
美文采集
什么是优采云采集?写作推出智能采集工具写作
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-08-24 19:12
疫情期间,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然没有面对面工作那么高效。出于这个原因优采云采集专利权采集tools。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助操作采集信息,还可以准确分析数据趋势,从而帮助增加收入。
什么是优采云采集?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
如何使用优采云采集进行搜索?
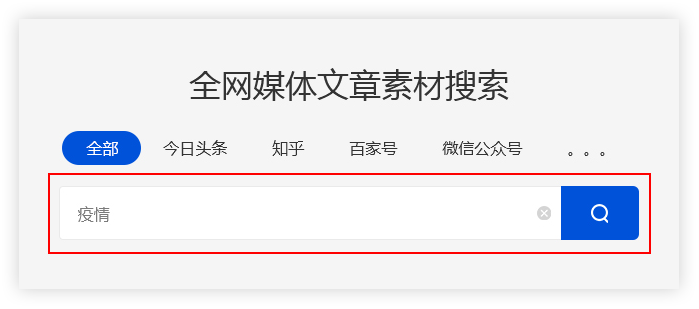
输入关键词
优采云采集根据用户输入的关键词,搜索引擎通过程序自动进入主流的自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
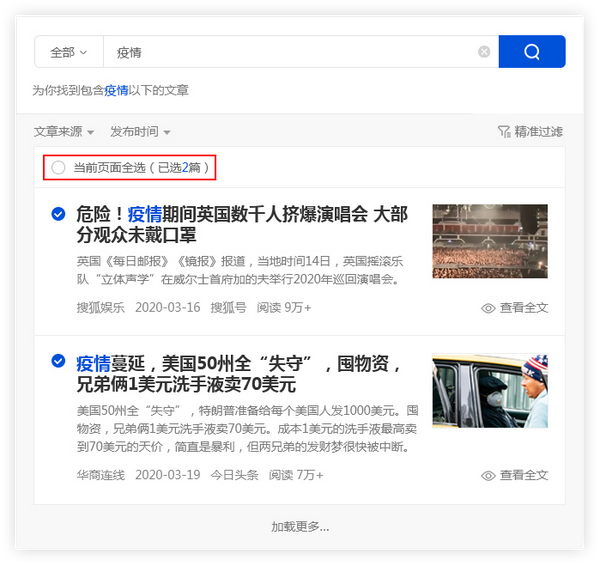
保存搜索材料
优采云采集具有批量保存搜索资料的功能。
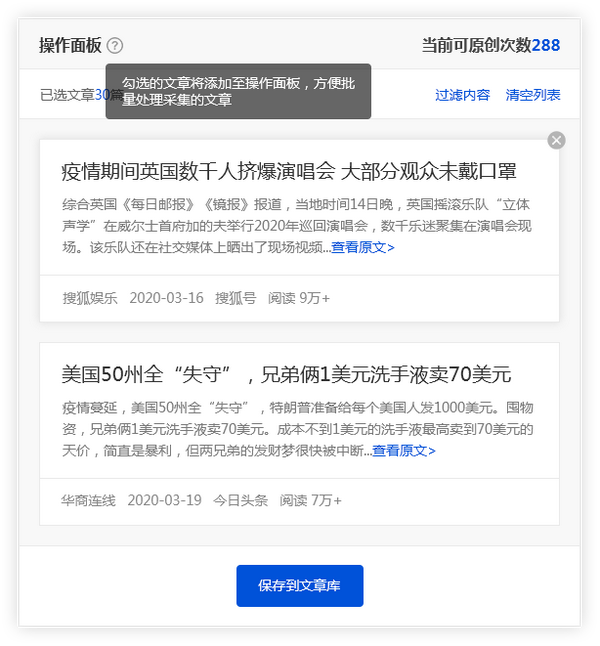
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
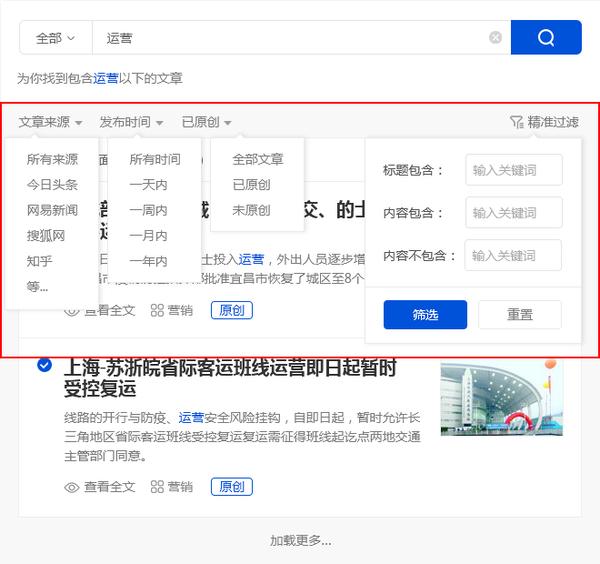
精准过滤
搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
广告过滤 查看全部
什么是优采云采集?写作推出智能采集工具写作
疫情期间,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然没有面对面工作那么高效。出于这个原因优采云采集专利权采集tools。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助操作采集信息,还可以准确分析数据趋势,从而帮助增加收入。
什么是优采云采集?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
如何使用优采云采集进行搜索?
输入关键词
优采云采集根据用户输入的关键词,搜索引擎通过程序自动进入主流的自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。

保存搜索材料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
精准过滤
搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
广告过滤
极客邦新产品——极客搜索,整合技术文章资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-08-15 00:02
近日,极客帮发布了一款新产品——极客搜索,它整合了极客帮下的文章sources技术。抱着尝鲜的态度,我也试了一下,发现搜索速度极快。分析为什么这么快,主要有两点:1、resources太少!!!,12个公众号加起来5161文章; 2、使用Vue框架异步加载数据。这个产品还是很有用的,推荐一下,希望能快速增加可搜索的技术资源。
最近想用采集一些文章来做分词。这个接口是用vue写的,所以所有的数据都是通过接口,所以数据采集极其方便,所以心血来潮,趁着产品刚刚上线,防爬机制应该不会强,所以采集拥有极客邦的所有公众号数据。一:文章采集
主要分为采集文章链接和原文采集两步。
1、采集文章链接,通过搜索界面,抓取所有文章链接
从返回的数据中可以抓取文章原文本的链接,下一步就是链接采集原文本的数据。
2、原信息采集
使用scrapy框架获取采集微信文章数据,共5151篇采集文章。
具体代码见文末地址
二:数据分析
接下来,我对采集的文章做了一些简单的统计。
1、哪个公众号写得最多文章
infoQ 写了最多的文章,998 篇,占 19.35%。 StuQ以835篇文章排名第二,占比16.19%,EGONetworks以802篇文章排名第三,占比15.55%。这三部分恰好是极客科技的三大业务。
2、文章每日发布总数
随着越来越多的公众号开通,文章的数量不断上升,2017年达到每月250多篇,编辑能力很强。
文章每天发帖数统计:很规律,周一到周五发帖多,周六周日发帖少。周六周日努力工作的人。
3、文章词频统计
对所有文章词进行切分,然后统计词频。
Top 10:我们、一、数据、技术、罐头、服务、使用、需求、问题、系统
前 10 个词是:我们需要使用系统来服务技术或数据问题。是不是在暗示什么?我可以为你开发一个吗?商机就在这里。由于没有对分词结果做任何调整,所以出现了很多常用的修饰语等。这是一项对体力要求很高的工作,稍后会完成。
4、作者统计
基于文章作者的统计数据。前 10 名:StuQ、EGO、InfoQ、徐川、大嘉硕、陈媛媛、Q News、Indigo K 和郭亮、Stark Academy、Daniel V Classroom。
5、文章Title 趋势
文章标题的命名也反映了一段时间的趋势,所以我提取了所有文章标题并进行了分词。通过自定义jieba的字典,去掉很多修饰符等,得到如下结果。
2015:技术第一,这也符合极客的特点。我们提到了很多直播和微课堂,主要是StuQ公众号广告太多。当然,你也可以看到一些过去流行的词,比如互联网金融、大数据、创业、容器技术。
2016 年:技术仍然位居第一。出现了云计算、开源等词。同时,国内也有很多大公司如阿里、AWS、百度、京东等。
2017年:技术在不断变化,机器学习、深度学习、人工智能、AI等词汇的使用量不断增加,与当前的学习热潮相吻合。
从文章title的命名来看,极客帮微信公众号的内容基本紧跟最新科技趋势。把握科技发展趋势,分析题目即可。
三:总结
本文的主要工作是数据采集和分析。对于数据采集,不难,使用scrapy可以快速完成。数据分析比较耗时,我只做了一些简单的统计。后面会根据数据做一些文本关联分析。
数据的显示地址,源码也已经放在github,crawler-geekbang/geekbang at master · xuxping/crawler-geekbang · GitHub 查看全部
极客邦新产品——极客搜索,整合技术文章资源
近日,极客帮发布了一款新产品——极客搜索,它整合了极客帮下的文章sources技术。抱着尝鲜的态度,我也试了一下,发现搜索速度极快。分析为什么这么快,主要有两点:1、resources太少!!!,12个公众号加起来5161文章; 2、使用Vue框架异步加载数据。这个产品还是很有用的,推荐一下,希望能快速增加可搜索的技术资源。

最近想用采集一些文章来做分词。这个接口是用vue写的,所以所有的数据都是通过接口,所以数据采集极其方便,所以心血来潮,趁着产品刚刚上线,防爬机制应该不会强,所以采集拥有极客邦的所有公众号数据。一:文章采集
主要分为采集文章链接和原文采集两步。
1、采集文章链接,通过搜索界面,抓取所有文章链接

从返回的数据中可以抓取文章原文本的链接,下一步就是链接采集原文本的数据。
2、原信息采集
使用scrapy框架获取采集微信文章数据,共5151篇采集文章。

具体代码见文末地址
二:数据分析
接下来,我对采集的文章做了一些简单的统计。
1、哪个公众号写得最多文章
infoQ 写了最多的文章,998 篇,占 19.35%。 StuQ以835篇文章排名第二,占比16.19%,EGONetworks以802篇文章排名第三,占比15.55%。这三部分恰好是极客科技的三大业务。

2、文章每日发布总数
随着越来越多的公众号开通,文章的数量不断上升,2017年达到每月250多篇,编辑能力很强。

文章每天发帖数统计:很规律,周一到周五发帖多,周六周日发帖少。周六周日努力工作的人。

3、文章词频统计
对所有文章词进行切分,然后统计词频。
Top 10:我们、一、数据、技术、罐头、服务、使用、需求、问题、系统

前 10 个词是:我们需要使用系统来服务技术或数据问题。是不是在暗示什么?我可以为你开发一个吗?商机就在这里。由于没有对分词结果做任何调整,所以出现了很多常用的修饰语等。这是一项对体力要求很高的工作,稍后会完成。
4、作者统计
基于文章作者的统计数据。前 10 名:StuQ、EGO、InfoQ、徐川、大嘉硕、陈媛媛、Q News、Indigo K 和郭亮、Stark Academy、Daniel V Classroom。

5、文章Title 趋势
文章标题的命名也反映了一段时间的趋势,所以我提取了所有文章标题并进行了分词。通过自定义jieba的字典,去掉很多修饰符等,得到如下结果。
2015:技术第一,这也符合极客的特点。我们提到了很多直播和微课堂,主要是StuQ公众号广告太多。当然,你也可以看到一些过去流行的词,比如互联网金融、大数据、创业、容器技术。

2016 年:技术仍然位居第一。出现了云计算、开源等词。同时,国内也有很多大公司如阿里、AWS、百度、京东等。

2017年:技术在不断变化,机器学习、深度学习、人工智能、AI等词汇的使用量不断增加,与当前的学习热潮相吻合。

从文章title的命名来看,极客帮微信公众号的内容基本紧跟最新科技趋势。把握科技发展趋势,分析题目即可。
三:总结
本文的主要工作是数据采集和分析。对于数据采集,不难,使用scrapy可以快速完成。数据分析比较耗时,我只做了一些简单的统计。后面会根据数据做一些文本关联分析。
数据的显示地址,源码也已经放在github,crawler-geekbang/geekbang at master · xuxping/crawler-geekbang · GitHub
优采云采集推出智能信息收集东西,让你的运营更精准
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-08-10 20:11
疫情时代,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然不如面对面工作有效。为此优采云采集特智能信息采集的东西。
相信很多经营者都接触过采集东西。目前,市场上有很多不同种类的采集品。很多人认为采集东西只是作为文章热/节日话题等信息采集的辅助工具。事实上,它不仅仅是这样。 成熟的采集工具不仅可以帮助运营部门采集信息,还可以正确分析数据趋势,从而帮助增加收入。
优采云采集是自媒体材料搜滚、文章原创一键发布的运营工具,可有效提升新媒体运营效率,降低企业成本。
优采云采集按照用户输入的关键词自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据高级算法匹配更准确的内容,提高搜索内容的正确率。
例如:
用户需要采集与疫情相关的材料,在首页输入“流行”关键词。 优采云采集 将搜索结果整合为一列。
优采云采集具有批量保留搜索资料的功能。
点击【全选当前页面】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
优采云采集支持一次性过滤掉文章中的所有图片、联系方式等表白信息,解决新媒体运营快速找素材的需求。
优采云采集独有的智能搜索功能,保证数据的完整性。
用户可以点击标题进入原页面,获取文章的来源、浏览量、发布日期等信息,帮助用户分析文章的热度。
3、优采云采集能给你带来什么
减少采集材料时:
大大减少了搜索时间,帮助运营商更好更快地存储优质材料。
快速采集全网热门话题:
轻松获取各种主流自媒体的热门内容,及时更新最新热门内容,搜索效率翻倍。
智能过滤供述信息:
告白信息智能过滤,完美解决新媒体运营商快速查找素材的需求。
有助于提高工作效率:
海量素材+关键词价值选择+主流自媒体中优质素材快速搜索+智能识别文章最新和热门+持续更新,有助于提升新媒体运营效果。
简单的操作,让你在海量数据中发现价值,优采云采集,高效的文章一键采集工具。 查看全部
优采云采集推出智能信息收集东西,让你的运营更精准
疫情时代,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然不如面对面工作有效。为此优采云采集特智能信息采集的东西。
相信很多经营者都接触过采集东西。目前,市场上有很多不同种类的采集品。很多人认为采集东西只是作为文章热/节日话题等信息采集的辅助工具。事实上,它不仅仅是这样。 成熟的采集工具不仅可以帮助运营部门采集信息,还可以正确分析数据趋势,从而帮助增加收入。
优采云采集是自媒体材料搜滚、文章原创一键发布的运营工具,可有效提升新媒体运营效率,降低企业成本。
优采云采集按照用户输入的关键词自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据高级算法匹配更准确的内容,提高搜索内容的正确率。
例如:
用户需要采集与疫情相关的材料,在首页输入“流行”关键词。 优采云采集 将搜索结果整合为一列。
优采云采集具有批量保留搜索资料的功能。
点击【全选当前页面】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
优采云采集支持一次性过滤掉文章中的所有图片、联系方式等表白信息,解决新媒体运营快速找素材的需求。
优采云采集独有的智能搜索功能,保证数据的完整性。
用户可以点击标题进入原页面,获取文章的来源、浏览量、发布日期等信息,帮助用户分析文章的热度。
3、优采云采集能给你带来什么
减少采集材料时:
大大减少了搜索时间,帮助运营商更好更快地存储优质材料。
快速采集全网热门话题:
轻松获取各种主流自媒体的热门内容,及时更新最新热门内容,搜索效率翻倍。
智能过滤供述信息:
告白信息智能过滤,完美解决新媒体运营商快速查找素材的需求。
有助于提高工作效率:
海量素材+关键词价值选择+主流自媒体中优质素材快速搜索+智能识别文章最新和热门+持续更新,有助于提升新媒体运营效果。
简单的操作,让你在海量数据中发现价值,优采云采集,高效的文章一键采集工具。
自适应美文源码美文阅读模板(5)--PC/电脑版演示地址
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-07-29 07:50
2021新帝国cms7.5自适应美式源码阅读模板文章templateitag+sitemap+百度推送+采集+安装教程
----------------------------------------------- ---------------------------------
PC/电脑版演示地址:
WAP/手机版演示地址:(请使用手机访问)
----------------------------------------------- ---------------------------------
源代码是EmpirecmsUTF8版本。如需GBK版本请自行转码!
这个模板是楼主自己复制的。不修改Empire程序默认的表前缀,不保留各种恶心的AD广告。
模板简洁大方,访问快捷,移动端优化美观用户体验。
适用于文章资讯美文句等文章资讯通网站等!
所有功能后台管理,已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用,采集精选优质源站,模板精美同时兼顾SEO搜索引擎优化。全站静态生成,有利于收录和关键词布局和内容页面优化!
功能列表:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。 (标签链接样式可选择ID或拼音)
2、内置百度推送插件,实时数据推送到步行搜索引擎。
3、带优采云采集规则,可以自己采集海量数据,全自动无人值守采集。
4、built-in网站map 站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示网站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
----------------------------------------------- -------------------------------------------------- --
●Empirecms7.5UTF-8
●系统开源,域名不限。
●同步生成WAP移动终端简单实用。
●大小约140MB
●简单的安装方法,详细的安装教程。
●TAG标签聚合
----------------------------------------------- -------------------------------------------------- --
查看全部
自适应美文源码美文阅读模板(5)--PC/电脑版演示地址
2021新帝国cms7.5自适应美式源码阅读模板文章templateitag+sitemap+百度推送+采集+安装教程
----------------------------------------------- ---------------------------------
PC/电脑版演示地址:
WAP/手机版演示地址:(请使用手机访问)
----------------------------------------------- ---------------------------------
源代码是EmpirecmsUTF8版本。如需GBK版本请自行转码!
这个模板是楼主自己复制的。不修改Empire程序默认的表前缀,不保留各种恶心的AD广告。
模板简洁大方,访问快捷,移动端优化美观用户体验。
适用于文章资讯美文句等文章资讯通网站等!
所有功能后台管理,已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用,采集精选优质源站,模板精美同时兼顾SEO搜索引擎优化。全站静态生成,有利于收录和关键词布局和内容页面优化!
功能列表:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。 (标签链接样式可选择ID或拼音)
2、内置百度推送插件,实时数据推送到步行搜索引擎。
3、带优采云采集规则,可以自己采集海量数据,全自动无人值守采集。
4、built-in网站map 站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示网站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
----------------------------------------------- -------------------------------------------------- --
●Empirecms7.5UTF-8
●系统开源,域名不限。
●同步生成WAP移动终端简单实用。
●大小约140MB
●简单的安装方法,详细的安装教程。
●TAG标签聚合
----------------------------------------------- -------------------------------------------------- --



微信编辑器有可以采集文章的吗?怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-07-11 01:19
微信编辑器可以采集文章吗?
采集文章,这种编辑器还行,可以试试排版编辑器,右边采集文章,进入公众号图文链接,可以放官方账号你在里面看到的文章采集去版面人,然后点击右边的复制粘贴去公众平台,素材管理,新建图文留言,简单方便。
如何添加采集文章?
右侧有一个采集文章按钮。您可以一键点击采集文章到采集library。然后您可以通过选择编辑器页面右侧的导入按钮轻松完成。
大量发送伪原创文章、采集网站有什么影响吗?
非常不推荐这样做。如果是新站点,估计不会让你通过新站点的检查期。内容在互联网上重复。蜘蛛对网站的评价会很低,即使是新站之后。检查期间,这么多采集信息不利于收录。另外,璐璐算法主要针对采集信息,对网站的惩罚很严重。
如何批量处理采集网站文章?
可以用于采集的软件有很多,比如优采云,优采云可以用于batch采集文章注:网站batch采集的文章内容质量不是很好。建议手动采集和网站进行伪原创发布。这样,你的网站内容就会很好,在搜索引擎上排名很快。我自己总结了这些东西。经验,SEO 是一种相对较慢的技术。不要太担心。你越担心,排名就越困难。希望你不要太担心,希望能帮到你
如果使用采集others网站文章软件,是否涉及侵权?可以指定吗?
查看全部
微信编辑器有可以采集文章的吗?怎么办?
微信编辑器可以采集文章吗?

采集文章,这种编辑器还行,可以试试排版编辑器,右边采集文章,进入公众号图文链接,可以放官方账号你在里面看到的文章采集去版面人,然后点击右边的复制粘贴去公众平台,素材管理,新建图文留言,简单方便。
如何添加采集文章?

右侧有一个采集文章按钮。您可以一键点击采集文章到采集library。然后您可以通过选择编辑器页面右侧的导入按钮轻松完成。
大量发送伪原创文章、采集网站有什么影响吗?

非常不推荐这样做。如果是新站点,估计不会让你通过新站点的检查期。内容在互联网上重复。蜘蛛对网站的评价会很低,即使是新站之后。检查期间,这么多采集信息不利于收录。另外,璐璐算法主要针对采集信息,对网站的惩罚很严重。
如何批量处理采集网站文章?

可以用于采集的软件有很多,比如优采云,优采云可以用于batch采集文章注:网站batch采集的文章内容质量不是很好。建议手动采集和网站进行伪原创发布。这样,你的网站内容就会很好,在搜索引擎上排名很快。我自己总结了这些东西。经验,SEO 是一种相对较慢的技术。不要太担心。你越担心,排名就越困难。希望你不要太担心,希望能帮到你
如果使用采集others网站文章软件,是否涉及侵权?可以指定吗?

出售网站二级目录网站收录上1000基本你在友情链接交易平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-06-15 05:09
源代码功能详情
1、内置大量文章,安装后可以省时省力;
2、内置高效采集插件,每天自动采集1次(间隔可自行修改),真正无人值守;
3、内置10条采集规则;
4、 1个内置缓存插件,减轻前端访问压力;
5、网站管理简单快捷,后台基本可以修改前端显示信息,无需代码;
6、程序全部开源,不做任何加密,不定期提供升级;
7、采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,管理方便;
8、采集不用担心规则失效。我们拥有强大的技术团队,将提供规则升级服务;
9、图片默认使用远程地址,节省空间,本地可设置保存。
源码适合人群
1、劳族
白天上班,晚上休息。这个程序满足你。安装完成配置无误后,等待网站升级,真正无人值守。
2、做站群
有些人有几百个站,雇人要花钱。最好设置一个无人值守的采集站,既省事又省钱。
源代码盈利方法
1、广告联盟/网站广告/淘客
这个没什么好说的,它需要流量。
2、 出售友情链接
网站收录上1000 基本上你在友情链接交易平台上卖朋友没问题。
3、卖网站二级目录
网站收录好了 有人需要收录自然会找到你的。
4、卖站
网站收录上来卖5、6bai 没问题,权重上来多卖。
源代码环境
支持环境:Windows/linux PHP5.3/4/5/6 7.1 mysql5.+
推荐环境:linux php7.1 mysql5.6
程序安装文档
详见源码中付费安装文档
查看全部
出售网站二级目录网站收录上1000基本你在友情链接交易平台
源代码功能详情
1、内置大量文章,安装后可以省时省力;
2、内置高效采集插件,每天自动采集1次(间隔可自行修改),真正无人值守;
3、内置10条采集规则;
4、 1个内置缓存插件,减轻前端访问压力;
5、网站管理简单快捷,后台基本可以修改前端显示信息,无需代码;
6、程序全部开源,不做任何加密,不定期提供升级;
7、采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,管理方便;
8、采集不用担心规则失效。我们拥有强大的技术团队,将提供规则升级服务;
9、图片默认使用远程地址,节省空间,本地可设置保存。
源码适合人群
1、劳族
白天上班,晚上休息。这个程序满足你。安装完成配置无误后,等待网站升级,真正无人值守。
2、做站群
有些人有几百个站,雇人要花钱。最好设置一个无人值守的采集站,既省事又省钱。
源代码盈利方法
1、广告联盟/网站广告/淘客
这个没什么好说的,它需要流量。
2、 出售友情链接
网站收录上1000 基本上你在友情链接交易平台上卖朋友没问题。
3、卖网站二级目录
网站收录好了 有人需要收录自然会找到你的。
4、卖站
网站收录上来卖5、6bai 没问题,权重上来多卖。
源代码环境
支持环境:Windows/linux PHP5.3/4/5/6 7.1 mysql5.+
推荐环境:linux php7.1 mysql5.6
程序安装文档
详见源码中付费安装文档


打开非找你微信编辑器的入口都在地址栏复制
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-05-20 04:03
微信美国文字资料采集 [文件1:微信美国文字资料采集] 网站的三个入口位于编辑器的右侧(如2)所示,在这里不多说了) 。如何采集以微信精选为例:首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能(如1)所示,它将自动复制文章网址],只有一点,没有此功能网站,只能顺从地从地址栏中复制。打开微信编辑器(如果使用的是计算机版本,右侧还有采集按钮,请点击在其上,将弹出一个采集提示框,使用快捷键ctrl + v,粘贴第一步中复制的URL,然后单击“ 采集整个文章文章”。在采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮,将其粘贴并发布到微信公众平台即可。[第二部分:微信美国文字资料[ 采集]中国互联网和移动互联网的规模急剧增加,每天产生的信息不计其数。 采集网页中收录大量信息的数据,然后在工作和生活中使用,已变得非常普遍,并且也已演变为大数据时代的趋势。随着信息量的增加和网页结构的复杂性,数据获取的难度不断提高。对于过去的简单和少量数据,可以通过手动复制和粘贴轻松地采集。例如,为了充实博客或展示学术报告,我们将从互联网文章,期刊,图片等中提取一些内容。现在,我们对数据的使用越来越广泛,公司需要大量数据进行分析业务发展趋势,挖掘潜在机会并做出正确的决定;他们需要以多种方式理解人民的心声,以促进服务业的转型;医疗,教育,金融...如果没有数据,他们都无法实现快速发展。
这些数据大部分来自公共Internet,来自人们在网络上输入的大量文本,图片和其他可能有价值的信息。由于大量的信息和数据,采集不再可以手动获取它们,因此网络爬网工具已进入人们的视野,并取代了手册采集作为获取数据的最新捷径。当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过http协议直接请求网页的源代码,并设置采集的规则以实现网页数据的爬网,无论是图片,文本还是文件都可以被爬网。这种搜寻工具的优点是稳定且非常快。用户需要了解网页源代码的相关知识,然后将其设置在爬网工具上,然后可以将其完全移交给该工具。 采集。世兴的这种爬网工具还收录更多功能,例如优采云 采集器(;此外,优采云 采集器中的数据替换,过滤,重复数据删除以及其他处理和数据发布等功能,它还支持辅助代理服务器可满足插件扩展等的三种不同目的,并集成了各种智能功能;另一种是使用特定的网页元素定位和采集器引擎来模拟人们对打开网页和单击Web内容的想法,采集通过浏览器可视化呈现的内容,其优点在于可视化和灵活性,虽然可能不及优采云 采集器类型的采集器,但处理复杂的网页(例如优采云)更容易优采云系列浏览器的另一种产品,两种工具都有各自的优势,用户可以根据需要进行选择,对于更高的抓取需求,可以将两种类型的软件结合使用以方便对接,而同一品牌的两种软件可以同时使用。用于r组合。
借助Web爬行工具,图形数据甚至压缩文件,音频和其他数据的获取变得非常简单,就像人类的每一项伟大发明将引领时代的进步一样,大数据时代也需要大趋势。我们与时俱进,运用智慧控制行为,并利用数据赢得未来。为了获取数据,Web爬网工具将带来真正的效率。 [论文三:微信美国文字资料采集]微信图形信息模板/素材模板大全微信图形信息编辑器/带有素材的图像热门阅读(114 1)评论(0)标签:/ 查看全部
打开非找你微信编辑器的入口都在地址栏复制
微信美国文字资料采集 [文件1:微信美国文字资料采集] 网站的三个入口位于编辑器的右侧(如2)所示,在这里不多说了) 。如何采集以微信精选为例:首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能(如1)所示,它将自动复制文章网址],只有一点,没有此功能网站,只能顺从地从地址栏中复制。打开微信编辑器(如果使用的是计算机版本,右侧还有采集按钮,请点击在其上,将弹出一个采集提示框,使用快捷键ctrl + v,粘贴第一步中复制的URL,然后单击“ 采集整个文章文章”。在采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮,将其粘贴并发布到微信公众平台即可。[第二部分:微信美国文字资料[ 采集]中国互联网和移动互联网的规模急剧增加,每天产生的信息不计其数。 采集网页中收录大量信息的数据,然后在工作和生活中使用,已变得非常普遍,并且也已演变为大数据时代的趋势。随着信息量的增加和网页结构的复杂性,数据获取的难度不断提高。对于过去的简单和少量数据,可以通过手动复制和粘贴轻松地采集。例如,为了充实博客或展示学术报告,我们将从互联网文章,期刊,图片等中提取一些内容。现在,我们对数据的使用越来越广泛,公司需要大量数据进行分析业务发展趋势,挖掘潜在机会并做出正确的决定;他们需要以多种方式理解人民的心声,以促进服务业的转型;医疗,教育,金融...如果没有数据,他们都无法实现快速发展。
这些数据大部分来自公共Internet,来自人们在网络上输入的大量文本,图片和其他可能有价值的信息。由于大量的信息和数据,采集不再可以手动获取它们,因此网络爬网工具已进入人们的视野,并取代了手册采集作为获取数据的最新捷径。当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过http协议直接请求网页的源代码,并设置采集的规则以实现网页数据的爬网,无论是图片,文本还是文件都可以被爬网。这种搜寻工具的优点是稳定且非常快。用户需要了解网页源代码的相关知识,然后将其设置在爬网工具上,然后可以将其完全移交给该工具。 采集。世兴的这种爬网工具还收录更多功能,例如优采云 采集器(;此外,优采云 采集器中的数据替换,过滤,重复数据删除以及其他处理和数据发布等功能,它还支持辅助代理服务器可满足插件扩展等的三种不同目的,并集成了各种智能功能;另一种是使用特定的网页元素定位和采集器引擎来模拟人们对打开网页和单击Web内容的想法,采集通过浏览器可视化呈现的内容,其优点在于可视化和灵活性,虽然可能不及优采云 采集器类型的采集器,但处理复杂的网页(例如优采云)更容易优采云系列浏览器的另一种产品,两种工具都有各自的优势,用户可以根据需要进行选择,对于更高的抓取需求,可以将两种类型的软件结合使用以方便对接,而同一品牌的两种软件可以同时使用。用于r组合。
借助Web爬行工具,图形数据甚至压缩文件,音频和其他数据的获取变得非常简单,就像人类的每一项伟大发明将引领时代的进步一样,大数据时代也需要大趋势。我们与时俱进,运用智慧控制行为,并利用数据赢得未来。为了获取数据,Web爬网工具将带来真正的效率。 [论文三:微信美国文字资料采集]微信图形信息模板/素材模板大全微信图形信息编辑器/带有素材的图像热门阅读(114 1)评论(0)标签:/
两个网站关于“卷积神经网络”的期刊数据量
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-04-27 01:13
最近由于公司的需求采集 HowNet数据(标题,来源,关键字,作者,单位,分类号,摘要,类似文档等),因为HowNet太强大而无法阻止爬网,因此内容页面链接是加密,请尝试使用Pyspider,scrapy和selenium无法进入内容页面并直接跳到CNKI主页。因此,我不得不使用HowNet的界面来执行采集:以下是两本网站关于“卷积神经网络”的期刊,并将其数据量进行了比较,如下图所示:
image.png
image.png
仔细查看会发现网站是一个发布请求,并且焦点集中在带有参数的请求上。打开先见之明,搜索所需内容,按f2键,然后查看参数中的表单数据。就像我要使用的是卷积神经网络[k13]型日志一样,您可以在此处用您的参数替换它们。
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
以下是实现代码:
# encoding='utf-8'
import json
import re
from lxml import etree
import requests
import codecs
class CNKI(object):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
cookies = {
'Cookie': 'Ecp_ClientId=4181108101501154830; cnkiUserKey=ec1ef785-3872-fac6-cad3-402229207945; UM_distinctid=166f12b44b1654-05e4c1a8d86edc-b79183d-1fa400-166f12b44b2ac8; KEYWORD=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%24%E5%8D%B7%E7%A7%AF%20%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C; Ecp_IpLoginFail=1811121.119.135.10; amid=73b0014b-8b61-4e24-a333-8774cb4dd8bd; SID=110105; CNZZDATA1257838113=579682214-1541655561-http%253A%252F%252Fsearch.cnki.net%252F%7C1542070177'}
param = {
'Accept': 'text/html, */*; q=0.01',
'Accept - Encoding': 'gzip, deflate',
'Accept - Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep - alive',
'Content - Type': 'application / x - www - form - urlencoded;charset = UTF - 8',
'Host': 'yuanjian.cnki.net',
'Origin': 'http: // yuanjian.cnki.net',
'Referer': 'http: // yuanjian.cnki.net / Search / Result',
'X - Requested - With': 'XMLHttpRequest'}
def content(self):
li = []
# 遍历总页数
for j in range(1, 134):
for i in range(j, j + 1):
url = 'http://yuanjian.cnki.net/Search/Result'
print('当前页', i)
# post 传参
formdata = {'Type': 1,
'ArticleType': 1,
'Theme': '卷积神经网络',
'Page': i}
print(formdata)
try:
r = requests.post(url, data=formdata, headers=self.headers, cookies=self.cookies, params=self.param)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = etree.HTML(r.text)
# 链接列表
url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
# 关键词列表
key_wordlist = []
all_items = data.xpath("//*[@id='article_result']/div/div")
for i in range(1, len(all_items) + 1):
key_word = data.xpath("//*[@id='article_result']/div/div[%s]/div[1]/p[1]/a/text()" % i)
key_words = ';'.join(key_word)
key_wordlist.append(key_words)
# 来源
source_items = data.xpath("//*[@id='article_result']/div/div")
for j in range(1, len(source_items) + 1):
sources = data.xpath("//*[@id='article_result']/div/div/p[3]/a[1]/span/text()")
for index, url in enumerate(url_list):
items = {}
try:
print('当前链接:', url)
content = requests.get(url, headers=self.headers)
contents = etree.HTML(content.text)
# 论文题目
title = contents.xpath("//h1[@class='xx_title']/text()")[0]
print('标题:', title)
# 来源
source = sources[index]
items['source'] = source
print('来源:', source)
items['title'] = title
# 关键字
each_key_words = key_wordlist[index]
print('关键字:', each_key_words)
items['keywordsEn'] = ''
items['keywordsCh'] = each_key_words
# 作者
author = contents.xpath("//*[@id='content']/div[2]/div[3]/a/text()")
items['author'] = author
print('作者:', author)
# 单位
unit = contents.xpath("//*[@id='content']/div[2]/div[5]/a[1]/text()")
units = ''.join(unit).strip(';')
items['unit'] = units
print('单位:', units)
# 分类号
classify = contents.xpath("//*[@id='content']/div[2]/div[5]/text()")[-1]
items['classify'] = classify
print('分类号:', classify)
# 摘要
abstract = contents.xpath("//div[@class='xx_font'][1]/text()")[1].strip()
print('摘要:', abstract)
items['abstractCh'] = abstract
items['abstractEn'] = ''
# 相似文献
similar = contents.xpath(
"//*[@id='xiangsi']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
si = ''.join(similar).replace('\r\n', '').split('期')
po = []
for i in si:
sis = i + '期'
if len(sis) > 3:
po.append(sis)
items['similar_article'] = po
li.append(items)
except Exception as e:
print(e)
print(len(li))
except Exception as e:
print(e)
return li
if __name__ == '__main__':
con = CNKI()
items = con.content()
print(items)
try:
with codecs.open('./cnki_data.json', 'a+', encoding="utf-8") as fp:
for i in items:
fp.write(json.dumps(i, ensure_ascii=False) + ",\n")
except IOError as err:
print('error' + str(err))
finally:
fp.close()
结束〜
小白,希望对大家有帮助。如果有问题,请纠正我。 查看全部
两个网站关于“卷积神经网络”的期刊数据量
最近由于公司的需求采集 HowNet数据(标题,来源,关键字,作者,单位,分类号,摘要,类似文档等),因为HowNet太强大而无法阻止爬网,因此内容页面链接是加密,请尝试使用Pyspider,scrapy和selenium无法进入内容页面并直接跳到CNKI主页。因此,我不得不使用HowNet的界面来执行采集:以下是两本网站关于“卷积神经网络”的期刊,并将其数据量进行了比较,如下图所示:

image.png

image.png
仔细查看会发现网站是一个发布请求,并且焦点集中在带有参数的请求上。打开先见之明,搜索所需内容,按f2键,然后查看参数中的表单数据。就像我要使用的是卷积神经网络[k13]型日志一样,您可以在此处用您的参数替换它们。
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
以下是实现代码:
# encoding='utf-8'
import json
import re
from lxml import etree
import requests
import codecs
class CNKI(object):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
cookies = {
'Cookie': 'Ecp_ClientId=4181108101501154830; cnkiUserKey=ec1ef785-3872-fac6-cad3-402229207945; UM_distinctid=166f12b44b1654-05e4c1a8d86edc-b79183d-1fa400-166f12b44b2ac8; KEYWORD=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%24%E5%8D%B7%E7%A7%AF%20%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C; Ecp_IpLoginFail=1811121.119.135.10; amid=73b0014b-8b61-4e24-a333-8774cb4dd8bd; SID=110105; CNZZDATA1257838113=579682214-1541655561-http%253A%252F%252Fsearch.cnki.net%252F%7C1542070177'}
param = {
'Accept': 'text/html, */*; q=0.01',
'Accept - Encoding': 'gzip, deflate',
'Accept - Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep - alive',
'Content - Type': 'application / x - www - form - urlencoded;charset = UTF - 8',
'Host': 'yuanjian.cnki.net',
'Origin': 'http: // yuanjian.cnki.net',
'Referer': 'http: // yuanjian.cnki.net / Search / Result',
'X - Requested - With': 'XMLHttpRequest'}
def content(self):
li = []
# 遍历总页数
for j in range(1, 134):
for i in range(j, j + 1):
url = 'http://yuanjian.cnki.net/Search/Result'
print('当前页', i)
# post 传参
formdata = {'Type': 1,
'ArticleType': 1,
'Theme': '卷积神经网络',
'Page': i}
print(formdata)
try:
r = requests.post(url, data=formdata, headers=self.headers, cookies=self.cookies, params=self.param)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = etree.HTML(r.text)
# 链接列表
url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
# 关键词列表
key_wordlist = []
all_items = data.xpath("//*[@id='article_result']/div/div")
for i in range(1, len(all_items) + 1):
key_word = data.xpath("//*[@id='article_result']/div/div[%s]/div[1]/p[1]/a/text()" % i)
key_words = ';'.join(key_word)
key_wordlist.append(key_words)
# 来源
source_items = data.xpath("//*[@id='article_result']/div/div")
for j in range(1, len(source_items) + 1):
sources = data.xpath("//*[@id='article_result']/div/div/p[3]/a[1]/span/text()")
for index, url in enumerate(url_list):
items = {}
try:
print('当前链接:', url)
content = requests.get(url, headers=self.headers)
contents = etree.HTML(content.text)
# 论文题目
title = contents.xpath("//h1[@class='xx_title']/text()")[0]
print('标题:', title)
# 来源
source = sources[index]
items['source'] = source
print('来源:', source)
items['title'] = title
# 关键字
each_key_words = key_wordlist[index]
print('关键字:', each_key_words)
items['keywordsEn'] = ''
items['keywordsCh'] = each_key_words
# 作者
author = contents.xpath("//*[@id='content']/div[2]/div[3]/a/text()")
items['author'] = author
print('作者:', author)
# 单位
unit = contents.xpath("//*[@id='content']/div[2]/div[5]/a[1]/text()")
units = ''.join(unit).strip(';')
items['unit'] = units
print('单位:', units)
# 分类号
classify = contents.xpath("//*[@id='content']/div[2]/div[5]/text()")[-1]
items['classify'] = classify
print('分类号:', classify)
# 摘要
abstract = contents.xpath("//div[@class='xx_font'][1]/text()")[1].strip()
print('摘要:', abstract)
items['abstractCh'] = abstract
items['abstractEn'] = ''
# 相似文献
similar = contents.xpath(
"//*[@id='xiangsi']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
si = ''.join(similar).replace('\r\n', '').split('期')
po = []
for i in si:
sis = i + '期'
if len(sis) > 3:
po.append(sis)
items['similar_article'] = po
li.append(items)
except Exception as e:
print(e)
print(len(li))
except Exception as e:
print(e)
return li
if __name__ == '__main__':
con = CNKI()
items = con.content()
print(items)
try:
with codecs.open('./cnki_data.json', 'a+', encoding="utf-8") as fp:
for i in items:
fp.write(json.dumps(i, ensure_ascii=False) + ",\n")
except IOError as err:
print('error' + str(err))
finally:
fp.close()
结束〜
小白,希望对大家有帮助。如果有问题,请纠正我。
分享:微信美文素材采集的相关文档搜索
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2020-11-25 13:12
的相关文档
微信美国文字资料采集
[第1条:微信美国文字资料采集]
三个网站的入口都在编辑器的右侧(如2)中所示,在此我不再赘述。
如何采集以微信选择为例:
1.首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能
(如1)所示,文章 URL会自动复制到一个位置,而没有此功能的网站只能很好
地址栏中的好副本。
2.打开“找不到您”的微信编辑器(如果您使用的是计算机版本,则右侧也有
一个采集按钮,单击它会弹出采集提示框,使用快捷键ctrl + v粘贴第一个
一步一步复制URL,然后单击“ 采集整篇文章文章”。
在3.采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮即可粘贴并发布到微信公众平台。
[第2节:微信美国文字资料采集]
中国互联网和移动互联网的规模急剧增加,每天产生无数信息。 采集数据在具有大量信息的网页上用于工作和生活。
中国已经变得非常普遍,并已演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂性,数据获取的难度不断增加
促销。对于过去的简单和少量数据,只需手动复制和粘贴
例如,很容易采集来充实我们的博客或展示学术文章
报告,某些文章,期刊,图片等将从Internet上提取。现在我们是对的
数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会并做出正确的决策;他们需要从多个方面了解人们的心声并进行宣传
服务转换;医疗,教育,金融...没有数据就无法实现快速发展。
这些数据大部分来自公共互联网,是人们在网页中输入的大量文本,
图片和其他可能有价值的信息,这些信息数据由于数量巨大而无法再通信
使用手动采集进行获取,因此网络抓取工具已进入人们的视野,
并替换手册采集作为获取数据的最新捷径。
当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过http协议直接请求网页的源代码,并设置采集的规则以实现网页数据
爬行,无论是图片,文本还是文件,都可以爬行。这类抓取工作
优点是它稳定且非常快。用户需要知道网页的源代码。
进行一些了解,然后将其设置在采集器上,您可以将其完全留给工具
采集。狮兴的爬虫还包括更多功能,例如优采云采集器
(数据中的数据替换,过滤,重复数据删除以及其他处理和数据发布;此外,火灾
Che 采集器还支持辅助代理服务器,以满足插件扩展等的三种不同目的,从而将各种智能功能集成在一起。
另一种方法是使用特定的网页元素定位和采集器引擎来模拟人们打开网页并单击
网络内容的思考,采集已由浏览器可视化呈现的内容。优点
它具有可视化和灵活性。它的速度可能不及优采云采集器类型的采集器,但是它更易于处理复杂的网页,例如优采云系列的另一产品优采云浏览器。两种工具都有自己的优势。用户可以根据自己的需要进行选择。更多
对抓取的需求很高,可以将两种软件一起使用,为方便对接,可以
选择两个相同品牌的软件进行组合。
使用网络抓取工具,可以获得图形数据甚至压缩文件,音频和其他数据
它已经变得简单了。正如人类的每一项伟大发明都会引领时代的进步一样,大数据时代的大趋势也要求我们与时俱进,运用智慧控制行为,并利用数据赢得未来。为了获取数据,Web爬网工具将带来真正的高效率。
[第三部分:微信美国文字资料采集]
微信图形消息模板/材料模板大全微信图形消息编辑器/收录材料的图片的大众阅读(1141)评论(0)标签:/ 查看全部
搜索微信美闻资料采集
的相关文档
微信美国文字资料采集
[第1条:微信美国文字资料采集]
三个网站的入口都在编辑器的右侧(如2)中所示,在此我不再赘述。
如何采集以微信选择为例:
1.首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能
(如1)所示,文章 URL会自动复制到一个位置,而没有此功能的网站只能很好
地址栏中的好副本。
2.打开“找不到您”的微信编辑器(如果您使用的是计算机版本,则右侧也有
一个采集按钮,单击它会弹出采集提示框,使用快捷键ctrl + v粘贴第一个
一步一步复制URL,然后单击“ 采集整篇文章文章”。
在3.采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮即可粘贴并发布到微信公众平台。
[第2节:微信美国文字资料采集]
中国互联网和移动互联网的规模急剧增加,每天产生无数信息。 采集数据在具有大量信息的网页上用于工作和生活。
中国已经变得非常普遍,并已演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂性,数据获取的难度不断增加
促销。对于过去的简单和少量数据,只需手动复制和粘贴
例如,很容易采集来充实我们的博客或展示学术文章
报告,某些文章,期刊,图片等将从Internet上提取。现在我们是对的
数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会并做出正确的决策;他们需要从多个方面了解人们的心声并进行宣传
服务转换;医疗,教育,金融...没有数据就无法实现快速发展。
这些数据大部分来自公共互联网,是人们在网页中输入的大量文本,
图片和其他可能有价值的信息,这些信息数据由于数量巨大而无法再通信
使用手动采集进行获取,因此网络抓取工具已进入人们的视野,
并替换手册采集作为获取数据的最新捷径。
当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过http协议直接请求网页的源代码,并设置采集的规则以实现网页数据
爬行,无论是图片,文本还是文件,都可以爬行。这类抓取工作
优点是它稳定且非常快。用户需要知道网页的源代码。
进行一些了解,然后将其设置在采集器上,您可以将其完全留给工具
采集。狮兴的爬虫还包括更多功能,例如优采云采集器
(数据中的数据替换,过滤,重复数据删除以及其他处理和数据发布;此外,火灾
Che 采集器还支持辅助代理服务器,以满足插件扩展等的三种不同目的,从而将各种智能功能集成在一起。
另一种方法是使用特定的网页元素定位和采集器引擎来模拟人们打开网页并单击
网络内容的思考,采集已由浏览器可视化呈现的内容。优点
它具有可视化和灵活性。它的速度可能不及优采云采集器类型的采集器,但是它更易于处理复杂的网页,例如优采云系列的另一产品优采云浏览器。两种工具都有自己的优势。用户可以根据自己的需要进行选择。更多
对抓取的需求很高,可以将两种软件一起使用,为方便对接,可以
选择两个相同品牌的软件进行组合。
使用网络抓取工具,可以获得图形数据甚至压缩文件,音频和其他数据
它已经变得简单了。正如人类的每一项伟大发明都会引领时代的进步一样,大数据时代的大趋势也要求我们与时俱进,运用智慧控制行为,并利用数据赢得未来。为了获取数据,Web爬网工具将带来真正的高效率。
[第三部分:微信美国文字资料采集]
微信图形消息模板/材料模板大全微信图形消息编辑器/收录材料的图片的大众阅读(1141)评论(0)标签:/
分享:微信美文素材采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 496 次浏览 • 2020-11-15 13:00
第1部分:微信美国文字资料采集
三个网站的入口在编辑器的右侧(如2)所示,在这里不多说了。
如何采集以微信选择为例:
1.首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能(如1)所示,它将自动复制文章 URL,无需此功能网站]只能听从地址栏中的复制。
2.打开不需要的微信编辑器(如果使用的是计算机版本,则右侧还有采集按钮,单击它会弹出一个采集提示框,请使用快捷键ctrl + v,粘贴第一步中复制的URL,然后单击“ 采集整篇文章文章”。
在3.采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮即可粘贴并发布到微信公众平台。
第二部分:微信美国文字资料采集
中国互联网和移动互联网的规模急剧增加,每天产生无数信息。 采集网页中收录大量信息的数据,然后在工作和生活中使用,已变得非常普遍,并且也演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂性,数据获取的难度也在增加。对于过去的简单和少量数据,可以通过手动复制和粘贴轻松地采集。例如,为了充实我们的博客或展示学术报告,我们将从互联网上提取一些文章,期刊,图片等。但是现在我们对数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会并做出正确的决策;他们需要从多方面理解人们的声音,以促进服务转型。医疗,教育和金融……没有数据,任何人都无法迅速发展。
这些数据大多数来自公共Internet,来自人们在网络上输入的大量文本,图片和其他可能有价值的信息。由于大量的信息和数据,采集不再可以手动获得它们,因此Web爬网工具已进入人们的视野,并取代了手册采集作为数据获取的最新捷径。
当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过HTTP协议直接请求网页的源代码,并设置采集的规则以实现网页数据的爬网,无论是图片,文本还是文件都可以被爬网。这种搜寻工具的优点是稳定且非常快速。用户需要了解网页源代码的相关知识,然后在爬网工具上进行设置以完成交付。用工具转到采集。世兴的爬网工具还收录更多功能,例如优采云采集器(;中,优采云采集器]中的数据替换,过滤,重置和其他处理以及数据发布等功能,还支持辅助代理服务器,满足三种不同用途的插件扩展等,并集成了各种智能功能。
另一种方法是使用特定的网页元素定位和采集器引擎来模拟人们打开网页并单击网页内容的想法。 采集浏览器以可视方式呈现的内容。它的优势在于可视化和灵活性,虽然可能不及优采云采集器类型的采集器,但它更易于处理复杂的网页,例如优采云浏览器(优采云的另一种产品)系列。两种工具都有各自的优势。用户可以根据自己的需要进行选择。为了满足更高的爬网需求,可以同时使用两种类型的软件。为了方便对接,可以使用两个相同品牌的软件进行组合。
使用Web爬行工具,图形数据甚至压缩文件,音频和其他数据的获取变得非常简单,就像人类的每一项伟大发明将引领时代的进步一样,大数据时代也需要大趋势。我们与时俱进,运用智慧控制行为,并利用数据确定未来。为了获取数据,Web爬网工具将带来真正的高效率。
第三部分:微信美国文字资料采集
微信图形信息模板/素材模板大全微信图形信息编辑器/包括素材图片人气排行 查看全部
微信美国文字资料采集
第1部分:微信美国文字资料采集
三个网站的入口在编辑器的右侧(如2)所示,在这里不多说了。
如何采集以微信选择为例:
1.首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能(如1)所示,它将自动复制文章 URL,无需此功能网站]只能听从地址栏中的复制。
2.打开不需要的微信编辑器(如果使用的是计算机版本,则右侧还有采集按钮,单击它会弹出一个采集提示框,请使用快捷键ctrl + v,粘贴第一步中复制的URL,然后单击“ 采集整篇文章文章”。
在3.采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮即可粘贴并发布到微信公众平台。
第二部分:微信美国文字资料采集
中国互联网和移动互联网的规模急剧增加,每天产生无数信息。 采集网页中收录大量信息的数据,然后在工作和生活中使用,已变得非常普遍,并且也演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂性,数据获取的难度也在增加。对于过去的简单和少量数据,可以通过手动复制和粘贴轻松地采集。例如,为了充实我们的博客或展示学术报告,我们将从互联网上提取一些文章,期刊,图片等。但是现在我们对数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会并做出正确的决策;他们需要从多方面理解人们的声音,以促进服务转型。医疗,教育和金融……没有数据,任何人都无法迅速发展。
这些数据大多数来自公共Internet,来自人们在网络上输入的大量文本,图片和其他可能有价值的信息。由于大量的信息和数据,采集不再可以手动获得它们,因此Web爬网工具已进入人们的视野,并取代了手册采集作为数据获取的最新捷径。
当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过HTTP协议直接请求网页的源代码,并设置采集的规则以实现网页数据的爬网,无论是图片,文本还是文件都可以被爬网。这种搜寻工具的优点是稳定且非常快速。用户需要了解网页源代码的相关知识,然后在爬网工具上进行设置以完成交付。用工具转到采集。世兴的爬网工具还收录更多功能,例如优采云采集器(;中,优采云采集器]中的数据替换,过滤,重置和其他处理以及数据发布等功能,还支持辅助代理服务器,满足三种不同用途的插件扩展等,并集成了各种智能功能。
另一种方法是使用特定的网页元素定位和采集器引擎来模拟人们打开网页并单击网页内容的想法。 采集浏览器以可视方式呈现的内容。它的优势在于可视化和灵活性,虽然可能不及优采云采集器类型的采集器,但它更易于处理复杂的网页,例如优采云浏览器(优采云的另一种产品)系列。两种工具都有各自的优势。用户可以根据自己的需要进行选择。为了满足更高的爬网需求,可以同时使用两种类型的软件。为了方便对接,可以使用两个相同品牌的软件进行组合。
使用Web爬行工具,图形数据甚至压缩文件,音频和其他数据的获取变得非常简单,就像人类的每一项伟大发明将引领时代的进步一样,大数据时代也需要大趋势。我们与时俱进,运用智慧控制行为,并利用数据确定未来。为了获取数据,Web爬网工具将带来真正的高效率。
第三部分:微信美国文字资料采集
微信图形信息模板/素材模板大全微信图形信息编辑器/包括素材图片人气排行
推荐文章:微信公众号文章采集的入口--历史消息页详解
采集交流 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2020-10-12 12:01
采集 WeChat文章和采集 网站具有相同的内容,并且都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如先前文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有正式帐户中唯一的一个。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址无效之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果要自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的官方帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
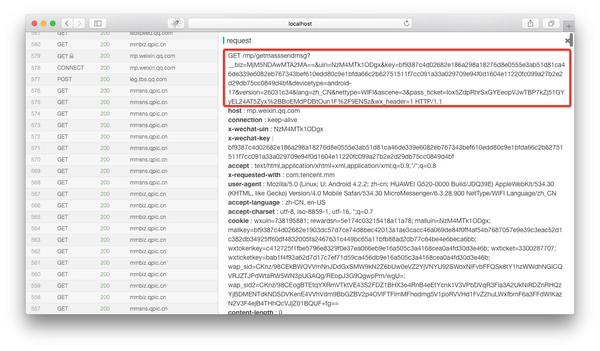
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址是localhost:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接到最前面后,可以在浏览器中打开。
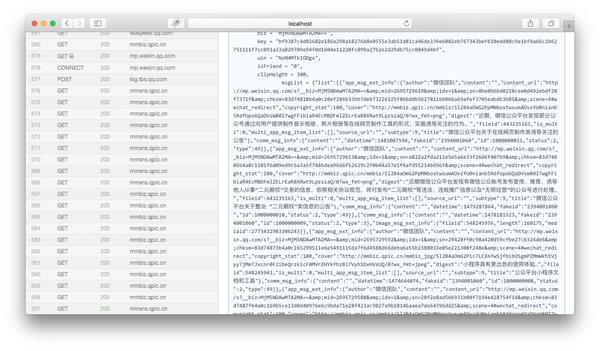
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值,并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍了一些重要信息,其他信息则省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的历史消息内容,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页面的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy将msgList变量值与服务器异步地匹配,然后使用php的json_decode将json从服务器解析为数组。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要采集中的一个正式帐户的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。
现在,我们可以通过官方帐户的历史新闻获得文章列表。在下一篇文章文章中,我将根据历史新闻中的文章链接地址介绍如何获取文章的特定内容。在保存文章,封面图片和全文检索方面也有一些经验。
如果您认为我不清楚自己写的是什么,或者如果我不了解某些内容,请在下面留言。或骚扰微信帐户的翠金,就像感觉良好一样。
持续更新,建设微信公众号文章批处理采集系统
微信公众号文章采集输入-历史新闻页面的详细说明
微信公众号文章页面的分析和采集
提高微信公众号文章采集的效率,先进使用anyproxy 查看全部
微信公众号文章采集输入-历史新闻页面的详细说明
采集 WeChat文章和采集 网站具有相同的内容,并且都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如先前文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有正式帐户中唯一的一个。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址无效之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果要自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的官方帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址是localhost:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接到最前面后,可以在浏览器中打开。
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值,并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍了一些重要信息,其他信息则省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的历史消息内容,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页面的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy将msgList变量值与服务器异步地匹配,然后使用php的json_decode将json从服务器解析为数组。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要采集中的一个正式帐户的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。
现在,我们可以通过官方帐户的历史新闻获得文章列表。在下一篇文章文章中,我将根据历史新闻中的文章链接地址介绍如何获取文章的特定内容。在保存文章,封面图片和全文检索方面也有一些经验。
如果您认为我不清楚自己写的是什么,或者如果我不了解某些内容,请在下面留言。或骚扰微信帐户的翠金,就像感觉良好一样。
持续更新,建设微信公众号文章批处理采集系统
微信公众号文章采集输入-历史新闻页面的详细说明
微信公众号文章页面的分析和采集
提高微信公众号文章采集的效率,先进使用anyproxy
什么是优采云采集?写作推出智能采集工具写作
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-08-24 19:12
疫情期间,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然没有面对面工作那么高效。出于这个原因优采云采集专利权采集tools。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助操作采集信息,还可以准确分析数据趋势,从而帮助增加收入。
什么是优采云采集?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
如何使用优采云采集进行搜索?
输入关键词
优采云采集根据用户输入的关键词,搜索引擎通过程序自动进入主流的自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
保存搜索材料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
精准过滤
搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
广告过滤 查看全部
什么是优采云采集?写作推出智能采集工具写作
疫情期间,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然没有面对面工作那么高效。出于这个原因优采云采集专利权采集tools。
相信很多运营商都接触过采集tools。现在市场上有很多种采集tools。很多人认为采集工具只是文章hot/festival 话题等信息采集 的辅助工具,其实不仅如此。一个成熟的采集工具不仅可以帮助操作采集信息,还可以准确分析数据趋势,从而帮助增加收入。
什么是优采云采集?
优采云采集是自媒体材料搜、文章原创的运营工具,一键发布,有效提高新媒体运营效率,降低企业成本。
如何使用优采云采集进行搜索?
输入关键词
优采云采集根据用户输入的关键词,搜索引擎通过程序自动进入主流的自媒体数据源。
优采云采集基于高级算法匹配更准确的内容,提高搜索内容的准确性。
例如:
用户需要采集与疫情相关的资料,在主页输入关键词“流行病”。 优采云采集 会将搜索结果整合到一个列表中。
保存搜索材料
优采云采集具有批量保存搜索资料的功能。
点击【全选当前页】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
精准过滤
搜索过滤器
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
广告过滤
极客邦新产品——极客搜索,整合技术文章资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-08-15 00:02
近日,极客帮发布了一款新产品——极客搜索,它整合了极客帮下的文章sources技术。抱着尝鲜的态度,我也试了一下,发现搜索速度极快。分析为什么这么快,主要有两点:1、resources太少!!!,12个公众号加起来5161文章; 2、使用Vue框架异步加载数据。这个产品还是很有用的,推荐一下,希望能快速增加可搜索的技术资源。
最近想用采集一些文章来做分词。这个接口是用vue写的,所以所有的数据都是通过接口,所以数据采集极其方便,所以心血来潮,趁着产品刚刚上线,防爬机制应该不会强,所以采集拥有极客邦的所有公众号数据。一:文章采集
主要分为采集文章链接和原文采集两步。
1、采集文章链接,通过搜索界面,抓取所有文章链接
从返回的数据中可以抓取文章原文本的链接,下一步就是链接采集原文本的数据。
2、原信息采集
使用scrapy框架获取采集微信文章数据,共5151篇采集文章。
具体代码见文末地址
二:数据分析
接下来,我对采集的文章做了一些简单的统计。
1、哪个公众号写得最多文章
infoQ 写了最多的文章,998 篇,占 19.35%。 StuQ以835篇文章排名第二,占比16.19%,EGONetworks以802篇文章排名第三,占比15.55%。这三部分恰好是极客科技的三大业务。
2、文章每日发布总数
随着越来越多的公众号开通,文章的数量不断上升,2017年达到每月250多篇,编辑能力很强。
文章每天发帖数统计:很规律,周一到周五发帖多,周六周日发帖少。周六周日努力工作的人。
3、文章词频统计
对所有文章词进行切分,然后统计词频。
Top 10:我们、一、数据、技术、罐头、服务、使用、需求、问题、系统
前 10 个词是:我们需要使用系统来服务技术或数据问题。是不是在暗示什么?我可以为你开发一个吗?商机就在这里。由于没有对分词结果做任何调整,所以出现了很多常用的修饰语等。这是一项对体力要求很高的工作,稍后会完成。
4、作者统计
基于文章作者的统计数据。前 10 名:StuQ、EGO、InfoQ、徐川、大嘉硕、陈媛媛、Q News、Indigo K 和郭亮、Stark Academy、Daniel V Classroom。
5、文章Title 趋势
文章标题的命名也反映了一段时间的趋势,所以我提取了所有文章标题并进行了分词。通过自定义jieba的字典,去掉很多修饰符等,得到如下结果。
2015:技术第一,这也符合极客的特点。我们提到了很多直播和微课堂,主要是StuQ公众号广告太多。当然,你也可以看到一些过去流行的词,比如互联网金融、大数据、创业、容器技术。
2016 年:技术仍然位居第一。出现了云计算、开源等词。同时,国内也有很多大公司如阿里、AWS、百度、京东等。
2017年:技术在不断变化,机器学习、深度学习、人工智能、AI等词汇的使用量不断增加,与当前的学习热潮相吻合。
从文章title的命名来看,极客帮微信公众号的内容基本紧跟最新科技趋势。把握科技发展趋势,分析题目即可。
三:总结
本文的主要工作是数据采集和分析。对于数据采集,不难,使用scrapy可以快速完成。数据分析比较耗时,我只做了一些简单的统计。后面会根据数据做一些文本关联分析。
数据的显示地址,源码也已经放在github,crawler-geekbang/geekbang at master · xuxping/crawler-geekbang · GitHub 查看全部
极客邦新产品——极客搜索,整合技术文章资源
近日,极客帮发布了一款新产品——极客搜索,它整合了极客帮下的文章sources技术。抱着尝鲜的态度,我也试了一下,发现搜索速度极快。分析为什么这么快,主要有两点:1、resources太少!!!,12个公众号加起来5161文章; 2、使用Vue框架异步加载数据。这个产品还是很有用的,推荐一下,希望能快速增加可搜索的技术资源。
最近想用采集一些文章来做分词。这个接口是用vue写的,所以所有的数据都是通过接口,所以数据采集极其方便,所以心血来潮,趁着产品刚刚上线,防爬机制应该不会强,所以采集拥有极客邦的所有公众号数据。一:文章采集
主要分为采集文章链接和原文采集两步。
1、采集文章链接,通过搜索界面,抓取所有文章链接
从返回的数据中可以抓取文章原文本的链接,下一步就是链接采集原文本的数据。
2、原信息采集
使用scrapy框架获取采集微信文章数据,共5151篇采集文章。
具体代码见文末地址
二:数据分析
接下来,我对采集的文章做了一些简单的统计。
1、哪个公众号写得最多文章
infoQ 写了最多的文章,998 篇,占 19.35%。 StuQ以835篇文章排名第二,占比16.19%,EGONetworks以802篇文章排名第三,占比15.55%。这三部分恰好是极客科技的三大业务。
2、文章每日发布总数
随着越来越多的公众号开通,文章的数量不断上升,2017年达到每月250多篇,编辑能力很强。
文章每天发帖数统计:很规律,周一到周五发帖多,周六周日发帖少。周六周日努力工作的人。
3、文章词频统计
对所有文章词进行切分,然后统计词频。
Top 10:我们、一、数据、技术、罐头、服务、使用、需求、问题、系统
前 10 个词是:我们需要使用系统来服务技术或数据问题。是不是在暗示什么?我可以为你开发一个吗?商机就在这里。由于没有对分词结果做任何调整,所以出现了很多常用的修饰语等。这是一项对体力要求很高的工作,稍后会完成。
4、作者统计
基于文章作者的统计数据。前 10 名:StuQ、EGO、InfoQ、徐川、大嘉硕、陈媛媛、Q News、Indigo K 和郭亮、Stark Academy、Daniel V Classroom。
5、文章Title 趋势
文章标题的命名也反映了一段时间的趋势,所以我提取了所有文章标题并进行了分词。通过自定义jieba的字典,去掉很多修饰符等,得到如下结果。
2015:技术第一,这也符合极客的特点。我们提到了很多直播和微课堂,主要是StuQ公众号广告太多。当然,你也可以看到一些过去流行的词,比如互联网金融、大数据、创业、容器技术。
2016 年:技术仍然位居第一。出现了云计算、开源等词。同时,国内也有很多大公司如阿里、AWS、百度、京东等。
2017年:技术在不断变化,机器学习、深度学习、人工智能、AI等词汇的使用量不断增加,与当前的学习热潮相吻合。
从文章title的命名来看,极客帮微信公众号的内容基本紧跟最新科技趋势。把握科技发展趋势,分析题目即可。
三:总结
本文的主要工作是数据采集和分析。对于数据采集,不难,使用scrapy可以快速完成。数据分析比较耗时,我只做了一些简单的统计。后面会根据数据做一些文本关联分析。
数据的显示地址,源码也已经放在github,crawler-geekbang/geekbang at master · xuxping/crawler-geekbang · GitHub
优采云采集推出智能信息收集东西,让你的运营更精准
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-08-10 20:11
疫情时代,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然不如面对面工作有效。为此优采云采集特智能信息采集的东西。
相信很多经营者都接触过采集东西。目前,市场上有很多不同种类的采集品。很多人认为采集东西只是作为文章热/节日话题等信息采集的辅助工具。事实上,它不仅仅是这样。 成熟的采集工具不仅可以帮助运营部门采集信息,还可以正确分析数据趋势,从而帮助增加收入。
优采云采集是自媒体材料搜滚、文章原创一键发布的运营工具,可有效提升新媒体运营效率,降低企业成本。
优采云采集按照用户输入的关键词自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据高级算法匹配更准确的内容,提高搜索内容的正确率。
例如:
用户需要采集与疫情相关的材料,在首页输入“流行”关键词。 优采云采集 将搜索结果整合为一列。
优采云采集具有批量保留搜索资料的功能。
点击【全选当前页面】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
优采云采集支持一次性过滤掉文章中的所有图片、联系方式等表白信息,解决新媒体运营快速找素材的需求。
优采云采集独有的智能搜索功能,保证数据的完整性。
用户可以点击标题进入原页面,获取文章的来源、浏览量、发布日期等信息,帮助用户分析文章的热度。
3、优采云采集能给你带来什么
减少采集材料时:
大大减少了搜索时间,帮助运营商更好更快地存储优质材料。
快速采集全网热门话题:
轻松获取各种主流自媒体的热门内容,及时更新最新热门内容,搜索效率翻倍。
智能过滤供述信息:
告白信息智能过滤,完美解决新媒体运营商快速查找素材的需求。
有助于提高工作效率:
海量素材+关键词价值选择+主流自媒体中优质素材快速搜索+智能识别文章最新和热门+持续更新,有助于提升新媒体运营效果。
简单的操作,让你在海量数据中发现价值,优采云采集,高效的文章一键采集工具。 查看全部
优采云采集推出智能信息收集东西,让你的运营更精准
疫情时代,很多企业不得不选择远程在线办公。互联网是受疫情影响较小的行业之一。然而,远程办公仍然不如面对面工作有效。为此优采云采集特智能信息采集的东西。
相信很多经营者都接触过采集东西。目前,市场上有很多不同种类的采集品。很多人认为采集东西只是作为文章热/节日话题等信息采集的辅助工具。事实上,它不仅仅是这样。 成熟的采集工具不仅可以帮助运营部门采集信息,还可以正确分析数据趋势,从而帮助增加收入。
优采云采集是自媒体材料搜滚、文章原创一键发布的运营工具,可有效提升新媒体运营效率,降低企业成本。
优采云采集按照用户输入的关键词自动进入主流自媒体数据源的搜索引擎进行搜索。
优采云采集根据高级算法匹配更准确的内容,提高搜索内容的正确率。
例如:
用户需要采集与疫情相关的材料,在首页输入“流行”关键词。 优采云采集 将搜索结果整合为一列。
优采云采集具有批量保留搜索资料的功能。
点击【全选当前页面】功能,勾选需要的文章,文章会添加到操作面板中,方便用户批量保存。
优采云采集支持根据标题、内容、时间、平台、是否原创等参数进行过滤,使搜索内容更加准确。
优采云采集支持一次性过滤掉文章中的所有图片、联系方式等表白信息,解决新媒体运营快速找素材的需求。
优采云采集独有的智能搜索功能,保证数据的完整性。
用户可以点击标题进入原页面,获取文章的来源、浏览量、发布日期等信息,帮助用户分析文章的热度。
3、优采云采集能给你带来什么
减少采集材料时:
大大减少了搜索时间,帮助运营商更好更快地存储优质材料。
快速采集全网热门话题:
轻松获取各种主流自媒体的热门内容,及时更新最新热门内容,搜索效率翻倍。
智能过滤供述信息:
告白信息智能过滤,完美解决新媒体运营商快速查找素材的需求。
有助于提高工作效率:
海量素材+关键词价值选择+主流自媒体中优质素材快速搜索+智能识别文章最新和热门+持续更新,有助于提升新媒体运营效果。
简单的操作,让你在海量数据中发现价值,优采云采集,高效的文章一键采集工具。
自适应美文源码美文阅读模板(5)--PC/电脑版演示地址
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-07-29 07:50
2021新帝国cms7.5自适应美式源码阅读模板文章templateitag+sitemap+百度推送+采集+安装教程
----------------------------------------------- ---------------------------------
PC/电脑版演示地址:
WAP/手机版演示地址:(请使用手机访问)
----------------------------------------------- ---------------------------------
源代码是EmpirecmsUTF8版本。如需GBK版本请自行转码!
这个模板是楼主自己复制的。不修改Empire程序默认的表前缀,不保留各种恶心的AD广告。
模板简洁大方,访问快捷,移动端优化美观用户体验。
适用于文章资讯美文句等文章资讯通网站等!
所有功能后台管理,已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用,采集精选优质源站,模板精美同时兼顾SEO搜索引擎优化。全站静态生成,有利于收录和关键词布局和内容页面优化!
功能列表:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。 (标签链接样式可选择ID或拼音)
2、内置百度推送插件,实时数据推送到步行搜索引擎。
3、带优采云采集规则,可以自己采集海量数据,全自动无人值守采集。
4、built-in网站map 站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示网站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
----------------------------------------------- -------------------------------------------------- --
●Empirecms7.5UTF-8
●系统开源,域名不限。
●同步生成WAP移动终端简单实用。
●大小约140MB
●简单的安装方法,详细的安装教程。
●TAG标签聚合
----------------------------------------------- -------------------------------------------------- --
查看全部
自适应美文源码美文阅读模板(5)--PC/电脑版演示地址
2021新帝国cms7.5自适应美式源码阅读模板文章templateitag+sitemap+百度推送+采集+安装教程
----------------------------------------------- ---------------------------------
PC/电脑版演示地址:
WAP/手机版演示地址:(请使用手机访问)
----------------------------------------------- ---------------------------------
源代码是EmpirecmsUTF8版本。如需GBK版本请自行转码!
这个模板是楼主自己复制的。不修改Empire程序默认的表前缀,不保留各种恶心的AD广告。
模板简洁大方,访问快捷,移动端优化美观用户体验。
适用于文章资讯美文句等文章资讯通网站等!
所有功能后台管理,已预留广告位(如需添加广告位请联系店主添加)。
模板使用标签灵活调用,采集精选优质源站,模板精美同时兼顾SEO搜索引擎优化。全站静态生成,有利于收录和关键词布局和内容页面优化!
功能列表:
1、内置ITAG插件,标签可以拼音,标签分类可用,功能更强大,更容易生成词库。 (标签链接样式可选择ID或拼音)
2、内置百度推送插件,实时数据推送到步行搜索引擎。
3、带优采云采集规则,可以自己采集海量数据,全自动无人值守采集。
4、built-in网站map 站点地图插件
本产品是整个站点的源代码,不仅是模板,还有演示站点的所有数据。
详情请看演示网站,更直观。
注意:演示站机器配置低,有延迟是正常的。这与模板程序无关。
----------------------------------------------- -------------------------------------------------- --
●Empirecms7.5UTF-8
●系统开源,域名不限。
●同步生成WAP移动终端简单实用。
●大小约140MB
●简单的安装方法,详细的安装教程。
●TAG标签聚合
----------------------------------------------- -------------------------------------------------- --
微信编辑器有可以采集文章的吗?怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-07-11 01:19
微信编辑器可以采集文章吗?
采集文章,这种编辑器还行,可以试试排版编辑器,右边采集文章,进入公众号图文链接,可以放官方账号你在里面看到的文章采集去版面人,然后点击右边的复制粘贴去公众平台,素材管理,新建图文留言,简单方便。
如何添加采集文章?
右侧有一个采集文章按钮。您可以一键点击采集文章到采集library。然后您可以通过选择编辑器页面右侧的导入按钮轻松完成。
大量发送伪原创文章、采集网站有什么影响吗?
非常不推荐这样做。如果是新站点,估计不会让你通过新站点的检查期。内容在互联网上重复。蜘蛛对网站的评价会很低,即使是新站之后。检查期间,这么多采集信息不利于收录。另外,璐璐算法主要针对采集信息,对网站的惩罚很严重。
如何批量处理采集网站文章?
可以用于采集的软件有很多,比如优采云,优采云可以用于batch采集文章注:网站batch采集的文章内容质量不是很好。建议手动采集和网站进行伪原创发布。这样,你的网站内容就会很好,在搜索引擎上排名很快。我自己总结了这些东西。经验,SEO 是一种相对较慢的技术。不要太担心。你越担心,排名就越困难。希望你不要太担心,希望能帮到你
如果使用采集others网站文章软件,是否涉及侵权?可以指定吗?
查看全部
微信编辑器有可以采集文章的吗?怎么办?
微信编辑器可以采集文章吗?
采集文章,这种编辑器还行,可以试试排版编辑器,右边采集文章,进入公众号图文链接,可以放官方账号你在里面看到的文章采集去版面人,然后点击右边的复制粘贴去公众平台,素材管理,新建图文留言,简单方便。
如何添加采集文章?
右侧有一个采集文章按钮。您可以一键点击采集文章到采集library。然后您可以通过选择编辑器页面右侧的导入按钮轻松完成。
大量发送伪原创文章、采集网站有什么影响吗?
非常不推荐这样做。如果是新站点,估计不会让你通过新站点的检查期。内容在互联网上重复。蜘蛛对网站的评价会很低,即使是新站之后。检查期间,这么多采集信息不利于收录。另外,璐璐算法主要针对采集信息,对网站的惩罚很严重。
如何批量处理采集网站文章?
可以用于采集的软件有很多,比如优采云,优采云可以用于batch采集文章注:网站batch采集的文章内容质量不是很好。建议手动采集和网站进行伪原创发布。这样,你的网站内容就会很好,在搜索引擎上排名很快。我自己总结了这些东西。经验,SEO 是一种相对较慢的技术。不要太担心。你越担心,排名就越困难。希望你不要太担心,希望能帮到你
如果使用采集others网站文章软件,是否涉及侵权?可以指定吗?
出售网站二级目录网站收录上1000基本你在友情链接交易平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-06-15 05:09
源代码功能详情
1、内置大量文章,安装后可以省时省力;
2、内置高效采集插件,每天自动采集1次(间隔可自行修改),真正无人值守;
3、内置10条采集规则;
4、 1个内置缓存插件,减轻前端访问压力;
5、网站管理简单快捷,后台基本可以修改前端显示信息,无需代码;
6、程序全部开源,不做任何加密,不定期提供升级;
7、采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,管理方便;
8、采集不用担心规则失效。我们拥有强大的技术团队,将提供规则升级服务;
9、图片默认使用远程地址,节省空间,本地可设置保存。
源码适合人群
1、劳族
白天上班,晚上休息。这个程序满足你。安装完成配置无误后,等待网站升级,真正无人值守。
2、做站群
有些人有几百个站,雇人要花钱。最好设置一个无人值守的采集站,既省事又省钱。
源代码盈利方法
1、广告联盟/网站广告/淘客
这个没什么好说的,它需要流量。
2、 出售友情链接
网站收录上1000 基本上你在友情链接交易平台上卖朋友没问题。
3、卖网站二级目录
网站收录好了 有人需要收录自然会找到你的。
4、卖站
网站收录上来卖5、6bai 没问题,权重上来多卖。
源代码环境
支持环境:Windows/linux PHP5.3/4/5/6 7.1 mysql5.+
推荐环境:linux php7.1 mysql5.6
程序安装文档
详见源码中付费安装文档
查看全部
出售网站二级目录网站收录上1000基本你在友情链接交易平台
源代码功能详情
1、内置大量文章,安装后可以省时省力;
2、内置高效采集插件,每天自动采集1次(间隔可自行修改),真正无人值守;
3、内置10条采集规则;
4、 1个内置缓存插件,减轻前端访问压力;
5、网站管理简单快捷,后台基本可以修改前端显示信息,无需代码;
6、程序全部开源,不做任何加密,不定期提供升级;
7、采用前端HTML5+CSS3响应式布局,多终端兼容(pc+手机+平板),数据同步,管理方便;
8、采集不用担心规则失效。我们拥有强大的技术团队,将提供规则升级服务;
9、图片默认使用远程地址,节省空间,本地可设置保存。
源码适合人群
1、劳族
白天上班,晚上休息。这个程序满足你。安装完成配置无误后,等待网站升级,真正无人值守。
2、做站群
有些人有几百个站,雇人要花钱。最好设置一个无人值守的采集站,既省事又省钱。
源代码盈利方法
1、广告联盟/网站广告/淘客
这个没什么好说的,它需要流量。
2、 出售友情链接
网站收录上1000 基本上你在友情链接交易平台上卖朋友没问题。
3、卖网站二级目录
网站收录好了 有人需要收录自然会找到你的。
4、卖站
网站收录上来卖5、6bai 没问题,权重上来多卖。
源代码环境
支持环境:Windows/linux PHP5.3/4/5/6 7.1 mysql5.+
推荐环境:linux php7.1 mysql5.6
程序安装文档
详见源码中付费安装文档
打开非找你微信编辑器的入口都在地址栏复制
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-05-20 04:03
微信美国文字资料采集 [文件1:微信美国文字资料采集] 网站的三个入口位于编辑器的右侧(如2)所示,在这里不多说了) 。如何采集以微信精选为例:首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能(如1)所示,它将自动复制文章网址],只有一点,没有此功能网站,只能顺从地从地址栏中复制。打开微信编辑器(如果使用的是计算机版本,右侧还有采集按钮,请点击在其上,将弹出一个采集提示框,使用快捷键ctrl + v,粘贴第一步中复制的URL,然后单击“ 采集整个文章文章”。在采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮,将其粘贴并发布到微信公众平台即可。[第二部分:微信美国文字资料[ 采集]中国互联网和移动互联网的规模急剧增加,每天产生的信息不计其数。 采集网页中收录大量信息的数据,然后在工作和生活中使用,已变得非常普遍,并且也已演变为大数据时代的趋势。随着信息量的增加和网页结构的复杂性,数据获取的难度不断提高。对于过去的简单和少量数据,可以通过手动复制和粘贴轻松地采集。例如,为了充实博客或展示学术报告,我们将从互联网文章,期刊,图片等中提取一些内容。现在,我们对数据的使用越来越广泛,公司需要大量数据进行分析业务发展趋势,挖掘潜在机会并做出正确的决定;他们需要以多种方式理解人民的心声,以促进服务业的转型;医疗,教育,金融...如果没有数据,他们都无法实现快速发展。
这些数据大部分来自公共Internet,来自人们在网络上输入的大量文本,图片和其他可能有价值的信息。由于大量的信息和数据,采集不再可以手动获取它们,因此网络爬网工具已进入人们的视野,并取代了手册采集作为获取数据的最新捷径。当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过http协议直接请求网页的源代码,并设置采集的规则以实现网页数据的爬网,无论是图片,文本还是文件都可以被爬网。这种搜寻工具的优点是稳定且非常快。用户需要了解网页源代码的相关知识,然后将其设置在爬网工具上,然后可以将其完全移交给该工具。 采集。世兴的这种爬网工具还收录更多功能,例如优采云 采集器(;此外,优采云 采集器中的数据替换,过滤,重复数据删除以及其他处理和数据发布等功能,它还支持辅助代理服务器可满足插件扩展等的三种不同目的,并集成了各种智能功能;另一种是使用特定的网页元素定位和采集器引擎来模拟人们对打开网页和单击Web内容的想法,采集通过浏览器可视化呈现的内容,其优点在于可视化和灵活性,虽然可能不及优采云 采集器类型的采集器,但处理复杂的网页(例如优采云)更容易优采云系列浏览器的另一种产品,两种工具都有各自的优势,用户可以根据需要进行选择,对于更高的抓取需求,可以将两种类型的软件结合使用以方便对接,而同一品牌的两种软件可以同时使用。用于r组合。
借助Web爬行工具,图形数据甚至压缩文件,音频和其他数据的获取变得非常简单,就像人类的每一项伟大发明将引领时代的进步一样,大数据时代也需要大趋势。我们与时俱进,运用智慧控制行为,并利用数据赢得未来。为了获取数据,Web爬网工具将带来真正的效率。 [论文三:微信美国文字资料采集]微信图形信息模板/素材模板大全微信图形信息编辑器/带有素材的图像热门阅读(114 1)评论(0)标签:/ 查看全部
打开非找你微信编辑器的入口都在地址栏复制
微信美国文字资料采集 [文件1:微信美国文字资料采集] 网站的三个入口位于编辑器的右侧(如2)所示,在这里不多说了) 。如何采集以微信精选为例:首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能(如1)所示,它将自动复制文章网址],只有一点,没有此功能网站,只能顺从地从地址栏中复制。打开微信编辑器(如果使用的是计算机版本,右侧还有采集按钮,请点击在其上,将弹出一个采集提示框,使用快捷键ctrl + v,粘贴第一步中复制的URL,然后单击“ 采集整个文章文章”。在采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮,将其粘贴并发布到微信公众平台即可。[第二部分:微信美国文字资料[ 采集]中国互联网和移动互联网的规模急剧增加,每天产生的信息不计其数。 采集网页中收录大量信息的数据,然后在工作和生活中使用,已变得非常普遍,并且也已演变为大数据时代的趋势。随着信息量的增加和网页结构的复杂性,数据获取的难度不断提高。对于过去的简单和少量数据,可以通过手动复制和粘贴轻松地采集。例如,为了充实博客或展示学术报告,我们将从互联网文章,期刊,图片等中提取一些内容。现在,我们对数据的使用越来越广泛,公司需要大量数据进行分析业务发展趋势,挖掘潜在机会并做出正确的决定;他们需要以多种方式理解人民的心声,以促进服务业的转型;医疗,教育,金融...如果没有数据,他们都无法实现快速发展。
这些数据大部分来自公共Internet,来自人们在网络上输入的大量文本,图片和其他可能有价值的信息。由于大量的信息和数据,采集不再可以手动获取它们,因此网络爬网工具已进入人们的视野,并取代了手册采集作为获取数据的最新捷径。当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过http协议直接请求网页的源代码,并设置采集的规则以实现网页数据的爬网,无论是图片,文本还是文件都可以被爬网。这种搜寻工具的优点是稳定且非常快。用户需要了解网页源代码的相关知识,然后将其设置在爬网工具上,然后可以将其完全移交给该工具。 采集。世兴的这种爬网工具还收录更多功能,例如优采云 采集器(;此外,优采云 采集器中的数据替换,过滤,重复数据删除以及其他处理和数据发布等功能,它还支持辅助代理服务器可满足插件扩展等的三种不同目的,并集成了各种智能功能;另一种是使用特定的网页元素定位和采集器引擎来模拟人们对打开网页和单击Web内容的想法,采集通过浏览器可视化呈现的内容,其优点在于可视化和灵活性,虽然可能不及优采云 采集器类型的采集器,但处理复杂的网页(例如优采云)更容易优采云系列浏览器的另一种产品,两种工具都有各自的优势,用户可以根据需要进行选择,对于更高的抓取需求,可以将两种类型的软件结合使用以方便对接,而同一品牌的两种软件可以同时使用。用于r组合。
借助Web爬行工具,图形数据甚至压缩文件,音频和其他数据的获取变得非常简单,就像人类的每一项伟大发明将引领时代的进步一样,大数据时代也需要大趋势。我们与时俱进,运用智慧控制行为,并利用数据赢得未来。为了获取数据,Web爬网工具将带来真正的效率。 [论文三:微信美国文字资料采集]微信图形信息模板/素材模板大全微信图形信息编辑器/带有素材的图像热门阅读(114 1)评论(0)标签:/
两个网站关于“卷积神经网络”的期刊数据量
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-04-27 01:13
最近由于公司的需求采集 HowNet数据(标题,来源,关键字,作者,单位,分类号,摘要,类似文档等),因为HowNet太强大而无法阻止爬网,因此内容页面链接是加密,请尝试使用Pyspider,scrapy和selenium无法进入内容页面并直接跳到CNKI主页。因此,我不得不使用HowNet的界面来执行采集:以下是两本网站关于“卷积神经网络”的期刊,并将其数据量进行了比较,如下图所示:
image.png
image.png
仔细查看会发现网站是一个发布请求,并且焦点集中在带有参数的请求上。打开先见之明,搜索所需内容,按f2键,然后查看参数中的表单数据。就像我要使用的是卷积神经网络[k13]型日志一样,您可以在此处用您的参数替换它们。
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
以下是实现代码:
# encoding='utf-8'
import json
import re
from lxml import etree
import requests
import codecs
class CNKI(object):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
cookies = {
'Cookie': 'Ecp_ClientId=4181108101501154830; cnkiUserKey=ec1ef785-3872-fac6-cad3-402229207945; UM_distinctid=166f12b44b1654-05e4c1a8d86edc-b79183d-1fa400-166f12b44b2ac8; KEYWORD=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%24%E5%8D%B7%E7%A7%AF%20%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C; Ecp_IpLoginFail=1811121.119.135.10; amid=73b0014b-8b61-4e24-a333-8774cb4dd8bd; SID=110105; CNZZDATA1257838113=579682214-1541655561-http%253A%252F%252Fsearch.cnki.net%252F%7C1542070177'}
param = {
'Accept': 'text/html, */*; q=0.01',
'Accept - Encoding': 'gzip, deflate',
'Accept - Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep - alive',
'Content - Type': 'application / x - www - form - urlencoded;charset = UTF - 8',
'Host': 'yuanjian.cnki.net',
'Origin': 'http: // yuanjian.cnki.net',
'Referer': 'http: // yuanjian.cnki.net / Search / Result',
'X - Requested - With': 'XMLHttpRequest'}
def content(self):
li = []
# 遍历总页数
for j in range(1, 134):
for i in range(j, j + 1):
url = 'http://yuanjian.cnki.net/Search/Result'
print('当前页', i)
# post 传参
formdata = {'Type': 1,
'ArticleType': 1,
'Theme': '卷积神经网络',
'Page': i}
print(formdata)
try:
r = requests.post(url, data=formdata, headers=self.headers, cookies=self.cookies, params=self.param)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = etree.HTML(r.text)
# 链接列表
url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
# 关键词列表
key_wordlist = []
all_items = data.xpath("//*[@id='article_result']/div/div")
for i in range(1, len(all_items) + 1):
key_word = data.xpath("//*[@id='article_result']/div/div[%s]/div[1]/p[1]/a/text()" % i)
key_words = ';'.join(key_word)
key_wordlist.append(key_words)
# 来源
source_items = data.xpath("//*[@id='article_result']/div/div")
for j in range(1, len(source_items) + 1):
sources = data.xpath("//*[@id='article_result']/div/div/p[3]/a[1]/span/text()")
for index, url in enumerate(url_list):
items = {}
try:
print('当前链接:', url)
content = requests.get(url, headers=self.headers)
contents = etree.HTML(content.text)
# 论文题目
title = contents.xpath("//h1[@class='xx_title']/text()")[0]
print('标题:', title)
# 来源
source = sources[index]
items['source'] = source
print('来源:', source)
items['title'] = title
# 关键字
each_key_words = key_wordlist[index]
print('关键字:', each_key_words)
items['keywordsEn'] = ''
items['keywordsCh'] = each_key_words
# 作者
author = contents.xpath("//*[@id='content']/div[2]/div[3]/a/text()")
items['author'] = author
print('作者:', author)
# 单位
unit = contents.xpath("//*[@id='content']/div[2]/div[5]/a[1]/text()")
units = ''.join(unit).strip(';')
items['unit'] = units
print('单位:', units)
# 分类号
classify = contents.xpath("//*[@id='content']/div[2]/div[5]/text()")[-1]
items['classify'] = classify
print('分类号:', classify)
# 摘要
abstract = contents.xpath("//div[@class='xx_font'][1]/text()")[1].strip()
print('摘要:', abstract)
items['abstractCh'] = abstract
items['abstractEn'] = ''
# 相似文献
similar = contents.xpath(
"//*[@id='xiangsi']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
si = ''.join(similar).replace('\r\n', '').split('期')
po = []
for i in si:
sis = i + '期'
if len(sis) > 3:
po.append(sis)
items['similar_article'] = po
li.append(items)
except Exception as e:
print(e)
print(len(li))
except Exception as e:
print(e)
return li
if __name__ == '__main__':
con = CNKI()
items = con.content()
print(items)
try:
with codecs.open('./cnki_data.json', 'a+', encoding="utf-8") as fp:
for i in items:
fp.write(json.dumps(i, ensure_ascii=False) + ",\n")
except IOError as err:
print('error' + str(err))
finally:
fp.close()
结束〜
小白,希望对大家有帮助。如果有问题,请纠正我。 查看全部
两个网站关于“卷积神经网络”的期刊数据量
最近由于公司的需求采集 HowNet数据(标题,来源,关键字,作者,单位,分类号,摘要,类似文档等),因为HowNet太强大而无法阻止爬网,因此内容页面链接是加密,请尝试使用Pyspider,scrapy和selenium无法进入内容页面并直接跳到CNKI主页。因此,我不得不使用HowNet的界面来执行采集:以下是两本网站关于“卷积神经网络”的期刊,并将其数据量进行了比较,如下图所示:
image.png
image.png
仔细查看会发现网站是一个发布请求,并且焦点集中在带有参数的请求上。打开先见之明,搜索所需内容,按f2键,然后查看参数中的表单数据。就像我要使用的是卷积神经网络[k13]型日志一样,您可以在此处用您的参数替换它们。
formdata = {'Type': 1,
'Order': 1,
'Islegal': 'false',
'ArticleType': 1,
'Theme': '卷积神经网络',
'searchType': 'MulityTermsSearch',
'ParamIsNullOrEmpty': 'true',
'Page': i}
以下是实现代码:
# encoding='utf-8'
import json
import re
from lxml import etree
import requests
import codecs
class CNKI(object):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'}
cookies = {
'Cookie': 'Ecp_ClientId=4181108101501154830; cnkiUserKey=ec1ef785-3872-fac6-cad3-402229207945; UM_distinctid=166f12b44b1654-05e4c1a8d86edc-b79183d-1fa400-166f12b44b2ac8; KEYWORD=%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%24%E5%8D%B7%E7%A7%AF%20%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C; Ecp_IpLoginFail=1811121.119.135.10; amid=73b0014b-8b61-4e24-a333-8774cb4dd8bd; SID=110105; CNZZDATA1257838113=579682214-1541655561-http%253A%252F%252Fsearch.cnki.net%252F%7C1542070177'}
param = {
'Accept': 'text/html, */*; q=0.01',
'Accept - Encoding': 'gzip, deflate',
'Accept - Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep - alive',
'Content - Type': 'application / x - www - form - urlencoded;charset = UTF - 8',
'Host': 'yuanjian.cnki.net',
'Origin': 'http: // yuanjian.cnki.net',
'Referer': 'http: // yuanjian.cnki.net / Search / Result',
'X - Requested - With': 'XMLHttpRequest'}
def content(self):
li = []
# 遍历总页数
for j in range(1, 134):
for i in range(j, j + 1):
url = 'http://yuanjian.cnki.net/Search/Result'
print('当前页', i)
# post 传参
formdata = {'Type': 1,
'ArticleType': 1,
'Theme': '卷积神经网络',
'Page': i}
print(formdata)
try:
r = requests.post(url, data=formdata, headers=self.headers, cookies=self.cookies, params=self.param)
r.raise_for_status()
r.encoding = r.apparent_encoding
data = etree.HTML(r.text)
# 链接列表
url_list = data.xpath("//*[@id='article_result']/div/div/p[1]/a[1]/@href")
# 关键词列表
key_wordlist = []
all_items = data.xpath("//*[@id='article_result']/div/div")
for i in range(1, len(all_items) + 1):
key_word = data.xpath("//*[@id='article_result']/div/div[%s]/div[1]/p[1]/a/text()" % i)
key_words = ';'.join(key_word)
key_wordlist.append(key_words)
# 来源
source_items = data.xpath("//*[@id='article_result']/div/div")
for j in range(1, len(source_items) + 1):
sources = data.xpath("//*[@id='article_result']/div/div/p[3]/a[1]/span/text()")
for index, url in enumerate(url_list):
items = {}
try:
print('当前链接:', url)
content = requests.get(url, headers=self.headers)
contents = etree.HTML(content.text)
# 论文题目
title = contents.xpath("//h1[@class='xx_title']/text()")[0]
print('标题:', title)
# 来源
source = sources[index]
items['source'] = source
print('来源:', source)
items['title'] = title
# 关键字
each_key_words = key_wordlist[index]
print('关键字:', each_key_words)
items['keywordsEn'] = ''
items['keywordsCh'] = each_key_words
# 作者
author = contents.xpath("//*[@id='content']/div[2]/div[3]/a/text()")
items['author'] = author
print('作者:', author)
# 单位
unit = contents.xpath("//*[@id='content']/div[2]/div[5]/a[1]/text()")
units = ''.join(unit).strip(';')
items['unit'] = units
print('单位:', units)
# 分类号
classify = contents.xpath("//*[@id='content']/div[2]/div[5]/text()")[-1]
items['classify'] = classify
print('分类号:', classify)
# 摘要
abstract = contents.xpath("//div[@class='xx_font'][1]/text()")[1].strip()
print('摘要:', abstract)
items['abstractCh'] = abstract
items['abstractEn'] = ''
# 相似文献
similar = contents.xpath(
"//*[@id='xiangsi']/table[2]/tbody/tr[3]/td/table/tbody/tr/td/text()")
si = ''.join(similar).replace('\r\n', '').split('期')
po = []
for i in si:
sis = i + '期'
if len(sis) > 3:
po.append(sis)
items['similar_article'] = po
li.append(items)
except Exception as e:
print(e)
print(len(li))
except Exception as e:
print(e)
return li
if __name__ == '__main__':
con = CNKI()
items = con.content()
print(items)
try:
with codecs.open('./cnki_data.json', 'a+', encoding="utf-8") as fp:
for i in items:
fp.write(json.dumps(i, ensure_ascii=False) + ",\n")
except IOError as err:
print('error' + str(err))
finally:
fp.close()
结束〜
小白,希望对大家有帮助。如果有问题,请纠正我。
分享:微信美文素材采集的相关文档搜索
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2020-11-25 13:12
的相关文档
微信美国文字资料采集
[第1条:微信美国文字资料采集]
三个网站的入口都在编辑器的右侧(如2)中所示,在此我不再赘述。
如何采集以微信选择为例:
1.首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能
(如1)所示,文章 URL会自动复制到一个位置,而没有此功能的网站只能很好
地址栏中的好副本。
2.打开“找不到您”的微信编辑器(如果您使用的是计算机版本,则右侧也有
一个采集按钮,单击它会弹出采集提示框,使用快捷键ctrl + v粘贴第一个
一步一步复制URL,然后单击“ 采集整篇文章文章”。
在3.采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮即可粘贴并发布到微信公众平台。
[第2节:微信美国文字资料采集]
中国互联网和移动互联网的规模急剧增加,每天产生无数信息。 采集数据在具有大量信息的网页上用于工作和生活。
中国已经变得非常普遍,并已演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂性,数据获取的难度不断增加
促销。对于过去的简单和少量数据,只需手动复制和粘贴
例如,很容易采集来充实我们的博客或展示学术文章
报告,某些文章,期刊,图片等将从Internet上提取。现在我们是对的
数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会并做出正确的决策;他们需要从多个方面了解人们的心声并进行宣传
服务转换;医疗,教育,金融...没有数据就无法实现快速发展。
这些数据大部分来自公共互联网,是人们在网页中输入的大量文本,
图片和其他可能有价值的信息,这些信息数据由于数量巨大而无法再通信
使用手动采集进行获取,因此网络抓取工具已进入人们的视野,
并替换手册采集作为获取数据的最新捷径。
当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过http协议直接请求网页的源代码,并设置采集的规则以实现网页数据
爬行,无论是图片,文本还是文件,都可以爬行。这类抓取工作
优点是它稳定且非常快。用户需要知道网页的源代码。
进行一些了解,然后将其设置在采集器上,您可以将其完全留给工具
采集。狮兴的爬虫还包括更多功能,例如优采云采集器
(数据中的数据替换,过滤,重复数据删除以及其他处理和数据发布;此外,火灾
Che 采集器还支持辅助代理服务器,以满足插件扩展等的三种不同目的,从而将各种智能功能集成在一起。
另一种方法是使用特定的网页元素定位和采集器引擎来模拟人们打开网页并单击
网络内容的思考,采集已由浏览器可视化呈现的内容。优点
它具有可视化和灵活性。它的速度可能不及优采云采集器类型的采集器,但是它更易于处理复杂的网页,例如优采云系列的另一产品优采云浏览器。两种工具都有自己的优势。用户可以根据自己的需要进行选择。更多
对抓取的需求很高,可以将两种软件一起使用,为方便对接,可以
选择两个相同品牌的软件进行组合。
使用网络抓取工具,可以获得图形数据甚至压缩文件,音频和其他数据
它已经变得简单了。正如人类的每一项伟大发明都会引领时代的进步一样,大数据时代的大趋势也要求我们与时俱进,运用智慧控制行为,并利用数据赢得未来。为了获取数据,Web爬网工具将带来真正的高效率。
[第三部分:微信美国文字资料采集]
微信图形消息模板/材料模板大全微信图形消息编辑器/收录材料的图片的大众阅读(1141)评论(0)标签:/ 查看全部
搜索微信美闻资料采集
的相关文档
微信美国文字资料采集
[第1条:微信美国文字资料采集]
三个网站的入口都在编辑器的右侧(如2)中所示,在此我不再赘述。
如何采集以微信选择为例:
1.首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能
(如1)所示,文章 URL会自动复制到一个位置,而没有此功能的网站只能很好
地址栏中的好副本。
2.打开“找不到您”的微信编辑器(如果您使用的是计算机版本,则右侧也有
一个采集按钮,单击它会弹出采集提示框,使用快捷键ctrl + v粘贴第一个
一步一步复制URL,然后单击“ 采集整篇文章文章”。
在3.采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮即可粘贴并发布到微信公众平台。
[第2节:微信美国文字资料采集]
中国互联网和移动互联网的规模急剧增加,每天产生无数信息。 采集数据在具有大量信息的网页上用于工作和生活。
中国已经变得非常普遍,并已演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂性,数据获取的难度不断增加
促销。对于过去的简单和少量数据,只需手动复制和粘贴
例如,很容易采集来充实我们的博客或展示学术文章
报告,某些文章,期刊,图片等将从Internet上提取。现在我们是对的
数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会并做出正确的决策;他们需要从多个方面了解人们的心声并进行宣传
服务转换;医疗,教育,金融...没有数据就无法实现快速发展。
这些数据大部分来自公共互联网,是人们在网页中输入的大量文本,
图片和其他可能有价值的信息,这些信息数据由于数量巨大而无法再通信
使用手动采集进行获取,因此网络抓取工具已进入人们的视野,
并替换手册采集作为获取数据的最新捷径。
当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过http协议直接请求网页的源代码,并设置采集的规则以实现网页数据
爬行,无论是图片,文本还是文件,都可以爬行。这类抓取工作
优点是它稳定且非常快。用户需要知道网页的源代码。
进行一些了解,然后将其设置在采集器上,您可以将其完全留给工具
采集。狮兴的爬虫还包括更多功能,例如优采云采集器
(数据中的数据替换,过滤,重复数据删除以及其他处理和数据发布;此外,火灾
Che 采集器还支持辅助代理服务器,以满足插件扩展等的三种不同目的,从而将各种智能功能集成在一起。
另一种方法是使用特定的网页元素定位和采集器引擎来模拟人们打开网页并单击
网络内容的思考,采集已由浏览器可视化呈现的内容。优点
它具有可视化和灵活性。它的速度可能不及优采云采集器类型的采集器,但是它更易于处理复杂的网页,例如优采云系列的另一产品优采云浏览器。两种工具都有自己的优势。用户可以根据自己的需要进行选择。更多
对抓取的需求很高,可以将两种软件一起使用,为方便对接,可以
选择两个相同品牌的软件进行组合。
使用网络抓取工具,可以获得图形数据甚至压缩文件,音频和其他数据
它已经变得简单了。正如人类的每一项伟大发明都会引领时代的进步一样,大数据时代的大趋势也要求我们与时俱进,运用智慧控制行为,并利用数据赢得未来。为了获取数据,Web爬网工具将带来真正的高效率。
[第三部分:微信美国文字资料采集]
微信图形消息模板/材料模板大全微信图形消息编辑器/收录材料的图片的大众阅读(1141)评论(0)标签:/
分享:微信美文素材采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 496 次浏览 • 2020-11-15 13:00
第1部分:微信美国文字资料采集
三个网站的入口在编辑器的右侧(如2)所示,在这里不多说了。
如何采集以微信选择为例:
1.首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能(如1)所示,它将自动复制文章 URL,无需此功能网站]只能听从地址栏中的复制。
2.打开不需要的微信编辑器(如果使用的是计算机版本,则右侧还有采集按钮,单击它会弹出一个采集提示框,请使用快捷键ctrl + v,粘贴第一步中复制的URL,然后单击“ 采集整篇文章文章”。
在3.采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮即可粘贴并发布到微信公众平台。
第二部分:微信美国文字资料采集
中国互联网和移动互联网的规模急剧增加,每天产生无数信息。 采集网页中收录大量信息的数据,然后在工作和生活中使用,已变得非常普遍,并且也演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂性,数据获取的难度也在增加。对于过去的简单和少量数据,可以通过手动复制和粘贴轻松地采集。例如,为了充实我们的博客或展示学术报告,我们将从互联网上提取一些文章,期刊,图片等。但是现在我们对数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会并做出正确的决策;他们需要从多方面理解人们的声音,以促进服务转型。医疗,教育和金融……没有数据,任何人都无法迅速发展。
这些数据大多数来自公共Internet,来自人们在网络上输入的大量文本,图片和其他可能有价值的信息。由于大量的信息和数据,采集不再可以手动获得它们,因此Web爬网工具已进入人们的视野,并取代了手册采集作为数据获取的最新捷径。
当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过HTTP协议直接请求网页的源代码,并设置采集的规则以实现网页数据的爬网,无论是图片,文本还是文件都可以被爬网。这种搜寻工具的优点是稳定且非常快速。用户需要了解网页源代码的相关知识,然后在爬网工具上进行设置以完成交付。用工具转到采集。世兴的爬网工具还收录更多功能,例如优采云采集器(;中,优采云采集器]中的数据替换,过滤,重置和其他处理以及数据发布等功能,还支持辅助代理服务器,满足三种不同用途的插件扩展等,并集成了各种智能功能。
另一种方法是使用特定的网页元素定位和采集器引擎来模拟人们打开网页并单击网页内容的想法。 采集浏览器以可视方式呈现的内容。它的优势在于可视化和灵活性,虽然可能不及优采云采集器类型的采集器,但它更易于处理复杂的网页,例如优采云浏览器(优采云的另一种产品)系列。两种工具都有各自的优势。用户可以根据自己的需要进行选择。为了满足更高的爬网需求,可以同时使用两种类型的软件。为了方便对接,可以使用两个相同品牌的软件进行组合。
使用Web爬行工具,图形数据甚至压缩文件,音频和其他数据的获取变得非常简单,就像人类的每一项伟大发明将引领时代的进步一样,大数据时代也需要大趋势。我们与时俱进,运用智慧控制行为,并利用数据确定未来。为了获取数据,Web爬网工具将带来真正的高效率。
第三部分:微信美国文字资料采集
微信图形信息模板/素材模板大全微信图形信息编辑器/包括素材图片人气排行 查看全部
微信美国文字资料采集
第1部分:微信美国文字资料采集
三个网站的入口在编辑器的右侧(如2)所示,在这里不多说了。
如何采集以微信选择为例:
1.首先打开文章文章复制文章 URL,微信精选具有一键复制URL功能(如1)所示,它将自动复制文章 URL,无需此功能网站]只能听从地址栏中的复制。
2.打开不需要的微信编辑器(如果使用的是计算机版本,则右侧还有采集按钮,单击它会弹出一个采集提示框,请使用快捷键ctrl + v,粘贴第一步中复制的URL,然后单击“ 采集整篇文章文章”。
在3.采集之后,您可以在编辑器中编辑和修改文章。修改完成后,只需单击右侧的复制按钮即可粘贴并发布到微信公众平台。
第二部分:微信美国文字资料采集
中国互联网和移动互联网的规模急剧增加,每天产生无数信息。 采集网页中收录大量信息的数据,然后在工作和生活中使用,已变得非常普遍,并且也演变成大数据时代的趋势。
随着信息量的增加和网页结构的复杂性,数据获取的难度也在增加。对于过去的简单和少量数据,可以通过手动复制和粘贴轻松地采集。例如,为了充实我们的博客或展示学术报告,我们将从互联网上提取一些文章,期刊,图片等。但是现在我们对数据的使用变得更加广泛。企业需要大量数据来分析业务发展趋势,挖掘潜在机会并做出正确的决策;他们需要从多方面理解人们的声音,以促进服务转型。医疗,教育和金融……没有数据,任何人都无法迅速发展。
这些数据大多数来自公共Internet,来自人们在网络上输入的大量文本,图片和其他可能有价值的信息。由于大量的信息和数据,采集不再可以手动获得它们,因此Web爬网工具已进入人们的视野,并取代了手册采集作为数据获取的最新捷径。
当前,有两种类型的具有大量用户的Web爬网工具。一种是源代码分析类型,它通过HTTP协议直接请求网页的源代码,并设置采集的规则以实现网页数据的爬网,无论是图片,文本还是文件都可以被爬网。这种搜寻工具的优点是稳定且非常快速。用户需要了解网页源代码的相关知识,然后在爬网工具上进行设置以完成交付。用工具转到采集。世兴的爬网工具还收录更多功能,例如优采云采集器(;中,优采云采集器]中的数据替换,过滤,重置和其他处理以及数据发布等功能,还支持辅助代理服务器,满足三种不同用途的插件扩展等,并集成了各种智能功能。
另一种方法是使用特定的网页元素定位和采集器引擎来模拟人们打开网页并单击网页内容的想法。 采集浏览器以可视方式呈现的内容。它的优势在于可视化和灵活性,虽然可能不及优采云采集器类型的采集器,但它更易于处理复杂的网页,例如优采云浏览器(优采云的另一种产品)系列。两种工具都有各自的优势。用户可以根据自己的需要进行选择。为了满足更高的爬网需求,可以同时使用两种类型的软件。为了方便对接,可以使用两个相同品牌的软件进行组合。
使用Web爬行工具,图形数据甚至压缩文件,音频和其他数据的获取变得非常简单,就像人类的每一项伟大发明将引领时代的进步一样,大数据时代也需要大趋势。我们与时俱进,运用智慧控制行为,并利用数据确定未来。为了获取数据,Web爬网工具将带来真正的高效率。
第三部分:微信美国文字资料采集
微信图形信息模板/素材模板大全微信图形信息编辑器/包括素材图片人气排行
推荐文章:微信公众号文章采集的入口--历史消息页详解
采集交流 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2020-10-12 12:01
采集 WeChat文章和采集 网站具有相同的内容,并且都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如先前文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有正式帐户中唯一的一个。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址无效之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果要自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的官方帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址是localhost:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接到最前面后,可以在浏览器中打开。
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值,并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍了一些重要信息,其他信息则省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的历史消息内容,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页面的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy将msgList变量值与服务器异步地匹配,然后使用php的json_decode将json从服务器解析为数组。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要采集中的一个正式帐户的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。
现在,我们可以通过官方帐户的历史新闻获得文章列表。在下一篇文章文章中,我将根据历史新闻中的文章链接地址介绍如何获取文章的特定内容。在保存文章,封面图片和全文检索方面也有一些经验。
如果您认为我不清楚自己写的是什么,或者如果我不了解某些内容,请在下面留言。或骚扰微信帐户的翠金,就像感觉良好一样。
持续更新,建设微信公众号文章批处理采集系统
微信公众号文章采集输入-历史新闻页面的详细说明
微信公众号文章页面的分析和采集
提高微信公众号文章采集的效率,先进使用anyproxy 查看全部
微信公众号文章采集输入-历史新闻页面的详细说明
采集 WeChat文章和采集 网站具有相同的内容,并且都需要从列表页面开始。而微信文章的列表页面是官方账户中的观看历史信息页面。互联网上的其他一些微信采集器现在使用搜狗进行搜索。尽管采集的方法简单得多,但内容并不完整。因此,我们仍然必须来自最标准,最全面的官方帐户历史记录信息页面采集。
由于微信的限制,我们可以复制到的链接不完整,并且无法在浏览器中打开内容。因此,我们需要使用anyproxy通过上一篇文章文章中介绍的方法来获取完整的微信官方帐户历史记录消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
如先前文章文章所述,biz参数是官方帐户的ID,而uin是用户的ID。目前,uin是所有正式帐户中唯一的一个。另外两个重要参数key和pass_ticket是微信客户端上的补充参数。
因此,在该地址无效之前,我们可以通过在浏览器中查看原创文本来获取历史消息的文章列表。如果要自动分析内容,我们还可以使用尚未过期的密钥来编写程序。例如,使用pass_ticket的链接地址提交它,然后通过php程序获取文章列表。
最近,一个朋友告诉我,他的采集目标是一个单一的官方帐户,我认为没有必要使用上一篇文章文章中编写的批处理采集方法。因此,让我们看一下历史新闻页面中如何获取文章列表。通过分析文章列表,我们可以获得该官方帐户的所有内容链接地址,然后采集内容就可以了。
如果在anyproxy Web界面中正确配置了证书,则可以显示https的内容。 Web界面的地址是localhost:8002,其中localhost可以替换为您自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,然后单击它,该记录的详细信息将显示在右侧:
红色框是完整的链接地址。将微信公众平台的域名拼接到最前面后,可以在浏览器中打开。
然后将页面下拉至html内容的末尾,我们可以看到json变量是历史新闻的文章列表:
我们复制msgList的变量值,并使用json格式化工具对其进行分析,我们可以看到json具有以下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对此json的简要分析(此处仅介绍了一些重要信息,其他信息则省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里要提到的另一件事是,如果您想获得更长的历史消息内容,则需要在电话或仿真器中下拉页面。当您到达底部时,微信会自动读取它。下一页的内容。下一页的链接地址和历史消息页面的链接地址也是以getmasssendmsg开头的地址。但是内容只是json,没有html。只需直接解析json。
这时,您可以使用上一篇文章文章中介绍的方法来使用anyproxy将msgList变量值与服务器异步地匹配,然后使用php的json_decode将json从服务器解析为数组。然后遍历循环数组。我们可以获取每篇文章的标题和链接地址文章。
如果您只需要采集中的一个正式帐户的内容,则可以在每日批量发布后通过anyproxy获得带有key和pass_ticket的完整链接地址。然后自己制作一个程序,然后手动将地址提交给您的程序。使用php等语言定期匹配msgList,然后解析json。这样,无需修改anyproxy规则,也无需制作采集队列和跳转页面。
现在,我们可以通过官方帐户的历史新闻获得文章列表。在下一篇文章文章中,我将根据历史新闻中的文章链接地址介绍如何获取文章的特定内容。在保存文章,封面图片和全文检索方面也有一些经验。
如果您认为我不清楚自己写的是什么,或者如果我不了解某些内容,请在下面留言。或骚扰微信帐户的翠金,就像感觉良好一样。
持续更新,建设微信公众号文章批处理采集系统
微信公众号文章采集输入-历史新闻页面的详细说明
微信公众号文章页面的分析和采集
提高微信公众号文章采集的效率,先进使用anyproxy

