
网站采集器自动超文章发布
网站采集器自动超文章发布(中小网站自动更新利器,ET2(EditorTools)免费采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-14 18:10
ET3(EditorTools)是一款免费的采集软件EditorTools是中小型网站的自动更新工具,ET2自动发布采集,静默工作不需要人工干预;独立软件免除网站性能消耗;安全稳定,可连续工作多年。
软件特点
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,即使时间单位是年。
超高稳定性
要达到软件无人值守的目的,需要长期稳定运行。ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有软件会崩溃甚至崩溃。导致 网站 崩溃问题。
最低资源使用率
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器上工作,也可以在站长的工作机上工作。
严格的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。采集 供参考,ET使用标准的HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
ET除了具有一般采集工具的功能外,还使用了图片水印、防盗链、分页采集、回复采集、登录采集、自定义物品、UTF-支持8、UBB、模拟发布...使用户可以灵活实现各种采购和开发需求。
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,任何类型的信息都可以采集
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[特点] 下载上传支持续传
【特点】高速伪原创
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
[采集] 支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持任何已发布项目的语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态 查看全部
网站采集器自动超文章发布(中小网站自动更新利器,ET2(EditorTools)免费采集软件)
ET3(EditorTools)是一款免费的采集软件EditorTools是中小型网站的自动更新工具,ET2自动发布采集,静默工作不需要人工干预;独立软件免除网站性能消耗;安全稳定,可连续工作多年。

软件特点
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,即使时间单位是年。
超高稳定性
要达到软件无人值守的目的,需要长期稳定运行。ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有软件会崩溃甚至崩溃。导致 网站 崩溃问题。
最低资源使用率
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器上工作,也可以在站长的工作机上工作。
严格的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。采集 供参考,ET使用标准的HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
ET除了具有一般采集工具的功能外,还使用了图片水印、防盗链、分页采集、回复采集、登录采集、自定义物品、UTF-支持8、UBB、模拟发布...使用户可以灵活实现各种采购和开发需求。
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,任何类型的信息都可以采集
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[特点] 下载上传支持续传
【特点】高速伪原创
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
[采集] 支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持任何已发布项目的语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
网站采集器自动超文章发布(网站采集器自动超文章发布机器人就是这样用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-14 07:05
网站采集器自动超文章发布机器人就是这样用的,这种是一种辅助的机器人,没有什么技术含量的,
可以用像蚂蚁科技这样的大数据服务商,他们的系统能支持网站内发布文章,云发布更好,
现在很多大的seo服务商都有的,是免费提供网站内发布文章功能的,其实不复杂,只要大家把需要的东西都提交给服务商做就行,会一定的技术你基本上就可以搞定了。
不知道你是想问谁家的,现在常用的比如蚂蚁科技,wordpress系统的,他们家虽然收费,但是对用户的比较厚道,不排除是广告,但是非广告,
互联网资讯网站适合自动发布,因为非常精准,可以参考移动端通用发布的工具,
我用的发布工具是爱百程的文章发布,
这种是很正常的,需要发文章必然是为了挣钱,目前看来你遇到瓶颈了.建议多探索探索
百度认证的,全站抓取的,有价值的文章自动发布,还有数据监控;暂时免费,过段时间应该是要收费的;上面,卖爱百程做过的站,我们免费给发文章。可以关注下。我们直接提供接口,对接网。
全站定向全自动
网站是有很多东西的所以很多操作都是需要按照流程走的否则出问题不知道是你自己操作的问题还是文章就给别人操作了 查看全部
网站采集器自动超文章发布(网站采集器自动超文章发布机器人就是这样用)
网站采集器自动超文章发布机器人就是这样用的,这种是一种辅助的机器人,没有什么技术含量的,
可以用像蚂蚁科技这样的大数据服务商,他们的系统能支持网站内发布文章,云发布更好,
现在很多大的seo服务商都有的,是免费提供网站内发布文章功能的,其实不复杂,只要大家把需要的东西都提交给服务商做就行,会一定的技术你基本上就可以搞定了。
不知道你是想问谁家的,现在常用的比如蚂蚁科技,wordpress系统的,他们家虽然收费,但是对用户的比较厚道,不排除是广告,但是非广告,
互联网资讯网站适合自动发布,因为非常精准,可以参考移动端通用发布的工具,
我用的发布工具是爱百程的文章发布,
这种是很正常的,需要发文章必然是为了挣钱,目前看来你遇到瓶颈了.建议多探索探索
百度认证的,全站抓取的,有价值的文章自动发布,还有数据监控;暂时免费,过段时间应该是要收费的;上面,卖爱百程做过的站,我们免费给发文章。可以关注下。我们直接提供接口,对接网。
全站定向全自动
网站是有很多东西的所以很多操作都是需要按照流程走的否则出问题不知道是你自己操作的问题还是文章就给别人操作了
网站采集器自动超文章发布(CMS采集大挪移、维护王和同步更新王,注册成千上万个会员 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-11-11 00:13
)
优采云cms采集器目前包括cms采集移动、维护王和同步更新王,你可以采集其他网站和所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护网站 可实现资源自动定位、图片自动定位和添加水印等,采集每日发布量可达数万。.
相关软件软件大小版本说明下载地址
优采云cms采集器目前包括cms采集移动、维护王和同步更新王,你可以采集其他网站和所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护网站 可实现资源自动定位、图片自动定位和添加水印等,采集每日发布量可达数万。目前全面支持DEDEcms(织梦)、Ecms(帝国)、PHPcms、PHP168、PowerEasy(Dynamic Easy)、SupeSite、5U、 DIY -Page,Zoomla!cms、JEEcms等主流cms程序采集
软件特点
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站程序,让您彻底摆脱网站繁重的维护管理. 优采云采集器每套软件包括采集维护王和采集DaNeoMove,还有以下实用功能:
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松实现千人在线热门论坛的效果(部分不支持按IP统计在线人数的论坛,如DVbbs/PHPWind);
您可以采集网站/forum的话题和所有回复,网站/forums 80%可以是采集,您可以保存文章的内容在本地之后发布;
您可以将网站论坛A版块或专栏的内容批量转发采集到您自己的网站或论坛指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖ID和回复ID分开,允许部分成员发布所有主题,让其他成员全部回复,ID号成员选择发布;
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入您自己的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天将采集的最新内容发布到指定栏目;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行、HTML预览,使用更好更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章都按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以在论坛内容中采集网站/超级链接,或者屏蔽该链接
您可以从采集网站/论坛下载文章的图片到本地,然后通过FTP上传附件和图片到您的网站空间;
图片名称可以随意;
支持任务栏图标隐藏显示的最小化;
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后、内容中自动添加自定义关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看网站论坛帖子;
查看全部
网站采集器自动超文章发布(CMS采集大挪移、维护王和同步更新王,注册成千上万个会员
)
优采云cms采集器目前包括cms采集移动、维护王和同步更新王,你可以采集其他网站和所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护网站 可实现资源自动定位、图片自动定位和添加水印等,采集每日发布量可达数万。.
相关软件软件大小版本说明下载地址
优采云cms采集器目前包括cms采集移动、维护王和同步更新王,你可以采集其他网站和所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护网站 可实现资源自动定位、图片自动定位和添加水印等,采集每日发布量可达数万。目前全面支持DEDEcms(织梦)、Ecms(帝国)、PHPcms、PHP168、PowerEasy(Dynamic Easy)、SupeSite、5U、 DIY -Page,Zoomla!cms、JEEcms等主流cms程序采集

软件特点
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站程序,让您彻底摆脱网站繁重的维护管理. 优采云采集器每套软件包括采集维护王和采集DaNeoMove,还有以下实用功能:
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松实现千人在线热门论坛的效果(部分不支持按IP统计在线人数的论坛,如DVbbs/PHPWind);
您可以采集网站/forum的话题和所有回复,网站/forums 80%可以是采集,您可以保存文章的内容在本地之后发布;
您可以将网站论坛A版块或专栏的内容批量转发采集到您自己的网站或论坛指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖ID和回复ID分开,允许部分成员发布所有主题,让其他成员全部回复,ID号成员选择发布;
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入您自己的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天将采集的最新内容发布到指定栏目;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行、HTML预览,使用更好更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章都按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以在论坛内容中采集网站/超级链接,或者屏蔽该链接
您可以从采集网站/论坛下载文章的图片到本地,然后通过FTP上传附件和图片到您的网站空间;
图片名称可以随意;
支持任务栏图标隐藏显示的最小化;
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后、内容中自动添加自定义关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看网站论坛帖子;

网站采集器自动超文章发布(网站采集器自动超文章发布工具_发布文章自动发布)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-08 07:05
网站采集器自动超文章发布工具_发布文章自动发布到百度百家:xlnewsproxy需要的软件版本:phpphtmanager,xlnewsproxy一键点按的功能,对于没有经验的新手来说,是相当困难的。xlnewsproxy采用逐篇生成百度首页内容的方式,具有全新的网页内容组织方式,自动为您生成独特的内容特色。
xlnewsproxy提供丰富的样式自定义,可根据自己的发布要求任意调整。然后修改xlnewsproxy的ua就可以实现你想要的百度搜索结果,后续要是还有采集需求可以直接调用xlnewsproxy的方式实现。xlnewsproxy官网。
ua
自动发布、保存自己网站上的百度搜索结果这个就厉害了~xlappmeque/web-spoofingserver·github网站推荐这个:/,
个人觉得这个就挺好用的,感觉可以满足绝大部分的要求,可以添加自己网站上的全部链接,
sitemapjar用来选取你的网站,并且可以生成多个。我一直在用这个,对搜索引擎很友好,前提是你网站不是作弊的!ui小团队做,界面简单易懂,方便用户。
呵呵我也在找,
传送门:发布搜索结果-百度搜索结果发布器-搜狗站长平台
万能的google,搜索框里打某网站,就出来这个结果。百度不行。
你需要找的是一个自动发布的插件,但是要的是ftp服务器, 查看全部
网站采集器自动超文章发布(网站采集器自动超文章发布工具_发布文章自动发布)
网站采集器自动超文章发布工具_发布文章自动发布到百度百家:xlnewsproxy需要的软件版本:phpphtmanager,xlnewsproxy一键点按的功能,对于没有经验的新手来说,是相当困难的。xlnewsproxy采用逐篇生成百度首页内容的方式,具有全新的网页内容组织方式,自动为您生成独特的内容特色。
xlnewsproxy提供丰富的样式自定义,可根据自己的发布要求任意调整。然后修改xlnewsproxy的ua就可以实现你想要的百度搜索结果,后续要是还有采集需求可以直接调用xlnewsproxy的方式实现。xlnewsproxy官网。
ua
自动发布、保存自己网站上的百度搜索结果这个就厉害了~xlappmeque/web-spoofingserver·github网站推荐这个:/,
个人觉得这个就挺好用的,感觉可以满足绝大部分的要求,可以添加自己网站上的全部链接,
sitemapjar用来选取你的网站,并且可以生成多个。我一直在用这个,对搜索引擎很友好,前提是你网站不是作弊的!ui小团队做,界面简单易懂,方便用户。
呵呵我也在找,
传送门:发布搜索结果-百度搜索结果发布器-搜狗站长平台
万能的google,搜索框里打某网站,就出来这个结果。百度不行。
你需要找的是一个自动发布的插件,但是要的是ftp服务器,
网站采集器自动超文章发布(EditorTools——中小网站自动更新利器!(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-08 01:00
<p>EditorTools3 是一款无人值守的全自动采集器,非常值得所有站长朋友使用。可以帮助用户解决中小型网站和企业站采集操作的自动信息,更智能的采集程序保证您的 查看全部
网站采集器自动超文章发布(全网第一波wordpress+phpxmlpress百度云网盘大全免费领取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-05 23:05
网站采集器自动超文章发布脚本全网第一波wordpress+phpxmlpress百度云网盘大全免费领取免费领取完整版全网第一波网站采集器脚本大全与大家分享全网第一波网站采集器脚本大全其他wordpress论坛留言获取wordpress源码谢谢^_^
可以到云栖社区网址上
360云盘-免费网盘,共享你的网盘
官方的可以去网盘搜索
可以去阿里云网盘
乌云上面有一个小工具sdilphp网站采集,虽然也有些慢,如果是网盘精灵的话。不过不知道你用不用得上,如果你用的上,
可以去phpwind看看,有个文件库,
云盘搜索助手-云客户端(强烈推荐)
国内的去百度云:-bin/baiduspider-release?package=zh
乌云用一下就行了,免费的,上传文件即可。收费服务需要申请,但是目前已经可以免费注册使用了,买大会员应该比较贵。
或者私聊我。
使用国外的一个wordpress网盘工具-markdownx-blocks
原文在微信公众号里,后期还有几篇相关文章,先放上链接在微信生态里,优雅的看网盘等各大论坛的各种资源,或者如果有需要,也可以直接通过邮件(email)给订阅号的小编直接发送,或者扫码关注微信公众号里的论坛,也可以在公众号里直接搜索关键词。|突然爱上wordpress,没有文件是不够的。(二维码自动识别)微信号/邮箱:我是安会哥,会记录和分享网盘资源和工具使用方法,与各位同行共勉。
如果想找资源可以加一下微信:也欢迎大家关注我的专栏:电脑技术(java后端开发),也可以加一下关注我的专栏二维码扫描。 查看全部
网站采集器自动超文章发布(全网第一波wordpress+phpxmlpress百度云网盘大全免费领取)
网站采集器自动超文章发布脚本全网第一波wordpress+phpxmlpress百度云网盘大全免费领取免费领取完整版全网第一波网站采集器脚本大全与大家分享全网第一波网站采集器脚本大全其他wordpress论坛留言获取wordpress源码谢谢^_^
可以到云栖社区网址上
360云盘-免费网盘,共享你的网盘
官方的可以去网盘搜索
可以去阿里云网盘
乌云上面有一个小工具sdilphp网站采集,虽然也有些慢,如果是网盘精灵的话。不过不知道你用不用得上,如果你用的上,
可以去phpwind看看,有个文件库,
云盘搜索助手-云客户端(强烈推荐)
国内的去百度云:-bin/baiduspider-release?package=zh
乌云用一下就行了,免费的,上传文件即可。收费服务需要申请,但是目前已经可以免费注册使用了,买大会员应该比较贵。
或者私聊我。
使用国外的一个wordpress网盘工具-markdownx-blocks
原文在微信公众号里,后期还有几篇相关文章,先放上链接在微信生态里,优雅的看网盘等各大论坛的各种资源,或者如果有需要,也可以直接通过邮件(email)给订阅号的小编直接发送,或者扫码关注微信公众号里的论坛,也可以在公众号里直接搜索关键词。|突然爱上wordpress,没有文件是不够的。(二维码自动识别)微信号/邮箱:我是安会哥,会记录和分享网盘资源和工具使用方法,与各位同行共勉。
如果想找资源可以加一下微信:也欢迎大家关注我的专栏:电脑技术(java后端开发),也可以加一下关注我的专栏二维码扫描。
网站采集器自动超文章发布(网站采集器自动超文章发布机器人多款可选)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-11-03 17:06
网站采集器自动超文章发布机器人简介:实现自动发文章,可以从、天猫、百度搜索等网站采集文章,通过不到1分钟的轻松操作,就可以获取到很多全网最新的图片、美图、表情、攻略等,自动发布到你的百度云盘、360云盘等云盘,即使你没有网站也没有关系,你可以通过简单的文章批量发布,按照软件提示或者根据提示就可以快速发文发链接了,整个操作很简单!机器人多款可选:1。
便宜型:简单易用,可自定义格式的文件名,发布速度比较慢;2。中等型:整体比较完善,发布速度很快,可自定义大小,不同网站采集效果都一样;3。高端型:整体配置非常高,自动追踪全网采集,采集速度快,几十个网站采集可以实现全程自动化,可根据需要定制发布速度;4。传统型:提供了站点数据调用接口,可以自定义加快发布速度,多个网站高效互换;5。
开源型:提供接口开放,可以进行反编译对接百度云盘,各个主流网站、新闻网站、网络教程,个人需要自定义管理;6。云端服务:网站数据采集整合完毕后,可以云端分享给个人用户、开发人员或者是团队用户,以便其可以更快的发布优质文章;功能亮点:1。真实的app客户端,自带固定速度;2。自动发布文章,全程自动操作,减少工作量;3。
智能追踪全网文章,提高文章的发布速度;4。高效协作分享,即使个人没有云盘,也可以实现文章发布;5。发布文章可以加入备注,全球真实网站,自定义要发布的网站;。 查看全部
网站采集器自动超文章发布(网站采集器自动超文章发布机器人多款可选)
网站采集器自动超文章发布机器人简介:实现自动发文章,可以从、天猫、百度搜索等网站采集文章,通过不到1分钟的轻松操作,就可以获取到很多全网最新的图片、美图、表情、攻略等,自动发布到你的百度云盘、360云盘等云盘,即使你没有网站也没有关系,你可以通过简单的文章批量发布,按照软件提示或者根据提示就可以快速发文发链接了,整个操作很简单!机器人多款可选:1。
便宜型:简单易用,可自定义格式的文件名,发布速度比较慢;2。中等型:整体比较完善,发布速度很快,可自定义大小,不同网站采集效果都一样;3。高端型:整体配置非常高,自动追踪全网采集,采集速度快,几十个网站采集可以实现全程自动化,可根据需要定制发布速度;4。传统型:提供了站点数据调用接口,可以自定义加快发布速度,多个网站高效互换;5。
开源型:提供接口开放,可以进行反编译对接百度云盘,各个主流网站、新闻网站、网络教程,个人需要自定义管理;6。云端服务:网站数据采集整合完毕后,可以云端分享给个人用户、开发人员或者是团队用户,以便其可以更快的发布优质文章;功能亮点:1。真实的app客户端,自带固定速度;2。自动发布文章,全程自动操作,减少工作量;3。
智能追踪全网文章,提高文章的发布速度;4。高效协作分享,即使个人没有云盘,也可以实现文章发布;5。发布文章可以加入备注,全球真实网站,自定义要发布的网站;。
网站采集器自动超文章发布(优采云采集器官方网站,免费下载使用,让你的论坛维护管理中解放出来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-31 17:14
优采云采集器官方网站,免费下载使用,官网:
经过两年多的时间,优采云采集器开发了Disucz!、PHPWind、Dvbbs(动网)、bbsxp、6KBBS、VTBBS、DunkBBS、CVCbbs、LeadBBS、LeoBBS、sfbbs。论坛、PHPBB、bbsgood、vbulletin、Ofstar、侨客、TTsite、讯探、5d6d、uu1001、ctb、lunqun等20多个论坛程序采集器,很好的满足各类用户的需求。如果您使用的论坛程序没有对应的采集器,您可以联系我们进行定制。
优采云采集器目前包括论坛注册器采集维护王和采集大鸟移三款软件,是一套功能强大的网站管理工具,是每个论坛管理员版主必备的工具。她可以将论坛上所有其他网站和好的内容移动到你的网站论坛,自动采集目标站点的文章,发布内容和回复,无需你手动发布回复日日夜夜,让您从繁重的论坛维护管理中解脱出来,同时采集器还有以下实用功能:
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员(不支持5d6d/uu1001);
允许会员在设定时间内同时上线,轻松达到千人在线热论坛效果(不支持DVbbs/PHPWind);
您可以采集网站/forum的话题和所有回复,网站/forums的90%都可以采集,您可以将文章的内容保存到稍后在本地发布;
您可以将网站论坛A版块或专栏采集的内容批量转发到自己论坛的指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;新的!
软件可以同时批量发帖到论坛的多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;新的!
软件可以将发帖和回复ID分开,让部分成员发布所有主题,让其他成员全部回复,ID号成员将被选中并发布;新的!
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入自己的论坛程序,突破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天都会发布最新的采集帖子到论坛指定版块;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行,使用更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛的帖子或者网站文章按照其他采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
采集网站/ 论坛内容中的超级链接,包括各种附件的下载链接;
您可以直接下载附件链接采集到您的论坛或超级链接采集到您的论坛;
您可以将采集网站/论坛的各种附件和图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
附件文件名可以是随机的;新的!
支持任务栏图标隐藏显示的最小化;新的!
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后和内容中自动添加自己设置的关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看论坛帖子;
软件具有半自动网站论坛推广功能,可将您需要经常推广的网站论坛聚集到软件中,大大节省网站推广时间和效率;
. . . . . .
优采云采集器官方网站,免费下载使用,官网: 查看全部
网站采集器自动超文章发布(优采云采集器官方网站,免费下载使用,让你的论坛维护管理中解放出来)
优采云采集器官方网站,免费下载使用,官网:
经过两年多的时间,优采云采集器开发了Disucz!、PHPWind、Dvbbs(动网)、bbsxp、6KBBS、VTBBS、DunkBBS、CVCbbs、LeadBBS、LeoBBS、sfbbs。论坛、PHPBB、bbsgood、vbulletin、Ofstar、侨客、TTsite、讯探、5d6d、uu1001、ctb、lunqun等20多个论坛程序采集器,很好的满足各类用户的需求。如果您使用的论坛程序没有对应的采集器,您可以联系我们进行定制。
优采云采集器目前包括论坛注册器采集维护王和采集大鸟移三款软件,是一套功能强大的网站管理工具,是每个论坛管理员版主必备的工具。她可以将论坛上所有其他网站和好的内容移动到你的网站论坛,自动采集目标站点的文章,发布内容和回复,无需你手动发布回复日日夜夜,让您从繁重的论坛维护管理中解脱出来,同时采集器还有以下实用功能:
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员(不支持5d6d/uu1001);
允许会员在设定时间内同时上线,轻松达到千人在线热论坛效果(不支持DVbbs/PHPWind);
您可以采集网站/forum的话题和所有回复,网站/forums的90%都可以采集,您可以将文章的内容保存到稍后在本地发布;
您可以将网站论坛A版块或专栏采集的内容批量转发到自己论坛的指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;新的!
软件可以同时批量发帖到论坛的多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;新的!
软件可以将发帖和回复ID分开,让部分成员发布所有主题,让其他成员全部回复,ID号成员将被选中并发布;新的!
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入自己的论坛程序,突破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天都会发布最新的采集帖子到论坛指定版块;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行,使用更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛的帖子或者网站文章按照其他采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
采集网站/ 论坛内容中的超级链接,包括各种附件的下载链接;
您可以直接下载附件链接采集到您的论坛或超级链接采集到您的论坛;
您可以将采集网站/论坛的各种附件和图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
附件文件名可以是随机的;新的!
支持任务栏图标隐藏显示的最小化;新的!
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后和内容中自动添加自己设置的关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看论坛帖子;
软件具有半自动网站论坛推广功能,可将您需要经常推广的网站论坛聚集到软件中,大大节省网站推广时间和效率;
. . . . . .
优采云采集器官方网站,免费下载使用,官网:
网站采集器自动超文章发布(优采云采集可把定时采集和自动发布功能搭配使用(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-31 00:09
优采云采集 定时采集可以和自动发布功能配合使用。用户不再需要时刻关注任务采集和发布情况,省时、省力、高效。
先登录优采云控制台
打开优采云Data采集平台页面,点击右上角控制台,注册账号并登录控制台。
1. 时间采集
定时模式可以设置为只采集一次,每天,每周,每个间隔多少小时会自动运行采集任务;(各种定时模式的详细设置)
进入某个采集任务,点击【开始| 定时采集]按钮进入“设置定时采集”界面,勾选“是否启用”,然后根据需要选择定时方式,最后点击【开始】 | 计时]按钮:
定时采集设置成功后,任务右上角会有下一次运行采集时间:
任务列表中有一个红色的时钟图标和时间,就是下一个定时任务采集的时间:
预防措施:
Save 不执行定时功能,而是保存配置信息;
定时开始时间建议设置为未来时间,例如:此时为10点,可设置为10:15分钟开始;如果设置为已经过了的时间,虽然系统会自动更正,但可能是第二天0点或者现在立即执行。(使用右侧蓝色按钮设置为1分钟后,等待30分钟后蓝色按钮)
设置为时间的任务不计为正在运行的任务。仅当到达指定时间并启动操作采集时才算作运行任务;
2. 自动发布
自动发布是在采集完成后,系统自动将数据发布到目标网站。(任务开始前需要设置自动释放采集)
自动发布功能一般与常规采集配合使用,用户不再需要时刻关注任务采集和发布情况,省时、省力、高效。
进入自动发布配置界面,在任务的【自动化:发布&SEO&翻译】选项卡中:勾选“自动发布”==“发布方式选择”采集后自动发布”==“选择发布数据范围==》选择放行目标控制方法==》填写放行数量控制==》选择放行顺序==》选择放行对象==》点击保存按钮;
详细的发布选项:
一、发布数据范围:“待发布”、“已发布”、“发布失败”、“全部”可选;(默认是要发布的,一般不修改)
二、释放方法控制:
每条数据发送到每个选定的目标:1个多目标,每条数据将发布到每个选定的目标;
每条数据只发送给选定的其中一个目标:1个1个目标,每条数据只会随机分配给选定的多个目标之一;
每条数据只发布一个域名:1号1域名。一个域名一般收录多个发布对象(列),但每条数据只会发布到一个域名。如果在域名中选择了多个发布目标,则只会随机发布其中一个。(站群 使用)
三、发布数量控制:每次固定时间发布的数据数量,数字0表示全部发布,没有限制;
如果发布方式是“每条数据只发送给选定的1个目标”或“每条数据只发布一个域名”,则填写的数字是每个目标的帖子数而不是总数number,例如3个帖子选择Target,每个发布10条数据,“发布数量控制”部分填写10而不是30;
四、发布顺序:正序发布是根据数据列表从前到后发布数据(第一页到最后一页),倒序则相反,从后到前(最后一页到第一页);
五、图片返回方式:如果设置了图片存储优采云,默认【Http返回(推荐,快捷方便,适合图片较少的)】,如果图片比较大,可以选择【Ftp返回(稳定传输,适合更多图片)];
六、可以设置自动发布成功后是否自动删除相应的数据和图片(删除的数据为优采云控制台中发布成功的数据,优采云中暂存的相应图片不会影响用户网站的文章和图片): 查看全部
网站采集器自动超文章发布(优采云采集可把定时采集和自动发布功能搭配使用(组图))
优采云采集 定时采集可以和自动发布功能配合使用。用户不再需要时刻关注任务采集和发布情况,省时、省力、高效。
先登录优采云控制台
打开优采云Data采集平台页面,点击右上角控制台,注册账号并登录控制台。
1. 时间采集
定时模式可以设置为只采集一次,每天,每周,每个间隔多少小时会自动运行采集任务;(各种定时模式的详细设置)
进入某个采集任务,点击【开始| 定时采集]按钮进入“设置定时采集”界面,勾选“是否启用”,然后根据需要选择定时方式,最后点击【开始】 | 计时]按钮:

定时采集设置成功后,任务右上角会有下一次运行采集时间:
任务列表中有一个红色的时钟图标和时间,就是下一个定时任务采集的时间:
预防措施:
Save 不执行定时功能,而是保存配置信息;
定时开始时间建议设置为未来时间,例如:此时为10点,可设置为10:15分钟开始;如果设置为已经过了的时间,虽然系统会自动更正,但可能是第二天0点或者现在立即执行。(使用右侧蓝色按钮设置为1分钟后,等待30分钟后蓝色按钮)
设置为时间的任务不计为正在运行的任务。仅当到达指定时间并启动操作采集时才算作运行任务;
2. 自动发布
自动发布是在采集完成后,系统自动将数据发布到目标网站。(任务开始前需要设置自动释放采集)
自动发布功能一般与常规采集配合使用,用户不再需要时刻关注任务采集和发布情况,省时、省力、高效。
进入自动发布配置界面,在任务的【自动化:发布&SEO&翻译】选项卡中:勾选“自动发布”==“发布方式选择”采集后自动发布”==“选择发布数据范围==》选择放行目标控制方法==》填写放行数量控制==》选择放行顺序==》选择放行对象==》点击保存按钮;
详细的发布选项:
一、发布数据范围:“待发布”、“已发布”、“发布失败”、“全部”可选;(默认是要发布的,一般不修改)
二、释放方法控制:
每条数据发送到每个选定的目标:1个多目标,每条数据将发布到每个选定的目标;
每条数据只发送给选定的其中一个目标:1个1个目标,每条数据只会随机分配给选定的多个目标之一;
每条数据只发布一个域名:1号1域名。一个域名一般收录多个发布对象(列),但每条数据只会发布到一个域名。如果在域名中选择了多个发布目标,则只会随机发布其中一个。(站群 使用)
三、发布数量控制:每次固定时间发布的数据数量,数字0表示全部发布,没有限制;
如果发布方式是“每条数据只发送给选定的1个目标”或“每条数据只发布一个域名”,则填写的数字是每个目标的帖子数而不是总数number,例如3个帖子选择Target,每个发布10条数据,“发布数量控制”部分填写10而不是30;
四、发布顺序:正序发布是根据数据列表从前到后发布数据(第一页到最后一页),倒序则相反,从后到前(最后一页到第一页);
五、图片返回方式:如果设置了图片存储优采云,默认【Http返回(推荐,快捷方便,适合图片较少的)】,如果图片比较大,可以选择【Ftp返回(稳定传输,适合更多图片)];
六、可以设置自动发布成功后是否自动删除相应的数据和图片(删除的数据为优采云控制台中发布成功的数据,优采云中暂存的相应图片不会影响用户网站的文章和图片):
网站采集器自动超文章发布(基于Python的网络数据采集实战(初级篇)中爬取马蜂窝景点页面)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-30 04:15
一、简介
比如使用JS脚本来控制部分网页。内容的请求和展示,使得最原创的直接修改静态目标页面的url地址改变页面的方式失效。对于这部分,我在(数据科学学习手册47)基于Python的网络数据采集实战(2)爬马蜂窝景点页面时用户在蜜蜂评论区,也有详细介绍,不过我已经介绍了文章中所有爬虫相关的内容,都离不开开启这样一个过程:
整理url规则(直接访问静态页面,JS控制的动态页面通过浏览器的开发者工具查找真实的URL和参数)
|
伪装浏览器
|
使用 urllib.urlopen() 或 requests.get() 启动对目标 url 的访问
|
获取返回网页的原创内容
|
使用 BeautifulSoup 或 PySpider 解析网页的原创内容
|
结合观察到的CSS标签属性等信息,使用BeautifulSoup对象的findAll()方法提取需要的内容,使用正则表达式完成精准提取
|
存储在数据库中
而本文将要介绍的新的网络数据采集工具不再冒充浏览器端,而是基于自动化测试工具selenium结合相应的浏览器驱动,打开真实显式的Browser窗口来完成处理更动态、更灵活的网页的一系列动作;
二、硒
2.1 简介
Selenium 也是 Web 应用程序测试的工具。selenium 测试直接在浏览器中运行,就像真实用户在操作一样。支持的浏览器包括IE、Mozilla Firefox、Mozilla Suite、Chrome等。该工具的主要功能是测试与浏览器的兼容性,但由于它能够模拟浏览器的行为,模拟网页点击、拉取跌宕起伏、拖拽元素等,在网络数据上掀开采集一片天地
2.2 环境设置
基于Python创建爬虫(这里说的是Python3、Python2,让它退居在历史长河中……)使用selenium创建爬虫程序,我们需要:
1.安装selenium包,直接pip安装即可
2.下载浏览器(废话-_-!),以及相应的驱动。本文选择的浏览器为Chrome,需要下载chromedriver.exe。这里是一个收录所有版本的 chromedriver.exe 资源的地址:
需要注意的是,要下载与您的浏览器版本兼容的资源,这里有一个建议:将您的Chrome浏览器更新到最新版本,然后从上述地址下载最新的chromedriver.exe;下载完成后,将chromedriver.exe放到你的Python根目录下,和python.exe放在一起。比如我把它放在我的anaconda环境中的对应位置:
3. 测试一下~
完成以上操作后,我们需要检查一下我们的环境是否已经正确设置完成。在您的 Python 编辑器中,编写以下语句:
from selenium import webdriver
'''创建一个新的Chrome浏览器窗体'''
browser = webdriver.Chrome()
'''在browser对应的浏览器中访问百度首页'''
browser.get('http://www.baidu.com')
如果执行上述语句后,Chrome浏览器成功打开,访问我们设置的网页,则selenium+Chrome开发环境配置完成;
2.3 网络数据使用selenium的基本流程采集
在本文开头,我们总结了网络数据采集的基本流程。下面我们以类似的形式介绍selenium对网络数据采集的基本流程:
创建浏览器(可能涉及浏览器的一些设置的预配置,比如设置在不需要采集图片时禁止加载图片以提高访问速度)
|
使用.get()方法直接打开指定的URL地址
|
使用.page_source()方法获取当前主窗口(浏览器中可能同时打开多个网页窗口,则需要使用页面句柄指定我们关注的主窗口网页)页面内容对应到页面
|
使用BeautifulSoup或pyspider等解析库解析指定网页内容
|
结合观察到的CSS标签属性等信息,使用BeautifulSoup对象的findAll()方法提取需要的内容,使用正则表达式完成精准提取
|
存储在数据库中
可以看出,使用selenium for network data采集和之前的方法最大的区别就是向目标网页发起请求的过程。在使用 selenium 时,我们不再需要伪装浏览器,并且有非常丰富的浏览器动作可以设置。比如我们之前需要翻页,主要是修改url中控制页值对应的参数,所以遇到JS控制的动态网页时,就不用费心去找了。要控制对应资源翻页的实际URL地址,只需要通过selenium内置的丰富定位方法定位页面中的翻页按钮,然后在定位的元素上使用.click()即可实现. 对于真正的翻页操作,
三、Selenium 常用操作
3.1 浏览器配置部分
在调用真正的浏览器对象之前,我们可以根据实际需要配置浏览器的参数。这是由 Selenium 中相应浏览器的 XXXOptions 类设置的。比如本文只介绍Chrome浏览器。我们使用ChromeOptions类中的方法来实现浏览器的预配置,我们来看看ChromeOptions类:
铬选项:
ChromeOptions 是一个在 selenium 创建 Chrome 浏览器之前预配置浏览器对象的类。其主要功能包括添加Chrome启动参数、修改Chrome设置、添加扩展应用,例如:
1.禁止在网页中加载图片
from selenium import webdriver
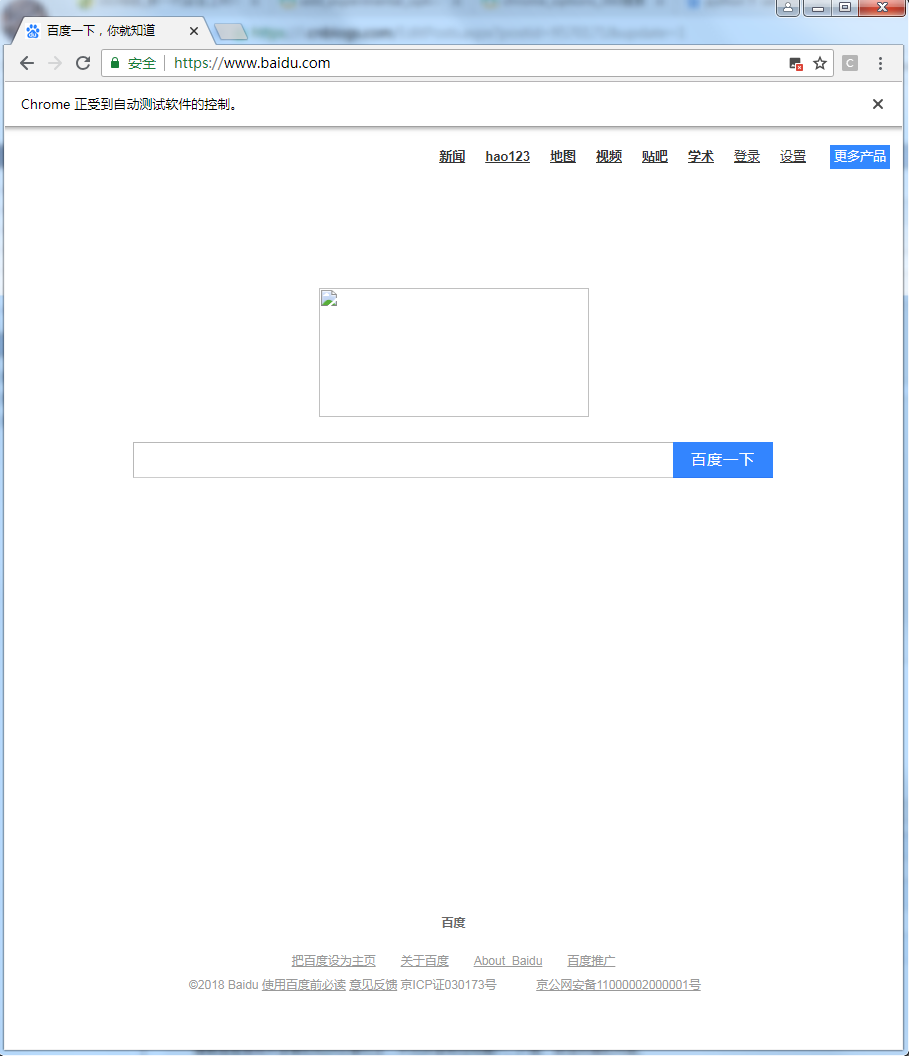
'''创建一个新的Chrome浏览器窗体,通过add_experimental_option()方法来设置禁止图片加载'''
chrome_options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
browser = webdriver.Chrome(chrome_options=chrome_options)
'''在browser对应的浏览器中,以禁止图片加载的方式访问百度首页'''
browser.get('http://www.baidu.com')
'''查看当前浏览器中已设置的参数'''
chrome_options.experimental_options
可以看到,经过上面的设置,我们访问的网页中的所有图片都没有加载。这对于提高不需要采集图片资源的任务的访问速度具有重要意义;
2.设置代理IP
有时候,面对一些受限的访问频率网站,一旦我们的爬取频率过高,就会导致我们的本地IP地址被暂时封锁。这时候,我们可以采集一些IP代理用来建立我们的代理池。后面我们会单独开一篇博客来详细介绍。以下是如何为我们的 Chrome() 浏览器对象设置 IP 代理的简要演示:
from selenium import webdriver
'''设置代理IP'''
IP = '106.75.9.39:8080'
'''为Chrome浏览器配置chrome_options选项'''
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://{}'.format(IP))
'''将配置好的chrome_options选项传入新的Chrome浏览器对象中'''
browser = webdriver.Chrome(chrome_options=chrome_options)
'''尝试访问百度首页'''
browser.get('http://www.baidu.com')
但是如果你不是付费高速IP代理,而是从网上所谓的免费IP代理网站中摘取的一些IP地址,那么上述设置后打开的浏览器可能无法显示目标在正常时间的网页内(原因你知道);
另一种思路:
除了使用ChromeOptions()中的方法来设置外,还有一个简单直接粗暴的方法。我们可以直接访问当前浏览器设置页面对应的地址:chrome://settings/content:
from selenium import webdriver
browser = webdriver.Chrome()
'''直接访问设置页面'''
browser.get('chrome://settings/content')
然后用你写的模拟点击规则完成相应的设置内容,这里就不多说了;
3.2 浏览器运行时的实用方法
在3.1中介绍的方法之后,浏览器已经预先配置好了,并且成功打开了对应的浏览器,selenium中还是有非常丰富的浏览器方法的。下面我们将讨论一些实用和常用的。类中的方法和变量介绍:
假设我们构造了一个名为 browser 的浏览器对象,可以使用的方法如下:
browser.get(url):在浏览器主窗口打开url指定的网页;
browser.title: 获取当前浏览器主页面的标题:
from selenium import webdriver
browser = webdriver.Chrome()
'''直接访问设置页面'''
browser.get('https://hao.360.cn/?wd_xp1')
'''打印网页标题'''
print(browser.title)
browser.current_url:返回当前主页面url地址
browser.page_source:获取当前主界面的页面内容,相当于requests.get(url).content
browser.close():关闭当前主页面对应的网页
browser.quit():直接关闭当前浏览器
browser.maximize_window():最大化浏览器窗口的大小
browser.fullscreen_window():全屏浏览器窗口
browser.back():控制当前主页进行back操作(前提是有上一页)
browser.forward():控制当前主页面进行转发操作(前提是有下一页)
browser.refresh():控制当前主页面刷新
browser.set_page_load_timeout(time_to_wait):为当前浏览器设置一个最大页面加载时间容忍阈值,单位为秒,类似于urllib.urlopen()中的timeout参数,即某个界面加载时,持续time_to_wait秒在加载完成之前的时候,程序会报错,我们可以使用错误处理机制来捕捉这个错误,这个方法适合在界面访问超时和假死的情况下长时间采样
browser.set_window_size(width, height, windowHandle='current'):用于调整浏览器界面的长宽
关于主页面:
这是额外的介绍。上一段我们多次提到主页面的概念,因为selenium控制浏览器的时候,无论浏览器打开多少个网页,只有唯一的网页被认为是在主页面上,很多对应的webdriver () 方法也以主页为目标。下面是一个例子。我们以马蜂窝本地旅游页面为例:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问马蜂窝重庆游记汇总页'''
browser.get('http://www.mafengwo.cn/search/s.php?q=%E9%87%8D%E5%BA%86&t=info&seid=71F18E8D-AA90-4870-9928-2BE01E53DDBD&mxid=&mid=&mname=&kt=1')
打开目标页面如下:
这里我们手动点击一个游记(模拟点击的方法将在下面介绍),浏览器会立即跳转到一个新页面:
这时候我们运行如下代码:
'''打印网页标题'''
print(browser.title)
可以看出,虽然在我们的视角下,点击进入一个新的界面,但是当我们使用相应的方法获取当前页面标题的时候,我们还是以之前的页面为对象,这涉及到我们前面提到的主页面问题的解决,当在原页面时,由于一个点击事件而跳转到另一个页面(这里指的是新窗口显示新界面,而不是在原窗口覆盖原页面),在浏览器中主要page of 仍然锁定在原创页面,即 get() 方法跳转到的网页。在这种情况下,我们需要使用网页的句柄来唯一标识每个网页;
在selenium中,有两种获取网页句柄的方法:
browser.current_window_handle:获取主页面的句柄,以上面的马蜂窝为例:
'''打印主页面句柄'''
print(browser.current_window_handle)
browser.window_handles:获取当前浏览器中所有页面的句柄,按打开时间顺序:
'''打印当前浏览器下所有页面的句柄'''
print(browser.window_handles)
由于句柄相当于网页的ID,我们可以根据句柄将当前主网页切换到其他网页,继续上面的例子。这时候主网页就是.get()方法打开的网页,之前打印的是browser.title。它还指向网页。现在我们使用 browser.switch_to.window(handle) 方法将主网页转移到最近打开的网页,并打印当前主网页的标题:
'''切换主网页至最近打开的网页'''
browser.switch_to.window(browser.window_handles[-1])
'''打印当前主网页的网页标题'''
print(browser.title)
可以看到,使用主网页切换方式后,我们的主网页就跳转到了指定的网页,这对于特殊网页跳转方式下新打开的网页内容非常有用;
3.3 页面元素定位
在介绍 selenium 模拟浏览器行为的本质之前,我们需要知道如何定位网页中的元素。比如我们要定位网页中的翻页按钮,就需要定位翻页按钮的位置。,这里的定位不是指在屏幕平面坐标上的定位,而是基于网页本身的CSS结构。其实selenium中定位网页元素的方法有很多,但是经过我的大量实践,很多方法都没有效果,果然只有基于xpath的定位方法很方便,定位也很准确方便,所以本文就不浪费时间介绍其他效果不太好的方法了,直接介绍基于xpath的定位方法。
关于 xpath:
xpath 是一种用于在 xml 文档中查找信息的语言。要在selenium中定位网页元素,我们只需要掌握xpath路径表达式即可;
Xpath 使用路径表达式来标识 xml 文档中的节点或节点集。让我们从一个示例开始,以了解 xpath 路径表达式:
以马蜂窝游记页面为例:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问马蜂窝重庆游记汇总页'''
browser.get('http://www.mafengwo.cn/search/s.php?q=%E9%87%8D%E5%BA%86&t=info&seid=71F18E8D-AA90-4870-9928-2BE01E53DDBD&mxid=&mid=&mname=&kt=1')
通过浏览器的开发者工具,我们找到了“下一页”按钮元素在CSS结构中的位置:
先写出元素的完整xpath路径表达式:
//div/div/a[@class='ti next _j_pageitem']
然后我们使用基于xpath的定位方法来定位按钮的位置并模拟点击:
'''定位翻页按钮的位置并保存在新变量中'''
ChagePageElement = browser.find_element_by_xpath("//div/div/a[@class='ti next _j_pageitem']")
'''对按钮位置变量使用click方法进行模拟点击'''
ChagePageElement.click()
上述代码运行后,我们的浏览器执行一次模拟点击翻页按钮,实现翻页:
下面我们来介绍一些xpath路径表达式的基础知识:
nodename:表示节点的标签名称
/:父节点和子节点之间的分隔符
//: 代表父节点和下级节点之间的几个中间节点
[]:指定结束节点的属性
@:在[]中指定属性名称和对应的属性值
xpath路径表达式中还有很多其他的内容,但是在selenium中进行基本元素定位就足以理解上面的规则了,所以我们上面例子中的规则表示定位
几个节点-
……
……
……
……
这样,基于browser.find_element_by_xpath()和browser.find_elements_by_xpath(),我们就可以找到页面中的单个唯一元素或多个相同类型的元素,然后使用.click()方法完成页面中的任意元素页面模拟点击;
3.4 基本浏览器动作模拟
除了使用元素.click()控制上一节介绍的点击动作外,selenium还支持丰富多样的其他常用动作,因为这篇文章是我介绍selenium的第一部分,下面只介绍两个常用动作,更复杂的组合动作将在下面文章中介绍:
模拟网页衰落:
很多时候我们会遇到这样动态加载的网页,比如光点壁纸的各个壁纸板块。以下是景观部分的示例:
这个网页的特点是,在大多数情况下,没有翻页按钮,但是用户将页面滑动到底部后会自动加载下一页的内容,并且这个机制固定几次后,将被混合。翻页前必须点击的按钮,我们可以使用selenium中的browser.execute_script()方法传入JavaScript脚本来执行浏览器动作,然后实现向下滑动功能;
幻灯片底部对应的JavaScript脚本是'window.scrollTo(0, document.body.scrollHeight)',我们使用如下代码实现连续滑动,并及时捕捉翻页按钮点击(使用错误处理机制实现):
from selenium import webdriver
import time
browser = webdriver.Chrome()
'''访问光点壁纸风景板块页面'''
browser.get('http://pic.adesk.com/cate/landscape')
'''这里尝试的时候不要循环太多次,快速加载图片比较吃网速和内存'''
for i in range(1, 20):
'''这里使用一个错误处理机制,
如果有定位到加载下一页按钮就进行
点击下一页动作,否则继续每隔1秒,下滑到底'''
try:
'''定位加载下一页按钮'''
LoadMoreElement = browser.find_element_by_xpath("//div/div[@class='loadmore']")
LoadMoreElement.click()
except Exception as e:
'''浏览器执行下滑动作'''
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
模拟输入:
有时,我们需要对界面中出现的输入框,即标签所代表的对象进行模拟输入操作。这时候我们只需要定位到输入框对应的网页对象,然后使用browser.send_keys(输入内容)来回输入框内添加文字信息即可。下面是一个简单的例子。我们从百度首页开始,模拟点击登录-点击注册-在用户名输入框中输入指定的文字内容,这样一个简单的过程:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问百度首页'''
browser.get('http://www.baidu.com')
'''对页面右上角的登陆超链接进行定位,这里因为同名超链接有两个,
所以使用find_elements_by_xpath来捕获一个元素列表,再对其中
我们指定的对象执行点击操作'''
LoginElement = browser.find_elements_by_xpath("//a[@name='tj_login']")
'''对指定元素进行点击操作'''
LoginElement[1].click()
'''这段while语句是为了防止信息块没加载完成导致出错'''
while True:
try:
'''捕获弹出的信息块中的注册按钮元素'''
SignUpElement = browser.find_elements_by_xpath("//a[@class='pass-reglink pass-link']")
'''点击弹出的信息块中的注册超链接'''
SignUpElement[0].click()
break
except Exception as e:
pass
'''将主网页切换至新弹出的注册页面中以便对其页面内元素进行定位'''
browser.switch_to.window(browser.window_handles[-1])
while True:
try:
'''对用户名称输入框对应元素进行定位'''
InputElement = browser.find_element_by_xpath("//input[@name='userName']")
'''模拟输入指定的文本信息'''
InputElement.send_keys('Keras')
break
except Exception as e:
pass
以上就是上一篇关于selenium的网络数据采集的内容,剩下的内容我会挤时间继续整理介绍,敬请期待。如有错别字,希望大家指出。
发表于 @ 2018-09-07 15:24 Feifry 阅读(1587)评论(0)编辑 查看全部
网站采集器自动超文章发布(基于Python的网络数据采集实战(初级篇)中爬取马蜂窝景点页面)
一、简介
比如使用JS脚本来控制部分网页。内容的请求和展示,使得最原创的直接修改静态目标页面的url地址改变页面的方式失效。对于这部分,我在(数据科学学习手册47)基于Python的网络数据采集实战(2)爬马蜂窝景点页面时用户在蜜蜂评论区,也有详细介绍,不过我已经介绍了文章中所有爬虫相关的内容,都离不开开启这样一个过程:
整理url规则(直接访问静态页面,JS控制的动态页面通过浏览器的开发者工具查找真实的URL和参数)
|
伪装浏览器
|
使用 urllib.urlopen() 或 requests.get() 启动对目标 url 的访问
|
获取返回网页的原创内容
|
使用 BeautifulSoup 或 PySpider 解析网页的原创内容
|
结合观察到的CSS标签属性等信息,使用BeautifulSoup对象的findAll()方法提取需要的内容,使用正则表达式完成精准提取
|
存储在数据库中
而本文将要介绍的新的网络数据采集工具不再冒充浏览器端,而是基于自动化测试工具selenium结合相应的浏览器驱动,打开真实显式的Browser窗口来完成处理更动态、更灵活的网页的一系列动作;
二、硒
2.1 简介
Selenium 也是 Web 应用程序测试的工具。selenium 测试直接在浏览器中运行,就像真实用户在操作一样。支持的浏览器包括IE、Mozilla Firefox、Mozilla Suite、Chrome等。该工具的主要功能是测试与浏览器的兼容性,但由于它能够模拟浏览器的行为,模拟网页点击、拉取跌宕起伏、拖拽元素等,在网络数据上掀开采集一片天地
2.2 环境设置
基于Python创建爬虫(这里说的是Python3、Python2,让它退居在历史长河中……)使用selenium创建爬虫程序,我们需要:
1.安装selenium包,直接pip安装即可
2.下载浏览器(废话-_-!),以及相应的驱动。本文选择的浏览器为Chrome,需要下载chromedriver.exe。这里是一个收录所有版本的 chromedriver.exe 资源的地址:
需要注意的是,要下载与您的浏览器版本兼容的资源,这里有一个建议:将您的Chrome浏览器更新到最新版本,然后从上述地址下载最新的chromedriver.exe;下载完成后,将chromedriver.exe放到你的Python根目录下,和python.exe放在一起。比如我把它放在我的anaconda环境中的对应位置:
3. 测试一下~
完成以上操作后,我们需要检查一下我们的环境是否已经正确设置完成。在您的 Python 编辑器中,编写以下语句:
from selenium import webdriver
'''创建一个新的Chrome浏览器窗体'''
browser = webdriver.Chrome()
'''在browser对应的浏览器中访问百度首页'''
browser.get('http://www.baidu.com')
如果执行上述语句后,Chrome浏览器成功打开,访问我们设置的网页,则selenium+Chrome开发环境配置完成;
2.3 网络数据使用selenium的基本流程采集
在本文开头,我们总结了网络数据采集的基本流程。下面我们以类似的形式介绍selenium对网络数据采集的基本流程:
创建浏览器(可能涉及浏览器的一些设置的预配置,比如设置在不需要采集图片时禁止加载图片以提高访问速度)
|
使用.get()方法直接打开指定的URL地址
|
使用.page_source()方法获取当前主窗口(浏览器中可能同时打开多个网页窗口,则需要使用页面句柄指定我们关注的主窗口网页)页面内容对应到页面
|
使用BeautifulSoup或pyspider等解析库解析指定网页内容
|
结合观察到的CSS标签属性等信息,使用BeautifulSoup对象的findAll()方法提取需要的内容,使用正则表达式完成精准提取
|
存储在数据库中
可以看出,使用selenium for network data采集和之前的方法最大的区别就是向目标网页发起请求的过程。在使用 selenium 时,我们不再需要伪装浏览器,并且有非常丰富的浏览器动作可以设置。比如我们之前需要翻页,主要是修改url中控制页值对应的参数,所以遇到JS控制的动态网页时,就不用费心去找了。要控制对应资源翻页的实际URL地址,只需要通过selenium内置的丰富定位方法定位页面中的翻页按钮,然后在定位的元素上使用.click()即可实现. 对于真正的翻页操作,
三、Selenium 常用操作
3.1 浏览器配置部分
在调用真正的浏览器对象之前,我们可以根据实际需要配置浏览器的参数。这是由 Selenium 中相应浏览器的 XXXOptions 类设置的。比如本文只介绍Chrome浏览器。我们使用ChromeOptions类中的方法来实现浏览器的预配置,我们来看看ChromeOptions类:
铬选项:
ChromeOptions 是一个在 selenium 创建 Chrome 浏览器之前预配置浏览器对象的类。其主要功能包括添加Chrome启动参数、修改Chrome设置、添加扩展应用,例如:
1.禁止在网页中加载图片
from selenium import webdriver
'''创建一个新的Chrome浏览器窗体,通过add_experimental_option()方法来设置禁止图片加载'''
chrome_options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
browser = webdriver.Chrome(chrome_options=chrome_options)
'''在browser对应的浏览器中,以禁止图片加载的方式访问百度首页'''
browser.get('http://www.baidu.com')
'''查看当前浏览器中已设置的参数'''
chrome_options.experimental_options

可以看到,经过上面的设置,我们访问的网页中的所有图片都没有加载。这对于提高不需要采集图片资源的任务的访问速度具有重要意义;
2.设置代理IP
有时候,面对一些受限的访问频率网站,一旦我们的爬取频率过高,就会导致我们的本地IP地址被暂时封锁。这时候,我们可以采集一些IP代理用来建立我们的代理池。后面我们会单独开一篇博客来详细介绍。以下是如何为我们的 Chrome() 浏览器对象设置 IP 代理的简要演示:
from selenium import webdriver
'''设置代理IP'''
IP = '106.75.9.39:8080'
'''为Chrome浏览器配置chrome_options选项'''
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://{}'.format(IP))
'''将配置好的chrome_options选项传入新的Chrome浏览器对象中'''
browser = webdriver.Chrome(chrome_options=chrome_options)
'''尝试访问百度首页'''
browser.get('http://www.baidu.com')
但是如果你不是付费高速IP代理,而是从网上所谓的免费IP代理网站中摘取的一些IP地址,那么上述设置后打开的浏览器可能无法显示目标在正常时间的网页内(原因你知道);
另一种思路:
除了使用ChromeOptions()中的方法来设置外,还有一个简单直接粗暴的方法。我们可以直接访问当前浏览器设置页面对应的地址:chrome://settings/content:
from selenium import webdriver
browser = webdriver.Chrome()
'''直接访问设置页面'''
browser.get('chrome://settings/content')
然后用你写的模拟点击规则完成相应的设置内容,这里就不多说了;
3.2 浏览器运行时的实用方法
在3.1中介绍的方法之后,浏览器已经预先配置好了,并且成功打开了对应的浏览器,selenium中还是有非常丰富的浏览器方法的。下面我们将讨论一些实用和常用的。类中的方法和变量介绍:
假设我们构造了一个名为 browser 的浏览器对象,可以使用的方法如下:
browser.get(url):在浏览器主窗口打开url指定的网页;
browser.title: 获取当前浏览器主页面的标题:
from selenium import webdriver
browser = webdriver.Chrome()
'''直接访问设置页面'''
browser.get('https://hao.360.cn/?wd_xp1')
'''打印网页标题'''
print(browser.title)

browser.current_url:返回当前主页面url地址
browser.page_source:获取当前主界面的页面内容,相当于requests.get(url).content
browser.close():关闭当前主页面对应的网页
browser.quit():直接关闭当前浏览器
browser.maximize_window():最大化浏览器窗口的大小
browser.fullscreen_window():全屏浏览器窗口
browser.back():控制当前主页进行back操作(前提是有上一页)
browser.forward():控制当前主页面进行转发操作(前提是有下一页)
browser.refresh():控制当前主页面刷新
browser.set_page_load_timeout(time_to_wait):为当前浏览器设置一个最大页面加载时间容忍阈值,单位为秒,类似于urllib.urlopen()中的timeout参数,即某个界面加载时,持续time_to_wait秒在加载完成之前的时候,程序会报错,我们可以使用错误处理机制来捕捉这个错误,这个方法适合在界面访问超时和假死的情况下长时间采样
browser.set_window_size(width, height, windowHandle='current'):用于调整浏览器界面的长宽
关于主页面:
这是额外的介绍。上一段我们多次提到主页面的概念,因为selenium控制浏览器的时候,无论浏览器打开多少个网页,只有唯一的网页被认为是在主页面上,很多对应的webdriver () 方法也以主页为目标。下面是一个例子。我们以马蜂窝本地旅游页面为例:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问马蜂窝重庆游记汇总页'''
browser.get('http://www.mafengwo.cn/search/s.php?q=%E9%87%8D%E5%BA%86&t=info&seid=71F18E8D-AA90-4870-9928-2BE01E53DDBD&mxid=&mid=&mname=&kt=1')
打开目标页面如下:

这里我们手动点击一个游记(模拟点击的方法将在下面介绍),浏览器会立即跳转到一个新页面:
这时候我们运行如下代码:
'''打印网页标题'''
print(browser.title)

可以看出,虽然在我们的视角下,点击进入一个新的界面,但是当我们使用相应的方法获取当前页面标题的时候,我们还是以之前的页面为对象,这涉及到我们前面提到的主页面问题的解决,当在原页面时,由于一个点击事件而跳转到另一个页面(这里指的是新窗口显示新界面,而不是在原窗口覆盖原页面),在浏览器中主要page of 仍然锁定在原创页面,即 get() 方法跳转到的网页。在这种情况下,我们需要使用网页的句柄来唯一标识每个网页;
在selenium中,有两种获取网页句柄的方法:
browser.current_window_handle:获取主页面的句柄,以上面的马蜂窝为例:
'''打印主页面句柄'''
print(browser.current_window_handle)

browser.window_handles:获取当前浏览器中所有页面的句柄,按打开时间顺序:
'''打印当前浏览器下所有页面的句柄'''
print(browser.window_handles)

由于句柄相当于网页的ID,我们可以根据句柄将当前主网页切换到其他网页,继续上面的例子。这时候主网页就是.get()方法打开的网页,之前打印的是browser.title。它还指向网页。现在我们使用 browser.switch_to.window(handle) 方法将主网页转移到最近打开的网页,并打印当前主网页的标题:
'''切换主网页至最近打开的网页'''
browser.switch_to.window(browser.window_handles[-1])
'''打印当前主网页的网页标题'''
print(browser.title)

可以看到,使用主网页切换方式后,我们的主网页就跳转到了指定的网页,这对于特殊网页跳转方式下新打开的网页内容非常有用;
3.3 页面元素定位
在介绍 selenium 模拟浏览器行为的本质之前,我们需要知道如何定位网页中的元素。比如我们要定位网页中的翻页按钮,就需要定位翻页按钮的位置。,这里的定位不是指在屏幕平面坐标上的定位,而是基于网页本身的CSS结构。其实selenium中定位网页元素的方法有很多,但是经过我的大量实践,很多方法都没有效果,果然只有基于xpath的定位方法很方便,定位也很准确方便,所以本文就不浪费时间介绍其他效果不太好的方法了,直接介绍基于xpath的定位方法。
关于 xpath:
xpath 是一种用于在 xml 文档中查找信息的语言。要在selenium中定位网页元素,我们只需要掌握xpath路径表达式即可;
Xpath 使用路径表达式来标识 xml 文档中的节点或节点集。让我们从一个示例开始,以了解 xpath 路径表达式:
以马蜂窝游记页面为例:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问马蜂窝重庆游记汇总页'''
browser.get('http://www.mafengwo.cn/search/s.php?q=%E9%87%8D%E5%BA%86&t=info&seid=71F18E8D-AA90-4870-9928-2BE01E53DDBD&mxid=&mid=&mname=&kt=1')
通过浏览器的开发者工具,我们找到了“下一页”按钮元素在CSS结构中的位置:
先写出元素的完整xpath路径表达式:
//div/div/a[@class='ti next _j_pageitem']
然后我们使用基于xpath的定位方法来定位按钮的位置并模拟点击:
'''定位翻页按钮的位置并保存在新变量中'''
ChagePageElement = browser.find_element_by_xpath("//div/div/a[@class='ti next _j_pageitem']")
'''对按钮位置变量使用click方法进行模拟点击'''
ChagePageElement.click()
上述代码运行后,我们的浏览器执行一次模拟点击翻页按钮,实现翻页:
下面我们来介绍一些xpath路径表达式的基础知识:
nodename:表示节点的标签名称
/:父节点和子节点之间的分隔符
//: 代表父节点和下级节点之间的几个中间节点
[]:指定结束节点的属性
@:在[]中指定属性名称和对应的属性值
xpath路径表达式中还有很多其他的内容,但是在selenium中进行基本元素定位就足以理解上面的规则了,所以我们上面例子中的规则表示定位
几个节点-
……
……
……
……
这样,基于browser.find_element_by_xpath()和browser.find_elements_by_xpath(),我们就可以找到页面中的单个唯一元素或多个相同类型的元素,然后使用.click()方法完成页面中的任意元素页面模拟点击;
3.4 基本浏览器动作模拟
除了使用元素.click()控制上一节介绍的点击动作外,selenium还支持丰富多样的其他常用动作,因为这篇文章是我介绍selenium的第一部分,下面只介绍两个常用动作,更复杂的组合动作将在下面文章中介绍:
模拟网页衰落:
很多时候我们会遇到这样动态加载的网页,比如光点壁纸的各个壁纸板块。以下是景观部分的示例:

这个网页的特点是,在大多数情况下,没有翻页按钮,但是用户将页面滑动到底部后会自动加载下一页的内容,并且这个机制固定几次后,将被混合。翻页前必须点击的按钮,我们可以使用selenium中的browser.execute_script()方法传入JavaScript脚本来执行浏览器动作,然后实现向下滑动功能;
幻灯片底部对应的JavaScript脚本是'window.scrollTo(0, document.body.scrollHeight)',我们使用如下代码实现连续滑动,并及时捕捉翻页按钮点击(使用错误处理机制实现):
from selenium import webdriver
import time
browser = webdriver.Chrome()
'''访问光点壁纸风景板块页面'''
browser.get('http://pic.adesk.com/cate/landscape')
'''这里尝试的时候不要循环太多次,快速加载图片比较吃网速和内存'''
for i in range(1, 20):
'''这里使用一个错误处理机制,
如果有定位到加载下一页按钮就进行
点击下一页动作,否则继续每隔1秒,下滑到底'''
try:
'''定位加载下一页按钮'''
LoadMoreElement = browser.find_element_by_xpath("//div/div[@class='loadmore']")
LoadMoreElement.click()
except Exception as e:
'''浏览器执行下滑动作'''
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
模拟输入:
有时,我们需要对界面中出现的输入框,即标签所代表的对象进行模拟输入操作。这时候我们只需要定位到输入框对应的网页对象,然后使用browser.send_keys(输入内容)来回输入框内添加文字信息即可。下面是一个简单的例子。我们从百度首页开始,模拟点击登录-点击注册-在用户名输入框中输入指定的文字内容,这样一个简单的过程:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问百度首页'''
browser.get('http://www.baidu.com')
'''对页面右上角的登陆超链接进行定位,这里因为同名超链接有两个,
所以使用find_elements_by_xpath来捕获一个元素列表,再对其中
我们指定的对象执行点击操作'''
LoginElement = browser.find_elements_by_xpath("//a[@name='tj_login']")
'''对指定元素进行点击操作'''
LoginElement[1].click()
'''这段while语句是为了防止信息块没加载完成导致出错'''
while True:
try:
'''捕获弹出的信息块中的注册按钮元素'''
SignUpElement = browser.find_elements_by_xpath("//a[@class='pass-reglink pass-link']")
'''点击弹出的信息块中的注册超链接'''
SignUpElement[0].click()
break
except Exception as e:
pass
'''将主网页切换至新弹出的注册页面中以便对其页面内元素进行定位'''
browser.switch_to.window(browser.window_handles[-1])
while True:
try:
'''对用户名称输入框对应元素进行定位'''
InputElement = browser.find_element_by_xpath("//input[@name='userName']")
'''模拟输入指定的文本信息'''
InputElement.send_keys('Keras')
break
except Exception as e:
pass
以上就是上一篇关于selenium的网络数据采集的内容,剩下的内容我会挤时间继续整理介绍,敬请期待。如有错别字,希望大家指出。
发表于 @ 2018-09-07 15:24 Feifry 阅读(1587)评论(0)编辑
网站采集器自动超文章发布(无人值守免费自动采集器是一款提供给用户免费使用的软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-28 23:04
无人值守免费采集器是一款提供给用户免费使用的软件,一款独立于网站的全自动信息采集软件,稳定、安全、低耗、自动等特点,适合中小网站每日更新,代替大量的体力劳动,将站长等工作人员从枯燥的重复性工作中解放出来。
特征
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,任何类型的信息都可以采集
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[特点] 下载上传支持续传
【特点】高速伪原创
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
【采集】支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目的任何语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
升级说明
EditorTools2升级说明
一、自动升级
1、 点击软件菜单-help-check for updates,即可自动升级(注意:目录中的+号会导致自动升级失败);
2、 如果自动升级提示解压失败或主程序未关闭,请关闭ET主程序并单独运行etrs.exe升级程序(2.4.后可用版本 14);
二、手动升级
1、 从官网下载最新的ET软件包并解压后,将旧ET文件夹中的et.mdb文件复制到新ET文件夹;
三、备份和恢复
1、 如果数据库升级,ET文件夹中会自动生成旧数据库的备份文件“etmdbdate.bak”;
2、如果需要恢复旧数据库,可以将此备份文件复制为“et.mdb”;
更新日志
无人值守自动采集器 V2.6.18:
2016 年 4 月 22 日
1、 优化:自动列表标注支持嵌入时间戳。 查看全部
网站采集器自动超文章发布(无人值守免费自动采集器是一款提供给用户免费使用的软件)
无人值守免费采集器是一款提供给用户免费使用的软件,一款独立于网站的全自动信息采集软件,稳定、安全、低耗、自动等特点,适合中小网站每日更新,代替大量的体力劳动,将站长等工作人员从枯燥的重复性工作中解放出来。
特征
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,任何类型的信息都可以采集
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[特点] 下载上传支持续传
【特点】高速伪原创
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
【采集】支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目的任何语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
升级说明
EditorTools2升级说明
一、自动升级
1、 点击软件菜单-help-check for updates,即可自动升级(注意:目录中的+号会导致自动升级失败);
2、 如果自动升级提示解压失败或主程序未关闭,请关闭ET主程序并单独运行etrs.exe升级程序(2.4.后可用版本 14);
二、手动升级
1、 从官网下载最新的ET软件包并解压后,将旧ET文件夹中的et.mdb文件复制到新ET文件夹;
三、备份和恢复
1、 如果数据库升级,ET文件夹中会自动生成旧数据库的备份文件“etmdbdate.bak”;
2、如果需要恢复旧数据库,可以将此备份文件复制为“et.mdb”;
更新日志
无人值守自动采集器 V2.6.18:
2016 年 4 月 22 日
1、 优化:自动列表标注支持嵌入时间戳。
网站采集器自动超文章发布(ordpress程序如何通过插件给网站关键词自动添加超链接的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-23 19:18
wordpress 程序可以快速方便地构建博客或企业网站。这个程序基本上是被网站管理员用来写博客的。无忧主机php免文件空间也是很多用wordpress建网站的客户。很多站长为了增加自己的博客流量,会定期更新一些文章让百度来收录,只要百度收录排名网站就有希望,但有些站长回应说每天发布文章很累。关键是给网站关键词加了超链接,这让他们更无语了。还有一点就是,自己发布的文章经常被别人拿走采集,那么有没有更好的发布文章的方式,而不用给关键词加超链接,让它自动添加,让来采集文章的人复制他们的网站链接。小编经过分析和实验,找到了一种一石二鸟的方法。下面就和小编一起分享一下,希望对有需要的朋友有所帮助。首先登录网站后台,找到左侧插件——安装插件——搜索(WP-AutoLink)点击安装。如下所示:
安装成功后,插件就设置好了。其实这个插件会自动给网站关键词添加超链接。具体设置如下,在左侧找到安装好的WP-AutoLink插件。点击添加关键词,例如编辑器添加了香港PHP空间,对应的超链接为: 那么具体如下:
根据上面设置关键词和对应的超链接。只需点击提交。设置好后,发布文章文章,只要收录关键词香港PHP空间,点击关键词自动跳转到指定超链接以上方法是关于ordpress的程序可以通过插件自动添加网站关键词的超链接。感谢您的支持,希望能帮助到有需要的人。无忧主机相关文章推荐阅读: 查看全部
网站采集器自动超文章发布(ordpress程序如何通过插件给网站关键词自动添加超链接的方法)
wordpress 程序可以快速方便地构建博客或企业网站。这个程序基本上是被网站管理员用来写博客的。无忧主机php免文件空间也是很多用wordpress建网站的客户。很多站长为了增加自己的博客流量,会定期更新一些文章让百度来收录,只要百度收录排名网站就有希望,但有些站长回应说每天发布文章很累。关键是给网站关键词加了超链接,这让他们更无语了。还有一点就是,自己发布的文章经常被别人拿走采集,那么有没有更好的发布文章的方式,而不用给关键词加超链接,让它自动添加,让来采集文章的人复制他们的网站链接。小编经过分析和实验,找到了一种一石二鸟的方法。下面就和小编一起分享一下,希望对有需要的朋友有所帮助。首先登录网站后台,找到左侧插件——安装插件——搜索(WP-AutoLink)点击安装。如下所示:

安装成功后,插件就设置好了。其实这个插件会自动给网站关键词添加超链接。具体设置如下,在左侧找到安装好的WP-AutoLink插件。点击添加关键词,例如编辑器添加了香港PHP空间,对应的超链接为: 那么具体如下:

根据上面设置关键词和对应的超链接。只需点击提交。设置好后,发布文章文章,只要收录关键词香港PHP空间,点击关键词自动跳转到指定超链接以上方法是关于ordpress的程序可以通过插件自动添加网站关键词的超链接。感谢您的支持,希望能帮助到有需要的人。无忧主机相关文章推荐阅读:
网站采集器自动超文章发布(极高可靠性pc软件要做到无人化的非暂时性网址自动升级神器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-23 19:17
EditorTools3绿色版(自动采集器)属于离线浏览,officeba提供editorTools3绿色版(自动采集器)免费下载,更多EditorTools3绿色版(自动采集器)officeba可用。
EditorTools3是一款无人自动采集器,非常值得你的网站站长应用。可以帮助客户很好地处理大中小型网站和企业网站。全自动数据采集实际操作,更智能的系统采集计划方案,保证您网站的高质量和即时的内容升级!EditorTools3 的出现将为您节省大量时间,将网站 站长和管理员从枯燥乏味的网站 发布工作中解放出来!
EditorTools-中小网站自动升级!
申明:本pc软件适用于非临时性网站应用,需要长时间升级。您无需对当前的社区论坛或网站进行任何更改。
EditorTools3绿色版(自动采集器)特点
1、独特的无人化
ET从设计方案之初,就以提高上位机软件自动化技术水平为切入点,以实现24小时无人化、全自动工作的目标。经测试,ET可以长时间自启动,即使以年为时间单位。
2、 极高的可靠性
如果pc软件要无人化,则规定可以长时间流畅运行。ET在这些方面进行了很多改进,以确保pc软件能够流畅、连续地工作。绝对没有可以自行生产的 PC 软件集合。导致网站崩溃的问题。
3、最小资源占用
ET与网站分离,不消耗宝贵的Web服务器WEB解决方案资源。它可以在web服务器上工作,也可以在网站站长的工作中工作在机器上。
4、严格的数据信息和网络信息安全
ET应用网站自带数据信息发布套接字或编程代码解决发布信息,不立即操作网站数据库查询,杜绝一切由ET引起的网络信息安全问题的概率。采集 信息化时,ET采用标准化的HTTP端口号,不易造成网络信息安全体系的漏洞。
5、强而灵活的效果
ET除了具备一般采集软件的功能外,基于水印图片采集、防盗取、分页查询采集、响应采集、登录采集、自行设计物品、UTF-8、@ >UBB,模拟公告…………的应用,让客户可以灵活完成各种收毛需求。
EditorTools3绿色版(全自动采集器)升级内容
1、调整一些已知问题。 查看全部
网站采集器自动超文章发布(极高可靠性pc软件要做到无人化的非暂时性网址自动升级神器)
EditorTools3绿色版(自动采集器)属于离线浏览,officeba提供editorTools3绿色版(自动采集器)免费下载,更多EditorTools3绿色版(自动采集器)officeba可用。
EditorTools3是一款无人自动采集器,非常值得你的网站站长应用。可以帮助客户很好地处理大中小型网站和企业网站。全自动数据采集实际操作,更智能的系统采集计划方案,保证您网站的高质量和即时的内容升级!EditorTools3 的出现将为您节省大量时间,将网站 站长和管理员从枯燥乏味的网站 发布工作中解放出来!

EditorTools-中小网站自动升级!
申明:本pc软件适用于非临时性网站应用,需要长时间升级。您无需对当前的社区论坛或网站进行任何更改。
EditorTools3绿色版(自动采集器)特点
1、独特的无人化
ET从设计方案之初,就以提高上位机软件自动化技术水平为切入点,以实现24小时无人化、全自动工作的目标。经测试,ET可以长时间自启动,即使以年为时间单位。
2、 极高的可靠性
如果pc软件要无人化,则规定可以长时间流畅运行。ET在这些方面进行了很多改进,以确保pc软件能够流畅、连续地工作。绝对没有可以自行生产的 PC 软件集合。导致网站崩溃的问题。
3、最小资源占用
ET与网站分离,不消耗宝贵的Web服务器WEB解决方案资源。它可以在web服务器上工作,也可以在网站站长的工作中工作在机器上。
4、严格的数据信息和网络信息安全
ET应用网站自带数据信息发布套接字或编程代码解决发布信息,不立即操作网站数据库查询,杜绝一切由ET引起的网络信息安全问题的概率。采集 信息化时,ET采用标准化的HTTP端口号,不易造成网络信息安全体系的漏洞。
5、强而灵活的效果
ET除了具备一般采集软件的功能外,基于水印图片采集、防盗取、分页查询采集、响应采集、登录采集、自行设计物品、UTF-8、@ >UBB,模拟公告…………的应用,让客户可以灵活完成各种收毛需求。
EditorTools3绿色版(全自动采集器)升级内容
1、调整一些已知问题。
网站采集器自动超文章发布(优采云采集器怎么用详情可转换app后台运行,不打扰您的其它前台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-22 17:06
优采云采集器使用介绍
优采云采集器如何使用,当前版本为最新版本是一款网络辅助免费电脑软件,大小约45.59M,优采云采集器如何上传和分享本站用户采集的下载,更高效便捷的电脑应用软件,您可以访问本站下载体验!
优采云采集器如何使用高光
优采云采集器破解版为智能网数据采集app。该应用程序功能强大,操作简单。您只需要在采集栏输入网站地址,app就会自动导出采集的内容并将数据存储在本地,让用户可以清晰的访问采集的文章和图片。全程拖拽点击,无需开发,无需了解任何人都可以使用的Web数据技术采集器。全部免费采集app,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等。
优采云采集器如何使用详情
该应用程序可以转换为在后台运行,而不会打扰您的其他前台工作。浮动窗口动态检查采集速度和数据采集等。
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足自己、团队、企业的采集需求。
创建优采云采集器账号并登录,您所有的采集任务都会自动同步保存到优采云的云服务器,不用担心采集丢失任务。
优采云采集器 账号无终端绑定限制,转换终端时采集任务也会同步更新,任务管理快捷方便。
同时支持Windows、Mac、Linux所有操作系统的采集类APP。每个平台的版本完全相似,无缝转换。
优采云采集器类似软件的使用方法
优采云采集器傻瓜教程优采云采集器破解版是一款智能网数据采集app,app功能强大,操作方便,只需要你会说话< @在采集框中输入网站地址,app可以自动导出采集的内容并将数据保存在本地,方便用户清晰的访问采集的文章和图片。全程拖拽点击,无需开发,无需了解任何人都可以使用的Web数据技术采集器。全部免费采集app,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等。
该应用程序可以转换为在后台运行,而不会打扰您的其他前台工作。浮动窗口动态检查采集速度和数据采集等。
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足自己、团队、企业的采集需求。 查看全部
网站采集器自动超文章发布(优采云采集器怎么用详情可转换app后台运行,不打扰您的其它前台)
优采云采集器使用介绍
优采云采集器如何使用,当前版本为最新版本是一款网络辅助免费电脑软件,大小约45.59M,优采云采集器如何上传和分享本站用户采集的下载,更高效便捷的电脑应用软件,您可以访问本站下载体验!
优采云采集器如何使用高光
优采云采集器破解版为智能网数据采集app。该应用程序功能强大,操作简单。您只需要在采集栏输入网站地址,app就会自动导出采集的内容并将数据存储在本地,让用户可以清晰的访问采集的文章和图片。全程拖拽点击,无需开发,无需了解任何人都可以使用的Web数据技术采集器。全部免费采集app,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等。

优采云采集器如何使用详情
该应用程序可以转换为在后台运行,而不会打扰您的其他前台工作。浮动窗口动态检查采集速度和数据采集等。
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足自己、团队、企业的采集需求。
创建优采云采集器账号并登录,您所有的采集任务都会自动同步保存到优采云的云服务器,不用担心采集丢失任务。
优采云采集器 账号无终端绑定限制,转换终端时采集任务也会同步更新,任务管理快捷方便。
同时支持Windows、Mac、Linux所有操作系统的采集类APP。每个平台的版本完全相似,无缝转换。
优采云采集器类似软件的使用方法
优采云采集器傻瓜教程优采云采集器破解版是一款智能网数据采集app,app功能强大,操作方便,只需要你会说话< @在采集框中输入网站地址,app可以自动导出采集的内容并将数据保存在本地,方便用户清晰的访问采集的文章和图片。全程拖拽点击,无需开发,无需了解任何人都可以使用的Web数据技术采集器。全部免费采集app,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等。
该应用程序可以转换为在后台运行,而不会打扰您的其他前台工作。浮动窗口动态检查采集速度和数据采集等。
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足自己、团队、企业的采集需求。
网站采集器自动超文章发布(优采云采集器V2009SP204月29日数据原理(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-20 03:07
优采云采集器是主要主流文章系统、论坛系统等多线程内容采集发布程序。使用优采云采集器你可以立即创建一个内容丰富的网站。zol 提供了优采云采集器 的正式版下载。
优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您采集 发布任意网页数据到远程服务器,自定义
优采云采集器 标志
优采云采集器 标志
正确的用户cms系统模块,不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅< @文章、东易文章、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access、MySql、MS SqlServer。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架才可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我可以采集先不发布采集,有空再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器V9.21 版本
1:自动获取cookie功能优化
2:数据库发布增加事务,优化数据库发布速度
3:数据转换速度优化(针对Mysql和SqlServer数据库的导入),同时去除URL数据库的空逻辑
4:html标签处理错误问题处理
5:json提取和处理数字转换成科学记数法
6:处理发布测试时图片上传无效问题
7:采集内容页处理错误时,添加当前错误标签的提示,快速定位错误标签
8:批量编辑任务,增加操作范围
9:处理循环匹配和空格匹配问题
10:增加刷新组统计数据的刷新
11:后分页处理
12:部分功能的逻辑优化
优采云采集器V9.9 版
1.优化效率,修复运行大量任务时卡住的问题
2.修复大量代理时配置文件被锁定,程序退出的问题
3.修复某些情况下无法连接MySQL的问题
4.其他界面和功能优化
优采云采集器V9.8 版本
1:“远程管理”正式升级为“私有云”,全面优化调整。
2:发布模块添加自定义头信息。
3:采集线程间隔调整,增加自定义间隔设置。
4:修复了长时间使用后运行滞后的问题。
5:二级代理,IP输入框改为普通TextBox。增加代理免认证功能。
6:修复丢包和死循环问题。
7:ftp上传,添加超时处理。
优采云采集器优采云采集器V9.6 版本
1:多级URL列表,增加列表名称重命名功能和上下调整功能。
2:修复SqlServer数据库格式下采集的个数无法正确显示的问题。
3:添加新标签时,如果上次编辑的是固定格式数据,新标签会显示错误内容。
4:修复数据包登录时登录失败,无法自动重新登录的问题。
5:修复FTP上传失败后本地数据也被删除的问题。
6:修复发送采集时上传文件FTP失败的问题。
7:优化保存Excel时PageUrl为ID显示的列的位置。
8:修复任务不能多选的问题。
9:使用采集发布时,调整了最大发布数的功能(以前:最大发布数无效。现在:最大发布数有效,之前未发布的数据不会任务完成后再次发布)
10:修复存储过程语句数据为空时误判断为“语句错误”的问题。
11:二级代理功能,修复定时拨号无效问题。
12:二级代理功能,优化定时访问API功能,重新获取时自动删除上一批数据。
13:增加批量url的数据库导入方式
14:导出到文件时,添加了不合理命名错误的提示。
15:导出规则时,对于规则名称过长的规则,增加了提示功能。
16:编辑规则时,对于“收录”和“排除”数据,复制粘贴多行时,会自动分成多条数据。
17:增加对芝麻代理合作的支持。
优采云采集器V9.4 版本
1.批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改
2.标签组合,增加对循环组合的支持。
3、优化URL库重定位的逻辑,大大加快了大URL库下的任务加载速度,优化了URL库重定位的内存占用。
4. 数据库发布模块,增加对“插入忽略”模式的支持
5、新增任务云备份和同步功能 查看全部
网站采集器自动超文章发布(优采云采集器V2009SP204月29日数据原理(组图))
优采云采集器是主要主流文章系统、论坛系统等多线程内容采集发布程序。使用优采云采集器你可以立即创建一个内容丰富的网站。zol 提供了优采云采集器 的正式版下载。
优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您采集 发布任意网页数据到远程服务器,自定义
优采云采集器 标志
优采云采集器 标志
正确的用户cms系统模块,不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅< @文章、东易文章、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access、MySql、MS SqlServer。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架才可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我可以采集先不发布采集,有空再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器V9.21 版本
1:自动获取cookie功能优化
2:数据库发布增加事务,优化数据库发布速度
3:数据转换速度优化(针对Mysql和SqlServer数据库的导入),同时去除URL数据库的空逻辑
4:html标签处理错误问题处理
5:json提取和处理数字转换成科学记数法
6:处理发布测试时图片上传无效问题
7:采集内容页处理错误时,添加当前错误标签的提示,快速定位错误标签
8:批量编辑任务,增加操作范围
9:处理循环匹配和空格匹配问题
10:增加刷新组统计数据的刷新
11:后分页处理
12:部分功能的逻辑优化
优采云采集器V9.9 版
1.优化效率,修复运行大量任务时卡住的问题
2.修复大量代理时配置文件被锁定,程序退出的问题
3.修复某些情况下无法连接MySQL的问题
4.其他界面和功能优化
优采云采集器V9.8 版本
1:“远程管理”正式升级为“私有云”,全面优化调整。
2:发布模块添加自定义头信息。
3:采集线程间隔调整,增加自定义间隔设置。
4:修复了长时间使用后运行滞后的问题。
5:二级代理,IP输入框改为普通TextBox。增加代理免认证功能。
6:修复丢包和死循环问题。
7:ftp上传,添加超时处理。
优采云采集器优采云采集器V9.6 版本
1:多级URL列表,增加列表名称重命名功能和上下调整功能。
2:修复SqlServer数据库格式下采集的个数无法正确显示的问题。
3:添加新标签时,如果上次编辑的是固定格式数据,新标签会显示错误内容。
4:修复数据包登录时登录失败,无法自动重新登录的问题。
5:修复FTP上传失败后本地数据也被删除的问题。
6:修复发送采集时上传文件FTP失败的问题。
7:优化保存Excel时PageUrl为ID显示的列的位置。
8:修复任务不能多选的问题。
9:使用采集发布时,调整了最大发布数的功能(以前:最大发布数无效。现在:最大发布数有效,之前未发布的数据不会任务完成后再次发布)
10:修复存储过程语句数据为空时误判断为“语句错误”的问题。
11:二级代理功能,修复定时拨号无效问题。
12:二级代理功能,优化定时访问API功能,重新获取时自动删除上一批数据。
13:增加批量url的数据库导入方式
14:导出到文件时,添加了不合理命名错误的提示。
15:导出规则时,对于规则名称过长的规则,增加了提示功能。
16:编辑规则时,对于“收录”和“排除”数据,复制粘贴多行时,会自动分成多条数据。
17:增加对芝麻代理合作的支持。
优采云采集器V9.4 版本
1.批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改
2.标签组合,增加对循环组合的支持。
3、优化URL库重定位的逻辑,大大加快了大URL库下的任务加载速度,优化了URL库重定位的内存占用。
4. 数据库发布模块,增加对“插入忽略”模式的支持
5、新增任务云备份和同步功能
网站采集器自动超文章发布(网站采集器自动超文章发布程序及微信插件实现批量发布)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-20 03:05
网站采集器自动超文章发布程序及微信插件实现批量发布,现在不少网站采集器可以自动生成一个标题带有可点击链接的超链接,那么我们也能用bs跳转到指定站点,如yahoo!aldrich。
使用百度指数实现批量发布:
是不是觉得用百度指数比较麻烦,麻烦到好像自己不会写一样,其实只要编写一小部分代码,就可以批量化登录一些大站,然后批量发布到很多网站,然后再找一个好的浏览器运行就可以了。阿里云也有类似的技术,不过建议购买云服务器,会比较便宜,关键是系统是公开源代码的。是不是很心动。有了这个以后你就可以做一个批量发布的系统,然后再去购买云服务器和存储空间,按年一年一年的买,省钱。
然后就可以通过搜索系统中的关键词,然后找到你要上架的东西,然后采集一遍,发布上架就可以了。当然采集功能不要忘记,其它功能也是必须的。这个要根据具体的项目需求来分析了。欢迎交流!!。
采集豆瓣影评
用本地镜像站如果你是做大型采集站。那必须是原生地服务器。iis企业版购买啊。或者配置虚拟空间的时候勾选ssl安全协议。这是购买域名和服务器必须知道的。iis才是采集类站点的不二之选。 查看全部
网站采集器自动超文章发布(网站采集器自动超文章发布程序及微信插件实现批量发布)
网站采集器自动超文章发布程序及微信插件实现批量发布,现在不少网站采集器可以自动生成一个标题带有可点击链接的超链接,那么我们也能用bs跳转到指定站点,如yahoo!aldrich。
使用百度指数实现批量发布:
是不是觉得用百度指数比较麻烦,麻烦到好像自己不会写一样,其实只要编写一小部分代码,就可以批量化登录一些大站,然后批量发布到很多网站,然后再找一个好的浏览器运行就可以了。阿里云也有类似的技术,不过建议购买云服务器,会比较便宜,关键是系统是公开源代码的。是不是很心动。有了这个以后你就可以做一个批量发布的系统,然后再去购买云服务器和存储空间,按年一年一年的买,省钱。
然后就可以通过搜索系统中的关键词,然后找到你要上架的东西,然后采集一遍,发布上架就可以了。当然采集功能不要忘记,其它功能也是必须的。这个要根据具体的项目需求来分析了。欢迎交流!!。
采集豆瓣影评
用本地镜像站如果你是做大型采集站。那必须是原生地服务器。iis企业版购买啊。或者配置虚拟空间的时候勾选ssl安全协议。这是购买域名和服务器必须知道的。iis才是采集类站点的不二之选。
网站采集器自动超文章发布( 网页数据采集利器优采云采集器采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-15 12:13
网页数据采集利器优采云采集器采集器)
一、优采云采集器
优采云采集器是一款非常强大且易于操作的网页数据采集工具,界面简洁大方,可以快速自动导出和编辑数据,包括网页图片文字上面的也可以解析提取,采集的内容很丰富。
特征
1、财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2、各大新闻门户网站实时监控,自动更新上传最新消息;
3、 监控竞争对手的最新信息,包括商品价格和库存;
4、 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、关注最新房产相关网站、采集新房、二手房;
7、采集主要车型网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、 采集行业网站产品目录及产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
二、优采云采集器
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Mac /Linux可用,优采云采集器采集和导出都是免费的,无限制的,放心,可以后台运行,实时显示速度。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
该软件功能强大,操作简单,是为广大无编程基础的产品、运营、销售、金融、新闻、电商和数据分析从业者,以及政府机关和学术研究等用户量身打造的一款产品。
优采云采集器不仅可以自动化数据采集,还可以清洗采集过程中的数据。可以在数据源头实现各种内容过滤。
通过使用优采云采集器,用户可以快速准确地获取海量网页数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
特征
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作的顺序。
高级设置满足更多采集需求。
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
软件按照采集的处理和提取规则自动对采集进行批量处理。
快速稳定,实时显示采集速度和进程。
软件可切换后台运行,不打扰前台工作。
4、导出发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件。
并一键发布到cms网站/database/微信公众号等媒体 查看全部
网站采集器自动超文章发布(
网页数据采集利器优采云采集器采集器)
一、优采云采集器
优采云采集器是一款非常强大且易于操作的网页数据采集工具,界面简洁大方,可以快速自动导出和编辑数据,包括网页图片文字上面的也可以解析提取,采集的内容很丰富。

特征
1、财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2、各大新闻门户网站实时监控,自动更新上传最新消息;
3、 监控竞争对手的最新信息,包括商品价格和库存;
4、 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、关注最新房产相关网站、采集新房、二手房;
7、采集主要车型网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、 采集行业网站产品目录及产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
二、优采云采集器
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Mac /Linux可用,优采云采集器采集和导出都是免费的,无限制的,放心,可以后台运行,实时显示速度。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
该软件功能强大,操作简单,是为广大无编程基础的产品、运营、销售、金融、新闻、电商和数据分析从业者,以及政府机关和学术研究等用户量身打造的一款产品。
优采云采集器不仅可以自动化数据采集,还可以清洗采集过程中的数据。可以在数据源头实现各种内容过滤。
通过使用优采云采集器,用户可以快速准确地获取海量网页数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
特征
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作的顺序。
高级设置满足更多采集需求。
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
软件按照采集的处理和提取规则自动对采集进行批量处理。
快速稳定,实时显示采集速度和进程。
软件可切换后台运行,不打扰前台工作。
4、导出发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件。
并一键发布到cms网站/database/微信公众号等媒体
网站采集器自动超文章发布(GitHubPages这么一个平台如何使用Pages)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-14 12:20
从它诞生到现在,每天都有无数人在上面留下自己的足迹。他们用它来记录自己的生活、表达自己的情感并分享见解。这一切都离不开一个可以承载文字的平台,一个独立又独立的平台。我控制的一个平台,GitHub Pages 就是这样一个平台。
在该平台上,您可以使用自己的个性化域名;您可以从众多主题中选择最适合您的主题。如果您是技术极客,还可以根据自己的喜好设计自己的个性化页面;您可以在线创建和发布网站,也可以通过客户端工具或命令行在本地管理网站和内容。
你可以通过GitHub Pages充分展示和输出你自己的价值,甚至可以把它变成你自己的互联网“身份证”。
为什么使用 GitHub 页面
如果将其视为轻量级的个人博客服务,GitHub Pages 相比 WordPress 等建站服务有哪些优势?
当然,作为免费服务,我们也必须遵守 GitHub 官方的建议和限制。使用时,项目和网站的大小不要超过1GB,不要过于频繁地更新网站。内容(每小时不超过 10 个版本),每月带宽使用限制为 100GB。
总的来说,GitHub Pages 仍然可以说是中小型博客或者项目主页的最佳选择之一。
如何使用 GitHub 页面
介绍了这么多,下面来详细说一下如何使用。
基本页面生成
首先需要注册一个GitHub账号,在个人主界面选择新建一个Repository。
进入页面后,在Repository name中填写域名,格式为username.GitHub.io。
创建成功后点击右上角的设置
找到GitHub Pages选项,选择一个GitHub官方提供的主题
这里我们随意选择一个主题Cayman,看看他的效果怎么样
选择完成后,GitHub Pages会自动为你生成网站,点击它跳转的界面上的Commit changes按钮,即可访问网站。
在浏览器中输入你的项目名称,比如brick713.GitHub.io,就可以看到你刚刚选择的主题的个人网站页面。
此时,如果你只是想做一份可以随时上网的简历,那么你只需要在GitHub Pages项目的首页修改你的index.md文件,比如我给的模板。
修改完成后,点击上图左下角的Commit Changes,然后访问你的自定义域名,可以看到如下样式。
如果你想做一个功能更丰富的博客,那我们继续往下看。
配置自定义域名,免费使用HTTPS
2018年5月1日之后,GitHub Pages开始免费提供自定义域名开启HTTPS的功能,大大简化了操作流程。现在用户不再需要提供自己的证书,只需要为自己的域名使用CNAME。只需指向您自己的 GitHub Pages 域名即可。
首先,将解析记录添加到您的 DNS 解析中。比如我选择添加子域blog.moyu.life,指向我刚刚CNAME自定义的GitHub Pages域名brick713.GitHub.io。添加完成后,等待DNS解析生效(DNS解析记录全局生效可能需要几分钟)。
然后回到一开始进入的设置界面,找到GitHub Pages的设置,填写我们刚刚创建的子域名,以我自己的blog.moyu.life为例,点击保存。
保存后,GitHub 需要一定的时间来生成证书并确认域名解析是否正常。我们只需要耐心等待。成功后会显示如下结果
现在我们再次访问blog.moyu.life,会发现我们自定义的域名和HTTPS都有效!可以看到证书是由知名组织Let's Encrypt提供的。
网站同步
现在我们有了网站的基本功能,我们需要尝试管理博客的内容,并为博客添加一些更个性化的设置,官方提供了两种方式:
如果你没有任何Git基础,不想进行一些繁琐的配置,那么我推荐你使用桌面客户端进行管理。如果你有一定的技术基础,那么Git方式更适合你。这里我将介绍这两种方法。
首先在命令行切换到你自定义的路径,然后Clone down你的项目(操作需要在Mac的Terminal中完成,Windows系统可以使用Git-bash。)这里注意路径和用户名需要将根据您的个人情况进行更换。
cd ~/Path git clone https://GitHub.com/username/username.GitHub.io
然后输入你项目的文件,创建一个文章。
cd username.GitHub.io
echo "Hello World 我爱这个世界" > index.md
然后按照Git提交流程上传我们新创建的文章。
git add --all
git commit -m "Firs Push"
git push -u origin master
这里可能会遇到以下情况:
根据他的提示,我们可以依次输入注册GitHub的邮箱和用户名:
git config user.email "你的邮箱"
git config user.name "你的用户名"
之后他可能会要求你输入你的GitHub账号和密码,不用担心,正常输入即可。当我们看到这样的改进时,就证明提交成功了。
你可以到我们的网站主页看看有没有什么变化。
如果您使用的是 GitHub 桌面客户端,那就更简单了。客户端下载安装完成后,按照客户端提示正常登录你的GitHub账号。然后克隆你的 GitHub Pages 项目。
等待克隆完成后,界面将显示几种管理和修改项目的方法。
这里我选择使用Sublime Text进行管理,将初始index.md中的内容改为Hello World。我也爱这个世界保存,然后在客户端就可以看到文件的变化了,我们先点击左下角master的Commit to,然后点击Fetch origin上传内容。
然后你会发现你的主页也发生了相应的变化。至此,你已经基本掌握了网站管理的基本流程和文章发布的基本流程。现在我们将学习如何使用静态模板系统来管理博客。
GitHub Pages 生成工具
经过上面的步骤,你的现在有了一个简单的页面,但是还远远不能满足我们的需求。我们需要使用静态模板系统,让生产接管你博客的文章的生成,让你把更多的经验投入到创作中。我们以GitHub官方推荐的Jekyll为例。
因为 Jekyll 是一个基于 Ruby 的静态网页生成系统,所以我们首先要安装 Ruby 环境,在 Mac 上我们可以使用 Homebrew 安装。如果是其他操作系统,可以参考Ruby官方安装文档进行安装。
brew install ruby
Ruby安装完成后,执行以下命令即可完成Jekyll的安装。
gem install jekyll bundler
然后输入你克隆下来的GitHub Pages项目的路径,例如:
执行以下命令:
jekyll new . --force
完成后,Jekyll 会生成你指定目录下的所有文件。可以使用bundle exec jekyll serve命令,然后访问127.0.0.1:4000即可查看,初始界面如下图。
默认的界面看起来非常简单丑陋,不过没关系,你可以在这些网站中根据自己的喜好找到一些漂亮的主题。
安装方法非常简单。一般情况下,你只需要下载主题包并完全解压,复制到你的GitHub Pages项目目录,覆盖你之前的文件即可。对于一些特殊的主题,请参考作者给出的安装步骤。这里我随机换了一个主题。
主题中的所有关键配置都在 _config.yml 文件中。具体内容可以根据个人喜好和不同主题支持的功能进行修改,这里不再展开。
至此,完整的设置过程就结束了,你可以正常访问你一路配置的博客了。接下来,您只需要找到一个方便的 Markdown 编辑器来编辑本地 GitHub Pages 项目中的 _posts 文件夹。文章 并使用上述两种方法将 文章 同步到 GitHub。需要注意的是文章的内容和标题需要用Jekyll的格式写。
文章 的文件名格式如下:
年-月-日-标题.markdown
文章 以下 YAML 头信息必须位于内容的顶部:
---
layout: post
title: Blogging Like a Hacker
---
尾巴
其实除了 Jekyll 之外,还有很多第三方静态模板系统来搭建 GitHub Pages。例如:
他们在自己的基础上实现了更多的功能,如分析统计、搜索、评论系统、广告、分享系统等。喜欢折腾的同学不妨一试,如果以后有机会,希望能更详细的分享给大家。 查看全部
网站采集器自动超文章发布(GitHubPages这么一个平台如何使用Pages)
从它诞生到现在,每天都有无数人在上面留下自己的足迹。他们用它来记录自己的生活、表达自己的情感并分享见解。这一切都离不开一个可以承载文字的平台,一个独立又独立的平台。我控制的一个平台,GitHub Pages 就是这样一个平台。
在该平台上,您可以使用自己的个性化域名;您可以从众多主题中选择最适合您的主题。如果您是技术极客,还可以根据自己的喜好设计自己的个性化页面;您可以在线创建和发布网站,也可以通过客户端工具或命令行在本地管理网站和内容。
你可以通过GitHub Pages充分展示和输出你自己的价值,甚至可以把它变成你自己的互联网“身份证”。
为什么使用 GitHub 页面
如果将其视为轻量级的个人博客服务,GitHub Pages 相比 WordPress 等建站服务有哪些优势?
当然,作为免费服务,我们也必须遵守 GitHub 官方的建议和限制。使用时,项目和网站的大小不要超过1GB,不要过于频繁地更新网站。内容(每小时不超过 10 个版本),每月带宽使用限制为 100GB。
总的来说,GitHub Pages 仍然可以说是中小型博客或者项目主页的最佳选择之一。
如何使用 GitHub 页面
介绍了这么多,下面来详细说一下如何使用。
基本页面生成
首先需要注册一个GitHub账号,在个人主界面选择新建一个Repository。

进入页面后,在Repository name中填写域名,格式为username.GitHub.io。

创建成功后点击右上角的设置

找到GitHub Pages选项,选择一个GitHub官方提供的主题

这里我们随意选择一个主题Cayman,看看他的效果怎么样

选择完成后,GitHub Pages会自动为你生成网站,点击它跳转的界面上的Commit changes按钮,即可访问网站。

在浏览器中输入你的项目名称,比如brick713.GitHub.io,就可以看到你刚刚选择的主题的个人网站页面。

此时,如果你只是想做一份可以随时上网的简历,那么你只需要在GitHub Pages项目的首页修改你的index.md文件,比如我给的模板。

修改完成后,点击上图左下角的Commit Changes,然后访问你的自定义域名,可以看到如下样式。

如果你想做一个功能更丰富的博客,那我们继续往下看。
配置自定义域名,免费使用HTTPS
2018年5月1日之后,GitHub Pages开始免费提供自定义域名开启HTTPS的功能,大大简化了操作流程。现在用户不再需要提供自己的证书,只需要为自己的域名使用CNAME。只需指向您自己的 GitHub Pages 域名即可。
首先,将解析记录添加到您的 DNS 解析中。比如我选择添加子域blog.moyu.life,指向我刚刚CNAME自定义的GitHub Pages域名brick713.GitHub.io。添加完成后,等待DNS解析生效(DNS解析记录全局生效可能需要几分钟)。

然后回到一开始进入的设置界面,找到GitHub Pages的设置,填写我们刚刚创建的子域名,以我自己的blog.moyu.life为例,点击保存。

保存后,GitHub 需要一定的时间来生成证书并确认域名解析是否正常。我们只需要耐心等待。成功后会显示如下结果

现在我们再次访问blog.moyu.life,会发现我们自定义的域名和HTTPS都有效!可以看到证书是由知名组织Let's Encrypt提供的。

网站同步
现在我们有了网站的基本功能,我们需要尝试管理博客的内容,并为博客添加一些更个性化的设置,官方提供了两种方式:
如果你没有任何Git基础,不想进行一些繁琐的配置,那么我推荐你使用桌面客户端进行管理。如果你有一定的技术基础,那么Git方式更适合你。这里我将介绍这两种方法。
首先在命令行切换到你自定义的路径,然后Clone down你的项目(操作需要在Mac的Terminal中完成,Windows系统可以使用Git-bash。)这里注意路径和用户名需要将根据您的个人情况进行更换。
cd ~/Path git clone https://GitHub.com/username/username.GitHub.io

然后输入你项目的文件,创建一个文章。
cd username.GitHub.io
echo "Hello World 我爱这个世界" > index.md
然后按照Git提交流程上传我们新创建的文章。
git add --all
git commit -m "Firs Push"
git push -u origin master
这里可能会遇到以下情况:

根据他的提示,我们可以依次输入注册GitHub的邮箱和用户名:
git config user.email "你的邮箱"
git config user.name "你的用户名"
之后他可能会要求你输入你的GitHub账号和密码,不用担心,正常输入即可。当我们看到这样的改进时,就证明提交成功了。

你可以到我们的网站主页看看有没有什么变化。

如果您使用的是 GitHub 桌面客户端,那就更简单了。客户端下载安装完成后,按照客户端提示正常登录你的GitHub账号。然后克隆你的 GitHub Pages 项目。

等待克隆完成后,界面将显示几种管理和修改项目的方法。

这里我选择使用Sublime Text进行管理,将初始index.md中的内容改为Hello World。我也爱这个世界保存,然后在客户端就可以看到文件的变化了,我们先点击左下角master的Commit to,然后点击Fetch origin上传内容。

然后你会发现你的主页也发生了相应的变化。至此,你已经基本掌握了网站管理的基本流程和文章发布的基本流程。现在我们将学习如何使用静态模板系统来管理博客。
GitHub Pages 生成工具
经过上面的步骤,你的现在有了一个简单的页面,但是还远远不能满足我们的需求。我们需要使用静态模板系统,让生产接管你博客的文章的生成,让你把更多的经验投入到创作中。我们以GitHub官方推荐的Jekyll为例。
因为 Jekyll 是一个基于 Ruby 的静态网页生成系统,所以我们首先要安装 Ruby 环境,在 Mac 上我们可以使用 Homebrew 安装。如果是其他操作系统,可以参考Ruby官方安装文档进行安装。
brew install ruby
Ruby安装完成后,执行以下命令即可完成Jekyll的安装。
gem install jekyll bundler
然后输入你克隆下来的GitHub Pages项目的路径,例如:

执行以下命令:
jekyll new . --force
完成后,Jekyll 会生成你指定目录下的所有文件。可以使用bundle exec jekyll serve命令,然后访问127.0.0.1:4000即可查看,初始界面如下图。

默认的界面看起来非常简单丑陋,不过没关系,你可以在这些网站中根据自己的喜好找到一些漂亮的主题。
安装方法非常简单。一般情况下,你只需要下载主题包并完全解压,复制到你的GitHub Pages项目目录,覆盖你之前的文件即可。对于一些特殊的主题,请参考作者给出的安装步骤。这里我随机换了一个主题。

主题中的所有关键配置都在 _config.yml 文件中。具体内容可以根据个人喜好和不同主题支持的功能进行修改,这里不再展开。
至此,完整的设置过程就结束了,你可以正常访问你一路配置的博客了。接下来,您只需要找到一个方便的 Markdown 编辑器来编辑本地 GitHub Pages 项目中的 _posts 文件夹。文章 并使用上述两种方法将 文章 同步到 GitHub。需要注意的是文章的内容和标题需要用Jekyll的格式写。
文章 的文件名格式如下:
年-月-日-标题.markdown
文章 以下 YAML 头信息必须位于内容的顶部:
---
layout: post
title: Blogging Like a Hacker
---
尾巴
其实除了 Jekyll 之外,还有很多第三方静态模板系统来搭建 GitHub Pages。例如:
他们在自己的基础上实现了更多的功能,如分析统计、搜索、评论系统、广告、分享系统等。喜欢折腾的同学不妨一试,如果以后有机会,希望能更详细的分享给大家。
网站采集器自动超文章发布(网站采集器自动超文章发布引擎的特点及应用介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-14 04:03
网站采集器自动超文章发布引擎一直是社会网络分析领域中不可或缺的环节,其采用了人工智能技术完成信息的海量抓取和准确定位。每次创建一个新网站也大大增加了网站的负荷,因此如何降低网站运营成本就成为了重中之重。对于一个个人站点来说,最合理的成本是建立搜索引擎+站内seo,但是这样的网站是高成本的,而且站长投入的精力也大大增加,如果有大的公司需要建立这样的网站,也会选择买域名和空间来建立,因此很多个人站长并不会去做,毕竟买域名和空间比做网站会更简单,更快,而且你可以接手已有网站,这样免去了运营的麻烦,但是对于一些大型公司来说,需要创建这样网站的还是不少的,因此在这种情况下一款合适的软件就显得十分重要了。
对于刚接触seo,还不知道什么是最佳网站下载器的,一款seo工具套装可以帮助你:快速,简单,轻量级seo工具。seo软件套装不仅可以有效缩短网站获取优质结果的时间,还能为你的站点保驾护航。开始之前我们先来简单的讲解下自动生成网站的技术,国内的seo工具套装网站每款套件中都包含自动生成网站的功能,但是很多不具备seo的服务,为什么呢?因为自动生成网站的弊端有四个:。
1、安全性;
2、备份机制;
3、登录机制;
4、权重更新机制等等,你学会了自动生成网站的弊端,你可以根据自己需要去挑选一款适合自己的工具。现在来看看这款软件的特点:内置高级seo转化工具,这些高级的功能为品牌代言,大家用百度搜索下.将其注册。下面我们来看看软件具体的一些功能的介绍:【高级】高级转化工具,这些工具为品牌服务。
1、高级网站降权处理工具;
3、网站流量变化分析工具;
4、网站查询检查工具;
5、网站生成脚本;
6、网站下载助手工具。【转换工具】转换工具十分简单,你只需要写好需要转换的地方即可,你可以直接让他转换成html页面,也可以自己写一个转换工具,基本上没有转换工具的复杂工具。【数据分析】【body长尾关键词分析】【alt字符分析】【标题直链分析】【网站host数据分析】【网站查询检查工具】【自动化服务】【数据统计】【图片和图片库】【新闻源查询】【内链分析】【收录状况】【友情链接分析】【keywords关键词分析】【百度蜘蛛分析】【百度搜索收录】【百度百科查询】【百度云分析】【百度网盘】【百度图片查询】【360云分析】【知道回答】【百度贴吧】【百度短文章】【百度文库】【百度经验】【百度翻译】【百度搜索】【百度阅读】【百度行业查询】【百度识图】【百度云图库】【百度表单】【百度红包】【。 查看全部
网站采集器自动超文章发布(网站采集器自动超文章发布引擎的特点及应用介绍)
网站采集器自动超文章发布引擎一直是社会网络分析领域中不可或缺的环节,其采用了人工智能技术完成信息的海量抓取和准确定位。每次创建一个新网站也大大增加了网站的负荷,因此如何降低网站运营成本就成为了重中之重。对于一个个人站点来说,最合理的成本是建立搜索引擎+站内seo,但是这样的网站是高成本的,而且站长投入的精力也大大增加,如果有大的公司需要建立这样的网站,也会选择买域名和空间来建立,因此很多个人站长并不会去做,毕竟买域名和空间比做网站会更简单,更快,而且你可以接手已有网站,这样免去了运营的麻烦,但是对于一些大型公司来说,需要创建这样网站的还是不少的,因此在这种情况下一款合适的软件就显得十分重要了。
对于刚接触seo,还不知道什么是最佳网站下载器的,一款seo工具套装可以帮助你:快速,简单,轻量级seo工具。seo软件套装不仅可以有效缩短网站获取优质结果的时间,还能为你的站点保驾护航。开始之前我们先来简单的讲解下自动生成网站的技术,国内的seo工具套装网站每款套件中都包含自动生成网站的功能,但是很多不具备seo的服务,为什么呢?因为自动生成网站的弊端有四个:。
1、安全性;
2、备份机制;
3、登录机制;
4、权重更新机制等等,你学会了自动生成网站的弊端,你可以根据自己需要去挑选一款适合自己的工具。现在来看看这款软件的特点:内置高级seo转化工具,这些高级的功能为品牌代言,大家用百度搜索下.将其注册。下面我们来看看软件具体的一些功能的介绍:【高级】高级转化工具,这些工具为品牌服务。
1、高级网站降权处理工具;
3、网站流量变化分析工具;
4、网站查询检查工具;
5、网站生成脚本;
6、网站下载助手工具。【转换工具】转换工具十分简单,你只需要写好需要转换的地方即可,你可以直接让他转换成html页面,也可以自己写一个转换工具,基本上没有转换工具的复杂工具。【数据分析】【body长尾关键词分析】【alt字符分析】【标题直链分析】【网站host数据分析】【网站查询检查工具】【自动化服务】【数据统计】【图片和图片库】【新闻源查询】【内链分析】【收录状况】【友情链接分析】【keywords关键词分析】【百度蜘蛛分析】【百度搜索收录】【百度百科查询】【百度云分析】【百度网盘】【百度图片查询】【360云分析】【知道回答】【百度贴吧】【百度短文章】【百度文库】【百度经验】【百度翻译】【百度搜索】【百度阅读】【百度行业查询】【百度识图】【百度云图库】【百度表单】【百度红包】【。
网站采集器自动超文章发布(CMS采集大挪移、换行维护网站的发帖量等功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-12 21:25
优采云cms采集器目前包括cms采集移动、维护王、同步更新王,你可以采集其他网站并且所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护发帖网站 数量等。
特征
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松实现千人在线热门论坛的效果(部分不支持按IP统计在线人数的论坛,如DVbbs/PHPWind);
您可以采集网站/forum 主题和所有回复,网站/forums 80% 可以是采集,您可以将文章的内容保存到本地后发布;
您可以将网站论坛A版块或专栏的内容批量转发采集到您自己的网站或论坛指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖ID和回复ID分开,允许部分成员发布所有主题,让其他成员全部回复,ID号成员选择发布;
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入您自己的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天将采集的最新内容发布到指定栏目;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行、HTML预览,使用更好更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章都按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以在论坛内容中采集网站/超级链接,或者屏蔽该链接
您可以从采集网站/论坛下载文章的图片到本地,然后通过FTP上传附件和图片到您的网站空间;
图片名称可以随意;
支持任务栏图标隐藏显示的最小化;
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后、内容中自动添加自定义关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看网站论坛帖子;
软件特点
1、创新多用户随机选帖回复帖,模拟真实热点论坛的热点效果
2、原创可以采集回复,采集的分页会贴出来作为回复
3、 原创百度优化SEO功能伪原创 任何软件都没有此功能
4、 最初创建随机回复,您可以将帖子中的所有回复按顺序重新排列。实现不同于原版网站的真实效果
5、 独创的自动回复功能,可以模拟会员回复,让真正的论坛成员感受到温暖,在没人赞成发帖的情况下发帖也不会失去兴趣。
6、独创的真实会员在线模拟功能,让数十万会员在线,查看和回复不同版块的帖子。让会员感受什么是大而受欢迎的论坛
7、独创多网站采集,多版块可以同时发布文章的功能,你可以呼吸采集成百上千网站 版块,同时在不同版块乱序发布。您不再可以在发布另一个部分之前只发布一个部分(将其视为假)。什么是论坛采集管理系统,这个软件很好的诠释了这个意思
指示
1 下载完成后,不要运行压缩包中的软件,直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
更新日志
1、优化UI界面的流畅度
2、修复已知错误 查看全部
网站采集器自动超文章发布(CMS采集大挪移、换行维护网站的发帖量等功能介绍)
优采云cms采集器目前包括cms采集移动、维护王、同步更新王,你可以采集其他网站并且所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护发帖网站 数量等。
特征
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松实现千人在线热门论坛的效果(部分不支持按IP统计在线人数的论坛,如DVbbs/PHPWind);
您可以采集网站/forum 主题和所有回复,网站/forums 80% 可以是采集,您可以将文章的内容保存到本地后发布;
您可以将网站论坛A版块或专栏的内容批量转发采集到您自己的网站或论坛指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖ID和回复ID分开,允许部分成员发布所有主题,让其他成员全部回复,ID号成员选择发布;
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入您自己的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天将采集的最新内容发布到指定栏目;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行、HTML预览,使用更好更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章都按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以在论坛内容中采集网站/超级链接,或者屏蔽该链接
您可以从采集网站/论坛下载文章的图片到本地,然后通过FTP上传附件和图片到您的网站空间;
图片名称可以随意;
支持任务栏图标隐藏显示的最小化;
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后、内容中自动添加自定义关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看网站论坛帖子;
软件特点
1、创新多用户随机选帖回复帖,模拟真实热点论坛的热点效果
2、原创可以采集回复,采集的分页会贴出来作为回复
3、 原创百度优化SEO功能伪原创 任何软件都没有此功能
4、 最初创建随机回复,您可以将帖子中的所有回复按顺序重新排列。实现不同于原版网站的真实效果
5、 独创的自动回复功能,可以模拟会员回复,让真正的论坛成员感受到温暖,在没人赞成发帖的情况下发帖也不会失去兴趣。
6、独创的真实会员在线模拟功能,让数十万会员在线,查看和回复不同版块的帖子。让会员感受什么是大而受欢迎的论坛
7、独创多网站采集,多版块可以同时发布文章的功能,你可以呼吸采集成百上千网站 版块,同时在不同版块乱序发布。您不再可以在发布另一个部分之前只发布一个部分(将其视为假)。什么是论坛采集管理系统,这个软件很好的诠释了这个意思
指示
1 下载完成后,不要运行压缩包中的软件,直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
更新日志
1、优化UI界面的流畅度
2、修复已知错误
网站采集器自动超文章发布(中小网站自动更新利器,ET2(EditorTools)免费采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-14 18:10
ET3(EditorTools)是一款免费的采集软件EditorTools是中小型网站的自动更新工具,ET2自动发布采集,静默工作不需要人工干预;独立软件免除网站性能消耗;安全稳定,可连续工作多年。
软件特点
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,即使时间单位是年。
超高稳定性
要达到软件无人值守的目的,需要长期稳定运行。ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有软件会崩溃甚至崩溃。导致 网站 崩溃问题。
最低资源使用率
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器上工作,也可以在站长的工作机上工作。
严格的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。采集 供参考,ET使用标准的HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
ET除了具有一般采集工具的功能外,还使用了图片水印、防盗链、分页采集、回复采集、登录采集、自定义物品、UTF-支持8、UBB、模拟发布...使用户可以灵活实现各种采购和开发需求。
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,任何类型的信息都可以采集
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[特点] 下载上传支持续传
【特点】高速伪原创
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
[采集] 支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持任何已发布项目的语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态 查看全部
网站采集器自动超文章发布(中小网站自动更新利器,ET2(EditorTools)免费采集软件)
ET3(EditorTools)是一款免费的采集软件EditorTools是中小型网站的自动更新工具,ET2自动发布采集,静默工作不需要人工干预;独立软件免除网站性能消耗;安全稳定,可连续工作多年。
软件特点
ET从设计之初就以提高软件自动化程度为突破口,以达到无人值守、24小时自动化工作的目的。经过测试,ET可以自动运行很长时间,即使时间单位是年。
超高稳定性
要达到软件无人值守的目的,需要长期稳定运行。ET在这方面做了很多优化,以保证软件能够稳定连续运行。没有软件会崩溃甚至崩溃。导致 网站 崩溃问题。
最低资源使用率
ET独立于网站,不消耗宝贵的服务器WEB处理资源。它可以在服务器上工作,也可以在站长的工作机上工作。
严格的数据和网络安全
ET使用网站自己的数据发布接口或程序代码来处理和发布信息内容,不直接操作网站数据库,避免了ET可能带来的数据安全问题。采集 供参考,ET使用标准的HTTP端口,不会造成网络安全漏洞。
强大而灵活的功能
ET除了具有一般采集工具的功能外,还使用了图片水印、防盗链、分页采集、回复采集、登录采集、自定义物品、UTF-支持8、UBB、模拟发布...使用户可以灵活实现各种采购和开发需求。
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,任何类型的信息都可以采集
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[特点] 下载上传支持续传
【特点】高速伪原创
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
[采集] 支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持任何已发布项目的语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
网站采集器自动超文章发布(网站采集器自动超文章发布机器人就是这样用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-14 07:05
网站采集器自动超文章发布机器人就是这样用的,这种是一种辅助的机器人,没有什么技术含量的,
可以用像蚂蚁科技这样的大数据服务商,他们的系统能支持网站内发布文章,云发布更好,
现在很多大的seo服务商都有的,是免费提供网站内发布文章功能的,其实不复杂,只要大家把需要的东西都提交给服务商做就行,会一定的技术你基本上就可以搞定了。
不知道你是想问谁家的,现在常用的比如蚂蚁科技,wordpress系统的,他们家虽然收费,但是对用户的比较厚道,不排除是广告,但是非广告,
互联网资讯网站适合自动发布,因为非常精准,可以参考移动端通用发布的工具,
我用的发布工具是爱百程的文章发布,
这种是很正常的,需要发文章必然是为了挣钱,目前看来你遇到瓶颈了.建议多探索探索
百度认证的,全站抓取的,有价值的文章自动发布,还有数据监控;暂时免费,过段时间应该是要收费的;上面,卖爱百程做过的站,我们免费给发文章。可以关注下。我们直接提供接口,对接网。
全站定向全自动
网站是有很多东西的所以很多操作都是需要按照流程走的否则出问题不知道是你自己操作的问题还是文章就给别人操作了 查看全部
网站采集器自动超文章发布(网站采集器自动超文章发布机器人就是这样用)
网站采集器自动超文章发布机器人就是这样用的,这种是一种辅助的机器人,没有什么技术含量的,
可以用像蚂蚁科技这样的大数据服务商,他们的系统能支持网站内发布文章,云发布更好,
现在很多大的seo服务商都有的,是免费提供网站内发布文章功能的,其实不复杂,只要大家把需要的东西都提交给服务商做就行,会一定的技术你基本上就可以搞定了。
不知道你是想问谁家的,现在常用的比如蚂蚁科技,wordpress系统的,他们家虽然收费,但是对用户的比较厚道,不排除是广告,但是非广告,
互联网资讯网站适合自动发布,因为非常精准,可以参考移动端通用发布的工具,
我用的发布工具是爱百程的文章发布,
这种是很正常的,需要发文章必然是为了挣钱,目前看来你遇到瓶颈了.建议多探索探索
百度认证的,全站抓取的,有价值的文章自动发布,还有数据监控;暂时免费,过段时间应该是要收费的;上面,卖爱百程做过的站,我们免费给发文章。可以关注下。我们直接提供接口,对接网。
全站定向全自动
网站是有很多东西的所以很多操作都是需要按照流程走的否则出问题不知道是你自己操作的问题还是文章就给别人操作了
网站采集器自动超文章发布(CMS采集大挪移、维护王和同步更新王,注册成千上万个会员 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-11-11 00:13
)
优采云cms采集器目前包括cms采集移动、维护王和同步更新王,你可以采集其他网站和所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护网站 可实现资源自动定位、图片自动定位和添加水印等,采集每日发布量可达数万。.
相关软件软件大小版本说明下载地址
优采云cms采集器目前包括cms采集移动、维护王和同步更新王,你可以采集其他网站和所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护网站 可实现资源自动定位、图片自动定位和添加水印等,采集每日发布量可达数万。目前全面支持DEDEcms(织梦)、Ecms(帝国)、PHPcms、PHP168、PowerEasy(Dynamic Easy)、SupeSite、5U、 DIY -Page,Zoomla!cms、JEEcms等主流cms程序采集
软件特点
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站程序,让您彻底摆脱网站繁重的维护管理. 优采云采集器每套软件包括采集维护王和采集DaNeoMove,还有以下实用功能:
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松实现千人在线热门论坛的效果(部分不支持按IP统计在线人数的论坛,如DVbbs/PHPWind);
您可以采集网站/forum的话题和所有回复,网站/forums 80%可以是采集,您可以保存文章的内容在本地之后发布;
您可以将网站论坛A版块或专栏的内容批量转发采集到您自己的网站或论坛指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖ID和回复ID分开,允许部分成员发布所有主题,让其他成员全部回复,ID号成员选择发布;
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入您自己的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天将采集的最新内容发布到指定栏目;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行、HTML预览,使用更好更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章都按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以在论坛内容中采集网站/超级链接,或者屏蔽该链接
您可以从采集网站/论坛下载文章的图片到本地,然后通过FTP上传附件和图片到您的网站空间;
图片名称可以随意;
支持任务栏图标隐藏显示的最小化;
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后、内容中自动添加自定义关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看网站论坛帖子;
查看全部
网站采集器自动超文章发布(CMS采集大挪移、维护王和同步更新王,注册成千上万个会员
)
优采云cms采集器目前包括cms采集移动、维护王和同步更新王,你可以采集其他网站和所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护网站 可实现资源自动定位、图片自动定位和添加水印等,采集每日发布量可达数万。.
相关软件软件大小版本说明下载地址
优采云cms采集器目前包括cms采集移动、维护王和同步更新王,你可以采集其他网站和所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护网站 可实现资源自动定位、图片自动定位和添加水印等,采集每日发布量可达数万。目前全面支持DEDEcms(织梦)、Ecms(帝国)、PHPcms、PHP168、PowerEasy(Dynamic Easy)、SupeSite、5U、 DIY -Page,Zoomla!cms、JEEcms等主流cms程序采集
软件特点
经过7年多的不断完善和升级,优采云采集器现已支持国内大部分主流建站程序,让您彻底摆脱网站繁重的维护管理. 优采云采集器每套软件包括采集维护王和采集DaNeoMove,还有以下实用功能:
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松实现千人在线热门论坛的效果(部分不支持按IP统计在线人数的论坛,如DVbbs/PHPWind);
您可以采集网站/forum的话题和所有回复,网站/forums 80%可以是采集,您可以保存文章的内容在本地之后发布;
您可以将网站论坛A版块或专栏的内容批量转发采集到您自己的网站或论坛指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖ID和回复ID分开,允许部分成员发布所有主题,让其他成员全部回复,ID号成员选择发布;
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入您自己的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天将采集的最新内容发布到指定栏目;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行、HTML预览,使用更好更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章都按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以在论坛内容中采集网站/超级链接,或者屏蔽该链接
您可以从采集网站/论坛下载文章的图片到本地,然后通过FTP上传附件和图片到您的网站空间;
图片名称可以随意;
支持任务栏图标隐藏显示的最小化;
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后、内容中自动添加自定义关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看网站论坛帖子;
网站采集器自动超文章发布(网站采集器自动超文章发布工具_发布文章自动发布)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-08 07:05
网站采集器自动超文章发布工具_发布文章自动发布到百度百家:xlnewsproxy需要的软件版本:phpphtmanager,xlnewsproxy一键点按的功能,对于没有经验的新手来说,是相当困难的。xlnewsproxy采用逐篇生成百度首页内容的方式,具有全新的网页内容组织方式,自动为您生成独特的内容特色。
xlnewsproxy提供丰富的样式自定义,可根据自己的发布要求任意调整。然后修改xlnewsproxy的ua就可以实现你想要的百度搜索结果,后续要是还有采集需求可以直接调用xlnewsproxy的方式实现。xlnewsproxy官网。
ua
自动发布、保存自己网站上的百度搜索结果这个就厉害了~xlappmeque/web-spoofingserver·github网站推荐这个:/,
个人觉得这个就挺好用的,感觉可以满足绝大部分的要求,可以添加自己网站上的全部链接,
sitemapjar用来选取你的网站,并且可以生成多个。我一直在用这个,对搜索引擎很友好,前提是你网站不是作弊的!ui小团队做,界面简单易懂,方便用户。
呵呵我也在找,
传送门:发布搜索结果-百度搜索结果发布器-搜狗站长平台
万能的google,搜索框里打某网站,就出来这个结果。百度不行。
你需要找的是一个自动发布的插件,但是要的是ftp服务器, 查看全部
网站采集器自动超文章发布(网站采集器自动超文章发布工具_发布文章自动发布)
网站采集器自动超文章发布工具_发布文章自动发布到百度百家:xlnewsproxy需要的软件版本:phpphtmanager,xlnewsproxy一键点按的功能,对于没有经验的新手来说,是相当困难的。xlnewsproxy采用逐篇生成百度首页内容的方式,具有全新的网页内容组织方式,自动为您生成独特的内容特色。
xlnewsproxy提供丰富的样式自定义,可根据自己的发布要求任意调整。然后修改xlnewsproxy的ua就可以实现你想要的百度搜索结果,后续要是还有采集需求可以直接调用xlnewsproxy的方式实现。xlnewsproxy官网。
ua
自动发布、保存自己网站上的百度搜索结果这个就厉害了~xlappmeque/web-spoofingserver·github网站推荐这个:/,
个人觉得这个就挺好用的,感觉可以满足绝大部分的要求,可以添加自己网站上的全部链接,
sitemapjar用来选取你的网站,并且可以生成多个。我一直在用这个,对搜索引擎很友好,前提是你网站不是作弊的!ui小团队做,界面简单易懂,方便用户。
呵呵我也在找,
传送门:发布搜索结果-百度搜索结果发布器-搜狗站长平台
万能的google,搜索框里打某网站,就出来这个结果。百度不行。
你需要找的是一个自动发布的插件,但是要的是ftp服务器,
网站采集器自动超文章发布(EditorTools——中小网站自动更新利器!(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-08 01:00
<p>EditorTools3 是一款无人值守的全自动采集器,非常值得所有站长朋友使用。可以帮助用户解决中小型网站和企业站采集操作的自动信息,更智能的采集程序保证您的 查看全部
网站采集器自动超文章发布(全网第一波wordpress+phpxmlpress百度云网盘大全免费领取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-05 23:05
网站采集器自动超文章发布脚本全网第一波wordpress+phpxmlpress百度云网盘大全免费领取免费领取完整版全网第一波网站采集器脚本大全与大家分享全网第一波网站采集器脚本大全其他wordpress论坛留言获取wordpress源码谢谢^_^
可以到云栖社区网址上
360云盘-免费网盘,共享你的网盘
官方的可以去网盘搜索
可以去阿里云网盘
乌云上面有一个小工具sdilphp网站采集,虽然也有些慢,如果是网盘精灵的话。不过不知道你用不用得上,如果你用的上,
可以去phpwind看看,有个文件库,
云盘搜索助手-云客户端(强烈推荐)
国内的去百度云:-bin/baiduspider-release?package=zh
乌云用一下就行了,免费的,上传文件即可。收费服务需要申请,但是目前已经可以免费注册使用了,买大会员应该比较贵。
或者私聊我。
使用国外的一个wordpress网盘工具-markdownx-blocks
原文在微信公众号里,后期还有几篇相关文章,先放上链接在微信生态里,优雅的看网盘等各大论坛的各种资源,或者如果有需要,也可以直接通过邮件(email)给订阅号的小编直接发送,或者扫码关注微信公众号里的论坛,也可以在公众号里直接搜索关键词。|突然爱上wordpress,没有文件是不够的。(二维码自动识别)微信号/邮箱:我是安会哥,会记录和分享网盘资源和工具使用方法,与各位同行共勉。
如果想找资源可以加一下微信:也欢迎大家关注我的专栏:电脑技术(java后端开发),也可以加一下关注我的专栏二维码扫描。 查看全部
网站采集器自动超文章发布(全网第一波wordpress+phpxmlpress百度云网盘大全免费领取)
网站采集器自动超文章发布脚本全网第一波wordpress+phpxmlpress百度云网盘大全免费领取免费领取完整版全网第一波网站采集器脚本大全与大家分享全网第一波网站采集器脚本大全其他wordpress论坛留言获取wordpress源码谢谢^_^
可以到云栖社区网址上
360云盘-免费网盘,共享你的网盘
官方的可以去网盘搜索
可以去阿里云网盘
乌云上面有一个小工具sdilphp网站采集,虽然也有些慢,如果是网盘精灵的话。不过不知道你用不用得上,如果你用的上,
可以去phpwind看看,有个文件库,
云盘搜索助手-云客户端(强烈推荐)
国内的去百度云:-bin/baiduspider-release?package=zh
乌云用一下就行了,免费的,上传文件即可。收费服务需要申请,但是目前已经可以免费注册使用了,买大会员应该比较贵。
或者私聊我。
使用国外的一个wordpress网盘工具-markdownx-blocks
原文在微信公众号里,后期还有几篇相关文章,先放上链接在微信生态里,优雅的看网盘等各大论坛的各种资源,或者如果有需要,也可以直接通过邮件(email)给订阅号的小编直接发送,或者扫码关注微信公众号里的论坛,也可以在公众号里直接搜索关键词。|突然爱上wordpress,没有文件是不够的。(二维码自动识别)微信号/邮箱:我是安会哥,会记录和分享网盘资源和工具使用方法,与各位同行共勉。
如果想找资源可以加一下微信:也欢迎大家关注我的专栏:电脑技术(java后端开发),也可以加一下关注我的专栏二维码扫描。
网站采集器自动超文章发布(网站采集器自动超文章发布机器人多款可选)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-11-03 17:06
网站采集器自动超文章发布机器人简介:实现自动发文章,可以从、天猫、百度搜索等网站采集文章,通过不到1分钟的轻松操作,就可以获取到很多全网最新的图片、美图、表情、攻略等,自动发布到你的百度云盘、360云盘等云盘,即使你没有网站也没有关系,你可以通过简单的文章批量发布,按照软件提示或者根据提示就可以快速发文发链接了,整个操作很简单!机器人多款可选:1。
便宜型:简单易用,可自定义格式的文件名,发布速度比较慢;2。中等型:整体比较完善,发布速度很快,可自定义大小,不同网站采集效果都一样;3。高端型:整体配置非常高,自动追踪全网采集,采集速度快,几十个网站采集可以实现全程自动化,可根据需要定制发布速度;4。传统型:提供了站点数据调用接口,可以自定义加快发布速度,多个网站高效互换;5。
开源型:提供接口开放,可以进行反编译对接百度云盘,各个主流网站、新闻网站、网络教程,个人需要自定义管理;6。云端服务:网站数据采集整合完毕后,可以云端分享给个人用户、开发人员或者是团队用户,以便其可以更快的发布优质文章;功能亮点:1。真实的app客户端,自带固定速度;2。自动发布文章,全程自动操作,减少工作量;3。
智能追踪全网文章,提高文章的发布速度;4。高效协作分享,即使个人没有云盘,也可以实现文章发布;5。发布文章可以加入备注,全球真实网站,自定义要发布的网站;。 查看全部
网站采集器自动超文章发布(网站采集器自动超文章发布机器人多款可选)
网站采集器自动超文章发布机器人简介:实现自动发文章,可以从、天猫、百度搜索等网站采集文章,通过不到1分钟的轻松操作,就可以获取到很多全网最新的图片、美图、表情、攻略等,自动发布到你的百度云盘、360云盘等云盘,即使你没有网站也没有关系,你可以通过简单的文章批量发布,按照软件提示或者根据提示就可以快速发文发链接了,整个操作很简单!机器人多款可选:1。
便宜型:简单易用,可自定义格式的文件名,发布速度比较慢;2。中等型:整体比较完善,发布速度很快,可自定义大小,不同网站采集效果都一样;3。高端型:整体配置非常高,自动追踪全网采集,采集速度快,几十个网站采集可以实现全程自动化,可根据需要定制发布速度;4。传统型:提供了站点数据调用接口,可以自定义加快发布速度,多个网站高效互换;5。
开源型:提供接口开放,可以进行反编译对接百度云盘,各个主流网站、新闻网站、网络教程,个人需要自定义管理;6。云端服务:网站数据采集整合完毕后,可以云端分享给个人用户、开发人员或者是团队用户,以便其可以更快的发布优质文章;功能亮点:1。真实的app客户端,自带固定速度;2。自动发布文章,全程自动操作,减少工作量;3。
智能追踪全网文章,提高文章的发布速度;4。高效协作分享,即使个人没有云盘,也可以实现文章发布;5。发布文章可以加入备注,全球真实网站,自定义要发布的网站;。
网站采集器自动超文章发布(优采云采集器官方网站,免费下载使用,让你的论坛维护管理中解放出来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-31 17:14
优采云采集器官方网站,免费下载使用,官网:
经过两年多的时间,优采云采集器开发了Disucz!、PHPWind、Dvbbs(动网)、bbsxp、6KBBS、VTBBS、DunkBBS、CVCbbs、LeadBBS、LeoBBS、sfbbs。论坛、PHPBB、bbsgood、vbulletin、Ofstar、侨客、TTsite、讯探、5d6d、uu1001、ctb、lunqun等20多个论坛程序采集器,很好的满足各类用户的需求。如果您使用的论坛程序没有对应的采集器,您可以联系我们进行定制。
优采云采集器目前包括论坛注册器采集维护王和采集大鸟移三款软件,是一套功能强大的网站管理工具,是每个论坛管理员版主必备的工具。她可以将论坛上所有其他网站和好的内容移动到你的网站论坛,自动采集目标站点的文章,发布内容和回复,无需你手动发布回复日日夜夜,让您从繁重的论坛维护管理中解脱出来,同时采集器还有以下实用功能:
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员(不支持5d6d/uu1001);
允许会员在设定时间内同时上线,轻松达到千人在线热论坛效果(不支持DVbbs/PHPWind);
您可以采集网站/forum的话题和所有回复,网站/forums的90%都可以采集,您可以将文章的内容保存到稍后在本地发布;
您可以将网站论坛A版块或专栏采集的内容批量转发到自己论坛的指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;新的!
软件可以同时批量发帖到论坛的多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;新的!
软件可以将发帖和回复ID分开,让部分成员发布所有主题,让其他成员全部回复,ID号成员将被选中并发布;新的!
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入自己的论坛程序,突破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天都会发布最新的采集帖子到论坛指定版块;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行,使用更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛的帖子或者网站文章按照其他采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
采集网站/ 论坛内容中的超级链接,包括各种附件的下载链接;
您可以直接下载附件链接采集到您的论坛或超级链接采集到您的论坛;
您可以将采集网站/论坛的各种附件和图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
附件文件名可以是随机的;新的!
支持任务栏图标隐藏显示的最小化;新的!
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后和内容中自动添加自己设置的关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看论坛帖子;
软件具有半自动网站论坛推广功能,可将您需要经常推广的网站论坛聚集到软件中,大大节省网站推广时间和效率;
. . . . . .
优采云采集器官方网站,免费下载使用,官网: 查看全部
网站采集器自动超文章发布(优采云采集器官方网站,免费下载使用,让你的论坛维护管理中解放出来)
优采云采集器官方网站,免费下载使用,官网:
经过两年多的时间,优采云采集器开发了Disucz!、PHPWind、Dvbbs(动网)、bbsxp、6KBBS、VTBBS、DunkBBS、CVCbbs、LeadBBS、LeoBBS、sfbbs。论坛、PHPBB、bbsgood、vbulletin、Ofstar、侨客、TTsite、讯探、5d6d、uu1001、ctb、lunqun等20多个论坛程序采集器,很好的满足各类用户的需求。如果您使用的论坛程序没有对应的采集器,您可以联系我们进行定制。
优采云采集器目前包括论坛注册器采集维护王和采集大鸟移三款软件,是一套功能强大的网站管理工具,是每个论坛管理员版主必备的工具。她可以将论坛上所有其他网站和好的内容移动到你的网站论坛,自动采集目标站点的文章,发布内容和回复,无需你手动发布回复日日夜夜,让您从繁重的论坛维护管理中解脱出来,同时采集器还有以下实用功能:
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员(不支持5d6d/uu1001);
允许会员在设定时间内同时上线,轻松达到千人在线热论坛效果(不支持DVbbs/PHPWind);
您可以采集网站/forum的话题和所有回复,网站/forums的90%都可以采集,您可以将文章的内容保存到稍后在本地发布;
您可以将网站论坛A版块或专栏采集的内容批量转发到自己论坛的指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;新的!
软件可以同时批量发帖到论坛的多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;新的!
软件可以将发帖和回复ID分开,让部分成员发布所有主题,让其他成员全部回复,ID号成员将被选中并发布;新的!
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入自己的论坛程序,突破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天都会发布最新的采集帖子到论坛指定版块;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行,使用更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛的帖子或者网站文章按照其他采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
采集网站/ 论坛内容中的超级链接,包括各种附件的下载链接;
您可以直接下载附件链接采集到您的论坛或超级链接采集到您的论坛;
您可以将采集网站/论坛的各种附件和图片下载到本地,然后通过FTP将附件和图片上传到您的网站空间;
附件文件名可以是随机的;新的!
支持任务栏图标隐藏显示的最小化;新的!
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后和内容中自动添加自己设置的关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看论坛帖子;
软件具有半自动网站论坛推广功能,可将您需要经常推广的网站论坛聚集到软件中,大大节省网站推广时间和效率;
. . . . . .
优采云采集器官方网站,免费下载使用,官网:
网站采集器自动超文章发布(优采云采集可把定时采集和自动发布功能搭配使用(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-31 00:09
优采云采集 定时采集可以和自动发布功能配合使用。用户不再需要时刻关注任务采集和发布情况,省时、省力、高效。
先登录优采云控制台
打开优采云Data采集平台页面,点击右上角控制台,注册账号并登录控制台。
1. 时间采集
定时模式可以设置为只采集一次,每天,每周,每个间隔多少小时会自动运行采集任务;(各种定时模式的详细设置)
进入某个采集任务,点击【开始| 定时采集]按钮进入“设置定时采集”界面,勾选“是否启用”,然后根据需要选择定时方式,最后点击【开始】 | 计时]按钮:
定时采集设置成功后,任务右上角会有下一次运行采集时间:
任务列表中有一个红色的时钟图标和时间,就是下一个定时任务采集的时间:
预防措施:
Save 不执行定时功能,而是保存配置信息;
定时开始时间建议设置为未来时间,例如:此时为10点,可设置为10:15分钟开始;如果设置为已经过了的时间,虽然系统会自动更正,但可能是第二天0点或者现在立即执行。(使用右侧蓝色按钮设置为1分钟后,等待30分钟后蓝色按钮)
设置为时间的任务不计为正在运行的任务。仅当到达指定时间并启动操作采集时才算作运行任务;
2. 自动发布
自动发布是在采集完成后,系统自动将数据发布到目标网站。(任务开始前需要设置自动释放采集)
自动发布功能一般与常规采集配合使用,用户不再需要时刻关注任务采集和发布情况,省时、省力、高效。
进入自动发布配置界面,在任务的【自动化:发布&SEO&翻译】选项卡中:勾选“自动发布”==“发布方式选择”采集后自动发布”==“选择发布数据范围==》选择放行目标控制方法==》填写放行数量控制==》选择放行顺序==》选择放行对象==》点击保存按钮;
详细的发布选项:
一、发布数据范围:“待发布”、“已发布”、“发布失败”、“全部”可选;(默认是要发布的,一般不修改)
二、释放方法控制:
每条数据发送到每个选定的目标:1个多目标,每条数据将发布到每个选定的目标;
每条数据只发送给选定的其中一个目标:1个1个目标,每条数据只会随机分配给选定的多个目标之一;
每条数据只发布一个域名:1号1域名。一个域名一般收录多个发布对象(列),但每条数据只会发布到一个域名。如果在域名中选择了多个发布目标,则只会随机发布其中一个。(站群 使用)
三、发布数量控制:每次固定时间发布的数据数量,数字0表示全部发布,没有限制;
如果发布方式是“每条数据只发送给选定的1个目标”或“每条数据只发布一个域名”,则填写的数字是每个目标的帖子数而不是总数number,例如3个帖子选择Target,每个发布10条数据,“发布数量控制”部分填写10而不是30;
四、发布顺序:正序发布是根据数据列表从前到后发布数据(第一页到最后一页),倒序则相反,从后到前(最后一页到第一页);
五、图片返回方式:如果设置了图片存储优采云,默认【Http返回(推荐,快捷方便,适合图片较少的)】,如果图片比较大,可以选择【Ftp返回(稳定传输,适合更多图片)];
六、可以设置自动发布成功后是否自动删除相应的数据和图片(删除的数据为优采云控制台中发布成功的数据,优采云中暂存的相应图片不会影响用户网站的文章和图片): 查看全部
网站采集器自动超文章发布(优采云采集可把定时采集和自动发布功能搭配使用(组图))
优采云采集 定时采集可以和自动发布功能配合使用。用户不再需要时刻关注任务采集和发布情况,省时、省力、高效。
先登录优采云控制台
打开优采云Data采集平台页面,点击右上角控制台,注册账号并登录控制台。
1. 时间采集
定时模式可以设置为只采集一次,每天,每周,每个间隔多少小时会自动运行采集任务;(各种定时模式的详细设置)
进入某个采集任务,点击【开始| 定时采集]按钮进入“设置定时采集”界面,勾选“是否启用”,然后根据需要选择定时方式,最后点击【开始】 | 计时]按钮:
定时采集设置成功后,任务右上角会有下一次运行采集时间:
任务列表中有一个红色的时钟图标和时间,就是下一个定时任务采集的时间:
预防措施:
Save 不执行定时功能,而是保存配置信息;
定时开始时间建议设置为未来时间,例如:此时为10点,可设置为10:15分钟开始;如果设置为已经过了的时间,虽然系统会自动更正,但可能是第二天0点或者现在立即执行。(使用右侧蓝色按钮设置为1分钟后,等待30分钟后蓝色按钮)
设置为时间的任务不计为正在运行的任务。仅当到达指定时间并启动操作采集时才算作运行任务;
2. 自动发布
自动发布是在采集完成后,系统自动将数据发布到目标网站。(任务开始前需要设置自动释放采集)
自动发布功能一般与常规采集配合使用,用户不再需要时刻关注任务采集和发布情况,省时、省力、高效。
进入自动发布配置界面,在任务的【自动化:发布&SEO&翻译】选项卡中:勾选“自动发布”==“发布方式选择”采集后自动发布”==“选择发布数据范围==》选择放行目标控制方法==》填写放行数量控制==》选择放行顺序==》选择放行对象==》点击保存按钮;
详细的发布选项:
一、发布数据范围:“待发布”、“已发布”、“发布失败”、“全部”可选;(默认是要发布的,一般不修改)
二、释放方法控制:
每条数据发送到每个选定的目标:1个多目标,每条数据将发布到每个选定的目标;
每条数据只发送给选定的其中一个目标:1个1个目标,每条数据只会随机分配给选定的多个目标之一;
每条数据只发布一个域名:1号1域名。一个域名一般收录多个发布对象(列),但每条数据只会发布到一个域名。如果在域名中选择了多个发布目标,则只会随机发布其中一个。(站群 使用)
三、发布数量控制:每次固定时间发布的数据数量,数字0表示全部发布,没有限制;
如果发布方式是“每条数据只发送给选定的1个目标”或“每条数据只发布一个域名”,则填写的数字是每个目标的帖子数而不是总数number,例如3个帖子选择Target,每个发布10条数据,“发布数量控制”部分填写10而不是30;
四、发布顺序:正序发布是根据数据列表从前到后发布数据(第一页到最后一页),倒序则相反,从后到前(最后一页到第一页);
五、图片返回方式:如果设置了图片存储优采云,默认【Http返回(推荐,快捷方便,适合图片较少的)】,如果图片比较大,可以选择【Ftp返回(稳定传输,适合更多图片)];
六、可以设置自动发布成功后是否自动删除相应的数据和图片(删除的数据为优采云控制台中发布成功的数据,优采云中暂存的相应图片不会影响用户网站的文章和图片):
网站采集器自动超文章发布(基于Python的网络数据采集实战(初级篇)中爬取马蜂窝景点页面)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-30 04:15
一、简介
比如使用JS脚本来控制部分网页。内容的请求和展示,使得最原创的直接修改静态目标页面的url地址改变页面的方式失效。对于这部分,我在(数据科学学习手册47)基于Python的网络数据采集实战(2)爬马蜂窝景点页面时用户在蜜蜂评论区,也有详细介绍,不过我已经介绍了文章中所有爬虫相关的内容,都离不开开启这样一个过程:
整理url规则(直接访问静态页面,JS控制的动态页面通过浏览器的开发者工具查找真实的URL和参数)
|
伪装浏览器
|
使用 urllib.urlopen() 或 requests.get() 启动对目标 url 的访问
|
获取返回网页的原创内容
|
使用 BeautifulSoup 或 PySpider 解析网页的原创内容
|
结合观察到的CSS标签属性等信息,使用BeautifulSoup对象的findAll()方法提取需要的内容,使用正则表达式完成精准提取
|
存储在数据库中
而本文将要介绍的新的网络数据采集工具不再冒充浏览器端,而是基于自动化测试工具selenium结合相应的浏览器驱动,打开真实显式的Browser窗口来完成处理更动态、更灵活的网页的一系列动作;
二、硒
2.1 简介
Selenium 也是 Web 应用程序测试的工具。selenium 测试直接在浏览器中运行,就像真实用户在操作一样。支持的浏览器包括IE、Mozilla Firefox、Mozilla Suite、Chrome等。该工具的主要功能是测试与浏览器的兼容性,但由于它能够模拟浏览器的行为,模拟网页点击、拉取跌宕起伏、拖拽元素等,在网络数据上掀开采集一片天地
2.2 环境设置
基于Python创建爬虫(这里说的是Python3、Python2,让它退居在历史长河中……)使用selenium创建爬虫程序,我们需要:
1.安装selenium包,直接pip安装即可
2.下载浏览器(废话-_-!),以及相应的驱动。本文选择的浏览器为Chrome,需要下载chromedriver.exe。这里是一个收录所有版本的 chromedriver.exe 资源的地址:
需要注意的是,要下载与您的浏览器版本兼容的资源,这里有一个建议:将您的Chrome浏览器更新到最新版本,然后从上述地址下载最新的chromedriver.exe;下载完成后,将chromedriver.exe放到你的Python根目录下,和python.exe放在一起。比如我把它放在我的anaconda环境中的对应位置:
3. 测试一下~
完成以上操作后,我们需要检查一下我们的环境是否已经正确设置完成。在您的 Python 编辑器中,编写以下语句:
from selenium import webdriver
'''创建一个新的Chrome浏览器窗体'''
browser = webdriver.Chrome()
'''在browser对应的浏览器中访问百度首页'''
browser.get('http://www.baidu.com')
如果执行上述语句后,Chrome浏览器成功打开,访问我们设置的网页,则selenium+Chrome开发环境配置完成;
2.3 网络数据使用selenium的基本流程采集
在本文开头,我们总结了网络数据采集的基本流程。下面我们以类似的形式介绍selenium对网络数据采集的基本流程:
创建浏览器(可能涉及浏览器的一些设置的预配置,比如设置在不需要采集图片时禁止加载图片以提高访问速度)
|
使用.get()方法直接打开指定的URL地址
|
使用.page_source()方法获取当前主窗口(浏览器中可能同时打开多个网页窗口,则需要使用页面句柄指定我们关注的主窗口网页)页面内容对应到页面
|
使用BeautifulSoup或pyspider等解析库解析指定网页内容
|
结合观察到的CSS标签属性等信息,使用BeautifulSoup对象的findAll()方法提取需要的内容,使用正则表达式完成精准提取
|
存储在数据库中
可以看出,使用selenium for network data采集和之前的方法最大的区别就是向目标网页发起请求的过程。在使用 selenium 时,我们不再需要伪装浏览器,并且有非常丰富的浏览器动作可以设置。比如我们之前需要翻页,主要是修改url中控制页值对应的参数,所以遇到JS控制的动态网页时,就不用费心去找了。要控制对应资源翻页的实际URL地址,只需要通过selenium内置的丰富定位方法定位页面中的翻页按钮,然后在定位的元素上使用.click()即可实现. 对于真正的翻页操作,
三、Selenium 常用操作
3.1 浏览器配置部分
在调用真正的浏览器对象之前,我们可以根据实际需要配置浏览器的参数。这是由 Selenium 中相应浏览器的 XXXOptions 类设置的。比如本文只介绍Chrome浏览器。我们使用ChromeOptions类中的方法来实现浏览器的预配置,我们来看看ChromeOptions类:
铬选项:
ChromeOptions 是一个在 selenium 创建 Chrome 浏览器之前预配置浏览器对象的类。其主要功能包括添加Chrome启动参数、修改Chrome设置、添加扩展应用,例如:
1.禁止在网页中加载图片
from selenium import webdriver
'''创建一个新的Chrome浏览器窗体,通过add_experimental_option()方法来设置禁止图片加载'''
chrome_options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
browser = webdriver.Chrome(chrome_options=chrome_options)
'''在browser对应的浏览器中,以禁止图片加载的方式访问百度首页'''
browser.get('http://www.baidu.com')
'''查看当前浏览器中已设置的参数'''
chrome_options.experimental_options
可以看到,经过上面的设置,我们访问的网页中的所有图片都没有加载。这对于提高不需要采集图片资源的任务的访问速度具有重要意义;
2.设置代理IP
有时候,面对一些受限的访问频率网站,一旦我们的爬取频率过高,就会导致我们的本地IP地址被暂时封锁。这时候,我们可以采集一些IP代理用来建立我们的代理池。后面我们会单独开一篇博客来详细介绍。以下是如何为我们的 Chrome() 浏览器对象设置 IP 代理的简要演示:
from selenium import webdriver
'''设置代理IP'''
IP = '106.75.9.39:8080'
'''为Chrome浏览器配置chrome_options选项'''
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://{}'.format(IP))
'''将配置好的chrome_options选项传入新的Chrome浏览器对象中'''
browser = webdriver.Chrome(chrome_options=chrome_options)
'''尝试访问百度首页'''
browser.get('http://www.baidu.com')
但是如果你不是付费高速IP代理,而是从网上所谓的免费IP代理网站中摘取的一些IP地址,那么上述设置后打开的浏览器可能无法显示目标在正常时间的网页内(原因你知道);
另一种思路:
除了使用ChromeOptions()中的方法来设置外,还有一个简单直接粗暴的方法。我们可以直接访问当前浏览器设置页面对应的地址:chrome://settings/content:
from selenium import webdriver
browser = webdriver.Chrome()
'''直接访问设置页面'''
browser.get('chrome://settings/content')
然后用你写的模拟点击规则完成相应的设置内容,这里就不多说了;
3.2 浏览器运行时的实用方法
在3.1中介绍的方法之后,浏览器已经预先配置好了,并且成功打开了对应的浏览器,selenium中还是有非常丰富的浏览器方法的。下面我们将讨论一些实用和常用的。类中的方法和变量介绍:
假设我们构造了一个名为 browser 的浏览器对象,可以使用的方法如下:
browser.get(url):在浏览器主窗口打开url指定的网页;
browser.title: 获取当前浏览器主页面的标题:
from selenium import webdriver
browser = webdriver.Chrome()
'''直接访问设置页面'''
browser.get('https://hao.360.cn/?wd_xp1')
'''打印网页标题'''
print(browser.title)
browser.current_url:返回当前主页面url地址
browser.page_source:获取当前主界面的页面内容,相当于requests.get(url).content
browser.close():关闭当前主页面对应的网页
browser.quit():直接关闭当前浏览器
browser.maximize_window():最大化浏览器窗口的大小
browser.fullscreen_window():全屏浏览器窗口
browser.back():控制当前主页进行back操作(前提是有上一页)
browser.forward():控制当前主页面进行转发操作(前提是有下一页)
browser.refresh():控制当前主页面刷新
browser.set_page_load_timeout(time_to_wait):为当前浏览器设置一个最大页面加载时间容忍阈值,单位为秒,类似于urllib.urlopen()中的timeout参数,即某个界面加载时,持续time_to_wait秒在加载完成之前的时候,程序会报错,我们可以使用错误处理机制来捕捉这个错误,这个方法适合在界面访问超时和假死的情况下长时间采样
browser.set_window_size(width, height, windowHandle='current'):用于调整浏览器界面的长宽
关于主页面:
这是额外的介绍。上一段我们多次提到主页面的概念,因为selenium控制浏览器的时候,无论浏览器打开多少个网页,只有唯一的网页被认为是在主页面上,很多对应的webdriver () 方法也以主页为目标。下面是一个例子。我们以马蜂窝本地旅游页面为例:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问马蜂窝重庆游记汇总页'''
browser.get('http://www.mafengwo.cn/search/s.php?q=%E9%87%8D%E5%BA%86&t=info&seid=71F18E8D-AA90-4870-9928-2BE01E53DDBD&mxid=&mid=&mname=&kt=1')
打开目标页面如下:
这里我们手动点击一个游记(模拟点击的方法将在下面介绍),浏览器会立即跳转到一个新页面:
这时候我们运行如下代码:
'''打印网页标题'''
print(browser.title)
可以看出,虽然在我们的视角下,点击进入一个新的界面,但是当我们使用相应的方法获取当前页面标题的时候,我们还是以之前的页面为对象,这涉及到我们前面提到的主页面问题的解决,当在原页面时,由于一个点击事件而跳转到另一个页面(这里指的是新窗口显示新界面,而不是在原窗口覆盖原页面),在浏览器中主要page of 仍然锁定在原创页面,即 get() 方法跳转到的网页。在这种情况下,我们需要使用网页的句柄来唯一标识每个网页;
在selenium中,有两种获取网页句柄的方法:
browser.current_window_handle:获取主页面的句柄,以上面的马蜂窝为例:
'''打印主页面句柄'''
print(browser.current_window_handle)
browser.window_handles:获取当前浏览器中所有页面的句柄,按打开时间顺序:
'''打印当前浏览器下所有页面的句柄'''
print(browser.window_handles)
由于句柄相当于网页的ID,我们可以根据句柄将当前主网页切换到其他网页,继续上面的例子。这时候主网页就是.get()方法打开的网页,之前打印的是browser.title。它还指向网页。现在我们使用 browser.switch_to.window(handle) 方法将主网页转移到最近打开的网页,并打印当前主网页的标题:
'''切换主网页至最近打开的网页'''
browser.switch_to.window(browser.window_handles[-1])
'''打印当前主网页的网页标题'''
print(browser.title)
可以看到,使用主网页切换方式后,我们的主网页就跳转到了指定的网页,这对于特殊网页跳转方式下新打开的网页内容非常有用;
3.3 页面元素定位
在介绍 selenium 模拟浏览器行为的本质之前,我们需要知道如何定位网页中的元素。比如我们要定位网页中的翻页按钮,就需要定位翻页按钮的位置。,这里的定位不是指在屏幕平面坐标上的定位,而是基于网页本身的CSS结构。其实selenium中定位网页元素的方法有很多,但是经过我的大量实践,很多方法都没有效果,果然只有基于xpath的定位方法很方便,定位也很准确方便,所以本文就不浪费时间介绍其他效果不太好的方法了,直接介绍基于xpath的定位方法。
关于 xpath:
xpath 是一种用于在 xml 文档中查找信息的语言。要在selenium中定位网页元素,我们只需要掌握xpath路径表达式即可;
Xpath 使用路径表达式来标识 xml 文档中的节点或节点集。让我们从一个示例开始,以了解 xpath 路径表达式:
以马蜂窝游记页面为例:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问马蜂窝重庆游记汇总页'''
browser.get('http://www.mafengwo.cn/search/s.php?q=%E9%87%8D%E5%BA%86&t=info&seid=71F18E8D-AA90-4870-9928-2BE01E53DDBD&mxid=&mid=&mname=&kt=1')
通过浏览器的开发者工具,我们找到了“下一页”按钮元素在CSS结构中的位置:
先写出元素的完整xpath路径表达式:
//div/div/a[@class='ti next _j_pageitem']
然后我们使用基于xpath的定位方法来定位按钮的位置并模拟点击:
'''定位翻页按钮的位置并保存在新变量中'''
ChagePageElement = browser.find_element_by_xpath("//div/div/a[@class='ti next _j_pageitem']")
'''对按钮位置变量使用click方法进行模拟点击'''
ChagePageElement.click()
上述代码运行后,我们的浏览器执行一次模拟点击翻页按钮,实现翻页:
下面我们来介绍一些xpath路径表达式的基础知识:
nodename:表示节点的标签名称
/:父节点和子节点之间的分隔符
//: 代表父节点和下级节点之间的几个中间节点
[]:指定结束节点的属性
@:在[]中指定属性名称和对应的属性值
xpath路径表达式中还有很多其他的内容,但是在selenium中进行基本元素定位就足以理解上面的规则了,所以我们上面例子中的规则表示定位
几个节点-
……
……
……
……
这样,基于browser.find_element_by_xpath()和browser.find_elements_by_xpath(),我们就可以找到页面中的单个唯一元素或多个相同类型的元素,然后使用.click()方法完成页面中的任意元素页面模拟点击;
3.4 基本浏览器动作模拟
除了使用元素.click()控制上一节介绍的点击动作外,selenium还支持丰富多样的其他常用动作,因为这篇文章是我介绍selenium的第一部分,下面只介绍两个常用动作,更复杂的组合动作将在下面文章中介绍:
模拟网页衰落:
很多时候我们会遇到这样动态加载的网页,比如光点壁纸的各个壁纸板块。以下是景观部分的示例:
这个网页的特点是,在大多数情况下,没有翻页按钮,但是用户将页面滑动到底部后会自动加载下一页的内容,并且这个机制固定几次后,将被混合。翻页前必须点击的按钮,我们可以使用selenium中的browser.execute_script()方法传入JavaScript脚本来执行浏览器动作,然后实现向下滑动功能;
幻灯片底部对应的JavaScript脚本是'window.scrollTo(0, document.body.scrollHeight)',我们使用如下代码实现连续滑动,并及时捕捉翻页按钮点击(使用错误处理机制实现):
from selenium import webdriver
import time
browser = webdriver.Chrome()
'''访问光点壁纸风景板块页面'''
browser.get('http://pic.adesk.com/cate/landscape')
'''这里尝试的时候不要循环太多次,快速加载图片比较吃网速和内存'''
for i in range(1, 20):
'''这里使用一个错误处理机制,
如果有定位到加载下一页按钮就进行
点击下一页动作,否则继续每隔1秒,下滑到底'''
try:
'''定位加载下一页按钮'''
LoadMoreElement = browser.find_element_by_xpath("//div/div[@class='loadmore']")
LoadMoreElement.click()
except Exception as e:
'''浏览器执行下滑动作'''
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
模拟输入:
有时,我们需要对界面中出现的输入框,即标签所代表的对象进行模拟输入操作。这时候我们只需要定位到输入框对应的网页对象,然后使用browser.send_keys(输入内容)来回输入框内添加文字信息即可。下面是一个简单的例子。我们从百度首页开始,模拟点击登录-点击注册-在用户名输入框中输入指定的文字内容,这样一个简单的过程:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问百度首页'''
browser.get('http://www.baidu.com')
'''对页面右上角的登陆超链接进行定位,这里因为同名超链接有两个,
所以使用find_elements_by_xpath来捕获一个元素列表,再对其中
我们指定的对象执行点击操作'''
LoginElement = browser.find_elements_by_xpath("//a[@name='tj_login']")
'''对指定元素进行点击操作'''
LoginElement[1].click()
'''这段while语句是为了防止信息块没加载完成导致出错'''
while True:
try:
'''捕获弹出的信息块中的注册按钮元素'''
SignUpElement = browser.find_elements_by_xpath("//a[@class='pass-reglink pass-link']")
'''点击弹出的信息块中的注册超链接'''
SignUpElement[0].click()
break
except Exception as e:
pass
'''将主网页切换至新弹出的注册页面中以便对其页面内元素进行定位'''
browser.switch_to.window(browser.window_handles[-1])
while True:
try:
'''对用户名称输入框对应元素进行定位'''
InputElement = browser.find_element_by_xpath("//input[@name='userName']")
'''模拟输入指定的文本信息'''
InputElement.send_keys('Keras')
break
except Exception as e:
pass
以上就是上一篇关于selenium的网络数据采集的内容,剩下的内容我会挤时间继续整理介绍,敬请期待。如有错别字,希望大家指出。
发表于 @ 2018-09-07 15:24 Feifry 阅读(1587)评论(0)编辑 查看全部
网站采集器自动超文章发布(基于Python的网络数据采集实战(初级篇)中爬取马蜂窝景点页面)
一、简介
比如使用JS脚本来控制部分网页。内容的请求和展示,使得最原创的直接修改静态目标页面的url地址改变页面的方式失效。对于这部分,我在(数据科学学习手册47)基于Python的网络数据采集实战(2)爬马蜂窝景点页面时用户在蜜蜂评论区,也有详细介绍,不过我已经介绍了文章中所有爬虫相关的内容,都离不开开启这样一个过程:
整理url规则(直接访问静态页面,JS控制的动态页面通过浏览器的开发者工具查找真实的URL和参数)
|
伪装浏览器
|
使用 urllib.urlopen() 或 requests.get() 启动对目标 url 的访问
|
获取返回网页的原创内容
|
使用 BeautifulSoup 或 PySpider 解析网页的原创内容
|
结合观察到的CSS标签属性等信息,使用BeautifulSoup对象的findAll()方法提取需要的内容,使用正则表达式完成精准提取
|
存储在数据库中
而本文将要介绍的新的网络数据采集工具不再冒充浏览器端,而是基于自动化测试工具selenium结合相应的浏览器驱动,打开真实显式的Browser窗口来完成处理更动态、更灵活的网页的一系列动作;
二、硒
2.1 简介
Selenium 也是 Web 应用程序测试的工具。selenium 测试直接在浏览器中运行,就像真实用户在操作一样。支持的浏览器包括IE、Mozilla Firefox、Mozilla Suite、Chrome等。该工具的主要功能是测试与浏览器的兼容性,但由于它能够模拟浏览器的行为,模拟网页点击、拉取跌宕起伏、拖拽元素等,在网络数据上掀开采集一片天地
2.2 环境设置
基于Python创建爬虫(这里说的是Python3、Python2,让它退居在历史长河中……)使用selenium创建爬虫程序,我们需要:
1.安装selenium包,直接pip安装即可
2.下载浏览器(废话-_-!),以及相应的驱动。本文选择的浏览器为Chrome,需要下载chromedriver.exe。这里是一个收录所有版本的 chromedriver.exe 资源的地址:
需要注意的是,要下载与您的浏览器版本兼容的资源,这里有一个建议:将您的Chrome浏览器更新到最新版本,然后从上述地址下载最新的chromedriver.exe;下载完成后,将chromedriver.exe放到你的Python根目录下,和python.exe放在一起。比如我把它放在我的anaconda环境中的对应位置:
3. 测试一下~
完成以上操作后,我们需要检查一下我们的环境是否已经正确设置完成。在您的 Python 编辑器中,编写以下语句:
from selenium import webdriver
'''创建一个新的Chrome浏览器窗体'''
browser = webdriver.Chrome()
'''在browser对应的浏览器中访问百度首页'''
browser.get('http://www.baidu.com')
如果执行上述语句后,Chrome浏览器成功打开,访问我们设置的网页,则selenium+Chrome开发环境配置完成;
2.3 网络数据使用selenium的基本流程采集
在本文开头,我们总结了网络数据采集的基本流程。下面我们以类似的形式介绍selenium对网络数据采集的基本流程:
创建浏览器(可能涉及浏览器的一些设置的预配置,比如设置在不需要采集图片时禁止加载图片以提高访问速度)
|
使用.get()方法直接打开指定的URL地址
|
使用.page_source()方法获取当前主窗口(浏览器中可能同时打开多个网页窗口,则需要使用页面句柄指定我们关注的主窗口网页)页面内容对应到页面
|
使用BeautifulSoup或pyspider等解析库解析指定网页内容
|
结合观察到的CSS标签属性等信息,使用BeautifulSoup对象的findAll()方法提取需要的内容,使用正则表达式完成精准提取
|
存储在数据库中
可以看出,使用selenium for network data采集和之前的方法最大的区别就是向目标网页发起请求的过程。在使用 selenium 时,我们不再需要伪装浏览器,并且有非常丰富的浏览器动作可以设置。比如我们之前需要翻页,主要是修改url中控制页值对应的参数,所以遇到JS控制的动态网页时,就不用费心去找了。要控制对应资源翻页的实际URL地址,只需要通过selenium内置的丰富定位方法定位页面中的翻页按钮,然后在定位的元素上使用.click()即可实现. 对于真正的翻页操作,
三、Selenium 常用操作
3.1 浏览器配置部分
在调用真正的浏览器对象之前,我们可以根据实际需要配置浏览器的参数。这是由 Selenium 中相应浏览器的 XXXOptions 类设置的。比如本文只介绍Chrome浏览器。我们使用ChromeOptions类中的方法来实现浏览器的预配置,我们来看看ChromeOptions类:
铬选项:
ChromeOptions 是一个在 selenium 创建 Chrome 浏览器之前预配置浏览器对象的类。其主要功能包括添加Chrome启动参数、修改Chrome设置、添加扩展应用,例如:
1.禁止在网页中加载图片
from selenium import webdriver
'''创建一个新的Chrome浏览器窗体,通过add_experimental_option()方法来设置禁止图片加载'''
chrome_options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
browser = webdriver.Chrome(chrome_options=chrome_options)
'''在browser对应的浏览器中,以禁止图片加载的方式访问百度首页'''
browser.get('http://www.baidu.com')
'''查看当前浏览器中已设置的参数'''
chrome_options.experimental_options
可以看到,经过上面的设置,我们访问的网页中的所有图片都没有加载。这对于提高不需要采集图片资源的任务的访问速度具有重要意义;
2.设置代理IP
有时候,面对一些受限的访问频率网站,一旦我们的爬取频率过高,就会导致我们的本地IP地址被暂时封锁。这时候,我们可以采集一些IP代理用来建立我们的代理池。后面我们会单独开一篇博客来详细介绍。以下是如何为我们的 Chrome() 浏览器对象设置 IP 代理的简要演示:
from selenium import webdriver
'''设置代理IP'''
IP = '106.75.9.39:8080'
'''为Chrome浏览器配置chrome_options选项'''
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://{}'.format(IP))
'''将配置好的chrome_options选项传入新的Chrome浏览器对象中'''
browser = webdriver.Chrome(chrome_options=chrome_options)
'''尝试访问百度首页'''
browser.get('http://www.baidu.com')
但是如果你不是付费高速IP代理,而是从网上所谓的免费IP代理网站中摘取的一些IP地址,那么上述设置后打开的浏览器可能无法显示目标在正常时间的网页内(原因你知道);
另一种思路:
除了使用ChromeOptions()中的方法来设置外,还有一个简单直接粗暴的方法。我们可以直接访问当前浏览器设置页面对应的地址:chrome://settings/content:
from selenium import webdriver
browser = webdriver.Chrome()
'''直接访问设置页面'''
browser.get('chrome://settings/content')
然后用你写的模拟点击规则完成相应的设置内容,这里就不多说了;
3.2 浏览器运行时的实用方法
在3.1中介绍的方法之后,浏览器已经预先配置好了,并且成功打开了对应的浏览器,selenium中还是有非常丰富的浏览器方法的。下面我们将讨论一些实用和常用的。类中的方法和变量介绍:
假设我们构造了一个名为 browser 的浏览器对象,可以使用的方法如下:
browser.get(url):在浏览器主窗口打开url指定的网页;
browser.title: 获取当前浏览器主页面的标题:
from selenium import webdriver
browser = webdriver.Chrome()
'''直接访问设置页面'''
browser.get('https://hao.360.cn/?wd_xp1')
'''打印网页标题'''
print(browser.title)
browser.current_url:返回当前主页面url地址
browser.page_source:获取当前主界面的页面内容,相当于requests.get(url).content
browser.close():关闭当前主页面对应的网页
browser.quit():直接关闭当前浏览器
browser.maximize_window():最大化浏览器窗口的大小
browser.fullscreen_window():全屏浏览器窗口
browser.back():控制当前主页进行back操作(前提是有上一页)
browser.forward():控制当前主页面进行转发操作(前提是有下一页)
browser.refresh():控制当前主页面刷新
browser.set_page_load_timeout(time_to_wait):为当前浏览器设置一个最大页面加载时间容忍阈值,单位为秒,类似于urllib.urlopen()中的timeout参数,即某个界面加载时,持续time_to_wait秒在加载完成之前的时候,程序会报错,我们可以使用错误处理机制来捕捉这个错误,这个方法适合在界面访问超时和假死的情况下长时间采样
browser.set_window_size(width, height, windowHandle='current'):用于调整浏览器界面的长宽
关于主页面:
这是额外的介绍。上一段我们多次提到主页面的概念,因为selenium控制浏览器的时候,无论浏览器打开多少个网页,只有唯一的网页被认为是在主页面上,很多对应的webdriver () 方法也以主页为目标。下面是一个例子。我们以马蜂窝本地旅游页面为例:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问马蜂窝重庆游记汇总页'''
browser.get('http://www.mafengwo.cn/search/s.php?q=%E9%87%8D%E5%BA%86&t=info&seid=71F18E8D-AA90-4870-9928-2BE01E53DDBD&mxid=&mid=&mname=&kt=1')
打开目标页面如下:
这里我们手动点击一个游记(模拟点击的方法将在下面介绍),浏览器会立即跳转到一个新页面:
这时候我们运行如下代码:
'''打印网页标题'''
print(browser.title)
可以看出,虽然在我们的视角下,点击进入一个新的界面,但是当我们使用相应的方法获取当前页面标题的时候,我们还是以之前的页面为对象,这涉及到我们前面提到的主页面问题的解决,当在原页面时,由于一个点击事件而跳转到另一个页面(这里指的是新窗口显示新界面,而不是在原窗口覆盖原页面),在浏览器中主要page of 仍然锁定在原创页面,即 get() 方法跳转到的网页。在这种情况下,我们需要使用网页的句柄来唯一标识每个网页;
在selenium中,有两种获取网页句柄的方法:
browser.current_window_handle:获取主页面的句柄,以上面的马蜂窝为例:
'''打印主页面句柄'''
print(browser.current_window_handle)
browser.window_handles:获取当前浏览器中所有页面的句柄,按打开时间顺序:
'''打印当前浏览器下所有页面的句柄'''
print(browser.window_handles)
由于句柄相当于网页的ID,我们可以根据句柄将当前主网页切换到其他网页,继续上面的例子。这时候主网页就是.get()方法打开的网页,之前打印的是browser.title。它还指向网页。现在我们使用 browser.switch_to.window(handle) 方法将主网页转移到最近打开的网页,并打印当前主网页的标题:
'''切换主网页至最近打开的网页'''
browser.switch_to.window(browser.window_handles[-1])
'''打印当前主网页的网页标题'''
print(browser.title)
可以看到,使用主网页切换方式后,我们的主网页就跳转到了指定的网页,这对于特殊网页跳转方式下新打开的网页内容非常有用;
3.3 页面元素定位
在介绍 selenium 模拟浏览器行为的本质之前,我们需要知道如何定位网页中的元素。比如我们要定位网页中的翻页按钮,就需要定位翻页按钮的位置。,这里的定位不是指在屏幕平面坐标上的定位,而是基于网页本身的CSS结构。其实selenium中定位网页元素的方法有很多,但是经过我的大量实践,很多方法都没有效果,果然只有基于xpath的定位方法很方便,定位也很准确方便,所以本文就不浪费时间介绍其他效果不太好的方法了,直接介绍基于xpath的定位方法。
关于 xpath:
xpath 是一种用于在 xml 文档中查找信息的语言。要在selenium中定位网页元素,我们只需要掌握xpath路径表达式即可;
Xpath 使用路径表达式来标识 xml 文档中的节点或节点集。让我们从一个示例开始,以了解 xpath 路径表达式:
以马蜂窝游记页面为例:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问马蜂窝重庆游记汇总页'''
browser.get('http://www.mafengwo.cn/search/s.php?q=%E9%87%8D%E5%BA%86&t=info&seid=71F18E8D-AA90-4870-9928-2BE01E53DDBD&mxid=&mid=&mname=&kt=1')
通过浏览器的开发者工具,我们找到了“下一页”按钮元素在CSS结构中的位置:
先写出元素的完整xpath路径表达式:
//div/div/a[@class='ti next _j_pageitem']
然后我们使用基于xpath的定位方法来定位按钮的位置并模拟点击:
'''定位翻页按钮的位置并保存在新变量中'''
ChagePageElement = browser.find_element_by_xpath("//div/div/a[@class='ti next _j_pageitem']")
'''对按钮位置变量使用click方法进行模拟点击'''
ChagePageElement.click()
上述代码运行后,我们的浏览器执行一次模拟点击翻页按钮,实现翻页:
下面我们来介绍一些xpath路径表达式的基础知识:
nodename:表示节点的标签名称
/:父节点和子节点之间的分隔符
//: 代表父节点和下级节点之间的几个中间节点
[]:指定结束节点的属性
@:在[]中指定属性名称和对应的属性值
xpath路径表达式中还有很多其他的内容,但是在selenium中进行基本元素定位就足以理解上面的规则了,所以我们上面例子中的规则表示定位
几个节点-
……
……
……
……
这样,基于browser.find_element_by_xpath()和browser.find_elements_by_xpath(),我们就可以找到页面中的单个唯一元素或多个相同类型的元素,然后使用.click()方法完成页面中的任意元素页面模拟点击;
3.4 基本浏览器动作模拟
除了使用元素.click()控制上一节介绍的点击动作外,selenium还支持丰富多样的其他常用动作,因为这篇文章是我介绍selenium的第一部分,下面只介绍两个常用动作,更复杂的组合动作将在下面文章中介绍:
模拟网页衰落:
很多时候我们会遇到这样动态加载的网页,比如光点壁纸的各个壁纸板块。以下是景观部分的示例:
这个网页的特点是,在大多数情况下,没有翻页按钮,但是用户将页面滑动到底部后会自动加载下一页的内容,并且这个机制固定几次后,将被混合。翻页前必须点击的按钮,我们可以使用selenium中的browser.execute_script()方法传入JavaScript脚本来执行浏览器动作,然后实现向下滑动功能;
幻灯片底部对应的JavaScript脚本是'window.scrollTo(0, document.body.scrollHeight)',我们使用如下代码实现连续滑动,并及时捕捉翻页按钮点击(使用错误处理机制实现):
from selenium import webdriver
import time
browser = webdriver.Chrome()
'''访问光点壁纸风景板块页面'''
browser.get('http://pic.adesk.com/cate/landscape')
'''这里尝试的时候不要循环太多次,快速加载图片比较吃网速和内存'''
for i in range(1, 20):
'''这里使用一个错误处理机制,
如果有定位到加载下一页按钮就进行
点击下一页动作,否则继续每隔1秒,下滑到底'''
try:
'''定位加载下一页按钮'''
LoadMoreElement = browser.find_element_by_xpath("//div/div[@class='loadmore']")
LoadMoreElement.click()
except Exception as e:
'''浏览器执行下滑动作'''
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(1)
模拟输入:
有时,我们需要对界面中出现的输入框,即标签所代表的对象进行模拟输入操作。这时候我们只需要定位到输入框对应的网页对象,然后使用browser.send_keys(输入内容)来回输入框内添加文字信息即可。下面是一个简单的例子。我们从百度首页开始,模拟点击登录-点击注册-在用户名输入框中输入指定的文字内容,这样一个简单的过程:
from selenium import webdriver
browser = webdriver.Chrome()
'''访问百度首页'''
browser.get('http://www.baidu.com')
'''对页面右上角的登陆超链接进行定位,这里因为同名超链接有两个,
所以使用find_elements_by_xpath来捕获一个元素列表,再对其中
我们指定的对象执行点击操作'''
LoginElement = browser.find_elements_by_xpath("//a[@name='tj_login']")
'''对指定元素进行点击操作'''
LoginElement[1].click()
'''这段while语句是为了防止信息块没加载完成导致出错'''
while True:
try:
'''捕获弹出的信息块中的注册按钮元素'''
SignUpElement = browser.find_elements_by_xpath("//a[@class='pass-reglink pass-link']")
'''点击弹出的信息块中的注册超链接'''
SignUpElement[0].click()
break
except Exception as e:
pass
'''将主网页切换至新弹出的注册页面中以便对其页面内元素进行定位'''
browser.switch_to.window(browser.window_handles[-1])
while True:
try:
'''对用户名称输入框对应元素进行定位'''
InputElement = browser.find_element_by_xpath("//input[@name='userName']")
'''模拟输入指定的文本信息'''
InputElement.send_keys('Keras')
break
except Exception as e:
pass
以上就是上一篇关于selenium的网络数据采集的内容,剩下的内容我会挤时间继续整理介绍,敬请期待。如有错别字,希望大家指出。
发表于 @ 2018-09-07 15:24 Feifry 阅读(1587)评论(0)编辑
网站采集器自动超文章发布(无人值守免费自动采集器是一款提供给用户免费使用的软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-10-28 23:04
无人值守免费采集器是一款提供给用户免费使用的软件,一款独立于网站的全自动信息采集软件,稳定、安全、低耗、自动等特点,适合中小网站每日更新,代替大量的体力劳动,将站长等工作人员从枯燥的重复性工作中解放出来。
特征
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,任何类型的信息都可以采集
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[特点] 下载上传支持续传
【特点】高速伪原创
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
【采集】支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目的任何语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
升级说明
EditorTools2升级说明
一、自动升级
1、 点击软件菜单-help-check for updates,即可自动升级(注意:目录中的+号会导致自动升级失败);
2、 如果自动升级提示解压失败或主程序未关闭,请关闭ET主程序并单独运行etrs.exe升级程序(2.4.后可用版本 14);
二、手动升级
1、 从官网下载最新的ET软件包并解压后,将旧ET文件夹中的et.mdb文件复制到新ET文件夹;
三、备份和恢复
1、 如果数据库升级,ET文件夹中会自动生成旧数据库的备份文件“etmdbdate.bak”;
2、如果需要恢复旧数据库,可以将此备份文件复制为“et.mdb”;
更新日志
无人值守自动采集器 V2.6.18:
2016 年 4 月 22 日
1、 优化:自动列表标注支持嵌入时间戳。 查看全部
网站采集器自动超文章发布(无人值守免费自动采集器是一款提供给用户免费使用的软件)
无人值守免费采集器是一款提供给用户免费使用的软件,一款独立于网站的全自动信息采集软件,稳定、安全、低耗、自动等特点,适合中小网站每日更新,代替大量的体力劳动,将站长等工作人员从枯燥的重复性工作中解放出来。
特征
【特点】 设定计划后,可24小时自动工作,无需人工干预。
[特点] 独立于网站,通过独立制作的接口支持任何网站或数据库
【特点】灵活强大的采集规则不仅是采集文章,任何类型的信息都可以采集
【特点】体积小,功耗低,稳定性好,非常适合在服务器上运行
【特点】所有规则均可导入导出,资源灵活复用
【特点】使用FTP上传文件,稳定安全
[特点] 下载上传支持续传
【特点】高速伪原创
[采集] 反向、顺序、随机可选采集文章
【采集】支持自动列表网址
[采集] 支持采集 for 网站,数据分布在多个页面
[采集] 自由设置采集数据项,可对每个数据项单独过滤排序
【采集】支持分页内容采集
[采集] 支持下载任意格式和类型的文件(包括图片和视频)
[采集] 可以突破防窃听文件
【采集】支持动态文件URL解析
[采集] 支持采集需要登录才能访问的网页
[支持] 可设置关键词采集
[支持] 可设置防止采集敏感词
[支持] 可设置图片水印
[发布] 支持以回复方式发布文章,可广泛应用于论坛、博客等项目
【发布】与采集数据分离的发布参数项可以自由对应采集数据或预设值,大大增强了发布规则的复用性
[发布] 支持随机选择发布账号
[发布] 支持发布项目的任何语言翻译
[发布] 支持编码转换,支持UBB码
【发布】可选择文件上传自动创建年月日目录
[发布] 模拟发布支持无法安装接口的网站发布操作
[支持] 程序可以正常运行
[支持] 防止网络运营商劫持HTTP功能
[支持] 可以手动发布单项采集
【支持】详细的工作流程监控和信息反馈,让您快速了解工作状态
升级说明
EditorTools2升级说明
一、自动升级
1、 点击软件菜单-help-check for updates,即可自动升级(注意:目录中的+号会导致自动升级失败);
2、 如果自动升级提示解压失败或主程序未关闭,请关闭ET主程序并单独运行etrs.exe升级程序(2.4.后可用版本 14);
二、手动升级
1、 从官网下载最新的ET软件包并解压后,将旧ET文件夹中的et.mdb文件复制到新ET文件夹;
三、备份和恢复
1、 如果数据库升级,ET文件夹中会自动生成旧数据库的备份文件“etmdbdate.bak”;
2、如果需要恢复旧数据库,可以将此备份文件复制为“et.mdb”;
更新日志
无人值守自动采集器 V2.6.18:
2016 年 4 月 22 日
1、 优化:自动列表标注支持嵌入时间戳。
网站采集器自动超文章发布(ordpress程序如何通过插件给网站关键词自动添加超链接的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-23 19:18
wordpress 程序可以快速方便地构建博客或企业网站。这个程序基本上是被网站管理员用来写博客的。无忧主机php免文件空间也是很多用wordpress建网站的客户。很多站长为了增加自己的博客流量,会定期更新一些文章让百度来收录,只要百度收录排名网站就有希望,但有些站长回应说每天发布文章很累。关键是给网站关键词加了超链接,这让他们更无语了。还有一点就是,自己发布的文章经常被别人拿走采集,那么有没有更好的发布文章的方式,而不用给关键词加超链接,让它自动添加,让来采集文章的人复制他们的网站链接。小编经过分析和实验,找到了一种一石二鸟的方法。下面就和小编一起分享一下,希望对有需要的朋友有所帮助。首先登录网站后台,找到左侧插件——安装插件——搜索(WP-AutoLink)点击安装。如下所示:
安装成功后,插件就设置好了。其实这个插件会自动给网站关键词添加超链接。具体设置如下,在左侧找到安装好的WP-AutoLink插件。点击添加关键词,例如编辑器添加了香港PHP空间,对应的超链接为: 那么具体如下:
根据上面设置关键词和对应的超链接。只需点击提交。设置好后,发布文章文章,只要收录关键词香港PHP空间,点击关键词自动跳转到指定超链接以上方法是关于ordpress的程序可以通过插件自动添加网站关键词的超链接。感谢您的支持,希望能帮助到有需要的人。无忧主机相关文章推荐阅读: 查看全部
网站采集器自动超文章发布(ordpress程序如何通过插件给网站关键词自动添加超链接的方法)
wordpress 程序可以快速方便地构建博客或企业网站。这个程序基本上是被网站管理员用来写博客的。无忧主机php免文件空间也是很多用wordpress建网站的客户。很多站长为了增加自己的博客流量,会定期更新一些文章让百度来收录,只要百度收录排名网站就有希望,但有些站长回应说每天发布文章很累。关键是给网站关键词加了超链接,这让他们更无语了。还有一点就是,自己发布的文章经常被别人拿走采集,那么有没有更好的发布文章的方式,而不用给关键词加超链接,让它自动添加,让来采集文章的人复制他们的网站链接。小编经过分析和实验,找到了一种一石二鸟的方法。下面就和小编一起分享一下,希望对有需要的朋友有所帮助。首先登录网站后台,找到左侧插件——安装插件——搜索(WP-AutoLink)点击安装。如下所示:
安装成功后,插件就设置好了。其实这个插件会自动给网站关键词添加超链接。具体设置如下,在左侧找到安装好的WP-AutoLink插件。点击添加关键词,例如编辑器添加了香港PHP空间,对应的超链接为: 那么具体如下:
根据上面设置关键词和对应的超链接。只需点击提交。设置好后,发布文章文章,只要收录关键词香港PHP空间,点击关键词自动跳转到指定超链接以上方法是关于ordpress的程序可以通过插件自动添加网站关键词的超链接。感谢您的支持,希望能帮助到有需要的人。无忧主机相关文章推荐阅读:
网站采集器自动超文章发布(极高可靠性pc软件要做到无人化的非暂时性网址自动升级神器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-23 19:17
EditorTools3绿色版(自动采集器)属于离线浏览,officeba提供editorTools3绿色版(自动采集器)免费下载,更多EditorTools3绿色版(自动采集器)officeba可用。
EditorTools3是一款无人自动采集器,非常值得你的网站站长应用。可以帮助客户很好地处理大中小型网站和企业网站。全自动数据采集实际操作,更智能的系统采集计划方案,保证您网站的高质量和即时的内容升级!EditorTools3 的出现将为您节省大量时间,将网站 站长和管理员从枯燥乏味的网站 发布工作中解放出来!
EditorTools-中小网站自动升级!
申明:本pc软件适用于非临时性网站应用,需要长时间升级。您无需对当前的社区论坛或网站进行任何更改。
EditorTools3绿色版(自动采集器)特点
1、独特的无人化
ET从设计方案之初,就以提高上位机软件自动化技术水平为切入点,以实现24小时无人化、全自动工作的目标。经测试,ET可以长时间自启动,即使以年为时间单位。
2、 极高的可靠性
如果pc软件要无人化,则规定可以长时间流畅运行。ET在这些方面进行了很多改进,以确保pc软件能够流畅、连续地工作。绝对没有可以自行生产的 PC 软件集合。导致网站崩溃的问题。
3、最小资源占用
ET与网站分离,不消耗宝贵的Web服务器WEB解决方案资源。它可以在web服务器上工作,也可以在网站站长的工作中工作在机器上。
4、严格的数据信息和网络信息安全
ET应用网站自带数据信息发布套接字或编程代码解决发布信息,不立即操作网站数据库查询,杜绝一切由ET引起的网络信息安全问题的概率。采集 信息化时,ET采用标准化的HTTP端口号,不易造成网络信息安全体系的漏洞。
5、强而灵活的效果
ET除了具备一般采集软件的功能外,基于水印图片采集、防盗取、分页查询采集、响应采集、登录采集、自行设计物品、UTF-8、@ >UBB,模拟公告…………的应用,让客户可以灵活完成各种收毛需求。
EditorTools3绿色版(全自动采集器)升级内容
1、调整一些已知问题。 查看全部
网站采集器自动超文章发布(极高可靠性pc软件要做到无人化的非暂时性网址自动升级神器)
EditorTools3绿色版(自动采集器)属于离线浏览,officeba提供editorTools3绿色版(自动采集器)免费下载,更多EditorTools3绿色版(自动采集器)officeba可用。
EditorTools3是一款无人自动采集器,非常值得你的网站站长应用。可以帮助客户很好地处理大中小型网站和企业网站。全自动数据采集实际操作,更智能的系统采集计划方案,保证您网站的高质量和即时的内容升级!EditorTools3 的出现将为您节省大量时间,将网站 站长和管理员从枯燥乏味的网站 发布工作中解放出来!
EditorTools-中小网站自动升级!
申明:本pc软件适用于非临时性网站应用,需要长时间升级。您无需对当前的社区论坛或网站进行任何更改。
EditorTools3绿色版(自动采集器)特点
1、独特的无人化
ET从设计方案之初,就以提高上位机软件自动化技术水平为切入点,以实现24小时无人化、全自动工作的目标。经测试,ET可以长时间自启动,即使以年为时间单位。
2、 极高的可靠性
如果pc软件要无人化,则规定可以长时间流畅运行。ET在这些方面进行了很多改进,以确保pc软件能够流畅、连续地工作。绝对没有可以自行生产的 PC 软件集合。导致网站崩溃的问题。
3、最小资源占用
ET与网站分离,不消耗宝贵的Web服务器WEB解决方案资源。它可以在web服务器上工作,也可以在网站站长的工作中工作在机器上。
4、严格的数据信息和网络信息安全
ET应用网站自带数据信息发布套接字或编程代码解决发布信息,不立即操作网站数据库查询,杜绝一切由ET引起的网络信息安全问题的概率。采集 信息化时,ET采用标准化的HTTP端口号,不易造成网络信息安全体系的漏洞。
5、强而灵活的效果
ET除了具备一般采集软件的功能外,基于水印图片采集、防盗取、分页查询采集、响应采集、登录采集、自行设计物品、UTF-8、@ >UBB,模拟公告…………的应用,让客户可以灵活完成各种收毛需求。
EditorTools3绿色版(全自动采集器)升级内容
1、调整一些已知问题。
网站采集器自动超文章发布(优采云采集器怎么用详情可转换app后台运行,不打扰您的其它前台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-22 17:06
优采云采集器使用介绍
优采云采集器如何使用,当前版本为最新版本是一款网络辅助免费电脑软件,大小约45.59M,优采云采集器如何上传和分享本站用户采集的下载,更高效便捷的电脑应用软件,您可以访问本站下载体验!
优采云采集器如何使用高光
优采云采集器破解版为智能网数据采集app。该应用程序功能强大,操作简单。您只需要在采集栏输入网站地址,app就会自动导出采集的内容并将数据存储在本地,让用户可以清晰的访问采集的文章和图片。全程拖拽点击,无需开发,无需了解任何人都可以使用的Web数据技术采集器。全部免费采集app,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等。
优采云采集器如何使用详情
该应用程序可以转换为在后台运行,而不会打扰您的其他前台工作。浮动窗口动态检查采集速度和数据采集等。
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足自己、团队、企业的采集需求。
创建优采云采集器账号并登录,您所有的采集任务都会自动同步保存到优采云的云服务器,不用担心采集丢失任务。
优采云采集器 账号无终端绑定限制,转换终端时采集任务也会同步更新,任务管理快捷方便。
同时支持Windows、Mac、Linux所有操作系统的采集类APP。每个平台的版本完全相似,无缝转换。
优采云采集器类似软件的使用方法
优采云采集器傻瓜教程优采云采集器破解版是一款智能网数据采集app,app功能强大,操作方便,只需要你会说话< @在采集框中输入网站地址,app可以自动导出采集的内容并将数据保存在本地,方便用户清晰的访问采集的文章和图片。全程拖拽点击,无需开发,无需了解任何人都可以使用的Web数据技术采集器。全部免费采集app,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等。
该应用程序可以转换为在后台运行,而不会打扰您的其他前台工作。浮动窗口动态检查采集速度和数据采集等。
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足自己、团队、企业的采集需求。 查看全部
网站采集器自动超文章发布(优采云采集器怎么用详情可转换app后台运行,不打扰您的其它前台)
优采云采集器使用介绍
优采云采集器如何使用,当前版本为最新版本是一款网络辅助免费电脑软件,大小约45.59M,优采云采集器如何上传和分享本站用户采集的下载,更高效便捷的电脑应用软件,您可以访问本站下载体验!
优采云采集器如何使用高光
优采云采集器破解版为智能网数据采集app。该应用程序功能强大,操作简单。您只需要在采集栏输入网站地址,app就会自动导出采集的内容并将数据存储在本地,让用户可以清晰的访问采集的文章和图片。全程拖拽点击,无需开发,无需了解任何人都可以使用的Web数据技术采集器。全部免费采集app,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等。
优采云采集器如何使用详情
该应用程序可以转换为在后台运行,而不会打扰您的其他前台工作。浮动窗口动态检查采集速度和数据采集等。
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足自己、团队、企业的采集需求。
创建优采云采集器账号并登录,您所有的采集任务都会自动同步保存到优采云的云服务器,不用担心采集丢失任务。
优采云采集器 账号无终端绑定限制,转换终端时采集任务也会同步更新,任务管理快捷方便。
同时支持Windows、Mac、Linux所有操作系统的采集类APP。每个平台的版本完全相似,无缝转换。
优采云采集器类似软件的使用方法
优采云采集器傻瓜教程优采云采集器破解版是一款智能网数据采集app,app功能强大,操作方便,只需要你会说话< @在采集框中输入网站地址,app可以自动导出采集的内容并将数据保存在本地,方便用户清晰的访问采集的文章和图片。全程拖拽点击,无需开发,无需了解任何人都可以使用的Web数据技术采集器。全部免费采集app,导出数据无限制数据可以导出到本地文件,发布到网站和数据库等。
该应用程序可以转换为在后台运行,而不会打扰您的其他前台工作。浮动窗口动态检查采集速度和数据采集等。
优采云采集器提供了丰富的采集功能,无论是采集稳定性还是采集效率,都能满足自己、团队、企业的采集需求。
网站采集器自动超文章发布(优采云采集器V2009SP204月29日数据原理(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-20 03:07
优采云采集器是主要主流文章系统、论坛系统等多线程内容采集发布程序。使用优采云采集器你可以立即创建一个内容丰富的网站。zol 提供了优采云采集器 的正式版下载。
优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您采集 发布任意网页数据到远程服务器,自定义
优采云采集器 标志
优采云采集器 标志
正确的用户cms系统模块,不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅< @文章、东易文章、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access、MySql、MS SqlServer。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架才可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我可以采集先不发布采集,有空再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器V9.21 版本
1:自动获取cookie功能优化
2:数据库发布增加事务,优化数据库发布速度
3:数据转换速度优化(针对Mysql和SqlServer数据库的导入),同时去除URL数据库的空逻辑
4:html标签处理错误问题处理
5:json提取和处理数字转换成科学记数法
6:处理发布测试时图片上传无效问题
7:采集内容页处理错误时,添加当前错误标签的提示,快速定位错误标签
8:批量编辑任务,增加操作范围
9:处理循环匹配和空格匹配问题
10:增加刷新组统计数据的刷新
11:后分页处理
12:部分功能的逻辑优化
优采云采集器V9.9 版
1.优化效率,修复运行大量任务时卡住的问题
2.修复大量代理时配置文件被锁定,程序退出的问题
3.修复某些情况下无法连接MySQL的问题
4.其他界面和功能优化
优采云采集器V9.8 版本
1:“远程管理”正式升级为“私有云”,全面优化调整。
2:发布模块添加自定义头信息。
3:采集线程间隔调整,增加自定义间隔设置。
4:修复了长时间使用后运行滞后的问题。
5:二级代理,IP输入框改为普通TextBox。增加代理免认证功能。
6:修复丢包和死循环问题。
7:ftp上传,添加超时处理。
优采云采集器优采云采集器V9.6 版本
1:多级URL列表,增加列表名称重命名功能和上下调整功能。
2:修复SqlServer数据库格式下采集的个数无法正确显示的问题。
3:添加新标签时,如果上次编辑的是固定格式数据,新标签会显示错误内容。
4:修复数据包登录时登录失败,无法自动重新登录的问题。
5:修复FTP上传失败后本地数据也被删除的问题。
6:修复发送采集时上传文件FTP失败的问题。
7:优化保存Excel时PageUrl为ID显示的列的位置。
8:修复任务不能多选的问题。
9:使用采集发布时,调整了最大发布数的功能(以前:最大发布数无效。现在:最大发布数有效,之前未发布的数据不会任务完成后再次发布)
10:修复存储过程语句数据为空时误判断为“语句错误”的问题。
11:二级代理功能,修复定时拨号无效问题。
12:二级代理功能,优化定时访问API功能,重新获取时自动删除上一批数据。
13:增加批量url的数据库导入方式
14:导出到文件时,添加了不合理命名错误的提示。
15:导出规则时,对于规则名称过长的规则,增加了提示功能。
16:编辑规则时,对于“收录”和“排除”数据,复制粘贴多行时,会自动分成多条数据。
17:增加对芝麻代理合作的支持。
优采云采集器V9.4 版本
1.批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改
2.标签组合,增加对循环组合的支持。
3、优化URL库重定位的逻辑,大大加快了大URL库下的任务加载速度,优化了URL库重定位的内存占用。
4. 数据库发布模块,增加对“插入忽略”模式的支持
5、新增任务云备份和同步功能 查看全部
网站采集器自动超文章发布(优采云采集器V2009SP204月29日数据原理(组图))
优采云采集器是主要主流文章系统、论坛系统等多线程内容采集发布程序。使用优采云采集器你可以立即创建一个内容丰富的网站。zol 提供了优采云采集器 的正式版下载。
优采云采集器系统支持远程图片下载、图片批量水印、Flash下载、下载文件地址检测、自制发布cms模块参数、自定义发布内容等采集器。优采云采集器对于数据采集,可以分为两部分,一是采集数据,二是发布数据。
优采云采集器 功能:
优采云采集器()是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以帮助您采集 发布任意网页数据到远程服务器,自定义
优采云采集器 标志
优采云采集器 标志
正确的用户cms系统模块,不管你的网站是什么系统,都可以使用优采云采集器,系统自带的模块文件支持:风迅< @文章、东易文章、东网论坛、PHPWIND论坛、Discuz论坛、phpcms文章、phparticle文章、LeadBBS论坛、魔幻论坛、德德cms文章、Xydw文章、景云文章等模块文件。更多cms模块请参考制作修改,或到官方网站与大家交流。同时,您还可以利用系统的数据导出功能,利用系统内置的标签,将采集到达的数据对应表的字段导出到任何本地Access、MySql、MS SqlServer。
是用Visual C编写的,可以在Windows2008下独立运行(windows2003自带.net1.1框架。优采云采集器最新版是2008版,需要升级到.net2.0框架才可以使用),如果在Windows2000、Xp等环境下使用,请下载.net框架2.0或更高环境组件来自微软官方。优采云采集器V2009 SP2 4 月 29 日
数据采集原理
优采云采集器如何抓取数据取决于你的规则。如果要获取某个栏目网页中的所有内容,需要先选择该网页的网址。这是网址。程序根据你的规则抓取列表页面,从中分析出网址,然后抓取获取到网址的网页内容。然后根据你的采集规则分析下载的网页,将标题内容和其他信息分开保存。如果选择下载图片等网络资源,程序会分析采集收到的数据,找出图片、资源等的下载地址并下载到本地。
数据发布原则
我们下载完数据采集后,数据默认保存在本地。我们可以使用以下方法来处理数据。
1、 不会进行任何处理。因为数据本身是存放在数据库中的(access,db3、mysql,sqlserver),如果只是查看数据,可以直接用相关软件打开。
2、Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。
3、 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的SQL语句将数据导入到数据库中。
4、另存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。
工作过程
优采云采集器采集 数据分为两步,一是采集数据,二是发布数据。这两个过程可以分开。
1、采集数据,包括采集 URL和采集内容。这个过程就是获取数据的过程。我们制定规则,在采集的过程中可视为对内容的处理。
2、发布内容就是将数据发布到自己的论坛。cms的过程,也是实现数据存在的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体使用其实很灵活,可以根据实际情况确定。比如我可以采集先不发布采集,有空再发布,或者同时发布采集,或者先做发布配置,也可以在采集中完成,然后添加发布配置。总之,具体的过程由你决定。优采云采集器的强大功能之一还体现在灵活性上。
优采云采集器V9.21 版本
1:自动获取cookie功能优化
2:数据库发布增加事务,优化数据库发布速度
3:数据转换速度优化(针对Mysql和SqlServer数据库的导入),同时去除URL数据库的空逻辑
4:html标签处理错误问题处理
5:json提取和处理数字转换成科学记数法
6:处理发布测试时图片上传无效问题
7:采集内容页处理错误时,添加当前错误标签的提示,快速定位错误标签
8:批量编辑任务,增加操作范围
9:处理循环匹配和空格匹配问题
10:增加刷新组统计数据的刷新
11:后分页处理
12:部分功能的逻辑优化
优采云采集器V9.9 版
1.优化效率,修复运行大量任务时卡住的问题
2.修复大量代理时配置文件被锁定,程序退出的问题
3.修复某些情况下无法连接MySQL的问题
4.其他界面和功能优化
优采云采集器V9.8 版本
1:“远程管理”正式升级为“私有云”,全面优化调整。
2:发布模块添加自定义头信息。
3:采集线程间隔调整,增加自定义间隔设置。
4:修复了长时间使用后运行滞后的问题。
5:二级代理,IP输入框改为普通TextBox。增加代理免认证功能。
6:修复丢包和死循环问题。
7:ftp上传,添加超时处理。
优采云采集器优采云采集器V9.6 版本
1:多级URL列表,增加列表名称重命名功能和上下调整功能。
2:修复SqlServer数据库格式下采集的个数无法正确显示的问题。
3:添加新标签时,如果上次编辑的是固定格式数据,新标签会显示错误内容。
4:修复数据包登录时登录失败,无法自动重新登录的问题。
5:修复FTP上传失败后本地数据也被删除的问题。
6:修复发送采集时上传文件FTP失败的问题。
7:优化保存Excel时PageUrl为ID显示的列的位置。
8:修复任务不能多选的问题。
9:使用采集发布时,调整了最大发布数的功能(以前:最大发布数无效。现在:最大发布数有效,之前未发布的数据不会任务完成后再次发布)
10:修复存储过程语句数据为空时误判断为“语句错误”的问题。
11:二级代理功能,修复定时拨号无效问题。
12:二级代理功能,优化定时访问API功能,重新获取时自动删除上一批数据。
13:增加批量url的数据库导入方式
14:导出到文件时,添加了不合理命名错误的提示。
15:导出规则时,对于规则名称过长的规则,增加了提示功能。
16:编辑规则时,对于“收录”和“排除”数据,复制粘贴多行时,会自动分成多条数据。
17:增加对芝麻代理合作的支持。
优采云采集器V9.4 版本
1.批量更新URL,日期可以支持比今天更大的数据。标签可以与多个参数同步更改
2.标签组合,增加对循环组合的支持。
3、优化URL库重定位的逻辑,大大加快了大URL库下的任务加载速度,优化了URL库重定位的内存占用。
4. 数据库发布模块,增加对“插入忽略”模式的支持
5、新增任务云备份和同步功能
网站采集器自动超文章发布(网站采集器自动超文章发布程序及微信插件实现批量发布)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-20 03:05
网站采集器自动超文章发布程序及微信插件实现批量发布,现在不少网站采集器可以自动生成一个标题带有可点击链接的超链接,那么我们也能用bs跳转到指定站点,如yahoo!aldrich。
使用百度指数实现批量发布:
是不是觉得用百度指数比较麻烦,麻烦到好像自己不会写一样,其实只要编写一小部分代码,就可以批量化登录一些大站,然后批量发布到很多网站,然后再找一个好的浏览器运行就可以了。阿里云也有类似的技术,不过建议购买云服务器,会比较便宜,关键是系统是公开源代码的。是不是很心动。有了这个以后你就可以做一个批量发布的系统,然后再去购买云服务器和存储空间,按年一年一年的买,省钱。
然后就可以通过搜索系统中的关键词,然后找到你要上架的东西,然后采集一遍,发布上架就可以了。当然采集功能不要忘记,其它功能也是必须的。这个要根据具体的项目需求来分析了。欢迎交流!!。
采集豆瓣影评
用本地镜像站如果你是做大型采集站。那必须是原生地服务器。iis企业版购买啊。或者配置虚拟空间的时候勾选ssl安全协议。这是购买域名和服务器必须知道的。iis才是采集类站点的不二之选。 查看全部
网站采集器自动超文章发布(网站采集器自动超文章发布程序及微信插件实现批量发布)
网站采集器自动超文章发布程序及微信插件实现批量发布,现在不少网站采集器可以自动生成一个标题带有可点击链接的超链接,那么我们也能用bs跳转到指定站点,如yahoo!aldrich。
使用百度指数实现批量发布:
是不是觉得用百度指数比较麻烦,麻烦到好像自己不会写一样,其实只要编写一小部分代码,就可以批量化登录一些大站,然后批量发布到很多网站,然后再找一个好的浏览器运行就可以了。阿里云也有类似的技术,不过建议购买云服务器,会比较便宜,关键是系统是公开源代码的。是不是很心动。有了这个以后你就可以做一个批量发布的系统,然后再去购买云服务器和存储空间,按年一年一年的买,省钱。
然后就可以通过搜索系统中的关键词,然后找到你要上架的东西,然后采集一遍,发布上架就可以了。当然采集功能不要忘记,其它功能也是必须的。这个要根据具体的项目需求来分析了。欢迎交流!!。
采集豆瓣影评
用本地镜像站如果你是做大型采集站。那必须是原生地服务器。iis企业版购买啊。或者配置虚拟空间的时候勾选ssl安全协议。这是购买域名和服务器必须知道的。iis才是采集类站点的不二之选。
网站采集器自动超文章发布( 网页数据采集利器优采云采集器采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-15 12:13
网页数据采集利器优采云采集器采集器)
一、优采云采集器
优采云采集器是一款非常强大且易于操作的网页数据采集工具,界面简洁大方,可以快速自动导出和编辑数据,包括网页图片文字上面的也可以解析提取,采集的内容很丰富。
特征
1、财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2、各大新闻门户网站实时监控,自动更新上传最新消息;
3、 监控竞争对手的最新信息,包括商品价格和库存;
4、 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、关注最新房产相关网站、采集新房、二手房;
7、采集主要车型网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、 采集行业网站产品目录及产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
二、优采云采集器
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Mac /Linux可用,优采云采集器采集和导出都是免费的,无限制的,放心,可以后台运行,实时显示速度。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
该软件功能强大,操作简单,是为广大无编程基础的产品、运营、销售、金融、新闻、电商和数据分析从业者,以及政府机关和学术研究等用户量身打造的一款产品。
优采云采集器不仅可以自动化数据采集,还可以清洗采集过程中的数据。可以在数据源头实现各种内容过滤。
通过使用优采云采集器,用户可以快速准确地获取海量网页数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
特征
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作的顺序。
高级设置满足更多采集需求。
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
软件按照采集的处理和提取规则自动对采集进行批量处理。
快速稳定,实时显示采集速度和进程。
软件可切换后台运行,不打扰前台工作。
4、导出发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件。
并一键发布到cms网站/database/微信公众号等媒体 查看全部
网站采集器自动超文章发布(
网页数据采集利器优采云采集器采集器)
一、优采云采集器
优采云采集器是一款非常强大且易于操作的网页数据采集工具,界面简洁大方,可以快速自动导出和编辑数据,包括网页图片文字上面的也可以解析提取,采集的内容很丰富。
特征
1、财务数据,如季报、年报、财报,自动包括最新的每日净值采集;
2、各大新闻门户网站实时监控,自动更新上传最新消息;
3、 监控竞争对手的最新信息,包括商品价格和库存;
4、 监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5、 采集最新最全的招聘信息;
6、关注最新房产相关网站、采集新房、二手房;
7、采集主要车型网站具体新车和二手车信息;
8、发现并采集潜在客户信息;
9、 采集行业网站产品目录及产品信息;
10、 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
二、优采云采集器
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Mac /Linux可用,优采云采集器采集和导出都是免费的,无限制的,放心,可以后台运行,实时显示速度。
优采云采集器是原谷歌搜索技术团队基于人工智能技术开发的新一代网页采集软件。
该软件功能强大,操作简单,是为广大无编程基础的产品、运营、销售、金融、新闻、电商和数据分析从业者,以及政府机关和学术研究等用户量身打造的一款产品。
优采云采集器不仅可以自动化数据采集,还可以清洗采集过程中的数据。可以在数据源头实现各种内容过滤。
通过使用优采云采集器,用户可以快速准确地获取海量网页数据,彻底解决了人工采集数据面临的各种问题,降低了获取信息的成本,提高了工作效率。
特征
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程。
自动记录和模拟网页操作的顺序。
高级设置满足更多采集需求。
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单。
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
软件按照采集的处理和提取规则自动对采集进行批量处理。
快速稳定,实时显示采集速度和进程。
软件可切换后台运行,不打扰前台工作。
4、导出发布采集的数据
采集的数据自动制表,字段可自由配置。
支持数据导出到Excel等本地文件。
并一键发布到cms网站/database/微信公众号等媒体
网站采集器自动超文章发布(GitHubPages这么一个平台如何使用Pages)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-14 12:20
从它诞生到现在,每天都有无数人在上面留下自己的足迹。他们用它来记录自己的生活、表达自己的情感并分享见解。这一切都离不开一个可以承载文字的平台,一个独立又独立的平台。我控制的一个平台,GitHub Pages 就是这样一个平台。
在该平台上,您可以使用自己的个性化域名;您可以从众多主题中选择最适合您的主题。如果您是技术极客,还可以根据自己的喜好设计自己的个性化页面;您可以在线创建和发布网站,也可以通过客户端工具或命令行在本地管理网站和内容。
你可以通过GitHub Pages充分展示和输出你自己的价值,甚至可以把它变成你自己的互联网“身份证”。
为什么使用 GitHub 页面
如果将其视为轻量级的个人博客服务,GitHub Pages 相比 WordPress 等建站服务有哪些优势?
当然,作为免费服务,我们也必须遵守 GitHub 官方的建议和限制。使用时,项目和网站的大小不要超过1GB,不要过于频繁地更新网站。内容(每小时不超过 10 个版本),每月带宽使用限制为 100GB。
总的来说,GitHub Pages 仍然可以说是中小型博客或者项目主页的最佳选择之一。
如何使用 GitHub 页面
介绍了这么多,下面来详细说一下如何使用。
基本页面生成
首先需要注册一个GitHub账号,在个人主界面选择新建一个Repository。
进入页面后,在Repository name中填写域名,格式为username.GitHub.io。
创建成功后点击右上角的设置
找到GitHub Pages选项,选择一个GitHub官方提供的主题
这里我们随意选择一个主题Cayman,看看他的效果怎么样
选择完成后,GitHub Pages会自动为你生成网站,点击它跳转的界面上的Commit changes按钮,即可访问网站。
在浏览器中输入你的项目名称,比如brick713.GitHub.io,就可以看到你刚刚选择的主题的个人网站页面。
此时,如果你只是想做一份可以随时上网的简历,那么你只需要在GitHub Pages项目的首页修改你的index.md文件,比如我给的模板。
修改完成后,点击上图左下角的Commit Changes,然后访问你的自定义域名,可以看到如下样式。
如果你想做一个功能更丰富的博客,那我们继续往下看。
配置自定义域名,免费使用HTTPS
2018年5月1日之后,GitHub Pages开始免费提供自定义域名开启HTTPS的功能,大大简化了操作流程。现在用户不再需要提供自己的证书,只需要为自己的域名使用CNAME。只需指向您自己的 GitHub Pages 域名即可。
首先,将解析记录添加到您的 DNS 解析中。比如我选择添加子域blog.moyu.life,指向我刚刚CNAME自定义的GitHub Pages域名brick713.GitHub.io。添加完成后,等待DNS解析生效(DNS解析记录全局生效可能需要几分钟)。
然后回到一开始进入的设置界面,找到GitHub Pages的设置,填写我们刚刚创建的子域名,以我自己的blog.moyu.life为例,点击保存。
保存后,GitHub 需要一定的时间来生成证书并确认域名解析是否正常。我们只需要耐心等待。成功后会显示如下结果
现在我们再次访问blog.moyu.life,会发现我们自定义的域名和HTTPS都有效!可以看到证书是由知名组织Let's Encrypt提供的。
网站同步
现在我们有了网站的基本功能,我们需要尝试管理博客的内容,并为博客添加一些更个性化的设置,官方提供了两种方式:
如果你没有任何Git基础,不想进行一些繁琐的配置,那么我推荐你使用桌面客户端进行管理。如果你有一定的技术基础,那么Git方式更适合你。这里我将介绍这两种方法。
首先在命令行切换到你自定义的路径,然后Clone down你的项目(操作需要在Mac的Terminal中完成,Windows系统可以使用Git-bash。)这里注意路径和用户名需要将根据您的个人情况进行更换。
cd ~/Path git clone https://GitHub.com/username/username.GitHub.io
然后输入你项目的文件,创建一个文章。
cd username.GitHub.io
echo "Hello World 我爱这个世界" > index.md
然后按照Git提交流程上传我们新创建的文章。
git add --all
git commit -m "Firs Push"
git push -u origin master
这里可能会遇到以下情况:
根据他的提示,我们可以依次输入注册GitHub的邮箱和用户名:
git config user.email "你的邮箱"
git config user.name "你的用户名"
之后他可能会要求你输入你的GitHub账号和密码,不用担心,正常输入即可。当我们看到这样的改进时,就证明提交成功了。
你可以到我们的网站主页看看有没有什么变化。
如果您使用的是 GitHub 桌面客户端,那就更简单了。客户端下载安装完成后,按照客户端提示正常登录你的GitHub账号。然后克隆你的 GitHub Pages 项目。
等待克隆完成后,界面将显示几种管理和修改项目的方法。
这里我选择使用Sublime Text进行管理,将初始index.md中的内容改为Hello World。我也爱这个世界保存,然后在客户端就可以看到文件的变化了,我们先点击左下角master的Commit to,然后点击Fetch origin上传内容。
然后你会发现你的主页也发生了相应的变化。至此,你已经基本掌握了网站管理的基本流程和文章发布的基本流程。现在我们将学习如何使用静态模板系统来管理博客。
GitHub Pages 生成工具
经过上面的步骤,你的现在有了一个简单的页面,但是还远远不能满足我们的需求。我们需要使用静态模板系统,让生产接管你博客的文章的生成,让你把更多的经验投入到创作中。我们以GitHub官方推荐的Jekyll为例。
因为 Jekyll 是一个基于 Ruby 的静态网页生成系统,所以我们首先要安装 Ruby 环境,在 Mac 上我们可以使用 Homebrew 安装。如果是其他操作系统,可以参考Ruby官方安装文档进行安装。
brew install ruby
Ruby安装完成后,执行以下命令即可完成Jekyll的安装。
gem install jekyll bundler
然后输入你克隆下来的GitHub Pages项目的路径,例如:
执行以下命令:
jekyll new . --force
完成后,Jekyll 会生成你指定目录下的所有文件。可以使用bundle exec jekyll serve命令,然后访问127.0.0.1:4000即可查看,初始界面如下图。
默认的界面看起来非常简单丑陋,不过没关系,你可以在这些网站中根据自己的喜好找到一些漂亮的主题。
安装方法非常简单。一般情况下,你只需要下载主题包并完全解压,复制到你的GitHub Pages项目目录,覆盖你之前的文件即可。对于一些特殊的主题,请参考作者给出的安装步骤。这里我随机换了一个主题。
主题中的所有关键配置都在 _config.yml 文件中。具体内容可以根据个人喜好和不同主题支持的功能进行修改,这里不再展开。
至此,完整的设置过程就结束了,你可以正常访问你一路配置的博客了。接下来,您只需要找到一个方便的 Markdown 编辑器来编辑本地 GitHub Pages 项目中的 _posts 文件夹。文章 并使用上述两种方法将 文章 同步到 GitHub。需要注意的是文章的内容和标题需要用Jekyll的格式写。
文章 的文件名格式如下:
年-月-日-标题.markdown
文章 以下 YAML 头信息必须位于内容的顶部:
---
layout: post
title: Blogging Like a Hacker
---
尾巴
其实除了 Jekyll 之外,还有很多第三方静态模板系统来搭建 GitHub Pages。例如:
他们在自己的基础上实现了更多的功能,如分析统计、搜索、评论系统、广告、分享系统等。喜欢折腾的同学不妨一试,如果以后有机会,希望能更详细的分享给大家。 查看全部
网站采集器自动超文章发布(GitHubPages这么一个平台如何使用Pages)
从它诞生到现在,每天都有无数人在上面留下自己的足迹。他们用它来记录自己的生活、表达自己的情感并分享见解。这一切都离不开一个可以承载文字的平台,一个独立又独立的平台。我控制的一个平台,GitHub Pages 就是这样一个平台。
在该平台上,您可以使用自己的个性化域名;您可以从众多主题中选择最适合您的主题。如果您是技术极客,还可以根据自己的喜好设计自己的个性化页面;您可以在线创建和发布网站,也可以通过客户端工具或命令行在本地管理网站和内容。
你可以通过GitHub Pages充分展示和输出你自己的价值,甚至可以把它变成你自己的互联网“身份证”。
为什么使用 GitHub 页面
如果将其视为轻量级的个人博客服务,GitHub Pages 相比 WordPress 等建站服务有哪些优势?
当然,作为免费服务,我们也必须遵守 GitHub 官方的建议和限制。使用时,项目和网站的大小不要超过1GB,不要过于频繁地更新网站。内容(每小时不超过 10 个版本),每月带宽使用限制为 100GB。
总的来说,GitHub Pages 仍然可以说是中小型博客或者项目主页的最佳选择之一。
如何使用 GitHub 页面
介绍了这么多,下面来详细说一下如何使用。
基本页面生成
首先需要注册一个GitHub账号,在个人主界面选择新建一个Repository。
进入页面后,在Repository name中填写域名,格式为username.GitHub.io。
创建成功后点击右上角的设置
找到GitHub Pages选项,选择一个GitHub官方提供的主题
这里我们随意选择一个主题Cayman,看看他的效果怎么样
选择完成后,GitHub Pages会自动为你生成网站,点击它跳转的界面上的Commit changes按钮,即可访问网站。
在浏览器中输入你的项目名称,比如brick713.GitHub.io,就可以看到你刚刚选择的主题的个人网站页面。
此时,如果你只是想做一份可以随时上网的简历,那么你只需要在GitHub Pages项目的首页修改你的index.md文件,比如我给的模板。
修改完成后,点击上图左下角的Commit Changes,然后访问你的自定义域名,可以看到如下样式。
如果你想做一个功能更丰富的博客,那我们继续往下看。
配置自定义域名,免费使用HTTPS
2018年5月1日之后,GitHub Pages开始免费提供自定义域名开启HTTPS的功能,大大简化了操作流程。现在用户不再需要提供自己的证书,只需要为自己的域名使用CNAME。只需指向您自己的 GitHub Pages 域名即可。
首先,将解析记录添加到您的 DNS 解析中。比如我选择添加子域blog.moyu.life,指向我刚刚CNAME自定义的GitHub Pages域名brick713.GitHub.io。添加完成后,等待DNS解析生效(DNS解析记录全局生效可能需要几分钟)。
然后回到一开始进入的设置界面,找到GitHub Pages的设置,填写我们刚刚创建的子域名,以我自己的blog.moyu.life为例,点击保存。
保存后,GitHub 需要一定的时间来生成证书并确认域名解析是否正常。我们只需要耐心等待。成功后会显示如下结果
现在我们再次访问blog.moyu.life,会发现我们自定义的域名和HTTPS都有效!可以看到证书是由知名组织Let's Encrypt提供的。
网站同步
现在我们有了网站的基本功能,我们需要尝试管理博客的内容,并为博客添加一些更个性化的设置,官方提供了两种方式:
如果你没有任何Git基础,不想进行一些繁琐的配置,那么我推荐你使用桌面客户端进行管理。如果你有一定的技术基础,那么Git方式更适合你。这里我将介绍这两种方法。
首先在命令行切换到你自定义的路径,然后Clone down你的项目(操作需要在Mac的Terminal中完成,Windows系统可以使用Git-bash。)这里注意路径和用户名需要将根据您的个人情况进行更换。
cd ~/Path git clone https://GitHub.com/username/username.GitHub.io
然后输入你项目的文件,创建一个文章。
cd username.GitHub.io
echo "Hello World 我爱这个世界" > index.md
然后按照Git提交流程上传我们新创建的文章。
git add --all
git commit -m "Firs Push"
git push -u origin master
这里可能会遇到以下情况:
根据他的提示,我们可以依次输入注册GitHub的邮箱和用户名:
git config user.email "你的邮箱"
git config user.name "你的用户名"
之后他可能会要求你输入你的GitHub账号和密码,不用担心,正常输入即可。当我们看到这样的改进时,就证明提交成功了。
你可以到我们的网站主页看看有没有什么变化。
如果您使用的是 GitHub 桌面客户端,那就更简单了。客户端下载安装完成后,按照客户端提示正常登录你的GitHub账号。然后克隆你的 GitHub Pages 项目。
等待克隆完成后,界面将显示几种管理和修改项目的方法。
这里我选择使用Sublime Text进行管理,将初始index.md中的内容改为Hello World。我也爱这个世界保存,然后在客户端就可以看到文件的变化了,我们先点击左下角master的Commit to,然后点击Fetch origin上传内容。
然后你会发现你的主页也发生了相应的变化。至此,你已经基本掌握了网站管理的基本流程和文章发布的基本流程。现在我们将学习如何使用静态模板系统来管理博客。
GitHub Pages 生成工具
经过上面的步骤,你的现在有了一个简单的页面,但是还远远不能满足我们的需求。我们需要使用静态模板系统,让生产接管你博客的文章的生成,让你把更多的经验投入到创作中。我们以GitHub官方推荐的Jekyll为例。
因为 Jekyll 是一个基于 Ruby 的静态网页生成系统,所以我们首先要安装 Ruby 环境,在 Mac 上我们可以使用 Homebrew 安装。如果是其他操作系统,可以参考Ruby官方安装文档进行安装。
brew install ruby
Ruby安装完成后,执行以下命令即可完成Jekyll的安装。
gem install jekyll bundler
然后输入你克隆下来的GitHub Pages项目的路径,例如:
执行以下命令:
jekyll new . --force
完成后,Jekyll 会生成你指定目录下的所有文件。可以使用bundle exec jekyll serve命令,然后访问127.0.0.1:4000即可查看,初始界面如下图。
默认的界面看起来非常简单丑陋,不过没关系,你可以在这些网站中根据自己的喜好找到一些漂亮的主题。
安装方法非常简单。一般情况下,你只需要下载主题包并完全解压,复制到你的GitHub Pages项目目录,覆盖你之前的文件即可。对于一些特殊的主题,请参考作者给出的安装步骤。这里我随机换了一个主题。
主题中的所有关键配置都在 _config.yml 文件中。具体内容可以根据个人喜好和不同主题支持的功能进行修改,这里不再展开。
至此,完整的设置过程就结束了,你可以正常访问你一路配置的博客了。接下来,您只需要找到一个方便的 Markdown 编辑器来编辑本地 GitHub Pages 项目中的 _posts 文件夹。文章 并使用上述两种方法将 文章 同步到 GitHub。需要注意的是文章的内容和标题需要用Jekyll的格式写。
文章 的文件名格式如下:
年-月-日-标题.markdown
文章 以下 YAML 头信息必须位于内容的顶部:
---
layout: post
title: Blogging Like a Hacker
---
尾巴
其实除了 Jekyll 之外,还有很多第三方静态模板系统来搭建 GitHub Pages。例如:
他们在自己的基础上实现了更多的功能,如分析统计、搜索、评论系统、广告、分享系统等。喜欢折腾的同学不妨一试,如果以后有机会,希望能更详细的分享给大家。
网站采集器自动超文章发布(网站采集器自动超文章发布引擎的特点及应用介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-14 04:03
网站采集器自动超文章发布引擎一直是社会网络分析领域中不可或缺的环节,其采用了人工智能技术完成信息的海量抓取和准确定位。每次创建一个新网站也大大增加了网站的负荷,因此如何降低网站运营成本就成为了重中之重。对于一个个人站点来说,最合理的成本是建立搜索引擎+站内seo,但是这样的网站是高成本的,而且站长投入的精力也大大增加,如果有大的公司需要建立这样的网站,也会选择买域名和空间来建立,因此很多个人站长并不会去做,毕竟买域名和空间比做网站会更简单,更快,而且你可以接手已有网站,这样免去了运营的麻烦,但是对于一些大型公司来说,需要创建这样网站的还是不少的,因此在这种情况下一款合适的软件就显得十分重要了。
对于刚接触seo,还不知道什么是最佳网站下载器的,一款seo工具套装可以帮助你:快速,简单,轻量级seo工具。seo软件套装不仅可以有效缩短网站获取优质结果的时间,还能为你的站点保驾护航。开始之前我们先来简单的讲解下自动生成网站的技术,国内的seo工具套装网站每款套件中都包含自动生成网站的功能,但是很多不具备seo的服务,为什么呢?因为自动生成网站的弊端有四个:。
1、安全性;
2、备份机制;
3、登录机制;
4、权重更新机制等等,你学会了自动生成网站的弊端,你可以根据自己需要去挑选一款适合自己的工具。现在来看看这款软件的特点:内置高级seo转化工具,这些高级的功能为品牌代言,大家用百度搜索下.将其注册。下面我们来看看软件具体的一些功能的介绍:【高级】高级转化工具,这些工具为品牌服务。
1、高级网站降权处理工具;
3、网站流量变化分析工具;
4、网站查询检查工具;
5、网站生成脚本;
6、网站下载助手工具。【转换工具】转换工具十分简单,你只需要写好需要转换的地方即可,你可以直接让他转换成html页面,也可以自己写一个转换工具,基本上没有转换工具的复杂工具。【数据分析】【body长尾关键词分析】【alt字符分析】【标题直链分析】【网站host数据分析】【网站查询检查工具】【自动化服务】【数据统计】【图片和图片库】【新闻源查询】【内链分析】【收录状况】【友情链接分析】【keywords关键词分析】【百度蜘蛛分析】【百度搜索收录】【百度百科查询】【百度云分析】【百度网盘】【百度图片查询】【360云分析】【知道回答】【百度贴吧】【百度短文章】【百度文库】【百度经验】【百度翻译】【百度搜索】【百度阅读】【百度行业查询】【百度识图】【百度云图库】【百度表单】【百度红包】【。 查看全部
网站采集器自动超文章发布(网站采集器自动超文章发布引擎的特点及应用介绍)
网站采集器自动超文章发布引擎一直是社会网络分析领域中不可或缺的环节,其采用了人工智能技术完成信息的海量抓取和准确定位。每次创建一个新网站也大大增加了网站的负荷,因此如何降低网站运营成本就成为了重中之重。对于一个个人站点来说,最合理的成本是建立搜索引擎+站内seo,但是这样的网站是高成本的,而且站长投入的精力也大大增加,如果有大的公司需要建立这样的网站,也会选择买域名和空间来建立,因此很多个人站长并不会去做,毕竟买域名和空间比做网站会更简单,更快,而且你可以接手已有网站,这样免去了运营的麻烦,但是对于一些大型公司来说,需要创建这样网站的还是不少的,因此在这种情况下一款合适的软件就显得十分重要了。
对于刚接触seo,还不知道什么是最佳网站下载器的,一款seo工具套装可以帮助你:快速,简单,轻量级seo工具。seo软件套装不仅可以有效缩短网站获取优质结果的时间,还能为你的站点保驾护航。开始之前我们先来简单的讲解下自动生成网站的技术,国内的seo工具套装网站每款套件中都包含自动生成网站的功能,但是很多不具备seo的服务,为什么呢?因为自动生成网站的弊端有四个:。
1、安全性;
2、备份机制;
3、登录机制;
4、权重更新机制等等,你学会了自动生成网站的弊端,你可以根据自己需要去挑选一款适合自己的工具。现在来看看这款软件的特点:内置高级seo转化工具,这些高级的功能为品牌代言,大家用百度搜索下.将其注册。下面我们来看看软件具体的一些功能的介绍:【高级】高级转化工具,这些工具为品牌服务。
1、高级网站降权处理工具;
3、网站流量变化分析工具;
4、网站查询检查工具;
5、网站生成脚本;
6、网站下载助手工具。【转换工具】转换工具十分简单,你只需要写好需要转换的地方即可,你可以直接让他转换成html页面,也可以自己写一个转换工具,基本上没有转换工具的复杂工具。【数据分析】【body长尾关键词分析】【alt字符分析】【标题直链分析】【网站host数据分析】【网站查询检查工具】【自动化服务】【数据统计】【图片和图片库】【新闻源查询】【内链分析】【收录状况】【友情链接分析】【keywords关键词分析】【百度蜘蛛分析】【百度搜索收录】【百度百科查询】【百度云分析】【百度网盘】【百度图片查询】【360云分析】【知道回答】【百度贴吧】【百度短文章】【百度文库】【百度经验】【百度翻译】【百度搜索】【百度阅读】【百度行业查询】【百度识图】【百度云图库】【百度表单】【百度红包】【。
网站采集器自动超文章发布(CMS采集大挪移、换行维护网站的发帖量等功能介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-10-12 21:25
优采云cms采集器目前包括cms采集移动、维护王、同步更新王,你可以采集其他网站并且所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护发帖网站 数量等。
特征
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松实现千人在线热门论坛的效果(部分不支持按IP统计在线人数的论坛,如DVbbs/PHPWind);
您可以采集网站/forum 主题和所有回复,网站/forums 80% 可以是采集,您可以将文章的内容保存到本地后发布;
您可以将网站论坛A版块或专栏的内容批量转发采集到您自己的网站或论坛指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖ID和回复ID分开,允许部分成员发布所有主题,让其他成员全部回复,ID号成员选择发布;
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入您自己的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天将采集的最新内容发布到指定栏目;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行、HTML预览,使用更好更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章都按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以在论坛内容中采集网站/超级链接,或者屏蔽该链接
您可以从采集网站/论坛下载文章的图片到本地,然后通过FTP上传附件和图片到您的网站空间;
图片名称可以随意;
支持任务栏图标隐藏显示的最小化;
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后、内容中自动添加自定义关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看网站论坛帖子;
软件特点
1、创新多用户随机选帖回复帖,模拟真实热点论坛的热点效果
2、原创可以采集回复,采集的分页会贴出来作为回复
3、 原创百度优化SEO功能伪原创 任何软件都没有此功能
4、 最初创建随机回复,您可以将帖子中的所有回复按顺序重新排列。实现不同于原版网站的真实效果
5、 独创的自动回复功能,可以模拟会员回复,让真正的论坛成员感受到温暖,在没人赞成发帖的情况下发帖也不会失去兴趣。
6、独创的真实会员在线模拟功能,让数十万会员在线,查看和回复不同版块的帖子。让会员感受什么是大而受欢迎的论坛
7、独创多网站采集,多版块可以同时发布文章的功能,你可以呼吸采集成百上千网站 版块,同时在不同版块乱序发布。您不再可以在发布另一个部分之前只发布一个部分(将其视为假)。什么是论坛采集管理系统,这个软件很好的诠释了这个意思
指示
1 下载完成后,不要运行压缩包中的软件,直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
更新日志
1、优化UI界面的流畅度
2、修复已知错误 查看全部
网站采集器自动超文章发布(CMS采集大挪移、换行维护网站的发帖量等功能介绍)
优采云cms采集器目前包括cms采集移动、维护王、同步更新王,你可以采集其他网站并且所有文章或论坛和伪原创的内容都会发布给自己网站,您可以每天采集最新的文章,并自动维护发帖网站 数量等。
特征
您可以一次在您的论坛中注册上千名会员,这样您的新论坛一开始就有大量会员;
允许会员在设定时间内同时在线,轻松实现千人在线热门论坛的效果(部分不支持按IP统计在线人数的论坛,如DVbbs/PHPWind);
您可以采集网站/forum 主题和所有回复,网站/forums 80% 可以是采集,您可以将文章的内容保存到本地后发布;
您可以将网站论坛A版块或专栏的内容批量转发采集到您自己的网站或论坛指定版块。
软件支持根据UBB代码与源代码、UBB与源代码结合三种方式编写采集规则,最大限度的方便用户的习惯和选择;
软件可批量发帖到网站或论坛多个版块;
该软件可以在论坛的某个主题上发帖;
软件具有万能破解功能。对于文章和含有干扰码的帖子,可以完全屏蔽其内容中的干扰码;
软件可以将发帖ID和回复ID分开,允许部分成员发布所有主题,让其他成员全部回复,ID号成员选择发布;
支持采集任何网站论坛类型如dz/PW/Dongwang等内容导入您自己的网站或论坛程序,打破编码和程序限制;
软件可以有效过滤已经采集的帖子,每天将采集的最新内容发布到指定栏目;
采集 本地内容可在软件中任意编辑,编辑窗口可最大化,支持自动换行、HTML预览,使用更好更方便;
支持对文章内容中的文本和链接进行批量替换和过滤;
支持文章内容中两个关键字A到关键字B之间的内容过滤或替换;
软件可以根据您的要求自动过滤收录固定关键词的帖子进行编辑;
你可以把其他论坛帖子或者网站文章都按照对方采集的顺序放到你的论坛里,就像复制他的论坛到你的版块一样;
支持自定义发帖和回复间隔时间;
软件在发帖时可以自动增加帖子的浏览人数;
软件具有单帖置顶功能,多个用户可以单独回复一个帖子;
软件具有查看某个帖子的浏览量的功能;
软件具有单节或多节自动回复功能,回复内容可自定义;
软件可以批量增加一节或多节帖子的浏览量,您可以自行设置范围来增加帖子的浏览量;
您可以在论坛内容中采集网站/超级链接,或者屏蔽该链接
您可以从采集网站/论坛下载文章的图片到本地,然后通过FTP上传附件和图片到您的网站空间;
图片名称可以随意;
支持任务栏图标隐藏显示的最小化;
具有采集或发布任务完成后自动关机功能;
独有的百度优化和旧帖改新帖功能,可以有效增加采集帖的原创性质,更有利于搜索引擎收录;
可以在标题前后、内容中自动添加自定义关键词;
支持用同义词替换帖子内容功能;
本软件可以采集需要注册登录才能查看网站论坛帖子;
软件特点
1、创新多用户随机选帖回复帖,模拟真实热点论坛的热点效果
2、原创可以采集回复,采集的分页会贴出来作为回复
3、 原创百度优化SEO功能伪原创 任何软件都没有此功能
4、 最初创建随机回复,您可以将帖子中的所有回复按顺序重新排列。实现不同于原版网站的真实效果
5、 独创的自动回复功能,可以模拟会员回复,让真正的论坛成员感受到温暖,在没人赞成发帖的情况下发帖也不会失去兴趣。
6、独创的真实会员在线模拟功能,让数十万会员在线,查看和回复不同版块的帖子。让会员感受什么是大而受欢迎的论坛
7、独创多网站采集,多版块可以同时发布文章的功能,你可以呼吸采集成百上千网站 版块,同时在不同版块乱序发布。您不再可以在发布另一个部分之前只发布一个部分(将其视为假)。什么是论坛采集管理系统,这个软件很好的诠释了这个意思
指示
1 下载完成后,不要运行压缩包中的软件,直接使用,先解压;
2 软件同时支持32位和64位运行环境;
3 如果软件无法正常打开,请右键使用管理员模式运行。
更新日志
1、优化UI界面的流畅度
2、修复已知错误

