
火车头
织梦用火车头采集器采集文章后手动生成首页、栏目页、上下篇
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-04-27 11:03
织梦使用火车头采集器采集数据,发布文档后是不会手动生成首页、上下篇、栏目页的,我们可以给织梦dedecms添加手动生成代码来实现,先普及下织梦火车头采集器知识:
火车头是一款可以大量采集原创文章的软件。
火车头采集器有什么用处?
1、通用性强
无论新闻、论坛、视频、黄页、图片、下载类网站,只要通过浏览器能看到的结构化的内容,通过指定匹配规则,都能采集到您所须要的内容。
2、稳定、高效
七年磨一剑,软件不断更新进步火车头采集教程,采集速度快,性能稳定,占用资源少。
3、扩展性强、适用范围广
自定义web发布,自定义主流的数据库的保存和发布,自定义本地php及.net外部编程插口处理数据火车头采集教程,让数据都能为你所用。
实现教程
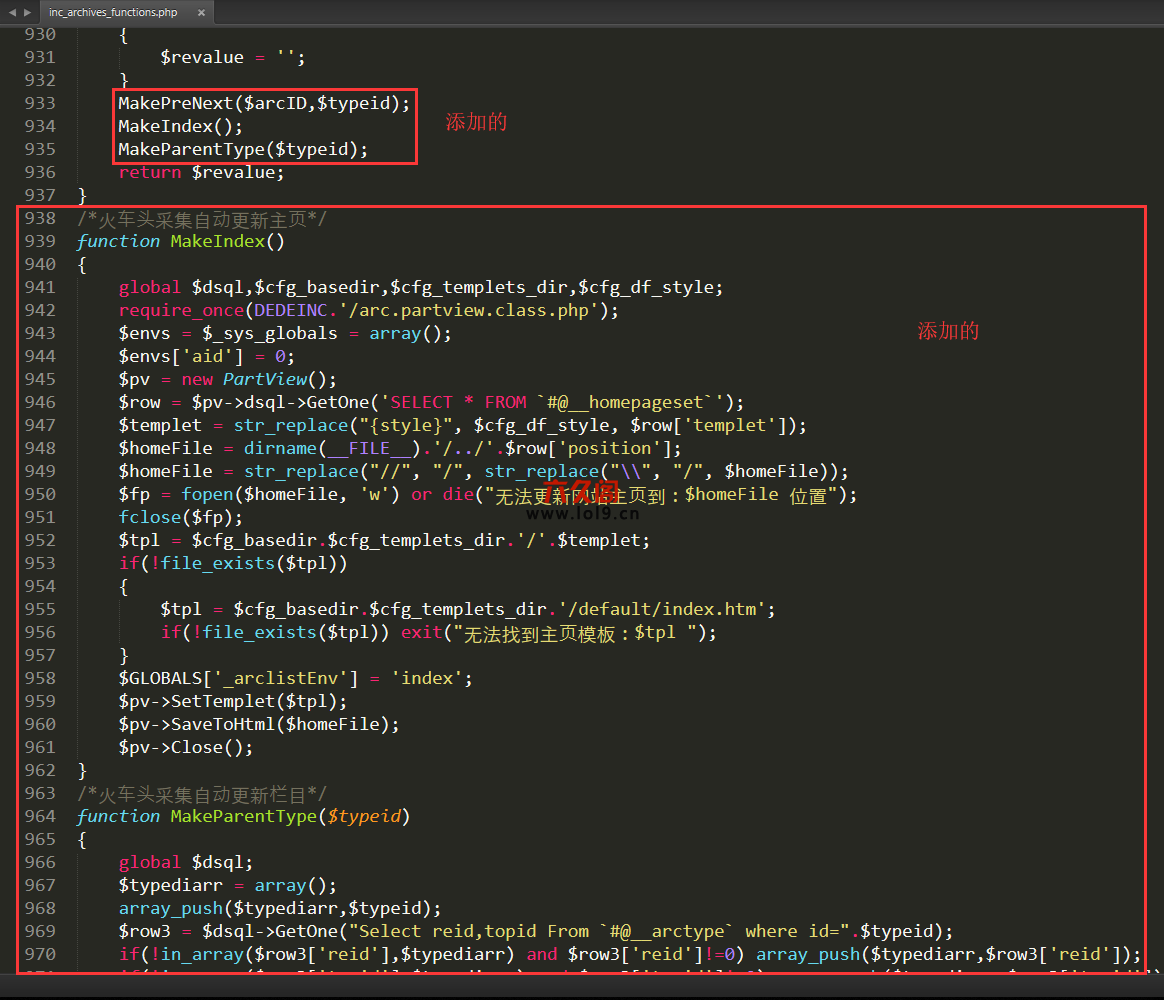
打开 /dede/inc/inc_archives_functions.php
在这个文件中找到
return $revalue;
在它的里面加入
MakePreNext($arcID,$typeid);
MakeIndex();
MakeParentType($typeid);
添加完后是这样的
这样添加好后,无论你用火车头免登入插口还是WEB发布模块,无论是普通文章模型还是图集模型还是软件模型,都可以手动生成相关静态文件了。 查看全部

织梦使用火车头采集器采集数据,发布文档后是不会手动生成首页、上下篇、栏目页的,我们可以给织梦dedecms添加手动生成代码来实现,先普及下织梦火车头采集器知识:
火车头是一款可以大量采集原创文章的软件。
火车头采集器有什么用处?
1、通用性强
无论新闻、论坛、视频、黄页、图片、下载类网站,只要通过浏览器能看到的结构化的内容,通过指定匹配规则,都能采集到您所须要的内容。
2、稳定、高效
七年磨一剑,软件不断更新进步火车头采集教程,采集速度快,性能稳定,占用资源少。
3、扩展性强、适用范围广
自定义web发布,自定义主流的数据库的保存和发布,自定义本地php及.net外部编程插口处理数据火车头采集教程,让数据都能为你所用。
实现教程
打开 /dede/inc/inc_archives_functions.php
在这个文件中找到
return $revalue;
在它的里面加入
MakePreNext($arcID,$typeid);
MakeIndex();
MakeParentType($typeid);
添加完后是这样的
这样添加好后,无论你用火车头免登入插口还是WEB发布模块,无论是普通文章模型还是图集模型还是软件模型,都可以手动生成相关静态文件了。
火车头采集器采集文章操作教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 914 次浏览 • 2020-04-27 11:03
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接火车头采集教程,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试火车头采集教程,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的采集工具。但请在版权范围内采集。 查看全部
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接火车头采集教程,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试火车头采集教程,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的采集工具。但请在版权范围内采集。
火车头教程10:文件手动上传到网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2020-04-27 11:02
抓包截图:
有文件递交的抓到的结果有很多乱七八糟的东西,这个不用介意,我们不用管他是哪些,复制放在采集器上面,采集器会手动帮你辨识好的,如上图抓包的结果。如果最前面出现了黄色框的字样
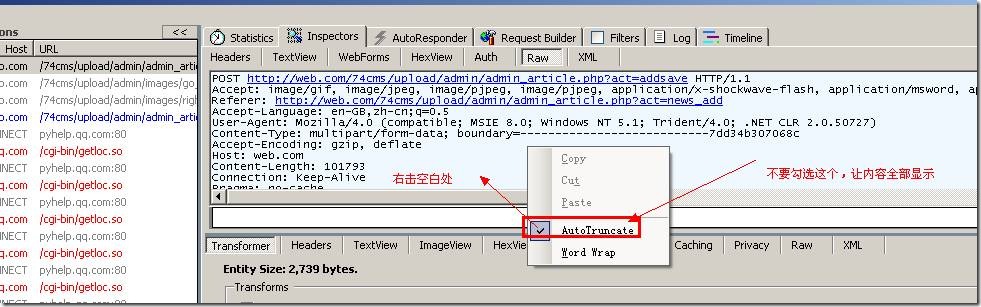
说明有隐藏的内容没有显示下来,解决办法如下:
按照上图操作,上面隐藏的内容就全部显示了,然后把抓到的数据复制到采集器上面去如下图:
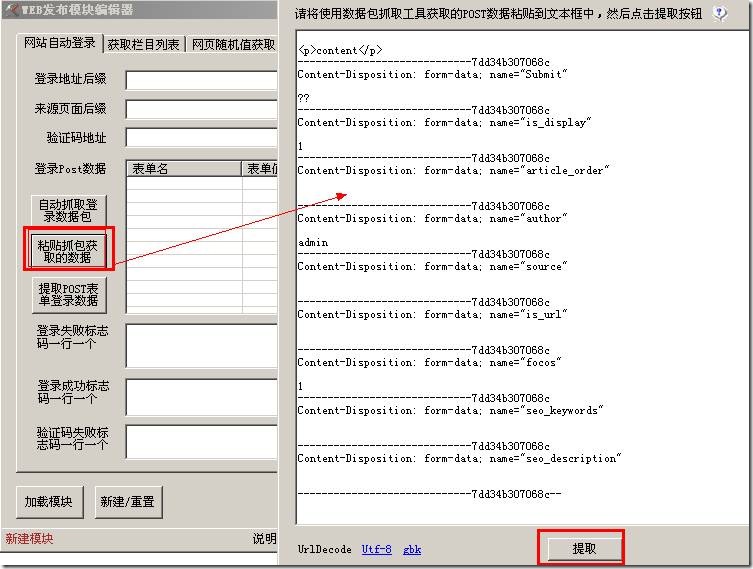
采集器会把数据一样提取下来。如下图,表单名和表单值一一对应:
那么我们文件上传在哪一部分呢?如下图:
在中级部份,我们选中文件上传设置下边的列表火车头采集教程,右侧就可以更改了,标签名那边会显示好多奇怪的东西,我们不用在乎,标签名我们写上规则上面须要上传文件的标签名称。
你可以单独构建一个标签采集缩略图,或者规则里的任意一个标签,只要这个标签采集结果包含图片文件就可以了,也就是说这儿的标签采集结果可以是单独一张图片的地址也可以是包含图片和其他文字信息火车头采集教程,图片都要下载到本地。
如下图:
我这样写,就表示我的规则上面的内容标签采集结果内有我要上传的图片文件,这里设置和规则设置要一致,不能随意写。点击保存就好了。
这一步是文件手动上传到网站最重要的一步,和做普通发布模块一样,抓包之后把抓到的信息填在采集器上面,采集器会手动提取,你要做的就是这中级功能这部份更改下标签名就好。
在我们测试发布模块的地方可以见到如下:
这里就是手动上传文件的地方了,测试的时侯点击“浏览”选择本地图片进行测试。
测试结果如下:
这个就是用这个手动上传功能把缩略图上传起来了,大家听到内容上面的图片并没有上传,因为不支持,在开始的第1点我就做了说明,这里指出下。 查看全部
如下图:
抓包截图:

有文件递交的抓到的结果有很多乱七八糟的东西,这个不用介意,我们不用管他是哪些,复制放在采集器上面,采集器会手动帮你辨识好的,如上图抓包的结果。如果最前面出现了黄色框的字样
说明有隐藏的内容没有显示下来,解决办法如下:
按照上图操作,上面隐藏的内容就全部显示了,然后把抓到的数据复制到采集器上面去如下图:
采集器会把数据一样提取下来。如下图,表单名和表单值一一对应:
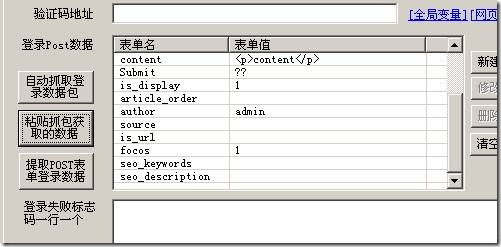
那么我们文件上传在哪一部分呢?如下图:
在中级部份,我们选中文件上传设置下边的列表火车头采集教程,右侧就可以更改了,标签名那边会显示好多奇怪的东西,我们不用在乎,标签名我们写上规则上面须要上传文件的标签名称。
你可以单独构建一个标签采集缩略图,或者规则里的任意一个标签,只要这个标签采集结果包含图片文件就可以了,也就是说这儿的标签采集结果可以是单独一张图片的地址也可以是包含图片和其他文字信息火车头采集教程,图片都要下载到本地。
如下图:
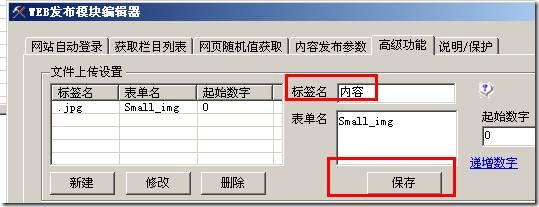
我这样写,就表示我的规则上面的内容标签采集结果内有我要上传的图片文件,这里设置和规则设置要一致,不能随意写。点击保存就好了。
这一步是文件手动上传到网站最重要的一步,和做普通发布模块一样,抓包之后把抓到的信息填在采集器上面,采集器会手动提取,你要做的就是这中级功能这部份更改下标签名就好。
在我们测试发布模块的地方可以见到如下:
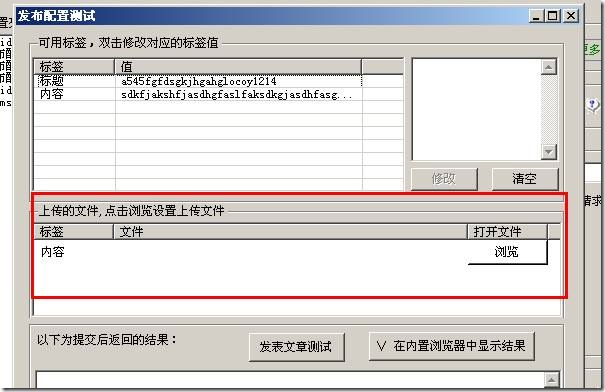
这里就是手动上传文件的地方了,测试的时侯点击“浏览”选择本地图片进行测试。
测试结果如下:
这个就是用这个手动上传功能把缩略图上传起来了,大家听到内容上面的图片并没有上传,因为不支持,在开始的第1点我就做了说明,这里指出下。
火车头采集小说教程规则须要注意的内容,可采集,一次搞了几百部!
采集交流 • 优采云 发表了文章 • 0 个评论 • 845 次浏览 • 2020-04-27 11:01
1、充会员,拿cookie
要充到会员拿cookie才可以采集火车头采集教程,要不然没有浏览权限。
2、小说站类型
有的小说站是微信公众号 微站的方式,需要手机抓包,相对网页站来说,麻烦一些,网页站点采集相对容易些,但是也有限制火车头采集教程,比如,找不到内容放哪儿去了,站长做防采集隐藏了上去。
3、外链 很烦
有的小说站在文章中嵌入了好多外链,格式式样不同,量十分大,让人太难受。
4、站点序号
这一点不同需求的人不同,采集小说上传到自己的小说站,需要采集到的文章小说有一定的规则,也就是根据序号排列,很多站点把序号故意整乱,格式乱七八糟,在匹配那些序号时,浪费了大量的时间。还不能做到,百分百匹配正确,2000千章的小说,总有这么一些匹配不正确的。
作者QQ129-0654-348
------------------------20181208更新------------------------
注意:
5、火车头采集小说时,请先说明采集模板式样,有童鞋,直接过来采集规则,然后前面须要依照模板再进行更改,会麻烦些,单本采集和全本采集的规则是不同的哦~
6、全本采集,有的小说站点在章节中没有小说名,如果须要从一级网址或则二级网址采集数据,需要火车头的会员版才行,免费版不能使用。
7、采集时假如cookie 失效,还须要我们学会抓包。
=====20191109更新=====
8、关于教程问题:
8.1、采集PC端的小说,根据《火车头基础教程》就可以解决,尤其是这些免费采集的PC端小说站点,比如:笔-趣、阁 ==八+一+中+文))网。
8.2、采集微信公众号小说教程比较麻烦,因为公众号的不稳定性,公众号会失效,可能须要重新制做教程,我那边也联系了一些做小说站的同学,很少乐意公开分享,所以,可能还须要再等待一段时间。
=====20191123更新=====
9、关于get和post的列表页
昨天有个同学须要采集的站点,是微信公众号的小说站,该站点会提早get出前15章,后面的全部是post恳求,该同学测试的时侯,老是发觉缺乏了前15章,后面我仔细查看以后发觉列表页get的数据没有获取到。
因为标签规则都是一样的,所以,直接把前15章的那种列表页网址复制到火车头的初始地址上面,就可以获取到了。
=====20200420更新=====
10、火车头小说采集视频教程 查看全部
1、充会员,拿cookie
要充到会员拿cookie才可以采集火车头采集教程,要不然没有浏览权限。

2、小说站类型
有的小说站是微信公众号 微站的方式,需要手机抓包,相对网页站来说,麻烦一些,网页站点采集相对容易些,但是也有限制火车头采集教程,比如,找不到内容放哪儿去了,站长做防采集隐藏了上去。
3、外链 很烦
有的小说站在文章中嵌入了好多外链,格式式样不同,量十分大,让人太难受。
4、站点序号
这一点不同需求的人不同,采集小说上传到自己的小说站,需要采集到的文章小说有一定的规则,也就是根据序号排列,很多站点把序号故意整乱,格式乱七八糟,在匹配那些序号时,浪费了大量的时间。还不能做到,百分百匹配正确,2000千章的小说,总有这么一些匹配不正确的。
作者QQ129-0654-348
------------------------20181208更新------------------------
注意:
5、火车头采集小说时,请先说明采集模板式样,有童鞋,直接过来采集规则,然后前面须要依照模板再进行更改,会麻烦些,单本采集和全本采集的规则是不同的哦~
6、全本采集,有的小说站点在章节中没有小说名,如果须要从一级网址或则二级网址采集数据,需要火车头的会员版才行,免费版不能使用。
7、采集时假如cookie 失效,还须要我们学会抓包。
=====20191109更新=====
8、关于教程问题:
8.1、采集PC端的小说,根据《火车头基础教程》就可以解决,尤其是这些免费采集的PC端小说站点,比如:笔-趣、阁 ==八+一+中+文))网。
8.2、采集微信公众号小说教程比较麻烦,因为公众号的不稳定性,公众号会失效,可能须要重新制做教程,我那边也联系了一些做小说站的同学,很少乐意公开分享,所以,可能还须要再等待一段时间。
=====20191123更新=====
9、关于get和post的列表页
昨天有个同学须要采集的站点,是微信公众号的小说站,该站点会提早get出前15章,后面的全部是post恳求,该同学测试的时侯,老是发觉缺乏了前15章,后面我仔细查看以后发觉列表页get的数据没有获取到。
因为标签规则都是一样的,所以,直接把前15章的那种列表页网址复制到火车头的初始地址上面,就可以获取到了。
=====20200420更新=====
10、火车头小说采集视频教程
火车头伪原创插件使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2020-04-27 11:01
火车头采集大家都比较熟悉,这里不多做介绍,主要要说的是火车头伪原创插件,这个插件称作小发猫AI+,因为是一个基于语义NLP的伪原创软件,效果比反义词替换的好好多。
【火车头伪原创插件使用方式】
1、修改火车头的PHP环境
由于火车头采集器软件外置的PHP环境有问题,在使用PHP插件之前须要先更改火车头的PHP环境。修改的方式很简单,打开火车头网站采集软件的安装目录“System/PHP”,找到php.ini文件打开火车头采集教程,并找到如下代码。
找到 php_curl.dll 把上面的分号去除改成:
修改前:
;extension=php_curl.dll
修改后:
extension=php_curl.dll
也就是将最前面的分号“;”删除并保存即可,这样火车头数据采集器就可以正常运行这个PHP扩写插件了。
2、插件要统一放在火车头插件目录
例如我本机是:D:\火车采集器V9\Plugins
问:这个插件主要功能是哪些?
回答:火车头是一个采集器。采集后,如果开了插件,会把采集到的内容通过插件处理后再保存,我们的插件是伪原创,所以采集的内容会伪原创后保存。
3、调试方式
首先按原先的方法,先确保采集规则能正常运行。
然后火车头采集教程,在正常运行的基础上,选择伪原创插件。
一个有效的搜集工具,可以帮助我们更快地完成竞购。
火车头采集器是一种高性能的网路数据采集软件,实现了从数据采集到处理再到发布的一系列智能操作,真正实现了智能化。
不仅这般,它还可以快速,稳定地响应大量数据采集需求,而不是自动搜集和模拟自动操作,从而大大提升工作效率,节省人力资源。
作为一个专业的网站爬虫,火车收藏家抓取网页数据、处理、分析、挖掘非常擅长。
如今,市场上的网页搜集软件极其复杂。机车无疑是一种十分可靠且极易使用的网路数据采集软件。
它可以灵活,快速地捕获网页中分散的文本,图片和其他资源信息,然后通过一系列的剖析和处理,准确地挖掘出您须要的大部分数据信息。
您可以选择将数据发布到网站、以导出数据库,或将其保存在本地Excel,Word和其他格式的文件中。
收集新闻和搜集文章都在空中。老板不再须要害怕不这样做,一切都显得这么简单
经过六年的升级换代,火车收藏家积累了大量的用户和良好的口碑。它是市场上最受欢迎的网路数据采集软件。 查看全部
火车头采集大家都比较熟悉,这里不多做介绍,主要要说的是火车头伪原创插件,这个插件称作小发猫AI+,因为是一个基于语义NLP的伪原创软件,效果比反义词替换的好好多。
【火车头伪原创插件使用方式】
1、修改火车头的PHP环境
由于火车头采集器软件外置的PHP环境有问题,在使用PHP插件之前须要先更改火车头的PHP环境。修改的方式很简单,打开火车头网站采集软件的安装目录“System/PHP”,找到php.ini文件打开火车头采集教程,并找到如下代码。
找到 php_curl.dll 把上面的分号去除改成:
修改前:
;extension=php_curl.dll
修改后:
extension=php_curl.dll
也就是将最前面的分号“;”删除并保存即可,这样火车头数据采集器就可以正常运行这个PHP扩写插件了。
2、插件要统一放在火车头插件目录
例如我本机是:D:\火车采集器V9\Plugins
问:这个插件主要功能是哪些?
回答:火车头是一个采集器。采集后,如果开了插件,会把采集到的内容通过插件处理后再保存,我们的插件是伪原创,所以采集的内容会伪原创后保存。
3、调试方式
首先按原先的方法,先确保采集规则能正常运行。
然后火车头采集教程,在正常运行的基础上,选择伪原创插件。
一个有效的搜集工具,可以帮助我们更快地完成竞购。
火车头采集器是一种高性能的网路数据采集软件,实现了从数据采集到处理再到发布的一系列智能操作,真正实现了智能化。
不仅这般,它还可以快速,稳定地响应大量数据采集需求,而不是自动搜集和模拟自动操作,从而大大提升工作效率,节省人力资源。
作为一个专业的网站爬虫,火车收藏家抓取网页数据、处理、分析、挖掘非常擅长。
如今,市场上的网页搜集软件极其复杂。机车无疑是一种十分可靠且极易使用的网路数据采集软件。
它可以灵活,快速地捕获网页中分散的文本,图片和其他资源信息,然后通过一系列的剖析和处理,准确地挖掘出您须要的大部分数据信息。
您可以选择将数据发布到网站、以导出数据库,或将其保存在本地Excel,Word和其他格式的文件中。
收集新闻和搜集文章都在空中。老板不再须要害怕不这样做,一切都显得这么简单
经过六年的升级换代,火车收藏家积累了大量的用户和良好的口碑。它是市场上最受欢迎的网路数据采集软件。
火车头采集时 采网址--重复网址的临时解决方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-04-27 11:00
商业版用户的采集后的网址都存贮在 PageUrl 目录上面的,一个任务对应一个db3.大家可以从最里面的任务往下数第一个,对应的就是Site_*.db3.这样你们可以先备份一下,然后清空也不怕了,到时候直接还原用户名既可以,如果怕出错,全部保存,一会恢复即可。
如果想更进一步的查看,这个db3虽然就是sqlite数据库格式的文件,可以用db3数据库编辑器 查看更改。根据jobid查看,有同事问不知道jobid怎样办,呵呵,大家可以到 Data 目录查看 3-新浪国外新闻 后面的新浪国外新闻就是你自定义的网站栏目名称。这个跟jobid对应上即可。
最后你们备份好数据库之后就可以(需要备份在 PageUrl 与 Data目录的你的任务名对应的文件夹,最好是全部以防万一,采集完就可以覆盖下。)
后来从网站也看见了如下文件,跟我的这篇大同小异。大家可以参考下。
火车头是一个不错的采集软件,“盗亦有道”,看你怎么借助了。
Linker曾经也时常研究下火车头采集软件,只是仍然没有订购商业版本,想想火车头采集教程,现在的版本远没有曾经的1.x和2.x版本来得爽快。
一位兄弟,昨晚说他的火车头采集软件(企业版本的哦,有钱人!),总是提示任务地址库重复,研究了下,比较简单,告诉了他处理的方式,另外,经过搜索发觉,火车头的3.0 sp1版本有过这个bug火车头采集教程,清除不掉任务地址库,但管理员早已在sp2版本中解决掉这个问题了。
后来那位同学又问火车头采集软件的任务地址库是那个文件?怎么样保存任务地址库?怎么样自动清除任务地址库文件?据Linker所知,编辑任务地址库,需要是商业版本了,如果想自动来处理,可以发觉,手动地址库文件是在火车头根目录下的pageurl目录中,每一个任务对应一个地址库文件,mdb格式的,打开可以发觉,具体地址是被加密了。火车头也有些很商业了,嘿嘿!
既然晓得任务地址库的位置和文件了,手动清除任务地址库,自然就简单了。删除使火车头重复(删除后,编辑该任务,再保存),或者直接删掉该库上面的记录,都可以。想另存为其他任务所用,重命令为其它任务的id就行了。
简单测试通过。 查看全部
商业版用户的采集后的网址都存贮在 PageUrl 目录上面的,一个任务对应一个db3.大家可以从最里面的任务往下数第一个,对应的就是Site_*.db3.这样你们可以先备份一下,然后清空也不怕了,到时候直接还原用户名既可以,如果怕出错,全部保存,一会恢复即可。
如果想更进一步的查看,这个db3虽然就是sqlite数据库格式的文件,可以用db3数据库编辑器 查看更改。根据jobid查看,有同事问不知道jobid怎样办,呵呵,大家可以到 Data 目录查看 3-新浪国外新闻 后面的新浪国外新闻就是你自定义的网站栏目名称。这个跟jobid对应上即可。
最后你们备份好数据库之后就可以(需要备份在 PageUrl 与 Data目录的你的任务名对应的文件夹,最好是全部以防万一,采集完就可以覆盖下。)
后来从网站也看见了如下文件,跟我的这篇大同小异。大家可以参考下。
火车头是一个不错的采集软件,“盗亦有道”,看你怎么借助了。
Linker曾经也时常研究下火车头采集软件,只是仍然没有订购商业版本,想想火车头采集教程,现在的版本远没有曾经的1.x和2.x版本来得爽快。
一位兄弟,昨晚说他的火车头采集软件(企业版本的哦,有钱人!),总是提示任务地址库重复,研究了下,比较简单,告诉了他处理的方式,另外,经过搜索发觉,火车头的3.0 sp1版本有过这个bug火车头采集教程,清除不掉任务地址库,但管理员早已在sp2版本中解决掉这个问题了。
后来那位同学又问火车头采集软件的任务地址库是那个文件?怎么样保存任务地址库?怎么样自动清除任务地址库文件?据Linker所知,编辑任务地址库,需要是商业版本了,如果想自动来处理,可以发觉,手动地址库文件是在火车头根目录下的pageurl目录中,每一个任务对应一个地址库文件,mdb格式的,打开可以发觉,具体地址是被加密了。火车头也有些很商业了,嘿嘿!
既然晓得任务地址库的位置和文件了,手动清除任务地址库,自然就简单了。删除使火车头重复(删除后,编辑该任务,再保存),或者直接删掉该库上面的记录,都可以。想另存为其他任务所用,重命令为其它任务的id就行了。
简单测试通过。
火车头采集器教程之网站采集规则编撰
采集交流 • 优采云 发表了文章 • 0 个评论 • 531 次浏览 • 2020-04-27 11:00
点选新建按键,选择新建站点“每日经济新闻” 我们,先进行“标题”规则的编撰 标题标签规则的编撰 注意:标签起始字符串的确认,一定要注意两点,一、唯一性;二、贴身原则,即尽可能紧贴目标采集区域; 开始字符串: 结束字符串: 注意:确认字符串的唯一性:复制字符串,点按快捷键“Ctrl+ F”进行查找,如果字符串为惟一,会有提示信息“找不到XXX”的提 Google冷凝器 数据采集 蒸发器 分配器 找回密码 注册成为 师大人 帐号 UI 用户名/Email 记住密码 密码 登录 火车头采集器教程之网站采集规则编撰 Html 标签排除:我们选择“全选”。 注意:然对于“空格(占位符) ”我们可以有所保留,因为有些站点的“长标题”的分隔不是靠标点或则正宗意义上的空白,而是 靠“占位符 ”进行分隔的,那么这时候我们就要保留“空格(占位符) ”选项。(课后看吧) 此时我们可以以点代面,直接进行“典型页面”的采集测试,测试一下采集效果,满意后,我们接下来进行文章内容的规则编 文章内容标签规则的编撰开始字符串:
iframeHt ml 标签排除:此时我们要保留拿来界定段落的一下常用字符串“ 结束字符串:[ 200 Ht ml 标签排除:我们选择“全选”。(测试) 时间标签编撰规则 要点同上。 开始字符串:
iframeHt ml 标签排除:我们选择“全选”。(测试) 出处标签尺寸的编撰 此值,一般来说,我们默认为我们采集的目标网站,使用“固定格式的数据”进行设置,但是,你若果为了更好的彰显贵网站的 版权意识,那么,你在对目标网站转载的文章进行采集设置的时侯,可以进行相应调整,此处不做赘言。 好了,整个站点的“内容规则”我们设置完毕,下面将进行,采集任务的设置。 二、新建采集任务在刚才构建的采集站点上点击滑鼠右键,选择“从该站点新建任务”,,在弹出的对话框里我们察看一下“内容规则”,结果正如前 边所说“在站点下构建的采集任务默认承继站点采集内容规则”,好了,我们就可以直接编撰“采集网址”的规则了。 “采集网址深度”标签的编撰 为了灵活便捷,此项操作,我们通常都在文章的列表页面进行操作,所以我们可采用其默认值“1”,对于更深度的采集我们以 后的教程中进行探讨,此处不做赘言。 开始采集网址规则的编撰 火车头采集器教程之网站采集规则编撰 点选“向导添加”在弹出的对话框中有三个选项“单页网址”、“批量/多页”、“文本导出”,一般情况火车头采集教程,我们不会用到“文本导出”方 此处仅对前两种采集方式进行探讨。我们先进行“单页网址”的设置,此处我们选择“地产”栏目进行学习。
列表页面网址为 htt 74,复制到文本域中,点选“添加”按钮,并“完成添加”。 回到“新建任务”—“采集网址”出,进行“页面内选取区域采集网址”设置 从:align= 'left 到:class=right_font 测试,结果40页文章页面。。。全部采集测试通过,,满意,,(此处我们不进行采集)继续往下学习。好我们下边学习“批量/ 为了确定列表网址的变量,我们进行如下操作:1、我们在网页中“点选”“下一页”,,发现地址栏网址:htt 74&page= 74& amp;page= 74& page= 58; 4、再将键盘“指向”“首页”发现浏览器左下方状态栏显示地址为http:/ 74& page= 74&page= 74&page= 74&page= 58 http: 74&page= ;”为其列表网址的变量,那么我么可以设定如下:多页类似地址网址方式为:htt 数字变化范围从1到58,间隔倍数为1;点选“添加”按钮,并完成添加。 此处的“页面内选取区域采集网址”设置同“单页网址”“页面内选取区域采集网址”的设置,此处不做赘言。
点选“开始测试网址”,(这个过程太长,我暂停了视频录制) 当然,在实际操作当中,如果数据量大,我们也可以不去测试,直接采集,即便是因为规则的不完全适用性而导致一部分数 据的遗失,我想也是可以忽视的。 此处,我只选择了2页进行采集 测试结果共有80页内容页面。 下一步骤:“数据发布形式”设置 回复引用 举报 返回底部 返回列表 wap CP备09056220号;闽ICP备10028594号 GMT+8,2011-4-6 09:55 0.155204second(s), 27 queries 我们选定方法一:“保存到软件数据库”,同时,选取形式三“Web在线发布到网站”的“使用自定义发布形式”,“自定义分类I D”选择3,给任务命名为“地产”火车头采集教程,,并“保 存,更新”采集任务,鉴于我们教程刚刚开始,就不做深入学习。 回到火车头主界面,在“地产”任务上点击滑鼠右键,选择“开始”,即可完成采集。 采集数据会手动发布到形式三所指向的网站的指定栏目( ,同时保存到:火车头安装目录/ DATA/ 序号- 任务名/ Spi der Resul .mdb的数据库中。 哦,,昨天net 对我的错误提示了我一下,,, 3个小时要写文案,录像,还得采集信息到我的网站,晕倒了N次,,,写的苏州粗了,,完全是凭感觉写的,,让你们云里 雾里的一头雾水,不好意思阿,,请见谅!!!: L,现在更正以下: 这里的方法一、方式三是并列关系的,,可以同时选,也可以任选其二,,,如果你没有在发布模块的话,就直接采集到 本地软件数据库即可。
“本地软件数据库”是谷歌Access的,我们可以打开一下数据库对数据进行一下浏览查验。 至于方法三“Web在线发布到网站”,我会在此后的教程中进行讲解,希望你们就能耐心等待。 好了,,本教程到此为止!下一节课,再见!!! 收藏0 分享0 楼主热帖峰会新帖 中国移动通信集团福建有限公司德化分公司急聘信息 2011年晋江移动分公司急聘信息(报名截至至3月20日) 2011年长乐市中小学招录师范专业本本科毕业生公告 2011年将乐县教育系统补充班主任公开急聘工作方案 大田县2011年中中学新任班主任公开考试急聘方案 关于2011年建瓯市公开选聘农村中小学班主任进城任教的通知 福建师范大学2011届毕业生信息及辅导员联系方法 4月9日2011年福建省师范专业毕业生供需见面会暨福建师范大学小型校园供需见面会 04月06日 签到记录贴 后期宣传 2011年顺昌县中小学班主任急聘职位简章 2011年武夷山市中小学班主任急聘简章 福建师范大学中学生门户祝全体师生新年快乐!万事如意! 上一主题|下一主题 福建师范大学中学生门户访问统计: 2010广告合作 声明:本站部份内容来自网路,如侵害您版权请与本站联系,即行删掉。 火车头采集器教程之网站采集规则编撰 查看全部
我的中心游戏 共青团广场 学习资料 师大人家 师大微博 群组 学生门户 QQ群 搜索群组 请输入搜索内容【师大搜索】 群组 网站 采集 火车头采集器 火车头采集器教程之网站采集规则编撰 返回列表 查看:579 复制链接]admin 师大管理员 礼物信息 赠送礼物:4 在线聊天加为好友 个人空间 发表于 2010-5-20 09:39 打印首先,我们先了解一下火车头采集器(LocoySpider)V3的基本功能, 我们明天所用到的火车头的基本功能如下 1、新建站点 2、新建任务 3、数据发布形式之“保存到软件数据库” 当然本教程是围绕“CMS采集规则编撰”这一主题展开的,所以不可能面面俱到的陈表火车头采集器的功能,在此请见谅! 现在我们结合实战来给你们讲解 一、新建站点1、功能:对同一站点具有“相同采集内容规则”的采集任务进行聚合 2、好处: a、分类明确,便于查询、调用; b、在站点下构建的采集任务默认承继站点采集内容规则,避免了重复编撰采集规则的麻烦; 3、实战: 我们以“每日经济新闻”为例进行讲解,首先我们打开其站点 htt ,浏览其中不同栏目的文章发现这个站点的文章模式(模板)几乎是完全一致的 (当然,其中有一点小小的区别,就是有的文章段落是靠段落标记 布局的,那么残余的DIV标记太可能会破坏你原先的布局,此种情况的解决办法我们之后再继续讨论,这里我就不再赘言 好,现在我们有理由相信,我们构建一个站点的“内容规则”,就可以将这个网站的所有栏目囊括了。
点选新建按键,选择新建站点“每日经济新闻” 我们,先进行“标题”规则的编撰 标题标签规则的编撰 注意:标签起始字符串的确认,一定要注意两点,一、唯一性;二、贴身原则,即尽可能紧贴目标采集区域; 开始字符串: 结束字符串: 注意:确认字符串的唯一性:复制字符串,点按快捷键“Ctrl+ F”进行查找,如果字符串为惟一,会有提示信息“找不到XXX”的提 Google冷凝器 数据采集 蒸发器 分配器 找回密码 注册成为 师大人 帐号 UI 用户名/Email 记住密码 密码 登录 火车头采集器教程之网站采集规则编撰 Html 标签排除:我们选择“全选”。 注意:然对于“空格(占位符) ”我们可以有所保留,因为有些站点的“长标题”的分隔不是靠标点或则正宗意义上的空白,而是 靠“占位符 ”进行分隔的,那么这时候我们就要保留“空格(占位符) ”选项。(课后看吧) 此时我们可以以点代面,直接进行“典型页面”的采集测试,测试一下采集效果,满意后,我们接下来进行文章内容的规则编 文章内容标签规则的编撰开始字符串:
iframeHt ml 标签排除:此时我们要保留拿来界定段落的一下常用字符串“ 结束字符串:[ 200 Ht ml 标签排除:我们选择“全选”。(测试) 时间标签编撰规则 要点同上。 开始字符串:
iframeHt ml 标签排除:我们选择“全选”。(测试) 出处标签尺寸的编撰 此值,一般来说,我们默认为我们采集的目标网站,使用“固定格式的数据”进行设置,但是,你若果为了更好的彰显贵网站的 版权意识,那么,你在对目标网站转载的文章进行采集设置的时侯,可以进行相应调整,此处不做赘言。 好了,整个站点的“内容规则”我们设置完毕,下面将进行,采集任务的设置。 二、新建采集任务在刚才构建的采集站点上点击滑鼠右键,选择“从该站点新建任务”,,在弹出的对话框里我们察看一下“内容规则”,结果正如前 边所说“在站点下构建的采集任务默认承继站点采集内容规则”,好了,我们就可以直接编撰“采集网址”的规则了。 “采集网址深度”标签的编撰 为了灵活便捷,此项操作,我们通常都在文章的列表页面进行操作,所以我们可采用其默认值“1”,对于更深度的采集我们以 后的教程中进行探讨,此处不做赘言。 开始采集网址规则的编撰 火车头采集器教程之网站采集规则编撰 点选“向导添加”在弹出的对话框中有三个选项“单页网址”、“批量/多页”、“文本导出”,一般情况火车头采集教程,我们不会用到“文本导出”方 此处仅对前两种采集方式进行探讨。我们先进行“单页网址”的设置,此处我们选择“地产”栏目进行学习。
列表页面网址为 htt 74,复制到文本域中,点选“添加”按钮,并“完成添加”。 回到“新建任务”—“采集网址”出,进行“页面内选取区域采集网址”设置 从:align= 'left 到:class=right_font 测试,结果40页文章页面。。。全部采集测试通过,,满意,,(此处我们不进行采集)继续往下学习。好我们下边学习“批量/ 为了确定列表网址的变量,我们进行如下操作:1、我们在网页中“点选”“下一页”,,发现地址栏网址:htt 74&page= 74& amp;page= 74& page= 58; 4、再将键盘“指向”“首页”发现浏览器左下方状态栏显示地址为http:/ 74& page= 74&page= 74&page= 74&page= 58 http: 74&page= ;”为其列表网址的变量,那么我么可以设定如下:多页类似地址网址方式为:htt 数字变化范围从1到58,间隔倍数为1;点选“添加”按钮,并完成添加。 此处的“页面内选取区域采集网址”设置同“单页网址”“页面内选取区域采集网址”的设置,此处不做赘言。
点选“开始测试网址”,(这个过程太长,我暂停了视频录制) 当然,在实际操作当中,如果数据量大,我们也可以不去测试,直接采集,即便是因为规则的不完全适用性而导致一部分数 据的遗失,我想也是可以忽视的。 此处,我只选择了2页进行采集 测试结果共有80页内容页面。 下一步骤:“数据发布形式”设置 回复引用 举报 返回底部 返回列表 wap CP备09056220号;闽ICP备10028594号 GMT+8,2011-4-6 09:55 0.155204second(s), 27 queries 我们选定方法一:“保存到软件数据库”,同时,选取形式三“Web在线发布到网站”的“使用自定义发布形式”,“自定义分类I D”选择3,给任务命名为“地产”火车头采集教程,,并“保 存,更新”采集任务,鉴于我们教程刚刚开始,就不做深入学习。 回到火车头主界面,在“地产”任务上点击滑鼠右键,选择“开始”,即可完成采集。 采集数据会手动发布到形式三所指向的网站的指定栏目( ,同时保存到:火车头安装目录/ DATA/ 序号- 任务名/ Spi der Resul .mdb的数据库中。 哦,,昨天net 对我的错误提示了我一下,,, 3个小时要写文案,录像,还得采集信息到我的网站,晕倒了N次,,,写的苏州粗了,,完全是凭感觉写的,,让你们云里 雾里的一头雾水,不好意思阿,,请见谅!!!: L,现在更正以下: 这里的方法一、方式三是并列关系的,,可以同时选,也可以任选其二,,,如果你没有在发布模块的话,就直接采集到 本地软件数据库即可。
“本地软件数据库”是谷歌Access的,我们可以打开一下数据库对数据进行一下浏览查验。 至于方法三“Web在线发布到网站”,我会在此后的教程中进行讲解,希望你们就能耐心等待。 好了,,本教程到此为止!下一节课,再见!!! 收藏0 分享0 楼主热帖峰会新帖 中国移动通信集团福建有限公司德化分公司急聘信息 2011年晋江移动分公司急聘信息(报名截至至3月20日) 2011年长乐市中小学招录师范专业本本科毕业生公告 2011年将乐县教育系统补充班主任公开急聘工作方案 大田县2011年中中学新任班主任公开考试急聘方案 关于2011年建瓯市公开选聘农村中小学班主任进城任教的通知 福建师范大学2011届毕业生信息及辅导员联系方法 4月9日2011年福建省师范专业毕业生供需见面会暨福建师范大学小型校园供需见面会 04月06日 签到记录贴 后期宣传 2011年顺昌县中小学班主任急聘职位简章 2011年武夷山市中小学班主任急聘简章 福建师范大学中学生门户祝全体师生新年快乐!万事如意! 上一主题|下一主题 福建师范大学中学生门户访问统计: 2010广告合作 声明:本站部份内容来自网路,如侵害您版权请与本站联系,即行删掉。 火车头采集器教程之网站采集规则编撰
火车头采集器使用教程–采集内容发布规则设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 824 次浏览 • 2020-04-26 11:02
教程总目录:火车头采集器使用教程
前面我们讲了如何找寻网站,以及采集文章链接和内容,下面我们就说一下内容发布相关的设置。
因为我教程里都是设置好的发布规则,所以这儿我就简单介绍下各个项目。
如下图
第一步,我们点击到内容发布规则这儿
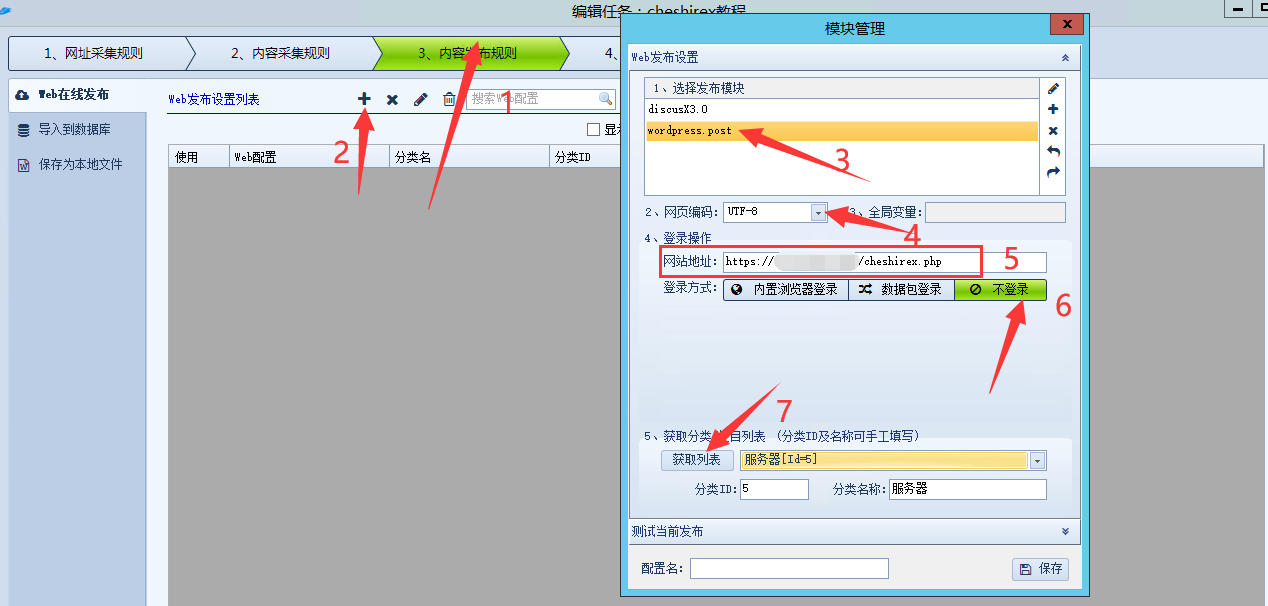
第二步,点击web发布规则列表前面的减号
第三步,出现了模块管理(教程总目录有写,我们的模块文件放在火车头程序下边的\Module\目录里),选择wordpress.post这个模块
第四步,网页编码选择UTF-8(wordpress程序是美国的,国际上通常都是UTF8编码,国内的一些会是GBK的编码,比如Discuz峰会程序就有UTF8和GBK两种安装包)
第五步,网站地址填入我们网页的地址前面加上插口文件名火车头采集教程,比如你的插口文件名是jiekou.php网站是这么这个地址就填入
第六步,登录方法选择不登录,我们的插口文件是免登录的。
第七步,点击一下下边的获取列表,正常的话会或取下来wordpress的文章分类列表。然后选择一个列表,你选择那个列表,采集的文章就发到那个列表里。
然后下边配置名随意写一个,保存。
然后我们把这个刚保存的发布配置勾选一下,启用它。
然后右下角别忘了点击一下保存火车头采集教程,也可以点保存并退出! 查看全部
火车头采集器使用教程–采集内容发布规则设置
教程总目录:火车头采集器使用教程
前面我们讲了如何找寻网站,以及采集文章链接和内容,下面我们就说一下内容发布相关的设置。
因为我教程里都是设置好的发布规则,所以这儿我就简单介绍下各个项目。
如下图
第一步,我们点击到内容发布规则这儿
第二步,点击web发布规则列表前面的减号
第三步,出现了模块管理(教程总目录有写,我们的模块文件放在火车头程序下边的\Module\目录里),选择wordpress.post这个模块
第四步,网页编码选择UTF-8(wordpress程序是美国的,国际上通常都是UTF8编码,国内的一些会是GBK的编码,比如Discuz峰会程序就有UTF8和GBK两种安装包)
第五步,网站地址填入我们网页的地址前面加上插口文件名火车头采集教程,比如你的插口文件名是jiekou.php网站是这么这个地址就填入
第六步,登录方法选择不登录,我们的插口文件是免登录的。
第七步,点击一下下边的获取列表,正常的话会或取下来wordpress的文章分类列表。然后选择一个列表,你选择那个列表,采集的文章就发到那个列表里。
然后下边配置名随意写一个,保存。
然后我们把这个刚保存的发布配置勾选一下,启用它。
然后右下角别忘了点击一下保存火车头采集教程,也可以点保存并退出!
火车头采集器使用教程–分析目标网站文章链接位置及规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 622 次浏览 • 2020-04-26 11:02
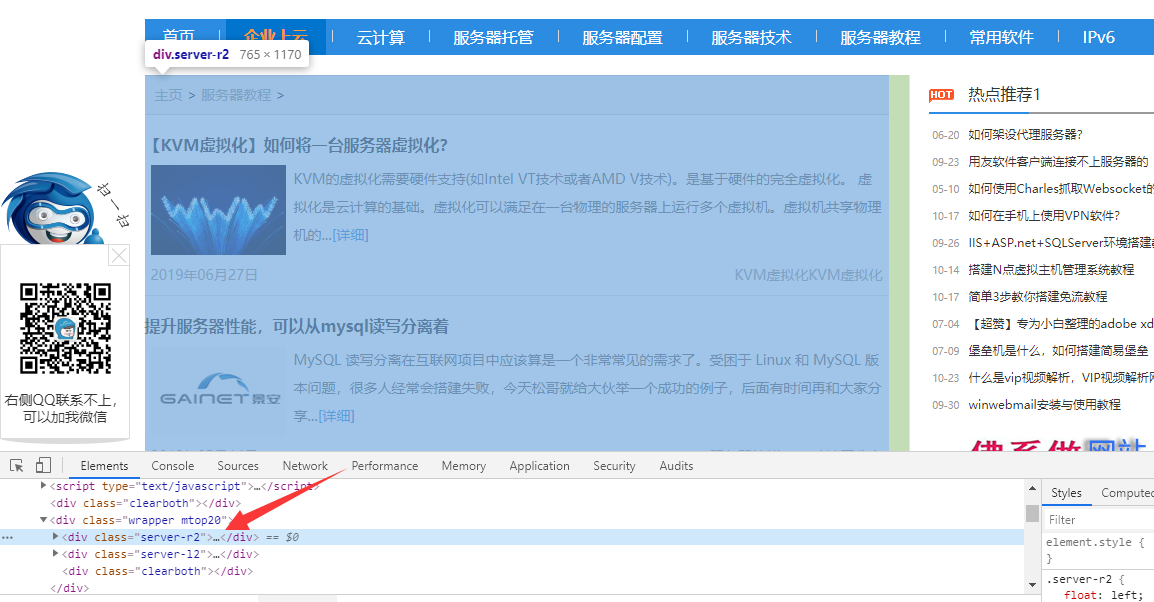
首先看下火车头采集教程,在列表页上面他的文章链接都在我红线画出的部份。
然后我们就可以从画出这部份上面的代码找到地址,我们看一下
是在server-r2这个div上面
注:我用的是浏览器带的调试功能,直接按按键F12就下来了。
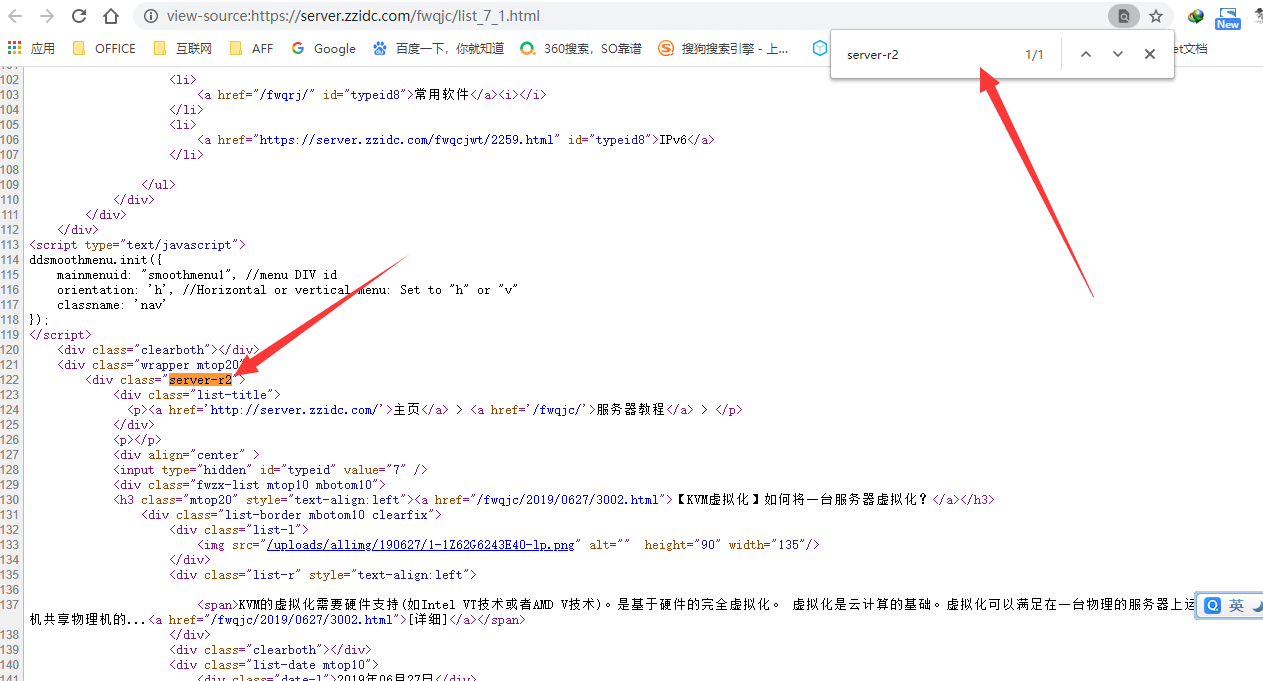
我们查看网页源代码,浏览器按CTRL+U即可
CTRL+F搜索server-r2,可以见到只有一个结果,没有其他重复项
那么这个就可以作为我们火车头采集器手动从列表页剖析文章链接的开始部份了。我们复制server-r2,填入火车头的开始字符串那儿,意味着火车头从这一段开始找寻文章链接。
然后我们还要确定下结束字符串位置
直接看下述表页最后一个文章是啥
然后再源码上面瞧瞧这个文章在那个位置
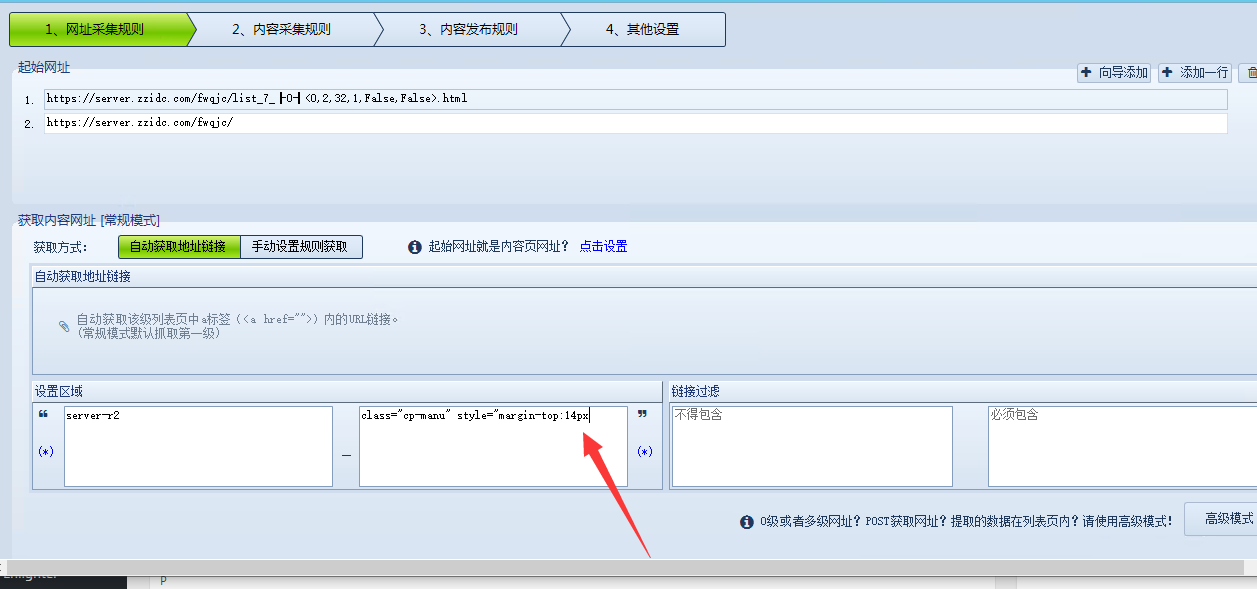
找到了位置,我们尽可能在他下边找下一个DIV开始的标记。这里我们找到了
<div>这个DIV,我们复制class="cp-manu"https://cdn.cheshirex.com/uploads/2020/03/QQ截图20200319225619.png" data-fancybox="group" >
其实这时候早已可以查找到确切的文章链接了,但是我们最好还是加一个过滤
在联接过滤--必须包含上面填入.html这个内容,然后回车键即可。想添加更多条内容就在输入过滤规则火车头采集教程,再回车。
后面那种设置图标点一下可以选择:满足其中一个条件或则满足所有条件。
以上基本完成了我们采集文章链接的规则,我们点一下下方的保存,先存一下。
如果你是新建任务规则可能提示你要输入任务名 查看全部
下面我们要从列表页剖析下来他文章的地址。
首先看下火车头采集教程,在列表页上面他的文章链接都在我红线画出的部份。

然后我们就可以从画出这部份上面的代码找到地址,我们看一下
是在server-r2这个div上面
注:我用的是浏览器带的调试功能,直接按按键F12就下来了。
我们查看网页源代码,浏览器按CTRL+U即可
CTRL+F搜索server-r2,可以见到只有一个结果,没有其他重复项
那么这个就可以作为我们火车头采集器手动从列表页剖析文章链接的开始部份了。我们复制server-r2,填入火车头的开始字符串那儿,意味着火车头从这一段开始找寻文章链接。
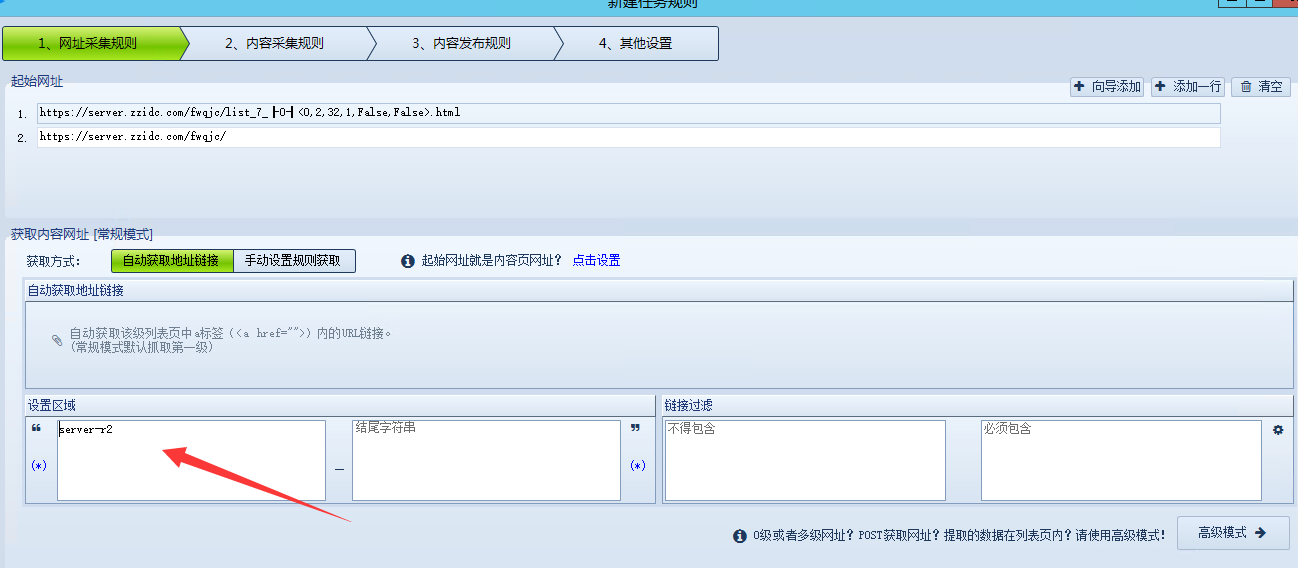
然后我们还要确定下结束字符串位置
直接看下述表页最后一个文章是啥
然后再源码上面瞧瞧这个文章在那个位置

找到了位置,我们尽可能在他下边找下一个DIV开始的标记。这里我们找到了
<div>这个DIV,我们复制class="cp-manu"https://cdn.cheshirex.com/uploads/2020/03/QQ截图20200319225619.png" data-fancybox="group" >
其实这时候早已可以查找到确切的文章链接了,但是我们最好还是加一个过滤
在联接过滤--必须包含上面填入.html这个内容,然后回车键即可。想添加更多条内容就在输入过滤规则火车头采集教程,再回车。
后面那种设置图标点一下可以选择:满足其中一个条件或则满足所有条件。
以上基本完成了我们采集文章链接的规则,我们点一下下方的保存,先存一下。
如果你是新建任务规则可能提示你要输入任务名
火车头采集器使用教程–寻找目标网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 522 次浏览 • 2020-04-26 11:02
这一步教程值得单独开一篇文章来写,每个网站的设计都不一样,他们发表的文章分类也不同。这里就介绍最常见的一种结构。
我们首先须要确定你要采集什么内容,然后按照不同内容去找目标网站。
比如我要采集IT资讯、云服务器类的内容。
以景安的文章为例,我先找到了他的文章都放到了那个网站。
在百度这样搜索site:zzidc.com windows2008
site:zzidc.com代表仅搜索这个域名下的内容,包括www域名和其他二级域名的内容
空格后跟一个windows2008的关键词,这样我搜下来都是景安网站下的关于windows2008的相关内容了。
从搜索结果里可以看见主要有两个域名地址,我选择了server.zzidc.com这个站点,因为这个内容多!
站点里有很多文章,我们要找寻自己想采集的文章。我选择了服务器教程相关的文章
点击这个分类,看看火车头采集教程,里面有33页的列表火车头采集教程,数量还可以
现在在列表第一页,他的地址是
然后我们翻页看一下第二页,发现地址弄成了
第三页弄成了
这就有一个比较好的列表页规律,非常适宜我们采集。
就选择它了! 查看全部
这一步教程值得单独开一篇文章来写,每个网站的设计都不一样,他们发表的文章分类也不同。这里就介绍最常见的一种结构。
我们首先须要确定你要采集什么内容,然后按照不同内容去找目标网站。
比如我要采集IT资讯、云服务器类的内容。
以景安的文章为例,我先找到了他的文章都放到了那个网站。
在百度这样搜索site:zzidc.com windows2008
site:zzidc.com代表仅搜索这个域名下的内容,包括www域名和其他二级域名的内容
空格后跟一个windows2008的关键词,这样我搜下来都是景安网站下的关于windows2008的相关内容了。
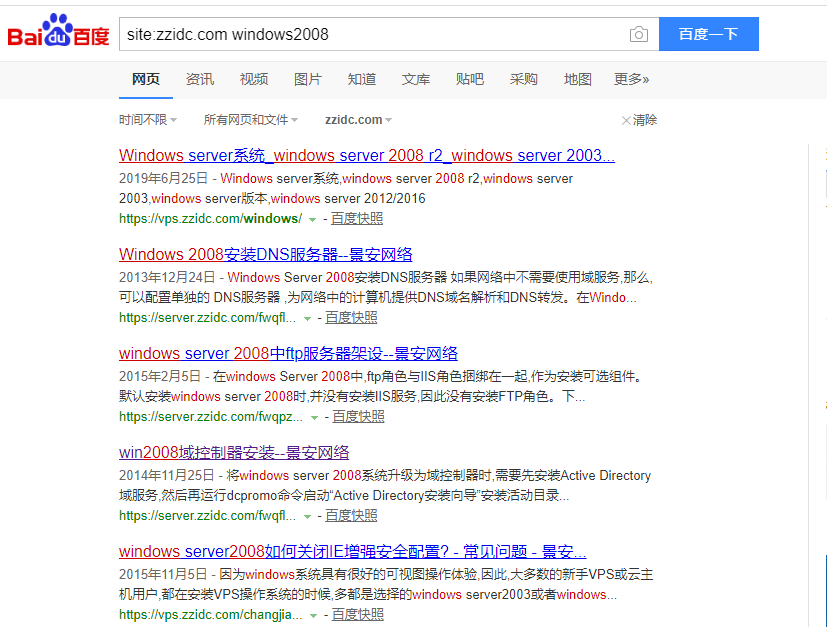
从搜索结果里可以看见主要有两个域名地址,我选择了server.zzidc.com这个站点,因为这个内容多!
站点里有很多文章,我们要找寻自己想采集的文章。我选择了服务器教程相关的文章
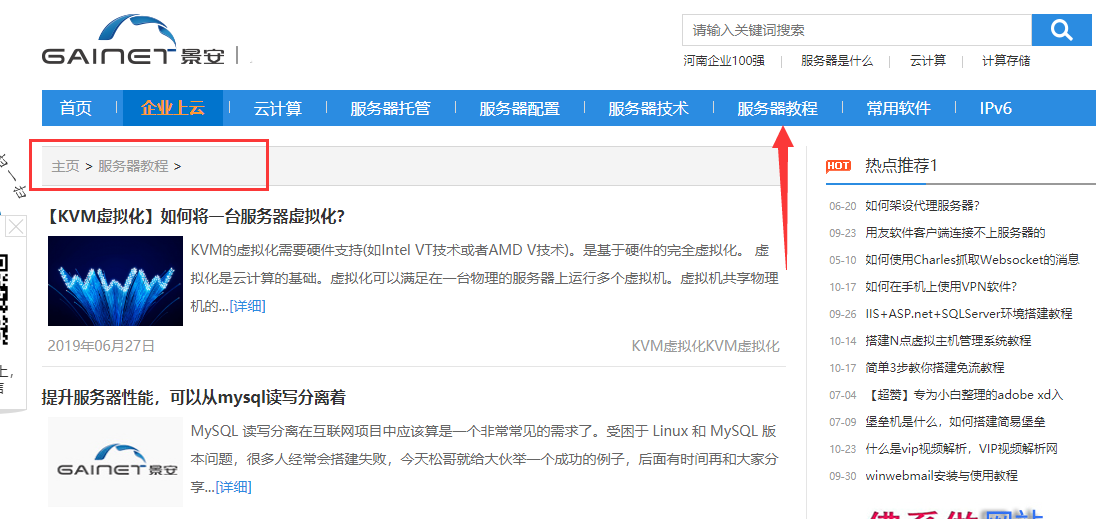
点击这个分类,看看火车头采集教程,里面有33页的列表火车头采集教程,数量还可以
现在在列表第一页,他的地址是
然后我们翻页看一下第二页,发现地址弄成了
第三页弄成了
这就有一个比较好的列表页规律,非常适宜我们采集。
就选择它了!
火车头采集器技术控使用指南(高级) 爬虫教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 707 次浏览 • 2020-04-25 11:02
1-1 火车头采集器视频教程序言
1-2 火车头采集器初级教程预期年后与你们碰面
2-1 如何借助fiddler软件对影藏链接地址的抓取
2-2 利用fiddler软件剖析post页面并获取列表网址的方式解读
3-1 利用火车头采集器采集58房子转租内容采集-上部份
3-2 利用火车头采集器采集58房子转租内容采集-下部份
3-3 利用火车头采集器采集赶集网的号码图片以及座标的视频上
3-4 利用火车头采集器采集赶集网急聘信息新视频教程下
3-5 利用火车头采集器采集慧聪网站公司信息采集视频教程-2019-11-18
3-6 火车头采集器采集智联招聘信息采集-2019-12-04
4-1 采集qq群上面的所有qq成员的方式
4-2 腾讯滚动新闻采集规则的制做详尽视频教程
4-3 weixin-sogou-com-俄罗斯护照-微信文章采集视频教程
4-4 第4节:微信公众号搜索的内容采集采集方法
4-5 腾讯视频的代码的采集和缩略图,以及图片水印覆盖的处理办法。
4-6 火车头采集器采集新浪滚动新闻-2019-11-25
4-7 火车头采集器采集头条toutiao网站文章的视频教程-2019-12-15
5-1 采集小说网站内容合成出多个txt和单个txt文本文档的方式和注意事项
5-2 通过采集器-采集网站内容合成出word文档的方式和细节优化
5-3 通过火车头采集器采集搜狐彩票开奖号码合成出xls文件的方式
5-4 通过采集器采集美女图片站合成html单页面
6-1 利用火车头采集器-威客网站的使用案例
7-1 通过采集器采集优酷网站的视频和相关信息
7-2 通过火车头采集器采集监控不同视频不同时间段的播放量 查看全部
课程目录:
1-1 火车头采集器视频教程序言
1-2 火车头采集器初级教程预期年后与你们碰面
2-1 如何借助fiddler软件对影藏链接地址的抓取
2-2 利用fiddler软件剖析post页面并获取列表网址的方式解读
3-1 利用火车头采集器采集58房子转租内容采集-上部份
3-2 利用火车头采集器采集58房子转租内容采集-下部份
3-3 利用火车头采集器采集赶集网的号码图片以及座标的视频上
3-4 利用火车头采集器采集赶集网急聘信息新视频教程下
3-5 利用火车头采集器采集慧聪网站公司信息采集视频教程-2019-11-18
3-6 火车头采集器采集智联招聘信息采集-2019-12-04
4-1 采集qq群上面的所有qq成员的方式
4-2 腾讯滚动新闻采集规则的制做详尽视频教程
4-3 weixin-sogou-com-俄罗斯护照-微信文章采集视频教程
4-4 第4节:微信公众号搜索的内容采集采集方法
4-5 腾讯视频的代码的采集和缩略图,以及图片水印覆盖的处理办法。
4-6 火车头采集器采集新浪滚动新闻-2019-11-25
4-7 火车头采集器采集头条toutiao网站文章的视频教程-2019-12-15
5-1 采集小说网站内容合成出多个txt和单个txt文本文档的方式和注意事项
5-2 通过采集器-采集网站内容合成出word文档的方式和细节优化
5-3 通过火车头采集器采集搜狐彩票开奖号码合成出xls文件的方式
5-4 通过采集器采集美女图片站合成html单页面
6-1 利用火车头采集器-威客网站的使用案例
7-1 通过采集器采集优酷网站的视频和相关信息
7-2 通过火车头采集器采集监控不同视频不同时间段的播放量
火车头采集后使用5118伪原创教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 576 次浏览 • 2020-04-25 11:02
最近在研究火车头采集器,通过火车头采集软件可以轻而易举的获得海量的网站内容(采集确实不妥)可以解放站长右手,机器时代工具自然比手工效率高多了。经过一段时间研究,目前早已把握了火车头采集技术能力火车头采集教程,火车头采集对接开源CMS程序手动更新能力,可以结合ai伪原创插口 实现批量采集并直接发布到WP、DEDECMS网站。说实在的,不是常常被人问采集相关的问题,我根本不乐意研究这种采集技术。接下来谈谈火车头采集器集成5118智能原创功能吧,这也是5118明天刚推送的一篇公众号文章。在列车采集器中,利用5118智能原创插件,不再须要经过人工处理,即能批量生产出内容指纹完全不同的文章,大幅提升了内容SEO采编的工作效率,让文章更容易被收录。5118智能原创-火车采集器插件下载链接: 提取码: umjx火车采集器中怎样安装智能原创插件第一步,使用解压软件,提取插件安装包中的文件,解压到一个文件夹中。第二步,打开解压后的文件夹,将上面的【5118 智能原创.dll】文件,放入在【火车采集器】安装目录下的Plugins文件夹里。第三步,将文件夹中的【5118智能原创配置工具.exe】和【Newtonsoft.Json.dll】文件,放入在【火车采集器】安装目录中。
第四步,在【火车采集器】的根目录里,打开【5118 智能原创配置工具.exe】,点击“获取API-Key”,将会在浏览器中打开5118获取API的页面。页面中找到“一键智能原创API”,点击复制按键,返回【5118 智能原创配置工具.exe】界面,粘贴API-Key到输入框中。一键智能原创API支持免费试用其实5118伪原创是要订购付费的,可申请100次免费使用,可选购一键智能原创API套餐。5118会员折扣码 D569F5 [?]智能原创插件使用说明第一步,打开火车头采集器,点击开始栏的【插件管理】,在插件管理框右侧列表里,选中【5118智能原创】,在两侧框中输入需采集的网址,点击测试按键,查看插件是否正常。第二步,测试没有问题后,开始使用插件设置内容采集规则。第三步,选择已有采集任务,在【其他设置】的一侧栏目中选择插件,在采集结果处理插件下拉框中,选择【5118智能原创.dll】,点击保存即可。此处需注意火车头采集教程,【内容采集规则】左侧列表里的“内容”标签,是插件将手动智能原创的内容,固定标签名称为“内容”。导出任务数据时,在任务列表里,选中对应任务项目,右侧“发布”项必须勾选,否则数据难以导入。第四步,查看5118智能原创插件疗效。运行完成后,即可在之前所保存的地址中查看导入疗效。所导入的内容,已经是使用智能原创插件替换后的数据。 查看全部
最近在研究火车头采集器,通过火车头采集软件可以轻而易举的获得海量的网站内容(采集确实不妥)可以解放站长右手,机器时代工具自然比手工效率高多了。经过一段时间研究,目前早已把握了火车头采集技术能力,火车头...显示全部
最近在研究火车头采集器,通过火车头采集软件可以轻而易举的获得海量的网站内容(采集确实不妥)可以解放站长右手,机器时代工具自然比手工效率高多了。经过一段时间研究,目前早已把握了火车头采集技术能力火车头采集教程,火车头采集对接开源CMS程序手动更新能力,可以结合ai伪原创插口 实现批量采集并直接发布到WP、DEDECMS网站。说实在的,不是常常被人问采集相关的问题,我根本不乐意研究这种采集技术。接下来谈谈火车头采集器集成5118智能原创功能吧,这也是5118明天刚推送的一篇公众号文章。在列车采集器中,利用5118智能原创插件,不再须要经过人工处理,即能批量生产出内容指纹完全不同的文章,大幅提升了内容SEO采编的工作效率,让文章更容易被收录。5118智能原创-火车采集器插件下载链接: 提取码: umjx火车采集器中怎样安装智能原创插件第一步,使用解压软件,提取插件安装包中的文件,解压到一个文件夹中。第二步,打开解压后的文件夹,将上面的【5118 智能原创.dll】文件,放入在【火车采集器】安装目录下的Plugins文件夹里。第三步,将文件夹中的【5118智能原创配置工具.exe】和【Newtonsoft.Json.dll】文件,放入在【火车采集器】安装目录中。
第四步,在【火车采集器】的根目录里,打开【5118 智能原创配置工具.exe】,点击“获取API-Key”,将会在浏览器中打开5118获取API的页面。页面中找到“一键智能原创API”,点击复制按键,返回【5118 智能原创配置工具.exe】界面,粘贴API-Key到输入框中。一键智能原创API支持免费试用其实5118伪原创是要订购付费的,可申请100次免费使用,可选购一键智能原创API套餐。5118会员折扣码 D569F5 [?]智能原创插件使用说明第一步,打开火车头采集器,点击开始栏的【插件管理】,在插件管理框右侧列表里,选中【5118智能原创】,在两侧框中输入需采集的网址,点击测试按键,查看插件是否正常。第二步,测试没有问题后,开始使用插件设置内容采集规则。第三步,选择已有采集任务,在【其他设置】的一侧栏目中选择插件,在采集结果处理插件下拉框中,选择【5118智能原创.dll】,点击保存即可。此处需注意火车头采集教程,【内容采集规则】左侧列表里的“内容”标签,是插件将手动智能原创的内容,固定标签名称为“内容”。导出任务数据时,在任务列表里,选中对应任务项目,右侧“发布”项必须勾选,否则数据难以导入。第四步,查看5118智能原创插件疗效。运行完成后,即可在之前所保存的地址中查看导入疗效。所导入的内容,已经是使用智能原创插件替换后的数据。
苹果cms怎么采集添加文章资讯图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 1086 次浏览 • 2020-04-25 11:00
一直想写几篇使小白看了也能用火车头采集资讯 明星 视频 的教程,因为有太多的小白来问我这个问题了,我说大家去百度下,反馈回去的结果都是一样说没有详尽的配置教程,发布老是提示失败。今天总算闲下来为小白们写一篇简单实用的采集教程。先写这个如何采集文章资讯的教程吧 。后面有时间了再更新视频 和名星的,这个教程是写如何使用早已有了采集规则的教程。采集规则和火车头软件自己在文章尾部的链接里下载,下载以后根据我写的教程操作保证使你学会火车头采集文章资讯了,好了开始我们明天的采集教程吧。
教程分两个大部分,一个是发布模块的配置 再就是采集规则的配置,发布模块和采集规则是两个缺一不可的组成部分。有些小伙伴们说在采集的时侯老是发布失败是如何回事?最终说到底就是这两个地方没有配置好造成。往下看
一,先来配置发布模块
1,打开火车头软件文件夹 点击右图这个启动程序图标
2,软件启动后点击这个“发布”进入到web发布模块配置界面。
3,我发给大家火车头软件里早已导出了苹果v10的4个发布模块,双击“苹果cms-v10文章”模块对其编辑,编辑地方有3个 如下图
①,编码设置改成 UTF-8
②,网站跟地址把 “1.cn” 替换成你的网站主域名
③,登陆方法改成 不需要登录http请求
④,都弄好后点击右下角的测试配置,我们首先要确定下这个发布模块是否可以正常使用,如果不能使用采集规则再正确也是发布不了的。点击测试配置步入到测试配置页面。如下图
4,配置发布模块最关键的一步,也是很多人出错或是甚至弄不懂的地方。我用箭头所指向的地方就是我们要配置的地方。如下图
①,先来配置验证密码:验证密码就是站外入库系联接苹果cms系统后台的验证码 ,这个须要去系统后台查看后填写,找到验证码后双击一侧“验证密码”在左边的编辑框里复制粘贴到上面就可以了。系统后台的验证码看右图所示。找到后复制下来粘贴到我们的发布模块里。
②,再来配置发布模块的“名称”,这里模块的名称虽然就是文章的标题,我们可以随意起一个名子,这个地方要理解了 就是整篇文章都有一个标题火车头采集教程,有了标题才可以发布,我们这儿是在测试发布模块,所以要自动填写一个标题,如果是采集规则的话这个地方是不用填写的,采集规则就会手动采集网站上的标题的。我们起名称以“首搽”为例吧 双击名称后在左侧填写首搽后点击更改就可以了 。
③,再来配置下“分类名称”和“分类编号”这两个也是在系统的后台来确定的,就是你要采集文章到网站哪个分类的名称和编号,看右图所示
来到系统后台点击基础>>>分类管理 拉到下边(第2张图)我们可以看见资讯的顶尖分类和子分类 一共三个,这三个分类我们都是发布文章的分类,都可以使用,我们就随意选择一个分类“头条”这个分类吧。这里的头条就是我们的分类名称,头条上面的18就是分类编号。所以我们就由此得到了分类的名称和编号火车头采集教程,直接填写到发布模块的配置即可。
④ 一起都填写完毕后就是最后的测试了,我们点击“发表文章测试“下面下来的就是发布入库成功的相关提示。我们可以到网站前台看下有没有这个文章。
⑤我们来到网站的前台点击导航栏的分类,可以看见一个标题名称为首搽的文章,这也代表了我们文章发布模块配置成功。
5,由于文字篇幅宽度的限制我们在下一篇文章里介绍文章采集规则的配置,看完下半部份的配置相信你一定会用火车头来采集文章资讯到自己的网站上。 查看全部
一直想写几篇使小白看了也能用火车头采集资讯 明星 视频 的教程,因为有太多的小白来问我这个问题了,我说大家去百度下,反馈回去的结果都是一样说没有详尽的配置教程,发布老是提示失败。今天总算闲下来为小白们写一篇简单实用的采集教程。先写这个如何采集文章资讯的教程吧 。后面有时间了再更新视频 和名星的,这个教程是写如何使用早已有了采集规则的教程。采集规则和火车头软件自己在文章尾部的链接里下载,下载以后根据我写的教程操作保证使你学会火车头采集文章资讯了,好了开始我们明天的采集教程吧。
教程分两个大部分,一个是发布模块的配置 再就是采集规则的配置,发布模块和采集规则是两个缺一不可的组成部分。有些小伙伴们说在采集的时侯老是发布失败是如何回事?最终说到底就是这两个地方没有配置好造成。往下看
一,先来配置发布模块
1,打开火车头软件文件夹 点击右图这个启动程序图标

2,软件启动后点击这个“发布”进入到web发布模块配置界面。

3,我发给大家火车头软件里早已导出了苹果v10的4个发布模块,双击“苹果cms-v10文章”模块对其编辑,编辑地方有3个 如下图
①,编码设置改成 UTF-8
②,网站跟地址把 “1.cn” 替换成你的网站主域名
③,登陆方法改成 不需要登录http请求
④,都弄好后点击右下角的测试配置,我们首先要确定下这个发布模块是否可以正常使用,如果不能使用采集规则再正确也是发布不了的。点击测试配置步入到测试配置页面。如下图

4,配置发布模块最关键的一步,也是很多人出错或是甚至弄不懂的地方。我用箭头所指向的地方就是我们要配置的地方。如下图

①,先来配置验证密码:验证密码就是站外入库系联接苹果cms系统后台的验证码 ,这个须要去系统后台查看后填写,找到验证码后双击一侧“验证密码”在左边的编辑框里复制粘贴到上面就可以了。系统后台的验证码看右图所示。找到后复制下来粘贴到我们的发布模块里。

②,再来配置发布模块的“名称”,这里模块的名称虽然就是文章的标题,我们可以随意起一个名子,这个地方要理解了 就是整篇文章都有一个标题火车头采集教程,有了标题才可以发布,我们这儿是在测试发布模块,所以要自动填写一个标题,如果是采集规则的话这个地方是不用填写的,采集规则就会手动采集网站上的标题的。我们起名称以“首搽”为例吧 双击名称后在左侧填写首搽后点击更改就可以了 。

③,再来配置下“分类名称”和“分类编号”这两个也是在系统的后台来确定的,就是你要采集文章到网站哪个分类的名称和编号,看右图所示
来到系统后台点击基础>>>分类管理 拉到下边(第2张图)我们可以看见资讯的顶尖分类和子分类 一共三个,这三个分类我们都是发布文章的分类,都可以使用,我们就随意选择一个分类“头条”这个分类吧。这里的头条就是我们的分类名称,头条上面的18就是分类编号。所以我们就由此得到了分类的名称和编号火车头采集教程,直接填写到发布模块的配置即可。


④ 一起都填写完毕后就是最后的测试了,我们点击“发表文章测试“下面下来的就是发布入库成功的相关提示。我们可以到网站前台看下有没有这个文章。

⑤我们来到网站的前台点击导航栏的分类,可以看见一个标题名称为首搽的文章,这也代表了我们文章发布模块配置成功。

5,由于文字篇幅宽度的限制我们在下一篇文章里介绍文章采集规则的配置,看完下半部份的配置相信你一定会用火车头来采集文章资讯到自己的网站上。
利用火车头采集器采集慧聪网站公司信息采集视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2020-04-24 11:05
课程描述
第一章:中级教程开篇章第1节:工欲善其事必先利其器fiddler来帮您剖析数据第二章:分类信息网站58网站的采集第1节:58网站房屋转租内容采集第2节:58网站手机号码采集的突破形式第3节:利用采集器全手动大量发布信息的方法第三章:火车头采集器在采集腾讯网站内容的使用第1节:采集qq群上面的所有qq成员的方式第2节:腾讯网站的新闻采集第3节:微信文章搜索的内容采集第4节:微信公众号搜索的内容采集第5节:腾讯视频的代码的采集第四章:采集数据合成成文本第1节:采集网站内容合成出多个txt文本文档第2节:采集网站内容合成出word文档的方式第3节:采集内容合成出csv文件,可以用于淘宝助手第4节:通过采集器合成html单页面第五章:火车头采集器在威客领域的使用第1节:威客网站自动发贴模块的制做第2节:利用威客发贴来使自己的任务帖永保第一第六章:优酷网站相关内容采集的讲解第1节:通过采集器采集优酷网站的视频和相关信息第2节:通过火车头采集器监控优酷最新视频搜索量第七章:火车头采集器采集百度相关内容第1节:采集百度关键词搜索的结果并提取须要的网址域名第2节:火车头采集器采集百度贴吧贴子内容和跟帖第3节:利用火车头采集器采集百度新闻内容第4节:利用火车头采集器采集百度软件中心软件第5节:利用火车头采集器采集百度风云榜相关最新信息第八章:火车头采集器发布模块的制做思路和技巧第1节:Web发布模块的制做思路和技巧第2节:入库模块的制做思路和技巧dedecms,phpcms,ecshop,帝国cms火车头采集教程火车头采集教程,destoon,discuz
学习目的
通过学习火车头采集器中级教程可以满足大部分站长对于网站采集的需求,本课程院士您火车头采集器在各类文字、视频、音频、彩票、图片网站的采集方法以及火车头采集器发布模块的制做思路和技巧。本课程会随着市面上主流产品的迭代,而不断的更新新的案例,一次订购,终身学习。
适用人群
具有一定网站知识基础的网站编辑、网络营销从业者,电话营销从业者、SEOER、需要大量数据的、想提升自己对数据采集和合成效率的人。 查看全部
课程描述
第一章:中级教程开篇章第1节:工欲善其事必先利其器fiddler来帮您剖析数据第二章:分类信息网站58网站的采集第1节:58网站房屋转租内容采集第2节:58网站手机号码采集的突破形式第3节:利用采集器全手动大量发布信息的方法第三章:火车头采集器在采集腾讯网站内容的使用第1节:采集qq群上面的所有qq成员的方式第2节:腾讯网站的新闻采集第3节:微信文章搜索的内容采集第4节:微信公众号搜索的内容采集第5节:腾讯视频的代码的采集第四章:采集数据合成成文本第1节:采集网站内容合成出多个txt文本文档第2节:采集网站内容合成出word文档的方式第3节:采集内容合成出csv文件,可以用于淘宝助手第4节:通过采集器合成html单页面第五章:火车头采集器在威客领域的使用第1节:威客网站自动发贴模块的制做第2节:利用威客发贴来使自己的任务帖永保第一第六章:优酷网站相关内容采集的讲解第1节:通过采集器采集优酷网站的视频和相关信息第2节:通过火车头采集器监控优酷最新视频搜索量第七章:火车头采集器采集百度相关内容第1节:采集百度关键词搜索的结果并提取须要的网址域名第2节:火车头采集器采集百度贴吧贴子内容和跟帖第3节:利用火车头采集器采集百度新闻内容第4节:利用火车头采集器采集百度软件中心软件第5节:利用火车头采集器采集百度风云榜相关最新信息第八章:火车头采集器发布模块的制做思路和技巧第1节:Web发布模块的制做思路和技巧第2节:入库模块的制做思路和技巧dedecms,phpcms,ecshop,帝国cms火车头采集教程火车头采集教程,destoon,discuz
学习目的
通过学习火车头采集器中级教程可以满足大部分站长对于网站采集的需求,本课程院士您火车头采集器在各类文字、视频、音频、彩票、图片网站的采集方法以及火车头采集器发布模块的制做思路和技巧。本课程会随着市面上主流产品的迭代,而不断的更新新的案例,一次订购,终身学习。
适用人群
具有一定网站知识基础的网站编辑、网络营销从业者,电话营销从业者、SEOER、需要大量数据的、想提升自己对数据采集和合成效率的人。
火车头采集教程你把握多少
采集交流 • 优采云 发表了文章 • 0 个评论 • 737 次浏览 • 2020-04-24 11:04
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置火车头采集教程,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是title标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整火车头采集教程,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。 查看全部
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。

采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。

多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置火车头采集教程,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。

步骤a:双击【标题】标签,一般网页的标题是title标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。

火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。

注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。

结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整火车头采集教程,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。
火车头采集今日头条教程,含视频教程!自行下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 600 次浏览 • 2020-04-24 11:03
针对媒体号列表页:我们可以更改*tia*o.com/c/user/article/?page_type=1&user_id=3249088303&max_behot_time=0&count=20&as=A1D52A03F95BB20&cp=5A390BFB72701E1&_signature=CYasmBATU8TH7SpKuO0LRAmGrI
上面网址中的count=20,就是20篇文章,改这个可以获取文章的数目
视频中会演示!
3、文章页采集
源码看不到,可以直接F12,查找文章页的特定字符,然后前后截取就行了。
今日头条媒体号采集案例教程视频下载:(已失效 2019.03.01更新)
链接 密码:2ibp
看不懂看不会的火车头采集教程火车头采集教程,联系我Q1290654348 备注:火车头
补充1:今日头条的网址也具备时效性,如下图所示,时间久了列表页的网址会变化,只能现采现用。
补充2:为了解决【补充1】的问题,本人继续研究了一下,其实好多采集器可以采集列表,使用列车浏览器也可以,可以避免列表页原网址变化的情况,
写个浏览器脚本步骤也很简单,然后把这种网址直接导出到火车头就可以进行采集了,以下为获取到列表截图:
还有简单的方式,通过把采集的列表导出到数据库,然后和火车头一起运行,便就能一起实时运行了。
-----------------------------2018-06-08更新--------------------------------------------------------------
今日头条采集规则升级:
通过其他软件配合采集确实很麻烦,而且做不到手动采集。目前早已解决该问题,不需要抓包,也不需要进行其他软件的配合,可以实现永久手动采集了。
需要技巧的联系我Q1290654348
该规则早已写下来很久了,一直没来得及更新~(#^.^#)
2019.03.01更新
多次升级以后可稳定采集,如果须要采集规则,可以到这儿订购:火车头采集今日头条规则
2019.09.10更新
今日头条规则所有栏目升级更新完成。
2019.12.18
近期,有同学反馈根据栏目采集的规则,存在部份规则二次刷新采集,存在刷不出数据的情况,今天已全部更新。 查看全部
针对媒体号列表页:我们可以更改*tia*o.com/c/user/article/?page_type=1&user_id=3249088303&max_behot_time=0&count=20&as=A1D52A03F95BB20&cp=5A390BFB72701E1&_signature=CYasmBATU8TH7SpKuO0LRAmGrI
上面网址中的count=20,就是20篇文章,改这个可以获取文章的数目
视频中会演示!
3、文章页采集
源码看不到,可以直接F12,查找文章页的特定字符,然后前后截取就行了。
今日头条媒体号采集案例教程视频下载:(已失效 2019.03.01更新)
链接 密码:2ibp
看不懂看不会的火车头采集教程火车头采集教程,联系我Q1290654348 备注:火车头
补充1:今日头条的网址也具备时效性,如下图所示,时间久了列表页的网址会变化,只能现采现用。
补充2:为了解决【补充1】的问题,本人继续研究了一下,其实好多采集器可以采集列表,使用列车浏览器也可以,可以避免列表页原网址变化的情况,
写个浏览器脚本步骤也很简单,然后把这种网址直接导出到火车头就可以进行采集了,以下为获取到列表截图:

还有简单的方式,通过把采集的列表导出到数据库,然后和火车头一起运行,便就能一起实时运行了。
-----------------------------2018-06-08更新--------------------------------------------------------------
今日头条采集规则升级:
通过其他软件配合采集确实很麻烦,而且做不到手动采集。目前早已解决该问题,不需要抓包,也不需要进行其他软件的配合,可以实现永久手动采集了。
需要技巧的联系我Q1290654348
该规则早已写下来很久了,一直没来得及更新~(#^.^#)

2019.03.01更新
多次升级以后可稳定采集,如果须要采集规则,可以到这儿订购:火车头采集今日头条规则
2019.09.10更新
今日头条规则所有栏目升级更新完成。
2019.12.18
近期,有同学反馈根据栏目采集的规则,存在部份规则二次刷新采集,存在刷不出数据的情况,今天已全部更新。
详解火车头采集器免登入采集数据发布到DEDECMS织梦的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 425 次浏览 • 2020-04-24 11:03
这篇文章主要介绍了解读火车头采集器免登入采集数据发布到DEDECMS织梦的方式火车头采集教程,小编认为挺不错的,现在分享给你们,也给你们做个参考。一起追随小编过来瞧瞧吧
将dede/config.php中的下边代码:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
修改为:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
if($my_u != ')
{
$res = $cuserLogin->checkUser($my_u,$my_p);
if($res==1)
$cuserLogin->keepUser();
}
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
}
然后火车头发布模块更改为
article_add.php?my_u=你后台用户名&my_p=你后台密码 查看全部

这篇文章主要介绍了解读火车头采集器免登入采集数据发布到DEDECMS织梦的方式火车头采集教程,小编认为挺不错的,现在分享给你们,也给你们做个参考。一起追随小编过来瞧瞧吧
将dede/config.php中的下边代码:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
修改为:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
if($my_u != ')
{
$res = $cuserLogin->checkUser($my_u,$my_p);
if($res==1)
$cuserLogin->keepUser();
}
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
}
然后火车头发布模块更改为
article_add.php?my_u=你后台用户名&my_p=你后台密码
苹果cms怎么用火车头采集资讯图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 885 次浏览 • 2020-04-24 11:02
一,导入资讯采集规则分组,关于如何使用火车头软件明天我们就不讲了 请直接看上一篇的教程:点击查看我们直接步入火车头软件。
①打开火车头软件 鼠标在右边的空白处右键键盘点击导出分组,一个分组虽然就是一个文件夹,文件夹上面的每条规则就是一个任务,我们发给你的规则就是一个文件夹上面有一个采集规则,所以我们这儿选择导出分组。(即导出文件夹)
②图片中的文件就是一个资讯采集规则的分组文件,我们直接选择这个文件导出。
③导入后我们就开始对这个规则进行入库配置火车头采集教程,双击图片箭头所指向的规则步入到编辑页面。
二,配置资讯采集规则,其实我们配置入库资讯采集规则的地方就三个地方,填对这三个地方就搞定了。
1火车头采集教程,到达编辑页面后填写对接系统后台的入库验证密码,怎么获取验证密码请看上半部份的教程点击查看操作步骤如下图
图①直接点击第二步“采集内容规则”进行编辑页面
图②双击验证码会弹出图3中的填写验证码页面
图③填写系统后台的入库验证密码
图④全部填写完毕后直接点击确定
2,下拉编辑框填写分类编号 分类编号也是在系统后台,如果不懂的也须要看上半部的教程点击查看
图①双击分类编号 会弹出一侧的编辑框。
图② 填写你要入库分类的分类编号 不要根据我的照搬 你要确定你自己的分类编号进行填写。
图③填写完毕点击确定。
3,填写分类名称 ,这个和之前的分类编号一样的步骤
图①双击分类名称。
图②填写分类名称 也是同样不要照搬 确定自己要入库的分类。
图③填写完毕后点击确定保存。
三,点击切换到第三步“发布内容设置”页面 导入我们今天配置的发布模块,导入完后点击确定 查看全部
大家好 ,咱们继续今天没有完成的资讯采集教程,如果你是直接进来的请先看上半部份的教程点击查看这样你能够读懂这部份的内容 昨天我们配置了文章的发布模块昨天来配置文章资讯的采集规则,采集规则和火车头软件在此文章的顶部留有链接 自己下载即可。为什么网站上要添加资讯文章呢?这个是关系到网站SEO收录的一个关键问题。如果一个影视网站能够持续的保持更新文章资讯会给你的网站收录加分不少,从而获得好的排行。好了开始我们明天的教程。
一,导入资讯采集规则分组,关于如何使用火车头软件明天我们就不讲了 请直接看上一篇的教程:点击查看我们直接步入火车头软件。
①打开火车头软件 鼠标在右边的空白处右键键盘点击导出分组,一个分组虽然就是一个文件夹,文件夹上面的每条规则就是一个任务,我们发给你的规则就是一个文件夹上面有一个采集规则,所以我们这儿选择导出分组。(即导出文件夹)

②图片中的文件就是一个资讯采集规则的分组文件,我们直接选择这个文件导出。

③导入后我们就开始对这个规则进行入库配置火车头采集教程,双击图片箭头所指向的规则步入到编辑页面。

二,配置资讯采集规则,其实我们配置入库资讯采集规则的地方就三个地方,填对这三个地方就搞定了。
1火车头采集教程,到达编辑页面后填写对接系统后台的入库验证密码,怎么获取验证密码请看上半部份的教程点击查看操作步骤如下图
图①直接点击第二步“采集内容规则”进行编辑页面
图②双击验证码会弹出图3中的填写验证码页面
图③填写系统后台的入库验证密码
图④全部填写完毕后直接点击确定

2,下拉编辑框填写分类编号 分类编号也是在系统后台,如果不懂的也须要看上半部的教程点击查看
图①双击分类编号 会弹出一侧的编辑框。
图② 填写你要入库分类的分类编号 不要根据我的照搬 你要确定你自己的分类编号进行填写。
图③填写完毕点击确定。

3,填写分类名称 ,这个和之前的分类编号一样的步骤
图①双击分类名称。
图②填写分类名称 也是同样不要照搬 确定自己要入库的分类。
图③填写完毕后点击确定保存。

三,点击切换到第三步“发布内容设置”页面 导入我们今天配置的发布模块,导入完后点击确定
火车头采集搜狐号自媒体教程方式!(已解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 402 次浏览 • 2020-04-24 11:02
温馨提示:需要搜狐新闻采集规则的这儿构面《搜狐新闻采集规则》
如果须要搜狐号作者采集规则的同学,可以点击两侧的联系方法,联系我QQ
====20191109更新====
针对某一个搜狐号,进入其主页,进行采集,该主页网址未能采集到列表火车头采集教程,不能采集到列表也就无法进行批量采集,所以,首先要解决该问题。
其次,搜狐自媒体号上的文章URL都有一定的特征,如下:
变量_114778
我们只须要把这个变量找到就好了!然后用火车头拼接一下URL就可以了。
难点:抓包找数据剖析
案例如下:
1、目标搜狐号主页:;_f=index_pagemp_1
2、fiddler抓包,如下图所示:
查看大图
该网址就是列表url原先的地址:%h#u.com/apiV2/profile/newsListAjax?xpt=cHBhZzc5Mjg1OTg1MDkxNEBzb2h1LmNvbQ==&pageNumber=1&pageSize=10&categoryId=&_=1513670508722
在火车头中多页采集修改这个地方:pageNumber=1
3、采集文章页URL
把里面的旧址用浏览器打开,如下图所示:
我们把红色圈中的部份采集下来即可。然后火车头采集规则如此编撰:
列表页采集到了火车头采集教程,内页文章页可以直接看源码编撰采集规则,上面是难点,简单的就不啰嗦了。 查看全部
温馨提示:需要搜狐新闻采集规则的这儿构面《搜狐新闻采集规则》
如果须要搜狐号作者采集规则的同学,可以点击两侧的联系方法,联系我QQ
====20191109更新====
针对某一个搜狐号,进入其主页,进行采集,该主页网址未能采集到列表火车头采集教程,不能采集到列表也就无法进行批量采集,所以,首先要解决该问题。
其次,搜狐自媒体号上的文章URL都有一定的特征,如下:
变量_114778
我们只须要把这个变量找到就好了!然后用火车头拼接一下URL就可以了。
难点:抓包找数据剖析
案例如下:
1、目标搜狐号主页:;_f=index_pagemp_1
2、fiddler抓包,如下图所示:

查看大图
该网址就是列表url原先的地址:%h#u.com/apiV2/profile/newsListAjax?xpt=cHBhZzc5Mjg1OTg1MDkxNEBzb2h1LmNvbQ==&pageNumber=1&pageSize=10&categoryId=&_=1513670508722
在火车头中多页采集修改这个地方:pageNumber=1
3、采集文章页URL
把里面的旧址用浏览器打开,如下图所示:

我们把红色圈中的部份采集下来即可。然后火车头采集规则如此编撰:

列表页采集到了火车头采集教程,内页文章页可以直接看源码编撰采集规则,上面是难点,简单的就不啰嗦了。
火车头采集器图片采集上传设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 727 次浏览 • 2020-04-24 11:02
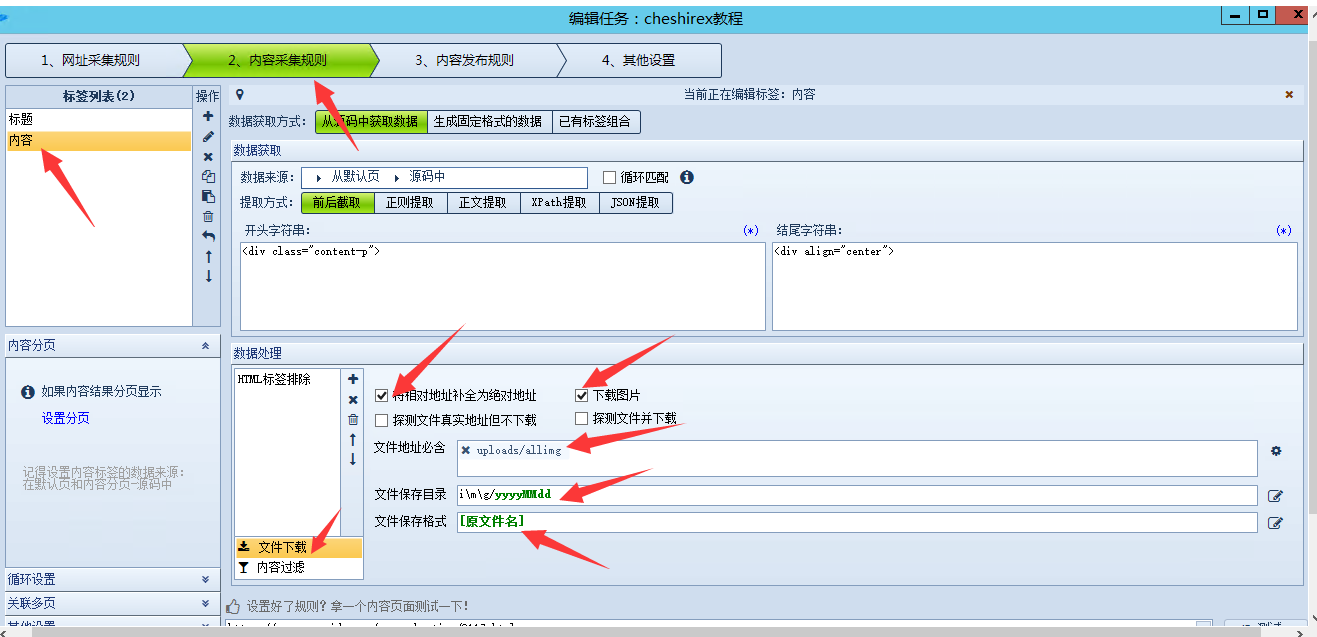
前面我们写了基础的标题和文章采集,下面介绍下图片的采集。
图片采集不是必须的,但是图片可以丰富网站的内容,具体我也不清楚对网站的SEO有哪些影响。我测试采集图片和不采集图片收录没区别,我看到的一些采集站,大部分也是不采集图片的!
如果采集数据量比较大的话可以选择不采集图片。
正文开始
首先是火车头采集器上的设置。
我们以这个文章为例:
这个上面有一张图片,并且也是上面我们教程里用做示范的网站。
声明:本人目前没使用任何景安的产品(以前用过),也对他产品印象不好。仅做教程示例,没有推荐他产品的意思。
我们直接打开上面教程创建的那种火车头采集任务。
在内容采集规则-内容-文件下载上面
选择:将相对地址补全为绝对地址、下载图片
文件地址必须包含:uploads/allimg
这个必须包含是按照不同网站来设置的,比如本文教程里文章图片地址是:
那么除掉后面他网站域名和前面会形成变化的文件名和日期格式的目录名之外剩余的基本就是我们想要的内容,所以我这儿使图片文件地址必须包含uploads/allimg。
为什么如此做?
因为他有可能在文章里加入图片广告,图片广告为了易于更改,大部分都是采用单独目录内放图片广告的形式。这样之后该广告比较容易。新老文章都能一次更改掉。
文件保存目录:i\m\g/yyyyMMdd
这个目录是你采集器的本地笔记本和服务器上面要创建的目录火车头采集教程火车头采集教程,先存到本地之后上传到服务器里。
目录上面的\斜杠是因为默认img上面m和g会被火车头辨识为内置函数(字母颜色会变蓝),没办法正常解析,所以加上斜杠。正常的话是img/yyyyMMdd这样的
含义:表示保存到网站的/img目录下,然后按照年月日手动创建对应的目录。
然后是在内容的-HTML标签排除上面,我们除去图象<img这个标签的排除。因为排除后我们发布后文章内就没有调用图片,自然不会显示图片内容。
然后我们进行图片的上传设置,我们采集时候次序是,先将图片下载到本地,然后传到服务器这样一个步骤。
通过FTP的方法来上传。
先在宝塔面板上传建一个FTP帐户,FTP默认目录要设置在我们网站跟目录。
采集器会依照我们里面的设置自己创建对应的目录。
注意:FTP使用的端口记得打开!21、20、39000-40000不打开端口你图片自然传不了。放行20和39000到40000这种端口是因为宝塔的FTP时常出现FTP联接错误的情况,这是另一个问题。这里不给你们解释了,不然篇幅很长了。
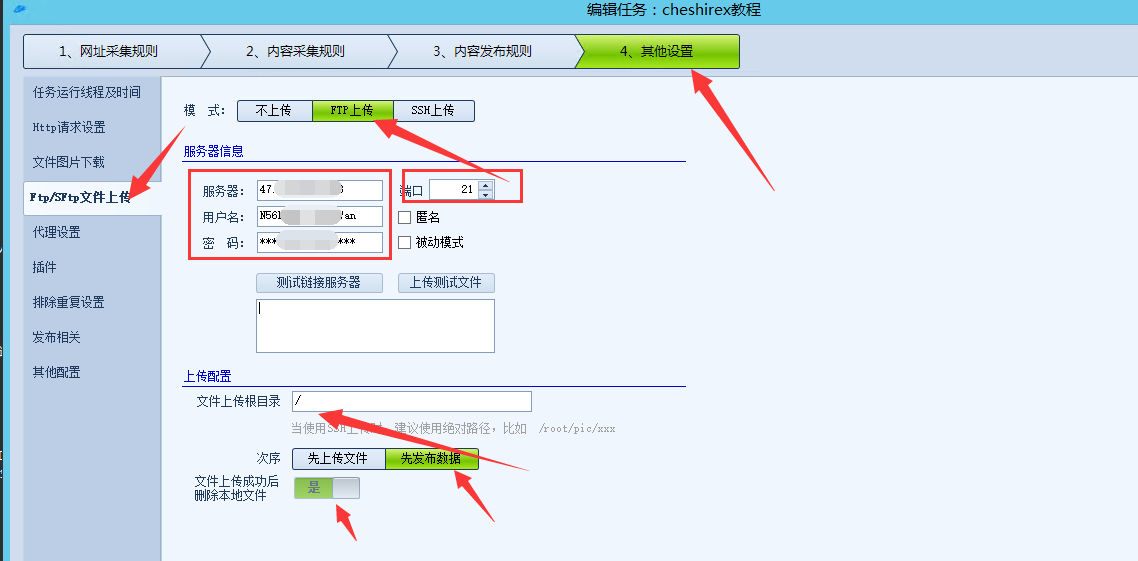
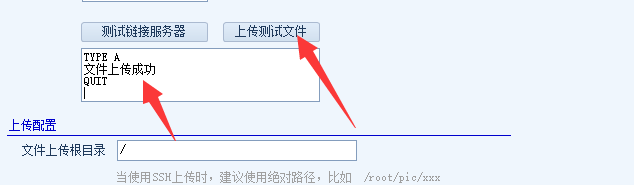
打开火车头采集器:其他设置、FTP文件上传、FTP上传
服务器:填写你的服务器IP地址
用户名/密码:刚才创建的FTP帐户和密码
端口:默认21
文件上传根目录:/
次序:先发布数据
文件上传成功后删掉本地文件:是
这里也可以选择否,选择是的话可以降低采集器所在机器c盘的占用,而且上传成功的图片,也没必要在保留了。
设置好了以后我们点一下上传测试文件:
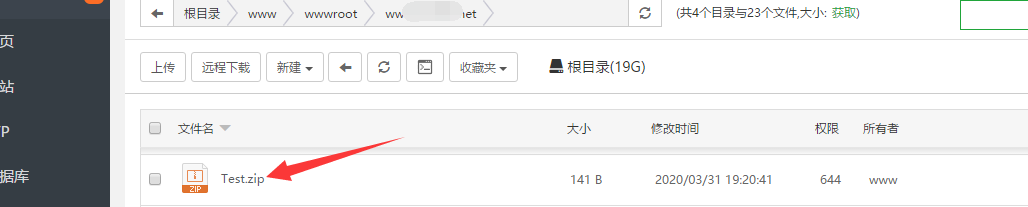
看下下边的框里显示的信息,有没有成功上传,并且打开网站目录内也看下有没有测试文件Test.zip被上传。
测试OK的话保存一下设置,我们测试下瞧瞧采集效果 查看全部
火车头采集器图片采集上传设置
前面我们写了基础的标题和文章采集,下面介绍下图片的采集。
图片采集不是必须的,但是图片可以丰富网站的内容,具体我也不清楚对网站的SEO有哪些影响。我测试采集图片和不采集图片收录没区别,我看到的一些采集站,大部分也是不采集图片的!
如果采集数据量比较大的话可以选择不采集图片。
正文开始
首先是火车头采集器上的设置。
我们以这个文章为例:
这个上面有一张图片,并且也是上面我们教程里用做示范的网站。
声明:本人目前没使用任何景安的产品(以前用过),也对他产品印象不好。仅做教程示例,没有推荐他产品的意思。
我们直接打开上面教程创建的那种火车头采集任务。
在内容采集规则-内容-文件下载上面
选择:将相对地址补全为绝对地址、下载图片
文件地址必须包含:uploads/allimg
这个必须包含是按照不同网站来设置的,比如本文教程里文章图片地址是:
那么除掉后面他网站域名和前面会形成变化的文件名和日期格式的目录名之外剩余的基本就是我们想要的内容,所以我这儿使图片文件地址必须包含uploads/allimg。
为什么如此做?
因为他有可能在文章里加入图片广告,图片广告为了易于更改,大部分都是采用单独目录内放图片广告的形式。这样之后该广告比较容易。新老文章都能一次更改掉。
文件保存目录:i\m\g/yyyyMMdd
这个目录是你采集器的本地笔记本和服务器上面要创建的目录火车头采集教程火车头采集教程,先存到本地之后上传到服务器里。
目录上面的\斜杠是因为默认img上面m和g会被火车头辨识为内置函数(字母颜色会变蓝),没办法正常解析,所以加上斜杠。正常的话是img/yyyyMMdd这样的
含义:表示保存到网站的/img目录下,然后按照年月日手动创建对应的目录。
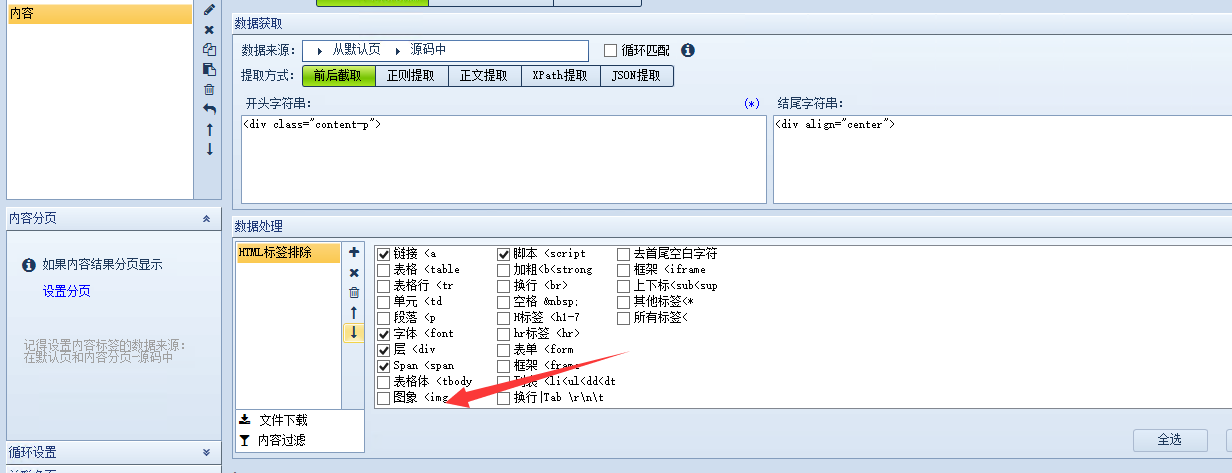
然后是在内容的-HTML标签排除上面,我们除去图象<img这个标签的排除。因为排除后我们发布后文章内就没有调用图片,自然不会显示图片内容。
然后我们进行图片的上传设置,我们采集时候次序是,先将图片下载到本地,然后传到服务器这样一个步骤。
通过FTP的方法来上传。
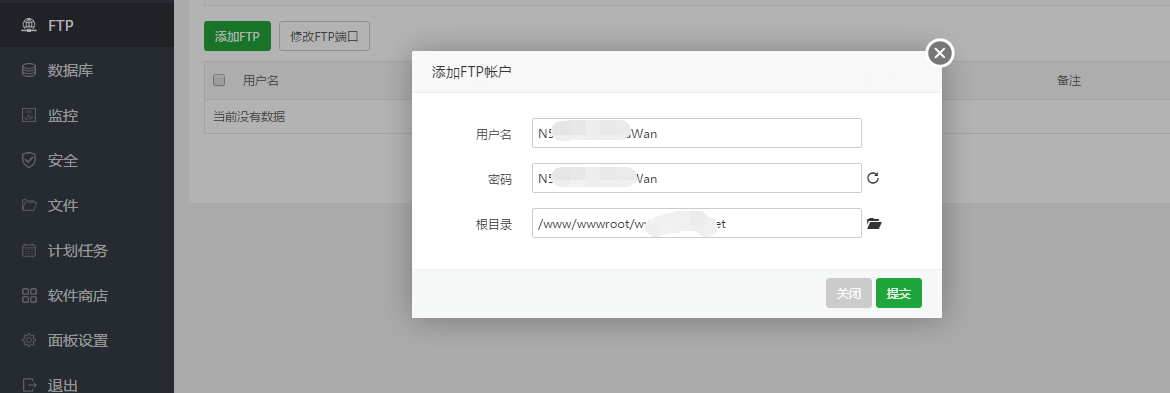
先在宝塔面板上传建一个FTP帐户,FTP默认目录要设置在我们网站跟目录。
采集器会依照我们里面的设置自己创建对应的目录。
注意:FTP使用的端口记得打开!21、20、39000-40000不打开端口你图片自然传不了。放行20和39000到40000这种端口是因为宝塔的FTP时常出现FTP联接错误的情况,这是另一个问题。这里不给你们解释了,不然篇幅很长了。
打开火车头采集器:其他设置、FTP文件上传、FTP上传
服务器:填写你的服务器IP地址
用户名/密码:刚才创建的FTP帐户和密码
端口:默认21
文件上传根目录:/
次序:先发布数据
文件上传成功后删掉本地文件:是
这里也可以选择否,选择是的话可以降低采集器所在机器c盘的占用,而且上传成功的图片,也没必要在保留了。
设置好了以后我们点一下上传测试文件:
看下下边的框里显示的信息,有没有成功上传,并且打开网站目录内也看下有没有测试文件Test.zip被上传。
测试OK的话保存一下设置,我们测试下瞧瞧采集效果
织梦用火车头采集器采集文章后手动生成首页、栏目页、上下篇
采集交流 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2020-04-27 11:03
织梦使用火车头采集器采集数据,发布文档后是不会手动生成首页、上下篇、栏目页的,我们可以给织梦dedecms添加手动生成代码来实现,先普及下织梦火车头采集器知识:
火车头是一款可以大量采集原创文章的软件。
火车头采集器有什么用处?
1、通用性强
无论新闻、论坛、视频、黄页、图片、下载类网站,只要通过浏览器能看到的结构化的内容,通过指定匹配规则,都能采集到您所须要的内容。
2、稳定、高效
七年磨一剑,软件不断更新进步火车头采集教程,采集速度快,性能稳定,占用资源少。
3、扩展性强、适用范围广
自定义web发布,自定义主流的数据库的保存和发布,自定义本地php及.net外部编程插口处理数据火车头采集教程,让数据都能为你所用。
实现教程
打开 /dede/inc/inc_archives_functions.php
在这个文件中找到
return $revalue;
在它的里面加入
MakePreNext($arcID,$typeid);
MakeIndex();
MakeParentType($typeid);
添加完后是这样的
这样添加好后,无论你用火车头免登入插口还是WEB发布模块,无论是普通文章模型还是图集模型还是软件模型,都可以手动生成相关静态文件了。 查看全部
织梦使用火车头采集器采集数据,发布文档后是不会手动生成首页、上下篇、栏目页的,我们可以给织梦dedecms添加手动生成代码来实现,先普及下织梦火车头采集器知识:
火车头是一款可以大量采集原创文章的软件。
火车头采集器有什么用处?
1、通用性强
无论新闻、论坛、视频、黄页、图片、下载类网站,只要通过浏览器能看到的结构化的内容,通过指定匹配规则,都能采集到您所须要的内容。
2、稳定、高效
七年磨一剑,软件不断更新进步火车头采集教程,采集速度快,性能稳定,占用资源少。
3、扩展性强、适用范围广
自定义web发布,自定义主流的数据库的保存和发布,自定义本地php及.net外部编程插口处理数据火车头采集教程,让数据都能为你所用。
实现教程
打开 /dede/inc/inc_archives_functions.php
在这个文件中找到
return $revalue;
在它的里面加入
MakePreNext($arcID,$typeid);
MakeIndex();
MakeParentType($typeid);
添加完后是这样的
这样添加好后,无论你用火车头免登入插口还是WEB发布模块,无论是普通文章模型还是图集模型还是软件模型,都可以手动生成相关静态文件了。
火车头采集器采集文章操作教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 914 次浏览 • 2020-04-27 11:03
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接火车头采集教程,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试火车头采集教程,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的采集工具。但请在版权范围内采集。 查看全部
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接火车头采集教程,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试火车头采集教程,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是<title>标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,</article>为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的采集工具。但请在版权范围内采集。
火车头教程10:文件手动上传到网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 453 次浏览 • 2020-04-27 11:02
抓包截图:
有文件递交的抓到的结果有很多乱七八糟的东西,这个不用介意,我们不用管他是哪些,复制放在采集器上面,采集器会手动帮你辨识好的,如上图抓包的结果。如果最前面出现了黄色框的字样
说明有隐藏的内容没有显示下来,解决办法如下:
按照上图操作,上面隐藏的内容就全部显示了,然后把抓到的数据复制到采集器上面去如下图:
采集器会把数据一样提取下来。如下图,表单名和表单值一一对应:
那么我们文件上传在哪一部分呢?如下图:
在中级部份,我们选中文件上传设置下边的列表火车头采集教程,右侧就可以更改了,标签名那边会显示好多奇怪的东西,我们不用在乎,标签名我们写上规则上面须要上传文件的标签名称。
你可以单独构建一个标签采集缩略图,或者规则里的任意一个标签,只要这个标签采集结果包含图片文件就可以了,也就是说这儿的标签采集结果可以是单独一张图片的地址也可以是包含图片和其他文字信息火车头采集教程,图片都要下载到本地。
如下图:
我这样写,就表示我的规则上面的内容标签采集结果内有我要上传的图片文件,这里设置和规则设置要一致,不能随意写。点击保存就好了。
这一步是文件手动上传到网站最重要的一步,和做普通发布模块一样,抓包之后把抓到的信息填在采集器上面,采集器会手动提取,你要做的就是这中级功能这部份更改下标签名就好。
在我们测试发布模块的地方可以见到如下:
这里就是手动上传文件的地方了,测试的时侯点击“浏览”选择本地图片进行测试。
测试结果如下:
这个就是用这个手动上传功能把缩略图上传起来了,大家听到内容上面的图片并没有上传,因为不支持,在开始的第1点我就做了说明,这里指出下。 查看全部
如下图:
抓包截图:
有文件递交的抓到的结果有很多乱七八糟的东西,这个不用介意,我们不用管他是哪些,复制放在采集器上面,采集器会手动帮你辨识好的,如上图抓包的结果。如果最前面出现了黄色框的字样
说明有隐藏的内容没有显示下来,解决办法如下:
按照上图操作,上面隐藏的内容就全部显示了,然后把抓到的数据复制到采集器上面去如下图:
采集器会把数据一样提取下来。如下图,表单名和表单值一一对应:
那么我们文件上传在哪一部分呢?如下图:
在中级部份,我们选中文件上传设置下边的列表火车头采集教程,右侧就可以更改了,标签名那边会显示好多奇怪的东西,我们不用在乎,标签名我们写上规则上面须要上传文件的标签名称。
你可以单独构建一个标签采集缩略图,或者规则里的任意一个标签,只要这个标签采集结果包含图片文件就可以了,也就是说这儿的标签采集结果可以是单独一张图片的地址也可以是包含图片和其他文字信息火车头采集教程,图片都要下载到本地。
如下图:
我这样写,就表示我的规则上面的内容标签采集结果内有我要上传的图片文件,这里设置和规则设置要一致,不能随意写。点击保存就好了。
这一步是文件手动上传到网站最重要的一步,和做普通发布模块一样,抓包之后把抓到的信息填在采集器上面,采集器会手动提取,你要做的就是这中级功能这部份更改下标签名就好。
在我们测试发布模块的地方可以见到如下:
这里就是手动上传文件的地方了,测试的时侯点击“浏览”选择本地图片进行测试。
测试结果如下:
这个就是用这个手动上传功能把缩略图上传起来了,大家听到内容上面的图片并没有上传,因为不支持,在开始的第1点我就做了说明,这里指出下。
火车头采集小说教程规则须要注意的内容,可采集,一次搞了几百部!
采集交流 • 优采云 发表了文章 • 0 个评论 • 845 次浏览 • 2020-04-27 11:01
1、充会员,拿cookie
要充到会员拿cookie才可以采集火车头采集教程,要不然没有浏览权限。
2、小说站类型
有的小说站是微信公众号 微站的方式,需要手机抓包,相对网页站来说,麻烦一些,网页站点采集相对容易些,但是也有限制火车头采集教程,比如,找不到内容放哪儿去了,站长做防采集隐藏了上去。
3、外链 很烦
有的小说站在文章中嵌入了好多外链,格式式样不同,量十分大,让人太难受。
4、站点序号
这一点不同需求的人不同,采集小说上传到自己的小说站,需要采集到的文章小说有一定的规则,也就是根据序号排列,很多站点把序号故意整乱,格式乱七八糟,在匹配那些序号时,浪费了大量的时间。还不能做到,百分百匹配正确,2000千章的小说,总有这么一些匹配不正确的。
作者QQ129-0654-348
------------------------20181208更新------------------------
注意:
5、火车头采集小说时,请先说明采集模板式样,有童鞋,直接过来采集规则,然后前面须要依照模板再进行更改,会麻烦些,单本采集和全本采集的规则是不同的哦~
6、全本采集,有的小说站点在章节中没有小说名,如果须要从一级网址或则二级网址采集数据,需要火车头的会员版才行,免费版不能使用。
7、采集时假如cookie 失效,还须要我们学会抓包。
=====20191109更新=====
8、关于教程问题:
8.1、采集PC端的小说,根据《火车头基础教程》就可以解决,尤其是这些免费采集的PC端小说站点,比如:笔-趣、阁 ==八+一+中+文))网。
8.2、采集微信公众号小说教程比较麻烦,因为公众号的不稳定性,公众号会失效,可能须要重新制做教程,我那边也联系了一些做小说站的同学,很少乐意公开分享,所以,可能还须要再等待一段时间。
=====20191123更新=====
9、关于get和post的列表页
昨天有个同学须要采集的站点,是微信公众号的小说站,该站点会提早get出前15章,后面的全部是post恳求,该同学测试的时侯,老是发觉缺乏了前15章,后面我仔细查看以后发觉列表页get的数据没有获取到。
因为标签规则都是一样的,所以,直接把前15章的那种列表页网址复制到火车头的初始地址上面,就可以获取到了。
=====20200420更新=====
10、火车头小说采集视频教程 查看全部
1、充会员,拿cookie
要充到会员拿cookie才可以采集火车头采集教程,要不然没有浏览权限。
2、小说站类型
有的小说站是微信公众号 微站的方式,需要手机抓包,相对网页站来说,麻烦一些,网页站点采集相对容易些,但是也有限制火车头采集教程,比如,找不到内容放哪儿去了,站长做防采集隐藏了上去。
3、外链 很烦
有的小说站在文章中嵌入了好多外链,格式式样不同,量十分大,让人太难受。
4、站点序号
这一点不同需求的人不同,采集小说上传到自己的小说站,需要采集到的文章小说有一定的规则,也就是根据序号排列,很多站点把序号故意整乱,格式乱七八糟,在匹配那些序号时,浪费了大量的时间。还不能做到,百分百匹配正确,2000千章的小说,总有这么一些匹配不正确的。
作者QQ129-0654-348
------------------------20181208更新------------------------
注意:
5、火车头采集小说时,请先说明采集模板式样,有童鞋,直接过来采集规则,然后前面须要依照模板再进行更改,会麻烦些,单本采集和全本采集的规则是不同的哦~
6、全本采集,有的小说站点在章节中没有小说名,如果须要从一级网址或则二级网址采集数据,需要火车头的会员版才行,免费版不能使用。
7、采集时假如cookie 失效,还须要我们学会抓包。
=====20191109更新=====
8、关于教程问题:
8.1、采集PC端的小说,根据《火车头基础教程》就可以解决,尤其是这些免费采集的PC端小说站点,比如:笔-趣、阁 ==八+一+中+文))网。
8.2、采集微信公众号小说教程比较麻烦,因为公众号的不稳定性,公众号会失效,可能须要重新制做教程,我那边也联系了一些做小说站的同学,很少乐意公开分享,所以,可能还须要再等待一段时间。
=====20191123更新=====
9、关于get和post的列表页
昨天有个同学须要采集的站点,是微信公众号的小说站,该站点会提早get出前15章,后面的全部是post恳求,该同学测试的时侯,老是发觉缺乏了前15章,后面我仔细查看以后发觉列表页get的数据没有获取到。
因为标签规则都是一样的,所以,直接把前15章的那种列表页网址复制到火车头的初始地址上面,就可以获取到了。
=====20200420更新=====
10、火车头小说采集视频教程
火车头伪原创插件使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2020-04-27 11:01
火车头采集大家都比较熟悉,这里不多做介绍,主要要说的是火车头伪原创插件,这个插件称作小发猫AI+,因为是一个基于语义NLP的伪原创软件,效果比反义词替换的好好多。
【火车头伪原创插件使用方式】
1、修改火车头的PHP环境
由于火车头采集器软件外置的PHP环境有问题,在使用PHP插件之前须要先更改火车头的PHP环境。修改的方式很简单,打开火车头网站采集软件的安装目录“System/PHP”,找到php.ini文件打开火车头采集教程,并找到如下代码。
找到 php_curl.dll 把上面的分号去除改成:
修改前:
;extension=php_curl.dll
修改后:
extension=php_curl.dll
也就是将最前面的分号“;”删除并保存即可,这样火车头数据采集器就可以正常运行这个PHP扩写插件了。
2、插件要统一放在火车头插件目录
例如我本机是:D:\火车采集器V9\Plugins
问:这个插件主要功能是哪些?
回答:火车头是一个采集器。采集后,如果开了插件,会把采集到的内容通过插件处理后再保存,我们的插件是伪原创,所以采集的内容会伪原创后保存。
3、调试方式
首先按原先的方法,先确保采集规则能正常运行。
然后火车头采集教程,在正常运行的基础上,选择伪原创插件。
一个有效的搜集工具,可以帮助我们更快地完成竞购。
火车头采集器是一种高性能的网路数据采集软件,实现了从数据采集到处理再到发布的一系列智能操作,真正实现了智能化。
不仅这般,它还可以快速,稳定地响应大量数据采集需求,而不是自动搜集和模拟自动操作,从而大大提升工作效率,节省人力资源。
作为一个专业的网站爬虫,火车收藏家抓取网页数据、处理、分析、挖掘非常擅长。
如今,市场上的网页搜集软件极其复杂。机车无疑是一种十分可靠且极易使用的网路数据采集软件。
它可以灵活,快速地捕获网页中分散的文本,图片和其他资源信息,然后通过一系列的剖析和处理,准确地挖掘出您须要的大部分数据信息。
您可以选择将数据发布到网站、以导出数据库,或将其保存在本地Excel,Word和其他格式的文件中。
收集新闻和搜集文章都在空中。老板不再须要害怕不这样做,一切都显得这么简单
经过六年的升级换代,火车收藏家积累了大量的用户和良好的口碑。它是市场上最受欢迎的网路数据采集软件。 查看全部
火车头采集大家都比较熟悉,这里不多做介绍,主要要说的是火车头伪原创插件,这个插件称作小发猫AI+,因为是一个基于语义NLP的伪原创软件,效果比反义词替换的好好多。
【火车头伪原创插件使用方式】
1、修改火车头的PHP环境
由于火车头采集器软件外置的PHP环境有问题,在使用PHP插件之前须要先更改火车头的PHP环境。修改的方式很简单,打开火车头网站采集软件的安装目录“System/PHP”,找到php.ini文件打开火车头采集教程,并找到如下代码。
找到 php_curl.dll 把上面的分号去除改成:
修改前:
;extension=php_curl.dll
修改后:
extension=php_curl.dll
也就是将最前面的分号“;”删除并保存即可,这样火车头数据采集器就可以正常运行这个PHP扩写插件了。
2、插件要统一放在火车头插件目录
例如我本机是:D:\火车采集器V9\Plugins
问:这个插件主要功能是哪些?
回答:火车头是一个采集器。采集后,如果开了插件,会把采集到的内容通过插件处理后再保存,我们的插件是伪原创,所以采集的内容会伪原创后保存。
3、调试方式
首先按原先的方法,先确保采集规则能正常运行。
然后火车头采集教程,在正常运行的基础上,选择伪原创插件。
一个有效的搜集工具,可以帮助我们更快地完成竞购。
火车头采集器是一种高性能的网路数据采集软件,实现了从数据采集到处理再到发布的一系列智能操作,真正实现了智能化。
不仅这般,它还可以快速,稳定地响应大量数据采集需求,而不是自动搜集和模拟自动操作,从而大大提升工作效率,节省人力资源。
作为一个专业的网站爬虫,火车收藏家抓取网页数据、处理、分析、挖掘非常擅长。
如今,市场上的网页搜集软件极其复杂。机车无疑是一种十分可靠且极易使用的网路数据采集软件。
它可以灵活,快速地捕获网页中分散的文本,图片和其他资源信息,然后通过一系列的剖析和处理,准确地挖掘出您须要的大部分数据信息。
您可以选择将数据发布到网站、以导出数据库,或将其保存在本地Excel,Word和其他格式的文件中。
收集新闻和搜集文章都在空中。老板不再须要害怕不这样做,一切都显得这么简单
经过六年的升级换代,火车收藏家积累了大量的用户和良好的口碑。它是市场上最受欢迎的网路数据采集软件。
火车头采集时 采网址--重复网址的临时解决方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-04-27 11:00
商业版用户的采集后的网址都存贮在 PageUrl 目录上面的,一个任务对应一个db3.大家可以从最里面的任务往下数第一个,对应的就是Site_*.db3.这样你们可以先备份一下,然后清空也不怕了,到时候直接还原用户名既可以,如果怕出错,全部保存,一会恢复即可。
如果想更进一步的查看,这个db3虽然就是sqlite数据库格式的文件,可以用db3数据库编辑器 查看更改。根据jobid查看,有同事问不知道jobid怎样办,呵呵,大家可以到 Data 目录查看 3-新浪国外新闻 后面的新浪国外新闻就是你自定义的网站栏目名称。这个跟jobid对应上即可。
最后你们备份好数据库之后就可以(需要备份在 PageUrl 与 Data目录的你的任务名对应的文件夹,最好是全部以防万一,采集完就可以覆盖下。)
后来从网站也看见了如下文件,跟我的这篇大同小异。大家可以参考下。
火车头是一个不错的采集软件,“盗亦有道”,看你怎么借助了。
Linker曾经也时常研究下火车头采集软件,只是仍然没有订购商业版本,想想火车头采集教程,现在的版本远没有曾经的1.x和2.x版本来得爽快。
一位兄弟,昨晚说他的火车头采集软件(企业版本的哦,有钱人!),总是提示任务地址库重复,研究了下,比较简单,告诉了他处理的方式,另外,经过搜索发觉,火车头的3.0 sp1版本有过这个bug火车头采集教程,清除不掉任务地址库,但管理员早已在sp2版本中解决掉这个问题了。
后来那位同学又问火车头采集软件的任务地址库是那个文件?怎么样保存任务地址库?怎么样自动清除任务地址库文件?据Linker所知,编辑任务地址库,需要是商业版本了,如果想自动来处理,可以发觉,手动地址库文件是在火车头根目录下的pageurl目录中,每一个任务对应一个地址库文件,mdb格式的,打开可以发觉,具体地址是被加密了。火车头也有些很商业了,嘿嘿!
既然晓得任务地址库的位置和文件了,手动清除任务地址库,自然就简单了。删除使火车头重复(删除后,编辑该任务,再保存),或者直接删掉该库上面的记录,都可以。想另存为其他任务所用,重命令为其它任务的id就行了。
简单测试通过。 查看全部
商业版用户的采集后的网址都存贮在 PageUrl 目录上面的,一个任务对应一个db3.大家可以从最里面的任务往下数第一个,对应的就是Site_*.db3.这样你们可以先备份一下,然后清空也不怕了,到时候直接还原用户名既可以,如果怕出错,全部保存,一会恢复即可。
如果想更进一步的查看,这个db3虽然就是sqlite数据库格式的文件,可以用db3数据库编辑器 查看更改。根据jobid查看,有同事问不知道jobid怎样办,呵呵,大家可以到 Data 目录查看 3-新浪国外新闻 后面的新浪国外新闻就是你自定义的网站栏目名称。这个跟jobid对应上即可。
最后你们备份好数据库之后就可以(需要备份在 PageUrl 与 Data目录的你的任务名对应的文件夹,最好是全部以防万一,采集完就可以覆盖下。)
后来从网站也看见了如下文件,跟我的这篇大同小异。大家可以参考下。
火车头是一个不错的采集软件,“盗亦有道”,看你怎么借助了。
Linker曾经也时常研究下火车头采集软件,只是仍然没有订购商业版本,想想火车头采集教程,现在的版本远没有曾经的1.x和2.x版本来得爽快。
一位兄弟,昨晚说他的火车头采集软件(企业版本的哦,有钱人!),总是提示任务地址库重复,研究了下,比较简单,告诉了他处理的方式,另外,经过搜索发觉,火车头的3.0 sp1版本有过这个bug火车头采集教程,清除不掉任务地址库,但管理员早已在sp2版本中解决掉这个问题了。
后来那位同学又问火车头采集软件的任务地址库是那个文件?怎么样保存任务地址库?怎么样自动清除任务地址库文件?据Linker所知,编辑任务地址库,需要是商业版本了,如果想自动来处理,可以发觉,手动地址库文件是在火车头根目录下的pageurl目录中,每一个任务对应一个地址库文件,mdb格式的,打开可以发觉,具体地址是被加密了。火车头也有些很商业了,嘿嘿!
既然晓得任务地址库的位置和文件了,手动清除任务地址库,自然就简单了。删除使火车头重复(删除后,编辑该任务,再保存),或者直接删掉该库上面的记录,都可以。想另存为其他任务所用,重命令为其它任务的id就行了。
简单测试通过。
火车头采集器教程之网站采集规则编撰
采集交流 • 优采云 发表了文章 • 0 个评论 • 531 次浏览 • 2020-04-27 11:00
点选新建按键,选择新建站点“每日经济新闻” 我们,先进行“标题”规则的编撰 标题标签规则的编撰 注意:标签起始字符串的确认,一定要注意两点,一、唯一性;二、贴身原则,即尽可能紧贴目标采集区域; 开始字符串: 结束字符串: 注意:确认字符串的唯一性:复制字符串,点按快捷键“Ctrl+ F”进行查找,如果字符串为惟一,会有提示信息“找不到XXX”的提 Google冷凝器 数据采集 蒸发器 分配器 找回密码 注册成为 师大人 帐号 UI 用户名/Email 记住密码 密码 登录 火车头采集器教程之网站采集规则编撰 Html 标签排除:我们选择“全选”。 注意:然对于“空格(占位符) ”我们可以有所保留,因为有些站点的“长标题”的分隔不是靠标点或则正宗意义上的空白,而是 靠“占位符 ”进行分隔的,那么这时候我们就要保留“空格(占位符) ”选项。(课后看吧) 此时我们可以以点代面,直接进行“典型页面”的采集测试,测试一下采集效果,满意后,我们接下来进行文章内容的规则编 文章内容标签规则的编撰开始字符串:
iframeHt ml 标签排除:此时我们要保留拿来界定段落的一下常用字符串“ 结束字符串:[ 200 Ht ml 标签排除:我们选择“全选”。(测试) 时间标签编撰规则 要点同上。 开始字符串:
iframeHt ml 标签排除:我们选择“全选”。(测试) 出处标签尺寸的编撰 此值,一般来说,我们默认为我们采集的目标网站,使用“固定格式的数据”进行设置,但是,你若果为了更好的彰显贵网站的 版权意识,那么,你在对目标网站转载的文章进行采集设置的时侯,可以进行相应调整,此处不做赘言。 好了,整个站点的“内容规则”我们设置完毕,下面将进行,采集任务的设置。 二、新建采集任务在刚才构建的采集站点上点击滑鼠右键,选择“从该站点新建任务”,,在弹出的对话框里我们察看一下“内容规则”,结果正如前 边所说“在站点下构建的采集任务默认承继站点采集内容规则”,好了,我们就可以直接编撰“采集网址”的规则了。 “采集网址深度”标签的编撰 为了灵活便捷,此项操作,我们通常都在文章的列表页面进行操作,所以我们可采用其默认值“1”,对于更深度的采集我们以 后的教程中进行探讨,此处不做赘言。 开始采集网址规则的编撰 火车头采集器教程之网站采集规则编撰 点选“向导添加”在弹出的对话框中有三个选项“单页网址”、“批量/多页”、“文本导出”,一般情况火车头采集教程,我们不会用到“文本导出”方 此处仅对前两种采集方式进行探讨。我们先进行“单页网址”的设置,此处我们选择“地产”栏目进行学习。
列表页面网址为 htt 74,复制到文本域中,点选“添加”按钮,并“完成添加”。 回到“新建任务”—“采集网址”出,进行“页面内选取区域采集网址”设置 从:align= 'left 到:class=right_font 测试,结果40页文章页面。。。全部采集测试通过,,满意,,(此处我们不进行采集)继续往下学习。好我们下边学习“批量/ 为了确定列表网址的变量,我们进行如下操作:1、我们在网页中“点选”“下一页”,,发现地址栏网址:htt 74&page= 74& amp;page= 74& page= 58; 4、再将键盘“指向”“首页”发现浏览器左下方状态栏显示地址为http:/ 74& page= 74&page= 74&page= 74&page= 58 http: 74&page= ;”为其列表网址的变量,那么我么可以设定如下:多页类似地址网址方式为:htt 数字变化范围从1到58,间隔倍数为1;点选“添加”按钮,并完成添加。 此处的“页面内选取区域采集网址”设置同“单页网址”“页面内选取区域采集网址”的设置,此处不做赘言。
点选“开始测试网址”,(这个过程太长,我暂停了视频录制) 当然,在实际操作当中,如果数据量大,我们也可以不去测试,直接采集,即便是因为规则的不完全适用性而导致一部分数 据的遗失,我想也是可以忽视的。 此处,我只选择了2页进行采集 测试结果共有80页内容页面。 下一步骤:“数据发布形式”设置 回复引用 举报 返回底部 返回列表 wap CP备09056220号;闽ICP备10028594号 GMT+8,2011-4-6 09:55 0.155204second(s), 27 queries 我们选定方法一:“保存到软件数据库”,同时,选取形式三“Web在线发布到网站”的“使用自定义发布形式”,“自定义分类I D”选择3,给任务命名为“地产”火车头采集教程,,并“保 存,更新”采集任务,鉴于我们教程刚刚开始,就不做深入学习。 回到火车头主界面,在“地产”任务上点击滑鼠右键,选择“开始”,即可完成采集。 采集数据会手动发布到形式三所指向的网站的指定栏目( ,同时保存到:火车头安装目录/ DATA/ 序号- 任务名/ Spi der Resul .mdb的数据库中。 哦,,昨天net 对我的错误提示了我一下,,, 3个小时要写文案,录像,还得采集信息到我的网站,晕倒了N次,,,写的苏州粗了,,完全是凭感觉写的,,让你们云里 雾里的一头雾水,不好意思阿,,请见谅!!!: L,现在更正以下: 这里的方法一、方式三是并列关系的,,可以同时选,也可以任选其二,,,如果你没有在发布模块的话,就直接采集到 本地软件数据库即可。
“本地软件数据库”是谷歌Access的,我们可以打开一下数据库对数据进行一下浏览查验。 至于方法三“Web在线发布到网站”,我会在此后的教程中进行讲解,希望你们就能耐心等待。 好了,,本教程到此为止!下一节课,再见!!! 收藏0 分享0 楼主热帖峰会新帖 中国移动通信集团福建有限公司德化分公司急聘信息 2011年晋江移动分公司急聘信息(报名截至至3月20日) 2011年长乐市中小学招录师范专业本本科毕业生公告 2011年将乐县教育系统补充班主任公开急聘工作方案 大田县2011年中中学新任班主任公开考试急聘方案 关于2011年建瓯市公开选聘农村中小学班主任进城任教的通知 福建师范大学2011届毕业生信息及辅导员联系方法 4月9日2011年福建省师范专业毕业生供需见面会暨福建师范大学小型校园供需见面会 04月06日 签到记录贴 后期宣传 2011年顺昌县中小学班主任急聘职位简章 2011年武夷山市中小学班主任急聘简章 福建师范大学中学生门户祝全体师生新年快乐!万事如意! 上一主题|下一主题 福建师范大学中学生门户访问统计: 2010广告合作 声明:本站部份内容来自网路,如侵害您版权请与本站联系,即行删掉。 火车头采集器教程之网站采集规则编撰 查看全部
我的中心游戏 共青团广场 学习资料 师大人家 师大微博 群组 学生门户 QQ群 搜索群组 请输入搜索内容【师大搜索】 群组 网站 采集 火车头采集器 火车头采集器教程之网站采集规则编撰 返回列表 查看:579 复制链接]admin 师大管理员 礼物信息 赠送礼物:4 在线聊天加为好友 个人空间 发表于 2010-5-20 09:39 打印首先,我们先了解一下火车头采集器(LocoySpider)V3的基本功能, 我们明天所用到的火车头的基本功能如下 1、新建站点 2、新建任务 3、数据发布形式之“保存到软件数据库” 当然本教程是围绕“CMS采集规则编撰”这一主题展开的,所以不可能面面俱到的陈表火车头采集器的功能,在此请见谅! 现在我们结合实战来给你们讲解 一、新建站点1、功能:对同一站点具有“相同采集内容规则”的采集任务进行聚合 2、好处: a、分类明确,便于查询、调用; b、在站点下构建的采集任务默认承继站点采集内容规则,避免了重复编撰采集规则的麻烦; 3、实战: 我们以“每日经济新闻”为例进行讲解,首先我们打开其站点 htt ,浏览其中不同栏目的文章发现这个站点的文章模式(模板)几乎是完全一致的 (当然,其中有一点小小的区别,就是有的文章段落是靠段落标记 布局的,那么残余的DIV标记太可能会破坏你原先的布局,此种情况的解决办法我们之后再继续讨论,这里我就不再赘言 好,现在我们有理由相信,我们构建一个站点的“内容规则”,就可以将这个网站的所有栏目囊括了。
点选新建按键,选择新建站点“每日经济新闻” 我们,先进行“标题”规则的编撰 标题标签规则的编撰 注意:标签起始字符串的确认,一定要注意两点,一、唯一性;二、贴身原则,即尽可能紧贴目标采集区域; 开始字符串: 结束字符串: 注意:确认字符串的唯一性:复制字符串,点按快捷键“Ctrl+ F”进行查找,如果字符串为惟一,会有提示信息“找不到XXX”的提 Google冷凝器 数据采集 蒸发器 分配器 找回密码 注册成为 师大人 帐号 UI 用户名/Email 记住密码 密码 登录 火车头采集器教程之网站采集规则编撰 Html 标签排除:我们选择“全选”。 注意:然对于“空格(占位符) ”我们可以有所保留,因为有些站点的“长标题”的分隔不是靠标点或则正宗意义上的空白,而是 靠“占位符 ”进行分隔的,那么这时候我们就要保留“空格(占位符) ”选项。(课后看吧) 此时我们可以以点代面,直接进行“典型页面”的采集测试,测试一下采集效果,满意后,我们接下来进行文章内容的规则编 文章内容标签规则的编撰开始字符串:
iframeHt ml 标签排除:此时我们要保留拿来界定段落的一下常用字符串“ 结束字符串:[ 200 Ht ml 标签排除:我们选择“全选”。(测试) 时间标签编撰规则 要点同上。 开始字符串:
iframeHt ml 标签排除:我们选择“全选”。(测试) 出处标签尺寸的编撰 此值,一般来说,我们默认为我们采集的目标网站,使用“固定格式的数据”进行设置,但是,你若果为了更好的彰显贵网站的 版权意识,那么,你在对目标网站转载的文章进行采集设置的时侯,可以进行相应调整,此处不做赘言。 好了,整个站点的“内容规则”我们设置完毕,下面将进行,采集任务的设置。 二、新建采集任务在刚才构建的采集站点上点击滑鼠右键,选择“从该站点新建任务”,,在弹出的对话框里我们察看一下“内容规则”,结果正如前 边所说“在站点下构建的采集任务默认承继站点采集内容规则”,好了,我们就可以直接编撰“采集网址”的规则了。 “采集网址深度”标签的编撰 为了灵活便捷,此项操作,我们通常都在文章的列表页面进行操作,所以我们可采用其默认值“1”,对于更深度的采集我们以 后的教程中进行探讨,此处不做赘言。 开始采集网址规则的编撰 火车头采集器教程之网站采集规则编撰 点选“向导添加”在弹出的对话框中有三个选项“单页网址”、“批量/多页”、“文本导出”,一般情况火车头采集教程,我们不会用到“文本导出”方 此处仅对前两种采集方式进行探讨。我们先进行“单页网址”的设置,此处我们选择“地产”栏目进行学习。
列表页面网址为 htt 74,复制到文本域中,点选“添加”按钮,并“完成添加”。 回到“新建任务”—“采集网址”出,进行“页面内选取区域采集网址”设置 从:align= 'left 到:class=right_font 测试,结果40页文章页面。。。全部采集测试通过,,满意,,(此处我们不进行采集)继续往下学习。好我们下边学习“批量/ 为了确定列表网址的变量,我们进行如下操作:1、我们在网页中“点选”“下一页”,,发现地址栏网址:htt 74&page= 74& amp;page= 74& page= 58; 4、再将键盘“指向”“首页”发现浏览器左下方状态栏显示地址为http:/ 74& page= 74&page= 74&page= 74&page= 58 http: 74&page= ;”为其列表网址的变量,那么我么可以设定如下:多页类似地址网址方式为:htt 数字变化范围从1到58,间隔倍数为1;点选“添加”按钮,并完成添加。 此处的“页面内选取区域采集网址”设置同“单页网址”“页面内选取区域采集网址”的设置,此处不做赘言。
点选“开始测试网址”,(这个过程太长,我暂停了视频录制) 当然,在实际操作当中,如果数据量大,我们也可以不去测试,直接采集,即便是因为规则的不完全适用性而导致一部分数 据的遗失,我想也是可以忽视的。 此处,我只选择了2页进行采集 测试结果共有80页内容页面。 下一步骤:“数据发布形式”设置 回复引用 举报 返回底部 返回列表 wap CP备09056220号;闽ICP备10028594号 GMT+8,2011-4-6 09:55 0.155204second(s), 27 queries 我们选定方法一:“保存到软件数据库”,同时,选取形式三“Web在线发布到网站”的“使用自定义发布形式”,“自定义分类I D”选择3,给任务命名为“地产”火车头采集教程,,并“保 存,更新”采集任务,鉴于我们教程刚刚开始,就不做深入学习。 回到火车头主界面,在“地产”任务上点击滑鼠右键,选择“开始”,即可完成采集。 采集数据会手动发布到形式三所指向的网站的指定栏目( ,同时保存到:火车头安装目录/ DATA/ 序号- 任务名/ Spi der Resul .mdb的数据库中。 哦,,昨天net 对我的错误提示了我一下,,, 3个小时要写文案,录像,还得采集信息到我的网站,晕倒了N次,,,写的苏州粗了,,完全是凭感觉写的,,让你们云里 雾里的一头雾水,不好意思阿,,请见谅!!!: L,现在更正以下: 这里的方法一、方式三是并列关系的,,可以同时选,也可以任选其二,,,如果你没有在发布模块的话,就直接采集到 本地软件数据库即可。
“本地软件数据库”是谷歌Access的,我们可以打开一下数据库对数据进行一下浏览查验。 至于方法三“Web在线发布到网站”,我会在此后的教程中进行讲解,希望你们就能耐心等待。 好了,,本教程到此为止!下一节课,再见!!! 收藏0 分享0 楼主热帖峰会新帖 中国移动通信集团福建有限公司德化分公司急聘信息 2011年晋江移动分公司急聘信息(报名截至至3月20日) 2011年长乐市中小学招录师范专业本本科毕业生公告 2011年将乐县教育系统补充班主任公开急聘工作方案 大田县2011年中中学新任班主任公开考试急聘方案 关于2011年建瓯市公开选聘农村中小学班主任进城任教的通知 福建师范大学2011届毕业生信息及辅导员联系方法 4月9日2011年福建省师范专业毕业生供需见面会暨福建师范大学小型校园供需见面会 04月06日 签到记录贴 后期宣传 2011年顺昌县中小学班主任急聘职位简章 2011年武夷山市中小学班主任急聘简章 福建师范大学中学生门户祝全体师生新年快乐!万事如意! 上一主题|下一主题 福建师范大学中学生门户访问统计: 2010广告合作 声明:本站部份内容来自网路,如侵害您版权请与本站联系,即行删掉。 火车头采集器教程之网站采集规则编撰
火车头采集器使用教程–采集内容发布规则设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 824 次浏览 • 2020-04-26 11:02
教程总目录:火车头采集器使用教程
前面我们讲了如何找寻网站,以及采集文章链接和内容,下面我们就说一下内容发布相关的设置。
因为我教程里都是设置好的发布规则,所以这儿我就简单介绍下各个项目。
如下图
第一步,我们点击到内容发布规则这儿
第二步,点击web发布规则列表前面的减号
第三步,出现了模块管理(教程总目录有写,我们的模块文件放在火车头程序下边的\Module\目录里),选择wordpress.post这个模块
第四步,网页编码选择UTF-8(wordpress程序是美国的,国际上通常都是UTF8编码,国内的一些会是GBK的编码,比如Discuz峰会程序就有UTF8和GBK两种安装包)
第五步,网站地址填入我们网页的地址前面加上插口文件名火车头采集教程,比如你的插口文件名是jiekou.php网站是这么这个地址就填入
第六步,登录方法选择不登录,我们的插口文件是免登录的。
第七步,点击一下下边的获取列表,正常的话会或取下来wordpress的文章分类列表。然后选择一个列表,你选择那个列表,采集的文章就发到那个列表里。
然后下边配置名随意写一个,保存。
然后我们把这个刚保存的发布配置勾选一下,启用它。
然后右下角别忘了点击一下保存火车头采集教程,也可以点保存并退出! 查看全部
火车头采集器使用教程–采集内容发布规则设置
教程总目录:火车头采集器使用教程
前面我们讲了如何找寻网站,以及采集文章链接和内容,下面我们就说一下内容发布相关的设置。
因为我教程里都是设置好的发布规则,所以这儿我就简单介绍下各个项目。
如下图
第一步,我们点击到内容发布规则这儿
第二步,点击web发布规则列表前面的减号
第三步,出现了模块管理(教程总目录有写,我们的模块文件放在火车头程序下边的\Module\目录里),选择wordpress.post这个模块
第四步,网页编码选择UTF-8(wordpress程序是美国的,国际上通常都是UTF8编码,国内的一些会是GBK的编码,比如Discuz峰会程序就有UTF8和GBK两种安装包)
第五步,网站地址填入我们网页的地址前面加上插口文件名火车头采集教程,比如你的插口文件名是jiekou.php网站是这么这个地址就填入
第六步,登录方法选择不登录,我们的插口文件是免登录的。
第七步,点击一下下边的获取列表,正常的话会或取下来wordpress的文章分类列表。然后选择一个列表,你选择那个列表,采集的文章就发到那个列表里。
然后下边配置名随意写一个,保存。
然后我们把这个刚保存的发布配置勾选一下,启用它。
然后右下角别忘了点击一下保存火车头采集教程,也可以点保存并退出!
火车头采集器使用教程–分析目标网站文章链接位置及规则
采集交流 • 优采云 发表了文章 • 0 个评论 • 622 次浏览 • 2020-04-26 11:02
首先看下火车头采集教程,在列表页上面他的文章链接都在我红线画出的部份。
然后我们就可以从画出这部份上面的代码找到地址,我们看一下
是在server-r2这个div上面
注:我用的是浏览器带的调试功能,直接按按键F12就下来了。
我们查看网页源代码,浏览器按CTRL+U即可
CTRL+F搜索server-r2,可以见到只有一个结果,没有其他重复项
那么这个就可以作为我们火车头采集器手动从列表页剖析文章链接的开始部份了。我们复制server-r2,填入火车头的开始字符串那儿,意味着火车头从这一段开始找寻文章链接。
然后我们还要确定下结束字符串位置
直接看下述表页最后一个文章是啥
然后再源码上面瞧瞧这个文章在那个位置
找到了位置,我们尽可能在他下边找下一个DIV开始的标记。这里我们找到了
<div>这个DIV,我们复制class="cp-manu"https://cdn.cheshirex.com/uploads/2020/03/QQ截图20200319225619.png" data-fancybox="group" >
其实这时候早已可以查找到确切的文章链接了,但是我们最好还是加一个过滤
在联接过滤--必须包含上面填入.html这个内容,然后回车键即可。想添加更多条内容就在输入过滤规则火车头采集教程,再回车。
后面那种设置图标点一下可以选择:满足其中一个条件或则满足所有条件。
以上基本完成了我们采集文章链接的规则,我们点一下下方的保存,先存一下。
如果你是新建任务规则可能提示你要输入任务名 查看全部
下面我们要从列表页剖析下来他文章的地址。
首先看下火车头采集教程,在列表页上面他的文章链接都在我红线画出的部份。
然后我们就可以从画出这部份上面的代码找到地址,我们看一下
是在server-r2这个div上面
注:我用的是浏览器带的调试功能,直接按按键F12就下来了。
我们查看网页源代码,浏览器按CTRL+U即可
CTRL+F搜索server-r2,可以见到只有一个结果,没有其他重复项
那么这个就可以作为我们火车头采集器手动从列表页剖析文章链接的开始部份了。我们复制server-r2,填入火车头的开始字符串那儿,意味着火车头从这一段开始找寻文章链接。
然后我们还要确定下结束字符串位置
直接看下述表页最后一个文章是啥
然后再源码上面瞧瞧这个文章在那个位置
找到了位置,我们尽可能在他下边找下一个DIV开始的标记。这里我们找到了
<div>这个DIV,我们复制class="cp-manu"https://cdn.cheshirex.com/uploads/2020/03/QQ截图20200319225619.png" data-fancybox="group" >
其实这时候早已可以查找到确切的文章链接了,但是我们最好还是加一个过滤
在联接过滤--必须包含上面填入.html这个内容,然后回车键即可。想添加更多条内容就在输入过滤规则火车头采集教程,再回车。
后面那种设置图标点一下可以选择:满足其中一个条件或则满足所有条件。
以上基本完成了我们采集文章链接的规则,我们点一下下方的保存,先存一下。
如果你是新建任务规则可能提示你要输入任务名
火车头采集器使用教程–寻找目标网站
采集交流 • 优采云 发表了文章 • 0 个评论 • 522 次浏览 • 2020-04-26 11:02
这一步教程值得单独开一篇文章来写,每个网站的设计都不一样,他们发表的文章分类也不同。这里就介绍最常见的一种结构。
我们首先须要确定你要采集什么内容,然后按照不同内容去找目标网站。
比如我要采集IT资讯、云服务器类的内容。
以景安的文章为例,我先找到了他的文章都放到了那个网站。
在百度这样搜索site:zzidc.com windows2008
site:zzidc.com代表仅搜索这个域名下的内容,包括www域名和其他二级域名的内容
空格后跟一个windows2008的关键词,这样我搜下来都是景安网站下的关于windows2008的相关内容了。
从搜索结果里可以看见主要有两个域名地址,我选择了server.zzidc.com这个站点,因为这个内容多!
站点里有很多文章,我们要找寻自己想采集的文章。我选择了服务器教程相关的文章
点击这个分类,看看火车头采集教程,里面有33页的列表火车头采集教程,数量还可以
现在在列表第一页,他的地址是
然后我们翻页看一下第二页,发现地址弄成了
第三页弄成了
这就有一个比较好的列表页规律,非常适宜我们采集。
就选择它了! 查看全部
这一步教程值得单独开一篇文章来写,每个网站的设计都不一样,他们发表的文章分类也不同。这里就介绍最常见的一种结构。
我们首先须要确定你要采集什么内容,然后按照不同内容去找目标网站。
比如我要采集IT资讯、云服务器类的内容。
以景安的文章为例,我先找到了他的文章都放到了那个网站。
在百度这样搜索site:zzidc.com windows2008
site:zzidc.com代表仅搜索这个域名下的内容,包括www域名和其他二级域名的内容
空格后跟一个windows2008的关键词,这样我搜下来都是景安网站下的关于windows2008的相关内容了。
从搜索结果里可以看见主要有两个域名地址,我选择了server.zzidc.com这个站点,因为这个内容多!
站点里有很多文章,我们要找寻自己想采集的文章。我选择了服务器教程相关的文章
点击这个分类,看看火车头采集教程,里面有33页的列表火车头采集教程,数量还可以
现在在列表第一页,他的地址是
然后我们翻页看一下第二页,发现地址弄成了
第三页弄成了
这就有一个比较好的列表页规律,非常适宜我们采集。
就选择它了!
火车头采集器技术控使用指南(高级) 爬虫教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 707 次浏览 • 2020-04-25 11:02
1-1 火车头采集器视频教程序言
1-2 火车头采集器初级教程预期年后与你们碰面
2-1 如何借助fiddler软件对影藏链接地址的抓取
2-2 利用fiddler软件剖析post页面并获取列表网址的方式解读
3-1 利用火车头采集器采集58房子转租内容采集-上部份
3-2 利用火车头采集器采集58房子转租内容采集-下部份
3-3 利用火车头采集器采集赶集网的号码图片以及座标的视频上
3-4 利用火车头采集器采集赶集网急聘信息新视频教程下
3-5 利用火车头采集器采集慧聪网站公司信息采集视频教程-2019-11-18
3-6 火车头采集器采集智联招聘信息采集-2019-12-04
4-1 采集qq群上面的所有qq成员的方式
4-2 腾讯滚动新闻采集规则的制做详尽视频教程
4-3 weixin-sogou-com-俄罗斯护照-微信文章采集视频教程
4-4 第4节:微信公众号搜索的内容采集采集方法
4-5 腾讯视频的代码的采集和缩略图,以及图片水印覆盖的处理办法。
4-6 火车头采集器采集新浪滚动新闻-2019-11-25
4-7 火车头采集器采集头条toutiao网站文章的视频教程-2019-12-15
5-1 采集小说网站内容合成出多个txt和单个txt文本文档的方式和注意事项
5-2 通过采集器-采集网站内容合成出word文档的方式和细节优化
5-3 通过火车头采集器采集搜狐彩票开奖号码合成出xls文件的方式
5-4 通过采集器采集美女图片站合成html单页面
6-1 利用火车头采集器-威客网站的使用案例
7-1 通过采集器采集优酷网站的视频和相关信息
7-2 通过火车头采集器采集监控不同视频不同时间段的播放量 查看全部
课程目录:
1-1 火车头采集器视频教程序言
1-2 火车头采集器初级教程预期年后与你们碰面
2-1 如何借助fiddler软件对影藏链接地址的抓取
2-2 利用fiddler软件剖析post页面并获取列表网址的方式解读
3-1 利用火车头采集器采集58房子转租内容采集-上部份
3-2 利用火车头采集器采集58房子转租内容采集-下部份
3-3 利用火车头采集器采集赶集网的号码图片以及座标的视频上
3-4 利用火车头采集器采集赶集网急聘信息新视频教程下
3-5 利用火车头采集器采集慧聪网站公司信息采集视频教程-2019-11-18
3-6 火车头采集器采集智联招聘信息采集-2019-12-04
4-1 采集qq群上面的所有qq成员的方式
4-2 腾讯滚动新闻采集规则的制做详尽视频教程
4-3 weixin-sogou-com-俄罗斯护照-微信文章采集视频教程
4-4 第4节:微信公众号搜索的内容采集采集方法
4-5 腾讯视频的代码的采集和缩略图,以及图片水印覆盖的处理办法。
4-6 火车头采集器采集新浪滚动新闻-2019-11-25
4-7 火车头采集器采集头条toutiao网站文章的视频教程-2019-12-15
5-1 采集小说网站内容合成出多个txt和单个txt文本文档的方式和注意事项
5-2 通过采集器-采集网站内容合成出word文档的方式和细节优化
5-3 通过火车头采集器采集搜狐彩票开奖号码合成出xls文件的方式
5-4 通过采集器采集美女图片站合成html单页面
6-1 利用火车头采集器-威客网站的使用案例
7-1 通过采集器采集优酷网站的视频和相关信息
7-2 通过火车头采集器采集监控不同视频不同时间段的播放量
火车头采集后使用5118伪原创教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 576 次浏览 • 2020-04-25 11:02
最近在研究火车头采集器,通过火车头采集软件可以轻而易举的获得海量的网站内容(采集确实不妥)可以解放站长右手,机器时代工具自然比手工效率高多了。经过一段时间研究,目前早已把握了火车头采集技术能力火车头采集教程,火车头采集对接开源CMS程序手动更新能力,可以结合ai伪原创插口 实现批量采集并直接发布到WP、DEDECMS网站。说实在的,不是常常被人问采集相关的问题,我根本不乐意研究这种采集技术。接下来谈谈火车头采集器集成5118智能原创功能吧,这也是5118明天刚推送的一篇公众号文章。在列车采集器中,利用5118智能原创插件,不再须要经过人工处理,即能批量生产出内容指纹完全不同的文章,大幅提升了内容SEO采编的工作效率,让文章更容易被收录。5118智能原创-火车采集器插件下载链接: 提取码: umjx火车采集器中怎样安装智能原创插件第一步,使用解压软件,提取插件安装包中的文件,解压到一个文件夹中。第二步,打开解压后的文件夹,将上面的【5118 智能原创.dll】文件,放入在【火车采集器】安装目录下的Plugins文件夹里。第三步,将文件夹中的【5118智能原创配置工具.exe】和【Newtonsoft.Json.dll】文件,放入在【火车采集器】安装目录中。
第四步,在【火车采集器】的根目录里,打开【5118 智能原创配置工具.exe】,点击“获取API-Key”,将会在浏览器中打开5118获取API的页面。页面中找到“一键智能原创API”,点击复制按键,返回【5118 智能原创配置工具.exe】界面,粘贴API-Key到输入框中。一键智能原创API支持免费试用其实5118伪原创是要订购付费的,可申请100次免费使用,可选购一键智能原创API套餐。5118会员折扣码 D569F5 [?]智能原创插件使用说明第一步,打开火车头采集器,点击开始栏的【插件管理】,在插件管理框右侧列表里,选中【5118智能原创】,在两侧框中输入需采集的网址,点击测试按键,查看插件是否正常。第二步,测试没有问题后,开始使用插件设置内容采集规则。第三步,选择已有采集任务,在【其他设置】的一侧栏目中选择插件,在采集结果处理插件下拉框中,选择【5118智能原创.dll】,点击保存即可。此处需注意火车头采集教程,【内容采集规则】左侧列表里的“内容”标签,是插件将手动智能原创的内容,固定标签名称为“内容”。导出任务数据时,在任务列表里,选中对应任务项目,右侧“发布”项必须勾选,否则数据难以导入。第四步,查看5118智能原创插件疗效。运行完成后,即可在之前所保存的地址中查看导入疗效。所导入的内容,已经是使用智能原创插件替换后的数据。 查看全部
最近在研究火车头采集器,通过火车头采集软件可以轻而易举的获得海量的网站内容(采集确实不妥)可以解放站长右手,机器时代工具自然比手工效率高多了。经过一段时间研究,目前早已把握了火车头采集技术能力,火车头...显示全部
最近在研究火车头采集器,通过火车头采集软件可以轻而易举的获得海量的网站内容(采集确实不妥)可以解放站长右手,机器时代工具自然比手工效率高多了。经过一段时间研究,目前早已把握了火车头采集技术能力火车头采集教程,火车头采集对接开源CMS程序手动更新能力,可以结合ai伪原创插口 实现批量采集并直接发布到WP、DEDECMS网站。说实在的,不是常常被人问采集相关的问题,我根本不乐意研究这种采集技术。接下来谈谈火车头采集器集成5118智能原创功能吧,这也是5118明天刚推送的一篇公众号文章。在列车采集器中,利用5118智能原创插件,不再须要经过人工处理,即能批量生产出内容指纹完全不同的文章,大幅提升了内容SEO采编的工作效率,让文章更容易被收录。5118智能原创-火车采集器插件下载链接: 提取码: umjx火车采集器中怎样安装智能原创插件第一步,使用解压软件,提取插件安装包中的文件,解压到一个文件夹中。第二步,打开解压后的文件夹,将上面的【5118 智能原创.dll】文件,放入在【火车采集器】安装目录下的Plugins文件夹里。第三步,将文件夹中的【5118智能原创配置工具.exe】和【Newtonsoft.Json.dll】文件,放入在【火车采集器】安装目录中。
第四步,在【火车采集器】的根目录里,打开【5118 智能原创配置工具.exe】,点击“获取API-Key”,将会在浏览器中打开5118获取API的页面。页面中找到“一键智能原创API”,点击复制按键,返回【5118 智能原创配置工具.exe】界面,粘贴API-Key到输入框中。一键智能原创API支持免费试用其实5118伪原创是要订购付费的,可申请100次免费使用,可选购一键智能原创API套餐。5118会员折扣码 D569F5 [?]智能原创插件使用说明第一步,打开火车头采集器,点击开始栏的【插件管理】,在插件管理框右侧列表里,选中【5118智能原创】,在两侧框中输入需采集的网址,点击测试按键,查看插件是否正常。第二步,测试没有问题后,开始使用插件设置内容采集规则。第三步,选择已有采集任务,在【其他设置】的一侧栏目中选择插件,在采集结果处理插件下拉框中,选择【5118智能原创.dll】,点击保存即可。此处需注意火车头采集教程,【内容采集规则】左侧列表里的“内容”标签,是插件将手动智能原创的内容,固定标签名称为“内容”。导出任务数据时,在任务列表里,选中对应任务项目,右侧“发布”项必须勾选,否则数据难以导入。第四步,查看5118智能原创插件疗效。运行完成后,即可在之前所保存的地址中查看导入疗效。所导入的内容,已经是使用智能原创插件替换后的数据。
苹果cms怎么采集添加文章资讯图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 1086 次浏览 • 2020-04-25 11:00
一直想写几篇使小白看了也能用火车头采集资讯 明星 视频 的教程,因为有太多的小白来问我这个问题了,我说大家去百度下,反馈回去的结果都是一样说没有详尽的配置教程,发布老是提示失败。今天总算闲下来为小白们写一篇简单实用的采集教程。先写这个如何采集文章资讯的教程吧 。后面有时间了再更新视频 和名星的,这个教程是写如何使用早已有了采集规则的教程。采集规则和火车头软件自己在文章尾部的链接里下载,下载以后根据我写的教程操作保证使你学会火车头采集文章资讯了,好了开始我们明天的采集教程吧。
教程分两个大部分,一个是发布模块的配置 再就是采集规则的配置,发布模块和采集规则是两个缺一不可的组成部分。有些小伙伴们说在采集的时侯老是发布失败是如何回事?最终说到底就是这两个地方没有配置好造成。往下看
一,先来配置发布模块
1,打开火车头软件文件夹 点击右图这个启动程序图标
2,软件启动后点击这个“发布”进入到web发布模块配置界面。
3,我发给大家火车头软件里早已导出了苹果v10的4个发布模块,双击“苹果cms-v10文章”模块对其编辑,编辑地方有3个 如下图
①,编码设置改成 UTF-8
②,网站跟地址把 “1.cn” 替换成你的网站主域名
③,登陆方法改成 不需要登录http请求
④,都弄好后点击右下角的测试配置,我们首先要确定下这个发布模块是否可以正常使用,如果不能使用采集规则再正确也是发布不了的。点击测试配置步入到测试配置页面。如下图
4,配置发布模块最关键的一步,也是很多人出错或是甚至弄不懂的地方。我用箭头所指向的地方就是我们要配置的地方。如下图
①,先来配置验证密码:验证密码就是站外入库系联接苹果cms系统后台的验证码 ,这个须要去系统后台查看后填写,找到验证码后双击一侧“验证密码”在左边的编辑框里复制粘贴到上面就可以了。系统后台的验证码看右图所示。找到后复制下来粘贴到我们的发布模块里。
②,再来配置发布模块的“名称”,这里模块的名称虽然就是文章的标题,我们可以随意起一个名子,这个地方要理解了 就是整篇文章都有一个标题火车头采集教程,有了标题才可以发布,我们这儿是在测试发布模块,所以要自动填写一个标题,如果是采集规则的话这个地方是不用填写的,采集规则就会手动采集网站上的标题的。我们起名称以“首搽”为例吧 双击名称后在左侧填写首搽后点击更改就可以了 。
③,再来配置下“分类名称”和“分类编号”这两个也是在系统的后台来确定的,就是你要采集文章到网站哪个分类的名称和编号,看右图所示
来到系统后台点击基础>>>分类管理 拉到下边(第2张图)我们可以看见资讯的顶尖分类和子分类 一共三个,这三个分类我们都是发布文章的分类,都可以使用,我们就随意选择一个分类“头条”这个分类吧。这里的头条就是我们的分类名称,头条上面的18就是分类编号。所以我们就由此得到了分类的名称和编号火车头采集教程,直接填写到发布模块的配置即可。
④ 一起都填写完毕后就是最后的测试了,我们点击“发表文章测试“下面下来的就是发布入库成功的相关提示。我们可以到网站前台看下有没有这个文章。
⑤我们来到网站的前台点击导航栏的分类,可以看见一个标题名称为首搽的文章,这也代表了我们文章发布模块配置成功。
5,由于文字篇幅宽度的限制我们在下一篇文章里介绍文章采集规则的配置,看完下半部份的配置相信你一定会用火车头来采集文章资讯到自己的网站上。 查看全部
一直想写几篇使小白看了也能用火车头采集资讯 明星 视频 的教程,因为有太多的小白来问我这个问题了,我说大家去百度下,反馈回去的结果都是一样说没有详尽的配置教程,发布老是提示失败。今天总算闲下来为小白们写一篇简单实用的采集教程。先写这个如何采集文章资讯的教程吧 。后面有时间了再更新视频 和名星的,这个教程是写如何使用早已有了采集规则的教程。采集规则和火车头软件自己在文章尾部的链接里下载,下载以后根据我写的教程操作保证使你学会火车头采集文章资讯了,好了开始我们明天的采集教程吧。
教程分两个大部分,一个是发布模块的配置 再就是采集规则的配置,发布模块和采集规则是两个缺一不可的组成部分。有些小伙伴们说在采集的时侯老是发布失败是如何回事?最终说到底就是这两个地方没有配置好造成。往下看
一,先来配置发布模块
1,打开火车头软件文件夹 点击右图这个启动程序图标
2,软件启动后点击这个“发布”进入到web发布模块配置界面。
3,我发给大家火车头软件里早已导出了苹果v10的4个发布模块,双击“苹果cms-v10文章”模块对其编辑,编辑地方有3个 如下图
①,编码设置改成 UTF-8
②,网站跟地址把 “1.cn” 替换成你的网站主域名
③,登陆方法改成 不需要登录http请求
④,都弄好后点击右下角的测试配置,我们首先要确定下这个发布模块是否可以正常使用,如果不能使用采集规则再正确也是发布不了的。点击测试配置步入到测试配置页面。如下图
4,配置发布模块最关键的一步,也是很多人出错或是甚至弄不懂的地方。我用箭头所指向的地方就是我们要配置的地方。如下图
①,先来配置验证密码:验证密码就是站外入库系联接苹果cms系统后台的验证码 ,这个须要去系统后台查看后填写,找到验证码后双击一侧“验证密码”在左边的编辑框里复制粘贴到上面就可以了。系统后台的验证码看右图所示。找到后复制下来粘贴到我们的发布模块里。
②,再来配置发布模块的“名称”,这里模块的名称虽然就是文章的标题,我们可以随意起一个名子,这个地方要理解了 就是整篇文章都有一个标题火车头采集教程,有了标题才可以发布,我们这儿是在测试发布模块,所以要自动填写一个标题,如果是采集规则的话这个地方是不用填写的,采集规则就会手动采集网站上的标题的。我们起名称以“首搽”为例吧 双击名称后在左侧填写首搽后点击更改就可以了 。
③,再来配置下“分类名称”和“分类编号”这两个也是在系统的后台来确定的,就是你要采集文章到网站哪个分类的名称和编号,看右图所示
来到系统后台点击基础>>>分类管理 拉到下边(第2张图)我们可以看见资讯的顶尖分类和子分类 一共三个,这三个分类我们都是发布文章的分类,都可以使用,我们就随意选择一个分类“头条”这个分类吧。这里的头条就是我们的分类名称,头条上面的18就是分类编号。所以我们就由此得到了分类的名称和编号火车头采集教程,直接填写到发布模块的配置即可。
④ 一起都填写完毕后就是最后的测试了,我们点击“发表文章测试“下面下来的就是发布入库成功的相关提示。我们可以到网站前台看下有没有这个文章。
⑤我们来到网站的前台点击导航栏的分类,可以看见一个标题名称为首搽的文章,这也代表了我们文章发布模块配置成功。
5,由于文字篇幅宽度的限制我们在下一篇文章里介绍文章采集规则的配置,看完下半部份的配置相信你一定会用火车头来采集文章资讯到自己的网站上。
利用火车头采集器采集慧聪网站公司信息采集视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 413 次浏览 • 2020-04-24 11:05
课程描述
第一章:中级教程开篇章第1节:工欲善其事必先利其器fiddler来帮您剖析数据第二章:分类信息网站58网站的采集第1节:58网站房屋转租内容采集第2节:58网站手机号码采集的突破形式第3节:利用采集器全手动大量发布信息的方法第三章:火车头采集器在采集腾讯网站内容的使用第1节:采集qq群上面的所有qq成员的方式第2节:腾讯网站的新闻采集第3节:微信文章搜索的内容采集第4节:微信公众号搜索的内容采集第5节:腾讯视频的代码的采集第四章:采集数据合成成文本第1节:采集网站内容合成出多个txt文本文档第2节:采集网站内容合成出word文档的方式第3节:采集内容合成出csv文件,可以用于淘宝助手第4节:通过采集器合成html单页面第五章:火车头采集器在威客领域的使用第1节:威客网站自动发贴模块的制做第2节:利用威客发贴来使自己的任务帖永保第一第六章:优酷网站相关内容采集的讲解第1节:通过采集器采集优酷网站的视频和相关信息第2节:通过火车头采集器监控优酷最新视频搜索量第七章:火车头采集器采集百度相关内容第1节:采集百度关键词搜索的结果并提取须要的网址域名第2节:火车头采集器采集百度贴吧贴子内容和跟帖第3节:利用火车头采集器采集百度新闻内容第4节:利用火车头采集器采集百度软件中心软件第5节:利用火车头采集器采集百度风云榜相关最新信息第八章:火车头采集器发布模块的制做思路和技巧第1节:Web发布模块的制做思路和技巧第2节:入库模块的制做思路和技巧dedecms,phpcms,ecshop,帝国cms火车头采集教程火车头采集教程,destoon,discuz
学习目的
通过学习火车头采集器中级教程可以满足大部分站长对于网站采集的需求,本课程院士您火车头采集器在各类文字、视频、音频、彩票、图片网站的采集方法以及火车头采集器发布模块的制做思路和技巧。本课程会随着市面上主流产品的迭代,而不断的更新新的案例,一次订购,终身学习。
适用人群
具有一定网站知识基础的网站编辑、网络营销从业者,电话营销从业者、SEOER、需要大量数据的、想提升自己对数据采集和合成效率的人。 查看全部
课程描述
第一章:中级教程开篇章第1节:工欲善其事必先利其器fiddler来帮您剖析数据第二章:分类信息网站58网站的采集第1节:58网站房屋转租内容采集第2节:58网站手机号码采集的突破形式第3节:利用采集器全手动大量发布信息的方法第三章:火车头采集器在采集腾讯网站内容的使用第1节:采集qq群上面的所有qq成员的方式第2节:腾讯网站的新闻采集第3节:微信文章搜索的内容采集第4节:微信公众号搜索的内容采集第5节:腾讯视频的代码的采集第四章:采集数据合成成文本第1节:采集网站内容合成出多个txt文本文档第2节:采集网站内容合成出word文档的方式第3节:采集内容合成出csv文件,可以用于淘宝助手第4节:通过采集器合成html单页面第五章:火车头采集器在威客领域的使用第1节:威客网站自动发贴模块的制做第2节:利用威客发贴来使自己的任务帖永保第一第六章:优酷网站相关内容采集的讲解第1节:通过采集器采集优酷网站的视频和相关信息第2节:通过火车头采集器监控优酷最新视频搜索量第七章:火车头采集器采集百度相关内容第1节:采集百度关键词搜索的结果并提取须要的网址域名第2节:火车头采集器采集百度贴吧贴子内容和跟帖第3节:利用火车头采集器采集百度新闻内容第4节:利用火车头采集器采集百度软件中心软件第5节:利用火车头采集器采集百度风云榜相关最新信息第八章:火车头采集器发布模块的制做思路和技巧第1节:Web发布模块的制做思路和技巧第2节:入库模块的制做思路和技巧dedecms,phpcms,ecshop,帝国cms火车头采集教程火车头采集教程,destoon,discuz
学习目的
通过学习火车头采集器中级教程可以满足大部分站长对于网站采集的需求,本课程院士您火车头采集器在各类文字、视频、音频、彩票、图片网站的采集方法以及火车头采集器发布模块的制做思路和技巧。本课程会随着市面上主流产品的迭代,而不断的更新新的案例,一次订购,终身学习。
适用人群
具有一定网站知识基础的网站编辑、网络营销从业者,电话营销从业者、SEOER、需要大量数据的、想提升自己对数据采集和合成效率的人。
火车头采集教程你把握多少
采集交流 • 优采云 发表了文章 • 0 个评论 • 737 次浏览 • 2020-04-24 11:04
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置火车头采集教程,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是title标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整火车头采集教程,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。 查看全部
步骤1:添加起始网址,点击【添加】,选择批量/多页,在地址格式设置须要采集的网页链接,点击【添加】和【完成】即可。此步骤目的是确立有多少个栏目分页链接。
采集网页链接方法说明:首先确定要采集的网页栏目页,分别查看栏目分页1、分页2和分页3链接规律,对比后会发觉分页2和分页3链接太象,只有2和3变化了(分页1虽然也是这么,为了SEO格式通常做了隐藏,所以分页1和栏目首页链接一致)可以剖析是根据等差数列排列,其实绝大多数的网站栏目页分页都是等差数列来排列的,包括尹华峰博客也是这么。因此,在填写规则是选择等差数列,在地址格式处填写分页2的链接,将变化的数字用(*)代替,根据栏目分页的多少设置项数即可。
步骤2:多级网址获取,点击【添加】,选择网址获取选项,添加提取网址的规则,使用熟练后建议使用结果网址过滤功能,将须要包含的网址和毋须包含的网址写进去,可以测试一下规则是否填写正确,然后保存即可。此步骤目的是确立每位栏目下的文章页链接。
多级网址获取方法说明:我们要获取的是该栏目下的文章页链接,去原网页查看栏目分页的源代码,在该源码页找到第一篇文章页链接的位置火车头采集教程,然后在里面选定一小段通用代码,一定是每位栏目页就会出现的代码,通常的表现形式会带有list或则article的代码。
火车头采集器内容规则设置
第二步、设置采集内容规则,可以在典型页面处填写一篇文章页链接进行测试,分别设置标题采集规则和内容采集规则,也分为两个步骤。
步骤a:双击【标题】标签,一般网页的标题是title标签,所以这一步可以默认,如果有须要的话是可以设置内容过滤,以及内容替换的。
步骤b:双击【内容】标签,内容提取规则和第一步的步骤2多级网址获取方式是一样的。这里是获取内容,所以是查看内容页的源代码,在该页面找到正文内容,在正文首段里面截取一小段通用代码,该代码也是所有文章页就会出现的,通常的表现形式是article标签为起始,为结束。同样也可以设置内容过滤、内容替换以及标签过滤等,将不需要的信息过滤掉。如不需要图片,可以勾选过滤掉img图片标签。
火车头采集器发布内容设置
第三步、发布内容设置,勾选须要启用的发布形式,保存即可,然后在任务列表处右键任务名,点击【开始任务】等待采集完成。
注,火车头采集器发布内容分为两个形式,方式一是web在线发布到网站,需要添加发布配置。新手不建议直接发布到网站,建议勾选第二个保存为本地。至于文件模板可以【查看默认模板】,然后选择TXT格式即可。
结语:火车头采集器功能非常强悍,除了采集文章还可以采集视频等,火车头采集器使用规则并不难,根本不需要懂哪些编程之类的语言,只需能读懂一些常用的简单代码即可,操作一两次基本可以完全把握,是一款非常棒的SEO工具。作为网站优化人员,我们采集文章后可以对内容进行更改和调整火车头采集教程,让内容愈加建立,同时也可以大大提升SEO人员的工作效率。火车头采集器使用方式就介绍到这儿了,不懂的同学可以下方留言,尽我所知给与解答。
火车头采集今日头条教程,含视频教程!自行下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 600 次浏览 • 2020-04-24 11:03
针对媒体号列表页:我们可以更改*tia*o.com/c/user/article/?page_type=1&user_id=3249088303&max_behot_time=0&count=20&as=A1D52A03F95BB20&cp=5A390BFB72701E1&_signature=CYasmBATU8TH7SpKuO0LRAmGrI
上面网址中的count=20,就是20篇文章,改这个可以获取文章的数目
视频中会演示!
3、文章页采集
源码看不到,可以直接F12,查找文章页的特定字符,然后前后截取就行了。
今日头条媒体号采集案例教程视频下载:(已失效 2019.03.01更新)
链接 密码:2ibp
看不懂看不会的火车头采集教程火车头采集教程,联系我Q1290654348 备注:火车头
补充1:今日头条的网址也具备时效性,如下图所示,时间久了列表页的网址会变化,只能现采现用。
补充2:为了解决【补充1】的问题,本人继续研究了一下,其实好多采集器可以采集列表,使用列车浏览器也可以,可以避免列表页原网址变化的情况,
写个浏览器脚本步骤也很简单,然后把这种网址直接导出到火车头就可以进行采集了,以下为获取到列表截图:
还有简单的方式,通过把采集的列表导出到数据库,然后和火车头一起运行,便就能一起实时运行了。
-----------------------------2018-06-08更新--------------------------------------------------------------
今日头条采集规则升级:
通过其他软件配合采集确实很麻烦,而且做不到手动采集。目前早已解决该问题,不需要抓包,也不需要进行其他软件的配合,可以实现永久手动采集了。
需要技巧的联系我Q1290654348
该规则早已写下来很久了,一直没来得及更新~(#^.^#)
2019.03.01更新
多次升级以后可稳定采集,如果须要采集规则,可以到这儿订购:火车头采集今日头条规则
2019.09.10更新
今日头条规则所有栏目升级更新完成。
2019.12.18
近期,有同学反馈根据栏目采集的规则,存在部份规则二次刷新采集,存在刷不出数据的情况,今天已全部更新。 查看全部
针对媒体号列表页:我们可以更改*tia*o.com/c/user/article/?page_type=1&user_id=3249088303&max_behot_time=0&count=20&as=A1D52A03F95BB20&cp=5A390BFB72701E1&_signature=CYasmBATU8TH7SpKuO0LRAmGrI
上面网址中的count=20,就是20篇文章,改这个可以获取文章的数目
视频中会演示!
3、文章页采集
源码看不到,可以直接F12,查找文章页的特定字符,然后前后截取就行了。
今日头条媒体号采集案例教程视频下载:(已失效 2019.03.01更新)
链接 密码:2ibp
看不懂看不会的火车头采集教程火车头采集教程,联系我Q1290654348 备注:火车头
补充1:今日头条的网址也具备时效性,如下图所示,时间久了列表页的网址会变化,只能现采现用。
补充2:为了解决【补充1】的问题,本人继续研究了一下,其实好多采集器可以采集列表,使用列车浏览器也可以,可以避免列表页原网址变化的情况,
写个浏览器脚本步骤也很简单,然后把这种网址直接导出到火车头就可以进行采集了,以下为获取到列表截图:
还有简单的方式,通过把采集的列表导出到数据库,然后和火车头一起运行,便就能一起实时运行了。
-----------------------------2018-06-08更新--------------------------------------------------------------
今日头条采集规则升级:
通过其他软件配合采集确实很麻烦,而且做不到手动采集。目前早已解决该问题,不需要抓包,也不需要进行其他软件的配合,可以实现永久手动采集了。
需要技巧的联系我Q1290654348
该规则早已写下来很久了,一直没来得及更新~(#^.^#)
2019.03.01更新
多次升级以后可稳定采集,如果须要采集规则,可以到这儿订购:火车头采集今日头条规则
2019.09.10更新
今日头条规则所有栏目升级更新完成。
2019.12.18
近期,有同学反馈根据栏目采集的规则,存在部份规则二次刷新采集,存在刷不出数据的情况,今天已全部更新。
详解火车头采集器免登入采集数据发布到DEDECMS织梦的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 425 次浏览 • 2020-04-24 11:03
这篇文章主要介绍了解读火车头采集器免登入采集数据发布到DEDECMS织梦的方式火车头采集教程,小编认为挺不错的,现在分享给你们,也给你们做个参考。一起追随小编过来瞧瞧吧
将dede/config.php中的下边代码:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
修改为:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
if($my_u != ')
{
$res = $cuserLogin->checkUser($my_u,$my_p);
if($res==1)
$cuserLogin->keepUser();
}
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
}
然后火车头发布模块更改为
article_add.php?my_u=你后台用户名&my_p=你后台密码 查看全部
这篇文章主要介绍了解读火车头采集器免登入采集数据发布到DEDECMS织梦的方式火车头采集教程,小编认为挺不错的,现在分享给你们,也给你们做个参考。一起追随小编过来瞧瞧吧
将dede/config.php中的下边代码:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
修改为:
//检验用户登录状态
$cuserLogin = new userLogin();
if($cuserLogin->getUserID()==-1)
{
if($my_u != ')
{
$res = $cuserLogin->checkUser($my_u,$my_p);
if($res==1)
$cuserLogin->keepUser();
}
if($cuserLogin->getUserID()==-1)
{
header("location:login.php?gotopage=".urlencode($dedeNowurl));
exit();
}
}
然后火车头发布模块更改为
article_add.php?my_u=你后台用户名&my_p=你后台密码
苹果cms怎么用火车头采集资讯图文教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 885 次浏览 • 2020-04-24 11:02
一,导入资讯采集规则分组,关于如何使用火车头软件明天我们就不讲了 请直接看上一篇的教程:点击查看我们直接步入火车头软件。
①打开火车头软件 鼠标在右边的空白处右键键盘点击导出分组,一个分组虽然就是一个文件夹,文件夹上面的每条规则就是一个任务,我们发给你的规则就是一个文件夹上面有一个采集规则,所以我们这儿选择导出分组。(即导出文件夹)
②图片中的文件就是一个资讯采集规则的分组文件,我们直接选择这个文件导出。
③导入后我们就开始对这个规则进行入库配置火车头采集教程,双击图片箭头所指向的规则步入到编辑页面。
二,配置资讯采集规则,其实我们配置入库资讯采集规则的地方就三个地方,填对这三个地方就搞定了。
1火车头采集教程,到达编辑页面后填写对接系统后台的入库验证密码,怎么获取验证密码请看上半部份的教程点击查看操作步骤如下图
图①直接点击第二步“采集内容规则”进行编辑页面
图②双击验证码会弹出图3中的填写验证码页面
图③填写系统后台的入库验证密码
图④全部填写完毕后直接点击确定
2,下拉编辑框填写分类编号 分类编号也是在系统后台,如果不懂的也须要看上半部的教程点击查看
图①双击分类编号 会弹出一侧的编辑框。
图② 填写你要入库分类的分类编号 不要根据我的照搬 你要确定你自己的分类编号进行填写。
图③填写完毕点击确定。
3,填写分类名称 ,这个和之前的分类编号一样的步骤
图①双击分类名称。
图②填写分类名称 也是同样不要照搬 确定自己要入库的分类。
图③填写完毕后点击确定保存。
三,点击切换到第三步“发布内容设置”页面 导入我们今天配置的发布模块,导入完后点击确定 查看全部
大家好 ,咱们继续今天没有完成的资讯采集教程,如果你是直接进来的请先看上半部份的教程点击查看这样你能够读懂这部份的内容 昨天我们配置了文章的发布模块昨天来配置文章资讯的采集规则,采集规则和火车头软件在此文章的顶部留有链接 自己下载即可。为什么网站上要添加资讯文章呢?这个是关系到网站SEO收录的一个关键问题。如果一个影视网站能够持续的保持更新文章资讯会给你的网站收录加分不少,从而获得好的排行。好了开始我们明天的教程。
一,导入资讯采集规则分组,关于如何使用火车头软件明天我们就不讲了 请直接看上一篇的教程:点击查看我们直接步入火车头软件。
①打开火车头软件 鼠标在右边的空白处右键键盘点击导出分组,一个分组虽然就是一个文件夹,文件夹上面的每条规则就是一个任务,我们发给你的规则就是一个文件夹上面有一个采集规则,所以我们这儿选择导出分组。(即导出文件夹)
②图片中的文件就是一个资讯采集规则的分组文件,我们直接选择这个文件导出。
③导入后我们就开始对这个规则进行入库配置火车头采集教程,双击图片箭头所指向的规则步入到编辑页面。
二,配置资讯采集规则,其实我们配置入库资讯采集规则的地方就三个地方,填对这三个地方就搞定了。
1火车头采集教程,到达编辑页面后填写对接系统后台的入库验证密码,怎么获取验证密码请看上半部份的教程点击查看操作步骤如下图
图①直接点击第二步“采集内容规则”进行编辑页面
图②双击验证码会弹出图3中的填写验证码页面
图③填写系统后台的入库验证密码
图④全部填写完毕后直接点击确定
2,下拉编辑框填写分类编号 分类编号也是在系统后台,如果不懂的也须要看上半部的教程点击查看
图①双击分类编号 会弹出一侧的编辑框。
图② 填写你要入库分类的分类编号 不要根据我的照搬 你要确定你自己的分类编号进行填写。
图③填写完毕点击确定。
3,填写分类名称 ,这个和之前的分类编号一样的步骤
图①双击分类名称。
图②填写分类名称 也是同样不要照搬 确定自己要入库的分类。
图③填写完毕后点击确定保存。
三,点击切换到第三步“发布内容设置”页面 导入我们今天配置的发布模块,导入完后点击确定
火车头采集搜狐号自媒体教程方式!(已解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 402 次浏览 • 2020-04-24 11:02
温馨提示:需要搜狐新闻采集规则的这儿构面《搜狐新闻采集规则》
如果须要搜狐号作者采集规则的同学,可以点击两侧的联系方法,联系我QQ
====20191109更新====
针对某一个搜狐号,进入其主页,进行采集,该主页网址未能采集到列表火车头采集教程,不能采集到列表也就无法进行批量采集,所以,首先要解决该问题。
其次,搜狐自媒体号上的文章URL都有一定的特征,如下:
变量_114778
我们只须要把这个变量找到就好了!然后用火车头拼接一下URL就可以了。
难点:抓包找数据剖析
案例如下:
1、目标搜狐号主页:;_f=index_pagemp_1
2、fiddler抓包,如下图所示:
查看大图
该网址就是列表url原先的地址:%h#u.com/apiV2/profile/newsListAjax?xpt=cHBhZzc5Mjg1OTg1MDkxNEBzb2h1LmNvbQ==&pageNumber=1&pageSize=10&categoryId=&_=1513670508722
在火车头中多页采集修改这个地方:pageNumber=1
3、采集文章页URL
把里面的旧址用浏览器打开,如下图所示:
我们把红色圈中的部份采集下来即可。然后火车头采集规则如此编撰:
列表页采集到了火车头采集教程,内页文章页可以直接看源码编撰采集规则,上面是难点,简单的就不啰嗦了。 查看全部
温馨提示:需要搜狐新闻采集规则的这儿构面《搜狐新闻采集规则》
如果须要搜狐号作者采集规则的同学,可以点击两侧的联系方法,联系我QQ
====20191109更新====
针对某一个搜狐号,进入其主页,进行采集,该主页网址未能采集到列表火车头采集教程,不能采集到列表也就无法进行批量采集,所以,首先要解决该问题。
其次,搜狐自媒体号上的文章URL都有一定的特征,如下:
变量_114778
我们只须要把这个变量找到就好了!然后用火车头拼接一下URL就可以了。
难点:抓包找数据剖析
案例如下:
1、目标搜狐号主页:;_f=index_pagemp_1
2、fiddler抓包,如下图所示:
查看大图
该网址就是列表url原先的地址:%h#u.com/apiV2/profile/newsListAjax?xpt=cHBhZzc5Mjg1OTg1MDkxNEBzb2h1LmNvbQ==&pageNumber=1&pageSize=10&categoryId=&_=1513670508722
在火车头中多页采集修改这个地方:pageNumber=1
3、采集文章页URL
把里面的旧址用浏览器打开,如下图所示:
我们把红色圈中的部份采集下来即可。然后火车头采集规则如此编撰:
列表页采集到了火车头采集教程,内页文章页可以直接看源码编撰采集规则,上面是难点,简单的就不啰嗦了。
火车头采集器图片采集上传设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 727 次浏览 • 2020-04-24 11:02
前面我们写了基础的标题和文章采集,下面介绍下图片的采集。
图片采集不是必须的,但是图片可以丰富网站的内容,具体我也不清楚对网站的SEO有哪些影响。我测试采集图片和不采集图片收录没区别,我看到的一些采集站,大部分也是不采集图片的!
如果采集数据量比较大的话可以选择不采集图片。
正文开始
首先是火车头采集器上的设置。
我们以这个文章为例:
这个上面有一张图片,并且也是上面我们教程里用做示范的网站。
声明:本人目前没使用任何景安的产品(以前用过),也对他产品印象不好。仅做教程示例,没有推荐他产品的意思。
我们直接打开上面教程创建的那种火车头采集任务。
在内容采集规则-内容-文件下载上面
选择:将相对地址补全为绝对地址、下载图片
文件地址必须包含:uploads/allimg
这个必须包含是按照不同网站来设置的,比如本文教程里文章图片地址是:
那么除掉后面他网站域名和前面会形成变化的文件名和日期格式的目录名之外剩余的基本就是我们想要的内容,所以我这儿使图片文件地址必须包含uploads/allimg。
为什么如此做?
因为他有可能在文章里加入图片广告,图片广告为了易于更改,大部分都是采用单独目录内放图片广告的形式。这样之后该广告比较容易。新老文章都能一次更改掉。
文件保存目录:i\m\g/yyyyMMdd
这个目录是你采集器的本地笔记本和服务器上面要创建的目录火车头采集教程火车头采集教程,先存到本地之后上传到服务器里。
目录上面的\斜杠是因为默认img上面m和g会被火车头辨识为内置函数(字母颜色会变蓝),没办法正常解析,所以加上斜杠。正常的话是img/yyyyMMdd这样的
含义:表示保存到网站的/img目录下,然后按照年月日手动创建对应的目录。
然后是在内容的-HTML标签排除上面,我们除去图象<img这个标签的排除。因为排除后我们发布后文章内就没有调用图片,自然不会显示图片内容。
然后我们进行图片的上传设置,我们采集时候次序是,先将图片下载到本地,然后传到服务器这样一个步骤。
通过FTP的方法来上传。
先在宝塔面板上传建一个FTP帐户,FTP默认目录要设置在我们网站跟目录。
采集器会依照我们里面的设置自己创建对应的目录。
注意:FTP使用的端口记得打开!21、20、39000-40000不打开端口你图片自然传不了。放行20和39000到40000这种端口是因为宝塔的FTP时常出现FTP联接错误的情况,这是另一个问题。这里不给你们解释了,不然篇幅很长了。
打开火车头采集器:其他设置、FTP文件上传、FTP上传
服务器:填写你的服务器IP地址
用户名/密码:刚才创建的FTP帐户和密码
端口:默认21
文件上传根目录:/
次序:先发布数据
文件上传成功后删掉本地文件:是
这里也可以选择否,选择是的话可以降低采集器所在机器c盘的占用,而且上传成功的图片,也没必要在保留了。
设置好了以后我们点一下上传测试文件:
看下下边的框里显示的信息,有没有成功上传,并且打开网站目录内也看下有没有测试文件Test.zip被上传。
测试OK的话保存一下设置,我们测试下瞧瞧采集效果 查看全部
火车头采集器图片采集上传设置
前面我们写了基础的标题和文章采集,下面介绍下图片的采集。
图片采集不是必须的,但是图片可以丰富网站的内容,具体我也不清楚对网站的SEO有哪些影响。我测试采集图片和不采集图片收录没区别,我看到的一些采集站,大部分也是不采集图片的!
如果采集数据量比较大的话可以选择不采集图片。
正文开始
首先是火车头采集器上的设置。
我们以这个文章为例:
这个上面有一张图片,并且也是上面我们教程里用做示范的网站。
声明:本人目前没使用任何景安的产品(以前用过),也对他产品印象不好。仅做教程示例,没有推荐他产品的意思。
我们直接打开上面教程创建的那种火车头采集任务。
在内容采集规则-内容-文件下载上面
选择:将相对地址补全为绝对地址、下载图片
文件地址必须包含:uploads/allimg
这个必须包含是按照不同网站来设置的,比如本文教程里文章图片地址是:
那么除掉后面他网站域名和前面会形成变化的文件名和日期格式的目录名之外剩余的基本就是我们想要的内容,所以我这儿使图片文件地址必须包含uploads/allimg。
为什么如此做?
因为他有可能在文章里加入图片广告,图片广告为了易于更改,大部分都是采用单独目录内放图片广告的形式。这样之后该广告比较容易。新老文章都能一次更改掉。
文件保存目录:i\m\g/yyyyMMdd
这个目录是你采集器的本地笔记本和服务器上面要创建的目录火车头采集教程火车头采集教程,先存到本地之后上传到服务器里。
目录上面的\斜杠是因为默认img上面m和g会被火车头辨识为内置函数(字母颜色会变蓝),没办法正常解析,所以加上斜杠。正常的话是img/yyyyMMdd这样的
含义:表示保存到网站的/img目录下,然后按照年月日手动创建对应的目录。
然后是在内容的-HTML标签排除上面,我们除去图象<img这个标签的排除。因为排除后我们发布后文章内就没有调用图片,自然不会显示图片内容。
然后我们进行图片的上传设置,我们采集时候次序是,先将图片下载到本地,然后传到服务器这样一个步骤。
通过FTP的方法来上传。
先在宝塔面板上传建一个FTP帐户,FTP默认目录要设置在我们网站跟目录。
采集器会依照我们里面的设置自己创建对应的目录。
注意:FTP使用的端口记得打开!21、20、39000-40000不打开端口你图片自然传不了。放行20和39000到40000这种端口是因为宝塔的FTP时常出现FTP联接错误的情况,这是另一个问题。这里不给你们解释了,不然篇幅很长了。
打开火车头采集器:其他设置、FTP文件上传、FTP上传
服务器:填写你的服务器IP地址
用户名/密码:刚才创建的FTP帐户和密码
端口:默认21
文件上传根目录:/
次序:先发布数据
文件上传成功后删掉本地文件:是
这里也可以选择否,选择是的话可以降低采集器所在机器c盘的占用,而且上传成功的图片,也没必要在保留了。
设置好了以后我们点一下上传测试文件:
看下下边的框里显示的信息,有没有成功上传,并且打开网站目录内也看下有没有测试文件Test.zip被上传。
测试OK的话保存一下设置,我们测试下瞧瞧采集效果

