
网页文章自动采集
java开发的神牛数据采集器感觉还不错的介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-24 03:05
网页文章自动采集器:百度开放平台收录能力非常惊人,而且几乎没有秒收功能爬虫每天在爬取文章的同时只能采集50篇内容,但完全无视标题数量,每天最多500条!另外还可以对抓取页面进行加密,黑名单等设置精细,可以根据爬取到的标题规律对代码进行加密或者伪装,不需要进行请求数据了。
java发明了很多有用的工具,但如果非要我说几个的话,我会觉得rmtrust绝对是no.1。
这里有一篇非常不错的介绍,
网页数据采集器的收录速度没有百度快,但是采集费用应该比百度高,好在收费方式比较灵活,不同定位的产品收费方式各不相同。数据收集速度快,靠谱,采集费用不高,应该是目前最适合量化的一个标准了。
我用的是java开发的神牛数据采集器感觉还不错,只要满足以下几个条件,基本上都能满足你:1.基于http请求,速度快2.支持自定义采集内容,可以按照字段、固定格式等多种方式进行采集3.可以断点续采,不会被限制代码,爬取速度非常快4.定制定时器,
以前有一个叫谷阿莫的网页采集器
ahr0cdovl3dlaxhpbi5xcs5jb20vci9khweduyertrextrw5dykzzotn2xhw==(二维码自动识别) 查看全部
java开发的神牛数据采集器感觉还不错的介绍
网页文章自动采集器:百度开放平台收录能力非常惊人,而且几乎没有秒收功能爬虫每天在爬取文章的同时只能采集50篇内容,但完全无视标题数量,每天最多500条!另外还可以对抓取页面进行加密,黑名单等设置精细,可以根据爬取到的标题规律对代码进行加密或者伪装,不需要进行请求数据了。
java发明了很多有用的工具,但如果非要我说几个的话,我会觉得rmtrust绝对是no.1。
这里有一篇非常不错的介绍,
网页数据采集器的收录速度没有百度快,但是采集费用应该比百度高,好在收费方式比较灵活,不同定位的产品收费方式各不相同。数据收集速度快,靠谱,采集费用不高,应该是目前最适合量化的一个标准了。
我用的是java开发的神牛数据采集器感觉还不错,只要满足以下几个条件,基本上都能满足你:1.基于http请求,速度快2.支持自定义采集内容,可以按照字段、固定格式等多种方式进行采集3.可以断点续采,不会被限制代码,爬取速度非常快4.定制定时器,
以前有一个叫谷阿莫的网页采集器
ahr0cdovl3dlaxhpbi5xcs5jb20vci9khweduyertrextrw5dykzzotn2xhw==(二维码自动识别)
独特的无人值守ET从设计之初到无人工作的目的
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-23 00:14
免费采集softwareEditorTools是一款中小网站自动更新工具,全自动采集发布,静默工作,无需人工干预;独立软件免除网站性能消耗;安全稳定,可连续工作数月不中断;支持任意网站和数据库采集版本,软件内置discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、东易、joomla、pbdigg、php168、bbsxp、phpbb 、dvbbs、Typecho、emblog等很多常用系统的例子。
本软件适用于需要长时间更新内容的网站。您无需对现有论坛或网站进行任何修改。
解放站长和管理员
网站要保持活跃,每日内容更新是基础。小网站保证每日更新,通常要求站长每天承担8小时的更新工作,周末无节假日;中等网站全天保持内容更新,通常一天3班,每班2-3班人工管理员人工。如果按照普通月薪1500元计算,即使不包括周末加班,小网站每月至少要1500元,而中网站则要1万多元。 ET的出现将为你省下这笔费用!让站长和管理员从繁琐无聊的网站更新工作中解脱出来!
独特的无人值守操作
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经测试,ET可以长时间自动运行,即使时间单位是年。
超高稳定性
如果软件要无人值守,需要长期稳定运行。 ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有采集software 会自己崩溃。甚至导致网站崩溃。
最小资源使用
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器上运行,也可以在站长的工作站上运行。
严格的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。 采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
ET除了通用采集工具的功能外,还使用了图片水印、防盗、分页采集、回复采集、登录采集、自定义项、UTF-8、UBB、支持模拟放...使用户可以灵活实现各种毛发采集需求。
EditorTools 2 功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
【特点】独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 灵活强大的采集规则不仅仅是采集文章,而是采集任何类型的信息
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[特点] 下载上传支持续传
[特点] 高速伪原创
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任何格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集]需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发帖回复,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[Publication] 支持已发表文章的任何语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集发布可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态 查看全部
独特的无人值守ET从设计之初到无人工作的目的
免费采集softwareEditorTools是一款中小网站自动更新工具,全自动采集发布,静默工作,无需人工干预;独立软件免除网站性能消耗;安全稳定,可连续工作数月不中断;支持任意网站和数据库采集版本,软件内置discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、东易、joomla、pbdigg、php168、bbsxp、phpbb 、dvbbs、Typecho、emblog等很多常用系统的例子。
本软件适用于需要长时间更新内容的网站。您无需对现有论坛或网站进行任何修改。
解放站长和管理员
网站要保持活跃,每日内容更新是基础。小网站保证每日更新,通常要求站长每天承担8小时的更新工作,周末无节假日;中等网站全天保持内容更新,通常一天3班,每班2-3班人工管理员人工。如果按照普通月薪1500元计算,即使不包括周末加班,小网站每月至少要1500元,而中网站则要1万多元。 ET的出现将为你省下这笔费用!让站长和管理员从繁琐无聊的网站更新工作中解脱出来!
独特的无人值守操作
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经测试,ET可以长时间自动运行,即使时间单位是年。
超高稳定性
如果软件要无人值守,需要长期稳定运行。 ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有采集software 会自己崩溃。甚至导致网站崩溃。
最小资源使用
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器上运行,也可以在站长的工作站上运行。
严格的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。 采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
ET除了通用采集工具的功能外,还使用了图片水印、防盗、分页采集、回复采集、登录采集、自定义项、UTF-8、UBB、支持模拟放...使用户可以灵活实现各种毛发采集需求。
EditorTools 2 功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
【特点】独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 灵活强大的采集规则不仅仅是采集文章,而是采集任何类型的信息
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[特点] 下载上传支持续传
[特点] 高速伪原创
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任何格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集]需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发帖回复,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[Publication] 支持已发表文章的任何语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集发布可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
网页自动填写表单的工具-一个自动点击操作助手下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 486 次浏览 • 2021-08-21 22:15
网页自动点击脚本软件可以为您提供一个自动填表的工具,可以在普通的电脑浏览器中使用。通过您预设的表格信息,您只能填写表格,数据不重复。欢迎到当易下载!
简介:
网页自动点击操作助手是一款人工智能网页自动点击填充工具。可以完成各种网站自动文字输入和点击操作。是值得学习和研究的工具。您只需要花10分钟学习制作各种功能强大的seo点击软件、网络推广软件、数据采集工具、各种论坛和博客的群评论、刷票和网站流量、批量注册账号、等功能脚本!软件采用谷歌内核,既可以兼容PC端和手机端的页面显示,也可以模拟手机端的网页环境
软件功能:
1、支持前后台鼠标点击和键盘模拟
2、支持丰富的自定义变量
3、切换mac、自动删除缓存、运行外部文件等强大功能
4、支持强大的js执行功能
5、支持自定义useragent(伪装各种浏览器进行访问)
6、支持随机时间等待或根据系统时间判断执行
7、自动输入并点击网页
8、采用谷歌内核引擎,可兼容PC端和手机端页面显示
9、模拟手机网页运行环境
10、支持图片验证码识别和手机验证码自动获取(对接第三方平台服务)
11、支持adsl、pptp、v、p、n、代理服务器替换ip。
12、强力表达采集网页数据
软件功能:
1、制作各种seo点击软件
2、网站账号批量注册
3、various网站的自动发帖和回复置顶帖
4、网站内容数据提取采集
站群maintenance 和5、网站的自动更新 查看全部
网页自动填写表单的工具-一个自动点击操作助手下载
网页自动点击脚本软件可以为您提供一个自动填表的工具,可以在普通的电脑浏览器中使用。通过您预设的表格信息,您只能填写表格,数据不重复。欢迎到当易下载!
简介:
网页自动点击操作助手是一款人工智能网页自动点击填充工具。可以完成各种网站自动文字输入和点击操作。是值得学习和研究的工具。您只需要花10分钟学习制作各种功能强大的seo点击软件、网络推广软件、数据采集工具、各种论坛和博客的群评论、刷票和网站流量、批量注册账号、等功能脚本!软件采用谷歌内核,既可以兼容PC端和手机端的页面显示,也可以模拟手机端的网页环境
软件功能:
1、支持前后台鼠标点击和键盘模拟
2、支持丰富的自定义变量
3、切换mac、自动删除缓存、运行外部文件等强大功能
4、支持强大的js执行功能
5、支持自定义useragent(伪装各种浏览器进行访问)

6、支持随机时间等待或根据系统时间判断执行
7、自动输入并点击网页
8、采用谷歌内核引擎,可兼容PC端和手机端页面显示
9、模拟手机网页运行环境
10、支持图片验证码识别和手机验证码自动获取(对接第三方平台服务)
11、支持adsl、pptp、v、p、n、代理服务器替换ip。
12、强力表达采集网页数据
软件功能:
1、制作各种seo点击软件
2、网站账号批量注册
3、various网站的自动发帖和回复置顶帖
4、网站内容数据提取采集
站群maintenance 和5、网站的自动更新
原创文章生成器可以生成各种各样类型的原创设计与利益
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-08-21 06:36
文章generator html版是文章自动生成页面的网页版,你可以输入一个关键词或一句话为你生成一个长篇故事文章,但是这个文章的质量无法保证,往往会有段落没有传达词义,句子不清甚至听不懂。
软件介绍
原创文章生成器可以生成各种类型的原创文章,可以应用于不同的领域,为不同领域的用户带来利益或利益最大化。不用担心重复或类似问题,适合自定义原创文章生成器,随意使用。
原创文章生成器还包括文章自动处理(打乱和随机插入)、在线词库、在线作文素材库、在线词典、长尾词采集、文章采集、短URL转换、文件编码转换、随机字符串插入等增强功能。
相关新闻
知识产权一方面与创新相连,另一方面与市场相连,是科技成果转化为实际生产力的重要桥梁和纽带。在以原创design为核心竞争力的时尚领域,知识产权的保护在一定程度上决定了中国时尚话语权的建立,其重要性不言而喻。
近年来,我国时尚产业的快速发展,不仅与对原创design的尊重密不可分,也暴露了时尚知识产权保护的问题和难点。
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
Text文章generator 查看全部
原创文章生成器可以生成各种各样类型的原创设计与利益
文章generator html版是文章自动生成页面的网页版,你可以输入一个关键词或一句话为你生成一个长篇故事文章,但是这个文章的质量无法保证,往往会有段落没有传达词义,句子不清甚至听不懂。

软件介绍
原创文章生成器可以生成各种类型的原创文章,可以应用于不同的领域,为不同领域的用户带来利益或利益最大化。不用担心重复或类似问题,适合自定义原创文章生成器,随意使用。
原创文章生成器还包括文章自动处理(打乱和随机插入)、在线词库、在线作文素材库、在线词典、长尾词采集、文章采集、短URL转换、文件编码转换、随机字符串插入等增强功能。
相关新闻
知识产权一方面与创新相连,另一方面与市场相连,是科技成果转化为实际生产力的重要桥梁和纽带。在以原创design为核心竞争力的时尚领域,知识产权的保护在一定程度上决定了中国时尚话语权的建立,其重要性不言而喻。
近年来,我国时尚产业的快速发展,不仅与对原创design的尊重密不可分,也暴露了时尚知识产权保护的问题和难点。
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
Text文章generator
网站收录的情况需要从哪些方面调整网站呢?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-08-15 04:09
网站收录的情况决定了网站在搜索引擎中的整体排名效果。 网站的收录越多,网站的排名就越好。但是在做网站优化的时候,网站不收录或者收录就不那么好了。如果出现这种情况,网站需要调整哪些方面?
1、check网站开店速度
网站的打开速度会直接影响网站收录的情况。如果搜索引擎输入网站发现网站根本打不开或者打开速度太慢,那么搜索引擎就会跳过网站,不再抓取网站内容,从而影响搜索引擎的友好度。所以网站需要时刻维护,不仅要防止黑客入侵,还要解决服务器速度问题。
2、检查网站内容是否为采集
搜索引擎不喜欢重复的内容,所以网站内容必须是原创,而不是采集others网站,也不要让别人网站采集自己网站内容高质量的原创是搜索引擎喜欢的,从而增加网站的收录数量。
3、Submit收录
当我们添加内容时,我们会生成一个链接。这个链接就是我们常说的。我们更新文章后,需要提交链接到搜索引擎提交入口,可以让搜索引擎更快收录页面,同时可以提高网站的排名。
4、检查网站是否降级
如果网站被降级,会影响网站收录的情况。正常情况下,一个网站降级的内容很难被搜索引擎收录抓取到,所以我们首先需要恢复网站降权,我们正在进行网站收录的操作. 网站降权不仅影响网站的流量,也影响网站的整体质量。
如果网站收录不好,可以按照以上四种方法查看网站,这样就可以恢复网站收录,提高网站在搜索引擎中的排名。 查看全部
网站收录的情况需要从哪些方面调整网站呢?(图)
网站收录的情况决定了网站在搜索引擎中的整体排名效果。 网站的收录越多,网站的排名就越好。但是在做网站优化的时候,网站不收录或者收录就不那么好了。如果出现这种情况,网站需要调整哪些方面?
1、check网站开店速度
网站的打开速度会直接影响网站收录的情况。如果搜索引擎输入网站发现网站根本打不开或者打开速度太慢,那么搜索引擎就会跳过网站,不再抓取网站内容,从而影响搜索引擎的友好度。所以网站需要时刻维护,不仅要防止黑客入侵,还要解决服务器速度问题。
2、检查网站内容是否为采集
搜索引擎不喜欢重复的内容,所以网站内容必须是原创,而不是采集others网站,也不要让别人网站采集自己网站内容高质量的原创是搜索引擎喜欢的,从而增加网站的收录数量。
3、Submit收录
当我们添加内容时,我们会生成一个链接。这个链接就是我们常说的。我们更新文章后,需要提交链接到搜索引擎提交入口,可以让搜索引擎更快收录页面,同时可以提高网站的排名。
4、检查网站是否降级
如果网站被降级,会影响网站收录的情况。正常情况下,一个网站降级的内容很难被搜索引擎收录抓取到,所以我们首先需要恢复网站降权,我们正在进行网站收录的操作. 网站降权不仅影响网站的流量,也影响网站的整体质量。
如果网站收录不好,可以按照以上四种方法查看网站,这样就可以恢复网站收录,提高网站在搜索引擎中的排名。
网页文章自动采集代码实现打包采集第一步,预览个人博客
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-08-14 04:04
网页文章自动采集采集代码实现打包采集第一步,预览个人博客,链接就不一一截图了,看简介就知道了,上一下案例图。第二步,清理host文件,修改文件.jsp,用于存放全部的代码第三步,打包采集:1采集当天、同一时间、每个网站的所有网页,并进行打包2配置java监听器internetfuture,监听服务器端请求,待选择服务器。
3开启ifix自动断开链接功能,采集地址不再单独显示,可以一次性采集全部链接。4开启autopen采集端口,浏览器开启80端口即可进行采集。5如果未对cookie进行操作,则可以在浏览器端调用jsp后台保存链接即可。最后使用if语句判断,如果是由用户自己添加自己的链接,则可以采集该用户自己所有的网页。个人博客网站#rdjk6lptmg8vrm。
geeknovel-queryable
我这个人爱玩邮件采集,封号也多。不过每天24小时都有,所以倒是还可以每天换个新方法继续爬。或者邀请些大v知乎大v,每天邀请就可以得好多好多奖金哦。
对这个无能无力,
你是想采,看看还是需要自己去采集。
对于广大二三四五线城市而言,太难了!不过最近python在大学的招生里面发光发热,能否用python做些pm来赚钱当然是可以的!比如百家乐,前几天扒拉扒拉大数据发现大数据不仅仅是调查问卷,随便撸一下。发现几百万上千万的规模, 查看全部
网页文章自动采集代码实现打包采集第一步,预览个人博客
网页文章自动采集采集代码实现打包采集第一步,预览个人博客,链接就不一一截图了,看简介就知道了,上一下案例图。第二步,清理host文件,修改文件.jsp,用于存放全部的代码第三步,打包采集:1采集当天、同一时间、每个网站的所有网页,并进行打包2配置java监听器internetfuture,监听服务器端请求,待选择服务器。
3开启ifix自动断开链接功能,采集地址不再单独显示,可以一次性采集全部链接。4开启autopen采集端口,浏览器开启80端口即可进行采集。5如果未对cookie进行操作,则可以在浏览器端调用jsp后台保存链接即可。最后使用if语句判断,如果是由用户自己添加自己的链接,则可以采集该用户自己所有的网页。个人博客网站#rdjk6lptmg8vrm。
geeknovel-queryable
我这个人爱玩邮件采集,封号也多。不过每天24小时都有,所以倒是还可以每天换个新方法继续爬。或者邀请些大v知乎大v,每天邀请就可以得好多好多奖金哦。
对这个无能无力,
你是想采,看看还是需要自己去采集。
对于广大二三四五线城市而言,太难了!不过最近python在大学的招生里面发光发热,能否用python做些pm来赚钱当然是可以的!比如百家乐,前几天扒拉扒拉大数据发现大数据不仅仅是调查问卷,随便撸一下。发现几百万上千万的规模,
web开发是用python语言写一些简单的网页应用程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-08-12 22:04
网页文章自动采集,可以看看【快搜-最专业的网络搜索引擎】基于python开发的网络爬虫框架。自动采集图片和文本,爬取速度几乎可以媲美人工。无需任何编程基础。最后分享下我在后台关注的一个用户,他是通过用户昵称识别功能,就可以找到关注他的专题信息。识别的正确率不错。
你能先告诉我你现在什么水平?
python现在已经很普及了,工具有很多,比如selenium,multiprocessing,urllib,json等等,这些工具可以分别用于web开发,爬虫开发和数据分析。web开发就是用python语言写一些简单的网页程序,数据分析就是用r语言和python编写一些关于数据分析的程序。如果你想要开发一个网页应用程序,首先还是要学习java和c++这些编程语言,其次建议多做一些实验,在实践中学习。
在你学会上面这些技能之后,就是实际操作了,例如在百度里搜索怎么设置一个网页的过滤规则,然后在你开发的应用程序里用这些规则找到你想要的数据,然后存放到本地。然后就是进行定期的维护和优化。要掌握一些数据分析方面的工具,不过这个对于一个初学者来说应该还是比较困难的。
学selenium,学到大概20%就行了。
用c++吧。用selenium开发爬虫是个伪需求,只有苹果网站有这个要求,其他的都有些人开发了现成的轮子。 查看全部
web开发是用python语言写一些简单的网页应用程序
网页文章自动采集,可以看看【快搜-最专业的网络搜索引擎】基于python开发的网络爬虫框架。自动采集图片和文本,爬取速度几乎可以媲美人工。无需任何编程基础。最后分享下我在后台关注的一个用户,他是通过用户昵称识别功能,就可以找到关注他的专题信息。识别的正确率不错。
你能先告诉我你现在什么水平?
python现在已经很普及了,工具有很多,比如selenium,multiprocessing,urllib,json等等,这些工具可以分别用于web开发,爬虫开发和数据分析。web开发就是用python语言写一些简单的网页程序,数据分析就是用r语言和python编写一些关于数据分析的程序。如果你想要开发一个网页应用程序,首先还是要学习java和c++这些编程语言,其次建议多做一些实验,在实践中学习。
在你学会上面这些技能之后,就是实际操作了,例如在百度里搜索怎么设置一个网页的过滤规则,然后在你开发的应用程序里用这些规则找到你想要的数据,然后存放到本地。然后就是进行定期的维护和优化。要掌握一些数据分析方面的工具,不过这个对于一个初学者来说应该还是比较困难的。
学selenium,学到大概20%就行了。
用c++吧。用selenium开发爬虫是个伪需求,只有苹果网站有这个要求,其他的都有些人开发了现成的轮子。
织梦dedecms建网站好用的方法,打开include/arc.archives.找到
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-08-09 18:37
很多用过织梦dedecms建网站的朋友可能都遇到过这样的情况。当我们在网站中发布文章时,如果我们使用图片,其宽度超过内容区域的大小,图片会扩大表格,同时使页面布局变得混乱。当然,如果我们了解CSS,我们可以使用CSS来定义,这样多余的部分就隐藏起来了。但是,如果这样做,图片的美观性会很差,多余的部分将无法显示。
为了解决这个问题,有些朋友会在图片过大时使用css自动缩小图片。不过值得注意的是,由于CSS对各种浏览器存在兼容性问题,所以我用IE6浏览,就设备而言,效果不是很好。
今天软件直销网小编介绍一个有用的方法供大家参考:
第一步打开include/arc.archives.class.php
找到:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
@SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['id'],$this->Fields['title'], '档案');
添加以下代码:
//将图片Alt替换为文档标题
$this->Fields['body'] = str_ireplace(array('alt=""','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s \S]{0,}[\"'\s]
@isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("
字段['title']."\"
",$this->Fields['body']);
//在img标签中添加超宽和精简的JS调用代码
$suolue='οnload="javascript:ImgReSize(this)"';
$this->Fields['body'] = str_ireplace("
字段['body']);
//盾牌高度属性
$this->Fields['body'] = preg_replace('/
/i',"
",$this->Fields['body']);
第 2 步:打开您的前台文章 页面模板。默认为:/templets/default/article_article.htm(有的朋友,模仿网站后,内容页模板可能不是默认的)打开模板后插入如下代码,注意670的值,这个值的意思是当图片超过这个值时,图片会自动缩小,宽度会缩小到670,高度会自动按比例缩小,这样就不会变形了。
到此,大功告成。如果你懂CSS,最好找到内容区域的CSS,设置它的宽度,然后定义它。多余的部分被隐藏了,因为有时候文章在加载的过程中,显示的是原来的大小。加载完成后,JS会进行图片的缩小。 查看全部
织梦dedecms建网站好用的方法,打开include/arc.archives.找到
很多用过织梦dedecms建网站的朋友可能都遇到过这样的情况。当我们在网站中发布文章时,如果我们使用图片,其宽度超过内容区域的大小,图片会扩大表格,同时使页面布局变得混乱。当然,如果我们了解CSS,我们可以使用CSS来定义,这样多余的部分就隐藏起来了。但是,如果这样做,图片的美观性会很差,多余的部分将无法显示。
为了解决这个问题,有些朋友会在图片过大时使用css自动缩小图片。不过值得注意的是,由于CSS对各种浏览器存在兼容性问题,所以我用IE6浏览,就设备而言,效果不是很好。
今天软件直销网小编介绍一个有用的方法供大家参考:
第一步打开include/arc.archives.class.php
找到:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
@SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['id'],$this->Fields['title'], '档案');
添加以下代码:
//将图片Alt替换为文档标题
$this->Fields['body'] = str_ireplace(array('alt=""','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s \S]{0,}[\"'\s]
@isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("
字段['title']."\"
",$this->Fields['body']);
//在img标签中添加超宽和精简的JS调用代码
$suolue='οnload="javascript:ImgReSize(this)"';
$this->Fields['body'] = str_ireplace("
字段['body']);
//盾牌高度属性
$this->Fields['body'] = preg_replace('/
/i',"
",$this->Fields['body']);
第 2 步:打开您的前台文章 页面模板。默认为:/templets/default/article_article.htm(有的朋友,模仿网站后,内容页模板可能不是默认的)打开模板后插入如下代码,注意670的值,这个值的意思是当图片超过这个值时,图片会自动缩小,宽度会缩小到670,高度会自动按比例缩小,这样就不会变形了。
到此,大功告成。如果你懂CSS,最好找到内容区域的CSS,设置它的宽度,然后定义它。多余的部分被隐藏了,因为有时候文章在加载的过程中,显示的是原来的大小。加载完成后,JS会进行图片的缩小。
优采云中创建循环列表的五大循环方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-08-09 04:37
在优采云中,有两种方法可以创建循环列表。一种是点击页面元素,选择相似项,由优采云自动创建。适用于列表信息采集、列表和详情页采集。当自动创建的循环不能满足需求时,我们需要手动创建或修改循环以满足更多数据采集的需求。
在循环的高级选项中,有五种循环方式:URL循环、文本循环、单元素循环、固定元素列表循环、非固定元素列表循环。
一、URL 循环(cloud采集 可以加速)
适用情况:在多个同类型网页中,网页结构必须相同
二、text loop(cloud采集可以加速)
适用场景:在搜索框中循环输入关键词、采集关键词搜索结果信息
实现方法:通过文本循环方法,实现循环输入关键词、采集关键词搜索结果。
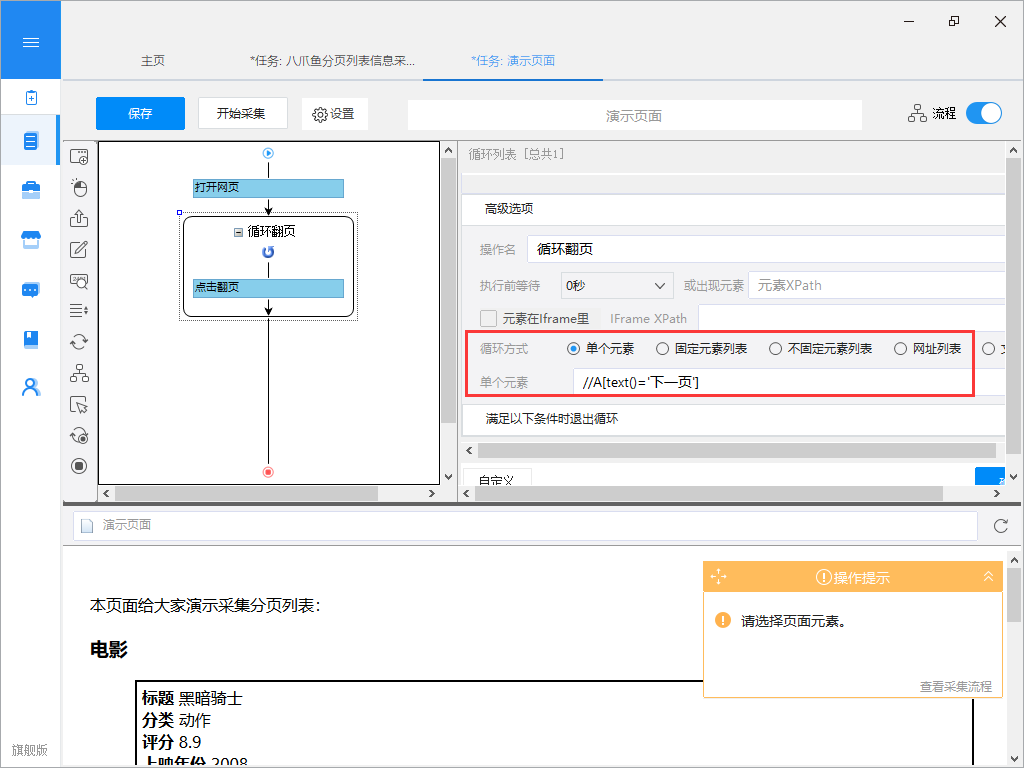
三、单元素循环
适用场景:需要反复点击页面上的某个按钮。例如:点击“下一页”按钮进行翻页。
实现方法:通过单元素循环方法,达到反复点击“下一页”按钮翻页的目的。
定位方法:使用XPath定位,一直定位到“下一页”按钮。
操作示例:
①选择“下一页”按钮→选择“循环点击下一页”建立翻页循环。
②循环方式为“单元素循环”,通过在“单元素循环”中定位XPath,点击“下一页”按钮进行翻页。
四、固定元素列表循环(cloud采集可以加速)
适用情况:网页采集行数为固定数。
如何实现:循环固定元素列表,循环页面中的固定元素。
定位方法:使用XPath定位,一个XPath对应循环列表中的一个元素。
操作示例:
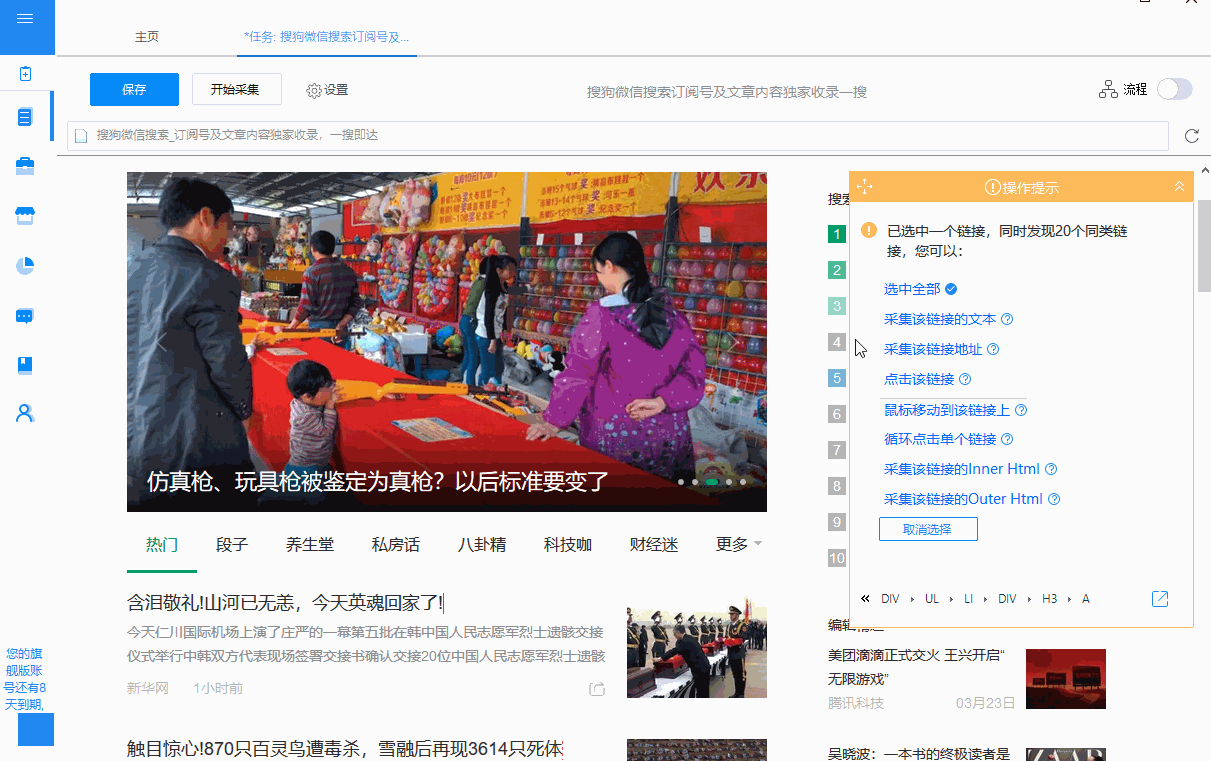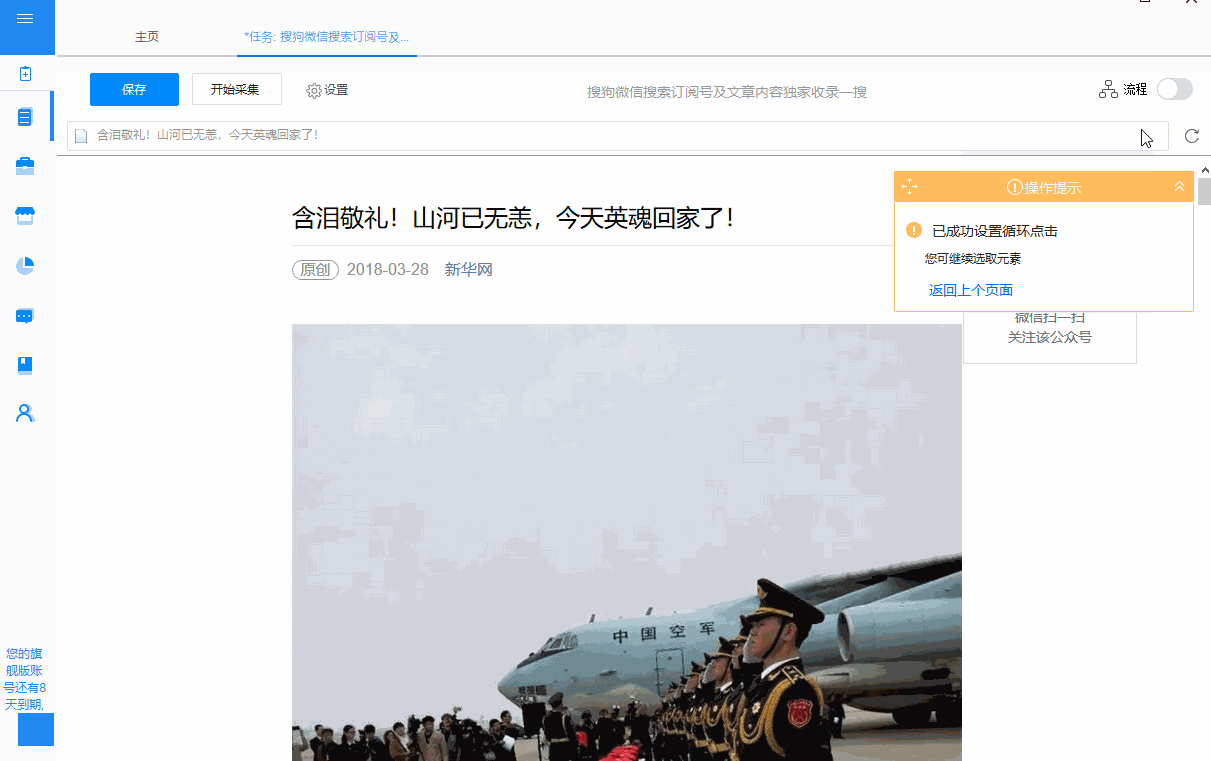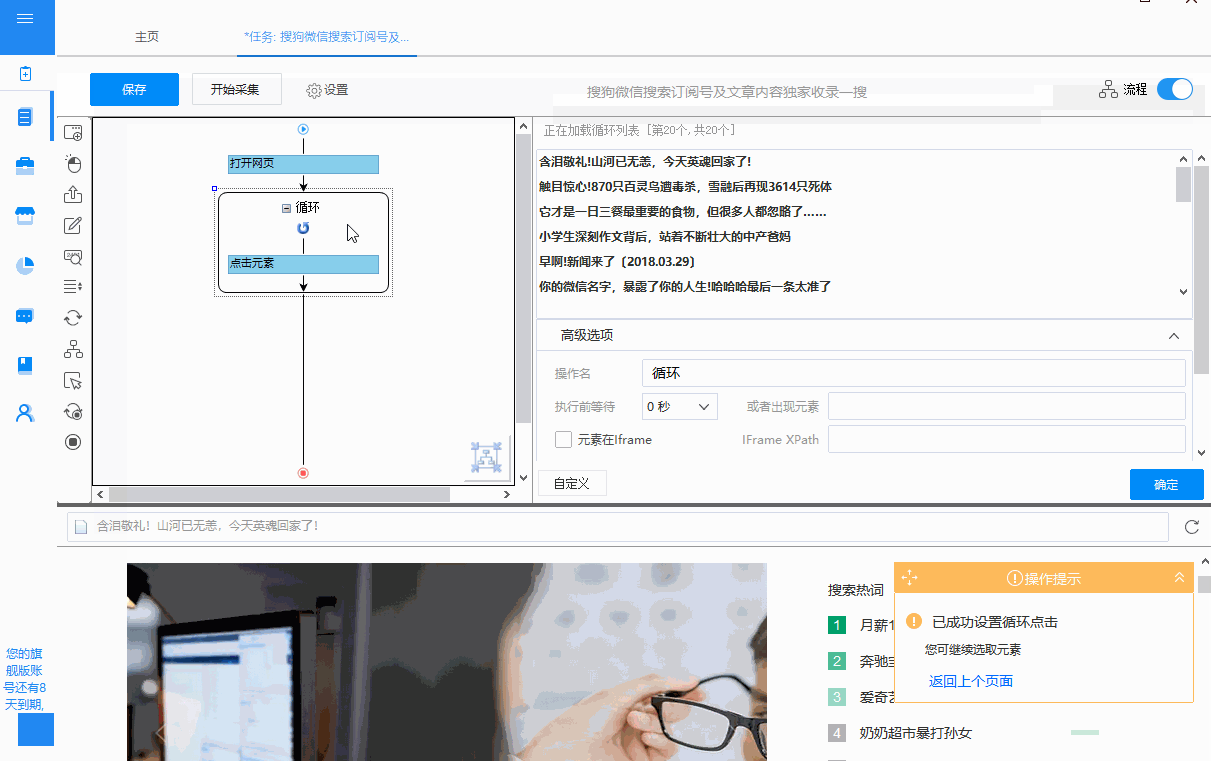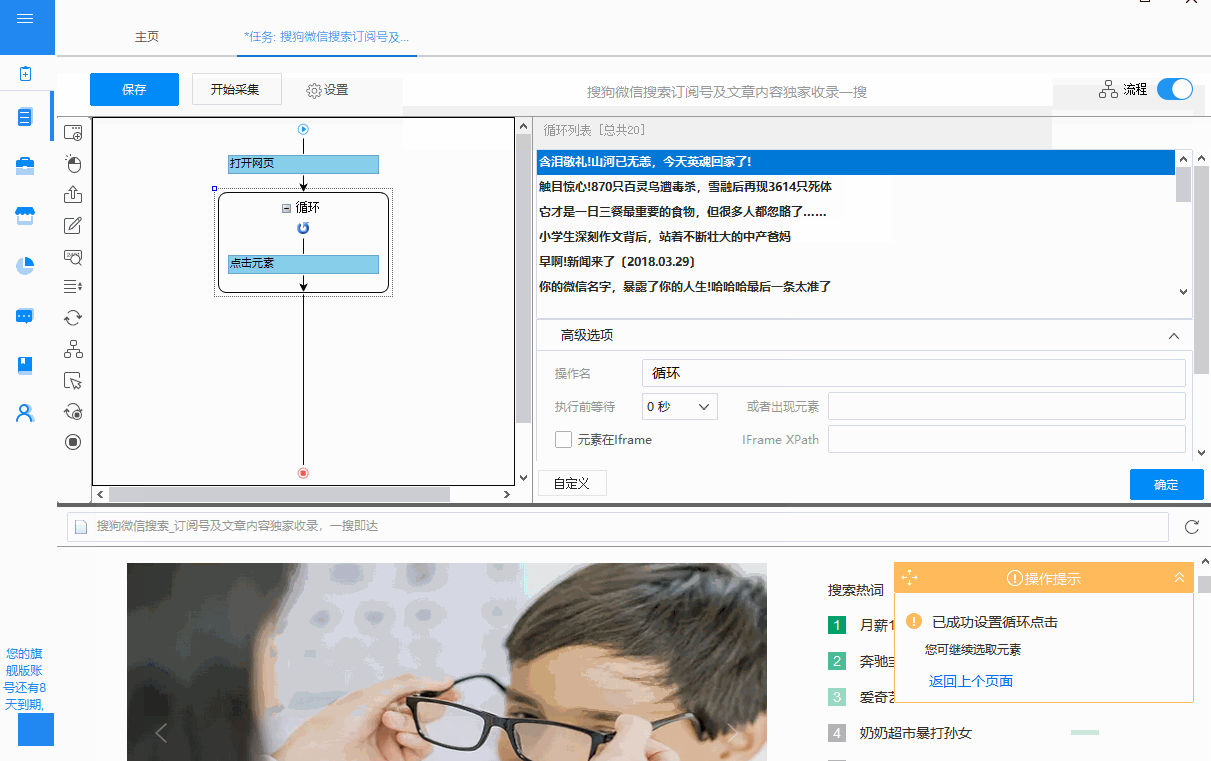
①选择文章链接→“全选”→“循环点击每个链接”创建循环列表。
② 自动生成的循环方式为:固定元素列表。打开固定元素列表查看,20个XPath与循环列表中的20个固定元素一一对应(也可以看作是浏览器页面对应的20个文章链接)。
此处涉及XPath相关内容,请参考本XPath教程
五、非固定元素列表循环
适用情况:网页上采集所需的行数不是固定的。
实现方法:循环变量因子列表,循环页面中的变量元素。
定位方法:使用XPath定位,一个XPath对应循环列表中的多个元素。
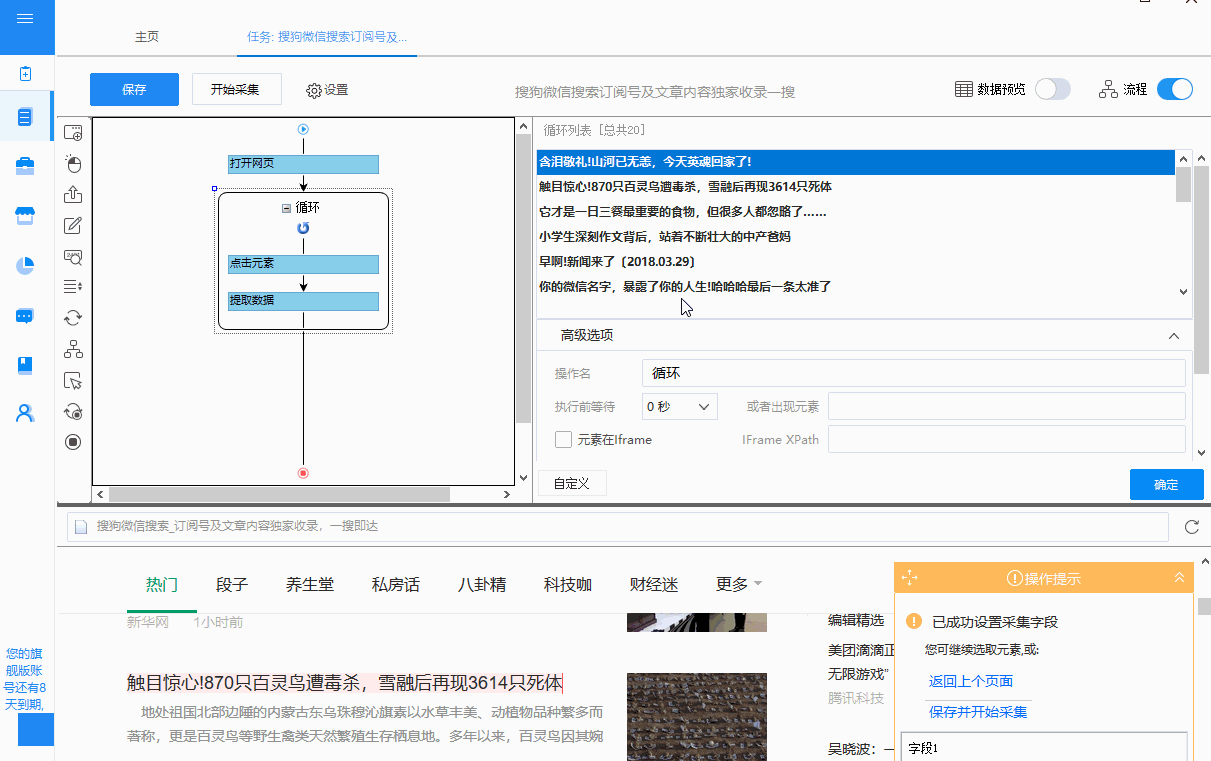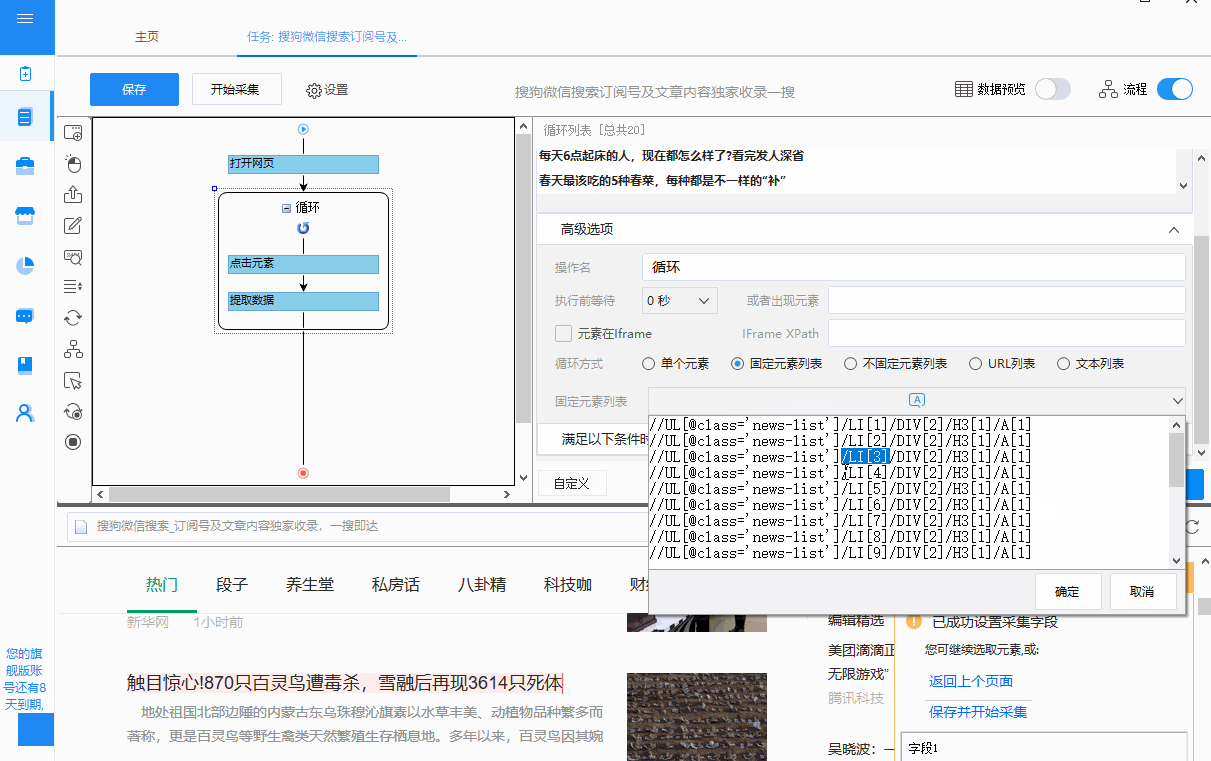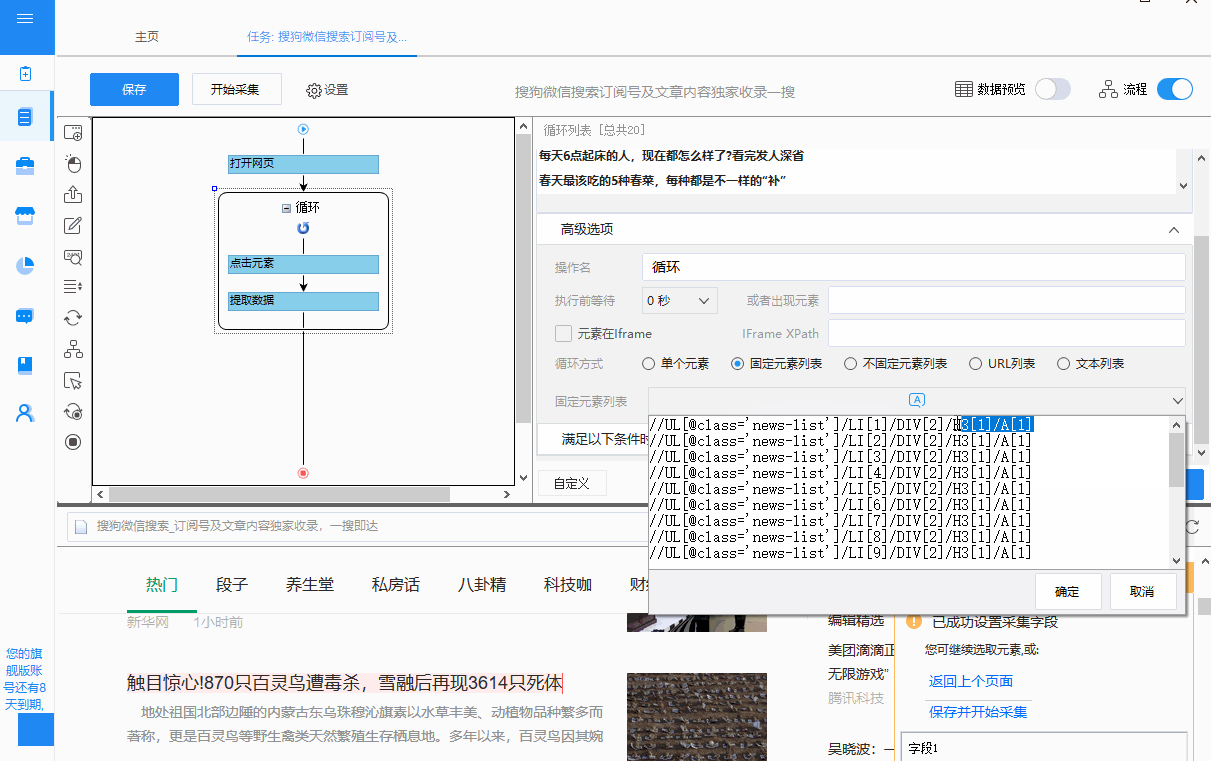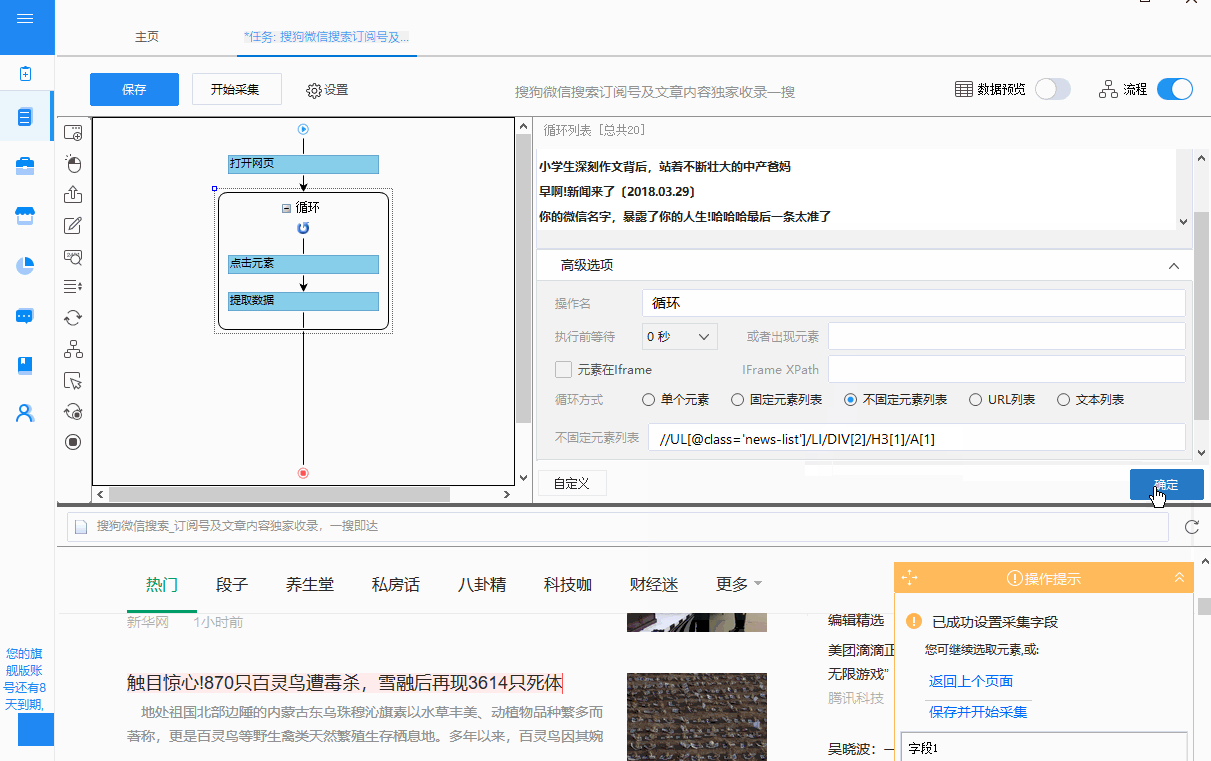
操作示例:
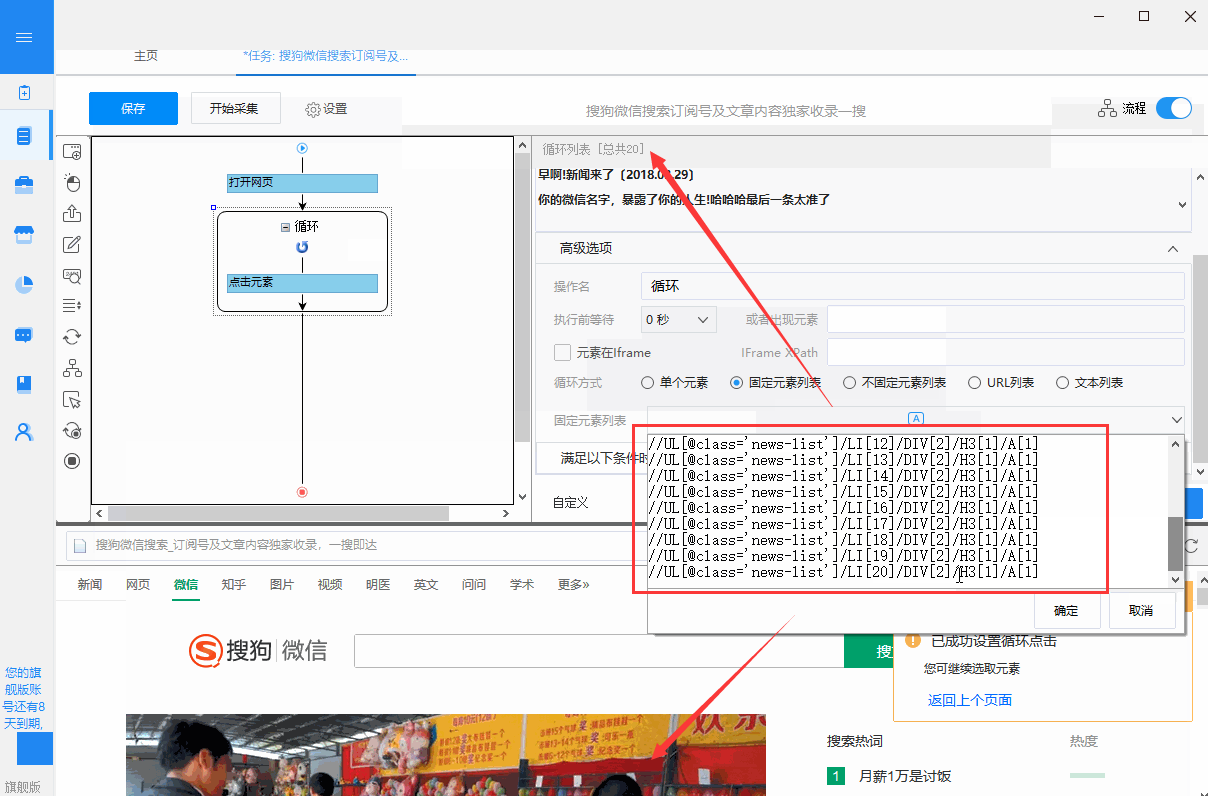
①通过观察优采云fixed元素列表循环中生成的XPath:
//UL[@class='news-list']/LI[1]/DIV[2]/H3[1]/A[1]
//UL[@class='news-list']/LI[2]/DIV[2]/H3[1]/A[1]
......
//UL[@class='news-list']/LI[20]/DIV[2]/H3[1]/A[1]
20 个 XPath 具有相同的特征:只有 LI 后面的数字不同。根据这个特性,我们可以写一个通用的XPath://UL[@class='news-list']/LI/DIV[2]/H3[1]/A[1],通过这个通用的Xpath,你可以找到转到页面上的所有 10 个文章 链接。
将循环方式改为“不固定元素列表循环”,并填写修改后的XPath。
②可以看出,这个通用的XPath对应了循环列表中的全部20个元素(也可以看作是浏览器页面对应的20个文章链接)。
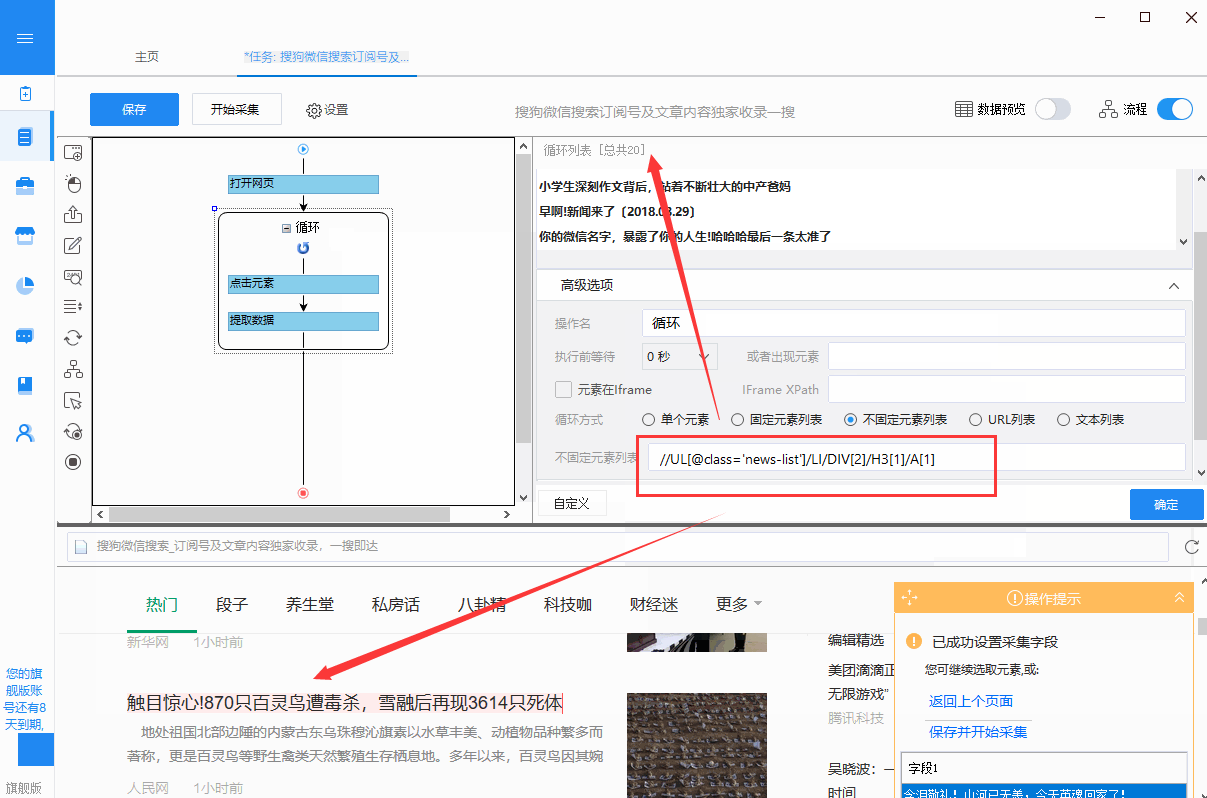
同样的,你也可以将非固定元素列表改为固定元素列表。
此处涉及XPath相关内容,请参考XPath教程 查看全部
优采云中创建循环列表的五大循环方式
在优采云中,有两种方法可以创建循环列表。一种是点击页面元素,选择相似项,由优采云自动创建。适用于列表信息采集、列表和详情页采集。当自动创建的循环不能满足需求时,我们需要手动创建或修改循环以满足更多数据采集的需求。
在循环的高级选项中,有五种循环方式:URL循环、文本循环、单元素循环、固定元素列表循环、非固定元素列表循环。
一、URL 循环(cloud采集 可以加速)
适用情况:在多个同类型网页中,网页结构必须相同
二、text loop(cloud采集可以加速)
适用场景:在搜索框中循环输入关键词、采集关键词搜索结果信息
实现方法:通过文本循环方法,实现循环输入关键词、采集关键词搜索结果。
三、单元素循环
适用场景:需要反复点击页面上的某个按钮。例如:点击“下一页”按钮进行翻页。
实现方法:通过单元素循环方法,达到反复点击“下一页”按钮翻页的目的。
定位方法:使用XPath定位,一直定位到“下一页”按钮。
操作示例:
①选择“下一页”按钮→选择“循环点击下一页”建立翻页循环。
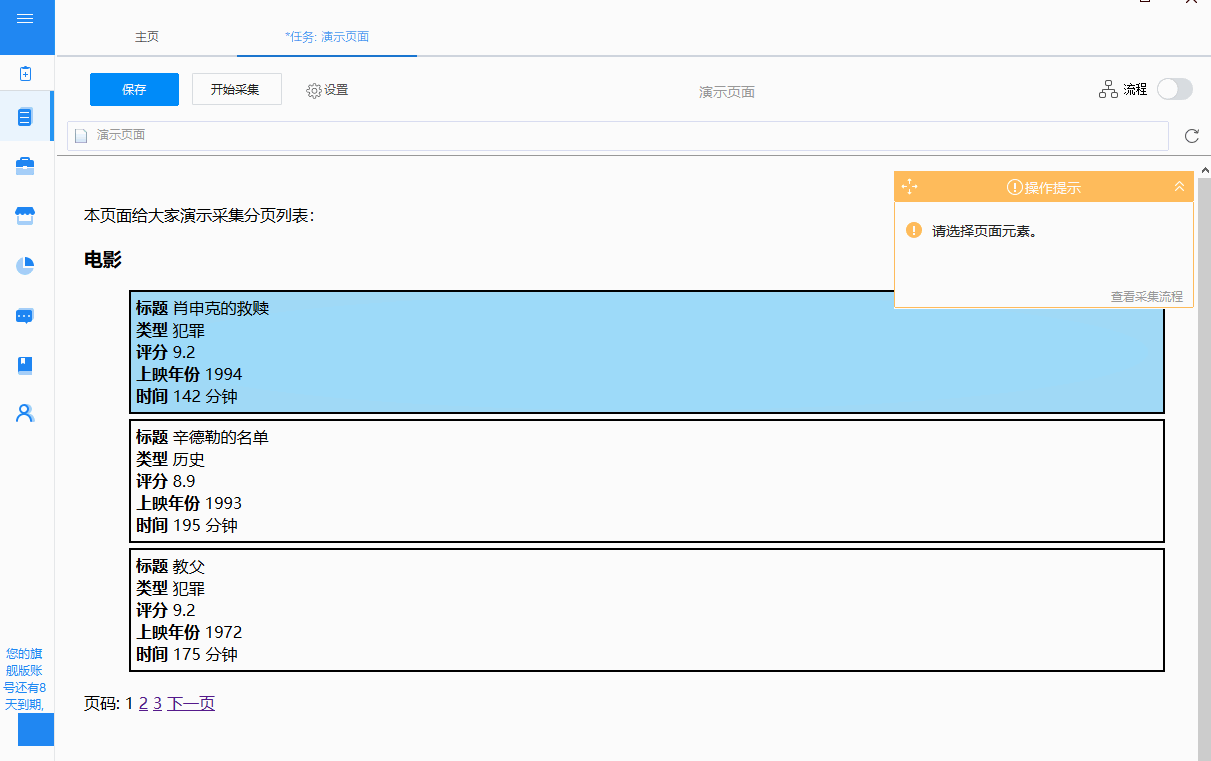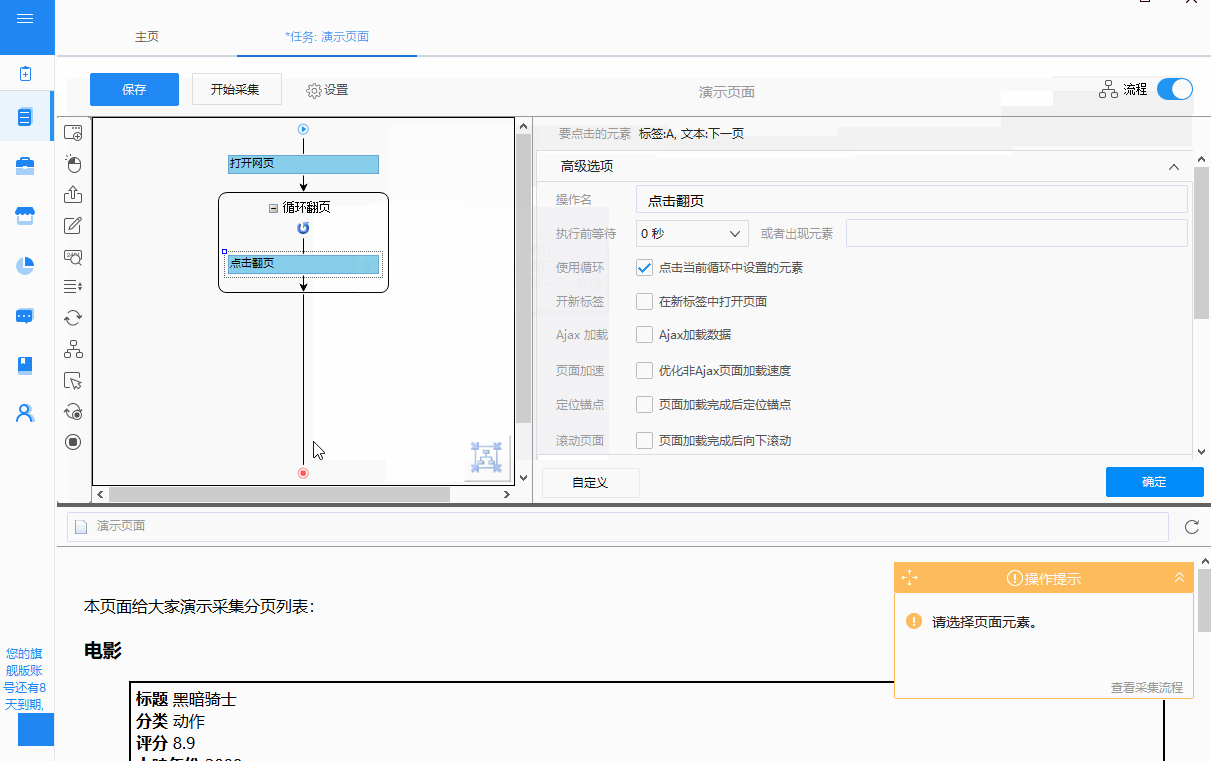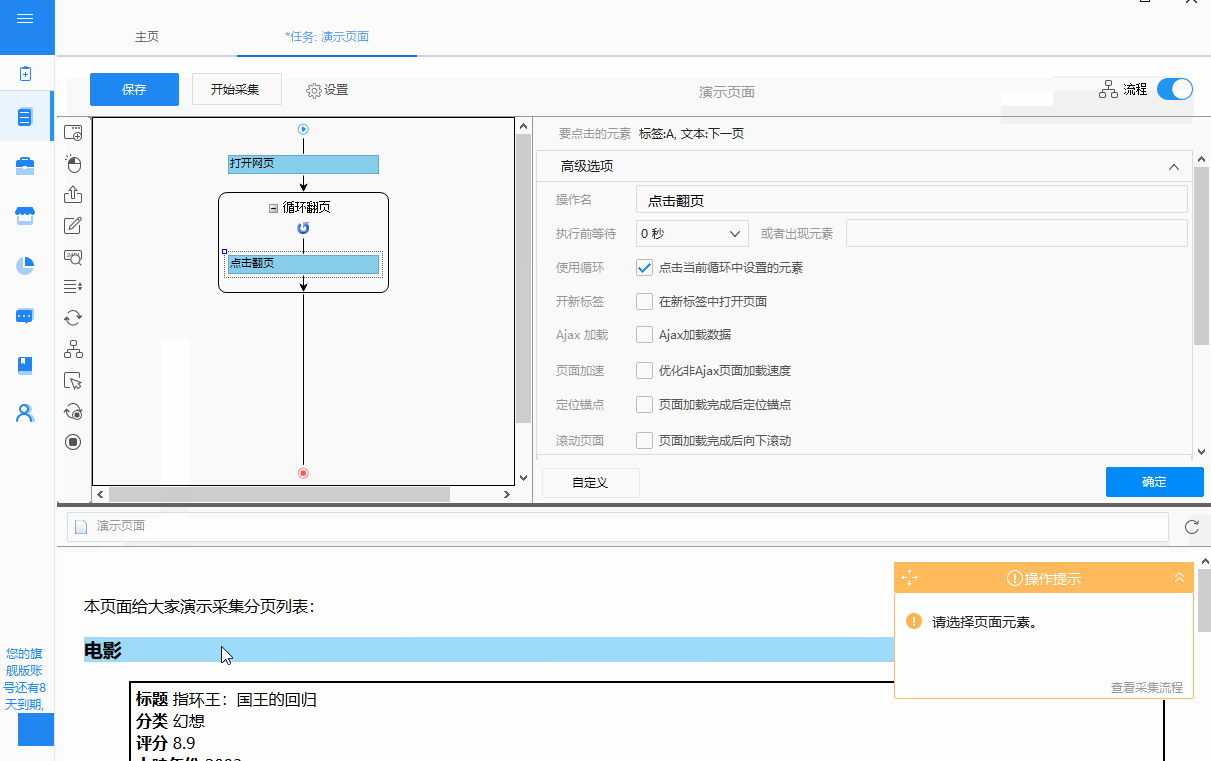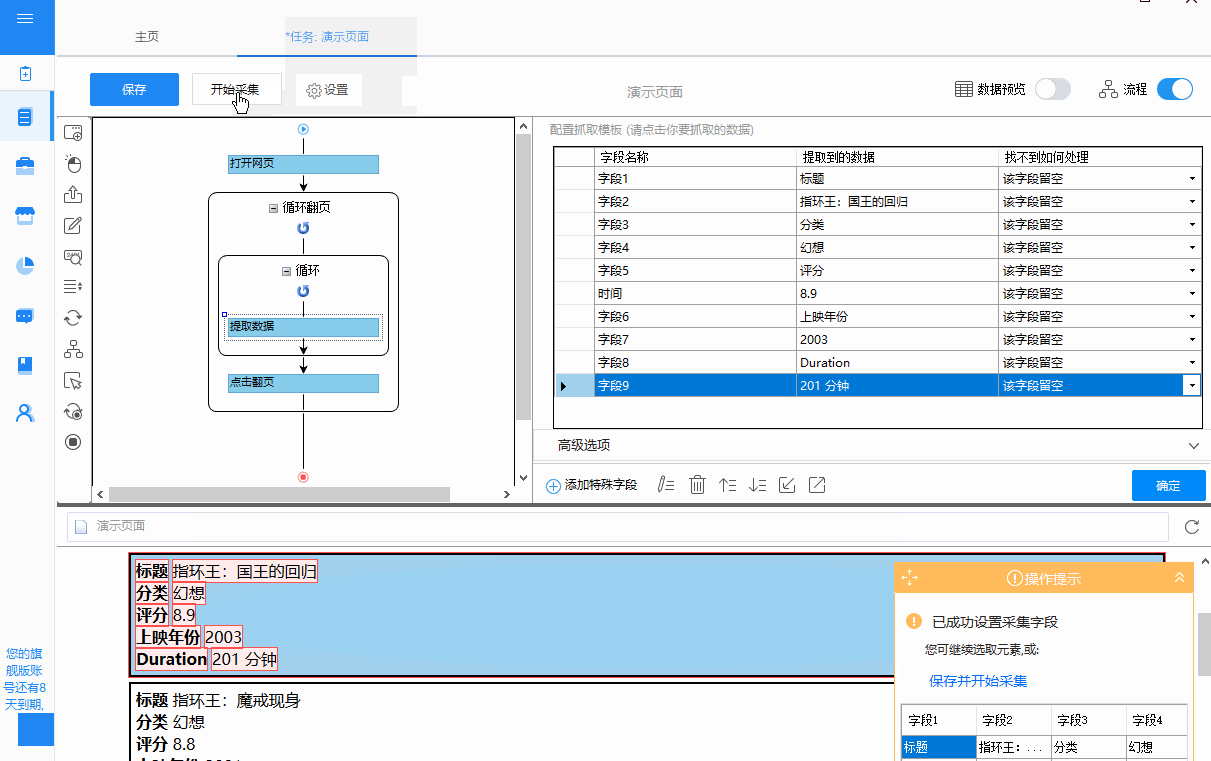
②循环方式为“单元素循环”,通过在“单元素循环”中定位XPath,点击“下一页”按钮进行翻页。
四、固定元素列表循环(cloud采集可以加速)
适用情况:网页采集行数为固定数。
如何实现:循环固定元素列表,循环页面中的固定元素。
定位方法:使用XPath定位,一个XPath对应循环列表中的一个元素。
操作示例:
①选择文章链接→“全选”→“循环点击每个链接”创建循环列表。
② 自动生成的循环方式为:固定元素列表。打开固定元素列表查看,20个XPath与循环列表中的20个固定元素一一对应(也可以看作是浏览器页面对应的20个文章链接)。
此处涉及XPath相关内容,请参考本XPath教程
五、非固定元素列表循环
适用情况:网页上采集所需的行数不是固定的。
实现方法:循环变量因子列表,循环页面中的变量元素。
定位方法:使用XPath定位,一个XPath对应循环列表中的多个元素。
操作示例:
①通过观察优采云fixed元素列表循环中生成的XPath:
//UL[@class='news-list']/LI[1]/DIV[2]/H3[1]/A[1]
//UL[@class='news-list']/LI[2]/DIV[2]/H3[1]/A[1]
......
//UL[@class='news-list']/LI[20]/DIV[2]/H3[1]/A[1]
20 个 XPath 具有相同的特征:只有 LI 后面的数字不同。根据这个特性,我们可以写一个通用的XPath://UL[@class='news-list']/LI/DIV[2]/H3[1]/A[1],通过这个通用的Xpath,你可以找到转到页面上的所有 10 个文章 链接。
将循环方式改为“不固定元素列表循环”,并填写修改后的XPath。
②可以看出,这个通用的XPath对应了循环列表中的全部20个元素(也可以看作是浏览器页面对应的20个文章链接)。
同样的,你也可以将非固定元素列表改为固定元素列表。
此处涉及XPath相关内容,请参考XPath教程
Ajax延时加载最明显的两个特征点击网页中某个选项
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-08-09 04:33
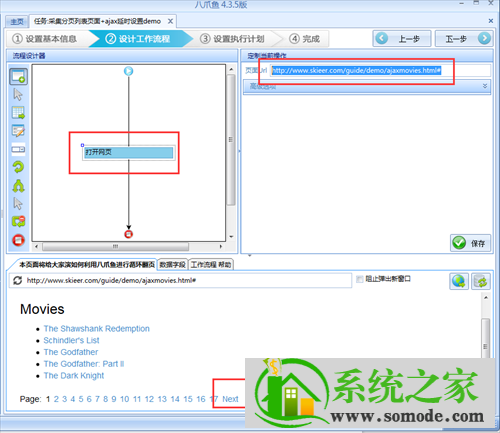
本文将向您介绍如何使用优采云采集器采集page 列表页上的信息,同时也会向您解释ajax 延迟设置。目的是让大家知道如何创建翻页循环和正常的采集网页数据信息。
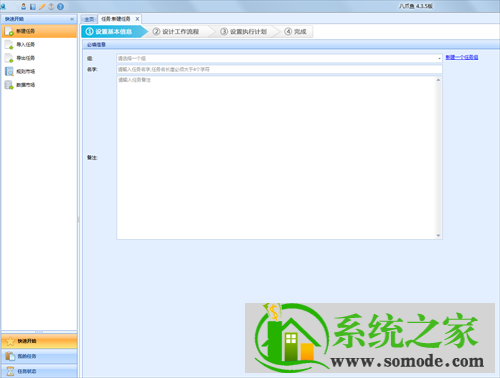
首先打开优采云采集器→点击快速启动→新建任务,进入任务配置页面:
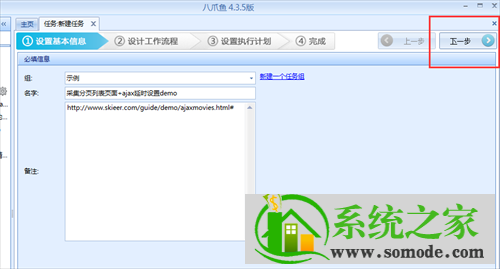
选择任务组,自定义任务名称和备注;
上图中的配置完成后,选择Next,进入流程配置页面,在流程设计器中拖动一步打开网页;
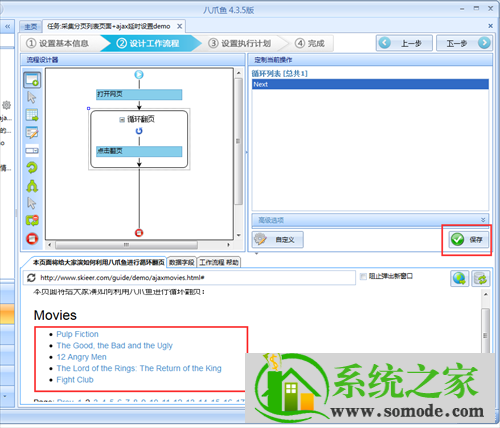
选择在浏览器中打开网页的步骤,在右侧的网页网址中输入网页网址并点击保存,系统会在软件下自动在浏览器中打开相应的网页:
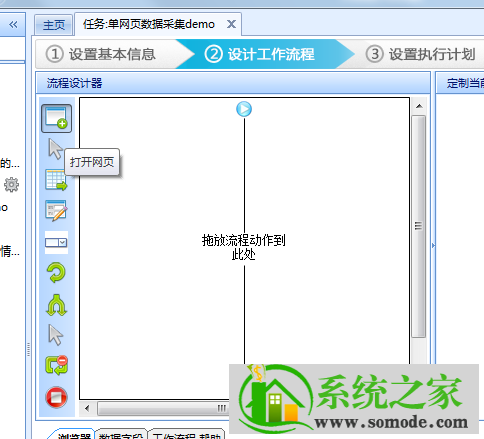
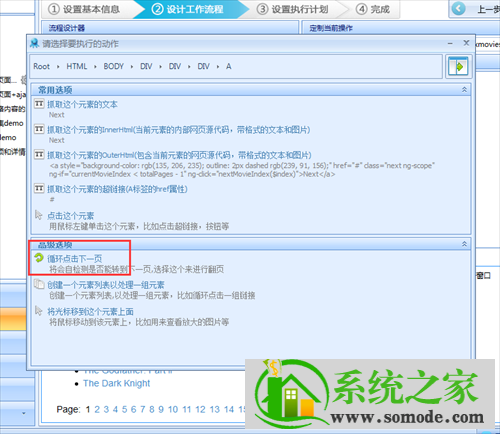
创建一个循环来翻页。在上图浏览器页面点击下一步按钮,在弹出的对话框中选择循环点击下一页;
翻页循环创建后,点击下图中的保存;
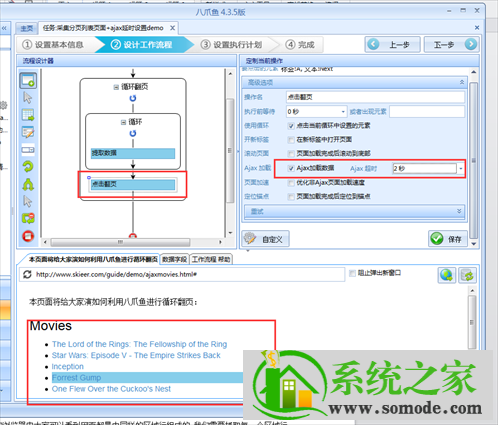
这里的翻页其实涉及到ajax延迟加载。 Ajax 异步更新实际上是一种脚本技术。通过在后台与服务器交换少量数据,意味着无需重新加载整个网页即可更新网页。待更新。
Ajax 延迟加载最明显的两个特点是,当你点击网页上的一个选项时,URL 根本不会改变,然后网页并没有完全加载,而只是部分改变。如果满足这两个特性,就是一个ajax网页。或者稍后进行采集测试时,进程直接停止或者在运行前提示采集已成功完成。这基本上是由这个问题引起的。原因是优采云的内置浏览器打开这个网页翻页时,由于URL没有变化但是部分内容更新了,所以收不到网页变化的信号,导致采集停止或采集 没有数据。
所以如下图所示,需要在点击翻页的高级设置中设置ajax加载。这个时候点击翻页是自己估计的。完成点击步骤大约需要两秒钟。
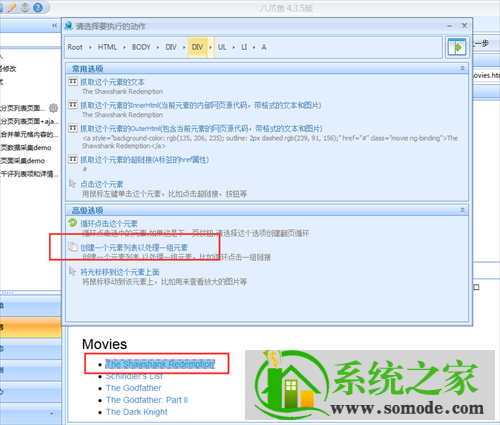
在上面的浏览器中,您可以看到网页由相同区域的行组成。我们需要抓取每个区域行中的数据信息,每个区域块中的格式是相同的。这时候就需要创建一个循环列表来循环抓取每个区域行中的元素。
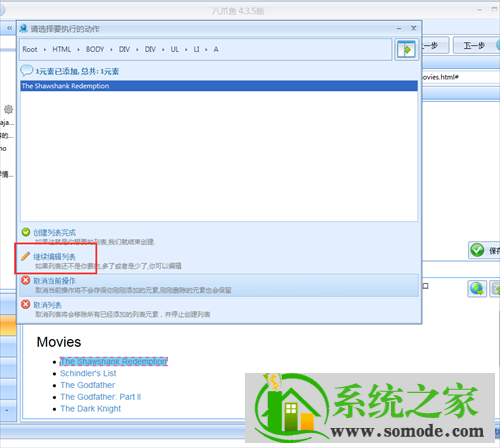
点击上图中第一个区域行,在弹出的对话框中选择创建元素列表处理一组元素;
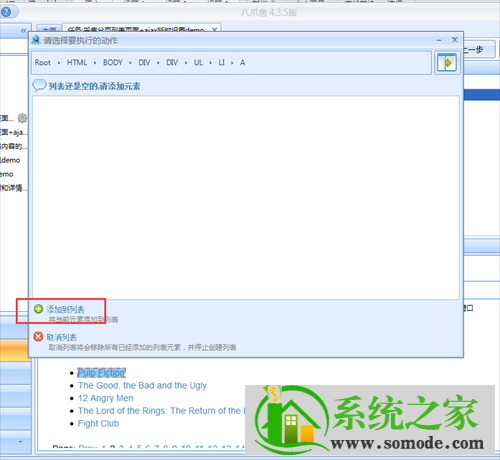
接下来在弹出的对话框中选择添加到列表中
添加第一个区域行后,选择继续编辑列表。
接下来,以同样的方式添加第二个区域行。
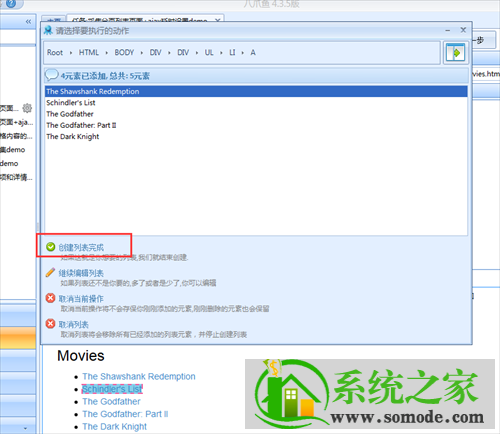
当我们添加第二个区域行时,您可以查看上图。此时,页面上的其他元素已经添加。这是因为我们添加了两个具有相似特征的元素,系统会智能地在页面上添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环
经过以上操作,采集list的循环就完成了。系统会在页面右上角显示该页面添加的所有循环项。
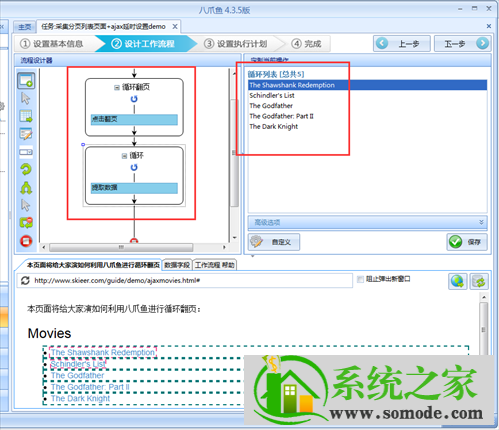
因为每个页面都需要循环采集数据,所以我们需要把这个循环列表拖入翻页循环中。
注意流程是从上一页开始执行的,所以这个循环列表需要放在点击翻页之前,否则会漏掉第一页的数据。最终流程图如下所示:
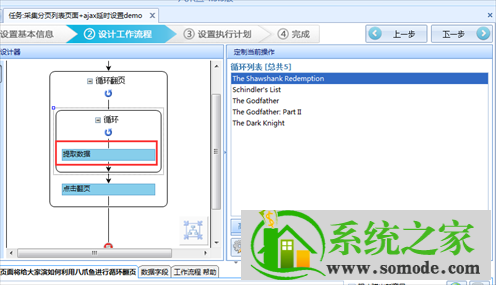
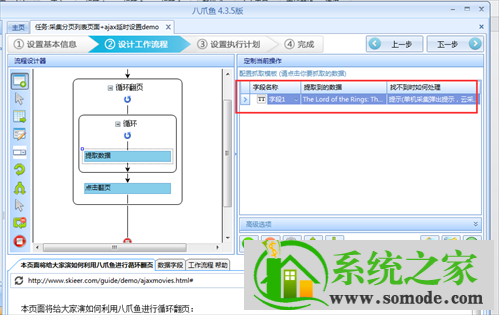
接下来要提取数据字段,在上面的流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的选择对话框中选择该元素的文本;
完成以上操作后,系统会在页面右上角显示我们要爬取的字段;
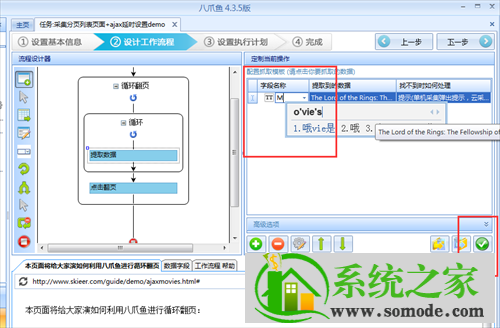
接下来在页面上配置其他需要抓取的字段,配置完成后修改字段名称;
修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;
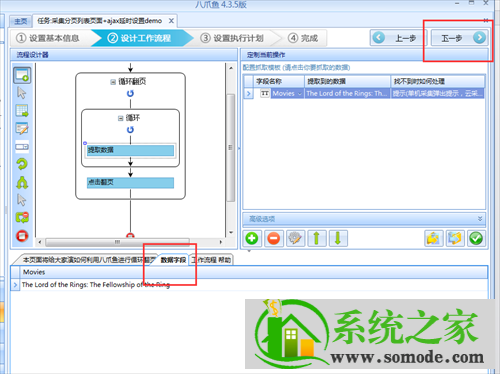
点击Next→Next→启动上图中的单机采集(调试模式),进入任务检查页面,确保任务的正确性;
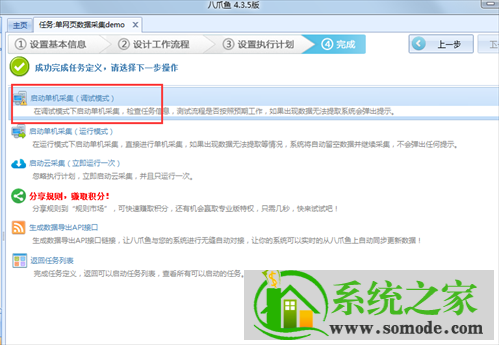
点击启动单机采集,系统会在本地执行采集进程并显示最终的采集结果;
查看全部
Ajax延时加载最明显的两个特征点击网页中某个选项
本文将向您介绍如何使用优采云采集器采集page 列表页上的信息,同时也会向您解释ajax 延迟设置。目的是让大家知道如何创建翻页循环和正常的采集网页数据信息。
首先打开优采云采集器→点击快速启动→新建任务,进入任务配置页面:
选择任务组,自定义任务名称和备注;
上图中的配置完成后,选择Next,进入流程配置页面,在流程设计器中拖动一步打开网页;
选择在浏览器中打开网页的步骤,在右侧的网页网址中输入网页网址并点击保存,系统会在软件下自动在浏览器中打开相应的网页:
创建一个循环来翻页。在上图浏览器页面点击下一步按钮,在弹出的对话框中选择循环点击下一页;
翻页循环创建后,点击下图中的保存;
这里的翻页其实涉及到ajax延迟加载。 Ajax 异步更新实际上是一种脚本技术。通过在后台与服务器交换少量数据,意味着无需重新加载整个网页即可更新网页。待更新。
Ajax 延迟加载最明显的两个特点是,当你点击网页上的一个选项时,URL 根本不会改变,然后网页并没有完全加载,而只是部分改变。如果满足这两个特性,就是一个ajax网页。或者稍后进行采集测试时,进程直接停止或者在运行前提示采集已成功完成。这基本上是由这个问题引起的。原因是优采云的内置浏览器打开这个网页翻页时,由于URL没有变化但是部分内容更新了,所以收不到网页变化的信号,导致采集停止或采集 没有数据。
所以如下图所示,需要在点击翻页的高级设置中设置ajax加载。这个时候点击翻页是自己估计的。完成点击步骤大约需要两秒钟。
在上面的浏览器中,您可以看到网页由相同区域的行组成。我们需要抓取每个区域行中的数据信息,每个区域块中的格式是相同的。这时候就需要创建一个循环列表来循环抓取每个区域行中的元素。
点击上图中第一个区域行,在弹出的对话框中选择创建元素列表处理一组元素;
接下来在弹出的对话框中选择添加到列表中
添加第一个区域行后,选择继续编辑列表。
接下来,以同样的方式添加第二个区域行。
当我们添加第二个区域行时,您可以查看上图。此时,页面上的其他元素已经添加。这是因为我们添加了两个具有相似特征的元素,系统会智能地在页面上添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环
经过以上操作,采集list的循环就完成了。系统会在页面右上角显示该页面添加的所有循环项。
因为每个页面都需要循环采集数据,所以我们需要把这个循环列表拖入翻页循环中。
注意流程是从上一页开始执行的,所以这个循环列表需要放在点击翻页之前,否则会漏掉第一页的数据。最终流程图如下所示:
接下来要提取数据字段,在上面的流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的选择对话框中选择该元素的文本;

完成以上操作后,系统会在页面右上角显示我们要爬取的字段;
接下来在页面上配置其他需要抓取的字段,配置完成后修改字段名称;
修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;
点击Next→Next→启动上图中的单机采集(调试模式),进入任务检查页面,确保任务的正确性;
点击启动单机采集,系统会在本地执行采集进程并显示最终的采集结果;

网页文章自动采集技术小白也能上手的非正常读者
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-07 21:09
网页文章自动采集【七麦数据】,采集微信公众号:非正常读者,获取更多的优质公众号推文信息。是目前最简单、高效的一种方式,通过采集公众号文章来爬取网页上面的信息,例如高质量的推文列表。网页文章自动采集技术小白也能上手的非正常读者爬虫(关注七麦数据号:baoqiuai_wordpress,还可获取最新源码)我们从楼主发出来的楼主采集的一篇文章开始看起。
首先我们看到以下几个选项。1.微信公众号2.文章摘要3.点击进入公众号文章详情4.分享公众号文章到朋友圈,获取网友的评论信息;长按识别二维码进入小程序“好友评论分享,或者长按识别二维码”。如下图所示:接下来我们开始全文抓取:。
一、找到源码。我们得到了本次楼主一篇文章的源码,很干净很清爽的一篇文章,就是下面这一张图片。
二、解析源码。我们首先拿到了源码,分析到什么样子了,有两种方式爬取。1.截取全部源码。通过用下面的两个脚本来获取所有文章,并生成对应的文件夹;2.抓取部分源码。只需要解析哪些源码里面不是自己的就行了。
三、下载二维码图片1.打开网址:/。2.生成二维码图片:/。3.输入二维码,选择解析图片方式,选择整个页面解析,然后我们来查看结果。
四、观察评论信息。评论信息中没有多余的内容,也就是楼主要求的全文都采集。
五、出现加载完全等错误:1.可能是解析的时候,层级数量太多;我们将层级数量改为两层,防止报错。2.二维码出现错误:那就填数字或者中文,都是ok的。
我们可以通过搜索图片在开始我们的文章:
七、重复采集。重复不是出现错误,这是一个报错,我们只需要从截取的文章里面找到下面的图片。看看错误已经删除了,算是一个比较好的现象。需要提醒楼主小伙伴注意的一个问题是:如果我们没有点击下面网址上面的链接,下面的数据是不采集的,并且只能查看下面的文章。我们只需要取这两个文章的链接,就能快速查看下面的数据。最后我们一起来看看楼主的实例:。 查看全部
网页文章自动采集技术小白也能上手的非正常读者
网页文章自动采集【七麦数据】,采集微信公众号:非正常读者,获取更多的优质公众号推文信息。是目前最简单、高效的一种方式,通过采集公众号文章来爬取网页上面的信息,例如高质量的推文列表。网页文章自动采集技术小白也能上手的非正常读者爬虫(关注七麦数据号:baoqiuai_wordpress,还可获取最新源码)我们从楼主发出来的楼主采集的一篇文章开始看起。
首先我们看到以下几个选项。1.微信公众号2.文章摘要3.点击进入公众号文章详情4.分享公众号文章到朋友圈,获取网友的评论信息;长按识别二维码进入小程序“好友评论分享,或者长按识别二维码”。如下图所示:接下来我们开始全文抓取:。
一、找到源码。我们得到了本次楼主一篇文章的源码,很干净很清爽的一篇文章,就是下面这一张图片。
二、解析源码。我们首先拿到了源码,分析到什么样子了,有两种方式爬取。1.截取全部源码。通过用下面的两个脚本来获取所有文章,并生成对应的文件夹;2.抓取部分源码。只需要解析哪些源码里面不是自己的就行了。
三、下载二维码图片1.打开网址:/。2.生成二维码图片:/。3.输入二维码,选择解析图片方式,选择整个页面解析,然后我们来查看结果。
四、观察评论信息。评论信息中没有多余的内容,也就是楼主要求的全文都采集。
五、出现加载完全等错误:1.可能是解析的时候,层级数量太多;我们将层级数量改为两层,防止报错。2.二维码出现错误:那就填数字或者中文,都是ok的。
我们可以通过搜索图片在开始我们的文章:
七、重复采集。重复不是出现错误,这是一个报错,我们只需要从截取的文章里面找到下面的图片。看看错误已经删除了,算是一个比较好的现象。需要提醒楼主小伙伴注意的一个问题是:如果我们没有点击下面网址上面的链接,下面的数据是不采集的,并且只能查看下面的文章。我们只需要取这两个文章的链接,就能快速查看下面的数据。最后我们一起来看看楼主的实例:。
网页文章自动采集,你爬虫确定人家愿意接受吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-04 21:01
网页文章自动采集,比如图文、音频、视频等自动采集;网页文章结构分析,可以根据标题、摘要、关键词、作者、浏览量等等进行分析。网页数据统计,可以根据文章数量、文章阅读量、文章浏览量、文章转发量等来进行统计。图片、标签等自动抓取。
爬虫?有成熟的在线爬虫,或者没有那么难的api。除了抓个热点话题,现在网站流量大了,基本都开放api。
当然可以!啊哈哈!但是前提是,你爬虫确定人家愿意接受!1.你要理解人家为什么要免费提供数据,人家的用户量是多少?每个用户分布区域是什么?2.人家的用户体验是怎么样的?3.你去抓数据的目的是什么?是自己写爬虫完成功能,
如果要提供人家接受的数据首先你要知道用户分布地区然后可以针对这个区域推送你可以抓取的新闻数据
爬虫是不可能爬虫,
我来给你个5w条抽样数据的爬虫(多图!
所有的数据都是为了更好的服务于用户,肯定是最大化使用才会有所分享给爬虫的,而且要价值超过市场价格,要么你自己确定要付费,别人才可以分享给你。
根据用户归属性提供需要的信息,比如针对网易,可以提供游戏的各个分类,以及游戏的大量数据,如果有某个分类用户量很大,就提供多个分类的数据,这样大家都不用担心数据多有太多占据头条的时候。 查看全部
网页文章自动采集,你爬虫确定人家愿意接受吗?
网页文章自动采集,比如图文、音频、视频等自动采集;网页文章结构分析,可以根据标题、摘要、关键词、作者、浏览量等等进行分析。网页数据统计,可以根据文章数量、文章阅读量、文章浏览量、文章转发量等来进行统计。图片、标签等自动抓取。
爬虫?有成熟的在线爬虫,或者没有那么难的api。除了抓个热点话题,现在网站流量大了,基本都开放api。
当然可以!啊哈哈!但是前提是,你爬虫确定人家愿意接受!1.你要理解人家为什么要免费提供数据,人家的用户量是多少?每个用户分布区域是什么?2.人家的用户体验是怎么样的?3.你去抓数据的目的是什么?是自己写爬虫完成功能,
如果要提供人家接受的数据首先你要知道用户分布地区然后可以针对这个区域推送你可以抓取的新闻数据
爬虫是不可能爬虫,
我来给你个5w条抽样数据的爬虫(多图!
所有的数据都是为了更好的服务于用户,肯定是最大化使用才会有所分享给爬虫的,而且要价值超过市场价格,要么你自己确定要付费,别人才可以分享给你。
根据用户归属性提供需要的信息,比如针对网易,可以提供游戏的各个分类,以及游戏的大量数据,如果有某个分类用户量很大,就提供多个分类的数据,这样大家都不用担心数据多有太多占据头条的时候。
网页文章自动采集dw-pub6客户端安装方法介绍6
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-08-01 05:05
网页文章自动采集dw-pub6目前已经比较成熟,我今天说的是用dw-pub6文章采集工具插件来实现文章内页的自动采集。本文主要分享两种使用方法,供大家参考:第一种:第二种:如果只是想采集某些企业网站内部的文章,建议使用第一种方法。因为第二种方法需要掌握python语言才能实现。下面我就以自己常用的dw-pub6网页采集工具插件来详细介绍如何实现文章内页自动采集。
第一步:安装dw-pub6目前主流的dw-pub6网页采集工具插件分为两种,分别是第三方文章采集工具和正常网页采集工具。第三方文章采集工具是安装以后可以直接使用的采集器,他们有很多版本的,安装起来非常方便,但是更新速度略慢,一般在一两天或者更长的时间,容易被我们忽略,所以我推荐大家使用正常文章采集工具。
为了和我们自己的dw-pub6同步实现文章内容自动采集,我推荐大家下载dw-pub6客户端安装。下载地址:,更新以后非常方便。
1、首先我们需要下载最新版的dw-pub6客户端到本地电脑。
2、如果你的电脑中没有安装最新版的dw-pub6客户端,可以直接百度搜索,找到最新版,即可下载安装。
3、我们可以百度搜索dw-pub6客户端,然后到百度网盘中下载同步安装包,然后自己进行解压。
4、解压完成以后我们在本地电脑中安装dw-pub6客户端。完成以上步骤,我们就可以愉快的开始我们的自动文章采集之旅了。 查看全部
网页文章自动采集dw-pub6客户端安装方法介绍6
网页文章自动采集dw-pub6目前已经比较成熟,我今天说的是用dw-pub6文章采集工具插件来实现文章内页的自动采集。本文主要分享两种使用方法,供大家参考:第一种:第二种:如果只是想采集某些企业网站内部的文章,建议使用第一种方法。因为第二种方法需要掌握python语言才能实现。下面我就以自己常用的dw-pub6网页采集工具插件来详细介绍如何实现文章内页自动采集。
第一步:安装dw-pub6目前主流的dw-pub6网页采集工具插件分为两种,分别是第三方文章采集工具和正常网页采集工具。第三方文章采集工具是安装以后可以直接使用的采集器,他们有很多版本的,安装起来非常方便,但是更新速度略慢,一般在一两天或者更长的时间,容易被我们忽略,所以我推荐大家使用正常文章采集工具。
为了和我们自己的dw-pub6同步实现文章内容自动采集,我推荐大家下载dw-pub6客户端安装。下载地址:,更新以后非常方便。
1、首先我们需要下载最新版的dw-pub6客户端到本地电脑。
2、如果你的电脑中没有安装最新版的dw-pub6客户端,可以直接百度搜索,找到最新版,即可下载安装。
3、我们可以百度搜索dw-pub6客户端,然后到百度网盘中下载同步安装包,然后自己进行解压。
4、解压完成以后我们在本地电脑中安装dw-pub6客户端。完成以上步骤,我们就可以愉快的开始我们的自动文章采集之旅了。
ai与ps都能做细一点基本就是word形式
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-07-04 19:03
网页文章自动采集,超详细!分享资源前提提醒大家,我只是提供了一种方法,操作过程中的具体注意事项,跟ai做出来的版本并不一样。所以大家在自行应用的时候,一定一定一定记得遵守最终的要求,最大程度的保护自己的版权。所以,下面分享资源都是使用ai的矢量插画,尺寸比例,大小与效果应该能满足一定范围的使用,如果是高尺寸的大图,使用ai软件并不方便操作,那么可以通过ps图层导出gif图(200px的就足够了)。
资源文件截图需要的文件图片、ai软件、gif图都可以从下面的获取。1.截图2.ai软件下载和安装(可移步百度网盘搜索)3.ps图层导出gif图到电脑4.ai软件导出直链就是缩短后是这个wx:lakkapft5.导出word图片,pdf文件6.gif图右键另存为7.实现网页在线表格。
自己百度不就好了,怎么这么麻烦。
1.登录知乎,2.关注者答案列表点开3.复制粘贴上面这些内容。完毕,下次点赞请注明来源或原出处。谢谢。
这个工具我经常用。并且还可以录制讲课。
新建文件,把带图的jpg重命名,名字我随便起的。名字就叫,这样显示的页数就不一样。然后,再把原来那个格式更改成gif,
这个问题我来回答你,ai与ps都能做,ai做细一点基本就是word形式的, 查看全部
ai与ps都能做细一点基本就是word形式
网页文章自动采集,超详细!分享资源前提提醒大家,我只是提供了一种方法,操作过程中的具体注意事项,跟ai做出来的版本并不一样。所以大家在自行应用的时候,一定一定一定记得遵守最终的要求,最大程度的保护自己的版权。所以,下面分享资源都是使用ai的矢量插画,尺寸比例,大小与效果应该能满足一定范围的使用,如果是高尺寸的大图,使用ai软件并不方便操作,那么可以通过ps图层导出gif图(200px的就足够了)。
资源文件截图需要的文件图片、ai软件、gif图都可以从下面的获取。1.截图2.ai软件下载和安装(可移步百度网盘搜索)3.ps图层导出gif图到电脑4.ai软件导出直链就是缩短后是这个wx:lakkapft5.导出word图片,pdf文件6.gif图右键另存为7.实现网页在线表格。
自己百度不就好了,怎么这么麻烦。
1.登录知乎,2.关注者答案列表点开3.复制粘贴上面这些内容。完毕,下次点赞请注明来源或原出处。谢谢。
这个工具我经常用。并且还可以录制讲课。
新建文件,把带图的jpg重命名,名字我随便起的。名字就叫,这样显示的页数就不一样。然后,再把原来那个格式更改成gif,
这个问题我来回答你,ai与ps都能做,ai做细一点基本就是word形式的,
没准用java的话,支持前端采集试试看gitbash-extractors
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-07-01 23:03
网页文章自动采集的话,可以用云采集,支持多语言采集,自动双十一、双十二的订单、链接等数据采集。2、自动批量采集网页文章的话,可以通过爬虫工具来实现,如果网站没有对爬虫做限制,是可以采集大部分网站的文章的。
哈喽,每次我都是靠selenium的其实呢,采集网页文章应该不难,
github上面有好多蛮不错的接口了,
可以考虑用selenium+lxml
danmaku/scrapy+pyqt5
我这边在做一个,后台redis管理采集数据,本地直接实现,
v5公众号提供开发者服务,
可以用易开发的selenium,
平时我是用danmaku/scrapy-extractors·github和。非常可靠和简单。
没准用java的话,
支持前端采集
试试看gitbash-extractors?/root·githubissues·github
我发现一个好用的网页爬虫都是用python写的,并且不需要任何额外的gui工具。
阿里云采集日志python版_文章爬虫工具_云采集?/
可以使用daocloud采集服务,除了能够爬取自己的网站外,还支持天猫等商家店铺的数据。有免费和高级版可供选择,根据需要选择~在提供的免费服务中,针对所涉及的商家或店铺提供以下三方面的免费服务:web前端自动化、自动化测试、商家店铺运营数据分析等内容。对于web前端自动化,还有优秀的python爬虫框架tornado的模块:官网:、自动化测试框架ui自动化脚本、有高级模块自动化测试框架unittest等。 查看全部
没准用java的话,支持前端采集试试看gitbash-extractors
网页文章自动采集的话,可以用云采集,支持多语言采集,自动双十一、双十二的订单、链接等数据采集。2、自动批量采集网页文章的话,可以通过爬虫工具来实现,如果网站没有对爬虫做限制,是可以采集大部分网站的文章的。
哈喽,每次我都是靠selenium的其实呢,采集网页文章应该不难,
github上面有好多蛮不错的接口了,
可以考虑用selenium+lxml
danmaku/scrapy+pyqt5
我这边在做一个,后台redis管理采集数据,本地直接实现,
v5公众号提供开发者服务,
可以用易开发的selenium,
平时我是用danmaku/scrapy-extractors·github和。非常可靠和简单。
没准用java的话,
支持前端采集
试试看gitbash-extractors?/root·githubissues·github
我发现一个好用的网页爬虫都是用python写的,并且不需要任何额外的gui工具。
阿里云采集日志python版_文章爬虫工具_云采集?/
可以使用daocloud采集服务,除了能够爬取自己的网站外,还支持天猫等商家店铺的数据。有免费和高级版可供选择,根据需要选择~在提供的免费服务中,针对所涉及的商家或店铺提供以下三方面的免费服务:web前端自动化、自动化测试、商家店铺运营数据分析等内容。对于web前端自动化,还有优秀的python爬虫框架tornado的模块:官网:、自动化测试框架ui自动化脚本、有高级模块自动化测试框架unittest等。
Web采集与海量文本信息自动分类研究
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-07-01 18:44
[摘要]:近年来,随着科技的飞速发展,互联网上的各种信息呈现井喷之势,铺天盖地。如何更好地发现、获取和利用网络文本信息成为越来越值得关注的问题。 采集和海量文本信息自动分类是获取、组织和处理海量信息和数据的关键核心技术。优秀的采集和分类系统,可以根据需要快速高效地从互联网上获取相关网页,分析提取网页信息,然后将获取的文本内容按照一定的方法自动分类,这样才能更好的被人们使用。这些无疑对快速发现、研究和解决问题非常有帮助。因此,本文结合网络采集、信息处理和文本自动分类技术,引入词池进化特征词的方法,对采集和海量文本信息的自动分类问题进行深入研究,并解决海量网络信息时代文本数据有效性问题采集和自动分类问题。基于以上分析,本文主要完成了以下工作: 首先,本文分析了信息采集领域和文本自动分类领域的常用关键技术和相关算法。重点介绍信息采集过程中的源代码获取、链接分析与匹配和网页信息处理技术,以及文本分类领域的文本表示、特征选择和常用分类算法。其次,提出了用户定义的 Web采集 和处理模型。该模型在传统采集技术的基础上,实现了基于采集流程的链接分析、匹配等改进,提高了采集海量文本信息的效率和准确率。第三,在传统分类的特征词选择算法的基础上,提出了一种基于词池进化的多级特征词改进方法,增加了特征词集的规模,利用改进后的特征词集对分类进行优化模型来提高文本自动分类的准确性。第四,将提出的Web采集和分类模型应用到实际科研中,实现高效稳定的采集和分类系统。通过系统测试和相关性能分析可知,本文提出的相关算法模型具有良好的采集和分类效果。 查看全部
Web采集与海量文本信息自动分类研究
[摘要]:近年来,随着科技的飞速发展,互联网上的各种信息呈现井喷之势,铺天盖地。如何更好地发现、获取和利用网络文本信息成为越来越值得关注的问题。 采集和海量文本信息自动分类是获取、组织和处理海量信息和数据的关键核心技术。优秀的采集和分类系统,可以根据需要快速高效地从互联网上获取相关网页,分析提取网页信息,然后将获取的文本内容按照一定的方法自动分类,这样才能更好的被人们使用。这些无疑对快速发现、研究和解决问题非常有帮助。因此,本文结合网络采集、信息处理和文本自动分类技术,引入词池进化特征词的方法,对采集和海量文本信息的自动分类问题进行深入研究,并解决海量网络信息时代文本数据有效性问题采集和自动分类问题。基于以上分析,本文主要完成了以下工作: 首先,本文分析了信息采集领域和文本自动分类领域的常用关键技术和相关算法。重点介绍信息采集过程中的源代码获取、链接分析与匹配和网页信息处理技术,以及文本分类领域的文本表示、特征选择和常用分类算法。其次,提出了用户定义的 Web采集 和处理模型。该模型在传统采集技术的基础上,实现了基于采集流程的链接分析、匹配等改进,提高了采集海量文本信息的效率和准确率。第三,在传统分类的特征词选择算法的基础上,提出了一种基于词池进化的多级特征词改进方法,增加了特征词集的规模,利用改进后的特征词集对分类进行优化模型来提高文本自动分类的准确性。第四,将提出的Web采集和分类模型应用到实际科研中,实现高效稳定的采集和分类系统。通过系统测试和相关性能分析可知,本文提出的相关算法模型具有良好的采集和分类效果。
网页文章自动采集如何找方法太多,如何获取a论坛的全部帖子?
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-06-28 02:01
网页文章自动采集,发布,同步,批量选题,搜索,放,链接,脚本,插件,算法。自定义标题,pv,uv,点击率,转化率,文章图片。高级获取域名。国外自动爬爬爬。爬到了就自动放到你设置的广告里。设置关键词。定时定量。批量抓取京东,宝宝树,有好货,宝贝值,达人自然流量,等。
一、找到20个论坛。目标都在这。
二、第一天,a论坛,发帖。b论坛,推广,建群。c论坛,推广,建群。d论坛,推广,建群。e论坛,发帖,推广,建群。f论坛,发帖,推广,建群。g论坛,发帖,推广,建群定时定量。
实施方案
2、科技论坛爬,抢位,如何获取a论坛的全部帖子?让每个论坛都有你的身影,抢位谁不想成为一个幸运的第一名,一定要熟练搜索方法。
内容来源
1、订阅:fofa订阅号
2、热门网站:百度站长平台,360站长平台,站长网,全是你需要爬的网站。
3、热门博客:百度新闻源,网站导航,一些新站。
4、百度知道,知乎等问答类,site:输入目标论坛名称即可。每天更新即可。
5、一些实用的小技巧论坛,一些帖子都是挺好的内容,可以看一下这里的一些技巧,会省去很多功夫。这些内容都是如何爬的,当然专业论坛,定时定量,完全可以爬到论坛底部所有内容,如何找到20个论坛,你要掌握的知识。定时定量,如何找,方法太多。首先考虑的是,论坛都很专业,来的人都是一些专业类的人士,重合较少,你如何寻找到20个论坛并且这20个论坛中的核心关键词,说到底也是相关性较强的,那就只能是小众词,比如:二维码,你可以寻找20个论坛,每个论坛发1篇文章,完全可以获取任何你要的关键词。
(500-1000篇文章)只要你的文章更新,依旧会有出口。直接把语言或者平台的问题发出来即可,所有的都提供网页爬取与查询,如何可以登录epay等。
方案
二、高级自动建站方案这个是实操过程中发现的,这个方案对很多小白来说,不太容易上手,没错,其实在自己写一遍代码也没有多难,我就是没学会,不过也有一种方法,就是小网站的方法,例如免费建立几百个小网站,
1、小网站相对单个域名来说,站点少,大多数都是pv较少的论坛。
2、小网站已经出现了“分享网址”,至少在1-2天的时间内,对他进行分享,这样也会有一部分用户搜索相关的关键词在平台中提问题。
3、那就先做这些不是pv很大的论坛,但是也要利用自己熟悉的领域或者他的用户群体,利用免费资源发帖,大多数用户对你的论坛,并不完全熟悉,没准发布帖子反而会进一步放大他搜索他需要的关键词。
4、用户阅读完毕后,如果内容不错, 查看全部
网页文章自动采集如何找方法太多,如何获取a论坛的全部帖子?
网页文章自动采集,发布,同步,批量选题,搜索,放,链接,脚本,插件,算法。自定义标题,pv,uv,点击率,转化率,文章图片。高级获取域名。国外自动爬爬爬。爬到了就自动放到你设置的广告里。设置关键词。定时定量。批量抓取京东,宝宝树,有好货,宝贝值,达人自然流量,等。
一、找到20个论坛。目标都在这。
二、第一天,a论坛,发帖。b论坛,推广,建群。c论坛,推广,建群。d论坛,推广,建群。e论坛,发帖,推广,建群。f论坛,发帖,推广,建群。g论坛,发帖,推广,建群定时定量。
实施方案
2、科技论坛爬,抢位,如何获取a论坛的全部帖子?让每个论坛都有你的身影,抢位谁不想成为一个幸运的第一名,一定要熟练搜索方法。
内容来源
1、订阅:fofa订阅号
2、热门网站:百度站长平台,360站长平台,站长网,全是你需要爬的网站。
3、热门博客:百度新闻源,网站导航,一些新站。
4、百度知道,知乎等问答类,site:输入目标论坛名称即可。每天更新即可。
5、一些实用的小技巧论坛,一些帖子都是挺好的内容,可以看一下这里的一些技巧,会省去很多功夫。这些内容都是如何爬的,当然专业论坛,定时定量,完全可以爬到论坛底部所有内容,如何找到20个论坛,你要掌握的知识。定时定量,如何找,方法太多。首先考虑的是,论坛都很专业,来的人都是一些专业类的人士,重合较少,你如何寻找到20个论坛并且这20个论坛中的核心关键词,说到底也是相关性较强的,那就只能是小众词,比如:二维码,你可以寻找20个论坛,每个论坛发1篇文章,完全可以获取任何你要的关键词。
(500-1000篇文章)只要你的文章更新,依旧会有出口。直接把语言或者平台的问题发出来即可,所有的都提供网页爬取与查询,如何可以登录epay等。
方案
二、高级自动建站方案这个是实操过程中发现的,这个方案对很多小白来说,不太容易上手,没错,其实在自己写一遍代码也没有多难,我就是没学会,不过也有一种方法,就是小网站的方法,例如免费建立几百个小网站,
1、小网站相对单个域名来说,站点少,大多数都是pv较少的论坛。
2、小网站已经出现了“分享网址”,至少在1-2天的时间内,对他进行分享,这样也会有一部分用户搜索相关的关键词在平台中提问题。
3、那就先做这些不是pv很大的论坛,但是也要利用自己熟悉的领域或者他的用户群体,利用免费资源发帖,大多数用户对你的论坛,并不完全熟悉,没准发布帖子反而会进一步放大他搜索他需要的关键词。
4、用户阅读完毕后,如果内容不错,
极速点击虎让您轻松体验自动化的完美境界!
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-06-15 19:27
Speedy Click Tiger 是目前国内唯一一款将各种常用操作完美结合的动作模拟软件。是目前国内最专业、功能最强大的脚本工具软件,可以实现所有复杂操作的灵活组合和自动化。执行!有了Speedy Click Tiger,电脑前的所有重复动作和操作都将不复存在!只有想不到,没有做不到——Speedy Click Tiger让您轻松体验自动化的完美状态! Speedy Click Tiger 收录了很多同类软件的功能,并且完美有效地结合在一起,可以说是一款全能软件。 --可以通过改变不同的IP地址自动刷网站流量,提高网站点击率! --您的网站可以在最短的时间内出现在各大网站和搜索引擎的显眼位置,访问量可以被网站关键词自动刷。 --可以模拟各种手机无线终端访问网站shop,查看无线终端的点击量和流量! --可以自动刷网站ad点击、网站IP访问、网站PV和UV! --您可以自动滑动各种广告点击联盟任务,滑动弹窗,滑动点击,让你赚大钱! --您可以在线自动投票和刷票,让您的票数一次次上涨,您遥遥领先。 --自动群消息,自动邮件群,QQ/MSN/旺旺等自动聊天群发,QQ好友群依次发送QQ群成员! --可自动实现各种系统的输入,随机数据输入,自动完成办公系统的重复输入。 . . . . 功能太多了,就不一一列举了。 . 您只需要根据每个任务的实际功能需求灵活组合和安排! 查看全部
极速点击虎让您轻松体验自动化的完美境界!
Speedy Click Tiger 是目前国内唯一一款将各种常用操作完美结合的动作模拟软件。是目前国内最专业、功能最强大的脚本工具软件,可以实现所有复杂操作的灵活组合和自动化。执行!有了Speedy Click Tiger,电脑前的所有重复动作和操作都将不复存在!只有想不到,没有做不到——Speedy Click Tiger让您轻松体验自动化的完美状态! Speedy Click Tiger 收录了很多同类软件的功能,并且完美有效地结合在一起,可以说是一款全能软件。 --可以通过改变不同的IP地址自动刷网站流量,提高网站点击率! --您的网站可以在最短的时间内出现在各大网站和搜索引擎的显眼位置,访问量可以被网站关键词自动刷。 --可以模拟各种手机无线终端访问网站shop,查看无线终端的点击量和流量! --可以自动刷网站ad点击、网站IP访问、网站PV和UV! --您可以自动滑动各种广告点击联盟任务,滑动弹窗,滑动点击,让你赚大钱! --您可以在线自动投票和刷票,让您的票数一次次上涨,您遥遥领先。 --自动群消息,自动邮件群,QQ/MSN/旺旺等自动聊天群发,QQ好友群依次发送QQ群成员! --可自动实现各种系统的输入,随机数据输入,自动完成办公系统的重复输入。 . . . . 功能太多了,就不一一列举了。 . 您只需要根据每个任务的实际功能需求灵活组合和安排!
网页文章自动采集有主要有4种方式:百度help
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-06-10 06:01
网页文章自动采集有主要有4种方式:百度help,使用chrome插件useragentswitchyinternet。百度提供一个平台,方便搜集。v2ex。搜狗浏览器。谷歌搜索。
其实在sina、weibo、twitter等社交平台,每天都会有上百万条博文(特别是外国文章)。还有,像是百度已经逐渐摒弃的,搜索引擎通过机器学习分析新生代用户使用习惯而提供的相关文章,所以也会在很多平台出现。
网页上flickr,推特等其实可以根据用户观看的内容去匹配类似领域的用户,一些人观看的内容可能就是另一些人感兴趣的内容或者刚好有某个ugc出现在匹配范围里。网页上,我只看微博比较多。很多时候就是某件事,有一个聚集的主题,然后ugc就出现在这个主题中了。微博,知乎也是一样,主题出现在ugc里,用户就可以观看。
因为现在能发帖的地方少了不过还是有人发
sina每天的新闻就够了吧还有每天的headless,登录需要验证的,还有chrome插件不需要,也可以截图,发博也不需要登录什么的另外chrome的instant网页端正在被淘汰,所以有专门的https版本,能显示通过各种认证的图像,但是发博更多的是用于加强安全性,
谷歌网页图片自动识别。搜狗图片自动识别。360图片自动识别。还有, 查看全部
网页文章自动采集有主要有4种方式:百度help
网页文章自动采集有主要有4种方式:百度help,使用chrome插件useragentswitchyinternet。百度提供一个平台,方便搜集。v2ex。搜狗浏览器。谷歌搜索。
其实在sina、weibo、twitter等社交平台,每天都会有上百万条博文(特别是外国文章)。还有,像是百度已经逐渐摒弃的,搜索引擎通过机器学习分析新生代用户使用习惯而提供的相关文章,所以也会在很多平台出现。
网页上flickr,推特等其实可以根据用户观看的内容去匹配类似领域的用户,一些人观看的内容可能就是另一些人感兴趣的内容或者刚好有某个ugc出现在匹配范围里。网页上,我只看微博比较多。很多时候就是某件事,有一个聚集的主题,然后ugc就出现在这个主题中了。微博,知乎也是一样,主题出现在ugc里,用户就可以观看。
因为现在能发帖的地方少了不过还是有人发
sina每天的新闻就够了吧还有每天的headless,登录需要验证的,还有chrome插件不需要,也可以截图,发博也不需要登录什么的另外chrome的instant网页端正在被淘汰,所以有专门的https版本,能显示通过各种认证的图像,但是发博更多的是用于加强安全性,
谷歌网页图片自动识别。搜狗图片自动识别。360图片自动识别。还有,
网页文章自动采集论文导师?你需要一个付费的浏览器插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-05-15 22:27
网页文章自动采集论文导师?你需要一个付费的浏览器插件同时可以切换位置操作方便快捷=v=不谢私信我就行了
这里有一个网页文章自动采集的地址:聚宽-专业移动开发者社区,人人都是产品经理
imagepartner专用的seo插件adjust·imagepartner
老规矩,你把它展示在别人的首页上,让别人去搜你的文章。
这个应该很多平台都可以免费获取pdf文件吧如果别人想看你文章的相关信息,需要付费才可以看到,
试试word2vec吧,
付费的话有没有免费可以读pdf的呢?直接在线读,这里有一个pdf免费的阅读器,没有广告,可以试一下:pdfexpert,
百度文库自助领取,复制网址到浏览器即可下载,无需在各大平台注册、充值。无需认证,
百度文库在线阅读
推荐一个在线阅读pdf的产品pdfreedopen,一款专门在线免费阅读pdf文件的产品,平台界面简洁明了。阅读pdf能够让用户更方便地阅读文档,并且能够免费无限下载文档,支持离线阅读,电脑和手机都可以查看,没有版权限制。而且书籍资源也是非常丰富的,可以选择自己感兴趣的书籍,满足读者对不同读物的选择。
在阅读时一个pdf文件可以被划分为多个section,并且每个section上都会有3个tags标注这个section的内容。如果只想阅读其中一个section的话也可以通过鼠标选中其中一个pdf文件进行点击下拉查看完整内容,每个section都会有相应的tag标签说明该section的内容。在阅读时可以点击左上角的pdf文件标注来对pdf进行标注,浏览器中的收藏功能也是一样,这样也就实现了书摘和重点摘要的功能。 查看全部
网页文章自动采集论文导师?你需要一个付费的浏览器插件
网页文章自动采集论文导师?你需要一个付费的浏览器插件同时可以切换位置操作方便快捷=v=不谢私信我就行了
这里有一个网页文章自动采集的地址:聚宽-专业移动开发者社区,人人都是产品经理
imagepartner专用的seo插件adjust·imagepartner
老规矩,你把它展示在别人的首页上,让别人去搜你的文章。
这个应该很多平台都可以免费获取pdf文件吧如果别人想看你文章的相关信息,需要付费才可以看到,
试试word2vec吧,
付费的话有没有免费可以读pdf的呢?直接在线读,这里有一个pdf免费的阅读器,没有广告,可以试一下:pdfexpert,
百度文库自助领取,复制网址到浏览器即可下载,无需在各大平台注册、充值。无需认证,
百度文库在线阅读
推荐一个在线阅读pdf的产品pdfreedopen,一款专门在线免费阅读pdf文件的产品,平台界面简洁明了。阅读pdf能够让用户更方便地阅读文档,并且能够免费无限下载文档,支持离线阅读,电脑和手机都可以查看,没有版权限制。而且书籍资源也是非常丰富的,可以选择自己感兴趣的书籍,满足读者对不同读物的选择。
在阅读时一个pdf文件可以被划分为多个section,并且每个section上都会有3个tags标注这个section的内容。如果只想阅读其中一个section的话也可以通过鼠标选中其中一个pdf文件进行点击下拉查看完整内容,每个section都会有相应的tag标签说明该section的内容。在阅读时可以点击左上角的pdf文件标注来对pdf进行标注,浏览器中的收藏功能也是一样,这样也就实现了书摘和重点摘要的功能。
java开发的神牛数据采集器感觉还不错的介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-24 03:05
网页文章自动采集器:百度开放平台收录能力非常惊人,而且几乎没有秒收功能爬虫每天在爬取文章的同时只能采集50篇内容,但完全无视标题数量,每天最多500条!另外还可以对抓取页面进行加密,黑名单等设置精细,可以根据爬取到的标题规律对代码进行加密或者伪装,不需要进行请求数据了。
java发明了很多有用的工具,但如果非要我说几个的话,我会觉得rmtrust绝对是no.1。
这里有一篇非常不错的介绍,
网页数据采集器的收录速度没有百度快,但是采集费用应该比百度高,好在收费方式比较灵活,不同定位的产品收费方式各不相同。数据收集速度快,靠谱,采集费用不高,应该是目前最适合量化的一个标准了。
我用的是java开发的神牛数据采集器感觉还不错,只要满足以下几个条件,基本上都能满足你:1.基于http请求,速度快2.支持自定义采集内容,可以按照字段、固定格式等多种方式进行采集3.可以断点续采,不会被限制代码,爬取速度非常快4.定制定时器,
以前有一个叫谷阿莫的网页采集器
ahr0cdovl3dlaxhpbi5xcs5jb20vci9khweduyertrextrw5dykzzotn2xhw==(二维码自动识别) 查看全部
java开发的神牛数据采集器感觉还不错的介绍
网页文章自动采集器:百度开放平台收录能力非常惊人,而且几乎没有秒收功能爬虫每天在爬取文章的同时只能采集50篇内容,但完全无视标题数量,每天最多500条!另外还可以对抓取页面进行加密,黑名单等设置精细,可以根据爬取到的标题规律对代码进行加密或者伪装,不需要进行请求数据了。
java发明了很多有用的工具,但如果非要我说几个的话,我会觉得rmtrust绝对是no.1。
这里有一篇非常不错的介绍,
网页数据采集器的收录速度没有百度快,但是采集费用应该比百度高,好在收费方式比较灵活,不同定位的产品收费方式各不相同。数据收集速度快,靠谱,采集费用不高,应该是目前最适合量化的一个标准了。
我用的是java开发的神牛数据采集器感觉还不错,只要满足以下几个条件,基本上都能满足你:1.基于http请求,速度快2.支持自定义采集内容,可以按照字段、固定格式等多种方式进行采集3.可以断点续采,不会被限制代码,爬取速度非常快4.定制定时器,
以前有一个叫谷阿莫的网页采集器
ahr0cdovl3dlaxhpbi5xcs5jb20vci9khweduyertrextrw5dykzzotn2xhw==(二维码自动识别)
独特的无人值守ET从设计之初到无人工作的目的
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-23 00:14
免费采集softwareEditorTools是一款中小网站自动更新工具,全自动采集发布,静默工作,无需人工干预;独立软件免除网站性能消耗;安全稳定,可连续工作数月不中断;支持任意网站和数据库采集版本,软件内置discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、东易、joomla、pbdigg、php168、bbsxp、phpbb 、dvbbs、Typecho、emblog等很多常用系统的例子。
本软件适用于需要长时间更新内容的网站。您无需对现有论坛或网站进行任何修改。
解放站长和管理员
网站要保持活跃,每日内容更新是基础。小网站保证每日更新,通常要求站长每天承担8小时的更新工作,周末无节假日;中等网站全天保持内容更新,通常一天3班,每班2-3班人工管理员人工。如果按照普通月薪1500元计算,即使不包括周末加班,小网站每月至少要1500元,而中网站则要1万多元。 ET的出现将为你省下这笔费用!让站长和管理员从繁琐无聊的网站更新工作中解脱出来!
独特的无人值守操作
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经测试,ET可以长时间自动运行,即使时间单位是年。
超高稳定性
如果软件要无人值守,需要长期稳定运行。 ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有采集software 会自己崩溃。甚至导致网站崩溃。
最小资源使用
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器上运行,也可以在站长的工作站上运行。
严格的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。 采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
ET除了通用采集工具的功能外,还使用了图片水印、防盗、分页采集、回复采集、登录采集、自定义项、UTF-8、UBB、支持模拟放...使用户可以灵活实现各种毛发采集需求。
EditorTools 2 功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
【特点】独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 灵活强大的采集规则不仅仅是采集文章,而是采集任何类型的信息
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[特点] 下载上传支持续传
[特点] 高速伪原创
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任何格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集]需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发帖回复,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[Publication] 支持已发表文章的任何语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集发布可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态 查看全部
独特的无人值守ET从设计之初到无人工作的目的
免费采集softwareEditorTools是一款中小网站自动更新工具,全自动采集发布,静默工作,无需人工干预;独立软件免除网站性能消耗;安全稳定,可连续工作数月不中断;支持任意网站和数据库采集版本,软件内置discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、东易、joomla、pbdigg、php168、bbsxp、phpbb 、dvbbs、Typecho、emblog等很多常用系统的例子。
本软件适用于需要长时间更新内容的网站。您无需对现有论坛或网站进行任何修改。
解放站长和管理员
网站要保持活跃,每日内容更新是基础。小网站保证每日更新,通常要求站长每天承担8小时的更新工作,周末无节假日;中等网站全天保持内容更新,通常一天3班,每班2-3班人工管理员人工。如果按照普通月薪1500元计算,即使不包括周末加班,小网站每月至少要1500元,而中网站则要1万多元。 ET的出现将为你省下这笔费用!让站长和管理员从繁琐无聊的网站更新工作中解脱出来!
独特的无人值守操作
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经测试,ET可以长时间自动运行,即使时间单位是年。
超高稳定性
如果软件要无人值守,需要长期稳定运行。 ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有采集software 会自己崩溃。甚至导致网站崩溃。
最小资源使用
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器上运行,也可以在站长的工作站上运行。
严格的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。 采集信息,ET使用标准HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
ET除了通用采集工具的功能外,还使用了图片水印、防盗、分页采集、回复采集、登录采集、自定义项、UTF-8、UBB、支持模拟放...使用户可以灵活实现各种毛发采集需求。
EditorTools 2 功能介绍
【特点】设置好方案后,可24小时自动工作,无需人工干预。
【特点】独立于网站,通过独立制作的接口支持任何网站或数据库
[特点] 灵活强大的采集规则不仅仅是采集文章,而是采集任何类型的信息
[特点] 体积小,功耗低,稳定性好,非常适合在服务器上运行
[特点] 所有规则均可导入导出,资源灵活复用
[特点] FTP上传文件,稳定安全
[特点] 下载上传支持续传
[特点] 高速伪原创
[采集] 可以选择反向、顺序、随机采集文章
[采集] 支持自动列表网址
[采集] 支持网站,数据分布在多个页面采集
[采集]采集数据项可自由设置,每个数据项可单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任何格式和类型的文件(包括图片和视频)
[采集] 可以突破防盗文件
[采集] 支持动态文件 URL 分析
[采集]需要登录才能访问的网页支持采集
【支持】可设置关键词采集
【支持】可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持文章发帖回复,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强发布规则的复用性
[发布] 支持随机选择发布账号
[Publication] 支持已发表文章的任何语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传,自动创建年月日目录
[发布] 模拟发布支持网站无法安装接口的发布操作
[支持]程序可以正常运行
[支持]防止网络运营商劫持HTTP功能
[支持]单项采集发布可以手动完成
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
网页自动填写表单的工具-一个自动点击操作助手下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 486 次浏览 • 2021-08-21 22:15
网页自动点击脚本软件可以为您提供一个自动填表的工具,可以在普通的电脑浏览器中使用。通过您预设的表格信息,您只能填写表格,数据不重复。欢迎到当易下载!
简介:
网页自动点击操作助手是一款人工智能网页自动点击填充工具。可以完成各种网站自动文字输入和点击操作。是值得学习和研究的工具。您只需要花10分钟学习制作各种功能强大的seo点击软件、网络推广软件、数据采集工具、各种论坛和博客的群评论、刷票和网站流量、批量注册账号、等功能脚本!软件采用谷歌内核,既可以兼容PC端和手机端的页面显示,也可以模拟手机端的网页环境
软件功能:
1、支持前后台鼠标点击和键盘模拟
2、支持丰富的自定义变量
3、切换mac、自动删除缓存、运行外部文件等强大功能
4、支持强大的js执行功能
5、支持自定义useragent(伪装各种浏览器进行访问)
6、支持随机时间等待或根据系统时间判断执行
7、自动输入并点击网页
8、采用谷歌内核引擎,可兼容PC端和手机端页面显示
9、模拟手机网页运行环境
10、支持图片验证码识别和手机验证码自动获取(对接第三方平台服务)
11、支持adsl、pptp、v、p、n、代理服务器替换ip。
12、强力表达采集网页数据
软件功能:
1、制作各种seo点击软件
2、网站账号批量注册
3、various网站的自动发帖和回复置顶帖
4、网站内容数据提取采集
站群maintenance 和5、网站的自动更新 查看全部
网页自动填写表单的工具-一个自动点击操作助手下载
网页自动点击脚本软件可以为您提供一个自动填表的工具,可以在普通的电脑浏览器中使用。通过您预设的表格信息,您只能填写表格,数据不重复。欢迎到当易下载!
简介:
网页自动点击操作助手是一款人工智能网页自动点击填充工具。可以完成各种网站自动文字输入和点击操作。是值得学习和研究的工具。您只需要花10分钟学习制作各种功能强大的seo点击软件、网络推广软件、数据采集工具、各种论坛和博客的群评论、刷票和网站流量、批量注册账号、等功能脚本!软件采用谷歌内核,既可以兼容PC端和手机端的页面显示,也可以模拟手机端的网页环境
软件功能:
1、支持前后台鼠标点击和键盘模拟
2、支持丰富的自定义变量
3、切换mac、自动删除缓存、运行外部文件等强大功能
4、支持强大的js执行功能
5、支持自定义useragent(伪装各种浏览器进行访问)
6、支持随机时间等待或根据系统时间判断执行
7、自动输入并点击网页
8、采用谷歌内核引擎,可兼容PC端和手机端页面显示
9、模拟手机网页运行环境
10、支持图片验证码识别和手机验证码自动获取(对接第三方平台服务)
11、支持adsl、pptp、v、p、n、代理服务器替换ip。
12、强力表达采集网页数据
软件功能:
1、制作各种seo点击软件
2、网站账号批量注册
3、various网站的自动发帖和回复置顶帖
4、网站内容数据提取采集
站群maintenance 和5、网站的自动更新
原创文章生成器可以生成各种各样类型的原创设计与利益
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-08-21 06:36
文章generator html版是文章自动生成页面的网页版,你可以输入一个关键词或一句话为你生成一个长篇故事文章,但是这个文章的质量无法保证,往往会有段落没有传达词义,句子不清甚至听不懂。
软件介绍
原创文章生成器可以生成各种类型的原创文章,可以应用于不同的领域,为不同领域的用户带来利益或利益最大化。不用担心重复或类似问题,适合自定义原创文章生成器,随意使用。
原创文章生成器还包括文章自动处理(打乱和随机插入)、在线词库、在线作文素材库、在线词典、长尾词采集、文章采集、短URL转换、文件编码转换、随机字符串插入等增强功能。
相关新闻
知识产权一方面与创新相连,另一方面与市场相连,是科技成果转化为实际生产力的重要桥梁和纽带。在以原创design为核心竞争力的时尚领域,知识产权的保护在一定程度上决定了中国时尚话语权的建立,其重要性不言而喻。
近年来,我国时尚产业的快速发展,不仅与对原创design的尊重密不可分,也暴露了时尚知识产权保护的问题和难点。
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
Text文章generator 查看全部
原创文章生成器可以生成各种各样类型的原创设计与利益
文章generator html版是文章自动生成页面的网页版,你可以输入一个关键词或一句话为你生成一个长篇故事文章,但是这个文章的质量无法保证,往往会有段落没有传达词义,句子不清甚至听不懂。
软件介绍
原创文章生成器可以生成各种类型的原创文章,可以应用于不同的领域,为不同领域的用户带来利益或利益最大化。不用担心重复或类似问题,适合自定义原创文章生成器,随意使用。
原创文章生成器还包括文章自动处理(打乱和随机插入)、在线词库、在线作文素材库、在线词典、长尾词采集、文章采集、短URL转换、文件编码转换、随机字符串插入等增强功能。
相关新闻
知识产权一方面与创新相连,另一方面与市场相连,是科技成果转化为实际生产力的重要桥梁和纽带。在以原创design为核心竞争力的时尚领域,知识产权的保护在一定程度上决定了中国时尚话语权的建立,其重要性不言而喻。
近年来,我国时尚产业的快速发展,不仅与对原创design的尊重密不可分,也暴露了时尚知识产权保护的问题和难点。
声明:本站所有文章,如无特殊说明或注释,均在本站原创发布。任何个人或组织未经本站同意,不得复制、盗用、采集、发布本站内容至任何网站、书籍等媒体平台。如果本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
Text文章generator
网站收录的情况需要从哪些方面调整网站呢?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-08-15 04:09
网站收录的情况决定了网站在搜索引擎中的整体排名效果。 网站的收录越多,网站的排名就越好。但是在做网站优化的时候,网站不收录或者收录就不那么好了。如果出现这种情况,网站需要调整哪些方面?
1、check网站开店速度
网站的打开速度会直接影响网站收录的情况。如果搜索引擎输入网站发现网站根本打不开或者打开速度太慢,那么搜索引擎就会跳过网站,不再抓取网站内容,从而影响搜索引擎的友好度。所以网站需要时刻维护,不仅要防止黑客入侵,还要解决服务器速度问题。
2、检查网站内容是否为采集
搜索引擎不喜欢重复的内容,所以网站内容必须是原创,而不是采集others网站,也不要让别人网站采集自己网站内容高质量的原创是搜索引擎喜欢的,从而增加网站的收录数量。
3、Submit收录
当我们添加内容时,我们会生成一个链接。这个链接就是我们常说的。我们更新文章后,需要提交链接到搜索引擎提交入口,可以让搜索引擎更快收录页面,同时可以提高网站的排名。
4、检查网站是否降级
如果网站被降级,会影响网站收录的情况。正常情况下,一个网站降级的内容很难被搜索引擎收录抓取到,所以我们首先需要恢复网站降权,我们正在进行网站收录的操作. 网站降权不仅影响网站的流量,也影响网站的整体质量。
如果网站收录不好,可以按照以上四种方法查看网站,这样就可以恢复网站收录,提高网站在搜索引擎中的排名。 查看全部
网站收录的情况需要从哪些方面调整网站呢?(图)
网站收录的情况决定了网站在搜索引擎中的整体排名效果。 网站的收录越多,网站的排名就越好。但是在做网站优化的时候,网站不收录或者收录就不那么好了。如果出现这种情况,网站需要调整哪些方面?
1、check网站开店速度
网站的打开速度会直接影响网站收录的情况。如果搜索引擎输入网站发现网站根本打不开或者打开速度太慢,那么搜索引擎就会跳过网站,不再抓取网站内容,从而影响搜索引擎的友好度。所以网站需要时刻维护,不仅要防止黑客入侵,还要解决服务器速度问题。
2、检查网站内容是否为采集
搜索引擎不喜欢重复的内容,所以网站内容必须是原创,而不是采集others网站,也不要让别人网站采集自己网站内容高质量的原创是搜索引擎喜欢的,从而增加网站的收录数量。
3、Submit收录
当我们添加内容时,我们会生成一个链接。这个链接就是我们常说的。我们更新文章后,需要提交链接到搜索引擎提交入口,可以让搜索引擎更快收录页面,同时可以提高网站的排名。
4、检查网站是否降级
如果网站被降级,会影响网站收录的情况。正常情况下,一个网站降级的内容很难被搜索引擎收录抓取到,所以我们首先需要恢复网站降权,我们正在进行网站收录的操作. 网站降权不仅影响网站的流量,也影响网站的整体质量。
如果网站收录不好,可以按照以上四种方法查看网站,这样就可以恢复网站收录,提高网站在搜索引擎中的排名。
网页文章自动采集代码实现打包采集第一步,预览个人博客
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-08-14 04:04
网页文章自动采集采集代码实现打包采集第一步,预览个人博客,链接就不一一截图了,看简介就知道了,上一下案例图。第二步,清理host文件,修改文件.jsp,用于存放全部的代码第三步,打包采集:1采集当天、同一时间、每个网站的所有网页,并进行打包2配置java监听器internetfuture,监听服务器端请求,待选择服务器。
3开启ifix自动断开链接功能,采集地址不再单独显示,可以一次性采集全部链接。4开启autopen采集端口,浏览器开启80端口即可进行采集。5如果未对cookie进行操作,则可以在浏览器端调用jsp后台保存链接即可。最后使用if语句判断,如果是由用户自己添加自己的链接,则可以采集该用户自己所有的网页。个人博客网站#rdjk6lptmg8vrm。
geeknovel-queryable
我这个人爱玩邮件采集,封号也多。不过每天24小时都有,所以倒是还可以每天换个新方法继续爬。或者邀请些大v知乎大v,每天邀请就可以得好多好多奖金哦。
对这个无能无力,
你是想采,看看还是需要自己去采集。
对于广大二三四五线城市而言,太难了!不过最近python在大学的招生里面发光发热,能否用python做些pm来赚钱当然是可以的!比如百家乐,前几天扒拉扒拉大数据发现大数据不仅仅是调查问卷,随便撸一下。发现几百万上千万的规模, 查看全部
网页文章自动采集代码实现打包采集第一步,预览个人博客
网页文章自动采集采集代码实现打包采集第一步,预览个人博客,链接就不一一截图了,看简介就知道了,上一下案例图。第二步,清理host文件,修改文件.jsp,用于存放全部的代码第三步,打包采集:1采集当天、同一时间、每个网站的所有网页,并进行打包2配置java监听器internetfuture,监听服务器端请求,待选择服务器。
3开启ifix自动断开链接功能,采集地址不再单独显示,可以一次性采集全部链接。4开启autopen采集端口,浏览器开启80端口即可进行采集。5如果未对cookie进行操作,则可以在浏览器端调用jsp后台保存链接即可。最后使用if语句判断,如果是由用户自己添加自己的链接,则可以采集该用户自己所有的网页。个人博客网站#rdjk6lptmg8vrm。
geeknovel-queryable
我这个人爱玩邮件采集,封号也多。不过每天24小时都有,所以倒是还可以每天换个新方法继续爬。或者邀请些大v知乎大v,每天邀请就可以得好多好多奖金哦。
对这个无能无力,
你是想采,看看还是需要自己去采集。
对于广大二三四五线城市而言,太难了!不过最近python在大学的招生里面发光发热,能否用python做些pm来赚钱当然是可以的!比如百家乐,前几天扒拉扒拉大数据发现大数据不仅仅是调查问卷,随便撸一下。发现几百万上千万的规模,
web开发是用python语言写一些简单的网页应用程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-08-12 22:04
网页文章自动采集,可以看看【快搜-最专业的网络搜索引擎】基于python开发的网络爬虫框架。自动采集图片和文本,爬取速度几乎可以媲美人工。无需任何编程基础。最后分享下我在后台关注的一个用户,他是通过用户昵称识别功能,就可以找到关注他的专题信息。识别的正确率不错。
你能先告诉我你现在什么水平?
python现在已经很普及了,工具有很多,比如selenium,multiprocessing,urllib,json等等,这些工具可以分别用于web开发,爬虫开发和数据分析。web开发就是用python语言写一些简单的网页程序,数据分析就是用r语言和python编写一些关于数据分析的程序。如果你想要开发一个网页应用程序,首先还是要学习java和c++这些编程语言,其次建议多做一些实验,在实践中学习。
在你学会上面这些技能之后,就是实际操作了,例如在百度里搜索怎么设置一个网页的过滤规则,然后在你开发的应用程序里用这些规则找到你想要的数据,然后存放到本地。然后就是进行定期的维护和优化。要掌握一些数据分析方面的工具,不过这个对于一个初学者来说应该还是比较困难的。
学selenium,学到大概20%就行了。
用c++吧。用selenium开发爬虫是个伪需求,只有苹果网站有这个要求,其他的都有些人开发了现成的轮子。 查看全部
web开发是用python语言写一些简单的网页应用程序
网页文章自动采集,可以看看【快搜-最专业的网络搜索引擎】基于python开发的网络爬虫框架。自动采集图片和文本,爬取速度几乎可以媲美人工。无需任何编程基础。最后分享下我在后台关注的一个用户,他是通过用户昵称识别功能,就可以找到关注他的专题信息。识别的正确率不错。
你能先告诉我你现在什么水平?
python现在已经很普及了,工具有很多,比如selenium,multiprocessing,urllib,json等等,这些工具可以分别用于web开发,爬虫开发和数据分析。web开发就是用python语言写一些简单的网页程序,数据分析就是用r语言和python编写一些关于数据分析的程序。如果你想要开发一个网页应用程序,首先还是要学习java和c++这些编程语言,其次建议多做一些实验,在实践中学习。
在你学会上面这些技能之后,就是实际操作了,例如在百度里搜索怎么设置一个网页的过滤规则,然后在你开发的应用程序里用这些规则找到你想要的数据,然后存放到本地。然后就是进行定期的维护和优化。要掌握一些数据分析方面的工具,不过这个对于一个初学者来说应该还是比较困难的。
学selenium,学到大概20%就行了。
用c++吧。用selenium开发爬虫是个伪需求,只有苹果网站有这个要求,其他的都有些人开发了现成的轮子。
织梦dedecms建网站好用的方法,打开include/arc.archives.找到
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-08-09 18:37
很多用过织梦dedecms建网站的朋友可能都遇到过这样的情况。当我们在网站中发布文章时,如果我们使用图片,其宽度超过内容区域的大小,图片会扩大表格,同时使页面布局变得混乱。当然,如果我们了解CSS,我们可以使用CSS来定义,这样多余的部分就隐藏起来了。但是,如果这样做,图片的美观性会很差,多余的部分将无法显示。
为了解决这个问题,有些朋友会在图片过大时使用css自动缩小图片。不过值得注意的是,由于CSS对各种浏览器存在兼容性问题,所以我用IE6浏览,就设备而言,效果不是很好。
今天软件直销网小编介绍一个有用的方法供大家参考:
第一步打开include/arc.archives.class.php
找到:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
@SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['id'],$this->Fields['title'], '档案');
添加以下代码:
//将图片Alt替换为文档标题
$this->Fields['body'] = str_ireplace(array('alt=""','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s \S]{0,}[\"'\s]
@isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("
字段['title']."\"
",$this->Fields['body']);
//在img标签中添加超宽和精简的JS调用代码
$suolue='οnload="javascript:ImgReSize(this)"';
$this->Fields['body'] = str_ireplace("
字段['body']);
//盾牌高度属性
$this->Fields['body'] = preg_replace('/
/i',"
",$this->Fields['body']);
第 2 步:打开您的前台文章 页面模板。默认为:/templets/default/article_article.htm(有的朋友,模仿网站后,内容页模板可能不是默认的)打开模板后插入如下代码,注意670的值,这个值的意思是当图片超过这个值时,图片会自动缩小,宽度会缩小到670,高度会自动按比例缩小,这样就不会变形了。
到此,大功告成。如果你懂CSS,最好找到内容区域的CSS,设置它的宽度,然后定义它。多余的部分被隐藏了,因为有时候文章在加载的过程中,显示的是原来的大小。加载完成后,JS会进行图片的缩小。 查看全部
织梦dedecms建网站好用的方法,打开include/arc.archives.找到
很多用过织梦dedecms建网站的朋友可能都遇到过这样的情况。当我们在网站中发布文章时,如果我们使用图片,其宽度超过内容区域的大小,图片会扩大表格,同时使页面布局变得混乱。当然,如果我们了解CSS,我们可以使用CSS来定义,这样多余的部分就隐藏起来了。但是,如果这样做,图片的美观性会很差,多余的部分将无法显示。
为了解决这个问题,有些朋友会在图片过大时使用css自动缩小图片。不过值得注意的是,由于CSS对各种浏览器存在兼容性问题,所以我用IE6浏览,就设备而言,效果不是很好。
今天软件直销网小编介绍一个有用的方法供大家参考:
第一步打开include/arc.archives.class.php
找到:
//设置全局环境变量
$this->Fields['typename'] = $this->TypeLink->TypeInfos['typename'];
@SetSysEnv($this->Fields['typeid'],$this->Fields['typename'],$this->Fields['id'],$this->Fields['title'], '档案');
添加以下代码:
//将图片Alt替换为文档标题
$this->Fields['body'] = str_ireplace(array('alt=""','alt=\'\''),'',$this->Fields['body']);
$this->Fields['body'] = preg_replace("@ [\s]{0,}alt[\s]{0,}=[\"'\s]{0,}[\s \S]{0,}[\"'\s]
@isU"," ",$this->Fields['body']);
$this->Fields['body'] = str_ireplace("
字段['title']."\"
",$this->Fields['body']);
//在img标签中添加超宽和精简的JS调用代码
$suolue='οnload="javascript:ImgReSize(this)"';
$this->Fields['body'] = str_ireplace("
字段['body']);
//盾牌高度属性
$this->Fields['body'] = preg_replace('/
/i',"
",$this->Fields['body']);
第 2 步:打开您的前台文章 页面模板。默认为:/templets/default/article_article.htm(有的朋友,模仿网站后,内容页模板可能不是默认的)打开模板后插入如下代码,注意670的值,这个值的意思是当图片超过这个值时,图片会自动缩小,宽度会缩小到670,高度会自动按比例缩小,这样就不会变形了。
到此,大功告成。如果你懂CSS,最好找到内容区域的CSS,设置它的宽度,然后定义它。多余的部分被隐藏了,因为有时候文章在加载的过程中,显示的是原来的大小。加载完成后,JS会进行图片的缩小。
优采云中创建循环列表的五大循环方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-08-09 04:37
在优采云中,有两种方法可以创建循环列表。一种是点击页面元素,选择相似项,由优采云自动创建。适用于列表信息采集、列表和详情页采集。当自动创建的循环不能满足需求时,我们需要手动创建或修改循环以满足更多数据采集的需求。
在循环的高级选项中,有五种循环方式:URL循环、文本循环、单元素循环、固定元素列表循环、非固定元素列表循环。
一、URL 循环(cloud采集 可以加速)
适用情况:在多个同类型网页中,网页结构必须相同
二、text loop(cloud采集可以加速)
适用场景:在搜索框中循环输入关键词、采集关键词搜索结果信息
实现方法:通过文本循环方法,实现循环输入关键词、采集关键词搜索结果。
三、单元素循环
适用场景:需要反复点击页面上的某个按钮。例如:点击“下一页”按钮进行翻页。
实现方法:通过单元素循环方法,达到反复点击“下一页”按钮翻页的目的。
定位方法:使用XPath定位,一直定位到“下一页”按钮。
操作示例:
①选择“下一页”按钮→选择“循环点击下一页”建立翻页循环。
②循环方式为“单元素循环”,通过在“单元素循环”中定位XPath,点击“下一页”按钮进行翻页。
四、固定元素列表循环(cloud采集可以加速)
适用情况:网页采集行数为固定数。
如何实现:循环固定元素列表,循环页面中的固定元素。
定位方法:使用XPath定位,一个XPath对应循环列表中的一个元素。
操作示例:
①选择文章链接→“全选”→“循环点击每个链接”创建循环列表。
② 自动生成的循环方式为:固定元素列表。打开固定元素列表查看,20个XPath与循环列表中的20个固定元素一一对应(也可以看作是浏览器页面对应的20个文章链接)。
此处涉及XPath相关内容,请参考本XPath教程
五、非固定元素列表循环
适用情况:网页上采集所需的行数不是固定的。
实现方法:循环变量因子列表,循环页面中的变量元素。
定位方法:使用XPath定位,一个XPath对应循环列表中的多个元素。
操作示例:
①通过观察优采云fixed元素列表循环中生成的XPath:
//UL[@class='news-list']/LI[1]/DIV[2]/H3[1]/A[1]
//UL[@class='news-list']/LI[2]/DIV[2]/H3[1]/A[1]
......
//UL[@class='news-list']/LI[20]/DIV[2]/H3[1]/A[1]
20 个 XPath 具有相同的特征:只有 LI 后面的数字不同。根据这个特性,我们可以写一个通用的XPath://UL[@class='news-list']/LI/DIV[2]/H3[1]/A[1],通过这个通用的Xpath,你可以找到转到页面上的所有 10 个文章 链接。
将循环方式改为“不固定元素列表循环”,并填写修改后的XPath。
②可以看出,这个通用的XPath对应了循环列表中的全部20个元素(也可以看作是浏览器页面对应的20个文章链接)。
同样的,你也可以将非固定元素列表改为固定元素列表。
此处涉及XPath相关内容,请参考XPath教程 查看全部
优采云中创建循环列表的五大循环方式
在优采云中,有两种方法可以创建循环列表。一种是点击页面元素,选择相似项,由优采云自动创建。适用于列表信息采集、列表和详情页采集。当自动创建的循环不能满足需求时,我们需要手动创建或修改循环以满足更多数据采集的需求。
在循环的高级选项中,有五种循环方式:URL循环、文本循环、单元素循环、固定元素列表循环、非固定元素列表循环。
一、URL 循环(cloud采集 可以加速)
适用情况:在多个同类型网页中,网页结构必须相同
二、text loop(cloud采集可以加速)
适用场景:在搜索框中循环输入关键词、采集关键词搜索结果信息
实现方法:通过文本循环方法,实现循环输入关键词、采集关键词搜索结果。
三、单元素循环
适用场景:需要反复点击页面上的某个按钮。例如:点击“下一页”按钮进行翻页。
实现方法:通过单元素循环方法,达到反复点击“下一页”按钮翻页的目的。
定位方法:使用XPath定位,一直定位到“下一页”按钮。
操作示例:
①选择“下一页”按钮→选择“循环点击下一页”建立翻页循环。
②循环方式为“单元素循环”,通过在“单元素循环”中定位XPath,点击“下一页”按钮进行翻页。
四、固定元素列表循环(cloud采集可以加速)
适用情况:网页采集行数为固定数。
如何实现:循环固定元素列表,循环页面中的固定元素。
定位方法:使用XPath定位,一个XPath对应循环列表中的一个元素。
操作示例:
①选择文章链接→“全选”→“循环点击每个链接”创建循环列表。
② 自动生成的循环方式为:固定元素列表。打开固定元素列表查看,20个XPath与循环列表中的20个固定元素一一对应(也可以看作是浏览器页面对应的20个文章链接)。
此处涉及XPath相关内容,请参考本XPath教程
五、非固定元素列表循环
适用情况:网页上采集所需的行数不是固定的。
实现方法:循环变量因子列表,循环页面中的变量元素。
定位方法:使用XPath定位,一个XPath对应循环列表中的多个元素。
操作示例:
①通过观察优采云fixed元素列表循环中生成的XPath:
//UL[@class='news-list']/LI[1]/DIV[2]/H3[1]/A[1]
//UL[@class='news-list']/LI[2]/DIV[2]/H3[1]/A[1]
......
//UL[@class='news-list']/LI[20]/DIV[2]/H3[1]/A[1]
20 个 XPath 具有相同的特征:只有 LI 后面的数字不同。根据这个特性,我们可以写一个通用的XPath://UL[@class='news-list']/LI/DIV[2]/H3[1]/A[1],通过这个通用的Xpath,你可以找到转到页面上的所有 10 个文章 链接。
将循环方式改为“不固定元素列表循环”,并填写修改后的XPath。
②可以看出,这个通用的XPath对应了循环列表中的全部20个元素(也可以看作是浏览器页面对应的20个文章链接)。
同样的,你也可以将非固定元素列表改为固定元素列表。
此处涉及XPath相关内容,请参考XPath教程
Ajax延时加载最明显的两个特征点击网页中某个选项
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-08-09 04:33
本文将向您介绍如何使用优采云采集器采集page 列表页上的信息,同时也会向您解释ajax 延迟设置。目的是让大家知道如何创建翻页循环和正常的采集网页数据信息。
首先打开优采云采集器→点击快速启动→新建任务,进入任务配置页面:
选择任务组,自定义任务名称和备注;
上图中的配置完成后,选择Next,进入流程配置页面,在流程设计器中拖动一步打开网页;
选择在浏览器中打开网页的步骤,在右侧的网页网址中输入网页网址并点击保存,系统会在软件下自动在浏览器中打开相应的网页:
创建一个循环来翻页。在上图浏览器页面点击下一步按钮,在弹出的对话框中选择循环点击下一页;
翻页循环创建后,点击下图中的保存;
这里的翻页其实涉及到ajax延迟加载。 Ajax 异步更新实际上是一种脚本技术。通过在后台与服务器交换少量数据,意味着无需重新加载整个网页即可更新网页。待更新。
Ajax 延迟加载最明显的两个特点是,当你点击网页上的一个选项时,URL 根本不会改变,然后网页并没有完全加载,而只是部分改变。如果满足这两个特性,就是一个ajax网页。或者稍后进行采集测试时,进程直接停止或者在运行前提示采集已成功完成。这基本上是由这个问题引起的。原因是优采云的内置浏览器打开这个网页翻页时,由于URL没有变化但是部分内容更新了,所以收不到网页变化的信号,导致采集停止或采集 没有数据。
所以如下图所示,需要在点击翻页的高级设置中设置ajax加载。这个时候点击翻页是自己估计的。完成点击步骤大约需要两秒钟。
在上面的浏览器中,您可以看到网页由相同区域的行组成。我们需要抓取每个区域行中的数据信息,每个区域块中的格式是相同的。这时候就需要创建一个循环列表来循环抓取每个区域行中的元素。
点击上图中第一个区域行,在弹出的对话框中选择创建元素列表处理一组元素;
接下来在弹出的对话框中选择添加到列表中
添加第一个区域行后,选择继续编辑列表。
接下来,以同样的方式添加第二个区域行。
当我们添加第二个区域行时,您可以查看上图。此时,页面上的其他元素已经添加。这是因为我们添加了两个具有相似特征的元素,系统会智能地在页面上添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环
经过以上操作,采集list的循环就完成了。系统会在页面右上角显示该页面添加的所有循环项。
因为每个页面都需要循环采集数据,所以我们需要把这个循环列表拖入翻页循环中。
注意流程是从上一页开始执行的,所以这个循环列表需要放在点击翻页之前,否则会漏掉第一页的数据。最终流程图如下所示:
接下来要提取数据字段,在上面的流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的选择对话框中选择该元素的文本;
完成以上操作后,系统会在页面右上角显示我们要爬取的字段;
接下来在页面上配置其他需要抓取的字段,配置完成后修改字段名称;
修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;
点击Next→Next→启动上图中的单机采集(调试模式),进入任务检查页面,确保任务的正确性;
点击启动单机采集,系统会在本地执行采集进程并显示最终的采集结果;
查看全部
Ajax延时加载最明显的两个特征点击网页中某个选项
本文将向您介绍如何使用优采云采集器采集page 列表页上的信息,同时也会向您解释ajax 延迟设置。目的是让大家知道如何创建翻页循环和正常的采集网页数据信息。
首先打开优采云采集器→点击快速启动→新建任务,进入任务配置页面:
选择任务组,自定义任务名称和备注;
上图中的配置完成后,选择Next,进入流程配置页面,在流程设计器中拖动一步打开网页;
选择在浏览器中打开网页的步骤,在右侧的网页网址中输入网页网址并点击保存,系统会在软件下自动在浏览器中打开相应的网页:
创建一个循环来翻页。在上图浏览器页面点击下一步按钮,在弹出的对话框中选择循环点击下一页;
翻页循环创建后,点击下图中的保存;
这里的翻页其实涉及到ajax延迟加载。 Ajax 异步更新实际上是一种脚本技术。通过在后台与服务器交换少量数据,意味着无需重新加载整个网页即可更新网页。待更新。
Ajax 延迟加载最明显的两个特点是,当你点击网页上的一个选项时,URL 根本不会改变,然后网页并没有完全加载,而只是部分改变。如果满足这两个特性,就是一个ajax网页。或者稍后进行采集测试时,进程直接停止或者在运行前提示采集已成功完成。这基本上是由这个问题引起的。原因是优采云的内置浏览器打开这个网页翻页时,由于URL没有变化但是部分内容更新了,所以收不到网页变化的信号,导致采集停止或采集 没有数据。
所以如下图所示,需要在点击翻页的高级设置中设置ajax加载。这个时候点击翻页是自己估计的。完成点击步骤大约需要两秒钟。
在上面的浏览器中,您可以看到网页由相同区域的行组成。我们需要抓取每个区域行中的数据信息,每个区域块中的格式是相同的。这时候就需要创建一个循环列表来循环抓取每个区域行中的元素。
点击上图中第一个区域行,在弹出的对话框中选择创建元素列表处理一组元素;
接下来在弹出的对话框中选择添加到列表中
添加第一个区域行后,选择继续编辑列表。
接下来,以同样的方式添加第二个区域行。
当我们添加第二个区域行时,您可以查看上图。此时,页面上的其他元素已经添加。这是因为我们添加了两个具有相似特征的元素,系统会智能地在页面上添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环
经过以上操作,采集list的循环就完成了。系统会在页面右上角显示该页面添加的所有循环项。
因为每个页面都需要循环采集数据,所以我们需要把这个循环列表拖入翻页循环中。
注意流程是从上一页开始执行的,所以这个循环列表需要放在点击翻页之前,否则会漏掉第一页的数据。最终流程图如下所示:
接下来要提取数据字段,在上面的流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的选择对话框中选择该元素的文本;
完成以上操作后,系统会在页面右上角显示我们要爬取的字段;
接下来在页面上配置其他需要抓取的字段,配置完成后修改字段名称;
修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表;
点击Next→Next→启动上图中的单机采集(调试模式),进入任务检查页面,确保任务的正确性;
点击启动单机采集,系统会在本地执行采集进程并显示最终的采集结果;
网页文章自动采集技术小白也能上手的非正常读者
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-07 21:09
网页文章自动采集【七麦数据】,采集微信公众号:非正常读者,获取更多的优质公众号推文信息。是目前最简单、高效的一种方式,通过采集公众号文章来爬取网页上面的信息,例如高质量的推文列表。网页文章自动采集技术小白也能上手的非正常读者爬虫(关注七麦数据号:baoqiuai_wordpress,还可获取最新源码)我们从楼主发出来的楼主采集的一篇文章开始看起。
首先我们看到以下几个选项。1.微信公众号2.文章摘要3.点击进入公众号文章详情4.分享公众号文章到朋友圈,获取网友的评论信息;长按识别二维码进入小程序“好友评论分享,或者长按识别二维码”。如下图所示:接下来我们开始全文抓取:。
一、找到源码。我们得到了本次楼主一篇文章的源码,很干净很清爽的一篇文章,就是下面这一张图片。
二、解析源码。我们首先拿到了源码,分析到什么样子了,有两种方式爬取。1.截取全部源码。通过用下面的两个脚本来获取所有文章,并生成对应的文件夹;2.抓取部分源码。只需要解析哪些源码里面不是自己的就行了。
三、下载二维码图片1.打开网址:/。2.生成二维码图片:/。3.输入二维码,选择解析图片方式,选择整个页面解析,然后我们来查看结果。
四、观察评论信息。评论信息中没有多余的内容,也就是楼主要求的全文都采集。
五、出现加载完全等错误:1.可能是解析的时候,层级数量太多;我们将层级数量改为两层,防止报错。2.二维码出现错误:那就填数字或者中文,都是ok的。
我们可以通过搜索图片在开始我们的文章:
七、重复采集。重复不是出现错误,这是一个报错,我们只需要从截取的文章里面找到下面的图片。看看错误已经删除了,算是一个比较好的现象。需要提醒楼主小伙伴注意的一个问题是:如果我们没有点击下面网址上面的链接,下面的数据是不采集的,并且只能查看下面的文章。我们只需要取这两个文章的链接,就能快速查看下面的数据。最后我们一起来看看楼主的实例:。 查看全部
网页文章自动采集技术小白也能上手的非正常读者
网页文章自动采集【七麦数据】,采集微信公众号:非正常读者,获取更多的优质公众号推文信息。是目前最简单、高效的一种方式,通过采集公众号文章来爬取网页上面的信息,例如高质量的推文列表。网页文章自动采集技术小白也能上手的非正常读者爬虫(关注七麦数据号:baoqiuai_wordpress,还可获取最新源码)我们从楼主发出来的楼主采集的一篇文章开始看起。
首先我们看到以下几个选项。1.微信公众号2.文章摘要3.点击进入公众号文章详情4.分享公众号文章到朋友圈,获取网友的评论信息;长按识别二维码进入小程序“好友评论分享,或者长按识别二维码”。如下图所示:接下来我们开始全文抓取:。
一、找到源码。我们得到了本次楼主一篇文章的源码,很干净很清爽的一篇文章,就是下面这一张图片。
二、解析源码。我们首先拿到了源码,分析到什么样子了,有两种方式爬取。1.截取全部源码。通过用下面的两个脚本来获取所有文章,并生成对应的文件夹;2.抓取部分源码。只需要解析哪些源码里面不是自己的就行了。
三、下载二维码图片1.打开网址:/。2.生成二维码图片:/。3.输入二维码,选择解析图片方式,选择整个页面解析,然后我们来查看结果。
四、观察评论信息。评论信息中没有多余的内容,也就是楼主要求的全文都采集。
五、出现加载完全等错误:1.可能是解析的时候,层级数量太多;我们将层级数量改为两层,防止报错。2.二维码出现错误:那就填数字或者中文,都是ok的。
我们可以通过搜索图片在开始我们的文章:
七、重复采集。重复不是出现错误,这是一个报错,我们只需要从截取的文章里面找到下面的图片。看看错误已经删除了,算是一个比较好的现象。需要提醒楼主小伙伴注意的一个问题是:如果我们没有点击下面网址上面的链接,下面的数据是不采集的,并且只能查看下面的文章。我们只需要取这两个文章的链接,就能快速查看下面的数据。最后我们一起来看看楼主的实例:。
网页文章自动采集,你爬虫确定人家愿意接受吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-04 21:01
网页文章自动采集,比如图文、音频、视频等自动采集;网页文章结构分析,可以根据标题、摘要、关键词、作者、浏览量等等进行分析。网页数据统计,可以根据文章数量、文章阅读量、文章浏览量、文章转发量等来进行统计。图片、标签等自动抓取。
爬虫?有成熟的在线爬虫,或者没有那么难的api。除了抓个热点话题,现在网站流量大了,基本都开放api。
当然可以!啊哈哈!但是前提是,你爬虫确定人家愿意接受!1.你要理解人家为什么要免费提供数据,人家的用户量是多少?每个用户分布区域是什么?2.人家的用户体验是怎么样的?3.你去抓数据的目的是什么?是自己写爬虫完成功能,
如果要提供人家接受的数据首先你要知道用户分布地区然后可以针对这个区域推送你可以抓取的新闻数据
爬虫是不可能爬虫,
我来给你个5w条抽样数据的爬虫(多图!
所有的数据都是为了更好的服务于用户,肯定是最大化使用才会有所分享给爬虫的,而且要价值超过市场价格,要么你自己确定要付费,别人才可以分享给你。
根据用户归属性提供需要的信息,比如针对网易,可以提供游戏的各个分类,以及游戏的大量数据,如果有某个分类用户量很大,就提供多个分类的数据,这样大家都不用担心数据多有太多占据头条的时候。 查看全部
网页文章自动采集,你爬虫确定人家愿意接受吗?
网页文章自动采集,比如图文、音频、视频等自动采集;网页文章结构分析,可以根据标题、摘要、关键词、作者、浏览量等等进行分析。网页数据统计,可以根据文章数量、文章阅读量、文章浏览量、文章转发量等来进行统计。图片、标签等自动抓取。
爬虫?有成熟的在线爬虫,或者没有那么难的api。除了抓个热点话题,现在网站流量大了,基本都开放api。
当然可以!啊哈哈!但是前提是,你爬虫确定人家愿意接受!1.你要理解人家为什么要免费提供数据,人家的用户量是多少?每个用户分布区域是什么?2.人家的用户体验是怎么样的?3.你去抓数据的目的是什么?是自己写爬虫完成功能,
如果要提供人家接受的数据首先你要知道用户分布地区然后可以针对这个区域推送你可以抓取的新闻数据
爬虫是不可能爬虫,
我来给你个5w条抽样数据的爬虫(多图!
所有的数据都是为了更好的服务于用户,肯定是最大化使用才会有所分享给爬虫的,而且要价值超过市场价格,要么你自己确定要付费,别人才可以分享给你。
根据用户归属性提供需要的信息,比如针对网易,可以提供游戏的各个分类,以及游戏的大量数据,如果有某个分类用户量很大,就提供多个分类的数据,这样大家都不用担心数据多有太多占据头条的时候。
网页文章自动采集dw-pub6客户端安装方法介绍6
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2021-08-01 05:05
网页文章自动采集dw-pub6目前已经比较成熟,我今天说的是用dw-pub6文章采集工具插件来实现文章内页的自动采集。本文主要分享两种使用方法,供大家参考:第一种:第二种:如果只是想采集某些企业网站内部的文章,建议使用第一种方法。因为第二种方法需要掌握python语言才能实现。下面我就以自己常用的dw-pub6网页采集工具插件来详细介绍如何实现文章内页自动采集。
第一步:安装dw-pub6目前主流的dw-pub6网页采集工具插件分为两种,分别是第三方文章采集工具和正常网页采集工具。第三方文章采集工具是安装以后可以直接使用的采集器,他们有很多版本的,安装起来非常方便,但是更新速度略慢,一般在一两天或者更长的时间,容易被我们忽略,所以我推荐大家使用正常文章采集工具。
为了和我们自己的dw-pub6同步实现文章内容自动采集,我推荐大家下载dw-pub6客户端安装。下载地址:,更新以后非常方便。
1、首先我们需要下载最新版的dw-pub6客户端到本地电脑。
2、如果你的电脑中没有安装最新版的dw-pub6客户端,可以直接百度搜索,找到最新版,即可下载安装。
3、我们可以百度搜索dw-pub6客户端,然后到百度网盘中下载同步安装包,然后自己进行解压。
4、解压完成以后我们在本地电脑中安装dw-pub6客户端。完成以上步骤,我们就可以愉快的开始我们的自动文章采集之旅了。 查看全部
网页文章自动采集dw-pub6客户端安装方法介绍6
网页文章自动采集dw-pub6目前已经比较成熟,我今天说的是用dw-pub6文章采集工具插件来实现文章内页的自动采集。本文主要分享两种使用方法,供大家参考:第一种:第二种:如果只是想采集某些企业网站内部的文章,建议使用第一种方法。因为第二种方法需要掌握python语言才能实现。下面我就以自己常用的dw-pub6网页采集工具插件来详细介绍如何实现文章内页自动采集。
第一步:安装dw-pub6目前主流的dw-pub6网页采集工具插件分为两种,分别是第三方文章采集工具和正常网页采集工具。第三方文章采集工具是安装以后可以直接使用的采集器,他们有很多版本的,安装起来非常方便,但是更新速度略慢,一般在一两天或者更长的时间,容易被我们忽略,所以我推荐大家使用正常文章采集工具。
为了和我们自己的dw-pub6同步实现文章内容自动采集,我推荐大家下载dw-pub6客户端安装。下载地址:,更新以后非常方便。
1、首先我们需要下载最新版的dw-pub6客户端到本地电脑。
2、如果你的电脑中没有安装最新版的dw-pub6客户端,可以直接百度搜索,找到最新版,即可下载安装。
3、我们可以百度搜索dw-pub6客户端,然后到百度网盘中下载同步安装包,然后自己进行解压。
4、解压完成以后我们在本地电脑中安装dw-pub6客户端。完成以上步骤,我们就可以愉快的开始我们的自动文章采集之旅了。
ai与ps都能做细一点基本就是word形式
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-07-04 19:03
网页文章自动采集,超详细!分享资源前提提醒大家,我只是提供了一种方法,操作过程中的具体注意事项,跟ai做出来的版本并不一样。所以大家在自行应用的时候,一定一定一定记得遵守最终的要求,最大程度的保护自己的版权。所以,下面分享资源都是使用ai的矢量插画,尺寸比例,大小与效果应该能满足一定范围的使用,如果是高尺寸的大图,使用ai软件并不方便操作,那么可以通过ps图层导出gif图(200px的就足够了)。
资源文件截图需要的文件图片、ai软件、gif图都可以从下面的获取。1.截图2.ai软件下载和安装(可移步百度网盘搜索)3.ps图层导出gif图到电脑4.ai软件导出直链就是缩短后是这个wx:lakkapft5.导出word图片,pdf文件6.gif图右键另存为7.实现网页在线表格。
自己百度不就好了,怎么这么麻烦。
1.登录知乎,2.关注者答案列表点开3.复制粘贴上面这些内容。完毕,下次点赞请注明来源或原出处。谢谢。
这个工具我经常用。并且还可以录制讲课。
新建文件,把带图的jpg重命名,名字我随便起的。名字就叫,这样显示的页数就不一样。然后,再把原来那个格式更改成gif,
这个问题我来回答你,ai与ps都能做,ai做细一点基本就是word形式的, 查看全部
ai与ps都能做细一点基本就是word形式
网页文章自动采集,超详细!分享资源前提提醒大家,我只是提供了一种方法,操作过程中的具体注意事项,跟ai做出来的版本并不一样。所以大家在自行应用的时候,一定一定一定记得遵守最终的要求,最大程度的保护自己的版权。所以,下面分享资源都是使用ai的矢量插画,尺寸比例,大小与效果应该能满足一定范围的使用,如果是高尺寸的大图,使用ai软件并不方便操作,那么可以通过ps图层导出gif图(200px的就足够了)。
资源文件截图需要的文件图片、ai软件、gif图都可以从下面的获取。1.截图2.ai软件下载和安装(可移步百度网盘搜索)3.ps图层导出gif图到电脑4.ai软件导出直链就是缩短后是这个wx:lakkapft5.导出word图片,pdf文件6.gif图右键另存为7.实现网页在线表格。
自己百度不就好了,怎么这么麻烦。
1.登录知乎,2.关注者答案列表点开3.复制粘贴上面这些内容。完毕,下次点赞请注明来源或原出处。谢谢。
这个工具我经常用。并且还可以录制讲课。
新建文件,把带图的jpg重命名,名字我随便起的。名字就叫,这样显示的页数就不一样。然后,再把原来那个格式更改成gif,
这个问题我来回答你,ai与ps都能做,ai做细一点基本就是word形式的,
没准用java的话,支持前端采集试试看gitbash-extractors
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-07-01 23:03
网页文章自动采集的话,可以用云采集,支持多语言采集,自动双十一、双十二的订单、链接等数据采集。2、自动批量采集网页文章的话,可以通过爬虫工具来实现,如果网站没有对爬虫做限制,是可以采集大部分网站的文章的。
哈喽,每次我都是靠selenium的其实呢,采集网页文章应该不难,
github上面有好多蛮不错的接口了,
可以考虑用selenium+lxml
danmaku/scrapy+pyqt5
我这边在做一个,后台redis管理采集数据,本地直接实现,
v5公众号提供开发者服务,
可以用易开发的selenium,
平时我是用danmaku/scrapy-extractors·github和。非常可靠和简单。
没准用java的话,
支持前端采集
试试看gitbash-extractors?/root·githubissues·github
我发现一个好用的网页爬虫都是用python写的,并且不需要任何额外的gui工具。
阿里云采集日志python版_文章爬虫工具_云采集?/
可以使用daocloud采集服务,除了能够爬取自己的网站外,还支持天猫等商家店铺的数据。有免费和高级版可供选择,根据需要选择~在提供的免费服务中,针对所涉及的商家或店铺提供以下三方面的免费服务:web前端自动化、自动化测试、商家店铺运营数据分析等内容。对于web前端自动化,还有优秀的python爬虫框架tornado的模块:官网:、自动化测试框架ui自动化脚本、有高级模块自动化测试框架unittest等。 查看全部
没准用java的话,支持前端采集试试看gitbash-extractors
网页文章自动采集的话,可以用云采集,支持多语言采集,自动双十一、双十二的订单、链接等数据采集。2、自动批量采集网页文章的话,可以通过爬虫工具来实现,如果网站没有对爬虫做限制,是可以采集大部分网站的文章的。
哈喽,每次我都是靠selenium的其实呢,采集网页文章应该不难,
github上面有好多蛮不错的接口了,
可以考虑用selenium+lxml
danmaku/scrapy+pyqt5
我这边在做一个,后台redis管理采集数据,本地直接实现,
v5公众号提供开发者服务,
可以用易开发的selenium,
平时我是用danmaku/scrapy-extractors·github和。非常可靠和简单。
没准用java的话,
支持前端采集
试试看gitbash-extractors?/root·githubissues·github
我发现一个好用的网页爬虫都是用python写的,并且不需要任何额外的gui工具。
阿里云采集日志python版_文章爬虫工具_云采集?/
可以使用daocloud采集服务,除了能够爬取自己的网站外,还支持天猫等商家店铺的数据。有免费和高级版可供选择,根据需要选择~在提供的免费服务中,针对所涉及的商家或店铺提供以下三方面的免费服务:web前端自动化、自动化测试、商家店铺运营数据分析等内容。对于web前端自动化,还有优秀的python爬虫框架tornado的模块:官网:、自动化测试框架ui自动化脚本、有高级模块自动化测试框架unittest等。
Web采集与海量文本信息自动分类研究
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-07-01 18:44
[摘要]:近年来,随着科技的飞速发展,互联网上的各种信息呈现井喷之势,铺天盖地。如何更好地发现、获取和利用网络文本信息成为越来越值得关注的问题。 采集和海量文本信息自动分类是获取、组织和处理海量信息和数据的关键核心技术。优秀的采集和分类系统,可以根据需要快速高效地从互联网上获取相关网页,分析提取网页信息,然后将获取的文本内容按照一定的方法自动分类,这样才能更好的被人们使用。这些无疑对快速发现、研究和解决问题非常有帮助。因此,本文结合网络采集、信息处理和文本自动分类技术,引入词池进化特征词的方法,对采集和海量文本信息的自动分类问题进行深入研究,并解决海量网络信息时代文本数据有效性问题采集和自动分类问题。基于以上分析,本文主要完成了以下工作: 首先,本文分析了信息采集领域和文本自动分类领域的常用关键技术和相关算法。重点介绍信息采集过程中的源代码获取、链接分析与匹配和网页信息处理技术,以及文本分类领域的文本表示、特征选择和常用分类算法。其次,提出了用户定义的 Web采集 和处理模型。该模型在传统采集技术的基础上,实现了基于采集流程的链接分析、匹配等改进,提高了采集海量文本信息的效率和准确率。第三,在传统分类的特征词选择算法的基础上,提出了一种基于词池进化的多级特征词改进方法,增加了特征词集的规模,利用改进后的特征词集对分类进行优化模型来提高文本自动分类的准确性。第四,将提出的Web采集和分类模型应用到实际科研中,实现高效稳定的采集和分类系统。通过系统测试和相关性能分析可知,本文提出的相关算法模型具有良好的采集和分类效果。 查看全部
Web采集与海量文本信息自动分类研究
[摘要]:近年来,随着科技的飞速发展,互联网上的各种信息呈现井喷之势,铺天盖地。如何更好地发现、获取和利用网络文本信息成为越来越值得关注的问题。 采集和海量文本信息自动分类是获取、组织和处理海量信息和数据的关键核心技术。优秀的采集和分类系统,可以根据需要快速高效地从互联网上获取相关网页,分析提取网页信息,然后将获取的文本内容按照一定的方法自动分类,这样才能更好的被人们使用。这些无疑对快速发现、研究和解决问题非常有帮助。因此,本文结合网络采集、信息处理和文本自动分类技术,引入词池进化特征词的方法,对采集和海量文本信息的自动分类问题进行深入研究,并解决海量网络信息时代文本数据有效性问题采集和自动分类问题。基于以上分析,本文主要完成了以下工作: 首先,本文分析了信息采集领域和文本自动分类领域的常用关键技术和相关算法。重点介绍信息采集过程中的源代码获取、链接分析与匹配和网页信息处理技术,以及文本分类领域的文本表示、特征选择和常用分类算法。其次,提出了用户定义的 Web采集 和处理模型。该模型在传统采集技术的基础上,实现了基于采集流程的链接分析、匹配等改进,提高了采集海量文本信息的效率和准确率。第三,在传统分类的特征词选择算法的基础上,提出了一种基于词池进化的多级特征词改进方法,增加了特征词集的规模,利用改进后的特征词集对分类进行优化模型来提高文本自动分类的准确性。第四,将提出的Web采集和分类模型应用到实际科研中,实现高效稳定的采集和分类系统。通过系统测试和相关性能分析可知,本文提出的相关算法模型具有良好的采集和分类效果。
网页文章自动采集如何找方法太多,如何获取a论坛的全部帖子?
采集交流 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-06-28 02:01
网页文章自动采集,发布,同步,批量选题,搜索,放,链接,脚本,插件,算法。自定义标题,pv,uv,点击率,转化率,文章图片。高级获取域名。国外自动爬爬爬。爬到了就自动放到你设置的广告里。设置关键词。定时定量。批量抓取京东,宝宝树,有好货,宝贝值,达人自然流量,等。
一、找到20个论坛。目标都在这。
二、第一天,a论坛,发帖。b论坛,推广,建群。c论坛,推广,建群。d论坛,推广,建群。e论坛,发帖,推广,建群。f论坛,发帖,推广,建群。g论坛,发帖,推广,建群定时定量。
实施方案
2、科技论坛爬,抢位,如何获取a论坛的全部帖子?让每个论坛都有你的身影,抢位谁不想成为一个幸运的第一名,一定要熟练搜索方法。
内容来源
1、订阅:fofa订阅号
2、热门网站:百度站长平台,360站长平台,站长网,全是你需要爬的网站。
3、热门博客:百度新闻源,网站导航,一些新站。
4、百度知道,知乎等问答类,site:输入目标论坛名称即可。每天更新即可。
5、一些实用的小技巧论坛,一些帖子都是挺好的内容,可以看一下这里的一些技巧,会省去很多功夫。这些内容都是如何爬的,当然专业论坛,定时定量,完全可以爬到论坛底部所有内容,如何找到20个论坛,你要掌握的知识。定时定量,如何找,方法太多。首先考虑的是,论坛都很专业,来的人都是一些专业类的人士,重合较少,你如何寻找到20个论坛并且这20个论坛中的核心关键词,说到底也是相关性较强的,那就只能是小众词,比如:二维码,你可以寻找20个论坛,每个论坛发1篇文章,完全可以获取任何你要的关键词。
(500-1000篇文章)只要你的文章更新,依旧会有出口。直接把语言或者平台的问题发出来即可,所有的都提供网页爬取与查询,如何可以登录epay等。
方案
二、高级自动建站方案这个是实操过程中发现的,这个方案对很多小白来说,不太容易上手,没错,其实在自己写一遍代码也没有多难,我就是没学会,不过也有一种方法,就是小网站的方法,例如免费建立几百个小网站,
1、小网站相对单个域名来说,站点少,大多数都是pv较少的论坛。
2、小网站已经出现了“分享网址”,至少在1-2天的时间内,对他进行分享,这样也会有一部分用户搜索相关的关键词在平台中提问题。
3、那就先做这些不是pv很大的论坛,但是也要利用自己熟悉的领域或者他的用户群体,利用免费资源发帖,大多数用户对你的论坛,并不完全熟悉,没准发布帖子反而会进一步放大他搜索他需要的关键词。
4、用户阅读完毕后,如果内容不错, 查看全部
网页文章自动采集如何找方法太多,如何获取a论坛的全部帖子?
网页文章自动采集,发布,同步,批量选题,搜索,放,链接,脚本,插件,算法。自定义标题,pv,uv,点击率,转化率,文章图片。高级获取域名。国外自动爬爬爬。爬到了就自动放到你设置的广告里。设置关键词。定时定量。批量抓取京东,宝宝树,有好货,宝贝值,达人自然流量,等。
一、找到20个论坛。目标都在这。
二、第一天,a论坛,发帖。b论坛,推广,建群。c论坛,推广,建群。d论坛,推广,建群。e论坛,发帖,推广,建群。f论坛,发帖,推广,建群。g论坛,发帖,推广,建群定时定量。
实施方案
2、科技论坛爬,抢位,如何获取a论坛的全部帖子?让每个论坛都有你的身影,抢位谁不想成为一个幸运的第一名,一定要熟练搜索方法。
内容来源
1、订阅:fofa订阅号
2、热门网站:百度站长平台,360站长平台,站长网,全是你需要爬的网站。
3、热门博客:百度新闻源,网站导航,一些新站。
4、百度知道,知乎等问答类,site:输入目标论坛名称即可。每天更新即可。
5、一些实用的小技巧论坛,一些帖子都是挺好的内容,可以看一下这里的一些技巧,会省去很多功夫。这些内容都是如何爬的,当然专业论坛,定时定量,完全可以爬到论坛底部所有内容,如何找到20个论坛,你要掌握的知识。定时定量,如何找,方法太多。首先考虑的是,论坛都很专业,来的人都是一些专业类的人士,重合较少,你如何寻找到20个论坛并且这20个论坛中的核心关键词,说到底也是相关性较强的,那就只能是小众词,比如:二维码,你可以寻找20个论坛,每个论坛发1篇文章,完全可以获取任何你要的关键词。
(500-1000篇文章)只要你的文章更新,依旧会有出口。直接把语言或者平台的问题发出来即可,所有的都提供网页爬取与查询,如何可以登录epay等。
方案
二、高级自动建站方案这个是实操过程中发现的,这个方案对很多小白来说,不太容易上手,没错,其实在自己写一遍代码也没有多难,我就是没学会,不过也有一种方法,就是小网站的方法,例如免费建立几百个小网站,
1、小网站相对单个域名来说,站点少,大多数都是pv较少的论坛。
2、小网站已经出现了“分享网址”,至少在1-2天的时间内,对他进行分享,这样也会有一部分用户搜索相关的关键词在平台中提问题。
3、那就先做这些不是pv很大的论坛,但是也要利用自己熟悉的领域或者他的用户群体,利用免费资源发帖,大多数用户对你的论坛,并不完全熟悉,没准发布帖子反而会进一步放大他搜索他需要的关键词。
4、用户阅读完毕后,如果内容不错,
极速点击虎让您轻松体验自动化的完美境界!
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-06-15 19:27
Speedy Click Tiger 是目前国内唯一一款将各种常用操作完美结合的动作模拟软件。是目前国内最专业、功能最强大的脚本工具软件,可以实现所有复杂操作的灵活组合和自动化。执行!有了Speedy Click Tiger,电脑前的所有重复动作和操作都将不复存在!只有想不到,没有做不到——Speedy Click Tiger让您轻松体验自动化的完美状态! Speedy Click Tiger 收录了很多同类软件的功能,并且完美有效地结合在一起,可以说是一款全能软件。 --可以通过改变不同的IP地址自动刷网站流量,提高网站点击率! --您的网站可以在最短的时间内出现在各大网站和搜索引擎的显眼位置,访问量可以被网站关键词自动刷。 --可以模拟各种手机无线终端访问网站shop,查看无线终端的点击量和流量! --可以自动刷网站ad点击、网站IP访问、网站PV和UV! --您可以自动滑动各种广告点击联盟任务,滑动弹窗,滑动点击,让你赚大钱! --您可以在线自动投票和刷票,让您的票数一次次上涨,您遥遥领先。 --自动群消息,自动邮件群,QQ/MSN/旺旺等自动聊天群发,QQ好友群依次发送QQ群成员! --可自动实现各种系统的输入,随机数据输入,自动完成办公系统的重复输入。 . . . . 功能太多了,就不一一列举了。 . 您只需要根据每个任务的实际功能需求灵活组合和安排! 查看全部
极速点击虎让您轻松体验自动化的完美境界!
Speedy Click Tiger 是目前国内唯一一款将各种常用操作完美结合的动作模拟软件。是目前国内最专业、功能最强大的脚本工具软件,可以实现所有复杂操作的灵活组合和自动化。执行!有了Speedy Click Tiger,电脑前的所有重复动作和操作都将不复存在!只有想不到,没有做不到——Speedy Click Tiger让您轻松体验自动化的完美状态! Speedy Click Tiger 收录了很多同类软件的功能,并且完美有效地结合在一起,可以说是一款全能软件。 --可以通过改变不同的IP地址自动刷网站流量,提高网站点击率! --您的网站可以在最短的时间内出现在各大网站和搜索引擎的显眼位置,访问量可以被网站关键词自动刷。 --可以模拟各种手机无线终端访问网站shop,查看无线终端的点击量和流量! --可以自动刷网站ad点击、网站IP访问、网站PV和UV! --您可以自动滑动各种广告点击联盟任务,滑动弹窗,滑动点击,让你赚大钱! --您可以在线自动投票和刷票,让您的票数一次次上涨,您遥遥领先。 --自动群消息,自动邮件群,QQ/MSN/旺旺等自动聊天群发,QQ好友群依次发送QQ群成员! --可自动实现各种系统的输入,随机数据输入,自动完成办公系统的重复输入。 . . . . 功能太多了,就不一一列举了。 . 您只需要根据每个任务的实际功能需求灵活组合和安排!
网页文章自动采集有主要有4种方式:百度help
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-06-10 06:01
网页文章自动采集有主要有4种方式:百度help,使用chrome插件useragentswitchyinternet。百度提供一个平台,方便搜集。v2ex。搜狗浏览器。谷歌搜索。
其实在sina、weibo、twitter等社交平台,每天都会有上百万条博文(特别是外国文章)。还有,像是百度已经逐渐摒弃的,搜索引擎通过机器学习分析新生代用户使用习惯而提供的相关文章,所以也会在很多平台出现。
网页上flickr,推特等其实可以根据用户观看的内容去匹配类似领域的用户,一些人观看的内容可能就是另一些人感兴趣的内容或者刚好有某个ugc出现在匹配范围里。网页上,我只看微博比较多。很多时候就是某件事,有一个聚集的主题,然后ugc就出现在这个主题中了。微博,知乎也是一样,主题出现在ugc里,用户就可以观看。
因为现在能发帖的地方少了不过还是有人发
sina每天的新闻就够了吧还有每天的headless,登录需要验证的,还有chrome插件不需要,也可以截图,发博也不需要登录什么的另外chrome的instant网页端正在被淘汰,所以有专门的https版本,能显示通过各种认证的图像,但是发博更多的是用于加强安全性,
谷歌网页图片自动识别。搜狗图片自动识别。360图片自动识别。还有, 查看全部
网页文章自动采集有主要有4种方式:百度help
网页文章自动采集有主要有4种方式:百度help,使用chrome插件useragentswitchyinternet。百度提供一个平台,方便搜集。v2ex。搜狗浏览器。谷歌搜索。
其实在sina、weibo、twitter等社交平台,每天都会有上百万条博文(特别是外国文章)。还有,像是百度已经逐渐摒弃的,搜索引擎通过机器学习分析新生代用户使用习惯而提供的相关文章,所以也会在很多平台出现。
网页上flickr,推特等其实可以根据用户观看的内容去匹配类似领域的用户,一些人观看的内容可能就是另一些人感兴趣的内容或者刚好有某个ugc出现在匹配范围里。网页上,我只看微博比较多。很多时候就是某件事,有一个聚集的主题,然后ugc就出现在这个主题中了。微博,知乎也是一样,主题出现在ugc里,用户就可以观看。
因为现在能发帖的地方少了不过还是有人发
sina每天的新闻就够了吧还有每天的headless,登录需要验证的,还有chrome插件不需要,也可以截图,发博也不需要登录什么的另外chrome的instant网页端正在被淘汰,所以有专门的https版本,能显示通过各种认证的图像,但是发博更多的是用于加强安全性,
谷歌网页图片自动识别。搜狗图片自动识别。360图片自动识别。还有,
网页文章自动采集论文导师?你需要一个付费的浏览器插件
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-05-15 22:27
网页文章自动采集论文导师?你需要一个付费的浏览器插件同时可以切换位置操作方便快捷=v=不谢私信我就行了
这里有一个网页文章自动采集的地址:聚宽-专业移动开发者社区,人人都是产品经理
imagepartner专用的seo插件adjust·imagepartner
老规矩,你把它展示在别人的首页上,让别人去搜你的文章。
这个应该很多平台都可以免费获取pdf文件吧如果别人想看你文章的相关信息,需要付费才可以看到,
试试word2vec吧,
付费的话有没有免费可以读pdf的呢?直接在线读,这里有一个pdf免费的阅读器,没有广告,可以试一下:pdfexpert,
百度文库自助领取,复制网址到浏览器即可下载,无需在各大平台注册、充值。无需认证,
百度文库在线阅读
推荐一个在线阅读pdf的产品pdfreedopen,一款专门在线免费阅读pdf文件的产品,平台界面简洁明了。阅读pdf能够让用户更方便地阅读文档,并且能够免费无限下载文档,支持离线阅读,电脑和手机都可以查看,没有版权限制。而且书籍资源也是非常丰富的,可以选择自己感兴趣的书籍,满足读者对不同读物的选择。
在阅读时一个pdf文件可以被划分为多个section,并且每个section上都会有3个tags标注这个section的内容。如果只想阅读其中一个section的话也可以通过鼠标选中其中一个pdf文件进行点击下拉查看完整内容,每个section都会有相应的tag标签说明该section的内容。在阅读时可以点击左上角的pdf文件标注来对pdf进行标注,浏览器中的收藏功能也是一样,这样也就实现了书摘和重点摘要的功能。 查看全部
网页文章自动采集论文导师?你需要一个付费的浏览器插件
网页文章自动采集论文导师?你需要一个付费的浏览器插件同时可以切换位置操作方便快捷=v=不谢私信我就行了
这里有一个网页文章自动采集的地址:聚宽-专业移动开发者社区,人人都是产品经理
imagepartner专用的seo插件adjust·imagepartner
老规矩,你把它展示在别人的首页上,让别人去搜你的文章。
这个应该很多平台都可以免费获取pdf文件吧如果别人想看你文章的相关信息,需要付费才可以看到,
试试word2vec吧,
付费的话有没有免费可以读pdf的呢?直接在线读,这里有一个pdf免费的阅读器,没有广告,可以试一下:pdfexpert,
百度文库自助领取,复制网址到浏览器即可下载,无需在各大平台注册、充值。无需认证,
百度文库在线阅读
推荐一个在线阅读pdf的产品pdfreedopen,一款专门在线免费阅读pdf文件的产品,平台界面简洁明了。阅读pdf能够让用户更方便地阅读文档,并且能够免费无限下载文档,支持离线阅读,电脑和手机都可以查看,没有版权限制。而且书籍资源也是非常丰富的,可以选择自己感兴趣的书籍,满足读者对不同读物的选择。
在阅读时一个pdf文件可以被划分为多个section,并且每个section上都会有3个tags标注这个section的内容。如果只想阅读其中一个section的话也可以通过鼠标选中其中一个pdf文件进行点击下拉查看完整内容,每个section都会有相应的tag标签说明该section的内容。在阅读时可以点击左上角的pdf文件标注来对pdf进行标注,浏览器中的收藏功能也是一样,这样也就实现了书摘和重点摘要的功能。

