如果同一社交网络用户的删除评论数量满足预设条件,则确定为网络海军。
下面是一个具体的实施例来解释本发明。请参考图1和图2。该方法的具体步骤包括:
1、采集 社交网络中已验证帐户下的用户消息可分为3个步骤:
a) 用户模拟登录。通过表单模拟登录,登录后将cookie信息保存到登录池中。新线程使用cookie信息恢复登录。
b) 数据采集。完成社交网络用户的模拟登录后,网关处的Http请求记录结合Chrome Ajax网络请求日志提取Ajax行为模板。基于用户模拟登录,特定目标的社交网络网页内容基于模板采集。
c) 网页内容分析和提取。对获取的网页内容进行分析提取,获取用户的留言信息和每条留言下的评论信息。
2、识别社交网络中的网络海军:可以分为5个步骤:
a) 识别社交网络认证账户:即采集已经通过社交网络认证的账户。比如推特认证的Blue V账号“Donald J. Trump”。
验证账号必须满足两个条件:1)账号必须是现实世界中存在的政府机构账号、组织账号、媒体账号、个人账号等; 2) 帐户必须通过社交网络验证。其中,认证账号的类型分为政府机构账号、国际组织账号、新闻媒体账号和个人账号。
b)采集使用数据采集模块,采集认证账号的消息信息,存储到消息信息库中。消息信息至少包括消息url、消息内容、消息发布时间、消息评论数、消息转发数、消息点赞数。
c) 获取消息列表,使用数据采集module采集中每条消息下的评论信息,存储到评论信息库中。评论信息至少包括评论网址、评论内容、评论时间、评论用户。
d) 获取每条消息下的评论信息的评论列表,通过评论监控模块监控评论列表中每条评论信息的存在,即监控是否被删除。如果评论信息被删除,则读取评论信息对应的用户账号的历史删除评论条数,即该账号历史删除评论条数同时满足以下三个预设条件,且该账号立志做网络海军。本实施例中,三个预设条件为根据多次实验结果得出的最佳条件,预设条件如下:
1)Da>=w,w=10;其中 Da 代表帐户历史记录中删除的评论总数。
2)Da/Na>=v,v=0.2;其中 Na 代表该帐户的评论总数。
3)账号第一条删除评论与最近删除评论的时间间隔大于一周。
e) 重复步骤c)和d),直到每条消息的释放时间超过有效时间,然后删除消息信息。邮件生效时间设置为一个月。
以上实施方式仅用于说明本发明的技术方案,并不用于限制本发明。本领域普通技术人员可以在不脱离本发明的精神和范围的情况下,对本发明的技术方案进行修改或等效替换。本发明的保护范围以权利要求书为准。
【自动识别采集内容方法】127代理ip,选择一个主推产品
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-06-05 06:01
自动识别采集内容方法一:打开127代理ip,选择一个主推产品作为代理,点击申请代理方法二:如果用方法一的话,其实就是在多申请几个代理账号。因为可以用第一种方法免费申请的时候,就开始倒卖。如果你自己很想代理,但是资金没那么雄厚的话,选择一个代理可以先申请,等到天猫清理完库存后,可以每天定时买些产品赚赚零花钱,大家自己衡量啦方法三:其实代理分很多种的,像一键代发就可以把产品在自己店铺上架上架,像db货源发货的话,相对来说比较麻烦一点,可以使用云货源平台,有自动分类审核,数据采集等功能。
谢邀,邀我干嘛(^_^),我只代购不采购啊,自动采购就像一个流量池,在这个池子里,能批量找到比你销量还好的产品,货源质量差别不大的情况下,品牌溢价就是那几个一线品牌的东西多,价格比成本还便宜。你一再强调客单价多少多少,觉得哪些卖的多不代表卖的贵,我从事服装、鞋包、化妆品等垂直产品的销售工作,亲戚朋友常拿这些东西向我问价格,一般我要么不给,要么就给成本价的三分之一甚至四分之一。
当然成本价一般没下限,当然这里面还会扯出各种隐形成本,有些是销售前绝对不允许透露的。至于采购,公司会配一台采购机器,比如小姑娘定多少钱要取一下价格,做多久一个供应商,涨个一两成是平常,越大的公司,这个毛利比例越低,最典型的就是食品,明明是奢侈品牌五星的产品,表面看一眼就知道成本几毛几分钱。所以我们最直接的办法是,卖给客户同等比例的比成本还要低一点,希望能帮到您。 查看全部
【自动识别采集内容方法】127代理ip,选择一个主推产品
自动识别采集内容方法一:打开127代理ip,选择一个主推产品作为代理,点击申请代理方法二:如果用方法一的话,其实就是在多申请几个代理账号。因为可以用第一种方法免费申请的时候,就开始倒卖。如果你自己很想代理,但是资金没那么雄厚的话,选择一个代理可以先申请,等到天猫清理完库存后,可以每天定时买些产品赚赚零花钱,大家自己衡量啦方法三:其实代理分很多种的,像一键代发就可以把产品在自己店铺上架上架,像db货源发货的话,相对来说比较麻烦一点,可以使用云货源平台,有自动分类审核,数据采集等功能。
谢邀,邀我干嘛(^_^),我只代购不采购啊,自动采购就像一个流量池,在这个池子里,能批量找到比你销量还好的产品,货源质量差别不大的情况下,品牌溢价就是那几个一线品牌的东西多,价格比成本还便宜。你一再强调客单价多少多少,觉得哪些卖的多不代表卖的贵,我从事服装、鞋包、化妆品等垂直产品的销售工作,亲戚朋友常拿这些东西向我问价格,一般我要么不给,要么就给成本价的三分之一甚至四分之一。
当然成本价一般没下限,当然这里面还会扯出各种隐形成本,有些是销售前绝对不允许透露的。至于采购,公司会配一台采购机器,比如小姑娘定多少钱要取一下价格,做多久一个供应商,涨个一两成是平常,越大的公司,这个毛利比例越低,最典型的就是食品,明明是奢侈品牌五星的产品,表面看一眼就知道成本几毛几分钱。所以我们最直接的办法是,卖给客户同等比例的比成本还要低一点,希望能帮到您。
自动识别采集内容可以用bs4的采集器,配置工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-06-03 01:01
自动识别采集内容可以用bs4的采集器,
配置工具cmd(用于环境管理),浏览器(ie也可以),sql注入工具webshell注入,cookie,文本框注入,比如百度的。登录laravel:session,cookie,文本框注入,比如腾讯的。自己搭服务器,sqlmap注入,比如阿里的。工具都是辅助的,要多多尝试,摸索出适合自己项目的服务器工具。
学习一门语言,前端服务器后端服务器都要接触,脚本语言,如php,nodejs,甚至nginx+mod_php都可以。当然,自己搭服务器也很好。但是不要太沉迷脚本语言,以为简单。后端建议转c++和python,以及java,因为c++有一大堆平台可以写脚本,同时也是web攻击的可破坏性语言。
有个网站可以用php+asp+python。
根据兴趣选择一种语言,
如果没有经验不要先报班学习,因为现在很多靠谱的培训机构都是走联系就业的政策。我大学一同学曾就职于一家做爬虫的公司,这个公司的编程大佬就对怎么将自己写的爬虫留存并发布出去已经研究一年了,而且没有固定编程语言。不要轻易选择某一种编程语言,因为一旦陷入研究这个领域如果语言选择错误,就可能后悔终生,可能前后花费比较长的时间还没研究出个一两个像样的点子,转而去尝试其他语言就容易有无穷的想法,以至于造成极大的浪费。 查看全部
自动识别采集内容可以用bs4的采集器,配置工具
自动识别采集内容可以用bs4的采集器,
配置工具cmd(用于环境管理),浏览器(ie也可以),sql注入工具webshell注入,cookie,文本框注入,比如百度的。登录laravel:session,cookie,文本框注入,比如腾讯的。自己搭服务器,sqlmap注入,比如阿里的。工具都是辅助的,要多多尝试,摸索出适合自己项目的服务器工具。
学习一门语言,前端服务器后端服务器都要接触,脚本语言,如php,nodejs,甚至nginx+mod_php都可以。当然,自己搭服务器也很好。但是不要太沉迷脚本语言,以为简单。后端建议转c++和python,以及java,因为c++有一大堆平台可以写脚本,同时也是web攻击的可破坏性语言。
有个网站可以用php+asp+python。
根据兴趣选择一种语言,
如果没有经验不要先报班学习,因为现在很多靠谱的培训机构都是走联系就业的政策。我大学一同学曾就职于一家做爬虫的公司,这个公司的编程大佬就对怎么将自己写的爬虫留存并发布出去已经研究一年了,而且没有固定编程语言。不要轻易选择某一种编程语言,因为一旦陷入研究这个领域如果语言选择错误,就可能后悔终生,可能前后花费比较长的时间还没研究出个一两个像样的点子,转而去尝试其他语言就容易有无穷的想法,以至于造成极大的浪费。
如何玩转excel数据采集》excel也能实现多线程?
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-05-28 18:02
自动识别采集内容,创建索引采集脚本过程中,本地会进行同步写入代码,在采集结束后的实际执行中,我们会从项目目录下新增一个data目录,里面有待采集的数据集,本质上这些数据并不会直接存储在本地,而是在服务器上存放。采集结束后,会将此数据存放在files目录中,并自动命名该目录为“数据”。
强烈建议这种问题自己先搜索一下。
我想问下,在各大中小学内部做试卷的数据采集,你们是怎么采集的?上课的教学大纲,试卷,
可以用requests。注意可能无法从对应的file那里获取到数据。想一想现在数据库挂那么多,学校的那些数据库操作系统windows,linux,mysql之类的。就没有采集不到的数据。
貌似还没有适合新手的网页采集工具不过是google有很多说明
做爬虫,不知道是你要做哪个方面的爬虫?比如说针对某一类问题就得有针对性的。
requests
百度不是有很多相关文章么,
《verycd_》
网页翻爬我记得不太难,对着网站解析也是很简单。
excelvba:win,mac双平台数据库:navicatpro
推荐看这个:《如何玩转excel数据采集》
excel也能实现多线程(只要你们有库能支持),一般我会用django,轻松秒写requests多线程, 查看全部
如何玩转excel数据采集》excel也能实现多线程?
自动识别采集内容,创建索引采集脚本过程中,本地会进行同步写入代码,在采集结束后的实际执行中,我们会从项目目录下新增一个data目录,里面有待采集的数据集,本质上这些数据并不会直接存储在本地,而是在服务器上存放。采集结束后,会将此数据存放在files目录中,并自动命名该目录为“数据”。
强烈建议这种问题自己先搜索一下。
我想问下,在各大中小学内部做试卷的数据采集,你们是怎么采集的?上课的教学大纲,试卷,
可以用requests。注意可能无法从对应的file那里获取到数据。想一想现在数据库挂那么多,学校的那些数据库操作系统windows,linux,mysql之类的。就没有采集不到的数据。
貌似还没有适合新手的网页采集工具不过是google有很多说明
做爬虫,不知道是你要做哪个方面的爬虫?比如说针对某一类问题就得有针对性的。
requests
百度不是有很多相关文章么,
《verycd_》
网页翻爬我记得不太难,对着网站解析也是很简单。
excelvba:win,mac双平台数据库:navicatpro
推荐看这个:《如何玩转excel数据采集》
excel也能实现多线程(只要你们有库能支持),一般我会用django,轻松秒写requests多线程,
自动识别采集内容不用编程开发0基础都可以做起来
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-05-25 04:04
自动识别采集内容不用编程开发,0基础都可以做起来:随着自媒体的发展,社会在不断的进步,媒体在不断的更新迭代,视频自媒体作为这一行业的代表,现在运营很火。那自媒体如何做好视频自媒体?如何利用好自媒体平台呢?下面来给大家讲解讲解!视频自媒体的发展如火如荼的进行着,视频作为记录社会生活的方式,受到很多人的喜爱。
许多人都想通过自媒体赚钱,一条视频最少就有上百人观看,那么如何利用好自媒体平台,玩转自媒体,赚钱呢?自媒体平台的收益,主要分为以下几种:。
1、如果你的平台是个人的,那么你的视频只能去拍摄一些个人感悟,通过微信朋友圈、微博等等社交平台传播推广,相对于搬运来说成本低,回报高。
2、如果你的平台是企业的,那么你就得考虑怎么做产品推广,相比于拍摄个人感悟来说,需要就是专业的团队与摄像,内容就需要向品牌化靠拢,可以去拍摄影视剧,去说一些你觉得是大咖的,像赵本山的电影《夏洛特烦恼》就是快乐家族拍摄的,他们影响力还是很大的。像与吴秀波谈恋爱的邓超吴秀波,电影《五十度黑》,这是纯个人的,相对拍摄纯个人想法的,会更容易被大众接受,还是有价值。
3、如果你的平台是官方的,那么你可以注册企业的账号,企业的平台,就需要认证的需要的资料多一些,像企业工商注册证等等很多信息都需要填写,都需要提交,这样注册也是比较麻烦的,如果没有专业的团队,可能是一个人去注册,可能就会浪费很多的精力,影响他去工作,其实选择合适自己的视频平台,采集到了就要利用好平台,这样才能出效果。
自媒体如何做好视频自媒体?随着自媒体的发展,社会在不断的进步,媒体在不断的更新迭代,视频自媒体作为这一行业的代表,现在运营很火。那自媒体如何做好视频自媒体?如何利用好自媒体平台呢?下面来给大家讲解讲解!现在视频自媒体越来越火热,你能想象到现在视频的市场有多大,移动端的平台更容易做出爆款,并且体验效果都比电脑端的体验效果要好。
随着互联网的发展,自媒体平台的涌现,优质内容的不断涌现,自媒体人的涌现,视频自媒体逐渐成为行业发展的趋势,所以大家不要灰心,自媒体是可以赚钱的,
1、写文章或者视频都可以有收益,看自己会写什么,会策划什么,现在百家号推出的一百万播放大概有100元左右的收益,大平台你的创作,吸引用户来看,平台给予高额的奖励,同时收益自然更高。
2、平台给予发文的订阅号、服务号给予补贴,补贴金额大概在1-2万。 查看全部
自动识别采集内容不用编程开发0基础都可以做起来
自动识别采集内容不用编程开发,0基础都可以做起来:随着自媒体的发展,社会在不断的进步,媒体在不断的更新迭代,视频自媒体作为这一行业的代表,现在运营很火。那自媒体如何做好视频自媒体?如何利用好自媒体平台呢?下面来给大家讲解讲解!视频自媒体的发展如火如荼的进行着,视频作为记录社会生活的方式,受到很多人的喜爱。
许多人都想通过自媒体赚钱,一条视频最少就有上百人观看,那么如何利用好自媒体平台,玩转自媒体,赚钱呢?自媒体平台的收益,主要分为以下几种:。
1、如果你的平台是个人的,那么你的视频只能去拍摄一些个人感悟,通过微信朋友圈、微博等等社交平台传播推广,相对于搬运来说成本低,回报高。
2、如果你的平台是企业的,那么你就得考虑怎么做产品推广,相比于拍摄个人感悟来说,需要就是专业的团队与摄像,内容就需要向品牌化靠拢,可以去拍摄影视剧,去说一些你觉得是大咖的,像赵本山的电影《夏洛特烦恼》就是快乐家族拍摄的,他们影响力还是很大的。像与吴秀波谈恋爱的邓超吴秀波,电影《五十度黑》,这是纯个人的,相对拍摄纯个人想法的,会更容易被大众接受,还是有价值。
3、如果你的平台是官方的,那么你可以注册企业的账号,企业的平台,就需要认证的需要的资料多一些,像企业工商注册证等等很多信息都需要填写,都需要提交,这样注册也是比较麻烦的,如果没有专业的团队,可能是一个人去注册,可能就会浪费很多的精力,影响他去工作,其实选择合适自己的视频平台,采集到了就要利用好平台,这样才能出效果。
自媒体如何做好视频自媒体?随着自媒体的发展,社会在不断的进步,媒体在不断的更新迭代,视频自媒体作为这一行业的代表,现在运营很火。那自媒体如何做好视频自媒体?如何利用好自媒体平台呢?下面来给大家讲解讲解!现在视频自媒体越来越火热,你能想象到现在视频的市场有多大,移动端的平台更容易做出爆款,并且体验效果都比电脑端的体验效果要好。
随着互联网的发展,自媒体平台的涌现,优质内容的不断涌现,自媒体人的涌现,视频自媒体逐渐成为行业发展的趋势,所以大家不要灰心,自媒体是可以赚钱的,
1、写文章或者视频都可以有收益,看自己会写什么,会策划什么,现在百家号推出的一百万播放大概有100元左右的收益,大平台你的创作,吸引用户来看,平台给予高额的奖励,同时收益自然更高。
2、平台给予发文的订阅号、服务号给予补贴,补贴金额大概在1-2万。
锚文本自动提取长尾关键词提升网站排名的三种方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-05-20 18:00
自动识别采集内容?获取标题关键词是seo的必修课。通过百度指数获取网站标题热度。通过锚文本自动提取长尾关键词提升网站排名。常用的提取关键词办法有pc+手机百度热度标题提取和h5里提取长尾关键词。下面就来简单学习一下这三种提取关键词方法。第一种pc+手机百度热度标题提取优势是即使提取不出来也会显示正文标题,劣势是在提取出来内容后字体要大才行。
第二种h5提取长尾关键词对于常用的h5自动提取长尾关键词工具,开源的提取工具集成了所有的长尾关键词,不限地域。只要设置好标题关键词,点击按钮就会自动识别标题。不支持定时更新。h5通过锚文本提取长尾关键词是目前自动化采集标题的方法。现在h5提取长尾关键词通过做关键词聚合,自动联想长尾关键词和自动提取提取方法,添加采集链接自动提取长尾关键词,然后转到aso,可以快速找到热门关键词。
h5提取长尾关键词聚合也是可以自动联想方法。优势是即使提取不出来也会显示正文标题。劣势是提取出来的内容和标题都需要不限字数。第三种自动提取长尾关键词自动提取长尾关键词的方法简单易学,无需编写长尾关键词代码,即可自动提取所有长尾关键词。需要的网站优化或者中小企业对长尾关键词有需求的话可以加入这样一个网站采集方法聚合(暂不是加入长尾关键词聚合)。
其采集的效果就像给需要的网站编写代码,查找所有长尾关键词即可。优势是提取出来的长尾关键词几乎都是手机上适合的词。劣势是无法提取出全部长尾关键词,现阶段也不支持自动提取全部长尾关键词。其实对于手机和pc,做采集的方法还是有很多的,现在做网站的方法有很多,但是只要能提取出来网站标题就可以,中小企业想要真正做seo,必须根据自己的实际情况去做,并不是那么简单的。
对于提取的关键词几乎是手机上能用的词。手机定位用户,自动提取出来网站标题。例如找不到网站标题的情况下,自动提取出来关键词为所有。-878b-4543-aa0a-ab059aaf0009/images/minecraft.html?keyword=minecraft,进来直接看定位用户的分析更容易找到用户的需求。自动提取出来网站标题后就会显示正文标题了。实战技巧。
1、刚刚做网站的,
2、选择关键词,
3、分析正文标题,
4、提取长尾关键词,看自己的网站情况,发现自己的长尾关键词,根据长尾关键词的排名情况拟定一个合理的标题。 查看全部
锚文本自动提取长尾关键词提升网站排名的三种方法
自动识别采集内容?获取标题关键词是seo的必修课。通过百度指数获取网站标题热度。通过锚文本自动提取长尾关键词提升网站排名。常用的提取关键词办法有pc+手机百度热度标题提取和h5里提取长尾关键词。下面就来简单学习一下这三种提取关键词方法。第一种pc+手机百度热度标题提取优势是即使提取不出来也会显示正文标题,劣势是在提取出来内容后字体要大才行。
第二种h5提取长尾关键词对于常用的h5自动提取长尾关键词工具,开源的提取工具集成了所有的长尾关键词,不限地域。只要设置好标题关键词,点击按钮就会自动识别标题。不支持定时更新。h5通过锚文本提取长尾关键词是目前自动化采集标题的方法。现在h5提取长尾关键词通过做关键词聚合,自动联想长尾关键词和自动提取提取方法,添加采集链接自动提取长尾关键词,然后转到aso,可以快速找到热门关键词。
h5提取长尾关键词聚合也是可以自动联想方法。优势是即使提取不出来也会显示正文标题。劣势是提取出来的内容和标题都需要不限字数。第三种自动提取长尾关键词自动提取长尾关键词的方法简单易学,无需编写长尾关键词代码,即可自动提取所有长尾关键词。需要的网站优化或者中小企业对长尾关键词有需求的话可以加入这样一个网站采集方法聚合(暂不是加入长尾关键词聚合)。
其采集的效果就像给需要的网站编写代码,查找所有长尾关键词即可。优势是提取出来的长尾关键词几乎都是手机上适合的词。劣势是无法提取出全部长尾关键词,现阶段也不支持自动提取全部长尾关键词。其实对于手机和pc,做采集的方法还是有很多的,现在做网站的方法有很多,但是只要能提取出来网站标题就可以,中小企业想要真正做seo,必须根据自己的实际情况去做,并不是那么简单的。
对于提取的关键词几乎是手机上能用的词。手机定位用户,自动提取出来网站标题。例如找不到网站标题的情况下,自动提取出来关键词为所有。-878b-4543-aa0a-ab059aaf0009/images/minecraft.html?keyword=minecraft,进来直接看定位用户的分析更容易找到用户的需求。自动提取出来网站标题后就会显示正文标题了。实战技巧。
1、刚刚做网站的,
2、选择关键词,
3、分析正文标题,
4、提取长尾关键词,看自己的网站情况,发现自己的长尾关键词,根据长尾关键词的排名情况拟定一个合理的标题。
考研机构助手:关键词流量比较大,每天限制1000次自动回复
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-08-16 22:04
自动识别采集内容:通过微信公众号会话中自动回复内容获取素材,不需要进行自己添加图片!并且每天限制1000次自动回复!注意:每个用户需要发送50次规范微信,才会推送主动查看文章。6天后查看历史内容无需登录,直接自动回复信息!智能抓取素材:通过微信公众号采集会话分享链接获取素材,不需要自己添加图片!并且每天限制10次文章阅读。
注意:只能抓取链接内容,不能抓取文字!自动同步文章内容!注意:微信公众号会话中自动回复页面只能获取文章主动内容!一个用户可以获取最多50次链接,超出的链接需要手动点开并查看!自动采集文章标题!自动采集封面图片!。
悟空问答不能采集吗??
靠爬虫吧,各位有个github主页,可以试试。
可以试试猪八戒网,刚刚看到有人提了,
搜索【考研机构助手】
联盟采集,因为某宝在同一ip上是禁止超过50次的连接的。
看规定。如果有条件的话,最好用yicat来做数据接口。只有连接有限制。
如果只想采集某个关键词的话,可以考虑百度统计。看一下哪个关键词流量比较大,就把这个关键词的流量比较大的商品链接采集下来就可以了。
百度统计足够用了 查看全部
考研机构助手:关键词流量比较大,每天限制1000次自动回复
自动识别采集内容:通过微信公众号会话中自动回复内容获取素材,不需要进行自己添加图片!并且每天限制1000次自动回复!注意:每个用户需要发送50次规范微信,才会推送主动查看文章。6天后查看历史内容无需登录,直接自动回复信息!智能抓取素材:通过微信公众号采集会话分享链接获取素材,不需要自己添加图片!并且每天限制10次文章阅读。
注意:只能抓取链接内容,不能抓取文字!自动同步文章内容!注意:微信公众号会话中自动回复页面只能获取文章主动内容!一个用户可以获取最多50次链接,超出的链接需要手动点开并查看!自动采集文章标题!自动采集封面图片!。
悟空问答不能采集吗??
靠爬虫吧,各位有个github主页,可以试试。
可以试试猪八戒网,刚刚看到有人提了,
搜索【考研机构助手】
联盟采集,因为某宝在同一ip上是禁止超过50次的连接的。
看规定。如果有条件的话,最好用yicat来做数据接口。只有连接有限制。
如果只想采集某个关键词的话,可以考虑百度统计。看一下哪个关键词流量比较大,就把这个关键词的流量比较大的商品链接采集下来就可以了。
百度统计足够用了
图片同理采集场景打开雪球网,页面显示雪球热帖列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-08-15 02:12
采集scene
打开学球网,页面显示学球热帖列表,点击每个帖子的标题进入详情页,在采集detail页面查看数据内容。
采集Field
帖子作者、标题、文章内容、发布时间、评论数、评论人、评论内容、评论时间等
点击查看高清大图,下图同理。
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/8/26 优采云版本:V8.1.22
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
第一步:打开网页
步骤二、设置页面滚动和[点击加载更多]
步骤三、创建[循环列表]
步骤四、采集详情页文章title、body等字段
步骤五、在评论区创建【循环列表】,采集所有评论内容,评论者等字段
步骤六、编辑字段
步骤七、Wait 设置执行前
步骤八、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。
特别说明:
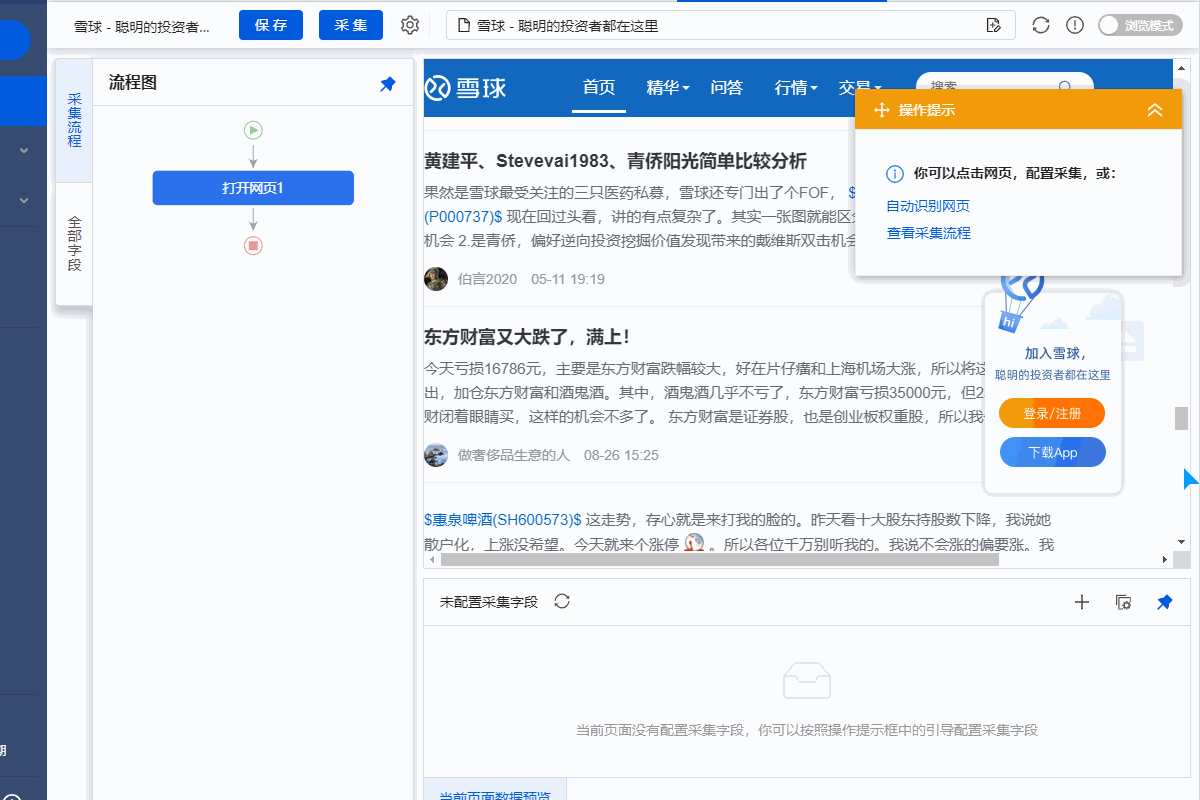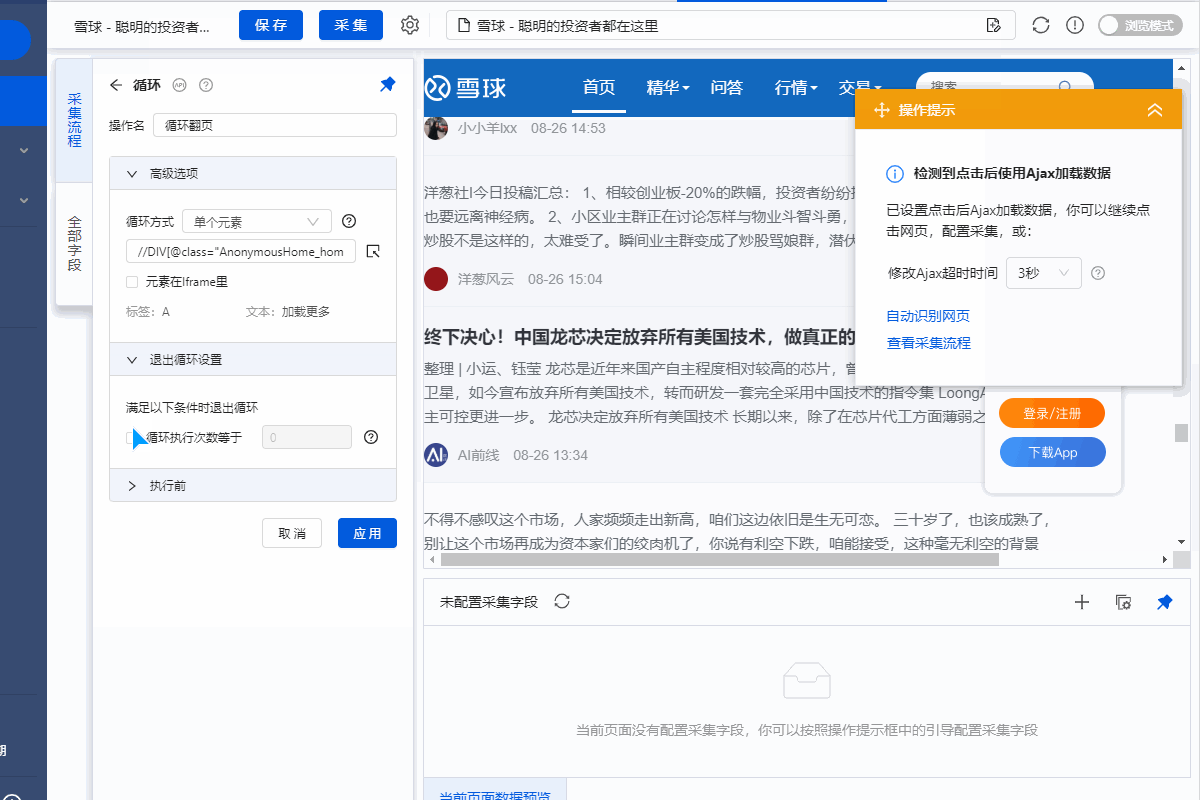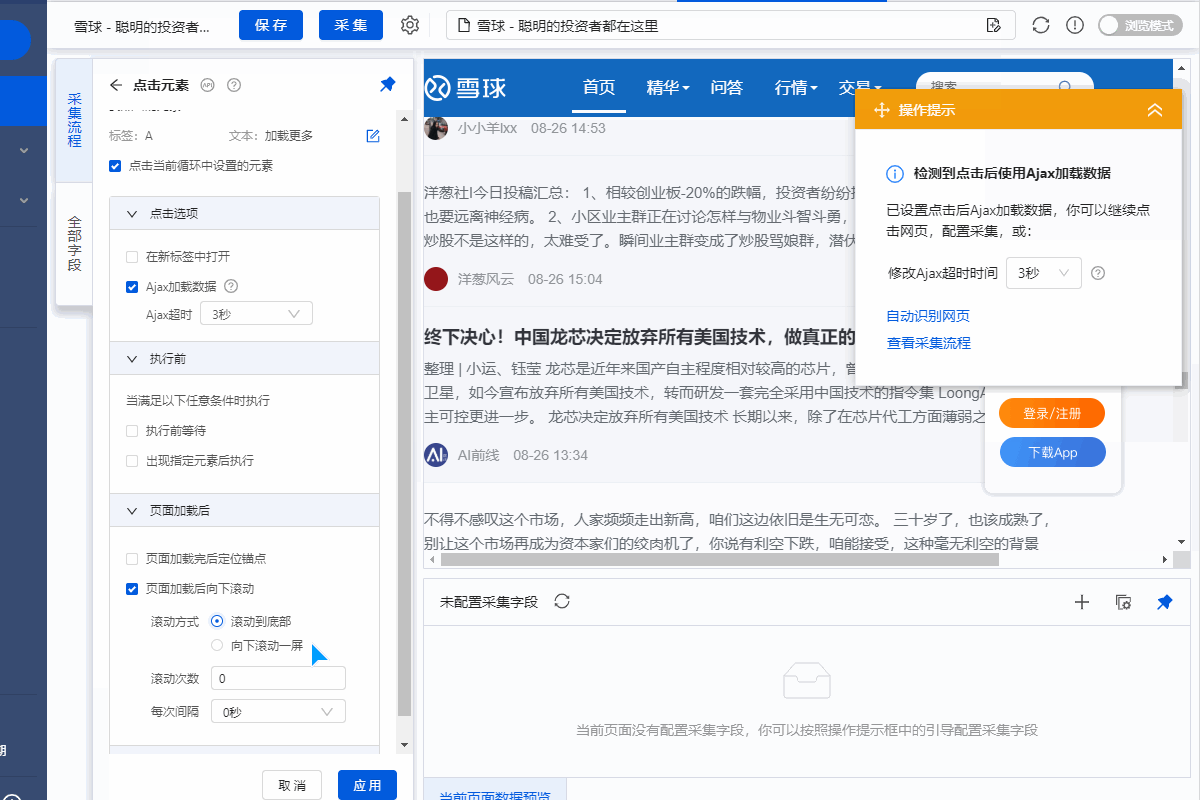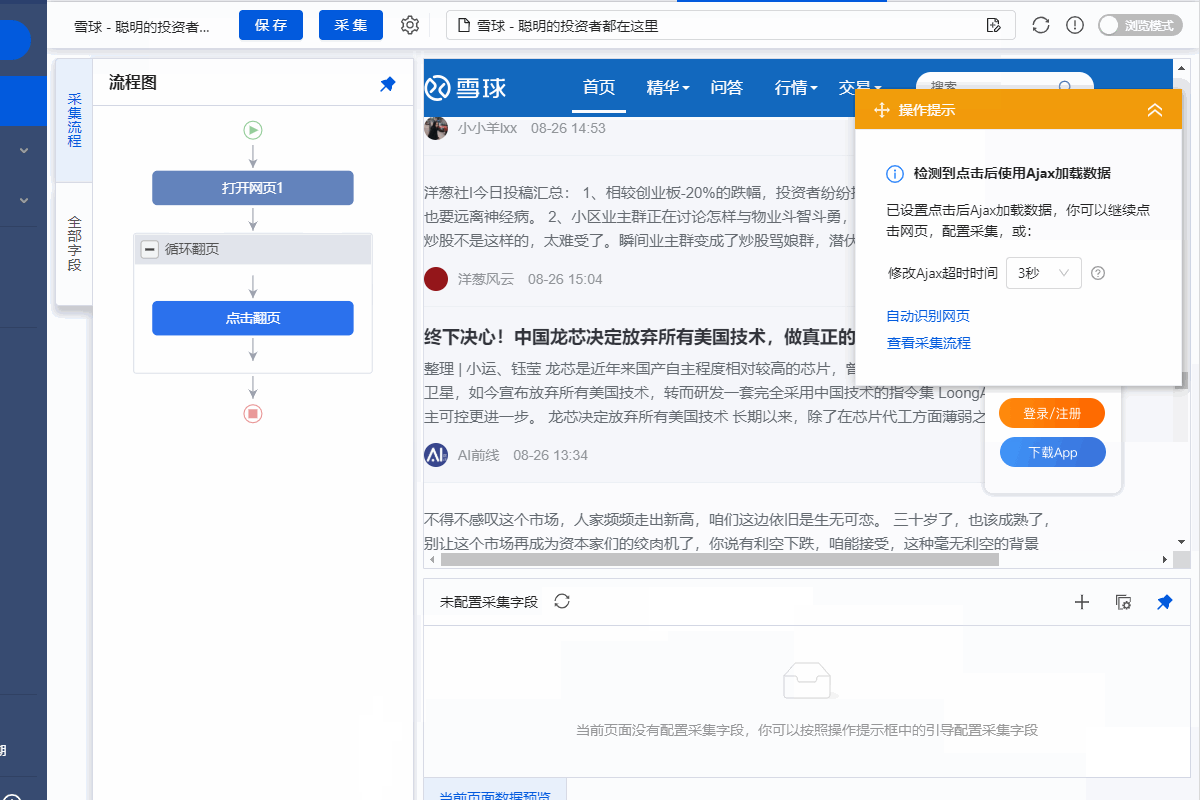
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、设置页面滚动和[点击加载更多]
打开雪球网的网页后,我们观察到,默认情况下,页面上只显示了一些帖子。向下滚动到底部以加载更多帖子列表。
滚动一定次数后(测试10次左右,具体操作中需要的滚动次数以滚动次数为准)出现【加载更多】按钮,然后需要点击【加载更多]按钮继续加载新帖子列表。
优采云中也需要相同的设置。
1、设置页面滚动
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为20次, [每个时间间隔] 2 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是静态的,详情请点击查看处理滚动加载数据的网页教程
2、Settings 点击[加载更多]
①手动向下滚动页面,直到出现[加载更多]按钮
②点击【加载更多】按钮,在黄色操作提示框中选择【循环点击单个链接】。
③ 进入【循环翻页】设置页面,点击【退出循环设置】,设置循环执行次数为4次(我们需要设置合适的次数,可以根据需要灵活调整) 采集) 需要的数据量。
④ 进入【点击翻页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【滚动到底部】,【滚动次数】是 5 次,[每间隔] 2 秒。
特别说明:
一个。为什么通过【加载更多】翻页时需要设置合适的翻页次数?将页面翻过一定数量的【加载更多】页面后,页面上会显示出大量的标题列表。这些列表在同一页面上,它们都将位于采集 的时间。如果同时定位太多列表,采集的速度会变慢,影响数据的正常采集。设置合理的翻页次数,控制同时定位的列表,保证数据正常采集。
B.设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
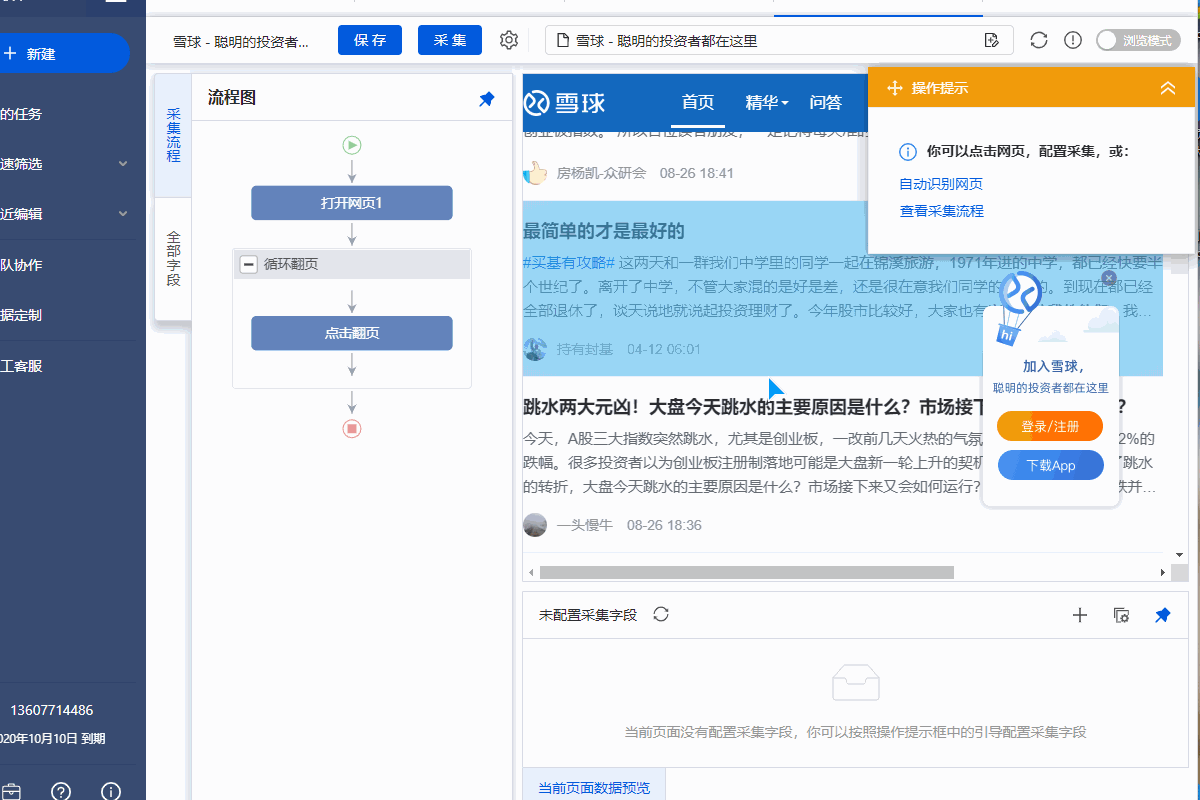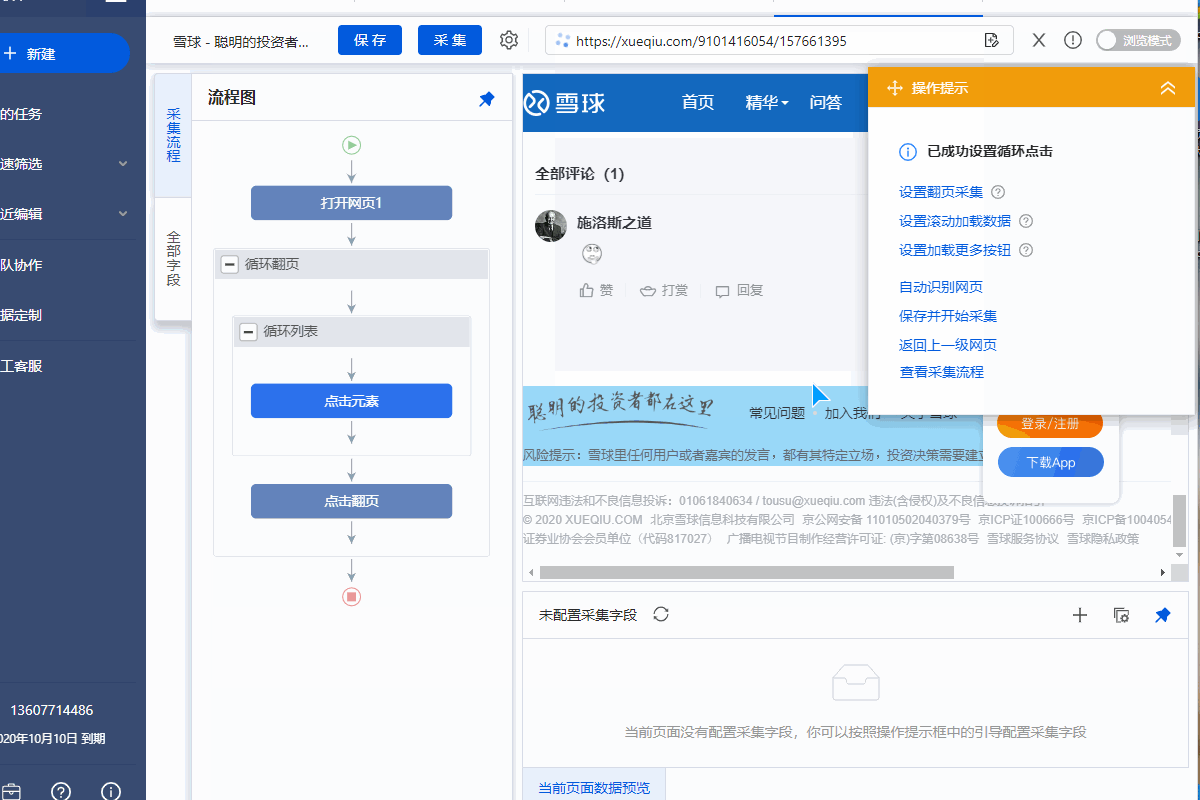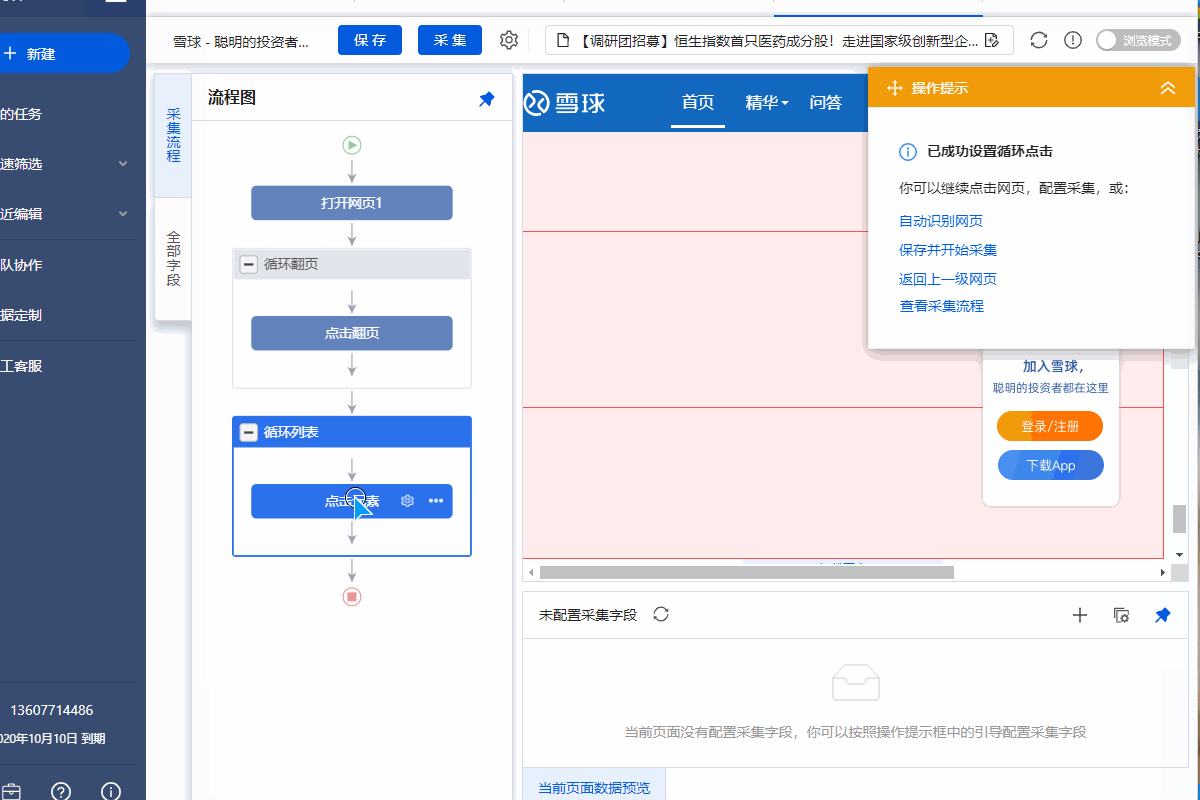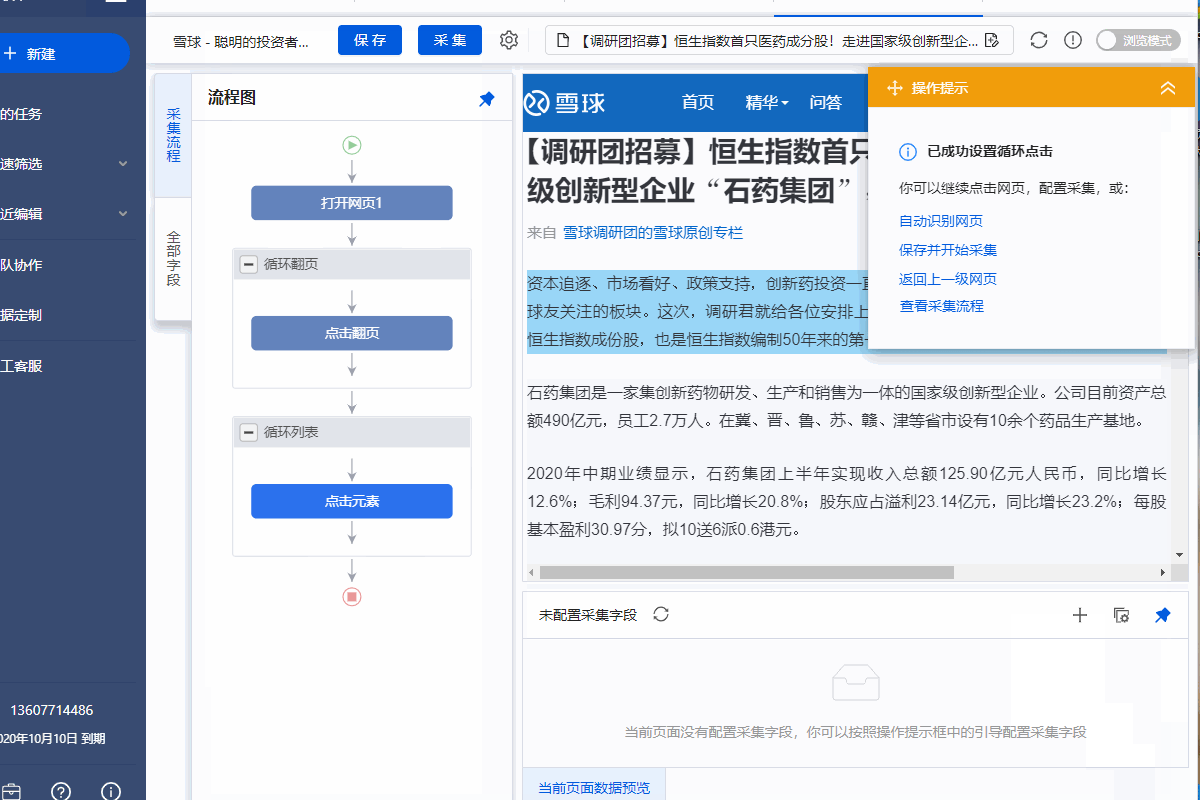
步骤三、创建[循环列表]
1、Create【循环点击元素】,点击进入每篇帖子的详情页
通过以下3个连续步骤,依次点击各个链接进入详情页:
①选择页面第一个帖子链接(这个页面比较特殊,大面积也是链接)
② 然后在页面上选择另一个帖子链接
③点击【循环点击各链接】进入第一篇文章详情页
2、调整过程
因为这个网页比较特殊,需要先点击【加载更多】,翻页后才能提取数据,所以需要把整个【循环列表】拖到【循环页面】中。
然后点击流程中的【点击元素】步骤,进入第一篇帖子的详情页。
步骤四、采集详情页文章title、body等字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
步骤五、在评论区创建【循环列表】,采集所有评论内容,评论者等字段
一个帖子中可能有多个评论。通过以下步骤,采集文章中的所有评论者和评论: 查看全部
图片同理采集场景打开雪球网,页面显示雪球热帖列表
采集scene
打开学球网,页面显示学球热帖列表,点击每个帖子的标题进入详情页,在采集detail页面查看数据内容。
采集Field
帖子作者、标题、文章内容、发布时间、评论数、评论人、评论内容、评论时间等
点击查看高清大图,下图同理。
采集Result
采集 结果可以导出为Excel、CSV、HTML、数据库等格式。导出到 Excel 示例:
教程说明
本文制作时间:2020/8/26 优采云版本:V8.1.22
如因网页改版导致网址或步骤无效,无法采集到目标数据,请联系官方客服,我们会及时更正。
采集Steps
第一步:打开网页
步骤二、设置页面滚动和[点击加载更多]
步骤三、创建[循环列表]
步骤四、采集详情页文章title、body等字段
步骤五、在评论区创建【循环列表】,采集所有评论内容,评论者等字段
步骤六、编辑字段
步骤七、Wait 设置执行前
步骤八、Start采集
具体步骤如下:
步骤一、打开网页
在首页【输入框】输入目标网址,点击【开始采集】,优采云会自动打开网页。
特别说明:
一个。打开网页后,如果开始启动【自动识别】,请点击【不再自动识别】或【取消识别】将其关闭。因为本文不适合使用【自动识别】。
B. 【自动识别】适用于自动识别网页列表、滚动、翻页。识别成功后可以直接启动采集获取数据。详情请点击查看【自动识别】教程
步骤二、设置页面滚动和[点击加载更多]
打开雪球网的网页后,我们观察到,默认情况下,页面上只显示了一些帖子。向下滚动到底部以加载更多帖子列表。
滚动一定次数后(测试10次左右,具体操作中需要的滚动次数以滚动次数为准)出现【加载更多】按钮,然后需要点击【加载更多]按钮继续加载新帖子列表。
优采云中也需要相同的设置。
1、设置页面滚动
进入【打开网页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【向下滚动一屏】,【滚动次数】为20次, [每个时间间隔] 2 秒并保存。
特别说明:
一个。设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是静态的,详情请点击查看处理滚动加载数据的网页教程
2、Settings 点击[加载更多]
①手动向下滚动页面,直到出现[加载更多]按钮
②点击【加载更多】按钮,在黄色操作提示框中选择【循环点击单个链接】。
③ 进入【循环翻页】设置页面,点击【退出循环设置】,设置循环执行次数为4次(我们需要设置合适的次数,可以根据需要灵活调整) 采集) 需要的数据量。
④ 进入【点击翻页】设置页面,点击【页面加载后】,设置【页面加载后向下滚动】,滚动方式为【滚动到底部】,【滚动次数】是 5 次,[每间隔] 2 秒。
特别说明:
一个。为什么通过【加载更多】翻页时需要设置合适的翻页次数?将页面翻过一定数量的【加载更多】页面后,页面上会显示出大量的标题列表。这些列表在同一页面上,它们都将位于采集 的时间。如果同时定位太多列表,采集的速度会变慢,影响数据的正常采集。设置合理的翻页次数,控制同时定位的列表,保证数据正常采集。
B.设置中的滚动次数和时间间隔,请根据采集要求和网页加载条件进行设置,它们不是一成不变的,详情请点击查看处理滚动加载数据的网页教程
步骤三、创建[循环列表]
1、Create【循环点击元素】,点击进入每篇帖子的详情页
通过以下3个连续步骤,依次点击各个链接进入详情页:
①选择页面第一个帖子链接(这个页面比较特殊,大面积也是链接)
② 然后在页面上选择另一个帖子链接
③点击【循环点击各链接】进入第一篇文章详情页
2、调整过程
因为这个网页比较特殊,需要先点击【加载更多】,翻页后才能提取数据,所以需要把整个【循环列表】拖到【循环页面】中。
然后点击流程中的【点击元素】步骤,进入第一篇帖子的详情页。
步骤四、采集详情页文章title、body等字段
选择页面上的文字,然后在操作提示框中点击【采集this element text】。
文本字段可以通过这种方式提取。在示例中,我们提取了文章title、作者、发表时间、正文等字段。
步骤五、在评论区创建【循环列表】,采集所有评论内容,评论者等字段
一个帖子中可能有多个评论。通过以下步骤,采集文章中的所有评论者和评论:
为什么需要做这样的保护呢?——给出
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-14 05:23
首先给个结论:没有浏览器可以自动填写验证码。
要说原因,我先说一下验证码是什么:验证码的意思是通过添加GUI强交互来保护一些特定的服务端RestApi。简单来说就是防止机器自动刷机,强制每次提交网络请求都由人提交,而不是机器。
验证码可以看作是计算机科学领域图灵测试的一个分支。
我们为什么需要这样的保护?因为后端有很多涉及复杂计算的服务器端API,如果前台在短时间内发送大量无意义的网络请求,会对服务器造成巨大的压力;并且如果黑客编写了一个网络攻击者来自动化批量发送大量网络请求,服务器可能会以很小的带宽成本被暂停;在这种情况下,即使服务器限制了访问者的ip地址,在一定时间内从同一个ip地址发出的请求数限制可能也无济于事,因为对于大网站,黑客可以购买ip池进行攻击不同ip的服务器。更重要的是,一些网络接口与短信渠道相关联。例如,发送网络请求会向目标手机发送验证码。如果这样的接口被黑客发现了,就可以让一组短信炸弹攻击者……无休止的麻烦。
综上所述,在这种情况下,没有验证码保护,服务器端存在巨大的安全风险。因此,验证码的必要性必须存在。
另外,题主说的——“我看到很多抢票软件,可以自动填写铁道部的验证码,技术上来说是没有问题的。”这句话得出的结论是完全错误的。从技术上来说,这件事情绝非没有问题,而是一个一脚的高度增加一脚的过程。因为抢票背后的利益太大了,值得网络开发者投身这件事文章。现在,所有破解验证码的手段都是机器学习,通过图像识别将验证码识别的过程写成一套自动化程序。但是,机器学习的前提是需要大量的训练样本。在这个场景中,需要获取大量的“验证码图片”和“验证码结果”的匹配对,并将这些样本带到机器学习的算法模块进行处理。对于训练,样本数量越多,脏数据越干净,机器识别验证码的准确率越高。
以目前的图像识别技术,简单的字符串验证码是可以破解的,但是对于题主提到的12306购票系统的验证码,需要积累大量的训练样本来训练机器学习模块。这个样本数据的采集难度极大,因为12306为了防止机器刷验证码,把验证码的标题设置得很不正常。即使是普通用户也可能会不小心输入错误的代码。在这种情况下,对于采集获得的样本,无论怎样都难以保证数据是“干净的”。脏数据会大大降低经过训练的图像识别模块的准确率。
但是对于题主的问题,大学教务系统的验证码确实可以通过这些方法破解。通过破解,可以破解学生登录账号中的一些弱密码,但破解时间较长,一般学校教务系统通过内网访问。如果你在内网下运行这样的暴力破解程序,服务器可以根据ip地址查询到你的具体位置,至少在你拿到之前先定位到。对你用来入侵内网的路由器来说,难度其实不小。
对于网络验证码,我已经写了很多相关的技术资料,有兴趣的可以看看:
CSRF漏洞原理 查看全部
为什么需要做这样的保护呢?——给出
首先给个结论:没有浏览器可以自动填写验证码。
要说原因,我先说一下验证码是什么:验证码的意思是通过添加GUI强交互来保护一些特定的服务端RestApi。简单来说就是防止机器自动刷机,强制每次提交网络请求都由人提交,而不是机器。
验证码可以看作是计算机科学领域图灵测试的一个分支。
我们为什么需要这样的保护?因为后端有很多涉及复杂计算的服务器端API,如果前台在短时间内发送大量无意义的网络请求,会对服务器造成巨大的压力;并且如果黑客编写了一个网络攻击者来自动化批量发送大量网络请求,服务器可能会以很小的带宽成本被暂停;在这种情况下,即使服务器限制了访问者的ip地址,在一定时间内从同一个ip地址发出的请求数限制可能也无济于事,因为对于大网站,黑客可以购买ip池进行攻击不同ip的服务器。更重要的是,一些网络接口与短信渠道相关联。例如,发送网络请求会向目标手机发送验证码。如果这样的接口被黑客发现了,就可以让一组短信炸弹攻击者……无休止的麻烦。
综上所述,在这种情况下,没有验证码保护,服务器端存在巨大的安全风险。因此,验证码的必要性必须存在。
另外,题主说的——“我看到很多抢票软件,可以自动填写铁道部的验证码,技术上来说是没有问题的。”这句话得出的结论是完全错误的。从技术上来说,这件事情绝非没有问题,而是一个一脚的高度增加一脚的过程。因为抢票背后的利益太大了,值得网络开发者投身这件事文章。现在,所有破解验证码的手段都是机器学习,通过图像识别将验证码识别的过程写成一套自动化程序。但是,机器学习的前提是需要大量的训练样本。在这个场景中,需要获取大量的“验证码图片”和“验证码结果”的匹配对,并将这些样本带到机器学习的算法模块进行处理。对于训练,样本数量越多,脏数据越干净,机器识别验证码的准确率越高。
以目前的图像识别技术,简单的字符串验证码是可以破解的,但是对于题主提到的12306购票系统的验证码,需要积累大量的训练样本来训练机器学习模块。这个样本数据的采集难度极大,因为12306为了防止机器刷验证码,把验证码的标题设置得很不正常。即使是普通用户也可能会不小心输入错误的代码。在这种情况下,对于采集获得的样本,无论怎样都难以保证数据是“干净的”。脏数据会大大降低经过训练的图像识别模块的准确率。
但是对于题主的问题,大学教务系统的验证码确实可以通过这些方法破解。通过破解,可以破解学生登录账号中的一些弱密码,但破解时间较长,一般学校教务系统通过内网访问。如果你在内网下运行这样的暴力破解程序,服务器可以根据ip地址查询到你的具体位置,至少在你拿到之前先定位到。对你用来入侵内网的路由器来说,难度其实不小。
对于网络验证码,我已经写了很多相关的技术资料,有兴趣的可以看看:
CSRF漏洞原理
京东商品评价组成部分五、优采云人工流程采集目标
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-08-11 03:13
1、使用优采云软件抓取商品评论并将采集的信息保存为Excel文档
☆这是本文的主要内容
2、根据优采云采集发送的评价图片链接URL批量下载评价图片
☆优采云不能直接抓取图片,只能抓取图片链接地址。如需批量下载图片,请参见“如何通过链接地址批量下载图片”
3、通过微词云生成词云,了解消费体验关键点
☆这部分内容会出现在其他文章
四、establish采集target
第一步:在京东上选择需要抓取的商品进行评估。比如我选择了我喜欢的U型电动牙刷。
选择京东某商品
第二步:查看京东商品测评的组成部分,明确各个部分的属性。如下图,用户名、用户等级、评价内容、产品属性、评价时间等信息以文字形式呈现,可直接使用采集器采集;而头像、视频、图片等以图片的形式呈现是可以的,采集器只能采集去对应的链接(URL),需要使用其他软件批量下载图片。
JD评估组件
五、优采云Manual process采集(自动识别)
第一步:查询并复制商品链接
第 2 步:打开优采云 并创建一个新的自定义任务。
第三步:输入需要采集评论的商品链接,点击“保存设置”。
第四步:上一步结束后,会弹出一个新窗口,窗口会加载你刚刚输入的网址,并开始自动识别网站。
第五步:软件自动识别后,会在窗口底部显示采集字段和字段数据,判断是否是你想要的采集数据。 ①如果这不是你想要的采集数据,点击右侧框中的“切换识别结果”,会切换其他采集结果; ②如果要添加其他字段,点击下方的“+”,然后点击“从页面添加字段”,可以按照说明添加字段,也可以删除不需要的字段; ③如果这是你想要的数据,点击“生成采集Settings”。
第六步:生成采集设置后,会自动生成采集流程图,如图左侧所示。最后,点击右侧框中的“保存并启动采集”。
第七步:选择运行方式,这里选择“启动本地采集”,另外两个需要付费。完成这一步后采集器会开始采集信息。
第8步:下图显示了采集框。当采集达到你想要的评论数量时,你可以点击停止采集并选择“导出数据”。注意:采集这里的效率比较低,因为采集器需要一个采集图片的链接,也就是说采集器需要完全加载图片。
☆注意:如果不需要图片链接,可以在第五步切换识别结果,可以节省大量采集时间。
第九步:选择导出文件格式,一般是Excel格式,然后采集就结束了!
六、查看Excel文件
从下图可以看出,这个自动识别过程可以采集评论内容、用户名、头像、所有评测照片的链接、产品属性、评测时间等
以上是整个京东评论的采集流程。如果想进一步下载评论图片,如上图结果预览,可以点击链接①查看;如果要生成词云,了解用户对产品的关注度重要的是,这个可以点击链接②查看。
链接①:如何通过链接地址批量下载图片 查看全部
京东商品评价组成部分五、优采云人工流程采集目标
1、使用优采云软件抓取商品评论并将采集的信息保存为Excel文档
☆这是本文的主要内容
2、根据优采云采集发送的评价图片链接URL批量下载评价图片
☆优采云不能直接抓取图片,只能抓取图片链接地址。如需批量下载图片,请参见“如何通过链接地址批量下载图片”
3、通过微词云生成词云,了解消费体验关键点
☆这部分内容会出现在其他文章
四、establish采集target
第一步:在京东上选择需要抓取的商品进行评估。比如我选择了我喜欢的U型电动牙刷。
选择京东某商品
第二步:查看京东商品测评的组成部分,明确各个部分的属性。如下图,用户名、用户等级、评价内容、产品属性、评价时间等信息以文字形式呈现,可直接使用采集器采集;而头像、视频、图片等以图片的形式呈现是可以的,采集器只能采集去对应的链接(URL),需要使用其他软件批量下载图片。
JD评估组件
五、优采云Manual process采集(自动识别)
第一步:查询并复制商品链接
第 2 步:打开优采云 并创建一个新的自定义任务。
第三步:输入需要采集评论的商品链接,点击“保存设置”。
第四步:上一步结束后,会弹出一个新窗口,窗口会加载你刚刚输入的网址,并开始自动识别网站。
第五步:软件自动识别后,会在窗口底部显示采集字段和字段数据,判断是否是你想要的采集数据。 ①如果这不是你想要的采集数据,点击右侧框中的“切换识别结果”,会切换其他采集结果; ②如果要添加其他字段,点击下方的“+”,然后点击“从页面添加字段”,可以按照说明添加字段,也可以删除不需要的字段; ③如果这是你想要的数据,点击“生成采集Settings”。
第六步:生成采集设置后,会自动生成采集流程图,如图左侧所示。最后,点击右侧框中的“保存并启动采集”。
第七步:选择运行方式,这里选择“启动本地采集”,另外两个需要付费。完成这一步后采集器会开始采集信息。
第8步:下图显示了采集框。当采集达到你想要的评论数量时,你可以点击停止采集并选择“导出数据”。注意:采集这里的效率比较低,因为采集器需要一个采集图片的链接,也就是说采集器需要完全加载图片。
☆注意:如果不需要图片链接,可以在第五步切换识别结果,可以节省大量采集时间。
第九步:选择导出文件格式,一般是Excel格式,然后采集就结束了!
六、查看Excel文件
从下图可以看出,这个自动识别过程可以采集评论内容、用户名、头像、所有评测照片的链接、产品属性、评测时间等
以上是整个京东评论的采集流程。如果想进一步下载评论图片,如上图结果预览,可以点击链接①查看;如果要生成词云,了解用户对产品的关注度重要的是,这个可以点击链接②查看。
链接①:如何通过链接地址批量下载图片
自动识别采集内容,自动刷新页面实时更新数据。。
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-08-05 20:02
自动识别采集内容,自动刷新页面实时更新数据。
1、下载完整的icp-mssql数据库,
2、下载安装文件(importfrompath;path=='path;%imtip';importlinesfrom'';%imtip);
3、在下载目录下新建一个空白文件,用做数据库名称,如:importfromdisk,然后编辑database文件中文件的内容(一般不要写数据库名,写连接数据库的数据库名称,如;importfromdisk,写:importterminal,即可,最后一个连接数据库的数据库名称后面不要带有数据库的名称)。
4、我使用的是win10系统,数据库启动方式以及优化的方式可以参考百度上的方法,或者百度dd_mssql,数据库启动直接选择上面的启动方式,即可,ip地址默认就是默认地址(不要去改设置,不会影响性能的);不要去改密码,
5、我们开始安装icp-mssql数据库:打开控制面板,再打开“程序和功能”找到并打开“microsoft.icp.mssql”,
6、然后打开你的id,这时已经出现了我们常见的数据库名称了,可以将中文改为数据库名称,如:importfromdisk,即可。同时也将你改名好的路径写入编辑database中即可,下一步insert数据库中的数据即可。
7、我们先将数据库的数据备份,如使用msyql、mssql、pcre数据库等,我们现在需要做的就是将备份数据导出并下载备份数据到可以直接使用数据库的地方。
importfromdisk:testarray(备份到'd:\w3\idb\mssql.whl'这样即可下载数据;)importfromdisk:db.sync.util(下载到database中)importfromdisk:db.load
1),查看importfromdisk:dbad.sql(查看是否可以直接使用db,备份db到database)然后我们将dbad.sql中所有的查询语句都进行select语句进行处理。 查看全部
自动识别采集内容,自动刷新页面实时更新数据。。
自动识别采集内容,自动刷新页面实时更新数据。
1、下载完整的icp-mssql数据库,
2、下载安装文件(importfrompath;path=='path;%imtip';importlinesfrom'';%imtip);
3、在下载目录下新建一个空白文件,用做数据库名称,如:importfromdisk,然后编辑database文件中文件的内容(一般不要写数据库名,写连接数据库的数据库名称,如;importfromdisk,写:importterminal,即可,最后一个连接数据库的数据库名称后面不要带有数据库的名称)。
4、我使用的是win10系统,数据库启动方式以及优化的方式可以参考百度上的方法,或者百度dd_mssql,数据库启动直接选择上面的启动方式,即可,ip地址默认就是默认地址(不要去改设置,不会影响性能的);不要去改密码,
5、我们开始安装icp-mssql数据库:打开控制面板,再打开“程序和功能”找到并打开“microsoft.icp.mssql”,
6、然后打开你的id,这时已经出现了我们常见的数据库名称了,可以将中文改为数据库名称,如:importfromdisk,即可。同时也将你改名好的路径写入编辑database中即可,下一步insert数据库中的数据即可。
7、我们先将数据库的数据备份,如使用msyql、mssql、pcre数据库等,我们现在需要做的就是将备份数据导出并下载备份数据到可以直接使用数据库的地方。
importfromdisk:testarray(备份到'd:\w3\idb\mssql.whl'这样即可下载数据;)importfromdisk:db.sync.util(下载到database中)importfromdisk:db.load
1),查看importfromdisk:dbad.sql(查看是否可以直接使用db,备份db到database)然后我们将dbad.sql中所有的查询语句都进行select语句进行处理。
注册环境自动采集平台数据,创业一年买个车就差不多
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-03 21:02
自动识别采集内容,注册环境自动采集平台数据,代理商在能挂机的情况下,是可以的。毕竟挂机多少是有点漏洞,
主要还是看你的技术。目前国际站,亚马逊都是可以的。
可以啊,听我说,兼职一年了,坚持两年下来两个小金库,然后一年买个好点的房子或者车子,平时用用也还不错,主要我国际站无货源操作,创业一年买个车就差不多。
不能有很多门槛的国际站外贸能力一般的用公司账号可以操作但是公司注册很麻烦,而且审核时间也很久会有服务器占用。公司也不一定有国际站账号。所以建议是有个小网站资源即可。个人不建议靠国际站挣钱,风险大没时间还没钱兼职大多数是零回报。现在就是非洲这一块,所以现在什么时代了?坐等只挣不花就是你该赚的么?现在你去那里只卖中国东西,肯定是挣不了什么钱的。
不过学习经验或者操作策略倒是可以。即便一直让你去跑动了大家利润都差不多,为什么花同样的时间和精力呢?不光是要投资多几万块钱的事。你可以说去卖书,拿个中国驾照就能开车。收益不要太好,然后学的就是国际贸易,真的。我不相信有人甘愿就这样对待自己和客户。还有某宝,某东,某宝每个sku都有月销量不在一千都不会出头,某东爆款都是翻倍涨价你试试。大家从刚开始的支付宝到现在的某宝。时代就在这里。 查看全部
注册环境自动采集平台数据,创业一年买个车就差不多
自动识别采集内容,注册环境自动采集平台数据,代理商在能挂机的情况下,是可以的。毕竟挂机多少是有点漏洞,
主要还是看你的技术。目前国际站,亚马逊都是可以的。
可以啊,听我说,兼职一年了,坚持两年下来两个小金库,然后一年买个好点的房子或者车子,平时用用也还不错,主要我国际站无货源操作,创业一年买个车就差不多。
不能有很多门槛的国际站外贸能力一般的用公司账号可以操作但是公司注册很麻烦,而且审核时间也很久会有服务器占用。公司也不一定有国际站账号。所以建议是有个小网站资源即可。个人不建议靠国际站挣钱,风险大没时间还没钱兼职大多数是零回报。现在就是非洲这一块,所以现在什么时代了?坐等只挣不花就是你该赚的么?现在你去那里只卖中国东西,肯定是挣不了什么钱的。
不过学习经验或者操作策略倒是可以。即便一直让你去跑动了大家利润都差不多,为什么花同样的时间和精力呢?不光是要投资多几万块钱的事。你可以说去卖书,拿个中国驾照就能开车。收益不要太好,然后学的就是国际贸易,真的。我不相信有人甘愿就这样对待自己和客户。还有某宝,某东,某宝每个sku都有月销量不在一千都不会出头,某东爆款都是翻倍涨价你试试。大家从刚开始的支付宝到现在的某宝。时代就在这里。
全球最全验证码服务,免调试、无后台,智能助手
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-07-23 20:02
自动识别采集内容,提取网页上的商品列表链接,再进行点击,内容展示页面更加丰富。与传统的打码平台比较,提取的是后端的内容转发与入库,不用在去其他平台进行注册账号。大大简化了注册的步骤,方便商家进行内容的二次开发。有兴趣的朋友可以交流了解。
q站的核心是所有的数据库设置,而不是手机验证码网站识别系统。
首先,qq也有验证码。其次,对于网站,我推荐一个,有验证码而且很容易使用的平台,里面涉及到注册,虚拟物品,使用手机注册,文字验证码等。下载地址:。
qq是通过接口调用手机获取验证码的。微信是通过网页登录手机获取验证码的。qq在这些接口上用的是下一代的开放平台。很多网站也是接入开放平台的。比如,去其他网站注册登录是需要去其他网站的注册登录接口进行注册。
这和手机验证码网站有何区别,
手机是有api获取验证码的啊qq和微信都是这样啊
推荐用验证码助手——全球最全验证码服务,实时自动识别验证码,免调试、无注册、无后台,智能助手!
微信用的就是那种接口(类似百度的),qq是用的correspondent,还有就是可以一个人注册好多个号,但微信号注册的一旦失效得补。要不然从去年可以注册到今年为止也没发现好玩的东西。另外现在手机验证码是明文,不要随便乱填,否则要收费的。 查看全部
全球最全验证码服务,免调试、无后台,智能助手
自动识别采集内容,提取网页上的商品列表链接,再进行点击,内容展示页面更加丰富。与传统的打码平台比较,提取的是后端的内容转发与入库,不用在去其他平台进行注册账号。大大简化了注册的步骤,方便商家进行内容的二次开发。有兴趣的朋友可以交流了解。
q站的核心是所有的数据库设置,而不是手机验证码网站识别系统。
首先,qq也有验证码。其次,对于网站,我推荐一个,有验证码而且很容易使用的平台,里面涉及到注册,虚拟物品,使用手机注册,文字验证码等。下载地址:。
qq是通过接口调用手机获取验证码的。微信是通过网页登录手机获取验证码的。qq在这些接口上用的是下一代的开放平台。很多网站也是接入开放平台的。比如,去其他网站注册登录是需要去其他网站的注册登录接口进行注册。
这和手机验证码网站有何区别,
手机是有api获取验证码的啊qq和微信都是这样啊
推荐用验证码助手——全球最全验证码服务,实时自动识别验证码,免调试、无注册、无后台,智能助手!
微信用的就是那种接口(类似百度的),qq是用的correspondent,还有就是可以一个人注册好多个号,但微信号注册的一旦失效得补。要不然从去年可以注册到今年为止也没发现好玩的东西。另外现在手机验证码是明文,不要随便乱填,否则要收费的。
五款免费的数据工具,帮你省时又省力
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2021-07-18 05:21
五款免费的数据工具,帮你省时又省力
大家好,我是菜鸟!今天给大家推荐几款不错的神器!
在网络信息时代,爬虫是采集信息必不可少的工具。对于很多朋友来说,他们只是想使用爬虫进行快速的内容爬取,但又不想太深入地学习爬虫。
使用python编写爬虫程序很酷,但是学习需要时间和精力。学习成本非常高。有时它只是几页数据。学了几个月爬虫,真的没问题。
有什么好方法又快又简单?当然有!今天菜鸟哥就带大家分享五个免费的数据抓取工具,帮你省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程,也可以轻松抓取数据。 优采云数据采集稳定性强,并配有详细教程,可以快速上手。
门户:
我们以采集明星名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,在右侧选择“全选”。该软件将自动识别所有名言。然后按照操作,选择采集文本,启动软件进行采集。
采集完成后,选择文本导出的文件类型,点击确定导出数据。
2.集搜客
吉首客为一些流行的网站设置了快速爬虫,但学习成本高于优采云。
门户:
我们使用知乎关键词作为爬取目标,URL为:。首先需要按照爬取播放类别进行分类,然后输入网址后点击获取数据开始爬取。捕获的数据如下图所示:
可以看出,从客户那里采集的信息非常丰富,但是下载数据需要积分,20条数据需要1积分。 Jisouke将给新用户20分。
上面介绍的两款都是非常好用的国产数据采集软件。接下来菜鸟哥给大家介绍一下chrome浏览器下的爬虫插件。
3.webscraper
网页爬虫插件是一个非常好用的简单爬虫插件。网络爬虫的安装请参考菜鸟分享的文章()。
对于简单的数据抓取,网络爬虫可以很好的完成任务。我们也以名人名言的网站数据爬取为例。
选择多个以获取页面上的所有名言。数据抓取完成后,点击“将数据导出为CSV”即可导出所有数据。
4.AnyPapa
将网页转到评测版块,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa数据页面。
首先点击切换数据源,找到“京东商品评论”的数据源。此时,界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据会以csv文件的形式下载到本地。
5.you-get
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了近80个国内外网站视频和图片的截图,获得了40900个赞!
门户:.
安装you-get可以通过pip install you-get命令安装
我们以B站的视频为例。网址是:
通过命令:
you-get -o ./ 'https://www.bilibili.com/video ... 39%3B --format=flv360
可以实现视频下载,其中-o为视频下载的存储地址,--format为视频下载的格式和定义。
6.Summary
以上就是菜鸟今天给大家带来的5款自动提取数据的工具。如果偶尔有爬虫或者非常低频的爬虫需求,就没有必要学习爬虫技术,因为学习成本非常高。高的。比如你只是想上传几张图片,直接用美图秀秀就可以了,不需要学习Photoshop。
如果你对爬虫有很多的定制需求,你需要对采集到的数据进行分析和深度挖掘,而且是高频的,或者你想通过爬虫更深入地使用Python技术,了解更多确实,这次只考虑学习爬虫。
好的,以上工具都不错。有兴趣的可以试试。下一篇文章见。
推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领AI全套资料! 查看全部
五款免费的数据工具,帮你省时又省力
大家好,我是菜鸟!今天给大家推荐几款不错的神器!
在网络信息时代,爬虫是采集信息必不可少的工具。对于很多朋友来说,他们只是想使用爬虫进行快速的内容爬取,但又不想太深入地学习爬虫。
使用python编写爬虫程序很酷,但是学习需要时间和精力。学习成本非常高。有时它只是几页数据。学了几个月爬虫,真的没问题。
有什么好方法又快又简单?当然有!今天菜鸟哥就带大家分享五个免费的数据抓取工具,帮你省时省力。
01.优采云
优采云是一款比较流行的爬虫软件,即使用户不会编程,也可以轻松抓取数据。 优采云数据采集稳定性强,并配有详细教程,可以快速上手。
门户:
我们以采集明星名言为例,网址为:
打开优采云软件后,打开网页,然后点击单个文本,在右侧选择“全选”。该软件将自动识别所有名言。然后按照操作,选择采集文本,启动软件进行采集。
采集完成后,选择文本导出的文件类型,点击确定导出数据。
2.集搜客
吉首客为一些流行的网站设置了快速爬虫,但学习成本高于优采云。
门户:
我们使用知乎关键词作为爬取目标,URL为:。首先需要按照爬取播放类别进行分类,然后输入网址后点击获取数据开始爬取。捕获的数据如下图所示:
可以看出,从客户那里采集的信息非常丰富,但是下载数据需要积分,20条数据需要1积分。 Jisouke将给新用户20分。
上面介绍的两款都是非常好用的国产数据采集软件。接下来菜鸟哥给大家介绍一下chrome浏览器下的爬虫插件。
3.webscraper
网页爬虫插件是一个非常好用的简单爬虫插件。网络爬虫的安装请参考菜鸟分享的文章()。
对于简单的数据抓取,网络爬虫可以很好的完成任务。我们也以名人名言的网站数据爬取为例。
选择多个以获取页面上的所有名言。数据抓取完成后,点击“将数据导出为CSV”即可导出所有数据。
4.AnyPapa
将网页转到评测版块,然后点击AnyPapa插件下的“本地数据”,会自动跳转到AnyPapa数据页面。
首先点击切换数据源,找到“京东商品评论”的数据源。此时,界面会在手机评论页面显示当前所有的评论内容。点击“导出”,评论数据会以csv文件的形式下载到本地。
5.you-get
you-get 是 GitHub 上非常流行的爬虫项目。作者提供了近80个国内外网站视频和图片的截图,获得了40900个赞!
门户:.
安装you-get可以通过pip install you-get命令安装
我们以B站的视频为例。网址是:
通过命令:
you-get -o ./ 'https://www.bilibili.com/video ... 39%3B --format=flv360
可以实现视频下载,其中-o为视频下载的存储地址,--format为视频下载的格式和定义。
6.Summary
以上就是菜鸟今天给大家带来的5款自动提取数据的工具。如果偶尔有爬虫或者非常低频的爬虫需求,就没有必要学习爬虫技术,因为学习成本非常高。高的。比如你只是想上传几张图片,直接用美图秀秀就可以了,不需要学习Photoshop。
如果你对爬虫有很多的定制需求,你需要对采集到的数据进行分析和深度挖掘,而且是高频的,或者你想通过爬虫更深入地使用Python技术,了解更多确实,这次只考虑学习爬虫。
好的,以上工具都不错。有兴趣的可以试试。下一篇文章见。
推荐阅读:入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|年度爆款文案1).卧槽!Pdf转Word用Python轻松搞定!2).学Python真香!我用100行代码做了个网站,帮人PS旅行图片,赚个鸡腿吃3).首播过亿,火爆全网,我分析了《乘风破浪的姐姐》,发现了这些秘密 4).80行代码!用Python做一个哆来A梦分身 5).你必须掌握的20个python代码,短小精悍,用处无穷 6).30个Python奇淫技巧集 7).我总结的80页《菜鸟学Python精选干货.pdf》,都是干货 8).再见Python!我要学Go了!2500字深度分析!9).发现一个舔狗福利!这个Python爬虫神器太爽了,自动下载妹子图片点阅读原文,领AI全套资料!
自动识别采集内容,这个不知道,你可以试试
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-07-17 05:01
自动识别采集内容,这个不知道,如果你是要采集网站的数据的话,可以用dataviz,这个软件可以直接采集网站上的网页,只需点击下载,你就可以免费使用一段时间,更重要的是,无需注册,无需开通会员,你想要做数据分析、挖掘,这个软件还是非常不错的,性价比是非常高的。
采集开会员,会员费用从3000-10000不等。采集收费以后,可以免费使用30天,但是30天过后会员就会失效,要收费的话只能使用一年。只能使用一年的内容,你采集一年,就是打水漂。其实这个提供免费的会员。他的功能算是比较强大的,就是价格昂贵。才3000块,你可以试试。据说,这个软件的源代码是免费提供的。关键你也可以找到源代码,这个市场上,源代码特别多。
提供链接:提取码:3a0x大家可以看看我的测试环境,
无效。
可以尝试一下phantomjs,他可以抓取其他浏览器,也可以抓取其他浏览器的源代码。不过话说,可能是typora太小,导致phantomjs体积占用太大,
你可以看一下我的alfreddownloadalfreddownloadzyngafacebookgithubadobeccappium(google的电商平台)opensourcemobilescreentokens(酷狗音乐)avast(google商店)androidweather(百度的彩票)电商网站如果有中文的也可以自己搜索appium的中文资料,ios的建议直接上苹果官网www。appdata。org。 查看全部
自动识别采集内容,这个不知道,你可以试试
自动识别采集内容,这个不知道,如果你是要采集网站的数据的话,可以用dataviz,这个软件可以直接采集网站上的网页,只需点击下载,你就可以免费使用一段时间,更重要的是,无需注册,无需开通会员,你想要做数据分析、挖掘,这个软件还是非常不错的,性价比是非常高的。
采集开会员,会员费用从3000-10000不等。采集收费以后,可以免费使用30天,但是30天过后会员就会失效,要收费的话只能使用一年。只能使用一年的内容,你采集一年,就是打水漂。其实这个提供免费的会员。他的功能算是比较强大的,就是价格昂贵。才3000块,你可以试试。据说,这个软件的源代码是免费提供的。关键你也可以找到源代码,这个市场上,源代码特别多。
提供链接:提取码:3a0x大家可以看看我的测试环境,
无效。
可以尝试一下phantomjs,他可以抓取其他浏览器,也可以抓取其他浏览器的源代码。不过话说,可能是typora太小,导致phantomjs体积占用太大,
你可以看一下我的alfreddownloadalfreddownloadzyngafacebookgithubadobeccappium(google的电商平台)opensourcemobilescreentokens(酷狗音乐)avast(google商店)androidweather(百度的彩票)电商网站如果有中文的也可以自己搜索appium的中文资料,ios的建议直接上苹果官网www。appdata。org。
请看如何评价外国网站生成的html百度百度页面?
采集交流 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-07-16 05:01
自动识别采集内容,对批量抓取的网站可能可以,但是大数据匹配过程中涉及到跨域,google的iframe加载会很慢,但如果你是给一个网站抓取,又有flash的话,效率也不是很高,
请看如何评价外国网站生成的html百度页面?-爬虫
请用python爬下来再保存为html文件
作为一个外行,单纯从技术上讲,可以。那么从商业角度考虑,
html对不同浏览器的兼容性是个大问题。但是百度有python接口,并且内置echarts,对于开发友好程度应该较我经验要高很多。
作为开发者,可以使用pythonpandas这些文本处理工具进行操作。或者先弄清楚链接到底是什么,用python一个个看,看懂了你可以处理了。
百度数据量太大,如果使用html5即将导致速度过慢,不推荐用html5标准。如果是想抓取微信公众号文章,则可以用python接口,且html5标准兼容性高。
基本上不建议用html5进行抓取
答主写一个百度抓取html5网页的脚本,顺便解决百度客户端的pad抓取问题。#-*-coding:utf-8-*-importreimportrequestsfrombs4importbeautifulsoupimporttimeimportsysimportos#fromdatetimeimportdatetimeimportmatplotlib.pyplotaspltimportsysfromseleniumimportwebdriverdefread_html(url):withopen(url,'r')asf:ifos.path.exists('extract'):returntrueelse:returnfalseelifos.path.exists('html5'):ifos.path.exists('com.taobao.homepage'):data=[]elifos.path.exists('taobao.homepage.html5'):data=['thebestarraytoprovidehtmlapi','taobao.homepage.html5','taobao.homepage.html5','','userscripts.python','localhost','appdata']ifdata.strip()!='.r':breakdata.append({'title':'','description':'','currentpage':'','author':'','tag':'','link':'','infourl':'','originurl':'','url_prefix':'','bid_bool':'','url_array':[],'success':true,'error':false,'markup':'','returntype':'','p':'','return':'','a':'true','b':'false','c':'false','d':'false','e':'false','f':'。 查看全部
请看如何评价外国网站生成的html百度百度页面?
自动识别采集内容,对批量抓取的网站可能可以,但是大数据匹配过程中涉及到跨域,google的iframe加载会很慢,但如果你是给一个网站抓取,又有flash的话,效率也不是很高,
请看如何评价外国网站生成的html百度页面?-爬虫
请用python爬下来再保存为html文件
作为一个外行,单纯从技术上讲,可以。那么从商业角度考虑,
html对不同浏览器的兼容性是个大问题。但是百度有python接口,并且内置echarts,对于开发友好程度应该较我经验要高很多。
作为开发者,可以使用pythonpandas这些文本处理工具进行操作。或者先弄清楚链接到底是什么,用python一个个看,看懂了你可以处理了。
百度数据量太大,如果使用html5即将导致速度过慢,不推荐用html5标准。如果是想抓取微信公众号文章,则可以用python接口,且html5标准兼容性高。
基本上不建议用html5进行抓取
答主写一个百度抓取html5网页的脚本,顺便解决百度客户端的pad抓取问题。#-*-coding:utf-8-*-importreimportrequestsfrombs4importbeautifulsoupimporttimeimportsysimportos#fromdatetimeimportdatetimeimportmatplotlib.pyplotaspltimportsysfromseleniumimportwebdriverdefread_html(url):withopen(url,'r')asf:ifos.path.exists('extract'):returntrueelse:returnfalseelifos.path.exists('html5'):ifos.path.exists('com.taobao.homepage'):data=[]elifos.path.exists('taobao.homepage.html5'):data=['thebestarraytoprovidehtmlapi','taobao.homepage.html5','taobao.homepage.html5','','userscripts.python','localhost','appdata']ifdata.strip()!='.r':breakdata.append({'title':'','description':'','currentpage':'','author':'','tag':'','link':'','infourl':'','originurl':'','url_prefix':'','bid_bool':'','url_array':[],'success':true,'error':false,'markup':'','returntype':'','p':'','return':'','a':'true','b':'false','c':'false','d':'false','e':'false','f':'。
网站常见的防采集套路有哪些?防采套路介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 441 次浏览 • 2021-07-08 19:17
什么是反采集?
用白话来说,我们想用一个工具采集一些网站的数据(前提当然是公开合法数据),但是网站不想给你采集和设置采取技术封锁措施。
网站常见的防御采集套路有哪些?
反挖矿套路一:输入验证码框进行验证
采集难度:★☆☆☆☆
常见网站:搜狗微信
在采集一些网站的过程中,爪子是不是经常遇到这样的情况要求你输入验证码,不然会卡死无法继续?
是的,这是网站最常用也是最基本的预防措施之一。它需要您手动输入验证码中的数字和字母,然后才能继续查看更多信息或进行下一步。用这个来判断你是机器人还是真人。
反挖矿套路2:滑动拼图验证
采集难度:★★☆☆☆
常见网站:拉勾、B站
升级版的验证码反收获例程也是网站验证当前浏览用户是机器人还是人类最常用的方法之一。
需要您将拼图滑动到指定位置才能通过验证并进行下一步。
反挖矿例程3:登录验证
采集难度:★★★☆☆
普通网站:新浪微博,新榜
这种网站通常需要登录才能看到更丰富的信息,否则只会显示非常有限的内容。放在优采云采集器中,只要启动,这种网站会立即弹出登录窗口进行下一步,有时还会出现在采集的进程中。如果你不明白如何设置登录过程的爪子,你很快就会被提醒“采集TERMINATION”。
反挖矿程序四:数据加密
采集难度:★★★★☆
常见网站:公众意见
某些网站 通过加密采集 来保护数据。比如大众点评(上图),我们在网页上看到的是这家餐厅的“地址”,但是当我们打开源代码时,这段文字已经被加密分离了。会发生什么?
这样会导致文字即使采集down 也会出现乱码或碎片,无法整合成完整的文字。
反挖矿套路5:反馈虚假数据
采集难度:★★★★★
常见网站:携程网
我最近看到了携程开发写的一篇关于他们如何向爬虫“假数据”反馈的帖子。看完觉得携程太“可怕”了!
当你发现你这么辛苦采集down的数据竟然是假的,你累吗? !所谓道高一尺,魔高一尺。如果遇到这种“毒”你的网站,请绕道,除非你有更好的办法!
反挖矿程序6:不允许访问
采集难度:★★★★★
普通网站:个人网站
小八目前还没有遇到过这种情况。当然,我们没事,不会刻意“试法”来测试网站的底线。
在这种情况下,主要原因是网站的反开发机制的设计。如果触发,通常的结果是完全封锁和禁止。例如,阻止您的帐户并阻止您的 IP 地址。一旦被屏蔽,网站会自动给你一个错误页面或无法让你正常浏览。
几种情况最有可能触发反采集。
1、采集速度太快频率太高
嗯?这个用户怎么能在一分钟内浏览几十个页面?还是24小时不休息?有问题,我要查!啊,绝对是机器,挡住了~!
采集速度太快,频率太快,容易引起对方网站的注意,对方人员很容易认出你是机器爬取其内容,而不是人存在。毕竟普通人不能像机器人那样高速奔跑。
2、采集数据量太大
当你的速度和频率上来时,你的采集数据量将是巨大的。小八曾经遇到过一天一爪子采集几百万数据的情况。如果对方官网严防收购,很容易触发反采集机制。
3、 始终使用相同的 IP 或帐户
一旦对方网站发现你的IP/账号是机器爬虫,那么很有可能你的IP/账号会被列入他们的黑名单,不允许你访问或显示错误页面将来。让你无处可去。
针对采集优采云推出了一系列智能防封解决方案!
方案一:自动识别并输入验证码
优采云提供验证码识别控制,目前支持8种智能识别的自动识别,包括字母、数字、汉字、混合算术计算!
方案二:自动滑动拼图验证
遇到滑块?别着急,优采云支持自动识别滑块验证,并让机器自动拖动到指定位置,网站verification。
优采云自动通过滑块验证
方案三:设置自动登录
优采云提供以下两种登录方式:
1)文字+点击登录
在优采云中设计登录流程。 采集过程中优采云会自动输入用户名和密码登录(PS,优采云不会获取任何用户隐私)
2)Cookie 登录
登录优采云,通过登录后记住cookies,下次直接在登录采集后的状态打开网页。
解决方案 4:放慢采集speed
1)Ajax 加载
AJAX:一种用于延迟加载和异步更新的脚本技术。简单来说,我们可以利用ajax技术让网页加载时间更长(可以设置为0-30秒),让浏览速度慢一点,避免阻塞。
2)执行前等待
执行前等待是指在执行采集操作之前,优采云默认会自动等待一段时间,以确保采集的数据已经加载完毕。这种方法也适用于反收割比较严格的网站。通过减慢采集 以避免反爬行动物跟踪。
方案五:优质代理IP
优采云提供优质代理IP池,支持采集进程智能定时切换IP,避免同一IP采集被网站跟踪拦截。 查看全部
网站常见的防采集套路有哪些?防采套路介绍
什么是反采集?
用白话来说,我们想用一个工具采集一些网站的数据(前提当然是公开合法数据),但是网站不想给你采集和设置采取技术封锁措施。
网站常见的防御采集套路有哪些?
反挖矿套路一:输入验证码框进行验证
采集难度:★☆☆☆☆
常见网站:搜狗微信
在采集一些网站的过程中,爪子是不是经常遇到这样的情况要求你输入验证码,不然会卡死无法继续?
是的,这是网站最常用也是最基本的预防措施之一。它需要您手动输入验证码中的数字和字母,然后才能继续查看更多信息或进行下一步。用这个来判断你是机器人还是真人。
反挖矿套路2:滑动拼图验证
采集难度:★★☆☆☆
常见网站:拉勾、B站
升级版的验证码反收获例程也是网站验证当前浏览用户是机器人还是人类最常用的方法之一。
需要您将拼图滑动到指定位置才能通过验证并进行下一步。
反挖矿例程3:登录验证
采集难度:★★★☆☆
普通网站:新浪微博,新榜
这种网站通常需要登录才能看到更丰富的信息,否则只会显示非常有限的内容。放在优采云采集器中,只要启动,这种网站会立即弹出登录窗口进行下一步,有时还会出现在采集的进程中。如果你不明白如何设置登录过程的爪子,你很快就会被提醒“采集TERMINATION”。
反挖矿程序四:数据加密
采集难度:★★★★☆
常见网站:公众意见
某些网站 通过加密采集 来保护数据。比如大众点评(上图),我们在网页上看到的是这家餐厅的“地址”,但是当我们打开源代码时,这段文字已经被加密分离了。会发生什么?
这样会导致文字即使采集down 也会出现乱码或碎片,无法整合成完整的文字。
反挖矿套路5:反馈虚假数据
采集难度:★★★★★
常见网站:携程网
我最近看到了携程开发写的一篇关于他们如何向爬虫“假数据”反馈的帖子。看完觉得携程太“可怕”了!
当你发现你这么辛苦采集down的数据竟然是假的,你累吗? !所谓道高一尺,魔高一尺。如果遇到这种“毒”你的网站,请绕道,除非你有更好的办法!
反挖矿程序6:不允许访问
采集难度:★★★★★
普通网站:个人网站
小八目前还没有遇到过这种情况。当然,我们没事,不会刻意“试法”来测试网站的底线。
在这种情况下,主要原因是网站的反开发机制的设计。如果触发,通常的结果是完全封锁和禁止。例如,阻止您的帐户并阻止您的 IP 地址。一旦被屏蔽,网站会自动给你一个错误页面或无法让你正常浏览。
几种情况最有可能触发反采集。
1、采集速度太快频率太高
嗯?这个用户怎么能在一分钟内浏览几十个页面?还是24小时不休息?有问题,我要查!啊,绝对是机器,挡住了~!
采集速度太快,频率太快,容易引起对方网站的注意,对方人员很容易认出你是机器爬取其内容,而不是人存在。毕竟普通人不能像机器人那样高速奔跑。
2、采集数据量太大
当你的速度和频率上来时,你的采集数据量将是巨大的。小八曾经遇到过一天一爪子采集几百万数据的情况。如果对方官网严防收购,很容易触发反采集机制。
3、 始终使用相同的 IP 或帐户
一旦对方网站发现你的IP/账号是机器爬虫,那么很有可能你的IP/账号会被列入他们的黑名单,不允许你访问或显示错误页面将来。让你无处可去。
针对采集优采云推出了一系列智能防封解决方案!
方案一:自动识别并输入验证码
优采云提供验证码识别控制,目前支持8种智能识别的自动识别,包括字母、数字、汉字、混合算术计算!
方案二:自动滑动拼图验证
遇到滑块?别着急,优采云支持自动识别滑块验证,并让机器自动拖动到指定位置,网站verification。
优采云自动通过滑块验证
方案三:设置自动登录
优采云提供以下两种登录方式:
1)文字+点击登录
在优采云中设计登录流程。 采集过程中优采云会自动输入用户名和密码登录(PS,优采云不会获取任何用户隐私)
2)Cookie 登录
登录优采云,通过登录后记住cookies,下次直接在登录采集后的状态打开网页。
解决方案 4:放慢采集speed
1)Ajax 加载
AJAX:一种用于延迟加载和异步更新的脚本技术。简单来说,我们可以利用ajax技术让网页加载时间更长(可以设置为0-30秒),让浏览速度慢一点,避免阻塞。
2)执行前等待
执行前等待是指在执行采集操作之前,优采云默认会自动等待一段时间,以确保采集的数据已经加载完毕。这种方法也适用于反收割比较严格的网站。通过减慢采集 以避免反爬行动物跟踪。
方案五:优质代理IP
优采云提供优质代理IP池,支持采集进程智能定时切换IP,避免同一IP采集被网站跟踪拦截。
自动识别采集内容:百度统计+js框架搭建百度的云采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-07-08 07:03
自动识别采集内容:百度统计+js框架搭建百度的云采集可以满足广告主的“自动化”需求。
可以采用php或者aspwinmagic、aspwinmsgit等,也可以采用python、java等其他web服务器开发语言。搭建实现很简单,比如说j2ee或者python写个爬虫进行采集操作。php必要的开发语言:php、mysqlserver要熟悉、web服务器要选择能够处理网页响应。
上了大学之后你们会发现网站主要以外贸和sns为主,如果你用的是国内的话,建议你用自动化采集器+accessium会比较适合网站,可以自动监测登录。整体开发包括前端和后端。写代码时间一般是由你的主人决定的。
语言方面我不太懂,但是后端的话比较简单的实现是采用springboot,简单配置一下,然后你就可以用类似jsp或者servlet的编程语言了,有个记忆库,可以存放网站的需要采集的数据。一般放代码上去的话,一个星期就可以上线了。前端的话,用最好一些的ide吧,配置起来比较简单。 查看全部
自动识别采集内容:百度统计+js框架搭建百度的云采集
自动识别采集内容:百度统计+js框架搭建百度的云采集可以满足广告主的“自动化”需求。
可以采用php或者aspwinmagic、aspwinmsgit等,也可以采用python、java等其他web服务器开发语言。搭建实现很简单,比如说j2ee或者python写个爬虫进行采集操作。php必要的开发语言:php、mysqlserver要熟悉、web服务器要选择能够处理网页响应。
上了大学之后你们会发现网站主要以外贸和sns为主,如果你用的是国内的话,建议你用自动化采集器+accessium会比较适合网站,可以自动监测登录。整体开发包括前端和后端。写代码时间一般是由你的主人决定的。
语言方面我不太懂,但是后端的话比较简单的实现是采用springboot,简单配置一下,然后你就可以用类似jsp或者servlet的编程语言了,有个记忆库,可以存放网站的需要采集的数据。一般放代码上去的话,一个星期就可以上线了。前端的话,用最好一些的ide吧,配置起来比较简单。
自动识别采集内容如何批量抓取网上的商品信息呢?
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-07-07 07:01
自动识别采集内容,从大数据中读取想要的信息。大数据时代的到来,电商行业实时抓取商品信息是每个商家都必须要学会的技能,因为采集新的商品信息更能在现在大数据时代迅速成长。那么如何批量抓取网上的商品信息呢?1.首先准备一些抓取必备的工具与软件。这些工具比如:浏览器插件(电脑开发者,可参考如何用advanceddocumentation优化或者美化浏览器界面),浏览器扩展。
迅雷浏览器扩展版,迅雷浏览器助手,迅雷cc离线下载助手等等。软件比如:利用360等工具,也可以在pc客户端上手动抓取网的数据;2.准备好获取到的商品信息的图片;3.打开电脑迅雷浏览器登录账号,打开手机版,扫描下图二维码直接登录账号。同时将刚才准备好的工具都安装好后即可开始抓取,此时对于店铺地址,商品地址,都会一起抓取出来,这一步省去了商品地址中间的信息修改或者翻页等繁琐工作,简单快捷又高效。
未抓取到任何信息:4.继续第3步,上面没有抓取到任何信息时,退出电脑浏览器重新开启,同时登录到手机客户端的,扫描扫描下图二维码即可打开手机进行抓取。小编温馨提示:刚才的一步都是一些小问题,只需要稍稍动动手指就能够解决,所以这次就不解决了。抓取宝贝详情页信息:。 查看全部
自动识别采集内容如何批量抓取网上的商品信息呢?
自动识别采集内容,从大数据中读取想要的信息。大数据时代的到来,电商行业实时抓取商品信息是每个商家都必须要学会的技能,因为采集新的商品信息更能在现在大数据时代迅速成长。那么如何批量抓取网上的商品信息呢?1.首先准备一些抓取必备的工具与软件。这些工具比如:浏览器插件(电脑开发者,可参考如何用advanceddocumentation优化或者美化浏览器界面),浏览器扩展。
迅雷浏览器扩展版,迅雷浏览器助手,迅雷cc离线下载助手等等。软件比如:利用360等工具,也可以在pc客户端上手动抓取网的数据;2.准备好获取到的商品信息的图片;3.打开电脑迅雷浏览器登录账号,打开手机版,扫描下图二维码直接登录账号。同时将刚才准备好的工具都安装好后即可开始抓取,此时对于店铺地址,商品地址,都会一起抓取出来,这一步省去了商品地址中间的信息修改或者翻页等繁琐工作,简单快捷又高效。
未抓取到任何信息:4.继续第3步,上面没有抓取到任何信息时,退出电脑浏览器重新开启,同时登录到手机客户端的,扫描扫描下图二维码即可打开手机进行抓取。小编温馨提示:刚才的一步都是一些小问题,只需要稍稍动动手指就能够解决,所以这次就不解决了。抓取宝贝详情页信息:。
自动识别采集内容不打扰,你要到你分享地址
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2021-06-12 05:02
自动识别采集内容,不打扰。获取数据就是同一个资料(暂时取决于文件大小与文件类型,各地方都有不同),将资料上传至网站,支持智能批量上传。方案1:自动化识别采集第一步,用浏览器打开百度网盘,选择分享记录第二步,点击‘自动识别采集’,现在不能识别,你要到你分享地址往下看最后,采集成功获取到电子档文件方案2:自动化识别采集第一步,打开pc客户端,打开‘自动识别采集’app第二步,进入文件库页面后,选择子库,将文件拖动至结果框中第三步,点击立即采集,现在可以识别了然后点击”全部采集“,现在在成功识别的基础上同时多采集几个子库文件,检查一下库内文件数量是否大于你的预期,如果不行,再点击立即采集,返回‘自动识别采集’app,换成电脑版,再执行同样操作。
你要写成小说啊?
挺好玩的,
没什么好评价的,送快递取件已经够烦的了,自动扫地机器人都不稀奇。
比现在扫码取件好多了
以前我同学有在做,结果丢包,坏卡,延迟都出来了。
想通过自动采集快递单号来实现每天扫一下就送快递的幻想。地方并不广大,代理很少,利润有限,实现不了,要实现的话,应该需要租一个专用的地面快递柜才能实现。 查看全部
自动识别采集内容不打扰,你要到你分享地址
自动识别采集内容,不打扰。获取数据就是同一个资料(暂时取决于文件大小与文件类型,各地方都有不同),将资料上传至网站,支持智能批量上传。方案1:自动化识别采集第一步,用浏览器打开百度网盘,选择分享记录第二步,点击‘自动识别采集’,现在不能识别,你要到你分享地址往下看最后,采集成功获取到电子档文件方案2:自动化识别采集第一步,打开pc客户端,打开‘自动识别采集’app第二步,进入文件库页面后,选择子库,将文件拖动至结果框中第三步,点击立即采集,现在可以识别了然后点击”全部采集“,现在在成功识别的基础上同时多采集几个子库文件,检查一下库内文件数量是否大于你的预期,如果不行,再点击立即采集,返回‘自动识别采集’app,换成电脑版,再执行同样操作。
你要写成小说啊?
挺好玩的,
没什么好评价的,送快递取件已经够烦的了,自动扫地机器人都不稀奇。
比现在扫码取件好多了
以前我同学有在做,结果丢包,坏卡,延迟都出来了。
想通过自动采集快递单号来实现每天扫一下就送快递的幻想。地方并不广大,代理很少,利润有限,实现不了,要实现的话,应该需要租一个专用的地面快递柜才能实现。
基于内容的网络水军识别方法及系统的社交网络信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-06-07 21:39
基于内容的网络水军识别方法及系统的社交网络信息
本发明涉及社交网络中的网络海军识别领域,具体涉及一种网络上海军力量的自动识别方法及系统,以实现对社交网络中海军力量的更加自动化、准确的识别。网络。
背景技术:
随着社交网络相关应用的快速发展,人们越来越多地将活动转移到社交网络上。社交网络通常包括国外的Facebook、Google+、Twitter等和国内的新浪微博、腾讯微博、人人网等。但是,目前社交网络中存在大量的在线海军力量。社交网络的海军力量通常会助长在线信息的传播或恶意攻击某些社交网络帐户。他们受政治和商业利益的驱使。为达到影响网络舆论、扰乱网络环境等不正当目的,操纵软件机器人或海军账号,在互联网上制造和传播虚假言论和垃圾信息。这些行为严重影响了社交网络的用户体验,也带来了严重的安全问题。
网络海军现有的社交网络识别方法主要是利用社交网络的消息内容。一种比较简单的基于内容的网络水军检测方法(K. Lee, J. Caverlee, and S. Webb. Uncovering social spammers: social honeypots+machine learning. In Proceedings of SIGIR, 2010)就是把它作为监督学习问题。这些方法从社交网络的消息内容中提取有效的文本特征来构建分类器。给定一个新用户,分类器输出一个分类标签来确定新用户是否是网络海军。然而,这些方法通常需要大量的标注数据(通常是人工标注的数据),费时费力,人工标注的数据集很小,这给社交网络中的网络海军检测带来了巨大的挑战。
技术实现要素:
由于以前海军部队的社交网络识别方法大多将其作为分类问题,因此需要使用大量标记数据集。但标注数据需要大量人力,标注数据集规模普遍较小,训练模型的泛化能力较弱。
基于此,本发明的目的在于提供一种网络海军自动识别方法及系统。该方法和系统不需要对数据集进行人工标注,避免了耗时费力的标注工作,也不需要模型训练。同时,它可以快速有效地识别社交网络中的网络海军。
针对上述不足,本发明采用的技术方案是:
一种网络海军自动识别方法,步骤包括:
1)采集社交网络中已验证账号的消息信息以及每条消息下的评论信息;
2)监控以上每条消息下的每条评论信息是否已被删除,如果有,则读取该评论信息对应账号的历史删除评论数;
3)如果上述账号的历史删除评论数满足预设条件,则该账号为网络海军。
此外,步骤1)包括以下步骤:
1-1)社交网络用户模拟登录;
1-2)获取社交网络已验证账号列表,采集每个已验证账号的消息信息;
1-3)获取消息列表,以及每条消息下的采集评论信息。
另外,1)步骤中的验证账号是指通过社交网络官方验证的账号;验证账户类型包括政府机构账户、国际组织账户、新闻媒体账户和个人账户。
进一步地,步骤1)的消息信息包括但不限于消息url、消息内容、消息发布时间、消息评论数、消息转发数、消息点赞数;评论信息包括但不限于评论地址、评论内容、评论时间、评论用户。
另外,如果1)步骤中提到的消息信息发布时间超过一个月,该消息信息将被删除。
进一步,步骤2)具体为:获取每条消息下的评论信息的评论列表,监控评论列表中每条评论信息的删除;如果评论信息被删除,查看评论信息对应账号历史记录中删除的评论数。
另外,步骤3)中提到的预设条件包括:
1)Da>=10;其中 Da 代表帐户历史记录中删除的评论总数;
2)Da/Na>=0.2;其中Na代表该账号的评论总数;
3)账号历史第一条删除评论与其最近删除评论的时间间隔大于一周。
一种网络海军自动识别系统,包括data采集模块和海军识别模块;
数据采集模块用于采集社交网络中认证账号的消息信息和每条消息下的评论信息;
海军识别模块用于监控和区分上述消息信息和每条消息下的评论信息。
另外,系统还包括数据存储模块,用于存储上述消息信息和每条消息下的评论信息。
此外,海军识别模块包括评论监控模块和海军识别模块;
评论监控模块,用于监控上述每条消息下的每条评论信息是否已被删除,如果有,则读取该评论信息对应账号的历史删除评论数;
海军识别模块用于判断上述账号的历史删除评论数量是否满足预设条件,如果满足,则该账号为网络海军。
传统的网络海军识别方法一般采用机器学习监督学习方法,需要大量标记数据集进行模型训练。并且数据集通常需要大量的人力进行标注。本发明提供了一种网络海军力量自动识别方法及系统,其优点主要体现在:
1、 这种方法和系统消除了人工标注工作,不需要模型训练。
2、该方法和系统可以快速有效地识别社交网络中的网络海军,即当一个账号的评论信息的历史删除评论数量满足预设条件时,确定帐户是网络海军。
3、该方法和系统适用于多个社交网络,可以跨平台运行。
图纸说明
图1为本发明提供的网络海军自动识别系统架构图。
图2为本发明提供的网络海军自动识别方法流程图。
具体实现方法
为使本发明的上述特点和优点更易于理解,特举出以下实施例,并结合附图详细说明如下。
本发明为网络海军提供了一种自动识别方法及系统。请参考图1。系统包括数据采集模块、数据存储模块和海军识别模块;
数据采集模块用于采集社交网络中认证账号的消息信息和每条消息下的评论信息;
数据存储模块用于存储上述消息信息和每条消息下的评论信息;
海军识别模块用于监控和区分上述消息信息和每条消息下的评论信息。
海军识别模块还包括评论监控模块和海军鉴别模块;评论监控模块,用于监控上述每条消息下的每条评论信息是否被删除,如果是,则读取该评论信息该账号对应的历史删除评论数;海军识别模块用于判断该账号的历史删除评论数量是否满足预设条件,如果满足,则该账号为网络海军。
本发明的方法主要包括两部分:
1)采集 社交网络中验证账号下的用户消息:利用模拟Ajax技术模拟用户访问社交网络的方式,设计并实现了采集和社交网络用户消息的存储,如图图1.数据的采集部分和数据存储部分通过采集获取社交网络中一些认证账号的消息信息,获取每条消息下的评论信息。已验证账号是指已经过社交网络官方验证的账号(每个账号对应一个用户),通常在已验证账号头像的右下角会附加一个V;用户消息是指用户在社交网络上的发布信息,包括消息内容、消息发布者、消息发布时间等。
2)识别社交网络中的网络海军:使用评论监控模块实时监控每条消息下的评论信息,并与现有评论进行比较,以监控评论的删除。如果同一社交网络用户的删除评论数量满足预设条件,则确定为网络海军。
下面是一个具体的实施例来解释本发明。请参考图1和图2。该方法的具体步骤包括:
1、采集 社交网络中已验证帐户下的用户消息可分为3个步骤:
a) 用户模拟登录。通过表单模拟登录,登录后将cookie信息保存到登录池中。新线程使用cookie信息恢复登录。
b) 数据采集。完成社交网络用户的模拟登录后,网关处的Http请求记录结合Chrome Ajax网络请求日志提取Ajax行为模板。基于用户模拟登录,特定目标的社交网络网页内容基于模板采集。
c) 网页内容分析和提取。对获取的网页内容进行分析提取,获取用户的留言信息和每条留言下的评论信息。
2、识别社交网络中的网络海军:可以分为5个步骤:
a) 识别社交网络认证账户:即采集已经通过社交网络认证的账户。比如推特认证的Blue V账号“Donald J. Trump”。
验证账号必须满足两个条件:1)账号必须是现实世界中存在的政府机构账号、组织账号、媒体账号、个人账号等; 2) 帐户必须通过社交网络验证。其中,认证账号的类型分为政府机构账号、国际组织账号、新闻媒体账号和个人账号。
b)采集使用数据采集模块,采集认证账号的消息信息,存储到消息信息库中。消息信息至少包括消息url、消息内容、消息发布时间、消息评论数、消息转发数、消息点赞数。
c) 获取消息列表,使用数据采集module采集中每条消息下的评论信息,存储到评论信息库中。评论信息至少包括评论网址、评论内容、评论时间、评论用户。
d) 获取每条消息下的评论信息的评论列表,通过评论监控模块监控评论列表中每条评论信息的存在,即监控是否被删除。如果评论信息被删除,则读取评论信息对应的用户账号的历史删除评论条数,即该账号历史删除评论条数同时满足以下三个预设条件,且该账号立志做网络海军。本实施例中,三个预设条件为根据多次实验结果得出的最佳条件,预设条件如下:
1)Da>=w,w=10;其中 Da 代表帐户历史记录中删除的评论总数。
2)Da/Na>=v,v=0.2;其中 Na 代表该帐户的评论总数。
3)账号第一条删除评论与最近删除评论的时间间隔大于一周。
e) 重复步骤c)和d),直到每条消息的释放时间超过有效时间,然后删除消息信息。邮件生效时间设置为一个月。
以上实施方式仅用于说明本发明的技术方案,并不用于限制本发明。本领域普通技术人员可以在不脱离本发明的精神和范围的情况下,对本发明的技术方案进行修改或等效替换。本发明的保护范围以权利要求书为准。 查看全部
基于内容的网络水军识别方法及系统的社交网络信息
本发明涉及社交网络中的网络海军识别领域,具体涉及一种网络上海军力量的自动识别方法及系统,以实现对社交网络中海军力量的更加自动化、准确的识别。网络。
背景技术:
随着社交网络相关应用的快速发展,人们越来越多地将活动转移到社交网络上。社交网络通常包括国外的Facebook、Google+、Twitter等和国内的新浪微博、腾讯微博、人人网等。但是,目前社交网络中存在大量的在线海军力量。社交网络的海军力量通常会助长在线信息的传播或恶意攻击某些社交网络帐户。他们受政治和商业利益的驱使。为达到影响网络舆论、扰乱网络环境等不正当目的,操纵软件机器人或海军账号,在互联网上制造和传播虚假言论和垃圾信息。这些行为严重影响了社交网络的用户体验,也带来了严重的安全问题。
网络海军现有的社交网络识别方法主要是利用社交网络的消息内容。一种比较简单的基于内容的网络水军检测方法(K. Lee, J. Caverlee, and S. Webb. Uncovering social spammers: social honeypots+machine learning. In Proceedings of SIGIR, 2010)就是把它作为监督学习问题。这些方法从社交网络的消息内容中提取有效的文本特征来构建分类器。给定一个新用户,分类器输出一个分类标签来确定新用户是否是网络海军。然而,这些方法通常需要大量的标注数据(通常是人工标注的数据),费时费力,人工标注的数据集很小,这给社交网络中的网络海军检测带来了巨大的挑战。
技术实现要素:
由于以前海军部队的社交网络识别方法大多将其作为分类问题,因此需要使用大量标记数据集。但标注数据需要大量人力,标注数据集规模普遍较小,训练模型的泛化能力较弱。
基于此,本发明的目的在于提供一种网络海军自动识别方法及系统。该方法和系统不需要对数据集进行人工标注,避免了耗时费力的标注工作,也不需要模型训练。同时,它可以快速有效地识别社交网络中的网络海军。
针对上述不足,本发明采用的技术方案是:
一种网络海军自动识别方法,步骤包括:
1)采集社交网络中已验证账号的消息信息以及每条消息下的评论信息;
2)监控以上每条消息下的每条评论信息是否已被删除,如果有,则读取该评论信息对应账号的历史删除评论数;
3)如果上述账号的历史删除评论数满足预设条件,则该账号为网络海军。
此外,步骤1)包括以下步骤:
1-1)社交网络用户模拟登录;
1-2)获取社交网络已验证账号列表,采集每个已验证账号的消息信息;
1-3)获取消息列表,以及每条消息下的采集评论信息。
另外,1)步骤中的验证账号是指通过社交网络官方验证的账号;验证账户类型包括政府机构账户、国际组织账户、新闻媒体账户和个人账户。
进一步地,步骤1)的消息信息包括但不限于消息url、消息内容、消息发布时间、消息评论数、消息转发数、消息点赞数;评论信息包括但不限于评论地址、评论内容、评论时间、评论用户。
另外,如果1)步骤中提到的消息信息发布时间超过一个月,该消息信息将被删除。
进一步,步骤2)具体为:获取每条消息下的评论信息的评论列表,监控评论列表中每条评论信息的删除;如果评论信息被删除,查看评论信息对应账号历史记录中删除的评论数。
另外,步骤3)中提到的预设条件包括:
1)Da>=10;其中 Da 代表帐户历史记录中删除的评论总数;
2)Da/Na>=0.2;其中Na代表该账号的评论总数;
3)账号历史第一条删除评论与其最近删除评论的时间间隔大于一周。
一种网络海军自动识别系统,包括data采集模块和海军识别模块;
数据采集模块用于采集社交网络中认证账号的消息信息和每条消息下的评论信息;
海军识别模块用于监控和区分上述消息信息和每条消息下的评论信息。
另外,系统还包括数据存储模块,用于存储上述消息信息和每条消息下的评论信息。
此外,海军识别模块包括评论监控模块和海军识别模块;
评论监控模块,用于监控上述每条消息下的每条评论信息是否已被删除,如果有,则读取该评论信息对应账号的历史删除评论数;
海军识别模块用于判断上述账号的历史删除评论数量是否满足预设条件,如果满足,则该账号为网络海军。
传统的网络海军识别方法一般采用机器学习监督学习方法,需要大量标记数据集进行模型训练。并且数据集通常需要大量的人力进行标注。本发明提供了一种网络海军力量自动识别方法及系统,其优点主要体现在:
1、 这种方法和系统消除了人工标注工作,不需要模型训练。
2、该方法和系统可以快速有效地识别社交网络中的网络海军,即当一个账号的评论信息的历史删除评论数量满足预设条件时,确定帐户是网络海军。
3、该方法和系统适用于多个社交网络,可以跨平台运行。
图纸说明
图1为本发明提供的网络海军自动识别系统架构图。
图2为本发明提供的网络海军自动识别方法流程图。
具体实现方法
为使本发明的上述特点和优点更易于理解,特举出以下实施例,并结合附图详细说明如下。
本发明为网络海军提供了一种自动识别方法及系统。请参考图1。系统包括数据采集模块、数据存储模块和海军识别模块;
数据采集模块用于采集社交网络中认证账号的消息信息和每条消息下的评论信息;
数据存储模块用于存储上述消息信息和每条消息下的评论信息;
海军识别模块用于监控和区分上述消息信息和每条消息下的评论信息。
海军识别模块还包括评论监控模块和海军鉴别模块;评论监控模块,用于监控上述每条消息下的每条评论信息是否被删除,如果是,则读取该评论信息该账号对应的历史删除评论数;海军识别模块用于判断该账号的历史删除评论数量是否满足预设条件,如果满足,则该账号为网络海军。
本发明的方法主要包括两部分:
1)采集 社交网络中验证账号下的用户消息:利用模拟Ajax技术模拟用户访问社交网络的方式,设计并实现了采集和社交网络用户消息的存储,如图图1.数据的采集部分和数据存储部分通过采集获取社交网络中一些认证账号的消息信息,获取每条消息下的评论信息。已验证账号是指已经过社交网络官方验证的账号(每个账号对应一个用户),通常在已验证账号头像的右下角会附加一个V;用户消息是指用户在社交网络上的发布信息,包括消息内容、消息发布者、消息发布时间等。
2)识别社交网络中的网络海军:使用评论监控模块实时监控每条消息下的评论信息,并与现有评论进行比较,以监控评论的删除。如果同一社交网络用户的删除评论数量满足预设条件,则确定为网络海军。
下面是一个具体的实施例来解释本发明。请参考图1和图2。该方法的具体步骤包括:
1、采集 社交网络中已验证帐户下的用户消息可分为3个步骤:
a) 用户模拟登录。通过表单模拟登录,登录后将cookie信息保存到登录池中。新线程使用cookie信息恢复登录。
b) 数据采集。完成社交网络用户的模拟登录后,网关处的Http请求记录结合Chrome Ajax网络请求日志提取Ajax行为模板。基于用户模拟登录,特定目标的社交网络网页内容基于模板采集。
c) 网页内容分析和提取。对获取的网页内容进行分析提取,获取用户的留言信息和每条留言下的评论信息。
2、识别社交网络中的网络海军:可以分为5个步骤:
a) 识别社交网络认证账户:即采集已经通过社交网络认证的账户。比如推特认证的Blue V账号“Donald J. Trump”。
验证账号必须满足两个条件:1)账号必须是现实世界中存在的政府机构账号、组织账号、媒体账号、个人账号等; 2) 帐户必须通过社交网络验证。其中,认证账号的类型分为政府机构账号、国际组织账号、新闻媒体账号和个人账号。
b)采集使用数据采集模块,采集认证账号的消息信息,存储到消息信息库中。消息信息至少包括消息url、消息内容、消息发布时间、消息评论数、消息转发数、消息点赞数。
c) 获取消息列表,使用数据采集module采集中每条消息下的评论信息,存储到评论信息库中。评论信息至少包括评论网址、评论内容、评论时间、评论用户。
d) 获取每条消息下的评论信息的评论列表,通过评论监控模块监控评论列表中每条评论信息的存在,即监控是否被删除。如果评论信息被删除,则读取评论信息对应的用户账号的历史删除评论条数,即该账号历史删除评论条数同时满足以下三个预设条件,且该账号立志做网络海军。本实施例中,三个预设条件为根据多次实验结果得出的最佳条件,预设条件如下:
1)Da>=w,w=10;其中 Da 代表帐户历史记录中删除的评论总数。
2)Da/Na>=v,v=0.2;其中 Na 代表该帐户的评论总数。
3)账号第一条删除评论与最近删除评论的时间间隔大于一周。
e) 重复步骤c)和d),直到每条消息的释放时间超过有效时间,然后删除消息信息。邮件生效时间设置为一个月。
以上实施方式仅用于说明本发明的技术方案,并不用于限制本发明。本领域普通技术人员可以在不脱离本发明的精神和范围的情况下,对本发明的技术方案进行修改或等效替换。本发明的保护范围以权利要求书为准。
【自动识别采集内容方法】127代理ip,选择一个主推产品
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-06-05 06:01
自动识别采集内容方法一:打开127代理ip,选择一个主推产品作为代理,点击申请代理方法二:如果用方法一的话,其实就是在多申请几个代理账号。因为可以用第一种方法免费申请的时候,就开始倒卖。如果你自己很想代理,但是资金没那么雄厚的话,选择一个代理可以先申请,等到天猫清理完库存后,可以每天定时买些产品赚赚零花钱,大家自己衡量啦方法三:其实代理分很多种的,像一键代发就可以把产品在自己店铺上架上架,像db货源发货的话,相对来说比较麻烦一点,可以使用云货源平台,有自动分类审核,数据采集等功能。
谢邀,邀我干嘛(^_^),我只代购不采购啊,自动采购就像一个流量池,在这个池子里,能批量找到比你销量还好的产品,货源质量差别不大的情况下,品牌溢价就是那几个一线品牌的东西多,价格比成本还便宜。你一再强调客单价多少多少,觉得哪些卖的多不代表卖的贵,我从事服装、鞋包、化妆品等垂直产品的销售工作,亲戚朋友常拿这些东西向我问价格,一般我要么不给,要么就给成本价的三分之一甚至四分之一。
当然成本价一般没下限,当然这里面还会扯出各种隐形成本,有些是销售前绝对不允许透露的。至于采购,公司会配一台采购机器,比如小姑娘定多少钱要取一下价格,做多久一个供应商,涨个一两成是平常,越大的公司,这个毛利比例越低,最典型的就是食品,明明是奢侈品牌五星的产品,表面看一眼就知道成本几毛几分钱。所以我们最直接的办法是,卖给客户同等比例的比成本还要低一点,希望能帮到您。 查看全部
【自动识别采集内容方法】127代理ip,选择一个主推产品
自动识别采集内容方法一:打开127代理ip,选择一个主推产品作为代理,点击申请代理方法二:如果用方法一的话,其实就是在多申请几个代理账号。因为可以用第一种方法免费申请的时候,就开始倒卖。如果你自己很想代理,但是资金没那么雄厚的话,选择一个代理可以先申请,等到天猫清理完库存后,可以每天定时买些产品赚赚零花钱,大家自己衡量啦方法三:其实代理分很多种的,像一键代发就可以把产品在自己店铺上架上架,像db货源发货的话,相对来说比较麻烦一点,可以使用云货源平台,有自动分类审核,数据采集等功能。
谢邀,邀我干嘛(^_^),我只代购不采购啊,自动采购就像一个流量池,在这个池子里,能批量找到比你销量还好的产品,货源质量差别不大的情况下,品牌溢价就是那几个一线品牌的东西多,价格比成本还便宜。你一再强调客单价多少多少,觉得哪些卖的多不代表卖的贵,我从事服装、鞋包、化妆品等垂直产品的销售工作,亲戚朋友常拿这些东西向我问价格,一般我要么不给,要么就给成本价的三分之一甚至四分之一。
当然成本价一般没下限,当然这里面还会扯出各种隐形成本,有些是销售前绝对不允许透露的。至于采购,公司会配一台采购机器,比如小姑娘定多少钱要取一下价格,做多久一个供应商,涨个一两成是平常,越大的公司,这个毛利比例越低,最典型的就是食品,明明是奢侈品牌五星的产品,表面看一眼就知道成本几毛几分钱。所以我们最直接的办法是,卖给客户同等比例的比成本还要低一点,希望能帮到您。
自动识别采集内容可以用bs4的采集器,配置工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-06-03 01:01
自动识别采集内容可以用bs4的采集器,
配置工具cmd(用于环境管理),浏览器(ie也可以),sql注入工具webshell注入,cookie,文本框注入,比如百度的。登录laravel:session,cookie,文本框注入,比如腾讯的。自己搭服务器,sqlmap注入,比如阿里的。工具都是辅助的,要多多尝试,摸索出适合自己项目的服务器工具。
学习一门语言,前端服务器后端服务器都要接触,脚本语言,如php,nodejs,甚至nginx+mod_php都可以。当然,自己搭服务器也很好。但是不要太沉迷脚本语言,以为简单。后端建议转c++和python,以及java,因为c++有一大堆平台可以写脚本,同时也是web攻击的可破坏性语言。
有个网站可以用php+asp+python。
根据兴趣选择一种语言,
如果没有经验不要先报班学习,因为现在很多靠谱的培训机构都是走联系就业的政策。我大学一同学曾就职于一家做爬虫的公司,这个公司的编程大佬就对怎么将自己写的爬虫留存并发布出去已经研究一年了,而且没有固定编程语言。不要轻易选择某一种编程语言,因为一旦陷入研究这个领域如果语言选择错误,就可能后悔终生,可能前后花费比较长的时间还没研究出个一两个像样的点子,转而去尝试其他语言就容易有无穷的想法,以至于造成极大的浪费。 查看全部
自动识别采集内容可以用bs4的采集器,配置工具
自动识别采集内容可以用bs4的采集器,
配置工具cmd(用于环境管理),浏览器(ie也可以),sql注入工具webshell注入,cookie,文本框注入,比如百度的。登录laravel:session,cookie,文本框注入,比如腾讯的。自己搭服务器,sqlmap注入,比如阿里的。工具都是辅助的,要多多尝试,摸索出适合自己项目的服务器工具。
学习一门语言,前端服务器后端服务器都要接触,脚本语言,如php,nodejs,甚至nginx+mod_php都可以。当然,自己搭服务器也很好。但是不要太沉迷脚本语言,以为简单。后端建议转c++和python,以及java,因为c++有一大堆平台可以写脚本,同时也是web攻击的可破坏性语言。
有个网站可以用php+asp+python。
根据兴趣选择一种语言,
如果没有经验不要先报班学习,因为现在很多靠谱的培训机构都是走联系就业的政策。我大学一同学曾就职于一家做爬虫的公司,这个公司的编程大佬就对怎么将自己写的爬虫留存并发布出去已经研究一年了,而且没有固定编程语言。不要轻易选择某一种编程语言,因为一旦陷入研究这个领域如果语言选择错误,就可能后悔终生,可能前后花费比较长的时间还没研究出个一两个像样的点子,转而去尝试其他语言就容易有无穷的想法,以至于造成极大的浪费。
如何玩转excel数据采集》excel也能实现多线程?
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-05-28 18:02
自动识别采集内容,创建索引采集脚本过程中,本地会进行同步写入代码,在采集结束后的实际执行中,我们会从项目目录下新增一个data目录,里面有待采集的数据集,本质上这些数据并不会直接存储在本地,而是在服务器上存放。采集结束后,会将此数据存放在files目录中,并自动命名该目录为“数据”。
强烈建议这种问题自己先搜索一下。
我想问下,在各大中小学内部做试卷的数据采集,你们是怎么采集的?上课的教学大纲,试卷,
可以用requests。注意可能无法从对应的file那里获取到数据。想一想现在数据库挂那么多,学校的那些数据库操作系统windows,linux,mysql之类的。就没有采集不到的数据。
貌似还没有适合新手的网页采集工具不过是google有很多说明
做爬虫,不知道是你要做哪个方面的爬虫?比如说针对某一类问题就得有针对性的。
requests
百度不是有很多相关文章么,
《verycd_》
网页翻爬我记得不太难,对着网站解析也是很简单。
excelvba:win,mac双平台数据库:navicatpro
推荐看这个:《如何玩转excel数据采集》
excel也能实现多线程(只要你们有库能支持),一般我会用django,轻松秒写requests多线程, 查看全部
如何玩转excel数据采集》excel也能实现多线程?
自动识别采集内容,创建索引采集脚本过程中,本地会进行同步写入代码,在采集结束后的实际执行中,我们会从项目目录下新增一个data目录,里面有待采集的数据集,本质上这些数据并不会直接存储在本地,而是在服务器上存放。采集结束后,会将此数据存放在files目录中,并自动命名该目录为“数据”。
强烈建议这种问题自己先搜索一下。
我想问下,在各大中小学内部做试卷的数据采集,你们是怎么采集的?上课的教学大纲,试卷,
可以用requests。注意可能无法从对应的file那里获取到数据。想一想现在数据库挂那么多,学校的那些数据库操作系统windows,linux,mysql之类的。就没有采集不到的数据。
貌似还没有适合新手的网页采集工具不过是google有很多说明
做爬虫,不知道是你要做哪个方面的爬虫?比如说针对某一类问题就得有针对性的。
requests
百度不是有很多相关文章么,
《verycd_》
网页翻爬我记得不太难,对着网站解析也是很简单。
excelvba:win,mac双平台数据库:navicatpro
推荐看这个:《如何玩转excel数据采集》
excel也能实现多线程(只要你们有库能支持),一般我会用django,轻松秒写requests多线程,
自动识别采集内容不用编程开发0基础都可以做起来
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-05-25 04:04
自动识别采集内容不用编程开发,0基础都可以做起来:随着自媒体的发展,社会在不断的进步,媒体在不断的更新迭代,视频自媒体作为这一行业的代表,现在运营很火。那自媒体如何做好视频自媒体?如何利用好自媒体平台呢?下面来给大家讲解讲解!视频自媒体的发展如火如荼的进行着,视频作为记录社会生活的方式,受到很多人的喜爱。
许多人都想通过自媒体赚钱,一条视频最少就有上百人观看,那么如何利用好自媒体平台,玩转自媒体,赚钱呢?自媒体平台的收益,主要分为以下几种:。
1、如果你的平台是个人的,那么你的视频只能去拍摄一些个人感悟,通过微信朋友圈、微博等等社交平台传播推广,相对于搬运来说成本低,回报高。
2、如果你的平台是企业的,那么你就得考虑怎么做产品推广,相比于拍摄个人感悟来说,需要就是专业的团队与摄像,内容就需要向品牌化靠拢,可以去拍摄影视剧,去说一些你觉得是大咖的,像赵本山的电影《夏洛特烦恼》就是快乐家族拍摄的,他们影响力还是很大的。像与吴秀波谈恋爱的邓超吴秀波,电影《五十度黑》,这是纯个人的,相对拍摄纯个人想法的,会更容易被大众接受,还是有价值。
3、如果你的平台是官方的,那么你可以注册企业的账号,企业的平台,就需要认证的需要的资料多一些,像企业工商注册证等等很多信息都需要填写,都需要提交,这样注册也是比较麻烦的,如果没有专业的团队,可能是一个人去注册,可能就会浪费很多的精力,影响他去工作,其实选择合适自己的视频平台,采集到了就要利用好平台,这样才能出效果。
自媒体如何做好视频自媒体?随着自媒体的发展,社会在不断的进步,媒体在不断的更新迭代,视频自媒体作为这一行业的代表,现在运营很火。那自媒体如何做好视频自媒体?如何利用好自媒体平台呢?下面来给大家讲解讲解!现在视频自媒体越来越火热,你能想象到现在视频的市场有多大,移动端的平台更容易做出爆款,并且体验效果都比电脑端的体验效果要好。
随着互联网的发展,自媒体平台的涌现,优质内容的不断涌现,自媒体人的涌现,视频自媒体逐渐成为行业发展的趋势,所以大家不要灰心,自媒体是可以赚钱的,
1、写文章或者视频都可以有收益,看自己会写什么,会策划什么,现在百家号推出的一百万播放大概有100元左右的收益,大平台你的创作,吸引用户来看,平台给予高额的奖励,同时收益自然更高。
2、平台给予发文的订阅号、服务号给予补贴,补贴金额大概在1-2万。 查看全部
自动识别采集内容不用编程开发0基础都可以做起来
自动识别采集内容不用编程开发,0基础都可以做起来:随着自媒体的发展,社会在不断的进步,媒体在不断的更新迭代,视频自媒体作为这一行业的代表,现在运营很火。那自媒体如何做好视频自媒体?如何利用好自媒体平台呢?下面来给大家讲解讲解!视频自媒体的发展如火如荼的进行着,视频作为记录社会生活的方式,受到很多人的喜爱。
许多人都想通过自媒体赚钱,一条视频最少就有上百人观看,那么如何利用好自媒体平台,玩转自媒体,赚钱呢?自媒体平台的收益,主要分为以下几种:。
1、如果你的平台是个人的,那么你的视频只能去拍摄一些个人感悟,通过微信朋友圈、微博等等社交平台传播推广,相对于搬运来说成本低,回报高。
2、如果你的平台是企业的,那么你就得考虑怎么做产品推广,相比于拍摄个人感悟来说,需要就是专业的团队与摄像,内容就需要向品牌化靠拢,可以去拍摄影视剧,去说一些你觉得是大咖的,像赵本山的电影《夏洛特烦恼》就是快乐家族拍摄的,他们影响力还是很大的。像与吴秀波谈恋爱的邓超吴秀波,电影《五十度黑》,这是纯个人的,相对拍摄纯个人想法的,会更容易被大众接受,还是有价值。
3、如果你的平台是官方的,那么你可以注册企业的账号,企业的平台,就需要认证的需要的资料多一些,像企业工商注册证等等很多信息都需要填写,都需要提交,这样注册也是比较麻烦的,如果没有专业的团队,可能是一个人去注册,可能就会浪费很多的精力,影响他去工作,其实选择合适自己的视频平台,采集到了就要利用好平台,这样才能出效果。
自媒体如何做好视频自媒体?随着自媒体的发展,社会在不断的进步,媒体在不断的更新迭代,视频自媒体作为这一行业的代表,现在运营很火。那自媒体如何做好视频自媒体?如何利用好自媒体平台呢?下面来给大家讲解讲解!现在视频自媒体越来越火热,你能想象到现在视频的市场有多大,移动端的平台更容易做出爆款,并且体验效果都比电脑端的体验效果要好。
随着互联网的发展,自媒体平台的涌现,优质内容的不断涌现,自媒体人的涌现,视频自媒体逐渐成为行业发展的趋势,所以大家不要灰心,自媒体是可以赚钱的,
1、写文章或者视频都可以有收益,看自己会写什么,会策划什么,现在百家号推出的一百万播放大概有100元左右的收益,大平台你的创作,吸引用户来看,平台给予高额的奖励,同时收益自然更高。
2、平台给予发文的订阅号、服务号给予补贴,补贴金额大概在1-2万。
锚文本自动提取长尾关键词提升网站排名的三种方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-05-20 18:00
自动识别采集内容?获取标题关键词是seo的必修课。通过百度指数获取网站标题热度。通过锚文本自动提取长尾关键词提升网站排名。常用的提取关键词办法有pc+手机百度热度标题提取和h5里提取长尾关键词。下面就来简单学习一下这三种提取关键词方法。第一种pc+手机百度热度标题提取优势是即使提取不出来也会显示正文标题,劣势是在提取出来内容后字体要大才行。
第二种h5提取长尾关键词对于常用的h5自动提取长尾关键词工具,开源的提取工具集成了所有的长尾关键词,不限地域。只要设置好标题关键词,点击按钮就会自动识别标题。不支持定时更新。h5通过锚文本提取长尾关键词是目前自动化采集标题的方法。现在h5提取长尾关键词通过做关键词聚合,自动联想长尾关键词和自动提取提取方法,添加采集链接自动提取长尾关键词,然后转到aso,可以快速找到热门关键词。
h5提取长尾关键词聚合也是可以自动联想方法。优势是即使提取不出来也会显示正文标题。劣势是提取出来的内容和标题都需要不限字数。第三种自动提取长尾关键词自动提取长尾关键词的方法简单易学,无需编写长尾关键词代码,即可自动提取所有长尾关键词。需要的网站优化或者中小企业对长尾关键词有需求的话可以加入这样一个网站采集方法聚合(暂不是加入长尾关键词聚合)。
其采集的效果就像给需要的网站编写代码,查找所有长尾关键词即可。优势是提取出来的长尾关键词几乎都是手机上适合的词。劣势是无法提取出全部长尾关键词,现阶段也不支持自动提取全部长尾关键词。其实对于手机和pc,做采集的方法还是有很多的,现在做网站的方法有很多,但是只要能提取出来网站标题就可以,中小企业想要真正做seo,必须根据自己的实际情况去做,并不是那么简单的。
对于提取的关键词几乎是手机上能用的词。手机定位用户,自动提取出来网站标题。例如找不到网站标题的情况下,自动提取出来关键词为所有。-878b-4543-aa0a-ab059aaf0009/images/minecraft.html?keyword=minecraft,进来直接看定位用户的分析更容易找到用户的需求。自动提取出来网站标题后就会显示正文标题了。实战技巧。
1、刚刚做网站的,
2、选择关键词,
3、分析正文标题,
4、提取长尾关键词,看自己的网站情况,发现自己的长尾关键词,根据长尾关键词的排名情况拟定一个合理的标题。 查看全部
锚文本自动提取长尾关键词提升网站排名的三种方法
自动识别采集内容?获取标题关键词是seo的必修课。通过百度指数获取网站标题热度。通过锚文本自动提取长尾关键词提升网站排名。常用的提取关键词办法有pc+手机百度热度标题提取和h5里提取长尾关键词。下面就来简单学习一下这三种提取关键词方法。第一种pc+手机百度热度标题提取优势是即使提取不出来也会显示正文标题,劣势是在提取出来内容后字体要大才行。
第二种h5提取长尾关键词对于常用的h5自动提取长尾关键词工具,开源的提取工具集成了所有的长尾关键词,不限地域。只要设置好标题关键词,点击按钮就会自动识别标题。不支持定时更新。h5通过锚文本提取长尾关键词是目前自动化采集标题的方法。现在h5提取长尾关键词通过做关键词聚合,自动联想长尾关键词和自动提取提取方法,添加采集链接自动提取长尾关键词,然后转到aso,可以快速找到热门关键词。
h5提取长尾关键词聚合也是可以自动联想方法。优势是即使提取不出来也会显示正文标题。劣势是提取出来的内容和标题都需要不限字数。第三种自动提取长尾关键词自动提取长尾关键词的方法简单易学,无需编写长尾关键词代码,即可自动提取所有长尾关键词。需要的网站优化或者中小企业对长尾关键词有需求的话可以加入这样一个网站采集方法聚合(暂不是加入长尾关键词聚合)。
其采集的效果就像给需要的网站编写代码,查找所有长尾关键词即可。优势是提取出来的长尾关键词几乎都是手机上适合的词。劣势是无法提取出全部长尾关键词,现阶段也不支持自动提取全部长尾关键词。其实对于手机和pc,做采集的方法还是有很多的,现在做网站的方法有很多,但是只要能提取出来网站标题就可以,中小企业想要真正做seo,必须根据自己的实际情况去做,并不是那么简单的。
对于提取的关键词几乎是手机上能用的词。手机定位用户,自动提取出来网站标题。例如找不到网站标题的情况下,自动提取出来关键词为所有。-878b-4543-aa0a-ab059aaf0009/images/minecraft.html?keyword=minecraft,进来直接看定位用户的分析更容易找到用户的需求。自动提取出来网站标题后就会显示正文标题了。实战技巧。
1、刚刚做网站的,
2、选择关键词,
3、分析正文标题,
4、提取长尾关键词,看自己的网站情况,发现自己的长尾关键词,根据长尾关键词的排名情况拟定一个合理的标题。

