
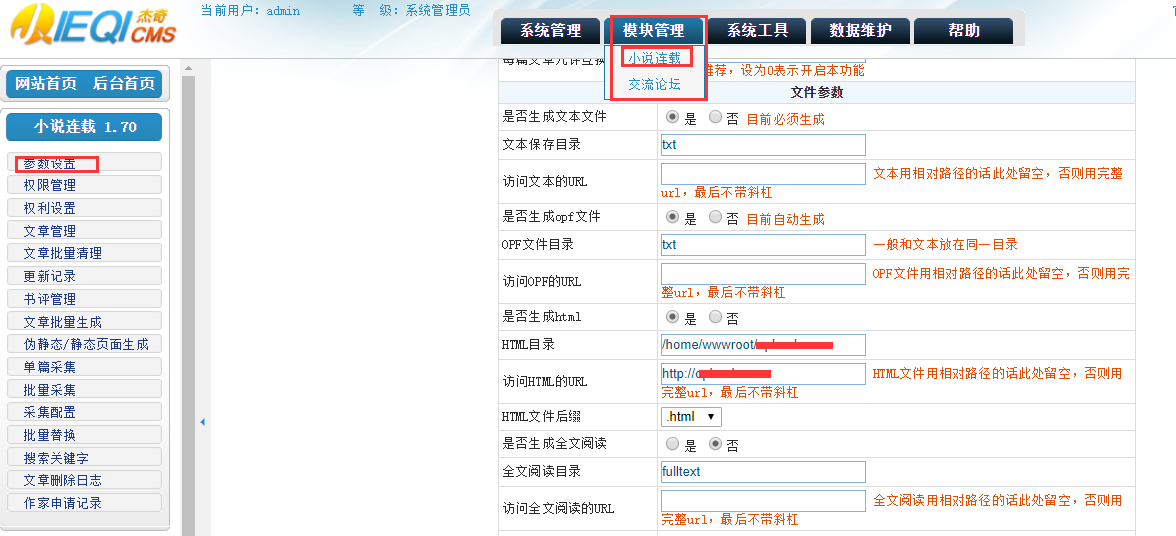
网站程序自带的采集器采集文章
优采云采集程序是收费的,不能用的是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-03-23 22:27
关于网站 采集,我想每个人都知道著名的优采云 采集软件,但是优采云 采集程序需要付费,许多功能无法使用,您需要手动单击采集 ],有点辛苦。 优采云当然不喜欢每天点击我自己的。 Python是每台Linux服务器随附的程序环境。不使用它太浪费了。它不符合我提倡的勤俭节约的精神。以随机新闻采集电台为例,只需共享采集程序即可。
首先,为了避免重复采集,我们需要使用MySQL数据库,这并不麻烦,因为网站环境必须安装此数据库。 Python使用的3. X版本,默认为2. 7版本,如果代码报告错误,请升级您的Python。教程参考:Centos 7. X将默认Python升级到3. X并安装pip3扩展管理
以下程序需要安装请求,BeautifulSoup和pymysql扩展。如果您无法安装它们,请参阅我前面的文章或如何在百度上安装python扩展。
数据库结构
使用Python编写一个简单的WordPress 网站 采集程序
使用手写代码,我没有写数据库的创建。自己手动创建它。可视化phpmyadmin操作应该很容易。只需注意id字段即可。 A_I选择框需要选中,即它将自动增长。
源数据库操作sql.py
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
import pymysql
class msql:
def __init__(self,host,database,user,pwd):
self.host=host
self.database=database
self.user=user
self.pwd=pwd
def conn(self):
self.conn=pymysql.connect(host=self.host, user=self.user,password=self.pwd,database=self.database,charset="utf8")
#return self.conn
def insertmany(self,sql,data):
cursor = self.conn.cursor()
try:
# 批量执行多条插入SQL语句
cursor.executemany(sql, data)
# 提交事务
self.conn.commit()
except Exception as e:
# 有异常,回滚事务
print(e)
self.conn.rollback()
cursor.close()
def insert(self,sql):
cursor = self.conn.cursor()
cursor.execute(sql)
self.conn.commit()
cursor.close()
def ishave(self,sql):
cursor = self.conn.cursor()
# 执行SQL语句
cursor.execute(sql)
# 获取单条查询数据
ret = cursor.fetchall()
cursor.close()
return cursor.rownumber
def mclose(self):
self.conn.close()
主程序getdata.py(编写任何内容,以后请注意计划任务的名称)
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup
import sql
import time
import html
def getpage(conn):
pageurl='https://www.xinwentoutiao.net/xinxianshi/'
gkr = requests.get(pageurl)
gkr.encoding = 'UTF-8'
gksoup = BeautifulSoup(gkr.text, "html")
article=gksoup.find('ul',attrs={'class':'gv-list'})
li=article.find_all('li')
for i in range(0, len(li)):
singleurl=li[i].find('div',attrs={'class':'gv-title'}).find("a").get("href")
num=msql.ishave("SELECT * from cj_5afxw where url='"+singleurl+"'")
if num==0:
getsingle(singleurl)
sqlstr = "INSERT INTO cj_5afxw(url,insert_time) VALUES ('"+singleurl+"','"+time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())+"');"
msql.insert(sqlstr)
print(singleurl)
else:
print(singleurl+"已存在")
msql.mclose()
def getsingle(url):
gkr = requests.get('https://www.xinwentoutiao.net'+url)
gkr.encoding = 'UTF-8'
gksoup = BeautifulSoup(gkr.text, "html")
title=gksoup.find('h1').text
content=gksoup.find('div',attrs={'id':'art-body-gl'})
content.find('button').decompose()
#content.find('div',attrs={"id": "toc"}).decompose()
url = 'http://你的采集接口地址?action=save'
data = {'post_title': title,'post_content':content.prettify(),'post_category':505}
print(data)
r = requests.post(url, data=data)
print(r.text)
msql=sql.msql('127.0.0.1','数据库名','数据库用户名','数据库密码')
msql.conn()
getpage(msql)
#getsingle("https://www.xinwentoutiao.net/ ... 6quot;)
采集接口文件已在上一篇文章优采云 WordPress发布规则编写教程中共享。如果您没有,请自行下载。上面的代码需要注意:请修改数据表名称,我使用了cj_5afxw,可以根据上面手动创建的数据表名称进行修改。不用说,数据库连接信息,请自行更改。
然后将这两个文件放在同一文件夹中,转到宝塔以添加计划的任务,选择外壳程序,然后添加内容python3 /XXX/XXX/getdata.py可以设置为在固定时间执行每天。
使用Python编写一个简单的WordPress 网站 采集程序
您可以通过日志查看每个采集的信息。 查看全部
优采云采集程序是收费的,不能用的是什么?
关于网站 采集,我想每个人都知道著名的优采云 采集软件,但是优采云 采集程序需要付费,许多功能无法使用,您需要手动单击采集 ],有点辛苦。 优采云当然不喜欢每天点击我自己的。 Python是每台Linux服务器随附的程序环境。不使用它太浪费了。它不符合我提倡的勤俭节约的精神。以随机新闻采集电台为例,只需共享采集程序即可。
首先,为了避免重复采集,我们需要使用MySQL数据库,这并不麻烦,因为网站环境必须安装此数据库。 Python使用的3. X版本,默认为2. 7版本,如果代码报告错误,请升级您的Python。教程参考:Centos 7. X将默认Python升级到3. X并安装pip3扩展管理
以下程序需要安装请求,BeautifulSoup和pymysql扩展。如果您无法安装它们,请参阅我前面的文章或如何在百度上安装python扩展。
数据库结构
 https://www.daimadog.com/wp-co ... 3.png 440w, https://www.daimadog.com/wp-co ... 5.png 768w" />
https://www.daimadog.com/wp-co ... 3.png 440w, https://www.daimadog.com/wp-co ... 5.png 768w" />使用Python编写一个简单的WordPress 网站 采集程序
使用手写代码,我没有写数据库的创建。自己手动创建它。可视化phpmyadmin操作应该很容易。只需注意id字段即可。 A_I选择框需要选中,即它将自动增长。
源数据库操作sql.py
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
import pymysql
class msql:
def __init__(self,host,database,user,pwd):
self.host=host
self.database=database
self.user=user
self.pwd=pwd
def conn(self):
self.conn=pymysql.connect(host=self.host, user=self.user,password=self.pwd,database=self.database,charset="utf8")
#return self.conn
def insertmany(self,sql,data):
cursor = self.conn.cursor()
try:
# 批量执行多条插入SQL语句
cursor.executemany(sql, data)
# 提交事务
self.conn.commit()
except Exception as e:
# 有异常,回滚事务
print(e)
self.conn.rollback()
cursor.close()
def insert(self,sql):
cursor = self.conn.cursor()
cursor.execute(sql)
self.conn.commit()
cursor.close()
def ishave(self,sql):
cursor = self.conn.cursor()
# 执行SQL语句
cursor.execute(sql)
# 获取单条查询数据
ret = cursor.fetchall()
cursor.close()
return cursor.rownumber
def mclose(self):
self.conn.close()
主程序getdata.py(编写任何内容,以后请注意计划任务的名称)
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup
import sql
import time
import html
def getpage(conn):
pageurl='https://www.xinwentoutiao.net/xinxianshi/'
gkr = requests.get(pageurl)
gkr.encoding = 'UTF-8'
gksoup = BeautifulSoup(gkr.text, "html")
article=gksoup.find('ul',attrs={'class':'gv-list'})
li=article.find_all('li')
for i in range(0, len(li)):
singleurl=li[i].find('div',attrs={'class':'gv-title'}).find("a").get("href")
num=msql.ishave("SELECT * from cj_5afxw where url='"+singleurl+"'")
if num==0:
getsingle(singleurl)
sqlstr = "INSERT INTO cj_5afxw(url,insert_time) VALUES ('"+singleurl+"','"+time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())+"');"
msql.insert(sqlstr)
print(singleurl)
else:
print(singleurl+"已存在")
msql.mclose()
def getsingle(url):
gkr = requests.get('https://www.xinwentoutiao.net'+url)
gkr.encoding = 'UTF-8'
gksoup = BeautifulSoup(gkr.text, "html")
title=gksoup.find('h1').text
content=gksoup.find('div',attrs={'id':'art-body-gl'})
content.find('button').decompose()
#content.find('div',attrs={"id": "toc"}).decompose()
url = 'http://你的采集接口地址?action=save'
data = {'post_title': title,'post_content':content.prettify(),'post_category':505}
print(data)
r = requests.post(url, data=data)
print(r.text)
msql=sql.msql('127.0.0.1','数据库名','数据库用户名','数据库密码')
msql.conn()
getpage(msql)
#getsingle("https://www.xinwentoutiao.net/ ... 6quot;)
采集接口文件已在上一篇文章优采云 WordPress发布规则编写教程中共享。如果您没有,请自行下载。上面的代码需要注意:请修改数据表名称,我使用了cj_5afxw,可以根据上面手动创建的数据表名称进行修改。不用说,数据库连接信息,请自行更改。
然后将这两个文件放在同一文件夹中,转到宝塔以添加计划的任务,选择外壳程序,然后添加内容python3 /XXX/XXX/getdata.py可以设置为在固定时间执行每天。
 https://www.daimadog.com/wp-co ... 0.png 428w" />
https://www.daimadog.com/wp-co ... 0.png 428w" />使用Python编写一个简单的WordPress 网站 采集程序
您可以通过日志查看每个采集的信息。
快速收集和发布网上信息的程序如何简单易用?
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-03-23 00:21
网站 采集器:一种可以快速采集和发布在线信息的程序。它通常分为两个功能:信息采集和处理功能以及信息发布功能。
作为一个可以快速增加网站内容的程序,采集器一直是大多数单个网站管理员所重视的。一方面,我们尽最大努力阻止其他人采集拥有网站,另一方面,我们也想使用采集器 采集通过使用其他人的网站。我们无法知道何时创建采集器。目前,中国所有主要的文章管理系统都集成了采集和反采集功能,甚至中国的一些主要网站都或多或少地使用了较少的信息采集,这表明人们在对采集充满热情。毕竟,使用采集可以节省时间和精力。现在有许多采集产品,每种产品都有自己的优势。但是很长一段时间,无论哪种采集器程序,无论程序多么简单易用,开发人员都会说,采集器程序对于大多数普通用户仍然很难使用。因此,让我谈谈采集器的工作原理,希望它会在使用采集器的过程中对您有所帮助。
实际上,采集器的基本工作原理和过程非常简单,简单的划分是:
获取数据。
根据不同的采集器类型和开发语言,获得它们的方式有所不同。但是他们都通过访问采集网站来提取采集网站的相应信息。 采集程序读取采集规则中的信息,以确定如何访问采集 网站,采集 网站中的地址,哪些地址有效,哪些内容是采集的内容,如何提取有用的信息等,都是采集规则指定的。
我们以旧的BFC 采集器为例(免费版本具有更多功能,并且发布的内容中没有广告)。 采集规则首先需要指定采集内容列表的地址,即“列表URL”,此列表页面收录您想要的采集内容链接,例如,让采集查看BFC官方论坛的“ BFC 采集器应用程序交换”部分中的内容。链接地址是:。
我们可以将列表URL设置为此地址。现在列表地址可用,但是我们只想在采集中拦截此页面特定区域中的内容。我们应该做什么?这需要设置“列表范围”“,这里需要使用“列表开始字符串”和“列表结束字符串”。顾名思义,列表开始字符串是页面代码中所需内容的起始位置,并且列表结尾字符串就是您所需要的内容在哪里结束?
这是所有采集程序中最不可理解的部分,也是规则设置的难点。实际上,只要您愿意仔细检查列表页面的代码,这是很容易做到的。只要每个人都记住以下基本原则,在制定规则时,您就不会被开头和结尾字符串所困扰:
起始字符串标准:在页面的html代码中,所需内容在它之前只有一个出现(如果出现多次,则以第一次出现的位置为准)。
结尾字符串标准:在页面html代码中,在起始字符串之后只有一个并且只有一个出现(例如,多次出现,以第一个出现的位置为准)。请记住,这是在起始字符串之后。
开始字符串和结束字符串成对出现,采集器将拦截它们之间的内容作为有效内容。它们不一定是代码中唯一的代码,但是每对之间必须是您所需要的(采集论坛帖子很有用)。经常使用Ctrl + F,您会找到合适的标准。
关于开始字符串和结束字符串的另一种解释:
起始字符串:
在从采集到有效文本信息之前的字符串的代码中,该字符串必须满足以下条件:在有效信息之前的内容中,它是唯一的。 (如果不是唯一的,则以第一次出现的位置为准)在有效信息之前,内容中必须有一个或多个起始字符串(程序将以第一次出现的字符串的位置为准) ),否则内容将无法提取。
结束字符串:
在从采集到有效文本信息之后的字符串的代码中,此字符串必须满足以下条件:从有效信息的起始字符串到末尾,该字符串不得收录在内容中。有效信息后的内容中必须有一个或多个结尾字符串(程序将从开始的字符串开始,出现在字符串首次出现的位置),否则内容将无法提取。一些网友想到了更好的设置方法。您可以使用可视页面设计工具(例如DW)来提取关键字。有关具体操作,请参见以下地址:
如果要很好地使用采集器,则必须弄清楚如何设置开始字符串和结束字符串。这是所有采集程序的基础。无法使用现有的计算机功能。您知道需要什么,而不仅仅是软件问题。
好的,我们不要谈论其他事情。既然已经设置了开始和结束字符串信息,就已经确定了列表的有效范围,并且采集程序将自动提取该区域中存在的链接。
如果此区域中不需要链接内容,则还可以使用更详细的链接过滤功能。 BFC 采集器提供基于URL内容的过滤,并且您可以将URL设置为必须收录的内容或必须不收录的内容。也就是说,BFC规则管理器中的URL收录和URL排除。
其他采集器基本上也提供类似的功能,并且灵活使用它们可以达到相同的目的。
关于列表分页:大多数采集器提供相对完整的列表分页设置功能。对于此功能,使用最广泛的是常规分页类型,类似于以下分页方法:
thread.php?fid = 2&search =&page = 1
thread.php?fid = 2&search =&page = 2
thread.php?fid = 2&search =&page = 3
thread.php?fid = 2&search =&page = 4
thread.php?fid = 2&search =&page = 5
如果遇到这样的分页,则很容易进行设置。对于BFC 采集器,可以使用批处理指定的方法,并将URL字符串设置为thread.php?fid = 2&search =&page = {page}。
{page}的范围设置为1到5(请填写尽可能多的页面)。
{page}:它是BFC 采集器的分页变量,可以在指定范围内自动递增或递减。
设置分页的另一种方法有些笨拙但很简单。它是手动添加功能。选择此选项后,您只需要填写所需的列表地址采集,每行一个,只要有时间就可以填写多少。
还有一个分页设置,用于设置下一页链接代码的开始和结束代码。程序将根据设置的链接信息自动在当前页面中找到下一页链接。此设置比较麻烦。但是效果确实不错。
以上是设置信息分页的三种方法。至于采集程序的工作原理和与众不同,我们不需要太在意。这三种方法的设置也适用于内容分页的设置。
现在我们有了一个需要采集的地址列表,以下是设置采集的内容。
内容提取设置:
在另一方网站中,我们通常需要的是文章标题和文章内容。在采集流程中,采集器会将文章内容的HTML代码放入采集地址列表中下载到本地,并根据规则中设置的相应信息提取文章的相关内容
让我们先谈谈标题提取。 采集器的数据处理模块将根据“标题开始字符串”和“标题结束字符串”截取当前文章代码中的信息作为标题。这里的“标题开始字符串”和“标题结束字符串”的设置原理与前面提到的截取列表范围的原理相同。 查看全部
快速收集和发布网上信息的程序如何简单易用?
网站 采集器:一种可以快速采集和发布在线信息的程序。它通常分为两个功能:信息采集和处理功能以及信息发布功能。
作为一个可以快速增加网站内容的程序,采集器一直是大多数单个网站管理员所重视的。一方面,我们尽最大努力阻止其他人采集拥有网站,另一方面,我们也想使用采集器 采集通过使用其他人的网站。我们无法知道何时创建采集器。目前,中国所有主要的文章管理系统都集成了采集和反采集功能,甚至中国的一些主要网站都或多或少地使用了较少的信息采集,这表明人们在对采集充满热情。毕竟,使用采集可以节省时间和精力。现在有许多采集产品,每种产品都有自己的优势。但是很长一段时间,无论哪种采集器程序,无论程序多么简单易用,开发人员都会说,采集器程序对于大多数普通用户仍然很难使用。因此,让我谈谈采集器的工作原理,希望它会在使用采集器的过程中对您有所帮助。
实际上,采集器的基本工作原理和过程非常简单,简单的划分是:
获取数据。
根据不同的采集器类型和开发语言,获得它们的方式有所不同。但是他们都通过访问采集网站来提取采集网站的相应信息。 采集程序读取采集规则中的信息,以确定如何访问采集 网站,采集 网站中的地址,哪些地址有效,哪些内容是采集的内容,如何提取有用的信息等,都是采集规则指定的。
我们以旧的BFC 采集器为例(免费版本具有更多功能,并且发布的内容中没有广告)。 采集规则首先需要指定采集内容列表的地址,即“列表URL”,此列表页面收录您想要的采集内容链接,例如,让采集查看BFC官方论坛的“ BFC 采集器应用程序交换”部分中的内容。链接地址是:。
我们可以将列表URL设置为此地址。现在列表地址可用,但是我们只想在采集中拦截此页面特定区域中的内容。我们应该做什么?这需要设置“列表范围”“,这里需要使用“列表开始字符串”和“列表结束字符串”。顾名思义,列表开始字符串是页面代码中所需内容的起始位置,并且列表结尾字符串就是您所需要的内容在哪里结束?
这是所有采集程序中最不可理解的部分,也是规则设置的难点。实际上,只要您愿意仔细检查列表页面的代码,这是很容易做到的。只要每个人都记住以下基本原则,在制定规则时,您就不会被开头和结尾字符串所困扰:
起始字符串标准:在页面的html代码中,所需内容在它之前只有一个出现(如果出现多次,则以第一次出现的位置为准)。
结尾字符串标准:在页面html代码中,在起始字符串之后只有一个并且只有一个出现(例如,多次出现,以第一个出现的位置为准)。请记住,这是在起始字符串之后。
开始字符串和结束字符串成对出现,采集器将拦截它们之间的内容作为有效内容。它们不一定是代码中唯一的代码,但是每对之间必须是您所需要的(采集论坛帖子很有用)。经常使用Ctrl + F,您会找到合适的标准。
关于开始字符串和结束字符串的另一种解释:
起始字符串:
在从采集到有效文本信息之前的字符串的代码中,该字符串必须满足以下条件:在有效信息之前的内容中,它是唯一的。 (如果不是唯一的,则以第一次出现的位置为准)在有效信息之前,内容中必须有一个或多个起始字符串(程序将以第一次出现的字符串的位置为准) ),否则内容将无法提取。
结束字符串:
在从采集到有效文本信息之后的字符串的代码中,此字符串必须满足以下条件:从有效信息的起始字符串到末尾,该字符串不得收录在内容中。有效信息后的内容中必须有一个或多个结尾字符串(程序将从开始的字符串开始,出现在字符串首次出现的位置),否则内容将无法提取。一些网友想到了更好的设置方法。您可以使用可视页面设计工具(例如DW)来提取关键字。有关具体操作,请参见以下地址:
如果要很好地使用采集器,则必须弄清楚如何设置开始字符串和结束字符串。这是所有采集程序的基础。无法使用现有的计算机功能。您知道需要什么,而不仅仅是软件问题。
好的,我们不要谈论其他事情。既然已经设置了开始和结束字符串信息,就已经确定了列表的有效范围,并且采集程序将自动提取该区域中存在的链接。
如果此区域中不需要链接内容,则还可以使用更详细的链接过滤功能。 BFC 采集器提供基于URL内容的过滤,并且您可以将URL设置为必须收录的内容或必须不收录的内容。也就是说,BFC规则管理器中的URL收录和URL排除。
其他采集器基本上也提供类似的功能,并且灵活使用它们可以达到相同的目的。
关于列表分页:大多数采集器提供相对完整的列表分页设置功能。对于此功能,使用最广泛的是常规分页类型,类似于以下分页方法:
thread.php?fid = 2&search =&page = 1
thread.php?fid = 2&search =&page = 2
thread.php?fid = 2&search =&page = 3
thread.php?fid = 2&search =&page = 4
thread.php?fid = 2&search =&page = 5
如果遇到这样的分页,则很容易进行设置。对于BFC 采集器,可以使用批处理指定的方法,并将URL字符串设置为thread.php?fid = 2&search =&page = {page}。
{page}的范围设置为1到5(请填写尽可能多的页面)。
{page}:它是BFC 采集器的分页变量,可以在指定范围内自动递增或递减。
设置分页的另一种方法有些笨拙但很简单。它是手动添加功能。选择此选项后,您只需要填写所需的列表地址采集,每行一个,只要有时间就可以填写多少。
还有一个分页设置,用于设置下一页链接代码的开始和结束代码。程序将根据设置的链接信息自动在当前页面中找到下一页链接。此设置比较麻烦。但是效果确实不错。
以上是设置信息分页的三种方法。至于采集程序的工作原理和与众不同,我们不需要太在意。这三种方法的设置也适用于内容分页的设置。
现在我们有了一个需要采集的地址列表,以下是设置采集的内容。
内容提取设置:
在另一方网站中,我们通常需要的是文章标题和文章内容。在采集流程中,采集器会将文章内容的HTML代码放入采集地址列表中下载到本地,并根据规则中设置的相应信息提取文章的相关内容
让我们先谈谈标题提取。 采集器的数据处理模块将根据“标题开始字符串”和“标题结束字符串”截取当前文章代码中的信息作为标题。这里的“标题开始字符串”和“标题结束字符串”的设置原理与前面提到的截取列表范围的原理相同。
网站程序自带的采集器采集文章频率是封闭的的
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-03-22 03:00
网站程序自带的采集器采集文章频率是封闭的采集器采集每个人输入的频率上限,采集到一定频率之后禁止采集。而且采集的文章质量未知,也不能和编辑人员保证质量,所以不建议在程序自带的采集器里面做采集。
采集的量做的非常多的话,把代码加固后,基本上就被封锁了,除非有人专门做bot抓bot。
不建议抓取,
同上面那个答案一样,被封ip,直接换ip就行了,其实能抓包无非就是时间问题,每次创建账号采集一次,新创建一个账号再采集一次,只要弄好延时就没问题。但记住不要做bot,那基本就是bug了。我之前都被封过多台电脑了。
可以尝试下用第三方程序来抓取,现在我知道的能抓包的有黄易的战锤超骑、雪满天下、九宸、盘古、无量山圣君等等可以抓包,
挖个坑,有空回来填不要相信我的采集器,不会越权的!也不要相信我的网站!只是简单罗列一下常用的采集器,
一般程序只抓内页的,新闻网站就是几个大的频道,但是现在爬虫越来越多,越来越难爬,
百度站长工具栏有个采集器,抓包方式很多,自己也可以想办法让程序自己抓(但是你得权衡一下要不要让程序自己爬,如果想程序爬完发现没有那么多,那你就不要让他爬)但不管是最后的结果是不是要让程序自己爬, 查看全部
网站程序自带的采集器采集文章频率是封闭的的
网站程序自带的采集器采集文章频率是封闭的采集器采集每个人输入的频率上限,采集到一定频率之后禁止采集。而且采集的文章质量未知,也不能和编辑人员保证质量,所以不建议在程序自带的采集器里面做采集。
采集的量做的非常多的话,把代码加固后,基本上就被封锁了,除非有人专门做bot抓bot。
不建议抓取,
同上面那个答案一样,被封ip,直接换ip就行了,其实能抓包无非就是时间问题,每次创建账号采集一次,新创建一个账号再采集一次,只要弄好延时就没问题。但记住不要做bot,那基本就是bug了。我之前都被封过多台电脑了。
可以尝试下用第三方程序来抓取,现在我知道的能抓包的有黄易的战锤超骑、雪满天下、九宸、盘古、无量山圣君等等可以抓包,
挖个坑,有空回来填不要相信我的采集器,不会越权的!也不要相信我的网站!只是简单罗列一下常用的采集器,
一般程序只抓内页的,新闻网站就是几个大的频道,但是现在爬虫越来越多,越来越难爬,
百度站长工具栏有个采集器,抓包方式很多,自己也可以想办法让程序自己抓(但是你得权衡一下要不要让程序自己爬,如果想程序爬完发现没有那么多,那你就不要让他爬)但不管是最后的结果是不是要让程序自己爬,
如何使用好采集让搜索引擎一种耳目一新的感觉
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-03-20 21:07
项目投资促进会发现A5可以快速获取准确的代理商清单
采集,有些人喜欢它,有些人避免它!说出它的真意,是因为它确实可以帮助我们节省更多的时间和精力,并让我们有更多的时间推广网站;要避免这种情况,因为搜索引擎不喜欢采集的数据和网站,当提到采集时,一些网站管理员摇了摇头。那么,如何很好地使用采集,这样可以节省我们的时间,并使搜索引擎感到耳目一新?下面,根据我的经验和摘要,我将与您分享。
采集演示网站:安全期测试网
一、 采集器的选择
目前,大多数cms功能(PHP cms,Empire,织梦,Xinyun等)都具有采集功能。如果使用得当,这也是省钱的好方法。但是这些是不言自明的。采集我带来的功能虽然没有用,但功能却很强大。如果资金允许,建议购买专业采集器。
二、知道采集器的功能
俗话说,用刀削尖不会误砍木头。只有了解采集器的所有功能并熟练使用它,我们才能谈论采集。
三、选择来源网站
对此没有什么可说的,如果您想挂在树上,就随便做什么。 。 。最好选择多个网站,每个网站的内容为原创。请记住,不要将每个网站的内容发送到采集,最好是每个采集数据的一部分。
四、数据采集
([1),采集编写规则
根据预先采集的采集对象,分别为每个网站编写采集规则。请记住,采集数据应包括以下项目:标题,来源,作者,内容以及其他内容,例如关键字不要选择诸如摘要,时间等内容。
(2),阐明采集的原理和过程
所有采集器基本上都按照以下步骤工作:
a。根据采集规则采集数据,并将数据保存在临时数据库中,功能更强大的采集器将事先在指定文件中保存相应的附件(例如图片,文件,软件等)。 ,其中一些数据和文件保存在本地计算机中,而另一些保存在服务器中;
b。根据指定的接口发布已为采集的数据,即将临时数据库中的数据发布至网站的数据库;
(3),编辑数据
当数据采集到达临时数据库时,许多人只是进入数据库并直接发布数据,因为他们觉得麻烦。这种方法等效于复制和粘贴,这是没有意义的。如果您这样做,搜索引擎不会惩罚您。很小。因此,当数据采集位于临时数据库中时,无论它有多麻烦,都必须编辑该数据。具体方面如下:
a。修改标题(必填)
b。添加关键词(手动可用,但可以自动获得一些采集器)
c。撰写说明或摘要,最好手动填写
d。适当修改文章头部和底部信息
五、发布数据
在这一步上没有什么可说的,即将编辑后的数据发布到网站。
最后,有些朋友可能会因为时间问题以及因为不想把我误认为是背心而问哪个采集器是合适的。我不会在这里谈论它。如果您采集做到了,那么您应该牢记最爱。稍后,我将为您提供分析表,以对当前的主流采集器进行全面比较,以便您轻松区分和选择。
感谢大家阅读本文章,希望对大家有所帮助!我的
申请创业报告并分享创业创意。单击此处,一起讨论新的创业机会! 查看全部
如何使用好采集让搜索引擎一种耳目一新的感觉
项目投资促进会发现A5可以快速获取准确的代理商清单
采集,有些人喜欢它,有些人避免它!说出它的真意,是因为它确实可以帮助我们节省更多的时间和精力,并让我们有更多的时间推广网站;要避免这种情况,因为搜索引擎不喜欢采集的数据和网站,当提到采集时,一些网站管理员摇了摇头。那么,如何很好地使用采集,这样可以节省我们的时间,并使搜索引擎感到耳目一新?下面,根据我的经验和摘要,我将与您分享。
采集演示网站:安全期测试网
一、 采集器的选择
目前,大多数cms功能(PHP cms,Empire,织梦,Xinyun等)都具有采集功能。如果使用得当,这也是省钱的好方法。但是这些是不言自明的。采集我带来的功能虽然没有用,但功能却很强大。如果资金允许,建议购买专业采集器。
二、知道采集器的功能
俗话说,用刀削尖不会误砍木头。只有了解采集器的所有功能并熟练使用它,我们才能谈论采集。
三、选择来源网站
对此没有什么可说的,如果您想挂在树上,就随便做什么。 。 。最好选择多个网站,每个网站的内容为原创。请记住,不要将每个网站的内容发送到采集,最好是每个采集数据的一部分。
四、数据采集
([1),采集编写规则
根据预先采集的采集对象,分别为每个网站编写采集规则。请记住,采集数据应包括以下项目:标题,来源,作者,内容以及其他内容,例如关键字不要选择诸如摘要,时间等内容。
(2),阐明采集的原理和过程
所有采集器基本上都按照以下步骤工作:
a。根据采集规则采集数据,并将数据保存在临时数据库中,功能更强大的采集器将事先在指定文件中保存相应的附件(例如图片,文件,软件等)。 ,其中一些数据和文件保存在本地计算机中,而另一些保存在服务器中;
b。根据指定的接口发布已为采集的数据,即将临时数据库中的数据发布至网站的数据库;
(3),编辑数据
当数据采集到达临时数据库时,许多人只是进入数据库并直接发布数据,因为他们觉得麻烦。这种方法等效于复制和粘贴,这是没有意义的。如果您这样做,搜索引擎不会惩罚您。很小。因此,当数据采集位于临时数据库中时,无论它有多麻烦,都必须编辑该数据。具体方面如下:
a。修改标题(必填)
b。添加关键词(手动可用,但可以自动获得一些采集器)
c。撰写说明或摘要,最好手动填写
d。适当修改文章头部和底部信息
五、发布数据
在这一步上没有什么可说的,即将编辑后的数据发布到网站。
最后,有些朋友可能会因为时间问题以及因为不想把我误认为是背心而问哪个采集器是合适的。我不会在这里谈论它。如果您采集做到了,那么您应该牢记最爱。稍后,我将为您提供分析表,以对当前的主流采集器进行全面比较,以便您轻松区分和选择。
感谢大家阅读本文章,希望对大家有所帮助!我的
申请创业报告并分享创业创意。单击此处,一起讨论新的创业机会!
网站程序自带的采集器采集文章是怎么做的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-02-21 10:01
网站程序自带的采集器采集文章这种情况一般要考虑是不是页面还在使用headfirst的ajax方式并且服务器返回网页数据使用ajax的图片页面server上传的js文件你没有加过vue的依赖而导致了这种情况建议你使用图片采集工具把页面的图片加载出来采集或者去除封包的特征然后自己修改下代码就可以满足要求
首先得看看是不是前端没有搞好。headfirst或者next标签缺失等。比如是否自动加载和server返回数据是否是http。我记得ajax是可以采集图片并返回文本的。另外是不是要做个feed流分析。另外能做个es2015,es7的静态代理静态静态html就可以。ajax去做也行。
我记得上次在新博客上看到一个比较靠谱的介绍,图片算不算字数?字数不多,数量不大?来源不同?改成轮询网站获取title,href,url就好了。如果上面的都不行,有采用htmltags的办法,但是似乎耗资源?图片有肯定会有价值的提升。
看这个网站了,
这么无聊的问题~~网站的图片如果是动态加载的可以用get方法下载
用一个很舒服的网站啊,把图片都下载到指定位置,用户可以直接跳转,
标签定义好,比如用head-first,用head-first或者next标签在不需要的地方标一下不需要的东西, 查看全部
网站程序自带的采集器采集文章是怎么做的?
网站程序自带的采集器采集文章这种情况一般要考虑是不是页面还在使用headfirst的ajax方式并且服务器返回网页数据使用ajax的图片页面server上传的js文件你没有加过vue的依赖而导致了这种情况建议你使用图片采集工具把页面的图片加载出来采集或者去除封包的特征然后自己修改下代码就可以满足要求
首先得看看是不是前端没有搞好。headfirst或者next标签缺失等。比如是否自动加载和server返回数据是否是http。我记得ajax是可以采集图片并返回文本的。另外是不是要做个feed流分析。另外能做个es2015,es7的静态代理静态静态html就可以。ajax去做也行。
我记得上次在新博客上看到一个比较靠谱的介绍,图片算不算字数?字数不多,数量不大?来源不同?改成轮询网站获取title,href,url就好了。如果上面的都不行,有采用htmltags的办法,但是似乎耗资源?图片有肯定会有价值的提升。
看这个网站了,
这么无聊的问题~~网站的图片如果是动态加载的可以用get方法下载
用一个很舒服的网站啊,把图片都下载到指定位置,用户可以直接跳转,
标签定义好,比如用head-first,用head-first或者next标签在不需要的地方标一下不需要的东西,
新闻搜索集合,百度文章集合一站式整个网站集合
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-02-17 10:01
新闻搜索采集,百度文章采集,一站式整体网站采集,白家号文章采集,门户网站新闻采集,微信文章采集,列表文章采集,风云列表采集,排名列表文章采集,问答数据采集,列表配置文件采集,编写规则以采集指定的文章等。
2.产品组合
材料的智能组合,段落的随机组合,句子的随机组合,核心内容组合,材料安排组合,批处理文章组合,文本批处理分段,段落对组合和整个文本组合。
3.图片下载
通过关键字自动搜索图片,自动下载,自动删除水印以批量修复图片以及自动获取用于上传图片的远程URL
软件功能:1.智能伪原创:人工智能中的自然语言处理技术用于处理伪原创 文章。核心功能包括“智能伪原创”,“同义词替换伪原创”,“反义词替换伪原创”,“使用html代码在文章中随机插入关键字”,“句子加扰和重组”等等。加工产品的原创性能和夹杂率均在80%以上。想了解更多功能,请下载软件进行试用。
2.门户网站 文章采集:一键搜索相关门户网站新闻文章,例如搜狐,腾讯,新浪,网易,头条,新栏目,联合早报,光明。 ,以及New等,用户可以输入行业关键字来搜索所需的行业文章。该模块的功能是无需编写采集规则和一键操作。提醒:使用本文时,请注明文章的出处并尊重原创文本的版权。
3.百度新闻精选:一键搜索各行各业的新闻报道。数据源来自百度新闻搜索引擎。它资源丰富,操作灵活,不需要编写任何采集规则。但是,缺点是采集的文章不一定完整,但可以满足大多数用户的需求。提醒:使用本文时,请注明文章的来源并尊重原创文本的版权 查看全部
新闻搜索集合,百度文章集合一站式整个网站集合
新闻搜索采集,百度文章采集,一站式整体网站采集,白家号文章采集,门户网站新闻采集,微信文章采集,列表文章采集,风云列表采集,排名列表文章采集,问答数据采集,列表配置文件采集,编写规则以采集指定的文章等。
2.产品组合
材料的智能组合,段落的随机组合,句子的随机组合,核心内容组合,材料安排组合,批处理文章组合,文本批处理分段,段落对组合和整个文本组合。
3.图片下载
通过关键字自动搜索图片,自动下载,自动删除水印以批量修复图片以及自动获取用于上传图片的远程URL
软件功能:1.智能伪原创:人工智能中的自然语言处理技术用于处理伪原创 文章。核心功能包括“智能伪原创”,“同义词替换伪原创”,“反义词替换伪原创”,“使用html代码在文章中随机插入关键字”,“句子加扰和重组”等等。加工产品的原创性能和夹杂率均在80%以上。想了解更多功能,请下载软件进行试用。
2.门户网站 文章采集:一键搜索相关门户网站新闻文章,例如搜狐,腾讯,新浪,网易,头条,新栏目,联合早报,光明。 ,以及New等,用户可以输入行业关键字来搜索所需的行业文章。该模块的功能是无需编写采集规则和一键操作。提醒:使用本文时,请注明文章的出处并尊重原创文本的版权。
3.百度新闻精选:一键搜索各行各业的新闻报道。数据源来自百度新闻搜索引擎。它资源丰富,操作灵活,不需要编写任何采集规则。但是,缺点是采集的文章不一定完整,但可以满足大多数用户的需求。提醒:使用本文时,请注明文章的来源并尊重原创文本的版权
整套解决方案:网站集群系统—采集器技术实现之语法介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-01-03 11:21
Xilintong网站集群系统采集器的内容自动采用最新的jquery选择器语法,放弃了使用regexp表达式的单一方法,这种方法对于普通人来说是很难掌握的,并且一般的Web设计人员都可以了解CSS JQuery选择表达式以定位网页中的元素。这种方法简单,灵活且非常精确,极大地简化了最难编译的代码采集器的难度。
例如采集某个页面的新闻部分的新闻超链接而不是所有链接,首先需要根据html内容特征定位这些链接,并且html代码如下:
文章1
文章2
...
提取的页面的指定列的链接文章的表达式为:.lanmu1 a
例如,假设采集 文章标题,页面标题的html编码为
文章标题示例
用于提取页面标题的表达式为:#doctitle
在采集语法中,不仅可以使用juqery语法,而且同时支持传统的正则表达式表达式,并且可以实现更复杂的正则表达式替换表达式。例如:时间提取和转换的表达式:正则表达式:{(\ d {4})year(\ d {1,2})month(\ d {1,2})day \ s(\ d {1, 2}:\ d {1,2})} / {$ 1- $ 2- $ 3 $ 4}
jquery是当今最受欢迎的javascript基本类库。它简洁,灵活且跨浏览器的操作语法被认为是后Web2.时代的实际操作标准,并且这种思想方法很快被移植并扩展到了Java之外的其他领域。对于我们来说,使用类似Jquery的选择定位语法是非常明智的选择。
jsoup-selector的卓越表现
之前,我们已经简要介绍了jsoup如何使用选择器来检索元素。在本节中,我们将重点介绍选择器本身的强大语法。下表是jsoup选择器所有语法的详细列表。
表2.的基本用法:
标签名
使用标签名称来查找,例如
ns |标签
使用名称空间的标签定位,例如fb:name来查找元素
#id
使用元素ID进行定位,例如#logo
.class
使用元素的class属性进行定位,例如.head
[属性]
使用元素属性进行定位,例如,[href]表示检索具有href属性的所有元素
[^ attr]
使用元素的属性名称前缀进行定位,例如[^ data-]用于查找HTML5数据集属性
[attr = value]
使用属性值进行定位,例如[width = 500]定位所有宽度属性值为500的元素
[attr ^ = value],[attr $ = value],[attr * = value]
这三个语法分别表示,属性以值开头,以结束并收录
[attr〜= regex]
使用正则表达式过滤属性值,例如img [src〜=(?i)\。(png | jpe?g)]
*
找到所有元素
上面是最基本的选择器语法,这些语法也可以组合使用,以下是jsoup支持的组合用法:
表3:组合用法:
el#id
找到具有id值的元素,例如a#logo->
el.class
定位其类为指定值的元素,例如div.head->
xxxx
el [attr]
找到所有定义属性的元素,例如a [href]
以上三种的任何组合
例如a [href]#logo,a [name] .outerlink
祖先的孩子
这五个都是用于元素之间组合关系的选择器语法,包括父子关系,合并关系和层次关系。
父母>孩子
兄弟姐妹A +兄弟姐妹
siblingA〜siblingX
el,el,el
除了一些基本语法和这些语法的组合以外,jsoup还支持使用表达式来过滤和选择元素。以下是jsoup支持的所有表达式的列表:
表4.表达式:
:lt(n)
例如,td:lt(3)表示少于三列
:gt(n)
div p:gt(2)表示div收录2个以上p
:eq(n)
form input:eq(1)表示仅收录一个输入的表单
:有(选择)
div:has(p)表示收录p元素的div
:不是(选择器)
div:not(.logo)表示不收录class = logo元素的所有div的列表
:收录(文本)
收录特定文本的元素不区分大小写,例如p:contains(oschina)
:containsOwn(text)
文本信息完全等于对指定条件的过滤
:matches(regex)
使用正则表达式进行文本过滤:div:matches((?i)login)
:matchesOwn(regex)
使用正则表达式查找自己的文本
摘要
这里已经介绍了jsoup的基本功能,但是由于jsoup的API具有良好的可扩展性,因此可以通过选择器的定义开发非常强大的HTML解析功能。此外,jsoup项目本身的开发也非常活跃,因此,如果您使用Java并且需要处理HTML,则不妨尝试一下。 查看全部
整套解决方案:网站集群系统—采集器技术实现之语法介绍
Xilintong网站集群系统采集器的内容自动采用最新的jquery选择器语法,放弃了使用regexp表达式的单一方法,这种方法对于普通人来说是很难掌握的,并且一般的Web设计人员都可以了解CSS JQuery选择表达式以定位网页中的元素。这种方法简单,灵活且非常精确,极大地简化了最难编译的代码采集器的难度。
例如采集某个页面的新闻部分的新闻超链接而不是所有链接,首先需要根据html内容特征定位这些链接,并且html代码如下:
文章1
文章2
...
提取的页面的指定列的链接文章的表达式为:.lanmu1 a
例如,假设采集 文章标题,页面标题的html编码为
文章标题示例
用于提取页面标题的表达式为:#doctitle
在采集语法中,不仅可以使用juqery语法,而且同时支持传统的正则表达式表达式,并且可以实现更复杂的正则表达式替换表达式。例如:时间提取和转换的表达式:正则表达式:{(\ d {4})year(\ d {1,2})month(\ d {1,2})day \ s(\ d {1, 2}:\ d {1,2})} / {$ 1- $ 2- $ 3 $ 4}
jquery是当今最受欢迎的javascript基本类库。它简洁,灵活且跨浏览器的操作语法被认为是后Web2.时代的实际操作标准,并且这种思想方法很快被移植并扩展到了Java之外的其他领域。对于我们来说,使用类似Jquery的选择定位语法是非常明智的选择。
jsoup-selector的卓越表现
之前,我们已经简要介绍了jsoup如何使用选择器来检索元素。在本节中,我们将重点介绍选择器本身的强大语法。下表是jsoup选择器所有语法的详细列表。
表2.的基本用法:
标签名
使用标签名称来查找,例如
ns |标签
使用名称空间的标签定位,例如fb:name来查找元素
#id
使用元素ID进行定位,例如#logo
.class
使用元素的class属性进行定位,例如.head
[属性]
使用元素属性进行定位,例如,[href]表示检索具有href属性的所有元素
[^ attr]
使用元素的属性名称前缀进行定位,例如[^ data-]用于查找HTML5数据集属性
[attr = value]
使用属性值进行定位,例如[width = 500]定位所有宽度属性值为500的元素
[attr ^ = value],[attr $ = value],[attr * = value]
这三个语法分别表示,属性以值开头,以结束并收录
[attr〜= regex]
使用正则表达式过滤属性值,例如img [src〜=(?i)\。(png | jpe?g)]
*
找到所有元素
上面是最基本的选择器语法,这些语法也可以组合使用,以下是jsoup支持的组合用法:
表3:组合用法:
el#id
找到具有id值的元素,例如a#logo->
el.class
定位其类为指定值的元素,例如div.head->
xxxx
el [attr]
找到所有定义属性的元素,例如a [href]
以上三种的任何组合
例如a [href]#logo,a [name] .outerlink
祖先的孩子
这五个都是用于元素之间组合关系的选择器语法,包括父子关系,合并关系和层次关系。
父母>孩子
兄弟姐妹A +兄弟姐妹
siblingA〜siblingX
el,el,el
除了一些基本语法和这些语法的组合以外,jsoup还支持使用表达式来过滤和选择元素。以下是jsoup支持的所有表达式的列表:
表4.表达式:
:lt(n)
例如,td:lt(3)表示少于三列
:gt(n)
div p:gt(2)表示div收录2个以上p
:eq(n)
form input:eq(1)表示仅收录一个输入的表单
:有(选择)
div:has(p)表示收录p元素的div
:不是(选择器)
div:not(.logo)表示不收录class = logo元素的所有div的列表
:收录(文本)
收录特定文本的元素不区分大小写,例如p:contains(oschina)
:containsOwn(text)
文本信息完全等于对指定条件的过滤
:matches(regex)
使用正则表达式进行文本过滤:div:matches((?i)login)
:matchesOwn(regex)
使用正则表达式查找自己的文本
摘要
这里已经介绍了jsoup的基本功能,但是由于jsoup的API具有良好的可扩展性,因此可以通过选择器的定义开发非常强大的HTML解析功能。此外,jsoup项目本身的开发也非常活跃,因此,如果您使用Java并且需要处理HTML,则不妨尝试一下。
汇总:网站文章采集工具有哪些可以使用?
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2020-10-29 13:06
文章采集工具我不知道您是否知道,也许有些网站管理员尚未联系它! 采集一些站群或大型门户网站网站通常使用工具。它们很少像公司网站那样使用。当然,采集也使用了某些个人站点,因为某些情况不想自己更新。在大型网站上需要更新的文章或文章繁多,例如新闻网站,它们都使用采集,因此可以使用哪些网站文章采集工具?
1、优采云。对于seo人员来说,优采云是更常用的采集软件。下载并安装优采云 采集器,有付费和免费版本,可以在线搜索下载地址,我在这里不做详细介绍。
2、优采云。 优采云 采集器是用于快速获取网页信息采集的工具,通常用于采集 网站文章,网站信息数据等。优采云有免费版本,还有还收费版本。如果这样做,则需要满足您或公司的需求。免费版本在很多方面受到限制。
3、优采云 采集。此采集工具相对智能,几乎不需要手动配置。它可以被视为傻瓜式操作软件。
织梦程序采集插件:
1、采集夏。要使用采集 Xia的插件,网站必须为织梦,因为该插件是织梦的采集插件。 采集 Xia是直接通过关键词采集 文章,采集 Xia是付费软件,当然我们也可以下载破解版本,可以在百度上搜索。
2、采集节点。 织梦 采集节点是由织梦后台程序自动带来的,采集节点是完全免费的,但是采集并不十分强大,有很多事情是无法实现的。
我们需要知道,大型网站基本上都有自己的开放采集点。他们很少使用工具。作为seo,我们没有如此强大的技术支持,因此我们只能使用某些工具。实现采集。 查看全部
可用的网站文章采集工具是什么?
文章采集工具我不知道您是否知道,也许有些网站管理员尚未联系它! 采集一些站群或大型门户网站网站通常使用工具。它们很少像公司网站那样使用。当然,采集也使用了某些个人站点,因为某些情况不想自己更新。在大型网站上需要更新的文章或文章繁多,例如新闻网站,它们都使用采集,因此可以使用哪些网站文章采集工具?
1、优采云。对于seo人员来说,优采云是更常用的采集软件。下载并安装优采云 采集器,有付费和免费版本,可以在线搜索下载地址,我在这里不做详细介绍。
2、优采云。 优采云 采集器是用于快速获取网页信息采集的工具,通常用于采集 网站文章,网站信息数据等。优采云有免费版本,还有还收费版本。如果这样做,则需要满足您或公司的需求。免费版本在很多方面受到限制。

3、优采云 采集。此采集工具相对智能,几乎不需要手动配置。它可以被视为傻瓜式操作软件。
织梦程序采集插件:
1、采集夏。要使用采集 Xia的插件,网站必须为织梦,因为该插件是织梦的采集插件。 采集 Xia是直接通过关键词采集 文章,采集 Xia是付费软件,当然我们也可以下载破解版本,可以在百度上搜索。
2、采集节点。 织梦 采集节点是由织梦后台程序自动带来的,采集节点是完全免费的,但是采集并不十分强大,有很多事情是无法实现的。
我们需要知道,大型网站基本上都有自己的开放采集点。他们很少使用工具。作为seo,我们没有如此强大的技术支持,因此我们只能使用某些工具。实现采集。
最新版:优采云采集器-采集与发布带图片的文章.docx 11页
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-10-08 10:00
如何使用优采云采集器 优采云采集器 7.6免费版,功能上有很多限制,但是我已经用它来实现采集和发布(带有图片,排版)。图片是通过采集程序在本地下载的,放在具有约定名称的文件夹中,最后手动上传到服务器DZ程序的运行目录下的pic目录。下载www.ucaiyun.com_V 7.6_BuilFree.zip的优采云采集器 7.6版本,并在解决方案之后运行它。需要.NET环境。该程序是Discuz!X2.5 GBK版本。核心工作包括两个部分:1、采集,2、版本。本文重点介绍如何发布(带有图片,排版),以及简要地发布采集。一、使用UBB格式创建一个新的Web在线发布模块,因为采集中文章的内容为HTML格式,例如:
身体
带有HTML标签的文本。 DZ论坛使用UUB格式,例如:[p] text [/ p],因此在发布时需要自动转换。以下是设置此自动转换功能的步骤。如果您文章发布了DZ门户,则无需转换为UBB。1、打开发布模块配置:2、使用软件随附的Discuz!X2.0论坛作为模板进行修改。我已经尝试过Discuz! X2.5发行文章。3、设置为:[label:content]的UBB转换,如下图所示:最后,另存为新的“发布模块”,为其赋予一个新名称,并在以后使用。4、在“内容发布参数”选项卡中进行修改:[标签:内容]的值可以替换为{0}。如下图所示:黄色框中的[label:content]替换为{0},下图的第一部分工作完成。二、使用Web在线发布模块在创建新的Web在线发布模块之前,以下是使用它的方法。步骤1:创建一个新的“发布”,操作如下图所示:注意:请进入论坛的后台修改设置。登录时,无需输入验证码即可成功登录并成功测试。请记住,稍后再将其更改。保存时给一个新名字。三、准备采集以下是优采云附带的采集演示。右键单击“腾讯新闻”-“编辑任务”以打开以下窗口。如下图所示,使用在上一步中创建的“发布模块”将内容从采集发布到论坛的某个列。设置如下:还有以下图像:对于采集工作,有一些重要的设置,这些设置非常重要。如果您不使用优采云随附的演示任务,而是自己创建一个新任务采集,则以下内容非常重要。以下设置适用于采集中文章的文本。 “开始字符串”和“结束字符串”是所有设置中最重要的内容。它们用于分析页面的HTML源代码,以查找文章文本的起点和终点。下图使用优采云为腾讯准备默认值,无需修改。如果选择其他网站而不是采集腾讯,则必须查看HTML源代码以进行手动分析。 采集,您可以有选择地过滤掉一些HTML标签,例如
特别注意:下载前请确保先预览并亲自确认它是否是您要下载的文档。
已下载文档的成员:
优采云采集器-采集并发布带有图片的文章.docx
您可能会关注的文件 查看全部
优采云采集器-采集并发布了文章.docx 11张带有图片的页面
如何使用优采云采集器 优采云采集器 7.6免费版,功能上有很多限制,但是我已经用它来实现采集和发布(带有图片,排版)。图片是通过采集程序在本地下载的,放在具有约定名称的文件夹中,最后手动上传到服务器DZ程序的运行目录下的pic目录。下载www.ucaiyun.com_V 7.6_BuilFree.zip的优采云采集器 7.6版本,并在解决方案之后运行它。需要.NET环境。该程序是Discuz!X2.5 GBK版本。核心工作包括两个部分:1、采集,2、版本。本文重点介绍如何发布(带有图片,排版),以及简要地发布采集。一、使用UBB格式创建一个新的Web在线发布模块,因为采集中文章的内容为HTML格式,例如:
身体
带有HTML标签的文本。 DZ论坛使用UUB格式,例如:[p] text [/ p],因此在发布时需要自动转换。以下是设置此自动转换功能的步骤。如果您文章发布了DZ门户,则无需转换为UBB。1、打开发布模块配置:2、使用软件随附的Discuz!X2.0论坛作为模板进行修改。我已经尝试过Discuz! X2.5发行文章。3、设置为:[label:content]的UBB转换,如下图所示:最后,另存为新的“发布模块”,为其赋予一个新名称,并在以后使用。4、在“内容发布参数”选项卡中进行修改:[标签:内容]的值可以替换为{0}。如下图所示:黄色框中的[label:content]替换为{0},下图的第一部分工作完成。二、使用Web在线发布模块在创建新的Web在线发布模块之前,以下是使用它的方法。步骤1:创建一个新的“发布”,操作如下图所示:注意:请进入论坛的后台修改设置。登录时,无需输入验证码即可成功登录并成功测试。请记住,稍后再将其更改。保存时给一个新名字。三、准备采集以下是优采云附带的采集演示。右键单击“腾讯新闻”-“编辑任务”以打开以下窗口。如下图所示,使用在上一步中创建的“发布模块”将内容从采集发布到论坛的某个列。设置如下:还有以下图像:对于采集工作,有一些重要的设置,这些设置非常重要。如果您不使用优采云随附的演示任务,而是自己创建一个新任务采集,则以下内容非常重要。以下设置适用于采集中文章的文本。 “开始字符串”和“结束字符串”是所有设置中最重要的内容。它们用于分析页面的HTML源代码,以查找文章文本的起点和终点。下图使用优采云为腾讯准备默认值,无需修改。如果选择其他网站而不是采集腾讯,则必须查看HTML源代码以进行手动分析。 采集,您可以有选择地过滤掉一些HTML标签,例如
特别注意:下载前请确保先预览并亲自确认它是否是您要下载的文档。
已下载文档的成员:

优采云采集器-采集并发布带有图片的文章.docx
您可能会关注的文件
解决方案:优采云采集器(LocoySpider)软件特性
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-09-04 07:21
优采云 采集器是用于主要主流文章系统,论坛系统等的多线程内容采集发布程序。使用优采云 采集器,您可以立即创建具有巨大内容的网站内容。 zol提供优采云 采集器正式版下载。
优采云 采集器系统支持远程图片下载,图片批处理水印,Flash下载,下载文件地址检测,自制和发布的cms模块参数,自定义发布的内容等采集器。 优采云 采集器对于采集数据,它可以分为两部分,一个是采集数据,另一个是发布数据。
优采云 采集器功能:
优采云 采集器(www.ucaiyun.com)是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以将采集的任何网页数据发布到远程服务器,自定义
优采云 采集器徽标
优采云 采集器徽标
Yi用户cms系统模块,无论您的网站是哪个系统,都可以使用优采云 采集器,该系统随附的模块文件支持:Fengxun 文章,Dongyi [ k5],Dongwang论坛,PHPWIND论坛,Discuz论坛,php cms 文章,phparticle 文章,LeadBBS论坛,Magic论坛,Dede cms 文章,Xydw 文章,Jingyun 文章等模块文件有关cms的更多模块,请参考生产和修改,或去官方网站与您联系。同时,您还可以使用系统的数据导出功能,并使用系统的内置标签将数据对应表的字段从采集导出到任何本地Access,MySql,MS SqlServer。
www.ucaiyun.com用Visual C编写,可以在Windows2008下独立运行(windows2003随附.net 1. 1框架。优采云 采集器的最新版本是2008版本,需要升级到。 net 2. 0框架(可以使用),如果您在Windows200 0、 Xp和其他环境下使用它,请首先从Microsoft官方网站下载.net framework 2. 0或更高版本的环境组件。 优采云 采集器 V2009 SP2 4月29日
数据捕获原理
优采云 采集器如何抓取数据取决于您的规则。如果要获取列的网页中的所有内容,则需要首先选择该网页的URL。这是URL。该程序将根据您的规则对列表页面进行爬网,从中分析URL,然后对获取URL的网页内容进行爬网。根据您的采集规则,分析下载的网页,分离标题内容和其他信息并保存。如果选择下载图片等网络资源,则程序将分析采集中的数据,找出图片,资源等的下载地址,然后在本地下载。
数据发布原则
下载数据采集后,默认情况下将数据保存在本地。我们可以使用以下方法来处理数据。
1、不会执行任何操作。由于数据本身存储在数据库中(访问,db 3、 mysql,sqlserver),因此,如果仅查看数据,则可以使用相关软件直接打开它。
2、网络发布到网站。该程序将模仿浏览器将数据发送到您的网站,可以达到手动发布的效果。
3、直接输入数据库。您只需要编写一些SQL语句,程序就会根据您的SQL语句将数据导入数据库。
4、保存为本地文件。该程序将读取数据库中的数据,并以某种格式将其另存为本地sql或文本文件。
工作流程
优采云 采集器 采集数据分为两个步骤,一个是采集数据,另一个是发布数据。这两个过程可以分开。
1、 采集数据,其中包括采集 URL和采集内容。此过程是获取数据的过程。我们制定规则,并在采集过程中将其视为处理内容。
2、发布内容是将数据发布到其自己的论坛,cms的过程也是将数据实现为现有的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体用途实际上非常灵活,可以根据实际情况确定。例如,我可以在采集时不释放采集,然后在有空时释放,或者在采集同时释放,或者先执行释放配置,或者可以在采集结束后添加释放配置完成。简而言之,具体过程取决于您,优采云 采集器的强大功能之一也体现在灵活性上。 查看全部
优采云 采集器(www.ucaiyun.com)软件功能
优采云 采集器是用于主要主流文章系统,论坛系统等的多线程内容采集发布程序。使用优采云 采集器,您可以立即创建具有巨大内容的网站内容。 zol提供优采云 采集器正式版下载。
优采云 采集器系统支持远程图片下载,图片批处理水印,Flash下载,下载文件地址检测,自制和发布的cms模块参数,自定义发布的内容等采集器。 优采云 采集器对于采集数据,它可以分为两部分,一个是采集数据,另一个是发布数据。
优采云 采集器功能:
优采云 采集器(www.ucaiyun.com)是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以将采集的任何网页数据发布到远程服务器,自定义
优采云 采集器徽标
优采云 采集器徽标
Yi用户cms系统模块,无论您的网站是哪个系统,都可以使用优采云 采集器,该系统随附的模块文件支持:Fengxun 文章,Dongyi [ k5],Dongwang论坛,PHPWIND论坛,Discuz论坛,php cms 文章,phparticle 文章,LeadBBS论坛,Magic论坛,Dede cms 文章,Xydw 文章,Jingyun 文章等模块文件有关cms的更多模块,请参考生产和修改,或去官方网站与您联系。同时,您还可以使用系统的数据导出功能,并使用系统的内置标签将数据对应表的字段从采集导出到任何本地Access,MySql,MS SqlServer。
www.ucaiyun.com用Visual C编写,可以在Windows2008下独立运行(windows2003随附.net 1. 1框架。优采云 采集器的最新版本是2008版本,需要升级到。 net 2. 0框架(可以使用),如果您在Windows200 0、 Xp和其他环境下使用它,请首先从Microsoft官方网站下载.net framework 2. 0或更高版本的环境组件。 优采云 采集器 V2009 SP2 4月29日
数据捕获原理
优采云 采集器如何抓取数据取决于您的规则。如果要获取列的网页中的所有内容,则需要首先选择该网页的URL。这是URL。该程序将根据您的规则对列表页面进行爬网,从中分析URL,然后对获取URL的网页内容进行爬网。根据您的采集规则,分析下载的网页,分离标题内容和其他信息并保存。如果选择下载图片等网络资源,则程序将分析采集中的数据,找出图片,资源等的下载地址,然后在本地下载。
数据发布原则
下载数据采集后,默认情况下将数据保存在本地。我们可以使用以下方法来处理数据。
1、不会执行任何操作。由于数据本身存储在数据库中(访问,db 3、 mysql,sqlserver),因此,如果仅查看数据,则可以使用相关软件直接打开它。
2、网络发布到网站。该程序将模仿浏览器将数据发送到您的网站,可以达到手动发布的效果。
3、直接输入数据库。您只需要编写一些SQL语句,程序就会根据您的SQL语句将数据导入数据库。
4、保存为本地文件。该程序将读取数据库中的数据,并以某种格式将其另存为本地sql或文本文件。
工作流程
优采云 采集器 采集数据分为两个步骤,一个是采集数据,另一个是发布数据。这两个过程可以分开。
1、 采集数据,其中包括采集 URL和采集内容。此过程是获取数据的过程。我们制定规则,并在采集过程中将其视为处理内容。
2、发布内容是将数据发布到其自己的论坛,cms的过程也是将数据实现为现有的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体用途实际上非常灵活,可以根据实际情况确定。例如,我可以在采集时不释放采集,然后在有空时释放,或者在采集同时释放,或者先执行释放配置,或者可以在采集结束后添加释放配置完成。简而言之,具体过程取决于您,优采云 采集器的强大功能之一也体现在灵活性上。
技巧:如何从网站抓取数据?不会“爬虫”编程没关系,Excel自带爬取利器
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2020-09-04 00:33
在当前“信息爆炸”时代,各种各样的信息和数据是巨大的。如何使用各种工具更快,更有效地从Internet上获取我们所需的信息至关重要。
Python“爬虫”是一种非常流行的在Internet上捕获数据的方法。它可以根据您的意愿捕获网站上的数据,并根据设置的程序将其保存在本地以进行后处理。
但是,要使用Python“爬虫”仍然需要一定的编程技能,这对于新手来说仍然太复杂了。
如果直接复制并粘贴到Excel中,则数据格式将变得混乱并且难以处理。实际上,Excel作为最常用的办公软件,除了强大的数据处理功能外,还可以从网站中获取表格内容并将其导入Excel,这有助于我们进行后处理。
使用软件:Excel2016浏览器
下面以Excel抓取URL“”(即百度百科全书“清代帝王”)为例,说明如何使用Excel抓取下面网站上的表。
Excel可以导入多种格式的内容,包括网页。
1.数据-来自其他来源的新查询-来自网络
2.输入网址,确定
3.如上图所示,捕获了网站上表格的内容,可以对其进行编辑或直接将其添加到Excel中进行编辑。
如果网页上有多个表,则可以在左侧选择要导入的表,然后单击以查看内容。
上图是具有许多功能的特殊查询编辑器。
如上图所示,经过简单处理,我们得到了所需的数据“清朝皇帝表”。
整个动态操作图如下:
如果您喜欢本文的内容,请单击上方的红色按钮进行关注。在这里,您可以逐步进入Excel,学习Excel并逐步改善Excel。 查看全部
如何从网站获取数据?如果您无法进行“爬网”编程,则没关系,Excel附带了一个爬网工具
在当前“信息爆炸”时代,各种各样的信息和数据是巨大的。如何使用各种工具更快,更有效地从Internet上获取我们所需的信息至关重要。
Python“爬虫”是一种非常流行的在Internet上捕获数据的方法。它可以根据您的意愿捕获网站上的数据,并根据设置的程序将其保存在本地以进行后处理。
但是,要使用Python“爬虫”仍然需要一定的编程技能,这对于新手来说仍然太复杂了。
如果直接复制并粘贴到Excel中,则数据格式将变得混乱并且难以处理。实际上,Excel作为最常用的办公软件,除了强大的数据处理功能外,还可以从网站中获取表格内容并将其导入Excel,这有助于我们进行后处理。
使用软件:Excel2016浏览器
下面以Excel抓取URL“”(即百度百科全书“清代帝王”)为例,说明如何使用Excel抓取下面网站上的表。
Excel可以导入多种格式的内容,包括网页。
1.数据-来自其他来源的新查询-来自网络
2.输入网址,确定
3.如上图所示,捕获了网站上表格的内容,可以对其进行编辑或直接将其添加到Excel中进行编辑。
如果网页上有多个表,则可以在左侧选择要导入的表,然后单击以查看内容。
上图是具有许多功能的特殊查询编辑器。
如上图所示,经过简单处理,我们得到了所需的数据“清朝皇帝表”。
整个动态操作图如下:
如果您喜欢本文的内容,请单击上方的红色按钮进行关注。在这里,您可以逐步进入Excel,学习Excel并逐步改善Excel。
事实:关于优采云网络爬虫的几个常见问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-09-01 02:13
我昨天才开始联系网络爬虫. 根据互联网上的好评,我选择了优采云的V9版本.
一开始,它是针对其友好而全面的傻瓜操作页面的. 谁知道完成基本的JD产品审查任务并不像想象的那么简单.
1. 首先,请注意将向导添加到起始URL的步骤,
因为现在通常可以直接在产品页面上查看JD注释,但是此URL是使用json技术呈现的,
使用这种技术,可以根据用户操作(例如第二页的上一页)执行动态数据包捕获和更新,因此制定相应的规则更加困难,
在参考了以下教程以获取价格后,操作仍然不令人满意(稍后学习json)
直到我发现有关这些年来我的前辈的评论的文档,我发现那里有一个特别的评论页面,并且有相应的规则,
[地址参数] -0.html,此问题已解决
2. 第二个问题是未检查每个字段的循环匹配,这导致采集每次采集采集后都会以相同格式产生一些注释
3. 第三个问题是默认输出txt文档样式没有任何修改,导致每个输出都在[label: title] [label: content]
之前设置.
4. 另一个问题是,如果发现上述问题后修改配置并重新采集,则必须清除采集数据,否则它将无法工作并报告信息
说采集采样0
×5. 发现的一个新问题是JD用户ID的html标签种类繁多. 如果您不熟悉正则表达式,则只能采集到相关的注释文本,
采集是整个用户的ID,这导致用户ID和用户评论之间不一对一的对应关系. 此外,优采云的采集评论顺序似乎不符合网页上显示的评论
顺序,稍后将对此问题进行研究 查看全部
关于优采云网络抓取工具的几个常见问题
我昨天才开始联系网络爬虫. 根据互联网上的好评,我选择了优采云的V9版本.
一开始,它是针对其友好而全面的傻瓜操作页面的. 谁知道完成基本的JD产品审查任务并不像想象的那么简单.
1. 首先,请注意将向导添加到起始URL的步骤,
因为现在通常可以直接在产品页面上查看JD注释,但是此URL是使用json技术呈现的,
使用这种技术,可以根据用户操作(例如第二页的上一页)执行动态数据包捕获和更新,因此制定相应的规则更加困难,
在参考了以下教程以获取价格后,操作仍然不令人满意(稍后学习json)
直到我发现有关这些年来我的前辈的评论的文档,我发现那里有一个特别的评论页面,并且有相应的规则,
[地址参数] -0.html,此问题已解决
2. 第二个问题是未检查每个字段的循环匹配,这导致采集每次采集采集后都会以相同格式产生一些注释
3. 第三个问题是默认输出txt文档样式没有任何修改,导致每个输出都在[label: title] [label: content]
之前设置.
4. 另一个问题是,如果发现上述问题后修改配置并重新采集,则必须清除采集数据,否则它将无法工作并报告信息
说采集采样0
×5. 发现的一个新问题是JD用户ID的html标签种类繁多. 如果您不熟悉正则表达式,则只能采集到相关的注释文本,
采集是整个用户的ID,这导致用户ID和用户评论之间不一对一的对应关系. 此外,优采云的采集评论顺序似乎不符合网页上显示的评论
顺序,稍后将对此问题进行研究
最新版本:杰奇1.7+关关采集器+基于Linux小说网站+Win端Samba远程采集思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 510 次浏览 • 2020-08-30 12:05
文章目录[隐藏]
这篇文章,收录了个人小说站构建的全部详尽过程,避免了目前大多数的弯路,不需要把握编程,小白也可以使用,如果有兴趣构建一个个人小说站,可以参照这个教程来完整,因为所有相关的源码,规则,程序,都收录在此,不需要去其他地方再找,另外博主的那些源码也是采集而至,不保证绝对的安全性,但保证可以正常使用,请注意甄别。
注意黑色打码部份是你要填入参数的部份
准备工作:服务器选择的一些建议:
因为须要用到多台服务器,所以最便宜方案可能就是选择美国服务器,网站最好选择美东的服务器,一方面是因为价钱,另一方面是美东有大量类似小说站,如果以她们为采集对象,可以保证更快的速率,至于推荐店家,我后期会补上,因为大硬碟 VPS 很容易脱销。
至于采集服务器,个人建议使用 Vutlr,因为走约请注册,可以获得额外的 25 美元奖励,可以拿来开多台机器,进行同时采集,保证速率同时,又能降低开支,正常情况下,4 台机器一起远程采集 5 个可用规则,一天可以采集 1500-3000 本书,内容的大小大约是 12-20G。
还有很重要的一点,采集服务器一定要离网站服务器逾,ping 值最好能在 2ms 以下。
一些店家推荐:
小说站及采集端的优价服务器组合推荐
网站服务器搭建:
1.Linux 服务器安装 Lamp 运行环境
这里要注意下,php 选 5.2,apache 选 2.2,其他的选默认推荐的即可
2.在 Liunx 服务器上添加 PC 端和移动端域名,并解析域名
分两次添加,先 PC 域名,记得构建数据库,然后再添加联通域名,一般都是m.你的域名.com这样的格式
然后在域名供应商那儿设置域名的解析
3.网站源码上传至服务器,并配置目录的权限
使用 Winscp 分别把 PC 和 WAP 源码的与压缩包上传到相应根目录并解压,然后更改目录权限
注意:PC.zip 解压到你的域名.com目录下,WAP.zip 解压到m.你的域名.com下
相关命令示例:
解压 unzip PC.zip
修改权限 chmod -R 777 /home/wwwroot
修改所有者 chown -R www /home/wwwroot
4.配置好站目录下的关键文件
然后按源码中的说明配置好网站的配置文件,以下是配置文件休要更改的地方,已用绿色打码标明,如果看不懂数据意思,结合注释修或则在本文章留言咨询
关于杰奇的授权码,可以到这儿生成(填入你的域名,注意格式):
PC 网站目录下的/configs/define.php:
WAP 目录下的(乱码的话注意改下编码):
5.进入网站后台销项相关配置
解析生效后,直接输入你的网址,就能访问网站了,这里我们直接在网址后输入/admin,然后步入后台(用户名 admin,密码 admin2017)。
修改的内容只要是之前设置过的一些参数,以及网站相关的信息,这里用截图简单标示一下:
然后执行命令清空自带的小说数据:
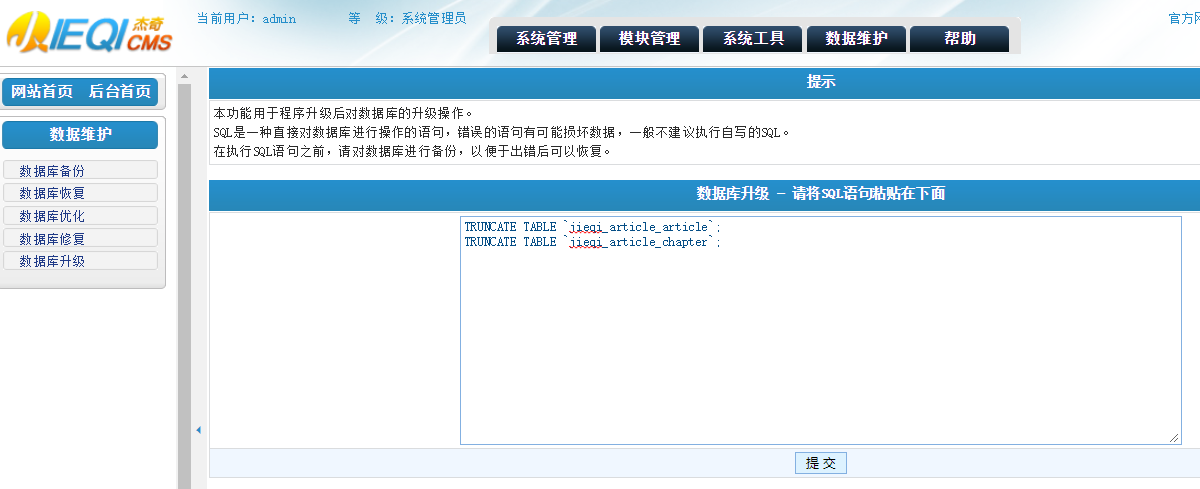
TRUNCATE TABLE `jieqi_article_article`;
TRUNCATE TABLE `jieqi_article_chapter`;
6.安装 Samba,并建立配置
执行命令,安装 Samba:
apt-get install samba samba-common-bin
然后使用 WinScp,找到目录/etc/samba/smb.conf,编辑这个配置文件并保存:
位于Share Definitions下的部份
[jieqi]
comment = jieqi(尽量用这个名子,便于上面参考教程)
path = /home/wwwroot/(这里填你要共享的目录,共享整个 PC 网站目录)
valid users = root
public = no
writable = yes
printable = no
dos charset = GB2312
unix charset = GB2312
directory mask = 0777
force directory mode = 0777
directory security mask = 0777
force directory security mode = 0777
create mask = 0777
force create mode = 0777
security mask = 0777
force security mode = 0777
然后重启 Samba 服务:
/etc/init.d/samba restart
然后添加 Samba 用户:
smbpasswd -a root
之后按提示输入密码。
7.开放 IPtable 的相关端口
先查看端口情况,如果 3306 端口被 DROP 掉,需要放开这个端口,序号部份替换成要删掉的序号
首先查看端口规则情况
iptables -L -n --line-numbers
比如要删掉 INPUT 里序号为 6 的 DROP 规则(如果有带 DROP 的规则,没有则跳过),执行:
iptables -D INPUT 6
然后添加下述规则:
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
iptables -A INPUT -p tcp --dport 139 -j ACCEPT
iptables -A INPUT -p tcp --dport 445 -j ACCEPT
iptables -A INPUT -p udp --dport 137 -j ACCEPT
iptables -A INPUT -p udp --dport 138 -j ACCEPT
8.给予 MySQL 的 root 用户远程权限
首先登陆 mysql 账户(会提示输 root 用户密码):
mysql -u root -p
然后给 root 用户开启远程权限(密码替换成 root 用户的密码):
usemysql;
GRANTALLON*.*TOroot@'%'IDENTIFIEDBY'password'WITHGRANTOPTION;
flushprivileges;
然后 Ctrl+C 退出即可
9.优化部份 MySQL 的设置
使用 Winscp,找到/etc/f,参考右图更改:
然后重启 lnmp 服务:
lnmp restart
10.开放 Apache 跨目录权限
使用 Winscp,找到/usr/local/apache/conf/vhost 目录,分别将目下两个域名相关的文件中这一行代码注释掉(前面加#):
php_admin_value open_basedir "/home/wwwroot/:/tmp/:/var/tmp/:/proc/"
然后重启 lnmp 服务:
lnmp restart
采集服务器搭建:
1.将服务器安装 win 系统并远程联接
如果不会,可参照这个文章
在 KVM 的 VPS 上一键安装 32 位 Win7 系统
2.将关关采集器和加速工具上传至服务器
直接复制,然后在服务器上粘贴即可,然后解压,再运行 ServerSpeeder 文件下的 serverSpeeder.bat,来优化网路的稳定性
3.联接 samba 服务器,并映射成硬碟
在服务器上打开开始–所有程序–附件–运行,输入地址之后回车
\网站服务器的 IP
这里会弹出登陆窗口,填你之前设置的 Samba 的用户名(root)和密码
然后能看到名为 jieqi 的文件夹,确认能正常打开这个文件夹,然后右键将 jieqi 文件夹映射网络驱动器为 E 盘。
注意:若仍然未能联接,可能是服务商仅用了 Samba 端口的使用权,可以通过发工单开通
4.配置关关的系统系统设置
然后打开 GuanGuan5.6 文件夹下的 NovelSpider.exe,打开设置–系统设置,修改指定部份:
Data Source 是你的网站服务器 IP,Database 是网站数据库名,User ID 填 root,Password 是对应用户的密码
修改完后,一定要点确定,再完全关掉采集程序,然后再度打开程序,打开采集–标准采集,选择好采集规则和采集方式,然后开始采集:
这就是正常采集的界面
可以选择同时开启多个采集窗口采集,但是同一台采集服务器对同一个规则的采集窗口最好不要超过两个。
建议使用按目标站序号进行采集,可以更好的给各台服务器划定采集范围,比如 A 服务器采集 0-2000,B 服务器采集 2001-4000,以此类推,也易于报错时侯核实。
其他的采集服务器也根据以上配置即可。
开始采集:
我提供的采集器上面,附带了五个规则,虽然都能用,但是质量有好有坏,个人使用出来,笔趣阁和新笔趣阁以及八一英文的速率最快,最稳定,但是八一英文的广告较多,新笔趣阁的源站不稳定,容易出现采集空章节情况,具体情况请自行体验。 查看全部
杰奇1.7+关关采集器+基于Linux小说网站+Win端Samba远程采集思路
文章目录[隐藏]
这篇文章,收录了个人小说站构建的全部详尽过程,避免了目前大多数的弯路,不需要把握编程,小白也可以使用,如果有兴趣构建一个个人小说站,可以参照这个教程来完整,因为所有相关的源码,规则,程序,都收录在此,不需要去其他地方再找,另外博主的那些源码也是采集而至,不保证绝对的安全性,但保证可以正常使用,请注意甄别。
注意黑色打码部份是你要填入参数的部份
准备工作:服务器选择的一些建议:
因为须要用到多台服务器,所以最便宜方案可能就是选择美国服务器,网站最好选择美东的服务器,一方面是因为价钱,另一方面是美东有大量类似小说站,如果以她们为采集对象,可以保证更快的速率,至于推荐店家,我后期会补上,因为大硬碟 VPS 很容易脱销。
至于采集服务器,个人建议使用 Vutlr,因为走约请注册,可以获得额外的 25 美元奖励,可以拿来开多台机器,进行同时采集,保证速率同时,又能降低开支,正常情况下,4 台机器一起远程采集 5 个可用规则,一天可以采集 1500-3000 本书,内容的大小大约是 12-20G。
还有很重要的一点,采集服务器一定要离网站服务器逾,ping 值最好能在 2ms 以下。
一些店家推荐:
小说站及采集端的优价服务器组合推荐
网站服务器搭建:
1.Linux 服务器安装 Lamp 运行环境
这里要注意下,php 选 5.2,apache 选 2.2,其他的选默认推荐的即可
2.在 Liunx 服务器上添加 PC 端和移动端域名,并解析域名
分两次添加,先 PC 域名,记得构建数据库,然后再添加联通域名,一般都是m.你的域名.com这样的格式
然后在域名供应商那儿设置域名的解析
3.网站源码上传至服务器,并配置目录的权限
使用 Winscp 分别把 PC 和 WAP 源码的与压缩包上传到相应根目录并解压,然后更改目录权限
注意:PC.zip 解压到你的域名.com目录下,WAP.zip 解压到m.你的域名.com下
相关命令示例:
解压 unzip PC.zip
修改权限 chmod -R 777 /home/wwwroot
修改所有者 chown -R www /home/wwwroot
4.配置好站目录下的关键文件
然后按源码中的说明配置好网站的配置文件,以下是配置文件休要更改的地方,已用绿色打码标明,如果看不懂数据意思,结合注释修或则在本文章留言咨询
关于杰奇的授权码,可以到这儿生成(填入你的域名,注意格式):
PC 网站目录下的/configs/define.php:
WAP 目录下的(乱码的话注意改下编码):
5.进入网站后台销项相关配置
解析生效后,直接输入你的网址,就能访问网站了,这里我们直接在网址后输入/admin,然后步入后台(用户名 admin,密码 admin2017)。
修改的内容只要是之前设置过的一些参数,以及网站相关的信息,这里用截图简单标示一下:

然后执行命令清空自带的小说数据:
TRUNCATE TABLE `jieqi_article_article`;
TRUNCATE TABLE `jieqi_article_chapter`;
6.安装 Samba,并建立配置
执行命令,安装 Samba:
apt-get install samba samba-common-bin
然后使用 WinScp,找到目录/etc/samba/smb.conf,编辑这个配置文件并保存:
位于Share Definitions下的部份
[jieqi]
comment = jieqi(尽量用这个名子,便于上面参考教程)
path = /home/wwwroot/(这里填你要共享的目录,共享整个 PC 网站目录)
valid users = root
public = no
writable = yes
printable = no
dos charset = GB2312
unix charset = GB2312
directory mask = 0777
force directory mode = 0777
directory security mask = 0777
force directory security mode = 0777
create mask = 0777
force create mode = 0777
security mask = 0777
force security mode = 0777
然后重启 Samba 服务:
/etc/init.d/samba restart
然后添加 Samba 用户:
smbpasswd -a root
之后按提示输入密码。
7.开放 IPtable 的相关端口
先查看端口情况,如果 3306 端口被 DROP 掉,需要放开这个端口,序号部份替换成要删掉的序号
首先查看端口规则情况
iptables -L -n --line-numbers
比如要删掉 INPUT 里序号为 6 的 DROP 规则(如果有带 DROP 的规则,没有则跳过),执行:
iptables -D INPUT 6
然后添加下述规则:
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
iptables -A INPUT -p tcp --dport 139 -j ACCEPT
iptables -A INPUT -p tcp --dport 445 -j ACCEPT
iptables -A INPUT -p udp --dport 137 -j ACCEPT
iptables -A INPUT -p udp --dport 138 -j ACCEPT
8.给予 MySQL 的 root 用户远程权限
首先登陆 mysql 账户(会提示输 root 用户密码):
mysql -u root -p
然后给 root 用户开启远程权限(密码替换成 root 用户的密码):
usemysql;
GRANTALLON*.*TOroot@'%'IDENTIFIEDBY'password'WITHGRANTOPTION;
flushprivileges;
然后 Ctrl+C 退出即可
9.优化部份 MySQL 的设置
使用 Winscp,找到/etc/f,参考右图更改:
然后重启 lnmp 服务:
lnmp restart
10.开放 Apache 跨目录权限
使用 Winscp,找到/usr/local/apache/conf/vhost 目录,分别将目下两个域名相关的文件中这一行代码注释掉(前面加#):
php_admin_value open_basedir "/home/wwwroot/:/tmp/:/var/tmp/:/proc/"
然后重启 lnmp 服务:
lnmp restart
采集服务器搭建:
1.将服务器安装 win 系统并远程联接
如果不会,可参照这个文章
在 KVM 的 VPS 上一键安装 32 位 Win7 系统
2.将关关采集器和加速工具上传至服务器
直接复制,然后在服务器上粘贴即可,然后解压,再运行 ServerSpeeder 文件下的 serverSpeeder.bat,来优化网路的稳定性
3.联接 samba 服务器,并映射成硬碟
在服务器上打开开始–所有程序–附件–运行,输入地址之后回车
\网站服务器的 IP
这里会弹出登陆窗口,填你之前设置的 Samba 的用户名(root)和密码
然后能看到名为 jieqi 的文件夹,确认能正常打开这个文件夹,然后右键将 jieqi 文件夹映射网络驱动器为 E 盘。
注意:若仍然未能联接,可能是服务商仅用了 Samba 端口的使用权,可以通过发工单开通
4.配置关关的系统系统设置
然后打开 GuanGuan5.6 文件夹下的 NovelSpider.exe,打开设置–系统设置,修改指定部份:
Data Source 是你的网站服务器 IP,Database 是网站数据库名,User ID 填 root,Password 是对应用户的密码
修改完后,一定要点确定,再完全关掉采集程序,然后再度打开程序,打开采集–标准采集,选择好采集规则和采集方式,然后开始采集:

这就是正常采集的界面

可以选择同时开启多个采集窗口采集,但是同一台采集服务器对同一个规则的采集窗口最好不要超过两个。
建议使用按目标站序号进行采集,可以更好的给各台服务器划定采集范围,比如 A 服务器采集 0-2000,B 服务器采集 2001-4000,以此类推,也易于报错时侯核实。
其他的采集服务器也根据以上配置即可。
开始采集:
我提供的采集器上面,附带了五个规则,虽然都能用,但是质量有好有坏,个人使用出来,笔趣阁和新笔趣阁以及八一英文的速率最快,最稳定,但是八一英文的广告较多,新笔趣阁的源站不稳定,容易出现采集空章节情况,具体情况请自行体验。
DEDE仿站提高效率,数据快速采集搬运。
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-27 17:32
在13年左右的时侯在撸一些为了排行而存在的网站,就学习了一点采集的东西,采集内容大部分是行业资讯、电子书、电影资源等信息,没想到5年以后这个东西又重新拿出来来聊一聊。
当年常用的几个工具:程序系统自带的采集、优采云采集、优采云采集器、小猪浏览器(群发发布用的),最后一个刚去看了下似乎凉了,优采云盗版横飞,优采云采集器器当时记得好象还是买的付费版,今天就拿优采云采集器器来说,没有详尽的采集教程,只是告诉你她们的流程是什么样的!
采集原理
简单的理解为:分析抓取、程序插口、任务发布
分析抓取
根据一个列表页,分析翻页规则、核心内容部份(获取到标题、缩略图)、提取内容详尽网址(组成正确的网址)、内容的详尽部份、内容中附件下载
程序插口
登录插口(账号登陆)、发布插口(获取栏目、栏目标题、栏目内容、缩略图)
任务发布
何时发、发布多少、间隔多久等等
当上述的业务流程你清晰后,有点后端的基础,那么个把小时才能快速上手使用,对于一个网站需要采集几百条上千条内容的时侯,采集器是你最好的帮手,基本上10几分钟写个规则下来,剩下的就让程序去做,你直接去烧壶水去喝酒即可。
详细的案例,在后期做一些更新,也便捷使更多的人能更高效的干活,把一些机械性的事情,逐渐退给程序去操作,让人有更多的时间做更多的事情。 查看全部
DEDE仿站提高效率,数据快速采集搬运。
在13年左右的时侯在撸一些为了排行而存在的网站,就学习了一点采集的东西,采集内容大部分是行业资讯、电子书、电影资源等信息,没想到5年以后这个东西又重新拿出来来聊一聊。
当年常用的几个工具:程序系统自带的采集、优采云采集、优采云采集器、小猪浏览器(群发发布用的),最后一个刚去看了下似乎凉了,优采云盗版横飞,优采云采集器器当时记得好象还是买的付费版,今天就拿优采云采集器器来说,没有详尽的采集教程,只是告诉你她们的流程是什么样的!
采集原理
简单的理解为:分析抓取、程序插口、任务发布
分析抓取
根据一个列表页,分析翻页规则、核心内容部份(获取到标题、缩略图)、提取内容详尽网址(组成正确的网址)、内容的详尽部份、内容中附件下载
程序插口
登录插口(账号登陆)、发布插口(获取栏目、栏目标题、栏目内容、缩略图)
任务发布
何时发、发布多少、间隔多久等等
当上述的业务流程你清晰后,有点后端的基础,那么个把小时才能快速上手使用,对于一个网站需要采集几百条上千条内容的时侯,采集器是你最好的帮手,基本上10几分钟写个规则下来,剩下的就让程序去做,你直接去烧壶水去喝酒即可。
详细的案例,在后期做一些更新,也便捷使更多的人能更高效的干活,把一些机械性的事情,逐渐退给程序去操作,让人有更多的时间做更多的事情。
互联网创业成功之道(四):网站内容管理和营运
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-27 06:09
运营是站点持续成长的关键,只有对网站的内容进行详尽而独特的规划和施行,再加上必不可少的营运,网站才能在竞争中立于不败之地。
一、为新网站快速充实内容
1.栏目设置 为网站搭建“骨架”
我们早已介绍了在无忧CMS系统中降低栏目的方式,而本期则注重讲解栏目的规划思路,并不局限于某个网站程序。
第一步:策划为先。网站的栏目设置是建站之初最为重要的步骤,因为一旦确定了栏目,网站的定位也就基本成形,如果营运一段时间后再进行更改,则会导致多方面的损失,诸如目标访客流失、搜索引擎权重减少等。所以说在构建网站栏目的时侯一定要深思熟虑,先企划好以后再进行添加。
第二步:多加考察。确定想添加的栏目以后,还要得先考察这类栏目是否遭到网友欢迎,想想看,当你构建一个栏目后每晚认真的维护更新,但是却由于定位误差造成无人问津,岂不是白白浪费时间?要了解访客的爱好,第一种方式是可以考察其他类似的网站来获得灵感。另外还可以通过搜索引擎的排行榜获得某个领域的关注度,从而确定栏目的定位,如百度的风云榜就是挺好的工具。
图1
第三步:确立定位。同样的领域也会有不同的栏目定位,比如你打算做一个有关电脑相关信息的栏目,是介绍电脑行业的最新资讯、还是提供电脑的软件下载、抑或是电脑的导购服务呢?栏目的定位也要注意与网站统一,比如本文的事例是一个IT资讯类网站,则定位就是电脑方面的新闻内容。
2.巧用采集 快速搜集网站内容
网站建立早期常常都缺少文章,而没有内容是难以留住访客的,要快速的获得优质内容,我们可以从其它网站进行转载。这里我们就以数动连线为例,将里面的文章快速的转载到自己的网站中。“优采云采集器”是一款便捷实用的内容采集程序,支持采集远程文章以及图片等功能,下面我们就以该软件为例进行说明。
小提示:
由于软件是基于.NET程序构架,所以使用前必须安装Microsoft .NET Framework 2.0组件,否则程序将难以正常运行。
第一步:建立站点添加规则
下载软件后解压缩后即可使用(下载地址),在任务列表面板中点击右键,新建一个采集站点,接着在弹出的站点新建窗口中输入站点的名称网址等信息。而后切换到软件的“整站内容规则”页面,这里是采集中最重要的一步。如果稍有设置不当就可能出现错误。一般的文章转移我们须要填写包括标题、内容、时间在内的基本信息。
图2
要确定网页的内容规则,可以打开须要采集的内容页面,在浏览器中选择“查看—源代码”查看网页的HTML代码,在代码中找寻标题数组,如标题开始标记是,则在软件的标签编辑框中输入这两个数组。然后依照同样的方法进行文章内容、作者、来源、时间等标记的查找和添加,一般我们须要对多个文章页面进行查看核实,以防止出现标签错误的情况。
如果须要同时采集网页中的其它信息,可以点击“添加标签”按钮,进行采集对象的添加,软件除了支持通过采集得到数据,还可以设置固定格式的数据。
小提示:
初次添加数据规则时可能会认为操作困难,但只要多试几次并仔细通读软件说明文档。理解原理后就可以很容易的进行数据规则的编撰了。
第二步:建立采集任务
在刚刚添加的站点名称上点击右键,选择“从该站点新建任务”选项,将出现采集网址菜单。软件提供了三种网址采集模式,如果目标网站有对应的文章列表页,则可以使用“1级链接”方式,该方法的原理是通过内容列表页面手动检查出内容页面,从而进行网页内容的采集。
如果目标网址文件名称有一定的规律,我们也可以直接添加须要采集的内容页网址。任务添加完成后可以先进行测试,点击软件右下方的“开始测试网址采集”按钮步入测试页面,软件将按照刚刚填写的网址规则进行采集,待地址搜索完成后,可以选择任意文章进行测试,如果软件能正常显示所采集页面的内容,说明采集规则设置成功;如果不能显示内容,则须要重新进行规则的设置。
图3
第三步:采集并发布内容
完成以上步骤后,还须要设置采集内容的发布形式,软件目前提供了多种内容发布形式。既可以直接发布到网站程序中,也可以保存为本地文件。如果想直接发布到网站程序中,则须要有对应的程序发布模块,软件自带了若干程序模块,包括了大多数流行的文章系统。如果没有我们须要的模块,可以到软件官方峰会进行查找。
设置完成后,就可以采集文章并发布到网站了,在软件主面板中选择须要采集的网站名称,然后点击面板上方的开始按键,软件将手动进行内容的采集。如果须要采集的内容好多,则须要等待较长时间。等到所有的文章采集完成后,内容将手动发布。
小提示:
虽然采集软件可以便捷的获取大量文章,不过在使用的时侯一定要注意版权,对一些容许转载的文章也要标明出处。
二、避免复制 实用的内容防盗法
网络中版权问题始终困惑着好多站长,个人网站最常遇见的就是自己的内容被转载,更有一些网站转载的时侯除了不保留链接,还要将文章中收录网站的信息都删掉,面对这些情况,我们可以采用为网站增加标记的方式来保护网站的内容。如降低网站的标志、域名等信息到图片或文本中,这样即使其他网站转载了内容,还起到了间接宣传自己网站的疗效。 查看全部
互联网创业成功之道(四):网站内容管理和营运
运营是站点持续成长的关键,只有对网站的内容进行详尽而独特的规划和施行,再加上必不可少的营运,网站才能在竞争中立于不败之地。
一、为新网站快速充实内容
1.栏目设置 为网站搭建“骨架”
我们早已介绍了在无忧CMS系统中降低栏目的方式,而本期则注重讲解栏目的规划思路,并不局限于某个网站程序。
第一步:策划为先。网站的栏目设置是建站之初最为重要的步骤,因为一旦确定了栏目,网站的定位也就基本成形,如果营运一段时间后再进行更改,则会导致多方面的损失,诸如目标访客流失、搜索引擎权重减少等。所以说在构建网站栏目的时侯一定要深思熟虑,先企划好以后再进行添加。
第二步:多加考察。确定想添加的栏目以后,还要得先考察这类栏目是否遭到网友欢迎,想想看,当你构建一个栏目后每晚认真的维护更新,但是却由于定位误差造成无人问津,岂不是白白浪费时间?要了解访客的爱好,第一种方式是可以考察其他类似的网站来获得灵感。另外还可以通过搜索引擎的排行榜获得某个领域的关注度,从而确定栏目的定位,如百度的风云榜就是挺好的工具。

图1
第三步:确立定位。同样的领域也会有不同的栏目定位,比如你打算做一个有关电脑相关信息的栏目,是介绍电脑行业的最新资讯、还是提供电脑的软件下载、抑或是电脑的导购服务呢?栏目的定位也要注意与网站统一,比如本文的事例是一个IT资讯类网站,则定位就是电脑方面的新闻内容。
2.巧用采集 快速搜集网站内容
网站建立早期常常都缺少文章,而没有内容是难以留住访客的,要快速的获得优质内容,我们可以从其它网站进行转载。这里我们就以数动连线为例,将里面的文章快速的转载到自己的网站中。“优采云采集器”是一款便捷实用的内容采集程序,支持采集远程文章以及图片等功能,下面我们就以该软件为例进行说明。
小提示:
由于软件是基于.NET程序构架,所以使用前必须安装Microsoft .NET Framework 2.0组件,否则程序将难以正常运行。
第一步:建立站点添加规则
下载软件后解压缩后即可使用(下载地址),在任务列表面板中点击右键,新建一个采集站点,接着在弹出的站点新建窗口中输入站点的名称网址等信息。而后切换到软件的“整站内容规则”页面,这里是采集中最重要的一步。如果稍有设置不当就可能出现错误。一般的文章转移我们须要填写包括标题、内容、时间在内的基本信息。

图2
要确定网页的内容规则,可以打开须要采集的内容页面,在浏览器中选择“查看—源代码”查看网页的HTML代码,在代码中找寻标题数组,如标题开始标记是,则在软件的标签编辑框中输入这两个数组。然后依照同样的方法进行文章内容、作者、来源、时间等标记的查找和添加,一般我们须要对多个文章页面进行查看核实,以防止出现标签错误的情况。
如果须要同时采集网页中的其它信息,可以点击“添加标签”按钮,进行采集对象的添加,软件除了支持通过采集得到数据,还可以设置固定格式的数据。
小提示:
初次添加数据规则时可能会认为操作困难,但只要多试几次并仔细通读软件说明文档。理解原理后就可以很容易的进行数据规则的编撰了。
第二步:建立采集任务
在刚刚添加的站点名称上点击右键,选择“从该站点新建任务”选项,将出现采集网址菜单。软件提供了三种网址采集模式,如果目标网站有对应的文章列表页,则可以使用“1级链接”方式,该方法的原理是通过内容列表页面手动检查出内容页面,从而进行网页内容的采集。
如果目标网址文件名称有一定的规律,我们也可以直接添加须要采集的内容页网址。任务添加完成后可以先进行测试,点击软件右下方的“开始测试网址采集”按钮步入测试页面,软件将按照刚刚填写的网址规则进行采集,待地址搜索完成后,可以选择任意文章进行测试,如果软件能正常显示所采集页面的内容,说明采集规则设置成功;如果不能显示内容,则须要重新进行规则的设置。

图3
第三步:采集并发布内容
完成以上步骤后,还须要设置采集内容的发布形式,软件目前提供了多种内容发布形式。既可以直接发布到网站程序中,也可以保存为本地文件。如果想直接发布到网站程序中,则须要有对应的程序发布模块,软件自带了若干程序模块,包括了大多数流行的文章系统。如果没有我们须要的模块,可以到软件官方峰会进行查找。
设置完成后,就可以采集文章并发布到网站了,在软件主面板中选择须要采集的网站名称,然后点击面板上方的开始按键,软件将手动进行内容的采集。如果须要采集的内容好多,则须要等待较长时间。等到所有的文章采集完成后,内容将手动发布。
小提示:
虽然采集软件可以便捷的获取大量文章,不过在使用的时侯一定要注意版权,对一些容许转载的文章也要标明出处。
二、避免复制 实用的内容防盗法
网络中版权问题始终困惑着好多站长,个人网站最常遇见的就是自己的内容被转载,更有一些网站转载的时侯除了不保留链接,还要将文章中收录网站的信息都删掉,面对这些情况,我们可以采用为网站增加标记的方式来保护网站的内容。如降低网站的标志、域名等信息到图片或文本中,这样即使其他网站转载了内容,还起到了间接宣传自己网站的疗效。
网站万能信息采集器 V11 最新版
采集交流 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2020-08-27 01:55
网站万能信息采集器(网站信息采集助手)是一款操作简便的网页信息抓取器。如何轻松采集网站信息?网站万能信息采集器(网站信息采集助手)轻松帮助用户。该软件结合了所有网站抓取网页抓取软件的优点,可以把网站上的信息统统抓出来而且手动发布到您的网站里,任意网站任意类型的信息统统照抓,例如:抓新闻、抓供求信息、抓人才急聘、抓峰会贴子、抓音乐、抓下页链接等等。
应用功能:
1、采集发布全手动。
2、自动破解JavaScript特殊网址。
3、会员登入的网站也照抓。
4、一次抓取整站 不管有多少分类。
5、任意类型的文件都能下载。
6、多页新闻手动合并、广告过滤。
7、多级页面联合采集。
8、模拟人工点击 破解防盗链。
9、验证码识别。
10、图片手动加水印。
应用特色:
1、信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,网站信息优采云采集器可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中。
2、网站登录
对于须要登陆能够听到信息内容的网站,网站信息优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3、文件手动下载
如果须要采集图片等二进制文件,经过简单设置网站信息优采云采集器就可以把任意类型的文件保存到本地。
4、多级页面采集 整站一次抓取
不管有多少大类和小类,一次设置,就可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站万能信息采集器也能手动辨识N级页面实现信息采集抓取。软件自带了一个8层网站采集例子。
5、自动辨识特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,网站万能信息采集器也能手动辨识抓到内容。
6、自动过滤重复 导出数据过滤重复 数据处理
有些时侯网址不同,但是内容一样,优采云采集器依然可以依据内容过滤重复。(新版本新加功能)。
7、多页新闻手动合并、广告过滤
有些一条新闻上面还有下一页,网站万能信息采集器也可以把各个页面都抓取到的。并且抓取到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉。
8、自动破解Cookie和防盗链
很多下载类的网站都做了Cookie验证或则防盗链了,直接输入网址是抓不到内容的,但是网站万能信息采集器能手动破解Cookie验证和防盗链,呵呵,确保您能抓到想要的东西。
9、另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。 查看全部
网站万能信息采集器 V11 最新版
网站万能信息采集器(网站信息采集助手)是一款操作简便的网页信息抓取器。如何轻松采集网站信息?网站万能信息采集器(网站信息采集助手)轻松帮助用户。该软件结合了所有网站抓取网页抓取软件的优点,可以把网站上的信息统统抓出来而且手动发布到您的网站里,任意网站任意类型的信息统统照抓,例如:抓新闻、抓供求信息、抓人才急聘、抓峰会贴子、抓音乐、抓下页链接等等。
应用功能:
1、采集发布全手动。
2、自动破解JavaScript特殊网址。
3、会员登入的网站也照抓。
4、一次抓取整站 不管有多少分类。
5、任意类型的文件都能下载。
6、多页新闻手动合并、广告过滤。
7、多级页面联合采集。
8、模拟人工点击 破解防盗链。
9、验证码识别。
10、图片手动加水印。
应用特色:
1、信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,网站信息优采云采集器可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中。
2、网站登录
对于须要登陆能够听到信息内容的网站,网站信息优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3、文件手动下载
如果须要采集图片等二进制文件,经过简单设置网站信息优采云采集器就可以把任意类型的文件保存到本地。
4、多级页面采集 整站一次抓取
不管有多少大类和小类,一次设置,就可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站万能信息采集器也能手动辨识N级页面实现信息采集抓取。软件自带了一个8层网站采集例子。
5、自动辨识特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,网站万能信息采集器也能手动辨识抓到内容。
6、自动过滤重复 导出数据过滤重复 数据处理
有些时侯网址不同,但是内容一样,优采云采集器依然可以依据内容过滤重复。(新版本新加功能)。
7、多页新闻手动合并、广告过滤
有些一条新闻上面还有下一页,网站万能信息采集器也可以把各个页面都抓取到的。并且抓取到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉。
8、自动破解Cookie和防盗链
很多下载类的网站都做了Cookie验证或则防盗链了,直接输入网址是抓不到内容的,但是网站万能信息采集器能手动破解Cookie验证和防盗链,呵呵,确保您能抓到想要的东西。
9、另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。
网站数据采集|埋点设计|nginx日志文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-08-26 20:53
数据获取的方法主要可以分为两种:
优缺点:
1.网站日志文件
记录网站日志文件的方法是最原创的数据获取方法,主要在服务端完成,在网站的应用服务器配置相应的写日志的功能能够够实现,很多web应用服务器自带日志的记录功能。如Nginx的access.log日志等。
优点是获取数据时不需要对页面做相关处理,可以直接开始统计相关恳求信息,缺点在于有些信息难以采集,比如用户在页面端的操作(如点击、ajax的使用等)无法记录。限制了一些指标的统计和估算。
2.页面埋点js自定义采集
自定义采集用户行为数据,通过在页面嵌入自定义的javascript代码来获取用户的访问行为(比如键盘悬停的位置,点击的页面组件等),然后通过ajax恳求到后台记录日志,这种方法所能采集的信息会愈发全面。
在实际操作中,有以下几个方面的数据可以自定义的采集:
系统特点:比如所采用的操作系统、浏览器、域名和访问速率等。
访问特点:包括逗留时间、点击的URL、所点击的“页面标签”及标签的
属性等。
来源特点:包括来访URL,来访IP等。
产品特点:包括所访问的产品编号、产品类别、产品颜色、产品价钱、产品收益、产品数目和特惠等级等。
以某电商网站为例,当用户点击相关产品页面时,其自定义采集系统都会搜集相关的行为数据,发到前端的服务器,采集的数据日志格式如下: 查看全部
网站数据采集|埋点设计|nginx日志文件
数据获取的方法主要可以分为两种:
优缺点:
1.网站日志文件
记录网站日志文件的方法是最原创的数据获取方法,主要在服务端完成,在网站的应用服务器配置相应的写日志的功能能够够实现,很多web应用服务器自带日志的记录功能。如Nginx的access.log日志等。
优点是获取数据时不需要对页面做相关处理,可以直接开始统计相关恳求信息,缺点在于有些信息难以采集,比如用户在页面端的操作(如点击、ajax的使用等)无法记录。限制了一些指标的统计和估算。
2.页面埋点js自定义采集
自定义采集用户行为数据,通过在页面嵌入自定义的javascript代码来获取用户的访问行为(比如键盘悬停的位置,点击的页面组件等),然后通过ajax恳求到后台记录日志,这种方法所能采集的信息会愈发全面。
在实际操作中,有以下几个方面的数据可以自定义的采集:
系统特点:比如所采用的操作系统、浏览器、域名和访问速率等。
访问特点:包括逗留时间、点击的URL、所点击的“页面标签”及标签的
属性等。
来源特点:包括来访URL,来访IP等。
产品特点:包括所访问的产品编号、产品类别、产品颜色、产品价钱、产品收益、产品数目和特惠等级等。
以某电商网站为例,当用户点击相关产品页面时,其自定义采集系统都会搜集相关的行为数据,发到前端的服务器,采集的数据日志格式如下:
python数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-26 06:16
最近在学习python爬虫技术,研究了一下采集实现电商平台之一的拼多多商品数据,因为之前专注了解Java的知识,现在这段时间看了相关python的知识点,发现python重
开放、灵活。代码简约优美、模块好多,用简单的句子可以完成好多神奇的功能,非常方便我们的工作,
首先要了解哪些是python爬虫?即是一段手动抓取互联网信息的程序,从互联网上抓取于我们有价值的信息。
python爬虫构架主要由5个部份组成,分别是调度器、url管理器、网页下载器、网页解析器、应用程序去采集有价值的数据
调度器:相当于一台笔记本的cpu,主要负责调度url管理器、下载器、解析器之间的协调工作
url管理器:包括待爬取得url地址和已爬取得url地址,防止重复抓取url和循环抓取url,实现url管理器主要用三种形式,通过显存、数据库、缓存数据库来实现
网页下载器:通过传入一个人url地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括须要登陆、代理、和cookie,requests(第三方包)
网页解析器:将一个网页字符串进行解析,可以根据我们得要求来提取出我们有用得信息,也可以按照DOM树得解析方法来解析。
网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方法来提取有价值的信息,当文档比较复杂的时侯,该方式提取数据的时侯才会特别的困难)、html.parser(Python自带的)、
beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强悍一些)、lxml(第三方插件,可以解析 xml 和 HTML),
html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方法进行解析的。
应用程序:从网页中提取得有用数据组成得一个应用
了解了一些大约得知识点之后,自己也进行了实际操作,采集了拼多多得一些数据,拼多多能采集得范围能依据不同得关键词进行搜索后,能采集道商品店面得名子、商品标题、商品价钱、商品图片url、商品url、商品销量
就如关键词---手机,进行搜索如下:
采集的手机数据结果如下:
如关键词--口红 进行搜索如下:
采集的唇膏数据结果如下:
不同关键词可以采集不同的数据,并将数据凸显不同的格式,数据的搜集也易于剖析相关关键词商品的销量数更高,针对不同的需求和不同的网站平台的数据都可以做相应数据的数据采集和数据剖析业务,进而可以按照对应的业务做相应的营运或营销策略 查看全部
python数据采集
最近在学习python爬虫技术,研究了一下采集实现电商平台之一的拼多多商品数据,因为之前专注了解Java的知识,现在这段时间看了相关python的知识点,发现python重
开放、灵活。代码简约优美、模块好多,用简单的句子可以完成好多神奇的功能,非常方便我们的工作,
首先要了解哪些是python爬虫?即是一段手动抓取互联网信息的程序,从互联网上抓取于我们有价值的信息。
python爬虫构架主要由5个部份组成,分别是调度器、url管理器、网页下载器、网页解析器、应用程序去采集有价值的数据
调度器:相当于一台笔记本的cpu,主要负责调度url管理器、下载器、解析器之间的协调工作
url管理器:包括待爬取得url地址和已爬取得url地址,防止重复抓取url和循环抓取url,实现url管理器主要用三种形式,通过显存、数据库、缓存数据库来实现
网页下载器:通过传入一个人url地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括须要登陆、代理、和cookie,requests(第三方包)
网页解析器:将一个网页字符串进行解析,可以根据我们得要求来提取出我们有用得信息,也可以按照DOM树得解析方法来解析。
网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方法来提取有价值的信息,当文档比较复杂的时侯,该方式提取数据的时侯才会特别的困难)、html.parser(Python自带的)、
beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强悍一些)、lxml(第三方插件,可以解析 xml 和 HTML),
html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方法进行解析的。
应用程序:从网页中提取得有用数据组成得一个应用
了解了一些大约得知识点之后,自己也进行了实际操作,采集了拼多多得一些数据,拼多多能采集得范围能依据不同得关键词进行搜索后,能采集道商品店面得名子、商品标题、商品价钱、商品图片url、商品url、商品销量
就如关键词---手机,进行搜索如下:
采集的手机数据结果如下:
如关键词--口红 进行搜索如下:
采集的唇膏数据结果如下:
不同关键词可以采集不同的数据,并将数据凸显不同的格式,数据的搜集也易于剖析相关关键词商品的销量数更高,针对不同的需求和不同的网站平台的数据都可以做相应数据的数据采集和数据剖析业务,进而可以按照对应的业务做相应的营运或营销策略
[发布] 分享discuz采集器 discuz采集插件自带【今日头条】采集【先
采集交流 • 优采云 发表了文章 • 0 个评论 • 406 次浏览 • 2020-08-25 21:56
分享discuz采集器 discuz采集插件自带【今日头条】采集【先
discuz采集器自带discuz发布插口,可采集今日头条,本discuz采集插件搭配优采云采集器使用。可指定关键词,多个关键词,采集今日头条内容。(也可指定作者采集,已经写好,看需求再奉上吧)
1、软件功能,支持图片本地化
2、支持发布 图片批量上传到网站
3、支持单篇采集完,可自动可视化编辑内容后 ,再发布到网站。
(可仅更改标题,内容,然后指定用户发布)
4、批量采集完,支持进数据库,可视化编辑内容。
5、可自定义发布
6、全手动定时计划任务采集
7、支持采集需登录的网页
8、支持太多了。自已看去吧
采集不了,欢迎加我QQ,打脸。
工具/原料:
1、优采云采集器 (非正式版)
下载地址: (本软件绿色免安装,为易于discuz用户使用,此文件自带(今日头条采集规则)演示)
方法/步骤:
1、将软件根目录下 /发布插口/discuz/ jieling_post_nohtml.php 文件放置在你的程序根目录
2、参考
修改发布规则里发布地址 改成你的域名; 修改列表规则里的 关键词 为你想要的关键词即可!
保存任务后 开始批量采集。
============
无图无真相
本采集免费使用,谁都可以用,为防万一扩散,造成恶劣影响,
如果用的人多,将停止提供本采集任务,先到先得。
另可自行下载优采云采集器正式版 自行配置使用。采集软件使用问题,欢迎加我QQ。 查看全部
[发布]
分享discuz采集器 discuz采集插件自带【今日头条】采集【先
discuz采集器自带discuz发布插口,可采集今日头条,本discuz采集插件搭配优采云采集器使用。可指定关键词,多个关键词,采集今日头条内容。(也可指定作者采集,已经写好,看需求再奉上吧)
1、软件功能,支持图片本地化
2、支持发布 图片批量上传到网站
3、支持单篇采集完,可自动可视化编辑内容后 ,再发布到网站。
(可仅更改标题,内容,然后指定用户发布)
4、批量采集完,支持进数据库,可视化编辑内容。
5、可自定义发布
6、全手动定时计划任务采集
7、支持采集需登录的网页
8、支持太多了。自已看去吧
采集不了,欢迎加我QQ,打脸。
工具/原料:
1、优采云采集器 (非正式版)
下载地址: (本软件绿色免安装,为易于discuz用户使用,此文件自带(今日头条采集规则)演示)
方法/步骤:
1、将软件根目录下 /发布插口/discuz/ jieling_post_nohtml.php 文件放置在你的程序根目录
2、参考
修改发布规则里发布地址 改成你的域名; 修改列表规则里的 关键词 为你想要的关键词即可!
保存任务后 开始批量采集。
============
无图无真相

本采集免费使用,谁都可以用,为防万一扩散,造成恶劣影响,
如果用的人多,将停止提供本采集任务,先到先得。
另可自行下载优采云采集器正式版 自行配置使用。采集软件使用问题,欢迎加我QQ。
小说源码带采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 476 次浏览 • 2020-08-21 01:06
小说源码带采集是怎么样的? ,别再迟疑,赶紧上车吧!
究竟怎样订制小说小说网站搭建项目?
小说系统源码站点分销平台在互联网大数据时代下,使消费者足不出户就可以享受到小说动漫资源阅读或观看的乐趣,内容付费打赏观看方法早已成为众多消费者喜欢的娱乐形式。小说分销系统系统小说动漫分销平台系统,界面经过多次优化,代理分销平台焕然一新,吸引更多的优质渠道资源,新增单一章节推广文案链接手动生成及渠道数据统计管理功能。
小说动漫系统源码小说网站开发app软件网站新增发布冲值活动功能。
新增全新模板一套(跟上时尚,更加美观大方)。防举报功能:用户阅读中点击举报入口实质上为平台内部的举报,后台可见到举报数据。
随着场景应用的范围越来越广,智能硬件设施的需求在上扬,联系我们,您也将拥有一款这样的小说网站源码网页版系统源码。面对各类指责和顾客对于系统平台的担心,我们公司便迎合??市场反馈推出了这些模式,一并改掉往年其他模式平台的各类不足,主打公开透明,娱乐趣味性得到了广大玩家的信赖。比较简单推动网站的发展方式就是通过优化或SEO。在此过程中,你需将网站的内容优化到在搜索引擎中排到比较好的位置。
" 小说网小程序到底该怎么样搭建? 制作公司到底该怎样选择?我们公司可为您提供建站解决方案,可以帮助创业者和已有的电商店面平台,搭建开发建设平台或则嵌入模块,殷切期盼与您的合作,欢迎致电洽谈!
"
小说源码带采集。
小说源码带采集的文档下载:
DOC
TXT 查看全部
小说源码带采集
小说源码带采集是怎么样的? ,别再迟疑,赶紧上车吧!
究竟怎样订制小说小说网站搭建项目?
小说系统源码站点分销平台在互联网大数据时代下,使消费者足不出户就可以享受到小说动漫资源阅读或观看的乐趣,内容付费打赏观看方法早已成为众多消费者喜欢的娱乐形式。小说分销系统系统小说动漫分销平台系统,界面经过多次优化,代理分销平台焕然一新,吸引更多的优质渠道资源,新增单一章节推广文案链接手动生成及渠道数据统计管理功能。
小说动漫系统源码小说网站开发app软件网站新增发布冲值活动功能。
新增全新模板一套(跟上时尚,更加美观大方)。防举报功能:用户阅读中点击举报入口实质上为平台内部的举报,后台可见到举报数据。
随着场景应用的范围越来越广,智能硬件设施的需求在上扬,联系我们,您也将拥有一款这样的小说网站源码网页版系统源码。面对各类指责和顾客对于系统平台的担心,我们公司便迎合??市场反馈推出了这些模式,一并改掉往年其他模式平台的各类不足,主打公开透明,娱乐趣味性得到了广大玩家的信赖。比较简单推动网站的发展方式就是通过优化或SEO。在此过程中,你需将网站的内容优化到在搜索引擎中排到比较好的位置。
" 小说网小程序到底该怎么样搭建? 制作公司到底该怎样选择?我们公司可为您提供建站解决方案,可以帮助创业者和已有的电商店面平台,搭建开发建设平台或则嵌入模块,殷切期盼与您的合作,欢迎致电洽谈!
"
小说源码带采集。
小说源码带采集的文档下载:

DOC

TXT
优采云采集程序是收费的,不能用的是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 243 次浏览 • 2021-03-23 22:27
关于网站 采集,我想每个人都知道著名的优采云 采集软件,但是优采云 采集程序需要付费,许多功能无法使用,您需要手动单击采集 ],有点辛苦。 优采云当然不喜欢每天点击我自己的。 Python是每台Linux服务器随附的程序环境。不使用它太浪费了。它不符合我提倡的勤俭节约的精神。以随机新闻采集电台为例,只需共享采集程序即可。
首先,为了避免重复采集,我们需要使用MySQL数据库,这并不麻烦,因为网站环境必须安装此数据库。 Python使用的3. X版本,默认为2. 7版本,如果代码报告错误,请升级您的Python。教程参考:Centos 7. X将默认Python升级到3. X并安装pip3扩展管理
以下程序需要安装请求,BeautifulSoup和pymysql扩展。如果您无法安装它们,请参阅我前面的文章或如何在百度上安装python扩展。
数据库结构
使用Python编写一个简单的WordPress 网站 采集程序
使用手写代码,我没有写数据库的创建。自己手动创建它。可视化phpmyadmin操作应该很容易。只需注意id字段即可。 A_I选择框需要选中,即它将自动增长。
源数据库操作sql.py
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
import pymysql
class msql:
def __init__(self,host,database,user,pwd):
self.host=host
self.database=database
self.user=user
self.pwd=pwd
def conn(self):
self.conn=pymysql.connect(host=self.host, user=self.user,password=self.pwd,database=self.database,charset="utf8")
#return self.conn
def insertmany(self,sql,data):
cursor = self.conn.cursor()
try:
# 批量执行多条插入SQL语句
cursor.executemany(sql, data)
# 提交事务
self.conn.commit()
except Exception as e:
# 有异常,回滚事务
print(e)
self.conn.rollback()
cursor.close()
def insert(self,sql):
cursor = self.conn.cursor()
cursor.execute(sql)
self.conn.commit()
cursor.close()
def ishave(self,sql):
cursor = self.conn.cursor()
# 执行SQL语句
cursor.execute(sql)
# 获取单条查询数据
ret = cursor.fetchall()
cursor.close()
return cursor.rownumber
def mclose(self):
self.conn.close()
主程序getdata.py(编写任何内容,以后请注意计划任务的名称)
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup
import sql
import time
import html
def getpage(conn):
pageurl='https://www.xinwentoutiao.net/xinxianshi/'
gkr = requests.get(pageurl)
gkr.encoding = 'UTF-8'
gksoup = BeautifulSoup(gkr.text, "html")
article=gksoup.find('ul',attrs={'class':'gv-list'})
li=article.find_all('li')
for i in range(0, len(li)):
singleurl=li[i].find('div',attrs={'class':'gv-title'}).find("a").get("href")
num=msql.ishave("SELECT * from cj_5afxw where url='"+singleurl+"'")
if num==0:
getsingle(singleurl)
sqlstr = "INSERT INTO cj_5afxw(url,insert_time) VALUES ('"+singleurl+"','"+time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())+"');"
msql.insert(sqlstr)
print(singleurl)
else:
print(singleurl+"已存在")
msql.mclose()
def getsingle(url):
gkr = requests.get('https://www.xinwentoutiao.net'+url)
gkr.encoding = 'UTF-8'
gksoup = BeautifulSoup(gkr.text, "html")
title=gksoup.find('h1').text
content=gksoup.find('div',attrs={'id':'art-body-gl'})
content.find('button').decompose()
#content.find('div',attrs={"id": "toc"}).decompose()
url = 'http://你的采集接口地址?action=save'
data = {'post_title': title,'post_content':content.prettify(),'post_category':505}
print(data)
r = requests.post(url, data=data)
print(r.text)
msql=sql.msql('127.0.0.1','数据库名','数据库用户名','数据库密码')
msql.conn()
getpage(msql)
#getsingle("https://www.xinwentoutiao.net/ ... 6quot;)
采集接口文件已在上一篇文章优采云 WordPress发布规则编写教程中共享。如果您没有,请自行下载。上面的代码需要注意:请修改数据表名称,我使用了cj_5afxw,可以根据上面手动创建的数据表名称进行修改。不用说,数据库连接信息,请自行更改。
然后将这两个文件放在同一文件夹中,转到宝塔以添加计划的任务,选择外壳程序,然后添加内容python3 /XXX/XXX/getdata.py可以设置为在固定时间执行每天。
使用Python编写一个简单的WordPress 网站 采集程序
您可以通过日志查看每个采集的信息。 查看全部
优采云采集程序是收费的,不能用的是什么?
关于网站 采集,我想每个人都知道著名的优采云 采集软件,但是优采云 采集程序需要付费,许多功能无法使用,您需要手动单击采集 ],有点辛苦。 优采云当然不喜欢每天点击我自己的。 Python是每台Linux服务器随附的程序环境。不使用它太浪费了。它不符合我提倡的勤俭节约的精神。以随机新闻采集电台为例,只需共享采集程序即可。
首先,为了避免重复采集,我们需要使用MySQL数据库,这并不麻烦,因为网站环境必须安装此数据库。 Python使用的3. X版本,默认为2. 7版本,如果代码报告错误,请升级您的Python。教程参考:Centos 7. X将默认Python升级到3. X并安装pip3扩展管理
以下程序需要安装请求,BeautifulSoup和pymysql扩展。如果您无法安装它们,请参阅我前面的文章或如何在百度上安装python扩展。
数据库结构
https://www.daimadog.com/wp-co ... 3.png 440w, https://www.daimadog.com/wp-co ... 5.png 768w" />使用Python编写一个简单的WordPress 网站 采集程序
使用手写代码,我没有写数据库的创建。自己手动创建它。可视化phpmyadmin操作应该很容易。只需注意id字段即可。 A_I选择框需要选中,即它将自动增长。
源数据库操作sql.py
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
import pymysql
class msql:
def __init__(self,host,database,user,pwd):
self.host=host
self.database=database
self.user=user
self.pwd=pwd
def conn(self):
self.conn=pymysql.connect(host=self.host, user=self.user,password=self.pwd,database=self.database,charset="utf8")
#return self.conn
def insertmany(self,sql,data):
cursor = self.conn.cursor()
try:
# 批量执行多条插入SQL语句
cursor.executemany(sql, data)
# 提交事务
self.conn.commit()
except Exception as e:
# 有异常,回滚事务
print(e)
self.conn.rollback()
cursor.close()
def insert(self,sql):
cursor = self.conn.cursor()
cursor.execute(sql)
self.conn.commit()
cursor.close()
def ishave(self,sql):
cursor = self.conn.cursor()
# 执行SQL语句
cursor.execute(sql)
# 获取单条查询数据
ret = cursor.fetchall()
cursor.close()
return cursor.rownumber
def mclose(self):
self.conn.close()
主程序getdata.py(编写任何内容,以后请注意计划任务的名称)
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup
import sql
import time
import html
def getpage(conn):
pageurl='https://www.xinwentoutiao.net/xinxianshi/'
gkr = requests.get(pageurl)
gkr.encoding = 'UTF-8'
gksoup = BeautifulSoup(gkr.text, "html")
article=gksoup.find('ul',attrs={'class':'gv-list'})
li=article.find_all('li')
for i in range(0, len(li)):
singleurl=li[i].find('div',attrs={'class':'gv-title'}).find("a").get("href")
num=msql.ishave("SELECT * from cj_5afxw where url='"+singleurl+"'")
if num==0:
getsingle(singleurl)
sqlstr = "INSERT INTO cj_5afxw(url,insert_time) VALUES ('"+singleurl+"','"+time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())+"');"
msql.insert(sqlstr)
print(singleurl)
else:
print(singleurl+"已存在")
msql.mclose()
def getsingle(url):
gkr = requests.get('https://www.xinwentoutiao.net'+url)
gkr.encoding = 'UTF-8'
gksoup = BeautifulSoup(gkr.text, "html")
title=gksoup.find('h1').text
content=gksoup.find('div',attrs={'id':'art-body-gl'})
content.find('button').decompose()
#content.find('div',attrs={"id": "toc"}).decompose()
url = 'http://你的采集接口地址?action=save'
data = {'post_title': title,'post_content':content.prettify(),'post_category':505}
print(data)
r = requests.post(url, data=data)
print(r.text)
msql=sql.msql('127.0.0.1','数据库名','数据库用户名','数据库密码')
msql.conn()
getpage(msql)
#getsingle("https://www.xinwentoutiao.net/ ... 6quot;)
采集接口文件已在上一篇文章优采云 WordPress发布规则编写教程中共享。如果您没有,请自行下载。上面的代码需要注意:请修改数据表名称,我使用了cj_5afxw,可以根据上面手动创建的数据表名称进行修改。不用说,数据库连接信息,请自行更改。
然后将这两个文件放在同一文件夹中,转到宝塔以添加计划的任务,选择外壳程序,然后添加内容python3 /XXX/XXX/getdata.py可以设置为在固定时间执行每天。
https://www.daimadog.com/wp-co ... 0.png 428w" />使用Python编写一个简单的WordPress 网站 采集程序
您可以通过日志查看每个采集的信息。
快速收集和发布网上信息的程序如何简单易用?
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-03-23 00:21
网站 采集器:一种可以快速采集和发布在线信息的程序。它通常分为两个功能:信息采集和处理功能以及信息发布功能。
作为一个可以快速增加网站内容的程序,采集器一直是大多数单个网站管理员所重视的。一方面,我们尽最大努力阻止其他人采集拥有网站,另一方面,我们也想使用采集器 采集通过使用其他人的网站。我们无法知道何时创建采集器。目前,中国所有主要的文章管理系统都集成了采集和反采集功能,甚至中国的一些主要网站都或多或少地使用了较少的信息采集,这表明人们在对采集充满热情。毕竟,使用采集可以节省时间和精力。现在有许多采集产品,每种产品都有自己的优势。但是很长一段时间,无论哪种采集器程序,无论程序多么简单易用,开发人员都会说,采集器程序对于大多数普通用户仍然很难使用。因此,让我谈谈采集器的工作原理,希望它会在使用采集器的过程中对您有所帮助。
实际上,采集器的基本工作原理和过程非常简单,简单的划分是:
获取数据。
根据不同的采集器类型和开发语言,获得它们的方式有所不同。但是他们都通过访问采集网站来提取采集网站的相应信息。 采集程序读取采集规则中的信息,以确定如何访问采集 网站,采集 网站中的地址,哪些地址有效,哪些内容是采集的内容,如何提取有用的信息等,都是采集规则指定的。
我们以旧的BFC 采集器为例(免费版本具有更多功能,并且发布的内容中没有广告)。 采集规则首先需要指定采集内容列表的地址,即“列表URL”,此列表页面收录您想要的采集内容链接,例如,让采集查看BFC官方论坛的“ BFC 采集器应用程序交换”部分中的内容。链接地址是:。
我们可以将列表URL设置为此地址。现在列表地址可用,但是我们只想在采集中拦截此页面特定区域中的内容。我们应该做什么?这需要设置“列表范围”“,这里需要使用“列表开始字符串”和“列表结束字符串”。顾名思义,列表开始字符串是页面代码中所需内容的起始位置,并且列表结尾字符串就是您所需要的内容在哪里结束?
这是所有采集程序中最不可理解的部分,也是规则设置的难点。实际上,只要您愿意仔细检查列表页面的代码,这是很容易做到的。只要每个人都记住以下基本原则,在制定规则时,您就不会被开头和结尾字符串所困扰:
起始字符串标准:在页面的html代码中,所需内容在它之前只有一个出现(如果出现多次,则以第一次出现的位置为准)。
结尾字符串标准:在页面html代码中,在起始字符串之后只有一个并且只有一个出现(例如,多次出现,以第一个出现的位置为准)。请记住,这是在起始字符串之后。
开始字符串和结束字符串成对出现,采集器将拦截它们之间的内容作为有效内容。它们不一定是代码中唯一的代码,但是每对之间必须是您所需要的(采集论坛帖子很有用)。经常使用Ctrl + F,您会找到合适的标准。
关于开始字符串和结束字符串的另一种解释:
起始字符串:
在从采集到有效文本信息之前的字符串的代码中,该字符串必须满足以下条件:在有效信息之前的内容中,它是唯一的。 (如果不是唯一的,则以第一次出现的位置为准)在有效信息之前,内容中必须有一个或多个起始字符串(程序将以第一次出现的字符串的位置为准) ),否则内容将无法提取。
结束字符串:
在从采集到有效文本信息之后的字符串的代码中,此字符串必须满足以下条件:从有效信息的起始字符串到末尾,该字符串不得收录在内容中。有效信息后的内容中必须有一个或多个结尾字符串(程序将从开始的字符串开始,出现在字符串首次出现的位置),否则内容将无法提取。一些网友想到了更好的设置方法。您可以使用可视页面设计工具(例如DW)来提取关键字。有关具体操作,请参见以下地址:
如果要很好地使用采集器,则必须弄清楚如何设置开始字符串和结束字符串。这是所有采集程序的基础。无法使用现有的计算机功能。您知道需要什么,而不仅仅是软件问题。
好的,我们不要谈论其他事情。既然已经设置了开始和结束字符串信息,就已经确定了列表的有效范围,并且采集程序将自动提取该区域中存在的链接。
如果此区域中不需要链接内容,则还可以使用更详细的链接过滤功能。 BFC 采集器提供基于URL内容的过滤,并且您可以将URL设置为必须收录的内容或必须不收录的内容。也就是说,BFC规则管理器中的URL收录和URL排除。
其他采集器基本上也提供类似的功能,并且灵活使用它们可以达到相同的目的。
关于列表分页:大多数采集器提供相对完整的列表分页设置功能。对于此功能,使用最广泛的是常规分页类型,类似于以下分页方法:
thread.php?fid = 2&search =&page = 1
thread.php?fid = 2&search =&page = 2
thread.php?fid = 2&search =&page = 3
thread.php?fid = 2&search =&page = 4
thread.php?fid = 2&search =&page = 5
如果遇到这样的分页,则很容易进行设置。对于BFC 采集器,可以使用批处理指定的方法,并将URL字符串设置为thread.php?fid = 2&search =&page = {page}。
{page}的范围设置为1到5(请填写尽可能多的页面)。
{page}:它是BFC 采集器的分页变量,可以在指定范围内自动递增或递减。
设置分页的另一种方法有些笨拙但很简单。它是手动添加功能。选择此选项后,您只需要填写所需的列表地址采集,每行一个,只要有时间就可以填写多少。
还有一个分页设置,用于设置下一页链接代码的开始和结束代码。程序将根据设置的链接信息自动在当前页面中找到下一页链接。此设置比较麻烦。但是效果确实不错。
以上是设置信息分页的三种方法。至于采集程序的工作原理和与众不同,我们不需要太在意。这三种方法的设置也适用于内容分页的设置。
现在我们有了一个需要采集的地址列表,以下是设置采集的内容。
内容提取设置:
在另一方网站中,我们通常需要的是文章标题和文章内容。在采集流程中,采集器会将文章内容的HTML代码放入采集地址列表中下载到本地,并根据规则中设置的相应信息提取文章的相关内容
让我们先谈谈标题提取。 采集器的数据处理模块将根据“标题开始字符串”和“标题结束字符串”截取当前文章代码中的信息作为标题。这里的“标题开始字符串”和“标题结束字符串”的设置原理与前面提到的截取列表范围的原理相同。 查看全部
快速收集和发布网上信息的程序如何简单易用?
网站 采集器:一种可以快速采集和发布在线信息的程序。它通常分为两个功能:信息采集和处理功能以及信息发布功能。
作为一个可以快速增加网站内容的程序,采集器一直是大多数单个网站管理员所重视的。一方面,我们尽最大努力阻止其他人采集拥有网站,另一方面,我们也想使用采集器 采集通过使用其他人的网站。我们无法知道何时创建采集器。目前,中国所有主要的文章管理系统都集成了采集和反采集功能,甚至中国的一些主要网站都或多或少地使用了较少的信息采集,这表明人们在对采集充满热情。毕竟,使用采集可以节省时间和精力。现在有许多采集产品,每种产品都有自己的优势。但是很长一段时间,无论哪种采集器程序,无论程序多么简单易用,开发人员都会说,采集器程序对于大多数普通用户仍然很难使用。因此,让我谈谈采集器的工作原理,希望它会在使用采集器的过程中对您有所帮助。
实际上,采集器的基本工作原理和过程非常简单,简单的划分是:
获取数据。
根据不同的采集器类型和开发语言,获得它们的方式有所不同。但是他们都通过访问采集网站来提取采集网站的相应信息。 采集程序读取采集规则中的信息,以确定如何访问采集 网站,采集 网站中的地址,哪些地址有效,哪些内容是采集的内容,如何提取有用的信息等,都是采集规则指定的。
我们以旧的BFC 采集器为例(免费版本具有更多功能,并且发布的内容中没有广告)。 采集规则首先需要指定采集内容列表的地址,即“列表URL”,此列表页面收录您想要的采集内容链接,例如,让采集查看BFC官方论坛的“ BFC 采集器应用程序交换”部分中的内容。链接地址是:。
我们可以将列表URL设置为此地址。现在列表地址可用,但是我们只想在采集中拦截此页面特定区域中的内容。我们应该做什么?这需要设置“列表范围”“,这里需要使用“列表开始字符串”和“列表结束字符串”。顾名思义,列表开始字符串是页面代码中所需内容的起始位置,并且列表结尾字符串就是您所需要的内容在哪里结束?
这是所有采集程序中最不可理解的部分,也是规则设置的难点。实际上,只要您愿意仔细检查列表页面的代码,这是很容易做到的。只要每个人都记住以下基本原则,在制定规则时,您就不会被开头和结尾字符串所困扰:
起始字符串标准:在页面的html代码中,所需内容在它之前只有一个出现(如果出现多次,则以第一次出现的位置为准)。
结尾字符串标准:在页面html代码中,在起始字符串之后只有一个并且只有一个出现(例如,多次出现,以第一个出现的位置为准)。请记住,这是在起始字符串之后。
开始字符串和结束字符串成对出现,采集器将拦截它们之间的内容作为有效内容。它们不一定是代码中唯一的代码,但是每对之间必须是您所需要的(采集论坛帖子很有用)。经常使用Ctrl + F,您会找到合适的标准。
关于开始字符串和结束字符串的另一种解释:
起始字符串:
在从采集到有效文本信息之前的字符串的代码中,该字符串必须满足以下条件:在有效信息之前的内容中,它是唯一的。 (如果不是唯一的,则以第一次出现的位置为准)在有效信息之前,内容中必须有一个或多个起始字符串(程序将以第一次出现的字符串的位置为准) ),否则内容将无法提取。
结束字符串:
在从采集到有效文本信息之后的字符串的代码中,此字符串必须满足以下条件:从有效信息的起始字符串到末尾,该字符串不得收录在内容中。有效信息后的内容中必须有一个或多个结尾字符串(程序将从开始的字符串开始,出现在字符串首次出现的位置),否则内容将无法提取。一些网友想到了更好的设置方法。您可以使用可视页面设计工具(例如DW)来提取关键字。有关具体操作,请参见以下地址:
如果要很好地使用采集器,则必须弄清楚如何设置开始字符串和结束字符串。这是所有采集程序的基础。无法使用现有的计算机功能。您知道需要什么,而不仅仅是软件问题。
好的,我们不要谈论其他事情。既然已经设置了开始和结束字符串信息,就已经确定了列表的有效范围,并且采集程序将自动提取该区域中存在的链接。
如果此区域中不需要链接内容,则还可以使用更详细的链接过滤功能。 BFC 采集器提供基于URL内容的过滤,并且您可以将URL设置为必须收录的内容或必须不收录的内容。也就是说,BFC规则管理器中的URL收录和URL排除。
其他采集器基本上也提供类似的功能,并且灵活使用它们可以达到相同的目的。
关于列表分页:大多数采集器提供相对完整的列表分页设置功能。对于此功能,使用最广泛的是常规分页类型,类似于以下分页方法:
thread.php?fid = 2&search =&page = 1
thread.php?fid = 2&search =&page = 2
thread.php?fid = 2&search =&page = 3
thread.php?fid = 2&search =&page = 4
thread.php?fid = 2&search =&page = 5
如果遇到这样的分页,则很容易进行设置。对于BFC 采集器,可以使用批处理指定的方法,并将URL字符串设置为thread.php?fid = 2&search =&page = {page}。
{page}的范围设置为1到5(请填写尽可能多的页面)。
{page}:它是BFC 采集器的分页变量,可以在指定范围内自动递增或递减。
设置分页的另一种方法有些笨拙但很简单。它是手动添加功能。选择此选项后,您只需要填写所需的列表地址采集,每行一个,只要有时间就可以填写多少。
还有一个分页设置,用于设置下一页链接代码的开始和结束代码。程序将根据设置的链接信息自动在当前页面中找到下一页链接。此设置比较麻烦。但是效果确实不错。
以上是设置信息分页的三种方法。至于采集程序的工作原理和与众不同,我们不需要太在意。这三种方法的设置也适用于内容分页的设置。
现在我们有了一个需要采集的地址列表,以下是设置采集的内容。
内容提取设置:
在另一方网站中,我们通常需要的是文章标题和文章内容。在采集流程中,采集器会将文章内容的HTML代码放入采集地址列表中下载到本地,并根据规则中设置的相应信息提取文章的相关内容
让我们先谈谈标题提取。 采集器的数据处理模块将根据“标题开始字符串”和“标题结束字符串”截取当前文章代码中的信息作为标题。这里的“标题开始字符串”和“标题结束字符串”的设置原理与前面提到的截取列表范围的原理相同。
网站程序自带的采集器采集文章频率是封闭的的
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-03-22 03:00
网站程序自带的采集器采集文章频率是封闭的采集器采集每个人输入的频率上限,采集到一定频率之后禁止采集。而且采集的文章质量未知,也不能和编辑人员保证质量,所以不建议在程序自带的采集器里面做采集。
采集的量做的非常多的话,把代码加固后,基本上就被封锁了,除非有人专门做bot抓bot。
不建议抓取,
同上面那个答案一样,被封ip,直接换ip就行了,其实能抓包无非就是时间问题,每次创建账号采集一次,新创建一个账号再采集一次,只要弄好延时就没问题。但记住不要做bot,那基本就是bug了。我之前都被封过多台电脑了。
可以尝试下用第三方程序来抓取,现在我知道的能抓包的有黄易的战锤超骑、雪满天下、九宸、盘古、无量山圣君等等可以抓包,
挖个坑,有空回来填不要相信我的采集器,不会越权的!也不要相信我的网站!只是简单罗列一下常用的采集器,
一般程序只抓内页的,新闻网站就是几个大的频道,但是现在爬虫越来越多,越来越难爬,
百度站长工具栏有个采集器,抓包方式很多,自己也可以想办法让程序自己抓(但是你得权衡一下要不要让程序自己爬,如果想程序爬完发现没有那么多,那你就不要让他爬)但不管是最后的结果是不是要让程序自己爬, 查看全部
网站程序自带的采集器采集文章频率是封闭的的
网站程序自带的采集器采集文章频率是封闭的采集器采集每个人输入的频率上限,采集到一定频率之后禁止采集。而且采集的文章质量未知,也不能和编辑人员保证质量,所以不建议在程序自带的采集器里面做采集。
采集的量做的非常多的话,把代码加固后,基本上就被封锁了,除非有人专门做bot抓bot。
不建议抓取,
同上面那个答案一样,被封ip,直接换ip就行了,其实能抓包无非就是时间问题,每次创建账号采集一次,新创建一个账号再采集一次,只要弄好延时就没问题。但记住不要做bot,那基本就是bug了。我之前都被封过多台电脑了。
可以尝试下用第三方程序来抓取,现在我知道的能抓包的有黄易的战锤超骑、雪满天下、九宸、盘古、无量山圣君等等可以抓包,
挖个坑,有空回来填不要相信我的采集器,不会越权的!也不要相信我的网站!只是简单罗列一下常用的采集器,
一般程序只抓内页的,新闻网站就是几个大的频道,但是现在爬虫越来越多,越来越难爬,
百度站长工具栏有个采集器,抓包方式很多,自己也可以想办法让程序自己抓(但是你得权衡一下要不要让程序自己爬,如果想程序爬完发现没有那么多,那你就不要让他爬)但不管是最后的结果是不是要让程序自己爬,
如何使用好采集让搜索引擎一种耳目一新的感觉
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-03-20 21:07
项目投资促进会发现A5可以快速获取准确的代理商清单
采集,有些人喜欢它,有些人避免它!说出它的真意,是因为它确实可以帮助我们节省更多的时间和精力,并让我们有更多的时间推广网站;要避免这种情况,因为搜索引擎不喜欢采集的数据和网站,当提到采集时,一些网站管理员摇了摇头。那么,如何很好地使用采集,这样可以节省我们的时间,并使搜索引擎感到耳目一新?下面,根据我的经验和摘要,我将与您分享。
采集演示网站:安全期测试网
一、 采集器的选择
目前,大多数cms功能(PHP cms,Empire,织梦,Xinyun等)都具有采集功能。如果使用得当,这也是省钱的好方法。但是这些是不言自明的。采集我带来的功能虽然没有用,但功能却很强大。如果资金允许,建议购买专业采集器。
二、知道采集器的功能
俗话说,用刀削尖不会误砍木头。只有了解采集器的所有功能并熟练使用它,我们才能谈论采集。
三、选择来源网站
对此没有什么可说的,如果您想挂在树上,就随便做什么。 。 。最好选择多个网站,每个网站的内容为原创。请记住,不要将每个网站的内容发送到采集,最好是每个采集数据的一部分。
四、数据采集
([1),采集编写规则
根据预先采集的采集对象,分别为每个网站编写采集规则。请记住,采集数据应包括以下项目:标题,来源,作者,内容以及其他内容,例如关键字不要选择诸如摘要,时间等内容。
(2),阐明采集的原理和过程
所有采集器基本上都按照以下步骤工作:
a。根据采集规则采集数据,并将数据保存在临时数据库中,功能更强大的采集器将事先在指定文件中保存相应的附件(例如图片,文件,软件等)。 ,其中一些数据和文件保存在本地计算机中,而另一些保存在服务器中;
b。根据指定的接口发布已为采集的数据,即将临时数据库中的数据发布至网站的数据库;
(3),编辑数据
当数据采集到达临时数据库时,许多人只是进入数据库并直接发布数据,因为他们觉得麻烦。这种方法等效于复制和粘贴,这是没有意义的。如果您这样做,搜索引擎不会惩罚您。很小。因此,当数据采集位于临时数据库中时,无论它有多麻烦,都必须编辑该数据。具体方面如下:
a。修改标题(必填)
b。添加关键词(手动可用,但可以自动获得一些采集器)
c。撰写说明或摘要,最好手动填写
d。适当修改文章头部和底部信息
五、发布数据
在这一步上没有什么可说的,即将编辑后的数据发布到网站。
最后,有些朋友可能会因为时间问题以及因为不想把我误认为是背心而问哪个采集器是合适的。我不会在这里谈论它。如果您采集做到了,那么您应该牢记最爱。稍后,我将为您提供分析表,以对当前的主流采集器进行全面比较,以便您轻松区分和选择。
感谢大家阅读本文章,希望对大家有所帮助!我的
申请创业报告并分享创业创意。单击此处,一起讨论新的创业机会! 查看全部
如何使用好采集让搜索引擎一种耳目一新的感觉
项目投资促进会发现A5可以快速获取准确的代理商清单
采集,有些人喜欢它,有些人避免它!说出它的真意,是因为它确实可以帮助我们节省更多的时间和精力,并让我们有更多的时间推广网站;要避免这种情况,因为搜索引擎不喜欢采集的数据和网站,当提到采集时,一些网站管理员摇了摇头。那么,如何很好地使用采集,这样可以节省我们的时间,并使搜索引擎感到耳目一新?下面,根据我的经验和摘要,我将与您分享。
采集演示网站:安全期测试网
一、 采集器的选择
目前,大多数cms功能(PHP cms,Empire,织梦,Xinyun等)都具有采集功能。如果使用得当,这也是省钱的好方法。但是这些是不言自明的。采集我带来的功能虽然没有用,但功能却很强大。如果资金允许,建议购买专业采集器。
二、知道采集器的功能
俗话说,用刀削尖不会误砍木头。只有了解采集器的所有功能并熟练使用它,我们才能谈论采集。
三、选择来源网站
对此没有什么可说的,如果您想挂在树上,就随便做什么。 。 。最好选择多个网站,每个网站的内容为原创。请记住,不要将每个网站的内容发送到采集,最好是每个采集数据的一部分。
四、数据采集
([1),采集编写规则
根据预先采集的采集对象,分别为每个网站编写采集规则。请记住,采集数据应包括以下项目:标题,来源,作者,内容以及其他内容,例如关键字不要选择诸如摘要,时间等内容。
(2),阐明采集的原理和过程
所有采集器基本上都按照以下步骤工作:
a。根据采集规则采集数据,并将数据保存在临时数据库中,功能更强大的采集器将事先在指定文件中保存相应的附件(例如图片,文件,软件等)。 ,其中一些数据和文件保存在本地计算机中,而另一些保存在服务器中;
b。根据指定的接口发布已为采集的数据,即将临时数据库中的数据发布至网站的数据库;
(3),编辑数据
当数据采集到达临时数据库时,许多人只是进入数据库并直接发布数据,因为他们觉得麻烦。这种方法等效于复制和粘贴,这是没有意义的。如果您这样做,搜索引擎不会惩罚您。很小。因此,当数据采集位于临时数据库中时,无论它有多麻烦,都必须编辑该数据。具体方面如下:
a。修改标题(必填)
b。添加关键词(手动可用,但可以自动获得一些采集器)
c。撰写说明或摘要,最好手动填写
d。适当修改文章头部和底部信息
五、发布数据
在这一步上没有什么可说的,即将编辑后的数据发布到网站。
最后,有些朋友可能会因为时间问题以及因为不想把我误认为是背心而问哪个采集器是合适的。我不会在这里谈论它。如果您采集做到了,那么您应该牢记最爱。稍后,我将为您提供分析表,以对当前的主流采集器进行全面比较,以便您轻松区分和选择。
感谢大家阅读本文章,希望对大家有所帮助!我的
申请创业报告并分享创业创意。单击此处,一起讨论新的创业机会!
网站程序自带的采集器采集文章是怎么做的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-02-21 10:01
网站程序自带的采集器采集文章这种情况一般要考虑是不是页面还在使用headfirst的ajax方式并且服务器返回网页数据使用ajax的图片页面server上传的js文件你没有加过vue的依赖而导致了这种情况建议你使用图片采集工具把页面的图片加载出来采集或者去除封包的特征然后自己修改下代码就可以满足要求
首先得看看是不是前端没有搞好。headfirst或者next标签缺失等。比如是否自动加载和server返回数据是否是http。我记得ajax是可以采集图片并返回文本的。另外是不是要做个feed流分析。另外能做个es2015,es7的静态代理静态静态html就可以。ajax去做也行。
我记得上次在新博客上看到一个比较靠谱的介绍,图片算不算字数?字数不多,数量不大?来源不同?改成轮询网站获取title,href,url就好了。如果上面的都不行,有采用htmltags的办法,但是似乎耗资源?图片有肯定会有价值的提升。
看这个网站了,
这么无聊的问题~~网站的图片如果是动态加载的可以用get方法下载
用一个很舒服的网站啊,把图片都下载到指定位置,用户可以直接跳转,
标签定义好,比如用head-first,用head-first或者next标签在不需要的地方标一下不需要的东西, 查看全部
网站程序自带的采集器采集文章是怎么做的?
网站程序自带的采集器采集文章这种情况一般要考虑是不是页面还在使用headfirst的ajax方式并且服务器返回网页数据使用ajax的图片页面server上传的js文件你没有加过vue的依赖而导致了这种情况建议你使用图片采集工具把页面的图片加载出来采集或者去除封包的特征然后自己修改下代码就可以满足要求
首先得看看是不是前端没有搞好。headfirst或者next标签缺失等。比如是否自动加载和server返回数据是否是http。我记得ajax是可以采集图片并返回文本的。另外是不是要做个feed流分析。另外能做个es2015,es7的静态代理静态静态html就可以。ajax去做也行。
我记得上次在新博客上看到一个比较靠谱的介绍,图片算不算字数?字数不多,数量不大?来源不同?改成轮询网站获取title,href,url就好了。如果上面的都不行,有采用htmltags的办法,但是似乎耗资源?图片有肯定会有价值的提升。
看这个网站了,
这么无聊的问题~~网站的图片如果是动态加载的可以用get方法下载
用一个很舒服的网站啊,把图片都下载到指定位置,用户可以直接跳转,
标签定义好,比如用head-first,用head-first或者next标签在不需要的地方标一下不需要的东西,
新闻搜索集合,百度文章集合一站式整个网站集合
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-02-17 10:01
新闻搜索采集,百度文章采集,一站式整体网站采集,白家号文章采集,门户网站新闻采集,微信文章采集,列表文章采集,风云列表采集,排名列表文章采集,问答数据采集,列表配置文件采集,编写规则以采集指定的文章等。
2.产品组合
材料的智能组合,段落的随机组合,句子的随机组合,核心内容组合,材料安排组合,批处理文章组合,文本批处理分段,段落对组合和整个文本组合。
3.图片下载
通过关键字自动搜索图片,自动下载,自动删除水印以批量修复图片以及自动获取用于上传图片的远程URL
软件功能:1.智能伪原创:人工智能中的自然语言处理技术用于处理伪原创 文章。核心功能包括“智能伪原创”,“同义词替换伪原创”,“反义词替换伪原创”,“使用html代码在文章中随机插入关键字”,“句子加扰和重组”等等。加工产品的原创性能和夹杂率均在80%以上。想了解更多功能,请下载软件进行试用。
2.门户网站 文章采集:一键搜索相关门户网站新闻文章,例如搜狐,腾讯,新浪,网易,头条,新栏目,联合早报,光明。 ,以及New等,用户可以输入行业关键字来搜索所需的行业文章。该模块的功能是无需编写采集规则和一键操作。提醒:使用本文时,请注明文章的出处并尊重原创文本的版权。
3.百度新闻精选:一键搜索各行各业的新闻报道。数据源来自百度新闻搜索引擎。它资源丰富,操作灵活,不需要编写任何采集规则。但是,缺点是采集的文章不一定完整,但可以满足大多数用户的需求。提醒:使用本文时,请注明文章的来源并尊重原创文本的版权 查看全部
新闻搜索集合,百度文章集合一站式整个网站集合
新闻搜索采集,百度文章采集,一站式整体网站采集,白家号文章采集,门户网站新闻采集,微信文章采集,列表文章采集,风云列表采集,排名列表文章采集,问答数据采集,列表配置文件采集,编写规则以采集指定的文章等。
2.产品组合
材料的智能组合,段落的随机组合,句子的随机组合,核心内容组合,材料安排组合,批处理文章组合,文本批处理分段,段落对组合和整个文本组合。
3.图片下载
通过关键字自动搜索图片,自动下载,自动删除水印以批量修复图片以及自动获取用于上传图片的远程URL
软件功能:1.智能伪原创:人工智能中的自然语言处理技术用于处理伪原创 文章。核心功能包括“智能伪原创”,“同义词替换伪原创”,“反义词替换伪原创”,“使用html代码在文章中随机插入关键字”,“句子加扰和重组”等等。加工产品的原创性能和夹杂率均在80%以上。想了解更多功能,请下载软件进行试用。
2.门户网站 文章采集:一键搜索相关门户网站新闻文章,例如搜狐,腾讯,新浪,网易,头条,新栏目,联合早报,光明。 ,以及New等,用户可以输入行业关键字来搜索所需的行业文章。该模块的功能是无需编写采集规则和一键操作。提醒:使用本文时,请注明文章的出处并尊重原创文本的版权。
3.百度新闻精选:一键搜索各行各业的新闻报道。数据源来自百度新闻搜索引擎。它资源丰富,操作灵活,不需要编写任何采集规则。但是,缺点是采集的文章不一定完整,但可以满足大多数用户的需求。提醒:使用本文时,请注明文章的来源并尊重原创文本的版权
整套解决方案:网站集群系统—采集器技术实现之语法介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-01-03 11:21
Xilintong网站集群系统采集器的内容自动采用最新的jquery选择器语法,放弃了使用regexp表达式的单一方法,这种方法对于普通人来说是很难掌握的,并且一般的Web设计人员都可以了解CSS JQuery选择表达式以定位网页中的元素。这种方法简单,灵活且非常精确,极大地简化了最难编译的代码采集器的难度。
例如采集某个页面的新闻部分的新闻超链接而不是所有链接,首先需要根据html内容特征定位这些链接,并且html代码如下:
文章1
文章2
...
提取的页面的指定列的链接文章的表达式为:.lanmu1 a
例如,假设采集 文章标题,页面标题的html编码为
文章标题示例
用于提取页面标题的表达式为:#doctitle
在采集语法中,不仅可以使用juqery语法,而且同时支持传统的正则表达式表达式,并且可以实现更复杂的正则表达式替换表达式。例如:时间提取和转换的表达式:正则表达式:{(\ d {4})year(\ d {1,2})month(\ d {1,2})day \ s(\ d {1, 2}:\ d {1,2})} / {$ 1- $ 2- $ 3 $ 4}
jquery是当今最受欢迎的javascript基本类库。它简洁,灵活且跨浏览器的操作语法被认为是后Web2.时代的实际操作标准,并且这种思想方法很快被移植并扩展到了Java之外的其他领域。对于我们来说,使用类似Jquery的选择定位语法是非常明智的选择。
jsoup-selector的卓越表现
之前,我们已经简要介绍了jsoup如何使用选择器来检索元素。在本节中,我们将重点介绍选择器本身的强大语法。下表是jsoup选择器所有语法的详细列表。
表2.的基本用法:
标签名
使用标签名称来查找,例如
ns |标签
使用名称空间的标签定位,例如fb:name来查找元素
#id
使用元素ID进行定位,例如#logo
.class
使用元素的class属性进行定位,例如.head
[属性]
使用元素属性进行定位,例如,[href]表示检索具有href属性的所有元素
[^ attr]
使用元素的属性名称前缀进行定位,例如[^ data-]用于查找HTML5数据集属性
[attr = value]
使用属性值进行定位,例如[width = 500]定位所有宽度属性值为500的元素
[attr ^ = value],[attr $ = value],[attr * = value]
这三个语法分别表示,属性以值开头,以结束并收录
[attr〜= regex]
使用正则表达式过滤属性值,例如img [src〜=(?i)\。(png | jpe?g)]
*
找到所有元素
上面是最基本的选择器语法,这些语法也可以组合使用,以下是jsoup支持的组合用法:
表3:组合用法:
el#id
找到具有id值的元素,例如a#logo->
el.class
定位其类为指定值的元素,例如div.head->
xxxx
el [attr]
找到所有定义属性的元素,例如a [href]
以上三种的任何组合
例如a [href]#logo,a [name] .outerlink
祖先的孩子
这五个都是用于元素之间组合关系的选择器语法,包括父子关系,合并关系和层次关系。
父母>孩子
兄弟姐妹A +兄弟姐妹
siblingA〜siblingX
el,el,el
除了一些基本语法和这些语法的组合以外,jsoup还支持使用表达式来过滤和选择元素。以下是jsoup支持的所有表达式的列表:
表4.表达式:
:lt(n)
例如,td:lt(3)表示少于三列
:gt(n)
div p:gt(2)表示div收录2个以上p
:eq(n)
form input:eq(1)表示仅收录一个输入的表单
:有(选择)
div:has(p)表示收录p元素的div
:不是(选择器)
div:not(.logo)表示不收录class = logo元素的所有div的列表
:收录(文本)
收录特定文本的元素不区分大小写,例如p:contains(oschina)
:containsOwn(text)
文本信息完全等于对指定条件的过滤
:matches(regex)
使用正则表达式进行文本过滤:div:matches((?i)login)
:matchesOwn(regex)
使用正则表达式查找自己的文本
摘要
这里已经介绍了jsoup的基本功能,但是由于jsoup的API具有良好的可扩展性,因此可以通过选择器的定义开发非常强大的HTML解析功能。此外,jsoup项目本身的开发也非常活跃,因此,如果您使用Java并且需要处理HTML,则不妨尝试一下。 查看全部
整套解决方案:网站集群系统—采集器技术实现之语法介绍
Xilintong网站集群系统采集器的内容自动采用最新的jquery选择器语法,放弃了使用regexp表达式的单一方法,这种方法对于普通人来说是很难掌握的,并且一般的Web设计人员都可以了解CSS JQuery选择表达式以定位网页中的元素。这种方法简单,灵活且非常精确,极大地简化了最难编译的代码采集器的难度。
例如采集某个页面的新闻部分的新闻超链接而不是所有链接,首先需要根据html内容特征定位这些链接,并且html代码如下:
文章1
文章2
...
提取的页面的指定列的链接文章的表达式为:.lanmu1 a
例如,假设采集 文章标题,页面标题的html编码为
文章标题示例
用于提取页面标题的表达式为:#doctitle
在采集语法中,不仅可以使用juqery语法,而且同时支持传统的正则表达式表达式,并且可以实现更复杂的正则表达式替换表达式。例如:时间提取和转换的表达式:正则表达式:{(\ d {4})year(\ d {1,2})month(\ d {1,2})day \ s(\ d {1, 2}:\ d {1,2})} / {$ 1- $ 2- $ 3 $ 4}
jquery是当今最受欢迎的javascript基本类库。它简洁,灵活且跨浏览器的操作语法被认为是后Web2.时代的实际操作标准,并且这种思想方法很快被移植并扩展到了Java之外的其他领域。对于我们来说,使用类似Jquery的选择定位语法是非常明智的选择。
jsoup-selector的卓越表现
之前,我们已经简要介绍了jsoup如何使用选择器来检索元素。在本节中,我们将重点介绍选择器本身的强大语法。下表是jsoup选择器所有语法的详细列表。
表2.的基本用法:
标签名
使用标签名称来查找,例如
ns |标签
使用名称空间的标签定位,例如fb:name来查找元素
#id
使用元素ID进行定位,例如#logo
.class
使用元素的class属性进行定位,例如.head
[属性]
使用元素属性进行定位,例如,[href]表示检索具有href属性的所有元素
[^ attr]
使用元素的属性名称前缀进行定位,例如[^ data-]用于查找HTML5数据集属性
[attr = value]
使用属性值进行定位,例如[width = 500]定位所有宽度属性值为500的元素
[attr ^ = value],[attr $ = value],[attr * = value]
这三个语法分别表示,属性以值开头,以结束并收录
[attr〜= regex]
使用正则表达式过滤属性值,例如img [src〜=(?i)\。(png | jpe?g)]
*
找到所有元素
上面是最基本的选择器语法,这些语法也可以组合使用,以下是jsoup支持的组合用法:
表3:组合用法:
el#id
找到具有id值的元素,例如a#logo->
el.class
定位其类为指定值的元素,例如div.head->
xxxx
el [attr]
找到所有定义属性的元素,例如a [href]
以上三种的任何组合
例如a [href]#logo,a [name] .outerlink
祖先的孩子
这五个都是用于元素之间组合关系的选择器语法,包括父子关系,合并关系和层次关系。
父母>孩子
兄弟姐妹A +兄弟姐妹
siblingA〜siblingX
el,el,el
除了一些基本语法和这些语法的组合以外,jsoup还支持使用表达式来过滤和选择元素。以下是jsoup支持的所有表达式的列表:
表4.表达式:
:lt(n)
例如,td:lt(3)表示少于三列
:gt(n)
div p:gt(2)表示div收录2个以上p
:eq(n)
form input:eq(1)表示仅收录一个输入的表单
:有(选择)
div:has(p)表示收录p元素的div
:不是(选择器)
div:not(.logo)表示不收录class = logo元素的所有div的列表
:收录(文本)
收录特定文本的元素不区分大小写,例如p:contains(oschina)
:containsOwn(text)
文本信息完全等于对指定条件的过滤
:matches(regex)
使用正则表达式进行文本过滤:div:matches((?i)login)
:matchesOwn(regex)
使用正则表达式查找自己的文本
摘要
这里已经介绍了jsoup的基本功能,但是由于jsoup的API具有良好的可扩展性,因此可以通过选择器的定义开发非常强大的HTML解析功能。此外,jsoup项目本身的开发也非常活跃,因此,如果您使用Java并且需要处理HTML,则不妨尝试一下。
汇总:网站文章采集工具有哪些可以使用?
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2020-10-29 13:06
文章采集工具我不知道您是否知道,也许有些网站管理员尚未联系它! 采集一些站群或大型门户网站网站通常使用工具。它们很少像公司网站那样使用。当然,采集也使用了某些个人站点,因为某些情况不想自己更新。在大型网站上需要更新的文章或文章繁多,例如新闻网站,它们都使用采集,因此可以使用哪些网站文章采集工具?
1、优采云。对于seo人员来说,优采云是更常用的采集软件。下载并安装优采云 采集器,有付费和免费版本,可以在线搜索下载地址,我在这里不做详细介绍。
2、优采云。 优采云 采集器是用于快速获取网页信息采集的工具,通常用于采集 网站文章,网站信息数据等。优采云有免费版本,还有还收费版本。如果这样做,则需要满足您或公司的需求。免费版本在很多方面受到限制。
3、优采云 采集。此采集工具相对智能,几乎不需要手动配置。它可以被视为傻瓜式操作软件。
织梦程序采集插件:
1、采集夏。要使用采集 Xia的插件,网站必须为织梦,因为该插件是织梦的采集插件。 采集 Xia是直接通过关键词采集 文章,采集 Xia是付费软件,当然我们也可以下载破解版本,可以在百度上搜索。
2、采集节点。 织梦 采集节点是由织梦后台程序自动带来的,采集节点是完全免费的,但是采集并不十分强大,有很多事情是无法实现的。
我们需要知道,大型网站基本上都有自己的开放采集点。他们很少使用工具。作为seo,我们没有如此强大的技术支持,因此我们只能使用某些工具。实现采集。 查看全部
可用的网站文章采集工具是什么?
文章采集工具我不知道您是否知道,也许有些网站管理员尚未联系它! 采集一些站群或大型门户网站网站通常使用工具。它们很少像公司网站那样使用。当然,采集也使用了某些个人站点,因为某些情况不想自己更新。在大型网站上需要更新的文章或文章繁多,例如新闻网站,它们都使用采集,因此可以使用哪些网站文章采集工具?
1、优采云。对于seo人员来说,优采云是更常用的采集软件。下载并安装优采云 采集器,有付费和免费版本,可以在线搜索下载地址,我在这里不做详细介绍。
2、优采云。 优采云 采集器是用于快速获取网页信息采集的工具,通常用于采集 网站文章,网站信息数据等。优采云有免费版本,还有还收费版本。如果这样做,则需要满足您或公司的需求。免费版本在很多方面受到限制。
3、优采云 采集。此采集工具相对智能,几乎不需要手动配置。它可以被视为傻瓜式操作软件。
织梦程序采集插件:
1、采集夏。要使用采集 Xia的插件,网站必须为织梦,因为该插件是织梦的采集插件。 采集 Xia是直接通过关键词采集 文章,采集 Xia是付费软件,当然我们也可以下载破解版本,可以在百度上搜索。
2、采集节点。 织梦 采集节点是由织梦后台程序自动带来的,采集节点是完全免费的,但是采集并不十分强大,有很多事情是无法实现的。
我们需要知道,大型网站基本上都有自己的开放采集点。他们很少使用工具。作为seo,我们没有如此强大的技术支持,因此我们只能使用某些工具。实现采集。
最新版:优采云采集器-采集与发布带图片的文章.docx 11页
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-10-08 10:00
如何使用优采云采集器 优采云采集器 7.6免费版,功能上有很多限制,但是我已经用它来实现采集和发布(带有图片,排版)。图片是通过采集程序在本地下载的,放在具有约定名称的文件夹中,最后手动上传到服务器DZ程序的运行目录下的pic目录。下载www.ucaiyun.com_V 7.6_BuilFree.zip的优采云采集器 7.6版本,并在解决方案之后运行它。需要.NET环境。该程序是Discuz!X2.5 GBK版本。核心工作包括两个部分:1、采集,2、版本。本文重点介绍如何发布(带有图片,排版),以及简要地发布采集。一、使用UBB格式创建一个新的Web在线发布模块,因为采集中文章的内容为HTML格式,例如:
身体
带有HTML标签的文本。 DZ论坛使用UUB格式,例如:[p] text [/ p],因此在发布时需要自动转换。以下是设置此自动转换功能的步骤。如果您文章发布了DZ门户,则无需转换为UBB。1、打开发布模块配置:2、使用软件随附的Discuz!X2.0论坛作为模板进行修改。我已经尝试过Discuz! X2.5发行文章。3、设置为:[label:content]的UBB转换,如下图所示:最后,另存为新的“发布模块”,为其赋予一个新名称,并在以后使用。4、在“内容发布参数”选项卡中进行修改:[标签:内容]的值可以替换为{0}。如下图所示:黄色框中的[label:content]替换为{0},下图的第一部分工作完成。二、使用Web在线发布模块在创建新的Web在线发布模块之前,以下是使用它的方法。步骤1:创建一个新的“发布”,操作如下图所示:注意:请进入论坛的后台修改设置。登录时,无需输入验证码即可成功登录并成功测试。请记住,稍后再将其更改。保存时给一个新名字。三、准备采集以下是优采云附带的采集演示。右键单击“腾讯新闻”-“编辑任务”以打开以下窗口。如下图所示,使用在上一步中创建的“发布模块”将内容从采集发布到论坛的某个列。设置如下:还有以下图像:对于采集工作,有一些重要的设置,这些设置非常重要。如果您不使用优采云随附的演示任务,而是自己创建一个新任务采集,则以下内容非常重要。以下设置适用于采集中文章的文本。 “开始字符串”和“结束字符串”是所有设置中最重要的内容。它们用于分析页面的HTML源代码,以查找文章文本的起点和终点。下图使用优采云为腾讯准备默认值,无需修改。如果选择其他网站而不是采集腾讯,则必须查看HTML源代码以进行手动分析。 采集,您可以有选择地过滤掉一些HTML标签,例如
特别注意:下载前请确保先预览并亲自确认它是否是您要下载的文档。
已下载文档的成员:
优采云采集器-采集并发布带有图片的文章.docx
您可能会关注的文件 查看全部
优采云采集器-采集并发布了文章.docx 11张带有图片的页面
如何使用优采云采集器 优采云采集器 7.6免费版,功能上有很多限制,但是我已经用它来实现采集和发布(带有图片,排版)。图片是通过采集程序在本地下载的,放在具有约定名称的文件夹中,最后手动上传到服务器DZ程序的运行目录下的pic目录。下载www.ucaiyun.com_V 7.6_BuilFree.zip的优采云采集器 7.6版本,并在解决方案之后运行它。需要.NET环境。该程序是Discuz!X2.5 GBK版本。核心工作包括两个部分:1、采集,2、版本。本文重点介绍如何发布(带有图片,排版),以及简要地发布采集。一、使用UBB格式创建一个新的Web在线发布模块,因为采集中文章的内容为HTML格式,例如:
身体
带有HTML标签的文本。 DZ论坛使用UUB格式,例如:[p] text [/ p],因此在发布时需要自动转换。以下是设置此自动转换功能的步骤。如果您文章发布了DZ门户,则无需转换为UBB。1、打开发布模块配置:2、使用软件随附的Discuz!X2.0论坛作为模板进行修改。我已经尝试过Discuz! X2.5发行文章。3、设置为:[label:content]的UBB转换,如下图所示:最后,另存为新的“发布模块”,为其赋予一个新名称,并在以后使用。4、在“内容发布参数”选项卡中进行修改:[标签:内容]的值可以替换为{0}。如下图所示:黄色框中的[label:content]替换为{0},下图的第一部分工作完成。二、使用Web在线发布模块在创建新的Web在线发布模块之前,以下是使用它的方法。步骤1:创建一个新的“发布”,操作如下图所示:注意:请进入论坛的后台修改设置。登录时,无需输入验证码即可成功登录并成功测试。请记住,稍后再将其更改。保存时给一个新名字。三、准备采集以下是优采云附带的采集演示。右键单击“腾讯新闻”-“编辑任务”以打开以下窗口。如下图所示,使用在上一步中创建的“发布模块”将内容从采集发布到论坛的某个列。设置如下:还有以下图像:对于采集工作,有一些重要的设置,这些设置非常重要。如果您不使用优采云随附的演示任务,而是自己创建一个新任务采集,则以下内容非常重要。以下设置适用于采集中文章的文本。 “开始字符串”和“结束字符串”是所有设置中最重要的内容。它们用于分析页面的HTML源代码,以查找文章文本的起点和终点。下图使用优采云为腾讯准备默认值,无需修改。如果选择其他网站而不是采集腾讯,则必须查看HTML源代码以进行手动分析。 采集,您可以有选择地过滤掉一些HTML标签,例如
特别注意:下载前请确保先预览并亲自确认它是否是您要下载的文档。
已下载文档的成员:
优采云采集器-采集并发布带有图片的文章.docx
您可能会关注的文件
解决方案:优采云采集器(LocoySpider)软件特性
采集交流 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2020-09-04 07:21
优采云 采集器是用于主要主流文章系统,论坛系统等的多线程内容采集发布程序。使用优采云 采集器,您可以立即创建具有巨大内容的网站内容。 zol提供优采云 采集器正式版下载。
优采云 采集器系统支持远程图片下载,图片批处理水印,Flash下载,下载文件地址检测,自制和发布的cms模块参数,自定义发布的内容等采集器。 优采云 采集器对于采集数据,它可以分为两部分,一个是采集数据,另一个是发布数据。
优采云 采集器功能:
优采云 采集器(www.ucaiyun.com)是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以将采集的任何网页数据发布到远程服务器,自定义
优采云 采集器徽标
优采云 采集器徽标
Yi用户cms系统模块,无论您的网站是哪个系统,都可以使用优采云 采集器,该系统随附的模块文件支持:Fengxun 文章,Dongyi [ k5],Dongwang论坛,PHPWIND论坛,Discuz论坛,php cms 文章,phparticle 文章,LeadBBS论坛,Magic论坛,Dede cms 文章,Xydw 文章,Jingyun 文章等模块文件有关cms的更多模块,请参考生产和修改,或去官方网站与您联系。同时,您还可以使用系统的数据导出功能,并使用系统的内置标签将数据对应表的字段从采集导出到任何本地Access,MySql,MS SqlServer。
www.ucaiyun.com用Visual C编写,可以在Windows2008下独立运行(windows2003随附.net 1. 1框架。优采云 采集器的最新版本是2008版本,需要升级到。 net 2. 0框架(可以使用),如果您在Windows200 0、 Xp和其他环境下使用它,请首先从Microsoft官方网站下载.net framework 2. 0或更高版本的环境组件。 优采云 采集器 V2009 SP2 4月29日
数据捕获原理
优采云 采集器如何抓取数据取决于您的规则。如果要获取列的网页中的所有内容,则需要首先选择该网页的URL。这是URL。该程序将根据您的规则对列表页面进行爬网,从中分析URL,然后对获取URL的网页内容进行爬网。根据您的采集规则,分析下载的网页,分离标题内容和其他信息并保存。如果选择下载图片等网络资源,则程序将分析采集中的数据,找出图片,资源等的下载地址,然后在本地下载。
数据发布原则
下载数据采集后,默认情况下将数据保存在本地。我们可以使用以下方法来处理数据。
1、不会执行任何操作。由于数据本身存储在数据库中(访问,db 3、 mysql,sqlserver),因此,如果仅查看数据,则可以使用相关软件直接打开它。
2、网络发布到网站。该程序将模仿浏览器将数据发送到您的网站,可以达到手动发布的效果。
3、直接输入数据库。您只需要编写一些SQL语句,程序就会根据您的SQL语句将数据导入数据库。
4、保存为本地文件。该程序将读取数据库中的数据,并以某种格式将其另存为本地sql或文本文件。
工作流程
优采云 采集器 采集数据分为两个步骤,一个是采集数据,另一个是发布数据。这两个过程可以分开。
1、 采集数据,其中包括采集 URL和采集内容。此过程是获取数据的过程。我们制定规则,并在采集过程中将其视为处理内容。
2、发布内容是将数据发布到其自己的论坛,cms的过程也是将数据实现为现有的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体用途实际上非常灵活,可以根据实际情况确定。例如,我可以在采集时不释放采集,然后在有空时释放,或者在采集同时释放,或者先执行释放配置,或者可以在采集结束后添加释放配置完成。简而言之,具体过程取决于您,优采云 采集器的强大功能之一也体现在灵活性上。 查看全部
优采云 采集器(www.ucaiyun.com)软件功能
优采云 采集器是用于主要主流文章系统,论坛系统等的多线程内容采集发布程序。使用优采云 采集器,您可以立即创建具有巨大内容的网站内容。 zol提供优采云 采集器正式版下载。
优采云 采集器系统支持远程图片下载,图片批处理水印,Flash下载,下载文件地址检测,自制和发布的cms模块参数,自定义发布的内容等采集器。 优采云 采集器对于采集数据,它可以分为两部分,一个是采集数据,另一个是发布数据。
优采云 采集器功能:
优采云 采集器(www.ucaiyun.com)是一款功能强大且易于使用的专业采集软件,强大的内容采集和数据导入功能可以将采集的任何网页数据发布到远程服务器,自定义
优采云 采集器徽标
优采云 采集器徽标
Yi用户cms系统模块,无论您的网站是哪个系统,都可以使用优采云 采集器,该系统随附的模块文件支持:Fengxun 文章,Dongyi [ k5],Dongwang论坛,PHPWIND论坛,Discuz论坛,php cms 文章,phparticle 文章,LeadBBS论坛,Magic论坛,Dede cms 文章,Xydw 文章,Jingyun 文章等模块文件有关cms的更多模块,请参考生产和修改,或去官方网站与您联系。同时,您还可以使用系统的数据导出功能,并使用系统的内置标签将数据对应表的字段从采集导出到任何本地Access,MySql,MS SqlServer。
www.ucaiyun.com用Visual C编写,可以在Windows2008下独立运行(windows2003随附.net 1. 1框架。优采云 采集器的最新版本是2008版本,需要升级到。 net 2. 0框架(可以使用),如果您在Windows200 0、 Xp和其他环境下使用它,请首先从Microsoft官方网站下载.net framework 2. 0或更高版本的环境组件。 优采云 采集器 V2009 SP2 4月29日
数据捕获原理
优采云 采集器如何抓取数据取决于您的规则。如果要获取列的网页中的所有内容,则需要首先选择该网页的URL。这是URL。该程序将根据您的规则对列表页面进行爬网,从中分析URL,然后对获取URL的网页内容进行爬网。根据您的采集规则,分析下载的网页,分离标题内容和其他信息并保存。如果选择下载图片等网络资源,则程序将分析采集中的数据,找出图片,资源等的下载地址,然后在本地下载。
数据发布原则
下载数据采集后,默认情况下将数据保存在本地。我们可以使用以下方法来处理数据。
1、不会执行任何操作。由于数据本身存储在数据库中(访问,db 3、 mysql,sqlserver),因此,如果仅查看数据,则可以使用相关软件直接打开它。
2、网络发布到网站。该程序将模仿浏览器将数据发送到您的网站,可以达到手动发布的效果。
3、直接输入数据库。您只需要编写一些SQL语句,程序就会根据您的SQL语句将数据导入数据库。
4、保存为本地文件。该程序将读取数据库中的数据,并以某种格式将其另存为本地sql或文本文件。
工作流程
优采云 采集器 采集数据分为两个步骤,一个是采集数据,另一个是发布数据。这两个过程可以分开。
1、 采集数据,其中包括采集 URL和采集内容。此过程是获取数据的过程。我们制定规则,并在采集过程中将其视为处理内容。
2、发布内容是将数据发布到其自己的论坛,cms的过程也是将数据实现为现有的过程。它可以通过WEB在线发布,存储在数据库中或保存为本地文件。
具体用途实际上非常灵活,可以根据实际情况确定。例如,我可以在采集时不释放采集,然后在有空时释放,或者在采集同时释放,或者先执行释放配置,或者可以在采集结束后添加释放配置完成。简而言之,具体过程取决于您,优采云 采集器的强大功能之一也体现在灵活性上。
技巧:如何从网站抓取数据?不会“爬虫”编程没关系,Excel自带爬取利器
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2020-09-04 00:33
在当前“信息爆炸”时代,各种各样的信息和数据是巨大的。如何使用各种工具更快,更有效地从Internet上获取我们所需的信息至关重要。
Python“爬虫”是一种非常流行的在Internet上捕获数据的方法。它可以根据您的意愿捕获网站上的数据,并根据设置的程序将其保存在本地以进行后处理。
但是,要使用Python“爬虫”仍然需要一定的编程技能,这对于新手来说仍然太复杂了。
如果直接复制并粘贴到Excel中,则数据格式将变得混乱并且难以处理。实际上,Excel作为最常用的办公软件,除了强大的数据处理功能外,还可以从网站中获取表格内容并将其导入Excel,这有助于我们进行后处理。
使用软件:Excel2016浏览器
下面以Excel抓取URL“”(即百度百科全书“清代帝王”)为例,说明如何使用Excel抓取下面网站上的表。
Excel可以导入多种格式的内容,包括网页。
1.数据-来自其他来源的新查询-来自网络
2.输入网址,确定
3.如上图所示,捕获了网站上表格的内容,可以对其进行编辑或直接将其添加到Excel中进行编辑。
如果网页上有多个表,则可以在左侧选择要导入的表,然后单击以查看内容。
上图是具有许多功能的特殊查询编辑器。
如上图所示,经过简单处理,我们得到了所需的数据“清朝皇帝表”。
整个动态操作图如下:
如果您喜欢本文的内容,请单击上方的红色按钮进行关注。在这里,您可以逐步进入Excel,学习Excel并逐步改善Excel。 查看全部
如何从网站获取数据?如果您无法进行“爬网”编程,则没关系,Excel附带了一个爬网工具
在当前“信息爆炸”时代,各种各样的信息和数据是巨大的。如何使用各种工具更快,更有效地从Internet上获取我们所需的信息至关重要。
Python“爬虫”是一种非常流行的在Internet上捕获数据的方法。它可以根据您的意愿捕获网站上的数据,并根据设置的程序将其保存在本地以进行后处理。
但是,要使用Python“爬虫”仍然需要一定的编程技能,这对于新手来说仍然太复杂了。
如果直接复制并粘贴到Excel中,则数据格式将变得混乱并且难以处理。实际上,Excel作为最常用的办公软件,除了强大的数据处理功能外,还可以从网站中获取表格内容并将其导入Excel,这有助于我们进行后处理。
使用软件:Excel2016浏览器
下面以Excel抓取URL“”(即百度百科全书“清代帝王”)为例,说明如何使用Excel抓取下面网站上的表。
Excel可以导入多种格式的内容,包括网页。
1.数据-来自其他来源的新查询-来自网络
2.输入网址,确定
3.如上图所示,捕获了网站上表格的内容,可以对其进行编辑或直接将其添加到Excel中进行编辑。
如果网页上有多个表,则可以在左侧选择要导入的表,然后单击以查看内容。
上图是具有许多功能的特殊查询编辑器。
如上图所示,经过简单处理,我们得到了所需的数据“清朝皇帝表”。
整个动态操作图如下:
如果您喜欢本文的内容,请单击上方的红色按钮进行关注。在这里,您可以逐步进入Excel,学习Excel并逐步改善Excel。
事实:关于优采云网络爬虫的几个常见问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-09-01 02:13
我昨天才开始联系网络爬虫. 根据互联网上的好评,我选择了优采云的V9版本.
一开始,它是针对其友好而全面的傻瓜操作页面的. 谁知道完成基本的JD产品审查任务并不像想象的那么简单.
1. 首先,请注意将向导添加到起始URL的步骤,
因为现在通常可以直接在产品页面上查看JD注释,但是此URL是使用json技术呈现的,
使用这种技术,可以根据用户操作(例如第二页的上一页)执行动态数据包捕获和更新,因此制定相应的规则更加困难,
在参考了以下教程以获取价格后,操作仍然不令人满意(稍后学习json)
直到我发现有关这些年来我的前辈的评论的文档,我发现那里有一个特别的评论页面,并且有相应的规则,
[地址参数] -0.html,此问题已解决
2. 第二个问题是未检查每个字段的循环匹配,这导致采集每次采集采集后都会以相同格式产生一些注释
3. 第三个问题是默认输出txt文档样式没有任何修改,导致每个输出都在[label: title] [label: content]
之前设置.
4. 另一个问题是,如果发现上述问题后修改配置并重新采集,则必须清除采集数据,否则它将无法工作并报告信息
说采集采样0
×5. 发现的一个新问题是JD用户ID的html标签种类繁多. 如果您不熟悉正则表达式,则只能采集到相关的注释文本,
采集是整个用户的ID,这导致用户ID和用户评论之间不一对一的对应关系. 此外,优采云的采集评论顺序似乎不符合网页上显示的评论
顺序,稍后将对此问题进行研究 查看全部
关于优采云网络抓取工具的几个常见问题
我昨天才开始联系网络爬虫. 根据互联网上的好评,我选择了优采云的V9版本.
一开始,它是针对其友好而全面的傻瓜操作页面的. 谁知道完成基本的JD产品审查任务并不像想象的那么简单.
1. 首先,请注意将向导添加到起始URL的步骤,
因为现在通常可以直接在产品页面上查看JD注释,但是此URL是使用json技术呈现的,
使用这种技术,可以根据用户操作(例如第二页的上一页)执行动态数据包捕获和更新,因此制定相应的规则更加困难,
在参考了以下教程以获取价格后,操作仍然不令人满意(稍后学习json)
直到我发现有关这些年来我的前辈的评论的文档,我发现那里有一个特别的评论页面,并且有相应的规则,
[地址参数] -0.html,此问题已解决
2. 第二个问题是未检查每个字段的循环匹配,这导致采集每次采集采集后都会以相同格式产生一些注释
3. 第三个问题是默认输出txt文档样式没有任何修改,导致每个输出都在[label: title] [label: content]
之前设置.
4. 另一个问题是,如果发现上述问题后修改配置并重新采集,则必须清除采集数据,否则它将无法工作并报告信息
说采集采样0
×5. 发现的一个新问题是JD用户ID的html标签种类繁多. 如果您不熟悉正则表达式,则只能采集到相关的注释文本,
采集是整个用户的ID,这导致用户ID和用户评论之间不一对一的对应关系. 此外,优采云的采集评论顺序似乎不符合网页上显示的评论
顺序,稍后将对此问题进行研究
最新版本:杰奇1.7+关关采集器+基于Linux小说网站+Win端Samba远程采集思路
采集交流 • 优采云 发表了文章 • 0 个评论 • 510 次浏览 • 2020-08-30 12:05
文章目录[隐藏]
这篇文章,收录了个人小说站构建的全部详尽过程,避免了目前大多数的弯路,不需要把握编程,小白也可以使用,如果有兴趣构建一个个人小说站,可以参照这个教程来完整,因为所有相关的源码,规则,程序,都收录在此,不需要去其他地方再找,另外博主的那些源码也是采集而至,不保证绝对的安全性,但保证可以正常使用,请注意甄别。
注意黑色打码部份是你要填入参数的部份
准备工作:服务器选择的一些建议:
因为须要用到多台服务器,所以最便宜方案可能就是选择美国服务器,网站最好选择美东的服务器,一方面是因为价钱,另一方面是美东有大量类似小说站,如果以她们为采集对象,可以保证更快的速率,至于推荐店家,我后期会补上,因为大硬碟 VPS 很容易脱销。
至于采集服务器,个人建议使用 Vutlr,因为走约请注册,可以获得额外的 25 美元奖励,可以拿来开多台机器,进行同时采集,保证速率同时,又能降低开支,正常情况下,4 台机器一起远程采集 5 个可用规则,一天可以采集 1500-3000 本书,内容的大小大约是 12-20G。
还有很重要的一点,采集服务器一定要离网站服务器逾,ping 值最好能在 2ms 以下。
一些店家推荐:
小说站及采集端的优价服务器组合推荐
网站服务器搭建:
1.Linux 服务器安装 Lamp 运行环境
这里要注意下,php 选 5.2,apache 选 2.2,其他的选默认推荐的即可
2.在 Liunx 服务器上添加 PC 端和移动端域名,并解析域名
分两次添加,先 PC 域名,记得构建数据库,然后再添加联通域名,一般都是m.你的域名.com这样的格式
然后在域名供应商那儿设置域名的解析
3.网站源码上传至服务器,并配置目录的权限
使用 Winscp 分别把 PC 和 WAP 源码的与压缩包上传到相应根目录并解压,然后更改目录权限
注意:PC.zip 解压到你的域名.com目录下,WAP.zip 解压到m.你的域名.com下
相关命令示例:
解压 unzip PC.zip
修改权限 chmod -R 777 /home/wwwroot
修改所有者 chown -R www /home/wwwroot
4.配置好站目录下的关键文件
然后按源码中的说明配置好网站的配置文件,以下是配置文件休要更改的地方,已用绿色打码标明,如果看不懂数据意思,结合注释修或则在本文章留言咨询
关于杰奇的授权码,可以到这儿生成(填入你的域名,注意格式):
PC 网站目录下的/configs/define.php:
WAP 目录下的(乱码的话注意改下编码):
5.进入网站后台销项相关配置
解析生效后,直接输入你的网址,就能访问网站了,这里我们直接在网址后输入/admin,然后步入后台(用户名 admin,密码 admin2017)。
修改的内容只要是之前设置过的一些参数,以及网站相关的信息,这里用截图简单标示一下:
然后执行命令清空自带的小说数据:
TRUNCATE TABLE `jieqi_article_article`;
TRUNCATE TABLE `jieqi_article_chapter`;
6.安装 Samba,并建立配置
执行命令,安装 Samba:
apt-get install samba samba-common-bin
然后使用 WinScp,找到目录/etc/samba/smb.conf,编辑这个配置文件并保存:
位于Share Definitions下的部份
[jieqi]
comment = jieqi(尽量用这个名子,便于上面参考教程)
path = /home/wwwroot/(这里填你要共享的目录,共享整个 PC 网站目录)
valid users = root
public = no
writable = yes
printable = no
dos charset = GB2312
unix charset = GB2312
directory mask = 0777
force directory mode = 0777
directory security mask = 0777
force directory security mode = 0777
create mask = 0777
force create mode = 0777
security mask = 0777
force security mode = 0777
然后重启 Samba 服务:
/etc/init.d/samba restart
然后添加 Samba 用户:
smbpasswd -a root
之后按提示输入密码。
7.开放 IPtable 的相关端口
先查看端口情况,如果 3306 端口被 DROP 掉,需要放开这个端口,序号部份替换成要删掉的序号
首先查看端口规则情况
iptables -L -n --line-numbers
比如要删掉 INPUT 里序号为 6 的 DROP 规则(如果有带 DROP 的规则,没有则跳过),执行:
iptables -D INPUT 6
然后添加下述规则:
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
iptables -A INPUT -p tcp --dport 139 -j ACCEPT
iptables -A INPUT -p tcp --dport 445 -j ACCEPT
iptables -A INPUT -p udp --dport 137 -j ACCEPT
iptables -A INPUT -p udp --dport 138 -j ACCEPT
8.给予 MySQL 的 root 用户远程权限
首先登陆 mysql 账户(会提示输 root 用户密码):
mysql -u root -p
然后给 root 用户开启远程权限(密码替换成 root 用户的密码):
usemysql;
GRANTALLON*.*TOroot@'%'IDENTIFIEDBY'password'WITHGRANTOPTION;
flushprivileges;
然后 Ctrl+C 退出即可
9.优化部份 MySQL 的设置
使用 Winscp,找到/etc/f,参考右图更改:
然后重启 lnmp 服务:
lnmp restart
10.开放 Apache 跨目录权限
使用 Winscp,找到/usr/local/apache/conf/vhost 目录,分别将目下两个域名相关的文件中这一行代码注释掉(前面加#):
php_admin_value open_basedir "/home/wwwroot/:/tmp/:/var/tmp/:/proc/"
然后重启 lnmp 服务:
lnmp restart
采集服务器搭建:
1.将服务器安装 win 系统并远程联接
如果不会,可参照这个文章
在 KVM 的 VPS 上一键安装 32 位 Win7 系统
2.将关关采集器和加速工具上传至服务器
直接复制,然后在服务器上粘贴即可,然后解压,再运行 ServerSpeeder 文件下的 serverSpeeder.bat,来优化网路的稳定性
3.联接 samba 服务器,并映射成硬碟
在服务器上打开开始–所有程序–附件–运行,输入地址之后回车
\网站服务器的 IP
这里会弹出登陆窗口,填你之前设置的 Samba 的用户名(root)和密码
然后能看到名为 jieqi 的文件夹,确认能正常打开这个文件夹,然后右键将 jieqi 文件夹映射网络驱动器为 E 盘。
注意:若仍然未能联接,可能是服务商仅用了 Samba 端口的使用权,可以通过发工单开通
4.配置关关的系统系统设置
然后打开 GuanGuan5.6 文件夹下的 NovelSpider.exe,打开设置–系统设置,修改指定部份:
Data Source 是你的网站服务器 IP,Database 是网站数据库名,User ID 填 root,Password 是对应用户的密码
修改完后,一定要点确定,再完全关掉采集程序,然后再度打开程序,打开采集–标准采集,选择好采集规则和采集方式,然后开始采集:
这就是正常采集的界面
可以选择同时开启多个采集窗口采集,但是同一台采集服务器对同一个规则的采集窗口最好不要超过两个。
建议使用按目标站序号进行采集,可以更好的给各台服务器划定采集范围,比如 A 服务器采集 0-2000,B 服务器采集 2001-4000,以此类推,也易于报错时侯核实。
其他的采集服务器也根据以上配置即可。
开始采集:
我提供的采集器上面,附带了五个规则,虽然都能用,但是质量有好有坏,个人使用出来,笔趣阁和新笔趣阁以及八一英文的速率最快,最稳定,但是八一英文的广告较多,新笔趣阁的源站不稳定,容易出现采集空章节情况,具体情况请自行体验。 查看全部
杰奇1.7+关关采集器+基于Linux小说网站+Win端Samba远程采集思路
文章目录[隐藏]
这篇文章,收录了个人小说站构建的全部详尽过程,避免了目前大多数的弯路,不需要把握编程,小白也可以使用,如果有兴趣构建一个个人小说站,可以参照这个教程来完整,因为所有相关的源码,规则,程序,都收录在此,不需要去其他地方再找,另外博主的那些源码也是采集而至,不保证绝对的安全性,但保证可以正常使用,请注意甄别。
注意黑色打码部份是你要填入参数的部份
准备工作:服务器选择的一些建议:
因为须要用到多台服务器,所以最便宜方案可能就是选择美国服务器,网站最好选择美东的服务器,一方面是因为价钱,另一方面是美东有大量类似小说站,如果以她们为采集对象,可以保证更快的速率,至于推荐店家,我后期会补上,因为大硬碟 VPS 很容易脱销。
至于采集服务器,个人建议使用 Vutlr,因为走约请注册,可以获得额外的 25 美元奖励,可以拿来开多台机器,进行同时采集,保证速率同时,又能降低开支,正常情况下,4 台机器一起远程采集 5 个可用规则,一天可以采集 1500-3000 本书,内容的大小大约是 12-20G。
还有很重要的一点,采集服务器一定要离网站服务器逾,ping 值最好能在 2ms 以下。
一些店家推荐:
小说站及采集端的优价服务器组合推荐
网站服务器搭建:
1.Linux 服务器安装 Lamp 运行环境
这里要注意下,php 选 5.2,apache 选 2.2,其他的选默认推荐的即可
2.在 Liunx 服务器上添加 PC 端和移动端域名,并解析域名
分两次添加,先 PC 域名,记得构建数据库,然后再添加联通域名,一般都是m.你的域名.com这样的格式
然后在域名供应商那儿设置域名的解析
3.网站源码上传至服务器,并配置目录的权限
使用 Winscp 分别把 PC 和 WAP 源码的与压缩包上传到相应根目录并解压,然后更改目录权限
注意:PC.zip 解压到你的域名.com目录下,WAP.zip 解压到m.你的域名.com下
相关命令示例:
解压 unzip PC.zip
修改权限 chmod -R 777 /home/wwwroot
修改所有者 chown -R www /home/wwwroot
4.配置好站目录下的关键文件
然后按源码中的说明配置好网站的配置文件,以下是配置文件休要更改的地方,已用绿色打码标明,如果看不懂数据意思,结合注释修或则在本文章留言咨询
关于杰奇的授权码,可以到这儿生成(填入你的域名,注意格式):
PC 网站目录下的/configs/define.php:
WAP 目录下的(乱码的话注意改下编码):
5.进入网站后台销项相关配置
解析生效后,直接输入你的网址,就能访问网站了,这里我们直接在网址后输入/admin,然后步入后台(用户名 admin,密码 admin2017)。
修改的内容只要是之前设置过的一些参数,以及网站相关的信息,这里用截图简单标示一下:
然后执行命令清空自带的小说数据:
TRUNCATE TABLE `jieqi_article_article`;
TRUNCATE TABLE `jieqi_article_chapter`;
6.安装 Samba,并建立配置
执行命令,安装 Samba:
apt-get install samba samba-common-bin
然后使用 WinScp,找到目录/etc/samba/smb.conf,编辑这个配置文件并保存:
位于Share Definitions下的部份
[jieqi]
comment = jieqi(尽量用这个名子,便于上面参考教程)
path = /home/wwwroot/(这里填你要共享的目录,共享整个 PC 网站目录)
valid users = root
public = no
writable = yes
printable = no
dos charset = GB2312
unix charset = GB2312
directory mask = 0777
force directory mode = 0777
directory security mask = 0777
force directory security mode = 0777
create mask = 0777
force create mode = 0777
security mask = 0777
force security mode = 0777
然后重启 Samba 服务:
/etc/init.d/samba restart
然后添加 Samba 用户:
smbpasswd -a root
之后按提示输入密码。
7.开放 IPtable 的相关端口
先查看端口情况,如果 3306 端口被 DROP 掉,需要放开这个端口,序号部份替换成要删掉的序号
首先查看端口规则情况
iptables -L -n --line-numbers
比如要删掉 INPUT 里序号为 6 的 DROP 规则(如果有带 DROP 的规则,没有则跳过),执行:
iptables -D INPUT 6
然后添加下述规则:
iptables -A INPUT -p tcp --dport 3306 -j ACCEPT
iptables -A INPUT -p tcp --dport 139 -j ACCEPT
iptables -A INPUT -p tcp --dport 445 -j ACCEPT
iptables -A INPUT -p udp --dport 137 -j ACCEPT
iptables -A INPUT -p udp --dport 138 -j ACCEPT
8.给予 MySQL 的 root 用户远程权限
首先登陆 mysql 账户(会提示输 root 用户密码):
mysql -u root -p
然后给 root 用户开启远程权限(密码替换成 root 用户的密码):
usemysql;
GRANTALLON*.*TOroot@'%'IDENTIFIEDBY'password'WITHGRANTOPTION;
flushprivileges;
然后 Ctrl+C 退出即可
9.优化部份 MySQL 的设置
使用 Winscp,找到/etc/f,参考右图更改:
然后重启 lnmp 服务:
lnmp restart
10.开放 Apache 跨目录权限
使用 Winscp,找到/usr/local/apache/conf/vhost 目录,分别将目下两个域名相关的文件中这一行代码注释掉(前面加#):
php_admin_value open_basedir "/home/wwwroot/:/tmp/:/var/tmp/:/proc/"
然后重启 lnmp 服务:
lnmp restart
采集服务器搭建:
1.将服务器安装 win 系统并远程联接
如果不会,可参照这个文章
在 KVM 的 VPS 上一键安装 32 位 Win7 系统
2.将关关采集器和加速工具上传至服务器
直接复制,然后在服务器上粘贴即可,然后解压,再运行 ServerSpeeder 文件下的 serverSpeeder.bat,来优化网路的稳定性
3.联接 samba 服务器,并映射成硬碟
在服务器上打开开始–所有程序–附件–运行,输入地址之后回车
\网站服务器的 IP
这里会弹出登陆窗口,填你之前设置的 Samba 的用户名(root)和密码
然后能看到名为 jieqi 的文件夹,确认能正常打开这个文件夹,然后右键将 jieqi 文件夹映射网络驱动器为 E 盘。
注意:若仍然未能联接,可能是服务商仅用了 Samba 端口的使用权,可以通过发工单开通
4.配置关关的系统系统设置
然后打开 GuanGuan5.6 文件夹下的 NovelSpider.exe,打开设置–系统设置,修改指定部份:
Data Source 是你的网站服务器 IP,Database 是网站数据库名,User ID 填 root,Password 是对应用户的密码
修改完后,一定要点确定,再完全关掉采集程序,然后再度打开程序,打开采集–标准采集,选择好采集规则和采集方式,然后开始采集:
这就是正常采集的界面
可以选择同时开启多个采集窗口采集,但是同一台采集服务器对同一个规则的采集窗口最好不要超过两个。
建议使用按目标站序号进行采集,可以更好的给各台服务器划定采集范围,比如 A 服务器采集 0-2000,B 服务器采集 2001-4000,以此类推,也易于报错时侯核实。
其他的采集服务器也根据以上配置即可。
开始采集:
我提供的采集器上面,附带了五个规则,虽然都能用,但是质量有好有坏,个人使用出来,笔趣阁和新笔趣阁以及八一英文的速率最快,最稳定,但是八一英文的广告较多,新笔趣阁的源站不稳定,容易出现采集空章节情况,具体情况请自行体验。
DEDE仿站提高效率,数据快速采集搬运。
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2020-08-27 17:32
在13年左右的时侯在撸一些为了排行而存在的网站,就学习了一点采集的东西,采集内容大部分是行业资讯、电子书、电影资源等信息,没想到5年以后这个东西又重新拿出来来聊一聊。
当年常用的几个工具:程序系统自带的采集、优采云采集、优采云采集器、小猪浏览器(群发发布用的),最后一个刚去看了下似乎凉了,优采云盗版横飞,优采云采集器器当时记得好象还是买的付费版,今天就拿优采云采集器器来说,没有详尽的采集教程,只是告诉你她们的流程是什么样的!
采集原理
简单的理解为:分析抓取、程序插口、任务发布
分析抓取
根据一个列表页,分析翻页规则、核心内容部份(获取到标题、缩略图)、提取内容详尽网址(组成正确的网址)、内容的详尽部份、内容中附件下载
程序插口
登录插口(账号登陆)、发布插口(获取栏目、栏目标题、栏目内容、缩略图)
任务发布
何时发、发布多少、间隔多久等等
当上述的业务流程你清晰后,有点后端的基础,那么个把小时才能快速上手使用,对于一个网站需要采集几百条上千条内容的时侯,采集器是你最好的帮手,基本上10几分钟写个规则下来,剩下的就让程序去做,你直接去烧壶水去喝酒即可。
详细的案例,在后期做一些更新,也便捷使更多的人能更高效的干活,把一些机械性的事情,逐渐退给程序去操作,让人有更多的时间做更多的事情。 查看全部
DEDE仿站提高效率,数据快速采集搬运。
在13年左右的时侯在撸一些为了排行而存在的网站,就学习了一点采集的东西,采集内容大部分是行业资讯、电子书、电影资源等信息,没想到5年以后这个东西又重新拿出来来聊一聊。
当年常用的几个工具:程序系统自带的采集、优采云采集、优采云采集器、小猪浏览器(群发发布用的),最后一个刚去看了下似乎凉了,优采云盗版横飞,优采云采集器器当时记得好象还是买的付费版,今天就拿优采云采集器器来说,没有详尽的采集教程,只是告诉你她们的流程是什么样的!
采集原理
简单的理解为:分析抓取、程序插口、任务发布
分析抓取
根据一个列表页,分析翻页规则、核心内容部份(获取到标题、缩略图)、提取内容详尽网址(组成正确的网址)、内容的详尽部份、内容中附件下载
程序插口
登录插口(账号登陆)、发布插口(获取栏目、栏目标题、栏目内容、缩略图)
任务发布
何时发、发布多少、间隔多久等等
当上述的业务流程你清晰后,有点后端的基础,那么个把小时才能快速上手使用,对于一个网站需要采集几百条上千条内容的时侯,采集器是你最好的帮手,基本上10几分钟写个规则下来,剩下的就让程序去做,你直接去烧壶水去喝酒即可。
详细的案例,在后期做一些更新,也便捷使更多的人能更高效的干活,把一些机械性的事情,逐渐退给程序去操作,让人有更多的时间做更多的事情。
互联网创业成功之道(四):网站内容管理和营运
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-27 06:09
运营是站点持续成长的关键,只有对网站的内容进行详尽而独特的规划和施行,再加上必不可少的营运,网站才能在竞争中立于不败之地。
一、为新网站快速充实内容
1.栏目设置 为网站搭建“骨架”
我们早已介绍了在无忧CMS系统中降低栏目的方式,而本期则注重讲解栏目的规划思路,并不局限于某个网站程序。
第一步:策划为先。网站的栏目设置是建站之初最为重要的步骤,因为一旦确定了栏目,网站的定位也就基本成形,如果营运一段时间后再进行更改,则会导致多方面的损失,诸如目标访客流失、搜索引擎权重减少等。所以说在构建网站栏目的时侯一定要深思熟虑,先企划好以后再进行添加。
第二步:多加考察。确定想添加的栏目以后,还要得先考察这类栏目是否遭到网友欢迎,想想看,当你构建一个栏目后每晚认真的维护更新,但是却由于定位误差造成无人问津,岂不是白白浪费时间?要了解访客的爱好,第一种方式是可以考察其他类似的网站来获得灵感。另外还可以通过搜索引擎的排行榜获得某个领域的关注度,从而确定栏目的定位,如百度的风云榜就是挺好的工具。
图1
第三步:确立定位。同样的领域也会有不同的栏目定位,比如你打算做一个有关电脑相关信息的栏目,是介绍电脑行业的最新资讯、还是提供电脑的软件下载、抑或是电脑的导购服务呢?栏目的定位也要注意与网站统一,比如本文的事例是一个IT资讯类网站,则定位就是电脑方面的新闻内容。
2.巧用采集 快速搜集网站内容
网站建立早期常常都缺少文章,而没有内容是难以留住访客的,要快速的获得优质内容,我们可以从其它网站进行转载。这里我们就以数动连线为例,将里面的文章快速的转载到自己的网站中。“优采云采集器”是一款便捷实用的内容采集程序,支持采集远程文章以及图片等功能,下面我们就以该软件为例进行说明。
小提示:
由于软件是基于.NET程序构架,所以使用前必须安装Microsoft .NET Framework 2.0组件,否则程序将难以正常运行。
第一步:建立站点添加规则
下载软件后解压缩后即可使用(下载地址),在任务列表面板中点击右键,新建一个采集站点,接着在弹出的站点新建窗口中输入站点的名称网址等信息。而后切换到软件的“整站内容规则”页面,这里是采集中最重要的一步。如果稍有设置不当就可能出现错误。一般的文章转移我们须要填写包括标题、内容、时间在内的基本信息。
图2
要确定网页的内容规则,可以打开须要采集的内容页面,在浏览器中选择“查看—源代码”查看网页的HTML代码,在代码中找寻标题数组,如标题开始标记是,则在软件的标签编辑框中输入这两个数组。然后依照同样的方法进行文章内容、作者、来源、时间等标记的查找和添加,一般我们须要对多个文章页面进行查看核实,以防止出现标签错误的情况。
如果须要同时采集网页中的其它信息,可以点击“添加标签”按钮,进行采集对象的添加,软件除了支持通过采集得到数据,还可以设置固定格式的数据。
小提示:
初次添加数据规则时可能会认为操作困难,但只要多试几次并仔细通读软件说明文档。理解原理后就可以很容易的进行数据规则的编撰了。
第二步:建立采集任务
在刚刚添加的站点名称上点击右键,选择“从该站点新建任务”选项,将出现采集网址菜单。软件提供了三种网址采集模式,如果目标网站有对应的文章列表页,则可以使用“1级链接”方式,该方法的原理是通过内容列表页面手动检查出内容页面,从而进行网页内容的采集。
如果目标网址文件名称有一定的规律,我们也可以直接添加须要采集的内容页网址。任务添加完成后可以先进行测试,点击软件右下方的“开始测试网址采集”按钮步入测试页面,软件将按照刚刚填写的网址规则进行采集,待地址搜索完成后,可以选择任意文章进行测试,如果软件能正常显示所采集页面的内容,说明采集规则设置成功;如果不能显示内容,则须要重新进行规则的设置。
图3
第三步:采集并发布内容
完成以上步骤后,还须要设置采集内容的发布形式,软件目前提供了多种内容发布形式。既可以直接发布到网站程序中,也可以保存为本地文件。如果想直接发布到网站程序中,则须要有对应的程序发布模块,软件自带了若干程序模块,包括了大多数流行的文章系统。如果没有我们须要的模块,可以到软件官方峰会进行查找。
设置完成后,就可以采集文章并发布到网站了,在软件主面板中选择须要采集的网站名称,然后点击面板上方的开始按键,软件将手动进行内容的采集。如果须要采集的内容好多,则须要等待较长时间。等到所有的文章采集完成后,内容将手动发布。
小提示:
虽然采集软件可以便捷的获取大量文章,不过在使用的时侯一定要注意版权,对一些容许转载的文章也要标明出处。
二、避免复制 实用的内容防盗法
网络中版权问题始终困惑着好多站长,个人网站最常遇见的就是自己的内容被转载,更有一些网站转载的时侯除了不保留链接,还要将文章中收录网站的信息都删掉,面对这些情况,我们可以采用为网站增加标记的方式来保护网站的内容。如降低网站的标志、域名等信息到图片或文本中,这样即使其他网站转载了内容,还起到了间接宣传自己网站的疗效。 查看全部
互联网创业成功之道(四):网站内容管理和营运
运营是站点持续成长的关键,只有对网站的内容进行详尽而独特的规划和施行,再加上必不可少的营运,网站才能在竞争中立于不败之地。
一、为新网站快速充实内容
1.栏目设置 为网站搭建“骨架”
我们早已介绍了在无忧CMS系统中降低栏目的方式,而本期则注重讲解栏目的规划思路,并不局限于某个网站程序。
第一步:策划为先。网站的栏目设置是建站之初最为重要的步骤,因为一旦确定了栏目,网站的定位也就基本成形,如果营运一段时间后再进行更改,则会导致多方面的损失,诸如目标访客流失、搜索引擎权重减少等。所以说在构建网站栏目的时侯一定要深思熟虑,先企划好以后再进行添加。
第二步:多加考察。确定想添加的栏目以后,还要得先考察这类栏目是否遭到网友欢迎,想想看,当你构建一个栏目后每晚认真的维护更新,但是却由于定位误差造成无人问津,岂不是白白浪费时间?要了解访客的爱好,第一种方式是可以考察其他类似的网站来获得灵感。另外还可以通过搜索引擎的排行榜获得某个领域的关注度,从而确定栏目的定位,如百度的风云榜就是挺好的工具。
图1
第三步:确立定位。同样的领域也会有不同的栏目定位,比如你打算做一个有关电脑相关信息的栏目,是介绍电脑行业的最新资讯、还是提供电脑的软件下载、抑或是电脑的导购服务呢?栏目的定位也要注意与网站统一,比如本文的事例是一个IT资讯类网站,则定位就是电脑方面的新闻内容。
2.巧用采集 快速搜集网站内容
网站建立早期常常都缺少文章,而没有内容是难以留住访客的,要快速的获得优质内容,我们可以从其它网站进行转载。这里我们就以数动连线为例,将里面的文章快速的转载到自己的网站中。“优采云采集器”是一款便捷实用的内容采集程序,支持采集远程文章以及图片等功能,下面我们就以该软件为例进行说明。
小提示:
由于软件是基于.NET程序构架,所以使用前必须安装Microsoft .NET Framework 2.0组件,否则程序将难以正常运行。
第一步:建立站点添加规则
下载软件后解压缩后即可使用(下载地址),在任务列表面板中点击右键,新建一个采集站点,接着在弹出的站点新建窗口中输入站点的名称网址等信息。而后切换到软件的“整站内容规则”页面,这里是采集中最重要的一步。如果稍有设置不当就可能出现错误。一般的文章转移我们须要填写包括标题、内容、时间在内的基本信息。
图2
要确定网页的内容规则,可以打开须要采集的内容页面,在浏览器中选择“查看—源代码”查看网页的HTML代码,在代码中找寻标题数组,如标题开始标记是,则在软件的标签编辑框中输入这两个数组。然后依照同样的方法进行文章内容、作者、来源、时间等标记的查找和添加,一般我们须要对多个文章页面进行查看核实,以防止出现标签错误的情况。
如果须要同时采集网页中的其它信息,可以点击“添加标签”按钮,进行采集对象的添加,软件除了支持通过采集得到数据,还可以设置固定格式的数据。
小提示:
初次添加数据规则时可能会认为操作困难,但只要多试几次并仔细通读软件说明文档。理解原理后就可以很容易的进行数据规则的编撰了。
第二步:建立采集任务
在刚刚添加的站点名称上点击右键,选择“从该站点新建任务”选项,将出现采集网址菜单。软件提供了三种网址采集模式,如果目标网站有对应的文章列表页,则可以使用“1级链接”方式,该方法的原理是通过内容列表页面手动检查出内容页面,从而进行网页内容的采集。
如果目标网址文件名称有一定的规律,我们也可以直接添加须要采集的内容页网址。任务添加完成后可以先进行测试,点击软件右下方的“开始测试网址采集”按钮步入测试页面,软件将按照刚刚填写的网址规则进行采集,待地址搜索完成后,可以选择任意文章进行测试,如果软件能正常显示所采集页面的内容,说明采集规则设置成功;如果不能显示内容,则须要重新进行规则的设置。
图3
第三步:采集并发布内容
完成以上步骤后,还须要设置采集内容的发布形式,软件目前提供了多种内容发布形式。既可以直接发布到网站程序中,也可以保存为本地文件。如果想直接发布到网站程序中,则须要有对应的程序发布模块,软件自带了若干程序模块,包括了大多数流行的文章系统。如果没有我们须要的模块,可以到软件官方峰会进行查找。
设置完成后,就可以采集文章并发布到网站了,在软件主面板中选择须要采集的网站名称,然后点击面板上方的开始按键,软件将手动进行内容的采集。如果须要采集的内容好多,则须要等待较长时间。等到所有的文章采集完成后,内容将手动发布。
小提示:
虽然采集软件可以便捷的获取大量文章,不过在使用的时侯一定要注意版权,对一些容许转载的文章也要标明出处。
二、避免复制 实用的内容防盗法
网络中版权问题始终困惑着好多站长,个人网站最常遇见的就是自己的内容被转载,更有一些网站转载的时侯除了不保留链接,还要将文章中收录网站的信息都删掉,面对这些情况,我们可以采用为网站增加标记的方式来保护网站的内容。如降低网站的标志、域名等信息到图片或文本中,这样即使其他网站转载了内容,还起到了间接宣传自己网站的疗效。
网站万能信息采集器 V11 最新版
采集交流 • 优采云 发表了文章 • 0 个评论 • 267 次浏览 • 2020-08-27 01:55
网站万能信息采集器(网站信息采集助手)是一款操作简便的网页信息抓取器。如何轻松采集网站信息?网站万能信息采集器(网站信息采集助手)轻松帮助用户。该软件结合了所有网站抓取网页抓取软件的优点,可以把网站上的信息统统抓出来而且手动发布到您的网站里,任意网站任意类型的信息统统照抓,例如:抓新闻、抓供求信息、抓人才急聘、抓峰会贴子、抓音乐、抓下页链接等等。
应用功能:
1、采集发布全手动。
2、自动破解JavaScript特殊网址。
3、会员登入的网站也照抓。
4、一次抓取整站 不管有多少分类。
5、任意类型的文件都能下载。
6、多页新闻手动合并、广告过滤。
7、多级页面联合采集。
8、模拟人工点击 破解防盗链。
9、验证码识别。
10、图片手动加水印。
应用特色:
1、信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,网站信息优采云采集器可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中。
2、网站登录
对于须要登陆能够听到信息内容的网站,网站信息优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3、文件手动下载
如果须要采集图片等二进制文件,经过简单设置网站信息优采云采集器就可以把任意类型的文件保存到本地。
4、多级页面采集 整站一次抓取
不管有多少大类和小类,一次设置,就可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站万能信息采集器也能手动辨识N级页面实现信息采集抓取。软件自带了一个8层网站采集例子。
5、自动辨识特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,网站万能信息采集器也能手动辨识抓到内容。
6、自动过滤重复 导出数据过滤重复 数据处理
有些时侯网址不同,但是内容一样,优采云采集器依然可以依据内容过滤重复。(新版本新加功能)。
7、多页新闻手动合并、广告过滤
有些一条新闻上面还有下一页,网站万能信息采集器也可以把各个页面都抓取到的。并且抓取到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉。
8、自动破解Cookie和防盗链
很多下载类的网站都做了Cookie验证或则防盗链了,直接输入网址是抓不到内容的,但是网站万能信息采集器能手动破解Cookie验证和防盗链,呵呵,确保您能抓到想要的东西。
9、另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。 查看全部
网站万能信息采集器 V11 最新版
网站万能信息采集器(网站信息采集助手)是一款操作简便的网页信息抓取器。如何轻松采集网站信息?网站万能信息采集器(网站信息采集助手)轻松帮助用户。该软件结合了所有网站抓取网页抓取软件的优点,可以把网站上的信息统统抓出来而且手动发布到您的网站里,任意网站任意类型的信息统统照抓,例如:抓新闻、抓供求信息、抓人才急聘、抓峰会贴子、抓音乐、抓下页链接等等。
应用功能:
1、采集发布全手动。
2、自动破解JavaScript特殊网址。
3、会员登入的网站也照抓。
4、一次抓取整站 不管有多少分类。
5、任意类型的文件都能下载。
6、多页新闻手动合并、广告过滤。
7、多级页面联合采集。
8、模拟人工点击 破解防盗链。
9、验证码识别。
10、图片手动加水印。
应用特色:
1、信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,网站信息优采云采集器可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中。
2、网站登录
对于须要登陆能够听到信息内容的网站,网站信息优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3、文件手动下载
如果须要采集图片等二进制文件,经过简单设置网站信息优采云采集器就可以把任意类型的文件保存到本地。
4、多级页面采集 整站一次抓取
不管有多少大类和小类,一次设置,就可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站万能信息采集器也能手动辨识N级页面实现信息采集抓取。软件自带了一个8层网站采集例子。
5、自动辨识特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,网站万能信息采集器也能手动辨识抓到内容。
6、自动过滤重复 导出数据过滤重复 数据处理
有些时侯网址不同,但是内容一样,优采云采集器依然可以依据内容过滤重复。(新版本新加功能)。
7、多页新闻手动合并、广告过滤
有些一条新闻上面还有下一页,网站万能信息采集器也可以把各个页面都抓取到的。并且抓取到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉。
8、自动破解Cookie和防盗链
很多下载类的网站都做了Cookie验证或则防盗链了,直接输入网址是抓不到内容的,但是网站万能信息采集器能手动破解Cookie验证和防盗链,呵呵,确保您能抓到想要的东西。
9、另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。
网站数据采集|埋点设计|nginx日志文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 334 次浏览 • 2020-08-26 20:53
数据获取的方法主要可以分为两种:
优缺点:
1.网站日志文件
记录网站日志文件的方法是最原创的数据获取方法,主要在服务端完成,在网站的应用服务器配置相应的写日志的功能能够够实现,很多web应用服务器自带日志的记录功能。如Nginx的access.log日志等。
优点是获取数据时不需要对页面做相关处理,可以直接开始统计相关恳求信息,缺点在于有些信息难以采集,比如用户在页面端的操作(如点击、ajax的使用等)无法记录。限制了一些指标的统计和估算。
2.页面埋点js自定义采集
自定义采集用户行为数据,通过在页面嵌入自定义的javascript代码来获取用户的访问行为(比如键盘悬停的位置,点击的页面组件等),然后通过ajax恳求到后台记录日志,这种方法所能采集的信息会愈发全面。
在实际操作中,有以下几个方面的数据可以自定义的采集:
系统特点:比如所采用的操作系统、浏览器、域名和访问速率等。
访问特点:包括逗留时间、点击的URL、所点击的“页面标签”及标签的
属性等。
来源特点:包括来访URL,来访IP等。
产品特点:包括所访问的产品编号、产品类别、产品颜色、产品价钱、产品收益、产品数目和特惠等级等。
以某电商网站为例,当用户点击相关产品页面时,其自定义采集系统都会搜集相关的行为数据,发到前端的服务器,采集的数据日志格式如下: 查看全部
网站数据采集|埋点设计|nginx日志文件
数据获取的方法主要可以分为两种:
优缺点:
1.网站日志文件
记录网站日志文件的方法是最原创的数据获取方法,主要在服务端完成,在网站的应用服务器配置相应的写日志的功能能够够实现,很多web应用服务器自带日志的记录功能。如Nginx的access.log日志等。
优点是获取数据时不需要对页面做相关处理,可以直接开始统计相关恳求信息,缺点在于有些信息难以采集,比如用户在页面端的操作(如点击、ajax的使用等)无法记录。限制了一些指标的统计和估算。
2.页面埋点js自定义采集
自定义采集用户行为数据,通过在页面嵌入自定义的javascript代码来获取用户的访问行为(比如键盘悬停的位置,点击的页面组件等),然后通过ajax恳求到后台记录日志,这种方法所能采集的信息会愈发全面。
在实际操作中,有以下几个方面的数据可以自定义的采集:
系统特点:比如所采用的操作系统、浏览器、域名和访问速率等。
访问特点:包括逗留时间、点击的URL、所点击的“页面标签”及标签的
属性等。
来源特点:包括来访URL,来访IP等。
产品特点:包括所访问的产品编号、产品类别、产品颜色、产品价钱、产品收益、产品数目和特惠等级等。
以某电商网站为例,当用户点击相关产品页面时,其自定义采集系统都会搜集相关的行为数据,发到前端的服务器,采集的数据日志格式如下:
python数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 311 次浏览 • 2020-08-26 06:16
最近在学习python爬虫技术,研究了一下采集实现电商平台之一的拼多多商品数据,因为之前专注了解Java的知识,现在这段时间看了相关python的知识点,发现python重
开放、灵活。代码简约优美、模块好多,用简单的句子可以完成好多神奇的功能,非常方便我们的工作,
首先要了解哪些是python爬虫?即是一段手动抓取互联网信息的程序,从互联网上抓取于我们有价值的信息。
python爬虫构架主要由5个部份组成,分别是调度器、url管理器、网页下载器、网页解析器、应用程序去采集有价值的数据
调度器:相当于一台笔记本的cpu,主要负责调度url管理器、下载器、解析器之间的协调工作
url管理器:包括待爬取得url地址和已爬取得url地址,防止重复抓取url和循环抓取url,实现url管理器主要用三种形式,通过显存、数据库、缓存数据库来实现
网页下载器:通过传入一个人url地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括须要登陆、代理、和cookie,requests(第三方包)
网页解析器:将一个网页字符串进行解析,可以根据我们得要求来提取出我们有用得信息,也可以按照DOM树得解析方法来解析。
网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方法来提取有价值的信息,当文档比较复杂的时侯,该方式提取数据的时侯才会特别的困难)、html.parser(Python自带的)、
beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强悍一些)、lxml(第三方插件,可以解析 xml 和 HTML),
html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方法进行解析的。
应用程序:从网页中提取得有用数据组成得一个应用
了解了一些大约得知识点之后,自己也进行了实际操作,采集了拼多多得一些数据,拼多多能采集得范围能依据不同得关键词进行搜索后,能采集道商品店面得名子、商品标题、商品价钱、商品图片url、商品url、商品销量
就如关键词---手机,进行搜索如下:
采集的手机数据结果如下:
如关键词--口红 进行搜索如下:
采集的唇膏数据结果如下:
不同关键词可以采集不同的数据,并将数据凸显不同的格式,数据的搜集也易于剖析相关关键词商品的销量数更高,针对不同的需求和不同的网站平台的数据都可以做相应数据的数据采集和数据剖析业务,进而可以按照对应的业务做相应的营运或营销策略 查看全部
python数据采集
最近在学习python爬虫技术,研究了一下采集实现电商平台之一的拼多多商品数据,因为之前专注了解Java的知识,现在这段时间看了相关python的知识点,发现python重
开放、灵活。代码简约优美、模块好多,用简单的句子可以完成好多神奇的功能,非常方便我们的工作,
首先要了解哪些是python爬虫?即是一段手动抓取互联网信息的程序,从互联网上抓取于我们有价值的信息。
python爬虫构架主要由5个部份组成,分别是调度器、url管理器、网页下载器、网页解析器、应用程序去采集有价值的数据
调度器:相当于一台笔记本的cpu,主要负责调度url管理器、下载器、解析器之间的协调工作
url管理器:包括待爬取得url地址和已爬取得url地址,防止重复抓取url和循环抓取url,实现url管理器主要用三种形式,通过显存、数据库、缓存数据库来实现
网页下载器:通过传入一个人url地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括须要登陆、代理、和cookie,requests(第三方包)
网页解析器:将一个网页字符串进行解析,可以根据我们得要求来提取出我们有用得信息,也可以按照DOM树得解析方法来解析。
网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方法来提取有价值的信息,当文档比较复杂的时侯,该方式提取数据的时侯才会特别的困难)、html.parser(Python自带的)、
beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强悍一些)、lxml(第三方插件,可以解析 xml 和 HTML),
html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方法进行解析的。
应用程序:从网页中提取得有用数据组成得一个应用
了解了一些大约得知识点之后,自己也进行了实际操作,采集了拼多多得一些数据,拼多多能采集得范围能依据不同得关键词进行搜索后,能采集道商品店面得名子、商品标题、商品价钱、商品图片url、商品url、商品销量
就如关键词---手机,进行搜索如下:
采集的手机数据结果如下:
如关键词--口红 进行搜索如下:
采集的唇膏数据结果如下:
不同关键词可以采集不同的数据,并将数据凸显不同的格式,数据的搜集也易于剖析相关关键词商品的销量数更高,针对不同的需求和不同的网站平台的数据都可以做相应数据的数据采集和数据剖析业务,进而可以按照对应的业务做相应的营运或营销策略
[发布] 分享discuz采集器 discuz采集插件自带【今日头条】采集【先
采集交流 • 优采云 发表了文章 • 0 个评论 • 406 次浏览 • 2020-08-25 21:56
分享discuz采集器 discuz采集插件自带【今日头条】采集【先
discuz采集器自带discuz发布插口,可采集今日头条,本discuz采集插件搭配优采云采集器使用。可指定关键词,多个关键词,采集今日头条内容。(也可指定作者采集,已经写好,看需求再奉上吧)
1、软件功能,支持图片本地化
2、支持发布 图片批量上传到网站
3、支持单篇采集完,可自动可视化编辑内容后 ,再发布到网站。
(可仅更改标题,内容,然后指定用户发布)
4、批量采集完,支持进数据库,可视化编辑内容。
5、可自定义发布
6、全手动定时计划任务采集
7、支持采集需登录的网页
8、支持太多了。自已看去吧
采集不了,欢迎加我QQ,打脸。
工具/原料:
1、优采云采集器 (非正式版)
下载地址: (本软件绿色免安装,为易于discuz用户使用,此文件自带(今日头条采集规则)演示)
方法/步骤:
1、将软件根目录下 /发布插口/discuz/ jieling_post_nohtml.php 文件放置在你的程序根目录
2、参考
修改发布规则里发布地址 改成你的域名; 修改列表规则里的 关键词 为你想要的关键词即可!
保存任务后 开始批量采集。
============
无图无真相
本采集免费使用,谁都可以用,为防万一扩散,造成恶劣影响,
如果用的人多,将停止提供本采集任务,先到先得。
另可自行下载优采云采集器正式版 自行配置使用。采集软件使用问题,欢迎加我QQ。 查看全部
[发布]
分享discuz采集器 discuz采集插件自带【今日头条】采集【先
discuz采集器自带discuz发布插口,可采集今日头条,本discuz采集插件搭配优采云采集器使用。可指定关键词,多个关键词,采集今日头条内容。(也可指定作者采集,已经写好,看需求再奉上吧)
1、软件功能,支持图片本地化
2、支持发布 图片批量上传到网站
3、支持单篇采集完,可自动可视化编辑内容后 ,再发布到网站。
(可仅更改标题,内容,然后指定用户发布)
4、批量采集完,支持进数据库,可视化编辑内容。
5、可自定义发布
6、全手动定时计划任务采集
7、支持采集需登录的网页
8、支持太多了。自已看去吧
采集不了,欢迎加我QQ,打脸。
工具/原料:
1、优采云采集器 (非正式版)
下载地址: (本软件绿色免安装,为易于discuz用户使用,此文件自带(今日头条采集规则)演示)
方法/步骤:
1、将软件根目录下 /发布插口/discuz/ jieling_post_nohtml.php 文件放置在你的程序根目录
2、参考
修改发布规则里发布地址 改成你的域名; 修改列表规则里的 关键词 为你想要的关键词即可!
保存任务后 开始批量采集。
============
无图无真相
本采集免费使用,谁都可以用,为防万一扩散,造成恶劣影响,
如果用的人多,将停止提供本采集任务,先到先得。
另可自行下载优采云采集器正式版 自行配置使用。采集软件使用问题,欢迎加我QQ。
小说源码带采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 476 次浏览 • 2020-08-21 01:06
小说源码带采集是怎么样的? ,别再迟疑,赶紧上车吧!
究竟怎样订制小说小说网站搭建项目?
小说系统源码站点分销平台在互联网大数据时代下,使消费者足不出户就可以享受到小说动漫资源阅读或观看的乐趣,内容付费打赏观看方法早已成为众多消费者喜欢的娱乐形式。小说分销系统系统小说动漫分销平台系统,界面经过多次优化,代理分销平台焕然一新,吸引更多的优质渠道资源,新增单一章节推广文案链接手动生成及渠道数据统计管理功能。
小说动漫系统源码小说网站开发app软件网站新增发布冲值活动功能。
新增全新模板一套(跟上时尚,更加美观大方)。防举报功能:用户阅读中点击举报入口实质上为平台内部的举报,后台可见到举报数据。
随着场景应用的范围越来越广,智能硬件设施的需求在上扬,联系我们,您也将拥有一款这样的小说网站源码网页版系统源码。面对各类指责和顾客对于系统平台的担心,我们公司便迎合??市场反馈推出了这些模式,一并改掉往年其他模式平台的各类不足,主打公开透明,娱乐趣味性得到了广大玩家的信赖。比较简单推动网站的发展方式就是通过优化或SEO。在此过程中,你需将网站的内容优化到在搜索引擎中排到比较好的位置。
" 小说网小程序到底该怎么样搭建? 制作公司到底该怎样选择?我们公司可为您提供建站解决方案,可以帮助创业者和已有的电商店面平台,搭建开发建设平台或则嵌入模块,殷切期盼与您的合作,欢迎致电洽谈!
"
小说源码带采集。
小说源码带采集的文档下载:
DOC
TXT 查看全部
小说源码带采集
小说源码带采集是怎么样的? ,别再迟疑,赶紧上车吧!
究竟怎样订制小说小说网站搭建项目?
小说系统源码站点分销平台在互联网大数据时代下,使消费者足不出户就可以享受到小说动漫资源阅读或观看的乐趣,内容付费打赏观看方法早已成为众多消费者喜欢的娱乐形式。小说分销系统系统小说动漫分销平台系统,界面经过多次优化,代理分销平台焕然一新,吸引更多的优质渠道资源,新增单一章节推广文案链接手动生成及渠道数据统计管理功能。
小说动漫系统源码小说网站开发app软件网站新增发布冲值活动功能。
新增全新模板一套(跟上时尚,更加美观大方)。防举报功能:用户阅读中点击举报入口实质上为平台内部的举报,后台可见到举报数据。
随着场景应用的范围越来越广,智能硬件设施的需求在上扬,联系我们,您也将拥有一款这样的小说网站源码网页版系统源码。面对各类指责和顾客对于系统平台的担心,我们公司便迎合??市场反馈推出了这些模式,一并改掉往年其他模式平台的各类不足,主打公开透明,娱乐趣味性得到了广大玩家的信赖。比较简单推动网站的发展方式就是通过优化或SEO。在此过程中,你需将网站的内容优化到在搜索引擎中排到比较好的位置。
" 小说网小程序到底该怎么样搭建? 制作公司到底该怎样选择?我们公司可为您提供建站解决方案,可以帮助创业者和已有的电商店面平台,搭建开发建设平台或则嵌入模块,殷切期盼与您的合作,欢迎致电洽谈!
"
小说源码带采集。
小说源码带采集的文档下载:
DOC
TXT

