
网页抓取数据百度百科
规模化网站,如何练SEO内功,快速拉升权重?
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-05-02 00:31
搜索引擎算法调整的过程中,总是会展现出多种类型的网站,甚至是短期高权重站点。
虽然SEO行业当下的环境紧缩,但大家仍然还是保留了那份热情,每出现一个权重站,总是想将其拆解的彻彻底底。
那么,规模化网站,如何短期练内功,快速拉升权重?
根据以往SEO实战经验,蝙蝠侠IT,将通过如下讨论:
1、页面质量评估
任何一个网站在某种角度上都是碎片化的,它由海量的页面组成,我们评定一个网站是否值得索引展现,实际上在某种程度上在评估每个页面的搜索展现价值。
我们只有将每个类型页面都细节标准化之后,才能以少聚多,短期拉升网站权重,因此,我们有必要思考:
①页面搜索需求
你的页面是否匹配了搜索需求,简单理解就是是否覆盖了具有一定搜索量的关键词,它需要你进行合理的关键词挖掘。
② 页面解决搜索需求的能力
这个页面的元素组成是否能够最大限度的解决你的用户搜索需求,它包括:
等等一系列能够更好的解读目标关键词搜索属性的元素。
③页面链接关系
页面中是否存在行业相关性行业的权威度链接,是否包含具有解释说明的价值链接。
④ 页面加载速度
毋庸质疑这已经是我们无数次提及的事情,无论是移动端还是PC端都控制在1.5秒之内吧。
⑤ 页面终端体验
这里我们主要强调一下,不要过度的进行弹窗广告吧,尽量避免屏占比比较高的广告横幅展现。
2、页面结构设计
标准化的页面结构是搜索引擎快速抓取与评估页面质量,建立索引评分一个重要的途径。
在完美的页面,合理的被搜索引擎爬行和抓取是前提,否则我们没有办法谈论后续的任何问题。
在这个过程中,我们可能需要关注:
① URL结构
其中伪静态URL形态,并不是唯一属性,我们只是希望整站的URL地址形态,具有一定的标准化,便利的方便搜索爬行与抓取。
而目录层级,直观影响搜索引擎访问的深度,层级太多,权威度比较低,很难引导深层次目录进行抓取。
同时,对于目录层级而言,它还起着站内结构元素分类的重要作用,比如:
不同属性的页面索引特征可能都存在一定的差异性。特别需要说明的是我们在做目录层级设计的时候,就需要考量到整站SEO属性流量的走向策略。
②面包屑导航
面包屑导航是我们经常被忽略的一个细节性问题,我们不止一次强调它承载着整站链接重要程度的重要参考因子。
同时它精准的告知搜索引擎当前页面的主题属性,这其中就包括:目录类别属性。
③ H标签布局
H标签这么多年很少被提及,但我们认为他是强化一个页面核心关键词与长尾关键词最为重要的技术指标,特别是对于规模性网站,我们有的时候需要合理的利用海量页面中的H标签。
3、页面流量流动
对于任何一个有商业转化为目的的网站来讲,思考整站流量走向是国内90%以上SEO机构经常会忽略的一个问题。
通常作为衡量规模网站指标的因素,都是完全独立于SEO技术指标,比如:
过度的追求数据指标,让我们制定网站内部策略的时候,更多的考量泛流量,甚至是不相关性流量。
这里在行业最具有代表性的网站就是阿里云,钉钉,新网等等知名云网站,完全借助网站权威度海量排名TAG聚合标题,而产生高权重属性标签。
在某种程度上可以说是存在一定的“SEO虚荣性指标”,而对实际业务转化真正起到多少作用,可能并不能存在合理性的统计与评估。
这就需要我们思考:
在制定站内策略的时候,是否需要充分考量,某一个部分流量的价值转化,从:
每一个环节实际上都需要巧妙设计,比如:一个独立的理财网站,它可能是以售卖基金为主。
对于一个基金而言它的属性有很多,比如:
我们在做词库统计与布局的时候,什么样的排名,关联什么样的流量,什么样的流量关联什么样的页面。
简单举例:
检索基金公司基础信息的人,它更多的是可能希望了解相关的信息介绍,因此在他产生购买意图的时候,我猜是倾向于货币型或者债券型基金。
相反,如果一个基金经理过往履历经常被访问的页面,那么这样的流量用户转化需求,可能就定位在股票型基金,或者混合型基金。
这样我们在做页面关联性的同时,就需要思考如何匹配潜在的需求,从而拉升页面用户的停留时间,推动产品转化,放大一个精准流量的SEO价值。
当然,这里我们还可以参考现有的流量生态,分析竞争对手相关产品的现状,我们就不深入展开。
实际上,一个完整的SEO策略,在某种程度上,更多的时间周期理论上应该放在站内策略上,当我们处理好站内策略,才可以进一步的开展SEO工作。
相关性阅读:
SEO学习SEO服务百度专区 查看全部
规模化网站,如何练SEO内功,快速拉升权重?
搜索引擎算法调整的过程中,总是会展现出多种类型的网站,甚至是短期高权重站点。
虽然SEO行业当下的环境紧缩,但大家仍然还是保留了那份热情,每出现一个权重站,总是想将其拆解的彻彻底底。
那么,规模化网站,如何短期练内功,快速拉升权重?
根据以往SEO实战经验,蝙蝠侠IT,将通过如下讨论:
1、页面质量评估
任何一个网站在某种角度上都是碎片化的,它由海量的页面组成,我们评定一个网站是否值得索引展现,实际上在某种程度上在评估每个页面的搜索展现价值。
我们只有将每个类型页面都细节标准化之后,才能以少聚多,短期拉升网站权重,因此,我们有必要思考:
①页面搜索需求
你的页面是否匹配了搜索需求,简单理解就是是否覆盖了具有一定搜索量的关键词,它需要你进行合理的关键词挖掘。
② 页面解决搜索需求的能力
这个页面的元素组成是否能够最大限度的解决你的用户搜索需求,它包括:
等等一系列能够更好的解读目标关键词搜索属性的元素。
③页面链接关系
页面中是否存在行业相关性行业的权威度链接,是否包含具有解释说明的价值链接。
④ 页面加载速度
毋庸质疑这已经是我们无数次提及的事情,无论是移动端还是PC端都控制在1.5秒之内吧。
⑤ 页面终端体验
这里我们主要强调一下,不要过度的进行弹窗广告吧,尽量避免屏占比比较高的广告横幅展现。
2、页面结构设计
标准化的页面结构是搜索引擎快速抓取与评估页面质量,建立索引评分一个重要的途径。
在完美的页面,合理的被搜索引擎爬行和抓取是前提,否则我们没有办法谈论后续的任何问题。
在这个过程中,我们可能需要关注:
① URL结构
其中伪静态URL形态,并不是唯一属性,我们只是希望整站的URL地址形态,具有一定的标准化,便利的方便搜索爬行与抓取。
而目录层级,直观影响搜索引擎访问的深度,层级太多,权威度比较低,很难引导深层次目录进行抓取。
同时,对于目录层级而言,它还起着站内结构元素分类的重要作用,比如:
不同属性的页面索引特征可能都存在一定的差异性。特别需要说明的是我们在做目录层级设计的时候,就需要考量到整站SEO属性流量的走向策略。
②面包屑导航
面包屑导航是我们经常被忽略的一个细节性问题,我们不止一次强调它承载着整站链接重要程度的重要参考因子。
同时它精准的告知搜索引擎当前页面的主题属性,这其中就包括:目录类别属性。
③ H标签布局
H标签这么多年很少被提及,但我们认为他是强化一个页面核心关键词与长尾关键词最为重要的技术指标,特别是对于规模性网站,我们有的时候需要合理的利用海量页面中的H标签。
3、页面流量流动
对于任何一个有商业转化为目的的网站来讲,思考整站流量走向是国内90%以上SEO机构经常会忽略的一个问题。
通常作为衡量规模网站指标的因素,都是完全独立于SEO技术指标,比如:
过度的追求数据指标,让我们制定网站内部策略的时候,更多的考量泛流量,甚至是不相关性流量。
这里在行业最具有代表性的网站就是阿里云,钉钉,新网等等知名云网站,完全借助网站权威度海量排名TAG聚合标题,而产生高权重属性标签。
在某种程度上可以说是存在一定的“SEO虚荣性指标”,而对实际业务转化真正起到多少作用,可能并不能存在合理性的统计与评估。
这就需要我们思考:
在制定站内策略的时候,是否需要充分考量,某一个部分流量的价值转化,从:
每一个环节实际上都需要巧妙设计,比如:一个独立的理财网站,它可能是以售卖基金为主。
对于一个基金而言它的属性有很多,比如:
我们在做词库统计与布局的时候,什么样的排名,关联什么样的流量,什么样的流量关联什么样的页面。
简单举例:
检索基金公司基础信息的人,它更多的是可能希望了解相关的信息介绍,因此在他产生购买意图的时候,我猜是倾向于货币型或者债券型基金。
相反,如果一个基金经理过往履历经常被访问的页面,那么这样的流量用户转化需求,可能就定位在股票型基金,或者混合型基金。
这样我们在做页面关联性的同时,就需要思考如何匹配潜在的需求,从而拉升页面用户的停留时间,推动产品转化,放大一个精准流量的SEO价值。
当然,这里我们还可以参考现有的流量生态,分析竞争对手相关产品的现状,我们就不深入展开。
实际上,一个完整的SEO策略,在某种程度上,更多的时间周期理论上应该放在站内策略上,当我们处理好站内策略,才可以进一步的开展SEO工作。
相关性阅读:
SEO学习SEO服务百度专区
网页抓取数据百度百科( python爬虫基本知识爬虫爬虫爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-04-20 14:36
python爬虫基本知识爬虫爬虫爬虫)
python爬虫基础知识,python爬虫知识
爬虫简介
根据百度百科的定义:网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常称为网页追逐者),是一种按照一定的规则对万维网信息进行自动爬取的行为。规则程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在发布大数据后了解了爬虫的技术
随着数据的海量增长,我们需要在互联网上选择需要的数据进行自己的研究和实验。这使用了爬虫技术。跟着小编第一次见见python爬虫吧!
一、请求-响应
在使用python语言实现爬虫时,主要用到了urllib和urllib2这两个库。首先用一段代码解释如下:
import urllib
import urllib2
url="http://www.baidu.com"
request=urllib2.Request(url)
response=urllib2.urlopen(request)
print response.read()
我们知道一个网页是由html作为骨架,js作为肌肉,css作为衣服组成的。以上代码实现的功能是将百度网页的源代码爬取到本地。
其中,url为要爬取的网页的URL; request 发出请求,response 是接受请求后给出的响应。最后read()函数的输出就是百度网页的源码。
二、GET-POST
两者都将数据传输到网页。最重要的区别是GET方法是以链接的形式直接访问的。该链接收录所有参数。当然,如果收录密码,这是一个不安全的选择,但是您可以直观地看到您提交的内容。
POST不会显示URL上的所有参数,但是如果要直接查看提交的内容,不是很方便,可以酌情选择。
POST方法:
GET方法:
import urllib
import urllib2
values={'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request=urllib2.Request(geturl)
response=urllib2.urlopen(request)
print response.read()
三、异常处理
处理异常时使用try-except语句。
import urllib2
try:
response=urllib2.urlopen("http://www.xxx.com")
except urllib2.URLError,e:
print e.reason
总结
以上就是小编为大家介绍的python爬虫基础知识。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。我还要感谢大家对助手之家的支持网站! 查看全部
网页抓取数据百度百科(
python爬虫基本知识爬虫爬虫爬虫)
python爬虫基础知识,python爬虫知识
爬虫简介
根据百度百科的定义:网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常称为网页追逐者),是一种按照一定的规则对万维网信息进行自动爬取的行为。规则程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在发布大数据后了解了爬虫的技术
随着数据的海量增长,我们需要在互联网上选择需要的数据进行自己的研究和实验。这使用了爬虫技术。跟着小编第一次见见python爬虫吧!
一、请求-响应
在使用python语言实现爬虫时,主要用到了urllib和urllib2这两个库。首先用一段代码解释如下:
import urllib
import urllib2
url="http://www.baidu.com"
request=urllib2.Request(url)
response=urllib2.urlopen(request)
print response.read()
我们知道一个网页是由html作为骨架,js作为肌肉,css作为衣服组成的。以上代码实现的功能是将百度网页的源代码爬取到本地。
其中,url为要爬取的网页的URL; request 发出请求,response 是接受请求后给出的响应。最后read()函数的输出就是百度网页的源码。
二、GET-POST
两者都将数据传输到网页。最重要的区别是GET方法是以链接的形式直接访问的。该链接收录所有参数。当然,如果收录密码,这是一个不安全的选择,但是您可以直观地看到您提交的内容。
POST不会显示URL上的所有参数,但是如果要直接查看提交的内容,不是很方便,可以酌情选择。
POST方法:
GET方法:
import urllib
import urllib2
values={'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request=urllib2.Request(geturl)
response=urllib2.urlopen(request)
print response.read()
三、异常处理
处理异常时使用try-except语句。
import urllib2
try:
response=urllib2.urlopen("http://www.xxx.com";)
except urllib2.URLError,e:
print e.reason
总结
以上就是小编为大家介绍的python爬虫基础知识。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。我还要感谢大家对助手之家的支持网站!
网页抓取数据百度百科(蜘蛛不会为什么搜索引擎优化,增加网站抓取规则的频率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-17 12:33
一、 蜘蛛爬行规则
搜索引擎中的蜘蛛需要将抓取到的网页放入数据库区域进行数据补充。如果通过程序计算分类,放在不同的搜索位置,搜索引擎就会形成一个稳定的收录排名。在这个过程中,蜘蛛抓取到的数据不一定是稳定的。很多数据经过程序计算后被其他好的网页排挤掉了。简单地说,蜘蛛不喜欢它,不想捕获页面。
蜘蛛的味道很独特,它捕捉到的网站,也就是我们所说的原创文章,只要你的文章原创网页@>Sex 很高,那么你的网页就会被蜘蛛抓到,这就是为什么越来越多的人需要 原创sex 来换取 文章。
只有这样,数据排名才会稳定。现在搜索引擎改变了策略,逐渐转向补充数据。他们喜欢将缓存机制和补充数据结合起来。这就是为什么搜索引擎优化,包括越来越难,我们也可以理解,今天有很多Pages不包括排名,而且每隔一段时间就包括排名。
二、增加网站的抓取频率
1、网站文章 质量提升
虽然做 SEO 的人知道如何改进 原创文章,但在搜索引擎中始终存在一个事实,即内容的质量和稀缺性永远无法同时满足这两个要求。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是受到蜘蛛的喜爱。
2、更新网站文章的频率
满足内容,关键是要做到正常的更新频率,这也是提高网页抓取的法宝。
3、网站速度不仅影响蜘蛛,还影响用户体验
蜘蛛访问,如果想要无障碍,加载过程可以在合理的速度范围内,保证蜘蛛在网页上顺畅爬行,没有任何加载延迟。如果经常遇到这个问题,那么蜘蛛就不会喜欢它 网站 ,爬行的频率会降低。
4、提高网站品牌知名度
如果你在网上混了很多,你会发现一个问题。当一些知名品牌推出新的网站时,他们会去一些新闻媒体报道。新闻来源网站报道后,会添加一些品牌词。即使没有诸如目标之类的链接,搜索引擎也会抓住这个网站。
5、选择PR高的域名
PR 是个老域名,所以要承载很大的分量,即使你的网站很久没有更新或者完全关闭了网站页面,搜索引擎也会爬,等待更新内容。如果有人从一开始就选择使用这样一个老域名,他也可以发展重定向,成为一个真正的可操作域名。
三、优质外链
如果你想让搜索引擎给网站更多的权重,你应该明白,在区分网站的权重时,搜索引擎会考虑有多少链接链接到其他网站,外部的质量链接、外链数据、外链的相关性网站,这些因素百度都应该考虑。一个高权重的网站外链质量也应该很高,如果外链质量达不到,权重值就上不去。所以如果网站管理员想要增加网站的权重值,要注意提高网站的外链质量。这些都很重要,要注意外链的质量。
四、高质量的内部链接
百度的权重值不仅取决于网站的内容,还取决于网站的内链构建。在查看网站时,百度搜索引擎会按照网站导航、网站内页锚文本链接等进入网站内页。网站 的内部页面。网站的导航栏可以适当的找到网站的其他内容,网站内容应该有相关的锚文本链接,既方便蜘蛛抓取,又减少了网站 的跳出率。所以网站的内链也很重要,如果网站的内链做得好,蜘蛛就会收录你的网站,因为你的链接不仅收录你的网页,还收录连接页面。
五、 蜘蛛爬行频率
如果是高权重的网站,更新频率会不一样,所以频率一般在几天或者一个月之间。网站质量越高,更新频率越快,蜘蛛会不断访问或更新网页。
六、高级空间
空间是 网站 的阈值。如果您的阈值太高,蜘蛛无法进入,它如何查看您的 网站 并区分您的 网站 的权重值?高门槛在这里意味着什么?也就是说,空间不稳定,服务器经常离线。这样一来,网站的访问速度是个大问题。如果蜘蛛爬取网页,网站经常打不开,下次对网站的检查会减少。因此,空间是 网站 上线之前最重要的问题。空间是独立IP,访问速度会更快,主机厂商的有效性需要详细规划。确保你的 网站 空间稳定,可以快速打开,而不是长时间不打开。
原创文章,作者:墨宇SEO,如转载请注明出处: 查看全部
网页抓取数据百度百科(蜘蛛不会为什么搜索引擎优化,增加网站抓取规则的频率)
一、 蜘蛛爬行规则
搜索引擎中的蜘蛛需要将抓取到的网页放入数据库区域进行数据补充。如果通过程序计算分类,放在不同的搜索位置,搜索引擎就会形成一个稳定的收录排名。在这个过程中,蜘蛛抓取到的数据不一定是稳定的。很多数据经过程序计算后被其他好的网页排挤掉了。简单地说,蜘蛛不喜欢它,不想捕获页面。
蜘蛛的味道很独特,它捕捉到的网站,也就是我们所说的原创文章,只要你的文章原创网页@>Sex 很高,那么你的网页就会被蜘蛛抓到,这就是为什么越来越多的人需要 原创sex 来换取 文章。
只有这样,数据排名才会稳定。现在搜索引擎改变了策略,逐渐转向补充数据。他们喜欢将缓存机制和补充数据结合起来。这就是为什么搜索引擎优化,包括越来越难,我们也可以理解,今天有很多Pages不包括排名,而且每隔一段时间就包括排名。
二、增加网站的抓取频率
1、网站文章 质量提升
虽然做 SEO 的人知道如何改进 原创文章,但在搜索引擎中始终存在一个事实,即内容的质量和稀缺性永远无法同时满足这两个要求。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是受到蜘蛛的喜爱。
2、更新网站文章的频率
满足内容,关键是要做到正常的更新频率,这也是提高网页抓取的法宝。
3、网站速度不仅影响蜘蛛,还影响用户体验
蜘蛛访问,如果想要无障碍,加载过程可以在合理的速度范围内,保证蜘蛛在网页上顺畅爬行,没有任何加载延迟。如果经常遇到这个问题,那么蜘蛛就不会喜欢它 网站 ,爬行的频率会降低。
4、提高网站品牌知名度
如果你在网上混了很多,你会发现一个问题。当一些知名品牌推出新的网站时,他们会去一些新闻媒体报道。新闻来源网站报道后,会添加一些品牌词。即使没有诸如目标之类的链接,搜索引擎也会抓住这个网站。
5、选择PR高的域名
PR 是个老域名,所以要承载很大的分量,即使你的网站很久没有更新或者完全关闭了网站页面,搜索引擎也会爬,等待更新内容。如果有人从一开始就选择使用这样一个老域名,他也可以发展重定向,成为一个真正的可操作域名。
三、优质外链
如果你想让搜索引擎给网站更多的权重,你应该明白,在区分网站的权重时,搜索引擎会考虑有多少链接链接到其他网站,外部的质量链接、外链数据、外链的相关性网站,这些因素百度都应该考虑。一个高权重的网站外链质量也应该很高,如果外链质量达不到,权重值就上不去。所以如果网站管理员想要增加网站的权重值,要注意提高网站的外链质量。这些都很重要,要注意外链的质量。
四、高质量的内部链接
百度的权重值不仅取决于网站的内容,还取决于网站的内链构建。在查看网站时,百度搜索引擎会按照网站导航、网站内页锚文本链接等进入网站内页。网站 的内部页面。网站的导航栏可以适当的找到网站的其他内容,网站内容应该有相关的锚文本链接,既方便蜘蛛抓取,又减少了网站 的跳出率。所以网站的内链也很重要,如果网站的内链做得好,蜘蛛就会收录你的网站,因为你的链接不仅收录你的网页,还收录连接页面。
五、 蜘蛛爬行频率
如果是高权重的网站,更新频率会不一样,所以频率一般在几天或者一个月之间。网站质量越高,更新频率越快,蜘蛛会不断访问或更新网页。
六、高级空间
空间是 网站 的阈值。如果您的阈值太高,蜘蛛无法进入,它如何查看您的 网站 并区分您的 网站 的权重值?高门槛在这里意味着什么?也就是说,空间不稳定,服务器经常离线。这样一来,网站的访问速度是个大问题。如果蜘蛛爬取网页,网站经常打不开,下次对网站的检查会减少。因此,空间是 网站 上线之前最重要的问题。空间是独立IP,访问速度会更快,主机厂商的有效性需要详细规划。确保你的 网站 空间稳定,可以快速打开,而不是长时间不打开。
原创文章,作者:墨宇SEO,如转载请注明出处:
网页抓取数据百度百科(1.分析目标本次实战篇的目的是什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-15 14:33
用python开发一个简单的爬虫:实战篇1.分析目标
这篇实战文章的目的是抓取百度百科python入口页面的标题和介绍,以及与之关联的入口页面的标题和介绍。
数据格式:
页面编码:UTF-8 2.网址管理器
代码如下:
# coding:utf8
class UrlManager(object):
def __init__(self):
# 初始化待爬取url集合和已爬取url集合
self.new_urls = set()
self.old_urls = set()
# 添加一个新的url到new_urls
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
# 获取一个待爬取的url,并将此url添加到old_urls
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
# 判断是否还有待爬取的url
def has_new_url(self):
return len(self.new_urls) != 0
# 添加多个url到new_urls
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
3. 网页下载器
代码如下:
# coding:utf8
import urllib2
class HtmlDownloader(object):
# 使用urllib2最简单的方法下载url页面内容
def download(self, url):
if url is None:
return None
resp = urllib2.urlopen(url)
if resp.getcode() != 200:
return None
return resp.read()
4. 网页解析器
代码如下:
# coding:utf8
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
# 得到页面相关的url
def _get_new_urls(self, page_url, soup):
new_urls = set()
# /view/123.htm
links = soup.find_all('a', href=re.compile(r'/view/\d+\.htm'))
for link in links:
new_url = link['href']
# 将/view/123.htm补充完整:http://baike.baidu.com/view/123.htm
new_full_url = urlparse.urljoin(page_url, new_url)
# 将解析到的unicode编码的网址转化为utf-8格式
new_urls.add(new_full_url.encode('utf-8'))
return new_urls
# 得到页面标题和简介
def _get_new_data(self, page_url, soup):
res_data = {}
# url
res_data['url'] = page_url
# 得到标题节点
# Python
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
# 得到简介节点
#
summary_node = soup.find('div', class_='lemma-summary')
res_data['summary'] = summary_node.get_text()
return res_data
# 对下载页面内容进行解析
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return None
soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
5.数据导出器
代码如下:
# coding:utf8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
# 收集数据
def collect_data(self, data):
if data is None:
return None
self.datas.append(data)
# 将收集到的数据生成一个HTML页面输出
def output_html(self):
fout = open('output.html', 'w')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
for data in self.datas:
fout.write('')
fout.write('%s' % data['url'].encode('utf-8'))
fout.write('%s' % data['title'].encode('utf-8'))
fout.write('%s' % data['summary'].encode('utf-8'))
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.close()
6.爬虫调度器
# coding:utf8
from baike1 import url_manager, html_downloader, html_parser, html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, url):
count = 1
self.urls.add_new_url(url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print 'craw %d:%s' % (count, new_url)
html_cont = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 100:
break
count += 1
except:
print 'craw failed'
self.outputer.output_html()
if __name__ == "__main__":
root_url = 'http://baike.baidu.com/view/21087.htm'
obj_spider = SpiderMain()
obj_spider.craw(root_url)
程序运行结果截图:
至此,一个很简单的爬虫就完成了,撒花! 查看全部
网页抓取数据百度百科(1.分析目标本次实战篇的目的是什么?(图))
用python开发一个简单的爬虫:实战篇1.分析目标
这篇实战文章的目的是抓取百度百科python入口页面的标题和介绍,以及与之关联的入口页面的标题和介绍。
数据格式:
页面编码:UTF-8 2.网址管理器
代码如下:
# coding:utf8
class UrlManager(object):
def __init__(self):
# 初始化待爬取url集合和已爬取url集合
self.new_urls = set()
self.old_urls = set()
# 添加一个新的url到new_urls
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
# 获取一个待爬取的url,并将此url添加到old_urls
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
# 判断是否还有待爬取的url
def has_new_url(self):
return len(self.new_urls) != 0
# 添加多个url到new_urls
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
3. 网页下载器
代码如下:
# coding:utf8
import urllib2
class HtmlDownloader(object):
# 使用urllib2最简单的方法下载url页面内容
def download(self, url):
if url is None:
return None
resp = urllib2.urlopen(url)
if resp.getcode() != 200:
return None
return resp.read()
4. 网页解析器
代码如下:
# coding:utf8
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
# 得到页面相关的url
def _get_new_urls(self, page_url, soup):
new_urls = set()
# /view/123.htm
links = soup.find_all('a', href=re.compile(r'/view/\d+\.htm'))
for link in links:
new_url = link['href']
# 将/view/123.htm补充完整:http://baike.baidu.com/view/123.htm
new_full_url = urlparse.urljoin(page_url, new_url)
# 将解析到的unicode编码的网址转化为utf-8格式
new_urls.add(new_full_url.encode('utf-8'))
return new_urls
# 得到页面标题和简介
def _get_new_data(self, page_url, soup):
res_data = {}
# url
res_data['url'] = page_url
# 得到标题节点
# Python
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
# 得到简介节点
#
summary_node = soup.find('div', class_='lemma-summary')
res_data['summary'] = summary_node.get_text()
return res_data
# 对下载页面内容进行解析
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return None
soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
5.数据导出器
代码如下:
# coding:utf8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
# 收集数据
def collect_data(self, data):
if data is None:
return None
self.datas.append(data)
# 将收集到的数据生成一个HTML页面输出
def output_html(self):
fout = open('output.html', 'w')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
for data in self.datas:
fout.write('')
fout.write('%s' % data['url'].encode('utf-8'))
fout.write('%s' % data['title'].encode('utf-8'))
fout.write('%s' % data['summary'].encode('utf-8'))
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.close()
6.爬虫调度器
# coding:utf8
from baike1 import url_manager, html_downloader, html_parser, html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, url):
count = 1
self.urls.add_new_url(url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print 'craw %d:%s' % (count, new_url)
html_cont = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 100:
break
count += 1
except:
print 'craw failed'
self.outputer.output_html()
if __name__ == "__main__":
root_url = 'http://baike.baidu.com/view/21087.htm'
obj_spider = SpiderMain()
obj_spider.craw(root_url)
程序运行结果截图:

至此,一个很简单的爬虫就完成了,撒花!
网页抓取数据百度百科(如何写好爬虫之前数据的基本步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-04-15 14:31
一、前言
在开始写爬虫之前,我们先来了解一下爬虫
首先,我们需要知道什么是爬虫。这里直接引用百度百科的定义。网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常被称为网页追逐者),是一种根据一定的规则、程序或脚本自动从万维网上爬取信息的网络爬虫。
这些还不够,我们还需要知道爬取数据的基本步骤。
爬虫爬取数据一般分为三步获取网页
做没有稻草的砖。我们需要的是数据都在网页中。如果我们无法获取网页,那么无论代码打得多么好,都是没有用的。所以爬虫的第一步一定是抓取网页。
好的
拿到网页后,我们要做的就是分析网页的结构,定位要爬取的信息,然后提取出来
保存信息
获取信息后,一般需要保存信息以备下次使用。
完成以上三步后,会写一个简单的爬虫( ̄▽ ̄)》,然后开始写壁纸爬虫
二、开始写爬虫
图片1
红框是我们要爬取的图片。
在开始写代码之前,首先要理清思路,这样可以让我们的思路更清晰,写代码更流畅,代码更简洁。
对于爬虫脚本,我们一般需要考虑以下几点: 爬什么:我们想从网页中获取什么数据
如何攀爬:使用什么库?我需要使用框架吗?有ajax接口吗?
爬取步骤:哪个先爬,哪个后爬
以我们的项目为例:爬什么:
我们的目标是下载网页中的图片。下载图片首先要获取图片的地址,图片的地址在网页中。
所以我们需要爬取网页中图片的地址。
攀登方式:
图片有几十到上百张,下载量不大。无需使用框架,直接使用requests库。
使用 xpath 解析网页。
爬取步骤:
第一步:分析网页,写入图片的xpath路径
第 2 步:获取带有 requests 库的网页
第三步:使用lxml库解析网页
第四步:通过xpath获取图片链接
第五步:下载图片
第 6 步:命名并保存图像
分析完毕,开始爬取!
第一步是分析网页,在浏览器中打开网页,按F12进入开发者模式,选择Elements选项卡,如图:
图二
使用元素选择器:
图三
找到标签后,我们就可以写出标签的xpath路径了。这个比较简单,就不详细写了。如果您有任何问题,您可以发表评论。
图片标签的xpath路径:
#地图地址
路径 = '//a[@title]/img/@src'
#为了方便给图片起名字,我也顺便把图片名字往下爬了
name = '//a[@title]/img/@alt'
下一步是应用我们所学的知识。废话不多说,直接上代码:
#-*- 编码:utf-8 -*
导入请求
从 lxml 导入 etree
#网站地址
网址 = '#39;
# 获取网页
r = requests.get(url)
r.encoding = r.apparent_encoding
#解析网页
dom = etree.HTML(r.text)
#获取图片img标签
#先获取图片所在的img标签,然后分别获取图片链接和名称
img_path = '//a[@title]/img'
imgs = dom.xpath(img_path)
#获取图片的链接和名称并下载保存
对于 imgs 中的 img:
相对路径“。” #xpath 的代表上层标签
#不要忘记xpath总是返回一个列表!
src = img.xpath('./@src')[0]
名称 = img.xpath('./@alt')[0]
#下载图片
图片 = requests.get(src)
#name 并保存图片
使用 open(name+'.jpg', 'wb') 作为 f:
f.write(image.content)
运行结果:
图片4
这样,我们就完成了一个简单版的壁纸爬虫。为什么叫简单版?原因如下:图片太小,根本不能当壁纸(其实我很懒( ̄▽ ̄)》),要获取高清壁纸的话,还需要点击图片转到下一页。为简单起见,我只是爬取了首页的缩略图。
不能自动翻页,一次只能下载一页图片。翻页可以在网页中获取到下一页的链接,或者找到URL的变化规律 查看全部
网页抓取数据百度百科(如何写好爬虫之前数据的基本步骤)
一、前言
在开始写爬虫之前,我们先来了解一下爬虫
首先,我们需要知道什么是爬虫。这里直接引用百度百科的定义。网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常被称为网页追逐者),是一种根据一定的规则、程序或脚本自动从万维网上爬取信息的网络爬虫。
这些还不够,我们还需要知道爬取数据的基本步骤。
爬虫爬取数据一般分为三步获取网页
做没有稻草的砖。我们需要的是数据都在网页中。如果我们无法获取网页,那么无论代码打得多么好,都是没有用的。所以爬虫的第一步一定是抓取网页。
好的
拿到网页后,我们要做的就是分析网页的结构,定位要爬取的信息,然后提取出来
保存信息
获取信息后,一般需要保存信息以备下次使用。
完成以上三步后,会写一个简单的爬虫( ̄▽ ̄)》,然后开始写壁纸爬虫
二、开始写爬虫
图片1
红框是我们要爬取的图片。
在开始写代码之前,首先要理清思路,这样可以让我们的思路更清晰,写代码更流畅,代码更简洁。
对于爬虫脚本,我们一般需要考虑以下几点: 爬什么:我们想从网页中获取什么数据
如何攀爬:使用什么库?我需要使用框架吗?有ajax接口吗?
爬取步骤:哪个先爬,哪个后爬
以我们的项目为例:爬什么:
我们的目标是下载网页中的图片。下载图片首先要获取图片的地址,图片的地址在网页中。
所以我们需要爬取网页中图片的地址。
攀登方式:
图片有几十到上百张,下载量不大。无需使用框架,直接使用requests库。
使用 xpath 解析网页。
爬取步骤:
第一步:分析网页,写入图片的xpath路径
第 2 步:获取带有 requests 库的网页
第三步:使用lxml库解析网页
第四步:通过xpath获取图片链接
第五步:下载图片
第 6 步:命名并保存图像
分析完毕,开始爬取!
第一步是分析网页,在浏览器中打开网页,按F12进入开发者模式,选择Elements选项卡,如图:
图二
使用元素选择器:
图三
找到标签后,我们就可以写出标签的xpath路径了。这个比较简单,就不详细写了。如果您有任何问题,您可以发表评论。
图片标签的xpath路径:
#地图地址
路径 = '//a[@title]/img/@src'
#为了方便给图片起名字,我也顺便把图片名字往下爬了
name = '//a[@title]/img/@alt'
下一步是应用我们所学的知识。废话不多说,直接上代码:
#-*- 编码:utf-8 -*
导入请求
从 lxml 导入 etree
#网站地址
网址 = '#39;
# 获取网页
r = requests.get(url)
r.encoding = r.apparent_encoding
#解析网页
dom = etree.HTML(r.text)
#获取图片img标签
#先获取图片所在的img标签,然后分别获取图片链接和名称
img_path = '//a[@title]/img'
imgs = dom.xpath(img_path)
#获取图片的链接和名称并下载保存
对于 imgs 中的 img:
相对路径“。” #xpath 的代表上层标签
#不要忘记xpath总是返回一个列表!
src = img.xpath('./@src')[0]
名称 = img.xpath('./@alt')[0]
#下载图片
图片 = requests.get(src)
#name 并保存图片
使用 open(name+'.jpg', 'wb') 作为 f:
f.write(image.content)
运行结果:
图片4
这样,我们就完成了一个简单版的壁纸爬虫。为什么叫简单版?原因如下:图片太小,根本不能当壁纸(其实我很懒( ̄▽ ̄)》),要获取高清壁纸的话,还需要点击图片转到下一页。为简单起见,我只是爬取了首页的缩略图。
不能自动翻页,一次只能下载一页图片。翻页可以在网页中获取到下一页的链接,或者找到URL的变化规律
网页抓取数据百度百科( Python感兴趣“入门”点根本不存在!(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-15 03:13
Python感兴趣“入门”点根本不存在!(上))
“开始”是一个很好的动力,但可能会很慢。如果你手头或脑子里有一个项目,在实践中你会被目标驱动,而不是像学习模块那样慢慢学习。
此外,如果知识系统中的每个知识点都是图中的一个点,并且依赖关系是边,那么图一定不是有向无环图。因为学习A的经验可以帮助你学习B。因此,你不需要学习如何“入门”,因为这样的“入门”点根本不存在!您需要学习的是如何做更大的事情,并且在此过程中,您将很快了解您需要学习的内容。当然,你可以争辩说你需要先了解Python,否则你怎么学Python做爬虫呢?但实际上,你可以在做这个爬虫的过程中学习Python。
看到前面很多回答中提到的“技能”——用什么软件怎么爬,那我就说说“道”和“技能”——爬虫是如何工作的,以及如何在Python中实现。
对Python感兴趣的朋友,记得私信小编“007”领取全套Python资料。
长话短说,总结一下,你需要学习:
基本爬虫工作原理 基本http爬虫,scrapyBloom Filter 如果需要大规模的网页抓取,需要学习分布式爬虫的概念。其实没那么神秘,你只需要学习如何维护一个所有集群机器都可以有效共享的分布式队列。最简单的实现是python-rqrq和scrapy的结合:darkrho/scrapy-redis 后续处理,网页提取 grangier/python-goose,存储(Mongodb)
这是一个简短的故事:
说说从我写的一个集群爬下整个豆瓣的经历吧。
1)首先你需要了解爬虫是如何工作的
想象一下,你是一只蜘蛛,现在你被放到了互联网“网络”上。好吧,您需要浏览所有网页。怎么做?没问题,你可以从任何地方开始,比如人民日报的首页,称为初始页,用$表示。
在人民日报的主页上,你会看到各种指向该页面的链接。于是你高高兴兴地爬到了“国内新闻”页面。太好了,你已经爬了两页(首页和国内新闻)!暂时不管你爬下来的页面怎么处理,你可以想象你把这个页面复制成html放到你身上了。
突然你发现,在国内新闻页面上,有一个返回“首页”的链接。作为一只聪明的蜘蛛,你必须知道你不必爬回来,因为你已经看到了。所以,你需要用你的大脑来保存你已经看过的页面的地址。这样,每次看到可能需要爬取的新链接时,首先在脑海中检查一下是否已经到过这个页面地址。如果你去过,不要去。
好吧,理论上,如果从初始页面可以到达所有页面,那么就可以证明你可以爬取所有页面。
那么如何在 Python 中实现呢?非常简单
import Queue
initial_page = "http://www.renminribao.com"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
#一直进行直到海枯石烂
while(True):
if url_queue.size()>0:
#拿出队例中第一个的url
current_url = url_queue.get()
#把这个url代表的网页存储好
store(current_url)
#提取把这个url里链向的url
for next_url in extract_urls(current_url):
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break
它已经是非常伪代码了。
所有爬虫的中坚力量都在这里,我们来分析一下为什么爬虫其实是很复杂的东西——搜索引擎公司通常有一个完整的团队来维护和开发。
2)效率
如果你直接处理上面的代码,直接运行,你要花一整年的时间才能爬下豆瓣的全部内容。更不用说像谷歌这样的搜索引擎需要爬取整个内容网络。
哪里有问题?要爬的页面太多,上面的代码太慢了。假设全网有N个网站,那么分析权重判断的复杂度是N*log(N),因为所有网页都需要遍历一次,需要log(N)的复杂度每次重复使用该集合。. 好的,好的,我知道 Python 的 set 实现是散列 - 但这仍然太慢,至少内存效率不高。
通常的判断方法是什么?布隆过滤器。简而言之,它仍然是一种哈希方法,但它的特点是可以使用固定内存(不随url的数量增长)来判断url是否已经在集合中,效率为O(1)不幸的是,世界上没有免费的午餐。唯一的问题是如果这个url不在集合中,BF可以100%确定这个url没有被看到。但是如果这个url在设置,它会告诉你:这个 url 应该已经存在了,但是我有 2% 的不确定性。注意,当你分配足够的内存时,这里的不确定性会变得非常小。一个简单的教程:Bloom Filters by Example。
注意这个特性,如果url看过,可能小概率会重复(没关系,多看就不会累死)。但是如果没有看到,就会看到(这很重要,否则我们会错过一些页面!)。
好的,现在我们正在接近处理权重的最快方法。另一个瓶颈 - 你只有一台机器。不管你有多少带宽,只要你的机器下载网页的速度是瓶颈,那你就只能提速了。如果一台机器不够用 - 使用多台!当然,我们假设每台机器都进入了最高效率——使用多线程(在 Python 的情况下是多进程)。
3)集群爬取
爬豆瓣的时候,我用了100多台机器,24小时不间断地跑了一个月。想象一下,如果你只用一台机器运行 100 个月......
那么,假设你现在有 100 台机器可用,如何在 Python 中实现分布式爬虫算法呢?
我们将这100台机器中的99台算力较小的机器称为slave,另一台较大的机器称为master,然后查看上面代码中的url_queue,如果我们可以把这个队列放在这台master机器上,那么所有slave都可以与master通信通过网络。每当从站完成下载网页时,它都会向主站请求新的网页以进行爬网。并且每次slave捕获一个新的网页,它会将网页上的所有链接发送到master的队列中。同样,布隆过滤器也放在master上,但是现在master只发送肯定不会被访问的url给slave。Bloom Filter放在master的内存中,访问的url放在运行在master上的Redis中,保证了所有操作都是O(1).(至少摊销是O(1),
考虑如何在 Python 中做到这一点:
在每台slave上安装scrapy,然后每台机器都成为具有抓取能力的slave,在master上安装redis和rq作为分布式队列使用。
然后代码写成
#slave.py
current_url = request_from_master()
to_send = []
for next_url in extract_urls(current_url):
to_send.append(next_url)
store(current_url);
send_to_master(to_send)
#master.py
distributed_queue = DistributedQueue()
bf = BloomFilter()
initial_pages = "www.renmingribao.com"
while(True):
if request == 'GET':
if distributed_queue.size()>0:
send(distributed_queue.get())
else:
break
elif request == 'POST':
bf.put(request.url)
好吧,你可以想象,有人已经给你写了你需要的东西:darkrho/scrapy-redis · GitHub
4)勘探和后处理
虽然上面使用了很多“简单”,但要真正实现一个商业规模可用的爬虫并不是一件容易的事。上面的代码用于爬取整个网站,问题不大。
但是如果附加你需要这些后处理,比如
有效存储(数据库应该如何安排),有效权重判断(这里指的是网页权重判断,我们不想爬取抄袭它的人民日报和大民日报) 有效信息提取(例如,如何提取所有网页上的信息地址是提取出来的,“朝阳区奋进路中华路”),搜索引擎通常不需要存储所有信息,比如我保存的图片...及时更新(预测此网页多久更新一次)
可以想象,这里的每一点都可以被许多研究人员研究数十年。即便如此,“路漫漫其修远兮,我要上上下下寻找。” 查看全部
网页抓取数据百度百科(
Python感兴趣“入门”点根本不存在!(上))
“开始”是一个很好的动力,但可能会很慢。如果你手头或脑子里有一个项目,在实践中你会被目标驱动,而不是像学习模块那样慢慢学习。
此外,如果知识系统中的每个知识点都是图中的一个点,并且依赖关系是边,那么图一定不是有向无环图。因为学习A的经验可以帮助你学习B。因此,你不需要学习如何“入门”,因为这样的“入门”点根本不存在!您需要学习的是如何做更大的事情,并且在此过程中,您将很快了解您需要学习的内容。当然,你可以争辩说你需要先了解Python,否则你怎么学Python做爬虫呢?但实际上,你可以在做这个爬虫的过程中学习Python。
看到前面很多回答中提到的“技能”——用什么软件怎么爬,那我就说说“道”和“技能”——爬虫是如何工作的,以及如何在Python中实现。
对Python感兴趣的朋友,记得私信小编“007”领取全套Python资料。
长话短说,总结一下,你需要学习:
基本爬虫工作原理 基本http爬虫,scrapyBloom Filter 如果需要大规模的网页抓取,需要学习分布式爬虫的概念。其实没那么神秘,你只需要学习如何维护一个所有集群机器都可以有效共享的分布式队列。最简单的实现是python-rqrq和scrapy的结合:darkrho/scrapy-redis 后续处理,网页提取 grangier/python-goose,存储(Mongodb)
这是一个简短的故事:
说说从我写的一个集群爬下整个豆瓣的经历吧。
1)首先你需要了解爬虫是如何工作的
想象一下,你是一只蜘蛛,现在你被放到了互联网“网络”上。好吧,您需要浏览所有网页。怎么做?没问题,你可以从任何地方开始,比如人民日报的首页,称为初始页,用$表示。
在人民日报的主页上,你会看到各种指向该页面的链接。于是你高高兴兴地爬到了“国内新闻”页面。太好了,你已经爬了两页(首页和国内新闻)!暂时不管你爬下来的页面怎么处理,你可以想象你把这个页面复制成html放到你身上了。
突然你发现,在国内新闻页面上,有一个返回“首页”的链接。作为一只聪明的蜘蛛,你必须知道你不必爬回来,因为你已经看到了。所以,你需要用你的大脑来保存你已经看过的页面的地址。这样,每次看到可能需要爬取的新链接时,首先在脑海中检查一下是否已经到过这个页面地址。如果你去过,不要去。
好吧,理论上,如果从初始页面可以到达所有页面,那么就可以证明你可以爬取所有页面。
那么如何在 Python 中实现呢?非常简单
import Queue
initial_page = "http://www.renminribao.com"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
#一直进行直到海枯石烂
while(True):
if url_queue.size()>0:
#拿出队例中第一个的url
current_url = url_queue.get()
#把这个url代表的网页存储好
store(current_url)
#提取把这个url里链向的url
for next_url in extract_urls(current_url):
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break
它已经是非常伪代码了。
所有爬虫的中坚力量都在这里,我们来分析一下为什么爬虫其实是很复杂的东西——搜索引擎公司通常有一个完整的团队来维护和开发。
2)效率
如果你直接处理上面的代码,直接运行,你要花一整年的时间才能爬下豆瓣的全部内容。更不用说像谷歌这样的搜索引擎需要爬取整个内容网络。
哪里有问题?要爬的页面太多,上面的代码太慢了。假设全网有N个网站,那么分析权重判断的复杂度是N*log(N),因为所有网页都需要遍历一次,需要log(N)的复杂度每次重复使用该集合。. 好的,好的,我知道 Python 的 set 实现是散列 - 但这仍然太慢,至少内存效率不高。
通常的判断方法是什么?布隆过滤器。简而言之,它仍然是一种哈希方法,但它的特点是可以使用固定内存(不随url的数量增长)来判断url是否已经在集合中,效率为O(1)不幸的是,世界上没有免费的午餐。唯一的问题是如果这个url不在集合中,BF可以100%确定这个url没有被看到。但是如果这个url在设置,它会告诉你:这个 url 应该已经存在了,但是我有 2% 的不确定性。注意,当你分配足够的内存时,这里的不确定性会变得非常小。一个简单的教程:Bloom Filters by Example。
注意这个特性,如果url看过,可能小概率会重复(没关系,多看就不会累死)。但是如果没有看到,就会看到(这很重要,否则我们会错过一些页面!)。
好的,现在我们正在接近处理权重的最快方法。另一个瓶颈 - 你只有一台机器。不管你有多少带宽,只要你的机器下载网页的速度是瓶颈,那你就只能提速了。如果一台机器不够用 - 使用多台!当然,我们假设每台机器都进入了最高效率——使用多线程(在 Python 的情况下是多进程)。
3)集群爬取
爬豆瓣的时候,我用了100多台机器,24小时不间断地跑了一个月。想象一下,如果你只用一台机器运行 100 个月......
那么,假设你现在有 100 台机器可用,如何在 Python 中实现分布式爬虫算法呢?
我们将这100台机器中的99台算力较小的机器称为slave,另一台较大的机器称为master,然后查看上面代码中的url_queue,如果我们可以把这个队列放在这台master机器上,那么所有slave都可以与master通信通过网络。每当从站完成下载网页时,它都会向主站请求新的网页以进行爬网。并且每次slave捕获一个新的网页,它会将网页上的所有链接发送到master的队列中。同样,布隆过滤器也放在master上,但是现在master只发送肯定不会被访问的url给slave。Bloom Filter放在master的内存中,访问的url放在运行在master上的Redis中,保证了所有操作都是O(1).(至少摊销是O(1),
考虑如何在 Python 中做到这一点:
在每台slave上安装scrapy,然后每台机器都成为具有抓取能力的slave,在master上安装redis和rq作为分布式队列使用。
然后代码写成
#slave.py
current_url = request_from_master()
to_send = []
for next_url in extract_urls(current_url):
to_send.append(next_url)
store(current_url);
send_to_master(to_send)
#master.py
distributed_queue = DistributedQueue()
bf = BloomFilter()
initial_pages = "www.renmingribao.com"
while(True):
if request == 'GET':
if distributed_queue.size()>0:
send(distributed_queue.get())
else:
break
elif request == 'POST':
bf.put(request.url)
好吧,你可以想象,有人已经给你写了你需要的东西:darkrho/scrapy-redis · GitHub
4)勘探和后处理
虽然上面使用了很多“简单”,但要真正实现一个商业规模可用的爬虫并不是一件容易的事。上面的代码用于爬取整个网站,问题不大。
但是如果附加你需要这些后处理,比如
有效存储(数据库应该如何安排),有效权重判断(这里指的是网页权重判断,我们不想爬取抄袭它的人民日报和大民日报) 有效信息提取(例如,如何提取所有网页上的信息地址是提取出来的,“朝阳区奋进路中华路”),搜索引擎通常不需要存储所有信息,比如我保存的图片...及时更新(预测此网页多久更新一次)
可以想象,这里的每一点都可以被许多研究人员研究数十年。即便如此,“路漫漫其修远兮,我要上上下下寻找。”
网页抓取数据百度百科(如何编写一个爬虫的python聚集地!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-13 21:10
最近在做一个项目,需要使用网络爬虫从特定的网站爬取数据,所以打算写一个爬虫系列文章跟大家分享一下如何编写爬虫。下面的文章文章介绍python爬虫的基础知识。有兴趣的朋友可以看看。
爬虫简介
根据百度百科定义:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
随着数据的海量增长,我们需要在互联网上选择需要的数据进行自己的研究分析和实验。这使用了爬虫技术。跟着小编第一次认识python爬虫吧!
一、请求-响应
使用python语言实现爬虫时,主要用到了urllib和urllib2这两个库。首先,用一段代码来说明以下内容:
import urllib
import urllib2
url="http://www.baidu.com"
request=urllib2.Request(url)
response=urllib2.urlopen(request)
print response.read()
我们知道一个网页是由html作为骨架,js作为肌肉,css作为衣服组成的。上面代码实现的功能是将百度网页的源码爬取到本地。
其中,url为要爬取的网页的URL;request 发出请求,response 是接受请求后给出的响应。最后read()函数的输出就是百度网页的源码。
二、GET-POST
两者都将数据传递到网页。最重要的区别是GET方法是以链接的形式直接访问的。该链接收录所有参数。当然,如果它收录密码,这是一个不安全的选择,但你可以直观地做到这一点。查看您提交的内容。
POST不会显示URL上的所有参数,但是如果要直接查看提交的内容,不是很方便,可以酌情选择。
POST 方法:
import urllib
import urllib2
values={
'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url='https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn'
request=urllib2.Request(url,data)
response=urllib2.urlopen(request)
print response.read()
获取方法:
import urllib
import urllib2
values={
'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request=urllib2.Request(geturl)
response=urllib2.urlopen(request)
print response.read()
三、异常处理
处理异常时,使用 try-except 语句。
import urllib2
try:
response=urllib2.urlopen("http://www.xxx.com")
except urllib2.URLError,e:
print e.reason
最后给大家推荐一个口碑不错的蟒蛇聚集地【点击进入】。有很多前辈的学习技巧、学习心得、面试技巧、职场心得等分享,我们精心准备了零基础的入门资料和实战项目资料。, 程序员每天定期讲解Python技术,分享一些学习方法和需要注意的小细节
总结
以上就是小编为大家介绍的python爬虫基础知识。我希望它对你有帮助。如果您有任何问题,请给我留言 查看全部
网页抓取数据百度百科(如何编写一个爬虫的python聚集地!)
最近在做一个项目,需要使用网络爬虫从特定的网站爬取数据,所以打算写一个爬虫系列文章跟大家分享一下如何编写爬虫。下面的文章文章介绍python爬虫的基础知识。有兴趣的朋友可以看看。
爬虫简介
根据百度百科定义:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
随着数据的海量增长,我们需要在互联网上选择需要的数据进行自己的研究分析和实验。这使用了爬虫技术。跟着小编第一次认识python爬虫吧!
一、请求-响应
使用python语言实现爬虫时,主要用到了urllib和urllib2这两个库。首先,用一段代码来说明以下内容:
import urllib
import urllib2
url="http://www.baidu.com"
request=urllib2.Request(url)
response=urllib2.urlopen(request)
print response.read()
我们知道一个网页是由html作为骨架,js作为肌肉,css作为衣服组成的。上面代码实现的功能是将百度网页的源码爬取到本地。
其中,url为要爬取的网页的URL;request 发出请求,response 是接受请求后给出的响应。最后read()函数的输出就是百度网页的源码。
二、GET-POST
两者都将数据传递到网页。最重要的区别是GET方法是以链接的形式直接访问的。该链接收录所有参数。当然,如果它收录密码,这是一个不安全的选择,但你可以直观地做到这一点。查看您提交的内容。
POST不会显示URL上的所有参数,但是如果要直接查看提交的内容,不是很方便,可以酌情选择。
POST 方法:
import urllib
import urllib2
values={
'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url='https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn'
request=urllib2.Request(url,data)
response=urllib2.urlopen(request)
print response.read()
获取方法:
import urllib
import urllib2
values={
'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request=urllib2.Request(geturl)
response=urllib2.urlopen(request)
print response.read()
三、异常处理
处理异常时,使用 try-except 语句。
import urllib2
try:
response=urllib2.urlopen("http://www.xxx.com";)
except urllib2.URLError,e:
print e.reason
最后给大家推荐一个口碑不错的蟒蛇聚集地【点击进入】。有很多前辈的学习技巧、学习心得、面试技巧、职场心得等分享,我们精心准备了零基础的入门资料和实战项目资料。, 程序员每天定期讲解Python技术,分享一些学习方法和需要注意的小细节
总结
以上就是小编为大家介绍的python爬虫基础知识。我希望它对你有帮助。如果您有任何问题,请给我留言
网页抓取数据百度百科(浏览器模拟登录的实现过程1、获取所需要的参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-12 14:10
模拟登录原理
一般情况下,用户通过浏览器登录网站时,会在特定的登录界面输入个人登录信息,提交后可以返回收录数据的网页。浏览器层面的机制是浏览器提交一个收录必要信息的http Request,服务器返回一个http Response。HTTP Request 内容包括以下 5 项:
URL = 基本 URL + 可选查询字符串
请求标头:必需或可选
饼干:可选
发布数据:当时的 POST 方法需要
http Response的内容包括以下两项:Html源码或图片、json字符串等。
Cookies:如果后续访问需要cookie,返回的内容会收录cookie
其中,URL是Uniform Resource Locator的缩写,是对可以从互联网上获取的资源的位置和访问方式的简明表示,包括主机部分和文件路径部分;Request Headers 是向服务请求信息的头部信息。收录编码格式、用户代理、提交主机和路径等信息;发布数据是指提交的用户、内容、格式参数等。Cookies是服务器发送给浏览器的文件,保存在本地,服务器用来识别用户,以及判断用户是否合法和一些登录信息。
网页抓取的工作原理
如上所述,模拟登录后,网站服务器会返回一个html文件。HTML 是一个带有严格语法和格式的标签的文本文件。数据特征,使用正则表达式来获取您需要的数据或表示可以进一步挖掘的数据的链接。
模拟登录的实现流程
1、获取所需参数 IE浏览器为开发者提供了强大的工具。获取参数的过程如下:
打开浏览器
输入网址
开发者工具
启用网络
网络流量捕获
输入密码和账号登录
查找发起者为“click”的第一条记录
细节
“请求标头”和“请求正文”
请求头和请求体收录客户端和浏览器交互的参数。有些参数是默认的,不需要设置;一些参数与用户本身有关,如用户名、密码、是否记住密码等;
一些参数是由客户端和服务器交互产生的。确定参数的步骤是,首先从字面上理解它们,其次在交互记录中搜索参数名称,观察这些参数是在哪个过程中产生的。请求正文中看到的一些参数是编码的,需要解码。
2、 获取登录百度账号需要的参数
按照以上步骤,使用IE9浏览器自带的工具,即可轻松获取相关参数。其中staticpage是跳转页面,解码后还是在“摘要”记录中知道.html。查找后发现token参数首先出现在URL的响应体中,需要在返回的页码中捕获;apiver 参数设置返回的文本是 json 格式还是 html 格式。除了请求头中的一般设置参数外,还有cookies,需要在登录过程中获取,以便与服务器交互。
3、 登录的具体代码实现
3.1 导入登录进程使用的库
重新进口;
导入 cookielib;
导入 urllib;
导入 urllib2;
re库解析正则表达式并爬取匹配;cookielib 库获取和管理 cookie;urllib 和 urllib2 库根据 URL 和 post 数据参数从服务器请求和解码数据。
3.2 cookie检测函数
通过检查cookiejar返回的cookie key是否与cookieNameList完全匹配来判断登录是否成功。
def checkAllCookiesExist(cookieNameList, cookieJar) :
cookiesDict = {};
对于 cookieNameList 中的每个CookieName:
cookiesDict[eachCookieName] = 假;
allCookieFound =真;
对于 cookieJar 中的 cookie:
if(cookie.name in cookiesDict.keys()) :
cookiesDict[cookie.name] = True;
对于 cookiesDict.keys() 中的 Cookie:
如果(不是 cookiesDict[eachCookie]):
allCookieFound = False;
休息;
返回所有CookieFound;
3.3 模拟登录百度
def emulateLoginBaidu():
cj = cookielib.CookieJar(); .
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj));
urllib2.install_opener(opener);
创建一个 cookieJar 对象来存储 cookie,与 http 处理程序绑定并打开安装。
print "[step1] 获取cookie BAIDUID";
baiduMainUrl = "";
resp = urllib2.urlopen(baiduMainUrl);
打开百度首页,获取cookie BAIDUID。
print "[step2]获取token值";
getapiUrl = "";
getapiResp = urllib2.urlopen(getapiUrl);
getapiRespHtml = getapiResp.read();
打印“getapiResp=”,getapiResp;
isfoundToken= re.search("bdPass\.api\.params\.login_token='(?P\w+)';",
getapiRespHtml);
上述程序用于获取post数据中的token参数。首先获取getapiUrl URL的html,然后使用re标准库中的搜索函数搜索匹配,返回一个表示匹配是否成功的布尔值。
如果(IsfoundToken):
tokenVal = IsfoundToken.group("tokenVal");
打印“tokenVal=”,tokenVal;
print "[step3] 模拟登录百度";
静态页面 = "";
baiduMainLoginUrl = "";
postDict = {
'字符集' : "utf-8",
“令牌”:令牌值,
'isPhone' : "假",
“索引”:“0”,
'safeflg' : "0",
“静态页面”:静态页面,
“登录类型”:“1”,
'tpl' : "mn",
'用户名' : "用户名",
'密码' : "密码",
'mem_pass' : "开",
}[3];
设置postdata参数值,不是每个参数都需要设置,有些参数是默认的。
postData = urllib.urlencode(postDict);
编码后数据。比如l编码的结果是http%3A%2F%2F%2Fcache%2Fuser%2Fhtml%2Fjump.html,其他参数类似。
req = urllib2.Request(baiduMainLoginUrl, postData);
resp = urllib2.urlopen(req);
Python标准库urllib2的两个函数分别提交用户请求和数据,并接受返回的数据
cookiesToCheck = ['BDUSS', 'PTOKEN', 'STOKEN', 'SAVEUSERID', 'UBI', 'HISTORY', 'USERNAMETYPE'];
爬取网页的实现过程
以上使用正则表达式成功抓取返回网页中的token。Python 的标准库 HTMLParser 提供了一个强大的功能来识别 html 文本标签和数据。使用时,从 HTMLParser 派生一个新的类,然后重新定义这些以 handler_ 开头的函数。几个常用的功能包括:
handle_startendtag 处理开始和结束标签
handle_starttag 处理开始标签,例如
handle_endtag 处理结束标签,例如
handle_charref 处理以 开头的特殊字符串,一般是内部代码表示的字符
handle_entityref 处理一些以&开头的特殊字符,比如
handle_data 处理数据,也就是数据中间的数据
下面的程序是用来抓取百度贴吧Movie Bar帖子的header做示范:
导入 HTMLParser
导入 urllib2 查看全部
网页抓取数据百度百科(浏览器模拟登录的实现过程1、获取所需要的参数)
模拟登录原理
一般情况下,用户通过浏览器登录网站时,会在特定的登录界面输入个人登录信息,提交后可以返回收录数据的网页。浏览器层面的机制是浏览器提交一个收录必要信息的http Request,服务器返回一个http Response。HTTP Request 内容包括以下 5 项:
URL = 基本 URL + 可选查询字符串
请求标头:必需或可选
饼干:可选
发布数据:当时的 POST 方法需要
http Response的内容包括以下两项:Html源码或图片、json字符串等。
Cookies:如果后续访问需要cookie,返回的内容会收录cookie
其中,URL是Uniform Resource Locator的缩写,是对可以从互联网上获取的资源的位置和访问方式的简明表示,包括主机部分和文件路径部分;Request Headers 是向服务请求信息的头部信息。收录编码格式、用户代理、提交主机和路径等信息;发布数据是指提交的用户、内容、格式参数等。Cookies是服务器发送给浏览器的文件,保存在本地,服务器用来识别用户,以及判断用户是否合法和一些登录信息。
网页抓取的工作原理
如上所述,模拟登录后,网站服务器会返回一个html文件。HTML 是一个带有严格语法和格式的标签的文本文件。数据特征,使用正则表达式来获取您需要的数据或表示可以进一步挖掘的数据的链接。
模拟登录的实现流程
1、获取所需参数 IE浏览器为开发者提供了强大的工具。获取参数的过程如下:
打开浏览器
输入网址
开发者工具
启用网络
网络流量捕获
输入密码和账号登录
查找发起者为“click”的第一条记录
细节
“请求标头”和“请求正文”
请求头和请求体收录客户端和浏览器交互的参数。有些参数是默认的,不需要设置;一些参数与用户本身有关,如用户名、密码、是否记住密码等;
一些参数是由客户端和服务器交互产生的。确定参数的步骤是,首先从字面上理解它们,其次在交互记录中搜索参数名称,观察这些参数是在哪个过程中产生的。请求正文中看到的一些参数是编码的,需要解码。
2、 获取登录百度账号需要的参数
按照以上步骤,使用IE9浏览器自带的工具,即可轻松获取相关参数。其中staticpage是跳转页面,解码后还是在“摘要”记录中知道.html。查找后发现token参数首先出现在URL的响应体中,需要在返回的页码中捕获;apiver 参数设置返回的文本是 json 格式还是 html 格式。除了请求头中的一般设置参数外,还有cookies,需要在登录过程中获取,以便与服务器交互。
3、 登录的具体代码实现
3.1 导入登录进程使用的库
重新进口;
导入 cookielib;
导入 urllib;
导入 urllib2;
re库解析正则表达式并爬取匹配;cookielib 库获取和管理 cookie;urllib 和 urllib2 库根据 URL 和 post 数据参数从服务器请求和解码数据。
3.2 cookie检测函数
通过检查cookiejar返回的cookie key是否与cookieNameList完全匹配来判断登录是否成功。
def checkAllCookiesExist(cookieNameList, cookieJar) :
cookiesDict = {};
对于 cookieNameList 中的每个CookieName:
cookiesDict[eachCookieName] = 假;
allCookieFound =真;
对于 cookieJar 中的 cookie:
if(cookie.name in cookiesDict.keys()) :
cookiesDict[cookie.name] = True;
对于 cookiesDict.keys() 中的 Cookie:
如果(不是 cookiesDict[eachCookie]):
allCookieFound = False;
休息;
返回所有CookieFound;
3.3 模拟登录百度
def emulateLoginBaidu():
cj = cookielib.CookieJar(); .
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj));
urllib2.install_opener(opener);
创建一个 cookieJar 对象来存储 cookie,与 http 处理程序绑定并打开安装。
print "[step1] 获取cookie BAIDUID";
baiduMainUrl = "";
resp = urllib2.urlopen(baiduMainUrl);
打开百度首页,获取cookie BAIDUID。
print "[step2]获取token值";
getapiUrl = "";
getapiResp = urllib2.urlopen(getapiUrl);
getapiRespHtml = getapiResp.read();
打印“getapiResp=”,getapiResp;
isfoundToken= re.search("bdPass\.api\.params\.login_token='(?P\w+)';",
getapiRespHtml);
上述程序用于获取post数据中的token参数。首先获取getapiUrl URL的html,然后使用re标准库中的搜索函数搜索匹配,返回一个表示匹配是否成功的布尔值。
如果(IsfoundToken):
tokenVal = IsfoundToken.group("tokenVal");
打印“tokenVal=”,tokenVal;
print "[step3] 模拟登录百度";
静态页面 = "";
baiduMainLoginUrl = "";
postDict = {
'字符集' : "utf-8",
“令牌”:令牌值,
'isPhone' : "假",
“索引”:“0”,
'safeflg' : "0",
“静态页面”:静态页面,
“登录类型”:“1”,
'tpl' : "mn",
'用户名' : "用户名",
'密码' : "密码",
'mem_pass' : "开",
}[3];
设置postdata参数值,不是每个参数都需要设置,有些参数是默认的。
postData = urllib.urlencode(postDict);
编码后数据。比如l编码的结果是http%3A%2F%2F%2Fcache%2Fuser%2Fhtml%2Fjump.html,其他参数类似。
req = urllib2.Request(baiduMainLoginUrl, postData);
resp = urllib2.urlopen(req);
Python标准库urllib2的两个函数分别提交用户请求和数据,并接受返回的数据
cookiesToCheck = ['BDUSS', 'PTOKEN', 'STOKEN', 'SAVEUSERID', 'UBI', 'HISTORY', 'USERNAMETYPE'];
爬取网页的实现过程
以上使用正则表达式成功抓取返回网页中的token。Python 的标准库 HTMLParser 提供了一个强大的功能来识别 html 文本标签和数据。使用时,从 HTMLParser 派生一个新的类,然后重新定义这些以 handler_ 开头的函数。几个常用的功能包括:
handle_startendtag 处理开始和结束标签
handle_starttag 处理开始标签,例如
handle_endtag 处理结束标签,例如
handle_charref 处理以 开头的特殊字符串,一般是内部代码表示的字符
handle_entityref 处理一些以&开头的特殊字符,比如
handle_data 处理数据,也就是数据中间的数据
下面的程序是用来抓取百度贴吧Movie Bar帖子的header做示范:
导入 HTMLParser
导入 urllib2
网页抓取数据百度百科(蜘蛛抓取第一步爬行和抓取爬行到你的网站网页网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-12 14:09
蜘蛛爬行第一步爬行爬行
爬到您的 网站 页面以查找合适的资源。蜘蛛有一个特点,就是它们的轨迹通常围绕着蜘蛛丝转,而我们之所以将搜索引擎机器人命名为蜘蛛,就是因为这个特点。当蜘蛛来到你的网站时,它会继续沿着你的网站中的链接(蛛丝)爬行,那么如何让蜘蛛更好的在你的网站中爬行就变成了我们的首要任务。抓取您的网页。引导蜘蛛爬行 这只是一个开始,一个好的开始意味着你会有一个很高的起点。通过自己的内链设计,网站中没有死角,蜘蛛可以轻松到达网站中的每一页,让蜘蛛进行第二步工作——爬的时候,会做事半功倍。在这一步的爬取过程中,需要注意简化网站的结构,去掉那些不必要的、不必要的冗余代码,因为这些会影响蜘蛛爬取网页的效率和效率。影响。还有一点需要注意的是,我们不建议将FLASH放在网站中,因为FLASH不容易被蜘蛛抓取,过多的FLASH会导致蜘蛛放弃抓取你的网站页面。
蜘蛛爬行第二步存储
爬取到链接对应的页面后,这些页面的内容将存储在搜索引擎的原创数据库中。一些文本内容将被抓取。
网站优化过程中不要盲目添加一些图片或动画flash文件到网站。这对搜索引擎抓取不利。这种排没有太大的价值,应该做更多的内容。
爬取搜索引擎的原创数据并不意味着你的网站内容一定会被百度采纳。搜索引擎还需要经过下一步。
蜘蛛爬行预处理第三步
搜索引擎仍然以(文本)为主。JS、CSS程序代码不可用于排名。蜘蛛对第一步提取的文本进行拆分和重组,形成新词。
去重(删除一些重复的内容,搜索引擎数据库中已经存在的内容)
那些要求我们优化SEO内容的人,不要完全照搬别人网站的内容。
删除停用词
停用词:是的,得到,土地,啊,哈,啊,因此,到,,,等等。减少不必要的计算 美丽中国 美丽中国
注意:抄袭别人的内容时,要求我们修改得更用力,而不是一两个字。我们在优化的时候需要做更多的改动,而且写法和别人不一样,主要是标题。
噪音消除
您的 网站 有很多弹出式广告。对于 网站 中有大量广告的 网站,蜘蛛不会以你的 网站 为焦点进行抓取。
我们不能随意在 网站 中添加弹出广告。
爬虫第四步,建索引
根据以上预处理的结果,对页面的key密度进行了合理的处理,内容匹配度高,反向链接多,导出链接少,对页面进行排序和索引,构建索引库。
站点:查询的参考值,而不是 网站 的完整索引量。(百度站长工具-索引量)百度对新站一般有一个月的评估期,抓到的网站放入百度索引库,不发布。
蜘蛛爬行第 5 步排名
搜索引擎经过搜索词处理、文档匹配、相关性计算、过滤调整、排名展示等一系列复杂任务后完成最终排名。
匹配度最高、流量最大、权重最高的站点会优先展示。收录-排名-点击-转化 查看全部
网页抓取数据百度百科(蜘蛛抓取第一步爬行和抓取爬行到你的网站网页网页)
蜘蛛爬行第一步爬行爬行
爬到您的 网站 页面以查找合适的资源。蜘蛛有一个特点,就是它们的轨迹通常围绕着蜘蛛丝转,而我们之所以将搜索引擎机器人命名为蜘蛛,就是因为这个特点。当蜘蛛来到你的网站时,它会继续沿着你的网站中的链接(蛛丝)爬行,那么如何让蜘蛛更好的在你的网站中爬行就变成了我们的首要任务。抓取您的网页。引导蜘蛛爬行 这只是一个开始,一个好的开始意味着你会有一个很高的起点。通过自己的内链设计,网站中没有死角,蜘蛛可以轻松到达网站中的每一页,让蜘蛛进行第二步工作——爬的时候,会做事半功倍。在这一步的爬取过程中,需要注意简化网站的结构,去掉那些不必要的、不必要的冗余代码,因为这些会影响蜘蛛爬取网页的效率和效率。影响。还有一点需要注意的是,我们不建议将FLASH放在网站中,因为FLASH不容易被蜘蛛抓取,过多的FLASH会导致蜘蛛放弃抓取你的网站页面。
蜘蛛爬行第二步存储
爬取到链接对应的页面后,这些页面的内容将存储在搜索引擎的原创数据库中。一些文本内容将被抓取。
网站优化过程中不要盲目添加一些图片或动画flash文件到网站。这对搜索引擎抓取不利。这种排没有太大的价值,应该做更多的内容。
爬取搜索引擎的原创数据并不意味着你的网站内容一定会被百度采纳。搜索引擎还需要经过下一步。
蜘蛛爬行预处理第三步
搜索引擎仍然以(文本)为主。JS、CSS程序代码不可用于排名。蜘蛛对第一步提取的文本进行拆分和重组,形成新词。
去重(删除一些重复的内容,搜索引擎数据库中已经存在的内容)
那些要求我们优化SEO内容的人,不要完全照搬别人网站的内容。
删除停用词
停用词:是的,得到,土地,啊,哈,啊,因此,到,,,等等。减少不必要的计算 美丽中国 美丽中国
注意:抄袭别人的内容时,要求我们修改得更用力,而不是一两个字。我们在优化的时候需要做更多的改动,而且写法和别人不一样,主要是标题。
噪音消除
您的 网站 有很多弹出式广告。对于 网站 中有大量广告的 网站,蜘蛛不会以你的 网站 为焦点进行抓取。
我们不能随意在 网站 中添加弹出广告。
爬虫第四步,建索引
根据以上预处理的结果,对页面的key密度进行了合理的处理,内容匹配度高,反向链接多,导出链接少,对页面进行排序和索引,构建索引库。
站点:查询的参考值,而不是 网站 的完整索引量。(百度站长工具-索引量)百度对新站一般有一个月的评估期,抓到的网站放入百度索引库,不发布。
蜘蛛爬行第 5 步排名
搜索引擎经过搜索词处理、文档匹配、相关性计算、过滤调整、排名展示等一系列复杂任务后完成最终排名。
匹配度最高、流量最大、权重最高的站点会优先展示。收录-排名-点击-转化
网页抓取数据百度百科( 一个介绍一个爬取动态网页的超简单的一个小demo)
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2022-04-12 03:28
一个介绍一个爬取动态网页的超简单的一个小demo)
一、 分析网页结构
前几篇文章介绍了传统静态界面的爬取。这次博主介绍了一个超级简单的爬取动态网页的小demo。
说起动态网页,你对它了解多少?
不知道动态网页的,博主给个链接,可以看百度百科_百度百科动态网页的详细解析以及小马福静态页和动态页的区别
不要怪博主没有解释清楚,因为博主本人对动态网页的概念也不是很了解。当博主整理自己的想法时,博主会专门写一篇博文——。-
简单来说,要获取静态网页的网页数据,只需要将网页的URL地址发送到服务器,动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要将请求文件的url地址发送给服务器,而不是网页的url地址。
,让我们开始进入正题。
本篇博文以高德地图开头:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候我们就可以判断是动态网页了。这时候,我们需要找到一个接口
点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求。它可以在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下更新网页某一部分的内容。即从数据库请求然后响应的数据是XHR类型的
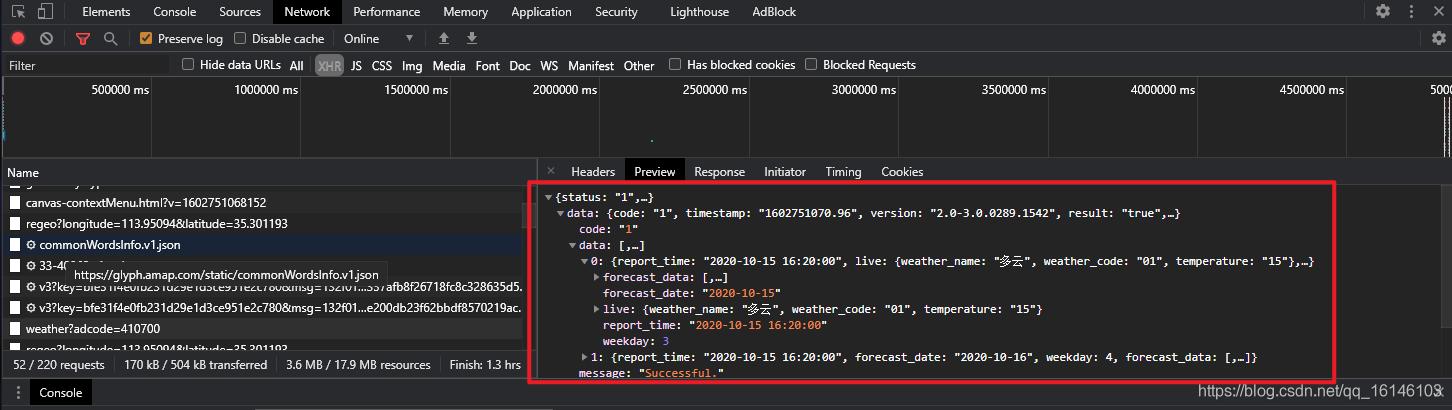
然后我们就可以开始在XHR类型下一一搜索,找到如下数据
通过查看标头获取 URL
打开后发现是这两天的天气情况。
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”这个键值中。
,找到了json数据,我们对比一下看看是不是我们要找的
通过比较,数据完全对应,这意味着我们已经获得了数据。
二、获取相关网址
'''
查询当前地点天气的url:https://www.amap.com/service/c ... 01417
各城市对应code的url:https://www.amap.com/service/weather?adcode=410700
备注:这两个url可以从Network中查看到
'''
123456
,我们已经获取了相关的URL,下面是具体的代码实现。至于怎么做,
我们知道json数据可以使用response.json()转换成字典,然后对字典进行操作。
三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和数字
先爬取网页,伪装成浏览器,添加header访问数据库地址,防止被识别和拦截。
url_city = "https://www.amap.com/service/c ... ot%3B
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
city = []
response = requests.get(url=url_city, headers=headers)
content = response.json()
print(content)
12345678910
得到我们想要的数据后,我们可以通过搜索发现cityByLetter中的数字和名字是我们需要的,然后我们就可以设置了。
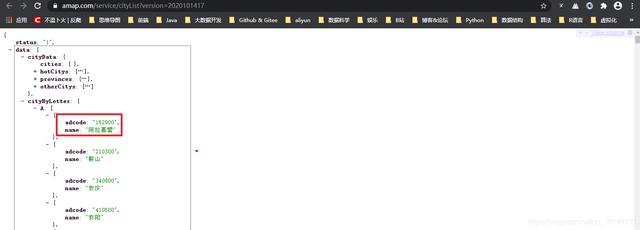
if "data" in content:
cityByLetter = content["data"]["cityByLetter"]
for k,v in cityByLetter.items():
city.extend(v)
return city
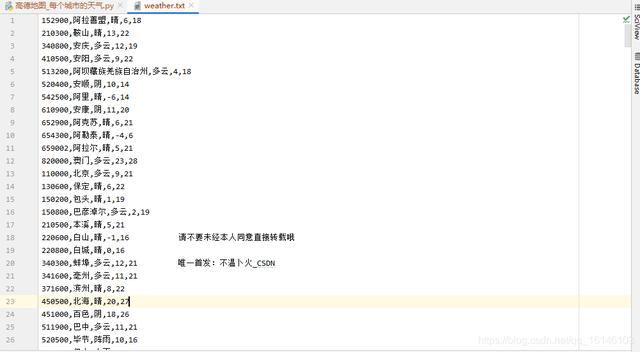
12345
3.2 根据号码查询天气
得到号码和名字,下面一定要查天气!
先看界面
通过上图可以确定最高温度、最低温度等。然后使用它进行数据爬取。
url_weather = "https://www.amap.com/service/weather?adcode={}"
response = requests.get(url=url_weather.format(adcode), headers=headers)
content = response.json()
item["weather_name"] = content["data"]["data"][0]["forecast_data"][0]["weather_name"]
item["min_temp"] = content["data"]["data"][0]["forecast_data"][0]["min_temp"]
item["max_temp"] = content["data"]["data"][0]["forecast_data"][0]["max_temp"]
print(item)
12345678
,我们的愿景已经实现。
四、完整代码
# encoding: utf-8
'''
@author 李华鑫
@create 2020-10-06 19:46
Mycsdn:https://buwenbuhuo.blog.csdn.net/
@contact: 459804692@qq.com
@software: Pycharm
@file: 高德地图_每个城市的天气.py
@Version:1.0
'''
import requests
url_city = "https://www.amap.com/service/c ... ot%3B
url_weather = "https://www.amap.com/service/weather?adcode={}"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
def get_city():
"""查询所有城市名称和编号"""
city = []
response = requests.get(url=url_city, headers=headers)
content = response.json()
if "data" in content:
cityByLetter = content["data"]["cityByLetter"]
for k, v in cityByLetter.items():
city.extend(v)
return city
def get_weather(adcode, name):
"""根据编号查询天气"""
item = {}
item["adcode"] = str(adcode)
item["name"] = name
response = requests.get(url=url_weather.format(adcode), headers=headers)
content = response.json()
item["weather_name"] = content["data"]["data"][0]["forecast_data"][0]["weather_name"]
item["min_temp"] = content["data"]["data"][0]["forecast_data"][0]["min_temp"]
item["max_temp"] = content["data"]["data"][0]["forecast_data"][0]["max_temp"]
return item
def save(item):
"""保存"""
print(item)
with open("./weather.txt","a",encoding="utf-8") as file:
file.write(",".join(item.values()))
file.write("\n")
if __name__ == '__main__':
city_list = get_city()
for city in city_list:
item = get_weather(city["adcode"],city["name"])
save(item)
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
五、保存结果
美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!
PS:如果不能解决问题,可以点击下方链接自行获取
Python免费学习资料及群交流答案点击加入 查看全部
网页抓取数据百度百科(
一个介绍一个爬取动态网页的超简单的一个小demo)

一、 分析网页结构
前几篇文章介绍了传统静态界面的爬取。这次博主介绍了一个超级简单的爬取动态网页的小demo。

说起动态网页,你对它了解多少?
不知道动态网页的,博主给个链接,可以看百度百科_百度百科动态网页的详细解析以及小马福静态页和动态页的区别

不要怪博主没有解释清楚,因为博主本人对动态网页的概念也不是很了解。当博主整理自己的想法时,博主会专门写一篇博文——。-
简单来说,要获取静态网页的网页数据,只需要将网页的URL地址发送到服务器,动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要将请求文件的url地址发送给服务器,而不是网页的url地址。
,让我们开始进入正题。
本篇博文以高德地图开头:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候我们就可以判断是动态网页了。这时候,我们需要找到一个接口

点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求。它可以在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下更新网页某一部分的内容。即从数据库请求然后响应的数据是XHR类型的
然后我们就可以开始在XHR类型下一一搜索,找到如下数据
通过查看标头获取 URL

打开后发现是这两天的天气情况。
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”这个键值中。
,找到了json数据,我们对比一下看看是不是我们要找的
通过比较,数据完全对应,这意味着我们已经获得了数据。
二、获取相关网址
'''
查询当前地点天气的url:https://www.amap.com/service/c ... 01417
各城市对应code的url:https://www.amap.com/service/weather?adcode=410700
备注:这两个url可以从Network中查看到
'''
123456
,我们已经获取了相关的URL,下面是具体的代码实现。至于怎么做,
我们知道json数据可以使用response.json()转换成字典,然后对字典进行操作。

三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和数字
先爬取网页,伪装成浏览器,添加header访问数据库地址,防止被识别和拦截。
url_city = "https://www.amap.com/service/c ... ot%3B
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
city = []
response = requests.get(url=url_city, headers=headers)
content = response.json()
print(content)
12345678910

得到我们想要的数据后,我们可以通过搜索发现cityByLetter中的数字和名字是我们需要的,然后我们就可以设置了。
if "data" in content:
cityByLetter = content["data"]["cityByLetter"]
for k,v in cityByLetter.items():
city.extend(v)
return city
12345

3.2 根据号码查询天气
得到号码和名字,下面一定要查天气!
先看界面

通过上图可以确定最高温度、最低温度等。然后使用它进行数据爬取。
url_weather = "https://www.amap.com/service/weather?adcode={}"
response = requests.get(url=url_weather.format(adcode), headers=headers)
content = response.json()
item["weather_name"] = content["data"]["data"][0]["forecast_data"][0]["weather_name"]
item["min_temp"] = content["data"]["data"][0]["forecast_data"][0]["min_temp"]
item["max_temp"] = content["data"]["data"][0]["forecast_data"][0]["max_temp"]
print(item)
12345678

,我们的愿景已经实现。

四、完整代码
# encoding: utf-8
'''
@author 李华鑫
@create 2020-10-06 19:46
Mycsdn:https://buwenbuhuo.blog.csdn.net/
@contact: 459804692@qq.com
@software: Pycharm
@file: 高德地图_每个城市的天气.py
@Version:1.0
'''
import requests
url_city = "https://www.amap.com/service/c ... ot%3B
url_weather = "https://www.amap.com/service/weather?adcode={}"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
def get_city():
"""查询所有城市名称和编号"""
city = []
response = requests.get(url=url_city, headers=headers)
content = response.json()
if "data" in content:
cityByLetter = content["data"]["cityByLetter"]
for k, v in cityByLetter.items():
city.extend(v)
return city
def get_weather(adcode, name):
"""根据编号查询天气"""
item = {}
item["adcode"] = str(adcode)
item["name"] = name
response = requests.get(url=url_weather.format(adcode), headers=headers)
content = response.json()
item["weather_name"] = content["data"]["data"][0]["forecast_data"][0]["weather_name"]
item["min_temp"] = content["data"]["data"][0]["forecast_data"][0]["min_temp"]
item["max_temp"] = content["data"]["data"][0]["forecast_data"][0]["max_temp"]
return item
def save(item):
"""保存"""
print(item)
with open("./weather.txt","a",encoding="utf-8") as file:
file.write(",".join(item.values()))
file.write("\n")
if __name__ == '__main__':
city_list = get_city()
for city in city_list:
item = get_weather(city["adcode"],city["name"])
save(item)
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
五、保存结果
美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!
PS:如果不能解决问题,可以点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
网页抓取数据百度百科(北京百度外包如何借助Dede采集插件让网站快速收录以及关键词排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-04-12 00:09
北京百度百科外包,公营企业业务范围包括:技术推广、技术转让、技术咨询、技术服务;计算机系统服务;软件开发; 软件咨询;设计、制作、代理、广告;产品设计; 包装装潢设计;模型设计;工艺美术设计;电脑动画设计;影视策划;教育咨询(中介服务除外);公共关系服务;企业规划;市场调查; 企业管理咨询;组织文化艺术交流活动(不包括商业演出);承办展览展览活动;会议服务;翻译服务; 自主开发产品的销售等
百度在北京外包,如何使用Dede采集插件让网站快收录和关键词排名,让网站快收录 之前我们要了解百度蜘蛛,百度蜘蛛对于不同的站点有不同的爬取规则。百度蜘蛛的爬取频率对于我们作为 SEO 公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。网站权重:权重越高网站百度蜘蛛爬得越频繁越深网站更新频率:更新频率越高,百度蜘蛛来的越多网站内容质量:百度将增加对网站content原创的抓取频率,内容更多、质量更高、处理用户问题的能力更强。传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。而优质的链接可以更好地引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。而优质的链接可以更好地引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。爬取 为了在互联网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息。减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。爬取 为了在互联网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息。减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。识别URL重定向互联网信息数据量很大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
百度在北京外包,如何使用飞飞cms采集让关键词排名和网站快收录,相信网站@的排名> 很多小伙伴的经历过天堂和地狱......百度在近端时间波动很大,很多网站排名直接被PASS掉了。很多人对百度的调整一无所知,只能等待恢复正常。虽然目前还没有百度推出新算法的迹象,但作为SEO优化者,我们还是要根据目前的百度算法体系来调整优化网站,否则波动不能怪“大环境”。今天给大家一个飞飞cms采集工具,可以批量管理网站。无论你有成百上千个不同的飞飞cms网站还是其他网站,都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms, People Renzhan< @cms、飞飞cms、Cyclone、站群、PBoot、Apple、Mito、搜外等各大cms,可同时批量管理采集伪原创 和发布推送工具) 查看全部
网页抓取数据百度百科(北京百度外包如何借助Dede采集插件让网站快速收录以及关键词排名)
北京百度百科外包,公营企业业务范围包括:技术推广、技术转让、技术咨询、技术服务;计算机系统服务;软件开发; 软件咨询;设计、制作、代理、广告;产品设计; 包装装潢设计;模型设计;工艺美术设计;电脑动画设计;影视策划;教育咨询(中介服务除外);公共关系服务;企业规划;市场调查; 企业管理咨询;组织文化艺术交流活动(不包括商业演出);承办展览展览活动;会议服务;翻译服务; 自主开发产品的销售等
百度在北京外包,如何使用Dede采集插件让网站快收录和关键词排名,让网站快收录 之前我们要了解百度蜘蛛,百度蜘蛛对于不同的站点有不同的爬取规则。百度蜘蛛的爬取频率对于我们作为 SEO 公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。网站权重:权重越高网站百度蜘蛛爬得越频繁越深网站更新频率:更新频率越高,百度蜘蛛来的越多网站内容质量:百度将增加对网站content原创的抓取频率,内容更多、质量更高、处理用户问题的能力更强。传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。而优质的链接可以更好地引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。而优质的链接可以更好地引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。爬取 为了在互联网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息。减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。爬取 为了在互联网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息。减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。识别URL重定向互联网信息数据量很大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
百度在北京外包,如何使用飞飞cms采集让关键词排名和网站快收录,相信网站@的排名> 很多小伙伴的经历过天堂和地狱......百度在近端时间波动很大,很多网站排名直接被PASS掉了。很多人对百度的调整一无所知,只能等待恢复正常。虽然目前还没有百度推出新算法的迹象,但作为SEO优化者,我们还是要根据目前的百度算法体系来调整优化网站,否则波动不能怪“大环境”。今天给大家一个飞飞cms采集工具,可以批量管理网站。无论你有成百上千个不同的飞飞cms网站还是其他网站,都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms, People Renzhan< @cms、飞飞cms、Cyclone、站群、PBoot、Apple、Mito、搜外等各大cms,可同时批量管理采集伪原创 和发布推送工具)
网页抓取数据百度百科(搜索引擎蜘蛛的工作原理是怎样的?蜘蛛这个事儿)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-08 00:00
做搜索引擎的时候,SEO人员都熟悉一个词,叫“蜘蛛爬行”。一些新人可能会想到互联网?蜘蛛?是不是因为有网,监控人员被比作蜘蛛?道理差不多,但不专业。今天,小编就和大家一起来解读一下搜索引擎蜘蛛。
一、什么是搜索引擎蜘蛛
的确,用白话理解,互联网可以理解为一个巨大的“蜘蛛网”,搜索引擎蜘蛛类似于实际的“机器人”。蜘蛛的主要任务是浏览庞大的蜘蛛网(Internet)中的信息,然后将信息爬取到搜索引擎的服务器,进而构建索引库。这就像一个机器人浏览我们的 网站 并将内容保存到它自己的计算机上。
搜索引擎蜘蛛
二、搜索引擎蜘蛛是如何工作的?
搜索引擎蜘蛛如何工作
一、 爬网。
每个独立的搜索引擎都会有自己的网络爬虫爬虫。爬虫蜘蛛跟随网页中的超链接分析,不断地访问和抓取更多的网页。抓取的网页称为网页快照。不用说,搜索引擎蜘蛛会定期抓取网页。如下:
1、权重优先:先参考链接权重,再结合深度优先和广度优先策略进行抓取。例如,如果链接的权重还不错,则先使用深度;如果重量非常低,请先使用宽度。
2、Revisiting Crawl:这个可以从字面上理解。因为搜索引擎主要使用单次重访和完整重访。所以我们在做网站内容的时候,一定要记得定期维护每日更新,这样蜘蛛才能更快的访问和爬取更多的收录。
二、处理网页。
搜索引擎爬取网页后,需要进行大量的预处理工作才能提供检索服务。其中,最重要的是提取关键词,建立索引库和索引。其他包括去除重复网页、分词(中文)、判断网页类型、超链接分析、计算网页的重要性/丰富度等。
处理网页分为以下几个部分:
1、网页结构:删除所有HTML代码,提取内容。
2、去噪:离开网页的主题。
3、重复检查:查找和删除重复的网页和内容。
4、分词:将文本的内容提取出来后,分成几个词,然后排列存储在索引数据库中。还要计算这个词在这个页面上出现了多少次。需要指出的是,关键词stacking就是借用这个原理来优化网站。这种做法是作弊。
5、链接分析:搜索引擎会查询分析这个页面有多少反向链接,导出链接有多少内部链接,然后判断这个页面有多少权重。
三、提供检索服务。
用户输入关键词进行检索,搜索引擎从索引库中找到与关键词匹配的网页。为了方便用户判断,除了网页的标题和URL外,还提供了网页摘要等信息。
所以如果你想做一个好的搜索引擎,让蜘蛛爬取你的网站,小编根据搜索引擎的特点做如下总结:
1.网站发布信息后多做分享或多发外链。它可以帮助您的 网站 尽快带来搜索引擎蜘蛛的访问。您还可以通过内部链接增加搜索引擎蜘蛛在网站的停留时间,以获得更好的排名。
2.定期最好每天发布新信息或更新网站内容,让蜘蛛更多地访问你的信息进行爬取。
3.发布优质信息,让用户体验长久停留,有利于搜索引擎蜘蛛判断你的网站高价值。
4.别想走捷径,一定要遵守搜索引擎的规则,做好内容,做好用户体验网站。
是不是收获满满,受益良多?其实在这里我想推荐一个好帮手。TA将提供更多互联网学习资料,同时免费帮你解答任何互联网问题,并提供完善的互联网服务,TA就是Think Enterprise Internet(),点击访问,你会发现更多精彩! 查看全部
网页抓取数据百度百科(搜索引擎蜘蛛的工作原理是怎样的?蜘蛛这个事儿)
做搜索引擎的时候,SEO人员都熟悉一个词,叫“蜘蛛爬行”。一些新人可能会想到互联网?蜘蛛?是不是因为有网,监控人员被比作蜘蛛?道理差不多,但不专业。今天,小编就和大家一起来解读一下搜索引擎蜘蛛。
一、什么是搜索引擎蜘蛛
的确,用白话理解,互联网可以理解为一个巨大的“蜘蛛网”,搜索引擎蜘蛛类似于实际的“机器人”。蜘蛛的主要任务是浏览庞大的蜘蛛网(Internet)中的信息,然后将信息爬取到搜索引擎的服务器,进而构建索引库。这就像一个机器人浏览我们的 网站 并将内容保存到它自己的计算机上。
搜索引擎蜘蛛
二、搜索引擎蜘蛛是如何工作的?
搜索引擎蜘蛛如何工作
一、 爬网。
每个独立的搜索引擎都会有自己的网络爬虫爬虫。爬虫蜘蛛跟随网页中的超链接分析,不断地访问和抓取更多的网页。抓取的网页称为网页快照。不用说,搜索引擎蜘蛛会定期抓取网页。如下:
1、权重优先:先参考链接权重,再结合深度优先和广度优先策略进行抓取。例如,如果链接的权重还不错,则先使用深度;如果重量非常低,请先使用宽度。
2、Revisiting Crawl:这个可以从字面上理解。因为搜索引擎主要使用单次重访和完整重访。所以我们在做网站内容的时候,一定要记得定期维护每日更新,这样蜘蛛才能更快的访问和爬取更多的收录。
二、处理网页。
搜索引擎爬取网页后,需要进行大量的预处理工作才能提供检索服务。其中,最重要的是提取关键词,建立索引库和索引。其他包括去除重复网页、分词(中文)、判断网页类型、超链接分析、计算网页的重要性/丰富度等。
处理网页分为以下几个部分:
1、网页结构:删除所有HTML代码,提取内容。
2、去噪:离开网页的主题。
3、重复检查:查找和删除重复的网页和内容。
4、分词:将文本的内容提取出来后,分成几个词,然后排列存储在索引数据库中。还要计算这个词在这个页面上出现了多少次。需要指出的是,关键词stacking就是借用这个原理来优化网站。这种做法是作弊。
5、链接分析:搜索引擎会查询分析这个页面有多少反向链接,导出链接有多少内部链接,然后判断这个页面有多少权重。
三、提供检索服务。
用户输入关键词进行检索,搜索引擎从索引库中找到与关键词匹配的网页。为了方便用户判断,除了网页的标题和URL外,还提供了网页摘要等信息。
所以如果你想做一个好的搜索引擎,让蜘蛛爬取你的网站,小编根据搜索引擎的特点做如下总结:
1.网站发布信息后多做分享或多发外链。它可以帮助您的 网站 尽快带来搜索引擎蜘蛛的访问。您还可以通过内部链接增加搜索引擎蜘蛛在网站的停留时间,以获得更好的排名。
2.定期最好每天发布新信息或更新网站内容,让蜘蛛更多地访问你的信息进行爬取。
3.发布优质信息,让用户体验长久停留,有利于搜索引擎蜘蛛判断你的网站高价值。
4.别想走捷径,一定要遵守搜索引擎的规则,做好内容,做好用户体验网站。
是不是收获满满,受益良多?其实在这里我想推荐一个好帮手。TA将提供更多互联网学习资料,同时免费帮你解答任何互联网问题,并提供完善的互联网服务,TA就是Think Enterprise Internet(),点击访问,你会发现更多精彩!
网页抓取数据百度百科(爬虫常见优秀网络爬虫有以下几种类型类型分析及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-07 10:01
)
什么是网络爬虫,百度百科是这样定义的
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。以下简称爬虫
爬虫作为一种自动化工具去代替人工操作,以此来节省成本和时间,爬虫不是乱爬,一个没有规则爬虫是没有存活的价值的,需要明确爬取的目标这样才能体现爬虫的价值,一般我们需要人为的设定一些规则,让爬虫按照这个规则去爬取。这里我从网络上找到了关于爬虫的几个分类
常见和优秀的网络爬虫有以下几种:
1.批量型网络爬虫:限制爬取的属性,包括爬取范围、具体目标、限制爬取时间、限制数据量、限制爬取页面,总之,明显的特征是有限的;
2.增量网络爬虫(万能爬虫):与前者相反,没有固定的限制,直到所有数据都被抓取完为止。这种类型一般用在网站或者搜索引擎的程序中;
3.垂直网络爬虫(焦点爬虫):可以简单理解为一个无限细化的增量网络爬虫,可以仔细筛选行业、内容、发布时间、页面大小等诸多因素。
以上内容来自:
除了这几类之外,还经常听到爬虫的搜索方式:
广度优先搜索
整个广度优先爬取过程从一系列种子节点开始,提取这些网页中的“子节点”(即超链接),放入队列依次爬取。处理后的链接需要放入一个表(通常称为已访问表)中。每次处理一个新的链接时,都需要检查该链接是否已经存在于Visited表中。如果存在,则证明该链接已被处理,跳过,不处理,否则进行下一步。(这就是我们后面提到的爬虫网址管理模块)
该算法的优势主要有以下三个原因:
重要的网页通常更接近种子。当我们浏览新闻网站时,热门信息通常会出现在比较显眼的位置。随着深入阅读,我们会发现得到的信息的价值已经不如从前了。
万维网的实际深度最多可以达到 17 层,但通往网页的路径总是很短。广度优先遍历会尽快到达页面。
广度优先有利于多个爬虫的协作爬取。多个爬虫的合作通常会先爬取站点中的链接,而且爬取非常封闭。
深度优先搜索
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。优点是能遍历一个Web 站点或深层嵌套的文档集合;缺点是因为Web结构相当深,,有可能造成一旦进去,再也出不来的情况发生,所以一般指定一个最大的深度。
最后,爬虫一般都有哪些模块?
网址管理器模块
一般用于维护已爬取的url和未爬取的url新增的url。如果当前爬取的url已经存在于队列中,则无需重复爬取,防止死循环。例如
我爬的列表中收录music.baidu.om,然后我继续爬取这个页面的所有链接,但是它收录,可想而知,如果不处理,会变成死循环,在百度首页和百度音乐页面循环,所以有一对列来维护URL很重要。
下面是一个python代码实现的例子。使用的deque双向队列,方便取出之前的url。
from collections import deque
class URLQueue():
def __init__(self):
self.queue = deque() # 待抓取的网页
self.visited = set() # 已经抓取过的网页
def new_url_size(self):
'''''
获取未爬取URL集合的大小
:return:
'''
return len(self.queue)
def old_url_size(self):
'''''
获取已爬取URL的大小
:return:
'''
return len(self.visited)
def has_new_url(self):
'''''
判断是否有未爬取的URL
:return:
'''
return self.new_url_size() != 0
def get_new_url(self):
'''''
获取一个未爬取的URL
:return:
'''
new_url = self.queue.popleft()#从左侧取出一个链接
self.old_urls.add(new_url)#记录已经抓取
return new_url
def add_new_url(self, url):
'''''
将新的URL添加到未爬取的URL集合
:param url: 单个url
:return:
'''
if url is None:
return False
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.append(url)
def add_new_urls(self, urlset):
'''''
将新的URL添加到未爬取的URL集合
:param urlset: url集合
:return:
'''
if urlset is None or len(urlset) == 0:
return
for url in urlset:
self.add_new_url(url)
HTML下载模块
HTML下载模块
该模块主要根据提供的url下载url对应的网页内容。使用模块requets-HTML,添加重试逻辑,设置最大重试次数,限制访问时间,防止程序因长期无响应而死机。
根据返回的状态码判断,如果访问成功,则返回源代码,否则开始重试,如果发生异常,则进行重试操作。
<p>from requests_html import HTMLSession
from fake_useragent import UserAgent
import requests
import time
import random
class Gethtml():
def __init__(self,url="http://wwww.baidu.com"):
self.ua = UserAgent()
self.url=url
self.session=HTMLSession(mock_browser=True)
#关于headers有个默认的方法 self.headers = default_headers()
#mock_browser 表示使用useragent
def get_source(self,url,retry=1):
if retry>3:
print("重试三次以上,跳出循环")
return None
while retry 查看全部
网页抓取数据百度百科(爬虫常见优秀网络爬虫有以下几种类型类型分析及应用
)
什么是网络爬虫,百度百科是这样定义的
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。以下简称爬虫
爬虫作为一种自动化工具去代替人工操作,以此来节省成本和时间,爬虫不是乱爬,一个没有规则爬虫是没有存活的价值的,需要明确爬取的目标这样才能体现爬虫的价值,一般我们需要人为的设定一些规则,让爬虫按照这个规则去爬取。这里我从网络上找到了关于爬虫的几个分类
常见和优秀的网络爬虫有以下几种:
1.批量型网络爬虫:限制爬取的属性,包括爬取范围、具体目标、限制爬取时间、限制数据量、限制爬取页面,总之,明显的特征是有限的;
2.增量网络爬虫(万能爬虫):与前者相反,没有固定的限制,直到所有数据都被抓取完为止。这种类型一般用在网站或者搜索引擎的程序中;
3.垂直网络爬虫(焦点爬虫):可以简单理解为一个无限细化的增量网络爬虫,可以仔细筛选行业、内容、发布时间、页面大小等诸多因素。
以上内容来自:
除了这几类之外,还经常听到爬虫的搜索方式:
广度优先搜索
整个广度优先爬取过程从一系列种子节点开始,提取这些网页中的“子节点”(即超链接),放入队列依次爬取。处理后的链接需要放入一个表(通常称为已访问表)中。每次处理一个新的链接时,都需要检查该链接是否已经存在于Visited表中。如果存在,则证明该链接已被处理,跳过,不处理,否则进行下一步。(这就是我们后面提到的爬虫网址管理模块)
该算法的优势主要有以下三个原因:
重要的网页通常更接近种子。当我们浏览新闻网站时,热门信息通常会出现在比较显眼的位置。随着深入阅读,我们会发现得到的信息的价值已经不如从前了。
万维网的实际深度最多可以达到 17 层,但通往网页的路径总是很短。广度优先遍历会尽快到达页面。
广度优先有利于多个爬虫的协作爬取。多个爬虫的合作通常会先爬取站点中的链接,而且爬取非常封闭。
深度优先搜索
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。优点是能遍历一个Web 站点或深层嵌套的文档集合;缺点是因为Web结构相当深,,有可能造成一旦进去,再也出不来的情况发生,所以一般指定一个最大的深度。
最后,爬虫一般都有哪些模块?
网址管理器模块
一般用于维护已爬取的url和未爬取的url新增的url。如果当前爬取的url已经存在于队列中,则无需重复爬取,防止死循环。例如
我爬的列表中收录music.baidu.om,然后我继续爬取这个页面的所有链接,但是它收录,可想而知,如果不处理,会变成死循环,在百度首页和百度音乐页面循环,所以有一对列来维护URL很重要。
下面是一个python代码实现的例子。使用的deque双向队列,方便取出之前的url。
from collections import deque
class URLQueue():
def __init__(self):
self.queue = deque() # 待抓取的网页
self.visited = set() # 已经抓取过的网页
def new_url_size(self):
'''''
获取未爬取URL集合的大小
:return:
'''
return len(self.queue)
def old_url_size(self):
'''''
获取已爬取URL的大小
:return:
'''
return len(self.visited)
def has_new_url(self):
'''''
判断是否有未爬取的URL
:return:
'''
return self.new_url_size() != 0
def get_new_url(self):
'''''
获取一个未爬取的URL
:return:
'''
new_url = self.queue.popleft()#从左侧取出一个链接
self.old_urls.add(new_url)#记录已经抓取
return new_url
def add_new_url(self, url):
'''''
将新的URL添加到未爬取的URL集合
:param url: 单个url
:return:
'''
if url is None:
return False
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.append(url)
def add_new_urls(self, urlset):
'''''
将新的URL添加到未爬取的URL集合
:param urlset: url集合
:return:
'''
if urlset is None or len(urlset) == 0:
return
for url in urlset:
self.add_new_url(url)
HTML下载模块
HTML下载模块
该模块主要根据提供的url下载url对应的网页内容。使用模块requets-HTML,添加重试逻辑,设置最大重试次数,限制访问时间,防止程序因长期无响应而死机。
根据返回的状态码判断,如果访问成功,则返回源代码,否则开始重试,如果发生异常,则进行重试操作。
<p>from requests_html import HTMLSession
from fake_useragent import UserAgent
import requests
import time
import random
class Gethtml():
def __init__(self,url="http://wwww.baidu.com";):
self.ua = UserAgent()
self.url=url
self.session=HTMLSession(mock_browser=True)
#关于headers有个默认的方法 self.headers = default_headers()
#mock_browser 表示使用useragent
def get_source(self,url,retry=1):
if retry>3:
print("重试三次以上,跳出循环")
return None
while retry
网页抓取数据百度百科(如何使用使用python来编写一些简单的网络爬虫?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-07 10:01
本文主要是个人python学习过程中的思考,希望对感兴趣的童鞋有所帮助。
百度百科对网络爬虫的定义是:“网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常称为网页追赶者)是一种按照一定规则进行的自动爬取。万维网上信息的程序或脚本”。使用网络爬虫,可以对来自互联网的个人兴趣数据进行个性化处理,完成一些目前搜索引擎无法完成的个性化搜索。说用python写一个网络爬虫其实是在模拟浏览器的工作过程,从网上抓取需要的信息,完成分析、提取、存储的过程。
为了更好的爬虫的工作过程,我们先来看看用户访问互联网资源的过程,用户在浏览器中输入:
例如,当用户输入完成,开始搜索时,用户请求的网页经过DNS完成域名解析,通过网络携带HTTP协议栈的数据,发送到服务器百度定位。将首页的数据返回给用户(假设这个过程中的所有进程都是正确的)。用户浏览器接收到百度响应数据后,通过浏览器解析数据,将百度主页呈现在用户面前。这里,百度返回的数据是HTTP协议栈封装的HTML/CSS/PHP数据。如上所述,当我们用python编写网络爬虫时也是如此。为了完成这个工作流程,我们需要掌握python的基本知识,
废话不多说,我们通过一些实际的例子来看看如何使用python编写一些简单的网络爬虫。 查看全部
网页抓取数据百度百科(如何使用使用python来编写一些简单的网络爬虫?(图))
本文主要是个人python学习过程中的思考,希望对感兴趣的童鞋有所帮助。
百度百科对网络爬虫的定义是:“网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常称为网页追赶者)是一种按照一定规则进行的自动爬取。万维网上信息的程序或脚本”。使用网络爬虫,可以对来自互联网的个人兴趣数据进行个性化处理,完成一些目前搜索引擎无法完成的个性化搜索。说用python写一个网络爬虫其实是在模拟浏览器的工作过程,从网上抓取需要的信息,完成分析、提取、存储的过程。
为了更好的爬虫的工作过程,我们先来看看用户访问互联网资源的过程,用户在浏览器中输入:
例如,当用户输入完成,开始搜索时,用户请求的网页经过DNS完成域名解析,通过网络携带HTTP协议栈的数据,发送到服务器百度定位。将首页的数据返回给用户(假设这个过程中的所有进程都是正确的)。用户浏览器接收到百度响应数据后,通过浏览器解析数据,将百度主页呈现在用户面前。这里,百度返回的数据是HTTP协议栈封装的HTML/CSS/PHP数据。如上所述,当我们用python编写网络爬虫时也是如此。为了完成这个工作流程,我们需要掌握python的基本知识,
废话不多说,我们通过一些实际的例子来看看如何使用python编写一些简单的网络爬虫。
网页抓取数据百度百科(简单的爬虫架构如上图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-04 08:19
什么是爬行动物?
爬虫是一种自动爬取互联网信息的程序,以便更好地利用数据进行相关分析并做出相关决策。
简单的爬虫架构
如上图所示,这个架构主要分为五个部分:
1. 爬虫主调度器
主要用于调度其他模块相互配合获取我们想要的数据
2. 网址管理器
主要管理两部分数据:未爬取的url和等待爬取的url数据
3. 下载器
从 url manager 中获取未抓取的 ulr,并使用 urllib 中的 request 模块抓取网络数据。
4. 解析器
从下载器获取的 html 数据解析出新的 url 和我们要提取的数据。
5. 出口商
将我们想要的数据输出到文件中。
使用第一眼网址管理器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:55
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
该模块的主要功能是管理带爬取和爬取的url,其中new_urls指的是要爬取的url,old_urls指的是已经爬取过的url,并且设置了数据结构,可以直接去重。
2. 下载器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:01
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
from urllib import request
class HtmlDownloader(object):
"""Html下载器"""
def download(self, url):
if url is None:
return None
response = request.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
这个比较简单,直接使用urllib中的request模块爬取数据
3. 解析器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:31
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
import re
from urllib import parse
from bs4 import BeautifulSoup
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 计算机程序设计语言
links = soup.find_all('a', href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
new_full_url = parse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
# url
res_data['url'] = page_url
#
# Python
# (计算机程序设计语言)
# 编辑
# 锁定
#
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
#
# Python
# [1]<a class="sup-anchor" name="ref_[1]_21087"> </a>
# (英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/), 是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,第一个公开发行版发行于1991年。Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议。Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进。Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写,比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。需要注意的是在您使用扩展类库时可能需要考虑平台问题,某些可能不提供跨平台的实现。7月20日,IEEE发布2017年编程语言排行榜:Python高居首位
# [2]<a class="sup-anchor" name="ref_[2]_21087"> </a>
# 。2018年3月,该语言作者在邮件列表上宣布 Python 2.7将于2020年1月1日终止支持。用户如果想要在这个日期之后继续得到与Python 2.7有关的支持,则需要付费给商业供应商。
# [3]<a class="sup-anchor" name="ref_[3]_21087"> </a>
#
#
summary_node = soup.find('div', class_='lemma-summary').find('div', class_='para')
res_data['summary'] = summary_node.get_text()
return res_data
def parse(self, page_url, html_content):
if page_url is None or html_content is None:
return
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
该模块主要解析下载器的数据。解析使用第三方库“BeautifulSoup”。如果没有安装,请先安装:
点安装beautifulsoup4
这里需要分析一下我们需要爬取的数据内容。这里我要爬取的内容是:百科词条的标题和介绍
- 首先,我们要看看标题的html标签格式是什么样子的。右击标题“Python”->勾选,可以看到它的标签如下:
#
# Python
# (计算机程序设计语言)
# 编辑
# 锁定
#
可以看出dd标签中的class属性在lemmaWgt-lemmaTitle-title的h1标签中,所以代码很简单:
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
同理,可以找出引言的标注规则。
4. 出口商:
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
f_out = None
try:
f_out = open('output.html', 'w', encoding='utf-8')
f_out.write("")
f_out.write("")
f_out.write("")
for data in self.datas:
f_out.write("")
f_out.write("%s" % data['url'])
f_out.write("%s" % data['title'])
f_out.write("%s" % data['summary'])
f_out.write("")
f_out.write("")
f_out.write("")
finally:
if f_out:
f_out.close()
这个模块也很简单。它主要存储我们想要的数据,并以html表格的形式输出到文件“output.html”中。不过需要注意的是,由于爬取的内容是中文的,所以一定要指定编码为utf-8,否则会出现乱码。
5. 最后,我们编写调度器并爬取 1000 个入口数据:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:23:26
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
from baike_spider import url_manager, html_downloader, html_parser, html_outputer
class Spider(object):
def __init__(self):
self.url_manager = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.html_parser = html_parser.HtmlParser()
self.html_outputer = html_outputer.HtmlOutputer()
def craw(self, rootUrl):
count = 1
self.url_manager.add_new_url(rootUrl)
while self.url_manager.has_new_url():
try:
new_url = self.url_manager.get_new_url()
print("craw%d -> %s" % (count, new_url))
content = self.downloader.download(new_url)
new_urls, data = self.html_parser.parse(new_url, content)
self.url_manager.add_new_urls(new_urls)
self.html_outputer.collect_data(data)
if count == 1000:
break
count = count + 1
except:
print('craw failed')
self.html_outputer.output_html()
root_url = "https://baike.baidu.com/item/Python/407313"
if __name__ == "__main__":
spider = Spider()
spider.craw(root_url)
起始 url 是 Python 入口的 url:root_url = ""
好的,运行调度程序并开始爬取数据。
看看上次运行的结果:
存储的文件是一个html文件,找到文件路径用浏览器打开,可以看到下图。
来源链接 查看全部
网页抓取数据百度百科(简单的爬虫架构如上图)
什么是爬行动物?
爬虫是一种自动爬取互联网信息的程序,以便更好地利用数据进行相关分析并做出相关决策。
简单的爬虫架构

如上图所示,这个架构主要分为五个部分:
1. 爬虫主调度器
主要用于调度其他模块相互配合获取我们想要的数据
2. 网址管理器
主要管理两部分数据:未爬取的url和等待爬取的url数据
3. 下载器
从 url manager 中获取未抓取的 ulr,并使用 urllib 中的 request 模块抓取网络数据。
4. 解析器
从下载器获取的 html 数据解析出新的 url 和我们要提取的数据。
5. 出口商
将我们想要的数据输出到文件中。
使用第一眼网址管理器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:55
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
该模块的主要功能是管理带爬取和爬取的url,其中new_urls指的是要爬取的url,old_urls指的是已经爬取过的url,并且设置了数据结构,可以直接去重。
2. 下载器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:01
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
from urllib import request
class HtmlDownloader(object):
"""Html下载器"""
def download(self, url):
if url is None:
return None
response = request.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
这个比较简单,直接使用urllib中的request模块爬取数据
3. 解析器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:31
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
import re
from urllib import parse
from bs4 import BeautifulSoup
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 计算机程序设计语言
links = soup.find_all('a', href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
new_full_url = parse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
# url
res_data['url'] = page_url
#
# Python
# (计算机程序设计语言)
# 编辑
# 锁定
#
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
#
# Python
# [1]<a class="sup-anchor" name="ref_[1]_21087"> </a>
# (英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/), 是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,第一个公开发行版发行于1991年。Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议。Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进。Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写,比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。需要注意的是在您使用扩展类库时可能需要考虑平台问题,某些可能不提供跨平台的实现。7月20日,IEEE发布2017年编程语言排行榜:Python高居首位
# [2]<a class="sup-anchor" name="ref_[2]_21087"> </a>
# 。2018年3月,该语言作者在邮件列表上宣布 Python 2.7将于2020年1月1日终止支持。用户如果想要在这个日期之后继续得到与Python 2.7有关的支持,则需要付费给商业供应商。
# [3]<a class="sup-anchor" name="ref_[3]_21087"> </a>
#
#
summary_node = soup.find('div', class_='lemma-summary').find('div', class_='para')
res_data['summary'] = summary_node.get_text()
return res_data
def parse(self, page_url, html_content):
if page_url is None or html_content is None:
return
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
该模块主要解析下载器的数据。解析使用第三方库“BeautifulSoup”。如果没有安装,请先安装:
点安装beautifulsoup4
这里需要分析一下我们需要爬取的数据内容。这里我要爬取的内容是:百科词条的标题和介绍

- 首先,我们要看看标题的html标签格式是什么样子的。右击标题“Python”->勾选,可以看到它的标签如下:
#
# Python
# (计算机程序设计语言)
# 编辑
# 锁定
#
可以看出dd标签中的class属性在lemmaWgt-lemmaTitle-title的h1标签中,所以代码很简单:
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
同理,可以找出引言的标注规则。
4. 出口商:
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
f_out = None
try:
f_out = open('output.html', 'w', encoding='utf-8')
f_out.write("")
f_out.write("")
f_out.write("")
for data in self.datas:
f_out.write("")
f_out.write("%s" % data['url'])
f_out.write("%s" % data['title'])
f_out.write("%s" % data['summary'])
f_out.write("")
f_out.write("")
f_out.write("")
finally:
if f_out:
f_out.close()
这个模块也很简单。它主要存储我们想要的数据,并以html表格的形式输出到文件“output.html”中。不过需要注意的是,由于爬取的内容是中文的,所以一定要指定编码为utf-8,否则会出现乱码。
5. 最后,我们编写调度器并爬取 1000 个入口数据:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:23:26
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
from baike_spider import url_manager, html_downloader, html_parser, html_outputer
class Spider(object):
def __init__(self):
self.url_manager = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.html_parser = html_parser.HtmlParser()
self.html_outputer = html_outputer.HtmlOutputer()
def craw(self, rootUrl):
count = 1
self.url_manager.add_new_url(rootUrl)
while self.url_manager.has_new_url():
try:
new_url = self.url_manager.get_new_url()
print("craw%d -> %s" % (count, new_url))
content = self.downloader.download(new_url)
new_urls, data = self.html_parser.parse(new_url, content)
self.url_manager.add_new_urls(new_urls)
self.html_outputer.collect_data(data)
if count == 1000:
break
count = count + 1
except:
print('craw failed')
self.html_outputer.output_html()
root_url = "https://baike.baidu.com/item/Python/407313"
if __name__ == "__main__":
spider = Spider()
spider.craw(root_url)
起始 url 是 Python 入口的 url:root_url = ""
好的,运行调度程序并开始爬取数据。
看看上次运行的结果:
存储的文件是一个html文件,找到文件路径用浏览器打开,可以看到下图。

来源链接
网页抓取数据百度百科(、描述、简称学校名称.xlsx最终成果步骤及步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2022-03-28 20:11
我在公众号上看到的文章感觉不错,适合练习。所以我自己做了。
不要胡说八道。
目的:手头有一个“学校名称.xlsx”表格。求这些学校的英文名称、描述、缩写
学校名称.xlsx
最后结果
第 1 步:分析
所需的学校信息一般可在百度百科中找到。那么让我们看看百度百科的数据能否满足我们的要求。
一、找学校去百度百科看看情况
以北京大学为例:英文名称、描述、缩写
在该界面中可用。
然后所有的信息也可以在页面源代码中看到。所以理论上,我们爬下这个页面的信息后,就可以做简单的处理了。
第 2 步:编写代码
1、需要的技术和软件包
import requests
import pandas as pd
from random import choice
from lxml import etree
import openpyxl
import logging
from concurrent.futures import ThreadPoolExecutor
from time import sleep
from random import random
阐明:
请求,对于 python 爬虫来说是必须的。这用于发送get请求并接收返回结果
pandas,数据分析的基础,是必须的。用于将 Excel 表中的学校名称用 pandas 读取后转换为列表,并成为百度百科网站的一部分。
随机的,
random 方法生成伪随机数。随时间使用。让程序随机休眠几秒,避免CPU一直被占用,导致电脑发热、死机,避免百度ip阻塞
选择方法,随机一种。这用于随机选择一个 http 标头。
lxml,用于解析网页返回数据(返回的数据是一堆网页代码,很多没用,还得解析成需要的英文名、缩写、描述)
openpyxl,用于写表
记录,记录
concurrent.futures,Python 多线程。我们要爬3000条左右的数据,单线程执行会很慢,多线程会快很多
时间,使用 sleep 方法让代码休眠。
2、写一个爬取数据的函数
def get_data(item):
try:
# 记录一下它原本的序号
sort_num = items.index(item)
# 随机生成请求头
headers = {
'User-Agent':choice(user_agent)
}
# 构造的url
url = f'https://baike.baidu.com/item/{item}'
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
sleep(random())
# Xpath解析提取数据
html = etree.HTML(rep.text)
description = ''.join(html.xpath('/html/head/meta[4]/@content'))
# 外文名
en_name = ','.join(html.xpath('//dl[@class="basicInfo-block basicInfo-left"]/dd[2]/text()')).strip()
# 中文简称 有的话 是在dd[3]标签下
simple_name = ''.join(html.xpath('//dl[@class="basicInfo-block basicInfo-left"]/dd[3]/text()')).strip()
sheet.append([item, simple_name, en_name, description, url, sort_num])
logging.info([item, simple_name, en_name, description, url, sort_num])
except Exception as e:
logging.info(e.args)
pass
3、编写一个多线程函数,将爬取解析后的数据保存到文件中。
# 函数调用 开多线程
def run():
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(get_data, items)
wb.save('成果.xlsx')
print('===================== 数据成功下载完成 ======================')
阐明:
地图(函数,可迭代,...)
指定的序列将根据提供的函数进行映射。
第一个参数函数使用参数序列中的每个元素调用函数函数,返回一个收录每个函数函数返回值的新列表。
说白了就是map(a,b),a是函数,b是序列。将 b 一个一个传入 a 执行。有点循环。
本例中的 b 是从表中获得的学校名称列表。大概有3000个左右,所以如果run()函数执行的话,要执行3000次
4、执行多线程函数
run()
5、跑步效果(不做动画,所以这个动画是大佬图的复制品)
6、终于得到一个result.xlsx文件
阐明:
上述代码需要复制到py文件中执行。
以上分别拆解,主要是为了说明。
最后:
我感慨道:如果你不辜负年轻的时候,你将在你的余生中加倍欺骗你。
以前上学的时候比较懒惰,基本没学过HTML相关的知识。现在看来元素定位太费劲了。
最后:
公众号好评如潮:师姐拿了成绩。xlsx对男友说:“你看,舔狗还是好用的”
参考:
xpath元素定位(相对路径)常用的5种方法 - 程序员大本营
原作者应该是叶廷云 叶廷云的博客 查看全部
网页抓取数据百度百科(、描述、简称学校名称.xlsx最终成果步骤及步骤)
我在公众号上看到的文章感觉不错,适合练习。所以我自己做了。
不要胡说八道。

目的:手头有一个“学校名称.xlsx”表格。求这些学校的英文名称、描述、缩写
学校名称.xlsx
最后结果
第 1 步:分析
所需的学校信息一般可在百度百科中找到。那么让我们看看百度百科的数据能否满足我们的要求。
一、找学校去百度百科看看情况
以北京大学为例:英文名称、描述、缩写
在该界面中可用。
然后所有的信息也可以在页面源代码中看到。所以理论上,我们爬下这个页面的信息后,就可以做简单的处理了。
第 2 步:编写代码
1、需要的技术和软件包
import requests
import pandas as pd
from random import choice
from lxml import etree
import openpyxl
import logging
from concurrent.futures import ThreadPoolExecutor
from time import sleep
from random import random
阐明:
请求,对于 python 爬虫来说是必须的。这用于发送get请求并接收返回结果
pandas,数据分析的基础,是必须的。用于将 Excel 表中的学校名称用 pandas 读取后转换为列表,并成为百度百科网站的一部分。
随机的,
random 方法生成伪随机数。随时间使用。让程序随机休眠几秒,避免CPU一直被占用,导致电脑发热、死机,避免百度ip阻塞
选择方法,随机一种。这用于随机选择一个 http 标头。
lxml,用于解析网页返回数据(返回的数据是一堆网页代码,很多没用,还得解析成需要的英文名、缩写、描述)
openpyxl,用于写表
记录,记录
concurrent.futures,Python 多线程。我们要爬3000条左右的数据,单线程执行会很慢,多线程会快很多
时间,使用 sleep 方法让代码休眠。
2、写一个爬取数据的函数
def get_data(item):
try:
# 记录一下它原本的序号
sort_num = items.index(item)
# 随机生成请求头
headers = {
'User-Agent':choice(user_agent)
}
# 构造的url
url = f'https://baike.baidu.com/item/{item}'
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
sleep(random())
# Xpath解析提取数据
html = etree.HTML(rep.text)
description = ''.join(html.xpath('/html/head/meta[4]/@content'))
# 外文名
en_name = ','.join(html.xpath('//dl[@class="basicInfo-block basicInfo-left"]/dd[2]/text()')).strip()
# 中文简称 有的话 是在dd[3]标签下
simple_name = ''.join(html.xpath('//dl[@class="basicInfo-block basicInfo-left"]/dd[3]/text()')).strip()
sheet.append([item, simple_name, en_name, description, url, sort_num])
logging.info([item, simple_name, en_name, description, url, sort_num])
except Exception as e:
logging.info(e.args)
pass
3、编写一个多线程函数,将爬取解析后的数据保存到文件中。
# 函数调用 开多线程
def run():
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(get_data, items)
wb.save('成果.xlsx')
print('===================== 数据成功下载完成 ======================')
阐明:
地图(函数,可迭代,...)
指定的序列将根据提供的函数进行映射。
第一个参数函数使用参数序列中的每个元素调用函数函数,返回一个收录每个函数函数返回值的新列表。
说白了就是map(a,b),a是函数,b是序列。将 b 一个一个传入 a 执行。有点循环。
本例中的 b 是从表中获得的学校名称列表。大概有3000个左右,所以如果run()函数执行的话,要执行3000次
4、执行多线程函数
run()
5、跑步效果(不做动画,所以这个动画是大佬图的复制品)

6、终于得到一个result.xlsx文件
阐明:
上述代码需要复制到py文件中执行。
以上分别拆解,主要是为了说明。
最后:
我感慨道:如果你不辜负年轻的时候,你将在你的余生中加倍欺骗你。
以前上学的时候比较懒惰,基本没学过HTML相关的知识。现在看来元素定位太费劲了。
最后:
公众号好评如潮:师姐拿了成绩。xlsx对男友说:“你看,舔狗还是好用的”
参考:
xpath元素定位(相对路径)常用的5种方法 - 程序员大本营
原作者应该是叶廷云 叶廷云的博客
网页抓取数据百度百科(爬虫能做什么?可以创建搜索引擎(Google,百度))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-28 10:20
在大数据的浪潮中,最有价值的就是数据。企业为了获取数据、处理数据和理解数据而花费大量资金。使用网络爬虫可以最有效地获取数据。
什么是爬行动物?
网络蜘蛛,也称为网络爬虫、蚂蚁、自动索引器,或(在 FOAF 软件概念中)WEB scutter,是“自动浏览网络”程序,或网络机器人。它们被互联网搜索引擎或其他类似的网站s广泛用于获取或更新这些网站s的内容和检索方法。他们可以自动采集他们可以访问的所有页面内容以供搜索引擎进一步处理(对下载的页面进行排序和排序),从而使用户可以更快地检索到他们需要的信息。
最常见的是互联网搜索引擎,它使用网络爬虫自动采集所有可访问的页面内容来获取或更新这些网站的内容和检索方法。在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是
下载信息,将信息中对用户无意义的内容(如网页代码)处理掉。资源库用于存储下载的数据资源并在其上建立索引。
如果你想每小时抓取一次网易新闻,那么你需要访问网易并进行数据请求,得到一个html格式的网页,然后通过网络爬虫的解析器进行过滤,最后存入数据库。
爬行动物能做什么?
可以创建搜索引擎(谷歌、百度)
可用于抢优采云票
逛一圈
简单来说,只要浏览器能打开就可以用爬虫实现
网络爬虫的分类?
网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。万能网络爬虫,又称Scalable Web Crawler,将爬取对象从一些种子URL(网络上的每个文件都有一个地址,即一个URL)扩展到整个Web,主要针对门户网站搜索引擎和大型网页服务。商采集数据。出于商业原因,他们的技术细节很少被公布。
Focused Crawler,也称为Topical Crawler,是一种只抓取与主题相关的网络资源的爬虫。大大节省了硬件和网络资源,而且保存的数据量少,更新速度快,也能很好地满足某些特定人群对特定领域信息的需求。
增量网络爬虫(Incremental Web Crawler)是指只爬取新生成或变化的数据的爬虫。可以在一定程度上保证爬取的数据尽可能是新的,不会重新下载不变的数据。可以有效减少数据下载量,及时更新爬取数据,减少时间和空间消耗。
深度网络爬虫(Deep Web Crawler)可以从深度网页爬取数据。一般来说,网页分为表面网页和深层网页。表层页面是指传统搜索引擎可以索引的页面,而深层页面是用户提交一些关键词才能获得的页面。例如,只有在用户注册后才能看到内容的页面是深层页面。
学习爬虫技术势在必行:在当前竞争激烈的信息社会中,如何利用数据分析站在信息不对称的一边,保持竞争优势,是数字工作者必备的技能。然而,在你想飞之前,你必须学会跑步。在分析数据之前,首先要学会爬取和处理数据,这样才能事半功倍。
【全文结束】 查看全部
网页抓取数据百度百科(爬虫能做什么?可以创建搜索引擎(Google,百度))
在大数据的浪潮中,最有价值的就是数据。企业为了获取数据、处理数据和理解数据而花费大量资金。使用网络爬虫可以最有效地获取数据。
什么是爬行动物?
网络蜘蛛,也称为网络爬虫、蚂蚁、自动索引器,或(在 FOAF 软件概念中)WEB scutter,是“自动浏览网络”程序,或网络机器人。它们被互联网搜索引擎或其他类似的网站s广泛用于获取或更新这些网站s的内容和检索方法。他们可以自动采集他们可以访问的所有页面内容以供搜索引擎进一步处理(对下载的页面进行排序和排序),从而使用户可以更快地检索到他们需要的信息。
最常见的是互联网搜索引擎,它使用网络爬虫自动采集所有可访问的页面内容来获取或更新这些网站的内容和检索方法。在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是
下载信息,将信息中对用户无意义的内容(如网页代码)处理掉。资源库用于存储下载的数据资源并在其上建立索引。
如果你想每小时抓取一次网易新闻,那么你需要访问网易并进行数据请求,得到一个html格式的网页,然后通过网络爬虫的解析器进行过滤,最后存入数据库。
爬行动物能做什么?
可以创建搜索引擎(谷歌、百度)
可用于抢优采云票
逛一圈
简单来说,只要浏览器能打开就可以用爬虫实现
网络爬虫的分类?
网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。万能网络爬虫,又称Scalable Web Crawler,将爬取对象从一些种子URL(网络上的每个文件都有一个地址,即一个URL)扩展到整个Web,主要针对门户网站搜索引擎和大型网页服务。商采集数据。出于商业原因,他们的技术细节很少被公布。
Focused Crawler,也称为Topical Crawler,是一种只抓取与主题相关的网络资源的爬虫。大大节省了硬件和网络资源,而且保存的数据量少,更新速度快,也能很好地满足某些特定人群对特定领域信息的需求。
增量网络爬虫(Incremental Web Crawler)是指只爬取新生成或变化的数据的爬虫。可以在一定程度上保证爬取的数据尽可能是新的,不会重新下载不变的数据。可以有效减少数据下载量,及时更新爬取数据,减少时间和空间消耗。
深度网络爬虫(Deep Web Crawler)可以从深度网页爬取数据。一般来说,网页分为表面网页和深层网页。表层页面是指传统搜索引擎可以索引的页面,而深层页面是用户提交一些关键词才能获得的页面。例如,只有在用户注册后才能看到内容的页面是深层页面。
学习爬虫技术势在必行:在当前竞争激烈的信息社会中,如何利用数据分析站在信息不对称的一边,保持竞争优势,是数字工作者必备的技能。然而,在你想飞之前,你必须学会跑步。在分析数据之前,首先要学会爬取和处理数据,这样才能事半功倍。
【全文结束】
网页抓取数据百度百科(网站在搜索引擎里的百度快照有什么几率?的条件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-26 21:17
网站在搜索引擎中的具体表现是每个SEO都非常关心的问题。SEO工程师经常根据快照分析网站的状态,并根据快照的更新进行调整,以便更好地优化或提高网站的综合指标。快照为搜索引擎应用中的分析网站提供了有利的条件因素。
我们以百度为例。其他搜索引擎的原理类似。百度快照的定义请参考百度搜索帮助:每个未被禁止搜索的网页都会自动在百度上生成一个临时缓存页面,称为“百度快照”。官方给百度快照的功能是当查询结果中要打开的网页打不开或者加载速度很慢时,“百度快照”可以快速浏览页面内容。
百度快照的原理,百度搜索引擎内部搜索程序在互联网上组织和处理数据的过程,文件数据的索引和存储的具体体现就是百度快照。通俗地说,百度获取数据的过程就是分发百度蜘蛛,在整个互联网通过链接相互通信时获取数据;百度快照是百度蜘蛛通过链接到达新的 网站 或单个页面时。当网站首页或单页数据存储时;百度内部机制会根据具体算法对数据进行分类、索引和缓存。刚看到截图。
我们经常会发现百度快照有时会更新,有时会长时间保持不变。百度快照的概率是多少?事实上,这一切都可以在服务器日志中看到。
很多站长抱怨百度快照一直卡在16、23、24一个月更新一次,有的甚至半年不更新;
快照也是搜索引擎的附加程序。作为搜索引擎的一部分,所有程序都需要处理最优结果,节省计算时间作为处理数据的前提。
因此,百度对每一个网站都有一个快照更新评级。这种现象在百度上很明显。当然,首页和内页的评分也是不一样的。我不会详述。
他打分的标准是对蜘蛛抓到的数据进行多次分析,数据大幅度更新(比较一组数据时,更新量大到一个值)
举个很概念的例子:如果百度标准数据更新值为7,你的页面蜘蛛第一次和第二次比较更新值是3,不达标,第三次比较第一次数据更新。8、OK截取第一次和第三次之间的时间间隔。
当然,这是一个非常笼统的说法。百度要多比较几遍,然后取一个平衡的量来判断。这不是我们能知道的,但我们知道这种算法的原理。
这种方式可以让快照程序有针对性地更新网站的快照,而不是不分类别地同时更新所有的网站,节省了大量的计算时间和成本
知道有这样的评分后,一切都好办了。百度尚未公开此评级。目前不知道百度需要多久重新评估和更新一个网站的评分
但是SEO需要做的就是让snapshot更新的更频繁,其实很简单
知道了原理,我们就有了具体的操作方法
第一步是查看你的服务器日志,了解百度蜘蛛抓取你的网站页面的规则
第二步,在知道蜘蛛爬取一个页面的时间间隔后,列出一个内容更新时间表
第三步,每隔两个连续的蜘蛛抓取间隔更新一次你的页面内容,重点是在这个时间段内更新(例如:你原本更新了10个小时的内容,但是这10个小时里蜘蛛来了3次那你得想办法把10小时的更新尽量压缩在一个区间——上面提到的时间只是一个例子,看具体情况网站最好经常更新。
关于百度快照的常见问题:
一、快照未更新
问题分析:导入链接的扇入面积不大,即网站的外部链接太少;.
解决方案:通过对百度快照定义原理的理解,百度只能通过链接和索引本站数据来创建快照,为百度蜘蛛创建更顺畅的多条路径到达网站是最好的解决方案。
二、快照更新不及时
问题分析:和不更新快照的问题是一样的,但是这里解释的原因是百度的审计机制会过滤网站的数据,甚至是手动审计。不能排除造成这种情况的原因。
解决方法:不要更新同一个快照,同时网站里面没有中国式的螃蟹内容。 查看全部
网页抓取数据百度百科(网站在搜索引擎里的百度快照有什么几率?的条件)
网站在搜索引擎中的具体表现是每个SEO都非常关心的问题。SEO工程师经常根据快照分析网站的状态,并根据快照的更新进行调整,以便更好地优化或提高网站的综合指标。快照为搜索引擎应用中的分析网站提供了有利的条件因素。
我们以百度为例。其他搜索引擎的原理类似。百度快照的定义请参考百度搜索帮助:每个未被禁止搜索的网页都会自动在百度上生成一个临时缓存页面,称为“百度快照”。官方给百度快照的功能是当查询结果中要打开的网页打不开或者加载速度很慢时,“百度快照”可以快速浏览页面内容。
百度快照的原理,百度搜索引擎内部搜索程序在互联网上组织和处理数据的过程,文件数据的索引和存储的具体体现就是百度快照。通俗地说,百度获取数据的过程就是分发百度蜘蛛,在整个互联网通过链接相互通信时获取数据;百度快照是百度蜘蛛通过链接到达新的 网站 或单个页面时。当网站首页或单页数据存储时;百度内部机制会根据具体算法对数据进行分类、索引和缓存。刚看到截图。
我们经常会发现百度快照有时会更新,有时会长时间保持不变。百度快照的概率是多少?事实上,这一切都可以在服务器日志中看到。
很多站长抱怨百度快照一直卡在16、23、24一个月更新一次,有的甚至半年不更新;
快照也是搜索引擎的附加程序。作为搜索引擎的一部分,所有程序都需要处理最优结果,节省计算时间作为处理数据的前提。
因此,百度对每一个网站都有一个快照更新评级。这种现象在百度上很明显。当然,首页和内页的评分也是不一样的。我不会详述。
他打分的标准是对蜘蛛抓到的数据进行多次分析,数据大幅度更新(比较一组数据时,更新量大到一个值)
举个很概念的例子:如果百度标准数据更新值为7,你的页面蜘蛛第一次和第二次比较更新值是3,不达标,第三次比较第一次数据更新。8、OK截取第一次和第三次之间的时间间隔。
当然,这是一个非常笼统的说法。百度要多比较几遍,然后取一个平衡的量来判断。这不是我们能知道的,但我们知道这种算法的原理。
这种方式可以让快照程序有针对性地更新网站的快照,而不是不分类别地同时更新所有的网站,节省了大量的计算时间和成本
知道有这样的评分后,一切都好办了。百度尚未公开此评级。目前不知道百度需要多久重新评估和更新一个网站的评分
但是SEO需要做的就是让snapshot更新的更频繁,其实很简单
知道了原理,我们就有了具体的操作方法
第一步是查看你的服务器日志,了解百度蜘蛛抓取你的网站页面的规则
第二步,在知道蜘蛛爬取一个页面的时间间隔后,列出一个内容更新时间表
第三步,每隔两个连续的蜘蛛抓取间隔更新一次你的页面内容,重点是在这个时间段内更新(例如:你原本更新了10个小时的内容,但是这10个小时里蜘蛛来了3次那你得想办法把10小时的更新尽量压缩在一个区间——上面提到的时间只是一个例子,看具体情况网站最好经常更新。
关于百度快照的常见问题:
一、快照未更新
问题分析:导入链接的扇入面积不大,即网站的外部链接太少;.
解决方案:通过对百度快照定义原理的理解,百度只能通过链接和索引本站数据来创建快照,为百度蜘蛛创建更顺畅的多条路径到达网站是最好的解决方案。
二、快照更新不及时
问题分析:和不更新快照的问题是一样的,但是这里解释的原因是百度的审计机制会过滤网站的数据,甚至是手动审计。不能排除造成这种情况的原因。
解决方法:不要更新同一个快照,同时网站里面没有中国式的螃蟹内容。
网页抓取数据百度百科(robotsrobots协议(robots.txt)Robots协议用来告知搜索引擎哪些页面能被抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-24 10:02
robotsrobots 协议 (robots.txt)
Robots协议用于通知搜索引擎哪些页面可以爬取,哪些页面不能爬取;网站中一些比较大的文件可以屏蔽掉,比如:图片、音乐、视频等,节省服务器带宽;它可以被阻止一些指向该站点的死链接。方便搜索引擎抓取网站内容;设置 网站 地图连接来引导蜘蛛抓取页面。(来自百度百科)
** robots.txt 放置在网页上,指定搜索引擎和网络爬虫可以访问和不能访问的页面**
话题分析
进入答题页面后,直接进入url上的robots.txt
看答案
备份
网页备份
index.php的备份文件是index.php.bax,直接访问下载,然后打开查看文件,可以找到flag
cookie(存储在用户本地终端上的数据)
Cookie,类型为“小文本文件”,是为了识别用户身份和进行会话跟踪而存储在用户本地终端上的一些数据(通常是加密的),由用户的客户端计算机临时或永久存储。资料(来自百度百科)
客户端保存的一小段文本信息,用于服务器识别
话题分析
输入cookies.php查看cookies
提示“查看网页响应”,刷新网页找到网站消息头中的flag
我不知道如何在 Google 中查看它
禁用按钮主题分析
标题如下,flag不能点击
F12 发现form有disable属性,删掉点击,点击就有答案了
HTML 表单的 disabled 属性
disabled 属性可以附加到 HTML 中的输入元素、按钮元素、选项元素等。给定此属性时,元素变为非交互元素
创建一个可以按下的按钮
able
浏览器显示如下,这个按钮可以点击
disable
浏览器显示如下,该按钮无法点击
弱认证
标题如下,是一个不需要登录验证和无限次登录的登录界面。这个弱密码可以通过暴力破解获得:
只需输入一个用户名,用户名为admin,然后使用admin作为用户名进行爆破。
我在虚拟机上用 Buipsuit 爆破
首先在浏览器中设置代理
之后在浏览器中输入用户名admin,密码输入一个随机数(输入123456,直接给出答案...不过为了爆一次,换成111111)@ >,Burpsuit 会拦截它,只要你可以开始特定的爆破步骤 Action —> 发送给 Intruder
Intruder —> Positions,清理变量后,选择密码作为变量
选择的爆破方式为集束炸弹
Payloads中的Payloads set和Payloads type默认选择,也可以使用自己的字典
选择线程等开始爆破 xff referer
现在在浏览器中设置代理ip,然后使用burpsuite,我在虚拟机上做
现在在 burp 套件上捕获数据包
然后将 X-Forwarded-For:123.123.123.123 添加到响应头
回复显示“必须来自”,然后将Referer:添加到响应头以获得答案
命令执行
Ping是操作系统常用的网络诊断工具,可以用来判断连接是否建立。是一种利用IP地址的唯一性发送数据包,根据反馈数据包和反馈时间来判断连接是否建立的方法。
首先判断链接是否建立,ping127.0.0.1可以连接。
然后在127.0.0.1中查找flag文件,在ping中注入命令并使用&&逻辑符号,可以看到/中有一个flag.txt文件家
打开这个文件,你可以看到标志。
simple_js
我不知道为什么这是答案。如果有人看到它,你能帮帮我吗?
Ctrl+u查看源码
<p>
JS
function dechiffre(pass_enc){
var pass = "70,65,85,88,32,80,65,83,83,87,79,82,68,32,72,65,72,65";
var tab = pass_enc.split(',');
var tab2 = pass.split(',');var i,j,k,l=0,m,n,o,p = "";i = 0;j = tab.length;
k = j + (l) + (n=0);
n = tab2.length;
for(i = (o=0); i 查看全部
网页抓取数据百度百科(robotsrobots协议(robots.txt)Robots协议用来告知搜索引擎哪些页面能被抓取)
robotsrobots 协议 (robots.txt)
Robots协议用于通知搜索引擎哪些页面可以爬取,哪些页面不能爬取;网站中一些比较大的文件可以屏蔽掉,比如:图片、音乐、视频等,节省服务器带宽;它可以被阻止一些指向该站点的死链接。方便搜索引擎抓取网站内容;设置 网站 地图连接来引导蜘蛛抓取页面。(来自百度百科)
** robots.txt 放置在网页上,指定搜索引擎和网络爬虫可以访问和不能访问的页面**
话题分析
进入答题页面后,直接进入url上的robots.txt
看答案
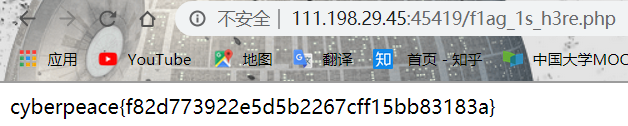
备份
网页备份

index.php的备份文件是index.php.bax,直接访问下载,然后打开查看文件,可以找到flag
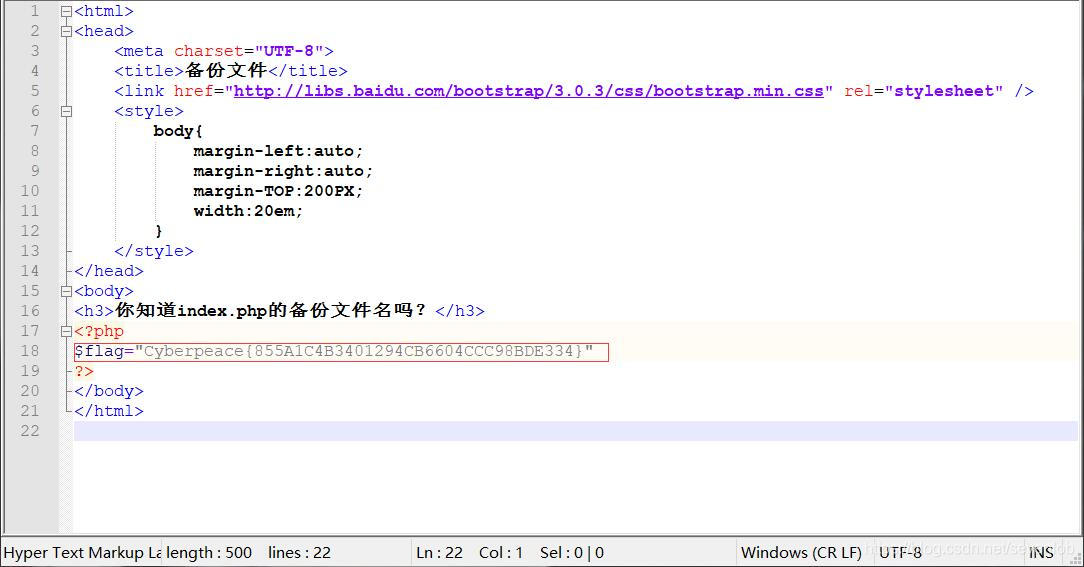
cookie(存储在用户本地终端上的数据)
Cookie,类型为“小文本文件”,是为了识别用户身份和进行会话跟踪而存储在用户本地终端上的一些数据(通常是加密的),由用户的客户端计算机临时或永久存储。资料(来自百度百科)
客户端保存的一小段文本信息,用于服务器识别
话题分析

输入cookies.php查看cookies
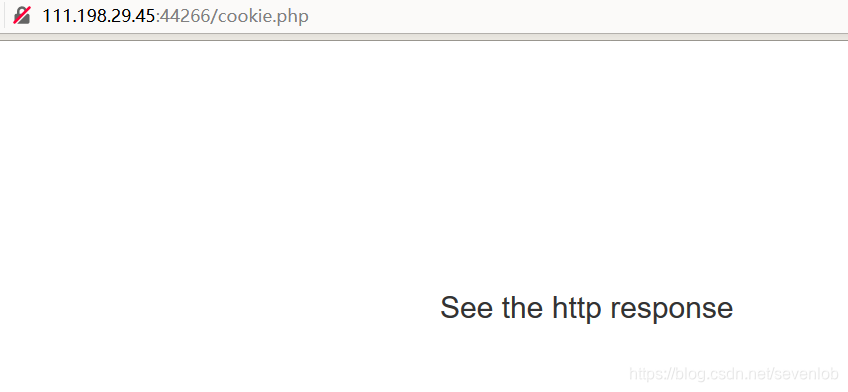
提示“查看网页响应”,刷新网页找到网站消息头中的flag
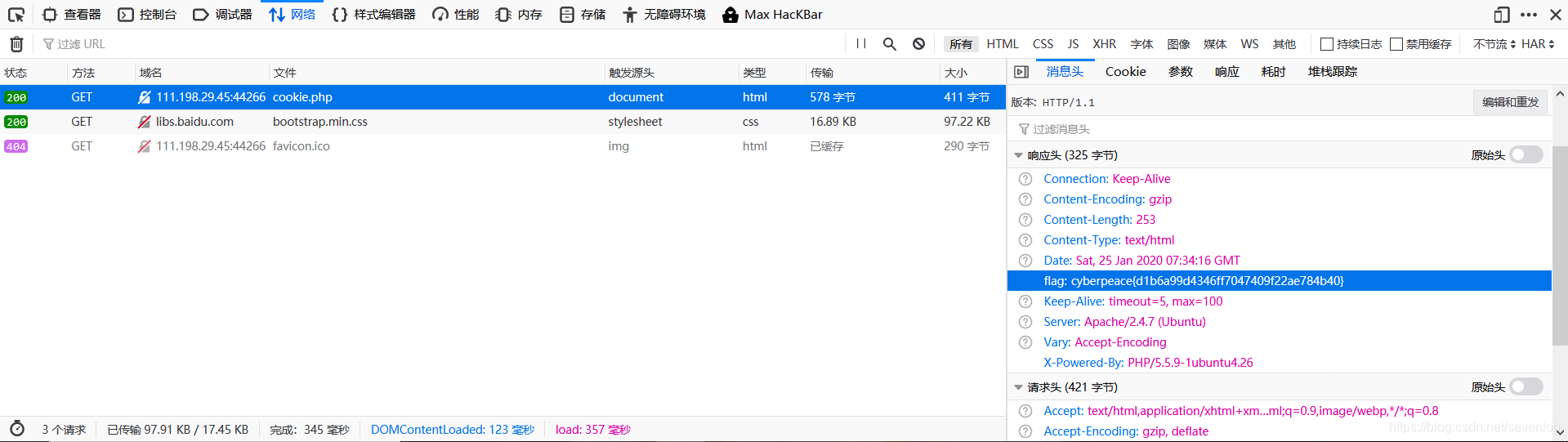
我不知道如何在 Google 中查看它
禁用按钮主题分析
标题如下,flag不能点击

F12 发现form有disable属性,删掉点击,点击就有答案了
HTML 表单的 disabled 属性
disabled 属性可以附加到 HTML 中的输入元素、按钮元素、选项元素等。给定此属性时,元素变为非交互元素
创建一个可以按下的按钮
able
浏览器显示如下,这个按钮可以点击

disable
浏览器显示如下,该按钮无法点击

弱认证
标题如下,是一个不需要登录验证和无限次登录的登录界面。这个弱密码可以通过暴力破解获得:
只需输入一个用户名,用户名为admin,然后使用admin作为用户名进行爆破。
我在虚拟机上用 Buipsuit 爆破
首先在浏览器中设置代理
之后在浏览器中输入用户名admin,密码输入一个随机数(输入123456,直接给出答案...不过为了爆一次,换成111111)@ >,Burpsuit 会拦截它,只要你可以开始特定的爆破步骤 Action —> 发送给 Intruder
Intruder —> Positions,清理变量后,选择密码作为变量
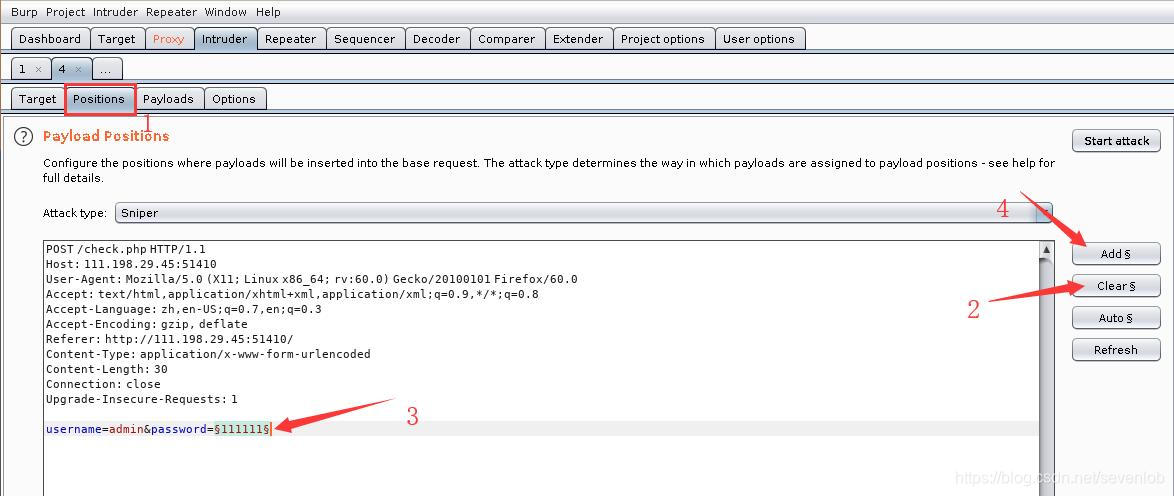
选择的爆破方式为集束炸弹
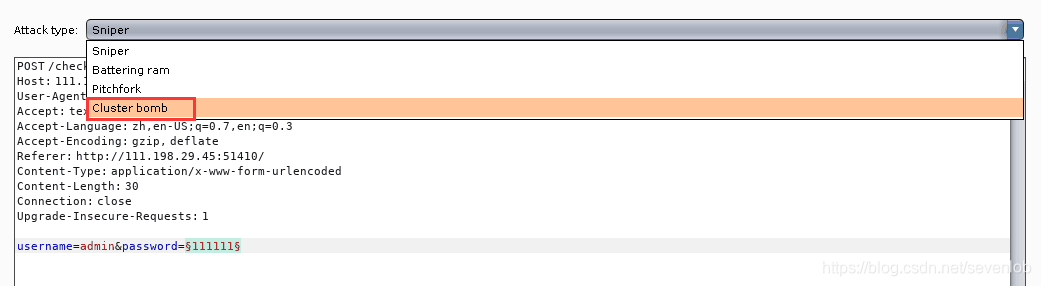
Payloads中的Payloads set和Payloads type默认选择,也可以使用自己的字典
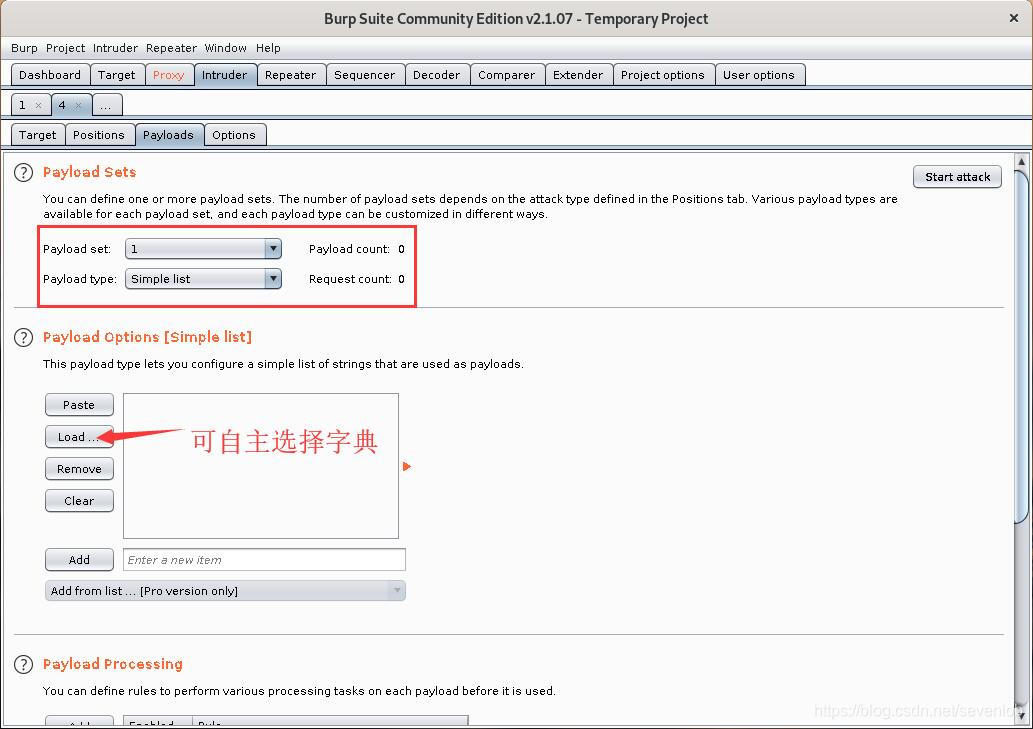
选择线程等开始爆破 xff referer
现在在浏览器中设置代理ip,然后使用burpsuite,我在虚拟机上做
现在在 burp 套件上捕获数据包
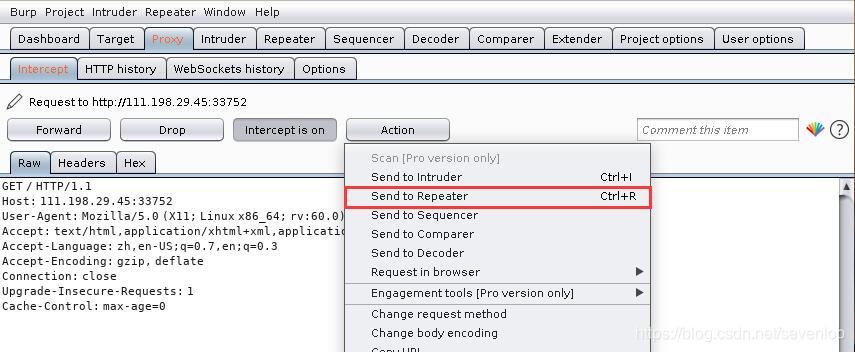
然后将 X-Forwarded-For:123.123.123.123 添加到响应头
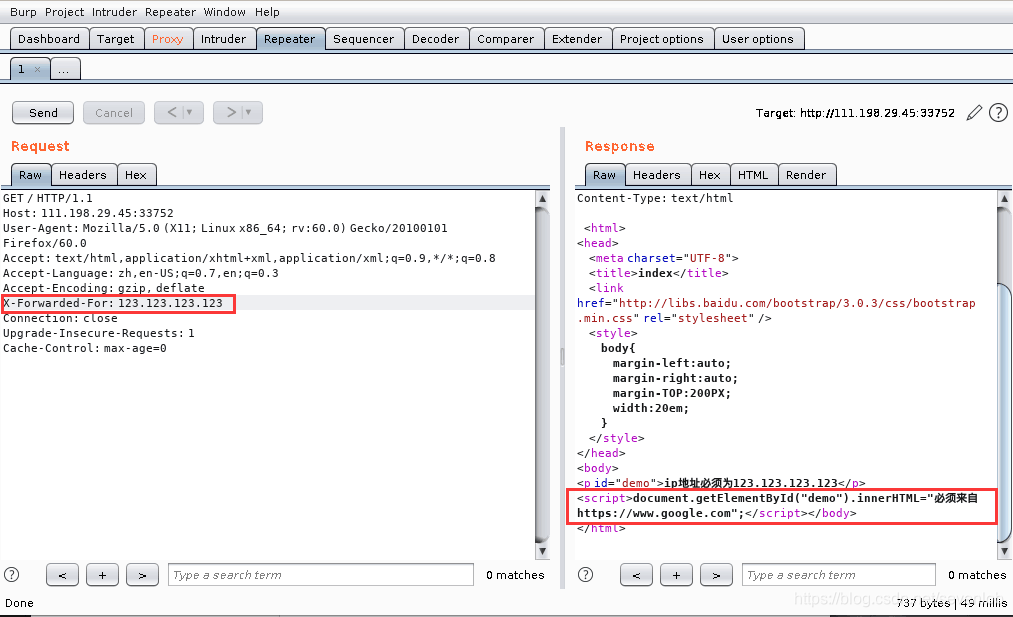
回复显示“必须来自”,然后将Referer:添加到响应头以获得答案
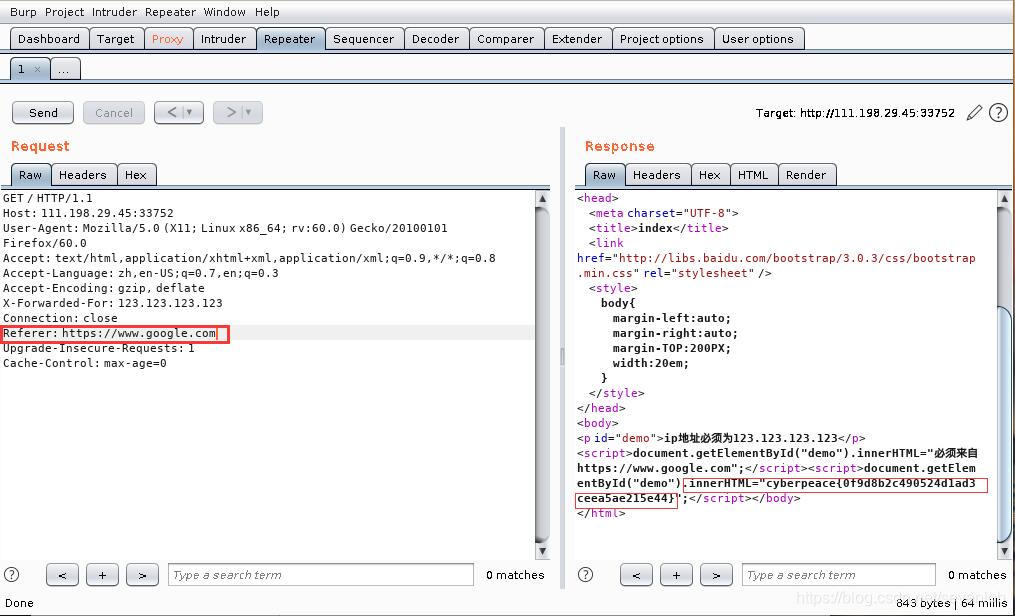
命令执行
Ping是操作系统常用的网络诊断工具,可以用来判断连接是否建立。是一种利用IP地址的唯一性发送数据包,根据反馈数据包和反馈时间来判断连接是否建立的方法。
首先判断链接是否建立,ping127.0.0.1可以连接。
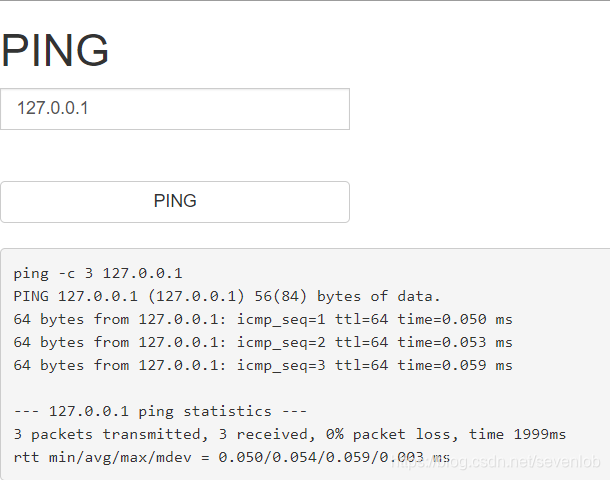
然后在127.0.0.1中查找flag文件,在ping中注入命令并使用&&逻辑符号,可以看到/中有一个flag.txt文件家
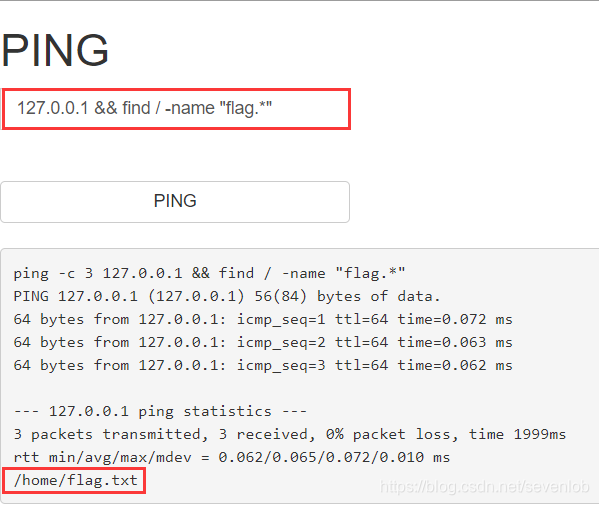
打开这个文件,你可以看到标志。
simple_js
我不知道为什么这是答案。如果有人看到它,你能帮帮我吗?
Ctrl+u查看源码
<p>
JS
function dechiffre(pass_enc){
var pass = "70,65,85,88,32,80,65,83,83,87,79,82,68,32,72,65,72,65";
var tab = pass_enc.split(',');
var tab2 = pass.split(',');var i,j,k,l=0,m,n,o,p = "";i = 0;j = tab.length;
k = j + (l) + (n=0);
n = tab2.length;
for(i = (o=0); i
网页抓取数据百度百科(爬虫nodejs适合垂直爬取的几种适合爬虫的语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-22 00:43
一、爬虫介绍
根据百度百科的定义:网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常被称为网络追逐者),是根据一定的规则或脚本自动爬取万维网上信息的程序. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。???随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
二、适合爬虫的几种语言
1.幻影
2017 年 4 月,该语言的核心开发者之一 Vitaly 辞去维护工作,表示不再维护。原话如下:我看不到PhantomJS的未来,作为一个单独开发者开发PhantomJS 2和2.5,简直就是地狱。即使最近发布了带有新的、闪亮的 QtWebKit 的 2.5 Beta 版本,我仍然不能真正支持 3 个平台。我们没有其他势力支持!
并且 Vitaly 发帖称 Chrome 59 将支持无头模式,用户最终会转向它。Chrome 比 PhantomJS 更快更稳定,而且不会像 PhantomJS 那样吃内存??????但这并不意味着语言的终结,语言仍然可以使用
2.casperJS
CasperJs 是基于 PhantomJs 的工具,可以比 PhantomJs 更方便的导航。就个人而言,我对这门语言了解不多,也没有过多阐述。
3.nodejs
nodejs适合垂直爬取,分布式爬取难度较大,对部分功能支持较弱,不推荐使用
4.Python
我喜欢python的语言,强烈推荐使用python,尤其是它的语言爬虫框架scrapy特别值得学习。支持xpath,可以定义多个爬虫,支持多线程爬取等,以后我会一步步入手。流程发给大家,附上源码
ps:另外可以使用c++、PHP、java等语言爬取网页。爬虫因人而异。我推荐的不一定是最好的。
三、python爬虫的优点
代码简洁明了,适合根据实际情况快速修改代码。网络的内容和布局会随时变化。python的快速发展是有优势的。如果不加修改或者少加修改写得好,其他高性能语言更有优势。(来自 知乎)
1)相比其他静态编程语言,如java、c#、C++、python,爬取网页的界面更加简洁;与其他动态脚本语言相比,如perl、shell、python urllib2 包提供了比较完整的访问web 文档的API。(当然,ruby 也是一个不错的选择。)另外,爬取网页有时需要模拟浏览器的行为,很多 网站 被屏蔽了用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理 抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。(摘自博客园)
以上就是前人为我们总结的诸多优势。我整理了其中两个供大家参考。
四、后续安排
后面给大家分享一下BeautifulSoup的安装和使用
使用 BS 抓取 网站 实例
Scrapy 安装和项目创建
Scrapy 的常见问题
Scrapy爬取网页实例
五、结束语我创建专栏已经半年多了,也没有太在意。很抱歉,但我会尽力向您展示一些我将来可以给您的,并附上完整的源代码。希望大家多多贡献,扩大本专栏 ps:给大家介绍几门课程和书籍。我觉得价格合适。可以根据情况学习: 课程:
Python爬虫实战简明教程38¥
第一个英文版爬虫magic-2-network协议和网页文本解析工具1.5¥
第一个英文版爬虫神通-3-新浪微博和推特数据采集1.5¥
爬虫2天实战--爬取腾讯应用宝5.2¥
正版python基础教程(第2版·修订版)python基础学习手册python编程入门经典书籍python从入门到实践精通新华书店正版书籍55元 查看全部
网页抓取数据百度百科(爬虫nodejs适合垂直爬取的几种适合爬虫的语言)
一、爬虫介绍
根据百度百科的定义:网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常被称为网络追逐者),是根据一定的规则或脚本自动爬取万维网上信息的程序. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。???随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
二、适合爬虫的几种语言
1.幻影
2017 年 4 月,该语言的核心开发者之一 Vitaly 辞去维护工作,表示不再维护。原话如下:我看不到PhantomJS的未来,作为一个单独开发者开发PhantomJS 2和2.5,简直就是地狱。即使最近发布了带有新的、闪亮的 QtWebKit 的 2.5 Beta 版本,我仍然不能真正支持 3 个平台。我们没有其他势力支持!
并且 Vitaly 发帖称 Chrome 59 将支持无头模式,用户最终会转向它。Chrome 比 PhantomJS 更快更稳定,而且不会像 PhantomJS 那样吃内存??????但这并不意味着语言的终结,语言仍然可以使用
2.casperJS
CasperJs 是基于 PhantomJs 的工具,可以比 PhantomJs 更方便的导航。就个人而言,我对这门语言了解不多,也没有过多阐述。
3.nodejs
nodejs适合垂直爬取,分布式爬取难度较大,对部分功能支持较弱,不推荐使用
4.Python
我喜欢python的语言,强烈推荐使用python,尤其是它的语言爬虫框架scrapy特别值得学习。支持xpath,可以定义多个爬虫,支持多线程爬取等,以后我会一步步入手。流程发给大家,附上源码
ps:另外可以使用c++、PHP、java等语言爬取网页。爬虫因人而异。我推荐的不一定是最好的。
三、python爬虫的优点
代码简洁明了,适合根据实际情况快速修改代码。网络的内容和布局会随时变化。python的快速发展是有优势的。如果不加修改或者少加修改写得好,其他高性能语言更有优势。(来自 知乎)
1)相比其他静态编程语言,如java、c#、C++、python,爬取网页的界面更加简洁;与其他动态脚本语言相比,如perl、shell、python urllib2 包提供了比较完整的访问web 文档的API。(当然,ruby 也是一个不错的选择。)另外,爬取网页有时需要模拟浏览器的行为,很多 网站 被屏蔽了用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理 抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。(摘自博客园)
以上就是前人为我们总结的诸多优势。我整理了其中两个供大家参考。
四、后续安排
后面给大家分享一下BeautifulSoup的安装和使用
使用 BS 抓取 网站 实例
Scrapy 安装和项目创建
Scrapy 的常见问题
Scrapy爬取网页实例
五、结束语我创建专栏已经半年多了,也没有太在意。很抱歉,但我会尽力向您展示一些我将来可以给您的,并附上完整的源代码。希望大家多多贡献,扩大本专栏 ps:给大家介绍几门课程和书籍。我觉得价格合适。可以根据情况学习: 课程:
Python爬虫实战简明教程38¥
第一个英文版爬虫magic-2-network协议和网页文本解析工具1.5¥
第一个英文版爬虫神通-3-新浪微博和推特数据采集1.5¥
爬虫2天实战--爬取腾讯应用宝5.2¥
正版python基础教程(第2版·修订版)python基础学习手册python编程入门经典书籍python从入门到实践精通新华书店正版书籍55元
规模化网站,如何练SEO内功,快速拉升权重?
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-05-02 00:31
搜索引擎算法调整的过程中,总是会展现出多种类型的网站,甚至是短期高权重站点。
虽然SEO行业当下的环境紧缩,但大家仍然还是保留了那份热情,每出现一个权重站,总是想将其拆解的彻彻底底。
那么,规模化网站,如何短期练内功,快速拉升权重?
根据以往SEO实战经验,蝙蝠侠IT,将通过如下讨论:
1、页面质量评估
任何一个网站在某种角度上都是碎片化的,它由海量的页面组成,我们评定一个网站是否值得索引展现,实际上在某种程度上在评估每个页面的搜索展现价值。
我们只有将每个类型页面都细节标准化之后,才能以少聚多,短期拉升网站权重,因此,我们有必要思考:
①页面搜索需求
你的页面是否匹配了搜索需求,简单理解就是是否覆盖了具有一定搜索量的关键词,它需要你进行合理的关键词挖掘。
② 页面解决搜索需求的能力
这个页面的元素组成是否能够最大限度的解决你的用户搜索需求,它包括:
等等一系列能够更好的解读目标关键词搜索属性的元素。
③页面链接关系
页面中是否存在行业相关性行业的权威度链接,是否包含具有解释说明的价值链接。
④ 页面加载速度
毋庸质疑这已经是我们无数次提及的事情,无论是移动端还是PC端都控制在1.5秒之内吧。
⑤ 页面终端体验
这里我们主要强调一下,不要过度的进行弹窗广告吧,尽量避免屏占比比较高的广告横幅展现。
2、页面结构设计
标准化的页面结构是搜索引擎快速抓取与评估页面质量,建立索引评分一个重要的途径。
在完美的页面,合理的被搜索引擎爬行和抓取是前提,否则我们没有办法谈论后续的任何问题。
在这个过程中,我们可能需要关注:
① URL结构
其中伪静态URL形态,并不是唯一属性,我们只是希望整站的URL地址形态,具有一定的标准化,便利的方便搜索爬行与抓取。
而目录层级,直观影响搜索引擎访问的深度,层级太多,权威度比较低,很难引导深层次目录进行抓取。
同时,对于目录层级而言,它还起着站内结构元素分类的重要作用,比如:
不同属性的页面索引特征可能都存在一定的差异性。特别需要说明的是我们在做目录层级设计的时候,就需要考量到整站SEO属性流量的走向策略。
②面包屑导航
面包屑导航是我们经常被忽略的一个细节性问题,我们不止一次强调它承载着整站链接重要程度的重要参考因子。
同时它精准的告知搜索引擎当前页面的主题属性,这其中就包括:目录类别属性。
③ H标签布局
H标签这么多年很少被提及,但我们认为他是强化一个页面核心关键词与长尾关键词最为重要的技术指标,特别是对于规模性网站,我们有的时候需要合理的利用海量页面中的H标签。
3、页面流量流动
对于任何一个有商业转化为目的的网站来讲,思考整站流量走向是国内90%以上SEO机构经常会忽略的一个问题。
通常作为衡量规模网站指标的因素,都是完全独立于SEO技术指标,比如:
过度的追求数据指标,让我们制定网站内部策略的时候,更多的考量泛流量,甚至是不相关性流量。
这里在行业最具有代表性的网站就是阿里云,钉钉,新网等等知名云网站,完全借助网站权威度海量排名TAG聚合标题,而产生高权重属性标签。
在某种程度上可以说是存在一定的“SEO虚荣性指标”,而对实际业务转化真正起到多少作用,可能并不能存在合理性的统计与评估。
这就需要我们思考:
在制定站内策略的时候,是否需要充分考量,某一个部分流量的价值转化,从:
每一个环节实际上都需要巧妙设计,比如:一个独立的理财网站,它可能是以售卖基金为主。
对于一个基金而言它的属性有很多,比如:
我们在做词库统计与布局的时候,什么样的排名,关联什么样的流量,什么样的流量关联什么样的页面。
简单举例:
检索基金公司基础信息的人,它更多的是可能希望了解相关的信息介绍,因此在他产生购买意图的时候,我猜是倾向于货币型或者债券型基金。
相反,如果一个基金经理过往履历经常被访问的页面,那么这样的流量用户转化需求,可能就定位在股票型基金,或者混合型基金。
这样我们在做页面关联性的同时,就需要思考如何匹配潜在的需求,从而拉升页面用户的停留时间,推动产品转化,放大一个精准流量的SEO价值。
当然,这里我们还可以参考现有的流量生态,分析竞争对手相关产品的现状,我们就不深入展开。
实际上,一个完整的SEO策略,在某种程度上,更多的时间周期理论上应该放在站内策略上,当我们处理好站内策略,才可以进一步的开展SEO工作。
相关性阅读:
SEO学习SEO服务百度专区 查看全部
规模化网站,如何练SEO内功,快速拉升权重?
搜索引擎算法调整的过程中,总是会展现出多种类型的网站,甚至是短期高权重站点。
虽然SEO行业当下的环境紧缩,但大家仍然还是保留了那份热情,每出现一个权重站,总是想将其拆解的彻彻底底。
那么,规模化网站,如何短期练内功,快速拉升权重?
根据以往SEO实战经验,蝙蝠侠IT,将通过如下讨论:
1、页面质量评估
任何一个网站在某种角度上都是碎片化的,它由海量的页面组成,我们评定一个网站是否值得索引展现,实际上在某种程度上在评估每个页面的搜索展现价值。
我们只有将每个类型页面都细节标准化之后,才能以少聚多,短期拉升网站权重,因此,我们有必要思考:
①页面搜索需求
你的页面是否匹配了搜索需求,简单理解就是是否覆盖了具有一定搜索量的关键词,它需要你进行合理的关键词挖掘。
② 页面解决搜索需求的能力
这个页面的元素组成是否能够最大限度的解决你的用户搜索需求,它包括:
等等一系列能够更好的解读目标关键词搜索属性的元素。
③页面链接关系
页面中是否存在行业相关性行业的权威度链接,是否包含具有解释说明的价值链接。
④ 页面加载速度
毋庸质疑这已经是我们无数次提及的事情,无论是移动端还是PC端都控制在1.5秒之内吧。
⑤ 页面终端体验
这里我们主要强调一下,不要过度的进行弹窗广告吧,尽量避免屏占比比较高的广告横幅展现。
2、页面结构设计
标准化的页面结构是搜索引擎快速抓取与评估页面质量,建立索引评分一个重要的途径。
在完美的页面,合理的被搜索引擎爬行和抓取是前提,否则我们没有办法谈论后续的任何问题。
在这个过程中,我们可能需要关注:
① URL结构
其中伪静态URL形态,并不是唯一属性,我们只是希望整站的URL地址形态,具有一定的标准化,便利的方便搜索爬行与抓取。
而目录层级,直观影响搜索引擎访问的深度,层级太多,权威度比较低,很难引导深层次目录进行抓取。
同时,对于目录层级而言,它还起着站内结构元素分类的重要作用,比如:
不同属性的页面索引特征可能都存在一定的差异性。特别需要说明的是我们在做目录层级设计的时候,就需要考量到整站SEO属性流量的走向策略。
②面包屑导航
面包屑导航是我们经常被忽略的一个细节性问题,我们不止一次强调它承载着整站链接重要程度的重要参考因子。
同时它精准的告知搜索引擎当前页面的主题属性,这其中就包括:目录类别属性。
③ H标签布局
H标签这么多年很少被提及,但我们认为他是强化一个页面核心关键词与长尾关键词最为重要的技术指标,特别是对于规模性网站,我们有的时候需要合理的利用海量页面中的H标签。
3、页面流量流动
对于任何一个有商业转化为目的的网站来讲,思考整站流量走向是国内90%以上SEO机构经常会忽略的一个问题。
通常作为衡量规模网站指标的因素,都是完全独立于SEO技术指标,比如:
过度的追求数据指标,让我们制定网站内部策略的时候,更多的考量泛流量,甚至是不相关性流量。
这里在行业最具有代表性的网站就是阿里云,钉钉,新网等等知名云网站,完全借助网站权威度海量排名TAG聚合标题,而产生高权重属性标签。
在某种程度上可以说是存在一定的“SEO虚荣性指标”,而对实际业务转化真正起到多少作用,可能并不能存在合理性的统计与评估。
这就需要我们思考:
在制定站内策略的时候,是否需要充分考量,某一个部分流量的价值转化,从:
每一个环节实际上都需要巧妙设计,比如:一个独立的理财网站,它可能是以售卖基金为主。
对于一个基金而言它的属性有很多,比如:
我们在做词库统计与布局的时候,什么样的排名,关联什么样的流量,什么样的流量关联什么样的页面。
简单举例:
检索基金公司基础信息的人,它更多的是可能希望了解相关的信息介绍,因此在他产生购买意图的时候,我猜是倾向于货币型或者债券型基金。
相反,如果一个基金经理过往履历经常被访问的页面,那么这样的流量用户转化需求,可能就定位在股票型基金,或者混合型基金。
这样我们在做页面关联性的同时,就需要思考如何匹配潜在的需求,从而拉升页面用户的停留时间,推动产品转化,放大一个精准流量的SEO价值。
当然,这里我们还可以参考现有的流量生态,分析竞争对手相关产品的现状,我们就不深入展开。
实际上,一个完整的SEO策略,在某种程度上,更多的时间周期理论上应该放在站内策略上,当我们处理好站内策略,才可以进一步的开展SEO工作。
相关性阅读:
SEO学习SEO服务百度专区
网页抓取数据百度百科( python爬虫基本知识爬虫爬虫爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-04-20 14:36
python爬虫基本知识爬虫爬虫爬虫)
python爬虫基础知识,python爬虫知识
爬虫简介
根据百度百科的定义:网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常称为网页追逐者),是一种按照一定的规则对万维网信息进行自动爬取的行为。规则程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在发布大数据后了解了爬虫的技术
随着数据的海量增长,我们需要在互联网上选择需要的数据进行自己的研究和实验。这使用了爬虫技术。跟着小编第一次见见python爬虫吧!
一、请求-响应
在使用python语言实现爬虫时,主要用到了urllib和urllib2这两个库。首先用一段代码解释如下:
import urllib
import urllib2
url="http://www.baidu.com"
request=urllib2.Request(url)
response=urllib2.urlopen(request)
print response.read()
我们知道一个网页是由html作为骨架,js作为肌肉,css作为衣服组成的。以上代码实现的功能是将百度网页的源代码爬取到本地。
其中,url为要爬取的网页的URL; request 发出请求,response 是接受请求后给出的响应。最后read()函数的输出就是百度网页的源码。
二、GET-POST
两者都将数据传输到网页。最重要的区别是GET方法是以链接的形式直接访问的。该链接收录所有参数。当然,如果收录密码,这是一个不安全的选择,但是您可以直观地看到您提交的内容。
POST不会显示URL上的所有参数,但是如果要直接查看提交的内容,不是很方便,可以酌情选择。
POST方法:
GET方法:
import urllib
import urllib2
values={'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request=urllib2.Request(geturl)
response=urllib2.urlopen(request)
print response.read()
三、异常处理
处理异常时使用try-except语句。
import urllib2
try:
response=urllib2.urlopen("http://www.xxx.com")
except urllib2.URLError,e:
print e.reason
总结
以上就是小编为大家介绍的python爬虫基础知识。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。我还要感谢大家对助手之家的支持网站! 查看全部
网页抓取数据百度百科(
python爬虫基本知识爬虫爬虫爬虫)
python爬虫基础知识,python爬虫知识
爬虫简介
根据百度百科的定义:网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常称为网页追逐者),是一种按照一定的规则对万维网信息进行自动爬取的行为。规则程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在发布大数据后了解了爬虫的技术
随着数据的海量增长,我们需要在互联网上选择需要的数据进行自己的研究和实验。这使用了爬虫技术。跟着小编第一次见见python爬虫吧!
一、请求-响应
在使用python语言实现爬虫时,主要用到了urllib和urllib2这两个库。首先用一段代码解释如下:
import urllib
import urllib2
url="http://www.baidu.com"
request=urllib2.Request(url)
response=urllib2.urlopen(request)
print response.read()
我们知道一个网页是由html作为骨架,js作为肌肉,css作为衣服组成的。以上代码实现的功能是将百度网页的源代码爬取到本地。
其中,url为要爬取的网页的URL; request 发出请求,response 是接受请求后给出的响应。最后read()函数的输出就是百度网页的源码。
二、GET-POST
两者都将数据传输到网页。最重要的区别是GET方法是以链接的形式直接访问的。该链接收录所有参数。当然,如果收录密码,这是一个不安全的选择,但是您可以直观地看到您提交的内容。
POST不会显示URL上的所有参数,但是如果要直接查看提交的内容,不是很方便,可以酌情选择。
POST方法:
GET方法:
import urllib
import urllib2
values={'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request=urllib2.Request(geturl)
response=urllib2.urlopen(request)
print response.read()
三、异常处理
处理异常时使用try-except语句。
import urllib2
try:
response=urllib2.urlopen("http://www.xxx.com";)
except urllib2.URLError,e:
print e.reason
总结
以上就是小编为大家介绍的python爬虫基础知识。我希望它对你有帮助。如有任何问题,请给我留言,小编会及时回复您。我还要感谢大家对助手之家的支持网站!
网页抓取数据百度百科(蜘蛛不会为什么搜索引擎优化,增加网站抓取规则的频率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-17 12:33
一、 蜘蛛爬行规则
搜索引擎中的蜘蛛需要将抓取到的网页放入数据库区域进行数据补充。如果通过程序计算分类,放在不同的搜索位置,搜索引擎就会形成一个稳定的收录排名。在这个过程中,蜘蛛抓取到的数据不一定是稳定的。很多数据经过程序计算后被其他好的网页排挤掉了。简单地说,蜘蛛不喜欢它,不想捕获页面。
蜘蛛的味道很独特,它捕捉到的网站,也就是我们所说的原创文章,只要你的文章原创网页@>Sex 很高,那么你的网页就会被蜘蛛抓到,这就是为什么越来越多的人需要 原创sex 来换取 文章。
只有这样,数据排名才会稳定。现在搜索引擎改变了策略,逐渐转向补充数据。他们喜欢将缓存机制和补充数据结合起来。这就是为什么搜索引擎优化,包括越来越难,我们也可以理解,今天有很多Pages不包括排名,而且每隔一段时间就包括排名。
二、增加网站的抓取频率
1、网站文章 质量提升
虽然做 SEO 的人知道如何改进 原创文章,但在搜索引擎中始终存在一个事实,即内容的质量和稀缺性永远无法同时满足这两个要求。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是受到蜘蛛的喜爱。
2、更新网站文章的频率
满足内容,关键是要做到正常的更新频率,这也是提高网页抓取的法宝。
3、网站速度不仅影响蜘蛛,还影响用户体验
蜘蛛访问,如果想要无障碍,加载过程可以在合理的速度范围内,保证蜘蛛在网页上顺畅爬行,没有任何加载延迟。如果经常遇到这个问题,那么蜘蛛就不会喜欢它 网站 ,爬行的频率会降低。
4、提高网站品牌知名度
如果你在网上混了很多,你会发现一个问题。当一些知名品牌推出新的网站时,他们会去一些新闻媒体报道。新闻来源网站报道后,会添加一些品牌词。即使没有诸如目标之类的链接,搜索引擎也会抓住这个网站。
5、选择PR高的域名
PR 是个老域名,所以要承载很大的分量,即使你的网站很久没有更新或者完全关闭了网站页面,搜索引擎也会爬,等待更新内容。如果有人从一开始就选择使用这样一个老域名,他也可以发展重定向,成为一个真正的可操作域名。
三、优质外链
如果你想让搜索引擎给网站更多的权重,你应该明白,在区分网站的权重时,搜索引擎会考虑有多少链接链接到其他网站,外部的质量链接、外链数据、外链的相关性网站,这些因素百度都应该考虑。一个高权重的网站外链质量也应该很高,如果外链质量达不到,权重值就上不去。所以如果网站管理员想要增加网站的权重值,要注意提高网站的外链质量。这些都很重要,要注意外链的质量。
四、高质量的内部链接
百度的权重值不仅取决于网站的内容,还取决于网站的内链构建。在查看网站时,百度搜索引擎会按照网站导航、网站内页锚文本链接等进入网站内页。网站 的内部页面。网站的导航栏可以适当的找到网站的其他内容,网站内容应该有相关的锚文本链接,既方便蜘蛛抓取,又减少了网站 的跳出率。所以网站的内链也很重要,如果网站的内链做得好,蜘蛛就会收录你的网站,因为你的链接不仅收录你的网页,还收录连接页面。
五、 蜘蛛爬行频率
如果是高权重的网站,更新频率会不一样,所以频率一般在几天或者一个月之间。网站质量越高,更新频率越快,蜘蛛会不断访问或更新网页。
六、高级空间
空间是 网站 的阈值。如果您的阈值太高,蜘蛛无法进入,它如何查看您的 网站 并区分您的 网站 的权重值?高门槛在这里意味着什么?也就是说,空间不稳定,服务器经常离线。这样一来,网站的访问速度是个大问题。如果蜘蛛爬取网页,网站经常打不开,下次对网站的检查会减少。因此,空间是 网站 上线之前最重要的问题。空间是独立IP,访问速度会更快,主机厂商的有效性需要详细规划。确保你的 网站 空间稳定,可以快速打开,而不是长时间不打开。
原创文章,作者:墨宇SEO,如转载请注明出处: 查看全部
网页抓取数据百度百科(蜘蛛不会为什么搜索引擎优化,增加网站抓取规则的频率)
一、 蜘蛛爬行规则
搜索引擎中的蜘蛛需要将抓取到的网页放入数据库区域进行数据补充。如果通过程序计算分类,放在不同的搜索位置,搜索引擎就会形成一个稳定的收录排名。在这个过程中,蜘蛛抓取到的数据不一定是稳定的。很多数据经过程序计算后被其他好的网页排挤掉了。简单地说,蜘蛛不喜欢它,不想捕获页面。
蜘蛛的味道很独特,它捕捉到的网站,也就是我们所说的原创文章,只要你的文章原创网页@>Sex 很高,那么你的网页就会被蜘蛛抓到,这就是为什么越来越多的人需要 原创sex 来换取 文章。
只有这样,数据排名才会稳定。现在搜索引擎改变了策略,逐渐转向补充数据。他们喜欢将缓存机制和补充数据结合起来。这就是为什么搜索引擎优化,包括越来越难,我们也可以理解,今天有很多Pages不包括排名,而且每隔一段时间就包括排名。
二、增加网站的抓取频率
1、网站文章 质量提升
虽然做 SEO 的人知道如何改进 原创文章,但在搜索引擎中始终存在一个事实,即内容的质量和稀缺性永远无法同时满足这两个要求。在创建内容时,我们必须满足每个潜在访问者的搜索需求,因为原创内容可能并不总是受到蜘蛛的喜爱。
2、更新网站文章的频率
满足内容,关键是要做到正常的更新频率,这也是提高网页抓取的法宝。
3、网站速度不仅影响蜘蛛,还影响用户体验
蜘蛛访问,如果想要无障碍,加载过程可以在合理的速度范围内,保证蜘蛛在网页上顺畅爬行,没有任何加载延迟。如果经常遇到这个问题,那么蜘蛛就不会喜欢它 网站 ,爬行的频率会降低。
4、提高网站品牌知名度
如果你在网上混了很多,你会发现一个问题。当一些知名品牌推出新的网站时,他们会去一些新闻媒体报道。新闻来源网站报道后,会添加一些品牌词。即使没有诸如目标之类的链接,搜索引擎也会抓住这个网站。
5、选择PR高的域名
PR 是个老域名,所以要承载很大的分量,即使你的网站很久没有更新或者完全关闭了网站页面,搜索引擎也会爬,等待更新内容。如果有人从一开始就选择使用这样一个老域名,他也可以发展重定向,成为一个真正的可操作域名。
三、优质外链
如果你想让搜索引擎给网站更多的权重,你应该明白,在区分网站的权重时,搜索引擎会考虑有多少链接链接到其他网站,外部的质量链接、外链数据、外链的相关性网站,这些因素百度都应该考虑。一个高权重的网站外链质量也应该很高,如果外链质量达不到,权重值就上不去。所以如果网站管理员想要增加网站的权重值,要注意提高网站的外链质量。这些都很重要,要注意外链的质量。
四、高质量的内部链接
百度的权重值不仅取决于网站的内容,还取决于网站的内链构建。在查看网站时,百度搜索引擎会按照网站导航、网站内页锚文本链接等进入网站内页。网站 的内部页面。网站的导航栏可以适当的找到网站的其他内容,网站内容应该有相关的锚文本链接,既方便蜘蛛抓取,又减少了网站 的跳出率。所以网站的内链也很重要,如果网站的内链做得好,蜘蛛就会收录你的网站,因为你的链接不仅收录你的网页,还收录连接页面。
五、 蜘蛛爬行频率
如果是高权重的网站,更新频率会不一样,所以频率一般在几天或者一个月之间。网站质量越高,更新频率越快,蜘蛛会不断访问或更新网页。
六、高级空间
空间是 网站 的阈值。如果您的阈值太高,蜘蛛无法进入,它如何查看您的 网站 并区分您的 网站 的权重值?高门槛在这里意味着什么?也就是说,空间不稳定,服务器经常离线。这样一来,网站的访问速度是个大问题。如果蜘蛛爬取网页,网站经常打不开,下次对网站的检查会减少。因此,空间是 网站 上线之前最重要的问题。空间是独立IP,访问速度会更快,主机厂商的有效性需要详细规划。确保你的 网站 空间稳定,可以快速打开,而不是长时间不打开。
原创文章,作者:墨宇SEO,如转载请注明出处:
网页抓取数据百度百科(1.分析目标本次实战篇的目的是什么?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-15 14:33
用python开发一个简单的爬虫:实战篇1.分析目标
这篇实战文章的目的是抓取百度百科python入口页面的标题和介绍,以及与之关联的入口页面的标题和介绍。
数据格式:
页面编码:UTF-8 2.网址管理器
代码如下:
# coding:utf8
class UrlManager(object):
def __init__(self):
# 初始化待爬取url集合和已爬取url集合
self.new_urls = set()
self.old_urls = set()
# 添加一个新的url到new_urls
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
# 获取一个待爬取的url,并将此url添加到old_urls
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
# 判断是否还有待爬取的url
def has_new_url(self):
return len(self.new_urls) != 0
# 添加多个url到new_urls
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
3. 网页下载器
代码如下:
# coding:utf8
import urllib2
class HtmlDownloader(object):
# 使用urllib2最简单的方法下载url页面内容
def download(self, url):
if url is None:
return None
resp = urllib2.urlopen(url)
if resp.getcode() != 200:
return None
return resp.read()
4. 网页解析器
代码如下:
# coding:utf8
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
# 得到页面相关的url
def _get_new_urls(self, page_url, soup):
new_urls = set()
# /view/123.htm
links = soup.find_all('a', href=re.compile(r'/view/\d+\.htm'))
for link in links:
new_url = link['href']
# 将/view/123.htm补充完整:http://baike.baidu.com/view/123.htm
new_full_url = urlparse.urljoin(page_url, new_url)
# 将解析到的unicode编码的网址转化为utf-8格式
new_urls.add(new_full_url.encode('utf-8'))
return new_urls
# 得到页面标题和简介
def _get_new_data(self, page_url, soup):
res_data = {}
# url
res_data['url'] = page_url
# 得到标题节点
# Python
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
# 得到简介节点
#
summary_node = soup.find('div', class_='lemma-summary')
res_data['summary'] = summary_node.get_text()
return res_data
# 对下载页面内容进行解析
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return None
soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
5.数据导出器
代码如下:
# coding:utf8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
# 收集数据
def collect_data(self, data):
if data is None:
return None
self.datas.append(data)
# 将收集到的数据生成一个HTML页面输出
def output_html(self):
fout = open('output.html', 'w')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
for data in self.datas:
fout.write('')
fout.write('%s' % data['url'].encode('utf-8'))
fout.write('%s' % data['title'].encode('utf-8'))
fout.write('%s' % data['summary'].encode('utf-8'))
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.close()
6.爬虫调度器
# coding:utf8
from baike1 import url_manager, html_downloader, html_parser, html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, url):
count = 1
self.urls.add_new_url(url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print 'craw %d:%s' % (count, new_url)
html_cont = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 100:
break
count += 1
except:
print 'craw failed'
self.outputer.output_html()
if __name__ == "__main__":
root_url = 'http://baike.baidu.com/view/21087.htm'
obj_spider = SpiderMain()
obj_spider.craw(root_url)
程序运行结果截图:
至此,一个很简单的爬虫就完成了,撒花! 查看全部
网页抓取数据百度百科(1.分析目标本次实战篇的目的是什么?(图))
用python开发一个简单的爬虫:实战篇1.分析目标
这篇实战文章的目的是抓取百度百科python入口页面的标题和介绍,以及与之关联的入口页面的标题和介绍。
数据格式:
页面编码:UTF-8 2.网址管理器
代码如下:
# coding:utf8
class UrlManager(object):
def __init__(self):
# 初始化待爬取url集合和已爬取url集合
self.new_urls = set()
self.old_urls = set()
# 添加一个新的url到new_urls
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
# 获取一个待爬取的url,并将此url添加到old_urls
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
# 判断是否还有待爬取的url
def has_new_url(self):
return len(self.new_urls) != 0
# 添加多个url到new_urls
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
3. 网页下载器
代码如下:
# coding:utf8
import urllib2
class HtmlDownloader(object):
# 使用urllib2最简单的方法下载url页面内容
def download(self, url):
if url is None:
return None
resp = urllib2.urlopen(url)
if resp.getcode() != 200:
return None
return resp.read()
4. 网页解析器
代码如下:
# coding:utf8
import re
import urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
# 得到页面相关的url
def _get_new_urls(self, page_url, soup):
new_urls = set()
# /view/123.htm
links = soup.find_all('a', href=re.compile(r'/view/\d+\.htm'))
for link in links:
new_url = link['href']
# 将/view/123.htm补充完整:http://baike.baidu.com/view/123.htm
new_full_url = urlparse.urljoin(page_url, new_url)
# 将解析到的unicode编码的网址转化为utf-8格式
new_urls.add(new_full_url.encode('utf-8'))
return new_urls
# 得到页面标题和简介
def _get_new_data(self, page_url, soup):
res_data = {}
# url
res_data['url'] = page_url
# 得到标题节点
# Python
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
# 得到简介节点
#
summary_node = soup.find('div', class_='lemma-summary')
res_data['summary'] = summary_node.get_text()
return res_data
# 对下载页面内容进行解析
def parse(self, page_url, html_cont):
if page_url is None or html_cont is None:
return None
soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
5.数据导出器
代码如下:
# coding:utf8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
# 收集数据
def collect_data(self, data):
if data is None:
return None
self.datas.append(data)
# 将收集到的数据生成一个HTML页面输出
def output_html(self):
fout = open('output.html', 'w')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.write('')
for data in self.datas:
fout.write('')
fout.write('%s' % data['url'].encode('utf-8'))
fout.write('%s' % data['title'].encode('utf-8'))
fout.write('%s' % data['summary'].encode('utf-8'))
fout.write('')
fout.write('')
fout.write('')
fout.write('')
fout.close()
6.爬虫调度器
# coding:utf8
from baike1 import url_manager, html_downloader, html_parser, html_outputer
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, url):
count = 1
self.urls.add_new_url(url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print 'craw %d:%s' % (count, new_url)
html_cont = self.downloader.download(new_url)
new_urls, new_data = self.parser.parse(new_url, html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
if count == 100:
break
count += 1
except:
print 'craw failed'
self.outputer.output_html()
if __name__ == "__main__":
root_url = 'http://baike.baidu.com/view/21087.htm'
obj_spider = SpiderMain()
obj_spider.craw(root_url)
程序运行结果截图:
至此,一个很简单的爬虫就完成了,撒花!
网页抓取数据百度百科(如何写好爬虫之前数据的基本步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-04-15 14:31
一、前言
在开始写爬虫之前,我们先来了解一下爬虫
首先,我们需要知道什么是爬虫。这里直接引用百度百科的定义。网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常被称为网页追逐者),是一种根据一定的规则、程序或脚本自动从万维网上爬取信息的网络爬虫。
这些还不够,我们还需要知道爬取数据的基本步骤。
爬虫爬取数据一般分为三步获取网页
做没有稻草的砖。我们需要的是数据都在网页中。如果我们无法获取网页,那么无论代码打得多么好,都是没有用的。所以爬虫的第一步一定是抓取网页。
好的
拿到网页后,我们要做的就是分析网页的结构,定位要爬取的信息,然后提取出来
保存信息
获取信息后,一般需要保存信息以备下次使用。
完成以上三步后,会写一个简单的爬虫( ̄▽ ̄)》,然后开始写壁纸爬虫
二、开始写爬虫
图片1
红框是我们要爬取的图片。
在开始写代码之前,首先要理清思路,这样可以让我们的思路更清晰,写代码更流畅,代码更简洁。
对于爬虫脚本,我们一般需要考虑以下几点: 爬什么:我们想从网页中获取什么数据
如何攀爬:使用什么库?我需要使用框架吗?有ajax接口吗?
爬取步骤:哪个先爬,哪个后爬
以我们的项目为例:爬什么:
我们的目标是下载网页中的图片。下载图片首先要获取图片的地址,图片的地址在网页中。
所以我们需要爬取网页中图片的地址。
攀登方式:
图片有几十到上百张,下载量不大。无需使用框架,直接使用requests库。
使用 xpath 解析网页。
爬取步骤:
第一步:分析网页,写入图片的xpath路径
第 2 步:获取带有 requests 库的网页
第三步:使用lxml库解析网页
第四步:通过xpath获取图片链接
第五步:下载图片
第 6 步:命名并保存图像
分析完毕,开始爬取!
第一步是分析网页,在浏览器中打开网页,按F12进入开发者模式,选择Elements选项卡,如图:
图二
使用元素选择器:
图三
找到标签后,我们就可以写出标签的xpath路径了。这个比较简单,就不详细写了。如果您有任何问题,您可以发表评论。
图片标签的xpath路径:
#地图地址
路径 = '//a[@title]/img/@src'
#为了方便给图片起名字,我也顺便把图片名字往下爬了
name = '//a[@title]/img/@alt'
下一步是应用我们所学的知识。废话不多说,直接上代码:
#-*- 编码:utf-8 -*
导入请求
从 lxml 导入 etree
#网站地址
网址 = '#39;
# 获取网页
r = requests.get(url)
r.encoding = r.apparent_encoding
#解析网页
dom = etree.HTML(r.text)
#获取图片img标签
#先获取图片所在的img标签,然后分别获取图片链接和名称
img_path = '//a[@title]/img'
imgs = dom.xpath(img_path)
#获取图片的链接和名称并下载保存
对于 imgs 中的 img:
相对路径“。” #xpath 的代表上层标签
#不要忘记xpath总是返回一个列表!
src = img.xpath('./@src')[0]
名称 = img.xpath('./@alt')[0]
#下载图片
图片 = requests.get(src)
#name 并保存图片
使用 open(name+'.jpg', 'wb') 作为 f:
f.write(image.content)
运行结果:
图片4
这样,我们就完成了一个简单版的壁纸爬虫。为什么叫简单版?原因如下:图片太小,根本不能当壁纸(其实我很懒( ̄▽ ̄)》),要获取高清壁纸的话,还需要点击图片转到下一页。为简单起见,我只是爬取了首页的缩略图。
不能自动翻页,一次只能下载一页图片。翻页可以在网页中获取到下一页的链接,或者找到URL的变化规律 查看全部
网页抓取数据百度百科(如何写好爬虫之前数据的基本步骤)
一、前言
在开始写爬虫之前,我们先来了解一下爬虫
首先,我们需要知道什么是爬虫。这里直接引用百度百科的定义。网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常被称为网页追逐者),是一种根据一定的规则、程序或脚本自动从万维网上爬取信息的网络爬虫。
这些还不够,我们还需要知道爬取数据的基本步骤。
爬虫爬取数据一般分为三步获取网页
做没有稻草的砖。我们需要的是数据都在网页中。如果我们无法获取网页,那么无论代码打得多么好,都是没有用的。所以爬虫的第一步一定是抓取网页。
好的
拿到网页后,我们要做的就是分析网页的结构,定位要爬取的信息,然后提取出来
保存信息
获取信息后,一般需要保存信息以备下次使用。
完成以上三步后,会写一个简单的爬虫( ̄▽ ̄)》,然后开始写壁纸爬虫
二、开始写爬虫
图片1
红框是我们要爬取的图片。
在开始写代码之前,首先要理清思路,这样可以让我们的思路更清晰,写代码更流畅,代码更简洁。
对于爬虫脚本,我们一般需要考虑以下几点: 爬什么:我们想从网页中获取什么数据
如何攀爬:使用什么库?我需要使用框架吗?有ajax接口吗?
爬取步骤:哪个先爬,哪个后爬
以我们的项目为例:爬什么:
我们的目标是下载网页中的图片。下载图片首先要获取图片的地址,图片的地址在网页中。
所以我们需要爬取网页中图片的地址。
攀登方式:
图片有几十到上百张,下载量不大。无需使用框架,直接使用requests库。
使用 xpath 解析网页。
爬取步骤:
第一步:分析网页,写入图片的xpath路径
第 2 步:获取带有 requests 库的网页
第三步:使用lxml库解析网页
第四步:通过xpath获取图片链接
第五步:下载图片
第 6 步:命名并保存图像
分析完毕,开始爬取!
第一步是分析网页,在浏览器中打开网页,按F12进入开发者模式,选择Elements选项卡,如图:
图二
使用元素选择器:
图三
找到标签后,我们就可以写出标签的xpath路径了。这个比较简单,就不详细写了。如果您有任何问题,您可以发表评论。
图片标签的xpath路径:
#地图地址
路径 = '//a[@title]/img/@src'
#为了方便给图片起名字,我也顺便把图片名字往下爬了
name = '//a[@title]/img/@alt'
下一步是应用我们所学的知识。废话不多说,直接上代码:
#-*- 编码:utf-8 -*
导入请求
从 lxml 导入 etree
#网站地址
网址 = '#39;
# 获取网页
r = requests.get(url)
r.encoding = r.apparent_encoding
#解析网页
dom = etree.HTML(r.text)
#获取图片img标签
#先获取图片所在的img标签,然后分别获取图片链接和名称
img_path = '//a[@title]/img'
imgs = dom.xpath(img_path)
#获取图片的链接和名称并下载保存
对于 imgs 中的 img:
相对路径“。” #xpath 的代表上层标签
#不要忘记xpath总是返回一个列表!
src = img.xpath('./@src')[0]
名称 = img.xpath('./@alt')[0]
#下载图片
图片 = requests.get(src)
#name 并保存图片
使用 open(name+'.jpg', 'wb') 作为 f:
f.write(image.content)
运行结果:
图片4
这样,我们就完成了一个简单版的壁纸爬虫。为什么叫简单版?原因如下:图片太小,根本不能当壁纸(其实我很懒( ̄▽ ̄)》),要获取高清壁纸的话,还需要点击图片转到下一页。为简单起见,我只是爬取了首页的缩略图。
不能自动翻页,一次只能下载一页图片。翻页可以在网页中获取到下一页的链接,或者找到URL的变化规律
网页抓取数据百度百科( Python感兴趣“入门”点根本不存在!(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-15 03:13
Python感兴趣“入门”点根本不存在!(上))
“开始”是一个很好的动力,但可能会很慢。如果你手头或脑子里有一个项目,在实践中你会被目标驱动,而不是像学习模块那样慢慢学习。
此外,如果知识系统中的每个知识点都是图中的一个点,并且依赖关系是边,那么图一定不是有向无环图。因为学习A的经验可以帮助你学习B。因此,你不需要学习如何“入门”,因为这样的“入门”点根本不存在!您需要学习的是如何做更大的事情,并且在此过程中,您将很快了解您需要学习的内容。当然,你可以争辩说你需要先了解Python,否则你怎么学Python做爬虫呢?但实际上,你可以在做这个爬虫的过程中学习Python。
看到前面很多回答中提到的“技能”——用什么软件怎么爬,那我就说说“道”和“技能”——爬虫是如何工作的,以及如何在Python中实现。
对Python感兴趣的朋友,记得私信小编“007”领取全套Python资料。
长话短说,总结一下,你需要学习:
基本爬虫工作原理 基本http爬虫,scrapyBloom Filter 如果需要大规模的网页抓取,需要学习分布式爬虫的概念。其实没那么神秘,你只需要学习如何维护一个所有集群机器都可以有效共享的分布式队列。最简单的实现是python-rqrq和scrapy的结合:darkrho/scrapy-redis 后续处理,网页提取 grangier/python-goose,存储(Mongodb)
这是一个简短的故事:
说说从我写的一个集群爬下整个豆瓣的经历吧。
1)首先你需要了解爬虫是如何工作的
想象一下,你是一只蜘蛛,现在你被放到了互联网“网络”上。好吧,您需要浏览所有网页。怎么做?没问题,你可以从任何地方开始,比如人民日报的首页,称为初始页,用$表示。
在人民日报的主页上,你会看到各种指向该页面的链接。于是你高高兴兴地爬到了“国内新闻”页面。太好了,你已经爬了两页(首页和国内新闻)!暂时不管你爬下来的页面怎么处理,你可以想象你把这个页面复制成html放到你身上了。
突然你发现,在国内新闻页面上,有一个返回“首页”的链接。作为一只聪明的蜘蛛,你必须知道你不必爬回来,因为你已经看到了。所以,你需要用你的大脑来保存你已经看过的页面的地址。这样,每次看到可能需要爬取的新链接时,首先在脑海中检查一下是否已经到过这个页面地址。如果你去过,不要去。
好吧,理论上,如果从初始页面可以到达所有页面,那么就可以证明你可以爬取所有页面。
那么如何在 Python 中实现呢?非常简单
import Queue
initial_page = "http://www.renminribao.com"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
#一直进行直到海枯石烂
while(True):
if url_queue.size()>0:
#拿出队例中第一个的url
current_url = url_queue.get()
#把这个url代表的网页存储好
store(current_url)
#提取把这个url里链向的url
for next_url in extract_urls(current_url):
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break
它已经是非常伪代码了。
所有爬虫的中坚力量都在这里,我们来分析一下为什么爬虫其实是很复杂的东西——搜索引擎公司通常有一个完整的团队来维护和开发。
2)效率
如果你直接处理上面的代码,直接运行,你要花一整年的时间才能爬下豆瓣的全部内容。更不用说像谷歌这样的搜索引擎需要爬取整个内容网络。
哪里有问题?要爬的页面太多,上面的代码太慢了。假设全网有N个网站,那么分析权重判断的复杂度是N*log(N),因为所有网页都需要遍历一次,需要log(N)的复杂度每次重复使用该集合。. 好的,好的,我知道 Python 的 set 实现是散列 - 但这仍然太慢,至少内存效率不高。
通常的判断方法是什么?布隆过滤器。简而言之,它仍然是一种哈希方法,但它的特点是可以使用固定内存(不随url的数量增长)来判断url是否已经在集合中,效率为O(1)不幸的是,世界上没有免费的午餐。唯一的问题是如果这个url不在集合中,BF可以100%确定这个url没有被看到。但是如果这个url在设置,它会告诉你:这个 url 应该已经存在了,但是我有 2% 的不确定性。注意,当你分配足够的内存时,这里的不确定性会变得非常小。一个简单的教程:Bloom Filters by Example。
注意这个特性,如果url看过,可能小概率会重复(没关系,多看就不会累死)。但是如果没有看到,就会看到(这很重要,否则我们会错过一些页面!)。
好的,现在我们正在接近处理权重的最快方法。另一个瓶颈 - 你只有一台机器。不管你有多少带宽,只要你的机器下载网页的速度是瓶颈,那你就只能提速了。如果一台机器不够用 - 使用多台!当然,我们假设每台机器都进入了最高效率——使用多线程(在 Python 的情况下是多进程)。
3)集群爬取
爬豆瓣的时候,我用了100多台机器,24小时不间断地跑了一个月。想象一下,如果你只用一台机器运行 100 个月......
那么,假设你现在有 100 台机器可用,如何在 Python 中实现分布式爬虫算法呢?
我们将这100台机器中的99台算力较小的机器称为slave,另一台较大的机器称为master,然后查看上面代码中的url_queue,如果我们可以把这个队列放在这台master机器上,那么所有slave都可以与master通信通过网络。每当从站完成下载网页时,它都会向主站请求新的网页以进行爬网。并且每次slave捕获一个新的网页,它会将网页上的所有链接发送到master的队列中。同样,布隆过滤器也放在master上,但是现在master只发送肯定不会被访问的url给slave。Bloom Filter放在master的内存中,访问的url放在运行在master上的Redis中,保证了所有操作都是O(1).(至少摊销是O(1),
考虑如何在 Python 中做到这一点:
在每台slave上安装scrapy,然后每台机器都成为具有抓取能力的slave,在master上安装redis和rq作为分布式队列使用。
然后代码写成
#slave.py
current_url = request_from_master()
to_send = []
for next_url in extract_urls(current_url):
to_send.append(next_url)
store(current_url);
send_to_master(to_send)
#master.py
distributed_queue = DistributedQueue()
bf = BloomFilter()
initial_pages = "www.renmingribao.com"
while(True):
if request == 'GET':
if distributed_queue.size()>0:
send(distributed_queue.get())
else:
break
elif request == 'POST':
bf.put(request.url)
好吧,你可以想象,有人已经给你写了你需要的东西:darkrho/scrapy-redis · GitHub
4)勘探和后处理
虽然上面使用了很多“简单”,但要真正实现一个商业规模可用的爬虫并不是一件容易的事。上面的代码用于爬取整个网站,问题不大。
但是如果附加你需要这些后处理,比如
有效存储(数据库应该如何安排),有效权重判断(这里指的是网页权重判断,我们不想爬取抄袭它的人民日报和大民日报) 有效信息提取(例如,如何提取所有网页上的信息地址是提取出来的,“朝阳区奋进路中华路”),搜索引擎通常不需要存储所有信息,比如我保存的图片...及时更新(预测此网页多久更新一次)
可以想象,这里的每一点都可以被许多研究人员研究数十年。即便如此,“路漫漫其修远兮,我要上上下下寻找。” 查看全部
网页抓取数据百度百科(
Python感兴趣“入门”点根本不存在!(上))
“开始”是一个很好的动力,但可能会很慢。如果你手头或脑子里有一个项目,在实践中你会被目标驱动,而不是像学习模块那样慢慢学习。
此外,如果知识系统中的每个知识点都是图中的一个点,并且依赖关系是边,那么图一定不是有向无环图。因为学习A的经验可以帮助你学习B。因此,你不需要学习如何“入门”,因为这样的“入门”点根本不存在!您需要学习的是如何做更大的事情,并且在此过程中,您将很快了解您需要学习的内容。当然,你可以争辩说你需要先了解Python,否则你怎么学Python做爬虫呢?但实际上,你可以在做这个爬虫的过程中学习Python。
看到前面很多回答中提到的“技能”——用什么软件怎么爬,那我就说说“道”和“技能”——爬虫是如何工作的,以及如何在Python中实现。
对Python感兴趣的朋友,记得私信小编“007”领取全套Python资料。
长话短说,总结一下,你需要学习:
基本爬虫工作原理 基本http爬虫,scrapyBloom Filter 如果需要大规模的网页抓取,需要学习分布式爬虫的概念。其实没那么神秘,你只需要学习如何维护一个所有集群机器都可以有效共享的分布式队列。最简单的实现是python-rqrq和scrapy的结合:darkrho/scrapy-redis 后续处理,网页提取 grangier/python-goose,存储(Mongodb)
这是一个简短的故事:
说说从我写的一个集群爬下整个豆瓣的经历吧。
1)首先你需要了解爬虫是如何工作的
想象一下,你是一只蜘蛛,现在你被放到了互联网“网络”上。好吧,您需要浏览所有网页。怎么做?没问题,你可以从任何地方开始,比如人民日报的首页,称为初始页,用$表示。
在人民日报的主页上,你会看到各种指向该页面的链接。于是你高高兴兴地爬到了“国内新闻”页面。太好了,你已经爬了两页(首页和国内新闻)!暂时不管你爬下来的页面怎么处理,你可以想象你把这个页面复制成html放到你身上了。
突然你发现,在国内新闻页面上,有一个返回“首页”的链接。作为一只聪明的蜘蛛,你必须知道你不必爬回来,因为你已经看到了。所以,你需要用你的大脑来保存你已经看过的页面的地址。这样,每次看到可能需要爬取的新链接时,首先在脑海中检查一下是否已经到过这个页面地址。如果你去过,不要去。
好吧,理论上,如果从初始页面可以到达所有页面,那么就可以证明你可以爬取所有页面。
那么如何在 Python 中实现呢?非常简单
import Queue
initial_page = "http://www.renminribao.com"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
#一直进行直到海枯石烂
while(True):
if url_queue.size()>0:
#拿出队例中第一个的url
current_url = url_queue.get()
#把这个url代表的网页存储好
store(current_url)
#提取把这个url里链向的url
for next_url in extract_urls(current_url):
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break
它已经是非常伪代码了。
所有爬虫的中坚力量都在这里,我们来分析一下为什么爬虫其实是很复杂的东西——搜索引擎公司通常有一个完整的团队来维护和开发。
2)效率
如果你直接处理上面的代码,直接运行,你要花一整年的时间才能爬下豆瓣的全部内容。更不用说像谷歌这样的搜索引擎需要爬取整个内容网络。
哪里有问题?要爬的页面太多,上面的代码太慢了。假设全网有N个网站,那么分析权重判断的复杂度是N*log(N),因为所有网页都需要遍历一次,需要log(N)的复杂度每次重复使用该集合。. 好的,好的,我知道 Python 的 set 实现是散列 - 但这仍然太慢,至少内存效率不高。
通常的判断方法是什么?布隆过滤器。简而言之,它仍然是一种哈希方法,但它的特点是可以使用固定内存(不随url的数量增长)来判断url是否已经在集合中,效率为O(1)不幸的是,世界上没有免费的午餐。唯一的问题是如果这个url不在集合中,BF可以100%确定这个url没有被看到。但是如果这个url在设置,它会告诉你:这个 url 应该已经存在了,但是我有 2% 的不确定性。注意,当你分配足够的内存时,这里的不确定性会变得非常小。一个简单的教程:Bloom Filters by Example。
注意这个特性,如果url看过,可能小概率会重复(没关系,多看就不会累死)。但是如果没有看到,就会看到(这很重要,否则我们会错过一些页面!)。
好的,现在我们正在接近处理权重的最快方法。另一个瓶颈 - 你只有一台机器。不管你有多少带宽,只要你的机器下载网页的速度是瓶颈,那你就只能提速了。如果一台机器不够用 - 使用多台!当然,我们假设每台机器都进入了最高效率——使用多线程(在 Python 的情况下是多进程)。
3)集群爬取
爬豆瓣的时候,我用了100多台机器,24小时不间断地跑了一个月。想象一下,如果你只用一台机器运行 100 个月......
那么,假设你现在有 100 台机器可用,如何在 Python 中实现分布式爬虫算法呢?
我们将这100台机器中的99台算力较小的机器称为slave,另一台较大的机器称为master,然后查看上面代码中的url_queue,如果我们可以把这个队列放在这台master机器上,那么所有slave都可以与master通信通过网络。每当从站完成下载网页时,它都会向主站请求新的网页以进行爬网。并且每次slave捕获一个新的网页,它会将网页上的所有链接发送到master的队列中。同样,布隆过滤器也放在master上,但是现在master只发送肯定不会被访问的url给slave。Bloom Filter放在master的内存中,访问的url放在运行在master上的Redis中,保证了所有操作都是O(1).(至少摊销是O(1),
考虑如何在 Python 中做到这一点:
在每台slave上安装scrapy,然后每台机器都成为具有抓取能力的slave,在master上安装redis和rq作为分布式队列使用。
然后代码写成
#slave.py
current_url = request_from_master()
to_send = []
for next_url in extract_urls(current_url):
to_send.append(next_url)
store(current_url);
send_to_master(to_send)
#master.py
distributed_queue = DistributedQueue()
bf = BloomFilter()
initial_pages = "www.renmingribao.com"
while(True):
if request == 'GET':
if distributed_queue.size()>0:
send(distributed_queue.get())
else:
break
elif request == 'POST':
bf.put(request.url)
好吧,你可以想象,有人已经给你写了你需要的东西:darkrho/scrapy-redis · GitHub
4)勘探和后处理
虽然上面使用了很多“简单”,但要真正实现一个商业规模可用的爬虫并不是一件容易的事。上面的代码用于爬取整个网站,问题不大。
但是如果附加你需要这些后处理,比如
有效存储(数据库应该如何安排),有效权重判断(这里指的是网页权重判断,我们不想爬取抄袭它的人民日报和大民日报) 有效信息提取(例如,如何提取所有网页上的信息地址是提取出来的,“朝阳区奋进路中华路”),搜索引擎通常不需要存储所有信息,比如我保存的图片...及时更新(预测此网页多久更新一次)
可以想象,这里的每一点都可以被许多研究人员研究数十年。即便如此,“路漫漫其修远兮,我要上上下下寻找。”
网页抓取数据百度百科(如何编写一个爬虫的python聚集地!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-13 21:10
最近在做一个项目,需要使用网络爬虫从特定的网站爬取数据,所以打算写一个爬虫系列文章跟大家分享一下如何编写爬虫。下面的文章文章介绍python爬虫的基础知识。有兴趣的朋友可以看看。
爬虫简介
根据百度百科定义:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
随着数据的海量增长,我们需要在互联网上选择需要的数据进行自己的研究分析和实验。这使用了爬虫技术。跟着小编第一次认识python爬虫吧!
一、请求-响应
使用python语言实现爬虫时,主要用到了urllib和urllib2这两个库。首先,用一段代码来说明以下内容:
import urllib
import urllib2
url="http://www.baidu.com"
request=urllib2.Request(url)
response=urllib2.urlopen(request)
print response.read()
我们知道一个网页是由html作为骨架,js作为肌肉,css作为衣服组成的。上面代码实现的功能是将百度网页的源码爬取到本地。
其中,url为要爬取的网页的URL;request 发出请求,response 是接受请求后给出的响应。最后read()函数的输出就是百度网页的源码。
二、GET-POST
两者都将数据传递到网页。最重要的区别是GET方法是以链接的形式直接访问的。该链接收录所有参数。当然,如果它收录密码,这是一个不安全的选择,但你可以直观地做到这一点。查看您提交的内容。
POST不会显示URL上的所有参数,但是如果要直接查看提交的内容,不是很方便,可以酌情选择。
POST 方法:
import urllib
import urllib2
values={
'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url='https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn'
request=urllib2.Request(url,data)
response=urllib2.urlopen(request)
print response.read()
获取方法:
import urllib
import urllib2
values={
'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request=urllib2.Request(geturl)
response=urllib2.urlopen(request)
print response.read()
三、异常处理
处理异常时,使用 try-except 语句。
import urllib2
try:
response=urllib2.urlopen("http://www.xxx.com")
except urllib2.URLError,e:
print e.reason
最后给大家推荐一个口碑不错的蟒蛇聚集地【点击进入】。有很多前辈的学习技巧、学习心得、面试技巧、职场心得等分享,我们精心准备了零基础的入门资料和实战项目资料。, 程序员每天定期讲解Python技术,分享一些学习方法和需要注意的小细节
总结
以上就是小编为大家介绍的python爬虫基础知识。我希望它对你有帮助。如果您有任何问题,请给我留言 查看全部
网页抓取数据百度百科(如何编写一个爬虫的python聚集地!)
最近在做一个项目,需要使用网络爬虫从特定的网站爬取数据,所以打算写一个爬虫系列文章跟大家分享一下如何编写爬虫。下面的文章文章介绍python爬虫的基础知识。有兴趣的朋友可以看看。
爬虫简介
根据百度百科定义:网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
随着数据的海量增长,我们需要在互联网上选择需要的数据进行自己的研究分析和实验。这使用了爬虫技术。跟着小编第一次认识python爬虫吧!
一、请求-响应
使用python语言实现爬虫时,主要用到了urllib和urllib2这两个库。首先,用一段代码来说明以下内容:
import urllib
import urllib2
url="http://www.baidu.com"
request=urllib2.Request(url)
response=urllib2.urlopen(request)
print response.read()
我们知道一个网页是由html作为骨架,js作为肌肉,css作为衣服组成的。上面代码实现的功能是将百度网页的源码爬取到本地。
其中,url为要爬取的网页的URL;request 发出请求,response 是接受请求后给出的响应。最后read()函数的输出就是百度网页的源码。
二、GET-POST
两者都将数据传递到网页。最重要的区别是GET方法是以链接的形式直接访问的。该链接收录所有参数。当然,如果它收录密码,这是一个不安全的选择,但你可以直观地做到这一点。查看您提交的内容。
POST不会显示URL上的所有参数,但是如果要直接查看提交的内容,不是很方便,可以酌情选择。
POST 方法:
import urllib
import urllib2
values={
'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url='https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn'
request=urllib2.Request(url,data)
response=urllib2.urlopen(request)
print response.read()
获取方法:
import urllib
import urllib2
values={
'username':'2680559065@qq.com','Password':'XXXX'}
data=urllib.urlencode(values)
url = "http://passport.csdn.net/account/login"
geturl = url + "?"+data
request=urllib2.Request(geturl)
response=urllib2.urlopen(request)
print response.read()
三、异常处理
处理异常时,使用 try-except 语句。
import urllib2
try:
response=urllib2.urlopen("http://www.xxx.com";)
except urllib2.URLError,e:
print e.reason
最后给大家推荐一个口碑不错的蟒蛇聚集地【点击进入】。有很多前辈的学习技巧、学习心得、面试技巧、职场心得等分享,我们精心准备了零基础的入门资料和实战项目资料。, 程序员每天定期讲解Python技术,分享一些学习方法和需要注意的小细节
总结
以上就是小编为大家介绍的python爬虫基础知识。我希望它对你有帮助。如果您有任何问题,请给我留言
网页抓取数据百度百科(浏览器模拟登录的实现过程1、获取所需要的参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-12 14:10
模拟登录原理
一般情况下,用户通过浏览器登录网站时,会在特定的登录界面输入个人登录信息,提交后可以返回收录数据的网页。浏览器层面的机制是浏览器提交一个收录必要信息的http Request,服务器返回一个http Response。HTTP Request 内容包括以下 5 项:
URL = 基本 URL + 可选查询字符串
请求标头:必需或可选
饼干:可选
发布数据:当时的 POST 方法需要
http Response的内容包括以下两项:Html源码或图片、json字符串等。
Cookies:如果后续访问需要cookie,返回的内容会收录cookie
其中,URL是Uniform Resource Locator的缩写,是对可以从互联网上获取的资源的位置和访问方式的简明表示,包括主机部分和文件路径部分;Request Headers 是向服务请求信息的头部信息。收录编码格式、用户代理、提交主机和路径等信息;发布数据是指提交的用户、内容、格式参数等。Cookies是服务器发送给浏览器的文件,保存在本地,服务器用来识别用户,以及判断用户是否合法和一些登录信息。
网页抓取的工作原理
如上所述,模拟登录后,网站服务器会返回一个html文件。HTML 是一个带有严格语法和格式的标签的文本文件。数据特征,使用正则表达式来获取您需要的数据或表示可以进一步挖掘的数据的链接。
模拟登录的实现流程
1、获取所需参数 IE浏览器为开发者提供了强大的工具。获取参数的过程如下:
打开浏览器
输入网址
开发者工具
启用网络
网络流量捕获
输入密码和账号登录
查找发起者为“click”的第一条记录
细节
“请求标头”和“请求正文”
请求头和请求体收录客户端和浏览器交互的参数。有些参数是默认的,不需要设置;一些参数与用户本身有关,如用户名、密码、是否记住密码等;
一些参数是由客户端和服务器交互产生的。确定参数的步骤是,首先从字面上理解它们,其次在交互记录中搜索参数名称,观察这些参数是在哪个过程中产生的。请求正文中看到的一些参数是编码的,需要解码。
2、 获取登录百度账号需要的参数
按照以上步骤,使用IE9浏览器自带的工具,即可轻松获取相关参数。其中staticpage是跳转页面,解码后还是在“摘要”记录中知道.html。查找后发现token参数首先出现在URL的响应体中,需要在返回的页码中捕获;apiver 参数设置返回的文本是 json 格式还是 html 格式。除了请求头中的一般设置参数外,还有cookies,需要在登录过程中获取,以便与服务器交互。
3、 登录的具体代码实现
3.1 导入登录进程使用的库
重新进口;
导入 cookielib;
导入 urllib;
导入 urllib2;
re库解析正则表达式并爬取匹配;cookielib 库获取和管理 cookie;urllib 和 urllib2 库根据 URL 和 post 数据参数从服务器请求和解码数据。
3.2 cookie检测函数
通过检查cookiejar返回的cookie key是否与cookieNameList完全匹配来判断登录是否成功。
def checkAllCookiesExist(cookieNameList, cookieJar) :
cookiesDict = {};
对于 cookieNameList 中的每个CookieName:
cookiesDict[eachCookieName] = 假;
allCookieFound =真;
对于 cookieJar 中的 cookie:
if(cookie.name in cookiesDict.keys()) :
cookiesDict[cookie.name] = True;
对于 cookiesDict.keys() 中的 Cookie:
如果(不是 cookiesDict[eachCookie]):
allCookieFound = False;
休息;
返回所有CookieFound;
3.3 模拟登录百度
def emulateLoginBaidu():
cj = cookielib.CookieJar(); .
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj));
urllib2.install_opener(opener);
创建一个 cookieJar 对象来存储 cookie,与 http 处理程序绑定并打开安装。
print "[step1] 获取cookie BAIDUID";
baiduMainUrl = "";
resp = urllib2.urlopen(baiduMainUrl);
打开百度首页,获取cookie BAIDUID。
print "[step2]获取token值";
getapiUrl = "";
getapiResp = urllib2.urlopen(getapiUrl);
getapiRespHtml = getapiResp.read();
打印“getapiResp=”,getapiResp;
isfoundToken= re.search("bdPass\.api\.params\.login_token='(?P\w+)';",
getapiRespHtml);
上述程序用于获取post数据中的token参数。首先获取getapiUrl URL的html,然后使用re标准库中的搜索函数搜索匹配,返回一个表示匹配是否成功的布尔值。
如果(IsfoundToken):
tokenVal = IsfoundToken.group("tokenVal");
打印“tokenVal=”,tokenVal;
print "[step3] 模拟登录百度";
静态页面 = "";
baiduMainLoginUrl = "";
postDict = {
'字符集' : "utf-8",
“令牌”:令牌值,
'isPhone' : "假",
“索引”:“0”,
'safeflg' : "0",
“静态页面”:静态页面,
“登录类型”:“1”,
'tpl' : "mn",
'用户名' : "用户名",
'密码' : "密码",
'mem_pass' : "开",
}[3];
设置postdata参数值,不是每个参数都需要设置,有些参数是默认的。
postData = urllib.urlencode(postDict);
编码后数据。比如l编码的结果是http%3A%2F%2F%2Fcache%2Fuser%2Fhtml%2Fjump.html,其他参数类似。
req = urllib2.Request(baiduMainLoginUrl, postData);
resp = urllib2.urlopen(req);
Python标准库urllib2的两个函数分别提交用户请求和数据,并接受返回的数据
cookiesToCheck = ['BDUSS', 'PTOKEN', 'STOKEN', 'SAVEUSERID', 'UBI', 'HISTORY', 'USERNAMETYPE'];
爬取网页的实现过程
以上使用正则表达式成功抓取返回网页中的token。Python 的标准库 HTMLParser 提供了一个强大的功能来识别 html 文本标签和数据。使用时,从 HTMLParser 派生一个新的类,然后重新定义这些以 handler_ 开头的函数。几个常用的功能包括:
handle_startendtag 处理开始和结束标签
handle_starttag 处理开始标签,例如
handle_endtag 处理结束标签,例如
handle_charref 处理以 开头的特殊字符串,一般是内部代码表示的字符
handle_entityref 处理一些以&开头的特殊字符,比如
handle_data 处理数据,也就是数据中间的数据
下面的程序是用来抓取百度贴吧Movie Bar帖子的header做示范:
导入 HTMLParser
导入 urllib2 查看全部
网页抓取数据百度百科(浏览器模拟登录的实现过程1、获取所需要的参数)
模拟登录原理
一般情况下,用户通过浏览器登录网站时,会在特定的登录界面输入个人登录信息,提交后可以返回收录数据的网页。浏览器层面的机制是浏览器提交一个收录必要信息的http Request,服务器返回一个http Response。HTTP Request 内容包括以下 5 项:
URL = 基本 URL + 可选查询字符串
请求标头:必需或可选
饼干:可选
发布数据:当时的 POST 方法需要
http Response的内容包括以下两项:Html源码或图片、json字符串等。
Cookies:如果后续访问需要cookie,返回的内容会收录cookie
其中,URL是Uniform Resource Locator的缩写,是对可以从互联网上获取的资源的位置和访问方式的简明表示,包括主机部分和文件路径部分;Request Headers 是向服务请求信息的头部信息。收录编码格式、用户代理、提交主机和路径等信息;发布数据是指提交的用户、内容、格式参数等。Cookies是服务器发送给浏览器的文件,保存在本地,服务器用来识别用户,以及判断用户是否合法和一些登录信息。
网页抓取的工作原理
如上所述,模拟登录后,网站服务器会返回一个html文件。HTML 是一个带有严格语法和格式的标签的文本文件。数据特征,使用正则表达式来获取您需要的数据或表示可以进一步挖掘的数据的链接。
模拟登录的实现流程
1、获取所需参数 IE浏览器为开发者提供了强大的工具。获取参数的过程如下:
打开浏览器
输入网址
开发者工具
启用网络
网络流量捕获
输入密码和账号登录
查找发起者为“click”的第一条记录
细节
“请求标头”和“请求正文”
请求头和请求体收录客户端和浏览器交互的参数。有些参数是默认的,不需要设置;一些参数与用户本身有关,如用户名、密码、是否记住密码等;
一些参数是由客户端和服务器交互产生的。确定参数的步骤是,首先从字面上理解它们,其次在交互记录中搜索参数名称,观察这些参数是在哪个过程中产生的。请求正文中看到的一些参数是编码的,需要解码。
2、 获取登录百度账号需要的参数
按照以上步骤,使用IE9浏览器自带的工具,即可轻松获取相关参数。其中staticpage是跳转页面,解码后还是在“摘要”记录中知道.html。查找后发现token参数首先出现在URL的响应体中,需要在返回的页码中捕获;apiver 参数设置返回的文本是 json 格式还是 html 格式。除了请求头中的一般设置参数外,还有cookies,需要在登录过程中获取,以便与服务器交互。
3、 登录的具体代码实现
3.1 导入登录进程使用的库
重新进口;
导入 cookielib;
导入 urllib;
导入 urllib2;
re库解析正则表达式并爬取匹配;cookielib 库获取和管理 cookie;urllib 和 urllib2 库根据 URL 和 post 数据参数从服务器请求和解码数据。
3.2 cookie检测函数
通过检查cookiejar返回的cookie key是否与cookieNameList完全匹配来判断登录是否成功。
def checkAllCookiesExist(cookieNameList, cookieJar) :
cookiesDict = {};
对于 cookieNameList 中的每个CookieName:
cookiesDict[eachCookieName] = 假;
allCookieFound =真;
对于 cookieJar 中的 cookie:
if(cookie.name in cookiesDict.keys()) :
cookiesDict[cookie.name] = True;
对于 cookiesDict.keys() 中的 Cookie:
如果(不是 cookiesDict[eachCookie]):
allCookieFound = False;
休息;
返回所有CookieFound;
3.3 模拟登录百度
def emulateLoginBaidu():
cj = cookielib.CookieJar(); .
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj));
urllib2.install_opener(opener);
创建一个 cookieJar 对象来存储 cookie,与 http 处理程序绑定并打开安装。
print "[step1] 获取cookie BAIDUID";
baiduMainUrl = "";
resp = urllib2.urlopen(baiduMainUrl);
打开百度首页,获取cookie BAIDUID。
print "[step2]获取token值";
getapiUrl = "";
getapiResp = urllib2.urlopen(getapiUrl);
getapiRespHtml = getapiResp.read();
打印“getapiResp=”,getapiResp;
isfoundToken= re.search("bdPass\.api\.params\.login_token='(?P\w+)';",
getapiRespHtml);
上述程序用于获取post数据中的token参数。首先获取getapiUrl URL的html,然后使用re标准库中的搜索函数搜索匹配,返回一个表示匹配是否成功的布尔值。
如果(IsfoundToken):
tokenVal = IsfoundToken.group("tokenVal");
打印“tokenVal=”,tokenVal;
print "[step3] 模拟登录百度";
静态页面 = "";
baiduMainLoginUrl = "";
postDict = {
'字符集' : "utf-8",
“令牌”:令牌值,
'isPhone' : "假",
“索引”:“0”,
'safeflg' : "0",
“静态页面”:静态页面,
“登录类型”:“1”,
'tpl' : "mn",
'用户名' : "用户名",
'密码' : "密码",
'mem_pass' : "开",
}[3];
设置postdata参数值,不是每个参数都需要设置,有些参数是默认的。
postData = urllib.urlencode(postDict);
编码后数据。比如l编码的结果是http%3A%2F%2F%2Fcache%2Fuser%2Fhtml%2Fjump.html,其他参数类似。
req = urllib2.Request(baiduMainLoginUrl, postData);
resp = urllib2.urlopen(req);
Python标准库urllib2的两个函数分别提交用户请求和数据,并接受返回的数据
cookiesToCheck = ['BDUSS', 'PTOKEN', 'STOKEN', 'SAVEUSERID', 'UBI', 'HISTORY', 'USERNAMETYPE'];
爬取网页的实现过程
以上使用正则表达式成功抓取返回网页中的token。Python 的标准库 HTMLParser 提供了一个强大的功能来识别 html 文本标签和数据。使用时,从 HTMLParser 派生一个新的类,然后重新定义这些以 handler_ 开头的函数。几个常用的功能包括:
handle_startendtag 处理开始和结束标签
handle_starttag 处理开始标签,例如
handle_endtag 处理结束标签,例如
handle_charref 处理以 开头的特殊字符串,一般是内部代码表示的字符
handle_entityref 处理一些以&开头的特殊字符,比如
handle_data 处理数据,也就是数据中间的数据
下面的程序是用来抓取百度贴吧Movie Bar帖子的header做示范:
导入 HTMLParser
导入 urllib2
网页抓取数据百度百科(蜘蛛抓取第一步爬行和抓取爬行到你的网站网页网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-12 14:09
蜘蛛爬行第一步爬行爬行
爬到您的 网站 页面以查找合适的资源。蜘蛛有一个特点,就是它们的轨迹通常围绕着蜘蛛丝转,而我们之所以将搜索引擎机器人命名为蜘蛛,就是因为这个特点。当蜘蛛来到你的网站时,它会继续沿着你的网站中的链接(蛛丝)爬行,那么如何让蜘蛛更好的在你的网站中爬行就变成了我们的首要任务。抓取您的网页。引导蜘蛛爬行 这只是一个开始,一个好的开始意味着你会有一个很高的起点。通过自己的内链设计,网站中没有死角,蜘蛛可以轻松到达网站中的每一页,让蜘蛛进行第二步工作——爬的时候,会做事半功倍。在这一步的爬取过程中,需要注意简化网站的结构,去掉那些不必要的、不必要的冗余代码,因为这些会影响蜘蛛爬取网页的效率和效率。影响。还有一点需要注意的是,我们不建议将FLASH放在网站中,因为FLASH不容易被蜘蛛抓取,过多的FLASH会导致蜘蛛放弃抓取你的网站页面。
蜘蛛爬行第二步存储
爬取到链接对应的页面后,这些页面的内容将存储在搜索引擎的原创数据库中。一些文本内容将被抓取。
网站优化过程中不要盲目添加一些图片或动画flash文件到网站。这对搜索引擎抓取不利。这种排没有太大的价值,应该做更多的内容。
爬取搜索引擎的原创数据并不意味着你的网站内容一定会被百度采纳。搜索引擎还需要经过下一步。
蜘蛛爬行预处理第三步
搜索引擎仍然以(文本)为主。JS、CSS程序代码不可用于排名。蜘蛛对第一步提取的文本进行拆分和重组,形成新词。
去重(删除一些重复的内容,搜索引擎数据库中已经存在的内容)
那些要求我们优化SEO内容的人,不要完全照搬别人网站的内容。
删除停用词
停用词:是的,得到,土地,啊,哈,啊,因此,到,,,等等。减少不必要的计算 美丽中国 美丽中国
注意:抄袭别人的内容时,要求我们修改得更用力,而不是一两个字。我们在优化的时候需要做更多的改动,而且写法和别人不一样,主要是标题。
噪音消除
您的 网站 有很多弹出式广告。对于 网站 中有大量广告的 网站,蜘蛛不会以你的 网站 为焦点进行抓取。
我们不能随意在 网站 中添加弹出广告。
爬虫第四步,建索引
根据以上预处理的结果,对页面的key密度进行了合理的处理,内容匹配度高,反向链接多,导出链接少,对页面进行排序和索引,构建索引库。
站点:查询的参考值,而不是 网站 的完整索引量。(百度站长工具-索引量)百度对新站一般有一个月的评估期,抓到的网站放入百度索引库,不发布。
蜘蛛爬行第 5 步排名
搜索引擎经过搜索词处理、文档匹配、相关性计算、过滤调整、排名展示等一系列复杂任务后完成最终排名。
匹配度最高、流量最大、权重最高的站点会优先展示。收录-排名-点击-转化 查看全部
网页抓取数据百度百科(蜘蛛抓取第一步爬行和抓取爬行到你的网站网页网页)
蜘蛛爬行第一步爬行爬行
爬到您的 网站 页面以查找合适的资源。蜘蛛有一个特点,就是它们的轨迹通常围绕着蜘蛛丝转,而我们之所以将搜索引擎机器人命名为蜘蛛,就是因为这个特点。当蜘蛛来到你的网站时,它会继续沿着你的网站中的链接(蛛丝)爬行,那么如何让蜘蛛更好的在你的网站中爬行就变成了我们的首要任务。抓取您的网页。引导蜘蛛爬行 这只是一个开始,一个好的开始意味着你会有一个很高的起点。通过自己的内链设计,网站中没有死角,蜘蛛可以轻松到达网站中的每一页,让蜘蛛进行第二步工作——爬的时候,会做事半功倍。在这一步的爬取过程中,需要注意简化网站的结构,去掉那些不必要的、不必要的冗余代码,因为这些会影响蜘蛛爬取网页的效率和效率。影响。还有一点需要注意的是,我们不建议将FLASH放在网站中,因为FLASH不容易被蜘蛛抓取,过多的FLASH会导致蜘蛛放弃抓取你的网站页面。
蜘蛛爬行第二步存储
爬取到链接对应的页面后,这些页面的内容将存储在搜索引擎的原创数据库中。一些文本内容将被抓取。
网站优化过程中不要盲目添加一些图片或动画flash文件到网站。这对搜索引擎抓取不利。这种排没有太大的价值,应该做更多的内容。
爬取搜索引擎的原创数据并不意味着你的网站内容一定会被百度采纳。搜索引擎还需要经过下一步。
蜘蛛爬行预处理第三步
搜索引擎仍然以(文本)为主。JS、CSS程序代码不可用于排名。蜘蛛对第一步提取的文本进行拆分和重组,形成新词。
去重(删除一些重复的内容,搜索引擎数据库中已经存在的内容)
那些要求我们优化SEO内容的人,不要完全照搬别人网站的内容。
删除停用词
停用词:是的,得到,土地,啊,哈,啊,因此,到,,,等等。减少不必要的计算 美丽中国 美丽中国
注意:抄袭别人的内容时,要求我们修改得更用力,而不是一两个字。我们在优化的时候需要做更多的改动,而且写法和别人不一样,主要是标题。
噪音消除
您的 网站 有很多弹出式广告。对于 网站 中有大量广告的 网站,蜘蛛不会以你的 网站 为焦点进行抓取。
我们不能随意在 网站 中添加弹出广告。
爬虫第四步,建索引
根据以上预处理的结果,对页面的key密度进行了合理的处理,内容匹配度高,反向链接多,导出链接少,对页面进行排序和索引,构建索引库。
站点:查询的参考值,而不是 网站 的完整索引量。(百度站长工具-索引量)百度对新站一般有一个月的评估期,抓到的网站放入百度索引库,不发布。
蜘蛛爬行第 5 步排名
搜索引擎经过搜索词处理、文档匹配、相关性计算、过滤调整、排名展示等一系列复杂任务后完成最终排名。
匹配度最高、流量最大、权重最高的站点会优先展示。收录-排名-点击-转化
网页抓取数据百度百科( 一个介绍一个爬取动态网页的超简单的一个小demo)
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2022-04-12 03:28
一个介绍一个爬取动态网页的超简单的一个小demo)
一、 分析网页结构
前几篇文章介绍了传统静态界面的爬取。这次博主介绍了一个超级简单的爬取动态网页的小demo。
说起动态网页,你对它了解多少?
不知道动态网页的,博主给个链接,可以看百度百科_百度百科动态网页的详细解析以及小马福静态页和动态页的区别
不要怪博主没有解释清楚,因为博主本人对动态网页的概念也不是很了解。当博主整理自己的想法时,博主会专门写一篇博文——。-
简单来说,要获取静态网页的网页数据,只需要将网页的URL地址发送到服务器,动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要将请求文件的url地址发送给服务器,而不是网页的url地址。
,让我们开始进入正题。
本篇博文以高德地图开头:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候我们就可以判断是动态网页了。这时候,我们需要找到一个接口
点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求。它可以在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下更新网页某一部分的内容。即从数据库请求然后响应的数据是XHR类型的
然后我们就可以开始在XHR类型下一一搜索,找到如下数据
通过查看标头获取 URL
打开后发现是这两天的天气情况。
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”这个键值中。
,找到了json数据,我们对比一下看看是不是我们要找的
通过比较,数据完全对应,这意味着我们已经获得了数据。
二、获取相关网址
'''
查询当前地点天气的url:https://www.amap.com/service/c ... 01417
各城市对应code的url:https://www.amap.com/service/weather?adcode=410700
备注:这两个url可以从Network中查看到
'''
123456
,我们已经获取了相关的URL,下面是具体的代码实现。至于怎么做,
我们知道json数据可以使用response.json()转换成字典,然后对字典进行操作。
三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和数字
先爬取网页,伪装成浏览器,添加header访问数据库地址,防止被识别和拦截。
url_city = "https://www.amap.com/service/c ... ot%3B
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
city = []
response = requests.get(url=url_city, headers=headers)
content = response.json()
print(content)
12345678910
得到我们想要的数据后,我们可以通过搜索发现cityByLetter中的数字和名字是我们需要的,然后我们就可以设置了。
if "data" in content:
cityByLetter = content["data"]["cityByLetter"]
for k,v in cityByLetter.items():
city.extend(v)
return city
12345
3.2 根据号码查询天气
得到号码和名字,下面一定要查天气!
先看界面
通过上图可以确定最高温度、最低温度等。然后使用它进行数据爬取。
url_weather = "https://www.amap.com/service/weather?adcode={}"
response = requests.get(url=url_weather.format(adcode), headers=headers)
content = response.json()
item["weather_name"] = content["data"]["data"][0]["forecast_data"][0]["weather_name"]
item["min_temp"] = content["data"]["data"][0]["forecast_data"][0]["min_temp"]
item["max_temp"] = content["data"]["data"][0]["forecast_data"][0]["max_temp"]
print(item)
12345678
,我们的愿景已经实现。
四、完整代码
# encoding: utf-8
'''
@author 李华鑫
@create 2020-10-06 19:46
Mycsdn:https://buwenbuhuo.blog.csdn.net/
@contact: 459804692@qq.com
@software: Pycharm
@file: 高德地图_每个城市的天气.py
@Version:1.0
'''
import requests
url_city = "https://www.amap.com/service/c ... ot%3B
url_weather = "https://www.amap.com/service/weather?adcode={}"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
def get_city():
"""查询所有城市名称和编号"""
city = []
response = requests.get(url=url_city, headers=headers)
content = response.json()
if "data" in content:
cityByLetter = content["data"]["cityByLetter"]
for k, v in cityByLetter.items():
city.extend(v)
return city
def get_weather(adcode, name):
"""根据编号查询天气"""
item = {}
item["adcode"] = str(adcode)
item["name"] = name
response = requests.get(url=url_weather.format(adcode), headers=headers)
content = response.json()
item["weather_name"] = content["data"]["data"][0]["forecast_data"][0]["weather_name"]
item["min_temp"] = content["data"]["data"][0]["forecast_data"][0]["min_temp"]
item["max_temp"] = content["data"]["data"][0]["forecast_data"][0]["max_temp"]
return item
def save(item):
"""保存"""
print(item)
with open("./weather.txt","a",encoding="utf-8") as file:
file.write(",".join(item.values()))
file.write("\n")
if __name__ == '__main__':
city_list = get_city()
for city in city_list:
item = get_weather(city["adcode"],city["name"])
save(item)
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
五、保存结果
美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!
PS:如果不能解决问题,可以点击下方链接自行获取
Python免费学习资料及群交流答案点击加入 查看全部
网页抓取数据百度百科(
一个介绍一个爬取动态网页的超简单的一个小demo)
一、 分析网页结构
前几篇文章介绍了传统静态界面的爬取。这次博主介绍了一个超级简单的爬取动态网页的小demo。
说起动态网页,你对它了解多少?
不知道动态网页的,博主给个链接,可以看百度百科_百度百科动态网页的详细解析以及小马福静态页和动态页的区别
不要怪博主没有解释清楚,因为博主本人对动态网页的概念也不是很了解。当博主整理自己的想法时,博主会专门写一篇博文——。-
简单来说,要获取静态网页的网页数据,只需要将网页的URL地址发送到服务器,动态网页的数据存储在后端数据库中。所以要获取动态网页的网页数据,我们需要将请求文件的url地址发送给服务器,而不是网页的url地址。
,让我们开始进入正题。
本篇博文以高德地图开头:
打开后发现里面有一堆div标签,但是没有我们需要的数据。这时候我们就可以判断是动态网页了。这时候,我们需要找到一个接口
点击网络选项卡,我们可以看到网页向服务器发送了很多请求,数据很多,查找时间太长了
我们点击XHR分类,可以减少很多不必要的文件,节省很多时间。
XHR 类型是通过 XMLHttpRequest 方法发送的请求。它可以在后台与服务器交换数据,这意味着可以在不加载整个网页的情况下更新网页某一部分的内容。即从数据库请求然后响应的数据是XHR类型的
然后我们就可以开始在XHR类型下一一搜索,找到如下数据
通过查看标头获取 URL
打开后发现是这两天的天气情况。
打开后我们可以看到上面的情况,这是一个json格式的文件。然后,它的数据信息以字典的形式存储,数据存储在“data”这个键值中。
,找到了json数据,我们对比一下看看是不是我们要找的
通过比较,数据完全对应,这意味着我们已经获得了数据。
二、获取相关网址
'''
查询当前地点天气的url:https://www.amap.com/service/c ... 01417
各城市对应code的url:https://www.amap.com/service/weather?adcode=410700
备注:这两个url可以从Network中查看到
'''
123456
,我们已经获取了相关的URL,下面是具体的代码实现。至于怎么做,
我们知道json数据可以使用response.json()转换成字典,然后对字典进行操作。
三、代码实现
知道数据的位置后,我们开始编写代码。
3.1 查询所有城市名称和数字
先爬取网页,伪装成浏览器,添加header访问数据库地址,防止被识别和拦截。
url_city = "https://www.amap.com/service/c ... ot%3B
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
city = []
response = requests.get(url=url_city, headers=headers)
content = response.json()
print(content)
12345678910
得到我们想要的数据后,我们可以通过搜索发现cityByLetter中的数字和名字是我们需要的,然后我们就可以设置了。
if "data" in content:
cityByLetter = content["data"]["cityByLetter"]
for k,v in cityByLetter.items():
city.extend(v)
return city
12345
3.2 根据号码查询天气
得到号码和名字,下面一定要查天气!
先看界面
通过上图可以确定最高温度、最低温度等。然后使用它进行数据爬取。
url_weather = "https://www.amap.com/service/weather?adcode={}"
response = requests.get(url=url_weather.format(adcode), headers=headers)
content = response.json()
item["weather_name"] = content["data"]["data"][0]["forecast_data"][0]["weather_name"]
item["min_temp"] = content["data"]["data"][0]["forecast_data"][0]["min_temp"]
item["max_temp"] = content["data"]["data"][0]["forecast_data"][0]["max_temp"]
print(item)
12345678
,我们的愿景已经实现。
四、完整代码
# encoding: utf-8
'''
@author 李华鑫
@create 2020-10-06 19:46
Mycsdn:https://buwenbuhuo.blog.csdn.net/
@contact: 459804692@qq.com
@software: Pycharm
@file: 高德地图_每个城市的天气.py
@Version:1.0
'''
import requests
url_city = "https://www.amap.com/service/c ... ot%3B
url_weather = "https://www.amap.com/service/weather?adcode={}"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
}
def get_city():
"""查询所有城市名称和编号"""
city = []
response = requests.get(url=url_city, headers=headers)
content = response.json()
if "data" in content:
cityByLetter = content["data"]["cityByLetter"]
for k, v in cityByLetter.items():
city.extend(v)
return city
def get_weather(adcode, name):
"""根据编号查询天气"""
item = {}
item["adcode"] = str(adcode)
item["name"] = name
response = requests.get(url=url_weather.format(adcode), headers=headers)
content = response.json()
item["weather_name"] = content["data"]["data"][0]["forecast_data"][0]["weather_name"]
item["min_temp"] = content["data"]["data"][0]["forecast_data"][0]["min_temp"]
item["max_temp"] = content["data"]["data"][0]["forecast_data"][0]["max_temp"]
return item
def save(item):
"""保存"""
print(item)
with open("./weather.txt","a",encoding="utf-8") as file:
file.write(",".join(item.values()))
file.write("\n")
if __name__ == '__main__':
city_list = get_city()
for city in city_list:
item = get_weather(city["adcode"],city["name"])
save(item)
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263
五、保存结果
美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!
PS:如果不能解决问题,可以点击下方链接自行获取
Python免费学习资料及群交流答案点击加入
网页抓取数据百度百科(北京百度外包如何借助Dede采集插件让网站快速收录以及关键词排名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-04-12 00:09
北京百度百科外包,公营企业业务范围包括:技术推广、技术转让、技术咨询、技术服务;计算机系统服务;软件开发; 软件咨询;设计、制作、代理、广告;产品设计; 包装装潢设计;模型设计;工艺美术设计;电脑动画设计;影视策划;教育咨询(中介服务除外);公共关系服务;企业规划;市场调查; 企业管理咨询;组织文化艺术交流活动(不包括商业演出);承办展览展览活动;会议服务;翻译服务; 自主开发产品的销售等
百度在北京外包,如何使用Dede采集插件让网站快收录和关键词排名,让网站快收录 之前我们要了解百度蜘蛛,百度蜘蛛对于不同的站点有不同的爬取规则。百度蜘蛛的爬取频率对于我们作为 SEO 公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。网站权重:权重越高网站百度蜘蛛爬得越频繁越深网站更新频率:更新频率越高,百度蜘蛛来的越多网站内容质量:百度将增加对网站content原创的抓取频率,内容更多、质量更高、处理用户问题的能力更强。传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。而优质的链接可以更好地引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。而优质的链接可以更好地引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。爬取 为了在互联网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息。减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。爬取 为了在互联网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息。减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。识别URL重定向互联网信息数据量很大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
百度在北京外包,如何使用飞飞cms采集让关键词排名和网站快收录,相信网站@的排名> 很多小伙伴的经历过天堂和地狱......百度在近端时间波动很大,很多网站排名直接被PASS掉了。很多人对百度的调整一无所知,只能等待恢复正常。虽然目前还没有百度推出新算法的迹象,但作为SEO优化者,我们还是要根据目前的百度算法体系来调整优化网站,否则波动不能怪“大环境”。今天给大家一个飞飞cms采集工具,可以批量管理网站。无论你有成百上千个不同的飞飞cms网站还是其他网站,都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms, People Renzhan< @cms、飞飞cms、Cyclone、站群、PBoot、Apple、Mito、搜外等各大cms,可同时批量管理采集伪原创 和发布推送工具) 查看全部
网页抓取数据百度百科(北京百度外包如何借助Dede采集插件让网站快速收录以及关键词排名)
北京百度百科外包,公营企业业务范围包括:技术推广、技术转让、技术咨询、技术服务;计算机系统服务;软件开发; 软件咨询;设计、制作、代理、广告;产品设计; 包装装潢设计;模型设计;工艺美术设计;电脑动画设计;影视策划;教育咨询(中介服务除外);公共关系服务;企业规划;市场调查; 企业管理咨询;组织文化艺术交流活动(不包括商业演出);承办展览展览活动;会议服务;翻译服务; 自主开发产品的销售等
百度在北京外包,如何使用Dede采集插件让网站快收录和关键词排名,让网站快收录 之前我们要了解百度蜘蛛,百度蜘蛛对于不同的站点有不同的爬取规则。百度蜘蛛的爬取频率对于我们作为 SEO 公司来说非常重要网站。一般来说,以下因素对蜘蛛爬行有重要影响。网站权重:权重越高网站百度蜘蛛爬得越频繁越深网站更新频率:更新频率越高,百度蜘蛛来的越多网站内容质量:百度将增加对网站content原创的抓取频率,内容更多、质量更高、处理用户问题的能力更强。传入链接:链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和抓取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。链接是页面的导入,优质的链接可以更好的引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。而优质的链接可以更好地引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。而优质的链接可以更好地引导百度蜘蛛进入和爬取。页面深度:页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。页面是否在首页导入,首页的导入可以更好的抓取和录入。网站爬取的友好性 为了在网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息. 减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。爬取 为了在互联网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息。减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。爬取 为了在互联网上爬取信息时获取越来越准确的信息,百度蜘蛛会制定使用带宽和所有资源获取信息的规则,并且也只会使用大规模的信息。减少了抓取 网站 的压力。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。识别URL重定向互联网信息数据量非常大,涉及的链接很多,但在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。识别URL重定向互联网信息数据量很大,涉及的链接很多,但是在这个过程中,页面链接可能会因为各种原因被重定向。在这个过程中,百度蜘蛛需要识别 URL 重定向。
合理使用百度蜘蛛抓取优先级 由于互联网信息量大,百度针对互联网信息抓取制定了多种优先抓取策略。目前的策略主要有:深度优先、广度优先、PR优先、反向链接优先、广度优先爬取的目的是爬取更多的URL,深度优先爬取的目的是爬取高质量的网页。这个策略是通过调度来计算和分配的。信息的爬取在爬取页面时经常会遇到页面质量低、链接质量低等问题。百度引入了绿萝、石榴等算法进行过滤。外部泄漏。获取无法爬取的数据可能会导致互联网上的各种问题导致百度蜘蛛无法爬取信息。在这种情况下,百度已经开启了手动提交数据。今天教大家如何使用快速采集高质量文章Dede采集插件制作网站快速收录。
百度在北京外包,如何使用飞飞cms采集让关键词排名和网站快收录,相信网站@的排名> 很多小伙伴的经历过天堂和地狱......百度在近端时间波动很大,很多网站排名直接被PASS掉了。很多人对百度的调整一无所知,只能等待恢复正常。虽然目前还没有百度推出新算法的迹象,但作为SEO优化者,我们还是要根据目前的百度算法体系来调整优化网站,否则波动不能怪“大环境”。今天给大家一个飞飞cms采集工具,可以批量管理网站。无论你有成百上千个不同的飞飞cms网站还是其他网站,都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。批量监控管理不同的cms网站数据(你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyoucms, People Renzhan< @cms、飞飞cms、Cyclone、站群、PBoot、Apple、Mito、搜外等各大cms,可同时批量管理采集伪原创 和发布推送工具)
网页抓取数据百度百科(搜索引擎蜘蛛的工作原理是怎样的?蜘蛛这个事儿)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-08 00:00
做搜索引擎的时候,SEO人员都熟悉一个词,叫“蜘蛛爬行”。一些新人可能会想到互联网?蜘蛛?是不是因为有网,监控人员被比作蜘蛛?道理差不多,但不专业。今天,小编就和大家一起来解读一下搜索引擎蜘蛛。
一、什么是搜索引擎蜘蛛
的确,用白话理解,互联网可以理解为一个巨大的“蜘蛛网”,搜索引擎蜘蛛类似于实际的“机器人”。蜘蛛的主要任务是浏览庞大的蜘蛛网(Internet)中的信息,然后将信息爬取到搜索引擎的服务器,进而构建索引库。这就像一个机器人浏览我们的 网站 并将内容保存到它自己的计算机上。
搜索引擎蜘蛛
二、搜索引擎蜘蛛是如何工作的?
搜索引擎蜘蛛如何工作
一、 爬网。
每个独立的搜索引擎都会有自己的网络爬虫爬虫。爬虫蜘蛛跟随网页中的超链接分析,不断地访问和抓取更多的网页。抓取的网页称为网页快照。不用说,搜索引擎蜘蛛会定期抓取网页。如下:
1、权重优先:先参考链接权重,再结合深度优先和广度优先策略进行抓取。例如,如果链接的权重还不错,则先使用深度;如果重量非常低,请先使用宽度。
2、Revisiting Crawl:这个可以从字面上理解。因为搜索引擎主要使用单次重访和完整重访。所以我们在做网站内容的时候,一定要记得定期维护每日更新,这样蜘蛛才能更快的访问和爬取更多的收录。
二、处理网页。
搜索引擎爬取网页后,需要进行大量的预处理工作才能提供检索服务。其中,最重要的是提取关键词,建立索引库和索引。其他包括去除重复网页、分词(中文)、判断网页类型、超链接分析、计算网页的重要性/丰富度等。
处理网页分为以下几个部分:
1、网页结构:删除所有HTML代码,提取内容。
2、去噪:离开网页的主题。
3、重复检查:查找和删除重复的网页和内容。
4、分词:将文本的内容提取出来后,分成几个词,然后排列存储在索引数据库中。还要计算这个词在这个页面上出现了多少次。需要指出的是,关键词stacking就是借用这个原理来优化网站。这种做法是作弊。
5、链接分析:搜索引擎会查询分析这个页面有多少反向链接,导出链接有多少内部链接,然后判断这个页面有多少权重。
三、提供检索服务。
用户输入关键词进行检索,搜索引擎从索引库中找到与关键词匹配的网页。为了方便用户判断,除了网页的标题和URL外,还提供了网页摘要等信息。
所以如果你想做一个好的搜索引擎,让蜘蛛爬取你的网站,小编根据搜索引擎的特点做如下总结:
1.网站发布信息后多做分享或多发外链。它可以帮助您的 网站 尽快带来搜索引擎蜘蛛的访问。您还可以通过内部链接增加搜索引擎蜘蛛在网站的停留时间,以获得更好的排名。
2.定期最好每天发布新信息或更新网站内容,让蜘蛛更多地访问你的信息进行爬取。
3.发布优质信息,让用户体验长久停留,有利于搜索引擎蜘蛛判断你的网站高价值。
4.别想走捷径,一定要遵守搜索引擎的规则,做好内容,做好用户体验网站。
是不是收获满满,受益良多?其实在这里我想推荐一个好帮手。TA将提供更多互联网学习资料,同时免费帮你解答任何互联网问题,并提供完善的互联网服务,TA就是Think Enterprise Internet(),点击访问,你会发现更多精彩! 查看全部
网页抓取数据百度百科(搜索引擎蜘蛛的工作原理是怎样的?蜘蛛这个事儿)
做搜索引擎的时候,SEO人员都熟悉一个词,叫“蜘蛛爬行”。一些新人可能会想到互联网?蜘蛛?是不是因为有网,监控人员被比作蜘蛛?道理差不多,但不专业。今天,小编就和大家一起来解读一下搜索引擎蜘蛛。
一、什么是搜索引擎蜘蛛
的确,用白话理解,互联网可以理解为一个巨大的“蜘蛛网”,搜索引擎蜘蛛类似于实际的“机器人”。蜘蛛的主要任务是浏览庞大的蜘蛛网(Internet)中的信息,然后将信息爬取到搜索引擎的服务器,进而构建索引库。这就像一个机器人浏览我们的 网站 并将内容保存到它自己的计算机上。
搜索引擎蜘蛛
二、搜索引擎蜘蛛是如何工作的?
搜索引擎蜘蛛如何工作
一、 爬网。
每个独立的搜索引擎都会有自己的网络爬虫爬虫。爬虫蜘蛛跟随网页中的超链接分析,不断地访问和抓取更多的网页。抓取的网页称为网页快照。不用说,搜索引擎蜘蛛会定期抓取网页。如下:
1、权重优先:先参考链接权重,再结合深度优先和广度优先策略进行抓取。例如,如果链接的权重还不错,则先使用深度;如果重量非常低,请先使用宽度。
2、Revisiting Crawl:这个可以从字面上理解。因为搜索引擎主要使用单次重访和完整重访。所以我们在做网站内容的时候,一定要记得定期维护每日更新,这样蜘蛛才能更快的访问和爬取更多的收录。
二、处理网页。
搜索引擎爬取网页后,需要进行大量的预处理工作才能提供检索服务。其中,最重要的是提取关键词,建立索引库和索引。其他包括去除重复网页、分词(中文)、判断网页类型、超链接分析、计算网页的重要性/丰富度等。
处理网页分为以下几个部分:
1、网页结构:删除所有HTML代码,提取内容。
2、去噪:离开网页的主题。
3、重复检查:查找和删除重复的网页和内容。
4、分词:将文本的内容提取出来后,分成几个词,然后排列存储在索引数据库中。还要计算这个词在这个页面上出现了多少次。需要指出的是,关键词stacking就是借用这个原理来优化网站。这种做法是作弊。
5、链接分析:搜索引擎会查询分析这个页面有多少反向链接,导出链接有多少内部链接,然后判断这个页面有多少权重。
三、提供检索服务。
用户输入关键词进行检索,搜索引擎从索引库中找到与关键词匹配的网页。为了方便用户判断,除了网页的标题和URL外,还提供了网页摘要等信息。
所以如果你想做一个好的搜索引擎,让蜘蛛爬取你的网站,小编根据搜索引擎的特点做如下总结:
1.网站发布信息后多做分享或多发外链。它可以帮助您的 网站 尽快带来搜索引擎蜘蛛的访问。您还可以通过内部链接增加搜索引擎蜘蛛在网站的停留时间,以获得更好的排名。
2.定期最好每天发布新信息或更新网站内容,让蜘蛛更多地访问你的信息进行爬取。
3.发布优质信息,让用户体验长久停留,有利于搜索引擎蜘蛛判断你的网站高价值。
4.别想走捷径,一定要遵守搜索引擎的规则,做好内容,做好用户体验网站。
是不是收获满满,受益良多?其实在这里我想推荐一个好帮手。TA将提供更多互联网学习资料,同时免费帮你解答任何互联网问题,并提供完善的互联网服务,TA就是Think Enterprise Internet(),点击访问,你会发现更多精彩!
网页抓取数据百度百科(爬虫常见优秀网络爬虫有以下几种类型类型分析及应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-07 10:01
)
什么是网络爬虫,百度百科是这样定义的
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。以下简称爬虫
爬虫作为一种自动化工具去代替人工操作,以此来节省成本和时间,爬虫不是乱爬,一个没有规则爬虫是没有存活的价值的,需要明确爬取的目标这样才能体现爬虫的价值,一般我们需要人为的设定一些规则,让爬虫按照这个规则去爬取。这里我从网络上找到了关于爬虫的几个分类
常见和优秀的网络爬虫有以下几种:
1.批量型网络爬虫:限制爬取的属性,包括爬取范围、具体目标、限制爬取时间、限制数据量、限制爬取页面,总之,明显的特征是有限的;
2.增量网络爬虫(万能爬虫):与前者相反,没有固定的限制,直到所有数据都被抓取完为止。这种类型一般用在网站或者搜索引擎的程序中;
3.垂直网络爬虫(焦点爬虫):可以简单理解为一个无限细化的增量网络爬虫,可以仔细筛选行业、内容、发布时间、页面大小等诸多因素。
以上内容来自:
除了这几类之外,还经常听到爬虫的搜索方式:
广度优先搜索
整个广度优先爬取过程从一系列种子节点开始,提取这些网页中的“子节点”(即超链接),放入队列依次爬取。处理后的链接需要放入一个表(通常称为已访问表)中。每次处理一个新的链接时,都需要检查该链接是否已经存在于Visited表中。如果存在,则证明该链接已被处理,跳过,不处理,否则进行下一步。(这就是我们后面提到的爬虫网址管理模块)
该算法的优势主要有以下三个原因:
重要的网页通常更接近种子。当我们浏览新闻网站时,热门信息通常会出现在比较显眼的位置。随着深入阅读,我们会发现得到的信息的价值已经不如从前了。
万维网的实际深度最多可以达到 17 层,但通往网页的路径总是很短。广度优先遍历会尽快到达页面。
广度优先有利于多个爬虫的协作爬取。多个爬虫的合作通常会先爬取站点中的链接,而且爬取非常封闭。
深度优先搜索
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。优点是能遍历一个Web 站点或深层嵌套的文档集合;缺点是因为Web结构相当深,,有可能造成一旦进去,再也出不来的情况发生,所以一般指定一个最大的深度。
最后,爬虫一般都有哪些模块?
网址管理器模块
一般用于维护已爬取的url和未爬取的url新增的url。如果当前爬取的url已经存在于队列中,则无需重复爬取,防止死循环。例如
我爬的列表中收录music.baidu.om,然后我继续爬取这个页面的所有链接,但是它收录,可想而知,如果不处理,会变成死循环,在百度首页和百度音乐页面循环,所以有一对列来维护URL很重要。
下面是一个python代码实现的例子。使用的deque双向队列,方便取出之前的url。
from collections import deque
class URLQueue():
def __init__(self):
self.queue = deque() # 待抓取的网页
self.visited = set() # 已经抓取过的网页
def new_url_size(self):
'''''
获取未爬取URL集合的大小
:return:
'''
return len(self.queue)
def old_url_size(self):
'''''
获取已爬取URL的大小
:return:
'''
return len(self.visited)
def has_new_url(self):
'''''
判断是否有未爬取的URL
:return:
'''
return self.new_url_size() != 0
def get_new_url(self):
'''''
获取一个未爬取的URL
:return:
'''
new_url = self.queue.popleft()#从左侧取出一个链接
self.old_urls.add(new_url)#记录已经抓取
return new_url
def add_new_url(self, url):
'''''
将新的URL添加到未爬取的URL集合
:param url: 单个url
:return:
'''
if url is None:
return False
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.append(url)
def add_new_urls(self, urlset):
'''''
将新的URL添加到未爬取的URL集合
:param urlset: url集合
:return:
'''
if urlset is None or len(urlset) == 0:
return
for url in urlset:
self.add_new_url(url)
HTML下载模块
HTML下载模块
该模块主要根据提供的url下载url对应的网页内容。使用模块requets-HTML,添加重试逻辑,设置最大重试次数,限制访问时间,防止程序因长期无响应而死机。
根据返回的状态码判断,如果访问成功,则返回源代码,否则开始重试,如果发生异常,则进行重试操作。
<p>from requests_html import HTMLSession
from fake_useragent import UserAgent
import requests
import time
import random
class Gethtml():
def __init__(self,url="http://wwww.baidu.com"):
self.ua = UserAgent()
self.url=url
self.session=HTMLSession(mock_browser=True)
#关于headers有个默认的方法 self.headers = default_headers()
#mock_browser 表示使用useragent
def get_source(self,url,retry=1):
if retry>3:
print("重试三次以上,跳出循环")
return None
while retry 查看全部
网页抓取数据百度百科(爬虫常见优秀网络爬虫有以下几种类型类型分析及应用
)
什么是网络爬虫,百度百科是这样定义的
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。以下简称爬虫
爬虫作为一种自动化工具去代替人工操作,以此来节省成本和时间,爬虫不是乱爬,一个没有规则爬虫是没有存活的价值的,需要明确爬取的目标这样才能体现爬虫的价值,一般我们需要人为的设定一些规则,让爬虫按照这个规则去爬取。这里我从网络上找到了关于爬虫的几个分类
常见和优秀的网络爬虫有以下几种:
1.批量型网络爬虫:限制爬取的属性,包括爬取范围、具体目标、限制爬取时间、限制数据量、限制爬取页面,总之,明显的特征是有限的;
2.增量网络爬虫(万能爬虫):与前者相反,没有固定的限制,直到所有数据都被抓取完为止。这种类型一般用在网站或者搜索引擎的程序中;
3.垂直网络爬虫(焦点爬虫):可以简单理解为一个无限细化的增量网络爬虫,可以仔细筛选行业、内容、发布时间、页面大小等诸多因素。
以上内容来自:
除了这几类之外,还经常听到爬虫的搜索方式:
广度优先搜索
整个广度优先爬取过程从一系列种子节点开始,提取这些网页中的“子节点”(即超链接),放入队列依次爬取。处理后的链接需要放入一个表(通常称为已访问表)中。每次处理一个新的链接时,都需要检查该链接是否已经存在于Visited表中。如果存在,则证明该链接已被处理,跳过,不处理,否则进行下一步。(这就是我们后面提到的爬虫网址管理模块)
该算法的优势主要有以下三个原因:
重要的网页通常更接近种子。当我们浏览新闻网站时,热门信息通常会出现在比较显眼的位置。随着深入阅读,我们会发现得到的信息的价值已经不如从前了。
万维网的实际深度最多可以达到 17 层,但通往网页的路径总是很短。广度优先遍历会尽快到达页面。
广度优先有利于多个爬虫的协作爬取。多个爬虫的合作通常会先爬取站点中的链接,而且爬取非常封闭。
深度优先搜索
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。优点是能遍历一个Web 站点或深层嵌套的文档集合;缺点是因为Web结构相当深,,有可能造成一旦进去,再也出不来的情况发生,所以一般指定一个最大的深度。
最后,爬虫一般都有哪些模块?
网址管理器模块
一般用于维护已爬取的url和未爬取的url新增的url。如果当前爬取的url已经存在于队列中,则无需重复爬取,防止死循环。例如
我爬的列表中收录music.baidu.om,然后我继续爬取这个页面的所有链接,但是它收录,可想而知,如果不处理,会变成死循环,在百度首页和百度音乐页面循环,所以有一对列来维护URL很重要。
下面是一个python代码实现的例子。使用的deque双向队列,方便取出之前的url。
from collections import deque
class URLQueue():
def __init__(self):
self.queue = deque() # 待抓取的网页
self.visited = set() # 已经抓取过的网页
def new_url_size(self):
'''''
获取未爬取URL集合的大小
:return:
'''
return len(self.queue)
def old_url_size(self):
'''''
获取已爬取URL的大小
:return:
'''
return len(self.visited)
def has_new_url(self):
'''''
判断是否有未爬取的URL
:return:
'''
return self.new_url_size() != 0
def get_new_url(self):
'''''
获取一个未爬取的URL
:return:
'''
new_url = self.queue.popleft()#从左侧取出一个链接
self.old_urls.add(new_url)#记录已经抓取
return new_url
def add_new_url(self, url):
'''''
将新的URL添加到未爬取的URL集合
:param url: 单个url
:return:
'''
if url is None:
return False
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.append(url)
def add_new_urls(self, urlset):
'''''
将新的URL添加到未爬取的URL集合
:param urlset: url集合
:return:
'''
if urlset is None or len(urlset) == 0:
return
for url in urlset:
self.add_new_url(url)
HTML下载模块
HTML下载模块
该模块主要根据提供的url下载url对应的网页内容。使用模块requets-HTML,添加重试逻辑,设置最大重试次数,限制访问时间,防止程序因长期无响应而死机。
根据返回的状态码判断,如果访问成功,则返回源代码,否则开始重试,如果发生异常,则进行重试操作。
<p>from requests_html import HTMLSession
from fake_useragent import UserAgent
import requests
import time
import random
class Gethtml():
def __init__(self,url="http://wwww.baidu.com";):
self.ua = UserAgent()
self.url=url
self.session=HTMLSession(mock_browser=True)
#关于headers有个默认的方法 self.headers = default_headers()
#mock_browser 表示使用useragent
def get_source(self,url,retry=1):
if retry>3:
print("重试三次以上,跳出循环")
return None
while retry
网页抓取数据百度百科(如何使用使用python来编写一些简单的网络爬虫?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-04-07 10:01
本文主要是个人python学习过程中的思考,希望对感兴趣的童鞋有所帮助。
百度百科对网络爬虫的定义是:“网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常称为网页追赶者)是一种按照一定规则进行的自动爬取。万维网上信息的程序或脚本”。使用网络爬虫,可以对来自互联网的个人兴趣数据进行个性化处理,完成一些目前搜索引擎无法完成的个性化搜索。说用python写一个网络爬虫其实是在模拟浏览器的工作过程,从网上抓取需要的信息,完成分析、提取、存储的过程。
为了更好的爬虫的工作过程,我们先来看看用户访问互联网资源的过程,用户在浏览器中输入:
例如,当用户输入完成,开始搜索时,用户请求的网页经过DNS完成域名解析,通过网络携带HTTP协议栈的数据,发送到服务器百度定位。将首页的数据返回给用户(假设这个过程中的所有进程都是正确的)。用户浏览器接收到百度响应数据后,通过浏览器解析数据,将百度主页呈现在用户面前。这里,百度返回的数据是HTTP协议栈封装的HTML/CSS/PHP数据。如上所述,当我们用python编写网络爬虫时也是如此。为了完成这个工作流程,我们需要掌握python的基本知识,
废话不多说,我们通过一些实际的例子来看看如何使用python编写一些简单的网络爬虫。 查看全部
网页抓取数据百度百科(如何使用使用python来编写一些简单的网络爬虫?(图))
本文主要是个人python学习过程中的思考,希望对感兴趣的童鞋有所帮助。
百度百科对网络爬虫的定义是:“网络爬虫(又称网络蜘蛛、网络机器人,在FOAF社区,更常称为网页追赶者)是一种按照一定规则进行的自动爬取。万维网上信息的程序或脚本”。使用网络爬虫,可以对来自互联网的个人兴趣数据进行个性化处理,完成一些目前搜索引擎无法完成的个性化搜索。说用python写一个网络爬虫其实是在模拟浏览器的工作过程,从网上抓取需要的信息,完成分析、提取、存储的过程。
为了更好的爬虫的工作过程,我们先来看看用户访问互联网资源的过程,用户在浏览器中输入:
例如,当用户输入完成,开始搜索时,用户请求的网页经过DNS完成域名解析,通过网络携带HTTP协议栈的数据,发送到服务器百度定位。将首页的数据返回给用户(假设这个过程中的所有进程都是正确的)。用户浏览器接收到百度响应数据后,通过浏览器解析数据,将百度主页呈现在用户面前。这里,百度返回的数据是HTTP协议栈封装的HTML/CSS/PHP数据。如上所述,当我们用python编写网络爬虫时也是如此。为了完成这个工作流程,我们需要掌握python的基本知识,
废话不多说,我们通过一些实际的例子来看看如何使用python编写一些简单的网络爬虫。
网页抓取数据百度百科(简单的爬虫架构如上图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-04 08:19
什么是爬行动物?
爬虫是一种自动爬取互联网信息的程序,以便更好地利用数据进行相关分析并做出相关决策。
简单的爬虫架构
如上图所示,这个架构主要分为五个部分:
1. 爬虫主调度器
主要用于调度其他模块相互配合获取我们想要的数据
2. 网址管理器
主要管理两部分数据:未爬取的url和等待爬取的url数据
3. 下载器
从 url manager 中获取未抓取的 ulr,并使用 urllib 中的 request 模块抓取网络数据。
4. 解析器
从下载器获取的 html 数据解析出新的 url 和我们要提取的数据。
5. 出口商
将我们想要的数据输出到文件中。
使用第一眼网址管理器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:55
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
该模块的主要功能是管理带爬取和爬取的url,其中new_urls指的是要爬取的url,old_urls指的是已经爬取过的url,并且设置了数据结构,可以直接去重。
2. 下载器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:01
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
from urllib import request
class HtmlDownloader(object):
"""Html下载器"""
def download(self, url):
if url is None:
return None
response = request.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
这个比较简单,直接使用urllib中的request模块爬取数据
3. 解析器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:31
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
import re
from urllib import parse
from bs4 import BeautifulSoup
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 计算机程序设计语言
links = soup.find_all('a', href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
new_full_url = parse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
# url
res_data['url'] = page_url
#
# Python
# (计算机程序设计语言)
# 编辑
# 锁定
#
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
#
# Python
# [1]<a class="sup-anchor" name="ref_[1]_21087"> </a>
# (英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/), 是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,第一个公开发行版发行于1991年。Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议。Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进。Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写,比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。需要注意的是在您使用扩展类库时可能需要考虑平台问题,某些可能不提供跨平台的实现。7月20日,IEEE发布2017年编程语言排行榜:Python高居首位
# [2]<a class="sup-anchor" name="ref_[2]_21087"> </a>
# 。2018年3月,该语言作者在邮件列表上宣布 Python 2.7将于2020年1月1日终止支持。用户如果想要在这个日期之后继续得到与Python 2.7有关的支持,则需要付费给商业供应商。
# [3]<a class="sup-anchor" name="ref_[3]_21087"> </a>
#
#
summary_node = soup.find('div', class_='lemma-summary').find('div', class_='para')
res_data['summary'] = summary_node.get_text()
return res_data
def parse(self, page_url, html_content):
if page_url is None or html_content is None:
return
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
该模块主要解析下载器的数据。解析使用第三方库“BeautifulSoup”。如果没有安装,请先安装:
点安装beautifulsoup4
这里需要分析一下我们需要爬取的数据内容。这里我要爬取的内容是:百科词条的标题和介绍
- 首先,我们要看看标题的html标签格式是什么样子的。右击标题“Python”->勾选,可以看到它的标签如下:
#
# Python
# (计算机程序设计语言)
# 编辑
# 锁定
#
可以看出dd标签中的class属性在lemmaWgt-lemmaTitle-title的h1标签中,所以代码很简单:
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
同理,可以找出引言的标注规则。
4. 出口商:
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
f_out = None
try:
f_out = open('output.html', 'w', encoding='utf-8')
f_out.write("")
f_out.write("")
f_out.write("")
for data in self.datas:
f_out.write("")
f_out.write("%s" % data['url'])
f_out.write("%s" % data['title'])
f_out.write("%s" % data['summary'])
f_out.write("")
f_out.write("")
f_out.write("")
finally:
if f_out:
f_out.close()
这个模块也很简单。它主要存储我们想要的数据,并以html表格的形式输出到文件“output.html”中。不过需要注意的是,由于爬取的内容是中文的,所以一定要指定编码为utf-8,否则会出现乱码。
5. 最后,我们编写调度器并爬取 1000 个入口数据:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:23:26
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
from baike_spider import url_manager, html_downloader, html_parser, html_outputer
class Spider(object):
def __init__(self):
self.url_manager = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.html_parser = html_parser.HtmlParser()
self.html_outputer = html_outputer.HtmlOutputer()
def craw(self, rootUrl):
count = 1
self.url_manager.add_new_url(rootUrl)
while self.url_manager.has_new_url():
try:
new_url = self.url_manager.get_new_url()
print("craw%d -> %s" % (count, new_url))
content = self.downloader.download(new_url)
new_urls, data = self.html_parser.parse(new_url, content)
self.url_manager.add_new_urls(new_urls)
self.html_outputer.collect_data(data)
if count == 1000:
break
count = count + 1
except:
print('craw failed')
self.html_outputer.output_html()
root_url = "https://baike.baidu.com/item/Python/407313"
if __name__ == "__main__":
spider = Spider()
spider.craw(root_url)
起始 url 是 Python 入口的 url:root_url = ""
好的,运行调度程序并开始爬取数据。
看看上次运行的结果:
存储的文件是一个html文件,找到文件路径用浏览器打开,可以看到下图。
来源链接 查看全部
网页抓取数据百度百科(简单的爬虫架构如上图)
什么是爬行动物?
爬虫是一种自动爬取互联网信息的程序,以便更好地利用数据进行相关分析并做出相关决策。
简单的爬虫架构
如上图所示,这个架构主要分为五个部分:
1. 爬虫主调度器
主要用于调度其他模块相互配合获取我们想要的数据
2. 网址管理器
主要管理两部分数据:未爬取的url和等待爬取的url数据
3. 下载器
从 url manager 中获取未抓取的 ulr,并使用 urllib 中的 request 模块抓取网络数据。
4. 解析器
从下载器获取的 html 数据解析出新的 url 和我们要提取的数据。
5. 出口商
将我们想要的数据输出到文件中。
使用第一眼网址管理器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:55
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
该模块的主要功能是管理带爬取和爬取的url,其中new_urls指的是要爬取的url,old_urls指的是已经爬取过的url,并且设置了数据结构,可以直接去重。
2. 下载器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:01
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
from urllib import request
class HtmlDownloader(object):
"""Html下载器"""
def download(self, url):
if url is None:
return None
response = request.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
这个比较简单,直接使用urllib中的request模块爬取数据
3. 解析器:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:25:31
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
import re
from urllib import parse
from bs4 import BeautifulSoup
class HtmlParser(object):
def _get_new_urls(self, page_url, soup):
new_urls = set()
# 计算机程序设计语言
links = soup.find_all('a', href=re.compile(r"/item/"))
for link in links:
new_url = link['href']
new_full_url = parse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self, page_url, soup):
res_data = {}
# url
res_data['url'] = page_url
#
# Python
# (计算机程序设计语言)
# 编辑
# 锁定
#
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
#
# Python
# [1]<a class="sup-anchor" name="ref_[1]_21087"> </a>
# (英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/), 是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,第一个公开发行版发行于1991年。Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议。Python语法简洁清晰,特色之一是强制用空白符(white space)作为语句缩进。Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写,比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。需要注意的是在您使用扩展类库时可能需要考虑平台问题,某些可能不提供跨平台的实现。7月20日,IEEE发布2017年编程语言排行榜:Python高居首位
# [2]<a class="sup-anchor" name="ref_[2]_21087"> </a>
# 。2018年3月,该语言作者在邮件列表上宣布 Python 2.7将于2020年1月1日终止支持。用户如果想要在这个日期之后继续得到与Python 2.7有关的支持,则需要付费给商业供应商。
# [3]<a class="sup-anchor" name="ref_[3]_21087"> </a>
#
#
summary_node = soup.find('div', class_='lemma-summary').find('div', class_='para')
res_data['summary'] = summary_node.get_text()
return res_data
def parse(self, page_url, html_content):
if page_url is None or html_content is None:
return
soup = BeautifulSoup(html_content, 'html.parser', from_encoding='utf-8')
new_urls = self._get_new_urls(page_url, soup)
new_data = self._get_new_data(page_url, soup)
return new_urls, new_data
该模块主要解析下载器的数据。解析使用第三方库“BeautifulSoup”。如果没有安装,请先安装:
点安装beautifulsoup4
这里需要分析一下我们需要爬取的数据内容。这里我要爬取的内容是:百科词条的标题和介绍
- 首先,我们要看看标题的html标签格式是什么样子的。右击标题“Python”->勾选,可以看到它的标签如下:
#
# Python
# (计算机程序设计语言)
# 编辑
# 锁定
#
可以看出dd标签中的class属性在lemmaWgt-lemmaTitle-title的h1标签中,所以代码很简单:
title_node = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title'] = title_node.get_text()
同理,可以找出引言的标注规则。
4. 出口商:
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
f_out = None
try:
f_out = open('output.html', 'w', encoding='utf-8')
f_out.write("")
f_out.write("")
f_out.write("")
for data in self.datas:
f_out.write("")
f_out.write("%s" % data['url'])
f_out.write("%s" % data['title'])
f_out.write("%s" % data['summary'])
f_out.write("")
f_out.write("")
f_out.write("")
finally:
if f_out:
f_out.close()
这个模块也很简单。它主要存储我们想要的数据,并以html表格的形式输出到文件“output.html”中。不过需要注意的是,由于爬取的内容是中文的,所以一定要指定编码为utf-8,否则会出现乱码。
5. 最后,我们编写调度器并爬取 1000 个入口数据:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-07-15 15:23:26
# @Author : zhulei (zhuleimailname@gmail.com)
# @Link : http://zhuleiblog.com
from baike_spider import url_manager, html_downloader, html_parser, html_outputer
class Spider(object):
def __init__(self):
self.url_manager = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.html_parser = html_parser.HtmlParser()
self.html_outputer = html_outputer.HtmlOutputer()
def craw(self, rootUrl):
count = 1
self.url_manager.add_new_url(rootUrl)
while self.url_manager.has_new_url():
try:
new_url = self.url_manager.get_new_url()
print("craw%d -> %s" % (count, new_url))
content = self.downloader.download(new_url)
new_urls, data = self.html_parser.parse(new_url, content)
self.url_manager.add_new_urls(new_urls)
self.html_outputer.collect_data(data)
if count == 1000:
break
count = count + 1
except:
print('craw failed')
self.html_outputer.output_html()
root_url = "https://baike.baidu.com/item/Python/407313"
if __name__ == "__main__":
spider = Spider()
spider.craw(root_url)
起始 url 是 Python 入口的 url:root_url = ""
好的,运行调度程序并开始爬取数据。
看看上次运行的结果:
存储的文件是一个html文件,找到文件路径用浏览器打开,可以看到下图。
来源链接
网页抓取数据百度百科(、描述、简称学校名称.xlsx最终成果步骤及步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2022-03-28 20:11
我在公众号上看到的文章感觉不错,适合练习。所以我自己做了。
不要胡说八道。
目的:手头有一个“学校名称.xlsx”表格。求这些学校的英文名称、描述、缩写
学校名称.xlsx
最后结果
第 1 步:分析
所需的学校信息一般可在百度百科中找到。那么让我们看看百度百科的数据能否满足我们的要求。
一、找学校去百度百科看看情况
以北京大学为例:英文名称、描述、缩写
在该界面中可用。
然后所有的信息也可以在页面源代码中看到。所以理论上,我们爬下这个页面的信息后,就可以做简单的处理了。
第 2 步:编写代码
1、需要的技术和软件包
import requests
import pandas as pd
from random import choice
from lxml import etree
import openpyxl
import logging
from concurrent.futures import ThreadPoolExecutor
from time import sleep
from random import random
阐明:
请求,对于 python 爬虫来说是必须的。这用于发送get请求并接收返回结果
pandas,数据分析的基础,是必须的。用于将 Excel 表中的学校名称用 pandas 读取后转换为列表,并成为百度百科网站的一部分。
随机的,
random 方法生成伪随机数。随时间使用。让程序随机休眠几秒,避免CPU一直被占用,导致电脑发热、死机,避免百度ip阻塞
选择方法,随机一种。这用于随机选择一个 http 标头。
lxml,用于解析网页返回数据(返回的数据是一堆网页代码,很多没用,还得解析成需要的英文名、缩写、描述)
openpyxl,用于写表
记录,记录
concurrent.futures,Python 多线程。我们要爬3000条左右的数据,单线程执行会很慢,多线程会快很多
时间,使用 sleep 方法让代码休眠。
2、写一个爬取数据的函数
def get_data(item):
try:
# 记录一下它原本的序号
sort_num = items.index(item)
# 随机生成请求头
headers = {
'User-Agent':choice(user_agent)
}
# 构造的url
url = f'https://baike.baidu.com/item/{item}'
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
sleep(random())
# Xpath解析提取数据
html = etree.HTML(rep.text)
description = ''.join(html.xpath('/html/head/meta[4]/@content'))
# 外文名
en_name = ','.join(html.xpath('//dl[@class="basicInfo-block basicInfo-left"]/dd[2]/text()')).strip()
# 中文简称 有的话 是在dd[3]标签下
simple_name = ''.join(html.xpath('//dl[@class="basicInfo-block basicInfo-left"]/dd[3]/text()')).strip()
sheet.append([item, simple_name, en_name, description, url, sort_num])
logging.info([item, simple_name, en_name, description, url, sort_num])
except Exception as e:
logging.info(e.args)
pass
3、编写一个多线程函数,将爬取解析后的数据保存到文件中。
# 函数调用 开多线程
def run():
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(get_data, items)
wb.save('成果.xlsx')
print('===================== 数据成功下载完成 ======================')
阐明:
地图(函数,可迭代,...)
指定的序列将根据提供的函数进行映射。
第一个参数函数使用参数序列中的每个元素调用函数函数,返回一个收录每个函数函数返回值的新列表。
说白了就是map(a,b),a是函数,b是序列。将 b 一个一个传入 a 执行。有点循环。
本例中的 b 是从表中获得的学校名称列表。大概有3000个左右,所以如果run()函数执行的话,要执行3000次
4、执行多线程函数
run()
5、跑步效果(不做动画,所以这个动画是大佬图的复制品)
6、终于得到一个result.xlsx文件
阐明:
上述代码需要复制到py文件中执行。
以上分别拆解,主要是为了说明。
最后:
我感慨道:如果你不辜负年轻的时候,你将在你的余生中加倍欺骗你。
以前上学的时候比较懒惰,基本没学过HTML相关的知识。现在看来元素定位太费劲了。
最后:
公众号好评如潮:师姐拿了成绩。xlsx对男友说:“你看,舔狗还是好用的”
参考:
xpath元素定位(相对路径)常用的5种方法 - 程序员大本营
原作者应该是叶廷云 叶廷云的博客 查看全部
网页抓取数据百度百科(、描述、简称学校名称.xlsx最终成果步骤及步骤)
我在公众号上看到的文章感觉不错,适合练习。所以我自己做了。
不要胡说八道。
目的:手头有一个“学校名称.xlsx”表格。求这些学校的英文名称、描述、缩写
学校名称.xlsx
最后结果
第 1 步:分析
所需的学校信息一般可在百度百科中找到。那么让我们看看百度百科的数据能否满足我们的要求。
一、找学校去百度百科看看情况
以北京大学为例:英文名称、描述、缩写
在该界面中可用。
然后所有的信息也可以在页面源代码中看到。所以理论上,我们爬下这个页面的信息后,就可以做简单的处理了。
第 2 步:编写代码
1、需要的技术和软件包
import requests
import pandas as pd
from random import choice
from lxml import etree
import openpyxl
import logging
from concurrent.futures import ThreadPoolExecutor
from time import sleep
from random import random
阐明:
请求,对于 python 爬虫来说是必须的。这用于发送get请求并接收返回结果
pandas,数据分析的基础,是必须的。用于将 Excel 表中的学校名称用 pandas 读取后转换为列表,并成为百度百科网站的一部分。
随机的,
random 方法生成伪随机数。随时间使用。让程序随机休眠几秒,避免CPU一直被占用,导致电脑发热、死机,避免百度ip阻塞
选择方法,随机一种。这用于随机选择一个 http 标头。
lxml,用于解析网页返回数据(返回的数据是一堆网页代码,很多没用,还得解析成需要的英文名、缩写、描述)
openpyxl,用于写表
记录,记录
concurrent.futures,Python 多线程。我们要爬3000条左右的数据,单线程执行会很慢,多线程会快很多
时间,使用 sleep 方法让代码休眠。
2、写一个爬取数据的函数
def get_data(item):
try:
# 记录一下它原本的序号
sort_num = items.index(item)
# 随机生成请求头
headers = {
'User-Agent':choice(user_agent)
}
# 构造的url
url = f'https://baike.baidu.com/item/{item}'
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
sleep(random())
# Xpath解析提取数据
html = etree.HTML(rep.text)
description = ''.join(html.xpath('/html/head/meta[4]/@content'))
# 外文名
en_name = ','.join(html.xpath('//dl[@class="basicInfo-block basicInfo-left"]/dd[2]/text()')).strip()
# 中文简称 有的话 是在dd[3]标签下
simple_name = ''.join(html.xpath('//dl[@class="basicInfo-block basicInfo-left"]/dd[3]/text()')).strip()
sheet.append([item, simple_name, en_name, description, url, sort_num])
logging.info([item, simple_name, en_name, description, url, sort_num])
except Exception as e:
logging.info(e.args)
pass
3、编写一个多线程函数,将爬取解析后的数据保存到文件中。
# 函数调用 开多线程
def run():
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(get_data, items)
wb.save('成果.xlsx')
print('===================== 数据成功下载完成 ======================')
阐明:
地图(函数,可迭代,...)
指定的序列将根据提供的函数进行映射。
第一个参数函数使用参数序列中的每个元素调用函数函数,返回一个收录每个函数函数返回值的新列表。
说白了就是map(a,b),a是函数,b是序列。将 b 一个一个传入 a 执行。有点循环。
本例中的 b 是从表中获得的学校名称列表。大概有3000个左右,所以如果run()函数执行的话,要执行3000次
4、执行多线程函数
run()
5、跑步效果(不做动画,所以这个动画是大佬图的复制品)
6、终于得到一个result.xlsx文件
阐明:
上述代码需要复制到py文件中执行。
以上分别拆解,主要是为了说明。
最后:
我感慨道:如果你不辜负年轻的时候,你将在你的余生中加倍欺骗你。
以前上学的时候比较懒惰,基本没学过HTML相关的知识。现在看来元素定位太费劲了。
最后:
公众号好评如潮:师姐拿了成绩。xlsx对男友说:“你看,舔狗还是好用的”
参考:
xpath元素定位(相对路径)常用的5种方法 - 程序员大本营
原作者应该是叶廷云 叶廷云的博客
网页抓取数据百度百科(爬虫能做什么?可以创建搜索引擎(Google,百度))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-28 10:20
在大数据的浪潮中,最有价值的就是数据。企业为了获取数据、处理数据和理解数据而花费大量资金。使用网络爬虫可以最有效地获取数据。
什么是爬行动物?
网络蜘蛛,也称为网络爬虫、蚂蚁、自动索引器,或(在 FOAF 软件概念中)WEB scutter,是“自动浏览网络”程序,或网络机器人。它们被互联网搜索引擎或其他类似的网站s广泛用于获取或更新这些网站s的内容和检索方法。他们可以自动采集他们可以访问的所有页面内容以供搜索引擎进一步处理(对下载的页面进行排序和排序),从而使用户可以更快地检索到他们需要的信息。
最常见的是互联网搜索引擎,它使用网络爬虫自动采集所有可访问的页面内容来获取或更新这些网站的内容和检索方法。在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是
下载信息,将信息中对用户无意义的内容(如网页代码)处理掉。资源库用于存储下载的数据资源并在其上建立索引。
如果你想每小时抓取一次网易新闻,那么你需要访问网易并进行数据请求,得到一个html格式的网页,然后通过网络爬虫的解析器进行过滤,最后存入数据库。
爬行动物能做什么?
可以创建搜索引擎(谷歌、百度)
可用于抢优采云票
逛一圈
简单来说,只要浏览器能打开就可以用爬虫实现
网络爬虫的分类?
网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。万能网络爬虫,又称Scalable Web Crawler,将爬取对象从一些种子URL(网络上的每个文件都有一个地址,即一个URL)扩展到整个Web,主要针对门户网站搜索引擎和大型网页服务。商采集数据。出于商业原因,他们的技术细节很少被公布。
Focused Crawler,也称为Topical Crawler,是一种只抓取与主题相关的网络资源的爬虫。大大节省了硬件和网络资源,而且保存的数据量少,更新速度快,也能很好地满足某些特定人群对特定领域信息的需求。
增量网络爬虫(Incremental Web Crawler)是指只爬取新生成或变化的数据的爬虫。可以在一定程度上保证爬取的数据尽可能是新的,不会重新下载不变的数据。可以有效减少数据下载量,及时更新爬取数据,减少时间和空间消耗。
深度网络爬虫(Deep Web Crawler)可以从深度网页爬取数据。一般来说,网页分为表面网页和深层网页。表层页面是指传统搜索引擎可以索引的页面,而深层页面是用户提交一些关键词才能获得的页面。例如,只有在用户注册后才能看到内容的页面是深层页面。
学习爬虫技术势在必行:在当前竞争激烈的信息社会中,如何利用数据分析站在信息不对称的一边,保持竞争优势,是数字工作者必备的技能。然而,在你想飞之前,你必须学会跑步。在分析数据之前,首先要学会爬取和处理数据,这样才能事半功倍。
【全文结束】 查看全部
网页抓取数据百度百科(爬虫能做什么?可以创建搜索引擎(Google,百度))
在大数据的浪潮中,最有价值的就是数据。企业为了获取数据、处理数据和理解数据而花费大量资金。使用网络爬虫可以最有效地获取数据。
什么是爬行动物?
网络蜘蛛,也称为网络爬虫、蚂蚁、自动索引器,或(在 FOAF 软件概念中)WEB scutter,是“自动浏览网络”程序,或网络机器人。它们被互联网搜索引擎或其他类似的网站s广泛用于获取或更新这些网站s的内容和检索方法。他们可以自动采集他们可以访问的所有页面内容以供搜索引擎进一步处理(对下载的页面进行排序和排序),从而使用户可以更快地检索到他们需要的信息。
最常见的是互联网搜索引擎,它使用网络爬虫自动采集所有可访问的页面内容来获取或更新这些网站的内容和检索方法。在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是
下载信息,将信息中对用户无意义的内容(如网页代码)处理掉。资源库用于存储下载的数据资源并在其上建立索引。
如果你想每小时抓取一次网易新闻,那么你需要访问网易并进行数据请求,得到一个html格式的网页,然后通过网络爬虫的解析器进行过滤,最后存入数据库。
爬行动物能做什么?
可以创建搜索引擎(谷歌、百度)
可用于抢优采云票
逛一圈
简单来说,只要浏览器能打开就可以用爬虫实现
网络爬虫的分类?
网络爬虫可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。万能网络爬虫,又称Scalable Web Crawler,将爬取对象从一些种子URL(网络上的每个文件都有一个地址,即一个URL)扩展到整个Web,主要针对门户网站搜索引擎和大型网页服务。商采集数据。出于商业原因,他们的技术细节很少被公布。
Focused Crawler,也称为Topical Crawler,是一种只抓取与主题相关的网络资源的爬虫。大大节省了硬件和网络资源,而且保存的数据量少,更新速度快,也能很好地满足某些特定人群对特定领域信息的需求。
增量网络爬虫(Incremental Web Crawler)是指只爬取新生成或变化的数据的爬虫。可以在一定程度上保证爬取的数据尽可能是新的,不会重新下载不变的数据。可以有效减少数据下载量,及时更新爬取数据,减少时间和空间消耗。
深度网络爬虫(Deep Web Crawler)可以从深度网页爬取数据。一般来说,网页分为表面网页和深层网页。表层页面是指传统搜索引擎可以索引的页面,而深层页面是用户提交一些关键词才能获得的页面。例如,只有在用户注册后才能看到内容的页面是深层页面。
学习爬虫技术势在必行:在当前竞争激烈的信息社会中,如何利用数据分析站在信息不对称的一边,保持竞争优势,是数字工作者必备的技能。然而,在你想飞之前,你必须学会跑步。在分析数据之前,首先要学会爬取和处理数据,这样才能事半功倍。
【全文结束】
网页抓取数据百度百科(网站在搜索引擎里的百度快照有什么几率?的条件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-26 21:17
网站在搜索引擎中的具体表现是每个SEO都非常关心的问题。SEO工程师经常根据快照分析网站的状态,并根据快照的更新进行调整,以便更好地优化或提高网站的综合指标。快照为搜索引擎应用中的分析网站提供了有利的条件因素。
我们以百度为例。其他搜索引擎的原理类似。百度快照的定义请参考百度搜索帮助:每个未被禁止搜索的网页都会自动在百度上生成一个临时缓存页面,称为“百度快照”。官方给百度快照的功能是当查询结果中要打开的网页打不开或者加载速度很慢时,“百度快照”可以快速浏览页面内容。
百度快照的原理,百度搜索引擎内部搜索程序在互联网上组织和处理数据的过程,文件数据的索引和存储的具体体现就是百度快照。通俗地说,百度获取数据的过程就是分发百度蜘蛛,在整个互联网通过链接相互通信时获取数据;百度快照是百度蜘蛛通过链接到达新的 网站 或单个页面时。当网站首页或单页数据存储时;百度内部机制会根据具体算法对数据进行分类、索引和缓存。刚看到截图。
我们经常会发现百度快照有时会更新,有时会长时间保持不变。百度快照的概率是多少?事实上,这一切都可以在服务器日志中看到。
很多站长抱怨百度快照一直卡在16、23、24一个月更新一次,有的甚至半年不更新;
快照也是搜索引擎的附加程序。作为搜索引擎的一部分,所有程序都需要处理最优结果,节省计算时间作为处理数据的前提。
因此,百度对每一个网站都有一个快照更新评级。这种现象在百度上很明显。当然,首页和内页的评分也是不一样的。我不会详述。
他打分的标准是对蜘蛛抓到的数据进行多次分析,数据大幅度更新(比较一组数据时,更新量大到一个值)
举个很概念的例子:如果百度标准数据更新值为7,你的页面蜘蛛第一次和第二次比较更新值是3,不达标,第三次比较第一次数据更新。8、OK截取第一次和第三次之间的时间间隔。
当然,这是一个非常笼统的说法。百度要多比较几遍,然后取一个平衡的量来判断。这不是我们能知道的,但我们知道这种算法的原理。
这种方式可以让快照程序有针对性地更新网站的快照,而不是不分类别地同时更新所有的网站,节省了大量的计算时间和成本
知道有这样的评分后,一切都好办了。百度尚未公开此评级。目前不知道百度需要多久重新评估和更新一个网站的评分
但是SEO需要做的就是让snapshot更新的更频繁,其实很简单
知道了原理,我们就有了具体的操作方法
第一步是查看你的服务器日志,了解百度蜘蛛抓取你的网站页面的规则
第二步,在知道蜘蛛爬取一个页面的时间间隔后,列出一个内容更新时间表
第三步,每隔两个连续的蜘蛛抓取间隔更新一次你的页面内容,重点是在这个时间段内更新(例如:你原本更新了10个小时的内容,但是这10个小时里蜘蛛来了3次那你得想办法把10小时的更新尽量压缩在一个区间——上面提到的时间只是一个例子,看具体情况网站最好经常更新。
关于百度快照的常见问题:
一、快照未更新
问题分析:导入链接的扇入面积不大,即网站的外部链接太少;.
解决方案:通过对百度快照定义原理的理解,百度只能通过链接和索引本站数据来创建快照,为百度蜘蛛创建更顺畅的多条路径到达网站是最好的解决方案。
二、快照更新不及时
问题分析:和不更新快照的问题是一样的,但是这里解释的原因是百度的审计机制会过滤网站的数据,甚至是手动审计。不能排除造成这种情况的原因。
解决方法:不要更新同一个快照,同时网站里面没有中国式的螃蟹内容。 查看全部
网页抓取数据百度百科(网站在搜索引擎里的百度快照有什么几率?的条件)
网站在搜索引擎中的具体表现是每个SEO都非常关心的问题。SEO工程师经常根据快照分析网站的状态,并根据快照的更新进行调整,以便更好地优化或提高网站的综合指标。快照为搜索引擎应用中的分析网站提供了有利的条件因素。
我们以百度为例。其他搜索引擎的原理类似。百度快照的定义请参考百度搜索帮助:每个未被禁止搜索的网页都会自动在百度上生成一个临时缓存页面,称为“百度快照”。官方给百度快照的功能是当查询结果中要打开的网页打不开或者加载速度很慢时,“百度快照”可以快速浏览页面内容。
百度快照的原理,百度搜索引擎内部搜索程序在互联网上组织和处理数据的过程,文件数据的索引和存储的具体体现就是百度快照。通俗地说,百度获取数据的过程就是分发百度蜘蛛,在整个互联网通过链接相互通信时获取数据;百度快照是百度蜘蛛通过链接到达新的 网站 或单个页面时。当网站首页或单页数据存储时;百度内部机制会根据具体算法对数据进行分类、索引和缓存。刚看到截图。
我们经常会发现百度快照有时会更新,有时会长时间保持不变。百度快照的概率是多少?事实上,这一切都可以在服务器日志中看到。
很多站长抱怨百度快照一直卡在16、23、24一个月更新一次,有的甚至半年不更新;
快照也是搜索引擎的附加程序。作为搜索引擎的一部分,所有程序都需要处理最优结果,节省计算时间作为处理数据的前提。
因此,百度对每一个网站都有一个快照更新评级。这种现象在百度上很明显。当然,首页和内页的评分也是不一样的。我不会详述。
他打分的标准是对蜘蛛抓到的数据进行多次分析,数据大幅度更新(比较一组数据时,更新量大到一个值)
举个很概念的例子:如果百度标准数据更新值为7,你的页面蜘蛛第一次和第二次比较更新值是3,不达标,第三次比较第一次数据更新。8、OK截取第一次和第三次之间的时间间隔。
当然,这是一个非常笼统的说法。百度要多比较几遍,然后取一个平衡的量来判断。这不是我们能知道的,但我们知道这种算法的原理。
这种方式可以让快照程序有针对性地更新网站的快照,而不是不分类别地同时更新所有的网站,节省了大量的计算时间和成本
知道有这样的评分后,一切都好办了。百度尚未公开此评级。目前不知道百度需要多久重新评估和更新一个网站的评分
但是SEO需要做的就是让snapshot更新的更频繁,其实很简单
知道了原理,我们就有了具体的操作方法
第一步是查看你的服务器日志,了解百度蜘蛛抓取你的网站页面的规则
第二步,在知道蜘蛛爬取一个页面的时间间隔后,列出一个内容更新时间表
第三步,每隔两个连续的蜘蛛抓取间隔更新一次你的页面内容,重点是在这个时间段内更新(例如:你原本更新了10个小时的内容,但是这10个小时里蜘蛛来了3次那你得想办法把10小时的更新尽量压缩在一个区间——上面提到的时间只是一个例子,看具体情况网站最好经常更新。
关于百度快照的常见问题:
一、快照未更新
问题分析:导入链接的扇入面积不大,即网站的外部链接太少;.
解决方案:通过对百度快照定义原理的理解,百度只能通过链接和索引本站数据来创建快照,为百度蜘蛛创建更顺畅的多条路径到达网站是最好的解决方案。
二、快照更新不及时
问题分析:和不更新快照的问题是一样的,但是这里解释的原因是百度的审计机制会过滤网站的数据,甚至是手动审计。不能排除造成这种情况的原因。
解决方法:不要更新同一个快照,同时网站里面没有中国式的螃蟹内容。
网页抓取数据百度百科(robotsrobots协议(robots.txt)Robots协议用来告知搜索引擎哪些页面能被抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-24 10:02
robotsrobots 协议 (robots.txt)
Robots协议用于通知搜索引擎哪些页面可以爬取,哪些页面不能爬取;网站中一些比较大的文件可以屏蔽掉,比如:图片、音乐、视频等,节省服务器带宽;它可以被阻止一些指向该站点的死链接。方便搜索引擎抓取网站内容;设置 网站 地图连接来引导蜘蛛抓取页面。(来自百度百科)
** robots.txt 放置在网页上,指定搜索引擎和网络爬虫可以访问和不能访问的页面**
话题分析
进入答题页面后,直接进入url上的robots.txt
看答案
备份
网页备份
index.php的备份文件是index.php.bax,直接访问下载,然后打开查看文件,可以找到flag
cookie(存储在用户本地终端上的数据)
Cookie,类型为“小文本文件”,是为了识别用户身份和进行会话跟踪而存储在用户本地终端上的一些数据(通常是加密的),由用户的客户端计算机临时或永久存储。资料(来自百度百科)
客户端保存的一小段文本信息,用于服务器识别
话题分析
输入cookies.php查看cookies
提示“查看网页响应”,刷新网页找到网站消息头中的flag
我不知道如何在 Google 中查看它
禁用按钮主题分析
标题如下,flag不能点击
F12 发现form有disable属性,删掉点击,点击就有答案了
HTML 表单的 disabled 属性
disabled 属性可以附加到 HTML 中的输入元素、按钮元素、选项元素等。给定此属性时,元素变为非交互元素
创建一个可以按下的按钮
able
浏览器显示如下,这个按钮可以点击
disable
浏览器显示如下,该按钮无法点击
弱认证
标题如下,是一个不需要登录验证和无限次登录的登录界面。这个弱密码可以通过暴力破解获得:
只需输入一个用户名,用户名为admin,然后使用admin作为用户名进行爆破。
我在虚拟机上用 Buipsuit 爆破
首先在浏览器中设置代理
之后在浏览器中输入用户名admin,密码输入一个随机数(输入123456,直接给出答案...不过为了爆一次,换成111111)@ >,Burpsuit 会拦截它,只要你可以开始特定的爆破步骤 Action —> 发送给 Intruder
Intruder —> Positions,清理变量后,选择密码作为变量
选择的爆破方式为集束炸弹
Payloads中的Payloads set和Payloads type默认选择,也可以使用自己的字典
选择线程等开始爆破 xff referer
现在在浏览器中设置代理ip,然后使用burpsuite,我在虚拟机上做
现在在 burp 套件上捕获数据包
然后将 X-Forwarded-For:123.123.123.123 添加到响应头
回复显示“必须来自”,然后将Referer:添加到响应头以获得答案
命令执行
Ping是操作系统常用的网络诊断工具,可以用来判断连接是否建立。是一种利用IP地址的唯一性发送数据包,根据反馈数据包和反馈时间来判断连接是否建立的方法。
首先判断链接是否建立,ping127.0.0.1可以连接。
然后在127.0.0.1中查找flag文件,在ping中注入命令并使用&&逻辑符号,可以看到/中有一个flag.txt文件家
打开这个文件,你可以看到标志。
simple_js
我不知道为什么这是答案。如果有人看到它,你能帮帮我吗?
Ctrl+u查看源码
<p>
JS
function dechiffre(pass_enc){
var pass = "70,65,85,88,32,80,65,83,83,87,79,82,68,32,72,65,72,65";
var tab = pass_enc.split(',');
var tab2 = pass.split(',');var i,j,k,l=0,m,n,o,p = "";i = 0;j = tab.length;
k = j + (l) + (n=0);
n = tab2.length;
for(i = (o=0); i 查看全部
网页抓取数据百度百科(robotsrobots协议(robots.txt)Robots协议用来告知搜索引擎哪些页面能被抓取)
robotsrobots 协议 (robots.txt)
Robots协议用于通知搜索引擎哪些页面可以爬取,哪些页面不能爬取;网站中一些比较大的文件可以屏蔽掉,比如:图片、音乐、视频等,节省服务器带宽;它可以被阻止一些指向该站点的死链接。方便搜索引擎抓取网站内容;设置 网站 地图连接来引导蜘蛛抓取页面。(来自百度百科)
** robots.txt 放置在网页上,指定搜索引擎和网络爬虫可以访问和不能访问的页面**
话题分析
进入答题页面后,直接进入url上的robots.txt
看答案
备份
网页备份
index.php的备份文件是index.php.bax,直接访问下载,然后打开查看文件,可以找到flag
cookie(存储在用户本地终端上的数据)
Cookie,类型为“小文本文件”,是为了识别用户身份和进行会话跟踪而存储在用户本地终端上的一些数据(通常是加密的),由用户的客户端计算机临时或永久存储。资料(来自百度百科)
客户端保存的一小段文本信息,用于服务器识别
话题分析
输入cookies.php查看cookies
提示“查看网页响应”,刷新网页找到网站消息头中的flag
我不知道如何在 Google 中查看它
禁用按钮主题分析
标题如下,flag不能点击
F12 发现form有disable属性,删掉点击,点击就有答案了
HTML 表单的 disabled 属性
disabled 属性可以附加到 HTML 中的输入元素、按钮元素、选项元素等。给定此属性时,元素变为非交互元素
创建一个可以按下的按钮
able
浏览器显示如下,这个按钮可以点击
disable
浏览器显示如下,该按钮无法点击
弱认证
标题如下,是一个不需要登录验证和无限次登录的登录界面。这个弱密码可以通过暴力破解获得:
只需输入一个用户名,用户名为admin,然后使用admin作为用户名进行爆破。
我在虚拟机上用 Buipsuit 爆破
首先在浏览器中设置代理
之后在浏览器中输入用户名admin,密码输入一个随机数(输入123456,直接给出答案...不过为了爆一次,换成111111)@ >,Burpsuit 会拦截它,只要你可以开始特定的爆破步骤 Action —> 发送给 Intruder
Intruder —> Positions,清理变量后,选择密码作为变量
选择的爆破方式为集束炸弹
Payloads中的Payloads set和Payloads type默认选择,也可以使用自己的字典
选择线程等开始爆破 xff referer
现在在浏览器中设置代理ip,然后使用burpsuite,我在虚拟机上做
现在在 burp 套件上捕获数据包
然后将 X-Forwarded-For:123.123.123.123 添加到响应头
回复显示“必须来自”,然后将Referer:添加到响应头以获得答案
命令执行
Ping是操作系统常用的网络诊断工具,可以用来判断连接是否建立。是一种利用IP地址的唯一性发送数据包,根据反馈数据包和反馈时间来判断连接是否建立的方法。
首先判断链接是否建立,ping127.0.0.1可以连接。
然后在127.0.0.1中查找flag文件,在ping中注入命令并使用&&逻辑符号,可以看到/中有一个flag.txt文件家
打开这个文件,你可以看到标志。
simple_js
我不知道为什么这是答案。如果有人看到它,你能帮帮我吗?
Ctrl+u查看源码
<p>
JS
function dechiffre(pass_enc){
var pass = "70,65,85,88,32,80,65,83,83,87,79,82,68,32,72,65,72,65";
var tab = pass_enc.split(',');
var tab2 = pass.split(',');var i,j,k,l=0,m,n,o,p = "";i = 0;j = tab.length;
k = j + (l) + (n=0);
n = tab2.length;
for(i = (o=0); i
网页抓取数据百度百科(爬虫nodejs适合垂直爬取的几种适合爬虫的语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-22 00:43
一、爬虫介绍
根据百度百科的定义:网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常被称为网络追逐者),是根据一定的规则或脚本自动爬取万维网上信息的程序. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。???随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
二、适合爬虫的几种语言
1.幻影
2017 年 4 月,该语言的核心开发者之一 Vitaly 辞去维护工作,表示不再维护。原话如下:我看不到PhantomJS的未来,作为一个单独开发者开发PhantomJS 2和2.5,简直就是地狱。即使最近发布了带有新的、闪亮的 QtWebKit 的 2.5 Beta 版本,我仍然不能真正支持 3 个平台。我们没有其他势力支持!
并且 Vitaly 发帖称 Chrome 59 将支持无头模式,用户最终会转向它。Chrome 比 PhantomJS 更快更稳定,而且不会像 PhantomJS 那样吃内存??????但这并不意味着语言的终结,语言仍然可以使用
2.casperJS
CasperJs 是基于 PhantomJs 的工具,可以比 PhantomJs 更方便的导航。就个人而言,我对这门语言了解不多,也没有过多阐述。
3.nodejs
nodejs适合垂直爬取,分布式爬取难度较大,对部分功能支持较弱,不推荐使用
4.Python
我喜欢python的语言,强烈推荐使用python,尤其是它的语言爬虫框架scrapy特别值得学习。支持xpath,可以定义多个爬虫,支持多线程爬取等,以后我会一步步入手。流程发给大家,附上源码
ps:另外可以使用c++、PHP、java等语言爬取网页。爬虫因人而异。我推荐的不一定是最好的。
三、python爬虫的优点
代码简洁明了,适合根据实际情况快速修改代码。网络的内容和布局会随时变化。python的快速发展是有优势的。如果不加修改或者少加修改写得好,其他高性能语言更有优势。(来自 知乎)
1)相比其他静态编程语言,如java、c#、C++、python,爬取网页的界面更加简洁;与其他动态脚本语言相比,如perl、shell、python urllib2 包提供了比较完整的访问web 文档的API。(当然,ruby 也是一个不错的选择。)另外,爬取网页有时需要模拟浏览器的行为,很多 网站 被屏蔽了用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理 抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。(摘自博客园)
以上就是前人为我们总结的诸多优势。我整理了其中两个供大家参考。
四、后续安排
后面给大家分享一下BeautifulSoup的安装和使用
使用 BS 抓取 网站 实例
Scrapy 安装和项目创建
Scrapy 的常见问题
Scrapy爬取网页实例
五、结束语我创建专栏已经半年多了,也没有太在意。很抱歉,但我会尽力向您展示一些我将来可以给您的,并附上完整的源代码。希望大家多多贡献,扩大本专栏 ps:给大家介绍几门课程和书籍。我觉得价格合适。可以根据情况学习: 课程:
Python爬虫实战简明教程38¥
第一个英文版爬虫magic-2-network协议和网页文本解析工具1.5¥
第一个英文版爬虫神通-3-新浪微博和推特数据采集1.5¥
爬虫2天实战--爬取腾讯应用宝5.2¥
正版python基础教程(第2版·修订版)python基础学习手册python编程入门经典书籍python从入门到实践精通新华书店正版书籍55元 查看全部
网页抓取数据百度百科(爬虫nodejs适合垂直爬取的几种适合爬虫的语言)
一、爬虫介绍
根据百度百科的定义:网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常被称为网络追逐者),是根据一定的规则或脚本自动爬取万维网上信息的程序. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。???随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
二、适合爬虫的几种语言
1.幻影
2017 年 4 月,该语言的核心开发者之一 Vitaly 辞去维护工作,表示不再维护。原话如下:我看不到PhantomJS的未来,作为一个单独开发者开发PhantomJS 2和2.5,简直就是地狱。即使最近发布了带有新的、闪亮的 QtWebKit 的 2.5 Beta 版本,我仍然不能真正支持 3 个平台。我们没有其他势力支持!
并且 Vitaly 发帖称 Chrome 59 将支持无头模式,用户最终会转向它。Chrome 比 PhantomJS 更快更稳定,而且不会像 PhantomJS 那样吃内存??????但这并不意味着语言的终结,语言仍然可以使用
2.casperJS
CasperJs 是基于 PhantomJs 的工具,可以比 PhantomJs 更方便的导航。就个人而言,我对这门语言了解不多,也没有过多阐述。
3.nodejs
nodejs适合垂直爬取,分布式爬取难度较大,对部分功能支持较弱,不推荐使用
4.Python
我喜欢python的语言,强烈推荐使用python,尤其是它的语言爬虫框架scrapy特别值得学习。支持xpath,可以定义多个爬虫,支持多线程爬取等,以后我会一步步入手。流程发给大家,附上源码
ps:另外可以使用c++、PHP、java等语言爬取网页。爬虫因人而异。我推荐的不一定是最好的。
三、python爬虫的优点
代码简洁明了,适合根据实际情况快速修改代码。网络的内容和布局会随时变化。python的快速发展是有优势的。如果不加修改或者少加修改写得好,其他高性能语言更有优势。(来自 知乎)
1)相比其他静态编程语言,如java、c#、C++、python,爬取网页的界面更加简洁;与其他动态脚本语言相比,如perl、shell、python urllib2 包提供了比较完整的访问web 文档的API。(当然,ruby 也是一个不错的选择。)另外,爬取网页有时需要模拟浏览器的行为,很多 网站 被屏蔽了用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理 抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。(摘自博客园)
以上就是前人为我们总结的诸多优势。我整理了其中两个供大家参考。
四、后续安排
后面给大家分享一下BeautifulSoup的安装和使用
使用 BS 抓取 网站 实例
Scrapy 安装和项目创建
Scrapy 的常见问题
Scrapy爬取网页实例
五、结束语我创建专栏已经半年多了,也没有太在意。很抱歉,但我会尽力向您展示一些我将来可以给您的,并附上完整的源代码。希望大家多多贡献,扩大本专栏 ps:给大家介绍几门课程和书籍。我觉得价格合适。可以根据情况学习: 课程:
Python爬虫实战简明教程38¥
第一个英文版爬虫magic-2-network协议和网页文本解析工具1.5¥
第一个英文版爬虫神通-3-新浪微博和推特数据采集1.5¥
爬虫2天实战--爬取腾讯应用宝5.2¥
正版python基础教程(第2版·修订版)python基础学习手册python编程入门经典书籍python从入门到实践精通新华书店正版书籍55元

