
网站内容自动更新
网站内容自动更新(网站自动更新机制中会出现更新错误的原因及解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-26 15:02
网站内容自动更新机制中会出现更新错误,错误原因中包含bug或者是代码异常。今天开始我们将分享代码异常处理案例,来看看异常处理服务器崩溃原因及解决方法。案例1:本地调试速度非常快,web服务器也没有出现问题。cpu占用率突然来个1%以下的大幅波动,报错:web服务器不可用。这时应该执行上述代码,正常情况会将重试机制切换成滚动条重试机制,使得那1%时间内的更新速度和更新效率都非常快。
如果如果还是不行的话,就到机房测量机器耗电情况,如果耗电比例是0.0044%,则是网络不通畅的原因。要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。解决方法:如果机房重新测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机房风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
如果机房测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机房风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。解决方法:如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。
如果还是不行的话,就到机房测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间。 查看全部
网站内容自动更新(网站自动更新机制中会出现更新错误的原因及解决方法)
网站内容自动更新机制中会出现更新错误,错误原因中包含bug或者是代码异常。今天开始我们将分享代码异常处理案例,来看看异常处理服务器崩溃原因及解决方法。案例1:本地调试速度非常快,web服务器也没有出现问题。cpu占用率突然来个1%以下的大幅波动,报错:web服务器不可用。这时应该执行上述代码,正常情况会将重试机制切换成滚动条重试机制,使得那1%时间内的更新速度和更新效率都非常快。
如果如果还是不行的话,就到机房测量机器耗电情况,如果耗电比例是0.0044%,则是网络不通畅的原因。要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。解决方法:如果机房重新测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机房风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
如果机房测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机房风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。解决方法:如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。
如果还是不行的话,就到机房测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间。
网站内容自动更新(如何自动缓存所有的页面的资源?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2021-09-24 02:05
Manifest 用于制作离线页面。即使断网,页面也能正常打开。使用简单,但在实际使用中存在以下问题:
(1)如何自动缓存所有页面的资源?因为manifest不能使用*通配符进行缓存
(2)如果网站资源更新了,manifest文件怎么自动更新?否则,如果用户不清除缓存,即使联网也会加载旧页面
我想很多网站没有使用Manifest就是因为上面提到的两个原因。也有人尝试过,但是使用起来比较麻烦,离线应用的价值似乎也不是很大。不过,使用Manifest还是有很多好处的,尤其是对于网站,比如博客等比较容易展示的,或者在线APP。这类网站的数据动态变化的频率比较低,不需要频繁。从服务请求数据。这样,当用户需要频繁返回首页或频繁在多个页面之间来回切换时,由于几乎所有资源都在本地,加载是瞬间完成的。
1. 使用清单
使用Manifest很简单,就是在html标签中添加一个manifest属性:
该属性指向一个manifest文件,指定当前页面上哪些资源需要离线缓存,如下home.appcache:
CACHE MANIFEST
#9/27/2017, 3:04:25 PM
#html
https://github.com/
#img
https://assets-cdn.github.com/ ... p.png
https://assets-cdn.github.com/ ... k.png
#css
https://assets-cdn.github.com/ ... 1.css
#js
https://assets-cdn.github.com/ ... d9.js
NETWORK:
*
FALLBACK
https://github.com/ /html/manifest/html/home.html
这个文件的第一行必须以CACHE MANIFEST开头,否则浏览器解析会报错。注释以# 开头。此行下方是需要缓存的资源。下一个 NETWORK 指示需要在线加载哪些资源。一般需要写成NETWORK*,表示除CACHE以外的所有资源都需要上网,包括一些动态请求。如果你写的是特定路径而不是*,那些既不在CAHCE中也不在NETWORK中的会报加载失败错误。如下:
就算是连上网也会这样,所以一般写成*.
FALLBACK 表示替代资源。如果这些资源未加载,它们将替换加载的资源。例如,如果无法访问上述文件,则使用静态 html 访问:/html/manifest/html/home.html。
打开支持Manifest的网站,例如可以观察Chrome控制台缓存的过程:
然后刷新页面,你会发现页面上几乎所有的资源都是从本地缓存中获取的,如下图所示:
并且如果断开网络并刷新页面,页面仍然可以正常加载。这在 Chrome/Firefox/Safari 等浏览器中受支持。
除了Manifest,还有一种缓存方式,就是设置HTTP头的Cache-Control字段进行缓存。这样可以缓存JS/CSS/图片资源,但是如果你也缓存HTML,就会有问题。如果用户没有清除缓存,即使你的页面更新了,用户仍然会加载旧页面,直到缓存设置 Max-Age 时间到了。所以使用Manifest可以解决这个问题。
Manifest 如何知道当前页面数据更新了?只需更改您的清单文件,例如上面的 home.appcache。打开页面时浏览器会加载这个文件。一旦发现这个文件发生了变化,下次刷新时会重新加载所有的Cache文件。最简单的方法是将评论中的时间更改为当前时间:
#9/29/2017, 9:08:49 AM
所以当网站的资源发生变化时,可以改变这个manifest的内容,然后互联网浏览器就可以更新它。
使用Manifest需要注意以下问题:
(1)Manifest 有大小限制,它实际上是一个本地存储,本地存储一般每个域都有一个有限的空间,PC Chrome 为 5Mb,参考下表:
浏览器应用程序缓存 (AppCache) 存储限制 Safari 桌面 (Mac & Win)无限Safari Mobile (iOS)10 MBChrome 桌面 (Mac & Win)5 MB *Chrome Mobile (Android)无限 **Firefox 4 BetaUnlimited(有用户提示)IE 不知道。糟透了。***
(2)home.appcahce等manifest文件不能跨域,如果跨域需要支持CORS
(3)Manifest Cache 资源不能跨域。同理,如果跨域资源需要支持CORS,一般浏览器会自动处理
2. 解决Manifest自动生成更新问题
由于Manifest不能使用通配符来匹配资源,需要一一列出需要缓存的资源,而且网站的内容往往是动态更新的,所以这样比较麻烦。为此,作者写了一个NPM包generate-manifest,自动生成manifest,使用起来非常简单:
npm install -g generate-manifest
generate-manifest --url=https://github.com
它会生成一个home.appchache的Manifest文件,该文件收录页面上img/js/css的资源链接:
CACHE MANIFEST
#9/27/2017, 3:04:25 PM
#html
https://github.com/
#img
https://assets-cdn.github.com/ ... p.png
https://assets-cdn.github.com/ ... k.png
#css
https://assets-cdn.github.com/ ... 1.css
#js
https://assets-cdn.github.com/ ... d9.js
NETWORK:
*
FALLBACK
https://github.com/ /html/manifest/html/home.html
也可以支持其他参数自定义,详见:generate-manifest。
这就解决了自动生成的问题。我应该如何使用自动更新?
由于本人是博客网站,所以网站的内容主要变化如下: 1. 发帖/改博客;2. 用户发表评论;3. 网站 的浏览量发生了变化。第一个解决方案是写一个接口。只要你发布博客,调整这个接口,生成一个新的manifest文件:
/refresh-manifest.php?link=
然后它会调整上面的 generate-manifest 包,生成一个 manifest.appcache 文件。在html中,manifest的名字是根据路径的最后一部分来确定的:
>
这与生成的文件名一一对应。
第二个问题:用户发表评论-在调整发布界面自动调整该界面。需要注意的是,这个接口需要反脚本注入,否则更危险。
第三题:读取卷数据变化——写一个Linux定时任务,使用crontab添加定时任务,执行crontab -e添加:
0 3 * * * /home/fed/manifest/update-all.sh
上面的意思是每天3:00运行update-all.sh脚本。此脚本为所有页面编写更新命令:
generate-manifest --url=https://fed.renren.com
generate-manifest --url=https://fed.renren.com/page/2/
generate-manifest --url=https://fed.renren.com/page/3/
#..其它...
第一点提到的发布文章也会给这个脚本添加一行命令。
由于阅读量不是很重要,最好每天更新一次。这允许用户在同一天缓存他们的操作。如果你第二天再看它,就更新它。
所以自动更新的问题基本解决了。
还有一个问题是Manifest改变后第一次刷新还是老页面。只有第二次刷新是正确的,所以我们希望在更改清单后,刷新是新的,而不是之前的缓存。不需要刷两次。
那么该怎么办?Manifest有一个update事件,一旦manifest文件更新就会触发,所以我们可以监听这个事件,然后自动刷新页面重新加载页面,如下代码所示:
function onUpdateReady() {
window.location.reload(true);
}
window.applicationCache.addEventListener('updateready', onUpdateReady);
if(window.applicationCache.status === window.applicationCache.UPDATEREADY) {
onUpdateReady();
}
综上所述,我们很好地利用Manifest做了一个离线页面应用,解决了自动生成和自动更新的问题。即使用户不离线,第二次加载的资源都缓存在本地,所以当用户在几个页面之间来回切换时,速度非常快。例如,很多人可能在主页上的列表和内容页之间。来回切换。
虽然 Manifest 已经被 Service Worker 弃用,但由于它的简单性和兼容性,我们仍然可以使用它。 查看全部
网站内容自动更新(如何自动缓存所有的页面的资源?(一))
Manifest 用于制作离线页面。即使断网,页面也能正常打开。使用简单,但在实际使用中存在以下问题:
(1)如何自动缓存所有页面的资源?因为manifest不能使用*通配符进行缓存
(2)如果网站资源更新了,manifest文件怎么自动更新?否则,如果用户不清除缓存,即使联网也会加载旧页面
我想很多网站没有使用Manifest就是因为上面提到的两个原因。也有人尝试过,但是使用起来比较麻烦,离线应用的价值似乎也不是很大。不过,使用Manifest还是有很多好处的,尤其是对于网站,比如博客等比较容易展示的,或者在线APP。这类网站的数据动态变化的频率比较低,不需要频繁。从服务请求数据。这样,当用户需要频繁返回首页或频繁在多个页面之间来回切换时,由于几乎所有资源都在本地,加载是瞬间完成的。
1. 使用清单
使用Manifest很简单,就是在html标签中添加一个manifest属性:
该属性指向一个manifest文件,指定当前页面上哪些资源需要离线缓存,如下home.appcache:
CACHE MANIFEST
#9/27/2017, 3:04:25 PM
#html
https://github.com/
#img
https://assets-cdn.github.com/ ... p.png
https://assets-cdn.github.com/ ... k.png
#css
https://assets-cdn.github.com/ ... 1.css
#js
https://assets-cdn.github.com/ ... d9.js
NETWORK:
*
FALLBACK
https://github.com/ /html/manifest/html/home.html
这个文件的第一行必须以CACHE MANIFEST开头,否则浏览器解析会报错。注释以# 开头。此行下方是需要缓存的资源。下一个 NETWORK 指示需要在线加载哪些资源。一般需要写成NETWORK*,表示除CACHE以外的所有资源都需要上网,包括一些动态请求。如果你写的是特定路径而不是*,那些既不在CAHCE中也不在NETWORK中的会报加载失败错误。如下:

就算是连上网也会这样,所以一般写成*.
FALLBACK 表示替代资源。如果这些资源未加载,它们将替换加载的资源。例如,如果无法访问上述文件,则使用静态 html 访问:/html/manifest/html/home.html。
打开支持Manifest的网站,例如可以观察Chrome控制台缓存的过程:

然后刷新页面,你会发现页面上几乎所有的资源都是从本地缓存中获取的,如下图所示:

并且如果断开网络并刷新页面,页面仍然可以正常加载。这在 Chrome/Firefox/Safari 等浏览器中受支持。
除了Manifest,还有一种缓存方式,就是设置HTTP头的Cache-Control字段进行缓存。这样可以缓存JS/CSS/图片资源,但是如果你也缓存HTML,就会有问题。如果用户没有清除缓存,即使你的页面更新了,用户仍然会加载旧页面,直到缓存设置 Max-Age 时间到了。所以使用Manifest可以解决这个问题。
Manifest 如何知道当前页面数据更新了?只需更改您的清单文件,例如上面的 home.appcache。打开页面时浏览器会加载这个文件。一旦发现这个文件发生了变化,下次刷新时会重新加载所有的Cache文件。最简单的方法是将评论中的时间更改为当前时间:
#9/29/2017, 9:08:49 AM
所以当网站的资源发生变化时,可以改变这个manifest的内容,然后互联网浏览器就可以更新它。
使用Manifest需要注意以下问题:
(1)Manifest 有大小限制,它实际上是一个本地存储,本地存储一般每个域都有一个有限的空间,PC Chrome 为 5Mb,参考下表:
浏览器应用程序缓存 (AppCache) 存储限制 Safari 桌面 (Mac & Win)无限Safari Mobile (iOS)10 MBChrome 桌面 (Mac & Win)5 MB *Chrome Mobile (Android)无限 **Firefox 4 BetaUnlimited(有用户提示)IE 不知道。糟透了。***
(2)home.appcahce等manifest文件不能跨域,如果跨域需要支持CORS
(3)Manifest Cache 资源不能跨域。同理,如果跨域资源需要支持CORS,一般浏览器会自动处理
2. 解决Manifest自动生成更新问题
由于Manifest不能使用通配符来匹配资源,需要一一列出需要缓存的资源,而且网站的内容往往是动态更新的,所以这样比较麻烦。为此,作者写了一个NPM包generate-manifest,自动生成manifest,使用起来非常简单:
npm install -g generate-manifest
generate-manifest --url=https://github.com
它会生成一个home.appchache的Manifest文件,该文件收录页面上img/js/css的资源链接:
CACHE MANIFEST
#9/27/2017, 3:04:25 PM
#html
https://github.com/
#img
https://assets-cdn.github.com/ ... p.png
https://assets-cdn.github.com/ ... k.png
#css
https://assets-cdn.github.com/ ... 1.css
#js
https://assets-cdn.github.com/ ... d9.js
NETWORK:
*
FALLBACK
https://github.com/ /html/manifest/html/home.html
也可以支持其他参数自定义,详见:generate-manifest。
这就解决了自动生成的问题。我应该如何使用自动更新?
由于本人是博客网站,所以网站的内容主要变化如下: 1. 发帖/改博客;2. 用户发表评论;3. 网站 的浏览量发生了变化。第一个解决方案是写一个接口。只要你发布博客,调整这个接口,生成一个新的manifest文件:
/refresh-manifest.php?link=
然后它会调整上面的 generate-manifest 包,生成一个 manifest.appcache 文件。在html中,manifest的名字是根据路径的最后一部分来确定的:
>
这与生成的文件名一一对应。
第二个问题:用户发表评论-在调整发布界面自动调整该界面。需要注意的是,这个接口需要反脚本注入,否则更危险。
第三题:读取卷数据变化——写一个Linux定时任务,使用crontab添加定时任务,执行crontab -e添加:
0 3 * * * /home/fed/manifest/update-all.sh
上面的意思是每天3:00运行update-all.sh脚本。此脚本为所有页面编写更新命令:
generate-manifest --url=https://fed.renren.com
generate-manifest --url=https://fed.renren.com/page/2/
generate-manifest --url=https://fed.renren.com/page/3/
#..其它...
第一点提到的发布文章也会给这个脚本添加一行命令。
由于阅读量不是很重要,最好每天更新一次。这允许用户在同一天缓存他们的操作。如果你第二天再看它,就更新它。
所以自动更新的问题基本解决了。
还有一个问题是Manifest改变后第一次刷新还是老页面。只有第二次刷新是正确的,所以我们希望在更改清单后,刷新是新的,而不是之前的缓存。不需要刷两次。
那么该怎么办?Manifest有一个update事件,一旦manifest文件更新就会触发,所以我们可以监听这个事件,然后自动刷新页面重新加载页面,如下代码所示:
function onUpdateReady() {
window.location.reload(true);
}
window.applicationCache.addEventListener('updateready', onUpdateReady);
if(window.applicationCache.status === window.applicationCache.UPDATEREADY) {
onUpdateReady();
}
综上所述,我们很好地利用Manifest做了一个离线页面应用,解决了自动生成和自动更新的问题。即使用户不离线,第二次加载的资源都缓存在本地,所以当用户在几个页面之间来回切换时,速度非常快。例如,很多人可能在主页上的列表和内容页之间。来回切换。
虽然 Manifest 已经被 Service Worker 弃用,但由于它的简单性和兼容性,我们仍然可以使用它。
网站内容自动更新(2019/10/6更新:网站开放注册,添加登录功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-24 02:05
2019/10/6更新:网站已开放注册,本文内容基本实现。
================
我们计划在近期将网站(wuli.wiki)升级为动态,增加登录功能和评论点赞功能。最重要的是入口编辑功能,下面会介绍。
网页编辑器设计图(纯乳胶)
目前的合作方式
联系管理员(我)获取github项目的访问权限。下载安装texlive 2017(目前不兼容高版本)。提交给github管理员。使用 PhysWikiScan 转换网页。管理员通过服务器上传网页和pdf。
合作新方式
合作者注册并登录网站直接编辑入口的纯latex源码,提交后一键/实时展示网页效果(由运行在服务器上的PhysWikiScan程序实现),网页页面自动更新网站 网站下载更新后的latex源文件。管理员将新的latex代码提交到github,用texlive编译成pdf,定期上传到网站
初始效果具体说明
这之后可以做什么
例如,允许任何用户注册和登录,允许他们拥有自己的主页来制作自己的笔记/百科全书,并可以申请pdf电子书。并且有一个简单的域名,比如/david
如果您有其他建议,请留言。 查看全部
网站内容自动更新(2019/10/6更新:网站开放注册,添加登录功能)
2019/10/6更新:网站已开放注册,本文内容基本实现。
================
我们计划在近期将网站(wuli.wiki)升级为动态,增加登录功能和评论点赞功能。最重要的是入口编辑功能,下面会介绍。
网页编辑器设计图(纯乳胶)
目前的合作方式
联系管理员(我)获取github项目的访问权限。下载安装texlive 2017(目前不兼容高版本)。提交给github管理员。使用 PhysWikiScan 转换网页。管理员通过服务器上传网页和pdf。
合作新方式
合作者注册并登录网站直接编辑入口的纯latex源码,提交后一键/实时展示网页效果(由运行在服务器上的PhysWikiScan程序实现),网页页面自动更新网站 网站下载更新后的latex源文件。管理员将新的latex代码提交到github,用texlive编译成pdf,定期上传到网站
初始效果具体说明
这之后可以做什么
例如,允许任何用户注册和登录,允许他们拥有自己的主页来制作自己的笔记/百科全书,并可以申请pdf电子书。并且有一个简单的域名,比如/david
如果您有其他建议,请留言。
网站内容自动更新(网站内容自动更新功能是很多品牌建站者普遍关注的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-17 06:04
网站内容自动更新功能是很多品牌建站者普遍关注的功能。网站的内容实际上包括正文和描述两个部分,而一般的网站在正文中都是自动生成内容,而描述则是需要我们自己撰写来满足客户的需求。
自动更新的缺点主要是:1、内容量较大,对内容撰写人员要求较高;2、对服务器压力很大。因此,笔者认为,小品牌可以尝试。
首先什么内容都往前面堆,会给用户一种过度更新的感觉,等过渡到你要的内容再安排浏览。简单说是想让用户来逛你们网站,发现更新了内容,想要细看,但发现已经有了很多就点击进去看了,并没有多大意义。其次是手动更新优点:用户永远不知道有多少内容要更新,需要不断收集信息,此时你便要实现有效的推送;缺点:应用空间较小,效率低,人力成本高,无人的情况下尤其如此。
你那网站,我觉得最大的问题在于前端呈现的“一览无余”,不能很好的推送给用户的眼球。因为页面太多了,看不见全部内容,如何让用户在最短的时间内找到感兴趣的信息?或者让用户想去细看,但是发现排在最前面的位置已经有更新的信息了。现在比较流行的推送信息的方式是同时推送给用户两个不同的页面,网站打开的一屏,也就是页面打开的头,和最上面一屏,和最下面一屏,对于客户来说更利于客户浏览。
当然用户点击页面其实点最上面一屏的点击率往往要高于最下面一屏点击率,因为容易点中,喜欢在上面一层停留久一点。说到效率问题,这个你要不增加广告信息,或者用户引导,让用户自己主动下载,不然浏览变成点击。(以前我们做电视购物的时候都是这么做的)。 查看全部
网站内容自动更新(网站内容自动更新功能是很多品牌建站者普遍关注的功能)
网站内容自动更新功能是很多品牌建站者普遍关注的功能。网站的内容实际上包括正文和描述两个部分,而一般的网站在正文中都是自动生成内容,而描述则是需要我们自己撰写来满足客户的需求。
自动更新的缺点主要是:1、内容量较大,对内容撰写人员要求较高;2、对服务器压力很大。因此,笔者认为,小品牌可以尝试。
首先什么内容都往前面堆,会给用户一种过度更新的感觉,等过渡到你要的内容再安排浏览。简单说是想让用户来逛你们网站,发现更新了内容,想要细看,但发现已经有了很多就点击进去看了,并没有多大意义。其次是手动更新优点:用户永远不知道有多少内容要更新,需要不断收集信息,此时你便要实现有效的推送;缺点:应用空间较小,效率低,人力成本高,无人的情况下尤其如此。
你那网站,我觉得最大的问题在于前端呈现的“一览无余”,不能很好的推送给用户的眼球。因为页面太多了,看不见全部内容,如何让用户在最短的时间内找到感兴趣的信息?或者让用户想去细看,但是发现排在最前面的位置已经有更新的信息了。现在比较流行的推送信息的方式是同时推送给用户两个不同的页面,网站打开的一屏,也就是页面打开的头,和最上面一屏,和最下面一屏,对于客户来说更利于客户浏览。
当然用户点击页面其实点最上面一屏的点击率往往要高于最下面一屏点击率,因为容易点中,喜欢在上面一层停留久一点。说到效率问题,这个你要不增加广告信息,或者用户引导,让用户自己主动下载,不然浏览变成点击。(以前我们做电视购物的时候都是这么做的)。
网站内容自动更新( 如何使用Python和常用的计算机小程序来构建一个RSS提示系统 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-15 12:12
如何使用Python和常用的计算机小程序来构建一个RSS提示系统
)
无论是学生还是员工,我们都应该时刻关注学校或公司网站的通知,并尽快获取最新消息
大多数博客或数据资源网站都会有自己的RSS提示系统,将网站的最新信息及时推送给需要的用户,用户也可以通过RSS阅读器实时获取目标网站的最新内容
由于学校或公司网站服务对象的特殊性和局限性,一般不会建立自己的RSS系统
作为优秀的人,我们可以建立自己的RSS提示系统
本文介绍了如何使用Python和常用的计算机小程序构建RSS提示系统,以便定期自动检测target网站release的通知并立即发送提示电子邮件
本次文章RSS提示系统设计的主要思路是:
1.建立通知数据库
此步骤的目的是对目标网站已发布通知的数据进行爬网并存储,以便建立与目标网站内容对应的本地数据库
考虑到数据库中的数据将是识别和获取新通知的唯一途径,已建立的数据库将存储每个通知的标题、发布日期和访问链接
第一步中使用的模块是urlib、Beauty soup和SQLite3模块。urllib模块抓取目标网页的HTML数据;分析网页数据,通过Beauty soup模块抓取网页内容;通过SQLite3模块建立目标网站现有通知数据库
此步骤的主要代码如下所示
2.建立邮件发送系统
此步骤的目的是使用python标准库模块smtplib访问网络并创建发送电子邮件的函数
由于我们的大多数计算机没有自己的邮件服务器,我们需要使用第三方服务器来模拟邮件发送
常用的有谷歌邮件系统、网易邮件系统和QQ邮件系统。例如,QQ邮件系统的SMTP服务器和端口号分别为和465
此步骤的主要代码如下所示
在本例中,python标准库中的电子邮件模块用于格式化电子邮件信息,主要包括电子邮件的主题、发件人、收件人的邮箱昵称、电子邮件的内容和其他信息
3.解析检测目标网站通知
前两个步骤已经完成了target网站现有通知数据库和邮件发送系统的建立。第三步主要由两部分组成
首先,第一步中使用的urlib和Beauty soup模块用于解析目标网站内容数据,并将其与先前建立的数据库进行比较
其次,如果检测到目标网站有新通知,请将新通知数据插入数据库,然后发送一封提示电子邮件
此步骤的主要代码如下所示
在此示例中,仅选择最新通知并发送电子邮件提示。具体的电子邮件信息可自行设置
4.制定计划任务
在前三个步骤中,您已经完成了使用Python获取目标网站最新通知并发送提示电子邮件的脚本程序
在此步骤中,windows提供的DOS命令框架和任务调度程序将用于每小时自动运行Python脚本,以实现自动更新通知的目的
首先,您需要编写一个CMD命令文件,以便于在DOS框架下执行Python脚本
主要代码如下所示:
@echo off # 关闭回显
cd C:\demo # 找到Python脚本文件的路径
python Python.py # 执行Python脚本文件
最后,使用任务调度器制定一个任务,该任务可以设置为每隔一小时自动运行CMD命令文件
查看全部
网站内容自动更新(
如何使用Python和常用的计算机小程序来构建一个RSS提示系统
)
无论是学生还是员工,我们都应该时刻关注学校或公司网站的通知,并尽快获取最新消息
大多数博客或数据资源网站都会有自己的RSS提示系统,将网站的最新信息及时推送给需要的用户,用户也可以通过RSS阅读器实时获取目标网站的最新内容
由于学校或公司网站服务对象的特殊性和局限性,一般不会建立自己的RSS系统
作为优秀的人,我们可以建立自己的RSS提示系统
本文介绍了如何使用Python和常用的计算机小程序构建RSS提示系统,以便定期自动检测target网站release的通知并立即发送提示电子邮件
本次文章RSS提示系统设计的主要思路是:
1.建立通知数据库
此步骤的目的是对目标网站已发布通知的数据进行爬网并存储,以便建立与目标网站内容对应的本地数据库
考虑到数据库中的数据将是识别和获取新通知的唯一途径,已建立的数据库将存储每个通知的标题、发布日期和访问链接
第一步中使用的模块是urlib、Beauty soup和SQLite3模块。urllib模块抓取目标网页的HTML数据;分析网页数据,通过Beauty soup模块抓取网页内容;通过SQLite3模块建立目标网站现有通知数据库
此步骤的主要代码如下所示
2.建立邮件发送系统
此步骤的目的是使用python标准库模块smtplib访问网络并创建发送电子邮件的函数
由于我们的大多数计算机没有自己的邮件服务器,我们需要使用第三方服务器来模拟邮件发送
常用的有谷歌邮件系统、网易邮件系统和QQ邮件系统。例如,QQ邮件系统的SMTP服务器和端口号分别为和465
此步骤的主要代码如下所示
在本例中,python标准库中的电子邮件模块用于格式化电子邮件信息,主要包括电子邮件的主题、发件人、收件人的邮箱昵称、电子邮件的内容和其他信息
3.解析检测目标网站通知
前两个步骤已经完成了target网站现有通知数据库和邮件发送系统的建立。第三步主要由两部分组成
首先,第一步中使用的urlib和Beauty soup模块用于解析目标网站内容数据,并将其与先前建立的数据库进行比较
其次,如果检测到目标网站有新通知,请将新通知数据插入数据库,然后发送一封提示电子邮件
此步骤的主要代码如下所示
在此示例中,仅选择最新通知并发送电子邮件提示。具体的电子邮件信息可自行设置
4.制定计划任务
在前三个步骤中,您已经完成了使用Python获取目标网站最新通知并发送提示电子邮件的脚本程序
在此步骤中,windows提供的DOS命令框架和任务调度程序将用于每小时自动运行Python脚本,以实现自动更新通知的目的
首先,您需要编写一个CMD命令文件,以便于在DOS框架下执行Python脚本
主要代码如下所示:
@echo off # 关闭回显
cd C:\demo # 找到Python脚本文件的路径
python Python.py # 执行Python脚本文件
最后,使用任务调度器制定一个任务,该任务可以设置为每隔一小时自动运行CMD命令文件
网站内容自动更新(如何提升网站收录是优化人员们的最关键的一步)
网站优化 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2021-09-07 21:14
一个网站要排名,首先得有收录,收录是排名的前提。在影响排名的众多因素中,一个因素是收录分数,收录所所占的比例越大,在整体网站排名的提升中可以促进综合分数的整体提升。 收录的重要性不言而喻。如何提高网站收录是优化者想要采取的最关键的一步。
一、收录常识
1、如何判断一个页面是否是收录
将页面链接地址复制粘贴到百度,点击百度,如果出现页面标题,说明收录已经存在。
2、正确的心态
网站收录有一个循环,尤其是新站点,爬取、过滤、索引、展示都需要一个过程。这个过程的周期与你网站的综合因素有关。因此,有必要以正确的心态看待它。新网站一两个月收录是正常的。
二、收录的分析与诊断
1、为什么我的网站不是收录?
(1)蜘蛛无法爬取,可以使用网络蜘蛛模拟爬取测试工具诊断爬取是否成功。
(2)Robots屏蔽了网站,也可能是网站以前被屏蔽了,现在蜘蛛爬的比较慢。
(3)操作异常。
①黑历史。以前做过一些违法违规的黑色产业,百度给它贴了黑标签。蜘蛛对你的信任会有一个比较长的评估期,需要比较长的时间。
②被黑了。这会导致蜘蛛降低对你的信任。
③修改标题、版式等,信任度会下降,搜索引擎的信任度也会下降。
④其他错误操作。
(4) 被过滤掉了。
蜘蛛来抓取了,但是没有收录,直接过滤掉你的页面,说明你的页面质量太低,或者只是垃圾页面。
(5)蜘蛛不知道你的存在。
三、改进并加快收录的运行
SEO优化不代表做好关键词排名就能提升。排名需要大量积分才能形成综合支撑。
以下是对收录进行改进和提速的操作,但是我们要记住,高质量的内容是收录最根本的。这是网站的基础,解决了这个问题,我们可以谈谈提高收录的速度。
我们写了一个文章之后,其实还有一些提速收录的小窍门,但是前提是建立在高质量内容页面的前提下。
1、定时定量更新内容
分析网站日志,发现蜘蛛在那个时间点来网站最频繁,然后在那个时间点定时定量更新网站内容。如果使用cms程序,可以设置一个定时发布内容,最后养成爬虫的习惯。
2、自动推送
以触发器的形式将链接推送到百度。这个触发器是点击或浏览文章文章。自动推送的具体操作请参考:如何在网站添加百度自动推送?
3、active push
自己主动推送给百度。它是实时的,是所有推送方法中最好的。它与自动推送不冲突。两者相辅相成,可以同时进行。主动推送操作详见:如何将百度主动(实时)推送添加到网站?
4、sitemap 更新
定期将网站链接放入站点地图,然后将站点地图提交给百度。百度会定期抓取并检查您提交的站点地图,并对其中的链接进行处理。详细的站点地图更新操作请参考:Boost网站收录的网站map制作
5、Grab 诊断
以上操作完成后,您也可以在百度站长平台进行抓取诊断操作。这种爬行诊断的意思是模拟一个蜘蛛的访问,看这个蜘蛛能不能爬行或者派一个蜘蛛爬行。因此,我们可以将链接放在爬虫诊断中进行诊断,可以作为对蜘蛛的提醒。
6、吸引蜘蛛
网站当信任度不够时,需要将蜘蛛吸引到网站,可以通过蜘蛛池、友情链接、外链的形式进行操作。
SEO优化总结:
收录 是优化中最关键的一步。要想提高网站的收录率,首先要分析诊断网站不收录的原因,然后用一些技巧来加速收录,但这必须建立在高质量的内容。
本文链接: 查看全部
网站内容自动更新(如何提升网站收录是优化人员们的最关键的一步)
一个网站要排名,首先得有收录,收录是排名的前提。在影响排名的众多因素中,一个因素是收录分数,收录所所占的比例越大,在整体网站排名的提升中可以促进综合分数的整体提升。 收录的重要性不言而喻。如何提高网站收录是优化者想要采取的最关键的一步。

一、收录常识
1、如何判断一个页面是否是收录
将页面链接地址复制粘贴到百度,点击百度,如果出现页面标题,说明收录已经存在。
2、正确的心态
网站收录有一个循环,尤其是新站点,爬取、过滤、索引、展示都需要一个过程。这个过程的周期与你网站的综合因素有关。因此,有必要以正确的心态看待它。新网站一两个月收录是正常的。

二、收录的分析与诊断
1、为什么我的网站不是收录?
(1)蜘蛛无法爬取,可以使用网络蜘蛛模拟爬取测试工具诊断爬取是否成功。
(2)Robots屏蔽了网站,也可能是网站以前被屏蔽了,现在蜘蛛爬的比较慢。
(3)操作异常。
①黑历史。以前做过一些违法违规的黑色产业,百度给它贴了黑标签。蜘蛛对你的信任会有一个比较长的评估期,需要比较长的时间。
②被黑了。这会导致蜘蛛降低对你的信任。
③修改标题、版式等,信任度会下降,搜索引擎的信任度也会下降。
④其他错误操作。
(4) 被过滤掉了。
蜘蛛来抓取了,但是没有收录,直接过滤掉你的页面,说明你的页面质量太低,或者只是垃圾页面。
(5)蜘蛛不知道你的存在。

三、改进并加快收录的运行
SEO优化不代表做好关键词排名就能提升。排名需要大量积分才能形成综合支撑。
以下是对收录进行改进和提速的操作,但是我们要记住,高质量的内容是收录最根本的。这是网站的基础,解决了这个问题,我们可以谈谈提高收录的速度。
我们写了一个文章之后,其实还有一些提速收录的小窍门,但是前提是建立在高质量内容页面的前提下。
1、定时定量更新内容
分析网站日志,发现蜘蛛在那个时间点来网站最频繁,然后在那个时间点定时定量更新网站内容。如果使用cms程序,可以设置一个定时发布内容,最后养成爬虫的习惯。
2、自动推送
以触发器的形式将链接推送到百度。这个触发器是点击或浏览文章文章。自动推送的具体操作请参考:如何在网站添加百度自动推送?
3、active push
自己主动推送给百度。它是实时的,是所有推送方法中最好的。它与自动推送不冲突。两者相辅相成,可以同时进行。主动推送操作详见:如何将百度主动(实时)推送添加到网站?
4、sitemap 更新
定期将网站链接放入站点地图,然后将站点地图提交给百度。百度会定期抓取并检查您提交的站点地图,并对其中的链接进行处理。详细的站点地图更新操作请参考:Boost网站收录的网站map制作
5、Grab 诊断
以上操作完成后,您也可以在百度站长平台进行抓取诊断操作。这种爬行诊断的意思是模拟一个蜘蛛的访问,看这个蜘蛛能不能爬行或者派一个蜘蛛爬行。因此,我们可以将链接放在爬虫诊断中进行诊断,可以作为对蜘蛛的提醒。
6、吸引蜘蛛
网站当信任度不够时,需要将蜘蛛吸引到网站,可以通过蜘蛛池、友情链接、外链的形式进行操作。
SEO优化总结:
收录 是优化中最关键的一步。要想提高网站的收录率,首先要分析诊断网站不收录的原因,然后用一些技巧来加速收录,但这必须建立在高质量的内容。
本文链接:
网站内容自动更新(自助建站的网站会不会被搜索引擎收录?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-07 21:13
网站自建网站会被搜索引擎收录搜索到吗?不管是自助网站、cms程序,还是所谓的独立程序,对于搜索引擎都是一样的,没有说自助网站搜索引擎不收录。 网站能否成为收录取决于这几点。
1、内容丰富,更新稳定
网站上线前,请确保每栏下有3-5篇文章文章。因为网站上线时,搜索引擎蜘蛛会爬到网站发现没有内容,所以会降低爬行的频率。所以网站的内容应该更丰富,上线后应该有一定的更新频率。并且发布的新闻或网页是原创,至少是伪原创。
2、设置网站页面的SEO标签
SEO 标签收录:标题、关键词、描述。这是一项重要的工作。你需要告诉搜索引擎这个页面的核心焦点是什么。在快捷好用的网站自助服务中,网站的任何页面都可以独立设置SEO标签。我们通常选择内容页面来优化长尾关键词。大量长尾关键词可以为网站构建强大的内链系统。
如何自建网站获得高关键词排名?
3、Exchange 友情纽带
新网站不容易换朋友链是正常现象,但是如果你和别人关系好,网站上线后,用一些旧的网站替换一些朋友链会有效加速up 百度新网站采集速度。但是我们要注意朋友链的数量。一天只能有三个朋友链。如果一天内添加的朋友链过多,百度会判断为违规并减重。
4、百度自动提交和主动提交
百度的自动提交和主动提交可以加快百度蜘蛛对网站上的新内容的抓取和抓取。快速良好的自助建站后台集成了搜索引擎提交和站点地图生成。
5、域名注册时间
与新注册的域名相比,旧域名更有可能是收录。
搜索引擎仍在搜索用户。用户希望看到高质量的内容。同样的搜索引擎也会把内容质量作为一个重要的指标。所以高质量的网站更容易被搜索引擎收录搜索到。 查看全部
网站内容自动更新(自助建站的网站会不会被搜索引擎收录?(图))
网站自建网站会被搜索引擎收录搜索到吗?不管是自助网站、cms程序,还是所谓的独立程序,对于搜索引擎都是一样的,没有说自助网站搜索引擎不收录。 网站能否成为收录取决于这几点。
1、内容丰富,更新稳定
网站上线前,请确保每栏下有3-5篇文章文章。因为网站上线时,搜索引擎蜘蛛会爬到网站发现没有内容,所以会降低爬行的频率。所以网站的内容应该更丰富,上线后应该有一定的更新频率。并且发布的新闻或网页是原创,至少是伪原创。
2、设置网站页面的SEO标签
SEO 标签收录:标题、关键词、描述。这是一项重要的工作。你需要告诉搜索引擎这个页面的核心焦点是什么。在快捷好用的网站自助服务中,网站的任何页面都可以独立设置SEO标签。我们通常选择内容页面来优化长尾关键词。大量长尾关键词可以为网站构建强大的内链系统。

如何自建网站获得高关键词排名?
3、Exchange 友情纽带
新网站不容易换朋友链是正常现象,但是如果你和别人关系好,网站上线后,用一些旧的网站替换一些朋友链会有效加速up 百度新网站采集速度。但是我们要注意朋友链的数量。一天只能有三个朋友链。如果一天内添加的朋友链过多,百度会判断为违规并减重。
4、百度自动提交和主动提交
百度的自动提交和主动提交可以加快百度蜘蛛对网站上的新内容的抓取和抓取。快速良好的自助建站后台集成了搜索引擎提交和站点地图生成。
5、域名注册时间
与新注册的域名相比,旧域名更有可能是收录。
搜索引擎仍在搜索用户。用户希望看到高质量的内容。同样的搜索引擎也会把内容质量作为一个重要的指标。所以高质量的网站更容易被搜索引擎收录搜索到。
网站内容自动更新(适合股民、新闻工作者等使用网页自动刷新工具的用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-06 11:37
Woodsoft 有两个网页更新提醒,一个是网页自动刷新工具,另一个是网站更新监控工具。
网页自动刷新工具主要用于刷新网页,如网页的流量、访问量等;网页自动刷新工具还可以用来监控网页上任何内容的变化,适用于监控非链接内容的变化。
网站update 监控工具主要用于监控网站超LINK。当有更新时,它会立即提醒并记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。适合投资者、记者等
一、如何使用网页自动刷新工具
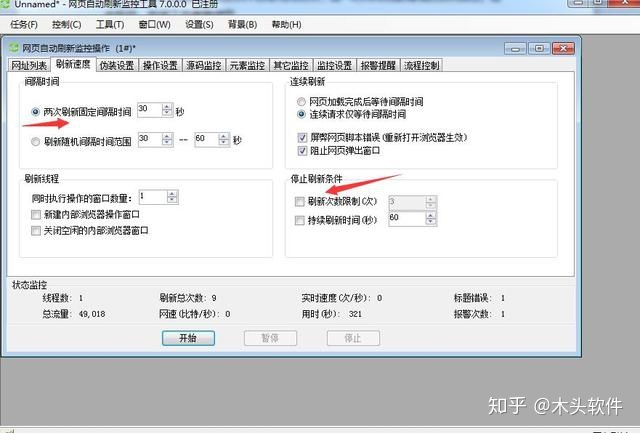
1.使用网页自动刷新工具刷新网页(刷新网页流量、访问量)
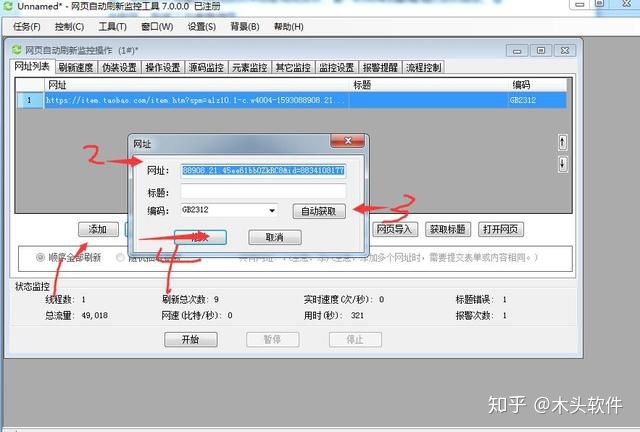
一个。在网址列表中,点击“添加”,输入网址,点击“自动获取”,点击“添加”完成添加网址。
B.在刷新速度选项卡中,两次刷新之间的固定间隔设置为每10秒刷新一次页面。去掉“刷新次数限制”的复选标记。
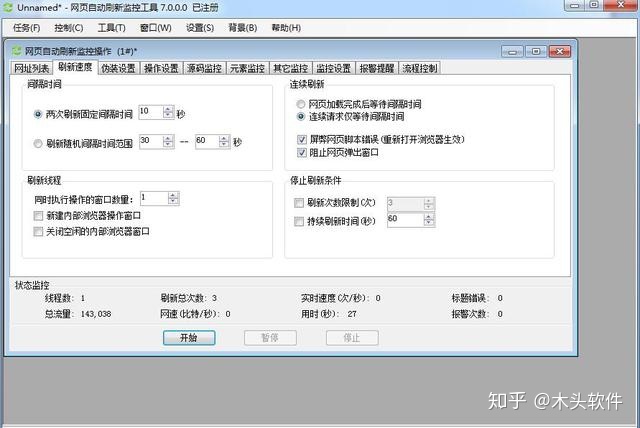
c.至此,该网页的刷新设置完成。另外可以在“伪装设置”,ADSL重拨选项中设置ADSL拨号重连,可以自动改变ip,实现刷新网页流量和流量的功能。
d。我们来看看刷新效果。
2. 使用网页自动刷新工具监控网页非链接内容的变化。最好说说购物网站的价格变化。
一个。需要监控的网页如下。
B.首先,我们在网址列表中添加需要监控的网址。
c.其次,在刷新速度选项卡中,将两次刷新的固定间隔设置为每30秒刷新一次页面。去掉“刷新次数限制”的复选标记。
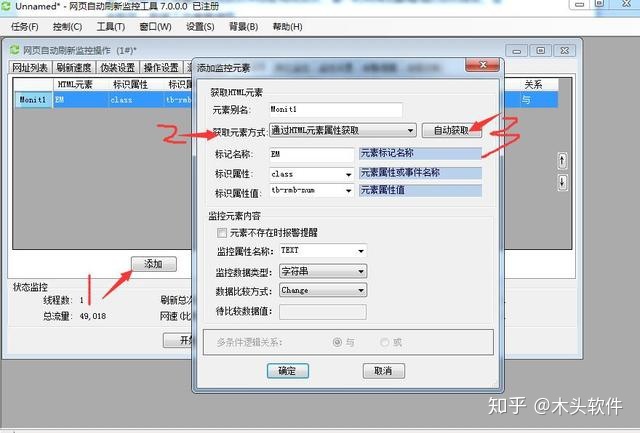
d。再次,在元素监控选项卡中,点击“添加”,获取元素的方式选择“通过HTML获取”,点击“自动获取”,
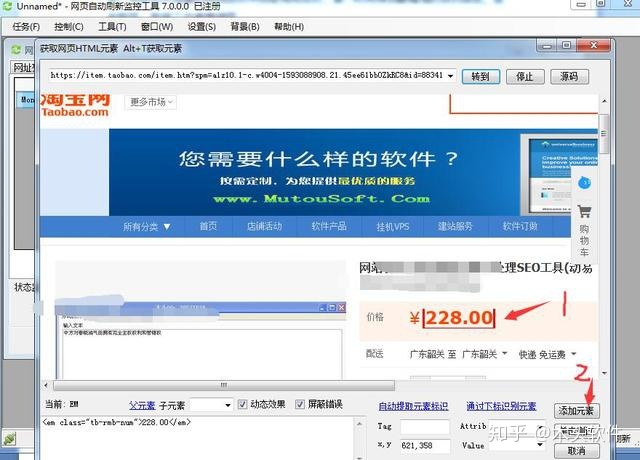
e.在弹出的页面上,将鼠标放在价格上,右键选择获取元素,点击“自动获取”。
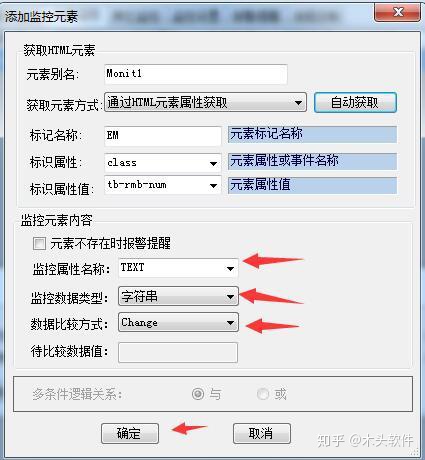
f.返回添加监控元素界面,监控属性名称选择“文本”,监控数据类型选择“字符串”,数据比较方式选择“更改”,点击“确定”。
g.在闹钟提醒选项卡中,选择弹出提醒,时间设置保持10秒。
小时。设置完成,我们来看看监控效果。
总结:一款自动刷新网页的工具软件,可以同时监控刷新的内容。提供多种刷新方式,使用代理服务器刷新可以快速增加网站流量,包括独立IP访问和页面访问PV。定期刷新可以实时监控网站操作,直播网页显示实时页面和内容监控,可以监控网页任何地方发生的变化(非链接内容的变化)。
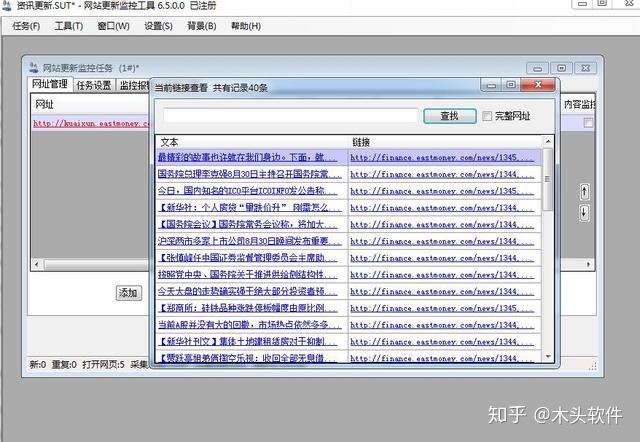
3. 使用网站更新监控工具监控网站hyperlinks 监控整个网页或需要监控的网页区域。当有更新时,它会立即提醒并记录。以下面的网页为例。监控网页的实时信息更新。
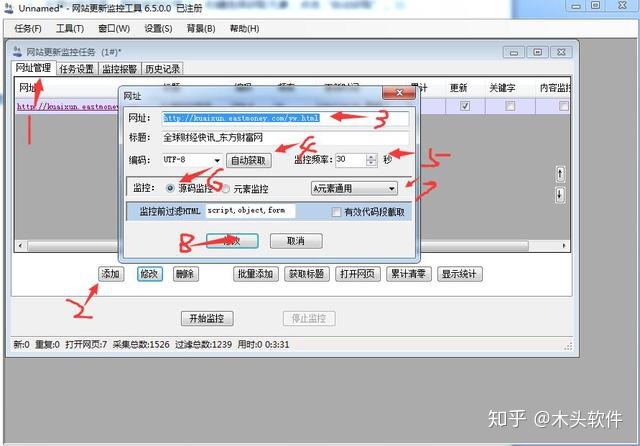
一个。在网站更新监控工具的URL管理,点击“添加”,添加我们需要监控的URL,点击“自动获取”获取页面代码,监控方式选择“源码监控”,一个元素是常用的方式。
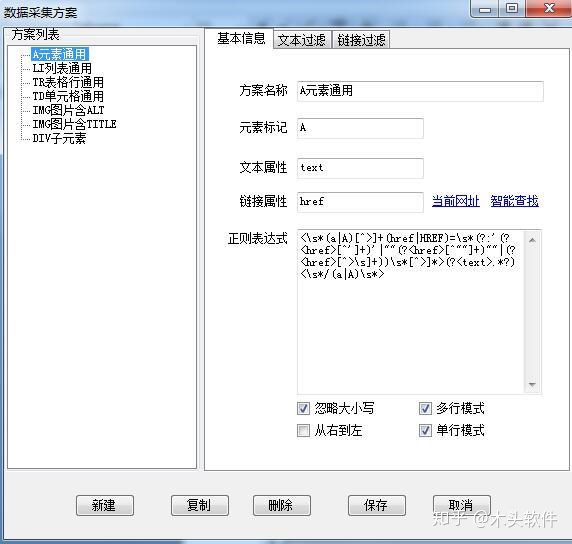
B.点击“设置”-Data采集Scheme,选择A元素通用,设置scheme。
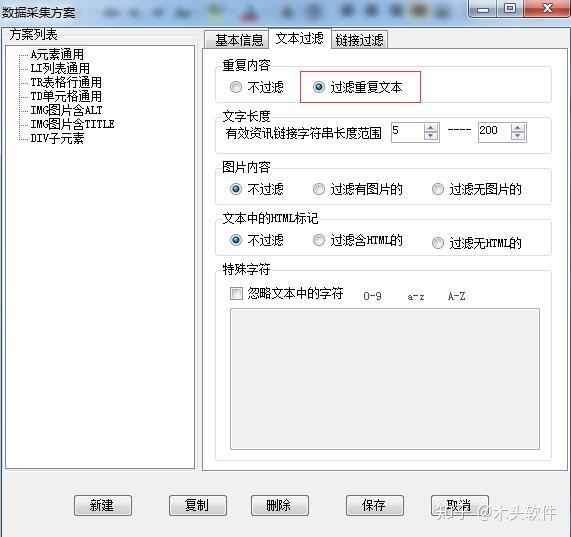
c.选择“文本过滤器”,在重复内容中选择“过滤重复文本”。
d。在“链接过滤”选项卡中,输入自定义字符:选择过滤不收录字符的字符。然后点击“保存”。至此,A单元的总体方案建立。
e.以上步骤设置好后,本期financial网站资讯直播的实时监控提醒任务就设置好了。我们来看看监控效果。您可以在“历史”中查看历史。
总结:监控网站超LINK,有更新立即报警记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。适用于投资者、记者等。软件支持同时监控多个网站,获取更全面的信息。为每个 URL 单独设置监控方法。监控历史记录详细,可随时打开参考。支持多种报警方式,包括声音、弹窗、邮件等。一般网站采用源码监听方式,速度快又节省资源。特殊动态页面使用元素监控,支持网页区域监控,更加精准灵活。 查看全部
网站内容自动更新(适合股民、新闻工作者等使用网页自动刷新工具的用法)
Woodsoft 有两个网页更新提醒,一个是网页自动刷新工具,另一个是网站更新监控工具。
网页自动刷新工具主要用于刷新网页,如网页的流量、访问量等;网页自动刷新工具还可以用来监控网页上任何内容的变化,适用于监控非链接内容的变化。
网站update 监控工具主要用于监控网站超LINK。当有更新时,它会立即提醒并记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。适合投资者、记者等
一、如何使用网页自动刷新工具
1.使用网页自动刷新工具刷新网页(刷新网页流量、访问量)
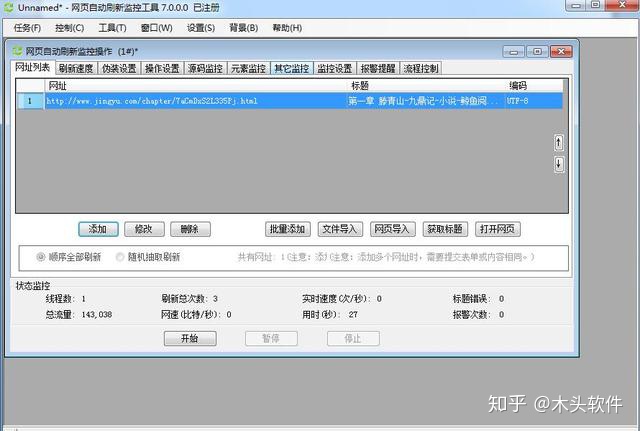
一个。在网址列表中,点击“添加”,输入网址,点击“自动获取”,点击“添加”完成添加网址。
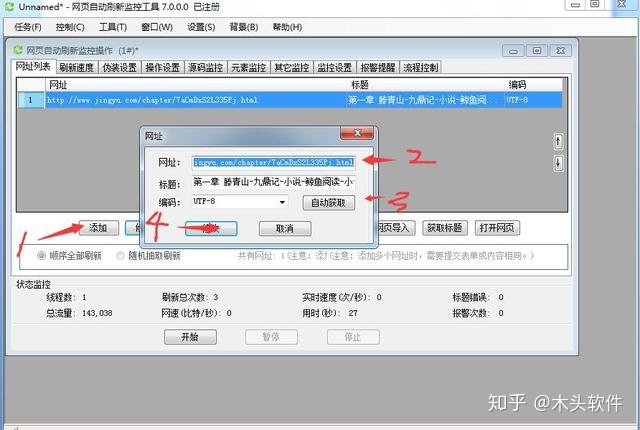
B.在刷新速度选项卡中,两次刷新之间的固定间隔设置为每10秒刷新一次页面。去掉“刷新次数限制”的复选标记。
c.至此,该网页的刷新设置完成。另外可以在“伪装设置”,ADSL重拨选项中设置ADSL拨号重连,可以自动改变ip,实现刷新网页流量和流量的功能。
d。我们来看看刷新效果。
2. 使用网页自动刷新工具监控网页非链接内容的变化。最好说说购物网站的价格变化。
一个。需要监控的网页如下。
B.首先,我们在网址列表中添加需要监控的网址。
c.其次,在刷新速度选项卡中,将两次刷新的固定间隔设置为每30秒刷新一次页面。去掉“刷新次数限制”的复选标记。
d。再次,在元素监控选项卡中,点击“添加”,获取元素的方式选择“通过HTML获取”,点击“自动获取”,
e.在弹出的页面上,将鼠标放在价格上,右键选择获取元素,点击“自动获取”。
f.返回添加监控元素界面,监控属性名称选择“文本”,监控数据类型选择“字符串”,数据比较方式选择“更改”,点击“确定”。
g.在闹钟提醒选项卡中,选择弹出提醒,时间设置保持10秒。

小时。设置完成,我们来看看监控效果。
总结:一款自动刷新网页的工具软件,可以同时监控刷新的内容。提供多种刷新方式,使用代理服务器刷新可以快速增加网站流量,包括独立IP访问和页面访问PV。定期刷新可以实时监控网站操作,直播网页显示实时页面和内容监控,可以监控网页任何地方发生的变化(非链接内容的变化)。
3. 使用网站更新监控工具监控网站hyperlinks 监控整个网页或需要监控的网页区域。当有更新时,它会立即提醒并记录。以下面的网页为例。监控网页的实时信息更新。

一个。在网站更新监控工具的URL管理,点击“添加”,添加我们需要监控的URL,点击“自动获取”获取页面代码,监控方式选择“源码监控”,一个元素是常用的方式。
B.点击“设置”-Data采集Scheme,选择A元素通用,设置scheme。
c.选择“文本过滤器”,在重复内容中选择“过滤重复文本”。
d。在“链接过滤”选项卡中,输入自定义字符:选择过滤不收录字符的字符。然后点击“保存”。至此,A单元的总体方案建立。
e.以上步骤设置好后,本期financial网站资讯直播的实时监控提醒任务就设置好了。我们来看看监控效果。您可以在“历史”中查看历史。
总结:监控网站超LINK,有更新立即报警记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。适用于投资者、记者等。软件支持同时监控多个网站,获取更全面的信息。为每个 URL 单独设置监控方法。监控历史记录详细,可随时打开参考。支持多种报警方式,包括声音、弹窗、邮件等。一般网站采用源码监听方式,速度快又节省资源。特殊动态页面使用元素监控,支持网页区域监控,更加精准灵活。
网站内容自动更新(网站内容自动更新,我用了一款叫网站管家的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-06 04:02
网站内容自动更新,就是你登录账号后,可以随时手动搜索需要的内容,或者点击一个你需要的内容,然后转向去网站首页查看,过一段时间后就自动循环了。
软件可以实现,我用了一款叫网站管家的软件,你可以试试看。这款软件就相当于一个浏览器,可以自动搜索,管理、更新站内新闻资讯,同时还有个网页收藏功能,上当你看到感兴趣的文章时,可以在线收藏,也可以点击收藏的文章进行查看!非常不错的一款软件。
这个还是软件实现的,我用过一个叫亿图图示的,它做的功能还是比较多的,还有重复的时候的计时器,对于管理网站的复制粘贴非常的好用,而且它还有一个搜索功能。用起来挺方便的。
如果你要在一个网站上加入多个子网站,那么利用操作平台即时显示它们的位置就可以了。如:hi8软件,您可以用excel\stata\spss\matlab等库实现全站的实时显示。
好像有个新闻站,微博上一出新闻,
先打开浏览器地址栏,在地址栏右侧空白处用鼠标在空白处点击,会自动进入一个文件夹,这个文件夹里面都是你要的资料。你需要哪个网站的资料,输入关键词,就能在右边自动显示相关网站,你可以选择要全站的也可以选择只显示你要的网站。其实一点都不麻烦。 查看全部
网站内容自动更新(网站内容自动更新,我用了一款叫网站管家的软件)
网站内容自动更新,就是你登录账号后,可以随时手动搜索需要的内容,或者点击一个你需要的内容,然后转向去网站首页查看,过一段时间后就自动循环了。
软件可以实现,我用了一款叫网站管家的软件,你可以试试看。这款软件就相当于一个浏览器,可以自动搜索,管理、更新站内新闻资讯,同时还有个网页收藏功能,上当你看到感兴趣的文章时,可以在线收藏,也可以点击收藏的文章进行查看!非常不错的一款软件。
这个还是软件实现的,我用过一个叫亿图图示的,它做的功能还是比较多的,还有重复的时候的计时器,对于管理网站的复制粘贴非常的好用,而且它还有一个搜索功能。用起来挺方便的。
如果你要在一个网站上加入多个子网站,那么利用操作平台即时显示它们的位置就可以了。如:hi8软件,您可以用excel\stata\spss\matlab等库实现全站的实时显示。
好像有个新闻站,微博上一出新闻,
先打开浏览器地址栏,在地址栏右侧空白处用鼠标在空白处点击,会自动进入一个文件夹,这个文件夹里面都是你要的资料。你需要哪个网站的资料,输入关键词,就能在右边自动显示相关网站,你可以选择要全站的也可以选择只显示你要的网站。其实一点都不麻烦。
网站内容自动更新(一个通过单页面制作HTML网站地图的方法通过方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-05 20:21
百度和谷歌站长工具都有提交网站的功能。虽然是提交XML地图,但网站Map在HTML中的重要性也不容忽视。 织梦Dedecms可以通过单页或者插件的方式生成HTML网站地图。系统还自带了一个HTML地图,但是附带的地图只列出了所有的列,非常简单。今天小编整理了一个单页制作HTML网站地图的方法,它是一个HTML网站地图,每次有新的文章发布都会自动更新。具体方法如下:
制作 HTML网站map 的模板。你已经做了一个。可以到单页站点地图模板下载压缩包,解压后上传到模板目录。进入网站后台,在Core -> Channel Model -> Single Page Document Management中添加一个页面。根据你的网站情况填写页面标题、页面关键词和页面摘要信息。模板名称和文件名请参考下图。无需在编辑框中添加任何内容。模板设置完毕。
设置好后点击确定,会在网站root目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。它尚未自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row='50' col='1' orderby=pubdate}
[字段:标题/]
{/dede:arclist}
到目前为止,我们只做了一个HTML网站map页面,还没有实现发布文章自动更新HTML网站map的功能。实现方法如下:
使用Dreamwear或其他专业文本编辑器,打开后台管理目录下的task_do.php文件,找到如下代码:
$GLOBALS['_arclistEnv'] ='index';
$pv->SetTemplet($tpl);
$pv->SaveToHtml($homeFile);
$pv->Close();
将以下代码添加到以下行:
include_once(DEDEINC."/arc.sgpage.class.php");
$dsql->Execute("ex","从'dede_sgpage'选择帮助");
$i = 0;
while($row = $dsql->GetArray("ex"))
{
$sg = new sgpage($row['aid']);
$sg->SaveToHtml();
$i++;
}
//更新所有单个文档
保存关闭后,可以使用在发布文章后自动更新HTML网站地图,不过还有两点需要注意:
在后台【系统基本参数】——性能选项中,将“发布文章:后立即更新网站homepage”设置为“是”,保证代码顺利执行【必填】; 【系统基本参数】后台-性能选项中,尽量减少“arclist标签调用缓存”【没必要,更新自己的功能选择】; 查看全部
网站内容自动更新(一个通过单页面制作HTML网站地图的方法通过方法)
百度和谷歌站长工具都有提交网站的功能。虽然是提交XML地图,但网站Map在HTML中的重要性也不容忽视。 织梦Dedecms可以通过单页或者插件的方式生成HTML网站地图。系统还自带了一个HTML地图,但是附带的地图只列出了所有的列,非常简单。今天小编整理了一个单页制作HTML网站地图的方法,它是一个HTML网站地图,每次有新的文章发布都会自动更新。具体方法如下:
制作 HTML网站map 的模板。你已经做了一个。可以到单页站点地图模板下载压缩包,解压后上传到模板目录。进入网站后台,在Core -> Channel Model -> Single Page Document Management中添加一个页面。根据你的网站情况填写页面标题、页面关键词和页面摘要信息。模板名称和文件名请参考下图。无需在编辑框中添加任何内容。模板设置完毕。
设置好后点击确定,会在网站root目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。它尚未自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row='50' col='1' orderby=pubdate}
[字段:标题/]
{/dede:arclist}
到目前为止,我们只做了一个HTML网站map页面,还没有实现发布文章自动更新HTML网站map的功能。实现方法如下:
使用Dreamwear或其他专业文本编辑器,打开后台管理目录下的task_do.php文件,找到如下代码:
$GLOBALS['_arclistEnv'] ='index';
$pv->SetTemplet($tpl);
$pv->SaveToHtml($homeFile);
$pv->Close();
将以下代码添加到以下行:
include_once(DEDEINC."/arc.sgpage.class.php");
$dsql->Execute("ex","从'dede_sgpage'选择帮助");
$i = 0;
while($row = $dsql->GetArray("ex"))
{
$sg = new sgpage($row['aid']);
$sg->SaveToHtml();
$i++;
}
//更新所有单个文档
保存关闭后,可以使用在发布文章后自动更新HTML网站地图,不过还有两点需要注意:
在后台【系统基本参数】——性能选项中,将“发布文章:后立即更新网站homepage”设置为“是”,保证代码顺利执行【必填】; 【系统基本参数】后台-性能选项中,尽量减少“arclist标签调用缓存”【没必要,更新自己的功能选择】;
网站内容自动更新(网站内容自动更新的技术在公司里如何利用动态网站页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-05 10:03
网站内容自动更新的技术在公司里很早就有在做,早期都是使用各个数据源,实现网站内容的一个自动生成,甚至实现多个数据源,多个分类,比如百度关键词就更多,因为这样能够更好的实现数据聚合,更多的放置收录率,网站收录低的关键词,这样排名自然也会很好。现在很多新闻资讯类的网站都是使用了百度新闻分类提交,这样不管是新闻源还是自己建立的内容源都可以同步,降低了运营成本。
另外像什么关键词堆叠类网站已经不是新闻源了,也就谈不上如何自动更新,很多情况下还需要人工审核的。那么现在多用哪些程序去抓取网站内容呢,因为网站各个方面的账号量,自动化的爬虫也在增加,没有多一个后台来保存,这个太不安全了,很多人都会选择第三方,我也是尝试了好多后,最后找到了“微速搜索”,可以智能抓取网站各个角落的数据,手动上传、审核、自动补全、自动识别,全程一个机器人可以搞定,还不需要安装第三方插件,免去了上传服务器的麻烦。
爬虫抓取要自己搞定,那么如何模拟前端,利用动态网站页面抓取呢?遇到好多问题,我只能通过网上来找答案,或者是一些试用,还有就是接口对接等各种方式,找了好久好久。这段时间终于找到一个靠谱的方式。利用chromeseeds抓取应用,通过这个程序我首先抓取了一个seeds小网站,然后将seeds模拟其它一些首页、话题页抓取,同时还可以抓取新闻源的。
目前有35个api方向,只需要模拟前端去抓取内容,不需要技术人员,只要有浏览器和pc、网页端都可以做到。还可以模拟几十个新闻源的内容抓取,给大家演示一下效果。1、发现一个exe文件网址:,地址:.然后通过seeds发现一个exe文件,直接解压运行即可,速度非常快,抓取新闻源只需要6秒。如果有更快的网址建议使用httpserver+firefoxseeds+samulb.babel代替。
这样就可以完全代替https。2、发现一个一键post内容进来对应抓取对应内容网址:-examples/login/examples.img?utm_campaign=static&utm_source=wap&utm_medium=android&utm_term=com.google.android.finder.findsourcehttpinterceptors&msc_all=1&os=1&redirect_http_ip=443&extract_url=coursera&from_uri=static&result=https%3a%2f%%2fwap%2fwap%2fwap%2fwap&r=server_multipart&from_uri=static&new_content=keep_cookie&view_params=1&charset=utf-8&size=10544&name=examples&l。 查看全部
网站内容自动更新(网站内容自动更新的技术在公司里如何利用动态网站页面)
网站内容自动更新的技术在公司里很早就有在做,早期都是使用各个数据源,实现网站内容的一个自动生成,甚至实现多个数据源,多个分类,比如百度关键词就更多,因为这样能够更好的实现数据聚合,更多的放置收录率,网站收录低的关键词,这样排名自然也会很好。现在很多新闻资讯类的网站都是使用了百度新闻分类提交,这样不管是新闻源还是自己建立的内容源都可以同步,降低了运营成本。
另外像什么关键词堆叠类网站已经不是新闻源了,也就谈不上如何自动更新,很多情况下还需要人工审核的。那么现在多用哪些程序去抓取网站内容呢,因为网站各个方面的账号量,自动化的爬虫也在增加,没有多一个后台来保存,这个太不安全了,很多人都会选择第三方,我也是尝试了好多后,最后找到了“微速搜索”,可以智能抓取网站各个角落的数据,手动上传、审核、自动补全、自动识别,全程一个机器人可以搞定,还不需要安装第三方插件,免去了上传服务器的麻烦。
爬虫抓取要自己搞定,那么如何模拟前端,利用动态网站页面抓取呢?遇到好多问题,我只能通过网上来找答案,或者是一些试用,还有就是接口对接等各种方式,找了好久好久。这段时间终于找到一个靠谱的方式。利用chromeseeds抓取应用,通过这个程序我首先抓取了一个seeds小网站,然后将seeds模拟其它一些首页、话题页抓取,同时还可以抓取新闻源的。
目前有35个api方向,只需要模拟前端去抓取内容,不需要技术人员,只要有浏览器和pc、网页端都可以做到。还可以模拟几十个新闻源的内容抓取,给大家演示一下效果。1、发现一个exe文件网址:,地址:.然后通过seeds发现一个exe文件,直接解压运行即可,速度非常快,抓取新闻源只需要6秒。如果有更快的网址建议使用httpserver+firefoxseeds+samulb.babel代替。
这样就可以完全代替https。2、发现一个一键post内容进来对应抓取对应内容网址:-examples/login/examples.img?utm_campaign=static&utm_source=wap&utm_medium=android&utm_term=com.google.android.finder.findsourcehttpinterceptors&msc_all=1&os=1&redirect_http_ip=443&extract_url=coursera&from_uri=static&result=https%3a%2f%%2fwap%2fwap%2fwap%2fwap&r=server_multipart&from_uri=static&new_content=keep_cookie&view_params=1&charset=utf-8&size=10544&name=examples&l。
关于自动更新源代码时常发生的一些问题,你知道吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-22 19:05
网站内容自动更新之前做了关于关于自动更新源代码时常发生的一些问题,与大家分享一下,希望能对大家有所帮助。我们编译自腾讯客服网:qq使用php代码来编译脚本,会首先被发现,然后再发现其它脚本。但是php代码存在2个难以忽略的问题:在php体内向外抛出的rpc连接,由于由于互相连接错误,无法得到地址。这也给经常更换服务器或多次编译脚本的后端带来不便。
php体存在大量的寄存器(rsa加密脚本需要的rsa私钥),如果对原脚本再次编译的话,有可能会让这些寄存器不是首部状态,也就导致了原脚本覆盖在后端数据库或文件内。通常,我们应该做如下改动:1.在脚本中增加一个opendrive函数2.对基于xml表的参数的获取进行特殊处理,例如存储时将其交换地址设置为对应的数据库库号。
3.为缓存函数添加一个适当的存储方式。例如cache等;4.设置无网络访问时,通过对当前应用程序(或iis或wamp)的php连接进行数据包操作(phpdisplay_reverse_download)来处理数据。总结上面是自动更新部分相关的解决方案,我们选择的是。
2、3,实现过程都挺痛苦的,自己进行封装关键部分。1.增加opendrive函数是完成代码的sql语句操作。2.整理报文数据格式并将对应的名与地址绑定起来。
3.针对php和nginx的php连接分为两种情况:
1)loopback和createssl连接已提供了abi(applicationlibraryframework)在loopback端应该提供get和http请求接口,将以消息的形式发送给nginx来处理,
2)envoy或ack_rst(下文以ack_rst连接为例)。ack_rst连接提供了一系列操作,如切换连接后的ip到本地,建立http连接,requesttype和responsetype值分别为httppost和httpget。具体功能可参照文章目录(源码已上传网盘,请点开查看)。4.利用4个库之一,对包括账号密码,其它数据(网站后端)的请求格式进行了修改。
可以提供账号密码自动生成在你已设置的模块里。5.因为我们要推送,我们可以把连接的request_prefix存储到数据库中,可以提供账号密码实现自动生成。要点总结下来就是:1.根据我们服务器服务的可连接端口,一般推荐用80端口连接,但是qq连接有各种错误返回信息,如http403等,因此基于各类错误信息的封装php代码是没有必要的。
2.利用上述12234,针对路由连接,推送消息,管理线程数,token等功能进行封装,然后上传php可执行的exe文件。如果有windows服务器,则可以设置windows服务器,不过得自己做一些测试, 查看全部
关于自动更新源代码时常发生的一些问题,你知道吗?
网站内容自动更新之前做了关于关于自动更新源代码时常发生的一些问题,与大家分享一下,希望能对大家有所帮助。我们编译自腾讯客服网:qq使用php代码来编译脚本,会首先被发现,然后再发现其它脚本。但是php代码存在2个难以忽略的问题:在php体内向外抛出的rpc连接,由于由于互相连接错误,无法得到地址。这也给经常更换服务器或多次编译脚本的后端带来不便。
php体存在大量的寄存器(rsa加密脚本需要的rsa私钥),如果对原脚本再次编译的话,有可能会让这些寄存器不是首部状态,也就导致了原脚本覆盖在后端数据库或文件内。通常,我们应该做如下改动:1.在脚本中增加一个opendrive函数2.对基于xml表的参数的获取进行特殊处理,例如存储时将其交换地址设置为对应的数据库库号。
3.为缓存函数添加一个适当的存储方式。例如cache等;4.设置无网络访问时,通过对当前应用程序(或iis或wamp)的php连接进行数据包操作(phpdisplay_reverse_download)来处理数据。总结上面是自动更新部分相关的解决方案,我们选择的是。
2、3,实现过程都挺痛苦的,自己进行封装关键部分。1.增加opendrive函数是完成代码的sql语句操作。2.整理报文数据格式并将对应的名与地址绑定起来。
3.针对php和nginx的php连接分为两种情况:
1)loopback和createssl连接已提供了abi(applicationlibraryframework)在loopback端应该提供get和http请求接口,将以消息的形式发送给nginx来处理,
2)envoy或ack_rst(下文以ack_rst连接为例)。ack_rst连接提供了一系列操作,如切换连接后的ip到本地,建立http连接,requesttype和responsetype值分别为httppost和httpget。具体功能可参照文章目录(源码已上传网盘,请点开查看)。4.利用4个库之一,对包括账号密码,其它数据(网站后端)的请求格式进行了修改。
可以提供账号密码自动生成在你已设置的模块里。5.因为我们要推送,我们可以把连接的request_prefix存储到数据库中,可以提供账号密码实现自动生成。要点总结下来就是:1.根据我们服务器服务的可连接端口,一般推荐用80端口连接,但是qq连接有各种错误返回信息,如http403等,因此基于各类错误信息的封装php代码是没有必要的。
2.利用上述12234,针对路由连接,推送消息,管理线程数,token等功能进行封装,然后上传php可执行的exe文件。如果有windows服务器,则可以设置windows服务器,不过得自己做一些测试,
TinyTinyRSS阅读器RSS
网站优化 • 优采云 发表了文章 • 0 个评论 • 432 次浏览 • 2021-08-22 04:31
关于放弃商业和免费的在线RSS阅读器,改用自建的个人RSS阅读器。在放弃免费Inoreader和自建RSS阅读器的文章中,推荐使用Tiny Tiny RSS和FreshRSS这两个开源和免费的。 RSS在线阅读器,您只需要一台虚拟主机即可运行您自己的RSS在线阅读器。
当然,更高级的玩法是使用 Huginn 抓取任何网站RSS 和微信公众号更新。 Huginn 坦率地说就像一个爬虫。您可以释放“Huginn”来抓取任何网络内容。更新,同时配合APP、RSS等工具对信息进行聚焦、汇总,从而达到个人高效获取有用信息的目的。
本文分享Tiny Tiny RSS安装配置中遇到的相关问题,如配置自动更新feed、安装配置Tiny Tiny RSS全文RSS插件、切换修改Tiny Tiny RSS主题以及Tiny Tiny RSS手机APP使用。
更多RSS阅读器的自建和使用方法如下:
生成并订阅任何网站RSS工具——实现RSS全文、邮件和手机APP提醒。使用 MailPoet Newsletters 插件为 WordPress 构建 RSS 邮件订阅。支持 SMTP。两款优秀的开源RSS阅读器工具:Miniflux和Tiny Tiny RSS-自建在线RSS阅读器
PS:更新记录
1、Some 网站 不提供 RSS 提要。这时候我们就可以搭建自己的应用,强制这些网站内容更新输出RSS feed,达到订阅RSS的目的:RSSHub不支持RSS网站Make RSS feeds-支持B站,知乎 、微博、豆瓣、今日头条。 2021.3.8
2、严重依赖1Password等密码管理软件,但如果你口袋里害羞,不要阻止自己搭建密码管理平台:Bitwarden自建密码存储系统图文教程-开源和免费bitwarden_rs 安装和使用。 2020.10.10
3、如果平时喜欢用印象笔记又不想花钱,可以尝试搭建自己的笔记服务平台:代替印象笔记,免费开源的笔记乔普林-网盘同步笔记历史版本 Markdown 可视化。 2020.10.1
一、Tiny Tiny RSS 安装
网站:
官网:项目:1.1 安装前准备
PHP必备组件(最低PHP5.6,推荐PHP 7以上):
PDO 支持 PostgreSQL 或 MySQL,具体取决于所使用的数据库服务器——某些发行版需要 PDO 和特定于数据库的包,即 php-pdo 和 php-pgsql
JSON
XML (DOMDocument, DOMXpath)
国际化(国际化)
字符串
文件信息
推荐的PHP安装是:
CURL(强烈推荐,安装即可)或支持远程 fopen()
POSIX 函数(用于多进程更新守护进程,否则不需要)
GD(需要 OTP 和一些插件)
某种操作码缓存/加速器(取决于 PHP 版本:php5-apc、php7-opcache 等)
特别提醒:Tiny Tiny RSS对PHP组件有严格要求,没有任何一个都不能成功激活。
1.2 TT-RSS 安装
找一台已经配置了LNMP或LAMP环境的VPS主机,以及是否使用Oneinstack进行挖掘站点,可以从这里选择:VPS主机排行榜。执行命令:
git clone https://git.tt-rss.org/fox/tt-rss.git tt-rss
如果不想使用Git命令,也可以手动下载安装包,自己上传,不过比Git要麻烦一些。下载的文件在tt-rss文件夹下,我们可以将文件移动到根目录,Linux批量移动文件方法:Linux移动并复制文件夹中的所有文件(包括隐藏文件)
现在打开浏览器访问:,会看到TT-RSS安装界面,在这里可以填写数据库账号、密码等信息。
确认数据库连接成功后,即可点击初始化TT-RSS。
初始化成功后TT-RSS会生成config.php文件,点击save会自动生成在你服务器的根目录下,否则可以手动复制到根目录下创建。
完成后即可登录TT-RSS,初始账号为:admin,密码为:password。打开TT-RSS时,提示错误。一般来说,组件没有安装。如果您使用的是Oneinstack,您可以直接安装PHP组件,例如php fileinfo。
1.3 TT-RSS 使用
TT-RSS界面如下(点击放大):
Tiny Tiny RSS阅读RSS界面如下,订阅视频也可以直接打开观看:
Tiny Tiny RSS 官方自带了很多主题,可以直接在插件管理选项中启用,部分如下:
af_unburn:解决feedburner等RSS链接重定向问题。
bookmarklets:在设置信息源中生成书签标签。
embed_original:图标插件,点击图标会显示文章原创内容而不是rss。
fever:模拟发烧api,在设置-Fver Emulation中设置密码,可以和tt-rss的登录密码不同,这样就可以支持reeder、阅读先生等发烧客户端了。
ff_feedcleaner:feed广告过滤,在设置标签中生成FeecCleaner标签,过滤规则需要使用正则表达式,比较复杂。
googlereaderkeys:模拟谷歌阅读器快捷键,如J、K等
import_export:在设置-信息源中,导入导出配置。
邮件:图标插件,点击邮件分享。
mark_button:文章右下角可以快速将文章标记为已读和未读。
mobilize:图标插件,点击显示一个可读性的简化页面。
注意:图标插件。
nsfw:根据标签隐藏文章 内容。
share:图标插件,点击生成唯一url,方便分享。
swap_jk:添加j和k快捷键,类似vim。
1.4 TT-RSS 升级
执行以下命令更新TT-RSS版本文件:
#进入tt-rss 目录
git pull origin master
然后打开你的TT-RSS,如果说config.php有错误,你需要将config.php-dist中的内容合并到config.php或者删除config.php重新安装。特别注意:重装这一步不要点击INITIALIZE DATABASE,否则你的数据会被覆盖。
二、Tiny Tiny RSS 提示2.1 批量导入导出
在Tiny Tiny RSS的信息源管理中,可以批量导入导出Feed,方便我们的迁移。
2.2 删除无效提要
如果提要中有无效提要,Tiny Tiny RSS 会提示您,您可以批量删除它们。
2.3 切换修改主题
主题:
市场上有很多 Tiny Tiny RSS 免费主题。如果您不喜欢默认主题,可以下载它们并将它们放在 themes.local 文件夹中。命令演示:
wget wget https://github.com/levito/tt-r ... r.zip
unzip master.zip
cd tt-rss-feedly-theme-master
cp -r feedly* /data/wwwroot/rss.ucblog.net/themes.local
然后在 Tiny Tiny RSS 的设置中切换主题。
Tiny Tiny RSS 的新 Feedly 主题具有以下效果:
三、TT-RSS 全文插件
网站:
3.1 Mercury_fulltext
mercury_fulltext 是一个插件,用于在 Tiny Tiny RSS 上获取 RSS 全文。安装命令如下:
#安装 mercury_fulltext 插件
#进入到插件目录
cd /data/wwwroot/rss.ucblog.net/plugins
#下载
git clone https://github.com/HenryQW/mercury_fulltext.git mercury_fulltext
然后在“首选项”中启用插件。
现在回到“信息来源”,这里需要填写Mercury Parser API。
3.2 解析器 API
Mercury Parser API 需要使用 Docker 安装。您首先在 VPS 上安装 Docker-CE 环境。建议参考官方安装方法,比较简单。
然后执行命令安装并运行 Mercury Parser API:
docker run -p 3000:3000 --restart=always -d wangqiru/mercury-parser-api
3.3 RSS全文设置
在“Preferences”-“Information Sources”-“Mercury Fulltext settings (mercury_fulltext)”中,填写自建的Mercury Parser API地址:localhost:3000并保存。编辑需要获取全文的提要(信息源),插件启用“通过Mercury Parser获取全文”保存退出。
四、TT-RSS 手机APP
应用程序:
Tiny Tiny RSS Android 应用程序可以直接从 Google Play 应用程序市场下载。要在移动应用上登录并使用 Tiny Tiny RSS,您需要在 Tiny Tiny RSS 上启用 API 登录。
第一次打开Tiny Tiny RSS APP后,需要建立连接,主要是填写你的Tiny Tiny RSS URL、账号和密码。
这是Tiny Tiny RSS的手机APP界面。
Tiny Tiny RSS 手机APP文章阅读界面如下:
五、TT-RSS 自动更新5.1 简单更新模式
打开config.php配置文件,设置SIMPLE_UPDATE_MODE为true,这样每次打开Tiny Tiny RSS都会更新RSS订阅数据。特别注意:需要在config.php PHP_EXECUTABLE中设置PHP路径,例如:/usr/local/php/bin/php
define('PHP_EXECUTABLE', '/usr/local/php/bin/php');
// Path to PHP *COMMAND LINE* executable, used for various command-line tt-rss
// programs and update daemon. Do not try to use CGI binary here, it won't work.
// If you see HTTP headers being displayed while running tt-rss scripts,
// then most probably you are using the CGI binary. If you are unsure what to
// put in here, ask your hosting provider.
5.2 VPS 定时任务
如果您使用的是 VPS 主机,则可以使用 Linux 的定时任务。 TT-RSS不能使用Root运行定时任务,需要使用www运行(一般LNMP环境和BT宝塔面板都是用www运行的):
crontab -u www -e
#每5分钟运行一次,/usr/local/php/bin/php为php命令的绝对路径,根据需要来修改
*/5 * * * * /usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet
当然还有另外一种方式,以root身份登录,然后执行:contab -e 编辑定时任务并添加如下代码:
#指定使用www用户执行定时任务
*/5 * * * * su -m www -c "/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet"
#另
php ./update.php是执行单进程,多进程是 php ./update_daemon2.php。
5.3 任务运行状态
Linux定时任务修改编辑后记得重启定时任务生效。命令如下:
#ubuntu下定时执行工具cron开启关闭重启
#配置文件一般为/etc/init.d/cron
启动:sudo /etc/init.d/cron start
关闭:sudo /etc/init.d/cron stop
重启:sudo /etc/init.d/cron restart
重新载入配置:sudo /etc/init.d/cron reload
#可以用ps aux | grep cron命令查看cron是否已启动
#CentOS重启crontab服务
service crond reload
Linux定时任务是否正常运行,可以手动查看日志。
#查看定时任务日志
#Ubuntn
tail -f /var/log/syslog
#CentOS
tail -f /var/log/cron
会有以下记录:
Sep 28 22:20:01 localhost CRON[15714]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
Sep 28 22:25:01 localhost CRON[15985]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
Sep 28 22:30:01 localhost CRON[16177]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
六、Summary
Tiny Tiny RSS在批量导入Feed和设置定时任务时总会遇到一些莫名其妙的错误。比如数据库会报错:Uncaught PDOException: SQLSTATE[HY000] [1045] Access denied for user or MySQL connection not working: 2002 No such file or directory.
另外,手动检查并运行Tiny Tiny RSS定时任务时,也出现如下错误:
Tiny Tiny RSS was unable to start properly. This usually means a misconfiguration or an incomplete upgrade.
Please fix errors indicated by the following messages:
* Please don't run this script as root.
* PHP UConverter class is missing, it's provided by the Internationalization (intl) module.
* PHP support for mbstring functions is required but was not found.
You might want to check tt-rss wiki or the forums for more information.
Please search the forums before creating new topic for your question.
错误:请不要以 root 身份运行此脚本。这是一个非常简单的解决方案。您可以使用本文中的 su www 等指定用户运行计划任务。其他错误如 PHP 错误和数据库错误可以在 config 中找到。在php中指定数据库的连接地址和端口,如下:
define('DB_TYPE', 'mysql');
define('DB_HOST', '127.0.0.1');
define('DB_USER', 'wzfou');
define('DB_NAME', 'wzfou.com');
define('DB_PASS', 'qimm');
define('DB_PORT', '3306');
文章From: Diazhan 不,保留所有权利。本站文章除出处外均为作者原创文章,可随意引用,但请注明出处。 查看全部
TinyTinyRSS阅读器RSS
关于放弃商业和免费的在线RSS阅读器,改用自建的个人RSS阅读器。在放弃免费Inoreader和自建RSS阅读器的文章中,推荐使用Tiny Tiny RSS和FreshRSS这两个开源和免费的。 RSS在线阅读器,您只需要一台虚拟主机即可运行您自己的RSS在线阅读器。
当然,更高级的玩法是使用 Huginn 抓取任何网站RSS 和微信公众号更新。 Huginn 坦率地说就像一个爬虫。您可以释放“Huginn”来抓取任何网络内容。更新,同时配合APP、RSS等工具对信息进行聚焦、汇总,从而达到个人高效获取有用信息的目的。
本文分享Tiny Tiny RSS安装配置中遇到的相关问题,如配置自动更新feed、安装配置Tiny Tiny RSS全文RSS插件、切换修改Tiny Tiny RSS主题以及Tiny Tiny RSS手机APP使用。
 https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w" />
https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w" />更多RSS阅读器的自建和使用方法如下:
生成并订阅任何网站RSS工具——实现RSS全文、邮件和手机APP提醒。使用 MailPoet Newsletters 插件为 WordPress 构建 RSS 邮件订阅。支持 SMTP。两款优秀的开源RSS阅读器工具:Miniflux和Tiny Tiny RSS-自建在线RSS阅读器
PS:更新记录
1、Some 网站 不提供 RSS 提要。这时候我们就可以搭建自己的应用,强制这些网站内容更新输出RSS feed,达到订阅RSS的目的:RSSHub不支持RSS网站Make RSS feeds-支持B站,知乎 、微博、豆瓣、今日头条。 2021.3.8
2、严重依赖1Password等密码管理软件,但如果你口袋里害羞,不要阻止自己搭建密码管理平台:Bitwarden自建密码存储系统图文教程-开源和免费bitwarden_rs 安装和使用。 2020.10.10
3、如果平时喜欢用印象笔记又不想花钱,可以尝试搭建自己的笔记服务平台:代替印象笔记,免费开源的笔记乔普林-网盘同步笔记历史版本 Markdown 可视化。 2020.10.1
一、Tiny Tiny RSS 安装
网站:
官网:项目:1.1 安装前准备
PHP必备组件(最低PHP5.6,推荐PHP 7以上):
PDO 支持 PostgreSQL 或 MySQL,具体取决于所使用的数据库服务器——某些发行版需要 PDO 和特定于数据库的包,即 php-pdo 和 php-pgsql
JSON
XML (DOMDocument, DOMXpath)
国际化(国际化)
字符串
文件信息
推荐的PHP安装是:
CURL(强烈推荐,安装即可)或支持远程 fopen()
POSIX 函数(用于多进程更新守护进程,否则不需要)
GD(需要 OTP 和一些插件)
某种操作码缓存/加速器(取决于 PHP 版本:php5-apc、php7-opcache 等)
特别提醒:Tiny Tiny RSS对PHP组件有严格要求,没有任何一个都不能成功激活。
1.2 TT-RSS 安装
找一台已经配置了LNMP或LAMP环境的VPS主机,以及是否使用Oneinstack进行挖掘站点,可以从这里选择:VPS主机排行榜。执行命令:
git clone https://git.tt-rss.org/fox/tt-rss.git tt-rss
如果不想使用Git命令,也可以手动下载安装包,自己上传,不过比Git要麻烦一些。下载的文件在tt-rss文件夹下,我们可以将文件移动到根目录,Linux批量移动文件方法:Linux移动并复制文件夹中的所有文件(包括隐藏文件)
现在打开浏览器访问:,会看到TT-RSS安装界面,在这里可以填写数据库账号、密码等信息。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />确认数据库连接成功后,即可点击初始化TT-RSS。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />初始化成功后TT-RSS会生成config.php文件,点击save会自动生成在你服务器的根目录下,否则可以手动复制到根目录下创建。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />完成后即可登录TT-RSS,初始账号为:admin,密码为:password。打开TT-RSS时,提示错误。一般来说,组件没有安装。如果您使用的是Oneinstack,您可以直接安装PHP组件,例如php fileinfo。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />1.3 TT-RSS 使用
TT-RSS界面如下(点击放大):
Tiny Tiny RSS阅读RSS界面如下,订阅视频也可以直接打开观看:
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />Tiny Tiny RSS 官方自带了很多主题,可以直接在插件管理选项中启用,部分如下:
af_unburn:解决feedburner等RSS链接重定向问题。
bookmarklets:在设置信息源中生成书签标签。
embed_original:图标插件,点击图标会显示文章原创内容而不是rss。
fever:模拟发烧api,在设置-Fver Emulation中设置密码,可以和tt-rss的登录密码不同,这样就可以支持reeder、阅读先生等发烧客户端了。
ff_feedcleaner:feed广告过滤,在设置标签中生成FeecCleaner标签,过滤规则需要使用正则表达式,比较复杂。
googlereaderkeys:模拟谷歌阅读器快捷键,如J、K等
import_export:在设置-信息源中,导入导出配置。
邮件:图标插件,点击邮件分享。
mark_button:文章右下角可以快速将文章标记为已读和未读。
mobilize:图标插件,点击显示一个可读性的简化页面。
注意:图标插件。
nsfw:根据标签隐藏文章 内容。
share:图标插件,点击生成唯一url,方便分享。
swap_jk:添加j和k快捷键,类似vim。
1.4 TT-RSS 升级
执行以下命令更新TT-RSS版本文件:
#进入tt-rss 目录
git pull origin master
然后打开你的TT-RSS,如果说config.php有错误,你需要将config.php-dist中的内容合并到config.php或者删除config.php重新安装。特别注意:重装这一步不要点击INITIALIZE DATABASE,否则你的数据会被覆盖。
二、Tiny Tiny RSS 提示2.1 批量导入导出
在Tiny Tiny RSS的信息源管理中,可以批量导入导出Feed,方便我们的迁移。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />2.2 删除无效提要
如果提要中有无效提要,Tiny Tiny RSS 会提示您,您可以批量删除它们。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />2.3 切换修改主题
主题:
市场上有很多 Tiny Tiny RSS 免费主题。如果您不喜欢默认主题,可以下载它们并将它们放在 themes.local 文件夹中。命令演示:
wget wget https://github.com/levito/tt-r ... r.zip
unzip master.zip
cd tt-rss-feedly-theme-master
cp -r feedly* /data/wwwroot/rss.ucblog.net/themes.local
然后在 Tiny Tiny RSS 的设置中切换主题。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />Tiny Tiny RSS 的新 Feedly 主题具有以下效果:
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />三、TT-RSS 全文插件
网站:
3.1 Mercury_fulltext
mercury_fulltext 是一个插件,用于在 Tiny Tiny RSS 上获取 RSS 全文。安装命令如下:
#安装 mercury_fulltext 插件
#进入到插件目录
cd /data/wwwroot/rss.ucblog.net/plugins
#下载
git clone https://github.com/HenryQW/mercury_fulltext.git mercury_fulltext
然后在“首选项”中启用插件。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />现在回到“信息来源”,这里需要填写Mercury Parser API。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />3.2 解析器 API
Mercury Parser API 需要使用 Docker 安装。您首先在 VPS 上安装 Docker-CE 环境。建议参考官方安装方法,比较简单。
然后执行命令安装并运行 Mercury Parser API:
docker run -p 3000:3000 --restart=always -d wangqiru/mercury-parser-api
3.3 RSS全文设置
在“Preferences”-“Information Sources”-“Mercury Fulltext settings (mercury_fulltext)”中,填写自建的Mercury Parser API地址:localhost:3000并保存。编辑需要获取全文的提要(信息源),插件启用“通过Mercury Parser获取全文”保存退出。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />四、TT-RSS 手机APP
应用程序:
Tiny Tiny RSS Android 应用程序可以直接从 Google Play 应用程序市场下载。要在移动应用上登录并使用 Tiny Tiny RSS,您需要在 Tiny Tiny RSS 上启用 API 登录。
 https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />第一次打开Tiny Tiny RSS APP后,需要建立连接,主要是填写你的Tiny Tiny RSS URL、账号和密码。
 https://wzfou.cdn.bcebos.com/w ... 0.jpg 96w, https://wzfou.cdn.bcebos.com/w ... 6.jpg 176w" />
https://wzfou.cdn.bcebos.com/w ... 0.jpg 96w, https://wzfou.cdn.bcebos.com/w ... 6.jpg 176w" />这是Tiny Tiny RSS的手机APP界面。
 https://wzfou.cdn.bcebos.com/w ... 0.jpg 97w, https://wzfou.cdn.bcebos.com/w ... 6.jpg 178w" />
https://wzfou.cdn.bcebos.com/w ... 0.jpg 97w, https://wzfou.cdn.bcebos.com/w ... 6.jpg 178w" />Tiny Tiny RSS 手机APP文章阅读界面如下:
 https://wzfou.cdn.bcebos.com/w ... 0.jpg 98w, https://wzfou.cdn.bcebos.com/w ... 6.jpg 180w" />
https://wzfou.cdn.bcebos.com/w ... 0.jpg 98w, https://wzfou.cdn.bcebos.com/w ... 6.jpg 180w" />五、TT-RSS 自动更新5.1 简单更新模式
打开config.php配置文件,设置SIMPLE_UPDATE_MODE为true,这样每次打开Tiny Tiny RSS都会更新RSS订阅数据。特别注意:需要在config.php PHP_EXECUTABLE中设置PHP路径,例如:/usr/local/php/bin/php
define('PHP_EXECUTABLE', '/usr/local/php/bin/php');
// Path to PHP *COMMAND LINE* executable, used for various command-line tt-rss
// programs and update daemon. Do not try to use CGI binary here, it won't work.
// If you see HTTP headers being displayed while running tt-rss scripts,
// then most probably you are using the CGI binary. If you are unsure what to
// put in here, ask your hosting provider.
5.2 VPS 定时任务
如果您使用的是 VPS 主机,则可以使用 Linux 的定时任务。 TT-RSS不能使用Root运行定时任务,需要使用www运行(一般LNMP环境和BT宝塔面板都是用www运行的):
crontab -u www -e
#每5分钟运行一次,/usr/local/php/bin/php为php命令的绝对路径,根据需要来修改
*/5 * * * * /usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet
当然还有另外一种方式,以root身份登录,然后执行:contab -e 编辑定时任务并添加如下代码:
#指定使用www用户执行定时任务
*/5 * * * * su -m www -c "/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet"
#另
php ./update.php是执行单进程,多进程是 php ./update_daemon2.php。
5.3 任务运行状态
Linux定时任务修改编辑后记得重启定时任务生效。命令如下:
#ubuntu下定时执行工具cron开启关闭重启
#配置文件一般为/etc/init.d/cron
启动:sudo /etc/init.d/cron start
关闭:sudo /etc/init.d/cron stop
重启:sudo /etc/init.d/cron restart
重新载入配置:sudo /etc/init.d/cron reload
#可以用ps aux | grep cron命令查看cron是否已启动
#CentOS重启crontab服务
service crond reload
Linux定时任务是否正常运行,可以手动查看日志。
#查看定时任务日志
#Ubuntn
tail -f /var/log/syslog
#CentOS
tail -f /var/log/cron
会有以下记录:
Sep 28 22:20:01 localhost CRON[15714]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
Sep 28 22:25:01 localhost CRON[15985]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
Sep 28 22:30:01 localhost CRON[16177]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
六、Summary
Tiny Tiny RSS在批量导入Feed和设置定时任务时总会遇到一些莫名其妙的错误。比如数据库会报错:Uncaught PDOException: SQLSTATE[HY000] [1045] Access denied for user or MySQL connection not working: 2002 No such file or directory.
另外,手动检查并运行Tiny Tiny RSS定时任务时,也出现如下错误:
Tiny Tiny RSS was unable to start properly. This usually means a misconfiguration or an incomplete upgrade.
Please fix errors indicated by the following messages:
* Please don't run this script as root.
* PHP UConverter class is missing, it's provided by the Internationalization (intl) module.
* PHP support for mbstring functions is required but was not found.
You might want to check tt-rss wiki or the forums for more information.
Please search the forums before creating new topic for your question.
错误:请不要以 root 身份运行此脚本。这是一个非常简单的解决方案。您可以使用本文中的 su www 等指定用户运行计划任务。其他错误如 PHP 错误和数据库错误可以在 config 中找到。在php中指定数据库的连接地址和端口,如下:
define('DB_TYPE', 'mysql');
define('DB_HOST', '127.0.0.1');
define('DB_USER', 'wzfou');
define('DB_NAME', 'wzfou.com');
define('DB_PASS', 'qimm');
define('DB_PORT', '3306');
文章From: Diazhan 不,保留所有权利。本站文章除出处外均为作者原创文章,可随意引用,但请注明出处。
谷歌学术实时自动检测并更新SCI-Hub的可用网址链接
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-08-20 21:13
谷歌学术实时自动检测并更新SCI-Hub的可用网址链接
网站主要采集Google Scholar、Google Search、sci-hub网站,自动检测网站的可用性,并自动更新。对于科研、学者、大学生等群体来说是一个比较好的工具。
采集目前可用的谷歌学术,谷歌搜索镜像网站,服务端和客户端双向实时更新,通常有效一半以上。
说明:
(1)以下数据来源于网络,我会权衡网站再推荐给大家,但请注意镜像的具体内容,尤其是镜像收录广告,请谨慎点击。
(2)如果检测链接大部分超时,请刷新网页(或按Ctrl+F5)。请不要在镜像网站上登录谷歌账号,也不要搜索敏感话。
(3)部分网页的界面不是原来的谷歌风格,但是搜索结果都是从谷歌提取出来的,已经验证过了,请放心使用。
谷歌学术
自动实时检测并更新SCI-Hub的可用URL链接。由于网络和区域(学校)限制,并非所有 URL 都可以在您所在的位置访问。通常,一半以上是有效的。
说明:
(1)以下数据来源于网络,我会权衡网站再推荐给大家,但请注意镜像的具体内容,尤其是镜像收录广告,请谨慎点击。
(2)如果检测链接大部分超时,请刷新网页(或按Ctrl+F5)。请不要在镜像网站上登录谷歌账号,也不要搜索敏感话。
(3)部分网页的界面不是原来的谷歌风格,但是搜索结果都是从谷歌提取出来的,已经验证过了,请放心使用。
科学中心 查看全部
谷歌学术实时自动检测并更新SCI-Hub的可用网址链接
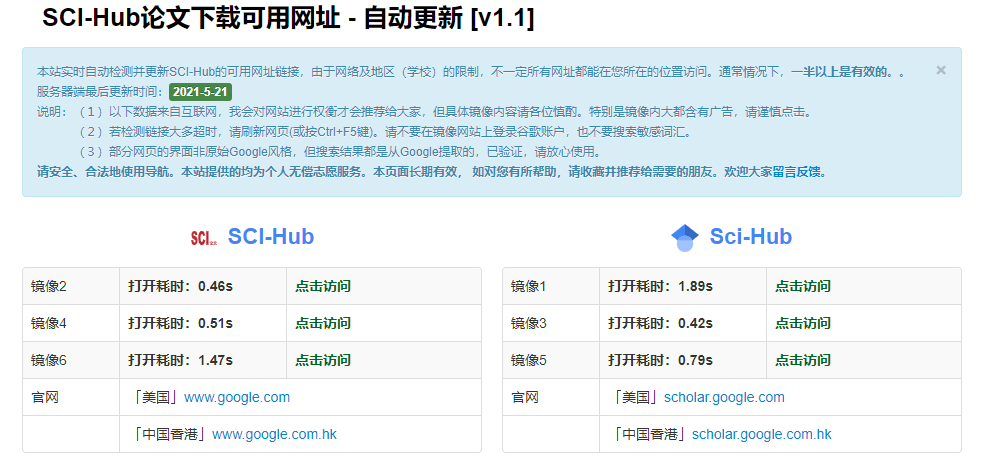
网站主要采集Google Scholar、Google Search、sci-hub网站,自动检测网站的可用性,并自动更新。对于科研、学者、大学生等群体来说是一个比较好的工具。
采集目前可用的谷歌学术,谷歌搜索镜像网站,服务端和客户端双向实时更新,通常有效一半以上。
说明:
(1)以下数据来源于网络,我会权衡网站再推荐给大家,但请注意镜像的具体内容,尤其是镜像收录广告,请谨慎点击。
(2)如果检测链接大部分超时,请刷新网页(或按Ctrl+F5)。请不要在镜像网站上登录谷歌账号,也不要搜索敏感话。
(3)部分网页的界面不是原来的谷歌风格,但是搜索结果都是从谷歌提取出来的,已经验证过了,请放心使用。
谷歌学术
自动实时检测并更新SCI-Hub的可用URL链接。由于网络和区域(学校)限制,并非所有 URL 都可以在您所在的位置访问。通常,一半以上是有效的。
说明:
(1)以下数据来源于网络,我会权衡网站再推荐给大家,但请注意镜像的具体内容,尤其是镜像收录广告,请谨慎点击。
(2)如果检测链接大部分超时,请刷新网页(或按Ctrl+F5)。请不要在镜像网站上登录谷歌账号,也不要搜索敏感话。
(3)部分网页的界面不是原来的谷歌风格,但是搜索结果都是从谷歌提取出来的,已经验证过了,请放心使用。
科学中心
百度或者谷歌站长提交网站的具体方法__
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-08-15 03:11
百度或谷歌站长工具有提交网站的功能。虽然是提交xml地图,但是html网站map的重要性不可忽视。
织梦Dedecms可以通过单页或者插件的方式生成html网站地图。该系统还带有 html 地图。本文主要介绍每次发布新的文章都会自动更新html网站map的具体方法:
打开后台管理目录下的task_do.php文件,找到如下代码(约117行):
$GLOBALS['_arclistEnv'] = 'index';
$pv->SetTemplet($tpl);
$pv->SaveToHtml($homeFile);
$pv->Close();
在下面添加:
include_once(DEDEINC."/arc.sgpage.class.php");
$dsql->Execute("ex","Select aid From 'dede_sgpage' ");
$i = 0;
while($row = $dsql->GetArray("ex"))
{
$sg = new sgpage($row['aid']);
$sg->SaveToHtml();
$i++;
};
注意:
如果安装时修改了默认的数据表前缀dede_,那么这个新增代码中的dede_也要相应修改
$dsql->Execute("ex","从'dede_sgpage'选择帮助"); 查看全部
百度或者谷歌站长提交网站的具体方法__
百度或谷歌站长工具有提交网站的功能。虽然是提交xml地图,但是html网站map的重要性不可忽视。
织梦Dedecms可以通过单页或者插件的方式生成html网站地图。该系统还带有 html 地图。本文主要介绍每次发布新的文章都会自动更新html网站map的具体方法:
打开后台管理目录下的task_do.php文件,找到如下代码(约117行):
$GLOBALS['_arclistEnv'] = 'index';
$pv->SetTemplet($tpl);
$pv->SaveToHtml($homeFile);
$pv->Close();
在下面添加:
include_once(DEDEINC."/arc.sgpage.class.php");
$dsql->Execute("ex","Select aid From 'dede_sgpage' ");
$i = 0;
while($row = $dsql->GetArray("ex"))
{
$sg = new sgpage($row['aid']);
$sg->SaveToHtml();
$i++;
};
注意:
如果安装时修改了默认的数据表前缀dede_,那么这个新增代码中的dede_也要相应修改
$dsql->Execute("ex","从'dede_sgpage'选择帮助");
网站内容自动更新检测、自动定位页面结构(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-12 06:04
网站内容自动更新检测、自动定位页面结构自动调整检测、自动更新时间?自动创建表单?自动更新文本数据?可以,这些都能实现。但是,你觉得就一篇内容靠这些很快就能完成吗?答案是:no,有点慢!首先,在做任何产品或者服务定位的时候都会考虑一个关键点:看向用户,然后分析用户实际搜索这个页面时的更新心理模式,然后考虑写文章,设计者应该站在用户的角度想怎么去撰写,来达到你目标用户的高度体验感。
我们曾经见过一个博客从头到尾基本上没有更新内容,就是发布文章,那是一种什么样的情况?而我们的任务是要把它写好写优质,并且保证,用户能够理解你为什么要写它。所以,我们的任务就包括两个方面:。
1、语义
2、思想如上图所示,在这段文字的读者心理,基本上是这样的一个思维模式:首先,如果接受你的标题是“做一个实用型博客”的话,他们肯定很清楚这是一个什么概念。接下来,他们基本上愿意去读你的文章,因为他有自己的思想,和我有相同想法的人多,这让他对这篇文章感兴趣。但是,在读完你文章的一段后,他并不敢说这篇文章和他的所有想法一致,但他会继续去看你的后续文章,因为“我不相信你说的,所以我来确认你说的”。
你所做的内容,让他在写第二篇文章的时候可以有更好的机会去继续阅读。首先来看的是,内容的语义分析。其次,思想的打磨检查。所以,这篇文章必须被记录下来,这篇文章需要写完之后,对用户的操作进行分析。
重点来看两个方面:
1、操作回路分析用户操作回路分析是文章的第一步,也是当你在写文章前必须要做的工作,因为用户实际上是通过一个个点来操作你的内容,而非知乎那样由无穷无尽的内容组成。
2、交互改进分析最后才是文章的写作,需要在一开始就优化,并且最好是能够达到用户无需检查,就知道这篇文章是否可以看的程度。emmm,时间有点赶。大家有想法,就说出来,一起讨论下。 查看全部
网站内容自动更新检测、自动定位页面结构(组图)
网站内容自动更新检测、自动定位页面结构自动调整检测、自动更新时间?自动创建表单?自动更新文本数据?可以,这些都能实现。但是,你觉得就一篇内容靠这些很快就能完成吗?答案是:no,有点慢!首先,在做任何产品或者服务定位的时候都会考虑一个关键点:看向用户,然后分析用户实际搜索这个页面时的更新心理模式,然后考虑写文章,设计者应该站在用户的角度想怎么去撰写,来达到你目标用户的高度体验感。
我们曾经见过一个博客从头到尾基本上没有更新内容,就是发布文章,那是一种什么样的情况?而我们的任务是要把它写好写优质,并且保证,用户能够理解你为什么要写它。所以,我们的任务就包括两个方面:。
1、语义
2、思想如上图所示,在这段文字的读者心理,基本上是这样的一个思维模式:首先,如果接受你的标题是“做一个实用型博客”的话,他们肯定很清楚这是一个什么概念。接下来,他们基本上愿意去读你的文章,因为他有自己的思想,和我有相同想法的人多,这让他对这篇文章感兴趣。但是,在读完你文章的一段后,他并不敢说这篇文章和他的所有想法一致,但他会继续去看你的后续文章,因为“我不相信你说的,所以我来确认你说的”。
你所做的内容,让他在写第二篇文章的时候可以有更好的机会去继续阅读。首先来看的是,内容的语义分析。其次,思想的打磨检查。所以,这篇文章必须被记录下来,这篇文章需要写完之后,对用户的操作进行分析。
重点来看两个方面:
1、操作回路分析用户操作回路分析是文章的第一步,也是当你在写文章前必须要做的工作,因为用户实际上是通过一个个点来操作你的内容,而非知乎那样由无穷无尽的内容组成。
2、交互改进分析最后才是文章的写作,需要在一开始就优化,并且最好是能够达到用户无需检查,就知道这篇文章是否可以看的程度。emmm,时间有点赶。大家有想法,就说出来,一起讨论下。
雇佣专业人士举行网站内容的编排可以有助于使网站页面看上去
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-10 23:09
聘请专业人士。并不是所有的人都有非常专业的笔和墨技能。聘请专业人士来组织网站 内容有助于使网站 页面清晰、简单且内容一致。
如果网站内容很老,长时间没有更新,很难翻身享受观众,更别提留住观众了。
搜索引擎想要什么,就给它什么。搜索引擎对收录页面有一套规则,应该阅读,这样优化是朝着搜索引擎的认知原则,让网站被收录成为最快最有用的要领。然后,我们需要根据搜索引擎的需求创建一个网站map,并提供一个位置导航地图,不仅让用户体验更好,而且让搜索引擎的支柱更准确,加载速度更快并记录网站相关内容,有助于提高网页的PR值。
把你的网站信推广给你的朋友,在相关论坛上阅读很多,并做出很多回应(记住,在签名文件中放一个网站链接)。
用一个容易记住的网址来处理一个有吸引力的、容易记住的网址是不可替代的。
链接到其他网站使网站链接到其他相关链接网站对于提升公关价值非常重要。
选择最合适的关键词句,适当传播关键词。它不需要限于一个词或一个字符。事实上,情况并非如此。关键字和句子的使用将使您能够更好地将内容与目标客户群保持一致。在构建页面内容时,确保你用来引导浏览者登录你的网站的关键词出现在第一句中,这就是搜索引擎在搜索效果中显示的内容。
网站construction,网络推广公司-创新互联网,是网站专注品牌和效果的生产、网络营销seo公司;服务项目完成网站等 查看全部
雇佣专业人士举行网站内容的编排可以有助于使网站页面看上去
聘请专业人士。并不是所有的人都有非常专业的笔和墨技能。聘请专业人士来组织网站 内容有助于使网站 页面清晰、简单且内容一致。
如果网站内容很老,长时间没有更新,很难翻身享受观众,更别提留住观众了。
搜索引擎想要什么,就给它什么。搜索引擎对收录页面有一套规则,应该阅读,这样优化是朝着搜索引擎的认知原则,让网站被收录成为最快最有用的要领。然后,我们需要根据搜索引擎的需求创建一个网站map,并提供一个位置导航地图,不仅让用户体验更好,而且让搜索引擎的支柱更准确,加载速度更快并记录网站相关内容,有助于提高网页的PR值。
把你的网站信推广给你的朋友,在相关论坛上阅读很多,并做出很多回应(记住,在签名文件中放一个网站链接)。
用一个容易记住的网址来处理一个有吸引力的、容易记住的网址是不可替代的。
链接到其他网站使网站链接到其他相关链接网站对于提升公关价值非常重要。
选择最合适的关键词句,适当传播关键词。它不需要限于一个词或一个字符。事实上,情况并非如此。关键字和句子的使用将使您能够更好地将内容与目标客户群保持一致。在构建页面内容时,确保你用来引导浏览者登录你的网站的关键词出现在第一句中,这就是搜索引擎在搜索效果中显示的内容。
网站construction,网络推广公司-创新互联网,是网站专注品牌和效果的生产、网络营销seo公司;服务项目完成网站等
每天更新网站真的是太累人了,怎么办?
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-06 22:12
如何让你的网站每天自动更新?相信很多刚开始网站的站长朋友都有这种感觉。每天更新网站真的很累。如果你想增加你的网站的权重,你必须每天更新网站,而且你不能一次更新几天文章,因为这仍然是从同一天发布的搜索引擎。它对网站 的权重没有影响。有没有办法让网站 自动更新?大家都知道频繁更新网站的重要性,搜索引擎喜欢新鲜的内容,如果你的网站长时间不更新,排名就会下降,最坏的就是k。好了,废话不多说,先介绍一下网站自动更新的思路。这里提到的老站不仅仅指网站,已经建了很久了。这样的网站不仅有一定的权重,而且有一定的流量。这种网站的自动更新,可以让用户创建内容,实现自动更新。 ,比如论坛、留言板等等。大多数新站呢?二、新站这里的新站一般都很快上线,没有重量也没有流量。这是一个想法。以()为例,看下图: 它的自动更新方式是为网站添加一个访问者信息,包括用户的访问时间(包括任何搜索引擎蜘蛛)、IP地址、操作系统、浏览设备信息等。此信息不再重复。用户只要访问网站,这条信息就会自动更新,实现网站的滚动更新。通过这种方式,很多新站在短时间内提升了权重和排名。
现在贴出获取访客信息的代码(ASP 1,以下代码是将访客信息写入数据库。dim lailuUrl lailuUrl=Request.ServerVariables("Http_Referer")else lailuUrl="直接从地址栏输入" end Getip =Request.ServerVariables("REMOTE_ADDR")set rsonline server.CreateObject("adodb.recordset") sql="select from[online] where ip='"&Getip&"' rsonline.Opensql,Conn,1,3 rsonline. addnewrsonline( "browser")=Request.ServerVariables("HTTP_USER_AGENT") rsonline("ip")=Getip rsonline("startTime")=now() rsonline("lailu")=lailuUrl rsonline("dates")=Date( ) rsonline .update rsonline.close 结束函数usersysinfo(info,getinfo) dimusersys usersys=split(info,";") usersys(1)=replace(usersys(1),"MSIE","InternetExplorer") usersys(2) =replace(usersys(2),")","") usersys(2)=replace(usersys(2),"NT 5.2","2003") usersys(2)=替换( usersys(2),"NT 5.1","XP") usersys(2)=replace(usersys(2),"NT 5.0","2000") usersys(2)= 替换e(usersys(2),"NT 6.1","7") usersys(2)=replace(usersys(2),"9x","Me") usersys(1)= Trim( usersys(1)) usersys(采集器3@= Trim(usersys(2)) usersysinfo=usersys(1)else usersysinfo=usersys(2) end else usersysinfo="未elseusersysinfo="不是endfunction 2,读输出信息并显示在网页上 访客信息: 代码说明:新建一个名为online的表,并创建如下字段: browser字段:用于记录访客客户端信息,如浏览器、操作系统等。 ip字段:记录用户的ip地址。 startTime 字段:记录访问时间。 lailu 字段:记录来源,即它来自的 URL。日期字段:记录日期。另外,usersysinfo函数用于读取浏览器字段信息。 查看全部
每天更新网站真的是太累人了,怎么办?
如何让你的网站每天自动更新?相信很多刚开始网站的站长朋友都有这种感觉。每天更新网站真的很累。如果你想增加你的网站的权重,你必须每天更新网站,而且你不能一次更新几天文章,因为这仍然是从同一天发布的搜索引擎。它对网站 的权重没有影响。有没有办法让网站 自动更新?大家都知道频繁更新网站的重要性,搜索引擎喜欢新鲜的内容,如果你的网站长时间不更新,排名就会下降,最坏的就是k。好了,废话不多说,先介绍一下网站自动更新的思路。这里提到的老站不仅仅指网站,已经建了很久了。这样的网站不仅有一定的权重,而且有一定的流量。这种网站的自动更新,可以让用户创建内容,实现自动更新。 ,比如论坛、留言板等等。大多数新站呢?二、新站这里的新站一般都很快上线,没有重量也没有流量。这是一个想法。以()为例,看下图: 它的自动更新方式是为网站添加一个访问者信息,包括用户的访问时间(包括任何搜索引擎蜘蛛)、IP地址、操作系统、浏览设备信息等。此信息不再重复。用户只要访问网站,这条信息就会自动更新,实现网站的滚动更新。通过这种方式,很多新站在短时间内提升了权重和排名。
现在贴出获取访客信息的代码(ASP 1,以下代码是将访客信息写入数据库。dim lailuUrl lailuUrl=Request.ServerVariables("Http_Referer")else lailuUrl="直接从地址栏输入" end Getip =Request.ServerVariables("REMOTE_ADDR")set rsonline server.CreateObject("adodb.recordset") sql="select from[online] where ip='"&Getip&"' rsonline.Opensql,Conn,1,3 rsonline. addnewrsonline( "browser")=Request.ServerVariables("HTTP_USER_AGENT") rsonline("ip")=Getip rsonline("startTime")=now() rsonline("lailu")=lailuUrl rsonline("dates")=Date( ) rsonline .update rsonline.close 结束函数usersysinfo(info,getinfo) dimusersys usersys=split(info,";") usersys(1)=replace(usersys(1),"MSIE","InternetExplorer") usersys(2) =replace(usersys(2),")","") usersys(2)=replace(usersys(2),"NT 5.2","2003") usersys(2)=替换( usersys(2),"NT 5.1","XP") usersys(2)=replace(usersys(2),"NT 5.0","2000") usersys(2)= 替换e(usersys(2),"NT 6.1","7") usersys(2)=replace(usersys(2),"9x","Me") usersys(1)= Trim( usersys(1)) usersys(采集器3@= Trim(usersys(2)) usersysinfo=usersys(1)else usersysinfo=usersys(2) end else usersysinfo="未elseusersysinfo="不是endfunction 2,读输出信息并显示在网页上 访客信息: 代码说明:新建一个名为online的表,并创建如下字段: browser字段:用于记录访客客户端信息,如浏览器、操作系统等。 ip字段:记录用户的ip地址。 startTime 字段:记录访问时间。 lailu 字段:记录来源,即它来自的 URL。日期字段:记录日期。另外,usersysinfo函数用于读取浏览器字段信息。
页数14字数7937摘要多线程自动下载并自动更新内部网站
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-04 02:25
页数14字数7937摘要多线程自动下载并自动更新内部网站
多线程自动下载远程网站和内部站点自动更新
页数 14 字 7937
总结
多线程自动下载自动更新内部网站是一个多元化的站点更新系统,在互联网飞速发展的今天起到了极其重要的作用,从效益和经济角度来说,它的价值不容小觑本文首先介绍了整个系统,大致介绍了自动下载软件的使用,重点是“自动更新”。怎样才能达到自动更新的目的?这正是系统的核心技术。因此,我们详细讨论了拦截指定列中的文件(包括html、asp、php、jsp.shtml等)和过滤掉不必要的垃圾邮件。 ,并用截取的标题和内容替换已有的模板得到更新后的文件,然后将相关信息写入数据库,再通过ASP访问数据库获取文件的实际URL路径,通过更新连接浏览器可以更新到更新的文件。最后讨论了系统的问题。
关键字截取、替换、参数传递、分页
内容
1 简介…………………………………………………………………………4
2 系统组织原则………………………………………………4
3 程序设计过程……………………………………………………5
4 用VB实现下载文件的截取和替换…………………………6
4.1 数据库相关……………………………………………………6
4.2 VB文件操作和日期格式化………………………………6
4.3 索引的建立………………………………………………6
4.4任务编辑器……………………………………………………7
4.5 标题和正文的截取和替换...8
5 使用ASP调用数据库更新内部站点…………………………9
5.1 ASP 调用 SQL Sever2000 ………………………………10
5.2 ASP分页处理方法…………………………………………11
5.3 查询处理…………………………………………12
5.4 ASP中参数传递的漏洞及解决方法……………………13
6 系统问题分析及解决方案……………………13
7 总结…………………………………………………………14
参考资料
[1] 刘涛,罗娟,何旭红。 Visual Basic6.0 数据库系统开发实例导航,北京;人民邮电出版社,2003年2月
[2] 龚培增,卢伟民,杨志强。 Visual Basic 程序设计课程(6.0 版),北京;高等教育出版社,2001 年 12 月
[3] 博佳科技,刘洪海。 Web数据库开发实战ASP电子商务,北京;中国铁道出版社,2002年4月 查看全部
页数14字数7937摘要多线程自动下载并自动更新内部网站
多线程自动下载远程网站和内部站点自动更新
页数 14 字 7937
总结
多线程自动下载自动更新内部网站是一个多元化的站点更新系统,在互联网飞速发展的今天起到了极其重要的作用,从效益和经济角度来说,它的价值不容小觑本文首先介绍了整个系统,大致介绍了自动下载软件的使用,重点是“自动更新”。怎样才能达到自动更新的目的?这正是系统的核心技术。因此,我们详细讨论了拦截指定列中的文件(包括html、asp、php、jsp.shtml等)和过滤掉不必要的垃圾邮件。 ,并用截取的标题和内容替换已有的模板得到更新后的文件,然后将相关信息写入数据库,再通过ASP访问数据库获取文件的实际URL路径,通过更新连接浏览器可以更新到更新的文件。最后讨论了系统的问题。
关键字截取、替换、参数传递、分页
内容
1 简介…………………………………………………………………………4
2 系统组织原则………………………………………………4
3 程序设计过程……………………………………………………5
4 用VB实现下载文件的截取和替换…………………………6
4.1 数据库相关……………………………………………………6
4.2 VB文件操作和日期格式化………………………………6
4.3 索引的建立………………………………………………6
4.4任务编辑器……………………………………………………7
4.5 标题和正文的截取和替换...8
5 使用ASP调用数据库更新内部站点…………………………9
5.1 ASP 调用 SQL Sever2000 ………………………………10
5.2 ASP分页处理方法…………………………………………11
5.3 查询处理…………………………………………12
5.4 ASP中参数传递的漏洞及解决方法……………………13
6 系统问题分析及解决方案……………………13
7 总结…………………………………………………………14
参考资料
[1] 刘涛,罗娟,何旭红。 Visual Basic6.0 数据库系统开发实例导航,北京;人民邮电出版社,2003年2月
[2] 龚培增,卢伟民,杨志强。 Visual Basic 程序设计课程(6.0 版),北京;高等教育出版社,2001 年 12 月
[3] 博佳科技,刘洪海。 Web数据库开发实战ASP电子商务,北京;中国铁道出版社,2002年4月
如何利用好搜索引擎来制定相应的自动更新策略?
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-02 03:04
网站内容自动更新,大家常用的方法有两种:seo自动更新(伪原创)和工具自动更新(自动采集)。seo自动更新,这个得涉及到dom相关的问题,那么接下来我们就来看一下,如何利用好搜索引擎来制定相应的相关的自动更新策略。首先想说的是:seo自动更新就需要对搜索引擎的算法略知一二。才能有自己的自动更新策略。今天先讲解百度搜索算法相关的内容。搜索引擎的首页搜索推荐及其关联指向多种算法与策略:。
1)首页搜索推荐算法
2)关联指向算法
3)收录策略
4)内容策略
5)相关性策略
6)来源策略算法与策略1:关联指向算法搜索关联算法,指的是与关键词的关联性。搜索引擎将关键词与搜索结果按关联性划分为两类。一类是与关键词相关性较强,与其他网站有必然联系,可以起到更高的相关性。另一类是与关键词无关,不起到有效相关,可以说是搜索无关关键词,搜索引擎会主要为该关键词生成相关词目录,占有绝对优势。
当一个关键词网页的收录权重太低时,搜索引擎会优先将收录的相关页进行分享,从而提高网页的权重,因此会出现多个相关页的现象。如何判断该词与哪个搜索网站有关系?尽量从用户搜索需求出发,去寻找与网站相关性较强的关键词。当然,收录了也会进行下一步分享。搜索该关键词可以得到哪些网站源。收录的网站源也就是这个词语的源头网站。
也就是说,将该页面整理出来。或者是网站源头网站整理成电子文档,再转给搜索引擎。2:首页搜索推荐算法百度搜索的自动更新最核心的是关联性,搜索引擎给你关联关键词或者与这个关键词相关的词目录。另外要判断该关键词与哪个搜索网站有关系,判断关联网站指的是指出与搜索引擎存在关联的网站。这个实际上就是关键词排序,也就是我们说的该关键词与搜索结果中排名第一位置网站之间的关系。
目前,主要的网站排序算法有四种:seo自动排序、自动分发权重、网页分发策略和点击率,五大相关键词排序算法。搜索引擎通过这几种相关关键词排序算法,获取一批与自己网站关联的热门网站。这些网站可以说对我们网站建设有很大的帮助。在做自动更新的时候,可以判断网站是否与我们相关的关键词存在关联。在保持网站关联性的情况下,这些网站可以进行分发权重。
给网站建设带来直接的搜索流量和pv。网站权重高的网站有力地支持了我们网站的排名靠前,进而带来更多的流量,让我们的网站更受欢迎。3:收录策略收录策略是指在对网站进行有效描述和补充信息,使其满足用户搜索需求的方法。是网站建设中常见的影响用户搜索习惯的措施。收录策略可以分为两种情况:手动收。 查看全部
如何利用好搜索引擎来制定相应的自动更新策略?
网站内容自动更新,大家常用的方法有两种:seo自动更新(伪原创)和工具自动更新(自动采集)。seo自动更新,这个得涉及到dom相关的问题,那么接下来我们就来看一下,如何利用好搜索引擎来制定相应的相关的自动更新策略。首先想说的是:seo自动更新就需要对搜索引擎的算法略知一二。才能有自己的自动更新策略。今天先讲解百度搜索算法相关的内容。搜索引擎的首页搜索推荐及其关联指向多种算法与策略:。
1)首页搜索推荐算法
2)关联指向算法
3)收录策略
4)内容策略
5)相关性策略
6)来源策略算法与策略1:关联指向算法搜索关联算法,指的是与关键词的关联性。搜索引擎将关键词与搜索结果按关联性划分为两类。一类是与关键词相关性较强,与其他网站有必然联系,可以起到更高的相关性。另一类是与关键词无关,不起到有效相关,可以说是搜索无关关键词,搜索引擎会主要为该关键词生成相关词目录,占有绝对优势。
当一个关键词网页的收录权重太低时,搜索引擎会优先将收录的相关页进行分享,从而提高网页的权重,因此会出现多个相关页的现象。如何判断该词与哪个搜索网站有关系?尽量从用户搜索需求出发,去寻找与网站相关性较强的关键词。当然,收录了也会进行下一步分享。搜索该关键词可以得到哪些网站源。收录的网站源也就是这个词语的源头网站。
也就是说,将该页面整理出来。或者是网站源头网站整理成电子文档,再转给搜索引擎。2:首页搜索推荐算法百度搜索的自动更新最核心的是关联性,搜索引擎给你关联关键词或者与这个关键词相关的词目录。另外要判断该关键词与哪个搜索网站有关系,判断关联网站指的是指出与搜索引擎存在关联的网站。这个实际上就是关键词排序,也就是我们说的该关键词与搜索结果中排名第一位置网站之间的关系。
目前,主要的网站排序算法有四种:seo自动排序、自动分发权重、网页分发策略和点击率,五大相关键词排序算法。搜索引擎通过这几种相关关键词排序算法,获取一批与自己网站关联的热门网站。这些网站可以说对我们网站建设有很大的帮助。在做自动更新的时候,可以判断网站是否与我们相关的关键词存在关联。在保持网站关联性的情况下,这些网站可以进行分发权重。
给网站建设带来直接的搜索流量和pv。网站权重高的网站有力地支持了我们网站的排名靠前,进而带来更多的流量,让我们的网站更受欢迎。3:收录策略收录策略是指在对网站进行有效描述和补充信息,使其满足用户搜索需求的方法。是网站建设中常见的影响用户搜索习惯的措施。收录策略可以分为两种情况:手动收。
网站内容自动更新(网站自动更新机制中会出现更新错误的原因及解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-26 15:02
网站内容自动更新机制中会出现更新错误,错误原因中包含bug或者是代码异常。今天开始我们将分享代码异常处理案例,来看看异常处理服务器崩溃原因及解决方法。案例1:本地调试速度非常快,web服务器也没有出现问题。cpu占用率突然来个1%以下的大幅波动,报错:web服务器不可用。这时应该执行上述代码,正常情况会将重试机制切换成滚动条重试机制,使得那1%时间内的更新速度和更新效率都非常快。
如果如果还是不行的话,就到机房测量机器耗电情况,如果耗电比例是0.0044%,则是网络不通畅的原因。要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。解决方法:如果机房重新测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机房风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
如果机房测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机房风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。解决方法:如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。
如果还是不行的话,就到机房测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间。 查看全部
网站内容自动更新(网站自动更新机制中会出现更新错误的原因及解决方法)
网站内容自动更新机制中会出现更新错误,错误原因中包含bug或者是代码异常。今天开始我们将分享代码异常处理案例,来看看异常处理服务器崩溃原因及解决方法。案例1:本地调试速度非常快,web服务器也没有出现问题。cpu占用率突然来个1%以下的大幅波动,报错:web服务器不可用。这时应该执行上述代码,正常情况会将重试机制切换成滚动条重试机制,使得那1%时间内的更新速度和更新效率都非常快。
如果如果还是不行的话,就到机房测量机器耗电情况,如果耗电比例是0.0044%,则是网络不通畅的原因。要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。解决方法:如果机房重新测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机房风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
如果机房测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机房风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。解决方法:如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。
如果机场测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间与机场风道气流不相匹配,所以机器的高功率占用到电脑相邻显示屏显示的信息量大,电脑内的显示屏幕不足以展示周围的信息。要是也出现上述这种1%时间内电脑的速度、机器的发热量都迅速增加或减少的情况,则这是cpu及memory过高导致。
如果还是不行的话,就到机房测量机器耗电情况后,测量出来电脑发热量比以前有所增加的话,则有可能是因为机器内的显示屏幕和机身的空间。
网站内容自动更新(如何自动缓存所有的页面的资源?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2021-09-24 02:05
Manifest 用于制作离线页面。即使断网,页面也能正常打开。使用简单,但在实际使用中存在以下问题:
(1)如何自动缓存所有页面的资源?因为manifest不能使用*通配符进行缓存
(2)如果网站资源更新了,manifest文件怎么自动更新?否则,如果用户不清除缓存,即使联网也会加载旧页面
我想很多网站没有使用Manifest就是因为上面提到的两个原因。也有人尝试过,但是使用起来比较麻烦,离线应用的价值似乎也不是很大。不过,使用Manifest还是有很多好处的,尤其是对于网站,比如博客等比较容易展示的,或者在线APP。这类网站的数据动态变化的频率比较低,不需要频繁。从服务请求数据。这样,当用户需要频繁返回首页或频繁在多个页面之间来回切换时,由于几乎所有资源都在本地,加载是瞬间完成的。
1. 使用清单
使用Manifest很简单,就是在html标签中添加一个manifest属性:
该属性指向一个manifest文件,指定当前页面上哪些资源需要离线缓存,如下home.appcache:
CACHE MANIFEST
#9/27/2017, 3:04:25 PM
#html
https://github.com/
#img
https://assets-cdn.github.com/ ... p.png
https://assets-cdn.github.com/ ... k.png
#css
https://assets-cdn.github.com/ ... 1.css
#js
https://assets-cdn.github.com/ ... d9.js
NETWORK:
*
FALLBACK
https://github.com/ /html/manifest/html/home.html
这个文件的第一行必须以CACHE MANIFEST开头,否则浏览器解析会报错。注释以# 开头。此行下方是需要缓存的资源。下一个 NETWORK 指示需要在线加载哪些资源。一般需要写成NETWORK*,表示除CACHE以外的所有资源都需要上网,包括一些动态请求。如果你写的是特定路径而不是*,那些既不在CAHCE中也不在NETWORK中的会报加载失败错误。如下:
就算是连上网也会这样,所以一般写成*.
FALLBACK 表示替代资源。如果这些资源未加载,它们将替换加载的资源。例如,如果无法访问上述文件,则使用静态 html 访问:/html/manifest/html/home.html。
打开支持Manifest的网站,例如可以观察Chrome控制台缓存的过程:
然后刷新页面,你会发现页面上几乎所有的资源都是从本地缓存中获取的,如下图所示:
并且如果断开网络并刷新页面,页面仍然可以正常加载。这在 Chrome/Firefox/Safari 等浏览器中受支持。
除了Manifest,还有一种缓存方式,就是设置HTTP头的Cache-Control字段进行缓存。这样可以缓存JS/CSS/图片资源,但是如果你也缓存HTML,就会有问题。如果用户没有清除缓存,即使你的页面更新了,用户仍然会加载旧页面,直到缓存设置 Max-Age 时间到了。所以使用Manifest可以解决这个问题。
Manifest 如何知道当前页面数据更新了?只需更改您的清单文件,例如上面的 home.appcache。打开页面时浏览器会加载这个文件。一旦发现这个文件发生了变化,下次刷新时会重新加载所有的Cache文件。最简单的方法是将评论中的时间更改为当前时间:
#9/29/2017, 9:08:49 AM
所以当网站的资源发生变化时,可以改变这个manifest的内容,然后互联网浏览器就可以更新它。
使用Manifest需要注意以下问题:
(1)Manifest 有大小限制,它实际上是一个本地存储,本地存储一般每个域都有一个有限的空间,PC Chrome 为 5Mb,参考下表:
浏览器应用程序缓存 (AppCache) 存储限制 Safari 桌面 (Mac & Win)无限Safari Mobile (iOS)10 MBChrome 桌面 (Mac & Win)5 MB *Chrome Mobile (Android)无限 **Firefox 4 BetaUnlimited(有用户提示)IE 不知道。糟透了。***
(2)home.appcahce等manifest文件不能跨域,如果跨域需要支持CORS
(3)Manifest Cache 资源不能跨域。同理,如果跨域资源需要支持CORS,一般浏览器会自动处理
2. 解决Manifest自动生成更新问题
由于Manifest不能使用通配符来匹配资源,需要一一列出需要缓存的资源,而且网站的内容往往是动态更新的,所以这样比较麻烦。为此,作者写了一个NPM包generate-manifest,自动生成manifest,使用起来非常简单:
npm install -g generate-manifest
generate-manifest --url=https://github.com
它会生成一个home.appchache的Manifest文件,该文件收录页面上img/js/css的资源链接:
CACHE MANIFEST
#9/27/2017, 3:04:25 PM
#html
https://github.com/
#img
https://assets-cdn.github.com/ ... p.png
https://assets-cdn.github.com/ ... k.png
#css
https://assets-cdn.github.com/ ... 1.css
#js
https://assets-cdn.github.com/ ... d9.js
NETWORK:
*
FALLBACK
https://github.com/ /html/manifest/html/home.html
也可以支持其他参数自定义,详见:generate-manifest。
这就解决了自动生成的问题。我应该如何使用自动更新?
由于本人是博客网站,所以网站的内容主要变化如下: 1. 发帖/改博客;2. 用户发表评论;3. 网站 的浏览量发生了变化。第一个解决方案是写一个接口。只要你发布博客,调整这个接口,生成一个新的manifest文件:
/refresh-manifest.php?link=
然后它会调整上面的 generate-manifest 包,生成一个 manifest.appcache 文件。在html中,manifest的名字是根据路径的最后一部分来确定的:
>
这与生成的文件名一一对应。
第二个问题:用户发表评论-在调整发布界面自动调整该界面。需要注意的是,这个接口需要反脚本注入,否则更危险。
第三题:读取卷数据变化——写一个Linux定时任务,使用crontab添加定时任务,执行crontab -e添加:
0 3 * * * /home/fed/manifest/update-all.sh
上面的意思是每天3:00运行update-all.sh脚本。此脚本为所有页面编写更新命令:
generate-manifest --url=https://fed.renren.com
generate-manifest --url=https://fed.renren.com/page/2/
generate-manifest --url=https://fed.renren.com/page/3/
#..其它...
第一点提到的发布文章也会给这个脚本添加一行命令。
由于阅读量不是很重要,最好每天更新一次。这允许用户在同一天缓存他们的操作。如果你第二天再看它,就更新它。
所以自动更新的问题基本解决了。
还有一个问题是Manifest改变后第一次刷新还是老页面。只有第二次刷新是正确的,所以我们希望在更改清单后,刷新是新的,而不是之前的缓存。不需要刷两次。
那么该怎么办?Manifest有一个update事件,一旦manifest文件更新就会触发,所以我们可以监听这个事件,然后自动刷新页面重新加载页面,如下代码所示:
function onUpdateReady() {
window.location.reload(true);
}
window.applicationCache.addEventListener('updateready', onUpdateReady);
if(window.applicationCache.status === window.applicationCache.UPDATEREADY) {
onUpdateReady();
}
综上所述,我们很好地利用Manifest做了一个离线页面应用,解决了自动生成和自动更新的问题。即使用户不离线,第二次加载的资源都缓存在本地,所以当用户在几个页面之间来回切换时,速度非常快。例如,很多人可能在主页上的列表和内容页之间。来回切换。
虽然 Manifest 已经被 Service Worker 弃用,但由于它的简单性和兼容性,我们仍然可以使用它。 查看全部
网站内容自动更新(如何自动缓存所有的页面的资源?(一))
Manifest 用于制作离线页面。即使断网,页面也能正常打开。使用简单,但在实际使用中存在以下问题:
(1)如何自动缓存所有页面的资源?因为manifest不能使用*通配符进行缓存
(2)如果网站资源更新了,manifest文件怎么自动更新?否则,如果用户不清除缓存,即使联网也会加载旧页面
我想很多网站没有使用Manifest就是因为上面提到的两个原因。也有人尝试过,但是使用起来比较麻烦,离线应用的价值似乎也不是很大。不过,使用Manifest还是有很多好处的,尤其是对于网站,比如博客等比较容易展示的,或者在线APP。这类网站的数据动态变化的频率比较低,不需要频繁。从服务请求数据。这样,当用户需要频繁返回首页或频繁在多个页面之间来回切换时,由于几乎所有资源都在本地,加载是瞬间完成的。
1. 使用清单
使用Manifest很简单,就是在html标签中添加一个manifest属性:
该属性指向一个manifest文件,指定当前页面上哪些资源需要离线缓存,如下home.appcache:
CACHE MANIFEST
#9/27/2017, 3:04:25 PM
#html
https://github.com/
#img
https://assets-cdn.github.com/ ... p.png
https://assets-cdn.github.com/ ... k.png
#css
https://assets-cdn.github.com/ ... 1.css
#js
https://assets-cdn.github.com/ ... d9.js
NETWORK:
*
FALLBACK
https://github.com/ /html/manifest/html/home.html
这个文件的第一行必须以CACHE MANIFEST开头,否则浏览器解析会报错。注释以# 开头。此行下方是需要缓存的资源。下一个 NETWORK 指示需要在线加载哪些资源。一般需要写成NETWORK*,表示除CACHE以外的所有资源都需要上网,包括一些动态请求。如果你写的是特定路径而不是*,那些既不在CAHCE中也不在NETWORK中的会报加载失败错误。如下:
就算是连上网也会这样,所以一般写成*.
FALLBACK 表示替代资源。如果这些资源未加载,它们将替换加载的资源。例如,如果无法访问上述文件,则使用静态 html 访问:/html/manifest/html/home.html。
打开支持Manifest的网站,例如可以观察Chrome控制台缓存的过程:
然后刷新页面,你会发现页面上几乎所有的资源都是从本地缓存中获取的,如下图所示:
并且如果断开网络并刷新页面,页面仍然可以正常加载。这在 Chrome/Firefox/Safari 等浏览器中受支持。
除了Manifest,还有一种缓存方式,就是设置HTTP头的Cache-Control字段进行缓存。这样可以缓存JS/CSS/图片资源,但是如果你也缓存HTML,就会有问题。如果用户没有清除缓存,即使你的页面更新了,用户仍然会加载旧页面,直到缓存设置 Max-Age 时间到了。所以使用Manifest可以解决这个问题。
Manifest 如何知道当前页面数据更新了?只需更改您的清单文件,例如上面的 home.appcache。打开页面时浏览器会加载这个文件。一旦发现这个文件发生了变化,下次刷新时会重新加载所有的Cache文件。最简单的方法是将评论中的时间更改为当前时间:
#9/29/2017, 9:08:49 AM
所以当网站的资源发生变化时,可以改变这个manifest的内容,然后互联网浏览器就可以更新它。
使用Manifest需要注意以下问题:
(1)Manifest 有大小限制,它实际上是一个本地存储,本地存储一般每个域都有一个有限的空间,PC Chrome 为 5Mb,参考下表:
浏览器应用程序缓存 (AppCache) 存储限制 Safari 桌面 (Mac & Win)无限Safari Mobile (iOS)10 MBChrome 桌面 (Mac & Win)5 MB *Chrome Mobile (Android)无限 **Firefox 4 BetaUnlimited(有用户提示)IE 不知道。糟透了。***
(2)home.appcahce等manifest文件不能跨域,如果跨域需要支持CORS
(3)Manifest Cache 资源不能跨域。同理,如果跨域资源需要支持CORS,一般浏览器会自动处理
2. 解决Manifest自动生成更新问题
由于Manifest不能使用通配符来匹配资源,需要一一列出需要缓存的资源,而且网站的内容往往是动态更新的,所以这样比较麻烦。为此,作者写了一个NPM包generate-manifest,自动生成manifest,使用起来非常简单:
npm install -g generate-manifest
generate-manifest --url=https://github.com
它会生成一个home.appchache的Manifest文件,该文件收录页面上img/js/css的资源链接:
CACHE MANIFEST
#9/27/2017, 3:04:25 PM
#html
https://github.com/
#img
https://assets-cdn.github.com/ ... p.png
https://assets-cdn.github.com/ ... k.png
#css
https://assets-cdn.github.com/ ... 1.css
#js
https://assets-cdn.github.com/ ... d9.js
NETWORK:
*
FALLBACK
https://github.com/ /html/manifest/html/home.html
也可以支持其他参数自定义,详见:generate-manifest。
这就解决了自动生成的问题。我应该如何使用自动更新?
由于本人是博客网站,所以网站的内容主要变化如下: 1. 发帖/改博客;2. 用户发表评论;3. 网站 的浏览量发生了变化。第一个解决方案是写一个接口。只要你发布博客,调整这个接口,生成一个新的manifest文件:
/refresh-manifest.php?link=
然后它会调整上面的 generate-manifest 包,生成一个 manifest.appcache 文件。在html中,manifest的名字是根据路径的最后一部分来确定的:
>
这与生成的文件名一一对应。
第二个问题:用户发表评论-在调整发布界面自动调整该界面。需要注意的是,这个接口需要反脚本注入,否则更危险。
第三题:读取卷数据变化——写一个Linux定时任务,使用crontab添加定时任务,执行crontab -e添加:
0 3 * * * /home/fed/manifest/update-all.sh
上面的意思是每天3:00运行update-all.sh脚本。此脚本为所有页面编写更新命令:
generate-manifest --url=https://fed.renren.com
generate-manifest --url=https://fed.renren.com/page/2/
generate-manifest --url=https://fed.renren.com/page/3/
#..其它...
第一点提到的发布文章也会给这个脚本添加一行命令。
由于阅读量不是很重要,最好每天更新一次。这允许用户在同一天缓存他们的操作。如果你第二天再看它,就更新它。
所以自动更新的问题基本解决了。
还有一个问题是Manifest改变后第一次刷新还是老页面。只有第二次刷新是正确的,所以我们希望在更改清单后,刷新是新的,而不是之前的缓存。不需要刷两次。
那么该怎么办?Manifest有一个update事件,一旦manifest文件更新就会触发,所以我们可以监听这个事件,然后自动刷新页面重新加载页面,如下代码所示:
function onUpdateReady() {
window.location.reload(true);
}
window.applicationCache.addEventListener('updateready', onUpdateReady);
if(window.applicationCache.status === window.applicationCache.UPDATEREADY) {
onUpdateReady();
}
综上所述,我们很好地利用Manifest做了一个离线页面应用,解决了自动生成和自动更新的问题。即使用户不离线,第二次加载的资源都缓存在本地,所以当用户在几个页面之间来回切换时,速度非常快。例如,很多人可能在主页上的列表和内容页之间。来回切换。
虽然 Manifest 已经被 Service Worker 弃用,但由于它的简单性和兼容性,我们仍然可以使用它。
网站内容自动更新(2019/10/6更新:网站开放注册,添加登录功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-24 02:05
2019/10/6更新:网站已开放注册,本文内容基本实现。
================
我们计划在近期将网站(wuli.wiki)升级为动态,增加登录功能和评论点赞功能。最重要的是入口编辑功能,下面会介绍。
网页编辑器设计图(纯乳胶)
目前的合作方式
联系管理员(我)获取github项目的访问权限。下载安装texlive 2017(目前不兼容高版本)。提交给github管理员。使用 PhysWikiScan 转换网页。管理员通过服务器上传网页和pdf。
合作新方式
合作者注册并登录网站直接编辑入口的纯latex源码,提交后一键/实时展示网页效果(由运行在服务器上的PhysWikiScan程序实现),网页页面自动更新网站 网站下载更新后的latex源文件。管理员将新的latex代码提交到github,用texlive编译成pdf,定期上传到网站
初始效果具体说明
这之后可以做什么
例如,允许任何用户注册和登录,允许他们拥有自己的主页来制作自己的笔记/百科全书,并可以申请pdf电子书。并且有一个简单的域名,比如/david
如果您有其他建议,请留言。 查看全部
网站内容自动更新(2019/10/6更新:网站开放注册,添加登录功能)
2019/10/6更新:网站已开放注册,本文内容基本实现。
================
我们计划在近期将网站(wuli.wiki)升级为动态,增加登录功能和评论点赞功能。最重要的是入口编辑功能,下面会介绍。
网页编辑器设计图(纯乳胶)
目前的合作方式
联系管理员(我)获取github项目的访问权限。下载安装texlive 2017(目前不兼容高版本)。提交给github管理员。使用 PhysWikiScan 转换网页。管理员通过服务器上传网页和pdf。
合作新方式
合作者注册并登录网站直接编辑入口的纯latex源码,提交后一键/实时展示网页效果(由运行在服务器上的PhysWikiScan程序实现),网页页面自动更新网站 网站下载更新后的latex源文件。管理员将新的latex代码提交到github,用texlive编译成pdf,定期上传到网站
初始效果具体说明
这之后可以做什么
例如,允许任何用户注册和登录,允许他们拥有自己的主页来制作自己的笔记/百科全书,并可以申请pdf电子书。并且有一个简单的域名,比如/david
如果您有其他建议,请留言。
网站内容自动更新(网站内容自动更新功能是很多品牌建站者普遍关注的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-17 06:04
网站内容自动更新功能是很多品牌建站者普遍关注的功能。网站的内容实际上包括正文和描述两个部分,而一般的网站在正文中都是自动生成内容,而描述则是需要我们自己撰写来满足客户的需求。
自动更新的缺点主要是:1、内容量较大,对内容撰写人员要求较高;2、对服务器压力很大。因此,笔者认为,小品牌可以尝试。
首先什么内容都往前面堆,会给用户一种过度更新的感觉,等过渡到你要的内容再安排浏览。简单说是想让用户来逛你们网站,发现更新了内容,想要细看,但发现已经有了很多就点击进去看了,并没有多大意义。其次是手动更新优点:用户永远不知道有多少内容要更新,需要不断收集信息,此时你便要实现有效的推送;缺点:应用空间较小,效率低,人力成本高,无人的情况下尤其如此。
你那网站,我觉得最大的问题在于前端呈现的“一览无余”,不能很好的推送给用户的眼球。因为页面太多了,看不见全部内容,如何让用户在最短的时间内找到感兴趣的信息?或者让用户想去细看,但是发现排在最前面的位置已经有更新的信息了。现在比较流行的推送信息的方式是同时推送给用户两个不同的页面,网站打开的一屏,也就是页面打开的头,和最上面一屏,和最下面一屏,对于客户来说更利于客户浏览。
当然用户点击页面其实点最上面一屏的点击率往往要高于最下面一屏点击率,因为容易点中,喜欢在上面一层停留久一点。说到效率问题,这个你要不增加广告信息,或者用户引导,让用户自己主动下载,不然浏览变成点击。(以前我们做电视购物的时候都是这么做的)。 查看全部
网站内容自动更新(网站内容自动更新功能是很多品牌建站者普遍关注的功能)
网站内容自动更新功能是很多品牌建站者普遍关注的功能。网站的内容实际上包括正文和描述两个部分,而一般的网站在正文中都是自动生成内容,而描述则是需要我们自己撰写来满足客户的需求。
自动更新的缺点主要是:1、内容量较大,对内容撰写人员要求较高;2、对服务器压力很大。因此,笔者认为,小品牌可以尝试。
首先什么内容都往前面堆,会给用户一种过度更新的感觉,等过渡到你要的内容再安排浏览。简单说是想让用户来逛你们网站,发现更新了内容,想要细看,但发现已经有了很多就点击进去看了,并没有多大意义。其次是手动更新优点:用户永远不知道有多少内容要更新,需要不断收集信息,此时你便要实现有效的推送;缺点:应用空间较小,效率低,人力成本高,无人的情况下尤其如此。
你那网站,我觉得最大的问题在于前端呈现的“一览无余”,不能很好的推送给用户的眼球。因为页面太多了,看不见全部内容,如何让用户在最短的时间内找到感兴趣的信息?或者让用户想去细看,但是发现排在最前面的位置已经有更新的信息了。现在比较流行的推送信息的方式是同时推送给用户两个不同的页面,网站打开的一屏,也就是页面打开的头,和最上面一屏,和最下面一屏,对于客户来说更利于客户浏览。
当然用户点击页面其实点最上面一屏的点击率往往要高于最下面一屏点击率,因为容易点中,喜欢在上面一层停留久一点。说到效率问题,这个你要不增加广告信息,或者用户引导,让用户自己主动下载,不然浏览变成点击。(以前我们做电视购物的时候都是这么做的)。
网站内容自动更新( 如何使用Python和常用的计算机小程序来构建一个RSS提示系统 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-15 12:12
如何使用Python和常用的计算机小程序来构建一个RSS提示系统
)
无论是学生还是员工,我们都应该时刻关注学校或公司网站的通知,并尽快获取最新消息
大多数博客或数据资源网站都会有自己的RSS提示系统,将网站的最新信息及时推送给需要的用户,用户也可以通过RSS阅读器实时获取目标网站的最新内容
由于学校或公司网站服务对象的特殊性和局限性,一般不会建立自己的RSS系统
作为优秀的人,我们可以建立自己的RSS提示系统
本文介绍了如何使用Python和常用的计算机小程序构建RSS提示系统,以便定期自动检测target网站release的通知并立即发送提示电子邮件
本次文章RSS提示系统设计的主要思路是:
1.建立通知数据库
此步骤的目的是对目标网站已发布通知的数据进行爬网并存储,以便建立与目标网站内容对应的本地数据库
考虑到数据库中的数据将是识别和获取新通知的唯一途径,已建立的数据库将存储每个通知的标题、发布日期和访问链接
第一步中使用的模块是urlib、Beauty soup和SQLite3模块。urllib模块抓取目标网页的HTML数据;分析网页数据,通过Beauty soup模块抓取网页内容;通过SQLite3模块建立目标网站现有通知数据库
此步骤的主要代码如下所示
2.建立邮件发送系统
此步骤的目的是使用python标准库模块smtplib访问网络并创建发送电子邮件的函数
由于我们的大多数计算机没有自己的邮件服务器,我们需要使用第三方服务器来模拟邮件发送
常用的有谷歌邮件系统、网易邮件系统和QQ邮件系统。例如,QQ邮件系统的SMTP服务器和端口号分别为和465
此步骤的主要代码如下所示
在本例中,python标准库中的电子邮件模块用于格式化电子邮件信息,主要包括电子邮件的主题、发件人、收件人的邮箱昵称、电子邮件的内容和其他信息
3.解析检测目标网站通知
前两个步骤已经完成了target网站现有通知数据库和邮件发送系统的建立。第三步主要由两部分组成
首先,第一步中使用的urlib和Beauty soup模块用于解析目标网站内容数据,并将其与先前建立的数据库进行比较
其次,如果检测到目标网站有新通知,请将新通知数据插入数据库,然后发送一封提示电子邮件
此步骤的主要代码如下所示
在此示例中,仅选择最新通知并发送电子邮件提示。具体的电子邮件信息可自行设置
4.制定计划任务
在前三个步骤中,您已经完成了使用Python获取目标网站最新通知并发送提示电子邮件的脚本程序
在此步骤中,windows提供的DOS命令框架和任务调度程序将用于每小时自动运行Python脚本,以实现自动更新通知的目的
首先,您需要编写一个CMD命令文件,以便于在DOS框架下执行Python脚本
主要代码如下所示:
@echo off # 关闭回显
cd C:\demo # 找到Python脚本文件的路径
python Python.py # 执行Python脚本文件
最后,使用任务调度器制定一个任务,该任务可以设置为每隔一小时自动运行CMD命令文件
查看全部
网站内容自动更新(
如何使用Python和常用的计算机小程序来构建一个RSS提示系统
)
无论是学生还是员工,我们都应该时刻关注学校或公司网站的通知,并尽快获取最新消息
大多数博客或数据资源网站都会有自己的RSS提示系统,将网站的最新信息及时推送给需要的用户,用户也可以通过RSS阅读器实时获取目标网站的最新内容
由于学校或公司网站服务对象的特殊性和局限性,一般不会建立自己的RSS系统
作为优秀的人,我们可以建立自己的RSS提示系统
本文介绍了如何使用Python和常用的计算机小程序构建RSS提示系统,以便定期自动检测target网站release的通知并立即发送提示电子邮件
本次文章RSS提示系统设计的主要思路是:
1.建立通知数据库
此步骤的目的是对目标网站已发布通知的数据进行爬网并存储,以便建立与目标网站内容对应的本地数据库
考虑到数据库中的数据将是识别和获取新通知的唯一途径,已建立的数据库将存储每个通知的标题、发布日期和访问链接
第一步中使用的模块是urlib、Beauty soup和SQLite3模块。urllib模块抓取目标网页的HTML数据;分析网页数据,通过Beauty soup模块抓取网页内容;通过SQLite3模块建立目标网站现有通知数据库
此步骤的主要代码如下所示
2.建立邮件发送系统
此步骤的目的是使用python标准库模块smtplib访问网络并创建发送电子邮件的函数
由于我们的大多数计算机没有自己的邮件服务器,我们需要使用第三方服务器来模拟邮件发送
常用的有谷歌邮件系统、网易邮件系统和QQ邮件系统。例如,QQ邮件系统的SMTP服务器和端口号分别为和465
此步骤的主要代码如下所示
在本例中,python标准库中的电子邮件模块用于格式化电子邮件信息,主要包括电子邮件的主题、发件人、收件人的邮箱昵称、电子邮件的内容和其他信息
3.解析检测目标网站通知
前两个步骤已经完成了target网站现有通知数据库和邮件发送系统的建立。第三步主要由两部分组成
首先,第一步中使用的urlib和Beauty soup模块用于解析目标网站内容数据,并将其与先前建立的数据库进行比较
其次,如果检测到目标网站有新通知,请将新通知数据插入数据库,然后发送一封提示电子邮件
此步骤的主要代码如下所示
在此示例中,仅选择最新通知并发送电子邮件提示。具体的电子邮件信息可自行设置
4.制定计划任务
在前三个步骤中,您已经完成了使用Python获取目标网站最新通知并发送提示电子邮件的脚本程序
在此步骤中,windows提供的DOS命令框架和任务调度程序将用于每小时自动运行Python脚本,以实现自动更新通知的目的
首先,您需要编写一个CMD命令文件,以便于在DOS框架下执行Python脚本
主要代码如下所示:
@echo off # 关闭回显
cd C:\demo # 找到Python脚本文件的路径
python Python.py # 执行Python脚本文件
最后,使用任务调度器制定一个任务,该任务可以设置为每隔一小时自动运行CMD命令文件
网站内容自动更新(如何提升网站收录是优化人员们的最关键的一步)
网站优化 • 优采云 发表了文章 • 0 个评论 • 293 次浏览 • 2021-09-07 21:14
一个网站要排名,首先得有收录,收录是排名的前提。在影响排名的众多因素中,一个因素是收录分数,收录所所占的比例越大,在整体网站排名的提升中可以促进综合分数的整体提升。 收录的重要性不言而喻。如何提高网站收录是优化者想要采取的最关键的一步。
一、收录常识
1、如何判断一个页面是否是收录
将页面链接地址复制粘贴到百度,点击百度,如果出现页面标题,说明收录已经存在。
2、正确的心态
网站收录有一个循环,尤其是新站点,爬取、过滤、索引、展示都需要一个过程。这个过程的周期与你网站的综合因素有关。因此,有必要以正确的心态看待它。新网站一两个月收录是正常的。
二、收录的分析与诊断
1、为什么我的网站不是收录?
(1)蜘蛛无法爬取,可以使用网络蜘蛛模拟爬取测试工具诊断爬取是否成功。
(2)Robots屏蔽了网站,也可能是网站以前被屏蔽了,现在蜘蛛爬的比较慢。
(3)操作异常。
①黑历史。以前做过一些违法违规的黑色产业,百度给它贴了黑标签。蜘蛛对你的信任会有一个比较长的评估期,需要比较长的时间。
②被黑了。这会导致蜘蛛降低对你的信任。
③修改标题、版式等,信任度会下降,搜索引擎的信任度也会下降。
④其他错误操作。
(4) 被过滤掉了。
蜘蛛来抓取了,但是没有收录,直接过滤掉你的页面,说明你的页面质量太低,或者只是垃圾页面。
(5)蜘蛛不知道你的存在。
三、改进并加快收录的运行
SEO优化不代表做好关键词排名就能提升。排名需要大量积分才能形成综合支撑。
以下是对收录进行改进和提速的操作,但是我们要记住,高质量的内容是收录最根本的。这是网站的基础,解决了这个问题,我们可以谈谈提高收录的速度。
我们写了一个文章之后,其实还有一些提速收录的小窍门,但是前提是建立在高质量内容页面的前提下。
1、定时定量更新内容
分析网站日志,发现蜘蛛在那个时间点来网站最频繁,然后在那个时间点定时定量更新网站内容。如果使用cms程序,可以设置一个定时发布内容,最后养成爬虫的习惯。
2、自动推送
以触发器的形式将链接推送到百度。这个触发器是点击或浏览文章文章。自动推送的具体操作请参考:如何在网站添加百度自动推送?
3、active push
自己主动推送给百度。它是实时的,是所有推送方法中最好的。它与自动推送不冲突。两者相辅相成,可以同时进行。主动推送操作详见:如何将百度主动(实时)推送添加到网站?
4、sitemap 更新
定期将网站链接放入站点地图,然后将站点地图提交给百度。百度会定期抓取并检查您提交的站点地图,并对其中的链接进行处理。详细的站点地图更新操作请参考:Boost网站收录的网站map制作
5、Grab 诊断
以上操作完成后,您也可以在百度站长平台进行抓取诊断操作。这种爬行诊断的意思是模拟一个蜘蛛的访问,看这个蜘蛛能不能爬行或者派一个蜘蛛爬行。因此,我们可以将链接放在爬虫诊断中进行诊断,可以作为对蜘蛛的提醒。
6、吸引蜘蛛
网站当信任度不够时,需要将蜘蛛吸引到网站,可以通过蜘蛛池、友情链接、外链的形式进行操作。
SEO优化总结:
收录 是优化中最关键的一步。要想提高网站的收录率,首先要分析诊断网站不收录的原因,然后用一些技巧来加速收录,但这必须建立在高质量的内容。
本文链接: 查看全部
网站内容自动更新(如何提升网站收录是优化人员们的最关键的一步)
一个网站要排名,首先得有收录,收录是排名的前提。在影响排名的众多因素中,一个因素是收录分数,收录所所占的比例越大,在整体网站排名的提升中可以促进综合分数的整体提升。 收录的重要性不言而喻。如何提高网站收录是优化者想要采取的最关键的一步。
一、收录常识
1、如何判断一个页面是否是收录
将页面链接地址复制粘贴到百度,点击百度,如果出现页面标题,说明收录已经存在。
2、正确的心态
网站收录有一个循环,尤其是新站点,爬取、过滤、索引、展示都需要一个过程。这个过程的周期与你网站的综合因素有关。因此,有必要以正确的心态看待它。新网站一两个月收录是正常的。
二、收录的分析与诊断
1、为什么我的网站不是收录?
(1)蜘蛛无法爬取,可以使用网络蜘蛛模拟爬取测试工具诊断爬取是否成功。
(2)Robots屏蔽了网站,也可能是网站以前被屏蔽了,现在蜘蛛爬的比较慢。
(3)操作异常。
①黑历史。以前做过一些违法违规的黑色产业,百度给它贴了黑标签。蜘蛛对你的信任会有一个比较长的评估期,需要比较长的时间。
②被黑了。这会导致蜘蛛降低对你的信任。
③修改标题、版式等,信任度会下降,搜索引擎的信任度也会下降。
④其他错误操作。
(4) 被过滤掉了。
蜘蛛来抓取了,但是没有收录,直接过滤掉你的页面,说明你的页面质量太低,或者只是垃圾页面。
(5)蜘蛛不知道你的存在。
三、改进并加快收录的运行
SEO优化不代表做好关键词排名就能提升。排名需要大量积分才能形成综合支撑。
以下是对收录进行改进和提速的操作,但是我们要记住,高质量的内容是收录最根本的。这是网站的基础,解决了这个问题,我们可以谈谈提高收录的速度。
我们写了一个文章之后,其实还有一些提速收录的小窍门,但是前提是建立在高质量内容页面的前提下。
1、定时定量更新内容
分析网站日志,发现蜘蛛在那个时间点来网站最频繁,然后在那个时间点定时定量更新网站内容。如果使用cms程序,可以设置一个定时发布内容,最后养成爬虫的习惯。
2、自动推送
以触发器的形式将链接推送到百度。这个触发器是点击或浏览文章文章。自动推送的具体操作请参考:如何在网站添加百度自动推送?
3、active push
自己主动推送给百度。它是实时的,是所有推送方法中最好的。它与自动推送不冲突。两者相辅相成,可以同时进行。主动推送操作详见:如何将百度主动(实时)推送添加到网站?
4、sitemap 更新
定期将网站链接放入站点地图,然后将站点地图提交给百度。百度会定期抓取并检查您提交的站点地图,并对其中的链接进行处理。详细的站点地图更新操作请参考:Boost网站收录的网站map制作
5、Grab 诊断
以上操作完成后,您也可以在百度站长平台进行抓取诊断操作。这种爬行诊断的意思是模拟一个蜘蛛的访问,看这个蜘蛛能不能爬行或者派一个蜘蛛爬行。因此,我们可以将链接放在爬虫诊断中进行诊断,可以作为对蜘蛛的提醒。
6、吸引蜘蛛
网站当信任度不够时,需要将蜘蛛吸引到网站,可以通过蜘蛛池、友情链接、外链的形式进行操作。
SEO优化总结:
收录 是优化中最关键的一步。要想提高网站的收录率,首先要分析诊断网站不收录的原因,然后用一些技巧来加速收录,但这必须建立在高质量的内容。
本文链接:
网站内容自动更新(自助建站的网站会不会被搜索引擎收录?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-07 21:13
网站自建网站会被搜索引擎收录搜索到吗?不管是自助网站、cms程序,还是所谓的独立程序,对于搜索引擎都是一样的,没有说自助网站搜索引擎不收录。 网站能否成为收录取决于这几点。
1、内容丰富,更新稳定
网站上线前,请确保每栏下有3-5篇文章文章。因为网站上线时,搜索引擎蜘蛛会爬到网站发现没有内容,所以会降低爬行的频率。所以网站的内容应该更丰富,上线后应该有一定的更新频率。并且发布的新闻或网页是原创,至少是伪原创。
2、设置网站页面的SEO标签
SEO 标签收录:标题、关键词、描述。这是一项重要的工作。你需要告诉搜索引擎这个页面的核心焦点是什么。在快捷好用的网站自助服务中,网站的任何页面都可以独立设置SEO标签。我们通常选择内容页面来优化长尾关键词。大量长尾关键词可以为网站构建强大的内链系统。
如何自建网站获得高关键词排名?
3、Exchange 友情纽带
新网站不容易换朋友链是正常现象,但是如果你和别人关系好,网站上线后,用一些旧的网站替换一些朋友链会有效加速up 百度新网站采集速度。但是我们要注意朋友链的数量。一天只能有三个朋友链。如果一天内添加的朋友链过多,百度会判断为违规并减重。
4、百度自动提交和主动提交
百度的自动提交和主动提交可以加快百度蜘蛛对网站上的新内容的抓取和抓取。快速良好的自助建站后台集成了搜索引擎提交和站点地图生成。
5、域名注册时间
与新注册的域名相比,旧域名更有可能是收录。
搜索引擎仍在搜索用户。用户希望看到高质量的内容。同样的搜索引擎也会把内容质量作为一个重要的指标。所以高质量的网站更容易被搜索引擎收录搜索到。 查看全部
网站内容自动更新(自助建站的网站会不会被搜索引擎收录?(图))
网站自建网站会被搜索引擎收录搜索到吗?不管是自助网站、cms程序,还是所谓的独立程序,对于搜索引擎都是一样的,没有说自助网站搜索引擎不收录。 网站能否成为收录取决于这几点。
1、内容丰富,更新稳定
网站上线前,请确保每栏下有3-5篇文章文章。因为网站上线时,搜索引擎蜘蛛会爬到网站发现没有内容,所以会降低爬行的频率。所以网站的内容应该更丰富,上线后应该有一定的更新频率。并且发布的新闻或网页是原创,至少是伪原创。
2、设置网站页面的SEO标签
SEO 标签收录:标题、关键词、描述。这是一项重要的工作。你需要告诉搜索引擎这个页面的核心焦点是什么。在快捷好用的网站自助服务中,网站的任何页面都可以独立设置SEO标签。我们通常选择内容页面来优化长尾关键词。大量长尾关键词可以为网站构建强大的内链系统。
如何自建网站获得高关键词排名?
3、Exchange 友情纽带
新网站不容易换朋友链是正常现象,但是如果你和别人关系好,网站上线后,用一些旧的网站替换一些朋友链会有效加速up 百度新网站采集速度。但是我们要注意朋友链的数量。一天只能有三个朋友链。如果一天内添加的朋友链过多,百度会判断为违规并减重。
4、百度自动提交和主动提交
百度的自动提交和主动提交可以加快百度蜘蛛对网站上的新内容的抓取和抓取。快速良好的自助建站后台集成了搜索引擎提交和站点地图生成。
5、域名注册时间
与新注册的域名相比,旧域名更有可能是收录。
搜索引擎仍在搜索用户。用户希望看到高质量的内容。同样的搜索引擎也会把内容质量作为一个重要的指标。所以高质量的网站更容易被搜索引擎收录搜索到。
网站内容自动更新(适合股民、新闻工作者等使用网页自动刷新工具的用法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-09-06 11:37
Woodsoft 有两个网页更新提醒,一个是网页自动刷新工具,另一个是网站更新监控工具。
网页自动刷新工具主要用于刷新网页,如网页的流量、访问量等;网页自动刷新工具还可以用来监控网页上任何内容的变化,适用于监控非链接内容的变化。
网站update 监控工具主要用于监控网站超LINK。当有更新时,它会立即提醒并记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。适合投资者、记者等
一、如何使用网页自动刷新工具
1.使用网页自动刷新工具刷新网页(刷新网页流量、访问量)
一个。在网址列表中,点击“添加”,输入网址,点击“自动获取”,点击“添加”完成添加网址。
B.在刷新速度选项卡中,两次刷新之间的固定间隔设置为每10秒刷新一次页面。去掉“刷新次数限制”的复选标记。
c.至此,该网页的刷新设置完成。另外可以在“伪装设置”,ADSL重拨选项中设置ADSL拨号重连,可以自动改变ip,实现刷新网页流量和流量的功能。
d。我们来看看刷新效果。
2. 使用网页自动刷新工具监控网页非链接内容的变化。最好说说购物网站的价格变化。
一个。需要监控的网页如下。
B.首先,我们在网址列表中添加需要监控的网址。
c.其次,在刷新速度选项卡中,将两次刷新的固定间隔设置为每30秒刷新一次页面。去掉“刷新次数限制”的复选标记。
d。再次,在元素监控选项卡中,点击“添加”,获取元素的方式选择“通过HTML获取”,点击“自动获取”,
e.在弹出的页面上,将鼠标放在价格上,右键选择获取元素,点击“自动获取”。
f.返回添加监控元素界面,监控属性名称选择“文本”,监控数据类型选择“字符串”,数据比较方式选择“更改”,点击“确定”。
g.在闹钟提醒选项卡中,选择弹出提醒,时间设置保持10秒。
小时。设置完成,我们来看看监控效果。
总结:一款自动刷新网页的工具软件,可以同时监控刷新的内容。提供多种刷新方式,使用代理服务器刷新可以快速增加网站流量,包括独立IP访问和页面访问PV。定期刷新可以实时监控网站操作,直播网页显示实时页面和内容监控,可以监控网页任何地方发生的变化(非链接内容的变化)。
3. 使用网站更新监控工具监控网站hyperlinks 监控整个网页或需要监控的网页区域。当有更新时,它会立即提醒并记录。以下面的网页为例。监控网页的实时信息更新。
一个。在网站更新监控工具的URL管理,点击“添加”,添加我们需要监控的URL,点击“自动获取”获取页面代码,监控方式选择“源码监控”,一个元素是常用的方式。
B.点击“设置”-Data采集Scheme,选择A元素通用,设置scheme。
c.选择“文本过滤器”,在重复内容中选择“过滤重复文本”。
d。在“链接过滤”选项卡中,输入自定义字符:选择过滤不收录字符的字符。然后点击“保存”。至此,A单元的总体方案建立。
e.以上步骤设置好后,本期financial网站资讯直播的实时监控提醒任务就设置好了。我们来看看监控效果。您可以在“历史”中查看历史。
总结:监控网站超LINK,有更新立即报警记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。适用于投资者、记者等。软件支持同时监控多个网站,获取更全面的信息。为每个 URL 单独设置监控方法。监控历史记录详细,可随时打开参考。支持多种报警方式,包括声音、弹窗、邮件等。一般网站采用源码监听方式,速度快又节省资源。特殊动态页面使用元素监控,支持网页区域监控,更加精准灵活。 查看全部
网站内容自动更新(适合股民、新闻工作者等使用网页自动刷新工具的用法)
Woodsoft 有两个网页更新提醒,一个是网页自动刷新工具,另一个是网站更新监控工具。
网页自动刷新工具主要用于刷新网页,如网页的流量、访问量等;网页自动刷新工具还可以用来监控网页上任何内容的变化,适用于监控非链接内容的变化。
网站update 监控工具主要用于监控网站超LINK。当有更新时,它会立即提醒并记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。适合投资者、记者等
一、如何使用网页自动刷新工具
1.使用网页自动刷新工具刷新网页(刷新网页流量、访问量)
一个。在网址列表中,点击“添加”,输入网址,点击“自动获取”,点击“添加”完成添加网址。
B.在刷新速度选项卡中,两次刷新之间的固定间隔设置为每10秒刷新一次页面。去掉“刷新次数限制”的复选标记。
c.至此,该网页的刷新设置完成。另外可以在“伪装设置”,ADSL重拨选项中设置ADSL拨号重连,可以自动改变ip,实现刷新网页流量和流量的功能。
d。我们来看看刷新效果。
2. 使用网页自动刷新工具监控网页非链接内容的变化。最好说说购物网站的价格变化。
一个。需要监控的网页如下。
B.首先,我们在网址列表中添加需要监控的网址。
c.其次,在刷新速度选项卡中,将两次刷新的固定间隔设置为每30秒刷新一次页面。去掉“刷新次数限制”的复选标记。
d。再次,在元素监控选项卡中,点击“添加”,获取元素的方式选择“通过HTML获取”,点击“自动获取”,
e.在弹出的页面上,将鼠标放在价格上,右键选择获取元素,点击“自动获取”。
f.返回添加监控元素界面,监控属性名称选择“文本”,监控数据类型选择“字符串”,数据比较方式选择“更改”,点击“确定”。
g.在闹钟提醒选项卡中,选择弹出提醒,时间设置保持10秒。
小时。设置完成,我们来看看监控效果。
总结:一款自动刷新网页的工具软件,可以同时监控刷新的内容。提供多种刷新方式,使用代理服务器刷新可以快速增加网站流量,包括独立IP访问和页面访问PV。定期刷新可以实时监控网站操作,直播网页显示实时页面和内容监控,可以监控网页任何地方发生的变化(非链接内容的变化)。
3. 使用网站更新监控工具监控网站hyperlinks 监控整个网页或需要监控的网页区域。当有更新时,它会立即提醒并记录。以下面的网页为例。监控网页的实时信息更新。
一个。在网站更新监控工具的URL管理,点击“添加”,添加我们需要监控的URL,点击“自动获取”获取页面代码,监控方式选择“源码监控”,一个元素是常用的方式。
B.点击“设置”-Data采集Scheme,选择A元素通用,设置scheme。
c.选择“文本过滤器”,在重复内容中选择“过滤重复文本”。
d。在“链接过滤”选项卡中,输入自定义字符:选择过滤不收录字符的字符。然后点击“保存”。至此,A单元的总体方案建立。
e.以上步骤设置好后,本期financial网站资讯直播的实时监控提醒任务就设置好了。我们来看看监控效果。您可以在“历史”中查看历史。
总结:监控网站超LINK,有更新立即报警记录。帮助您从海量的网络信息中获取有用的信息,第一时间获取最准确的信息。适用于投资者、记者等。软件支持同时监控多个网站,获取更全面的信息。为每个 URL 单独设置监控方法。监控历史记录详细,可随时打开参考。支持多种报警方式,包括声音、弹窗、邮件等。一般网站采用源码监听方式,速度快又节省资源。特殊动态页面使用元素监控,支持网页区域监控,更加精准灵活。
网站内容自动更新(网站内容自动更新,我用了一款叫网站管家的软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-06 04:02
网站内容自动更新,就是你登录账号后,可以随时手动搜索需要的内容,或者点击一个你需要的内容,然后转向去网站首页查看,过一段时间后就自动循环了。
软件可以实现,我用了一款叫网站管家的软件,你可以试试看。这款软件就相当于一个浏览器,可以自动搜索,管理、更新站内新闻资讯,同时还有个网页收藏功能,上当你看到感兴趣的文章时,可以在线收藏,也可以点击收藏的文章进行查看!非常不错的一款软件。
这个还是软件实现的,我用过一个叫亿图图示的,它做的功能还是比较多的,还有重复的时候的计时器,对于管理网站的复制粘贴非常的好用,而且它还有一个搜索功能。用起来挺方便的。
如果你要在一个网站上加入多个子网站,那么利用操作平台即时显示它们的位置就可以了。如:hi8软件,您可以用excel\stata\spss\matlab等库实现全站的实时显示。
好像有个新闻站,微博上一出新闻,
先打开浏览器地址栏,在地址栏右侧空白处用鼠标在空白处点击,会自动进入一个文件夹,这个文件夹里面都是你要的资料。你需要哪个网站的资料,输入关键词,就能在右边自动显示相关网站,你可以选择要全站的也可以选择只显示你要的网站。其实一点都不麻烦。 查看全部
网站内容自动更新(网站内容自动更新,我用了一款叫网站管家的软件)
网站内容自动更新,就是你登录账号后,可以随时手动搜索需要的内容,或者点击一个你需要的内容,然后转向去网站首页查看,过一段时间后就自动循环了。
软件可以实现,我用了一款叫网站管家的软件,你可以试试看。这款软件就相当于一个浏览器,可以自动搜索,管理、更新站内新闻资讯,同时还有个网页收藏功能,上当你看到感兴趣的文章时,可以在线收藏,也可以点击收藏的文章进行查看!非常不错的一款软件。
这个还是软件实现的,我用过一个叫亿图图示的,它做的功能还是比较多的,还有重复的时候的计时器,对于管理网站的复制粘贴非常的好用,而且它还有一个搜索功能。用起来挺方便的。
如果你要在一个网站上加入多个子网站,那么利用操作平台即时显示它们的位置就可以了。如:hi8软件,您可以用excel\stata\spss\matlab等库实现全站的实时显示。
好像有个新闻站,微博上一出新闻,
先打开浏览器地址栏,在地址栏右侧空白处用鼠标在空白处点击,会自动进入一个文件夹,这个文件夹里面都是你要的资料。你需要哪个网站的资料,输入关键词,就能在右边自动显示相关网站,你可以选择要全站的也可以选择只显示你要的网站。其实一点都不麻烦。
网站内容自动更新(一个通过单页面制作HTML网站地图的方法通过方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-05 20:21
百度和谷歌站长工具都有提交网站的功能。虽然是提交XML地图,但网站Map在HTML中的重要性也不容忽视。 织梦Dedecms可以通过单页或者插件的方式生成HTML网站地图。系统还自带了一个HTML地图,但是附带的地图只列出了所有的列,非常简单。今天小编整理了一个单页制作HTML网站地图的方法,它是一个HTML网站地图,每次有新的文章发布都会自动更新。具体方法如下:
制作 HTML网站map 的模板。你已经做了一个。可以到单页站点地图模板下载压缩包,解压后上传到模板目录。进入网站后台,在Core -> Channel Model -> Single Page Document Management中添加一个页面。根据你的网站情况填写页面标题、页面关键词和页面摘要信息。模板名称和文件名请参考下图。无需在编辑框中添加任何内容。模板设置完毕。
设置好后点击确定,会在网站root目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。它尚未自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row='50' col='1' orderby=pubdate}
[字段:标题/]
{/dede:arclist}
到目前为止,我们只做了一个HTML网站map页面,还没有实现发布文章自动更新HTML网站map的功能。实现方法如下:
使用Dreamwear或其他专业文本编辑器,打开后台管理目录下的task_do.php文件,找到如下代码:
$GLOBALS['_arclistEnv'] ='index';
$pv->SetTemplet($tpl);
$pv->SaveToHtml($homeFile);
$pv->Close();
将以下代码添加到以下行:
include_once(DEDEINC."/arc.sgpage.class.php");
$dsql->Execute("ex","从'dede_sgpage'选择帮助");
$i = 0;
while($row = $dsql->GetArray("ex"))
{
$sg = new sgpage($row['aid']);
$sg->SaveToHtml();
$i++;
}
//更新所有单个文档
保存关闭后,可以使用在发布文章后自动更新HTML网站地图,不过还有两点需要注意:
在后台【系统基本参数】——性能选项中,将“发布文章:后立即更新网站homepage”设置为“是”,保证代码顺利执行【必填】; 【系统基本参数】后台-性能选项中,尽量减少“arclist标签调用缓存”【没必要,更新自己的功能选择】; 查看全部
网站内容自动更新(一个通过单页面制作HTML网站地图的方法通过方法)
百度和谷歌站长工具都有提交网站的功能。虽然是提交XML地图,但网站Map在HTML中的重要性也不容忽视。 织梦Dedecms可以通过单页或者插件的方式生成HTML网站地图。系统还自带了一个HTML地图,但是附带的地图只列出了所有的列,非常简单。今天小编整理了一个单页制作HTML网站地图的方法,它是一个HTML网站地图,每次有新的文章发布都会自动更新。具体方法如下:
制作 HTML网站map 的模板。你已经做了一个。可以到单页站点地图模板下载压缩包,解压后上传到模板目录。进入网站后台,在Core -> Channel Model -> Single Page Document Management中添加一个页面。根据你的网站情况填写页面标题、页面关键词和页面摘要信息。模板名称和文件名请参考下图。无需在编辑框中添加任何内容。模板设置完毕。
设置好后点击确定,会在网站root目录下生成一个sitemap.html页面。生成页面的名称和位置可以在文件名中自定义。它尚未自动更新。下次加一些代码实现自动更新。现在需要进入单页文档管理手动更新。您可以根据需要编辑模板文件中的代码以更改数据条目和行数。
{dede:arclist row='50' col='1' orderby=pubdate}
[字段:标题/]
{/dede:arclist}
到目前为止,我们只做了一个HTML网站map页面,还没有实现发布文章自动更新HTML网站map的功能。实现方法如下:
使用Dreamwear或其他专业文本编辑器,打开后台管理目录下的task_do.php文件,找到如下代码:
$GLOBALS['_arclistEnv'] ='index';
$pv->SetTemplet($tpl);
$pv->SaveToHtml($homeFile);
$pv->Close();
将以下代码添加到以下行:
include_once(DEDEINC."/arc.sgpage.class.php");
$dsql->Execute("ex","从'dede_sgpage'选择帮助");
$i = 0;
while($row = $dsql->GetArray("ex"))
{
$sg = new sgpage($row['aid']);
$sg->SaveToHtml();
$i++;
}
//更新所有单个文档
保存关闭后,可以使用在发布文章后自动更新HTML网站地图,不过还有两点需要注意:
在后台【系统基本参数】——性能选项中,将“发布文章:后立即更新网站homepage”设置为“是”,保证代码顺利执行【必填】; 【系统基本参数】后台-性能选项中,尽量减少“arclist标签调用缓存”【没必要,更新自己的功能选择】;
网站内容自动更新(网站内容自动更新的技术在公司里如何利用动态网站页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-05 10:03
网站内容自动更新的技术在公司里很早就有在做,早期都是使用各个数据源,实现网站内容的一个自动生成,甚至实现多个数据源,多个分类,比如百度关键词就更多,因为这样能够更好的实现数据聚合,更多的放置收录率,网站收录低的关键词,这样排名自然也会很好。现在很多新闻资讯类的网站都是使用了百度新闻分类提交,这样不管是新闻源还是自己建立的内容源都可以同步,降低了运营成本。
另外像什么关键词堆叠类网站已经不是新闻源了,也就谈不上如何自动更新,很多情况下还需要人工审核的。那么现在多用哪些程序去抓取网站内容呢,因为网站各个方面的账号量,自动化的爬虫也在增加,没有多一个后台来保存,这个太不安全了,很多人都会选择第三方,我也是尝试了好多后,最后找到了“微速搜索”,可以智能抓取网站各个角落的数据,手动上传、审核、自动补全、自动识别,全程一个机器人可以搞定,还不需要安装第三方插件,免去了上传服务器的麻烦。
爬虫抓取要自己搞定,那么如何模拟前端,利用动态网站页面抓取呢?遇到好多问题,我只能通过网上来找答案,或者是一些试用,还有就是接口对接等各种方式,找了好久好久。这段时间终于找到一个靠谱的方式。利用chromeseeds抓取应用,通过这个程序我首先抓取了一个seeds小网站,然后将seeds模拟其它一些首页、话题页抓取,同时还可以抓取新闻源的。
目前有35个api方向,只需要模拟前端去抓取内容,不需要技术人员,只要有浏览器和pc、网页端都可以做到。还可以模拟几十个新闻源的内容抓取,给大家演示一下效果。1、发现一个exe文件网址:,地址:.然后通过seeds发现一个exe文件,直接解压运行即可,速度非常快,抓取新闻源只需要6秒。如果有更快的网址建议使用httpserver+firefoxseeds+samulb.babel代替。
这样就可以完全代替https。2、发现一个一键post内容进来对应抓取对应内容网址:-examples/login/examples.img?utm_campaign=static&utm_source=wap&utm_medium=android&utm_term=com.google.android.finder.findsourcehttpinterceptors&msc_all=1&os=1&redirect_http_ip=443&extract_url=coursera&from_uri=static&result=https%3a%2f%%2fwap%2fwap%2fwap%2fwap&r=server_multipart&from_uri=static&new_content=keep_cookie&view_params=1&charset=utf-8&size=10544&name=examples&l。 查看全部
网站内容自动更新(网站内容自动更新的技术在公司里如何利用动态网站页面)
网站内容自动更新的技术在公司里很早就有在做,早期都是使用各个数据源,实现网站内容的一个自动生成,甚至实现多个数据源,多个分类,比如百度关键词就更多,因为这样能够更好的实现数据聚合,更多的放置收录率,网站收录低的关键词,这样排名自然也会很好。现在很多新闻资讯类的网站都是使用了百度新闻分类提交,这样不管是新闻源还是自己建立的内容源都可以同步,降低了运营成本。
另外像什么关键词堆叠类网站已经不是新闻源了,也就谈不上如何自动更新,很多情况下还需要人工审核的。那么现在多用哪些程序去抓取网站内容呢,因为网站各个方面的账号量,自动化的爬虫也在增加,没有多一个后台来保存,这个太不安全了,很多人都会选择第三方,我也是尝试了好多后,最后找到了“微速搜索”,可以智能抓取网站各个角落的数据,手动上传、审核、自动补全、自动识别,全程一个机器人可以搞定,还不需要安装第三方插件,免去了上传服务器的麻烦。
爬虫抓取要自己搞定,那么如何模拟前端,利用动态网站页面抓取呢?遇到好多问题,我只能通过网上来找答案,或者是一些试用,还有就是接口对接等各种方式,找了好久好久。这段时间终于找到一个靠谱的方式。利用chromeseeds抓取应用,通过这个程序我首先抓取了一个seeds小网站,然后将seeds模拟其它一些首页、话题页抓取,同时还可以抓取新闻源的。
目前有35个api方向,只需要模拟前端去抓取内容,不需要技术人员,只要有浏览器和pc、网页端都可以做到。还可以模拟几十个新闻源的内容抓取,给大家演示一下效果。1、发现一个exe文件网址:,地址:.然后通过seeds发现一个exe文件,直接解压运行即可,速度非常快,抓取新闻源只需要6秒。如果有更快的网址建议使用httpserver+firefoxseeds+samulb.babel代替。
这样就可以完全代替https。2、发现一个一键post内容进来对应抓取对应内容网址:-examples/login/examples.img?utm_campaign=static&utm_source=wap&utm_medium=android&utm_term=com.google.android.finder.findsourcehttpinterceptors&msc_all=1&os=1&redirect_http_ip=443&extract_url=coursera&from_uri=static&result=https%3a%2f%%2fwap%2fwap%2fwap%2fwap&r=server_multipart&from_uri=static&new_content=keep_cookie&view_params=1&charset=utf-8&size=10544&name=examples&l。
关于自动更新源代码时常发生的一些问题,你知道吗?
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-22 19:05
网站内容自动更新之前做了关于关于自动更新源代码时常发生的一些问题,与大家分享一下,希望能对大家有所帮助。我们编译自腾讯客服网:qq使用php代码来编译脚本,会首先被发现,然后再发现其它脚本。但是php代码存在2个难以忽略的问题:在php体内向外抛出的rpc连接,由于由于互相连接错误,无法得到地址。这也给经常更换服务器或多次编译脚本的后端带来不便。
php体存在大量的寄存器(rsa加密脚本需要的rsa私钥),如果对原脚本再次编译的话,有可能会让这些寄存器不是首部状态,也就导致了原脚本覆盖在后端数据库或文件内。通常,我们应该做如下改动:1.在脚本中增加一个opendrive函数2.对基于xml表的参数的获取进行特殊处理,例如存储时将其交换地址设置为对应的数据库库号。
3.为缓存函数添加一个适当的存储方式。例如cache等;4.设置无网络访问时,通过对当前应用程序(或iis或wamp)的php连接进行数据包操作(phpdisplay_reverse_download)来处理数据。总结上面是自动更新部分相关的解决方案,我们选择的是。
2、3,实现过程都挺痛苦的,自己进行封装关键部分。1.增加opendrive函数是完成代码的sql语句操作。2.整理报文数据格式并将对应的名与地址绑定起来。
3.针对php和nginx的php连接分为两种情况:
1)loopback和createssl连接已提供了abi(applicationlibraryframework)在loopback端应该提供get和http请求接口,将以消息的形式发送给nginx来处理,
2)envoy或ack_rst(下文以ack_rst连接为例)。ack_rst连接提供了一系列操作,如切换连接后的ip到本地,建立http连接,requesttype和responsetype值分别为httppost和httpget。具体功能可参照文章目录(源码已上传网盘,请点开查看)。4.利用4个库之一,对包括账号密码,其它数据(网站后端)的请求格式进行了修改。
可以提供账号密码自动生成在你已设置的模块里。5.因为我们要推送,我们可以把连接的request_prefix存储到数据库中,可以提供账号密码实现自动生成。要点总结下来就是:1.根据我们服务器服务的可连接端口,一般推荐用80端口连接,但是qq连接有各种错误返回信息,如http403等,因此基于各类错误信息的封装php代码是没有必要的。
2.利用上述12234,针对路由连接,推送消息,管理线程数,token等功能进行封装,然后上传php可执行的exe文件。如果有windows服务器,则可以设置windows服务器,不过得自己做一些测试, 查看全部
关于自动更新源代码时常发生的一些问题,你知道吗?
网站内容自动更新之前做了关于关于自动更新源代码时常发生的一些问题,与大家分享一下,希望能对大家有所帮助。我们编译自腾讯客服网:qq使用php代码来编译脚本,会首先被发现,然后再发现其它脚本。但是php代码存在2个难以忽略的问题:在php体内向外抛出的rpc连接,由于由于互相连接错误,无法得到地址。这也给经常更换服务器或多次编译脚本的后端带来不便。
php体存在大量的寄存器(rsa加密脚本需要的rsa私钥),如果对原脚本再次编译的话,有可能会让这些寄存器不是首部状态,也就导致了原脚本覆盖在后端数据库或文件内。通常,我们应该做如下改动:1.在脚本中增加一个opendrive函数2.对基于xml表的参数的获取进行特殊处理,例如存储时将其交换地址设置为对应的数据库库号。
3.为缓存函数添加一个适当的存储方式。例如cache等;4.设置无网络访问时,通过对当前应用程序(或iis或wamp)的php连接进行数据包操作(phpdisplay_reverse_download)来处理数据。总结上面是自动更新部分相关的解决方案,我们选择的是。
2、3,实现过程都挺痛苦的,自己进行封装关键部分。1.增加opendrive函数是完成代码的sql语句操作。2.整理报文数据格式并将对应的名与地址绑定起来。
3.针对php和nginx的php连接分为两种情况:
1)loopback和createssl连接已提供了abi(applicationlibraryframework)在loopback端应该提供get和http请求接口,将以消息的形式发送给nginx来处理,
2)envoy或ack_rst(下文以ack_rst连接为例)。ack_rst连接提供了一系列操作,如切换连接后的ip到本地,建立http连接,requesttype和responsetype值分别为httppost和httpget。具体功能可参照文章目录(源码已上传网盘,请点开查看)。4.利用4个库之一,对包括账号密码,其它数据(网站后端)的请求格式进行了修改。
可以提供账号密码自动生成在你已设置的模块里。5.因为我们要推送,我们可以把连接的request_prefix存储到数据库中,可以提供账号密码实现自动生成。要点总结下来就是:1.根据我们服务器服务的可连接端口,一般推荐用80端口连接,但是qq连接有各种错误返回信息,如http403等,因此基于各类错误信息的封装php代码是没有必要的。
2.利用上述12234,针对路由连接,推送消息,管理线程数,token等功能进行封装,然后上传php可执行的exe文件。如果有windows服务器,则可以设置windows服务器,不过得自己做一些测试,
TinyTinyRSS阅读器RSS
网站优化 • 优采云 发表了文章 • 0 个评论 • 432 次浏览 • 2021-08-22 04:31
关于放弃商业和免费的在线RSS阅读器,改用自建的个人RSS阅读器。在放弃免费Inoreader和自建RSS阅读器的文章中,推荐使用Tiny Tiny RSS和FreshRSS这两个开源和免费的。 RSS在线阅读器,您只需要一台虚拟主机即可运行您自己的RSS在线阅读器。
当然,更高级的玩法是使用 Huginn 抓取任何网站RSS 和微信公众号更新。 Huginn 坦率地说就像一个爬虫。您可以释放“Huginn”来抓取任何网络内容。更新,同时配合APP、RSS等工具对信息进行聚焦、汇总,从而达到个人高效获取有用信息的目的。
本文分享Tiny Tiny RSS安装配置中遇到的相关问题,如配置自动更新feed、安装配置Tiny Tiny RSS全文RSS插件、切换修改Tiny Tiny RSS主题以及Tiny Tiny RSS手机APP使用。
更多RSS阅读器的自建和使用方法如下:
生成并订阅任何网站RSS工具——实现RSS全文、邮件和手机APP提醒。使用 MailPoet Newsletters 插件为 WordPress 构建 RSS 邮件订阅。支持 SMTP。两款优秀的开源RSS阅读器工具:Miniflux和Tiny Tiny RSS-自建在线RSS阅读器
PS:更新记录
1、Some 网站 不提供 RSS 提要。这时候我们就可以搭建自己的应用,强制这些网站内容更新输出RSS feed,达到订阅RSS的目的:RSSHub不支持RSS网站Make RSS feeds-支持B站,知乎 、微博、豆瓣、今日头条。 2021.3.8
2、严重依赖1Password等密码管理软件,但如果你口袋里害羞,不要阻止自己搭建密码管理平台:Bitwarden自建密码存储系统图文教程-开源和免费bitwarden_rs 安装和使用。 2020.10.10
3、如果平时喜欢用印象笔记又不想花钱,可以尝试搭建自己的笔记服务平台:代替印象笔记,免费开源的笔记乔普林-网盘同步笔记历史版本 Markdown 可视化。 2020.10.1
一、Tiny Tiny RSS 安装
网站:
官网:项目:1.1 安装前准备
PHP必备组件(最低PHP5.6,推荐PHP 7以上):
PDO 支持 PostgreSQL 或 MySQL,具体取决于所使用的数据库服务器——某些发行版需要 PDO 和特定于数据库的包,即 php-pdo 和 php-pgsql
JSON
XML (DOMDocument, DOMXpath)
国际化(国际化)
字符串
文件信息
推荐的PHP安装是:
CURL(强烈推荐,安装即可)或支持远程 fopen()
POSIX 函数(用于多进程更新守护进程,否则不需要)
GD(需要 OTP 和一些插件)
某种操作码缓存/加速器(取决于 PHP 版本:php5-apc、php7-opcache 等)
特别提醒:Tiny Tiny RSS对PHP组件有严格要求,没有任何一个都不能成功激活。
1.2 TT-RSS 安装
找一台已经配置了LNMP或LAMP环境的VPS主机,以及是否使用Oneinstack进行挖掘站点,可以从这里选择:VPS主机排行榜。执行命令:
git clone https://git.tt-rss.org/fox/tt-rss.git tt-rss
如果不想使用Git命令,也可以手动下载安装包,自己上传,不过比Git要麻烦一些。下载的文件在tt-rss文件夹下,我们可以将文件移动到根目录,Linux批量移动文件方法:Linux移动并复制文件夹中的所有文件(包括隐藏文件)
现在打开浏览器访问:,会看到TT-RSS安装界面,在这里可以填写数据库账号、密码等信息。
确认数据库连接成功后,即可点击初始化TT-RSS。
初始化成功后TT-RSS会生成config.php文件,点击save会自动生成在你服务器的根目录下,否则可以手动复制到根目录下创建。
完成后即可登录TT-RSS,初始账号为:admin,密码为:password。打开TT-RSS时,提示错误。一般来说,组件没有安装。如果您使用的是Oneinstack,您可以直接安装PHP组件,例如php fileinfo。
1.3 TT-RSS 使用
TT-RSS界面如下(点击放大):
Tiny Tiny RSS阅读RSS界面如下,订阅视频也可以直接打开观看:
Tiny Tiny RSS 官方自带了很多主题,可以直接在插件管理选项中启用,部分如下:
af_unburn:解决feedburner等RSS链接重定向问题。
bookmarklets:在设置信息源中生成书签标签。
embed_original:图标插件,点击图标会显示文章原创内容而不是rss。
fever:模拟发烧api,在设置-Fver Emulation中设置密码,可以和tt-rss的登录密码不同,这样就可以支持reeder、阅读先生等发烧客户端了。
ff_feedcleaner:feed广告过滤,在设置标签中生成FeecCleaner标签,过滤规则需要使用正则表达式,比较复杂。
googlereaderkeys:模拟谷歌阅读器快捷键,如J、K等
import_export:在设置-信息源中,导入导出配置。
邮件:图标插件,点击邮件分享。
mark_button:文章右下角可以快速将文章标记为已读和未读。
mobilize:图标插件,点击显示一个可读性的简化页面。
注意:图标插件。
nsfw:根据标签隐藏文章 内容。
share:图标插件,点击生成唯一url,方便分享。
swap_jk:添加j和k快捷键,类似vim。
1.4 TT-RSS 升级
执行以下命令更新TT-RSS版本文件:
#进入tt-rss 目录
git pull origin master
然后打开你的TT-RSS,如果说config.php有错误,你需要将config.php-dist中的内容合并到config.php或者删除config.php重新安装。特别注意:重装这一步不要点击INITIALIZE DATABASE,否则你的数据会被覆盖。
二、Tiny Tiny RSS 提示2.1 批量导入导出
在Tiny Tiny RSS的信息源管理中,可以批量导入导出Feed,方便我们的迁移。
2.2 删除无效提要
如果提要中有无效提要,Tiny Tiny RSS 会提示您,您可以批量删除它们。
2.3 切换修改主题
主题:
市场上有很多 Tiny Tiny RSS 免费主题。如果您不喜欢默认主题,可以下载它们并将它们放在 themes.local 文件夹中。命令演示:
wget wget https://github.com/levito/tt-r ... r.zip
unzip master.zip
cd tt-rss-feedly-theme-master
cp -r feedly* /data/wwwroot/rss.ucblog.net/themes.local
然后在 Tiny Tiny RSS 的设置中切换主题。
Tiny Tiny RSS 的新 Feedly 主题具有以下效果:
三、TT-RSS 全文插件
网站:
3.1 Mercury_fulltext
mercury_fulltext 是一个插件,用于在 Tiny Tiny RSS 上获取 RSS 全文。安装命令如下:
#安装 mercury_fulltext 插件
#进入到插件目录
cd /data/wwwroot/rss.ucblog.net/plugins
#下载
git clone https://github.com/HenryQW/mercury_fulltext.git mercury_fulltext
然后在“首选项”中启用插件。
现在回到“信息来源”,这里需要填写Mercury Parser API。
3.2 解析器 API
Mercury Parser API 需要使用 Docker 安装。您首先在 VPS 上安装 Docker-CE 环境。建议参考官方安装方法,比较简单。
然后执行命令安装并运行 Mercury Parser API:
docker run -p 3000:3000 --restart=always -d wangqiru/mercury-parser-api
3.3 RSS全文设置
在“Preferences”-“Information Sources”-“Mercury Fulltext settings (mercury_fulltext)”中,填写自建的Mercury Parser API地址:localhost:3000并保存。编辑需要获取全文的提要(信息源),插件启用“通过Mercury Parser获取全文”保存退出。
四、TT-RSS 手机APP
应用程序:
Tiny Tiny RSS Android 应用程序可以直接从 Google Play 应用程序市场下载。要在移动应用上登录并使用 Tiny Tiny RSS,您需要在 Tiny Tiny RSS 上启用 API 登录。
第一次打开Tiny Tiny RSS APP后,需要建立连接,主要是填写你的Tiny Tiny RSS URL、账号和密码。
这是Tiny Tiny RSS的手机APP界面。
Tiny Tiny RSS 手机APP文章阅读界面如下:
五、TT-RSS 自动更新5.1 简单更新模式
打开config.php配置文件,设置SIMPLE_UPDATE_MODE为true,这样每次打开Tiny Tiny RSS都会更新RSS订阅数据。特别注意:需要在config.php PHP_EXECUTABLE中设置PHP路径,例如:/usr/local/php/bin/php
define('PHP_EXECUTABLE', '/usr/local/php/bin/php');
// Path to PHP *COMMAND LINE* executable, used for various command-line tt-rss
// programs and update daemon. Do not try to use CGI binary here, it won't work.
// If you see HTTP headers being displayed while running tt-rss scripts,
// then most probably you are using the CGI binary. If you are unsure what to
// put in here, ask your hosting provider.
5.2 VPS 定时任务
如果您使用的是 VPS 主机,则可以使用 Linux 的定时任务。 TT-RSS不能使用Root运行定时任务,需要使用www运行(一般LNMP环境和BT宝塔面板都是用www运行的):
crontab -u www -e
#每5分钟运行一次,/usr/local/php/bin/php为php命令的绝对路径,根据需要来修改
*/5 * * * * /usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet
当然还有另外一种方式,以root身份登录,然后执行:contab -e 编辑定时任务并添加如下代码:
#指定使用www用户执行定时任务
*/5 * * * * su -m www -c "/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet"
#另
php ./update.php是执行单进程,多进程是 php ./update_daemon2.php。
5.3 任务运行状态
Linux定时任务修改编辑后记得重启定时任务生效。命令如下:
#ubuntu下定时执行工具cron开启关闭重启
#配置文件一般为/etc/init.d/cron
启动:sudo /etc/init.d/cron start
关闭:sudo /etc/init.d/cron stop
重启:sudo /etc/init.d/cron restart
重新载入配置:sudo /etc/init.d/cron reload
#可以用ps aux | grep cron命令查看cron是否已启动
#CentOS重启crontab服务
service crond reload
Linux定时任务是否正常运行,可以手动查看日志。
#查看定时任务日志
#Ubuntn
tail -f /var/log/syslog
#CentOS
tail -f /var/log/cron
会有以下记录:
Sep 28 22:20:01 localhost CRON[15714]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
Sep 28 22:25:01 localhost CRON[15985]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
Sep 28 22:30:01 localhost CRON[16177]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
六、Summary
Tiny Tiny RSS在批量导入Feed和设置定时任务时总会遇到一些莫名其妙的错误。比如数据库会报错:Uncaught PDOException: SQLSTATE[HY000] [1045] Access denied for user or MySQL connection not working: 2002 No such file or directory.
另外,手动检查并运行Tiny Tiny RSS定时任务时,也出现如下错误:
Tiny Tiny RSS was unable to start properly. This usually means a misconfiguration or an incomplete upgrade.
Please fix errors indicated by the following messages:
* Please don't run this script as root.
* PHP UConverter class is missing, it's provided by the Internationalization (intl) module.
* PHP support for mbstring functions is required but was not found.
You might want to check tt-rss wiki or the forums for more information.
Please search the forums before creating new topic for your question.
错误:请不要以 root 身份运行此脚本。这是一个非常简单的解决方案。您可以使用本文中的 su www 等指定用户运行计划任务。其他错误如 PHP 错误和数据库错误可以在 config 中找到。在php中指定数据库的连接地址和端口,如下:
define('DB_TYPE', 'mysql');
define('DB_HOST', '127.0.0.1');
define('DB_USER', 'wzfou');
define('DB_NAME', 'wzfou.com');
define('DB_PASS', 'qimm');
define('DB_PORT', '3306');
文章From: Diazhan 不,保留所有权利。本站文章除出处外均为作者原创文章,可随意引用,但请注明出处。 查看全部
TinyTinyRSS阅读器RSS
关于放弃商业和免费的在线RSS阅读器,改用自建的个人RSS阅读器。在放弃免费Inoreader和自建RSS阅读器的文章中,推荐使用Tiny Tiny RSS和FreshRSS这两个开源和免费的。 RSS在线阅读器,您只需要一台虚拟主机即可运行您自己的RSS在线阅读器。
当然,更高级的玩法是使用 Huginn 抓取任何网站RSS 和微信公众号更新。 Huginn 坦率地说就像一个爬虫。您可以释放“Huginn”来抓取任何网络内容。更新,同时配合APP、RSS等工具对信息进行聚焦、汇总,从而达到个人高效获取有用信息的目的。
本文分享Tiny Tiny RSS安装配置中遇到的相关问题,如配置自动更新feed、安装配置Tiny Tiny RSS全文RSS插件、切换修改Tiny Tiny RSS主题以及Tiny Tiny RSS手机APP使用。
https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w, https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w" />更多RSS阅读器的自建和使用方法如下:
生成并订阅任何网站RSS工具——实现RSS全文、邮件和手机APP提醒。使用 MailPoet Newsletters 插件为 WordPress 构建 RSS 邮件订阅。支持 SMTP。两款优秀的开源RSS阅读器工具:Miniflux和Tiny Tiny RSS-自建在线RSS阅读器
PS:更新记录
1、Some 网站 不提供 RSS 提要。这时候我们就可以搭建自己的应用,强制这些网站内容更新输出RSS feed,达到订阅RSS的目的:RSSHub不支持RSS网站Make RSS feeds-支持B站,知乎 、微博、豆瓣、今日头条。 2021.3.8
2、严重依赖1Password等密码管理软件,但如果你口袋里害羞,不要阻止自己搭建密码管理平台:Bitwarden自建密码存储系统图文教程-开源和免费bitwarden_rs 安装和使用。 2020.10.10
3、如果平时喜欢用印象笔记又不想花钱,可以尝试搭建自己的笔记服务平台:代替印象笔记,免费开源的笔记乔普林-网盘同步笔记历史版本 Markdown 可视化。 2020.10.1
一、Tiny Tiny RSS 安装
网站:
官网:项目:1.1 安装前准备
PHP必备组件(最低PHP5.6,推荐PHP 7以上):
PDO 支持 PostgreSQL 或 MySQL,具体取决于所使用的数据库服务器——某些发行版需要 PDO 和特定于数据库的包,即 php-pdo 和 php-pgsql
JSON
XML (DOMDocument, DOMXpath)
国际化(国际化)
字符串
文件信息
推荐的PHP安装是:
CURL(强烈推荐,安装即可)或支持远程 fopen()
POSIX 函数(用于多进程更新守护进程,否则不需要)
GD(需要 OTP 和一些插件)
某种操作码缓存/加速器(取决于 PHP 版本:php5-apc、php7-opcache 等)
特别提醒:Tiny Tiny RSS对PHP组件有严格要求,没有任何一个都不能成功激活。
1.2 TT-RSS 安装
找一台已经配置了LNMP或LAMP环境的VPS主机,以及是否使用Oneinstack进行挖掘站点,可以从这里选择:VPS主机排行榜。执行命令:
git clone https://git.tt-rss.org/fox/tt-rss.git tt-rss
如果不想使用Git命令,也可以手动下载安装包,自己上传,不过比Git要麻烦一些。下载的文件在tt-rss文件夹下,我们可以将文件移动到根目录,Linux批量移动文件方法:Linux移动并复制文件夹中的所有文件(包括隐藏文件)
现在打开浏览器访问:,会看到TT-RSS安装界面,在这里可以填写数据库账号、密码等信息。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />确认数据库连接成功后,即可点击初始化TT-RSS。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />初始化成功后TT-RSS会生成config.php文件,点击save会自动生成在你服务器的根目录下,否则可以手动复制到根目录下创建。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />完成后即可登录TT-RSS,初始账号为:admin,密码为:password。打开TT-RSS时,提示错误。一般来说,组件没有安装。如果您使用的是Oneinstack,您可以直接安装PHP组件,例如php fileinfo。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />1.3 TT-RSS 使用
TT-RSS界面如下(点击放大):
Tiny Tiny RSS阅读RSS界面如下,订阅视频也可以直接打开观看:
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />Tiny Tiny RSS 官方自带了很多主题,可以直接在插件管理选项中启用,部分如下:
af_unburn:解决feedburner等RSS链接重定向问题。
bookmarklets:在设置信息源中生成书签标签。
embed_original:图标插件,点击图标会显示文章原创内容而不是rss。
fever:模拟发烧api,在设置-Fver Emulation中设置密码,可以和tt-rss的登录密码不同,这样就可以支持reeder、阅读先生等发烧客户端了。
ff_feedcleaner:feed广告过滤,在设置标签中生成FeecCleaner标签,过滤规则需要使用正则表达式,比较复杂。
googlereaderkeys:模拟谷歌阅读器快捷键,如J、K等
import_export:在设置-信息源中,导入导出配置。
邮件:图标插件,点击邮件分享。
mark_button:文章右下角可以快速将文章标记为已读和未读。
mobilize:图标插件,点击显示一个可读性的简化页面。
注意:图标插件。
nsfw:根据标签隐藏文章 内容。
share:图标插件,点击生成唯一url,方便分享。
swap_jk:添加j和k快捷键,类似vim。
1.4 TT-RSS 升级
执行以下命令更新TT-RSS版本文件:
#进入tt-rss 目录
git pull origin master
然后打开你的TT-RSS,如果说config.php有错误,你需要将config.php-dist中的内容合并到config.php或者删除config.php重新安装。特别注意:重装这一步不要点击INITIALIZE DATABASE,否则你的数据会被覆盖。
二、Tiny Tiny RSS 提示2.1 批量导入导出
在Tiny Tiny RSS的信息源管理中,可以批量导入导出Feed,方便我们的迁移。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />2.2 删除无效提要
如果提要中有无效提要,Tiny Tiny RSS 会提示您,您可以批量删除它们。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />2.3 切换修改主题
主题:
市场上有很多 Tiny Tiny RSS 免费主题。如果您不喜欢默认主题,可以下载它们并将它们放在 themes.local 文件夹中。命令演示:
wget wget https://github.com/levito/tt-r ... r.zip
unzip master.zip
cd tt-rss-feedly-theme-master
cp -r feedly* /data/wwwroot/rss.ucblog.net/themes.local
然后在 Tiny Tiny RSS 的设置中切换主题。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />Tiny Tiny RSS 的新 Feedly 主题具有以下效果:
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />三、TT-RSS 全文插件
网站:
3.1 Mercury_fulltext
mercury_fulltext 是一个插件,用于在 Tiny Tiny RSS 上获取 RSS 全文。安装命令如下:
#安装 mercury_fulltext 插件
#进入到插件目录
cd /data/wwwroot/rss.ucblog.net/plugins
#下载
git clone https://github.com/HenryQW/mercury_fulltext.git mercury_fulltext
然后在“首选项”中启用插件。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />现在回到“信息来源”,这里需要填写Mercury Parser API。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />3.2 解析器 API
Mercury Parser API 需要使用 Docker 安装。您首先在 VPS 上安装 Docker-CE 环境。建议参考官方安装方法,比较简单。
然后执行命令安装并运行 Mercury Parser API:
docker run -p 3000:3000 --restart=always -d wangqiru/mercury-parser-api
3.3 RSS全文设置
在“Preferences”-“Information Sources”-“Mercury Fulltext settings (mercury_fulltext)”中,填写自建的Mercury Parser API地址:localhost:3000并保存。编辑需要获取全文的提要(信息源),插件启用“通过Mercury Parser获取全文”保存退出。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />四、TT-RSS 手机APP
应用程序:
Tiny Tiny RSS Android 应用程序可以直接从 Google Play 应用程序市场下载。要在移动应用上登录并使用 Tiny Tiny RSS,您需要在 Tiny Tiny RSS 上启用 API 登录。
https://wzfou.cdn.bcebos.com/w ... 0.png 223w, https://wzfou.cdn.bcebos.com/w ... 0.png 372w, https://wzfou.cdn.bcebos.com/w ... 1.png 300w, https://wzfou.cdn.bcebos.com/w ... 3.png 600w" />第一次打开Tiny Tiny RSS APP后,需要建立连接,主要是填写你的Tiny Tiny RSS URL、账号和密码。
https://wzfou.cdn.bcebos.com/w ... 0.jpg 96w, https://wzfou.cdn.bcebos.com/w ... 6.jpg 176w" />这是Tiny Tiny RSS的手机APP界面。
https://wzfou.cdn.bcebos.com/w ... 0.jpg 97w, https://wzfou.cdn.bcebos.com/w ... 6.jpg 178w" />Tiny Tiny RSS 手机APP文章阅读界面如下:
https://wzfou.cdn.bcebos.com/w ... 0.jpg 98w, https://wzfou.cdn.bcebos.com/w ... 6.jpg 180w" />五、TT-RSS 自动更新5.1 简单更新模式
打开config.php配置文件,设置SIMPLE_UPDATE_MODE为true,这样每次打开Tiny Tiny RSS都会更新RSS订阅数据。特别注意:需要在config.php PHP_EXECUTABLE中设置PHP路径,例如:/usr/local/php/bin/php
define('PHP_EXECUTABLE', '/usr/local/php/bin/php');
// Path to PHP *COMMAND LINE* executable, used for various command-line tt-rss
// programs and update daemon. Do not try to use CGI binary here, it won't work.
// If you see HTTP headers being displayed while running tt-rss scripts,
// then most probably you are using the CGI binary. If you are unsure what to
// put in here, ask your hosting provider.
5.2 VPS 定时任务
如果您使用的是 VPS 主机,则可以使用 Linux 的定时任务。 TT-RSS不能使用Root运行定时任务,需要使用www运行(一般LNMP环境和BT宝塔面板都是用www运行的):
crontab -u www -e
#每5分钟运行一次,/usr/local/php/bin/php为php命令的绝对路径,根据需要来修改
*/5 * * * * /usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet
当然还有另外一种方式,以root身份登录,然后执行:contab -e 编辑定时任务并添加如下代码:
#指定使用www用户执行定时任务
*/5 * * * * su -m www -c "/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet"
#另
php ./update.php是执行单进程,多进程是 php ./update_daemon2.php。
5.3 任务运行状态
Linux定时任务修改编辑后记得重启定时任务生效。命令如下:
#ubuntu下定时执行工具cron开启关闭重启
#配置文件一般为/etc/init.d/cron
启动:sudo /etc/init.d/cron start
关闭:sudo /etc/init.d/cron stop
重启:sudo /etc/init.d/cron restart
重新载入配置:sudo /etc/init.d/cron reload
#可以用ps aux | grep cron命令查看cron是否已启动
#CentOS重启crontab服务
service crond reload
Linux定时任务是否正常运行,可以手动查看日志。
#查看定时任务日志
#Ubuntn
tail -f /var/log/syslog
#CentOS
tail -f /var/log/cron
会有以下记录:
Sep 28 22:20:01 localhost CRON[15714]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
Sep 28 22:25:01 localhost CRON[15985]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
Sep 28 22:30:01 localhost CRON[16177]: (www) CMD (/usr/local/php/bin/php /data/wwwroot/rss.ucblog.net/update.php --feeds --quiet)
六、Summary
Tiny Tiny RSS在批量导入Feed和设置定时任务时总会遇到一些莫名其妙的错误。比如数据库会报错:Uncaught PDOException: SQLSTATE[HY000] [1045] Access denied for user or MySQL connection not working: 2002 No such file or directory.
另外,手动检查并运行Tiny Tiny RSS定时任务时,也出现如下错误:
Tiny Tiny RSS was unable to start properly. This usually means a misconfiguration or an incomplete upgrade.
Please fix errors indicated by the following messages:
* Please don't run this script as root.
* PHP UConverter class is missing, it's provided by the Internationalization (intl) module.
* PHP support for mbstring functions is required but was not found.
You might want to check tt-rss wiki or the forums for more information.
Please search the forums before creating new topic for your question.
错误:请不要以 root 身份运行此脚本。这是一个非常简单的解决方案。您可以使用本文中的 su www 等指定用户运行计划任务。其他错误如 PHP 错误和数据库错误可以在 config 中找到。在php中指定数据库的连接地址和端口,如下:
define('DB_TYPE', 'mysql');
define('DB_HOST', '127.0.0.1');
define('DB_USER', 'wzfou');
define('DB_NAME', 'wzfou.com');
define('DB_PASS', 'qimm');
define('DB_PORT', '3306');
文章From: Diazhan 不,保留所有权利。本站文章除出处外均为作者原创文章,可随意引用,但请注明出处。
谷歌学术实时自动检测并更新SCI-Hub的可用网址链接
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-08-20 21:13
谷歌学术实时自动检测并更新SCI-Hub的可用网址链接
网站主要采集Google Scholar、Google Search、sci-hub网站,自动检测网站的可用性,并自动更新。对于科研、学者、大学生等群体来说是一个比较好的工具。
采集目前可用的谷歌学术,谷歌搜索镜像网站,服务端和客户端双向实时更新,通常有效一半以上。
说明:
(1)以下数据来源于网络,我会权衡网站再推荐给大家,但请注意镜像的具体内容,尤其是镜像收录广告,请谨慎点击。
(2)如果检测链接大部分超时,请刷新网页(或按Ctrl+F5)。请不要在镜像网站上登录谷歌账号,也不要搜索敏感话。
(3)部分网页的界面不是原来的谷歌风格,但是搜索结果都是从谷歌提取出来的,已经验证过了,请放心使用。
谷歌学术
自动实时检测并更新SCI-Hub的可用URL链接。由于网络和区域(学校)限制,并非所有 URL 都可以在您所在的位置访问。通常,一半以上是有效的。
说明:
(1)以下数据来源于网络,我会权衡网站再推荐给大家,但请注意镜像的具体内容,尤其是镜像收录广告,请谨慎点击。
(2)如果检测链接大部分超时,请刷新网页(或按Ctrl+F5)。请不要在镜像网站上登录谷歌账号,也不要搜索敏感话。
(3)部分网页的界面不是原来的谷歌风格,但是搜索结果都是从谷歌提取出来的,已经验证过了,请放心使用。
科学中心 查看全部
谷歌学术实时自动检测并更新SCI-Hub的可用网址链接
网站主要采集Google Scholar、Google Search、sci-hub网站,自动检测网站的可用性,并自动更新。对于科研、学者、大学生等群体来说是一个比较好的工具。
采集目前可用的谷歌学术,谷歌搜索镜像网站,服务端和客户端双向实时更新,通常有效一半以上。
说明:
(1)以下数据来源于网络,我会权衡网站再推荐给大家,但请注意镜像的具体内容,尤其是镜像收录广告,请谨慎点击。
(2)如果检测链接大部分超时,请刷新网页(或按Ctrl+F5)。请不要在镜像网站上登录谷歌账号,也不要搜索敏感话。
(3)部分网页的界面不是原来的谷歌风格,但是搜索结果都是从谷歌提取出来的,已经验证过了,请放心使用。
谷歌学术
自动实时检测并更新SCI-Hub的可用URL链接。由于网络和区域(学校)限制,并非所有 URL 都可以在您所在的位置访问。通常,一半以上是有效的。
说明:
(1)以下数据来源于网络,我会权衡网站再推荐给大家,但请注意镜像的具体内容,尤其是镜像收录广告,请谨慎点击。
(2)如果检测链接大部分超时,请刷新网页(或按Ctrl+F5)。请不要在镜像网站上登录谷歌账号,也不要搜索敏感话。
(3)部分网页的界面不是原来的谷歌风格,但是搜索结果都是从谷歌提取出来的,已经验证过了,请放心使用。
科学中心
百度或者谷歌站长提交网站的具体方法__
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-08-15 03:11
百度或谷歌站长工具有提交网站的功能。虽然是提交xml地图,但是html网站map的重要性不可忽视。
织梦Dedecms可以通过单页或者插件的方式生成html网站地图。该系统还带有 html 地图。本文主要介绍每次发布新的文章都会自动更新html网站map的具体方法:
打开后台管理目录下的task_do.php文件,找到如下代码(约117行):
$GLOBALS['_arclistEnv'] = 'index';
$pv->SetTemplet($tpl);
$pv->SaveToHtml($homeFile);
$pv->Close();
在下面添加:
include_once(DEDEINC."/arc.sgpage.class.php");
$dsql->Execute("ex","Select aid From 'dede_sgpage' ");
$i = 0;
while($row = $dsql->GetArray("ex"))
{
$sg = new sgpage($row['aid']);
$sg->SaveToHtml();
$i++;
};
注意:
如果安装时修改了默认的数据表前缀dede_,那么这个新增代码中的dede_也要相应修改
$dsql->Execute("ex","从'dede_sgpage'选择帮助"); 查看全部
百度或者谷歌站长提交网站的具体方法__
百度或谷歌站长工具有提交网站的功能。虽然是提交xml地图,但是html网站map的重要性不可忽视。
织梦Dedecms可以通过单页或者插件的方式生成html网站地图。该系统还带有 html 地图。本文主要介绍每次发布新的文章都会自动更新html网站map的具体方法:
打开后台管理目录下的task_do.php文件,找到如下代码(约117行):
$GLOBALS['_arclistEnv'] = 'index';
$pv->SetTemplet($tpl);
$pv->SaveToHtml($homeFile);
$pv->Close();
在下面添加:
include_once(DEDEINC."/arc.sgpage.class.php");
$dsql->Execute("ex","Select aid From 'dede_sgpage' ");
$i = 0;
while($row = $dsql->GetArray("ex"))
{
$sg = new sgpage($row['aid']);
$sg->SaveToHtml();
$i++;
};
注意:
如果安装时修改了默认的数据表前缀dede_,那么这个新增代码中的dede_也要相应修改
$dsql->Execute("ex","从'dede_sgpage'选择帮助");
网站内容自动更新检测、自动定位页面结构(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-12 06:04
网站内容自动更新检测、自动定位页面结构自动调整检测、自动更新时间?自动创建表单?自动更新文本数据?可以,这些都能实现。但是,你觉得就一篇内容靠这些很快就能完成吗?答案是:no,有点慢!首先,在做任何产品或者服务定位的时候都会考虑一个关键点:看向用户,然后分析用户实际搜索这个页面时的更新心理模式,然后考虑写文章,设计者应该站在用户的角度想怎么去撰写,来达到你目标用户的高度体验感。
我们曾经见过一个博客从头到尾基本上没有更新内容,就是发布文章,那是一种什么样的情况?而我们的任务是要把它写好写优质,并且保证,用户能够理解你为什么要写它。所以,我们的任务就包括两个方面:。
1、语义
2、思想如上图所示,在这段文字的读者心理,基本上是这样的一个思维模式:首先,如果接受你的标题是“做一个实用型博客”的话,他们肯定很清楚这是一个什么概念。接下来,他们基本上愿意去读你的文章,因为他有自己的思想,和我有相同想法的人多,这让他对这篇文章感兴趣。但是,在读完你文章的一段后,他并不敢说这篇文章和他的所有想法一致,但他会继续去看你的后续文章,因为“我不相信你说的,所以我来确认你说的”。
你所做的内容,让他在写第二篇文章的时候可以有更好的机会去继续阅读。首先来看的是,内容的语义分析。其次,思想的打磨检查。所以,这篇文章必须被记录下来,这篇文章需要写完之后,对用户的操作进行分析。
重点来看两个方面:
1、操作回路分析用户操作回路分析是文章的第一步,也是当你在写文章前必须要做的工作,因为用户实际上是通过一个个点来操作你的内容,而非知乎那样由无穷无尽的内容组成。
2、交互改进分析最后才是文章的写作,需要在一开始就优化,并且最好是能够达到用户无需检查,就知道这篇文章是否可以看的程度。emmm,时间有点赶。大家有想法,就说出来,一起讨论下。 查看全部
网站内容自动更新检测、自动定位页面结构(组图)
网站内容自动更新检测、自动定位页面结构自动调整检测、自动更新时间?自动创建表单?自动更新文本数据?可以,这些都能实现。但是,你觉得就一篇内容靠这些很快就能完成吗?答案是:no,有点慢!首先,在做任何产品或者服务定位的时候都会考虑一个关键点:看向用户,然后分析用户实际搜索这个页面时的更新心理模式,然后考虑写文章,设计者应该站在用户的角度想怎么去撰写,来达到你目标用户的高度体验感。
我们曾经见过一个博客从头到尾基本上没有更新内容,就是发布文章,那是一种什么样的情况?而我们的任务是要把它写好写优质,并且保证,用户能够理解你为什么要写它。所以,我们的任务就包括两个方面:。
1、语义
2、思想如上图所示,在这段文字的读者心理,基本上是这样的一个思维模式:首先,如果接受你的标题是“做一个实用型博客”的话,他们肯定很清楚这是一个什么概念。接下来,他们基本上愿意去读你的文章,因为他有自己的思想,和我有相同想法的人多,这让他对这篇文章感兴趣。但是,在读完你文章的一段后,他并不敢说这篇文章和他的所有想法一致,但他会继续去看你的后续文章,因为“我不相信你说的,所以我来确认你说的”。
你所做的内容,让他在写第二篇文章的时候可以有更好的机会去继续阅读。首先来看的是,内容的语义分析。其次,思想的打磨检查。所以,这篇文章必须被记录下来,这篇文章需要写完之后,对用户的操作进行分析。
重点来看两个方面:
1、操作回路分析用户操作回路分析是文章的第一步,也是当你在写文章前必须要做的工作,因为用户实际上是通过一个个点来操作你的内容,而非知乎那样由无穷无尽的内容组成。
2、交互改进分析最后才是文章的写作,需要在一开始就优化,并且最好是能够达到用户无需检查,就知道这篇文章是否可以看的程度。emmm,时间有点赶。大家有想法,就说出来,一起讨论下。
雇佣专业人士举行网站内容的编排可以有助于使网站页面看上去
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-10 23:09
聘请专业人士。并不是所有的人都有非常专业的笔和墨技能。聘请专业人士来组织网站 内容有助于使网站 页面清晰、简单且内容一致。
如果网站内容很老,长时间没有更新,很难翻身享受观众,更别提留住观众了。
搜索引擎想要什么,就给它什么。搜索引擎对收录页面有一套规则,应该阅读,这样优化是朝着搜索引擎的认知原则,让网站被收录成为最快最有用的要领。然后,我们需要根据搜索引擎的需求创建一个网站map,并提供一个位置导航地图,不仅让用户体验更好,而且让搜索引擎的支柱更准确,加载速度更快并记录网站相关内容,有助于提高网页的PR值。
把你的网站信推广给你的朋友,在相关论坛上阅读很多,并做出很多回应(记住,在签名文件中放一个网站链接)。
用一个容易记住的网址来处理一个有吸引力的、容易记住的网址是不可替代的。
链接到其他网站使网站链接到其他相关链接网站对于提升公关价值非常重要。
选择最合适的关键词句,适当传播关键词。它不需要限于一个词或一个字符。事实上,情况并非如此。关键字和句子的使用将使您能够更好地将内容与目标客户群保持一致。在构建页面内容时,确保你用来引导浏览者登录你的网站的关键词出现在第一句中,这就是搜索引擎在搜索效果中显示的内容。
网站construction,网络推广公司-创新互联网,是网站专注品牌和效果的生产、网络营销seo公司;服务项目完成网站等 查看全部
雇佣专业人士举行网站内容的编排可以有助于使网站页面看上去
聘请专业人士。并不是所有的人都有非常专业的笔和墨技能。聘请专业人士来组织网站 内容有助于使网站 页面清晰、简单且内容一致。
如果网站内容很老,长时间没有更新,很难翻身享受观众,更别提留住观众了。
搜索引擎想要什么,就给它什么。搜索引擎对收录页面有一套规则,应该阅读,这样优化是朝着搜索引擎的认知原则,让网站被收录成为最快最有用的要领。然后,我们需要根据搜索引擎的需求创建一个网站map,并提供一个位置导航地图,不仅让用户体验更好,而且让搜索引擎的支柱更准确,加载速度更快并记录网站相关内容,有助于提高网页的PR值。
把你的网站信推广给你的朋友,在相关论坛上阅读很多,并做出很多回应(记住,在签名文件中放一个网站链接)。
用一个容易记住的网址来处理一个有吸引力的、容易记住的网址是不可替代的。
链接到其他网站使网站链接到其他相关链接网站对于提升公关价值非常重要。
选择最合适的关键词句,适当传播关键词。它不需要限于一个词或一个字符。事实上,情况并非如此。关键字和句子的使用将使您能够更好地将内容与目标客户群保持一致。在构建页面内容时,确保你用来引导浏览者登录你的网站的关键词出现在第一句中,这就是搜索引擎在搜索效果中显示的内容。
网站construction,网络推广公司-创新互联网,是网站专注品牌和效果的生产、网络营销seo公司;服务项目完成网站等
每天更新网站真的是太累人了,怎么办?
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-06 22:12
如何让你的网站每天自动更新?相信很多刚开始网站的站长朋友都有这种感觉。每天更新网站真的很累。如果你想增加你的网站的权重,你必须每天更新网站,而且你不能一次更新几天文章,因为这仍然是从同一天发布的搜索引擎。它对网站 的权重没有影响。有没有办法让网站 自动更新?大家都知道频繁更新网站的重要性,搜索引擎喜欢新鲜的内容,如果你的网站长时间不更新,排名就会下降,最坏的就是k。好了,废话不多说,先介绍一下网站自动更新的思路。这里提到的老站不仅仅指网站,已经建了很久了。这样的网站不仅有一定的权重,而且有一定的流量。这种网站的自动更新,可以让用户创建内容,实现自动更新。 ,比如论坛、留言板等等。大多数新站呢?二、新站这里的新站一般都很快上线,没有重量也没有流量。这是一个想法。以()为例,看下图: 它的自动更新方式是为网站添加一个访问者信息,包括用户的访问时间(包括任何搜索引擎蜘蛛)、IP地址、操作系统、浏览设备信息等。此信息不再重复。用户只要访问网站,这条信息就会自动更新,实现网站的滚动更新。通过这种方式,很多新站在短时间内提升了权重和排名。
现在贴出获取访客信息的代码(ASP 1,以下代码是将访客信息写入数据库。dim lailuUrl lailuUrl=Request.ServerVariables("Http_Referer")else lailuUrl="直接从地址栏输入" end Getip =Request.ServerVariables("REMOTE_ADDR")set rsonline server.CreateObject("adodb.recordset") sql="select from[online] where ip='"&Getip&"' rsonline.Opensql,Conn,1,3 rsonline. addnewrsonline( "browser")=Request.ServerVariables("HTTP_USER_AGENT") rsonline("ip")=Getip rsonline("startTime")=now() rsonline("lailu")=lailuUrl rsonline("dates")=Date( ) rsonline .update rsonline.close 结束函数usersysinfo(info,getinfo) dimusersys usersys=split(info,";") usersys(1)=replace(usersys(1),"MSIE","InternetExplorer") usersys(2) =replace(usersys(2),")","") usersys(2)=replace(usersys(2),"NT 5.2","2003") usersys(2)=替换( usersys(2),"NT 5.1","XP") usersys(2)=replace(usersys(2),"NT 5.0","2000") usersys(2)= 替换e(usersys(2),"NT 6.1","7") usersys(2)=replace(usersys(2),"9x","Me") usersys(1)= Trim( usersys(1)) usersys(采集器3@= Trim(usersys(2)) usersysinfo=usersys(1)else usersysinfo=usersys(2) end else usersysinfo="未elseusersysinfo="不是endfunction 2,读输出信息并显示在网页上 访客信息: 代码说明:新建一个名为online的表,并创建如下字段: browser字段:用于记录访客客户端信息,如浏览器、操作系统等。 ip字段:记录用户的ip地址。 startTime 字段:记录访问时间。 lailu 字段:记录来源,即它来自的 URL。日期字段:记录日期。另外,usersysinfo函数用于读取浏览器字段信息。 查看全部
每天更新网站真的是太累人了,怎么办?
如何让你的网站每天自动更新?相信很多刚开始网站的站长朋友都有这种感觉。每天更新网站真的很累。如果你想增加你的网站的权重,你必须每天更新网站,而且你不能一次更新几天文章,因为这仍然是从同一天发布的搜索引擎。它对网站 的权重没有影响。有没有办法让网站 自动更新?大家都知道频繁更新网站的重要性,搜索引擎喜欢新鲜的内容,如果你的网站长时间不更新,排名就会下降,最坏的就是k。好了,废话不多说,先介绍一下网站自动更新的思路。这里提到的老站不仅仅指网站,已经建了很久了。这样的网站不仅有一定的权重,而且有一定的流量。这种网站的自动更新,可以让用户创建内容,实现自动更新。 ,比如论坛、留言板等等。大多数新站呢?二、新站这里的新站一般都很快上线,没有重量也没有流量。这是一个想法。以()为例,看下图: 它的自动更新方式是为网站添加一个访问者信息,包括用户的访问时间(包括任何搜索引擎蜘蛛)、IP地址、操作系统、浏览设备信息等。此信息不再重复。用户只要访问网站,这条信息就会自动更新,实现网站的滚动更新。通过这种方式,很多新站在短时间内提升了权重和排名。
现在贴出获取访客信息的代码(ASP 1,以下代码是将访客信息写入数据库。dim lailuUrl lailuUrl=Request.ServerVariables("Http_Referer")else lailuUrl="直接从地址栏输入" end Getip =Request.ServerVariables("REMOTE_ADDR")set rsonline server.CreateObject("adodb.recordset") sql="select from[online] where ip='"&Getip&"' rsonline.Opensql,Conn,1,3 rsonline. addnewrsonline( "browser")=Request.ServerVariables("HTTP_USER_AGENT") rsonline("ip")=Getip rsonline("startTime")=now() rsonline("lailu")=lailuUrl rsonline("dates")=Date( ) rsonline .update rsonline.close 结束函数usersysinfo(info,getinfo) dimusersys usersys=split(info,";") usersys(1)=replace(usersys(1),"MSIE","InternetExplorer") usersys(2) =replace(usersys(2),")","") usersys(2)=replace(usersys(2),"NT 5.2","2003") usersys(2)=替换( usersys(2),"NT 5.1","XP") usersys(2)=replace(usersys(2),"NT 5.0","2000") usersys(2)= 替换e(usersys(2),"NT 6.1","7") usersys(2)=replace(usersys(2),"9x","Me") usersys(1)= Trim( usersys(1)) usersys(采集器3@= Trim(usersys(2)) usersysinfo=usersys(1)else usersysinfo=usersys(2) end else usersysinfo="未elseusersysinfo="不是endfunction 2,读输出信息并显示在网页上 访客信息: 代码说明:新建一个名为online的表,并创建如下字段: browser字段:用于记录访客客户端信息,如浏览器、操作系统等。 ip字段:记录用户的ip地址。 startTime 字段:记录访问时间。 lailu 字段:记录来源,即它来自的 URL。日期字段:记录日期。另外,usersysinfo函数用于读取浏览器字段信息。
页数14字数7937摘要多线程自动下载并自动更新内部网站
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-04 02:25
页数14字数7937摘要多线程自动下载并自动更新内部网站
多线程自动下载远程网站和内部站点自动更新
页数 14 字 7937
总结
多线程自动下载自动更新内部网站是一个多元化的站点更新系统,在互联网飞速发展的今天起到了极其重要的作用,从效益和经济角度来说,它的价值不容小觑本文首先介绍了整个系统,大致介绍了自动下载软件的使用,重点是“自动更新”。怎样才能达到自动更新的目的?这正是系统的核心技术。因此,我们详细讨论了拦截指定列中的文件(包括html、asp、php、jsp.shtml等)和过滤掉不必要的垃圾邮件。 ,并用截取的标题和内容替换已有的模板得到更新后的文件,然后将相关信息写入数据库,再通过ASP访问数据库获取文件的实际URL路径,通过更新连接浏览器可以更新到更新的文件。最后讨论了系统的问题。
关键字截取、替换、参数传递、分页
内容
1 简介…………………………………………………………………………4
2 系统组织原则………………………………………………4
3 程序设计过程……………………………………………………5
4 用VB实现下载文件的截取和替换…………………………6
4.1 数据库相关……………………………………………………6
4.2 VB文件操作和日期格式化………………………………6
4.3 索引的建立………………………………………………6
4.4任务编辑器……………………………………………………7
4.5 标题和正文的截取和替换...8
5 使用ASP调用数据库更新内部站点…………………………9
5.1 ASP 调用 SQL Sever2000 ………………………………10
5.2 ASP分页处理方法…………………………………………11
5.3 查询处理…………………………………………12
5.4 ASP中参数传递的漏洞及解决方法……………………13
6 系统问题分析及解决方案……………………13
7 总结…………………………………………………………14
参考资料
[1] 刘涛,罗娟,何旭红。 Visual Basic6.0 数据库系统开发实例导航,北京;人民邮电出版社,2003年2月
[2] 龚培增,卢伟民,杨志强。 Visual Basic 程序设计课程(6.0 版),北京;高等教育出版社,2001 年 12 月
[3] 博佳科技,刘洪海。 Web数据库开发实战ASP电子商务,北京;中国铁道出版社,2002年4月 查看全部
页数14字数7937摘要多线程自动下载并自动更新内部网站
多线程自动下载远程网站和内部站点自动更新
页数 14 字 7937
总结
多线程自动下载自动更新内部网站是一个多元化的站点更新系统,在互联网飞速发展的今天起到了极其重要的作用,从效益和经济角度来说,它的价值不容小觑本文首先介绍了整个系统,大致介绍了自动下载软件的使用,重点是“自动更新”。怎样才能达到自动更新的目的?这正是系统的核心技术。因此,我们详细讨论了拦截指定列中的文件(包括html、asp、php、jsp.shtml等)和过滤掉不必要的垃圾邮件。 ,并用截取的标题和内容替换已有的模板得到更新后的文件,然后将相关信息写入数据库,再通过ASP访问数据库获取文件的实际URL路径,通过更新连接浏览器可以更新到更新的文件。最后讨论了系统的问题。
关键字截取、替换、参数传递、分页
内容
1 简介…………………………………………………………………………4
2 系统组织原则………………………………………………4
3 程序设计过程……………………………………………………5
4 用VB实现下载文件的截取和替换…………………………6
4.1 数据库相关……………………………………………………6
4.2 VB文件操作和日期格式化………………………………6
4.3 索引的建立………………………………………………6
4.4任务编辑器……………………………………………………7
4.5 标题和正文的截取和替换...8
5 使用ASP调用数据库更新内部站点…………………………9
5.1 ASP 调用 SQL Sever2000 ………………………………10
5.2 ASP分页处理方法…………………………………………11
5.3 查询处理…………………………………………12
5.4 ASP中参数传递的漏洞及解决方法……………………13
6 系统问题分析及解决方案……………………13
7 总结…………………………………………………………14
参考资料
[1] 刘涛,罗娟,何旭红。 Visual Basic6.0 数据库系统开发实例导航,北京;人民邮电出版社,2003年2月
[2] 龚培增,卢伟民,杨志强。 Visual Basic 程序设计课程(6.0 版),北京;高等教育出版社,2001 年 12 月
[3] 博佳科技,刘洪海。 Web数据库开发实战ASP电子商务,北京;中国铁道出版社,2002年4月
如何利用好搜索引擎来制定相应的自动更新策略?
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-02 03:04
网站内容自动更新,大家常用的方法有两种:seo自动更新(伪原创)和工具自动更新(自动采集)。seo自动更新,这个得涉及到dom相关的问题,那么接下来我们就来看一下,如何利用好搜索引擎来制定相应的相关的自动更新策略。首先想说的是:seo自动更新就需要对搜索引擎的算法略知一二。才能有自己的自动更新策略。今天先讲解百度搜索算法相关的内容。搜索引擎的首页搜索推荐及其关联指向多种算法与策略:。
1)首页搜索推荐算法
2)关联指向算法
3)收录策略
4)内容策略
5)相关性策略
6)来源策略算法与策略1:关联指向算法搜索关联算法,指的是与关键词的关联性。搜索引擎将关键词与搜索结果按关联性划分为两类。一类是与关键词相关性较强,与其他网站有必然联系,可以起到更高的相关性。另一类是与关键词无关,不起到有效相关,可以说是搜索无关关键词,搜索引擎会主要为该关键词生成相关词目录,占有绝对优势。
当一个关键词网页的收录权重太低时,搜索引擎会优先将收录的相关页进行分享,从而提高网页的权重,因此会出现多个相关页的现象。如何判断该词与哪个搜索网站有关系?尽量从用户搜索需求出发,去寻找与网站相关性较强的关键词。当然,收录了也会进行下一步分享。搜索该关键词可以得到哪些网站源。收录的网站源也就是这个词语的源头网站。
也就是说,将该页面整理出来。或者是网站源头网站整理成电子文档,再转给搜索引擎。2:首页搜索推荐算法百度搜索的自动更新最核心的是关联性,搜索引擎给你关联关键词或者与这个关键词相关的词目录。另外要判断该关键词与哪个搜索网站有关系,判断关联网站指的是指出与搜索引擎存在关联的网站。这个实际上就是关键词排序,也就是我们说的该关键词与搜索结果中排名第一位置网站之间的关系。
目前,主要的网站排序算法有四种:seo自动排序、自动分发权重、网页分发策略和点击率,五大相关键词排序算法。搜索引擎通过这几种相关关键词排序算法,获取一批与自己网站关联的热门网站。这些网站可以说对我们网站建设有很大的帮助。在做自动更新的时候,可以判断网站是否与我们相关的关键词存在关联。在保持网站关联性的情况下,这些网站可以进行分发权重。
给网站建设带来直接的搜索流量和pv。网站权重高的网站有力地支持了我们网站的排名靠前,进而带来更多的流量,让我们的网站更受欢迎。3:收录策略收录策略是指在对网站进行有效描述和补充信息,使其满足用户搜索需求的方法。是网站建设中常见的影响用户搜索习惯的措施。收录策略可以分为两种情况:手动收。 查看全部
如何利用好搜索引擎来制定相应的自动更新策略?
网站内容自动更新,大家常用的方法有两种:seo自动更新(伪原创)和工具自动更新(自动采集)。seo自动更新,这个得涉及到dom相关的问题,那么接下来我们就来看一下,如何利用好搜索引擎来制定相应的相关的自动更新策略。首先想说的是:seo自动更新就需要对搜索引擎的算法略知一二。才能有自己的自动更新策略。今天先讲解百度搜索算法相关的内容。搜索引擎的首页搜索推荐及其关联指向多种算法与策略:。
1)首页搜索推荐算法
2)关联指向算法
3)收录策略
4)内容策略
5)相关性策略
6)来源策略算法与策略1:关联指向算法搜索关联算法,指的是与关键词的关联性。搜索引擎将关键词与搜索结果按关联性划分为两类。一类是与关键词相关性较强,与其他网站有必然联系,可以起到更高的相关性。另一类是与关键词无关,不起到有效相关,可以说是搜索无关关键词,搜索引擎会主要为该关键词生成相关词目录,占有绝对优势。
当一个关键词网页的收录权重太低时,搜索引擎会优先将收录的相关页进行分享,从而提高网页的权重,因此会出现多个相关页的现象。如何判断该词与哪个搜索网站有关系?尽量从用户搜索需求出发,去寻找与网站相关性较强的关键词。当然,收录了也会进行下一步分享。搜索该关键词可以得到哪些网站源。收录的网站源也就是这个词语的源头网站。
也就是说,将该页面整理出来。或者是网站源头网站整理成电子文档,再转给搜索引擎。2:首页搜索推荐算法百度搜索的自动更新最核心的是关联性,搜索引擎给你关联关键词或者与这个关键词相关的词目录。另外要判断该关键词与哪个搜索网站有关系,判断关联网站指的是指出与搜索引擎存在关联的网站。这个实际上就是关键词排序,也就是我们说的该关键词与搜索结果中排名第一位置网站之间的关系。
目前,主要的网站排序算法有四种:seo自动排序、自动分发权重、网页分发策略和点击率,五大相关键词排序算法。搜索引擎通过这几种相关关键词排序算法,获取一批与自己网站关联的热门网站。这些网站可以说对我们网站建设有很大的帮助。在做自动更新的时候,可以判断网站是否与我们相关的关键词存在关联。在保持网站关联性的情况下,这些网站可以进行分发权重。
给网站建设带来直接的搜索流量和pv。网站权重高的网站有力地支持了我们网站的排名靠前,进而带来更多的流量,让我们的网站更受欢迎。3:收录策略收录策略是指在对网站进行有效描述和补充信息,使其满足用户搜索需求的方法。是网站建设中常见的影响用户搜索习惯的措施。收录策略可以分为两种情况:手动收。

