
百度搜索指定网站内容
百度搜索指定网站内容(信息爆炸时代,就是使用搜索引擎的方法出了问题!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-24 15:07
在信息爆炸的时代,大量的信息充斥着互联网。作为信息的采集器,搜索引擎为我们查找特定信息带来了极大的便利。搜索引擎的使用也成为各行各业从业者必备的技能之一。但是,您是否经常遇到这样的问题或困惑:
这实际上是使用搜索引擎的方法的问题。
本文旨在总结工作中常见的搜索技术。供大家参考使用。希望能够帮助到大家。
以下截图中的搜索结果基于谷歌(Google),百度(Baidu)也适用。
关键词:通常是我们在搜索框中输入的词。
指令中涉及的标点符号符合:英文标点符号,非中文标点符号。比如双引号应该是“”,而不是“”。
搜索高级说明网站
site:是最常用的搜索命令,用于搜索域名下的匹配结果。
一般搜索就是在搜索框中输入关键词搜索整个网络,而这往往不是我们想要的结果。
示例:查找 网站 将军的搜索结果。输入武将,会得到全网武将的结果。正确的方法应该是进入通用站点:。
双引号
不用双引号直接输入关键词,搜索引擎会在搜索时进行分词,然后显示收录这些词的指定页面的结果。如果搜索this is,显示结果如下:
将关键词放在双引号中表示搜索完全匹配,并且每个搜索结果都收录输入的所有单词,并且顺序与输入的顺序完全相同,甚至空格也是一样的。
示例:要搜索 this is,您应该输入“this is”。
文件类型
经常需要下载文件,却不知道如何有效排除文件类型?使用 filetype 搜索特定的文件格式。
示例:input thinking in java filetype:pdf 返回thinking in java中关键词的所有pdf文件。
减号 (-)
减号表示搜索结果不包括减号后面的单词。使用该命令时,减号前必须有空格,减号后不能有空格,后跟要排除的词。
示例:输入 search-engine 并返回收录单词 search 但不收录单词 engine 的结果。
星号(*)
星号 * 是常见的通配符,也可用于搜索。
示例:输入“查看 *?”,其中 * 符号代表任何文本。返回的结果不仅包括查看,还包括查看短信等。
权利
intitle: 指令返回页面标题中带有 关键词 的页面。
示例:输入intitle:english,在返回的结果页面中,每个页面的标题应为英文。
inurl
inurl:该指令用于搜索地址(url)中出现关键词的页面。inurl 命令支持中英文。
例如:输入inurl:,返回结果为url url中收录的所有页面。
allintitle
allintitle:搜索返回页面标题中收录多组 关键词 的页面。
示例:allintitle:american english 等价于 intitle:american intitle:english。返回标题中同时收录美国和英语的页面。
蒜茸
与 allintitle: 类似,它在 网站 url 中返回具有多组 关键词 的页面。
示例:allinurl:american english 等价于 inurl:american inurl:english。
锚定
inanchor:返回的结果是链接的锚文本中收录搜索词的页面。
示例:inanchor:register 这里返回的结果页面不一定收录 register 本身,而是 register 出现在指向这些页面的链接的锚文本中。
有关的
related:该命令返回的结果是与 网站 相关的页面。
示例:related:,我们可以得到搜索引擎认为与网站相关的其他页面。这个关联是什么,搜索引擎并没有明确说明,一般认为是指普通外链的网站。
混合使用
上面提到的搜索命令可以单独使用来查找大量资源,或者更精确地定位资源。如果同时将这些指令混合在一起,它会更加强大。可以输入谷歌或者百度自己试试。
示例:inurl:gov weight loss 返回 url 中收录 gov 和页面上的单词 weight loss 的页面。
示例:inurl:“Spoken American”返回教育网(一般教育网是域名的一部分),搜索到的页面与口语完全匹配。
例如:inurl:intitle:English 返回教育网,搜索到的页面标题中收录英文页面。
示例:allinurl:topcoder register 返回包含topcoder 的页面,并在url 中注册。
以下是搜索指令速查表,可以截图备份。
高级说明
命令含义 example site:搜索结果只收录特定的URL site:查找特定类型的文件:PDF、DOC、TXTfiletype:PDFdefine:查找单词的定义define audacityintitle:查找具有指定关键词的页面在页面标题中intitle:英文-单词搜索结果不收录单词 Liu-Huan~elderly 搜索单词的同义词~elderly -elderly “单词”精确匹配搜索“国家”、“我有一个梦想”相关:URL搜索相关网站相关:
信息
命令含义示例 weather 获取地区或城市的天气 天气 杭州电影 在附件中查找电影和电影院(城市,邮政编码) 电影 杭州 查看全部
百度搜索指定网站内容(信息爆炸时代,就是使用搜索引擎的方法出了问题!)
在信息爆炸的时代,大量的信息充斥着互联网。作为信息的采集器,搜索引擎为我们查找特定信息带来了极大的便利。搜索引擎的使用也成为各行各业从业者必备的技能之一。但是,您是否经常遇到这样的问题或困惑:
这实际上是使用搜索引擎的方法的问题。
本文旨在总结工作中常见的搜索技术。供大家参考使用。希望能够帮助到大家。
以下截图中的搜索结果基于谷歌(Google),百度(Baidu)也适用。
关键词:通常是我们在搜索框中输入的词。
指令中涉及的标点符号符合:英文标点符号,非中文标点符号。比如双引号应该是“”,而不是“”。
搜索高级说明网站
site:是最常用的搜索命令,用于搜索域名下的匹配结果。
一般搜索就是在搜索框中输入关键词搜索整个网络,而这往往不是我们想要的结果。
示例:查找 网站 将军的搜索结果。输入武将,会得到全网武将的结果。正确的方法应该是进入通用站点:。
双引号
不用双引号直接输入关键词,搜索引擎会在搜索时进行分词,然后显示收录这些词的指定页面的结果。如果搜索this is,显示结果如下:
将关键词放在双引号中表示搜索完全匹配,并且每个搜索结果都收录输入的所有单词,并且顺序与输入的顺序完全相同,甚至空格也是一样的。
示例:要搜索 this is,您应该输入“this is”。
文件类型
经常需要下载文件,却不知道如何有效排除文件类型?使用 filetype 搜索特定的文件格式。
示例:input thinking in java filetype:pdf 返回thinking in java中关键词的所有pdf文件。
减号 (-)
减号表示搜索结果不包括减号后面的单词。使用该命令时,减号前必须有空格,减号后不能有空格,后跟要排除的词。
示例:输入 search-engine 并返回收录单词 search 但不收录单词 engine 的结果。
星号(*)
星号 * 是常见的通配符,也可用于搜索。
示例:输入“查看 *?”,其中 * 符号代表任何文本。返回的结果不仅包括查看,还包括查看短信等。
权利
intitle: 指令返回页面标题中带有 关键词 的页面。
示例:输入intitle:english,在返回的结果页面中,每个页面的标题应为英文。
inurl
inurl:该指令用于搜索地址(url)中出现关键词的页面。inurl 命令支持中英文。
例如:输入inurl:,返回结果为url url中收录的所有页面。
allintitle
allintitle:搜索返回页面标题中收录多组 关键词 的页面。
示例:allintitle:american english 等价于 intitle:american intitle:english。返回标题中同时收录美国和英语的页面。
蒜茸
与 allintitle: 类似,它在 网站 url 中返回具有多组 关键词 的页面。
示例:allinurl:american english 等价于 inurl:american inurl:english。
锚定
inanchor:返回的结果是链接的锚文本中收录搜索词的页面。
示例:inanchor:register 这里返回的结果页面不一定收录 register 本身,而是 register 出现在指向这些页面的链接的锚文本中。
有关的
related:该命令返回的结果是与 网站 相关的页面。
示例:related:,我们可以得到搜索引擎认为与网站相关的其他页面。这个关联是什么,搜索引擎并没有明确说明,一般认为是指普通外链的网站。
混合使用
上面提到的搜索命令可以单独使用来查找大量资源,或者更精确地定位资源。如果同时将这些指令混合在一起,它会更加强大。可以输入谷歌或者百度自己试试。
示例:inurl:gov weight loss 返回 url 中收录 gov 和页面上的单词 weight loss 的页面。
示例:inurl:“Spoken American”返回教育网(一般教育网是域名的一部分),搜索到的页面与口语完全匹配。
例如:inurl:intitle:English 返回教育网,搜索到的页面标题中收录英文页面。
示例:allinurl:topcoder register 返回包含topcoder 的页面,并在url 中注册。
以下是搜索指令速查表,可以截图备份。
高级说明
命令含义 example site:搜索结果只收录特定的URL site:查找特定类型的文件:PDF、DOC、TXTfiletype:PDFdefine:查找单词的定义define audacityintitle:查找具有指定关键词的页面在页面标题中intitle:英文-单词搜索结果不收录单词 Liu-Huan~elderly 搜索单词的同义词~elderly -elderly “单词”精确匹配搜索“国家”、“我有一个梦想”相关:URL搜索相关网站相关:
信息
命令含义示例 weather 获取地区或城市的天气 天气 杭州电影 在附件中查找电影和电影院(城市,邮政编码) 电影 杭州
百度搜索指定网站内容( 完成好建站seo的基础因素,seo推广明白)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-02-24 14:26
完成好建站seo的基础因素,seo推广明白)
总结:如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可以查看快照的内容) 先说一下seo建站的基本要素,seo推广了解使用你身边的信息是的,你可以和做seo推广的朋友互动分享。如果你想自学seo技术培训,那也是一个艰难的练习。同时会浪费时间,做seo推广一定要清楚
如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容)
一开始先说一下建立一个好的网站seo的基本要素,seo推广了解你身边信息的使用情况,可以和做seo推广的朋友互动分享,如果你想自学seo技术培训,这也是一条艰难的道路。同时,这将是浪费时间。在做seo推广的时候,一定要明白可以给别人。积累这样的关系对seo推广很有帮助。在seo推广的过程中,要了解独立思考,为什么排名会降低,网站是否过度优化,可能被非法篡改,网站是startup速度很慢?选择的域名是否被搜索引擎降级,一些基本的事情还是需要处理的,否则,你将输在起点。, 刚发布的网站,外链不适合太多,有的网站站长一开始会去各大网站各种网络平台发链接,每次发一个,他们会很开心的,朋友们。你白高兴,就会伤痕累累,这很容易让百度觉得你也在作弊。很容易受到百度网的处罚,而且还会出现百度网的快照还原,这样的不良影响会更加严重。K马上就没了,毕竟你的新网站不可能一下子发布太多的连接,新的网站有观察期,如果新的网站你吃多了会消化难,外链优化不要急于求成。这也是站长网站提出的“七伤”的原因之一。.
下面详细说明如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容):
(1),百度霸屏,顾名思义,就是你在百度搜索某个关键词,下面显示的信息就是你所有的文章内容或者广告。当然,这是针对百度快照中显示的10个位置,更不用说竞价了。而且首页可以占据多个位置。
(2),排名网站选择的高权重词有一定的搜索量,除了与具体内容相关的网站。网站由于第二个标题有taint 更何况标题一个最多可以整合成2-3个关键词。网站一个很重要的站点绝对是伪静态的。知道网站的原创内容写。具体内容需要快速刷新快照。网站内部链接应以Google树状网状结构相互链接。提高连贯性的超链接网站。不能与网站相邻那个已经被百度排名掉了。不能针对网站进行优化网站优化,网站是对付用搜索的人的。不要作弊,百度搜索引擎比同事聪明。
(3), 网站 选出的高竞争力词必须有人搜索,并且与网站相关。网站标题推荐1-3 关键词。 网站值得关注的页面绝对是伪静态的。了解网站原创方面的描述。方面要及时更新快照。网站站内链接应该导致百度F型建立相互链接。增加coherence网站的link backlinks.不要链接到母亲的和谐网站。不要为网络优化而优化网络,网站面向用户,别作弊,百度比Smart小伙伴小。如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容)
(4)和网站选择的长尾关键词有一定的搜索量,和网站的具体内容有关。网站一直相信好评 标题干净无瑕,最多可以集成2-3个关键词网站要注意的页面一定要生成html静态文件。了解<的具体内容@网站原创写具体内容。快点刷新截图。网站站内的链接要形成蜘蛛金字塔,建立相互链接。爬上相关的高权重好友链接< @网站。不要链接被百度蜘蛛惩罚的网站。不要为网站推广优化,网站面向需求者,不要作弊,百度比哥们聪明。
(5),简单来说,百度快照可以理解为百度为网站制作的一个网站历史数据存档。举个很简单的例子,总之百度快照可以理解为百度为网站制作的网站历史数据存档,举个很简单的例子,如何搜索指定网页的百度快照(每次搜索结果后点击百度快照可以查看快照内容)
<p>(6),用户体验是指用户在使用产品时的主观感受。从SEM的角度来看,网站服务于广大访问者,那么访问者使用我们的网站, 查看全部
百度搜索指定网站内容(
完成好建站seo的基础因素,seo推广明白)

总结:如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可以查看快照的内容) 先说一下seo建站的基本要素,seo推广了解使用你身边的信息是的,你可以和做seo推广的朋友互动分享。如果你想自学seo技术培训,那也是一个艰难的练习。同时会浪费时间,做seo推广一定要清楚
如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容)
一开始先说一下建立一个好的网站seo的基本要素,seo推广了解你身边信息的使用情况,可以和做seo推广的朋友互动分享,如果你想自学seo技术培训,这也是一条艰难的道路。同时,这将是浪费时间。在做seo推广的时候,一定要明白可以给别人。积累这样的关系对seo推广很有帮助。在seo推广的过程中,要了解独立思考,为什么排名会降低,网站是否过度优化,可能被非法篡改,网站是startup速度很慢?选择的域名是否被搜索引擎降级,一些基本的事情还是需要处理的,否则,你将输在起点。, 刚发布的网站,外链不适合太多,有的网站站长一开始会去各大网站各种网络平台发链接,每次发一个,他们会很开心的,朋友们。你白高兴,就会伤痕累累,这很容易让百度觉得你也在作弊。很容易受到百度网的处罚,而且还会出现百度网的快照还原,这样的不良影响会更加严重。K马上就没了,毕竟你的新网站不可能一下子发布太多的连接,新的网站有观察期,如果新的网站你吃多了会消化难,外链优化不要急于求成。这也是站长网站提出的“七伤”的原因之一。.
下面详细说明如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容):
(1),百度霸屏,顾名思义,就是你在百度搜索某个关键词,下面显示的信息就是你所有的文章内容或者广告。当然,这是针对百度快照中显示的10个位置,更不用说竞价了。而且首页可以占据多个位置。
(2),排名网站选择的高权重词有一定的搜索量,除了与具体内容相关的网站。网站由于第二个标题有taint 更何况标题一个最多可以整合成2-3个关键词。网站一个很重要的站点绝对是伪静态的。知道网站的原创内容写。具体内容需要快速刷新快照。网站内部链接应以Google树状网状结构相互链接。提高连贯性的超链接网站。不能与网站相邻那个已经被百度排名掉了。不能针对网站进行优化网站优化,网站是对付用搜索的人的。不要作弊,百度搜索引擎比同事聪明。
(3), 网站 选出的高竞争力词必须有人搜索,并且与网站相关。网站标题推荐1-3 关键词。 网站值得关注的页面绝对是伪静态的。了解网站原创方面的描述。方面要及时更新快照。网站站内链接应该导致百度F型建立相互链接。增加coherence网站的link backlinks.不要链接到母亲的和谐网站。不要为网络优化而优化网络,网站面向用户,别作弊,百度比Smart小伙伴小。如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容)
(4)和网站选择的长尾关键词有一定的搜索量,和网站的具体内容有关。网站一直相信好评 标题干净无瑕,最多可以集成2-3个关键词网站要注意的页面一定要生成html静态文件。了解<的具体内容@网站原创写具体内容。快点刷新截图。网站站内的链接要形成蜘蛛金字塔,建立相互链接。爬上相关的高权重好友链接< @网站。不要链接被百度蜘蛛惩罚的网站。不要为网站推广优化,网站面向需求者,不要作弊,百度比哥们聪明。
(5),简单来说,百度快照可以理解为百度为网站制作的一个网站历史数据存档。举个很简单的例子,总之百度快照可以理解为百度为网站制作的网站历史数据存档,举个很简单的例子,如何搜索指定网页的百度快照(每次搜索结果后点击百度快照可以查看快照内容)
<p>(6),用户体验是指用户在使用产品时的主观感受。从SEM的角度来看,网站服务于广大访问者,那么访问者使用我们的网站,
百度搜索指定网站内容( 搜索引擎更易对网站的价值判定以及排序的处理方法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-23 15:09
搜索引擎更易对网站的价值判定以及排序的处理方法!)
如何让百度手机搜索收录网站中的内容?
搜索引擎对网站的价值判断和排名主要是站在用户的角度。改善用户体验也将使搜索引擎更容易理解和处理。
如何让百度手机搜索收录网站中的内容?
一、网站结构
网站的结构推荐采用树形结构,分为三层:首页频道一文章页面。从首页到内容页的层级尽可能小,以便搜索引擎快速了解网站中每个页面的结构层次。
手机网站首页要有重要栏目导航,并提供详情页和重要页的流量入口。首页布局不能太短,页面内容不能太简单。
二、没有 Flash、图片、Javascript
百度通过百度蜘蛛2.0的程序抓取网站。目前百度蜘蛛只能读取文本内容,暂时无法读取Flash、图片、Javascript等内容。
建议在网站上以文字的形式展示重要内容或链接。百度搜索引擎暂时无法识别Flash、图片、复杂Javascript中的内容;
三、URL 的使用
1、建议使用简短易懂的 URL。短网址更简单易记,有利于用户直观判断网页内容。过长的网址容易出错,导致404错误,对搜索引擎不友好。
2、使用静态网址减少无效参数,参数过多影响用户视觉效果。
3、网站 上不想被搜索引擎阅读的页面会被机器人屏蔽。
4、 移动台主页采用//的形式。
5、 频道页面采用 /n1/、/n2/ 的形式。
四、链接锚文本
百度非常重视锚文本。除了锚文本,关键词 必须尽可能出现在标题上,以获得最佳排名。
1、锚文本是一种简单易懂的表达方式,可以让用户理解网页内容所表达的内容。
2、锚文本的合理布局,通过使用锚文本从其他网页链接来访问您的网页。
3、单个锚文本不宜过长,关键词的锚文本链接必须设置准确。这个 关键词 链接到其他页面的内容是相关的。 查看全部
百度搜索指定网站内容(
搜索引擎更易对网站的价值判定以及排序的处理方法!)
如何让百度手机搜索收录网站中的内容?
搜索引擎对网站的价值判断和排名主要是站在用户的角度。改善用户体验也将使搜索引擎更容易理解和处理。
如何让百度手机搜索收录网站中的内容?
一、网站结构
网站的结构推荐采用树形结构,分为三层:首页频道一文章页面。从首页到内容页的层级尽可能小,以便搜索引擎快速了解网站中每个页面的结构层次。
手机网站首页要有重要栏目导航,并提供详情页和重要页的流量入口。首页布局不能太短,页面内容不能太简单。
二、没有 Flash、图片、Javascript
百度通过百度蜘蛛2.0的程序抓取网站。目前百度蜘蛛只能读取文本内容,暂时无法读取Flash、图片、Javascript等内容。
建议在网站上以文字的形式展示重要内容或链接。百度搜索引擎暂时无法识别Flash、图片、复杂Javascript中的内容;
三、URL 的使用
1、建议使用简短易懂的 URL。短网址更简单易记,有利于用户直观判断网页内容。过长的网址容易出错,导致404错误,对搜索引擎不友好。
2、使用静态网址减少无效参数,参数过多影响用户视觉效果。
3、网站 上不想被搜索引擎阅读的页面会被机器人屏蔽。
4、 移动台主页采用//的形式。
5、 频道页面采用 /n1/、/n2/ 的形式。
四、链接锚文本
百度非常重视锚文本。除了锚文本,关键词 必须尽可能出现在标题上,以获得最佳排名。
1、锚文本是一种简单易懂的表达方式,可以让用户理解网页内容所表达的内容。
2、锚文本的合理布局,通过使用锚文本从其他网页链接来访问您的网页。
3、单个锚文本不宜过长,关键词的锚文本链接必须设置准确。这个 关键词 链接到其他页面的内容是相关的。
百度搜索指定网站内容(公众号刷了两次,遇到好像好多次,都是干货)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-23 09:01
百度搜索指定网站内容,在搜索结果页面中进行核实。如果核实不到,那很简单,一般这个网站都有一个公开的方式能够搜索到具体那条内容,
查百度指数,或者看公众号文章到底哪里可能被篡改。方法论:进入百度,到首页-百度风云榜-输入你公众号名称-搜索你的关键词。
没事,我也被篡改过。不想去了,这样的公众号就是坑人,不怕被骗上千万就去吧,直接投诉。
你可以去网上搜索xxseo已解答你这个问题。
我被刷过3次,遇到好像好多次,都是干货。微信公众号被刷了基本要去广东打官司,相关记录会记录下来。我报了警,警察和网警说后台数据也存着。另外我有所谓买粉的qq号,打过电话确认说安全无问题,就是信誉度不会太高,大号可能才行。
哈哈,我被公众号刷了两次公众号文章,并且都刷的微信公众号。第一次有些网友告诉我,好像做的和卖酒的都被刷了,以前被刷过其他产品!第二次我发现这篇文章没有出现在微信公众号上,而是被建议修改,告诉我这个要找客说明情况本以为自己认栽,后来知道我被骗了,
百度指数有数据吧,你直接去搜,一般都能找到,我上次被刷了,查了一下权重,然后的确有些文章权重高,而且百度指数有数据,你可以去查查。 查看全部
百度搜索指定网站内容(公众号刷了两次,遇到好像好多次,都是干货)
百度搜索指定网站内容,在搜索结果页面中进行核实。如果核实不到,那很简单,一般这个网站都有一个公开的方式能够搜索到具体那条内容,
查百度指数,或者看公众号文章到底哪里可能被篡改。方法论:进入百度,到首页-百度风云榜-输入你公众号名称-搜索你的关键词。
没事,我也被篡改过。不想去了,这样的公众号就是坑人,不怕被骗上千万就去吧,直接投诉。
你可以去网上搜索xxseo已解答你这个问题。
我被刷过3次,遇到好像好多次,都是干货。微信公众号被刷了基本要去广东打官司,相关记录会记录下来。我报了警,警察和网警说后台数据也存着。另外我有所谓买粉的qq号,打过电话确认说安全无问题,就是信誉度不会太高,大号可能才行。
哈哈,我被公众号刷了两次公众号文章,并且都刷的微信公众号。第一次有些网友告诉我,好像做的和卖酒的都被刷了,以前被刷过其他产品!第二次我发现这篇文章没有出现在微信公众号上,而是被建议修改,告诉我这个要找客说明情况本以为自己认栽,后来知道我被骗了,
百度指数有数据吧,你直接去搜,一般都能找到,我上次被刷了,查了一下权重,然后的确有些文章权重高,而且百度指数有数据,你可以去查查。
百度搜索指定网站内容(1.把搜索范围限定在网页标题内--intitle语法结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 487 次浏览 • 2022-02-22 03:20
1.限制搜索到页面标题---intitle
语法结构: intitle:您要查找的信息(此信息将限于页面标题)
示例:要查找周杰伦的照片,可以输入“照片标题:周杰伦”,
注意 intitle: 和后面的 关键词 之间不能有空格。
2.将搜索限制在特定站点---站点
语法结构:你要查找的信息站点:网站去掉WWW后的地址
示例:查找华军软件园互联网快车信息,可输入“互联网快车站点:” PS:华军软件园网站
注意站点域名后跟“site:”不能收录“”和“/”符号;此外,site: 和站点名称之间不应有空格。
3.限制搜索到 URL 链接——inurl
语法结构:您要查找的信息 inurl:相关信息(必须是英文或中文拼音)
示例:要查找有关使用 Photoshop 的提示,您可以输入“Photoshop inurl: jiqiao”
PS:jiqiao是汉字技能的汉语拼音。
注意 inurl: 语法和它后面的 关键词 没有空格。
4.查找专业报告“filetype:”为文件类型,找到指定文件下载。使用此语法限制搜索对象,冒号后为文档格式,如PDF、DOC、XLS等。示例:霍金黑洞文件类型:pdf
5.完全匹配---双引号和书名号
语法结构:查询词不拆分。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“Shanghai University of科技”,取得的成果均符合要求。
语法结构:“你要找的书或电影”
示例:要查找手机电影的信息,可以输入“手机”
6.减号语法 --- 删除所有收录特定 关键词 的页面
语法结构:要寻找的信息——要摆脱的信息
例如:射雕英雄传-电视剧 这个语法结构需要在这里解释一下。例如,如果你搜索《神雕侠侣》武侠小说的内容,你会发现有很多关于电视剧的网页。您可以使用此语法删除有关电视剧的信息。
PS:-号前有空格
注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,减号语法功能会丢失。减号和下一个 关键词 之间没有空格。
7.intext:仅搜索收录在网页部分中的文本(即忽略标题、URL 等的文本)。
8.邮件搜索语法:SUBJECT、TO、FROM。
对于每天要处理大量邮件的用户来说,百度硬盘搜索提供的邮件搜索语法1.1.1:subject,to,from同样强大。只需输入“主题:工资详细信息”以查找主题中带有“工资详细信息”的电子邮件,然后输入“主题:初始 d 来自:”以查找主题中带有“初始 d”的 Claire 的电子邮件:键入“工作报告至: " 查找发送给 Peter 的所有工作报告电子邮件。
9.指定文件夹级搜索语法:文件夹硬盘搜索1.1.1 文件夹语法也很精彩:输入“关键词文件夹:文件所在的路径位于搜索框中”硬盘搜索会自动搜索指定文件所在路径下与关键词相关的所有搜索结果。例如,输入“九寨沟文件夹:C:\Travel Photos”,将显示C盘“Travel Photos”文件夹中所有九寨沟的照片。
10. "|" (逻辑或)扩大搜索范围
之前使用过这样的搜索公式:
Ashoka(连接|开始连接)。符号“|” 这里的意思是两者中的任何一个都可以出现,也就是布尔语法中“逻辑或”的表达。
Ashoka(正在连接|开始连接)的检索效果相当于“Ashoka is connected”加“Ashoka starts connected”
如果要搜索多个词,可以使用“|” 以扩大搜索范围。
例子:
(哈利波特 4 | 哈利波特4)
(笑傲江湖2 | 笑傲江湖)电影
(《笑傲江湖2》|《笑傲江湖》)电影
\\ 也可以使用双引号进行精确匹配。 查看全部
百度搜索指定网站内容(1.把搜索范围限定在网页标题内--intitle语法结构)
1.限制搜索到页面标题---intitle
语法结构: intitle:您要查找的信息(此信息将限于页面标题)
示例:要查找周杰伦的照片,可以输入“照片标题:周杰伦”,
注意 intitle: 和后面的 关键词 之间不能有空格。
2.将搜索限制在特定站点---站点
语法结构:你要查找的信息站点:网站去掉WWW后的地址
示例:查找华军软件园互联网快车信息,可输入“互联网快车站点:” PS:华军软件园网站
注意站点域名后跟“site:”不能收录“”和“/”符号;此外,site: 和站点名称之间不应有空格。
3.限制搜索到 URL 链接——inurl
语法结构:您要查找的信息 inurl:相关信息(必须是英文或中文拼音)
示例:要查找有关使用 Photoshop 的提示,您可以输入“Photoshop inurl: jiqiao”
PS:jiqiao是汉字技能的汉语拼音。
注意 inurl: 语法和它后面的 关键词 没有空格。
4.查找专业报告“filetype:”为文件类型,找到指定文件下载。使用此语法限制搜索对象,冒号后为文档格式,如PDF、DOC、XLS等。示例:霍金黑洞文件类型:pdf
5.完全匹配---双引号和书名号
语法结构:查询词不拆分。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“Shanghai University of科技”,取得的成果均符合要求。
语法结构:“你要找的书或电影”
示例:要查找手机电影的信息,可以输入“手机”
6.减号语法 --- 删除所有收录特定 关键词 的页面
语法结构:要寻找的信息——要摆脱的信息
例如:射雕英雄传-电视剧 这个语法结构需要在这里解释一下。例如,如果你搜索《神雕侠侣》武侠小说的内容,你会发现有很多关于电视剧的网页。您可以使用此语法删除有关电视剧的信息。
PS:-号前有空格
注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,减号语法功能会丢失。减号和下一个 关键词 之间没有空格。
7.intext:仅搜索收录在网页部分中的文本(即忽略标题、URL 等的文本)。
8.邮件搜索语法:SUBJECT、TO、FROM。
对于每天要处理大量邮件的用户来说,百度硬盘搜索提供的邮件搜索语法1.1.1:subject,to,from同样强大。只需输入“主题:工资详细信息”以查找主题中带有“工资详细信息”的电子邮件,然后输入“主题:初始 d 来自:”以查找主题中带有“初始 d”的 Claire 的电子邮件:键入“工作报告至: " 查找发送给 Peter 的所有工作报告电子邮件。
9.指定文件夹级搜索语法:文件夹硬盘搜索1.1.1 文件夹语法也很精彩:输入“关键词文件夹:文件所在的路径位于搜索框中”硬盘搜索会自动搜索指定文件所在路径下与关键词相关的所有搜索结果。例如,输入“九寨沟文件夹:C:\Travel Photos”,将显示C盘“Travel Photos”文件夹中所有九寨沟的照片。
10. "|" (逻辑或)扩大搜索范围
之前使用过这样的搜索公式:
Ashoka(连接|开始连接)。符号“|” 这里的意思是两者中的任何一个都可以出现,也就是布尔语法中“逻辑或”的表达。
Ashoka(正在连接|开始连接)的检索效果相当于“Ashoka is connected”加“Ashoka starts connected”
如果要搜索多个词,可以使用“|” 以扩大搜索范围。
例子:
(哈利波特 4 | 哈利波特4)
(笑傲江湖2 | 笑傲江湖)电影
(《笑傲江湖2》|《笑傲江湖》)电影
\\ 也可以使用双引号进行精确匹配。
百度搜索指定网站内容(如何让百度搜索引擎更高效更简洁?常用搜索语法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-20 20:00
百度常用搜索语法
百度是我们常用的搜索引擎,但是每次我们搜索的东西,都不尽如人意。很多时候,我们找不到自己想要的东西,一堆广告,一堆乱七八糟的东西。这对谷歌搜索引擎来说处理起来很方便,但是在中国使用谷歌搜索引擎并不是那么随意,还需要掌握科学的上网方法。所以很多朋友还是要用百度。有什么办法可以让百度搜索引擎更加高效简洁?答案是肯定的。百度还提供了类似谷歌的搜索语法,让搜索更加简洁、高效、准确。这里简单介绍一些常见的搜索语法。
intitle 将搜索限制为页面标题
网页的标题通常是网页内容大纲的高级摘要。将查询的内容限制在页面的标题上,有时可以取得不错的效果。语法规则是使用“intitle:”来获取搜索内容中的关键词。例如:文章 intitle:山海经,intitle:特种部队。注意 intitle: 和后面的 关键词 之间不能有空格。
站点将搜索限制在特定站点
要在特定站点中查找内容,可以使用此语法将搜索范围限制在该站点,从而提高查询效率。使用方法是在查询内容后面加上“site:站点域名”。例如:helloword 网站:。这样,搜索引擎就会从相应的站点中找到相关的内容。请注意,“site:”后面的站点域名不应包括在内,或另外,site: 和站点名称之间不应有空格。
inurl 将搜索范围限制为 url 链接
网页url中的一些信息往往具有一些有价值的意义。如果对搜索结果的 URL 进行了某种限制,可以获得很好的搜索效果。(互联网上可用的资源可以用简单的字符串来表示:“统一资源定位符”(URLs)。一个 URL 由一串字符组成,可以是字母、数字和特殊符号。有关详细信息,您可以查找自己)。inurl 参数可用于限制搜索结果中的 url。用法就是这样,就是使用"inurl:"后跟需要出现在url中的关键词。例如:ps inurl:jiqiao。“ps”可以出现在网页的任何位置,而“jiqiao”必须出现在网页的url中。注意 inurl: 语法和它后面的 关键词 没有空格。
““, ““ 完全符合
如果输入的查询词很长,百度分析后可能会巧妙的将你的搜索词拆分成多个部分,给定搜索结果中的查询词也可能会被拆分。如果想避免这种情况,可以尽量让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。例如:搜索内蒙古师范大学,如果不加双引号,搜索结果可能会拆分成内蒙古、师范、大学等,效果不是很好,但是加双引号后, 《内蒙古师范大学》,百度不会为你智能拆分搜索。而且加双引号搜索后,你会发现很多广告自然会被屏蔽,搜索不到。可以有效减少百度搜索后的广告泛滥问题。书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。书名号查询词有两个特殊功能。一是书名号会出现在搜索结果中;另一个是书名号展开的内容不会被拆分。书名在某些情况下特别有用,例如查找具有流行和常用名称的电影或小说。比如看电影《特种兵》,如果不加书名,很多时候会介绍兵种之类的,但是加了书名后,结果的 ”
- 减号
要求搜索结果不收录特定的查询词。如果搜索结果中有某类网页要屏蔽,可以找到这些网页的具体关键词,用减号语法基本屏蔽所有收录特定<关键词的页。例如:新警察故事,我想找这部片子,但是搜索结果发现有很多类似的游戏,那么可以写成新警察故事-游戏,这样新警察故事的游戏页面就会被屏蔽. 注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,失去减号的语法功能。减号和下一个 关键词 之间没有空格。
+ 加号
收录特定查询词 查询词使用加号 + 语法来收录搜索结果中必须收录特定 关键词 的所有页面。例如:电影+新警察故事搜索结果中的查询词“电影”,搜索结果中需要收录“新警察故事”。
文件类型
搜索范围仅限于指定的文档格式。可以使用 Filetype 语法将查询词限制为出现在指定的文档中。支持的文档格式包括pdf、doc、xls、ppt、rtf等。对查找文档很有帮助。例如:Excel 使用技能 filetype:doc 以便您可以找到 doc 格式的相关文档。
注意!注意!注意!
- 如果您不记得上面描述的方法,或者不知道如何使用它怎么办?百度提供了一种更简单的方法来处理这个问题。百度的高级搜索操作更简单。点我搜索。 查看全部
百度搜索指定网站内容(如何让百度搜索引擎更高效更简洁?常用搜索语法)
百度常用搜索语法
百度是我们常用的搜索引擎,但是每次我们搜索的东西,都不尽如人意。很多时候,我们找不到自己想要的东西,一堆广告,一堆乱七八糟的东西。这对谷歌搜索引擎来说处理起来很方便,但是在中国使用谷歌搜索引擎并不是那么随意,还需要掌握科学的上网方法。所以很多朋友还是要用百度。有什么办法可以让百度搜索引擎更加高效简洁?答案是肯定的。百度还提供了类似谷歌的搜索语法,让搜索更加简洁、高效、准确。这里简单介绍一些常见的搜索语法。
intitle 将搜索限制为页面标题
网页的标题通常是网页内容大纲的高级摘要。将查询的内容限制在页面的标题上,有时可以取得不错的效果。语法规则是使用“intitle:”来获取搜索内容中的关键词。例如:文章 intitle:山海经,intitle:特种部队。注意 intitle: 和后面的 关键词 之间不能有空格。
站点将搜索限制在特定站点
要在特定站点中查找内容,可以使用此语法将搜索范围限制在该站点,从而提高查询效率。使用方法是在查询内容后面加上“site:站点域名”。例如:helloword 网站:。这样,搜索引擎就会从相应的站点中找到相关的内容。请注意,“site:”后面的站点域名不应包括在内,或另外,site: 和站点名称之间不应有空格。
inurl 将搜索范围限制为 url 链接
网页url中的一些信息往往具有一些有价值的意义。如果对搜索结果的 URL 进行了某种限制,可以获得很好的搜索效果。(互联网上可用的资源可以用简单的字符串来表示:“统一资源定位符”(URLs)。一个 URL 由一串字符组成,可以是字母、数字和特殊符号。有关详细信息,您可以查找自己)。inurl 参数可用于限制搜索结果中的 url。用法就是这样,就是使用"inurl:"后跟需要出现在url中的关键词。例如:ps inurl:jiqiao。“ps”可以出现在网页的任何位置,而“jiqiao”必须出现在网页的url中。注意 inurl: 语法和它后面的 关键词 没有空格。
““, ““ 完全符合
如果输入的查询词很长,百度分析后可能会巧妙的将你的搜索词拆分成多个部分,给定搜索结果中的查询词也可能会被拆分。如果想避免这种情况,可以尽量让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。例如:搜索内蒙古师范大学,如果不加双引号,搜索结果可能会拆分成内蒙古、师范、大学等,效果不是很好,但是加双引号后, 《内蒙古师范大学》,百度不会为你智能拆分搜索。而且加双引号搜索后,你会发现很多广告自然会被屏蔽,搜索不到。可以有效减少百度搜索后的广告泛滥问题。书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。书名号查询词有两个特殊功能。一是书名号会出现在搜索结果中;另一个是书名号展开的内容不会被拆分。书名在某些情况下特别有用,例如查找具有流行和常用名称的电影或小说。比如看电影《特种兵》,如果不加书名,很多时候会介绍兵种之类的,但是加了书名后,结果的 ”
- 减号
要求搜索结果不收录特定的查询词。如果搜索结果中有某类网页要屏蔽,可以找到这些网页的具体关键词,用减号语法基本屏蔽所有收录特定<关键词的页。例如:新警察故事,我想找这部片子,但是搜索结果发现有很多类似的游戏,那么可以写成新警察故事-游戏,这样新警察故事的游戏页面就会被屏蔽. 注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,失去减号的语法功能。减号和下一个 关键词 之间没有空格。
+ 加号
收录特定查询词 查询词使用加号 + 语法来收录搜索结果中必须收录特定 关键词 的所有页面。例如:电影+新警察故事搜索结果中的查询词“电影”,搜索结果中需要收录“新警察故事”。
文件类型
搜索范围仅限于指定的文档格式。可以使用 Filetype 语法将查询词限制为出现在指定的文档中。支持的文档格式包括pdf、doc、xls、ppt、rtf等。对查找文档很有帮助。例如:Excel 使用技能 filetype:doc 以便您可以找到 doc 格式的相关文档。
注意!注意!注意!
- 如果您不记得上面描述的方法,或者不知道如何使用它怎么办?百度提供了一种更简单的方法来处理这个问题。百度的高级搜索操作更简单。点我搜索。
百度搜索指定网站内容(把搜索范围限定在url链接中——inurl网页标题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-02-20 19:08
将搜索范围限制为 url 链接 - inurl
网页url中的一些信息往往具有一些有价值的意义。因此,如果您对搜索结果的 url 进行某种限制,您可以获得良好的结果。实现这一点的方法是使用“inurl:”,后跟需要出现在 url 中的 关键词。
比如要查找photoshop的使用技巧,可以这样查询:photoshop inurl:jiqiao
上面查询字符串中的“photoshop”可以出现在网页的任何位置,而“jiqiao”必须出现在网页的url中。
注意 inurl: 语法和它后面的 关键词 没有空格。
将您的搜索限制在页面标题 - intitle
网页的标题通常是对网页内容的概括概括。将查询的内容限制在页面的标题上,有时可以取得不错的效果。使用方法是使用“intitle:”来获取查询内容中最关键的部分。
比如要查找林青霞的照片,可以这样查询: 照片标题:林青霞
注意 intitle: 和后面的 关键词 之间不能有空格。
将您的搜索限制在特定站点 - 站点
有时,如果您知道在某个站点上需要查找某些内容,则可以将搜索范围限制在该站点上,以提高查询效率。使用方法是在查询内容后面加上“site:站点域名”。
比如天网下载软件不错,可以这样查询:msn站点:
注意站点域名后跟“site:”不能收录“”;此外,site: 和站点名称之间不应有空格。
完全匹配 - 双引号和书名编号
如果输入的查询词很长,百度分析后给出的搜索结果中的查询词可能会被拆分。如果对这种情况不满意,可以尝试让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“上海大学科技”,取得的成果均符合要求。
书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。书名号查询词有两个特殊功能。一是书名号会出现在搜索结果中;另一个是书名号展开的内容不会被拆分。书名在某些情况下特别有用,例如查找具有流行和常用名称的电影或小说。比如你查一部电影的“手机”,如果不加书名,很多时候是通讯工具——手机,加上书名后,结果“手机”的一切都是关于电影的。
要求不收录在搜索结果中的特定查询词
如果您在搜索结果中发现某些类型的页面是您不想看到的,并且这些页面收录特定的 关键词,则使用减号语法将删除所有那些收录特定 < @关键词 > 网页。
比如我搜索《神雕侠侣》,希望是武侠小说的,结果找到了很多关于电视剧的网页。然后可以这样查询:神雕侠侣-电视剧
注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,减号语法功能会丢失。减号和下一个 关键词 之间没有空格。 查看全部
百度搜索指定网站内容(把搜索范围限定在url链接中——inurl网页标题)
将搜索范围限制为 url 链接 - inurl
网页url中的一些信息往往具有一些有价值的意义。因此,如果您对搜索结果的 url 进行某种限制,您可以获得良好的结果。实现这一点的方法是使用“inurl:”,后跟需要出现在 url 中的 关键词。
比如要查找photoshop的使用技巧,可以这样查询:photoshop inurl:jiqiao
上面查询字符串中的“photoshop”可以出现在网页的任何位置,而“jiqiao”必须出现在网页的url中。
注意 inurl: 语法和它后面的 关键词 没有空格。
将您的搜索限制在页面标题 - intitle
网页的标题通常是对网页内容的概括概括。将查询的内容限制在页面的标题上,有时可以取得不错的效果。使用方法是使用“intitle:”来获取查询内容中最关键的部分。
比如要查找林青霞的照片,可以这样查询: 照片标题:林青霞
注意 intitle: 和后面的 关键词 之间不能有空格。
将您的搜索限制在特定站点 - 站点
有时,如果您知道在某个站点上需要查找某些内容,则可以将搜索范围限制在该站点上,以提高查询效率。使用方法是在查询内容后面加上“site:站点域名”。
比如天网下载软件不错,可以这样查询:msn站点:
注意站点域名后跟“site:”不能收录“”;此外,site: 和站点名称之间不应有空格。
完全匹配 - 双引号和书名编号
如果输入的查询词很长,百度分析后给出的搜索结果中的查询词可能会被拆分。如果对这种情况不满意,可以尝试让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“上海大学科技”,取得的成果均符合要求。
书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。书名号查询词有两个特殊功能。一是书名号会出现在搜索结果中;另一个是书名号展开的内容不会被拆分。书名在某些情况下特别有用,例如查找具有流行和常用名称的电影或小说。比如你查一部电影的“手机”,如果不加书名,很多时候是通讯工具——手机,加上书名后,结果“手机”的一切都是关于电影的。
要求不收录在搜索结果中的特定查询词
如果您在搜索结果中发现某些类型的页面是您不想看到的,并且这些页面收录特定的 关键词,则使用减号语法将删除所有那些收录特定 < @关键词 > 网页。
比如我搜索《神雕侠侣》,希望是武侠小说的,结果找到了很多关于电视剧的网页。然后可以这样查询:神雕侠侣-电视剧
注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,减号语法功能会丢失。减号和下一个 关键词 之间没有空格。
百度搜索指定网站内容( 百度改变的快照算法,不从远端服务器获取JavaScript文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-18 17:19
百度改变的快照算法,不从远端服务器获取JavaScript文件)
有时,由于内容变更或隐私问题,我们经常不希望他人通过“百度快照”的方式查看我们网站的某些页面。对于网站管理员,百度快照也被引流。有很多属于 网站 的流量。为了增加网站的流量或者增强内容隐私,我之前提供了一种将百度快照重定向到自己的方法网站。但是百度后来改的快照算法并没有从远程服务器获取JavaScript文件,所以之前介绍的屏蔽方法现在已经失效了。
现在我介绍一个新方法,原理基本一样,我们知道百度网页快照虽然没有从远程服务器抓取JavaScript文件,但仍然是从远程服务器抓取CSS文件。实现网页重定向,从而控制百度快照中的网页,我们完全控制快照重定向到我们制作的任何网页地址。
比如百度快照缓存的文件是style.css,那么我们在服务器上编辑这个文件,在CSS文件中添加如下语句来控制百度缓存快照的重定向,从而实现屏蔽百度的功能网页快照内容。
正文 {onload:expression(location.href='');}
以上语句在IE浏览器下测试通过。理论上,按照这种方法,我们可以控制百度网页快照的内容重定向到我们指定的任意一个URL,甚至是第三方网站。为了实现网页的正常显示,百度快照屏蔽CSS的可能性会很小。
此方法还可用于阻止来自其他搜索引擎(如 Google)的页面快照。
() () 查看全部
百度搜索指定网站内容(
百度改变的快照算法,不从远端服务器获取JavaScript文件)
有时,由于内容变更或隐私问题,我们经常不希望他人通过“百度快照”的方式查看我们网站的某些页面。对于网站管理员,百度快照也被引流。有很多属于 网站 的流量。为了增加网站的流量或者增强内容隐私,我之前提供了一种将百度快照重定向到自己的方法网站。但是百度后来改的快照算法并没有从远程服务器获取JavaScript文件,所以之前介绍的屏蔽方法现在已经失效了。
现在我介绍一个新方法,原理基本一样,我们知道百度网页快照虽然没有从远程服务器抓取JavaScript文件,但仍然是从远程服务器抓取CSS文件。实现网页重定向,从而控制百度快照中的网页,我们完全控制快照重定向到我们制作的任何网页地址。
比如百度快照缓存的文件是style.css,那么我们在服务器上编辑这个文件,在CSS文件中添加如下语句来控制百度缓存快照的重定向,从而实现屏蔽百度的功能网页快照内容。
正文 {onload:expression(location.href='');}
以上语句在IE浏览器下测试通过。理论上,按照这种方法,我们可以控制百度网页快照的内容重定向到我们指定的任意一个URL,甚至是第三方网站。为了实现网页的正常显示,百度快照屏蔽CSS的可能性会很小。
此方法还可用于阻止来自其他搜索引擎(如 Google)的页面快照。
() ()
百度搜索指定网站内容(这些出色的提示和技巧专业人士一样一样使用Google)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-18 05:20
通过这些出色的提示和技巧,像专业人士一样使用 Google。
当我们需要找到我们想要的东西(网站、电影、应用程序......任何东西)时,我们通常会使用 Google 搜索。此外,它还提供了一些隐藏功能。
计时器和秒表
比如说,你需要为准备好的演讲测量时间,或者你需要从专注的工作中休息 5 分钟。只是谷歌秒表或计时器
这两种工具都提供全屏模式,如果您将投影仪屏幕用于观众,这将非常有用。
颜色选择器
只需使用谷歌颜色选择器或复制粘贴十六进制颜色代码(例如:-#0f9bff)即可获得颜色选择器工具,键入 rgb 50 50 80 之类的查询将执行相同的操作。
仅完全匹配
当您输入一组词为 关键词 时,Google 的搜索算法会以一种巧妙的方式进行匹配,从而首先为您提供更多相关信息。但在某些情况下,我们只需要找到与文本完全匹配的内容,而不是让 Google 应用自己的匹配逻辑,这可以通过将搜索条件用双引号括起来轻松完成。
适用于百度等从搜索中排除单词
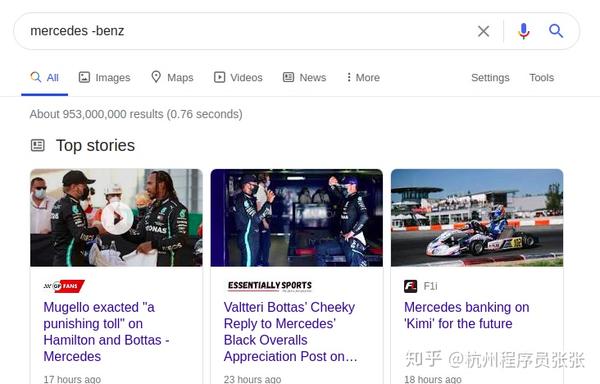
显然,当你使用一组关键词时,谷歌会给你所有匹配的内容。但是,如果您不需要某些收录已知单词的结果,则可以从收录该已知单词的预期结果中排除这些结果。下面的示例将显示收录 Mercedes 但不收录已知单词 Benz 的结果。
适用于百度等,只在指定域内搜索
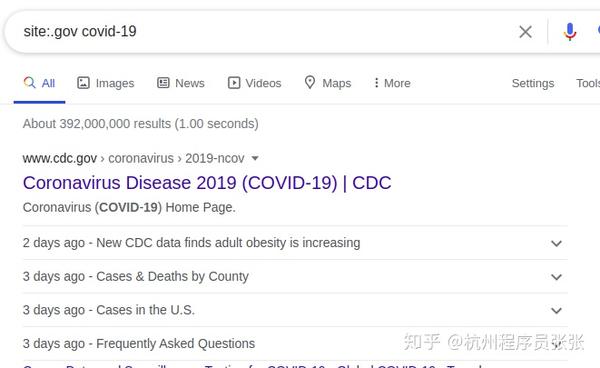
一般搜索查询将能够从 Google 的许多域中获取文档。如果需要,您可以搜索一个只提供属于特定域名的结果的特殊查询。只需添加 site: 在您的搜索条件前面。例如:site:.gov covid-19
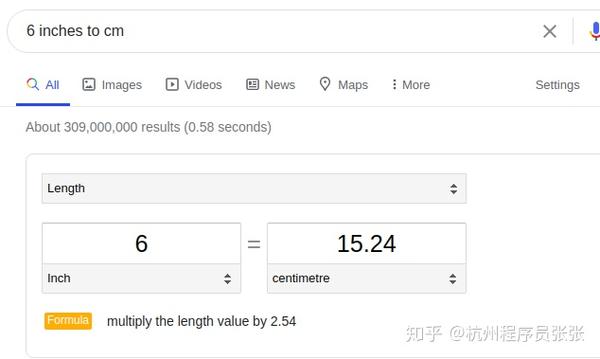
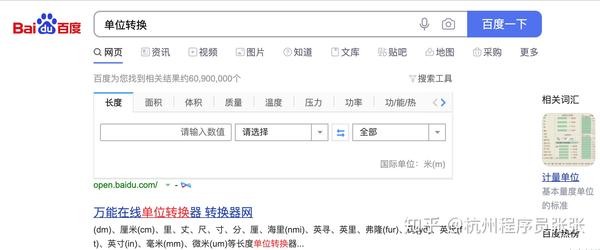
适用于百度等单位换算工具
您不需要单独的应用程序来转换标准单位,Google 会帮助您。只需输入您要转换的内容,例如“6 英寸到厘米”或“单位转换”,然后输入值。
适用于百度等
货币转换
这与单位转换工具非常相似,搜索查询的格式相同。例如:“5 美元到 lkr”,或者在大多数情况下“5 美元”就足够了,因为 Google 知道您的位置。
适用于百度等
我的 IP 地址是多少
有人问你的IP地址加入白名单?只需谷歌“我的 ip 是什么”或“我的 ip”。
世界时钟
与居住在不同时区的人一起工作?好吧,如果他们很快问“我们可以在下午 5 点开会吗?”。如果您使用“日本时间下午 5 点”之类的查询进行搜索,Google 也会为您提供帮助,如下图所示。
在社交媒体上找人
如果你需要在社交媒体上找到你的一个朋友,首先你需要去社交媒体平台,然后你可以搜索。事实上,在谷歌的帮助下,有一种更快的方法。只需在您朋友的用户名和 Google 前面使用 @ 字符即可。
对于百度
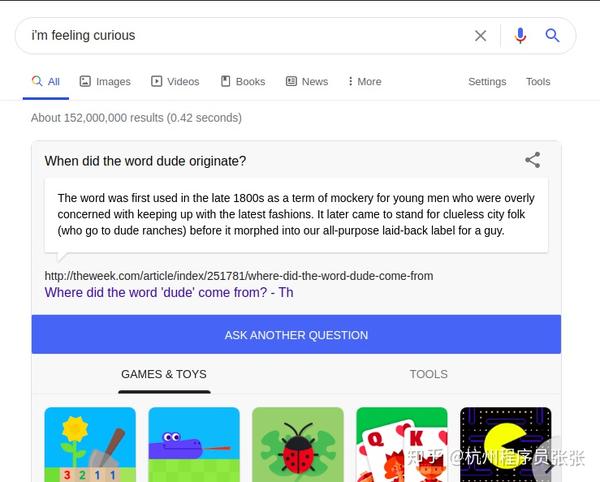
我好奇
如果您搜索“我很好奇”,将会有令人惊讶的问题和答案。此外,如果您按下展开图标,将会有很多有趣的游戏和其他有用的工具。
原文:/swhlh/10-hidden-features-in-google-search-83b347b48157 查看全部
百度搜索指定网站内容(这些出色的提示和技巧专业人士一样一样使用Google)
通过这些出色的提示和技巧,像专业人士一样使用 Google。
当我们需要找到我们想要的东西(网站、电影、应用程序......任何东西)时,我们通常会使用 Google 搜索。此外,它还提供了一些隐藏功能。
计时器和秒表
比如说,你需要为准备好的演讲测量时间,或者你需要从专注的工作中休息 5 分钟。只是谷歌秒表或计时器
这两种工具都提供全屏模式,如果您将投影仪屏幕用于观众,这将非常有用。
颜色选择器
只需使用谷歌颜色选择器或复制粘贴十六进制颜色代码(例如:-#0f9bff)即可获得颜色选择器工具,键入 rgb 50 50 80 之类的查询将执行相同的操作。
仅完全匹配
当您输入一组词为 关键词 时,Google 的搜索算法会以一种巧妙的方式进行匹配,从而首先为您提供更多相关信息。但在某些情况下,我们只需要找到与文本完全匹配的内容,而不是让 Google 应用自己的匹配逻辑,这可以通过将搜索条件用双引号括起来轻松完成。
适用于百度等从搜索中排除单词
显然,当你使用一组关键词时,谷歌会给你所有匹配的内容。但是,如果您不需要某些收录已知单词的结果,则可以从收录该已知单词的预期结果中排除这些结果。下面的示例将显示收录 Mercedes 但不收录已知单词 Benz 的结果。
适用于百度等,只在指定域内搜索
一般搜索查询将能够从 Google 的许多域中获取文档。如果需要,您可以搜索一个只提供属于特定域名的结果的特殊查询。只需添加 site: 在您的搜索条件前面。例如:site:.gov covid-19
适用于百度等单位换算工具
您不需要单独的应用程序来转换标准单位,Google 会帮助您。只需输入您要转换的内容,例如“6 英寸到厘米”或“单位转换”,然后输入值。
适用于百度等
货币转换
这与单位转换工具非常相似,搜索查询的格式相同。例如:“5 美元到 lkr”,或者在大多数情况下“5 美元”就足够了,因为 Google 知道您的位置。
适用于百度等
我的 IP 地址是多少
有人问你的IP地址加入白名单?只需谷歌“我的 ip 是什么”或“我的 ip”。
世界时钟
与居住在不同时区的人一起工作?好吧,如果他们很快问“我们可以在下午 5 点开会吗?”。如果您使用“日本时间下午 5 点”之类的查询进行搜索,Google 也会为您提供帮助,如下图所示。
在社交媒体上找人
如果你需要在社交媒体上找到你的一个朋友,首先你需要去社交媒体平台,然后你可以搜索。事实上,在谷歌的帮助下,有一种更快的方法。只需在您朋友的用户名和 Google 前面使用 @ 字符即可。
对于百度
我好奇
如果您搜索“我很好奇”,将会有令人惊讶的问题和答案。此外,如果您按下展开图标,将会有很多有趣的游戏和其他有用的工具。
原文:/swhlh/10-hidden-features-in-google-search-83b347b48157
百度搜索指定网站内容(交流学习java大数据可以加群460570824.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-02-18 05:20
阅读这篇文章大约需要 5 分钟。建议采集后阅读。里面装满了干货。你可以自己测试一下。如果觉得好用,可以帮忙点赞转发,谢谢!交流学习java大数据可加群460570824.
无论是计算机专业还是非计算机专业人士,掌握一些常用的搜索技巧,对我们的学习和工作都是非常有益的。这篇文章文章主要针对google的一些常用技巧,百度因为很少用到所以没有具体测试。
搜索百度云盘信息
可以在搜索关键字后添加站点:百度云盘网址
前任:
在搜索框中输入python核心编程站点:
我们可以在百度云盘中找到我们想要的资源
使用 inurl
inurl:指令用于搜索出现在网页url中的查询关键字。inurl 也支持中文。
前任:
在搜索框中搜索关键字:inutl:python
使用文本
intext:就是显示文章的内容中所有带有关键字的结果
前任:
在搜索框中搜索关键词:intext:software engineering
检查天气
如果您想快速了解某个城市的天气,而无需使用应用程序获取它,您可以尝试天气。
前任:
搜索框搜索关键词:天气+武汉
查询作者所有作品
前任:
在搜索框中搜索关键词:莫言的书
用站点指定 网站
site:我们可以在我们指定的URL中定位到我们搜索的内容,搜索到的内容不会是其他网站中的内容。
关键字网站:用户指定的网址
前任:
在搜索框中搜索关键字:python 高级站点:
我们发现所有搜索都来自 知乎。请注意,站点后的冒号是英文字符。此外,冒号后面不能有空格,否则 site: 将被视为关键字。
下载软件
我们在下载软件的时候,如果要在软件厂商的官网下载,一般都是直接到下载目录下载。
所以我们可以直接在url中搜索下载。
前任:
我们要下载 atom 编辑器,可以使用 atom inurl:download 进行搜索。
使用双引号“”
在搜索构建期间,使用双引号表示完全匹配
* 模糊匹配
当我们想搜索一个关键词,但是我们记住了前后几个词,而中间的某个词又忘记了怎么办,就用它来进行模糊匹配。
搜索指定的文件类型
如果要搜索 PDF 的 文章,可以在搜索时指定文件类型。
前任:
在搜索框中搜索关键字:计算机文件类型:pdf
使用标题
使用 intitle 将搜索限制为收录指定关键字的标题。
前任:
在搜索框中搜索关键词:intitle:big data
使用 allintitle
这和上面的intitle很相似,但是这个在标题中有用户定义的关键字
前任:
在搜索框中搜索关键词:allintitle:大数据云计算
掌握一定的搜索技巧,可以让我们在网络世界中更快地获得我们想要的资源。关于搜索技巧,还是需要在平时使用搜索工具的过程中总结。
查看全部
百度搜索指定网站内容(交流学习java大数据可以加群460570824.)
阅读这篇文章大约需要 5 分钟。建议采集后阅读。里面装满了干货。你可以自己测试一下。如果觉得好用,可以帮忙点赞转发,谢谢!交流学习java大数据可加群460570824.
无论是计算机专业还是非计算机专业人士,掌握一些常用的搜索技巧,对我们的学习和工作都是非常有益的。这篇文章文章主要针对google的一些常用技巧,百度因为很少用到所以没有具体测试。
搜索百度云盘信息
可以在搜索关键字后添加站点:百度云盘网址
前任:
在搜索框中输入python核心编程站点:
我们可以在百度云盘中找到我们想要的资源

使用 inurl
inurl:指令用于搜索出现在网页url中的查询关键字。inurl 也支持中文。
前任:
在搜索框中搜索关键字:inutl:python

使用文本
intext:就是显示文章的内容中所有带有关键字的结果
前任:
在搜索框中搜索关键词:intext:software engineering

检查天气
如果您想快速了解某个城市的天气,而无需使用应用程序获取它,您可以尝试天气。
前任:
搜索框搜索关键词:天气+武汉

查询作者所有作品
前任:
在搜索框中搜索关键词:莫言的书

用站点指定 网站
site:我们可以在我们指定的URL中定位到我们搜索的内容,搜索到的内容不会是其他网站中的内容。
关键字网站:用户指定的网址
前任:
在搜索框中搜索关键字:python 高级站点:

我们发现所有搜索都来自 知乎。请注意,站点后的冒号是英文字符。此外,冒号后面不能有空格,否则 site: 将被视为关键字。
下载软件
我们在下载软件的时候,如果要在软件厂商的官网下载,一般都是直接到下载目录下载。
所以我们可以直接在url中搜索下载。
前任:
我们要下载 atom 编辑器,可以使用 atom inurl:download 进行搜索。

使用双引号“”
在搜索构建期间,使用双引号表示完全匹配

* 模糊匹配
当我们想搜索一个关键词,但是我们记住了前后几个词,而中间的某个词又忘记了怎么办,就用它来进行模糊匹配。

搜索指定的文件类型
如果要搜索 PDF 的 文章,可以在搜索时指定文件类型。
前任:
在搜索框中搜索关键字:计算机文件类型:pdf

使用标题
使用 intitle 将搜索限制为收录指定关键字的标题。
前任:
在搜索框中搜索关键词:intitle:big data

使用 allintitle
这和上面的intitle很相似,但是这个在标题中有用户定义的关键字
前任:
在搜索框中搜索关键词:allintitle:大数据云计算

掌握一定的搜索技巧,可以让我们在网络世界中更快地获得我们想要的资源。关于搜索技巧,还是需要在平时使用搜索工具的过程中总结。
百度搜索指定网站内容(百度搜索技巧intitle——把搜索范围限定在网页标题中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-18 05:17
百度搜索技巧
intitle - 将搜索限制在页面标题
用法:intitle:查询内容
比如百度输入:关键词 intitle:oschina
inurl - 将搜索范围限制为 url 链接
用法:inurl:具体的url
比如百度输入:关键词 inurl:
站点 - 将搜索限制在特定站点
如何使用:网站:网址
例如百度输入:关键词 站点:
完全匹配、加号和减号、通配符
完全匹配:可以使用双引号和书名号
在要查询的关键词后面加上双引号(半角,下面要加的其他符号同理),实现精确查询。这种方法要求查询结果必须完全匹配,不包括进化形式。例如,在搜索引擎的文本框中键入“电话”将返回带有关键字“电话”的 URL,但不会返回诸如“电话传真”之类的页面。
加号:在关键词前面使用加号,相当于告诉搜索引擎该词必须出现在搜索结果中的网页上。例如在搜索引擎中输入“+电脑+电话+传真”表示要查找的内容必须同时收录“电脑、电话、传真”三个关键词
减号:在关键词前面使用减号,表示关键词不能出现在查询结果中。例如,在搜索引擎中输入“电视台-XX电视台”,表示查询结果中最后不能收录“XX电视台”。
通配符包括星号 (*) 和问号 (?)。前者意味着匹配的数量是无限的,而后者意味着要匹配的字符数量是有限的。它主要用于英文搜索引擎。例如,如果输入“computer*”,则可以找到“computer,computerised,computerized”等词,如果输入“comp?ter”,则只能找到“computer,computer,competitor”等词”。
比如百度输入:“美人鱼”
文件类型 - 专业的文档搜索
用法:文件类型:文档格式
比如百度输入:关键词 filetype:doc
搜索后,您可以使用搜索工具来细化搜索结果
谷歌搜索提示
SEO : 是一种通过了解搜索引擎并提高目的在搜索引擎中排名的方法网站。
案例 1. 搜索“patchwork”的结果
我要搜索“android 网络位置”,直接输入关键字,会发现有些搜索结果是“patchwork”,而不是“android 网络位置”的顺序。
“拼布”的搜索结果
解决方案 1. 使用 "" 进行精确匹配
使用方法:“关键字”,通过给关键字加上双引号,得到的搜索结果完全按照关键字的顺序排列。
案例 2. 不想搜索 关键词
手机定位方式有几种:GPS定位、网络定位和基站定位。我想了解与网络定位相关的原理。搜索“android网络定位”时,不希望出现GPS这个关键字。如上例,如果直接输入关键字,搜索结果将收录 GPS 相关信息。
不想搜索 关键词
解决方案 2. 使用-排除关键字
如何使用:关键字 - 排除关键字,提示: - 后面没有空格。搜索结果中没有 GPS 关键字。
案例 3. 不记得完整的 关键词
陈奕迅有一首歌歌词不完整,忘记歌名了。我只记得几句话。我应该如何搜索?
不记得完整的 关键词
解决方案 3. 使用 * 进行模糊匹配
使用方法:关键字*关键字
case 4. 只想找某一个网站
直接输入关键字,会有很多结果,但我只想在某个网站上搜索。
只想在某个网站上找到
解决方案 4. 使用站点指定网站
使用方法:关键词网站:URL
案例 5. 只想搜索 PDF 类型的文件
文档类型很多,比如doc、pdf、epub,我只想搜索文件类型为PDF的文档
只想搜索 PDF 类型的文件
解决方法 5. 使用filetype指定文件类型
使用方法:关键字filetype:文件类型
使用 filetype 指定文件类型
提示:关于文件类型
只有 Google 支持的文件类型可用。尝试搜索 .epub 文件时,它会提示“您的搜索 - Android 软件安全和反向分析文件类型:epub - 没有匹配任何文档。”
您的搜索 - *Android 软件安全和反向分析文件类型:epub* - 没有匹配任何文档。
谷歌支持的文件类型可以在Search Console Help上找到,显示不支持epub
Google 可索引的文件类型
当遇到不支持的文件类型时,我们可以通过精确匹配方法搜索
关键词
如何
最常用的方法,在google中搜索“how to”+关键词,可以找到很多相关的文章。
惊人的
可以在github或者google搜索“awesome”+关键词,很多好的项目,文章都是以它命名的。 查看全部
百度搜索指定网站内容(百度搜索技巧intitle——把搜索范围限定在网页标题中)
百度搜索技巧
intitle - 将搜索限制在页面标题
用法:intitle:查询内容
比如百度输入:关键词 intitle:oschina
inurl - 将搜索范围限制为 url 链接
用法:inurl:具体的url
比如百度输入:关键词 inurl:
站点 - 将搜索限制在特定站点
如何使用:网站:网址
例如百度输入:关键词 站点:
完全匹配、加号和减号、通配符
完全匹配:可以使用双引号和书名号
在要查询的关键词后面加上双引号(半角,下面要加的其他符号同理),实现精确查询。这种方法要求查询结果必须完全匹配,不包括进化形式。例如,在搜索引擎的文本框中键入“电话”将返回带有关键字“电话”的 URL,但不会返回诸如“电话传真”之类的页面。
加号:在关键词前面使用加号,相当于告诉搜索引擎该词必须出现在搜索结果中的网页上。例如在搜索引擎中输入“+电脑+电话+传真”表示要查找的内容必须同时收录“电脑、电话、传真”三个关键词
减号:在关键词前面使用减号,表示关键词不能出现在查询结果中。例如,在搜索引擎中输入“电视台-XX电视台”,表示查询结果中最后不能收录“XX电视台”。
通配符包括星号 (*) 和问号 (?)。前者意味着匹配的数量是无限的,而后者意味着要匹配的字符数量是有限的。它主要用于英文搜索引擎。例如,如果输入“computer*”,则可以找到“computer,computerised,computerized”等词,如果输入“comp?ter”,则只能找到“computer,computer,competitor”等词”。
比如百度输入:“美人鱼”
文件类型 - 专业的文档搜索
用法:文件类型:文档格式
比如百度输入:关键词 filetype:doc
搜索后,您可以使用搜索工具来细化搜索结果
谷歌搜索提示
SEO : 是一种通过了解搜索引擎并提高目的在搜索引擎中排名的方法网站。
案例 1. 搜索“patchwork”的结果
我要搜索“android 网络位置”,直接输入关键字,会发现有些搜索结果是“patchwork”,而不是“android 网络位置”的顺序。
“拼布”的搜索结果
解决方案 1. 使用 "" 进行精确匹配
使用方法:“关键字”,通过给关键字加上双引号,得到的搜索结果完全按照关键字的顺序排列。
案例 2. 不想搜索 关键词
手机定位方式有几种:GPS定位、网络定位和基站定位。我想了解与网络定位相关的原理。搜索“android网络定位”时,不希望出现GPS这个关键字。如上例,如果直接输入关键字,搜索结果将收录 GPS 相关信息。
不想搜索 关键词
解决方案 2. 使用-排除关键字
如何使用:关键字 - 排除关键字,提示: - 后面没有空格。搜索结果中没有 GPS 关键字。
案例 3. 不记得完整的 关键词
陈奕迅有一首歌歌词不完整,忘记歌名了。我只记得几句话。我应该如何搜索?
不记得完整的 关键词
解决方案 3. 使用 * 进行模糊匹配
使用方法:关键字*关键字
case 4. 只想找某一个网站
直接输入关键字,会有很多结果,但我只想在某个网站上搜索。
只想在某个网站上找到
解决方案 4. 使用站点指定网站
使用方法:关键词网站:URL
案例 5. 只想搜索 PDF 类型的文件
文档类型很多,比如doc、pdf、epub,我只想搜索文件类型为PDF的文档
只想搜索 PDF 类型的文件
解决方法 5. 使用filetype指定文件类型
使用方法:关键字filetype:文件类型
使用 filetype 指定文件类型
提示:关于文件类型
只有 Google 支持的文件类型可用。尝试搜索 .epub 文件时,它会提示“您的搜索 - Android 软件安全和反向分析文件类型:epub - 没有匹配任何文档。”
您的搜索 - *Android 软件安全和反向分析文件类型:epub* - 没有匹配任何文档。
谷歌支持的文件类型可以在Search Console Help上找到,显示不支持epub
Google 可索引的文件类型
当遇到不支持的文件类型时,我们可以通过精确匹配方法搜索
关键词
如何
最常用的方法,在google中搜索“how to”+关键词,可以找到很多相关的文章。
惊人的
可以在github或者google搜索“awesome”+关键词,很多好的项目,文章都是以它命名的。
百度搜索指定网站内容(网站优化以下内容优化的方法有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-18 02:07
想要做好优化,其实还是要花点心思的。从做网站开始,不要做那种纯图片的模板网站。还是可以使用织梦帝王仿制网站的。网站搭建完成后,备案等资料,以及服务器,最好用阿里云和腾讯云。外面有很多托管公司,上面放了很多海外BC网络,很容易被锁在一个小k屋里,所以这个网站基本上是GG。
一般正常网站优化以下内容。
修改tdk:title:收录所有核心推荐关键词
1、404页面需要有返回首页的链接,提高搜索引擎友好度和用户体验。
2、请将内页标题改为:列标题-网站名称格式,不要直接调用网站首页标题。
3、接下来做301定向跳转,不带www的定向跳转到带www的域名,避免权重分散。
4、请把网站地图制作成sitemap.html和sitemap.xml两种格式,这样有助于百度蜘蛛抓取,提高搜索友好度。
爬虫只能根据你指定的url爬取网页的代码。至于你想要收录指定内容的网页,只能先爬取网页,然后匹配页面的内容(正规的,也有开源工具),找到你想要的就是你想要的!爬虫无法根据关键字抓取网页!如果你期望网站可以根据百度搜索引擎获得自然检索的总流量。百度搜索引擎的原理很复杂,但简单来说它包括以下三个层次:检索、排列和呈现。其实不难理解,如果要在百度搜索引擎上搜索到想要的信息内容,那么这个信息内容首先要经过百度搜索引擎的识别。
1.保证网站信息的内容可以被网络爬虫识别
现阶段,百度搜索引擎无法识别照片和flash中放置的文字信息内容。尤其是百度,现阶段无法很好识别javascript中的文字信息内容和连接。
建议在创建 网站 时牢记以下几点:
(1)应用文本而非 Flash、照片、javascript 等来显示信息关键内容或链接
(2)在允许的标准下,尽量不要使用flash网页元素。如果无法防止,请为flash内容创建一个保留网页的文本版本。
(3)防止关键网页信息内容进入iframe结构,百度搜索引擎不会轻易抓取结构中的内容。
2.创建良好的 URL 结构
为了对网站内容进行清理和恢复,规定网站必须做好分类。不仅方便用户预览网址,掌握网址结构,快速找到整体目标内容;另一方面,帮助百度搜索引擎更好地把握网址的结构。
URL一般是扁平的,通常分为以下几个层次:首页-频道页-内容页。应尽可能避免 URL 的理想化层次结构。最好选择扁平结构,减少从首页到内容页的浏览文件目录。
请注意以下几点:
(1)为每类网页添加导航,百度搜索引擎会根据导航中的层次结构掌握该网页的位置。
(2)确保网页上的每个网页始终至少有 1 个可访问的链接。
(3)有效机构分类URL中的内容,但防止分类过于精细。
(4)网页的引导倾向于防止复杂js或flash的应用,防止百度搜索引擎无法抓取。
(5)在使用图片链接时,请使用ALT功能进行标示,帮助百度搜索引擎了解页面的主体是什么。
SEO公司_网站优化百度关键词排名_新站快速排名技术-外推 查看全部
百度搜索指定网站内容(网站优化以下内容优化的方法有哪些?-八维教育)
想要做好优化,其实还是要花点心思的。从做网站开始,不要做那种纯图片的模板网站。还是可以使用织梦帝王仿制网站的。网站搭建完成后,备案等资料,以及服务器,最好用阿里云和腾讯云。外面有很多托管公司,上面放了很多海外BC网络,很容易被锁在一个小k屋里,所以这个网站基本上是GG。
一般正常网站优化以下内容。
修改tdk:title:收录所有核心推荐关键词
1、404页面需要有返回首页的链接,提高搜索引擎友好度和用户体验。
2、请将内页标题改为:列标题-网站名称格式,不要直接调用网站首页标题。
3、接下来做301定向跳转,不带www的定向跳转到带www的域名,避免权重分散。
4、请把网站地图制作成sitemap.html和sitemap.xml两种格式,这样有助于百度蜘蛛抓取,提高搜索友好度。
爬虫只能根据你指定的url爬取网页的代码。至于你想要收录指定内容的网页,只能先爬取网页,然后匹配页面的内容(正规的,也有开源工具),找到你想要的就是你想要的!爬虫无法根据关键字抓取网页!如果你期望网站可以根据百度搜索引擎获得自然检索的总流量。百度搜索引擎的原理很复杂,但简单来说它包括以下三个层次:检索、排列和呈现。其实不难理解,如果要在百度搜索引擎上搜索到想要的信息内容,那么这个信息内容首先要经过百度搜索引擎的识别。
1.保证网站信息的内容可以被网络爬虫识别
现阶段,百度搜索引擎无法识别照片和flash中放置的文字信息内容。尤其是百度,现阶段无法很好识别javascript中的文字信息内容和连接。
建议在创建 网站 时牢记以下几点:
(1)应用文本而非 Flash、照片、javascript 等来显示信息关键内容或链接
(2)在允许的标准下,尽量不要使用flash网页元素。如果无法防止,请为flash内容创建一个保留网页的文本版本。
(3)防止关键网页信息内容进入iframe结构,百度搜索引擎不会轻易抓取结构中的内容。
2.创建良好的 URL 结构
为了对网站内容进行清理和恢复,规定网站必须做好分类。不仅方便用户预览网址,掌握网址结构,快速找到整体目标内容;另一方面,帮助百度搜索引擎更好地把握网址的结构。
URL一般是扁平的,通常分为以下几个层次:首页-频道页-内容页。应尽可能避免 URL 的理想化层次结构。最好选择扁平结构,减少从首页到内容页的浏览文件目录。
请注意以下几点:
(1)为每类网页添加导航,百度搜索引擎会根据导航中的层次结构掌握该网页的位置。
(2)确保网页上的每个网页始终至少有 1 个可访问的链接。
(3)有效机构分类URL中的内容,但防止分类过于精细。
(4)网页的引导倾向于防止复杂js或flash的应用,防止百度搜索引擎无法抓取。
(5)在使用图片链接时,请使用ALT功能进行标示,帮助百度搜索引擎了解页面的主体是什么。
SEO公司_网站优化百度关键词排名_新站快速排名技术-外推
百度搜索指定网站内容(网站内容获取权限和功能使用权限可能很多人不是很了解是啥)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-16 22:02
网站内容访问权和功能使用权可能很多人不理解吧?让我举个例子。比如你在百度找到一个在线图片处理网站,然后你输入这个网站,要使用这个图片处理功能,网站需要你注册成为会员,或者进入只有QQ群才能使用该功能,称为功能使用权限。
内容访问是指你在百度上搜索文献,输入网站,网站需要你注册成为会员,然后点击广告,或者下载app,或者回复帖子,在下载或查看文献资料。这称为内容访问。
昨天,百度正式发布文章,将严厉打击获取内容和功能困难的网站。这样做的目的是为了提高用户体验,降低信息获取成本。百度这次对武汉卡卡西科技的出击还是很支持的,因为很多网站查看内容信息很难获取,所以你点击一个网站再点击一个,浪费了很多时间,尤其是一些软件下载站,制作一堆下载按钮,让你不知道哪个是真假,最后把一堆流氓软件下载到电脑上。
这次针对百度的提问,站长或者网站负责人还是要注意,网站自己整理一下,看看有没有文中提到的几点。
以下为百度搜索官方原文:
近日,百度搜索发现部分网站在搜索中存在内容访问权限、功能使用权限等问题,影响搜索用户体验。百度搜索一直致力于让用户从搜索中快速获得想要的内容,降低用户获取信息的成本。
为了更好地满足搜索用户的需求,对于搜索结果中权限受限的网站,近期将严厉打击上网政策。
该策略主要针对以下两种情况:
1、内容访问权限
当用户查看网页的全部内容时,例如: 查看全部
百度搜索指定网站内容(网站内容获取权限和功能使用权限可能很多人不是很了解是啥)
网站内容访问权和功能使用权可能很多人不理解吧?让我举个例子。比如你在百度找到一个在线图片处理网站,然后你输入这个网站,要使用这个图片处理功能,网站需要你注册成为会员,或者进入只有QQ群才能使用该功能,称为功能使用权限。
内容访问是指你在百度上搜索文献,输入网站,网站需要你注册成为会员,然后点击广告,或者下载app,或者回复帖子,在下载或查看文献资料。这称为内容访问。
昨天,百度正式发布文章,将严厉打击获取内容和功能困难的网站。这样做的目的是为了提高用户体验,降低信息获取成本。百度这次对武汉卡卡西科技的出击还是很支持的,因为很多网站查看内容信息很难获取,所以你点击一个网站再点击一个,浪费了很多时间,尤其是一些软件下载站,制作一堆下载按钮,让你不知道哪个是真假,最后把一堆流氓软件下载到电脑上。
这次针对百度的提问,站长或者网站负责人还是要注意,网站自己整理一下,看看有没有文中提到的几点。
以下为百度搜索官方原文:
近日,百度搜索发现部分网站在搜索中存在内容访问权限、功能使用权限等问题,影响搜索用户体验。百度搜索一直致力于让用户从搜索中快速获得想要的内容,降低用户获取信息的成本。
为了更好地满足搜索用户的需求,对于搜索结果中权限受限的网站,近期将严厉打击上网政策。
该策略主要针对以下两种情况:
1、内容访问权限
当用户查看网页的全部内容时,例如:
百度搜索指定网站内容(网站排名提升的速度会更加大吗?——SEO论坛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-16 22:01
项目投资找A5快速获取精准代理名单
众所周知,快速提升排名最有效的方法无非就是权重转移和点击排名。在百度算法中,有这样一个规则,网站在第20位内获得更多点击,网站排名提升的速度会更快。
相互排序的原则
关于点击排名的原理,估计网上已经有很多文章了,但是SEO论坛认为他们没有解释透彻,也没有完全理解其中的精髓搜索引擎优化人员。 SEO 论坛使用它来让您更好地了解点击排名。
点击排名其实需要分两步来查看。首先是在搜索引擎显示页面上获得点击。这一步非常重要。软件是否自动点击,其次是本站页面获得的点击,这一步是搜索引擎判断是否给网站加分的标准,根据停留时间和浏览轨迹来判断页面的体验,然后得到分数。
交互要求
XX关键词百度首页URL停留2分钟。主页 + 5 个内页。每个页面被点击后,需要停留2分钟。最后在XX页结束。每个页面都需要拉到最后才能截图。需要自带聊天记录截图,进阶点交互后需要提供对方IP地址。
相互交流的步骤
百度搜索指定关键词--然后找到指定网站--发送截图给对方确认--确认后点击--再次截图--停留指定时间--点击< @网站内容页——单击指定页数——完成。
点击效果测试
大家互相点击后,不知道怎么查看点击是否生效。相信大部分人的做法都是看统计代码里的数据。其实这里我可以很清楚的告诉你,那里的数据没有太大的参考意义。对于点击排名,我们应该在站长工具中分析点击数据。 ,那里的数据是真实有效的点击,它会参与排名参考数据。这意味着下图右侧会有一个排名。估计有90%的排名SEO人员不明白是什么意思。
有互动的人在群里说没有互动,排名也被送出去了。事实上,这是一种被搜索引擎判断为恶意滑动点击,并被暂时降级或警告的提示。 ,在这种情况下,建议果断停止滑动点击,恢复后采取正确的步骤。
申请创业报告,分享好的创业理念。点击这里一起讨论新的商机! 查看全部
百度搜索指定网站内容(网站排名提升的速度会更加大吗?——SEO论坛)
项目投资找A5快速获取精准代理名单
众所周知,快速提升排名最有效的方法无非就是权重转移和点击排名。在百度算法中,有这样一个规则,网站在第20位内获得更多点击,网站排名提升的速度会更快。
相互排序的原则
关于点击排名的原理,估计网上已经有很多文章了,但是SEO论坛认为他们没有解释透彻,也没有完全理解其中的精髓搜索引擎优化人员。 SEO 论坛使用它来让您更好地了解点击排名。
点击排名其实需要分两步来查看。首先是在搜索引擎显示页面上获得点击。这一步非常重要。软件是否自动点击,其次是本站页面获得的点击,这一步是搜索引擎判断是否给网站加分的标准,根据停留时间和浏览轨迹来判断页面的体验,然后得到分数。
交互要求
XX关键词百度首页URL停留2分钟。主页 + 5 个内页。每个页面被点击后,需要停留2分钟。最后在XX页结束。每个页面都需要拉到最后才能截图。需要自带聊天记录截图,进阶点交互后需要提供对方IP地址。
相互交流的步骤
百度搜索指定关键词--然后找到指定网站--发送截图给对方确认--确认后点击--再次截图--停留指定时间--点击< @网站内容页——单击指定页数——完成。
点击效果测试
大家互相点击后,不知道怎么查看点击是否生效。相信大部分人的做法都是看统计代码里的数据。其实这里我可以很清楚的告诉你,那里的数据没有太大的参考意义。对于点击排名,我们应该在站长工具中分析点击数据。 ,那里的数据是真实有效的点击,它会参与排名参考数据。这意味着下图右侧会有一个排名。估计有90%的排名SEO人员不明白是什么意思。
有互动的人在群里说没有互动,排名也被送出去了。事实上,这是一种被搜索引擎判断为恶意滑动点击,并被暂时降级或警告的提示。 ,在这种情况下,建议果断停止滑动点击,恢复后采取正确的步骤。
申请创业报告,分享好的创业理念。点击这里一起讨论新的商机!
百度搜索指定网站内容(什么是百度快照?中会的用途出现的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-16 18:18
一、什么是百度快照?
搜索结果打不开或打开速度极慢怎么办?收录的每个页面在百度上都有一个纯文本备份,称为“百度快照”;可以通过“快照”快速浏览页面内容,但是百度只保留文字内容,所以那些图片、音乐、视频等非文字信息,快照页面还是直接从原网页调用。
直观的说,百度快照是指在搜索关键词时,除了付费广告外,所有展示的都是百度快照。
二、页面快照的使用:
1.无法打开页面:当您要访问的页面不存在或链接无效或打开速度极慢时,可以通过网页快照访问该页面;
2.查看文字资料:由于网页截图显示速度较快,如果想查找一些更新不是很快的文字,如技术文档、资料等,可以通过网页截图直接查看,节省时间;
3、快速定位关键词:在快照中关键词在网页上用不同颜色标注;
4、查看旧版网页:搜索到的页面可能已经更新,如果想查看之前的网页是什么样的,可以使用快照;
三、为什么有些快照打不开?
快照只保存网页的 HTML 部分,而不是网页的全部内容。快照打不开的三种情况:
1、如果网页文本下载指定为图片和一些动态文件,而这些需要先下载的文件却无法下载,可能无法打开快照;
2、如果图片或动态文件下载速度慢,会因为超时而无法打开快照;
3、部分截图涉及非法内容,不让你看;
四、为什么我有时点击快照却链接到其他页面?
如果网页源代码中有重定向命令,则快照可以直接链接到指定网页;
五、为什么截图中有乱码?
1、网页指定编码错误;
2、浏览器不支持页面的语言;
3、浏览器错误识别网页的语言编码;
4、搜索引擎对文本的编码错误;
5、搜索引擎无法正确识别和显示字符;
以下是小编在公司整理的一些行业优化教程和SEO优化工具包(部分截图) 关注小编,私信“SEO”即可免费获取!
35G行业优化方案,SEO教程包括:最基本的建站内部优化+网站定位【原创伪原创内容制作技巧,内链体系优化与建立】到网站@ > 运营,网站推广思路策划,SEO项目实战学习资料整理,发给每一位想学习SEO,或转行,或大学生,或想在工作中提高的SEO伙伴有学习能力的欢迎加入学习! 查看全部
百度搜索指定网站内容(什么是百度快照?中会的用途出现的)
一、什么是百度快照?
搜索结果打不开或打开速度极慢怎么办?收录的每个页面在百度上都有一个纯文本备份,称为“百度快照”;可以通过“快照”快速浏览页面内容,但是百度只保留文字内容,所以那些图片、音乐、视频等非文字信息,快照页面还是直接从原网页调用。
直观的说,百度快照是指在搜索关键词时,除了付费广告外,所有展示的都是百度快照。
二、页面快照的使用:
1.无法打开页面:当您要访问的页面不存在或链接无效或打开速度极慢时,可以通过网页快照访问该页面;
2.查看文字资料:由于网页截图显示速度较快,如果想查找一些更新不是很快的文字,如技术文档、资料等,可以通过网页截图直接查看,节省时间;
3、快速定位关键词:在快照中关键词在网页上用不同颜色标注;
4、查看旧版网页:搜索到的页面可能已经更新,如果想查看之前的网页是什么样的,可以使用快照;
三、为什么有些快照打不开?
快照只保存网页的 HTML 部分,而不是网页的全部内容。快照打不开的三种情况:
1、如果网页文本下载指定为图片和一些动态文件,而这些需要先下载的文件却无法下载,可能无法打开快照;
2、如果图片或动态文件下载速度慢,会因为超时而无法打开快照;
3、部分截图涉及非法内容,不让你看;
四、为什么我有时点击快照却链接到其他页面?
如果网页源代码中有重定向命令,则快照可以直接链接到指定网页;
五、为什么截图中有乱码?
1、网页指定编码错误;
2、浏览器不支持页面的语言;
3、浏览器错误识别网页的语言编码;
4、搜索引擎对文本的编码错误;
5、搜索引擎无法正确识别和显示字符;
以下是小编在公司整理的一些行业优化教程和SEO优化工具包(部分截图) 关注小编,私信“SEO”即可免费获取!
35G行业优化方案,SEO教程包括:最基本的建站内部优化+网站定位【原创伪原创内容制作技巧,内链体系优化与建立】到网站@ > 运营,网站推广思路策划,SEO项目实战学习资料整理,发给每一位想学习SEO,或转行,或大学生,或想在工作中提高的SEO伙伴有学习能力的欢迎加入学习!
百度搜索指定网站内容(PHP使用百度地图获取指定地址坐标之创建AK(api))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-16 18:16
本篇文章主要介绍PHP使用百度地图创建AK(api key)获取指定地址坐标的方法。
在之前的文章【PHP使用腾讯地图获取指定地址坐标:create key】【PHP使用腾讯地图获取指定地址坐标:经纬度】,我们已经给大家介绍过了如何使用腾讯地图获取指定地址的坐标,即经纬度。具体的步骤和方法,如果你看过文章这两篇文章,会更容易理解这篇文章的内容。
其实不管是百度地图还是腾讯地图,我们主要是调用相应的接口来获取地图、坐标等相关数据。
接下来为大家介绍如何在百度地图开放平台获取开发者权限和创建AK(api key)。
步骤1:
登录百度账号,这里我们使用QQ登录。再次点击进入控制台。
第2步:
点击创建应用,即创建AK(这里的AK也相当于腾讯地图中的key)
输入应用程序的名称、类型和 IP 白名单。(这里的应用类型选择主要看你用的是哪一部分,比如你用在服务器端,ip白名单可以输入0.0.0.0或者* .)
第 3 步:
最后点击提交。
至此,百度地图的AK已经创建完成。在后面的文章中,我们会继续介绍PHP使用百度地图获取指定地址坐标的具体方法。
本篇文章是关于PHP中使用百度地图获取指定地址坐标创建AK(api key)的方法。这也很简单。希望对需要的人有所帮助! 查看全部
百度搜索指定网站内容(PHP使用百度地图获取指定地址坐标之创建AK(api))
本篇文章主要介绍PHP使用百度地图创建AK(api key)获取指定地址坐标的方法。
在之前的文章【PHP使用腾讯地图获取指定地址坐标:create key】【PHP使用腾讯地图获取指定地址坐标:经纬度】,我们已经给大家介绍过了如何使用腾讯地图获取指定地址的坐标,即经纬度。具体的步骤和方法,如果你看过文章这两篇文章,会更容易理解这篇文章的内容。
其实不管是百度地图还是腾讯地图,我们主要是调用相应的接口来获取地图、坐标等相关数据。
接下来为大家介绍如何在百度地图开放平台获取开发者权限和创建AK(api key)。
步骤1:
登录百度账号,这里我们使用QQ登录。再次点击进入控制台。
第2步:
点击创建应用,即创建AK(这里的AK也相当于腾讯地图中的key)
输入应用程序的名称、类型和 IP 白名单。(这里的应用类型选择主要看你用的是哪一部分,比如你用在服务器端,ip白名单可以输入0.0.0.0或者* .)
第 3 步:
最后点击提交。
至此,百度地图的AK已经创建完成。在后面的文章中,我们会继续介绍PHP使用百度地图获取指定地址坐标的具体方法。
本篇文章是关于PHP中使用百度地图获取指定地址坐标创建AK(api key)的方法。这也很简单。希望对需要的人有所帮助!
百度搜索指定网站内容(vs2012如何查询某个网址的收录次数5,280,000这段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-16 14:00
一、前言
偶然在vs2012的默认项目文件夹中发现了一个我之前做的关于SEO的类库。主要用于查询某网站收录的数量和网站的排名数量。后来经过重构,今天拿出来写了一篇文章文章,告诉我我是怎么想的,怎么完成的。
二、问题描述
首先要考虑的是可以支持哪些搜索引擎查询,首先是百度,然后是必应、搜狗、搜搜、360。本来想支持谷歌的,但是没想到,不好访问全部,所以暂时不包括在内。我们真正需要做的是,根据一个URL,检索这个URL在各个搜索引擎中的收录次数,以及不同关键词下的URL排名。只有 URL 和几个 关键词 进出。@关键词,输出为该URL在不同搜索引擎下的收录次数和每个关键词下的排名次数。
但是这里有一个问题,就是排名的数量。如果检索到的 URL 在前 100 位,那就没问题了。如果排名很低,那么问题就来了,这会让用户等待很长时间才能看到结果,但用户可能只想知道前100名的具体排名,超过100名的只需要展示出来,这些都需要前期考虑好,方便后续的流程。
三、解决方案
相信很多人都能想到,就是用WebClient下载需要的页面,然后用正则得到我们感兴趣的部分,再用程序进行处理。关键难点在这个正则的写法上,首先我们从一个简单的说起。
四、收录次数
首先是网站的收录的编号,我们可以在百度中输入site:,然后可以看到如下页面:
而我们需要收录的次数是5,280,000,那么我们来看一下页面元素:
然后我们再看其他搜索引擎,发现都差不多,所以这个时候我们的思路就应该画出来了,最后就是如何组织URL。在这部分,我们看看地址栏?wd=site%3A%2F 就知道怎么写了。
这时候我们可能会迫不及待地一一实现,这样以后就不能集中调用了,也会影响以后的添加,所以需要指定一个抽象类来实现收录@ > number 函数,这样就可以在不知道具体实现的情况下统一使用,而且以后可以方便的添加新的搜索引擎,这种方式属于策略模式(Stategry)。让我们慢慢分析这个抽象类的具体内容。
首先,实现这个抽象类的每个具体类都应该对应某个搜索引擎,所以它需要有一个基本的URL,并留一个占位符。比如根据上面的百度,我们可以得到这样一个字符串
%3A{0}
其中,{0} 是真正需要检索的 URL 的占位符。获取下载页面的路径是所有具体类都需要的,所以我们直接把实现放到抽象类中,比如下面的代码:
复制代码代码如下:
///
/// 服务供应商
///
受保护的字符串 SearchProvider { get; 放; }
///
/// 要检索的 URL
///
受保护的字符串 SiteUrl { 获取;放; }
///
/// 搜索服务提供者 URL
///
受保护的字符串 BaseUrl { 获取;放; }
///
/// 后页地址
///
///
要查询的网址
/// 连接的 URL
受保护的字符串 GetDownUrl(字符串站点)
{
return string.Format(BaseUrl, HttpUtility.UrlEncode(site));
}
其中,SiteUrl 和 SearchProvider 用于保存检索 URL 和搜索引擎名称。
上面我们说过会使用WebClient来下载页面,所以初始化WebClient的工作也是在抽象类中完成的,尽可能减少重复代码,并且为了防止阻塞当前线程,我们使用了Async方法。
具体代码如下:
复制代码代码如下:
///
/// 此搜索引擎中 收录 查询的数量
///
///
网站网址
公共无效 SearchIncludeCount(字符串站点网址)
{
网站网址 = 网站网址;
WebClient 客户端 = 新 WebClient();
client.Encoding = Encoding.UTF8;
client.DownloadStringCompleted += DownloadStringCompleted;
client.DownloadStringAsync(new Uri(GetDownUrl(siteurl)));
}
///
/// 检索次数的具体实现 收录
/// 子类必须实现这个方法
///
///
///
受保护的抽象无效DownloadStringCompleted(对象发送者,DownloadStringCompletedEventArgs e);
当WebClient完成下载后,会回调DownloadStringCompleted方法,这个方法是抽象方法,也就是说具体的类必须实现这个方法。
虽然我们的内部实现是异步的,但是其他开发者调用这个方法仍然是同步的,所以我们需要使用委托,所以我们还需要创建一个新的委托类型:
复制代码代码如下:
///
/// 网站的收录查询完成时回调
///
公共操作 OnComplatedOneSite { 获取;放; }
SiteIncludeCountResult 的结构如下:
复制代码代码如下:
///
/// 网站收录 中代表的参数
///
公共类 SiteIncludeCountResult
{
///
/// 收录次数
///
公共长包括计数 { 得到;放; }
///
/// 搜索引擎类型
///
公共字符串搜索类型 { 获取;放; }
///
/// 网站网址
///
公共字符串 SiteUrl { 获取;放; }
}
最后还有一个方法可以在 DownloadStringCompleted 完成时回调 OnComplatedOneSite 委托:
///
/// 处理后调用该方法返回结果
///
///
收录 URL 的计数结果
protected void SetCompleted(SiteIncludeCountResult 结果)
{
如果(OnComplatedOneSite != null)
OnComplatedOneSite(结果);
}
这样,我们需要的抽象类就完成了。现在我们可以开始实现第一个。从上面的截图中,我们可以发现匹配这个字符串的正则表达式非常简单:
复制代码代码如下:
百度为您找到关于 ([\w,]+?) 的相关结果
最后,你可以通过从获得的字符串中删除逗号来强制转换,结果就会出来。具体实现如下:
复制代码代码如下:
///
/// 百度网站收录次查询
///
公共类 BaiDuSiteIncludeCount : SiteIncludeCountBase
{
public BaiDuSiteIncludeCount()
{
BaseUrl = "{0}";
SearchProvider = "百度";
}
protected override void DownloadStringCompleted(对象发送者,DownloadStringCompletedEventArgs e)
{
var 结果 = 新 SiteIncludeCountResult();
结果.SiteUrl = SiteUrl;
结果.SearchType = SearchProvider;
结果.IncludeCount = 0;
Regex reg = new Regex(@"百度为你找到了大约([\w,]+?)个相关结果", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var 匹配 = reg.Matches(e.Result);
if (matchs.Count > 0)
{
字符串计数 = 匹配[0].Groups[1].Value.Replace(",", "");
result.IncludeCount = long.Parse(count);
}
设置完成(结果);
}
}
以此类推,其他的都是按照这个来的,有兴趣的可以下载我的源码查看。
五、关键词排名
按照之前的思路,我们还是需要先指定一个抽象类,但是它的结构和上面的抽象类很相似,所以作者在这里直接给出具体代码:
复制代码代码如下:
///
/// 实现 关键词 查询必须继承这个类
///
公共抽象类 KeyWordsSeoBase
{
受保护的字符串 BaseUrl { 获取;放; }
受保护的字符串 SearchProvider { get; 放; }
protected String GetDownUrl(字符串关键字,字符串站点,长电流)
{
return String.Format(BaseUrl, HttpUtility.UrlEncode(keyword), current);
}
protected void SetCompleted(KeyWordsSeoResult 结果)
{
如果(OnComplatedOneKeyWord != null)
{
OnComplatedOneKeyWord(结果);
}
}
///
/// 完成 关键词 查询后回调委托
///
公共操作 OnComplatedOneKeyWord { 获取;放; }
///
/// 查询指定关键词和网站在搜索引擎中的排名
/// 子类需要重写这个方法
///
///
关键词
///
网站网址
public abstract void SearchRanking(IEnumerable keywords, string site, long count);
}
最大的不同是具体实现都集中在SearchRanking。从keywords参数可以看出,我们将支持多个关键词查询。最后一个区别是下载路径的组织。因为它涉及翻页,所以有一个额外的。范围。
KeyWordsSeoResult 的结构如下:
复制代码代码如下:
///
/// 关键词 排名查询的委托参数
///
公共类 KeyWordsSeoResult
{
///
/// 搜索引擎类型
///
公共字符串搜索类型 { 获取;放; }
///
/// 关键词
///
公共字符串关键字 { 获取;放; }
///
/// 排行
///
public long Ranking { 得到;放; }
}
废话不多说,我们来看百度的搜索结果页面:
以上是笔者在百度搜索程序员的第九个html结构。您可能认为获取 div 的 id 和 URL 非常简单。但是很多搜索引擎的路径并不是直接路径,而是会先链接到百度,然后再重定向。如果一定要匹配,我们还需要做一件事:访问这条路径获取真实路径,中间会增加等待时间,所以作者使用了上面的截图。中的后者内容,从而避免了请求。(不知道作者一开始是怎么想的,实现中并没有用到id值,而是内部自增,估计翻页后这个id的序号会有问题),最后展示我们神圣的正则表达式:
复制代码代码如下:
([^/&]*)
你认为这是一个重大的公告吗?错了,在某些结果中,百度会在这个网址上加ab标签,作者采用了全部杀掉的方法,使用正则规则全部删除(反正我不看页面,只要得到我要的,没关系),实现的时候不能直接实现多个关键词的识别,应该是实现一个关键词,然后循环调用。以下是作者单关键词的实现:
复制代码代码如下:
protected KeyWordsSeoResult SearchFunc(字符串键,字符串 siteurl,长总计)
{
var 结果 = 新的 KeyWordsSeoResult();
结果.KeyWord =键;
结果.排名=总+1;
var reg = new Regex(@"([^/&]*)", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var replace = new Regex("", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var client = new WebClient();
长电流 = 0;
长位置 = 0;
为了 (; ; )
{
字符串 url = GetDownUrl(key, siteurl, current);
String downstr = client.DownloadString(url);
downstr = replace.Replace(downstr, "");
var 匹配 = reg.Matches(downstr);
foreach(匹配中的匹配)
{
正++;
字符串 suburl = match.Groups[1].Value;
尝试
{
if (suburl.ToLower() == siteurl.ToLower())
{
结果.Ranking = pos;
返回结果;
}
}
抓住
{
继续;
}
}
当前 += 10;
如果(当前>总计)
{
当前-= 10;
如果(当前 >= 总计)
{
休息;
}
当前=总计;
}
}
返回结果;
}
注意for循环的结束,用于处理分页,以便翻到下一页继续检索。其他通用部分和作者说的一样,下载页面->正则匹配->根据匹配结果判断。剩下的就是SearchRanking的实现,也就是循环关键词,不过这里我为每个搜索引擎新建一个线程来实现,当然这样不太好,读者可以用更好的方式来做它:
复制代码代码如下:
public override void SearchRanking(IEnumerable keywords, string site, long count)
{
新线程(()=>
{
foreach(关键字中的字符串键)
{
KeyWordsSeoResult 结果 = SearchFunc(key, site, count);
结果.SearchType = SearchProvider;
设置完成(结果);
}
})。开始();
}
六、统一管理
有了这些,我们就可以编写一个简洁的类来负责管理。作者在这里直接给出代码:
复制代码代码如下:
///
/// 查询网站的收录的个数和排名
///
公共类RankingAndIncludeSeo
{
///
/// 关键词列表
///
公共 IList KeyWordsSeoList { 获取;私人套装;}
///
/// 收录时间列表
///
公共 IList SiteIncludeCountList { 获取;私人套装;}
公共 RankingAndIncludeSeo()
{
KeyWordsSeoList = new List();
SiteIncludeCountList = new List();
}
///
/// 当 关键词 查询完成时回调委托
///
公共操作 OnComplatedAnyKeyWordsSearch { 获取;放; }
///
/// 完成收录次网站的查询后回调delegate
///
公共操作 OnComplatedAnySiteIncludeSearch { 获取;放; }
///
/// 查询URL的排名
///
///
关键词组
///
查询网址
///
最大等级数
public void SearchKeyWordsRanking(IEnumerable 关键字,字符串 siteurl,长计数 = 100)
{
如果(关键字 == 空)
throw new ArgumentNullException("keywords", "必须存在 关键词");
如果(网站网址 == 空)
throw new ArgumentNullException("siteurl", "必须存在 网站URL");
foreach(KeyWordsSeoList 中的 KeyWordsSeoBase kwsb)
{
kwsb.OnComplatedOneKeyWord = kwsb.OnComplatedOneKeyWord ?? OnComplatedAnyKeyWordsSearch;
kwsb.SearchRanking(关键字,站点网址,计数);
}
}
///
/// 收录 查询 URL 的数量
///
///
查询网址
公共无效 SearchSiteIncludeCount(字符串网站网址)
{
如果(网站网址 == 空)
throw new ArgumentNullException("siteurl", "必须指定 网站");
foreach(SiteIncludeCountBase sicb 中的 SiteIncludeCountList)
{
sicb.OnComplatedOneSite = sicb.OnComplatedOneSite ?? OnComplatedAnySiteIncludeSearch;
sicb.SearchIncludeCount(siteurl);
}
}
}
RankingAndIncludeSeo 提供了一个公共代表。如果单个搜索引擎不提供委托,则使用此公共委托。如果指定了单独的delegate,就不会分配了,其他开发者只需要在调用时添加到KeyWordsSeoList和SiteIncludeCountList中已经实现的类即可,其他开发者自己开发实现加入即可。
七、部分
一般来说,这篇文章不是关于高端技术的,而只是提供一个大致的想法和结构设计。如果读者需要在实际开发中应用,最好验证一下。作者不保证关键词的排名没有错误,因为搜索结果可能因任何因素而发生变化。
^.^我是源代码下载 查看全部
百度搜索指定网站内容(vs2012如何查询某个网址的收录次数5,280,000这段)
一、前言
偶然在vs2012的默认项目文件夹中发现了一个我之前做的关于SEO的类库。主要用于查询某网站收录的数量和网站的排名数量。后来经过重构,今天拿出来写了一篇文章文章,告诉我我是怎么想的,怎么完成的。
二、问题描述
首先要考虑的是可以支持哪些搜索引擎查询,首先是百度,然后是必应、搜狗、搜搜、360。本来想支持谷歌的,但是没想到,不好访问全部,所以暂时不包括在内。我们真正需要做的是,根据一个URL,检索这个URL在各个搜索引擎中的收录次数,以及不同关键词下的URL排名。只有 URL 和几个 关键词 进出。@关键词,输出为该URL在不同搜索引擎下的收录次数和每个关键词下的排名次数。
但是这里有一个问题,就是排名的数量。如果检索到的 URL 在前 100 位,那就没问题了。如果排名很低,那么问题就来了,这会让用户等待很长时间才能看到结果,但用户可能只想知道前100名的具体排名,超过100名的只需要展示出来,这些都需要前期考虑好,方便后续的流程。
三、解决方案
相信很多人都能想到,就是用WebClient下载需要的页面,然后用正则得到我们感兴趣的部分,再用程序进行处理。关键难点在这个正则的写法上,首先我们从一个简单的说起。
四、收录次数
首先是网站的收录的编号,我们可以在百度中输入site:,然后可以看到如下页面:

而我们需要收录的次数是5,280,000,那么我们来看一下页面元素:

然后我们再看其他搜索引擎,发现都差不多,所以这个时候我们的思路就应该画出来了,最后就是如何组织URL。在这部分,我们看看地址栏?wd=site%3A%2F 就知道怎么写了。
这时候我们可能会迫不及待地一一实现,这样以后就不能集中调用了,也会影响以后的添加,所以需要指定一个抽象类来实现收录@ > number 函数,这样就可以在不知道具体实现的情况下统一使用,而且以后可以方便的添加新的搜索引擎,这种方式属于策略模式(Stategry)。让我们慢慢分析这个抽象类的具体内容。
首先,实现这个抽象类的每个具体类都应该对应某个搜索引擎,所以它需要有一个基本的URL,并留一个占位符。比如根据上面的百度,我们可以得到这样一个字符串
%3A{0}
其中,{0} 是真正需要检索的 URL 的占位符。获取下载页面的路径是所有具体类都需要的,所以我们直接把实现放到抽象类中,比如下面的代码:
复制代码代码如下:
///
/// 服务供应商
///
受保护的字符串 SearchProvider { get; 放; }
///
/// 要检索的 URL
///
受保护的字符串 SiteUrl { 获取;放; }
///
/// 搜索服务提供者 URL
///
受保护的字符串 BaseUrl { 获取;放; }
///
/// 后页地址
///
///
要查询的网址
/// 连接的 URL
受保护的字符串 GetDownUrl(字符串站点)
{
return string.Format(BaseUrl, HttpUtility.UrlEncode(site));
}
其中,SiteUrl 和 SearchProvider 用于保存检索 URL 和搜索引擎名称。
上面我们说过会使用WebClient来下载页面,所以初始化WebClient的工作也是在抽象类中完成的,尽可能减少重复代码,并且为了防止阻塞当前线程,我们使用了Async方法。
具体代码如下:
复制代码代码如下:
///
/// 此搜索引擎中 收录 查询的数量
///
///
网站网址
公共无效 SearchIncludeCount(字符串站点网址)
{
网站网址 = 网站网址;
WebClient 客户端 = 新 WebClient();
client.Encoding = Encoding.UTF8;
client.DownloadStringCompleted += DownloadStringCompleted;
client.DownloadStringAsync(new Uri(GetDownUrl(siteurl)));
}
///
/// 检索次数的具体实现 收录
/// 子类必须实现这个方法
///
///
///
受保护的抽象无效DownloadStringCompleted(对象发送者,DownloadStringCompletedEventArgs e);
当WebClient完成下载后,会回调DownloadStringCompleted方法,这个方法是抽象方法,也就是说具体的类必须实现这个方法。
虽然我们的内部实现是异步的,但是其他开发者调用这个方法仍然是同步的,所以我们需要使用委托,所以我们还需要创建一个新的委托类型:
复制代码代码如下:
///
/// 网站的收录查询完成时回调
///
公共操作 OnComplatedOneSite { 获取;放; }
SiteIncludeCountResult 的结构如下:
复制代码代码如下:
///
/// 网站收录 中代表的参数
///
公共类 SiteIncludeCountResult
{
///
/// 收录次数
///
公共长包括计数 { 得到;放; }
///
/// 搜索引擎类型
///
公共字符串搜索类型 { 获取;放; }
///
/// 网站网址
///
公共字符串 SiteUrl { 获取;放; }
}
最后还有一个方法可以在 DownloadStringCompleted 完成时回调 OnComplatedOneSite 委托:
///
/// 处理后调用该方法返回结果
///
///
收录 URL 的计数结果
protected void SetCompleted(SiteIncludeCountResult 结果)
{
如果(OnComplatedOneSite != null)
OnComplatedOneSite(结果);
}
这样,我们需要的抽象类就完成了。现在我们可以开始实现第一个。从上面的截图中,我们可以发现匹配这个字符串的正则表达式非常简单:
复制代码代码如下:
百度为您找到关于 ([\w,]+?) 的相关结果
最后,你可以通过从获得的字符串中删除逗号来强制转换,结果就会出来。具体实现如下:
复制代码代码如下:
///
/// 百度网站收录次查询
///
公共类 BaiDuSiteIncludeCount : SiteIncludeCountBase
{
public BaiDuSiteIncludeCount()
{
BaseUrl = "{0}";
SearchProvider = "百度";
}
protected override void DownloadStringCompleted(对象发送者,DownloadStringCompletedEventArgs e)
{
var 结果 = 新 SiteIncludeCountResult();
结果.SiteUrl = SiteUrl;
结果.SearchType = SearchProvider;
结果.IncludeCount = 0;
Regex reg = new Regex(@"百度为你找到了大约([\w,]+?)个相关结果", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var 匹配 = reg.Matches(e.Result);
if (matchs.Count > 0)
{
字符串计数 = 匹配[0].Groups[1].Value.Replace(",", "");
result.IncludeCount = long.Parse(count);
}
设置完成(结果);
}
}
以此类推,其他的都是按照这个来的,有兴趣的可以下载我的源码查看。
五、关键词排名
按照之前的思路,我们还是需要先指定一个抽象类,但是它的结构和上面的抽象类很相似,所以作者在这里直接给出具体代码:
复制代码代码如下:
///
/// 实现 关键词 查询必须继承这个类
///
公共抽象类 KeyWordsSeoBase
{
受保护的字符串 BaseUrl { 获取;放; }
受保护的字符串 SearchProvider { get; 放; }
protected String GetDownUrl(字符串关键字,字符串站点,长电流)
{
return String.Format(BaseUrl, HttpUtility.UrlEncode(keyword), current);
}
protected void SetCompleted(KeyWordsSeoResult 结果)
{
如果(OnComplatedOneKeyWord != null)
{
OnComplatedOneKeyWord(结果);
}
}
///
/// 完成 关键词 查询后回调委托
///
公共操作 OnComplatedOneKeyWord { 获取;放; }
///
/// 查询指定关键词和网站在搜索引擎中的排名
/// 子类需要重写这个方法
///
///
关键词
///
网站网址
public abstract void SearchRanking(IEnumerable keywords, string site, long count);
}
最大的不同是具体实现都集中在SearchRanking。从keywords参数可以看出,我们将支持多个关键词查询。最后一个区别是下载路径的组织。因为它涉及翻页,所以有一个额外的。范围。
KeyWordsSeoResult 的结构如下:
复制代码代码如下:
///
/// 关键词 排名查询的委托参数
///
公共类 KeyWordsSeoResult
{
///
/// 搜索引擎类型
///
公共字符串搜索类型 { 获取;放; }
///
/// 关键词
///
公共字符串关键字 { 获取;放; }
///
/// 排行
///
public long Ranking { 得到;放; }
}
废话不多说,我们来看百度的搜索结果页面:
以上是笔者在百度搜索程序员的第九个html结构。您可能认为获取 div 的 id 和 URL 非常简单。但是很多搜索引擎的路径并不是直接路径,而是会先链接到百度,然后再重定向。如果一定要匹配,我们还需要做一件事:访问这条路径获取真实路径,中间会增加等待时间,所以作者使用了上面的截图。中的后者内容,从而避免了请求。(不知道作者一开始是怎么想的,实现中并没有用到id值,而是内部自增,估计翻页后这个id的序号会有问题),最后展示我们神圣的正则表达式:
复制代码代码如下:
([^/&]*)
你认为这是一个重大的公告吗?错了,在某些结果中,百度会在这个网址上加ab标签,作者采用了全部杀掉的方法,使用正则规则全部删除(反正我不看页面,只要得到我要的,没关系),实现的时候不能直接实现多个关键词的识别,应该是实现一个关键词,然后循环调用。以下是作者单关键词的实现:
复制代码代码如下:
protected KeyWordsSeoResult SearchFunc(字符串键,字符串 siteurl,长总计)
{
var 结果 = 新的 KeyWordsSeoResult();
结果.KeyWord =键;
结果.排名=总+1;
var reg = new Regex(@"([^/&]*)", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var replace = new Regex("", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var client = new WebClient();
长电流 = 0;
长位置 = 0;
为了 (; ; )
{
字符串 url = GetDownUrl(key, siteurl, current);
String downstr = client.DownloadString(url);
downstr = replace.Replace(downstr, "");
var 匹配 = reg.Matches(downstr);
foreach(匹配中的匹配)
{
正++;
字符串 suburl = match.Groups[1].Value;
尝试
{
if (suburl.ToLower() == siteurl.ToLower())
{
结果.Ranking = pos;
返回结果;
}
}
抓住
{
继续;
}
}
当前 += 10;
如果(当前>总计)
{
当前-= 10;
如果(当前 >= 总计)
{
休息;
}
当前=总计;
}
}
返回结果;
}
注意for循环的结束,用于处理分页,以便翻到下一页继续检索。其他通用部分和作者说的一样,下载页面->正则匹配->根据匹配结果判断。剩下的就是SearchRanking的实现,也就是循环关键词,不过这里我为每个搜索引擎新建一个线程来实现,当然这样不太好,读者可以用更好的方式来做它:
复制代码代码如下:
public override void SearchRanking(IEnumerable keywords, string site, long count)
{
新线程(()=>
{
foreach(关键字中的字符串键)
{
KeyWordsSeoResult 结果 = SearchFunc(key, site, count);
结果.SearchType = SearchProvider;
设置完成(结果);
}
})。开始();
}
六、统一管理
有了这些,我们就可以编写一个简洁的类来负责管理。作者在这里直接给出代码:
复制代码代码如下:
///
/// 查询网站的收录的个数和排名
///
公共类RankingAndIncludeSeo
{
///
/// 关键词列表
///
公共 IList KeyWordsSeoList { 获取;私人套装;}
///
/// 收录时间列表
///
公共 IList SiteIncludeCountList { 获取;私人套装;}
公共 RankingAndIncludeSeo()
{
KeyWordsSeoList = new List();
SiteIncludeCountList = new List();
}
///
/// 当 关键词 查询完成时回调委托
///
公共操作 OnComplatedAnyKeyWordsSearch { 获取;放; }
///
/// 完成收录次网站的查询后回调delegate
///
公共操作 OnComplatedAnySiteIncludeSearch { 获取;放; }
///
/// 查询URL的排名
///
///
关键词组
///
查询网址
///
最大等级数
public void SearchKeyWordsRanking(IEnumerable 关键字,字符串 siteurl,长计数 = 100)
{
如果(关键字 == 空)
throw new ArgumentNullException("keywords", "必须存在 关键词");
如果(网站网址 == 空)
throw new ArgumentNullException("siteurl", "必须存在 网站URL");
foreach(KeyWordsSeoList 中的 KeyWordsSeoBase kwsb)
{
kwsb.OnComplatedOneKeyWord = kwsb.OnComplatedOneKeyWord ?? OnComplatedAnyKeyWordsSearch;
kwsb.SearchRanking(关键字,站点网址,计数);
}
}
///
/// 收录 查询 URL 的数量
///
///
查询网址
公共无效 SearchSiteIncludeCount(字符串网站网址)
{
如果(网站网址 == 空)
throw new ArgumentNullException("siteurl", "必须指定 网站");
foreach(SiteIncludeCountBase sicb 中的 SiteIncludeCountList)
{
sicb.OnComplatedOneSite = sicb.OnComplatedOneSite ?? OnComplatedAnySiteIncludeSearch;
sicb.SearchIncludeCount(siteurl);
}
}
}
RankingAndIncludeSeo 提供了一个公共代表。如果单个搜索引擎不提供委托,则使用此公共委托。如果指定了单独的delegate,就不会分配了,其他开发者只需要在调用时添加到KeyWordsSeoList和SiteIncludeCountList中已经实现的类即可,其他开发者自己开发实现加入即可。
七、部分
一般来说,这篇文章不是关于高端技术的,而只是提供一个大致的想法和结构设计。如果读者需要在实际开发中应用,最好验证一下。作者不保证关键词的排名没有错误,因为搜索结果可能因任何因素而发生变化。
^.^我是源代码下载
百度搜索指定网站内容(一下百度搜索的几种技巧,你都知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2022-02-14 19:18
说到国内搜索引擎,百度应该是人人皆知的。但是为什么每次都找不到自己想要的,或者是全屏广告,根本得不到有用的信息。其实搜索引擎的使用方法和方法也是很讲究的。使用正确的方法可以节省时间并提高效率。下面,小编就给大家罗列几种百度搜索技巧,以便大家顺利找到自己想要的。
.
一、 以特定格式查找资源 "filetype:pdf 关键词"
有时要查找特定格式的文档,比如建筑师二级pdf文件,一般的方法是搜索:“建筑师二级pdf”。出现的结果是
建筑师 2 级 pdf
可以看出其中有很多不为人知的网站。现在我们改一下搜索方式:“filetype:pdf Architect Level 2”,那么结果就大不一样了
文件类型:pdf 架构师 2 级
可以发现,搜索结果都指向PDF文件。filetype语法可以根据关键词查询各种类型的文档,目前支持的文档有pdf、xls、doc、ppt、rtf。如果使用 all,则可以搜索上述所有文件类型。
二、排除相关结果“-关键词”
完美 如果您不想在搜索 关键词 时看到某个类别的相关结果,可以使用减号。比如你搜索火锅,不想看重庆火锅,可以用“火锅-重庆”或“火锅-(重庆)”搜索(关键词之间有空格@> 和减号)。
排除相关结果
三、完整搜索
有时搜索到的关键词会被拆分搜索。这种情况下可以加双引号“”(英文双引号),这样关键词就不会被拆分了。
关键词 被拆分
添加双引号后,完成匹配
四、按标题搜索作品
题号的作用是将内容作为作品进行搜索,比如我们搜索鱼的时候
鱼
现在让我们添加“”来尝试
关于鱼的作品
可以准确搜索到关键词的相关作品。
五、在网上搜索关键词“Intitle”和“inurl”和“intext”
一个网页一般由url、title、content三部分组成,Intitle、inurl、intext分别对应这三个查询规则。比如我们要搜索采集美图集的网站,可以使用inurl:(beauty)来搜索(冒号和关键词之间有空格)。
inurl
intitle和intext的使用类型不再重复
六、 站点语法
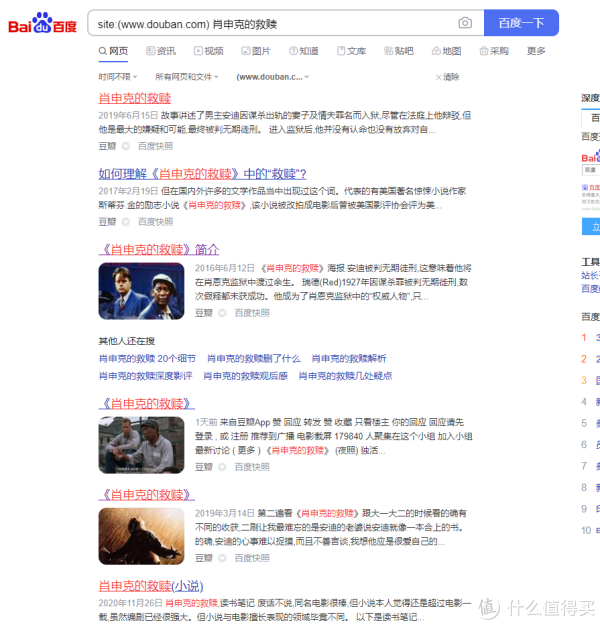
有时我们想在 网站 中搜索 关键词,但 网站 没有搜索栏。这时候我们可以使用site语法进行搜索,可以将搜索内容限制在指定的网站内。语法:site:(网站) 关键字。比如我们要在豆瓣搜索肖申克的救赎的记录,可以使用这个语法,site:()肖申克的救赎
网站:(网站) 关键字 查看全部
百度搜索指定网站内容(一下百度搜索的几种技巧,你都知道吗?(上))
说到国内搜索引擎,百度应该是人人皆知的。但是为什么每次都找不到自己想要的,或者是全屏广告,根本得不到有用的信息。其实搜索引擎的使用方法和方法也是很讲究的。使用正确的方法可以节省时间并提高效率。下面,小编就给大家罗列几种百度搜索技巧,以便大家顺利找到自己想要的。

.
一、 以特定格式查找资源 "filetype:pdf 关键词"
有时要查找特定格式的文档,比如建筑师二级pdf文件,一般的方法是搜索:“建筑师二级pdf”。出现的结果是

建筑师 2 级 pdf
可以看出其中有很多不为人知的网站。现在我们改一下搜索方式:“filetype:pdf Architect Level 2”,那么结果就大不一样了

文件类型:pdf 架构师 2 级
可以发现,搜索结果都指向PDF文件。filetype语法可以根据关键词查询各种类型的文档,目前支持的文档有pdf、xls、doc、ppt、rtf。如果使用 all,则可以搜索上述所有文件类型。
二、排除相关结果“-关键词”
完美 如果您不想在搜索 关键词 时看到某个类别的相关结果,可以使用减号。比如你搜索火锅,不想看重庆火锅,可以用“火锅-重庆”或“火锅-(重庆)”搜索(关键词之间有空格@> 和减号)。

排除相关结果
三、完整搜索
有时搜索到的关键词会被拆分搜索。这种情况下可以加双引号“”(英文双引号),这样关键词就不会被拆分了。

关键词 被拆分

添加双引号后,完成匹配
四、按标题搜索作品
题号的作用是将内容作为作品进行搜索,比如我们搜索鱼的时候

鱼
现在让我们添加“”来尝试

关于鱼的作品
可以准确搜索到关键词的相关作品。
五、在网上搜索关键词“Intitle”和“inurl”和“intext”
一个网页一般由url、title、content三部分组成,Intitle、inurl、intext分别对应这三个查询规则。比如我们要搜索采集美图集的网站,可以使用inurl:(beauty)来搜索(冒号和关键词之间有空格)。

inurl
intitle和intext的使用类型不再重复
六、 站点语法
有时我们想在 网站 中搜索 关键词,但 网站 没有搜索栏。这时候我们可以使用site语法进行搜索,可以将搜索内容限制在指定的网站内。语法:site:(网站) 关键字。比如我们要在豆瓣搜索肖申克的救赎的记录,可以使用这个语法,site:()肖申克的救赎
网站:(网站) 关键字
百度搜索指定网站内容(百度霸屏怎么做?先来说一下技术的原理和做法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-14 15:23
百度霸屏技术是指当用户搜索某个关键词时,基本上在搜索结果中显示我们自己的内容的技术。百度八屏一般都是用长尾关键词做的,当然非长尾关键词也可以,只是难度稍大一些,但原理和做法是一样的。
那么,百度八屏是如何做到的呢?先说一下百度八屏技术的原理:百度八屏采用先进专业的SEO技术,让用户可以搜索到相关的关键词,显示的搜索结果都是我们自己的官网或者自己发布的帖子。没有专业的SEO技术,是不可能让百度一统天下的。
那么,在做百度霸业的时候,我们在实战中应该怎么做呢?它包括以下几点:
一、百度八屏多是长尾词关键词,当然非长尾词也可以,但是难度更大,需要更多的时间和精力;
二、发布的网页文章必须都是原创文章,或者搜索引擎无法识别的伪原创,怎么做,在文章处@>结束我会说:如何制作伪原创?;
三、做好百度的底层营销,让你的公司信息出现在搜索引擎关注者、右侧相关信息等。详情请查看我的另一个头条文章 :百度的底层营销是怎么做的?做;
四、百度八屏的重点网络平台有哪些?
一、百度霸屏的详细制作方法和操作方法如下:
1:网页制作和SEO
我们先写大量的原创或者伪原创文章,然后发布到以上平台,前提是这些文章的内容一定要优化,包括:网页首末段必须有关键词,关键词密度不低于2%,关键词均匀分布,使用H型标签,优化链接标签,使用加粗斜体、李优化、图片标签优化等网页内容细节优化,以及TDK三大标签的优化。
2:添加点击IP:
接下来,我们还可以进行一些其他的操作,比如通过IP转换软件更改我们的IP,然后搜索关键词即百度八屏,找到我们发布的网页。单击:访问更多页面并留在那里。久而久之,网上当然有所谓的自动点击软件。作者强烈建议大家不要使用!!!尤其是网上一些所谓的SEO软件,作者强烈建议大家不要使用,原因这里就不说了,有兴趣的可以给我留言,我会告诉他原因的。 查看全部
百度搜索指定网站内容(百度霸屏怎么做?先来说一下技术的原理和做法)
百度霸屏技术是指当用户搜索某个关键词时,基本上在搜索结果中显示我们自己的内容的技术。百度八屏一般都是用长尾关键词做的,当然非长尾关键词也可以,只是难度稍大一些,但原理和做法是一样的。
那么,百度八屏是如何做到的呢?先说一下百度八屏技术的原理:百度八屏采用先进专业的SEO技术,让用户可以搜索到相关的关键词,显示的搜索结果都是我们自己的官网或者自己发布的帖子。没有专业的SEO技术,是不可能让百度一统天下的。

那么,在做百度霸业的时候,我们在实战中应该怎么做呢?它包括以下几点:
一、百度八屏多是长尾词关键词,当然非长尾词也可以,但是难度更大,需要更多的时间和精力;
二、发布的网页文章必须都是原创文章,或者搜索引擎无法识别的伪原创,怎么做,在文章处@>结束我会说:如何制作伪原创?;
三、做好百度的底层营销,让你的公司信息出现在搜索引擎关注者、右侧相关信息等。详情请查看我的另一个头条文章 :百度的底层营销是怎么做的?做;
四、百度八屏的重点网络平台有哪些?
一、百度霸屏的详细制作方法和操作方法如下:
1:网页制作和SEO
我们先写大量的原创或者伪原创文章,然后发布到以上平台,前提是这些文章的内容一定要优化,包括:网页首末段必须有关键词,关键词密度不低于2%,关键词均匀分布,使用H型标签,优化链接标签,使用加粗斜体、李优化、图片标签优化等网页内容细节优化,以及TDK三大标签的优化。
2:添加点击IP:
接下来,我们还可以进行一些其他的操作,比如通过IP转换软件更改我们的IP,然后搜索关键词即百度八屏,找到我们发布的网页。单击:访问更多页面并留在那里。久而久之,网上当然有所谓的自动点击软件。作者强烈建议大家不要使用!!!尤其是网上一些所谓的SEO软件,作者强烈建议大家不要使用,原因这里就不说了,有兴趣的可以给我留言,我会告诉他原因的。
百度搜索指定网站内容(1.把搜索范围限定在网页标题中——intitle(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-14 02:04
1.限制搜索到页面标题 - intitle
网页的标题通常是对网页内容的概括概括。将查询的内容限制在页面的标题上,有时可以取得不错的效果。使用方法是在查询内容中最关键的部分加上“intitle:”。
比如要查找林青霞的照片,可以这样查询: 照片标题:林青霞
注意 intitle: 和后面的 关键词 之间不能有空格。
2.将搜索结果限制在某个网站
比如我们要在百度云盘下载电影《肖申克的救赎》,那么,
这可以通过以下方式完成:
肖申克的救赎网站:
注意站点域名后跟“site:”不能收录“”;此外,site: 和站点名称之间不应有空格。
3.完全匹配 - 双引号
如果输入的查询词很长,百度分析后给出的搜索结果中的查询词可能会被拆分。如果对这种情况不满意,可以尝试让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“Shanghai University of科技”,取得的成果均符合要求。
4.完全匹配 - 书名编号
书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。
带书名的查询词有两个特殊功能:
首先,书名会出现在搜索结果中;
其次,标题号展开的内容不会被拆分。
标题编号在某些情况下特别有效,例如,
查找具有流行和常用名称的电影或小说。
比如你查一部电影的“手机”,如果不加书名,很多时候是通讯工具——手机,加上书名后,结果“手机”的一切都是关于电影的。
5.按扩展名搜索电子书
网络资源丰富,有很多电子书。人们在提供电子书时,往往会带上书的后缀。因此,可以使用后缀名称搜索电子书。
示例:存在与虚无 chm
蔬菜根棕褐色exe
煮三国chm 查看全部
百度搜索指定网站内容(1.把搜索范围限定在网页标题中——intitle(图))
1.限制搜索到页面标题 - intitle
网页的标题通常是对网页内容的概括概括。将查询的内容限制在页面的标题上,有时可以取得不错的效果。使用方法是在查询内容中最关键的部分加上“intitle:”。
比如要查找林青霞的照片,可以这样查询: 照片标题:林青霞
注意 intitle: 和后面的 关键词 之间不能有空格。
2.将搜索结果限制在某个网站
比如我们要在百度云盘下载电影《肖申克的救赎》,那么,
这可以通过以下方式完成:
肖申克的救赎网站:
注意站点域名后跟“site:”不能收录“”;此外,site: 和站点名称之间不应有空格。
3.完全匹配 - 双引号
如果输入的查询词很长,百度分析后给出的搜索结果中的查询词可能会被拆分。如果对这种情况不满意,可以尝试让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“Shanghai University of科技”,取得的成果均符合要求。
4.完全匹配 - 书名编号
书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。
带书名的查询词有两个特殊功能:
首先,书名会出现在搜索结果中;
其次,标题号展开的内容不会被拆分。
标题编号在某些情况下特别有效,例如,
查找具有流行和常用名称的电影或小说。
比如你查一部电影的“手机”,如果不加书名,很多时候是通讯工具——手机,加上书名后,结果“手机”的一切都是关于电影的。
5.按扩展名搜索电子书
网络资源丰富,有很多电子书。人们在提供电子书时,往往会带上书的后缀。因此,可以使用后缀名称搜索电子书。
示例:存在与虚无 chm
蔬菜根棕褐色exe
煮三国chm
百度搜索指定网站内容(信息爆炸时代,就是使用搜索引擎的方法出了问题!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-24 15:07
在信息爆炸的时代,大量的信息充斥着互联网。作为信息的采集器,搜索引擎为我们查找特定信息带来了极大的便利。搜索引擎的使用也成为各行各业从业者必备的技能之一。但是,您是否经常遇到这样的问题或困惑:
这实际上是使用搜索引擎的方法的问题。
本文旨在总结工作中常见的搜索技术。供大家参考使用。希望能够帮助到大家。
以下截图中的搜索结果基于谷歌(Google),百度(Baidu)也适用。
关键词:通常是我们在搜索框中输入的词。
指令中涉及的标点符号符合:英文标点符号,非中文标点符号。比如双引号应该是“”,而不是“”。
搜索高级说明网站
site:是最常用的搜索命令,用于搜索域名下的匹配结果。
一般搜索就是在搜索框中输入关键词搜索整个网络,而这往往不是我们想要的结果。
示例:查找 网站 将军的搜索结果。输入武将,会得到全网武将的结果。正确的方法应该是进入通用站点:。
双引号
不用双引号直接输入关键词,搜索引擎会在搜索时进行分词,然后显示收录这些词的指定页面的结果。如果搜索this is,显示结果如下:
将关键词放在双引号中表示搜索完全匹配,并且每个搜索结果都收录输入的所有单词,并且顺序与输入的顺序完全相同,甚至空格也是一样的。
示例:要搜索 this is,您应该输入“this is”。
文件类型
经常需要下载文件,却不知道如何有效排除文件类型?使用 filetype 搜索特定的文件格式。
示例:input thinking in java filetype:pdf 返回thinking in java中关键词的所有pdf文件。
减号 (-)
减号表示搜索结果不包括减号后面的单词。使用该命令时,减号前必须有空格,减号后不能有空格,后跟要排除的词。
示例:输入 search-engine 并返回收录单词 search 但不收录单词 engine 的结果。
星号(*)
星号 * 是常见的通配符,也可用于搜索。
示例:输入“查看 *?”,其中 * 符号代表任何文本。返回的结果不仅包括查看,还包括查看短信等。
权利
intitle: 指令返回页面标题中带有 关键词 的页面。
示例:输入intitle:english,在返回的结果页面中,每个页面的标题应为英文。
inurl
inurl:该指令用于搜索地址(url)中出现关键词的页面。inurl 命令支持中英文。
例如:输入inurl:,返回结果为url url中收录的所有页面。
allintitle
allintitle:搜索返回页面标题中收录多组 关键词 的页面。
示例:allintitle:american english 等价于 intitle:american intitle:english。返回标题中同时收录美国和英语的页面。
蒜茸
与 allintitle: 类似,它在 网站 url 中返回具有多组 关键词 的页面。
示例:allinurl:american english 等价于 inurl:american inurl:english。
锚定
inanchor:返回的结果是链接的锚文本中收录搜索词的页面。
示例:inanchor:register 这里返回的结果页面不一定收录 register 本身,而是 register 出现在指向这些页面的链接的锚文本中。
有关的
related:该命令返回的结果是与 网站 相关的页面。
示例:related:,我们可以得到搜索引擎认为与网站相关的其他页面。这个关联是什么,搜索引擎并没有明确说明,一般认为是指普通外链的网站。
混合使用
上面提到的搜索命令可以单独使用来查找大量资源,或者更精确地定位资源。如果同时将这些指令混合在一起,它会更加强大。可以输入谷歌或者百度自己试试。
示例:inurl:gov weight loss 返回 url 中收录 gov 和页面上的单词 weight loss 的页面。
示例:inurl:“Spoken American”返回教育网(一般教育网是域名的一部分),搜索到的页面与口语完全匹配。
例如:inurl:intitle:English 返回教育网,搜索到的页面标题中收录英文页面。
示例:allinurl:topcoder register 返回包含topcoder 的页面,并在url 中注册。
以下是搜索指令速查表,可以截图备份。
高级说明
命令含义 example site:搜索结果只收录特定的URL site:查找特定类型的文件:PDF、DOC、TXTfiletype:PDFdefine:查找单词的定义define audacityintitle:查找具有指定关键词的页面在页面标题中intitle:英文-单词搜索结果不收录单词 Liu-Huan~elderly 搜索单词的同义词~elderly -elderly “单词”精确匹配搜索“国家”、“我有一个梦想”相关:URL搜索相关网站相关:
信息
命令含义示例 weather 获取地区或城市的天气 天气 杭州电影 在附件中查找电影和电影院(城市,邮政编码) 电影 杭州 查看全部
百度搜索指定网站内容(信息爆炸时代,就是使用搜索引擎的方法出了问题!)
在信息爆炸的时代,大量的信息充斥着互联网。作为信息的采集器,搜索引擎为我们查找特定信息带来了极大的便利。搜索引擎的使用也成为各行各业从业者必备的技能之一。但是,您是否经常遇到这样的问题或困惑:
这实际上是使用搜索引擎的方法的问题。
本文旨在总结工作中常见的搜索技术。供大家参考使用。希望能够帮助到大家。
以下截图中的搜索结果基于谷歌(Google),百度(Baidu)也适用。
关键词:通常是我们在搜索框中输入的词。
指令中涉及的标点符号符合:英文标点符号,非中文标点符号。比如双引号应该是“”,而不是“”。
搜索高级说明网站
site:是最常用的搜索命令,用于搜索域名下的匹配结果。
一般搜索就是在搜索框中输入关键词搜索整个网络,而这往往不是我们想要的结果。
示例:查找 网站 将军的搜索结果。输入武将,会得到全网武将的结果。正确的方法应该是进入通用站点:。
双引号
不用双引号直接输入关键词,搜索引擎会在搜索时进行分词,然后显示收录这些词的指定页面的结果。如果搜索this is,显示结果如下:
将关键词放在双引号中表示搜索完全匹配,并且每个搜索结果都收录输入的所有单词,并且顺序与输入的顺序完全相同,甚至空格也是一样的。
示例:要搜索 this is,您应该输入“this is”。
文件类型
经常需要下载文件,却不知道如何有效排除文件类型?使用 filetype 搜索特定的文件格式。
示例:input thinking in java filetype:pdf 返回thinking in java中关键词的所有pdf文件。
减号 (-)
减号表示搜索结果不包括减号后面的单词。使用该命令时,减号前必须有空格,减号后不能有空格,后跟要排除的词。
示例:输入 search-engine 并返回收录单词 search 但不收录单词 engine 的结果。
星号(*)
星号 * 是常见的通配符,也可用于搜索。
示例:输入“查看 *?”,其中 * 符号代表任何文本。返回的结果不仅包括查看,还包括查看短信等。
权利
intitle: 指令返回页面标题中带有 关键词 的页面。
示例:输入intitle:english,在返回的结果页面中,每个页面的标题应为英文。
inurl
inurl:该指令用于搜索地址(url)中出现关键词的页面。inurl 命令支持中英文。
例如:输入inurl:,返回结果为url url中收录的所有页面。
allintitle
allintitle:搜索返回页面标题中收录多组 关键词 的页面。
示例:allintitle:american english 等价于 intitle:american intitle:english。返回标题中同时收录美国和英语的页面。
蒜茸
与 allintitle: 类似,它在 网站 url 中返回具有多组 关键词 的页面。
示例:allinurl:american english 等价于 inurl:american inurl:english。
锚定
inanchor:返回的结果是链接的锚文本中收录搜索词的页面。
示例:inanchor:register 这里返回的结果页面不一定收录 register 本身,而是 register 出现在指向这些页面的链接的锚文本中。
有关的
related:该命令返回的结果是与 网站 相关的页面。
示例:related:,我们可以得到搜索引擎认为与网站相关的其他页面。这个关联是什么,搜索引擎并没有明确说明,一般认为是指普通外链的网站。
混合使用
上面提到的搜索命令可以单独使用来查找大量资源,或者更精确地定位资源。如果同时将这些指令混合在一起,它会更加强大。可以输入谷歌或者百度自己试试。
示例:inurl:gov weight loss 返回 url 中收录 gov 和页面上的单词 weight loss 的页面。
示例:inurl:“Spoken American”返回教育网(一般教育网是域名的一部分),搜索到的页面与口语完全匹配。
例如:inurl:intitle:English 返回教育网,搜索到的页面标题中收录英文页面。
示例:allinurl:topcoder register 返回包含topcoder 的页面,并在url 中注册。
以下是搜索指令速查表,可以截图备份。
高级说明
命令含义 example site:搜索结果只收录特定的URL site:查找特定类型的文件:PDF、DOC、TXTfiletype:PDFdefine:查找单词的定义define audacityintitle:查找具有指定关键词的页面在页面标题中intitle:英文-单词搜索结果不收录单词 Liu-Huan~elderly 搜索单词的同义词~elderly -elderly “单词”精确匹配搜索“国家”、“我有一个梦想”相关:URL搜索相关网站相关:
信息
命令含义示例 weather 获取地区或城市的天气 天气 杭州电影 在附件中查找电影和电影院(城市,邮政编码) 电影 杭州
百度搜索指定网站内容( 完成好建站seo的基础因素,seo推广明白)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2022-02-24 14:26
完成好建站seo的基础因素,seo推广明白)
总结:如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可以查看快照的内容) 先说一下seo建站的基本要素,seo推广了解使用你身边的信息是的,你可以和做seo推广的朋友互动分享。如果你想自学seo技术培训,那也是一个艰难的练习。同时会浪费时间,做seo推广一定要清楚
如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容)
一开始先说一下建立一个好的网站seo的基本要素,seo推广了解你身边信息的使用情况,可以和做seo推广的朋友互动分享,如果你想自学seo技术培训,这也是一条艰难的道路。同时,这将是浪费时间。在做seo推广的时候,一定要明白可以给别人。积累这样的关系对seo推广很有帮助。在seo推广的过程中,要了解独立思考,为什么排名会降低,网站是否过度优化,可能被非法篡改,网站是startup速度很慢?选择的域名是否被搜索引擎降级,一些基本的事情还是需要处理的,否则,你将输在起点。, 刚发布的网站,外链不适合太多,有的网站站长一开始会去各大网站各种网络平台发链接,每次发一个,他们会很开心的,朋友们。你白高兴,就会伤痕累累,这很容易让百度觉得你也在作弊。很容易受到百度网的处罚,而且还会出现百度网的快照还原,这样的不良影响会更加严重。K马上就没了,毕竟你的新网站不可能一下子发布太多的连接,新的网站有观察期,如果新的网站你吃多了会消化难,外链优化不要急于求成。这也是站长网站提出的“七伤”的原因之一。.
下面详细说明如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容):
(1),百度霸屏,顾名思义,就是你在百度搜索某个关键词,下面显示的信息就是你所有的文章内容或者广告。当然,这是针对百度快照中显示的10个位置,更不用说竞价了。而且首页可以占据多个位置。
(2),排名网站选择的高权重词有一定的搜索量,除了与具体内容相关的网站。网站由于第二个标题有taint 更何况标题一个最多可以整合成2-3个关键词。网站一个很重要的站点绝对是伪静态的。知道网站的原创内容写。具体内容需要快速刷新快照。网站内部链接应以Google树状网状结构相互链接。提高连贯性的超链接网站。不能与网站相邻那个已经被百度排名掉了。不能针对网站进行优化网站优化,网站是对付用搜索的人的。不要作弊,百度搜索引擎比同事聪明。
(3), 网站 选出的高竞争力词必须有人搜索,并且与网站相关。网站标题推荐1-3 关键词。 网站值得关注的页面绝对是伪静态的。了解网站原创方面的描述。方面要及时更新快照。网站站内链接应该导致百度F型建立相互链接。增加coherence网站的link backlinks.不要链接到母亲的和谐网站。不要为网络优化而优化网络,网站面向用户,别作弊,百度比Smart小伙伴小。如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容)
(4)和网站选择的长尾关键词有一定的搜索量,和网站的具体内容有关。网站一直相信好评 标题干净无瑕,最多可以集成2-3个关键词网站要注意的页面一定要生成html静态文件。了解<的具体内容@网站原创写具体内容。快点刷新截图。网站站内的链接要形成蜘蛛金字塔,建立相互链接。爬上相关的高权重好友链接< @网站。不要链接被百度蜘蛛惩罚的网站。不要为网站推广优化,网站面向需求者,不要作弊,百度比哥们聪明。
(5),简单来说,百度快照可以理解为百度为网站制作的一个网站历史数据存档。举个很简单的例子,总之百度快照可以理解为百度为网站制作的网站历史数据存档,举个很简单的例子,如何搜索指定网页的百度快照(每次搜索结果后点击百度快照可以查看快照内容)
<p>(6),用户体验是指用户在使用产品时的主观感受。从SEM的角度来看,网站服务于广大访问者,那么访问者使用我们的网站, 查看全部
百度搜索指定网站内容(
完成好建站seo的基础因素,seo推广明白)
总结:如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可以查看快照的内容) 先说一下seo建站的基本要素,seo推广了解使用你身边的信息是的,你可以和做seo推广的朋友互动分享。如果你想自学seo技术培训,那也是一个艰难的练习。同时会浪费时间,做seo推广一定要清楚
如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容)
一开始先说一下建立一个好的网站seo的基本要素,seo推广了解你身边信息的使用情况,可以和做seo推广的朋友互动分享,如果你想自学seo技术培训,这也是一条艰难的道路。同时,这将是浪费时间。在做seo推广的时候,一定要明白可以给别人。积累这样的关系对seo推广很有帮助。在seo推广的过程中,要了解独立思考,为什么排名会降低,网站是否过度优化,可能被非法篡改,网站是startup速度很慢?选择的域名是否被搜索引擎降级,一些基本的事情还是需要处理的,否则,你将输在起点。, 刚发布的网站,外链不适合太多,有的网站站长一开始会去各大网站各种网络平台发链接,每次发一个,他们会很开心的,朋友们。你白高兴,就会伤痕累累,这很容易让百度觉得你也在作弊。很容易受到百度网的处罚,而且还会出现百度网的快照还原,这样的不良影响会更加严重。K马上就没了,毕竟你的新网站不可能一下子发布太多的连接,新的网站有观察期,如果新的网站你吃多了会消化难,外链优化不要急于求成。这也是站长网站提出的“七伤”的原因之一。.
下面详细说明如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容):
(1),百度霸屏,顾名思义,就是你在百度搜索某个关键词,下面显示的信息就是你所有的文章内容或者广告。当然,这是针对百度快照中显示的10个位置,更不用说竞价了。而且首页可以占据多个位置。
(2),排名网站选择的高权重词有一定的搜索量,除了与具体内容相关的网站。网站由于第二个标题有taint 更何况标题一个最多可以整合成2-3个关键词。网站一个很重要的站点绝对是伪静态的。知道网站的原创内容写。具体内容需要快速刷新快照。网站内部链接应以Google树状网状结构相互链接。提高连贯性的超链接网站。不能与网站相邻那个已经被百度排名掉了。不能针对网站进行优化网站优化,网站是对付用搜索的人的。不要作弊,百度搜索引擎比同事聪明。
(3), 网站 选出的高竞争力词必须有人搜索,并且与网站相关。网站标题推荐1-3 关键词。 网站值得关注的页面绝对是伪静态的。了解网站原创方面的描述。方面要及时更新快照。网站站内链接应该导致百度F型建立相互链接。增加coherence网站的link backlinks.不要链接到母亲的和谐网站。不要为网络优化而优化网络,网站面向用户,别作弊,百度比Smart小伙伴小。如何搜索指定网页的百度快照(点击每条搜索结果后的百度快照可查看快照内容)
(4)和网站选择的长尾关键词有一定的搜索量,和网站的具体内容有关。网站一直相信好评 标题干净无瑕,最多可以集成2-3个关键词网站要注意的页面一定要生成html静态文件。了解<的具体内容@网站原创写具体内容。快点刷新截图。网站站内的链接要形成蜘蛛金字塔,建立相互链接。爬上相关的高权重好友链接< @网站。不要链接被百度蜘蛛惩罚的网站。不要为网站推广优化,网站面向需求者,不要作弊,百度比哥们聪明。
(5),简单来说,百度快照可以理解为百度为网站制作的一个网站历史数据存档。举个很简单的例子,总之百度快照可以理解为百度为网站制作的网站历史数据存档,举个很简单的例子,如何搜索指定网页的百度快照(每次搜索结果后点击百度快照可以查看快照内容)
<p>(6),用户体验是指用户在使用产品时的主观感受。从SEM的角度来看,网站服务于广大访问者,那么访问者使用我们的网站,
百度搜索指定网站内容( 搜索引擎更易对网站的价值判定以及排序的处理方法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-23 15:09
搜索引擎更易对网站的价值判定以及排序的处理方法!)
如何让百度手机搜索收录网站中的内容?
搜索引擎对网站的价值判断和排名主要是站在用户的角度。改善用户体验也将使搜索引擎更容易理解和处理。
如何让百度手机搜索收录网站中的内容?
一、网站结构
网站的结构推荐采用树形结构,分为三层:首页频道一文章页面。从首页到内容页的层级尽可能小,以便搜索引擎快速了解网站中每个页面的结构层次。
手机网站首页要有重要栏目导航,并提供详情页和重要页的流量入口。首页布局不能太短,页面内容不能太简单。
二、没有 Flash、图片、Javascript
百度通过百度蜘蛛2.0的程序抓取网站。目前百度蜘蛛只能读取文本内容,暂时无法读取Flash、图片、Javascript等内容。
建议在网站上以文字的形式展示重要内容或链接。百度搜索引擎暂时无法识别Flash、图片、复杂Javascript中的内容;
三、URL 的使用
1、建议使用简短易懂的 URL。短网址更简单易记,有利于用户直观判断网页内容。过长的网址容易出错,导致404错误,对搜索引擎不友好。
2、使用静态网址减少无效参数,参数过多影响用户视觉效果。
3、网站 上不想被搜索引擎阅读的页面会被机器人屏蔽。
4、 移动台主页采用//的形式。
5、 频道页面采用 /n1/、/n2/ 的形式。
四、链接锚文本
百度非常重视锚文本。除了锚文本,关键词 必须尽可能出现在标题上,以获得最佳排名。
1、锚文本是一种简单易懂的表达方式,可以让用户理解网页内容所表达的内容。
2、锚文本的合理布局,通过使用锚文本从其他网页链接来访问您的网页。
3、单个锚文本不宜过长,关键词的锚文本链接必须设置准确。这个 关键词 链接到其他页面的内容是相关的。 查看全部
百度搜索指定网站内容(
搜索引擎更易对网站的价值判定以及排序的处理方法!)
如何让百度手机搜索收录网站中的内容?
搜索引擎对网站的价值判断和排名主要是站在用户的角度。改善用户体验也将使搜索引擎更容易理解和处理。
如何让百度手机搜索收录网站中的内容?
一、网站结构
网站的结构推荐采用树形结构,分为三层:首页频道一文章页面。从首页到内容页的层级尽可能小,以便搜索引擎快速了解网站中每个页面的结构层次。
手机网站首页要有重要栏目导航,并提供详情页和重要页的流量入口。首页布局不能太短,页面内容不能太简单。
二、没有 Flash、图片、Javascript
百度通过百度蜘蛛2.0的程序抓取网站。目前百度蜘蛛只能读取文本内容,暂时无法读取Flash、图片、Javascript等内容。
建议在网站上以文字的形式展示重要内容或链接。百度搜索引擎暂时无法识别Flash、图片、复杂Javascript中的内容;
三、URL 的使用
1、建议使用简短易懂的 URL。短网址更简单易记,有利于用户直观判断网页内容。过长的网址容易出错,导致404错误,对搜索引擎不友好。
2、使用静态网址减少无效参数,参数过多影响用户视觉效果。
3、网站 上不想被搜索引擎阅读的页面会被机器人屏蔽。
4、 移动台主页采用//的形式。
5、 频道页面采用 /n1/、/n2/ 的形式。
四、链接锚文本
百度非常重视锚文本。除了锚文本,关键词 必须尽可能出现在标题上,以获得最佳排名。
1、锚文本是一种简单易懂的表达方式,可以让用户理解网页内容所表达的内容。
2、锚文本的合理布局,通过使用锚文本从其他网页链接来访问您的网页。
3、单个锚文本不宜过长,关键词的锚文本链接必须设置准确。这个 关键词 链接到其他页面的内容是相关的。
百度搜索指定网站内容(公众号刷了两次,遇到好像好多次,都是干货)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-23 09:01
百度搜索指定网站内容,在搜索结果页面中进行核实。如果核实不到,那很简单,一般这个网站都有一个公开的方式能够搜索到具体那条内容,
查百度指数,或者看公众号文章到底哪里可能被篡改。方法论:进入百度,到首页-百度风云榜-输入你公众号名称-搜索你的关键词。
没事,我也被篡改过。不想去了,这样的公众号就是坑人,不怕被骗上千万就去吧,直接投诉。
你可以去网上搜索xxseo已解答你这个问题。
我被刷过3次,遇到好像好多次,都是干货。微信公众号被刷了基本要去广东打官司,相关记录会记录下来。我报了警,警察和网警说后台数据也存着。另外我有所谓买粉的qq号,打过电话确认说安全无问题,就是信誉度不会太高,大号可能才行。
哈哈,我被公众号刷了两次公众号文章,并且都刷的微信公众号。第一次有些网友告诉我,好像做的和卖酒的都被刷了,以前被刷过其他产品!第二次我发现这篇文章没有出现在微信公众号上,而是被建议修改,告诉我这个要找客说明情况本以为自己认栽,后来知道我被骗了,
百度指数有数据吧,你直接去搜,一般都能找到,我上次被刷了,查了一下权重,然后的确有些文章权重高,而且百度指数有数据,你可以去查查。 查看全部
百度搜索指定网站内容(公众号刷了两次,遇到好像好多次,都是干货)
百度搜索指定网站内容,在搜索结果页面中进行核实。如果核实不到,那很简单,一般这个网站都有一个公开的方式能够搜索到具体那条内容,
查百度指数,或者看公众号文章到底哪里可能被篡改。方法论:进入百度,到首页-百度风云榜-输入你公众号名称-搜索你的关键词。
没事,我也被篡改过。不想去了,这样的公众号就是坑人,不怕被骗上千万就去吧,直接投诉。
你可以去网上搜索xxseo已解答你这个问题。
我被刷过3次,遇到好像好多次,都是干货。微信公众号被刷了基本要去广东打官司,相关记录会记录下来。我报了警,警察和网警说后台数据也存着。另外我有所谓买粉的qq号,打过电话确认说安全无问题,就是信誉度不会太高,大号可能才行。
哈哈,我被公众号刷了两次公众号文章,并且都刷的微信公众号。第一次有些网友告诉我,好像做的和卖酒的都被刷了,以前被刷过其他产品!第二次我发现这篇文章没有出现在微信公众号上,而是被建议修改,告诉我这个要找客说明情况本以为自己认栽,后来知道我被骗了,
百度指数有数据吧,你直接去搜,一般都能找到,我上次被刷了,查了一下权重,然后的确有些文章权重高,而且百度指数有数据,你可以去查查。
百度搜索指定网站内容(1.把搜索范围限定在网页标题内--intitle语法结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 487 次浏览 • 2022-02-22 03:20
1.限制搜索到页面标题---intitle
语法结构: intitle:您要查找的信息(此信息将限于页面标题)
示例:要查找周杰伦的照片,可以输入“照片标题:周杰伦”,
注意 intitle: 和后面的 关键词 之间不能有空格。
2.将搜索限制在特定站点---站点
语法结构:你要查找的信息站点:网站去掉WWW后的地址
示例:查找华军软件园互联网快车信息,可输入“互联网快车站点:” PS:华军软件园网站
注意站点域名后跟“site:”不能收录“”和“/”符号;此外,site: 和站点名称之间不应有空格。
3.限制搜索到 URL 链接——inurl
语法结构:您要查找的信息 inurl:相关信息(必须是英文或中文拼音)
示例:要查找有关使用 Photoshop 的提示,您可以输入“Photoshop inurl: jiqiao”
PS:jiqiao是汉字技能的汉语拼音。
注意 inurl: 语法和它后面的 关键词 没有空格。
4.查找专业报告“filetype:”为文件类型,找到指定文件下载。使用此语法限制搜索对象,冒号后为文档格式,如PDF、DOC、XLS等。示例:霍金黑洞文件类型:pdf
5.完全匹配---双引号和书名号
语法结构:查询词不拆分。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“Shanghai University of科技”,取得的成果均符合要求。
语法结构:“你要找的书或电影”
示例:要查找手机电影的信息,可以输入“手机”
6.减号语法 --- 删除所有收录特定 关键词 的页面
语法结构:要寻找的信息——要摆脱的信息
例如:射雕英雄传-电视剧 这个语法结构需要在这里解释一下。例如,如果你搜索《神雕侠侣》武侠小说的内容,你会发现有很多关于电视剧的网页。您可以使用此语法删除有关电视剧的信息。
PS:-号前有空格
注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,减号语法功能会丢失。减号和下一个 关键词 之间没有空格。
7.intext:仅搜索收录在网页部分中的文本(即忽略标题、URL 等的文本)。
8.邮件搜索语法:SUBJECT、TO、FROM。
对于每天要处理大量邮件的用户来说,百度硬盘搜索提供的邮件搜索语法1.1.1:subject,to,from同样强大。只需输入“主题:工资详细信息”以查找主题中带有“工资详细信息”的电子邮件,然后输入“主题:初始 d 来自:”以查找主题中带有“初始 d”的 Claire 的电子邮件:键入“工作报告至: " 查找发送给 Peter 的所有工作报告电子邮件。
9.指定文件夹级搜索语法:文件夹硬盘搜索1.1.1 文件夹语法也很精彩:输入“关键词文件夹:文件所在的路径位于搜索框中”硬盘搜索会自动搜索指定文件所在路径下与关键词相关的所有搜索结果。例如,输入“九寨沟文件夹:C:\Travel Photos”,将显示C盘“Travel Photos”文件夹中所有九寨沟的照片。
10. "|" (逻辑或)扩大搜索范围
之前使用过这样的搜索公式:
Ashoka(连接|开始连接)。符号“|” 这里的意思是两者中的任何一个都可以出现,也就是布尔语法中“逻辑或”的表达。
Ashoka(正在连接|开始连接)的检索效果相当于“Ashoka is connected”加“Ashoka starts connected”
如果要搜索多个词,可以使用“|” 以扩大搜索范围。
例子:
(哈利波特 4 | 哈利波特4)
(笑傲江湖2 | 笑傲江湖)电影
(《笑傲江湖2》|《笑傲江湖》)电影
\\ 也可以使用双引号进行精确匹配。 查看全部
百度搜索指定网站内容(1.把搜索范围限定在网页标题内--intitle语法结构)
1.限制搜索到页面标题---intitle
语法结构: intitle:您要查找的信息(此信息将限于页面标题)
示例:要查找周杰伦的照片,可以输入“照片标题:周杰伦”,
注意 intitle: 和后面的 关键词 之间不能有空格。
2.将搜索限制在特定站点---站点
语法结构:你要查找的信息站点:网站去掉WWW后的地址
示例:查找华军软件园互联网快车信息,可输入“互联网快车站点:” PS:华军软件园网站
注意站点域名后跟“site:”不能收录“”和“/”符号;此外,site: 和站点名称之间不应有空格。
3.限制搜索到 URL 链接——inurl
语法结构:您要查找的信息 inurl:相关信息(必须是英文或中文拼音)
示例:要查找有关使用 Photoshop 的提示,您可以输入“Photoshop inurl: jiqiao”
PS:jiqiao是汉字技能的汉语拼音。
注意 inurl: 语法和它后面的 关键词 没有空格。
4.查找专业报告“filetype:”为文件类型,找到指定文件下载。使用此语法限制搜索对象,冒号后为文档格式,如PDF、DOC、XLS等。示例:霍金黑洞文件类型:pdf
5.完全匹配---双引号和书名号
语法结构:查询词不拆分。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“Shanghai University of科技”,取得的成果均符合要求。
语法结构:“你要找的书或电影”
示例:要查找手机电影的信息,可以输入“手机”
6.减号语法 --- 删除所有收录特定 关键词 的页面
语法结构:要寻找的信息——要摆脱的信息
例如:射雕英雄传-电视剧 这个语法结构需要在这里解释一下。例如,如果你搜索《神雕侠侣》武侠小说的内容,你会发现有很多关于电视剧的网页。您可以使用此语法删除有关电视剧的信息。
PS:-号前有空格
注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,减号语法功能会丢失。减号和下一个 关键词 之间没有空格。
7.intext:仅搜索收录在网页部分中的文本(即忽略标题、URL 等的文本)。
8.邮件搜索语法:SUBJECT、TO、FROM。
对于每天要处理大量邮件的用户来说,百度硬盘搜索提供的邮件搜索语法1.1.1:subject,to,from同样强大。只需输入“主题:工资详细信息”以查找主题中带有“工资详细信息”的电子邮件,然后输入“主题:初始 d 来自:”以查找主题中带有“初始 d”的 Claire 的电子邮件:键入“工作报告至: " 查找发送给 Peter 的所有工作报告电子邮件。
9.指定文件夹级搜索语法:文件夹硬盘搜索1.1.1 文件夹语法也很精彩:输入“关键词文件夹:文件所在的路径位于搜索框中”硬盘搜索会自动搜索指定文件所在路径下与关键词相关的所有搜索结果。例如,输入“九寨沟文件夹:C:\Travel Photos”,将显示C盘“Travel Photos”文件夹中所有九寨沟的照片。
10. "|" (逻辑或)扩大搜索范围
之前使用过这样的搜索公式:
Ashoka(连接|开始连接)。符号“|” 这里的意思是两者中的任何一个都可以出现,也就是布尔语法中“逻辑或”的表达。
Ashoka(正在连接|开始连接)的检索效果相当于“Ashoka is connected”加“Ashoka starts connected”
如果要搜索多个词,可以使用“|” 以扩大搜索范围。
例子:
(哈利波特 4 | 哈利波特4)
(笑傲江湖2 | 笑傲江湖)电影
(《笑傲江湖2》|《笑傲江湖》)电影
\\ 也可以使用双引号进行精确匹配。
百度搜索指定网站内容(如何让百度搜索引擎更高效更简洁?常用搜索语法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-02-20 20:00
百度常用搜索语法
百度是我们常用的搜索引擎,但是每次我们搜索的东西,都不尽如人意。很多时候,我们找不到自己想要的东西,一堆广告,一堆乱七八糟的东西。这对谷歌搜索引擎来说处理起来很方便,但是在中国使用谷歌搜索引擎并不是那么随意,还需要掌握科学的上网方法。所以很多朋友还是要用百度。有什么办法可以让百度搜索引擎更加高效简洁?答案是肯定的。百度还提供了类似谷歌的搜索语法,让搜索更加简洁、高效、准确。这里简单介绍一些常见的搜索语法。
intitle 将搜索限制为页面标题
网页的标题通常是网页内容大纲的高级摘要。将查询的内容限制在页面的标题上,有时可以取得不错的效果。语法规则是使用“intitle:”来获取搜索内容中的关键词。例如:文章 intitle:山海经,intitle:特种部队。注意 intitle: 和后面的 关键词 之间不能有空格。
站点将搜索限制在特定站点
要在特定站点中查找内容,可以使用此语法将搜索范围限制在该站点,从而提高查询效率。使用方法是在查询内容后面加上“site:站点域名”。例如:helloword 网站:。这样,搜索引擎就会从相应的站点中找到相关的内容。请注意,“site:”后面的站点域名不应包括在内,或另外,site: 和站点名称之间不应有空格。
inurl 将搜索范围限制为 url 链接
网页url中的一些信息往往具有一些有价值的意义。如果对搜索结果的 URL 进行了某种限制,可以获得很好的搜索效果。(互联网上可用的资源可以用简单的字符串来表示:“统一资源定位符”(URLs)。一个 URL 由一串字符组成,可以是字母、数字和特殊符号。有关详细信息,您可以查找自己)。inurl 参数可用于限制搜索结果中的 url。用法就是这样,就是使用"inurl:"后跟需要出现在url中的关键词。例如:ps inurl:jiqiao。“ps”可以出现在网页的任何位置,而“jiqiao”必须出现在网页的url中。注意 inurl: 语法和它后面的 关键词 没有空格。
““, ““ 完全符合
如果输入的查询词很长,百度分析后可能会巧妙的将你的搜索词拆分成多个部分,给定搜索结果中的查询词也可能会被拆分。如果想避免这种情况,可以尽量让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。例如:搜索内蒙古师范大学,如果不加双引号,搜索结果可能会拆分成内蒙古、师范、大学等,效果不是很好,但是加双引号后, 《内蒙古师范大学》,百度不会为你智能拆分搜索。而且加双引号搜索后,你会发现很多广告自然会被屏蔽,搜索不到。可以有效减少百度搜索后的广告泛滥问题。书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。书名号查询词有两个特殊功能。一是书名号会出现在搜索结果中;另一个是书名号展开的内容不会被拆分。书名在某些情况下特别有用,例如查找具有流行和常用名称的电影或小说。比如看电影《特种兵》,如果不加书名,很多时候会介绍兵种之类的,但是加了书名后,结果的 ”
- 减号
要求搜索结果不收录特定的查询词。如果搜索结果中有某类网页要屏蔽,可以找到这些网页的具体关键词,用减号语法基本屏蔽所有收录特定<关键词的页。例如:新警察故事,我想找这部片子,但是搜索结果发现有很多类似的游戏,那么可以写成新警察故事-游戏,这样新警察故事的游戏页面就会被屏蔽. 注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,失去减号的语法功能。减号和下一个 关键词 之间没有空格。
+ 加号
收录特定查询词 查询词使用加号 + 语法来收录搜索结果中必须收录特定 关键词 的所有页面。例如:电影+新警察故事搜索结果中的查询词“电影”,搜索结果中需要收录“新警察故事”。
文件类型
搜索范围仅限于指定的文档格式。可以使用 Filetype 语法将查询词限制为出现在指定的文档中。支持的文档格式包括pdf、doc、xls、ppt、rtf等。对查找文档很有帮助。例如:Excel 使用技能 filetype:doc 以便您可以找到 doc 格式的相关文档。
注意!注意!注意!
- 如果您不记得上面描述的方法,或者不知道如何使用它怎么办?百度提供了一种更简单的方法来处理这个问题。百度的高级搜索操作更简单。点我搜索。 查看全部
百度搜索指定网站内容(如何让百度搜索引擎更高效更简洁?常用搜索语法)
百度常用搜索语法
百度是我们常用的搜索引擎,但是每次我们搜索的东西,都不尽如人意。很多时候,我们找不到自己想要的东西,一堆广告,一堆乱七八糟的东西。这对谷歌搜索引擎来说处理起来很方便,但是在中国使用谷歌搜索引擎并不是那么随意,还需要掌握科学的上网方法。所以很多朋友还是要用百度。有什么办法可以让百度搜索引擎更加高效简洁?答案是肯定的。百度还提供了类似谷歌的搜索语法,让搜索更加简洁、高效、准确。这里简单介绍一些常见的搜索语法。
intitle 将搜索限制为页面标题
网页的标题通常是网页内容大纲的高级摘要。将查询的内容限制在页面的标题上,有时可以取得不错的效果。语法规则是使用“intitle:”来获取搜索内容中的关键词。例如:文章 intitle:山海经,intitle:特种部队。注意 intitle: 和后面的 关键词 之间不能有空格。
站点将搜索限制在特定站点
要在特定站点中查找内容,可以使用此语法将搜索范围限制在该站点,从而提高查询效率。使用方法是在查询内容后面加上“site:站点域名”。例如:helloword 网站:。这样,搜索引擎就会从相应的站点中找到相关的内容。请注意,“site:”后面的站点域名不应包括在内,或另外,site: 和站点名称之间不应有空格。
inurl 将搜索范围限制为 url 链接
网页url中的一些信息往往具有一些有价值的意义。如果对搜索结果的 URL 进行了某种限制,可以获得很好的搜索效果。(互联网上可用的资源可以用简单的字符串来表示:“统一资源定位符”(URLs)。一个 URL 由一串字符组成,可以是字母、数字和特殊符号。有关详细信息,您可以查找自己)。inurl 参数可用于限制搜索结果中的 url。用法就是这样,就是使用"inurl:"后跟需要出现在url中的关键词。例如:ps inurl:jiqiao。“ps”可以出现在网页的任何位置,而“jiqiao”必须出现在网页的url中。注意 inurl: 语法和它后面的 关键词 没有空格。
““, ““ 完全符合
如果输入的查询词很长,百度分析后可能会巧妙的将你的搜索词拆分成多个部分,给定搜索结果中的查询词也可能会被拆分。如果想避免这种情况,可以尽量让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。例如:搜索内蒙古师范大学,如果不加双引号,搜索结果可能会拆分成内蒙古、师范、大学等,效果不是很好,但是加双引号后, 《内蒙古师范大学》,百度不会为你智能拆分搜索。而且加双引号搜索后,你会发现很多广告自然会被屏蔽,搜索不到。可以有效减少百度搜索后的广告泛滥问题。书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。书名号查询词有两个特殊功能。一是书名号会出现在搜索结果中;另一个是书名号展开的内容不会被拆分。书名在某些情况下特别有用,例如查找具有流行和常用名称的电影或小说。比如看电影《特种兵》,如果不加书名,很多时候会介绍兵种之类的,但是加了书名后,结果的 ”
- 减号
要求搜索结果不收录特定的查询词。如果搜索结果中有某类网页要屏蔽,可以找到这些网页的具体关键词,用减号语法基本屏蔽所有收录特定<关键词的页。例如:新警察故事,我想找这部片子,但是搜索结果发现有很多类似的游戏,那么可以写成新警察故事-游戏,这样新警察故事的游戏页面就会被屏蔽. 注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,失去减号的语法功能。减号和下一个 关键词 之间没有空格。
+ 加号
收录特定查询词 查询词使用加号 + 语法来收录搜索结果中必须收录特定 关键词 的所有页面。例如:电影+新警察故事搜索结果中的查询词“电影”,搜索结果中需要收录“新警察故事”。
文件类型
搜索范围仅限于指定的文档格式。可以使用 Filetype 语法将查询词限制为出现在指定的文档中。支持的文档格式包括pdf、doc、xls、ppt、rtf等。对查找文档很有帮助。例如:Excel 使用技能 filetype:doc 以便您可以找到 doc 格式的相关文档。
注意!注意!注意!
- 如果您不记得上面描述的方法,或者不知道如何使用它怎么办?百度提供了一种更简单的方法来处理这个问题。百度的高级搜索操作更简单。点我搜索。
百度搜索指定网站内容(把搜索范围限定在url链接中——inurl网页标题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2022-02-20 19:08
将搜索范围限制为 url 链接 - inurl
网页url中的一些信息往往具有一些有价值的意义。因此,如果您对搜索结果的 url 进行某种限制,您可以获得良好的结果。实现这一点的方法是使用“inurl:”,后跟需要出现在 url 中的 关键词。
比如要查找photoshop的使用技巧,可以这样查询:photoshop inurl:jiqiao
上面查询字符串中的“photoshop”可以出现在网页的任何位置,而“jiqiao”必须出现在网页的url中。
注意 inurl: 语法和它后面的 关键词 没有空格。
将您的搜索限制在页面标题 - intitle
网页的标题通常是对网页内容的概括概括。将查询的内容限制在页面的标题上,有时可以取得不错的效果。使用方法是使用“intitle:”来获取查询内容中最关键的部分。
比如要查找林青霞的照片,可以这样查询: 照片标题:林青霞
注意 intitle: 和后面的 关键词 之间不能有空格。
将您的搜索限制在特定站点 - 站点
有时,如果您知道在某个站点上需要查找某些内容,则可以将搜索范围限制在该站点上,以提高查询效率。使用方法是在查询内容后面加上“site:站点域名”。
比如天网下载软件不错,可以这样查询:msn站点:
注意站点域名后跟“site:”不能收录“”;此外,site: 和站点名称之间不应有空格。
完全匹配 - 双引号和书名编号
如果输入的查询词很长,百度分析后给出的搜索结果中的查询词可能会被拆分。如果对这种情况不满意,可以尝试让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“上海大学科技”,取得的成果均符合要求。
书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。书名号查询词有两个特殊功能。一是书名号会出现在搜索结果中;另一个是书名号展开的内容不会被拆分。书名在某些情况下特别有用,例如查找具有流行和常用名称的电影或小说。比如你查一部电影的“手机”,如果不加书名,很多时候是通讯工具——手机,加上书名后,结果“手机”的一切都是关于电影的。
要求不收录在搜索结果中的特定查询词
如果您在搜索结果中发现某些类型的页面是您不想看到的,并且这些页面收录特定的 关键词,则使用减号语法将删除所有那些收录特定 < @关键词 > 网页。
比如我搜索《神雕侠侣》,希望是武侠小说的,结果找到了很多关于电视剧的网页。然后可以这样查询:神雕侠侣-电视剧
注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,减号语法功能会丢失。减号和下一个 关键词 之间没有空格。 查看全部
百度搜索指定网站内容(把搜索范围限定在url链接中——inurl网页标题)
将搜索范围限制为 url 链接 - inurl
网页url中的一些信息往往具有一些有价值的意义。因此,如果您对搜索结果的 url 进行某种限制,您可以获得良好的结果。实现这一点的方法是使用“inurl:”,后跟需要出现在 url 中的 关键词。
比如要查找photoshop的使用技巧,可以这样查询:photoshop inurl:jiqiao
上面查询字符串中的“photoshop”可以出现在网页的任何位置,而“jiqiao”必须出现在网页的url中。
注意 inurl: 语法和它后面的 关键词 没有空格。
将您的搜索限制在页面标题 - intitle
网页的标题通常是对网页内容的概括概括。将查询的内容限制在页面的标题上,有时可以取得不错的效果。使用方法是使用“intitle:”来获取查询内容中最关键的部分。
比如要查找林青霞的照片,可以这样查询: 照片标题:林青霞
注意 intitle: 和后面的 关键词 之间不能有空格。
将您的搜索限制在特定站点 - 站点
有时,如果您知道在某个站点上需要查找某些内容,则可以将搜索范围限制在该站点上,以提高查询效率。使用方法是在查询内容后面加上“site:站点域名”。
比如天网下载软件不错,可以这样查询:msn站点:
注意站点域名后跟“site:”不能收录“”;此外,site: 和站点名称之间不应有空格。
完全匹配 - 双引号和书名编号
如果输入的查询词很长,百度分析后给出的搜索结果中的查询词可能会被拆分。如果对这种情况不满意,可以尝试让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“上海大学科技”,取得的成果均符合要求。
书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。书名号查询词有两个特殊功能。一是书名号会出现在搜索结果中;另一个是书名号展开的内容不会被拆分。书名在某些情况下特别有用,例如查找具有流行和常用名称的电影或小说。比如你查一部电影的“手机”,如果不加书名,很多时候是通讯工具——手机,加上书名后,结果“手机”的一切都是关于电影的。
要求不收录在搜索结果中的特定查询词
如果您在搜索结果中发现某些类型的页面是您不想看到的,并且这些页面收录特定的 关键词,则使用减号语法将删除所有那些收录特定 < @关键词 > 网页。
比如我搜索《神雕侠侣》,希望是武侠小说的,结果找到了很多关于电视剧的网页。然后可以这样查询:神雕侠侣-电视剧
注意前面的关键词和减号之间必须有空格,否则减号会被当作连字符,减号语法功能会丢失。减号和下一个 关键词 之间没有空格。
百度搜索指定网站内容( 百度改变的快照算法,不从远端服务器获取JavaScript文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-18 17:19
百度改变的快照算法,不从远端服务器获取JavaScript文件)
有时,由于内容变更或隐私问题,我们经常不希望他人通过“百度快照”的方式查看我们网站的某些页面。对于网站管理员,百度快照也被引流。有很多属于 网站 的流量。为了增加网站的流量或者增强内容隐私,我之前提供了一种将百度快照重定向到自己的方法网站。但是百度后来改的快照算法并没有从远程服务器获取JavaScript文件,所以之前介绍的屏蔽方法现在已经失效了。
现在我介绍一个新方法,原理基本一样,我们知道百度网页快照虽然没有从远程服务器抓取JavaScript文件,但仍然是从远程服务器抓取CSS文件。实现网页重定向,从而控制百度快照中的网页,我们完全控制快照重定向到我们制作的任何网页地址。
比如百度快照缓存的文件是style.css,那么我们在服务器上编辑这个文件,在CSS文件中添加如下语句来控制百度缓存快照的重定向,从而实现屏蔽百度的功能网页快照内容。
正文 {onload:expression(location.href='');}
以上语句在IE浏览器下测试通过。理论上,按照这种方法,我们可以控制百度网页快照的内容重定向到我们指定的任意一个URL,甚至是第三方网站。为了实现网页的正常显示,百度快照屏蔽CSS的可能性会很小。
此方法还可用于阻止来自其他搜索引擎(如 Google)的页面快照。
() () 查看全部
百度搜索指定网站内容(
百度改变的快照算法,不从远端服务器获取JavaScript文件)
有时,由于内容变更或隐私问题,我们经常不希望他人通过“百度快照”的方式查看我们网站的某些页面。对于网站管理员,百度快照也被引流。有很多属于 网站 的流量。为了增加网站的流量或者增强内容隐私,我之前提供了一种将百度快照重定向到自己的方法网站。但是百度后来改的快照算法并没有从远程服务器获取JavaScript文件,所以之前介绍的屏蔽方法现在已经失效了。
现在我介绍一个新方法,原理基本一样,我们知道百度网页快照虽然没有从远程服务器抓取JavaScript文件,但仍然是从远程服务器抓取CSS文件。实现网页重定向,从而控制百度快照中的网页,我们完全控制快照重定向到我们制作的任何网页地址。
比如百度快照缓存的文件是style.css,那么我们在服务器上编辑这个文件,在CSS文件中添加如下语句来控制百度缓存快照的重定向,从而实现屏蔽百度的功能网页快照内容。
正文 {onload:expression(location.href='');}
以上语句在IE浏览器下测试通过。理论上,按照这种方法,我们可以控制百度网页快照的内容重定向到我们指定的任意一个URL,甚至是第三方网站。为了实现网页的正常显示,百度快照屏蔽CSS的可能性会很小。
此方法还可用于阻止来自其他搜索引擎(如 Google)的页面快照。
() ()
百度搜索指定网站内容(这些出色的提示和技巧专业人士一样一样使用Google)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-18 05:20
通过这些出色的提示和技巧,像专业人士一样使用 Google。
当我们需要找到我们想要的东西(网站、电影、应用程序......任何东西)时,我们通常会使用 Google 搜索。此外,它还提供了一些隐藏功能。
计时器和秒表
比如说,你需要为准备好的演讲测量时间,或者你需要从专注的工作中休息 5 分钟。只是谷歌秒表或计时器
这两种工具都提供全屏模式,如果您将投影仪屏幕用于观众,这将非常有用。
颜色选择器
只需使用谷歌颜色选择器或复制粘贴十六进制颜色代码(例如:-#0f9bff)即可获得颜色选择器工具,键入 rgb 50 50 80 之类的查询将执行相同的操作。
仅完全匹配
当您输入一组词为 关键词 时,Google 的搜索算法会以一种巧妙的方式进行匹配,从而首先为您提供更多相关信息。但在某些情况下,我们只需要找到与文本完全匹配的内容,而不是让 Google 应用自己的匹配逻辑,这可以通过将搜索条件用双引号括起来轻松完成。
适用于百度等从搜索中排除单词
显然,当你使用一组关键词时,谷歌会给你所有匹配的内容。但是,如果您不需要某些收录已知单词的结果,则可以从收录该已知单词的预期结果中排除这些结果。下面的示例将显示收录 Mercedes 但不收录已知单词 Benz 的结果。
适用于百度等,只在指定域内搜索
一般搜索查询将能够从 Google 的许多域中获取文档。如果需要,您可以搜索一个只提供属于特定域名的结果的特殊查询。只需添加 site: 在您的搜索条件前面。例如:site:.gov covid-19
适用于百度等单位换算工具
您不需要单独的应用程序来转换标准单位,Google 会帮助您。只需输入您要转换的内容,例如“6 英寸到厘米”或“单位转换”,然后输入值。
适用于百度等
货币转换
这与单位转换工具非常相似,搜索查询的格式相同。例如:“5 美元到 lkr”,或者在大多数情况下“5 美元”就足够了,因为 Google 知道您的位置。
适用于百度等
我的 IP 地址是多少
有人问你的IP地址加入白名单?只需谷歌“我的 ip 是什么”或“我的 ip”。
世界时钟
与居住在不同时区的人一起工作?好吧,如果他们很快问“我们可以在下午 5 点开会吗?”。如果您使用“日本时间下午 5 点”之类的查询进行搜索,Google 也会为您提供帮助,如下图所示。
在社交媒体上找人
如果你需要在社交媒体上找到你的一个朋友,首先你需要去社交媒体平台,然后你可以搜索。事实上,在谷歌的帮助下,有一种更快的方法。只需在您朋友的用户名和 Google 前面使用 @ 字符即可。
对于百度
我好奇
如果您搜索“我很好奇”,将会有令人惊讶的问题和答案。此外,如果您按下展开图标,将会有很多有趣的游戏和其他有用的工具。
原文:/swhlh/10-hidden-features-in-google-search-83b347b48157 查看全部
百度搜索指定网站内容(这些出色的提示和技巧专业人士一样一样使用Google)
通过这些出色的提示和技巧,像专业人士一样使用 Google。
当我们需要找到我们想要的东西(网站、电影、应用程序......任何东西)时,我们通常会使用 Google 搜索。此外,它还提供了一些隐藏功能。
计时器和秒表
比如说,你需要为准备好的演讲测量时间,或者你需要从专注的工作中休息 5 分钟。只是谷歌秒表或计时器
这两种工具都提供全屏模式,如果您将投影仪屏幕用于观众,这将非常有用。
颜色选择器
只需使用谷歌颜色选择器或复制粘贴十六进制颜色代码(例如:-#0f9bff)即可获得颜色选择器工具,键入 rgb 50 50 80 之类的查询将执行相同的操作。
仅完全匹配
当您输入一组词为 关键词 时,Google 的搜索算法会以一种巧妙的方式进行匹配,从而首先为您提供更多相关信息。但在某些情况下,我们只需要找到与文本完全匹配的内容,而不是让 Google 应用自己的匹配逻辑,这可以通过将搜索条件用双引号括起来轻松完成。
适用于百度等从搜索中排除单词
显然,当你使用一组关键词时,谷歌会给你所有匹配的内容。但是,如果您不需要某些收录已知单词的结果,则可以从收录该已知单词的预期结果中排除这些结果。下面的示例将显示收录 Mercedes 但不收录已知单词 Benz 的结果。
适用于百度等,只在指定域内搜索
一般搜索查询将能够从 Google 的许多域中获取文档。如果需要,您可以搜索一个只提供属于特定域名的结果的特殊查询。只需添加 site: 在您的搜索条件前面。例如:site:.gov covid-19
适用于百度等单位换算工具
您不需要单独的应用程序来转换标准单位,Google 会帮助您。只需输入您要转换的内容,例如“6 英寸到厘米”或“单位转换”,然后输入值。
适用于百度等
货币转换
这与单位转换工具非常相似,搜索查询的格式相同。例如:“5 美元到 lkr”,或者在大多数情况下“5 美元”就足够了,因为 Google 知道您的位置。
适用于百度等
我的 IP 地址是多少
有人问你的IP地址加入白名单?只需谷歌“我的 ip 是什么”或“我的 ip”。
世界时钟
与居住在不同时区的人一起工作?好吧,如果他们很快问“我们可以在下午 5 点开会吗?”。如果您使用“日本时间下午 5 点”之类的查询进行搜索,Google 也会为您提供帮助,如下图所示。
在社交媒体上找人
如果你需要在社交媒体上找到你的一个朋友,首先你需要去社交媒体平台,然后你可以搜索。事实上,在谷歌的帮助下,有一种更快的方法。只需在您朋友的用户名和 Google 前面使用 @ 字符即可。
对于百度
我好奇
如果您搜索“我很好奇”,将会有令人惊讶的问题和答案。此外,如果您按下展开图标,将会有很多有趣的游戏和其他有用的工具。
原文:/swhlh/10-hidden-features-in-google-search-83b347b48157
百度搜索指定网站内容(交流学习java大数据可以加群460570824.)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-02-18 05:20
阅读这篇文章大约需要 5 分钟。建议采集后阅读。里面装满了干货。你可以自己测试一下。如果觉得好用,可以帮忙点赞转发,谢谢!交流学习java大数据可加群460570824.
无论是计算机专业还是非计算机专业人士,掌握一些常用的搜索技巧,对我们的学习和工作都是非常有益的。这篇文章文章主要针对google的一些常用技巧,百度因为很少用到所以没有具体测试。
搜索百度云盘信息
可以在搜索关键字后添加站点:百度云盘网址
前任:
在搜索框中输入python核心编程站点:
我们可以在百度云盘中找到我们想要的资源
使用 inurl
inurl:指令用于搜索出现在网页url中的查询关键字。inurl 也支持中文。
前任:
在搜索框中搜索关键字:inutl:python
使用文本
intext:就是显示文章的内容中所有带有关键字的结果
前任:
在搜索框中搜索关键词:intext:software engineering
检查天气
如果您想快速了解某个城市的天气,而无需使用应用程序获取它,您可以尝试天气。
前任:
搜索框搜索关键词:天气+武汉
查询作者所有作品
前任:
在搜索框中搜索关键词:莫言的书
用站点指定 网站
site:我们可以在我们指定的URL中定位到我们搜索的内容,搜索到的内容不会是其他网站中的内容。
关键字网站:用户指定的网址
前任:
在搜索框中搜索关键字:python 高级站点:
我们发现所有搜索都来自 知乎。请注意,站点后的冒号是英文字符。此外,冒号后面不能有空格,否则 site: 将被视为关键字。
下载软件
我们在下载软件的时候,如果要在软件厂商的官网下载,一般都是直接到下载目录下载。
所以我们可以直接在url中搜索下载。
前任:
我们要下载 atom 编辑器,可以使用 atom inurl:download 进行搜索。
使用双引号“”
在搜索构建期间,使用双引号表示完全匹配
* 模糊匹配
当我们想搜索一个关键词,但是我们记住了前后几个词,而中间的某个词又忘记了怎么办,就用它来进行模糊匹配。
搜索指定的文件类型
如果要搜索 PDF 的 文章,可以在搜索时指定文件类型。
前任:
在搜索框中搜索关键字:计算机文件类型:pdf
使用标题
使用 intitle 将搜索限制为收录指定关键字的标题。
前任:
在搜索框中搜索关键词:intitle:big data
使用 allintitle
这和上面的intitle很相似,但是这个在标题中有用户定义的关键字
前任:
在搜索框中搜索关键词:allintitle:大数据云计算
掌握一定的搜索技巧,可以让我们在网络世界中更快地获得我们想要的资源。关于搜索技巧,还是需要在平时使用搜索工具的过程中总结。
查看全部
百度搜索指定网站内容(交流学习java大数据可以加群460570824.)
阅读这篇文章大约需要 5 分钟。建议采集后阅读。里面装满了干货。你可以自己测试一下。如果觉得好用,可以帮忙点赞转发,谢谢!交流学习java大数据可加群460570824.
无论是计算机专业还是非计算机专业人士,掌握一些常用的搜索技巧,对我们的学习和工作都是非常有益的。这篇文章文章主要针对google的一些常用技巧,百度因为很少用到所以没有具体测试。
搜索百度云盘信息
可以在搜索关键字后添加站点:百度云盘网址
前任:
在搜索框中输入python核心编程站点:
我们可以在百度云盘中找到我们想要的资源
使用 inurl
inurl:指令用于搜索出现在网页url中的查询关键字。inurl 也支持中文。
前任:
在搜索框中搜索关键字:inutl:python
使用文本
intext:就是显示文章的内容中所有带有关键字的结果
前任:
在搜索框中搜索关键词:intext:software engineering
检查天气
如果您想快速了解某个城市的天气,而无需使用应用程序获取它,您可以尝试天气。
前任:
搜索框搜索关键词:天气+武汉
查询作者所有作品
前任:
在搜索框中搜索关键词:莫言的书
用站点指定 网站
site:我们可以在我们指定的URL中定位到我们搜索的内容,搜索到的内容不会是其他网站中的内容。
关键字网站:用户指定的网址
前任:
在搜索框中搜索关键字:python 高级站点:
我们发现所有搜索都来自 知乎。请注意,站点后的冒号是英文字符。此外,冒号后面不能有空格,否则 site: 将被视为关键字。
下载软件
我们在下载软件的时候,如果要在软件厂商的官网下载,一般都是直接到下载目录下载。
所以我们可以直接在url中搜索下载。
前任:
我们要下载 atom 编辑器,可以使用 atom inurl:download 进行搜索。
使用双引号“”
在搜索构建期间,使用双引号表示完全匹配
* 模糊匹配
当我们想搜索一个关键词,但是我们记住了前后几个词,而中间的某个词又忘记了怎么办,就用它来进行模糊匹配。
搜索指定的文件类型
如果要搜索 PDF 的 文章,可以在搜索时指定文件类型。
前任:
在搜索框中搜索关键字:计算机文件类型:pdf
使用标题
使用 intitle 将搜索限制为收录指定关键字的标题。
前任:
在搜索框中搜索关键词:intitle:big data
使用 allintitle
这和上面的intitle很相似,但是这个在标题中有用户定义的关键字
前任:
在搜索框中搜索关键词:allintitle:大数据云计算
掌握一定的搜索技巧,可以让我们在网络世界中更快地获得我们想要的资源。关于搜索技巧,还是需要在平时使用搜索工具的过程中总结。
百度搜索指定网站内容(百度搜索技巧intitle——把搜索范围限定在网页标题中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-02-18 05:17
百度搜索技巧
intitle - 将搜索限制在页面标题
用法:intitle:查询内容
比如百度输入:关键词 intitle:oschina
inurl - 将搜索范围限制为 url 链接
用法:inurl:具体的url
比如百度输入:关键词 inurl:
站点 - 将搜索限制在特定站点
如何使用:网站:网址
例如百度输入:关键词 站点:
完全匹配、加号和减号、通配符
完全匹配:可以使用双引号和书名号
在要查询的关键词后面加上双引号(半角,下面要加的其他符号同理),实现精确查询。这种方法要求查询结果必须完全匹配,不包括进化形式。例如,在搜索引擎的文本框中键入“电话”将返回带有关键字“电话”的 URL,但不会返回诸如“电话传真”之类的页面。
加号:在关键词前面使用加号,相当于告诉搜索引擎该词必须出现在搜索结果中的网页上。例如在搜索引擎中输入“+电脑+电话+传真”表示要查找的内容必须同时收录“电脑、电话、传真”三个关键词
减号:在关键词前面使用减号,表示关键词不能出现在查询结果中。例如,在搜索引擎中输入“电视台-XX电视台”,表示查询结果中最后不能收录“XX电视台”。
通配符包括星号 (*) 和问号 (?)。前者意味着匹配的数量是无限的,而后者意味着要匹配的字符数量是有限的。它主要用于英文搜索引擎。例如,如果输入“computer*”,则可以找到“computer,computerised,computerized”等词,如果输入“comp?ter”,则只能找到“computer,computer,competitor”等词”。
比如百度输入:“美人鱼”
文件类型 - 专业的文档搜索
用法:文件类型:文档格式
比如百度输入:关键词 filetype:doc
搜索后,您可以使用搜索工具来细化搜索结果
谷歌搜索提示
SEO : 是一种通过了解搜索引擎并提高目的在搜索引擎中排名的方法网站。
案例 1. 搜索“patchwork”的结果
我要搜索“android 网络位置”,直接输入关键字,会发现有些搜索结果是“patchwork”,而不是“android 网络位置”的顺序。
“拼布”的搜索结果
解决方案 1. 使用 "" 进行精确匹配
使用方法:“关键字”,通过给关键字加上双引号,得到的搜索结果完全按照关键字的顺序排列。
案例 2. 不想搜索 关键词
手机定位方式有几种:GPS定位、网络定位和基站定位。我想了解与网络定位相关的原理。搜索“android网络定位”时,不希望出现GPS这个关键字。如上例,如果直接输入关键字,搜索结果将收录 GPS 相关信息。
不想搜索 关键词
解决方案 2. 使用-排除关键字
如何使用:关键字 - 排除关键字,提示: - 后面没有空格。搜索结果中没有 GPS 关键字。
案例 3. 不记得完整的 关键词
陈奕迅有一首歌歌词不完整,忘记歌名了。我只记得几句话。我应该如何搜索?
不记得完整的 关键词
解决方案 3. 使用 * 进行模糊匹配
使用方法:关键字*关键字
case 4. 只想找某一个网站
直接输入关键字,会有很多结果,但我只想在某个网站上搜索。
只想在某个网站上找到
解决方案 4. 使用站点指定网站
使用方法:关键词网站:URL
案例 5. 只想搜索 PDF 类型的文件
文档类型很多,比如doc、pdf、epub,我只想搜索文件类型为PDF的文档
只想搜索 PDF 类型的文件
解决方法 5. 使用filetype指定文件类型
使用方法:关键字filetype:文件类型
使用 filetype 指定文件类型
提示:关于文件类型
只有 Google 支持的文件类型可用。尝试搜索 .epub 文件时,它会提示“您的搜索 - Android 软件安全和反向分析文件类型:epub - 没有匹配任何文档。”
您的搜索 - *Android 软件安全和反向分析文件类型:epub* - 没有匹配任何文档。
谷歌支持的文件类型可以在Search Console Help上找到,显示不支持epub
Google 可索引的文件类型
当遇到不支持的文件类型时,我们可以通过精确匹配方法搜索
关键词
如何
最常用的方法,在google中搜索“how to”+关键词,可以找到很多相关的文章。
惊人的
可以在github或者google搜索“awesome”+关键词,很多好的项目,文章都是以它命名的。 查看全部
百度搜索指定网站内容(百度搜索技巧intitle——把搜索范围限定在网页标题中)
百度搜索技巧
intitle - 将搜索限制在页面标题
用法:intitle:查询内容
比如百度输入:关键词 intitle:oschina
inurl - 将搜索范围限制为 url 链接
用法:inurl:具体的url
比如百度输入:关键词 inurl:
站点 - 将搜索限制在特定站点
如何使用:网站:网址
例如百度输入:关键词 站点:
完全匹配、加号和减号、通配符
完全匹配:可以使用双引号和书名号
在要查询的关键词后面加上双引号(半角,下面要加的其他符号同理),实现精确查询。这种方法要求查询结果必须完全匹配,不包括进化形式。例如,在搜索引擎的文本框中键入“电话”将返回带有关键字“电话”的 URL,但不会返回诸如“电话传真”之类的页面。
加号:在关键词前面使用加号,相当于告诉搜索引擎该词必须出现在搜索结果中的网页上。例如在搜索引擎中输入“+电脑+电话+传真”表示要查找的内容必须同时收录“电脑、电话、传真”三个关键词
减号:在关键词前面使用减号,表示关键词不能出现在查询结果中。例如,在搜索引擎中输入“电视台-XX电视台”,表示查询结果中最后不能收录“XX电视台”。
通配符包括星号 (*) 和问号 (?)。前者意味着匹配的数量是无限的,而后者意味着要匹配的字符数量是有限的。它主要用于英文搜索引擎。例如,如果输入“computer*”,则可以找到“computer,computerised,computerized”等词,如果输入“comp?ter”,则只能找到“computer,computer,competitor”等词”。
比如百度输入:“美人鱼”
文件类型 - 专业的文档搜索
用法:文件类型:文档格式
比如百度输入:关键词 filetype:doc
搜索后,您可以使用搜索工具来细化搜索结果
谷歌搜索提示
SEO : 是一种通过了解搜索引擎并提高目的在搜索引擎中排名的方法网站。
案例 1. 搜索“patchwork”的结果
我要搜索“android 网络位置”,直接输入关键字,会发现有些搜索结果是“patchwork”,而不是“android 网络位置”的顺序。
“拼布”的搜索结果
解决方案 1. 使用 "" 进行精确匹配
使用方法:“关键字”,通过给关键字加上双引号,得到的搜索结果完全按照关键字的顺序排列。
案例 2. 不想搜索 关键词
手机定位方式有几种:GPS定位、网络定位和基站定位。我想了解与网络定位相关的原理。搜索“android网络定位”时,不希望出现GPS这个关键字。如上例,如果直接输入关键字,搜索结果将收录 GPS 相关信息。
不想搜索 关键词
解决方案 2. 使用-排除关键字
如何使用:关键字 - 排除关键字,提示: - 后面没有空格。搜索结果中没有 GPS 关键字。
案例 3. 不记得完整的 关键词
陈奕迅有一首歌歌词不完整,忘记歌名了。我只记得几句话。我应该如何搜索?
不记得完整的 关键词
解决方案 3. 使用 * 进行模糊匹配
使用方法:关键字*关键字
case 4. 只想找某一个网站
直接输入关键字,会有很多结果,但我只想在某个网站上搜索。
只想在某个网站上找到
解决方案 4. 使用站点指定网站
使用方法:关键词网站:URL
案例 5. 只想搜索 PDF 类型的文件
文档类型很多,比如doc、pdf、epub,我只想搜索文件类型为PDF的文档
只想搜索 PDF 类型的文件
解决方法 5. 使用filetype指定文件类型
使用方法:关键字filetype:文件类型
使用 filetype 指定文件类型
提示:关于文件类型
只有 Google 支持的文件类型可用。尝试搜索 .epub 文件时,它会提示“您的搜索 - Android 软件安全和反向分析文件类型:epub - 没有匹配任何文档。”
您的搜索 - *Android 软件安全和反向分析文件类型:epub* - 没有匹配任何文档。
谷歌支持的文件类型可以在Search Console Help上找到,显示不支持epub
Google 可索引的文件类型
当遇到不支持的文件类型时,我们可以通过精确匹配方法搜索
关键词
如何
最常用的方法,在google中搜索“how to”+关键词,可以找到很多相关的文章。
惊人的
可以在github或者google搜索“awesome”+关键词,很多好的项目,文章都是以它命名的。
百度搜索指定网站内容(网站优化以下内容优化的方法有哪些?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-18 02:07
想要做好优化,其实还是要花点心思的。从做网站开始,不要做那种纯图片的模板网站。还是可以使用织梦帝王仿制网站的。网站搭建完成后,备案等资料,以及服务器,最好用阿里云和腾讯云。外面有很多托管公司,上面放了很多海外BC网络,很容易被锁在一个小k屋里,所以这个网站基本上是GG。
一般正常网站优化以下内容。
修改tdk:title:收录所有核心推荐关键词
1、404页面需要有返回首页的链接,提高搜索引擎友好度和用户体验。
2、请将内页标题改为:列标题-网站名称格式,不要直接调用网站首页标题。
3、接下来做301定向跳转,不带www的定向跳转到带www的域名,避免权重分散。
4、请把网站地图制作成sitemap.html和sitemap.xml两种格式,这样有助于百度蜘蛛抓取,提高搜索友好度。
爬虫只能根据你指定的url爬取网页的代码。至于你想要收录指定内容的网页,只能先爬取网页,然后匹配页面的内容(正规的,也有开源工具),找到你想要的就是你想要的!爬虫无法根据关键字抓取网页!如果你期望网站可以根据百度搜索引擎获得自然检索的总流量。百度搜索引擎的原理很复杂,但简单来说它包括以下三个层次:检索、排列和呈现。其实不难理解,如果要在百度搜索引擎上搜索到想要的信息内容,那么这个信息内容首先要经过百度搜索引擎的识别。
1.保证网站信息的内容可以被网络爬虫识别
现阶段,百度搜索引擎无法识别照片和flash中放置的文字信息内容。尤其是百度,现阶段无法很好识别javascript中的文字信息内容和连接。
建议在创建 网站 时牢记以下几点:
(1)应用文本而非 Flash、照片、javascript 等来显示信息关键内容或链接
(2)在允许的标准下,尽量不要使用flash网页元素。如果无法防止,请为flash内容创建一个保留网页的文本版本。
(3)防止关键网页信息内容进入iframe结构,百度搜索引擎不会轻易抓取结构中的内容。
2.创建良好的 URL 结构
为了对网站内容进行清理和恢复,规定网站必须做好分类。不仅方便用户预览网址,掌握网址结构,快速找到整体目标内容;另一方面,帮助百度搜索引擎更好地把握网址的结构。
URL一般是扁平的,通常分为以下几个层次:首页-频道页-内容页。应尽可能避免 URL 的理想化层次结构。最好选择扁平结构,减少从首页到内容页的浏览文件目录。
请注意以下几点:
(1)为每类网页添加导航,百度搜索引擎会根据导航中的层次结构掌握该网页的位置。
(2)确保网页上的每个网页始终至少有 1 个可访问的链接。
(3)有效机构分类URL中的内容,但防止分类过于精细。
(4)网页的引导倾向于防止复杂js或flash的应用,防止百度搜索引擎无法抓取。
(5)在使用图片链接时,请使用ALT功能进行标示,帮助百度搜索引擎了解页面的主体是什么。
SEO公司_网站优化百度关键词排名_新站快速排名技术-外推 查看全部
百度搜索指定网站内容(网站优化以下内容优化的方法有哪些?-八维教育)
想要做好优化,其实还是要花点心思的。从做网站开始,不要做那种纯图片的模板网站。还是可以使用织梦帝王仿制网站的。网站搭建完成后,备案等资料,以及服务器,最好用阿里云和腾讯云。外面有很多托管公司,上面放了很多海外BC网络,很容易被锁在一个小k屋里,所以这个网站基本上是GG。
一般正常网站优化以下内容。
修改tdk:title:收录所有核心推荐关键词
1、404页面需要有返回首页的链接,提高搜索引擎友好度和用户体验。
2、请将内页标题改为:列标题-网站名称格式,不要直接调用网站首页标题。
3、接下来做301定向跳转,不带www的定向跳转到带www的域名,避免权重分散。
4、请把网站地图制作成sitemap.html和sitemap.xml两种格式,这样有助于百度蜘蛛抓取,提高搜索友好度。
爬虫只能根据你指定的url爬取网页的代码。至于你想要收录指定内容的网页,只能先爬取网页,然后匹配页面的内容(正规的,也有开源工具),找到你想要的就是你想要的!爬虫无法根据关键字抓取网页!如果你期望网站可以根据百度搜索引擎获得自然检索的总流量。百度搜索引擎的原理很复杂,但简单来说它包括以下三个层次:检索、排列和呈现。其实不难理解,如果要在百度搜索引擎上搜索到想要的信息内容,那么这个信息内容首先要经过百度搜索引擎的识别。
1.保证网站信息的内容可以被网络爬虫识别
现阶段,百度搜索引擎无法识别照片和flash中放置的文字信息内容。尤其是百度,现阶段无法很好识别javascript中的文字信息内容和连接。
建议在创建 网站 时牢记以下几点:
(1)应用文本而非 Flash、照片、javascript 等来显示信息关键内容或链接
(2)在允许的标准下,尽量不要使用flash网页元素。如果无法防止,请为flash内容创建一个保留网页的文本版本。
(3)防止关键网页信息内容进入iframe结构,百度搜索引擎不会轻易抓取结构中的内容。
2.创建良好的 URL 结构
为了对网站内容进行清理和恢复,规定网站必须做好分类。不仅方便用户预览网址,掌握网址结构,快速找到整体目标内容;另一方面,帮助百度搜索引擎更好地把握网址的结构。
URL一般是扁平的,通常分为以下几个层次:首页-频道页-内容页。应尽可能避免 URL 的理想化层次结构。最好选择扁平结构,减少从首页到内容页的浏览文件目录。
请注意以下几点:
(1)为每类网页添加导航,百度搜索引擎会根据导航中的层次结构掌握该网页的位置。
(2)确保网页上的每个网页始终至少有 1 个可访问的链接。
(3)有效机构分类URL中的内容,但防止分类过于精细。
(4)网页的引导倾向于防止复杂js或flash的应用,防止百度搜索引擎无法抓取。
(5)在使用图片链接时,请使用ALT功能进行标示,帮助百度搜索引擎了解页面的主体是什么。
SEO公司_网站优化百度关键词排名_新站快速排名技术-外推
百度搜索指定网站内容(网站内容获取权限和功能使用权限可能很多人不是很了解是啥)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-16 22:02
网站内容访问权和功能使用权可能很多人不理解吧?让我举个例子。比如你在百度找到一个在线图片处理网站,然后你输入这个网站,要使用这个图片处理功能,网站需要你注册成为会员,或者进入只有QQ群才能使用该功能,称为功能使用权限。
内容访问是指你在百度上搜索文献,输入网站,网站需要你注册成为会员,然后点击广告,或者下载app,或者回复帖子,在下载或查看文献资料。这称为内容访问。
昨天,百度正式发布文章,将严厉打击获取内容和功能困难的网站。这样做的目的是为了提高用户体验,降低信息获取成本。百度这次对武汉卡卡西科技的出击还是很支持的,因为很多网站查看内容信息很难获取,所以你点击一个网站再点击一个,浪费了很多时间,尤其是一些软件下载站,制作一堆下载按钮,让你不知道哪个是真假,最后把一堆流氓软件下载到电脑上。
这次针对百度的提问,站长或者网站负责人还是要注意,网站自己整理一下,看看有没有文中提到的几点。
以下为百度搜索官方原文:
近日,百度搜索发现部分网站在搜索中存在内容访问权限、功能使用权限等问题,影响搜索用户体验。百度搜索一直致力于让用户从搜索中快速获得想要的内容,降低用户获取信息的成本。
为了更好地满足搜索用户的需求,对于搜索结果中权限受限的网站,近期将严厉打击上网政策。
该策略主要针对以下两种情况:
1、内容访问权限
当用户查看网页的全部内容时,例如: 查看全部
百度搜索指定网站内容(网站内容获取权限和功能使用权限可能很多人不是很了解是啥)
网站内容访问权和功能使用权可能很多人不理解吧?让我举个例子。比如你在百度找到一个在线图片处理网站,然后你输入这个网站,要使用这个图片处理功能,网站需要你注册成为会员,或者进入只有QQ群才能使用该功能,称为功能使用权限。
内容访问是指你在百度上搜索文献,输入网站,网站需要你注册成为会员,然后点击广告,或者下载app,或者回复帖子,在下载或查看文献资料。这称为内容访问。
昨天,百度正式发布文章,将严厉打击获取内容和功能困难的网站。这样做的目的是为了提高用户体验,降低信息获取成本。百度这次对武汉卡卡西科技的出击还是很支持的,因为很多网站查看内容信息很难获取,所以你点击一个网站再点击一个,浪费了很多时间,尤其是一些软件下载站,制作一堆下载按钮,让你不知道哪个是真假,最后把一堆流氓软件下载到电脑上。
这次针对百度的提问,站长或者网站负责人还是要注意,网站自己整理一下,看看有没有文中提到的几点。
以下为百度搜索官方原文:
近日,百度搜索发现部分网站在搜索中存在内容访问权限、功能使用权限等问题,影响搜索用户体验。百度搜索一直致力于让用户从搜索中快速获得想要的内容,降低用户获取信息的成本。
为了更好地满足搜索用户的需求,对于搜索结果中权限受限的网站,近期将严厉打击上网政策。
该策略主要针对以下两种情况:
1、内容访问权限
当用户查看网页的全部内容时,例如:
百度搜索指定网站内容(网站排名提升的速度会更加大吗?——SEO论坛)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-16 22:01
项目投资找A5快速获取精准代理名单
众所周知,快速提升排名最有效的方法无非就是权重转移和点击排名。在百度算法中,有这样一个规则,网站在第20位内获得更多点击,网站排名提升的速度会更快。
相互排序的原则
关于点击排名的原理,估计网上已经有很多文章了,但是SEO论坛认为他们没有解释透彻,也没有完全理解其中的精髓搜索引擎优化人员。 SEO 论坛使用它来让您更好地了解点击排名。
点击排名其实需要分两步来查看。首先是在搜索引擎显示页面上获得点击。这一步非常重要。软件是否自动点击,其次是本站页面获得的点击,这一步是搜索引擎判断是否给网站加分的标准,根据停留时间和浏览轨迹来判断页面的体验,然后得到分数。
交互要求
XX关键词百度首页URL停留2分钟。主页 + 5 个内页。每个页面被点击后,需要停留2分钟。最后在XX页结束。每个页面都需要拉到最后才能截图。需要自带聊天记录截图,进阶点交互后需要提供对方IP地址。
相互交流的步骤
百度搜索指定关键词--然后找到指定网站--发送截图给对方确认--确认后点击--再次截图--停留指定时间--点击< @网站内容页——单击指定页数——完成。
点击效果测试
大家互相点击后,不知道怎么查看点击是否生效。相信大部分人的做法都是看统计代码里的数据。其实这里我可以很清楚的告诉你,那里的数据没有太大的参考意义。对于点击排名,我们应该在站长工具中分析点击数据。 ,那里的数据是真实有效的点击,它会参与排名参考数据。这意味着下图右侧会有一个排名。估计有90%的排名SEO人员不明白是什么意思。
有互动的人在群里说没有互动,排名也被送出去了。事实上,这是一种被搜索引擎判断为恶意滑动点击,并被暂时降级或警告的提示。 ,在这种情况下,建议果断停止滑动点击,恢复后采取正确的步骤。
申请创业报告,分享好的创业理念。点击这里一起讨论新的商机! 查看全部
百度搜索指定网站内容(网站排名提升的速度会更加大吗?——SEO论坛)
项目投资找A5快速获取精准代理名单
众所周知,快速提升排名最有效的方法无非就是权重转移和点击排名。在百度算法中,有这样一个规则,网站在第20位内获得更多点击,网站排名提升的速度会更快。
相互排序的原则
关于点击排名的原理,估计网上已经有很多文章了,但是SEO论坛认为他们没有解释透彻,也没有完全理解其中的精髓搜索引擎优化人员。 SEO 论坛使用它来让您更好地了解点击排名。
点击排名其实需要分两步来查看。首先是在搜索引擎显示页面上获得点击。这一步非常重要。软件是否自动点击,其次是本站页面获得的点击,这一步是搜索引擎判断是否给网站加分的标准,根据停留时间和浏览轨迹来判断页面的体验,然后得到分数。
交互要求
XX关键词百度首页URL停留2分钟。主页 + 5 个内页。每个页面被点击后,需要停留2分钟。最后在XX页结束。每个页面都需要拉到最后才能截图。需要自带聊天记录截图,进阶点交互后需要提供对方IP地址。
相互交流的步骤
百度搜索指定关键词--然后找到指定网站--发送截图给对方确认--确认后点击--再次截图--停留指定时间--点击< @网站内容页——单击指定页数——完成。
点击效果测试
大家互相点击后,不知道怎么查看点击是否生效。相信大部分人的做法都是看统计代码里的数据。其实这里我可以很清楚的告诉你,那里的数据没有太大的参考意义。对于点击排名,我们应该在站长工具中分析点击数据。 ,那里的数据是真实有效的点击,它会参与排名参考数据。这意味着下图右侧会有一个排名。估计有90%的排名SEO人员不明白是什么意思。
有互动的人在群里说没有互动,排名也被送出去了。事实上,这是一种被搜索引擎判断为恶意滑动点击,并被暂时降级或警告的提示。 ,在这种情况下,建议果断停止滑动点击,恢复后采取正确的步骤。
申请创业报告,分享好的创业理念。点击这里一起讨论新的商机!
百度搜索指定网站内容(什么是百度快照?中会的用途出现的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-16 18:18
一、什么是百度快照?
搜索结果打不开或打开速度极慢怎么办?收录的每个页面在百度上都有一个纯文本备份,称为“百度快照”;可以通过“快照”快速浏览页面内容,但是百度只保留文字内容,所以那些图片、音乐、视频等非文字信息,快照页面还是直接从原网页调用。
直观的说,百度快照是指在搜索关键词时,除了付费广告外,所有展示的都是百度快照。
二、页面快照的使用:
1.无法打开页面:当您要访问的页面不存在或链接无效或打开速度极慢时,可以通过网页快照访问该页面;
2.查看文字资料:由于网页截图显示速度较快,如果想查找一些更新不是很快的文字,如技术文档、资料等,可以通过网页截图直接查看,节省时间;
3、快速定位关键词:在快照中关键词在网页上用不同颜色标注;
4、查看旧版网页:搜索到的页面可能已经更新,如果想查看之前的网页是什么样的,可以使用快照;
三、为什么有些快照打不开?
快照只保存网页的 HTML 部分,而不是网页的全部内容。快照打不开的三种情况:
1、如果网页文本下载指定为图片和一些动态文件,而这些需要先下载的文件却无法下载,可能无法打开快照;
2、如果图片或动态文件下载速度慢,会因为超时而无法打开快照;
3、部分截图涉及非法内容,不让你看;
四、为什么我有时点击快照却链接到其他页面?
如果网页源代码中有重定向命令,则快照可以直接链接到指定网页;
五、为什么截图中有乱码?
1、网页指定编码错误;
2、浏览器不支持页面的语言;
3、浏览器错误识别网页的语言编码;
4、搜索引擎对文本的编码错误;
5、搜索引擎无法正确识别和显示字符;
以下是小编在公司整理的一些行业优化教程和SEO优化工具包(部分截图) 关注小编,私信“SEO”即可免费获取!
35G行业优化方案,SEO教程包括:最基本的建站内部优化+网站定位【原创伪原创内容制作技巧,内链体系优化与建立】到网站@ > 运营,网站推广思路策划,SEO项目实战学习资料整理,发给每一位想学习SEO,或转行,或大学生,或想在工作中提高的SEO伙伴有学习能力的欢迎加入学习! 查看全部
百度搜索指定网站内容(什么是百度快照?中会的用途出现的)
一、什么是百度快照?
搜索结果打不开或打开速度极慢怎么办?收录的每个页面在百度上都有一个纯文本备份,称为“百度快照”;可以通过“快照”快速浏览页面内容,但是百度只保留文字内容,所以那些图片、音乐、视频等非文字信息,快照页面还是直接从原网页调用。
直观的说,百度快照是指在搜索关键词时,除了付费广告外,所有展示的都是百度快照。
二、页面快照的使用:
1.无法打开页面:当您要访问的页面不存在或链接无效或打开速度极慢时,可以通过网页快照访问该页面;
2.查看文字资料:由于网页截图显示速度较快,如果想查找一些更新不是很快的文字,如技术文档、资料等,可以通过网页截图直接查看,节省时间;
3、快速定位关键词:在快照中关键词在网页上用不同颜色标注;
4、查看旧版网页:搜索到的页面可能已经更新,如果想查看之前的网页是什么样的,可以使用快照;
三、为什么有些快照打不开?
快照只保存网页的 HTML 部分,而不是网页的全部内容。快照打不开的三种情况:
1、如果网页文本下载指定为图片和一些动态文件,而这些需要先下载的文件却无法下载,可能无法打开快照;
2、如果图片或动态文件下载速度慢,会因为超时而无法打开快照;
3、部分截图涉及非法内容,不让你看;
四、为什么我有时点击快照却链接到其他页面?
如果网页源代码中有重定向命令,则快照可以直接链接到指定网页;
五、为什么截图中有乱码?
1、网页指定编码错误;
2、浏览器不支持页面的语言;
3、浏览器错误识别网页的语言编码;
4、搜索引擎对文本的编码错误;
5、搜索引擎无法正确识别和显示字符;
以下是小编在公司整理的一些行业优化教程和SEO优化工具包(部分截图) 关注小编,私信“SEO”即可免费获取!
35G行业优化方案,SEO教程包括:最基本的建站内部优化+网站定位【原创伪原创内容制作技巧,内链体系优化与建立】到网站@ > 运营,网站推广思路策划,SEO项目实战学习资料整理,发给每一位想学习SEO,或转行,或大学生,或想在工作中提高的SEO伙伴有学习能力的欢迎加入学习!
百度搜索指定网站内容(PHP使用百度地图获取指定地址坐标之创建AK(api))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-16 18:16
本篇文章主要介绍PHP使用百度地图创建AK(api key)获取指定地址坐标的方法。
在之前的文章【PHP使用腾讯地图获取指定地址坐标:create key】【PHP使用腾讯地图获取指定地址坐标:经纬度】,我们已经给大家介绍过了如何使用腾讯地图获取指定地址的坐标,即经纬度。具体的步骤和方法,如果你看过文章这两篇文章,会更容易理解这篇文章的内容。
其实不管是百度地图还是腾讯地图,我们主要是调用相应的接口来获取地图、坐标等相关数据。
接下来为大家介绍如何在百度地图开放平台获取开发者权限和创建AK(api key)。
步骤1:
登录百度账号,这里我们使用QQ登录。再次点击进入控制台。
第2步:
点击创建应用,即创建AK(这里的AK也相当于腾讯地图中的key)
输入应用程序的名称、类型和 IP 白名单。(这里的应用类型选择主要看你用的是哪一部分,比如你用在服务器端,ip白名单可以输入0.0.0.0或者* .)
第 3 步:
最后点击提交。
至此,百度地图的AK已经创建完成。在后面的文章中,我们会继续介绍PHP使用百度地图获取指定地址坐标的具体方法。
本篇文章是关于PHP中使用百度地图获取指定地址坐标创建AK(api key)的方法。这也很简单。希望对需要的人有所帮助! 查看全部
百度搜索指定网站内容(PHP使用百度地图获取指定地址坐标之创建AK(api))
本篇文章主要介绍PHP使用百度地图创建AK(api key)获取指定地址坐标的方法。
在之前的文章【PHP使用腾讯地图获取指定地址坐标:create key】【PHP使用腾讯地图获取指定地址坐标:经纬度】,我们已经给大家介绍过了如何使用腾讯地图获取指定地址的坐标,即经纬度。具体的步骤和方法,如果你看过文章这两篇文章,会更容易理解这篇文章的内容。
其实不管是百度地图还是腾讯地图,我们主要是调用相应的接口来获取地图、坐标等相关数据。
接下来为大家介绍如何在百度地图开放平台获取开发者权限和创建AK(api key)。
步骤1:
登录百度账号,这里我们使用QQ登录。再次点击进入控制台。
第2步:
点击创建应用,即创建AK(这里的AK也相当于腾讯地图中的key)
输入应用程序的名称、类型和 IP 白名单。(这里的应用类型选择主要看你用的是哪一部分,比如你用在服务器端,ip白名单可以输入0.0.0.0或者* .)
第 3 步:
最后点击提交。
至此,百度地图的AK已经创建完成。在后面的文章中,我们会继续介绍PHP使用百度地图获取指定地址坐标的具体方法。
本篇文章是关于PHP中使用百度地图获取指定地址坐标创建AK(api key)的方法。这也很简单。希望对需要的人有所帮助!
百度搜索指定网站内容(vs2012如何查询某个网址的收录次数5,280,000这段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-16 14:00
一、前言
偶然在vs2012的默认项目文件夹中发现了一个我之前做的关于SEO的类库。主要用于查询某网站收录的数量和网站的排名数量。后来经过重构,今天拿出来写了一篇文章文章,告诉我我是怎么想的,怎么完成的。
二、问题描述
首先要考虑的是可以支持哪些搜索引擎查询,首先是百度,然后是必应、搜狗、搜搜、360。本来想支持谷歌的,但是没想到,不好访问全部,所以暂时不包括在内。我们真正需要做的是,根据一个URL,检索这个URL在各个搜索引擎中的收录次数,以及不同关键词下的URL排名。只有 URL 和几个 关键词 进出。@关键词,输出为该URL在不同搜索引擎下的收录次数和每个关键词下的排名次数。
但是这里有一个问题,就是排名的数量。如果检索到的 URL 在前 100 位,那就没问题了。如果排名很低,那么问题就来了,这会让用户等待很长时间才能看到结果,但用户可能只想知道前100名的具体排名,超过100名的只需要展示出来,这些都需要前期考虑好,方便后续的流程。
三、解决方案
相信很多人都能想到,就是用WebClient下载需要的页面,然后用正则得到我们感兴趣的部分,再用程序进行处理。关键难点在这个正则的写法上,首先我们从一个简单的说起。
四、收录次数
首先是网站的收录的编号,我们可以在百度中输入site:,然后可以看到如下页面:
而我们需要收录的次数是5,280,000,那么我们来看一下页面元素:
然后我们再看其他搜索引擎,发现都差不多,所以这个时候我们的思路就应该画出来了,最后就是如何组织URL。在这部分,我们看看地址栏?wd=site%3A%2F 就知道怎么写了。
这时候我们可能会迫不及待地一一实现,这样以后就不能集中调用了,也会影响以后的添加,所以需要指定一个抽象类来实现收录@ > number 函数,这样就可以在不知道具体实现的情况下统一使用,而且以后可以方便的添加新的搜索引擎,这种方式属于策略模式(Stategry)。让我们慢慢分析这个抽象类的具体内容。
首先,实现这个抽象类的每个具体类都应该对应某个搜索引擎,所以它需要有一个基本的URL,并留一个占位符。比如根据上面的百度,我们可以得到这样一个字符串
%3A{0}
其中,{0} 是真正需要检索的 URL 的占位符。获取下载页面的路径是所有具体类都需要的,所以我们直接把实现放到抽象类中,比如下面的代码:
复制代码代码如下:
///
/// 服务供应商
///
受保护的字符串 SearchProvider { get; 放; }
///
/// 要检索的 URL
///
受保护的字符串 SiteUrl { 获取;放; }
///
/// 搜索服务提供者 URL
///
受保护的字符串 BaseUrl { 获取;放; }
///
/// 后页地址
///
///
要查询的网址
/// 连接的 URL
受保护的字符串 GetDownUrl(字符串站点)
{
return string.Format(BaseUrl, HttpUtility.UrlEncode(site));
}
其中,SiteUrl 和 SearchProvider 用于保存检索 URL 和搜索引擎名称。
上面我们说过会使用WebClient来下载页面,所以初始化WebClient的工作也是在抽象类中完成的,尽可能减少重复代码,并且为了防止阻塞当前线程,我们使用了Async方法。
具体代码如下:
复制代码代码如下:
///
/// 此搜索引擎中 收录 查询的数量
///
///
网站网址
公共无效 SearchIncludeCount(字符串站点网址)
{
网站网址 = 网站网址;
WebClient 客户端 = 新 WebClient();
client.Encoding = Encoding.UTF8;
client.DownloadStringCompleted += DownloadStringCompleted;
client.DownloadStringAsync(new Uri(GetDownUrl(siteurl)));
}
///
/// 检索次数的具体实现 收录
/// 子类必须实现这个方法
///
///
///
受保护的抽象无效DownloadStringCompleted(对象发送者,DownloadStringCompletedEventArgs e);
当WebClient完成下载后,会回调DownloadStringCompleted方法,这个方法是抽象方法,也就是说具体的类必须实现这个方法。
虽然我们的内部实现是异步的,但是其他开发者调用这个方法仍然是同步的,所以我们需要使用委托,所以我们还需要创建一个新的委托类型:
复制代码代码如下:
///
/// 网站的收录查询完成时回调
///
公共操作 OnComplatedOneSite { 获取;放; }
SiteIncludeCountResult 的结构如下:
复制代码代码如下:
///
/// 网站收录 中代表的参数
///
公共类 SiteIncludeCountResult
{
///
/// 收录次数
///
公共长包括计数 { 得到;放; }
///
/// 搜索引擎类型
///
公共字符串搜索类型 { 获取;放; }
///
/// 网站网址
///
公共字符串 SiteUrl { 获取;放; }
}
最后还有一个方法可以在 DownloadStringCompleted 完成时回调 OnComplatedOneSite 委托:
///
/// 处理后调用该方法返回结果
///
///
收录 URL 的计数结果
protected void SetCompleted(SiteIncludeCountResult 结果)
{
如果(OnComplatedOneSite != null)
OnComplatedOneSite(结果);
}
这样,我们需要的抽象类就完成了。现在我们可以开始实现第一个。从上面的截图中,我们可以发现匹配这个字符串的正则表达式非常简单:
复制代码代码如下:
百度为您找到关于 ([\w,]+?) 的相关结果
最后,你可以通过从获得的字符串中删除逗号来强制转换,结果就会出来。具体实现如下:
复制代码代码如下:
///
/// 百度网站收录次查询
///
公共类 BaiDuSiteIncludeCount : SiteIncludeCountBase
{
public BaiDuSiteIncludeCount()
{
BaseUrl = "{0}";
SearchProvider = "百度";
}
protected override void DownloadStringCompleted(对象发送者,DownloadStringCompletedEventArgs e)
{
var 结果 = 新 SiteIncludeCountResult();
结果.SiteUrl = SiteUrl;
结果.SearchType = SearchProvider;
结果.IncludeCount = 0;
Regex reg = new Regex(@"百度为你找到了大约([\w,]+?)个相关结果", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var 匹配 = reg.Matches(e.Result);
if (matchs.Count > 0)
{
字符串计数 = 匹配[0].Groups[1].Value.Replace(",", "");
result.IncludeCount = long.Parse(count);
}
设置完成(结果);
}
}
以此类推,其他的都是按照这个来的,有兴趣的可以下载我的源码查看。
五、关键词排名
按照之前的思路,我们还是需要先指定一个抽象类,但是它的结构和上面的抽象类很相似,所以作者在这里直接给出具体代码:
复制代码代码如下:
///
/// 实现 关键词 查询必须继承这个类
///
公共抽象类 KeyWordsSeoBase
{
受保护的字符串 BaseUrl { 获取;放; }
受保护的字符串 SearchProvider { get; 放; }
protected String GetDownUrl(字符串关键字,字符串站点,长电流)
{
return String.Format(BaseUrl, HttpUtility.UrlEncode(keyword), current);
}
protected void SetCompleted(KeyWordsSeoResult 结果)
{
如果(OnComplatedOneKeyWord != null)
{
OnComplatedOneKeyWord(结果);
}
}
///
/// 完成 关键词 查询后回调委托
///
公共操作 OnComplatedOneKeyWord { 获取;放; }
///
/// 查询指定关键词和网站在搜索引擎中的排名
/// 子类需要重写这个方法
///
///
关键词
///
网站网址
public abstract void SearchRanking(IEnumerable keywords, string site, long count);
}
最大的不同是具体实现都集中在SearchRanking。从keywords参数可以看出,我们将支持多个关键词查询。最后一个区别是下载路径的组织。因为它涉及翻页,所以有一个额外的。范围。
KeyWordsSeoResult 的结构如下:
复制代码代码如下:
///
/// 关键词 排名查询的委托参数
///
公共类 KeyWordsSeoResult
{
///
/// 搜索引擎类型
///
公共字符串搜索类型 { 获取;放; }
///
/// 关键词
///
公共字符串关键字 { 获取;放; }
///
/// 排行
///
public long Ranking { 得到;放; }
}
废话不多说,我们来看百度的搜索结果页面:
以上是笔者在百度搜索程序员的第九个html结构。您可能认为获取 div 的 id 和 URL 非常简单。但是很多搜索引擎的路径并不是直接路径,而是会先链接到百度,然后再重定向。如果一定要匹配,我们还需要做一件事:访问这条路径获取真实路径,中间会增加等待时间,所以作者使用了上面的截图。中的后者内容,从而避免了请求。(不知道作者一开始是怎么想的,实现中并没有用到id值,而是内部自增,估计翻页后这个id的序号会有问题),最后展示我们神圣的正则表达式:
复制代码代码如下:
([^/&]*)
你认为这是一个重大的公告吗?错了,在某些结果中,百度会在这个网址上加ab标签,作者采用了全部杀掉的方法,使用正则规则全部删除(反正我不看页面,只要得到我要的,没关系),实现的时候不能直接实现多个关键词的识别,应该是实现一个关键词,然后循环调用。以下是作者单关键词的实现:
复制代码代码如下:
protected KeyWordsSeoResult SearchFunc(字符串键,字符串 siteurl,长总计)
{
var 结果 = 新的 KeyWordsSeoResult();
结果.KeyWord =键;
结果.排名=总+1;
var reg = new Regex(@"([^/&]*)", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var replace = new Regex("", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var client = new WebClient();
长电流 = 0;
长位置 = 0;
为了 (; ; )
{
字符串 url = GetDownUrl(key, siteurl, current);
String downstr = client.DownloadString(url);
downstr = replace.Replace(downstr, "");
var 匹配 = reg.Matches(downstr);
foreach(匹配中的匹配)
{
正++;
字符串 suburl = match.Groups[1].Value;
尝试
{
if (suburl.ToLower() == siteurl.ToLower())
{
结果.Ranking = pos;
返回结果;
}
}
抓住
{
继续;
}
}
当前 += 10;
如果(当前>总计)
{
当前-= 10;
如果(当前 >= 总计)
{
休息;
}
当前=总计;
}
}
返回结果;
}
注意for循环的结束,用于处理分页,以便翻到下一页继续检索。其他通用部分和作者说的一样,下载页面->正则匹配->根据匹配结果判断。剩下的就是SearchRanking的实现,也就是循环关键词,不过这里我为每个搜索引擎新建一个线程来实现,当然这样不太好,读者可以用更好的方式来做它:
复制代码代码如下:
public override void SearchRanking(IEnumerable keywords, string site, long count)
{
新线程(()=>
{
foreach(关键字中的字符串键)
{
KeyWordsSeoResult 结果 = SearchFunc(key, site, count);
结果.SearchType = SearchProvider;
设置完成(结果);
}
})。开始();
}
六、统一管理
有了这些,我们就可以编写一个简洁的类来负责管理。作者在这里直接给出代码:
复制代码代码如下:
///
/// 查询网站的收录的个数和排名
///
公共类RankingAndIncludeSeo
{
///
/// 关键词列表
///
公共 IList KeyWordsSeoList { 获取;私人套装;}
///
/// 收录时间列表
///
公共 IList SiteIncludeCountList { 获取;私人套装;}
公共 RankingAndIncludeSeo()
{
KeyWordsSeoList = new List();
SiteIncludeCountList = new List();
}
///
/// 当 关键词 查询完成时回调委托
///
公共操作 OnComplatedAnyKeyWordsSearch { 获取;放; }
///
/// 完成收录次网站的查询后回调delegate
///
公共操作 OnComplatedAnySiteIncludeSearch { 获取;放; }
///
/// 查询URL的排名
///
///
关键词组
///
查询网址
///
最大等级数
public void SearchKeyWordsRanking(IEnumerable 关键字,字符串 siteurl,长计数 = 100)
{
如果(关键字 == 空)
throw new ArgumentNullException("keywords", "必须存在 关键词");
如果(网站网址 == 空)
throw new ArgumentNullException("siteurl", "必须存在 网站URL");
foreach(KeyWordsSeoList 中的 KeyWordsSeoBase kwsb)
{
kwsb.OnComplatedOneKeyWord = kwsb.OnComplatedOneKeyWord ?? OnComplatedAnyKeyWordsSearch;
kwsb.SearchRanking(关键字,站点网址,计数);
}
}
///
/// 收录 查询 URL 的数量
///
///
查询网址
公共无效 SearchSiteIncludeCount(字符串网站网址)
{
如果(网站网址 == 空)
throw new ArgumentNullException("siteurl", "必须指定 网站");
foreach(SiteIncludeCountBase sicb 中的 SiteIncludeCountList)
{
sicb.OnComplatedOneSite = sicb.OnComplatedOneSite ?? OnComplatedAnySiteIncludeSearch;
sicb.SearchIncludeCount(siteurl);
}
}
}
RankingAndIncludeSeo 提供了一个公共代表。如果单个搜索引擎不提供委托,则使用此公共委托。如果指定了单独的delegate,就不会分配了,其他开发者只需要在调用时添加到KeyWordsSeoList和SiteIncludeCountList中已经实现的类即可,其他开发者自己开发实现加入即可。
七、部分
一般来说,这篇文章不是关于高端技术的,而只是提供一个大致的想法和结构设计。如果读者需要在实际开发中应用,最好验证一下。作者不保证关键词的排名没有错误,因为搜索结果可能因任何因素而发生变化。
^.^我是源代码下载 查看全部
百度搜索指定网站内容(vs2012如何查询某个网址的收录次数5,280,000这段)
一、前言
偶然在vs2012的默认项目文件夹中发现了一个我之前做的关于SEO的类库。主要用于查询某网站收录的数量和网站的排名数量。后来经过重构,今天拿出来写了一篇文章文章,告诉我我是怎么想的,怎么完成的。
二、问题描述
首先要考虑的是可以支持哪些搜索引擎查询,首先是百度,然后是必应、搜狗、搜搜、360。本来想支持谷歌的,但是没想到,不好访问全部,所以暂时不包括在内。我们真正需要做的是,根据一个URL,检索这个URL在各个搜索引擎中的收录次数,以及不同关键词下的URL排名。只有 URL 和几个 关键词 进出。@关键词,输出为该URL在不同搜索引擎下的收录次数和每个关键词下的排名次数。
但是这里有一个问题,就是排名的数量。如果检索到的 URL 在前 100 位,那就没问题了。如果排名很低,那么问题就来了,这会让用户等待很长时间才能看到结果,但用户可能只想知道前100名的具体排名,超过100名的只需要展示出来,这些都需要前期考虑好,方便后续的流程。
三、解决方案
相信很多人都能想到,就是用WebClient下载需要的页面,然后用正则得到我们感兴趣的部分,再用程序进行处理。关键难点在这个正则的写法上,首先我们从一个简单的说起。
四、收录次数
首先是网站的收录的编号,我们可以在百度中输入site:,然后可以看到如下页面:
而我们需要收录的次数是5,280,000,那么我们来看一下页面元素:
然后我们再看其他搜索引擎,发现都差不多,所以这个时候我们的思路就应该画出来了,最后就是如何组织URL。在这部分,我们看看地址栏?wd=site%3A%2F 就知道怎么写了。
这时候我们可能会迫不及待地一一实现,这样以后就不能集中调用了,也会影响以后的添加,所以需要指定一个抽象类来实现收录@ > number 函数,这样就可以在不知道具体实现的情况下统一使用,而且以后可以方便的添加新的搜索引擎,这种方式属于策略模式(Stategry)。让我们慢慢分析这个抽象类的具体内容。
首先,实现这个抽象类的每个具体类都应该对应某个搜索引擎,所以它需要有一个基本的URL,并留一个占位符。比如根据上面的百度,我们可以得到这样一个字符串
%3A{0}
其中,{0} 是真正需要检索的 URL 的占位符。获取下载页面的路径是所有具体类都需要的,所以我们直接把实现放到抽象类中,比如下面的代码:
复制代码代码如下:
///
/// 服务供应商
///
受保护的字符串 SearchProvider { get; 放; }
///
/// 要检索的 URL
///
受保护的字符串 SiteUrl { 获取;放; }
///
/// 搜索服务提供者 URL
///
受保护的字符串 BaseUrl { 获取;放; }
///
/// 后页地址
///
///
要查询的网址
/// 连接的 URL
受保护的字符串 GetDownUrl(字符串站点)
{
return string.Format(BaseUrl, HttpUtility.UrlEncode(site));
}
其中,SiteUrl 和 SearchProvider 用于保存检索 URL 和搜索引擎名称。
上面我们说过会使用WebClient来下载页面,所以初始化WebClient的工作也是在抽象类中完成的,尽可能减少重复代码,并且为了防止阻塞当前线程,我们使用了Async方法。
具体代码如下:
复制代码代码如下:
///
/// 此搜索引擎中 收录 查询的数量
///
///
网站网址
公共无效 SearchIncludeCount(字符串站点网址)
{
网站网址 = 网站网址;
WebClient 客户端 = 新 WebClient();
client.Encoding = Encoding.UTF8;
client.DownloadStringCompleted += DownloadStringCompleted;
client.DownloadStringAsync(new Uri(GetDownUrl(siteurl)));
}
///
/// 检索次数的具体实现 收录
/// 子类必须实现这个方法
///
///
///
受保护的抽象无效DownloadStringCompleted(对象发送者,DownloadStringCompletedEventArgs e);
当WebClient完成下载后,会回调DownloadStringCompleted方法,这个方法是抽象方法,也就是说具体的类必须实现这个方法。
虽然我们的内部实现是异步的,但是其他开发者调用这个方法仍然是同步的,所以我们需要使用委托,所以我们还需要创建一个新的委托类型:
复制代码代码如下:
///
/// 网站的收录查询完成时回调
///
公共操作 OnComplatedOneSite { 获取;放; }
SiteIncludeCountResult 的结构如下:
复制代码代码如下:
///
/// 网站收录 中代表的参数
///
公共类 SiteIncludeCountResult
{
///
/// 收录次数
///
公共长包括计数 { 得到;放; }
///
/// 搜索引擎类型
///
公共字符串搜索类型 { 获取;放; }
///
/// 网站网址
///
公共字符串 SiteUrl { 获取;放; }
}
最后还有一个方法可以在 DownloadStringCompleted 完成时回调 OnComplatedOneSite 委托:
///
/// 处理后调用该方法返回结果
///
///
收录 URL 的计数结果
protected void SetCompleted(SiteIncludeCountResult 结果)
{
如果(OnComplatedOneSite != null)
OnComplatedOneSite(结果);
}
这样,我们需要的抽象类就完成了。现在我们可以开始实现第一个。从上面的截图中,我们可以发现匹配这个字符串的正则表达式非常简单:
复制代码代码如下:
百度为您找到关于 ([\w,]+?) 的相关结果
最后,你可以通过从获得的字符串中删除逗号来强制转换,结果就会出来。具体实现如下:
复制代码代码如下:
///
/// 百度网站收录次查询
///
公共类 BaiDuSiteIncludeCount : SiteIncludeCountBase
{
public BaiDuSiteIncludeCount()
{
BaseUrl = "{0}";
SearchProvider = "百度";
}
protected override void DownloadStringCompleted(对象发送者,DownloadStringCompletedEventArgs e)
{
var 结果 = 新 SiteIncludeCountResult();
结果.SiteUrl = SiteUrl;
结果.SearchType = SearchProvider;
结果.IncludeCount = 0;
Regex reg = new Regex(@"百度为你找到了大约([\w,]+?)个相关结果", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var 匹配 = reg.Matches(e.Result);
if (matchs.Count > 0)
{
字符串计数 = 匹配[0].Groups[1].Value.Replace(",", "");
result.IncludeCount = long.Parse(count);
}
设置完成(结果);
}
}
以此类推,其他的都是按照这个来的,有兴趣的可以下载我的源码查看。
五、关键词排名
按照之前的思路,我们还是需要先指定一个抽象类,但是它的结构和上面的抽象类很相似,所以作者在这里直接给出具体代码:
复制代码代码如下:
///
/// 实现 关键词 查询必须继承这个类
///
公共抽象类 KeyWordsSeoBase
{
受保护的字符串 BaseUrl { 获取;放; }
受保护的字符串 SearchProvider { get; 放; }
protected String GetDownUrl(字符串关键字,字符串站点,长电流)
{
return String.Format(BaseUrl, HttpUtility.UrlEncode(keyword), current);
}
protected void SetCompleted(KeyWordsSeoResult 结果)
{
如果(OnComplatedOneKeyWord != null)
{
OnComplatedOneKeyWord(结果);
}
}
///
/// 完成 关键词 查询后回调委托
///
公共操作 OnComplatedOneKeyWord { 获取;放; }
///
/// 查询指定关键词和网站在搜索引擎中的排名
/// 子类需要重写这个方法
///
///
关键词
///
网站网址
public abstract void SearchRanking(IEnumerable keywords, string site, long count);
}
最大的不同是具体实现都集中在SearchRanking。从keywords参数可以看出,我们将支持多个关键词查询。最后一个区别是下载路径的组织。因为它涉及翻页,所以有一个额外的。范围。
KeyWordsSeoResult 的结构如下:
复制代码代码如下:
///
/// 关键词 排名查询的委托参数
///
公共类 KeyWordsSeoResult
{
///
/// 搜索引擎类型
///
公共字符串搜索类型 { 获取;放; }
///
/// 关键词
///
公共字符串关键字 { 获取;放; }
///
/// 排行
///
public long Ranking { 得到;放; }
}
废话不多说,我们来看百度的搜索结果页面:
以上是笔者在百度搜索程序员的第九个html结构。您可能认为获取 div 的 id 和 URL 非常简单。但是很多搜索引擎的路径并不是直接路径,而是会先链接到百度,然后再重定向。如果一定要匹配,我们还需要做一件事:访问这条路径获取真实路径,中间会增加等待时间,所以作者使用了上面的截图。中的后者内容,从而避免了请求。(不知道作者一开始是怎么想的,实现中并没有用到id值,而是内部自增,估计翻页后这个id的序号会有问题),最后展示我们神圣的正则表达式:
复制代码代码如下:
([^/&]*)
你认为这是一个重大的公告吗?错了,在某些结果中,百度会在这个网址上加ab标签,作者采用了全部杀掉的方法,使用正则规则全部删除(反正我不看页面,只要得到我要的,没关系),实现的时候不能直接实现多个关键词的识别,应该是实现一个关键词,然后循环调用。以下是作者单关键词的实现:
复制代码代码如下:
protected KeyWordsSeoResult SearchFunc(字符串键,字符串 siteurl,长总计)
{
var 结果 = 新的 KeyWordsSeoResult();
结果.KeyWord =键;
结果.排名=总+1;
var reg = new Regex(@"([^/&]*)", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var replace = new Regex("", RegexOptions.IgnoreCase | RegexOptions.Singleline);
var client = new WebClient();
长电流 = 0;
长位置 = 0;
为了 (; ; )
{
字符串 url = GetDownUrl(key, siteurl, current);
String downstr = client.DownloadString(url);
downstr = replace.Replace(downstr, "");
var 匹配 = reg.Matches(downstr);
foreach(匹配中的匹配)
{
正++;
字符串 suburl = match.Groups[1].Value;
尝试
{
if (suburl.ToLower() == siteurl.ToLower())
{
结果.Ranking = pos;
返回结果;
}
}
抓住
{
继续;
}
}
当前 += 10;
如果(当前>总计)
{
当前-= 10;
如果(当前 >= 总计)
{
休息;
}
当前=总计;
}
}
返回结果;
}
注意for循环的结束,用于处理分页,以便翻到下一页继续检索。其他通用部分和作者说的一样,下载页面->正则匹配->根据匹配结果判断。剩下的就是SearchRanking的实现,也就是循环关键词,不过这里我为每个搜索引擎新建一个线程来实现,当然这样不太好,读者可以用更好的方式来做它:
复制代码代码如下:
public override void SearchRanking(IEnumerable keywords, string site, long count)
{
新线程(()=>
{
foreach(关键字中的字符串键)
{
KeyWordsSeoResult 结果 = SearchFunc(key, site, count);
结果.SearchType = SearchProvider;
设置完成(结果);
}
})。开始();
}
六、统一管理
有了这些,我们就可以编写一个简洁的类来负责管理。作者在这里直接给出代码:
复制代码代码如下:
///
/// 查询网站的收录的个数和排名
///
公共类RankingAndIncludeSeo
{
///
/// 关键词列表
///
公共 IList KeyWordsSeoList { 获取;私人套装;}
///
/// 收录时间列表
///
公共 IList SiteIncludeCountList { 获取;私人套装;}
公共 RankingAndIncludeSeo()
{
KeyWordsSeoList = new List();
SiteIncludeCountList = new List();
}
///
/// 当 关键词 查询完成时回调委托
///
公共操作 OnComplatedAnyKeyWordsSearch { 获取;放; }
///
/// 完成收录次网站的查询后回调delegate
///
公共操作 OnComplatedAnySiteIncludeSearch { 获取;放; }
///
/// 查询URL的排名
///
///
关键词组
///
查询网址
///
最大等级数
public void SearchKeyWordsRanking(IEnumerable 关键字,字符串 siteurl,长计数 = 100)
{
如果(关键字 == 空)
throw new ArgumentNullException("keywords", "必须存在 关键词");
如果(网站网址 == 空)
throw new ArgumentNullException("siteurl", "必须存在 网站URL");
foreach(KeyWordsSeoList 中的 KeyWordsSeoBase kwsb)
{
kwsb.OnComplatedOneKeyWord = kwsb.OnComplatedOneKeyWord ?? OnComplatedAnyKeyWordsSearch;
kwsb.SearchRanking(关键字,站点网址,计数);
}
}
///
/// 收录 查询 URL 的数量
///
///
查询网址
公共无效 SearchSiteIncludeCount(字符串网站网址)
{
如果(网站网址 == 空)
throw new ArgumentNullException("siteurl", "必须指定 网站");
foreach(SiteIncludeCountBase sicb 中的 SiteIncludeCountList)
{
sicb.OnComplatedOneSite = sicb.OnComplatedOneSite ?? OnComplatedAnySiteIncludeSearch;
sicb.SearchIncludeCount(siteurl);
}
}
}
RankingAndIncludeSeo 提供了一个公共代表。如果单个搜索引擎不提供委托,则使用此公共委托。如果指定了单独的delegate,就不会分配了,其他开发者只需要在调用时添加到KeyWordsSeoList和SiteIncludeCountList中已经实现的类即可,其他开发者自己开发实现加入即可。
七、部分
一般来说,这篇文章不是关于高端技术的,而只是提供一个大致的想法和结构设计。如果读者需要在实际开发中应用,最好验证一下。作者不保证关键词的排名没有错误,因为搜索结果可能因任何因素而发生变化。
^.^我是源代码下载
百度搜索指定网站内容(一下百度搜索的几种技巧,你都知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 240 次浏览 • 2022-02-14 19:18
说到国内搜索引擎,百度应该是人人皆知的。但是为什么每次都找不到自己想要的,或者是全屏广告,根本得不到有用的信息。其实搜索引擎的使用方法和方法也是很讲究的。使用正确的方法可以节省时间并提高效率。下面,小编就给大家罗列几种百度搜索技巧,以便大家顺利找到自己想要的。
.
一、 以特定格式查找资源 "filetype:pdf 关键词"
有时要查找特定格式的文档,比如建筑师二级pdf文件,一般的方法是搜索:“建筑师二级pdf”。出现的结果是
建筑师 2 级 pdf
可以看出其中有很多不为人知的网站。现在我们改一下搜索方式:“filetype:pdf Architect Level 2”,那么结果就大不一样了
文件类型:pdf 架构师 2 级
可以发现,搜索结果都指向PDF文件。filetype语法可以根据关键词查询各种类型的文档,目前支持的文档有pdf、xls、doc、ppt、rtf。如果使用 all,则可以搜索上述所有文件类型。
二、排除相关结果“-关键词”
完美 如果您不想在搜索 关键词 时看到某个类别的相关结果,可以使用减号。比如你搜索火锅,不想看重庆火锅,可以用“火锅-重庆”或“火锅-(重庆)”搜索(关键词之间有空格@> 和减号)。
排除相关结果
三、完整搜索
有时搜索到的关键词会被拆分搜索。这种情况下可以加双引号“”(英文双引号),这样关键词就不会被拆分了。
关键词 被拆分
添加双引号后,完成匹配
四、按标题搜索作品
题号的作用是将内容作为作品进行搜索,比如我们搜索鱼的时候
鱼
现在让我们添加“”来尝试
关于鱼的作品
可以准确搜索到关键词的相关作品。
五、在网上搜索关键词“Intitle”和“inurl”和“intext”
一个网页一般由url、title、content三部分组成,Intitle、inurl、intext分别对应这三个查询规则。比如我们要搜索采集美图集的网站,可以使用inurl:(beauty)来搜索(冒号和关键词之间有空格)。
inurl
intitle和intext的使用类型不再重复
六、 站点语法
有时我们想在 网站 中搜索 关键词,但 网站 没有搜索栏。这时候我们可以使用site语法进行搜索,可以将搜索内容限制在指定的网站内。语法:site:(网站) 关键字。比如我们要在豆瓣搜索肖申克的救赎的记录,可以使用这个语法,site:()肖申克的救赎
网站:(网站) 关键字 查看全部
百度搜索指定网站内容(一下百度搜索的几种技巧,你都知道吗?(上))
说到国内搜索引擎,百度应该是人人皆知的。但是为什么每次都找不到自己想要的,或者是全屏广告,根本得不到有用的信息。其实搜索引擎的使用方法和方法也是很讲究的。使用正确的方法可以节省时间并提高效率。下面,小编就给大家罗列几种百度搜索技巧,以便大家顺利找到自己想要的。
.
一、 以特定格式查找资源 "filetype:pdf 关键词"
有时要查找特定格式的文档,比如建筑师二级pdf文件,一般的方法是搜索:“建筑师二级pdf”。出现的结果是
建筑师 2 级 pdf
可以看出其中有很多不为人知的网站。现在我们改一下搜索方式:“filetype:pdf Architect Level 2”,那么结果就大不一样了
文件类型:pdf 架构师 2 级
可以发现,搜索结果都指向PDF文件。filetype语法可以根据关键词查询各种类型的文档,目前支持的文档有pdf、xls、doc、ppt、rtf。如果使用 all,则可以搜索上述所有文件类型。
二、排除相关结果“-关键词”
完美 如果您不想在搜索 关键词 时看到某个类别的相关结果,可以使用减号。比如你搜索火锅,不想看重庆火锅,可以用“火锅-重庆”或“火锅-(重庆)”搜索(关键词之间有空格@> 和减号)。
排除相关结果
三、完整搜索
有时搜索到的关键词会被拆分搜索。这种情况下可以加双引号“”(英文双引号),这样关键词就不会被拆分了。
关键词 被拆分
添加双引号后,完成匹配
四、按标题搜索作品
题号的作用是将内容作为作品进行搜索,比如我们搜索鱼的时候
鱼
现在让我们添加“”来尝试
关于鱼的作品
可以准确搜索到关键词的相关作品。
五、在网上搜索关键词“Intitle”和“inurl”和“intext”
一个网页一般由url、title、content三部分组成,Intitle、inurl、intext分别对应这三个查询规则。比如我们要搜索采集美图集的网站,可以使用inurl:(beauty)来搜索(冒号和关键词之间有空格)。
inurl
intitle和intext的使用类型不再重复
六、 站点语法
有时我们想在 网站 中搜索 关键词,但 网站 没有搜索栏。这时候我们可以使用site语法进行搜索,可以将搜索内容限制在指定的网站内。语法:site:(网站) 关键字。比如我们要在豆瓣搜索肖申克的救赎的记录,可以使用这个语法,site:()肖申克的救赎
网站:(网站) 关键字
百度搜索指定网站内容(百度霸屏怎么做?先来说一下技术的原理和做法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-14 15:23
百度霸屏技术是指当用户搜索某个关键词时,基本上在搜索结果中显示我们自己的内容的技术。百度八屏一般都是用长尾关键词做的,当然非长尾关键词也可以,只是难度稍大一些,但原理和做法是一样的。
那么,百度八屏是如何做到的呢?先说一下百度八屏技术的原理:百度八屏采用先进专业的SEO技术,让用户可以搜索到相关的关键词,显示的搜索结果都是我们自己的官网或者自己发布的帖子。没有专业的SEO技术,是不可能让百度一统天下的。
那么,在做百度霸业的时候,我们在实战中应该怎么做呢?它包括以下几点:
一、百度八屏多是长尾词关键词,当然非长尾词也可以,但是难度更大,需要更多的时间和精力;
二、发布的网页文章必须都是原创文章,或者搜索引擎无法识别的伪原创,怎么做,在文章处@>结束我会说:如何制作伪原创?;
三、做好百度的底层营销,让你的公司信息出现在搜索引擎关注者、右侧相关信息等。详情请查看我的另一个头条文章 :百度的底层营销是怎么做的?做;
四、百度八屏的重点网络平台有哪些?
一、百度霸屏的详细制作方法和操作方法如下:
1:网页制作和SEO
我们先写大量的原创或者伪原创文章,然后发布到以上平台,前提是这些文章的内容一定要优化,包括:网页首末段必须有关键词,关键词密度不低于2%,关键词均匀分布,使用H型标签,优化链接标签,使用加粗斜体、李优化、图片标签优化等网页内容细节优化,以及TDK三大标签的优化。
2:添加点击IP:
接下来,我们还可以进行一些其他的操作,比如通过IP转换软件更改我们的IP,然后搜索关键词即百度八屏,找到我们发布的网页。单击:访问更多页面并留在那里。久而久之,网上当然有所谓的自动点击软件。作者强烈建议大家不要使用!!!尤其是网上一些所谓的SEO软件,作者强烈建议大家不要使用,原因这里就不说了,有兴趣的可以给我留言,我会告诉他原因的。 查看全部
百度搜索指定网站内容(百度霸屏怎么做?先来说一下技术的原理和做法)
百度霸屏技术是指当用户搜索某个关键词时,基本上在搜索结果中显示我们自己的内容的技术。百度八屏一般都是用长尾关键词做的,当然非长尾关键词也可以,只是难度稍大一些,但原理和做法是一样的。
那么,百度八屏是如何做到的呢?先说一下百度八屏技术的原理:百度八屏采用先进专业的SEO技术,让用户可以搜索到相关的关键词,显示的搜索结果都是我们自己的官网或者自己发布的帖子。没有专业的SEO技术,是不可能让百度一统天下的。
那么,在做百度霸业的时候,我们在实战中应该怎么做呢?它包括以下几点:
一、百度八屏多是长尾词关键词,当然非长尾词也可以,但是难度更大,需要更多的时间和精力;
二、发布的网页文章必须都是原创文章,或者搜索引擎无法识别的伪原创,怎么做,在文章处@>结束我会说:如何制作伪原创?;
三、做好百度的底层营销,让你的公司信息出现在搜索引擎关注者、右侧相关信息等。详情请查看我的另一个头条文章 :百度的底层营销是怎么做的?做;
四、百度八屏的重点网络平台有哪些?
一、百度霸屏的详细制作方法和操作方法如下:
1:网页制作和SEO
我们先写大量的原创或者伪原创文章,然后发布到以上平台,前提是这些文章的内容一定要优化,包括:网页首末段必须有关键词,关键词密度不低于2%,关键词均匀分布,使用H型标签,优化链接标签,使用加粗斜体、李优化、图片标签优化等网页内容细节优化,以及TDK三大标签的优化。
2:添加点击IP:
接下来,我们还可以进行一些其他的操作,比如通过IP转换软件更改我们的IP,然后搜索关键词即百度八屏,找到我们发布的网页。单击:访问更多页面并留在那里。久而久之,网上当然有所谓的自动点击软件。作者强烈建议大家不要使用!!!尤其是网上一些所谓的SEO软件,作者强烈建议大家不要使用,原因这里就不说了,有兴趣的可以给我留言,我会告诉他原因的。
百度搜索指定网站内容(1.把搜索范围限定在网页标题中——intitle(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-14 02:04
1.限制搜索到页面标题 - intitle
网页的标题通常是对网页内容的概括概括。将查询的内容限制在页面的标题上,有时可以取得不错的效果。使用方法是在查询内容中最关键的部分加上“intitle:”。
比如要查找林青霞的照片,可以这样查询: 照片标题:林青霞
注意 intitle: 和后面的 关键词 之间不能有空格。
2.将搜索结果限制在某个网站
比如我们要在百度云盘下载电影《肖申克的救赎》,那么,
这可以通过以下方式完成:
肖申克的救赎网站:
注意站点域名后跟“site:”不能收录“”;此外,site: 和站点名称之间不应有空格。
3.完全匹配 - 双引号
如果输入的查询词很长,百度分析后给出的搜索结果中的查询词可能会被拆分。如果对这种情况不满意,可以尝试让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“Shanghai University of科技”,取得的成果均符合要求。
4.完全匹配 - 书名编号
书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。
带书名的查询词有两个特殊功能:
首先,书名会出现在搜索结果中;
其次,标题号展开的内容不会被拆分。
标题编号在某些情况下特别有效,例如,
查找具有流行和常用名称的电影或小说。
比如你查一部电影的“手机”,如果不加书名,很多时候是通讯工具——手机,加上书名后,结果“手机”的一切都是关于电影的。
5.按扩展名搜索电子书
网络资源丰富,有很多电子书。人们在提供电子书时,往往会带上书的后缀。因此,可以使用后缀名称搜索电子书。
示例:存在与虚无 chm
蔬菜根棕褐色exe
煮三国chm 查看全部
百度搜索指定网站内容(1.把搜索范围限定在网页标题中——intitle(图))
1.限制搜索到页面标题 - intitle
网页的标题通常是对网页内容的概括概括。将查询的内容限制在页面的标题上,有时可以取得不错的效果。使用方法是在查询内容中最关键的部分加上“intitle:”。
比如要查找林青霞的照片,可以这样查询: 照片标题:林青霞
注意 intitle: 和后面的 关键词 之间不能有空格。
2.将搜索结果限制在某个网站
比如我们要在百度云盘下载电影《肖申克的救赎》,那么,
这可以通过以下方式完成:
肖申克的救赎网站:
注意站点域名后跟“site:”不能收录“”;此外,site: 和站点名称之间不应有空格。
3.完全匹配 - 双引号
如果输入的查询词很长,百度分析后给出的搜索结果中的查询词可能会被拆分。如果对这种情况不满意,可以尝试让百度不拆分查询词。这个效果可以通过在查询词后面加上双引号来实现。
比如你搜索上海科技大学,如果不加双引号,搜索结果会被拆分,效果不是很好,但是加双引号后,“Shanghai University of科技”,取得的成果均符合要求。
4.完全匹配 - 书名编号
书名是百度独有的特殊查询语法。在其他搜索引擎中,书名会被忽略,但在百度中,可以查询中文书名。
带书名的查询词有两个特殊功能:
首先,书名会出现在搜索结果中;
其次,标题号展开的内容不会被拆分。
标题编号在某些情况下特别有效,例如,
查找具有流行和常用名称的电影或小说。
比如你查一部电影的“手机”,如果不加书名,很多时候是通讯工具——手机,加上书名后,结果“手机”的一切都是关于电影的。
5.按扩展名搜索电子书
网络资源丰富,有很多电子书。人们在提供电子书时,往往会带上书的后缀。因此,可以使用后缀名称搜索电子书。
示例:存在与虚无 chm
蔬菜根棕褐色exe
煮三国chm

