
相关性分析
数据剖析 | 基于智能标签,精准管理数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-03 19:03
腾讯:社交广告,不同用户的朋友圈或则其他媒体场景下的广告信息是不同的,会基于用户特点推荐。
头条:信息价值,根据用户浏览信息,分析用户相关喜好,针对剖析结果推荐相关的信息流,越关注某类内容,获取相关的信息越多。
如上几种场景的逻辑就是:基于不断剖析用户的行为,生成用户的特点画像,然后再基于用户标签,定制化的推荐相关内容。
2、基本概念
通过前面的场景,衍生下来两个概念:
用户画像
用户画像,作为一种描绘目标用户、联系用户诉求与设计方向的有效工具,把该用户相关联的数据的可视化的诠释,就产生了用户画像。用户画像在各领域得到了广泛的应用,最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
标签数据
标签在生活中十分常见,比如商品标签,个人标签,行业标签,例如提及996就想到程序员,提到程序员就想到格子衫。
标签是把分散的多方数据进行整合划入统一的技术平台,并对那些数据进行标准化和细分,进行结构化储存和更新管理,让业务线可以把这种细分结果推向现有的互动营销环境里的平台,产生价值,这些数据称为标签数据,也就是常说的标签库。数据标签的概念也是在近来几年大数据的发展中不断火爆上去的。
标签价值
标签的核心价值,或者说最常用的场景:实时智能推荐,精准化数字营销。
二、数据标签1、标签界定
属性标签
属性标签是变化最小的,例如用户实名认证以后,基于身分信息获取相关:性别,生日,出生年月,年龄,等相关标签。变动频度小,且最具有精准性。
行为标签
行为标签就是用户通过在产品上的一系列操作,基于行为日志剖析得出:例如订购能力、消费爱好、季节性消费标签等。在信息流的APP上,通过相关浏览行为,不断推荐用户感兴趣的内容就是基于该逻辑。
规则标签
根据业务场景需求,配置指定规则,基于规则生成剖析结果,例如:
这类标签可以基于动态的规则配置,经过估算和剖析,生成描述结果,也就是规则标签。
拟合标签
拟合类的标签最具有复杂性,通过用户上述几种标签,智能组合剖析,给的预测值,例如:未婚、浏览相关婚宴内容,通过剖析预测用户即将举行婚宴,得到一个拟合结果:预测即将订婚。这个预测逻辑也可以反向执行,用户订购小孩用具:预测未婚已育。
这就是数据时代常说的一句话:用户在某个应用上一通操作过后,算法剖析的结果可能比用户对自己的描述还要真实。
2、标签加工流程
数据采集
数据采集的渠道相对较多,比如同一APP内的各类业务线:购物、支付、理财、外卖、信息浏览等等。通过数据通道传输到统一的数据聚合平台。有了这种海量日志数据的支撑,才具有数据剖析的基础条件。不管是数据智能,深度学习,算法等都是构建在海量数据的基础条件上,这样就能获取具有价值的剖析结果。
数据加工
结合如上业务,通过对海量数据的加工,分析和提取,获取相对精准的用户标签,这里还有关键的一步,就是对已有的用户标签进行不断的验证和修补,尤其是规则类和拟合类的相关标签。
标签库
通过标签库,管理复杂的标签结果,除了复杂的标签,和基于时间线的标签变,标签数据到这儿,已经具有相当大的价值,可以围绕标签库开放一些收费服务,例如常见的,用户在某电商APP浏览个别商品,可以在某信息流平台见到商品推荐。大数据时代就是如此令人觉得智能和窒息。
标签业务
数据走了一大圈转换成标签,自然还是要回归到业务层面,通过对标签数据的用户的剖析,可以进行精准营销,和智能推荐等相关操作,电商应用中可以提升成交量,信息流中可以更好的吸引用户。
应用层
把上述业务开发成服务,集成到具有的应用层面,不断提高应用服务的质量,不断的吸引用户,提供服务。当然用户的数据不断在应用层面形成,在转入数据采集服务中,最终产生完整的闭环流程。
3、应用案例
从流程和业务层面描述都是简单的,到开发层面就会显得复杂和不好处理,这可能就是产品和开发之间的芥蒂。
标签的数据类型
不同标签的剖析结果须要用不同的数据类型描述智能标签采集器,在标签体系中,常用描述标签的数据类型如下:枚举、数值、日期、布尔、文本类型。不同的类型须要不一样的剖析流程。
商品和标签
这里提供一个基础案例,用商品的标签来剖析商品,例如通过商品产地,价格,状态等条件,来查询产品库有多少符合条件的商品。
数据表设计
主要分四张表:标签分类智能标签采集器,标签库,标签值,标签数据。
CREATE TABLE `tc_tag_catalog` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '名称',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签层级目录';
CREATE TABLE `tc_tag_cloud` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_id` INT (11) NOT NULL COMMENT '目录ID',
`tag_name` VARCHAR (100) DEFAULT '' COMMENT '标签名称',
`tag_code` INT (11) DEFAULT NULL COMMENT '标签编码',
`bind_column` VARCHAR (100) DEFAULT '' COMMENT '绑定数据列',
`data_type` INT (2) NOT NULL COMMENT '1枚举,2数值,3日期,4布尔,5值类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR (150) DEFAULT NULL COMMENT '备注',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签云';
CREATE TABLE `tc_tag_data_enum` (
`tag_code` INT (11) NOT NULL COMMENT '标签编码',
`data_value` VARCHAR (150) NOT NULL COMMENT '枚举值',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
KEY `tag_code_index` (`tag_code`) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签枚举值';
CREATE TABLE `tc_tag_data_set` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`product_name` VARCHAR (100) DEFAULT '' COMMENT '商品名称',
`unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT '单价',
`is_shelves` INT (1) DEFAULT '1' COMMENT '是否上架:1否,2是',
`origin_place` VARCHAR (100) DEFAULT '' COMMENT '产地',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签数据集';
模拟入参插口
这里的参数应当是基于需求,动态选定,进行组织到一起:
例如图片中这儿给定的标签值列表,称为枚举值。
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List tagParamList = new ArrayList() ;
TagParam tagParam1 = new TagParam(1,"产地","origin_place") ;
List valueList1 = new ArrayList() ;
valueList1.add("深圳");
valueList1.add("广东");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"价格","unit_price") ;
List valueList2 = new ArrayList() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"生产日期","create_time") ;
List valueList3 = new ArrayList() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"是否上架","is_shelves") ;
List valueList4 = new ArrayList() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"产品名称","product_name") ;
List valueList5 = new ArrayList() ;
valueList5.add("智能");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result:" + count ;
}
}
参数解析查询
通过对参数的解析,最终产生查询的SQL句子,获取精准的结果数据。
@Service
public class TagDataSetServiceImpl extends ServiceImpl implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1枚举,2数值,3日期,4布尔,5值类型
List valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* 最终执行的 SQL
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('深圳', '广东')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%智能%'
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
可能有人会说这不就是个查询流程吗?如果有这样的疑惑,把上述案例换成用户查询,标签数据的价值会更直观。
三、智能画像1、基本概念
用户画像
作为一种绘制目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
行业画像
通过行业属性标签,行业下用户标签的综合剖析,生成行业剖析报告,提供极有价值的导向,这是最近两年非常热门的应用。
画像补全
通过不断剖析用户数据,丰富标签库,使用户的画像愈发丰富立体。
2、画像报告
通过标签数据的剖析,生成一份剖析报告,报告内容包含丰富的用户标签统计数据。
例如:90后画像报告
这个报告,互联网用户一定或多或少都听到过。主要是一些标签统计,共性标签展示,或者什么群体对80后三观影响最大,收入来源,学历等各类剖析评析。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent 查看全部
头条:信息价值,根据用户浏览信息,分析用户相关喜好,针对剖析结果推荐相关的信息流,越关注某类内容,获取相关的信息越多。
如上几种场景的逻辑就是:基于不断剖析用户的行为,生成用户的特点画像,然后再基于用户标签,定制化的推荐相关内容。
2、基本概念
通过前面的场景,衍生下来两个概念:
用户画像
用户画像,作为一种描绘目标用户、联系用户诉求与设计方向的有效工具,把该用户相关联的数据的可视化的诠释,就产生了用户画像。用户画像在各领域得到了广泛的应用,最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
标签数据
标签在生活中十分常见,比如商品标签,个人标签,行业标签,例如提及996就想到程序员,提到程序员就想到格子衫。
标签是把分散的多方数据进行整合划入统一的技术平台,并对那些数据进行标准化和细分,进行结构化储存和更新管理,让业务线可以把这种细分结果推向现有的互动营销环境里的平台,产生价值,这些数据称为标签数据,也就是常说的标签库。数据标签的概念也是在近来几年大数据的发展中不断火爆上去的。
标签价值
标签的核心价值,或者说最常用的场景:实时智能推荐,精准化数字营销。
二、数据标签1、标签界定
属性标签
属性标签是变化最小的,例如用户实名认证以后,基于身分信息获取相关:性别,生日,出生年月,年龄,等相关标签。变动频度小,且最具有精准性。
行为标签
行为标签就是用户通过在产品上的一系列操作,基于行为日志剖析得出:例如订购能力、消费爱好、季节性消费标签等。在信息流的APP上,通过相关浏览行为,不断推荐用户感兴趣的内容就是基于该逻辑。
规则标签
根据业务场景需求,配置指定规则,基于规则生成剖析结果,例如:
这类标签可以基于动态的规则配置,经过估算和剖析,生成描述结果,也就是规则标签。
拟合标签
拟合类的标签最具有复杂性,通过用户上述几种标签,智能组合剖析,给的预测值,例如:未婚、浏览相关婚宴内容,通过剖析预测用户即将举行婚宴,得到一个拟合结果:预测即将订婚。这个预测逻辑也可以反向执行,用户订购小孩用具:预测未婚已育。
这就是数据时代常说的一句话:用户在某个应用上一通操作过后,算法剖析的结果可能比用户对自己的描述还要真实。
2、标签加工流程
数据采集
数据采集的渠道相对较多,比如同一APP内的各类业务线:购物、支付、理财、外卖、信息浏览等等。通过数据通道传输到统一的数据聚合平台。有了这种海量日志数据的支撑,才具有数据剖析的基础条件。不管是数据智能,深度学习,算法等都是构建在海量数据的基础条件上,这样就能获取具有价值的剖析结果。
数据加工
结合如上业务,通过对海量数据的加工,分析和提取,获取相对精准的用户标签,这里还有关键的一步,就是对已有的用户标签进行不断的验证和修补,尤其是规则类和拟合类的相关标签。
标签库
通过标签库,管理复杂的标签结果,除了复杂的标签,和基于时间线的标签变,标签数据到这儿,已经具有相当大的价值,可以围绕标签库开放一些收费服务,例如常见的,用户在某电商APP浏览个别商品,可以在某信息流平台见到商品推荐。大数据时代就是如此令人觉得智能和窒息。
标签业务
数据走了一大圈转换成标签,自然还是要回归到业务层面,通过对标签数据的用户的剖析,可以进行精准营销,和智能推荐等相关操作,电商应用中可以提升成交量,信息流中可以更好的吸引用户。
应用层
把上述业务开发成服务,集成到具有的应用层面,不断提高应用服务的质量,不断的吸引用户,提供服务。当然用户的数据不断在应用层面形成,在转入数据采集服务中,最终产生完整的闭环流程。
3、应用案例
从流程和业务层面描述都是简单的,到开发层面就会显得复杂和不好处理,这可能就是产品和开发之间的芥蒂。
标签的数据类型
不同标签的剖析结果须要用不同的数据类型描述智能标签采集器,在标签体系中,常用描述标签的数据类型如下:枚举、数值、日期、布尔、文本类型。不同的类型须要不一样的剖析流程。
商品和标签
这里提供一个基础案例,用商品的标签来剖析商品,例如通过商品产地,价格,状态等条件,来查询产品库有多少符合条件的商品。
数据表设计
主要分四张表:标签分类智能标签采集器,标签库,标签值,标签数据。
CREATE TABLE `tc_tag_catalog` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '名称',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签层级目录';
CREATE TABLE `tc_tag_cloud` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_id` INT (11) NOT NULL COMMENT '目录ID',
`tag_name` VARCHAR (100) DEFAULT '' COMMENT '标签名称',
`tag_code` INT (11) DEFAULT NULL COMMENT '标签编码',
`bind_column` VARCHAR (100) DEFAULT '' COMMENT '绑定数据列',
`data_type` INT (2) NOT NULL COMMENT '1枚举,2数值,3日期,4布尔,5值类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR (150) DEFAULT NULL COMMENT '备注',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签云';
CREATE TABLE `tc_tag_data_enum` (
`tag_code` INT (11) NOT NULL COMMENT '标签编码',
`data_value` VARCHAR (150) NOT NULL COMMENT '枚举值',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
KEY `tag_code_index` (`tag_code`) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签枚举值';
CREATE TABLE `tc_tag_data_set` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`product_name` VARCHAR (100) DEFAULT '' COMMENT '商品名称',
`unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT '单价',
`is_shelves` INT (1) DEFAULT '1' COMMENT '是否上架:1否,2是',
`origin_place` VARCHAR (100) DEFAULT '' COMMENT '产地',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签数据集';
模拟入参插口
这里的参数应当是基于需求,动态选定,进行组织到一起:
例如图片中这儿给定的标签值列表,称为枚举值。
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List tagParamList = new ArrayList() ;
TagParam tagParam1 = new TagParam(1,"产地","origin_place") ;
List valueList1 = new ArrayList() ;
valueList1.add("深圳");
valueList1.add("广东");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"价格","unit_price") ;
List valueList2 = new ArrayList() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"生产日期","create_time") ;
List valueList3 = new ArrayList() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"是否上架","is_shelves") ;
List valueList4 = new ArrayList() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"产品名称","product_name") ;
List valueList5 = new ArrayList() ;
valueList5.add("智能");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result:" + count ;
}
}
参数解析查询
通过对参数的解析,最终产生查询的SQL句子,获取精准的结果数据。
@Service
public class TagDataSetServiceImpl extends ServiceImpl implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1枚举,2数值,3日期,4布尔,5值类型
List valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* 最终执行的 SQL
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('深圳', '广东')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%智能%'
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
可能有人会说这不就是个查询流程吗?如果有这样的疑惑,把上述案例换成用户查询,标签数据的价值会更直观。
三、智能画像1、基本概念
用户画像
作为一种绘制目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
行业画像
通过行业属性标签,行业下用户标签的综合剖析,生成行业剖析报告,提供极有价值的导向,这是最近两年非常热门的应用。
画像补全
通过不断剖析用户数据,丰富标签库,使用户的画像愈发丰富立体。
2、画像报告
通过标签数据的剖析,生成一份剖析报告,报告内容包含丰富的用户标签统计数据。
例如:90后画像报告
这个报告,互联网用户一定或多或少都听到过。主要是一些标签统计,共性标签展示,或者什么群体对80后三观影响最大,收入来源,学历等各类剖析评析。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent 查看全部
腾讯:社交广告,不同用户的朋友圈或则其他媒体场景下的广告信息是不同的,会基于用户特点推荐。
头条:信息价值,根据用户浏览信息,分析用户相关喜好,针对剖析结果推荐相关的信息流,越关注某类内容,获取相关的信息越多。
如上几种场景的逻辑就是:基于不断剖析用户的行为,生成用户的特点画像,然后再基于用户标签,定制化的推荐相关内容。
2、基本概念
通过前面的场景,衍生下来两个概念:
用户画像
用户画像,作为一种描绘目标用户、联系用户诉求与设计方向的有效工具,把该用户相关联的数据的可视化的诠释,就产生了用户画像。用户画像在各领域得到了广泛的应用,最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
标签数据
标签在生活中十分常见,比如商品标签,个人标签,行业标签,例如提及996就想到程序员,提到程序员就想到格子衫。
标签是把分散的多方数据进行整合划入统一的技术平台,并对那些数据进行标准化和细分,进行结构化储存和更新管理,让业务线可以把这种细分结果推向现有的互动营销环境里的平台,产生价值,这些数据称为标签数据,也就是常说的标签库。数据标签的概念也是在近来几年大数据的发展中不断火爆上去的。
标签价值
标签的核心价值,或者说最常用的场景:实时智能推荐,精准化数字营销。
二、数据标签1、标签界定
属性标签
属性标签是变化最小的,例如用户实名认证以后,基于身分信息获取相关:性别,生日,出生年月,年龄,等相关标签。变动频度小,且最具有精准性。
行为标签
行为标签就是用户通过在产品上的一系列操作,基于行为日志剖析得出:例如订购能力、消费爱好、季节性消费标签等。在信息流的APP上,通过相关浏览行为,不断推荐用户感兴趣的内容就是基于该逻辑。
规则标签
根据业务场景需求,配置指定规则,基于规则生成剖析结果,例如:
这类标签可以基于动态的规则配置,经过估算和剖析,生成描述结果,也就是规则标签。
拟合标签
拟合类的标签最具有复杂性,通过用户上述几种标签,智能组合剖析,给的预测值,例如:未婚、浏览相关婚宴内容,通过剖析预测用户即将举行婚宴,得到一个拟合结果:预测即将订婚。这个预测逻辑也可以反向执行,用户订购小孩用具:预测未婚已育。
这就是数据时代常说的一句话:用户在某个应用上一通操作过后,算法剖析的结果可能比用户对自己的描述还要真实。
2、标签加工流程

数据采集
数据采集的渠道相对较多,比如同一APP内的各类业务线:购物、支付、理财、外卖、信息浏览等等。通过数据通道传输到统一的数据聚合平台。有了这种海量日志数据的支撑,才具有数据剖析的基础条件。不管是数据智能,深度学习,算法等都是构建在海量数据的基础条件上,这样就能获取具有价值的剖析结果。
数据加工
结合如上业务,通过对海量数据的加工,分析和提取,获取相对精准的用户标签,这里还有关键的一步,就是对已有的用户标签进行不断的验证和修补,尤其是规则类和拟合类的相关标签。
标签库
通过标签库,管理复杂的标签结果,除了复杂的标签,和基于时间线的标签变,标签数据到这儿,已经具有相当大的价值,可以围绕标签库开放一些收费服务,例如常见的,用户在某电商APP浏览个别商品,可以在某信息流平台见到商品推荐。大数据时代就是如此令人觉得智能和窒息。
标签业务
数据走了一大圈转换成标签,自然还是要回归到业务层面,通过对标签数据的用户的剖析,可以进行精准营销,和智能推荐等相关操作,电商应用中可以提升成交量,信息流中可以更好的吸引用户。
应用层
把上述业务开发成服务,集成到具有的应用层面,不断提高应用服务的质量,不断的吸引用户,提供服务。当然用户的数据不断在应用层面形成,在转入数据采集服务中,最终产生完整的闭环流程。
3、应用案例
从流程和业务层面描述都是简单的,到开发层面就会显得复杂和不好处理,这可能就是产品和开发之间的芥蒂。
标签的数据类型
不同标签的剖析结果须要用不同的数据类型描述智能标签采集器,在标签体系中,常用描述标签的数据类型如下:枚举、数值、日期、布尔、文本类型。不同的类型须要不一样的剖析流程。
商品和标签
这里提供一个基础案例,用商品的标签来剖析商品,例如通过商品产地,价格,状态等条件,来查询产品库有多少符合条件的商品。
数据表设计
主要分四张表:标签分类智能标签采集器,标签库,标签值,标签数据。
CREATE TABLE `tc_tag_catalog` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '名称',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签层级目录';
CREATE TABLE `tc_tag_cloud` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_id` INT (11) NOT NULL COMMENT '目录ID',
`tag_name` VARCHAR (100) DEFAULT '' COMMENT '标签名称',
`tag_code` INT (11) DEFAULT NULL COMMENT '标签编码',
`bind_column` VARCHAR (100) DEFAULT '' COMMENT '绑定数据列',
`data_type` INT (2) NOT NULL COMMENT '1枚举,2数值,3日期,4布尔,5值类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR (150) DEFAULT NULL COMMENT '备注',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签云';
CREATE TABLE `tc_tag_data_enum` (
`tag_code` INT (11) NOT NULL COMMENT '标签编码',
`data_value` VARCHAR (150) NOT NULL COMMENT '枚举值',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
KEY `tag_code_index` (`tag_code`) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签枚举值';
CREATE TABLE `tc_tag_data_set` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`product_name` VARCHAR (100) DEFAULT '' COMMENT '商品名称',
`unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT '单价',
`is_shelves` INT (1) DEFAULT '1' COMMENT '是否上架:1否,2是',
`origin_place` VARCHAR (100) DEFAULT '' COMMENT '产地',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签数据集';
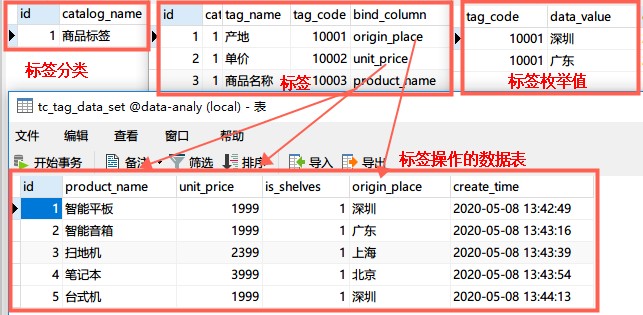
模拟入参插口
这里的参数应当是基于需求,动态选定,进行组织到一起:

例如图片中这儿给定的标签值列表,称为枚举值。
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List tagParamList = new ArrayList() ;
TagParam tagParam1 = new TagParam(1,"产地","origin_place") ;
List valueList1 = new ArrayList() ;
valueList1.add("深圳");
valueList1.add("广东");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"价格","unit_price") ;
List valueList2 = new ArrayList() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"生产日期","create_time") ;
List valueList3 = new ArrayList() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"是否上架","is_shelves") ;
List valueList4 = new ArrayList() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"产品名称","product_name") ;
List valueList5 = new ArrayList() ;
valueList5.add("智能");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result:" + count ;
}
}
参数解析查询
通过对参数的解析,最终产生查询的SQL句子,获取精准的结果数据。
@Service
public class TagDataSetServiceImpl extends ServiceImpl implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1枚举,2数值,3日期,4布尔,5值类型
List valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* 最终执行的 SQL
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('深圳', '广东')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%智能%'
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
可能有人会说这不就是个查询流程吗?如果有这样的疑惑,把上述案例换成用户查询,标签数据的价值会更直观。
三、智能画像1、基本概念
用户画像
作为一种绘制目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
行业画像
通过行业属性标签,行业下用户标签的综合剖析,生成行业剖析报告,提供极有价值的导向,这是最近两年非常热门的应用。
画像补全
通过不断剖析用户数据,丰富标签库,使用户的画像愈发丰富立体。
2、画像报告
通过标签数据的剖析,生成一份剖析报告,报告内容包含丰富的用户标签统计数据。
例如:90后画像报告
这个报告,互联网用户一定或多或少都听到过。主要是一些标签统计,共性标签展示,或者什么群体对80后三观影响最大,收入来源,学历等各类剖析评析。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent
聚焦爬虫常见算法剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-05-17 08:02
电脑知识与技术 数据库与信息管理 聚焦爬虫常见算法剖析 陈 丽 君 (浙江越秀外国语学院 浙江湖州 312000) [摘 要] 聚焦爬虫收集与特定主题相关的页面,为搜索引擎建立页面集。传统的聚焦爬虫采用向量空间模型和局部搜索算法,精确 率和召回率都比较低。文章分析了聚焦爬虫存在的问题及其相应的解决方式。最后对未来的研究方向进行了展望。 [关键词] 搜索引擎; 聚焦爬虫; 算法 不同于google、百度等通用搜索引擎,聚焦爬虫(也称为主题 爬虫)是一个能下载相关Web页的程序或自动化脚本。随着Web 页面的迅速攀升和特定领域搜索的需求,近年来,聚焦爬虫在工业 和学术界造成了广泛关注。 第一个聚焦爬虫是Chakrabarti于1999提出的[1]。聚焦爬虫一 般由两种算法来保证抓取特定领域的信息,一是Web剖析算法, 依据URL的指向判定Web页面的相关程度和质量;二是Web搜索 算法,它决定着被爬取URL的最佳顺序。 一、常见算法 1.Web页面剖析算法 目前,已出现了许多页面剖析算法,一般可以分为两大类: 基于内容的和基于链接结构的。前者通过剖析一个实际Web页的 HTML文档,来获取关于页面自身的相关性信息。
例如,在文档索 引技术的帮助下,可以从文档中抽取关键词或句子,依此确定该 文档是否与指定域相关。另外,也可以用VSM(向量空间模型) 与指定域的标准文档比较。对于前者,相关研究者发觉,Web链 接结构中包含有许多制作者蕴涵的信息,而这种信息对剖析文档 的相关性和质量起着重要作用。例如,当一个页面A指向另一个页 面B时,就意味着A页面的作者暗示着页面B也富含类似的内容。另 外,页面包含的接入链接越多就意味着该页面越重要。基于链接分 析的算法主要有PageRank和HITS。 2.Web搜索算法 该算法的主要目的是确定最优的URL访问顺序。与页面剖析算法 一样,搜索也有许多算法,以Breadth-first和Best-first最为流行。 2.1 Breadth-first搜索 该算法的思想比较简单,所有在当前层中的URL还会根据上一 层中它们被发觉的次序访问,其最大特征是不分辨页面的质量和主 题,所以最适合于通用搜索。但最近也有研究[2]表明,如果假定 当前层中的所有URL都是与主题相关的,那么它们的下一层URL也 会与主题相关。这样,Breadth-first就可用作收集一定质量的主题 相关页面,即聚焦搜索算法。
但是,当抓取相当数目的页面后,该算法会引入许多噪声信息 (非相关信息),或形成主题甩尾现象。已有研究人员提出将此算 法与页面剖析算法相结合[4],先用Breadth-first收集页面,再用页 面剖析算法过滤掉不相关的页面,这样即使降低了噪声信息,但降 低了算法的效率。 2.2 Best-first搜索 该算法目前比较流行。与Breadth-first不同,该算法不是简单 地根据被发觉的顺序访问,而是采用某种启发式思想(比如页面分 析的结果)来调整URL在队列中的排序,排在后面的被觉得是与主 题更接近的页面,要优先访问,反之,则推后甚至不被访问。因 此,Best-first搜索显著要比Breadth-first搜索更优越。 并且,Best-first是一个局部搜索算法,它只关心以前访问节 点周围的页面空间,因此会丧失许多相关页面,最后收集的页面质 量也不会很高。 二、存在问题 1.页面剖析算法 页面剖析是聚焦爬虫的重要组成部份,如果页面剖析算法对页 面的判定不够确切,将会影响到搜索算法,导致搜集到页面的质量 偏低。因此,实现一个高效的页面剖析算法是做好聚焦爬虫的第一 步。
Web文档一般富含噪声,比如极少数的文本、图像、脚本等 对分类器没用的数据。而且,不同制作者在风格、语言、结构上 存在很大的差别。因此,采用简单的相似性函数(如tf-idf等)的 VSM很难取得令人满意的疗效。 一种解决的方式是,组合各类基于内容的相似性测度方式,可 以提升分类的准确率[4]。比如遗传算法等全局搜索模式也是一种 潜在的解决方案。 2.局部搜索算法 局部搜索算法的特征是,访问当初访问过节点周围的邻居节 点,这样假如一个相关页没有被现有URL所指向,那么聚焦爬虫就 会丧失对这个相关页面的访问。而且,如果在两个相关页面中间隔 有不相关的页面,聚焦爬虫也会舍弃对后一个相关页面的访问。因 此,采用局部搜索算法的聚焦爬虫只能够发觉围绕在起始种子集周 围的相关页面,它们仅仅是整个Web相关页面集的有限子集,而 丧失了该子集外的相关页面。 通过对Web结构的研究,人们发觉了Web社区[3],也即在线 的Web页自然地按照特定的链接结构分成了不同的组,组内页面 都接近于个别主题或兴趣。聚焦爬虫的目的就是要获取所有的属于 那些相关社区的页面,然而,Web社区的以下三种特点,使得局 部搜索算法不再适用于集聚爬虫。
(1)主题相像的社区之间,采用的不是直接的互相链接,而 是互相引用的关系。在商业领域,这是一个相当普遍现象。例如, Yahoo新闻、MSN新闻、Google新闻都提供相同或相像的新闻信 Algorithm Analysis of Focused Crawler Chen Lijun (Zhejiang Yuexiu University of Foreign Languages, Shaoxing Zhejing 312000, China) Abstract: Focused crawlers can selectively retrieve web documents relevant to a specific domain to build collections for domain- specific search engines. Traditional focused crawlers normally adopting the simple Vector Space Model and local Web search algorithms typically only find relevant Web pages with low precision and recall. This work describes and analyses problems associated with traditional focused crawlers and some potential solutions. The future directions are addressed. Key words: search engine; focused crawler; algorithm 笔记本知识与技术 数据库与信息管理 息,但因为竞争关系,它们并不包含彼此之间的链接。
因此,即使 它们都被作为相关Web社区的起始页面种子集,聚焦爬虫还是会 丧失一些相关的页面。 (2)相关页面之间可能被非相关的社区所隔断。有研究表 明,大多数相关域就会被起码1~12个非相关页面所分隔,平均非 相关间隔页面数为5,而聚焦爬虫在碰到非相关页面后不会继续访 问后续的页面,造成了大量相关页面的流失。 (3)虽然链接在相关页面间存在,但不是互相的单向链接, 而是双向的。也即两个相关的社区A和B,A和B之间存在着链接, 并且仅仅是一个方向的,比如只有从A到B的链接,而不存在从B到 A的链接。这样,当爬行顺序从A开始时网络爬虫算法书籍,B社区同样能被发觉,但 若爬行顺序是从B开始时,则A社区就不能从B中被发觉,造成A中 的相关页流失。 三、 解决方式 一种最简单的解决方式是提供更多的起始种子集,但这样也增 加了成本和时间,而且随着Web页面的迅速降低,这种解决方式 并不可取。 另一种解决方式是采用隧道技术[5],它基于启发式方法解决 简单的全局优化问题。当聚焦爬虫遇见非相关的页面时,不是马上 舍弃继续搜索,而是在一定搜索深度(该值须要事先指定)范围内 继续搜索。
相关实验结果表明,隧道技术能发觉更多的相关页面, 并且,由于它没有改变局部搜索的本性,不能从根本上解决问题。 同时,噪音也被引入进来,降低了页面搜集质量。 研究人员通过对Web规模的研究发觉,主要搜索引擎之间索引 的重叠内容极少,因此,可以组合各类不同搜索引擎搜索结果中比 较靠前的结果,也就是元搜索技术,来解决局部搜索导致的问题。 四、未来展望 近些年来,研究人员发觉Web信息的分布存在一定的相似性, 因而考虑先进行训练,使爬虫具备一定的“经验知识”,通过这种 知识预测将来的回报。比如McCallum[6]引入巩固学习过程,先利 用巩固学习算法估算每位链接的回报价值Q,用Q值相同或相仿的 链接文本信息训练一个贝叶斯分类器,再对未知的链接文本,用该 分类器估算链接属于该类的机率,并借此机率为权重估算链接的综 合价值。也可以借助“智能搜索”技术,通过在线学习链接结构特 征,用于指导搜索过程。 五、结语 随着网页呈指数级的快速下降,以及人们对搜索结果精度要求的 不断提升,新的算法不断涌现,如基于机器学习的剖析算法、相似性 判定的遗传算法等。相信在研究人员的继续努力下,还会出现更多更 加确切、更加快速的新算法,不断增强人们对搜索结果的满意度。
参考文献: [1] Chakrabarti, S., Berg, M.V.D., and Dom, B., Focused crawling: A New Approach to Topic-Sepcific Web Resouce Discovery. In Proceedings of the 8th International WWW Conf. 1999.Toronto, Canada. [2] Najork, M. and Wiener, J.L., Breadth-First Search Crawling Yields High-Quality Pages. In Proceedings of the 10th International WWW Conf. 2001. Hong Kong, China. [3] Flake, G.W., Lawrence, S., and Giles, C.L., Efficient Identification of Web Communities. In Proceediings of the 6 th ACM SIGKDD International Conf. 2000. Massachusetts, USA. [4] Qin, J. and Chen, H., Using Genetic Algorithm in Building Domain-Specific Collections: An Experiment in the Nanotechnology Domain. In Proceedings of the 38th Annual Hawaii International Conf. 2005. Hawaii, USA. [5] Bergmark, D., Lagoze, C., and Sbityakov, A., Focused Crawls, Tunneling, and Digital Libraries. In Porceedings of the 6th European Conf. 2002. Rome, Italy. [6] Rennie J, McCallum A. Using Reinforcement Learning to Spider the Web Efficiently. In Proc. of the International Conference on Machine Learning(ICML’99),1999. 取系数绝对值较大法适宜小波变换后的HL频带图象、LH频 带图象、HH频带图象等高频成份较丰富,亮度、对比度较高的图 象;融合图象中基本保留源图象的特点,图像对比度与源图象基本 相同。
小波变换的作用是对讯号解相关,并将讯号的全部信息集中 到一部分具有大幅值的小波系数中。这些大的小波系数富含的能量 远比小系数富含的能量大,从而在讯号的构建中,大的系数比小的 系数更重要。 3.3 一致性检查 图象中相邻象素点之间可能存在着空间冗余,因此空间上相邻 的点太可能属于同一图象的特点,因此应当对它们采用同一种方式 进行估算。根据这一思想,H.Li等提出用大多数原则对决策因子d 进行一致性检查。如果融合后的图象C在某个区域的中心点上的系 数来自于源图象A,而该点周围的点的系数均来自于源图象B,则 将中心点的系数替换为图象B的系数。 3.4 综合方式 源图象A,B分别进行小波分解,对小波变换后的LL频带图象 采取加权平均法,为了提升图象的质量,还可以在加权平均后采 用高斯低通滤波。对LH频带、HL频带、HH频带采用取系数绝对值 较大法,即取源图象A,B中小波系数较大的作为C的小波系数。另 外,为了尽量避开引入噪音,还应进行一致性检查,即若C上某点 的小波系数取自源图象A,而其周围的点均取自源图象B,则将该 点的小波系数改为源图象B的小波系数。 4 图像融合的现况及发展前景 近些年来,虽然图象融合技术发展迅速,但这仍是个没有统一理 论框架的新领域。
首先,影响图象融合疗效的诱因好多,例如,融 合算法的选定、小波基的选定以及小波分解层数的选择等;其次, 须要构建客观的图象融合技术评价标准;最后,特征级图象融和决 策级图象融合还有待长足的发展。 现有研究结果显示,对不同的频带采用了不同的融合算法结果 表明,对于低频部份采用加权方式较好,对于高频部份采用带一致 性检查的系数绝对值较大法融合疗效较好。 5 结束语 多传感图象融合技术作为信息融合研究领域的一项重要内 容网络爬虫算法书籍,将会在军事、遥感、机器人视觉和医学图象处理等领域得到广 泛应用。 参考文献: [1] 李敏,张小英,毛捷. 基于邻域残差加权平均的小波图象融合 [J]. 理论与技巧,2008,27(1):5-6 [2] 王攀峰,杜云飞,周海芳,杨学军. 基于复小波变换的遥感图象并行 融合算法 [J]. 计算机工程与科学,2008,30(3):35-39 [3] 闫敬文. 数字图像处理(MATLAB版)[M]. 国防工业出版社,2007. [4] 曹杰,龚声蓉,刘纯平. 一种新的基于小波变换的多聚焦图象融 合算法[J]. 计算机工程与应用,2007,43(24):47-50 [5] 任娜,郭敏,胡丽华,张景虎. 基于图象块分割及小波空间频度 的多聚焦图象融合法[J]. 科学技术与工程,2008,8(2):411-414 [6] 成礼智,王红霞,罗永. 小波的理论与应用[M]. 科学出版社,2006. [7] 蔡娜,姚志强,沙晋明. 基于小波变换的遥感图象融合方式[J]. 莆田学院学报,2008,15(2):79-82 [8] 胡钢,秦新强,田径. 像素级多传感图象融合技术[J]. 沈阳工 程学院学报,2007,3(2):148-152 (上接42页) 查看全部
例如,在文档索 引技术的帮助下,可以从文档中抽取关键词或句子,依此确定该 文档是否与指定域相关。另外,也可以用VSM(向量空间模型) 与指定域的标准文档比较。对于前者,相关研究者发觉,Web链 接结构中包含有许多制作者蕴涵的信息,而这种信息对剖析文档 的相关性和质量起着重要作用。例如,当一个页面A指向另一个页 面B时,就意味着A页面的作者暗示着页面B也富含类似的内容。另 外,页面包含的接入链接越多就意味着该页面越重要。基于链接分 析的算法主要有PageRank和HITS。 2.Web搜索算法 该算法的主要目的是确定最优的URL访问顺序。与页面剖析算法 一样,搜索也有许多算法,以Breadth-first和Best-first最为流行。 2.1 Breadth-first搜索 该算法的思想比较简单,所有在当前层中的URL还会根据上一 层中它们被发觉的次序访问,其最大特征是不分辨页面的质量和主 题,所以最适合于通用搜索。但最近也有研究[2]表明,如果假定 当前层中的所有URL都是与主题相关的,那么它们的下一层URL也 会与主题相关。这样,Breadth-first就可用作收集一定质量的主题 相关页面,即聚焦搜索算法。
但是,当抓取相当数目的页面后,该算法会引入许多噪声信息 (非相关信息),或形成主题甩尾现象。已有研究人员提出将此算 法与页面剖析算法相结合[4],先用Breadth-first收集页面,再用页 面剖析算法过滤掉不相关的页面,这样即使降低了噪声信息,但降 低了算法的效率。 2.2 Best-first搜索 该算法目前比较流行。与Breadth-first不同,该算法不是简单 地根据被发觉的顺序访问,而是采用某种启发式思想(比如页面分 析的结果)来调整URL在队列中的排序,排在后面的被觉得是与主 题更接近的页面,要优先访问,反之,则推后甚至不被访问。因 此,Best-first搜索显著要比Breadth-first搜索更优越。 并且,Best-first是一个局部搜索算法,它只关心以前访问节 点周围的页面空间,因此会丧失许多相关页面,最后收集的页面质 量也不会很高。 二、存在问题 1.页面剖析算法 页面剖析是聚焦爬虫的重要组成部份,如果页面剖析算法对页 面的判定不够确切,将会影响到搜索算法,导致搜集到页面的质量 偏低。因此,实现一个高效的页面剖析算法是做好聚焦爬虫的第一 步。
Web文档一般富含噪声,比如极少数的文本、图像、脚本等 对分类器没用的数据。而且,不同制作者在风格、语言、结构上 存在很大的差别。因此,采用简单的相似性函数(如tf-idf等)的 VSM很难取得令人满意的疗效。 一种解决的方式是,组合各类基于内容的相似性测度方式,可 以提升分类的准确率[4]。比如遗传算法等全局搜索模式也是一种 潜在的解决方案。 2.局部搜索算法 局部搜索算法的特征是,访问当初访问过节点周围的邻居节 点,这样假如一个相关页没有被现有URL所指向,那么聚焦爬虫就 会丧失对这个相关页面的访问。而且,如果在两个相关页面中间隔 有不相关的页面,聚焦爬虫也会舍弃对后一个相关页面的访问。因 此,采用局部搜索算法的聚焦爬虫只能够发觉围绕在起始种子集周 围的相关页面,它们仅仅是整个Web相关页面集的有限子集,而 丧失了该子集外的相关页面。 通过对Web结构的研究,人们发觉了Web社区[3],也即在线 的Web页自然地按照特定的链接结构分成了不同的组,组内页面 都接近于个别主题或兴趣。聚焦爬虫的目的就是要获取所有的属于 那些相关社区的页面,然而,Web社区的以下三种特点,使得局 部搜索算法不再适用于集聚爬虫。
(1)主题相像的社区之间,采用的不是直接的互相链接,而 是互相引用的关系。在商业领域,这是一个相当普遍现象。例如, Yahoo新闻、MSN新闻、Google新闻都提供相同或相像的新闻信 Algorithm Analysis of Focused Crawler Chen Lijun (Zhejiang Yuexiu University of Foreign Languages, Shaoxing Zhejing 312000, China) Abstract: Focused crawlers can selectively retrieve web documents relevant to a specific domain to build collections for domain- specific search engines. Traditional focused crawlers normally adopting the simple Vector Space Model and local Web search algorithms typically only find relevant Web pages with low precision and recall. This work describes and analyses problems associated with traditional focused crawlers and some potential solutions. The future directions are addressed. Key words: search engine; focused crawler; algorithm 笔记本知识与技术 数据库与信息管理 息,但因为竞争关系,它们并不包含彼此之间的链接。
因此,即使 它们都被作为相关Web社区的起始页面种子集,聚焦爬虫还是会 丧失一些相关的页面。 (2)相关页面之间可能被非相关的社区所隔断。有研究表 明,大多数相关域就会被起码1~12个非相关页面所分隔,平均非 相关间隔页面数为5,而聚焦爬虫在碰到非相关页面后不会继续访 问后续的页面,造成了大量相关页面的流失。 (3)虽然链接在相关页面间存在,但不是互相的单向链接, 而是双向的。也即两个相关的社区A和B,A和B之间存在着链接, 并且仅仅是一个方向的,比如只有从A到B的链接,而不存在从B到 A的链接。这样,当爬行顺序从A开始时网络爬虫算法书籍,B社区同样能被发觉,但 若爬行顺序是从B开始时,则A社区就不能从B中被发觉,造成A中 的相关页流失。 三、 解决方式 一种最简单的解决方式是提供更多的起始种子集,但这样也增 加了成本和时间,而且随着Web页面的迅速降低,这种解决方式 并不可取。 另一种解决方式是采用隧道技术[5],它基于启发式方法解决 简单的全局优化问题。当聚焦爬虫遇见非相关的页面时,不是马上 舍弃继续搜索,而是在一定搜索深度(该值须要事先指定)范围内 继续搜索。
相关实验结果表明,隧道技术能发觉更多的相关页面, 并且,由于它没有改变局部搜索的本性,不能从根本上解决问题。 同时,噪音也被引入进来,降低了页面搜集质量。 研究人员通过对Web规模的研究发觉,主要搜索引擎之间索引 的重叠内容极少,因此,可以组合各类不同搜索引擎搜索结果中比 较靠前的结果,也就是元搜索技术,来解决局部搜索导致的问题。 四、未来展望 近些年来,研究人员发觉Web信息的分布存在一定的相似性, 因而考虑先进行训练,使爬虫具备一定的“经验知识”,通过这种 知识预测将来的回报。比如McCallum[6]引入巩固学习过程,先利 用巩固学习算法估算每位链接的回报价值Q,用Q值相同或相仿的 链接文本信息训练一个贝叶斯分类器,再对未知的链接文本,用该 分类器估算链接属于该类的机率,并借此机率为权重估算链接的综 合价值。也可以借助“智能搜索”技术,通过在线学习链接结构特 征,用于指导搜索过程。 五、结语 随着网页呈指数级的快速下降,以及人们对搜索结果精度要求的 不断提升,新的算法不断涌现,如基于机器学习的剖析算法、相似性 判定的遗传算法等。相信在研究人员的继续努力下,还会出现更多更 加确切、更加快速的新算法,不断增强人们对搜索结果的满意度。
参考文献: [1] Chakrabarti, S., Berg, M.V.D., and Dom, B., Focused crawling: A New Approach to Topic-Sepcific Web Resouce Discovery. In Proceedings of the 8th International WWW Conf. 1999.Toronto, Canada. [2] Najork, M. and Wiener, J.L., Breadth-First Search Crawling Yields High-Quality Pages. In Proceedings of the 10th International WWW Conf. 2001. Hong Kong, China. [3] Flake, G.W., Lawrence, S., and Giles, C.L., Efficient Identification of Web Communities. In Proceediings of the 6 th ACM SIGKDD International Conf. 2000. Massachusetts, USA. [4] Qin, J. and Chen, H., Using Genetic Algorithm in Building Domain-Specific Collections: An Experiment in the Nanotechnology Domain. In Proceedings of the 38th Annual Hawaii International Conf. 2005. Hawaii, USA. [5] Bergmark, D., Lagoze, C., and Sbityakov, A., Focused Crawls, Tunneling, and Digital Libraries. In Porceedings of the 6th European Conf. 2002. Rome, Italy. [6] Rennie J, McCallum A. Using Reinforcement Learning to Spider the Web Efficiently. In Proc. of the International Conference on Machine Learning(ICML’99),1999. 取系数绝对值较大法适宜小波变换后的HL频带图象、LH频 带图象、HH频带图象等高频成份较丰富,亮度、对比度较高的图 象;融合图象中基本保留源图象的特点,图像对比度与源图象基本 相同。
小波变换的作用是对讯号解相关,并将讯号的全部信息集中 到一部分具有大幅值的小波系数中。这些大的小波系数富含的能量 远比小系数富含的能量大,从而在讯号的构建中,大的系数比小的 系数更重要。 3.3 一致性检查 图象中相邻象素点之间可能存在着空间冗余,因此空间上相邻 的点太可能属于同一图象的特点,因此应当对它们采用同一种方式 进行估算。根据这一思想,H.Li等提出用大多数原则对决策因子d 进行一致性检查。如果融合后的图象C在某个区域的中心点上的系 数来自于源图象A,而该点周围的点的系数均来自于源图象B,则 将中心点的系数替换为图象B的系数。 3.4 综合方式 源图象A,B分别进行小波分解,对小波变换后的LL频带图象 采取加权平均法,为了提升图象的质量,还可以在加权平均后采 用高斯低通滤波。对LH频带、HL频带、HH频带采用取系数绝对值 较大法,即取源图象A,B中小波系数较大的作为C的小波系数。另 外,为了尽量避开引入噪音,还应进行一致性检查,即若C上某点 的小波系数取自源图象A,而其周围的点均取自源图象B,则将该 点的小波系数改为源图象B的小波系数。 4 图像融合的现况及发展前景 近些年来,虽然图象融合技术发展迅速,但这仍是个没有统一理 论框架的新领域。
首先,影响图象融合疗效的诱因好多,例如,融 合算法的选定、小波基的选定以及小波分解层数的选择等;其次, 须要构建客观的图象融合技术评价标准;最后,特征级图象融和决 策级图象融合还有待长足的发展。 现有研究结果显示,对不同的频带采用了不同的融合算法结果 表明,对于低频部份采用加权方式较好,对于高频部份采用带一致 性检查的系数绝对值较大法融合疗效较好。 5 结束语 多传感图象融合技术作为信息融合研究领域的一项重要内 容网络爬虫算法书籍,将会在军事、遥感、机器人视觉和医学图象处理等领域得到广 泛应用。 参考文献: [1] 李敏,张小英,毛捷. 基于邻域残差加权平均的小波图象融合 [J]. 理论与技巧,2008,27(1):5-6 [2] 王攀峰,杜云飞,周海芳,杨学军. 基于复小波变换的遥感图象并行 融合算法 [J]. 计算机工程与科学,2008,30(3):35-39 [3] 闫敬文. 数字图像处理(MATLAB版)[M]. 国防工业出版社,2007. [4] 曹杰,龚声蓉,刘纯平. 一种新的基于小波变换的多聚焦图象融 合算法[J]. 计算机工程与应用,2007,43(24):47-50 [5] 任娜,郭敏,胡丽华,张景虎. 基于图象块分割及小波空间频度 的多聚焦图象融合法[J]. 科学技术与工程,2008,8(2):411-414 [6] 成礼智,王红霞,罗永. 小波的理论与应用[M]. 科学出版社,2006. [7] 蔡娜,姚志强,沙晋明. 基于小波变换的遥感图象融合方式[J]. 莆田学院学报,2008,15(2):79-82 [8] 胡钢,秦新强,田径. 像素级多传感图象融合技术[J]. 沈阳工 程学院学报,2007,3(2):148-152 (上接42页) 查看全部
电脑知识与技术 数据库与信息管理 聚焦爬虫常见算法剖析 陈 丽 君 (浙江越秀外国语学院 浙江湖州 312000) [摘 要] 聚焦爬虫收集与特定主题相关的页面,为搜索引擎建立页面集。传统的聚焦爬虫采用向量空间模型和局部搜索算法,精确 率和召回率都比较低。文章分析了聚焦爬虫存在的问题及其相应的解决方式。最后对未来的研究方向进行了展望。 [关键词] 搜索引擎; 聚焦爬虫; 算法 不同于google、百度等通用搜索引擎,聚焦爬虫(也称为主题 爬虫)是一个能下载相关Web页的程序或自动化脚本。随着Web 页面的迅速攀升和特定领域搜索的需求,近年来,聚焦爬虫在工业 和学术界造成了广泛关注。 第一个聚焦爬虫是Chakrabarti于1999提出的[1]。聚焦爬虫一 般由两种算法来保证抓取特定领域的信息,一是Web剖析算法, 依据URL的指向判定Web页面的相关程度和质量;二是Web搜索 算法,它决定着被爬取URL的最佳顺序。 一、常见算法 1.Web页面剖析算法 目前,已出现了许多页面剖析算法,一般可以分为两大类: 基于内容的和基于链接结构的。前者通过剖析一个实际Web页的 HTML文档,来获取关于页面自身的相关性信息。
例如,在文档索 引技术的帮助下,可以从文档中抽取关键词或句子,依此确定该 文档是否与指定域相关。另外,也可以用VSM(向量空间模型) 与指定域的标准文档比较。对于前者,相关研究者发觉,Web链 接结构中包含有许多制作者蕴涵的信息,而这种信息对剖析文档 的相关性和质量起着重要作用。例如,当一个页面A指向另一个页 面B时,就意味着A页面的作者暗示着页面B也富含类似的内容。另 外,页面包含的接入链接越多就意味着该页面越重要。基于链接分 析的算法主要有PageRank和HITS。 2.Web搜索算法 该算法的主要目的是确定最优的URL访问顺序。与页面剖析算法 一样,搜索也有许多算法,以Breadth-first和Best-first最为流行。 2.1 Breadth-first搜索 该算法的思想比较简单,所有在当前层中的URL还会根据上一 层中它们被发觉的次序访问,其最大特征是不分辨页面的质量和主 题,所以最适合于通用搜索。但最近也有研究[2]表明,如果假定 当前层中的所有URL都是与主题相关的,那么它们的下一层URL也 会与主题相关。这样,Breadth-first就可用作收集一定质量的主题 相关页面,即聚焦搜索算法。
但是,当抓取相当数目的页面后,该算法会引入许多噪声信息 (非相关信息),或形成主题甩尾现象。已有研究人员提出将此算 法与页面剖析算法相结合[4],先用Breadth-first收集页面,再用页 面剖析算法过滤掉不相关的页面,这样即使降低了噪声信息,但降 低了算法的效率。 2.2 Best-first搜索 该算法目前比较流行。与Breadth-first不同,该算法不是简单 地根据被发觉的顺序访问,而是采用某种启发式思想(比如页面分 析的结果)来调整URL在队列中的排序,排在后面的被觉得是与主 题更接近的页面,要优先访问,反之,则推后甚至不被访问。因 此,Best-first搜索显著要比Breadth-first搜索更优越。 并且,Best-first是一个局部搜索算法,它只关心以前访问节 点周围的页面空间,因此会丧失许多相关页面,最后收集的页面质 量也不会很高。 二、存在问题 1.页面剖析算法 页面剖析是聚焦爬虫的重要组成部份,如果页面剖析算法对页 面的判定不够确切,将会影响到搜索算法,导致搜集到页面的质量 偏低。因此,实现一个高效的页面剖析算法是做好聚焦爬虫的第一 步。
Web文档一般富含噪声,比如极少数的文本、图像、脚本等 对分类器没用的数据。而且,不同制作者在风格、语言、结构上 存在很大的差别。因此,采用简单的相似性函数(如tf-idf等)的 VSM很难取得令人满意的疗效。 一种解决的方式是,组合各类基于内容的相似性测度方式,可 以提升分类的准确率[4]。比如遗传算法等全局搜索模式也是一种 潜在的解决方案。 2.局部搜索算法 局部搜索算法的特征是,访问当初访问过节点周围的邻居节 点,这样假如一个相关页没有被现有URL所指向,那么聚焦爬虫就 会丧失对这个相关页面的访问。而且,如果在两个相关页面中间隔 有不相关的页面,聚焦爬虫也会舍弃对后一个相关页面的访问。因 此,采用局部搜索算法的聚焦爬虫只能够发觉围绕在起始种子集周 围的相关页面,它们仅仅是整个Web相关页面集的有限子集,而 丧失了该子集外的相关页面。 通过对Web结构的研究,人们发觉了Web社区[3],也即在线 的Web页自然地按照特定的链接结构分成了不同的组,组内页面 都接近于个别主题或兴趣。聚焦爬虫的目的就是要获取所有的属于 那些相关社区的页面,然而,Web社区的以下三种特点,使得局 部搜索算法不再适用于集聚爬虫。
(1)主题相像的社区之间,采用的不是直接的互相链接,而 是互相引用的关系。在商业领域,这是一个相当普遍现象。例如, Yahoo新闻、MSN新闻、Google新闻都提供相同或相像的新闻信 Algorithm Analysis of Focused Crawler Chen Lijun (Zhejiang Yuexiu University of Foreign Languages, Shaoxing Zhejing 312000, China) Abstract: Focused crawlers can selectively retrieve web documents relevant to a specific domain to build collections for domain- specific search engines. Traditional focused crawlers normally adopting the simple Vector Space Model and local Web search algorithms typically only find relevant Web pages with low precision and recall. This work describes and analyses problems associated with traditional focused crawlers and some potential solutions. The future directions are addressed. Key words: search engine; focused crawler; algorithm 笔记本知识与技术 数据库与信息管理 息,但因为竞争关系,它们并不包含彼此之间的链接。
因此,即使 它们都被作为相关Web社区的起始页面种子集,聚焦爬虫还是会 丧失一些相关的页面。 (2)相关页面之间可能被非相关的社区所隔断。有研究表 明,大多数相关域就会被起码1~12个非相关页面所分隔,平均非 相关间隔页面数为5,而聚焦爬虫在碰到非相关页面后不会继续访 问后续的页面,造成了大量相关页面的流失。 (3)虽然链接在相关页面间存在,但不是互相的单向链接, 而是双向的。也即两个相关的社区A和B,A和B之间存在着链接, 并且仅仅是一个方向的,比如只有从A到B的链接,而不存在从B到 A的链接。这样,当爬行顺序从A开始时网络爬虫算法书籍,B社区同样能被发觉,但 若爬行顺序是从B开始时,则A社区就不能从B中被发觉,造成A中 的相关页流失。 三、 解决方式 一种最简单的解决方式是提供更多的起始种子集,但这样也增 加了成本和时间,而且随着Web页面的迅速降低,这种解决方式 并不可取。 另一种解决方式是采用隧道技术[5],它基于启发式方法解决 简单的全局优化问题。当聚焦爬虫遇见非相关的页面时,不是马上 舍弃继续搜索,而是在一定搜索深度(该值须要事先指定)范围内 继续搜索。
相关实验结果表明,隧道技术能发觉更多的相关页面, 并且,由于它没有改变局部搜索的本性,不能从根本上解决问题。 同时,噪音也被引入进来,降低了页面搜集质量。 研究人员通过对Web规模的研究发觉,主要搜索引擎之间索引 的重叠内容极少,因此,可以组合各类不同搜索引擎搜索结果中比 较靠前的结果,也就是元搜索技术,来解决局部搜索导致的问题。 四、未来展望 近些年来,研究人员发觉Web信息的分布存在一定的相似性, 因而考虑先进行训练,使爬虫具备一定的“经验知识”,通过这种 知识预测将来的回报。比如McCallum[6]引入巩固学习过程,先利 用巩固学习算法估算每位链接的回报价值Q,用Q值相同或相仿的 链接文本信息训练一个贝叶斯分类器,再对未知的链接文本,用该 分类器估算链接属于该类的机率,并借此机率为权重估算链接的综 合价值。也可以借助“智能搜索”技术,通过在线学习链接结构特 征,用于指导搜索过程。 五、结语 随着网页呈指数级的快速下降,以及人们对搜索结果精度要求的 不断提升,新的算法不断涌现,如基于机器学习的剖析算法、相似性 判定的遗传算法等。相信在研究人员的继续努力下,还会出现更多更 加确切、更加快速的新算法,不断增强人们对搜索结果的满意度。
参考文献: [1] Chakrabarti, S., Berg, M.V.D., and Dom, B., Focused crawling: A New Approach to Topic-Sepcific Web Resouce Discovery. In Proceedings of the 8th International WWW Conf. 1999.Toronto, Canada. [2] Najork, M. and Wiener, J.L., Breadth-First Search Crawling Yields High-Quality Pages. In Proceedings of the 10th International WWW Conf. 2001. Hong Kong, China. [3] Flake, G.W., Lawrence, S., and Giles, C.L., Efficient Identification of Web Communities. In Proceediings of the 6 th ACM SIGKDD International Conf. 2000. Massachusetts, USA. [4] Qin, J. and Chen, H., Using Genetic Algorithm in Building Domain-Specific Collections: An Experiment in the Nanotechnology Domain. In Proceedings of the 38th Annual Hawaii International Conf. 2005. Hawaii, USA. [5] Bergmark, D., Lagoze, C., and Sbityakov, A., Focused Crawls, Tunneling, and Digital Libraries. In Porceedings of the 6th European Conf. 2002. Rome, Italy. [6] Rennie J, McCallum A. Using Reinforcement Learning to Spider the Web Efficiently. In Proc. of the International Conference on Machine Learning(ICML’99),1999. 取系数绝对值较大法适宜小波变换后的HL频带图象、LH频 带图象、HH频带图象等高频成份较丰富,亮度、对比度较高的图 象;融合图象中基本保留源图象的特点,图像对比度与源图象基本 相同。
小波变换的作用是对讯号解相关,并将讯号的全部信息集中 到一部分具有大幅值的小波系数中。这些大的小波系数富含的能量 远比小系数富含的能量大,从而在讯号的构建中,大的系数比小的 系数更重要。 3.3 一致性检查 图象中相邻象素点之间可能存在着空间冗余,因此空间上相邻 的点太可能属于同一图象的特点,因此应当对它们采用同一种方式 进行估算。根据这一思想,H.Li等提出用大多数原则对决策因子d 进行一致性检查。如果融合后的图象C在某个区域的中心点上的系 数来自于源图象A,而该点周围的点的系数均来自于源图象B,则 将中心点的系数替换为图象B的系数。 3.4 综合方式 源图象A,B分别进行小波分解,对小波变换后的LL频带图象 采取加权平均法,为了提升图象的质量,还可以在加权平均后采 用高斯低通滤波。对LH频带、HL频带、HH频带采用取系数绝对值 较大法,即取源图象A,B中小波系数较大的作为C的小波系数。另 外,为了尽量避开引入噪音,还应进行一致性检查,即若C上某点 的小波系数取自源图象A,而其周围的点均取自源图象B,则将该 点的小波系数改为源图象B的小波系数。 4 图像融合的现况及发展前景 近些年来,虽然图象融合技术发展迅速,但这仍是个没有统一理 论框架的新领域。
首先,影响图象融合疗效的诱因好多,例如,融 合算法的选定、小波基的选定以及小波分解层数的选择等;其次, 须要构建客观的图象融合技术评价标准;最后,特征级图象融和决 策级图象融合还有待长足的发展。 现有研究结果显示,对不同的频带采用了不同的融合算法结果 表明,对于低频部份采用加权方式较好,对于高频部份采用带一致 性检查的系数绝对值较大法融合疗效较好。 5 结束语 多传感图象融合技术作为信息融合研究领域的一项重要内 容网络爬虫算法书籍,将会在军事、遥感、机器人视觉和医学图象处理等领域得到广 泛应用。 参考文献: [1] 李敏,张小英,毛捷. 基于邻域残差加权平均的小波图象融合 [J]. 理论与技巧,2008,27(1):5-6 [2] 王攀峰,杜云飞,周海芳,杨学军. 基于复小波变换的遥感图象并行 融合算法 [J]. 计算机工程与科学,2008,30(3):35-39 [3] 闫敬文. 数字图像处理(MATLAB版)[M]. 国防工业出版社,2007. [4] 曹杰,龚声蓉,刘纯平. 一种新的基于小波变换的多聚焦图象融 合算法[J]. 计算机工程与应用,2007,43(24):47-50 [5] 任娜,郭敏,胡丽华,张景虎. 基于图象块分割及小波空间频度 的多聚焦图象融合法[J]. 科学技术与工程,2008,8(2):411-414 [6] 成礼智,王红霞,罗永. 小波的理论与应用[M]. 科学出版社,2006. [7] 蔡娜,姚志强,沙晋明. 基于小波变换的遥感图象融合方式[J]. 莆田学院学报,2008,15(2):79-82 [8] 胡钢,秦新强,田径. 像素级多传感图象融合技术[J]. 沈阳工 程学院学报,2007,3(2):148-152 (上接42页)
网络爬虫技术在大数据审计中的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-05-10 08:03
[提要]在大数据审计面临着众多机遇和挑战的大背景下,有效清晰的数据在审计过程中发挥着重大作用大数据网络爬虫原理,本文剖析不同的审计数据的特性以及采集审计数据的方式。在传统数据采集方法基础上研究怎样基于Python借助网路爬虫采集审计数据,以为大数据审计技术的发展提供支持。
关键词:网络爬虫;数据采集;审计剖析;Python
本文为2017年安徽财贸职业学院“内涵提高全员行动计划”科学研究项目(人文社科):“大数据在审计剖析程序中的运用研究”(项目编号:2017nhrwc15)
中图分类号:F239 文献标识码:A
收录日期:2019年1月18日
一、引言
无论是国家审计还是民间审计,在现今社会经济发展过程中都起到了非常重要的作用,为经济发展“保驾护航”。大数据目前也是各国研究的重点和热点,并将大数据的研究和应用上升到了战略层次。美国注册会计师协会(AICPA)在2014年就对大数据可能对审计形成的影响进行了剖析。在全球信息化的大背景下,如何借助大数据增加审计风险,提高审计效率依然是一个十分重要的命题。2015年中共中央办公厅、国务院办公厅《关于完善审计制度若干重大问题的框架意见》及配套文件中明晰提出“构建大数据审计工作模式,构建国家审计数据系统和数字化审计平台,探索完善审计实时监督系统,实施联网审计”。刘国城、王会金(2017)将大数据审计平台拆分为采集、预处理、分析和可视化四个子平台,基于方式支撑、过程建模和运行机理等方面对各个子平台作以专项研究,旨在为大数据审计实践提供建设性思路。秦荣生(2014)指出大数据、云计算技术的形成和发展,正在逐步影响审计技术和技巧的发展。
大数据具有数据体量巨大、处理速率快、数量种类多和商业价值高的特性。被审计对象的信息化使得审计人员在审计方式上愈发的信息化,如果将这种大量的、散落的、无序的数据进行集中化、结构化,将其弄成才能便捷获得可读取的审计数据,并通过审计剖析程序发觉愈发有效和清晰的审计线索,那么大数据将会发挥重大的商业价值。由此可见,数据是审计剖析的重要前提,获取高质量数据常常就能帮助审计人员快速发觉风险点进行应对,大大提升审计的效率和疗效。目前,尚未有成熟的审计大数据搜集与整理技术,这影响了大数据在审计中使用的效率。本文将基于目前大数据的研究现况,主要阐述审计人员应该怎样借助网路爬虫技术从网路渠道获取所需审计数据,从而扩展审计数据的范围,获得更多的审计线索,提高审计剖析疗效。
二、审计大数据采集分析
(一)审计大数据类型。大数据审计区别于传统的审计模式,传统审计模式倾向于根据被审计单位提供的相关资料去鉴证其是否真实可靠。而大数据审计是一种实时审计,强调审计人员应该主动地去获取企业内部和企业外部的数据,企业内部的业务数据主要借助被审计单位提供,而外部数据,比如法律、银行、税务、供应商、客户、物流等其他数据须要审计人员去挖掘和剖析。从目前来看,审计大数据可以分为两类:一类是结构化数据,它由明晰定义的数据类型组成,比如数字、货币、日期等,其模式可以让其便于搜索。这种数据通常存储在数据库里,比如企业ERP系统中的销售数据、生产数据、财务数据等;另一类是非结构化数据,是指这些不便捷用数据库二维逻辑来表现的数据,如办公文档、文本、图片、HTML图象等,审计人员须要的外部数据以非结构化数据类型居多。
(二)审计大数据采集方法
1、直接拷贝读取。审计人员首先判定出自己须要的审计数据,然后按照被审计单位使用的财务软件(如用友、用友)的使用特性,利用软件数据库早已预设好的指令去提取转换审计人员所须要的数据,并将其保存为Excel等格式。
2、开放数据互联(ODBC)。如果被审计单位与审计人员使用的是可以对接的数据库,可以通过相关的数据访问插口访问被审计单位所使用的业务系统数据库,并将数据进行还原后转出,成为审计人员可以直接借助的数据。
3、中间文件采集。指审计人员与被审计单位约定好数据的格式,被审计单位根据要求将自己的相关数据转换成约定的格式,比如说文本文件格式,这种大部分数据库都还能直接读取的格式,从而省去了两种不同数据库对接的问题。
4、网上采集。除了被审计单位或则上级审计机关提供的相关数据以外,审计人员依然须要从被审计单位外部获得相关的工商、税务、行业、媒体等公开数据以进行多方面的审计剖析,这些数据并不是被直接提供的结构化数据,需要审计人员采用一定的方式从网上进行采集。
目前,审计数据采集大部分采用的是上述的前三种方式,往往依托一定的数据库基础,能够获得的信息大多基于被审计单位,最后一种网上采集数据的方式因为没有统一的方式和技术,耗费大量时间和经历,往往未能实现,这大大限制了审计人员进行审计剖析的范围,同时也让审计的取证率无法达到预期,从某种程度上提升了审计风险。在大数据审计背景下,审计人员执行剖析程序不能仅仅将眼光局限于内部数据,更应该从网路公开数据中获取愈发全面的信息,但是这种信息大多以网页等格式存在,难以被审计人员直接用于剖析,所以本文提出可以借助网路爬虫技术抓取网页上的信息,并整理成一定的格式,方便审计人员从海量数据中发觉审计线索,使审计剖析程序发挥更大的效用。
三、网络爬虫在审计大数据采集中的应用
网络爬虫技术又被称为网路蜘蛛,是一种根据被设定的规则手动获取网页内容的程序脚本。目前,网络爬虫技术被越来越多的运用于互联网中,它还能依据不同的程序代码设定指令,自动获取网页内任何权限的信息数据。程序开始后,按照设定程序,网络爬虫会不断地从URL抓取用户须要的内容,直到满足停止条件,并对抓取到的数据进行分类整合处理大数据网络爬虫原理,用户可以按照自己的查询需求,从中筛选自己所须要的数据。通过网路爬虫还能为大数据剖析提供更高质量的数据源。
利用网路爬虫技术施行审计剖析程序的过程主要有以下几步:首先,锁定目标。根据审计目标确定想要获取的目标数据,明确这种数据主要分布的网页是哪些;其次,目标网页剖析。为了更高效率的抓取到相关数据,要对目标网页进行结构上的剖析,主要是其数据访问的路径和逻辑;再次,数据抓取。通过选择好的软件执行命令,获得数据结果进行保存;最后,数据剖析。将通过上述程序获得的数据进行清洗,获得目标数据,可以结合例如SQL查询、Excel剖析、数据可视化等技术对数据进行进一步的剖析、扩展和确认。
利用网路爬虫技术施行审计剖析程序的原理主要是能否从被审计单位外部获取愈发充足的、高质量的审计数据,而这种数据比被审计单位提供的数据愈发可靠,同时可以将获取的新数据与被审计单位提供的内部数据进行对比,帮助审计人员扩大范围,发现更多相关线索,同时也促使审计证据愈发充分可靠。
四、网络爬虫在审计大数据采集中应用案例
XX集团有限公司创建于1957年,现已发展产生节能环保、钢铁制造及金属贸易、智能健康、教育与技术服务等产业格局的小型企业集团。截至2017年底,拥有全资及控股一级子公司34家。2017年,完成销售收入933亿元、利润25亿元,甲会计师事务所接受委托对该公司进行2017年年度财务报表审计。审计人员在审计过程中发觉该公司下一子公司有大量进行一次性交易的顾客,并且这种顾客都采用了赊购的形式,所以审计人员对这种交易形成了怀疑,认为被审计单位的应收账款“存在”认定有重大错报风险。为进一步获得审计证据,审计人员首先须要被审计单位提供数据库内关于顾客的信息并进行查验以验证这种顾客的真实性。此时,被审计单位提供信息的可靠性较差,审计人员只能考虑从外部获得审计数据进行比较剖析,从而判定顾客信息的准确性。如果考虑直接从官方网站获得具体工商数据,审计人员将面临权限受限和工作量巨大等问题。此时,网络爬虫技术才能为这一困局提供挺好的解决方案,提高工作效率。
在选择网路爬虫技术时,审计人员选择了目前应用范围相对较广的Python。相对于其他网路爬虫技术,基于Python的网路爬虫技术具有以下优点:一是简约便捷。Python语言最大的特征就是只须要一个简单的编辑器才能满足大部分用户的网路爬虫技术需求,可以使操作人员很快的适应环境,而不用耗费过多的精力;二是具有框架技术。如果所须要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强悍的模板来实现爬虫,仅仅须要根据需求进行简单的更改就可以使用,而不是去进行重新的开发。
审计人员通过Python实现了网路爬虫,从“天眼查”网站上获取相关企业的工商信息。其中部份代码如图1所示,获得的部份结果如表1、图2所示。最终审计人员通过网路爬虫技术迅速获得了审计须要的相关数据,筛选出目标企业,进一步进行了审计剖析,与被审计单位提供的有关信息进行比对,得出了其中有18家企业信息涉嫌作假,实为虚构交易的推论,为预收账款的进一步审计提供了重要审计证据。(图1、图2、表1)
五、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。本文通过研究大数据的特性,以及对审计数据的采集办法进行剖析,提出了基于Python的数据爬虫在审计数据采集中的运用,帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计剖析奠定了基础,这也为大数据在审计中的应用技术研究提供了支持。
(作者单位:安徽财贸职业学院)
主要参考文献:
[1]秦荣生.大数据、云计算技术对审计的影响研究[J].审计研究,2014(6).
[2]刘国城,王会金.大数据审计平台建立研究[J].审计研究,2017(11).
[3]韦玮.精通Python网络爬虫[M].北京机械工业出版社,2017. 查看全部
关键词:网络爬虫;数据采集;审计剖析;Python
本文为2017年安徽财贸职业学院“内涵提高全员行动计划”科学研究项目(人文社科):“大数据在审计剖析程序中的运用研究”(项目编号:2017nhrwc15)
中图分类号:F239 文献标识码:A
收录日期:2019年1月18日
一、引言
无论是国家审计还是民间审计,在现今社会经济发展过程中都起到了非常重要的作用,为经济发展“保驾护航”。大数据目前也是各国研究的重点和热点,并将大数据的研究和应用上升到了战略层次。美国注册会计师协会(AICPA)在2014年就对大数据可能对审计形成的影响进行了剖析。在全球信息化的大背景下,如何借助大数据增加审计风险,提高审计效率依然是一个十分重要的命题。2015年中共中央办公厅、国务院办公厅《关于完善审计制度若干重大问题的框架意见》及配套文件中明晰提出“构建大数据审计工作模式,构建国家审计数据系统和数字化审计平台,探索完善审计实时监督系统,实施联网审计”。刘国城、王会金(2017)将大数据审计平台拆分为采集、预处理、分析和可视化四个子平台,基于方式支撑、过程建模和运行机理等方面对各个子平台作以专项研究,旨在为大数据审计实践提供建设性思路。秦荣生(2014)指出大数据、云计算技术的形成和发展,正在逐步影响审计技术和技巧的发展。
大数据具有数据体量巨大、处理速率快、数量种类多和商业价值高的特性。被审计对象的信息化使得审计人员在审计方式上愈发的信息化,如果将这种大量的、散落的、无序的数据进行集中化、结构化,将其弄成才能便捷获得可读取的审计数据,并通过审计剖析程序发觉愈发有效和清晰的审计线索,那么大数据将会发挥重大的商业价值。由此可见,数据是审计剖析的重要前提,获取高质量数据常常就能帮助审计人员快速发觉风险点进行应对,大大提升审计的效率和疗效。目前,尚未有成熟的审计大数据搜集与整理技术,这影响了大数据在审计中使用的效率。本文将基于目前大数据的研究现况,主要阐述审计人员应该怎样借助网路爬虫技术从网路渠道获取所需审计数据,从而扩展审计数据的范围,获得更多的审计线索,提高审计剖析疗效。
二、审计大数据采集分析
(一)审计大数据类型。大数据审计区别于传统的审计模式,传统审计模式倾向于根据被审计单位提供的相关资料去鉴证其是否真实可靠。而大数据审计是一种实时审计,强调审计人员应该主动地去获取企业内部和企业外部的数据,企业内部的业务数据主要借助被审计单位提供,而外部数据,比如法律、银行、税务、供应商、客户、物流等其他数据须要审计人员去挖掘和剖析。从目前来看,审计大数据可以分为两类:一类是结构化数据,它由明晰定义的数据类型组成,比如数字、货币、日期等,其模式可以让其便于搜索。这种数据通常存储在数据库里,比如企业ERP系统中的销售数据、生产数据、财务数据等;另一类是非结构化数据,是指这些不便捷用数据库二维逻辑来表现的数据,如办公文档、文本、图片、HTML图象等,审计人员须要的外部数据以非结构化数据类型居多。
(二)审计大数据采集方法
1、直接拷贝读取。审计人员首先判定出自己须要的审计数据,然后按照被审计单位使用的财务软件(如用友、用友)的使用特性,利用软件数据库早已预设好的指令去提取转换审计人员所须要的数据,并将其保存为Excel等格式。
2、开放数据互联(ODBC)。如果被审计单位与审计人员使用的是可以对接的数据库,可以通过相关的数据访问插口访问被审计单位所使用的业务系统数据库,并将数据进行还原后转出,成为审计人员可以直接借助的数据。
3、中间文件采集。指审计人员与被审计单位约定好数据的格式,被审计单位根据要求将自己的相关数据转换成约定的格式,比如说文本文件格式,这种大部分数据库都还能直接读取的格式,从而省去了两种不同数据库对接的问题。
4、网上采集。除了被审计单位或则上级审计机关提供的相关数据以外,审计人员依然须要从被审计单位外部获得相关的工商、税务、行业、媒体等公开数据以进行多方面的审计剖析,这些数据并不是被直接提供的结构化数据,需要审计人员采用一定的方式从网上进行采集。
目前,审计数据采集大部分采用的是上述的前三种方式,往往依托一定的数据库基础,能够获得的信息大多基于被审计单位,最后一种网上采集数据的方式因为没有统一的方式和技术,耗费大量时间和经历,往往未能实现,这大大限制了审计人员进行审计剖析的范围,同时也让审计的取证率无法达到预期,从某种程度上提升了审计风险。在大数据审计背景下,审计人员执行剖析程序不能仅仅将眼光局限于内部数据,更应该从网路公开数据中获取愈发全面的信息,但是这种信息大多以网页等格式存在,难以被审计人员直接用于剖析,所以本文提出可以借助网路爬虫技术抓取网页上的信息,并整理成一定的格式,方便审计人员从海量数据中发觉审计线索,使审计剖析程序发挥更大的效用。
三、网络爬虫在审计大数据采集中的应用
网络爬虫技术又被称为网路蜘蛛,是一种根据被设定的规则手动获取网页内容的程序脚本。目前,网络爬虫技术被越来越多的运用于互联网中,它还能依据不同的程序代码设定指令,自动获取网页内任何权限的信息数据。程序开始后,按照设定程序,网络爬虫会不断地从URL抓取用户须要的内容,直到满足停止条件,并对抓取到的数据进行分类整合处理大数据网络爬虫原理,用户可以按照自己的查询需求,从中筛选自己所须要的数据。通过网路爬虫还能为大数据剖析提供更高质量的数据源。
利用网路爬虫技术施行审计剖析程序的过程主要有以下几步:首先,锁定目标。根据审计目标确定想要获取的目标数据,明确这种数据主要分布的网页是哪些;其次,目标网页剖析。为了更高效率的抓取到相关数据,要对目标网页进行结构上的剖析,主要是其数据访问的路径和逻辑;再次,数据抓取。通过选择好的软件执行命令,获得数据结果进行保存;最后,数据剖析。将通过上述程序获得的数据进行清洗,获得目标数据,可以结合例如SQL查询、Excel剖析、数据可视化等技术对数据进行进一步的剖析、扩展和确认。
利用网路爬虫技术施行审计剖析程序的原理主要是能否从被审计单位外部获取愈发充足的、高质量的审计数据,而这种数据比被审计单位提供的数据愈发可靠,同时可以将获取的新数据与被审计单位提供的内部数据进行对比,帮助审计人员扩大范围,发现更多相关线索,同时也促使审计证据愈发充分可靠。
四、网络爬虫在审计大数据采集中应用案例
XX集团有限公司创建于1957年,现已发展产生节能环保、钢铁制造及金属贸易、智能健康、教育与技术服务等产业格局的小型企业集团。截至2017年底,拥有全资及控股一级子公司34家。2017年,完成销售收入933亿元、利润25亿元,甲会计师事务所接受委托对该公司进行2017年年度财务报表审计。审计人员在审计过程中发觉该公司下一子公司有大量进行一次性交易的顾客,并且这种顾客都采用了赊购的形式,所以审计人员对这种交易形成了怀疑,认为被审计单位的应收账款“存在”认定有重大错报风险。为进一步获得审计证据,审计人员首先须要被审计单位提供数据库内关于顾客的信息并进行查验以验证这种顾客的真实性。此时,被审计单位提供信息的可靠性较差,审计人员只能考虑从外部获得审计数据进行比较剖析,从而判定顾客信息的准确性。如果考虑直接从官方网站获得具体工商数据,审计人员将面临权限受限和工作量巨大等问题。此时,网络爬虫技术才能为这一困局提供挺好的解决方案,提高工作效率。
在选择网路爬虫技术时,审计人员选择了目前应用范围相对较广的Python。相对于其他网路爬虫技术,基于Python的网路爬虫技术具有以下优点:一是简约便捷。Python语言最大的特征就是只须要一个简单的编辑器才能满足大部分用户的网路爬虫技术需求,可以使操作人员很快的适应环境,而不用耗费过多的精力;二是具有框架技术。如果所须要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强悍的模板来实现爬虫,仅仅须要根据需求进行简单的更改就可以使用,而不是去进行重新的开发。
审计人员通过Python实现了网路爬虫,从“天眼查”网站上获取相关企业的工商信息。其中部份代码如图1所示,获得的部份结果如表1、图2所示。最终审计人员通过网路爬虫技术迅速获得了审计须要的相关数据,筛选出目标企业,进一步进行了审计剖析,与被审计单位提供的有关信息进行比对,得出了其中有18家企业信息涉嫌作假,实为虚构交易的推论,为预收账款的进一步审计提供了重要审计证据。(图1、图2、表1)
五、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。本文通过研究大数据的特性,以及对审计数据的采集办法进行剖析,提出了基于Python的数据爬虫在审计数据采集中的运用,帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计剖析奠定了基础,这也为大数据在审计中的应用技术研究提供了支持。
(作者单位:安徽财贸职业学院)
主要参考文献:
[1]秦荣生.大数据、云计算技术对审计的影响研究[J].审计研究,2014(6).
[2]刘国城,王会金.大数据审计平台建立研究[J].审计研究,2017(11).
[3]韦玮.精通Python网络爬虫[M].北京机械工业出版社,2017. 查看全部
[提要]在大数据审计面临着众多机遇和挑战的大背景下,有效清晰的数据在审计过程中发挥着重大作用大数据网络爬虫原理,本文剖析不同的审计数据的特性以及采集审计数据的方式。在传统数据采集方法基础上研究怎样基于Python借助网路爬虫采集审计数据,以为大数据审计技术的发展提供支持。
关键词:网络爬虫;数据采集;审计剖析;Python
本文为2017年安徽财贸职业学院“内涵提高全员行动计划”科学研究项目(人文社科):“大数据在审计剖析程序中的运用研究”(项目编号:2017nhrwc15)
中图分类号:F239 文献标识码:A
收录日期:2019年1月18日
一、引言
无论是国家审计还是民间审计,在现今社会经济发展过程中都起到了非常重要的作用,为经济发展“保驾护航”。大数据目前也是各国研究的重点和热点,并将大数据的研究和应用上升到了战略层次。美国注册会计师协会(AICPA)在2014年就对大数据可能对审计形成的影响进行了剖析。在全球信息化的大背景下,如何借助大数据增加审计风险,提高审计效率依然是一个十分重要的命题。2015年中共中央办公厅、国务院办公厅《关于完善审计制度若干重大问题的框架意见》及配套文件中明晰提出“构建大数据审计工作模式,构建国家审计数据系统和数字化审计平台,探索完善审计实时监督系统,实施联网审计”。刘国城、王会金(2017)将大数据审计平台拆分为采集、预处理、分析和可视化四个子平台,基于方式支撑、过程建模和运行机理等方面对各个子平台作以专项研究,旨在为大数据审计实践提供建设性思路。秦荣生(2014)指出大数据、云计算技术的形成和发展,正在逐步影响审计技术和技巧的发展。
大数据具有数据体量巨大、处理速率快、数量种类多和商业价值高的特性。被审计对象的信息化使得审计人员在审计方式上愈发的信息化,如果将这种大量的、散落的、无序的数据进行集中化、结构化,将其弄成才能便捷获得可读取的审计数据,并通过审计剖析程序发觉愈发有效和清晰的审计线索,那么大数据将会发挥重大的商业价值。由此可见,数据是审计剖析的重要前提,获取高质量数据常常就能帮助审计人员快速发觉风险点进行应对,大大提升审计的效率和疗效。目前,尚未有成熟的审计大数据搜集与整理技术,这影响了大数据在审计中使用的效率。本文将基于目前大数据的研究现况,主要阐述审计人员应该怎样借助网路爬虫技术从网路渠道获取所需审计数据,从而扩展审计数据的范围,获得更多的审计线索,提高审计剖析疗效。
二、审计大数据采集分析
(一)审计大数据类型。大数据审计区别于传统的审计模式,传统审计模式倾向于根据被审计单位提供的相关资料去鉴证其是否真实可靠。而大数据审计是一种实时审计,强调审计人员应该主动地去获取企业内部和企业外部的数据,企业内部的业务数据主要借助被审计单位提供,而外部数据,比如法律、银行、税务、供应商、客户、物流等其他数据须要审计人员去挖掘和剖析。从目前来看,审计大数据可以分为两类:一类是结构化数据,它由明晰定义的数据类型组成,比如数字、货币、日期等,其模式可以让其便于搜索。这种数据通常存储在数据库里,比如企业ERP系统中的销售数据、生产数据、财务数据等;另一类是非结构化数据,是指这些不便捷用数据库二维逻辑来表现的数据,如办公文档、文本、图片、HTML图象等,审计人员须要的外部数据以非结构化数据类型居多。
(二)审计大数据采集方法
1、直接拷贝读取。审计人员首先判定出自己须要的审计数据,然后按照被审计单位使用的财务软件(如用友、用友)的使用特性,利用软件数据库早已预设好的指令去提取转换审计人员所须要的数据,并将其保存为Excel等格式。
2、开放数据互联(ODBC)。如果被审计单位与审计人员使用的是可以对接的数据库,可以通过相关的数据访问插口访问被审计单位所使用的业务系统数据库,并将数据进行还原后转出,成为审计人员可以直接借助的数据。
3、中间文件采集。指审计人员与被审计单位约定好数据的格式,被审计单位根据要求将自己的相关数据转换成约定的格式,比如说文本文件格式,这种大部分数据库都还能直接读取的格式,从而省去了两种不同数据库对接的问题。
4、网上采集。除了被审计单位或则上级审计机关提供的相关数据以外,审计人员依然须要从被审计单位外部获得相关的工商、税务、行业、媒体等公开数据以进行多方面的审计剖析,这些数据并不是被直接提供的结构化数据,需要审计人员采用一定的方式从网上进行采集。
目前,审计数据采集大部分采用的是上述的前三种方式,往往依托一定的数据库基础,能够获得的信息大多基于被审计单位,最后一种网上采集数据的方式因为没有统一的方式和技术,耗费大量时间和经历,往往未能实现,这大大限制了审计人员进行审计剖析的范围,同时也让审计的取证率无法达到预期,从某种程度上提升了审计风险。在大数据审计背景下,审计人员执行剖析程序不能仅仅将眼光局限于内部数据,更应该从网路公开数据中获取愈发全面的信息,但是这种信息大多以网页等格式存在,难以被审计人员直接用于剖析,所以本文提出可以借助网路爬虫技术抓取网页上的信息,并整理成一定的格式,方便审计人员从海量数据中发觉审计线索,使审计剖析程序发挥更大的效用。
三、网络爬虫在审计大数据采集中的应用
网络爬虫技术又被称为网路蜘蛛,是一种根据被设定的规则手动获取网页内容的程序脚本。目前,网络爬虫技术被越来越多的运用于互联网中,它还能依据不同的程序代码设定指令,自动获取网页内任何权限的信息数据。程序开始后,按照设定程序,网络爬虫会不断地从URL抓取用户须要的内容,直到满足停止条件,并对抓取到的数据进行分类整合处理大数据网络爬虫原理,用户可以按照自己的查询需求,从中筛选自己所须要的数据。通过网路爬虫还能为大数据剖析提供更高质量的数据源。
利用网路爬虫技术施行审计剖析程序的过程主要有以下几步:首先,锁定目标。根据审计目标确定想要获取的目标数据,明确这种数据主要分布的网页是哪些;其次,目标网页剖析。为了更高效率的抓取到相关数据,要对目标网页进行结构上的剖析,主要是其数据访问的路径和逻辑;再次,数据抓取。通过选择好的软件执行命令,获得数据结果进行保存;最后,数据剖析。将通过上述程序获得的数据进行清洗,获得目标数据,可以结合例如SQL查询、Excel剖析、数据可视化等技术对数据进行进一步的剖析、扩展和确认。
利用网路爬虫技术施行审计剖析程序的原理主要是能否从被审计单位外部获取愈发充足的、高质量的审计数据,而这种数据比被审计单位提供的数据愈发可靠,同时可以将获取的新数据与被审计单位提供的内部数据进行对比,帮助审计人员扩大范围,发现更多相关线索,同时也促使审计证据愈发充分可靠。
四、网络爬虫在审计大数据采集中应用案例
XX集团有限公司创建于1957年,现已发展产生节能环保、钢铁制造及金属贸易、智能健康、教育与技术服务等产业格局的小型企业集团。截至2017年底,拥有全资及控股一级子公司34家。2017年,完成销售收入933亿元、利润25亿元,甲会计师事务所接受委托对该公司进行2017年年度财务报表审计。审计人员在审计过程中发觉该公司下一子公司有大量进行一次性交易的顾客,并且这种顾客都采用了赊购的形式,所以审计人员对这种交易形成了怀疑,认为被审计单位的应收账款“存在”认定有重大错报风险。为进一步获得审计证据,审计人员首先须要被审计单位提供数据库内关于顾客的信息并进行查验以验证这种顾客的真实性。此时,被审计单位提供信息的可靠性较差,审计人员只能考虑从外部获得审计数据进行比较剖析,从而判定顾客信息的准确性。如果考虑直接从官方网站获得具体工商数据,审计人员将面临权限受限和工作量巨大等问题。此时,网络爬虫技术才能为这一困局提供挺好的解决方案,提高工作效率。
在选择网路爬虫技术时,审计人员选择了目前应用范围相对较广的Python。相对于其他网路爬虫技术,基于Python的网路爬虫技术具有以下优点:一是简约便捷。Python语言最大的特征就是只须要一个简单的编辑器才能满足大部分用户的网路爬虫技术需求,可以使操作人员很快的适应环境,而不用耗费过多的精力;二是具有框架技术。如果所须要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强悍的模板来实现爬虫,仅仅须要根据需求进行简单的更改就可以使用,而不是去进行重新的开发。
审计人员通过Python实现了网路爬虫,从“天眼查”网站上获取相关企业的工商信息。其中部份代码如图1所示,获得的部份结果如表1、图2所示。最终审计人员通过网路爬虫技术迅速获得了审计须要的相关数据,筛选出目标企业,进一步进行了审计剖析,与被审计单位提供的有关信息进行比对,得出了其中有18家企业信息涉嫌作假,实为虚构交易的推论,为预收账款的进一步审计提供了重要审计证据。(图1、图2、表1)
五、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。本文通过研究大数据的特性,以及对审计数据的采集办法进行剖析,提出了基于Python的数据爬虫在审计数据采集中的运用,帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计剖析奠定了基础,这也为大数据在审计中的应用技术研究提供了支持。
(作者单位:安徽财贸职业学院)
主要参考文献:
[1]秦荣生.大数据、云计算技术对审计的影响研究[J].审计研究,2014(6).
[2]刘国城,王会金.大数据审计平台建立研究[J].审计研究,2017(11).
[3]韦玮.精通Python网络爬虫[M].北京机械工业出版社,2017.
数据剖析 | 基于智能标签,精准管理数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-03 19:03
腾讯:社交广告,不同用户的朋友圈或则其他媒体场景下的广告信息是不同的,会基于用户特点推荐。
头条:信息价值,根据用户浏览信息,分析用户相关喜好,针对剖析结果推荐相关的信息流,越关注某类内容,获取相关的信息越多。
如上几种场景的逻辑就是:基于不断剖析用户的行为,生成用户的特点画像,然后再基于用户标签,定制化的推荐相关内容。
2、基本概念
通过前面的场景,衍生下来两个概念:
用户画像
用户画像,作为一种描绘目标用户、联系用户诉求与设计方向的有效工具,把该用户相关联的数据的可视化的诠释,就产生了用户画像。用户画像在各领域得到了广泛的应用,最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
标签数据
标签在生活中十分常见,比如商品标签,个人标签,行业标签,例如提及996就想到程序员,提到程序员就想到格子衫。
标签是把分散的多方数据进行整合划入统一的技术平台,并对那些数据进行标准化和细分,进行结构化储存和更新管理,让业务线可以把这种细分结果推向现有的互动营销环境里的平台,产生价值,这些数据称为标签数据,也就是常说的标签库。数据标签的概念也是在近来几年大数据的发展中不断火爆上去的。
标签价值
标签的核心价值,或者说最常用的场景:实时智能推荐,精准化数字营销。
二、数据标签1、标签界定
属性标签
属性标签是变化最小的,例如用户实名认证以后,基于身分信息获取相关:性别,生日,出生年月,年龄,等相关标签。变动频度小,且最具有精准性。
行为标签
行为标签就是用户通过在产品上的一系列操作,基于行为日志剖析得出:例如订购能力、消费爱好、季节性消费标签等。在信息流的APP上,通过相关浏览行为,不断推荐用户感兴趣的内容就是基于该逻辑。
规则标签
根据业务场景需求,配置指定规则,基于规则生成剖析结果,例如:
这类标签可以基于动态的规则配置,经过估算和剖析,生成描述结果,也就是规则标签。
拟合标签
拟合类的标签最具有复杂性,通过用户上述几种标签,智能组合剖析,给的预测值,例如:未婚、浏览相关婚宴内容,通过剖析预测用户即将举行婚宴,得到一个拟合结果:预测即将订婚。这个预测逻辑也可以反向执行,用户订购小孩用具:预测未婚已育。
这就是数据时代常说的一句话:用户在某个应用上一通操作过后,算法剖析的结果可能比用户对自己的描述还要真实。
2、标签加工流程
数据采集
数据采集的渠道相对较多,比如同一APP内的各类业务线:购物、支付、理财、外卖、信息浏览等等。通过数据通道传输到统一的数据聚合平台。有了这种海量日志数据的支撑,才具有数据剖析的基础条件。不管是数据智能,深度学习,算法等都是构建在海量数据的基础条件上,这样就能获取具有价值的剖析结果。
数据加工
结合如上业务,通过对海量数据的加工,分析和提取,获取相对精准的用户标签,这里还有关键的一步,就是对已有的用户标签进行不断的验证和修补,尤其是规则类和拟合类的相关标签。
标签库
通过标签库,管理复杂的标签结果,除了复杂的标签,和基于时间线的标签变,标签数据到这儿,已经具有相当大的价值,可以围绕标签库开放一些收费服务,例如常见的,用户在某电商APP浏览个别商品,可以在某信息流平台见到商品推荐。大数据时代就是如此令人觉得智能和窒息。
标签业务
数据走了一大圈转换成标签,自然还是要回归到业务层面,通过对标签数据的用户的剖析,可以进行精准营销,和智能推荐等相关操作,电商应用中可以提升成交量,信息流中可以更好的吸引用户。
应用层
把上述业务开发成服务,集成到具有的应用层面,不断提高应用服务的质量,不断的吸引用户,提供服务。当然用户的数据不断在应用层面形成,在转入数据采集服务中,最终产生完整的闭环流程。
3、应用案例
从流程和业务层面描述都是简单的,到开发层面就会显得复杂和不好处理,这可能就是产品和开发之间的芥蒂。
标签的数据类型
不同标签的剖析结果须要用不同的数据类型描述智能标签采集器,在标签体系中,常用描述标签的数据类型如下:枚举、数值、日期、布尔、文本类型。不同的类型须要不一样的剖析流程。
商品和标签
这里提供一个基础案例,用商品的标签来剖析商品,例如通过商品产地,价格,状态等条件,来查询产品库有多少符合条件的商品。
数据表设计
主要分四张表:标签分类智能标签采集器,标签库,标签值,标签数据。
CREATE TABLE `tc_tag_catalog` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '名称',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签层级目录';
CREATE TABLE `tc_tag_cloud` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_id` INT (11) NOT NULL COMMENT '目录ID',
`tag_name` VARCHAR (100) DEFAULT '' COMMENT '标签名称',
`tag_code` INT (11) DEFAULT NULL COMMENT '标签编码',
`bind_column` VARCHAR (100) DEFAULT '' COMMENT '绑定数据列',
`data_type` INT (2) NOT NULL COMMENT '1枚举,2数值,3日期,4布尔,5值类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR (150) DEFAULT NULL COMMENT '备注',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签云';
CREATE TABLE `tc_tag_data_enum` (
`tag_code` INT (11) NOT NULL COMMENT '标签编码',
`data_value` VARCHAR (150) NOT NULL COMMENT '枚举值',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
KEY `tag_code_index` (`tag_code`) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签枚举值';
CREATE TABLE `tc_tag_data_set` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`product_name` VARCHAR (100) DEFAULT '' COMMENT '商品名称',
`unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT '单价',
`is_shelves` INT (1) DEFAULT '1' COMMENT '是否上架:1否,2是',
`origin_place` VARCHAR (100) DEFAULT '' COMMENT '产地',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签数据集';
模拟入参插口
这里的参数应当是基于需求,动态选定,进行组织到一起:
例如图片中这儿给定的标签值列表,称为枚举值。
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List tagParamList = new ArrayList() ;
TagParam tagParam1 = new TagParam(1,"产地","origin_place") ;
List valueList1 = new ArrayList() ;
valueList1.add("深圳");
valueList1.add("广东");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"价格","unit_price") ;
List valueList2 = new ArrayList() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"生产日期","create_time") ;
List valueList3 = new ArrayList() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"是否上架","is_shelves") ;
List valueList4 = new ArrayList() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"产品名称","product_name") ;
List valueList5 = new ArrayList() ;
valueList5.add("智能");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result:" + count ;
}
}
参数解析查询
通过对参数的解析,最终产生查询的SQL句子,获取精准的结果数据。
@Service
public class TagDataSetServiceImpl extends ServiceImpl implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1枚举,2数值,3日期,4布尔,5值类型
List valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* 最终执行的 SQL
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('深圳', '广东')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%智能%'
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
可能有人会说这不就是个查询流程吗?如果有这样的疑惑,把上述案例换成用户查询,标签数据的价值会更直观。
三、智能画像1、基本概念
用户画像
作为一种绘制目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
行业画像
通过行业属性标签,行业下用户标签的综合剖析,生成行业剖析报告,提供极有价值的导向,这是最近两年非常热门的应用。
画像补全
通过不断剖析用户数据,丰富标签库,使用户的画像愈发丰富立体。
2、画像报告
通过标签数据的剖析,生成一份剖析报告,报告内容包含丰富的用户标签统计数据。
例如:90后画像报告
这个报告,互联网用户一定或多或少都听到过。主要是一些标签统计,共性标签展示,或者什么群体对80后三观影响最大,收入来源,学历等各类剖析评析。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent 查看全部
头条:信息价值,根据用户浏览信息,分析用户相关喜好,针对剖析结果推荐相关的信息流,越关注某类内容,获取相关的信息越多。
如上几种场景的逻辑就是:基于不断剖析用户的行为,生成用户的特点画像,然后再基于用户标签,定制化的推荐相关内容。
2、基本概念
通过前面的场景,衍生下来两个概念:
用户画像
用户画像,作为一种描绘目标用户、联系用户诉求与设计方向的有效工具,把该用户相关联的数据的可视化的诠释,就产生了用户画像。用户画像在各领域得到了广泛的应用,最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
标签数据
标签在生活中十分常见,比如商品标签,个人标签,行业标签,例如提及996就想到程序员,提到程序员就想到格子衫。
标签是把分散的多方数据进行整合划入统一的技术平台,并对那些数据进行标准化和细分,进行结构化储存和更新管理,让业务线可以把这种细分结果推向现有的互动营销环境里的平台,产生价值,这些数据称为标签数据,也就是常说的标签库。数据标签的概念也是在近来几年大数据的发展中不断火爆上去的。
标签价值
标签的核心价值,或者说最常用的场景:实时智能推荐,精准化数字营销。
二、数据标签1、标签界定
属性标签
属性标签是变化最小的,例如用户实名认证以后,基于身分信息获取相关:性别,生日,出生年月,年龄,等相关标签。变动频度小,且最具有精准性。
行为标签
行为标签就是用户通过在产品上的一系列操作,基于行为日志剖析得出:例如订购能力、消费爱好、季节性消费标签等。在信息流的APP上,通过相关浏览行为,不断推荐用户感兴趣的内容就是基于该逻辑。
规则标签
根据业务场景需求,配置指定规则,基于规则生成剖析结果,例如:
这类标签可以基于动态的规则配置,经过估算和剖析,生成描述结果,也就是规则标签。
拟合标签
拟合类的标签最具有复杂性,通过用户上述几种标签,智能组合剖析,给的预测值,例如:未婚、浏览相关婚宴内容,通过剖析预测用户即将举行婚宴,得到一个拟合结果:预测即将订婚。这个预测逻辑也可以反向执行,用户订购小孩用具:预测未婚已育。
这就是数据时代常说的一句话:用户在某个应用上一通操作过后,算法剖析的结果可能比用户对自己的描述还要真实。
2、标签加工流程
数据采集
数据采集的渠道相对较多,比如同一APP内的各类业务线:购物、支付、理财、外卖、信息浏览等等。通过数据通道传输到统一的数据聚合平台。有了这种海量日志数据的支撑,才具有数据剖析的基础条件。不管是数据智能,深度学习,算法等都是构建在海量数据的基础条件上,这样就能获取具有价值的剖析结果。
数据加工
结合如上业务,通过对海量数据的加工,分析和提取,获取相对精准的用户标签,这里还有关键的一步,就是对已有的用户标签进行不断的验证和修补,尤其是规则类和拟合类的相关标签。
标签库
通过标签库,管理复杂的标签结果,除了复杂的标签,和基于时间线的标签变,标签数据到这儿,已经具有相当大的价值,可以围绕标签库开放一些收费服务,例如常见的,用户在某电商APP浏览个别商品,可以在某信息流平台见到商品推荐。大数据时代就是如此令人觉得智能和窒息。
标签业务
数据走了一大圈转换成标签,自然还是要回归到业务层面,通过对标签数据的用户的剖析,可以进行精准营销,和智能推荐等相关操作,电商应用中可以提升成交量,信息流中可以更好的吸引用户。
应用层
把上述业务开发成服务,集成到具有的应用层面,不断提高应用服务的质量,不断的吸引用户,提供服务。当然用户的数据不断在应用层面形成,在转入数据采集服务中,最终产生完整的闭环流程。
3、应用案例
从流程和业务层面描述都是简单的,到开发层面就会显得复杂和不好处理,这可能就是产品和开发之间的芥蒂。
标签的数据类型
不同标签的剖析结果须要用不同的数据类型描述智能标签采集器,在标签体系中,常用描述标签的数据类型如下:枚举、数值、日期、布尔、文本类型。不同的类型须要不一样的剖析流程。
商品和标签
这里提供一个基础案例,用商品的标签来剖析商品,例如通过商品产地,价格,状态等条件,来查询产品库有多少符合条件的商品。
数据表设计
主要分四张表:标签分类智能标签采集器,标签库,标签值,标签数据。
CREATE TABLE `tc_tag_catalog` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '名称',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签层级目录';
CREATE TABLE `tc_tag_cloud` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_id` INT (11) NOT NULL COMMENT '目录ID',
`tag_name` VARCHAR (100) DEFAULT '' COMMENT '标签名称',
`tag_code` INT (11) DEFAULT NULL COMMENT '标签编码',
`bind_column` VARCHAR (100) DEFAULT '' COMMENT '绑定数据列',
`data_type` INT (2) NOT NULL COMMENT '1枚举,2数值,3日期,4布尔,5值类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR (150) DEFAULT NULL COMMENT '备注',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签云';
CREATE TABLE `tc_tag_data_enum` (
`tag_code` INT (11) NOT NULL COMMENT '标签编码',
`data_value` VARCHAR (150) NOT NULL COMMENT '枚举值',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
KEY `tag_code_index` (`tag_code`) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签枚举值';
CREATE TABLE `tc_tag_data_set` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`product_name` VARCHAR (100) DEFAULT '' COMMENT '商品名称',
`unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT '单价',
`is_shelves` INT (1) DEFAULT '1' COMMENT '是否上架:1否,2是',
`origin_place` VARCHAR (100) DEFAULT '' COMMENT '产地',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签数据集';
模拟入参插口
这里的参数应当是基于需求,动态选定,进行组织到一起:
例如图片中这儿给定的标签值列表,称为枚举值。
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List tagParamList = new ArrayList() ;
TagParam tagParam1 = new TagParam(1,"产地","origin_place") ;
List valueList1 = new ArrayList() ;
valueList1.add("深圳");
valueList1.add("广东");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"价格","unit_price") ;
List valueList2 = new ArrayList() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"生产日期","create_time") ;
List valueList3 = new ArrayList() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"是否上架","is_shelves") ;
List valueList4 = new ArrayList() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"产品名称","product_name") ;
List valueList5 = new ArrayList() ;
valueList5.add("智能");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result:" + count ;
}
}
参数解析查询
通过对参数的解析,最终产生查询的SQL句子,获取精准的结果数据。
@Service
public class TagDataSetServiceImpl extends ServiceImpl implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1枚举,2数值,3日期,4布尔,5值类型
List valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* 最终执行的 SQL
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('深圳', '广东')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%智能%'
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
可能有人会说这不就是个查询流程吗?如果有这样的疑惑,把上述案例换成用户查询,标签数据的价值会更直观。
三、智能画像1、基本概念
用户画像
作为一种绘制目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
行业画像
通过行业属性标签,行业下用户标签的综合剖析,生成行业剖析报告,提供极有价值的导向,这是最近两年非常热门的应用。
画像补全
通过不断剖析用户数据,丰富标签库,使用户的画像愈发丰富立体。
2、画像报告
通过标签数据的剖析,生成一份剖析报告,报告内容包含丰富的用户标签统计数据。
例如:90后画像报告
这个报告,互联网用户一定或多或少都听到过。主要是一些标签统计,共性标签展示,或者什么群体对80后三观影响最大,收入来源,学历等各类剖析评析。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent 查看全部
腾讯:社交广告,不同用户的朋友圈或则其他媒体场景下的广告信息是不同的,会基于用户特点推荐。
头条:信息价值,根据用户浏览信息,分析用户相关喜好,针对剖析结果推荐相关的信息流,越关注某类内容,获取相关的信息越多。
如上几种场景的逻辑就是:基于不断剖析用户的行为,生成用户的特点画像,然后再基于用户标签,定制化的推荐相关内容。
2、基本概念
通过前面的场景,衍生下来两个概念:
用户画像
用户画像,作为一种描绘目标用户、联系用户诉求与设计方向的有效工具,把该用户相关联的数据的可视化的诠释,就产生了用户画像。用户画像在各领域得到了广泛的应用,最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
标签数据
标签在生活中十分常见,比如商品标签,个人标签,行业标签,例如提及996就想到程序员,提到程序员就想到格子衫。
标签是把分散的多方数据进行整合划入统一的技术平台,并对那些数据进行标准化和细分,进行结构化储存和更新管理,让业务线可以把这种细分结果推向现有的互动营销环境里的平台,产生价值,这些数据称为标签数据,也就是常说的标签库。数据标签的概念也是在近来几年大数据的发展中不断火爆上去的。
标签价值
标签的核心价值,或者说最常用的场景:实时智能推荐,精准化数字营销。
二、数据标签1、标签界定
属性标签
属性标签是变化最小的,例如用户实名认证以后,基于身分信息获取相关:性别,生日,出生年月,年龄,等相关标签。变动频度小,且最具有精准性。
行为标签
行为标签就是用户通过在产品上的一系列操作,基于行为日志剖析得出:例如订购能力、消费爱好、季节性消费标签等。在信息流的APP上,通过相关浏览行为,不断推荐用户感兴趣的内容就是基于该逻辑。
规则标签
根据业务场景需求,配置指定规则,基于规则生成剖析结果,例如:
这类标签可以基于动态的规则配置,经过估算和剖析,生成描述结果,也就是规则标签。
拟合标签
拟合类的标签最具有复杂性,通过用户上述几种标签,智能组合剖析,给的预测值,例如:未婚、浏览相关婚宴内容,通过剖析预测用户即将举行婚宴,得到一个拟合结果:预测即将订婚。这个预测逻辑也可以反向执行,用户订购小孩用具:预测未婚已育。
这就是数据时代常说的一句话:用户在某个应用上一通操作过后,算法剖析的结果可能比用户对自己的描述还要真实。
2、标签加工流程
数据采集
数据采集的渠道相对较多,比如同一APP内的各类业务线:购物、支付、理财、外卖、信息浏览等等。通过数据通道传输到统一的数据聚合平台。有了这种海量日志数据的支撑,才具有数据剖析的基础条件。不管是数据智能,深度学习,算法等都是构建在海量数据的基础条件上,这样就能获取具有价值的剖析结果。
数据加工
结合如上业务,通过对海量数据的加工,分析和提取,获取相对精准的用户标签,这里还有关键的一步,就是对已有的用户标签进行不断的验证和修补,尤其是规则类和拟合类的相关标签。
标签库
通过标签库,管理复杂的标签结果,除了复杂的标签,和基于时间线的标签变,标签数据到这儿,已经具有相当大的价值,可以围绕标签库开放一些收费服务,例如常见的,用户在某电商APP浏览个别商品,可以在某信息流平台见到商品推荐。大数据时代就是如此令人觉得智能和窒息。
标签业务
数据走了一大圈转换成标签,自然还是要回归到业务层面,通过对标签数据的用户的剖析,可以进行精准营销,和智能推荐等相关操作,电商应用中可以提升成交量,信息流中可以更好的吸引用户。
应用层
把上述业务开发成服务,集成到具有的应用层面,不断提高应用服务的质量,不断的吸引用户,提供服务。当然用户的数据不断在应用层面形成,在转入数据采集服务中,最终产生完整的闭环流程。
3、应用案例
从流程和业务层面描述都是简单的,到开发层面就会显得复杂和不好处理,这可能就是产品和开发之间的芥蒂。
标签的数据类型
不同标签的剖析结果须要用不同的数据类型描述智能标签采集器,在标签体系中,常用描述标签的数据类型如下:枚举、数值、日期、布尔、文本类型。不同的类型须要不一样的剖析流程。
商品和标签
这里提供一个基础案例,用商品的标签来剖析商品,例如通过商品产地,价格,状态等条件,来查询产品库有多少符合条件的商品。
数据表设计
主要分四张表:标签分类智能标签采集器,标签库,标签值,标签数据。
CREATE TABLE `tc_tag_catalog` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_name` VARCHAR (50) NOT NULL DEFAULT '' COMMENT '名称',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签层级目录';
CREATE TABLE `tc_tag_cloud` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`catalog_id` INT (11) NOT NULL COMMENT '目录ID',
`tag_name` VARCHAR (100) DEFAULT '' COMMENT '标签名称',
`tag_code` INT (11) DEFAULT NULL COMMENT '标签编码',
`bind_column` VARCHAR (100) DEFAULT '' COMMENT '绑定数据列',
`data_type` INT (2) NOT NULL COMMENT '1枚举,2数值,3日期,4布尔,5值类型',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
`remark` VARCHAR (150) DEFAULT NULL COMMENT '备注',
`state` INT (1) DEFAULT '1' COMMENT '状态1启用,2禁用',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签云';
CREATE TABLE `tc_tag_data_enum` (
`tag_code` INT (11) NOT NULL COMMENT '标签编码',
`data_value` VARCHAR (150) NOT NULL COMMENT '枚举值',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
KEY `tag_code_index` (`tag_code`) USING BTREE
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签枚举值';
CREATE TABLE `tc_tag_data_set` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`product_name` VARCHAR (100) DEFAULT '' COMMENT '商品名称',
`unit_price` DECIMAL (10, 2) DEFAULT '0.00' COMMENT '单价',
`is_shelves` INT (1) DEFAULT '1' COMMENT '是否上架:1否,2是',
`origin_place` VARCHAR (100) DEFAULT '' COMMENT '产地',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '标签数据集';
模拟入参插口
这里的参数应当是基于需求,动态选定,进行组织到一起:
例如图片中这儿给定的标签值列表,称为枚举值。
@RestController
public class AnalyzeController {
@Resource
private TagDataSetService tagDataSetService ;
@GetMapping("/analyze")
public String analyze (){
List tagParamList = new ArrayList() ;
TagParam tagParam1 = new TagParam(1,"产地","origin_place") ;
List valueList1 = new ArrayList() ;
valueList1.add("深圳");
valueList1.add("广东");
tagParam1.setValueList(valueList1);
tagParamList.add(tagParam1) ;
TagParam tagParam2 = new TagParam(2,"价格","unit_price") ;
List valueList2 = new ArrayList() ;
valueList2.add("1999");
tagParam2.setValueList(valueList2);
tagParamList.add(tagParam2) ;
TagParam tagParam3 = new TagParam(3,"生产日期","create_time") ;
List valueList3 = new ArrayList() ;
valueList3.add("2020-05-01 13:43:54");
tagParam3.setValueList(valueList3);
tagParamList.add(tagParam3) ;
TagParam tagParam4 = new TagParam(4,"是否上架","is_shelves") ;
List valueList4 = new ArrayList() ;
valueList4.add("1");
tagParam4.setValueList(valueList4);
tagParamList.add(tagParam4) ;
TagParam tagParam5 = new TagParam(5,"产品名称","product_name") ;
List valueList5 = new ArrayList() ;
valueList5.add("智能");
tagParam5.setValueList(valueList5);
tagParamList.add(tagParam5) ;
Integer count = tagDataSetService.analyze(tagParamList) ;
return "Result:" + count ;
}
}
参数解析查询
通过对参数的解析,最终产生查询的SQL句子,获取精准的结果数据。
@Service
public class TagDataSetServiceImpl extends ServiceImpl implements TagDataSetService {
@Resource
private TagDataSetMapper tagDataSetMapper ;
@Override
public Integer analyze(List tagParamList) {
StringBuffer querySQL = new StringBuffer() ;
for (TagParam tagParam:tagParamList){
querySQL.append(" AND ") ;
querySQL.append(tagParam.getBindColumn()) ;
// 1枚举,2数值,3日期,4布尔,5值类型
List valueList = tagParam.getValueList();
switch (tagParam.getDataType()){
case 1:
querySQL.append(" IN (") ;
for (int i = 0 ; i < valueList.size() ;i++){
if (i != valueList.size()-1){
querySQL.append("'").append(valueList.get(i)).append("',");
} else {
querySQL.append("'").append(valueList.get(i)).append("'");
}
}
querySQL.append(" )") ;
break;
case 2:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 3:
querySQL.append(">='").append(tagParam.getValueList().get(0)).append("'") ;
break;
case 4:
querySQL.append("=").append(tagParam.getValueList().get(0)) ;
break;
case 5:
querySQL.append(" LIKE '%").append(tagParam.getValueList().get(0)).append("%'") ;
break;
default:
break;
}
}
/* 最终执行的 SQL
SELECT COUNT(*) FROM tc_tag_data_set
WHERE 1 = 1
AND origin_place IN ('深圳', '广东')
AND unit_price = 1999
AND create_time >= '2020-05-01 13:43:54'
AND is_shelves = 1
AND product_name LIKE '%智能%'
*/
String whereCondition = String.valueOf(querySQL);
return tagDataSetMapper.analyze(whereCondition);
}
}
可能有人会说这不就是个查询流程吗?如果有这样的疑惑,把上述案例换成用户查询,标签数据的价值会更直观。
三、智能画像1、基本概念
用户画像
作为一种绘制目标用户、联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。最初是在电商领域得到应用的,在大数据时代背景下,用户信息参杂在网路中,将用户的每位具体信息具象成标签,利用这种标签将用户形象具体化,从而为用户提供有针对性的服务。
行业画像
通过行业属性标签,行业下用户标签的综合剖析,生成行业剖析报告,提供极有价值的导向,这是最近两年非常热门的应用。
画像补全
通过不断剖析用户数据,丰富标签库,使用户的画像愈发丰富立体。
2、画像报告
通过标签数据的剖析,生成一份剖析报告,报告内容包含丰富的用户标签统计数据。
例如:90后画像报告
这个报告,互联网用户一定或多或少都听到过。主要是一些标签统计,共性标签展示,或者什么群体对80后三观影响最大,收入来源,学历等各类剖析评析。
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent
聚焦爬虫常见算法剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-05-17 08:02
电脑知识与技术 数据库与信息管理 聚焦爬虫常见算法剖析 陈 丽 君 (浙江越秀外国语学院 浙江湖州 312000) [摘 要] 聚焦爬虫收集与特定主题相关的页面,为搜索引擎建立页面集。传统的聚焦爬虫采用向量空间模型和局部搜索算法,精确 率和召回率都比较低。文章分析了聚焦爬虫存在的问题及其相应的解决方式。最后对未来的研究方向进行了展望。 [关键词] 搜索引擎; 聚焦爬虫; 算法 不同于google、百度等通用搜索引擎,聚焦爬虫(也称为主题 爬虫)是一个能下载相关Web页的程序或自动化脚本。随着Web 页面的迅速攀升和特定领域搜索的需求,近年来,聚焦爬虫在工业 和学术界造成了广泛关注。 第一个聚焦爬虫是Chakrabarti于1999提出的[1]。聚焦爬虫一 般由两种算法来保证抓取特定领域的信息,一是Web剖析算法, 依据URL的指向判定Web页面的相关程度和质量;二是Web搜索 算法,它决定着被爬取URL的最佳顺序。 一、常见算法 1.Web页面剖析算法 目前,已出现了许多页面剖析算法,一般可以分为两大类: 基于内容的和基于链接结构的。前者通过剖析一个实际Web页的 HTML文档,来获取关于页面自身的相关性信息。
例如,在文档索 引技术的帮助下,可以从文档中抽取关键词或句子,依此确定该 文档是否与指定域相关。另外,也可以用VSM(向量空间模型) 与指定域的标准文档比较。对于前者,相关研究者发觉,Web链 接结构中包含有许多制作者蕴涵的信息,而这种信息对剖析文档 的相关性和质量起着重要作用。例如,当一个页面A指向另一个页 面B时,就意味着A页面的作者暗示着页面B也富含类似的内容。另 外,页面包含的接入链接越多就意味着该页面越重要。基于链接分 析的算法主要有PageRank和HITS。 2.Web搜索算法 该算法的主要目的是确定最优的URL访问顺序。与页面剖析算法 一样,搜索也有许多算法,以Breadth-first和Best-first最为流行。 2.1 Breadth-first搜索 该算法的思想比较简单,所有在当前层中的URL还会根据上一 层中它们被发觉的次序访问,其最大特征是不分辨页面的质量和主 题,所以最适合于通用搜索。但最近也有研究[2]表明,如果假定 当前层中的所有URL都是与主题相关的,那么它们的下一层URL也 会与主题相关。这样,Breadth-first就可用作收集一定质量的主题 相关页面,即聚焦搜索算法。
但是,当抓取相当数目的页面后,该算法会引入许多噪声信息 (非相关信息),或形成主题甩尾现象。已有研究人员提出将此算 法与页面剖析算法相结合[4],先用Breadth-first收集页面,再用页 面剖析算法过滤掉不相关的页面,这样即使降低了噪声信息,但降 低了算法的效率。 2.2 Best-first搜索 该算法目前比较流行。与Breadth-first不同,该算法不是简单 地根据被发觉的顺序访问,而是采用某种启发式思想(比如页面分 析的结果)来调整URL在队列中的排序,排在后面的被觉得是与主 题更接近的页面,要优先访问,反之,则推后甚至不被访问。因 此,Best-first搜索显著要比Breadth-first搜索更优越。 并且,Best-first是一个局部搜索算法,它只关心以前访问节 点周围的页面空间,因此会丧失许多相关页面,最后收集的页面质 量也不会很高。 二、存在问题 1.页面剖析算法 页面剖析是聚焦爬虫的重要组成部份,如果页面剖析算法对页 面的判定不够确切,将会影响到搜索算法,导致搜集到页面的质量 偏低。因此,实现一个高效的页面剖析算法是做好聚焦爬虫的第一 步。
Web文档一般富含噪声,比如极少数的文本、图像、脚本等 对分类器没用的数据。而且,不同制作者在风格、语言、结构上 存在很大的差别。因此,采用简单的相似性函数(如tf-idf等)的 VSM很难取得令人满意的疗效。 一种解决的方式是,组合各类基于内容的相似性测度方式,可 以提升分类的准确率[4]。比如遗传算法等全局搜索模式也是一种 潜在的解决方案。 2.局部搜索算法 局部搜索算法的特征是,访问当初访问过节点周围的邻居节 点,这样假如一个相关页没有被现有URL所指向,那么聚焦爬虫就 会丧失对这个相关页面的访问。而且,如果在两个相关页面中间隔 有不相关的页面,聚焦爬虫也会舍弃对后一个相关页面的访问。因 此,采用局部搜索算法的聚焦爬虫只能够发觉围绕在起始种子集周 围的相关页面,它们仅仅是整个Web相关页面集的有限子集,而 丧失了该子集外的相关页面。 通过对Web结构的研究,人们发觉了Web社区[3],也即在线 的Web页自然地按照特定的链接结构分成了不同的组,组内页面 都接近于个别主题或兴趣。聚焦爬虫的目的就是要获取所有的属于 那些相关社区的页面,然而,Web社区的以下三种特点,使得局 部搜索算法不再适用于集聚爬虫。
(1)主题相像的社区之间,采用的不是直接的互相链接,而 是互相引用的关系。在商业领域,这是一个相当普遍现象。例如, Yahoo新闻、MSN新闻、Google新闻都提供相同或相像的新闻信 Algorithm Analysis of Focused Crawler Chen Lijun (Zhejiang Yuexiu University of Foreign Languages, Shaoxing Zhejing 312000, China) Abstract: Focused crawlers can selectively retrieve web documents relevant to a specific domain to build collections for domain- specific search engines. Traditional focused crawlers normally adopting the simple Vector Space Model and local Web search algorithms typically only find relevant Web pages with low precision and recall. This work describes and analyses problems associated with traditional focused crawlers and some potential solutions. The future directions are addressed. Key words: search engine; focused crawler; algorithm 笔记本知识与技术 数据库与信息管理 息,但因为竞争关系,它们并不包含彼此之间的链接。
因此,即使 它们都被作为相关Web社区的起始页面种子集,聚焦爬虫还是会 丧失一些相关的页面。 (2)相关页面之间可能被非相关的社区所隔断。有研究表 明,大多数相关域就会被起码1~12个非相关页面所分隔,平均非 相关间隔页面数为5,而聚焦爬虫在碰到非相关页面后不会继续访 问后续的页面,造成了大量相关页面的流失。 (3)虽然链接在相关页面间存在,但不是互相的单向链接, 而是双向的。也即两个相关的社区A和B,A和B之间存在着链接, 并且仅仅是一个方向的,比如只有从A到B的链接,而不存在从B到 A的链接。这样,当爬行顺序从A开始时网络爬虫算法书籍,B社区同样能被发觉,但 若爬行顺序是从B开始时,则A社区就不能从B中被发觉,造成A中 的相关页流失。 三、 解决方式 一种最简单的解决方式是提供更多的起始种子集,但这样也增 加了成本和时间,而且随着Web页面的迅速降低,这种解决方式 并不可取。 另一种解决方式是采用隧道技术[5],它基于启发式方法解决 简单的全局优化问题。当聚焦爬虫遇见非相关的页面时,不是马上 舍弃继续搜索,而是在一定搜索深度(该值须要事先指定)范围内 继续搜索。
相关实验结果表明,隧道技术能发觉更多的相关页面, 并且,由于它没有改变局部搜索的本性,不能从根本上解决问题。 同时,噪音也被引入进来,降低了页面搜集质量。 研究人员通过对Web规模的研究发觉,主要搜索引擎之间索引 的重叠内容极少,因此,可以组合各类不同搜索引擎搜索结果中比 较靠前的结果,也就是元搜索技术,来解决局部搜索导致的问题。 四、未来展望 近些年来,研究人员发觉Web信息的分布存在一定的相似性, 因而考虑先进行训练,使爬虫具备一定的“经验知识”,通过这种 知识预测将来的回报。比如McCallum[6]引入巩固学习过程,先利 用巩固学习算法估算每位链接的回报价值Q,用Q值相同或相仿的 链接文本信息训练一个贝叶斯分类器,再对未知的链接文本,用该 分类器估算链接属于该类的机率,并借此机率为权重估算链接的综 合价值。也可以借助“智能搜索”技术,通过在线学习链接结构特 征,用于指导搜索过程。 五、结语 随着网页呈指数级的快速下降,以及人们对搜索结果精度要求的 不断提升,新的算法不断涌现,如基于机器学习的剖析算法、相似性 判定的遗传算法等。相信在研究人员的继续努力下,还会出现更多更 加确切、更加快速的新算法,不断增强人们对搜索结果的满意度。
参考文献: [1] Chakrabarti, S., Berg, M.V.D., and Dom, B., Focused crawling: A New Approach to Topic-Sepcific Web Resouce Discovery. In Proceedings of the 8th International WWW Conf. 1999.Toronto, Canada. [2] Najork, M. and Wiener, J.L., Breadth-First Search Crawling Yields High-Quality Pages. In Proceedings of the 10th International WWW Conf. 2001. Hong Kong, China. [3] Flake, G.W., Lawrence, S., and Giles, C.L., Efficient Identification of Web Communities. In Proceediings of the 6 th ACM SIGKDD International Conf. 2000. Massachusetts, USA. [4] Qin, J. and Chen, H., Using Genetic Algorithm in Building Domain-Specific Collections: An Experiment in the Nanotechnology Domain. In Proceedings of the 38th Annual Hawaii International Conf. 2005. Hawaii, USA. [5] Bergmark, D., Lagoze, C., and Sbityakov, A., Focused Crawls, Tunneling, and Digital Libraries. In Porceedings of the 6th European Conf. 2002. Rome, Italy. [6] Rennie J, McCallum A. Using Reinforcement Learning to Spider the Web Efficiently. In Proc. of the International Conference on Machine Learning(ICML’99),1999. 取系数绝对值较大法适宜小波变换后的HL频带图象、LH频 带图象、HH频带图象等高频成份较丰富,亮度、对比度较高的图 象;融合图象中基本保留源图象的特点,图像对比度与源图象基本 相同。
小波变换的作用是对讯号解相关,并将讯号的全部信息集中 到一部分具有大幅值的小波系数中。这些大的小波系数富含的能量 远比小系数富含的能量大,从而在讯号的构建中,大的系数比小的 系数更重要。 3.3 一致性检查 图象中相邻象素点之间可能存在着空间冗余,因此空间上相邻 的点太可能属于同一图象的特点,因此应当对它们采用同一种方式 进行估算。根据这一思想,H.Li等提出用大多数原则对决策因子d 进行一致性检查。如果融合后的图象C在某个区域的中心点上的系 数来自于源图象A,而该点周围的点的系数均来自于源图象B,则 将中心点的系数替换为图象B的系数。 3.4 综合方式 源图象A,B分别进行小波分解,对小波变换后的LL频带图象 采取加权平均法,为了提升图象的质量,还可以在加权平均后采 用高斯低通滤波。对LH频带、HL频带、HH频带采用取系数绝对值 较大法,即取源图象A,B中小波系数较大的作为C的小波系数。另 外,为了尽量避开引入噪音,还应进行一致性检查,即若C上某点 的小波系数取自源图象A,而其周围的点均取自源图象B,则将该 点的小波系数改为源图象B的小波系数。 4 图像融合的现况及发展前景 近些年来,虽然图象融合技术发展迅速,但这仍是个没有统一理 论框架的新领域。
首先,影响图象融合疗效的诱因好多,例如,融 合算法的选定、小波基的选定以及小波分解层数的选择等;其次, 须要构建客观的图象融合技术评价标准;最后,特征级图象融和决 策级图象融合还有待长足的发展。 现有研究结果显示,对不同的频带采用了不同的融合算法结果 表明,对于低频部份采用加权方式较好,对于高频部份采用带一致 性检查的系数绝对值较大法融合疗效较好。 5 结束语 多传感图象融合技术作为信息融合研究领域的一项重要内 容网络爬虫算法书籍,将会在军事、遥感、机器人视觉和医学图象处理等领域得到广 泛应用。 参考文献: [1] 李敏,张小英,毛捷. 基于邻域残差加权平均的小波图象融合 [J]. 理论与技巧,2008,27(1):5-6 [2] 王攀峰,杜云飞,周海芳,杨学军. 基于复小波变换的遥感图象并行 融合算法 [J]. 计算机工程与科学,2008,30(3):35-39 [3] 闫敬文. 数字图像处理(MATLAB版)[M]. 国防工业出版社,2007. [4] 曹杰,龚声蓉,刘纯平. 一种新的基于小波变换的多聚焦图象融 合算法[J]. 计算机工程与应用,2007,43(24):47-50 [5] 任娜,郭敏,胡丽华,张景虎. 基于图象块分割及小波空间频度 的多聚焦图象融合法[J]. 科学技术与工程,2008,8(2):411-414 [6] 成礼智,王红霞,罗永. 小波的理论与应用[M]. 科学出版社,2006. [7] 蔡娜,姚志强,沙晋明. 基于小波变换的遥感图象融合方式[J]. 莆田学院学报,2008,15(2):79-82 [8] 胡钢,秦新强,田径. 像素级多传感图象融合技术[J]. 沈阳工 程学院学报,2007,3(2):148-152 (上接42页) 查看全部
例如,在文档索 引技术的帮助下,可以从文档中抽取关键词或句子,依此确定该 文档是否与指定域相关。另外,也可以用VSM(向量空间模型) 与指定域的标准文档比较。对于前者,相关研究者发觉,Web链 接结构中包含有许多制作者蕴涵的信息,而这种信息对剖析文档 的相关性和质量起着重要作用。例如,当一个页面A指向另一个页 面B时,就意味着A页面的作者暗示着页面B也富含类似的内容。另 外,页面包含的接入链接越多就意味着该页面越重要。基于链接分 析的算法主要有PageRank和HITS。 2.Web搜索算法 该算法的主要目的是确定最优的URL访问顺序。与页面剖析算法 一样,搜索也有许多算法,以Breadth-first和Best-first最为流行。 2.1 Breadth-first搜索 该算法的思想比较简单,所有在当前层中的URL还会根据上一 层中它们被发觉的次序访问,其最大特征是不分辨页面的质量和主 题,所以最适合于通用搜索。但最近也有研究[2]表明,如果假定 当前层中的所有URL都是与主题相关的,那么它们的下一层URL也 会与主题相关。这样,Breadth-first就可用作收集一定质量的主题 相关页面,即聚焦搜索算法。
但是,当抓取相当数目的页面后,该算法会引入许多噪声信息 (非相关信息),或形成主题甩尾现象。已有研究人员提出将此算 法与页面剖析算法相结合[4],先用Breadth-first收集页面,再用页 面剖析算法过滤掉不相关的页面,这样即使降低了噪声信息,但降 低了算法的效率。 2.2 Best-first搜索 该算法目前比较流行。与Breadth-first不同,该算法不是简单 地根据被发觉的顺序访问,而是采用某种启发式思想(比如页面分 析的结果)来调整URL在队列中的排序,排在后面的被觉得是与主 题更接近的页面,要优先访问,反之,则推后甚至不被访问。因 此,Best-first搜索显著要比Breadth-first搜索更优越。 并且,Best-first是一个局部搜索算法,它只关心以前访问节 点周围的页面空间,因此会丧失许多相关页面,最后收集的页面质 量也不会很高。 二、存在问题 1.页面剖析算法 页面剖析是聚焦爬虫的重要组成部份,如果页面剖析算法对页 面的判定不够确切,将会影响到搜索算法,导致搜集到页面的质量 偏低。因此,实现一个高效的页面剖析算法是做好聚焦爬虫的第一 步。
Web文档一般富含噪声,比如极少数的文本、图像、脚本等 对分类器没用的数据。而且,不同制作者在风格、语言、结构上 存在很大的差别。因此,采用简单的相似性函数(如tf-idf等)的 VSM很难取得令人满意的疗效。 一种解决的方式是,组合各类基于内容的相似性测度方式,可 以提升分类的准确率[4]。比如遗传算法等全局搜索模式也是一种 潜在的解决方案。 2.局部搜索算法 局部搜索算法的特征是,访问当初访问过节点周围的邻居节 点,这样假如一个相关页没有被现有URL所指向,那么聚焦爬虫就 会丧失对这个相关页面的访问。而且,如果在两个相关页面中间隔 有不相关的页面,聚焦爬虫也会舍弃对后一个相关页面的访问。因 此,采用局部搜索算法的聚焦爬虫只能够发觉围绕在起始种子集周 围的相关页面,它们仅仅是整个Web相关页面集的有限子集,而 丧失了该子集外的相关页面。 通过对Web结构的研究,人们发觉了Web社区[3],也即在线 的Web页自然地按照特定的链接结构分成了不同的组,组内页面 都接近于个别主题或兴趣。聚焦爬虫的目的就是要获取所有的属于 那些相关社区的页面,然而,Web社区的以下三种特点,使得局 部搜索算法不再适用于集聚爬虫。
(1)主题相像的社区之间,采用的不是直接的互相链接,而 是互相引用的关系。在商业领域,这是一个相当普遍现象。例如, Yahoo新闻、MSN新闻、Google新闻都提供相同或相像的新闻信 Algorithm Analysis of Focused Crawler Chen Lijun (Zhejiang Yuexiu University of Foreign Languages, Shaoxing Zhejing 312000, China) Abstract: Focused crawlers can selectively retrieve web documents relevant to a specific domain to build collections for domain- specific search engines. Traditional focused crawlers normally adopting the simple Vector Space Model and local Web search algorithms typically only find relevant Web pages with low precision and recall. This work describes and analyses problems associated with traditional focused crawlers and some potential solutions. The future directions are addressed. Key words: search engine; focused crawler; algorithm 笔记本知识与技术 数据库与信息管理 息,但因为竞争关系,它们并不包含彼此之间的链接。
因此,即使 它们都被作为相关Web社区的起始页面种子集,聚焦爬虫还是会 丧失一些相关的页面。 (2)相关页面之间可能被非相关的社区所隔断。有研究表 明,大多数相关域就会被起码1~12个非相关页面所分隔,平均非 相关间隔页面数为5,而聚焦爬虫在碰到非相关页面后不会继续访 问后续的页面,造成了大量相关页面的流失。 (3)虽然链接在相关页面间存在,但不是互相的单向链接, 而是双向的。也即两个相关的社区A和B,A和B之间存在着链接, 并且仅仅是一个方向的,比如只有从A到B的链接,而不存在从B到 A的链接。这样,当爬行顺序从A开始时网络爬虫算法书籍,B社区同样能被发觉,但 若爬行顺序是从B开始时,则A社区就不能从B中被发觉,造成A中 的相关页流失。 三、 解决方式 一种最简单的解决方式是提供更多的起始种子集,但这样也增 加了成本和时间,而且随着Web页面的迅速降低,这种解决方式 并不可取。 另一种解决方式是采用隧道技术[5],它基于启发式方法解决 简单的全局优化问题。当聚焦爬虫遇见非相关的页面时,不是马上 舍弃继续搜索,而是在一定搜索深度(该值须要事先指定)范围内 继续搜索。
相关实验结果表明,隧道技术能发觉更多的相关页面, 并且,由于它没有改变局部搜索的本性,不能从根本上解决问题。 同时,噪音也被引入进来,降低了页面搜集质量。 研究人员通过对Web规模的研究发觉,主要搜索引擎之间索引 的重叠内容极少,因此,可以组合各类不同搜索引擎搜索结果中比 较靠前的结果,也就是元搜索技术,来解决局部搜索导致的问题。 四、未来展望 近些年来,研究人员发觉Web信息的分布存在一定的相似性, 因而考虑先进行训练,使爬虫具备一定的“经验知识”,通过这种 知识预测将来的回报。比如McCallum[6]引入巩固学习过程,先利 用巩固学习算法估算每位链接的回报价值Q,用Q值相同或相仿的 链接文本信息训练一个贝叶斯分类器,再对未知的链接文本,用该 分类器估算链接属于该类的机率,并借此机率为权重估算链接的综 合价值。也可以借助“智能搜索”技术,通过在线学习链接结构特 征,用于指导搜索过程。 五、结语 随着网页呈指数级的快速下降,以及人们对搜索结果精度要求的 不断提升,新的算法不断涌现,如基于机器学习的剖析算法、相似性 判定的遗传算法等。相信在研究人员的继续努力下,还会出现更多更 加确切、更加快速的新算法,不断增强人们对搜索结果的满意度。
参考文献: [1] Chakrabarti, S., Berg, M.V.D., and Dom, B., Focused crawling: A New Approach to Topic-Sepcific Web Resouce Discovery. In Proceedings of the 8th International WWW Conf. 1999.Toronto, Canada. [2] Najork, M. and Wiener, J.L., Breadth-First Search Crawling Yields High-Quality Pages. In Proceedings of the 10th International WWW Conf. 2001. Hong Kong, China. [3] Flake, G.W., Lawrence, S., and Giles, C.L., Efficient Identification of Web Communities. In Proceediings of the 6 th ACM SIGKDD International Conf. 2000. Massachusetts, USA. [4] Qin, J. and Chen, H., Using Genetic Algorithm in Building Domain-Specific Collections: An Experiment in the Nanotechnology Domain. In Proceedings of the 38th Annual Hawaii International Conf. 2005. Hawaii, USA. [5] Bergmark, D., Lagoze, C., and Sbityakov, A., Focused Crawls, Tunneling, and Digital Libraries. In Porceedings of the 6th European Conf. 2002. Rome, Italy. [6] Rennie J, McCallum A. Using Reinforcement Learning to Spider the Web Efficiently. In Proc. of the International Conference on Machine Learning(ICML’99),1999. 取系数绝对值较大法适宜小波变换后的HL频带图象、LH频 带图象、HH频带图象等高频成份较丰富,亮度、对比度较高的图 象;融合图象中基本保留源图象的特点,图像对比度与源图象基本 相同。
小波变换的作用是对讯号解相关,并将讯号的全部信息集中 到一部分具有大幅值的小波系数中。这些大的小波系数富含的能量 远比小系数富含的能量大,从而在讯号的构建中,大的系数比小的 系数更重要。 3.3 一致性检查 图象中相邻象素点之间可能存在着空间冗余,因此空间上相邻 的点太可能属于同一图象的特点,因此应当对它们采用同一种方式 进行估算。根据这一思想,H.Li等提出用大多数原则对决策因子d 进行一致性检查。如果融合后的图象C在某个区域的中心点上的系 数来自于源图象A,而该点周围的点的系数均来自于源图象B,则 将中心点的系数替换为图象B的系数。 3.4 综合方式 源图象A,B分别进行小波分解,对小波变换后的LL频带图象 采取加权平均法,为了提升图象的质量,还可以在加权平均后采 用高斯低通滤波。对LH频带、HL频带、HH频带采用取系数绝对值 较大法,即取源图象A,B中小波系数较大的作为C的小波系数。另 外,为了尽量避开引入噪音,还应进行一致性检查,即若C上某点 的小波系数取自源图象A,而其周围的点均取自源图象B,则将该 点的小波系数改为源图象B的小波系数。 4 图像融合的现况及发展前景 近些年来,虽然图象融合技术发展迅速,但这仍是个没有统一理 论框架的新领域。
首先,影响图象融合疗效的诱因好多,例如,融 合算法的选定、小波基的选定以及小波分解层数的选择等;其次, 须要构建客观的图象融合技术评价标准;最后,特征级图象融和决 策级图象融合还有待长足的发展。 现有研究结果显示,对不同的频带采用了不同的融合算法结果 表明,对于低频部份采用加权方式较好,对于高频部份采用带一致 性检查的系数绝对值较大法融合疗效较好。 5 结束语 多传感图象融合技术作为信息融合研究领域的一项重要内 容网络爬虫算法书籍,将会在军事、遥感、机器人视觉和医学图象处理等领域得到广 泛应用。 参考文献: [1] 李敏,张小英,毛捷. 基于邻域残差加权平均的小波图象融合 [J]. 理论与技巧,2008,27(1):5-6 [2] 王攀峰,杜云飞,周海芳,杨学军. 基于复小波变换的遥感图象并行 融合算法 [J]. 计算机工程与科学,2008,30(3):35-39 [3] 闫敬文. 数字图像处理(MATLAB版)[M]. 国防工业出版社,2007. [4] 曹杰,龚声蓉,刘纯平. 一种新的基于小波变换的多聚焦图象融 合算法[J]. 计算机工程与应用,2007,43(24):47-50 [5] 任娜,郭敏,胡丽华,张景虎. 基于图象块分割及小波空间频度 的多聚焦图象融合法[J]. 科学技术与工程,2008,8(2):411-414 [6] 成礼智,王红霞,罗永. 小波的理论与应用[M]. 科学出版社,2006. [7] 蔡娜,姚志强,沙晋明. 基于小波变换的遥感图象融合方式[J]. 莆田学院学报,2008,15(2):79-82 [8] 胡钢,秦新强,田径. 像素级多传感图象融合技术[J]. 沈阳工 程学院学报,2007,3(2):148-152 (上接42页) 查看全部
电脑知识与技术 数据库与信息管理 聚焦爬虫常见算法剖析 陈 丽 君 (浙江越秀外国语学院 浙江湖州 312000) [摘 要] 聚焦爬虫收集与特定主题相关的页面,为搜索引擎建立页面集。传统的聚焦爬虫采用向量空间模型和局部搜索算法,精确 率和召回率都比较低。文章分析了聚焦爬虫存在的问题及其相应的解决方式。最后对未来的研究方向进行了展望。 [关键词] 搜索引擎; 聚焦爬虫; 算法 不同于google、百度等通用搜索引擎,聚焦爬虫(也称为主题 爬虫)是一个能下载相关Web页的程序或自动化脚本。随着Web 页面的迅速攀升和特定领域搜索的需求,近年来,聚焦爬虫在工业 和学术界造成了广泛关注。 第一个聚焦爬虫是Chakrabarti于1999提出的[1]。聚焦爬虫一 般由两种算法来保证抓取特定领域的信息,一是Web剖析算法, 依据URL的指向判定Web页面的相关程度和质量;二是Web搜索 算法,它决定着被爬取URL的最佳顺序。 一、常见算法 1.Web页面剖析算法 目前,已出现了许多页面剖析算法,一般可以分为两大类: 基于内容的和基于链接结构的。前者通过剖析一个实际Web页的 HTML文档,来获取关于页面自身的相关性信息。
例如,在文档索 引技术的帮助下,可以从文档中抽取关键词或句子,依此确定该 文档是否与指定域相关。另外,也可以用VSM(向量空间模型) 与指定域的标准文档比较。对于前者,相关研究者发觉,Web链 接结构中包含有许多制作者蕴涵的信息,而这种信息对剖析文档 的相关性和质量起着重要作用。例如,当一个页面A指向另一个页 面B时,就意味着A页面的作者暗示着页面B也富含类似的内容。另 外,页面包含的接入链接越多就意味着该页面越重要。基于链接分 析的算法主要有PageRank和HITS。 2.Web搜索算法 该算法的主要目的是确定最优的URL访问顺序。与页面剖析算法 一样,搜索也有许多算法,以Breadth-first和Best-first最为流行。 2.1 Breadth-first搜索 该算法的思想比较简单,所有在当前层中的URL还会根据上一 层中它们被发觉的次序访问,其最大特征是不分辨页面的质量和主 题,所以最适合于通用搜索。但最近也有研究[2]表明,如果假定 当前层中的所有URL都是与主题相关的,那么它们的下一层URL也 会与主题相关。这样,Breadth-first就可用作收集一定质量的主题 相关页面,即聚焦搜索算法。
但是,当抓取相当数目的页面后,该算法会引入许多噪声信息 (非相关信息),或形成主题甩尾现象。已有研究人员提出将此算 法与页面剖析算法相结合[4],先用Breadth-first收集页面,再用页 面剖析算法过滤掉不相关的页面,这样即使降低了噪声信息,但降 低了算法的效率。 2.2 Best-first搜索 该算法目前比较流行。与Breadth-first不同,该算法不是简单 地根据被发觉的顺序访问,而是采用某种启发式思想(比如页面分 析的结果)来调整URL在队列中的排序,排在后面的被觉得是与主 题更接近的页面,要优先访问,反之,则推后甚至不被访问。因 此,Best-first搜索显著要比Breadth-first搜索更优越。 并且,Best-first是一个局部搜索算法,它只关心以前访问节 点周围的页面空间,因此会丧失许多相关页面,最后收集的页面质 量也不会很高。 二、存在问题 1.页面剖析算法 页面剖析是聚焦爬虫的重要组成部份,如果页面剖析算法对页 面的判定不够确切,将会影响到搜索算法,导致搜集到页面的质量 偏低。因此,实现一个高效的页面剖析算法是做好聚焦爬虫的第一 步。
Web文档一般富含噪声,比如极少数的文本、图像、脚本等 对分类器没用的数据。而且,不同制作者在风格、语言、结构上 存在很大的差别。因此,采用简单的相似性函数(如tf-idf等)的 VSM很难取得令人满意的疗效。 一种解决的方式是,组合各类基于内容的相似性测度方式,可 以提升分类的准确率[4]。比如遗传算法等全局搜索模式也是一种 潜在的解决方案。 2.局部搜索算法 局部搜索算法的特征是,访问当初访问过节点周围的邻居节 点,这样假如一个相关页没有被现有URL所指向,那么聚焦爬虫就 会丧失对这个相关页面的访问。而且,如果在两个相关页面中间隔 有不相关的页面,聚焦爬虫也会舍弃对后一个相关页面的访问。因 此,采用局部搜索算法的聚焦爬虫只能够发觉围绕在起始种子集周 围的相关页面,它们仅仅是整个Web相关页面集的有限子集,而 丧失了该子集外的相关页面。 通过对Web结构的研究,人们发觉了Web社区[3],也即在线 的Web页自然地按照特定的链接结构分成了不同的组,组内页面 都接近于个别主题或兴趣。聚焦爬虫的目的就是要获取所有的属于 那些相关社区的页面,然而,Web社区的以下三种特点,使得局 部搜索算法不再适用于集聚爬虫。
(1)主题相像的社区之间,采用的不是直接的互相链接,而 是互相引用的关系。在商业领域,这是一个相当普遍现象。例如, Yahoo新闻、MSN新闻、Google新闻都提供相同或相像的新闻信 Algorithm Analysis of Focused Crawler Chen Lijun (Zhejiang Yuexiu University of Foreign Languages, Shaoxing Zhejing 312000, China) Abstract: Focused crawlers can selectively retrieve web documents relevant to a specific domain to build collections for domain- specific search engines. Traditional focused crawlers normally adopting the simple Vector Space Model and local Web search algorithms typically only find relevant Web pages with low precision and recall. This work describes and analyses problems associated with traditional focused crawlers and some potential solutions. The future directions are addressed. Key words: search engine; focused crawler; algorithm 笔记本知识与技术 数据库与信息管理 息,但因为竞争关系,它们并不包含彼此之间的链接。
因此,即使 它们都被作为相关Web社区的起始页面种子集,聚焦爬虫还是会 丧失一些相关的页面。 (2)相关页面之间可能被非相关的社区所隔断。有研究表 明,大多数相关域就会被起码1~12个非相关页面所分隔,平均非 相关间隔页面数为5,而聚焦爬虫在碰到非相关页面后不会继续访 问后续的页面,造成了大量相关页面的流失。 (3)虽然链接在相关页面间存在,但不是互相的单向链接, 而是双向的。也即两个相关的社区A和B,A和B之间存在着链接, 并且仅仅是一个方向的,比如只有从A到B的链接,而不存在从B到 A的链接。这样,当爬行顺序从A开始时网络爬虫算法书籍,B社区同样能被发觉,但 若爬行顺序是从B开始时,则A社区就不能从B中被发觉,造成A中 的相关页流失。 三、 解决方式 一种最简单的解决方式是提供更多的起始种子集,但这样也增 加了成本和时间,而且随着Web页面的迅速降低,这种解决方式 并不可取。 另一种解决方式是采用隧道技术[5],它基于启发式方法解决 简单的全局优化问题。当聚焦爬虫遇见非相关的页面时,不是马上 舍弃继续搜索,而是在一定搜索深度(该值须要事先指定)范围内 继续搜索。
相关实验结果表明,隧道技术能发觉更多的相关页面, 并且,由于它没有改变局部搜索的本性,不能从根本上解决问题。 同时,噪音也被引入进来,降低了页面搜集质量。 研究人员通过对Web规模的研究发觉,主要搜索引擎之间索引 的重叠内容极少,因此,可以组合各类不同搜索引擎搜索结果中比 较靠前的结果,也就是元搜索技术,来解决局部搜索导致的问题。 四、未来展望 近些年来,研究人员发觉Web信息的分布存在一定的相似性, 因而考虑先进行训练,使爬虫具备一定的“经验知识”,通过这种 知识预测将来的回报。比如McCallum[6]引入巩固学习过程,先利 用巩固学习算法估算每位链接的回报价值Q,用Q值相同或相仿的 链接文本信息训练一个贝叶斯分类器,再对未知的链接文本,用该 分类器估算链接属于该类的机率,并借此机率为权重估算链接的综 合价值。也可以借助“智能搜索”技术,通过在线学习链接结构特 征,用于指导搜索过程。 五、结语 随着网页呈指数级的快速下降,以及人们对搜索结果精度要求的 不断提升,新的算法不断涌现,如基于机器学习的剖析算法、相似性 判定的遗传算法等。相信在研究人员的继续努力下,还会出现更多更 加确切、更加快速的新算法,不断增强人们对搜索结果的满意度。
参考文献: [1] Chakrabarti, S., Berg, M.V.D., and Dom, B., Focused crawling: A New Approach to Topic-Sepcific Web Resouce Discovery. In Proceedings of the 8th International WWW Conf. 1999.Toronto, Canada. [2] Najork, M. and Wiener, J.L., Breadth-First Search Crawling Yields High-Quality Pages. In Proceedings of the 10th International WWW Conf. 2001. Hong Kong, China. [3] Flake, G.W., Lawrence, S., and Giles, C.L., Efficient Identification of Web Communities. In Proceediings of the 6 th ACM SIGKDD International Conf. 2000. Massachusetts, USA. [4] Qin, J. and Chen, H., Using Genetic Algorithm in Building Domain-Specific Collections: An Experiment in the Nanotechnology Domain. In Proceedings of the 38th Annual Hawaii International Conf. 2005. Hawaii, USA. [5] Bergmark, D., Lagoze, C., and Sbityakov, A., Focused Crawls, Tunneling, and Digital Libraries. In Porceedings of the 6th European Conf. 2002. Rome, Italy. [6] Rennie J, McCallum A. Using Reinforcement Learning to Spider the Web Efficiently. In Proc. of the International Conference on Machine Learning(ICML’99),1999. 取系数绝对值较大法适宜小波变换后的HL频带图象、LH频 带图象、HH频带图象等高频成份较丰富,亮度、对比度较高的图 象;融合图象中基本保留源图象的特点,图像对比度与源图象基本 相同。
小波变换的作用是对讯号解相关,并将讯号的全部信息集中 到一部分具有大幅值的小波系数中。这些大的小波系数富含的能量 远比小系数富含的能量大,从而在讯号的构建中,大的系数比小的 系数更重要。 3.3 一致性检查 图象中相邻象素点之间可能存在着空间冗余,因此空间上相邻 的点太可能属于同一图象的特点,因此应当对它们采用同一种方式 进行估算。根据这一思想,H.Li等提出用大多数原则对决策因子d 进行一致性检查。如果融合后的图象C在某个区域的中心点上的系 数来自于源图象A,而该点周围的点的系数均来自于源图象B,则 将中心点的系数替换为图象B的系数。 3.4 综合方式 源图象A,B分别进行小波分解,对小波变换后的LL频带图象 采取加权平均法,为了提升图象的质量,还可以在加权平均后采 用高斯低通滤波。对LH频带、HL频带、HH频带采用取系数绝对值 较大法,即取源图象A,B中小波系数较大的作为C的小波系数。另 外,为了尽量避开引入噪音,还应进行一致性检查,即若C上某点 的小波系数取自源图象A,而其周围的点均取自源图象B,则将该 点的小波系数改为源图象B的小波系数。 4 图像融合的现况及发展前景 近些年来,虽然图象融合技术发展迅速,但这仍是个没有统一理 论框架的新领域。
首先,影响图象融合疗效的诱因好多,例如,融 合算法的选定、小波基的选定以及小波分解层数的选择等;其次, 须要构建客观的图象融合技术评价标准;最后,特征级图象融和决 策级图象融合还有待长足的发展。 现有研究结果显示,对不同的频带采用了不同的融合算法结果 表明,对于低频部份采用加权方式较好,对于高频部份采用带一致 性检查的系数绝对值较大法融合疗效较好。 5 结束语 多传感图象融合技术作为信息融合研究领域的一项重要内 容网络爬虫算法书籍,将会在军事、遥感、机器人视觉和医学图象处理等领域得到广 泛应用。 参考文献: [1] 李敏,张小英,毛捷. 基于邻域残差加权平均的小波图象融合 [J]. 理论与技巧,2008,27(1):5-6 [2] 王攀峰,杜云飞,周海芳,杨学军. 基于复小波变换的遥感图象并行 融合算法 [J]. 计算机工程与科学,2008,30(3):35-39 [3] 闫敬文. 数字图像处理(MATLAB版)[M]. 国防工业出版社,2007. [4] 曹杰,龚声蓉,刘纯平. 一种新的基于小波变换的多聚焦图象融 合算法[J]. 计算机工程与应用,2007,43(24):47-50 [5] 任娜,郭敏,胡丽华,张景虎. 基于图象块分割及小波空间频度 的多聚焦图象融合法[J]. 科学技术与工程,2008,8(2):411-414 [6] 成礼智,王红霞,罗永. 小波的理论与应用[M]. 科学出版社,2006. [7] 蔡娜,姚志强,沙晋明. 基于小波变换的遥感图象融合方式[J]. 莆田学院学报,2008,15(2):79-82 [8] 胡钢,秦新强,田径. 像素级多传感图象融合技术[J]. 沈阳工 程学院学报,2007,3(2):148-152 (上接42页)
网络爬虫技术在大数据审计中的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2020-05-10 08:03
[提要]在大数据审计面临着众多机遇和挑战的大背景下,有效清晰的数据在审计过程中发挥着重大作用大数据网络爬虫原理,本文剖析不同的审计数据的特性以及采集审计数据的方式。在传统数据采集方法基础上研究怎样基于Python借助网路爬虫采集审计数据,以为大数据审计技术的发展提供支持。
关键词:网络爬虫;数据采集;审计剖析;Python
本文为2017年安徽财贸职业学院“内涵提高全员行动计划”科学研究项目(人文社科):“大数据在审计剖析程序中的运用研究”(项目编号:2017nhrwc15)
中图分类号:F239 文献标识码:A
收录日期:2019年1月18日
一、引言
无论是国家审计还是民间审计,在现今社会经济发展过程中都起到了非常重要的作用,为经济发展“保驾护航”。大数据目前也是各国研究的重点和热点,并将大数据的研究和应用上升到了战略层次。美国注册会计师协会(AICPA)在2014年就对大数据可能对审计形成的影响进行了剖析。在全球信息化的大背景下,如何借助大数据增加审计风险,提高审计效率依然是一个十分重要的命题。2015年中共中央办公厅、国务院办公厅《关于完善审计制度若干重大问题的框架意见》及配套文件中明晰提出“构建大数据审计工作模式,构建国家审计数据系统和数字化审计平台,探索完善审计实时监督系统,实施联网审计”。刘国城、王会金(2017)将大数据审计平台拆分为采集、预处理、分析和可视化四个子平台,基于方式支撑、过程建模和运行机理等方面对各个子平台作以专项研究,旨在为大数据审计实践提供建设性思路。秦荣生(2014)指出大数据、云计算技术的形成和发展,正在逐步影响审计技术和技巧的发展。
大数据具有数据体量巨大、处理速率快、数量种类多和商业价值高的特性。被审计对象的信息化使得审计人员在审计方式上愈发的信息化,如果将这种大量的、散落的、无序的数据进行集中化、结构化,将其弄成才能便捷获得可读取的审计数据,并通过审计剖析程序发觉愈发有效和清晰的审计线索,那么大数据将会发挥重大的商业价值。由此可见,数据是审计剖析的重要前提,获取高质量数据常常就能帮助审计人员快速发觉风险点进行应对,大大提升审计的效率和疗效。目前,尚未有成熟的审计大数据搜集与整理技术,这影响了大数据在审计中使用的效率。本文将基于目前大数据的研究现况,主要阐述审计人员应该怎样借助网路爬虫技术从网路渠道获取所需审计数据,从而扩展审计数据的范围,获得更多的审计线索,提高审计剖析疗效。
二、审计大数据采集分析
(一)审计大数据类型。大数据审计区别于传统的审计模式,传统审计模式倾向于根据被审计单位提供的相关资料去鉴证其是否真实可靠。而大数据审计是一种实时审计,强调审计人员应该主动地去获取企业内部和企业外部的数据,企业内部的业务数据主要借助被审计单位提供,而外部数据,比如法律、银行、税务、供应商、客户、物流等其他数据须要审计人员去挖掘和剖析。从目前来看,审计大数据可以分为两类:一类是结构化数据,它由明晰定义的数据类型组成,比如数字、货币、日期等,其模式可以让其便于搜索。这种数据通常存储在数据库里,比如企业ERP系统中的销售数据、生产数据、财务数据等;另一类是非结构化数据,是指这些不便捷用数据库二维逻辑来表现的数据,如办公文档、文本、图片、HTML图象等,审计人员须要的外部数据以非结构化数据类型居多。
(二)审计大数据采集方法
1、直接拷贝读取。审计人员首先判定出自己须要的审计数据,然后按照被审计单位使用的财务软件(如用友、用友)的使用特性,利用软件数据库早已预设好的指令去提取转换审计人员所须要的数据,并将其保存为Excel等格式。
2、开放数据互联(ODBC)。如果被审计单位与审计人员使用的是可以对接的数据库,可以通过相关的数据访问插口访问被审计单位所使用的业务系统数据库,并将数据进行还原后转出,成为审计人员可以直接借助的数据。
3、中间文件采集。指审计人员与被审计单位约定好数据的格式,被审计单位根据要求将自己的相关数据转换成约定的格式,比如说文本文件格式,这种大部分数据库都还能直接读取的格式,从而省去了两种不同数据库对接的问题。
4、网上采集。除了被审计单位或则上级审计机关提供的相关数据以外,审计人员依然须要从被审计单位外部获得相关的工商、税务、行业、媒体等公开数据以进行多方面的审计剖析,这些数据并不是被直接提供的结构化数据,需要审计人员采用一定的方式从网上进行采集。
目前,审计数据采集大部分采用的是上述的前三种方式,往往依托一定的数据库基础,能够获得的信息大多基于被审计单位,最后一种网上采集数据的方式因为没有统一的方式和技术,耗费大量时间和经历,往往未能实现,这大大限制了审计人员进行审计剖析的范围,同时也让审计的取证率无法达到预期,从某种程度上提升了审计风险。在大数据审计背景下,审计人员执行剖析程序不能仅仅将眼光局限于内部数据,更应该从网路公开数据中获取愈发全面的信息,但是这种信息大多以网页等格式存在,难以被审计人员直接用于剖析,所以本文提出可以借助网路爬虫技术抓取网页上的信息,并整理成一定的格式,方便审计人员从海量数据中发觉审计线索,使审计剖析程序发挥更大的效用。
三、网络爬虫在审计大数据采集中的应用
网络爬虫技术又被称为网路蜘蛛,是一种根据被设定的规则手动获取网页内容的程序脚本。目前,网络爬虫技术被越来越多的运用于互联网中,它还能依据不同的程序代码设定指令,自动获取网页内任何权限的信息数据。程序开始后,按照设定程序,网络爬虫会不断地从URL抓取用户须要的内容,直到满足停止条件,并对抓取到的数据进行分类整合处理大数据网络爬虫原理,用户可以按照自己的查询需求,从中筛选自己所须要的数据。通过网路爬虫还能为大数据剖析提供更高质量的数据源。
利用网路爬虫技术施行审计剖析程序的过程主要有以下几步:首先,锁定目标。根据审计目标确定想要获取的目标数据,明确这种数据主要分布的网页是哪些;其次,目标网页剖析。为了更高效率的抓取到相关数据,要对目标网页进行结构上的剖析,主要是其数据访问的路径和逻辑;再次,数据抓取。通过选择好的软件执行命令,获得数据结果进行保存;最后,数据剖析。将通过上述程序获得的数据进行清洗,获得目标数据,可以结合例如SQL查询、Excel剖析、数据可视化等技术对数据进行进一步的剖析、扩展和确认。
利用网路爬虫技术施行审计剖析程序的原理主要是能否从被审计单位外部获取愈发充足的、高质量的审计数据,而这种数据比被审计单位提供的数据愈发可靠,同时可以将获取的新数据与被审计单位提供的内部数据进行对比,帮助审计人员扩大范围,发现更多相关线索,同时也促使审计证据愈发充分可靠。
四、网络爬虫在审计大数据采集中应用案例
XX集团有限公司创建于1957年,现已发展产生节能环保、钢铁制造及金属贸易、智能健康、教育与技术服务等产业格局的小型企业集团。截至2017年底,拥有全资及控股一级子公司34家。2017年,完成销售收入933亿元、利润25亿元,甲会计师事务所接受委托对该公司进行2017年年度财务报表审计。审计人员在审计过程中发觉该公司下一子公司有大量进行一次性交易的顾客,并且这种顾客都采用了赊购的形式,所以审计人员对这种交易形成了怀疑,认为被审计单位的应收账款“存在”认定有重大错报风险。为进一步获得审计证据,审计人员首先须要被审计单位提供数据库内关于顾客的信息并进行查验以验证这种顾客的真实性。此时,被审计单位提供信息的可靠性较差,审计人员只能考虑从外部获得审计数据进行比较剖析,从而判定顾客信息的准确性。如果考虑直接从官方网站获得具体工商数据,审计人员将面临权限受限和工作量巨大等问题。此时,网络爬虫技术才能为这一困局提供挺好的解决方案,提高工作效率。
在选择网路爬虫技术时,审计人员选择了目前应用范围相对较广的Python。相对于其他网路爬虫技术,基于Python的网路爬虫技术具有以下优点:一是简约便捷。Python语言最大的特征就是只须要一个简单的编辑器才能满足大部分用户的网路爬虫技术需求,可以使操作人员很快的适应环境,而不用耗费过多的精力;二是具有框架技术。如果所须要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强悍的模板来实现爬虫,仅仅须要根据需求进行简单的更改就可以使用,而不是去进行重新的开发。
审计人员通过Python实现了网路爬虫,从“天眼查”网站上获取相关企业的工商信息。其中部份代码如图1所示,获得的部份结果如表1、图2所示。最终审计人员通过网路爬虫技术迅速获得了审计须要的相关数据,筛选出目标企业,进一步进行了审计剖析,与被审计单位提供的有关信息进行比对,得出了其中有18家企业信息涉嫌作假,实为虚构交易的推论,为预收账款的进一步审计提供了重要审计证据。(图1、图2、表1)
五、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。本文通过研究大数据的特性,以及对审计数据的采集办法进行剖析,提出了基于Python的数据爬虫在审计数据采集中的运用,帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计剖析奠定了基础,这也为大数据在审计中的应用技术研究提供了支持。
(作者单位:安徽财贸职业学院)
主要参考文献:
[1]秦荣生.大数据、云计算技术对审计的影响研究[J].审计研究,2014(6).
[2]刘国城,王会金.大数据审计平台建立研究[J].审计研究,2017(11).
[3]韦玮.精通Python网络爬虫[M].北京机械工业出版社,2017. 查看全部
关键词:网络爬虫;数据采集;审计剖析;Python
本文为2017年安徽财贸职业学院“内涵提高全员行动计划”科学研究项目(人文社科):“大数据在审计剖析程序中的运用研究”(项目编号:2017nhrwc15)
中图分类号:F239 文献标识码:A
收录日期:2019年1月18日
一、引言
无论是国家审计还是民间审计,在现今社会经济发展过程中都起到了非常重要的作用,为经济发展“保驾护航”。大数据目前也是各国研究的重点和热点,并将大数据的研究和应用上升到了战略层次。美国注册会计师协会(AICPA)在2014年就对大数据可能对审计形成的影响进行了剖析。在全球信息化的大背景下,如何借助大数据增加审计风险,提高审计效率依然是一个十分重要的命题。2015年中共中央办公厅、国务院办公厅《关于完善审计制度若干重大问题的框架意见》及配套文件中明晰提出“构建大数据审计工作模式,构建国家审计数据系统和数字化审计平台,探索完善审计实时监督系统,实施联网审计”。刘国城、王会金(2017)将大数据审计平台拆分为采集、预处理、分析和可视化四个子平台,基于方式支撑、过程建模和运行机理等方面对各个子平台作以专项研究,旨在为大数据审计实践提供建设性思路。秦荣生(2014)指出大数据、云计算技术的形成和发展,正在逐步影响审计技术和技巧的发展。
大数据具有数据体量巨大、处理速率快、数量种类多和商业价值高的特性。被审计对象的信息化使得审计人员在审计方式上愈发的信息化,如果将这种大量的、散落的、无序的数据进行集中化、结构化,将其弄成才能便捷获得可读取的审计数据,并通过审计剖析程序发觉愈发有效和清晰的审计线索,那么大数据将会发挥重大的商业价值。由此可见,数据是审计剖析的重要前提,获取高质量数据常常就能帮助审计人员快速发觉风险点进行应对,大大提升审计的效率和疗效。目前,尚未有成熟的审计大数据搜集与整理技术,这影响了大数据在审计中使用的效率。本文将基于目前大数据的研究现况,主要阐述审计人员应该怎样借助网路爬虫技术从网路渠道获取所需审计数据,从而扩展审计数据的范围,获得更多的审计线索,提高审计剖析疗效。
二、审计大数据采集分析
(一)审计大数据类型。大数据审计区别于传统的审计模式,传统审计模式倾向于根据被审计单位提供的相关资料去鉴证其是否真实可靠。而大数据审计是一种实时审计,强调审计人员应该主动地去获取企业内部和企业外部的数据,企业内部的业务数据主要借助被审计单位提供,而外部数据,比如法律、银行、税务、供应商、客户、物流等其他数据须要审计人员去挖掘和剖析。从目前来看,审计大数据可以分为两类:一类是结构化数据,它由明晰定义的数据类型组成,比如数字、货币、日期等,其模式可以让其便于搜索。这种数据通常存储在数据库里,比如企业ERP系统中的销售数据、生产数据、财务数据等;另一类是非结构化数据,是指这些不便捷用数据库二维逻辑来表现的数据,如办公文档、文本、图片、HTML图象等,审计人员须要的外部数据以非结构化数据类型居多。
(二)审计大数据采集方法
1、直接拷贝读取。审计人员首先判定出自己须要的审计数据,然后按照被审计单位使用的财务软件(如用友、用友)的使用特性,利用软件数据库早已预设好的指令去提取转换审计人员所须要的数据,并将其保存为Excel等格式。
2、开放数据互联(ODBC)。如果被审计单位与审计人员使用的是可以对接的数据库,可以通过相关的数据访问插口访问被审计单位所使用的业务系统数据库,并将数据进行还原后转出,成为审计人员可以直接借助的数据。
3、中间文件采集。指审计人员与被审计单位约定好数据的格式,被审计单位根据要求将自己的相关数据转换成约定的格式,比如说文本文件格式,这种大部分数据库都还能直接读取的格式,从而省去了两种不同数据库对接的问题。
4、网上采集。除了被审计单位或则上级审计机关提供的相关数据以外,审计人员依然须要从被审计单位外部获得相关的工商、税务、行业、媒体等公开数据以进行多方面的审计剖析,这些数据并不是被直接提供的结构化数据,需要审计人员采用一定的方式从网上进行采集。
目前,审计数据采集大部分采用的是上述的前三种方式,往往依托一定的数据库基础,能够获得的信息大多基于被审计单位,最后一种网上采集数据的方式因为没有统一的方式和技术,耗费大量时间和经历,往往未能实现,这大大限制了审计人员进行审计剖析的范围,同时也让审计的取证率无法达到预期,从某种程度上提升了审计风险。在大数据审计背景下,审计人员执行剖析程序不能仅仅将眼光局限于内部数据,更应该从网路公开数据中获取愈发全面的信息,但是这种信息大多以网页等格式存在,难以被审计人员直接用于剖析,所以本文提出可以借助网路爬虫技术抓取网页上的信息,并整理成一定的格式,方便审计人员从海量数据中发觉审计线索,使审计剖析程序发挥更大的效用。
三、网络爬虫在审计大数据采集中的应用
网络爬虫技术又被称为网路蜘蛛,是一种根据被设定的规则手动获取网页内容的程序脚本。目前,网络爬虫技术被越来越多的运用于互联网中,它还能依据不同的程序代码设定指令,自动获取网页内任何权限的信息数据。程序开始后,按照设定程序,网络爬虫会不断地从URL抓取用户须要的内容,直到满足停止条件,并对抓取到的数据进行分类整合处理大数据网络爬虫原理,用户可以按照自己的查询需求,从中筛选自己所须要的数据。通过网路爬虫还能为大数据剖析提供更高质量的数据源。
利用网路爬虫技术施行审计剖析程序的过程主要有以下几步:首先,锁定目标。根据审计目标确定想要获取的目标数据,明确这种数据主要分布的网页是哪些;其次,目标网页剖析。为了更高效率的抓取到相关数据,要对目标网页进行结构上的剖析,主要是其数据访问的路径和逻辑;再次,数据抓取。通过选择好的软件执行命令,获得数据结果进行保存;最后,数据剖析。将通过上述程序获得的数据进行清洗,获得目标数据,可以结合例如SQL查询、Excel剖析、数据可视化等技术对数据进行进一步的剖析、扩展和确认。
利用网路爬虫技术施行审计剖析程序的原理主要是能否从被审计单位外部获取愈发充足的、高质量的审计数据,而这种数据比被审计单位提供的数据愈发可靠,同时可以将获取的新数据与被审计单位提供的内部数据进行对比,帮助审计人员扩大范围,发现更多相关线索,同时也促使审计证据愈发充分可靠。
四、网络爬虫在审计大数据采集中应用案例
XX集团有限公司创建于1957年,现已发展产生节能环保、钢铁制造及金属贸易、智能健康、教育与技术服务等产业格局的小型企业集团。截至2017年底,拥有全资及控股一级子公司34家。2017年,完成销售收入933亿元、利润25亿元,甲会计师事务所接受委托对该公司进行2017年年度财务报表审计。审计人员在审计过程中发觉该公司下一子公司有大量进行一次性交易的顾客,并且这种顾客都采用了赊购的形式,所以审计人员对这种交易形成了怀疑,认为被审计单位的应收账款“存在”认定有重大错报风险。为进一步获得审计证据,审计人员首先须要被审计单位提供数据库内关于顾客的信息并进行查验以验证这种顾客的真实性。此时,被审计单位提供信息的可靠性较差,审计人员只能考虑从外部获得审计数据进行比较剖析,从而判定顾客信息的准确性。如果考虑直接从官方网站获得具体工商数据,审计人员将面临权限受限和工作量巨大等问题。此时,网络爬虫技术才能为这一困局提供挺好的解决方案,提高工作效率。
在选择网路爬虫技术时,审计人员选择了目前应用范围相对较广的Python。相对于其他网路爬虫技术,基于Python的网路爬虫技术具有以下优点:一是简约便捷。Python语言最大的特征就是只须要一个简单的编辑器才能满足大部分用户的网路爬虫技术需求,可以使操作人员很快的适应环境,而不用耗费过多的精力;二是具有框架技术。如果所须要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强悍的模板来实现爬虫,仅仅须要根据需求进行简单的更改就可以使用,而不是去进行重新的开发。
审计人员通过Python实现了网路爬虫,从“天眼查”网站上获取相关企业的工商信息。其中部份代码如图1所示,获得的部份结果如表1、图2所示。最终审计人员通过网路爬虫技术迅速获得了审计须要的相关数据,筛选出目标企业,进一步进行了审计剖析,与被审计单位提供的有关信息进行比对,得出了其中有18家企业信息涉嫌作假,实为虚构交易的推论,为预收账款的进一步审计提供了重要审计证据。(图1、图2、表1)
五、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。本文通过研究大数据的特性,以及对审计数据的采集办法进行剖析,提出了基于Python的数据爬虫在审计数据采集中的运用,帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计剖析奠定了基础,这也为大数据在审计中的应用技术研究提供了支持。
(作者单位:安徽财贸职业学院)
主要参考文献:
[1]秦荣生.大数据、云计算技术对审计的影响研究[J].审计研究,2014(6).
[2]刘国城,王会金.大数据审计平台建立研究[J].审计研究,2017(11).
[3]韦玮.精通Python网络爬虫[M].北京机械工业出版社,2017. 查看全部
[提要]在大数据审计面临着众多机遇和挑战的大背景下,有效清晰的数据在审计过程中发挥着重大作用大数据网络爬虫原理,本文剖析不同的审计数据的特性以及采集审计数据的方式。在传统数据采集方法基础上研究怎样基于Python借助网路爬虫采集审计数据,以为大数据审计技术的发展提供支持。
关键词:网络爬虫;数据采集;审计剖析;Python
本文为2017年安徽财贸职业学院“内涵提高全员行动计划”科学研究项目(人文社科):“大数据在审计剖析程序中的运用研究”(项目编号:2017nhrwc15)
中图分类号:F239 文献标识码:A
收录日期:2019年1月18日
一、引言
无论是国家审计还是民间审计,在现今社会经济发展过程中都起到了非常重要的作用,为经济发展“保驾护航”。大数据目前也是各国研究的重点和热点,并将大数据的研究和应用上升到了战略层次。美国注册会计师协会(AICPA)在2014年就对大数据可能对审计形成的影响进行了剖析。在全球信息化的大背景下,如何借助大数据增加审计风险,提高审计效率依然是一个十分重要的命题。2015年中共中央办公厅、国务院办公厅《关于完善审计制度若干重大问题的框架意见》及配套文件中明晰提出“构建大数据审计工作模式,构建国家审计数据系统和数字化审计平台,探索完善审计实时监督系统,实施联网审计”。刘国城、王会金(2017)将大数据审计平台拆分为采集、预处理、分析和可视化四个子平台,基于方式支撑、过程建模和运行机理等方面对各个子平台作以专项研究,旨在为大数据审计实践提供建设性思路。秦荣生(2014)指出大数据、云计算技术的形成和发展,正在逐步影响审计技术和技巧的发展。
大数据具有数据体量巨大、处理速率快、数量种类多和商业价值高的特性。被审计对象的信息化使得审计人员在审计方式上愈发的信息化,如果将这种大量的、散落的、无序的数据进行集中化、结构化,将其弄成才能便捷获得可读取的审计数据,并通过审计剖析程序发觉愈发有效和清晰的审计线索,那么大数据将会发挥重大的商业价值。由此可见,数据是审计剖析的重要前提,获取高质量数据常常就能帮助审计人员快速发觉风险点进行应对,大大提升审计的效率和疗效。目前,尚未有成熟的审计大数据搜集与整理技术,这影响了大数据在审计中使用的效率。本文将基于目前大数据的研究现况,主要阐述审计人员应该怎样借助网路爬虫技术从网路渠道获取所需审计数据,从而扩展审计数据的范围,获得更多的审计线索,提高审计剖析疗效。
二、审计大数据采集分析
(一)审计大数据类型。大数据审计区别于传统的审计模式,传统审计模式倾向于根据被审计单位提供的相关资料去鉴证其是否真实可靠。而大数据审计是一种实时审计,强调审计人员应该主动地去获取企业内部和企业外部的数据,企业内部的业务数据主要借助被审计单位提供,而外部数据,比如法律、银行、税务、供应商、客户、物流等其他数据须要审计人员去挖掘和剖析。从目前来看,审计大数据可以分为两类:一类是结构化数据,它由明晰定义的数据类型组成,比如数字、货币、日期等,其模式可以让其便于搜索。这种数据通常存储在数据库里,比如企业ERP系统中的销售数据、生产数据、财务数据等;另一类是非结构化数据,是指这些不便捷用数据库二维逻辑来表现的数据,如办公文档、文本、图片、HTML图象等,审计人员须要的外部数据以非结构化数据类型居多。
(二)审计大数据采集方法
1、直接拷贝读取。审计人员首先判定出自己须要的审计数据,然后按照被审计单位使用的财务软件(如用友、用友)的使用特性,利用软件数据库早已预设好的指令去提取转换审计人员所须要的数据,并将其保存为Excel等格式。
2、开放数据互联(ODBC)。如果被审计单位与审计人员使用的是可以对接的数据库,可以通过相关的数据访问插口访问被审计单位所使用的业务系统数据库,并将数据进行还原后转出,成为审计人员可以直接借助的数据。
3、中间文件采集。指审计人员与被审计单位约定好数据的格式,被审计单位根据要求将自己的相关数据转换成约定的格式,比如说文本文件格式,这种大部分数据库都还能直接读取的格式,从而省去了两种不同数据库对接的问题。
4、网上采集。除了被审计单位或则上级审计机关提供的相关数据以外,审计人员依然须要从被审计单位外部获得相关的工商、税务、行业、媒体等公开数据以进行多方面的审计剖析,这些数据并不是被直接提供的结构化数据,需要审计人员采用一定的方式从网上进行采集。
目前,审计数据采集大部分采用的是上述的前三种方式,往往依托一定的数据库基础,能够获得的信息大多基于被审计单位,最后一种网上采集数据的方式因为没有统一的方式和技术,耗费大量时间和经历,往往未能实现,这大大限制了审计人员进行审计剖析的范围,同时也让审计的取证率无法达到预期,从某种程度上提升了审计风险。在大数据审计背景下,审计人员执行剖析程序不能仅仅将眼光局限于内部数据,更应该从网路公开数据中获取愈发全面的信息,但是这种信息大多以网页等格式存在,难以被审计人员直接用于剖析,所以本文提出可以借助网路爬虫技术抓取网页上的信息,并整理成一定的格式,方便审计人员从海量数据中发觉审计线索,使审计剖析程序发挥更大的效用。
三、网络爬虫在审计大数据采集中的应用
网络爬虫技术又被称为网路蜘蛛,是一种根据被设定的规则手动获取网页内容的程序脚本。目前,网络爬虫技术被越来越多的运用于互联网中,它还能依据不同的程序代码设定指令,自动获取网页内任何权限的信息数据。程序开始后,按照设定程序,网络爬虫会不断地从URL抓取用户须要的内容,直到满足停止条件,并对抓取到的数据进行分类整合处理大数据网络爬虫原理,用户可以按照自己的查询需求,从中筛选自己所须要的数据。通过网路爬虫还能为大数据剖析提供更高质量的数据源。
利用网路爬虫技术施行审计剖析程序的过程主要有以下几步:首先,锁定目标。根据审计目标确定想要获取的目标数据,明确这种数据主要分布的网页是哪些;其次,目标网页剖析。为了更高效率的抓取到相关数据,要对目标网页进行结构上的剖析,主要是其数据访问的路径和逻辑;再次,数据抓取。通过选择好的软件执行命令,获得数据结果进行保存;最后,数据剖析。将通过上述程序获得的数据进行清洗,获得目标数据,可以结合例如SQL查询、Excel剖析、数据可视化等技术对数据进行进一步的剖析、扩展和确认。
利用网路爬虫技术施行审计剖析程序的原理主要是能否从被审计单位外部获取愈发充足的、高质量的审计数据,而这种数据比被审计单位提供的数据愈发可靠,同时可以将获取的新数据与被审计单位提供的内部数据进行对比,帮助审计人员扩大范围,发现更多相关线索,同时也促使审计证据愈发充分可靠。
四、网络爬虫在审计大数据采集中应用案例
XX集团有限公司创建于1957年,现已发展产生节能环保、钢铁制造及金属贸易、智能健康、教育与技术服务等产业格局的小型企业集团。截至2017年底,拥有全资及控股一级子公司34家。2017年,完成销售收入933亿元、利润25亿元,甲会计师事务所接受委托对该公司进行2017年年度财务报表审计。审计人员在审计过程中发觉该公司下一子公司有大量进行一次性交易的顾客,并且这种顾客都采用了赊购的形式,所以审计人员对这种交易形成了怀疑,认为被审计单位的应收账款“存在”认定有重大错报风险。为进一步获得审计证据,审计人员首先须要被审计单位提供数据库内关于顾客的信息并进行查验以验证这种顾客的真实性。此时,被审计单位提供信息的可靠性较差,审计人员只能考虑从外部获得审计数据进行比较剖析,从而判定顾客信息的准确性。如果考虑直接从官方网站获得具体工商数据,审计人员将面临权限受限和工作量巨大等问题。此时,网络爬虫技术才能为这一困局提供挺好的解决方案,提高工作效率。
在选择网路爬虫技术时,审计人员选择了目前应用范围相对较广的Python。相对于其他网路爬虫技术,基于Python的网路爬虫技术具有以下优点:一是简约便捷。Python语言最大的特征就是只须要一个简单的编辑器才能满足大部分用户的网路爬虫技术需求,可以使操作人员很快的适应环境,而不用耗费过多的精力;二是具有框架技术。如果所须要抓取的数据量较大,则可以使用Python的Scrapy框架实现,它能提供一个功能强悍的模板来实现爬虫,仅仅须要根据需求进行简单的更改就可以使用,而不是去进行重新的开发。
审计人员通过Python实现了网路爬虫,从“天眼查”网站上获取相关企业的工商信息。其中部份代码如图1所示,获得的部份结果如表1、图2所示。最终审计人员通过网路爬虫技术迅速获得了审计须要的相关数据,筛选出目标企业,进一步进行了审计剖析,与被审计单位提供的有关信息进行比对,得出了其中有18家企业信息涉嫌作假,实为虚构交易的推论,为预收账款的进一步审计提供了重要审计证据。(图1、图2、表1)
五、结语
随着大数据在审计中的运用广泛,高效的数据采集办法也是值得研究的重要内容。本文通过研究大数据的特性,以及对审计数据的采集办法进行剖析,提出了基于Python的数据爬虫在审计数据采集中的运用,帮助审计人员快速高效地从网页上获得相关数据,为进一步的审计剖析奠定了基础,这也为大数据在审计中的应用技术研究提供了支持。
(作者单位:安徽财贸职业学院)
主要参考文献:
[1]秦荣生.大数据、云计算技术对审计的影响研究[J].审计研究,2014(6).
[2]刘国城,王会金.大数据审计平台建立研究[J].审计研究,2017(11).
[3]韦玮.精通Python网络爬虫[M].北京机械工业出版社,2017.

