
网站源码
DEDE织梦采集侠破解版(无限制完整源码) 2.8 最新版 (图文)
站长必读 • 优采云 发表了文章 • 0 个评论 • 518 次浏览 • 2020-07-21 08:02
织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8织梦采集侠2.92破解版,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器织梦采集侠2.92破解版,清理缓存有时清的不干净】
6, PHP版本必须5.3+ 查看全部
DEDE织梦采集侠破解版是一款必备全手动采集伪原创SEO插件,新云网提供其专业破解版本的下载。采集侠正文辨识技术是采集侠多年的技术积累,自主研制了一套汉字剖析和处理的核心系统,目前该系统辨识精度处于领先水平,即便和强悍的搜索引擎中的文字剖析能力也有得一比,优于有道紧跟百度。采集侠正是基于该核心技术研制的一个卓越的采集软件,我们更懂得百度。

织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8织梦采集侠2.92破解版,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器织梦采集侠2.92破解版,清理缓存有时清的不干净】
6, PHP版本必须5.3+
帝国cms7.2仿九库小说手动采集源码+wap与app(修复版)
站长必读 • 优采云 发表了文章 • 0 个评论 • 783 次浏览 • 2020-07-19 08:02
8.排行榜,站内聊天体系和签到送积分
9.优采云采集,自动采集其他站,伪原创,也可以做盗版小说站
10.txt 下载功能帝国cms自动采集发布,自动生成章节下载,自动判定更新,自动添加文本广告
11.程序有伪静态规则,可以不用静态页面,下载手动生成 txt 和看书弹幕疗效
12.本程序含安卓app开源包,开源包我使会安卓的同学帮忙测试了一下,只须要自己对接插口即可使用!功能并不是太建立,只有正常阅读一些功能。
安装说明
将网站解压到更目录浏览域名/beifen/
账号admin 密码admin888 验证码admin888
进入后配置数据库帐号和密码,然后步入数据还原操作,还原到你须要的那种数据库
然后更改e/config/config.php上面的数据库帐号和密码还有数据库名子
手机版类似
然后直接打开网站域名/e/admin/
账号admin 密码123456
进入后台,点刷新,从数据缓存到首页更新,从右想左,从上到下帝国cms自动采集发布,全部刷新一次
手机版必须绑定域名,不然图片路径和qq登陆都不行,公用一个数据库把域名解析到m文件夹下就好了
后台帐号admin密码 123456
可以在pc后台更改wap模板,点击模板-切换wap即可
前台演示帐号admin 密码123456
手机版qq登陆工用pc的要配置cookie作用域,可以百度,我回头讲到博客上,
采集不要随便采集,如果采集请记住更改成是前台投稿的,这样后期做原创不会出现干扰,在表里有一个数组,修改即可
下方为图片展示
查看全部

8.排行榜,站内聊天体系和签到送积分
9.优采云采集,自动采集其他站,伪原创,也可以做盗版小说站
10.txt 下载功能帝国cms自动采集发布,自动生成章节下载,自动判定更新,自动添加文本广告
11.程序有伪静态规则,可以不用静态页面,下载手动生成 txt 和看书弹幕疗效
12.本程序含安卓app开源包,开源包我使会安卓的同学帮忙测试了一下,只须要自己对接插口即可使用!功能并不是太建立,只有正常阅读一些功能。
安装说明
将网站解压到更目录浏览域名/beifen/
账号admin 密码admin888 验证码admin888
进入后配置数据库帐号和密码,然后步入数据还原操作,还原到你须要的那种数据库
然后更改e/config/config.php上面的数据库帐号和密码还有数据库名子
手机版类似
然后直接打开网站域名/e/admin/
账号admin 密码123456
进入后台,点刷新,从数据缓存到首页更新,从右想左,从上到下帝国cms自动采集发布,全部刷新一次
手机版必须绑定域名,不然图片路径和qq登陆都不行,公用一个数据库把域名解析到m文件夹下就好了
后台帐号admin密码 123456
可以在pc后台更改wap模板,点击模板-切换wap即可
前台演示帐号admin 密码123456
手机版qq登陆工用pc的要配置cookie作用域,可以百度,我回头讲到博客上,
采集不要随便采集,如果采集请记住更改成是前台投稿的,这样后期做原创不会出现干扰,在表里有一个数组,修改即可
下方为图片展示



dedecms内核小说阅读网模板-小说流量站-小说源码带整站数据
站长必读 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2020-07-19 08:01
配合织梦采集侠采集一下,不过本人我不推荐采集,采集的重复率高百度不会收录太多,只会对自己的站点导致不好的影响,有站长说我伪原创,伪原创通常都是搅乱排序和增减关键词或则替换关键词为主,一点疗效没有,反而打破了小说站点的可读性,我建议喜欢小说的顾客可以拿来做一下原创,推荐出去以后只要渐渐有流量了,坚持出来还是十分不错的,小说站靠文字的积累,耐心的沉淀!
★模板安装说明★
空间必须支持php+mysql
1、将程序上传到网站根目录
2、运行 你的域名/install/ 按提示安装程序(请不要更改数据表前缀)
3、登录后台 你的域名/dede/
4、点击“系统”——“数据库备份/还原”——“数据还原”织梦小说源码带采集,完成还原数据
备注:数据库自带4万条小说数据,因备份文件有点大,所以传到云盘供你们下载。下载以后将backupdata文件夹复制到data目录覆盖即可。
5、点击“系统”——“系统基本参数”,设置网站基本信息
6、点击“生成”——“一键更新网站”——“更新所有”,开始更新
7、基本完成
后台管理地址/dede,管理账号和密码都是:admin。
备份文件云盘下载地址见压缩文件。 查看全部
设计美工很不错的小说流量站,宽屏织梦小说源码带采集,做广告联盟精品程序,dedecms-UTF8最新版本,非常漂亮的小说源码,简洁大气,自带5W条数据,dedecms-UTF8最新版本静态容易收录,测试无任何错误,安装即可使用!
配合织梦采集侠采集一下,不过本人我不推荐采集,采集的重复率高百度不会收录太多,只会对自己的站点导致不好的影响,有站长说我伪原创,伪原创通常都是搅乱排序和增减关键词或则替换关键词为主,一点疗效没有,反而打破了小说站点的可读性,我建议喜欢小说的顾客可以拿来做一下原创,推荐出去以后只要渐渐有流量了,坚持出来还是十分不错的,小说站靠文字的积累,耐心的沉淀!
★模板安装说明★
空间必须支持php+mysql
1、将程序上传到网站根目录
2、运行 你的域名/install/ 按提示安装程序(请不要更改数据表前缀)
3、登录后台 你的域名/dede/
4、点击“系统”——“数据库备份/还原”——“数据还原”织梦小说源码带采集,完成还原数据
备注:数据库自带4万条小说数据,因备份文件有点大,所以传到云盘供你们下载。下载以后将backupdata文件夹复制到data目录覆盖即可。
5、点击“系统”——“系统基本参数”,设置网站基本信息
6、点击“生成”——“一键更新网站”——“更新所有”,开始更新
7、基本完成
后台管理地址/dede,管理账号和密码都是:admin。
备份文件云盘下载地址见压缩文件。
ptcms精美小说阅读网站源码(带采集规则)
站长必读 • 优采云 发表了文章 • 0 个评论 • 482 次浏览 • 2020-07-17 08:02
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家()文章网站源码带采集,是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载文章网站源码带采集,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:) 查看全部
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家()文章网站源码带采集,是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载文章网站源码带采集,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
天人文章管理系统Asp网站源码(带手机版)v5.33UTF8
站长必读 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2020-07-14 08:01
16、系统支持文章投稿,会员可在个人中心进行投稿,并获得管理员设定的积分。
17、多种形式的互动功能,例如会员签到、会员投稿、游客留言、游客评论等功能。
天人文章管理系统特色功能介绍: 1、按钮功能:
按钮颜色分为两种,一种是红色,一种是蓝色。蓝色按键是添加、修改之类较为安全,不会导致数据遗失的功能。红色按键是删掉、恢复之类若误操作会导致数据遗失的功能,故按键使用颜色分辨及配合对话框提示会最大程度保证操作准确性。
2、单行文本框:
当填写完表单时,将光标定位在单行文本框中敲打回车键,可取代点击递交表单按键的功能。此功能可便捷用户快速递交表单。
3、复选框与单选框:
在选中复选框或单选框时,为了降低键盘点选的方便性,点击其旁边的文字同样还能起到选择复选框或单选框的作用。
4、弹窗对话框:
弹窗对话框是系统对管理员作出操作的回应,通常情况下可点击弹窗对话框里面的确定按键,同时也可以敲打空格或回车键进行快速确定操作。
5、后台功能面板:
后台的功能面板中所有须要键盘点选或鼠标录入的地方都最大限度的紧靠两侧菜单老y文章管理系统采集功能怎么设置分页,这样可提升点击两侧菜单与两侧功能的效率,可使管理员大部分时间只需把注意力集中在功能面板的两侧即可完成大部分的操作,而不需要满屏幕的转移眼神,例如单选,多选,删除老y文章管理系统采集功能怎么设置分页,增加,修改等按键及文本框。
6、后台验证码免输入:
对于每晚的前几次登陆网站来说,验证码对与错都不会影响你的登入。
此项设置是为了便捷管理员不用确切的输入验证码就可以登入后台,同时为了保证安全性,可以在后台设置每日免验证码登陆的次数,可按照你日常登陆网站的规律了设定。操作方法:后台–站点设置–网站后台每日免验证码登入次数–在文本框中输入整数即可(建议不要超过3)
注:
1、程序开源,使用功能无任何限制,本程序正在申请计算机软件著作权,修改程序源代码前请查看程序代码中的版权注释信息
2、官网有关于本程序的使用教程及操作方法
后台应用中心可安装,模板、扫码打赏插件、手机版与笔记本版智能管理插件、屏蔽复制与滑鼠右键插件、老y文章系统数据迁移至天人工具、OK3W文章系统数据迁移至天人工具、用户注册后手动登入插件、悬浮贴边客服插件、会员前台全功能编辑器插件、广告可视化管理插件、前台顶部自定义内容插件、畅言、友言、多说万能评论插件、电脑版整站背景图插件、万能伪静态规则生成插件、手机版广告插件、手机版内容阅读权限插件、QQ登陆插件等等
恭喜,此资源为免费资源,请先登入
1. 充值比列:1:1
2. 升级VIP或冲值均手动到帐。
3. 下载权限,请登陆后直接看下载按键后面说明。
4. 虚拟物品具有可复制性,无问题一经售出,概不退钱哦;
5. 源码默认是没有安装教程的,如果上面有那也是随机的。
6. 所有资源不提供免费安装与技术支持,如需技术支持请联系客服。 查看全部
15、会员管理,管理员可在后台添加会员,此功能与前台会员注册的疗效相同。同时也可以管理会员、审核会员、设定会员等级积分等。
16、系统支持文章投稿,会员可在个人中心进行投稿,并获得管理员设定的积分。
17、多种形式的互动功能,例如会员签到、会员投稿、游客留言、游客评论等功能。
天人文章管理系统特色功能介绍: 1、按钮功能:
按钮颜色分为两种,一种是红色,一种是蓝色。蓝色按键是添加、修改之类较为安全,不会导致数据遗失的功能。红色按键是删掉、恢复之类若误操作会导致数据遗失的功能,故按键使用颜色分辨及配合对话框提示会最大程度保证操作准确性。
2、单行文本框:
当填写完表单时,将光标定位在单行文本框中敲打回车键,可取代点击递交表单按键的功能。此功能可便捷用户快速递交表单。
3、复选框与单选框:
在选中复选框或单选框时,为了降低键盘点选的方便性,点击其旁边的文字同样还能起到选择复选框或单选框的作用。
4、弹窗对话框:
弹窗对话框是系统对管理员作出操作的回应,通常情况下可点击弹窗对话框里面的确定按键,同时也可以敲打空格或回车键进行快速确定操作。
5、后台功能面板:
后台的功能面板中所有须要键盘点选或鼠标录入的地方都最大限度的紧靠两侧菜单老y文章管理系统采集功能怎么设置分页,这样可提升点击两侧菜单与两侧功能的效率,可使管理员大部分时间只需把注意力集中在功能面板的两侧即可完成大部分的操作,而不需要满屏幕的转移眼神,例如单选,多选,删除老y文章管理系统采集功能怎么设置分页,增加,修改等按键及文本框。
6、后台验证码免输入:
对于每晚的前几次登陆网站来说,验证码对与错都不会影响你的登入。
此项设置是为了便捷管理员不用确切的输入验证码就可以登入后台,同时为了保证安全性,可以在后台设置每日免验证码登陆的次数,可按照你日常登陆网站的规律了设定。操作方法:后台–站点设置–网站后台每日免验证码登入次数–在文本框中输入整数即可(建议不要超过3)
注:
1、程序开源,使用功能无任何限制,本程序正在申请计算机软件著作权,修改程序源代码前请查看程序代码中的版权注释信息
2、官网有关于本程序的使用教程及操作方法
后台应用中心可安装,模板、扫码打赏插件、手机版与笔记本版智能管理插件、屏蔽复制与滑鼠右键插件、老y文章系统数据迁移至天人工具、OK3W文章系统数据迁移至天人工具、用户注册后手动登入插件、悬浮贴边客服插件、会员前台全功能编辑器插件、广告可视化管理插件、前台顶部自定义内容插件、畅言、友言、多说万能评论插件、电脑版整站背景图插件、万能伪静态规则生成插件、手机版广告插件、手机版内容阅读权限插件、QQ登陆插件等等


恭喜,此资源为免费资源,请先登入
1. 充值比列:1:1
2. 升级VIP或冲值均手动到帐。
3. 下载权限,请登陆后直接看下载按键后面说明。
4. 虚拟物品具有可复制性,无问题一经售出,概不退钱哦;
5. 源码默认是没有安装教程的,如果上面有那也是随机的。
6. 所有资源不提供免费安装与技术支持,如需技术支持请联系客服。
【原创源码】网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2020-07-02 08:01
最近因为女朋友工作需求,需要获取各大团购网站上的店家信息,这样自动一个一个点不得气死,于是我就写了一个网络爬虫来解决这个问题,是用java写的,主要用到了两个开源库,httpclient和jsoup...用来获取网页数据和得到想要的数据,不过最好是有点web基础网络爬虫代码,这样就可以只要想要的值,不然会有很多没用的数据,后期还要自动删掉,比较麻烦...下面附上源码和说明...
[Asm] 纯文本查看 复制代码
public static String getHtmlByUrl(String url){
String html = null;
HttpClient httpClient = new DefaultHttpClient();//创建httpClient对象
HttpGet httpget = new HttpGet(url);//以get方式请求该URL
try {
HttpResponse responce = httpClient.execute(httpget);//得到responce对象
int resStatu = responce.getStatusLine().getStatusCode();//返回码
if (resStatu==HttpStatus.SC_OK) {//200正常 其他就不对
//获得相应实体
HttpEntity entity = responce.getEntity();
if (entity!=null) {
//html = EntityUtils.toString(entity);//获得html源代码
InputStream in = entity.getContent();
entity.getContentType();
Scanner sc = new Scanner(in);
StringBuffer str = new StringBuffer("utf-8");
while(sc.hasNextLine()){
str.append(sc.nextLine());
}
html = str.toString();
//sc.close();
}
}
} catch (Exception e) {
System.out.println("访问【"+url+"】出现异常!");
e.printStackTrace();
} finally {
httpClient.getConnectionManager().shutdown();
}
return html;
}
上面的就是httpclient库的内容,用它来获取html页面的数据
[Java] 纯文本查看 复制代码
public static void main(String[] args) throws WriteException, IOException {
String html = getHtmlByUrl("需要获取数据的网址");
if (html!=null&&!"".equals(html)) {
Document doc = Jsoup.parse(html);
Elements linksElements = doc.select("div.basic>a"); //如果有web基础的话,可以设置一下这里,知道自己想要的数据
for (Element ele:linksElements) {
String href = ele.attr("href");
String title = ele.text();
System.out.println(href+","+title);
}
}
}
这个就是解析获取来的html数据,找到自己想要的数据....
然后把取到的数据存入excel获取txt里就随大伙便了,不过这个方式有一个漏洞就是,只能取静态页面,动态页面未能实现,我还要再继续研究一下,研究下来了,再发下来,如果有哪些不懂的网络爬虫代码,可以问我,知道的一定告诉你们,希望你们多评分,多鼓励,非常谢谢!!!! 查看全部

最近因为女朋友工作需求,需要获取各大团购网站上的店家信息,这样自动一个一个点不得气死,于是我就写了一个网络爬虫来解决这个问题,是用java写的,主要用到了两个开源库,httpclient和jsoup...用来获取网页数据和得到想要的数据,不过最好是有点web基础网络爬虫代码,这样就可以只要想要的值,不然会有很多没用的数据,后期还要自动删掉,比较麻烦...下面附上源码和说明...
[Asm] 纯文本查看 复制代码
public static String getHtmlByUrl(String url){
String html = null;
HttpClient httpClient = new DefaultHttpClient();//创建httpClient对象
HttpGet httpget = new HttpGet(url);//以get方式请求该URL
try {
HttpResponse responce = httpClient.execute(httpget);//得到responce对象
int resStatu = responce.getStatusLine().getStatusCode();//返回码
if (resStatu==HttpStatus.SC_OK) {//200正常 其他就不对
//获得相应实体
HttpEntity entity = responce.getEntity();
if (entity!=null) {
//html = EntityUtils.toString(entity);//获得html源代码
InputStream in = entity.getContent();
entity.getContentType();
Scanner sc = new Scanner(in);
StringBuffer str = new StringBuffer("utf-8");
while(sc.hasNextLine()){
str.append(sc.nextLine());
}
html = str.toString();
//sc.close();
}
}
} catch (Exception e) {
System.out.println("访问【"+url+"】出现异常!");
e.printStackTrace();
} finally {
httpClient.getConnectionManager().shutdown();
}
return html;
}
上面的就是httpclient库的内容,用它来获取html页面的数据
[Java] 纯文本查看 复制代码
public static void main(String[] args) throws WriteException, IOException {
String html = getHtmlByUrl("需要获取数据的网址");
if (html!=null&&!"".equals(html)) {
Document doc = Jsoup.parse(html);
Elements linksElements = doc.select("div.basic>a"); //如果有web基础的话,可以设置一下这里,知道自己想要的数据
for (Element ele:linksElements) {
String href = ele.attr("href");
String title = ele.text();
System.out.println(href+","+title);
}
}
}
这个就是解析获取来的html数据,找到自己想要的数据....
然后把取到的数据存入excel获取txt里就随大伙便了,不过这个方式有一个漏洞就是,只能取静态页面,动态页面未能实现,我还要再继续研究一下,研究下来了,再发下来,如果有哪些不懂的网络爬虫代码,可以问我,知道的一定告诉你们,希望你们多评分,多鼓励,非常谢谢!!!!
DEDE织梦采集侠无限制完整版下载v2.8 源码版
采集交流 • 优采云 发表了文章 • 0 个评论 • 441 次浏览 • 2020-06-08 08:00
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3织梦采集侠破解版,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+ 查看全部
其实DEDE织梦采集侠无限制完整版可以做到万无一失的使你少花钱去享受软件的收费内容,DEDE织梦采集侠破解版使用上去真心不赖,而且附送了最全的DEDE织梦采集侠无限制完整版使用方式,保证你一步到位织梦采集侠破解版,你会喜欢的。
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3织梦采集侠破解版,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
PHP爬虫编撰
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2020-06-04 08:04
PHP(外文名:PHP: Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用开源脚本语言。语法吸收了C语言、Java和Perl的特性,利于学习,使用广泛,主要适用于Web开发领域。PHP 独特的句型混和了C、Java、Perl以及PHP自创的句型。它可以比CGI或则Perl更快速地执行动态网页。用PHP作出的动态页面与其他的编程语言相比,PHP是将程序嵌入到HTML(标准通用标记语言下的一个应用)文档中去执行,执行效率比完全生成HTML标记的CGI要高许多;PHP还可以执行编译后代码,编译可以达到加密和优化代码运行php网络爬虫软件,使代码运行更快。——百度百科的描述。
二、爬虫有哪些用?
爬虫有哪些用?先说一下爬虫是哪些东西,我觉得爬虫就是一个网路信息搜集程序,也许我自己的理解有错误,也请你们给我见谅。既然爬虫是一个网路信息搜集程序,那就是拿来搜集信息,并且搜集的信息是在网路里面的。如果还是不太清楚爬虫有什么用php网络爬虫软件,我就举几个爬虫应用的事例:搜索引擎就须要爬虫搜集网路信息供人们去搜索;大数据的数据,数据从那里来?就是可以通过爬虫在网路中爬取(收集)而来。
三、通常看到爬虫会想到 Python,但为何我用 PHP,而不用 Python 呢?
Python 我说实话,我不会 Python。( Python 我真不会,想知道可能你要去百度一下,因为 Python 我真不会。)PHP 写东西我仍然都是觉得,你只要想出算法程序就早已下来了,不用考虑太多数据类型的问题。PHP 的句型和其他编程语言差不多,就算你开始不会 PHP,你也可以马上上手。PHP的句型和其他编程语言差不多,就算你开始不会 PHP,你也可以马上上手。的看法有错。)本人虽然也是初学 PHP,想通过写一些东西提升自己的水平。(下面可能有些代码会使你认为不够规范,欢迎见谅,谢谢。)
四、PHP爬虫第一步
PHP爬虫第一步,第一步......第一步其实就是搭建 PHP 的运行环境,没有环境PHP又如何能运行呢?就像虾不能离开水一样。(我见识还不够,可能我举的虾的事例不够好,请见谅。)在Windows的系统下我使用 WAMP,而在Linux的系统下我使用 LNMP 或者 LAMP。
WAMP:Windows + Apache + Mysql + PHP
LAMP:Linux + Apache + Mysql + PHP
LNMP:Linux + Nginx + Mysql + PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache或Nginx、Mysql 以及 PHP 这些都是 PHP Web 的基本配置环境。网上有 PHP Web 环境的安装包,这些安装包使用很方便,不需要每给东西安装以及配置。但若果你对这种集成安装包害怕安全问题,你可以到这种程序的官网下载之后在网上找配置教程就可以了。(说真的,我真心的不会单独去弄,我认为很麻烦。)
五、 PHP爬虫第二步
(感觉自己屁话很多,应该马上来一段代码!!!)
<?php
// 爬虫核心功能:获取网页源码
$html = file_get_contents("https://www.baidu.com/index.html");
// 通过 php 的 file_get_contents 函数获取百度首页源码,并传给 $html 变量
echo $html;
// 输出 $html
?>
爬虫网路核心功能早已写下来了,为什么说就如此几行代码就把爬虫核心功能写下来了呢?我猜有人早已明白了吧,其实是因为爬虫是数据获取的程序,就里面几行代码虽然早已才能获取数据了,所以爬虫的核心功能早已写下来了。可能有人会说“你这个也很菜了吧!有哪些用?”,虽然我是太菜,但请别说出来,让我好好装个X。(又说了两行屁话,不好意思。)
其实爬虫是拿来干嘛,主要看你想使它来干嘛。就像我前些日子为了好玩写了一个搜索引擎网站出来,当然网站很菜,结果排序没有规律,很多都查不到。我的搜索引擎的爬虫就是要写一个适合于搜索引擎的爬虫。所以为了便捷我也就用写搜索引擎的爬虫为目标讲解。当然了,我搜索引擎的爬虫还是不够建立,不健全的地方都是要大家自己去创造,去建立。
六、 搜索引擎爬虫的限制
搜索引擎的爬虫有时候不是不能那种网站的页面获取页面源码,而是有robot.txt文件,有该文件的网站,就代表站主不希望爬虫去爬取页面源码。(不过若果你就是想要获取的话,就算有也一样会去爬吧!)
我搜索引擎的爬虫虽然还有好多不足而造成的限制,例如可能由于未能运行 JS 脚本所以未能获取页面源码。又或则网站有反爬虫的机制引起不能获取到页面源码。有反爬虫机制的网站就如:知乎,知乎就是有反爬虫的机制的网站。
七、以弄搜索引擎爬虫为例,准备写该爬虫须要的东西
PHP 编写基础正则表达式(你也可以使用Xpath,对不起,我不会使用)数据库的使用(本文使用 MySql 数据库)运行环境(只要有能运行 PHP 网站的环境和数据库就OK)
八、搜索引擎获取页面源码并获取页面的标题信息
<?PHP
// 通过 file_get_contents 函数获取百度页面源码
$html = file_get_contents("https://www.baidu.com/index.html");
// 通过 preg_replace 函数使页面源码由多行变单行
$htmlOneLine = preg_replace("/\r|\n|\t/","",$html);
// 通过 preg_match 函数提取获取页面的标题信息
preg_match("/<title>(.*)<\/title>/iU",$htmlOne,$titleArr);
// 由于 preg_match 函数的结果是数组的形式
$title = $titleArr[1];
// 通过 echo 函数输出标题信息
echo $title;
?>
报错误示例:
Warning: file_get_contents("127.0.0.1/index.php") [function.file-get-contents]: failed to open stream: Invalid argument in E:\website\blog\test.php on line 25
https是SSL加密合同,如果出现获取页面晨报里面的错误,代表你的 PHP 可能少了OpenSSL 的模块,你可以到网上查找解决办法。
九、搜索引擎爬虫的特征
虽然我没见过象“百度”,“Google”它们的爬虫,可是我自己通过推测,以及在实际爬去过程当中遇见的一些问题,自己总结的几个特性。(可能有不对的地方,或者缺乏的地方,欢迎见谅,谢谢。)
通用性
通用性是因为我觉得搜索引擎的爬虫一开始并不是针对哪一个网站制定的,所以要求能爬取到的网站尽可能的多,这是第一点。而第二点,就是获取网页的信息就是这些,一开始不会由于个别某些特殊小网站而舍弃个别信息不提取,举个反例:一个小网站的一个网页meta标签里没有描述信息(description)或者关键词信息(keyword),就直接舍弃了描述信息或则关键词信息的提取,当然假如真的某一个页面没有这种信息我会提取页面里的文字内容作为填充,反正就是尽可能达到爬取的网页信息每位网页的信息项都要一样。这是我觉得的搜索引擎爬虫的通用性,当然我的看法可能是错误的。(我说得可能不是很好,我仍然在学习。)
不确定性
不确定性就是我的爬虫获取哪些网页我是控制不够全面的,只能控制我能想到的情况,这也是由于我写的算法就是这样的缘由,我的算法就是爬取获取到的页面里的所有链接,再去爬去获取到的那些链接,其实是因为搜索引擎并不是搜某一些东西,而是尽可能的多,因为只有更多的信息,才能找到一个最贴切用户想要的答案。所以我就认为搜索引擎的爬虫就要有不确定性。(我自己再看了一遍,也有点认为自己说得有点使自己看不懂,请见谅,欢迎见谅,提问,谢谢了!)
下面的视频是我的搜索网站的使用视频,而搜到的信息就是通过自己写的 PHP 爬虫获取到的。(这个网站我早已不再继续维护了,所以有缺乏之处,请见谅。)
十、到如今可能出现的问题
获取的源码出现乱码
<?PHP
// 乱码解决办法,把其他编码格式通过 mb_convert_encoding 函数统一转为 UTF-8 格式
$html = mb_convert_encoding($html,'UTF-8','UTF-8,GBK,GB2312,BIG5');
// 还有一种因为gzip所以出现乱码的,我会在以后讲
?>
2. 获取不到标题信息
<?PHP
// 获取不到标题信息解决办法,首先判断是否能获取到页面源码
// 如果能获取到但还是不能获取到标题信息
// 我猜测的问题是:因为我教的是使用正则表达式获取的,源码没有变成一行,获取起来就会出现问题
$htmlOneLine=preg_replace("/\r|\n|\t/","",$html);
?>
3.获取不到页面源码
<?PHP
// 像新浪微博你可能获取到的是“Sina Visitor System”
// 解决办法添加header信息
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n",
)
);
$context = stream_context_create($opts);
$html = file_get_contents($domain,0,$context,0,150000);
// 这样就能获取到新浪微博的页面了
?>
十一、获取一个网页时的处理思路
我们先不去想好多网页,因为好多网页也就是一个循环。
获取页面源码通过源码提取页面的哪些信息提取的信息要如何处理处理后放不放进数据库
十二、按照十一的思路的代码
<?php
// 一、获取源码
// 假设我们要获取淘宝首页
$html = file_get_content("https://www.taobao.com");
// 二、提取标题和文本
// 三、提取信息处理
// 处理页面源码,多行变单行
$htmlOneLine = preg_replace("/\r|\n|\t/","",$html);
// 获取标题信息
preg_match("/<title>(.*)<\/title>/iU",$htmlOneLine,$titleArr);
// 保留标题信息
$titleOK = $titleArr[1];
// 获取页面中的文本信息
// 处理前面不需要的head标签
$htmlText = preg_replace("/<html>(.*)<\/head>/","",$htmlOneLine);
// 处理style和script标签及内容
$htmlText = preg_replace("/<style(.*)>(.*)</style>|<script(.*)>(.*)</script>/iU","",$htmlText);
// 处理多余标签
$htmlText = preg_replace("/<(\/)?(.+)>/","",$htmlText);
// 四、保存到数据库
// 略
?>
十三、PHP 保存页面的图片思路
获取页面源码获取页面的图片链接使用函数保存图片
十四、保存图片示例代码
<?php
// 使用file_get_contents()函数获取图片
$img = file_get_contents("http://127.0.0.1/photo.jpg");
// 使用file_put_contents()函数保存图片
file_put_contents("photo.jpg",$img);
?>
十五、gzip解压
本来我以为自己写的爬虫早已写得差不多了,就是不仅反爬虫的网站难以爬取外,应该是都可以爬了。但有三天我去尝试爬去bilibili的时侯出现问题了,我发觉如何我数据库上面的都是乱码,而且标题哪些的都没有,好奇怪!后来我才晓得原先是因为GZIP的压缩,原来我直接使用file_get_content函数获取的页面是未经过解压的页面,所有都是乱码!好了,然后我晓得问题出现在哪里了,接下来就是想解决办法了。(其实那时候的我是完全不知道如何解决解压gzip的,都靠搜索引擎,哈哈哈哈哈)。
我得到了两个解决办法:
在 request header 那里告诉对方服务器,我这爬虫(不。。。应该是我这浏览器)不支持gzip的解压,就麻烦你不要压缩,直接把数据发给我吧!
// 这是request header(请求头)
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n".
"accept-encoding:"
)
);
// 我把accept-encodeing(能接收编码)设为空,代表不接受gzip
2. 如果告诉了对方服务器本浏览器(爬虫)不支持解压gzip,可他还是继续发gzip的数据给你,那就没有办法了,只好默默的在搜索引擎找php解压gzip的解压函数——gzdecode()。
// 废话:好久没更新了,因为近来又在重复造轮子,不过好开心-- 2019.01.14
十六、子链接的获取
网页爬虫就好比手动的网页源码另存为操作,可是假如真的是一个一个网址自动输入给爬虫去爬取的话,那还倒不如人手另存为呢!所以在这里就得解析到这些子链接,一个网页似乎会有好多的a标签,而这种a标签的href属性值都会是一个子链接。(这句如何觉得有一点屁话呢?应该你们都晓得吧!)通过好多种工具的解析得到了原始的子链接(我没用html的工具,就是用了正则表达式及工具)为什么叫原始数据,因为这些子链接有很多不是URL链接,又或则是一些不完整的链接,又或则你是要爬一个网站,不要爬虫跑出去的时侯,还得消除一些并非那种网站的链接,防止爬虫跑出去。下面我列出一些原始子链接。(其实就是我喷到的坑。。。)
http://wxample.com/
./index.html
index.html
//example.com/index.html
javascript:;
../index.html
http://example2.com/index.html
你可以看得到这儿有很多种链接,有完整的绝对路径的链接,也有不完整的相对路径链接,有的还跑来了javascript,如果是相对路径或javascript的链接,直接给爬虫去爬,肯定使爬虫一脸懵,因为不完整或根本就不是一个链接。所以就须要对子链接补全或则扔掉。
十七、子链接的处理
上面屁话了一大堆后,接下来还是继续屁话。好了,处理虽然就是去重、丢弃以及补全。
对于相同的子链接遗弃不保存对于相对路径链接补全对于不是链接的链接遗弃(不是链接的链接是哪些东西?自己都认为的奇怪。。。。)
对于第一种我就不多说了,相信你们都晓得该如何做。
对付第二种的方式我就写一个才能运行相对路径的方式下来就OK了,通过父链接来进行相对路径转绝对路径。(有空补代码给你们。。。不好意思了)
对于第三种也正则匹配一下就完了。 查看全部
一、PHP 是哪些东西?
PHP(外文名:PHP: Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用开源脚本语言。语法吸收了C语言、Java和Perl的特性,利于学习,使用广泛,主要适用于Web开发领域。PHP 独特的句型混和了C、Java、Perl以及PHP自创的句型。它可以比CGI或则Perl更快速地执行动态网页。用PHP作出的动态页面与其他的编程语言相比,PHP是将程序嵌入到HTML(标准通用标记语言下的一个应用)文档中去执行,执行效率比完全生成HTML标记的CGI要高许多;PHP还可以执行编译后代码,编译可以达到加密和优化代码运行php网络爬虫软件,使代码运行更快。——百度百科的描述。
二、爬虫有哪些用?
爬虫有哪些用?先说一下爬虫是哪些东西,我觉得爬虫就是一个网路信息搜集程序,也许我自己的理解有错误,也请你们给我见谅。既然爬虫是一个网路信息搜集程序,那就是拿来搜集信息,并且搜集的信息是在网路里面的。如果还是不太清楚爬虫有什么用php网络爬虫软件,我就举几个爬虫应用的事例:搜索引擎就须要爬虫搜集网路信息供人们去搜索;大数据的数据,数据从那里来?就是可以通过爬虫在网路中爬取(收集)而来。
三、通常看到爬虫会想到 Python,但为何我用 PHP,而不用 Python 呢?
Python 我说实话,我不会 Python。( Python 我真不会,想知道可能你要去百度一下,因为 Python 我真不会。)PHP 写东西我仍然都是觉得,你只要想出算法程序就早已下来了,不用考虑太多数据类型的问题。PHP 的句型和其他编程语言差不多,就算你开始不会 PHP,你也可以马上上手。PHP的句型和其他编程语言差不多,就算你开始不会 PHP,你也可以马上上手。的看法有错。)本人虽然也是初学 PHP,想通过写一些东西提升自己的水平。(下面可能有些代码会使你认为不够规范,欢迎见谅,谢谢。)
四、PHP爬虫第一步
PHP爬虫第一步,第一步......第一步其实就是搭建 PHP 的运行环境,没有环境PHP又如何能运行呢?就像虾不能离开水一样。(我见识还不够,可能我举的虾的事例不够好,请见谅。)在Windows的系统下我使用 WAMP,而在Linux的系统下我使用 LNMP 或者 LAMP。
WAMP:Windows + Apache + Mysql + PHP
LAMP:Linux + Apache + Mysql + PHP
LNMP:Linux + Nginx + Mysql + PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache或Nginx、Mysql 以及 PHP 这些都是 PHP Web 的基本配置环境。网上有 PHP Web 环境的安装包,这些安装包使用很方便,不需要每给东西安装以及配置。但若果你对这种集成安装包害怕安全问题,你可以到这种程序的官网下载之后在网上找配置教程就可以了。(说真的,我真心的不会单独去弄,我认为很麻烦。)
五、 PHP爬虫第二步
(感觉自己屁话很多,应该马上来一段代码!!!)
<?php
// 爬虫核心功能:获取网页源码
$html = file_get_contents("https://www.baidu.com/index.html");
// 通过 php 的 file_get_contents 函数获取百度首页源码,并传给 $html 变量
echo $html;
// 输出 $html
?>
爬虫网路核心功能早已写下来了,为什么说就如此几行代码就把爬虫核心功能写下来了呢?我猜有人早已明白了吧,其实是因为爬虫是数据获取的程序,就里面几行代码虽然早已才能获取数据了,所以爬虫的核心功能早已写下来了。可能有人会说“你这个也很菜了吧!有哪些用?”,虽然我是太菜,但请别说出来,让我好好装个X。(又说了两行屁话,不好意思。)
其实爬虫是拿来干嘛,主要看你想使它来干嘛。就像我前些日子为了好玩写了一个搜索引擎网站出来,当然网站很菜,结果排序没有规律,很多都查不到。我的搜索引擎的爬虫就是要写一个适合于搜索引擎的爬虫。所以为了便捷我也就用写搜索引擎的爬虫为目标讲解。当然了,我搜索引擎的爬虫还是不够建立,不健全的地方都是要大家自己去创造,去建立。
六、 搜索引擎爬虫的限制
搜索引擎的爬虫有时候不是不能那种网站的页面获取页面源码,而是有robot.txt文件,有该文件的网站,就代表站主不希望爬虫去爬取页面源码。(不过若果你就是想要获取的话,就算有也一样会去爬吧!)
我搜索引擎的爬虫虽然还有好多不足而造成的限制,例如可能由于未能运行 JS 脚本所以未能获取页面源码。又或则网站有反爬虫的机制引起不能获取到页面源码。有反爬虫机制的网站就如:知乎,知乎就是有反爬虫的机制的网站。
七、以弄搜索引擎爬虫为例,准备写该爬虫须要的东西
PHP 编写基础正则表达式(你也可以使用Xpath,对不起,我不会使用)数据库的使用(本文使用 MySql 数据库)运行环境(只要有能运行 PHP 网站的环境和数据库就OK)
八、搜索引擎获取页面源码并获取页面的标题信息
<?PHP
// 通过 file_get_contents 函数获取百度页面源码
$html = file_get_contents("https://www.baidu.com/index.html");
// 通过 preg_replace 函数使页面源码由多行变单行
$htmlOneLine = preg_replace("/\r|\n|\t/","",$html);
// 通过 preg_match 函数提取获取页面的标题信息
preg_match("/<title>(.*)<\/title>/iU",$htmlOne,$titleArr);
// 由于 preg_match 函数的结果是数组的形式
$title = $titleArr[1];
// 通过 echo 函数输出标题信息
echo $title;
?>
报错误示例:
Warning: file_get_contents("127.0.0.1/index.php") [function.file-get-contents]: failed to open stream: Invalid argument in E:\website\blog\test.php on line 25
https是SSL加密合同,如果出现获取页面晨报里面的错误,代表你的 PHP 可能少了OpenSSL 的模块,你可以到网上查找解决办法。
九、搜索引擎爬虫的特征
虽然我没见过象“百度”,“Google”它们的爬虫,可是我自己通过推测,以及在实际爬去过程当中遇见的一些问题,自己总结的几个特性。(可能有不对的地方,或者缺乏的地方,欢迎见谅,谢谢。)
通用性
通用性是因为我觉得搜索引擎的爬虫一开始并不是针对哪一个网站制定的,所以要求能爬取到的网站尽可能的多,这是第一点。而第二点,就是获取网页的信息就是这些,一开始不会由于个别某些特殊小网站而舍弃个别信息不提取,举个反例:一个小网站的一个网页meta标签里没有描述信息(description)或者关键词信息(keyword),就直接舍弃了描述信息或则关键词信息的提取,当然假如真的某一个页面没有这种信息我会提取页面里的文字内容作为填充,反正就是尽可能达到爬取的网页信息每位网页的信息项都要一样。这是我觉得的搜索引擎爬虫的通用性,当然我的看法可能是错误的。(我说得可能不是很好,我仍然在学习。)
不确定性
不确定性就是我的爬虫获取哪些网页我是控制不够全面的,只能控制我能想到的情况,这也是由于我写的算法就是这样的缘由,我的算法就是爬取获取到的页面里的所有链接,再去爬去获取到的那些链接,其实是因为搜索引擎并不是搜某一些东西,而是尽可能的多,因为只有更多的信息,才能找到一个最贴切用户想要的答案。所以我就认为搜索引擎的爬虫就要有不确定性。(我自己再看了一遍,也有点认为自己说得有点使自己看不懂,请见谅,欢迎见谅,提问,谢谢了!)
下面的视频是我的搜索网站的使用视频,而搜到的信息就是通过自己写的 PHP 爬虫获取到的。(这个网站我早已不再继续维护了,所以有缺乏之处,请见谅。)

十、到如今可能出现的问题
获取的源码出现乱码
<?PHP
// 乱码解决办法,把其他编码格式通过 mb_convert_encoding 函数统一转为 UTF-8 格式
$html = mb_convert_encoding($html,'UTF-8','UTF-8,GBK,GB2312,BIG5');
// 还有一种因为gzip所以出现乱码的,我会在以后讲
?>
2. 获取不到标题信息
<?PHP
// 获取不到标题信息解决办法,首先判断是否能获取到页面源码
// 如果能获取到但还是不能获取到标题信息
// 我猜测的问题是:因为我教的是使用正则表达式获取的,源码没有变成一行,获取起来就会出现问题
$htmlOneLine=preg_replace("/\r|\n|\t/","",$html);
?>
3.获取不到页面源码
<?PHP
// 像新浪微博你可能获取到的是“Sina Visitor System”
// 解决办法添加header信息
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n",
)
);
$context = stream_context_create($opts);
$html = file_get_contents($domain,0,$context,0,150000);
// 这样就能获取到新浪微博的页面了
?>
十一、获取一个网页时的处理思路
我们先不去想好多网页,因为好多网页也就是一个循环。
获取页面源码通过源码提取页面的哪些信息提取的信息要如何处理处理后放不放进数据库
十二、按照十一的思路的代码
<?php
// 一、获取源码
// 假设我们要获取淘宝首页
$html = file_get_content("https://www.taobao.com");
// 二、提取标题和文本
// 三、提取信息处理
// 处理页面源码,多行变单行
$htmlOneLine = preg_replace("/\r|\n|\t/","",$html);
// 获取标题信息
preg_match("/<title>(.*)<\/title>/iU",$htmlOneLine,$titleArr);
// 保留标题信息
$titleOK = $titleArr[1];
// 获取页面中的文本信息
// 处理前面不需要的head标签
$htmlText = preg_replace("/<html>(.*)<\/head>/","",$htmlOneLine);
// 处理style和script标签及内容
$htmlText = preg_replace("/<style(.*)>(.*)</style>|<script(.*)>(.*)</script>/iU","",$htmlText);
// 处理多余标签
$htmlText = preg_replace("/<(\/)?(.+)>/","",$htmlText);
// 四、保存到数据库
// 略
?>
十三、PHP 保存页面的图片思路
获取页面源码获取页面的图片链接使用函数保存图片
十四、保存图片示例代码
<?php
// 使用file_get_contents()函数获取图片
$img = file_get_contents("http://127.0.0.1/photo.jpg");
// 使用file_put_contents()函数保存图片
file_put_contents("photo.jpg",$img);
?>
十五、gzip解压
本来我以为自己写的爬虫早已写得差不多了,就是不仅反爬虫的网站难以爬取外,应该是都可以爬了。但有三天我去尝试爬去bilibili的时侯出现问题了,我发觉如何我数据库上面的都是乱码,而且标题哪些的都没有,好奇怪!后来我才晓得原先是因为GZIP的压缩,原来我直接使用file_get_content函数获取的页面是未经过解压的页面,所有都是乱码!好了,然后我晓得问题出现在哪里了,接下来就是想解决办法了。(其实那时候的我是完全不知道如何解决解压gzip的,都靠搜索引擎,哈哈哈哈哈)。
我得到了两个解决办法:
在 request header 那里告诉对方服务器,我这爬虫(不。。。应该是我这浏览器)不支持gzip的解压,就麻烦你不要压缩,直接把数据发给我吧!
// 这是request header(请求头)
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n".
"accept-encoding:"
)
);
// 我把accept-encodeing(能接收编码)设为空,代表不接受gzip
2. 如果告诉了对方服务器本浏览器(爬虫)不支持解压gzip,可他还是继续发gzip的数据给你,那就没有办法了,只好默默的在搜索引擎找php解压gzip的解压函数——gzdecode()。
// 废话:好久没更新了,因为近来又在重复造轮子,不过好开心-- 2019.01.14
十六、子链接的获取
网页爬虫就好比手动的网页源码另存为操作,可是假如真的是一个一个网址自动输入给爬虫去爬取的话,那还倒不如人手另存为呢!所以在这里就得解析到这些子链接,一个网页似乎会有好多的a标签,而这种a标签的href属性值都会是一个子链接。(这句如何觉得有一点屁话呢?应该你们都晓得吧!)通过好多种工具的解析得到了原始的子链接(我没用html的工具,就是用了正则表达式及工具)为什么叫原始数据,因为这些子链接有很多不是URL链接,又或则是一些不完整的链接,又或则你是要爬一个网站,不要爬虫跑出去的时侯,还得消除一些并非那种网站的链接,防止爬虫跑出去。下面我列出一些原始子链接。(其实就是我喷到的坑。。。)
http://wxample.com/
./index.html
index.html
//example.com/index.html
javascript:;
../index.html
http://example2.com/index.html
你可以看得到这儿有很多种链接,有完整的绝对路径的链接,也有不完整的相对路径链接,有的还跑来了javascript,如果是相对路径或javascript的链接,直接给爬虫去爬,肯定使爬虫一脸懵,因为不完整或根本就不是一个链接。所以就须要对子链接补全或则扔掉。
十七、子链接的处理
上面屁话了一大堆后,接下来还是继续屁话。好了,处理虽然就是去重、丢弃以及补全。
对于相同的子链接遗弃不保存对于相对路径链接补全对于不是链接的链接遗弃(不是链接的链接是哪些东西?自己都认为的奇怪。。。。)
对于第一种我就不多说了,相信你们都晓得该如何做。
对付第二种的方式我就写一个才能运行相对路径的方式下来就OK了,通过父链接来进行相对路径转绝对路径。(有空补代码给你们。。。不好意思了)
对于第三种也正则匹配一下就完了。
基于Python网路爬虫的设计与实现毕业论文+源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 558 次浏览 • 2020-05-25 08:02
本课题的主要目的是设计面向定向网站的网路爬虫程序,同时须要满足不同的性能要求,详细涉及到定向网路爬虫的各个细节与应用环节。
搜索引擎作为一个辅助人们检索信息的工具。但是,这些通用性搜索引擎也存在着一定的局限性。不同领域、不同背景的用户常常具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。为了解决这个问题,一个灵活的爬虫有着无可替代的重要意义。
网络爬虫应用智能自构造技术,随着不同主题的网站,可以手动剖析构造URL,去重。网络爬虫使用多线程技术,让爬虫具备更强大的抓取能力。对网路爬虫的联接网路设置联接及读取时间,避免无限制的等待。为了适应不同需求,使网路爬虫可以按照预先设定的主题实现对特定主题的爬取。研究网路爬虫的原理并实现爬虫的相关功能,并将爬去的数据清洗以后存入数据库,后期可视化显示。
关键词:网络爬虫网络爬虫+代码,定向爬取,多线程网络爬虫+代码,Mongodb
The main purpose of this project is to design subject-oriented web crawler process, which require to meet different performance and related to the various details of the targeted web crawler and application in detail.
Search engine is a tool to help people retrieve information. However, these general search engines also have some limitations. Users in different fields and backgrounds tend to have different purposes and needs, and the results returned by general search engines contain a large number of web pages that users don't care about. In order to solve this problem, it is of great significance for a flexible crawler.
Web crawler application of intelligent self construction technology, with the different themes of the site, you can automatically analyze the structure of URL, and cancel duplicate part. Web crawler use multi-threading technology, so that the crawler has a more powerful ability to grab. Setting connection and reading time of the network crawler is to avoid unlimited waiting. In order to adapt to the different needs, the web crawler can base on the preset themes to realize to filch the specific topics. What’s more, we should study the principle of the web crawler ,realize the relevant functions of reptiles, save the stolen data to the database after cleaning and in late achieve the visual display.
Keywords:Web crawler,Directional climb,multi-threading,mongodb
目录
6
7
1)爬虫代码文件构成如图:
全套结业设计论文现成成品资料请咨询 查看全部

本课题的主要目的是设计面向定向网站的网路爬虫程序,同时须要满足不同的性能要求,详细涉及到定向网路爬虫的各个细节与应用环节。
搜索引擎作为一个辅助人们检索信息的工具。但是,这些通用性搜索引擎也存在着一定的局限性。不同领域、不同背景的用户常常具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。为了解决这个问题,一个灵活的爬虫有着无可替代的重要意义。
网络爬虫应用智能自构造技术,随着不同主题的网站,可以手动剖析构造URL,去重。网络爬虫使用多线程技术,让爬虫具备更强大的抓取能力。对网路爬虫的联接网路设置联接及读取时间,避免无限制的等待。为了适应不同需求,使网路爬虫可以按照预先设定的主题实现对特定主题的爬取。研究网路爬虫的原理并实现爬虫的相关功能,并将爬去的数据清洗以后存入数据库,后期可视化显示。
关键词:网络爬虫网络爬虫+代码,定向爬取,多线程网络爬虫+代码,Mongodb
The main purpose of this project is to design subject-oriented web crawler process, which require to meet different performance and related to the various details of the targeted web crawler and application in detail.
Search engine is a tool to help people retrieve information. However, these general search engines also have some limitations. Users in different fields and backgrounds tend to have different purposes and needs, and the results returned by general search engines contain a large number of web pages that users don't care about. In order to solve this problem, it is of great significance for a flexible crawler.
Web crawler application of intelligent self construction technology, with the different themes of the site, you can automatically analyze the structure of URL, and cancel duplicate part. Web crawler use multi-threading technology, so that the crawler has a more powerful ability to grab. Setting connection and reading time of the network crawler is to avoid unlimited waiting. In order to adapt to the different needs, the web crawler can base on the preset themes to realize to filch the specific topics. What’s more, we should study the principle of the web crawler ,realize the relevant functions of reptiles, save the stolen data to the database after cleaning and in late achieve the visual display.
Keywords:Web crawler,Directional climb,multi-threading,mongodb
目录
6
7
1)爬虫代码文件构成如图:




全套结业设计论文现成成品资料请咨询
DEDE织梦采集侠破解版(无限制完整源码)下载 2.8 最新版
采集交流 • 优采云 发表了文章 • 0 个评论 • 443 次浏览 • 2020-05-25 08:01
Tags:软件源码源码
DEDE织梦采集侠破解版是一款必备全手动采集伪原创SEO插件,新云网提供其专业破解版本的下载。采集侠正文辨识技术是采集侠多年的技术积累,自主研制了一套汉字剖析和处理的核心系统,目前该系统辨识精度处于领先水平,即便和强悍的搜索引擎中的文字剖析能力也有得一比,优于有道紧跟百度。采集侠正是基于该核心技术研制的一个卓越的采集软件,我们更懂得百度。
织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件采集侠授权码 生成器,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话采集侠授权码 生成器,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
采集侠定向规则采集教程请参照其官网: 查看全部

Tags:软件源码源码
DEDE织梦采集侠破解版是一款必备全手动采集伪原创SEO插件,新云网提供其专业破解版本的下载。采集侠正文辨识技术是采集侠多年的技术积累,自主研制了一套汉字剖析和处理的核心系统,目前该系统辨识精度处于领先水平,即便和强悍的搜索引擎中的文字剖析能力也有得一比,优于有道紧跟百度。采集侠正是基于该核心技术研制的一个卓越的采集软件,我们更懂得百度。

织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件采集侠授权码 生成器,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话采集侠授权码 生成器,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
采集侠定向规则采集教程请参照其官网:
好站长资源免费分享精品源码,建站技术,服务器安全防护等等各种网路资源分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 435 次浏览 • 2020-05-21 08:00
前段时间帮几个顾客安装过,功能还算很不错的,在这里完全免费分享下来。源码没有任何的限制,任何域名都可以正常使用。以下部份说明为转载过来,具体的请自行下载测试。
9-9 全面升级程序模板,导航升级,以及宝贝展示升级,添加分享,原价折扣价,销量全部展示,图片修改为正方形310*310都是依照顾客的需求优化的。
优化原本值得买页面,以及升级文章页面改成哪些值得买页面,优化值得逛页面,增加品牌团。支持后台添加品牌上传图片
9-30号升级程序内核功能以及优化相关小问题。详细请看演示。增加404,全站宝贝描述,后台文章编辑器,前台文章调用,预告采集,宝贝显示款式,全面升级
9-9号全面升级页面降低品牌团等等多功能
8-29 修复后台一键手动采集价格0元错误
8-21升级程序飞天侠50完美修复:无需api一键采集,u站采集,全新安装包,修复手机版,增加报考页面,以及安装不需要恢复数据,增加伪静态规则。。。。
6.0的内核和性能比5.0的好好多,并且降低独立缓存技术。加速网站。 后期更新升级。。。
支持,后台一键手动采集,以及各个地方相关logo直接后台上传更改即可,非常简便飞天侠50完美修复:无需api一键采集,u站采集,新手也会操作。
客服,等等后台可以操作,支持显示宝贝详尽,后台单品采集可以采集宝贝详尽,支持u站采集宝贝详尽。
会员系统,报名系统,后台系统全面升级,
前台有些广告位没有设置,后期会更新教程给你们。
本次升级有使用6.0的可以直接覆盖升级,但是没有宝贝详尽。6.0亮点:u站采,淘宝网采集一键手动采集,单品采集,宝贝描述,后台可以在线升级。。功能赶超所有版本飞天侠,全网惟一一家可以更新的,几千客户体验和支持我们,谢谢大家选择我们,我们程序以优价分享,结交更多好朋友,本站开启超级群,和开放群。还有更多功能后期继续上线,后台在线升级哈
以上部份说明为转载过来,具体的请自行下载测试
下面演示图片100%为我们亲测截图 查看全部

前段时间帮几个顾客安装过,功能还算很不错的,在这里完全免费分享下来。源码没有任何的限制,任何域名都可以正常使用。以下部份说明为转载过来,具体的请自行下载测试。
9-9 全面升级程序模板,导航升级,以及宝贝展示升级,添加分享,原价折扣价,销量全部展示,图片修改为正方形310*310都是依照顾客的需求优化的。
优化原本值得买页面,以及升级文章页面改成哪些值得买页面,优化值得逛页面,增加品牌团。支持后台添加品牌上传图片
9-30号升级程序内核功能以及优化相关小问题。详细请看演示。增加404,全站宝贝描述,后台文章编辑器,前台文章调用,预告采集,宝贝显示款式,全面升级
9-9号全面升级页面降低品牌团等等多功能
8-29 修复后台一键手动采集价格0元错误
8-21升级程序飞天侠50完美修复:无需api一键采集,u站采集,全新安装包,修复手机版,增加报考页面,以及安装不需要恢复数据,增加伪静态规则。。。。
6.0的内核和性能比5.0的好好多,并且降低独立缓存技术。加速网站。 后期更新升级。。。
支持,后台一键手动采集,以及各个地方相关logo直接后台上传更改即可,非常简便飞天侠50完美修复:无需api一键采集,u站采集,新手也会操作。
客服,等等后台可以操作,支持显示宝贝详尽,后台单品采集可以采集宝贝详尽,支持u站采集宝贝详尽。
会员系统,报名系统,后台系统全面升级,
前台有些广告位没有设置,后期会更新教程给你们。
本次升级有使用6.0的可以直接覆盖升级,但是没有宝贝详尽。6.0亮点:u站采,淘宝网采集一键手动采集,单品采集,宝贝描述,后台可以在线升级。。功能赶超所有版本飞天侠,全网惟一一家可以更新的,几千客户体验和支持我们,谢谢大家选择我们,我们程序以优价分享,结交更多好朋友,本站开启超级群,和开放群。还有更多功能后期继续上线,后台在线升级哈
以上部份说明为转载过来,具体的请自行下载测试
下面演示图片100%为我们亲测截图
DEDE织梦采集侠v2.8破解版_无限制完整源码[已亲测]
采集交流 • 优采云 发表了文章 • 0 个评论 • 524 次浏览 • 2020-05-17 08:02
内容摘要:许多使用织梦源码的小伙伴,有时候须要一个插件来采集文章,但是采集插件是收费的,小六正在使用的是织梦采集侠,是须要收费的,不过现今看来也不需要了,因为我们有破解版的织梦采集侠v2.8破解版。好的如今我们开始破解织梦采集侠破解教程。先说明一下:织梦网站安装教程自己安装好,小六在这里只是演示破解采集侠模块。织梦采集侠V2.8...
许多使用织梦源码的小伙伴,有时候须要一个插件来采集文章,但是采集插件是收费的,小六正在使用的是织梦采集侠,是须要收费的,不过现今看来也不需要了,因为我们有破解版的织梦采集侠v2.8破解版。好的现今我们开始破解织梦采集侠破解教程。先说明一下:织梦网站安装教程自己安装好,小六在这里只是演示破解采集侠模块。
织梦采集侠V2.8教程开始:
第一步:首先下载文章附件,解压文件dede采集侠,把“采集侠官方插件.zip”也解压了吧!
第二步:打开这个采集侠网址,根据上面的视频教程把这个插件安装起来,下图就是官网教程开始的第一步,把插件安装起来。
第三步:把采集侠插件安装好了之后我们就开始我们的破解啦dede采集侠,先看一下你安装的是GBK还是UTF8,安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!安装的是UTF8的我就解压这个文件。
第四步:用FTP工具联接到你的网站,上传三个文件。三个文件的位置如下:
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
温馨提示:
1、破解程序使用对域名无限制
2、覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净
3、PHP版本必须5.3+ 查看全部

内容摘要:许多使用织梦源码的小伙伴,有时候须要一个插件来采集文章,但是采集插件是收费的,小六正在使用的是织梦采集侠,是须要收费的,不过现今看来也不需要了,因为我们有破解版的织梦采集侠v2.8破解版。好的如今我们开始破解织梦采集侠破解教程。先说明一下:织梦网站安装教程自己安装好,小六在这里只是演示破解采集侠模块。织梦采集侠V2.8...
许多使用织梦源码的小伙伴,有时候须要一个插件来采集文章,但是采集插件是收费的,小六正在使用的是织梦采集侠,是须要收费的,不过现今看来也不需要了,因为我们有破解版的织梦采集侠v2.8破解版。好的现今我们开始破解织梦采集侠破解教程。先说明一下:织梦网站安装教程自己安装好,小六在这里只是演示破解采集侠模块。
织梦采集侠V2.8教程开始:
第一步:首先下载文章附件,解压文件dede采集侠,把“采集侠官方插件.zip”也解压了吧!


第二步:打开这个采集侠网址,根据上面的视频教程把这个插件安装起来,下图就是官网教程开始的第一步,把插件安装起来。

第三步:把采集侠插件安装好了之后我们就开始我们的破解啦dede采集侠,先看一下你安装的是GBK还是UTF8,安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!安装的是UTF8的我就解压这个文件。

第四步:用FTP工具联接到你的网站,上传三个文件。三个文件的位置如下:
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下


温馨提示:
1、破解程序使用对域名无限制
2、覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净
3、PHP版本必须5.3+
DEDE织梦采集侠破解版 v2.8 完整源码无限制版
采集交流 • 优采云 发表了文章 • 0 个评论 • 530 次浏览 • 2020-05-17 08:00
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台采集侠2.8破解版下载,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
覆盖破解文件的时侯不用管这种文件。 查看全部
DEDE织梦采集侠破解版 完整源码无限制版,采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择采集侠2.8破解版下载,因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。

1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台采集侠2.8破解版下载,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
覆盖破解文件的时侯不用管这种文件。
织梦小说网站源码带采集 小说源码带会员wap站 自动采集自动更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 561 次浏览 • 2020-05-06 08:04
安装费用:(咨询特惠),(使用我们的服务器免费安装) ,自带2条采集规则!好评截图再送一条!
安装环境:PHP5.2,MYSQL,win2003 2008 32位系统!
使用我们的服务器的,我们免费帮安装百度手动推送工具(不是使用我们的服务器的,安装百度手动推送工具费用(咨询特惠))
购买服务器时请注意,如果没有服务器也可以选购我们的服务器,地址:
【重点说明1】
1、网页版采集+火车站采集
2、火车站:可以“按单本采集”,也可以“按栏目采集”!
【重点说明2】
1、会员系统
【重点说明3】
1、众所周知,织梦DEDE的文章内容是存贮在mysql数据库中的,采集内容到百万级别的时侯,数据库会特别的大,十几G甚至几十G文章网站源码带采集,这个时侯网站访问会特别的慢。
2、通过技术手段,将文章内容储存在硬碟,mysql数据库只储存链接,从而将数据库极大的压缩减少,防止后期网站因数据库过大而崩溃
3、比较一下,其它小说源码的,30G的小说内容须要数据库30G文章网站源码带采集,新版源码30G的小说内容须要数据1G,采集再多也不用害怕数据库问题!
【TXT下载功能惊艳升级】
这个源码下载功能太强悍,可以预先生成TXT、ZIP文件(非自动,是手动生成),也可以在网友点击下载的时侯才调用数据库里的内容手动生成TXT、ZIP提供下载,并且,只要有一个人下载过,另一个人再下载时都会直接调用生成好的TXT、ZIP文件下载。【独创的TXT生成功能,不用害怕多人同时下载会打垮服务器】
另外,源码支持RAR下载,但是须要自动生成RAR,如果没有生成,会手动跳转到TXT下载。
升级1,TXT文件支持背部、尾部动态添加广告功能,TXT中的广告可自定义。
升级2,ZIP文件支持打包广告文件, 将广告文件放在指定文件夹中,程序手动生成ZIP的时侯,会把那种文件夹里的所有广告文件一起打包成ZIP提供网友下载,这个广告疗效是相当好的。
升级3,自动生成二维码提供扫描下载!
黑色版 : 查看全部
懂的可以自己安装,有说明,不懂的可以请我们安装,
安装费用:(咨询特惠),(使用我们的服务器免费安装) ,自带2条采集规则!好评截图再送一条!
安装环境:PHP5.2,MYSQL,win2003 2008 32位系统!
使用我们的服务器的,我们免费帮安装百度手动推送工具(不是使用我们的服务器的,安装百度手动推送工具费用(咨询特惠))
购买服务器时请注意,如果没有服务器也可以选购我们的服务器,地址:
【重点说明1】
1、网页版采集+火车站采集
2、火车站:可以“按单本采集”,也可以“按栏目采集”!
【重点说明2】
1、会员系统
【重点说明3】
1、众所周知,织梦DEDE的文章内容是存贮在mysql数据库中的,采集内容到百万级别的时侯,数据库会特别的大,十几G甚至几十G文章网站源码带采集,这个时侯网站访问会特别的慢。
2、通过技术手段,将文章内容储存在硬碟,mysql数据库只储存链接,从而将数据库极大的压缩减少,防止后期网站因数据库过大而崩溃
3、比较一下,其它小说源码的,30G的小说内容须要数据库30G文章网站源码带采集,新版源码30G的小说内容须要数据1G,采集再多也不用害怕数据库问题!
【TXT下载功能惊艳升级】
这个源码下载功能太强悍,可以预先生成TXT、ZIP文件(非自动,是手动生成),也可以在网友点击下载的时侯才调用数据库里的内容手动生成TXT、ZIP提供下载,并且,只要有一个人下载过,另一个人再下载时都会直接调用生成好的TXT、ZIP文件下载。【独创的TXT生成功能,不用害怕多人同时下载会打垮服务器】
另外,源码支持RAR下载,但是须要自动生成RAR,如果没有生成,会手动跳转到TXT下载。
升级1,TXT文件支持背部、尾部动态添加广告功能,TXT中的广告可自定义。
升级2,ZIP文件支持打包广告文件, 将广告文件放在指定文件夹中,程序手动生成ZIP的时侯,会把那种文件夹里的所有广告文件一起打包成ZIP提供网友下载,这个广告疗效是相当好的。
升级3,自动生成二维码提供扫描下载!
黑色版 :
DEDE织梦采集侠破解版(无限制完整源码) 2.8 最新版
采集交流 • 优采云 发表了文章 • 0 个评论 • 480 次浏览 • 2020-04-13 11:08
99下载网提供搜索引擎笔记本软件织梦采集侠2.8破解版下载,织梦采集侠2.8破解版文件大小为355 KB,欢迎来99软件下载DEDE织梦采集侠破解版(无限制完整源码) 2.8 最新版,本站所有软件都免费下载。
DEDE织梦采集侠破解版是一款必备全手动采集伪原创SEO插件,新云网提供其专业破解版本的下载。采集侠正文辨识技术是采集侠多年的技术积累,自主研制了一套汉字剖析和处理的核心系统,目前该系统辨识精度处于领先水平,即便和强悍的搜索引擎中的文字剖析能力也有得一比,优于有道紧跟百度。采集侠正是基于该核心技术研制的一个卓越的采集软件,我们更懂得百度。
织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的织梦采集侠2.8破解版,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台织梦采集侠2.8破解版,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
采集侠定向规则采集教程请参照其官网: 查看全部

99下载网提供搜索引擎笔记本软件织梦采集侠2.8破解版下载,织梦采集侠2.8破解版文件大小为355 KB,欢迎来99软件下载DEDE织梦采集侠破解版(无限制完整源码) 2.8 最新版,本站所有软件都免费下载。
DEDE织梦采集侠破解版是一款必备全手动采集伪原创SEO插件,新云网提供其专业破解版本的下载。采集侠正文辨识技术是采集侠多年的技术积累,自主研制了一套汉字剖析和处理的核心系统,目前该系统辨识精度处于领先水平,即便和强悍的搜索引擎中的文字剖析能力也有得一比,优于有道紧跟百度。采集侠正是基于该核心技术研制的一个卓越的采集软件,我们更懂得百度。
织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的织梦采集侠2.8破解版,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台织梦采集侠2.8破解版,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
采集侠定向规则采集教程请参照其官网:
织梦cms资源教程网源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-04-08 11:07
本次为你们带来最新织梦cms资源教程网源码,这是一款自适应性源码,会依照不同的环境进行智能更改以适应相关的采集搭建需求。织梦cms源码特性就是愈发灵活,非常适宜进行一些网站扩展操作。有相关资源教程网搭建需求的朋友们不妨试试吧!
良好的用户口碑
丰富的开源经验
灵活的模块组合
让网站更丰富、方便网站扩展
简单易用的模板引擎
让界面想怎样换就如何换
便捷自定义模型
自己扩充网站后续功能,省去众多苦恼
php版本5.6以上,MySQL5.6以上
上传源码至根目录后解压,域名+install/index.php进行安装,安装完后步入后台登陆
登录后到系统设置中的数据库备份/还原中点击右上角的数据还原即可,后台默认帐户密码为admin admin
PC官方版
安卓官方手机版
IOS官方手机版
vs2010英文旗舰版是一个集成环境,它简化了有关创建、调试和布署应用程序的基本任务。借助于 Visual Studio 2010 专业版,您可以恣意发挥您的想象力并轻松实现您的目标。借助于功能强悍的设计图面和使得设计人员和开发人员协同工作的能力,尽情发挥您的创造力,让您的梦想成真。在一个面向日渐增多的平台(包括 Silverlight、SharePoint 和云应用程序)的个性化环境中工作,使用现有技术推动编码过程。对测试先行的开发的集成支持和新的调试工具可使您快速查找和修补所有 bug,并有助于确保实现高质量解决方案。
Windows 7; Windows Server 2003 R2 (32-Bit x86); Windows Server 2003 R2 x64 editions; Windows Server 2003 Service Pack 2; Windows Server 2008 R2; Windows Server 2008 Service Pack 2; Windows Vista Service Pack 2; Windows XP Service Pack 3
Windows XP (x86) Service Pack 3 – 除 Starter Edition 之外的所有版本
Windows Vista(x86 和 x64)Service Pack 2 - 除 Starter Edition 之外的所有版本
Windows 7(x86 和 x64)
Windows Server 2003(x86 和 x64)Service Pack 2 – 所有版本
如果不存在 MSXML6,则用户须要安装它
Windows Server 2003 R2(x86 和 x64)- 所有版本
Windows Server 2008(x86 和 x64)Service Pack 2 – 所有版本
Windows Server 2008 R2 (x64) – 所有版本
它将是精典的一个版本,相当于当初的6.0版。
新功能还包括:
(1)C# 4.0中的动态类型和动态编程;
(2)多显示器支持;
(3)使用Visual Studio 2010的特点支持TDD;
(4)支持Office ;
(5)Quick Search特点;
(6)C++ 0x新特点;
(7)IDE提高;
(8)使用Visual C++ 2010创建Ribbon界面;
(9)新增基于.NET平台的语言
而按照谷歌发布的一份官方文档声称,Visual Studio 2010和.NET Framework 4.0将在下边五个方面有所创新: ·民主化的应用程序生命周期管理 在一个组织中,应用程序生命周期管理(ALM)将涉入到多个角色。但是在传统意义上,这一过程中的每位角色并不是完全平等的。Visual Studio Team System 2010将坚持构筑一个功能平等、共同分担的平台以用于组织内的应用程序生命周期管理过程。 ·顺应新的技术时尚 每年,业界内的新技术和新趋势层出不穷。通过Visual Studio 2010,微软将为开发者提供合适的工具和框架,以支持软件开发中最新的构架,开发和布署。 ·让开发商惊喜 从Visual Studio的第一个版本开始,微软就将提升开发人员的工作效率和灵活性作为自己的目标。Visual Studio 2010将继续关注而且明显地改进开发者最核心的开发体验。 ·下一代平台浪潮的弄潮儿 微软将继续投资于市场领先的操作系统,工具软件和服务器平台,为顾客创造更高的价值。使用Visual Studio 2010,将可以在新一代的应用平台上,为你的顾客创造令人惊奇的解决方案。 · 跨部门的应用 客户将在不同规模的组织内创建应用,跨度从单个部门到整个企业。
Visual Studio 2010将确保在如此笼统的范围内的应用开发都得到支持。
创建第一个C项目
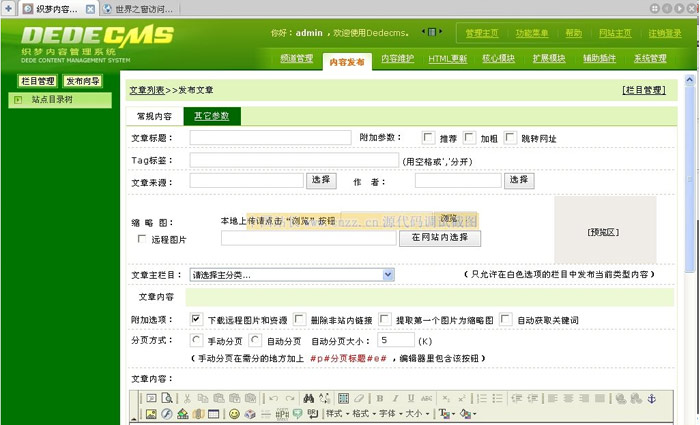
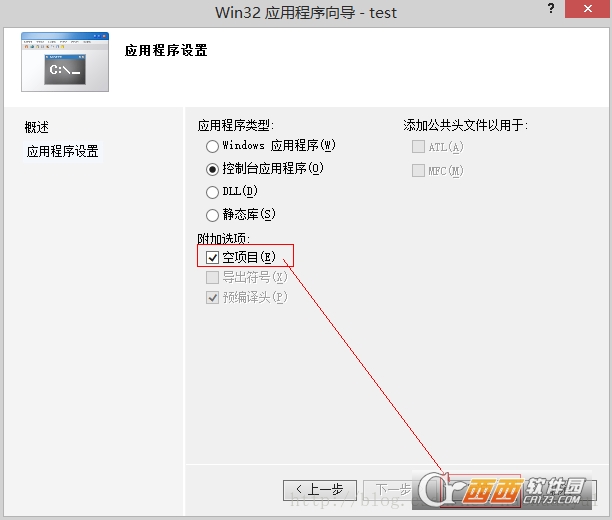
运行vs10,点击【新建项目】,弹出如下新建项目框,选择【Visual c++】—>【win32控制台应用程序】,输入项目名称和位置,也可选择默认,然后单击【确定】。
弹出如下应用程序向导框,单击【下一步】
选择【空项目】,单击【完成】
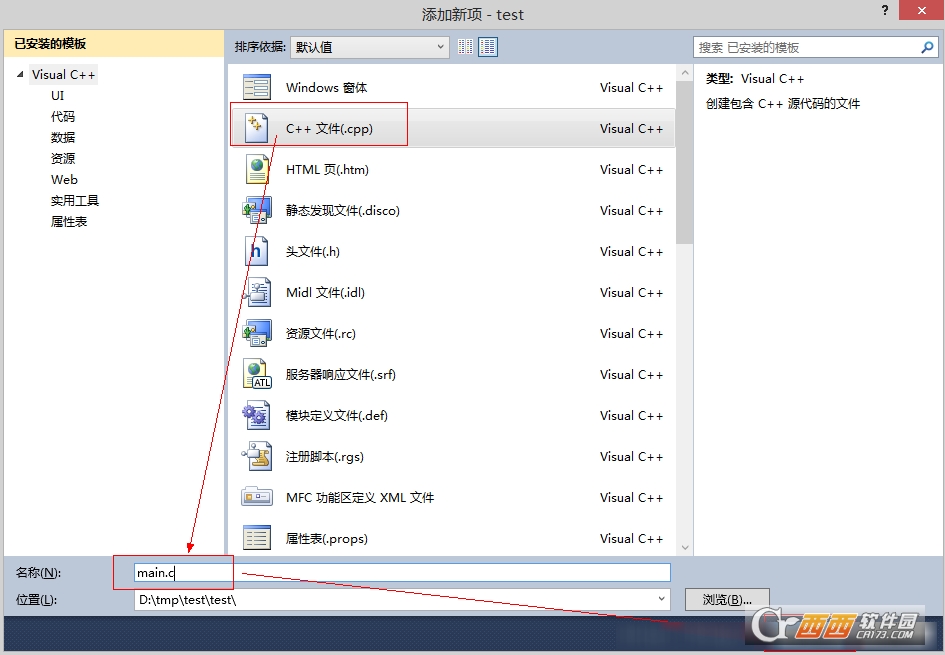
然后织梦cms相关学习技术资料免费下载,在项目右侧栏就可以看见刚刚新建的项目了(本人创建的是test),然后,右键【源文件】—>【添加】—>【新建项】,如下:
然后,弹出如下添加新项框,选择【c++文件】,输入文件名称,点击【添加】即可。
此时,在两侧源文件下就可以看见新建的文件了,如本人创建的main.c文件,然后输入程序,按【Ctrl+F5】运行即可,示例如下:
按【F5】表示调试。
PC官方版
安卓官方手机版
IOS官方手机版
Visual Studio Community 2015是免费的,具备所有为Windows、iOS、Android设备或是云服务器开发桌面、移动、网页应用的全套功能。这个版本针对小公司、初创企业、学生和开源软件开发者们,开发的非企业级软件。它提供了一个统一的客户端和服务器开发的平台,支持联通跨平台开发,可扩充,编程功能先进、高效。
VS2015版本针对多个平台添加了新的开发工具,支持开发Win10全平台通用应用程序,包括Windows10手机、Win10 PC、Xbox以及HoloLens提高现实等。另外,通过VS2015,开发人员还可以使用Apache Cordova、Xamarin或C++等语言或技术开发iOS和安卓平台应用。针对WEB和服务器开发,你可以使用Python、Node.js技术以及C#,Visual Basic或F#语言。
Visual Studio 2015明天如期放出了即将版本。Visual Studio 2015包括许多新功能和更新,如通用Windows应用开发工具、面向iOS、Android、Windows的跨平台联通开发工具(包括Xamarin、Apache Cordova、Unity)、可移植C++库、适用于Android的本机活动C++模板等等,对Cordova,Xamarin , C++的跨平台支持都非常好。让你通过一个工具完成了iOS ,Android ,Windows 三个平台的应用,绝对是Windows 10乃至跨平台开发的首选神器。
跨平台支持成为VS2015最新DNA。在智能移动端App开发,支持无论是面向何种智能设备,无论是支持Native应用,还是基于HTML5的混和应用,都可以利用VS2015的编码、调试,智能提示等强悍功能帮助程序员快速开发。特别是Xamarin的安装包早已集成进VS2015,Visual Studio还可以进行Apple Watch的应用开发哦!
此番发布的Visual Studio 2015正式版包含32/64位的安装镜像和相关工具,标准版、企业版、专业版、测试专业版、精简版等各个版本都有,支持繁体英文等多国语言,MSDN开发者如今就可以下载使用了。
与此同时,Visual Studio 2013 Update 5、.NET Framework 4.6正式版也早已发布,不过Team Foundation Server 2015暂未放出,只给了一个Team Foundation Server 2013 Update 5。
整个Visual Studio 2015 是包括Visual Studio、Visual Studio Online、Visual Studio Code。Visual Studio Online 提供完整的,轻量级别的,基于微软云平台的,软件全生命周期支持,Online版本和TFS2015为开发团队提供基于DevOps理念的完整解决方案。帮助开发者完成应用的管理、工作、开发、联调、测试和发布全生命周期工作,并提供高效工具完成应用使用状况和使用情况的监控。
Visual Code提供第一个来自谷歌的跨平台开发工具,支持开发人员在windows、linux、Mac上都可以开发ASP.NET或则NodeJS的应用。
Visual Studio Community 2013– 新的、免费的、全功能版本的 Visual Studio,可以拿来开发桌面、移动、Web 和云应用织梦cms相关学习技术资料免费下载,只容许开发非企业应用的。
Visual Studio 2015 预览版和 .NET 2015 预览版– Visual Studio 2015 支持 Windows、iOS 和 Android 等应用的跨平台开发,内置 Apache Cordova 支持。微软和 Xamarin 宣布简化在 Visual Studio 中安装 Xamarin 的流程,并宣布将于明年年末发布的免费版 Xamarin Starter Edition 中降低对 Visual Studio 的支持。 查看全部
本次为你们带来最新织梦cms资源教程网源码,这是一款自适应性源码,会依照不同的环境进行智能更改以适应相关的采集搭建需求。织梦cms源码特性就是愈发灵活,非常适宜进行一些网站扩展操作。有相关资源教程网搭建需求的朋友们不妨试试吧!

良好的用户口碑
丰富的开源经验
灵活的模块组合
让网站更丰富、方便网站扩展
简单易用的模板引擎
让界面想怎样换就如何换
便捷自定义模型
自己扩充网站后续功能,省去众多苦恼
php版本5.6以上,MySQL5.6以上
上传源码至根目录后解压,域名+install/index.php进行安装,安装完后步入后台登陆
登录后到系统设置中的数据库备份/还原中点击右上角的数据还原即可,后台默认帐户密码为admin admin
PC官方版
安卓官方手机版
IOS官方手机版
vs2010英文旗舰版是一个集成环境,它简化了有关创建、调试和布署应用程序的基本任务。借助于 Visual Studio 2010 专业版,您可以恣意发挥您的想象力并轻松实现您的目标。借助于功能强悍的设计图面和使得设计人员和开发人员协同工作的能力,尽情发挥您的创造力,让您的梦想成真。在一个面向日渐增多的平台(包括 Silverlight、SharePoint 和云应用程序)的个性化环境中工作,使用现有技术推动编码过程。对测试先行的开发的集成支持和新的调试工具可使您快速查找和修补所有 bug,并有助于确保实现高质量解决方案。
Windows 7; Windows Server 2003 R2 (32-Bit x86); Windows Server 2003 R2 x64 editions; Windows Server 2003 Service Pack 2; Windows Server 2008 R2; Windows Server 2008 Service Pack 2; Windows Vista Service Pack 2; Windows XP Service Pack 3
Windows XP (x86) Service Pack 3 – 除 Starter Edition 之外的所有版本
Windows Vista(x86 和 x64)Service Pack 2 - 除 Starter Edition 之外的所有版本
Windows 7(x86 和 x64)
Windows Server 2003(x86 和 x64)Service Pack 2 – 所有版本
如果不存在 MSXML6,则用户须要安装它
Windows Server 2003 R2(x86 和 x64)- 所有版本
Windows Server 2008(x86 和 x64)Service Pack 2 – 所有版本
Windows Server 2008 R2 (x64) – 所有版本
它将是精典的一个版本,相当于当初的6.0版。
新功能还包括:
(1)C# 4.0中的动态类型和动态编程;
(2)多显示器支持;
(3)使用Visual Studio 2010的特点支持TDD;
(4)支持Office ;
(5)Quick Search特点;
(6)C++ 0x新特点;
(7)IDE提高;
(8)使用Visual C++ 2010创建Ribbon界面;
(9)新增基于.NET平台的语言
而按照谷歌发布的一份官方文档声称,Visual Studio 2010和.NET Framework 4.0将在下边五个方面有所创新: ·民主化的应用程序生命周期管理 在一个组织中,应用程序生命周期管理(ALM)将涉入到多个角色。但是在传统意义上,这一过程中的每位角色并不是完全平等的。Visual Studio Team System 2010将坚持构筑一个功能平等、共同分担的平台以用于组织内的应用程序生命周期管理过程。 ·顺应新的技术时尚 每年,业界内的新技术和新趋势层出不穷。通过Visual Studio 2010,微软将为开发者提供合适的工具和框架,以支持软件开发中最新的构架,开发和布署。 ·让开发商惊喜 从Visual Studio的第一个版本开始,微软就将提升开发人员的工作效率和灵活性作为自己的目标。Visual Studio 2010将继续关注而且明显地改进开发者最核心的开发体验。 ·下一代平台浪潮的弄潮儿 微软将继续投资于市场领先的操作系统,工具软件和服务器平台,为顾客创造更高的价值。使用Visual Studio 2010,将可以在新一代的应用平台上,为你的顾客创造令人惊奇的解决方案。 · 跨部门的应用 客户将在不同规模的组织内创建应用,跨度从单个部门到整个企业。
Visual Studio 2010将确保在如此笼统的范围内的应用开发都得到支持。
创建第一个C项目
运行vs10,点击【新建项目】,弹出如下新建项目框,选择【Visual c++】—>【win32控制台应用程序】,输入项目名称和位置,也可选择默认,然后单击【确定】。

弹出如下应用程序向导框,单击【下一步】

选择【空项目】,单击【完成】
然后织梦cms相关学习技术资料免费下载,在项目右侧栏就可以看见刚刚新建的项目了(本人创建的是test),然后,右键【源文件】—>【添加】—>【新建项】,如下:

然后,弹出如下添加新项框,选择【c++文件】,输入文件名称,点击【添加】即可。
此时,在两侧源文件下就可以看见新建的文件了,如本人创建的main.c文件,然后输入程序,按【Ctrl+F5】运行即可,示例如下:

按【F5】表示调试。
PC官方版
安卓官方手机版
IOS官方手机版
Visual Studio Community 2015是免费的,具备所有为Windows、iOS、Android设备或是云服务器开发桌面、移动、网页应用的全套功能。这个版本针对小公司、初创企业、学生和开源软件开发者们,开发的非企业级软件。它提供了一个统一的客户端和服务器开发的平台,支持联通跨平台开发,可扩充,编程功能先进、高效。
VS2015版本针对多个平台添加了新的开发工具,支持开发Win10全平台通用应用程序,包括Windows10手机、Win10 PC、Xbox以及HoloLens提高现实等。另外,通过VS2015,开发人员还可以使用Apache Cordova、Xamarin或C++等语言或技术开发iOS和安卓平台应用。针对WEB和服务器开发,你可以使用Python、Node.js技术以及C#,Visual Basic或F#语言。
Visual Studio 2015明天如期放出了即将版本。Visual Studio 2015包括许多新功能和更新,如通用Windows应用开发工具、面向iOS、Android、Windows的跨平台联通开发工具(包括Xamarin、Apache Cordova、Unity)、可移植C++库、适用于Android的本机活动C++模板等等,对Cordova,Xamarin , C++的跨平台支持都非常好。让你通过一个工具完成了iOS ,Android ,Windows 三个平台的应用,绝对是Windows 10乃至跨平台开发的首选神器。
跨平台支持成为VS2015最新DNA。在智能移动端App开发,支持无论是面向何种智能设备,无论是支持Native应用,还是基于HTML5的混和应用,都可以利用VS2015的编码、调试,智能提示等强悍功能帮助程序员快速开发。特别是Xamarin的安装包早已集成进VS2015,Visual Studio还可以进行Apple Watch的应用开发哦!
此番发布的Visual Studio 2015正式版包含32/64位的安装镜像和相关工具,标准版、企业版、专业版、测试专业版、精简版等各个版本都有,支持繁体英文等多国语言,MSDN开发者如今就可以下载使用了。
与此同时,Visual Studio 2013 Update 5、.NET Framework 4.6正式版也早已发布,不过Team Foundation Server 2015暂未放出,只给了一个Team Foundation Server 2013 Update 5。
整个Visual Studio 2015 是包括Visual Studio、Visual Studio Online、Visual Studio Code。Visual Studio Online 提供完整的,轻量级别的,基于微软云平台的,软件全生命周期支持,Online版本和TFS2015为开发团队提供基于DevOps理念的完整解决方案。帮助开发者完成应用的管理、工作、开发、联调、测试和发布全生命周期工作,并提供高效工具完成应用使用状况和使用情况的监控。
Visual Code提供第一个来自谷歌的跨平台开发工具,支持开发人员在windows、linux、Mac上都可以开发ASP.NET或则NodeJS的应用。

Visual Studio Community 2013– 新的、免费的、全功能版本的 Visual Studio,可以拿来开发桌面、移动、Web 和云应用织梦cms相关学习技术资料免费下载,只容许开发非企业应用的。
Visual Studio 2015 预览版和 .NET 2015 预览版– Visual Studio 2015 支持 Windows、iOS 和 Android 等应用的跨平台开发,内置 Apache Cordova 支持。微软和 Xamarin 宣布简化在 Visual Studio 中安装 Xamarin 的流程,并宣布将于明年年末发布的免费版 Xamarin Starter Edition 中降低对 Visual Studio 的支持。
HTML5响应式红色商务企业dedecms整站源码(支持移动端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-04-08 11:01
蓝色高档商务网路公司整站源码是以织梦内核为网站操作系统的企业模板
页面风格扁平大气,整站主色采用红色,黑色进行搭配,首页的内容设计布局并没用采用那个大量留白的设计风格愈发养眼用户视觉体验疗效棒。
内容相对比较紧凑,更适宜中小型公司企业站使用。当然,这既然是一套高档模板高端响应式网络公司织梦整站源码,那肯定是采用了响应式的设计,
在任何浏览器设备下都可完美呈现,所以也可通用于大多数企业站,如:电子商务公司,外贸企业,网络工作室,等等。
★模板安装方式★
1.把文件上传到你的站点的根目录,然后运行 你的域名/install/index.php 安装,根据提示填写好相关信息,点“下一步”...即可完成安装。
注:若提示难以安装,页面出现DIY字样。请步入install文件夹,将install_lock.txt文件删除。把index.php.bak文件改为index.php即可!
2.安装好后,在后台“系统”—“数据库备份/恢复”,点右上角“还原数据”—“开始还原数据”,恢复数据库。
3.进入后台你的域名/dede,点“系统”—“系统参数设置”这里,修改一下网站设置高端响应式网络公司织梦整站源码,重新点一下“确定”(没有这一步,有时候会导致更新后,前台显示织梦默认模板内容)。
4.后台,点"生成"—"更新系统缓存"
5.后台,点“生成” - “一键更新网站” - “更新所有”,重新生成一次所有页面,OK 完成。
后台地址:你的域名/dede
管理员帐号:admin
管理员密码:admin
如果安装后出现网站错位和无数据的情况,请复查以下三点设置
一. 网站程序必须置于根目录
二. 进入后台[系统]-[系统基本参数],修改“站点根网址”为你的网址,或者留空。
三. 进入后台[核心]-[网站栏目管理],点击顶部按键中的“更新排序”。
至此,模板安装结束 查看全部
蓝色高档商务网路公司整站源码是以织梦内核为网站操作系统的企业模板
页面风格扁平大气,整站主色采用红色,黑色进行搭配,首页的内容设计布局并没用采用那个大量留白的设计风格愈发养眼用户视觉体验疗效棒。
内容相对比较紧凑,更适宜中小型公司企业站使用。当然,这既然是一套高档模板高端响应式网络公司织梦整站源码,那肯定是采用了响应式的设计,
在任何浏览器设备下都可完美呈现,所以也可通用于大多数企业站,如:电子商务公司,外贸企业,网络工作室,等等。
★模板安装方式★
1.把文件上传到你的站点的根目录,然后运行 你的域名/install/index.php 安装,根据提示填写好相关信息,点“下一步”...即可完成安装。
注:若提示难以安装,页面出现DIY字样。请步入install文件夹,将install_lock.txt文件删除。把index.php.bak文件改为index.php即可!
2.安装好后,在后台“系统”—“数据库备份/恢复”,点右上角“还原数据”—“开始还原数据”,恢复数据库。
3.进入后台你的域名/dede,点“系统”—“系统参数设置”这里,修改一下网站设置高端响应式网络公司织梦整站源码,重新点一下“确定”(没有这一步,有时候会导致更新后,前台显示织梦默认模板内容)。
4.后台,点"生成"—"更新系统缓存"
5.后台,点“生成” - “一键更新网站” - “更新所有”,重新生成一次所有页面,OK 完成。
后台地址:你的域名/dede
管理员帐号:admin
管理员密码:admin
如果安装后出现网站错位和无数据的情况,请复查以下三点设置
一. 网站程序必须置于根目录
二. 进入后台[系统]-[系统基本参数],修改“站点根网址”为你的网址,或者留空。
三. 进入后台[核心]-[网站栏目管理],点击顶部按键中的“更新排序”。
至此,模板安装结束
免费网站织梦源码 织梦cms 织梦模板下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2020-04-07 11:01
模板建站的优势和劣势
优势1、建站便捷:企业网站模板,一般是建站公司通过剖析市场和行业的需求而做下来的企业网站模板,用户订购模版后通过套用CMS等自助建站系统,再添加、丰富网站内容后完成企业建站。
优势2、有行业特点:每一个企业模板的制做都是经过市场调查,分析行业特点、用户体验以及使用者的综合需求而确定模板的制做,这类企业模板有着一定的专业性和相关性。
优势3、一般价钱实惠:企业网站模板在制做以后可以进行批量的推出,总成本要比订制一个网站低上许多。
如何正确选择建站模板
无论是免费模板还是付费模板,它的制做成本低,不排除在这个行业中的企业仅仅是借助模板来挣钱,他们并不对模板的质量进行负责和保障,甚至有些企业网站模板是经过多手订购,加以更改和出售的,在你使用模板之前一定要注意以下几点:
1、当你使用某个建站平台的网站模板进行建站的时侯,不要被此网站上漂亮的图文广告,营销手段所愚弄。应先进行考察,尤其是可以瞧瞧她们的案例库,看看实际用户做下来的疗效。
2、选择一个自定义强悍的模板,特别是可以控制网站上模块的输出,这样可以避免重复性代码输出,通过调整模块位置,和自定义输出的模块,达到奇特的显示疗效,从而就能最大程度丰富网站显示的方法,从而给用户一个好的印象。而后端的代码也会显示的完全不一样,给搜索引擎的印象也是好的。
3、在订购模板之前对行业所能提供的服务进行咨询,以免引起出现问题时无人问津的结果,甚至有些应用插件也有二次付费的情况。
4、对程序代码要有一定的了解,尤其是在想要搭建一个须要做优化的网站的时侯,应该选择符合优化规则的模板。
一般象织梦模板之家这样的自助建站平台,其模板仍然在不断更新,同时模板和功能是一体的,可以直接调用,而且模板本身根本就无需下载,直接可以使用。对于中小微企业和创业团队而言,选择织梦模板之家这样的建站平台,是性价比和安全上都不错的。
作为拥有国外HTML5模板库的建站工具织梦cms模板下载,织梦模板之家拥有上千套多种专业设计的HTML5模板织梦cms模板下载,20多种不同行业的模板库,方便顾客快速选择自己所需类型。
总结:
如果我们对网站建设的页面、功能要求较高,而且自身有相关的建站知识,还能接受订制价位的人群可以选择订制建站。如果我们只是须要一个标准化的企业网站,对企业建站也不是太了解,那么就可以选择企业模板建站。只要在确定模板之前,选出一套适宜的建站系统,并查看建站系统的后台布局、功能以及管理方法等,综合考虑后选择一套适宜企业网站需求的模板。 查看全部
模板建站的优势和劣势
优势1、建站便捷:企业网站模板,一般是建站公司通过剖析市场和行业的需求而做下来的企业网站模板,用户订购模版后通过套用CMS等自助建站系统,再添加、丰富网站内容后完成企业建站。
优势2、有行业特点:每一个企业模板的制做都是经过市场调查,分析行业特点、用户体验以及使用者的综合需求而确定模板的制做,这类企业模板有着一定的专业性和相关性。
优势3、一般价钱实惠:企业网站模板在制做以后可以进行批量的推出,总成本要比订制一个网站低上许多。
如何正确选择建站模板
无论是免费模板还是付费模板,它的制做成本低,不排除在这个行业中的企业仅仅是借助模板来挣钱,他们并不对模板的质量进行负责和保障,甚至有些企业网站模板是经过多手订购,加以更改和出售的,在你使用模板之前一定要注意以下几点:
1、当你使用某个建站平台的网站模板进行建站的时侯,不要被此网站上漂亮的图文广告,营销手段所愚弄。应先进行考察,尤其是可以瞧瞧她们的案例库,看看实际用户做下来的疗效。
2、选择一个自定义强悍的模板,特别是可以控制网站上模块的输出,这样可以避免重复性代码输出,通过调整模块位置,和自定义输出的模块,达到奇特的显示疗效,从而就能最大程度丰富网站显示的方法,从而给用户一个好的印象。而后端的代码也会显示的完全不一样,给搜索引擎的印象也是好的。
3、在订购模板之前对行业所能提供的服务进行咨询,以免引起出现问题时无人问津的结果,甚至有些应用插件也有二次付费的情况。
4、对程序代码要有一定的了解,尤其是在想要搭建一个须要做优化的网站的时侯,应该选择符合优化规则的模板。
一般象织梦模板之家这样的自助建站平台,其模板仍然在不断更新,同时模板和功能是一体的,可以直接调用,而且模板本身根本就无需下载,直接可以使用。对于中小微企业和创业团队而言,选择织梦模板之家这样的建站平台,是性价比和安全上都不错的。
作为拥有国外HTML5模板库的建站工具织梦cms模板下载,织梦模板之家拥有上千套多种专业设计的HTML5模板织梦cms模板下载,20多种不同行业的模板库,方便顾客快速选择自己所需类型。
总结:
如果我们对网站建设的页面、功能要求较高,而且自身有相关的建站知识,还能接受订制价位的人群可以选择订制建站。如果我们只是须要一个标准化的企业网站,对企业建站也不是太了解,那么就可以选择企业模板建站。只要在确定模板之前,选出一套适宜的建站系统,并查看建站系统的后台布局、功能以及管理方法等,综合考虑后选择一套适宜企业网站需求的模板。
DEDE织梦采集侠破解版(无限制完整源码) 2.8 最新版 (图文)
站长必读 • 优采云 发表了文章 • 0 个评论 • 518 次浏览 • 2020-07-21 08:02
织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8织梦采集侠2.92破解版,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器织梦采集侠2.92破解版,清理缓存有时清的不干净】
6, PHP版本必须5.3+ 查看全部
DEDE织梦采集侠破解版是一款必备全手动采集伪原创SEO插件,新云网提供其专业破解版本的下载。采集侠正文辨识技术是采集侠多年的技术积累,自主研制了一套汉字剖析和处理的核心系统,目前该系统辨识精度处于领先水平,即便和强悍的搜索引擎中的文字剖析能力也有得一比,优于有道紧跟百度。采集侠正是基于该核心技术研制的一个卓越的采集软件,我们更懂得百度。
织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8织梦采集侠2.92破解版,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器织梦采集侠2.92破解版,清理缓存有时清的不干净】
6, PHP版本必须5.3+
帝国cms7.2仿九库小说手动采集源码+wap与app(修复版)
站长必读 • 优采云 发表了文章 • 0 个评论 • 783 次浏览 • 2020-07-19 08:02
8.排行榜,站内聊天体系和签到送积分
9.优采云采集,自动采集其他站,伪原创,也可以做盗版小说站
10.txt 下载功能帝国cms自动采集发布,自动生成章节下载,自动判定更新,自动添加文本广告
11.程序有伪静态规则,可以不用静态页面,下载手动生成 txt 和看书弹幕疗效
12.本程序含安卓app开源包,开源包我使会安卓的同学帮忙测试了一下,只须要自己对接插口即可使用!功能并不是太建立,只有正常阅读一些功能。
安装说明
将网站解压到更目录浏览域名/beifen/
账号admin 密码admin888 验证码admin888
进入后配置数据库帐号和密码,然后步入数据还原操作,还原到你须要的那种数据库
然后更改e/config/config.php上面的数据库帐号和密码还有数据库名子
手机版类似
然后直接打开网站域名/e/admin/
账号admin 密码123456
进入后台,点刷新,从数据缓存到首页更新,从右想左,从上到下帝国cms自动采集发布,全部刷新一次
手机版必须绑定域名,不然图片路径和qq登陆都不行,公用一个数据库把域名解析到m文件夹下就好了
后台帐号admin密码 123456
可以在pc后台更改wap模板,点击模板-切换wap即可
前台演示帐号admin 密码123456
手机版qq登陆工用pc的要配置cookie作用域,可以百度,我回头讲到博客上,
采集不要随便采集,如果采集请记住更改成是前台投稿的,这样后期做原创不会出现干扰,在表里有一个数组,修改即可
下方为图片展示
查看全部
8.排行榜,站内聊天体系和签到送积分
9.优采云采集,自动采集其他站,伪原创,也可以做盗版小说站
10.txt 下载功能帝国cms自动采集发布,自动生成章节下载,自动判定更新,自动添加文本广告
11.程序有伪静态规则,可以不用静态页面,下载手动生成 txt 和看书弹幕疗效
12.本程序含安卓app开源包,开源包我使会安卓的同学帮忙测试了一下,只须要自己对接插口即可使用!功能并不是太建立,只有正常阅读一些功能。
安装说明
将网站解压到更目录浏览域名/beifen/
账号admin 密码admin888 验证码admin888
进入后配置数据库帐号和密码,然后步入数据还原操作,还原到你须要的那种数据库
然后更改e/config/config.php上面的数据库帐号和密码还有数据库名子
手机版类似
然后直接打开网站域名/e/admin/
账号admin 密码123456
进入后台,点刷新,从数据缓存到首页更新,从右想左,从上到下帝国cms自动采集发布,全部刷新一次
手机版必须绑定域名,不然图片路径和qq登陆都不行,公用一个数据库把域名解析到m文件夹下就好了
后台帐号admin密码 123456
可以在pc后台更改wap模板,点击模板-切换wap即可
前台演示帐号admin 密码123456
手机版qq登陆工用pc的要配置cookie作用域,可以百度,我回头讲到博客上,
采集不要随便采集,如果采集请记住更改成是前台投稿的,这样后期做原创不会出现干扰,在表里有一个数组,修改即可
下方为图片展示
dedecms内核小说阅读网模板-小说流量站-小说源码带整站数据
站长必读 • 优采云 发表了文章 • 0 个评论 • 328 次浏览 • 2020-07-19 08:01
配合织梦采集侠采集一下,不过本人我不推荐采集,采集的重复率高百度不会收录太多,只会对自己的站点导致不好的影响,有站长说我伪原创,伪原创通常都是搅乱排序和增减关键词或则替换关键词为主,一点疗效没有,反而打破了小说站点的可读性,我建议喜欢小说的顾客可以拿来做一下原创,推荐出去以后只要渐渐有流量了,坚持出来还是十分不错的,小说站靠文字的积累,耐心的沉淀!
★模板安装说明★
空间必须支持php+mysql
1、将程序上传到网站根目录
2、运行 你的域名/install/ 按提示安装程序(请不要更改数据表前缀)
3、登录后台 你的域名/dede/
4、点击“系统”——“数据库备份/还原”——“数据还原”织梦小说源码带采集,完成还原数据
备注:数据库自带4万条小说数据,因备份文件有点大,所以传到云盘供你们下载。下载以后将backupdata文件夹复制到data目录覆盖即可。
5、点击“系统”——“系统基本参数”,设置网站基本信息
6、点击“生成”——“一键更新网站”——“更新所有”,开始更新
7、基本完成
后台管理地址/dede,管理账号和密码都是:admin。
备份文件云盘下载地址见压缩文件。 查看全部
设计美工很不错的小说流量站,宽屏织梦小说源码带采集,做广告联盟精品程序,dedecms-UTF8最新版本,非常漂亮的小说源码,简洁大气,自带5W条数据,dedecms-UTF8最新版本静态容易收录,测试无任何错误,安装即可使用!
配合织梦采集侠采集一下,不过本人我不推荐采集,采集的重复率高百度不会收录太多,只会对自己的站点导致不好的影响,有站长说我伪原创,伪原创通常都是搅乱排序和增减关键词或则替换关键词为主,一点疗效没有,反而打破了小说站点的可读性,我建议喜欢小说的顾客可以拿来做一下原创,推荐出去以后只要渐渐有流量了,坚持出来还是十分不错的,小说站靠文字的积累,耐心的沉淀!
★模板安装说明★
空间必须支持php+mysql
1、将程序上传到网站根目录
2、运行 你的域名/install/ 按提示安装程序(请不要更改数据表前缀)
3、登录后台 你的域名/dede/
4、点击“系统”——“数据库备份/还原”——“数据还原”织梦小说源码带采集,完成还原数据
备注:数据库自带4万条小说数据,因备份文件有点大,所以传到云盘供你们下载。下载以后将backupdata文件夹复制到data目录覆盖即可。
5、点击“系统”——“系统基本参数”,设置网站基本信息
6、点击“生成”——“一键更新网站”——“更新所有”,开始更新
7、基本完成
后台管理地址/dede,管理账号和密码都是:admin。
备份文件云盘下载地址见压缩文件。
ptcms精美小说阅读网站源码(带采集规则)
站长必读 • 优采云 发表了文章 • 0 个评论 • 482 次浏览 • 2020-07-17 08:02
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家()文章网站源码带采集,是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载文章网站源码带采集,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:) 查看全部
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家()文章网站源码带采集,是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
网站地图
在线客服
站码之家(),是一家网站源码、风格模版、教程资源、 网站! 运营维护技术等于一体的交流分享网站,全站95%的资源都是免费下载文章网站源码带采集,对于资源我们是每晚更新,每个亲测资源最新最全-(如果我们有侵害了您权益的资源请联系我们删掉QQ邮箱:)
天人文章管理系统Asp网站源码(带手机版)v5.33UTF8
站长必读 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2020-07-14 08:01
16、系统支持文章投稿,会员可在个人中心进行投稿,并获得管理员设定的积分。
17、多种形式的互动功能,例如会员签到、会员投稿、游客留言、游客评论等功能。
天人文章管理系统特色功能介绍: 1、按钮功能:
按钮颜色分为两种,一种是红色,一种是蓝色。蓝色按键是添加、修改之类较为安全,不会导致数据遗失的功能。红色按键是删掉、恢复之类若误操作会导致数据遗失的功能,故按键使用颜色分辨及配合对话框提示会最大程度保证操作准确性。
2、单行文本框:
当填写完表单时,将光标定位在单行文本框中敲打回车键,可取代点击递交表单按键的功能。此功能可便捷用户快速递交表单。
3、复选框与单选框:
在选中复选框或单选框时,为了降低键盘点选的方便性,点击其旁边的文字同样还能起到选择复选框或单选框的作用。
4、弹窗对话框:
弹窗对话框是系统对管理员作出操作的回应,通常情况下可点击弹窗对话框里面的确定按键,同时也可以敲打空格或回车键进行快速确定操作。
5、后台功能面板:
后台的功能面板中所有须要键盘点选或鼠标录入的地方都最大限度的紧靠两侧菜单老y文章管理系统采集功能怎么设置分页,这样可提升点击两侧菜单与两侧功能的效率,可使管理员大部分时间只需把注意力集中在功能面板的两侧即可完成大部分的操作,而不需要满屏幕的转移眼神,例如单选,多选,删除老y文章管理系统采集功能怎么设置分页,增加,修改等按键及文本框。
6、后台验证码免输入:
对于每晚的前几次登陆网站来说,验证码对与错都不会影响你的登入。
此项设置是为了便捷管理员不用确切的输入验证码就可以登入后台,同时为了保证安全性,可以在后台设置每日免验证码登陆的次数,可按照你日常登陆网站的规律了设定。操作方法:后台–站点设置–网站后台每日免验证码登入次数–在文本框中输入整数即可(建议不要超过3)
注:
1、程序开源,使用功能无任何限制,本程序正在申请计算机软件著作权,修改程序源代码前请查看程序代码中的版权注释信息
2、官网有关于本程序的使用教程及操作方法
后台应用中心可安装,模板、扫码打赏插件、手机版与笔记本版智能管理插件、屏蔽复制与滑鼠右键插件、老y文章系统数据迁移至天人工具、OK3W文章系统数据迁移至天人工具、用户注册后手动登入插件、悬浮贴边客服插件、会员前台全功能编辑器插件、广告可视化管理插件、前台顶部自定义内容插件、畅言、友言、多说万能评论插件、电脑版整站背景图插件、万能伪静态规则生成插件、手机版广告插件、手机版内容阅读权限插件、QQ登陆插件等等
恭喜,此资源为免费资源,请先登入
1. 充值比列:1:1
2. 升级VIP或冲值均手动到帐。
3. 下载权限,请登陆后直接看下载按键后面说明。
4. 虚拟物品具有可复制性,无问题一经售出,概不退钱哦;
5. 源码默认是没有安装教程的,如果上面有那也是随机的。
6. 所有资源不提供免费安装与技术支持,如需技术支持请联系客服。 查看全部
15、会员管理,管理员可在后台添加会员,此功能与前台会员注册的疗效相同。同时也可以管理会员、审核会员、设定会员等级积分等。
16、系统支持文章投稿,会员可在个人中心进行投稿,并获得管理员设定的积分。
17、多种形式的互动功能,例如会员签到、会员投稿、游客留言、游客评论等功能。
天人文章管理系统特色功能介绍: 1、按钮功能:
按钮颜色分为两种,一种是红色,一种是蓝色。蓝色按键是添加、修改之类较为安全,不会导致数据遗失的功能。红色按键是删掉、恢复之类若误操作会导致数据遗失的功能,故按键使用颜色分辨及配合对话框提示会最大程度保证操作准确性。
2、单行文本框:
当填写完表单时,将光标定位在单行文本框中敲打回车键,可取代点击递交表单按键的功能。此功能可便捷用户快速递交表单。
3、复选框与单选框:
在选中复选框或单选框时,为了降低键盘点选的方便性,点击其旁边的文字同样还能起到选择复选框或单选框的作用。
4、弹窗对话框:
弹窗对话框是系统对管理员作出操作的回应,通常情况下可点击弹窗对话框里面的确定按键,同时也可以敲打空格或回车键进行快速确定操作。
5、后台功能面板:
后台的功能面板中所有须要键盘点选或鼠标录入的地方都最大限度的紧靠两侧菜单老y文章管理系统采集功能怎么设置分页,这样可提升点击两侧菜单与两侧功能的效率,可使管理员大部分时间只需把注意力集中在功能面板的两侧即可完成大部分的操作,而不需要满屏幕的转移眼神,例如单选,多选,删除老y文章管理系统采集功能怎么设置分页,增加,修改等按键及文本框。
6、后台验证码免输入:
对于每晚的前几次登陆网站来说,验证码对与错都不会影响你的登入。
此项设置是为了便捷管理员不用确切的输入验证码就可以登入后台,同时为了保证安全性,可以在后台设置每日免验证码登陆的次数,可按照你日常登陆网站的规律了设定。操作方法:后台–站点设置–网站后台每日免验证码登入次数–在文本框中输入整数即可(建议不要超过3)
注:
1、程序开源,使用功能无任何限制,本程序正在申请计算机软件著作权,修改程序源代码前请查看程序代码中的版权注释信息
2、官网有关于本程序的使用教程及操作方法
后台应用中心可安装,模板、扫码打赏插件、手机版与笔记本版智能管理插件、屏蔽复制与滑鼠右键插件、老y文章系统数据迁移至天人工具、OK3W文章系统数据迁移至天人工具、用户注册后手动登入插件、悬浮贴边客服插件、会员前台全功能编辑器插件、广告可视化管理插件、前台顶部自定义内容插件、畅言、友言、多说万能评论插件、电脑版整站背景图插件、万能伪静态规则生成插件、手机版广告插件、手机版内容阅读权限插件、QQ登陆插件等等
恭喜,此资源为免费资源,请先登入
1. 充值比列:1:1
2. 升级VIP或冲值均手动到帐。
3. 下载权限,请登陆后直接看下载按键后面说明。
4. 虚拟物品具有可复制性,无问题一经售出,概不退钱哦;
5. 源码默认是没有安装教程的,如果上面有那也是随机的。
6. 所有资源不提供免费安装与技术支持,如需技术支持请联系客服。
【原创源码】网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 363 次浏览 • 2020-07-02 08:01
最近因为女朋友工作需求,需要获取各大团购网站上的店家信息,这样自动一个一个点不得气死,于是我就写了一个网络爬虫来解决这个问题,是用java写的,主要用到了两个开源库,httpclient和jsoup...用来获取网页数据和得到想要的数据,不过最好是有点web基础网络爬虫代码,这样就可以只要想要的值,不然会有很多没用的数据,后期还要自动删掉,比较麻烦...下面附上源码和说明...
[Asm] 纯文本查看 复制代码
public static String getHtmlByUrl(String url){
String html = null;
HttpClient httpClient = new DefaultHttpClient();//创建httpClient对象
HttpGet httpget = new HttpGet(url);//以get方式请求该URL
try {
HttpResponse responce = httpClient.execute(httpget);//得到responce对象
int resStatu = responce.getStatusLine().getStatusCode();//返回码
if (resStatu==HttpStatus.SC_OK) {//200正常 其他就不对
//获得相应实体
HttpEntity entity = responce.getEntity();
if (entity!=null) {
//html = EntityUtils.toString(entity);//获得html源代码
InputStream in = entity.getContent();
entity.getContentType();
Scanner sc = new Scanner(in);
StringBuffer str = new StringBuffer("utf-8");
while(sc.hasNextLine()){
str.append(sc.nextLine());
}
html = str.toString();
//sc.close();
}
}
} catch (Exception e) {
System.out.println("访问【"+url+"】出现异常!");
e.printStackTrace();
} finally {
httpClient.getConnectionManager().shutdown();
}
return html;
}
上面的就是httpclient库的内容,用它来获取html页面的数据
[Java] 纯文本查看 复制代码
public static void main(String[] args) throws WriteException, IOException {
String html = getHtmlByUrl("需要获取数据的网址");
if (html!=null&&!"".equals(html)) {
Document doc = Jsoup.parse(html);
Elements linksElements = doc.select("div.basic>a"); //如果有web基础的话,可以设置一下这里,知道自己想要的数据
for (Element ele:linksElements) {
String href = ele.attr("href");
String title = ele.text();
System.out.println(href+","+title);
}
}
}
这个就是解析获取来的html数据,找到自己想要的数据....
然后把取到的数据存入excel获取txt里就随大伙便了,不过这个方式有一个漏洞就是,只能取静态页面,动态页面未能实现,我还要再继续研究一下,研究下来了,再发下来,如果有哪些不懂的网络爬虫代码,可以问我,知道的一定告诉你们,希望你们多评分,多鼓励,非常谢谢!!!! 查看全部
最近因为女朋友工作需求,需要获取各大团购网站上的店家信息,这样自动一个一个点不得气死,于是我就写了一个网络爬虫来解决这个问题,是用java写的,主要用到了两个开源库,httpclient和jsoup...用来获取网页数据和得到想要的数据,不过最好是有点web基础网络爬虫代码,这样就可以只要想要的值,不然会有很多没用的数据,后期还要自动删掉,比较麻烦...下面附上源码和说明...
[Asm] 纯文本查看 复制代码
public static String getHtmlByUrl(String url){
String html = null;
HttpClient httpClient = new DefaultHttpClient();//创建httpClient对象
HttpGet httpget = new HttpGet(url);//以get方式请求该URL
try {
HttpResponse responce = httpClient.execute(httpget);//得到responce对象
int resStatu = responce.getStatusLine().getStatusCode();//返回码
if (resStatu==HttpStatus.SC_OK) {//200正常 其他就不对
//获得相应实体
HttpEntity entity = responce.getEntity();
if (entity!=null) {
//html = EntityUtils.toString(entity);//获得html源代码
InputStream in = entity.getContent();
entity.getContentType();
Scanner sc = new Scanner(in);
StringBuffer str = new StringBuffer("utf-8");
while(sc.hasNextLine()){
str.append(sc.nextLine());
}
html = str.toString();
//sc.close();
}
}
} catch (Exception e) {
System.out.println("访问【"+url+"】出现异常!");
e.printStackTrace();
} finally {
httpClient.getConnectionManager().shutdown();
}
return html;
}
上面的就是httpclient库的内容,用它来获取html页面的数据
[Java] 纯文本查看 复制代码
public static void main(String[] args) throws WriteException, IOException {
String html = getHtmlByUrl("需要获取数据的网址");
if (html!=null&&!"".equals(html)) {
Document doc = Jsoup.parse(html);
Elements linksElements = doc.select("div.basic>a"); //如果有web基础的话,可以设置一下这里,知道自己想要的数据
for (Element ele:linksElements) {
String href = ele.attr("href");
String title = ele.text();
System.out.println(href+","+title);
}
}
}
这个就是解析获取来的html数据,找到自己想要的数据....
然后把取到的数据存入excel获取txt里就随大伙便了,不过这个方式有一个漏洞就是,只能取静态页面,动态页面未能实现,我还要再继续研究一下,研究下来了,再发下来,如果有哪些不懂的网络爬虫代码,可以问我,知道的一定告诉你们,希望你们多评分,多鼓励,非常谢谢!!!!
DEDE织梦采集侠无限制完整版下载v2.8 源码版
采集交流 • 优采云 发表了文章 • 0 个评论 • 441 次浏览 • 2020-06-08 08:00
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3织梦采集侠破解版,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+ 查看全部
其实DEDE织梦采集侠无限制完整版可以做到万无一失的使你少花钱去享受软件的收费内容,DEDE织梦采集侠破解版使用上去真心不赖,而且附送了最全的DEDE织梦采集侠无限制完整版使用方式,保证你一步到位织梦采集侠破解版,你会喜欢的。
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3织梦采集侠破解版,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
PHP爬虫编撰
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2020-06-04 08:04
PHP(外文名:PHP: Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用开源脚本语言。语法吸收了C语言、Java和Perl的特性,利于学习,使用广泛,主要适用于Web开发领域。PHP 独特的句型混和了C、Java、Perl以及PHP自创的句型。它可以比CGI或则Perl更快速地执行动态网页。用PHP作出的动态页面与其他的编程语言相比,PHP是将程序嵌入到HTML(标准通用标记语言下的一个应用)文档中去执行,执行效率比完全生成HTML标记的CGI要高许多;PHP还可以执行编译后代码,编译可以达到加密和优化代码运行php网络爬虫软件,使代码运行更快。——百度百科的描述。
二、爬虫有哪些用?
爬虫有哪些用?先说一下爬虫是哪些东西,我觉得爬虫就是一个网路信息搜集程序,也许我自己的理解有错误,也请你们给我见谅。既然爬虫是一个网路信息搜集程序,那就是拿来搜集信息,并且搜集的信息是在网路里面的。如果还是不太清楚爬虫有什么用php网络爬虫软件,我就举几个爬虫应用的事例:搜索引擎就须要爬虫搜集网路信息供人们去搜索;大数据的数据,数据从那里来?就是可以通过爬虫在网路中爬取(收集)而来。
三、通常看到爬虫会想到 Python,但为何我用 PHP,而不用 Python 呢?
Python 我说实话,我不会 Python。( Python 我真不会,想知道可能你要去百度一下,因为 Python 我真不会。)PHP 写东西我仍然都是觉得,你只要想出算法程序就早已下来了,不用考虑太多数据类型的问题。PHP 的句型和其他编程语言差不多,就算你开始不会 PHP,你也可以马上上手。PHP的句型和其他编程语言差不多,就算你开始不会 PHP,你也可以马上上手。的看法有错。)本人虽然也是初学 PHP,想通过写一些东西提升自己的水平。(下面可能有些代码会使你认为不够规范,欢迎见谅,谢谢。)
四、PHP爬虫第一步
PHP爬虫第一步,第一步......第一步其实就是搭建 PHP 的运行环境,没有环境PHP又如何能运行呢?就像虾不能离开水一样。(我见识还不够,可能我举的虾的事例不够好,请见谅。)在Windows的系统下我使用 WAMP,而在Linux的系统下我使用 LNMP 或者 LAMP。
WAMP:Windows + Apache + Mysql + PHP
LAMP:Linux + Apache + Mysql + PHP
LNMP:Linux + Nginx + Mysql + PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache或Nginx、Mysql 以及 PHP 这些都是 PHP Web 的基本配置环境。网上有 PHP Web 环境的安装包,这些安装包使用很方便,不需要每给东西安装以及配置。但若果你对这种集成安装包害怕安全问题,你可以到这种程序的官网下载之后在网上找配置教程就可以了。(说真的,我真心的不会单独去弄,我认为很麻烦。)
五、 PHP爬虫第二步
(感觉自己屁话很多,应该马上来一段代码!!!)
<?php
// 爬虫核心功能:获取网页源码
$html = file_get_contents("https://www.baidu.com/index.html");
// 通过 php 的 file_get_contents 函数获取百度首页源码,并传给 $html 变量
echo $html;
// 输出 $html
?>
爬虫网路核心功能早已写下来了,为什么说就如此几行代码就把爬虫核心功能写下来了呢?我猜有人早已明白了吧,其实是因为爬虫是数据获取的程序,就里面几行代码虽然早已才能获取数据了,所以爬虫的核心功能早已写下来了。可能有人会说“你这个也很菜了吧!有哪些用?”,虽然我是太菜,但请别说出来,让我好好装个X。(又说了两行屁话,不好意思。)
其实爬虫是拿来干嘛,主要看你想使它来干嘛。就像我前些日子为了好玩写了一个搜索引擎网站出来,当然网站很菜,结果排序没有规律,很多都查不到。我的搜索引擎的爬虫就是要写一个适合于搜索引擎的爬虫。所以为了便捷我也就用写搜索引擎的爬虫为目标讲解。当然了,我搜索引擎的爬虫还是不够建立,不健全的地方都是要大家自己去创造,去建立。
六、 搜索引擎爬虫的限制
搜索引擎的爬虫有时候不是不能那种网站的页面获取页面源码,而是有robot.txt文件,有该文件的网站,就代表站主不希望爬虫去爬取页面源码。(不过若果你就是想要获取的话,就算有也一样会去爬吧!)
我搜索引擎的爬虫虽然还有好多不足而造成的限制,例如可能由于未能运行 JS 脚本所以未能获取页面源码。又或则网站有反爬虫的机制引起不能获取到页面源码。有反爬虫机制的网站就如:知乎,知乎就是有反爬虫的机制的网站。
七、以弄搜索引擎爬虫为例,准备写该爬虫须要的东西
PHP 编写基础正则表达式(你也可以使用Xpath,对不起,我不会使用)数据库的使用(本文使用 MySql 数据库)运行环境(只要有能运行 PHP 网站的环境和数据库就OK)
八、搜索引擎获取页面源码并获取页面的标题信息
<?PHP
// 通过 file_get_contents 函数获取百度页面源码
$html = file_get_contents("https://www.baidu.com/index.html");
// 通过 preg_replace 函数使页面源码由多行变单行
$htmlOneLine = preg_replace("/\r|\n|\t/","",$html);
// 通过 preg_match 函数提取获取页面的标题信息
preg_match("/<title>(.*)<\/title>/iU",$htmlOne,$titleArr);
// 由于 preg_match 函数的结果是数组的形式
$title = $titleArr[1];
// 通过 echo 函数输出标题信息
echo $title;
?>
报错误示例:
Warning: file_get_contents("127.0.0.1/index.php") [function.file-get-contents]: failed to open stream: Invalid argument in E:\website\blog\test.php on line 25
https是SSL加密合同,如果出现获取页面晨报里面的错误,代表你的 PHP 可能少了OpenSSL 的模块,你可以到网上查找解决办法。
九、搜索引擎爬虫的特征
虽然我没见过象“百度”,“Google”它们的爬虫,可是我自己通过推测,以及在实际爬去过程当中遇见的一些问题,自己总结的几个特性。(可能有不对的地方,或者缺乏的地方,欢迎见谅,谢谢。)
通用性
通用性是因为我觉得搜索引擎的爬虫一开始并不是针对哪一个网站制定的,所以要求能爬取到的网站尽可能的多,这是第一点。而第二点,就是获取网页的信息就是这些,一开始不会由于个别某些特殊小网站而舍弃个别信息不提取,举个反例:一个小网站的一个网页meta标签里没有描述信息(description)或者关键词信息(keyword),就直接舍弃了描述信息或则关键词信息的提取,当然假如真的某一个页面没有这种信息我会提取页面里的文字内容作为填充,反正就是尽可能达到爬取的网页信息每位网页的信息项都要一样。这是我觉得的搜索引擎爬虫的通用性,当然我的看法可能是错误的。(我说得可能不是很好,我仍然在学习。)
不确定性
不确定性就是我的爬虫获取哪些网页我是控制不够全面的,只能控制我能想到的情况,这也是由于我写的算法就是这样的缘由,我的算法就是爬取获取到的页面里的所有链接,再去爬去获取到的那些链接,其实是因为搜索引擎并不是搜某一些东西,而是尽可能的多,因为只有更多的信息,才能找到一个最贴切用户想要的答案。所以我就认为搜索引擎的爬虫就要有不确定性。(我自己再看了一遍,也有点认为自己说得有点使自己看不懂,请见谅,欢迎见谅,提问,谢谢了!)
下面的视频是我的搜索网站的使用视频,而搜到的信息就是通过自己写的 PHP 爬虫获取到的。(这个网站我早已不再继续维护了,所以有缺乏之处,请见谅。)
十、到如今可能出现的问题
获取的源码出现乱码
<?PHP
// 乱码解决办法,把其他编码格式通过 mb_convert_encoding 函数统一转为 UTF-8 格式
$html = mb_convert_encoding($html,'UTF-8','UTF-8,GBK,GB2312,BIG5');
// 还有一种因为gzip所以出现乱码的,我会在以后讲
?>
2. 获取不到标题信息
<?PHP
// 获取不到标题信息解决办法,首先判断是否能获取到页面源码
// 如果能获取到但还是不能获取到标题信息
// 我猜测的问题是:因为我教的是使用正则表达式获取的,源码没有变成一行,获取起来就会出现问题
$htmlOneLine=preg_replace("/\r|\n|\t/","",$html);
?>
3.获取不到页面源码
<?PHP
// 像新浪微博你可能获取到的是“Sina Visitor System”
// 解决办法添加header信息
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n",
)
);
$context = stream_context_create($opts);
$html = file_get_contents($domain,0,$context,0,150000);
// 这样就能获取到新浪微博的页面了
?>
十一、获取一个网页时的处理思路
我们先不去想好多网页,因为好多网页也就是一个循环。
获取页面源码通过源码提取页面的哪些信息提取的信息要如何处理处理后放不放进数据库
十二、按照十一的思路的代码
<?php
// 一、获取源码
// 假设我们要获取淘宝首页
$html = file_get_content("https://www.taobao.com");
// 二、提取标题和文本
// 三、提取信息处理
// 处理页面源码,多行变单行
$htmlOneLine = preg_replace("/\r|\n|\t/","",$html);
// 获取标题信息
preg_match("/<title>(.*)<\/title>/iU",$htmlOneLine,$titleArr);
// 保留标题信息
$titleOK = $titleArr[1];
// 获取页面中的文本信息
// 处理前面不需要的head标签
$htmlText = preg_replace("/<html>(.*)<\/head>/","",$htmlOneLine);
// 处理style和script标签及内容
$htmlText = preg_replace("/<style(.*)>(.*)</style>|<script(.*)>(.*)</script>/iU","",$htmlText);
// 处理多余标签
$htmlText = preg_replace("/<(\/)?(.+)>/","",$htmlText);
// 四、保存到数据库
// 略
?>
十三、PHP 保存页面的图片思路
获取页面源码获取页面的图片链接使用函数保存图片
十四、保存图片示例代码
<?php
// 使用file_get_contents()函数获取图片
$img = file_get_contents("http://127.0.0.1/photo.jpg");
// 使用file_put_contents()函数保存图片
file_put_contents("photo.jpg",$img);
?>
十五、gzip解压
本来我以为自己写的爬虫早已写得差不多了,就是不仅反爬虫的网站难以爬取外,应该是都可以爬了。但有三天我去尝试爬去bilibili的时侯出现问题了,我发觉如何我数据库上面的都是乱码,而且标题哪些的都没有,好奇怪!后来我才晓得原先是因为GZIP的压缩,原来我直接使用file_get_content函数获取的页面是未经过解压的页面,所有都是乱码!好了,然后我晓得问题出现在哪里了,接下来就是想解决办法了。(其实那时候的我是完全不知道如何解决解压gzip的,都靠搜索引擎,哈哈哈哈哈)。
我得到了两个解决办法:
在 request header 那里告诉对方服务器,我这爬虫(不。。。应该是我这浏览器)不支持gzip的解压,就麻烦你不要压缩,直接把数据发给我吧!
// 这是request header(请求头)
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n".
"accept-encoding:"
)
);
// 我把accept-encodeing(能接收编码)设为空,代表不接受gzip
2. 如果告诉了对方服务器本浏览器(爬虫)不支持解压gzip,可他还是继续发gzip的数据给你,那就没有办法了,只好默默的在搜索引擎找php解压gzip的解压函数——gzdecode()。
// 废话:好久没更新了,因为近来又在重复造轮子,不过好开心-- 2019.01.14
十六、子链接的获取
网页爬虫就好比手动的网页源码另存为操作,可是假如真的是一个一个网址自动输入给爬虫去爬取的话,那还倒不如人手另存为呢!所以在这里就得解析到这些子链接,一个网页似乎会有好多的a标签,而这种a标签的href属性值都会是一个子链接。(这句如何觉得有一点屁话呢?应该你们都晓得吧!)通过好多种工具的解析得到了原始的子链接(我没用html的工具,就是用了正则表达式及工具)为什么叫原始数据,因为这些子链接有很多不是URL链接,又或则是一些不完整的链接,又或则你是要爬一个网站,不要爬虫跑出去的时侯,还得消除一些并非那种网站的链接,防止爬虫跑出去。下面我列出一些原始子链接。(其实就是我喷到的坑。。。)
http://wxample.com/
./index.html
index.html
//example.com/index.html
javascript:;
../index.html
http://example2.com/index.html
你可以看得到这儿有很多种链接,有完整的绝对路径的链接,也有不完整的相对路径链接,有的还跑来了javascript,如果是相对路径或javascript的链接,直接给爬虫去爬,肯定使爬虫一脸懵,因为不完整或根本就不是一个链接。所以就须要对子链接补全或则扔掉。
十七、子链接的处理
上面屁话了一大堆后,接下来还是继续屁话。好了,处理虽然就是去重、丢弃以及补全。
对于相同的子链接遗弃不保存对于相对路径链接补全对于不是链接的链接遗弃(不是链接的链接是哪些东西?自己都认为的奇怪。。。。)
对于第一种我就不多说了,相信你们都晓得该如何做。
对付第二种的方式我就写一个才能运行相对路径的方式下来就OK了,通过父链接来进行相对路径转绝对路径。(有空补代码给你们。。。不好意思了)
对于第三种也正则匹配一下就完了。 查看全部
一、PHP 是哪些东西?
PHP(外文名:PHP: Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用开源脚本语言。语法吸收了C语言、Java和Perl的特性,利于学习,使用广泛,主要适用于Web开发领域。PHP 独特的句型混和了C、Java、Perl以及PHP自创的句型。它可以比CGI或则Perl更快速地执行动态网页。用PHP作出的动态页面与其他的编程语言相比,PHP是将程序嵌入到HTML(标准通用标记语言下的一个应用)文档中去执行,执行效率比完全生成HTML标记的CGI要高许多;PHP还可以执行编译后代码,编译可以达到加密和优化代码运行php网络爬虫软件,使代码运行更快。——百度百科的描述。
二、爬虫有哪些用?
爬虫有哪些用?先说一下爬虫是哪些东西,我觉得爬虫就是一个网路信息搜集程序,也许我自己的理解有错误,也请你们给我见谅。既然爬虫是一个网路信息搜集程序,那就是拿来搜集信息,并且搜集的信息是在网路里面的。如果还是不太清楚爬虫有什么用php网络爬虫软件,我就举几个爬虫应用的事例:搜索引擎就须要爬虫搜集网路信息供人们去搜索;大数据的数据,数据从那里来?就是可以通过爬虫在网路中爬取(收集)而来。
三、通常看到爬虫会想到 Python,但为何我用 PHP,而不用 Python 呢?
Python 我说实话,我不会 Python。( Python 我真不会,想知道可能你要去百度一下,因为 Python 我真不会。)PHP 写东西我仍然都是觉得,你只要想出算法程序就早已下来了,不用考虑太多数据类型的问题。PHP 的句型和其他编程语言差不多,就算你开始不会 PHP,你也可以马上上手。PHP的句型和其他编程语言差不多,就算你开始不会 PHP,你也可以马上上手。的看法有错。)本人虽然也是初学 PHP,想通过写一些东西提升自己的水平。(下面可能有些代码会使你认为不够规范,欢迎见谅,谢谢。)
四、PHP爬虫第一步
PHP爬虫第一步,第一步......第一步其实就是搭建 PHP 的运行环境,没有环境PHP又如何能运行呢?就像虾不能离开水一样。(我见识还不够,可能我举的虾的事例不够好,请见谅。)在Windows的系统下我使用 WAMP,而在Linux的系统下我使用 LNMP 或者 LAMP。
WAMP:Windows + Apache + Mysql + PHP
LAMP:Linux + Apache + Mysql + PHP
LNMP:Linux + Nginx + Mysql + PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache或Nginx、Mysql 以及 PHP 这些都是 PHP Web 的基本配置环境。网上有 PHP Web 环境的安装包,这些安装包使用很方便,不需要每给东西安装以及配置。但若果你对这种集成安装包害怕安全问题,你可以到这种程序的官网下载之后在网上找配置教程就可以了。(说真的,我真心的不会单独去弄,我认为很麻烦。)
五、 PHP爬虫第二步
(感觉自己屁话很多,应该马上来一段代码!!!)
<?php
// 爬虫核心功能:获取网页源码
$html = file_get_contents("https://www.baidu.com/index.html");
// 通过 php 的 file_get_contents 函数获取百度首页源码,并传给 $html 变量
echo $html;
// 输出 $html
?>
爬虫网路核心功能早已写下来了,为什么说就如此几行代码就把爬虫核心功能写下来了呢?我猜有人早已明白了吧,其实是因为爬虫是数据获取的程序,就里面几行代码虽然早已才能获取数据了,所以爬虫的核心功能早已写下来了。可能有人会说“你这个也很菜了吧!有哪些用?”,虽然我是太菜,但请别说出来,让我好好装个X。(又说了两行屁话,不好意思。)
其实爬虫是拿来干嘛,主要看你想使它来干嘛。就像我前些日子为了好玩写了一个搜索引擎网站出来,当然网站很菜,结果排序没有规律,很多都查不到。我的搜索引擎的爬虫就是要写一个适合于搜索引擎的爬虫。所以为了便捷我也就用写搜索引擎的爬虫为目标讲解。当然了,我搜索引擎的爬虫还是不够建立,不健全的地方都是要大家自己去创造,去建立。
六、 搜索引擎爬虫的限制
搜索引擎的爬虫有时候不是不能那种网站的页面获取页面源码,而是有robot.txt文件,有该文件的网站,就代表站主不希望爬虫去爬取页面源码。(不过若果你就是想要获取的话,就算有也一样会去爬吧!)
我搜索引擎的爬虫虽然还有好多不足而造成的限制,例如可能由于未能运行 JS 脚本所以未能获取页面源码。又或则网站有反爬虫的机制引起不能获取到页面源码。有反爬虫机制的网站就如:知乎,知乎就是有反爬虫的机制的网站。
七、以弄搜索引擎爬虫为例,准备写该爬虫须要的东西
PHP 编写基础正则表达式(你也可以使用Xpath,对不起,我不会使用)数据库的使用(本文使用 MySql 数据库)运行环境(只要有能运行 PHP 网站的环境和数据库就OK)
八、搜索引擎获取页面源码并获取页面的标题信息
<?PHP
// 通过 file_get_contents 函数获取百度页面源码
$html = file_get_contents("https://www.baidu.com/index.html");
// 通过 preg_replace 函数使页面源码由多行变单行
$htmlOneLine = preg_replace("/\r|\n|\t/","",$html);
// 通过 preg_match 函数提取获取页面的标题信息
preg_match("/<title>(.*)<\/title>/iU",$htmlOne,$titleArr);
// 由于 preg_match 函数的结果是数组的形式
$title = $titleArr[1];
// 通过 echo 函数输出标题信息
echo $title;
?>
报错误示例:
Warning: file_get_contents("127.0.0.1/index.php") [function.file-get-contents]: failed to open stream: Invalid argument in E:\website\blog\test.php on line 25
https是SSL加密合同,如果出现获取页面晨报里面的错误,代表你的 PHP 可能少了OpenSSL 的模块,你可以到网上查找解决办法。
九、搜索引擎爬虫的特征
虽然我没见过象“百度”,“Google”它们的爬虫,可是我自己通过推测,以及在实际爬去过程当中遇见的一些问题,自己总结的几个特性。(可能有不对的地方,或者缺乏的地方,欢迎见谅,谢谢。)
通用性
通用性是因为我觉得搜索引擎的爬虫一开始并不是针对哪一个网站制定的,所以要求能爬取到的网站尽可能的多,这是第一点。而第二点,就是获取网页的信息就是这些,一开始不会由于个别某些特殊小网站而舍弃个别信息不提取,举个反例:一个小网站的一个网页meta标签里没有描述信息(description)或者关键词信息(keyword),就直接舍弃了描述信息或则关键词信息的提取,当然假如真的某一个页面没有这种信息我会提取页面里的文字内容作为填充,反正就是尽可能达到爬取的网页信息每位网页的信息项都要一样。这是我觉得的搜索引擎爬虫的通用性,当然我的看法可能是错误的。(我说得可能不是很好,我仍然在学习。)
不确定性
不确定性就是我的爬虫获取哪些网页我是控制不够全面的,只能控制我能想到的情况,这也是由于我写的算法就是这样的缘由,我的算法就是爬取获取到的页面里的所有链接,再去爬去获取到的那些链接,其实是因为搜索引擎并不是搜某一些东西,而是尽可能的多,因为只有更多的信息,才能找到一个最贴切用户想要的答案。所以我就认为搜索引擎的爬虫就要有不确定性。(我自己再看了一遍,也有点认为自己说得有点使自己看不懂,请见谅,欢迎见谅,提问,谢谢了!)
下面的视频是我的搜索网站的使用视频,而搜到的信息就是通过自己写的 PHP 爬虫获取到的。(这个网站我早已不再继续维护了,所以有缺乏之处,请见谅。)
十、到如今可能出现的问题
获取的源码出现乱码
<?PHP
// 乱码解决办法,把其他编码格式通过 mb_convert_encoding 函数统一转为 UTF-8 格式
$html = mb_convert_encoding($html,'UTF-8','UTF-8,GBK,GB2312,BIG5');
// 还有一种因为gzip所以出现乱码的,我会在以后讲
?>
2. 获取不到标题信息
<?PHP
// 获取不到标题信息解决办法,首先判断是否能获取到页面源码
// 如果能获取到但还是不能获取到标题信息
// 我猜测的问题是:因为我教的是使用正则表达式获取的,源码没有变成一行,获取起来就会出现问题
$htmlOneLine=preg_replace("/\r|\n|\t/","",$html);
?>
3.获取不到页面源码
<?PHP
// 像新浪微博你可能获取到的是“Sina Visitor System”
// 解决办法添加header信息
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n",
)
);
$context = stream_context_create($opts);
$html = file_get_contents($domain,0,$context,0,150000);
// 这样就能获取到新浪微博的页面了
?>
十一、获取一个网页时的处理思路
我们先不去想好多网页,因为好多网页也就是一个循环。
获取页面源码通过源码提取页面的哪些信息提取的信息要如何处理处理后放不放进数据库
十二、按照十一的思路的代码
<?php
// 一、获取源码
// 假设我们要获取淘宝首页
$html = file_get_content("https://www.taobao.com");
// 二、提取标题和文本
// 三、提取信息处理
// 处理页面源码,多行变单行
$htmlOneLine = preg_replace("/\r|\n|\t/","",$html);
// 获取标题信息
preg_match("/<title>(.*)<\/title>/iU",$htmlOneLine,$titleArr);
// 保留标题信息
$titleOK = $titleArr[1];
// 获取页面中的文本信息
// 处理前面不需要的head标签
$htmlText = preg_replace("/<html>(.*)<\/head>/","",$htmlOneLine);
// 处理style和script标签及内容
$htmlText = preg_replace("/<style(.*)>(.*)</style>|<script(.*)>(.*)</script>/iU","",$htmlText);
// 处理多余标签
$htmlText = preg_replace("/<(\/)?(.+)>/","",$htmlText);
// 四、保存到数据库
// 略
?>
十三、PHP 保存页面的图片思路
获取页面源码获取页面的图片链接使用函数保存图片
十四、保存图片示例代码
<?php
// 使用file_get_contents()函数获取图片
$img = file_get_contents("http://127.0.0.1/photo.jpg");
// 使用file_put_contents()函数保存图片
file_put_contents("photo.jpg",$img);
?>
十五、gzip解压
本来我以为自己写的爬虫早已写得差不多了,就是不仅反爬虫的网站难以爬取外,应该是都可以爬了。但有三天我去尝试爬去bilibili的时侯出现问题了,我发觉如何我数据库上面的都是乱码,而且标题哪些的都没有,好奇怪!后来我才晓得原先是因为GZIP的压缩,原来我直接使用file_get_content函数获取的页面是未经过解压的页面,所有都是乱码!好了,然后我晓得问题出现在哪里了,接下来就是想解决办法了。(其实那时候的我是完全不知道如何解决解压gzip的,都靠搜索引擎,哈哈哈哈哈)。
我得到了两个解决办法:
在 request header 那里告诉对方服务器,我这爬虫(不。。。应该是我这浏览器)不支持gzip的解压,就麻烦你不要压缩,直接把数据发给我吧!
// 这是request header(请求头)
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n".
"accept-encoding:"
)
);
// 我把accept-encodeing(能接收编码)设为空,代表不接受gzip
2. 如果告诉了对方服务器本浏览器(爬虫)不支持解压gzip,可他还是继续发gzip的数据给你,那就没有办法了,只好默默的在搜索引擎找php解压gzip的解压函数——gzdecode()。
// 废话:好久没更新了,因为近来又在重复造轮子,不过好开心-- 2019.01.14
十六、子链接的获取
网页爬虫就好比手动的网页源码另存为操作,可是假如真的是一个一个网址自动输入给爬虫去爬取的话,那还倒不如人手另存为呢!所以在这里就得解析到这些子链接,一个网页似乎会有好多的a标签,而这种a标签的href属性值都会是一个子链接。(这句如何觉得有一点屁话呢?应该你们都晓得吧!)通过好多种工具的解析得到了原始的子链接(我没用html的工具,就是用了正则表达式及工具)为什么叫原始数据,因为这些子链接有很多不是URL链接,又或则是一些不完整的链接,又或则你是要爬一个网站,不要爬虫跑出去的时侯,还得消除一些并非那种网站的链接,防止爬虫跑出去。下面我列出一些原始子链接。(其实就是我喷到的坑。。。)
http://wxample.com/
./index.html
index.html
//example.com/index.html
javascript:;
../index.html
http://example2.com/index.html
你可以看得到这儿有很多种链接,有完整的绝对路径的链接,也有不完整的相对路径链接,有的还跑来了javascript,如果是相对路径或javascript的链接,直接给爬虫去爬,肯定使爬虫一脸懵,因为不完整或根本就不是一个链接。所以就须要对子链接补全或则扔掉。
十七、子链接的处理
上面屁话了一大堆后,接下来还是继续屁话。好了,处理虽然就是去重、丢弃以及补全。
对于相同的子链接遗弃不保存对于相对路径链接补全对于不是链接的链接遗弃(不是链接的链接是哪些东西?自己都认为的奇怪。。。。)
对于第一种我就不多说了,相信你们都晓得该如何做。
对付第二种的方式我就写一个才能运行相对路径的方式下来就OK了,通过父链接来进行相对路径转绝对路径。(有空补代码给你们。。。不好意思了)
对于第三种也正则匹配一下就完了。
基于Python网路爬虫的设计与实现毕业论文+源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 558 次浏览 • 2020-05-25 08:02
本课题的主要目的是设计面向定向网站的网路爬虫程序,同时须要满足不同的性能要求,详细涉及到定向网路爬虫的各个细节与应用环节。
搜索引擎作为一个辅助人们检索信息的工具。但是,这些通用性搜索引擎也存在着一定的局限性。不同领域、不同背景的用户常常具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。为了解决这个问题,一个灵活的爬虫有着无可替代的重要意义。
网络爬虫应用智能自构造技术,随着不同主题的网站,可以手动剖析构造URL,去重。网络爬虫使用多线程技术,让爬虫具备更强大的抓取能力。对网路爬虫的联接网路设置联接及读取时间,避免无限制的等待。为了适应不同需求,使网路爬虫可以按照预先设定的主题实现对特定主题的爬取。研究网路爬虫的原理并实现爬虫的相关功能,并将爬去的数据清洗以后存入数据库,后期可视化显示。
关键词:网络爬虫网络爬虫+代码,定向爬取,多线程网络爬虫+代码,Mongodb
The main purpose of this project is to design subject-oriented web crawler process, which require to meet different performance and related to the various details of the targeted web crawler and application in detail.
Search engine is a tool to help people retrieve information. However, these general search engines also have some limitations. Users in different fields and backgrounds tend to have different purposes and needs, and the results returned by general search engines contain a large number of web pages that users don't care about. In order to solve this problem, it is of great significance for a flexible crawler.
Web crawler application of intelligent self construction technology, with the different themes of the site, you can automatically analyze the structure of URL, and cancel duplicate part. Web crawler use multi-threading technology, so that the crawler has a more powerful ability to grab. Setting connection and reading time of the network crawler is to avoid unlimited waiting. In order to adapt to the different needs, the web crawler can base on the preset themes to realize to filch the specific topics. What’s more, we should study the principle of the web crawler ,realize the relevant functions of reptiles, save the stolen data to the database after cleaning and in late achieve the visual display.
Keywords:Web crawler,Directional climb,multi-threading,mongodb
目录
6
7
1)爬虫代码文件构成如图:
全套结业设计论文现成成品资料请咨询 查看全部
本课题的主要目的是设计面向定向网站的网路爬虫程序,同时须要满足不同的性能要求,详细涉及到定向网路爬虫的各个细节与应用环节。
搜索引擎作为一个辅助人们检索信息的工具。但是,这些通用性搜索引擎也存在着一定的局限性。不同领域、不同背景的用户常常具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。为了解决这个问题,一个灵活的爬虫有着无可替代的重要意义。
网络爬虫应用智能自构造技术,随着不同主题的网站,可以手动剖析构造URL,去重。网络爬虫使用多线程技术,让爬虫具备更强大的抓取能力。对网路爬虫的联接网路设置联接及读取时间,避免无限制的等待。为了适应不同需求,使网路爬虫可以按照预先设定的主题实现对特定主题的爬取。研究网路爬虫的原理并实现爬虫的相关功能,并将爬去的数据清洗以后存入数据库,后期可视化显示。
关键词:网络爬虫网络爬虫+代码,定向爬取,多线程网络爬虫+代码,Mongodb
The main purpose of this project is to design subject-oriented web crawler process, which require to meet different performance and related to the various details of the targeted web crawler and application in detail.
Search engine is a tool to help people retrieve information. However, these general search engines also have some limitations. Users in different fields and backgrounds tend to have different purposes and needs, and the results returned by general search engines contain a large number of web pages that users don't care about. In order to solve this problem, it is of great significance for a flexible crawler.
Web crawler application of intelligent self construction technology, with the different themes of the site, you can automatically analyze the structure of URL, and cancel duplicate part. Web crawler use multi-threading technology, so that the crawler has a more powerful ability to grab. Setting connection and reading time of the network crawler is to avoid unlimited waiting. In order to adapt to the different needs, the web crawler can base on the preset themes to realize to filch the specific topics. What’s more, we should study the principle of the web crawler ,realize the relevant functions of reptiles, save the stolen data to the database after cleaning and in late achieve the visual display.
Keywords:Web crawler,Directional climb,multi-threading,mongodb
目录
6
7
1)爬虫代码文件构成如图:
全套结业设计论文现成成品资料请咨询
DEDE织梦采集侠破解版(无限制完整源码)下载 2.8 最新版
采集交流 • 优采云 发表了文章 • 0 个评论 • 443 次浏览 • 2020-05-25 08:01
Tags:软件源码源码
DEDE织梦采集侠破解版是一款必备全手动采集伪原创SEO插件,新云网提供其专业破解版本的下载。采集侠正文辨识技术是采集侠多年的技术积累,自主研制了一套汉字剖析和处理的核心系统,目前该系统辨识精度处于领先水平,即便和强悍的搜索引擎中的文字剖析能力也有得一比,优于有道紧跟百度。采集侠正是基于该核心技术研制的一个卓越的采集软件,我们更懂得百度。
织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件采集侠授权码 生成器,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话采集侠授权码 生成器,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
采集侠定向规则采集教程请参照其官网: 查看全部
Tags:软件源码源码
DEDE织梦采集侠破解版是一款必备全手动采集伪原创SEO插件,新云网提供其专业破解版本的下载。采集侠正文辨识技术是采集侠多年的技术积累,自主研制了一套汉字剖析和处理的核心系统,目前该系统辨识精度处于领先水平,即便和强悍的搜索引擎中的文字剖析能力也有得一比,优于有道紧跟百度。采集侠正是基于该核心技术研制的一个卓越的采集软件,我们更懂得百度。
织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件采集侠授权码 生成器,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话采集侠授权码 生成器,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
采集侠定向规则采集教程请参照其官网:
好站长资源免费分享精品源码,建站技术,服务器安全防护等等各种网路资源分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 435 次浏览 • 2020-05-21 08:00
前段时间帮几个顾客安装过,功能还算很不错的,在这里完全免费分享下来。源码没有任何的限制,任何域名都可以正常使用。以下部份说明为转载过来,具体的请自行下载测试。
9-9 全面升级程序模板,导航升级,以及宝贝展示升级,添加分享,原价折扣价,销量全部展示,图片修改为正方形310*310都是依照顾客的需求优化的。
优化原本值得买页面,以及升级文章页面改成哪些值得买页面,优化值得逛页面,增加品牌团。支持后台添加品牌上传图片
9-30号升级程序内核功能以及优化相关小问题。详细请看演示。增加404,全站宝贝描述,后台文章编辑器,前台文章调用,预告采集,宝贝显示款式,全面升级
9-9号全面升级页面降低品牌团等等多功能
8-29 修复后台一键手动采集价格0元错误
8-21升级程序飞天侠50完美修复:无需api一键采集,u站采集,全新安装包,修复手机版,增加报考页面,以及安装不需要恢复数据,增加伪静态规则。。。。
6.0的内核和性能比5.0的好好多,并且降低独立缓存技术。加速网站。 后期更新升级。。。
支持,后台一键手动采集,以及各个地方相关logo直接后台上传更改即可,非常简便飞天侠50完美修复:无需api一键采集,u站采集,新手也会操作。
客服,等等后台可以操作,支持显示宝贝详尽,后台单品采集可以采集宝贝详尽,支持u站采集宝贝详尽。
会员系统,报名系统,后台系统全面升级,
前台有些广告位没有设置,后期会更新教程给你们。
本次升级有使用6.0的可以直接覆盖升级,但是没有宝贝详尽。6.0亮点:u站采,淘宝网采集一键手动采集,单品采集,宝贝描述,后台可以在线升级。。功能赶超所有版本飞天侠,全网惟一一家可以更新的,几千客户体验和支持我们,谢谢大家选择我们,我们程序以优价分享,结交更多好朋友,本站开启超级群,和开放群。还有更多功能后期继续上线,后台在线升级哈
以上部份说明为转载过来,具体的请自行下载测试
下面演示图片100%为我们亲测截图 查看全部
前段时间帮几个顾客安装过,功能还算很不错的,在这里完全免费分享下来。源码没有任何的限制,任何域名都可以正常使用。以下部份说明为转载过来,具体的请自行下载测试。
9-9 全面升级程序模板,导航升级,以及宝贝展示升级,添加分享,原价折扣价,销量全部展示,图片修改为正方形310*310都是依照顾客的需求优化的。
优化原本值得买页面,以及升级文章页面改成哪些值得买页面,优化值得逛页面,增加品牌团。支持后台添加品牌上传图片
9-30号升级程序内核功能以及优化相关小问题。详细请看演示。增加404,全站宝贝描述,后台文章编辑器,前台文章调用,预告采集,宝贝显示款式,全面升级
9-9号全面升级页面降低品牌团等等多功能
8-29 修复后台一键手动采集价格0元错误
8-21升级程序飞天侠50完美修复:无需api一键采集,u站采集,全新安装包,修复手机版,增加报考页面,以及安装不需要恢复数据,增加伪静态规则。。。。
6.0的内核和性能比5.0的好好多,并且降低独立缓存技术。加速网站。 后期更新升级。。。
支持,后台一键手动采集,以及各个地方相关logo直接后台上传更改即可,非常简便飞天侠50完美修复:无需api一键采集,u站采集,新手也会操作。
客服,等等后台可以操作,支持显示宝贝详尽,后台单品采集可以采集宝贝详尽,支持u站采集宝贝详尽。
会员系统,报名系统,后台系统全面升级,
前台有些广告位没有设置,后期会更新教程给你们。
本次升级有使用6.0的可以直接覆盖升级,但是没有宝贝详尽。6.0亮点:u站采,淘宝网采集一键手动采集,单品采集,宝贝描述,后台可以在线升级。。功能赶超所有版本飞天侠,全网惟一一家可以更新的,几千客户体验和支持我们,谢谢大家选择我们,我们程序以优价分享,结交更多好朋友,本站开启超级群,和开放群。还有更多功能后期继续上线,后台在线升级哈
以上部份说明为转载过来,具体的请自行下载测试
下面演示图片100%为我们亲测截图
DEDE织梦采集侠v2.8破解版_无限制完整源码[已亲测]
采集交流 • 优采云 发表了文章 • 0 个评论 • 524 次浏览 • 2020-05-17 08:02
内容摘要:许多使用织梦源码的小伙伴,有时候须要一个插件来采集文章,但是采集插件是收费的,小六正在使用的是织梦采集侠,是须要收费的,不过现今看来也不需要了,因为我们有破解版的织梦采集侠v2.8破解版。好的如今我们开始破解织梦采集侠破解教程。先说明一下:织梦网站安装教程自己安装好,小六在这里只是演示破解采集侠模块。织梦采集侠V2.8...
许多使用织梦源码的小伙伴,有时候须要一个插件来采集文章,但是采集插件是收费的,小六正在使用的是织梦采集侠,是须要收费的,不过现今看来也不需要了,因为我们有破解版的织梦采集侠v2.8破解版。好的现今我们开始破解织梦采集侠破解教程。先说明一下:织梦网站安装教程自己安装好,小六在这里只是演示破解采集侠模块。
织梦采集侠V2.8教程开始:
第一步:首先下载文章附件,解压文件dede采集侠,把“采集侠官方插件.zip”也解压了吧!
第二步:打开这个采集侠网址,根据上面的视频教程把这个插件安装起来,下图就是官网教程开始的第一步,把插件安装起来。
第三步:把采集侠插件安装好了之后我们就开始我们的破解啦dede采集侠,先看一下你安装的是GBK还是UTF8,安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!安装的是UTF8的我就解压这个文件。
第四步:用FTP工具联接到你的网站,上传三个文件。三个文件的位置如下:
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
温馨提示:
1、破解程序使用对域名无限制
2、覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净
3、PHP版本必须5.3+ 查看全部
内容摘要:许多使用织梦源码的小伙伴,有时候须要一个插件来采集文章,但是采集插件是收费的,小六正在使用的是织梦采集侠,是须要收费的,不过现今看来也不需要了,因为我们有破解版的织梦采集侠v2.8破解版。好的如今我们开始破解织梦采集侠破解教程。先说明一下:织梦网站安装教程自己安装好,小六在这里只是演示破解采集侠模块。织梦采集侠V2.8...
许多使用织梦源码的小伙伴,有时候须要一个插件来采集文章,但是采集插件是收费的,小六正在使用的是织梦采集侠,是须要收费的,不过现今看来也不需要了,因为我们有破解版的织梦采集侠v2.8破解版。好的现今我们开始破解织梦采集侠破解教程。先说明一下:织梦网站安装教程自己安装好,小六在这里只是演示破解采集侠模块。
织梦采集侠V2.8教程开始:
第一步:首先下载文章附件,解压文件dede采集侠,把“采集侠官方插件.zip”也解压了吧!
第二步:打开这个采集侠网址,根据上面的视频教程把这个插件安装起来,下图就是官网教程开始的第一步,把插件安装起来。
第三步:把采集侠插件安装好了之后我们就开始我们的破解啦dede采集侠,先看一下你安装的是GBK还是UTF8,安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!安装的是UTF8的我就解压这个文件。
第四步:用FTP工具联接到你的网站,上传三个文件。三个文件的位置如下:
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
温馨提示:
1、破解程序使用对域名无限制
2、覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净
3、PHP版本必须5.3+
DEDE织梦采集侠破解版 v2.8 完整源码无限制版
采集交流 • 优采云 发表了文章 • 0 个评论 • 530 次浏览 • 2020-05-17 08:00
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台采集侠2.8破解版下载,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
覆盖破解文件的时侯不用管这种文件。 查看全部
DEDE织梦采集侠破解版 完整源码无限制版,采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择采集侠2.8破解版下载,因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台采集侠2.8破解版下载,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
覆盖破解文件的时侯不用管这种文件。
织梦小说网站源码带采集 小说源码带会员wap站 自动采集自动更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 561 次浏览 • 2020-05-06 08:04
安装费用:(咨询特惠),(使用我们的服务器免费安装) ,自带2条采集规则!好评截图再送一条!
安装环境:PHP5.2,MYSQL,win2003 2008 32位系统!
使用我们的服务器的,我们免费帮安装百度手动推送工具(不是使用我们的服务器的,安装百度手动推送工具费用(咨询特惠))
购买服务器时请注意,如果没有服务器也可以选购我们的服务器,地址:
【重点说明1】
1、网页版采集+火车站采集
2、火车站:可以“按单本采集”,也可以“按栏目采集”!
【重点说明2】
1、会员系统
【重点说明3】
1、众所周知,织梦DEDE的文章内容是存贮在mysql数据库中的,采集内容到百万级别的时侯,数据库会特别的大,十几G甚至几十G文章网站源码带采集,这个时侯网站访问会特别的慢。
2、通过技术手段,将文章内容储存在硬碟,mysql数据库只储存链接,从而将数据库极大的压缩减少,防止后期网站因数据库过大而崩溃
3、比较一下,其它小说源码的,30G的小说内容须要数据库30G文章网站源码带采集,新版源码30G的小说内容须要数据1G,采集再多也不用害怕数据库问题!
【TXT下载功能惊艳升级】
这个源码下载功能太强悍,可以预先生成TXT、ZIP文件(非自动,是手动生成),也可以在网友点击下载的时侯才调用数据库里的内容手动生成TXT、ZIP提供下载,并且,只要有一个人下载过,另一个人再下载时都会直接调用生成好的TXT、ZIP文件下载。【独创的TXT生成功能,不用害怕多人同时下载会打垮服务器】
另外,源码支持RAR下载,但是须要自动生成RAR,如果没有生成,会手动跳转到TXT下载。
升级1,TXT文件支持背部、尾部动态添加广告功能,TXT中的广告可自定义。
升级2,ZIP文件支持打包广告文件, 将广告文件放在指定文件夹中,程序手动生成ZIP的时侯,会把那种文件夹里的所有广告文件一起打包成ZIP提供网友下载,这个广告疗效是相当好的。
升级3,自动生成二维码提供扫描下载!
黑色版 : 查看全部
懂的可以自己安装,有说明,不懂的可以请我们安装,
安装费用:(咨询特惠),(使用我们的服务器免费安装) ,自带2条采集规则!好评截图再送一条!
安装环境:PHP5.2,MYSQL,win2003 2008 32位系统!
使用我们的服务器的,我们免费帮安装百度手动推送工具(不是使用我们的服务器的,安装百度手动推送工具费用(咨询特惠))
购买服务器时请注意,如果没有服务器也可以选购我们的服务器,地址:
【重点说明1】
1、网页版采集+火车站采集
2、火车站:可以“按单本采集”,也可以“按栏目采集”!
【重点说明2】
1、会员系统
【重点说明3】
1、众所周知,织梦DEDE的文章内容是存贮在mysql数据库中的,采集内容到百万级别的时侯,数据库会特别的大,十几G甚至几十G文章网站源码带采集,这个时侯网站访问会特别的慢。
2、通过技术手段,将文章内容储存在硬碟,mysql数据库只储存链接,从而将数据库极大的压缩减少,防止后期网站因数据库过大而崩溃
3、比较一下,其它小说源码的,30G的小说内容须要数据库30G文章网站源码带采集,新版源码30G的小说内容须要数据1G,采集再多也不用害怕数据库问题!
【TXT下载功能惊艳升级】
这个源码下载功能太强悍,可以预先生成TXT、ZIP文件(非自动,是手动生成),也可以在网友点击下载的时侯才调用数据库里的内容手动生成TXT、ZIP提供下载,并且,只要有一个人下载过,另一个人再下载时都会直接调用生成好的TXT、ZIP文件下载。【独创的TXT生成功能,不用害怕多人同时下载会打垮服务器】
另外,源码支持RAR下载,但是须要自动生成RAR,如果没有生成,会手动跳转到TXT下载。
升级1,TXT文件支持背部、尾部动态添加广告功能,TXT中的广告可自定义。
升级2,ZIP文件支持打包广告文件, 将广告文件放在指定文件夹中,程序手动生成ZIP的时侯,会把那种文件夹里的所有广告文件一起打包成ZIP提供网友下载,这个广告疗效是相当好的。
升级3,自动生成二维码提供扫描下载!
黑色版 :
DEDE织梦采集侠破解版(无限制完整源码) 2.8 最新版
采集交流 • 优采云 发表了文章 • 0 个评论 • 480 次浏览 • 2020-04-13 11:08
99下载网提供搜索引擎笔记本软件织梦采集侠2.8破解版下载,织梦采集侠2.8破解版文件大小为355 KB,欢迎来99软件下载DEDE织梦采集侠破解版(无限制完整源码) 2.8 最新版,本站所有软件都免费下载。
DEDE织梦采集侠破解版是一款必备全手动采集伪原创SEO插件,新云网提供其专业破解版本的下载。采集侠正文辨识技术是采集侠多年的技术积累,自主研制了一套汉字剖析和处理的核心系统,目前该系统辨识精度处于领先水平,即便和强悍的搜索引擎中的文字剖析能力也有得一比,优于有道紧跟百度。采集侠正是基于该核心技术研制的一个卓越的采集软件,我们更懂得百度。
织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的织梦采集侠2.8破解版,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台织梦采集侠2.8破解版,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
采集侠定向规则采集教程请参照其官网: 查看全部
99下载网提供搜索引擎笔记本软件织梦采集侠2.8破解版下载,织梦采集侠2.8破解版文件大小为355 KB,欢迎来99软件下载DEDE织梦采集侠破解版(无限制完整源码) 2.8 最新版,本站所有软件都免费下载。
DEDE织梦采集侠破解版是一款必备全手动采集伪原创SEO插件,新云网提供其专业破解版本的下载。采集侠正文辨识技术是采集侠多年的技术积累,自主研制了一套汉字剖析和处理的核心系统,目前该系统辨识精度处于领先水平,即便和强悍的搜索引擎中的文字剖析能力也有得一比,优于有道紧跟百度。采集侠正是基于该核心技术研制的一个卓越的采集软件,我们更懂得百度。
织梦采集侠是一款基于织梦DEDECMS的专业站群系统/站群软件,可以按照关键词、RSS和页面监控等方法定时定量采集,进行伪原创SEO优化后更新发布,无需编撰采集规则!
采集版分UTF8和GBK两个版本,根据自己使用的dedecms版本来选择!
因文件是用mac系统打包的,会自带_MACOSX、.DS_Store文件,不影响使用,有强迫症的可以删掉。覆盖破解文件的时侯不用管这种文件。
1,【您自行去采集侠官方下载最新v2.8版本假如官网不能打开就用我备份好的织梦采集侠2.8破解版,解压后有个采集侠官方插件文件夹,自行选择安装对应的版本),然后安装到您的织梦后台织梦采集侠2.8破解版,如果之前安装过2.7版本,请先删掉!】
2,注意安装的时侯版本千万不要选错了,UTF8就装UTF8,GBK就用GBK的不要混用!
3,【覆盖破解文件】(共三个文件CaiJiXia、include和Plugins)
Plugins : 直接覆盖到网站的根目录
include : 直接覆盖到网站的根目录
CaiJiXia: 网站默认后台是dede,如果你没有更改后台目录的话那就是覆盖 /dede/apps/下面,如果后台访问路径被更改过的话,那就把dede换成你更改的名称。例:dede已更改成test, 那就覆盖/test/apps/目录下
4,【破解程序使用对域名无限制】
5, 【覆盖后须要清除下浏览器缓存, 推荐使用微软或则火狐浏览器,不要用IE内核浏览器,清理缓存有时清的不干净】
6, PHP版本必须5.3+
采集侠定向规则采集教程请参照其官网:
织梦cms资源教程网源码
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-04-08 11:07
本次为你们带来最新织梦cms资源教程网源码,这是一款自适应性源码,会依照不同的环境进行智能更改以适应相关的采集搭建需求。织梦cms源码特性就是愈发灵活,非常适宜进行一些网站扩展操作。有相关资源教程网搭建需求的朋友们不妨试试吧!
良好的用户口碑
丰富的开源经验
灵活的模块组合
让网站更丰富、方便网站扩展
简单易用的模板引擎
让界面想怎样换就如何换
便捷自定义模型
自己扩充网站后续功能,省去众多苦恼
php版本5.6以上,MySQL5.6以上
上传源码至根目录后解压,域名+install/index.php进行安装,安装完后步入后台登陆
登录后到系统设置中的数据库备份/还原中点击右上角的数据还原即可,后台默认帐户密码为admin admin
PC官方版
安卓官方手机版
IOS官方手机版
vs2010英文旗舰版是一个集成环境,它简化了有关创建、调试和布署应用程序的基本任务。借助于 Visual Studio 2010 专业版,您可以恣意发挥您的想象力并轻松实现您的目标。借助于功能强悍的设计图面和使得设计人员和开发人员协同工作的能力,尽情发挥您的创造力,让您的梦想成真。在一个面向日渐增多的平台(包括 Silverlight、SharePoint 和云应用程序)的个性化环境中工作,使用现有技术推动编码过程。对测试先行的开发的集成支持和新的调试工具可使您快速查找和修补所有 bug,并有助于确保实现高质量解决方案。
Windows 7; Windows Server 2003 R2 (32-Bit x86); Windows Server 2003 R2 x64 editions; Windows Server 2003 Service Pack 2; Windows Server 2008 R2; Windows Server 2008 Service Pack 2; Windows Vista Service Pack 2; Windows XP Service Pack 3
Windows XP (x86) Service Pack 3 – 除 Starter Edition 之外的所有版本
Windows Vista(x86 和 x64)Service Pack 2 - 除 Starter Edition 之外的所有版本
Windows 7(x86 和 x64)
Windows Server 2003(x86 和 x64)Service Pack 2 – 所有版本
如果不存在 MSXML6,则用户须要安装它
Windows Server 2003 R2(x86 和 x64)- 所有版本
Windows Server 2008(x86 和 x64)Service Pack 2 – 所有版本
Windows Server 2008 R2 (x64) – 所有版本
它将是精典的一个版本,相当于当初的6.0版。
新功能还包括:
(1)C# 4.0中的动态类型和动态编程;
(2)多显示器支持;
(3)使用Visual Studio 2010的特点支持TDD;
(4)支持Office ;
(5)Quick Search特点;
(6)C++ 0x新特点;
(7)IDE提高;
(8)使用Visual C++ 2010创建Ribbon界面;
(9)新增基于.NET平台的语言
而按照谷歌发布的一份官方文档声称,Visual Studio 2010和.NET Framework 4.0将在下边五个方面有所创新: ·民主化的应用程序生命周期管理 在一个组织中,应用程序生命周期管理(ALM)将涉入到多个角色。但是在传统意义上,这一过程中的每位角色并不是完全平等的。Visual Studio Team System 2010将坚持构筑一个功能平等、共同分担的平台以用于组织内的应用程序生命周期管理过程。 ·顺应新的技术时尚 每年,业界内的新技术和新趋势层出不穷。通过Visual Studio 2010,微软将为开发者提供合适的工具和框架,以支持软件开发中最新的构架,开发和布署。 ·让开发商惊喜 从Visual Studio的第一个版本开始,微软就将提升开发人员的工作效率和灵活性作为自己的目标。Visual Studio 2010将继续关注而且明显地改进开发者最核心的开发体验。 ·下一代平台浪潮的弄潮儿 微软将继续投资于市场领先的操作系统,工具软件和服务器平台,为顾客创造更高的价值。使用Visual Studio 2010,将可以在新一代的应用平台上,为你的顾客创造令人惊奇的解决方案。 · 跨部门的应用 客户将在不同规模的组织内创建应用,跨度从单个部门到整个企业。
Visual Studio 2010将确保在如此笼统的范围内的应用开发都得到支持。
创建第一个C项目
运行vs10,点击【新建项目】,弹出如下新建项目框,选择【Visual c++】—>【win32控制台应用程序】,输入项目名称和位置,也可选择默认,然后单击【确定】。
弹出如下应用程序向导框,单击【下一步】
选择【空项目】,单击【完成】
然后织梦cms相关学习技术资料免费下载,在项目右侧栏就可以看见刚刚新建的项目了(本人创建的是test),然后,右键【源文件】—>【添加】—>【新建项】,如下:
然后,弹出如下添加新项框,选择【c++文件】,输入文件名称,点击【添加】即可。
此时,在两侧源文件下就可以看见新建的文件了,如本人创建的main.c文件,然后输入程序,按【Ctrl+F5】运行即可,示例如下:
按【F5】表示调试。
PC官方版
安卓官方手机版
IOS官方手机版
Visual Studio Community 2015是免费的,具备所有为Windows、iOS、Android设备或是云服务器开发桌面、移动、网页应用的全套功能。这个版本针对小公司、初创企业、学生和开源软件开发者们,开发的非企业级软件。它提供了一个统一的客户端和服务器开发的平台,支持联通跨平台开发,可扩充,编程功能先进、高效。
VS2015版本针对多个平台添加了新的开发工具,支持开发Win10全平台通用应用程序,包括Windows10手机、Win10 PC、Xbox以及HoloLens提高现实等。另外,通过VS2015,开发人员还可以使用Apache Cordova、Xamarin或C++等语言或技术开发iOS和安卓平台应用。针对WEB和服务器开发,你可以使用Python、Node.js技术以及C#,Visual Basic或F#语言。
Visual Studio 2015明天如期放出了即将版本。Visual Studio 2015包括许多新功能和更新,如通用Windows应用开发工具、面向iOS、Android、Windows的跨平台联通开发工具(包括Xamarin、Apache Cordova、Unity)、可移植C++库、适用于Android的本机活动C++模板等等,对Cordova,Xamarin , C++的跨平台支持都非常好。让你通过一个工具完成了iOS ,Android ,Windows 三个平台的应用,绝对是Windows 10乃至跨平台开发的首选神器。
跨平台支持成为VS2015最新DNA。在智能移动端App开发,支持无论是面向何种智能设备,无论是支持Native应用,还是基于HTML5的混和应用,都可以利用VS2015的编码、调试,智能提示等强悍功能帮助程序员快速开发。特别是Xamarin的安装包早已集成进VS2015,Visual Studio还可以进行Apple Watch的应用开发哦!
此番发布的Visual Studio 2015正式版包含32/64位的安装镜像和相关工具,标准版、企业版、专业版、测试专业版、精简版等各个版本都有,支持繁体英文等多国语言,MSDN开发者如今就可以下载使用了。
与此同时,Visual Studio 2013 Update 5、.NET Framework 4.6正式版也早已发布,不过Team Foundation Server 2015暂未放出,只给了一个Team Foundation Server 2013 Update 5。
整个Visual Studio 2015 是包括Visual Studio、Visual Studio Online、Visual Studio Code。Visual Studio Online 提供完整的,轻量级别的,基于微软云平台的,软件全生命周期支持,Online版本和TFS2015为开发团队提供基于DevOps理念的完整解决方案。帮助开发者完成应用的管理、工作、开发、联调、测试和发布全生命周期工作,并提供高效工具完成应用使用状况和使用情况的监控。
Visual Code提供第一个来自谷歌的跨平台开发工具,支持开发人员在windows、linux、Mac上都可以开发ASP.NET或则NodeJS的应用。
Visual Studio Community 2013– 新的、免费的、全功能版本的 Visual Studio,可以拿来开发桌面、移动、Web 和云应用织梦cms相关学习技术资料免费下载,只容许开发非企业应用的。
Visual Studio 2015 预览版和 .NET 2015 预览版– Visual Studio 2015 支持 Windows、iOS 和 Android 等应用的跨平台开发,内置 Apache Cordova 支持。微软和 Xamarin 宣布简化在 Visual Studio 中安装 Xamarin 的流程,并宣布将于明年年末发布的免费版 Xamarin Starter Edition 中降低对 Visual Studio 的支持。 查看全部
本次为你们带来最新织梦cms资源教程网源码,这是一款自适应性源码,会依照不同的环境进行智能更改以适应相关的采集搭建需求。织梦cms源码特性就是愈发灵活,非常适宜进行一些网站扩展操作。有相关资源教程网搭建需求的朋友们不妨试试吧!
良好的用户口碑
丰富的开源经验
灵活的模块组合
让网站更丰富、方便网站扩展
简单易用的模板引擎
让界面想怎样换就如何换
便捷自定义模型
自己扩充网站后续功能,省去众多苦恼
php版本5.6以上,MySQL5.6以上
上传源码至根目录后解压,域名+install/index.php进行安装,安装完后步入后台登陆
登录后到系统设置中的数据库备份/还原中点击右上角的数据还原即可,后台默认帐户密码为admin admin
PC官方版
安卓官方手机版
IOS官方手机版
vs2010英文旗舰版是一个集成环境,它简化了有关创建、调试和布署应用程序的基本任务。借助于 Visual Studio 2010 专业版,您可以恣意发挥您的想象力并轻松实现您的目标。借助于功能强悍的设计图面和使得设计人员和开发人员协同工作的能力,尽情发挥您的创造力,让您的梦想成真。在一个面向日渐增多的平台(包括 Silverlight、SharePoint 和云应用程序)的个性化环境中工作,使用现有技术推动编码过程。对测试先行的开发的集成支持和新的调试工具可使您快速查找和修补所有 bug,并有助于确保实现高质量解决方案。
Windows 7; Windows Server 2003 R2 (32-Bit x86); Windows Server 2003 R2 x64 editions; Windows Server 2003 Service Pack 2; Windows Server 2008 R2; Windows Server 2008 Service Pack 2; Windows Vista Service Pack 2; Windows XP Service Pack 3
Windows XP (x86) Service Pack 3 – 除 Starter Edition 之外的所有版本
Windows Vista(x86 和 x64)Service Pack 2 - 除 Starter Edition 之外的所有版本
Windows 7(x86 和 x64)
Windows Server 2003(x86 和 x64)Service Pack 2 – 所有版本
如果不存在 MSXML6,则用户须要安装它
Windows Server 2003 R2(x86 和 x64)- 所有版本
Windows Server 2008(x86 和 x64)Service Pack 2 – 所有版本
Windows Server 2008 R2 (x64) – 所有版本
它将是精典的一个版本,相当于当初的6.0版。
新功能还包括:
(1)C# 4.0中的动态类型和动态编程;
(2)多显示器支持;
(3)使用Visual Studio 2010的特点支持TDD;
(4)支持Office ;
(5)Quick Search特点;
(6)C++ 0x新特点;
(7)IDE提高;
(8)使用Visual C++ 2010创建Ribbon界面;
(9)新增基于.NET平台的语言
而按照谷歌发布的一份官方文档声称,Visual Studio 2010和.NET Framework 4.0将在下边五个方面有所创新: ·民主化的应用程序生命周期管理 在一个组织中,应用程序生命周期管理(ALM)将涉入到多个角色。但是在传统意义上,这一过程中的每位角色并不是完全平等的。Visual Studio Team System 2010将坚持构筑一个功能平等、共同分担的平台以用于组织内的应用程序生命周期管理过程。 ·顺应新的技术时尚 每年,业界内的新技术和新趋势层出不穷。通过Visual Studio 2010,微软将为开发者提供合适的工具和框架,以支持软件开发中最新的构架,开发和布署。 ·让开发商惊喜 从Visual Studio的第一个版本开始,微软就将提升开发人员的工作效率和灵活性作为自己的目标。Visual Studio 2010将继续关注而且明显地改进开发者最核心的开发体验。 ·下一代平台浪潮的弄潮儿 微软将继续投资于市场领先的操作系统,工具软件和服务器平台,为顾客创造更高的价值。使用Visual Studio 2010,将可以在新一代的应用平台上,为你的顾客创造令人惊奇的解决方案。 · 跨部门的应用 客户将在不同规模的组织内创建应用,跨度从单个部门到整个企业。
Visual Studio 2010将确保在如此笼统的范围内的应用开发都得到支持。
创建第一个C项目
运行vs10,点击【新建项目】,弹出如下新建项目框,选择【Visual c++】—>【win32控制台应用程序】,输入项目名称和位置,也可选择默认,然后单击【确定】。
弹出如下应用程序向导框,单击【下一步】
选择【空项目】,单击【完成】
然后织梦cms相关学习技术资料免费下载,在项目右侧栏就可以看见刚刚新建的项目了(本人创建的是test),然后,右键【源文件】—>【添加】—>【新建项】,如下:
然后,弹出如下添加新项框,选择【c++文件】,输入文件名称,点击【添加】即可。
此时,在两侧源文件下就可以看见新建的文件了,如本人创建的main.c文件,然后输入程序,按【Ctrl+F5】运行即可,示例如下:
按【F5】表示调试。
PC官方版
安卓官方手机版
IOS官方手机版
Visual Studio Community 2015是免费的,具备所有为Windows、iOS、Android设备或是云服务器开发桌面、移动、网页应用的全套功能。这个版本针对小公司、初创企业、学生和开源软件开发者们,开发的非企业级软件。它提供了一个统一的客户端和服务器开发的平台,支持联通跨平台开发,可扩充,编程功能先进、高效。
VS2015版本针对多个平台添加了新的开发工具,支持开发Win10全平台通用应用程序,包括Windows10手机、Win10 PC、Xbox以及HoloLens提高现实等。另外,通过VS2015,开发人员还可以使用Apache Cordova、Xamarin或C++等语言或技术开发iOS和安卓平台应用。针对WEB和服务器开发,你可以使用Python、Node.js技术以及C#,Visual Basic或F#语言。
Visual Studio 2015明天如期放出了即将版本。Visual Studio 2015包括许多新功能和更新,如通用Windows应用开发工具、面向iOS、Android、Windows的跨平台联通开发工具(包括Xamarin、Apache Cordova、Unity)、可移植C++库、适用于Android的本机活动C++模板等等,对Cordova,Xamarin , C++的跨平台支持都非常好。让你通过一个工具完成了iOS ,Android ,Windows 三个平台的应用,绝对是Windows 10乃至跨平台开发的首选神器。
跨平台支持成为VS2015最新DNA。在智能移动端App开发,支持无论是面向何种智能设备,无论是支持Native应用,还是基于HTML5的混和应用,都可以利用VS2015的编码、调试,智能提示等强悍功能帮助程序员快速开发。特别是Xamarin的安装包早已集成进VS2015,Visual Studio还可以进行Apple Watch的应用开发哦!
此番发布的Visual Studio 2015正式版包含32/64位的安装镜像和相关工具,标准版、企业版、专业版、测试专业版、精简版等各个版本都有,支持繁体英文等多国语言,MSDN开发者如今就可以下载使用了。
与此同时,Visual Studio 2013 Update 5、.NET Framework 4.6正式版也早已发布,不过Team Foundation Server 2015暂未放出,只给了一个Team Foundation Server 2013 Update 5。
整个Visual Studio 2015 是包括Visual Studio、Visual Studio Online、Visual Studio Code。Visual Studio Online 提供完整的,轻量级别的,基于微软云平台的,软件全生命周期支持,Online版本和TFS2015为开发团队提供基于DevOps理念的完整解决方案。帮助开发者完成应用的管理、工作、开发、联调、测试和发布全生命周期工作,并提供高效工具完成应用使用状况和使用情况的监控。
Visual Code提供第一个来自谷歌的跨平台开发工具,支持开发人员在windows、linux、Mac上都可以开发ASP.NET或则NodeJS的应用。
Visual Studio Community 2013– 新的、免费的、全功能版本的 Visual Studio,可以拿来开发桌面、移动、Web 和云应用织梦cms相关学习技术资料免费下载,只容许开发非企业应用的。
Visual Studio 2015 预览版和 .NET 2015 预览版– Visual Studio 2015 支持 Windows、iOS 和 Android 等应用的跨平台开发,内置 Apache Cordova 支持。微软和 Xamarin 宣布简化在 Visual Studio 中安装 Xamarin 的流程,并宣布将于明年年末发布的免费版 Xamarin Starter Edition 中降低对 Visual Studio 的支持。
HTML5响应式红色商务企业dedecms整站源码(支持移动端)
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-04-08 11:01
蓝色高档商务网路公司整站源码是以织梦内核为网站操作系统的企业模板
页面风格扁平大气,整站主色采用红色,黑色进行搭配,首页的内容设计布局并没用采用那个大量留白的设计风格愈发养眼用户视觉体验疗效棒。
内容相对比较紧凑,更适宜中小型公司企业站使用。当然,这既然是一套高档模板高端响应式网络公司织梦整站源码,那肯定是采用了响应式的设计,
在任何浏览器设备下都可完美呈现,所以也可通用于大多数企业站,如:电子商务公司,外贸企业,网络工作室,等等。
★模板安装方式★
1.把文件上传到你的站点的根目录,然后运行 你的域名/install/index.php 安装,根据提示填写好相关信息,点“下一步”...即可完成安装。
注:若提示难以安装,页面出现DIY字样。请步入install文件夹,将install_lock.txt文件删除。把index.php.bak文件改为index.php即可!
2.安装好后,在后台“系统”—“数据库备份/恢复”,点右上角“还原数据”—“开始还原数据”,恢复数据库。
3.进入后台你的域名/dede,点“系统”—“系统参数设置”这里,修改一下网站设置高端响应式网络公司织梦整站源码,重新点一下“确定”(没有这一步,有时候会导致更新后,前台显示织梦默认模板内容)。
4.后台,点"生成"—"更新系统缓存"
5.后台,点“生成” - “一键更新网站” - “更新所有”,重新生成一次所有页面,OK 完成。
后台地址:你的域名/dede
管理员帐号:admin
管理员密码:admin
如果安装后出现网站错位和无数据的情况,请复查以下三点设置
一. 网站程序必须置于根目录
二. 进入后台[系统]-[系统基本参数],修改“站点根网址”为你的网址,或者留空。
三. 进入后台[核心]-[网站栏目管理],点击顶部按键中的“更新排序”。
至此,模板安装结束 查看全部
蓝色高档商务网路公司整站源码是以织梦内核为网站操作系统的企业模板
页面风格扁平大气,整站主色采用红色,黑色进行搭配,首页的内容设计布局并没用采用那个大量留白的设计风格愈发养眼用户视觉体验疗效棒。
内容相对比较紧凑,更适宜中小型公司企业站使用。当然,这既然是一套高档模板高端响应式网络公司织梦整站源码,那肯定是采用了响应式的设计,
在任何浏览器设备下都可完美呈现,所以也可通用于大多数企业站,如:电子商务公司,外贸企业,网络工作室,等等。
★模板安装方式★
1.把文件上传到你的站点的根目录,然后运行 你的域名/install/index.php 安装,根据提示填写好相关信息,点“下一步”...即可完成安装。
注:若提示难以安装,页面出现DIY字样。请步入install文件夹,将install_lock.txt文件删除。把index.php.bak文件改为index.php即可!
2.安装好后,在后台“系统”—“数据库备份/恢复”,点右上角“还原数据”—“开始还原数据”,恢复数据库。
3.进入后台你的域名/dede,点“系统”—“系统参数设置”这里,修改一下网站设置高端响应式网络公司织梦整站源码,重新点一下“确定”(没有这一步,有时候会导致更新后,前台显示织梦默认模板内容)。
4.后台,点"生成"—"更新系统缓存"
5.后台,点“生成” - “一键更新网站” - “更新所有”,重新生成一次所有页面,OK 完成。
后台地址:你的域名/dede
管理员帐号:admin
管理员密码:admin
如果安装后出现网站错位和无数据的情况,请复查以下三点设置
一. 网站程序必须置于根目录
二. 进入后台[系统]-[系统基本参数],修改“站点根网址”为你的网址,或者留空。
三. 进入后台[核心]-[网站栏目管理],点击顶部按键中的“更新排序”。
至此,模板安装结束
免费网站织梦源码 织梦cms 织梦模板下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 353 次浏览 • 2020-04-07 11:01
模板建站的优势和劣势
优势1、建站便捷:企业网站模板,一般是建站公司通过剖析市场和行业的需求而做下来的企业网站模板,用户订购模版后通过套用CMS等自助建站系统,再添加、丰富网站内容后完成企业建站。
优势2、有行业特点:每一个企业模板的制做都是经过市场调查,分析行业特点、用户体验以及使用者的综合需求而确定模板的制做,这类企业模板有着一定的专业性和相关性。
优势3、一般价钱实惠:企业网站模板在制做以后可以进行批量的推出,总成本要比订制一个网站低上许多。
如何正确选择建站模板
无论是免费模板还是付费模板,它的制做成本低,不排除在这个行业中的企业仅仅是借助模板来挣钱,他们并不对模板的质量进行负责和保障,甚至有些企业网站模板是经过多手订购,加以更改和出售的,在你使用模板之前一定要注意以下几点:
1、当你使用某个建站平台的网站模板进行建站的时侯,不要被此网站上漂亮的图文广告,营销手段所愚弄。应先进行考察,尤其是可以瞧瞧她们的案例库,看看实际用户做下来的疗效。
2、选择一个自定义强悍的模板,特别是可以控制网站上模块的输出,这样可以避免重复性代码输出,通过调整模块位置,和自定义输出的模块,达到奇特的显示疗效,从而就能最大程度丰富网站显示的方法,从而给用户一个好的印象。而后端的代码也会显示的完全不一样,给搜索引擎的印象也是好的。
3、在订购模板之前对行业所能提供的服务进行咨询,以免引起出现问题时无人问津的结果,甚至有些应用插件也有二次付费的情况。
4、对程序代码要有一定的了解,尤其是在想要搭建一个须要做优化的网站的时侯,应该选择符合优化规则的模板。
一般象织梦模板之家这样的自助建站平台,其模板仍然在不断更新,同时模板和功能是一体的,可以直接调用,而且模板本身根本就无需下载,直接可以使用。对于中小微企业和创业团队而言,选择织梦模板之家这样的建站平台,是性价比和安全上都不错的。
作为拥有国外HTML5模板库的建站工具织梦cms模板下载,织梦模板之家拥有上千套多种专业设计的HTML5模板织梦cms模板下载,20多种不同行业的模板库,方便顾客快速选择自己所需类型。
总结:
如果我们对网站建设的页面、功能要求较高,而且自身有相关的建站知识,还能接受订制价位的人群可以选择订制建站。如果我们只是须要一个标准化的企业网站,对企业建站也不是太了解,那么就可以选择企业模板建站。只要在确定模板之前,选出一套适宜的建站系统,并查看建站系统的后台布局、功能以及管理方法等,综合考虑后选择一套适宜企业网站需求的模板。 查看全部
模板建站的优势和劣势
优势1、建站便捷:企业网站模板,一般是建站公司通过剖析市场和行业的需求而做下来的企业网站模板,用户订购模版后通过套用CMS等自助建站系统,再添加、丰富网站内容后完成企业建站。
优势2、有行业特点:每一个企业模板的制做都是经过市场调查,分析行业特点、用户体验以及使用者的综合需求而确定模板的制做,这类企业模板有着一定的专业性和相关性。
优势3、一般价钱实惠:企业网站模板在制做以后可以进行批量的推出,总成本要比订制一个网站低上许多。
如何正确选择建站模板
无论是免费模板还是付费模板,它的制做成本低,不排除在这个行业中的企业仅仅是借助模板来挣钱,他们并不对模板的质量进行负责和保障,甚至有些企业网站模板是经过多手订购,加以更改和出售的,在你使用模板之前一定要注意以下几点:
1、当你使用某个建站平台的网站模板进行建站的时侯,不要被此网站上漂亮的图文广告,营销手段所愚弄。应先进行考察,尤其是可以瞧瞧她们的案例库,看看实际用户做下来的疗效。
2、选择一个自定义强悍的模板,特别是可以控制网站上模块的输出,这样可以避免重复性代码输出,通过调整模块位置,和自定义输出的模块,达到奇特的显示疗效,从而就能最大程度丰富网站显示的方法,从而给用户一个好的印象。而后端的代码也会显示的完全不一样,给搜索引擎的印象也是好的。
3、在订购模板之前对行业所能提供的服务进行咨询,以免引起出现问题时无人问津的结果,甚至有些应用插件也有二次付费的情况。
4、对程序代码要有一定的了解,尤其是在想要搭建一个须要做优化的网站的时侯,应该选择符合优化规则的模板。
一般象织梦模板之家这样的自助建站平台,其模板仍然在不断更新,同时模板和功能是一体的,可以直接调用,而且模板本身根本就无需下载,直接可以使用。对于中小微企业和创业团队而言,选择织梦模板之家这样的建站平台,是性价比和安全上都不错的。
作为拥有国外HTML5模板库的建站工具织梦cms模板下载,织梦模板之家拥有上千套多种专业设计的HTML5模板织梦cms模板下载,20多种不同行业的模板库,方便顾客快速选择自己所需类型。
总结:
如果我们对网站建设的页面、功能要求较高,而且自身有相关的建站知识,还能接受订制价位的人群可以选择订制建站。如果我们只是须要一个标准化的企业网站,对企业建站也不是太了解,那么就可以选择企业模板建站。只要在确定模板之前,选出一套适宜的建站系统,并查看建站系统的后台布局、功能以及管理方法等,综合考虑后选择一套适宜企业网站需求的模板。

