
网页抓取
网页抓取工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 594 次浏览 • 2020-08-03 15:03
优采云是一款专业的互联网数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能,准确挖掘出所需数据,是行业内领先的网页采集工具网站文章采集器,有着诸多的使用人数和良好的口碑。
优采云功能特点介绍
优采云能做哪些?
为什么选择优采云?
能采集99%的网页
几乎所有网页都能采集,只要网页源代码中能看到的公开内容即可采集到!
速度是普通采集器的7倍
采用分布式高速处理系统,反复优化性能,让采集速度快到飞起来!
和复制/粘贴一样确切
“采集/发布”如同“复制/粘贴”一样精准,用户要的全都是真谛,怎能有遗漏!
网页采集的代名词
独具十二年磨炼,成就业界领先品牌,想到网页采集,就想到优采云!
谁在用优采云?
电子商务:淘宝淘宝
抓取、筛选和剖析出精算、营销、投保、服务、理赔等各个环节的统计数据,科学设定费率;筛选最适产品向其推送。实现精准营销、精准定价、精准管理,精准服务。
企业人员:某品牌保险
采集同类商品的属性、评价、价格,销量占比等数据,得出商品的相关特点信息因而进行标题优化,根据同类经验制造热卖,提升淘宝的营运水平与效率。
网站站长:视频网站
对采集到的视频数据进行流量剖析,排序,分析用户喜好,选取受众偏好内容进行定时手动发布更新,保障精品内容不断涌现,提升网站流量,助力内容与营销升级。
人个需求:科研人员
帮助科研人员完成大量科研数据的检索、采集,快速批量下载大量的文件内容,取代冗长乏味的自动操作,省时省力,大幅提高工作效率。
用户口碑
跑得快ZWH
优采云采集器软件太强悍,也很容易上手,服务挺好,非常谢谢东东、小谢、小赵。他们人都挺好
135*****235
我没有用过采集,在网上听到列车采集的评论比较好,就去看了,先用敢个免费的,客服挺有耐心,水平也高.我就用了基础版.现在客服的指导下,用得挺好,点无数个赞.
秋琴风
很好的采集器,之前也用过其他采集器只有最后还是选择这个
斌斌3111991
客服(小谢)很悉心,我还害怕我问的问题太多了,客服会不耐烦,事实证明,我想多了。
sooting2000
优采云是我用过最好用的采集软件,以前用别的,觉得优采云用上去麻烦网站文章采集器,实际了解使用后,其实优采云使用比其他软件还要简单,规则也容易写。不错,我用的是旗舰版,这一千多花得值啊
ejunn
我是优采云的老fans了,优采云功能强悍,客服人员热情专业,基本上所有的网站都可以编成规则采集。 查看全部

优采云是一款专业的互联网数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能,准确挖掘出所需数据,是行业内领先的网页采集工具网站文章采集器,有着诸多的使用人数和良好的口碑。
优采云功能特点介绍
优采云能做哪些?
为什么选择优采云?

能采集99%的网页
几乎所有网页都能采集,只要网页源代码中能看到的公开内容即可采集到!

速度是普通采集器的7倍
采用分布式高速处理系统,反复优化性能,让采集速度快到飞起来!

和复制/粘贴一样确切
“采集/发布”如同“复制/粘贴”一样精准,用户要的全都是真谛,怎能有遗漏!

网页采集的代名词
独具十二年磨炼,成就业界领先品牌,想到网页采集,就想到优采云!
谁在用优采云?
电子商务:淘宝淘宝
抓取、筛选和剖析出精算、营销、投保、服务、理赔等各个环节的统计数据,科学设定费率;筛选最适产品向其推送。实现精准营销、精准定价、精准管理,精准服务。
企业人员:某品牌保险
采集同类商品的属性、评价、价格,销量占比等数据,得出商品的相关特点信息因而进行标题优化,根据同类经验制造热卖,提升淘宝的营运水平与效率。
网站站长:视频网站
对采集到的视频数据进行流量剖析,排序,分析用户喜好,选取受众偏好内容进行定时手动发布更新,保障精品内容不断涌现,提升网站流量,助力内容与营销升级。
人个需求:科研人员
帮助科研人员完成大量科研数据的检索、采集,快速批量下载大量的文件内容,取代冗长乏味的自动操作,省时省力,大幅提高工作效率。
用户口碑

跑得快ZWH
优采云采集器软件太强悍,也很容易上手,服务挺好,非常谢谢东东、小谢、小赵。他们人都挺好
135*****235
我没有用过采集,在网上听到列车采集的评论比较好,就去看了,先用敢个免费的,客服挺有耐心,水平也高.我就用了基础版.现在客服的指导下,用得挺好,点无数个赞.
秋琴风
很好的采集器,之前也用过其他采集器只有最后还是选择这个

斌斌3111991
客服(小谢)很悉心,我还害怕我问的问题太多了,客服会不耐烦,事实证明,我想多了。

sooting2000
优采云是我用过最好用的采集软件,以前用别的,觉得优采云用上去麻烦网站文章采集器,实际了解使用后,其实优采云使用比其他软件还要简单,规则也容易写。不错,我用的是旗舰版,这一千多花得值啊

ejunn
我是优采云的老fans了,优采云功能强悍,客服人员热情专业,基本上所有的网站都可以编成规则采集。
SEO优化:禁止搜索引擎收录的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-08-01 08:00
搜索引擎使用spider程序手动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检测该网站的根域下是否有一个叫 做 robots.txt的纯文本文件,这个文件用于指定spider在您网站上的抓取范围。您可以在您的网站中创建一个robots.txt,在文件中 声明 该网站中不想被搜索引擎收录的部份或则指定搜索引擎只收录特定的部份。
请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才须要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿构建robots.txt文件。
2. robots.txt文件置于那里?
robots.txt 文件应当放置在网站根目录下。举例来说,当spider访问一个网站(比如 )时,首先会检测该网站中是否存在 robots.txt这个文件,如果 Spider找到这个文件,它还会依据这个文件的内容,来确定它访问权限的 范围。
网站 URL
相应的 robots.txt的 URL
:80/
:80/robots.txt
:1234/
:1234/robots.txt
3. 我在robots.txt中设置了严禁百度收录我网站的内容,为何还出现在百度搜索结果中?
如果其他网站链接了您robots.txt文件中设置的严禁收录的网页,那么这种网页依然可能会出现在百度的搜索结果中,但您的网页上的内容不会被抓取、建入索引和显示,百度搜索结果中展示的仅是其他网站对您相关网页的描述。
4. 禁止搜索引擎跟踪网页的链接,而只对网页建索引
如果您不想搜索引擎追踪此网页上的链接,且不传递链接的权重,请将此元标记置入网页的 部分:
如果您不想百度追踪某一条特定链接,百度还支持更精确的控制,请将此标记直接写在某条链接上:
signin
要容许其他搜索引擎跟踪,但仅避免百度跟踪您网页的链接,请将此元标记置入网页的 部分:
Baiduspider" content="nofollow">
5. 禁止搜索引擎在搜索结果中显示网页快照,而只对网页建索引
要避免所有搜索引擎显示您网站的快照,请将此元标记置入网页的部份:
要容许其他搜索引擎显示快照,但仅避免百度显示,请使用以下标记:
Baiduspider" content="noarchive">
注:此标记只是严禁百度显示该网页的快照,百度会继续为网页建索引,并在搜索结果中显示网页摘要。
6. 我想严禁百度图片搜索收录个别图片,该怎么设置?
禁止Baiduspider抓取网站上所有图片、禁止或容许Baiduspider抓取网站上的某种特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件用法举例”中的例10、11、12。
7. robots.txt文件的格式
"robots.txt"文件包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
":"
在该文件中可以使用#进行注解,具体使用方式和UNIX中的惯例一样。该文件中的记录一般以一行或多行User-agent开始搜索引擎禁止的方式优化网站,后面加上若干Disallow和Allow行,详细情况如下:
User-agent:
该项的值用于描述搜索引擎robot的名子。在"robots.txt"文件中,如果有多条User-agent记录说明有多个robot会 受 到"robots.txt"的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则对任何robot均有 效, 在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。如果在"robots.txt"文件中,加 入"User- agent:SomeBot"和若干Disallow、Allow行,那么名为"SomeBot"只遭到"User- agent:SomeBot"后面的 Disallow和Allow行的限制。
Disallow:
该 项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会 被 robot访问。例如"Disallow:/help"禁止robot访问/help.html、/helpabc.html、 /help /index.html,而"Disallow:/help/"则容许robot访问/help.html、/helpabc.html搜索引擎禁止的方式优化网站,不 能访问 /help/index.html。"Disallow:"说明容许robot访问该网站的所有url,在"/robots.txt"文件中,至 少要有一条Disallow记录。如果"/robots.txt"不存在或则为空文件,则对于所有的搜索引擎robot,该网站都是开放的。
Allow:
该项的值用于描述希望被访问的一组URL,与Disallow项相像,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头 的 URL 是容许robot访问的。例如"Allow:/hibaidu"允许robot访问/hibaidu.htm、 /hibaiducom.html、 /hibaidu/com.html。一个网站的所有URL默认是Allow的,所以Allow一般与 Disallow搭配使用,实现准许访问一部分网页同时严禁访问其它所有URL的功能。
使用"*"and"$":
Baiduspider支持使用转义"*"和"$"来模糊匹配url。
"$" 匹配行结束符。
"*" 匹配0或多个任意字符。
注:我们会严格遵循robots的相关合同,请注意分辨您不想被抓取或收录的目录的大小写,我们会对robots中所写的文件和您不想被抓取和收录的目录做精确匹配,否则robots协议未能生效。
8. URL匹配举例
Allow或Disallow的值
URL
匹配结果
/tmp
/tmp
yes
/tmp
/tmp.html
yes
/tmp
/tmp/a.html
yes
/tmp
/tmphoho
no
/Hello*
/Hello.html
yes
/He*lo
/Hello,lolo
yes
/Heap*lo
/Hello,lolo
no
html$
/tmpa.html
yes
/a.html$
/a.html
yes
htm$
/a.html
no
9. robots.txt文件用法举例
例1. 禁止所有搜索引擎访问网站的任何部份
下载该robots.txt文件
User-agent: *
Disallow: /
例2. 允许所有的robot访问
(或者也可以建一个空文件 "/robots.txt")
User-agent: *
Allow: /
例3. 仅严禁Baiduspider访问您的网站
User-agent: Baiduspider
Disallow: /
例4. 仅容许Baiduspider访问您的网站
User-agent: Baiduspider
Allow: /
User-agent: *
Disallow: /
例5. 仅容许Baiduspider以及Googlebot访问
User-agent: Baiduspider
Allow: /
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /
例6. 禁止spider访问特定目录
在这个事例中,该网站有三个目录对搜索引擎的访问做了限制,即robot不会访问这三个目录。需要注意的是对每一个目录必须分开申明,而不能写成 "Disallow: /cgi-bin/ /tmp/"。
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
例7. 允许访问特定目录中的部份url
User-agent: *
Allow: /cgi-bin/see
Allow: /tmp/hi
Allow: /~joe/look
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
例8. 使用"*"限制访问url
禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
User-agent: *
Disallow: /cgi-bin/*.htm
例9. 使用"$"限制访问url
仅准许访问以".htm"为后缀的URL。
User-agent: *
Allow: /*.htm$
Disallow: /
例10. 禁止访问网站中所有的动态页面
User-agent: *
Disallow: /*?*
例11. 禁止Baiduspider抓取网站上所有图片
仅容许抓取网页,禁止抓取任何图片。
User-agent: Baiduspider
Disallow: /*.jpg$
Disallow: /*.jpeg$
Disallow: /*.gif$
Disallow: /*.png$
Disallow: /*.bmp$
例12. 仅容许Baiduspider抓取网页和.gif格式图片
允许抓取网页和gif格式图片,不容许抓取其他格式图片
User-agent: Baiduspider
Allow: /*.gif$
Disallow: /*.jpg$
Disallow: /*.jpeg$
Disallow: /*.png$
Disallow: /*.bmp$
例13. 仅严禁Baiduspider抓取.jpg格式图片
User-agent: Baiduspider
Disallow: /*.jpg$
10. robots.txt文件参考资料
robots.txt文件的更具体设置,请参看以下链接:
Web Server Administrator's Guide to the Robots Exclusion Protocol
HTML Author's Guide to the Robots Exclusion Protocol
The original 1994 protocol description, as currently deployed
The revised Internet-Draft specification, which is not yet completed or implemented 查看全部
1. 什么是robots.txt文件?
搜索引擎使用spider程序手动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检测该网站的根域下是否有一个叫 做 robots.txt的纯文本文件,这个文件用于指定spider在您网站上的抓取范围。您可以在您的网站中创建一个robots.txt,在文件中 声明 该网站中不想被搜索引擎收录的部份或则指定搜索引擎只收录特定的部份。
请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才须要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿构建robots.txt文件。
2. robots.txt文件置于那里?
robots.txt 文件应当放置在网站根目录下。举例来说,当spider访问一个网站(比如 )时,首先会检测该网站中是否存在 robots.txt这个文件,如果 Spider找到这个文件,它还会依据这个文件的内容,来确定它访问权限的 范围。
网站 URL
相应的 robots.txt的 URL
:80/
:80/robots.txt
:1234/
:1234/robots.txt
3. 我在robots.txt中设置了严禁百度收录我网站的内容,为何还出现在百度搜索结果中?
如果其他网站链接了您robots.txt文件中设置的严禁收录的网页,那么这种网页依然可能会出现在百度的搜索结果中,但您的网页上的内容不会被抓取、建入索引和显示,百度搜索结果中展示的仅是其他网站对您相关网页的描述。
4. 禁止搜索引擎跟踪网页的链接,而只对网页建索引
如果您不想搜索引擎追踪此网页上的链接,且不传递链接的权重,请将此元标记置入网页的 部分:
如果您不想百度追踪某一条特定链接,百度还支持更精确的控制,请将此标记直接写在某条链接上:
signin
要容许其他搜索引擎跟踪,但仅避免百度跟踪您网页的链接,请将此元标记置入网页的 部分:
Baiduspider" content="nofollow">
5. 禁止搜索引擎在搜索结果中显示网页快照,而只对网页建索引
要避免所有搜索引擎显示您网站的快照,请将此元标记置入网页的部份:
要容许其他搜索引擎显示快照,但仅避免百度显示,请使用以下标记:
Baiduspider" content="noarchive">
注:此标记只是严禁百度显示该网页的快照,百度会继续为网页建索引,并在搜索结果中显示网页摘要。
6. 我想严禁百度图片搜索收录个别图片,该怎么设置?
禁止Baiduspider抓取网站上所有图片、禁止或容许Baiduspider抓取网站上的某种特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件用法举例”中的例10、11、12。
7. robots.txt文件的格式
"robots.txt"文件包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
":"
在该文件中可以使用#进行注解,具体使用方式和UNIX中的惯例一样。该文件中的记录一般以一行或多行User-agent开始搜索引擎禁止的方式优化网站,后面加上若干Disallow和Allow行,详细情况如下:
User-agent:
该项的值用于描述搜索引擎robot的名子。在"robots.txt"文件中,如果有多条User-agent记录说明有多个robot会 受 到"robots.txt"的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则对任何robot均有 效, 在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。如果在"robots.txt"文件中,加 入"User- agent:SomeBot"和若干Disallow、Allow行,那么名为"SomeBot"只遭到"User- agent:SomeBot"后面的 Disallow和Allow行的限制。
Disallow:
该 项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会 被 robot访问。例如"Disallow:/help"禁止robot访问/help.html、/helpabc.html、 /help /index.html,而"Disallow:/help/"则容许robot访问/help.html、/helpabc.html搜索引擎禁止的方式优化网站,不 能访问 /help/index.html。"Disallow:"说明容许robot访问该网站的所有url,在"/robots.txt"文件中,至 少要有一条Disallow记录。如果"/robots.txt"不存在或则为空文件,则对于所有的搜索引擎robot,该网站都是开放的。
Allow:
该项的值用于描述希望被访问的一组URL,与Disallow项相像,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头 的 URL 是容许robot访问的。例如"Allow:/hibaidu"允许robot访问/hibaidu.htm、 /hibaiducom.html、 /hibaidu/com.html。一个网站的所有URL默认是Allow的,所以Allow一般与 Disallow搭配使用,实现准许访问一部分网页同时严禁访问其它所有URL的功能。
使用"*"and"$":
Baiduspider支持使用转义"*"和"$"来模糊匹配url。
"$" 匹配行结束符。
"*" 匹配0或多个任意字符。
注:我们会严格遵循robots的相关合同,请注意分辨您不想被抓取或收录的目录的大小写,我们会对robots中所写的文件和您不想被抓取和收录的目录做精确匹配,否则robots协议未能生效。
8. URL匹配举例
Allow或Disallow的值
URL
匹配结果
/tmp
/tmp
yes
/tmp
/tmp.html
yes
/tmp
/tmp/a.html
yes
/tmp
/tmphoho
no
/Hello*
/Hello.html
yes
/He*lo
/Hello,lolo
yes
/Heap*lo
/Hello,lolo
no
html$
/tmpa.html
yes
/a.html$
/a.html
yes
htm$
/a.html
no
9. robots.txt文件用法举例
例1. 禁止所有搜索引擎访问网站的任何部份
下载该robots.txt文件
User-agent: *
Disallow: /
例2. 允许所有的robot访问
(或者也可以建一个空文件 "/robots.txt")
User-agent: *
Allow: /
例3. 仅严禁Baiduspider访问您的网站
User-agent: Baiduspider
Disallow: /
例4. 仅容许Baiduspider访问您的网站
User-agent: Baiduspider
Allow: /
User-agent: *
Disallow: /
例5. 仅容许Baiduspider以及Googlebot访问
User-agent: Baiduspider
Allow: /
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /
例6. 禁止spider访问特定目录
在这个事例中,该网站有三个目录对搜索引擎的访问做了限制,即robot不会访问这三个目录。需要注意的是对每一个目录必须分开申明,而不能写成 "Disallow: /cgi-bin/ /tmp/"。
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
例7. 允许访问特定目录中的部份url
User-agent: *
Allow: /cgi-bin/see
Allow: /tmp/hi
Allow: /~joe/look
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
例8. 使用"*"限制访问url
禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
User-agent: *
Disallow: /cgi-bin/*.htm
例9. 使用"$"限制访问url
仅准许访问以".htm"为后缀的URL。
User-agent: *
Allow: /*.htm$
Disallow: /
例10. 禁止访问网站中所有的动态页面
User-agent: *
Disallow: /*?*
例11. 禁止Baiduspider抓取网站上所有图片
仅容许抓取网页,禁止抓取任何图片。
User-agent: Baiduspider
Disallow: /*.jpg$
Disallow: /*.jpeg$
Disallow: /*.gif$
Disallow: /*.png$
Disallow: /*.bmp$
例12. 仅容许Baiduspider抓取网页和.gif格式图片
允许抓取网页和gif格式图片,不容许抓取其他格式图片
User-agent: Baiduspider
Allow: /*.gif$
Disallow: /*.jpg$
Disallow: /*.jpeg$
Disallow: /*.png$
Disallow: /*.bmp$
例13. 仅严禁Baiduspider抓取.jpg格式图片
User-agent: Baiduspider
Disallow: /*.jpg$
10. robots.txt文件参考资料
robots.txt文件的更具体设置,请参看以下链接:
Web Server Administrator's Guide to the Robots Exclusion Protocol
HTML Author's Guide to the Robots Exclusion Protocol
The original 1994 protocol description, as currently deployed
The revised Internet-Draft specification, which is not yet completed or implemented
网络爬虫是哪些?它的主要功能和作用有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2020-07-04 08:01
网络爬虫,又被称为“网页蜘蛛,网络机器人”,在FOAF社区中间,经常被称为“网页追逐者”。网络爬虫,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
网络爬虫,按照系统结构和实现技术,大致可以分为:“通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫”等四种不同类型。实际上,网络爬虫系统,通常是由几种爬虫技术相结合实现的。
一、 通用网路爬虫
通用网路爬虫,又称“全网爬虫”,爬行对象从一些种子URL(统一资源定位符) 扩充到整个万维网,主要为“门户站点搜索引擎”和“大型Web服务提供商”采集数据。由于商业缘由,它们的技术细节甚少被公布下来。这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为等待刷新的页面太多,通常采用“并行工作”的方法,但须要较长时间能够刷新一次页面。通用网路爬虫,虽然存在着一定的缺陷,但它适用于为搜索引擎平台搜索广泛的主题,有较强的应用价值。
二、聚焦网络爬虫
聚焦网络爬虫,又称“主题网路爬虫”,是指选择性地爬行,那些与预先定义好的主题相关的页面的网路爬虫。和通用网路爬虫相比,聚焦网路爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网路爬虫相比,增加了“链接评价模块”以及“内容评价模块”。聚焦网路爬虫爬行策略实现的关键是,评价页面内容和链接的重要性。不同的方式估算出的重要性不同,由此引起链接的访问次序也不同。
三、增量式网络爬虫
是指对已下载网页采取增量式更新,和只爬行新形成的或则早已发生变化网页的爬虫网络爬虫技术是什么,它还能在一定程度上保证网络爬虫技术是什么,所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。
四、深层网络爬虫
Web 页面,按存在形式可以分为“表层网页”和“深层网页”。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。
深层网页是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web 页面。例如:那些用户注册后内容才可见的网页,就属于深层网页。
随着计算机网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。搜索引擎,例如传统的“通用搜索引擎”平台:Google(谷歌)、Yahoo!(雅虎)、百度等,作为一个辅助人们检索万维网信息的工具,成为互联网用户访问万维网的入口和渠道。
但是,这些“通用搜索引擎平台”也存在着一定的局限性,如:
1、 不同领域、不同职业、不同背景的用户,往往具有不同的检索目的和需求,通用搜索引擎所返回的结果,包含了大量用户并不关心的网页,或者与用户搜索结果无关的网页。
2、 通用搜索引擎的目标是,实现尽可能大的网路覆盖率,有限的搜索引擎服务器资源,与无限的网路数据资源之间的矛盾将进一步加深。
3、 万维网数据方式的丰富和网路技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎常常对这种信息浓度密集,且具有一定结构的数据无能为力,不能挺好地发觉和获取。
4、通用搜索引擎,大多提供基于“关键字”的检索,难以支持按照语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的“聚焦网路爬虫”应运而生。聚焦网路爬虫,是一个手动下载网页的程序,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息。
与“通用网路爬虫”不同,聚焦网络爬虫并不追求大的覆盖,而是将目标定为抓取“与某一特定主题内容相关的网页”,为面向主题的用户查询,准备数据资源。
“聚焦网路爬虫”的工作原理以及关键技术概述:
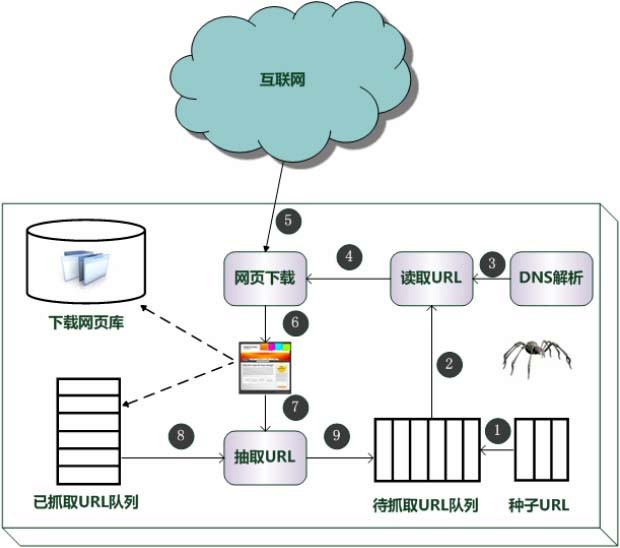
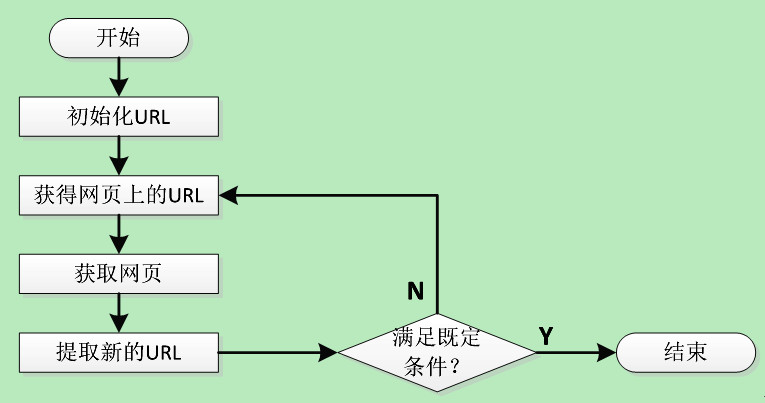
网络爬虫,是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫,从一个或若干初始网页的URL(统一资源定位符)开始,获得初始网页上的URL(统一资源定位符),在抓取网页的过程中,不断从当前页面上抽取新的URL(统一资源定位符)放入队列,直到满足系统的一定停止条件。
“聚焦网路爬虫”的工作流程较为复杂,需要按照一定的“网页分析算法”过滤与主题无关的链接,保留有用的链接,并将其倒入等待抓取的URL(统一资源定位符)队列。然后,它将按照一定的搜索策略,从队列中选择下一步要抓取的网页URL(统一资源定位符),并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。对于“聚焦网路爬虫”来说,这一过程所得到的剖析结果,还可能对之后的抓取过程给出反馈和指导。
相对于通用网路爬虫,聚焦网路爬虫还须要解决三个主要问题:
1、对抓取目标的描述或定义;
2、对网页或数据的剖析与过滤;
3、对URL(统一资源定位符)的搜索策略。
网络爬虫碰到的问题:
早在2007 年底,互联网上的网页数目就早已超出160 亿个,研究表明接近30%的页面是重复的。动态页面的存在,客户端、服务器端脚本语言的应用,使得指向相同Web信息的 URL(统一资源定位符)数量呈指数级下降。
上述特点促使网路爬虫面临一定的困难,主要彰显在 Web信息的巨大容量,使得爬虫在给定的时间内,只能下载少量网页。有研究表明,没有那个搜索引擎才能索引超出16%的互联网Web 页面,即使才能提取全部页面,也没有足够的空间来储存。
为了提升爬行效率,爬虫须要在单位时间内尽可能多的获取高质量页面,这是它面临的困局之一。
当前有五种表示页面质量高低的方法:1、页面与爬行主题之间的相似度;2、页面在 Web 图中的入度大小;3、指向它的所有页面平均残差之和;4、页面在 Web 图中的出度大小;5、页面的信息位置。
为了提升爬行速率,网络爬虫一般会采取“并行爬行”的工作方式,这种工作方式也造成了新的问题:
1、重复性(并行运行的爬虫或爬行线程同时运行时,增加了重复页面);
2、质量问题(并行运行时,每个爬虫或爬行线程只能获取部份页面,导致页面质量下滑);
3、通信带宽代价(并行运行时,各个爬虫或爬行线程之间不可避开要进行一些通讯,需要花费一定的带宽资源)。
并行运行时,网络爬虫一般采用三种形式:
1、独立形式(各个爬虫独立爬行页面,互不通讯);
2、动态分配方法(由一个中央协调器动态协调分配 URL 给各个爬虫);
3、静态分配方法(URL 事先界定给各个爬虫)。
亿速云,作为一家专业的IDC(互联网数据中心)业务服务提供商、拥有丰富行业底蕴的专业云计算服务提供商,一直专注于技术创新和构建更好的服务品质,致力于为广大用户,提供高性价比、高可用性的“裸金属服务器、云服务器、高防服务器、高防IP、香港服务器、日本服务器、美国服务器、SSL证书”等专业产品与服务。 查看全部
网络爬虫,又被称为“网页蜘蛛,网络机器人”,在FOAF社区中间,经常被称为“网页追逐者”。网络爬虫,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。

网络爬虫,按照系统结构和实现技术,大致可以分为:“通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫”等四种不同类型。实际上,网络爬虫系统,通常是由几种爬虫技术相结合实现的。
一、 通用网路爬虫
通用网路爬虫,又称“全网爬虫”,爬行对象从一些种子URL(统一资源定位符) 扩充到整个万维网,主要为“门户站点搜索引擎”和“大型Web服务提供商”采集数据。由于商业缘由,它们的技术细节甚少被公布下来。这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为等待刷新的页面太多,通常采用“并行工作”的方法,但须要较长时间能够刷新一次页面。通用网路爬虫,虽然存在着一定的缺陷,但它适用于为搜索引擎平台搜索广泛的主题,有较强的应用价值。
二、聚焦网络爬虫
聚焦网络爬虫,又称“主题网路爬虫”,是指选择性地爬行,那些与预先定义好的主题相关的页面的网路爬虫。和通用网路爬虫相比,聚焦网路爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网路爬虫相比,增加了“链接评价模块”以及“内容评价模块”。聚焦网路爬虫爬行策略实现的关键是,评价页面内容和链接的重要性。不同的方式估算出的重要性不同,由此引起链接的访问次序也不同。
三、增量式网络爬虫
是指对已下载网页采取增量式更新,和只爬行新形成的或则早已发生变化网页的爬虫网络爬虫技术是什么,它还能在一定程度上保证网络爬虫技术是什么,所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。
四、深层网络爬虫
Web 页面,按存在形式可以分为“表层网页”和“深层网页”。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。
深层网页是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web 页面。例如:那些用户注册后内容才可见的网页,就属于深层网页。
随着计算机网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。搜索引擎,例如传统的“通用搜索引擎”平台:Google(谷歌)、Yahoo!(雅虎)、百度等,作为一个辅助人们检索万维网信息的工具,成为互联网用户访问万维网的入口和渠道。
但是,这些“通用搜索引擎平台”也存在着一定的局限性,如:
1、 不同领域、不同职业、不同背景的用户,往往具有不同的检索目的和需求,通用搜索引擎所返回的结果,包含了大量用户并不关心的网页,或者与用户搜索结果无关的网页。
2、 通用搜索引擎的目标是,实现尽可能大的网路覆盖率,有限的搜索引擎服务器资源,与无限的网路数据资源之间的矛盾将进一步加深。
3、 万维网数据方式的丰富和网路技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎常常对这种信息浓度密集,且具有一定结构的数据无能为力,不能挺好地发觉和获取。
4、通用搜索引擎,大多提供基于“关键字”的检索,难以支持按照语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的“聚焦网路爬虫”应运而生。聚焦网路爬虫,是一个手动下载网页的程序,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息。
与“通用网路爬虫”不同,聚焦网络爬虫并不追求大的覆盖,而是将目标定为抓取“与某一特定主题内容相关的网页”,为面向主题的用户查询,准备数据资源。
“聚焦网路爬虫”的工作原理以及关键技术概述:
网络爬虫,是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫,从一个或若干初始网页的URL(统一资源定位符)开始,获得初始网页上的URL(统一资源定位符),在抓取网页的过程中,不断从当前页面上抽取新的URL(统一资源定位符)放入队列,直到满足系统的一定停止条件。
“聚焦网路爬虫”的工作流程较为复杂,需要按照一定的“网页分析算法”过滤与主题无关的链接,保留有用的链接,并将其倒入等待抓取的URL(统一资源定位符)队列。然后,它将按照一定的搜索策略,从队列中选择下一步要抓取的网页URL(统一资源定位符),并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。对于“聚焦网路爬虫”来说,这一过程所得到的剖析结果,还可能对之后的抓取过程给出反馈和指导。
相对于通用网路爬虫,聚焦网路爬虫还须要解决三个主要问题:
1、对抓取目标的描述或定义;
2、对网页或数据的剖析与过滤;
3、对URL(统一资源定位符)的搜索策略。
网络爬虫碰到的问题:
早在2007 年底,互联网上的网页数目就早已超出160 亿个,研究表明接近30%的页面是重复的。动态页面的存在,客户端、服务器端脚本语言的应用,使得指向相同Web信息的 URL(统一资源定位符)数量呈指数级下降。
上述特点促使网路爬虫面临一定的困难,主要彰显在 Web信息的巨大容量,使得爬虫在给定的时间内,只能下载少量网页。有研究表明,没有那个搜索引擎才能索引超出16%的互联网Web 页面,即使才能提取全部页面,也没有足够的空间来储存。
为了提升爬行效率,爬虫须要在单位时间内尽可能多的获取高质量页面,这是它面临的困局之一。
当前有五种表示页面质量高低的方法:1、页面与爬行主题之间的相似度;2、页面在 Web 图中的入度大小;3、指向它的所有页面平均残差之和;4、页面在 Web 图中的出度大小;5、页面的信息位置。
为了提升爬行速率,网络爬虫一般会采取“并行爬行”的工作方式,这种工作方式也造成了新的问题:
1、重复性(并行运行的爬虫或爬行线程同时运行时,增加了重复页面);
2、质量问题(并行运行时,每个爬虫或爬行线程只能获取部份页面,导致页面质量下滑);
3、通信带宽代价(并行运行时,各个爬虫或爬行线程之间不可避开要进行一些通讯,需要花费一定的带宽资源)。
并行运行时,网络爬虫一般采用三种形式:
1、独立形式(各个爬虫独立爬行页面,互不通讯);
2、动态分配方法(由一个中央协调器动态协调分配 URL 给各个爬虫);
3、静态分配方法(URL 事先界定给各个爬虫)。
亿速云,作为一家专业的IDC(互联网数据中心)业务服务提供商、拥有丰富行业底蕴的专业云计算服务提供商,一直专注于技术创新和构建更好的服务品质,致力于为广大用户,提供高性价比、高可用性的“裸金属服务器、云服务器、高防服务器、高防IP、香港服务器、日本服务器、美国服务器、SSL证书”等专业产品与服务。
网络爬虫的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 367 次浏览 • 2020-07-02 08:01
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler 查看全部
第11卷第4期2012年 4月软件导刊Software Guide Vo l. ll NO.4 组己旦2网路爬虫的设计与实现王娟,吴金鹏(贵州|民族学院计算机与信息工程学院,贵州l 贵阳 550025)摘 要:搜索引擎技术随着互联网的日渐壮大而急速发展。作为搜索引擎不可或缺的组成部分,网络爬虫的作用变得尤为重要网络爬虫设计,它的性能直接决定了在庞大的互联网上进行网页信息采集的质量。设计并实现了通用爬虫和限定爬虫。关键词:网络爬虫;通用爬虫;限定爬虫中图分类号 :TP393 文献标识码 :A。哥|言网路爬虫称作网路蜘蛛,它为搜索引擎从万维网上下载网页,并顺着网页的相关链接在 Web 中采集资源,是一个功能太强的网页手动抓取程序,也是搜索引擎的重要组成部份,爬虫设计的优劣直接决定着整个搜索引擎的性能及扩充能力。网络爬虫根据系统结构和实现技术,大致可以分为:通用网路爬虫、主题网路爬虫、增量式网路爬虫、深层网路爬虫 o 实际应用中一般是将几种爬虫技术相结合。1 通用爬虫的设计与实现1. 1 工作原理通用网路爬虫按照预先设定的一个或若干初始种子URL 开始,以此获得初始网页上的 URL 列表,在爬行过程中不断从 URL 队列中获一个个的 URL,进而访问并下载该页面。
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler
网络爬虫技术之同时抓取多个网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 872 次浏览 • 2020-06-26 08:01
$curlobj = curl_init(); //创建一个curl 的资源,下面要用的curl_setopt($curlobj,CURLOPT_URL,""); //获取资源curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); //请求结果不直接复印 $output = curl_exec($cu
爬虫爬取多个不相同网页
任务四‘’’本任务要求你们完成一个简单的爬虫项目,包括网页爬取、信息提取以及数据保存在完成本次任务时,建议你们认真思索,结合自己的逻辑,完成任务。注意:本任务的得分将根据任务递交时间的先后次序与任务正确率结合来估算,由于每个朋友的题目都不相同,建议不要剽窃,一旦发觉剽窃情况,本次任务判为0分’’’from typing import Any, Tuple‘’’第一题:请使用爬虫技术...
Scrapy爬取多层级网页内容的方法
# -*- coding: utf-8 -*-import scrapyfrom Avv.items import AvvItemclass AvSpider(scrapy.Spider):name = 'av' # 爬虫名allowed_domains = ['/'] # 爬虫作用域# 爬取第2页到最后一页的代码url = ...
爬虫——scrapy框架爬取多个页面影片的二级子页面的详尽信息
文章目录需求:总结:代码:movieinfo.pyitems.pymiddleware.pypipelines.py结果:附加:需求:scrapy框架,爬取某影片网页面的每位影片的一级页面的名子爬取每部影片二级页面的详尽信息使用代理ip保存日志文件存为csv文件总结:1、xpath解析使用extract()的各类情况剖析
网络爬虫初步:从一个入口链接开始不断抓取页面中的网址并入库
前言: 在上一篇《网络爬虫初步:从访问网页到数据解析》中,我们讨论了怎样爬取网页,对爬取的网页进行解析,以及访问被拒绝的网站。在这一篇博客中,我们可以来了解一下领到解析的数据可以做的风波。在这篇博客中,我主要是说明要做的两件事,一是入库,二是遍历领到的链接继续访问。如此往复,这样就构成了一个网络爬虫的雏型。笔者环境: 系统: Windows 7...
php爬虫
Php爬虫,爬取数据,识图猜词语一、寻找数据1,寻找相关网站数据剖析网站换页特点剖析得出不仅第一页,第二页开始index加页面数写一个函数,专门拼接须要访问的页面public function getcy($id=3,$num=3){$i=$id;...
爬取多个页面的数据
代码如下:# -*- coding:utf8 -*-#导入requests库,取别称resimport requests as res#导入bs4包,取别称bsfrom bs4 import BeautifulSoup as bs#导入数据库驱动包import MySQLdb#声明页面从哪开始j = 1#循环遍历每位页面while j 111:##获取目标网站的网页
Python爬虫实例(3)-用BeautifulSoup爬取多个可翻页网页上的多张相片
# -*- coding: utf-8 -*-#导入第三方包和模块import requestsfrom bs4 import BeautifulSoupimport os#在本地新建一个文件夹,命名为test_img,用以保存下载的图片folder = 'test_img'if not os.path.exists(folder):os.makedirs(folder)#定义
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、有时候启动以后没任何反应3S然后程序停止。问哪些会这样,求解
webmagic爬虫自学(三)爬取CSDN【列表+详情的基本页面组合】的页面,使用基于注解的方法
1
如何实现两个页面的跳转
_addEvent:function(){var btn;btn=this._getWidgetByName(this._startGav,"Button_7");//获取按键的点击实风波btn.addTouchEventListener(this._inputHandler.bind(this),this._startGav);},_inputHandler:
爬虫——第二次试验(网站多页爬取代码)
实验目的熟练把握requests库中get技巧的使用把握借助requests库爬取多页网页内容的方式2.1 爬取百度贴吧与某主题相关的贴子,并将爬取到的内容保存到文件中(爬取多页)import requestsdef get_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ...
给你们推荐几种实现网页数据抓取的方法
相信所有个人网站的站长都有抓取他人数据的经历吧,目前抓取他人网站数据的方法无非两种形式: 一、使用第三方工具,其中最知名的是优采云采集器,在此不做介绍。 二、自己写程序抓取,这种方法要求站长自己写程序
java爬取百度百科词条
lz在之前的一篇博客中,用python实现了爬取百度百科的词条,就在怎么用java来实现相同的功能,果不其然,java用一个jsoup的第三方库工具就可以很简单地实现爬取百度百科的词条。同样的,将这个爬取过程分成5个部份来实现。分别是connectnet联接url部份、parsehtml获取html相关内容部份、startspyder部份、store储存url部份、urlmanager的url管理
关于使用Java实现的简单网路爬虫Demo
什么是网络爬虫?网络爬虫又叫蜘蛛,网络蜘蛛是通过网页的链接地址来找寻网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当作一个网站,那么网路蜘蛛就可以用这个原理把互联网上所有的网页都抓取出来。所以要想抓取网路上的数据,不仅须要爬虫程序还须要一个可以接受
Java爬虫爬取python百度百科词条及相关词条页面
Java爬虫爬取python百度百科词条及相关词条页面本实例爬取关于python词条页面及关联词条页面的简介网络爬虫论坛,把词条的简介写入txt文本中, 本实例疗效:实例基于使用第三方jar包Jsoup1首先剖析python词条页面:可以发觉其他词条的超链接都带有"/item"以及词条的简介都包含在class为
python scrapy项目下spiders内多个爬虫同时运行
一般创建了scrapy文件夹后,可能须要写多个爬虫,如果想使它们同时运行而不是顺次运行的话,得怎样做?a、在spiders目录的同级目录下创建一个commands目录网络爬虫论坛,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只更改run()方法即可!import osfrom ...
算法设计中关于优先队列式分支限界法解装载问题的代码下载
分支限界法中的优先队列式分支限界法解装载问题相关下载链接:
软件调试张银奎(7)下载
软件调试张银奎(4)软件调试张银奎(4)软件调试张银奎(4)相关下载链接:
WimTool-WIM文件处理工具安装版下载
WimTool-WIM文件处理工具安装版相关下载链接:
相关热词c#如何获得线程名c# usb 采集器c# sort()c#面对对象的三大特点c# 打印 等比缩放c#弹出右键菜单c# 系统托盘图标c# 键值对 键可以重复c# 鼠标移起来提示c#结构体定义
我们是挺有底线的 查看全部
$curlobj = curl_init(); //创建一个curl 的资源,下面要用的curl_setopt($curlobj,CURLOPT_URL,""); //获取资源curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); //请求结果不直接复印 $output = curl_exec($cu
爬虫爬取多个不相同网页
任务四‘’’本任务要求你们完成一个简单的爬虫项目,包括网页爬取、信息提取以及数据保存在完成本次任务时,建议你们认真思索,结合自己的逻辑,完成任务。注意:本任务的得分将根据任务递交时间的先后次序与任务正确率结合来估算,由于每个朋友的题目都不相同,建议不要剽窃,一旦发觉剽窃情况,本次任务判为0分’’’from typing import Any, Tuple‘’’第一题:请使用爬虫技术...
Scrapy爬取多层级网页内容的方法
# -*- coding: utf-8 -*-import scrapyfrom Avv.items import AvvItemclass AvSpider(scrapy.Spider):name = 'av' # 爬虫名allowed_domains = ['/'] # 爬虫作用域# 爬取第2页到最后一页的代码url = ...

爬虫——scrapy框架爬取多个页面影片的二级子页面的详尽信息
文章目录需求:总结:代码:movieinfo.pyitems.pymiddleware.pypipelines.py结果:附加:需求:scrapy框架,爬取某影片网页面的每位影片的一级页面的名子爬取每部影片二级页面的详尽信息使用代理ip保存日志文件存为csv文件总结:1、xpath解析使用extract()的各类情况剖析
网络爬虫初步:从一个入口链接开始不断抓取页面中的网址并入库
前言: 在上一篇《网络爬虫初步:从访问网页到数据解析》中,我们讨论了怎样爬取网页,对爬取的网页进行解析,以及访问被拒绝的网站。在这一篇博客中,我们可以来了解一下领到解析的数据可以做的风波。在这篇博客中,我主要是说明要做的两件事,一是入库,二是遍历领到的链接继续访问。如此往复,这样就构成了一个网络爬虫的雏型。笔者环境: 系统: Windows 7...
php爬虫
Php爬虫,爬取数据,识图猜词语一、寻找数据1,寻找相关网站数据剖析网站换页特点剖析得出不仅第一页,第二页开始index加页面数写一个函数,专门拼接须要访问的页面public function getcy($id=3,$num=3){$i=$id;...
爬取多个页面的数据
代码如下:# -*- coding:utf8 -*-#导入requests库,取别称resimport requests as res#导入bs4包,取别称bsfrom bs4 import BeautifulSoup as bs#导入数据库驱动包import MySQLdb#声明页面从哪开始j = 1#循环遍历每位页面while j 111:##获取目标网站的网页
Python爬虫实例(3)-用BeautifulSoup爬取多个可翻页网页上的多张相片
# -*- coding: utf-8 -*-#导入第三方包和模块import requestsfrom bs4 import BeautifulSoupimport os#在本地新建一个文件夹,命名为test_img,用以保存下载的图片folder = 'test_img'if not os.path.exists(folder):os.makedirs(folder)#定义

用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、有时候启动以后没任何反应3S然后程序停止。问哪些会这样,求解
webmagic爬虫自学(三)爬取CSDN【列表+详情的基本页面组合】的页面,使用基于注解的方法
1
如何实现两个页面的跳转
_addEvent:function(){var btn;btn=this._getWidgetByName(this._startGav,"Button_7");//获取按键的点击实风波btn.addTouchEventListener(this._inputHandler.bind(this),this._startGav);},_inputHandler:
爬虫——第二次试验(网站多页爬取代码)
实验目的熟练把握requests库中get技巧的使用把握借助requests库爬取多页网页内容的方式2.1 爬取百度贴吧与某主题相关的贴子,并将爬取到的内容保存到文件中(爬取多页)import requestsdef get_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ...
给你们推荐几种实现网页数据抓取的方法
相信所有个人网站的站长都有抓取他人数据的经历吧,目前抓取他人网站数据的方法无非两种形式: 一、使用第三方工具,其中最知名的是优采云采集器,在此不做介绍。 二、自己写程序抓取,这种方法要求站长自己写程序
java爬取百度百科词条
lz在之前的一篇博客中,用python实现了爬取百度百科的词条,就在怎么用java来实现相同的功能,果不其然,java用一个jsoup的第三方库工具就可以很简单地实现爬取百度百科的词条。同样的,将这个爬取过程分成5个部份来实现。分别是connectnet联接url部份、parsehtml获取html相关内容部份、startspyder部份、store储存url部份、urlmanager的url管理
关于使用Java实现的简单网路爬虫Demo
什么是网络爬虫?网络爬虫又叫蜘蛛,网络蜘蛛是通过网页的链接地址来找寻网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当作一个网站,那么网路蜘蛛就可以用这个原理把互联网上所有的网页都抓取出来。所以要想抓取网路上的数据,不仅须要爬虫程序还须要一个可以接受
Java爬虫爬取python百度百科词条及相关词条页面
Java爬虫爬取python百度百科词条及相关词条页面本实例爬取关于python词条页面及关联词条页面的简介网络爬虫论坛,把词条的简介写入txt文本中, 本实例疗效:实例基于使用第三方jar包Jsoup1首先剖析python词条页面:可以发觉其他词条的超链接都带有"/item"以及词条的简介都包含在class为
python scrapy项目下spiders内多个爬虫同时运行
一般创建了scrapy文件夹后,可能须要写多个爬虫,如果想使它们同时运行而不是顺次运行的话,得怎样做?a、在spiders目录的同级目录下创建一个commands目录网络爬虫论坛,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只更改run()方法即可!import osfrom ...
算法设计中关于优先队列式分支限界法解装载问题的代码下载
分支限界法中的优先队列式分支限界法解装载问题相关下载链接:
软件调试张银奎(7)下载
软件调试张银奎(4)软件调试张银奎(4)软件调试张银奎(4)相关下载链接:
WimTool-WIM文件处理工具安装版下载
WimTool-WIM文件处理工具安装版相关下载链接:
相关热词c#如何获得线程名c# usb 采集器c# sort()c#面对对象的三大特点c# 打印 等比缩放c#弹出右键菜单c# 系统托盘图标c# 键值对 键可以重复c# 鼠标移起来提示c#结构体定义
我们是挺有底线的
网络爬虫技术(新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-06-22 08:00
网络爬虫技术网路机器人1.概念: 它们是 Web 上孤身运行的软件程序,它们不断地筛选数据,做出自己的 决定, 能够使用 Web 获取文本或则进行搜索查询,按部就班地完成各自的任务。 2.分类: 购物机器人、聊天机器人、搜索机器人(网络爬虫)等。搜索引擎1.概念: 从网路上获得网站网页资料,能够构建数据库并提供查询的系统 。 2.分类(按工作原理) : 全文搜索引擎、分类目录。 1> 全文搜索引擎数据库是借助网路爬虫通过网路上的各类链接手动获取大量 网页信息内容,并按一定的规则剖析整理产生的。 (百度、Google) 2> 分类目录:按目录分类的网站链接列表而已 ,通过人工的方法搜集整理网 站资料产生的数据库。(国内的搜狐)网络爬虫1.概念: 网络爬虫也叫网路蜘蛛,它是一个根据一定的规则手动提取网页程序,其会手动 的通过网路抓取互联网上的网页,这种技术通常可能拿来检测你的站点上所有的链接 是否是都是有效的。当然爬虫技术,更为中级的技术是把网页中的相关数据保存出来,可以成 为搜索引擎。 搜索引擎使用网络爬虫找寻网路内容,网络上的 HTML 文档使用超链接联接了上去, 就像织成了一张网,网络爬虫也叫网路蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序 将这个网页抓出来,将内容抽取下来,同时抽取超链接,作为进一步爬行的线索。
网络爬虫 总是要从某个起点开始爬,这个起点称作种子,你可以告诉它,也可以到一些网址列表网站 上获取。 2.区别: 网络爬虫 分类 工作原理 通用爬虫 从一个或多个初始网页的 URL 开 始,获取初始网页的 URL,抓取网 页的同时爬虫技术,从当前网页提取相关的 URL 放入队列中,直到满足程序的 停止条件。 聚集爬虫 根据一定的网页剖析算法过滤与主题无 关的链接,保留有用的链接(爬行的范围 是受控的)放到待抓取的队列中,通过一 定的搜索策略从队列中选择下一步要抓 取的 URL,重复以上步骤,直到满足程 序的停止条件。 1. 增加了一些网页分析算法和网页搜 索策略 2. 对 被 爬 虫 抓 取 的 网 页 将 会 被 系 统 存贮,进行一定的剖析、过滤,并 建立索引,以便以后的查询和检 索,这一过程所得到的剖析结果还 可能对之后的抓取过程给出反馈不同点和指导。 缺点 1. 不同领域、 不同背景的用户有 不同的检索目的和需求, 通用 搜索引擎所返回的结果包含 大量用户不关心的网页。 2. 通用引擎的目标是大的网路覆 盖率。 3. 只支持关键字搜索, 不支持按照 语义的搜索。 4. 通用搜索引擎对一些象图片、 音 频等信 息 含 量 密 集 且 具 有 一 定结构的数据难以获取。
广度优先算法 1. 对抓取目标的描述或定义。 2. 对网页和数据的剖析和过滤。 3. 对 URL 的搜索策略。 以上三个是须要解决的问题。算法现有聚焦爬虫对抓取目标的描述可分为基于目标网页特点、 基于目标数据模式和基于领 域概念 3 种。 基于目标网页特点的爬虫所抓取、 存储并索引的对象通常为网站或网页。 根据种子样本 获取方法可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如 Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标明的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特点可以是网页的内容特点,也可以是网页的链接结构特点,等等。 3.算法/策略 名称 分类 网页分析算法 1.基于网路拓扑结构 1>网页细度剖析算法 2>网站粒度剖析算法 3>网页块细度剖析算法 2.基于网页内容 1>针对以文本和超链接为主的 网页 2>针对从结构化的数据源动态生 成的网页。 3>针对数据介于第一类和第二类 之间 3.基于用户访问行为 网页搜索策略 1.深度优先策略 2.广度优先策略 3.最佳优先策略一些算法的介绍 1> 网页分析算法1.1 基于网路拓扑的剖析算法? 基于网页之间的链接, 通过已知的网页或数据, 来对与其有直接或间接链接关系的对象 (可以是网页或网站等) 作出评价的算法。
又分为网页细度、 网站粒度和网页块细度这三种。 1.1.1 网页(Webpage)粒度的剖析算法 PageRank 和 HITS 算法是最常见的链接剖析算法, 两者都是通过对网页间链接度的递归 和规范化估算,得到每位网页的重要度评价。PageRank 算法其实考虑了用户访问行为的随 机性和 Sink 网页的存在,但忽视了绝大多数用户访问时带有目的性,即网页和链接与查询 主题的相关性。针对这个问题,HITS 算法提出了两个关键的概念:权威型网页(authority) 和中心型网页(hub) 。 基于链接的抓取的问题是相关页面主题团之间的隧洞现象, 即好多在抓取路径上偏离主 题的网页也指向目标网页,局部评价策略中断了在当前路径上的抓取行为。文献[21]提出了 一种基于反向链接(BackLink)的分层式上下文模型(Context Model) ,用于描述指向目标 网页一定化学跳数直径内的网页拓扑图的中心 Layer0 为目标网页,将网页根据指向目标网 页的数学跳数进行层次界定,从内层网页指向外层网页的链接称为反向链接。? 1.1.2 网站粒度的剖析算法 网站粒度的资源发觉和管理策略也比网页细度的更简单有效。
网站粒度的爬虫抓取的关 键之处在于站点的界定和站点等级(SiteRank)的估算。 SiteRank 的估算方式与 PageRank 类似, 但是须要对网站之间的链接作一定程度具象,并在一定的模型下估算链接的权重。 网站划分情况分为按域名界定和按 IP 地址界定两种。文献[18]讨论了在分布式情况下, 通过对同一个域名下不同主机、服务器的 IP 地址进行站点界定,构造站点图,利用类似 Pa geRank 的方式评价 SiteRank。同时,根据不同文件在各个站点上的分布情况,构造文档图, 结合 SiteRank 分布式估算得到 DocRank。文献[18]证明,利用分布式的 SiteRank 计算,不仅 大大增加了单机站点的算法代价, 而且克服了单独站点对整个网路覆盖率有限的缺点。 附带 的一个优点是,常见 PageRank 造假无法对 SiteRank 进行愚弄。? 1.1.3 网页块细度的剖析算法 在一个页面中, 往往富含多个指向其他页面的链接, 这些链接中只有一部分是指向主题 相关网页的,或依照网页的链接锚文本表明其具有较高重要性。但是,在 PageRank 和 HIT S 算法中,没有对那些链接作分辨,因此经常给网页剖析带来广告等噪音链接的干扰。
在网 页块级别(Block?level) 进行链接剖析的算法的基本思想是通过 VIPS 网页分割算法将网页分 为不同的网页块(page block),然后对这种网页块构建 page?to?block block?to?page的 和 链接矩阵,? 分别记为 Z 和 X。于是,在 page?to? page 图上的网页块级别的 PageRank 为? W?p=X×Z ? block?to?block图上的 BlockRank 为?W?b=Z×X ? ; 在 。 已经有人实现了块级 别的 PageRank 和 HITS 算法,并通过实验证明,效率和准确率都比传统的对应算法要好。 1.2 基于网页内容的网页分析算法 基于网页内容的剖析算法指的是借助网页内容(文本、数据等资源)特征进行的网页评 价。网页的内容从原先的以超文本为主,发展到后来动态页面(或称为 Hidden Web)数据 为主,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的 400~500 倍。另一方面,多媒体数据、Web Service 等各类网路资源方式也日渐丰富。因此,基于网页内容的剖析算法也从原先的较为单纯的文本检索方式, 发展为囊括网页数据抽取、 机器学 习、数据挖掘、语义理解等多种方式的综合应用。
本节按照网页数据方式的不同,将基于网 页内容的剖析算法, 归纳以下三类: 第一种针对以文本和超链接为主的无结构或结构很简单 的网页;第二种针对从结构化的数据源(如 RDBMS)动态生成的页面,其数据不能直接批 量访问;第三种针对的数据界于第一和第二类数据之间,具有较好的结构,显示遵照一定模 式或风格,且可以直接访问。 1.2.1 基于文本的网页剖析算法 1) 纯文本分类与聚类算法 很大程度上借用了文本检索的技术。 文本剖析算法可以快速有效的对网页进行分类和聚 类,但是因为忽视了网页间和网页内部的结构信息,很少单独使用。? 2) 超文本分类和聚类算法 2> 网页搜索策略 2. 广度优先搜索策略 广度优先搜索策略是指在抓取过程中, 在完成当前层次的搜索后, 才进行下一层次的搜 索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索 方法。 也有好多研究将广度优先搜索策略应用于聚焦爬虫中。 其基本思想是觉得与初始 URL 在一定链接距离内的网页具有主题相关性的机率很大。 另外一种方式是将广度优先搜索与网 页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。
这些方式 的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。 2. 最佳优先搜索策略 最佳优先搜索策略根据一定的网页分析算法,预测候选 URL 与目标网页的相似度,或 与主题的相关性,并选定评价最好的一个或几个 URL 进行抓取。它只访问经过网页剖析算 法预测为“有用”的网页。 存在的一个问题是, 在爬虫抓取路径上的好多相关网页可能被忽视, 因为最佳优先策略是一种局部最优搜索算法。因此须要将最佳优先结合具体的应用进行改 进,以跳出局部最优点。将在第 4 节中结合网页分析算法作具体的讨论。研究表明,这样的 闭环调整可以将无关网页数目减少 30%~90%。 3. 搜索引擎原理之网路爬虫是怎样工作的? 在互联网中,网页之间的链接关系是无规律的,它们的关系十分复杂。如果一个爬虫从 一个起点开始爬行,那么它将会碰到无数的分支,由此生成无数条的爬行路径,如果聘期爬 行,就有可能永远也爬不到头,因此要对它加以控制,制定其爬行的规则。世界上没有一种 爬虫还能抓取到互联网所有的网页, 所以就要在提升其爬行速率的同时, 也要提升其爬行网 页的质量。 网络爬虫在搜索引擎中占有重要位置,对搜索引擎的查全、查准都有影响,决定了搜索 引擎数据容量的大小, 而且网路爬虫的优劣之间影响搜索引擎结果页中的死链接的个数。
搜 索引擎爬虫有深度优先策略和广度优先策略,另外,识别垃圾网页,避免抓取重复网页,也 是高性能爬虫的设计目标。 爬虫的作用是为了搜索引擎抓取大量的数据, 抓取的对象是整个互联网上的网页。 爬虫 程序不可能抓取所有的网页,因为在抓取的同时,Web 的规模也在减小,所以一个好的爬 虫程序通常就能在短时间内抓取更多的网页。 一般爬虫程序的起点都选择在一个小型综合型的网站,这样的网站已经囊括了大部分高质量的站点,爬虫程序就顺着那些链接爬行。在爬 行过程中,最重要的就是判定一个网页是否早已被爬行过。 在爬虫开始的时侯, 需要给爬虫输送一个 URL 列表, 这个列表中的 URL 地址便是爬虫 的起始位置,爬虫从这种 URL 出发,开始了爬行,一直不断地发觉新的 URL,然后再按照 策略爬行这种新发觉的 URL,如此永远反复下去。一般的爬虫都自己完善 DNS 缓冲,建立 DNS 缓冲的目的是推动 URL 解析成 IP 地址的速率。 查看全部

网络爬虫技术网路机器人1.概念: 它们是 Web 上孤身运行的软件程序,它们不断地筛选数据,做出自己的 决定, 能够使用 Web 获取文本或则进行搜索查询,按部就班地完成各自的任务。 2.分类: 购物机器人、聊天机器人、搜索机器人(网络爬虫)等。搜索引擎1.概念: 从网路上获得网站网页资料,能够构建数据库并提供查询的系统 。 2.分类(按工作原理) : 全文搜索引擎、分类目录。 1> 全文搜索引擎数据库是借助网路爬虫通过网路上的各类链接手动获取大量 网页信息内容,并按一定的规则剖析整理产生的。 (百度、Google) 2> 分类目录:按目录分类的网站链接列表而已 ,通过人工的方法搜集整理网 站资料产生的数据库。(国内的搜狐)网络爬虫1.概念: 网络爬虫也叫网路蜘蛛,它是一个根据一定的规则手动提取网页程序,其会手动 的通过网路抓取互联网上的网页,这种技术通常可能拿来检测你的站点上所有的链接 是否是都是有效的。当然爬虫技术,更为中级的技术是把网页中的相关数据保存出来,可以成 为搜索引擎。 搜索引擎使用网络爬虫找寻网路内容,网络上的 HTML 文档使用超链接联接了上去, 就像织成了一张网,网络爬虫也叫网路蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序 将这个网页抓出来,将内容抽取下来,同时抽取超链接,作为进一步爬行的线索。
网络爬虫 总是要从某个起点开始爬,这个起点称作种子,你可以告诉它,也可以到一些网址列表网站 上获取。 2.区别: 网络爬虫 分类 工作原理 通用爬虫 从一个或多个初始网页的 URL 开 始,获取初始网页的 URL,抓取网 页的同时爬虫技术,从当前网页提取相关的 URL 放入队列中,直到满足程序的 停止条件。 聚集爬虫 根据一定的网页剖析算法过滤与主题无 关的链接,保留有用的链接(爬行的范围 是受控的)放到待抓取的队列中,通过一 定的搜索策略从队列中选择下一步要抓 取的 URL,重复以上步骤,直到满足程 序的停止条件。 1. 增加了一些网页分析算法和网页搜 索策略 2. 对 被 爬 虫 抓 取 的 网 页 将 会 被 系 统 存贮,进行一定的剖析、过滤,并 建立索引,以便以后的查询和检 索,这一过程所得到的剖析结果还 可能对之后的抓取过程给出反馈不同点和指导。 缺点 1. 不同领域、 不同背景的用户有 不同的检索目的和需求, 通用 搜索引擎所返回的结果包含 大量用户不关心的网页。 2. 通用引擎的目标是大的网路覆 盖率。 3. 只支持关键字搜索, 不支持按照 语义的搜索。 4. 通用搜索引擎对一些象图片、 音 频等信 息 含 量 密 集 且 具 有 一 定结构的数据难以获取。
广度优先算法 1. 对抓取目标的描述或定义。 2. 对网页和数据的剖析和过滤。 3. 对 URL 的搜索策略。 以上三个是须要解决的问题。算法现有聚焦爬虫对抓取目标的描述可分为基于目标网页特点、 基于目标数据模式和基于领 域概念 3 种。 基于目标网页特点的爬虫所抓取、 存储并索引的对象通常为网站或网页。 根据种子样本 获取方法可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如 Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标明的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特点可以是网页的内容特点,也可以是网页的链接结构特点,等等。 3.算法/策略 名称 分类 网页分析算法 1.基于网路拓扑结构 1>网页细度剖析算法 2>网站粒度剖析算法 3>网页块细度剖析算法 2.基于网页内容 1>针对以文本和超链接为主的 网页 2>针对从结构化的数据源动态生 成的网页。 3>针对数据介于第一类和第二类 之间 3.基于用户访问行为 网页搜索策略 1.深度优先策略 2.广度优先策略 3.最佳优先策略一些算法的介绍 1> 网页分析算法1.1 基于网路拓扑的剖析算法? 基于网页之间的链接, 通过已知的网页或数据, 来对与其有直接或间接链接关系的对象 (可以是网页或网站等) 作出评价的算法。
又分为网页细度、 网站粒度和网页块细度这三种。 1.1.1 网页(Webpage)粒度的剖析算法 PageRank 和 HITS 算法是最常见的链接剖析算法, 两者都是通过对网页间链接度的递归 和规范化估算,得到每位网页的重要度评价。PageRank 算法其实考虑了用户访问行为的随 机性和 Sink 网页的存在,但忽视了绝大多数用户访问时带有目的性,即网页和链接与查询 主题的相关性。针对这个问题,HITS 算法提出了两个关键的概念:权威型网页(authority) 和中心型网页(hub) 。 基于链接的抓取的问题是相关页面主题团之间的隧洞现象, 即好多在抓取路径上偏离主 题的网页也指向目标网页,局部评价策略中断了在当前路径上的抓取行为。文献[21]提出了 一种基于反向链接(BackLink)的分层式上下文模型(Context Model) ,用于描述指向目标 网页一定化学跳数直径内的网页拓扑图的中心 Layer0 为目标网页,将网页根据指向目标网 页的数学跳数进行层次界定,从内层网页指向外层网页的链接称为反向链接。? 1.1.2 网站粒度的剖析算法 网站粒度的资源发觉和管理策略也比网页细度的更简单有效。
网站粒度的爬虫抓取的关 键之处在于站点的界定和站点等级(SiteRank)的估算。 SiteRank 的估算方式与 PageRank 类似, 但是须要对网站之间的链接作一定程度具象,并在一定的模型下估算链接的权重。 网站划分情况分为按域名界定和按 IP 地址界定两种。文献[18]讨论了在分布式情况下, 通过对同一个域名下不同主机、服务器的 IP 地址进行站点界定,构造站点图,利用类似 Pa geRank 的方式评价 SiteRank。同时,根据不同文件在各个站点上的分布情况,构造文档图, 结合 SiteRank 分布式估算得到 DocRank。文献[18]证明,利用分布式的 SiteRank 计算,不仅 大大增加了单机站点的算法代价, 而且克服了单独站点对整个网路覆盖率有限的缺点。 附带 的一个优点是,常见 PageRank 造假无法对 SiteRank 进行愚弄。? 1.1.3 网页块细度的剖析算法 在一个页面中, 往往富含多个指向其他页面的链接, 这些链接中只有一部分是指向主题 相关网页的,或依照网页的链接锚文本表明其具有较高重要性。但是,在 PageRank 和 HIT S 算法中,没有对那些链接作分辨,因此经常给网页剖析带来广告等噪音链接的干扰。
在网 页块级别(Block?level) 进行链接剖析的算法的基本思想是通过 VIPS 网页分割算法将网页分 为不同的网页块(page block),然后对这种网页块构建 page?to?block block?to?page的 和 链接矩阵,? 分别记为 Z 和 X。于是,在 page?to? page 图上的网页块级别的 PageRank 为? W?p=X×Z ? block?to?block图上的 BlockRank 为?W?b=Z×X ? ; 在 。 已经有人实现了块级 别的 PageRank 和 HITS 算法,并通过实验证明,效率和准确率都比传统的对应算法要好。 1.2 基于网页内容的网页分析算法 基于网页内容的剖析算法指的是借助网页内容(文本、数据等资源)特征进行的网页评 价。网页的内容从原先的以超文本为主,发展到后来动态页面(或称为 Hidden Web)数据 为主,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的 400~500 倍。另一方面,多媒体数据、Web Service 等各类网路资源方式也日渐丰富。因此,基于网页内容的剖析算法也从原先的较为单纯的文本检索方式, 发展为囊括网页数据抽取、 机器学 习、数据挖掘、语义理解等多种方式的综合应用。
本节按照网页数据方式的不同,将基于网 页内容的剖析算法, 归纳以下三类: 第一种针对以文本和超链接为主的无结构或结构很简单 的网页;第二种针对从结构化的数据源(如 RDBMS)动态生成的页面,其数据不能直接批 量访问;第三种针对的数据界于第一和第二类数据之间,具有较好的结构,显示遵照一定模 式或风格,且可以直接访问。 1.2.1 基于文本的网页剖析算法 1) 纯文本分类与聚类算法 很大程度上借用了文本检索的技术。 文本剖析算法可以快速有效的对网页进行分类和聚 类,但是因为忽视了网页间和网页内部的结构信息,很少单独使用。? 2) 超文本分类和聚类算法 2> 网页搜索策略 2. 广度优先搜索策略 广度优先搜索策略是指在抓取过程中, 在完成当前层次的搜索后, 才进行下一层次的搜 索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索 方法。 也有好多研究将广度优先搜索策略应用于聚焦爬虫中。 其基本思想是觉得与初始 URL 在一定链接距离内的网页具有主题相关性的机率很大。 另外一种方式是将广度优先搜索与网 页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。
这些方式 的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。 2. 最佳优先搜索策略 最佳优先搜索策略根据一定的网页分析算法,预测候选 URL 与目标网页的相似度,或 与主题的相关性,并选定评价最好的一个或几个 URL 进行抓取。它只访问经过网页剖析算 法预测为“有用”的网页。 存在的一个问题是, 在爬虫抓取路径上的好多相关网页可能被忽视, 因为最佳优先策略是一种局部最优搜索算法。因此须要将最佳优先结合具体的应用进行改 进,以跳出局部最优点。将在第 4 节中结合网页分析算法作具体的讨论。研究表明,这样的 闭环调整可以将无关网页数目减少 30%~90%。 3. 搜索引擎原理之网路爬虫是怎样工作的? 在互联网中,网页之间的链接关系是无规律的,它们的关系十分复杂。如果一个爬虫从 一个起点开始爬行,那么它将会碰到无数的分支,由此生成无数条的爬行路径,如果聘期爬 行,就有可能永远也爬不到头,因此要对它加以控制,制定其爬行的规则。世界上没有一种 爬虫还能抓取到互联网所有的网页, 所以就要在提升其爬行速率的同时, 也要提升其爬行网 页的质量。 网络爬虫在搜索引擎中占有重要位置,对搜索引擎的查全、查准都有影响,决定了搜索 引擎数据容量的大小, 而且网路爬虫的优劣之间影响搜索引擎结果页中的死链接的个数。
搜 索引擎爬虫有深度优先策略和广度优先策略,另外,识别垃圾网页,避免抓取重复网页,也 是高性能爬虫的设计目标。 爬虫的作用是为了搜索引擎抓取大量的数据, 抓取的对象是整个互联网上的网页。 爬虫 程序不可能抓取所有的网页,因为在抓取的同时,Web 的规模也在减小,所以一个好的爬 虫程序通常就能在短时间内抓取更多的网页。 一般爬虫程序的起点都选择在一个小型综合型的网站,这样的网站已经囊括了大部分高质量的站点,爬虫程序就顺着那些链接爬行。在爬 行过程中,最重要的就是判定一个网页是否早已被爬行过。 在爬虫开始的时侯, 需要给爬虫输送一个 URL 列表, 这个列表中的 URL 地址便是爬虫 的起始位置,爬虫从这种 URL 出发,开始了爬行,一直不断地发觉新的 URL,然后再按照 策略爬行这种新发觉的 URL,如此永远反复下去。一般的爬虫都自己完善 DNS 缓冲,建立 DNS 缓冲的目的是推动 URL 解析成 IP 地址的速率。
大数据采集之网路爬虫的基本流程及抓取策略
采集交流 • 优采云 发表了文章 • 0 个评论 • 536 次浏览 • 2020-06-08 08:01
本篇教程阐述了大数据采集之网路爬虫的基本流程及抓取策略,希望阅读本篇文章以后你们有所收获,帮助你们对相关内容的理解愈发深入。
大数据时代下,数据采集推动着数据剖析,数据剖析促进发展。但是在这个过程中会出现好多问题。拿最简单最基础的爬虫采集数据为例,过程中还会面临,IP被封,爬取受限、违法操作等多种问题,所以在爬去数据之前,一定要了解好预爬网站是否涉及违规操作,找到合适的代理IP访问网站等一系列问题。
掌握爬虫技术也成为现今技术流的营销推广人员必须把握的。爬虫入门,这些知识你必须了解。
一、网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总大数据网络爬虫原理,这样就产生了该未知页面的PageRank值,从而参与排序。
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
3.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
4.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路然后再转到下一个起始页,继续跟踪链接。
三、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
太阳软件,一个好用的互联网推广换IP工具大数据网络爬虫原理,海量IP,一键切换,提升权重,必不可少! 查看全部

本篇教程阐述了大数据采集之网路爬虫的基本流程及抓取策略,希望阅读本篇文章以后你们有所收获,帮助你们对相关内容的理解愈发深入。
大数据时代下,数据采集推动着数据剖析,数据剖析促进发展。但是在这个过程中会出现好多问题。拿最简单最基础的爬虫采集数据为例,过程中还会面临,IP被封,爬取受限、违法操作等多种问题,所以在爬去数据之前,一定要了解好预爬网站是否涉及违规操作,找到合适的代理IP访问网站等一系列问题。
掌握爬虫技术也成为现今技术流的营销推广人员必须把握的。爬虫入门,这些知识你必须了解。
一、网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总大数据网络爬虫原理,这样就产生了该未知页面的PageRank值,从而参与排序。
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
3.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
4.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路然后再转到下一个起始页,继续跟踪链接。
三、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
太阳软件,一个好用的互联网推广换IP工具大数据网络爬虫原理,海量IP,一键切换,提升权重,必不可少!
三种开源网路爬虫性能比较
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2020-06-05 08:02
在信息化时代,针对通用搜索引擎信息量大、查询准度和深度兼差等缺点,垂直搜索引擎已步入了用户认可和使用周期。垂直搜索是针对某一个行业的专业搜索引擎,是对网页库中的某类专门的信息进行一次整合,定向分数组抽取出须要的数据进行处理后再以某种方式返回给用户[1].相比通用搜索引擎则变得愈发专注、具体和深入。目前,垂直搜索引擎多用于行业信息获取和特色语料库建设等方面,且已卓见现实深远成效。
网络爬虫是一个手动提取和手动下载网页的程序开源网络爬虫,可为搜索引擎从互联网上下载网页,并按照既定的抓取目标,有选择地访问互联网上的网页与相关的链接,获取所须要的信息。按照功能用途,网络爬虫分为通用爬虫和聚焦爬虫,这是搜索引擎一个核心组成部份。
1 聚焦爬虫的工作原理及关键技术剖析
1. 1 聚焦爬虫的工作原理
聚焦爬虫是专门为查询某一主题而设计的网页采集工具,并不追求大范围覆盖,而是将目标预定为抓取与某一特定主题内容相关的网页,如此即为面向主题的用户查询打算数据资源。垂直搜索引擎可借助其实现对网页主题信息的挖掘以及发觉,聚焦爬虫的工作原理是:
( 1) 爬虫从一个或若干起始网页 URL 链接开始工作;( 2) 通过特定的主题相关性算法判定并过滤掉与主题无关的链接;( 3) 将有用链接加入待抓取的 URL 队列;( 4) 根据一定的搜索策略从待抓取 URL 队列中选择下一步要抓取的网页 URL.重复以上步骤,直至满足退出条件时停止[2].
1. 2 聚焦爬虫的几个关键技术
根据聚焦爬虫的工作原理,在设计聚焦爬虫时,需要考虑问题可做如下阐述。
1. 2. 1 待抓取网站目标的定义与描述的问题
开发聚焦爬虫时,应考虑对于抓取目标的定义与描述,究竟是带有目标网页特点的网页级信息,还是针对目标网页上的结构化数据。前者因其具有结构化的数据信息特点,在爬虫抓取信息后,还需从结构化的网页中抽取相关信息; 而对于前者,爬虫则直接解析 Web 页面,提取并加工相关的结构化数据信息,该类爬虫以便订制自适应于特定网页模板的结果网站。
1. 2. 2 爬虫的 URL 搜索策略问题
开发聚焦爬虫时,常见的 URL 搜索策略主要包括深度优先搜索策略、广度优先搜索策略、最佳优先搜索策略等[3].在此给出对应策略的规则剖析如下。
( 1) 深度优先搜索策略
该搜索策略采用了后进先出的队列形式,从起始 URL出发,不停搜索网页的下一级页面直到最后无 URL 链接的网页页面结束; 爬虫再回到起始 URL 地址,继续追寻 URL的其它 URL 链接,直到不再有 URL 可搜索为止,当所有页面都结束时,URL 列表即根据插叙的方法将搜索的 URL 队列送入爬虫待抓取队列。
( 2) 广度优先搜索策略
该搜索策略采用了先进先出的队列形式,从起始 URL出发,在搜索了初始 Web 的所有 URL 链接后,再继续搜索下一层 URL 链接,直至所有 URL 搜索完毕。URL 列表将依照其步入队列的次序送入爬虫待抓取队列。
( 3) 最佳优先搜索策略
该搜索策略采用了一种局部优先搜索算法,从起始 URL出发,按照一定的剖析算法,对页面候选的 URL 进行预测,预测目标网页的相似度或主题相关性,当相关性达到一定的阀值后,URL 列表则根据相关数值高低次序送入爬虫待抓取队列。
1. 2. 3 爬虫对网页页面的剖析和主题相关性判定算法
聚焦爬虫在对网页 Web 的 URL 进行扩充时,还须要对网页内容进行剖析和信息的提取开源网络爬虫,用以确定该获取 URL 页面是否与采集的主题相关。目前常用的网页的剖析算法包括: 基于网路拓扑、基于网页内容和基于领域概念的剖析算法[4].下面给出这三类算法的原理实现。
( 1) 基于网路拓扑关系的剖析算法
基于网路拓扑关系的剖析算法就是可以通过已知的网页页面或数据,对与其有直接或间接链接关系的对象做出评价的实现过程。该算法又分为网页细度、网站粒度和网页块细度三种。着名的 PageRank 和 HITS 算法就是基于网路拓扑关系的典型代表。
( 2) 基于网页内容的剖析算法
基于网页内容的剖析算法指的是借助网页内容( 文本、数据等资源) 特征进行的网页评价。该方式已从最初的文本检索方式,向网页数据抽取、数据挖掘和自然语言等多领域方向发展。
( 3) 基于领域概念的剖析算法
基于领域概念的剖析算法则是将领域本体分解为由不同的概念、实体及其之间的关系,包括与之对应的词汇项组成。网页中的关键词在通过与领域本体对应的辞典分别转换以后,将进行计数和加权,由此得出与所选领域的相关度。 查看全部
0 引 言
在信息化时代,针对通用搜索引擎信息量大、查询准度和深度兼差等缺点,垂直搜索引擎已步入了用户认可和使用周期。垂直搜索是针对某一个行业的专业搜索引擎,是对网页库中的某类专门的信息进行一次整合,定向分数组抽取出须要的数据进行处理后再以某种方式返回给用户[1].相比通用搜索引擎则变得愈发专注、具体和深入。目前,垂直搜索引擎多用于行业信息获取和特色语料库建设等方面,且已卓见现实深远成效。
网络爬虫是一个手动提取和手动下载网页的程序开源网络爬虫,可为搜索引擎从互联网上下载网页,并按照既定的抓取目标,有选择地访问互联网上的网页与相关的链接,获取所须要的信息。按照功能用途,网络爬虫分为通用爬虫和聚焦爬虫,这是搜索引擎一个核心组成部份。
1 聚焦爬虫的工作原理及关键技术剖析
1. 1 聚焦爬虫的工作原理
聚焦爬虫是专门为查询某一主题而设计的网页采集工具,并不追求大范围覆盖,而是将目标预定为抓取与某一特定主题内容相关的网页,如此即为面向主题的用户查询打算数据资源。垂直搜索引擎可借助其实现对网页主题信息的挖掘以及发觉,聚焦爬虫的工作原理是:
( 1) 爬虫从一个或若干起始网页 URL 链接开始工作;( 2) 通过特定的主题相关性算法判定并过滤掉与主题无关的链接;( 3) 将有用链接加入待抓取的 URL 队列;( 4) 根据一定的搜索策略从待抓取 URL 队列中选择下一步要抓取的网页 URL.重复以上步骤,直至满足退出条件时停止[2].
1. 2 聚焦爬虫的几个关键技术
根据聚焦爬虫的工作原理,在设计聚焦爬虫时,需要考虑问题可做如下阐述。
1. 2. 1 待抓取网站目标的定义与描述的问题
开发聚焦爬虫时,应考虑对于抓取目标的定义与描述,究竟是带有目标网页特点的网页级信息,还是针对目标网页上的结构化数据。前者因其具有结构化的数据信息特点,在爬虫抓取信息后,还需从结构化的网页中抽取相关信息; 而对于前者,爬虫则直接解析 Web 页面,提取并加工相关的结构化数据信息,该类爬虫以便订制自适应于特定网页模板的结果网站。
1. 2. 2 爬虫的 URL 搜索策略问题
开发聚焦爬虫时,常见的 URL 搜索策略主要包括深度优先搜索策略、广度优先搜索策略、最佳优先搜索策略等[3].在此给出对应策略的规则剖析如下。
( 1) 深度优先搜索策略
该搜索策略采用了后进先出的队列形式,从起始 URL出发,不停搜索网页的下一级页面直到最后无 URL 链接的网页页面结束; 爬虫再回到起始 URL 地址,继续追寻 URL的其它 URL 链接,直到不再有 URL 可搜索为止,当所有页面都结束时,URL 列表即根据插叙的方法将搜索的 URL 队列送入爬虫待抓取队列。
( 2) 广度优先搜索策略
该搜索策略采用了先进先出的队列形式,从起始 URL出发,在搜索了初始 Web 的所有 URL 链接后,再继续搜索下一层 URL 链接,直至所有 URL 搜索完毕。URL 列表将依照其步入队列的次序送入爬虫待抓取队列。
( 3) 最佳优先搜索策略
该搜索策略采用了一种局部优先搜索算法,从起始 URL出发,按照一定的剖析算法,对页面候选的 URL 进行预测,预测目标网页的相似度或主题相关性,当相关性达到一定的阀值后,URL 列表则根据相关数值高低次序送入爬虫待抓取队列。
1. 2. 3 爬虫对网页页面的剖析和主题相关性判定算法
聚焦爬虫在对网页 Web 的 URL 进行扩充时,还须要对网页内容进行剖析和信息的提取开源网络爬虫,用以确定该获取 URL 页面是否与采集的主题相关。目前常用的网页的剖析算法包括: 基于网路拓扑、基于网页内容和基于领域概念的剖析算法[4].下面给出这三类算法的原理实现。
( 1) 基于网路拓扑关系的剖析算法
基于网路拓扑关系的剖析算法就是可以通过已知的网页页面或数据,对与其有直接或间接链接关系的对象做出评价的实现过程。该算法又分为网页细度、网站粒度和网页块细度三种。着名的 PageRank 和 HITS 算法就是基于网路拓扑关系的典型代表。
( 2) 基于网页内容的剖析算法
基于网页内容的剖析算法指的是借助网页内容( 文本、数据等资源) 特征进行的网页评价。该方式已从最初的文本检索方式,向网页数据抽取、数据挖掘和自然语言等多领域方向发展。
( 3) 基于领域概念的剖析算法
基于领域概念的剖析算法则是将领域本体分解为由不同的概念、实体及其之间的关系,包括与之对应的词汇项组成。网页中的关键词在通过与领域本体对应的辞典分别转换以后,将进行计数和加权,由此得出与所选领域的相关度。
网络爬虫基本原理解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2020-05-28 08:01
“ 只推荐有价值的技术性文章优才学院
网络爬虫是索引擎抓取系统的重要组成部份。爬虫的主要目的是将互联网上的网页下载到本地产生一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
一、网络爬虫的基本结构及工作流程
一个通用的网路爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路以后再转到下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以里面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就产生了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
四、更新策略
互联网是实时变化的,具有太强的动态性。网页更新策略主要是决定何时更新之前早已下载过的页面。常见的更新策略又以下三种:
1.历史参考策略
顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略
尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。
3.降维抽样策略
前面提及的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一网络爬虫原理,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多的系统负担;第二,要是新的网页完全没有历史信息网络爬虫原理,就难以确定更新策略。
这种策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新频度也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样,以她们的更新周期作为整个类别的更新周期。基本思路如图:
五、分布式抓取系统结构
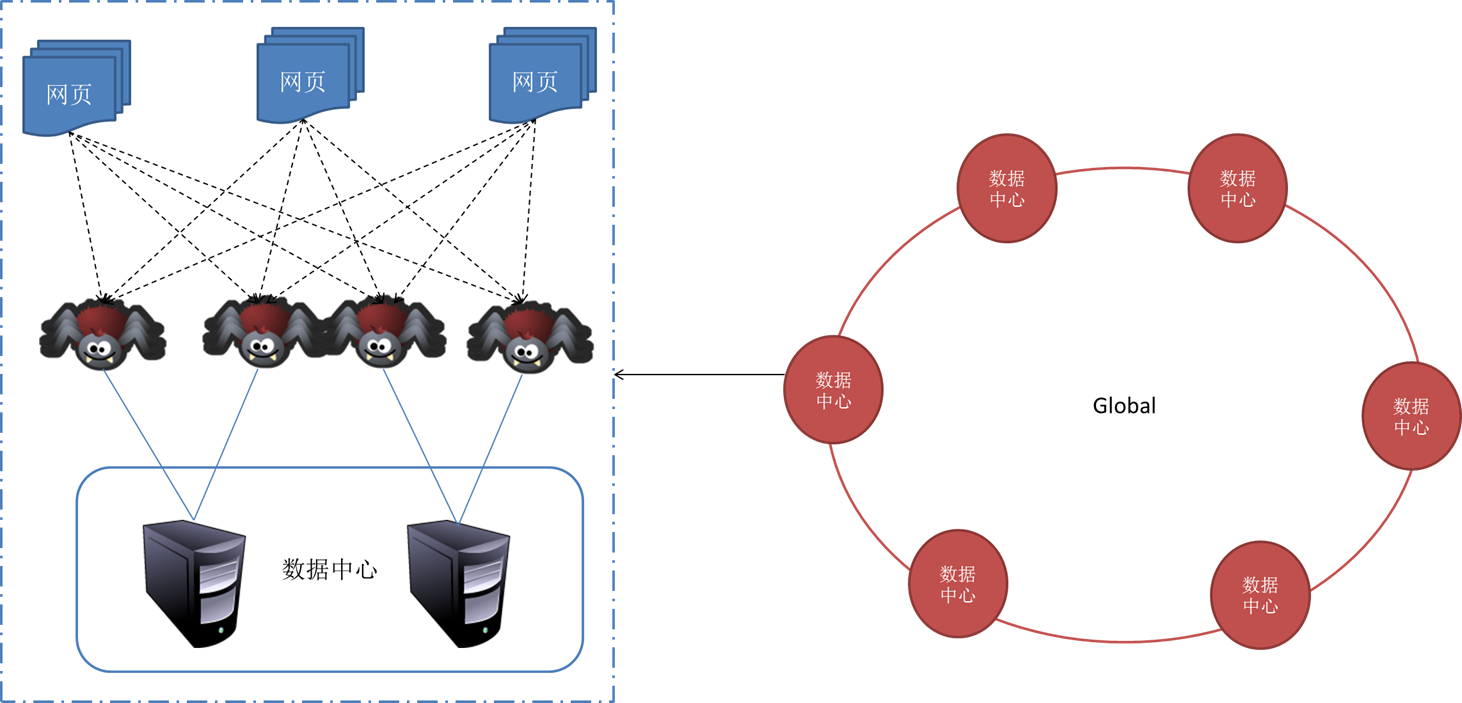
一般来说,抓取系统须要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往须要多个抓取程序一起来处理。一般来说抓取系统常常是一个分布式的三层结构。如图所示:
最下一层是分布在不同地理位置的数据中心,在每位数据中心里有若干台抓取服务器,而每台抓取服务器上可能布署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方法有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器不仅维护待抓取URL队列以及分发URL之外,还要负责调处各个Slave服务器的负载情况。以免个别Slave服务器过分悠闲或则操劳。
这种模式下,Master常常容易成为系统困局。
2.对方程(Peer to Peer)
对等式的基本结构如图所示:
在这些模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后估算H mod m(其中m是服务器的数目,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
举例:假设对于URL ,计算器hash值H=8,m=3,则H mod m=2,因此由编号为2的服务器进行该链接的抓取。假设这时候是0号服务器领到这个URL,那么它将该URL转给服务器2,由服务器2进行抓取。
这种模式有一个问题,当有一台服务器关机或则添加新的服务器,那么所有URL的哈希求余的结果就都要变化。也就是说,这种方法的扩展性不佳。针对这些情况,又有一种改进方案被提下来。这种改进的方案是一致性哈希法来确定服务器分工。其基本结构如图所示:
一致性哈希将URL的主域名进行哈希运算,映射为一个范围在0-232之间的某个数。而将这个范围平均的分配给m台服务器,根据URL主域名哈希运算的值所处的范围判定是哪台服务器来进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则根据顺时针延后,由下一台服务器进行抓取。这样的话,及时某台服务器出现问题,也不会影响其他的工作。 查看全部

“ 只推荐有价值的技术性文章优才学院
网络爬虫是索引擎抓取系统的重要组成部份。爬虫的主要目的是将互联网上的网页下载到本地产生一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
一、网络爬虫的基本结构及工作流程
一个通用的网路爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路以后再转到下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以里面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就产生了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
四、更新策略
互联网是实时变化的,具有太强的动态性。网页更新策略主要是决定何时更新之前早已下载过的页面。常见的更新策略又以下三种:
1.历史参考策略
顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略
尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。
3.降维抽样策略
前面提及的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一网络爬虫原理,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多的系统负担;第二,要是新的网页完全没有历史信息网络爬虫原理,就难以确定更新策略。
这种策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新频度也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样,以她们的更新周期作为整个类别的更新周期。基本思路如图:
五、分布式抓取系统结构
一般来说,抓取系统须要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往须要多个抓取程序一起来处理。一般来说抓取系统常常是一个分布式的三层结构。如图所示:
最下一层是分布在不同地理位置的数据中心,在每位数据中心里有若干台抓取服务器,而每台抓取服务器上可能布署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方法有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器不仅维护待抓取URL队列以及分发URL之外,还要负责调处各个Slave服务器的负载情况。以免个别Slave服务器过分悠闲或则操劳。
这种模式下,Master常常容易成为系统困局。
2.对方程(Peer to Peer)
对等式的基本结构如图所示:
在这些模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后估算H mod m(其中m是服务器的数目,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
举例:假设对于URL ,计算器hash值H=8,m=3,则H mod m=2,因此由编号为2的服务器进行该链接的抓取。假设这时候是0号服务器领到这个URL,那么它将该URL转给服务器2,由服务器2进行抓取。
这种模式有一个问题,当有一台服务器关机或则添加新的服务器,那么所有URL的哈希求余的结果就都要变化。也就是说,这种方法的扩展性不佳。针对这些情况,又有一种改进方案被提下来。这种改进的方案是一致性哈希法来确定服务器分工。其基本结构如图所示:
一致性哈希将URL的主域名进行哈希运算,映射为一个范围在0-232之间的某个数。而将这个范围平均的分配给m台服务器,根据URL主域名哈希运算的值所处的范围判定是哪台服务器来进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则根据顺时针延后,由下一台服务器进行抓取。这样的话,及时某台服务器出现问题,也不会影响其他的工作。
Java做爬虫也太牛
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-05-20 08:00
首先我们封装一个Http恳求的工具类,用HttpURLConnection实现,当然你也可以用HttpClient, 或者直接用Jsoup来恳求(下面会提到Jsoup)。
工具类实现比较简单,就一个get方式,读取恳求地址的响应内容,这边我们拿来抓取网页的内容,这边没有用代理java爬虫技术,在真正的抓取过程中,当你大量恳求某个网站的时侯,对方会有一系列的策略来禁用你的恳求,这个时侯代理就排上用场了,通过代理设置不同的IP来抓取数据。
接下来我们随意找一个有图片的网页,来试试抓取功能
首先将网页的内容抓取出来,然后用正则的方法解析出网页的标签,再解析img的地址。执行程序我们可以得到下边的内容:
通过前面的地址我们就可以将图片下载到本地了,下面我们写个图片下载的方式:
这样就很简单的实现了一个抓取而且提取图片的功能了,看起来还是比较麻烦哈,要写正则之类的 ,下面给你们介绍一种更简单的方法,如果你熟悉jQuery的话对提取元素就很简单了,这个框架就是Jsoup。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
添加jsoup的依赖:
使用jsoup以后提取的代码只须要简单的几行即可:
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag的方式提取出所有的图片标签,循环遍历,通过attr方式获取图片的src属性,然后下载图片。
Jsoup使用上去十分简单,当然还有好多其他解析网页的操作,大家可以去瞧瞧资料学习一下。
下面我们再来升级一下,做成一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按键,然后把图片手动下载出来java爬虫技术,我们可以用swing写界面。
执行main方式首先下来的就是我们的界面了,如下:
屏幕快照 2018-06-18 09.50.34 PM.png
输入地址,点击提取按键即可下载图片。
课程推荐
大数据时代,如何产生大数据。
大用户量,每天好多日志。
搞个爬虫,抓几十亿数据过来剖析剖析。
并不是只有Python能够做爬虫,Java照样可以。
今天带你们来写一个简单的图片抓取程序,将网页上的图片全部下载出来
image
本课程将率领你们一步一步编撰爬虫程序,爬到我们想要的数据,非登录的或则须要登录的都爬出来。
学完本课程将学员培养成为合格的Java网路爬虫工程师,并能胜任相关爬虫工作;
学完才能熟练使用XPath表达式进行信息提取;
学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,自动模拟进行Ajax异步恳求数据;
熟练把握jsoup提取网页数据。
selenium进行控制浏览器抓取数据。
课程大纲
HttpURLConnection用法解读
静态网页抓取
jsoup解析提取网页信息
模拟ajax进行POST恳求抓取数据
模拟登录网站抓取数据
selenium抓取网页实战
htmlunit抓取动态网页数据
IP代理池建立
多线程抓取实战
WebMagic框架实战爬虫
抓取图书数据
图书数据储存mongodb 查看全部
首先我们封装一个Http恳求的工具类,用HttpURLConnection实现,当然你也可以用HttpClient, 或者直接用Jsoup来恳求(下面会提到Jsoup)。
工具类实现比较简单,就一个get方式,读取恳求地址的响应内容,这边我们拿来抓取网页的内容,这边没有用代理java爬虫技术,在真正的抓取过程中,当你大量恳求某个网站的时侯,对方会有一系列的策略来禁用你的恳求,这个时侯代理就排上用场了,通过代理设置不同的IP来抓取数据。
接下来我们随意找一个有图片的网页,来试试抓取功能
首先将网页的内容抓取出来,然后用正则的方法解析出网页的标签,再解析img的地址。执行程序我们可以得到下边的内容:
通过前面的地址我们就可以将图片下载到本地了,下面我们写个图片下载的方式:
这样就很简单的实现了一个抓取而且提取图片的功能了,看起来还是比较麻烦哈,要写正则之类的 ,下面给你们介绍一种更简单的方法,如果你熟悉jQuery的话对提取元素就很简单了,这个框架就是Jsoup。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
添加jsoup的依赖:
使用jsoup以后提取的代码只须要简单的几行即可:
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag的方式提取出所有的图片标签,循环遍历,通过attr方式获取图片的src属性,然后下载图片。
Jsoup使用上去十分简单,当然还有好多其他解析网页的操作,大家可以去瞧瞧资料学习一下。
下面我们再来升级一下,做成一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按键,然后把图片手动下载出来java爬虫技术,我们可以用swing写界面。
执行main方式首先下来的就是我们的界面了,如下:
屏幕快照 2018-06-18 09.50.34 PM.png
输入地址,点击提取按键即可下载图片。
课程推荐
大数据时代,如何产生大数据。
大用户量,每天好多日志。
搞个爬虫,抓几十亿数据过来剖析剖析。
并不是只有Python能够做爬虫,Java照样可以。
今天带你们来写一个简单的图片抓取程序,将网页上的图片全部下载出来
image
本课程将率领你们一步一步编撰爬虫程序,爬到我们想要的数据,非登录的或则须要登录的都爬出来。
学完本课程将学员培养成为合格的Java网路爬虫工程师,并能胜任相关爬虫工作;
学完才能熟练使用XPath表达式进行信息提取;
学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,自动模拟进行Ajax异步恳求数据;
熟练把握jsoup提取网页数据。
selenium进行控制浏览器抓取数据。
课程大纲
HttpURLConnection用法解读
静态网页抓取
jsoup解析提取网页信息
模拟ajax进行POST恳求抓取数据
模拟登录网站抓取数据
selenium抓取网页实战
htmlunit抓取动态网页数据
IP代理池建立
多线程抓取实战
WebMagic框架实战爬虫
抓取图书数据
图书数据储存mongodb
网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-05-14 08:09
网络爬虫又名“网络蜘蛛”,是通过网页的链接地址来找寻网页,从网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到根据某种策略把互联网上所有的网页都抓取完为止的技术。
[编辑]
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫(General Purpose Web Crawler)、主题网路爬虫(Topical Web Crawler)、深层网络爬虫(Deep Web Crawler)。实际应用中一般是将系统几种爬虫技术互相结合。
(一)通用网路爬虫(general purpose web crawler)
通用网路爬虫按照预先设定的一个或若干初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获一个的URL,进而访问并下载该页面。页面下载后页面解析器除去页面上的HTML标记后得到页面内容,将摘要、URL等信息保存到Web数据库中,同时抽取当前页面上新的URL,保存到URL队列,直到满足系统停止条件。其工作流程如图1所示。
通用爬虫主要存在以下几方面的局限性:1)由于抓取目标是尽可能大的覆盖网路,所以爬行的结果中包含大量用户不需要的网页;2)不能挺好地搜索和获取信息浓度密集且具有一定结构的数据;3)通用搜索引擎大多是基于关键字的检索,对于支持语义信息的查询和索引擎智能化的要求无法实现。
由此可见,通用爬虫想在爬行网页时,既保证网页的质量和数目,又要保证网页的时效性是很难实现的。
(二)主题网路爬虫(Topical Web Crawler)
1.主题爬虫原理
主题爬虫并不追求大的覆盖率,也不是全盘接受所有的网页和URL,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息,不仅客服了通用爬虫存在的问题,而H-返回的数据资源更精确。主题爬虫的基本工作原理是根据预先确定的主题,分析超链接和刚才抓取的网页内容,获取下一个要爬行的URL,尽可能保证多爬行与主题相关的网页,因此主题爬虫要解决以下关键问题:1)如何判断一个早已抓取的网页是否与主题相关;2)如何过滤掉海量的网页中与主题不相关的或则相关度较低的网页;3)如何有目的、有控制的抓取与特定主题相关的web页面信息;4)如何决定待访问URL的访问顺序;5)如何提升主题爬虫的覆盖度;6)如何协调抓取目标的描述或定义与网页分析算法及候选URL排序算法之问的关系;7)如何找寻和发觉高质量网页和关键资源。高质量网页和关键资源除了可以大大提升主题爬虫收集Web页面的效率和质量,还可以为主题表示模型的优化等应用提供支持。
2.主题爬虫模块设计
主题爬虫的目标是尽可能多的发觉和收集与预定主题相关的网页网络爬虫,其最大特征在于具备剖析网页内容和判断主题相关度的能力。根据主题爬虫的工作原理,下面设计了一个主题爬虫系统,主要有页面采集模块、页面剖析模块、相关度估算模块、页面过滤模块和链接排序模块几部份组成网络爬虫,其总体功能模块结构如图2所示。
页面采集模块:主要是依据待访问URL队列进行页面下载,再交给网页剖析模型处理以抽取网页主题向量空间模型。该模块是任何爬虫系统都必不可少的模块。页面剖析模块:该模块的功能是对采集到的页面进行剖析,主要用于联接超链接排序模块和页面相关度估算模块。
页面相关度估算模块:该模块是整个系统的核心模块,主要用于评估与主题的相关度,并提供相关的爬行策略用以指导爬虫的爬行过程。URL的超链接评价得分越高,爬行的优先级就越高。其主要思想是,在系统爬行之前,页面相关度估算模块按照用户输入的关键字和初始文本信息进行学习,训练一个页面相关度评价模型。当一个被觉得是主题相关的页面爬行出来以后,该页面就被送入页面相关度评价器估算其主题相关度值,若该值小于或等于给定的某俦值,则该页面就被存入页面库,否则遗弃¨。页面过滤模块:过滤掉与主题无关的链接,同时将该URL及其所有蕴涵的子链接一并清除。通过过滤,爬虫就无需遍历与主题不相关的页面,从而保证了爬行效率。排序模块:将过滤后页面根据优先级高低加入到待访问的URL队列里。
3.主题爬虫流程设计
主题爬虫须要依照一定的网页剖析算法,过滤掉与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它会依照一定的搜索策略从待抓取的队列中选择下一个要抓取的URL,并重复上述过程,直到满足系统停止条件为止。所有被抓取网页就会被系统储存,经过一定的剖析、过滤,然后构建索引,以便用户查询和检索;这一过程所得到的剖析结果可以对之后的抓取过程提供反馈和指导。其工作流程如图3所示。
4.深度网路爬虫(Deep Web Crawler)
1994年Dr.jillEllsworth提出DeepWeb(深层页面)的概念,即DeepWeb是指普通搜索引擎无法发觉的信息内容的Web页面¨。DeepWeb中的信息量比普通的网页信息量多,而且质量更高。但是普通的搜索引擎因为技术限制而收集不到这种高质量、高权威的信息。这些信息一般隐藏在深度Web页面的小型动态数据库中,涉及数据集成、中文语义辨识等众多领域。如此庞大的信息资源假如没有合理的、高效的方式去获取,将是巨大的损失。因此,对于深度网爬行技术的研究具有极为重大的现实意义和理论价值。
常规的网路爬虫在运行中难以发觉隐藏在普通网页中的信息和规律,缺乏一定的主动性和智能性。比如须要输入用户名和密码的页面,或者包含页脚导航的页面均未能爬行。深度爬虫的设计针对常规网路爬虫的那些不足,将其结构做以改进,增加了表单剖析和页面状态保持两个部份,其结构如图4所示,通过剖析网页的结构并将其归类为普通网页或存在更多信息的深度网页,针对深度网页构造合适的表单参数而且递交,以得到更多的页面。深度爬虫的流程图如图4所示。深度爬虫与常规爬虫的不同是,深度爬虫在下载完成页面然后并没有立刻遍历其中的所有超链接,而是使用一定的算法将其进行分类,对于不同的类别采取不同的方式估算查询参数,并将参数再度递交到服务器。如果递交的查询参数正确,那么将会得到隐藏的页面和链接。深度爬虫的目标是尽可能多地访问和搜集互联网上的网页,由于深度页面是通过递交表单的形式访问,因此爬行深度页面存在以下三个方面的困难:1)深度爬虫须要有高效的算法去应对数目巨大的深层页面数据;2)很多服务器端DeepWeb要求校准表单输入,如用户名、密码、校验码等,如果校准失败,将不能爬到DeepWeb数据;3)需要JavaScript等脚本支持剖析客户端DeepWeb。
[编辑]
(1)IP地址搜索策略
IP地址搜索策略是先给爬虫一个起始的IP地址,然后按照IP地址以递增的形式搜索本IP地址段后的每一个地址中的文档,它完全不考虑各文档中指向其它Web站点的超级链接地址。这种搜索策略的优点是搜索比较全面,因此能否发觉这些没被其它文档引用的新文档的信息源;但是缺点是不适宜大规模搜索。
(2)深度优先搜索策略
深度优先搜索是一种在开发爬虫初期使用较多的方式。它的目的是要达到被搜索结构的叶结点(即这些不包含任何超链的HTML文件)。例如,在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,也就是说在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索顺着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索早已结束。
(3)宽度优先搜索策略
宽度优先搜索的过程是先搜索完一个Web页面中所有的超级链接,然后再继续搜索下一层,直到底层为止。例如,一个HTML文件中有三个超链,选择其中之一并处理相应的HTML文件,然后不再选择第二个HTML文件中的任何超链,而是返回并选择第二个超链,处理相应的HTML文件,再返回,选择第三个超链并处理相应的HTML文件。当一层上的所有超链都已被选择过,就可以开始在刚刚处理过的HIML文件中搜索其余的超链。
宽度优先搜索策略的优点:一个是保证了对浅层的优先处理,当遇见一个无穷尽的深层分支时,不会造成陷进www中的深层文档中出现出不来的情况发生;另一个是它能在两个HTML文件之间找到最短路径。
宽度优先搜索策略一般是实现爬虫的最佳策略,因为它容易实现,而且具备大多数期望的功能。但是假如要遍历一个指定的站点或则深层嵌套的HTML文件集,用长度优先搜索策略则须要耗费比较长的时间才会抵达深层的HTML文件。
[编辑]
于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报.2011,5 蔡笑伦.网络爬虫技术的发展趁机[J].科技信息.2010,12
来自"https://wiki.mbalib.com/wiki/% ... ot%3B
本条目对我有帮助8
赏
MBA智库APP
扫一扫,下载MBA智库APP 查看全部
[编辑]
网络爬虫又名“网络蜘蛛”,是通过网页的链接地址来找寻网页,从网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到根据某种策略把互联网上所有的网页都抓取完为止的技术。
[编辑]
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫(General Purpose Web Crawler)、主题网路爬虫(Topical Web Crawler)、深层网络爬虫(Deep Web Crawler)。实际应用中一般是将系统几种爬虫技术互相结合。
(一)通用网路爬虫(general purpose web crawler)
通用网路爬虫按照预先设定的一个或若干初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获一个的URL,进而访问并下载该页面。页面下载后页面解析器除去页面上的HTML标记后得到页面内容,将摘要、URL等信息保存到Web数据库中,同时抽取当前页面上新的URL,保存到URL队列,直到满足系统停止条件。其工作流程如图1所示。

通用爬虫主要存在以下几方面的局限性:1)由于抓取目标是尽可能大的覆盖网路,所以爬行的结果中包含大量用户不需要的网页;2)不能挺好地搜索和获取信息浓度密集且具有一定结构的数据;3)通用搜索引擎大多是基于关键字的检索,对于支持语义信息的查询和索引擎智能化的要求无法实现。
由此可见,通用爬虫想在爬行网页时,既保证网页的质量和数目,又要保证网页的时效性是很难实现的。
(二)主题网路爬虫(Topical Web Crawler)
1.主题爬虫原理
主题爬虫并不追求大的覆盖率,也不是全盘接受所有的网页和URL,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息,不仅客服了通用爬虫存在的问题,而H-返回的数据资源更精确。主题爬虫的基本工作原理是根据预先确定的主题,分析超链接和刚才抓取的网页内容,获取下一个要爬行的URL,尽可能保证多爬行与主题相关的网页,因此主题爬虫要解决以下关键问题:1)如何判断一个早已抓取的网页是否与主题相关;2)如何过滤掉海量的网页中与主题不相关的或则相关度较低的网页;3)如何有目的、有控制的抓取与特定主题相关的web页面信息;4)如何决定待访问URL的访问顺序;5)如何提升主题爬虫的覆盖度;6)如何协调抓取目标的描述或定义与网页分析算法及候选URL排序算法之问的关系;7)如何找寻和发觉高质量网页和关键资源。高质量网页和关键资源除了可以大大提升主题爬虫收集Web页面的效率和质量,还可以为主题表示模型的优化等应用提供支持。
2.主题爬虫模块设计
主题爬虫的目标是尽可能多的发觉和收集与预定主题相关的网页网络爬虫,其最大特征在于具备剖析网页内容和判断主题相关度的能力。根据主题爬虫的工作原理,下面设计了一个主题爬虫系统,主要有页面采集模块、页面剖析模块、相关度估算模块、页面过滤模块和链接排序模块几部份组成网络爬虫,其总体功能模块结构如图2所示。

页面采集模块:主要是依据待访问URL队列进行页面下载,再交给网页剖析模型处理以抽取网页主题向量空间模型。该模块是任何爬虫系统都必不可少的模块。页面剖析模块:该模块的功能是对采集到的页面进行剖析,主要用于联接超链接排序模块和页面相关度估算模块。
页面相关度估算模块:该模块是整个系统的核心模块,主要用于评估与主题的相关度,并提供相关的爬行策略用以指导爬虫的爬行过程。URL的超链接评价得分越高,爬行的优先级就越高。其主要思想是,在系统爬行之前,页面相关度估算模块按照用户输入的关键字和初始文本信息进行学习,训练一个页面相关度评价模型。当一个被觉得是主题相关的页面爬行出来以后,该页面就被送入页面相关度评价器估算其主题相关度值,若该值小于或等于给定的某俦值,则该页面就被存入页面库,否则遗弃¨。页面过滤模块:过滤掉与主题无关的链接,同时将该URL及其所有蕴涵的子链接一并清除。通过过滤,爬虫就无需遍历与主题不相关的页面,从而保证了爬行效率。排序模块:将过滤后页面根据优先级高低加入到待访问的URL队列里。
3.主题爬虫流程设计
主题爬虫须要依照一定的网页剖析算法,过滤掉与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它会依照一定的搜索策略从待抓取的队列中选择下一个要抓取的URL,并重复上述过程,直到满足系统停止条件为止。所有被抓取网页就会被系统储存,经过一定的剖析、过滤,然后构建索引,以便用户查询和检索;这一过程所得到的剖析结果可以对之后的抓取过程提供反馈和指导。其工作流程如图3所示。

4.深度网路爬虫(Deep Web Crawler)
1994年Dr.jillEllsworth提出DeepWeb(深层页面)的概念,即DeepWeb是指普通搜索引擎无法发觉的信息内容的Web页面¨。DeepWeb中的信息量比普通的网页信息量多,而且质量更高。但是普通的搜索引擎因为技术限制而收集不到这种高质量、高权威的信息。这些信息一般隐藏在深度Web页面的小型动态数据库中,涉及数据集成、中文语义辨识等众多领域。如此庞大的信息资源假如没有合理的、高效的方式去获取,将是巨大的损失。因此,对于深度网爬行技术的研究具有极为重大的现实意义和理论价值。
常规的网路爬虫在运行中难以发觉隐藏在普通网页中的信息和规律,缺乏一定的主动性和智能性。比如须要输入用户名和密码的页面,或者包含页脚导航的页面均未能爬行。深度爬虫的设计针对常规网路爬虫的那些不足,将其结构做以改进,增加了表单剖析和页面状态保持两个部份,其结构如图4所示,通过剖析网页的结构并将其归类为普通网页或存在更多信息的深度网页,针对深度网页构造合适的表单参数而且递交,以得到更多的页面。深度爬虫的流程图如图4所示。深度爬虫与常规爬虫的不同是,深度爬虫在下载完成页面然后并没有立刻遍历其中的所有超链接,而是使用一定的算法将其进行分类,对于不同的类别采取不同的方式估算查询参数,并将参数再度递交到服务器。如果递交的查询参数正确,那么将会得到隐藏的页面和链接。深度爬虫的目标是尽可能多地访问和搜集互联网上的网页,由于深度页面是通过递交表单的形式访问,因此爬行深度页面存在以下三个方面的困难:1)深度爬虫须要有高效的算法去应对数目巨大的深层页面数据;2)很多服务器端DeepWeb要求校准表单输入,如用户名、密码、校验码等,如果校准失败,将不能爬到DeepWeb数据;3)需要JavaScript等脚本支持剖析客户端DeepWeb。

[编辑]
(1)IP地址搜索策略
IP地址搜索策略是先给爬虫一个起始的IP地址,然后按照IP地址以递增的形式搜索本IP地址段后的每一个地址中的文档,它完全不考虑各文档中指向其它Web站点的超级链接地址。这种搜索策略的优点是搜索比较全面,因此能否发觉这些没被其它文档引用的新文档的信息源;但是缺点是不适宜大规模搜索。
(2)深度优先搜索策略
深度优先搜索是一种在开发爬虫初期使用较多的方式。它的目的是要达到被搜索结构的叶结点(即这些不包含任何超链的HTML文件)。例如,在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,也就是说在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索顺着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索早已结束。
(3)宽度优先搜索策略
宽度优先搜索的过程是先搜索完一个Web页面中所有的超级链接,然后再继续搜索下一层,直到底层为止。例如,一个HTML文件中有三个超链,选择其中之一并处理相应的HTML文件,然后不再选择第二个HTML文件中的任何超链,而是返回并选择第二个超链,处理相应的HTML文件,再返回,选择第三个超链并处理相应的HTML文件。当一层上的所有超链都已被选择过,就可以开始在刚刚处理过的HIML文件中搜索其余的超链。
宽度优先搜索策略的优点:一个是保证了对浅层的优先处理,当遇见一个无穷尽的深层分支时,不会造成陷进www中的深层文档中出现出不来的情况发生;另一个是它能在两个HTML文件之间找到最短路径。
宽度优先搜索策略一般是实现爬虫的最佳策略,因为它容易实现,而且具备大多数期望的功能。但是假如要遍历一个指定的站点或则深层嵌套的HTML文件集,用长度优先搜索策略则须要耗费比较长的时间才会抵达深层的HTML文件。
[编辑]
于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报.2011,5 蔡笑伦.网络爬虫技术的发展趁机[J].科技信息.2010,12
来自"https://wiki.mbalib.com/wiki/% ... ot%3B
本条目对我有帮助8
赏
MBA智库APP

扫一扫,下载MBA智库APP
20款最常使用的网路爬虫工具推荐(2018)教程文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2020-05-09 08:00
另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。精品文档精品文档据悉,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 ScraperScraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub精品文档精品文档Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页,甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据,并将网站信息分割开来,然后提取有效信息,形成可用的集合。 但是要手动提取精确数据就须要付费版本了,同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHub精品文档精品文档Parsehub 是一个太棒的网路爬虫,支持从使用 AJAX 技术,JavaScript,cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。精品文档精品文档7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。精品文档精品文档总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问,Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周网络爬虫软件下载,每天或每小时安排抓取任务。10.80legs精品文档精品文档80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content GraberContent Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。它更适宜具有中级编程技能的人,因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
精品文档精品文档12. UiPathUiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。处理复杂的 UI 时,此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。精品文档精品文档其实,在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。精品文档精品文档2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。精品文档 查看全部
精品文档20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。它的作用是从任何网站获取特定的或 更新的数据并储存出来。网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程,使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴,我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中网络爬虫软件下载,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼是一款免费且功能强悍的网站爬虫,用于从网站上提取你须要的几乎所有 类型的数据。你可以使用八爪鱼来采集市面上几乎所有的网站。八爪鱼提供两种精品文档精品文档采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后,其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。 你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。
另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。精品文档精品文档据悉,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 ScraperScraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub精品文档精品文档Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页,甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据,并将网站信息分割开来,然后提取有效信息,形成可用的集合。 但是要手动提取精确数据就须要付费版本了,同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHub精品文档精品文档Parsehub 是一个太棒的网路爬虫,支持从使用 AJAX 技术,JavaScript,cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。精品文档精品文档7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。精品文档精品文档总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问,Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周网络爬虫软件下载,每天或每小时安排抓取任务。10.80legs精品文档精品文档80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content GraberContent Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。它更适宜具有中级编程技能的人,因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
精品文档精品文档12. UiPathUiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。处理复杂的 UI 时,此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。精品文档精品文档其实,在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。精品文档精品文档2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。精品文档
33款可用来抓数据的开源爬虫软件工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 480 次浏览 • 2020-05-07 08:02
爬虫,即网路爬虫,是一种手动获取网页内容的程序。是搜索引擎的重要组成部份,因此搜索引擎优化很大程度上就是针对爬虫而作出的优化。
网络爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
世界上已然成形的爬虫软件多达上百种,本文对较为著名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非小型、复杂的搜索引擎,因为好多兄弟只是想爬取数据,而非营运一个搜索引擎。
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spiders并才能在Web站上的每位页面被解析然后降低几行代码调用。 Arachnid的下载包中包含两个spider应用程序事例用于演示怎么使用该框架。
特点:微型爬虫框架,含有一个大型HTML解析器
许可证:GPL
crawlzilla 是一个帮你轻松构建搜索引擎的自由软件,有了它,你就不用借助商业公司的搜索引擎,也不用再苦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能剖析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有英文动词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个便捷好用易安裝的搜索平台。
授权合同: Apache License 2
开发语言: Java JavaScript SHELL
操作系统: Linux
特点:安装简易,拥有英文动词功能
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部份,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库储存网页信息。
特点:由守护进程执行,使用数据库储存网页信息
Heritrix 是一个由 java 开发的、开源的网路爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:
特点:严格遵循robots文件的排除指示和META robots标签
heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3合同。
用户可以通过heyDr建立自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据打算。
特点:轻量级开源多线程垂直检索爬虫框架
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面
jcrawl是一款精巧性能优良的的web爬虫,它可以从网页抓取各类类型的文件,基于用户定义的符号,比如email,qq.
特点:轻量、性能优良,可以从网页抓取各类类型的文件
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [ConfigName]
URL一定要加上合同名称,如:,否则会报错。如果市掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用哪些插件,结果储存方法等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider十分容易扩充,可以借助它开发强悍的网页抓取与数据剖析工具。要做到这种,需要对JSpider的原理有深入的了 解,然后按照自己的需求开发插件,撰写配置文件。
特点:功能强悍,容易扩充
用JAVA编撰的web 搜索和爬虫,包括全文和分类垂直搜索,以及动词系统
特点:包括全文和分类垂直搜索,以及动词系统
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方式,如果依照布署在哪里分网页爬虫软件,可以分成:
服务器侧:
一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前太流行)等做,可以速率做得很快,一般综合搜索引擎的爬虫这样做。但是网页爬虫软件,如果对方厌恶爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗损的带宽也是很贵的。建议看一下Beautiful soap。
客户端:
一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或则比价服务或则推荐引擎,相对容易好多,这类爬虫不是哪些页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价钱信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以布署好多,而且可以挺有侵略性,对方很难封锁。
MetaSeeker中的网路爬虫就属于前者。
MetaSeeker工具包借助Mozilla平台的能力,只要是Firefox见到的东西,它都能提取。
特点:网页抓取、信息提取、数据抽取工具包,操作简单
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还挺不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各种峰会,贴吧,以及各种CMS系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方式:
下载一侧的.war包导出到eclipse中,使用WebContent/sql下的wcc.sql文件构建一个范例数据库,修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。然后运行SystemCore,运行时侯会在控制台,无参数会执行默认的example.xml的配置文件,带参数时侯名称为配置文件名。
系统自带了3个事例,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz峰会的内容。
特点:通过XML配置文件实现高度可定制性与可扩展性
Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath如何获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
特点:灵活、扩展性强,微内核+插件式构架,通过简单的配置就可以完成数据抓取,无需编撰一句代码
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持手动重试、自定义UA/cookie等功能。
webmagic包含强悍的页面抽取功能,开发者可以方便的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:
查看源代码:
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献
Web-Harvest是一个Java开源Web数据抽取工具。它就能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这种技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑如何处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
授权合同:Apache
开发语言:Java
特点:由两部份组成:爬虫工作平台和WebSPHINX类包
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是建立基于p2p Web索引网路的一个新技巧.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
特点:基于P2P的分布式Web搜索引擎
QuickRecon是一个简单的信息搜集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats找寻人际关系等。QuickRecon使用python编撰,支持linux和 windows操作系统。
特点:具有查找子域名名称、收集电子邮件地址并找寻人际关系等功能
这是一个十分简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~
github源代码:
特点:基于Twisted的异步处理框架,文档齐全
HiSpider is a fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
工作流程:
授权合同: BSD
开发语言: C/C++
操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
特点:高性能的爬虫软件,只负责抓取不负责解析
Methabot 是一个经过速率优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
特点:过速率优化、可抓取WEB、FTP及本地文件系统
源代码:
NWebCrawler是一款开源,C#开发网路爬虫程序。
特性:
授权合同: GPLv2
开发语言: C#
操作系统: Windows
项目主页:
特点:统计信息、执行过程可视化
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研制等的数据支持,但切勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数目的限制、获取微博数目的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和演出当前作品,制作派生作品。 你不可将当前作品用于商业目的。
5.x版本早已发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以及调节恳求频度的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现今测试的结果看,已经才能满足自用。
本程序的特征:
6个后台工作线程,最大限度挖掘爬虫性能潜力!界面上提供参数设置,灵活便捷抛弃app.config配置文件,自己实现配置信息的加密储存,保护数据库账号信息手动调整恳求频度,防止超限,也防止过慢,降低效率任意对爬虫控制,可随时暂停、继续、停止爬虫良好的用户体验
授权合同: GPLv3
开发语言: C# .NET
操作系统: Windows
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望递交你的代码.
github源代码:
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite储存数据
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接字段开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回去的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自Open-Open
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源
网站数据采集软件 网络矿工[url=https://www.ucaiyun.com/]采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
特点:功能丰富,毫不逊色于商业软件
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
特点:开源多线程网络爬虫,有许多有趣的功能
29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并才能索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它构建针对某一领域的垂直搜索引擎是最好的选择。
演示:
特点:具有采集网页内容、提交表单功能
ThinkUp 是一个可以采集推特,facebook等社交网路数据的社会媒体视角引擎。通过采集个人的社交网络帐号中的数据,对其存档以及处理的交互剖析工具,并将数据图形化便于更直观的查看。
github源码:
特点:采集推特、脸谱等社交网路数据的社会媒体视角引擎,可进行交互剖析并将结果以可视化方式诠释
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了天猫、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML都会做程序模板,免费开放下载,是广大淘客站长的首选。 查看全部
要玩大数据,没有数据如何玩?这里推荐一些33款开源爬虫软件给你们。
爬虫,即网路爬虫,是一种手动获取网页内容的程序。是搜索引擎的重要组成部份,因此搜索引擎优化很大程度上就是针对爬虫而作出的优化。
网络爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
世界上已然成形的爬虫软件多达上百种,本文对较为著名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非小型、复杂的搜索引擎,因为好多兄弟只是想爬取数据,而非营运一个搜索引擎。
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spiders并才能在Web站上的每位页面被解析然后降低几行代码调用。 Arachnid的下载包中包含两个spider应用程序事例用于演示怎么使用该框架。
特点:微型爬虫框架,含有一个大型HTML解析器
许可证:GPL
crawlzilla 是一个帮你轻松构建搜索引擎的自由软件,有了它,你就不用借助商业公司的搜索引擎,也不用再苦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能剖析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有英文动词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个便捷好用易安裝的搜索平台。
授权合同: Apache License 2
开发语言: Java JavaScript SHELL
操作系统: Linux
特点:安装简易,拥有英文动词功能
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部份,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库储存网页信息。
特点:由守护进程执行,使用数据库储存网页信息
Heritrix 是一个由 java 开发的、开源的网路爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:
特点:严格遵循robots文件的排除指示和META robots标签

heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3合同。
用户可以通过heyDr建立自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据打算。
特点:轻量级开源多线程垂直检索爬虫框架
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面
jcrawl是一款精巧性能优良的的web爬虫,它可以从网页抓取各类类型的文件,基于用户定义的符号,比如email,qq.
特点:轻量、性能优良,可以从网页抓取各类类型的文件
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [ConfigName]
URL一定要加上合同名称,如:,否则会报错。如果市掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用哪些插件,结果储存方法等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider十分容易扩充,可以借助它开发强悍的网页抓取与数据剖析工具。要做到这种,需要对JSpider的原理有深入的了 解,然后按照自己的需求开发插件,撰写配置文件。
特点:功能强悍,容易扩充
用JAVA编撰的web 搜索和爬虫,包括全文和分类垂直搜索,以及动词系统
特点:包括全文和分类垂直搜索,以及动词系统
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方式,如果依照布署在哪里分网页爬虫软件,可以分成:
服务器侧:
一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前太流行)等做,可以速率做得很快,一般综合搜索引擎的爬虫这样做。但是网页爬虫软件,如果对方厌恶爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗损的带宽也是很贵的。建议看一下Beautiful soap。
客户端:
一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或则比价服务或则推荐引擎,相对容易好多,这类爬虫不是哪些页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价钱信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以布署好多,而且可以挺有侵略性,对方很难封锁。
MetaSeeker中的网路爬虫就属于前者。
MetaSeeker工具包借助Mozilla平台的能力,只要是Firefox见到的东西,它都能提取。
特点:网页抓取、信息提取、数据抽取工具包,操作简单
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还挺不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各种峰会,贴吧,以及各种CMS系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方式:
下载一侧的.war包导出到eclipse中,使用WebContent/sql下的wcc.sql文件构建一个范例数据库,修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。然后运行SystemCore,运行时侯会在控制台,无参数会执行默认的example.xml的配置文件,带参数时侯名称为配置文件名。
系统自带了3个事例,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz峰会的内容。
特点:通过XML配置文件实现高度可定制性与可扩展性
Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath如何获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
特点:灵活、扩展性强,微内核+插件式构架,通过简单的配置就可以完成数据抓取,无需编撰一句代码
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。

webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持手动重试、自定义UA/cookie等功能。
webmagic包含强悍的页面抽取功能,开发者可以方便的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:
查看源代码:
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献
Web-Harvest是一个Java开源Web数据抽取工具。它就能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这种技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑如何处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
授权合同:Apache
开发语言:Java
特点:由两部份组成:爬虫工作平台和WebSPHINX类包
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是建立基于p2p Web索引网路的一个新技巧.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
特点:基于P2P的分布式Web搜索引擎
QuickRecon是一个简单的信息搜集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats找寻人际关系等。QuickRecon使用python编撰,支持linux和 windows操作系统。
特点:具有查找子域名名称、收集电子邮件地址并找寻人际关系等功能
这是一个十分简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~
github源代码:
特点:基于Twisted的异步处理框架,文档齐全
HiSpider is a fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
工作流程:
授权合同: BSD
开发语言: C/C++
操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
特点:高性能的爬虫软件,只负责抓取不负责解析
Methabot 是一个经过速率优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
特点:过速率优化、可抓取WEB、FTP及本地文件系统
源代码:
NWebCrawler是一款开源,C#开发网路爬虫程序。
特性:
授权合同: GPLv2
开发语言: C#
操作系统: Windows
项目主页:
特点:统计信息、执行过程可视化
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研制等的数据支持,但切勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数目的限制、获取微博数目的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和演出当前作品,制作派生作品。 你不可将当前作品用于商业目的。
5.x版本早已发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以及调节恳求频度的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现今测试的结果看,已经才能满足自用。
本程序的特征:
6个后台工作线程,最大限度挖掘爬虫性能潜力!界面上提供参数设置,灵活便捷抛弃app.config配置文件,自己实现配置信息的加密储存,保护数据库账号信息手动调整恳求频度,防止超限,也防止过慢,降低效率任意对爬虫控制,可随时暂停、继续、停止爬虫良好的用户体验
授权合同: GPLv3
开发语言: C# .NET
操作系统: Windows
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望递交你的代码.
github源代码:
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite储存数据
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接字段开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回去的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自Open-Open
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源
网站数据采集软件 网络矿工[url=https://www.ucaiyun.com/]采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
特点:功能丰富,毫不逊色于商业软件
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
特点:开源多线程网络爬虫,有许多有趣的功能
29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并才能索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它构建针对某一领域的垂直搜索引擎是最好的选择。
演示:
特点:具有采集网页内容、提交表单功能
ThinkUp 是一个可以采集推特,facebook等社交网路数据的社会媒体视角引擎。通过采集个人的社交网络帐号中的数据,对其存档以及处理的交互剖析工具,并将数据图形化便于更直观的查看。
github源码:
特点:采集推特、脸谱等社交网路数据的社会媒体视角引擎,可进行交互剖析并将结果以可视化方式诠释
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了天猫、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML都会做程序模板,免费开放下载,是广大淘客站长的首选。
20款最常使用的网路爬虫工具推荐(2018)
采集交流 • 优采云 发表了文章 • 0 个评论 • 445 次浏览 • 2020-05-06 08:04
八爪鱼·云采集网络爬虫软件 20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。 它的作用是从任何网站获取特定的或 更新的数据并储存出来。 网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程, 使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴, 我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼·云采集网络爬虫软件 八爪鱼是一款免费且功能强悍的网站爬虫, 用于从网站上提取你须要的几乎所有 类型的数据。 你可以使用八爪鱼来采集市面上几乎所有的网站。 八爪鱼提供两种 采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后, 其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。
你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack八爪鱼·云采集网络爬虫软件 作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows网站爬虫软件,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。 你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。此外,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 Scraper八爪鱼·云采集网络爬虫软件 Scraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets 。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub八爪鱼·云采集网络爬虫软件 Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。 还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页, 甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据, 并将网站信息分割开来, 然后提取有效信息, 形成可用的集合。 但是要手动提取精确数据就须要付费版本了, 同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHubParsehub 是一个太棒的网路爬虫, 支持从使用 AJAX 技术, JavaScript, cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。八爪鱼·云采集网络爬虫软件 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。 它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。八爪鱼·云采集网络爬虫软件 7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周网站爬虫软件,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。八爪鱼·云采集网络爬虫软件 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。 总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问, Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
八爪鱼·云采集网络爬虫软件 为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周,每天或每小时安排抓取任务。10.80legs80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content Graber八爪鱼·云采集网络爬虫软件 Content Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。 它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。 它更适宜具有中级编程技能的人, 因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。 允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
12. UiPath八爪鱼·云采集网络爬虫软件 UiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。 处理复杂的 UI 时, 此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。八爪鱼·云采集网络爬虫软件 总之, 在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部

八爪鱼·云采集网络爬虫软件 20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。 它的作用是从任何网站获取特定的或 更新的数据并储存出来。 网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程, 使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴, 我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼·云采集网络爬虫软件 八爪鱼是一款免费且功能强悍的网站爬虫, 用于从网站上提取你须要的几乎所有 类型的数据。 你可以使用八爪鱼来采集市面上几乎所有的网站。 八爪鱼提供两种 采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后, 其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。
你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack八爪鱼·云采集网络爬虫软件 作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows网站爬虫软件,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。 你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。此外,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 Scraper八爪鱼·云采集网络爬虫软件 Scraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets 。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub八爪鱼·云采集网络爬虫软件 Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。 还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页, 甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据, 并将网站信息分割开来, 然后提取有效信息, 形成可用的集合。 但是要手动提取精确数据就须要付费版本了, 同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHubParsehub 是一个太棒的网路爬虫, 支持从使用 AJAX 技术, JavaScript, cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。八爪鱼·云采集网络爬虫软件 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。 它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。八爪鱼·云采集网络爬虫软件 7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周网站爬虫软件,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。八爪鱼·云采集网络爬虫软件 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。 总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问, Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
八爪鱼·云采集网络爬虫软件 为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周,每天或每小时安排抓取任务。10.80legs80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content Graber八爪鱼·云采集网络爬虫软件 Content Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。 它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。 它更适宜具有中级编程技能的人, 因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。 允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
12. UiPath八爪鱼·云采集网络爬虫软件 UiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。 处理复杂的 UI 时, 此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。八爪鱼·云采集网络爬虫软件 总之, 在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
利用网路爬虫技术快速确切寻觅目的图书的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2020-05-04 08:07
【专利摘要】本发明公开了一种借助网路爬虫技术快速确切找寻目的图书的方式,流程如下:录入电子图书构建电子图书库,将录入的图书分类装入不同的子网页中,输入须要阅读图书的关键词,利用网路爬虫技术对与目的图书有关的图书网页进行抓取,对抓取得网页进行剖析,分析后输出过滤后的图书,选择目的图书进行阅读。本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类网络爬虫书籍,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利说明】利用网路爬虫技术快速确切找寻目的图书的方式
发明领域
[0001]本发明涉及一种阅读电子图书过程中确切快速选购目的图书的方式,属于网路【技术领域】。
【背景技术】
[0002]电子图书馆,是随着电版物的出现,网络通信技术的发展,而渐渐出现的。电子图书馆,具有储存能力大、速度快、保存时间长、成本低、便于交流等特性。光盘这一海量存储器、能够储存比传统图书高几千倍的信息,比微缩胶卷要多得多,而且包括图像、视频、声音,等等。利用电子技术,在这一种图书馆,我们能很快地从浩如烟海的图书中,查找到自己所须要的信息资料。这种图书馆,保存信息量的时间要长得多,不存在腐烂、生虫等问题。利用网路,在远在几千里、万里的单位、家中,都可以使用这些图书,效率极高。在广袤的书海中,想要快速确切的找到目标图书并不是这么容易,为我们阅读电子图书带来了一定的困难,阻碍了电子图书的发展。
【发明内容】
[0003]本发明为解决目前在电子图书馆中快速找寻目的图书的问题,提供一种借助网路爬虫技术快速确切寻觅目的图书的方式。本发明包括以下步骤:
[0004]步骤一:录入电子图书构建电子图书库;
[0005]步骤二:将录入的图书分类装入不同的子网页中;
[0006]步骤三:输入须要阅读图书的关键词;
[0007]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0008]步骤五:对抓取得网页进行剖析;
[0009]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0010]发明疗效:本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利附图】
【附图说明】
[0011]图1为借助网路爬虫技术快速确切找寻目的图书方式的流程图。
【具体施行方法】
[0012]【具体施行方法】:参见借助网路爬虫技术快速确切找寻目的图书方式的流程图1,本施行方法由以下步骤组成:
[0013]步骤一:录入电子图书构建电子图书库;
[0014]步骤二:将录入的图书分类装入不同的子网页中;[0015]步骤三:输入须要阅读图书的关键词;
[0016]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0017]步骤五:对抓取得网页进行剖析;
[0018]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0019]录入的电子图书必须对其按图书的种类对其进行命名,录入的图书的子网页早已录入图书的种类赋于了不同的域名,收索须要的电子图书须要输入该图书的图书名,或所属的学科种类,网络爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取,对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
[0020]对于本领域技术人员而言,显然本发明不限于上述示范性施行例的细节,而且在不背离本发明的精神或基本特点的情况下,能够以其他的具体方式实现本发明。因此网络爬虫书籍,无论从哪一点来看,均应将发明例看作是示范性的,而且是非限制性的,本发明的范围由所附权力要求而不是上述说明限定,因此借以将落在权力要求的等同要件的含意和范围内的所有变化涵盖在本发明内。不应将权力要求中的任何附图标记视为限制所涉及的权力要求。
【权利要求】
1.一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于它由以下步骤实现: 步骤一:录入电子图书,建立电子图书库; 步骤二:将录入的图书分类装入不同的子网页中; 步骤三:输入须要阅读图书的关键词; 步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取; 步骤五:对抓取得网页进行剖析; 步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
2.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤二中所述录入的电子图书必须对其按图书的种类对其进行命名。
3.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述录入的图书的子网页早已录入图书的种类赋于了不同的域名。
4.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述收索须要的电子图书须要输入该图书的图书名,或所属的学科种类。
5.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述网路爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取。
6.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
【文档编号】G06F17/30GK103744945SQ201310754637
【公开日】2014年4月23日 申请日期:2013年12月31日 优先权日:2013年12月31日
【发明者】朱龙腾 申请人:上海伯释信息科技有限公司 查看全部
利用网路爬虫技术快速确切寻觅目的图书的方式
【专利摘要】本发明公开了一种借助网路爬虫技术快速确切找寻目的图书的方式,流程如下:录入电子图书构建电子图书库,将录入的图书分类装入不同的子网页中,输入须要阅读图书的关键词,利用网路爬虫技术对与目的图书有关的图书网页进行抓取,对抓取得网页进行剖析,分析后输出过滤后的图书,选择目的图书进行阅读。本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类网络爬虫书籍,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利说明】利用网路爬虫技术快速确切找寻目的图书的方式
发明领域
[0001]本发明涉及一种阅读电子图书过程中确切快速选购目的图书的方式,属于网路【技术领域】。
【背景技术】
[0002]电子图书馆,是随着电版物的出现,网络通信技术的发展,而渐渐出现的。电子图书馆,具有储存能力大、速度快、保存时间长、成本低、便于交流等特性。光盘这一海量存储器、能够储存比传统图书高几千倍的信息,比微缩胶卷要多得多,而且包括图像、视频、声音,等等。利用电子技术,在这一种图书馆,我们能很快地从浩如烟海的图书中,查找到自己所须要的信息资料。这种图书馆,保存信息量的时间要长得多,不存在腐烂、生虫等问题。利用网路,在远在几千里、万里的单位、家中,都可以使用这些图书,效率极高。在广袤的书海中,想要快速确切的找到目标图书并不是这么容易,为我们阅读电子图书带来了一定的困难,阻碍了电子图书的发展。
【发明内容】
[0003]本发明为解决目前在电子图书馆中快速找寻目的图书的问题,提供一种借助网路爬虫技术快速确切寻觅目的图书的方式。本发明包括以下步骤:
[0004]步骤一:录入电子图书构建电子图书库;
[0005]步骤二:将录入的图书分类装入不同的子网页中;
[0006]步骤三:输入须要阅读图书的关键词;
[0007]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0008]步骤五:对抓取得网页进行剖析;
[0009]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0010]发明疗效:本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利附图】
【附图说明】
[0011]图1为借助网路爬虫技术快速确切找寻目的图书方式的流程图。
【具体施行方法】
[0012]【具体施行方法】:参见借助网路爬虫技术快速确切找寻目的图书方式的流程图1,本施行方法由以下步骤组成:
[0013]步骤一:录入电子图书构建电子图书库;
[0014]步骤二:将录入的图书分类装入不同的子网页中;[0015]步骤三:输入须要阅读图书的关键词;
[0016]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0017]步骤五:对抓取得网页进行剖析;
[0018]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0019]录入的电子图书必须对其按图书的种类对其进行命名,录入的图书的子网页早已录入图书的种类赋于了不同的域名,收索须要的电子图书须要输入该图书的图书名,或所属的学科种类,网络爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取,对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
[0020]对于本领域技术人员而言,显然本发明不限于上述示范性施行例的细节,而且在不背离本发明的精神或基本特点的情况下,能够以其他的具体方式实现本发明。因此网络爬虫书籍,无论从哪一点来看,均应将发明例看作是示范性的,而且是非限制性的,本发明的范围由所附权力要求而不是上述说明限定,因此借以将落在权力要求的等同要件的含意和范围内的所有变化涵盖在本发明内。不应将权力要求中的任何附图标记视为限制所涉及的权力要求。
【权利要求】
1.一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于它由以下步骤实现: 步骤一:录入电子图书,建立电子图书库; 步骤二:将录入的图书分类装入不同的子网页中; 步骤三:输入须要阅读图书的关键词; 步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取; 步骤五:对抓取得网页进行剖析; 步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
2.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤二中所述录入的电子图书必须对其按图书的种类对其进行命名。
3.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述录入的图书的子网页早已录入图书的种类赋于了不同的域名。
4.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述收索须要的电子图书须要输入该图书的图书名,或所属的学科种类。
5.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述网路爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取。
6.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
【文档编号】G06F17/30GK103744945SQ201310754637
【公开日】2014年4月23日 申请日期:2013年12月31日 优先权日:2013年12月31日
【发明者】朱龙腾 申请人:上海伯释信息科技有限公司
网络爬虫基本原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-05-03 08:00
网络爬虫基本原理23.05.2019基本描述 需要理解的算法 数据分类抓取策略 更新策略23.05.2019网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的 抓取万维网信息的程序或则脚本,是搜索引擎的重要组成。传统爬虫从一个或若 干初始网页的开始,获得初始网页上的,在抓取网页的过程中,不断从当前页面 上抽取新的装入队列,直到满足系统的一定停止条件。23.05.2019聚焦爬虫传统爬虫从一个或若干初始网页的开始,获得初始网页上的,在抓取网页的过程 中,不断从当前页面上抽取新的装入队列,直到满足系统的一定停止条件。聚焦爬 虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的队列。然后网络爬虫原理,它将按照一定的搜索策略从 队列中选择下一步要抓取的网页,并重复上述过程,直到达到系统的某一条件时 停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤, 并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分 析结果还可能对之后的抓取过程给出反馈和指导。23.05.2019简单流程 ::作为初始解析 网页数据 分析下载网页库种子待抓取已抓取下载网页 进入已抓取队列从队列信息中抽 取新的23.05.2019须要理解的算法.关键字匹配 :: 字符串匹配 算法(算法) 有限自动机算法 *算法.网页内容冗余 :: 卡时.大数目网页处理 :: *分布式.防止重复遍历 :: 字符串23.05.2019数据分类.已下载未过期网页 .已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的, 一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就过期了。
.待下载网页:也就是待抓取队列中的这些页面。 .可知网页:还没有抓取出来,也没有在待抓取队列中,但是可以通过对已抓取页面或则待 抓取对应页面进行剖析获取到的,认为是可知网页。 .不可知网页:还有一部分网页,爬虫是难以直接抓取下载的23.05.2019数据分类 ::已知网页已抓取未过期 已抓取已过期23.05.2019数据分类 ::不可知网页23.05.2019抓取策略 :: 暴力.深度优先搜索 .广度优先搜索 .大站优先策略对于待抓取队列中的所有网页,根据所属的网站进行分类。对于待下载页面数 多的网站,优先下载。这个策略也因而称作大站优先策略。23.05.2019抓取策略 :: 技巧.反向链接数策略 反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会 使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全 准确评价网页的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。23.05.2019抓取策略 :: 技巧策略 算法借鉴了算法的思想。
对于早已下载的网页,连同待抓取队列中的,形成网页集合网络爬虫原理,计算每位页面的值,计算完以后,将待抓取队列中的根据值的大小排列, 并根据该次序抓取页面。策略策略 该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金()。当下载了某个页面然后,将的现金平摊给所有从中剖析 出的链接,并且将的现金清空。对于待抓取队列中的所有页面根据现金数进行排 序。23.05.2019更新策略 :: 可持久化数据结构.历史参考策略 顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。.用户体验策略 尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的 网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用 户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的 影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。23.05.2019更新策略 :: 统计学改进.聚类抽样策略 前面提及的两种更新策略都有一个前提:需要网页的历史信息。
这样就存在两个问题:第一,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多 的系统负担;第二,要是新的网页完全没有历史信息,就难以确定更新策略。而降维抽样策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新 频率也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样, 以她们的更新周期作为整个类别的更新周期。23.05.2019的个人博客《这就是搜索引擎——核心技术解读》 张俊林 电子工业出版社《搜索引擎技术基础》刘奕群等 清华大学出版社23.05.2019ACM2013 查看全部

网络爬虫基本原理23.05.2019基本描述 需要理解的算法 数据分类抓取策略 更新策略23.05.2019网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的 抓取万维网信息的程序或则脚本,是搜索引擎的重要组成。传统爬虫从一个或若 干初始网页的开始,获得初始网页上的,在抓取网页的过程中,不断从当前页面 上抽取新的装入队列,直到满足系统的一定停止条件。23.05.2019聚焦爬虫传统爬虫从一个或若干初始网页的开始,获得初始网页上的,在抓取网页的过程 中,不断从当前页面上抽取新的装入队列,直到满足系统的一定停止条件。聚焦爬 虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的队列。然后网络爬虫原理,它将按照一定的搜索策略从 队列中选择下一步要抓取的网页,并重复上述过程,直到达到系统的某一条件时 停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤, 并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分 析结果还可能对之后的抓取过程给出反馈和指导。23.05.2019简单流程 ::作为初始解析 网页数据 分析下载网页库种子待抓取已抓取下载网页 进入已抓取队列从队列信息中抽 取新的23.05.2019须要理解的算法.关键字匹配 :: 字符串匹配 算法(算法) 有限自动机算法 *算法.网页内容冗余 :: 卡时.大数目网页处理 :: *分布式.防止重复遍历 :: 字符串23.05.2019数据分类.已下载未过期网页 .已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的, 一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就过期了。
.待下载网页:也就是待抓取队列中的这些页面。 .可知网页:还没有抓取出来,也没有在待抓取队列中,但是可以通过对已抓取页面或则待 抓取对应页面进行剖析获取到的,认为是可知网页。 .不可知网页:还有一部分网页,爬虫是难以直接抓取下载的23.05.2019数据分类 ::已知网页已抓取未过期 已抓取已过期23.05.2019数据分类 ::不可知网页23.05.2019抓取策略 :: 暴力.深度优先搜索 .广度优先搜索 .大站优先策略对于待抓取队列中的所有网页,根据所属的网站进行分类。对于待下载页面数 多的网站,优先下载。这个策略也因而称作大站优先策略。23.05.2019抓取策略 :: 技巧.反向链接数策略 反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会 使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全 准确评价网页的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。23.05.2019抓取策略 :: 技巧策略 算法借鉴了算法的思想。
对于早已下载的网页,连同待抓取队列中的,形成网页集合网络爬虫原理,计算每位页面的值,计算完以后,将待抓取队列中的根据值的大小排列, 并根据该次序抓取页面。策略策略 该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金()。当下载了某个页面然后,将的现金平摊给所有从中剖析 出的链接,并且将的现金清空。对于待抓取队列中的所有页面根据现金数进行排 序。23.05.2019更新策略 :: 可持久化数据结构.历史参考策略 顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。.用户体验策略 尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的 网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用 户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的 影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。23.05.2019更新策略 :: 统计学改进.聚类抽样策略 前面提及的两种更新策略都有一个前提:需要网页的历史信息。
这样就存在两个问题:第一,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多 的系统负担;第二,要是新的网页完全没有历史信息,就难以确定更新策略。而降维抽样策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新 频率也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样, 以她们的更新周期作为整个类别的更新周期。23.05.2019的个人博客《这就是搜索引擎——核心技术解读》 张俊林 电子工业出版社《搜索引擎技术基础》刘奕群等 清华大学出版社23.05.2019ACM2013
网络爬虫是哪些?网络爬虫是怎样工作的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 408 次浏览 • 2020-05-02 08:08
摘要:一篇文章了解爬虫的前世今生与未来
什么是网络爬虫?
网络爬虫,也称为网页抓取和网页数据提取,基本上是指通过超文本传输协议(HTTP)或通过网页浏览器获取万维网上可用的数据。(摘自Wikipedia)
网络爬虫是怎样工作的?
通常,爬取网页数据时,只须要2个步骤。
打开网页→将具体的数据从网页中复制并导入到表格或数据库中。
这一切是怎么开始的?
尽管对许多人来说,网络爬虫听上去象是“大数据”或“机器学习”一类的新概念,但实际上,网络数据抓取的历史要长得多,可以溯源到万维网(或浅显的“互联网”)诞生之时。
一开始,互联网还没有搜索。在搜索引擎被开发下来之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
随后,互联网发展上去,最终有数百万级的网页生成,这些网页包含大量不同的方式的数据,其中包括文本、图像、视频和音频。互联网弄成了一个开放的数据源。
随着数据资源显得十分丰富且容易搜索,人们发觉从网页上找到她们想要的信息是一件极其简单的事情,他们一般分布在大量的网站上。但另一个问题出现了,当她们想要数据的时侯,并非每位网站都提供下载按键,如果进行自动复制其实是极其低效且平庸的。
这就是网路爬虫诞生的诱因。网络爬虫实际上是由网页机器人/爬虫驱动的,其功能与搜索引擎相同。简单来说就是,抓取和复制。唯一的不同可能是规模。网络数据抓取是从特定的网站提取特定的数据,而搜索引擎一般是在万维网上搜索出大部分的网站。
时间轴
1989年万维网的诞生
从技术上讲,万维网和因特网有所不同。前者是指信息空间,后者是由数台计算机联接上去的内部网路。
感谢Tim Berners-Lee,万维网的发明者,他发明的三件东西,往后成为了我们日常生活中的一部分。
1990年第一个网络浏览器
它也由Tim Berners-Lee发明,被称为WorldWide网页(无空间),以WWW项目命名。在网路出现一年后,人们有了一条途径去浏览它并与之互动。
1991年第一个网页服务器和第一个 网页页面
网页的数目以缓慢的速率下降。到1994年,HTTP服务器的数目超过200台。
1993年6月第一台网页机器人——万维网漫游器
虽然它的功能和昨天的网页机器人一样,但它只是拿来检测网页的大小。
1993年12月首个基于爬虫的网路搜索引擎—JumpStation
由于当时网路上的网站并不多,搜索引擎过去经常依赖人工网站管理员来搜集和编辑链接,使其成为一种特定的格式。
JumpStation带来了新的飞越。它是第一个借助网路机器人的WWW搜索引擎。
从那时起,人们开始使用这种程序化的网路爬虫程序来搜集和组织互联网。从Infoseek、Altavista和Excite,到现在的必应和微软,搜索引擎机器人的核心依旧保持不变:
找到一个网页页面,下载(获取)它,抓取网页页面上显示的所有信息,然后将其添加到搜索引擎的数据库中。
由于网页页面是为人类用户设计的,不是为了自动化使用,即使开发了网页机器人,计算机工程师和科学家一直很难进行网路数据抓取,更不用说普通人了。因此,人们仍然致力于让网路爬虫显得愈发容易使用。
2000年网页API和API爬虫
API表示应用程序编程插口。它是一个插口,通过提供搭建好的模块,使开发程序愈加方便。
2000年,Salesforce和eBay推出了自己的API,程序员可以用它访问并下载一些公开数据。
从那时起,许多网站都提供网页API使人们可以访问她们的公共数据库。
发送一组HTTP请求,然后接收JSON或XML的回馈。
网页API通过搜集网站提供的数据,为开发人员提供了一种更友好的网路爬虫形式。
2004 年Python Beautiful Soup
不是所有的网站都提供API。即使她们提供了,他们也不一定会提供你想要的所有数据。因此,程序员们仍在开发一种才能建立网路爬虫的方式。
2004年,Beautiful Soup发布。它是一个为Python设计的库。
在计算机编程中,库是脚本模块的集合,就像常用的算法一样,它容许不用重画就可以使用,从而简化了编程过程。
通过简单的命令,Beautiful Soup可以理解站点的结构,并帮助从HTML容器中解析内容。它被觉得是用于网路爬虫的最复杂和最先进的库,也是现今最常见和最流行的方式之一。
2005-2006年网路抓取软件的可视化
2006年,Stefan Andresen和他的Kapow软件(Kofax于2013年竞购)发布了网页集成平台6.0版本,这是一种可视化的网路爬虫软件,它容许用户轻松简单的选择网页内容,并将这种数据构造成可用的excel文件或数据库。
八爪鱼数据采集器
最终,可视化的网路数据抓取软件可以使大量非程序员自己进行网路爬虫。
从那时起,网络抓取开始成为主流。现在,对于非程序员来说,他们可以很容易地找到80多个可提供可视化过程的的数据采集软件。
网络爬虫未来将怎样发展?
我们总是想要更多的数据。我们搜集数据,处理数据,并把数据转换成各种各样的成品,比如研究,洞察剖析,信息,故事,资产等等。我们过去经常耗费大量的时间、精力和金钱在找寻和搜集数据上,以至于只有大公司和组织能够负担得起。
在2018年,我们所知的万维网网络爬虫技术是什么,或浅显的“互联网”,由超过18亿个网站组成。只需点击几下键盘,就可以获得这么巨大的数据量。随着越来越多的人上网,每秒形成的数据也越来越多。
如今,是一个比历史上任何时期都要便捷的时代。任何个人、公司和组织都还能获得她们想要的数据,只要这种数据在网页上是公开可用的。
多亏了网路爬虫/机器人、API、标准数据库和各类开箱即用的软件,一旦有人有了获取数据的意愿,就有了获取数据的方式。或者,他们也可以求救于这些她们接触得到又支付的起费用的专业人士。
在自由职业任务平台guru.com上搜索“网络爬虫”时,你可以得到10088个搜索结果,这意味着超过10000名自由职业者在这个网站上提供网路抓取服务。
而在同类的网站,Upwork上的搜索结果有13190个,fievere.com上的结果是1024个。
各行各业的公司对网路数据的需求不断下降,推动了网路抓取行业的发展,带来了新的市场、就业机会和商业机会。
与此同时,与其他新兴行业一样,网络抓取也伴随着法律方面的疑虑。
围绕网路爬虫合法性的讨论情况仍存在。它的合法与否与具体案例背景相关。目前,这种趋势下诞生的许多有趣的法律问题一直没有得到解答,或者取决于十分具体的案例背景。
虽然网路抓取早已存在了太长一段时间,但法庭才刚才开基础大数据相关的法律理论的应用。
由于与网路爬取和数据抓取的仍处于发展阶段,所以它的发展一直未稳定出来且难以预测。然而,有一件事是肯定的,那就是,只要有互联网,就有网路抓取。
是网路抓取使新生的互联网显得可以搜索,使爆炸式下降的互联网显得愈发容易访问和获取。
毫无疑问网络爬虫技术是什么,在可预见的未来,互联网和网路抓取,将继续稳定地往前迈向。 查看全部
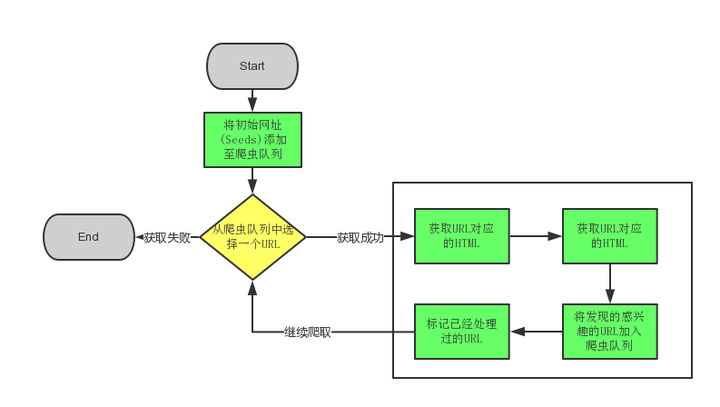
摘要:一篇文章了解爬虫的前世今生与未来
什么是网络爬虫?
网络爬虫,也称为网页抓取和网页数据提取,基本上是指通过超文本传输协议(HTTP)或通过网页浏览器获取万维网上可用的数据。(摘自Wikipedia)
网络爬虫是怎样工作的?
通常,爬取网页数据时,只须要2个步骤。
打开网页→将具体的数据从网页中复制并导入到表格或数据库中。
这一切是怎么开始的?
尽管对许多人来说,网络爬虫听上去象是“大数据”或“机器学习”一类的新概念,但实际上,网络数据抓取的历史要长得多,可以溯源到万维网(或浅显的“互联网”)诞生之时。
一开始,互联网还没有搜索。在搜索引擎被开发下来之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
随后,互联网发展上去,最终有数百万级的网页生成,这些网页包含大量不同的方式的数据,其中包括文本、图像、视频和音频。互联网弄成了一个开放的数据源。
随着数据资源显得十分丰富且容易搜索,人们发觉从网页上找到她们想要的信息是一件极其简单的事情,他们一般分布在大量的网站上。但另一个问题出现了,当她们想要数据的时侯,并非每位网站都提供下载按键,如果进行自动复制其实是极其低效且平庸的。

这就是网路爬虫诞生的诱因。网络爬虫实际上是由网页机器人/爬虫驱动的,其功能与搜索引擎相同。简单来说就是,抓取和复制。唯一的不同可能是规模。网络数据抓取是从特定的网站提取特定的数据,而搜索引擎一般是在万维网上搜索出大部分的网站。
时间轴
1989年万维网的诞生

从技术上讲,万维网和因特网有所不同。前者是指信息空间,后者是由数台计算机联接上去的内部网路。
感谢Tim Berners-Lee,万维网的发明者,他发明的三件东西,往后成为了我们日常生活中的一部分。
1990年第一个网络浏览器
它也由Tim Berners-Lee发明,被称为WorldWide网页(无空间),以WWW项目命名。在网路出现一年后,人们有了一条途径去浏览它并与之互动。
1991年第一个网页服务器和第一个 网页页面
网页的数目以缓慢的速率下降。到1994年,HTTP服务器的数目超过200台。
1993年6月第一台网页机器人——万维网漫游器
虽然它的功能和昨天的网页机器人一样,但它只是拿来检测网页的大小。
1993年12月首个基于爬虫的网路搜索引擎—JumpStation

由于当时网路上的网站并不多,搜索引擎过去经常依赖人工网站管理员来搜集和编辑链接,使其成为一种特定的格式。
JumpStation带来了新的飞越。它是第一个借助网路机器人的WWW搜索引擎。
从那时起,人们开始使用这种程序化的网路爬虫程序来搜集和组织互联网。从Infoseek、Altavista和Excite,到现在的必应和微软,搜索引擎机器人的核心依旧保持不变:
找到一个网页页面,下载(获取)它,抓取网页页面上显示的所有信息,然后将其添加到搜索引擎的数据库中。
由于网页页面是为人类用户设计的,不是为了自动化使用,即使开发了网页机器人,计算机工程师和科学家一直很难进行网路数据抓取,更不用说普通人了。因此,人们仍然致力于让网路爬虫显得愈发容易使用。
2000年网页API和API爬虫

API表示应用程序编程插口。它是一个插口,通过提供搭建好的模块,使开发程序愈加方便。
2000年,Salesforce和eBay推出了自己的API,程序员可以用它访问并下载一些公开数据。
从那时起,许多网站都提供网页API使人们可以访问她们的公共数据库。
发送一组HTTP请求,然后接收JSON或XML的回馈。
网页API通过搜集网站提供的数据,为开发人员提供了一种更友好的网路爬虫形式。
2004 年Python Beautiful Soup

不是所有的网站都提供API。即使她们提供了,他们也不一定会提供你想要的所有数据。因此,程序员们仍在开发一种才能建立网路爬虫的方式。
2004年,Beautiful Soup发布。它是一个为Python设计的库。
在计算机编程中,库是脚本模块的集合,就像常用的算法一样,它容许不用重画就可以使用,从而简化了编程过程。
通过简单的命令,Beautiful Soup可以理解站点的结构,并帮助从HTML容器中解析内容。它被觉得是用于网路爬虫的最复杂和最先进的库,也是现今最常见和最流行的方式之一。
2005-2006年网路抓取软件的可视化
2006年,Stefan Andresen和他的Kapow软件(Kofax于2013年竞购)发布了网页集成平台6.0版本,这是一种可视化的网路爬虫软件,它容许用户轻松简单的选择网页内容,并将这种数据构造成可用的excel文件或数据库。
八爪鱼数据采集器
最终,可视化的网路数据抓取软件可以使大量非程序员自己进行网路爬虫。
从那时起,网络抓取开始成为主流。现在,对于非程序员来说,他们可以很容易地找到80多个可提供可视化过程的的数据采集软件。
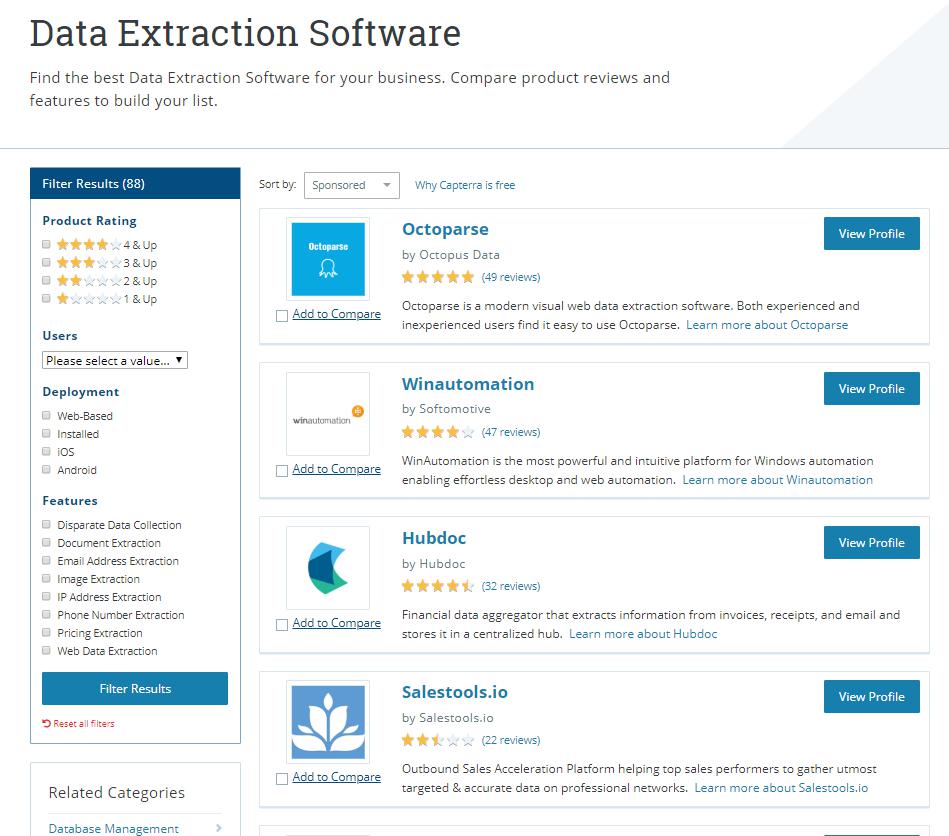
网络爬虫未来将怎样发展?
我们总是想要更多的数据。我们搜集数据,处理数据,并把数据转换成各种各样的成品,比如研究,洞察剖析,信息,故事,资产等等。我们过去经常耗费大量的时间、精力和金钱在找寻和搜集数据上,以至于只有大公司和组织能够负担得起。
在2018年,我们所知的万维网网络爬虫技术是什么,或浅显的“互联网”,由超过18亿个网站组成。只需点击几下键盘,就可以获得这么巨大的数据量。随着越来越多的人上网,每秒形成的数据也越来越多。

如今,是一个比历史上任何时期都要便捷的时代。任何个人、公司和组织都还能获得她们想要的数据,只要这种数据在网页上是公开可用的。
多亏了网路爬虫/机器人、API、标准数据库和各类开箱即用的软件,一旦有人有了获取数据的意愿,就有了获取数据的方式。或者,他们也可以求救于这些她们接触得到又支付的起费用的专业人士。
在自由职业任务平台guru.com上搜索“网络爬虫”时,你可以得到10088个搜索结果,这意味着超过10000名自由职业者在这个网站上提供网路抓取服务。
而在同类的网站,Upwork上的搜索结果有13190个,fievere.com上的结果是1024个。
各行各业的公司对网路数据的需求不断下降,推动了网路抓取行业的发展,带来了新的市场、就业机会和商业机会。

与此同时,与其他新兴行业一样,网络抓取也伴随着法律方面的疑虑。
围绕网路爬虫合法性的讨论情况仍存在。它的合法与否与具体案例背景相关。目前,这种趋势下诞生的许多有趣的法律问题一直没有得到解答,或者取决于十分具体的案例背景。
虽然网路抓取早已存在了太长一段时间,但法庭才刚才开基础大数据相关的法律理论的应用。
由于与网路爬取和数据抓取的仍处于发展阶段,所以它的发展一直未稳定出来且难以预测。然而,有一件事是肯定的,那就是,只要有互联网,就有网路抓取。

是网路抓取使新生的互联网显得可以搜索,使爆炸式下降的互联网显得愈发容易访问和获取。
毫无疑问网络爬虫技术是什么,在可预见的未来,互联网和网路抓取,将继续稳定地往前迈向。
网页抓取工具:一个简单的文章采集示例 (1)
采集交流 • 优采云 发表了文章 • 0 个评论 • 479 次浏览 • 2020-04-18 09:53
网页抓取工具:一个简单的文章采集示例 通过采集网页抓取工具列车采集器官网的 faq 为例来说明采集器采集的原理和 过程。 本例以 演示地址网站文章采集软件, 以列车采集器 V9 为工具 进行示例说明。 (1)新建个采集规则 选择一个分组上右击,选择“新建任务”,如下图:(2)添加起始网址 在这里我们须要采集 5 页数据。 分析网址变量规律 第一页地址: 第二页地址: 第三页地址: 由此我们可以推断出 p=后的数字就是分页的意思,我们用[地址参数]表示: 所以设置如下:地址格式:把变化的分页数字用[地址参数]表示。 数字变化:从 1 开始文章采集,即第一页;每次递增 1,即每次分页的变化规律数字; 共 5 项,即一共采集 5 页。 预览:采集器会根据前面设置的生成一部分网址,让你来判读添加的是否正确。 然后确定即可 (3)[常规模式]获取内容网址 常规模式:该模式默认抓取一级地址,即从起始页源代码中获取到内容页 A 链 接。 在这里给你们演示用 自动获取地址链接 +设置区域 的 方式来获取。 查看页面源代码找到文章地址所在的区域:设置如下: 注:更详尽的剖析说明可以参考本指南: 操作指南 > 软件操作 > 网址采集规则 > 获取内容网址点击网址采集测试,看看测试疗效(3)内容采集网址 以 为例讲解标签采集 注:更详尽的剖析说明可以下载参考官网的用户指南。
操作指南 > 软件操作 > 内容采集规则 > 标签编辑 我们首先查看它的页面源代码网站文章采集软件,找到我们“标题”所在位置的代码:<title>导入 Excle 是跳出对话框~打开 Excle 出错 - 火车采集器帮助中心</title>分析得出: 开头字符串为:<title> 结尾字符串为:</title> 数据处理——内容替换/排除:需要把- 火车采集器帮助中心 给替换为空内容标签的设置原理也是类似的,找到内容所在源码中的位置剖析得出: 开头字符串为:<div id="cmsContent"> 结尾字符串为:</div> 数据处理——HTML 标签排除:把不需要的 A 链接等过滤再设置个“来源”字段这样一个简单的文章采集规则就做好了, 使用通用的网页抓取工具列车采集器并 按照这个示例的步骤就可以进行其它类型数据采集的扩充啦。 查看全部

网页抓取工具:一个简单的文章采集示例 通过采集网页抓取工具列车采集器官网的 faq 为例来说明采集器采集的原理和 过程。 本例以 演示地址网站文章采集软件, 以列车采集器 V9 为工具 进行示例说明。 (1)新建个采集规则 选择一个分组上右击,选择“新建任务”,如下图:(2)添加起始网址 在这里我们须要采集 5 页数据。 分析网址变量规律 第一页地址: 第二页地址: 第三页地址: 由此我们可以推断出 p=后的数字就是分页的意思,我们用[地址参数]表示: 所以设置如下:地址格式:把变化的分页数字用[地址参数]表示。 数字变化:从 1 开始文章采集,即第一页;每次递增 1,即每次分页的变化规律数字; 共 5 项,即一共采集 5 页。 预览:采集器会根据前面设置的生成一部分网址,让你来判读添加的是否正确。 然后确定即可 (3)[常规模式]获取内容网址 常规模式:该模式默认抓取一级地址,即从起始页源代码中获取到内容页 A 链 接。 在这里给你们演示用 自动获取地址链接 +设置区域 的 方式来获取。 查看页面源代码找到文章地址所在的区域:设置如下: 注:更详尽的剖析说明可以参考本指南: 操作指南 > 软件操作 > 网址采集规则 > 获取内容网址点击网址采集测试,看看测试疗效(3)内容采集网址 以 为例讲解标签采集 注:更详尽的剖析说明可以下载参考官网的用户指南。
操作指南 > 软件操作 > 内容采集规则 > 标签编辑 我们首先查看它的页面源代码网站文章采集软件,找到我们“标题”所在位置的代码:<title>导入 Excle 是跳出对话框~打开 Excle 出错 - 火车采集器帮助中心</title>分析得出: 开头字符串为:<title> 结尾字符串为:</title> 数据处理——内容替换/排除:需要把- 火车采集器帮助中心 给替换为空内容标签的设置原理也是类似的,找到内容所在源码中的位置剖析得出: 开头字符串为:<div id="cmsContent"> 结尾字符串为:</div> 数据处理——HTML 标签排除:把不需要的 A 链接等过滤再设置个“来源”字段这样一个简单的文章采集规则就做好了, 使用通用的网页抓取工具列车采集器并 按照这个示例的步骤就可以进行其它类型数据采集的扩充啦。
网页抓取工具必读的文章采集实例
采集交流 • 优采云 发表了文章 • 0 个评论 • 549 次浏览 • 2020-04-18 09:48
以 为例讲解标签采集
注:更详尽的剖析说明可以参考本指南
操作指南 > 软件操作 > 内容采集规则 > 标签编辑
我们首先查看它的页面源代码采集文章工具,找到我们“标题”所在位置的代码:
<title>导入Excle是跳出对话框~打开Excle出错 - 火车采集器帮助中心</title>
分析得出: 开头字符串为:<title>
结尾字符串为:</title>
数据处理——内容替换/排除:需要把- 火车采集器帮助中心给替换为空
内容标签的设置原理也是类似的,找到内容所在源码中的位置
分析得出: 开头字符串为:<div id="cmsContent">
结尾字符串为:</div>
数据处理——HTML标签排除:把不需要的A链接等 过滤
再设置个“来源”字段
这样一个简单的文章采集规则就做好了,不知道网友们学会了没有呢,网页抓取工具顾名思义是适用于网页上的数据抓取采集文章工具,从前面的事例你们也可以看出,这类软件主要是通过源代码剖析才解析数据的。这里还有一些情况是没有列举的,比如登陆采集,使用代理采集等,如果对网页抓取工具感兴趣的可以登入采集器官网自行学习一下。 查看全部

以 为例讲解标签采集
注:更详尽的剖析说明可以参考本指南
操作指南 > 软件操作 > 内容采集规则 > 标签编辑
我们首先查看它的页面源代码采集文章工具,找到我们“标题”所在位置的代码:
<title>导入Excle是跳出对话框~打开Excle出错 - 火车采集器帮助中心</title>
分析得出: 开头字符串为:<title>
结尾字符串为:</title>
数据处理——内容替换/排除:需要把- 火车采集器帮助中心给替换为空
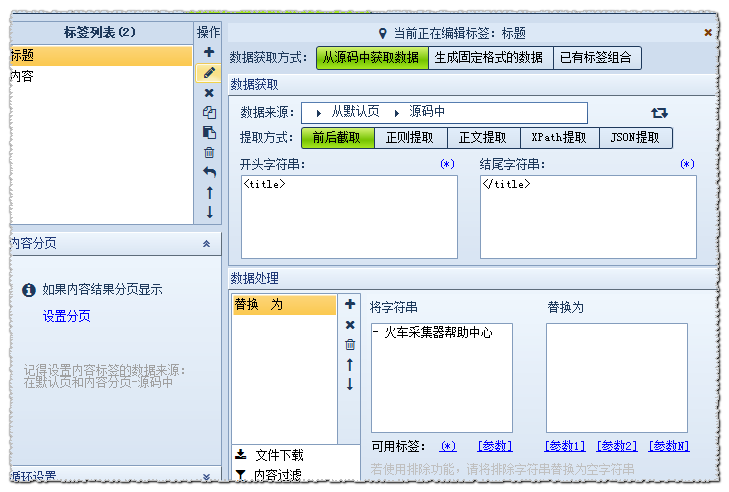
内容标签的设置原理也是类似的,找到内容所在源码中的位置

分析得出: 开头字符串为:<div id="cmsContent">
结尾字符串为:</div>
数据处理——HTML标签排除:把不需要的A链接等 过滤
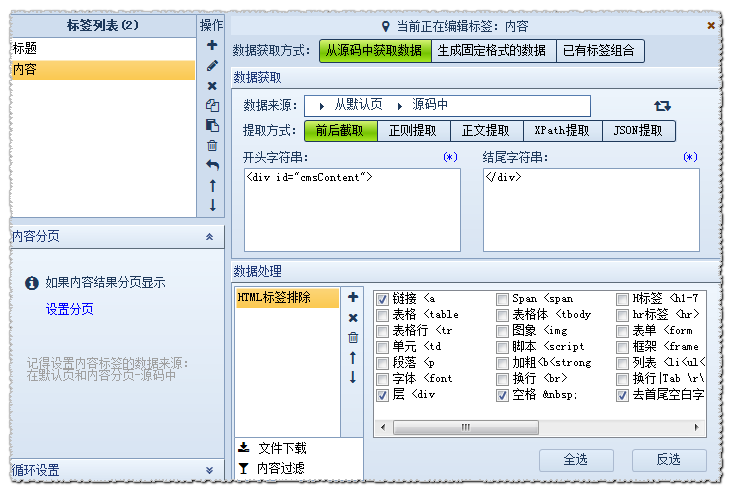
再设置个“来源”字段
这样一个简单的文章采集规则就做好了,不知道网友们学会了没有呢,网页抓取工具顾名思义是适用于网页上的数据抓取采集文章工具,从前面的事例你们也可以看出,这类软件主要是通过源代码剖析才解析数据的。这里还有一些情况是没有列举的,比如登陆采集,使用代理采集等,如果对网页抓取工具感兴趣的可以登入采集器官网自行学习一下。
网页抓取工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 594 次浏览 • 2020-08-03 15:03
优采云是一款专业的互联网数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能,准确挖掘出所需数据,是行业内领先的网页采集工具网站文章采集器,有着诸多的使用人数和良好的口碑。
优采云功能特点介绍
优采云能做哪些?
为什么选择优采云?
能采集99%的网页
几乎所有网页都能采集,只要网页源代码中能看到的公开内容即可采集到!
速度是普通采集器的7倍
采用分布式高速处理系统,反复优化性能,让采集速度快到飞起来!
和复制/粘贴一样确切
“采集/发布”如同“复制/粘贴”一样精准,用户要的全都是真谛,怎能有遗漏!
网页采集的代名词
独具十二年磨炼,成就业界领先品牌,想到网页采集,就想到优采云!
谁在用优采云?
电子商务:淘宝淘宝
抓取、筛选和剖析出精算、营销、投保、服务、理赔等各个环节的统计数据,科学设定费率;筛选最适产品向其推送。实现精准营销、精准定价、精准管理,精准服务。
企业人员:某品牌保险
采集同类商品的属性、评价、价格,销量占比等数据,得出商品的相关特点信息因而进行标题优化,根据同类经验制造热卖,提升淘宝的营运水平与效率。
网站站长:视频网站
对采集到的视频数据进行流量剖析,排序,分析用户喜好,选取受众偏好内容进行定时手动发布更新,保障精品内容不断涌现,提升网站流量,助力内容与营销升级。
人个需求:科研人员
帮助科研人员完成大量科研数据的检索、采集,快速批量下载大量的文件内容,取代冗长乏味的自动操作,省时省力,大幅提高工作效率。
用户口碑
跑得快ZWH
优采云采集器软件太强悍,也很容易上手,服务挺好,非常谢谢东东、小谢、小赵。他们人都挺好
135*****235
我没有用过采集,在网上听到列车采集的评论比较好,就去看了,先用敢个免费的,客服挺有耐心,水平也高.我就用了基础版.现在客服的指导下,用得挺好,点无数个赞.
秋琴风
很好的采集器,之前也用过其他采集器只有最后还是选择这个
斌斌3111991
客服(小谢)很悉心,我还害怕我问的问题太多了,客服会不耐烦,事实证明,我想多了。
sooting2000
优采云是我用过最好用的采集软件,以前用别的,觉得优采云用上去麻烦网站文章采集器,实际了解使用后,其实优采云使用比其他软件还要简单,规则也容易写。不错,我用的是旗舰版,这一千多花得值啊
ejunn
我是优采云的老fans了,优采云功能强悍,客服人员热情专业,基本上所有的网站都可以编成规则采集。 查看全部
优采云是一款专业的互联网数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能,准确挖掘出所需数据,是行业内领先的网页采集工具网站文章采集器,有着诸多的使用人数和良好的口碑。
优采云功能特点介绍
优采云能做哪些?
为什么选择优采云?
能采集99%的网页
几乎所有网页都能采集,只要网页源代码中能看到的公开内容即可采集到!
速度是普通采集器的7倍
采用分布式高速处理系统,反复优化性能,让采集速度快到飞起来!
和复制/粘贴一样确切
“采集/发布”如同“复制/粘贴”一样精准,用户要的全都是真谛,怎能有遗漏!
网页采集的代名词
独具十二年磨炼,成就业界领先品牌,想到网页采集,就想到优采云!
谁在用优采云?
电子商务:淘宝淘宝
抓取、筛选和剖析出精算、营销、投保、服务、理赔等各个环节的统计数据,科学设定费率;筛选最适产品向其推送。实现精准营销、精准定价、精准管理,精准服务。
企业人员:某品牌保险
采集同类商品的属性、评价、价格,销量占比等数据,得出商品的相关特点信息因而进行标题优化,根据同类经验制造热卖,提升淘宝的营运水平与效率。
网站站长:视频网站
对采集到的视频数据进行流量剖析,排序,分析用户喜好,选取受众偏好内容进行定时手动发布更新,保障精品内容不断涌现,提升网站流量,助力内容与营销升级。
人个需求:科研人员
帮助科研人员完成大量科研数据的检索、采集,快速批量下载大量的文件内容,取代冗长乏味的自动操作,省时省力,大幅提高工作效率。
用户口碑
跑得快ZWH
优采云采集器软件太强悍,也很容易上手,服务挺好,非常谢谢东东、小谢、小赵。他们人都挺好
135*****235
我没有用过采集,在网上听到列车采集的评论比较好,就去看了,先用敢个免费的,客服挺有耐心,水平也高.我就用了基础版.现在客服的指导下,用得挺好,点无数个赞.
秋琴风
很好的采集器,之前也用过其他采集器只有最后还是选择这个
斌斌3111991
客服(小谢)很悉心,我还害怕我问的问题太多了,客服会不耐烦,事实证明,我想多了。
sooting2000
优采云是我用过最好用的采集软件,以前用别的,觉得优采云用上去麻烦网站文章采集器,实际了解使用后,其实优采云使用比其他软件还要简单,规则也容易写。不错,我用的是旗舰版,这一千多花得值啊
ejunn
我是优采云的老fans了,优采云功能强悍,客服人员热情专业,基本上所有的网站都可以编成规则采集。
SEO优化:禁止搜索引擎收录的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 335 次浏览 • 2020-08-01 08:00
搜索引擎使用spider程序手动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检测该网站的根域下是否有一个叫 做 robots.txt的纯文本文件,这个文件用于指定spider在您网站上的抓取范围。您可以在您的网站中创建一个robots.txt,在文件中 声明 该网站中不想被搜索引擎收录的部份或则指定搜索引擎只收录特定的部份。
请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才须要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿构建robots.txt文件。
2. robots.txt文件置于那里?
robots.txt 文件应当放置在网站根目录下。举例来说,当spider访问一个网站(比如 )时,首先会检测该网站中是否存在 robots.txt这个文件,如果 Spider找到这个文件,它还会依据这个文件的内容,来确定它访问权限的 范围。
网站 URL
相应的 robots.txt的 URL
:80/
:80/robots.txt
:1234/
:1234/robots.txt
3. 我在robots.txt中设置了严禁百度收录我网站的内容,为何还出现在百度搜索结果中?
如果其他网站链接了您robots.txt文件中设置的严禁收录的网页,那么这种网页依然可能会出现在百度的搜索结果中,但您的网页上的内容不会被抓取、建入索引和显示,百度搜索结果中展示的仅是其他网站对您相关网页的描述。
4. 禁止搜索引擎跟踪网页的链接,而只对网页建索引
如果您不想搜索引擎追踪此网页上的链接,且不传递链接的权重,请将此元标记置入网页的 部分:
如果您不想百度追踪某一条特定链接,百度还支持更精确的控制,请将此标记直接写在某条链接上:
signin
要容许其他搜索引擎跟踪,但仅避免百度跟踪您网页的链接,请将此元标记置入网页的 部分:
Baiduspider" content="nofollow">
5. 禁止搜索引擎在搜索结果中显示网页快照,而只对网页建索引
要避免所有搜索引擎显示您网站的快照,请将此元标记置入网页的部份:
要容许其他搜索引擎显示快照,但仅避免百度显示,请使用以下标记:
Baiduspider" content="noarchive">
注:此标记只是严禁百度显示该网页的快照,百度会继续为网页建索引,并在搜索结果中显示网页摘要。
6. 我想严禁百度图片搜索收录个别图片,该怎么设置?
禁止Baiduspider抓取网站上所有图片、禁止或容许Baiduspider抓取网站上的某种特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件用法举例”中的例10、11、12。
7. robots.txt文件的格式
"robots.txt"文件包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
":"
在该文件中可以使用#进行注解,具体使用方式和UNIX中的惯例一样。该文件中的记录一般以一行或多行User-agent开始搜索引擎禁止的方式优化网站,后面加上若干Disallow和Allow行,详细情况如下:
User-agent:
该项的值用于描述搜索引擎robot的名子。在"robots.txt"文件中,如果有多条User-agent记录说明有多个robot会 受 到"robots.txt"的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则对任何robot均有 效, 在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。如果在"robots.txt"文件中,加 入"User- agent:SomeBot"和若干Disallow、Allow行,那么名为"SomeBot"只遭到"User- agent:SomeBot"后面的 Disallow和Allow行的限制。
Disallow:
该 项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会 被 robot访问。例如"Disallow:/help"禁止robot访问/help.html、/helpabc.html、 /help /index.html,而"Disallow:/help/"则容许robot访问/help.html、/helpabc.html搜索引擎禁止的方式优化网站,不 能访问 /help/index.html。"Disallow:"说明容许robot访问该网站的所有url,在"/robots.txt"文件中,至 少要有一条Disallow记录。如果"/robots.txt"不存在或则为空文件,则对于所有的搜索引擎robot,该网站都是开放的。
Allow:
该项的值用于描述希望被访问的一组URL,与Disallow项相像,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头 的 URL 是容许robot访问的。例如"Allow:/hibaidu"允许robot访问/hibaidu.htm、 /hibaiducom.html、 /hibaidu/com.html。一个网站的所有URL默认是Allow的,所以Allow一般与 Disallow搭配使用,实现准许访问一部分网页同时严禁访问其它所有URL的功能。
使用"*"and"$":
Baiduspider支持使用转义"*"和"$"来模糊匹配url。
"$" 匹配行结束符。
"*" 匹配0或多个任意字符。
注:我们会严格遵循robots的相关合同,请注意分辨您不想被抓取或收录的目录的大小写,我们会对robots中所写的文件和您不想被抓取和收录的目录做精确匹配,否则robots协议未能生效。
8. URL匹配举例
Allow或Disallow的值
URL
匹配结果
/tmp
/tmp
yes
/tmp
/tmp.html
yes
/tmp
/tmp/a.html
yes
/tmp
/tmphoho
no
/Hello*
/Hello.html
yes
/He*lo
/Hello,lolo
yes
/Heap*lo
/Hello,lolo
no
html$
/tmpa.html
yes
/a.html$
/a.html
yes
htm$
/a.html
no
9. robots.txt文件用法举例
例1. 禁止所有搜索引擎访问网站的任何部份
下载该robots.txt文件
User-agent: *
Disallow: /
例2. 允许所有的robot访问
(或者也可以建一个空文件 "/robots.txt")
User-agent: *
Allow: /
例3. 仅严禁Baiduspider访问您的网站
User-agent: Baiduspider
Disallow: /
例4. 仅容许Baiduspider访问您的网站
User-agent: Baiduspider
Allow: /
User-agent: *
Disallow: /
例5. 仅容许Baiduspider以及Googlebot访问
User-agent: Baiduspider
Allow: /
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /
例6. 禁止spider访问特定目录
在这个事例中,该网站有三个目录对搜索引擎的访问做了限制,即robot不会访问这三个目录。需要注意的是对每一个目录必须分开申明,而不能写成 "Disallow: /cgi-bin/ /tmp/"。
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
例7. 允许访问特定目录中的部份url
User-agent: *
Allow: /cgi-bin/see
Allow: /tmp/hi
Allow: /~joe/look
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
例8. 使用"*"限制访问url
禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
User-agent: *
Disallow: /cgi-bin/*.htm
例9. 使用"$"限制访问url
仅准许访问以".htm"为后缀的URL。
User-agent: *
Allow: /*.htm$
Disallow: /
例10. 禁止访问网站中所有的动态页面
User-agent: *
Disallow: /*?*
例11. 禁止Baiduspider抓取网站上所有图片
仅容许抓取网页,禁止抓取任何图片。
User-agent: Baiduspider
Disallow: /*.jpg$
Disallow: /*.jpeg$
Disallow: /*.gif$
Disallow: /*.png$
Disallow: /*.bmp$
例12. 仅容许Baiduspider抓取网页和.gif格式图片
允许抓取网页和gif格式图片,不容许抓取其他格式图片
User-agent: Baiduspider
Allow: /*.gif$
Disallow: /*.jpg$
Disallow: /*.jpeg$
Disallow: /*.png$
Disallow: /*.bmp$
例13. 仅严禁Baiduspider抓取.jpg格式图片
User-agent: Baiduspider
Disallow: /*.jpg$
10. robots.txt文件参考资料
robots.txt文件的更具体设置,请参看以下链接:
Web Server Administrator's Guide to the Robots Exclusion Protocol
HTML Author's Guide to the Robots Exclusion Protocol
The original 1994 protocol description, as currently deployed
The revised Internet-Draft specification, which is not yet completed or implemented 查看全部
1. 什么是robots.txt文件?
搜索引擎使用spider程序手动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检测该网站的根域下是否有一个叫 做 robots.txt的纯文本文件,这个文件用于指定spider在您网站上的抓取范围。您可以在您的网站中创建一个robots.txt,在文件中 声明 该网站中不想被搜索引擎收录的部份或则指定搜索引擎只收录特定的部份。
请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才须要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿构建robots.txt文件。
2. robots.txt文件置于那里?
robots.txt 文件应当放置在网站根目录下。举例来说,当spider访问一个网站(比如 )时,首先会检测该网站中是否存在 robots.txt这个文件,如果 Spider找到这个文件,它还会依据这个文件的内容,来确定它访问权限的 范围。
网站 URL
相应的 robots.txt的 URL
:80/
:80/robots.txt
:1234/
:1234/robots.txt
3. 我在robots.txt中设置了严禁百度收录我网站的内容,为何还出现在百度搜索结果中?
如果其他网站链接了您robots.txt文件中设置的严禁收录的网页,那么这种网页依然可能会出现在百度的搜索结果中,但您的网页上的内容不会被抓取、建入索引和显示,百度搜索结果中展示的仅是其他网站对您相关网页的描述。
4. 禁止搜索引擎跟踪网页的链接,而只对网页建索引
如果您不想搜索引擎追踪此网页上的链接,且不传递链接的权重,请将此元标记置入网页的 部分:
如果您不想百度追踪某一条特定链接,百度还支持更精确的控制,请将此标记直接写在某条链接上:
signin
要容许其他搜索引擎跟踪,但仅避免百度跟踪您网页的链接,请将此元标记置入网页的 部分:
Baiduspider" content="nofollow">
5. 禁止搜索引擎在搜索结果中显示网页快照,而只对网页建索引
要避免所有搜索引擎显示您网站的快照,请将此元标记置入网页的部份:
要容许其他搜索引擎显示快照,但仅避免百度显示,请使用以下标记:
Baiduspider" content="noarchive">
注:此标记只是严禁百度显示该网页的快照,百度会继续为网页建索引,并在搜索结果中显示网页摘要。
6. 我想严禁百度图片搜索收录个别图片,该怎么设置?
禁止Baiduspider抓取网站上所有图片、禁止或容许Baiduspider抓取网站上的某种特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件用法举例”中的例10、11、12。
7. robots.txt文件的格式
"robots.txt"文件包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示:
":"
在该文件中可以使用#进行注解,具体使用方式和UNIX中的惯例一样。该文件中的记录一般以一行或多行User-agent开始搜索引擎禁止的方式优化网站,后面加上若干Disallow和Allow行,详细情况如下:
User-agent:
该项的值用于描述搜索引擎robot的名子。在"robots.txt"文件中,如果有多条User-agent记录说明有多个robot会 受 到"robots.txt"的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则对任何robot均有 效, 在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。如果在"robots.txt"文件中,加 入"User- agent:SomeBot"和若干Disallow、Allow行,那么名为"SomeBot"只遭到"User- agent:SomeBot"后面的 Disallow和Allow行的限制。
Disallow:
该 项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会 被 robot访问。例如"Disallow:/help"禁止robot访问/help.html、/helpabc.html、 /help /index.html,而"Disallow:/help/"则容许robot访问/help.html、/helpabc.html搜索引擎禁止的方式优化网站,不 能访问 /help/index.html。"Disallow:"说明容许robot访问该网站的所有url,在"/robots.txt"文件中,至 少要有一条Disallow记录。如果"/robots.txt"不存在或则为空文件,则对于所有的搜索引擎robot,该网站都是开放的。
Allow:
该项的值用于描述希望被访问的一组URL,与Disallow项相像,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头 的 URL 是容许robot访问的。例如"Allow:/hibaidu"允许robot访问/hibaidu.htm、 /hibaiducom.html、 /hibaidu/com.html。一个网站的所有URL默认是Allow的,所以Allow一般与 Disallow搭配使用,实现准许访问一部分网页同时严禁访问其它所有URL的功能。
使用"*"and"$":
Baiduspider支持使用转义"*"和"$"来模糊匹配url。
"$" 匹配行结束符。
"*" 匹配0或多个任意字符。
注:我们会严格遵循robots的相关合同,请注意分辨您不想被抓取或收录的目录的大小写,我们会对robots中所写的文件和您不想被抓取和收录的目录做精确匹配,否则robots协议未能生效。
8. URL匹配举例
Allow或Disallow的值
URL
匹配结果
/tmp
/tmp
yes
/tmp
/tmp.html
yes
/tmp
/tmp/a.html
yes
/tmp
/tmphoho
no
/Hello*
/Hello.html
yes
/He*lo
/Hello,lolo
yes
/Heap*lo
/Hello,lolo
no
html$
/tmpa.html
yes
/a.html$
/a.html
yes
htm$
/a.html
no
9. robots.txt文件用法举例
例1. 禁止所有搜索引擎访问网站的任何部份
下载该robots.txt文件
User-agent: *
Disallow: /
例2. 允许所有的robot访问
(或者也可以建一个空文件 "/robots.txt")
User-agent: *
Allow: /
例3. 仅严禁Baiduspider访问您的网站
User-agent: Baiduspider
Disallow: /
例4. 仅容许Baiduspider访问您的网站
User-agent: Baiduspider
Allow: /
User-agent: *
Disallow: /
例5. 仅容许Baiduspider以及Googlebot访问
User-agent: Baiduspider
Allow: /
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /
例6. 禁止spider访问特定目录
在这个事例中,该网站有三个目录对搜索引擎的访问做了限制,即robot不会访问这三个目录。需要注意的是对每一个目录必须分开申明,而不能写成 "Disallow: /cgi-bin/ /tmp/"。
User-agent: *
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
例7. 允许访问特定目录中的部份url
User-agent: *
Allow: /cgi-bin/see
Allow: /tmp/hi
Allow: /~joe/look
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /~joe/
例8. 使用"*"限制访问url
禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
User-agent: *
Disallow: /cgi-bin/*.htm
例9. 使用"$"限制访问url
仅准许访问以".htm"为后缀的URL。
User-agent: *
Allow: /*.htm$
Disallow: /
例10. 禁止访问网站中所有的动态页面
User-agent: *
Disallow: /*?*
例11. 禁止Baiduspider抓取网站上所有图片
仅容许抓取网页,禁止抓取任何图片。
User-agent: Baiduspider
Disallow: /*.jpg$
Disallow: /*.jpeg$
Disallow: /*.gif$
Disallow: /*.png$
Disallow: /*.bmp$
例12. 仅容许Baiduspider抓取网页和.gif格式图片
允许抓取网页和gif格式图片,不容许抓取其他格式图片
User-agent: Baiduspider
Allow: /*.gif$
Disallow: /*.jpg$
Disallow: /*.jpeg$
Disallow: /*.png$
Disallow: /*.bmp$
例13. 仅严禁Baiduspider抓取.jpg格式图片
User-agent: Baiduspider
Disallow: /*.jpg$
10. robots.txt文件参考资料
robots.txt文件的更具体设置,请参看以下链接:
Web Server Administrator's Guide to the Robots Exclusion Protocol
HTML Author's Guide to the Robots Exclusion Protocol
The original 1994 protocol description, as currently deployed
The revised Internet-Draft specification, which is not yet completed or implemented
网络爬虫是哪些?它的主要功能和作用有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 586 次浏览 • 2020-07-04 08:01
网络爬虫,又被称为“网页蜘蛛,网络机器人”,在FOAF社区中间,经常被称为“网页追逐者”。网络爬虫,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
网络爬虫,按照系统结构和实现技术,大致可以分为:“通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫”等四种不同类型。实际上,网络爬虫系统,通常是由几种爬虫技术相结合实现的。
一、 通用网路爬虫
通用网路爬虫,又称“全网爬虫”,爬行对象从一些种子URL(统一资源定位符) 扩充到整个万维网,主要为“门户站点搜索引擎”和“大型Web服务提供商”采集数据。由于商业缘由,它们的技术细节甚少被公布下来。这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为等待刷新的页面太多,通常采用“并行工作”的方法,但须要较长时间能够刷新一次页面。通用网路爬虫,虽然存在着一定的缺陷,但它适用于为搜索引擎平台搜索广泛的主题,有较强的应用价值。
二、聚焦网络爬虫
聚焦网络爬虫,又称“主题网路爬虫”,是指选择性地爬行,那些与预先定义好的主题相关的页面的网路爬虫。和通用网路爬虫相比,聚焦网路爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网路爬虫相比,增加了“链接评价模块”以及“内容评价模块”。聚焦网路爬虫爬行策略实现的关键是,评价页面内容和链接的重要性。不同的方式估算出的重要性不同,由此引起链接的访问次序也不同。
三、增量式网络爬虫
是指对已下载网页采取增量式更新,和只爬行新形成的或则早已发生变化网页的爬虫网络爬虫技术是什么,它还能在一定程度上保证网络爬虫技术是什么,所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。
四、深层网络爬虫
Web 页面,按存在形式可以分为“表层网页”和“深层网页”。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。
深层网页是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web 页面。例如:那些用户注册后内容才可见的网页,就属于深层网页。
随着计算机网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。搜索引擎,例如传统的“通用搜索引擎”平台:Google(谷歌)、Yahoo!(雅虎)、百度等,作为一个辅助人们检索万维网信息的工具,成为互联网用户访问万维网的入口和渠道。
但是,这些“通用搜索引擎平台”也存在着一定的局限性,如:
1、 不同领域、不同职业、不同背景的用户,往往具有不同的检索目的和需求,通用搜索引擎所返回的结果,包含了大量用户并不关心的网页,或者与用户搜索结果无关的网页。
2、 通用搜索引擎的目标是,实现尽可能大的网路覆盖率,有限的搜索引擎服务器资源,与无限的网路数据资源之间的矛盾将进一步加深。
3、 万维网数据方式的丰富和网路技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎常常对这种信息浓度密集,且具有一定结构的数据无能为力,不能挺好地发觉和获取。
4、通用搜索引擎,大多提供基于“关键字”的检索,难以支持按照语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的“聚焦网路爬虫”应运而生。聚焦网路爬虫,是一个手动下载网页的程序,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息。
与“通用网路爬虫”不同,聚焦网络爬虫并不追求大的覆盖,而是将目标定为抓取“与某一特定主题内容相关的网页”,为面向主题的用户查询,准备数据资源。
“聚焦网路爬虫”的工作原理以及关键技术概述:
网络爬虫,是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫,从一个或若干初始网页的URL(统一资源定位符)开始,获得初始网页上的URL(统一资源定位符),在抓取网页的过程中,不断从当前页面上抽取新的URL(统一资源定位符)放入队列,直到满足系统的一定停止条件。
“聚焦网路爬虫”的工作流程较为复杂,需要按照一定的“网页分析算法”过滤与主题无关的链接,保留有用的链接,并将其倒入等待抓取的URL(统一资源定位符)队列。然后,它将按照一定的搜索策略,从队列中选择下一步要抓取的网页URL(统一资源定位符),并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。对于“聚焦网路爬虫”来说,这一过程所得到的剖析结果,还可能对之后的抓取过程给出反馈和指导。
相对于通用网路爬虫,聚焦网路爬虫还须要解决三个主要问题:
1、对抓取目标的描述或定义;
2、对网页或数据的剖析与过滤;
3、对URL(统一资源定位符)的搜索策略。
网络爬虫碰到的问题:
早在2007 年底,互联网上的网页数目就早已超出160 亿个,研究表明接近30%的页面是重复的。动态页面的存在,客户端、服务器端脚本语言的应用,使得指向相同Web信息的 URL(统一资源定位符)数量呈指数级下降。
上述特点促使网路爬虫面临一定的困难,主要彰显在 Web信息的巨大容量,使得爬虫在给定的时间内,只能下载少量网页。有研究表明,没有那个搜索引擎才能索引超出16%的互联网Web 页面,即使才能提取全部页面,也没有足够的空间来储存。
为了提升爬行效率,爬虫须要在单位时间内尽可能多的获取高质量页面,这是它面临的困局之一。
当前有五种表示页面质量高低的方法:1、页面与爬行主题之间的相似度;2、页面在 Web 图中的入度大小;3、指向它的所有页面平均残差之和;4、页面在 Web 图中的出度大小;5、页面的信息位置。
为了提升爬行速率,网络爬虫一般会采取“并行爬行”的工作方式,这种工作方式也造成了新的问题:
1、重复性(并行运行的爬虫或爬行线程同时运行时,增加了重复页面);
2、质量问题(并行运行时,每个爬虫或爬行线程只能获取部份页面,导致页面质量下滑);
3、通信带宽代价(并行运行时,各个爬虫或爬行线程之间不可避开要进行一些通讯,需要花费一定的带宽资源)。
并行运行时,网络爬虫一般采用三种形式:
1、独立形式(各个爬虫独立爬行页面,互不通讯);
2、动态分配方法(由一个中央协调器动态协调分配 URL 给各个爬虫);
3、静态分配方法(URL 事先界定给各个爬虫)。
亿速云,作为一家专业的IDC(互联网数据中心)业务服务提供商、拥有丰富行业底蕴的专业云计算服务提供商,一直专注于技术创新和构建更好的服务品质,致力于为广大用户,提供高性价比、高可用性的“裸金属服务器、云服务器、高防服务器、高防IP、香港服务器、日本服务器、美国服务器、SSL证书”等专业产品与服务。 查看全部
网络爬虫,又被称为“网页蜘蛛,网络机器人”,在FOAF社区中间,经常被称为“网页追逐者”。网络爬虫,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
网络爬虫,按照系统结构和实现技术,大致可以分为:“通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫”等四种不同类型。实际上,网络爬虫系统,通常是由几种爬虫技术相结合实现的。
一、 通用网路爬虫
通用网路爬虫,又称“全网爬虫”,爬行对象从一些种子URL(统一资源定位符) 扩充到整个万维网,主要为“门户站点搜索引擎”和“大型Web服务提供商”采集数据。由于商业缘由,它们的技术细节甚少被公布下来。这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为等待刷新的页面太多,通常采用“并行工作”的方法,但须要较长时间能够刷新一次页面。通用网路爬虫,虽然存在着一定的缺陷,但它适用于为搜索引擎平台搜索广泛的主题,有较强的应用价值。
二、聚焦网络爬虫
聚焦网络爬虫,又称“主题网路爬虫”,是指选择性地爬行,那些与预先定义好的主题相关的页面的网路爬虫。和通用网路爬虫相比,聚焦网路爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网路爬虫相比,增加了“链接评价模块”以及“内容评价模块”。聚焦网路爬虫爬行策略实现的关键是,评价页面内容和链接的重要性。不同的方式估算出的重要性不同,由此引起链接的访问次序也不同。
三、增量式网络爬虫
是指对已下载网页采取增量式更新,和只爬行新形成的或则早已发生变化网页的爬虫网络爬虫技术是什么,它还能在一定程度上保证网络爬虫技术是什么,所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。
四、深层网络爬虫
Web 页面,按存在形式可以分为“表层网页”和“深层网页”。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。
深层网页是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web 页面。例如:那些用户注册后内容才可见的网页,就属于深层网页。
随着计算机网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。搜索引擎,例如传统的“通用搜索引擎”平台:Google(谷歌)、Yahoo!(雅虎)、百度等,作为一个辅助人们检索万维网信息的工具,成为互联网用户访问万维网的入口和渠道。
但是,这些“通用搜索引擎平台”也存在着一定的局限性,如:
1、 不同领域、不同职业、不同背景的用户,往往具有不同的检索目的和需求,通用搜索引擎所返回的结果,包含了大量用户并不关心的网页,或者与用户搜索结果无关的网页。
2、 通用搜索引擎的目标是,实现尽可能大的网路覆盖率,有限的搜索引擎服务器资源,与无限的网路数据资源之间的矛盾将进一步加深。
3、 万维网数据方式的丰富和网路技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎常常对这种信息浓度密集,且具有一定结构的数据无能为力,不能挺好地发觉和获取。
4、通用搜索引擎,大多提供基于“关键字”的检索,难以支持按照语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的“聚焦网路爬虫”应运而生。聚焦网路爬虫,是一个手动下载网页的程序,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息。
与“通用网路爬虫”不同,聚焦网络爬虫并不追求大的覆盖,而是将目标定为抓取“与某一特定主题内容相关的网页”,为面向主题的用户查询,准备数据资源。
“聚焦网路爬虫”的工作原理以及关键技术概述:
网络爬虫,是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫,从一个或若干初始网页的URL(统一资源定位符)开始,获得初始网页上的URL(统一资源定位符),在抓取网页的过程中,不断从当前页面上抽取新的URL(统一资源定位符)放入队列,直到满足系统的一定停止条件。
“聚焦网路爬虫”的工作流程较为复杂,需要按照一定的“网页分析算法”过滤与主题无关的链接,保留有用的链接,并将其倒入等待抓取的URL(统一资源定位符)队列。然后,它将按照一定的搜索策略,从队列中选择下一步要抓取的网页URL(统一资源定位符),并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。对于“聚焦网路爬虫”来说,这一过程所得到的剖析结果,还可能对之后的抓取过程给出反馈和指导。
相对于通用网路爬虫,聚焦网路爬虫还须要解决三个主要问题:
1、对抓取目标的描述或定义;
2、对网页或数据的剖析与过滤;
3、对URL(统一资源定位符)的搜索策略。
网络爬虫碰到的问题:
早在2007 年底,互联网上的网页数目就早已超出160 亿个,研究表明接近30%的页面是重复的。动态页面的存在,客户端、服务器端脚本语言的应用,使得指向相同Web信息的 URL(统一资源定位符)数量呈指数级下降。
上述特点促使网路爬虫面临一定的困难,主要彰显在 Web信息的巨大容量,使得爬虫在给定的时间内,只能下载少量网页。有研究表明,没有那个搜索引擎才能索引超出16%的互联网Web 页面,即使才能提取全部页面,也没有足够的空间来储存。
为了提升爬行效率,爬虫须要在单位时间内尽可能多的获取高质量页面,这是它面临的困局之一。
当前有五种表示页面质量高低的方法:1、页面与爬行主题之间的相似度;2、页面在 Web 图中的入度大小;3、指向它的所有页面平均残差之和;4、页面在 Web 图中的出度大小;5、页面的信息位置。
为了提升爬行速率,网络爬虫一般会采取“并行爬行”的工作方式,这种工作方式也造成了新的问题:
1、重复性(并行运行的爬虫或爬行线程同时运行时,增加了重复页面);
2、质量问题(并行运行时,每个爬虫或爬行线程只能获取部份页面,导致页面质量下滑);
3、通信带宽代价(并行运行时,各个爬虫或爬行线程之间不可避开要进行一些通讯,需要花费一定的带宽资源)。
并行运行时,网络爬虫一般采用三种形式:
1、独立形式(各个爬虫独立爬行页面,互不通讯);
2、动态分配方法(由一个中央协调器动态协调分配 URL 给各个爬虫);
3、静态分配方法(URL 事先界定给各个爬虫)。
亿速云,作为一家专业的IDC(互联网数据中心)业务服务提供商、拥有丰富行业底蕴的专业云计算服务提供商,一直专注于技术创新和构建更好的服务品质,致力于为广大用户,提供高性价比、高可用性的“裸金属服务器、云服务器、高防服务器、高防IP、香港服务器、日本服务器、美国服务器、SSL证书”等专业产品与服务。
网络爬虫的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 367 次浏览 • 2020-07-02 08:01
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler 查看全部
第11卷第4期2012年 4月软件导刊Software Guide Vo l. ll NO.4 组己旦2网路爬虫的设计与实现王娟,吴金鹏(贵州|民族学院计算机与信息工程学院,贵州l 贵阳 550025)摘 要:搜索引擎技术随着互联网的日渐壮大而急速发展。作为搜索引擎不可或缺的组成部分,网络爬虫的作用变得尤为重要网络爬虫设计,它的性能直接决定了在庞大的互联网上进行网页信息采集的质量。设计并实现了通用爬虫和限定爬虫。关键词:网络爬虫;通用爬虫;限定爬虫中图分类号 :TP393 文献标识码 :A。哥|言网路爬虫称作网路蜘蛛,它为搜索引擎从万维网上下载网页,并顺着网页的相关链接在 Web 中采集资源,是一个功能太强的网页手动抓取程序,也是搜索引擎的重要组成部份,爬虫设计的优劣直接决定着整个搜索引擎的性能及扩充能力。网络爬虫根据系统结构和实现技术,大致可以分为:通用网路爬虫、主题网路爬虫、增量式网路爬虫、深层网路爬虫 o 实际应用中一般是将几种爬虫技术相结合。1 通用爬虫的设计与实现1. 1 工作原理通用网路爬虫按照预先设定的一个或若干初始种子URL 开始,以此获得初始网页上的 URL 列表,在爬行过程中不断从 URL 队列中获一个个的 URL,进而访问并下载该页面。
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler
网络爬虫技术之同时抓取多个网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 872 次浏览 • 2020-06-26 08:01
$curlobj = curl_init(); //创建一个curl 的资源,下面要用的curl_setopt($curlobj,CURLOPT_URL,""); //获取资源curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); //请求结果不直接复印 $output = curl_exec($cu
爬虫爬取多个不相同网页
任务四‘’’本任务要求你们完成一个简单的爬虫项目,包括网页爬取、信息提取以及数据保存在完成本次任务时,建议你们认真思索,结合自己的逻辑,完成任务。注意:本任务的得分将根据任务递交时间的先后次序与任务正确率结合来估算,由于每个朋友的题目都不相同,建议不要剽窃,一旦发觉剽窃情况,本次任务判为0分’’’from typing import Any, Tuple‘’’第一题:请使用爬虫技术...
Scrapy爬取多层级网页内容的方法
# -*- coding: utf-8 -*-import scrapyfrom Avv.items import AvvItemclass AvSpider(scrapy.Spider):name = 'av' # 爬虫名allowed_domains = ['/'] # 爬虫作用域# 爬取第2页到最后一页的代码url = ...
爬虫——scrapy框架爬取多个页面影片的二级子页面的详尽信息
文章目录需求:总结:代码:movieinfo.pyitems.pymiddleware.pypipelines.py结果:附加:需求:scrapy框架,爬取某影片网页面的每位影片的一级页面的名子爬取每部影片二级页面的详尽信息使用代理ip保存日志文件存为csv文件总结:1、xpath解析使用extract()的各类情况剖析
网络爬虫初步:从一个入口链接开始不断抓取页面中的网址并入库
前言: 在上一篇《网络爬虫初步:从访问网页到数据解析》中,我们讨论了怎样爬取网页,对爬取的网页进行解析,以及访问被拒绝的网站。在这一篇博客中,我们可以来了解一下领到解析的数据可以做的风波。在这篇博客中,我主要是说明要做的两件事,一是入库,二是遍历领到的链接继续访问。如此往复,这样就构成了一个网络爬虫的雏型。笔者环境: 系统: Windows 7...
php爬虫
Php爬虫,爬取数据,识图猜词语一、寻找数据1,寻找相关网站数据剖析网站换页特点剖析得出不仅第一页,第二页开始index加页面数写一个函数,专门拼接须要访问的页面public function getcy($id=3,$num=3){$i=$id;...
爬取多个页面的数据
代码如下:# -*- coding:utf8 -*-#导入requests库,取别称resimport requests as res#导入bs4包,取别称bsfrom bs4 import BeautifulSoup as bs#导入数据库驱动包import MySQLdb#声明页面从哪开始j = 1#循环遍历每位页面while j 111:##获取目标网站的网页
Python爬虫实例(3)-用BeautifulSoup爬取多个可翻页网页上的多张相片
# -*- coding: utf-8 -*-#导入第三方包和模块import requestsfrom bs4 import BeautifulSoupimport os#在本地新建一个文件夹,命名为test_img,用以保存下载的图片folder = 'test_img'if not os.path.exists(folder):os.makedirs(folder)#定义
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、有时候启动以后没任何反应3S然后程序停止。问哪些会这样,求解
webmagic爬虫自学(三)爬取CSDN【列表+详情的基本页面组合】的页面,使用基于注解的方法
1
如何实现两个页面的跳转
_addEvent:function(){var btn;btn=this._getWidgetByName(this._startGav,"Button_7");//获取按键的点击实风波btn.addTouchEventListener(this._inputHandler.bind(this),this._startGav);},_inputHandler:
爬虫——第二次试验(网站多页爬取代码)
实验目的熟练把握requests库中get技巧的使用把握借助requests库爬取多页网页内容的方式2.1 爬取百度贴吧与某主题相关的贴子,并将爬取到的内容保存到文件中(爬取多页)import requestsdef get_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ...
给你们推荐几种实现网页数据抓取的方法
相信所有个人网站的站长都有抓取他人数据的经历吧,目前抓取他人网站数据的方法无非两种形式: 一、使用第三方工具,其中最知名的是优采云采集器,在此不做介绍。 二、自己写程序抓取,这种方法要求站长自己写程序
java爬取百度百科词条
lz在之前的一篇博客中,用python实现了爬取百度百科的词条,就在怎么用java来实现相同的功能,果不其然,java用一个jsoup的第三方库工具就可以很简单地实现爬取百度百科的词条。同样的,将这个爬取过程分成5个部份来实现。分别是connectnet联接url部份、parsehtml获取html相关内容部份、startspyder部份、store储存url部份、urlmanager的url管理
关于使用Java实现的简单网路爬虫Demo
什么是网络爬虫?网络爬虫又叫蜘蛛,网络蜘蛛是通过网页的链接地址来找寻网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当作一个网站,那么网路蜘蛛就可以用这个原理把互联网上所有的网页都抓取出来。所以要想抓取网路上的数据,不仅须要爬虫程序还须要一个可以接受
Java爬虫爬取python百度百科词条及相关词条页面
Java爬虫爬取python百度百科词条及相关词条页面本实例爬取关于python词条页面及关联词条页面的简介网络爬虫论坛,把词条的简介写入txt文本中, 本实例疗效:实例基于使用第三方jar包Jsoup1首先剖析python词条页面:可以发觉其他词条的超链接都带有"/item"以及词条的简介都包含在class为
python scrapy项目下spiders内多个爬虫同时运行
一般创建了scrapy文件夹后,可能须要写多个爬虫,如果想使它们同时运行而不是顺次运行的话,得怎样做?a、在spiders目录的同级目录下创建一个commands目录网络爬虫论坛,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只更改run()方法即可!import osfrom ...
算法设计中关于优先队列式分支限界法解装载问题的代码下载
分支限界法中的优先队列式分支限界法解装载问题相关下载链接:
软件调试张银奎(7)下载
软件调试张银奎(4)软件调试张银奎(4)软件调试张银奎(4)相关下载链接:
WimTool-WIM文件处理工具安装版下载
WimTool-WIM文件处理工具安装版相关下载链接:
相关热词c#如何获得线程名c# usb 采集器c# sort()c#面对对象的三大特点c# 打印 等比缩放c#弹出右键菜单c# 系统托盘图标c# 键值对 键可以重复c# 鼠标移起来提示c#结构体定义
我们是挺有底线的 查看全部
$curlobj = curl_init(); //创建一个curl 的资源,下面要用的curl_setopt($curlobj,CURLOPT_URL,""); //获取资源curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); //请求结果不直接复印 $output = curl_exec($cu
爬虫爬取多个不相同网页
任务四‘’’本任务要求你们完成一个简单的爬虫项目,包括网页爬取、信息提取以及数据保存在完成本次任务时,建议你们认真思索,结合自己的逻辑,完成任务。注意:本任务的得分将根据任务递交时间的先后次序与任务正确率结合来估算,由于每个朋友的题目都不相同,建议不要剽窃,一旦发觉剽窃情况,本次任务判为0分’’’from typing import Any, Tuple‘’’第一题:请使用爬虫技术...
Scrapy爬取多层级网页内容的方法
# -*- coding: utf-8 -*-import scrapyfrom Avv.items import AvvItemclass AvSpider(scrapy.Spider):name = 'av' # 爬虫名allowed_domains = ['/'] # 爬虫作用域# 爬取第2页到最后一页的代码url = ...
爬虫——scrapy框架爬取多个页面影片的二级子页面的详尽信息
文章目录需求:总结:代码:movieinfo.pyitems.pymiddleware.pypipelines.py结果:附加:需求:scrapy框架,爬取某影片网页面的每位影片的一级页面的名子爬取每部影片二级页面的详尽信息使用代理ip保存日志文件存为csv文件总结:1、xpath解析使用extract()的各类情况剖析
网络爬虫初步:从一个入口链接开始不断抓取页面中的网址并入库
前言: 在上一篇《网络爬虫初步:从访问网页到数据解析》中,我们讨论了怎样爬取网页,对爬取的网页进行解析,以及访问被拒绝的网站。在这一篇博客中,我们可以来了解一下领到解析的数据可以做的风波。在这篇博客中,我主要是说明要做的两件事,一是入库,二是遍历领到的链接继续访问。如此往复,这样就构成了一个网络爬虫的雏型。笔者环境: 系统: Windows 7...
php爬虫
Php爬虫,爬取数据,识图猜词语一、寻找数据1,寻找相关网站数据剖析网站换页特点剖析得出不仅第一页,第二页开始index加页面数写一个函数,专门拼接须要访问的页面public function getcy($id=3,$num=3){$i=$id;...
爬取多个页面的数据
代码如下:# -*- coding:utf8 -*-#导入requests库,取别称resimport requests as res#导入bs4包,取别称bsfrom bs4 import BeautifulSoup as bs#导入数据库驱动包import MySQLdb#声明页面从哪开始j = 1#循环遍历每位页面while j 111:##获取目标网站的网页
Python爬虫实例(3)-用BeautifulSoup爬取多个可翻页网页上的多张相片
# -*- coding: utf-8 -*-#导入第三方包和模块import requestsfrom bs4 import BeautifulSoupimport os#在本地新建一个文件夹,命名为test_img,用以保存下载的图片folder = 'test_img'if not os.path.exists(folder):os.makedirs(folder)#定义
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、有时候启动以后没任何反应3S然后程序停止。问哪些会这样,求解
webmagic爬虫自学(三)爬取CSDN【列表+详情的基本页面组合】的页面,使用基于注解的方法
1
如何实现两个页面的跳转
_addEvent:function(){var btn;btn=this._getWidgetByName(this._startGav,"Button_7");//获取按键的点击实风波btn.addTouchEventListener(this._inputHandler.bind(this),this._startGav);},_inputHandler:
爬虫——第二次试验(网站多页爬取代码)
实验目的熟练把握requests库中get技巧的使用把握借助requests库爬取多页网页内容的方式2.1 爬取百度贴吧与某主题相关的贴子,并将爬取到的内容保存到文件中(爬取多页)import requestsdef get_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ...
给你们推荐几种实现网页数据抓取的方法
相信所有个人网站的站长都有抓取他人数据的经历吧,目前抓取他人网站数据的方法无非两种形式: 一、使用第三方工具,其中最知名的是优采云采集器,在此不做介绍。 二、自己写程序抓取,这种方法要求站长自己写程序
java爬取百度百科词条
lz在之前的一篇博客中,用python实现了爬取百度百科的词条,就在怎么用java来实现相同的功能,果不其然,java用一个jsoup的第三方库工具就可以很简单地实现爬取百度百科的词条。同样的,将这个爬取过程分成5个部份来实现。分别是connectnet联接url部份、parsehtml获取html相关内容部份、startspyder部份、store储存url部份、urlmanager的url管理
关于使用Java实现的简单网路爬虫Demo
什么是网络爬虫?网络爬虫又叫蜘蛛,网络蜘蛛是通过网页的链接地址来找寻网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当作一个网站,那么网路蜘蛛就可以用这个原理把互联网上所有的网页都抓取出来。所以要想抓取网路上的数据,不仅须要爬虫程序还须要一个可以接受
Java爬虫爬取python百度百科词条及相关词条页面
Java爬虫爬取python百度百科词条及相关词条页面本实例爬取关于python词条页面及关联词条页面的简介网络爬虫论坛,把词条的简介写入txt文本中, 本实例疗效:实例基于使用第三方jar包Jsoup1首先剖析python词条页面:可以发觉其他词条的超链接都带有"/item"以及词条的简介都包含在class为
python scrapy项目下spiders内多个爬虫同时运行
一般创建了scrapy文件夹后,可能须要写多个爬虫,如果想使它们同时运行而不是顺次运行的话,得怎样做?a、在spiders目录的同级目录下创建一个commands目录网络爬虫论坛,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只更改run()方法即可!import osfrom ...
算法设计中关于优先队列式分支限界法解装载问题的代码下载
分支限界法中的优先队列式分支限界法解装载问题相关下载链接:
软件调试张银奎(7)下载
软件调试张银奎(4)软件调试张银奎(4)软件调试张银奎(4)相关下载链接:
WimTool-WIM文件处理工具安装版下载
WimTool-WIM文件处理工具安装版相关下载链接:
相关热词c#如何获得线程名c# usb 采集器c# sort()c#面对对象的三大特点c# 打印 等比缩放c#弹出右键菜单c# 系统托盘图标c# 键值对 键可以重复c# 鼠标移起来提示c#结构体定义
我们是挺有底线的
网络爬虫技术(新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-06-22 08:00
网络爬虫技术网路机器人1.概念: 它们是 Web 上孤身运行的软件程序,它们不断地筛选数据,做出自己的 决定, 能够使用 Web 获取文本或则进行搜索查询,按部就班地完成各自的任务。 2.分类: 购物机器人、聊天机器人、搜索机器人(网络爬虫)等。搜索引擎1.概念: 从网路上获得网站网页资料,能够构建数据库并提供查询的系统 。 2.分类(按工作原理) : 全文搜索引擎、分类目录。 1> 全文搜索引擎数据库是借助网路爬虫通过网路上的各类链接手动获取大量 网页信息内容,并按一定的规则剖析整理产生的。 (百度、Google) 2> 分类目录:按目录分类的网站链接列表而已 ,通过人工的方法搜集整理网 站资料产生的数据库。(国内的搜狐)网络爬虫1.概念: 网络爬虫也叫网路蜘蛛,它是一个根据一定的规则手动提取网页程序,其会手动 的通过网路抓取互联网上的网页,这种技术通常可能拿来检测你的站点上所有的链接 是否是都是有效的。当然爬虫技术,更为中级的技术是把网页中的相关数据保存出来,可以成 为搜索引擎。 搜索引擎使用网络爬虫找寻网路内容,网络上的 HTML 文档使用超链接联接了上去, 就像织成了一张网,网络爬虫也叫网路蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序 将这个网页抓出来,将内容抽取下来,同时抽取超链接,作为进一步爬行的线索。
网络爬虫 总是要从某个起点开始爬,这个起点称作种子,你可以告诉它,也可以到一些网址列表网站 上获取。 2.区别: 网络爬虫 分类 工作原理 通用爬虫 从一个或多个初始网页的 URL 开 始,获取初始网页的 URL,抓取网 页的同时爬虫技术,从当前网页提取相关的 URL 放入队列中,直到满足程序的 停止条件。 聚集爬虫 根据一定的网页剖析算法过滤与主题无 关的链接,保留有用的链接(爬行的范围 是受控的)放到待抓取的队列中,通过一 定的搜索策略从队列中选择下一步要抓 取的 URL,重复以上步骤,直到满足程 序的停止条件。 1. 增加了一些网页分析算法和网页搜 索策略 2. 对 被 爬 虫 抓 取 的 网 页 将 会 被 系 统 存贮,进行一定的剖析、过滤,并 建立索引,以便以后的查询和检 索,这一过程所得到的剖析结果还 可能对之后的抓取过程给出反馈不同点和指导。 缺点 1. 不同领域、 不同背景的用户有 不同的检索目的和需求, 通用 搜索引擎所返回的结果包含 大量用户不关心的网页。 2. 通用引擎的目标是大的网路覆 盖率。 3. 只支持关键字搜索, 不支持按照 语义的搜索。 4. 通用搜索引擎对一些象图片、 音 频等信 息 含 量 密 集 且 具 有 一 定结构的数据难以获取。
广度优先算法 1. 对抓取目标的描述或定义。 2. 对网页和数据的剖析和过滤。 3. 对 URL 的搜索策略。 以上三个是须要解决的问题。算法现有聚焦爬虫对抓取目标的描述可分为基于目标网页特点、 基于目标数据模式和基于领 域概念 3 种。 基于目标网页特点的爬虫所抓取、 存储并索引的对象通常为网站或网页。 根据种子样本 获取方法可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如 Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标明的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特点可以是网页的内容特点,也可以是网页的链接结构特点,等等。 3.算法/策略 名称 分类 网页分析算法 1.基于网路拓扑结构 1>网页细度剖析算法 2>网站粒度剖析算法 3>网页块细度剖析算法 2.基于网页内容 1>针对以文本和超链接为主的 网页 2>针对从结构化的数据源动态生 成的网页。 3>针对数据介于第一类和第二类 之间 3.基于用户访问行为 网页搜索策略 1.深度优先策略 2.广度优先策略 3.最佳优先策略一些算法的介绍 1> 网页分析算法1.1 基于网路拓扑的剖析算法? 基于网页之间的链接, 通过已知的网页或数据, 来对与其有直接或间接链接关系的对象 (可以是网页或网站等) 作出评价的算法。
又分为网页细度、 网站粒度和网页块细度这三种。 1.1.1 网页(Webpage)粒度的剖析算法 PageRank 和 HITS 算法是最常见的链接剖析算法, 两者都是通过对网页间链接度的递归 和规范化估算,得到每位网页的重要度评价。PageRank 算法其实考虑了用户访问行为的随 机性和 Sink 网页的存在,但忽视了绝大多数用户访问时带有目的性,即网页和链接与查询 主题的相关性。针对这个问题,HITS 算法提出了两个关键的概念:权威型网页(authority) 和中心型网页(hub) 。 基于链接的抓取的问题是相关页面主题团之间的隧洞现象, 即好多在抓取路径上偏离主 题的网页也指向目标网页,局部评价策略中断了在当前路径上的抓取行为。文献[21]提出了 一种基于反向链接(BackLink)的分层式上下文模型(Context Model) ,用于描述指向目标 网页一定化学跳数直径内的网页拓扑图的中心 Layer0 为目标网页,将网页根据指向目标网 页的数学跳数进行层次界定,从内层网页指向外层网页的链接称为反向链接。? 1.1.2 网站粒度的剖析算法 网站粒度的资源发觉和管理策略也比网页细度的更简单有效。
网站粒度的爬虫抓取的关 键之处在于站点的界定和站点等级(SiteRank)的估算。 SiteRank 的估算方式与 PageRank 类似, 但是须要对网站之间的链接作一定程度具象,并在一定的模型下估算链接的权重。 网站划分情况分为按域名界定和按 IP 地址界定两种。文献[18]讨论了在分布式情况下, 通过对同一个域名下不同主机、服务器的 IP 地址进行站点界定,构造站点图,利用类似 Pa geRank 的方式评价 SiteRank。同时,根据不同文件在各个站点上的分布情况,构造文档图, 结合 SiteRank 分布式估算得到 DocRank。文献[18]证明,利用分布式的 SiteRank 计算,不仅 大大增加了单机站点的算法代价, 而且克服了单独站点对整个网路覆盖率有限的缺点。 附带 的一个优点是,常见 PageRank 造假无法对 SiteRank 进行愚弄。? 1.1.3 网页块细度的剖析算法 在一个页面中, 往往富含多个指向其他页面的链接, 这些链接中只有一部分是指向主题 相关网页的,或依照网页的链接锚文本表明其具有较高重要性。但是,在 PageRank 和 HIT S 算法中,没有对那些链接作分辨,因此经常给网页剖析带来广告等噪音链接的干扰。
在网 页块级别(Block?level) 进行链接剖析的算法的基本思想是通过 VIPS 网页分割算法将网页分 为不同的网页块(page block),然后对这种网页块构建 page?to?block block?to?page的 和 链接矩阵,? 分别记为 Z 和 X。于是,在 page?to? page 图上的网页块级别的 PageRank 为? W?p=X×Z ? block?to?block图上的 BlockRank 为?W?b=Z×X ? ; 在 。 已经有人实现了块级 别的 PageRank 和 HITS 算法,并通过实验证明,效率和准确率都比传统的对应算法要好。 1.2 基于网页内容的网页分析算法 基于网页内容的剖析算法指的是借助网页内容(文本、数据等资源)特征进行的网页评 价。网页的内容从原先的以超文本为主,发展到后来动态页面(或称为 Hidden Web)数据 为主,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的 400~500 倍。另一方面,多媒体数据、Web Service 等各类网路资源方式也日渐丰富。因此,基于网页内容的剖析算法也从原先的较为单纯的文本检索方式, 发展为囊括网页数据抽取、 机器学 习、数据挖掘、语义理解等多种方式的综合应用。
本节按照网页数据方式的不同,将基于网 页内容的剖析算法, 归纳以下三类: 第一种针对以文本和超链接为主的无结构或结构很简单 的网页;第二种针对从结构化的数据源(如 RDBMS)动态生成的页面,其数据不能直接批 量访问;第三种针对的数据界于第一和第二类数据之间,具有较好的结构,显示遵照一定模 式或风格,且可以直接访问。 1.2.1 基于文本的网页剖析算法 1) 纯文本分类与聚类算法 很大程度上借用了文本检索的技术。 文本剖析算法可以快速有效的对网页进行分类和聚 类,但是因为忽视了网页间和网页内部的结构信息,很少单独使用。? 2) 超文本分类和聚类算法 2> 网页搜索策略 2. 广度优先搜索策略 广度优先搜索策略是指在抓取过程中, 在完成当前层次的搜索后, 才进行下一层次的搜 索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索 方法。 也有好多研究将广度优先搜索策略应用于聚焦爬虫中。 其基本思想是觉得与初始 URL 在一定链接距离内的网页具有主题相关性的机率很大。 另外一种方式是将广度优先搜索与网 页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。
这些方式 的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。 2. 最佳优先搜索策略 最佳优先搜索策略根据一定的网页分析算法,预测候选 URL 与目标网页的相似度,或 与主题的相关性,并选定评价最好的一个或几个 URL 进行抓取。它只访问经过网页剖析算 法预测为“有用”的网页。 存在的一个问题是, 在爬虫抓取路径上的好多相关网页可能被忽视, 因为最佳优先策略是一种局部最优搜索算法。因此须要将最佳优先结合具体的应用进行改 进,以跳出局部最优点。将在第 4 节中结合网页分析算法作具体的讨论。研究表明,这样的 闭环调整可以将无关网页数目减少 30%~90%。 3. 搜索引擎原理之网路爬虫是怎样工作的? 在互联网中,网页之间的链接关系是无规律的,它们的关系十分复杂。如果一个爬虫从 一个起点开始爬行,那么它将会碰到无数的分支,由此生成无数条的爬行路径,如果聘期爬 行,就有可能永远也爬不到头,因此要对它加以控制,制定其爬行的规则。世界上没有一种 爬虫还能抓取到互联网所有的网页, 所以就要在提升其爬行速率的同时, 也要提升其爬行网 页的质量。 网络爬虫在搜索引擎中占有重要位置,对搜索引擎的查全、查准都有影响,决定了搜索 引擎数据容量的大小, 而且网路爬虫的优劣之间影响搜索引擎结果页中的死链接的个数。
搜 索引擎爬虫有深度优先策略和广度优先策略,另外,识别垃圾网页,避免抓取重复网页,也 是高性能爬虫的设计目标。 爬虫的作用是为了搜索引擎抓取大量的数据, 抓取的对象是整个互联网上的网页。 爬虫 程序不可能抓取所有的网页,因为在抓取的同时,Web 的规模也在减小,所以一个好的爬 虫程序通常就能在短时间内抓取更多的网页。 一般爬虫程序的起点都选择在一个小型综合型的网站,这样的网站已经囊括了大部分高质量的站点,爬虫程序就顺着那些链接爬行。在爬 行过程中,最重要的就是判定一个网页是否早已被爬行过。 在爬虫开始的时侯, 需要给爬虫输送一个 URL 列表, 这个列表中的 URL 地址便是爬虫 的起始位置,爬虫从这种 URL 出发,开始了爬行,一直不断地发觉新的 URL,然后再按照 策略爬行这种新发觉的 URL,如此永远反复下去。一般的爬虫都自己完善 DNS 缓冲,建立 DNS 缓冲的目的是推动 URL 解析成 IP 地址的速率。 查看全部
网络爬虫技术网路机器人1.概念: 它们是 Web 上孤身运行的软件程序,它们不断地筛选数据,做出自己的 决定, 能够使用 Web 获取文本或则进行搜索查询,按部就班地完成各自的任务。 2.分类: 购物机器人、聊天机器人、搜索机器人(网络爬虫)等。搜索引擎1.概念: 从网路上获得网站网页资料,能够构建数据库并提供查询的系统 。 2.分类(按工作原理) : 全文搜索引擎、分类目录。 1> 全文搜索引擎数据库是借助网路爬虫通过网路上的各类链接手动获取大量 网页信息内容,并按一定的规则剖析整理产生的。 (百度、Google) 2> 分类目录:按目录分类的网站链接列表而已 ,通过人工的方法搜集整理网 站资料产生的数据库。(国内的搜狐)网络爬虫1.概念: 网络爬虫也叫网路蜘蛛,它是一个根据一定的规则手动提取网页程序,其会手动 的通过网路抓取互联网上的网页,这种技术通常可能拿来检测你的站点上所有的链接 是否是都是有效的。当然爬虫技术,更为中级的技术是把网页中的相关数据保存出来,可以成 为搜索引擎。 搜索引擎使用网络爬虫找寻网路内容,网络上的 HTML 文档使用超链接联接了上去, 就像织成了一张网,网络爬虫也叫网路蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序 将这个网页抓出来,将内容抽取下来,同时抽取超链接,作为进一步爬行的线索。
网络爬虫 总是要从某个起点开始爬,这个起点称作种子,你可以告诉它,也可以到一些网址列表网站 上获取。 2.区别: 网络爬虫 分类 工作原理 通用爬虫 从一个或多个初始网页的 URL 开 始,获取初始网页的 URL,抓取网 页的同时爬虫技术,从当前网页提取相关的 URL 放入队列中,直到满足程序的 停止条件。 聚集爬虫 根据一定的网页剖析算法过滤与主题无 关的链接,保留有用的链接(爬行的范围 是受控的)放到待抓取的队列中,通过一 定的搜索策略从队列中选择下一步要抓 取的 URL,重复以上步骤,直到满足程 序的停止条件。 1. 增加了一些网页分析算法和网页搜 索策略 2. 对 被 爬 虫 抓 取 的 网 页 将 会 被 系 统 存贮,进行一定的剖析、过滤,并 建立索引,以便以后的查询和检 索,这一过程所得到的剖析结果还 可能对之后的抓取过程给出反馈不同点和指导。 缺点 1. 不同领域、 不同背景的用户有 不同的检索目的和需求, 通用 搜索引擎所返回的结果包含 大量用户不关心的网页。 2. 通用引擎的目标是大的网路覆 盖率。 3. 只支持关键字搜索, 不支持按照 语义的搜索。 4. 通用搜索引擎对一些象图片、 音 频等信 息 含 量 密 集 且 具 有 一 定结构的数据难以获取。
广度优先算法 1. 对抓取目标的描述或定义。 2. 对网页和数据的剖析和过滤。 3. 对 URL 的搜索策略。 以上三个是须要解决的问题。算法现有聚焦爬虫对抓取目标的描述可分为基于目标网页特点、 基于目标数据模式和基于领 域概念 3 种。 基于目标网页特点的爬虫所抓取、 存储并索引的对象通常为网站或网页。 根据种子样本 获取方法可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如 Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标明的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特点可以是网页的内容特点,也可以是网页的链接结构特点,等等。 3.算法/策略 名称 分类 网页分析算法 1.基于网路拓扑结构 1>网页细度剖析算法 2>网站粒度剖析算法 3>网页块细度剖析算法 2.基于网页内容 1>针对以文本和超链接为主的 网页 2>针对从结构化的数据源动态生 成的网页。 3>针对数据介于第一类和第二类 之间 3.基于用户访问行为 网页搜索策略 1.深度优先策略 2.广度优先策略 3.最佳优先策略一些算法的介绍 1> 网页分析算法1.1 基于网路拓扑的剖析算法? 基于网页之间的链接, 通过已知的网页或数据, 来对与其有直接或间接链接关系的对象 (可以是网页或网站等) 作出评价的算法。
又分为网页细度、 网站粒度和网页块细度这三种。 1.1.1 网页(Webpage)粒度的剖析算法 PageRank 和 HITS 算法是最常见的链接剖析算法, 两者都是通过对网页间链接度的递归 和规范化估算,得到每位网页的重要度评价。PageRank 算法其实考虑了用户访问行为的随 机性和 Sink 网页的存在,但忽视了绝大多数用户访问时带有目的性,即网页和链接与查询 主题的相关性。针对这个问题,HITS 算法提出了两个关键的概念:权威型网页(authority) 和中心型网页(hub) 。 基于链接的抓取的问题是相关页面主题团之间的隧洞现象, 即好多在抓取路径上偏离主 题的网页也指向目标网页,局部评价策略中断了在当前路径上的抓取行为。文献[21]提出了 一种基于反向链接(BackLink)的分层式上下文模型(Context Model) ,用于描述指向目标 网页一定化学跳数直径内的网页拓扑图的中心 Layer0 为目标网页,将网页根据指向目标网 页的数学跳数进行层次界定,从内层网页指向外层网页的链接称为反向链接。? 1.1.2 网站粒度的剖析算法 网站粒度的资源发觉和管理策略也比网页细度的更简单有效。
网站粒度的爬虫抓取的关 键之处在于站点的界定和站点等级(SiteRank)的估算。 SiteRank 的估算方式与 PageRank 类似, 但是须要对网站之间的链接作一定程度具象,并在一定的模型下估算链接的权重。 网站划分情况分为按域名界定和按 IP 地址界定两种。文献[18]讨论了在分布式情况下, 通过对同一个域名下不同主机、服务器的 IP 地址进行站点界定,构造站点图,利用类似 Pa geRank 的方式评价 SiteRank。同时,根据不同文件在各个站点上的分布情况,构造文档图, 结合 SiteRank 分布式估算得到 DocRank。文献[18]证明,利用分布式的 SiteRank 计算,不仅 大大增加了单机站点的算法代价, 而且克服了单独站点对整个网路覆盖率有限的缺点。 附带 的一个优点是,常见 PageRank 造假无法对 SiteRank 进行愚弄。? 1.1.3 网页块细度的剖析算法 在一个页面中, 往往富含多个指向其他页面的链接, 这些链接中只有一部分是指向主题 相关网页的,或依照网页的链接锚文本表明其具有较高重要性。但是,在 PageRank 和 HIT S 算法中,没有对那些链接作分辨,因此经常给网页剖析带来广告等噪音链接的干扰。
在网 页块级别(Block?level) 进行链接剖析的算法的基本思想是通过 VIPS 网页分割算法将网页分 为不同的网页块(page block),然后对这种网页块构建 page?to?block block?to?page的 和 链接矩阵,? 分别记为 Z 和 X。于是,在 page?to? page 图上的网页块级别的 PageRank 为? W?p=X×Z ? block?to?block图上的 BlockRank 为?W?b=Z×X ? ; 在 。 已经有人实现了块级 别的 PageRank 和 HITS 算法,并通过实验证明,效率和准确率都比传统的对应算法要好。 1.2 基于网页内容的网页分析算法 基于网页内容的剖析算法指的是借助网页内容(文本、数据等资源)特征进行的网页评 价。网页的内容从原先的以超文本为主,发展到后来动态页面(或称为 Hidden Web)数据 为主,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的 400~500 倍。另一方面,多媒体数据、Web Service 等各类网路资源方式也日渐丰富。因此,基于网页内容的剖析算法也从原先的较为单纯的文本检索方式, 发展为囊括网页数据抽取、 机器学 习、数据挖掘、语义理解等多种方式的综合应用。
本节按照网页数据方式的不同,将基于网 页内容的剖析算法, 归纳以下三类: 第一种针对以文本和超链接为主的无结构或结构很简单 的网页;第二种针对从结构化的数据源(如 RDBMS)动态生成的页面,其数据不能直接批 量访问;第三种针对的数据界于第一和第二类数据之间,具有较好的结构,显示遵照一定模 式或风格,且可以直接访问。 1.2.1 基于文本的网页剖析算法 1) 纯文本分类与聚类算法 很大程度上借用了文本检索的技术。 文本剖析算法可以快速有效的对网页进行分类和聚 类,但是因为忽视了网页间和网页内部的结构信息,很少单独使用。? 2) 超文本分类和聚类算法 2> 网页搜索策略 2. 广度优先搜索策略 广度优先搜索策略是指在抓取过程中, 在完成当前层次的搜索后, 才进行下一层次的搜 索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索 方法。 也有好多研究将广度优先搜索策略应用于聚焦爬虫中。 其基本思想是觉得与初始 URL 在一定链接距离内的网页具有主题相关性的机率很大。 另外一种方式是将广度优先搜索与网 页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。
这些方式 的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。 2. 最佳优先搜索策略 最佳优先搜索策略根据一定的网页分析算法,预测候选 URL 与目标网页的相似度,或 与主题的相关性,并选定评价最好的一个或几个 URL 进行抓取。它只访问经过网页剖析算 法预测为“有用”的网页。 存在的一个问题是, 在爬虫抓取路径上的好多相关网页可能被忽视, 因为最佳优先策略是一种局部最优搜索算法。因此须要将最佳优先结合具体的应用进行改 进,以跳出局部最优点。将在第 4 节中结合网页分析算法作具体的讨论。研究表明,这样的 闭环调整可以将无关网页数目减少 30%~90%。 3. 搜索引擎原理之网路爬虫是怎样工作的? 在互联网中,网页之间的链接关系是无规律的,它们的关系十分复杂。如果一个爬虫从 一个起点开始爬行,那么它将会碰到无数的分支,由此生成无数条的爬行路径,如果聘期爬 行,就有可能永远也爬不到头,因此要对它加以控制,制定其爬行的规则。世界上没有一种 爬虫还能抓取到互联网所有的网页, 所以就要在提升其爬行速率的同时, 也要提升其爬行网 页的质量。 网络爬虫在搜索引擎中占有重要位置,对搜索引擎的查全、查准都有影响,决定了搜索 引擎数据容量的大小, 而且网路爬虫的优劣之间影响搜索引擎结果页中的死链接的个数。
搜 索引擎爬虫有深度优先策略和广度优先策略,另外,识别垃圾网页,避免抓取重复网页,也 是高性能爬虫的设计目标。 爬虫的作用是为了搜索引擎抓取大量的数据, 抓取的对象是整个互联网上的网页。 爬虫 程序不可能抓取所有的网页,因为在抓取的同时,Web 的规模也在减小,所以一个好的爬 虫程序通常就能在短时间内抓取更多的网页。 一般爬虫程序的起点都选择在一个小型综合型的网站,这样的网站已经囊括了大部分高质量的站点,爬虫程序就顺着那些链接爬行。在爬 行过程中,最重要的就是判定一个网页是否早已被爬行过。 在爬虫开始的时侯, 需要给爬虫输送一个 URL 列表, 这个列表中的 URL 地址便是爬虫 的起始位置,爬虫从这种 URL 出发,开始了爬行,一直不断地发觉新的 URL,然后再按照 策略爬行这种新发觉的 URL,如此永远反复下去。一般的爬虫都自己完善 DNS 缓冲,建立 DNS 缓冲的目的是推动 URL 解析成 IP 地址的速率。
大数据采集之网路爬虫的基本流程及抓取策略
采集交流 • 优采云 发表了文章 • 0 个评论 • 536 次浏览 • 2020-06-08 08:01
本篇教程阐述了大数据采集之网路爬虫的基本流程及抓取策略,希望阅读本篇文章以后你们有所收获,帮助你们对相关内容的理解愈发深入。
大数据时代下,数据采集推动着数据剖析,数据剖析促进发展。但是在这个过程中会出现好多问题。拿最简单最基础的爬虫采集数据为例,过程中还会面临,IP被封,爬取受限、违法操作等多种问题,所以在爬去数据之前,一定要了解好预爬网站是否涉及违规操作,找到合适的代理IP访问网站等一系列问题。
掌握爬虫技术也成为现今技术流的营销推广人员必须把握的。爬虫入门,这些知识你必须了解。
一、网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总大数据网络爬虫原理,这样就产生了该未知页面的PageRank值,从而参与排序。
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
3.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
4.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路然后再转到下一个起始页,继续跟踪链接。
三、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
太阳软件,一个好用的互联网推广换IP工具大数据网络爬虫原理,海量IP,一键切换,提升权重,必不可少! 查看全部
本篇教程阐述了大数据采集之网路爬虫的基本流程及抓取策略,希望阅读本篇文章以后你们有所收获,帮助你们对相关内容的理解愈发深入。
大数据时代下,数据采集推动着数据剖析,数据剖析促进发展。但是在这个过程中会出现好多问题。拿最简单最基础的爬虫采集数据为例,过程中还会面临,IP被封,爬取受限、违法操作等多种问题,所以在爬去数据之前,一定要了解好预爬网站是否涉及违规操作,找到合适的代理IP访问网站等一系列问题。
掌握爬虫技术也成为现今技术流的营销推广人员必须把握的。爬虫入门,这些知识你必须了解。
一、网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.PartialPageRank策略
PartialPageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总大数据网络爬虫原理,这样就产生了该未知页面的PageRank值,从而参与排序。
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
3.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
4.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路然后再转到下一个起始页,继续跟踪链接。
三、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
太阳软件,一个好用的互联网推广换IP工具大数据网络爬虫原理,海量IP,一键切换,提升权重,必不可少!
三种开源网路爬虫性能比较
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2020-06-05 08:02
在信息化时代,针对通用搜索引擎信息量大、查询准度和深度兼差等缺点,垂直搜索引擎已步入了用户认可和使用周期。垂直搜索是针对某一个行业的专业搜索引擎,是对网页库中的某类专门的信息进行一次整合,定向分数组抽取出须要的数据进行处理后再以某种方式返回给用户[1].相比通用搜索引擎则变得愈发专注、具体和深入。目前,垂直搜索引擎多用于行业信息获取和特色语料库建设等方面,且已卓见现实深远成效。
网络爬虫是一个手动提取和手动下载网页的程序开源网络爬虫,可为搜索引擎从互联网上下载网页,并按照既定的抓取目标,有选择地访问互联网上的网页与相关的链接,获取所须要的信息。按照功能用途,网络爬虫分为通用爬虫和聚焦爬虫,这是搜索引擎一个核心组成部份。
1 聚焦爬虫的工作原理及关键技术剖析
1. 1 聚焦爬虫的工作原理
聚焦爬虫是专门为查询某一主题而设计的网页采集工具,并不追求大范围覆盖,而是将目标预定为抓取与某一特定主题内容相关的网页,如此即为面向主题的用户查询打算数据资源。垂直搜索引擎可借助其实现对网页主题信息的挖掘以及发觉,聚焦爬虫的工作原理是:
( 1) 爬虫从一个或若干起始网页 URL 链接开始工作;( 2) 通过特定的主题相关性算法判定并过滤掉与主题无关的链接;( 3) 将有用链接加入待抓取的 URL 队列;( 4) 根据一定的搜索策略从待抓取 URL 队列中选择下一步要抓取的网页 URL.重复以上步骤,直至满足退出条件时停止[2].
1. 2 聚焦爬虫的几个关键技术
根据聚焦爬虫的工作原理,在设计聚焦爬虫时,需要考虑问题可做如下阐述。
1. 2. 1 待抓取网站目标的定义与描述的问题
开发聚焦爬虫时,应考虑对于抓取目标的定义与描述,究竟是带有目标网页特点的网页级信息,还是针对目标网页上的结构化数据。前者因其具有结构化的数据信息特点,在爬虫抓取信息后,还需从结构化的网页中抽取相关信息; 而对于前者,爬虫则直接解析 Web 页面,提取并加工相关的结构化数据信息,该类爬虫以便订制自适应于特定网页模板的结果网站。
1. 2. 2 爬虫的 URL 搜索策略问题
开发聚焦爬虫时,常见的 URL 搜索策略主要包括深度优先搜索策略、广度优先搜索策略、最佳优先搜索策略等[3].在此给出对应策略的规则剖析如下。
( 1) 深度优先搜索策略
该搜索策略采用了后进先出的队列形式,从起始 URL出发,不停搜索网页的下一级页面直到最后无 URL 链接的网页页面结束; 爬虫再回到起始 URL 地址,继续追寻 URL的其它 URL 链接,直到不再有 URL 可搜索为止,当所有页面都结束时,URL 列表即根据插叙的方法将搜索的 URL 队列送入爬虫待抓取队列。
( 2) 广度优先搜索策略
该搜索策略采用了先进先出的队列形式,从起始 URL出发,在搜索了初始 Web 的所有 URL 链接后,再继续搜索下一层 URL 链接,直至所有 URL 搜索完毕。URL 列表将依照其步入队列的次序送入爬虫待抓取队列。
( 3) 最佳优先搜索策略
该搜索策略采用了一种局部优先搜索算法,从起始 URL出发,按照一定的剖析算法,对页面候选的 URL 进行预测,预测目标网页的相似度或主题相关性,当相关性达到一定的阀值后,URL 列表则根据相关数值高低次序送入爬虫待抓取队列。
1. 2. 3 爬虫对网页页面的剖析和主题相关性判定算法
聚焦爬虫在对网页 Web 的 URL 进行扩充时,还须要对网页内容进行剖析和信息的提取开源网络爬虫,用以确定该获取 URL 页面是否与采集的主题相关。目前常用的网页的剖析算法包括: 基于网路拓扑、基于网页内容和基于领域概念的剖析算法[4].下面给出这三类算法的原理实现。
( 1) 基于网路拓扑关系的剖析算法
基于网路拓扑关系的剖析算法就是可以通过已知的网页页面或数据,对与其有直接或间接链接关系的对象做出评价的实现过程。该算法又分为网页细度、网站粒度和网页块细度三种。着名的 PageRank 和 HITS 算法就是基于网路拓扑关系的典型代表。
( 2) 基于网页内容的剖析算法
基于网页内容的剖析算法指的是借助网页内容( 文本、数据等资源) 特征进行的网页评价。该方式已从最初的文本检索方式,向网页数据抽取、数据挖掘和自然语言等多领域方向发展。
( 3) 基于领域概念的剖析算法
基于领域概念的剖析算法则是将领域本体分解为由不同的概念、实体及其之间的关系,包括与之对应的词汇项组成。网页中的关键词在通过与领域本体对应的辞典分别转换以后,将进行计数和加权,由此得出与所选领域的相关度。 查看全部
0 引 言
在信息化时代,针对通用搜索引擎信息量大、查询准度和深度兼差等缺点,垂直搜索引擎已步入了用户认可和使用周期。垂直搜索是针对某一个行业的专业搜索引擎,是对网页库中的某类专门的信息进行一次整合,定向分数组抽取出须要的数据进行处理后再以某种方式返回给用户[1].相比通用搜索引擎则变得愈发专注、具体和深入。目前,垂直搜索引擎多用于行业信息获取和特色语料库建设等方面,且已卓见现实深远成效。
网络爬虫是一个手动提取和手动下载网页的程序开源网络爬虫,可为搜索引擎从互联网上下载网页,并按照既定的抓取目标,有选择地访问互联网上的网页与相关的链接,获取所须要的信息。按照功能用途,网络爬虫分为通用爬虫和聚焦爬虫,这是搜索引擎一个核心组成部份。
1 聚焦爬虫的工作原理及关键技术剖析
1. 1 聚焦爬虫的工作原理
聚焦爬虫是专门为查询某一主题而设计的网页采集工具,并不追求大范围覆盖,而是将目标预定为抓取与某一特定主题内容相关的网页,如此即为面向主题的用户查询打算数据资源。垂直搜索引擎可借助其实现对网页主题信息的挖掘以及发觉,聚焦爬虫的工作原理是:
( 1) 爬虫从一个或若干起始网页 URL 链接开始工作;( 2) 通过特定的主题相关性算法判定并过滤掉与主题无关的链接;( 3) 将有用链接加入待抓取的 URL 队列;( 4) 根据一定的搜索策略从待抓取 URL 队列中选择下一步要抓取的网页 URL.重复以上步骤,直至满足退出条件时停止[2].
1. 2 聚焦爬虫的几个关键技术
根据聚焦爬虫的工作原理,在设计聚焦爬虫时,需要考虑问题可做如下阐述。
1. 2. 1 待抓取网站目标的定义与描述的问题
开发聚焦爬虫时,应考虑对于抓取目标的定义与描述,究竟是带有目标网页特点的网页级信息,还是针对目标网页上的结构化数据。前者因其具有结构化的数据信息特点,在爬虫抓取信息后,还需从结构化的网页中抽取相关信息; 而对于前者,爬虫则直接解析 Web 页面,提取并加工相关的结构化数据信息,该类爬虫以便订制自适应于特定网页模板的结果网站。
1. 2. 2 爬虫的 URL 搜索策略问题
开发聚焦爬虫时,常见的 URL 搜索策略主要包括深度优先搜索策略、广度优先搜索策略、最佳优先搜索策略等[3].在此给出对应策略的规则剖析如下。
( 1) 深度优先搜索策略
该搜索策略采用了后进先出的队列形式,从起始 URL出发,不停搜索网页的下一级页面直到最后无 URL 链接的网页页面结束; 爬虫再回到起始 URL 地址,继续追寻 URL的其它 URL 链接,直到不再有 URL 可搜索为止,当所有页面都结束时,URL 列表即根据插叙的方法将搜索的 URL 队列送入爬虫待抓取队列。
( 2) 广度优先搜索策略
该搜索策略采用了先进先出的队列形式,从起始 URL出发,在搜索了初始 Web 的所有 URL 链接后,再继续搜索下一层 URL 链接,直至所有 URL 搜索完毕。URL 列表将依照其步入队列的次序送入爬虫待抓取队列。
( 3) 最佳优先搜索策略
该搜索策略采用了一种局部优先搜索算法,从起始 URL出发,按照一定的剖析算法,对页面候选的 URL 进行预测,预测目标网页的相似度或主题相关性,当相关性达到一定的阀值后,URL 列表则根据相关数值高低次序送入爬虫待抓取队列。
1. 2. 3 爬虫对网页页面的剖析和主题相关性判定算法
聚焦爬虫在对网页 Web 的 URL 进行扩充时,还须要对网页内容进行剖析和信息的提取开源网络爬虫,用以确定该获取 URL 页面是否与采集的主题相关。目前常用的网页的剖析算法包括: 基于网路拓扑、基于网页内容和基于领域概念的剖析算法[4].下面给出这三类算法的原理实现。
( 1) 基于网路拓扑关系的剖析算法
基于网路拓扑关系的剖析算法就是可以通过已知的网页页面或数据,对与其有直接或间接链接关系的对象做出评价的实现过程。该算法又分为网页细度、网站粒度和网页块细度三种。着名的 PageRank 和 HITS 算法就是基于网路拓扑关系的典型代表。
( 2) 基于网页内容的剖析算法
基于网页内容的剖析算法指的是借助网页内容( 文本、数据等资源) 特征进行的网页评价。该方式已从最初的文本检索方式,向网页数据抽取、数据挖掘和自然语言等多领域方向发展。
( 3) 基于领域概念的剖析算法
基于领域概念的剖析算法则是将领域本体分解为由不同的概念、实体及其之间的关系,包括与之对应的词汇项组成。网页中的关键词在通过与领域本体对应的辞典分别转换以后,将进行计数和加权,由此得出与所选领域的相关度。
网络爬虫基本原理解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 329 次浏览 • 2020-05-28 08:01
“ 只推荐有价值的技术性文章优才学院
网络爬虫是索引擎抓取系统的重要组成部份。爬虫的主要目的是将互联网上的网页下载到本地产生一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
一、网络爬虫的基本结构及工作流程
一个通用的网路爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路以后再转到下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以里面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就产生了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
四、更新策略
互联网是实时变化的,具有太强的动态性。网页更新策略主要是决定何时更新之前早已下载过的页面。常见的更新策略又以下三种:
1.历史参考策略
顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略
尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。
3.降维抽样策略
前面提及的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一网络爬虫原理,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多的系统负担;第二,要是新的网页完全没有历史信息网络爬虫原理,就难以确定更新策略。
这种策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新频度也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样,以她们的更新周期作为整个类别的更新周期。基本思路如图:
五、分布式抓取系统结构
一般来说,抓取系统须要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往须要多个抓取程序一起来处理。一般来说抓取系统常常是一个分布式的三层结构。如图所示:
最下一层是分布在不同地理位置的数据中心,在每位数据中心里有若干台抓取服务器,而每台抓取服务器上可能布署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方法有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器不仅维护待抓取URL队列以及分发URL之外,还要负责调处各个Slave服务器的负载情况。以免个别Slave服务器过分悠闲或则操劳。
这种模式下,Master常常容易成为系统困局。
2.对方程(Peer to Peer)
对等式的基本结构如图所示:
在这些模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后估算H mod m(其中m是服务器的数目,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
举例:假设对于URL ,计算器hash值H=8,m=3,则H mod m=2,因此由编号为2的服务器进行该链接的抓取。假设这时候是0号服务器领到这个URL,那么它将该URL转给服务器2,由服务器2进行抓取。
这种模式有一个问题,当有一台服务器关机或则添加新的服务器,那么所有URL的哈希求余的结果就都要变化。也就是说,这种方法的扩展性不佳。针对这些情况,又有一种改进方案被提下来。这种改进的方案是一致性哈希法来确定服务器分工。其基本结构如图所示:
一致性哈希将URL的主域名进行哈希运算,映射为一个范围在0-232之间的某个数。而将这个范围平均的分配给m台服务器,根据URL主域名哈希运算的值所处的范围判定是哪台服务器来进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则根据顺时针延后,由下一台服务器进行抓取。这样的话,及时某台服务器出现问题,也不会影响其他的工作。 查看全部
“ 只推荐有价值的技术性文章优才学院
网络爬虫是索引擎抓取系统的重要组成部份。爬虫的主要目的是将互联网上的网页下载到本地产生一个或联网内容的镜像备份。这篇博客主要对爬虫以及抓取系统进行一个简单的概述。
一、网络爬虫的基本结构及工作流程
一个通用的网路爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选定一部分悉心选购的种子URL;
2.将这种URL倒入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载出来,存储进已下载网页库中。此外,将这种URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL倒入待抓取URL队列,从而步入下一个循环。
二、从爬虫的角度对互联网进行界定
对应的,可以将互联网的所有页面分为五个部份:
1.已下载未过期网页
2.已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的,一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就早已过期了。
3.待下载网页:也就是待抓取URL队列中的这些页面
4.可知网页:还没有抓取出来,也没有在待抓取URL队列中,但是可以通过对已抓取页面或则待抓取URL对应页面进行剖析获取到的URL,认为是可知网页。
5.还有一部分网页,爬虫是难以直接抓取下载的。称为不可知网页。
三、抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的次序排列也是一个很重要的问题,因为这涉及到先抓取那种页面,后抓取那个页面。而决定那些URL排列次序的方式,叫做抓取策略。下面重点介绍几种常见的抓取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路以后再转到下一个起始页,继续跟踪链接。我们以下面的图为例:
遍历的路径:A-F-G E-H-I B C D
2.宽度优先遍历策略
宽度优先遍历策略的基本思路是,将新下载网页中发觉的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。还是以里面的图为例:
遍历路径:A-B-C-D-E-F G H I
3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。
在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那种也的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。
4.Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于早已下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每位页面的PageRank值,计算完以后,将待抓取URL队列中的URL根据PageRank值的大小排列,并根据该次序抓取页面。
如果每次抓取一个页面,就重新估算PageRank值,一种折中方案是:每抓取K个页面后,重新估算一次PageRank值。但是此类情况都会有一个问题:对于早已下载出来的页面中剖析出的链接,也就是我们之前谈到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给那些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就产生了该未知页面的PageRank值,从而参与排序。下面举例说明:
5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P以后,将P的现金平摊给所有从P中剖析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面根据现金数进行排序。
6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因而称作大站优先策略。
四、更新策略
互联网是实时变化的,具有太强的动态性。网页更新策略主要是决定何时更新之前早已下载过的页面。常见的更新策略又以下三种:
1.历史参考策略
顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。
2.用户体验策略
尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。
3.降维抽样策略
前面提及的两种更新策略都有一个前提:需要网页的历史信息。这样就存在两个问题:第一网络爬虫原理,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多的系统负担;第二,要是新的网页完全没有历史信息网络爬虫原理,就难以确定更新策略。
这种策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新频度也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样,以她们的更新周期作为整个类别的更新周期。基本思路如图:
五、分布式抓取系统结构
一般来说,抓取系统须要面对的是整个互联网上数以亿计的网页。单个抓取程序不可能完成这样的任务。往往须要多个抓取程序一起来处理。一般来说抓取系统常常是一个分布式的三层结构。如图所示:
最下一层是分布在不同地理位置的数据中心,在每位数据中心里有若干台抓取服务器,而每台抓取服务器上可能布署了若干套爬虫程序。这就构成了一个基本的分布式抓取系统。
对于一个数据中心内的不同抓去服务器,协同工作的方法有几种:
1.主从式(Master-Slave)
主从式基本结构如图所示:
对于主从式而言,有一台专门的Master服务器来维护待抓取URL队列,它负责每次将URL分发到不同的Slave服务器,而Slave服务器则负责实际的网页下载工作。Master服务器不仅维护待抓取URL队列以及分发URL之外,还要负责调处各个Slave服务器的负载情况。以免个别Slave服务器过分悠闲或则操劳。
这种模式下,Master常常容易成为系统困局。
2.对方程(Peer to Peer)
对等式的基本结构如图所示:
在这些模式下,所有的抓取服务器在分工上没有不同。每一台抓取服务器都可以从待抓取在URL队列中获取URL,然后对该URL的主域名的hash值H,然后估算H mod m(其中m是服务器的数目,以上图为例,m为3),计算得到的数就是处理该URL的主机编号。
举例:假设对于URL ,计算器hash值H=8,m=3,则H mod m=2,因此由编号为2的服务器进行该链接的抓取。假设这时候是0号服务器领到这个URL,那么它将该URL转给服务器2,由服务器2进行抓取。
这种模式有一个问题,当有一台服务器关机或则添加新的服务器,那么所有URL的哈希求余的结果就都要变化。也就是说,这种方法的扩展性不佳。针对这些情况,又有一种改进方案被提下来。这种改进的方案是一致性哈希法来确定服务器分工。其基本结构如图所示:
一致性哈希将URL的主域名进行哈希运算,映射为一个范围在0-232之间的某个数。而将这个范围平均的分配给m台服务器,根据URL主域名哈希运算的值所处的范围判定是哪台服务器来进行抓取。
如果某一台服务器出现问题,那么本该由该服务器负责的网页则根据顺时针延后,由下一台服务器进行抓取。这样的话,及时某台服务器出现问题,也不会影响其他的工作。
Java做爬虫也太牛
采集交流 • 优采云 发表了文章 • 0 个评论 • 324 次浏览 • 2020-05-20 08:00
首先我们封装一个Http恳求的工具类,用HttpURLConnection实现,当然你也可以用HttpClient, 或者直接用Jsoup来恳求(下面会提到Jsoup)。
工具类实现比较简单,就一个get方式,读取恳求地址的响应内容,这边我们拿来抓取网页的内容,这边没有用代理java爬虫技术,在真正的抓取过程中,当你大量恳求某个网站的时侯,对方会有一系列的策略来禁用你的恳求,这个时侯代理就排上用场了,通过代理设置不同的IP来抓取数据。
接下来我们随意找一个有图片的网页,来试试抓取功能
首先将网页的内容抓取出来,然后用正则的方法解析出网页的标签,再解析img的地址。执行程序我们可以得到下边的内容:
通过前面的地址我们就可以将图片下载到本地了,下面我们写个图片下载的方式:
这样就很简单的实现了一个抓取而且提取图片的功能了,看起来还是比较麻烦哈,要写正则之类的 ,下面给你们介绍一种更简单的方法,如果你熟悉jQuery的话对提取元素就很简单了,这个框架就是Jsoup。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
添加jsoup的依赖:
使用jsoup以后提取的代码只须要简单的几行即可:
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag的方式提取出所有的图片标签,循环遍历,通过attr方式获取图片的src属性,然后下载图片。
Jsoup使用上去十分简单,当然还有好多其他解析网页的操作,大家可以去瞧瞧资料学习一下。
下面我们再来升级一下,做成一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按键,然后把图片手动下载出来java爬虫技术,我们可以用swing写界面。
执行main方式首先下来的就是我们的界面了,如下:
屏幕快照 2018-06-18 09.50.34 PM.png
输入地址,点击提取按键即可下载图片。
课程推荐
大数据时代,如何产生大数据。
大用户量,每天好多日志。
搞个爬虫,抓几十亿数据过来剖析剖析。
并不是只有Python能够做爬虫,Java照样可以。
今天带你们来写一个简单的图片抓取程序,将网页上的图片全部下载出来
image
本课程将率领你们一步一步编撰爬虫程序,爬到我们想要的数据,非登录的或则须要登录的都爬出来。
学完本课程将学员培养成为合格的Java网路爬虫工程师,并能胜任相关爬虫工作;
学完才能熟练使用XPath表达式进行信息提取;
学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,自动模拟进行Ajax异步恳求数据;
熟练把握jsoup提取网页数据。
selenium进行控制浏览器抓取数据。
课程大纲
HttpURLConnection用法解读
静态网页抓取
jsoup解析提取网页信息
模拟ajax进行POST恳求抓取数据
模拟登录网站抓取数据
selenium抓取网页实战
htmlunit抓取动态网页数据
IP代理池建立
多线程抓取实战
WebMagic框架实战爬虫
抓取图书数据
图书数据储存mongodb 查看全部
首先我们封装一个Http恳求的工具类,用HttpURLConnection实现,当然你也可以用HttpClient, 或者直接用Jsoup来恳求(下面会提到Jsoup)。
工具类实现比较简单,就一个get方式,读取恳求地址的响应内容,这边我们拿来抓取网页的内容,这边没有用代理java爬虫技术,在真正的抓取过程中,当你大量恳求某个网站的时侯,对方会有一系列的策略来禁用你的恳求,这个时侯代理就排上用场了,通过代理设置不同的IP来抓取数据。
接下来我们随意找一个有图片的网页,来试试抓取功能
首先将网页的内容抓取出来,然后用正则的方法解析出网页的标签,再解析img的地址。执行程序我们可以得到下边的内容:
通过前面的地址我们就可以将图片下载到本地了,下面我们写个图片下载的方式:
这样就很简单的实现了一个抓取而且提取图片的功能了,看起来还是比较麻烦哈,要写正则之类的 ,下面给你们介绍一种更简单的方法,如果你熟悉jQuery的话对提取元素就很简单了,这个框架就是Jsoup。
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
添加jsoup的依赖:
使用jsoup以后提取的代码只须要简单的几行即可:
通过Jsoup.parse创建一个文档对象,然后通过getElementsByTag的方式提取出所有的图片标签,循环遍历,通过attr方式获取图片的src属性,然后下载图片。
Jsoup使用上去十分简单,当然还有好多其他解析网页的操作,大家可以去瞧瞧资料学习一下。
下面我们再来升级一下,做成一个小工具,提供一个简单的界面,输入一个网页地址,点击提取按键,然后把图片手动下载出来java爬虫技术,我们可以用swing写界面。
执行main方式首先下来的就是我们的界面了,如下:
屏幕快照 2018-06-18 09.50.34 PM.png
输入地址,点击提取按键即可下载图片。
课程推荐
大数据时代,如何产生大数据。
大用户量,每天好多日志。
搞个爬虫,抓几十亿数据过来剖析剖析。
并不是只有Python能够做爬虫,Java照样可以。
今天带你们来写一个简单的图片抓取程序,将网页上的图片全部下载出来
image
本课程将率领你们一步一步编撰爬虫程序,爬到我们想要的数据,非登录的或则须要登录的都爬出来。
学完本课程将学员培养成为合格的Java网路爬虫工程师,并能胜任相关爬虫工作;
学完才能熟练使用XPath表达式进行信息提取;
学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,自动模拟进行Ajax异步恳求数据;
熟练把握jsoup提取网页数据。
selenium进行控制浏览器抓取数据。
课程大纲
HttpURLConnection用法解读
静态网页抓取
jsoup解析提取网页信息
模拟ajax进行POST恳求抓取数据
模拟登录网站抓取数据
selenium抓取网页实战
htmlunit抓取动态网页数据
IP代理池建立
多线程抓取实战
WebMagic框架实战爬虫
抓取图书数据
图书数据储存mongodb
网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-05-14 08:09
网络爬虫又名“网络蜘蛛”,是通过网页的链接地址来找寻网页,从网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到根据某种策略把互联网上所有的网页都抓取完为止的技术。
[编辑]
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫(General Purpose Web Crawler)、主题网路爬虫(Topical Web Crawler)、深层网络爬虫(Deep Web Crawler)。实际应用中一般是将系统几种爬虫技术互相结合。
(一)通用网路爬虫(general purpose web crawler)
通用网路爬虫按照预先设定的一个或若干初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获一个的URL,进而访问并下载该页面。页面下载后页面解析器除去页面上的HTML标记后得到页面内容,将摘要、URL等信息保存到Web数据库中,同时抽取当前页面上新的URL,保存到URL队列,直到满足系统停止条件。其工作流程如图1所示。
通用爬虫主要存在以下几方面的局限性:1)由于抓取目标是尽可能大的覆盖网路,所以爬行的结果中包含大量用户不需要的网页;2)不能挺好地搜索和获取信息浓度密集且具有一定结构的数据;3)通用搜索引擎大多是基于关键字的检索,对于支持语义信息的查询和索引擎智能化的要求无法实现。
由此可见,通用爬虫想在爬行网页时,既保证网页的质量和数目,又要保证网页的时效性是很难实现的。
(二)主题网路爬虫(Topical Web Crawler)
1.主题爬虫原理
主题爬虫并不追求大的覆盖率,也不是全盘接受所有的网页和URL,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息,不仅客服了通用爬虫存在的问题,而H-返回的数据资源更精确。主题爬虫的基本工作原理是根据预先确定的主题,分析超链接和刚才抓取的网页内容,获取下一个要爬行的URL,尽可能保证多爬行与主题相关的网页,因此主题爬虫要解决以下关键问题:1)如何判断一个早已抓取的网页是否与主题相关;2)如何过滤掉海量的网页中与主题不相关的或则相关度较低的网页;3)如何有目的、有控制的抓取与特定主题相关的web页面信息;4)如何决定待访问URL的访问顺序;5)如何提升主题爬虫的覆盖度;6)如何协调抓取目标的描述或定义与网页分析算法及候选URL排序算法之问的关系;7)如何找寻和发觉高质量网页和关键资源。高质量网页和关键资源除了可以大大提升主题爬虫收集Web页面的效率和质量,还可以为主题表示模型的优化等应用提供支持。
2.主题爬虫模块设计
主题爬虫的目标是尽可能多的发觉和收集与预定主题相关的网页网络爬虫,其最大特征在于具备剖析网页内容和判断主题相关度的能力。根据主题爬虫的工作原理,下面设计了一个主题爬虫系统,主要有页面采集模块、页面剖析模块、相关度估算模块、页面过滤模块和链接排序模块几部份组成网络爬虫,其总体功能模块结构如图2所示。
页面采集模块:主要是依据待访问URL队列进行页面下载,再交给网页剖析模型处理以抽取网页主题向量空间模型。该模块是任何爬虫系统都必不可少的模块。页面剖析模块:该模块的功能是对采集到的页面进行剖析,主要用于联接超链接排序模块和页面相关度估算模块。
页面相关度估算模块:该模块是整个系统的核心模块,主要用于评估与主题的相关度,并提供相关的爬行策略用以指导爬虫的爬行过程。URL的超链接评价得分越高,爬行的优先级就越高。其主要思想是,在系统爬行之前,页面相关度估算模块按照用户输入的关键字和初始文本信息进行学习,训练一个页面相关度评价模型。当一个被觉得是主题相关的页面爬行出来以后,该页面就被送入页面相关度评价器估算其主题相关度值,若该值小于或等于给定的某俦值,则该页面就被存入页面库,否则遗弃¨。页面过滤模块:过滤掉与主题无关的链接,同时将该URL及其所有蕴涵的子链接一并清除。通过过滤,爬虫就无需遍历与主题不相关的页面,从而保证了爬行效率。排序模块:将过滤后页面根据优先级高低加入到待访问的URL队列里。
3.主题爬虫流程设计
主题爬虫须要依照一定的网页剖析算法,过滤掉与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它会依照一定的搜索策略从待抓取的队列中选择下一个要抓取的URL,并重复上述过程,直到满足系统停止条件为止。所有被抓取网页就会被系统储存,经过一定的剖析、过滤,然后构建索引,以便用户查询和检索;这一过程所得到的剖析结果可以对之后的抓取过程提供反馈和指导。其工作流程如图3所示。
4.深度网路爬虫(Deep Web Crawler)
1994年Dr.jillEllsworth提出DeepWeb(深层页面)的概念,即DeepWeb是指普通搜索引擎无法发觉的信息内容的Web页面¨。DeepWeb中的信息量比普通的网页信息量多,而且质量更高。但是普通的搜索引擎因为技术限制而收集不到这种高质量、高权威的信息。这些信息一般隐藏在深度Web页面的小型动态数据库中,涉及数据集成、中文语义辨识等众多领域。如此庞大的信息资源假如没有合理的、高效的方式去获取,将是巨大的损失。因此,对于深度网爬行技术的研究具有极为重大的现实意义和理论价值。
常规的网路爬虫在运行中难以发觉隐藏在普通网页中的信息和规律,缺乏一定的主动性和智能性。比如须要输入用户名和密码的页面,或者包含页脚导航的页面均未能爬行。深度爬虫的设计针对常规网路爬虫的那些不足,将其结构做以改进,增加了表单剖析和页面状态保持两个部份,其结构如图4所示,通过剖析网页的结构并将其归类为普通网页或存在更多信息的深度网页,针对深度网页构造合适的表单参数而且递交,以得到更多的页面。深度爬虫的流程图如图4所示。深度爬虫与常规爬虫的不同是,深度爬虫在下载完成页面然后并没有立刻遍历其中的所有超链接,而是使用一定的算法将其进行分类,对于不同的类别采取不同的方式估算查询参数,并将参数再度递交到服务器。如果递交的查询参数正确,那么将会得到隐藏的页面和链接。深度爬虫的目标是尽可能多地访问和搜集互联网上的网页,由于深度页面是通过递交表单的形式访问,因此爬行深度页面存在以下三个方面的困难:1)深度爬虫须要有高效的算法去应对数目巨大的深层页面数据;2)很多服务器端DeepWeb要求校准表单输入,如用户名、密码、校验码等,如果校准失败,将不能爬到DeepWeb数据;3)需要JavaScript等脚本支持剖析客户端DeepWeb。
[编辑]
(1)IP地址搜索策略
IP地址搜索策略是先给爬虫一个起始的IP地址,然后按照IP地址以递增的形式搜索本IP地址段后的每一个地址中的文档,它完全不考虑各文档中指向其它Web站点的超级链接地址。这种搜索策略的优点是搜索比较全面,因此能否发觉这些没被其它文档引用的新文档的信息源;但是缺点是不适宜大规模搜索。
(2)深度优先搜索策略
深度优先搜索是一种在开发爬虫初期使用较多的方式。它的目的是要达到被搜索结构的叶结点(即这些不包含任何超链的HTML文件)。例如,在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,也就是说在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索顺着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索早已结束。
(3)宽度优先搜索策略
宽度优先搜索的过程是先搜索完一个Web页面中所有的超级链接,然后再继续搜索下一层,直到底层为止。例如,一个HTML文件中有三个超链,选择其中之一并处理相应的HTML文件,然后不再选择第二个HTML文件中的任何超链,而是返回并选择第二个超链,处理相应的HTML文件,再返回,选择第三个超链并处理相应的HTML文件。当一层上的所有超链都已被选择过,就可以开始在刚刚处理过的HIML文件中搜索其余的超链。
宽度优先搜索策略的优点:一个是保证了对浅层的优先处理,当遇见一个无穷尽的深层分支时,不会造成陷进www中的深层文档中出现出不来的情况发生;另一个是它能在两个HTML文件之间找到最短路径。
宽度优先搜索策略一般是实现爬虫的最佳策略,因为它容易实现,而且具备大多数期望的功能。但是假如要遍历一个指定的站点或则深层嵌套的HTML文件集,用长度优先搜索策略则须要耗费比较长的时间才会抵达深层的HTML文件。
[编辑]
于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报.2011,5 蔡笑伦.网络爬虫技术的发展趁机[J].科技信息.2010,12
来自"https://wiki.mbalib.com/wiki/% ... ot%3B
本条目对我有帮助8
赏
MBA智库APP
扫一扫,下载MBA智库APP 查看全部
[编辑]
网络爬虫又名“网络蜘蛛”,是通过网页的链接地址来找寻网页,从网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到根据某种策略把互联网上所有的网页都抓取完为止的技术。
[编辑]
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫(General Purpose Web Crawler)、主题网路爬虫(Topical Web Crawler)、深层网络爬虫(Deep Web Crawler)。实际应用中一般是将系统几种爬虫技术互相结合。
(一)通用网路爬虫(general purpose web crawler)
通用网路爬虫按照预先设定的一个或若干初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获一个的URL,进而访问并下载该页面。页面下载后页面解析器除去页面上的HTML标记后得到页面内容,将摘要、URL等信息保存到Web数据库中,同时抽取当前页面上新的URL,保存到URL队列,直到满足系统停止条件。其工作流程如图1所示。
通用爬虫主要存在以下几方面的局限性:1)由于抓取目标是尽可能大的覆盖网路,所以爬行的结果中包含大量用户不需要的网页;2)不能挺好地搜索和获取信息浓度密集且具有一定结构的数据;3)通用搜索引擎大多是基于关键字的检索,对于支持语义信息的查询和索引擎智能化的要求无法实现。
由此可见,通用爬虫想在爬行网页时,既保证网页的质量和数目,又要保证网页的时效性是很难实现的。
(二)主题网路爬虫(Topical Web Crawler)
1.主题爬虫原理
主题爬虫并不追求大的覆盖率,也不是全盘接受所有的网页和URL,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息,不仅客服了通用爬虫存在的问题,而H-返回的数据资源更精确。主题爬虫的基本工作原理是根据预先确定的主题,分析超链接和刚才抓取的网页内容,获取下一个要爬行的URL,尽可能保证多爬行与主题相关的网页,因此主题爬虫要解决以下关键问题:1)如何判断一个早已抓取的网页是否与主题相关;2)如何过滤掉海量的网页中与主题不相关的或则相关度较低的网页;3)如何有目的、有控制的抓取与特定主题相关的web页面信息;4)如何决定待访问URL的访问顺序;5)如何提升主题爬虫的覆盖度;6)如何协调抓取目标的描述或定义与网页分析算法及候选URL排序算法之问的关系;7)如何找寻和发觉高质量网页和关键资源。高质量网页和关键资源除了可以大大提升主题爬虫收集Web页面的效率和质量,还可以为主题表示模型的优化等应用提供支持。
2.主题爬虫模块设计
主题爬虫的目标是尽可能多的发觉和收集与预定主题相关的网页网络爬虫,其最大特征在于具备剖析网页内容和判断主题相关度的能力。根据主题爬虫的工作原理,下面设计了一个主题爬虫系统,主要有页面采集模块、页面剖析模块、相关度估算模块、页面过滤模块和链接排序模块几部份组成网络爬虫,其总体功能模块结构如图2所示。
页面采集模块:主要是依据待访问URL队列进行页面下载,再交给网页剖析模型处理以抽取网页主题向量空间模型。该模块是任何爬虫系统都必不可少的模块。页面剖析模块:该模块的功能是对采集到的页面进行剖析,主要用于联接超链接排序模块和页面相关度估算模块。
页面相关度估算模块:该模块是整个系统的核心模块,主要用于评估与主题的相关度,并提供相关的爬行策略用以指导爬虫的爬行过程。URL的超链接评价得分越高,爬行的优先级就越高。其主要思想是,在系统爬行之前,页面相关度估算模块按照用户输入的关键字和初始文本信息进行学习,训练一个页面相关度评价模型。当一个被觉得是主题相关的页面爬行出来以后,该页面就被送入页面相关度评价器估算其主题相关度值,若该值小于或等于给定的某俦值,则该页面就被存入页面库,否则遗弃¨。页面过滤模块:过滤掉与主题无关的链接,同时将该URL及其所有蕴涵的子链接一并清除。通过过滤,爬虫就无需遍历与主题不相关的页面,从而保证了爬行效率。排序模块:将过滤后页面根据优先级高低加入到待访问的URL队列里。
3.主题爬虫流程设计
主题爬虫须要依照一定的网页剖析算法,过滤掉与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它会依照一定的搜索策略从待抓取的队列中选择下一个要抓取的URL,并重复上述过程,直到满足系统停止条件为止。所有被抓取网页就会被系统储存,经过一定的剖析、过滤,然后构建索引,以便用户查询和检索;这一过程所得到的剖析结果可以对之后的抓取过程提供反馈和指导。其工作流程如图3所示。
4.深度网路爬虫(Deep Web Crawler)
1994年Dr.jillEllsworth提出DeepWeb(深层页面)的概念,即DeepWeb是指普通搜索引擎无法发觉的信息内容的Web页面¨。DeepWeb中的信息量比普通的网页信息量多,而且质量更高。但是普通的搜索引擎因为技术限制而收集不到这种高质量、高权威的信息。这些信息一般隐藏在深度Web页面的小型动态数据库中,涉及数据集成、中文语义辨识等众多领域。如此庞大的信息资源假如没有合理的、高效的方式去获取,将是巨大的损失。因此,对于深度网爬行技术的研究具有极为重大的现实意义和理论价值。
常规的网路爬虫在运行中难以发觉隐藏在普通网页中的信息和规律,缺乏一定的主动性和智能性。比如须要输入用户名和密码的页面,或者包含页脚导航的页面均未能爬行。深度爬虫的设计针对常规网路爬虫的那些不足,将其结构做以改进,增加了表单剖析和页面状态保持两个部份,其结构如图4所示,通过剖析网页的结构并将其归类为普通网页或存在更多信息的深度网页,针对深度网页构造合适的表单参数而且递交,以得到更多的页面。深度爬虫的流程图如图4所示。深度爬虫与常规爬虫的不同是,深度爬虫在下载完成页面然后并没有立刻遍历其中的所有超链接,而是使用一定的算法将其进行分类,对于不同的类别采取不同的方式估算查询参数,并将参数再度递交到服务器。如果递交的查询参数正确,那么将会得到隐藏的页面和链接。深度爬虫的目标是尽可能多地访问和搜集互联网上的网页,由于深度页面是通过递交表单的形式访问,因此爬行深度页面存在以下三个方面的困难:1)深度爬虫须要有高效的算法去应对数目巨大的深层页面数据;2)很多服务器端DeepWeb要求校准表单输入,如用户名、密码、校验码等,如果校准失败,将不能爬到DeepWeb数据;3)需要JavaScript等脚本支持剖析客户端DeepWeb。
[编辑]
(1)IP地址搜索策略
IP地址搜索策略是先给爬虫一个起始的IP地址,然后按照IP地址以递增的形式搜索本IP地址段后的每一个地址中的文档,它完全不考虑各文档中指向其它Web站点的超级链接地址。这种搜索策略的优点是搜索比较全面,因此能否发觉这些没被其它文档引用的新文档的信息源;但是缺点是不适宜大规模搜索。
(2)深度优先搜索策略
深度优先搜索是一种在开发爬虫初期使用较多的方式。它的目的是要达到被搜索结构的叶结点(即这些不包含任何超链的HTML文件)。例如,在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,也就是说在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索顺着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索早已结束。
(3)宽度优先搜索策略
宽度优先搜索的过程是先搜索完一个Web页面中所有的超级链接,然后再继续搜索下一层,直到底层为止。例如,一个HTML文件中有三个超链,选择其中之一并处理相应的HTML文件,然后不再选择第二个HTML文件中的任何超链,而是返回并选择第二个超链,处理相应的HTML文件,再返回,选择第三个超链并处理相应的HTML文件。当一层上的所有超链都已被选择过,就可以开始在刚刚处理过的HIML文件中搜索其余的超链。
宽度优先搜索策略的优点:一个是保证了对浅层的优先处理,当遇见一个无穷尽的深层分支时,不会造成陷进www中的深层文档中出现出不来的情况发生;另一个是它能在两个HTML文件之间找到最短路径。
宽度优先搜索策略一般是实现爬虫的最佳策略,因为它容易实现,而且具备大多数期望的功能。但是假如要遍历一个指定的站点或则深层嵌套的HTML文件集,用长度优先搜索策略则须要耗费比较长的时间才会抵达深层的HTML文件。
[编辑]
于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报.2011,5 蔡笑伦.网络爬虫技术的发展趁机[J].科技信息.2010,12
来自"https://wiki.mbalib.com/wiki/% ... ot%3B
本条目对我有帮助8
赏
MBA智库APP
扫一扫,下载MBA智库APP
20款最常使用的网路爬虫工具推荐(2018)教程文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2020-05-09 08:00
另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。精品文档精品文档据悉,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 ScraperScraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub精品文档精品文档Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页,甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据,并将网站信息分割开来,然后提取有效信息,形成可用的集合。 但是要手动提取精确数据就须要付费版本了,同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHub精品文档精品文档Parsehub 是一个太棒的网路爬虫,支持从使用 AJAX 技术,JavaScript,cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。精品文档精品文档7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。精品文档精品文档总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问,Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周网络爬虫软件下载,每天或每小时安排抓取任务。10.80legs精品文档精品文档80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content GraberContent Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。它更适宜具有中级编程技能的人,因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
精品文档精品文档12. UiPathUiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。处理复杂的 UI 时,此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。精品文档精品文档其实,在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。精品文档精品文档2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。精品文档 查看全部
精品文档20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。它的作用是从任何网站获取特定的或 更新的数据并储存出来。网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程,使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴,我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中网络爬虫软件下载,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼是一款免费且功能强悍的网站爬虫,用于从网站上提取你须要的几乎所有 类型的数据。你可以使用八爪鱼来采集市面上几乎所有的网站。八爪鱼提供两种精品文档精品文档采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后,其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。 你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。
另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。精品文档精品文档据悉,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 ScraperScraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub精品文档精品文档Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页,甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据,并将网站信息分割开来,然后提取有效信息,形成可用的集合。 但是要手动提取精确数据就须要付费版本了,同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHub精品文档精品文档Parsehub 是一个太棒的网路爬虫,支持从使用 AJAX 技术,JavaScript,cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。精品文档精品文档7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。精品文档精品文档总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问,Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周网络爬虫软件下载,每天或每小时安排抓取任务。10.80legs精品文档精品文档80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content GraberContent Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。它更适宜具有中级编程技能的人,因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
精品文档精品文档12. UiPathUiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。处理复杂的 UI 时,此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。精品文档精品文档其实,在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。精品文档精品文档2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。精品文档
33款可用来抓数据的开源爬虫软件工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 480 次浏览 • 2020-05-07 08:02
爬虫,即网路爬虫,是一种手动获取网页内容的程序。是搜索引擎的重要组成部份,因此搜索引擎优化很大程度上就是针对爬虫而作出的优化。
网络爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
世界上已然成形的爬虫软件多达上百种,本文对较为著名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非小型、复杂的搜索引擎,因为好多兄弟只是想爬取数据,而非营运一个搜索引擎。
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spiders并才能在Web站上的每位页面被解析然后降低几行代码调用。 Arachnid的下载包中包含两个spider应用程序事例用于演示怎么使用该框架。
特点:微型爬虫框架,含有一个大型HTML解析器
许可证:GPL
crawlzilla 是一个帮你轻松构建搜索引擎的自由软件,有了它,你就不用借助商业公司的搜索引擎,也不用再苦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能剖析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有英文动词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个便捷好用易安裝的搜索平台。
授权合同: Apache License 2
开发语言: Java JavaScript SHELL
操作系统: Linux
特点:安装简易,拥有英文动词功能
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部份,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库储存网页信息。
特点:由守护进程执行,使用数据库储存网页信息
Heritrix 是一个由 java 开发的、开源的网路爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:
特点:严格遵循robots文件的排除指示和META robots标签
heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3合同。
用户可以通过heyDr建立自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据打算。
特点:轻量级开源多线程垂直检索爬虫框架
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面
jcrawl是一款精巧性能优良的的web爬虫,它可以从网页抓取各类类型的文件,基于用户定义的符号,比如email,qq.
特点:轻量、性能优良,可以从网页抓取各类类型的文件
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [ConfigName]
URL一定要加上合同名称,如:,否则会报错。如果市掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用哪些插件,结果储存方法等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider十分容易扩充,可以借助它开发强悍的网页抓取与数据剖析工具。要做到这种,需要对JSpider的原理有深入的了 解,然后按照自己的需求开发插件,撰写配置文件。
特点:功能强悍,容易扩充
用JAVA编撰的web 搜索和爬虫,包括全文和分类垂直搜索,以及动词系统
特点:包括全文和分类垂直搜索,以及动词系统
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方式,如果依照布署在哪里分网页爬虫软件,可以分成:
服务器侧:
一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前太流行)等做,可以速率做得很快,一般综合搜索引擎的爬虫这样做。但是网页爬虫软件,如果对方厌恶爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗损的带宽也是很贵的。建议看一下Beautiful soap。
客户端:
一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或则比价服务或则推荐引擎,相对容易好多,这类爬虫不是哪些页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价钱信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以布署好多,而且可以挺有侵略性,对方很难封锁。
MetaSeeker中的网路爬虫就属于前者。
MetaSeeker工具包借助Mozilla平台的能力,只要是Firefox见到的东西,它都能提取。
特点:网页抓取、信息提取、数据抽取工具包,操作简单
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还挺不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各种峰会,贴吧,以及各种CMS系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方式:
下载一侧的.war包导出到eclipse中,使用WebContent/sql下的wcc.sql文件构建一个范例数据库,修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。然后运行SystemCore,运行时侯会在控制台,无参数会执行默认的example.xml的配置文件,带参数时侯名称为配置文件名。
系统自带了3个事例,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz峰会的内容。
特点:通过XML配置文件实现高度可定制性与可扩展性
Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath如何获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
特点:灵活、扩展性强,微内核+插件式构架,通过简单的配置就可以完成数据抓取,无需编撰一句代码
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持手动重试、自定义UA/cookie等功能。
webmagic包含强悍的页面抽取功能,开发者可以方便的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:
查看源代码:
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献
Web-Harvest是一个Java开源Web数据抽取工具。它就能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这种技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑如何处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
授权合同:Apache
开发语言:Java
特点:由两部份组成:爬虫工作平台和WebSPHINX类包
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是建立基于p2p Web索引网路的一个新技巧.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
特点:基于P2P的分布式Web搜索引擎
QuickRecon是一个简单的信息搜集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats找寻人际关系等。QuickRecon使用python编撰,支持linux和 windows操作系统。
特点:具有查找子域名名称、收集电子邮件地址并找寻人际关系等功能
这是一个十分简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~
github源代码:
特点:基于Twisted的异步处理框架,文档齐全
HiSpider is a fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
工作流程:
授权合同: BSD
开发语言: C/C++
操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
特点:高性能的爬虫软件,只负责抓取不负责解析
Methabot 是一个经过速率优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
特点:过速率优化、可抓取WEB、FTP及本地文件系统
源代码:
NWebCrawler是一款开源,C#开发网路爬虫程序。
特性:
授权合同: GPLv2
开发语言: C#
操作系统: Windows
项目主页:
特点:统计信息、执行过程可视化
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研制等的数据支持,但切勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数目的限制、获取微博数目的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和演出当前作品,制作派生作品。 你不可将当前作品用于商业目的。
5.x版本早已发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以及调节恳求频度的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现今测试的结果看,已经才能满足自用。
本程序的特征:
6个后台工作线程,最大限度挖掘爬虫性能潜力!界面上提供参数设置,灵活便捷抛弃app.config配置文件,自己实现配置信息的加密储存,保护数据库账号信息手动调整恳求频度,防止超限,也防止过慢,降低效率任意对爬虫控制,可随时暂停、继续、停止爬虫良好的用户体验
授权合同: GPLv3
开发语言: C# .NET
操作系统: Windows
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望递交你的代码.
github源代码:
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite储存数据
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接字段开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回去的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自Open-Open
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源
网站数据采集软件 网络矿工[url=https://www.ucaiyun.com/]采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
特点:功能丰富,毫不逊色于商业软件
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
特点:开源多线程网络爬虫,有许多有趣的功能
29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并才能索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它构建针对某一领域的垂直搜索引擎是最好的选择。
演示:
特点:具有采集网页内容、提交表单功能
ThinkUp 是一个可以采集推特,facebook等社交网路数据的社会媒体视角引擎。通过采集个人的社交网络帐号中的数据,对其存档以及处理的交互剖析工具,并将数据图形化便于更直观的查看。
github源码:
特点:采集推特、脸谱等社交网路数据的社会媒体视角引擎,可进行交互剖析并将结果以可视化方式诠释
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了天猫、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML都会做程序模板,免费开放下载,是广大淘客站长的首选。 查看全部
要玩大数据,没有数据如何玩?这里推荐一些33款开源爬虫软件给你们。
爬虫,即网路爬虫,是一种手动获取网页内容的程序。是搜索引擎的重要组成部份,因此搜索引擎优化很大程度上就是针对爬虫而作出的优化。
网络爬虫是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
世界上已然成形的爬虫软件多达上百种,本文对较为著名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非小型、复杂的搜索引擎,因为好多兄弟只是想爬取数据,而非营运一个搜索引擎。
Arachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器才能剖析包含HTML内容的输入流.通过实现Arachnid的泛型才能够开发一个简单的Web spiders并才能在Web站上的每位页面被解析然后降低几行代码调用。 Arachnid的下载包中包含两个spider应用程序事例用于演示怎么使用该框架。
特点:微型爬虫框架,含有一个大型HTML解析器
许可证:GPL
crawlzilla 是一个帮你轻松构建搜索引擎的自由软件,有了它,你就不用借助商业公司的搜索引擎,也不用再苦恼公司內部网站资料索引的问题。
由 nutch 专案为核心,并整合更多相关套件,并卡发设计安装与管理UI,让使用者更方便上手。
crawlzilla 除了爬取基本的 html 外,还能剖析网页上的文件,如( doc、pdf、ppt、ooo、rss )等多种文件格式,让你的搜索引擎不只是网页搜索引擎,而是网站的完整资料索引库。
拥有英文动词能力,让你的搜索更精准。
crawlzilla的特色与目标,最主要就是提供使用者一个便捷好用易安裝的搜索平台。
授权合同: Apache License 2
开发语言: Java JavaScript SHELL
操作系统: Linux
特点:安装简易,拥有英文动词功能
Ex-Crawler 是一个网页爬虫,采用 Java 开发,该项目分成两部份,一个是守护进程,另外一个是灵活可配置的 Web 爬虫。使用数据库储存网页信息。
特点:由守护进程执行,使用数据库储存网页信息
Heritrix 是一个由 java 开发的、开源的网路爬虫,用户可以使用它来从网上抓取想要的资源。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
Heritrix采用的是模块化的设计,各个模块由一个控制器类(CrawlController类)来协调,控制器是整体的核心。
代码托管:
特点:严格遵循robots文件的排除指示和META robots标签
heyDr是一款基于java的轻量级开源多线程垂直检索爬虫框架,遵循GNU GPL V3合同。
用户可以通过heyDr建立自己的垂直资源爬虫,用于搭建垂直搜索引擎前期的数据打算。
特点:轻量级开源多线程垂直检索爬虫框架
ItSucks是一个java web spider(web机器人,爬虫)开源项目。支持通过下载模板和正则表达式来定义下载规则。提供一个swing GUI操作界面。
特点:提供swing GUI操作界面
jcrawl是一款精巧性能优良的的web爬虫,它可以从网页抓取各类类型的文件,基于用户定义的符号,比如email,qq.
特点:轻量、性能优良,可以从网页抓取各类类型的文件
JSpider是一个用Java实现的WebSpider,JSpider的执行格式如下:
jspider [ConfigName]
URL一定要加上合同名称,如:,否则会报错。如果市掉ConfigName,则采用默认配置。
JSpider 的行为是由配置文件具体配置的,比如采用哪些插件,结果储存方法等等都在conf\[ConfigName]\目录下设置。JSpider默认的配置种类 很少,用途也不大。但是JSpider十分容易扩充,可以借助它开发强悍的网页抓取与数据剖析工具。要做到这种,需要对JSpider的原理有深入的了 解,然后按照自己的需求开发插件,撰写配置文件。
特点:功能强悍,容易扩充
用JAVA编撰的web 搜索和爬虫,包括全文和分类垂直搜索,以及动词系统
特点:包括全文和分类垂直搜索,以及动词系统
是一套完整的网页内容抓取、格式化、数据集成、存储管理和搜索解决方案。
网络爬虫有多种实现方式,如果依照布署在哪里分网页爬虫软件,可以分成:
服务器侧:
一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python(当前太流行)等做,可以速率做得很快,一般综合搜索引擎的爬虫这样做。但是网页爬虫软件,如果对方厌恶爬虫,很可能封掉你的IP,服务器IP又不容易 改,另外耗损的带宽也是很贵的。建议看一下Beautiful soap。
客户端:
一般实现定题爬虫,或者是聚焦爬虫,做综合搜索引擎不容易成功,而垂直搜诉或则比价服务或则推荐引擎,相对容易好多,这类爬虫不是哪些页面都 取的,而是只取你关系的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价钱信息,还有提取竞争对手广告信息的,搜一下Spyfu,很有趣。这类 爬虫可以布署好多,而且可以挺有侵略性,对方很难封锁。
MetaSeeker中的网路爬虫就属于前者。
MetaSeeker工具包借助Mozilla平台的能力,只要是Firefox见到的东西,它都能提取。
特点:网页抓取、信息提取、数据抽取工具包,操作简单
playfish是一个采用java技术,综合应用多个开源java组件实现的网页抓取工具,通过XML配置文件实现高度可定制性与可扩展性的网页抓取工具
应用开源jar包包括httpclient(内容读取),dom4j(配置文件解析),jericho(html解析),已经在 war包的lib下。
这个项目目前还挺不成熟,但是功能基本都完成了。要求使用者熟悉XML,熟悉正则表达式。目前通过这个工具可以抓取各种峰会,贴吧,以及各种CMS系统。像Discuz!,phpbb,论坛跟博客的文章,通过本工具都可以轻松抓取。抓取定义完全采用XML,适合Java开发人员使用。
使用方式:
下载一侧的.war包导出到eclipse中,使用WebContent/sql下的wcc.sql文件构建一个范例数据库,修改src包下wcc.core的dbConfig.txt,将用户名与密码设置成你自己的mysql用户名密码。然后运行SystemCore,运行时侯会在控制台,无参数会执行默认的example.xml的配置文件,带参数时侯名称为配置文件名。
系统自带了3个事例,分别为baidu.xml抓取百度知道,example.xml抓取我的javaeye的博客,bbs.xml抓取一个采用 discuz峰会的内容。
特点:通过XML配置文件实现高度可定制性与可扩展性
Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。
怎么使用?
首先,确定好你的目标网站以及目标网页(即某一类你想要获取数据的网页,例如网易新闻的新闻页面)
然后,打开目标页面,分析页面的HTML结构,得到你想要数据的XPath,具体XPath如何获取请看下文。
最后,在一个xml配置文件里填写好参数,运行Spiderman吧!
特点:灵活、扩展性强,微内核+插件式构架,通过简单的配置就可以完成数据抓取,无需编撰一句代码
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持手动重试、自定义UA/cookie等功能。
webmagic包含强悍的页面抽取功能,开发者可以方便的使用css selector、xpath和正则表达式进行链接和内容的提取,支持多个选择器链式调用。
webmagic的使用文档:
查看源代码:
特点:功能覆盖整个爬虫生命周期,使用Xpath和正则表达式进行链接和内容的提取。
备注:这是一款国产开源软件,由 黄亿华贡献
Web-Harvest是一个Java开源Web数据抽取工具。它就能搜集指定的Web页面并从这种页面中提取有用的数据。Web-Harvest主要是运用了象XSLT,XQuery,正则表达式等这种技术来实现对text/xml的操作。
其实现原理是,根据预先定义的配置文件用httpclient获取页面的全部内容(关于httpclient的内容,本博有些文章已介绍),然后运用XPath、XQuery、正则表达式等这种技术来实现对text/xml的内容筛选操作,选取精确的数据。前两年比较火的垂直搜索(比如:酷讯等)也是采用类似的原理实现的。Web-Harvest应用,关键就是理解和定义配置文件,其他的就是考虑如何处理数据的Java代码。当然在爬虫开始前,也可以把Java变量填充到配置文件中,实现动态的配置。
特点:运用XSLT、XQuery、正则表达式等技术来实现对Text或XML的操作,具有可视化的界面
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。Web爬虫(也叫作机器人或蜘蛛)是可以手动浏览与处理Web页面的程序。WebSPHINX由两部份组成:爬虫工作平台和WebSPHINX类包。
授权合同:Apache
开发语言:Java
特点:由两部份组成:爬虫工作平台和WebSPHINX类包
YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是建立基于p2p Web索引网路的一个新技巧.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
特点:基于P2P的分布式Web搜索引擎
QuickRecon是一个简单的信息搜集工具,它可以帮助你查找子域名名称、perform zone transfe、收集电子邮件地址和使用microformats找寻人际关系等。QuickRecon使用python编撰,支持linux和 windows操作系统。
特点:具有查找子域名名称、收集电子邮件地址并找寻人际关系等功能
这是一个十分简单易用的抓取工具。支持抓取javascript渲染的页面的简单实用高效的python网页爬虫抓取模块
特点:简洁、轻量、高效的网页抓取框架
备注:此软件也是由国人开放
github下载:
Scrapy 是一套基于基于Twisted的异步处理框架,纯python实现的爬虫框架,用户只须要订制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各类图片,非常之便捷~
github源代码:
特点:基于Twisted的异步处理框架,文档齐全
HiSpider is a fast and high performance spider with high speed
严格说只能是一个spider系统的框架, 没有细化需求, 目前只是能提取URL, URL排重, 异步DNS解析, 队列化任务, 支持N机分布式下载, 支持网站定向下载(需要配置hispiderd.ini whitelist).
特征和用法:
工作流程:
授权合同: BSD
开发语言: C/C++
操作系统: Linux
特点:支持多机分布式下载, 支持网站定向下载
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
特点:高性能的爬虫软件,只负责抓取不负责解析
Methabot 是一个经过速率优化的高可配置的 WEB、FTP、本地文件系统的爬虫软件。
特点:过速率优化、可抓取WEB、FTP及本地文件系统
源代码:
NWebCrawler是一款开源,C#开发网路爬虫程序。
特性:
授权合同: GPLv2
开发语言: C#
操作系统: Windows
项目主页:
特点:统计信息、执行过程可视化
国内第一个针对微博数据的爬虫程序!原名“新浪微博爬虫”。
登录后,可以指定用户为起点,以该用户的关注人、粉丝为线索,延人脉关系收集用户基本信息、微博数据、评论数据。
该应用获取的数据可作为科研、与新浪微博相关的研制等的数据支持,但切勿用于商业用途。该应用基于.NET2.0框架,需SQL SERVER作为后台数据库,并提供了针对SQL Server的数据库脚本文件。
另外,由于新浪微博API的限制,爬取的数据可能不够完整(如获取粉丝数目的限制、获取微博数目的限制等)
本程序版权归作者所有。你可以免费: 拷贝、分发、呈现和演出当前作品,制作派生作品。 你不可将当前作品用于商业目的。
5.x版本早已发布! 该版本共有6个后台工作线程:爬取用户基本信息的机器人、爬取用户关系的机器人、爬取用户标签的机器人、爬取微博内容的机器人、爬取微博评论的机器人,以及调节恳求频度的机器人。更高的性能!最大限度挖掘爬虫潜力! 以现今测试的结果看,已经才能满足自用。
本程序的特征:
6个后台工作线程,最大限度挖掘爬虫性能潜力!界面上提供参数设置,灵活便捷抛弃app.config配置文件,自己实现配置信息的加密储存,保护数据库账号信息手动调整恳求频度,防止超限,也防止过慢,降低效率任意对爬虫控制,可随时暂停、继续、停止爬虫良好的用户体验
授权合同: GPLv3
开发语言: C# .NET
操作系统: Windows
spidernet是一个以递归树为模型的多线程web爬虫程序, 支持text/html资源的获取. 可以设定爬行深度, 最大下载字节数限制, 支持gzip解码, 支持以gbk(gb2312)和utf8编码的资源; 存储于sqlite数据文件.
源码中TODO:标记描述了未完成功能, 希望递交你的代码.
github源代码:
特点:以递归树为模型的多线程web爬虫程序,支持以GBK (gb2312)和utf8编码的资源,使用sqlite储存数据
mart and Simple Web Crawler是一个Web爬虫框架。集成Lucene支持。该爬虫可以从单个链接或一个链接字段开始,提供两种遍历模式:最大迭代和最大深度。可以设置 过滤器限制爬回去的链接,默认提供三个过滤器ServerFilter、BeginningPathFilter和 RegularExpressionFilter,这三个过滤器可用AND、OR和NOT联合。在解析过程或页面加载前后都可以加监听器。介绍内容来自Open-Open
特点:多线程,支持抓取PDF/DOC/EXCEL等文档来源
网站数据采集软件 网络矿工[url=https://www.ucaiyun.com/]采集器(原soukey采摘)
Soukey采摘网站数据采集软件是一款基于.Net平台的开源软件,也是网站数据采集软件类型中惟一一款开源软件。尽管Soukey采摘开源,但并不会影响软件功能的提供,甚至要比一些商用软件的功能还要丰富。
特点:功能丰富,毫不逊色于商业软件
OpenWebSpider是一个开源多线程Web Spider(robot:机器人,crawler:爬虫)和包含许多有趣功能的搜索引擎。
特点:开源多线程网络爬虫,有许多有趣的功能
29、PhpDig
PhpDig是一个采用PHP开发的Web爬虫和搜索引擎。通过对动态和静态页面进行索引构建一个词汇表。当搜索查询时,它将按一定的排序规则显示包含关 键字的搜索结果页面。PhpDig包含一个模板系统并才能索引PDF,Word,Excel,和PowerPoint文档。PHPdig适用于专业化更 强、层次更深的个性化搜索引擎,利用它构建针对某一领域的垂直搜索引擎是最好的选择。
演示:
特点:具有采集网页内容、提交表单功能
ThinkUp 是一个可以采集推特,facebook等社交网路数据的社会媒体视角引擎。通过采集个人的社交网络帐号中的数据,对其存档以及处理的交互剖析工具,并将数据图形化便于更直观的查看。
github源码:
特点:采集推特、脸谱等社交网路数据的社会媒体视角引擎,可进行交互剖析并将结果以可视化方式诠释
微购社会化购物系统是一款基于ThinkPHP框架开发的开源的购物分享系统,同时它也是一套针对站长、开源的的淘宝客网站程序,它整合了天猫、天猫、淘宝客等300多家商品数据采集接口,为广大的淘宝客站长提供傻瓜式淘客建站服务,会HTML都会做程序模板,免费开放下载,是广大淘客站长的首选。
20款最常使用的网路爬虫工具推荐(2018)
采集交流 • 优采云 发表了文章 • 0 个评论 • 445 次浏览 • 2020-05-06 08:04
八爪鱼·云采集网络爬虫软件 20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。 它的作用是从任何网站获取特定的或 更新的数据并储存出来。 网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程, 使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴, 我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼·云采集网络爬虫软件 八爪鱼是一款免费且功能强悍的网站爬虫, 用于从网站上提取你须要的几乎所有 类型的数据。 你可以使用八爪鱼来采集市面上几乎所有的网站。 八爪鱼提供两种 采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后, 其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。
你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack八爪鱼·云采集网络爬虫软件 作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows网站爬虫软件,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。 你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。此外,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 Scraper八爪鱼·云采集网络爬虫软件 Scraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets 。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub八爪鱼·云采集网络爬虫软件 Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。 还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页, 甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据, 并将网站信息分割开来, 然后提取有效信息, 形成可用的集合。 但是要手动提取精确数据就须要付费版本了, 同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHubParsehub 是一个太棒的网路爬虫, 支持从使用 AJAX 技术, JavaScript, cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。八爪鱼·云采集网络爬虫软件 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。 它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。八爪鱼·云采集网络爬虫软件 7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周网站爬虫软件,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。八爪鱼·云采集网络爬虫软件 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。 总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问, Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
八爪鱼·云采集网络爬虫软件 为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周,每天或每小时安排抓取任务。10.80legs80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content Graber八爪鱼·云采集网络爬虫软件 Content Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。 它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。 它更适宜具有中级编程技能的人, 因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。 允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
12. UiPath八爪鱼·云采集网络爬虫软件 UiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。 处理复杂的 UI 时, 此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。八爪鱼·云采集网络爬虫软件 总之, 在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。 它的作用是从任何网站获取特定的或 更新的数据并储存出来。 网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程, 使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴, 我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼·云采集网络爬虫软件 八爪鱼是一款免费且功能强悍的网站爬虫, 用于从网站上提取你须要的几乎所有 类型的数据。 你可以使用八爪鱼来采集市面上几乎所有的网站。 八爪鱼提供两种 采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后, 其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。
你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack八爪鱼·云采集网络爬虫软件 作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows网站爬虫软件,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。 你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。此外,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 Scraper八爪鱼·云采集网络爬虫软件 Scraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets 。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub八爪鱼·云采集网络爬虫软件 Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。 还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页, 甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据, 并将网站信息分割开来, 然后提取有效信息, 形成可用的集合。 但是要手动提取精确数据就须要付费版本了, 同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHubParsehub 是一个太棒的网路爬虫, 支持从使用 AJAX 技术, JavaScript, cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。八爪鱼·云采集网络爬虫软件 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。 它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。八爪鱼·云采集网络爬虫软件 7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周网站爬虫软件,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。八爪鱼·云采集网络爬虫软件 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。 总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问, Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
八爪鱼·云采集网络爬虫软件 为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周,每天或每小时安排抓取任务。10.80legs80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content Graber八爪鱼·云采集网络爬虫软件 Content Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。 它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。 它更适宜具有中级编程技能的人, 因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。 允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
12. UiPath八爪鱼·云采集网络爬虫软件 UiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。 处理复杂的 UI 时, 此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。八爪鱼·云采集网络爬虫软件 总之, 在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
利用网路爬虫技术快速确切寻觅目的图书的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2020-05-04 08:07
【专利摘要】本发明公开了一种借助网路爬虫技术快速确切找寻目的图书的方式,流程如下:录入电子图书构建电子图书库,将录入的图书分类装入不同的子网页中,输入须要阅读图书的关键词,利用网路爬虫技术对与目的图书有关的图书网页进行抓取,对抓取得网页进行剖析,分析后输出过滤后的图书,选择目的图书进行阅读。本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类网络爬虫书籍,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利说明】利用网路爬虫技术快速确切找寻目的图书的方式
发明领域
[0001]本发明涉及一种阅读电子图书过程中确切快速选购目的图书的方式,属于网路【技术领域】。
【背景技术】
[0002]电子图书馆,是随着电版物的出现,网络通信技术的发展,而渐渐出现的。电子图书馆,具有储存能力大、速度快、保存时间长、成本低、便于交流等特性。光盘这一海量存储器、能够储存比传统图书高几千倍的信息,比微缩胶卷要多得多,而且包括图像、视频、声音,等等。利用电子技术,在这一种图书馆,我们能很快地从浩如烟海的图书中,查找到自己所须要的信息资料。这种图书馆,保存信息量的时间要长得多,不存在腐烂、生虫等问题。利用网路,在远在几千里、万里的单位、家中,都可以使用这些图书,效率极高。在广袤的书海中,想要快速确切的找到目标图书并不是这么容易,为我们阅读电子图书带来了一定的困难,阻碍了电子图书的发展。
【发明内容】
[0003]本发明为解决目前在电子图书馆中快速找寻目的图书的问题,提供一种借助网路爬虫技术快速确切寻觅目的图书的方式。本发明包括以下步骤:
[0004]步骤一:录入电子图书构建电子图书库;
[0005]步骤二:将录入的图书分类装入不同的子网页中;
[0006]步骤三:输入须要阅读图书的关键词;
[0007]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0008]步骤五:对抓取得网页进行剖析;
[0009]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0010]发明疗效:本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利附图】
【附图说明】
[0011]图1为借助网路爬虫技术快速确切找寻目的图书方式的流程图。
【具体施行方法】
[0012]【具体施行方法】:参见借助网路爬虫技术快速确切找寻目的图书方式的流程图1,本施行方法由以下步骤组成:
[0013]步骤一:录入电子图书构建电子图书库;
[0014]步骤二:将录入的图书分类装入不同的子网页中;[0015]步骤三:输入须要阅读图书的关键词;
[0016]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0017]步骤五:对抓取得网页进行剖析;
[0018]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0019]录入的电子图书必须对其按图书的种类对其进行命名,录入的图书的子网页早已录入图书的种类赋于了不同的域名,收索须要的电子图书须要输入该图书的图书名,或所属的学科种类,网络爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取,对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
[0020]对于本领域技术人员而言,显然本发明不限于上述示范性施行例的细节,而且在不背离本发明的精神或基本特点的情况下,能够以其他的具体方式实现本发明。因此网络爬虫书籍,无论从哪一点来看,均应将发明例看作是示范性的,而且是非限制性的,本发明的范围由所附权力要求而不是上述说明限定,因此借以将落在权力要求的等同要件的含意和范围内的所有变化涵盖在本发明内。不应将权力要求中的任何附图标记视为限制所涉及的权力要求。
【权利要求】
1.一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于它由以下步骤实现: 步骤一:录入电子图书,建立电子图书库; 步骤二:将录入的图书分类装入不同的子网页中; 步骤三:输入须要阅读图书的关键词; 步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取; 步骤五:对抓取得网页进行剖析; 步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
2.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤二中所述录入的电子图书必须对其按图书的种类对其进行命名。
3.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述录入的图书的子网页早已录入图书的种类赋于了不同的域名。
4.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述收索须要的电子图书须要输入该图书的图书名,或所属的学科种类。
5.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述网路爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取。
6.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
【文档编号】G06F17/30GK103744945SQ201310754637
【公开日】2014年4月23日 申请日期:2013年12月31日 优先权日:2013年12月31日
【发明者】朱龙腾 申请人:上海伯释信息科技有限公司 查看全部
利用网路爬虫技术快速确切寻觅目的图书的方式
【专利摘要】本发明公开了一种借助网路爬虫技术快速确切找寻目的图书的方式,流程如下:录入电子图书构建电子图书库,将录入的图书分类装入不同的子网页中,输入须要阅读图书的关键词,利用网路爬虫技术对与目的图书有关的图书网页进行抓取,对抓取得网页进行剖析,分析后输出过滤后的图书,选择目的图书进行阅读。本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类网络爬虫书籍,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利说明】利用网路爬虫技术快速确切找寻目的图书的方式
发明领域
[0001]本发明涉及一种阅读电子图书过程中确切快速选购目的图书的方式,属于网路【技术领域】。
【背景技术】
[0002]电子图书馆,是随着电版物的出现,网络通信技术的发展,而渐渐出现的。电子图书馆,具有储存能力大、速度快、保存时间长、成本低、便于交流等特性。光盘这一海量存储器、能够储存比传统图书高几千倍的信息,比微缩胶卷要多得多,而且包括图像、视频、声音,等等。利用电子技术,在这一种图书馆,我们能很快地从浩如烟海的图书中,查找到自己所须要的信息资料。这种图书馆,保存信息量的时间要长得多,不存在腐烂、生虫等问题。利用网路,在远在几千里、万里的单位、家中,都可以使用这些图书,效率极高。在广袤的书海中,想要快速确切的找到目标图书并不是这么容易,为我们阅读电子图书带来了一定的困难,阻碍了电子图书的发展。
【发明内容】
[0003]本发明为解决目前在电子图书馆中快速找寻目的图书的问题,提供一种借助网路爬虫技术快速确切寻觅目的图书的方式。本发明包括以下步骤:
[0004]步骤一:录入电子图书构建电子图书库;
[0005]步骤二:将录入的图书分类装入不同的子网页中;
[0006]步骤三:输入须要阅读图书的关键词;
[0007]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0008]步骤五:对抓取得网页进行剖析;
[0009]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0010]发明疗效:本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利附图】
【附图说明】
[0011]图1为借助网路爬虫技术快速确切找寻目的图书方式的流程图。
【具体施行方法】
[0012]【具体施行方法】:参见借助网路爬虫技术快速确切找寻目的图书方式的流程图1,本施行方法由以下步骤组成:
[0013]步骤一:录入电子图书构建电子图书库;
[0014]步骤二:将录入的图书分类装入不同的子网页中;[0015]步骤三:输入须要阅读图书的关键词;
[0016]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0017]步骤五:对抓取得网页进行剖析;
[0018]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0019]录入的电子图书必须对其按图书的种类对其进行命名,录入的图书的子网页早已录入图书的种类赋于了不同的域名,收索须要的电子图书须要输入该图书的图书名,或所属的学科种类,网络爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取,对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
[0020]对于本领域技术人员而言,显然本发明不限于上述示范性施行例的细节,而且在不背离本发明的精神或基本特点的情况下,能够以其他的具体方式实现本发明。因此网络爬虫书籍,无论从哪一点来看,均应将发明例看作是示范性的,而且是非限制性的,本发明的范围由所附权力要求而不是上述说明限定,因此借以将落在权力要求的等同要件的含意和范围内的所有变化涵盖在本发明内。不应将权力要求中的任何附图标记视为限制所涉及的权力要求。
【权利要求】
1.一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于它由以下步骤实现: 步骤一:录入电子图书,建立电子图书库; 步骤二:将录入的图书分类装入不同的子网页中; 步骤三:输入须要阅读图书的关键词; 步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取; 步骤五:对抓取得网页进行剖析; 步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
2.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤二中所述录入的电子图书必须对其按图书的种类对其进行命名。
3.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述录入的图书的子网页早已录入图书的种类赋于了不同的域名。
4.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述收索须要的电子图书须要输入该图书的图书名,或所属的学科种类。
5.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述网路爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取。
6.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
【文档编号】G06F17/30GK103744945SQ201310754637
【公开日】2014年4月23日 申请日期:2013年12月31日 优先权日:2013年12月31日
【发明者】朱龙腾 申请人:上海伯释信息科技有限公司
网络爬虫基本原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-05-03 08:00
网络爬虫基本原理23.05.2019基本描述 需要理解的算法 数据分类抓取策略 更新策略23.05.2019网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的 抓取万维网信息的程序或则脚本,是搜索引擎的重要组成。传统爬虫从一个或若 干初始网页的开始,获得初始网页上的,在抓取网页的过程中,不断从当前页面 上抽取新的装入队列,直到满足系统的一定停止条件。23.05.2019聚焦爬虫传统爬虫从一个或若干初始网页的开始,获得初始网页上的,在抓取网页的过程 中,不断从当前页面上抽取新的装入队列,直到满足系统的一定停止条件。聚焦爬 虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的队列。然后网络爬虫原理,它将按照一定的搜索策略从 队列中选择下一步要抓取的网页,并重复上述过程,直到达到系统的某一条件时 停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤, 并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分 析结果还可能对之后的抓取过程给出反馈和指导。23.05.2019简单流程 ::作为初始解析 网页数据 分析下载网页库种子待抓取已抓取下载网页 进入已抓取队列从队列信息中抽 取新的23.05.2019须要理解的算法.关键字匹配 :: 字符串匹配 算法(算法) 有限自动机算法 *算法.网页内容冗余 :: 卡时.大数目网页处理 :: *分布式.防止重复遍历 :: 字符串23.05.2019数据分类.已下载未过期网页 .已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的, 一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就过期了。
.待下载网页:也就是待抓取队列中的这些页面。 .可知网页:还没有抓取出来,也没有在待抓取队列中,但是可以通过对已抓取页面或则待 抓取对应页面进行剖析获取到的,认为是可知网页。 .不可知网页:还有一部分网页,爬虫是难以直接抓取下载的23.05.2019数据分类 ::已知网页已抓取未过期 已抓取已过期23.05.2019数据分类 ::不可知网页23.05.2019抓取策略 :: 暴力.深度优先搜索 .广度优先搜索 .大站优先策略对于待抓取队列中的所有网页,根据所属的网站进行分类。对于待下载页面数 多的网站,优先下载。这个策略也因而称作大站优先策略。23.05.2019抓取策略 :: 技巧.反向链接数策略 反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会 使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全 准确评价网页的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。23.05.2019抓取策略 :: 技巧策略 算法借鉴了算法的思想。
对于早已下载的网页,连同待抓取队列中的,形成网页集合网络爬虫原理,计算每位页面的值,计算完以后,将待抓取队列中的根据值的大小排列, 并根据该次序抓取页面。策略策略 该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金()。当下载了某个页面然后,将的现金平摊给所有从中剖析 出的链接,并且将的现金清空。对于待抓取队列中的所有页面根据现金数进行排 序。23.05.2019更新策略 :: 可持久化数据结构.历史参考策略 顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。.用户体验策略 尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的 网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用 户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的 影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。23.05.2019更新策略 :: 统计学改进.聚类抽样策略 前面提及的两种更新策略都有一个前提:需要网页的历史信息。
这样就存在两个问题:第一,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多 的系统负担;第二,要是新的网页完全没有历史信息,就难以确定更新策略。而降维抽样策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新 频率也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样, 以她们的更新周期作为整个类别的更新周期。23.05.2019的个人博客《这就是搜索引擎——核心技术解读》 张俊林 电子工业出版社《搜索引擎技术基础》刘奕群等 清华大学出版社23.05.2019ACM2013 查看全部
网络爬虫基本原理23.05.2019基本描述 需要理解的算法 数据分类抓取策略 更新策略23.05.2019网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的 抓取万维网信息的程序或则脚本,是搜索引擎的重要组成。传统爬虫从一个或若 干初始网页的开始,获得初始网页上的,在抓取网页的过程中,不断从当前页面 上抽取新的装入队列,直到满足系统的一定停止条件。23.05.2019聚焦爬虫传统爬虫从一个或若干初始网页的开始,获得初始网页上的,在抓取网页的过程 中,不断从当前页面上抽取新的装入队列,直到满足系统的一定停止条件。聚焦爬 虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的队列。然后网络爬虫原理,它将按照一定的搜索策略从 队列中选择下一步要抓取的网页,并重复上述过程,直到达到系统的某一条件时 停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤, 并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分 析结果还可能对之后的抓取过程给出反馈和指导。23.05.2019简单流程 ::作为初始解析 网页数据 分析下载网页库种子待抓取已抓取下载网页 进入已抓取队列从队列信息中抽 取新的23.05.2019须要理解的算法.关键字匹配 :: 字符串匹配 算法(算法) 有限自动机算法 *算法.网页内容冗余 :: 卡时.大数目网页处理 :: *分布式.防止重复遍历 :: 字符串23.05.2019数据分类.已下载未过期网页 .已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的, 一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就过期了。
.待下载网页:也就是待抓取队列中的这些页面。 .可知网页:还没有抓取出来,也没有在待抓取队列中,但是可以通过对已抓取页面或则待 抓取对应页面进行剖析获取到的,认为是可知网页。 .不可知网页:还有一部分网页,爬虫是难以直接抓取下载的23.05.2019数据分类 ::已知网页已抓取未过期 已抓取已过期23.05.2019数据分类 ::不可知网页23.05.2019抓取策略 :: 暴力.深度优先搜索 .广度优先搜索 .大站优先策略对于待抓取队列中的所有网页,根据所属的网站进行分类。对于待下载页面数 多的网站,优先下载。这个策略也因而称作大站优先策略。23.05.2019抓取策略 :: 技巧.反向链接数策略 反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会 使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全 准确评价网页的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。23.05.2019抓取策略 :: 技巧策略 算法借鉴了算法的思想。
对于早已下载的网页,连同待抓取队列中的,形成网页集合网络爬虫原理,计算每位页面的值,计算完以后,将待抓取队列中的根据值的大小排列, 并根据该次序抓取页面。策略策略 该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金()。当下载了某个页面然后,将的现金平摊给所有从中剖析 出的链接,并且将的现金清空。对于待抓取队列中的所有页面根据现金数进行排 序。23.05.2019更新策略 :: 可持久化数据结构.历史参考策略 顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。.用户体验策略 尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的 网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用 户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的 影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。23.05.2019更新策略 :: 统计学改进.聚类抽样策略 前面提及的两种更新策略都有一个前提:需要网页的历史信息。
这样就存在两个问题:第一,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多 的系统负担;第二,要是新的网页完全没有历史信息,就难以确定更新策略。而降维抽样策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新 频率也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样, 以她们的更新周期作为整个类别的更新周期。23.05.2019的个人博客《这就是搜索引擎——核心技术解读》 张俊林 电子工业出版社《搜索引擎技术基础》刘奕群等 清华大学出版社23.05.2019ACM2013
网络爬虫是哪些?网络爬虫是怎样工作的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 408 次浏览 • 2020-05-02 08:08
摘要:一篇文章了解爬虫的前世今生与未来
什么是网络爬虫?
网络爬虫,也称为网页抓取和网页数据提取,基本上是指通过超文本传输协议(HTTP)或通过网页浏览器获取万维网上可用的数据。(摘自Wikipedia)
网络爬虫是怎样工作的?
通常,爬取网页数据时,只须要2个步骤。
打开网页→将具体的数据从网页中复制并导入到表格或数据库中。
这一切是怎么开始的?
尽管对许多人来说,网络爬虫听上去象是“大数据”或“机器学习”一类的新概念,但实际上,网络数据抓取的历史要长得多,可以溯源到万维网(或浅显的“互联网”)诞生之时。
一开始,互联网还没有搜索。在搜索引擎被开发下来之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
随后,互联网发展上去,最终有数百万级的网页生成,这些网页包含大量不同的方式的数据,其中包括文本、图像、视频和音频。互联网弄成了一个开放的数据源。
随着数据资源显得十分丰富且容易搜索,人们发觉从网页上找到她们想要的信息是一件极其简单的事情,他们一般分布在大量的网站上。但另一个问题出现了,当她们想要数据的时侯,并非每位网站都提供下载按键,如果进行自动复制其实是极其低效且平庸的。
这就是网路爬虫诞生的诱因。网络爬虫实际上是由网页机器人/爬虫驱动的,其功能与搜索引擎相同。简单来说就是,抓取和复制。唯一的不同可能是规模。网络数据抓取是从特定的网站提取特定的数据,而搜索引擎一般是在万维网上搜索出大部分的网站。
时间轴
1989年万维网的诞生
从技术上讲,万维网和因特网有所不同。前者是指信息空间,后者是由数台计算机联接上去的内部网路。
感谢Tim Berners-Lee,万维网的发明者,他发明的三件东西,往后成为了我们日常生活中的一部分。
1990年第一个网络浏览器
它也由Tim Berners-Lee发明,被称为WorldWide网页(无空间),以WWW项目命名。在网路出现一年后,人们有了一条途径去浏览它并与之互动。
1991年第一个网页服务器和第一个 网页页面
网页的数目以缓慢的速率下降。到1994年,HTTP服务器的数目超过200台。
1993年6月第一台网页机器人——万维网漫游器
虽然它的功能和昨天的网页机器人一样,但它只是拿来检测网页的大小。
1993年12月首个基于爬虫的网路搜索引擎—JumpStation
由于当时网路上的网站并不多,搜索引擎过去经常依赖人工网站管理员来搜集和编辑链接,使其成为一种特定的格式。
JumpStation带来了新的飞越。它是第一个借助网路机器人的WWW搜索引擎。
从那时起,人们开始使用这种程序化的网路爬虫程序来搜集和组织互联网。从Infoseek、Altavista和Excite,到现在的必应和微软,搜索引擎机器人的核心依旧保持不变:
找到一个网页页面,下载(获取)它,抓取网页页面上显示的所有信息,然后将其添加到搜索引擎的数据库中。
由于网页页面是为人类用户设计的,不是为了自动化使用,即使开发了网页机器人,计算机工程师和科学家一直很难进行网路数据抓取,更不用说普通人了。因此,人们仍然致力于让网路爬虫显得愈发容易使用。
2000年网页API和API爬虫
API表示应用程序编程插口。它是一个插口,通过提供搭建好的模块,使开发程序愈加方便。
2000年,Salesforce和eBay推出了自己的API,程序员可以用它访问并下载一些公开数据。
从那时起,许多网站都提供网页API使人们可以访问她们的公共数据库。
发送一组HTTP请求,然后接收JSON或XML的回馈。
网页API通过搜集网站提供的数据,为开发人员提供了一种更友好的网路爬虫形式。
2004 年Python Beautiful Soup
不是所有的网站都提供API。即使她们提供了,他们也不一定会提供你想要的所有数据。因此,程序员们仍在开发一种才能建立网路爬虫的方式。
2004年,Beautiful Soup发布。它是一个为Python设计的库。
在计算机编程中,库是脚本模块的集合,就像常用的算法一样,它容许不用重画就可以使用,从而简化了编程过程。
通过简单的命令,Beautiful Soup可以理解站点的结构,并帮助从HTML容器中解析内容。它被觉得是用于网路爬虫的最复杂和最先进的库,也是现今最常见和最流行的方式之一。
2005-2006年网路抓取软件的可视化
2006年,Stefan Andresen和他的Kapow软件(Kofax于2013年竞购)发布了网页集成平台6.0版本,这是一种可视化的网路爬虫软件,它容许用户轻松简单的选择网页内容,并将这种数据构造成可用的excel文件或数据库。
八爪鱼数据采集器
最终,可视化的网路数据抓取软件可以使大量非程序员自己进行网路爬虫。
从那时起,网络抓取开始成为主流。现在,对于非程序员来说,他们可以很容易地找到80多个可提供可视化过程的的数据采集软件。
网络爬虫未来将怎样发展?
我们总是想要更多的数据。我们搜集数据,处理数据,并把数据转换成各种各样的成品,比如研究,洞察剖析,信息,故事,资产等等。我们过去经常耗费大量的时间、精力和金钱在找寻和搜集数据上,以至于只有大公司和组织能够负担得起。
在2018年,我们所知的万维网网络爬虫技术是什么,或浅显的“互联网”,由超过18亿个网站组成。只需点击几下键盘,就可以获得这么巨大的数据量。随着越来越多的人上网,每秒形成的数据也越来越多。
如今,是一个比历史上任何时期都要便捷的时代。任何个人、公司和组织都还能获得她们想要的数据,只要这种数据在网页上是公开可用的。
多亏了网路爬虫/机器人、API、标准数据库和各类开箱即用的软件,一旦有人有了获取数据的意愿,就有了获取数据的方式。或者,他们也可以求救于这些她们接触得到又支付的起费用的专业人士。
在自由职业任务平台guru.com上搜索“网络爬虫”时,你可以得到10088个搜索结果,这意味着超过10000名自由职业者在这个网站上提供网路抓取服务。
而在同类的网站,Upwork上的搜索结果有13190个,fievere.com上的结果是1024个。
各行各业的公司对网路数据的需求不断下降,推动了网路抓取行业的发展,带来了新的市场、就业机会和商业机会。
与此同时,与其他新兴行业一样,网络抓取也伴随着法律方面的疑虑。
围绕网路爬虫合法性的讨论情况仍存在。它的合法与否与具体案例背景相关。目前,这种趋势下诞生的许多有趣的法律问题一直没有得到解答,或者取决于十分具体的案例背景。
虽然网路抓取早已存在了太长一段时间,但法庭才刚才开基础大数据相关的法律理论的应用。
由于与网路爬取和数据抓取的仍处于发展阶段,所以它的发展一直未稳定出来且难以预测。然而,有一件事是肯定的,那就是,只要有互联网,就有网路抓取。
是网路抓取使新生的互联网显得可以搜索,使爆炸式下降的互联网显得愈发容易访问和获取。
毫无疑问网络爬虫技术是什么,在可预见的未来,互联网和网路抓取,将继续稳定地往前迈向。 查看全部
摘要:一篇文章了解爬虫的前世今生与未来
什么是网络爬虫?
网络爬虫,也称为网页抓取和网页数据提取,基本上是指通过超文本传输协议(HTTP)或通过网页浏览器获取万维网上可用的数据。(摘自Wikipedia)
网络爬虫是怎样工作的?
通常,爬取网页数据时,只须要2个步骤。
打开网页→将具体的数据从网页中复制并导入到表格或数据库中。
这一切是怎么开始的?
尽管对许多人来说,网络爬虫听上去象是“大数据”或“机器学习”一类的新概念,但实际上,网络数据抓取的历史要长得多,可以溯源到万维网(或浅显的“互联网”)诞生之时。
一开始,互联网还没有搜索。在搜索引擎被开发下来之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
随后,互联网发展上去,最终有数百万级的网页生成,这些网页包含大量不同的方式的数据,其中包括文本、图像、视频和音频。互联网弄成了一个开放的数据源。
随着数据资源显得十分丰富且容易搜索,人们发觉从网页上找到她们想要的信息是一件极其简单的事情,他们一般分布在大量的网站上。但另一个问题出现了,当她们想要数据的时侯,并非每位网站都提供下载按键,如果进行自动复制其实是极其低效且平庸的。
这就是网路爬虫诞生的诱因。网络爬虫实际上是由网页机器人/爬虫驱动的,其功能与搜索引擎相同。简单来说就是,抓取和复制。唯一的不同可能是规模。网络数据抓取是从特定的网站提取特定的数据,而搜索引擎一般是在万维网上搜索出大部分的网站。
时间轴
1989年万维网的诞生
从技术上讲,万维网和因特网有所不同。前者是指信息空间,后者是由数台计算机联接上去的内部网路。
感谢Tim Berners-Lee,万维网的发明者,他发明的三件东西,往后成为了我们日常生活中的一部分。
1990年第一个网络浏览器
它也由Tim Berners-Lee发明,被称为WorldWide网页(无空间),以WWW项目命名。在网路出现一年后,人们有了一条途径去浏览它并与之互动。
1991年第一个网页服务器和第一个 网页页面
网页的数目以缓慢的速率下降。到1994年,HTTP服务器的数目超过200台。
1993年6月第一台网页机器人——万维网漫游器
虽然它的功能和昨天的网页机器人一样,但它只是拿来检测网页的大小。
1993年12月首个基于爬虫的网路搜索引擎—JumpStation
由于当时网路上的网站并不多,搜索引擎过去经常依赖人工网站管理员来搜集和编辑链接,使其成为一种特定的格式。
JumpStation带来了新的飞越。它是第一个借助网路机器人的WWW搜索引擎。
从那时起,人们开始使用这种程序化的网路爬虫程序来搜集和组织互联网。从Infoseek、Altavista和Excite,到现在的必应和微软,搜索引擎机器人的核心依旧保持不变:
找到一个网页页面,下载(获取)它,抓取网页页面上显示的所有信息,然后将其添加到搜索引擎的数据库中。
由于网页页面是为人类用户设计的,不是为了自动化使用,即使开发了网页机器人,计算机工程师和科学家一直很难进行网路数据抓取,更不用说普通人了。因此,人们仍然致力于让网路爬虫显得愈发容易使用。
2000年网页API和API爬虫
API表示应用程序编程插口。它是一个插口,通过提供搭建好的模块,使开发程序愈加方便。
2000年,Salesforce和eBay推出了自己的API,程序员可以用它访问并下载一些公开数据。
从那时起,许多网站都提供网页API使人们可以访问她们的公共数据库。
发送一组HTTP请求,然后接收JSON或XML的回馈。
网页API通过搜集网站提供的数据,为开发人员提供了一种更友好的网路爬虫形式。
2004 年Python Beautiful Soup
不是所有的网站都提供API。即使她们提供了,他们也不一定会提供你想要的所有数据。因此,程序员们仍在开发一种才能建立网路爬虫的方式。
2004年,Beautiful Soup发布。它是一个为Python设计的库。
在计算机编程中,库是脚本模块的集合,就像常用的算法一样,它容许不用重画就可以使用,从而简化了编程过程。
通过简单的命令,Beautiful Soup可以理解站点的结构,并帮助从HTML容器中解析内容。它被觉得是用于网路爬虫的最复杂和最先进的库,也是现今最常见和最流行的方式之一。
2005-2006年网路抓取软件的可视化
2006年,Stefan Andresen和他的Kapow软件(Kofax于2013年竞购)发布了网页集成平台6.0版本,这是一种可视化的网路爬虫软件,它容许用户轻松简单的选择网页内容,并将这种数据构造成可用的excel文件或数据库。
八爪鱼数据采集器
最终,可视化的网路数据抓取软件可以使大量非程序员自己进行网路爬虫。
从那时起,网络抓取开始成为主流。现在,对于非程序员来说,他们可以很容易地找到80多个可提供可视化过程的的数据采集软件。
网络爬虫未来将怎样发展?
我们总是想要更多的数据。我们搜集数据,处理数据,并把数据转换成各种各样的成品,比如研究,洞察剖析,信息,故事,资产等等。我们过去经常耗费大量的时间、精力和金钱在找寻和搜集数据上,以至于只有大公司和组织能够负担得起。
在2018年,我们所知的万维网网络爬虫技术是什么,或浅显的“互联网”,由超过18亿个网站组成。只需点击几下键盘,就可以获得这么巨大的数据量。随着越来越多的人上网,每秒形成的数据也越来越多。
如今,是一个比历史上任何时期都要便捷的时代。任何个人、公司和组织都还能获得她们想要的数据,只要这种数据在网页上是公开可用的。
多亏了网路爬虫/机器人、API、标准数据库和各类开箱即用的软件,一旦有人有了获取数据的意愿,就有了获取数据的方式。或者,他们也可以求救于这些她们接触得到又支付的起费用的专业人士。
在自由职业任务平台guru.com上搜索“网络爬虫”时,你可以得到10088个搜索结果,这意味着超过10000名自由职业者在这个网站上提供网路抓取服务。
而在同类的网站,Upwork上的搜索结果有13190个,fievere.com上的结果是1024个。
各行各业的公司对网路数据的需求不断下降,推动了网路抓取行业的发展,带来了新的市场、就业机会和商业机会。
与此同时,与其他新兴行业一样,网络抓取也伴随着法律方面的疑虑。
围绕网路爬虫合法性的讨论情况仍存在。它的合法与否与具体案例背景相关。目前,这种趋势下诞生的许多有趣的法律问题一直没有得到解答,或者取决于十分具体的案例背景。
虽然网路抓取早已存在了太长一段时间,但法庭才刚才开基础大数据相关的法律理论的应用。
由于与网路爬取和数据抓取的仍处于发展阶段,所以它的发展一直未稳定出来且难以预测。然而,有一件事是肯定的,那就是,只要有互联网,就有网路抓取。
是网路抓取使新生的互联网显得可以搜索,使爆炸式下降的互联网显得愈发容易访问和获取。
毫无疑问网络爬虫技术是什么,在可预见的未来,互联网和网路抓取,将继续稳定地往前迈向。
网页抓取工具:一个简单的文章采集示例 (1)
采集交流 • 优采云 发表了文章 • 0 个评论 • 479 次浏览 • 2020-04-18 09:53
网页抓取工具:一个简单的文章采集示例 通过采集网页抓取工具列车采集器官网的 faq 为例来说明采集器采集的原理和 过程。 本例以 演示地址网站文章采集软件, 以列车采集器 V9 为工具 进行示例说明。 (1)新建个采集规则 选择一个分组上右击,选择“新建任务”,如下图:(2)添加起始网址 在这里我们须要采集 5 页数据。 分析网址变量规律 第一页地址: 第二页地址: 第三页地址: 由此我们可以推断出 p=后的数字就是分页的意思,我们用[地址参数]表示: 所以设置如下:地址格式:把变化的分页数字用[地址参数]表示。 数字变化:从 1 开始文章采集,即第一页;每次递增 1,即每次分页的变化规律数字; 共 5 项,即一共采集 5 页。 预览:采集器会根据前面设置的生成一部分网址,让你来判读添加的是否正确。 然后确定即可 (3)[常规模式]获取内容网址 常规模式:该模式默认抓取一级地址,即从起始页源代码中获取到内容页 A 链 接。 在这里给你们演示用 自动获取地址链接 +设置区域 的 方式来获取。 查看页面源代码找到文章地址所在的区域:设置如下: 注:更详尽的剖析说明可以参考本指南: 操作指南 > 软件操作 > 网址采集规则 > 获取内容网址点击网址采集测试,看看测试疗效(3)内容采集网址 以 为例讲解标签采集 注:更详尽的剖析说明可以下载参考官网的用户指南。
操作指南 > 软件操作 > 内容采集规则 > 标签编辑 我们首先查看它的页面源代码网站文章采集软件,找到我们“标题”所在位置的代码:<title>导入 Excle 是跳出对话框~打开 Excle 出错 - 火车采集器帮助中心</title>分析得出: 开头字符串为:<title> 结尾字符串为:</title> 数据处理——内容替换/排除:需要把- 火车采集器帮助中心 给替换为空内容标签的设置原理也是类似的,找到内容所在源码中的位置剖析得出: 开头字符串为:<div id="cmsContent"> 结尾字符串为:</div> 数据处理——HTML 标签排除:把不需要的 A 链接等过滤再设置个“来源”字段这样一个简单的文章采集规则就做好了, 使用通用的网页抓取工具列车采集器并 按照这个示例的步骤就可以进行其它类型数据采集的扩充啦。 查看全部
网页抓取工具:一个简单的文章采集示例 通过采集网页抓取工具列车采集器官网的 faq 为例来说明采集器采集的原理和 过程。 本例以 演示地址网站文章采集软件, 以列车采集器 V9 为工具 进行示例说明。 (1)新建个采集规则 选择一个分组上右击,选择“新建任务”,如下图:(2)添加起始网址 在这里我们须要采集 5 页数据。 分析网址变量规律 第一页地址: 第二页地址: 第三页地址: 由此我们可以推断出 p=后的数字就是分页的意思,我们用[地址参数]表示: 所以设置如下:地址格式:把变化的分页数字用[地址参数]表示。 数字变化:从 1 开始文章采集,即第一页;每次递增 1,即每次分页的变化规律数字; 共 5 项,即一共采集 5 页。 预览:采集器会根据前面设置的生成一部分网址,让你来判读添加的是否正确。 然后确定即可 (3)[常规模式]获取内容网址 常规模式:该模式默认抓取一级地址,即从起始页源代码中获取到内容页 A 链 接。 在这里给你们演示用 自动获取地址链接 +设置区域 的 方式来获取。 查看页面源代码找到文章地址所在的区域:设置如下: 注:更详尽的剖析说明可以参考本指南: 操作指南 > 软件操作 > 网址采集规则 > 获取内容网址点击网址采集测试,看看测试疗效(3)内容采集网址 以 为例讲解标签采集 注:更详尽的剖析说明可以下载参考官网的用户指南。
操作指南 > 软件操作 > 内容采集规则 > 标签编辑 我们首先查看它的页面源代码网站文章采集软件,找到我们“标题”所在位置的代码:<title>导入 Excle 是跳出对话框~打开 Excle 出错 - 火车采集器帮助中心</title>分析得出: 开头字符串为:<title> 结尾字符串为:</title> 数据处理——内容替换/排除:需要把- 火车采集器帮助中心 给替换为空内容标签的设置原理也是类似的,找到内容所在源码中的位置剖析得出: 开头字符串为:<div id="cmsContent"> 结尾字符串为:</div> 数据处理——HTML 标签排除:把不需要的 A 链接等过滤再设置个“来源”字段这样一个简单的文章采集规则就做好了, 使用通用的网页抓取工具列车采集器并 按照这个示例的步骤就可以进行其它类型数据采集的扩充啦。
网页抓取工具必读的文章采集实例
采集交流 • 优采云 发表了文章 • 0 个评论 • 549 次浏览 • 2020-04-18 09:48
以 为例讲解标签采集
注:更详尽的剖析说明可以参考本指南
操作指南 > 软件操作 > 内容采集规则 > 标签编辑
我们首先查看它的页面源代码采集文章工具,找到我们“标题”所在位置的代码:
<title>导入Excle是跳出对话框~打开Excle出错 - 火车采集器帮助中心</title>
分析得出: 开头字符串为:<title>
结尾字符串为:</title>
数据处理——内容替换/排除:需要把- 火车采集器帮助中心给替换为空
内容标签的设置原理也是类似的,找到内容所在源码中的位置
分析得出: 开头字符串为:<div id="cmsContent">
结尾字符串为:</div>
数据处理——HTML标签排除:把不需要的A链接等 过滤
再设置个“来源”字段
这样一个简单的文章采集规则就做好了,不知道网友们学会了没有呢,网页抓取工具顾名思义是适用于网页上的数据抓取采集文章工具,从前面的事例你们也可以看出,这类软件主要是通过源代码剖析才解析数据的。这里还有一些情况是没有列举的,比如登陆采集,使用代理采集等,如果对网页抓取工具感兴趣的可以登入采集器官网自行学习一下。 查看全部
以 为例讲解标签采集
注:更详尽的剖析说明可以参考本指南
操作指南 > 软件操作 > 内容采集规则 > 标签编辑
我们首先查看它的页面源代码采集文章工具,找到我们“标题”所在位置的代码:
<title>导入Excle是跳出对话框~打开Excle出错 - 火车采集器帮助中心</title>
分析得出: 开头字符串为:<title>
结尾字符串为:</title>
数据处理——内容替换/排除:需要把- 火车采集器帮助中心给替换为空
内容标签的设置原理也是类似的,找到内容所在源码中的位置
分析得出: 开头字符串为:<div id="cmsContent">
结尾字符串为:</div>
数据处理——HTML标签排除:把不需要的A链接等 过滤
再设置个“来源”字段
这样一个简单的文章采集规则就做好了,不知道网友们学会了没有呢,网页抓取工具顾名思义是适用于网页上的数据抓取采集文章工具,从前面的事例你们也可以看出,这类软件主要是通过源代码剖析才解析数据的。这里还有一些情况是没有列举的,比如登陆采集,使用代理采集等,如果对网页抓取工具感兴趣的可以登入采集器官网自行学习一下。

