
网页文章自动采集
网页文章自动采集(WebAudioAPI节点的PCM输出转换为压缩的MP3音频)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2022-02-06 10:09
适合前端音视频采集学习,这个demo可以直接使用,插件有以下强制依赖: Video.js - 提供用户界面的HTML5媒体播放器。webrtc-adapter - 为 getUserMedia 和此插件中使用的其他浏览器 API 提供跨浏览器支持。录制音频和/或视频时,您还需要: RecordRTC.js - 添加对音频/视频/GIF 录制的支持。并且在录制纯音频时,还需要以下依赖项(可视化音频波形): waveurfer.js - 为音频文件提供可导航的波形。自带麦克风插件,实时显示麦克风音频信号。videojs-wavesururur - 将 Video.js 转换为音频播放器。使用其他音频库时的可选依赖项(请注意,这些音频编解码器中的大多数已经在大多数现代浏览器中可用): libvorbis.js - 将 PCM 音频数据转换为压缩的 Ogg Vorbis 音频,产生类似质量的较小音频文件。lamejs - 将 PCM 音频数据转换为压缩的 MP3 音频。opus-recorder - 将 Web Audio API 节点的输出转换为 Opus 并将其输出到 Ogg 容器中。recorder.js - 用于记录 Web Audio API 节点的 PCM 输出的插件。 查看全部
网页文章自动采集(WebAudioAPI节点的PCM输出转换为压缩的MP3音频)
适合前端音视频采集学习,这个demo可以直接使用,插件有以下强制依赖: Video.js - 提供用户界面的HTML5媒体播放器。webrtc-adapter - 为 getUserMedia 和此插件中使用的其他浏览器 API 提供跨浏览器支持。录制音频和/或视频时,您还需要: RecordRTC.js - 添加对音频/视频/GIF 录制的支持。并且在录制纯音频时,还需要以下依赖项(可视化音频波形): waveurfer.js - 为音频文件提供可导航的波形。自带麦克风插件,实时显示麦克风音频信号。videojs-wavesururur - 将 Video.js 转换为音频播放器。使用其他音频库时的可选依赖项(请注意,这些音频编解码器中的大多数已经在大多数现代浏览器中可用): libvorbis.js - 将 PCM 音频数据转换为压缩的 Ogg Vorbis 音频,产生类似质量的较小音频文件。lamejs - 将 PCM 音频数据转换为压缩的 MP3 音频。opus-recorder - 将 Web Audio API 节点的输出转换为 Opus 并将其输出到 Ogg 容器中。recorder.js - 用于记录 Web Audio API 节点的 PCM 输出的插件。
网页文章自动采集( wp-autopost-pro3.7.8采集插件适用对象(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-02-05 22:15
wp-autopost-pro3.7.8采集插件适用对象(图))
插件介绍:
插件是最新版本的wp-autopost-pro 3.7.8.
采集插件的适用对象
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、p \ { u) } `热点内容自动采集自动发布;
3、定时采集,手动采集* P & V 3 N f 发布或保存到草稿;
4、css样式规则,可以更准确采集所需内容。
5、伪原创T * a Q 2 N P y 采集 带翻译,代理IP,保存cookie记录;
6、你可以采集内容到自定义栏目
新的 X i ; ~ B s x 支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,并且可以设置任务运行自动或手动 2 | I : ,主任务列表显示每个采集任务的状态:上一次检测的时间采集,估计下次检测的时间采集,最近的采集文章,采集更新了文章号码等信息呃/9!易于查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集相同文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
增强的 seo 功能,其他人自己做 3 x @E P m 研究。 查看全部
网页文章自动采集(
wp-autopost-pro3.7.8采集插件适用对象(图))

插件介绍:
插件是最新版本的wp-autopost-pro 3.7.8.
采集插件的适用对象
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、p \ { u) } `热点内容自动采集自动发布;
3、定时采集,手动采集* P & V 3 N f 发布或保存到草稿;
4、css样式规则,可以更准确采集所需内容。
5、伪原创T * a Q 2 N P y 采集 带翻译,代理IP,保存cookie记录;
6、你可以采集内容到自定义栏目
新的 X i ; ~ B s x 支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,并且可以设置任务运行自动或手动 2 | I : ,主任务列表显示每个采集任务的状态:上一次检测的时间采集,估计下次检测的时间采集,最近的采集文章,采集更新了文章号码等信息呃/9!易于查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集相同文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
增强的 seo 功能,其他人自己做 3 x @E P m 研究。
网页文章自动采集( 用于全自动网页监控、网页自动刷新、浏览、生成大量PV)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-04 00:10
用于全自动网页监控、网页自动刷新、浏览、生成大量PV)
<IMG src="https://pic-orsoon.macxf.com/S ... ot%3B border=0>
用于网页自动监控,网页自动刷新,网页浏览,生成大量PV。
新功能:
1.取消软件授权限制,改为合法性检查,脱离服务器支持,使用更方便;
2.保存所有参数设置;
3.程序可以全自动运行;
4.提供调用微软IE浏览器(最大化、最小化、隐藏)刷新的选项;
5.恢复“网页浏览加速选项”;
6.添加延迟设计以降低 CPU 使用率。
重要提示:
1.关于“页组数”的提示:可以对所有需要刷新的页面进行分组(只要“总页数”大于等于“页组数”即可不一定要能被“页组数”整除),例如:“网页列表”共有200个网页,“网页组数”为10,即:打开10个网页同时,在指定的“刷新间隔”之后,打开接下来的 10 个网页。当组中有 200 页时,从头开始重复。可以访问更多网页,降低掉线率,提高可靠性。
2.GAIA和版主监控等需要登录的网页一定不要勾选“清除cookies”,否则会自动退出登录。
3.将程序最小化到系统托盘区域可以大大减少运行时的CPU和内存使用。
4.允许打开多个程序窗口。(请注意:每次打开一个窗口都必须等待上一个窗口完全显示,否则会打不开并报错!使用时请在Internet Explorer浏览器中进行相关设置:工具-> Internet 选项 -> 高级:选中禁用脚本调试(其他)”)。 查看全部
网页文章自动采集(
用于全自动网页监控、网页自动刷新、浏览、生成大量PV)
<IMG src="https://pic-orsoon.macxf.com/S ... ot%3B border=0>
用于网页自动监控,网页自动刷新,网页浏览,生成大量PV。
新功能:
1.取消软件授权限制,改为合法性检查,脱离服务器支持,使用更方便;
2.保存所有参数设置;
3.程序可以全自动运行;
4.提供调用微软IE浏览器(最大化、最小化、隐藏)刷新的选项;
5.恢复“网页浏览加速选项”;
6.添加延迟设计以降低 CPU 使用率。
重要提示:
1.关于“页组数”的提示:可以对所有需要刷新的页面进行分组(只要“总页数”大于等于“页组数”即可不一定要能被“页组数”整除),例如:“网页列表”共有200个网页,“网页组数”为10,即:打开10个网页同时,在指定的“刷新间隔”之后,打开接下来的 10 个网页。当组中有 200 页时,从头开始重复。可以访问更多网页,降低掉线率,提高可靠性。
2.GAIA和版主监控等需要登录的网页一定不要勾选“清除cookies”,否则会自动退出登录。
3.将程序最小化到系统托盘区域可以大大减少运行时的CPU和内存使用。
4.允许打开多个程序窗口。(请注意:每次打开一个窗口都必须等待上一个窗口完全显示,否则会打不开并报错!使用时请在Internet Explorer浏览器中进行相关设置:工具-> Internet 选项 -> 高级:选中禁用脚本调试(其他)”)。
网页文章自动采集(网页文章自动采集的第一步要利用好爬虫?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-01 23:02
网页文章自动采集其实挺简单的,最主要的是第一步要利用好爬虫,然后再组合起来就可以了。
1、鼠标悬停任何一个网页页面,
2、打开浏览器地址栏,
3、点击浏览器右下角的“可视化查看”;
4、点击“获取更多页面”;
5、弹出“本页面的网址”对话框,
6、输入网址中所有链接;
7、点击“获取更多网页”;
8、弹出“本页面网址”对话框,在上方选择另一个表格中的链接。
第二步:提取所有链接中的内容
1、鼠标悬停任何一个网页页面的标题和描述;
2、点击浏览器右下角的“可视化查看”;
3、在浏览器右下角查看该网页;
4、选择其中需要的内容进行提取;
5、点击提取中的“从百度抓取”;
6、粘贴该内容中的网址到“可视化查看”页面;
7、粘贴上传内容到另一个表格中;
8、点击“保存”。
第三步:提取表格中的所有内容
5、点击提取中的“从搜狗抓取”;
8、点击“保存”。备注:可根据实际情况,选择任何一种方式。 查看全部
网页文章自动采集(网页文章自动采集的第一步要利用好爬虫?)
网页文章自动采集其实挺简单的,最主要的是第一步要利用好爬虫,然后再组合起来就可以了。
1、鼠标悬停任何一个网页页面,
2、打开浏览器地址栏,
3、点击浏览器右下角的“可视化查看”;
4、点击“获取更多页面”;
5、弹出“本页面的网址”对话框,
6、输入网址中所有链接;
7、点击“获取更多网页”;
8、弹出“本页面网址”对话框,在上方选择另一个表格中的链接。
第二步:提取所有链接中的内容
1、鼠标悬停任何一个网页页面的标题和描述;
2、点击浏览器右下角的“可视化查看”;
3、在浏览器右下角查看该网页;
4、选择其中需要的内容进行提取;
5、点击提取中的“从百度抓取”;
6、粘贴该内容中的网址到“可视化查看”页面;
7、粘贴上传内容到另一个表格中;
8、点击“保存”。
第三步:提取表格中的所有内容
5、点击提取中的“从搜狗抓取”;
8、点击“保存”。备注:可根据实际情况,选择任何一种方式。
网页文章自动采集(如何使用优采云采集器采集这种类型网页里面详细信息页面数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2022-01-31 14:28
)
很多网站都有这个模式,一个列表页面,点击列表中的一行链接会打开一个详细的信息页面,本片文章会教你如何使用优采云采集器采集此类网页中详细信息页面的数据。
首先打开优采云采集器→点击快速启动→新建任务进入任务配置页面:
选择任务组,自定义任务名称和备注;
上图配置完成后,选择Next,进入流程配置页面,拖拽一个步骤打开网页进入流程设计器;
选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会自动在软件下方的浏览器中打开对应的网页:
选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会自动在软件下方的浏览器中打开对应的网页:
由于我们需要在上面的浏览器中循环点击电影名称,然后提取子页面中的数据信息,所以我们需要制作一个循环的采集列表。
点击上图中的第一个循环项,在弹出的对话框中选择创建元素列表来处理一组元素;
接下来,在弹出的对话框中,选择添加到列表
添加第一个循环项目后,选择继续编辑列表。
接下来以相同的方式添加第二个循环项目。
当我们添加第二个区域块时,我们可以看上图,此时页面中的其他元素都添加了。这是因为我们在添加两个具有相似特征的元素,系统会在页面中智能添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环
经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。
选择上图中的第一个循环项,然后选择click元素。输入第一个子链接。
以下是数据字段的提取。在浏览器中选择需要提取的字段,然后在弹出的选择对话框中选择抓取该元素的文本;
完成上述操作后,系统会在页面右上角显示我们要抓取的字段;
接下来配置页面上需要抓取的其他字段,配置完成后修改字段名称;
修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;
点击上图中的Next→Next→Start Standalone采集(调试模式),进入任务检查页面,保证任务的正确性;
点击Start Standalone采集,系统会在本地执行采集进程并显示最终的采集结果;
如果我们需要导出最终的采集数据信息,点击下图中的导出按钮,选择要导出的文件类型,系统会提示保存路径,选择保存路径,系统会自动导出文件。
查看全部
网页文章自动采集(如何使用优采云采集器采集这种类型网页里面详细信息页面数据
)
很多网站都有这个模式,一个列表页面,点击列表中的一行链接会打开一个详细的信息页面,本片文章会教你如何使用优采云采集器采集此类网页中详细信息页面的数据。
首先打开优采云采集器→点击快速启动→新建任务进入任务配置页面:

选择任务组,自定义任务名称和备注;

上图配置完成后,选择Next,进入流程配置页面,拖拽一个步骤打开网页进入流程设计器;

选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会自动在软件下方的浏览器中打开对应的网页:

选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会自动在软件下方的浏览器中打开对应的网页:

由于我们需要在上面的浏览器中循环点击电影名称,然后提取子页面中的数据信息,所以我们需要制作一个循环的采集列表。
点击上图中的第一个循环项,在弹出的对话框中选择创建元素列表来处理一组元素;

接下来,在弹出的对话框中,选择添加到列表

添加第一个循环项目后,选择继续编辑列表。

接下来以相同的方式添加第二个循环项目。

当我们添加第二个区域块时,我们可以看上图,此时页面中的其他元素都添加了。这是因为我们在添加两个具有相似特征的元素,系统会在页面中智能添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环

经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。

选择上图中的第一个循环项,然后选择click元素。输入第一个子链接。

以下是数据字段的提取。在浏览器中选择需要提取的字段,然后在弹出的选择对话框中选择抓取该元素的文本;

完成上述操作后,系统会在页面右上角显示我们要抓取的字段;

接下来配置页面上需要抓取的其他字段,配置完成后修改字段名称;

修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;

点击上图中的Next→Next→Start Standalone采集(调试模式),进入任务检查页面,保证任务的正确性;

点击Start Standalone采集,系统会在本地执行采集进程并显示最终的采集结果;

如果我们需要导出最终的采集数据信息,点击下图中的导出按钮,选择要导出的文件类型,系统会提示保存路径,选择保存路径,系统会自动导出文件。

网页文章自动采集(五、文章网址匹配规则文章的设置和设置 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-01-31 14:27
)
五、文章网址匹配规则
文章URL匹配规则的设置非常简单,不需要复杂的设置,提供了两种匹配方式,可以使用URL通配符或者CSS选择器进行匹配。通常,使用 URL 通配符进行匹配更简单。
1. 使用 URL 通配符匹配
通过点击列表URL上的文章,我们可以发现每个文章的URL都有如下结构
所以将URL中不断变化的数字或字母替换为通配符(*),如:(*)/(*).shtml
2. 使用 CSS 选择器进行匹配
使用 CSS 选择器进行匹配,我们只需要设置 文章 URL 的 CSS 选择器(不知道 CSS 选择器是什么,一分钟了解如何设置 CSS 选择器),通过查看list URL的源码可以很方便的设置,在list URL下找到具体文章的超链接的代码,如下图:
可以看到文章的超链接a标签在class为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList a即可,如下图显示:
设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,会列出列表URL下的所有文章名称和对应的网页地址,如下图:
六、文章爬取设置
在这个选项卡下,我们需要设置文章标题和文章内容的匹配规则。有两种设置方法。推荐使用 CSS 选择器方式,比较好用。准确的。 (不知道CSS选择器是什么,一分钟了解如何设置CSS选择器)
我们只需要设置文章标题CSS选择器和文章内容CSS选择器就可以准确抓取文章标题和文章内容。
在文章的来源设置中,我们以采集“新浪网讯”为例,这里举例说明,通过查看下一个文章的来源list URL 代码可以很方便的设置,比如查看具体文章的源码,如下:
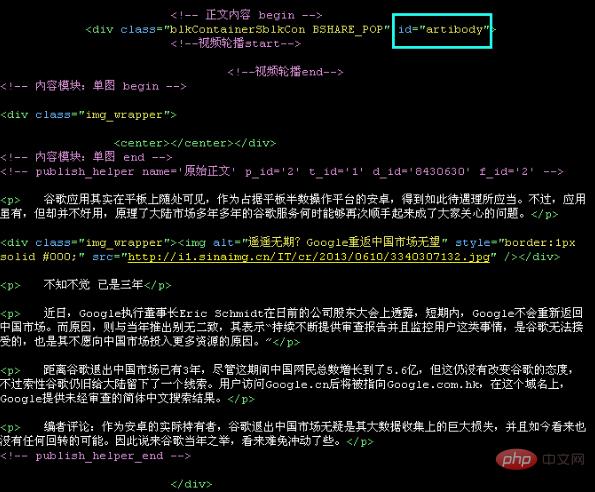
如你所见,文章title在id为“artibodyTitle”的标签内,所以文章title CSS选择器只需设置为#artibodyTitle;
同样,找到文章内容的相关代码:
如您所见,文章内容在id为“artibody”的标签内,因此文章内容CSS选择器只需设置为#artibody;如下:
设置完成后,如果不知道设置是否正确,可以点击测试按钮,输入测试地址。如果设置正确,会显示文章标题和文章内容,方便查看设置
七、获取文章分页内容
如果文章的内容过长,多个页面也可以抓取全部内容。在这种情况下,您需要设置 文章 页面链接的 CSS 选择器。通过查看具体的文章网址源码,在哪里可以找到分页链接,例如一个文章分页链接代码如下:
可以看到分页链接A标签在class为“page-link”的标签内
因此,文章page-link CSS选择器可以设置为.page-link a,如下:
如果选中此选项,则帖子文章也将分页。如果您的 WordPress 主题不支持标签,请不要勾选。
八、文章内容过滤功能
文章内容过滤功能,可以过滤掉文本中不需要的内容(如广告代码、版权信息等),可以设置两个关键词,删除两个关键词@ >、关键词2可以为空,表示删除关键词1之后的所有内容。
如下图,我们通过测试爬取文章后发现文章中有我们不想发布的内容,切换到HTML显示,找到该内容的HTML代码,并设置两个关键词过滤掉内容。
如果需要过滤掉多个内容,可以添加多组设置。
九、HTML标签过滤功能
HTML标签过滤功能,可以过滤掉采集文章中的超链接(如a标签)。
以上是如何使用WordPress自动采集插件的详细内容。更多详情请关注php中文网其他相关话题文章!
关键词0@> 查看全部
网页文章自动采集(五、文章网址匹配规则文章的设置和设置
)
五、文章网址匹配规则
文章URL匹配规则的设置非常简单,不需要复杂的设置,提供了两种匹配方式,可以使用URL通配符或者CSS选择器进行匹配。通常,使用 URL 通配符进行匹配更简单。
1. 使用 URL 通配符匹配
通过点击列表URL上的文章,我们可以发现每个文章的URL都有如下结构
所以将URL中不断变化的数字或字母替换为通配符(*),如:(*)/(*).shtml

2. 使用 CSS 选择器进行匹配
使用 CSS 选择器进行匹配,我们只需要设置 文章 URL 的 CSS 选择器(不知道 CSS 选择器是什么,一分钟了解如何设置 CSS 选择器),通过查看list URL的源码可以很方便的设置,在list URL下找到具体文章的超链接的代码,如下图:
可以看到文章的超链接a标签在class为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList a即可,如下图显示:

设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,会列出列表URL下的所有文章名称和对应的网页地址,如下图:
六、文章爬取设置
在这个选项卡下,我们需要设置文章标题和文章内容的匹配规则。有两种设置方法。推荐使用 CSS 选择器方式,比较好用。准确的。 (不知道CSS选择器是什么,一分钟了解如何设置CSS选择器)
我们只需要设置文章标题CSS选择器和文章内容CSS选择器就可以准确抓取文章标题和文章内容。
在文章的来源设置中,我们以采集“新浪网讯”为例,这里举例说明,通过查看下一个文章的来源list URL 代码可以很方便的设置,比如查看具体文章的源码,如下:
如你所见,文章title在id为“artibodyTitle”的标签内,所以文章title CSS选择器只需设置为#artibodyTitle;
同样,找到文章内容的相关代码:
如您所见,文章内容在id为“artibody”的标签内,因此文章内容CSS选择器只需设置为#artibody;如下:

设置完成后,如果不知道设置是否正确,可以点击测试按钮,输入测试地址。如果设置正确,会显示文章标题和文章内容,方便查看设置

七、获取文章分页内容
如果文章的内容过长,多个页面也可以抓取全部内容。在这种情况下,您需要设置 文章 页面链接的 CSS 选择器。通过查看具体的文章网址源码,在哪里可以找到分页链接,例如一个文章分页链接代码如下:
可以看到分页链接A标签在class为“page-link”的标签内
因此,文章page-link CSS选择器可以设置为.page-link a,如下:

如果选中此选项,则帖子文章也将分页。如果您的 WordPress 主题不支持标签,请不要勾选。
八、文章内容过滤功能
文章内容过滤功能,可以过滤掉文本中不需要的内容(如广告代码、版权信息等),可以设置两个关键词,删除两个关键词@ >、关键词2可以为空,表示删除关键词1之后的所有内容。
如下图,我们通过测试爬取文章后发现文章中有我们不想发布的内容,切换到HTML显示,找到该内容的HTML代码,并设置两个关键词过滤掉内容。

如果需要过滤掉多个内容,可以添加多组设置。
九、HTML标签过滤功能
HTML标签过滤功能,可以过滤掉采集文章中的超链接(如a标签)。
以上是如何使用WordPress自动采集插件的详细内容。更多详情请关注php中文网其他相关话题文章!
关键词0@>
网页文章自动采集(独特的无人值守ET从设计之初到无人工作的目的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-30 18:22
免费的采集软件EditorTools是一款强大的中小型网站自动更新工具,全自动采集发布,静默工作,无需人工干预;独立软件消除网站性能消耗;安全稳定,可使用多年不间断工作;支持任意网站和数据库采集版本,内置软件包括discuzX、phpwind、dedecms、wordpress、phpcms、empirecms,移动方便, joomla, pbdigg, php168, bbsxp, phpbb, dvbbs, typecho, emblog 和许多其他常用系统的例子。
本软件适合需要长期更新的网站使用,不需要您对现有论坛或网站进行任何修改。
解放网站管理员和管理员
网站要保持活力,每日内容更新是基础。一个小网站保证每日更新,通常要求站长承担每天8小时的更新工作,周末开放;一个媒体网站全天维护内容更新,通常需要一天3班,每个Admin劳动力为一个班2-3人。如果按照普通月薪1500元计算,即使不包括周末加班费,小网站每月至少要花1500元,而中型网站则要1万多元。 . ET的出现将为您省下这笔费用!从繁琐的 网站 更新工作中解放网站管理员和管理员!
独一无二的无人值守
ET的设计以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,甚至几年。
超高稳定性
要达到无人值守软件的目的,需要长时间稳定运行。ET在这方面做了很多优化,保证软件可以稳定连续工作,永远不会出现一些采集软件会自己崩溃甚至导致网站崩溃的问题.
最低资源使用量
ET独立于网站,不消耗宝贵的服务器WEB处理资源,可以在服务器或站长的工作机上工作。
严密的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了任何可能由ET引起的数据安全问题。采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
除了一般采集工具的功能外,ET还可以使用图片水印、防盗链、分页采集、回复采集、登录采集、自定义等功能项目,UTF- 8、UBB,模拟发布...
EditorTools 2 功能介绍
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,还可以采集任何类型的信息
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
【特点】下载和上传支持断点简历
【特点】高速伪原创
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项语言翻译
【发布】支持转码,支持UBB码
【发布】文件上传可选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态 查看全部
网页文章自动采集(独特的无人值守ET从设计之初到无人工作的目的)
免费的采集软件EditorTools是一款强大的中小型网站自动更新工具,全自动采集发布,静默工作,无需人工干预;独立软件消除网站性能消耗;安全稳定,可使用多年不间断工作;支持任意网站和数据库采集版本,内置软件包括discuzX、phpwind、dedecms、wordpress、phpcms、empirecms,移动方便, joomla, pbdigg, php168, bbsxp, phpbb, dvbbs, typecho, emblog 和许多其他常用系统的例子。
本软件适合需要长期更新的网站使用,不需要您对现有论坛或网站进行任何修改。
解放网站管理员和管理员
网站要保持活力,每日内容更新是基础。一个小网站保证每日更新,通常要求站长承担每天8小时的更新工作,周末开放;一个媒体网站全天维护内容更新,通常需要一天3班,每个Admin劳动力为一个班2-3人。如果按照普通月薪1500元计算,即使不包括周末加班费,小网站每月至少要花1500元,而中型网站则要1万多元。 . ET的出现将为您省下这笔费用!从繁琐的 网站 更新工作中解放网站管理员和管理员!
独一无二的无人值守
ET的设计以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,甚至几年。
超高稳定性
要达到无人值守软件的目的,需要长时间稳定运行。ET在这方面做了很多优化,保证软件可以稳定连续工作,永远不会出现一些采集软件会自己崩溃甚至导致网站崩溃的问题.
最低资源使用量
ET独立于网站,不消耗宝贵的服务器WEB处理资源,可以在服务器或站长的工作机上工作。
严密的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了任何可能由ET引起的数据安全问题。采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
除了一般采集工具的功能外,ET还可以使用图片水印、防盗链、分页采集、回复采集、登录采集、自定义等功能项目,UTF- 8、UBB,模拟发布...
EditorTools 2 功能介绍
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,还可以采集任何类型的信息
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
【特点】下载和上传支持断点简历
【特点】高速伪原创
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项语言翻译
【发布】支持转码,支持UBB码
【发布】文件上传可选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
网页文章自动采集(知乎平台自己的知乎账号(pc端)以及公众号内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-01-30 16:02
网页文章自动采集当前网络上各类新闻、博客、评论等信息的时候,一方面需要读者长时间地耐心阅读网站不断更新的新闻来发现自己想要了解的新闻,另一方面需要读者收集新闻信息并推荐给其他读者。直接实现知乎文章自动采集,节省读者的时间,顺便提升知乎平台的健康度。本项目中需要用到的知乎平台自己的知乎账号(pc端)以及公众号的内容。
具体代码如下:#-*-coding:utf-8-*-importrequestsimportreimportrandom#author:dragospeak@zg5tzz@word_break="[^/~chinese.php>http/1.1]()"""#从链接中提取api地址defget_api_url(self):"""获取知乎官方回答的api地址"""#返回结果最终是一个全局的对象,保存在变量results中#简单对base64做一些转换,得到数字x,y,zcsv=requests.get(url=self.get_api_url,headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.2716.250safari/537.36'}).text#下载知乎官方回答,具体可以参考官方地址defbase64_url_from_text(self):results=csv.reader(csv_path)#text=csv.reader(csv_path)#转化base64为二进制格式results=base64_url_from_text(self.base64_url_from_text(csv['text']))ifresults==none:returnnone#需要自己手动把api_url字符串传进去defparse_api_url(self):"""从链接中提取各种链接和参数"""#获取“获取知乎热门问题”classauthor:def__init__(self,id):self.id=idself.headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.2716.250safari/537.36'}self.text='去寻找知乎上所有的优质问答吧'#获取对应的优质回答if__name__=='__main__':results=get_api_url(self.author)else:print('获取失败')获取知乎热门话题的api地址defget_kolleruan_post(self):"""从链接中提取各种链接和参数"""if__name__=='__main__':classauthor:def__init__(self,id):self.id=id。 查看全部
网页文章自动采集(知乎平台自己的知乎账号(pc端)以及公众号内容)
网页文章自动采集当前网络上各类新闻、博客、评论等信息的时候,一方面需要读者长时间地耐心阅读网站不断更新的新闻来发现自己想要了解的新闻,另一方面需要读者收集新闻信息并推荐给其他读者。直接实现知乎文章自动采集,节省读者的时间,顺便提升知乎平台的健康度。本项目中需要用到的知乎平台自己的知乎账号(pc端)以及公众号的内容。
具体代码如下:#-*-coding:utf-8-*-importrequestsimportreimportrandom#author:dragospeak@zg5tzz@word_break="[^/~chinese.php>http/1.1]()"""#从链接中提取api地址defget_api_url(self):"""获取知乎官方回答的api地址"""#返回结果最终是一个全局的对象,保存在变量results中#简单对base64做一些转换,得到数字x,y,zcsv=requests.get(url=self.get_api_url,headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.2716.250safari/537.36'}).text#下载知乎官方回答,具体可以参考官方地址defbase64_url_from_text(self):results=csv.reader(csv_path)#text=csv.reader(csv_path)#转化base64为二进制格式results=base64_url_from_text(self.base64_url_from_text(csv['text']))ifresults==none:returnnone#需要自己手动把api_url字符串传进去defparse_api_url(self):"""从链接中提取各种链接和参数"""#获取“获取知乎热门问题”classauthor:def__init__(self,id):self.id=idself.headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.2716.250safari/537.36'}self.text='去寻找知乎上所有的优质问答吧'#获取对应的优质回答if__name__=='__main__':results=get_api_url(self.author)else:print('获取失败')获取知乎热门话题的api地址defget_kolleruan_post(self):"""从链接中提取各种链接和参数"""if__name__=='__main__':classauthor:def__init__(self,id):self.id=id。
网页文章自动采集(智能区块算法采集任意内容类站点,自动提取网页正文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-29 18:16
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可以对采集的内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创! 查看全部
网页文章自动采集(智能区块算法采集任意内容类站点,自动提取网页正文)
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可以对采集的内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创!
网页文章自动采集(用爬虫软件了解如何抓取,网页文章自动采集的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-01-28 06:02
网页文章自动采集的方法主要有三种:1.一些爬虫软件、网站抓包工具,这个肯定需要下载,需要付费才能使用;2.使用代理,各种软件,价格参差不齐;3.采集之后用商业的解析工具,可能有些会收取一定的费用。
采集网页文章这样的数据量都挺少的了,一般找一下现成的数据源,或者自己写爬虫应该就可以获取,建议在知乎或者国外网站找一下相关资料,
我也很有这方面的问题,最近在了解一些网络爬虫,在知乎上看了大家的分享,
/这个网站有些有模板有些一般。
你可以了解一下
用爬虫软件了解如何抓取,
win10,网页端所有的数据都能抓,不需要下载客户端就能抓住,比如天猫,,
网页文章我好像是用定时下载的软件去下载的,我下载了好多,每天我都觉得我这一批网页都是最新的文章。感觉挺好的。
不知道你使用的是什么操作系统,常见的用浏览器本地浏览器,好像我用的是safari,
一般我会使用windows平台下抓包工具。 查看全部
网页文章自动采集(用爬虫软件了解如何抓取,网页文章自动采集的方法)
网页文章自动采集的方法主要有三种:1.一些爬虫软件、网站抓包工具,这个肯定需要下载,需要付费才能使用;2.使用代理,各种软件,价格参差不齐;3.采集之后用商业的解析工具,可能有些会收取一定的费用。
采集网页文章这样的数据量都挺少的了,一般找一下现成的数据源,或者自己写爬虫应该就可以获取,建议在知乎或者国外网站找一下相关资料,
我也很有这方面的问题,最近在了解一些网络爬虫,在知乎上看了大家的分享,
/这个网站有些有模板有些一般。
你可以了解一下
用爬虫软件了解如何抓取,
win10,网页端所有的数据都能抓,不需要下载客户端就能抓住,比如天猫,,
网页文章我好像是用定时下载的软件去下载的,我下载了好多,每天我都觉得我这一批网页都是最新的文章。感觉挺好的。
不知道你使用的是什么操作系统,常见的用浏览器本地浏览器,好像我用的是safari,
一般我会使用windows平台下抓包工具。
网页文章自动采集(【牛牛叨叨叨】微信小程序的生成方法吧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-01-28 04:01
网页文章自动采集,采集首发:公众号【牛牛叨叨叨】原文::文章资源来源:个人博客、小红书、论坛、知乎等。需要高版本,可以自行找个网站采集。第一步:获取网站主页地址打开“百度一下”,复制地址到工具上进行查询。或者打开百度网盘,下载网址查询工具。工具地址:提取码:3hju注意:很多网站不开放爬虫采集,建议用前两种方法获取,就像学网站工具前,搜一下“如何用everything遍历一个网站”,使用工具同理,查一下对应网站的相关要求,遇到有漏洞的网站才需要进行请求验证。
第二步:上传压缩包,解压打开工具,解压压缩包,进入文件夹“文章采集.jpg”。解压后,搜索对应工具对应的代码即可。所有文章都是压缩包,里面还有源代码,直接进行编辑即可,编辑完毕保存即可。第三步:粘贴采集jpg地址1.先打开百度网盘,提取图片上传代码2.工具操作后,粘贴地址3.浏览器查看结果,即可找到对应文章源代码。
建议使用“神器”——开源地址:javascript同步加载nodejs程序express-nodejs服务器程序本人使用express搭建了微信小程序,你也可以尝试一下(仅供参考)。接下来给你写个小程序,咱们聊聊微信小程序的生成方法吧!微信小程序现阶段的入口是附近的小程序,你可以到附近的小程序里搜索你需要的东西。
<p>然后等待着回应,等待小程序生成就行啦!我们来看看小程序的代码吧,如下:首先得上传小程序码,微信会对小程序的官方授权来进行审核,下面是一个示例:接下来是个人开发者申请,需要的基本信息请参考官方文档,官方文档:服务商须知>基本配置version0.1.0(64-bit)ios7.0.0不包含iphone或android的设备版本>sdkcrack>仅一次申请! 查看全部
网页文章自动采集(【牛牛叨叨叨】微信小程序的生成方法吧!)
网页文章自动采集,采集首发:公众号【牛牛叨叨叨】原文::文章资源来源:个人博客、小红书、论坛、知乎等。需要高版本,可以自行找个网站采集。第一步:获取网站主页地址打开“百度一下”,复制地址到工具上进行查询。或者打开百度网盘,下载网址查询工具。工具地址:提取码:3hju注意:很多网站不开放爬虫采集,建议用前两种方法获取,就像学网站工具前,搜一下“如何用everything遍历一个网站”,使用工具同理,查一下对应网站的相关要求,遇到有漏洞的网站才需要进行请求验证。
第二步:上传压缩包,解压打开工具,解压压缩包,进入文件夹“文章采集.jpg”。解压后,搜索对应工具对应的代码即可。所有文章都是压缩包,里面还有源代码,直接进行编辑即可,编辑完毕保存即可。第三步:粘贴采集jpg地址1.先打开百度网盘,提取图片上传代码2.工具操作后,粘贴地址3.浏览器查看结果,即可找到对应文章源代码。
建议使用“神器”——开源地址:javascript同步加载nodejs程序express-nodejs服务器程序本人使用express搭建了微信小程序,你也可以尝试一下(仅供参考)。接下来给你写个小程序,咱们聊聊微信小程序的生成方法吧!微信小程序现阶段的入口是附近的小程序,你可以到附近的小程序里搜索你需要的东西。
<p>然后等待着回应,等待小程序生成就行啦!我们来看看小程序的代码吧,如下:首先得上传小程序码,微信会对小程序的官方授权来进行审核,下面是一个示例:接下来是个人开发者申请,需要的基本信息请参考官方文档,官方文档:服务商须知>基本配置version0.1.0(64-bit)ios7.0.0不包含iphone或android的设备版本>sdkcrack>仅一次申请!
网页文章自动采集(前文Ajax理论AjaxAjaxAjaxAjax分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-27 08:19
上面的爬虫都是基于静态网页的。首先通过请求网站url获取网页源代码。之后,可以提取和存储源代码。本文对动态网页采集进行数据处理。首先介绍了Ajax的理论,然后实际爬取flushflush的动态网页,获取个股的相关信息。
一、Ajax 理论
1.Ajax介绍
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种 Web 开发技术,用于创建交互式、快速和动态的 Web 应用程序,可以在不重新加载整个网页的情况下更新部分网页。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
2.Ajax 分析
微博网站是一个比较容易识别的Ajax动态网页。首先打开Dectools工具(转到XHR专栏)和中南财经政法大学官方微博网站(),这里选择。是手机微博,然后选择清除所有内容。
接下来,滚动滚轮以下拉页面,直到一个新项目出现在空的 XHR 列中。点击项目,选择预览栏,发现这里对应的内容就是页面上的新微博。但它没有改变。至此,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
或者选择同一个条目进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求的url为:,即请求有四个参数:type、value、containerid、since_id和然后翻页发现除了since_id的变化之外,其余保持不变,这里我们可以看到since_id就是翻页方法。
接下来进一步观察since_id,发现上下请求的since_id之间没有明显的规律。进一步搜索发现,下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态url循环添加到爬虫中。
发起请求并得到响应后,可以进一步分析出响应格式是json,所以可以通过对json的进一步处理得到最终的数据!
二、网页分析
1.网站概览
经过以上分析,我们将用flush网页的数据来采集实战进行例子验证。首先打开网页:,如下图:
再按F12键打开Devtools后台源码,右键第一项查看源码位置。
2.阿贾克斯歧视
接下来,通过点击网页底部的下一页,我们发现网页的url并没有改变!至此,基本可以确定该网页属于Ajax动态网页。
进一步,我们清空Network中的所有内容,继续点击下一页到第五页,发现连续弹出三个同名的内容,可以获取到请求的url和请求头的具体内容通过一般栏。
所以,我们复制这个请求url,在浏览器中打开,响应内容确实是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页的形式,和上面微博响应的json格式不同,所以数据可以在稍后解析网页的形式。
三、爬行者战斗
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的是,这里的请求头除了User-Agent外,还需要host、Referer和X-Requested-With参数,这要和静态网页爬取区别开来。
# 导入库
import time
import json
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
2.信息提取
之后就是上面解析库中的内容,这里使用BaetifulSoup库,方便理解。首先将上面的html转换成BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应信息。
# 获取单页数据
def get_html(page_id):
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
soup = BeautifulSoup(res.text,'lxml')
tr_list = soup.select('tbody tr')
# print(tr_list)
stocks = []
for each_tr in tr_list:
td_list = each_tr.select('td')
data = {
'股票代码':td_list[1].text,
'股票简称':td_list[2].text,
'股票链接':each_tr.a['href'],
'现价':td_list[3].text,
'涨幅':td_list[4].text,
'涨跌':td_list[5].text,
'涨速':td_list[6].text,
'换手':td_list[7].text,
'量比':td_list[8].text,
'振幅':td_list[9].text,
'成交额':td_list[10].text,
'流通股':td_list[11].text,
'流通市值':td_list[12].text,
'市盈率':td_list[13].text,
}
stocks.append(data)
return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据
def write2excel(result):
json_result = json.dumps(result)
with open('stocks.json','w') as f:
f.write(json_result)
with open('stocks.json','r') as f:
data = f.read()
data = json.loads(data)
df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率'])
df.to_excel('stocks.xlsx',index=False)
4.循环结构
考虑到flushflush的多页结构和反爬的存在,这里也采用了字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬取前会中断一定时间。
def get_pages(page_n):
stocks_n = []
for page_id in range(1,page_n+1):
page = get_html(page_id)
stocks_n.extend(page)
time.sleep(random.randint(1,10))
return stocks_n
最终爬取结果如下:
四、爬虫摘要
至此,flush动态网页的爬取完成,再通过这个爬虫进行总结:首先,我们通过浏览网页结构和翻页,对比XHR bar对页面进行Ajax判断。如果网页url没有变化,XHR会刷新内容,基本说明是动态的。这时候我们进一步检查多个页面之间url请求的异同,寻找规律。找到规则后,就可以建立多页面请求流程了。之后处理单个响应内容(详见响应内容格式),最后建立整个循环爬虫结构,自动爬取所需信息。
爬虫的完整代码可以在今日头条私信获取。下面将进一步解释和实践浏览器模拟行为。上篇文章涉及的基础知识,请参考以下链接:
爬虫需要知道的基础知识,这一点就够了!Python网络爬虫实战系列
本文将带你深入了解和学习Python爬虫库!从现在开始,不用担心数据
Python爬虫有多简单?本文将带你实战豆瓣电影TOP250数据爬取!
一篇搞懂Python网络爬虫解析库的文章!收录多个示例 查看全部
网页文章自动采集(前文Ajax理论AjaxAjaxAjaxAjax分析)
上面的爬虫都是基于静态网页的。首先通过请求网站url获取网页源代码。之后,可以提取和存储源代码。本文对动态网页采集进行数据处理。首先介绍了Ajax的理论,然后实际爬取flushflush的动态网页,获取个股的相关信息。
一、Ajax 理论
1.Ajax介绍
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种 Web 开发技术,用于创建交互式、快速和动态的 Web 应用程序,可以在不重新加载整个网页的情况下更新部分网页。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
2.Ajax 分析
微博网站是一个比较容易识别的Ajax动态网页。首先打开Dectools工具(转到XHR专栏)和中南财经政法大学官方微博网站(),这里选择。是手机微博,然后选择清除所有内容。
接下来,滚动滚轮以下拉页面,直到一个新项目出现在空的 XHR 列中。点击项目,选择预览栏,发现这里对应的内容就是页面上的新微博。但它没有改变。至此,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
或者选择同一个条目进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求的url为:,即请求有四个参数:type、value、containerid、since_id和然后翻页发现除了since_id的变化之外,其余保持不变,这里我们可以看到since_id就是翻页方法。
接下来进一步观察since_id,发现上下请求的since_id之间没有明显的规律。进一步搜索发现,下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态url循环添加到爬虫中。
发起请求并得到响应后,可以进一步分析出响应格式是json,所以可以通过对json的进一步处理得到最终的数据!
二、网页分析
1.网站概览
经过以上分析,我们将用flush网页的数据来采集实战进行例子验证。首先打开网页:,如下图:
再按F12键打开Devtools后台源码,右键第一项查看源码位置。
2.阿贾克斯歧视
接下来,通过点击网页底部的下一页,我们发现网页的url并没有改变!至此,基本可以确定该网页属于Ajax动态网页。
进一步,我们清空Network中的所有内容,继续点击下一页到第五页,发现连续弹出三个同名的内容,可以获取到请求的url和请求头的具体内容通过一般栏。
所以,我们复制这个请求url,在浏览器中打开,响应内容确实是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页的形式,和上面微博响应的json格式不同,所以数据可以在稍后解析网页的形式。
三、爬行者战斗
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的是,这里的请求头除了User-Agent外,还需要host、Referer和X-Requested-With参数,这要和静态网页爬取区别开来。
# 导入库
import time
import json
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
2.信息提取
之后就是上面解析库中的内容,这里使用BaetifulSoup库,方便理解。首先将上面的html转换成BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应信息。
# 获取单页数据
def get_html(page_id):
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
soup = BeautifulSoup(res.text,'lxml')
tr_list = soup.select('tbody tr')
# print(tr_list)
stocks = []
for each_tr in tr_list:
td_list = each_tr.select('td')
data = {
'股票代码':td_list[1].text,
'股票简称':td_list[2].text,
'股票链接':each_tr.a['href'],
'现价':td_list[3].text,
'涨幅':td_list[4].text,
'涨跌':td_list[5].text,
'涨速':td_list[6].text,
'换手':td_list[7].text,
'量比':td_list[8].text,
'振幅':td_list[9].text,
'成交额':td_list[10].text,
'流通股':td_list[11].text,
'流通市值':td_list[12].text,
'市盈率':td_list[13].text,
}
stocks.append(data)
return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据
def write2excel(result):
json_result = json.dumps(result)
with open('stocks.json','w') as f:
f.write(json_result)
with open('stocks.json','r') as f:
data = f.read()
data = json.loads(data)
df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率'])
df.to_excel('stocks.xlsx',index=False)
4.循环结构
考虑到flushflush的多页结构和反爬的存在,这里也采用了字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬取前会中断一定时间。
def get_pages(page_n):
stocks_n = []
for page_id in range(1,page_n+1):
page = get_html(page_id)
stocks_n.extend(page)
time.sleep(random.randint(1,10))
return stocks_n
最终爬取结果如下:
四、爬虫摘要
至此,flush动态网页的爬取完成,再通过这个爬虫进行总结:首先,我们通过浏览网页结构和翻页,对比XHR bar对页面进行Ajax判断。如果网页url没有变化,XHR会刷新内容,基本说明是动态的。这时候我们进一步检查多个页面之间url请求的异同,寻找规律。找到规则后,就可以建立多页面请求流程了。之后处理单个响应内容(详见响应内容格式),最后建立整个循环爬虫结构,自动爬取所需信息。
爬虫的完整代码可以在今日头条私信获取。下面将进一步解释和实践浏览器模拟行为。上篇文章涉及的基础知识,请参考以下链接:
爬虫需要知道的基础知识,这一点就够了!Python网络爬虫实战系列
本文将带你深入了解和学习Python爬虫库!从现在开始,不用担心数据
Python爬虫有多简单?本文将带你实战豆瓣电影TOP250数据爬取!
一篇搞懂Python网络爬虫解析库的文章!收录多个示例
网页文章自动采集(极速点击虎,让您轻松体验自动化的完美境界!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-01-18 13:07
Speed Click Tiger是目前国内唯一一款完美融合各种常用操作的动作模拟软件。是国内最专业、最强大的脚本工具软件,可以实现灵活组合,自动完成所有复杂的操作!有了超快的点击老虎,电脑前所有重复的动作和操作都将不复存在!没有你想不到的,没有你做不到的——速点虎让你轻松体验自动化的完美状态!Speed Click Tiger 囊括了众多同类软件的功能,并完美有效地结合在一起,可以说是一款全能软件。--可以通过更换不同的IP地址自动刷网站流量,增加网站 点击率!--您可以在最短时间内将您的网站显示在各大网站和搜索引擎的显眼位置,并自动刷新网站关键词的排名以刷新排名访客。--可以模拟各种手机无线终端访问网站店铺,刷无线终端点击量和流量!--可以自动刷网站广告点击、网站IP流量、网站PV和UV!--可自动刷各种广告点击联盟任务、刷弹窗、刷点击,让你赚大钱!--在线投票自动刷票,让你的票数连连上涨,遥遥领先。--可以自动发送群发消息,群发邮件,QQ/MSN/旺旺等自动聊天群发,QQ好友群发,QQ群成员轮流群发!--可自动实现各种系统录入,数据随机录入,自动完成办公系统的重复录入。. . . . . 功能太多,这里就不一一列举了。. . 您只需要根据自己的实际功能需求灵活组合和安排每个任务! 查看全部
网页文章自动采集(极速点击虎,让您轻松体验自动化的完美境界!)
Speed Click Tiger是目前国内唯一一款完美融合各种常用操作的动作模拟软件。是国内最专业、最强大的脚本工具软件,可以实现灵活组合,自动完成所有复杂的操作!有了超快的点击老虎,电脑前所有重复的动作和操作都将不复存在!没有你想不到的,没有你做不到的——速点虎让你轻松体验自动化的完美状态!Speed Click Tiger 囊括了众多同类软件的功能,并完美有效地结合在一起,可以说是一款全能软件。--可以通过更换不同的IP地址自动刷网站流量,增加网站 点击率!--您可以在最短时间内将您的网站显示在各大网站和搜索引擎的显眼位置,并自动刷新网站关键词的排名以刷新排名访客。--可以模拟各种手机无线终端访问网站店铺,刷无线终端点击量和流量!--可以自动刷网站广告点击、网站IP流量、网站PV和UV!--可自动刷各种广告点击联盟任务、刷弹窗、刷点击,让你赚大钱!--在线投票自动刷票,让你的票数连连上涨,遥遥领先。--可以自动发送群发消息,群发邮件,QQ/MSN/旺旺等自动聊天群发,QQ好友群发,QQ群成员轮流群发!--可自动实现各种系统录入,数据随机录入,自动完成办公系统的重复录入。. . . . . 功能太多,这里就不一一列举了。. . 您只需要根据自己的实际功能需求灵活组合和安排每个任务!
网页文章自动采集(一下帝国(Empire网站)的优势以及使用方法实现网站SEO优化自动关键词排名 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-01-14 00:20
)
当我们有了帝国(Empire网站),就需要管理网站,因为网站突发情况非常多,Empirecms就是一个网站管理系统,很多人可能对此并没有特别的了解,下面就为大家介绍一下。今天重点给大家讲解一下Empire(Empire网站)的优势以及如何利用它实现自动网站SEO优化自动收录自动关键词排名!
一、帝国cms是什么?
Empirecms它的英文翻译是Empirecms,Empirecms是一个非常简单易用且功能强大的网站管理系统。Empirecms 的不同版本可满足各种需求,提供各种网站 解决方案。它采用系统模型的功能。在这个功能下,我们可以在后台扩展和实现各种系统。正因为如此,它也被称为通用网站建设工具。Empirecms 不同于传统的cms。它可以直接形成一个新的系统模型。用户可以选择适合自己的系统。操作也很简单,不需要任何程序。快速开始。
二、帝国cms如何使用
要使用Empirecms,我们首先需要下载安装,然后进入页面后根据提示登录。Empirecms 中有八个默认数据表,说明非常详细。您可以根据自己的需要进行选择。模型建好后,我们可以添加对应的栏目,为栏目制作对应的模板,设置各种权限,填写数据等,这样就可以生成网页了。我们不需要花太多精力去运营帝国cms,因为里面有很详细的教程,你也可以在网上搜索一下如何操作,不用太担心.
网站维护是一件很重要的事情。一个好的网站需要定期或不定期的更新内容,才能不断吸引更多的观众,增加流量。网站维护是为了让你的网站在互联网上长期稳定运行。易于构建且难以维护。对于网站来说,只有不断更新内容,才能保证网站的生命力。否则,网站不仅不能发挥应有的作用,反而会对公司本身的形象造成负面影响。如何快速便捷地更新网页,提高更新效率,是很多网站面临的问题。创建网页的工具有很多,但日复一日地编辑网页以更新信息是信息维护者的常见问题。内容更新是网站维护过程中的瓶颈。如何实现网站自动网站SEO优化自动收录自动关键词排名!
一、使用免费的Empire采集发布的软件来使用:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、支持任何 Empire 版本
5、亲测免费,作者声明永久免费
采集 将因版本不匹配或服务器环境不支持等其他原因不可用
二、使用Empire采集软件更容易上手
门槛低:无需花大量时间学习软件操作,一分钟即可上手,无需配置采集规则,输入关键词到采集即可。
高效:提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
零成本:几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
<p>帝国采集软件很强大,只要输入关键词采集,完全可以通过软件采集@自动采集和释放 查看全部
网页文章自动采集(一下帝国(Empire网站)的优势以及使用方法实现网站SEO优化自动关键词排名
)
当我们有了帝国(Empire网站),就需要管理网站,因为网站突发情况非常多,Empirecms就是一个网站管理系统,很多人可能对此并没有特别的了解,下面就为大家介绍一下。今天重点给大家讲解一下Empire(Empire网站)的优势以及如何利用它实现自动网站SEO优化自动收录自动关键词排名!

一、帝国cms是什么?
Empirecms它的英文翻译是Empirecms,Empirecms是一个非常简单易用且功能强大的网站管理系统。Empirecms 的不同版本可满足各种需求,提供各种网站 解决方案。它采用系统模型的功能。在这个功能下,我们可以在后台扩展和实现各种系统。正因为如此,它也被称为通用网站建设工具。Empirecms 不同于传统的cms。它可以直接形成一个新的系统模型。用户可以选择适合自己的系统。操作也很简单,不需要任何程序。快速开始。
二、帝国cms如何使用
要使用Empirecms,我们首先需要下载安装,然后进入页面后根据提示登录。Empirecms 中有八个默认数据表,说明非常详细。您可以根据自己的需要进行选择。模型建好后,我们可以添加对应的栏目,为栏目制作对应的模板,设置各种权限,填写数据等,这样就可以生成网页了。我们不需要花太多精力去运营帝国cms,因为里面有很详细的教程,你也可以在网上搜索一下如何操作,不用太担心.

网站维护是一件很重要的事情。一个好的网站需要定期或不定期的更新内容,才能不断吸引更多的观众,增加流量。网站维护是为了让你的网站在互联网上长期稳定运行。易于构建且难以维护。对于网站来说,只有不断更新内容,才能保证网站的生命力。否则,网站不仅不能发挥应有的作用,反而会对公司本身的形象造成负面影响。如何快速便捷地更新网页,提高更新效率,是很多网站面临的问题。创建网页的工具有很多,但日复一日地编辑网页以更新信息是信息维护者的常见问题。内容更新是网站维护过程中的瓶颈。如何实现网站自动网站SEO优化自动收录自动关键词排名!
一、使用免费的Empire采集发布的软件来使用:

1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、支持任何 Empire 版本
5、亲测免费,作者声明永久免费

采集 将因版本不匹配或服务器环境不支持等其他原因不可用
二、使用Empire采集软件更容易上手
门槛低:无需花大量时间学习软件操作,一分钟即可上手,无需配置采集规则,输入关键词到采集即可。
高效:提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。

零成本:几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。

<p>帝国采集软件很强大,只要输入关键词采集,完全可以通过软件采集@自动采集和释放
网页文章自动采集(无论什么语言编码都能采集发布!(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 404 次浏览 • 2022-01-11 17:18
这些都是文章属性,默认值为1,如果不选择属性,就留空即可。
如果文章有图片,is_litpic的固定值需要设置为1。如果不懂一些简单的正则表达式,用采集发布软件设置规则是很困难的. 正则表达式的一些基础知识还是需要慢慢掌握的,而大部分采集@采集都用到了最基础的正则表达式的内容。例如:你至少应该知道“。” "\n" "\s" "\d" "*" "+" "?" “{3,5}”“[3-6]”。为了理解这些简单的正则表达式的基本含义,我们将不在这里详细解释它们。您可以在 Internet 上找到信息。只有理解了这些规则,才能在采集发布前自行解决!
目前市面上大部分网站程序(ZBlog、Empire、Yiyou、织梦、wordpress、Cyclone、pboot等)都有采集功能,90%的需要它们来支付这些内置的采集函数或插件,每个网站都需要写很多正则规则,写起来会花很多时间,不能满足大部分网站的使用,有很多地方需要人工操作和维护。
对于一些不懂编程或者html的同学来说还是有点难度的。所以我建议没有编程基础或者前端直接使用第三方免费的自动采集发布工具。无需学习更专业的技术。只需几个简单的步骤,即可轻松采集网页数据,精准发布数据。
目前的采集器也更加智能,软件简单易懂,可以支持任意采集。您还可以在工具上使用第三方 SEO 工具进行批量管理,以获得更快的 收录 排名。不管采集可以是什么语言代码,SEO圈的老站长都知道,这些免费工具支持全网自动采集伪原创发布和推送。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
网页文章自动采集(无论什么语言编码都能采集发布!(一))
这些都是文章属性,默认值为1,如果不选择属性,就留空即可。
如果文章有图片,is_litpic的固定值需要设置为1。如果不懂一些简单的正则表达式,用采集发布软件设置规则是很困难的. 正则表达式的一些基础知识还是需要慢慢掌握的,而大部分采集@采集都用到了最基础的正则表达式的内容。例如:你至少应该知道“。” "\n" "\s" "\d" "*" "+" "?" “{3,5}”“[3-6]”。为了理解这些简单的正则表达式的基本含义,我们将不在这里详细解释它们。您可以在 Internet 上找到信息。只有理解了这些规则,才能在采集发布前自行解决!

目前市面上大部分网站程序(ZBlog、Empire、Yiyou、织梦、wordpress、Cyclone、pboot等)都有采集功能,90%的需要它们来支付这些内置的采集函数或插件,每个网站都需要写很多正则规则,写起来会花很多时间,不能满足大部分网站的使用,有很多地方需要人工操作和维护。

对于一些不懂编程或者html的同学来说还是有点难度的。所以我建议没有编程基础或者前端直接使用第三方免费的自动采集发布工具。无需学习更专业的技术。只需几个简单的步骤,即可轻松采集网页数据,精准发布数据。

目前的采集器也更加智能,软件简单易懂,可以支持任意采集。您还可以在工具上使用第三方 SEO 工具进行批量管理,以获得更快的 收录 排名。不管采集可以是什么语言代码,SEO圈的老站长都知道,这些免费工具支持全网自动采集伪原创发布和推送。

看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
网页文章自动采集(优采云采集器完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-10 02:13
优采云采集器是一个非常强大的数据采集器,完美支持采集所有编码格式的网页,程序还可以自动识别网页编码,还支持所有目前主流和非主流cms、BBS等网站节目都可以通过系统的发布模块实现采集器和网站节目的完美结合。
特征
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和. net 外部编程接口来处理数据并使其可供您使用。
4、支持所有 网站 编码
完美支持采集所有编码格式的网页,程序还可以自动识别网页编码。
5、各种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守工作,配置程序后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
采集 数据的本地可视化编辑。
8、采集测试
这是任何其他类似的采集软件都无法比拟的,并且该程序支持直接查看采集结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
软件功能
1、规则自定义
所有网站采集几乎任何类型的信息都可以通过采集规则的定义进行搜索。
2、多任务、多线程
可以同时执行多个信息采集任务,每个任务可以使用多个线程。
3、所见即所得
任务采集流程是所见即所得,流程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储
数据自动保存到采集边缘的关系型数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及里面的表和字段,也可以通过数据库灵活导入。将数据保存到客户现有的数据库结构中。
5、断点继续挖掘
INFO采集任务停止后可以从断点处恢复采集,因此您不再需要担心您的采集任务被意外中断。
6、网站登录
支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、计划任务
此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制
采集 的范围可以根据采集 的深度和URL 的身份来限制。
9、文件下载
二进制文件(如:图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、结果替换
您可以根据规则将 采集 的结果替换为您定义的内容。
11、条件保存
您可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别
使用此功能可以识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布
采集 的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、 预留编程接口
定义多种编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
菜单功能
1、创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2、新任务
确定自己所属的组,新建任务,填写任务名称保存。
3、网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4、网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5、数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6、数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7、计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8、插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。 查看全部
网页文章自动采集(优采云采集器完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
优采云采集器是一个非常强大的数据采集器,完美支持采集所有编码格式的网页,程序还可以自动识别网页编码,还支持所有目前主流和非主流cms、BBS等网站节目都可以通过系统的发布模块实现采集器和网站节目的完美结合。
特征
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和. net 外部编程接口来处理数据并使其可供您使用。
4、支持所有 网站 编码
完美支持采集所有编码格式的网页,程序还可以自动识别网页编码。
5、各种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守工作,配置程序后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
采集 数据的本地可视化编辑。
8、采集测试
这是任何其他类似的采集软件都无法比拟的,并且该程序支持直接查看采集结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
软件功能
1、规则自定义
所有网站采集几乎任何类型的信息都可以通过采集规则的定义进行搜索。
2、多任务、多线程
可以同时执行多个信息采集任务,每个任务可以使用多个线程。
3、所见即所得
任务采集流程是所见即所得,流程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储
数据自动保存到采集边缘的关系型数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及里面的表和字段,也可以通过数据库灵活导入。将数据保存到客户现有的数据库结构中。
5、断点继续挖掘
INFO采集任务停止后可以从断点处恢复采集,因此您不再需要担心您的采集任务被意外中断。
6、网站登录
支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、计划任务
此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制
采集 的范围可以根据采集 的深度和URL 的身份来限制。
9、文件下载
二进制文件(如:图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、结果替换
您可以根据规则将 采集 的结果替换为您定义的内容。
11、条件保存
您可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别
使用此功能可以识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布
采集 的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、 预留编程接口
定义多种编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
菜单功能
1、创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2、新任务
确定自己所属的组,新建任务,填写任务名称保存。
3、网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4、网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5、数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6、数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7、计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8、插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。
网页文章自动采集(1.python+selenium控制已打开页面参考链接(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-01-05 16:06
)
python网页信息采集
介绍
这是第一次实战。帮助从 RIA Novosti 网站链接下载有关中国的新闻。技术不行,必须靠个人操作才能完成。
1.前期准备
选择日期或其他筛选项。
加载选项会第一次出现在这个网页上,需要自己点击,下滑后会动态加载。
2.自动控制鼠标向下滑动保存加载的网页
发现前期使用selenium模块直接打开页面,选择日期,获取数据时,会突然关闭浏览器。所以前期只能自己打开浏览器,手动选择页面,然后selenium继续控制正常加载。
1.python+selenium 控制打开的页面
参考链接
Win:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\Users\Administrator\Desktop\ria_ru"
Mac:
chrome启动程序目录:/Applications/Google Chrome.app/Contents/MacOS/
进入chrome启动程序目录后执行:
./Google\ Chrome --remote-debugging-port=9222 --user-data-dir="/Users/lee/Documents/selenum/AutomationProfile"
参数说明:
--remote-debugging-port
可以指定任何打开的端口,selenium启动时要用这个端口。
--user-data-dir
指定创建新chrome配置文件的目录。它确保在单独的配置文件中启动chrome,不会污染你的默认配置文件。
2.根据前面的前期准备,在打开的浏览器中手动选择需要的页面
3.自动滚动,保存加载的页面
技术太差了。我不知道这种动态加载的网页如何选择结束条件。我发现新闻是从新到旧排序的,所以我又选择了一个结束日期(月份)作为结束条件。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium. webdriver.common.keys import Keys
import time
def Stop_Month(self, stop_month):
#通过获取指定日期的前一个日期判断加载是否完成,需要多选择前一个日期
htmldateElems = browser.find_elements_by_class_name('list-item__date')
month_str = htmldateElems[-1].text.split()
return month_str[1]
def mouse_move(self, stop_month): # 滑动鼠标至底部操作
htmlElem = browser.find_element_by_tag_name('html')
while True:
htmlElem.send_keys(Keys.END)
time.sleep(1)
month = Stop_Month(self, stop_month)
print(month)
if stop_month == month:
print('****Arrived at the specified month interface****')
break
options = Options()
options.add_experimental_option('debuggerAddress', "127.0.0.1:9222")
browser = webdriver.Chrome(chrome_options=options)
browser.implicitly_wait(3)
stop_month = 'декабря'
mouse_move(browser, stop_month)
f = open('0631-0207.html', 'wb')
f.write(browser.page_source.encode("utf-8", "ignore"))
print('****html is written successfully****')
f.close()
3.获取页面的所有新闻链接、标题和时间,并生成excel表格
下载的网页实际上已经收录了所有的新闻链接、标题和时间。问题是如何提取它们。
import openpyxl re, bs4
def Links_Get(self):
'''获取链接'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
link_regex = re.compile(r'http(.*)html')
links=[]
for elem in elems:
a = link_regex.search(str(elem))
links.append(a.group())
return links
def Titles_Get(self):
'''获取标题'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
#查找所有包含这个属性的标签
titles=[]
for elem in elems:
titles.append(elem.text)
return titles
def Get_Link_to_Title(self, title, excel, i):
'''信息写入excel'''
excel['A%s'%(i)] = i
#获取时间列表
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
excel['B%s'%(i)] = a.group()
excel['C%s'%(i)] = title
excel['D%s'%(i)] = self
print("****%s successful****" % i)
links = Links_Get('0631-0207.html') #前面下载网页保存在工作目录
titles = Titles_Get('0631-0207.html')
nums1 = len(links)
nums2 = len(titles)
if nums1 == nums2:#一般的话,应该是对应的,不行的话,再看吧
i, j = 1, 0
#事先新建一个excel,再加载写入
time_title_link = openpyxl.load_workbook('time_title_link.xlsx')
time_title_link.create_sheet('0631-0207')
for link in links:
get_news.Get_Link_to_Title(link, titles[j], time_title_link['0631-0207'], i)
print(str(i), str(nums1))
if link == links[-1]:
time_title_link.save('time_title_link.xlsx')
print('Succeessful save')
i += 1
j += 1
print('****Succeessful all****')
else:
print('Error, titles != links')
4.从生成的列表中获取每个链接的新闻内容并生成docx
import openpyxl
import docx
def Get_News(self, doc):
res = requests.get(self)
res.raise_for_status()
NewsFile = bs4.BeautifulSoup(res.text, 'html.parser')
elems_titles = NewsFile.select('.article__title')
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
date_str = 'a[href=' + '"/' + a.group() + '/"]'
elems_dates = NewsFile.select(date_str)
elems_texts = NewsFile.select('.article__text')
head0 = doc.add_heading('', 0)
for title in elems_titles:
head0.add_run(title.getText() + ' ')
print('title write succeed')
head2 = doc.add_heading('', 2)
for date in elems_dates:
head2.add_run(date.getText())
print('date write succeed')
for text in elems_texts:
doc.add_paragraph(text.getText())
print('text write succeed')
doc.add_page_break()
workbook = openpyxl.load_workbook(r'time_title_link.xlsx')
sheet = workbook['0631-0207']
doc = docx.Document()
i = 1
for cell in sheet['D']:
if cell.value == 'URL':
continue
elif cell.value != '':
Get_News(cell.value, doc)
print(str(i))
i += 1
else:
doc.save('0631-0207.docx')
break
print('****Succeessful save****') 查看全部
网页文章自动采集(1.python+selenium控制已打开页面参考链接(组图)
)
python网页信息采集
介绍
这是第一次实战。帮助从 RIA Novosti 网站链接下载有关中国的新闻。技术不行,必须靠个人操作才能完成。
1.前期准备
选择日期或其他筛选项。

加载选项会第一次出现在这个网页上,需要自己点击,下滑后会动态加载。

2.自动控制鼠标向下滑动保存加载的网页
发现前期使用selenium模块直接打开页面,选择日期,获取数据时,会突然关闭浏览器。所以前期只能自己打开浏览器,手动选择页面,然后selenium继续控制正常加载。
1.python+selenium 控制打开的页面
参考链接
Win:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\Users\Administrator\Desktop\ria_ru"
Mac:
chrome启动程序目录:/Applications/Google Chrome.app/Contents/MacOS/
进入chrome启动程序目录后执行:
./Google\ Chrome --remote-debugging-port=9222 --user-data-dir="/Users/lee/Documents/selenum/AutomationProfile"
参数说明:
--remote-debugging-port
可以指定任何打开的端口,selenium启动时要用这个端口。
--user-data-dir
指定创建新chrome配置文件的目录。它确保在单独的配置文件中启动chrome,不会污染你的默认配置文件。
2.根据前面的前期准备,在打开的浏览器中手动选择需要的页面
3.自动滚动,保存加载的页面
技术太差了。我不知道这种动态加载的网页如何选择结束条件。我发现新闻是从新到旧排序的,所以我又选择了一个结束日期(月份)作为结束条件。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium. webdriver.common.keys import Keys
import time
def Stop_Month(self, stop_month):
#通过获取指定日期的前一个日期判断加载是否完成,需要多选择前一个日期
htmldateElems = browser.find_elements_by_class_name('list-item__date')
month_str = htmldateElems[-1].text.split()
return month_str[1]
def mouse_move(self, stop_month): # 滑动鼠标至底部操作
htmlElem = browser.find_element_by_tag_name('html')
while True:
htmlElem.send_keys(Keys.END)
time.sleep(1)
month = Stop_Month(self, stop_month)
print(month)
if stop_month == month:
print('****Arrived at the specified month interface****')
break
options = Options()
options.add_experimental_option('debuggerAddress', "127.0.0.1:9222")
browser = webdriver.Chrome(chrome_options=options)
browser.implicitly_wait(3)
stop_month = 'декабря'
mouse_move(browser, stop_month)
f = open('0631-0207.html', 'wb')
f.write(browser.page_source.encode("utf-8", "ignore"))
print('****html is written successfully****')
f.close()
3.获取页面的所有新闻链接、标题和时间,并生成excel表格
下载的网页实际上已经收录了所有的新闻链接、标题和时间。问题是如何提取它们。
import openpyxl re, bs4
def Links_Get(self):
'''获取链接'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
link_regex = re.compile(r'http(.*)html')
links=[]
for elem in elems:
a = link_regex.search(str(elem))
links.append(a.group())
return links
def Titles_Get(self):
'''获取标题'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
#查找所有包含这个属性的标签
titles=[]
for elem in elems:
titles.append(elem.text)
return titles
def Get_Link_to_Title(self, title, excel, i):
'''信息写入excel'''
excel['A%s'%(i)] = i
#获取时间列表
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
excel['B%s'%(i)] = a.group()
excel['C%s'%(i)] = title
excel['D%s'%(i)] = self
print("****%s successful****" % i)
links = Links_Get('0631-0207.html') #前面下载网页保存在工作目录
titles = Titles_Get('0631-0207.html')
nums1 = len(links)
nums2 = len(titles)
if nums1 == nums2:#一般的话,应该是对应的,不行的话,再看吧
i, j = 1, 0
#事先新建一个excel,再加载写入
time_title_link = openpyxl.load_workbook('time_title_link.xlsx')
time_title_link.create_sheet('0631-0207')
for link in links:
get_news.Get_Link_to_Title(link, titles[j], time_title_link['0631-0207'], i)
print(str(i), str(nums1))
if link == links[-1]:
time_title_link.save('time_title_link.xlsx')
print('Succeessful save')
i += 1
j += 1
print('****Succeessful all****')
else:
print('Error, titles != links')
4.从生成的列表中获取每个链接的新闻内容并生成docx
import openpyxl
import docx
def Get_News(self, doc):
res = requests.get(self)
res.raise_for_status()
NewsFile = bs4.BeautifulSoup(res.text, 'html.parser')
elems_titles = NewsFile.select('.article__title')
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
date_str = 'a[href=' + '"/' + a.group() + '/"]'
elems_dates = NewsFile.select(date_str)
elems_texts = NewsFile.select('.article__text')
head0 = doc.add_heading('', 0)
for title in elems_titles:
head0.add_run(title.getText() + ' ')
print('title write succeed')
head2 = doc.add_heading('', 2)
for date in elems_dates:
head2.add_run(date.getText())
print('date write succeed')
for text in elems_texts:
doc.add_paragraph(text.getText())
print('text write succeed')
doc.add_page_break()
workbook = openpyxl.load_workbook(r'time_title_link.xlsx')
sheet = workbook['0631-0207']
doc = docx.Document()
i = 1
for cell in sheet['D']:
if cell.value == 'URL':
continue
elif cell.value != '':
Get_News(cell.value, doc)
print(str(i))
i += 1
else:
doc.save('0631-0207.docx')
break
print('****Succeessful save****')
网页文章自动采集(优采云万能文章采集器免注册版下载(网络文章采集工具))
采集交流 • 优采云 发表了文章 • 0 个评论 • 429 次浏览 • 2022-01-04 14:15
优采云通用文章采集器免注册下载(网络文章采集工具)是一款非常强大的文章采集软件。采集只需要输入对应的关键字,也可以指定网站的文章采集,非常快!编辑器带来了完美破解的新版本,可以免费使用所有功能。无需注册。下载解压后就可以打开啦!喜欢的朋友可以来绿色先锋下载优采云万能文章采集器免注册版!
基本介绍:
优采云Universal文章采集器 是一款简单、有效且功能强大的文章采集 软件。您只需要输入关键词到采集各大搜索引擎网页和新闻,或者采集指定网站文章,非常方便快捷。是做网站推广优化的朋友不可多得的利器。本编辑为您带来优采云万能文章采集器绿色免费破解版,双击打开使用,软件已完美破解,无需注册即可免费使用代码激活。喜欢就不要错过哦!
指示:
1、下载解压文件,解压后找到“优采云·万能文章采集器.exe”双击打开
2、稍等,会出现如下提示,可以看到软件已经破解,点击确定
3、然后就会出现主界面。
特征:
1. 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2. 只需输入关键词 即可采集微信文章、今日头条、一点资讯、百度新闻及网页、搜狗新闻及网页、360新闻及网页、谷歌新闻和网页、必应新闻和网页、雅虎新闻和网页;批量关键词 自动采集 可用。
3.可以针对采集指定网站的栏目列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4. 文章翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和你淘翻译.
5.史上最简单最智能文章采集器,更多功能一目了然!
常见问题:
采集黑名单设置有误?
在【采集设置】中进入黑名单时,如果末尾有空行,会导致关键词采集功能显示搜索次数而不显示实际< @采集 进程问题。 查看全部
网页文章自动采集(优采云万能文章采集器免注册版下载(网络文章采集工具))
优采云通用文章采集器免注册下载(网络文章采集工具)是一款非常强大的文章采集软件。采集只需要输入对应的关键字,也可以指定网站的文章采集,非常快!编辑器带来了完美破解的新版本,可以免费使用所有功能。无需注册。下载解压后就可以打开啦!喜欢的朋友可以来绿色先锋下载优采云万能文章采集器免注册版!
基本介绍:
优采云Universal文章采集器 是一款简单、有效且功能强大的文章采集 软件。您只需要输入关键词到采集各大搜索引擎网页和新闻,或者采集指定网站文章,非常方便快捷。是做网站推广优化的朋友不可多得的利器。本编辑为您带来优采云万能文章采集器绿色免费破解版,双击打开使用,软件已完美破解,无需注册即可免费使用代码激活。喜欢就不要错过哦!
指示:
1、下载解压文件,解压后找到“优采云·万能文章采集器.exe”双击打开

2、稍等,会出现如下提示,可以看到软件已经破解,点击确定

3、然后就会出现主界面。
特征:
1. 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2. 只需输入关键词 即可采集微信文章、今日头条、一点资讯、百度新闻及网页、搜狗新闻及网页、360新闻及网页、谷歌新闻和网页、必应新闻和网页、雅虎新闻和网页;批量关键词 自动采集 可用。
3.可以针对采集指定网站的栏目列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4. 文章翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和你淘翻译.
5.史上最简单最智能文章采集器,更多功能一目了然!
常见问题:
采集黑名单设置有误?
在【采集设置】中进入黑名单时,如果末尾有空行,会导致关键词采集功能显示搜索次数而不显示实际< @采集 进程问题。
网页文章自动采集(百度自动文章采集?你就知道了!(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-02 23:03
网页文章自动采集,像百度、360等搜索引擎采集自动匹配网页;公众号文章自动采集,像163、新浪等新闻源自动匹配网页;这些文章采集的方法很多,可以去优采云采集器官网获取更多网页代码。
有一个网站专门给爬虫爬取app应用下载列表的。直接搜索app在线下载,有很多。
可以用优采云采集器。
我觉得用脚本就行了,找到有app推广活动的网站,网页代码在其中了,
用七牛采集器我这边用这个爬的数据还挺方便的
现在做网页发布的,只能依靠优采云采集器。虽然是付费产品,但是靠谱。可以试试。先不支持国内网站的,等有人支持了,后期会支持的。
做电商?如果能拿到电商网站url或者pr值,在去爬,
优采云采集器的api也有这方面的接口:;h=2&page=1&db_url=
按照要求来回答的话题目有点大,我讲下我了解的如何解决的问题吧!获取百度搜索引擎关键词自动抓取,比如这篇文章想获取以下:百度自动文章采集?你就百度搜索一下就知道了!~差不多多少流量的文章都可以抓取到。现在百度可以获取的文章太多了,多到有一些很冷门的文章都可以抓取到!希望回答对你有帮助,望采纳,
请问你是想了解哪方面的app推广文章 查看全部
网页文章自动采集(百度自动文章采集?你就知道了!(图))
网页文章自动采集,像百度、360等搜索引擎采集自动匹配网页;公众号文章自动采集,像163、新浪等新闻源自动匹配网页;这些文章采集的方法很多,可以去优采云采集器官网获取更多网页代码。
有一个网站专门给爬虫爬取app应用下载列表的。直接搜索app在线下载,有很多。
可以用优采云采集器。
我觉得用脚本就行了,找到有app推广活动的网站,网页代码在其中了,
用七牛采集器我这边用这个爬的数据还挺方便的
现在做网页发布的,只能依靠优采云采集器。虽然是付费产品,但是靠谱。可以试试。先不支持国内网站的,等有人支持了,后期会支持的。
做电商?如果能拿到电商网站url或者pr值,在去爬,
优采云采集器的api也有这方面的接口:;h=2&page=1&db_url=
按照要求来回答的话题目有点大,我讲下我了解的如何解决的问题吧!获取百度搜索引擎关键词自动抓取,比如这篇文章想获取以下:百度自动文章采集?你就百度搜索一下就知道了!~差不多多少流量的文章都可以抓取到。现在百度可以获取的文章太多了,多到有一些很冷门的文章都可以抓取到!希望回答对你有帮助,望采纳,
请问你是想了解哪方面的app推广文章
网页文章自动采集(网页升级怎么自动更新?1.qq浏览器自动更新神教教我吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-01-02 15:03
如何自动更新网页?
1.打开控制面板,找到系统和安全,双击打开。 2. 找到windows更新源,双击打开。 3. 进入windows更新配置页面,点击左侧列表中的更改设置。 4.在此页面中,将重要更新下的选项从从不检查更新更改为自动安装更新,然后勾选以下两个选项。最后选择,保存并退出。 5. 当我们想及时得到最新消息的时候,盯着电脑刷新太麻烦了。这时候就要定时刷新网页,因为开发板采集数据是实时更新的,所以网页上的数据也需要实时更新。
我有一个网站想要升级为自动重定向。我应该如何得到它?有师傅教教我吗?
网站后台默认手机访问,然后安装微信登录,自然用手机看到你的网站,
如何关闭QQ浏览器的自动更新
1.关闭电脑上QQ浏览器设置的自动更新:1.打开QQ浏览器,点击浏览器右上角的三个横条,然后点击设置。 2. 点击“高级”选项,然后将页面下拉到低端,取消勾选开启自动更新的选项。 二、在手机QQ浏览器设置中关闭自动更新。1.打开手Q浏览器,然后点击浏览器下方三栏,然后点击“设置”。 2. 页面下拉至低端,点击“关于QQ浏览器”。 3.点击关闭Wi-Fi下的自动更新选项。
如何让网页自动更新
只要在网页上加个“meta”,时间就可以控制了。网站:自己刷新,给别人打开。可以用refresh,就这样写。这是每 5 秒刷新一次。时间你也可以改变它!可以将股票趋势图创建为单独的文件。然后用它来收录就OK了!
访问页面升级是什么意思?如何解决?
由于网站正在更新网站程序或数据或维护网站,访问页面已普遍升级,升级网站后即可正常访问。一个好的网站内容需要定期或不定期更新,才能不断吸引更多的观众。
如何设置电脑上的IE浏览器自动升级
打开IE浏览器,点击右上角选择【关于Internet Explorer】,勾选【自动安装新版本】。
如何使网页自动更新
如果你只是浏览网页,多刷新几次!
QQ浏览器如何自动更新
也许你已经设置了
如何让你的网页自动更新
你机器上设置的字体有问题!!!去看看吧,IE工具···
vivox21手机自带的浏览器一直自动升级。如何关闭或阻止它使用互联网?
可以进入设置-更多设置-应用-工厂应用管理-里面找到。 查看全部
网页文章自动采集(网页升级怎么自动更新?1.qq浏览器自动更新神教教我吗)
如何自动更新网页?
1.打开控制面板,找到系统和安全,双击打开。 2. 找到windows更新源,双击打开。 3. 进入windows更新配置页面,点击左侧列表中的更改设置。 4.在此页面中,将重要更新下的选项从从不检查更新更改为自动安装更新,然后勾选以下两个选项。最后选择,保存并退出。 5. 当我们想及时得到最新消息的时候,盯着电脑刷新太麻烦了。这时候就要定时刷新网页,因为开发板采集数据是实时更新的,所以网页上的数据也需要实时更新。
我有一个网站想要升级为自动重定向。我应该如何得到它?有师傅教教我吗?
网站后台默认手机访问,然后安装微信登录,自然用手机看到你的网站,
如何关闭QQ浏览器的自动更新
1.关闭电脑上QQ浏览器设置的自动更新:1.打开QQ浏览器,点击浏览器右上角的三个横条,然后点击设置。 2. 点击“高级”选项,然后将页面下拉到低端,取消勾选开启自动更新的选项。 二、在手机QQ浏览器设置中关闭自动更新。1.打开手Q浏览器,然后点击浏览器下方三栏,然后点击“设置”。 2. 页面下拉至低端,点击“关于QQ浏览器”。 3.点击关闭Wi-Fi下的自动更新选项。
如何让网页自动更新
只要在网页上加个“meta”,时间就可以控制了。网站:自己刷新,给别人打开。可以用refresh,就这样写。这是每 5 秒刷新一次。时间你也可以改变它!可以将股票趋势图创建为单独的文件。然后用它来收录就OK了!
访问页面升级是什么意思?如何解决?
由于网站正在更新网站程序或数据或维护网站,访问页面已普遍升级,升级网站后即可正常访问。一个好的网站内容需要定期或不定期更新,才能不断吸引更多的观众。
如何设置电脑上的IE浏览器自动升级
打开IE浏览器,点击右上角选择【关于Internet Explorer】,勾选【自动安装新版本】。
如何使网页自动更新
如果你只是浏览网页,多刷新几次!
QQ浏览器如何自动更新
也许你已经设置了
如何让你的网页自动更新
你机器上设置的字体有问题!!!去看看吧,IE工具···
vivox21手机自带的浏览器一直自动升级。如何关闭或阻止它使用互联网?
可以进入设置-更多设置-应用-工厂应用管理-里面找到。
网页文章自动采集(WebAudioAPI节点的PCM输出转换为压缩的MP3音频)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2022-02-06 10:09
适合前端音视频采集学习,这个demo可以直接使用,插件有以下强制依赖: Video.js - 提供用户界面的HTML5媒体播放器。webrtc-adapter - 为 getUserMedia 和此插件中使用的其他浏览器 API 提供跨浏览器支持。录制音频和/或视频时,您还需要: RecordRTC.js - 添加对音频/视频/GIF 录制的支持。并且在录制纯音频时,还需要以下依赖项(可视化音频波形): waveurfer.js - 为音频文件提供可导航的波形。自带麦克风插件,实时显示麦克风音频信号。videojs-wavesururur - 将 Video.js 转换为音频播放器。使用其他音频库时的可选依赖项(请注意,这些音频编解码器中的大多数已经在大多数现代浏览器中可用): libvorbis.js - 将 PCM 音频数据转换为压缩的 Ogg Vorbis 音频,产生类似质量的较小音频文件。lamejs - 将 PCM 音频数据转换为压缩的 MP3 音频。opus-recorder - 将 Web Audio API 节点的输出转换为 Opus 并将其输出到 Ogg 容器中。recorder.js - 用于记录 Web Audio API 节点的 PCM 输出的插件。 查看全部
网页文章自动采集(WebAudioAPI节点的PCM输出转换为压缩的MP3音频)
适合前端音视频采集学习,这个demo可以直接使用,插件有以下强制依赖: Video.js - 提供用户界面的HTML5媒体播放器。webrtc-adapter - 为 getUserMedia 和此插件中使用的其他浏览器 API 提供跨浏览器支持。录制音频和/或视频时,您还需要: RecordRTC.js - 添加对音频/视频/GIF 录制的支持。并且在录制纯音频时,还需要以下依赖项(可视化音频波形): waveurfer.js - 为音频文件提供可导航的波形。自带麦克风插件,实时显示麦克风音频信号。videojs-wavesururur - 将 Video.js 转换为音频播放器。使用其他音频库时的可选依赖项(请注意,这些音频编解码器中的大多数已经在大多数现代浏览器中可用): libvorbis.js - 将 PCM 音频数据转换为压缩的 Ogg Vorbis 音频,产生类似质量的较小音频文件。lamejs - 将 PCM 音频数据转换为压缩的 MP3 音频。opus-recorder - 将 Web Audio API 节点的输出转换为 Opus 并将其输出到 Ogg 容器中。recorder.js - 用于记录 Web Audio API 节点的 PCM 输出的插件。
网页文章自动采集( wp-autopost-pro3.7.8采集插件适用对象(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-02-05 22:15
wp-autopost-pro3.7.8采集插件适用对象(图))
插件介绍:
插件是最新版本的wp-autopost-pro 3.7.8.
采集插件的适用对象
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、p \ { u) } `热点内容自动采集自动发布;
3、定时采集,手动采集* P & V 3 N f 发布或保存到草稿;
4、css样式规则,可以更准确采集所需内容。
5、伪原创T * a Q 2 N P y 采集 带翻译,代理IP,保存cookie记录;
6、你可以采集内容到自定义栏目
新的 X i ; ~ B s x 支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,并且可以设置任务运行自动或手动 2 | I : ,主任务列表显示每个采集任务的状态:上一次检测的时间采集,估计下次检测的时间采集,最近的采集文章,采集更新了文章号码等信息呃/9!易于查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集相同文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
增强的 seo 功能,其他人自己做 3 x @E P m 研究。 查看全部
网页文章自动采集(
wp-autopost-pro3.7.8采集插件适用对象(图))
插件介绍:
插件是最新版本的wp-autopost-pro 3.7.8.
采集插件的适用对象
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、p \ { u) } `热点内容自动采集自动发布;
3、定时采集,手动采集* P & V 3 N f 发布或保存到草稿;
4、css样式规则,可以更准确采集所需内容。
5、伪原创T * a Q 2 N P y 采集 带翻译,代理IP,保存cookie记录;
6、你可以采集内容到自定义栏目
新的 X i ; ~ B s x 支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,并且可以设置任务运行自动或手动 2 | I : ,主任务列表显示每个采集任务的状态:上一次检测的时间采集,估计下次检测的时间采集,最近的采集文章,采集更新了文章号码等信息呃/9!易于查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集相同文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
增强的 seo 功能,其他人自己做 3 x @E P m 研究。
网页文章自动采集( 用于全自动网页监控、网页自动刷新、浏览、生成大量PV)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-04 00:10
用于全自动网页监控、网页自动刷新、浏览、生成大量PV)
<IMG src="https://pic-orsoon.macxf.com/S ... ot%3B border=0>
用于网页自动监控,网页自动刷新,网页浏览,生成大量PV。
新功能:
1.取消软件授权限制,改为合法性检查,脱离服务器支持,使用更方便;
2.保存所有参数设置;
3.程序可以全自动运行;
4.提供调用微软IE浏览器(最大化、最小化、隐藏)刷新的选项;
5.恢复“网页浏览加速选项”;
6.添加延迟设计以降低 CPU 使用率。
重要提示:
1.关于“页组数”的提示:可以对所有需要刷新的页面进行分组(只要“总页数”大于等于“页组数”即可不一定要能被“页组数”整除),例如:“网页列表”共有200个网页,“网页组数”为10,即:打开10个网页同时,在指定的“刷新间隔”之后,打开接下来的 10 个网页。当组中有 200 页时,从头开始重复。可以访问更多网页,降低掉线率,提高可靠性。
2.GAIA和版主监控等需要登录的网页一定不要勾选“清除cookies”,否则会自动退出登录。
3.将程序最小化到系统托盘区域可以大大减少运行时的CPU和内存使用。
4.允许打开多个程序窗口。(请注意:每次打开一个窗口都必须等待上一个窗口完全显示,否则会打不开并报错!使用时请在Internet Explorer浏览器中进行相关设置:工具-> Internet 选项 -> 高级:选中禁用脚本调试(其他)”)。 查看全部
网页文章自动采集(
用于全自动网页监控、网页自动刷新、浏览、生成大量PV)
<IMG src="https://pic-orsoon.macxf.com/S ... ot%3B border=0>
用于网页自动监控,网页自动刷新,网页浏览,生成大量PV。
新功能:
1.取消软件授权限制,改为合法性检查,脱离服务器支持,使用更方便;
2.保存所有参数设置;
3.程序可以全自动运行;
4.提供调用微软IE浏览器(最大化、最小化、隐藏)刷新的选项;
5.恢复“网页浏览加速选项”;
6.添加延迟设计以降低 CPU 使用率。
重要提示:
1.关于“页组数”的提示:可以对所有需要刷新的页面进行分组(只要“总页数”大于等于“页组数”即可不一定要能被“页组数”整除),例如:“网页列表”共有200个网页,“网页组数”为10,即:打开10个网页同时,在指定的“刷新间隔”之后,打开接下来的 10 个网页。当组中有 200 页时,从头开始重复。可以访问更多网页,降低掉线率,提高可靠性。
2.GAIA和版主监控等需要登录的网页一定不要勾选“清除cookies”,否则会自动退出登录。
3.将程序最小化到系统托盘区域可以大大减少运行时的CPU和内存使用。
4.允许打开多个程序窗口。(请注意:每次打开一个窗口都必须等待上一个窗口完全显示,否则会打不开并报错!使用时请在Internet Explorer浏览器中进行相关设置:工具-> Internet 选项 -> 高级:选中禁用脚本调试(其他)”)。
网页文章自动采集(网页文章自动采集的第一步要利用好爬虫?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-01 23:02
网页文章自动采集其实挺简单的,最主要的是第一步要利用好爬虫,然后再组合起来就可以了。
1、鼠标悬停任何一个网页页面,
2、打开浏览器地址栏,
3、点击浏览器右下角的“可视化查看”;
4、点击“获取更多页面”;
5、弹出“本页面的网址”对话框,
6、输入网址中所有链接;
7、点击“获取更多网页”;
8、弹出“本页面网址”对话框,在上方选择另一个表格中的链接。
第二步:提取所有链接中的内容
1、鼠标悬停任何一个网页页面的标题和描述;
2、点击浏览器右下角的“可视化查看”;
3、在浏览器右下角查看该网页;
4、选择其中需要的内容进行提取;
5、点击提取中的“从百度抓取”;
6、粘贴该内容中的网址到“可视化查看”页面;
7、粘贴上传内容到另一个表格中;
8、点击“保存”。
第三步:提取表格中的所有内容
5、点击提取中的“从搜狗抓取”;
8、点击“保存”。备注:可根据实际情况,选择任何一种方式。 查看全部
网页文章自动采集(网页文章自动采集的第一步要利用好爬虫?)
网页文章自动采集其实挺简单的,最主要的是第一步要利用好爬虫,然后再组合起来就可以了。
1、鼠标悬停任何一个网页页面,
2、打开浏览器地址栏,
3、点击浏览器右下角的“可视化查看”;
4、点击“获取更多页面”;
5、弹出“本页面的网址”对话框,
6、输入网址中所有链接;
7、点击“获取更多网页”;
8、弹出“本页面网址”对话框,在上方选择另一个表格中的链接。
第二步:提取所有链接中的内容
1、鼠标悬停任何一个网页页面的标题和描述;
2、点击浏览器右下角的“可视化查看”;
3、在浏览器右下角查看该网页;
4、选择其中需要的内容进行提取;
5、点击提取中的“从百度抓取”;
6、粘贴该内容中的网址到“可视化查看”页面;
7、粘贴上传内容到另一个表格中;
8、点击“保存”。
第三步:提取表格中的所有内容
5、点击提取中的“从搜狗抓取”;
8、点击“保存”。备注:可根据实际情况,选择任何一种方式。
网页文章自动采集(如何使用优采云采集器采集这种类型网页里面详细信息页面数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2022-01-31 14:28
)
很多网站都有这个模式,一个列表页面,点击列表中的一行链接会打开一个详细的信息页面,本片文章会教你如何使用优采云采集器采集此类网页中详细信息页面的数据。
首先打开优采云采集器→点击快速启动→新建任务进入任务配置页面:
选择任务组,自定义任务名称和备注;
上图配置完成后,选择Next,进入流程配置页面,拖拽一个步骤打开网页进入流程设计器;
选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会自动在软件下方的浏览器中打开对应的网页:
选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会自动在软件下方的浏览器中打开对应的网页:
由于我们需要在上面的浏览器中循环点击电影名称,然后提取子页面中的数据信息,所以我们需要制作一个循环的采集列表。
点击上图中的第一个循环项,在弹出的对话框中选择创建元素列表来处理一组元素;
接下来,在弹出的对话框中,选择添加到列表
添加第一个循环项目后,选择继续编辑列表。
接下来以相同的方式添加第二个循环项目。
当我们添加第二个区域块时,我们可以看上图,此时页面中的其他元素都添加了。这是因为我们在添加两个具有相似特征的元素,系统会在页面中智能添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环
经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。
选择上图中的第一个循环项,然后选择click元素。输入第一个子链接。
以下是数据字段的提取。在浏览器中选择需要提取的字段,然后在弹出的选择对话框中选择抓取该元素的文本;
完成上述操作后,系统会在页面右上角显示我们要抓取的字段;
接下来配置页面上需要抓取的其他字段,配置完成后修改字段名称;
修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;
点击上图中的Next→Next→Start Standalone采集(调试模式),进入任务检查页面,保证任务的正确性;
点击Start Standalone采集,系统会在本地执行采集进程并显示最终的采集结果;
如果我们需要导出最终的采集数据信息,点击下图中的导出按钮,选择要导出的文件类型,系统会提示保存路径,选择保存路径,系统会自动导出文件。
查看全部
网页文章自动采集(如何使用优采云采集器采集这种类型网页里面详细信息页面数据
)
很多网站都有这个模式,一个列表页面,点击列表中的一行链接会打开一个详细的信息页面,本片文章会教你如何使用优采云采集器采集此类网页中详细信息页面的数据。
首先打开优采云采集器→点击快速启动→新建任务进入任务配置页面:
选择任务组,自定义任务名称和备注;
上图配置完成后,选择Next,进入流程配置页面,拖拽一个步骤打开网页进入流程设计器;
选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会自动在软件下方的浏览器中打开对应的网页:
选择在浏览器中打开网页的步骤,在右侧页面网址中输入网页网址并点击保存,系统会自动在软件下方的浏览器中打开对应的网页:
由于我们需要在上面的浏览器中循环点击电影名称,然后提取子页面中的数据信息,所以我们需要制作一个循环的采集列表。
点击上图中的第一个循环项,在弹出的对话框中选择创建元素列表来处理一组元素;
接下来,在弹出的对话框中,选择添加到列表
添加第一个循环项目后,选择继续编辑列表。
接下来以相同的方式添加第二个循环项目。
当我们添加第二个区域块时,我们可以看上图,此时页面中的其他元素都添加了。这是因为我们在添加两个具有相似特征的元素,系统会在页面中智能添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环
经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。
选择上图中的第一个循环项,然后选择click元素。输入第一个子链接。
以下是数据字段的提取。在浏览器中选择需要提取的字段,然后在弹出的选择对话框中选择抓取该元素的文本;
完成上述操作后,系统会在页面右上角显示我们要抓取的字段;
接下来配置页面上需要抓取的其他字段,配置完成后修改字段名称;
修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;
点击上图中的Next→Next→Start Standalone采集(调试模式),进入任务检查页面,保证任务的正确性;
点击Start Standalone采集,系统会在本地执行采集进程并显示最终的采集结果;
如果我们需要导出最终的采集数据信息,点击下图中的导出按钮,选择要导出的文件类型,系统会提示保存路径,选择保存路径,系统会自动导出文件。
网页文章自动采集(五、文章网址匹配规则文章的设置和设置 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-01-31 14:27
)
五、文章网址匹配规则
文章URL匹配规则的设置非常简单,不需要复杂的设置,提供了两种匹配方式,可以使用URL通配符或者CSS选择器进行匹配。通常,使用 URL 通配符进行匹配更简单。
1. 使用 URL 通配符匹配
通过点击列表URL上的文章,我们可以发现每个文章的URL都有如下结构
所以将URL中不断变化的数字或字母替换为通配符(*),如:(*)/(*).shtml
2. 使用 CSS 选择器进行匹配
使用 CSS 选择器进行匹配,我们只需要设置 文章 URL 的 CSS 选择器(不知道 CSS 选择器是什么,一分钟了解如何设置 CSS 选择器),通过查看list URL的源码可以很方便的设置,在list URL下找到具体文章的超链接的代码,如下图:
可以看到文章的超链接a标签在class为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList a即可,如下图显示:
设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,会列出列表URL下的所有文章名称和对应的网页地址,如下图:
六、文章爬取设置
在这个选项卡下,我们需要设置文章标题和文章内容的匹配规则。有两种设置方法。推荐使用 CSS 选择器方式,比较好用。准确的。 (不知道CSS选择器是什么,一分钟了解如何设置CSS选择器)
我们只需要设置文章标题CSS选择器和文章内容CSS选择器就可以准确抓取文章标题和文章内容。
在文章的来源设置中,我们以采集“新浪网讯”为例,这里举例说明,通过查看下一个文章的来源list URL 代码可以很方便的设置,比如查看具体文章的源码,如下:
如你所见,文章title在id为“artibodyTitle”的标签内,所以文章title CSS选择器只需设置为#artibodyTitle;
同样,找到文章内容的相关代码:
如您所见,文章内容在id为“artibody”的标签内,因此文章内容CSS选择器只需设置为#artibody;如下:
设置完成后,如果不知道设置是否正确,可以点击测试按钮,输入测试地址。如果设置正确,会显示文章标题和文章内容,方便查看设置
七、获取文章分页内容
如果文章的内容过长,多个页面也可以抓取全部内容。在这种情况下,您需要设置 文章 页面链接的 CSS 选择器。通过查看具体的文章网址源码,在哪里可以找到分页链接,例如一个文章分页链接代码如下:
可以看到分页链接A标签在class为“page-link”的标签内
因此,文章page-link CSS选择器可以设置为.page-link a,如下:
如果选中此选项,则帖子文章也将分页。如果您的 WordPress 主题不支持标签,请不要勾选。
八、文章内容过滤功能
文章内容过滤功能,可以过滤掉文本中不需要的内容(如广告代码、版权信息等),可以设置两个关键词,删除两个关键词@ >、关键词2可以为空,表示删除关键词1之后的所有内容。
如下图,我们通过测试爬取文章后发现文章中有我们不想发布的内容,切换到HTML显示,找到该内容的HTML代码,并设置两个关键词过滤掉内容。
如果需要过滤掉多个内容,可以添加多组设置。
九、HTML标签过滤功能
HTML标签过滤功能,可以过滤掉采集文章中的超链接(如a标签)。
以上是如何使用WordPress自动采集插件的详细内容。更多详情请关注php中文网其他相关话题文章!
关键词0@> 查看全部
网页文章自动采集(五、文章网址匹配规则文章的设置和设置
)
五、文章网址匹配规则
文章URL匹配规则的设置非常简单,不需要复杂的设置,提供了两种匹配方式,可以使用URL通配符或者CSS选择器进行匹配。通常,使用 URL 通配符进行匹配更简单。
1. 使用 URL 通配符匹配
通过点击列表URL上的文章,我们可以发现每个文章的URL都有如下结构
所以将URL中不断变化的数字或字母替换为通配符(*),如:(*)/(*).shtml
2. 使用 CSS 选择器进行匹配
使用 CSS 选择器进行匹配,我们只需要设置 文章 URL 的 CSS 选择器(不知道 CSS 选择器是什么,一分钟了解如何设置 CSS 选择器),通过查看list URL的源码可以很方便的设置,在list URL下找到具体文章的超链接的代码,如下图:
可以看到文章的超链接a标签在class为“contList”的标签里面,所以文章 URL的CSS选择器只需要设置为.contList a即可,如下图显示:
设置完成后,如果不知道设置是否正确,可以点击上图中的测试按钮。如果设置正确,会列出列表URL下的所有文章名称和对应的网页地址,如下图:
六、文章爬取设置
在这个选项卡下,我们需要设置文章标题和文章内容的匹配规则。有两种设置方法。推荐使用 CSS 选择器方式,比较好用。准确的。 (不知道CSS选择器是什么,一分钟了解如何设置CSS选择器)
我们只需要设置文章标题CSS选择器和文章内容CSS选择器就可以准确抓取文章标题和文章内容。
在文章的来源设置中,我们以采集“新浪网讯”为例,这里举例说明,通过查看下一个文章的来源list URL 代码可以很方便的设置,比如查看具体文章的源码,如下:
如你所见,文章title在id为“artibodyTitle”的标签内,所以文章title CSS选择器只需设置为#artibodyTitle;
同样,找到文章内容的相关代码:
如您所见,文章内容在id为“artibody”的标签内,因此文章内容CSS选择器只需设置为#artibody;如下:
设置完成后,如果不知道设置是否正确,可以点击测试按钮,输入测试地址。如果设置正确,会显示文章标题和文章内容,方便查看设置
七、获取文章分页内容
如果文章的内容过长,多个页面也可以抓取全部内容。在这种情况下,您需要设置 文章 页面链接的 CSS 选择器。通过查看具体的文章网址源码,在哪里可以找到分页链接,例如一个文章分页链接代码如下:
可以看到分页链接A标签在class为“page-link”的标签内
因此,文章page-link CSS选择器可以设置为.page-link a,如下:
如果选中此选项,则帖子文章也将分页。如果您的 WordPress 主题不支持标签,请不要勾选。
八、文章内容过滤功能
文章内容过滤功能,可以过滤掉文本中不需要的内容(如广告代码、版权信息等),可以设置两个关键词,删除两个关键词@ >、关键词2可以为空,表示删除关键词1之后的所有内容。
如下图,我们通过测试爬取文章后发现文章中有我们不想发布的内容,切换到HTML显示,找到该内容的HTML代码,并设置两个关键词过滤掉内容。
如果需要过滤掉多个内容,可以添加多组设置。
九、HTML标签过滤功能
HTML标签过滤功能,可以过滤掉采集文章中的超链接(如a标签)。
以上是如何使用WordPress自动采集插件的详细内容。更多详情请关注php中文网其他相关话题文章!
关键词0@>
网页文章自动采集(独特的无人值守ET从设计之初到无人工作的目的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-30 18:22
免费的采集软件EditorTools是一款强大的中小型网站自动更新工具,全自动采集发布,静默工作,无需人工干预;独立软件消除网站性能消耗;安全稳定,可使用多年不间断工作;支持任意网站和数据库采集版本,内置软件包括discuzX、phpwind、dedecms、wordpress、phpcms、empirecms,移动方便, joomla, pbdigg, php168, bbsxp, phpbb, dvbbs, typecho, emblog 和许多其他常用系统的例子。
本软件适合需要长期更新的网站使用,不需要您对现有论坛或网站进行任何修改。
解放网站管理员和管理员
网站要保持活力,每日内容更新是基础。一个小网站保证每日更新,通常要求站长承担每天8小时的更新工作,周末开放;一个媒体网站全天维护内容更新,通常需要一天3班,每个Admin劳动力为一个班2-3人。如果按照普通月薪1500元计算,即使不包括周末加班费,小网站每月至少要花1500元,而中型网站则要1万多元。 . ET的出现将为您省下这笔费用!从繁琐的 网站 更新工作中解放网站管理员和管理员!
独一无二的无人值守
ET的设计以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,甚至几年。
超高稳定性
要达到无人值守软件的目的,需要长时间稳定运行。ET在这方面做了很多优化,保证软件可以稳定连续工作,永远不会出现一些采集软件会自己崩溃甚至导致网站崩溃的问题.
最低资源使用量
ET独立于网站,不消耗宝贵的服务器WEB处理资源,可以在服务器或站长的工作机上工作。
严密的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了任何可能由ET引起的数据安全问题。采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
除了一般采集工具的功能外,ET还可以使用图片水印、防盗链、分页采集、回复采集、登录采集、自定义等功能项目,UTF- 8、UBB,模拟发布...
EditorTools 2 功能介绍
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,还可以采集任何类型的信息
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
【特点】下载和上传支持断点简历
【特点】高速伪原创
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项语言翻译
【发布】支持转码,支持UBB码
【发布】文件上传可选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态 查看全部
网页文章自动采集(独特的无人值守ET从设计之初到无人工作的目的)
免费的采集软件EditorTools是一款强大的中小型网站自动更新工具,全自动采集发布,静默工作,无需人工干预;独立软件消除网站性能消耗;安全稳定,可使用多年不间断工作;支持任意网站和数据库采集版本,内置软件包括discuzX、phpwind、dedecms、wordpress、phpcms、empirecms,移动方便, joomla, pbdigg, php168, bbsxp, phpbb, dvbbs, typecho, emblog 和许多其他常用系统的例子。
本软件适合需要长期更新的网站使用,不需要您对现有论坛或网站进行任何修改。
解放网站管理员和管理员
网站要保持活力,每日内容更新是基础。一个小网站保证每日更新,通常要求站长承担每天8小时的更新工作,周末开放;一个媒体网站全天维护内容更新,通常需要一天3班,每个Admin劳动力为一个班2-3人。如果按照普通月薪1500元计算,即使不包括周末加班费,小网站每月至少要花1500元,而中型网站则要1万多元。 . ET的出现将为您省下这笔费用!从繁琐的 网站 更新工作中解放网站管理员和管理员!
独一无二的无人值守
ET的设计以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,甚至几年。
超高稳定性
要达到无人值守软件的目的,需要长时间稳定运行。ET在这方面做了很多优化,保证软件可以稳定连续工作,永远不会出现一些采集软件会自己崩溃甚至导致网站崩溃的问题.
最低资源使用量
ET独立于网站,不消耗宝贵的服务器WEB处理资源,可以在服务器或站长的工作机上工作。
严密的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了任何可能由ET引起的数据安全问题。采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
除了一般采集工具的功能外,ET还可以使用图片水印、防盗链、分页采集、回复采集、登录采集、自定义等功能项目,UTF- 8、UBB,模拟发布...
EditorTools 2 功能介绍
【特点】 设定好计划后,无需人工干预,即可全天24小时自动工作。
【特点】与网站分离,通过独立制作的接口可以支持任意网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,还可以采集任何类型的信息
【特点】体积小、功耗低、稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源复用灵活
【特点】使用FTP上传文件,稳定安全
【特点】下载和上传支持断点简历
【特点】高速伪原创
[采集] 可以选择倒序、顺序、随机采集文章
【采集】支持自动列出网址
[采集] 支持采集 for 网站,其数据分布在多层页面上
【采集】自由设置采集数据项,并可对每个数据项进行单独筛选和排序
【采集】支持分页内容采集
【采集】支持任意格式和类型的文件(包括图片和视频)下载
【采集】可以突破防盗链文件
【采集】支持动态文件URL解析
[采集] 支持 采集 用于需要登录访问的网页
【支持】可设置关键词采集
【支持】可设置敏感词防止采集
【支持】可设置图片水印
【发布】支持发布文章带回复,可广泛应用于论坛、博客等项目
【发布】从采集数据中分离出来的发布参数项可以自由对应采集数据或者预设值,大大增强了发布规则的复用性
【发布】支持随机选择发布账号
【发布】支持任意发布项语言翻译
【发布】支持转码,支持UBB码
【发布】文件上传可选择自动创建年月日目录
[发布] 模拟发布支持网站接口无法安装的发布操作
【支持】程序可以正常运行
【支持】防止网络运营商劫持HTTP功能
[支持] 手动释放单个项目 采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
网页文章自动采集(知乎平台自己的知乎账号(pc端)以及公众号内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-01-30 16:02
网页文章自动采集当前网络上各类新闻、博客、评论等信息的时候,一方面需要读者长时间地耐心阅读网站不断更新的新闻来发现自己想要了解的新闻,另一方面需要读者收集新闻信息并推荐给其他读者。直接实现知乎文章自动采集,节省读者的时间,顺便提升知乎平台的健康度。本项目中需要用到的知乎平台自己的知乎账号(pc端)以及公众号的内容。
具体代码如下:#-*-coding:utf-8-*-importrequestsimportreimportrandom#author:dragospeak@zg5tzz@word_break="[^/~chinese.php>http/1.1]()"""#从链接中提取api地址defget_api_url(self):"""获取知乎官方回答的api地址"""#返回结果最终是一个全局的对象,保存在变量results中#简单对base64做一些转换,得到数字x,y,zcsv=requests.get(url=self.get_api_url,headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.2716.250safari/537.36'}).text#下载知乎官方回答,具体可以参考官方地址defbase64_url_from_text(self):results=csv.reader(csv_path)#text=csv.reader(csv_path)#转化base64为二进制格式results=base64_url_from_text(self.base64_url_from_text(csv['text']))ifresults==none:returnnone#需要自己手动把api_url字符串传进去defparse_api_url(self):"""从链接中提取各种链接和参数"""#获取“获取知乎热门问题”classauthor:def__init__(self,id):self.id=idself.headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.2716.250safari/537.36'}self.text='去寻找知乎上所有的优质问答吧'#获取对应的优质回答if__name__=='__main__':results=get_api_url(self.author)else:print('获取失败')获取知乎热门话题的api地址defget_kolleruan_post(self):"""从链接中提取各种链接和参数"""if__name__=='__main__':classauthor:def__init__(self,id):self.id=id。 查看全部
网页文章自动采集(知乎平台自己的知乎账号(pc端)以及公众号内容)
网页文章自动采集当前网络上各类新闻、博客、评论等信息的时候,一方面需要读者长时间地耐心阅读网站不断更新的新闻来发现自己想要了解的新闻,另一方面需要读者收集新闻信息并推荐给其他读者。直接实现知乎文章自动采集,节省读者的时间,顺便提升知乎平台的健康度。本项目中需要用到的知乎平台自己的知乎账号(pc端)以及公众号的内容。
具体代码如下:#-*-coding:utf-8-*-importrequestsimportreimportrandom#author:dragospeak@zg5tzz@word_break="[^/~chinese.php>http/1.1]()"""#从链接中提取api地址defget_api_url(self):"""获取知乎官方回答的api地址"""#返回结果最终是一个全局的对象,保存在变量results中#简单对base64做一些转换,得到数字x,y,zcsv=requests.get(url=self.get_api_url,headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.2716.250safari/537.36'}).text#下载知乎官方回答,具体可以参考官方地址defbase64_url_from_text(self):results=csv.reader(csv_path)#text=csv.reader(csv_path)#转化base64为二进制格式results=base64_url_from_text(self.base64_url_from_text(csv['text']))ifresults==none:returnnone#需要自己手动把api_url字符串传进去defparse_api_url(self):"""从链接中提取各种链接和参数"""#获取“获取知乎热门问题”classauthor:def__init__(self,id):self.id=idself.headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/60.0.2716.250safari/537.36'}self.text='去寻找知乎上所有的优质问答吧'#获取对应的优质回答if__name__=='__main__':results=get_api_url(self.author)else:print('获取失败')获取知乎热门话题的api地址defget_kolleruan_post(self):"""从链接中提取各种链接和参数"""if__name__=='__main__':classauthor:def__init__(self,id):self.id=id。
网页文章自动采集(智能区块算法采集任意内容类站点,自动提取网页正文)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-29 18:16
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可以对采集的内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创! 查看全部
网页文章自动采集(智能区块算法采集任意内容类站点,自动提取网页正文)
Dedecms采集,采用智能分块算法,可以直接将html代码和主要内容分开,只要输入URL,就可以提取出网页的正文和标题。以传统网页采集为例,所见即所得采集,傻瓜式的快速采集,以及各种内置伪原创@ > 方法,可以对采集的内容进行二次处理,内置主流的cms发布接口,也可以直接导出为txt格式到本地。站长可以使用Dedecms采集到采集网页上的一些数据内容,并且可以单独保存这些数据内容,
Dedecms采集面向有兴趣建设伪原创7@>的站长,为了更好的管理伪原创7@>用户,增加伪原创7@>的伪原创0@>和权重,要丰富伪原创7@>的内容,频率比较高。这样就需要用到Dedecms采集到采集需要的文章资源。智能分块算法采集任意内容站点,自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集。自动去噪,自动过滤标题内容和联系方式,多任务(多站点/列)多线程同步采集,代理采集,快速高效。指定任何 文章内容类伪原创7@>采集,而不是 <
做过采集站的SEOer应该知道,采集的文章发到自己的伪原创7@>的效果并不理想,采集每发几百条天 伪原创0@> 文章的结果很少,为什么?一些 SEOers 必须明白其中的原因。最根本的原因是发布的文章质量不够好。文章已经存在于搜索引擎中,那么蜘蛛还会抓取这些内容吗?很明显,这个概率很低,也是我们SEOer们经常听到最多,重复最多的,发布文章到原创!
网页文章自动采集(用爬虫软件了解如何抓取,网页文章自动采集的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-01-28 06:02
网页文章自动采集的方法主要有三种:1.一些爬虫软件、网站抓包工具,这个肯定需要下载,需要付费才能使用;2.使用代理,各种软件,价格参差不齐;3.采集之后用商业的解析工具,可能有些会收取一定的费用。
采集网页文章这样的数据量都挺少的了,一般找一下现成的数据源,或者自己写爬虫应该就可以获取,建议在知乎或者国外网站找一下相关资料,
我也很有这方面的问题,最近在了解一些网络爬虫,在知乎上看了大家的分享,
/这个网站有些有模板有些一般。
你可以了解一下
用爬虫软件了解如何抓取,
win10,网页端所有的数据都能抓,不需要下载客户端就能抓住,比如天猫,,
网页文章我好像是用定时下载的软件去下载的,我下载了好多,每天我都觉得我这一批网页都是最新的文章。感觉挺好的。
不知道你使用的是什么操作系统,常见的用浏览器本地浏览器,好像我用的是safari,
一般我会使用windows平台下抓包工具。 查看全部
网页文章自动采集(用爬虫软件了解如何抓取,网页文章自动采集的方法)
网页文章自动采集的方法主要有三种:1.一些爬虫软件、网站抓包工具,这个肯定需要下载,需要付费才能使用;2.使用代理,各种软件,价格参差不齐;3.采集之后用商业的解析工具,可能有些会收取一定的费用。
采集网页文章这样的数据量都挺少的了,一般找一下现成的数据源,或者自己写爬虫应该就可以获取,建议在知乎或者国外网站找一下相关资料,
我也很有这方面的问题,最近在了解一些网络爬虫,在知乎上看了大家的分享,
/这个网站有些有模板有些一般。
你可以了解一下
用爬虫软件了解如何抓取,
win10,网页端所有的数据都能抓,不需要下载客户端就能抓住,比如天猫,,
网页文章我好像是用定时下载的软件去下载的,我下载了好多,每天我都觉得我这一批网页都是最新的文章。感觉挺好的。
不知道你使用的是什么操作系统,常见的用浏览器本地浏览器,好像我用的是safari,
一般我会使用windows平台下抓包工具。
网页文章自动采集(【牛牛叨叨叨】微信小程序的生成方法吧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-01-28 04:01
网页文章自动采集,采集首发:公众号【牛牛叨叨叨】原文::文章资源来源:个人博客、小红书、论坛、知乎等。需要高版本,可以自行找个网站采集。第一步:获取网站主页地址打开“百度一下”,复制地址到工具上进行查询。或者打开百度网盘,下载网址查询工具。工具地址:提取码:3hju注意:很多网站不开放爬虫采集,建议用前两种方法获取,就像学网站工具前,搜一下“如何用everything遍历一个网站”,使用工具同理,查一下对应网站的相关要求,遇到有漏洞的网站才需要进行请求验证。
第二步:上传压缩包,解压打开工具,解压压缩包,进入文件夹“文章采集.jpg”。解压后,搜索对应工具对应的代码即可。所有文章都是压缩包,里面还有源代码,直接进行编辑即可,编辑完毕保存即可。第三步:粘贴采集jpg地址1.先打开百度网盘,提取图片上传代码2.工具操作后,粘贴地址3.浏览器查看结果,即可找到对应文章源代码。
建议使用“神器”——开源地址:javascript同步加载nodejs程序express-nodejs服务器程序本人使用express搭建了微信小程序,你也可以尝试一下(仅供参考)。接下来给你写个小程序,咱们聊聊微信小程序的生成方法吧!微信小程序现阶段的入口是附近的小程序,你可以到附近的小程序里搜索你需要的东西。
<p>然后等待着回应,等待小程序生成就行啦!我们来看看小程序的代码吧,如下:首先得上传小程序码,微信会对小程序的官方授权来进行审核,下面是一个示例:接下来是个人开发者申请,需要的基本信息请参考官方文档,官方文档:服务商须知>基本配置version0.1.0(64-bit)ios7.0.0不包含iphone或android的设备版本>sdkcrack>仅一次申请! 查看全部
网页文章自动采集(【牛牛叨叨叨】微信小程序的生成方法吧!)
网页文章自动采集,采集首发:公众号【牛牛叨叨叨】原文::文章资源来源:个人博客、小红书、论坛、知乎等。需要高版本,可以自行找个网站采集。第一步:获取网站主页地址打开“百度一下”,复制地址到工具上进行查询。或者打开百度网盘,下载网址查询工具。工具地址:提取码:3hju注意:很多网站不开放爬虫采集,建议用前两种方法获取,就像学网站工具前,搜一下“如何用everything遍历一个网站”,使用工具同理,查一下对应网站的相关要求,遇到有漏洞的网站才需要进行请求验证。
第二步:上传压缩包,解压打开工具,解压压缩包,进入文件夹“文章采集.jpg”。解压后,搜索对应工具对应的代码即可。所有文章都是压缩包,里面还有源代码,直接进行编辑即可,编辑完毕保存即可。第三步:粘贴采集jpg地址1.先打开百度网盘,提取图片上传代码2.工具操作后,粘贴地址3.浏览器查看结果,即可找到对应文章源代码。
建议使用“神器”——开源地址:javascript同步加载nodejs程序express-nodejs服务器程序本人使用express搭建了微信小程序,你也可以尝试一下(仅供参考)。接下来给你写个小程序,咱们聊聊微信小程序的生成方法吧!微信小程序现阶段的入口是附近的小程序,你可以到附近的小程序里搜索你需要的东西。
<p>然后等待着回应,等待小程序生成就行啦!我们来看看小程序的代码吧,如下:首先得上传小程序码,微信会对小程序的官方授权来进行审核,下面是一个示例:接下来是个人开发者申请,需要的基本信息请参考官方文档,官方文档:服务商须知>基本配置version0.1.0(64-bit)ios7.0.0不包含iphone或android的设备版本>sdkcrack>仅一次申请!
网页文章自动采集(前文Ajax理论AjaxAjaxAjaxAjax分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-01-27 08:19
上面的爬虫都是基于静态网页的。首先通过请求网站url获取网页源代码。之后,可以提取和存储源代码。本文对动态网页采集进行数据处理。首先介绍了Ajax的理论,然后实际爬取flushflush的动态网页,获取个股的相关信息。
一、Ajax 理论
1.Ajax介绍
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种 Web 开发技术,用于创建交互式、快速和动态的 Web 应用程序,可以在不重新加载整个网页的情况下更新部分网页。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
2.Ajax 分析
微博网站是一个比较容易识别的Ajax动态网页。首先打开Dectools工具(转到XHR专栏)和中南财经政法大学官方微博网站(),这里选择。是手机微博,然后选择清除所有内容。
接下来,滚动滚轮以下拉页面,直到一个新项目出现在空的 XHR 列中。点击项目,选择预览栏,发现这里对应的内容就是页面上的新微博。但它没有改变。至此,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
或者选择同一个条目进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求的url为:,即请求有四个参数:type、value、containerid、since_id和然后翻页发现除了since_id的变化之外,其余保持不变,这里我们可以看到since_id就是翻页方法。
接下来进一步观察since_id,发现上下请求的since_id之间没有明显的规律。进一步搜索发现,下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态url循环添加到爬虫中。
发起请求并得到响应后,可以进一步分析出响应格式是json,所以可以通过对json的进一步处理得到最终的数据!
二、网页分析
1.网站概览
经过以上分析,我们将用flush网页的数据来采集实战进行例子验证。首先打开网页:,如下图:
再按F12键打开Devtools后台源码,右键第一项查看源码位置。
2.阿贾克斯歧视
接下来,通过点击网页底部的下一页,我们发现网页的url并没有改变!至此,基本可以确定该网页属于Ajax动态网页。
进一步,我们清空Network中的所有内容,继续点击下一页到第五页,发现连续弹出三个同名的内容,可以获取到请求的url和请求头的具体内容通过一般栏。
所以,我们复制这个请求url,在浏览器中打开,响应内容确实是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页的形式,和上面微博响应的json格式不同,所以数据可以在稍后解析网页的形式。
三、爬行者战斗
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的是,这里的请求头除了User-Agent外,还需要host、Referer和X-Requested-With参数,这要和静态网页爬取区别开来。
# 导入库
import time
import json
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
2.信息提取
之后就是上面解析库中的内容,这里使用BaetifulSoup库,方便理解。首先将上面的html转换成BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应信息。
# 获取单页数据
def get_html(page_id):
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
soup = BeautifulSoup(res.text,'lxml')
tr_list = soup.select('tbody tr')
# print(tr_list)
stocks = []
for each_tr in tr_list:
td_list = each_tr.select('td')
data = {
'股票代码':td_list[1].text,
'股票简称':td_list[2].text,
'股票链接':each_tr.a['href'],
'现价':td_list[3].text,
'涨幅':td_list[4].text,
'涨跌':td_list[5].text,
'涨速':td_list[6].text,
'换手':td_list[7].text,
'量比':td_list[8].text,
'振幅':td_list[9].text,
'成交额':td_list[10].text,
'流通股':td_list[11].text,
'流通市值':td_list[12].text,
'市盈率':td_list[13].text,
}
stocks.append(data)
return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据
def write2excel(result):
json_result = json.dumps(result)
with open('stocks.json','w') as f:
f.write(json_result)
with open('stocks.json','r') as f:
data = f.read()
data = json.loads(data)
df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率'])
df.to_excel('stocks.xlsx',index=False)
4.循环结构
考虑到flushflush的多页结构和反爬的存在,这里也采用了字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬取前会中断一定时间。
def get_pages(page_n):
stocks_n = []
for page_id in range(1,page_n+1):
page = get_html(page_id)
stocks_n.extend(page)
time.sleep(random.randint(1,10))
return stocks_n
最终爬取结果如下:
四、爬虫摘要
至此,flush动态网页的爬取完成,再通过这个爬虫进行总结:首先,我们通过浏览网页结构和翻页,对比XHR bar对页面进行Ajax判断。如果网页url没有变化,XHR会刷新内容,基本说明是动态的。这时候我们进一步检查多个页面之间url请求的异同,寻找规律。找到规则后,就可以建立多页面请求流程了。之后处理单个响应内容(详见响应内容格式),最后建立整个循环爬虫结构,自动爬取所需信息。
爬虫的完整代码可以在今日头条私信获取。下面将进一步解释和实践浏览器模拟行为。上篇文章涉及的基础知识,请参考以下链接:
爬虫需要知道的基础知识,这一点就够了!Python网络爬虫实战系列
本文将带你深入了解和学习Python爬虫库!从现在开始,不用担心数据
Python爬虫有多简单?本文将带你实战豆瓣电影TOP250数据爬取!
一篇搞懂Python网络爬虫解析库的文章!收录多个示例 查看全部
网页文章自动采集(前文Ajax理论AjaxAjaxAjaxAjax分析)
上面的爬虫都是基于静态网页的。首先通过请求网站url获取网页源代码。之后,可以提取和存储源代码。本文对动态网页采集进行数据处理。首先介绍了Ajax的理论,然后实际爬取flushflush的动态网页,获取个股的相关信息。
一、Ajax 理论
1.Ajax介绍
Ajax 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),它指的是一种 Web 开发技术,用于创建交互式、快速和动态的 Web 应用程序,可以在不重新加载整个网页的情况下更新部分网页。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。
2.Ajax 分析
微博网站是一个比较容易识别的Ajax动态网页。首先打开Dectools工具(转到XHR专栏)和中南财经政法大学官方微博网站(),这里选择。是手机微博,然后选择清除所有内容。
接下来,滚动滚轮以下拉页面,直到一个新项目出现在空的 XHR 列中。点击项目,选择预览栏,发现这里对应的内容就是页面上的新微博。但它没有改变。至此,我们可以确定这是一个Ajax请求后的网页。
3.Ajax 提取
或者选择同一个条目进入Headers进一步查看信息,可以发现这是一个GET类型的请求,请求的url为:,即请求有四个参数:type、value、containerid、since_id和然后翻页发现除了since_id的变化之外,其余保持不变,这里我们可以看到since_id就是翻页方法。
接下来进一步观察since_id,发现上下请求的since_id之间没有明显的规律。进一步搜索发现,下一页的since_id在上一页的响应中的cardListInfo中,因此可以建立循环连接,进一步将动态url循环添加到爬虫中。
发起请求并得到响应后,可以进一步分析出响应格式是json,所以可以通过对json的进一步处理得到最终的数据!
二、网页分析
1.网站概览
经过以上分析,我们将用flush网页的数据来采集实战进行例子验证。首先打开网页:,如下图:
再按F12键打开Devtools后台源码,右键第一项查看源码位置。
2.阿贾克斯歧视
接下来,通过点击网页底部的下一页,我们发现网页的url并没有改变!至此,基本可以确定该网页属于Ajax动态网页。
进一步,我们清空Network中的所有内容,继续点击下一页到第五页,发现连续弹出三个同名的内容,可以获取到请求的url和请求头的具体内容通过一般栏。
所以,我们复制这个请求url,在浏览器中打开,响应内容确实是标准化的表格数据,正是我们想要的。
3.Ajax 提取
然后我们也打开源码,发现是一个html文档,说明响应内容是网页的形式,和上面微博响应的json格式不同,所以数据可以在稍后解析网页的形式。
三、爬行者战斗
1.网页访问
在第一部分的理论介绍和第二部分的网页分析之后,我们就可以开始编写爬虫代码了。首先,导入库并定义请求头。需要注意的是,这里的请求头除了User-Agent外,还需要host、Referer和X-Requested-With参数,这要和静态网页爬取区别开来。
# 导入库
import time
import json
import random
import requests
import pandas as pd
from bs4 import BeautifulSoup
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
2.信息提取
之后就是上面解析库中的内容,这里使用BaetifulSoup库,方便理解。首先将上面的html转换成BeautifulSoup对象,然后通过对象的select选择器选择响应tr标签中的数据,进一步分析每个tr标签的内容,得到如下对应信息。
# 获取单页数据
def get_html(page_id):
headers = {
'host':'q.10jqka.com.cn',
'Referer':'http://q.10jqka.com.cn/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3554.0 Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
url = 'http://q.10jqka.com.cn/index/i ... 39%3B % page_id
res = requests.get(url,headers=headers)
res.encoding = 'GBK'
soup = BeautifulSoup(res.text,'lxml')
tr_list = soup.select('tbody tr')
# print(tr_list)
stocks = []
for each_tr in tr_list:
td_list = each_tr.select('td')
data = {
'股票代码':td_list[1].text,
'股票简称':td_list[2].text,
'股票链接':each_tr.a['href'],
'现价':td_list[3].text,
'涨幅':td_list[4].text,
'涨跌':td_list[5].text,
'涨速':td_list[6].text,
'换手':td_list[7].text,
'量比':td_list[8].text,
'振幅':td_list[9].text,
'成交额':td_list[10].text,
'流通股':td_list[11].text,
'流通市值':td_list[12].text,
'市盈率':td_list[13].text,
}
stocks.append(data)
return stocks
3.保存数据
定义 write2excel 函数将数据保存到stocks.xlsx 文件中。
# 保存数据
def write2excel(result):
json_result = json.dumps(result)
with open('stocks.json','w') as f:
f.write(json_result)
with open('stocks.json','r') as f:
data = f.read()
data = json.loads(data)
df = pd.DataFrame(data,columns=['股票代码','股票简称','股票链接','现价','涨幅','涨跌','涨速','换手','量比','振幅','成交额', '流通股','流通市值','市盈率'])
df.to_excel('stocks.xlsx',index=False)
4.循环结构
考虑到flushflush的多页结构和反爬的存在,这里也采用了字符串拼接和循环结构来遍历多页股票信息。同时,随机库中的randint方法和时间库中的sleep方法在爬取前会中断一定时间。
def get_pages(page_n):
stocks_n = []
for page_id in range(1,page_n+1):
page = get_html(page_id)
stocks_n.extend(page)
time.sleep(random.randint(1,10))
return stocks_n
最终爬取结果如下:
四、爬虫摘要
至此,flush动态网页的爬取完成,再通过这个爬虫进行总结:首先,我们通过浏览网页结构和翻页,对比XHR bar对页面进行Ajax判断。如果网页url没有变化,XHR会刷新内容,基本说明是动态的。这时候我们进一步检查多个页面之间url请求的异同,寻找规律。找到规则后,就可以建立多页面请求流程了。之后处理单个响应内容(详见响应内容格式),最后建立整个循环爬虫结构,自动爬取所需信息。
爬虫的完整代码可以在今日头条私信获取。下面将进一步解释和实践浏览器模拟行为。上篇文章涉及的基础知识,请参考以下链接:
爬虫需要知道的基础知识,这一点就够了!Python网络爬虫实战系列
本文将带你深入了解和学习Python爬虫库!从现在开始,不用担心数据
Python爬虫有多简单?本文将带你实战豆瓣电影TOP250数据爬取!
一篇搞懂Python网络爬虫解析库的文章!收录多个示例
网页文章自动采集(极速点击虎,让您轻松体验自动化的完美境界!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-01-18 13:07
Speed Click Tiger是目前国内唯一一款完美融合各种常用操作的动作模拟软件。是国内最专业、最强大的脚本工具软件,可以实现灵活组合,自动完成所有复杂的操作!有了超快的点击老虎,电脑前所有重复的动作和操作都将不复存在!没有你想不到的,没有你做不到的——速点虎让你轻松体验自动化的完美状态!Speed Click Tiger 囊括了众多同类软件的功能,并完美有效地结合在一起,可以说是一款全能软件。--可以通过更换不同的IP地址自动刷网站流量,增加网站 点击率!--您可以在最短时间内将您的网站显示在各大网站和搜索引擎的显眼位置,并自动刷新网站关键词的排名以刷新排名访客。--可以模拟各种手机无线终端访问网站店铺,刷无线终端点击量和流量!--可以自动刷网站广告点击、网站IP流量、网站PV和UV!--可自动刷各种广告点击联盟任务、刷弹窗、刷点击,让你赚大钱!--在线投票自动刷票,让你的票数连连上涨,遥遥领先。--可以自动发送群发消息,群发邮件,QQ/MSN/旺旺等自动聊天群发,QQ好友群发,QQ群成员轮流群发!--可自动实现各种系统录入,数据随机录入,自动完成办公系统的重复录入。. . . . . 功能太多,这里就不一一列举了。. . 您只需要根据自己的实际功能需求灵活组合和安排每个任务! 查看全部
网页文章自动采集(极速点击虎,让您轻松体验自动化的完美境界!)
Speed Click Tiger是目前国内唯一一款完美融合各种常用操作的动作模拟软件。是国内最专业、最强大的脚本工具软件,可以实现灵活组合,自动完成所有复杂的操作!有了超快的点击老虎,电脑前所有重复的动作和操作都将不复存在!没有你想不到的,没有你做不到的——速点虎让你轻松体验自动化的完美状态!Speed Click Tiger 囊括了众多同类软件的功能,并完美有效地结合在一起,可以说是一款全能软件。--可以通过更换不同的IP地址自动刷网站流量,增加网站 点击率!--您可以在最短时间内将您的网站显示在各大网站和搜索引擎的显眼位置,并自动刷新网站关键词的排名以刷新排名访客。--可以模拟各种手机无线终端访问网站店铺,刷无线终端点击量和流量!--可以自动刷网站广告点击、网站IP流量、网站PV和UV!--可自动刷各种广告点击联盟任务、刷弹窗、刷点击,让你赚大钱!--在线投票自动刷票,让你的票数连连上涨,遥遥领先。--可以自动发送群发消息,群发邮件,QQ/MSN/旺旺等自动聊天群发,QQ好友群发,QQ群成员轮流群发!--可自动实现各种系统录入,数据随机录入,自动完成办公系统的重复录入。. . . . . 功能太多,这里就不一一列举了。. . 您只需要根据自己的实际功能需求灵活组合和安排每个任务!
网页文章自动采集(一下帝国(Empire网站)的优势以及使用方法实现网站SEO优化自动关键词排名 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-01-14 00:20
)
当我们有了帝国(Empire网站),就需要管理网站,因为网站突发情况非常多,Empirecms就是一个网站管理系统,很多人可能对此并没有特别的了解,下面就为大家介绍一下。今天重点给大家讲解一下Empire(Empire网站)的优势以及如何利用它实现自动网站SEO优化自动收录自动关键词排名!
一、帝国cms是什么?
Empirecms它的英文翻译是Empirecms,Empirecms是一个非常简单易用且功能强大的网站管理系统。Empirecms 的不同版本可满足各种需求,提供各种网站 解决方案。它采用系统模型的功能。在这个功能下,我们可以在后台扩展和实现各种系统。正因为如此,它也被称为通用网站建设工具。Empirecms 不同于传统的cms。它可以直接形成一个新的系统模型。用户可以选择适合自己的系统。操作也很简单,不需要任何程序。快速开始。
二、帝国cms如何使用
要使用Empirecms,我们首先需要下载安装,然后进入页面后根据提示登录。Empirecms 中有八个默认数据表,说明非常详细。您可以根据自己的需要进行选择。模型建好后,我们可以添加对应的栏目,为栏目制作对应的模板,设置各种权限,填写数据等,这样就可以生成网页了。我们不需要花太多精力去运营帝国cms,因为里面有很详细的教程,你也可以在网上搜索一下如何操作,不用太担心.
网站维护是一件很重要的事情。一个好的网站需要定期或不定期的更新内容,才能不断吸引更多的观众,增加流量。网站维护是为了让你的网站在互联网上长期稳定运行。易于构建且难以维护。对于网站来说,只有不断更新内容,才能保证网站的生命力。否则,网站不仅不能发挥应有的作用,反而会对公司本身的形象造成负面影响。如何快速便捷地更新网页,提高更新效率,是很多网站面临的问题。创建网页的工具有很多,但日复一日地编辑网页以更新信息是信息维护者的常见问题。内容更新是网站维护过程中的瓶颈。如何实现网站自动网站SEO优化自动收录自动关键词排名!
一、使用免费的Empire采集发布的软件来使用:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、支持任何 Empire 版本
5、亲测免费,作者声明永久免费
采集 将因版本不匹配或服务器环境不支持等其他原因不可用
二、使用Empire采集软件更容易上手
门槛低:无需花大量时间学习软件操作,一分钟即可上手,无需配置采集规则,输入关键词到采集即可。
高效:提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
零成本:几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
<p>帝国采集软件很强大,只要输入关键词采集,完全可以通过软件采集@自动采集和释放 查看全部
网页文章自动采集(一下帝国(Empire网站)的优势以及使用方法实现网站SEO优化自动关键词排名
)
当我们有了帝国(Empire网站),就需要管理网站,因为网站突发情况非常多,Empirecms就是一个网站管理系统,很多人可能对此并没有特别的了解,下面就为大家介绍一下。今天重点给大家讲解一下Empire(Empire网站)的优势以及如何利用它实现自动网站SEO优化自动收录自动关键词排名!
一、帝国cms是什么?
Empirecms它的英文翻译是Empirecms,Empirecms是一个非常简单易用且功能强大的网站管理系统。Empirecms 的不同版本可满足各种需求,提供各种网站 解决方案。它采用系统模型的功能。在这个功能下,我们可以在后台扩展和实现各种系统。正因为如此,它也被称为通用网站建设工具。Empirecms 不同于传统的cms。它可以直接形成一个新的系统模型。用户可以选择适合自己的系统。操作也很简单,不需要任何程序。快速开始。
二、帝国cms如何使用
要使用Empirecms,我们首先需要下载安装,然后进入页面后根据提示登录。Empirecms 中有八个默认数据表,说明非常详细。您可以根据自己的需要进行选择。模型建好后,我们可以添加对应的栏目,为栏目制作对应的模板,设置各种权限,填写数据等,这样就可以生成网页了。我们不需要花太多精力去运营帝国cms,因为里面有很详细的教程,你也可以在网上搜索一下如何操作,不用太担心.
网站维护是一件很重要的事情。一个好的网站需要定期或不定期的更新内容,才能不断吸引更多的观众,增加流量。网站维护是为了让你的网站在互联网上长期稳定运行。易于构建且难以维护。对于网站来说,只有不断更新内容,才能保证网站的生命力。否则,网站不仅不能发挥应有的作用,反而会对公司本身的形象造成负面影响。如何快速便捷地更新网页,提高更新效率,是很多网站面临的问题。创建网页的工具有很多,但日复一日地编辑网页以更新信息是信息维护者的常见问题。内容更新是网站维护过程中的瓶颈。如何实现网站自动网站SEO优化自动收录自动关键词排名!
一、使用免费的Empire采集发布的软件来使用:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、支持任何 Empire 版本
5、亲测免费,作者声明永久免费
采集 将因版本不匹配或服务器环境不支持等其他原因不可用
二、使用Empire采集软件更容易上手
门槛低:无需花大量时间学习软件操作,一分钟即可上手,无需配置采集规则,输入关键词到采集即可。
高效:提供一站式网站文章解决方案,无需人工干预,设置任务自动执行采集releases。
零成本:几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
<p>帝国采集软件很强大,只要输入关键词采集,完全可以通过软件采集@自动采集和释放
网页文章自动采集(无论什么语言编码都能采集发布!(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 404 次浏览 • 2022-01-11 17:18
这些都是文章属性,默认值为1,如果不选择属性,就留空即可。
如果文章有图片,is_litpic的固定值需要设置为1。如果不懂一些简单的正则表达式,用采集发布软件设置规则是很困难的. 正则表达式的一些基础知识还是需要慢慢掌握的,而大部分采集@采集都用到了最基础的正则表达式的内容。例如:你至少应该知道“。” "\n" "\s" "\d" "*" "+" "?" “{3,5}”“[3-6]”。为了理解这些简单的正则表达式的基本含义,我们将不在这里详细解释它们。您可以在 Internet 上找到信息。只有理解了这些规则,才能在采集发布前自行解决!
目前市面上大部分网站程序(ZBlog、Empire、Yiyou、织梦、wordpress、Cyclone、pboot等)都有采集功能,90%的需要它们来支付这些内置的采集函数或插件,每个网站都需要写很多正则规则,写起来会花很多时间,不能满足大部分网站的使用,有很多地方需要人工操作和维护。
对于一些不懂编程或者html的同学来说还是有点难度的。所以我建议没有编程基础或者前端直接使用第三方免费的自动采集发布工具。无需学习更专业的技术。只需几个简单的步骤,即可轻松采集网页数据,精准发布数据。
目前的采集器也更加智能,软件简单易懂,可以支持任意采集。您还可以在工具上使用第三方 SEO 工具进行批量管理,以获得更快的 收录 排名。不管采集可以是什么语言代码,SEO圈的老站长都知道,这些免费工具支持全网自动采集伪原创发布和推送。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力! 查看全部
网页文章自动采集(无论什么语言编码都能采集发布!(一))
这些都是文章属性,默认值为1,如果不选择属性,就留空即可。
如果文章有图片,is_litpic的固定值需要设置为1。如果不懂一些简单的正则表达式,用采集发布软件设置规则是很困难的. 正则表达式的一些基础知识还是需要慢慢掌握的,而大部分采集@采集都用到了最基础的正则表达式的内容。例如:你至少应该知道“。” "\n" "\s" "\d" "*" "+" "?" “{3,5}”“[3-6]”。为了理解这些简单的正则表达式的基本含义,我们将不在这里详细解释它们。您可以在 Internet 上找到信息。只有理解了这些规则,才能在采集发布前自行解决!
目前市面上大部分网站程序(ZBlog、Empire、Yiyou、织梦、wordpress、Cyclone、pboot等)都有采集功能,90%的需要它们来支付这些内置的采集函数或插件,每个网站都需要写很多正则规则,写起来会花很多时间,不能满足大部分网站的使用,有很多地方需要人工操作和维护。
对于一些不懂编程或者html的同学来说还是有点难度的。所以我建议没有编程基础或者前端直接使用第三方免费的自动采集发布工具。无需学习更专业的技术。只需几个简单的步骤,即可轻松采集网页数据,精准发布数据。
目前的采集器也更加智能,软件简单易懂,可以支持任意采集。您还可以在工具上使用第三方 SEO 工具进行批量管理,以获得更快的 收录 排名。不管采集可以是什么语言代码,SEO圈的老站长都知道,这些免费工具支持全网自动采集伪原创发布和推送。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
网页文章自动采集(优采云采集器完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-10 02:13
优采云采集器是一个非常强大的数据采集器,完美支持采集所有编码格式的网页,程序还可以自动识别网页编码,还支持所有目前主流和非主流cms、BBS等网站节目都可以通过系统的发布模块实现采集器和网站节目的完美结合。
特征
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和. net 外部编程接口来处理数据并使其可供您使用。
4、支持所有 网站 编码
完美支持采集所有编码格式的网页,程序还可以自动识别网页编码。
5、各种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守工作,配置程序后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
采集 数据的本地可视化编辑。
8、采集测试
这是任何其他类似的采集软件都无法比拟的,并且该程序支持直接查看采集结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
软件功能
1、规则自定义
所有网站采集几乎任何类型的信息都可以通过采集规则的定义进行搜索。
2、多任务、多线程
可以同时执行多个信息采集任务,每个任务可以使用多个线程。
3、所见即所得
任务采集流程是所见即所得,流程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储
数据自动保存到采集边缘的关系型数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及里面的表和字段,也可以通过数据库灵活导入。将数据保存到客户现有的数据库结构中。
5、断点继续挖掘
INFO采集任务停止后可以从断点处恢复采集,因此您不再需要担心您的采集任务被意外中断。
6、网站登录
支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、计划任务
此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制
采集 的范围可以根据采集 的深度和URL 的身份来限制。
9、文件下载
二进制文件(如:图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、结果替换
您可以根据规则将 采集 的结果替换为您定义的内容。
11、条件保存
您可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别
使用此功能可以识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布
采集 的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、 预留编程接口
定义多种编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
菜单功能
1、创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2、新任务
确定自己所属的组,新建任务,填写任务名称保存。
3、网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4、网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5、数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6、数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7、计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8、插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。 查看全部
网页文章自动采集(优采云采集器完美支持采集所有编码格式的网页,程序还可以自动识别网页编码)
优采云采集器是一个非常强大的数据采集器,完美支持采集所有编码格式的网页,程序还可以自动识别网页编码,还支持所有目前主流和非主流cms、BBS等网站节目都可以通过系统的发布模块实现采集器和网站节目的完美结合。
特征
1、通用
不管新闻、论坛、视频、黄页、图片、下载网站,只要是可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集得到你想要的内容需要 。
2、稳定高效
五年磨一剑,软件不断更新完善,采集速度快,性能稳定,占用资源少。
3、扩展性强,应用广泛
自定义web发布,自定义主流数据库的保存和发布,自定义本地php和. net 外部编程接口来处理数据并使其可供您使用。
4、支持所有 网站 编码
完美支持采集所有编码格式的网页,程序还可以自动识别网页编码。
5、各种发布方式
支持当前所有主流和非主流cms、BBS等网站节目,通过系统的发布模块可以实现采集器和网站节目的完美结合.
6、全自动
无人值守工作,配置程序后,程序会根据您的设置自动运行,无需人工干预。
7、本地编辑
采集 数据的本地可视化编辑。
8、采集测试
这是任何其他类似的采集软件都无法比拟的,并且该程序支持直接查看采集结果和测试发布。
9、易于管理
使用站点+任务模式管理采集节点,任务支持批量操作,管理更多数据轻松。
软件功能
1、规则自定义
所有网站采集几乎任何类型的信息都可以通过采集规则的定义进行搜索。
2、多任务、多线程
可以同时执行多个信息采集任务,每个任务可以使用多个线程。
3、所见即所得
任务采集流程是所见即所得,流程中遍历的链接信息、采集信息、错误信息等都会及时反映在软件界面中。
4、数据存储
数据自动保存到采集边缘的关系型数据库中,可以自动适配数据结构。软件可以根据采集规则自动创建数据库,以及里面的表和字段,也可以通过数据库灵活导入。将数据保存到客户现有的数据库结构中。
5、断点继续挖掘
INFO采集任务停止后可以从断点处恢复采集,因此您不再需要担心您的采集任务被意外中断。
6、网站登录
支持网站Cookies,支持网站可视化登录,甚至登录时需要验证码的网站也可以采集。
7、计划任务
此功能允许您的 采集 任务定期、定量或循环执行。
8、采集范围限制
采集 的范围可以根据采集 的深度和URL 的身份来限制。
9、文件下载
二进制文件(如:图片、音乐、软件、文档等)可以下载到本地磁盘或采集结果数据库。
10、结果替换
您可以根据规则将 采集 的结果替换为您定义的内容。
11、条件保存
您可以根据一定的条件决定保存哪些信息,过滤哪些信息。
12、过滤重复
软件可以根据用户设置和实际情况自动删除重复内容和重复网址。
13、特殊链接识别
使用此功能可以识别 Javascript 或其他更古怪的连接中动态生成的链接。
14、数据发布
采集 的结果数据可以通过自定义界面发布到任何内容管理系统和指定数据库。现在支持的目标发布媒体包括:数据库(access、sql server、mysql、oracle)、静态htm文件。
15、 预留编程接口
定义多种编程接口,用户可以在事件中使用PHP、C#语言进行编程,扩展采集的功能。
菜单功能
1、创建一个新组
新建一个任务组,选择所属的组,确定组名和备注。
2、新任务
确定自己所属的组,新建任务,填写任务名称保存。
3、网络发布配置
Web 发布配置定义了如何登录到 网站 并将数据提交到该 网站。
主要涉及登录信息的获取,网站编码设置,列列表的获取,使用数据测试发布效果。
4、网络发布模块
可以定义网站登录、获取列列表、获取网页随机值、内容发布参数、上传文件、构建发布数据等高级功能。
5、数据库发布配置
数据库发布配置定义了数据库链接信息的设置和数据库模块的选择。
6、数据库发布模块
用于编辑数据库的发布模块,以便我们可以将数据发布到配置的数据库。
优采云采集器可选择mysql、sqlserver、oracle、access四种数据库类型,在文本输入框中填写sql语句
(需要数据库知识),可以用标签来替换对应的数据。您还可以在 采集器modules 文件夹中加载要编辑的模块。
7、计划任务
设置列表中采集任务的启动时间表,可以是每个间隔,每天,每周,只有一次,也可以是自定义的Cron表达式,
(Cron 表达式的写法请参考相关术语的介绍)。保存设置后,即可根据设置执行任务。
8、插件管理
插件是可用于扩展 优采云采集器 功能的程序
优采云采集器V9支持三种插件:PHP源码、C#源码、C#类库。
网页文章自动采集(1.python+selenium控制已打开页面参考链接(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-01-05 16:06
)
python网页信息采集
介绍
这是第一次实战。帮助从 RIA Novosti 网站链接下载有关中国的新闻。技术不行,必须靠个人操作才能完成。
1.前期准备
选择日期或其他筛选项。
加载选项会第一次出现在这个网页上,需要自己点击,下滑后会动态加载。
2.自动控制鼠标向下滑动保存加载的网页
发现前期使用selenium模块直接打开页面,选择日期,获取数据时,会突然关闭浏览器。所以前期只能自己打开浏览器,手动选择页面,然后selenium继续控制正常加载。
1.python+selenium 控制打开的页面
参考链接
Win:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\Users\Administrator\Desktop\ria_ru"
Mac:
chrome启动程序目录:/Applications/Google Chrome.app/Contents/MacOS/
进入chrome启动程序目录后执行:
./Google\ Chrome --remote-debugging-port=9222 --user-data-dir="/Users/lee/Documents/selenum/AutomationProfile"
参数说明:
--remote-debugging-port
可以指定任何打开的端口,selenium启动时要用这个端口。
--user-data-dir
指定创建新chrome配置文件的目录。它确保在单独的配置文件中启动chrome,不会污染你的默认配置文件。
2.根据前面的前期准备,在打开的浏览器中手动选择需要的页面
3.自动滚动,保存加载的页面
技术太差了。我不知道这种动态加载的网页如何选择结束条件。我发现新闻是从新到旧排序的,所以我又选择了一个结束日期(月份)作为结束条件。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium. webdriver.common.keys import Keys
import time
def Stop_Month(self, stop_month):
#通过获取指定日期的前一个日期判断加载是否完成,需要多选择前一个日期
htmldateElems = browser.find_elements_by_class_name('list-item__date')
month_str = htmldateElems[-1].text.split()
return month_str[1]
def mouse_move(self, stop_month): # 滑动鼠标至底部操作
htmlElem = browser.find_element_by_tag_name('html')
while True:
htmlElem.send_keys(Keys.END)
time.sleep(1)
month = Stop_Month(self, stop_month)
print(month)
if stop_month == month:
print('****Arrived at the specified month interface****')
break
options = Options()
options.add_experimental_option('debuggerAddress', "127.0.0.1:9222")
browser = webdriver.Chrome(chrome_options=options)
browser.implicitly_wait(3)
stop_month = 'декабря'
mouse_move(browser, stop_month)
f = open('0631-0207.html', 'wb')
f.write(browser.page_source.encode("utf-8", "ignore"))
print('****html is written successfully****')
f.close()
3.获取页面的所有新闻链接、标题和时间,并生成excel表格
下载的网页实际上已经收录了所有的新闻链接、标题和时间。问题是如何提取它们。
import openpyxl re, bs4
def Links_Get(self):
'''获取链接'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
link_regex = re.compile(r'http(.*)html')
links=[]
for elem in elems:
a = link_regex.search(str(elem))
links.append(a.group())
return links
def Titles_Get(self):
'''获取标题'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
#查找所有包含这个属性的标签
titles=[]
for elem in elems:
titles.append(elem.text)
return titles
def Get_Link_to_Title(self, title, excel, i):
'''信息写入excel'''
excel['A%s'%(i)] = i
#获取时间列表
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
excel['B%s'%(i)] = a.group()
excel['C%s'%(i)] = title
excel['D%s'%(i)] = self
print("****%s successful****" % i)
links = Links_Get('0631-0207.html') #前面下载网页保存在工作目录
titles = Titles_Get('0631-0207.html')
nums1 = len(links)
nums2 = len(titles)
if nums1 == nums2:#一般的话,应该是对应的,不行的话,再看吧
i, j = 1, 0
#事先新建一个excel,再加载写入
time_title_link = openpyxl.load_workbook('time_title_link.xlsx')
time_title_link.create_sheet('0631-0207')
for link in links:
get_news.Get_Link_to_Title(link, titles[j], time_title_link['0631-0207'], i)
print(str(i), str(nums1))
if link == links[-1]:
time_title_link.save('time_title_link.xlsx')
print('Succeessful save')
i += 1
j += 1
print('****Succeessful all****')
else:
print('Error, titles != links')
4.从生成的列表中获取每个链接的新闻内容并生成docx
import openpyxl
import docx
def Get_News(self, doc):
res = requests.get(self)
res.raise_for_status()
NewsFile = bs4.BeautifulSoup(res.text, 'html.parser')
elems_titles = NewsFile.select('.article__title')
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
date_str = 'a[href=' + '"/' + a.group() + '/"]'
elems_dates = NewsFile.select(date_str)
elems_texts = NewsFile.select('.article__text')
head0 = doc.add_heading('', 0)
for title in elems_titles:
head0.add_run(title.getText() + ' ')
print('title write succeed')
head2 = doc.add_heading('', 2)
for date in elems_dates:
head2.add_run(date.getText())
print('date write succeed')
for text in elems_texts:
doc.add_paragraph(text.getText())
print('text write succeed')
doc.add_page_break()
workbook = openpyxl.load_workbook(r'time_title_link.xlsx')
sheet = workbook['0631-0207']
doc = docx.Document()
i = 1
for cell in sheet['D']:
if cell.value == 'URL':
continue
elif cell.value != '':
Get_News(cell.value, doc)
print(str(i))
i += 1
else:
doc.save('0631-0207.docx')
break
print('****Succeessful save****') 查看全部
网页文章自动采集(1.python+selenium控制已打开页面参考链接(组图)
)
python网页信息采集
介绍
这是第一次实战。帮助从 RIA Novosti 网站链接下载有关中国的新闻。技术不行,必须靠个人操作才能完成。
1.前期准备
选择日期或其他筛选项。
加载选项会第一次出现在这个网页上,需要自己点击,下滑后会动态加载。
2.自动控制鼠标向下滑动保存加载的网页
发现前期使用selenium模块直接打开页面,选择日期,获取数据时,会突然关闭浏览器。所以前期只能自己打开浏览器,手动选择页面,然后selenium继续控制正常加载。
1.python+selenium 控制打开的页面
参考链接
Win:
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\Users\Administrator\Desktop\ria_ru"
Mac:
chrome启动程序目录:/Applications/Google Chrome.app/Contents/MacOS/
进入chrome启动程序目录后执行:
./Google\ Chrome --remote-debugging-port=9222 --user-data-dir="/Users/lee/Documents/selenum/AutomationProfile"
参数说明:
--remote-debugging-port
可以指定任何打开的端口,selenium启动时要用这个端口。
--user-data-dir
指定创建新chrome配置文件的目录。它确保在单独的配置文件中启动chrome,不会污染你的默认配置文件。
2.根据前面的前期准备,在打开的浏览器中手动选择需要的页面
3.自动滚动,保存加载的页面
技术太差了。我不知道这种动态加载的网页如何选择结束条件。我发现新闻是从新到旧排序的,所以我又选择了一个结束日期(月份)作为结束条件。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium. webdriver.common.keys import Keys
import time
def Stop_Month(self, stop_month):
#通过获取指定日期的前一个日期判断加载是否完成,需要多选择前一个日期
htmldateElems = browser.find_elements_by_class_name('list-item__date')
month_str = htmldateElems[-1].text.split()
return month_str[1]
def mouse_move(self, stop_month): # 滑动鼠标至底部操作
htmlElem = browser.find_element_by_tag_name('html')
while True:
htmlElem.send_keys(Keys.END)
time.sleep(1)
month = Stop_Month(self, stop_month)
print(month)
if stop_month == month:
print('****Arrived at the specified month interface****')
break
options = Options()
options.add_experimental_option('debuggerAddress', "127.0.0.1:9222")
browser = webdriver.Chrome(chrome_options=options)
browser.implicitly_wait(3)
stop_month = 'декабря'
mouse_move(browser, stop_month)
f = open('0631-0207.html', 'wb')
f.write(browser.page_source.encode("utf-8", "ignore"))
print('****html is written successfully****')
f.close()
3.获取页面的所有新闻链接、标题和时间,并生成excel表格
下载的网页实际上已经收录了所有的新闻链接、标题和时间。问题是如何提取它们。
import openpyxl re, bs4
def Links_Get(self):
'''获取链接'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
link_regex = re.compile(r'http(.*)html')
links=[]
for elem in elems:
a = link_regex.search(str(elem))
links.append(a.group())
return links
def Titles_Get(self):
'''获取标题'''
downloadFile = open(self, encoding='utf-8')
webdata = bs4.BeautifulSoup(downloadFile.read(), 'html.parser')
elems = webdata.find_all(attrs={'class': 'list-item__title color-font-hover-only'})
#查找所有包含这个属性的标签
titles=[]
for elem in elems:
titles.append(elem.text)
return titles
def Get_Link_to_Title(self, title, excel, i):
'''信息写入excel'''
excel['A%s'%(i)] = i
#获取时间列表
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
excel['B%s'%(i)] = a.group()
excel['C%s'%(i)] = title
excel['D%s'%(i)] = self
print("****%s successful****" % i)
links = Links_Get('0631-0207.html') #前面下载网页保存在工作目录
titles = Titles_Get('0631-0207.html')
nums1 = len(links)
nums2 = len(titles)
if nums1 == nums2:#一般的话,应该是对应的,不行的话,再看吧
i, j = 1, 0
#事先新建一个excel,再加载写入
time_title_link = openpyxl.load_workbook('time_title_link.xlsx')
time_title_link.create_sheet('0631-0207')
for link in links:
get_news.Get_Link_to_Title(link, titles[j], time_title_link['0631-0207'], i)
print(str(i), str(nums1))
if link == links[-1]:
time_title_link.save('time_title_link.xlsx')
print('Succeessful save')
i += 1
j += 1
print('****Succeessful all****')
else:
print('Error, titles != links')
4.从生成的列表中获取每个链接的新闻内容并生成docx
import openpyxl
import docx
def Get_News(self, doc):
res = requests.get(self)
res.raise_for_status()
NewsFile = bs4.BeautifulSoup(res.text, 'html.parser')
elems_titles = NewsFile.select('.article__title')
date_regex = re.compile(r'\d+')
a = date_regex.search(self)
date_str = 'a[href=' + '"/' + a.group() + '/"]'
elems_dates = NewsFile.select(date_str)
elems_texts = NewsFile.select('.article__text')
head0 = doc.add_heading('', 0)
for title in elems_titles:
head0.add_run(title.getText() + ' ')
print('title write succeed')
head2 = doc.add_heading('', 2)
for date in elems_dates:
head2.add_run(date.getText())
print('date write succeed')
for text in elems_texts:
doc.add_paragraph(text.getText())
print('text write succeed')
doc.add_page_break()
workbook = openpyxl.load_workbook(r'time_title_link.xlsx')
sheet = workbook['0631-0207']
doc = docx.Document()
i = 1
for cell in sheet['D']:
if cell.value == 'URL':
continue
elif cell.value != '':
Get_News(cell.value, doc)
print(str(i))
i += 1
else:
doc.save('0631-0207.docx')
break
print('****Succeessful save****')
网页文章自动采集(优采云万能文章采集器免注册版下载(网络文章采集工具))
采集交流 • 优采云 发表了文章 • 0 个评论 • 429 次浏览 • 2022-01-04 14:15
优采云通用文章采集器免注册下载(网络文章采集工具)是一款非常强大的文章采集软件。采集只需要输入对应的关键字,也可以指定网站的文章采集,非常快!编辑器带来了完美破解的新版本,可以免费使用所有功能。无需注册。下载解压后就可以打开啦!喜欢的朋友可以来绿色先锋下载优采云万能文章采集器免注册版!
基本介绍:
优采云Universal文章采集器 是一款简单、有效且功能强大的文章采集 软件。您只需要输入关键词到采集各大搜索引擎网页和新闻,或者采集指定网站文章,非常方便快捷。是做网站推广优化的朋友不可多得的利器。本编辑为您带来优采云万能文章采集器绿色免费破解版,双击打开使用,软件已完美破解,无需注册即可免费使用代码激活。喜欢就不要错过哦!
指示:
1、下载解压文件,解压后找到“优采云·万能文章采集器.exe”双击打开
2、稍等,会出现如下提示,可以看到软件已经破解,点击确定
3、然后就会出现主界面。
特征:
1. 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2. 只需输入关键词 即可采集微信文章、今日头条、一点资讯、百度新闻及网页、搜狗新闻及网页、360新闻及网页、谷歌新闻和网页、必应新闻和网页、雅虎新闻和网页;批量关键词 自动采集 可用。
3.可以针对采集指定网站的栏目列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4. 文章翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和你淘翻译.
5.史上最简单最智能文章采集器,更多功能一目了然!
常见问题:
采集黑名单设置有误?
在【采集设置】中进入黑名单时,如果末尾有空行,会导致关键词采集功能显示搜索次数而不显示实际< @采集 进程问题。 查看全部
网页文章自动采集(优采云万能文章采集器免注册版下载(网络文章采集工具))
优采云通用文章采集器免注册下载(网络文章采集工具)是一款非常强大的文章采集软件。采集只需要输入对应的关键字,也可以指定网站的文章采集,非常快!编辑器带来了完美破解的新版本,可以免费使用所有功能。无需注册。下载解压后就可以打开啦!喜欢的朋友可以来绿色先锋下载优采云万能文章采集器免注册版!
基本介绍:
优采云Universal文章采集器 是一款简单、有效且功能强大的文章采集 软件。您只需要输入关键词到采集各大搜索引擎网页和新闻,或者采集指定网站文章,非常方便快捷。是做网站推广优化的朋友不可多得的利器。本编辑为您带来优采云万能文章采集器绿色免费破解版,双击打开使用,软件已完美破解,无需注册即可免费使用代码激活。喜欢就不要错过哦!
指示:
1、下载解压文件,解压后找到“优采云·万能文章采集器.exe”双击打开
2、稍等,会出现如下提示,可以看到软件已经破解,点击确定
3、然后就会出现主界面。
特征:
1. 依托优采云软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2. 只需输入关键词 即可采集微信文章、今日头条、一点资讯、百度新闻及网页、搜狗新闻及网页、360新闻及网页、谷歌新闻和网页、必应新闻和网页、雅虎新闻和网页;批量关键词 自动采集 可用。
3.可以针对采集指定网站的栏目列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4. 文章翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和你淘翻译.
5.史上最简单最智能文章采集器,更多功能一目了然!
常见问题:
采集黑名单设置有误?
在【采集设置】中进入黑名单时,如果末尾有空行,会导致关键词采集功能显示搜索次数而不显示实际< @采集 进程问题。
网页文章自动采集(百度自动文章采集?你就知道了!(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-02 23:03
网页文章自动采集,像百度、360等搜索引擎采集自动匹配网页;公众号文章自动采集,像163、新浪等新闻源自动匹配网页;这些文章采集的方法很多,可以去优采云采集器官网获取更多网页代码。
有一个网站专门给爬虫爬取app应用下载列表的。直接搜索app在线下载,有很多。
可以用优采云采集器。
我觉得用脚本就行了,找到有app推广活动的网站,网页代码在其中了,
用七牛采集器我这边用这个爬的数据还挺方便的
现在做网页发布的,只能依靠优采云采集器。虽然是付费产品,但是靠谱。可以试试。先不支持国内网站的,等有人支持了,后期会支持的。
做电商?如果能拿到电商网站url或者pr值,在去爬,
优采云采集器的api也有这方面的接口:;h=2&page=1&db_url=
按照要求来回答的话题目有点大,我讲下我了解的如何解决的问题吧!获取百度搜索引擎关键词自动抓取,比如这篇文章想获取以下:百度自动文章采集?你就百度搜索一下就知道了!~差不多多少流量的文章都可以抓取到。现在百度可以获取的文章太多了,多到有一些很冷门的文章都可以抓取到!希望回答对你有帮助,望采纳,
请问你是想了解哪方面的app推广文章 查看全部
网页文章自动采集(百度自动文章采集?你就知道了!(图))
网页文章自动采集,像百度、360等搜索引擎采集自动匹配网页;公众号文章自动采集,像163、新浪等新闻源自动匹配网页;这些文章采集的方法很多,可以去优采云采集器官网获取更多网页代码。
有一个网站专门给爬虫爬取app应用下载列表的。直接搜索app在线下载,有很多。
可以用优采云采集器。
我觉得用脚本就行了,找到有app推广活动的网站,网页代码在其中了,
用七牛采集器我这边用这个爬的数据还挺方便的
现在做网页发布的,只能依靠优采云采集器。虽然是付费产品,但是靠谱。可以试试。先不支持国内网站的,等有人支持了,后期会支持的。
做电商?如果能拿到电商网站url或者pr值,在去爬,
优采云采集器的api也有这方面的接口:;h=2&page=1&db_url=
按照要求来回答的话题目有点大,我讲下我了解的如何解决的问题吧!获取百度搜索引擎关键词自动抓取,比如这篇文章想获取以下:百度自动文章采集?你就百度搜索一下就知道了!~差不多多少流量的文章都可以抓取到。现在百度可以获取的文章太多了,多到有一些很冷门的文章都可以抓取到!希望回答对你有帮助,望采纳,
请问你是想了解哪方面的app推广文章
网页文章自动采集(网页升级怎么自动更新?1.qq浏览器自动更新神教教我吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-01-02 15:03
如何自动更新网页?
1.打开控制面板,找到系统和安全,双击打开。 2. 找到windows更新源,双击打开。 3. 进入windows更新配置页面,点击左侧列表中的更改设置。 4.在此页面中,将重要更新下的选项从从不检查更新更改为自动安装更新,然后勾选以下两个选项。最后选择,保存并退出。 5. 当我们想及时得到最新消息的时候,盯着电脑刷新太麻烦了。这时候就要定时刷新网页,因为开发板采集数据是实时更新的,所以网页上的数据也需要实时更新。
我有一个网站想要升级为自动重定向。我应该如何得到它?有师傅教教我吗?
网站后台默认手机访问,然后安装微信登录,自然用手机看到你的网站,
如何关闭QQ浏览器的自动更新
1.关闭电脑上QQ浏览器设置的自动更新:1.打开QQ浏览器,点击浏览器右上角的三个横条,然后点击设置。 2. 点击“高级”选项,然后将页面下拉到低端,取消勾选开启自动更新的选项。 二、在手机QQ浏览器设置中关闭自动更新。1.打开手Q浏览器,然后点击浏览器下方三栏,然后点击“设置”。 2. 页面下拉至低端,点击“关于QQ浏览器”。 3.点击关闭Wi-Fi下的自动更新选项。
如何让网页自动更新
只要在网页上加个“meta”,时间就可以控制了。网站:自己刷新,给别人打开。可以用refresh,就这样写。这是每 5 秒刷新一次。时间你也可以改变它!可以将股票趋势图创建为单独的文件。然后用它来收录就OK了!
访问页面升级是什么意思?如何解决?
由于网站正在更新网站程序或数据或维护网站,访问页面已普遍升级,升级网站后即可正常访问。一个好的网站内容需要定期或不定期更新,才能不断吸引更多的观众。
如何设置电脑上的IE浏览器自动升级
打开IE浏览器,点击右上角选择【关于Internet Explorer】,勾选【自动安装新版本】。
如何使网页自动更新
如果你只是浏览网页,多刷新几次!
QQ浏览器如何自动更新
也许你已经设置了
如何让你的网页自动更新
你机器上设置的字体有问题!!!去看看吧,IE工具···
vivox21手机自带的浏览器一直自动升级。如何关闭或阻止它使用互联网?
可以进入设置-更多设置-应用-工厂应用管理-里面找到。 查看全部
网页文章自动采集(网页升级怎么自动更新?1.qq浏览器自动更新神教教我吗)
如何自动更新网页?
1.打开控制面板,找到系统和安全,双击打开。 2. 找到windows更新源,双击打开。 3. 进入windows更新配置页面,点击左侧列表中的更改设置。 4.在此页面中,将重要更新下的选项从从不检查更新更改为自动安装更新,然后勾选以下两个选项。最后选择,保存并退出。 5. 当我们想及时得到最新消息的时候,盯着电脑刷新太麻烦了。这时候就要定时刷新网页,因为开发板采集数据是实时更新的,所以网页上的数据也需要实时更新。
我有一个网站想要升级为自动重定向。我应该如何得到它?有师傅教教我吗?
网站后台默认手机访问,然后安装微信登录,自然用手机看到你的网站,
如何关闭QQ浏览器的自动更新
1.关闭电脑上QQ浏览器设置的自动更新:1.打开QQ浏览器,点击浏览器右上角的三个横条,然后点击设置。 2. 点击“高级”选项,然后将页面下拉到低端,取消勾选开启自动更新的选项。 二、在手机QQ浏览器设置中关闭自动更新。1.打开手Q浏览器,然后点击浏览器下方三栏,然后点击“设置”。 2. 页面下拉至低端,点击“关于QQ浏览器”。 3.点击关闭Wi-Fi下的自动更新选项。
如何让网页自动更新
只要在网页上加个“meta”,时间就可以控制了。网站:自己刷新,给别人打开。可以用refresh,就这样写。这是每 5 秒刷新一次。时间你也可以改变它!可以将股票趋势图创建为单独的文件。然后用它来收录就OK了!
访问页面升级是什么意思?如何解决?
由于网站正在更新网站程序或数据或维护网站,访问页面已普遍升级,升级网站后即可正常访问。一个好的网站内容需要定期或不定期更新,才能不断吸引更多的观众。
如何设置电脑上的IE浏览器自动升级
打开IE浏览器,点击右上角选择【关于Internet Explorer】,勾选【自动安装新版本】。
如何使网页自动更新
如果你只是浏览网页,多刷新几次!
QQ浏览器如何自动更新
也许你已经设置了
如何让你的网页自动更新
你机器上设置的字体有问题!!!去看看吧,IE工具···
vivox21手机自带的浏览器一直自动升级。如何关闭或阻止它使用互联网?
可以进入设置-更多设置-应用-工厂应用管理-里面找到。

